
网页表格抓取
运维的报表之路,用 node.js 轻松发送 grafana 报表
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-06-01 19:06
在运维过程中,无论是监控还是报表,都会有一些通过邮件发送图表的需求,由于开源的 zabbix,grafana 和 kibana 等并不完全具有“想发送哪儿就发送哪儿”的图片生成功能,在 grafana 中我们也考虑了一些其他方法,比如 grafana webdav 和 grafana-image-renderer 的方案,但并不能满足我们的需求。我们通过 nodejs 的模块 puppeteer + nodemailer 实现了grafana pannel 图表的邮件报表功能,基本满足了我们在自动化报表这块的需求。原理Puppeteer 是一个提供了高级 API ,通过DevTools Protocol(开发工具协议)控制headless chrome 或 chromium 的 Node.js 库,默认的运行模式是无头的,但是可以配置成非无头的模式。无头浏览器是一种没有操作界面的浏览器,诸如selenium、PhantomJS、Puppeteer 等,常用于网页自动化测试,利用其提供的API,可以自动执行操作指令,它是测试利器,也是爬虫神器 。Puppeteer 是其中比较优秀的一个。Puppeteer 通过程序化地操作浏览器,与其进行模拟交互(例如点击、打字、导航等等)来控制要抓取的网页,通常也能获取网页的 DOM 或 HTML,因此也可以获取网页数据,对于一些动态网站来说,像 grafana 图表,JS 动态渲染的数据通常不能轻松获取,而自动化测试工具Puppeteer则可以轻松的做到,因为它是将 HTML 输入浏览器里运行的。
如果大家对 DevTools Protocol(开发工具协议)感兴趣,可以参考:
准备环境环境版本
centos
7.6
node
14.3.0
cnpm
6.1.1
cd /optwget https://cdn.npm.taobao.org/dis ... xztar -xf node-v14.3.0-linux-x64.tar.xz<br />vi /etc/profile#set for nodejsexport NODE_HOME=/opt/node-v14.3.0-linux-x64export PATH=$NODE_HOME/bin:$PATH<br />source /etc/profile<br />npm config set registry=http://registry.npm.taobao.orgnpm install -g cnpm --registry=https://registry.npm.taobao.org<br /># 截图存放位置mkdir /tmp/png/<br /># 项目位置mkdir /opt/GrafanaSnapProjectcd /opt/GrafanaSnapProjectcnpm i --save puppeteercnpm i --save nodemailer
源码逻辑
为了使逻辑更清晰,我把发邮件和获取截图分成两个模块 mailPush.js 和 getPicture.js
发邮件模块 mailPush.js 这块需要注意为每一个附件添加一个引用名称,便于把截图引用到正文里。
在nodejs 里使用${str1}${str2} hello进行字符串拼接。
/*function: send pictures in mail's html content via nodejsauthor: zuoguocai@126.com<br />*/<br />const nodemailer = require('nodemailer');<br />//定义您的邮件推送服务器let transporter = nodemailer.createTransport({ // 您的邮箱服务器地址 host: 'mail.exchangehost.com', port: 587, secure: false, auth: { user: 'yourEmail', //您的邮箱的账号 pass: 'yourPassword'//您的邮箱的密码 }, tls: { rejectUnauthorized: false }, });<br />function sendMymail(who,subject,title){ let mailOptions = { from: '"autoreport" ', //邮件来源 to: who, //邮件发送到哪里,多个邮箱使用逗号隔开 subject: subject, // 邮件主题 html: `${title}
报表1
cid:001
报表2
cid:002`, // html类型的邮件正文 attachments: [{ filename: '001.png',//附件名称 path: '/tmp/png/001.png', //附件的位置 cid: '001', //为附件添加一个引用名称 },{ filename: '002.png',//附件名称 path: '/tmp/png/002.png', //附件的位置 cid: '002', //为附件添加一个引用名称 }] };<br /> transporter.sendMail(mailOptions, (error, info) => { if (error) { return console.log(error); } console.log('Message %s sent: %s', info.messageId, info.response); });}<br />//测试用//sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表')<br />// 自定义发邮件模块,供引入exports.sendMymail = sendMymail;<br />// 作为引入模块使用//const sendModule = require('./mailPush.js');//sendModule.sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表');
puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,很适合在Linux 字符终端使用,不需要在Linux 上安装桌面工具。但需要在 Linux 中安装中文字体,如仿宋字体,避免在截图中出现乱码。说到字体,中文字体其实有很多,比如方正的徐静蕾体,adoble 思源字体。字体大家可以从网络上下载,阿里免费的可商用普惠字体,下载链接
Linux 中安装中文字体
yum -y install fontconfigcd /usr/share/fontsmkdir chinesecd chinese/使用lrzsz 上传字体,如仿宋体chmod -R 775 /usr/share/fonts/chineseyum -y install ttmkfdirttmkfdir -e /usr/share/X11/fonts/encodings/encodings.dirvi /etc/fonts/fonts.conf/usr/local/share/fonts/chinese<br />fc-list :lang=zh/usr/share/fonts/bitmap/fangsongti24.pcf.gz: Fangsong ti:style=Regular/usr/share/fonts/chinese/simfang.ttf: FangSong_GB2312:style=Regular/usr/share/fonts/bitmap/fangsongti16.pcf.gz: Fangsong ti:style=Regular
getPicture.js 模块主要用来模拟登陆,模拟操作。这里需要对用户名和密码参数化,在写这块逻辑时大家可以参考网络上 puppeteer 文档和一些案例。定位按钮和点击按钮这块比较繁琐和复杂,大家可以借助工具 puppeteer recorder 插件来辅助生成代码。本机电脑 chrome 扩展程序里安装 puppeteer recorder 插件,这里我们主要通过使用chrome 插件 puppeteer recorder 对 grafana 前端 CSS 选择器定位,模拟点击,确定元素位置,生成一些辅助代码。使用习惯跟 JMeter,LoadRunner 很像。如图1
我们分析一下 grafana 某个 dashboard ,都是有好多 pannel 组成的,点击某个 pannel 的下拉菜单,点击 view 可以预览这个 pannel 的图表情况。这样我们就可以使用工具单独录制这段操作的代码,放到我们整个项目里。
如图2
/*function: snapshot grafana pannel pictures via puppeteerauthor: zuoguocai@126.com*/<br />// 发送函数function sendPicture(){ // 引入自定义发邮件模块 const sendModule = require('./mailPush.js'); // 同时发送到多个邮箱,用逗号隔开 sendModule.sendMymail('guocai.zuo@gmail.com,zuoguocai@126.com','每周报表','^_^ OpenStack 监控报表');}<br />// 截图函数function getPicture(){<br /> const puppeteer = require('puppeteer'); //模拟登陆,grafana 登陆的用户名和密码 const account = `zuoguocai`; const password = `xxxxxx`;<br /> (async () => { const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox']}); const page = await browser.newPage(); await page.setViewport({width:1827, height:979}); await page.goto('https://yourgrafana.com'); await page.type('input[type="text"]', account); await page.type('#inputPassword', password); await page.click('button[type="submit"]'); await page.waitForNavigation({ waitUntil: 'load' });<br /> //await page.waitFor(1000); // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.waitForSelector('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.click('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/001.png'});<br /> // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.waitForSelector('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.click('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/002.png'});<br /> await browser.close();<br /> //调用发送函数 await sendPicture();})();}<br />// 调用定位并截图函数getPicture()
源码地址:
测试发送效果
node getPicture.js
打开邮件客户端,查看是否收到邮件报表。
关于定时发送和 grafana 时间范围选取时间选取范围直接可以拼接到grafana的url里,这块比较简单。定时任务调度需要自己写,或者使用 gocron 的定时任务来做。gocron 项目地址:如图3
不止于此puppeteer 很强大,可以用于前端自动化测试,并且不局限于生成截图,还有pdf等,这里只是很小一部分内容,大家可以去探索,我这里只是一种思路,代码写的并不好,大家可以进行扩展,比如截取kibana等的图表,增加异常处理,对图片cid进行再次封装,放到对象存储里,工具集成到运维管理平台里,供业务相关方订阅。作者简介:左国才,VIPKID运维工程师,笔名icai,主要研究Linux操作系统,数据库,云计算领域相关技术, 热爱开源技术,平时喜欢阅读高效运维公众号。近期好文:“高效运维”公众号诚邀广大技术人员投稿, 查看全部
运维的报表之路,用 node.js 轻松发送 grafana 报表
在运维过程中,无论是监控还是报表,都会有一些通过邮件发送图表的需求,由于开源的 zabbix,grafana 和 kibana 等并不完全具有“想发送哪儿就发送哪儿”的图片生成功能,在 grafana 中我们也考虑了一些其他方法,比如 grafana webdav 和 grafana-image-renderer 的方案,但并不能满足我们的需求。我们通过 nodejs 的模块 puppeteer + nodemailer 实现了grafana pannel 图表的邮件报表功能,基本满足了我们在自动化报表这块的需求。原理Puppeteer 是一个提供了高级 API ,通过DevTools Protocol(开发工具协议)控制headless chrome 或 chromium 的 Node.js 库,默认的运行模式是无头的,但是可以配置成非无头的模式。无头浏览器是一种没有操作界面的浏览器,诸如selenium、PhantomJS、Puppeteer 等,常用于网页自动化测试,利用其提供的API,可以自动执行操作指令,它是测试利器,也是爬虫神器 。Puppeteer 是其中比较优秀的一个。Puppeteer 通过程序化地操作浏览器,与其进行模拟交互(例如点击、打字、导航等等)来控制要抓取的网页,通常也能获取网页的 DOM 或 HTML,因此也可以获取网页数据,对于一些动态网站来说,像 grafana 图表,JS 动态渲染的数据通常不能轻松获取,而自动化测试工具Puppeteer则可以轻松的做到,因为它是将 HTML 输入浏览器里运行的。
如果大家对 DevTools Protocol(开发工具协议)感兴趣,可以参考:
准备环境环境版本
centos
7.6
node
14.3.0
cnpm
6.1.1
cd /optwget https://cdn.npm.taobao.org/dis ... xztar -xf node-v14.3.0-linux-x64.tar.xz<br />vi /etc/profile#set for nodejsexport NODE_HOME=/opt/node-v14.3.0-linux-x64export PATH=$NODE_HOME/bin:$PATH<br />source /etc/profile<br />npm config set registry=http://registry.npm.taobao.orgnpm install -g cnpm --registry=https://registry.npm.taobao.org<br /># 截图存放位置mkdir /tmp/png/<br /># 项目位置mkdir /opt/GrafanaSnapProjectcd /opt/GrafanaSnapProjectcnpm i --save puppeteercnpm i --save nodemailer
源码逻辑
为了使逻辑更清晰,我把发邮件和获取截图分成两个模块 mailPush.js 和 getPicture.js
发邮件模块 mailPush.js 这块需要注意为每一个附件添加一个引用名称,便于把截图引用到正文里。
在nodejs 里使用${str1}${str2} hello进行字符串拼接。
/*function: send pictures in mail's html content via nodejsauthor: zuoguocai@126.com<br />*/<br />const nodemailer = require('nodemailer');<br />//定义您的邮件推送服务器let transporter = nodemailer.createTransport({ // 您的邮箱服务器地址 host: 'mail.exchangehost.com', port: 587, secure: false, auth: { user: 'yourEmail', //您的邮箱的账号 pass: 'yourPassword'//您的邮箱的密码 }, tls: { rejectUnauthorized: false }, });<br />function sendMymail(who,subject,title){ let mailOptions = { from: '"autoreport" ', //邮件来源 to: who, //邮件发送到哪里,多个邮箱使用逗号隔开 subject: subject, // 邮件主题 html: `${title}
报表1
cid:001
报表2
cid:002`, // html类型的邮件正文 attachments: [{ filename: '001.png',//附件名称 path: '/tmp/png/001.png', //附件的位置 cid: '001', //为附件添加一个引用名称 },{ filename: '002.png',//附件名称 path: '/tmp/png/002.png', //附件的位置 cid: '002', //为附件添加一个引用名称 }] };<br /> transporter.sendMail(mailOptions, (error, info) => { if (error) { return console.log(error); } console.log('Message %s sent: %s', info.messageId, info.response); });}<br />//测试用//sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表')<br />// 自定义发邮件模块,供引入exports.sendMymail = sendMymail;<br />// 作为引入模块使用//const sendModule = require('./mailPush.js');//sendModule.sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表');
puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,很适合在Linux 字符终端使用,不需要在Linux 上安装桌面工具。但需要在 Linux 中安装中文字体,如仿宋字体,避免在截图中出现乱码。说到字体,中文字体其实有很多,比如方正的徐静蕾体,adoble 思源字体。字体大家可以从网络上下载,阿里免费的可商用普惠字体,下载链接
Linux 中安装中文字体
yum -y install fontconfigcd /usr/share/fontsmkdir chinesecd chinese/使用lrzsz 上传字体,如仿宋体chmod -R 775 /usr/share/fonts/chineseyum -y install ttmkfdirttmkfdir -e /usr/share/X11/fonts/encodings/encodings.dirvi /etc/fonts/fonts.conf/usr/local/share/fonts/chinese<br />fc-list :lang=zh/usr/share/fonts/bitmap/fangsongti24.pcf.gz: Fangsong ti:style=Regular/usr/share/fonts/chinese/simfang.ttf: FangSong_GB2312:style=Regular/usr/share/fonts/bitmap/fangsongti16.pcf.gz: Fangsong ti:style=Regular
getPicture.js 模块主要用来模拟登陆,模拟操作。这里需要对用户名和密码参数化,在写这块逻辑时大家可以参考网络上 puppeteer 文档和一些案例。定位按钮和点击按钮这块比较繁琐和复杂,大家可以借助工具 puppeteer recorder 插件来辅助生成代码。本机电脑 chrome 扩展程序里安装 puppeteer recorder 插件,这里我们主要通过使用chrome 插件 puppeteer recorder 对 grafana 前端 CSS 选择器定位,模拟点击,确定元素位置,生成一些辅助代码。使用习惯跟 JMeter,LoadRunner 很像。如图1
我们分析一下 grafana 某个 dashboard ,都是有好多 pannel 组成的,点击某个 pannel 的下拉菜单,点击 view 可以预览这个 pannel 的图表情况。这样我们就可以使用工具单独录制这段操作的代码,放到我们整个项目里。
如图2
/*function: snapshot grafana pannel pictures via puppeteerauthor: zuoguocai@126.com*/<br />// 发送函数function sendPicture(){ // 引入自定义发邮件模块 const sendModule = require('./mailPush.js'); // 同时发送到多个邮箱,用逗号隔开 sendModule.sendMymail('guocai.zuo@gmail.com,zuoguocai@126.com','每周报表','^_^ OpenStack 监控报表');}<br />// 截图函数function getPicture(){<br /> const puppeteer = require('puppeteer'); //模拟登陆,grafana 登陆的用户名和密码 const account = `zuoguocai`; const password = `xxxxxx`;<br /> (async () => { const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox']}); const page = await browser.newPage(); await page.setViewport({width:1827, height:979}); await page.goto('https://yourgrafana.com'); await page.type('input[type="text"]', account); await page.type('#inputPassword', password); await page.click('button[type="submit"]'); await page.waitForNavigation({ waitUntil: 'load' });<br /> //await page.waitFor(1000); // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.waitForSelector('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.click('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/001.png'});<br /> // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.waitForSelector('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.click('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/002.png'});<br /> await browser.close();<br /> //调用发送函数 await sendPicture();})();}<br />// 调用定位并截图函数getPicture()
源码地址:
测试发送效果
node getPicture.js
打开邮件客户端,查看是否收到邮件报表。
关于定时发送和 grafana 时间范围选取时间选取范围直接可以拼接到grafana的url里,这块比较简单。定时任务调度需要自己写,或者使用 gocron 的定时任务来做。gocron 项目地址:如图3
不止于此puppeteer 很强大,可以用于前端自动化测试,并且不局限于生成截图,还有pdf等,这里只是很小一部分内容,大家可以去探索,我这里只是一种思路,代码写的并不好,大家可以进行扩展,比如截取kibana等的图表,增加异常处理,对图片cid进行再次封装,放到对象存储里,工具集成到运维管理平台里,供业务相关方订阅。作者简介:左国才,VIPKID运维工程师,笔名icai,主要研究Linux操作系统,数据库,云计算领域相关技术, 热爱开源技术,平时喜欢阅读高效运维公众号。近期好文:“高效运维”公众号诚邀广大技术人员投稿,
深市股票涨跌数据的抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-05-21 19:08
【分享成果,随喜正能量】遇到不可理喻的事情,接受,处理,远离,不追问。最后这三个字,是生活教会我的最重要的三个字。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:深市股票涨跌数据的抓取
第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。
实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:
Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:
1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】成年人的世界,钱是活下去的筹码,并非多爱钱,只是无奈,没钱寸步难行,一睁开眼就需要钱的年代,不怕没命,就怕没钱。。 查看全部
深市股票涨跌数据的抓取
【分享成果,随喜正能量】遇到不可理喻的事情,接受,处理,远离,不追问。最后这三个字,是生活教会我的最重要的三个字。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:深市股票涨跌数据的抓取
第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。
实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:
Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:
1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】成年人的世界,钱是活下去的筹码,并非多爱钱,只是无奈,没钱寸步难行,一睁开眼就需要钱的年代,不怕没命,就怕没钱。。
使用excel抓取网页数据,制作自动更新的新型肺炎地图数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-06 23:15
Hello大家好,前几天跟大家分享了使用三维度图在excel中展示疫情数据,但是有粉丝提问到能不能做一个实现自动刷新的地图数据呢?当然可以,今天我们换一种方法来制作数据地图,下面就让我们来一起操作下吧
一、获取数据
首先我们复制上面的网址,然后新建一个excel,点击数据功能找到自网站,然后将我们复制的网址直接粘贴进去,紧接着我们点击确定,当进入导航器的界面后在预览窗口会出现三个项目,在这里table1就是我们想要的新型肺炎疫情数据,我们选择table1然后点转换数据,这样的话我们就进入了power query的编辑界面
二、整理数据
首先我们将疑似以及治愈这两列数据删除(如果需要也可以保留),紧接着我们将确诊这一列的数据格式设置为整数,然后点击添加列,为数据添加索引列,然后我们对索引列进行筛选,筛选条件设置为小于等于33,点击确定,这么做的目的是为了删除国外的数据。这样的话我们就得到了国内的数据
三、插入着色地图
紧接着我们点击数据的任何一个区域,然后点击插入功能组在图表中找到着色地图,紧接着我们点击地图按快捷键ctrl+1调出格式窗口,找到颜色序列,设置为三种颜色,将最大值的颜色设置为深红色,将中间设置为数值,颜色设置为红色,将值设置为500,最后将最小值设置为数字,颜色设置为浅红色,值设置为100
紧接着我们为数据添加数据标签,点击任意一个区域,然后点击图表旁边的加号,选择数据标签,紧接着我们点击数据标签按快捷键ctrl+1调出格式窗口,勾选类别名称,将值去掉,这样的话我们就为每个省份都添加上了个字的名称
四、设置自动刷新
紧接着我们点击表格的任何一个区域,然后点击查询功能组,找到数据,勾选刷新频率,将其设置为60分钟,这样的话每过1个小时就会自动的刷新一次数据。至此设置完毕
以上就是我们使用excel制作自动更新的疫情地图的方法,怎么样是不是非常简单呢?
我是excel从零到一,关注我持续分享更多excel技巧 查看全部
使用excel抓取网页数据,制作自动更新的新型肺炎地图数据
Hello大家好,前几天跟大家分享了使用三维度图在excel中展示疫情数据,但是有粉丝提问到能不能做一个实现自动刷新的地图数据呢?当然可以,今天我们换一种方法来制作数据地图,下面就让我们来一起操作下吧
一、获取数据
首先我们复制上面的网址,然后新建一个excel,点击数据功能找到自网站,然后将我们复制的网址直接粘贴进去,紧接着我们点击确定,当进入导航器的界面后在预览窗口会出现三个项目,在这里table1就是我们想要的新型肺炎疫情数据,我们选择table1然后点转换数据,这样的话我们就进入了power query的编辑界面
二、整理数据
首先我们将疑似以及治愈这两列数据删除(如果需要也可以保留),紧接着我们将确诊这一列的数据格式设置为整数,然后点击添加列,为数据添加索引列,然后我们对索引列进行筛选,筛选条件设置为小于等于33,点击确定,这么做的目的是为了删除国外的数据。这样的话我们就得到了国内的数据
三、插入着色地图
紧接着我们点击数据的任何一个区域,然后点击插入功能组在图表中找到着色地图,紧接着我们点击地图按快捷键ctrl+1调出格式窗口,找到颜色序列,设置为三种颜色,将最大值的颜色设置为深红色,将中间设置为数值,颜色设置为红色,将值设置为500,最后将最小值设置为数字,颜色设置为浅红色,值设置为100
紧接着我们为数据添加数据标签,点击任意一个区域,然后点击图表旁边的加号,选择数据标签,紧接着我们点击数据标签按快捷键ctrl+1调出格式窗口,勾选类别名称,将值去掉,这样的话我们就为每个省份都添加上了个字的名称
四、设置自动刷新
紧接着我们点击表格的任何一个区域,然后点击查询功能组,找到数据,勾选刷新频率,将其设置为60分钟,这样的话每过1个小时就会自动的刷新一次数据。至此设置完毕
以上就是我们使用excel制作自动更新的疫情地图的方法,怎么样是不是非常简单呢?
我是excel从零到一,关注我持续分享更多excel技巧
用 Python 抓取阿里云盘资源
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-05-06 23:13
前阵子阿里云盘大火,送了好多的容量空间。而且阿里云盘下载是不限速,这点比百度网盘好太多了。这两天看到一个第三方网站可以搜索阿里云盘上的资源,但是它的资源顺序不是按时间排序的。这种情况会造成排在前面时间久远的资源是一个已经失效的资源。小编这里用 python 抓取后重新排序。
网页分析
这个网站有两个搜索路线:搜索线路一和搜索线路二,本文章使用的是搜索线路二。
打开控制面板下的网络,一眼就看到一个 seach.html 的 get 请求。
上面带了好几个参数,四个关键参数:
也是在控制面板中,看出这个网页跳转到阿里云盘获取真实的的链接是在标题上面的。用 bs4 解析页面上的 div(class=resource-item border-dashed-eee) 标签下的 a 标签就能得到跳转网盘的地址,解析 div 下的 p 标签获取资源日期。
抓取与解析
首先安装需要的 bs4 第三方库用于解析页面。
pip3 install bs4<br />
下面是抓取解析网页的脚本代码,最后按日期降序排序。 <p>import requests<br />from bs4 import BeautifulSoup<br />import string<br /><br /><br />word = input('请输入要搜索的资源名称:')<br /> <br />headers = {<br /> 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'<br />}<br /><br />result_list = []<br />for i in range(1, 11):<br /> print('正在搜索第 {} 页'.format(i))<br /> params = {<br /> 'page': i,<br /> 'keyword': word,<br /> 'search_folder_or_file': 0,<br /> 'is_search_folder_content': 0,<br /> 'is_search_path_title': 0,<br /> 'category': 'all',<br /> 'file_extension': 'all',<br /> 'search_model': 0<br /> }<br /> response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)<br /> response_data = response_html.content.decode()<br /> <br /> soup = BeautifulSoup(response_data, "html.parser");<br /> divs = soup.find_all('div', class_='resource-item border-dashed-eee')<br /> <br /> if len(divs) 查看全部
用 Python 抓取阿里云盘资源
前阵子阿里云盘大火,送了好多的容量空间。而且阿里云盘下载是不限速,这点比百度网盘好太多了。这两天看到一个第三方网站可以搜索阿里云盘上的资源,但是它的资源顺序不是按时间排序的。这种情况会造成排在前面时间久远的资源是一个已经失效的资源。小编这里用 python 抓取后重新排序。
网页分析
这个网站有两个搜索路线:搜索线路一和搜索线路二,本文章使用的是搜索线路二。
打开控制面板下的网络,一眼就看到一个 seach.html 的 get 请求。
上面带了好几个参数,四个关键参数:
也是在控制面板中,看出这个网页跳转到阿里云盘获取真实的的链接是在标题上面的。用 bs4 解析页面上的 div(class=resource-item border-dashed-eee) 标签下的 a 标签就能得到跳转网盘的地址,解析 div 下的 p 标签获取资源日期。
抓取与解析
首先安装需要的 bs4 第三方库用于解析页面。
pip3 install bs4<br />
下面是抓取解析网页的脚本代码,最后按日期降序排序。 <p>import requests<br />from bs4 import BeautifulSoup<br />import string<br /><br /><br />word = input('请输入要搜索的资源名称:')<br /> <br />headers = {<br /> 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'<br />}<br /><br />result_list = []<br />for i in range(1, 11):<br /> print('正在搜索第 {} 页'.format(i))<br /> params = {<br /> 'page': i,<br /> 'keyword': word,<br /> 'search_folder_or_file': 0,<br /> 'is_search_folder_content': 0,<br /> 'is_search_path_title': 0,<br /> 'category': 'all',<br /> 'file_extension': 'all',<br /> 'search_model': 0<br /> }<br /> response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)<br /> response_data = response_html.content.decode()<br /> <br /> soup = BeautifulSoup(response_data, "html.parser");<br /> divs = soup.find_all('div', class_='resource-item border-dashed-eee')<br /> <br /> if len(divs)
网站抓取引子 - 获得网页中的表格
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-06 17:20
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素。具体使用如下: <p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address <br />url 查看全部
网站抓取引子 - 获得网页中的表格
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素。具体使用如下: <p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address <br />url
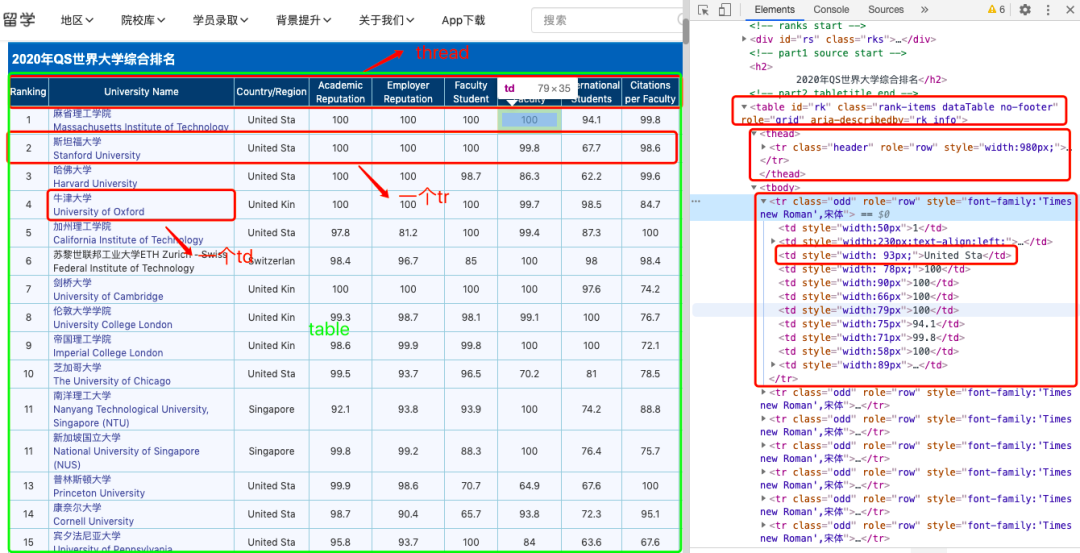
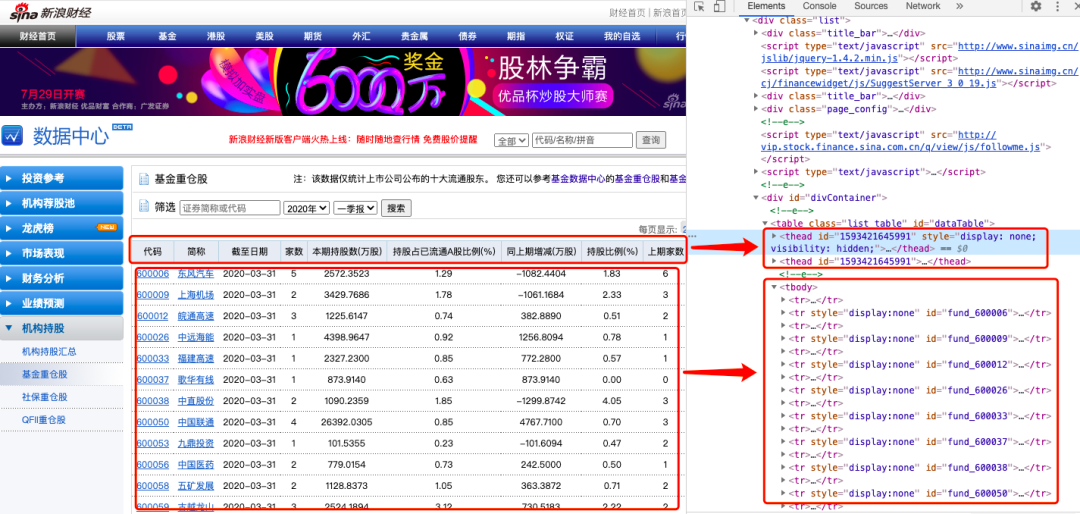
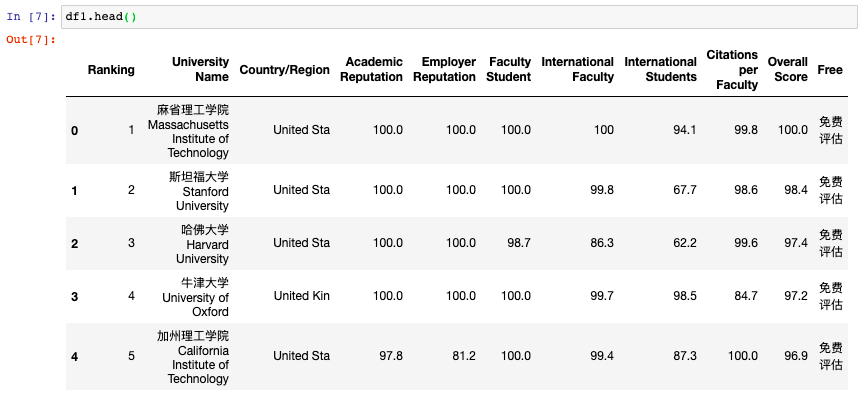
Python抓取网页表格(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-05-06 17:19
Python有很多包可以抓取数据,如selenium、requests、scrapy、pandas,每个包都有其适用性,个人认为在抓取数据时,代码简洁性和数据获取的准确性是需要考虑的因素,时间快慢倒不用太在意,毕竟用python抓数据本来就大大节省了时间,用不同的方法可能也就是1秒和1分钟的区别。
日常中我们总存在抓取表格数据的需求,本文试图用pandas最简洁的代码抓取表格数据,代码非常简单,也很容易上手。
随便选个网页:
比如爬取下图中定向工具的注册批文(当然wind里面也有数据,本文只是为了展示如何爬取表格型数据)
一、爬取当页
只需要两句关键代码就可以抓取出来,前两句是导入相关模块,第三句输入网址,第四句用pandas读取,由于该网页有很多表格,会以list格式存在ppn这个变量里,点击查看可以发行第十四张表格正是我们所需要的内容。
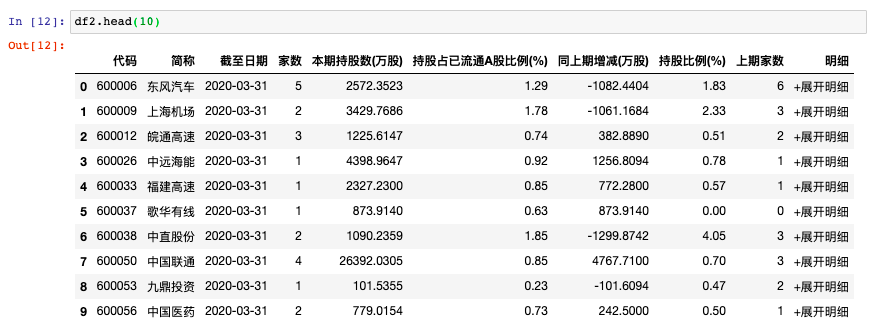
二、全部爬取
但是第一部分只抓取了第一页,如果想要把所有页都抓取出来,同样非常简单,只需编写一个循环。点击下一页可以发现其网址会发生相应改变:
页码会体现在index后面的数字,因此可以将url改为变量的组合,具体看第五句。第一和二句依然是导入相关模块,第三句是生成一个空矩阵,用于存储抓取完的结果,第四句至第八句是一个简单的循环,result变量就是每页抓取的结果,然后不断的添加到output里。最后output就是我们想要的结果。
查看全部
Python抓取网页表格(一)
Python有很多包可以抓取数据,如selenium、requests、scrapy、pandas,每个包都有其适用性,个人认为在抓取数据时,代码简洁性和数据获取的准确性是需要考虑的因素,时间快慢倒不用太在意,毕竟用python抓数据本来就大大节省了时间,用不同的方法可能也就是1秒和1分钟的区别。
日常中我们总存在抓取表格数据的需求,本文试图用pandas最简洁的代码抓取表格数据,代码非常简单,也很容易上手。
随便选个网页:
比如爬取下图中定向工具的注册批文(当然wind里面也有数据,本文只是为了展示如何爬取表格型数据)
一、爬取当页
只需要两句关键代码就可以抓取出来,前两句是导入相关模块,第三句输入网址,第四句用pandas读取,由于该网页有很多表格,会以list格式存在ppn这个变量里,点击查看可以发行第十四张表格正是我们所需要的内容。
二、全部爬取
但是第一部分只抓取了第一页,如果想要把所有页都抓取出来,同样非常简单,只需编写一个循环。点击下一页可以发现其网址会发生相应改变:
页码会体现在index后面的数字,因此可以将url改为变量的组合,具体看第五句。第一和二句依然是导入相关模块,第三句是生成一个空矩阵,用于存储抓取完的结果,第四句至第八句是一个简单的循环,result变量就是每页抓取的结果,然后不断的添加到output里。最后output就是我们想要的结果。
小码哥Flutter从入门到实战-大神精选(百度云 百度网盘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-04-30 12:27
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
官方建议大家先手动获取Connection,然后再从Connection中获取Table接口(注意:不是HTable类,而是Table接口):下面的方法都是Table接口提供的,具体的操作还是由HTable类实现的。首先是我们的put方法。4.3.2 put方法这个方法相当于增和改这两个操作。我们先构建一个Put对象出来,然后往这个对象里面添加这行需要的属性。我们很容易地可以联想到首当其冲的构造参数就是rowkey,所以最简单的Put构造函数就是:在HBase中有一个理念:所有数据皆为bytes。在HBase中数据最终都会被序列化为bytes[]保存,所以一切可以被序列化为bytes的对象都可以作为rowkey。最简单的将字符串转换为bytes[]的方法是使用Bytes提供的toBytes方法:Bytes是由HBase提供的用于将各种不同类型的数据格式转换为byte[]的工具类,然后我们设置这行数据的mycf列族的name列为jack:此时操作并没有执行下去,我们调用Table接口的put方法把数据真正保存起来:执行完后,我们用hbase shell来看下mytable这个表的数据:可以看到这条数据已经被保存到HBase中了,这就是最简单的新增语句。
那么修改呢?修改就是往同一个rowkey再执行一次put操作,将之前的数据覆盖掉。我们来做一下如何修改刚刚保存的这行数据。依然还是新建一个Put对象,用addColumn方法设置rowkey为row1,这回设置mycf:name为ted,然后保存:1.Put的构造函数Put最简单的构造方法是:Put的其他的构造方法:Put(ByteBuffer row)Put(Put putToCopy)Put(byte[] row, long ts)Put(ByteBuffer row, long ts)Put(byte[] rowArray, int rowOffset, int rowLength)Put(byte[] rowArray, int rowOffset, int rowLength, longts)2.addColumn和addImmutable的历史早期教程,提到的add(byte [] family, byte [] qualifier,byte [] value)方法已经被废弃,改成使用addColumn。addColumn方法有以下的几种调用方式:我们用的是第1种方式。第2、3种方法增加了时间戳(ts)参数,你可以手动地定义时间戳作为版本号。如果你做的是一个网页抓取的引擎,那手动定义时间戳就很有用了,你可以把网页的抓取时间当作时间戳存起来。这样每一个单元格里面就存储了一个网页的历史记录。你会发现除了addColumn,HBase还多出了一个addImmutable方法。 查看全部
小码哥Flutter从入门到实战-大神精选(百度云 百度网盘)
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
官方建议大家先手动获取Connection,然后再从Connection中获取Table接口(注意:不是HTable类,而是Table接口):下面的方法都是Table接口提供的,具体的操作还是由HTable类实现的。首先是我们的put方法。4.3.2 put方法这个方法相当于增和改这两个操作。我们先构建一个Put对象出来,然后往这个对象里面添加这行需要的属性。我们很容易地可以联想到首当其冲的构造参数就是rowkey,所以最简单的Put构造函数就是:在HBase中有一个理念:所有数据皆为bytes。在HBase中数据最终都会被序列化为bytes[]保存,所以一切可以被序列化为bytes的对象都可以作为rowkey。最简单的将字符串转换为bytes[]的方法是使用Bytes提供的toBytes方法:Bytes是由HBase提供的用于将各种不同类型的数据格式转换为byte[]的工具类,然后我们设置这行数据的mycf列族的name列为jack:此时操作并没有执行下去,我们调用Table接口的put方法把数据真正保存起来:执行完后,我们用hbase shell来看下mytable这个表的数据:可以看到这条数据已经被保存到HBase中了,这就是最简单的新增语句。
那么修改呢?修改就是往同一个rowkey再执行一次put操作,将之前的数据覆盖掉。我们来做一下如何修改刚刚保存的这行数据。依然还是新建一个Put对象,用addColumn方法设置rowkey为row1,这回设置mycf:name为ted,然后保存:1.Put的构造函数Put最简单的构造方法是:Put的其他的构造方法:Put(ByteBuffer row)Put(Put putToCopy)Put(byte[] row, long ts)Put(ByteBuffer row, long ts)Put(byte[] rowArray, int rowOffset, int rowLength)Put(byte[] rowArray, int rowOffset, int rowLength, longts)2.addColumn和addImmutable的历史早期教程,提到的add(byte [] family, byte [] qualifier,byte [] value)方法已经被废弃,改成使用addColumn。addColumn方法有以下的几种调用方式:我们用的是第1种方式。第2、3种方法增加了时间戳(ts)参数,你可以手动地定义时间戳作为版本号。如果你做的是一个网页抓取的引擎,那手动定义时间戳就很有用了,你可以把网页的抓取时间当作时间戳存起来。这样每一个单元格里面就存储了一个网页的历史记录。你会发现除了addColumn,HBase还多出了一个addImmutable方法。
Stata爬虫:爬取地区宏观数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2022-04-30 12:22
邮箱:
目录
4. 补充方法
5. 相关推文
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:
1. 基本原理
网络爬虫就是自动抓取网页信息的代码,也可以简单理解成代替繁琐的复制粘贴操作的手段。如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物 (数据)。从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的 HTML 代码爬到本地,进而提取自己需要的数据,存放起来使用,即请求网站并提取数据的自动化程序。
2. 基本步骤
Stata 进行网页表格爬取分为 3 个步骤:
网页分析:获取项目的源代码;请求并读入:把含有所需数据的源代码下载下来,并导入 Stata;处理数据:主要是对字符串进行处理,常用操作有分割 split、转置 sxpose、提取 (正则表达式或直接字符串提取) 等。
3. 爬虫案例
本文以爬取「地区宏观数据」中 “重庆市国内生产总值指数” 的数据为例,讲解如何使用 Stata 进行网页表格数据爬取。
图 1:条件筛选3.1 网页分析
图 2:获取信息源
我们在其中能找到这样一个链接,通过复制粘贴到浏览器,可以发现该链接下存放的是数据。具体链接形式如下:
在上述链接中,参数 p = 2 就是关键,将 2 替换成其他页数,就能返回对应页的数据源代码。
3.2 请求数据
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br />
由于这个网页没有设置反爬机制,所以可以直接使用 copy 命令进行下载。在这里,我们运用循环语句 forvalue 对前 4 页表格的信息进行下载。
3.3 读入数据
第一步:合并所有 txt 文件。
第二步:txt 文档中插入转行。观察到 all.txt 中的内容并无转行,为了方便 Stata 处理数据,需插入转行。对比文档内容与表格内容后,选择在
前插入转行。具体实现步骤如下:
图 3:观察何处插入转行
第三步:all.txt 文件读入 Stata
infix strL v 1-20000 using "all.txt", clear<br />format v %500s<br />
利用 infix 读取数据,然后把变量 v 的显示格式变成 %500s (这样看起来更宽)。导入后的数据如下图所示:
图 4:数据的雏形
第四步:解决乱码问题
若数据导入 Stata 后,无法正常显示,即出现乱码问题。在这里,我们可用下面一行命令解决乱码问题。若文字显示正常,则不需运行以下命令。
replace v = ustrfrom(v, "gb18030", 1)<br />
3.4 处理数据
第一步:分析网页代码
*数据保留<br />keep if index(v,`""')<br />split v,p(`""' )<br />split v2 ,p(`""' )<br />split v25 ,p(`""' )<br />keep v21 v22 v23 v24 v251<br />
*变量重命名<br />rename v21 国内生产总值指数<br />rename v22 第一产业生产总值指数<br />rename v23 第二产业生产总值指数<br />rename v24 第三产业生产总值指数<br />rename v251 人均国内生产总值指数<br />
*输出文件<br />export excel using "地区宏观数据.xlsx", firstrow(var) replace<br />shellout using "地区宏观数据.xlsx"<br />
图 5:结果展示
4. 补充方法
以下方法不用借助任何第三方工具,完全依靠 Stata 完成,具体代码如下:
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br /><br />forvalues i = 1(1)4{<br /> infix strL v 1-20000 using "temp`i'.txt", clear<br /> format v %500s<br /> replace v = ustrfrom(v, "gb18030", 1)<br /> keep if index(v,`""')<br /> split v, p(`""' )<br /><br /> forvalues j = 1(1)20{ //20为新产生变量数<br /> insobs 20<br /> replace v = v`j'[1] in `j'<br /> }<br /><br /> keep v<br /> split v, p(`""' )<br /> split v2, p(`""' )<br /> split v25, p(`""' )<br /> keep v21 v22 v23 v24 v251<br /><br /> rename v21 国内生产总值指数<br /> rename v22 第一产业生产总值指数<br /> rename v23 第二产业生产总值指数<br /> rename v24 第三产业生产总值指数<br /> rename v251 人均国内生产总值指数<br /><br /> save "temp`i'.dta", replace<br />}<br /><br />use temp1.dta, clear<br />forvalues i = 2(1)4{<br /> append using temp`i'<br />}<br />drop if 国内生产总值指数 == ""<br />save 地区宏观数据.dta, replace <br /><br />forvalues i = 1(1)4{<br /> erase temp`i'.dta<br />}<br />
5. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 爬虫 正则 文本, m
安装最新版 lianxh 命令:
ssc install lianxh, replace
专题:Python-R-Matlab
课程推荐:因果推断实用计量方法
主讲老师:丘嘉平教授
课程主页:
New! Stata 搜索神器:lianxh 和 songbl
搜: 推文、数据分享、期刊论文、重现代码 ……
安装:
. ssc install lianxh
. ssc install songbl
使用:
. lianxh DID 倍分法
. songbl all
关于我们
查看全部
Stata爬虫:爬取地区宏观数据
邮箱:
目录
4. 补充方法
5. 相关推文
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:
1. 基本原理
网络爬虫就是自动抓取网页信息的代码,也可以简单理解成代替繁琐的复制粘贴操作的手段。如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物 (数据)。从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的 HTML 代码爬到本地,进而提取自己需要的数据,存放起来使用,即请求网站并提取数据的自动化程序。
2. 基本步骤
Stata 进行网页表格爬取分为 3 个步骤:
网页分析:获取项目的源代码;请求并读入:把含有所需数据的源代码下载下来,并导入 Stata;处理数据:主要是对字符串进行处理,常用操作有分割 split、转置 sxpose、提取 (正则表达式或直接字符串提取) 等。
3. 爬虫案例
本文以爬取「地区宏观数据」中 “重庆市国内生产总值指数” 的数据为例,讲解如何使用 Stata 进行网页表格数据爬取。
图 1:条件筛选3.1 网页分析
图 2:获取信息源
我们在其中能找到这样一个链接,通过复制粘贴到浏览器,可以发现该链接下存放的是数据。具体链接形式如下:
在上述链接中,参数 p = 2 就是关键,将 2 替换成其他页数,就能返回对应页的数据源代码。
3.2 请求数据
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br />
由于这个网页没有设置反爬机制,所以可以直接使用 copy 命令进行下载。在这里,我们运用循环语句 forvalue 对前 4 页表格的信息进行下载。
3.3 读入数据
第一步:合并所有 txt 文件。
第二步:txt 文档中插入转行。观察到 all.txt 中的内容并无转行,为了方便 Stata 处理数据,需插入转行。对比文档内容与表格内容后,选择在
前插入转行。具体实现步骤如下:
图 3:观察何处插入转行
第三步:all.txt 文件读入 Stata
infix strL v 1-20000 using "all.txt", clear<br />format v %500s<br />
利用 infix 读取数据,然后把变量 v 的显示格式变成 %500s (这样看起来更宽)。导入后的数据如下图所示:
图 4:数据的雏形
第四步:解决乱码问题
若数据导入 Stata 后,无法正常显示,即出现乱码问题。在这里,我们可用下面一行命令解决乱码问题。若文字显示正常,则不需运行以下命令。
replace v = ustrfrom(v, "gb18030", 1)<br />
3.4 处理数据
第一步:分析网页代码
*数据保留<br />keep if index(v,`""')<br />split v,p(`""' )<br />split v2 ,p(`""' )<br />split v25 ,p(`""' )<br />keep v21 v22 v23 v24 v251<br />
*变量重命名<br />rename v21 国内生产总值指数<br />rename v22 第一产业生产总值指数<br />rename v23 第二产业生产总值指数<br />rename v24 第三产业生产总值指数<br />rename v251 人均国内生产总值指数<br />
*输出文件<br />export excel using "地区宏观数据.xlsx", firstrow(var) replace<br />shellout using "地区宏观数据.xlsx"<br />
图 5:结果展示
4. 补充方法
以下方法不用借助任何第三方工具,完全依靠 Stata 完成,具体代码如下:
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br /><br />forvalues i = 1(1)4{<br /> infix strL v 1-20000 using "temp`i'.txt", clear<br /> format v %500s<br /> replace v = ustrfrom(v, "gb18030", 1)<br /> keep if index(v,`""')<br /> split v, p(`""' )<br /><br /> forvalues j = 1(1)20{ //20为新产生变量数<br /> insobs 20<br /> replace v = v`j'[1] in `j'<br /> }<br /><br /> keep v<br /> split v, p(`""' )<br /> split v2, p(`""' )<br /> split v25, p(`""' )<br /> keep v21 v22 v23 v24 v251<br /><br /> rename v21 国内生产总值指数<br /> rename v22 第一产业生产总值指数<br /> rename v23 第二产业生产总值指数<br /> rename v24 第三产业生产总值指数<br /> rename v251 人均国内生产总值指数<br /><br /> save "temp`i'.dta", replace<br />}<br /><br />use temp1.dta, clear<br />forvalues i = 2(1)4{<br /> append using temp`i'<br />}<br />drop if 国内生产总值指数 == ""<br />save 地区宏观数据.dta, replace <br /><br />forvalues i = 1(1)4{<br /> erase temp`i'.dta<br />}<br />
5. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 爬虫 正则 文本, m
安装最新版 lianxh 命令:
ssc install lianxh, replace
专题:Python-R-Matlab
课程推荐:因果推断实用计量方法
主讲老师:丘嘉平教授
课程主页:
New! Stata 搜索神器:lianxh 和 songbl
搜: 推文、数据分享、期刊论文、重现代码 ……
安装:
. ssc install lianxh
. ssc install songbl
使用:
. lianxh DID 倍分法
. songbl all
关于我们
网页表格抓取 IE抓取资金主力流入的股票
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-30 12:14
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。 查看全部
网页表格抓取 IE抓取资金主力流入的股票
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。
在不影响SEO的前提下,如何重新设计网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-30 07:38
网站所有者中最大的误解之一是SEO只需要执行一次,不幸的是,事实并非如此。
在重新设计期间,许多部分都会更改,包括代码和页面。如果处理不当,可能会对网站的SEO产生负面影响,并影响网站的长期发展。但是,如果操作正确,重新设计网站也可以提高您的SEO实力。
步骤1:列出旧网站中的所有页面
第一步是下载网站的URL结构。重新设计意味着很多更改,这些更改也将影响URL的重组。因此,重要的是进行备份,否则会冒着影响网站排名的风险。
步骤2:重新设计需要在一个临时URL上进行
切勿在现有网站上进行重新设计。从长远来看,它可能会导致访客问题,并给您带来麻烦。最好的方法是复制您的网站并将其设置为临时URL。完成后;您可以开始对其进行更改。另一种选择是一旦完成所有必需的重新设计更改,便切换域。
如果您有可能为此感到挣扎,则始终可以从开发人员那里获得帮助。另一种选择是托管公司为您做。对您的主机提供商进行ping操作非常重要,因为此步骤将保护您免受将来的意外问题。
步骤3:测试新网站
太好了,您将现有网站复制到了新网站中。
但是,在开始重新设计项目之前,最好对网站进行端到端检查。在此检查中,您应该查看网站的多个方面,包括断开的链接,功能,CSS等。
您还可以使用XENU,这是一种免费工具,可以在您的网站上找到所有损坏的链接。
步骤4:执行适当的301重定向
下一步是在新旧网址之间进行301重定向。例如,如果您在旧网站上有一个“关于我们”页面,并且其URL是“”。
如果在重新设计期间,您的设计师将URL更改为“”,则最好实施适当的301重定向,以确保两个URL都能正常工作,并且您不会失去从您的SEO中获得的收益先前的网址。
如果操作不正确,搜索引擎将显示404个未找到的网页。通过执行301重定向,旧的URL将被重定向到新的URL。这是告诉搜索引擎网址已更改的技术方法,搜索引擎不会降权排名。
您可以使用.htaccess文件添加重定向,如下代码:
重定向301//new-url
如果您感到困惑并且不知道如何在WordPress上手动进行操作,则还可以尝试使用重定向插件,通过填写表格来进行操作。
注意:此步骤非常重要,无论如何都应这样做。
步骤5:跳转到新网站
设计和重定向完成所有工作后,就该切换到新网站了。如果您的网站很大,也可以分阶段进行增量更改。
步骤6:运行搜索引擎网站站长工具
下一步是确保到目前为止一切都成功。
为此,您可以利用搜索引擎网站站长之类的工具。该工具将使您检查是否有断开的链接。如果发现任何损坏的链接,为避免罚款,建议尽快将其修复。
步骤7:检查验证状态并重新提交
开发人员或设计人员通常会停止搜索引擎来爬网网站。如果是这种情况,那么您将需要在网站上恢复抓取工具。要检查状态,您需要使用搜寻器下的“以搜索引擎身份提取”选项。完成后,单击“获取并渲染”选项。如果两个测试均得出肯定结果,则说明您的网站是完全可爬网的。
另外,建议检查重新设计的网站是否经过验证。为此,您可以登录Bing和搜索引擎提供的相应网站站长工具。如果缺少验证,请重做并声明您的网站。
最后,点击“提交索引”按钮,将您的网站URL重新提交到搜索引擎索引中。
步骤8:Robot.txt
在重新设计期间,robot.txt文件可能需要改动,要检查它是否具有,可以在爬网下使用“robot.txt”选项。
第9步:提交站点地图
由于您的网站现在具有新的和经过修改的结构,因此将网站XML提交给Bing和搜索引擎。提交后,您的新网站将在接下来的几个小时内被抓取。
步骤10:监控变更
最后,监视变化并寻找任何潜在的增长非常重要,至少需要检测网站数据两到三个月,同时密切关注热门关键字的排名。
如果网站排名出现了大幅度波动,请试着分析为什么会发生这种情况,并在网站访问量快速下降的情况下寻求解决方案。
v: 查看全部
在不影响SEO的前提下,如何重新设计网站
网站所有者中最大的误解之一是SEO只需要执行一次,不幸的是,事实并非如此。
在重新设计期间,许多部分都会更改,包括代码和页面。如果处理不当,可能会对网站的SEO产生负面影响,并影响网站的长期发展。但是,如果操作正确,重新设计网站也可以提高您的SEO实力。
步骤1:列出旧网站中的所有页面
第一步是下载网站的URL结构。重新设计意味着很多更改,这些更改也将影响URL的重组。因此,重要的是进行备份,否则会冒着影响网站排名的风险。
步骤2:重新设计需要在一个临时URL上进行
切勿在现有网站上进行重新设计。从长远来看,它可能会导致访客问题,并给您带来麻烦。最好的方法是复制您的网站并将其设置为临时URL。完成后;您可以开始对其进行更改。另一种选择是一旦完成所有必需的重新设计更改,便切换域。
如果您有可能为此感到挣扎,则始终可以从开发人员那里获得帮助。另一种选择是托管公司为您做。对您的主机提供商进行ping操作非常重要,因为此步骤将保护您免受将来的意外问题。
步骤3:测试新网站
太好了,您将现有网站复制到了新网站中。
但是,在开始重新设计项目之前,最好对网站进行端到端检查。在此检查中,您应该查看网站的多个方面,包括断开的链接,功能,CSS等。
您还可以使用XENU,这是一种免费工具,可以在您的网站上找到所有损坏的链接。
步骤4:执行适当的301重定向
下一步是在新旧网址之间进行301重定向。例如,如果您在旧网站上有一个“关于我们”页面,并且其URL是“”。
如果在重新设计期间,您的设计师将URL更改为“”,则最好实施适当的301重定向,以确保两个URL都能正常工作,并且您不会失去从您的SEO中获得的收益先前的网址。
如果操作不正确,搜索引擎将显示404个未找到的网页。通过执行301重定向,旧的URL将被重定向到新的URL。这是告诉搜索引擎网址已更改的技术方法,搜索引擎不会降权排名。
您可以使用.htaccess文件添加重定向,如下代码:
重定向301//new-url
如果您感到困惑并且不知道如何在WordPress上手动进行操作,则还可以尝试使用重定向插件,通过填写表格来进行操作。
注意:此步骤非常重要,无论如何都应这样做。
步骤5:跳转到新网站
设计和重定向完成所有工作后,就该切换到新网站了。如果您的网站很大,也可以分阶段进行增量更改。
步骤6:运行搜索引擎网站站长工具
下一步是确保到目前为止一切都成功。
为此,您可以利用搜索引擎网站站长之类的工具。该工具将使您检查是否有断开的链接。如果发现任何损坏的链接,为避免罚款,建议尽快将其修复。
步骤7:检查验证状态并重新提交
开发人员或设计人员通常会停止搜索引擎来爬网网站。如果是这种情况,那么您将需要在网站上恢复抓取工具。要检查状态,您需要使用搜寻器下的“以搜索引擎身份提取”选项。完成后,单击“获取并渲染”选项。如果两个测试均得出肯定结果,则说明您的网站是完全可爬网的。
另外,建议检查重新设计的网站是否经过验证。为此,您可以登录Bing和搜索引擎提供的相应网站站长工具。如果缺少验证,请重做并声明您的网站。
最后,点击“提交索引”按钮,将您的网站URL重新提交到搜索引擎索引中。
步骤8:Robot.txt
在重新设计期间,robot.txt文件可能需要改动,要检查它是否具有,可以在爬网下使用“robot.txt”选项。
第9步:提交站点地图
由于您的网站现在具有新的和经过修改的结构,因此将网站XML提交给Bing和搜索引擎。提交后,您的新网站将在接下来的几个小时内被抓取。
步骤10:监控变更
最后,监视变化并寻找任何潜在的增长非常重要,至少需要检测网站数据两到三个月,同时密切关注热门关键字的排名。
如果网站排名出现了大幅度波动,请试着分析为什么会发生这种情况,并在网站访问量快速下降的情况下寻求解决方案。
v:
网页表格抓取 Darkweb(暗网) OSINT 2022 年调查资源
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-04-29 23:23
2021 年底,暗网格局发生了巨大变化——V2 洋葱域名终于被弃用,导致许多旧网站无法访问。
Tor 项目最终取消了“根本不安全”的域,敦促所有者和用户迁移
当前版本的 Tor 浏览器不再支持旧的 16 个字符的字符串域名,而是支持更长的 56 个字符的域名。使用 Tor 浏览器的旧的、预更新版本仍然可以访问一些 V2 域——但是没有多大意义,因为普遍的共识是继续前进。
现在是更新暗网 OSINT 调查工具包并在其中包含一些当代 2022 材料的时候了。
明网资源
Ahmia – 【】最古老、最可靠的 .onion 搜索引擎之一,可从暗网和明网访问。
洋葱搜索引擎 —【】用于搜索洋葱网站。它带有适用于 Chrome 和 Firefox 的浏览器扩展。各种支持的搜索选项包括图像、视频、地图和粘贴。
Tor Taxi – 【】一个带有多个不同洋葱域链接的启动板网站。它有一个方便的颜色编码系统,用于显示当前关闭的网站。
Darkweb Wiki—【】 一个有点混乱且不经常更新的洋葱站点列表——仍然是一个有价值的资源。
Hunchly –【】 以电子表格的形式提供有关洋葱域上升/下降的每日暗网报告。
IACA Darkweb Tools –【】 国际反犯罪学院提供的免费资源。
Reddit 社区 ——可以找到许多专门针对暗网各个方面的 subreddit,其中一些很受欢迎。但是,有 3 个始终良好且最新:
Discord – 一个新兴的 Reddit 替代品,用于新兴的在线社区和利基主题,Discord 在某些方面已经占据主导地位。虽然我还没有找到值得推荐的公开频道,但您可以使用暗网关键字搜索 可用的 Discord 服务器【】
暗网资源
Ahmia – 如上所述,但专门针对 Tor:
Haystak – 自称为“暗网最大的搜索引擎”,拥有数以千计的索引 .onion 域名——包括一些历史域名。
Kilos – 暗网市场搜索引擎,允许搜索供应商、列表、评论、论坛和论坛帖子。对于跨多个暗网实体进行广泛的基于关键字的搜索很有用。
TOR66—— 在标准搜索之上,这使得“新鲜洋葱”和“随机洋葱”匹配;谨慎行事,这些可以将您带到一些真正随机的站点。
Github 工具
首先,Apurv Singh Gautam 提供的很棒的工具列表可以 在这里找到【】 (但需要注意的是,我还没有使用或测试过所有这些工具)。
Onioff–【】 用于搜索 .onion URL 的 Python 工具。
OnionIngestor—【】用于抓取和收集暗网情报——与 Kibana 仪表板配合使用。
Onion Search– 【】从暗网搜索引擎抓取 .onion URL 的工具。
The Devils Eye– 【】用于在不连接 Tor 的情况下提取 .onion 站点链接和描述。
TorBot –【】 洋葱爬虫,许多附加功能仍在积极开发中。 查看全部
网页表格抓取 Darkweb(暗网) OSINT 2022 年调查资源
2021 年底,暗网格局发生了巨大变化——V2 洋葱域名终于被弃用,导致许多旧网站无法访问。
Tor 项目最终取消了“根本不安全”的域,敦促所有者和用户迁移
当前版本的 Tor 浏览器不再支持旧的 16 个字符的字符串域名,而是支持更长的 56 个字符的域名。使用 Tor 浏览器的旧的、预更新版本仍然可以访问一些 V2 域——但是没有多大意义,因为普遍的共识是继续前进。
现在是更新暗网 OSINT 调查工具包并在其中包含一些当代 2022 材料的时候了。
明网资源
Ahmia – 【】最古老、最可靠的 .onion 搜索引擎之一,可从暗网和明网访问。
洋葱搜索引擎 —【】用于搜索洋葱网站。它带有适用于 Chrome 和 Firefox 的浏览器扩展。各种支持的搜索选项包括图像、视频、地图和粘贴。
Tor Taxi – 【】一个带有多个不同洋葱域链接的启动板网站。它有一个方便的颜色编码系统,用于显示当前关闭的网站。
Darkweb Wiki—【】 一个有点混乱且不经常更新的洋葱站点列表——仍然是一个有价值的资源。
Hunchly –【】 以电子表格的形式提供有关洋葱域上升/下降的每日暗网报告。
IACA Darkweb Tools –【】 国际反犯罪学院提供的免费资源。
Reddit 社区 ——可以找到许多专门针对暗网各个方面的 subreddit,其中一些很受欢迎。但是,有 3 个始终良好且最新:
Discord – 一个新兴的 Reddit 替代品,用于新兴的在线社区和利基主题,Discord 在某些方面已经占据主导地位。虽然我还没有找到值得推荐的公开频道,但您可以使用暗网关键字搜索 可用的 Discord 服务器【】
暗网资源
Ahmia – 如上所述,但专门针对 Tor:
Haystak – 自称为“暗网最大的搜索引擎”,拥有数以千计的索引 .onion 域名——包括一些历史域名。
Kilos – 暗网市场搜索引擎,允许搜索供应商、列表、评论、论坛和论坛帖子。对于跨多个暗网实体进行广泛的基于关键字的搜索很有用。
TOR66—— 在标准搜索之上,这使得“新鲜洋葱”和“随机洋葱”匹配;谨慎行事,这些可以将您带到一些真正随机的站点。
Github 工具
首先,Apurv Singh Gautam 提供的很棒的工具列表可以 在这里找到【】 (但需要注意的是,我还没有使用或测试过所有这些工具)。
Onioff–【】 用于搜索 .onion URL 的 Python 工具。
OnionIngestor—【】用于抓取和收集暗网情报——与 Kibana 仪表板配合使用。
Onion Search– 【】从暗网搜索引擎抓取 .onion URL 的工具。
The Devils Eye– 【】用于在不连接 Tor 的情况下提取 .onion 站点链接和描述。
TorBot –【】 洋葱爬虫,许多附加功能仍在积极开发中。
网页表格抓取(我正在学习Python,尝试创建一个抓取多个页面的函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-19 21:11
)
我正在学习 Python,我正在尝试创建一个函数来从几个不同的网页获取疫苗接种率的网络抓取表 - 我们的数据和世界的 github 存储库。当网络抓取单个表和将其保存到数据框。
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://github.com/owid/covid- ... ot%3B
response = requests.get(url)
response
scraping_html_table_BD = BeautifulSoup(response.content, "lxml")
scraping_html_table_BD = scraping_html_table_BD.find_all("table", "js-csv-data csv-data js-file-line-container")
df = pd.read_html(str(scraping_html_table_BD))
BD_df = df[0]
但是,当我尝试创建一个抓取多个页面的函数时,我运气不佳。我一直在关注这个 网站 的教程、“使用一个脚本抓取多个页面”部分中的 3 以及第 4 和第 5 页上的 StackOverflow 问题。我首先尝试创建一个全局变量,但最终出现错误比如“递归错误:调用 Python 对象时超出了最大递归深度”。这是我管理过的最好的代码,因为它不会产生错误,但我还没有设法将输出保存到全局变量中。我真的很感谢你的帮助。
import pandas as pd
from bs4 import BeautifulSoup
import requests
link_list = ['/Bangladesh.csv',
'/Nepal.csv',
'/Mongolia.csv']
def get_info(page_url):
page = requests.get('https://github.com/owid/covid- ... 27%3B + page_url)
scape = BeautifulSoup(page.text, 'html.parser')
vaccination_rates = scape.find_all("table", "js-csv-data csv-data js-file-line-container")
result = {}
df = pd.read_html(str(vaccination_rates))
vaccination_rates = df[0]
df = pd.DataFrame(vaccination_rates)
print(df)
df.to_csv("testdata.csv", index=False)
for link in link_list:
get_info(link)
编辑:保存到 csv 文件时,我可以查看最终的网页迭代,但不能查看上一个链接中的数据。
new = pd.read_csv('testdata6.csv')
pd.set_option("display.max_rows", None, "display.max_columns", None)
new 查看全部
网页表格抓取(我正在学习Python,尝试创建一个抓取多个页面的函数
)
我正在学习 Python,我正在尝试创建一个函数来从几个不同的网页获取疫苗接种率的网络抓取表 - 我们的数据和世界的 github 存储库。当网络抓取单个表和将其保存到数据框。
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://github.com/owid/covid- ... ot%3B
response = requests.get(url)
response
scraping_html_table_BD = BeautifulSoup(response.content, "lxml")
scraping_html_table_BD = scraping_html_table_BD.find_all("table", "js-csv-data csv-data js-file-line-container")
df = pd.read_html(str(scraping_html_table_BD))
BD_df = df[0]
但是,当我尝试创建一个抓取多个页面的函数时,我运气不佳。我一直在关注这个 网站 的教程、“使用一个脚本抓取多个页面”部分中的 3 以及第 4 和第 5 页上的 StackOverflow 问题。我首先尝试创建一个全局变量,但最终出现错误比如“递归错误:调用 Python 对象时超出了最大递归深度”。这是我管理过的最好的代码,因为它不会产生错误,但我还没有设法将输出保存到全局变量中。我真的很感谢你的帮助。
import pandas as pd
from bs4 import BeautifulSoup
import requests
link_list = ['/Bangladesh.csv',
'/Nepal.csv',
'/Mongolia.csv']
def get_info(page_url):
page = requests.get('https://github.com/owid/covid- ... 27%3B + page_url)
scape = BeautifulSoup(page.text, 'html.parser')
vaccination_rates = scape.find_all("table", "js-csv-data csv-data js-file-line-container")
result = {}
df = pd.read_html(str(vaccination_rates))
vaccination_rates = df[0]
df = pd.DataFrame(vaccination_rates)
print(df)
df.to_csv("testdata.csv", index=False)
for link in link_list:
get_info(link)
编辑:保存到 csv 文件时,我可以查看最终的网页迭代,但不能查看上一个链接中的数据。
new = pd.read_csv('testdata6.csv')
pd.set_option("display.max_rows", None, "display.max_columns", None)
new
网页表格抓取( 会计从业资格考试:url数据如何提取数据?解决方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-19 21:10
会计从业资格考试:url数据如何提取数据?解决方法
)
如何在html页面中提取数据表中的数据内容?
请求的 url 数据
对了,我只抓一张表,希望能提取出关键表的数据。
我要捕获的数据是交易报告,但是HTML标签都是
造成了数据提取的困难。
賣空成交量 成交量</p>
代码 股票名称 股数 (SH) 金额 ($) 股数 (SH) 金额 ($)
1 長和 299,500 27,572,475 2,201,171 202,964,029
2 中電控股 61,000 4,622,825 1,452,853 110,040,699
3 香港中華煤氣 2,939,000 42,694,880 8,024,558 116,691,466
4 九龍倉集團 297,000 17,349,550 3,136,238 183,105,286
5 匯豐控股 1,102,800 73,202,940 8,630,868 572,622,103
6 電能實業 1,016,500 76,262,725 4,876,990 365,926,231
8 電訊盈科 731,000 3,478,240 13,579,323 64,672,175
10 恒隆集團 172,000 5,209,850 967,980 29,308,292
11 恒生銀行 189,000 30,047,370 1,075,185 170,873,130
12 恒基地產 94,000 4,025,500 1,382,533 59,183,598
14 希慎興業 33,000 1,167,900 642,424 22,747,393
16 新鴻基地產 425,000 45,490,800 1,635,959 175,284,039
17 新世界發展 651,000 5,833,670 10,135,381 90,633,244
19 太古股份公司A 132,000 10,405,600 554,962 43,709,235
20 會德豐 72,000 3,407,750 683,368 32,286,993
23 東亞銀行 451,600 14,991,890 1,817,000 60,295,348
27 銀河娛樂 1,134,000 40,408,550 15,089,117 538,712,668
31 航天控股 210,000 211,580 4,367,526 4,386,198
34 九龍建業 31,000 228,260 292,000 2,156,291
35 遠東發展 10,000 33,600 428,075 1,440,321
38 第一拖拉機股份 8,000 38,200 1,634,000 7,825,940
41 鷹君 12,000 422,400 470,146 16,546,562
45 大酒店 35,500 305,605 503,559 4,335,522
url = "http://www.hkex.com.hk/chi/sta ... ot%3B
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
应该如何提取表格的数据内容。
用beautifulsoup怎么这么麻烦,用刀杀鸡
你的网页只有一行数据,格式再简单不过了
可以直接复制页面上的数据,保存为txt,然后用readline、split、正则表达式提取数据,对吧?
解决方案一:
先定位卖空量的位置a=soup.find('a',attrs={'name':'short_ sell'}),然后根据pre->font的相邻关系,一路往下走直到没有列出 6 行结束
结果如下:
[['代號', '股票名稱', '股數(SH)', '金額($)', '股數(SH)', '金額($)'],
['1', '長和', '299,500', '27,572,475', '2,201,171', '202,964,029'],
['2', '中電控股', '61,000', '4,622,825', '1,452,853', '110,040,699'],
['3', '香港中華煤氣', '2,939,000', '42,694,880', '8,024,558', '116,691,466'],
....
源代码
import pprint
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.hkex.com.hk/chi/stat/smstat/dayquot/d170202c.htm')
r.encoding = 'big5'
soup = BeautifulSoup(r.text)
a = soup.find('a', attrs={'name':'short_selling'})
data = []
pre = a.find_parent('pre')
for line in pre.font.text.splitlines():
item = line.strip().split()
if len(item) == 6:
data.append(item)
end = False
for next_pre in pre.next_siblings:
for line in next_pre.font.text.splitlines():
item = line.strip().split()
if len(item) > 7:
item = item[1:2] + ["".join(item[1:-4])] + item[-4:]
elif len(item) < 6:
end = True
break
data.append(item)
if end:
break
pprint.pprint(data)
让我给你一个计划。
因为这些数据都是文本信息,没有标签包围。通过抓包,也没有发现特定的数据查询接口。所以数据应该是服务器生成好的通过html写死的发送给浏览器。
那么发现这些数据项每一个特定的属性都是占用同样的位置大小且居右对齐,而且每一项有特定的格式,可以使用正则表达式进行提取。
具体还是请您自行实现吧。 查看全部
网页表格抓取(
会计从业资格考试:url数据如何提取数据?解决方法
)
如何在html页面中提取数据表中的数据内容?
请求的 url 数据
对了,我只抓一张表,希望能提取出关键表的数据。
我要捕获的数据是交易报告,但是HTML标签都是
造成了数据提取的困难。
賣空成交量 成交量</p>
代码 股票名称 股数 (SH) 金额 ($) 股数 (SH) 金额 ($)
1 長和 299,500 27,572,475 2,201,171 202,964,029
2 中電控股 61,000 4,622,825 1,452,853 110,040,699
3 香港中華煤氣 2,939,000 42,694,880 8,024,558 116,691,466
4 九龍倉集團 297,000 17,349,550 3,136,238 183,105,286
5 匯豐控股 1,102,800 73,202,940 8,630,868 572,622,103
6 電能實業 1,016,500 76,262,725 4,876,990 365,926,231
8 電訊盈科 731,000 3,478,240 13,579,323 64,672,175
10 恒隆集團 172,000 5,209,850 967,980 29,308,292
11 恒生銀行 189,000 30,047,370 1,075,185 170,873,130
12 恒基地產 94,000 4,025,500 1,382,533 59,183,598
14 希慎興業 33,000 1,167,900 642,424 22,747,393
16 新鴻基地產 425,000 45,490,800 1,635,959 175,284,039
17 新世界發展 651,000 5,833,670 10,135,381 90,633,244
19 太古股份公司A 132,000 10,405,600 554,962 43,709,235
20 會德豐 72,000 3,407,750 683,368 32,286,993
23 東亞銀行 451,600 14,991,890 1,817,000 60,295,348
27 銀河娛樂 1,134,000 40,408,550 15,089,117 538,712,668
31 航天控股 210,000 211,580 4,367,526 4,386,198
34 九龍建業 31,000 228,260 292,000 2,156,291
35 遠東發展 10,000 33,600 428,075 1,440,321
38 第一拖拉機股份 8,000 38,200 1,634,000 7,825,940
41 鷹君 12,000 422,400 470,146 16,546,562
45 大酒店 35,500 305,605 503,559 4,335,522
url = "http://www.hkex.com.hk/chi/sta ... ot%3B
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
应该如何提取表格的数据内容。
用beautifulsoup怎么这么麻烦,用刀杀鸡
你的网页只有一行数据,格式再简单不过了
可以直接复制页面上的数据,保存为txt,然后用readline、split、正则表达式提取数据,对吧?
解决方案一:
先定位卖空量的位置a=soup.find('a',attrs={'name':'short_ sell'}),然后根据pre->font的相邻关系,一路往下走直到没有列出 6 行结束
结果如下:
[['代號', '股票名稱', '股數(SH)', '金額($)', '股數(SH)', '金額($)'],
['1', '長和', '299,500', '27,572,475', '2,201,171', '202,964,029'],
['2', '中電控股', '61,000', '4,622,825', '1,452,853', '110,040,699'],
['3', '香港中華煤氣', '2,939,000', '42,694,880', '8,024,558', '116,691,466'],
....
源代码
import pprint
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.hkex.com.hk/chi/stat/smstat/dayquot/d170202c.htm')
r.encoding = 'big5'
soup = BeautifulSoup(r.text)
a = soup.find('a', attrs={'name':'short_selling'})
data = []
pre = a.find_parent('pre')
for line in pre.font.text.splitlines():
item = line.strip().split()
if len(item) == 6:
data.append(item)
end = False
for next_pre in pre.next_siblings:
for line in next_pre.font.text.splitlines():
item = line.strip().split()
if len(item) > 7:
item = item[1:2] + ["".join(item[1:-4])] + item[-4:]
elif len(item) < 6:
end = True
break
data.append(item)
if end:
break
pprint.pprint(data)
让我给你一个计划。
因为这些数据都是文本信息,没有标签包围。通过抓包,也没有发现特定的数据查询接口。所以数据应该是服务器生成好的通过html写死的发送给浏览器。
那么发现这些数据项每一个特定的属性都是占用同样的位置大小且居右对齐,而且每一项有特定的格式,可以使用正则表达式进行提取。
具体还是请您自行实现吧。
网页表格抓取(一下excel文件网页数据的过程,实验环境win7+office2013)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-12 10:09
当然可以,但是使用起来不是很灵活,也不需要等待语言去抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个用于网页数据抓取的excel文件,双击打开文件,选择“数据”-“来自网络”,如下:
2.在弹出的子窗口中,输入要爬取的网页数据。这里使用“Import”进行捕获,如下:
3.导入成功后,抓取网页数据。数据如下,我们需要的数据已经成功抓取到:
4.如果要定时刷新数据,如果要爬取网页数据,可以点击“全部刷新”-“连接属性”自定义刷新频率。默认值为 60 分钟:
在弹出的“选择属性”窗口中抓取网页数据,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的网页数据抓取。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。 查看全部
网页表格抓取(一下excel文件网页数据的过程,实验环境win7+office2013)
当然可以,但是使用起来不是很灵活,也不需要等待语言去抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个用于网页数据抓取的excel文件,双击打开文件,选择“数据”-“来自网络”,如下:
2.在弹出的子窗口中,输入要爬取的网页数据。这里使用“Import”进行捕获,如下:
3.导入成功后,抓取网页数据。数据如下,我们需要的数据已经成功抓取到:

4.如果要定时刷新数据,如果要爬取网页数据,可以点击“全部刷新”-“连接属性”自定义刷新频率。默认值为 60 分钟:
在弹出的“选择属性”窗口中抓取网页数据,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的网页数据抓取。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。
网页表格抓取(我真的很努力尝试提取网络表的一些数据。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-11 11:37
我真的很难从网表中提取一些数据。我过去曾抓取过网络数据,但从未从表格中抓取过,所以我无法计算出来
我尝试了几种变体,但似乎没有任何效果,我已经多次更改类和子节点编号以反映每个项目,但我无法从表中得到任何东西
问)任何人都可以就表类以及如何从中提取提出建议吗?时间
我在这个论坛和其他论坛上阅读了几篇关于刮掉桌子的帖子,但没有任何帮助,因此这篇帖子
''''Data 1
On Error Resume Next
If doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0) Is Nothing Then
wsSheet.Cells(StartRow + myCounter, 1).Value = "-"
Else
On Error Resume Next
wsSheet.Cells(StartRow + myCounter, 1).Value = doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0).innerText
End If
我尝试了以下变体
doc.getElementsByClassName("content")(0)
doc.getElementsByClassName("content")(0)).Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("th").getElementsByTagName("td").Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0)
这是 html 的图像,我正在尝试输入 html 代码但无法让它看起来正确
一如既往地提前感谢 查看全部
网页表格抓取(我真的很努力尝试提取网络表的一些数据。。)
我真的很难从网表中提取一些数据。我过去曾抓取过网络数据,但从未从表格中抓取过,所以我无法计算出来
我尝试了几种变体,但似乎没有任何效果,我已经多次更改类和子节点编号以反映每个项目,但我无法从表中得到任何东西
问)任何人都可以就表类以及如何从中提取提出建议吗?时间
我在这个论坛和其他论坛上阅读了几篇关于刮掉桌子的帖子,但没有任何帮助,因此这篇帖子
''''Data 1
On Error Resume Next
If doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0) Is Nothing Then
wsSheet.Cells(StartRow + myCounter, 1).Value = "-"
Else
On Error Resume Next
wsSheet.Cells(StartRow + myCounter, 1).Value = doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0).innerText
End If
我尝试了以下变体
doc.getElementsByClassName("content")(0)
doc.getElementsByClassName("content")(0)).Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("th").getElementsByTagName("td").Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0)
这是 html 的图像,我正在尝试输入 html 代码但无法让它看起来正确

一如既往地提前感谢
网页表格抓取(RPA和爬虫有什么区别?转型进程中的闪耀之星)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-08 05:26
刚刚过去的2019年,是数字化转型过程中极为重要的一年。企业开始走上转型之路,各种技术的应用案例层出不穷。RPA 无疑是这波变革中的一颗闪亮之星。随着越来越多的企业关注RPA,一些问题也随之而来。
有人会直接问我们RPA和爬虫有什么区别。
毫不奇怪,每个人都将 RPA 与爬虫联系在一起。当使用RPA展示功能时,通常可以方便的设置一个RPA采集a网站具体信息的自动化工作流,并生成一个表格来演示数据排序的自动化。快速高效。这项工作看起来与爬虫的应用非常相似,但原理完全不同,只是RPA应用的冰山一角。
如果要回答RPA和爬虫有什么区别,简直就是“天地之别”。接下来,让我们仔细看看它们的区别。
定义
RPA的全称是Robotic Process Automation,即机器过程自动化。通过模仿人类的方式在计算机上进行一系列操作,可以实现在计算机上的所有人类操作行为,如复制、粘贴、数据录入、网页导航、打开、关闭等,并且可以重复按照一定的规律连续运行。
爬虫正式名称为data采集,一般称为spider,通过编程实现,可以自动采集从网上获取数据。获取数据的速度有时非常巨大,甚至可以达到数千万条数据。
使用技术
RPA属于AI人工智能的范畴,RPA通过设计过程模拟人类动作来执行任务。
爬虫使用Python开发脚本,通过发送http请求获取cookie或直接注入网页中获取数据。
适合现场
RPA可以应用于企业的各个部门。可广泛用于财务、人事、供应链、客户、销售和营销,以减少人工重复操作。具体操作层面,可以打开邮件、下载附件、登录网站和系统、读取数据库、移动文件和文件夹、复制粘贴、写入表格数据、网页数据抓取、文档数据抓取,连接系统API,进行if和else判断,进行计算等。
通过模仿一系列人类动作,RPA可以完成多种业务场景。它可以帮助财务部处理发票,帮助项目部审查合同,帮助HR处理新员工入职,并集成到整个供应链系统中,实现订单管理的自动化。也可以是24小时在线客服。
在日常工作中,它可以帮助员工自动采集数据、组织表格,甚至处理电子邮件。总之,企业中重复性和低价值的工作可以交给它,效率会大大提高,人力资源可以转移到更高价值的工作和决策上。借助RPA,企业的生产力将实现爆发式增长,从而可以创造更大的效益。
爬虫主要用于大数据采集,工作场景的局限性非常明显。如果使用不当,甚至适得其反,会给企业带来巨大的法律风险。
原理区别
RPA 像人一样工作,在系统 UI 上像人一样操作,点击鼠标、复制粘贴、打开文件或执行数据 采集 等等。因为它的核心是一个“模拟人”,所以它对系统施加的压力就如同一个人对系统的正常操作一样,没有多余的负载。可以说不会对系统造成任何影响。
爬虫通常使用python语言编写脚本直接操作HTML,可以非常灵活和精致(用正则表达式几乎无所不能)。在应用中主要扮演数据采集的角色,通过接口或者暴力破解的方式解析网页内容获取数据,采集效率高,会给后台造成巨大的负担,因此将被反爬虫机制禁止。
遵守
RPA已在银行、证券、保险、央企、国企、世界500强等各个领域投入使用。甚至国内外政府机构都在使用RPA软件机器人实现“智慧城市”的美好想象”。RPA属于人工智能智能的范畴,符合全球人工智能技术的发展趋势。各国都在鼓励使用RPA帮助企事业单位降本增效、改革升级。
爬虫的合规性视具体情况而定。由于多用于数据采集,爬虫所涉及的工作很容易侵犯个人隐私和企业数据安全,始终存在争议。使用不当会直接造成法律风险甚至严重的法律后果。
以上就是RPA和爬虫的区别,从中我们可以很明显的看出一个好的RPA产品比爬虫更智能、更通用、更安全、更高效、更商业化。显然,爬虫属于过去,而 RPA 创造未来。 查看全部
网页表格抓取(RPA和爬虫有什么区别?转型进程中的闪耀之星)
刚刚过去的2019年,是数字化转型过程中极为重要的一年。企业开始走上转型之路,各种技术的应用案例层出不穷。RPA 无疑是这波变革中的一颗闪亮之星。随着越来越多的企业关注RPA,一些问题也随之而来。
有人会直接问我们RPA和爬虫有什么区别。
毫不奇怪,每个人都将 RPA 与爬虫联系在一起。当使用RPA展示功能时,通常可以方便的设置一个RPA采集a网站具体信息的自动化工作流,并生成一个表格来演示数据排序的自动化。快速高效。这项工作看起来与爬虫的应用非常相似,但原理完全不同,只是RPA应用的冰山一角。
如果要回答RPA和爬虫有什么区别,简直就是“天地之别”。接下来,让我们仔细看看它们的区别。
定义
RPA的全称是Robotic Process Automation,即机器过程自动化。通过模仿人类的方式在计算机上进行一系列操作,可以实现在计算机上的所有人类操作行为,如复制、粘贴、数据录入、网页导航、打开、关闭等,并且可以重复按照一定的规律连续运行。
爬虫正式名称为data采集,一般称为spider,通过编程实现,可以自动采集从网上获取数据。获取数据的速度有时非常巨大,甚至可以达到数千万条数据。
使用技术
RPA属于AI人工智能的范畴,RPA通过设计过程模拟人类动作来执行任务。
爬虫使用Python开发脚本,通过发送http请求获取cookie或直接注入网页中获取数据。
适合现场
RPA可以应用于企业的各个部门。可广泛用于财务、人事、供应链、客户、销售和营销,以减少人工重复操作。具体操作层面,可以打开邮件、下载附件、登录网站和系统、读取数据库、移动文件和文件夹、复制粘贴、写入表格数据、网页数据抓取、文档数据抓取,连接系统API,进行if和else判断,进行计算等。
通过模仿一系列人类动作,RPA可以完成多种业务场景。它可以帮助财务部处理发票,帮助项目部审查合同,帮助HR处理新员工入职,并集成到整个供应链系统中,实现订单管理的自动化。也可以是24小时在线客服。
在日常工作中,它可以帮助员工自动采集数据、组织表格,甚至处理电子邮件。总之,企业中重复性和低价值的工作可以交给它,效率会大大提高,人力资源可以转移到更高价值的工作和决策上。借助RPA,企业的生产力将实现爆发式增长,从而可以创造更大的效益。
爬虫主要用于大数据采集,工作场景的局限性非常明显。如果使用不当,甚至适得其反,会给企业带来巨大的法律风险。
原理区别
RPA 像人一样工作,在系统 UI 上像人一样操作,点击鼠标、复制粘贴、打开文件或执行数据 采集 等等。因为它的核心是一个“模拟人”,所以它对系统施加的压力就如同一个人对系统的正常操作一样,没有多余的负载。可以说不会对系统造成任何影响。
爬虫通常使用python语言编写脚本直接操作HTML,可以非常灵活和精致(用正则表达式几乎无所不能)。在应用中主要扮演数据采集的角色,通过接口或者暴力破解的方式解析网页内容获取数据,采集效率高,会给后台造成巨大的负担,因此将被反爬虫机制禁止。
遵守
RPA已在银行、证券、保险、央企、国企、世界500强等各个领域投入使用。甚至国内外政府机构都在使用RPA软件机器人实现“智慧城市”的美好想象”。RPA属于人工智能智能的范畴,符合全球人工智能技术的发展趋势。各国都在鼓励使用RPA帮助企事业单位降本增效、改革升级。
爬虫的合规性视具体情况而定。由于多用于数据采集,爬虫所涉及的工作很容易侵犯个人隐私和企业数据安全,始终存在争议。使用不当会直接造成法律风险甚至严重的法律后果。
以上就是RPA和爬虫的区别,从中我们可以很明显的看出一个好的RPA产品比爬虫更智能、更通用、更安全、更高效、更商业化。显然,爬虫属于过去,而 RPA 创造未来。
网页表格抓取(尤利西斯伊斯兰教|我正在做以下页面的网络抓取工作:尤利西斯 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-05 08:06
)
尤利西斯人力资源
我正在对以下页面进行网络抓取:COVID,我需要做的是生成一个表格的 csv,该表格显示在页面上,但动态加载了我正在使用 selenium 的数据。问题是即使那样我也找不到收录以下代码的表格:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
#url of the page we want to scrape
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Firefox()
driver.get(url)
# this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
print(len(soup.find_all("table")))
driver.close()
driver.quit()
当我打印表单时,我得到 0,因为它找不到它。
萨姆苏尔伊斯兰教 |
我也在尝试使用数据提取并生成 csv 文件。希望对您有所帮助。
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import csv
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5) # delay for load properly
# # this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
table = soup.select_one('div.contenedor-general')
header = [[a.getText(strip=True,separator=' ')][0].split() for a in table.find_all('tr', {'class': 'header-table'})]
text1 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-1'})]
text2 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-2'})]
with open('outz.csv', 'w') as f:
wr = csv.writer(f, delimiter=',')
wr.writerow(header[0][1:])
for row in text1:
wr.writerow(row)
for row in text2:
wr.writerow(row) 查看全部
网页表格抓取(尤利西斯伊斯兰教|我正在做以下页面的网络抓取工作:尤利西斯
)
尤利西斯人力资源
我正在对以下页面进行网络抓取:COVID,我需要做的是生成一个表格的 csv,该表格显示在页面上,但动态加载了我正在使用 selenium 的数据。问题是即使那样我也找不到收录以下代码的表格:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
#url of the page we want to scrape
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Firefox()
driver.get(url)
# this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
print(len(soup.find_all("table")))
driver.close()
driver.quit()
当我打印表单时,我得到 0,因为它找不到它。
萨姆苏尔伊斯兰教 |
我也在尝试使用数据提取并生成 csv 文件。希望对您有所帮助。
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import csv
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5) # delay for load properly
# # this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
table = soup.select_one('div.contenedor-general')
header = [[a.getText(strip=True,separator=' ')][0].split() for a in table.find_all('tr', {'class': 'header-table'})]
text1 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-1'})]
text2 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-2'})]
with open('outz.csv', 'w') as f:
wr = csv.writer(f, delimiter=',')
wr.writerow(header[0][1:])
for row in text1:
wr.writerow(row)
for row in text2:
wr.writerow(row)
网页表格抓取(我正在尝试从上获取与梦幻足球运动员薪水相关的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-04 20:04
)
我正在尝试从 . 可以在此处找到我尝试采集数据的示例网页:. scsv 格式的数据可以方便地在每个页面上的 html“pre”标签下获得。我首先使用一个 for 循环来生成我想要从中刮取数据的所有 url,但随后我努力将这些页面中的所有数据转换为我想要的格式,一个收录所有刮取数据的最终数据表。我使用第二个 for 循环遍历所有 url,在每个页面上使用 read_html() 函数,然后使用 html_nodes('pre')%>%html_text() 提取感兴趣的数据。问题是,由于我的代码目前运行良好,这只是为收录整个 scsv 的每个页面创建一个大对象,而不是作为收录单个列(周、年、gid、名称、pos、团队、h/a、opt、dk 点数、dk 工资)。相反,我想要一个收录我要抓取的所有页面的这些单独列的数据表,但对网络抓取没有太多经验,也不知道如何解决这个问题。任何帮助将不胜感激。这是我到目前为止编写的代码:
<p>library(purrr)
library(rvest)
library(data.table)
library(stringr)
library(tidyr)
#Declare variables and empty data tables
path1 查看全部
网页表格抓取(我正在尝试从上获取与梦幻足球运动员薪水相关的数据
)
我正在尝试从 . 可以在此处找到我尝试采集数据的示例网页:. scsv 格式的数据可以方便地在每个页面上的 html“pre”标签下获得。我首先使用一个 for 循环来生成我想要从中刮取数据的所有 url,但随后我努力将这些页面中的所有数据转换为我想要的格式,一个收录所有刮取数据的最终数据表。我使用第二个 for 循环遍历所有 url,在每个页面上使用 read_html() 函数,然后使用 html_nodes('pre')%>%html_text() 提取感兴趣的数据。问题是,由于我的代码目前运行良好,这只是为收录整个 scsv 的每个页面创建一个大对象,而不是作为收录单个列(周、年、gid、名称、pos、团队、h/a、opt、dk 点数、dk 工资)。相反,我想要一个收录我要抓取的所有页面的这些单独列的数据表,但对网络抓取没有太多经验,也不知道如何解决这个问题。任何帮助将不胜感激。这是我到目前为止编写的代码:
<p>library(purrr)
library(rvest)
library(data.table)
library(stringr)
library(tidyr)
#Declare variables and empty data tables
path1
网页表格抓取( 如何用几行代码爬下所需数据?答案在这里!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-02 23:02
如何用几行代码爬下所需数据?答案在这里!)
众所周知,一般的爬虫套路无非就是构造请求、解析网页、提取元素、存储数据这几个步骤。requests 库主要用于构造请求,xpath、bs4、css、re 用于提取元素。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
那么,有没有什么办法只用几行代码就可以爬取所需的数据呢?答案是熊猫。自从J哥知道这件神器后,他尝试爬取了多个网页,并赢得了许多战斗。他再舒服不过了!这家伙也太适合初学者玩爬虫了!
本文目录如下:
定义
pandas 中的函数 pd.read_html() 非常强大,可以很方便的抓取表格数据。无需掌握正则表达式或xpath等工具,只需几行代码即可抓取网页数据。
原理表表格数据网页结构
pandas适合抓取表格数据,所以我们首先要知道什么样的网页有表格数据结构(有html基础的大佬可以自行跳过这部分)。
我们先来看一个简单的例子。(快捷键F12可以快速查看网页的HTML结构)
从上面网站可以看出,数据存放在一个table表中,thread是表头,tbody是表数据,tbody中的一个tr对应表中的一行,一个td对应到表中的一个元素。
让我们看另一个例子:
或许你找到规律了,Table结构中展示的表格数据,一般网页结构如下:
...
...
...
...
...
...
...
只要网页有以上结构,就可以尝试用pandas抓取数据。
pandas请求表数据流程
对于网页结构相似的表格数据,pd.read_html可以捕获网页上的所有表格数据,并以DataFrame的形式以列表的形式返回。
pd.read_html 语法和参数
基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
主要参数:
参数解释
io
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
跳过
跳过的行属性,例如 attrs = {'id': 'table'}
实战案例一:爬取世界大学排名(1页数据)
import pandas as pd
import csv
url1 = 'http://www.compassedu.hk/qs'
df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table
df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定了,我们来预览一下爬取的数据:
案例二:抓取新浪财经基金重仓股数据(6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = 'http://vip.stock.finance.sina. ... Fp%3D{page}'.format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print('第{page}页抓取完成'.format(page = i + 1))
df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码就搞定了,还是那么简单。不了解翻页爬虫的可以查看公众号历史“蔡J学Python”原创文章《实战|教你如何使用Python爬虫(附详细源代码)”,如果不能合并DataFrame可以理解,可以查看公众号历史原创文章《Basic|Pandas常用知识点总结(四)》)。
让我们预览爬取的数据:
案例3:抓取证监会披露的IPO数据(217页数据)
import pandas as pd
from pandas import DataFrame
import csv
import time
start = time.time() #程序计时
df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名
for i in range(1,218):
url3 ='http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)
df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名
df3 = pd.concat([df3,df3_2]) #数据合并
print('第{page}页抓取完成'.format(page=i))
df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件
end = time.time()
print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意过滤抓取到的Table数据,主要使用iloc方法。详情请参考公众号上一期原创文章《基础|Pandas常用知识点总结(三)》另外我还加了一个程序时序,就是方便查看爬行速度。
2分14秒爬下217页,4334条数据,相当不错。让我们预览爬取的数据:
需要注意的是,并不是所有的表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但是在网页的源码中,并不是表格格式,而是列表格式。这种形式不适合read_html爬取,必须使用selenium等其他方法。 查看全部
网页表格抓取(
如何用几行代码爬下所需数据?答案在这里!)

众所周知,一般的爬虫套路无非就是构造请求、解析网页、提取元素、存储数据这几个步骤。requests 库主要用于构造请求,xpath、bs4、css、re 用于提取元素。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
那么,有没有什么办法只用几行代码就可以爬取所需的数据呢?答案是熊猫。自从J哥知道这件神器后,他尝试爬取了多个网页,并赢得了许多战斗。他再舒服不过了!这家伙也太适合初学者玩爬虫了!
本文目录如下:

定义
pandas 中的函数 pd.read_html() 非常强大,可以很方便的抓取表格数据。无需掌握正则表达式或xpath等工具,只需几行代码即可抓取网页数据。
原理表表格数据网页结构
pandas适合抓取表格数据,所以我们首先要知道什么样的网页有表格数据结构(有html基础的大佬可以自行跳过这部分)。
我们先来看一个简单的例子。(快捷键F12可以快速查看网页的HTML结构)
从上面网站可以看出,数据存放在一个table表中,thread是表头,tbody是表数据,tbody中的一个tr对应表中的一行,一个td对应到表中的一个元素。
让我们看另一个例子:
或许你找到规律了,Table结构中展示的表格数据,一般网页结构如下:
...
...
...
...
...
...
...
只要网页有以上结构,就可以尝试用pandas抓取数据。
pandas请求表数据流程

对于网页结构相似的表格数据,pd.read_html可以捕获网页上的所有表格数据,并以DataFrame的形式以列表的形式返回。
pd.read_html 语法和参数
基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
主要参数:
参数解释
io
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
跳过
跳过的行属性,例如 attrs = {'id': 'table'}
实战案例一:爬取世界大学排名(1页数据)
import pandas as pd
import csv
url1 = 'http://www.compassedu.hk/qs'
df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table
df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定了,我们来预览一下爬取的数据:
案例二:抓取新浪财经基金重仓股数据(6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = 'http://vip.stock.finance.sina. ... Fp%3D{page}'.format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print('第{page}页抓取完成'.format(page = i + 1))
df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码就搞定了,还是那么简单。不了解翻页爬虫的可以查看公众号历史“蔡J学Python”原创文章《实战|教你如何使用Python爬虫(附详细源代码)”,如果不能合并DataFrame可以理解,可以查看公众号历史原创文章《Basic|Pandas常用知识点总结(四)》)。
让我们预览爬取的数据:
案例3:抓取证监会披露的IPO数据(217页数据)
import pandas as pd
from pandas import DataFrame
import csv
import time
start = time.time() #程序计时
df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名
for i in range(1,218):
url3 ='http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)
df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名
df3 = pd.concat([df3,df3_2]) #数据合并
print('第{page}页抓取完成'.format(page=i))
df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件
end = time.time()
print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意过滤抓取到的Table数据,主要使用iloc方法。详情请参考公众号上一期原创文章《基础|Pandas常用知识点总结(三)》另外我还加了一个程序时序,就是方便查看爬行速度。

2分14秒爬下217页,4334条数据,相当不错。让我们预览爬取的数据:
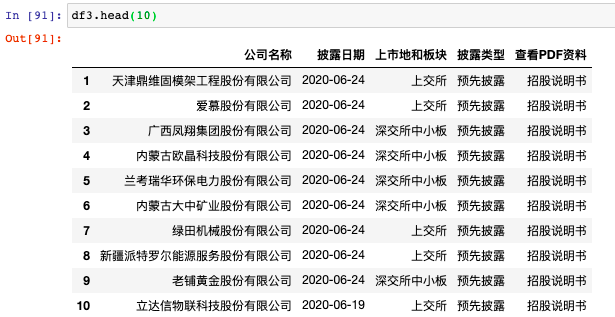
需要注意的是,并不是所有的表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但是在网页的源码中,并不是表格格式,而是列表格式。这种形式不适合read_html爬取,必须使用selenium等其他方法。
网页表格抓取(网站页面数据抓取插件允许我们将数据从网站抓取到本地 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-31 01:23
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。
查看全部
网页表格抓取(网站页面数据抓取插件允许我们将数据从网站抓取到本地
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。

使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。

一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。

视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。

二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。

三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。

1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。

5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。

网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。

运维的报表之路,用 node.js 轻松发送 grafana 报表
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-06-01 19:06
在运维过程中,无论是监控还是报表,都会有一些通过邮件发送图表的需求,由于开源的 zabbix,grafana 和 kibana 等并不完全具有“想发送哪儿就发送哪儿”的图片生成功能,在 grafana 中我们也考虑了一些其他方法,比如 grafana webdav 和 grafana-image-renderer 的方案,但并不能满足我们的需求。我们通过 nodejs 的模块 puppeteer + nodemailer 实现了grafana pannel 图表的邮件报表功能,基本满足了我们在自动化报表这块的需求。原理Puppeteer 是一个提供了高级 API ,通过DevTools Protocol(开发工具协议)控制headless chrome 或 chromium 的 Node.js 库,默认的运行模式是无头的,但是可以配置成非无头的模式。无头浏览器是一种没有操作界面的浏览器,诸如selenium、PhantomJS、Puppeteer 等,常用于网页自动化测试,利用其提供的API,可以自动执行操作指令,它是测试利器,也是爬虫神器 。Puppeteer 是其中比较优秀的一个。Puppeteer 通过程序化地操作浏览器,与其进行模拟交互(例如点击、打字、导航等等)来控制要抓取的网页,通常也能获取网页的 DOM 或 HTML,因此也可以获取网页数据,对于一些动态网站来说,像 grafana 图表,JS 动态渲染的数据通常不能轻松获取,而自动化测试工具Puppeteer则可以轻松的做到,因为它是将 HTML 输入浏览器里运行的。
如果大家对 DevTools Protocol(开发工具协议)感兴趣,可以参考:
准备环境环境版本
centos
7.6
node
14.3.0
cnpm
6.1.1
cd /optwget https://cdn.npm.taobao.org/dis ... xztar -xf node-v14.3.0-linux-x64.tar.xz<br />vi /etc/profile#set for nodejsexport NODE_HOME=/opt/node-v14.3.0-linux-x64export PATH=$NODE_HOME/bin:$PATH<br />source /etc/profile<br />npm config set registry=http://registry.npm.taobao.orgnpm install -g cnpm --registry=https://registry.npm.taobao.org<br /># 截图存放位置mkdir /tmp/png/<br /># 项目位置mkdir /opt/GrafanaSnapProjectcd /opt/GrafanaSnapProjectcnpm i --save puppeteercnpm i --save nodemailer
源码逻辑
为了使逻辑更清晰,我把发邮件和获取截图分成两个模块 mailPush.js 和 getPicture.js
发邮件模块 mailPush.js 这块需要注意为每一个附件添加一个引用名称,便于把截图引用到正文里。
在nodejs 里使用${str1}${str2} hello进行字符串拼接。
/*function: send pictures in mail's html content via nodejsauthor: zuoguocai@126.com<br />*/<br />const nodemailer = require('nodemailer');<br />//定义您的邮件推送服务器let transporter = nodemailer.createTransport({ // 您的邮箱服务器地址 host: 'mail.exchangehost.com', port: 587, secure: false, auth: { user: 'yourEmail', //您的邮箱的账号 pass: 'yourPassword'//您的邮箱的密码 }, tls: { rejectUnauthorized: false }, });<br />function sendMymail(who,subject,title){ let mailOptions = { from: '"autoreport" ', //邮件来源 to: who, //邮件发送到哪里,多个邮箱使用逗号隔开 subject: subject, // 邮件主题 html: `${title}
报表1
cid:001
报表2
cid:002`, // html类型的邮件正文 attachments: [{ filename: '001.png',//附件名称 path: '/tmp/png/001.png', //附件的位置 cid: '001', //为附件添加一个引用名称 },{ filename: '002.png',//附件名称 path: '/tmp/png/002.png', //附件的位置 cid: '002', //为附件添加一个引用名称 }] };<br /> transporter.sendMail(mailOptions, (error, info) => { if (error) { return console.log(error); } console.log('Message %s sent: %s', info.messageId, info.response); });}<br />//测试用//sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表')<br />// 自定义发邮件模块,供引入exports.sendMymail = sendMymail;<br />// 作为引入模块使用//const sendModule = require('./mailPush.js');//sendModule.sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表');
puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,很适合在Linux 字符终端使用,不需要在Linux 上安装桌面工具。但需要在 Linux 中安装中文字体,如仿宋字体,避免在截图中出现乱码。说到字体,中文字体其实有很多,比如方正的徐静蕾体,adoble 思源字体。字体大家可以从网络上下载,阿里免费的可商用普惠字体,下载链接
Linux 中安装中文字体
yum -y install fontconfigcd /usr/share/fontsmkdir chinesecd chinese/使用lrzsz 上传字体,如仿宋体chmod -R 775 /usr/share/fonts/chineseyum -y install ttmkfdirttmkfdir -e /usr/share/X11/fonts/encodings/encodings.dirvi /etc/fonts/fonts.conf/usr/local/share/fonts/chinese<br />fc-list :lang=zh/usr/share/fonts/bitmap/fangsongti24.pcf.gz: Fangsong ti:style=Regular/usr/share/fonts/chinese/simfang.ttf: FangSong_GB2312:style=Regular/usr/share/fonts/bitmap/fangsongti16.pcf.gz: Fangsong ti:style=Regular
getPicture.js 模块主要用来模拟登陆,模拟操作。这里需要对用户名和密码参数化,在写这块逻辑时大家可以参考网络上 puppeteer 文档和一些案例。定位按钮和点击按钮这块比较繁琐和复杂,大家可以借助工具 puppeteer recorder 插件来辅助生成代码。本机电脑 chrome 扩展程序里安装 puppeteer recorder 插件,这里我们主要通过使用chrome 插件 puppeteer recorder 对 grafana 前端 CSS 选择器定位,模拟点击,确定元素位置,生成一些辅助代码。使用习惯跟 JMeter,LoadRunner 很像。如图1
我们分析一下 grafana 某个 dashboard ,都是有好多 pannel 组成的,点击某个 pannel 的下拉菜单,点击 view 可以预览这个 pannel 的图表情况。这样我们就可以使用工具单独录制这段操作的代码,放到我们整个项目里。
如图2
/*function: snapshot grafana pannel pictures via puppeteerauthor: zuoguocai@126.com*/<br />// 发送函数function sendPicture(){ // 引入自定义发邮件模块 const sendModule = require('./mailPush.js'); // 同时发送到多个邮箱,用逗号隔开 sendModule.sendMymail('guocai.zuo@gmail.com,zuoguocai@126.com','每周报表','^_^ OpenStack 监控报表');}<br />// 截图函数function getPicture(){<br /> const puppeteer = require('puppeteer'); //模拟登陆,grafana 登陆的用户名和密码 const account = `zuoguocai`; const password = `xxxxxx`;<br /> (async () => { const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox']}); const page = await browser.newPage(); await page.setViewport({width:1827, height:979}); await page.goto('https://yourgrafana.com'); await page.type('input[type="text"]', account); await page.type('#inputPassword', password); await page.click('button[type="submit"]'); await page.waitForNavigation({ waitUntil: 'load' });<br /> //await page.waitFor(1000); // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.waitForSelector('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.click('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/001.png'});<br /> // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.waitForSelector('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.click('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/002.png'});<br /> await browser.close();<br /> //调用发送函数 await sendPicture();})();}<br />// 调用定位并截图函数getPicture()
源码地址:
测试发送效果
node getPicture.js
打开邮件客户端,查看是否收到邮件报表。
关于定时发送和 grafana 时间范围选取时间选取范围直接可以拼接到grafana的url里,这块比较简单。定时任务调度需要自己写,或者使用 gocron 的定时任务来做。gocron 项目地址:如图3
不止于此puppeteer 很强大,可以用于前端自动化测试,并且不局限于生成截图,还有pdf等,这里只是很小一部分内容,大家可以去探索,我这里只是一种思路,代码写的并不好,大家可以进行扩展,比如截取kibana等的图表,增加异常处理,对图片cid进行再次封装,放到对象存储里,工具集成到运维管理平台里,供业务相关方订阅。作者简介:左国才,VIPKID运维工程师,笔名icai,主要研究Linux操作系统,数据库,云计算领域相关技术, 热爱开源技术,平时喜欢阅读高效运维公众号。近期好文:“高效运维”公众号诚邀广大技术人员投稿, 查看全部
运维的报表之路,用 node.js 轻松发送 grafana 报表
在运维过程中,无论是监控还是报表,都会有一些通过邮件发送图表的需求,由于开源的 zabbix,grafana 和 kibana 等并不完全具有“想发送哪儿就发送哪儿”的图片生成功能,在 grafana 中我们也考虑了一些其他方法,比如 grafana webdav 和 grafana-image-renderer 的方案,但并不能满足我们的需求。我们通过 nodejs 的模块 puppeteer + nodemailer 实现了grafana pannel 图表的邮件报表功能,基本满足了我们在自动化报表这块的需求。原理Puppeteer 是一个提供了高级 API ,通过DevTools Protocol(开发工具协议)控制headless chrome 或 chromium 的 Node.js 库,默认的运行模式是无头的,但是可以配置成非无头的模式。无头浏览器是一种没有操作界面的浏览器,诸如selenium、PhantomJS、Puppeteer 等,常用于网页自动化测试,利用其提供的API,可以自动执行操作指令,它是测试利器,也是爬虫神器 。Puppeteer 是其中比较优秀的一个。Puppeteer 通过程序化地操作浏览器,与其进行模拟交互(例如点击、打字、导航等等)来控制要抓取的网页,通常也能获取网页的 DOM 或 HTML,因此也可以获取网页数据,对于一些动态网站来说,像 grafana 图表,JS 动态渲染的数据通常不能轻松获取,而自动化测试工具Puppeteer则可以轻松的做到,因为它是将 HTML 输入浏览器里运行的。
如果大家对 DevTools Protocol(开发工具协议)感兴趣,可以参考:
准备环境环境版本
centos
7.6
node
14.3.0
cnpm
6.1.1
cd /optwget https://cdn.npm.taobao.org/dis ... xztar -xf node-v14.3.0-linux-x64.tar.xz<br />vi /etc/profile#set for nodejsexport NODE_HOME=/opt/node-v14.3.0-linux-x64export PATH=$NODE_HOME/bin:$PATH<br />source /etc/profile<br />npm config set registry=http://registry.npm.taobao.orgnpm install -g cnpm --registry=https://registry.npm.taobao.org<br /># 截图存放位置mkdir /tmp/png/<br /># 项目位置mkdir /opt/GrafanaSnapProjectcd /opt/GrafanaSnapProjectcnpm i --save puppeteercnpm i --save nodemailer
源码逻辑
为了使逻辑更清晰,我把发邮件和获取截图分成两个模块 mailPush.js 和 getPicture.js
发邮件模块 mailPush.js 这块需要注意为每一个附件添加一个引用名称,便于把截图引用到正文里。
在nodejs 里使用${str1}${str2} hello进行字符串拼接。
/*function: send pictures in mail's html content via nodejsauthor: zuoguocai@126.com<br />*/<br />const nodemailer = require('nodemailer');<br />//定义您的邮件推送服务器let transporter = nodemailer.createTransport({ // 您的邮箱服务器地址 host: 'mail.exchangehost.com', port: 587, secure: false, auth: { user: 'yourEmail', //您的邮箱的账号 pass: 'yourPassword'//您的邮箱的密码 }, tls: { rejectUnauthorized: false }, });<br />function sendMymail(who,subject,title){ let mailOptions = { from: '"autoreport" ', //邮件来源 to: who, //邮件发送到哪里,多个邮箱使用逗号隔开 subject: subject, // 邮件主题 html: `${title}
报表1
cid:001
报表2
cid:002`, // html类型的邮件正文 attachments: [{ filename: '001.png',//附件名称 path: '/tmp/png/001.png', //附件的位置 cid: '001', //为附件添加一个引用名称 },{ filename: '002.png',//附件名称 path: '/tmp/png/002.png', //附件的位置 cid: '002', //为附件添加一个引用名称 }] };<br /> transporter.sendMail(mailOptions, (error, info) => { if (error) { return console.log(error); } console.log('Message %s sent: %s', info.messageId, info.response); });}<br />//测试用//sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表')<br />// 自定义发邮件模块,供引入exports.sendMymail = sendMymail;<br />// 作为引入模块使用//const sendModule = require('./mailPush.js');//sendModule.sendMymail('zuoguocai@126.com','每周报表','OpenStack 运营报表');
puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,很适合在Linux 字符终端使用,不需要在Linux 上安装桌面工具。但需要在 Linux 中安装中文字体,如仿宋字体,避免在截图中出现乱码。说到字体,中文字体其实有很多,比如方正的徐静蕾体,adoble 思源字体。字体大家可以从网络上下载,阿里免费的可商用普惠字体,下载链接
Linux 中安装中文字体
yum -y install fontconfigcd /usr/share/fontsmkdir chinesecd chinese/使用lrzsz 上传字体,如仿宋体chmod -R 775 /usr/share/fonts/chineseyum -y install ttmkfdirttmkfdir -e /usr/share/X11/fonts/encodings/encodings.dirvi /etc/fonts/fonts.conf/usr/local/share/fonts/chinese<br />fc-list :lang=zh/usr/share/fonts/bitmap/fangsongti24.pcf.gz: Fangsong ti:style=Regular/usr/share/fonts/chinese/simfang.ttf: FangSong_GB2312:style=Regular/usr/share/fonts/bitmap/fangsongti16.pcf.gz: Fangsong ti:style=Regular
getPicture.js 模块主要用来模拟登陆,模拟操作。这里需要对用户名和密码参数化,在写这块逻辑时大家可以参考网络上 puppeteer 文档和一些案例。定位按钮和点击按钮这块比较繁琐和复杂,大家可以借助工具 puppeteer recorder 插件来辅助生成代码。本机电脑 chrome 扩展程序里安装 puppeteer recorder 插件,这里我们主要通过使用chrome 插件 puppeteer recorder 对 grafana 前端 CSS 选择器定位,模拟点击,确定元素位置,生成一些辅助代码。使用习惯跟 JMeter,LoadRunner 很像。如图1
我们分析一下 grafana 某个 dashboard ,都是有好多 pannel 组成的,点击某个 pannel 的下拉菜单,点击 view 可以预览这个 pannel 的图表情况。这样我们就可以使用工具单独录制这段操作的代码,放到我们整个项目里。
如图2
/*function: snapshot grafana pannel pictures via puppeteerauthor: zuoguocai@126.com*/<br />// 发送函数function sendPicture(){ // 引入自定义发邮件模块 const sendModule = require('./mailPush.js'); // 同时发送到多个邮箱,用逗号隔开 sendModule.sendMymail('guocai.zuo@gmail.com,zuoguocai@126.com','每周报表','^_^ OpenStack 监控报表');}<br />// 截图函数function getPicture(){<br /> const puppeteer = require('puppeteer'); //模拟登陆,grafana 登陆的用户名和密码 const account = `zuoguocai`; const password = `xxxxxx`;<br /> (async () => { const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox']}); const page = await browser.newPage(); await page.setViewport({width:1827, height:979}); await page.goto('https://yourgrafana.com'); await page.type('input[type="text"]', account); await page.type('#inputPassword', password); await page.click('button[type="submit"]'); await page.waitForNavigation({ waitUntil: 'load' });<br /> //await page.waitFor(1000); // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.waitForSelector('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是19 await page.click('#panel-19 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/001.png'});<br /> // 替换为您的grafana dashboard的 url await page.goto('https://yourgrafana.com/d/-a3b-ddWz/hu-lian-wang-chu-kou-hui-zong?refresh=30s&orgId=1'); await page.waitFor(1000); // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.waitForSelector('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') // 替换为您的grafana dashboard panel 的编号,我这里是2 await page.click('#panel-2 > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-editor-container:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-height-helper:nth-child(1) > .panel-container:nth-child(1) .panel-menu-container:nth-child(3) > .fa:nth-child(1)') await page.waitForSelector('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.click('.open > .dropdown-menu > li:nth-child(1) > a > .dropdown-item-text') await page.waitFor(1000); await page.screenshot({path: '/tmp/png/002.png'});<br /> await browser.close();<br /> //调用发送函数 await sendPicture();})();}<br />// 调用定位并截图函数getPicture()
源码地址:
测试发送效果
node getPicture.js
打开邮件客户端,查看是否收到邮件报表。
关于定时发送和 grafana 时间范围选取时间选取范围直接可以拼接到grafana的url里,这块比较简单。定时任务调度需要自己写,或者使用 gocron 的定时任务来做。gocron 项目地址:如图3
不止于此puppeteer 很强大,可以用于前端自动化测试,并且不局限于生成截图,还有pdf等,这里只是很小一部分内容,大家可以去探索,我这里只是一种思路,代码写的并不好,大家可以进行扩展,比如截取kibana等的图表,增加异常处理,对图片cid进行再次封装,放到对象存储里,工具集成到运维管理平台里,供业务相关方订阅。作者简介:左国才,VIPKID运维工程师,笔名icai,主要研究Linux操作系统,数据库,云计算领域相关技术, 热爱开源技术,平时喜欢阅读高效运维公众号。近期好文:“高效运维”公众号诚邀广大技术人员投稿,
深市股票涨跌数据的抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-05-21 19:08
【分享成果,随喜正能量】遇到不可理喻的事情,接受,处理,远离,不追问。最后这三个字,是生活教会我的最重要的三个字。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:深市股票涨跌数据的抓取
第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。
实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:
Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:
1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】成年人的世界,钱是活下去的筹码,并非多爱钱,只是无奈,没钱寸步难行,一睁开眼就需要钱的年代,不怕没命,就怕没钱。。 查看全部
深市股票涨跌数据的抓取
【分享成果,随喜正能量】遇到不可理喻的事情,接受,处理,远离,不追问。最后这三个字,是生活教会我的最重要的三个字。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:深市股票涨跌数据的抓取
第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。
实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:
Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:
1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】成年人的世界,钱是活下去的筹码,并非多爱钱,只是无奈,没钱寸步难行,一睁开眼就需要钱的年代,不怕没命,就怕没钱。。
使用excel抓取网页数据,制作自动更新的新型肺炎地图数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-06 23:15
Hello大家好,前几天跟大家分享了使用三维度图在excel中展示疫情数据,但是有粉丝提问到能不能做一个实现自动刷新的地图数据呢?当然可以,今天我们换一种方法来制作数据地图,下面就让我们来一起操作下吧
一、获取数据
首先我们复制上面的网址,然后新建一个excel,点击数据功能找到自网站,然后将我们复制的网址直接粘贴进去,紧接着我们点击确定,当进入导航器的界面后在预览窗口会出现三个项目,在这里table1就是我们想要的新型肺炎疫情数据,我们选择table1然后点转换数据,这样的话我们就进入了power query的编辑界面
二、整理数据
首先我们将疑似以及治愈这两列数据删除(如果需要也可以保留),紧接着我们将确诊这一列的数据格式设置为整数,然后点击添加列,为数据添加索引列,然后我们对索引列进行筛选,筛选条件设置为小于等于33,点击确定,这么做的目的是为了删除国外的数据。这样的话我们就得到了国内的数据
三、插入着色地图
紧接着我们点击数据的任何一个区域,然后点击插入功能组在图表中找到着色地图,紧接着我们点击地图按快捷键ctrl+1调出格式窗口,找到颜色序列,设置为三种颜色,将最大值的颜色设置为深红色,将中间设置为数值,颜色设置为红色,将值设置为500,最后将最小值设置为数字,颜色设置为浅红色,值设置为100
紧接着我们为数据添加数据标签,点击任意一个区域,然后点击图表旁边的加号,选择数据标签,紧接着我们点击数据标签按快捷键ctrl+1调出格式窗口,勾选类别名称,将值去掉,这样的话我们就为每个省份都添加上了个字的名称
四、设置自动刷新
紧接着我们点击表格的任何一个区域,然后点击查询功能组,找到数据,勾选刷新频率,将其设置为60分钟,这样的话每过1个小时就会自动的刷新一次数据。至此设置完毕
以上就是我们使用excel制作自动更新的疫情地图的方法,怎么样是不是非常简单呢?
我是excel从零到一,关注我持续分享更多excel技巧 查看全部
使用excel抓取网页数据,制作自动更新的新型肺炎地图数据
Hello大家好,前几天跟大家分享了使用三维度图在excel中展示疫情数据,但是有粉丝提问到能不能做一个实现自动刷新的地图数据呢?当然可以,今天我们换一种方法来制作数据地图,下面就让我们来一起操作下吧
一、获取数据
首先我们复制上面的网址,然后新建一个excel,点击数据功能找到自网站,然后将我们复制的网址直接粘贴进去,紧接着我们点击确定,当进入导航器的界面后在预览窗口会出现三个项目,在这里table1就是我们想要的新型肺炎疫情数据,我们选择table1然后点转换数据,这样的话我们就进入了power query的编辑界面
二、整理数据
首先我们将疑似以及治愈这两列数据删除(如果需要也可以保留),紧接着我们将确诊这一列的数据格式设置为整数,然后点击添加列,为数据添加索引列,然后我们对索引列进行筛选,筛选条件设置为小于等于33,点击确定,这么做的目的是为了删除国外的数据。这样的话我们就得到了国内的数据
三、插入着色地图
紧接着我们点击数据的任何一个区域,然后点击插入功能组在图表中找到着色地图,紧接着我们点击地图按快捷键ctrl+1调出格式窗口,找到颜色序列,设置为三种颜色,将最大值的颜色设置为深红色,将中间设置为数值,颜色设置为红色,将值设置为500,最后将最小值设置为数字,颜色设置为浅红色,值设置为100
紧接着我们为数据添加数据标签,点击任意一个区域,然后点击图表旁边的加号,选择数据标签,紧接着我们点击数据标签按快捷键ctrl+1调出格式窗口,勾选类别名称,将值去掉,这样的话我们就为每个省份都添加上了个字的名称
四、设置自动刷新
紧接着我们点击表格的任何一个区域,然后点击查询功能组,找到数据,勾选刷新频率,将其设置为60分钟,这样的话每过1个小时就会自动的刷新一次数据。至此设置完毕
以上就是我们使用excel制作自动更新的疫情地图的方法,怎么样是不是非常简单呢?
我是excel从零到一,关注我持续分享更多excel技巧
用 Python 抓取阿里云盘资源
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-05-06 23:13
前阵子阿里云盘大火,送了好多的容量空间。而且阿里云盘下载是不限速,这点比百度网盘好太多了。这两天看到一个第三方网站可以搜索阿里云盘上的资源,但是它的资源顺序不是按时间排序的。这种情况会造成排在前面时间久远的资源是一个已经失效的资源。小编这里用 python 抓取后重新排序。
网页分析
这个网站有两个搜索路线:搜索线路一和搜索线路二,本文章使用的是搜索线路二。
打开控制面板下的网络,一眼就看到一个 seach.html 的 get 请求。
上面带了好几个参数,四个关键参数:
也是在控制面板中,看出这个网页跳转到阿里云盘获取真实的的链接是在标题上面的。用 bs4 解析页面上的 div(class=resource-item border-dashed-eee) 标签下的 a 标签就能得到跳转网盘的地址,解析 div 下的 p 标签获取资源日期。
抓取与解析
首先安装需要的 bs4 第三方库用于解析页面。
pip3 install bs4<br />
下面是抓取解析网页的脚本代码,最后按日期降序排序。 <p>import requests<br />from bs4 import BeautifulSoup<br />import string<br /><br /><br />word = input('请输入要搜索的资源名称:')<br /> <br />headers = {<br /> 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'<br />}<br /><br />result_list = []<br />for i in range(1, 11):<br /> print('正在搜索第 {} 页'.format(i))<br /> params = {<br /> 'page': i,<br /> 'keyword': word,<br /> 'search_folder_or_file': 0,<br /> 'is_search_folder_content': 0,<br /> 'is_search_path_title': 0,<br /> 'category': 'all',<br /> 'file_extension': 'all',<br /> 'search_model': 0<br /> }<br /> response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)<br /> response_data = response_html.content.decode()<br /> <br /> soup = BeautifulSoup(response_data, "html.parser");<br /> divs = soup.find_all('div', class_='resource-item border-dashed-eee')<br /> <br /> if len(divs) 查看全部
用 Python 抓取阿里云盘资源
前阵子阿里云盘大火,送了好多的容量空间。而且阿里云盘下载是不限速,这点比百度网盘好太多了。这两天看到一个第三方网站可以搜索阿里云盘上的资源,但是它的资源顺序不是按时间排序的。这种情况会造成排在前面时间久远的资源是一个已经失效的资源。小编这里用 python 抓取后重新排序。
网页分析
这个网站有两个搜索路线:搜索线路一和搜索线路二,本文章使用的是搜索线路二。
打开控制面板下的网络,一眼就看到一个 seach.html 的 get 请求。
上面带了好几个参数,四个关键参数:
也是在控制面板中,看出这个网页跳转到阿里云盘获取真实的的链接是在标题上面的。用 bs4 解析页面上的 div(class=resource-item border-dashed-eee) 标签下的 a 标签就能得到跳转网盘的地址,解析 div 下的 p 标签获取资源日期。
抓取与解析
首先安装需要的 bs4 第三方库用于解析页面。
pip3 install bs4<br />
下面是抓取解析网页的脚本代码,最后按日期降序排序。 <p>import requests<br />from bs4 import BeautifulSoup<br />import string<br /><br /><br />word = input('请输入要搜索的资源名称:')<br /> <br />headers = {<br /> 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'<br />}<br /><br />result_list = []<br />for i in range(1, 11):<br /> print('正在搜索第 {} 页'.format(i))<br /> params = {<br /> 'page': i,<br /> 'keyword': word,<br /> 'search_folder_or_file': 0,<br /> 'is_search_folder_content': 0,<br /> 'is_search_path_title': 0,<br /> 'category': 'all',<br /> 'file_extension': 'all',<br /> 'search_model': 0<br /> }<br /> response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)<br /> response_data = response_html.content.decode()<br /> <br /> soup = BeautifulSoup(response_data, "html.parser");<br /> divs = soup.find_all('div', class_='resource-item border-dashed-eee')<br /> <br /> if len(divs)
网站抓取引子 - 获得网页中的表格
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-06 17:20
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素。具体使用如下: <p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address <br />url 查看全部
网站抓取引子 - 获得网页中的表格
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素。具体使用如下: <p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address <br />url
Python抓取网页表格(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-05-06 17:19
Python有很多包可以抓取数据,如selenium、requests、scrapy、pandas,每个包都有其适用性,个人认为在抓取数据时,代码简洁性和数据获取的准确性是需要考虑的因素,时间快慢倒不用太在意,毕竟用python抓数据本来就大大节省了时间,用不同的方法可能也就是1秒和1分钟的区别。
日常中我们总存在抓取表格数据的需求,本文试图用pandas最简洁的代码抓取表格数据,代码非常简单,也很容易上手。
随便选个网页:
比如爬取下图中定向工具的注册批文(当然wind里面也有数据,本文只是为了展示如何爬取表格型数据)
一、爬取当页
只需要两句关键代码就可以抓取出来,前两句是导入相关模块,第三句输入网址,第四句用pandas读取,由于该网页有很多表格,会以list格式存在ppn这个变量里,点击查看可以发行第十四张表格正是我们所需要的内容。
二、全部爬取
但是第一部分只抓取了第一页,如果想要把所有页都抓取出来,同样非常简单,只需编写一个循环。点击下一页可以发现其网址会发生相应改变:
页码会体现在index后面的数字,因此可以将url改为变量的组合,具体看第五句。第一和二句依然是导入相关模块,第三句是生成一个空矩阵,用于存储抓取完的结果,第四句至第八句是一个简单的循环,result变量就是每页抓取的结果,然后不断的添加到output里。最后output就是我们想要的结果。
查看全部
Python抓取网页表格(一)
Python有很多包可以抓取数据,如selenium、requests、scrapy、pandas,每个包都有其适用性,个人认为在抓取数据时,代码简洁性和数据获取的准确性是需要考虑的因素,时间快慢倒不用太在意,毕竟用python抓数据本来就大大节省了时间,用不同的方法可能也就是1秒和1分钟的区别。
日常中我们总存在抓取表格数据的需求,本文试图用pandas最简洁的代码抓取表格数据,代码非常简单,也很容易上手。
随便选个网页:
比如爬取下图中定向工具的注册批文(当然wind里面也有数据,本文只是为了展示如何爬取表格型数据)
一、爬取当页
只需要两句关键代码就可以抓取出来,前两句是导入相关模块,第三句输入网址,第四句用pandas读取,由于该网页有很多表格,会以list格式存在ppn这个变量里,点击查看可以发行第十四张表格正是我们所需要的内容。
二、全部爬取
但是第一部分只抓取了第一页,如果想要把所有页都抓取出来,同样非常简单,只需编写一个循环。点击下一页可以发现其网址会发生相应改变:
页码会体现在index后面的数字,因此可以将url改为变量的组合,具体看第五句。第一和二句依然是导入相关模块,第三句是生成一个空矩阵,用于存储抓取完的结果,第四句至第八句是一个简单的循环,result变量就是每页抓取的结果,然后不断的添加到output里。最后output就是我们想要的结果。
小码哥Flutter从入门到实战-大神精选(百度云 百度网盘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-04-30 12:27
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
官方建议大家先手动获取Connection,然后再从Connection中获取Table接口(注意:不是HTable类,而是Table接口):下面的方法都是Table接口提供的,具体的操作还是由HTable类实现的。首先是我们的put方法。4.3.2 put方法这个方法相当于增和改这两个操作。我们先构建一个Put对象出来,然后往这个对象里面添加这行需要的属性。我们很容易地可以联想到首当其冲的构造参数就是rowkey,所以最简单的Put构造函数就是:在HBase中有一个理念:所有数据皆为bytes。在HBase中数据最终都会被序列化为bytes[]保存,所以一切可以被序列化为bytes的对象都可以作为rowkey。最简单的将字符串转换为bytes[]的方法是使用Bytes提供的toBytes方法:Bytes是由HBase提供的用于将各种不同类型的数据格式转换为byte[]的工具类,然后我们设置这行数据的mycf列族的name列为jack:此时操作并没有执行下去,我们调用Table接口的put方法把数据真正保存起来:执行完后,我们用hbase shell来看下mytable这个表的数据:可以看到这条数据已经被保存到HBase中了,这就是最简单的新增语句。
那么修改呢?修改就是往同一个rowkey再执行一次put操作,将之前的数据覆盖掉。我们来做一下如何修改刚刚保存的这行数据。依然还是新建一个Put对象,用addColumn方法设置rowkey为row1,这回设置mycf:name为ted,然后保存:1.Put的构造函数Put最简单的构造方法是:Put的其他的构造方法:Put(ByteBuffer row)Put(Put putToCopy)Put(byte[] row, long ts)Put(ByteBuffer row, long ts)Put(byte[] rowArray, int rowOffset, int rowLength)Put(byte[] rowArray, int rowOffset, int rowLength, longts)2.addColumn和addImmutable的历史早期教程,提到的add(byte [] family, byte [] qualifier,byte [] value)方法已经被废弃,改成使用addColumn。addColumn方法有以下的几种调用方式:我们用的是第1种方式。第2、3种方法增加了时间戳(ts)参数,你可以手动地定义时间戳作为版本号。如果你做的是一个网页抓取的引擎,那手动定义时间戳就很有用了,你可以把网页的抓取时间当作时间戳存起来。这样每一个单元格里面就存储了一个网页的历史记录。你会发现除了addColumn,HBase还多出了一个addImmutable方法。 查看全部
小码哥Flutter从入门到实战-大神精选(百度云 百度网盘)
含大数据、前沿技术、前端开发、后端开发、移动开发、数据分析、架构、人工智能、Python、Java、Android、前端、IOS、C++、大数据、GO、音视频软件测试、产品经理、运维、股票基金、人工智能AI
以下内容为填充,无视即可
官方建议大家先手动获取Connection,然后再从Connection中获取Table接口(注意:不是HTable类,而是Table接口):下面的方法都是Table接口提供的,具体的操作还是由HTable类实现的。首先是我们的put方法。4.3.2 put方法这个方法相当于增和改这两个操作。我们先构建一个Put对象出来,然后往这个对象里面添加这行需要的属性。我们很容易地可以联想到首当其冲的构造参数就是rowkey,所以最简单的Put构造函数就是:在HBase中有一个理念:所有数据皆为bytes。在HBase中数据最终都会被序列化为bytes[]保存,所以一切可以被序列化为bytes的对象都可以作为rowkey。最简单的将字符串转换为bytes[]的方法是使用Bytes提供的toBytes方法:Bytes是由HBase提供的用于将各种不同类型的数据格式转换为byte[]的工具类,然后我们设置这行数据的mycf列族的name列为jack:此时操作并没有执行下去,我们调用Table接口的put方法把数据真正保存起来:执行完后,我们用hbase shell来看下mytable这个表的数据:可以看到这条数据已经被保存到HBase中了,这就是最简单的新增语句。
那么修改呢?修改就是往同一个rowkey再执行一次put操作,将之前的数据覆盖掉。我们来做一下如何修改刚刚保存的这行数据。依然还是新建一个Put对象,用addColumn方法设置rowkey为row1,这回设置mycf:name为ted,然后保存:1.Put的构造函数Put最简单的构造方法是:Put的其他的构造方法:Put(ByteBuffer row)Put(Put putToCopy)Put(byte[] row, long ts)Put(ByteBuffer row, long ts)Put(byte[] rowArray, int rowOffset, int rowLength)Put(byte[] rowArray, int rowOffset, int rowLength, longts)2.addColumn和addImmutable的历史早期教程,提到的add(byte [] family, byte [] qualifier,byte [] value)方法已经被废弃,改成使用addColumn。addColumn方法有以下的几种调用方式:我们用的是第1种方式。第2、3种方法增加了时间戳(ts)参数,你可以手动地定义时间戳作为版本号。如果你做的是一个网页抓取的引擎,那手动定义时间戳就很有用了,你可以把网页的抓取时间当作时间戳存起来。这样每一个单元格里面就存储了一个网页的历史记录。你会发现除了addColumn,HBase还多出了一个addImmutable方法。
Stata爬虫:爬取地区宏观数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2022-04-30 12:22
邮箱:
目录
4. 补充方法
5. 相关推文
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:
1. 基本原理
网络爬虫就是自动抓取网页信息的代码,也可以简单理解成代替繁琐的复制粘贴操作的手段。如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物 (数据)。从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的 HTML 代码爬到本地,进而提取自己需要的数据,存放起来使用,即请求网站并提取数据的自动化程序。
2. 基本步骤
Stata 进行网页表格爬取分为 3 个步骤:
网页分析:获取项目的源代码;请求并读入:把含有所需数据的源代码下载下来,并导入 Stata;处理数据:主要是对字符串进行处理,常用操作有分割 split、转置 sxpose、提取 (正则表达式或直接字符串提取) 等。
3. 爬虫案例
本文以爬取「地区宏观数据」中 “重庆市国内生产总值指数” 的数据为例,讲解如何使用 Stata 进行网页表格数据爬取。
图 1:条件筛选3.1 网页分析
图 2:获取信息源
我们在其中能找到这样一个链接,通过复制粘贴到浏览器,可以发现该链接下存放的是数据。具体链接形式如下:
在上述链接中,参数 p = 2 就是关键,将 2 替换成其他页数,就能返回对应页的数据源代码。
3.2 请求数据
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br />
由于这个网页没有设置反爬机制,所以可以直接使用 copy 命令进行下载。在这里,我们运用循环语句 forvalue 对前 4 页表格的信息进行下载。
3.3 读入数据
第一步:合并所有 txt 文件。
第二步:txt 文档中插入转行。观察到 all.txt 中的内容并无转行,为了方便 Stata 处理数据,需插入转行。对比文档内容与表格内容后,选择在
前插入转行。具体实现步骤如下:
图 3:观察何处插入转行
第三步:all.txt 文件读入 Stata
infix strL v 1-20000 using "all.txt", clear<br />format v %500s<br />
利用 infix 读取数据,然后把变量 v 的显示格式变成 %500s (这样看起来更宽)。导入后的数据如下图所示:
图 4:数据的雏形
第四步:解决乱码问题
若数据导入 Stata 后,无法正常显示,即出现乱码问题。在这里,我们可用下面一行命令解决乱码问题。若文字显示正常,则不需运行以下命令。
replace v = ustrfrom(v, "gb18030", 1)<br />
3.4 处理数据
第一步:分析网页代码
*数据保留<br />keep if index(v,`""')<br />split v,p(`""' )<br />split v2 ,p(`""' )<br />split v25 ,p(`""' )<br />keep v21 v22 v23 v24 v251<br />
*变量重命名<br />rename v21 国内生产总值指数<br />rename v22 第一产业生产总值指数<br />rename v23 第二产业生产总值指数<br />rename v24 第三产业生产总值指数<br />rename v251 人均国内生产总值指数<br />
*输出文件<br />export excel using "地区宏观数据.xlsx", firstrow(var) replace<br />shellout using "地区宏观数据.xlsx"<br />
图 5:结果展示
4. 补充方法
以下方法不用借助任何第三方工具,完全依靠 Stata 完成,具体代码如下:
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br /><br />forvalues i = 1(1)4{<br /> infix strL v 1-20000 using "temp`i'.txt", clear<br /> format v %500s<br /> replace v = ustrfrom(v, "gb18030", 1)<br /> keep if index(v,`""')<br /> split v, p(`""' )<br /><br /> forvalues j = 1(1)20{ //20为新产生变量数<br /> insobs 20<br /> replace v = v`j'[1] in `j'<br /> }<br /><br /> keep v<br /> split v, p(`""' )<br /> split v2, p(`""' )<br /> split v25, p(`""' )<br /> keep v21 v22 v23 v24 v251<br /><br /> rename v21 国内生产总值指数<br /> rename v22 第一产业生产总值指数<br /> rename v23 第二产业生产总值指数<br /> rename v24 第三产业生产总值指数<br /> rename v251 人均国内生产总值指数<br /><br /> save "temp`i'.dta", replace<br />}<br /><br />use temp1.dta, clear<br />forvalues i = 2(1)4{<br /> append using temp`i'<br />}<br />drop if 国内生产总值指数 == ""<br />save 地区宏观数据.dta, replace <br /><br />forvalues i = 1(1)4{<br /> erase temp`i'.dta<br />}<br />
5. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 爬虫 正则 文本, m
安装最新版 lianxh 命令:
ssc install lianxh, replace
专题:Python-R-Matlab
课程推荐:因果推断实用计量方法
主讲老师:丘嘉平教授
课程主页:
New! Stata 搜索神器:lianxh 和 songbl
搜: 推文、数据分享、期刊论文、重现代码 ……
安装:
. ssc install lianxh
. ssc install songbl
使用:
. lianxh DID 倍分法
. songbl all
关于我们
查看全部
Stata爬虫:爬取地区宏观数据
邮箱:
目录
4. 补充方法
5. 相关推文
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:
1. 基本原理
网络爬虫就是自动抓取网页信息的代码,也可以简单理解成代替繁琐的复制粘贴操作的手段。如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物 (数据)。从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的 HTML 代码爬到本地,进而提取自己需要的数据,存放起来使用,即请求网站并提取数据的自动化程序。
2. 基本步骤
Stata 进行网页表格爬取分为 3 个步骤:
网页分析:获取项目的源代码;请求并读入:把含有所需数据的源代码下载下来,并导入 Stata;处理数据:主要是对字符串进行处理,常用操作有分割 split、转置 sxpose、提取 (正则表达式或直接字符串提取) 等。
3. 爬虫案例
本文以爬取「地区宏观数据」中 “重庆市国内生产总值指数” 的数据为例,讲解如何使用 Stata 进行网页表格数据爬取。
图 1:条件筛选3.1 网页分析
图 2:获取信息源
我们在其中能找到这样一个链接,通过复制粘贴到浏览器,可以发现该链接下存放的是数据。具体链接形式如下:
在上述链接中,参数 p = 2 就是关键,将 2 替换成其他页数,就能返回对应页的数据源代码。
3.2 请求数据
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br />
由于这个网页没有设置反爬机制,所以可以直接使用 copy 命令进行下载。在这里,我们运用循环语句 forvalue 对前 4 页表格的信息进行下载。
3.3 读入数据
第一步:合并所有 txt 文件。
第二步:txt 文档中插入转行。观察到 all.txt 中的内容并无转行,为了方便 Stata 处理数据,需插入转行。对比文档内容与表格内容后,选择在
前插入转行。具体实现步骤如下:
图 3:观察何处插入转行
第三步:all.txt 文件读入 Stata
infix strL v 1-20000 using "all.txt", clear<br />format v %500s<br />
利用 infix 读取数据,然后把变量 v 的显示格式变成 %500s (这样看起来更宽)。导入后的数据如下图所示:
图 4:数据的雏形
第四步:解决乱码问题
若数据导入 Stata 后,无法正常显示,即出现乱码问题。在这里,我们可用下面一行命令解决乱码问题。若文字显示正常,则不需运行以下命令。
replace v = ustrfrom(v, "gb18030", 1)<br />
3.4 处理数据
第一步:分析网页代码
*数据保留<br />keep if index(v,`""')<br />split v,p(`""' )<br />split v2 ,p(`""' )<br />split v25 ,p(`""' )<br />keep v21 v22 v23 v24 v251<br />
*变量重命名<br />rename v21 国内生产总值指数<br />rename v22 第一产业生产总值指数<br />rename v23 第二产业生产总值指数<br />rename v24 第三产业生产总值指数<br />rename v251 人均国内生产总值指数<br />
*输出文件<br />export excel using "地区宏观数据.xlsx", firstrow(var) replace<br />shellout using "地区宏观数据.xlsx"<br />
图 5:结果展示
4. 补充方法
以下方法不用借助任何第三方工具,完全依靠 Stata 完成,具体代码如下:
capt mkdir "./地区宏观数据"<br />cd "./地区宏观数据"<br /><br />forvalues i=1(1)4{<br /> *注意:引号中的文本不能换行,这里为了展示方便,对链接内容进行了换行,<br /> *读者在练习时,可删除换行符,将链接内容放到一行<br /> copy "http://calendar.hexun.com/area ... px%3F ///<br /> page=`i'&codeList=D0020000&citycode=500000&startdate=1949 ///<br /> &endDate=2020" "temp`i'.txt", replace<br />}<br /><br />forvalues i = 1(1)4{<br /> infix strL v 1-20000 using "temp`i'.txt", clear<br /> format v %500s<br /> replace v = ustrfrom(v, "gb18030", 1)<br /> keep if index(v,`""')<br /> split v, p(`""' )<br /><br /> forvalues j = 1(1)20{ //20为新产生变量数<br /> insobs 20<br /> replace v = v`j'[1] in `j'<br /> }<br /><br /> keep v<br /> split v, p(`""' )<br /> split v2, p(`""' )<br /> split v25, p(`""' )<br /> keep v21 v22 v23 v24 v251<br /><br /> rename v21 国内生产总值指数<br /> rename v22 第一产业生产总值指数<br /> rename v23 第二产业生产总值指数<br /> rename v24 第三产业生产总值指数<br /> rename v251 人均国内生产总值指数<br /><br /> save "temp`i'.dta", replace<br />}<br /><br />use temp1.dta, clear<br />forvalues i = 2(1)4{<br /> append using temp`i'<br />}<br />drop if 国内生产总值指数 == ""<br />save 地区宏观数据.dta, replace <br /><br />forvalues i = 1(1)4{<br /> erase temp`i'.dta<br />}<br />
5. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 爬虫 正则 文本, m
安装最新版 lianxh 命令:
ssc install lianxh, replace
专题:Python-R-Matlab
课程推荐:因果推断实用计量方法
主讲老师:丘嘉平教授
课程主页:
New! Stata 搜索神器:lianxh 和 songbl
搜: 推文、数据分享、期刊论文、重现代码 ……
安装:
. ssc install lianxh
. ssc install songbl
使用:
. lianxh DID 倍分法
. songbl all
关于我们
网页表格抓取 IE抓取资金主力流入的股票
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-30 12:14
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。 查看全部
网页表格抓取 IE抓取资金主力流入的股票
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。
在不影响SEO的前提下,如何重新设计网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-30 07:38
网站所有者中最大的误解之一是SEO只需要执行一次,不幸的是,事实并非如此。
在重新设计期间,许多部分都会更改,包括代码和页面。如果处理不当,可能会对网站的SEO产生负面影响,并影响网站的长期发展。但是,如果操作正确,重新设计网站也可以提高您的SEO实力。
步骤1:列出旧网站中的所有页面
第一步是下载网站的URL结构。重新设计意味着很多更改,这些更改也将影响URL的重组。因此,重要的是进行备份,否则会冒着影响网站排名的风险。
步骤2:重新设计需要在一个临时URL上进行
切勿在现有网站上进行重新设计。从长远来看,它可能会导致访客问题,并给您带来麻烦。最好的方法是复制您的网站并将其设置为临时URL。完成后;您可以开始对其进行更改。另一种选择是一旦完成所有必需的重新设计更改,便切换域。
如果您有可能为此感到挣扎,则始终可以从开发人员那里获得帮助。另一种选择是托管公司为您做。对您的主机提供商进行ping操作非常重要,因为此步骤将保护您免受将来的意外问题。
步骤3:测试新网站
太好了,您将现有网站复制到了新网站中。
但是,在开始重新设计项目之前,最好对网站进行端到端检查。在此检查中,您应该查看网站的多个方面,包括断开的链接,功能,CSS等。
您还可以使用XENU,这是一种免费工具,可以在您的网站上找到所有损坏的链接。
步骤4:执行适当的301重定向
下一步是在新旧网址之间进行301重定向。例如,如果您在旧网站上有一个“关于我们”页面,并且其URL是“”。
如果在重新设计期间,您的设计师将URL更改为“”,则最好实施适当的301重定向,以确保两个URL都能正常工作,并且您不会失去从您的SEO中获得的收益先前的网址。
如果操作不正确,搜索引擎将显示404个未找到的网页。通过执行301重定向,旧的URL将被重定向到新的URL。这是告诉搜索引擎网址已更改的技术方法,搜索引擎不会降权排名。
您可以使用.htaccess文件添加重定向,如下代码:
重定向301//new-url
如果您感到困惑并且不知道如何在WordPress上手动进行操作,则还可以尝试使用重定向插件,通过填写表格来进行操作。
注意:此步骤非常重要,无论如何都应这样做。
步骤5:跳转到新网站
设计和重定向完成所有工作后,就该切换到新网站了。如果您的网站很大,也可以分阶段进行增量更改。
步骤6:运行搜索引擎网站站长工具
下一步是确保到目前为止一切都成功。
为此,您可以利用搜索引擎网站站长之类的工具。该工具将使您检查是否有断开的链接。如果发现任何损坏的链接,为避免罚款,建议尽快将其修复。
步骤7:检查验证状态并重新提交
开发人员或设计人员通常会停止搜索引擎来爬网网站。如果是这种情况,那么您将需要在网站上恢复抓取工具。要检查状态,您需要使用搜寻器下的“以搜索引擎身份提取”选项。完成后,单击“获取并渲染”选项。如果两个测试均得出肯定结果,则说明您的网站是完全可爬网的。
另外,建议检查重新设计的网站是否经过验证。为此,您可以登录Bing和搜索引擎提供的相应网站站长工具。如果缺少验证,请重做并声明您的网站。
最后,点击“提交索引”按钮,将您的网站URL重新提交到搜索引擎索引中。
步骤8:Robot.txt
在重新设计期间,robot.txt文件可能需要改动,要检查它是否具有,可以在爬网下使用“robot.txt”选项。
第9步:提交站点地图
由于您的网站现在具有新的和经过修改的结构,因此将网站XML提交给Bing和搜索引擎。提交后,您的新网站将在接下来的几个小时内被抓取。
步骤10:监控变更
最后,监视变化并寻找任何潜在的增长非常重要,至少需要检测网站数据两到三个月,同时密切关注热门关键字的排名。
如果网站排名出现了大幅度波动,请试着分析为什么会发生这种情况,并在网站访问量快速下降的情况下寻求解决方案。
v: 查看全部
在不影响SEO的前提下,如何重新设计网站
网站所有者中最大的误解之一是SEO只需要执行一次,不幸的是,事实并非如此。
在重新设计期间,许多部分都会更改,包括代码和页面。如果处理不当,可能会对网站的SEO产生负面影响,并影响网站的长期发展。但是,如果操作正确,重新设计网站也可以提高您的SEO实力。
步骤1:列出旧网站中的所有页面
第一步是下载网站的URL结构。重新设计意味着很多更改,这些更改也将影响URL的重组。因此,重要的是进行备份,否则会冒着影响网站排名的风险。
步骤2:重新设计需要在一个临时URL上进行
切勿在现有网站上进行重新设计。从长远来看,它可能会导致访客问题,并给您带来麻烦。最好的方法是复制您的网站并将其设置为临时URL。完成后;您可以开始对其进行更改。另一种选择是一旦完成所有必需的重新设计更改,便切换域。
如果您有可能为此感到挣扎,则始终可以从开发人员那里获得帮助。另一种选择是托管公司为您做。对您的主机提供商进行ping操作非常重要,因为此步骤将保护您免受将来的意外问题。
步骤3:测试新网站
太好了,您将现有网站复制到了新网站中。
但是,在开始重新设计项目之前,最好对网站进行端到端检查。在此检查中,您应该查看网站的多个方面,包括断开的链接,功能,CSS等。
您还可以使用XENU,这是一种免费工具,可以在您的网站上找到所有损坏的链接。
步骤4:执行适当的301重定向
下一步是在新旧网址之间进行301重定向。例如,如果您在旧网站上有一个“关于我们”页面,并且其URL是“”。
如果在重新设计期间,您的设计师将URL更改为“”,则最好实施适当的301重定向,以确保两个URL都能正常工作,并且您不会失去从您的SEO中获得的收益先前的网址。
如果操作不正确,搜索引擎将显示404个未找到的网页。通过执行301重定向,旧的URL将被重定向到新的URL。这是告诉搜索引擎网址已更改的技术方法,搜索引擎不会降权排名。
您可以使用.htaccess文件添加重定向,如下代码:
重定向301//new-url
如果您感到困惑并且不知道如何在WordPress上手动进行操作,则还可以尝试使用重定向插件,通过填写表格来进行操作。
注意:此步骤非常重要,无论如何都应这样做。
步骤5:跳转到新网站
设计和重定向完成所有工作后,就该切换到新网站了。如果您的网站很大,也可以分阶段进行增量更改。
步骤6:运行搜索引擎网站站长工具
下一步是确保到目前为止一切都成功。
为此,您可以利用搜索引擎网站站长之类的工具。该工具将使您检查是否有断开的链接。如果发现任何损坏的链接,为避免罚款,建议尽快将其修复。
步骤7:检查验证状态并重新提交
开发人员或设计人员通常会停止搜索引擎来爬网网站。如果是这种情况,那么您将需要在网站上恢复抓取工具。要检查状态,您需要使用搜寻器下的“以搜索引擎身份提取”选项。完成后,单击“获取并渲染”选项。如果两个测试均得出肯定结果,则说明您的网站是完全可爬网的。
另外,建议检查重新设计的网站是否经过验证。为此,您可以登录Bing和搜索引擎提供的相应网站站长工具。如果缺少验证,请重做并声明您的网站。
最后,点击“提交索引”按钮,将您的网站URL重新提交到搜索引擎索引中。
步骤8:Robot.txt
在重新设计期间,robot.txt文件可能需要改动,要检查它是否具有,可以在爬网下使用“robot.txt”选项。
第9步:提交站点地图
由于您的网站现在具有新的和经过修改的结构,因此将网站XML提交给Bing和搜索引擎。提交后,您的新网站将在接下来的几个小时内被抓取。
步骤10:监控变更
最后,监视变化并寻找任何潜在的增长非常重要,至少需要检测网站数据两到三个月,同时密切关注热门关键字的排名。
如果网站排名出现了大幅度波动,请试着分析为什么会发生这种情况,并在网站访问量快速下降的情况下寻求解决方案。
v:
网页表格抓取 Darkweb(暗网) OSINT 2022 年调查资源
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-04-29 23:23
2021 年底,暗网格局发生了巨大变化——V2 洋葱域名终于被弃用,导致许多旧网站无法访问。
Tor 项目最终取消了“根本不安全”的域,敦促所有者和用户迁移
当前版本的 Tor 浏览器不再支持旧的 16 个字符的字符串域名,而是支持更长的 56 个字符的域名。使用 Tor 浏览器的旧的、预更新版本仍然可以访问一些 V2 域——但是没有多大意义,因为普遍的共识是继续前进。
现在是更新暗网 OSINT 调查工具包并在其中包含一些当代 2022 材料的时候了。
明网资源
Ahmia – 【】最古老、最可靠的 .onion 搜索引擎之一,可从暗网和明网访问。
洋葱搜索引擎 —【】用于搜索洋葱网站。它带有适用于 Chrome 和 Firefox 的浏览器扩展。各种支持的搜索选项包括图像、视频、地图和粘贴。
Tor Taxi – 【】一个带有多个不同洋葱域链接的启动板网站。它有一个方便的颜色编码系统,用于显示当前关闭的网站。
Darkweb Wiki—【】 一个有点混乱且不经常更新的洋葱站点列表——仍然是一个有价值的资源。
Hunchly –【】 以电子表格的形式提供有关洋葱域上升/下降的每日暗网报告。
IACA Darkweb Tools –【】 国际反犯罪学院提供的免费资源。
Reddit 社区 ——可以找到许多专门针对暗网各个方面的 subreddit,其中一些很受欢迎。但是,有 3 个始终良好且最新:
Discord – 一个新兴的 Reddit 替代品,用于新兴的在线社区和利基主题,Discord 在某些方面已经占据主导地位。虽然我还没有找到值得推荐的公开频道,但您可以使用暗网关键字搜索 可用的 Discord 服务器【】
暗网资源
Ahmia – 如上所述,但专门针对 Tor:
Haystak – 自称为“暗网最大的搜索引擎”,拥有数以千计的索引 .onion 域名——包括一些历史域名。
Kilos – 暗网市场搜索引擎,允许搜索供应商、列表、评论、论坛和论坛帖子。对于跨多个暗网实体进行广泛的基于关键字的搜索很有用。
TOR66—— 在标准搜索之上,这使得“新鲜洋葱”和“随机洋葱”匹配;谨慎行事,这些可以将您带到一些真正随机的站点。
Github 工具
首先,Apurv Singh Gautam 提供的很棒的工具列表可以 在这里找到【】 (但需要注意的是,我还没有使用或测试过所有这些工具)。
Onioff–【】 用于搜索 .onion URL 的 Python 工具。
OnionIngestor—【】用于抓取和收集暗网情报——与 Kibana 仪表板配合使用。
Onion Search– 【】从暗网搜索引擎抓取 .onion URL 的工具。
The Devils Eye– 【】用于在不连接 Tor 的情况下提取 .onion 站点链接和描述。
TorBot –【】 洋葱爬虫,许多附加功能仍在积极开发中。 查看全部
网页表格抓取 Darkweb(暗网) OSINT 2022 年调查资源
2021 年底,暗网格局发生了巨大变化——V2 洋葱域名终于被弃用,导致许多旧网站无法访问。
Tor 项目最终取消了“根本不安全”的域,敦促所有者和用户迁移
当前版本的 Tor 浏览器不再支持旧的 16 个字符的字符串域名,而是支持更长的 56 个字符的域名。使用 Tor 浏览器的旧的、预更新版本仍然可以访问一些 V2 域——但是没有多大意义,因为普遍的共识是继续前进。
现在是更新暗网 OSINT 调查工具包并在其中包含一些当代 2022 材料的时候了。
明网资源
Ahmia – 【】最古老、最可靠的 .onion 搜索引擎之一,可从暗网和明网访问。
洋葱搜索引擎 —【】用于搜索洋葱网站。它带有适用于 Chrome 和 Firefox 的浏览器扩展。各种支持的搜索选项包括图像、视频、地图和粘贴。
Tor Taxi – 【】一个带有多个不同洋葱域链接的启动板网站。它有一个方便的颜色编码系统,用于显示当前关闭的网站。
Darkweb Wiki—【】 一个有点混乱且不经常更新的洋葱站点列表——仍然是一个有价值的资源。
Hunchly –【】 以电子表格的形式提供有关洋葱域上升/下降的每日暗网报告。
IACA Darkweb Tools –【】 国际反犯罪学院提供的免费资源。
Reddit 社区 ——可以找到许多专门针对暗网各个方面的 subreddit,其中一些很受欢迎。但是,有 3 个始终良好且最新:
Discord – 一个新兴的 Reddit 替代品,用于新兴的在线社区和利基主题,Discord 在某些方面已经占据主导地位。虽然我还没有找到值得推荐的公开频道,但您可以使用暗网关键字搜索 可用的 Discord 服务器【】
暗网资源
Ahmia – 如上所述,但专门针对 Tor:
Haystak – 自称为“暗网最大的搜索引擎”,拥有数以千计的索引 .onion 域名——包括一些历史域名。
Kilos – 暗网市场搜索引擎,允许搜索供应商、列表、评论、论坛和论坛帖子。对于跨多个暗网实体进行广泛的基于关键字的搜索很有用。
TOR66—— 在标准搜索之上,这使得“新鲜洋葱”和“随机洋葱”匹配;谨慎行事,这些可以将您带到一些真正随机的站点。
Github 工具
首先,Apurv Singh Gautam 提供的很棒的工具列表可以 在这里找到【】 (但需要注意的是,我还没有使用或测试过所有这些工具)。
Onioff–【】 用于搜索 .onion URL 的 Python 工具。
OnionIngestor—【】用于抓取和收集暗网情报——与 Kibana 仪表板配合使用。
Onion Search– 【】从暗网搜索引擎抓取 .onion URL 的工具。
The Devils Eye– 【】用于在不连接 Tor 的情况下提取 .onion 站点链接和描述。
TorBot –【】 洋葱爬虫,许多附加功能仍在积极开发中。
网页表格抓取(我正在学习Python,尝试创建一个抓取多个页面的函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-19 21:11
)
我正在学习 Python,我正在尝试创建一个函数来从几个不同的网页获取疫苗接种率的网络抓取表 - 我们的数据和世界的 github 存储库。当网络抓取单个表和将其保存到数据框。
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://github.com/owid/covid- ... ot%3B
response = requests.get(url)
response
scraping_html_table_BD = BeautifulSoup(response.content, "lxml")
scraping_html_table_BD = scraping_html_table_BD.find_all("table", "js-csv-data csv-data js-file-line-container")
df = pd.read_html(str(scraping_html_table_BD))
BD_df = df[0]
但是,当我尝试创建一个抓取多个页面的函数时,我运气不佳。我一直在关注这个 网站 的教程、“使用一个脚本抓取多个页面”部分中的 3 以及第 4 和第 5 页上的 StackOverflow 问题。我首先尝试创建一个全局变量,但最终出现错误比如“递归错误:调用 Python 对象时超出了最大递归深度”。这是我管理过的最好的代码,因为它不会产生错误,但我还没有设法将输出保存到全局变量中。我真的很感谢你的帮助。
import pandas as pd
from bs4 import BeautifulSoup
import requests
link_list = ['/Bangladesh.csv',
'/Nepal.csv',
'/Mongolia.csv']
def get_info(page_url):
page = requests.get('https://github.com/owid/covid- ... 27%3B + page_url)
scape = BeautifulSoup(page.text, 'html.parser')
vaccination_rates = scape.find_all("table", "js-csv-data csv-data js-file-line-container")
result = {}
df = pd.read_html(str(vaccination_rates))
vaccination_rates = df[0]
df = pd.DataFrame(vaccination_rates)
print(df)
df.to_csv("testdata.csv", index=False)
for link in link_list:
get_info(link)
编辑:保存到 csv 文件时,我可以查看最终的网页迭代,但不能查看上一个链接中的数据。
new = pd.read_csv('testdata6.csv')
pd.set_option("display.max_rows", None, "display.max_columns", None)
new 查看全部
网页表格抓取(我正在学习Python,尝试创建一个抓取多个页面的函数
)
我正在学习 Python,我正在尝试创建一个函数来从几个不同的网页获取疫苗接种率的网络抓取表 - 我们的数据和世界的 github 存储库。当网络抓取单个表和将其保存到数据框。
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://github.com/owid/covid- ... ot%3B
response = requests.get(url)
response
scraping_html_table_BD = BeautifulSoup(response.content, "lxml")
scraping_html_table_BD = scraping_html_table_BD.find_all("table", "js-csv-data csv-data js-file-line-container")
df = pd.read_html(str(scraping_html_table_BD))
BD_df = df[0]
但是,当我尝试创建一个抓取多个页面的函数时,我运气不佳。我一直在关注这个 网站 的教程、“使用一个脚本抓取多个页面”部分中的 3 以及第 4 和第 5 页上的 StackOverflow 问题。我首先尝试创建一个全局变量,但最终出现错误比如“递归错误:调用 Python 对象时超出了最大递归深度”。这是我管理过的最好的代码,因为它不会产生错误,但我还没有设法将输出保存到全局变量中。我真的很感谢你的帮助。
import pandas as pd
from bs4 import BeautifulSoup
import requests
link_list = ['/Bangladesh.csv',
'/Nepal.csv',
'/Mongolia.csv']
def get_info(page_url):
page = requests.get('https://github.com/owid/covid- ... 27%3B + page_url)
scape = BeautifulSoup(page.text, 'html.parser')
vaccination_rates = scape.find_all("table", "js-csv-data csv-data js-file-line-container")
result = {}
df = pd.read_html(str(vaccination_rates))
vaccination_rates = df[0]
df = pd.DataFrame(vaccination_rates)
print(df)
df.to_csv("testdata.csv", index=False)
for link in link_list:
get_info(link)
编辑:保存到 csv 文件时,我可以查看最终的网页迭代,但不能查看上一个链接中的数据。
new = pd.read_csv('testdata6.csv')
pd.set_option("display.max_rows", None, "display.max_columns", None)
new
网页表格抓取( 会计从业资格考试:url数据如何提取数据?解决方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-19 21:10
会计从业资格考试:url数据如何提取数据?解决方法
)
如何在html页面中提取数据表中的数据内容?
请求的 url 数据
对了,我只抓一张表,希望能提取出关键表的数据。
我要捕获的数据是交易报告,但是HTML标签都是
造成了数据提取的困难。
賣空成交量 成交量</p>
代码 股票名称 股数 (SH) 金额 ($) 股数 (SH) 金额 ($)
1 長和 299,500 27,572,475 2,201,171 202,964,029
2 中電控股 61,000 4,622,825 1,452,853 110,040,699
3 香港中華煤氣 2,939,000 42,694,880 8,024,558 116,691,466
4 九龍倉集團 297,000 17,349,550 3,136,238 183,105,286
5 匯豐控股 1,102,800 73,202,940 8,630,868 572,622,103
6 電能實業 1,016,500 76,262,725 4,876,990 365,926,231
8 電訊盈科 731,000 3,478,240 13,579,323 64,672,175
10 恒隆集團 172,000 5,209,850 967,980 29,308,292
11 恒生銀行 189,000 30,047,370 1,075,185 170,873,130
12 恒基地產 94,000 4,025,500 1,382,533 59,183,598
14 希慎興業 33,000 1,167,900 642,424 22,747,393
16 新鴻基地產 425,000 45,490,800 1,635,959 175,284,039
17 新世界發展 651,000 5,833,670 10,135,381 90,633,244
19 太古股份公司A 132,000 10,405,600 554,962 43,709,235
20 會德豐 72,000 3,407,750 683,368 32,286,993
23 東亞銀行 451,600 14,991,890 1,817,000 60,295,348
27 銀河娛樂 1,134,000 40,408,550 15,089,117 538,712,668
31 航天控股 210,000 211,580 4,367,526 4,386,198
34 九龍建業 31,000 228,260 292,000 2,156,291
35 遠東發展 10,000 33,600 428,075 1,440,321
38 第一拖拉機股份 8,000 38,200 1,634,000 7,825,940
41 鷹君 12,000 422,400 470,146 16,546,562
45 大酒店 35,500 305,605 503,559 4,335,522
url = "http://www.hkex.com.hk/chi/sta ... ot%3B
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
应该如何提取表格的数据内容。
用beautifulsoup怎么这么麻烦,用刀杀鸡
你的网页只有一行数据,格式再简单不过了
可以直接复制页面上的数据,保存为txt,然后用readline、split、正则表达式提取数据,对吧?
解决方案一:
先定位卖空量的位置a=soup.find('a',attrs={'name':'short_ sell'}),然后根据pre->font的相邻关系,一路往下走直到没有列出 6 行结束
结果如下:
[['代號', '股票名稱', '股數(SH)', '金額($)', '股數(SH)', '金額($)'],
['1', '長和', '299,500', '27,572,475', '2,201,171', '202,964,029'],
['2', '中電控股', '61,000', '4,622,825', '1,452,853', '110,040,699'],
['3', '香港中華煤氣', '2,939,000', '42,694,880', '8,024,558', '116,691,466'],
....
源代码
import pprint
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.hkex.com.hk/chi/stat/smstat/dayquot/d170202c.htm')
r.encoding = 'big5'
soup = BeautifulSoup(r.text)
a = soup.find('a', attrs={'name':'short_selling'})
data = []
pre = a.find_parent('pre')
for line in pre.font.text.splitlines():
item = line.strip().split()
if len(item) == 6:
data.append(item)
end = False
for next_pre in pre.next_siblings:
for line in next_pre.font.text.splitlines():
item = line.strip().split()
if len(item) > 7:
item = item[1:2] + ["".join(item[1:-4])] + item[-4:]
elif len(item) < 6:
end = True
break
data.append(item)
if end:
break
pprint.pprint(data)
让我给你一个计划。
因为这些数据都是文本信息,没有标签包围。通过抓包,也没有发现特定的数据查询接口。所以数据应该是服务器生成好的通过html写死的发送给浏览器。
那么发现这些数据项每一个特定的属性都是占用同样的位置大小且居右对齐,而且每一项有特定的格式,可以使用正则表达式进行提取。
具体还是请您自行实现吧。 查看全部
网页表格抓取(
会计从业资格考试:url数据如何提取数据?解决方法
)
如何在html页面中提取数据表中的数据内容?
请求的 url 数据
对了,我只抓一张表,希望能提取出关键表的数据。
我要捕获的数据是交易报告,但是HTML标签都是
造成了数据提取的困难。
賣空成交量 成交量</p>
代码 股票名称 股数 (SH) 金额 ($) 股数 (SH) 金额 ($)
1 長和 299,500 27,572,475 2,201,171 202,964,029
2 中電控股 61,000 4,622,825 1,452,853 110,040,699
3 香港中華煤氣 2,939,000 42,694,880 8,024,558 116,691,466
4 九龍倉集團 297,000 17,349,550 3,136,238 183,105,286
5 匯豐控股 1,102,800 73,202,940 8,630,868 572,622,103
6 電能實業 1,016,500 76,262,725 4,876,990 365,926,231
8 電訊盈科 731,000 3,478,240 13,579,323 64,672,175
10 恒隆集團 172,000 5,209,850 967,980 29,308,292
11 恒生銀行 189,000 30,047,370 1,075,185 170,873,130
12 恒基地產 94,000 4,025,500 1,382,533 59,183,598
14 希慎興業 33,000 1,167,900 642,424 22,747,393
16 新鴻基地產 425,000 45,490,800 1,635,959 175,284,039
17 新世界發展 651,000 5,833,670 10,135,381 90,633,244
19 太古股份公司A 132,000 10,405,600 554,962 43,709,235
20 會德豐 72,000 3,407,750 683,368 32,286,993
23 東亞銀行 451,600 14,991,890 1,817,000 60,295,348
27 銀河娛樂 1,134,000 40,408,550 15,089,117 538,712,668
31 航天控股 210,000 211,580 4,367,526 4,386,198
34 九龍建業 31,000 228,260 292,000 2,156,291
35 遠東發展 10,000 33,600 428,075 1,440,321
38 第一拖拉機股份 8,000 38,200 1,634,000 7,825,940
41 鷹君 12,000 422,400 470,146 16,546,562
45 大酒店 35,500 305,605 503,559 4,335,522
url = "http://www.hkex.com.hk/chi/sta ... ot%3B
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
应该如何提取表格的数据内容。
用beautifulsoup怎么这么麻烦,用刀杀鸡
你的网页只有一行数据,格式再简单不过了
可以直接复制页面上的数据,保存为txt,然后用readline、split、正则表达式提取数据,对吧?
解决方案一:
先定位卖空量的位置a=soup.find('a',attrs={'name':'short_ sell'}),然后根据pre->font的相邻关系,一路往下走直到没有列出 6 行结束
结果如下:
[['代號', '股票名稱', '股數(SH)', '金額($)', '股數(SH)', '金額($)'],
['1', '長和', '299,500', '27,572,475', '2,201,171', '202,964,029'],
['2', '中電控股', '61,000', '4,622,825', '1,452,853', '110,040,699'],
['3', '香港中華煤氣', '2,939,000', '42,694,880', '8,024,558', '116,691,466'],
....
源代码
import pprint
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.hkex.com.hk/chi/stat/smstat/dayquot/d170202c.htm')
r.encoding = 'big5'
soup = BeautifulSoup(r.text)
a = soup.find('a', attrs={'name':'short_selling'})
data = []
pre = a.find_parent('pre')
for line in pre.font.text.splitlines():
item = line.strip().split()
if len(item) == 6:
data.append(item)
end = False
for next_pre in pre.next_siblings:
for line in next_pre.font.text.splitlines():
item = line.strip().split()
if len(item) > 7:
item = item[1:2] + ["".join(item[1:-4])] + item[-4:]
elif len(item) < 6:
end = True
break
data.append(item)
if end:
break
pprint.pprint(data)
让我给你一个计划。
因为这些数据都是文本信息,没有标签包围。通过抓包,也没有发现特定的数据查询接口。所以数据应该是服务器生成好的通过html写死的发送给浏览器。
那么发现这些数据项每一个特定的属性都是占用同样的位置大小且居右对齐,而且每一项有特定的格式,可以使用正则表达式进行提取。
具体还是请您自行实现吧。
网页表格抓取(一下excel文件网页数据的过程,实验环境win7+office2013)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-12 10:09
当然可以,但是使用起来不是很灵活,也不需要等待语言去抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个用于网页数据抓取的excel文件,双击打开文件,选择“数据”-“来自网络”,如下:
2.在弹出的子窗口中,输入要爬取的网页数据。这里使用“Import”进行捕获,如下:
3.导入成功后,抓取网页数据。数据如下,我们需要的数据已经成功抓取到:
4.如果要定时刷新数据,如果要爬取网页数据,可以点击“全部刷新”-“连接属性”自定义刷新频率。默认值为 60 分钟:
在弹出的“选择属性”窗口中抓取网页数据,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的网页数据抓取。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。 查看全部
网页表格抓取(一下excel文件网页数据的过程,实验环境win7+office2013)
当然可以,但是使用起来不是很灵活,也不需要等待语言去抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个用于网页数据抓取的excel文件,双击打开文件,选择“数据”-“来自网络”,如下:
2.在弹出的子窗口中,输入要爬取的网页数据。这里使用“Import”进行捕获,如下:
3.导入成功后,抓取网页数据。数据如下,我们需要的数据已经成功抓取到:
4.如果要定时刷新数据,如果要爬取网页数据,可以点击“全部刷新”-“连接属性”自定义刷新频率。默认值为 60 分钟:
在弹出的“选择属性”窗口中抓取网页数据,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的网页数据抓取。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。
网页表格抓取(我真的很努力尝试提取网络表的一些数据。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-11 11:37
我真的很难从网表中提取一些数据。我过去曾抓取过网络数据,但从未从表格中抓取过,所以我无法计算出来
我尝试了几种变体,但似乎没有任何效果,我已经多次更改类和子节点编号以反映每个项目,但我无法从表中得到任何东西
问)任何人都可以就表类以及如何从中提取提出建议吗?时间
我在这个论坛和其他论坛上阅读了几篇关于刮掉桌子的帖子,但没有任何帮助,因此这篇帖子
''''Data 1
On Error Resume Next
If doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0) Is Nothing Then
wsSheet.Cells(StartRow + myCounter, 1).Value = "-"
Else
On Error Resume Next
wsSheet.Cells(StartRow + myCounter, 1).Value = doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0).innerText
End If
我尝试了以下变体
doc.getElementsByClassName("content")(0)
doc.getElementsByClassName("content")(0)).Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("th").getElementsByTagName("td").Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0)
这是 html 的图像,我正在尝试输入 html 代码但无法让它看起来正确
一如既往地提前感谢 查看全部
网页表格抓取(我真的很努力尝试提取网络表的一些数据。。)
我真的很难从网表中提取一些数据。我过去曾抓取过网络数据,但从未从表格中抓取过,所以我无法计算出来
我尝试了几种变体,但似乎没有任何效果,我已经多次更改类和子节点编号以反映每个项目,但我无法从表中得到任何东西
问)任何人都可以就表类以及如何从中提取提出建议吗?时间
我在这个论坛和其他论坛上阅读了几篇关于刮掉桌子的帖子,但没有任何帮助,因此这篇帖子
''''Data 1
On Error Resume Next
If doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0) Is Nothing Then
wsSheet.Cells(StartRow + myCounter, 1).Value = "-"
Else
On Error Resume Next
wsSheet.Cells(StartRow + myCounter, 1).Value = doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0).innerText
End If
我尝试了以下变体
doc.getElementsByClassName("content")(0)
doc.getElementsByClassName("content")(0)).Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("th").getElementsByTagName("td").Children(0)
doc.getElementsByClassName("content")(0).getElementsByTagName("td").Children(0)
这是 html 的图像,我正在尝试输入 html 代码但无法让它看起来正确
一如既往地提前感谢
网页表格抓取(RPA和爬虫有什么区别?转型进程中的闪耀之星)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-08 05:26
刚刚过去的2019年,是数字化转型过程中极为重要的一年。企业开始走上转型之路,各种技术的应用案例层出不穷。RPA 无疑是这波变革中的一颗闪亮之星。随着越来越多的企业关注RPA,一些问题也随之而来。
有人会直接问我们RPA和爬虫有什么区别。
毫不奇怪,每个人都将 RPA 与爬虫联系在一起。当使用RPA展示功能时,通常可以方便的设置一个RPA采集a网站具体信息的自动化工作流,并生成一个表格来演示数据排序的自动化。快速高效。这项工作看起来与爬虫的应用非常相似,但原理完全不同,只是RPA应用的冰山一角。
如果要回答RPA和爬虫有什么区别,简直就是“天地之别”。接下来,让我们仔细看看它们的区别。
定义
RPA的全称是Robotic Process Automation,即机器过程自动化。通过模仿人类的方式在计算机上进行一系列操作,可以实现在计算机上的所有人类操作行为,如复制、粘贴、数据录入、网页导航、打开、关闭等,并且可以重复按照一定的规律连续运行。
爬虫正式名称为data采集,一般称为spider,通过编程实现,可以自动采集从网上获取数据。获取数据的速度有时非常巨大,甚至可以达到数千万条数据。
使用技术
RPA属于AI人工智能的范畴,RPA通过设计过程模拟人类动作来执行任务。
爬虫使用Python开发脚本,通过发送http请求获取cookie或直接注入网页中获取数据。
适合现场
RPA可以应用于企业的各个部门。可广泛用于财务、人事、供应链、客户、销售和营销,以减少人工重复操作。具体操作层面,可以打开邮件、下载附件、登录网站和系统、读取数据库、移动文件和文件夹、复制粘贴、写入表格数据、网页数据抓取、文档数据抓取,连接系统API,进行if和else判断,进行计算等。
通过模仿一系列人类动作,RPA可以完成多种业务场景。它可以帮助财务部处理发票,帮助项目部审查合同,帮助HR处理新员工入职,并集成到整个供应链系统中,实现订单管理的自动化。也可以是24小时在线客服。
在日常工作中,它可以帮助员工自动采集数据、组织表格,甚至处理电子邮件。总之,企业中重复性和低价值的工作可以交给它,效率会大大提高,人力资源可以转移到更高价值的工作和决策上。借助RPA,企业的生产力将实现爆发式增长,从而可以创造更大的效益。
爬虫主要用于大数据采集,工作场景的局限性非常明显。如果使用不当,甚至适得其反,会给企业带来巨大的法律风险。
原理区别
RPA 像人一样工作,在系统 UI 上像人一样操作,点击鼠标、复制粘贴、打开文件或执行数据 采集 等等。因为它的核心是一个“模拟人”,所以它对系统施加的压力就如同一个人对系统的正常操作一样,没有多余的负载。可以说不会对系统造成任何影响。
爬虫通常使用python语言编写脚本直接操作HTML,可以非常灵活和精致(用正则表达式几乎无所不能)。在应用中主要扮演数据采集的角色,通过接口或者暴力破解的方式解析网页内容获取数据,采集效率高,会给后台造成巨大的负担,因此将被反爬虫机制禁止。
遵守
RPA已在银行、证券、保险、央企、国企、世界500强等各个领域投入使用。甚至国内外政府机构都在使用RPA软件机器人实现“智慧城市”的美好想象”。RPA属于人工智能智能的范畴,符合全球人工智能技术的发展趋势。各国都在鼓励使用RPA帮助企事业单位降本增效、改革升级。
爬虫的合规性视具体情况而定。由于多用于数据采集,爬虫所涉及的工作很容易侵犯个人隐私和企业数据安全,始终存在争议。使用不当会直接造成法律风险甚至严重的法律后果。
以上就是RPA和爬虫的区别,从中我们可以很明显的看出一个好的RPA产品比爬虫更智能、更通用、更安全、更高效、更商业化。显然,爬虫属于过去,而 RPA 创造未来。 查看全部
网页表格抓取(RPA和爬虫有什么区别?转型进程中的闪耀之星)
刚刚过去的2019年,是数字化转型过程中极为重要的一年。企业开始走上转型之路,各种技术的应用案例层出不穷。RPA 无疑是这波变革中的一颗闪亮之星。随着越来越多的企业关注RPA,一些问题也随之而来。
有人会直接问我们RPA和爬虫有什么区别。
毫不奇怪,每个人都将 RPA 与爬虫联系在一起。当使用RPA展示功能时,通常可以方便的设置一个RPA采集a网站具体信息的自动化工作流,并生成一个表格来演示数据排序的自动化。快速高效。这项工作看起来与爬虫的应用非常相似,但原理完全不同,只是RPA应用的冰山一角。
如果要回答RPA和爬虫有什么区别,简直就是“天地之别”。接下来,让我们仔细看看它们的区别。
定义
RPA的全称是Robotic Process Automation,即机器过程自动化。通过模仿人类的方式在计算机上进行一系列操作,可以实现在计算机上的所有人类操作行为,如复制、粘贴、数据录入、网页导航、打开、关闭等,并且可以重复按照一定的规律连续运行。
爬虫正式名称为data采集,一般称为spider,通过编程实现,可以自动采集从网上获取数据。获取数据的速度有时非常巨大,甚至可以达到数千万条数据。
使用技术
RPA属于AI人工智能的范畴,RPA通过设计过程模拟人类动作来执行任务。
爬虫使用Python开发脚本,通过发送http请求获取cookie或直接注入网页中获取数据。
适合现场
RPA可以应用于企业的各个部门。可广泛用于财务、人事、供应链、客户、销售和营销,以减少人工重复操作。具体操作层面,可以打开邮件、下载附件、登录网站和系统、读取数据库、移动文件和文件夹、复制粘贴、写入表格数据、网页数据抓取、文档数据抓取,连接系统API,进行if和else判断,进行计算等。
通过模仿一系列人类动作,RPA可以完成多种业务场景。它可以帮助财务部处理发票,帮助项目部审查合同,帮助HR处理新员工入职,并集成到整个供应链系统中,实现订单管理的自动化。也可以是24小时在线客服。
在日常工作中,它可以帮助员工自动采集数据、组织表格,甚至处理电子邮件。总之,企业中重复性和低价值的工作可以交给它,效率会大大提高,人力资源可以转移到更高价值的工作和决策上。借助RPA,企业的生产力将实现爆发式增长,从而可以创造更大的效益。
爬虫主要用于大数据采集,工作场景的局限性非常明显。如果使用不当,甚至适得其反,会给企业带来巨大的法律风险。
原理区别
RPA 像人一样工作,在系统 UI 上像人一样操作,点击鼠标、复制粘贴、打开文件或执行数据 采集 等等。因为它的核心是一个“模拟人”,所以它对系统施加的压力就如同一个人对系统的正常操作一样,没有多余的负载。可以说不会对系统造成任何影响。
爬虫通常使用python语言编写脚本直接操作HTML,可以非常灵活和精致(用正则表达式几乎无所不能)。在应用中主要扮演数据采集的角色,通过接口或者暴力破解的方式解析网页内容获取数据,采集效率高,会给后台造成巨大的负担,因此将被反爬虫机制禁止。
遵守
RPA已在银行、证券、保险、央企、国企、世界500强等各个领域投入使用。甚至国内外政府机构都在使用RPA软件机器人实现“智慧城市”的美好想象”。RPA属于人工智能智能的范畴,符合全球人工智能技术的发展趋势。各国都在鼓励使用RPA帮助企事业单位降本增效、改革升级。
爬虫的合规性视具体情况而定。由于多用于数据采集,爬虫所涉及的工作很容易侵犯个人隐私和企业数据安全,始终存在争议。使用不当会直接造成法律风险甚至严重的法律后果。
以上就是RPA和爬虫的区别,从中我们可以很明显的看出一个好的RPA产品比爬虫更智能、更通用、更安全、更高效、更商业化。显然,爬虫属于过去,而 RPA 创造未来。
网页表格抓取(尤利西斯伊斯兰教|我正在做以下页面的网络抓取工作:尤利西斯 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-05 08:06
)
尤利西斯人力资源
我正在对以下页面进行网络抓取:COVID,我需要做的是生成一个表格的 csv,该表格显示在页面上,但动态加载了我正在使用 selenium 的数据。问题是即使那样我也找不到收录以下代码的表格:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
#url of the page we want to scrape
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Firefox()
driver.get(url)
# this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
print(len(soup.find_all("table")))
driver.close()
driver.quit()
当我打印表单时,我得到 0,因为它找不到它。
萨姆苏尔伊斯兰教 |
我也在尝试使用数据提取并生成 csv 文件。希望对您有所帮助。
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import csv
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5) # delay for load properly
# # this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
table = soup.select_one('div.contenedor-general')
header = [[a.getText(strip=True,separator=' ')][0].split() for a in table.find_all('tr', {'class': 'header-table'})]
text1 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-1'})]
text2 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-2'})]
with open('outz.csv', 'w') as f:
wr = csv.writer(f, delimiter=',')
wr.writerow(header[0][1:])
for row in text1:
wr.writerow(row)
for row in text2:
wr.writerow(row) 查看全部
网页表格抓取(尤利西斯伊斯兰教|我正在做以下页面的网络抓取工作:尤利西斯
)
尤利西斯人力资源
我正在对以下页面进行网络抓取:COVID,我需要做的是生成一个表格的 csv,该表格显示在页面上,但动态加载了我正在使用 selenium 的数据。问题是即使那样我也找不到收录以下代码的表格:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
#url of the page we want to scrape
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Firefox()
driver.get(url)
# this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
print(len(soup.find_all("table")))
driver.close()
driver.quit()
当我打印表单时,我得到 0,因为它找不到它。
萨姆苏尔伊斯兰教 |
我也在尝试使用数据提取并生成 csv 文件。希望对您有所帮助。
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import csv
url = "https://saluddigital.ssch.gob.mx/covid/"
# initiating the webdriver. Parameter includes the path of the webdriver.
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5) # delay for load properly
# # this is just to ensure that the page is loaded
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
table = soup.select_one('div.contenedor-general')
header = [[a.getText(strip=True,separator=' ')][0].split() for a in table.find_all('tr', {'class': 'header-table'})]
text1 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-1'})]
text2 = [t.text.strip().split() for t in soup.find_all('tr', {'class': 'ringlon-2'})]
with open('outz.csv', 'w') as f:
wr = csv.writer(f, delimiter=',')
wr.writerow(header[0][1:])
for row in text1:
wr.writerow(row)
for row in text2:
wr.writerow(row)
网页表格抓取(我正在尝试从上获取与梦幻足球运动员薪水相关的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-04 20:04
)
我正在尝试从 . 可以在此处找到我尝试采集数据的示例网页:. scsv 格式的数据可以方便地在每个页面上的 html“pre”标签下获得。我首先使用一个 for 循环来生成我想要从中刮取数据的所有 url,但随后我努力将这些页面中的所有数据转换为我想要的格式,一个收录所有刮取数据的最终数据表。我使用第二个 for 循环遍历所有 url,在每个页面上使用 read_html() 函数,然后使用 html_nodes('pre')%>%html_text() 提取感兴趣的数据。问题是,由于我的代码目前运行良好,这只是为收录整个 scsv 的每个页面创建一个大对象,而不是作为收录单个列(周、年、gid、名称、pos、团队、h/a、opt、dk 点数、dk 工资)。相反,我想要一个收录我要抓取的所有页面的这些单独列的数据表,但对网络抓取没有太多经验,也不知道如何解决这个问题。任何帮助将不胜感激。这是我到目前为止编写的代码:
<p>library(purrr)
library(rvest)
library(data.table)
library(stringr)
library(tidyr)
#Declare variables and empty data tables
path1 查看全部
网页表格抓取(我正在尝试从上获取与梦幻足球运动员薪水相关的数据
)
我正在尝试从 . 可以在此处找到我尝试采集数据的示例网页:. scsv 格式的数据可以方便地在每个页面上的 html“pre”标签下获得。我首先使用一个 for 循环来生成我想要从中刮取数据的所有 url,但随后我努力将这些页面中的所有数据转换为我想要的格式,一个收录所有刮取数据的最终数据表。我使用第二个 for 循环遍历所有 url,在每个页面上使用 read_html() 函数,然后使用 html_nodes('pre')%>%html_text() 提取感兴趣的数据。问题是,由于我的代码目前运行良好,这只是为收录整个 scsv 的每个页面创建一个大对象,而不是作为收录单个列(周、年、gid、名称、pos、团队、h/a、opt、dk 点数、dk 工资)。相反,我想要一个收录我要抓取的所有页面的这些单独列的数据表,但对网络抓取没有太多经验,也不知道如何解决这个问题。任何帮助将不胜感激。这是我到目前为止编写的代码:
<p>library(purrr)
library(rvest)
library(data.table)
library(stringr)
library(tidyr)
#Declare variables and empty data tables
path1
网页表格抓取( 如何用几行代码爬下所需数据?答案在这里!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-02 23:02
如何用几行代码爬下所需数据?答案在这里!)
众所周知,一般的爬虫套路无非就是构造请求、解析网页、提取元素、存储数据这几个步骤。requests 库主要用于构造请求,xpath、bs4、css、re 用于提取元素。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
那么,有没有什么办法只用几行代码就可以爬取所需的数据呢?答案是熊猫。自从J哥知道这件神器后,他尝试爬取了多个网页,并赢得了许多战斗。他再舒服不过了!这家伙也太适合初学者玩爬虫了!
本文目录如下:
定义
pandas 中的函数 pd.read_html() 非常强大,可以很方便的抓取表格数据。无需掌握正则表达式或xpath等工具,只需几行代码即可抓取网页数据。
原理表表格数据网页结构
pandas适合抓取表格数据,所以我们首先要知道什么样的网页有表格数据结构(有html基础的大佬可以自行跳过这部分)。
我们先来看一个简单的例子。(快捷键F12可以快速查看网页的HTML结构)
从上面网站可以看出,数据存放在一个table表中,thread是表头,tbody是表数据,tbody中的一个tr对应表中的一行,一个td对应到表中的一个元素。
让我们看另一个例子:
或许你找到规律了,Table结构中展示的表格数据,一般网页结构如下:
...
...
...
...
...
...
...
只要网页有以上结构,就可以尝试用pandas抓取数据。
pandas请求表数据流程
对于网页结构相似的表格数据,pd.read_html可以捕获网页上的所有表格数据,并以DataFrame的形式以列表的形式返回。
pd.read_html 语法和参数
基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
主要参数:
参数解释
io
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
跳过
跳过的行属性,例如 attrs = {'id': 'table'}
实战案例一:爬取世界大学排名(1页数据)
import pandas as pd
import csv
url1 = 'http://www.compassedu.hk/qs'
df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table
df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定了,我们来预览一下爬取的数据:
案例二:抓取新浪财经基金重仓股数据(6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = 'http://vip.stock.finance.sina. ... Fp%3D{page}'.format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print('第{page}页抓取完成'.format(page = i + 1))
df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码就搞定了,还是那么简单。不了解翻页爬虫的可以查看公众号历史“蔡J学Python”原创文章《实战|教你如何使用Python爬虫(附详细源代码)”,如果不能合并DataFrame可以理解,可以查看公众号历史原创文章《Basic|Pandas常用知识点总结(四)》)。
让我们预览爬取的数据:
案例3:抓取证监会披露的IPO数据(217页数据)
import pandas as pd
from pandas import DataFrame
import csv
import time
start = time.time() #程序计时
df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名
for i in range(1,218):
url3 ='http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)
df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名
df3 = pd.concat([df3,df3_2]) #数据合并
print('第{page}页抓取完成'.format(page=i))
df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件
end = time.time()
print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意过滤抓取到的Table数据,主要使用iloc方法。详情请参考公众号上一期原创文章《基础|Pandas常用知识点总结(三)》另外我还加了一个程序时序,就是方便查看爬行速度。
2分14秒爬下217页,4334条数据,相当不错。让我们预览爬取的数据:
需要注意的是,并不是所有的表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但是在网页的源码中,并不是表格格式,而是列表格式。这种形式不适合read_html爬取,必须使用selenium等其他方法。 查看全部
网页表格抓取(
如何用几行代码爬下所需数据?答案在这里!)
众所周知,一般的爬虫套路无非就是构造请求、解析网页、提取元素、存储数据这几个步骤。requests 库主要用于构造请求,xpath、bs4、css、re 用于提取元素。对于一个完整的爬虫来说,代码量可以从几十行到上百行不等。初学者的学习成本相对较高。
那么,有没有什么办法只用几行代码就可以爬取所需的数据呢?答案是熊猫。自从J哥知道这件神器后,他尝试爬取了多个网页,并赢得了许多战斗。他再舒服不过了!这家伙也太适合初学者玩爬虫了!
本文目录如下:
定义
pandas 中的函数 pd.read_html() 非常强大,可以很方便的抓取表格数据。无需掌握正则表达式或xpath等工具,只需几行代码即可抓取网页数据。
原理表表格数据网页结构
pandas适合抓取表格数据,所以我们首先要知道什么样的网页有表格数据结构(有html基础的大佬可以自行跳过这部分)。
我们先来看一个简单的例子。(快捷键F12可以快速查看网页的HTML结构)
从上面网站可以看出,数据存放在一个table表中,thread是表头,tbody是表数据,tbody中的一个tr对应表中的一行,一个td对应到表中的一个元素。
让我们看另一个例子:
或许你找到规律了,Table结构中展示的表格数据,一般网页结构如下:
...
...
...
...
...
...
...
只要网页有以上结构,就可以尝试用pandas抓取数据。
pandas请求表数据流程
对于网页结构相似的表格数据,pd.read_html可以捕获网页上的所有表格数据,并以DataFrame的形式以列表的形式返回。
pd.read_html 语法和参数
基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
主要参数:
参数解释
io
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
跳过
跳过的行属性,例如 attrs = {'id': 'table'}
实战案例一:爬取世界大学排名(1页数据)
import pandas as pd
import csv
url1 = 'http://www.compassedu.hk/qs'
df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table
df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定了,我们来预览一下爬取的数据:
案例二:抓取新浪财经基金重仓股数据(6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = 'http://vip.stock.finance.sina. ... Fp%3D{page}'.format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print('第{page}页抓取完成'.format(page = i + 1))
df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码就搞定了,还是那么简单。不了解翻页爬虫的可以查看公众号历史“蔡J学Python”原创文章《实战|教你如何使用Python爬虫(附详细源代码)”,如果不能合并DataFrame可以理解,可以查看公众号历史原创文章《Basic|Pandas常用知识点总结(四)》)。
让我们预览爬取的数据:
案例3:抓取证监会披露的IPO数据(217页数据)
import pandas as pd
from pandas import DataFrame
import csv
import time
start = time.time() #程序计时
df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名
for i in range(1,218):
url3 ='http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)
df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名
df3 = pd.concat([df3,df3_2]) #数据合并
print('第{page}页抓取完成'.format(page=i))
df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件
end = time.time()
print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意过滤抓取到的Table数据,主要使用iloc方法。详情请参考公众号上一期原创文章《基础|Pandas常用知识点总结(三)》另外我还加了一个程序时序,就是方便查看爬行速度。
2分14秒爬下217页,4334条数据,相当不错。让我们预览爬取的数据:
需要注意的是,并不是所有的表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但是在网页的源码中,并不是表格格式,而是列表格式。这种形式不适合read_html爬取,必须使用selenium等其他方法。
网页表格抓取(网站页面数据抓取插件允许我们将数据从网站抓取到本地 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-31 01:23
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。
查看全部
网页表格抓取(网站页面数据抓取插件允许我们将数据从网站抓取到本地
)
网站页面数据抓取插件,允许我们从网站直接抓取数据到我们的本地或页面。网站网页抓取(又称ScreenScraping、WebDataExtraction、WebHarvesting等)是一种用于从网站中提取大量数据的技术,将数据提取并保存到我们的网站/在数据库中。
使用 网站 页面数据抓取插件,我们可以一次创建多个抓取任务。可视化的界面让我们的操作变得简单,不需要我们专业的编程知识就可以完成爬取(如图)。
一、URL 视觉捕获
网站页面抓取软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作变得异常简单,我们只需要在图中的顺序中点击,就可以帮助我们进行单次抓取或者预设配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同的是我们只需要选择一个链接到我们要爬取的页面我们的网站。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们用于多个抓取任务。
二、关键词匹配泛爬
输入我们的关键词,匹配全网热门平台的内容,为我们抓取相关的热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
三、自动抓取
Autocrawl 将自动从我们选择的源页面中提取所有 url,并将任何新帖子添加到我们的网站。例如,假设我们的数据抓取任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以设置自动抓取到我们的数据抓取博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 的链接。
1.删除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2.自动化:网站页面数据抓取插件将根据预选或我们自己的预选递归地自动化每个页面的标题、标签、类别和图像。
3.从源页面选择一个标题或添加我们自己的。
4.我们可以选择源页面的多个区域,包括图片发布数据。
5.从源页面中选择一个类别或创建一个新类别。
6.标签:从源页面中选择标签或添加我们自己的标签。
7.特色图片:从源页面中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
网站页面数据采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。
关于网站页面数据采集的分享到此结束。如果你觉得有用,请点赞。大家的支持是博主更新的动力。

