
网站内容抓取工具
网站内容抓取工具(网站已经上线半个月了,为什么连首页都没收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-05 07:00
很多刚接触SEO的新手或公司经常会有这样的疑问:“网站上线半个月了,为什么首页都没有收录”?
相信很多SEO朋友都知道,在没有外链的情况下,很难被搜索引擎网站快速收录。不过君龙网络科技资深优化师表示,其实这个时候只要好好利用百度站长后台工具,还是可以达到快收录的效果的。那么,该怎么做呢?一起来了解一下吧。
第一次一、站长平台网站验证,添加百度统计代码
以百度为例,新站建站成功,正确填框内容后,应该去百度站长平台,添加网站并验证,这些步骤很简单,我经常用文件验证,对那些不懂代码的人来说简单快速。另外,建议增加百度统计。新站不管有流量还是有实用价值,先做。无论如何,这将在几个步骤中完成。作者测试了这两个步骤对收录很有好处。在其他平台上的操作类似的建议是使用搜索引擎的官方统计工具。
在 二、 提交机器人和站点地图,以及自动推送功能
当搜索引擎输入网站时,会先读取robots和sitemap这两个文件,并遵守文件中的协议。在站长平台上提交这两个文件,并进行检测和更新,可以引导蜘蛛爬取网站内容。因此,做好机器人和站点地图就显得尤为重要。
关于这两个文件的创建和使用,大家可以在百度上搜索相关内容,花一点时间就可以了解。最简单的方法就是创建两个TXT文件夹,改名为robots.txt和sitemap.txt,然后写入内容。sitemap.txt比较简单,把网站里面的所有链接依次复制就可以了。而已。最后上传到 网站 服务器。
另外,还可以在链接提交中使用自动推送,这个功能很强大,网站每次更新内容,都能及时推送到搜索引擎,蜘蛛可以发现新的内容立即收录 帮助很大。操作也很简单。
编号三、多用途爬虫诊断工具
经过测试,爬行诊断可以吸引蜘蛛。当首页不是收录的时候,我一天要爬2次以上。这是作者一直以来的做法。另外,这个worker可以查看网页的代码,从蜘蛛的角度查看网页的内容,还可以查看是否有黑链接。
解决收录的第一步是让蜘蛛发现网页。新站点之所以不收录和收录慢,是因为搜索引擎蜘蛛不知道这个网站,如果没有爬取内容,就没有索引。一般蜘蛛可以通过链接爬取网站,爬取网页。一般新站点是没有外链的,所以今天分享的方法不讲外链。返回搜狐,查看更多 查看全部
网站内容抓取工具(网站已经上线半个月了,为什么连首页都没收录?)
很多刚接触SEO的新手或公司经常会有这样的疑问:“网站上线半个月了,为什么首页都没有收录”?
相信很多SEO朋友都知道,在没有外链的情况下,很难被搜索引擎网站快速收录。不过君龙网络科技资深优化师表示,其实这个时候只要好好利用百度站长后台工具,还是可以达到快收录的效果的。那么,该怎么做呢?一起来了解一下吧。
第一次一、站长平台网站验证,添加百度统计代码
以百度为例,新站建站成功,正确填框内容后,应该去百度站长平台,添加网站并验证,这些步骤很简单,我经常用文件验证,对那些不懂代码的人来说简单快速。另外,建议增加百度统计。新站不管有流量还是有实用价值,先做。无论如何,这将在几个步骤中完成。作者测试了这两个步骤对收录很有好处。在其他平台上的操作类似的建议是使用搜索引擎的官方统计工具。
在 二、 提交机器人和站点地图,以及自动推送功能
当搜索引擎输入网站时,会先读取robots和sitemap这两个文件,并遵守文件中的协议。在站长平台上提交这两个文件,并进行检测和更新,可以引导蜘蛛爬取网站内容。因此,做好机器人和站点地图就显得尤为重要。
关于这两个文件的创建和使用,大家可以在百度上搜索相关内容,花一点时间就可以了解。最简单的方法就是创建两个TXT文件夹,改名为robots.txt和sitemap.txt,然后写入内容。sitemap.txt比较简单,把网站里面的所有链接依次复制就可以了。而已。最后上传到 网站 服务器。
另外,还可以在链接提交中使用自动推送,这个功能很强大,网站每次更新内容,都能及时推送到搜索引擎,蜘蛛可以发现新的内容立即收录 帮助很大。操作也很简单。
编号三、多用途爬虫诊断工具
经过测试,爬行诊断可以吸引蜘蛛。当首页不是收录的时候,我一天要爬2次以上。这是作者一直以来的做法。另外,这个worker可以查看网页的代码,从蜘蛛的角度查看网页的内容,还可以查看是否有黑链接。
解决收录的第一步是让蜘蛛发现网页。新站点之所以不收录和收录慢,是因为搜索引擎蜘蛛不知道这个网站,如果没有爬取内容,就没有索引。一般蜘蛛可以通过链接爬取网站,爬取网页。一般新站点是没有外链的,所以今天分享的方法不讲外链。返回搜狐,查看更多
网站内容抓取工具(ScreamingFrogSEOSpiderforMac是一个网站爬虫软件吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-05 06:18
Screaming Frog SEO Spider for Mac 是一款专门为抓取 URL 进行分析而设计的网络爬虫开发工具。您可以使用此软件快速抓取网站中可能出现的断开链接和服务器错误,或识别网站中的临时和永久重定向链接循环,还可以检查仪表板中可能出现的重复问题,例如URL 、页面标题、描述和内容。喜欢这个软件?
软件介绍
Screaming Frog SEO Spider for Mac 是一个 网站 爬虫,允许您爬取 网站 URL 并获取关键元素、分析和审计技术以及现场 SEO。
特征
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
快速总结
错误 - 客户端错误,例如链接断开和服务器错误(无响应、4XX、5XX)。
重定向 - 永久、临时重定向(3XX 响应)和 JS 重定向。
阻止的 URL - robots.txt 协议不允许查看和审查 URL。
被阻止的资源 - 在呈现模式下查看和审核被阻止的资源。
外部链接 - 所有外部链接及其状态代码。
协议 - URL 是安全的 (HTTPS) 还是不安全的 (HTTP)。
URI 问题 - 非 ASCII 字符、下划线、大写字符、参数或长 URL。
Duplicate Pages - Hash/MD5checksums 算法检查精确的重复页面。
页面标题 - 缺失、重复、超过 65 个字符、短、像素宽度被截断、相同或大于 h1。
元描述 - 缺失、重复、超过 156 个字符、短、像素宽度被截断或多个。
元关键字 - 主要用于参考,因为它们不被 Google、Bing 或 Yahoo 使用。
文件大小 - URL 和图像的大小。
响应时间。
最后修改的标题。
页面(爬行)深度。
字数。
H1 - 缺失、重复、超过 70 个字符、多个。
H2 - 缺失、重复、超过 70 个字符、多个。
Metabots - 索引、无索引、关注、nofollow、noarchive、nosnippet、noodp、noydir 等。
元刷新 - 包括目标页面和时间延迟。 查看全部
网站内容抓取工具(ScreamingFrogSEOSpiderforMac是一个网站爬虫软件吗?)
Screaming Frog SEO Spider for Mac 是一款专门为抓取 URL 进行分析而设计的网络爬虫开发工具。您可以使用此软件快速抓取网站中可能出现的断开链接和服务器错误,或识别网站中的临时和永久重定向链接循环,还可以检查仪表板中可能出现的重复问题,例如URL 、页面标题、描述和内容。喜欢这个软件?
软件介绍
Screaming Frog SEO Spider for Mac 是一个 网站 爬虫,允许您爬取 网站 URL 并获取关键元素、分析和审计技术以及现场 SEO。
特征
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
快速总结
错误 - 客户端错误,例如链接断开和服务器错误(无响应、4XX、5XX)。
重定向 - 永久、临时重定向(3XX 响应)和 JS 重定向。
阻止的 URL - robots.txt 协议不允许查看和审查 URL。
被阻止的资源 - 在呈现模式下查看和审核被阻止的资源。
外部链接 - 所有外部链接及其状态代码。
协议 - URL 是安全的 (HTTPS) 还是不安全的 (HTTP)。
URI 问题 - 非 ASCII 字符、下划线、大写字符、参数或长 URL。
Duplicate Pages - Hash/MD5checksums 算法检查精确的重复页面。
页面标题 - 缺失、重复、超过 65 个字符、短、像素宽度被截断、相同或大于 h1。
元描述 - 缺失、重复、超过 156 个字符、短、像素宽度被截断或多个。
元关键字 - 主要用于参考,因为它们不被 Google、Bing 或 Yahoo 使用。
文件大小 - URL 和图像的大小。
响应时间。
最后修改的标题。
页面(爬行)深度。
字数。
H1 - 缺失、重复、超过 70 个字符、多个。
H2 - 缺失、重复、超过 70 个字符、多个。
Metabots - 索引、无索引、关注、nofollow、noarchive、nosnippet、noodp、noydir 等。
元刷新 - 包括目标页面和时间延迟。
网站内容抓取工具(关键词热门排行及指数百度排行榜:八、网站流量统计工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2022-04-03 20:07
做一个网站优化者,不仅要懂得优化网站,还要懂得使用工具加快优化进度。本文将推广网站SEO优化是今天给大家一个非常实用的优化工具!
网站一款实用的SEO优化辅助工具!!
一、搜索引擎爬取内容模拟器
它可以模拟蜘蛛爬取指定的网页,包括文本、链接、关键字和描述信息等。
二、页面相似度检测工具
检查两个页面之间的相似度(如果相似度超过80%,你可能会被扣分)
三、站点地图制作工具
1、在线创建小型网站地图文件
2、使用工具制作媒体网站地图
在这里给大家推荐一款非常好用的免费网站地图制作软件:Site Map Builder
官方下载地址:
四、SEO优化辅助
中文分词()
五、百度索引
以图表的形式展示指定关键词在百度的关注度和媒体关注度。登录后,您可以定义一个列表。
六、关键词热门排名和索引
百度排名:
Overture关键词工具:
七、网站管理员工具
1、SEO 站长工具:
2、爱站工具:
3、站长助手:
八、网站流量统计工具
1、百度统计:
2、CNZZ 数据专家:
*是每个网站随时监控自己网站流量的实用工具
九、坏链接检查器
1、Xenu Link Sleuth()
2、W3C GLink 检查器()
十、网站历史查询工具
互联网档案馆(The Internet Archive)保存了自 1996 年以来在 Alexa 搜索引擎的帮助下获得的 网站 资料()
网站优化所需的SEO工具可以根据不同的用途分类:
反向链接检查工具:Yahoo Site Explorer、Open Site Explorer、Majestic SEO
关键字查询工具:百度索引、Google AdWords 关键字工具
关键词排名工具:百度搜索榜、搜狗热搜榜
搜索引擎工具:百度站长平台、360站长平台、搜狗站长平台
SEO效果分析工具:Alexa、CNZZ、百度统计
网站分析工具:站长平台
网站营销动力工具:Vortex 营销诊断工具
通过白帽技术对网站进行优化,也就是形式化的方式,结合网站营销力的优化,可以提升网站的排名,一定程度上提升营销力,带来更多流量和更高的转化率。以上网站SEO优化工具,后续会继续分享给大家。
大家好,我是乐见,欢迎大家关注乐见创业团队,分享创业知识,只讲大家可以入门的创业赚钱方法,分享最接地气的SEO赚钱实用干货。专注自媒体创业、营销、变现等干货分享。关注我了解更多。 查看全部
网站内容抓取工具(关键词热门排行及指数百度排行榜:八、网站流量统计工具)
做一个网站优化者,不仅要懂得优化网站,还要懂得使用工具加快优化进度。本文将推广网站SEO优化是今天给大家一个非常实用的优化工具!
网站一款实用的SEO优化辅助工具!!
一、搜索引擎爬取内容模拟器
它可以模拟蜘蛛爬取指定的网页,包括文本、链接、关键字和描述信息等。

二、页面相似度检测工具
检查两个页面之间的相似度(如果相似度超过80%,你可能会被扣分)
三、站点地图制作工具
1、在线创建小型网站地图文件
2、使用工具制作媒体网站地图
在这里给大家推荐一款非常好用的免费网站地图制作软件:Site Map Builder
官方下载地址:

四、SEO优化辅助
中文分词()
五、百度索引
以图表的形式展示指定关键词在百度的关注度和媒体关注度。登录后,您可以定义一个列表。

六、关键词热门排名和索引
百度排名:
Overture关键词工具:
七、网站管理员工具
1、SEO 站长工具:
2、爱站工具:
3、站长助手:

八、网站流量统计工具
1、百度统计:
2、CNZZ 数据专家:
*是每个网站随时监控自己网站流量的实用工具

九、坏链接检查器
1、Xenu Link Sleuth()
2、W3C GLink 检查器()
十、网站历史查询工具
互联网档案馆(The Internet Archive)保存了自 1996 年以来在 Alexa 搜索引擎的帮助下获得的 网站 资料()
网站优化所需的SEO工具可以根据不同的用途分类:
反向链接检查工具:Yahoo Site Explorer、Open Site Explorer、Majestic SEO
关键字查询工具:百度索引、Google AdWords 关键字工具
关键词排名工具:百度搜索榜、搜狗热搜榜
搜索引擎工具:百度站长平台、360站长平台、搜狗站长平台

SEO效果分析工具:Alexa、CNZZ、百度统计
网站分析工具:站长平台
网站营销动力工具:Vortex 营销诊断工具
通过白帽技术对网站进行优化,也就是形式化的方式,结合网站营销力的优化,可以提升网站的排名,一定程度上提升营销力,带来更多流量和更高的转化率。以上网站SEO优化工具,后续会继续分享给大家。
大家好,我是乐见,欢迎大家关注乐见创业团队,分享创业知识,只讲大家可以入门的创业赚钱方法,分享最接地气的SEO赚钱实用干货。专注自媒体创业、营销、变现等干货分享。关注我了解更多。
网站内容抓取工具(用Python编写的数据包工具被称为第二个Wireshark)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-03 20:06
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
斯卡皮
Scapy 是另一个不错的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试、网络发现。
下载 Scapy:
libcrafter
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数常见协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载库:
耶尔森氏菌
Yersinia 是一款功能强大的网络渗透测试工具,能够对各种网络协议进行渗透测试。如果你正在寻找一个数据包捕获工具,你可以试试这个工具。
下载耶尔森氏菌:
打包ETH
packETH 是另一种数据包处理工具。它是 Linux GUI 的以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以在此工具中设置数据包的数量和数据包之间的延迟,以及修改各种数据包内容。
下载包ETH:
Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
位扭
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络中生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
利宾斯
Libtins 也是制作、发送、嗅探和解析网络数据包的绝佳工具。该工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大、更高效地执行任务。
下载库:
网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
该工具最初名为 Hobbit,于 1995 年发布。
下载网猫:
电线编辑
WireEdit 是一个功能齐全的所见即所得网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。此工具可免费使用,但您必须联系公司以获得访问权限。它支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11等
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载 WireEdit:
epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
片段路由
Fragroute 是一个数据包处理工具,用于拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
毛塞赞
Mausezahn 是一个网络数据包编辑器,可让您发送各种网络数据包。此工具用于防火墙和 IDS 的渗透测试,但您可以在您的网络中使用此工具来查找安全漏洞。您还可以使用此工具来测试您的网络是否可以免受 DOS 攻击。值得注意的是,它使您可以完全控制 NIC 卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 可选 RX 模式用于抖动测量、Syslog 协议。
下载毛泽恩:
EIGRP 工具
这是一个 EIGRP 数据包生成器和嗅探器组合。它是为测试 EIGRP 路由协议的安全性而开发的。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它适用于 Linux、Mac OS 和 BSD 平台。
下载 EIGRP 工具: 查看全部
网站内容抓取工具(用Python编写的数据包工具被称为第二个Wireshark)
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
斯卡皮
Scapy 是另一个不错的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试、网络发现。
下载 Scapy:
libcrafter
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数常见协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载库:
耶尔森氏菌
Yersinia 是一款功能强大的网络渗透测试工具,能够对各种网络协议进行渗透测试。如果你正在寻找一个数据包捕获工具,你可以试试这个工具。
下载耶尔森氏菌:
打包ETH
packETH 是另一种数据包处理工具。它是 Linux GUI 的以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以在此工具中设置数据包的数量和数据包之间的延迟,以及修改各种数据包内容。
下载包ETH:
Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
位扭
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络中生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
利宾斯
Libtins 也是制作、发送、嗅探和解析网络数据包的绝佳工具。该工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大、更高效地执行任务。
下载库:
网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
该工具最初名为 Hobbit,于 1995 年发布。
下载网猫:
电线编辑
WireEdit 是一个功能齐全的所见即所得网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。此工具可免费使用,但您必须联系公司以获得访问权限。它支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11等
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载 WireEdit:
epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
片段路由
Fragroute 是一个数据包处理工具,用于拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
毛塞赞
Mausezahn 是一个网络数据包编辑器,可让您发送各种网络数据包。此工具用于防火墙和 IDS 的渗透测试,但您可以在您的网络中使用此工具来查找安全漏洞。您还可以使用此工具来测试您的网络是否可以免受 DOS 攻击。值得注意的是,它使您可以完全控制 NIC 卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 可选 RX 模式用于抖动测量、Syslog 协议。
下载毛泽恩:
EIGRP 工具
这是一个 EIGRP 数据包生成器和嗅探器组合。它是为测试 EIGRP 路由协议的安全性而开发的。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它适用于 Linux、Mac OS 和 BSD 平台。
下载 EIGRP 工具:
网站内容抓取工具(sitemap更名为链接提交后,百度之前提交归并到了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-01 11:29
项目投资找A5快速获取精准代理商名单
4月27日sitemap更名为链接提交后,合并原url提交,升级支持批量提交功能。社区版主李跃辉很快发现了这个变化,并尝试了新站点的提交。效果还不错。我想和你分享:
新站建成上线后,首先要做的任务当然是提交给百度,让蜘蛛爬行——这是基本常识。百度之前推出了网站登录地址()提交新站点,但是提交的时候看到一句“你提交的符合相关标准的网址会被百度搜索引擎收录@ > 标准1个月内。被处理。百度不保证能收录@>你提交的网站”有点担心,一个月太长了。
今天给大家推荐另一个提交词条:百度站长平台链接提交工具手动提交。链接提交工具是之前站点地图工具的升级版。除了主动推送和站点地图外,还加入了之前的url提交工具。这里不再有一个月的期限,蜘蛛抓取几乎是实时的,只要网站内容符合百度收录@>标准,都会很快处理收录@>。看到这里,有人说:切~~~,我们都是用主动推送和sitemap,还是手动提交。我想说的是:大哥!作为一个刚刚上线的站点,sitemap权限不是你想要的。哇!
以下是使用手动提交的步骤和注意事项:
1、首先当然是在百度站长平台验证网站
2、在数据提交下选择手动提交
注意:
1、提交网址时请填写已验证站点的链接。链接应包括首页、频道页、栏目页和您希望百度尽快收录@>的内容页。
2、一次最多提交 20 个,每行一个链接。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网站内容抓取工具(sitemap更名为链接提交后,百度之前提交归并到了)
项目投资找A5快速获取精准代理商名单
4月27日sitemap更名为链接提交后,合并原url提交,升级支持批量提交功能。社区版主李跃辉很快发现了这个变化,并尝试了新站点的提交。效果还不错。我想和你分享:
新站建成上线后,首先要做的任务当然是提交给百度,让蜘蛛爬行——这是基本常识。百度之前推出了网站登录地址()提交新站点,但是提交的时候看到一句“你提交的符合相关标准的网址会被百度搜索引擎收录@ > 标准1个月内。被处理。百度不保证能收录@>你提交的网站”有点担心,一个月太长了。
今天给大家推荐另一个提交词条:百度站长平台链接提交工具手动提交。链接提交工具是之前站点地图工具的升级版。除了主动推送和站点地图外,还加入了之前的url提交工具。这里不再有一个月的期限,蜘蛛抓取几乎是实时的,只要网站内容符合百度收录@>标准,都会很快处理收录@>。看到这里,有人说:切~~~,我们都是用主动推送和sitemap,还是手动提交。我想说的是:大哥!作为一个刚刚上线的站点,sitemap权限不是你想要的。哇!
以下是使用手动提交的步骤和注意事项:
1、首先当然是在百度站长平台验证网站
2、在数据提交下选择手动提交
注意:
1、提交网址时请填写已验证站点的链接。链接应包括首页、频道页、栏目页和您希望百度尽快收录@>的内容页。
2、一次最多提交 20 个,每行一个链接。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网站内容抓取工具( VPS多多小编2022-03-23?百度没有收录网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-30 06:10
VPS多多小编2022-03-23?百度没有收录网站)
为什么网站内容没有被百度提取收录
VPS多多编辑器2022-03-23
为什么网站内容没有被百度收录收录?
百度没有收录网站,可能是服务器本站的原因。
目前百度蜘蛛的爬取方式有两种,一种是主动爬取,一种是在百度站长平台的链接提交工具中获取数据。
如果网站内容很久没有收录了,建议使用主动推送功能推送首页数据,有利于抓取内页数据。
当然,这些都是针对新站点收录 的解决方案。如果不是新站,不是收录的原因是什么?
百度没有收录网站内容的原因分析。
首先,网站内容质量。
如果网站的大量内容是借用别人的,会导致百度没有收录,百度也加强了对合集网站的审核。
搜索引擎倾向于拥有高质量的原创内容,原创文章更容易满足用户需求,提升用户体验。
原创内容独特,在网上找不到想要的文章,网站很容易脱颖而出,获得百度给出的权重。
其次,蜘蛛爬行失败。
百度站长平台研究百度蜘蛛的日常爬取情况。网站更新内容时,可以将此内容提交给百度,也可以通过百度站长平台的爬取诊断进行测试,看爬取是否正常。
三是主动推送爬取配额。
如果网站页数突然增加,会影响蜘蛛抓取收录,所以网站在保证稳定访问的同时要注意网站的安全。
第四,Robots.txt 文件。
机器人文件告诉搜索引擎哪些页面可以和不能被抓取。有的站长会屏蔽一些不重要的文件,禁止蜘蛛爬行,可能会屏蔽重要的页面,可以查看Robots。
标题 五、 经常更改。
如果网站的标题变化频繁,搜索引擎将不知道网站的内容表达了什么,网站的内容与标题不匹配,影响时间收录 页面,因此错过了 收录 的最佳时机。
新网站百度非收录注意事项:
1、新站点的服务器/空间不稳定,有时打不开网站,使得蜘蛛难以抓取网页;
2、网站内容含有违禁词,违禁词被搜索引擎命中,此类网站将不被允许收录;
3、新站点被黑、跳转或挂断,导致站点无法正常访问,搜索引擎不是收录不安全站点;
4、域名双解析中不要操作301重定向,搜索引擎不知道哪个是主域名;
5、网站内容不完善会上线。频繁修改内容会导致搜索引擎不喜欢该网页,不会导致收录;
6、网站标题过长,列表堆积,作弊和快速排序优化导致页面不是收录;
7、新站排名收录不稳定也正常;
8、网站机器人被封禁,导致蜘蛛无法抓取网页,所以没有收录等;
以上为网站百度非分享内容收录,新网站百度非收录内容分享,希望对你有所帮助。 查看全部
网站内容抓取工具(
VPS多多小编2022-03-23?百度没有收录网站)
为什么网站内容没有被百度提取收录
VPS多多编辑器2022-03-23
为什么网站内容没有被百度收录收录?
百度没有收录网站,可能是服务器本站的原因。

目前百度蜘蛛的爬取方式有两种,一种是主动爬取,一种是在百度站长平台的链接提交工具中获取数据。
如果网站内容很久没有收录了,建议使用主动推送功能推送首页数据,有利于抓取内页数据。
当然,这些都是针对新站点收录 的解决方案。如果不是新站,不是收录的原因是什么?
百度没有收录网站内容的原因分析。
首先,网站内容质量。
如果网站的大量内容是借用别人的,会导致百度没有收录,百度也加强了对合集网站的审核。
搜索引擎倾向于拥有高质量的原创内容,原创文章更容易满足用户需求,提升用户体验。
原创内容独特,在网上找不到想要的文章,网站很容易脱颖而出,获得百度给出的权重。
其次,蜘蛛爬行失败。
百度站长平台研究百度蜘蛛的日常爬取情况。网站更新内容时,可以将此内容提交给百度,也可以通过百度站长平台的爬取诊断进行测试,看爬取是否正常。
三是主动推送爬取配额。
如果网站页数突然增加,会影响蜘蛛抓取收录,所以网站在保证稳定访问的同时要注意网站的安全。
第四,Robots.txt 文件。
机器人文件告诉搜索引擎哪些页面可以和不能被抓取。有的站长会屏蔽一些不重要的文件,禁止蜘蛛爬行,可能会屏蔽重要的页面,可以查看Robots。
标题 五、 经常更改。
如果网站的标题变化频繁,搜索引擎将不知道网站的内容表达了什么,网站的内容与标题不匹配,影响时间收录 页面,因此错过了 收录 的最佳时机。
新网站百度非收录注意事项:
1、新站点的服务器/空间不稳定,有时打不开网站,使得蜘蛛难以抓取网页;
2、网站内容含有违禁词,违禁词被搜索引擎命中,此类网站将不被允许收录;
3、新站点被黑、跳转或挂断,导致站点无法正常访问,搜索引擎不是收录不安全站点;
4、域名双解析中不要操作301重定向,搜索引擎不知道哪个是主域名;
5、网站内容不完善会上线。频繁修改内容会导致搜索引擎不喜欢该网页,不会导致收录;
6、网站标题过长,列表堆积,作弊和快速排序优化导致页面不是收录;
7、新站排名收录不稳定也正常;
8、网站机器人被封禁,导致蜘蛛无法抓取网页,所以没有收录等;
以上为网站百度非分享内容收录,新网站百度非收录内容分享,希望对你有所帮助。
网站内容抓取工具( 百度pider访问您的网站有什么影响?连接异常)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-26 03:11
百度pider访问您的网站有什么影响?连接异常)
一、什么是抓取异常?
对于普通用户在互联网上可以正常访问的内容,百度蜘蛛无法正常访问和爬取的情况属于异常爬取。
二、异常爬行对网站有何影响?
对于网站内容量大且无法正常抓取的情况,搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价。在爬取、索引和权重方面都会受到一定程度的负面影响,最终会影响到从百度获得的流量网站。
三、什么是服务器连接异常?
服务器连接异常有两种情况:一种是网站不稳定,百度pider在尝试连接时暂时无法连接到你的网站服务器;另一个是百度pider一直无法连接到你的网站>服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能无法正常运行。请检查网站的Web服务器(如Apache、IIS)是否安装并正常运行,并使用浏览器检查主页面是否可以正常访问。您的 网站 和主机也可能会阻止百度蜘蛛的访问。您需要检查 网站 和主机的防火墙。
四、什么是网络运营商异常?
有两家网络运营商:中国电信和中国联通。百度pider无法通过中国电信或中国网通访问您的网站。如果出现这种情况,您需要联系网络服务商,或者购买二级服务或CDN服务的空间。
五、什么是 DNS 例外?
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站的IP地址不对,或者你的域名服务商封杀了Baiduspider。请使用 whois 或主机检查您的 网站 IP 地址是否正确且可解析。如果没有,请联系域名注册商以更新您的 IP 地址。
六、什么是 IP 阻塞?
IP Blocking:限制网络的现有IP地址,禁止IP段内的用户访问内容。
仅当您的 网站 不希望百度 Pider 访问时才需要此设置。如果您希望百度pider访问您的网站,请检查百度pider IP是否被错误添加到相关设置中。你的网站所在的空间服务商也可能会封禁百度IP。此时,您需要联系您的服务提供商以更改设置。
七、什么是运营单位禁令?
UA 是用户代理。服务器通过UA识别访问者。当一个网站访问指定的UA并返回异常页面(如403500)或跳转到另一个页面时,称为UA阻塞。
仅当您不希望百度蜘蛛访问您的 网站 时才需要此设置。如果你想让百度Pide访问你的网站,用户代理中是否有百度Pide相关设置并及时修改。
八、什么是死链接?
无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接。
协议死链接:页面的TCP协议状态/HTTP协议状态明确指出死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限的页面,与原创内容无关。
对于死链接,建议将死链接提交给百度站长平台死链接工具进行处理,这样搜索引擎可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
九、什么是异常跳转?
将网络请求重定向到另一个位置是一个跳转。异常跳转是指以下几种情况
一、当前页面为无效页面(内容已被删除,死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
注意:如果长时间重定向到其他域名,比如更换网站上的域名,百度建议使用301重定向协议进行设置。
十、有哪些例外?
百度引荐来源网址例外:网页返回的行为与百度引荐来源网址的正常内容不同。
百度 UA 的例外:返回百度 UA 的网页的行为与页面的原创内容不同。
JS跳转异常:网页加载了百度无法识别的JS跳转代码,用户通过搜索结果进入网页后跳转。
意外阻塞导致压力过大:百度会根据网站规模、流量等信息自动设置合理的爬取压力,但在压力控制异常等异常情况下,服务器会受到意外保护根据自己的负载阻塞。在这种情况下,请在返回码中返回 503(表示“服务不可用”),以便百度蜘蛛过段时间再次尝试获取链接。如果 网站 空闲,则 网站 将被成功获取。 查看全部
网站内容抓取工具(
百度pider访问您的网站有什么影响?连接异常)

一、什么是抓取异常?
对于普通用户在互联网上可以正常访问的内容,百度蜘蛛无法正常访问和爬取的情况属于异常爬取。
二、异常爬行对网站有何影响?
对于网站内容量大且无法正常抓取的情况,搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价。在爬取、索引和权重方面都会受到一定程度的负面影响,最终会影响到从百度获得的流量网站。
三、什么是服务器连接异常?
服务器连接异常有两种情况:一种是网站不稳定,百度pider在尝试连接时暂时无法连接到你的网站服务器;另一个是百度pider一直无法连接到你的网站>服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能无法正常运行。请检查网站的Web服务器(如Apache、IIS)是否安装并正常运行,并使用浏览器检查主页面是否可以正常访问。您的 网站 和主机也可能会阻止百度蜘蛛的访问。您需要检查 网站 和主机的防火墙。
四、什么是网络运营商异常?
有两家网络运营商:中国电信和中国联通。百度pider无法通过中国电信或中国网通访问您的网站。如果出现这种情况,您需要联系网络服务商,或者购买二级服务或CDN服务的空间。
五、什么是 DNS 例外?
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站的IP地址不对,或者你的域名服务商封杀了Baiduspider。请使用 whois 或主机检查您的 网站 IP 地址是否正确且可解析。如果没有,请联系域名注册商以更新您的 IP 地址。
六、什么是 IP 阻塞?
IP Blocking:限制网络的现有IP地址,禁止IP段内的用户访问内容。
仅当您的 网站 不希望百度 Pider 访问时才需要此设置。如果您希望百度pider访问您的网站,请检查百度pider IP是否被错误添加到相关设置中。你的网站所在的空间服务商也可能会封禁百度IP。此时,您需要联系您的服务提供商以更改设置。
七、什么是运营单位禁令?
UA 是用户代理。服务器通过UA识别访问者。当一个网站访问指定的UA并返回异常页面(如403500)或跳转到另一个页面时,称为UA阻塞。
仅当您不希望百度蜘蛛访问您的 网站 时才需要此设置。如果你想让百度Pide访问你的网站,用户代理中是否有百度Pide相关设置并及时修改。
八、什么是死链接?
无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接。
协议死链接:页面的TCP协议状态/HTTP协议状态明确指出死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限的页面,与原创内容无关。
对于死链接,建议将死链接提交给百度站长平台死链接工具进行处理,这样搜索引擎可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
九、什么是异常跳转?
将网络请求重定向到另一个位置是一个跳转。异常跳转是指以下几种情况
一、当前页面为无效页面(内容已被删除,死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
注意:如果长时间重定向到其他域名,比如更换网站上的域名,百度建议使用301重定向协议进行设置。
十、有哪些例外?
百度引荐来源网址例外:网页返回的行为与百度引荐来源网址的正常内容不同。
百度 UA 的例外:返回百度 UA 的网页的行为与页面的原创内容不同。
JS跳转异常:网页加载了百度无法识别的JS跳转代码,用户通过搜索结果进入网页后跳转。
意外阻塞导致压力过大:百度会根据网站规模、流量等信息自动设置合理的爬取压力,但在压力控制异常等异常情况下,服务器会受到意外保护根据自己的负载阻塞。在这种情况下,请在返回码中返回 503(表示“服务不可用”),以便百度蜘蛛过段时间再次尝试获取链接。如果 网站 空闲,则 网站 将被成功获取。
网站内容抓取工具(收集电子邮件地址、竞争分析、网站检查、订价分析和客户数据收集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-25 23:01
采集电子邮件地址、竞争分析、网站检查、定价分析和客户数据采集——这些只是您可能需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,做诸如手部运动之类的事情是痛苦的、低效的,而且在某些情况下是不可能的。幸运的是,今天有各种各样的工具可以满足这些需求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一些编码知识并为更大、更困难的任务而设计的高级工具。html
Iconico HTML 文本提取器
假设您正在浏览竞争对手的 网站 并想要提取文本,或者您想要查看页面后面的 HTML 代码。但不幸的是,您发现右键单击被禁用,复制和粘贴也是如此。如今,许多 Web 开发人员正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,提取功能就像在网上冲浪一样简单。网络
UiPath
UIPath 有一套自动化流程的工具,包括一个网页内容抓取工具。使用该工具并获得几乎任何您想要的数据很容易 - 只需打开页面,进入工具中的设计菜单,然后单击“网络抓取”。除了网络刮板,屏幕刮板还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中抓取文本、表格数据和其他相关信息。api
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文档和内容。然后,您可以将此数据导出到 XML 文件、CSV 文件、JSON 或可选地使用 API。提取和导出数据后,可以使用 BI 工具对其进行分析和报告。互联网
HTMLtoText
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您所要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和一些其他详细信息,然后单击转换,您将获得所需的文本信息。刮擦
(有一个类似的工具 - )工具
八分法
Octoparse 的特点是它提供了一个“点击式”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送到各种文件格式。该工具包括从页面中提取电子邮件地址、从工作板中提取工作列表等功能。该工具适用于动态和静态网页和云采集(配置采集任务关闭也可以采集数据)。它提供了一个可以满足大多数用例的免费版本,而付费版本功能更丰富。学习
如果您抓取 网站 进行竞争分析,您可能会被禁止参与此活动。由于 Octoparse 收录一个在循环中识别您的 IP 地址的函数,它可以禁止您通过您的 IP 使用它。大数据
刮擦
这个免费的开源工具使用网络爬虫从 网站 中提取信息,并且需要一些高级技能和编码知识才能使用。但是,如果您愿意学习以自己的方式使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌都使用此工具。由于它是一个开源工具,这为用户提供了相当多的社区支持。网站
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将该信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,或者您可以创建计划作业以在特定时间提取您需要的数据。您可以从搜索引擎结果、网页甚至幻灯片中提取数据。最重要的是,Kimono 会在您设置每个工作流程时构建一个 API。这意味着当您返回 网站 以提取更多数据时,无需重新发明轮子。用户界面
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中的至少一个工具应该收录您需要的解决方案。无论您想要什么价格,您都应该能够找到您需要的工具。找出并决定哪一个最适合您。意识到大数据在蓬勃发展的业务中的重要性,采集所需信息的能力对您来说非常重要。
编译自:Dzone 查看全部
网站内容抓取工具(收集电子邮件地址、竞争分析、网站检查、订价分析和客户数据收集)
采集电子邮件地址、竞争分析、网站检查、定价分析和客户数据采集——这些只是您可能需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,做诸如手部运动之类的事情是痛苦的、低效的,而且在某些情况下是不可能的。幸运的是,今天有各种各样的工具可以满足这些需求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一些编码知识并为更大、更困难的任务而设计的高级工具。html
Iconico HTML 文本提取器
假设您正在浏览竞争对手的 网站 并想要提取文本,或者您想要查看页面后面的 HTML 代码。但不幸的是,您发现右键单击被禁用,复制和粘贴也是如此。如今,许多 Web 开发人员正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,提取功能就像在网上冲浪一样简单。网络
UiPath
UIPath 有一套自动化流程的工具,包括一个网页内容抓取工具。使用该工具并获得几乎任何您想要的数据很容易 - 只需打开页面,进入工具中的设计菜单,然后单击“网络抓取”。除了网络刮板,屏幕刮板还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中抓取文本、表格数据和其他相关信息。api
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文档和内容。然后,您可以将此数据导出到 XML 文件、CSV 文件、JSON 或可选地使用 API。提取和导出数据后,可以使用 BI 工具对其进行分析和报告。互联网
HTMLtoText
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您所要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和一些其他详细信息,然后单击转换,您将获得所需的文本信息。刮擦
(有一个类似的工具 - )工具
八分法
Octoparse 的特点是它提供了一个“点击式”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送到各种文件格式。该工具包括从页面中提取电子邮件地址、从工作板中提取工作列表等功能。该工具适用于动态和静态网页和云采集(配置采集任务关闭也可以采集数据)。它提供了一个可以满足大多数用例的免费版本,而付费版本功能更丰富。学习
如果您抓取 网站 进行竞争分析,您可能会被禁止参与此活动。由于 Octoparse 收录一个在循环中识别您的 IP 地址的函数,它可以禁止您通过您的 IP 使用它。大数据
刮擦
这个免费的开源工具使用网络爬虫从 网站 中提取信息,并且需要一些高级技能和编码知识才能使用。但是,如果您愿意学习以自己的方式使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌都使用此工具。由于它是一个开源工具,这为用户提供了相当多的社区支持。网站
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将该信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,或者您可以创建计划作业以在特定时间提取您需要的数据。您可以从搜索引擎结果、网页甚至幻灯片中提取数据。最重要的是,Kimono 会在您设置每个工作流程时构建一个 API。这意味着当您返回 网站 以提取更多数据时,无需重新发明轮子。用户界面
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中的至少一个工具应该收录您需要的解决方案。无论您想要什么价格,您都应该能够找到您需要的工具。找出并决定哪一个最适合您。意识到大数据在蓬勃发展的业务中的重要性,采集所需信息的能力对您来说非常重要。
编译自:Dzone
网站内容抓取工具(爬取一个网站的法律问题及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-24 06:41
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get('')soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
打印(汤。美化())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 URL 似乎收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
Dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in Dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = Dollar_tree_list[2] # 一个有代表性的例子 example_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']打印(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty listfor i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href)# check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # 再建立一个有代表性的例子 soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type='application/ld+json' 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type='application/ld+json')print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
类型(arco_json)打印(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # 为 city_hrefs 中的链接初始化空列表: locpage = requests.get(link) # 请求页面信息 locsoup = BeautifulSoup(locpage.text, 'html.parser') # 解析页面内容 locinfo = locsoup.find_all( type ='application/ld+json') # 提取特定元素 loccont = locinfo[1].contents[0] # 从 bs4 元素集合中获取内容 locjson = json.loads(loccont) # 转换为json locaddr = locjson[' address '] # 获取地址 locs_dict. append(locaddr) # 将地址添加到列表中
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, 'family_dollar_ID_locations.csv', sep = ',', index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = 'https://www.walgreens.com/storelistings/storesbycity.jsp?requestType=locator&state=ID'driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoup import jsonfrom pandas import DataFrame as dfpage = requests. get('./locations/')soup = BeautifulSoup(page.text, 'html.parser')# 查找所有状态链接state_list = soup. find_all(class_ = 'itemlist')state_links = []for i in state_list:cont = i. 内容[0]属性=续。attrshrefs = attr['href']state_links. append(hrefs)# find all city linkscity_links = []for link in state_links:page = requests. 获取(链接)汤= BeautifulSoup(page.text,'html。
parser') familydollar_list = 汤。find_all(class_ = 'itemlist') for store in familydollar_list:cont = store. 内容[0]属性=续。attrscity_hrefs = attr['href']city_links. append(city_hrefs)# 获取单独的商店链接store_links = []for link in city_links:locpage = requests. get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup. find_all(type='application/ld+json') for i in locinfo:loccont = i. 内容[0]locjson = json。加载(loccont)尝试:store_url = locjson['url']store_links.
append(store_url)except:pass# 获取地址和地理位置信息stores = []for store in store_links:storepage = requests. get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup. find_all(type='application/ld+json') for i in storeinfo:storecont=i. 内容[0]storejson = json. 加载(storecont)尝试:store_addr = storejson['address']store_addr. 更新(storejson['geo'])商店。append(store_addr)except:pass# 最终数据解析stores_df = df. from_records(商店)stores_df。
drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = 'Family Dollar'df. to_csv(stores_df, 'family_dollar_locations.csv', sep = ',', index = False)
作者注:本文改编自我于 2020 年 2 月 9 日在俄勒冈州波特兰市的 PyCascades 上的演讲。
通过: 查看全部
网站内容抓取工具(爬取一个网站的法律问题及解决办法(一))
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面

爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get('')soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
打印(汤。美化())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。

家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 URL 似乎收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
Dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in Dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = Dollar_tree_list[2] # 一个有代表性的例子 example_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']打印(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty listfor i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href)# check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # 再建立一个有代表性的例子 soup2 = BeautifulSoup(page2.text, 'html.parser')

家庭美元地图和代码
地址信息嵌套在 type='application/ld+json' 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type='application/ld+json')print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
类型(arco_json)打印(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # 为 city_hrefs 中的链接初始化空列表: locpage = requests.get(link) # 请求页面信息 locsoup = BeautifulSoup(locpage.text, 'html.parser') # 解析页面内容 locinfo = locsoup.find_all( type ='application/ld+json') # 提取特定元素 loccont = locinfo[1].contents[0] # 从 bs4 元素集合中获取内容 locjson = json.loads(loccont) # 转换为json locaddr = locjson[' address '] # 获取地址 locs_dict. append(locaddr) # 将地址添加到列表中
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, 'family_dollar_ID_locations.csv', sep = ',', index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:

虽然“查看页面源代码”提供了有关请求将获得什么的代码:

如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = 'https://www.walgreens.com/storelistings/storesbycity.jsp?requestType=locator&state=ID'driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:

家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoup import jsonfrom pandas import DataFrame as dfpage = requests. get('./locations/')soup = BeautifulSoup(page.text, 'html.parser')# 查找所有状态链接state_list = soup. find_all(class_ = 'itemlist')state_links = []for i in state_list:cont = i. 内容[0]属性=续。attrshrefs = attr['href']state_links. append(hrefs)# find all city linkscity_links = []for link in state_links:page = requests. 获取(链接)汤= BeautifulSoup(page.text,'html。
parser') familydollar_list = 汤。find_all(class_ = 'itemlist') for store in familydollar_list:cont = store. 内容[0]属性=续。attrscity_hrefs = attr['href']city_links. append(city_hrefs)# 获取单独的商店链接store_links = []for link in city_links:locpage = requests. get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup. find_all(type='application/ld+json') for i in locinfo:loccont = i. 内容[0]locjson = json。加载(loccont)尝试:store_url = locjson['url']store_links.
append(store_url)except:pass# 获取地址和地理位置信息stores = []for store in store_links:storepage = requests. get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup. find_all(type='application/ld+json') for i in storeinfo:storecont=i. 内容[0]storejson = json. 加载(storecont)尝试:store_addr = storejson['address']store_addr. 更新(storejson['geo'])商店。append(store_addr)except:pass# 最终数据解析stores_df = df. from_records(商店)stores_df。
drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = 'Family Dollar'df. to_csv(stores_df, 'family_dollar_locations.csv', sep = ',', index = False)
作者注:本文改编自我于 2020 年 2 月 9 日在俄勒冈州波特兰市的 PyCascades 上的演讲。
通过:
网站内容抓取工具(免费进行数据提取是可以的,怎么克服这些规则?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-24 01:07
免费数据提取是可能的,但它有一些缺点。比如网络不够稳定,IP容易被封。事实上,数据采集中最大的开销是使用代理服务器,网络爬虫使用代理服务器来防止 网站 检测网络爬虫,因为大多数 网站 不允许对它们进行自动化活动,所以您需要采取措施克服这些规则。以下是两种不同的网页抓取方法:
一、如果网站存储了他们所有关于HTML前端的信息,可以直接使用代码下载HTML内容,提取有用信息。
步骤:
1、检查 网站HTML
你想刮
2、,使用代码访问网站的URL,下载页面上的所有HTML内容
3、将下载格式化为可读格式
4、提取有用信息并以结构化格式保存
5、对于在网站多个页面上显示的信息,您可能需要重复步骤2-4以获得完整信息。
这种方法简单明了。但是,如果 网站 的前端结构发生变化,则需要相应地调整代码。
二、如果网站将数据存储在API中,用户每次访问网站网站都会查询API,可以模拟请求查询数据直接来自 API
步骤
1、检查要抓取的 URL 的 XHR Web 部分
2、找到为您提供所需数据的请求-响应
3、在您的代码中,模拟请求并根据请求类型(post 或 get)以及请求标头和有效负载从 API 检索数据。一般来说,从 API 获取的数据格式非常简洁。
4、提取你需要的有用信息
5、对于查询大小有限的 API,您将需要使用“for 循环”来重复检索所有数据
如果您能找到 API 请求,这绝对是首选方法。您收到的数据将更加结构化和稳定。这是因为与 网站 前端相比,公司不太可能更改其后端 API。但是,它比第一种方法稍微复杂一些,尤其是在需要身份验证时。 查看全部
网站内容抓取工具(免费进行数据提取是可以的,怎么克服这些规则?)
免费数据提取是可能的,但它有一些缺点。比如网络不够稳定,IP容易被封。事实上,数据采集中最大的开销是使用代理服务器,网络爬虫使用代理服务器来防止 网站 检测网络爬虫,因为大多数 网站 不允许对它们进行自动化活动,所以您需要采取措施克服这些规则。以下是两种不同的网页抓取方法:

一、如果网站存储了他们所有关于HTML前端的信息,可以直接使用代码下载HTML内容,提取有用信息。
步骤:
1、检查 网站HTML
你想刮
2、,使用代码访问网站的URL,下载页面上的所有HTML内容
3、将下载格式化为可读格式
4、提取有用信息并以结构化格式保存
5、对于在网站多个页面上显示的信息,您可能需要重复步骤2-4以获得完整信息。
这种方法简单明了。但是,如果 网站 的前端结构发生变化,则需要相应地调整代码。
二、如果网站将数据存储在API中,用户每次访问网站网站都会查询API,可以模拟请求查询数据直接来自 API
步骤
1、检查要抓取的 URL 的 XHR Web 部分
2、找到为您提供所需数据的请求-响应
3、在您的代码中,模拟请求并根据请求类型(post 或 get)以及请求标头和有效负载从 API 检索数据。一般来说,从 API 获取的数据格式非常简洁。
4、提取你需要的有用信息
5、对于查询大小有限的 API,您将需要使用“for 循环”来重复检索所有数据
如果您能找到 API 请求,这绝对是首选方法。您收到的数据将更加结构化和稳定。这是因为与 网站 前端相比,公司不太可能更改其后端 API。但是,它比第一种方法稍微复杂一些,尤其是在需要身份验证时。
网站内容抓取工具(为什么这些内容部分使用百度推荐有什么好处?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-24 01:03
一般来说,每个网站内容版块都有一个站点推荐阅读,比如这个博客,右边的内容也有一个推荐阅读,如下:
为什么这些内容部分使用百度推荐?使用百度推荐有什么好处?
百度推荐系统实现的前提是了解你的网站的所有内容,在进行分析推荐之前,基本原则是:
一种。用户第一次访问页面->触发JS代码->爬取页面->分析页面相关性
湾。用户二次访问页面->触发JS代码->获取推荐数据
百度推荐的具体实现如何?无论我们如何沟通,我们只需要关心推荐的过程。百度必须爬取网站的页面,才能达到推荐的效果。这是一个技术上永远无法绕过的链接。
为什么要使用百度推荐?首先,在文章页面左侧或底部添加百度推荐后,必须为用户推荐合适的内容。它必须立即掌握我们所有的 网站 内容,然后对其进行分析和分类,然后将其呈现给用户。这是一个无法绕过的链接,足以用于抓取目的。
为什么百度推荐的抓取很重要?试想一下,如果我们被百度推荐,我们会如何评价这个产品的质量?显然,用户数、展示次数、点击率、覆盖率等指标对我们有用。覆盖率是多少?如果一个 网站 有数百万页,你的建议可以在 80W 页面上,你的覆盖率是 80%。这个指标决定了百度推荐一定要把握好我们的页面,努力做到覆盖。只有这样,他们才能提高他们的展示、用户、点击等指标,也就是他们的核心KPI就是这个覆盖率。
也就是说,只要你用百度推荐,你的页面可能是百度收录,这比等蜘蛛爬要开心多了。您所要做的就是让点击器一次点击您的所有页面!
如何评估推荐的质量?
推荐质量的评价主要从推荐带来的流量和质量来衡量:
1、推荐带来流量“量”:点击推荐内容带来网站浏览量(pv),可直接在百度统计报告中查看!
2、推荐带来的流量质量:推荐带来的流量质量(平均访问时间、平均页面数、跳出率等)!
是不是有一定的原因,有兴趣的朋友可以去百度推荐一下,要不要用就看你了,不过我已经准备好了试用效果,和大家分享一下使用方法和效果将来!
【SEO问题解决】为什么网站都是原创,而关键词没有排名?
“为什么我的 网站 是 原创 但关键字没有排名?” 我已经为我的徒弟解决了这个问题,但我发现很多人仍然问我。今天陪SEO给大家详细解释一下是什么原因?在解释它们之间的各种问题之前,我们应该先了解一下原创内容是什么。根据百科对原文内容的解读,其内容如下:
1、作者主动提出的物质或精神成果,不抄袭和模仿,内容和形式具有独特的个性。
2、作者本人创作的具有文学、艺术或科学性质的作品,具有社会共识的价值。指的是自己写的文章,没有抄袭或者抄袭。(注:第3条不妥,但已经是互联网上的习惯规则,应该承认。)因此,站长和SEO从业者所说的“原创”应该是第3条所指的。描述的情况,只要是自己写的,就是他们的原创不抄袭别人的内容。它不要求“具有独特个性的物质或精神成就”或“社会共识价值”,即“原创”内容不等于“有价值”内容。正是这一点伴随着 SEO 总是增加“价值” 当谈到原创内容时,即“原创价值内容”。因为原创不代表价值,站长和SEO从业者所说的“原创”大多澄清文章是自己写的,不是抄袭别人的,所以文章的内容质量未知。非常重要的是,在文件中输入的内容在键盘被擦拭时也可以被认为是原创的,但是这个“原创”对于普通用户来说并没有真正的意义,更不用说任何阅读价值了。同样的,即使所有的文章都没有偏离网站的主题,但是文章没有实际的价值信息可以传达给用户,只有行业,那么这个“原创" 不值得。所以创造力不等于价值。虽然搜索引擎不能直接分析 原创<
在经营网站的过程中,网站管理员和SEO从业者不应该宣传他们有多少原创,而应该宣传他们网站上的内容是否与他们的目标用户相关潜在用户具有价值。事实上,在很多为原创做广告的网站作品中,很多内容都是围绕着要实现的关键词组装起来的,并不是特别具有可读性和价值好的。网站的内容很多,原创的内容很多,但是用户不错,老用户数量巨大。即使内容不是原创,它在搜索引擎中的排名和流量也会更好。还有很多网站原创内容比例很大,但是内容质量参差不齐,或者服务器响应慢,或者内容页面添加了很多广告。这严重影响了用户在网站中的阅读体验或其他问题,导致长期坚持原创内容不足以在搜索引擎中获得好的排名和流量。能够从目标用户需求的角度编写网站的所有内容。但是,随着国内网络的发展,任何一个网站都不可能让原创的所有内容都对用户具有性和价值。事实上,网站 操作并不完全需要 原创 内容。运营网站做长期SEO,内容需求要以用户价值为基础,以原创为补充。因此,在为网站做内容优化策略和内容编写时,首先要学会转置。假设你是目标用户,你想通过网站得到什么信息,网站可以帮你解决什么问题,能不能快速准确的找到产品或服务。网站您需要的服务等。
豆豆SEO最后,请网友们辩论意见:如何选择靠谱的SEO公司?
我们要找一家靠谱的优化公司。我们可以在百度上搜索“region + seo”这个词,在百度首页找到置顶网站。像这样的网站,我们平时注意自己的品牌是不会骗客户钱的。在为我们优化之前,我们通常会提前收取百分之几的费用,然后在排名完成后补上余额。如果排名失败,我们会将之前支付的款项退还给我们。这样我们的交易风险就会小很多。 查看全部
网站内容抓取工具(为什么这些内容部分使用百度推荐有什么好处?(组图))
一般来说,每个网站内容版块都有一个站点推荐阅读,比如这个博客,右边的内容也有一个推荐阅读,如下:
为什么这些内容部分使用百度推荐?使用百度推荐有什么好处?
百度推荐系统实现的前提是了解你的网站的所有内容,在进行分析推荐之前,基本原则是:
一种。用户第一次访问页面->触发JS代码->爬取页面->分析页面相关性
湾。用户二次访问页面->触发JS代码->获取推荐数据
百度推荐的具体实现如何?无论我们如何沟通,我们只需要关心推荐的过程。百度必须爬取网站的页面,才能达到推荐的效果。这是一个技术上永远无法绕过的链接。
为什么要使用百度推荐?首先,在文章页面左侧或底部添加百度推荐后,必须为用户推荐合适的内容。它必须立即掌握我们所有的 网站 内容,然后对其进行分析和分类,然后将其呈现给用户。这是一个无法绕过的链接,足以用于抓取目的。
为什么百度推荐的抓取很重要?试想一下,如果我们被百度推荐,我们会如何评价这个产品的质量?显然,用户数、展示次数、点击率、覆盖率等指标对我们有用。覆盖率是多少?如果一个 网站 有数百万页,你的建议可以在 80W 页面上,你的覆盖率是 80%。这个指标决定了百度推荐一定要把握好我们的页面,努力做到覆盖。只有这样,他们才能提高他们的展示、用户、点击等指标,也就是他们的核心KPI就是这个覆盖率。
也就是说,只要你用百度推荐,你的页面可能是百度收录,这比等蜘蛛爬要开心多了。您所要做的就是让点击器一次点击您的所有页面!
如何评估推荐的质量?
推荐质量的评价主要从推荐带来的流量和质量来衡量:
1、推荐带来流量“量”:点击推荐内容带来网站浏览量(pv),可直接在百度统计报告中查看!
2、推荐带来的流量质量:推荐带来的流量质量(平均访问时间、平均页面数、跳出率等)!
是不是有一定的原因,有兴趣的朋友可以去百度推荐一下,要不要用就看你了,不过我已经准备好了试用效果,和大家分享一下使用方法和效果将来!
【SEO问题解决】为什么网站都是原创,而关键词没有排名?
“为什么我的 网站 是 原创 但关键字没有排名?” 我已经为我的徒弟解决了这个问题,但我发现很多人仍然问我。今天陪SEO给大家详细解释一下是什么原因?在解释它们之间的各种问题之前,我们应该先了解一下原创内容是什么。根据百科对原文内容的解读,其内容如下:
1、作者主动提出的物质或精神成果,不抄袭和模仿,内容和形式具有独特的个性。
2、作者本人创作的具有文学、艺术或科学性质的作品,具有社会共识的价值。指的是自己写的文章,没有抄袭或者抄袭。(注:第3条不妥,但已经是互联网上的习惯规则,应该承认。)因此,站长和SEO从业者所说的“原创”应该是第3条所指的。描述的情况,只要是自己写的,就是他们的原创不抄袭别人的内容。它不要求“具有独特个性的物质或精神成就”或“社会共识价值”,即“原创”内容不等于“有价值”内容。正是这一点伴随着 SEO 总是增加“价值” 当谈到原创内容时,即“原创价值内容”。因为原创不代表价值,站长和SEO从业者所说的“原创”大多澄清文章是自己写的,不是抄袭别人的,所以文章的内容质量未知。非常重要的是,在文件中输入的内容在键盘被擦拭时也可以被认为是原创的,但是这个“原创”对于普通用户来说并没有真正的意义,更不用说任何阅读价值了。同样的,即使所有的文章都没有偏离网站的主题,但是文章没有实际的价值信息可以传达给用户,只有行业,那么这个“原创" 不值得。所以创造力不等于价值。虽然搜索引擎不能直接分析 原创<
在经营网站的过程中,网站管理员和SEO从业者不应该宣传他们有多少原创,而应该宣传他们网站上的内容是否与他们的目标用户相关潜在用户具有价值。事实上,在很多为原创做广告的网站作品中,很多内容都是围绕着要实现的关键词组装起来的,并不是特别具有可读性和价值好的。网站的内容很多,原创的内容很多,但是用户不错,老用户数量巨大。即使内容不是原创,它在搜索引擎中的排名和流量也会更好。还有很多网站原创内容比例很大,但是内容质量参差不齐,或者服务器响应慢,或者内容页面添加了很多广告。这严重影响了用户在网站中的阅读体验或其他问题,导致长期坚持原创内容不足以在搜索引擎中获得好的排名和流量。能够从目标用户需求的角度编写网站的所有内容。但是,随着国内网络的发展,任何一个网站都不可能让原创的所有内容都对用户具有性和价值。事实上,网站 操作并不完全需要 原创 内容。运营网站做长期SEO,内容需求要以用户价值为基础,以原创为补充。因此,在为网站做内容优化策略和内容编写时,首先要学会转置。假设你是目标用户,你想通过网站得到什么信息,网站可以帮你解决什么问题,能不能快速准确的找到产品或服务。网站您需要的服务等。
豆豆SEO最后,请网友们辩论意见:如何选择靠谱的SEO公司?
我们要找一家靠谱的优化公司。我们可以在百度上搜索“region + seo”这个词,在百度首页找到置顶网站。像这样的网站,我们平时注意自己的品牌是不会骗客户钱的。在为我们优化之前,我们通常会提前收取百分之几的费用,然后在排名完成后补上余额。如果排名失败,我们会将之前支付的款项退还给我们。这样我们的交易风险就会小很多。
网站内容抓取工具(SEO插件排名数学阅读索引您需要将您的网站和所有网络内容编入索引)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 15:36
SEO插件排名数学
阅读指数
您需要将您的 网站 和所有 Web 内容编入索引,以便从自然搜索中获得流量,及时索引内容是 SEO 的重要组成部分。如果没有索引,搜索引擎将无法找到您的 网站,这意味着您的 网站 将无法排名,并且没有人会在搜索结果中找到它。而且,如果发生这种情况,您将失去可能转化为潜在客户和客户的潜在流量。
Rank Math 的即时索引功能允许您向启用的搜索引擎提交 URL,并帮助您将 网站 及其内容编入索引,即使您不需要使用任何这些 网站 管理工具进行配置网站 的。让我们看看功能如何帮助您将 URL 提交到 Bing 和 .
1、这是什么?
是一项有效爬取 网站 的引以为豪的举措,从而减少了爬取足迹。各种引擎都采用了这个协议。
该协议的工作原理是允许 网站 向 API 提交一次 URL,该 URL 将与所有参与的搜索引擎共享。因此,您只需提交一次 网站 更改和 URL,所有参与的搜索引擎都会知道您的 网站 上的最新更改,以便更快地抓取、索引和反映这些更改在搜索结果中。
当您开始提交 URL 时,搜索引擎想要验证这些提交是否合法,并且来自 网站 本身,而不是来自任何恶意元素。因此,搜索引擎期望 网站 生成和验证唯一的 API 密钥。
幸运的是,Rank Math 会自动为您的 网站 生成一个 API 密钥,将其动态托管在您的 网站 上,并将其提供给搜索引擎,因此您不必费心费力,并且更专注于在您的 网站 上创建和管理内容。
2、如何配置自动 URL 提交?
要启用,请转到 Dashboard > Rank Math > Dashboard > Modules 并启用 Instant Index 模块,如下所示:
如何使用排名数学?
其余的可以在 Rank Math >> > 中配置。您可以选择/取消选择要自动提交的任何内容。选择帖子类型后,请确保 Rank Math 已生成 API 密钥。最后,单击“保存更改”以保存您的首选项。
如何使用排名数学?
现在,当您在 网站 上发布或编辑新帖子时,Rank Math 将自动将 URL 提交给 API。但是请注意,Rank Math 不会自动提交设置为的 URL。
3、手动提交网址
Rank Math 为手动提交 URL 提供了几种不同的选项。这是他们:
3.1、批量提交网址
要手动提交 URL,只需转到 Rank Math >> 提交 URL。您可以在此处为您的博客文章、主页或任何其他 Web 内容添加多个 URL(每行一个)。
然后单击提交 URL 按钮,所有添加的 URL 都将提交索引以进行索引,而无需实际访问 网站 管理工具或使用 API 密钥对其进行配置。
如何使用排名数学?3.2、提交个人帖子/页面
除了即时索引设置中的提交 URL 功能外,您还可以随时从编辑器中的帖子页面提交帖子(或页面)。
在帖子页面上,当您将鼠标悬停在帖子上时,您会看到一行选项。选择:选项,如下图。
如何使用排名数学?
当您的帖子成功提交后,您将在页面顶部看到类似于下图的通知。
如何使用排名数学?3.3、即时索引批量操作
在某些情况下,您可能需要从帖子页面提交多个 URL。在这种情况下,逐个提交 URL 会很繁琐,而 Rank Math 提供了批量操作,因此您可以节省时间。
要使用批量操作,请选择要提交的帖子。然后从批量操作中选择即时索引:提交页面选项,然后单击应用按钮。
如何使用排名数学?4、管理 API 密钥
您可以通过 " " 设置下的 Rank Math > " " 设置来管理 Rank Math 为协议生成的 API 密钥。
如何使用排名数学?4.1、更改界面密钥
API 密钥字段显示 Rank Math 自动为您的 网站 生成的 API 密钥。此 API 密钥可帮助您证明您的 网站 的所有权。
如果第三方知道 API 密钥,您始终可以通过单击“更改密钥”选项重新生成新密钥。Rank Math 将在几分钟内为您的 网站 生成一个新的 API 密钥。
如何使用排名数学?4.2、检查 API 密钥位置
如前所述,Rank Math 动态托管 API 密钥并将其提供给搜索引擎。如果您希望检查您的 API 密钥是否可供搜索引擎访问,您可以单击 API 密钥位置下的“检查密钥”按钮。将打开一个新选项卡并指向 Rank Math 托管 API 密钥的位置。
如何使用排名数学?
如果新标签显示您的 API 密钥,您可以放心,它将提供给搜索引擎以验证您的 网站(前提是此页面未被 bots.txt 阻止)。
如何使用排名数学?5、查看历史
要查看您提交的 URL,您可以随时访问“Rank Now Math”下的“”部分。您还可以检查与提交相关的响应代码。理想情况下,每当您提交任何有效且相关的 URL 时,它都应显示“200 - OK”。这意味着您提交的 URL 已成功提交,没有任何问题。
注意:用户最初会看到“202 - 已接受”状态。这意味着 API 已接受请求,但站点尚未使用 API 密钥进行身份验证。
如何使用排名数学?6、对出版商有什么好处?7、常见问题解答:您需要知道的一切
什么意思?
是一项开源计划,所有参与的搜索引擎都将发现内容的方式更改为推送方法。这是一个简单的 ping 协议,它可以让搜索引擎知道某个 URL 及其内容已被添加、更新或删除,从而允许搜索引擎通过更快的爬取和索引来快速反映搜索结果中的这种变化。
正在使用哪些搜索引擎?
该技术由 Bing 和 Inc. 开发,允许 网站 在创建、更新或删除其 网站 内容时轻松通知搜索引擎。目前,Bing 和 Bing 是唯一使用该功能的搜索引擎,但预计会有更多搜索引擎采用该功能。
Rank Math 中的模块如何工作?
启用该模块后,Rank Math 将自动为您的 网站 生成一个 API 密钥并动态托管它。对于已配置的帖子类型,Rank Math 将在创建、更新或删除新帖子时自动 ping,并且所有启用的搜索引擎都会知道 网站 上的最新更改。
我每天可以提交多少个 URL?
目前,此功能对每天可以提交的 URL 没有任何已知限制。但始终建议不要利用这一点。
提交了一个 URL,为什么我的 URL 没有被索引?
这是一种让搜索引擎了解您的 网站 更改的方法。但是,这些页面的抓取和索引完全由参与的搜索引擎自行决定。
使用并加速您的 SEO 结果
全速索引 网站 查看全部
网站内容抓取工具(SEO插件排名数学阅读索引您需要将您的网站和所有网络内容编入索引)
SEO插件排名数学
阅读指数
您需要将您的 网站 和所有 Web 内容编入索引,以便从自然搜索中获得流量,及时索引内容是 SEO 的重要组成部分。如果没有索引,搜索引擎将无法找到您的 网站,这意味着您的 网站 将无法排名,并且没有人会在搜索结果中找到它。而且,如果发生这种情况,您将失去可能转化为潜在客户和客户的潜在流量。
Rank Math 的即时索引功能允许您向启用的搜索引擎提交 URL,并帮助您将 网站 及其内容编入索引,即使您不需要使用任何这些 网站 管理工具进行配置网站 的。让我们看看功能如何帮助您将 URL 提交到 Bing 和 .
1、这是什么?
是一项有效爬取 网站 的引以为豪的举措,从而减少了爬取足迹。各种引擎都采用了这个协议。
该协议的工作原理是允许 网站 向 API 提交一次 URL,该 URL 将与所有参与的搜索引擎共享。因此,您只需提交一次 网站 更改和 URL,所有参与的搜索引擎都会知道您的 网站 上的最新更改,以便更快地抓取、索引和反映这些更改在搜索结果中。
当您开始提交 URL 时,搜索引擎想要验证这些提交是否合法,并且来自 网站 本身,而不是来自任何恶意元素。因此,搜索引擎期望 网站 生成和验证唯一的 API 密钥。
幸运的是,Rank Math 会自动为您的 网站 生成一个 API 密钥,将其动态托管在您的 网站 上,并将其提供给搜索引擎,因此您不必费心费力,并且更专注于在您的 网站 上创建和管理内容。
2、如何配置自动 URL 提交?
要启用,请转到 Dashboard > Rank Math > Dashboard > Modules 并启用 Instant Index 模块,如下所示:
如何使用排名数学?
其余的可以在 Rank Math >> > 中配置。您可以选择/取消选择要自动提交的任何内容。选择帖子类型后,请确保 Rank Math 已生成 API 密钥。最后,单击“保存更改”以保存您的首选项。
如何使用排名数学?
现在,当您在 网站 上发布或编辑新帖子时,Rank Math 将自动将 URL 提交给 API。但是请注意,Rank Math 不会自动提交设置为的 URL。
3、手动提交网址
Rank Math 为手动提交 URL 提供了几种不同的选项。这是他们:
3.1、批量提交网址
要手动提交 URL,只需转到 Rank Math >> 提交 URL。您可以在此处为您的博客文章、主页或任何其他 Web 内容添加多个 URL(每行一个)。
然后单击提交 URL 按钮,所有添加的 URL 都将提交索引以进行索引,而无需实际访问 网站 管理工具或使用 API 密钥对其进行配置。
如何使用排名数学?3.2、提交个人帖子/页面
除了即时索引设置中的提交 URL 功能外,您还可以随时从编辑器中的帖子页面提交帖子(或页面)。
在帖子页面上,当您将鼠标悬停在帖子上时,您会看到一行选项。选择:选项,如下图。
如何使用排名数学?
当您的帖子成功提交后,您将在页面顶部看到类似于下图的通知。
如何使用排名数学?3.3、即时索引批量操作
在某些情况下,您可能需要从帖子页面提交多个 URL。在这种情况下,逐个提交 URL 会很繁琐,而 Rank Math 提供了批量操作,因此您可以节省时间。

要使用批量操作,请选择要提交的帖子。然后从批量操作中选择即时索引:提交页面选项,然后单击应用按钮。
如何使用排名数学?4、管理 API 密钥
您可以通过 " " 设置下的 Rank Math > " " 设置来管理 Rank Math 为协议生成的 API 密钥。
如何使用排名数学?4.1、更改界面密钥
API 密钥字段显示 Rank Math 自动为您的 网站 生成的 API 密钥。此 API 密钥可帮助您证明您的 网站 的所有权。
如果第三方知道 API 密钥,您始终可以通过单击“更改密钥”选项重新生成新密钥。Rank Math 将在几分钟内为您的 网站 生成一个新的 API 密钥。
如何使用排名数学?4.2、检查 API 密钥位置
如前所述,Rank Math 动态托管 API 密钥并将其提供给搜索引擎。如果您希望检查您的 API 密钥是否可供搜索引擎访问,您可以单击 API 密钥位置下的“检查密钥”按钮。将打开一个新选项卡并指向 Rank Math 托管 API 密钥的位置。
如何使用排名数学?
如果新标签显示您的 API 密钥,您可以放心,它将提供给搜索引擎以验证您的 网站(前提是此页面未被 bots.txt 阻止)。
如何使用排名数学?5、查看历史
要查看您提交的 URL,您可以随时访问“Rank Now Math”下的“”部分。您还可以检查与提交相关的响应代码。理想情况下,每当您提交任何有效且相关的 URL 时,它都应显示“200 - OK”。这意味着您提交的 URL 已成功提交,没有任何问题。
注意:用户最初会看到“202 - 已接受”状态。这意味着 API 已接受请求,但站点尚未使用 API 密钥进行身份验证。
如何使用排名数学?6、对出版商有什么好处?7、常见问题解答:您需要知道的一切
什么意思?
是一项开源计划,所有参与的搜索引擎都将发现内容的方式更改为推送方法。这是一个简单的 ping 协议,它可以让搜索引擎知道某个 URL 及其内容已被添加、更新或删除,从而允许搜索引擎通过更快的爬取和索引来快速反映搜索结果中的这种变化。
正在使用哪些搜索引擎?
该技术由 Bing 和 Inc. 开发,允许 网站 在创建、更新或删除其 网站 内容时轻松通知搜索引擎。目前,Bing 和 Bing 是唯一使用该功能的搜索引擎,但预计会有更多搜索引擎采用该功能。
Rank Math 中的模块如何工作?
启用该模块后,Rank Math 将自动为您的 网站 生成一个 API 密钥并动态托管它。对于已配置的帖子类型,Rank Math 将在创建、更新或删除新帖子时自动 ping,并且所有启用的搜索引擎都会知道 网站 上的最新更改。
我每天可以提交多少个 URL?
目前,此功能对每天可以提交的 URL 没有任何已知限制。但始终建议不要利用这一点。
提交了一个 URL,为什么我的 URL 没有被索引?
这是一种让搜索引擎了解您的 网站 更改的方法。但是,这些页面的抓取和索引完全由参与的搜索引擎自行决定。
使用并加速您的 SEO 结果
全速索引 网站
网站内容抓取工具( 用PageAdmin采集让网站快速收录以及关键词排名,有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2022-03-21 15:34
用PageAdmin采集让网站快速收录以及关键词排名,有哪些)
随风起舞
03-07 11:02 阅读18
专注于
快速优化网站排行软件(网站快速刷排行工具)
使用PageAdmin采集让网站快速收录和关键词排名,在网站优化的过程中,可以得知我们想要网站@ >关键词在首页排名稳定。首先我们要做网站的基础工作,那么今天就给大家介绍一下网站的优化基础工作!
一、网站内容不断更新增加爬取频率
网站的内容质量对网站的收录有很重要的影响,所以在更新网站的内容时,一定要高质量原创 内容更新,会持续更新!
如果以上都没有问题,我们可以使用这个PageAdmincms采集工具实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习专业技术,只需几步即可轻松采集内容数据,用户只需在PageAdmincms采集、PageAdmin上进行简单设置cms采集准确采集文章根据用户设置的关键词设置,保证与行业一致文章@ >。采集文章 from 文章可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他PageAdmincms采集相比,这个PageAdmincms采集基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟搞定启动,只需要输入关键词即可实现采集(PageAdmincms采集也自带关键词采集的功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PageAdmincms采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容被插入或随机创作、随机读取等到一个“高度原创”中。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
使用这些 SEO 功能提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
一、精准定位
在做网站优化之前,首先要把握好我们网站行业的定位,以及产品的优缺点,这样我们在描述tdk的时候才能更加准确,这样百度蜘蛛可以掌握Take和评估网站。
二、关键词
1.关键词
很多人都知道,在进行网站优化之前,我们需要提供一些关键词进行优化。这些关键词是由制造业和商品的关键词选择的,一般情况下我们可以选择2-5个关键词,而网站需要在首页设置网站的顺序,后期优化推广。
2.长尾关键词
与长尾关键词相比,它的指数更低。长尾关键词可以精准帮助用户找到自己需要的内容。非常重要的作用。
3.品牌词
例如,产品的品牌,或者公司的名称,都可以作为品牌词。在推广核心关键词的同时,品牌词也可以通过采集进行推广和优化。
三、布局
网站的布局可以说尤为重要。首先,我们需要将关键词放在网站的首页、栏目等处,然后我们需要将关键词放在网站的长尾上。> 用品牌词布局,大家在布局关键词的时候一定要注意关键词的密度,可以适当。
五、链接建设
适当的内部和外部链接将更好地帮助网站进行流量。这方面的技巧需要站长自己去探索。也很难知道,做好网站的外链并不容易。.
上面介绍的内容是网站优化前需要做的基础内容。我希望这篇文章对你有所帮助。
六、网站关键词排名下降或消失,那么我们需要避免哪些常见错误呢?
1.垃圾链接
为网站买了很多垃圾外链,想网站快速提升排名,但是给网站加那么多垃圾外链真的有用吗?答案是否定的,你要知道,如果你在网站中添加很多质量极差的外链,很大程度上会受到百度搜索引擎的惩罚,而且百度搜索蜘蛛对垃圾邮件也很反感外部链接,会影响网站的爬取速度和更新时间,时间长了网站的内容不会被爬取,搜索关键词也不会排名,所以不要不要给 网站 的外链添加很多坏消息。
2.堆栈关键词
几年前,百度搜索引擎的排名机制还没有现在这么严谨可靠。关键词的排名可以通过在网站上叠加关键词的密度来提高,但是这种情况会严重影响用户的浏览体验,不会给用户带来有用的信息. 打开网站,只能看到成堆的关键词,但是这种情况随着百度搜索引擎本身的发展而变化,已经能够非常智能高效的区分出网站是和关键词叠加的,所以这样的方法已经失效了,而且如果做了,关键词@网站也会受到惩罚,所以不要让关键词@ > 堆积在 网站 上。
3.内容差
谈到内容的质量网站,那句老话总是内容为王。既然这么说,那一定是有道理的。搜索引擎的主要任务是当用户搜索某个 关键词 时,将最有用的内容或该词的 网站 呈现给用户。如果网站的内容质量不好,搜索引擎肯定不会向用户展示这样的网站。在你面前,这样的网站和关键词是不会排名的,所以网站的内容一定要做好。
4.网站注册
网站注册码其实就是网站被黑客入侵了。点击网站链接后,链接会自动跳转到其他非法的网站,如果网站出现这种情况,一定要及时处理网站注册问题。如果长时间不处理,网站的关键词排名会立即消失。所以网站一定要做好服务器保护工作,避免出现此类问题,从而保证网站关键词排名的稳定性。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事 查看全部
网站内容抓取工具(
用PageAdmin采集让网站快速收录以及关键词排名,有哪些)

随风起舞
03-07 11:02 阅读18
专注于
快速优化网站排行软件(网站快速刷排行工具)

使用PageAdmin采集让网站快速收录和关键词排名,在网站优化的过程中,可以得知我们想要网站@ >关键词在首页排名稳定。首先我们要做网站的基础工作,那么今天就给大家介绍一下网站的优化基础工作!
一、网站内容不断更新增加爬取频率
网站的内容质量对网站的收录有很重要的影响,所以在更新网站的内容时,一定要高质量原创 内容更新,会持续更新!
如果以上都没有问题,我们可以使用这个PageAdmincms采集工具实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习专业技术,只需几步即可轻松采集内容数据,用户只需在PageAdmincms采集、PageAdmin上进行简单设置cms采集准确采集文章根据用户设置的关键词设置,保证与行业一致文章@ >。采集文章 from 文章可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他PageAdmincms采集相比,这个PageAdmincms采集基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟搞定启动,只需要输入关键词即可实现采集(PageAdmincms采集也自带关键词采集的功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PageAdmincms采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容被插入或随机创作、随机读取等到一个“高度原创”中。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
使用这些 SEO 功能提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
一、精准定位
在做网站优化之前,首先要把握好我们网站行业的定位,以及产品的优缺点,这样我们在描述tdk的时候才能更加准确,这样百度蜘蛛可以掌握Take和评估网站。
二、关键词
1.关键词
很多人都知道,在进行网站优化之前,我们需要提供一些关键词进行优化。这些关键词是由制造业和商品的关键词选择的,一般情况下我们可以选择2-5个关键词,而网站需要在首页设置网站的顺序,后期优化推广。
2.长尾关键词
与长尾关键词相比,它的指数更低。长尾关键词可以精准帮助用户找到自己需要的内容。非常重要的作用。
3.品牌词
例如,产品的品牌,或者公司的名称,都可以作为品牌词。在推广核心关键词的同时,品牌词也可以通过采集进行推广和优化。
三、布局
网站的布局可以说尤为重要。首先,我们需要将关键词放在网站的首页、栏目等处,然后我们需要将关键词放在网站的长尾上。> 用品牌词布局,大家在布局关键词的时候一定要注意关键词的密度,可以适当。
五、链接建设
适当的内部和外部链接将更好地帮助网站进行流量。这方面的技巧需要站长自己去探索。也很难知道,做好网站的外链并不容易。.
上面介绍的内容是网站优化前需要做的基础内容。我希望这篇文章对你有所帮助。
六、网站关键词排名下降或消失,那么我们需要避免哪些常见错误呢?
1.垃圾链接
为网站买了很多垃圾外链,想网站快速提升排名,但是给网站加那么多垃圾外链真的有用吗?答案是否定的,你要知道,如果你在网站中添加很多质量极差的外链,很大程度上会受到百度搜索引擎的惩罚,而且百度搜索蜘蛛对垃圾邮件也很反感外部链接,会影响网站的爬取速度和更新时间,时间长了网站的内容不会被爬取,搜索关键词也不会排名,所以不要不要给 网站 的外链添加很多坏消息。
2.堆栈关键词
几年前,百度搜索引擎的排名机制还没有现在这么严谨可靠。关键词的排名可以通过在网站上叠加关键词的密度来提高,但是这种情况会严重影响用户的浏览体验,不会给用户带来有用的信息. 打开网站,只能看到成堆的关键词,但是这种情况随着百度搜索引擎本身的发展而变化,已经能够非常智能高效的区分出网站是和关键词叠加的,所以这样的方法已经失效了,而且如果做了,关键词@网站也会受到惩罚,所以不要让关键词@ > 堆积在 网站 上。
3.内容差
谈到内容的质量网站,那句老话总是内容为王。既然这么说,那一定是有道理的。搜索引擎的主要任务是当用户搜索某个 关键词 时,将最有用的内容或该词的 网站 呈现给用户。如果网站的内容质量不好,搜索引擎肯定不会向用户展示这样的网站。在你面前,这样的网站和关键词是不会排名的,所以网站的内容一定要做好。
4.网站注册
网站注册码其实就是网站被黑客入侵了。点击网站链接后,链接会自动跳转到其他非法的网站,如果网站出现这种情况,一定要及时处理网站注册问题。如果长时间不处理,网站的关键词排名会立即消失。所以网站一定要做好服务器保护工作,避免出现此类问题,从而保证网站关键词排名的稳定性。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事
网站内容抓取工具(关于网站推广不收录的原因都有哪些呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-18 14:09
网站建设完成后,下一步就是推广网站的工作,但是很多公司发现新建的网站是用来推广的,哪怕是一个老域名用的,效果不是很好 还行。虽然优质的文章内容每天都在更新,但在搜索引擎上却不是收录,那么网站推广不是收录的原因是什么?
1、擅长使用工具-百度站长资源平台。
为了满足用户做网站推广的需求,百度搜索引擎很早就推出了站长资源平台工具。这个工具可以理解为“加速器”的作用。它收录多种功能,最常用的是提交链接,以及反馈网站各种问题。
很多网站都不知道每天更新的内容在做推广的时候要以链接的形式提交给百度,就等着百度抓了。新网站即使是新域也有一个观察期,在此期间搜索引擎不会花太多时间查看网站。旧网站不同,因为很多东西已经在搜索引擎的索引库中。
2、是否屏蔽百度抓取。
网站在构建过程中,Robots文件一般是同步产生的,是网络协议文件。通常设计为禁止所有 网站 链接被抓取。有时网站制作完成后忘记修改这个文件,导致网站上线,但是没有蜘蛛爬取,整个网站被阻塞。
所以在 网站 构建完成后,一定要检查 Robots 文件是否阻塞了整个 网站。
3、服务器稳定。
如果网站经常因为服务问题打不开网站,或者不稳定,搜索引擎会减少网站的爬取量,甚至停止爬取网站。这是对网站的收录的致命一击。
4、网站不合理的结构。
网站组织布局对推广很重要网站。如果结构处理不好或者有一些程序代码,搜索引擎蜘蛛就会陷入死循环,无法形成有进有出的环境。,对搜索引擎很不友好。
5、网站的收录增加了,但是几天后收录的页面突然消失了。
网站有时候显示已经是收录了,但是过了一段时间,原来是收录的页面突然消失了。很多做网站推广的公司都遇到过这种类似的问题。这个问题有很多原因。
1)检查 网站 是否被黑客入侵(hacked)。
2)检查网站短期内是否建立了大量的外链、反链、友链。
3)检查网站是否有作弊嫌疑。
4)检查网站文章的内容是否按时、按量、有质量地更新。
5)如果以上都可以,那可能是网站的沙盒期(只有新站才有的功能)。
.
.
. 查看全部
网站内容抓取工具(关于网站推广不收录的原因都有哪些呢??)
网站建设完成后,下一步就是推广网站的工作,但是很多公司发现新建的网站是用来推广的,哪怕是一个老域名用的,效果不是很好 还行。虽然优质的文章内容每天都在更新,但在搜索引擎上却不是收录,那么网站推广不是收录的原因是什么?
1、擅长使用工具-百度站长资源平台。
为了满足用户做网站推广的需求,百度搜索引擎很早就推出了站长资源平台工具。这个工具可以理解为“加速器”的作用。它收录多种功能,最常用的是提交链接,以及反馈网站各种问题。
很多网站都不知道每天更新的内容在做推广的时候要以链接的形式提交给百度,就等着百度抓了。新网站即使是新域也有一个观察期,在此期间搜索引擎不会花太多时间查看网站。旧网站不同,因为很多东西已经在搜索引擎的索引库中。
2、是否屏蔽百度抓取。
网站在构建过程中,Robots文件一般是同步产生的,是网络协议文件。通常设计为禁止所有 网站 链接被抓取。有时网站制作完成后忘记修改这个文件,导致网站上线,但是没有蜘蛛爬取,整个网站被阻塞。
所以在 网站 构建完成后,一定要检查 Robots 文件是否阻塞了整个 网站。
3、服务器稳定。
如果网站经常因为服务问题打不开网站,或者不稳定,搜索引擎会减少网站的爬取量,甚至停止爬取网站。这是对网站的收录的致命一击。
4、网站不合理的结构。
网站组织布局对推广很重要网站。如果结构处理不好或者有一些程序代码,搜索引擎蜘蛛就会陷入死循环,无法形成有进有出的环境。,对搜索引擎很不友好。
5、网站的收录增加了,但是几天后收录的页面突然消失了。
网站有时候显示已经是收录了,但是过了一段时间,原来是收录的页面突然消失了。很多做网站推广的公司都遇到过这种类似的问题。这个问题有很多原因。
1)检查 网站 是否被黑客入侵(hacked)。
2)检查网站短期内是否建立了大量的外链、反链、友链。
3)检查网站是否有作弊嫌疑。
4)检查网站文章的内容是否按时、按量、有质量地更新。
5)如果以上都可以,那可能是网站的沙盒期(只有新站才有的功能)。
.
.
.
网站内容抓取工具( Gitemapx,其官网号称是永久免费的网站地图制作工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-18 05:05
Gitemapx,其官网号称是永久免费的网站地图制作工具)
在我们的SEO工作过程中,使用地图引导蜘蛛爬行爬行是一种非常好的行为。不过自从Sorghum seo从事seo工作以来,一直没有找到一款超级实用且免费的制图工具,一般都是在线的。它只能抢不到100块,所以对于很多人来说是非常苦恼的。Sorghum seo今天分享的软件叫Gitemap x,官网号称是永久免费的网站地图制作工具。那么下面的高粱seo就给大家详细介绍一下它的功能和特点:
一、自动生成XML、GZ、TXT和HTML格式的网站地图制作工具
Sitemap X可以根据您的需要自动生成四种不同格式的网站地图---XML、GZ、TXT和HTML,这四种网站地图是搜索引擎优化部分必不可少的。同时Sitemap X还可以自动生成Robots.txt文件,方便搜索引擎蜘蛛的检索。二、使用Sitemap X工具查找错误链接、死链接等问题网站
错误链接和死链接不仅会影响用户访问,还会阻止搜索引擎蜘蛛收录,从而影响您的网站用户体验和搜索引擎排名。使用SiteMap X网站地图制作工具,很容易发现网站中的问题,及时解决,保证页面正确。三、使用 Sitemap X 的 Ping 功能自动通知搜索引擎
SiteMap X 可以自动通知 (Ping) 搜索引擎 收录 您刚刚更新的页面。这样不仅可以加快网页的收录,还可以让你的网站从被动等待搜索引擎收录变成主动通知搜索引擎到收录@ >,从而增加搜索引擎的数量蜘蛛有多爱你网站在提高你的SEO排名方面发挥着作用。四、使用定时任务自动创建和上传网站地图文件
Sitemap X网站map maker内置定时任务功能和FTP功能,可以自动生成网站地图文件,并按时自动上传到您的网站空间。无需任何操作,SiteMap X将为您带来最完美的SEO效果。一定要试试永远免费的网站地图制作工具——Sitemap X。最后,sorghum seo 总结了使用地图的好处。使用网站map文件加速页面收录,提高SEO排名,网站maps可以帮助搜索引擎蜘蛛(如Googlebot)更快地找到现有页面并更新页面,从而引导蜘蛛爬行,加快蜘蛛收录的速度,从而有效提升SEO排名,大大增加你的网站流量。 查看全部
网站内容抓取工具(
Gitemapx,其官网号称是永久免费的网站地图制作工具)
在我们的SEO工作过程中,使用地图引导蜘蛛爬行爬行是一种非常好的行为。不过自从Sorghum seo从事seo工作以来,一直没有找到一款超级实用且免费的制图工具,一般都是在线的。它只能抢不到100块,所以对于很多人来说是非常苦恼的。Sorghum seo今天分享的软件叫Gitemap x,官网号称是永久免费的网站地图制作工具。那么下面的高粱seo就给大家详细介绍一下它的功能和特点:
一、自动生成XML、GZ、TXT和HTML格式的网站地图制作工具
Sitemap X可以根据您的需要自动生成四种不同格式的网站地图---XML、GZ、TXT和HTML,这四种网站地图是搜索引擎优化部分必不可少的。同时Sitemap X还可以自动生成Robots.txt文件,方便搜索引擎蜘蛛的检索。二、使用Sitemap X工具查找错误链接、死链接等问题网站
错误链接和死链接不仅会影响用户访问,还会阻止搜索引擎蜘蛛收录,从而影响您的网站用户体验和搜索引擎排名。使用SiteMap X网站地图制作工具,很容易发现网站中的问题,及时解决,保证页面正确。三、使用 Sitemap X 的 Ping 功能自动通知搜索引擎
SiteMap X 可以自动通知 (Ping) 搜索引擎 收录 您刚刚更新的页面。这样不仅可以加快网页的收录,还可以让你的网站从被动等待搜索引擎收录变成主动通知搜索引擎到收录@ >,从而增加搜索引擎的数量蜘蛛有多爱你网站在提高你的SEO排名方面发挥着作用。四、使用定时任务自动创建和上传网站地图文件
Sitemap X网站map maker内置定时任务功能和FTP功能,可以自动生成网站地图文件,并按时自动上传到您的网站空间。无需任何操作,SiteMap X将为您带来最完美的SEO效果。一定要试试永远免费的网站地图制作工具——Sitemap X。最后,sorghum seo 总结了使用地图的好处。使用网站map文件加速页面收录,提高SEO排名,网站maps可以帮助搜索引擎蜘蛛(如Googlebot)更快地找到现有页面并更新页面,从而引导蜘蛛爬行,加快蜘蛛收录的速度,从而有效提升SEO排名,大大增加你的网站流量。
网站内容抓取工具(Google管理员工具(使用Google网站管理员.TXT)提高流量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2022-03-17 03:22
使用GOOGLE管理员工具测试Robots.TXT和页面内容爬取,GOOGLE管理员可以说是与GOOGLE间接沟通的工具,虽然现在已经迁移,导致使用GOOGLE时经常出现搜索错误或者超时问题,但是工具目前GOOGLE发布的都是最权威的工具(谷歌分析、谷歌趋势、谷歌adwords、谷歌管理工具),尤其是“谷歌分析”、“谷歌管理工具”,其中最权威的分析工具之一。牛B的工具(小翔个人认为),一个是网站管理必备的工具之一,可能有些朋友不这么认为,但这两个工具对小翔的帮助很大。
百度发布《百度站长指南》时,在统计/投票中询问用户喜欢什么类型的站长工具,但现在投票统计已经完成,工具已经很久没有发布了。有句话说的好“给别人希望,却让别人失望”,不就是这样的“百度站长指南”吗,花了多长时间,可能三个月,但后来发布了,但有多少人对这个“希望”有感情,却以失望收场。
谷歌管理工具(使用谷歌网站管理工具增加流量谷歌对网站索引的统计、诊断和管理,包括站点地图提交和报告。欢迎使用一站式网站管理会员资源回答你关于爬取和索引的问题,并向你介绍改善和增加网站流量的产品和服务,从而增加你与访问者的联系。)这是 GOOGLE 上一段管理员的描述,描述了处理网站 相关问题,如站点索引、Sitemap 提交、网站 抓取、网站 诊断等。我们今天只解释 GOOGLE 抓取!
国平哥在他的博客中发表了一篇文章文章,称“谷歌站长工具”是“谷歌搜索工具”的缩小版,而GSA是一个打包谷歌整个软硬件的服务器。该服务器是一个小型谷歌搜索引擎。(虽然DJ小翔没见过,但知道在libaba里面有这样的服务器)
至于“GOOGLE Admin Tools - Lab - Crawl Like Googlebot”,不知道大家有没有知道,有多少朋友灵活掌握了这个功能。记得在SEO学习网博客中,介绍过一篇关于“GOOGLE爬虫”的文章!
我们点击爬取,然后GOOGLE引擎爬取后生成URL,——通过状态栏可以看到GOOGLE爬取了网站的“状态”,通过这些“状态”提示,我们可以了解到目前为止,GOOGLE对网站页面的爬取是“成功”、“失败”或“被Robots.txt拒绝”,为什么“失败”我们也可以借鉴这个工具。
小翔在他的博客中多次提到,一个网站没有蜘蛛可以爬,网站怎么可能是SE收录,模拟爬的工具有很多,但是有多少有模拟爬行吗?工具可以让 GOOGLE 抓取“权威”或“准确”。
并且我们可以“拿GOOGLE测试一下网站Robots.txt是否正确”,对于百度站长工具投票中的“Robots.txt是否写正确”,很多朋友希望百度站长工具能够推出这个工具来。懂SEO的朋友,从图上看出来了!百度站长工具上线Robots.txt测试工具我们不用等很久。现在我们可以使用GOOGLE站长工具来测试“Robots.txt Validity”和“Robots.txt Writing Correctness”,让更多的SEO初学者防止网站因为“不会写Robotx.tx”或者“写 Robotx.txt 错误”。
图中我们可以看到如果使用GOOGLE爬取,将网站写的协议爬入Robots会提示“rejected by Robots.txt”,如果Robots.txt无效,则会显示“成功”,这种方法是测试Robots.txt最可靠的方法。当然,对于XX SE来说,他有点违抗这个Robots.txt,所以没办法!
而“像GOOGLEBOT一样抓取”来检测Robots.txt只是他使用的方法之一。刚才我们说“GOOGLE抓取”可以模拟爬取网站的内容!
而且GOOGL抓取也可以模拟抓取网站的内容结果,这里的结果和SE快照差不多,但是用GOOGLE工具里的抓取比看快照更方便更准确!从这个结果我们可以分析,GOOGLE对页面的爬取,比如能否爬取JS、图片内容等等。
很久没有写文章了。上次答应大家,我会写一篇可以“测试Robots.txt正确性”的文章文章。现在我已经让每个人都满意了。“下一篇文章的话题文章”“大家也可以发在留言里,DJ小翔把自己知道的知识都分享给大家。毕竟小翔知道自己也得到了别人的帮助一个新手。这里同时,“谢谢!栏目猎眼大哥,感谢猎眼大哥这些天对我弟弟的帮助和关心。” 查看全部
网站内容抓取工具(Google管理员工具(使用Google网站管理员.TXT)提高流量)
使用GOOGLE管理员工具测试Robots.TXT和页面内容爬取,GOOGLE管理员可以说是与GOOGLE间接沟通的工具,虽然现在已经迁移,导致使用GOOGLE时经常出现搜索错误或者超时问题,但是工具目前GOOGLE发布的都是最权威的工具(谷歌分析、谷歌趋势、谷歌adwords、谷歌管理工具),尤其是“谷歌分析”、“谷歌管理工具”,其中最权威的分析工具之一。牛B的工具(小翔个人认为),一个是网站管理必备的工具之一,可能有些朋友不这么认为,但这两个工具对小翔的帮助很大。
百度发布《百度站长指南》时,在统计/投票中询问用户喜欢什么类型的站长工具,但现在投票统计已经完成,工具已经很久没有发布了。有句话说的好“给别人希望,却让别人失望”,不就是这样的“百度站长指南”吗,花了多长时间,可能三个月,但后来发布了,但有多少人对这个“希望”有感情,却以失望收场。
谷歌管理工具(使用谷歌网站管理工具增加流量谷歌对网站索引的统计、诊断和管理,包括站点地图提交和报告。欢迎使用一站式网站管理会员资源回答你关于爬取和索引的问题,并向你介绍改善和增加网站流量的产品和服务,从而增加你与访问者的联系。)这是 GOOGLE 上一段管理员的描述,描述了处理网站 相关问题,如站点索引、Sitemap 提交、网站 抓取、网站 诊断等。我们今天只解释 GOOGLE 抓取!
国平哥在他的博客中发表了一篇文章文章,称“谷歌站长工具”是“谷歌搜索工具”的缩小版,而GSA是一个打包谷歌整个软硬件的服务器。该服务器是一个小型谷歌搜索引擎。(虽然DJ小翔没见过,但知道在libaba里面有这样的服务器)

至于“GOOGLE Admin Tools - Lab - Crawl Like Googlebot”,不知道大家有没有知道,有多少朋友灵活掌握了这个功能。记得在SEO学习网博客中,介绍过一篇关于“GOOGLE爬虫”的文章!
我们点击爬取,然后GOOGLE引擎爬取后生成URL,——通过状态栏可以看到GOOGLE爬取了网站的“状态”,通过这些“状态”提示,我们可以了解到目前为止,GOOGLE对网站页面的爬取是“成功”、“失败”或“被Robots.txt拒绝”,为什么“失败”我们也可以借鉴这个工具。
小翔在他的博客中多次提到,一个网站没有蜘蛛可以爬,网站怎么可能是SE收录,模拟爬的工具有很多,但是有多少有模拟爬行吗?工具可以让 GOOGLE 抓取“权威”或“准确”。

并且我们可以“拿GOOGLE测试一下网站Robots.txt是否正确”,对于百度站长工具投票中的“Robots.txt是否写正确”,很多朋友希望百度站长工具能够推出这个工具来。懂SEO的朋友,从图上看出来了!百度站长工具上线Robots.txt测试工具我们不用等很久。现在我们可以使用GOOGLE站长工具来测试“Robots.txt Validity”和“Robots.txt Writing Correctness”,让更多的SEO初学者防止网站因为“不会写Robotx.tx”或者“写 Robotx.txt 错误”。

图中我们可以看到如果使用GOOGLE爬取,将网站写的协议爬入Robots会提示“rejected by Robots.txt”,如果Robots.txt无效,则会显示“成功”,这种方法是测试Robots.txt最可靠的方法。当然,对于XX SE来说,他有点违抗这个Robots.txt,所以没办法!
而“像GOOGLEBOT一样抓取”来检测Robots.txt只是他使用的方法之一。刚才我们说“GOOGLE抓取”可以模拟爬取网站的内容!

而且GOOGL抓取也可以模拟抓取网站的内容结果,这里的结果和SE快照差不多,但是用GOOGLE工具里的抓取比看快照更方便更准确!从这个结果我们可以分析,GOOGLE对页面的爬取,比如能否爬取JS、图片内容等等。
很久没有写文章了。上次答应大家,我会写一篇可以“测试Robots.txt正确性”的文章文章。现在我已经让每个人都满意了。“下一篇文章的话题文章”“大家也可以发在留言里,DJ小翔把自己知道的知识都分享给大家。毕竟小翔知道自己也得到了别人的帮助一个新手。这里同时,“谢谢!栏目猎眼大哥,感谢猎眼大哥这些天对我弟弟的帮助和关心。”
网站内容抓取工具( 什么是网络?时光机(Waybackmachine)下载网站的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-16 00:00
什么是网络?时光机(Waybackmachine)下载网站的原因)
什么是网络存档?
网络存档是网络的全面备份,似乎是在不同时间点进行的。 Web Archive 的使命是存储过去 15-20 年不同时间点的所有 Internet。我们开发了一个工具,可以从 Time Machine 下载 网站 并恢复因延迟支付托管费用或其他原因而丢失的 网站。这个所谓的时间机器下载器是一个网络爬虫,它访问并允许客户从 网站
下载
什么是 Wayback 机器下载? Wayback machine download 是 Wayback Machine Downloader 提供的用于恢复 网站 文件的包的名称。它包括 HTML、CSS、JS 和图像文件。要从 Time Machine 下载 网站,只需访问 Time Machine 并查找特定日期的 URL。请务必使用主页上的 URL,这样可以提供最佳结果。对比 Wayback Machine Web Archive 和 Time Machine 在某种程度上是同义词,无论出于何种意图和目的,您都无需区分两者。 Time Machine 只是 Web 存档的 网站 的名称,这个名称在 Internet 上广为人知,人们希望从中恢复丢失的内容或重建 网站。使用 Time Machine 下载器 (Wayback Downloader) 的原因 您从 Time Machine 下载 网站 的原因可能是什么?正如您在上面看到的,使用 Time Machine 下载工具的原因有很多。这是从时间机器下载 网站 的完美解决方案。如果您对上述问题有任何疑虑,请随时给我们留言。我们很乐意为您提供帮助。 查看全部
网站内容抓取工具(
什么是网络?时光机(Waybackmachine)下载网站的原因)
什么是网络存档?
网络存档是网络的全面备份,似乎是在不同时间点进行的。 Web Archive 的使命是存储过去 15-20 年不同时间点的所有 Internet。我们开发了一个工具,可以从 Time Machine 下载 网站 并恢复因延迟支付托管费用或其他原因而丢失的 网站。这个所谓的时间机器下载器是一个网络爬虫,它访问并允许客户从 网站
下载
什么是 Wayback 机器下载? Wayback machine download 是 Wayback Machine Downloader 提供的用于恢复 网站 文件的包的名称。它包括 HTML、CSS、JS 和图像文件。要从 Time Machine 下载 网站,只需访问 Time Machine 并查找特定日期的 URL。请务必使用主页上的 URL,这样可以提供最佳结果。对比 Wayback Machine Web Archive 和 Time Machine 在某种程度上是同义词,无论出于何种意图和目的,您都无需区分两者。 Time Machine 只是 Web 存档的 网站 的名称,这个名称在 Internet 上广为人知,人们希望从中恢复丢失的内容或重建 网站。使用 Time Machine 下载器 (Wayback Downloader) 的原因 您从 Time Machine 下载 网站 的原因可能是什么?正如您在上面看到的,使用 Time Machine 下载工具的原因有很多。这是从时间机器下载 网站 的完美解决方案。如果您对上述问题有任何疑虑,请随时给我们留言。我们很乐意为您提供帮助。
网站内容抓取工具(网站抓取建设指南、网站数据生产指南和网站死链处理指南)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-15 20:05
在网站的实际操作过程中,很多站长还是对百度的一些处理机制感到疑惑。例如:
……
如果您对这些问题感到疑惑,那么您应该阅读此文章!
近日,百度搜索研发工程师在百度搜索在线公开课中为大家分享了网站爬取构建指南、网站数据制作指南和网站死链接处理指南的相关内容。 ,回答了站长的很多问题。
以下是百度搜索在线公开课的一些重要答案:
网站抓斗施工指南
Q1:百度搜索会给新的网站更高的抓取频率吗?
A1:百度搜索会首先识别网站内容的质量,在抓取高质量内容的新站点的频率上会有一定的倾向,以帮助内容更好的展示。
Q2:如何让百度搜索知道我的网站是新站点?
A2:主要有两种方式:1、通过百度搜索资源平台——资源提交工具提交内容;2、完成网站工信部ICP备案。
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
网站数据生产指南
Q5:网站上线前应该发布多少条内容?是越多越好,还是以少量高质量打造优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容确实需要修改,并且修改后的内容质量还是不错的,不影响百度搜索对该页面的评价。
网站死链接处理指南
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容相关度高,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原创内容的相关性较低,建议将原创内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。当机器人被阻止时,链接是否应该区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。 查看全部
网站内容抓取工具(网站抓取建设指南、网站数据生产指南和网站死链处理指南)
在网站的实际操作过程中,很多站长还是对百度的一些处理机制感到疑惑。例如:
……
如果您对这些问题感到疑惑,那么您应该阅读此文章!
近日,百度搜索研发工程师在百度搜索在线公开课中为大家分享了网站爬取构建指南、网站数据制作指南和网站死链接处理指南的相关内容。 ,回答了站长的很多问题。

以下是百度搜索在线公开课的一些重要答案:
网站抓斗施工指南
Q1:百度搜索会给新的网站更高的抓取频率吗?
A1:百度搜索会首先识别网站内容的质量,在抓取高质量内容的新站点的频率上会有一定的倾向,以帮助内容更好的展示。
Q2:如何让百度搜索知道我的网站是新站点?
A2:主要有两种方式:1、通过百度搜索资源平台——资源提交工具提交内容;2、完成网站工信部ICP备案。
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
网站数据生产指南
Q5:网站上线前应该发布多少条内容?是越多越好,还是以少量高质量打造优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容确实需要修改,并且修改后的内容质量还是不错的,不影响百度搜索对该页面的评价。
网站死链接处理指南
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容相关度高,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原创内容的相关性较低,建议将原创内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。当机器人被阻止时,链接是否应该区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。
网站内容抓取工具(百度不收录内容页面的原因及解决方法原因分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-15 20:04
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
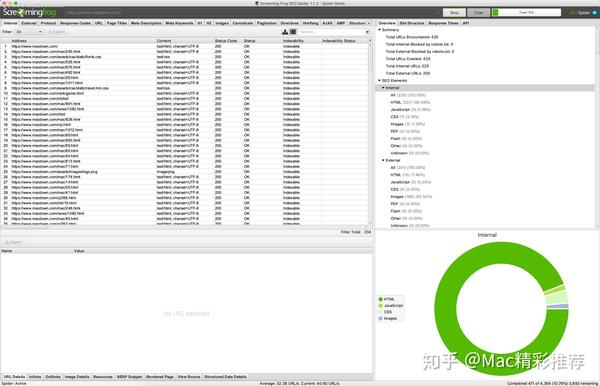
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对网站的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否有大量死链接,清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自上线以来,虽然是论坛形式,但我对论坛的内容管理一直非常严格。前期大部分内容贴都是我自己发布的原创或者伪原创,所以,可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是百度蜘蛛通过网站日志分析软件从9月2日到9月5日的爬取目录统计。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
所以我nofollow /bbx链接来阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接! 查看全部
网站内容抓取工具(百度不收录内容页面的原因及解决方法原因分析)
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对网站的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否有大量死链接,清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自上线以来,虽然是论坛形式,但我对论坛的内容管理一直非常严格。前期大部分内容贴都是我自己发布的原创或者伪原创,所以,可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是百度蜘蛛通过网站日志分析软件从9月2日到9月5日的爬取目录统计。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
所以我nofollow /bbx链接来阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接!
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-13 21:17
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。 查看全部
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。
网站内容抓取工具(网站已经上线半个月了,为什么连首页都没收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-05 07:00
很多刚接触SEO的新手或公司经常会有这样的疑问:“网站上线半个月了,为什么首页都没有收录”?
相信很多SEO朋友都知道,在没有外链的情况下,很难被搜索引擎网站快速收录。不过君龙网络科技资深优化师表示,其实这个时候只要好好利用百度站长后台工具,还是可以达到快收录的效果的。那么,该怎么做呢?一起来了解一下吧。
第一次一、站长平台网站验证,添加百度统计代码
以百度为例,新站建站成功,正确填框内容后,应该去百度站长平台,添加网站并验证,这些步骤很简单,我经常用文件验证,对那些不懂代码的人来说简单快速。另外,建议增加百度统计。新站不管有流量还是有实用价值,先做。无论如何,这将在几个步骤中完成。作者测试了这两个步骤对收录很有好处。在其他平台上的操作类似的建议是使用搜索引擎的官方统计工具。
在 二、 提交机器人和站点地图,以及自动推送功能
当搜索引擎输入网站时,会先读取robots和sitemap这两个文件,并遵守文件中的协议。在站长平台上提交这两个文件,并进行检测和更新,可以引导蜘蛛爬取网站内容。因此,做好机器人和站点地图就显得尤为重要。
关于这两个文件的创建和使用,大家可以在百度上搜索相关内容,花一点时间就可以了解。最简单的方法就是创建两个TXT文件夹,改名为robots.txt和sitemap.txt,然后写入内容。sitemap.txt比较简单,把网站里面的所有链接依次复制就可以了。而已。最后上传到 网站 服务器。
另外,还可以在链接提交中使用自动推送,这个功能很强大,网站每次更新内容,都能及时推送到搜索引擎,蜘蛛可以发现新的内容立即收录 帮助很大。操作也很简单。
编号三、多用途爬虫诊断工具
经过测试,爬行诊断可以吸引蜘蛛。当首页不是收录的时候,我一天要爬2次以上。这是作者一直以来的做法。另外,这个worker可以查看网页的代码,从蜘蛛的角度查看网页的内容,还可以查看是否有黑链接。
解决收录的第一步是让蜘蛛发现网页。新站点之所以不收录和收录慢,是因为搜索引擎蜘蛛不知道这个网站,如果没有爬取内容,就没有索引。一般蜘蛛可以通过链接爬取网站,爬取网页。一般新站点是没有外链的,所以今天分享的方法不讲外链。返回搜狐,查看更多 查看全部
网站内容抓取工具(网站已经上线半个月了,为什么连首页都没收录?)
很多刚接触SEO的新手或公司经常会有这样的疑问:“网站上线半个月了,为什么首页都没有收录”?
相信很多SEO朋友都知道,在没有外链的情况下,很难被搜索引擎网站快速收录。不过君龙网络科技资深优化师表示,其实这个时候只要好好利用百度站长后台工具,还是可以达到快收录的效果的。那么,该怎么做呢?一起来了解一下吧。
第一次一、站长平台网站验证,添加百度统计代码
以百度为例,新站建站成功,正确填框内容后,应该去百度站长平台,添加网站并验证,这些步骤很简单,我经常用文件验证,对那些不懂代码的人来说简单快速。另外,建议增加百度统计。新站不管有流量还是有实用价值,先做。无论如何,这将在几个步骤中完成。作者测试了这两个步骤对收录很有好处。在其他平台上的操作类似的建议是使用搜索引擎的官方统计工具。
在 二、 提交机器人和站点地图,以及自动推送功能
当搜索引擎输入网站时,会先读取robots和sitemap这两个文件,并遵守文件中的协议。在站长平台上提交这两个文件,并进行检测和更新,可以引导蜘蛛爬取网站内容。因此,做好机器人和站点地图就显得尤为重要。
关于这两个文件的创建和使用,大家可以在百度上搜索相关内容,花一点时间就可以了解。最简单的方法就是创建两个TXT文件夹,改名为robots.txt和sitemap.txt,然后写入内容。sitemap.txt比较简单,把网站里面的所有链接依次复制就可以了。而已。最后上传到 网站 服务器。
另外,还可以在链接提交中使用自动推送,这个功能很强大,网站每次更新内容,都能及时推送到搜索引擎,蜘蛛可以发现新的内容立即收录 帮助很大。操作也很简单。
编号三、多用途爬虫诊断工具
经过测试,爬行诊断可以吸引蜘蛛。当首页不是收录的时候,我一天要爬2次以上。这是作者一直以来的做法。另外,这个worker可以查看网页的代码,从蜘蛛的角度查看网页的内容,还可以查看是否有黑链接。
解决收录的第一步是让蜘蛛发现网页。新站点之所以不收录和收录慢,是因为搜索引擎蜘蛛不知道这个网站,如果没有爬取内容,就没有索引。一般蜘蛛可以通过链接爬取网站,爬取网页。一般新站点是没有外链的,所以今天分享的方法不讲外链。返回搜狐,查看更多
网站内容抓取工具(ScreamingFrogSEOSpiderforMac是一个网站爬虫软件吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-05 06:18
Screaming Frog SEO Spider for Mac 是一款专门为抓取 URL 进行分析而设计的网络爬虫开发工具。您可以使用此软件快速抓取网站中可能出现的断开链接和服务器错误,或识别网站中的临时和永久重定向链接循环,还可以检查仪表板中可能出现的重复问题,例如URL 、页面标题、描述和内容。喜欢这个软件?
软件介绍
Screaming Frog SEO Spider for Mac 是一个 网站 爬虫,允许您爬取 网站 URL 并获取关键元素、分析和审计技术以及现场 SEO。
特征
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
快速总结
错误 - 客户端错误,例如链接断开和服务器错误(无响应、4XX、5XX)。
重定向 - 永久、临时重定向(3XX 响应)和 JS 重定向。
阻止的 URL - robots.txt 协议不允许查看和审查 URL。
被阻止的资源 - 在呈现模式下查看和审核被阻止的资源。
外部链接 - 所有外部链接及其状态代码。
协议 - URL 是安全的 (HTTPS) 还是不安全的 (HTTP)。
URI 问题 - 非 ASCII 字符、下划线、大写字符、参数或长 URL。
Duplicate Pages - Hash/MD5checksums 算法检查精确的重复页面。
页面标题 - 缺失、重复、超过 65 个字符、短、像素宽度被截断、相同或大于 h1。
元描述 - 缺失、重复、超过 156 个字符、短、像素宽度被截断或多个。
元关键字 - 主要用于参考,因为它们不被 Google、Bing 或 Yahoo 使用。
文件大小 - URL 和图像的大小。
响应时间。
最后修改的标题。
页面(爬行)深度。
字数。
H1 - 缺失、重复、超过 70 个字符、多个。
H2 - 缺失、重复、超过 70 个字符、多个。
Metabots - 索引、无索引、关注、nofollow、noarchive、nosnippet、noodp、noydir 等。
元刷新 - 包括目标页面和时间延迟。 查看全部
网站内容抓取工具(ScreamingFrogSEOSpiderforMac是一个网站爬虫软件吗?)
Screaming Frog SEO Spider for Mac 是一款专门为抓取 URL 进行分析而设计的网络爬虫开发工具。您可以使用此软件快速抓取网站中可能出现的断开链接和服务器错误,或识别网站中的临时和永久重定向链接循环,还可以检查仪表板中可能出现的重复问题,例如URL 、页面标题、描述和内容。喜欢这个软件?
软件介绍
Screaming Frog SEO Spider for Mac 是一个 网站 爬虫,允许您爬取 网站 URL 并获取关键元素、分析和审计技术以及现场 SEO。
特征
1、找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2、审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
4、发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
5、使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
6、查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
7、生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
8、与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及着陆页的转化、目标、交易和收入。
9、抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
10、可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
快速总结
错误 - 客户端错误,例如链接断开和服务器错误(无响应、4XX、5XX)。
重定向 - 永久、临时重定向(3XX 响应)和 JS 重定向。
阻止的 URL - robots.txt 协议不允许查看和审查 URL。
被阻止的资源 - 在呈现模式下查看和审核被阻止的资源。
外部链接 - 所有外部链接及其状态代码。
协议 - URL 是安全的 (HTTPS) 还是不安全的 (HTTP)。
URI 问题 - 非 ASCII 字符、下划线、大写字符、参数或长 URL。
Duplicate Pages - Hash/MD5checksums 算法检查精确的重复页面。
页面标题 - 缺失、重复、超过 65 个字符、短、像素宽度被截断、相同或大于 h1。
元描述 - 缺失、重复、超过 156 个字符、短、像素宽度被截断或多个。
元关键字 - 主要用于参考,因为它们不被 Google、Bing 或 Yahoo 使用。
文件大小 - URL 和图像的大小。
响应时间。
最后修改的标题。
页面(爬行)深度。
字数。
H1 - 缺失、重复、超过 70 个字符、多个。
H2 - 缺失、重复、超过 70 个字符、多个。
Metabots - 索引、无索引、关注、nofollow、noarchive、nosnippet、noodp、noydir 等。
元刷新 - 包括目标页面和时间延迟。
网站内容抓取工具(关键词热门排行及指数百度排行榜:八、网站流量统计工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2022-04-03 20:07
做一个网站优化者,不仅要懂得优化网站,还要懂得使用工具加快优化进度。本文将推广网站SEO优化是今天给大家一个非常实用的优化工具!
网站一款实用的SEO优化辅助工具!!
一、搜索引擎爬取内容模拟器
它可以模拟蜘蛛爬取指定的网页,包括文本、链接、关键字和描述信息等。
二、页面相似度检测工具
检查两个页面之间的相似度(如果相似度超过80%,你可能会被扣分)
三、站点地图制作工具
1、在线创建小型网站地图文件
2、使用工具制作媒体网站地图
在这里给大家推荐一款非常好用的免费网站地图制作软件:Site Map Builder
官方下载地址:
四、SEO优化辅助
中文分词()
五、百度索引
以图表的形式展示指定关键词在百度的关注度和媒体关注度。登录后,您可以定义一个列表。
六、关键词热门排名和索引
百度排名:
Overture关键词工具:
七、网站管理员工具
1、SEO 站长工具:
2、爱站工具:
3、站长助手:
八、网站流量统计工具
1、百度统计:
2、CNZZ 数据专家:
*是每个网站随时监控自己网站流量的实用工具
九、坏链接检查器
1、Xenu Link Sleuth()
2、W3C GLink 检查器()
十、网站历史查询工具
互联网档案馆(The Internet Archive)保存了自 1996 年以来在 Alexa 搜索引擎的帮助下获得的 网站 资料()
网站优化所需的SEO工具可以根据不同的用途分类:
反向链接检查工具:Yahoo Site Explorer、Open Site Explorer、Majestic SEO
关键字查询工具:百度索引、Google AdWords 关键字工具
关键词排名工具:百度搜索榜、搜狗热搜榜
搜索引擎工具:百度站长平台、360站长平台、搜狗站长平台
SEO效果分析工具:Alexa、CNZZ、百度统计
网站分析工具:站长平台
网站营销动力工具:Vortex 营销诊断工具
通过白帽技术对网站进行优化,也就是形式化的方式,结合网站营销力的优化,可以提升网站的排名,一定程度上提升营销力,带来更多流量和更高的转化率。以上网站SEO优化工具,后续会继续分享给大家。
大家好,我是乐见,欢迎大家关注乐见创业团队,分享创业知识,只讲大家可以入门的创业赚钱方法,分享最接地气的SEO赚钱实用干货。专注自媒体创业、营销、变现等干货分享。关注我了解更多。 查看全部
网站内容抓取工具(关键词热门排行及指数百度排行榜:八、网站流量统计工具)
做一个网站优化者,不仅要懂得优化网站,还要懂得使用工具加快优化进度。本文将推广网站SEO优化是今天给大家一个非常实用的优化工具!
网站一款实用的SEO优化辅助工具!!
一、搜索引擎爬取内容模拟器
它可以模拟蜘蛛爬取指定的网页,包括文本、链接、关键字和描述信息等。
二、页面相似度检测工具
检查两个页面之间的相似度(如果相似度超过80%,你可能会被扣分)
三、站点地图制作工具
1、在线创建小型网站地图文件
2、使用工具制作媒体网站地图
在这里给大家推荐一款非常好用的免费网站地图制作软件:Site Map Builder
官方下载地址:
四、SEO优化辅助
中文分词()
五、百度索引
以图表的形式展示指定关键词在百度的关注度和媒体关注度。登录后,您可以定义一个列表。
六、关键词热门排名和索引
百度排名:
Overture关键词工具:
七、网站管理员工具
1、SEO 站长工具:
2、爱站工具:
3、站长助手:
八、网站流量统计工具
1、百度统计:
2、CNZZ 数据专家:
*是每个网站随时监控自己网站流量的实用工具
九、坏链接检查器
1、Xenu Link Sleuth()
2、W3C GLink 检查器()
十、网站历史查询工具
互联网档案馆(The Internet Archive)保存了自 1996 年以来在 Alexa 搜索引擎的帮助下获得的 网站 资料()
网站优化所需的SEO工具可以根据不同的用途分类:
反向链接检查工具:Yahoo Site Explorer、Open Site Explorer、Majestic SEO
关键字查询工具:百度索引、Google AdWords 关键字工具
关键词排名工具:百度搜索榜、搜狗热搜榜
搜索引擎工具:百度站长平台、360站长平台、搜狗站长平台
SEO效果分析工具:Alexa、CNZZ、百度统计
网站分析工具:站长平台
网站营销动力工具:Vortex 营销诊断工具
通过白帽技术对网站进行优化,也就是形式化的方式,结合网站营销力的优化,可以提升网站的排名,一定程度上提升营销力,带来更多流量和更高的转化率。以上网站SEO优化工具,后续会继续分享给大家。
大家好,我是乐见,欢迎大家关注乐见创业团队,分享创业知识,只讲大家可以入门的创业赚钱方法,分享最接地气的SEO赚钱实用干货。专注自媒体创业、营销、变现等干货分享。关注我了解更多。
网站内容抓取工具(用Python编写的数据包工具被称为第二个Wireshark)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-03 20:06
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
斯卡皮
Scapy 是另一个不错的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试、网络发现。
下载 Scapy:
libcrafter
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数常见协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载库:
耶尔森氏菌
Yersinia 是一款功能强大的网络渗透测试工具,能够对各种网络协议进行渗透测试。如果你正在寻找一个数据包捕获工具,你可以试试这个工具。
下载耶尔森氏菌:
打包ETH
packETH 是另一种数据包处理工具。它是 Linux GUI 的以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以在此工具中设置数据包的数量和数据包之间的延迟,以及修改各种数据包内容。
下载包ETH:
Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
位扭
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络中生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
利宾斯
Libtins 也是制作、发送、嗅探和解析网络数据包的绝佳工具。该工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大、更高效地执行任务。
下载库:
网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
该工具最初名为 Hobbit,于 1995 年发布。
下载网猫:
电线编辑
WireEdit 是一个功能齐全的所见即所得网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。此工具可免费使用,但您必须联系公司以获得访问权限。它支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11等
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载 WireEdit:
epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
片段路由
Fragroute 是一个数据包处理工具,用于拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
毛塞赞
Mausezahn 是一个网络数据包编辑器,可让您发送各种网络数据包。此工具用于防火墙和 IDS 的渗透测试,但您可以在您的网络中使用此工具来查找安全漏洞。您还可以使用此工具来测试您的网络是否可以免受 DOS 攻击。值得注意的是,它使您可以完全控制 NIC 卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 可选 RX 模式用于抖动测量、Syslog 协议。
下载毛泽恩:
EIGRP 工具
这是一个 EIGRP 数据包生成器和嗅探器组合。它是为测试 EIGRP 路由协议的安全性而开发的。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它适用于 Linux、Mac OS 和 BSD 平台。
下载 EIGRP 工具: 查看全部
网站内容抓取工具(用Python编写的数据包工具被称为第二个Wireshark)
通过使用 Ostinato,您可以轻松修改任何协议的任何字段。这个数据包工具也被称为第二个Wireshark。
下载 Ostinato:
斯卡皮
Scapy 是另一个不错的交互式数据包处理工具。这个工具是用 Python 编写的。它可以解码或伪造大量协议的数据包。Scapy 是一个值得尝试的工具。您可以执行各种任务,包括扫描、跟踪、探测、单元测试、网络发现。
下载 Scapy:
libcrafter
Libcrafter 与 Scapy 非常相似。该工具是用 C++ 编写的,可以更轻松地创建和解码网络数据包。它可以创建和解码大多数常见协议的数据包,捕获数据包并匹配请求或回复。该工具可以在多个线程中执行各种任务。
下载库:
耶尔森氏菌
Yersinia 是一款功能强大的网络渗透测试工具,能够对各种网络协议进行渗透测试。如果你正在寻找一个数据包捕获工具,你可以试试这个工具。
下载耶尔森氏菌:
打包ETH
packETH 是另一种数据包处理工具。它是 Linux GUI 的以太网工具。它允许您快速创建和发送数据包序列。与此列表中的其他工具一样,它支持各种协议来创建和发送数据包。您还可以在此工具中设置数据包的数量和数据包之间的延迟,以及修改各种数据包内容。
下载包ETH:
Colasoft 数据包生成器
Colasoft Packet Builder 也是一个用于创建和编辑网络数据包的免费工具。如果您是网络管理员,则可以使用此工具来测试您的网络。它适用于所有可用版本的 Windows 操作系统。
下载 Colasoft Packet Builder:
位扭
Bit-Twist 是一种不太流行但有用的工具,用于在实时流量中重新生成捕获的数据包。它使用 tcpdump 跟踪文件(.pcap 文件)在网络中生成数据包。它带有一个跟踪文件编辑器,允许您更改捕获的数据包中的任何特定字段。网络管理员可以使用此工具测试防火墙、IDS 和 IPS,并解决各种网络问题。你可以试试这个工具。
下载位扭曲:
利宾斯
Libtins 也是制作、发送、嗅探和解析网络数据包的绝佳工具。该工具是用 C++ 编写的。C++ 开发人员可以扩展此工具的功能,使其更强大、更高效地执行任务。
下载库:
网猫
Netcat 也是一种流行的工具,可以在 TCP 或 UDP 网络中读写数据。它可以创建几乎所有类型的网络连接和端口绑定。
该工具最初名为 Hobbit,于 1995 年发布。
下载网猫:
电线编辑
WireEdit 是一个功能齐全的所见即所得网络数据包编辑器。您可以在一个简单的界面中编辑所有数据包层。此工具可免费使用,但您必须联系公司以获得访问权限。它支持以太网、IPv4、IPv6、UDP、TCP、SCTP、ARP、RARP、DHCP、DHCPv6、ICMP、ICMPv6、IGMP、DNS、LLDP、RSVP、FTP、NETBIOS、GRE、IMAP、POP3、RTCP、RTP、SSH、 TELNET、NTP、LDAP、XMPP、VLAN、VXLAN、CIFS/SMB v1(原创)、BGP、OSPF、SMB3、iSCSI、SCSI、HTTP/1.1、OpenFlow 1.0-1.3、SIP、SDP、MSRP、MGCP、MEGACO(H.248)、H.245、H.323、CISCO Skinny、Q.931/H.225、SCCP、SCMG、SS7 ISUP、TCAP , GSM MAP R4, GSM SM-TP, M3UA, M2UA, M2PA, CAPWAP, IEEE 802.11等
它也是一个多平台工具。它适用于 Windows XP 及更高版本、Ubuntu 桌面和 Mac OSX。
下载 WireEdit:
epb – 以太网数据包庞巴迪
Epb-Ethernet Packet Bombardier 是一个类似的工具。它允许您发送自定义以太网数据包。该工具不提供任何图形用户界面,但易于使用。
您可以在此处了解有关此工具的更多信息:
片段路由
Fragroute 是一个数据包处理工具,用于拦截、修改和重写网络流量。您可以使用此工具执行大多数网络渗透测试,以检查网络的安全性。这个工具是开源的,并提供了一个命令行界面来使用。它适用于 Linux、BSD 和 Mac OS。
下载 Fragroute:~dugsong/fragroute/
毛塞赞
Mausezahn 是一个网络数据包编辑器,可让您发送各种网络数据包。此工具用于防火墙和 IDS 的渗透测试,但您可以在您的网络中使用此工具来查找安全漏洞。您还可以使用此工具来测试您的网络是否可以免受 DOS 攻击。值得注意的是,它使您可以完全控制 NIC 卡。它支持 ARP、BPDU 或 PVST、CDP、LLDP、IP、IGMP、UDP、TCP(无状态)、ICMP(部分)、DNS、RTP、RTP 可选 RX 模式用于抖动测量、Syslog 协议。
下载毛泽恩:
EIGRP 工具
这是一个 EIGRP 数据包生成器和嗅探器组合。它是为测试 EIGRP 路由协议的安全性而开发的。要使用此工具,您需要了解第 3 层 EIGRP 协议。这个工具也是一个带有命令行界面的开源工具。它适用于 Linux、Mac OS 和 BSD 平台。
下载 EIGRP 工具:
网站内容抓取工具(sitemap更名为链接提交后,百度之前提交归并到了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-01 11:29
项目投资找A5快速获取精准代理商名单
4月27日sitemap更名为链接提交后,合并原url提交,升级支持批量提交功能。社区版主李跃辉很快发现了这个变化,并尝试了新站点的提交。效果还不错。我想和你分享:
新站建成上线后,首先要做的任务当然是提交给百度,让蜘蛛爬行——这是基本常识。百度之前推出了网站登录地址()提交新站点,但是提交的时候看到一句“你提交的符合相关标准的网址会被百度搜索引擎收录@ > 标准1个月内。被处理。百度不保证能收录@>你提交的网站”有点担心,一个月太长了。
今天给大家推荐另一个提交词条:百度站长平台链接提交工具手动提交。链接提交工具是之前站点地图工具的升级版。除了主动推送和站点地图外,还加入了之前的url提交工具。这里不再有一个月的期限,蜘蛛抓取几乎是实时的,只要网站内容符合百度收录@>标准,都会很快处理收录@>。看到这里,有人说:切~~~,我们都是用主动推送和sitemap,还是手动提交。我想说的是:大哥!作为一个刚刚上线的站点,sitemap权限不是你想要的。哇!
以下是使用手动提交的步骤和注意事项:
1、首先当然是在百度站长平台验证网站
2、在数据提交下选择手动提交
注意:
1、提交网址时请填写已验证站点的链接。链接应包括首页、频道页、栏目页和您希望百度尽快收录@>的内容页。
2、一次最多提交 20 个,每行一个链接。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网站内容抓取工具(sitemap更名为链接提交后,百度之前提交归并到了)
项目投资找A5快速获取精准代理商名单
4月27日sitemap更名为链接提交后,合并原url提交,升级支持批量提交功能。社区版主李跃辉很快发现了这个变化,并尝试了新站点的提交。效果还不错。我想和你分享:
新站建成上线后,首先要做的任务当然是提交给百度,让蜘蛛爬行——这是基本常识。百度之前推出了网站登录地址()提交新站点,但是提交的时候看到一句“你提交的符合相关标准的网址会被百度搜索引擎收录@ > 标准1个月内。被处理。百度不保证能收录@>你提交的网站”有点担心,一个月太长了。
今天给大家推荐另一个提交词条:百度站长平台链接提交工具手动提交。链接提交工具是之前站点地图工具的升级版。除了主动推送和站点地图外,还加入了之前的url提交工具。这里不再有一个月的期限,蜘蛛抓取几乎是实时的,只要网站内容符合百度收录@>标准,都会很快处理收录@>。看到这里,有人说:切~~~,我们都是用主动推送和sitemap,还是手动提交。我想说的是:大哥!作为一个刚刚上线的站点,sitemap权限不是你想要的。哇!
以下是使用手动提交的步骤和注意事项:
1、首先当然是在百度站长平台验证网站
2、在数据提交下选择手动提交
注意:
1、提交网址时请填写已验证站点的链接。链接应包括首页、频道页、栏目页和您希望百度尽快收录@>的内容页。
2、一次最多提交 20 个,每行一个链接。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网站内容抓取工具( VPS多多小编2022-03-23?百度没有收录网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-30 06:10
VPS多多小编2022-03-23?百度没有收录网站)
为什么网站内容没有被百度提取收录
VPS多多编辑器2022-03-23
为什么网站内容没有被百度收录收录?
百度没有收录网站,可能是服务器本站的原因。
目前百度蜘蛛的爬取方式有两种,一种是主动爬取,一种是在百度站长平台的链接提交工具中获取数据。
如果网站内容很久没有收录了,建议使用主动推送功能推送首页数据,有利于抓取内页数据。
当然,这些都是针对新站点收录 的解决方案。如果不是新站,不是收录的原因是什么?
百度没有收录网站内容的原因分析。
首先,网站内容质量。
如果网站的大量内容是借用别人的,会导致百度没有收录,百度也加强了对合集网站的审核。
搜索引擎倾向于拥有高质量的原创内容,原创文章更容易满足用户需求,提升用户体验。
原创内容独特,在网上找不到想要的文章,网站很容易脱颖而出,获得百度给出的权重。
其次,蜘蛛爬行失败。
百度站长平台研究百度蜘蛛的日常爬取情况。网站更新内容时,可以将此内容提交给百度,也可以通过百度站长平台的爬取诊断进行测试,看爬取是否正常。
三是主动推送爬取配额。
如果网站页数突然增加,会影响蜘蛛抓取收录,所以网站在保证稳定访问的同时要注意网站的安全。
第四,Robots.txt 文件。
机器人文件告诉搜索引擎哪些页面可以和不能被抓取。有的站长会屏蔽一些不重要的文件,禁止蜘蛛爬行,可能会屏蔽重要的页面,可以查看Robots。
标题 五、 经常更改。
如果网站的标题变化频繁,搜索引擎将不知道网站的内容表达了什么,网站的内容与标题不匹配,影响时间收录 页面,因此错过了 收录 的最佳时机。
新网站百度非收录注意事项:
1、新站点的服务器/空间不稳定,有时打不开网站,使得蜘蛛难以抓取网页;
2、网站内容含有违禁词,违禁词被搜索引擎命中,此类网站将不被允许收录;
3、新站点被黑、跳转或挂断,导致站点无法正常访问,搜索引擎不是收录不安全站点;
4、域名双解析中不要操作301重定向,搜索引擎不知道哪个是主域名;
5、网站内容不完善会上线。频繁修改内容会导致搜索引擎不喜欢该网页,不会导致收录;
6、网站标题过长,列表堆积,作弊和快速排序优化导致页面不是收录;
7、新站排名收录不稳定也正常;
8、网站机器人被封禁,导致蜘蛛无法抓取网页,所以没有收录等;
以上为网站百度非分享内容收录,新网站百度非收录内容分享,希望对你有所帮助。 查看全部
网站内容抓取工具(
VPS多多小编2022-03-23?百度没有收录网站)
为什么网站内容没有被百度提取收录
VPS多多编辑器2022-03-23
为什么网站内容没有被百度收录收录?
百度没有收录网站,可能是服务器本站的原因。
目前百度蜘蛛的爬取方式有两种,一种是主动爬取,一种是在百度站长平台的链接提交工具中获取数据。
如果网站内容很久没有收录了,建议使用主动推送功能推送首页数据,有利于抓取内页数据。
当然,这些都是针对新站点收录 的解决方案。如果不是新站,不是收录的原因是什么?
百度没有收录网站内容的原因分析。
首先,网站内容质量。
如果网站的大量内容是借用别人的,会导致百度没有收录,百度也加强了对合集网站的审核。
搜索引擎倾向于拥有高质量的原创内容,原创文章更容易满足用户需求,提升用户体验。
原创内容独特,在网上找不到想要的文章,网站很容易脱颖而出,获得百度给出的权重。
其次,蜘蛛爬行失败。
百度站长平台研究百度蜘蛛的日常爬取情况。网站更新内容时,可以将此内容提交给百度,也可以通过百度站长平台的爬取诊断进行测试,看爬取是否正常。
三是主动推送爬取配额。
如果网站页数突然增加,会影响蜘蛛抓取收录,所以网站在保证稳定访问的同时要注意网站的安全。
第四,Robots.txt 文件。
机器人文件告诉搜索引擎哪些页面可以和不能被抓取。有的站长会屏蔽一些不重要的文件,禁止蜘蛛爬行,可能会屏蔽重要的页面,可以查看Robots。
标题 五、 经常更改。
如果网站的标题变化频繁,搜索引擎将不知道网站的内容表达了什么,网站的内容与标题不匹配,影响时间收录 页面,因此错过了 收录 的最佳时机。
新网站百度非收录注意事项:
1、新站点的服务器/空间不稳定,有时打不开网站,使得蜘蛛难以抓取网页;
2、网站内容含有违禁词,违禁词被搜索引擎命中,此类网站将不被允许收录;
3、新站点被黑、跳转或挂断,导致站点无法正常访问,搜索引擎不是收录不安全站点;
4、域名双解析中不要操作301重定向,搜索引擎不知道哪个是主域名;
5、网站内容不完善会上线。频繁修改内容会导致搜索引擎不喜欢该网页,不会导致收录;
6、网站标题过长,列表堆积,作弊和快速排序优化导致页面不是收录;
7、新站排名收录不稳定也正常;
8、网站机器人被封禁,导致蜘蛛无法抓取网页,所以没有收录等;
以上为网站百度非分享内容收录,新网站百度非收录内容分享,希望对你有所帮助。
网站内容抓取工具( 百度pider访问您的网站有什么影响?连接异常)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-26 03:11
百度pider访问您的网站有什么影响?连接异常)
一、什么是抓取异常?
对于普通用户在互联网上可以正常访问的内容,百度蜘蛛无法正常访问和爬取的情况属于异常爬取。
二、异常爬行对网站有何影响?
对于网站内容量大且无法正常抓取的情况,搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价。在爬取、索引和权重方面都会受到一定程度的负面影响,最终会影响到从百度获得的流量网站。
三、什么是服务器连接异常?
服务器连接异常有两种情况:一种是网站不稳定,百度pider在尝试连接时暂时无法连接到你的网站服务器;另一个是百度pider一直无法连接到你的网站>服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能无法正常运行。请检查网站的Web服务器(如Apache、IIS)是否安装并正常运行,并使用浏览器检查主页面是否可以正常访问。您的 网站 和主机也可能会阻止百度蜘蛛的访问。您需要检查 网站 和主机的防火墙。
四、什么是网络运营商异常?
有两家网络运营商:中国电信和中国联通。百度pider无法通过中国电信或中国网通访问您的网站。如果出现这种情况,您需要联系网络服务商,或者购买二级服务或CDN服务的空间。
五、什么是 DNS 例外?
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站的IP地址不对,或者你的域名服务商封杀了Baiduspider。请使用 whois 或主机检查您的 网站 IP 地址是否正确且可解析。如果没有,请联系域名注册商以更新您的 IP 地址。
六、什么是 IP 阻塞?
IP Blocking:限制网络的现有IP地址,禁止IP段内的用户访问内容。
仅当您的 网站 不希望百度 Pider 访问时才需要此设置。如果您希望百度pider访问您的网站,请检查百度pider IP是否被错误添加到相关设置中。你的网站所在的空间服务商也可能会封禁百度IP。此时,您需要联系您的服务提供商以更改设置。
七、什么是运营单位禁令?
UA 是用户代理。服务器通过UA识别访问者。当一个网站访问指定的UA并返回异常页面(如403500)或跳转到另一个页面时,称为UA阻塞。
仅当您不希望百度蜘蛛访问您的 网站 时才需要此设置。如果你想让百度Pide访问你的网站,用户代理中是否有百度Pide相关设置并及时修改。
八、什么是死链接?
无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接。
协议死链接:页面的TCP协议状态/HTTP协议状态明确指出死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限的页面,与原创内容无关。
对于死链接,建议将死链接提交给百度站长平台死链接工具进行处理,这样搜索引擎可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
九、什么是异常跳转?
将网络请求重定向到另一个位置是一个跳转。异常跳转是指以下几种情况
一、当前页面为无效页面(内容已被删除,死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
注意:如果长时间重定向到其他域名,比如更换网站上的域名,百度建议使用301重定向协议进行设置。
十、有哪些例外?
百度引荐来源网址例外:网页返回的行为与百度引荐来源网址的正常内容不同。
百度 UA 的例外:返回百度 UA 的网页的行为与页面的原创内容不同。
JS跳转异常:网页加载了百度无法识别的JS跳转代码,用户通过搜索结果进入网页后跳转。
意外阻塞导致压力过大:百度会根据网站规模、流量等信息自动设置合理的爬取压力,但在压力控制异常等异常情况下,服务器会受到意外保护根据自己的负载阻塞。在这种情况下,请在返回码中返回 503(表示“服务不可用”),以便百度蜘蛛过段时间再次尝试获取链接。如果 网站 空闲,则 网站 将被成功获取。 查看全部
网站内容抓取工具(
百度pider访问您的网站有什么影响?连接异常)
一、什么是抓取异常?
对于普通用户在互联网上可以正常访问的内容,百度蜘蛛无法正常访问和爬取的情况属于异常爬取。
二、异常爬行对网站有何影响?
对于网站内容量大且无法正常抓取的情况,搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价。在爬取、索引和权重方面都会受到一定程度的负面影响,最终会影响到从百度获得的流量网站。
三、什么是服务器连接异常?
服务器连接异常有两种情况:一种是网站不稳定,百度pider在尝试连接时暂时无法连接到你的网站服务器;另一个是百度pider一直无法连接到你的网站>服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能无法正常运行。请检查网站的Web服务器(如Apache、IIS)是否安装并正常运行,并使用浏览器检查主页面是否可以正常访问。您的 网站 和主机也可能会阻止百度蜘蛛的访问。您需要检查 网站 和主机的防火墙。
四、什么是网络运营商异常?
有两家网络运营商:中国电信和中国联通。百度pider无法通过中国电信或中国网通访问您的网站。如果出现这种情况,您需要联系网络服务商,或者购买二级服务或CDN服务的空间。
五、什么是 DNS 例外?
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站的IP地址不对,或者你的域名服务商封杀了Baiduspider。请使用 whois 或主机检查您的 网站 IP 地址是否正确且可解析。如果没有,请联系域名注册商以更新您的 IP 地址。
六、什么是 IP 阻塞?
IP Blocking:限制网络的现有IP地址,禁止IP段内的用户访问内容。
仅当您的 网站 不希望百度 Pider 访问时才需要此设置。如果您希望百度pider访问您的网站,请检查百度pider IP是否被错误添加到相关设置中。你的网站所在的空间服务商也可能会封禁百度IP。此时,您需要联系您的服务提供商以更改设置。
七、什么是运营单位禁令?
UA 是用户代理。服务器通过UA识别访问者。当一个网站访问指定的UA并返回异常页面(如403500)或跳转到另一个页面时,称为UA阻塞。
仅当您不希望百度蜘蛛访问您的 网站 时才需要此设置。如果你想让百度Pide访问你的网站,用户代理中是否有百度Pide相关设置并及时修改。
八、什么是死链接?
无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接。
协议死链接:页面的TCP协议状态/HTTP协议状态明确指出死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限的页面,与原创内容无关。
对于死链接,建议将死链接提交给百度站长平台死链接工具进行处理,这样搜索引擎可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
九、什么是异常跳转?
将网络请求重定向到另一个位置是一个跳转。异常跳转是指以下几种情况
一、当前页面为无效页面(内容已被删除,死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
注意:如果长时间重定向到其他域名,比如更换网站上的域名,百度建议使用301重定向协议进行设置。
十、有哪些例外?
百度引荐来源网址例外:网页返回的行为与百度引荐来源网址的正常内容不同。
百度 UA 的例外:返回百度 UA 的网页的行为与页面的原创内容不同。
JS跳转异常:网页加载了百度无法识别的JS跳转代码,用户通过搜索结果进入网页后跳转。
意外阻塞导致压力过大:百度会根据网站规模、流量等信息自动设置合理的爬取压力,但在压力控制异常等异常情况下,服务器会受到意外保护根据自己的负载阻塞。在这种情况下,请在返回码中返回 503(表示“服务不可用”),以便百度蜘蛛过段时间再次尝试获取链接。如果 网站 空闲,则 网站 将被成功获取。
网站内容抓取工具(收集电子邮件地址、竞争分析、网站检查、订价分析和客户数据收集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-25 23:01
采集电子邮件地址、竞争分析、网站检查、定价分析和客户数据采集——这些只是您可能需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,做诸如手部运动之类的事情是痛苦的、低效的,而且在某些情况下是不可能的。幸运的是,今天有各种各样的工具可以满足这些需求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一些编码知识并为更大、更困难的任务而设计的高级工具。html
Iconico HTML 文本提取器
假设您正在浏览竞争对手的 网站 并想要提取文本,或者您想要查看页面后面的 HTML 代码。但不幸的是,您发现右键单击被禁用,复制和粘贴也是如此。如今,许多 Web 开发人员正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,提取功能就像在网上冲浪一样简单。网络
UiPath
UIPath 有一套自动化流程的工具,包括一个网页内容抓取工具。使用该工具并获得几乎任何您想要的数据很容易 - 只需打开页面,进入工具中的设计菜单,然后单击“网络抓取”。除了网络刮板,屏幕刮板还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中抓取文本、表格数据和其他相关信息。api
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文档和内容。然后,您可以将此数据导出到 XML 文件、CSV 文件、JSON 或可选地使用 API。提取和导出数据后,可以使用 BI 工具对其进行分析和报告。互联网
HTMLtoText
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您所要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和一些其他详细信息,然后单击转换,您将获得所需的文本信息。刮擦
(有一个类似的工具 - )工具
八分法
Octoparse 的特点是它提供了一个“点击式”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送到各种文件格式。该工具包括从页面中提取电子邮件地址、从工作板中提取工作列表等功能。该工具适用于动态和静态网页和云采集(配置采集任务关闭也可以采集数据)。它提供了一个可以满足大多数用例的免费版本,而付费版本功能更丰富。学习
如果您抓取 网站 进行竞争分析,您可能会被禁止参与此活动。由于 Octoparse 收录一个在循环中识别您的 IP 地址的函数,它可以禁止您通过您的 IP 使用它。大数据
刮擦
这个免费的开源工具使用网络爬虫从 网站 中提取信息,并且需要一些高级技能和编码知识才能使用。但是,如果您愿意学习以自己的方式使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌都使用此工具。由于它是一个开源工具,这为用户提供了相当多的社区支持。网站
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将该信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,或者您可以创建计划作业以在特定时间提取您需要的数据。您可以从搜索引擎结果、网页甚至幻灯片中提取数据。最重要的是,Kimono 会在您设置每个工作流程时构建一个 API。这意味着当您返回 网站 以提取更多数据时,无需重新发明轮子。用户界面
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中的至少一个工具应该收录您需要的解决方案。无论您想要什么价格,您都应该能够找到您需要的工具。找出并决定哪一个最适合您。意识到大数据在蓬勃发展的业务中的重要性,采集所需信息的能力对您来说非常重要。
编译自:Dzone 查看全部
网站内容抓取工具(收集电子邮件地址、竞争分析、网站检查、订价分析和客户数据收集)
采集电子邮件地址、竞争分析、网站检查、定价分析和客户数据采集——这些只是您可能需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,做诸如手部运动之类的事情是痛苦的、低效的,而且在某些情况下是不可能的。幸运的是,今天有各种各样的工具可以满足这些需求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一些编码知识并为更大、更困难的任务而设计的高级工具。html
Iconico HTML 文本提取器
假设您正在浏览竞争对手的 网站 并想要提取文本,或者您想要查看页面后面的 HTML 代码。但不幸的是,您发现右键单击被禁用,复制和粘贴也是如此。如今,许多 Web 开发人员正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,并且该产品非常易于使用。您可以突出显示和复制文本,提取功能就像在网上冲浪一样简单。网络
UiPath
UIPath 有一套自动化流程的工具,包括一个网页内容抓取工具。使用该工具并获得几乎任何您想要的数据很容易 - 只需打开页面,进入工具中的设计菜单,然后单击“网络抓取”。除了网络刮板,屏幕刮板还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中抓取文本、表格数据和其他相关信息。api
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能业务工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文档和内容。然后,您可以将此数据导出到 XML 文件、CSV 文件、JSON 或可选地使用 API。提取和导出数据后,可以使用 BI 工具对其进行分析和报告。互联网
HTMLtoText
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您所要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和一些其他详细信息,然后单击转换,您将获得所需的文本信息。刮擦
(有一个类似的工具 - )工具
八分法
Octoparse 的特点是它提供了一个“点击式”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送到各种文件格式。该工具包括从页面中提取电子邮件地址、从工作板中提取工作列表等功能。该工具适用于动态和静态网页和云采集(配置采集任务关闭也可以采集数据)。它提供了一个可以满足大多数用例的免费版本,而付费版本功能更丰富。学习
如果您抓取 网站 进行竞争分析,您可能会被禁止参与此活动。由于 Octoparse 收录一个在循环中识别您的 IP 地址的函数,它可以禁止您通过您的 IP 使用它。大数据
刮擦
这个免费的开源工具使用网络爬虫从 网站 中提取信息,并且需要一些高级技能和编码知识才能使用。但是,如果您愿意学习以自己的方式使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌都使用此工具。由于它是一个开源工具,这为用户提供了相当多的社区支持。网站
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将该信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,或者您可以创建计划作业以在特定时间提取您需要的数据。您可以从搜索引擎结果、网页甚至幻灯片中提取数据。最重要的是,Kimono 会在您设置每个工作流程时构建一个 API。这意味着当您返回 网站 以提取更多数据时,无需重新发明轮子。用户界面
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中的至少一个工具应该收录您需要的解决方案。无论您想要什么价格,您都应该能够找到您需要的工具。找出并决定哪一个最适合您。意识到大数据在蓬勃发展的业务中的重要性,采集所需信息的能力对您来说非常重要。
编译自:Dzone
网站内容抓取工具(爬取一个网站的法律问题及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-24 06:41
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get('')soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
打印(汤。美化())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 URL 似乎收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
Dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in Dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = Dollar_tree_list[2] # 一个有代表性的例子 example_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']打印(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty listfor i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href)# check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # 再建立一个有代表性的例子 soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type='application/ld+json' 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type='application/ld+json')print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
类型(arco_json)打印(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # 为 city_hrefs 中的链接初始化空列表: locpage = requests.get(link) # 请求页面信息 locsoup = BeautifulSoup(locpage.text, 'html.parser') # 解析页面内容 locinfo = locsoup.find_all( type ='application/ld+json') # 提取特定元素 loccont = locinfo[1].contents[0] # 从 bs4 元素集合中获取内容 locjson = json.loads(loccont) # 转换为json locaddr = locjson[' address '] # 获取地址 locs_dict. append(locaddr) # 将地址添加到列表中
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, 'family_dollar_ID_locations.csv', sep = ',', index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = 'https://www.walgreens.com/storelistings/storesbycity.jsp?requestType=locator&state=ID'driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoup import jsonfrom pandas import DataFrame as dfpage = requests. get('./locations/')soup = BeautifulSoup(page.text, 'html.parser')# 查找所有状态链接state_list = soup. find_all(class_ = 'itemlist')state_links = []for i in state_list:cont = i. 内容[0]属性=续。attrshrefs = attr['href']state_links. append(hrefs)# find all city linkscity_links = []for link in state_links:page = requests. 获取(链接)汤= BeautifulSoup(page.text,'html。
parser') familydollar_list = 汤。find_all(class_ = 'itemlist') for store in familydollar_list:cont = store. 内容[0]属性=续。attrscity_hrefs = attr['href']city_links. append(city_hrefs)# 获取单独的商店链接store_links = []for link in city_links:locpage = requests. get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup. find_all(type='application/ld+json') for i in locinfo:loccont = i. 内容[0]locjson = json。加载(loccont)尝试:store_url = locjson['url']store_links.
append(store_url)except:pass# 获取地址和地理位置信息stores = []for store in store_links:storepage = requests. get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup. find_all(type='application/ld+json') for i in storeinfo:storecont=i. 内容[0]storejson = json. 加载(storecont)尝试:store_addr = storejson['address']store_addr. 更新(storejson['geo'])商店。append(store_addr)except:pass# 最终数据解析stores_df = df. from_records(商店)stores_df。
drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = 'Family Dollar'df. to_csv(stores_df, 'family_dollar_locations.csv', sep = ',', index = False)
作者注:本文改编自我于 2020 年 2 月 9 日在俄勒冈州波特兰市的 PyCascades 上的演讲。
通过: 查看全部
网站内容抓取工具(爬取一个网站的法律问题及解决办法(一))
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get('')soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
打印(汤。美化())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 URL 似乎收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
Dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in Dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = Dollar_tree_list[2] # 一个有代表性的例子 example_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']打印(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty listfor i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href)# check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # 再建立一个有代表性的例子 soup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type='application/ld+json' 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type='application/ld+json')print(arco[1])
地址信息在第二个列表成员中!我懂了!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
类型(arco_json)打印(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # 为 city_hrefs 中的链接初始化空列表: locpage = requests.get(link) # 请求页面信息 locsoup = BeautifulSoup(locpage.text, 'html.parser') # 解析页面内容 locinfo = locsoup.find_all( type ='application/ld+json') # 提取特定元素 loccont = locinfo[1].contents[0] # 从 bs4 元素集合中获取内容 locjson = json.loads(loccont) # 转换为json locaddr = locjson[' address '] # 获取地址 locs_dict. append(locaddr) # 将地址添加到列表中
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, 'family_dollar_ID_locations.csv', sep = ',', index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = 'https://www.walgreens.com/storelistings/storesbycity.jsp?requestType=locator&state=ID'driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoup import jsonfrom pandas import DataFrame as dfpage = requests. get('./locations/')soup = BeautifulSoup(page.text, 'html.parser')# 查找所有状态链接state_list = soup. find_all(class_ = 'itemlist')state_links = []for i in state_list:cont = i. 内容[0]属性=续。attrshrefs = attr['href']state_links. append(hrefs)# find all city linkscity_links = []for link in state_links:page = requests. 获取(链接)汤= BeautifulSoup(page.text,'html。
parser') familydollar_list = 汤。find_all(class_ = 'itemlist') for store in familydollar_list:cont = store. 内容[0]属性=续。attrscity_hrefs = attr['href']city_links. append(city_hrefs)# 获取单独的商店链接store_links = []for link in city_links:locpage = requests. get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup. find_all(type='application/ld+json') for i in locinfo:loccont = i. 内容[0]locjson = json。加载(loccont)尝试:store_url = locjson['url']store_links.
append(store_url)except:pass# 获取地址和地理位置信息stores = []for store in store_links:storepage = requests. get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup. find_all(type='application/ld+json') for i in storeinfo:storecont=i. 内容[0]storejson = json. 加载(storecont)尝试:store_addr = storejson['address']store_addr. 更新(storejson['geo'])商店。append(store_addr)except:pass# 最终数据解析stores_df = df. from_records(商店)stores_df。
drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = 'Family Dollar'df. to_csv(stores_df, 'family_dollar_locations.csv', sep = ',', index = False)
作者注:本文改编自我于 2020 年 2 月 9 日在俄勒冈州波特兰市的 PyCascades 上的演讲。
通过:
网站内容抓取工具(免费进行数据提取是可以的,怎么克服这些规则?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-24 01:07
免费数据提取是可能的,但它有一些缺点。比如网络不够稳定,IP容易被封。事实上,数据采集中最大的开销是使用代理服务器,网络爬虫使用代理服务器来防止 网站 检测网络爬虫,因为大多数 网站 不允许对它们进行自动化活动,所以您需要采取措施克服这些规则。以下是两种不同的网页抓取方法:
一、如果网站存储了他们所有关于HTML前端的信息,可以直接使用代码下载HTML内容,提取有用信息。
步骤:
1、检查 网站HTML
你想刮
2、,使用代码访问网站的URL,下载页面上的所有HTML内容
3、将下载格式化为可读格式
4、提取有用信息并以结构化格式保存
5、对于在网站多个页面上显示的信息,您可能需要重复步骤2-4以获得完整信息。
这种方法简单明了。但是,如果 网站 的前端结构发生变化,则需要相应地调整代码。
二、如果网站将数据存储在API中,用户每次访问网站网站都会查询API,可以模拟请求查询数据直接来自 API
步骤
1、检查要抓取的 URL 的 XHR Web 部分
2、找到为您提供所需数据的请求-响应
3、在您的代码中,模拟请求并根据请求类型(post 或 get)以及请求标头和有效负载从 API 检索数据。一般来说,从 API 获取的数据格式非常简洁。
4、提取你需要的有用信息
5、对于查询大小有限的 API,您将需要使用“for 循环”来重复检索所有数据
如果您能找到 API 请求,这绝对是首选方法。您收到的数据将更加结构化和稳定。这是因为与 网站 前端相比,公司不太可能更改其后端 API。但是,它比第一种方法稍微复杂一些,尤其是在需要身份验证时。 查看全部
网站内容抓取工具(免费进行数据提取是可以的,怎么克服这些规则?)
免费数据提取是可能的,但它有一些缺点。比如网络不够稳定,IP容易被封。事实上,数据采集中最大的开销是使用代理服务器,网络爬虫使用代理服务器来防止 网站 检测网络爬虫,因为大多数 网站 不允许对它们进行自动化活动,所以您需要采取措施克服这些规则。以下是两种不同的网页抓取方法:
一、如果网站存储了他们所有关于HTML前端的信息,可以直接使用代码下载HTML内容,提取有用信息。
步骤:
1、检查 网站HTML
你想刮
2、,使用代码访问网站的URL,下载页面上的所有HTML内容
3、将下载格式化为可读格式
4、提取有用信息并以结构化格式保存
5、对于在网站多个页面上显示的信息,您可能需要重复步骤2-4以获得完整信息。
这种方法简单明了。但是,如果 网站 的前端结构发生变化,则需要相应地调整代码。
二、如果网站将数据存储在API中,用户每次访问网站网站都会查询API,可以模拟请求查询数据直接来自 API
步骤
1、检查要抓取的 URL 的 XHR Web 部分
2、找到为您提供所需数据的请求-响应
3、在您的代码中,模拟请求并根据请求类型(post 或 get)以及请求标头和有效负载从 API 检索数据。一般来说,从 API 获取的数据格式非常简洁。
4、提取你需要的有用信息
5、对于查询大小有限的 API,您将需要使用“for 循环”来重复检索所有数据
如果您能找到 API 请求,这绝对是首选方法。您收到的数据将更加结构化和稳定。这是因为与 网站 前端相比,公司不太可能更改其后端 API。但是,它比第一种方法稍微复杂一些,尤其是在需要身份验证时。
网站内容抓取工具(为什么这些内容部分使用百度推荐有什么好处?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-24 01:03
一般来说,每个网站内容版块都有一个站点推荐阅读,比如这个博客,右边的内容也有一个推荐阅读,如下:
为什么这些内容部分使用百度推荐?使用百度推荐有什么好处?
百度推荐系统实现的前提是了解你的网站的所有内容,在进行分析推荐之前,基本原则是:
一种。用户第一次访问页面->触发JS代码->爬取页面->分析页面相关性
湾。用户二次访问页面->触发JS代码->获取推荐数据
百度推荐的具体实现如何?无论我们如何沟通,我们只需要关心推荐的过程。百度必须爬取网站的页面,才能达到推荐的效果。这是一个技术上永远无法绕过的链接。
为什么要使用百度推荐?首先,在文章页面左侧或底部添加百度推荐后,必须为用户推荐合适的内容。它必须立即掌握我们所有的 网站 内容,然后对其进行分析和分类,然后将其呈现给用户。这是一个无法绕过的链接,足以用于抓取目的。
为什么百度推荐的抓取很重要?试想一下,如果我们被百度推荐,我们会如何评价这个产品的质量?显然,用户数、展示次数、点击率、覆盖率等指标对我们有用。覆盖率是多少?如果一个 网站 有数百万页,你的建议可以在 80W 页面上,你的覆盖率是 80%。这个指标决定了百度推荐一定要把握好我们的页面,努力做到覆盖。只有这样,他们才能提高他们的展示、用户、点击等指标,也就是他们的核心KPI就是这个覆盖率。
也就是说,只要你用百度推荐,你的页面可能是百度收录,这比等蜘蛛爬要开心多了。您所要做的就是让点击器一次点击您的所有页面!
如何评估推荐的质量?
推荐质量的评价主要从推荐带来的流量和质量来衡量:
1、推荐带来流量“量”:点击推荐内容带来网站浏览量(pv),可直接在百度统计报告中查看!
2、推荐带来的流量质量:推荐带来的流量质量(平均访问时间、平均页面数、跳出率等)!
是不是有一定的原因,有兴趣的朋友可以去百度推荐一下,要不要用就看你了,不过我已经准备好了试用效果,和大家分享一下使用方法和效果将来!
【SEO问题解决】为什么网站都是原创,而关键词没有排名?
“为什么我的 网站 是 原创 但关键字没有排名?” 我已经为我的徒弟解决了这个问题,但我发现很多人仍然问我。今天陪SEO给大家详细解释一下是什么原因?在解释它们之间的各种问题之前,我们应该先了解一下原创内容是什么。根据百科对原文内容的解读,其内容如下:
1、作者主动提出的物质或精神成果,不抄袭和模仿,内容和形式具有独特的个性。
2、作者本人创作的具有文学、艺术或科学性质的作品,具有社会共识的价值。指的是自己写的文章,没有抄袭或者抄袭。(注:第3条不妥,但已经是互联网上的习惯规则,应该承认。)因此,站长和SEO从业者所说的“原创”应该是第3条所指的。描述的情况,只要是自己写的,就是他们的原创不抄袭别人的内容。它不要求“具有独特个性的物质或精神成就”或“社会共识价值”,即“原创”内容不等于“有价值”内容。正是这一点伴随着 SEO 总是增加“价值” 当谈到原创内容时,即“原创价值内容”。因为原创不代表价值,站长和SEO从业者所说的“原创”大多澄清文章是自己写的,不是抄袭别人的,所以文章的内容质量未知。非常重要的是,在文件中输入的内容在键盘被擦拭时也可以被认为是原创的,但是这个“原创”对于普通用户来说并没有真正的意义,更不用说任何阅读价值了。同样的,即使所有的文章都没有偏离网站的主题,但是文章没有实际的价值信息可以传达给用户,只有行业,那么这个“原创" 不值得。所以创造力不等于价值。虽然搜索引擎不能直接分析 原创<
在经营网站的过程中,网站管理员和SEO从业者不应该宣传他们有多少原创,而应该宣传他们网站上的内容是否与他们的目标用户相关潜在用户具有价值。事实上,在很多为原创做广告的网站作品中,很多内容都是围绕着要实现的关键词组装起来的,并不是特别具有可读性和价值好的。网站的内容很多,原创的内容很多,但是用户不错,老用户数量巨大。即使内容不是原创,它在搜索引擎中的排名和流量也会更好。还有很多网站原创内容比例很大,但是内容质量参差不齐,或者服务器响应慢,或者内容页面添加了很多广告。这严重影响了用户在网站中的阅读体验或其他问题,导致长期坚持原创内容不足以在搜索引擎中获得好的排名和流量。能够从目标用户需求的角度编写网站的所有内容。但是,随着国内网络的发展,任何一个网站都不可能让原创的所有内容都对用户具有性和价值。事实上,网站 操作并不完全需要 原创 内容。运营网站做长期SEO,内容需求要以用户价值为基础,以原创为补充。因此,在为网站做内容优化策略和内容编写时,首先要学会转置。假设你是目标用户,你想通过网站得到什么信息,网站可以帮你解决什么问题,能不能快速准确的找到产品或服务。网站您需要的服务等。
豆豆SEO最后,请网友们辩论意见:如何选择靠谱的SEO公司?
我们要找一家靠谱的优化公司。我们可以在百度上搜索“region + seo”这个词,在百度首页找到置顶网站。像这样的网站,我们平时注意自己的品牌是不会骗客户钱的。在为我们优化之前,我们通常会提前收取百分之几的费用,然后在排名完成后补上余额。如果排名失败,我们会将之前支付的款项退还给我们。这样我们的交易风险就会小很多。 查看全部
网站内容抓取工具(为什么这些内容部分使用百度推荐有什么好处?(组图))
一般来说,每个网站内容版块都有一个站点推荐阅读,比如这个博客,右边的内容也有一个推荐阅读,如下:
为什么这些内容部分使用百度推荐?使用百度推荐有什么好处?
百度推荐系统实现的前提是了解你的网站的所有内容,在进行分析推荐之前,基本原则是:
一种。用户第一次访问页面->触发JS代码->爬取页面->分析页面相关性
湾。用户二次访问页面->触发JS代码->获取推荐数据
百度推荐的具体实现如何?无论我们如何沟通,我们只需要关心推荐的过程。百度必须爬取网站的页面,才能达到推荐的效果。这是一个技术上永远无法绕过的链接。
为什么要使用百度推荐?首先,在文章页面左侧或底部添加百度推荐后,必须为用户推荐合适的内容。它必须立即掌握我们所有的 网站 内容,然后对其进行分析和分类,然后将其呈现给用户。这是一个无法绕过的链接,足以用于抓取目的。
为什么百度推荐的抓取很重要?试想一下,如果我们被百度推荐,我们会如何评价这个产品的质量?显然,用户数、展示次数、点击率、覆盖率等指标对我们有用。覆盖率是多少?如果一个 网站 有数百万页,你的建议可以在 80W 页面上,你的覆盖率是 80%。这个指标决定了百度推荐一定要把握好我们的页面,努力做到覆盖。只有这样,他们才能提高他们的展示、用户、点击等指标,也就是他们的核心KPI就是这个覆盖率。
也就是说,只要你用百度推荐,你的页面可能是百度收录,这比等蜘蛛爬要开心多了。您所要做的就是让点击器一次点击您的所有页面!
如何评估推荐的质量?
推荐质量的评价主要从推荐带来的流量和质量来衡量:
1、推荐带来流量“量”:点击推荐内容带来网站浏览量(pv),可直接在百度统计报告中查看!
2、推荐带来的流量质量:推荐带来的流量质量(平均访问时间、平均页面数、跳出率等)!
是不是有一定的原因,有兴趣的朋友可以去百度推荐一下,要不要用就看你了,不过我已经准备好了试用效果,和大家分享一下使用方法和效果将来!
【SEO问题解决】为什么网站都是原创,而关键词没有排名?
“为什么我的 网站 是 原创 但关键字没有排名?” 我已经为我的徒弟解决了这个问题,但我发现很多人仍然问我。今天陪SEO给大家详细解释一下是什么原因?在解释它们之间的各种问题之前,我们应该先了解一下原创内容是什么。根据百科对原文内容的解读,其内容如下:
1、作者主动提出的物质或精神成果,不抄袭和模仿,内容和形式具有独特的个性。
2、作者本人创作的具有文学、艺术或科学性质的作品,具有社会共识的价值。指的是自己写的文章,没有抄袭或者抄袭。(注:第3条不妥,但已经是互联网上的习惯规则,应该承认。)因此,站长和SEO从业者所说的“原创”应该是第3条所指的。描述的情况,只要是自己写的,就是他们的原创不抄袭别人的内容。它不要求“具有独特个性的物质或精神成就”或“社会共识价值”,即“原创”内容不等于“有价值”内容。正是这一点伴随着 SEO 总是增加“价值” 当谈到原创内容时,即“原创价值内容”。因为原创不代表价值,站长和SEO从业者所说的“原创”大多澄清文章是自己写的,不是抄袭别人的,所以文章的内容质量未知。非常重要的是,在文件中输入的内容在键盘被擦拭时也可以被认为是原创的,但是这个“原创”对于普通用户来说并没有真正的意义,更不用说任何阅读价值了。同样的,即使所有的文章都没有偏离网站的主题,但是文章没有实际的价值信息可以传达给用户,只有行业,那么这个“原创" 不值得。所以创造力不等于价值。虽然搜索引擎不能直接分析 原创<
在经营网站的过程中,网站管理员和SEO从业者不应该宣传他们有多少原创,而应该宣传他们网站上的内容是否与他们的目标用户相关潜在用户具有价值。事实上,在很多为原创做广告的网站作品中,很多内容都是围绕着要实现的关键词组装起来的,并不是特别具有可读性和价值好的。网站的内容很多,原创的内容很多,但是用户不错,老用户数量巨大。即使内容不是原创,它在搜索引擎中的排名和流量也会更好。还有很多网站原创内容比例很大,但是内容质量参差不齐,或者服务器响应慢,或者内容页面添加了很多广告。这严重影响了用户在网站中的阅读体验或其他问题,导致长期坚持原创内容不足以在搜索引擎中获得好的排名和流量。能够从目标用户需求的角度编写网站的所有内容。但是,随着国内网络的发展,任何一个网站都不可能让原创的所有内容都对用户具有性和价值。事实上,网站 操作并不完全需要 原创 内容。运营网站做长期SEO,内容需求要以用户价值为基础,以原创为补充。因此,在为网站做内容优化策略和内容编写时,首先要学会转置。假设你是目标用户,你想通过网站得到什么信息,网站可以帮你解决什么问题,能不能快速准确的找到产品或服务。网站您需要的服务等。
豆豆SEO最后,请网友们辩论意见:如何选择靠谱的SEO公司?
我们要找一家靠谱的优化公司。我们可以在百度上搜索“region + seo”这个词,在百度首页找到置顶网站。像这样的网站,我们平时注意自己的品牌是不会骗客户钱的。在为我们优化之前,我们通常会提前收取百分之几的费用,然后在排名完成后补上余额。如果排名失败,我们会将之前支付的款项退还给我们。这样我们的交易风险就会小很多。
网站内容抓取工具(SEO插件排名数学阅读索引您需要将您的网站和所有网络内容编入索引)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 15:36
SEO插件排名数学
阅读指数
您需要将您的 网站 和所有 Web 内容编入索引,以便从自然搜索中获得流量,及时索引内容是 SEO 的重要组成部分。如果没有索引,搜索引擎将无法找到您的 网站,这意味着您的 网站 将无法排名,并且没有人会在搜索结果中找到它。而且,如果发生这种情况,您将失去可能转化为潜在客户和客户的潜在流量。
Rank Math 的即时索引功能允许您向启用的搜索引擎提交 URL,并帮助您将 网站 及其内容编入索引,即使您不需要使用任何这些 网站 管理工具进行配置网站 的。让我们看看功能如何帮助您将 URL 提交到 Bing 和 .
1、这是什么?
是一项有效爬取 网站 的引以为豪的举措,从而减少了爬取足迹。各种引擎都采用了这个协议。
该协议的工作原理是允许 网站 向 API 提交一次 URL,该 URL 将与所有参与的搜索引擎共享。因此,您只需提交一次 网站 更改和 URL,所有参与的搜索引擎都会知道您的 网站 上的最新更改,以便更快地抓取、索引和反映这些更改在搜索结果中。
当您开始提交 URL 时,搜索引擎想要验证这些提交是否合法,并且来自 网站 本身,而不是来自任何恶意元素。因此,搜索引擎期望 网站 生成和验证唯一的 API 密钥。
幸运的是,Rank Math 会自动为您的 网站 生成一个 API 密钥,将其动态托管在您的 网站 上,并将其提供给搜索引擎,因此您不必费心费力,并且更专注于在您的 网站 上创建和管理内容。
2、如何配置自动 URL 提交?
要启用,请转到 Dashboard > Rank Math > Dashboard > Modules 并启用 Instant Index 模块,如下所示:
如何使用排名数学?
其余的可以在 Rank Math >> > 中配置。您可以选择/取消选择要自动提交的任何内容。选择帖子类型后,请确保 Rank Math 已生成 API 密钥。最后,单击“保存更改”以保存您的首选项。
如何使用排名数学?
现在,当您在 网站 上发布或编辑新帖子时,Rank Math 将自动将 URL 提交给 API。但是请注意,Rank Math 不会自动提交设置为的 URL。
3、手动提交网址
Rank Math 为手动提交 URL 提供了几种不同的选项。这是他们:
3.1、批量提交网址
要手动提交 URL,只需转到 Rank Math >> 提交 URL。您可以在此处为您的博客文章、主页或任何其他 Web 内容添加多个 URL(每行一个)。
然后单击提交 URL 按钮,所有添加的 URL 都将提交索引以进行索引,而无需实际访问 网站 管理工具或使用 API 密钥对其进行配置。
如何使用排名数学?3.2、提交个人帖子/页面
除了即时索引设置中的提交 URL 功能外,您还可以随时从编辑器中的帖子页面提交帖子(或页面)。
在帖子页面上,当您将鼠标悬停在帖子上时,您会看到一行选项。选择:选项,如下图。
如何使用排名数学?
当您的帖子成功提交后,您将在页面顶部看到类似于下图的通知。
如何使用排名数学?3.3、即时索引批量操作
在某些情况下,您可能需要从帖子页面提交多个 URL。在这种情况下,逐个提交 URL 会很繁琐,而 Rank Math 提供了批量操作,因此您可以节省时间。
要使用批量操作,请选择要提交的帖子。然后从批量操作中选择即时索引:提交页面选项,然后单击应用按钮。
如何使用排名数学?4、管理 API 密钥
您可以通过 " " 设置下的 Rank Math > " " 设置来管理 Rank Math 为协议生成的 API 密钥。
如何使用排名数学?4.1、更改界面密钥
API 密钥字段显示 Rank Math 自动为您的 网站 生成的 API 密钥。此 API 密钥可帮助您证明您的 网站 的所有权。
如果第三方知道 API 密钥,您始终可以通过单击“更改密钥”选项重新生成新密钥。Rank Math 将在几分钟内为您的 网站 生成一个新的 API 密钥。
如何使用排名数学?4.2、检查 API 密钥位置
如前所述,Rank Math 动态托管 API 密钥并将其提供给搜索引擎。如果您希望检查您的 API 密钥是否可供搜索引擎访问,您可以单击 API 密钥位置下的“检查密钥”按钮。将打开一个新选项卡并指向 Rank Math 托管 API 密钥的位置。
如何使用排名数学?
如果新标签显示您的 API 密钥,您可以放心,它将提供给搜索引擎以验证您的 网站(前提是此页面未被 bots.txt 阻止)。
如何使用排名数学?5、查看历史
要查看您提交的 URL,您可以随时访问“Rank Now Math”下的“”部分。您还可以检查与提交相关的响应代码。理想情况下,每当您提交任何有效且相关的 URL 时,它都应显示“200 - OK”。这意味着您提交的 URL 已成功提交,没有任何问题。
注意:用户最初会看到“202 - 已接受”状态。这意味着 API 已接受请求,但站点尚未使用 API 密钥进行身份验证。
如何使用排名数学?6、对出版商有什么好处?7、常见问题解答:您需要知道的一切
什么意思?
是一项开源计划,所有参与的搜索引擎都将发现内容的方式更改为推送方法。这是一个简单的 ping 协议,它可以让搜索引擎知道某个 URL 及其内容已被添加、更新或删除,从而允许搜索引擎通过更快的爬取和索引来快速反映搜索结果中的这种变化。
正在使用哪些搜索引擎?
该技术由 Bing 和 Inc. 开发,允许 网站 在创建、更新或删除其 网站 内容时轻松通知搜索引擎。目前,Bing 和 Bing 是唯一使用该功能的搜索引擎,但预计会有更多搜索引擎采用该功能。
Rank Math 中的模块如何工作?
启用该模块后,Rank Math 将自动为您的 网站 生成一个 API 密钥并动态托管它。对于已配置的帖子类型,Rank Math 将在创建、更新或删除新帖子时自动 ping,并且所有启用的搜索引擎都会知道 网站 上的最新更改。
我每天可以提交多少个 URL?
目前,此功能对每天可以提交的 URL 没有任何已知限制。但始终建议不要利用这一点。
提交了一个 URL,为什么我的 URL 没有被索引?
这是一种让搜索引擎了解您的 网站 更改的方法。但是,这些页面的抓取和索引完全由参与的搜索引擎自行决定。
使用并加速您的 SEO 结果
全速索引 网站 查看全部
网站内容抓取工具(SEO插件排名数学阅读索引您需要将您的网站和所有网络内容编入索引)
SEO插件排名数学
阅读指数
您需要将您的 网站 和所有 Web 内容编入索引,以便从自然搜索中获得流量,及时索引内容是 SEO 的重要组成部分。如果没有索引,搜索引擎将无法找到您的 网站,这意味着您的 网站 将无法排名,并且没有人会在搜索结果中找到它。而且,如果发生这种情况,您将失去可能转化为潜在客户和客户的潜在流量。
Rank Math 的即时索引功能允许您向启用的搜索引擎提交 URL,并帮助您将 网站 及其内容编入索引,即使您不需要使用任何这些 网站 管理工具进行配置网站 的。让我们看看功能如何帮助您将 URL 提交到 Bing 和 .
1、这是什么?
是一项有效爬取 网站 的引以为豪的举措,从而减少了爬取足迹。各种引擎都采用了这个协议。
该协议的工作原理是允许 网站 向 API 提交一次 URL,该 URL 将与所有参与的搜索引擎共享。因此,您只需提交一次 网站 更改和 URL,所有参与的搜索引擎都会知道您的 网站 上的最新更改,以便更快地抓取、索引和反映这些更改在搜索结果中。
当您开始提交 URL 时,搜索引擎想要验证这些提交是否合法,并且来自 网站 本身,而不是来自任何恶意元素。因此,搜索引擎期望 网站 生成和验证唯一的 API 密钥。
幸运的是,Rank Math 会自动为您的 网站 生成一个 API 密钥,将其动态托管在您的 网站 上,并将其提供给搜索引擎,因此您不必费心费力,并且更专注于在您的 网站 上创建和管理内容。
2、如何配置自动 URL 提交?
要启用,请转到 Dashboard > Rank Math > Dashboard > Modules 并启用 Instant Index 模块,如下所示:
如何使用排名数学?
其余的可以在 Rank Math >> > 中配置。您可以选择/取消选择要自动提交的任何内容。选择帖子类型后,请确保 Rank Math 已生成 API 密钥。最后,单击“保存更改”以保存您的首选项。
如何使用排名数学?
现在,当您在 网站 上发布或编辑新帖子时,Rank Math 将自动将 URL 提交给 API。但是请注意,Rank Math 不会自动提交设置为的 URL。
3、手动提交网址
Rank Math 为手动提交 URL 提供了几种不同的选项。这是他们:
3.1、批量提交网址
要手动提交 URL,只需转到 Rank Math >> 提交 URL。您可以在此处为您的博客文章、主页或任何其他 Web 内容添加多个 URL(每行一个)。
然后单击提交 URL 按钮,所有添加的 URL 都将提交索引以进行索引,而无需实际访问 网站 管理工具或使用 API 密钥对其进行配置。
如何使用排名数学?3.2、提交个人帖子/页面
除了即时索引设置中的提交 URL 功能外,您还可以随时从编辑器中的帖子页面提交帖子(或页面)。
在帖子页面上,当您将鼠标悬停在帖子上时,您会看到一行选项。选择:选项,如下图。
如何使用排名数学?
当您的帖子成功提交后,您将在页面顶部看到类似于下图的通知。
如何使用排名数学?3.3、即时索引批量操作
在某些情况下,您可能需要从帖子页面提交多个 URL。在这种情况下,逐个提交 URL 会很繁琐,而 Rank Math 提供了批量操作,因此您可以节省时间。
要使用批量操作,请选择要提交的帖子。然后从批量操作中选择即时索引:提交页面选项,然后单击应用按钮。
如何使用排名数学?4、管理 API 密钥
您可以通过 " " 设置下的 Rank Math > " " 设置来管理 Rank Math 为协议生成的 API 密钥。
如何使用排名数学?4.1、更改界面密钥
API 密钥字段显示 Rank Math 自动为您的 网站 生成的 API 密钥。此 API 密钥可帮助您证明您的 网站 的所有权。
如果第三方知道 API 密钥,您始终可以通过单击“更改密钥”选项重新生成新密钥。Rank Math 将在几分钟内为您的 网站 生成一个新的 API 密钥。
如何使用排名数学?4.2、检查 API 密钥位置
如前所述,Rank Math 动态托管 API 密钥并将其提供给搜索引擎。如果您希望检查您的 API 密钥是否可供搜索引擎访问,您可以单击 API 密钥位置下的“检查密钥”按钮。将打开一个新选项卡并指向 Rank Math 托管 API 密钥的位置。
如何使用排名数学?
如果新标签显示您的 API 密钥,您可以放心,它将提供给搜索引擎以验证您的 网站(前提是此页面未被 bots.txt 阻止)。
如何使用排名数学?5、查看历史
要查看您提交的 URL,您可以随时访问“Rank Now Math”下的“”部分。您还可以检查与提交相关的响应代码。理想情况下,每当您提交任何有效且相关的 URL 时,它都应显示“200 - OK”。这意味着您提交的 URL 已成功提交,没有任何问题。
注意:用户最初会看到“202 - 已接受”状态。这意味着 API 已接受请求,但站点尚未使用 API 密钥进行身份验证。
如何使用排名数学?6、对出版商有什么好处?7、常见问题解答:您需要知道的一切
什么意思?
是一项开源计划,所有参与的搜索引擎都将发现内容的方式更改为推送方法。这是一个简单的 ping 协议,它可以让搜索引擎知道某个 URL 及其内容已被添加、更新或删除,从而允许搜索引擎通过更快的爬取和索引来快速反映搜索结果中的这种变化。
正在使用哪些搜索引擎?
该技术由 Bing 和 Inc. 开发,允许 网站 在创建、更新或删除其 网站 内容时轻松通知搜索引擎。目前,Bing 和 Bing 是唯一使用该功能的搜索引擎,但预计会有更多搜索引擎采用该功能。
Rank Math 中的模块如何工作?
启用该模块后,Rank Math 将自动为您的 网站 生成一个 API 密钥并动态托管它。对于已配置的帖子类型,Rank Math 将在创建、更新或删除新帖子时自动 ping,并且所有启用的搜索引擎都会知道 网站 上的最新更改。
我每天可以提交多少个 URL?
目前,此功能对每天可以提交的 URL 没有任何已知限制。但始终建议不要利用这一点。
提交了一个 URL,为什么我的 URL 没有被索引?
这是一种让搜索引擎了解您的 网站 更改的方法。但是,这些页面的抓取和索引完全由参与的搜索引擎自行决定。
使用并加速您的 SEO 结果
全速索引 网站
网站内容抓取工具( 用PageAdmin采集让网站快速收录以及关键词排名,有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2022-03-21 15:34
用PageAdmin采集让网站快速收录以及关键词排名,有哪些)
随风起舞
03-07 11:02 阅读18
专注于
快速优化网站排行软件(网站快速刷排行工具)
使用PageAdmin采集让网站快速收录和关键词排名,在网站优化的过程中,可以得知我们想要网站@ >关键词在首页排名稳定。首先我们要做网站的基础工作,那么今天就给大家介绍一下网站的优化基础工作!
一、网站内容不断更新增加爬取频率
网站的内容质量对网站的收录有很重要的影响,所以在更新网站的内容时,一定要高质量原创 内容更新,会持续更新!
如果以上都没有问题,我们可以使用这个PageAdmincms采集工具实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习专业技术,只需几步即可轻松采集内容数据,用户只需在PageAdmincms采集、PageAdmin上进行简单设置cms采集准确采集文章根据用户设置的关键词设置,保证与行业一致文章@ >。采集文章 from 文章可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他PageAdmincms采集相比,这个PageAdmincms采集基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟搞定启动,只需要输入关键词即可实现采集(PageAdmincms采集也自带关键词采集的功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PageAdmincms采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容被插入或随机创作、随机读取等到一个“高度原创”中。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
使用这些 SEO 功能提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
一、精准定位
在做网站优化之前,首先要把握好我们网站行业的定位,以及产品的优缺点,这样我们在描述tdk的时候才能更加准确,这样百度蜘蛛可以掌握Take和评估网站。
二、关键词
1.关键词
很多人都知道,在进行网站优化之前,我们需要提供一些关键词进行优化。这些关键词是由制造业和商品的关键词选择的,一般情况下我们可以选择2-5个关键词,而网站需要在首页设置网站的顺序,后期优化推广。
2.长尾关键词
与长尾关键词相比,它的指数更低。长尾关键词可以精准帮助用户找到自己需要的内容。非常重要的作用。
3.品牌词
例如,产品的品牌,或者公司的名称,都可以作为品牌词。在推广核心关键词的同时,品牌词也可以通过采集进行推广和优化。
三、布局
网站的布局可以说尤为重要。首先,我们需要将关键词放在网站的首页、栏目等处,然后我们需要将关键词放在网站的长尾上。> 用品牌词布局,大家在布局关键词的时候一定要注意关键词的密度,可以适当。
五、链接建设
适当的内部和外部链接将更好地帮助网站进行流量。这方面的技巧需要站长自己去探索。也很难知道,做好网站的外链并不容易。.
上面介绍的内容是网站优化前需要做的基础内容。我希望这篇文章对你有所帮助。
六、网站关键词排名下降或消失,那么我们需要避免哪些常见错误呢?
1.垃圾链接
为网站买了很多垃圾外链,想网站快速提升排名,但是给网站加那么多垃圾外链真的有用吗?答案是否定的,你要知道,如果你在网站中添加很多质量极差的外链,很大程度上会受到百度搜索引擎的惩罚,而且百度搜索蜘蛛对垃圾邮件也很反感外部链接,会影响网站的爬取速度和更新时间,时间长了网站的内容不会被爬取,搜索关键词也不会排名,所以不要不要给 网站 的外链添加很多坏消息。
2.堆栈关键词
几年前,百度搜索引擎的排名机制还没有现在这么严谨可靠。关键词的排名可以通过在网站上叠加关键词的密度来提高,但是这种情况会严重影响用户的浏览体验,不会给用户带来有用的信息. 打开网站,只能看到成堆的关键词,但是这种情况随着百度搜索引擎本身的发展而变化,已经能够非常智能高效的区分出网站是和关键词叠加的,所以这样的方法已经失效了,而且如果做了,关键词@网站也会受到惩罚,所以不要让关键词@ > 堆积在 网站 上。
3.内容差
谈到内容的质量网站,那句老话总是内容为王。既然这么说,那一定是有道理的。搜索引擎的主要任务是当用户搜索某个 关键词 时,将最有用的内容或该词的 网站 呈现给用户。如果网站的内容质量不好,搜索引擎肯定不会向用户展示这样的网站。在你面前,这样的网站和关键词是不会排名的,所以网站的内容一定要做好。
4.网站注册
网站注册码其实就是网站被黑客入侵了。点击网站链接后,链接会自动跳转到其他非法的网站,如果网站出现这种情况,一定要及时处理网站注册问题。如果长时间不处理,网站的关键词排名会立即消失。所以网站一定要做好服务器保护工作,避免出现此类问题,从而保证网站关键词排名的稳定性。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事 查看全部
网站内容抓取工具(
用PageAdmin采集让网站快速收录以及关键词排名,有哪些)
随风起舞
03-07 11:02 阅读18
专注于
快速优化网站排行软件(网站快速刷排行工具)
使用PageAdmin采集让网站快速收录和关键词排名,在网站优化的过程中,可以得知我们想要网站@ >关键词在首页排名稳定。首先我们要做网站的基础工作,那么今天就给大家介绍一下网站的优化基础工作!
一、网站内容不断更新增加爬取频率
网站的内容质量对网站的收录有很重要的影响,所以在更新网站的内容时,一定要高质量原创 内容更新,会持续更新!
如果以上都没有问题,我们可以使用这个PageAdmincms采集工具实现采集伪原创自动发布和主动推送到搜索引擎。操作简单,无需学习专业技术,只需几步即可轻松采集内容数据,用户只需在PageAdmincms采集、PageAdmin上进行简单设置cms采集准确采集文章根据用户设置的关键词设置,保证与行业一致文章@ >。采集文章 from 文章可以选择本地保存,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他PageAdmincms采集相比,这个PageAdmincms采集基本没有规则,更别说花很多时间学习正则表达式或者html标签了,一分钟搞定启动,只需要输入关键词即可实现采集(PageAdmincms采集也自带关键词采集的功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这个PageAdmincms采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容被插入或随机创作、随机读取等到一个“高度原创”中。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
使用这些 SEO 功能提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
一、精准定位
在做网站优化之前,首先要把握好我们网站行业的定位,以及产品的优缺点,这样我们在描述tdk的时候才能更加准确,这样百度蜘蛛可以掌握Take和评估网站。
二、关键词
1.关键词
很多人都知道,在进行网站优化之前,我们需要提供一些关键词进行优化。这些关键词是由制造业和商品的关键词选择的,一般情况下我们可以选择2-5个关键词,而网站需要在首页设置网站的顺序,后期优化推广。
2.长尾关键词
与长尾关键词相比,它的指数更低。长尾关键词可以精准帮助用户找到自己需要的内容。非常重要的作用。
3.品牌词
例如,产品的品牌,或者公司的名称,都可以作为品牌词。在推广核心关键词的同时,品牌词也可以通过采集进行推广和优化。
三、布局
网站的布局可以说尤为重要。首先,我们需要将关键词放在网站的首页、栏目等处,然后我们需要将关键词放在网站的长尾上。> 用品牌词布局,大家在布局关键词的时候一定要注意关键词的密度,可以适当。
五、链接建设
适当的内部和外部链接将更好地帮助网站进行流量。这方面的技巧需要站长自己去探索。也很难知道,做好网站的外链并不容易。.
上面介绍的内容是网站优化前需要做的基础内容。我希望这篇文章对你有所帮助。
六、网站关键词排名下降或消失,那么我们需要避免哪些常见错误呢?
1.垃圾链接
为网站买了很多垃圾外链,想网站快速提升排名,但是给网站加那么多垃圾外链真的有用吗?答案是否定的,你要知道,如果你在网站中添加很多质量极差的外链,很大程度上会受到百度搜索引擎的惩罚,而且百度搜索蜘蛛对垃圾邮件也很反感外部链接,会影响网站的爬取速度和更新时间,时间长了网站的内容不会被爬取,搜索关键词也不会排名,所以不要不要给 网站 的外链添加很多坏消息。
2.堆栈关键词
几年前,百度搜索引擎的排名机制还没有现在这么严谨可靠。关键词的排名可以通过在网站上叠加关键词的密度来提高,但是这种情况会严重影响用户的浏览体验,不会给用户带来有用的信息. 打开网站,只能看到成堆的关键词,但是这种情况随着百度搜索引擎本身的发展而变化,已经能够非常智能高效的区分出网站是和关键词叠加的,所以这样的方法已经失效了,而且如果做了,关键词@网站也会受到惩罚,所以不要让关键词@ > 堆积在 网站 上。
3.内容差
谈到内容的质量网站,那句老话总是内容为王。既然这么说,那一定是有道理的。搜索引擎的主要任务是当用户搜索某个 关键词 时,将最有用的内容或该词的 网站 呈现给用户。如果网站的内容质量不好,搜索引擎肯定不会向用户展示这样的网站。在你面前,这样的网站和关键词是不会排名的,所以网站的内容一定要做好。
4.网站注册
网站注册码其实就是网站被黑客入侵了。点击网站链接后,链接会自动跳转到其他非法的网站,如果网站出现这种情况,一定要及时处理网站注册问题。如果长时间不处理,网站的关键词排名会立即消失。所以网站一定要做好服务器保护工作,避免出现此类问题,从而保证网站关键词排名的稳定性。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事
网站内容抓取工具(关于网站推广不收录的原因都有哪些呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-18 14:09
网站建设完成后,下一步就是推广网站的工作,但是很多公司发现新建的网站是用来推广的,哪怕是一个老域名用的,效果不是很好 还行。虽然优质的文章内容每天都在更新,但在搜索引擎上却不是收录,那么网站推广不是收录的原因是什么?
1、擅长使用工具-百度站长资源平台。
为了满足用户做网站推广的需求,百度搜索引擎很早就推出了站长资源平台工具。这个工具可以理解为“加速器”的作用。它收录多种功能,最常用的是提交链接,以及反馈网站各种问题。
很多网站都不知道每天更新的内容在做推广的时候要以链接的形式提交给百度,就等着百度抓了。新网站即使是新域也有一个观察期,在此期间搜索引擎不会花太多时间查看网站。旧网站不同,因为很多东西已经在搜索引擎的索引库中。
2、是否屏蔽百度抓取。
网站在构建过程中,Robots文件一般是同步产生的,是网络协议文件。通常设计为禁止所有 网站 链接被抓取。有时网站制作完成后忘记修改这个文件,导致网站上线,但是没有蜘蛛爬取,整个网站被阻塞。
所以在 网站 构建完成后,一定要检查 Robots 文件是否阻塞了整个 网站。
3、服务器稳定。
如果网站经常因为服务问题打不开网站,或者不稳定,搜索引擎会减少网站的爬取量,甚至停止爬取网站。这是对网站的收录的致命一击。
4、网站不合理的结构。
网站组织布局对推广很重要网站。如果结构处理不好或者有一些程序代码,搜索引擎蜘蛛就会陷入死循环,无法形成有进有出的环境。,对搜索引擎很不友好。
5、网站的收录增加了,但是几天后收录的页面突然消失了。
网站有时候显示已经是收录了,但是过了一段时间,原来是收录的页面突然消失了。很多做网站推广的公司都遇到过这种类似的问题。这个问题有很多原因。
1)检查 网站 是否被黑客入侵(hacked)。
2)检查网站短期内是否建立了大量的外链、反链、友链。
3)检查网站是否有作弊嫌疑。
4)检查网站文章的内容是否按时、按量、有质量地更新。
5)如果以上都可以,那可能是网站的沙盒期(只有新站才有的功能)。
.
.
. 查看全部
网站内容抓取工具(关于网站推广不收录的原因都有哪些呢??)
网站建设完成后,下一步就是推广网站的工作,但是很多公司发现新建的网站是用来推广的,哪怕是一个老域名用的,效果不是很好 还行。虽然优质的文章内容每天都在更新,但在搜索引擎上却不是收录,那么网站推广不是收录的原因是什么?
1、擅长使用工具-百度站长资源平台。
为了满足用户做网站推广的需求,百度搜索引擎很早就推出了站长资源平台工具。这个工具可以理解为“加速器”的作用。它收录多种功能,最常用的是提交链接,以及反馈网站各种问题。
很多网站都不知道每天更新的内容在做推广的时候要以链接的形式提交给百度,就等着百度抓了。新网站即使是新域也有一个观察期,在此期间搜索引擎不会花太多时间查看网站。旧网站不同,因为很多东西已经在搜索引擎的索引库中。
2、是否屏蔽百度抓取。
网站在构建过程中,Robots文件一般是同步产生的,是网络协议文件。通常设计为禁止所有 网站 链接被抓取。有时网站制作完成后忘记修改这个文件,导致网站上线,但是没有蜘蛛爬取,整个网站被阻塞。
所以在 网站 构建完成后,一定要检查 Robots 文件是否阻塞了整个 网站。
3、服务器稳定。
如果网站经常因为服务问题打不开网站,或者不稳定,搜索引擎会减少网站的爬取量,甚至停止爬取网站。这是对网站的收录的致命一击。
4、网站不合理的结构。
网站组织布局对推广很重要网站。如果结构处理不好或者有一些程序代码,搜索引擎蜘蛛就会陷入死循环,无法形成有进有出的环境。,对搜索引擎很不友好。
5、网站的收录增加了,但是几天后收录的页面突然消失了。
网站有时候显示已经是收录了,但是过了一段时间,原来是收录的页面突然消失了。很多做网站推广的公司都遇到过这种类似的问题。这个问题有很多原因。
1)检查 网站 是否被黑客入侵(hacked)。
2)检查网站短期内是否建立了大量的外链、反链、友链。
3)检查网站是否有作弊嫌疑。
4)检查网站文章的内容是否按时、按量、有质量地更新。
5)如果以上都可以,那可能是网站的沙盒期(只有新站才有的功能)。
.
.
.
网站内容抓取工具( Gitemapx,其官网号称是永久免费的网站地图制作工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-18 05:05
Gitemapx,其官网号称是永久免费的网站地图制作工具)
在我们的SEO工作过程中,使用地图引导蜘蛛爬行爬行是一种非常好的行为。不过自从Sorghum seo从事seo工作以来,一直没有找到一款超级实用且免费的制图工具,一般都是在线的。它只能抢不到100块,所以对于很多人来说是非常苦恼的。Sorghum seo今天分享的软件叫Gitemap x,官网号称是永久免费的网站地图制作工具。那么下面的高粱seo就给大家详细介绍一下它的功能和特点:
一、自动生成XML、GZ、TXT和HTML格式的网站地图制作工具
Sitemap X可以根据您的需要自动生成四种不同格式的网站地图---XML、GZ、TXT和HTML,这四种网站地图是搜索引擎优化部分必不可少的。同时Sitemap X还可以自动生成Robots.txt文件,方便搜索引擎蜘蛛的检索。二、使用Sitemap X工具查找错误链接、死链接等问题网站
错误链接和死链接不仅会影响用户访问,还会阻止搜索引擎蜘蛛收录,从而影响您的网站用户体验和搜索引擎排名。使用SiteMap X网站地图制作工具,很容易发现网站中的问题,及时解决,保证页面正确。三、使用 Sitemap X 的 Ping 功能自动通知搜索引擎
SiteMap X 可以自动通知 (Ping) 搜索引擎 收录 您刚刚更新的页面。这样不仅可以加快网页的收录,还可以让你的网站从被动等待搜索引擎收录变成主动通知搜索引擎到收录@ >,从而增加搜索引擎的数量蜘蛛有多爱你网站在提高你的SEO排名方面发挥着作用。四、使用定时任务自动创建和上传网站地图文件
Sitemap X网站map maker内置定时任务功能和FTP功能,可以自动生成网站地图文件,并按时自动上传到您的网站空间。无需任何操作,SiteMap X将为您带来最完美的SEO效果。一定要试试永远免费的网站地图制作工具——Sitemap X。最后,sorghum seo 总结了使用地图的好处。使用网站map文件加速页面收录,提高SEO排名,网站maps可以帮助搜索引擎蜘蛛(如Googlebot)更快地找到现有页面并更新页面,从而引导蜘蛛爬行,加快蜘蛛收录的速度,从而有效提升SEO排名,大大增加你的网站流量。 查看全部
网站内容抓取工具(
Gitemapx,其官网号称是永久免费的网站地图制作工具)
在我们的SEO工作过程中,使用地图引导蜘蛛爬行爬行是一种非常好的行为。不过自从Sorghum seo从事seo工作以来,一直没有找到一款超级实用且免费的制图工具,一般都是在线的。它只能抢不到100块,所以对于很多人来说是非常苦恼的。Sorghum seo今天分享的软件叫Gitemap x,官网号称是永久免费的网站地图制作工具。那么下面的高粱seo就给大家详细介绍一下它的功能和特点:
一、自动生成XML、GZ、TXT和HTML格式的网站地图制作工具
Sitemap X可以根据您的需要自动生成四种不同格式的网站地图---XML、GZ、TXT和HTML,这四种网站地图是搜索引擎优化部分必不可少的。同时Sitemap X还可以自动生成Robots.txt文件,方便搜索引擎蜘蛛的检索。二、使用Sitemap X工具查找错误链接、死链接等问题网站
错误链接和死链接不仅会影响用户访问,还会阻止搜索引擎蜘蛛收录,从而影响您的网站用户体验和搜索引擎排名。使用SiteMap X网站地图制作工具,很容易发现网站中的问题,及时解决,保证页面正确。三、使用 Sitemap X 的 Ping 功能自动通知搜索引擎
SiteMap X 可以自动通知 (Ping) 搜索引擎 收录 您刚刚更新的页面。这样不仅可以加快网页的收录,还可以让你的网站从被动等待搜索引擎收录变成主动通知搜索引擎到收录@ >,从而增加搜索引擎的数量蜘蛛有多爱你网站在提高你的SEO排名方面发挥着作用。四、使用定时任务自动创建和上传网站地图文件
Sitemap X网站map maker内置定时任务功能和FTP功能,可以自动生成网站地图文件,并按时自动上传到您的网站空间。无需任何操作,SiteMap X将为您带来最完美的SEO效果。一定要试试永远免费的网站地图制作工具——Sitemap X。最后,sorghum seo 总结了使用地图的好处。使用网站map文件加速页面收录,提高SEO排名,网站maps可以帮助搜索引擎蜘蛛(如Googlebot)更快地找到现有页面并更新页面,从而引导蜘蛛爬行,加快蜘蛛收录的速度,从而有效提升SEO排名,大大增加你的网站流量。
网站内容抓取工具(Google管理员工具(使用Google网站管理员.TXT)提高流量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2022-03-17 03:22
使用GOOGLE管理员工具测试Robots.TXT和页面内容爬取,GOOGLE管理员可以说是与GOOGLE间接沟通的工具,虽然现在已经迁移,导致使用GOOGLE时经常出现搜索错误或者超时问题,但是工具目前GOOGLE发布的都是最权威的工具(谷歌分析、谷歌趋势、谷歌adwords、谷歌管理工具),尤其是“谷歌分析”、“谷歌管理工具”,其中最权威的分析工具之一。牛B的工具(小翔个人认为),一个是网站管理必备的工具之一,可能有些朋友不这么认为,但这两个工具对小翔的帮助很大。
百度发布《百度站长指南》时,在统计/投票中询问用户喜欢什么类型的站长工具,但现在投票统计已经完成,工具已经很久没有发布了。有句话说的好“给别人希望,却让别人失望”,不就是这样的“百度站长指南”吗,花了多长时间,可能三个月,但后来发布了,但有多少人对这个“希望”有感情,却以失望收场。
谷歌管理工具(使用谷歌网站管理工具增加流量谷歌对网站索引的统计、诊断和管理,包括站点地图提交和报告。欢迎使用一站式网站管理会员资源回答你关于爬取和索引的问题,并向你介绍改善和增加网站流量的产品和服务,从而增加你与访问者的联系。)这是 GOOGLE 上一段管理员的描述,描述了处理网站 相关问题,如站点索引、Sitemap 提交、网站 抓取、网站 诊断等。我们今天只解释 GOOGLE 抓取!
国平哥在他的博客中发表了一篇文章文章,称“谷歌站长工具”是“谷歌搜索工具”的缩小版,而GSA是一个打包谷歌整个软硬件的服务器。该服务器是一个小型谷歌搜索引擎。(虽然DJ小翔没见过,但知道在libaba里面有这样的服务器)
至于“GOOGLE Admin Tools - Lab - Crawl Like Googlebot”,不知道大家有没有知道,有多少朋友灵活掌握了这个功能。记得在SEO学习网博客中,介绍过一篇关于“GOOGLE爬虫”的文章!
我们点击爬取,然后GOOGLE引擎爬取后生成URL,——通过状态栏可以看到GOOGLE爬取了网站的“状态”,通过这些“状态”提示,我们可以了解到目前为止,GOOGLE对网站页面的爬取是“成功”、“失败”或“被Robots.txt拒绝”,为什么“失败”我们也可以借鉴这个工具。
小翔在他的博客中多次提到,一个网站没有蜘蛛可以爬,网站怎么可能是SE收录,模拟爬的工具有很多,但是有多少有模拟爬行吗?工具可以让 GOOGLE 抓取“权威”或“准确”。
并且我们可以“拿GOOGLE测试一下网站Robots.txt是否正确”,对于百度站长工具投票中的“Robots.txt是否写正确”,很多朋友希望百度站长工具能够推出这个工具来。懂SEO的朋友,从图上看出来了!百度站长工具上线Robots.txt测试工具我们不用等很久。现在我们可以使用GOOGLE站长工具来测试“Robots.txt Validity”和“Robots.txt Writing Correctness”,让更多的SEO初学者防止网站因为“不会写Robotx.tx”或者“写 Robotx.txt 错误”。
图中我们可以看到如果使用GOOGLE爬取,将网站写的协议爬入Robots会提示“rejected by Robots.txt”,如果Robots.txt无效,则会显示“成功”,这种方法是测试Robots.txt最可靠的方法。当然,对于XX SE来说,他有点违抗这个Robots.txt,所以没办法!
而“像GOOGLEBOT一样抓取”来检测Robots.txt只是他使用的方法之一。刚才我们说“GOOGLE抓取”可以模拟爬取网站的内容!
而且GOOGL抓取也可以模拟抓取网站的内容结果,这里的结果和SE快照差不多,但是用GOOGLE工具里的抓取比看快照更方便更准确!从这个结果我们可以分析,GOOGLE对页面的爬取,比如能否爬取JS、图片内容等等。
很久没有写文章了。上次答应大家,我会写一篇可以“测试Robots.txt正确性”的文章文章。现在我已经让每个人都满意了。“下一篇文章的话题文章”“大家也可以发在留言里,DJ小翔把自己知道的知识都分享给大家。毕竟小翔知道自己也得到了别人的帮助一个新手。这里同时,“谢谢!栏目猎眼大哥,感谢猎眼大哥这些天对我弟弟的帮助和关心。” 查看全部
网站内容抓取工具(Google管理员工具(使用Google网站管理员.TXT)提高流量)
使用GOOGLE管理员工具测试Robots.TXT和页面内容爬取,GOOGLE管理员可以说是与GOOGLE间接沟通的工具,虽然现在已经迁移,导致使用GOOGLE时经常出现搜索错误或者超时问题,但是工具目前GOOGLE发布的都是最权威的工具(谷歌分析、谷歌趋势、谷歌adwords、谷歌管理工具),尤其是“谷歌分析”、“谷歌管理工具”,其中最权威的分析工具之一。牛B的工具(小翔个人认为),一个是网站管理必备的工具之一,可能有些朋友不这么认为,但这两个工具对小翔的帮助很大。
百度发布《百度站长指南》时,在统计/投票中询问用户喜欢什么类型的站长工具,但现在投票统计已经完成,工具已经很久没有发布了。有句话说的好“给别人希望,却让别人失望”,不就是这样的“百度站长指南”吗,花了多长时间,可能三个月,但后来发布了,但有多少人对这个“希望”有感情,却以失望收场。
谷歌管理工具(使用谷歌网站管理工具增加流量谷歌对网站索引的统计、诊断和管理,包括站点地图提交和报告。欢迎使用一站式网站管理会员资源回答你关于爬取和索引的问题,并向你介绍改善和增加网站流量的产品和服务,从而增加你与访问者的联系。)这是 GOOGLE 上一段管理员的描述,描述了处理网站 相关问题,如站点索引、Sitemap 提交、网站 抓取、网站 诊断等。我们今天只解释 GOOGLE 抓取!
国平哥在他的博客中发表了一篇文章文章,称“谷歌站长工具”是“谷歌搜索工具”的缩小版,而GSA是一个打包谷歌整个软硬件的服务器。该服务器是一个小型谷歌搜索引擎。(虽然DJ小翔没见过,但知道在libaba里面有这样的服务器)
至于“GOOGLE Admin Tools - Lab - Crawl Like Googlebot”,不知道大家有没有知道,有多少朋友灵活掌握了这个功能。记得在SEO学习网博客中,介绍过一篇关于“GOOGLE爬虫”的文章!
我们点击爬取,然后GOOGLE引擎爬取后生成URL,——通过状态栏可以看到GOOGLE爬取了网站的“状态”,通过这些“状态”提示,我们可以了解到目前为止,GOOGLE对网站页面的爬取是“成功”、“失败”或“被Robots.txt拒绝”,为什么“失败”我们也可以借鉴这个工具。
小翔在他的博客中多次提到,一个网站没有蜘蛛可以爬,网站怎么可能是SE收录,模拟爬的工具有很多,但是有多少有模拟爬行吗?工具可以让 GOOGLE 抓取“权威”或“准确”。
并且我们可以“拿GOOGLE测试一下网站Robots.txt是否正确”,对于百度站长工具投票中的“Robots.txt是否写正确”,很多朋友希望百度站长工具能够推出这个工具来。懂SEO的朋友,从图上看出来了!百度站长工具上线Robots.txt测试工具我们不用等很久。现在我们可以使用GOOGLE站长工具来测试“Robots.txt Validity”和“Robots.txt Writing Correctness”,让更多的SEO初学者防止网站因为“不会写Robotx.tx”或者“写 Robotx.txt 错误”。
图中我们可以看到如果使用GOOGLE爬取,将网站写的协议爬入Robots会提示“rejected by Robots.txt”,如果Robots.txt无效,则会显示“成功”,这种方法是测试Robots.txt最可靠的方法。当然,对于XX SE来说,他有点违抗这个Robots.txt,所以没办法!
而“像GOOGLEBOT一样抓取”来检测Robots.txt只是他使用的方法之一。刚才我们说“GOOGLE抓取”可以模拟爬取网站的内容!
而且GOOGL抓取也可以模拟抓取网站的内容结果,这里的结果和SE快照差不多,但是用GOOGLE工具里的抓取比看快照更方便更准确!从这个结果我们可以分析,GOOGLE对页面的爬取,比如能否爬取JS、图片内容等等。
很久没有写文章了。上次答应大家,我会写一篇可以“测试Robots.txt正确性”的文章文章。现在我已经让每个人都满意了。“下一篇文章的话题文章”“大家也可以发在留言里,DJ小翔把自己知道的知识都分享给大家。毕竟小翔知道自己也得到了别人的帮助一个新手。这里同时,“谢谢!栏目猎眼大哥,感谢猎眼大哥这些天对我弟弟的帮助和关心。”
网站内容抓取工具( 什么是网络?时光机(Waybackmachine)下载网站的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-16 00:00
什么是网络?时光机(Waybackmachine)下载网站的原因)
什么是网络存档?
网络存档是网络的全面备份,似乎是在不同时间点进行的。 Web Archive 的使命是存储过去 15-20 年不同时间点的所有 Internet。我们开发了一个工具,可以从 Time Machine 下载 网站 并恢复因延迟支付托管费用或其他原因而丢失的 网站。这个所谓的时间机器下载器是一个网络爬虫,它访问并允许客户从 网站
下载
什么是 Wayback 机器下载? Wayback machine download 是 Wayback Machine Downloader 提供的用于恢复 网站 文件的包的名称。它包括 HTML、CSS、JS 和图像文件。要从 Time Machine 下载 网站,只需访问 Time Machine 并查找特定日期的 URL。请务必使用主页上的 URL,这样可以提供最佳结果。对比 Wayback Machine Web Archive 和 Time Machine 在某种程度上是同义词,无论出于何种意图和目的,您都无需区分两者。 Time Machine 只是 Web 存档的 网站 的名称,这个名称在 Internet 上广为人知,人们希望从中恢复丢失的内容或重建 网站。使用 Time Machine 下载器 (Wayback Downloader) 的原因 您从 Time Machine 下载 网站 的原因可能是什么?正如您在上面看到的,使用 Time Machine 下载工具的原因有很多。这是从时间机器下载 网站 的完美解决方案。如果您对上述问题有任何疑虑,请随时给我们留言。我们很乐意为您提供帮助。 查看全部
网站内容抓取工具(
什么是网络?时光机(Waybackmachine)下载网站的原因)
什么是网络存档?
网络存档是网络的全面备份,似乎是在不同时间点进行的。 Web Archive 的使命是存储过去 15-20 年不同时间点的所有 Internet。我们开发了一个工具,可以从 Time Machine 下载 网站 并恢复因延迟支付托管费用或其他原因而丢失的 网站。这个所谓的时间机器下载器是一个网络爬虫,它访问并允许客户从 网站
下载
什么是 Wayback 机器下载? Wayback machine download 是 Wayback Machine Downloader 提供的用于恢复 网站 文件的包的名称。它包括 HTML、CSS、JS 和图像文件。要从 Time Machine 下载 网站,只需访问 Time Machine 并查找特定日期的 URL。请务必使用主页上的 URL,这样可以提供最佳结果。对比 Wayback Machine Web Archive 和 Time Machine 在某种程度上是同义词,无论出于何种意图和目的,您都无需区分两者。 Time Machine 只是 Web 存档的 网站 的名称,这个名称在 Internet 上广为人知,人们希望从中恢复丢失的内容或重建 网站。使用 Time Machine 下载器 (Wayback Downloader) 的原因 您从 Time Machine 下载 网站 的原因可能是什么?正如您在上面看到的,使用 Time Machine 下载工具的原因有很多。这是从时间机器下载 网站 的完美解决方案。如果您对上述问题有任何疑虑,请随时给我们留言。我们很乐意为您提供帮助。
网站内容抓取工具(网站抓取建设指南、网站数据生产指南和网站死链处理指南)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-15 20:05
在网站的实际操作过程中,很多站长还是对百度的一些处理机制感到疑惑。例如:
……
如果您对这些问题感到疑惑,那么您应该阅读此文章!
近日,百度搜索研发工程师在百度搜索在线公开课中为大家分享了网站爬取构建指南、网站数据制作指南和网站死链接处理指南的相关内容。 ,回答了站长的很多问题。
以下是百度搜索在线公开课的一些重要答案:
网站抓斗施工指南
Q1:百度搜索会给新的网站更高的抓取频率吗?
A1:百度搜索会首先识别网站内容的质量,在抓取高质量内容的新站点的频率上会有一定的倾向,以帮助内容更好的展示。
Q2:如何让百度搜索知道我的网站是新站点?
A2:主要有两种方式:1、通过百度搜索资源平台——资源提交工具提交内容;2、完成网站工信部ICP备案。
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
网站数据生产指南
Q5:网站上线前应该发布多少条内容?是越多越好,还是以少量高质量打造优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容确实需要修改,并且修改后的内容质量还是不错的,不影响百度搜索对该页面的评价。
网站死链接处理指南
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容相关度高,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原创内容的相关性较低,建议将原创内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。当机器人被阻止时,链接是否应该区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。 查看全部
网站内容抓取工具(网站抓取建设指南、网站数据生产指南和网站死链处理指南)
在网站的实际操作过程中,很多站长还是对百度的一些处理机制感到疑惑。例如:
……
如果您对这些问题感到疑惑,那么您应该阅读此文章!
近日,百度搜索研发工程师在百度搜索在线公开课中为大家分享了网站爬取构建指南、网站数据制作指南和网站死链接处理指南的相关内容。 ,回答了站长的很多问题。
以下是百度搜索在线公开课的一些重要答案:
网站抓斗施工指南
Q1:百度搜索会给新的网站更高的抓取频率吗?
A1:百度搜索会首先识别网站内容的质量,在抓取高质量内容的新站点的频率上会有一定的倾向,以帮助内容更好的展示。
Q2:如何让百度搜索知道我的网站是新站点?
A2:主要有两种方式:1、通过百度搜索资源平台——资源提交工具提交内容;2、完成网站工信部ICP备案。
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
网站数据生产指南
Q5:网站上线前应该发布多少条内容?是越多越好,还是以少量高质量打造优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容确实需要修改,并且修改后的内容质量还是不错的,不影响百度搜索对该页面的评价。
网站死链接处理指南
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容相关度高,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原创内容的相关性较低,建议将原创内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。当机器人被阻止时,链接是否应该区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。
网站内容抓取工具(百度不收录内容页面的原因及解决方法原因分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-15 20:04
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对网站的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否有大量死链接,清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自上线以来,虽然是论坛形式,但我对论坛的内容管理一直非常严格。前期大部分内容贴都是我自己发布的原创或者伪原创,所以,可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是百度蜘蛛通过网站日志分析软件从9月2日到9月5日的爬取目录统计。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
所以我nofollow /bbx链接来阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接! 查看全部
网站内容抓取工具(百度不收录内容页面的原因及解决方法原因分析)
相信很多网站都会遇到百度没有收录内容页面的现象,而通过站长统计工具查看流量来源,你会发现大部分流量来自网站的编辑尾部关键词,即网站的内容页,一旦百度不收录内容页,将对获取 网站 流量。如果你的网站也有百度没有收录内容页面的现象,那就跟我一起仔细分析一下原因吧。
百度没有收录内容页面的原因:
1、 网站内容质量太低
网站内容质量低是百度不收录的主要原因。8月22日,百度正式公布新算法“百度算法升级,将影响作弊网站收录和低质量内容”。在“站点排序”中,百度关注的是内容质量低的站点,尤其是采集内容的站点。所以,网站看来百度没有收录内容页面,先看看你的网站内容是否优质?
解决方法:调整网站内容的质量。如果网站的内容被复制粘贴,那么增加每日原创文章的数量,或者调整网站内容页面的布局,比如增加用户评论功能并添加相关文章推荐,旨在降低页面相似度,从而解决百度没有收录内容页面的现象。
2、 百度蜘蛛频繁爬取其他页面
排除网站的内容质量低的因素,网站的内容页仍然不是收录,然后查看网站的日志看百度蜘蛛是否针对某些目录和Pages经常被爬取,造成爬取的浪费。对搜索引擎爬取过程有一定了解的朋友都知道,百度蜘蛛每天对网站的爬取时间是有限的。页面爬取不充分、爬取不充分的现象。
解决方法:查看网站日志,屏蔽频繁爬取的页面,让百度蜘蛛在有限的时间内爬取更多的其他内容页面。
3、 其他因素总结
百度没有收录内容页面的原因有很多,比如:服务器因素、网站改版因素、网站大量死链接、网站链接深度因素太深了。
解决方案:服务器的稳定性很重要。如果网站长时间打不开,对百度对内容页的爬取是致命的;网站 不要频繁修改标题和描述信息以进行修订。;使用工具检测网站中是否有大量死链接,清除或阻止死链接爬取;如果链接地址太深,可以调整链接结构,因为目录太深的内容,百度蜘蛛很难抓取,甚至无法抓取。
以上,我总结了百度没有收录内容页面的三个原因,那么在实践中,如果使用了呢?下面是一个成功解决我的网站出现百度收录内容页面的例子。
先来看看百度收录近几天的情况表:
从图中数据可以看出,百度没有收录内容页面的现象在9月2日出现,经过调整在9月9日得到解决。
网站自上线以来,虽然是论坛形式,但我对论坛的内容管理一直非常严格。前期大部分内容贴都是我自己发布的原创或者伪原创,所以,可以排除网站内容质量低的原因。根据服务器的监控数据,网站的服务器最近一段时间运行正常,其他因素不多。看看百度蜘蛛爬不爬的问题。
上图是百度蜘蛛通过网站日志分析软件从9月2日到9月5日的爬取目录统计。发现百度蜘蛛频繁爬取/bbx目录。这个目录是方便宝箱的链接。现在很多本地论坛都用这个插件,里面的内容重复性极强。
所以我nofollow /bbx链接来阻止百度蜘蛛爬取这个目录。同时,在 robots.txt 文件中,我添加了 Disallow:/bbx 命令,以防止百度蜘蛛以双重权限爬取该目录。终于在 9 月 9 日,百度开始将 收录 恢复到内容页面。
当网站出现百度没有收录内容页面时,站长需要仔细检查是否有百度不爬自己操作的原因。结合百度日志的分析,可以客观的发现问题,从而解决问题。如果你的网站也有百度没有收录内容页面的现象,你也不确定,可以联系王继顺,我很乐意帮你解决。
本文为北京人民论坛结合论坛实际情况的样本提要。转载请自带链接!
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-13 21:17
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。 查看全部
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索会根据网站的内容质量、内容更新的频率、网站的规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当爬虫无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。

