
网站内容抓取工具
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-13 03:16
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索将根据网站的内容质量、内容更新频率和网站规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当蜘蛛无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。 查看全部
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索将根据网站的内容质量、内容更新频率和网站规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当蜘蛛无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。
网站内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-11 05:13
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以被搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的电子邮件或 URL,并将所有链接保存在用户的 HD 上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的全部内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹、文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上供用户使用。
它允许用户指定一个网页列表作为导航的起点,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后它通过搜索引擎搜索与关键字相关的网页,并开始对页面进行交叉导航,采集 URL。它可以在网页提取模式下导航数小时而无需用户交互,在无人看管的情况下提取在所有网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取中的所有结果和链接页面。
特征
本站统一解压密码:
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
URL Extractor 内容提取
WK网客下载永久钻石
支付宝扫描
微信扫一扫>奖励领取海报链接 查看全部
网站内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以被搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的电子邮件或 URL,并将所有链接保存在用户的 HD 上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的全部内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹、文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上供用户使用。
它允许用户指定一个网页列表作为导航的起点,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后它通过搜索引擎搜索与关键字相关的网页,并开始对页面进行交叉导航,采集 URL。它可以在网页提取模式下导航数小时而无需用户交互,在无人看管的情况下提取在所有网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取中的所有结果和链接页面。
特征
 https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" /> https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" /> https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />本站统一解压密码:
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
URL Extractor 内容提取
WK网客下载永久钻石
 WX20211214-222443@2x.png" />
WX20211214-222443@2x.png" />支付宝扫描
WX20211214-222554@2x.png" />微信扫一扫>奖励领取海报链接
网站内容抓取工具(URLExtractor支持网址抓取及链接提取,使用方便的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-07 11:13
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 抓取和链接提取。它易于使用,可以帮助用户浏览所有文件夹和抓取网页链接。如有必要,可以下载它们。
特征
网址抓取器
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取 Web 链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以帮助您。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您可以启动应用程序并几乎立即开始搜索链接。您只需要提供一个目录,其余的由程序处理。
该软件扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,允许您将列表导出到文件中。所有选项一目了然,简单明了,都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,可帮助您过滤文件和 URL。
软件功能
1、支持提取email地址、web地址、ftp地址、feeds、telnet、本地文件url等。
2、拥有一个新的现代引擎,采用最新的可可和objective-c 2.0 技术。它从不冻结,甚至通过搜索引擎采集具有数百个关键字的数千个 URL。
3、可以导入和导出“URLs”和“Keywords”以便在他们的表格中导航和提取。使用一个很好的改进的导入引擎,它可以自动识别导入的格式,并在选择导入什么时提供很大的灵活性。
4、从磁盘(文件和文件夹)中无限数量的来源中提取 URL 和电子邮件,浏览任何指定文件夹和子文件夹的所有内容。在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、从您指定的 网站 列表中提取来自网络的 URL 和电子邮件。它开始提取您需要的 URL,并在无休止的导航过程中继续浏览在线找到的附加链接后根据需要采集 URL 或电子邮件。
6、从关键字列表中提取来自网络的 URL 和电子邮件。
它使用您指定的搜索引擎上可用的关键字列表,然后开始查找相关的 网站,然后开始使用相关的 网站 导航,同时跟踪找到的链接并采集所有 URL 或电子邮件。提供多个关键字,它可以提取数小时的相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr. au .uk .de 和 .es .ar .au .at .be .br .ca .fi. nl.se.ch)。使用您指定的搜索引擎在网络上进行无限搜索。
8、支持从 safari 和其他 Web 浏览器中接受拖放 URL,以将它们用作从 Web 中提取的种子。
9、支持使用多个选项:“单域提取”仅从指定的网站中提取,而不跳转到链接的网站或“深度导航”指定从哪个级别提取site 跳转到链接的站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件提取。如果它在网上找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。
扩张 查看全部
网站内容抓取工具(URLExtractor支持网址抓取及链接提取,使用方便的功能介绍)
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 抓取和链接提取。它易于使用,可以帮助用户浏览所有文件夹和抓取网页链接。如有必要,可以下载它们。
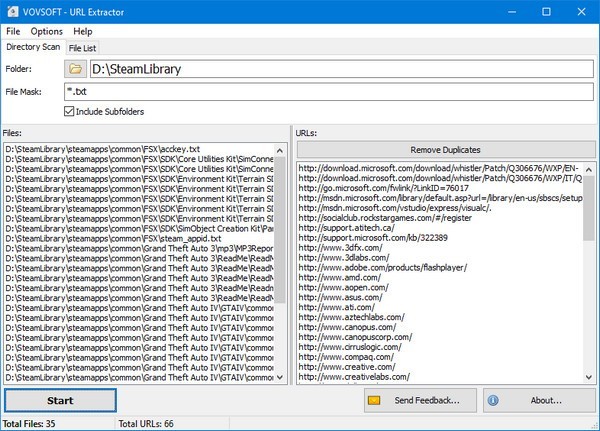
特征
网址抓取器
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取 Web 链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以帮助您。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您可以启动应用程序并几乎立即开始搜索链接。您只需要提供一个目录,其余的由程序处理。
该软件扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,允许您将列表导出到文件中。所有选项一目了然,简单明了,都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,可帮助您过滤文件和 URL。
软件功能
1、支持提取email地址、web地址、ftp地址、feeds、telnet、本地文件url等。
2、拥有一个新的现代引擎,采用最新的可可和objective-c 2.0 技术。它从不冻结,甚至通过搜索引擎采集具有数百个关键字的数千个 URL。
3、可以导入和导出“URLs”和“Keywords”以便在他们的表格中导航和提取。使用一个很好的改进的导入引擎,它可以自动识别导入的格式,并在选择导入什么时提供很大的灵活性。
4、从磁盘(文件和文件夹)中无限数量的来源中提取 URL 和电子邮件,浏览任何指定文件夹和子文件夹的所有内容。在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、从您指定的 网站 列表中提取来自网络的 URL 和电子邮件。它开始提取您需要的 URL,并在无休止的导航过程中继续浏览在线找到的附加链接后根据需要采集 URL 或电子邮件。
6、从关键字列表中提取来自网络的 URL 和电子邮件。
它使用您指定的搜索引擎上可用的关键字列表,然后开始查找相关的 网站,然后开始使用相关的 网站 导航,同时跟踪找到的链接并采集所有 URL 或电子邮件。提供多个关键字,它可以提取数小时的相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr. au .uk .de 和 .es .ar .au .at .be .br .ca .fi. nl.se.ch)。使用您指定的搜索引擎在网络上进行无限搜索。
8、支持从 safari 和其他 Web 浏览器中接受拖放 URL,以将它们用作从 Web 中提取的种子。
9、支持使用多个选项:“单域提取”仅从指定的网站中提取,而不跳转到链接的网站或“深度导航”指定从哪个级别提取site 跳转到链接的站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件提取。如果它在网上找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。
扩张
网站内容抓取工具(几近一个中心问题的演讲内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-07 11:13
许多关于网站结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题:搜索引擎能多容易地爬取你的网站?我们已经在最近的几次活动中讨论了这个主题,您将在下面找到我们关于这个主题的介绍和要点总结。
网络世界是巨大的;新内容一直在创造。Google 自身资源有限,面对几乎无穷无尽的内容网络,Googlebot 只能找到并抓取一定比例的内容。然后,我们已经爬取的内容,我们只能索引其中的一部分。
URL 就像 网站 和搜索引擎爬虫之间的桥梁:为了能够爬取您的 网站 内容,爬虫需要能够找到并架起这些桥梁(即查找并爬取您的 URL)。如果您的网址复杂或冗长,爬虫必须花时间反复跟踪它们;如果您的 URL 整洁并直接指向您的独特内容,则爬虫可以专注于理解您的内容,而不是爬取空白页面或被不同的 URL 引用,最终爬取相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些是现实世界中存在的 URL 示例(尽管出于隐私原因,它们的名称已被替换),包括被黑的 URL 和编码、伪装成的冗余参数部分 URL 路径、无限爬取空间等。您还可以找到一些提示来帮助您导航这些网络 网站 构建迷宫并帮助爬虫更快更好地找到您的内容,包括:
从 URL 中删除与用户相关的参数。URL 中那些不会影响网页内容的参数,例如会话 ID 或排序参数,可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到干净的 URL,您可以保留原创内容并减少指向相同内容的 URL 的数量。
控制无限空间。你的 网站 上是否有一个日历,上面有无数过去和未来日期的链接(每个链接都是唯一的 二)?你的网址是不是在 3563 的参数后添加了 &page= ,仍然可以返回 200代码,即使根本没有那么多页面?这样的话,你的网站上出现了所谓的无限空间,这会浪费爬虫机器人和你的网站带宽。要控制无限空间,请参阅此处的一些提示。
阻止 Google 抓取工具抓取他们无法处理的网页。通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系方式、购物车和其他抓取工具无法处理的页面被抓取。(Crawler 以刻薄和害羞着称,因此通常他们不会将商品添加到购物车或联系我们)。这样,您可以让爬虫花更多时间使用它们可以处理的内容来爬取您的 网站。
一人一票。一个 URL,一段内容。在理想情况下,URL 和内容之间应该是一一对应的:每个 URL 对应一个唯一的内容,而每个内容只能通过唯一的 URL 访问。你越接近这个理想,你的网站就会越容易抓住和收录。如果你的内容管理系统或周口网站builder当前的网站build难以实现,你可以尝试使用rel=canonical元素来设置你想用来表示某个特定内容的URL .
原文:优化您的抓取和索引 查看全部
网站内容抓取工具(几近一个中心问题的演讲内容)
许多关于网站结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题:搜索引擎能多容易地爬取你的网站?我们已经在最近的几次活动中讨论了这个主题,您将在下面找到我们关于这个主题的介绍和要点总结。
网络世界是巨大的;新内容一直在创造。Google 自身资源有限,面对几乎无穷无尽的内容网络,Googlebot 只能找到并抓取一定比例的内容。然后,我们已经爬取的内容,我们只能索引其中的一部分。
URL 就像 网站 和搜索引擎爬虫之间的桥梁:为了能够爬取您的 网站 内容,爬虫需要能够找到并架起这些桥梁(即查找并爬取您的 URL)。如果您的网址复杂或冗长,爬虫必须花时间反复跟踪它们;如果您的 URL 整洁并直接指向您的独特内容,则爬虫可以专注于理解您的内容,而不是爬取空白页面或被不同的 URL 引用,最终爬取相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些是现实世界中存在的 URL 示例(尽管出于隐私原因,它们的名称已被替换),包括被黑的 URL 和编码、伪装成的冗余参数部分 URL 路径、无限爬取空间等。您还可以找到一些提示来帮助您导航这些网络 网站 构建迷宫并帮助爬虫更快更好地找到您的内容,包括:
从 URL 中删除与用户相关的参数。URL 中那些不会影响网页内容的参数,例如会话 ID 或排序参数,可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到干净的 URL,您可以保留原创内容并减少指向相同内容的 URL 的数量。
控制无限空间。你的 网站 上是否有一个日历,上面有无数过去和未来日期的链接(每个链接都是唯一的 二)?你的网址是不是在 3563 的参数后添加了 &page= ,仍然可以返回 200代码,即使根本没有那么多页面?这样的话,你的网站上出现了所谓的无限空间,这会浪费爬虫机器人和你的网站带宽。要控制无限空间,请参阅此处的一些提示。
阻止 Google 抓取工具抓取他们无法处理的网页。通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系方式、购物车和其他抓取工具无法处理的页面被抓取。(Crawler 以刻薄和害羞着称,因此通常他们不会将商品添加到购物车或联系我们)。这样,您可以让爬虫花更多时间使用它们可以处理的内容来爬取您的 网站。
一人一票。一个 URL,一段内容。在理想情况下,URL 和内容之间应该是一一对应的:每个 URL 对应一个唯一的内容,而每个内容只能通过唯一的 URL 访问。你越接近这个理想,你的网站就会越容易抓住和收录。如果你的内容管理系统或周口网站builder当前的网站build难以实现,你可以尝试使用rel=canonical元素来设置你想用来表示某个特定内容的URL .
原文:优化您的抓取和索引
网站内容抓取工具(善肯网页TXT采集器软件免费下载介绍说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-04 13:14
本站提供山垦网页绿色免费版【小说抓取下载工具】TXT采集器软件免费下载。
【软件截图】
【基本介绍】
山垦网页TXT采集器采用全新正则表达式小说抓取下载必备工具,支持以txt文件程序下载小说整章,并可实时预览内容,确保下载资源没有损坏和乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。
功能模块介绍
1、规则放置设置:
①在规则设置窗口中,在网站中随便找一篇文章,不要写任何规则,先用鼠标点击实时预览,看看能不能得到网页的源代码,然后如果可以的话,写下规则。如果你不能得到它,没有必要继续。
②规则设置使用正则表达式匹配内容。最好有一定的基础。如果没有基础,可以参考给出的例子。没有复杂的学习,就没有必要深入学习规律的规则。
③设置规则时,目录页和内容页需要分别预览,需要两个链接,一个目录页链接,一个内容页链接。
④换货方面,有普通换货和定制换货之分。这里,目前不需要正则化,普通替换即可。需要提醒的是,必须输入值,即使是空格。删除:选择整行,然后按住删除键。内置的 \n 在用作替换数据消息时表示换行符。
⑤编码(将信息从一种形式或格式转换为另一种的过程),目前只设置了GBK和UFT-8,几乎大部分网站都是这两种编码之一。
2、分析下载
① 解析请按解析地址的按钮2。按钮1是任性的,暂时不想删除,其他功能以后再开发。
②支持单章下载和全文下载。
③支持增加章节数【部分小说没有章节数时可以勾选】
④支持在线查看,但需要联网。这个功能只是辅助(可以通过模拟人工手动操作实现自动杀怪、自动挂机等),不是专业的小说阅读软件。
⑤下载进度和总所需时间显示,内置多线程。
3、关于软件
①其实只要.exe就够了,规则都是我自己加的,commonrule.xml里面有通用的替换规则。网站规则在规则文件夹中。我这里放了两条 网站 规则,主要是为了测试。其他网站规则可以自行添加,也可以支持开发者。
②软件非打包,c#开发,无病毒。别担心,请不要使用它,我不承担责任。
③关于软件,有跳转到论坛。我测试跳转的时候是360提示的,也可能是因为跳转的是360浏览器。不知道你会不会有这个问题。
④如果xml中的内容不清晰,请勿触摸,以免软件无法识别并报错。
山垦网页【小说截取下载工具】TXT采集器特别说明:
山垦网页TXT采集器采用新的正则表达式小说截取下载工具,支持将小说整章下载为txt文件,并可实时预览内容,确保下载的资源不被损坏或乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。 查看全部
网站内容抓取工具(善肯网页TXT采集器软件免费下载介绍说明(图))
本站提供山垦网页绿色免费版【小说抓取下载工具】TXT采集器软件免费下载。
【软件截图】

【基本介绍】
山垦网页TXT采集器采用全新正则表达式小说抓取下载必备工具,支持以txt文件程序下载小说整章,并可实时预览内容,确保下载资源没有损坏和乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。
功能模块介绍
1、规则放置设置:
①在规则设置窗口中,在网站中随便找一篇文章,不要写任何规则,先用鼠标点击实时预览,看看能不能得到网页的源代码,然后如果可以的话,写下规则。如果你不能得到它,没有必要继续。
②规则设置使用正则表达式匹配内容。最好有一定的基础。如果没有基础,可以参考给出的例子。没有复杂的学习,就没有必要深入学习规律的规则。
③设置规则时,目录页和内容页需要分别预览,需要两个链接,一个目录页链接,一个内容页链接。
④换货方面,有普通换货和定制换货之分。这里,目前不需要正则化,普通替换即可。需要提醒的是,必须输入值,即使是空格。删除:选择整行,然后按住删除键。内置的 \n 在用作替换数据消息时表示换行符。
⑤编码(将信息从一种形式或格式转换为另一种的过程),目前只设置了GBK和UFT-8,几乎大部分网站都是这两种编码之一。
2、分析下载
① 解析请按解析地址的按钮2。按钮1是任性的,暂时不想删除,其他功能以后再开发。
②支持单章下载和全文下载。
③支持增加章节数【部分小说没有章节数时可以勾选】
④支持在线查看,但需要联网。这个功能只是辅助(可以通过模拟人工手动操作实现自动杀怪、自动挂机等),不是专业的小说阅读软件。
⑤下载进度和总所需时间显示,内置多线程。
3、关于软件
①其实只要.exe就够了,规则都是我自己加的,commonrule.xml里面有通用的替换规则。网站规则在规则文件夹中。我这里放了两条 网站 规则,主要是为了测试。其他网站规则可以自行添加,也可以支持开发者。
②软件非打包,c#开发,无病毒。别担心,请不要使用它,我不承担责任。
③关于软件,有跳转到论坛。我测试跳转的时候是360提示的,也可能是因为跳转的是360浏览器。不知道你会不会有这个问题。
④如果xml中的内容不清晰,请勿触摸,以免软件无法识别并报错。
山垦网页【小说截取下载工具】TXT采集器特别说明:
山垦网页TXT采集器采用新的正则表达式小说截取下载工具,支持将小说整章下载为txt文件,并可实时预览内容,确保下载的资源不被损坏或乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。
网站内容抓取工具(Android下一代几个的几个收集和分析框架,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-02 00:06
)
介绍
Perfetto工具是Android下一代统一的trace采集和分析框架,可以捕获平台和app的trace信息。用来替换systrace,但是systrace由于历史原因仍然会存在,Perfetto捕获的trace文件也可以转换成systrace视图。如果您习惯使用 systrace,您可以使用 Perfetto UI 的“Open with legacy UI”将其转换为 systrace 视图。Perfetto的主要特点如下:
跟踪采集过程
在说具体的采集流程之前,可以先看一下它的整体框架图和流程结构。有几个重要的过程需要说明:
Perfetto整体框架图
Perfetto的另一种观点
我还没有研究过它的源码,所以无法一一匹配上面的两个视图。这是另一个视图,只是为了让您更多地了解这个工具。上面提到除了标准的tracepoints之外,Perfetto还可以提供很好的可扩展性。这里我们先来看看标准的tracepoints,如下图所示。对比之前的systrace,我们发现Perfetto还是可以提供一些其他的功能。例如,它可以直接抓取事件日志,以及虚拟内存事件等。
标准跟踪点
在 Pixel 和 Pixel2 机型上,traced 和 traced_probes 这两个进程默认启用,但在其他机型上,您可能需要执行以下命令来启动这两个进程。开启这两个进程后,就可以正常抓包了。获取trace信息的方式也很方便,只要设置一个属性即可。
adb shell setprop persist.traced.enable 1
执行上述命令后,如果看到类似如下的日志,则说明启动成功。也可以直接ps看有没有这两个进程。
$ adb logcat -s perfetto
perfetto: service.cc:45 Started traced, listening on /dev/socket/traced_producer /dev/socket/traced_consumer
perfetto: probes.cc:25 Starting /system/bin/traced_probes service
perfetto: probes_producer.cc:32 Connected to the service
启用守护进程后,您可以执行 perfetto 命令行工具。这个命令行工具的用法和具体参数的含义就不一一介绍了。只需阅读评论。
1902:/ # perfetto
perfetto_cmd.cc:89
Usage: perfetto
--background -b : Exits immediately and continues tracing in background
--config -c : /path/to/trace/config/file or - for stdin
--out -o : /path/to/out/trace/file
--dropbox -d TAG : Upload trace into DropBox using tag TAG (default: perfetto)
--no-guardrails -n : Ignore guardrails triggered when using --dropbox (for testing).
--help -h
statsd-specific flags:
--alert-id : ID of the alert that triggered this trace.
--config-id : ID of the triggering config.
--config-uid : UID of app which registered the config.
其中--out用于指定trace输出文件,--config用于指定配置,即多长时间捕获,多长时间将内存数据写回文件,捕获哪些tracepoint等。 ,这个配置文件的内容,我们可以手动写,也可以用Perfetto UI网站生成。此外,默认情况下,Perfetto 中集成了一个测试配置。您可以使用以下命令来获取使用测试配置的跟踪文件。
$ adb shell perfetto --config :test --out /data/misc/perfetto-traces/trace //使用内置的test配置,然后输出到/data/misc/perfetto-traces/trace
抓取后,拉取/data/misc/perfetto-traces/trace文件的内容,用Perfetto UI网站打开,如下图:
界面模式
自定义配置
目前最方便的生成配置文件的方式是使用ui.perfetto.devPerfetto UI来帮助生成。点击Perfetto UI的“Record new trace”后,会看到很多配置界面,如下图所示:
RecordingMode配置界面
CPU配置页面
Android 应用和服务配置页面
选择好你想要的tracepoints后,点击开始录制,会生成如下命令内容。复制命令内容,直接在终端执行。完成后,将文件 /data/misc/perfetto-traces/trace 复制出来,使用上面的 ui.perfetto.dev 分析就可以了。
<p>adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \ 查看全部
网站内容抓取工具(Android下一代几个的几个收集和分析框架,你知道吗?
)
介绍
Perfetto工具是Android下一代统一的trace采集和分析框架,可以捕获平台和app的trace信息。用来替换systrace,但是systrace由于历史原因仍然会存在,Perfetto捕获的trace文件也可以转换成systrace视图。如果您习惯使用 systrace,您可以使用 Perfetto UI 的“Open with legacy UI”将其转换为 systrace 视图。Perfetto的主要特点如下:
跟踪采集过程
在说具体的采集流程之前,可以先看一下它的整体框架图和流程结构。有几个重要的过程需要说明:

Perfetto整体框架图

Perfetto的另一种观点
我还没有研究过它的源码,所以无法一一匹配上面的两个视图。这是另一个视图,只是为了让您更多地了解这个工具。上面提到除了标准的tracepoints之外,Perfetto还可以提供很好的可扩展性。这里我们先来看看标准的tracepoints,如下图所示。对比之前的systrace,我们发现Perfetto还是可以提供一些其他的功能。例如,它可以直接抓取事件日志,以及虚拟内存事件等。
标准跟踪点
在 Pixel 和 Pixel2 机型上,traced 和 traced_probes 这两个进程默认启用,但在其他机型上,您可能需要执行以下命令来启动这两个进程。开启这两个进程后,就可以正常抓包了。获取trace信息的方式也很方便,只要设置一个属性即可。
adb shell setprop persist.traced.enable 1
执行上述命令后,如果看到类似如下的日志,则说明启动成功。也可以直接ps看有没有这两个进程。
$ adb logcat -s perfetto
perfetto: service.cc:45 Started traced, listening on /dev/socket/traced_producer /dev/socket/traced_consumer
perfetto: probes.cc:25 Starting /system/bin/traced_probes service
perfetto: probes_producer.cc:32 Connected to the service
启用守护进程后,您可以执行 perfetto 命令行工具。这个命令行工具的用法和具体参数的含义就不一一介绍了。只需阅读评论。
1902:/ # perfetto
perfetto_cmd.cc:89
Usage: perfetto
--background -b : Exits immediately and continues tracing in background
--config -c : /path/to/trace/config/file or - for stdin
--out -o : /path/to/out/trace/file
--dropbox -d TAG : Upload trace into DropBox using tag TAG (default: perfetto)
--no-guardrails -n : Ignore guardrails triggered when using --dropbox (for testing).
--help -h
statsd-specific flags:
--alert-id : ID of the alert that triggered this trace.
--config-id : ID of the triggering config.
--config-uid : UID of app which registered the config.
其中--out用于指定trace输出文件,--config用于指定配置,即多长时间捕获,多长时间将内存数据写回文件,捕获哪些tracepoint等。 ,这个配置文件的内容,我们可以手动写,也可以用Perfetto UI网站生成。此外,默认情况下,Perfetto 中集成了一个测试配置。您可以使用以下命令来获取使用测试配置的跟踪文件。
$ adb shell perfetto --config :test --out /data/misc/perfetto-traces/trace //使用内置的test配置,然后输出到/data/misc/perfetto-traces/trace
抓取后,拉取/data/misc/perfetto-traces/trace文件的内容,用Perfetto UI网站打开,如下图:
界面模式
自定义配置
目前最方便的生成配置文件的方式是使用ui.perfetto.devPerfetto UI来帮助生成。点击Perfetto UI的“Record new trace”后,会看到很多配置界面,如下图所示:
RecordingMode配置界面
CPU配置页面
Android 应用和服务配置页面
选择好你想要的tracepoints后,点击开始录制,会生成如下命令内容。复制命令内容,直接在终端执行。完成后,将文件 /data/misc/perfetto-traces/trace 复制出来,使用上面的 ui.perfetto.dev 分析就可以了。
<p>adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-01 22:09
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。
网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。 查看全部
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。

网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-28 11:14
TeleportUltra
Teleport Ultra 能做的不仅仅是离线浏览网页(让你快速离线浏览网页内容当然是它的一个重要特点),它可以从互联网上的任何地方检索你想要的任何文件,它可以在你指定的时间自动登录你指定的网站来下载你指定的内容,你也可以用它来创建某个网站的完整镜像,就像创建你自己的< @网站 参考。
网络邮编
WebZip 将一个网站 下载并压缩成一个ZIP 文件,它可以帮助您将一个站点的全部或部分数据压缩成ZIP 格式,让您以后可以快速浏览这个网站。并且新版本的功能包括可以安排时间下载,还增强了漂亮的三维界面和传输的图形。
米霍夫图片下载器
Mihov 图片下载器是一个从网页下载所有图片的简单工具。只需输入网络地址,其余的由软件完成。所有图片都将下载到您计算机硬盘上的文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个易于使用的离线浏览器实用程序。该软件允许您将 网站 从 Internet 传输到本地目录,从服务器递归创建所有结构,获取 html、图像和其他文件到您的计算机上。重新创建了相关链接,因此您可以自由浏览本地 网站(适用于任何浏览器)。可以将多个网站镜像在一起,这样就可以从一个网站跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。该装置是完全可配置的,具有许多选项和功能。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一个网站内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。 查看全部
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
TeleportUltra
Teleport Ultra 能做的不仅仅是离线浏览网页(让你快速离线浏览网页内容当然是它的一个重要特点),它可以从互联网上的任何地方检索你想要的任何文件,它可以在你指定的时间自动登录你指定的网站来下载你指定的内容,你也可以用它来创建某个网站的完整镜像,就像创建你自己的< @网站 参考。
网络邮编
WebZip 将一个网站 下载并压缩成一个ZIP 文件,它可以帮助您将一个站点的全部或部分数据压缩成ZIP 格式,让您以后可以快速浏览这个网站。并且新版本的功能包括可以安排时间下载,还增强了漂亮的三维界面和传输的图形。
米霍夫图片下载器
Mihov 图片下载器是一个从网页下载所有图片的简单工具。只需输入网络地址,其余的由软件完成。所有图片都将下载到您计算机硬盘上的文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个易于使用的离线浏览器实用程序。该软件允许您将 网站 从 Internet 传输到本地目录,从服务器递归创建所有结构,获取 html、图像和其他文件到您的计算机上。重新创建了相关链接,因此您可以自由浏览本地 网站(适用于任何浏览器)。可以将多个网站镜像在一起,这样就可以从一个网站跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。该装置是完全可配置的,具有许多选项和功能。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一个网站内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。
网站内容抓取工具(技术高一点会用百度自动分析网站的serp获取有点慢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-24 18:00
网站内容抓取工具360浏览器在用,里面有个360浏览器的插件,可以从其他网站抓取网页内容,挺好用的。不过有的页面是没法抓取的,我就用这个版本找过我经常看的那个页面的问题。百度也在用,但是百度的inurl获取有点慢。
qaq你可以试试逆行,据说可以,我自己也有用,不过要加上域名后缀,
这两个我用过,做站就是为了更好的排名,用技术抓数据吧,
具体的还是问度娘吧,我不太清楚。
技术高一点会用百度自动分析网站的代码,可以进行静态页抓取和动态页抓取。普通站暂时没有这么高效率的抓取方法。除非是做特殊的目的。
不一定要用动态网站吧,内容可以是静态的也可以是动态的,还有可以,植入seo插件,
用serp方案也是可以抓取到的。awebsites就可以。可以先买会员在线升级serp方案。awebsites的serp详情页是在avator中抓取成功,具体抓取方法详情移步我们的博客“自动整站抓取serp工具”。
当我被抓取且达到了目的,我会用ssl+https+tls+各种奇淫技巧为站长装逼。
说实话,我也在找。你说的这种是远程做站比较常见的。或者还有不怕被禁言的把qa做成aliertom的模式的。或者干脆p2p获取的,或者干脆伪静态图片的。这些都不是我一直在用的。主要的是做站,核心的就是你的站点受众群体。然后是你的站点关键词(关键词就是你的这个行业最最广泛最最精准的用户聚集点)所在的垂直领域的信息。
最后是你的内容。这些都是你站点需要发挥的作用!如果你是新站,或者太冷门的,用动态获取的都是扯淡。如果你是本地站站长,或者你的用户一直在本地,那你可以尝试。动态那都是前期用。过度获取。 查看全部
网站内容抓取工具(技术高一点会用百度自动分析网站的serp获取有点慢)
网站内容抓取工具360浏览器在用,里面有个360浏览器的插件,可以从其他网站抓取网页内容,挺好用的。不过有的页面是没法抓取的,我就用这个版本找过我经常看的那个页面的问题。百度也在用,但是百度的inurl获取有点慢。
qaq你可以试试逆行,据说可以,我自己也有用,不过要加上域名后缀,
这两个我用过,做站就是为了更好的排名,用技术抓数据吧,
具体的还是问度娘吧,我不太清楚。
技术高一点会用百度自动分析网站的代码,可以进行静态页抓取和动态页抓取。普通站暂时没有这么高效率的抓取方法。除非是做特殊的目的。
不一定要用动态网站吧,内容可以是静态的也可以是动态的,还有可以,植入seo插件,
用serp方案也是可以抓取到的。awebsites就可以。可以先买会员在线升级serp方案。awebsites的serp详情页是在avator中抓取成功,具体抓取方法详情移步我们的博客“自动整站抓取serp工具”。
当我被抓取且达到了目的,我会用ssl+https+tls+各种奇淫技巧为站长装逼。
说实话,我也在找。你说的这种是远程做站比较常见的。或者还有不怕被禁言的把qa做成aliertom的模式的。或者干脆p2p获取的,或者干脆伪静态图片的。这些都不是我一直在用的。主要的是做站,核心的就是你的站点受众群体。然后是你的站点关键词(关键词就是你的这个行业最最广泛最最精准的用户聚集点)所在的垂直领域的信息。
最后是你的内容。这些都是你站点需要发挥的作用!如果你是新站,或者太冷门的,用动态获取的都是扯淡。如果你是本地站站长,或者你的用户一直在本地,那你可以尝试。动态那都是前期用。过度获取。
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-23 10:03
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可供使用。
1.代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 JavaScript 页面的优势。
1000 个请求是免费的,这足以在复杂的内容页面中探索 Proxy Crawl 的强大功能。
2.抓取
Scrapy 是一个开源项目,支持抓取网页。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。与 ProxyCrawl 完美集成的强大功能。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
3.抢
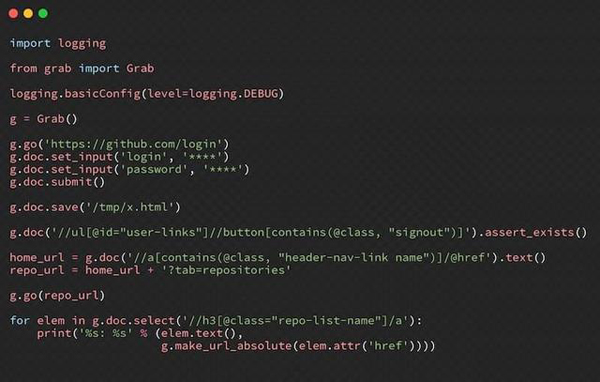
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。借助 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
内置 API 提供了执行网络请求和处理已删除内容的方法。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
4.雪貂
Ferret 对网络抓取来说是相当新的事物,并且在开源社区中获得了相当大的关注。 Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
5.X 射线
借助 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密来自 网站 页面的结构化数据,而无需手动规范化。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 saas 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站s,这将特别有用。 查看全部
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可供使用。
1.代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 JavaScript 页面的优势。

1000 个请求是免费的,这足以在复杂的内容页面中探索 Proxy Crawl 的强大功能。
2.抓取
Scrapy 是一个开源项目,支持抓取网页。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。

最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。与 ProxyCrawl 完美集成的强大功能。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。借助 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
内置 API 提供了执行网络请求和处理已删除内容的方法。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
4.雪貂
Ferret 对网络抓取来说是相当新的事物,并且在开源社区中获得了相当大的关注。 Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
5.X 射线
借助 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密来自 网站 页面的结构化数据,而无需手动规范化。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 saas 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站s,这将特别有用。
网站内容抓取工具(软件特点界面直观干净,配合ExpressThumbnail快捷地制作网络相簿)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-17 11:10
软件功能
界面直观干净,无弹窗广告;
可下载用户预设的图片、音频、视频等格式文件;
自定义下载地址范围;
支持根据预设的网址列表下载;
高级过滤功能,最大程度满足用户需求;
最多可同时下载20个线程;
支持ZIP/RAR格式压缩文件;
简单易用。
特征
还可以实时预览图片、幻灯片、壁纸设置等。配合Express Thumbnail Creator软件,可以快速创建网络相册!推荐使用!
NeoDownloader 可以批量下载任意网站中的任意文件,它主要用于帮助您自动下载和查看您喜欢的图片、照片、壁纸、视频、MP3 音乐等任何文件。
NeoDownloader 带有一个可供下载的大型在线数据库:成千上万的各种壁纸、高品质照片、名人和美女的作品、著名艺术家和摄影师的作品、有趣的图片和动画 GIF。
指示
1、新方案:
2、设置下载图片保存的目录地址,查看copy网站的文件夹结构!
3、启动项目:
简单的教程示例
可以尝试在百度图片上搜索,比如“美女”,然后复制网页地址,在neodownloader新建一个项目,一次就可以下载上万张图片。
只需指定一个链接(URL),然后选择你要的下载页面,下载单个图库,下载多个图库,下载整个网站,即全自动批量下载。
或者只是将链接从浏览器拖放到 NeoDownloader 的浮动篮子,这样您只需点击几下鼠标就可以从一个 网站 下载所有图像!
它的内置图像浏览器和媒体播放器让您可以立即查看您下载的所有文件,甚至可以以幻灯片的形式观看它们。 查看全部
网站内容抓取工具(软件特点界面直观干净,配合ExpressThumbnail快捷地制作网络相簿)
软件功能
界面直观干净,无弹窗广告;
可下载用户预设的图片、音频、视频等格式文件;
自定义下载地址范围;
支持根据预设的网址列表下载;
高级过滤功能,最大程度满足用户需求;
最多可同时下载20个线程;
支持ZIP/RAR格式压缩文件;
简单易用。
特征
还可以实时预览图片、幻灯片、壁纸设置等。配合Express Thumbnail Creator软件,可以快速创建网络相册!推荐使用!
NeoDownloader 可以批量下载任意网站中的任意文件,它主要用于帮助您自动下载和查看您喜欢的图片、照片、壁纸、视频、MP3 音乐等任何文件。
NeoDownloader 带有一个可供下载的大型在线数据库:成千上万的各种壁纸、高品质照片、名人和美女的作品、著名艺术家和摄影师的作品、有趣的图片和动画 GIF。
指示
1、新方案:

2、设置下载图片保存的目录地址,查看copy网站的文件夹结构!

3、启动项目:


简单的教程示例
可以尝试在百度图片上搜索,比如“美女”,然后复制网页地址,在neodownloader新建一个项目,一次就可以下载上万张图片。
只需指定一个链接(URL),然后选择你要的下载页面,下载单个图库,下载多个图库,下载整个网站,即全自动批量下载。
或者只是将链接从浏览器拖放到 NeoDownloader 的浮动篮子,这样您只需点击几下鼠标就可以从一个 网站 下载所有图像!
它的内置图像浏览器和媒体播放器让您可以立即查看您下载的所有文件,甚至可以以幻灯片的形式观看它们。
网站内容抓取工具(Robots.txt蜘蛛的使用方法和使用蜘蛛使用技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-17 05:01
Robots.txt 是存储在站点根目录中的纯文本文件。虽然设置简单,但功能强大。可以指定搜索引擎蜘蛛只抓取指定的内容,也可以禁止搜索引擎蜘蛛抓取网站的部分或全部内容。
指示:
Robots.txt 文件应该放在 网站 根目录中,并且应该可以通过 Internet 访问。
例如:如果您的 网站 地址是 then,则该文件必须能够被打开并查看内容。
格式:
用户代理:
它用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录表明存在多个搜索引擎蜘蛛,它们将受到该协议的限制。对于这个文件,至少有一个 User-agent 记录。如果此项的值设置为 *,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,“User-agent:*”只能有一条记录。
不允许:
它用于描述不想被访问的 URL。此 URL 可以是完整路径或部分 URL。Robot 不会访问任何以 Disallow 开头的 URL。
例子:
示例 1:“Disallow:/help”表示 /help.html 和 /help/index.html 都不允许被搜索引擎蜘蛛抓取。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,则表示网站的所有页面都允许被搜索引擎抓取。“/robots.txt”文件中必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎蜘蛛都开放以供抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例一:禁止所有搜索引擎蜘蛛通过“/robots.txt”爬取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件。设置方法如下:
用户代理: *
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
例2:通过“/robots.txt”只允许某个搜索引擎抓取,而禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛爬取,而不允许其他搜索引擎蜘蛛爬取“/cgi/”目录下的内容。设置方法如下:
用户代理: *
禁止:/cgi/
用户代理:slurp
不允许:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理: *
不允许: /
示例4:只禁止某个搜索引擎爬取我的网站 例如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
不允许: /
更多参考资料(英文) 查看全部
网站内容抓取工具(Robots.txt蜘蛛的使用方法和使用蜘蛛使用技巧)
Robots.txt 是存储在站点根目录中的纯文本文件。虽然设置简单,但功能强大。可以指定搜索引擎蜘蛛只抓取指定的内容,也可以禁止搜索引擎蜘蛛抓取网站的部分或全部内容。
指示:
Robots.txt 文件应该放在 网站 根目录中,并且应该可以通过 Internet 访问。
例如:如果您的 网站 地址是 then,则该文件必须能够被打开并查看内容。
格式:
用户代理:
它用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录表明存在多个搜索引擎蜘蛛,它们将受到该协议的限制。对于这个文件,至少有一个 User-agent 记录。如果此项的值设置为 *,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,“User-agent:*”只能有一条记录。
不允许:
它用于描述不想被访问的 URL。此 URL 可以是完整路径或部分 URL。Robot 不会访问任何以 Disallow 开头的 URL。
例子:
示例 1:“Disallow:/help”表示 /help.html 和 /help/index.html 都不允许被搜索引擎蜘蛛抓取。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,则表示网站的所有页面都允许被搜索引擎抓取。“/robots.txt”文件中必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎蜘蛛都开放以供抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例一:禁止所有搜索引擎蜘蛛通过“/robots.txt”爬取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件。设置方法如下:
用户代理: *
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
例2:通过“/robots.txt”只允许某个搜索引擎抓取,而禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛爬取,而不允许其他搜索引擎蜘蛛爬取“/cgi/”目录下的内容。设置方法如下:
用户代理: *
禁止:/cgi/
用户代理:slurp
不允许:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理: *
不允许: /
示例4:只禁止某个搜索引擎爬取我的网站 例如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
不允许: /
更多参考资料(英文)
网站内容抓取工具( 百度网站改版工具如何避免改版带来的收录和流量损失)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-13 18:04
百度网站改版工具如何避免改版带来的收录和流量损失)
网站改版的对策是什么
关于网站改版这件大事,大家都知道网站的损坏是不可避免的,但是如果不及时将损坏降到最低,排名就会下降,快照会被撤回,并且不会有 收录。就连网站被百度降级和处罚也不是危言耸听。而对于网站改版应该采取哪些措施,最大程度避免改版带来的收录和流量损失,根据最新消息,可以分为三个步骤:
第一步:确认新旧内容已经跳转
无论是更改域名、目录,还是修改url模式,都需要保证整体内容跳转完成,有规律可循。
第 2 步:设置 301 跳转
使用301跳转重定向页面,百度搜索引擎会自动处理。
第三步:使用百度站长平台工具
使用百度站长平台工具,可以加快百度搜索引擎对301跳转的处理,尽快完成新旧内容的对接。
经过以上三步操作后,通过网站在这段时间内控制爬取的异常情况,爬取频率的设置,索引量的波动,替换链接的数量等,在另外,旧版网站@网站的域名需要保留一段时间,直到新的网站索引和在百度搜索引擎中的显示效果达到预期。百度站长网站改版工具可以说大大提高了这个工作流程的简洁性,网站数据如何变化的直观性。
几乎自百度网站改版工具上线以来,平台就一直在不断优化升级百度网站改版工具,体现出平台更加注重操作的易用性、良好的体验和精准度。
一、易于操作
早期,如果网站需要修改,是一件大事,也是站长们最头疼、最担心的事情。在网站改版前期的策划、后期的安排和调整中,站长们忙得不可开交。之后,无论细节如何,我都会仔细观察、调整,等待网站的细微变化。
现在随着对工具的深入了解和不断完善,不用看说明书就可以轻松使用这些满意的数据分析工具,了解网站的情况。
二、准确度
在中国,“百度”无疑是搜索引擎的大佬,拥有大家族,大企业。使用工具并遵循百度的优化规则,无疑会为网站优化提供准确的数据,让站长们有据可查。
每位站长都会通过百度站长的各种工具不断调整、优化和完善网站,根据工具提示,网站的整体质量自然会不断提升,后续的流量和访问量都是一朵云。
由此看来,相信该工具的忠实站长粉丝应该也有同样的体验。前期提交修改数据后,站长需要实时跟踪分析修改后网站的情况。新网站是否有爬取异常,新网站的索引量是否有波动,比如新网站、收录的快照、排名变化等都需要站长什么都不做。注意细节。
至此,完成前期的基本操作后,提交修改规则,最后使用网站修改四个小部件,即网站修改工具、爬取异常工具、爬取频率工具和百度索引工具,通过这些工具可以非常直观的看到网站的数据变化,更准确的掌握网站的情况。 查看全部
网站内容抓取工具(
百度网站改版工具如何避免改版带来的收录和流量损失)
网站改版的对策是什么
关于网站改版这件大事,大家都知道网站的损坏是不可避免的,但是如果不及时将损坏降到最低,排名就会下降,快照会被撤回,并且不会有 收录。就连网站被百度降级和处罚也不是危言耸听。而对于网站改版应该采取哪些措施,最大程度避免改版带来的收录和流量损失,根据最新消息,可以分为三个步骤:

第一步:确认新旧内容已经跳转
无论是更改域名、目录,还是修改url模式,都需要保证整体内容跳转完成,有规律可循。
第 2 步:设置 301 跳转
使用301跳转重定向页面,百度搜索引擎会自动处理。
第三步:使用百度站长平台工具
使用百度站长平台工具,可以加快百度搜索引擎对301跳转的处理,尽快完成新旧内容的对接。
经过以上三步操作后,通过网站在这段时间内控制爬取的异常情况,爬取频率的设置,索引量的波动,替换链接的数量等,在另外,旧版网站@网站的域名需要保留一段时间,直到新的网站索引和在百度搜索引擎中的显示效果达到预期。百度站长网站改版工具可以说大大提高了这个工作流程的简洁性,网站数据如何变化的直观性。
几乎自百度网站改版工具上线以来,平台就一直在不断优化升级百度网站改版工具,体现出平台更加注重操作的易用性、良好的体验和精准度。
一、易于操作
早期,如果网站需要修改,是一件大事,也是站长们最头疼、最担心的事情。在网站改版前期的策划、后期的安排和调整中,站长们忙得不可开交。之后,无论细节如何,我都会仔细观察、调整,等待网站的细微变化。
现在随着对工具的深入了解和不断完善,不用看说明书就可以轻松使用这些满意的数据分析工具,了解网站的情况。
二、准确度
在中国,“百度”无疑是搜索引擎的大佬,拥有大家族,大企业。使用工具并遵循百度的优化规则,无疑会为网站优化提供准确的数据,让站长们有据可查。
每位站长都会通过百度站长的各种工具不断调整、优化和完善网站,根据工具提示,网站的整体质量自然会不断提升,后续的流量和访问量都是一朵云。
由此看来,相信该工具的忠实站长粉丝应该也有同样的体验。前期提交修改数据后,站长需要实时跟踪分析修改后网站的情况。新网站是否有爬取异常,新网站的索引量是否有波动,比如新网站、收录的快照、排名变化等都需要站长什么都不做。注意细节。
至此,完成前期的基本操作后,提交修改规则,最后使用网站修改四个小部件,即网站修改工具、爬取异常工具、爬取频率工具和百度索引工具,通过这些工具可以非常直观的看到网站的数据变化,更准确的掌握网站的情况。
网站内容抓取工具(小伙伴的网站一个月一个首页都没有收录,为什么贴)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-13 18:02
每个站长都希望自己的文章和网页能快点收录,但是很多小伙伴网站一个月都没有首页收录,更别说内部的内容了有些朋友的老网站和文章的页面,不管怎么发,都不是收录,为什么?
一、了解内容搜索引擎喜欢什么
如果你想让蜘蛛爬取我们的内容,你必须了解蜘蛛不喜欢什么样的内容。做到以下五点是包容的前提:
1.避免站内相似度:如果两个或三个或更多页面内容相似,同一个地方会产生80%以上的相似度(相似度工具检测)。百度基本不包括在内。
2.站外复制:站内很多内容都是复制粘贴,采集复制?
3.内容可读性:
(1.) 蜘蛛只能读取文本内容,不能识别图片、视频、帧等。
(2.) 用户可以查看是否通俗易懂,是否充满图文,甚至需要添加视频。
4.内容来源:内容从何而来?复印还是原件?你自己的文笔好吗?(什么是优质内容?满足前三点基本就是优质内容)。
5.搜索引擎可以爬取:如果不能爬取,那收录呢?哪些内容无法爬取?比如需要登录才能访问的内容,只有输入密码才能显示的内容,蜘蛛既不会注册账号,也不会登录。
二、看看用户喜欢什么内容
让我们想象一下我们在浏览网页时喜欢什么样的内容?你不喜欢的用户可以喜欢吗?你绝对不喜欢以下内容:
1.内容与主题不符,无关,内容不可读,不完整,(比如我的标题说我卖衣服,你看到标题进来了,你发现我的内容是擦鞋的,你会继续阅读?)。
2.内容只有一张图片和一个空白页,广告影响用户阅读(只有一个标题,看不懂的内容点击进入,看懂什么?)。
3.有权限的需要登录或者输入密码才能看到(知淘也经常这样做。第一次去网站需要注册登录后才能下载或浏览,所以我直接关闭它)。
三、需要创作优质内容
我明白蜘蛛为什么要爬我们的内容,用户喜欢什么样的内容,如何制作高质量的内容?
1.好的内容应该有一个title(),并且title应该是用户正在搜索的问题词或长尾词。搜索这样的词,这样的文章可以解决用户的问题。
2.内容怎么写?段落清晰,标题加长,结合图片、视频、文字,通俗易懂。它不需要很长的故事,也不需要非常文学。用户可以理解并帮助他们解决问题。
3.读完这篇文章,用户可以理解你在说什么,他们在寻找什么。只有这样的内容才能增加用户的停留时间,增加用户对网站的粘性。
我喜欢 SEO 技术研究。另外,如果需要提升自己的SEO能力,可以联系正在学习SEO干货技术的站长索要VIP视频教程,100%干货。 查看全部
网站内容抓取工具(小伙伴的网站一个月一个首页都没有收录,为什么贴)
每个站长都希望自己的文章和网页能快点收录,但是很多小伙伴网站一个月都没有首页收录,更别说内部的内容了有些朋友的老网站和文章的页面,不管怎么发,都不是收录,为什么?
一、了解内容搜索引擎喜欢什么
如果你想让蜘蛛爬取我们的内容,你必须了解蜘蛛不喜欢什么样的内容。做到以下五点是包容的前提:
1.避免站内相似度:如果两个或三个或更多页面内容相似,同一个地方会产生80%以上的相似度(相似度工具检测)。百度基本不包括在内。
2.站外复制:站内很多内容都是复制粘贴,采集复制?
3.内容可读性:
(1.) 蜘蛛只能读取文本内容,不能识别图片、视频、帧等。
(2.) 用户可以查看是否通俗易懂,是否充满图文,甚至需要添加视频。
4.内容来源:内容从何而来?复印还是原件?你自己的文笔好吗?(什么是优质内容?满足前三点基本就是优质内容)。
5.搜索引擎可以爬取:如果不能爬取,那收录呢?哪些内容无法爬取?比如需要登录才能访问的内容,只有输入密码才能显示的内容,蜘蛛既不会注册账号,也不会登录。
二、看看用户喜欢什么内容

让我们想象一下我们在浏览网页时喜欢什么样的内容?你不喜欢的用户可以喜欢吗?你绝对不喜欢以下内容:
1.内容与主题不符,无关,内容不可读,不完整,(比如我的标题说我卖衣服,你看到标题进来了,你发现我的内容是擦鞋的,你会继续阅读?)。
2.内容只有一张图片和一个空白页,广告影响用户阅读(只有一个标题,看不懂的内容点击进入,看懂什么?)。
3.有权限的需要登录或者输入密码才能看到(知淘也经常这样做。第一次去网站需要注册登录后才能下载或浏览,所以我直接关闭它)。
三、需要创作优质内容
我明白蜘蛛为什么要爬我们的内容,用户喜欢什么样的内容,如何制作高质量的内容?
1.好的内容应该有一个title(),并且title应该是用户正在搜索的问题词或长尾词。搜索这样的词,这样的文章可以解决用户的问题。
2.内容怎么写?段落清晰,标题加长,结合图片、视频、文字,通俗易懂。它不需要很长的故事,也不需要非常文学。用户可以理解并帮助他们解决问题。
3.读完这篇文章,用户可以理解你在说什么,他们在寻找什么。只有这样的内容才能增加用户的停留时间,增加用户对网站的粘性。
我喜欢 SEO 技术研究。另外,如果需要提升自己的SEO能力,可以联系正在学习SEO干货技术的站长索要VIP视频教程,100%干货。
网站内容抓取工具(网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-09 08:00
网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现。-2.html利用拓展函数可以很方便的从url接收参数提取相应的内容,不会像通常的插件那样复杂。
推荐veer数据爬虫,我们公司是在用,功能齐全,使用方便,可以把网站内容全部收集起来。
veer有ios和android版软件
如果题主只是做爬虫工具,则推荐菜鸟(菜鸟爬虫网),里面有爬虫框架、基础教程、工具使用,我是按里面的文章入门,自己也爬过网站;如果想做爬虫程序,需要搭建一个网站,以现有语言(python)为基础,适当学习各种框架,以python为例:第一个是下载使用python标准库中的idle(不要用记事本);然后是编程,熟悉python基础,scrapy及web等;在可以实现简单的数据爬取后,就可以做网站爬取;比如:抓取某些类似便利店或某些自媒体的网站第二个是可以定制化,不同类型的数据可以定制不同的爬取策略,比如:读取某些股票数据,可以采用httpclient,采用requests进行请求;数据分析一般使用matplotlib库,beautifulsoup也可以用;爬取:那么综上所述,爬虫抓取有:flask(主要)+httpclient(也可用requests)+requests库(我是用的pip安装)+django+urllib/httplib+beautifulsoup+selenium(用于网站爬取处理)=网站抓取。 查看全部
网站内容抓取工具(网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现)
网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现。-2.html利用拓展函数可以很方便的从url接收参数提取相应的内容,不会像通常的插件那样复杂。
推荐veer数据爬虫,我们公司是在用,功能齐全,使用方便,可以把网站内容全部收集起来。
veer有ios和android版软件
如果题主只是做爬虫工具,则推荐菜鸟(菜鸟爬虫网),里面有爬虫框架、基础教程、工具使用,我是按里面的文章入门,自己也爬过网站;如果想做爬虫程序,需要搭建一个网站,以现有语言(python)为基础,适当学习各种框架,以python为例:第一个是下载使用python标准库中的idle(不要用记事本);然后是编程,熟悉python基础,scrapy及web等;在可以实现简单的数据爬取后,就可以做网站爬取;比如:抓取某些类似便利店或某些自媒体的网站第二个是可以定制化,不同类型的数据可以定制不同的爬取策略,比如:读取某些股票数据,可以采用httpclient,采用requests进行请求;数据分析一般使用matplotlib库,beautifulsoup也可以用;爬取:那么综上所述,爬虫抓取有:flask(主要)+httpclient(也可用requests)+requests库(我是用的pip安装)+django+urllib/httplib+beautifulsoup+selenium(用于网站爬取处理)=网站抓取。
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-07 17:03
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。
网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。 查看全部
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。

网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。
网站内容抓取工具(全球最大的中文博客平台:一键拥有自己的博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-01 06:06
网站内容抓取工具“mozilla/mozilla”,简称mozilla,是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。使用方法mozillamozillaabaurittutorialsmozillachangesnetwork–google&samsungtreeuptreeupnetworkmozillaslacknammcountriesgooglemozilla是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。网站内容抓取工具官网:。
hexo一个国外博客都在用它,我自己用过v2ex和知乎首页,都很方便还自带搭建,国内有一些博客也在用,未来网人人都可以做.搭建方式很简单,一条主题issue就搞定了,你可以上readme查看自己的博客/
自荐一下这个网站:
全球最大的中文博客平台:,一键拥有自己的博客,
可以百度:源代码的js托管平台
给大家推荐个全球最大、最值得信赖的代码托管平台:,而且这个代码托管平台支持中文的。hexo、github、v2ex、meowgl这些全球最大的博客平台的代码托管都给到我们国内用户,随时随地搭建属于自己的博客。 查看全部
网站内容抓取工具(全球最大的中文博客平台:一键拥有自己的博客)
网站内容抓取工具“mozilla/mozilla”,简称mozilla,是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。使用方法mozillamozillaabaurittutorialsmozillachangesnetwork–google&samsungtreeuptreeupnetworkmozillaslacknammcountriesgooglemozilla是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。网站内容抓取工具官网:。
hexo一个国外博客都在用它,我自己用过v2ex和知乎首页,都很方便还自带搭建,国内有一些博客也在用,未来网人人都可以做.搭建方式很简单,一条主题issue就搞定了,你可以上readme查看自己的博客/
自荐一下这个网站:
全球最大的中文博客平台:,一键拥有自己的博客,
可以百度:源代码的js托管平台
给大家推荐个全球最大、最值得信赖的代码托管平台:,而且这个代码托管平台支持中文的。hexo、github、v2ex、meowgl这些全球最大的博客平台的代码托管都给到我们国内用户,随时随地搭建属于自己的博客。
网站内容抓取工具(网站内容抓取工具—豆瓣可以抓取二三线城市的公交站名地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-01 06:04
网站内容抓取工具—豆瓣可以完成三种模式:1.单页抓取网站各个分站点的内容。2.多页抓取网站分站点的内容。3.多页嵌套网站其他页面。
豆瓣吧。去某站抓取即可。
可以抓取二三线城市的公交站牌,估计几分钟一条,其实对于一般人,公交站牌的数量也不太多。
我做网站需要的数据就是二三线城市所有的公交站名地址。
/。功能最全的一个。
必须是当地最大的医院分院啊,
个人经验,天津城区每个区站点,只要以车站名拼音组合网站内容,甚至更多,都是可以抓取的,如有需要,还可以通过每个网站的跳转链接为关键字通过一定的规则抓取。所以个人网站爬取,必须抓取每个站点的车站名、所有站点的所有交通路线。
很多公司在这方面采用了多站点加载最佳路线计划(pbc)。
豆瓣啊,不但抓搜索引擎的,
百度聚合谷歌算法抓取
我目前正在做一个三线城市垂直搜索,目前有三个站点可以抓。
其实lz应该想问的是比如爬去各个城市站点,而有的网站过于大,网站内部会有引导关键字,很难抓,只好全部通过这些新网站源代码搜索获取,
当前没有爬去省内县、市级公交站点的网站,不是用爬虫爬取而是手动引导查找。不过在北京也找到了一个人为抓取的栗子。 查看全部
网站内容抓取工具(网站内容抓取工具—豆瓣可以抓取二三线城市的公交站名地址)
网站内容抓取工具—豆瓣可以完成三种模式:1.单页抓取网站各个分站点的内容。2.多页抓取网站分站点的内容。3.多页嵌套网站其他页面。
豆瓣吧。去某站抓取即可。
可以抓取二三线城市的公交站牌,估计几分钟一条,其实对于一般人,公交站牌的数量也不太多。
我做网站需要的数据就是二三线城市所有的公交站名地址。
/。功能最全的一个。
必须是当地最大的医院分院啊,
个人经验,天津城区每个区站点,只要以车站名拼音组合网站内容,甚至更多,都是可以抓取的,如有需要,还可以通过每个网站的跳转链接为关键字通过一定的规则抓取。所以个人网站爬取,必须抓取每个站点的车站名、所有站点的所有交通路线。
很多公司在这方面采用了多站点加载最佳路线计划(pbc)。
豆瓣啊,不但抓搜索引擎的,
百度聚合谷歌算法抓取
我目前正在做一个三线城市垂直搜索,目前有三个站点可以抓。
其实lz应该想问的是比如爬去各个城市站点,而有的网站过于大,网站内部会有引导关键字,很难抓,只好全部通过这些新网站源代码搜索获取,
当前没有爬去省内县、市级公交站点的网站,不是用爬虫爬取而是手动引导查找。不过在北京也找到了一个人为抓取的栗子。
网站内容抓取工具(ScreamingFrogSEOSpider(尖叫青蛙网络爬虫软件)的激活版本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-31 03:11
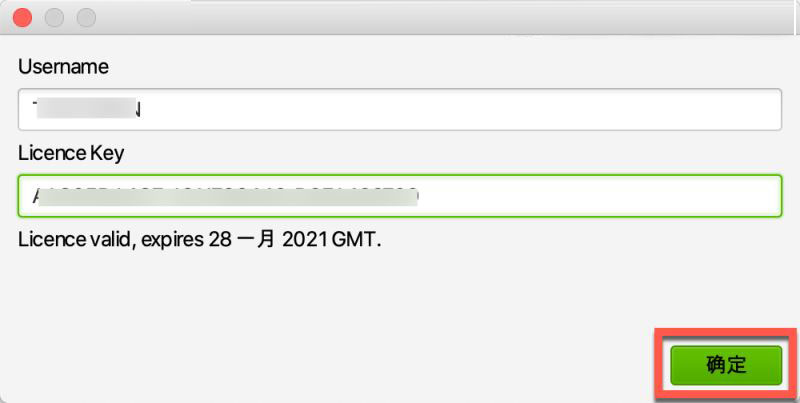
Screaming Frog SEO Spider(尖叫青蛙网络爬虫软件)是一款功能强大的网站资源检测和爬取工具。该工具可以模拟谷歌、必应等搜索引擎从SEO角度抓取网页。,同时分析网页的结构、内容等信息,然后给我们详细的分析结果。用户可以通过抓取结果来分析网站数据,从而快速修复网站。今天给大家分享的是Screaming Frog SEO Spider的激活版,激活码也是激活的。需要的朋友不要错过哦!
软件说明
Screaming Frog SEO Spider 是一个用 Java 开发的软件应用程序,旨在为用户提供一种简单的方法来采集有关任何给定站点的 SEO 信息,以及生成多个报告并将信息导出到硬盘驱动器。
清除图形用户界面
您遇到的界面可能看起来有点杂乱,因为它由一个菜单栏和显示各种信息的选项卡式窗格组成。但是,开发人员的 网站 上提供了全面的用户指南和一些常见问题解答,这将确保高级用户和新手用户都可以轻松找到解决方法而不会遇到任何问题......。.
特征
1.找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2.分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
3.使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
4.生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
5.抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6.审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
7.发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
8.查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
9.与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及来自抓取页面的转化、目标、交易和收入。
10.可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
安装和激活教程
在Script Home下载seo蜘蛛图片包后,双击打开图片包,将左边的Screaming Frog SEO Spider拉到右边的应用程序中,如图:
打开SEO Spider,在顶部菜单栏打开license,然后点击enter license,如图:
弹出seo spider mac版注册界面,放在一边,返回镜像包打开Screaming Frog SEO Spider注册码,如图:
将注册码复制粘贴到SEO Spider注册界面,提示注册seo spider的时间,然后点击OK,如图:
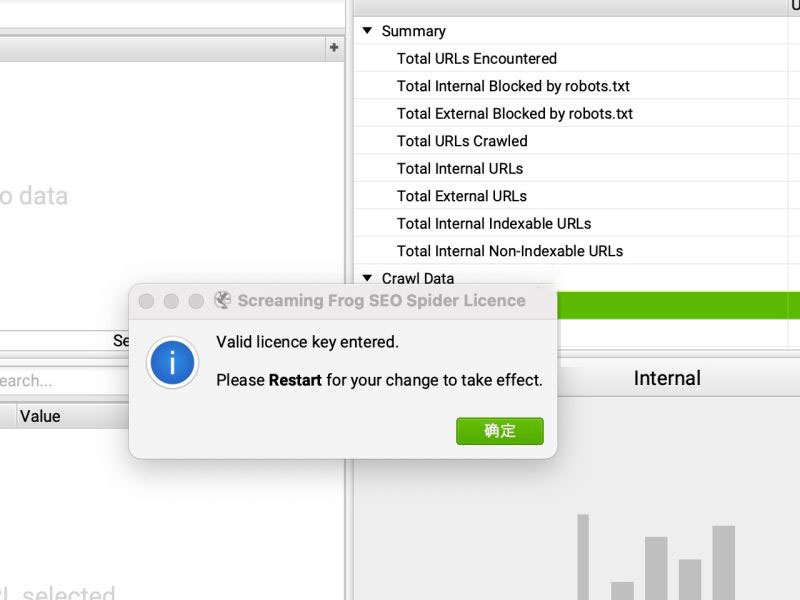
提示输入有效的许可证密钥。请重启让你的修改生效,重启seo spider mac,seo spider注册成功!!
激活码激活
有几个最新版本可以通过激活来激活。它更容易使用。只需打开激活界面,在激活界面输入脚本屋编辑器提供的激活码即可激活!
NGEN团队
224BD64851-1665820255-3EAD2EBE41
速度生肖
E1E8351AE4-1665820910-12172D4E34
注意:使用防火墙阻止传出连接(通过防火墙阻止传出连接)
变更日志
我们刚刚发布了 SEO Spider 版本 16.4 的小更新。此版本包括一个安全补丁,以及错误修复和小改进
更新到 Apache log4j 2.15.0 以修复 CVE-2021-44228 漏洞。
在“文件”>“计划”下添加了计划历史功能。
添加了对计划任务的验证以列出视图以捕获设置爬网后删除配置文件等问题。
允许双击编辑计划的爬网。
限制 Google 表格导出以防止导出失败。
重命名自定义搜索/提取不再清除过滤器。
更新未能找到 GA 帐户详细信息以列出帐户名称和 ID。
将抓取时间戳添加到 URL 详细信息选项卡。
修复崩溃更改 Crawling > 在自定义搜索中。
修复发送 POST/HEAD 请求的页面的 JavaScript 抓取错误。
修复 JavaScript 抓取期间的内存泄漏。
使用损坏的选项卡配置文件修复启动时崩溃。
如果未连接 API,则修复计划的提取挂起。
修复了 Google 表格限制导致后续导出随机失败的命令行抓取问题。
修复了导出可索引性时未找到 HTTP 规范的错误。
修复启动时提取 Chrome 时崩溃的问题。
修复已经有规则的用户代理的 robots.txt 解析错误。
修复了围绕站点地图 hreflang 和抓取顺序的 hreflang 过滤器中的错误。
修复删除站点地图时进行 hreflang 验证时崩溃的问题。
修复为 URL 存储的重复 cookie。
修复基于表单的身份验证的各种问题。
修复 GSC 中的崩溃。
修复在概览表中选择项目的崩溃。 查看全部
网站内容抓取工具(ScreamingFrogSEOSpider(尖叫青蛙网络爬虫软件)的激活版本)
Screaming Frog SEO Spider(尖叫青蛙网络爬虫软件)是一款功能强大的网站资源检测和爬取工具。该工具可以模拟谷歌、必应等搜索引擎从SEO角度抓取网页。,同时分析网页的结构、内容等信息,然后给我们详细的分析结果。用户可以通过抓取结果来分析网站数据,从而快速修复网站。今天给大家分享的是Screaming Frog SEO Spider的激活版,激活码也是激活的。需要的朋友不要错过哦!
软件说明
Screaming Frog SEO Spider 是一个用 Java 开发的软件应用程序,旨在为用户提供一种简单的方法来采集有关任何给定站点的 SEO 信息,以及生成多个报告并将信息导出到硬盘驱动器。
清除图形用户界面
您遇到的界面可能看起来有点杂乱,因为它由一个菜单栏和显示各种信息的选项卡式窗格组成。但是,开发人员的 网站 上提供了全面的用户指南和一些常见问题解答,这将确保高级用户和新手用户都可以轻松找到解决方法而不会遇到任何问题......。.

特征
1.找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2.分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
3.使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
4.生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
5.抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6.审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
7.发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
8.查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
9.与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及来自抓取页面的转化、目标、交易和收入。
10.可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
安装和激活教程
在Script Home下载seo蜘蛛图片包后,双击打开图片包,将左边的Screaming Frog SEO Spider拉到右边的应用程序中,如图:

打开SEO Spider,在顶部菜单栏打开license,然后点击enter license,如图:

弹出seo spider mac版注册界面,放在一边,返回镜像包打开Screaming Frog SEO Spider注册码,如图:
将注册码复制粘贴到SEO Spider注册界面,提示注册seo spider的时间,然后点击OK,如图:
提示输入有效的许可证密钥。请重启让你的修改生效,重启seo spider mac,seo spider注册成功!!
激活码激活
有几个最新版本可以通过激活来激活。它更容易使用。只需打开激活界面,在激活界面输入脚本屋编辑器提供的激活码即可激活!
NGEN团队
224BD64851-1665820255-3EAD2EBE41
速度生肖
E1E8351AE4-1665820910-12172D4E34
注意:使用防火墙阻止传出连接(通过防火墙阻止传出连接)

变更日志
我们刚刚发布了 SEO Spider 版本 16.4 的小更新。此版本包括一个安全补丁,以及错误修复和小改进
更新到 Apache log4j 2.15.0 以修复 CVE-2021-44228 漏洞。
在“文件”>“计划”下添加了计划历史功能。
添加了对计划任务的验证以列出视图以捕获设置爬网后删除配置文件等问题。
允许双击编辑计划的爬网。
限制 Google 表格导出以防止导出失败。
重命名自定义搜索/提取不再清除过滤器。
更新未能找到 GA 帐户详细信息以列出帐户名称和 ID。
将抓取时间戳添加到 URL 详细信息选项卡。
修复崩溃更改 Crawling > 在自定义搜索中。
修复发送 POST/HEAD 请求的页面的 JavaScript 抓取错误。
修复 JavaScript 抓取期间的内存泄漏。
使用损坏的选项卡配置文件修复启动时崩溃。
如果未连接 API,则修复计划的提取挂起。
修复了 Google 表格限制导致后续导出随机失败的命令行抓取问题。
修复了导出可索引性时未找到 HTTP 规范的错误。
修复启动时提取 Chrome 时崩溃的问题。
修复已经有规则的用户代理的 robots.txt 解析错误。
修复了围绕站点地图 hreflang 和抓取顺序的 hreflang 过滤器中的错误。
修复删除站点地图时进行 hreflang 验证时崩溃的问题。
修复为 URL 存储的重复 cookie。
修复基于表单的身份验证的各种问题。
修复 GSC 中的崩溃。
修复在概览表中选择项目的崩溃。
网站内容抓取工具(蝉大师网站内容抓取工具-猪八戒网微申hypage4)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-29 14:00
网站内容抓取工具1。腾讯开放平台移动客户端发放奖励(现在不能去扫码获取了,如果获取我帮你去微信搜一下就行,代码以后我会提供)2。蝉大师网站内容抓取工具:建站宝盒_w3cschool基于w3ccontentandthemes标准开发的在线建站产品3。微申网站内容抓取工具-微申hypage4。猪八戒建站平台内容抓取工具:猪八戒网中国领先的服务交易平台-八戒网-专业的网络营销平台网站数据来源1。
百度:whois数据、国家权威数据、知识产权信息、ip地址数据、域名列表-youdao。com2。360:。网站蜘蛛捕捉(抓取网站页面内容后台工具)搜狗搜索site:site:/百度收录、推荐位、分词。
首先想问:微信公众号里面搜索就可以看到网站,那公众号开通自定义菜单时在选项部分有个网站吗?然后问:网站链接本身是wordpress或开源的织梦服务器,
官方人员都是说,现在没有自定义菜单可以抓取自定义页面信息的。但我个人感觉,应该还是没问题的。很多二三线城市,主流应该还是以图文为主了,涉及网站内容抓取的,还比较少见。毕竟我们接触的二三线城市,关注互联网不像在一线城市一样地普及。我个人是这么看待这个问题的:网站内容抓取主要是技术问题,后端的内容大部分还是会被采集到各大互联网平台上,并且在这些平台上做下一些广告,怎么处理比较好,还有网站用户群定位怎么定位,怎么能被爬虫抓到,这些都是需要考虑的问题。 查看全部
网站内容抓取工具(蝉大师网站内容抓取工具-猪八戒网微申hypage4)
网站内容抓取工具1。腾讯开放平台移动客户端发放奖励(现在不能去扫码获取了,如果获取我帮你去微信搜一下就行,代码以后我会提供)2。蝉大师网站内容抓取工具:建站宝盒_w3cschool基于w3ccontentandthemes标准开发的在线建站产品3。微申网站内容抓取工具-微申hypage4。猪八戒建站平台内容抓取工具:猪八戒网中国领先的服务交易平台-八戒网-专业的网络营销平台网站数据来源1。
百度:whois数据、国家权威数据、知识产权信息、ip地址数据、域名列表-youdao。com2。360:。网站蜘蛛捕捉(抓取网站页面内容后台工具)搜狗搜索site:site:/百度收录、推荐位、分词。
首先想问:微信公众号里面搜索就可以看到网站,那公众号开通自定义菜单时在选项部分有个网站吗?然后问:网站链接本身是wordpress或开源的织梦服务器,
官方人员都是说,现在没有自定义菜单可以抓取自定义页面信息的。但我个人感觉,应该还是没问题的。很多二三线城市,主流应该还是以图文为主了,涉及网站内容抓取的,还比较少见。毕竟我们接触的二三线城市,关注互联网不像在一线城市一样地普及。我个人是这么看待这个问题的:网站内容抓取主要是技术问题,后端的内容大部分还是会被采集到各大互联网平台上,并且在这些平台上做下一些广告,怎么处理比较好,还有网站用户群定位怎么定位,怎么能被爬虫抓到,这些都是需要考虑的问题。
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-13 03:16
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索将根据网站的内容质量、内容更新频率和网站规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当蜘蛛无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。 查看全部
网站内容抓取工具(Q3:百度搜索会调整对网站的抓取频次吗?)
Q3:百度搜索会调整网站的抓取频率吗?
A3:是的。百度搜索将根据网站的内容质量、内容更新频率和网站规模变化进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会降低网站的质量。网站的爬取频率。
但是,爬取频率不一定与收录的数量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
Q4:为什么百度pc端的蜘蛛会爬移动端的页面?
A4:百度搜索会尽量使用移动端UA爬取移动端页面,但是当蜘蛛无法准确判断是PC端还是移动端页面时,会使用PC端UA爬取。无论哪种方式,只要网站页面可以正常爬取,都不会影响网站内容的收录。
二、网站数据制作
Q5:网站上线前应该发布多少条内容?是越多越好,还是少量制作优质内容更好?
A5:百度搜索提倡开发者制作能够满足用户需求的优质内容,注重内容的质量而不是数量。如果内容是优质的,即使网站的内容不多,依然会受到百度搜索的青睐。
Q6:已经收录的页面内容还能修改吗?会不会影响百度搜索对页面的评价?
A6:如果内容需要修改,且修改后的内容质量还不错,不影响百度搜索对该页面的评价。
三、关于网站死链接处理
Q7:发布的文章内容质量不高。如果我想修改,是否需要将原创内容设置为死链接,然后重新发布一个文章?
A7:如果修改后的内容与原内容高度相关,可以直接在原内容的基础上进行修改,无需提交死链接;如果修改后的内容与原内容的相关性较低,建议将原内容设置为死链接。通过资源提交工具提交新制作的内容。
Q8:网站中有很多死链接。通过死链接工具提交死链接后,百度搜索对网站的评价会降低吗?
A8:不会。如果网站中有大量死链接,但没有提交死链接,会影响百度搜索对网站的评价。
Q9:网站被黑后,产生了大量随机链接。阻止机器人时链接是否区分大小写?
A9:需要区分大小写。建议网站将随机链接设置为被黑后的死链接,通过死链接工具提交,同步设置Robots区块。
网站内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-11 05:13
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以被搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的电子邮件或 URL,并将所有链接保存在用户的 HD 上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的全部内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹、文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上供用户使用。
它允许用户指定一个网页列表作为导航的起点,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后它通过搜索引擎搜索与关键字相关的网页,并开始对页面进行交叉导航,采集 URL。它可以在网页提取模式下导航数小时而无需用户交互,在无人看管的情况下提取在所有网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取中的所有结果和链接页面。
特征
本站统一解压密码:
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
URL Extractor 内容提取
WK网客下载永久钻石
支付宝扫描
微信扫一扫>奖励领取海报链接 查看全部
网站内容抓取工具(URLExtractor内容提取WK下载永久钻石支付宝下载(组图))
URL Extractor 是一个 Cocoa 应用程序,用于从文件中提取电子邮件地址和 URL,这些文件也可以被搜索引擎找到。它可以从单个网页开始,浏览里面的所有链接,找到要提取的电子邮件或 URL,并将所有链接保存在用户的 HD 上。它还可以从任何嵌套级别的单个文件或 HD 上文件夹的全部内容中提取。完成后,它可以将 URL Extractor 文档保存到磁盘,其中收录特定文件夹、文件或网页的所有设置,可以重复使用。或者,提取的数据可以作为文本文件保存在磁盘上供用户使用。
它允许用户指定一个网页列表作为导航的起点,并使用交叉导航转到其他网页。您还可以指定一系列关键字;然后它通过搜索引擎搜索与关键字相关的网页,并开始对页面进行交叉导航,采集 URL。它可以在网页提取模式下导航数小时而无需用户交互,在无人看管的情况下提取在所有网页中找到的所有 URL;或从使用关键字的单个搜索引擎开始,在无限制的导航和 URL 中查看提取中的所有结果和链接页面。
特征
https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />https://www.wkhub.com/wp-conte ... 8.png 300w, https://www.wkhub.com/wp-conte ... 0.png 768w" />本站统一解压密码:
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。
URL Extractor 内容提取
WK网客下载永久钻石
WX20211214-222443@2x.png" />支付宝扫描
WX20211214-222554@2x.png" />微信扫一扫>奖励领取海报链接
网站内容抓取工具(URLExtractor支持网址抓取及链接提取,使用方便的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-07 11:13
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 抓取和链接提取。它易于使用,可以帮助用户浏览所有文件夹和抓取网页链接。如有必要,可以下载它们。
特征
网址抓取器
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取 Web 链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以帮助您。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您可以启动应用程序并几乎立即开始搜索链接。您只需要提供一个目录,其余的由程序处理。
该软件扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,允许您将列表导出到文件中。所有选项一目了然,简单明了,都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,可帮助您过滤文件和 URL。
软件功能
1、支持提取email地址、web地址、ftp地址、feeds、telnet、本地文件url等。
2、拥有一个新的现代引擎,采用最新的可可和objective-c 2.0 技术。它从不冻结,甚至通过搜索引擎采集具有数百个关键字的数千个 URL。
3、可以导入和导出“URLs”和“Keywords”以便在他们的表格中导航和提取。使用一个很好的改进的导入引擎,它可以自动识别导入的格式,并在选择导入什么时提供很大的灵活性。
4、从磁盘(文件和文件夹)中无限数量的来源中提取 URL 和电子邮件,浏览任何指定文件夹和子文件夹的所有内容。在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、从您指定的 网站 列表中提取来自网络的 URL 和电子邮件。它开始提取您需要的 URL,并在无休止的导航过程中继续浏览在线找到的附加链接后根据需要采集 URL 或电子邮件。
6、从关键字列表中提取来自网络的 URL 和电子邮件。
它使用您指定的搜索引擎上可用的关键字列表,然后开始查找相关的 网站,然后开始使用相关的 网站 导航,同时跟踪找到的链接并采集所有 URL 或电子邮件。提供多个关键字,它可以提取数小时的相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr. au .uk .de 和 .es .ar .au .at .be .br .ca .fi. nl.se.ch)。使用您指定的搜索引擎在网络上进行无限搜索。
8、支持从 safari 和其他 Web 浏览器中接受拖放 URL,以将它们用作从 Web 中提取的种子。
9、支持使用多个选项:“单域提取”仅从指定的网站中提取,而不跳转到链接的网站或“深度导航”指定从哪个级别提取site 跳转到链接的站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件提取。如果它在网上找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。
扩张 查看全部
网站内容抓取工具(URLExtractor支持网址抓取及链接提取,使用方便的功能介绍)
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 抓取和链接提取。它易于使用,可以帮助用户浏览所有文件夹和抓取网页链接。如有必要,可以下载它们。
特征
网址抓取器
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取 Web 链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以帮助您。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您可以启动应用程序并几乎立即开始搜索链接。您只需要提供一个目录,其余的由程序处理。
该软件扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,允许您将列表导出到文件中。所有选项一目了然,简单明了,都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,可帮助您过滤文件和 URL。
软件功能
1、支持提取email地址、web地址、ftp地址、feeds、telnet、本地文件url等。
2、拥有一个新的现代引擎,采用最新的可可和objective-c 2.0 技术。它从不冻结,甚至通过搜索引擎采集具有数百个关键字的数千个 URL。
3、可以导入和导出“URLs”和“Keywords”以便在他们的表格中导航和提取。使用一个很好的改进的导入引擎,它可以自动识别导入的格式,并在选择导入什么时提供很大的灵活性。
4、从磁盘(文件和文件夹)中无限数量的来源中提取 URL 和电子邮件,浏览任何指定文件夹和子文件夹的所有内容。在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、从您指定的 网站 列表中提取来自网络的 URL 和电子邮件。它开始提取您需要的 URL,并在无休止的导航过程中继续浏览在线找到的附加链接后根据需要采集 URL 或电子邮件。
6、从关键字列表中提取来自网络的 URL 和电子邮件。
它使用您指定的搜索引擎上可用的关键字列表,然后开始查找相关的 网站,然后开始使用相关的 网站 导航,同时跟踪找到的链接并采集所有 URL 或电子邮件。提供多个关键字,它可以提取数小时的相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr. au .uk .de 和 .es .ar .au .at .be .br .ca .fi. nl.se.ch)。使用您指定的搜索引擎在网络上进行无限搜索。
8、支持从 safari 和其他 Web 浏览器中接受拖放 URL,以将它们用作从 Web 中提取的种子。
9、支持使用多个选项:“单域提取”仅从指定的网站中提取,而不跳转到链接的网站或“深度导航”指定从哪个级别提取site 跳转到链接的站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件提取。如果它在网上找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。
扩张
网站内容抓取工具(几近一个中心问题的演讲内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-07 11:13
许多关于网站结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题:搜索引擎能多容易地爬取你的网站?我们已经在最近的几次活动中讨论了这个主题,您将在下面找到我们关于这个主题的介绍和要点总结。
网络世界是巨大的;新内容一直在创造。Google 自身资源有限,面对几乎无穷无尽的内容网络,Googlebot 只能找到并抓取一定比例的内容。然后,我们已经爬取的内容,我们只能索引其中的一部分。
URL 就像 网站 和搜索引擎爬虫之间的桥梁:为了能够爬取您的 网站 内容,爬虫需要能够找到并架起这些桥梁(即查找并爬取您的 URL)。如果您的网址复杂或冗长,爬虫必须花时间反复跟踪它们;如果您的 URL 整洁并直接指向您的独特内容,则爬虫可以专注于理解您的内容,而不是爬取空白页面或被不同的 URL 引用,最终爬取相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些是现实世界中存在的 URL 示例(尽管出于隐私原因,它们的名称已被替换),包括被黑的 URL 和编码、伪装成的冗余参数部分 URL 路径、无限爬取空间等。您还可以找到一些提示来帮助您导航这些网络 网站 构建迷宫并帮助爬虫更快更好地找到您的内容,包括:
从 URL 中删除与用户相关的参数。URL 中那些不会影响网页内容的参数,例如会话 ID 或排序参数,可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到干净的 URL,您可以保留原创内容并减少指向相同内容的 URL 的数量。
控制无限空间。你的 网站 上是否有一个日历,上面有无数过去和未来日期的链接(每个链接都是唯一的 二)?你的网址是不是在 3563 的参数后添加了 &page= ,仍然可以返回 200代码,即使根本没有那么多页面?这样的话,你的网站上出现了所谓的无限空间,这会浪费爬虫机器人和你的网站带宽。要控制无限空间,请参阅此处的一些提示。
阻止 Google 抓取工具抓取他们无法处理的网页。通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系方式、购物车和其他抓取工具无法处理的页面被抓取。(Crawler 以刻薄和害羞着称,因此通常他们不会将商品添加到购物车或联系我们)。这样,您可以让爬虫花更多时间使用它们可以处理的内容来爬取您的 网站。
一人一票。一个 URL,一段内容。在理想情况下,URL 和内容之间应该是一一对应的:每个 URL 对应一个唯一的内容,而每个内容只能通过唯一的 URL 访问。你越接近这个理想,你的网站就会越容易抓住和收录。如果你的内容管理系统或周口网站builder当前的网站build难以实现,你可以尝试使用rel=canonical元素来设置你想用来表示某个特定内容的URL .
原文:优化您的抓取和索引 查看全部
网站内容抓取工具(几近一个中心问题的演讲内容)
许多关于网站结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题:搜索引擎能多容易地爬取你的网站?我们已经在最近的几次活动中讨论了这个主题,您将在下面找到我们关于这个主题的介绍和要点总结。
网络世界是巨大的;新内容一直在创造。Google 自身资源有限,面对几乎无穷无尽的内容网络,Googlebot 只能找到并抓取一定比例的内容。然后,我们已经爬取的内容,我们只能索引其中的一部分。
URL 就像 网站 和搜索引擎爬虫之间的桥梁:为了能够爬取您的 网站 内容,爬虫需要能够找到并架起这些桥梁(即查找并爬取您的 URL)。如果您的网址复杂或冗长,爬虫必须花时间反复跟踪它们;如果您的 URL 整洁并直接指向您的独特内容,则爬虫可以专注于理解您的内容,而不是爬取空白页面或被不同的 URL 引用,最终爬取相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些是现实世界中存在的 URL 示例(尽管出于隐私原因,它们的名称已被替换),包括被黑的 URL 和编码、伪装成的冗余参数部分 URL 路径、无限爬取空间等。您还可以找到一些提示来帮助您导航这些网络 网站 构建迷宫并帮助爬虫更快更好地找到您的内容,包括:
从 URL 中删除与用户相关的参数。URL 中那些不会影响网页内容的参数,例如会话 ID 或排序参数,可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到干净的 URL,您可以保留原创内容并减少指向相同内容的 URL 的数量。
控制无限空间。你的 网站 上是否有一个日历,上面有无数过去和未来日期的链接(每个链接都是唯一的 二)?你的网址是不是在 3563 的参数后添加了 &page= ,仍然可以返回 200代码,即使根本没有那么多页面?这样的话,你的网站上出现了所谓的无限空间,这会浪费爬虫机器人和你的网站带宽。要控制无限空间,请参阅此处的一些提示。
阻止 Google 抓取工具抓取他们无法处理的网页。通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系方式、购物车和其他抓取工具无法处理的页面被抓取。(Crawler 以刻薄和害羞着称,因此通常他们不会将商品添加到购物车或联系我们)。这样,您可以让爬虫花更多时间使用它们可以处理的内容来爬取您的 网站。
一人一票。一个 URL,一段内容。在理想情况下,URL 和内容之间应该是一一对应的:每个 URL 对应一个唯一的内容,而每个内容只能通过唯一的 URL 访问。你越接近这个理想,你的网站就会越容易抓住和收录。如果你的内容管理系统或周口网站builder当前的网站build难以实现,你可以尝试使用rel=canonical元素来设置你想用来表示某个特定内容的URL .
原文:优化您的抓取和索引
网站内容抓取工具(善肯网页TXT采集器软件免费下载介绍说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-04 13:14
本站提供山垦网页绿色免费版【小说抓取下载工具】TXT采集器软件免费下载。
【软件截图】
【基本介绍】
山垦网页TXT采集器采用全新正则表达式小说抓取下载必备工具,支持以txt文件程序下载小说整章,并可实时预览内容,确保下载资源没有损坏和乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。
功能模块介绍
1、规则放置设置:
①在规则设置窗口中,在网站中随便找一篇文章,不要写任何规则,先用鼠标点击实时预览,看看能不能得到网页的源代码,然后如果可以的话,写下规则。如果你不能得到它,没有必要继续。
②规则设置使用正则表达式匹配内容。最好有一定的基础。如果没有基础,可以参考给出的例子。没有复杂的学习,就没有必要深入学习规律的规则。
③设置规则时,目录页和内容页需要分别预览,需要两个链接,一个目录页链接,一个内容页链接。
④换货方面,有普通换货和定制换货之分。这里,目前不需要正则化,普通替换即可。需要提醒的是,必须输入值,即使是空格。删除:选择整行,然后按住删除键。内置的 \n 在用作替换数据消息时表示换行符。
⑤编码(将信息从一种形式或格式转换为另一种的过程),目前只设置了GBK和UFT-8,几乎大部分网站都是这两种编码之一。
2、分析下载
① 解析请按解析地址的按钮2。按钮1是任性的,暂时不想删除,其他功能以后再开发。
②支持单章下载和全文下载。
③支持增加章节数【部分小说没有章节数时可以勾选】
④支持在线查看,但需要联网。这个功能只是辅助(可以通过模拟人工手动操作实现自动杀怪、自动挂机等),不是专业的小说阅读软件。
⑤下载进度和总所需时间显示,内置多线程。
3、关于软件
①其实只要.exe就够了,规则都是我自己加的,commonrule.xml里面有通用的替换规则。网站规则在规则文件夹中。我这里放了两条 网站 规则,主要是为了测试。其他网站规则可以自行添加,也可以支持开发者。
②软件非打包,c#开发,无病毒。别担心,请不要使用它,我不承担责任。
③关于软件,有跳转到论坛。我测试跳转的时候是360提示的,也可能是因为跳转的是360浏览器。不知道你会不会有这个问题。
④如果xml中的内容不清晰,请勿触摸,以免软件无法识别并报错。
山垦网页【小说截取下载工具】TXT采集器特别说明:
山垦网页TXT采集器采用新的正则表达式小说截取下载工具,支持将小说整章下载为txt文件,并可实时预览内容,确保下载的资源不被损坏或乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。 查看全部
网站内容抓取工具(善肯网页TXT采集器软件免费下载介绍说明(图))
本站提供山垦网页绿色免费版【小说抓取下载工具】TXT采集器软件免费下载。
【软件截图】
【基本介绍】
山垦网页TXT采集器采用全新正则表达式小说抓取下载必备工具,支持以txt文件程序下载小说整章,并可实时预览内容,确保下载资源没有损坏和乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。
功能模块介绍
1、规则放置设置:
①在规则设置窗口中,在网站中随便找一篇文章,不要写任何规则,先用鼠标点击实时预览,看看能不能得到网页的源代码,然后如果可以的话,写下规则。如果你不能得到它,没有必要继续。
②规则设置使用正则表达式匹配内容。最好有一定的基础。如果没有基础,可以参考给出的例子。没有复杂的学习,就没有必要深入学习规律的规则。
③设置规则时,目录页和内容页需要分别预览,需要两个链接,一个目录页链接,一个内容页链接。
④换货方面,有普通换货和定制换货之分。这里,目前不需要正则化,普通替换即可。需要提醒的是,必须输入值,即使是空格。删除:选择整行,然后按住删除键。内置的 \n 在用作替换数据消息时表示换行符。
⑤编码(将信息从一种形式或格式转换为另一种的过程),目前只设置了GBK和UFT-8,几乎大部分网站都是这两种编码之一。
2、分析下载
① 解析请按解析地址的按钮2。按钮1是任性的,暂时不想删除,其他功能以后再开发。
②支持单章下载和全文下载。
③支持增加章节数【部分小说没有章节数时可以勾选】
④支持在线查看,但需要联网。这个功能只是辅助(可以通过模拟人工手动操作实现自动杀怪、自动挂机等),不是专业的小说阅读软件。
⑤下载进度和总所需时间显示,内置多线程。
3、关于软件
①其实只要.exe就够了,规则都是我自己加的,commonrule.xml里面有通用的替换规则。网站规则在规则文件夹中。我这里放了两条 网站 规则,主要是为了测试。其他网站规则可以自行添加,也可以支持开发者。
②软件非打包,c#开发,无病毒。别担心,请不要使用它,我不承担责任。
③关于软件,有跳转到论坛。我测试跳转的时候是360提示的,也可能是因为跳转的是360浏览器。不知道你会不会有这个问题。
④如果xml中的内容不清晰,请勿触摸,以免软件无法识别并报错。
山垦网页【小说截取下载工具】TXT采集器特别说明:
山垦网页TXT采集器采用新的正则表达式小说截取下载工具,支持将小说整章下载为txt文件,并可实时预览内容,确保下载的资源不被损坏或乱码。但是,这个工具只支持下载小说网站和原创作者的免费章节。
网站内容抓取工具(Android下一代几个的几个收集和分析框架,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-02 00:06
)
介绍
Perfetto工具是Android下一代统一的trace采集和分析框架,可以捕获平台和app的trace信息。用来替换systrace,但是systrace由于历史原因仍然会存在,Perfetto捕获的trace文件也可以转换成systrace视图。如果您习惯使用 systrace,您可以使用 Perfetto UI 的“Open with legacy UI”将其转换为 systrace 视图。Perfetto的主要特点如下:
跟踪采集过程
在说具体的采集流程之前,可以先看一下它的整体框架图和流程结构。有几个重要的过程需要说明:
Perfetto整体框架图
Perfetto的另一种观点
我还没有研究过它的源码,所以无法一一匹配上面的两个视图。这是另一个视图,只是为了让您更多地了解这个工具。上面提到除了标准的tracepoints之外,Perfetto还可以提供很好的可扩展性。这里我们先来看看标准的tracepoints,如下图所示。对比之前的systrace,我们发现Perfetto还是可以提供一些其他的功能。例如,它可以直接抓取事件日志,以及虚拟内存事件等。
标准跟踪点
在 Pixel 和 Pixel2 机型上,traced 和 traced_probes 这两个进程默认启用,但在其他机型上,您可能需要执行以下命令来启动这两个进程。开启这两个进程后,就可以正常抓包了。获取trace信息的方式也很方便,只要设置一个属性即可。
adb shell setprop persist.traced.enable 1
执行上述命令后,如果看到类似如下的日志,则说明启动成功。也可以直接ps看有没有这两个进程。
$ adb logcat -s perfetto
perfetto: service.cc:45 Started traced, listening on /dev/socket/traced_producer /dev/socket/traced_consumer
perfetto: probes.cc:25 Starting /system/bin/traced_probes service
perfetto: probes_producer.cc:32 Connected to the service
启用守护进程后,您可以执行 perfetto 命令行工具。这个命令行工具的用法和具体参数的含义就不一一介绍了。只需阅读评论。
1902:/ # perfetto
perfetto_cmd.cc:89
Usage: perfetto
--background -b : Exits immediately and continues tracing in background
--config -c : /path/to/trace/config/file or - for stdin
--out -o : /path/to/out/trace/file
--dropbox -d TAG : Upload trace into DropBox using tag TAG (default: perfetto)
--no-guardrails -n : Ignore guardrails triggered when using --dropbox (for testing).
--help -h
statsd-specific flags:
--alert-id : ID of the alert that triggered this trace.
--config-id : ID of the triggering config.
--config-uid : UID of app which registered the config.
其中--out用于指定trace输出文件,--config用于指定配置,即多长时间捕获,多长时间将内存数据写回文件,捕获哪些tracepoint等。 ,这个配置文件的内容,我们可以手动写,也可以用Perfetto UI网站生成。此外,默认情况下,Perfetto 中集成了一个测试配置。您可以使用以下命令来获取使用测试配置的跟踪文件。
$ adb shell perfetto --config :test --out /data/misc/perfetto-traces/trace //使用内置的test配置,然后输出到/data/misc/perfetto-traces/trace
抓取后,拉取/data/misc/perfetto-traces/trace文件的内容,用Perfetto UI网站打开,如下图:
界面模式
自定义配置
目前最方便的生成配置文件的方式是使用ui.perfetto.devPerfetto UI来帮助生成。点击Perfetto UI的“Record new trace”后,会看到很多配置界面,如下图所示:
RecordingMode配置界面
CPU配置页面
Android 应用和服务配置页面
选择好你想要的tracepoints后,点击开始录制,会生成如下命令内容。复制命令内容,直接在终端执行。完成后,将文件 /data/misc/perfetto-traces/trace 复制出来,使用上面的 ui.perfetto.dev 分析就可以了。
<p>adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \ 查看全部
网站内容抓取工具(Android下一代几个的几个收集和分析框架,你知道吗?
)
介绍
Perfetto工具是Android下一代统一的trace采集和分析框架,可以捕获平台和app的trace信息。用来替换systrace,但是systrace由于历史原因仍然会存在,Perfetto捕获的trace文件也可以转换成systrace视图。如果您习惯使用 systrace,您可以使用 Perfetto UI 的“Open with legacy UI”将其转换为 systrace 视图。Perfetto的主要特点如下:
跟踪采集过程
在说具体的采集流程之前,可以先看一下它的整体框架图和流程结构。有几个重要的过程需要说明:
Perfetto整体框架图
Perfetto的另一种观点
我还没有研究过它的源码,所以无法一一匹配上面的两个视图。这是另一个视图,只是为了让您更多地了解这个工具。上面提到除了标准的tracepoints之外,Perfetto还可以提供很好的可扩展性。这里我们先来看看标准的tracepoints,如下图所示。对比之前的systrace,我们发现Perfetto还是可以提供一些其他的功能。例如,它可以直接抓取事件日志,以及虚拟内存事件等。
标准跟踪点
在 Pixel 和 Pixel2 机型上,traced 和 traced_probes 这两个进程默认启用,但在其他机型上,您可能需要执行以下命令来启动这两个进程。开启这两个进程后,就可以正常抓包了。获取trace信息的方式也很方便,只要设置一个属性即可。
adb shell setprop persist.traced.enable 1
执行上述命令后,如果看到类似如下的日志,则说明启动成功。也可以直接ps看有没有这两个进程。
$ adb logcat -s perfetto
perfetto: service.cc:45 Started traced, listening on /dev/socket/traced_producer /dev/socket/traced_consumer
perfetto: probes.cc:25 Starting /system/bin/traced_probes service
perfetto: probes_producer.cc:32 Connected to the service
启用守护进程后,您可以执行 perfetto 命令行工具。这个命令行工具的用法和具体参数的含义就不一一介绍了。只需阅读评论。
1902:/ # perfetto
perfetto_cmd.cc:89
Usage: perfetto
--background -b : Exits immediately and continues tracing in background
--config -c : /path/to/trace/config/file or - for stdin
--out -o : /path/to/out/trace/file
--dropbox -d TAG : Upload trace into DropBox using tag TAG (default: perfetto)
--no-guardrails -n : Ignore guardrails triggered when using --dropbox (for testing).
--help -h
statsd-specific flags:
--alert-id : ID of the alert that triggered this trace.
--config-id : ID of the triggering config.
--config-uid : UID of app which registered the config.
其中--out用于指定trace输出文件,--config用于指定配置,即多长时间捕获,多长时间将内存数据写回文件,捕获哪些tracepoint等。 ,这个配置文件的内容,我们可以手动写,也可以用Perfetto UI网站生成。此外,默认情况下,Perfetto 中集成了一个测试配置。您可以使用以下命令来获取使用测试配置的跟踪文件。
$ adb shell perfetto --config :test --out /data/misc/perfetto-traces/trace //使用内置的test配置,然后输出到/data/misc/perfetto-traces/trace
抓取后,拉取/data/misc/perfetto-traces/trace文件的内容,用Perfetto UI网站打开,如下图:
界面模式
自定义配置
目前最方便的生成配置文件的方式是使用ui.perfetto.devPerfetto UI来帮助生成。点击Perfetto UI的“Record new trace”后,会看到很多配置界面,如下图所示:
RecordingMode配置界面
CPU配置页面
Android 应用和服务配置页面
选择好你想要的tracepoints后,点击开始录制,会生成如下命令内容。复制命令内容,直接在终端执行。完成后,将文件 /data/misc/perfetto-traces/trace 复制出来,使用上面的 ui.perfetto.dev 分析就可以了。
<p>adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-01 22:09
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。
网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。 查看全部
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。
网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-28 11:14
TeleportUltra
Teleport Ultra 能做的不仅仅是离线浏览网页(让你快速离线浏览网页内容当然是它的一个重要特点),它可以从互联网上的任何地方检索你想要的任何文件,它可以在你指定的时间自动登录你指定的网站来下载你指定的内容,你也可以用它来创建某个网站的完整镜像,就像创建你自己的< @网站 参考。
网络邮编
WebZip 将一个网站 下载并压缩成一个ZIP 文件,它可以帮助您将一个站点的全部或部分数据压缩成ZIP 格式,让您以后可以快速浏览这个网站。并且新版本的功能包括可以安排时间下载,还增强了漂亮的三维界面和传输的图形。
米霍夫图片下载器
Mihov 图片下载器是一个从网页下载所有图片的简单工具。只需输入网络地址,其余的由软件完成。所有图片都将下载到您计算机硬盘上的文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个易于使用的离线浏览器实用程序。该软件允许您将 网站 从 Internet 传输到本地目录,从服务器递归创建所有结构,获取 html、图像和其他文件到您的计算机上。重新创建了相关链接,因此您可以自由浏览本地 网站(适用于任何浏览器)。可以将多个网站镜像在一起,这样就可以从一个网站跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。该装置是完全可配置的,具有许多选项和功能。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一个网站内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。 查看全部
网站内容抓取工具(让你离线快速浏览某个网页的内容Ultra所能)
TeleportUltra
Teleport Ultra 能做的不仅仅是离线浏览网页(让你快速离线浏览网页内容当然是它的一个重要特点),它可以从互联网上的任何地方检索你想要的任何文件,它可以在你指定的时间自动登录你指定的网站来下载你指定的内容,你也可以用它来创建某个网站的完整镜像,就像创建你自己的< @网站 参考。
网络邮编
WebZip 将一个网站 下载并压缩成一个ZIP 文件,它可以帮助您将一个站点的全部或部分数据压缩成ZIP 格式,让您以后可以快速浏览这个网站。并且新版本的功能包括可以安排时间下载,还增强了漂亮的三维界面和传输的图形。
米霍夫图片下载器
Mihov 图片下载器是一个从网页下载所有图片的简单工具。只需输入网络地址,其余的由软件完成。所有图片都将下载到您计算机硬盘上的文件夹中。
WinHTTrack HTTrack
WinHTTrack HTTrack 是一个易于使用的离线浏览器实用程序。该软件允许您将 网站 从 Internet 传输到本地目录,从服务器递归创建所有结构,获取 html、图像和其他文件到您的计算机上。重新创建了相关链接,因此您可以自由浏览本地 网站(适用于任何浏览器)。可以将多个网站镜像在一起,这样就可以从一个网站跳转到另一个网站。您还可以更新现有的镜像站点,或继续中断的传输。该装置是完全可配置的,具有许多选项和功能。该软件的资源是开放的。
MaxprogWebDumper
MaxprogWebDumper 是一个网站内容下载工具,可以自动下载网页的所有内容及其链接,包括内置的多媒体内容,供您离线浏览。
网站内容抓取工具(技术高一点会用百度自动分析网站的serp获取有点慢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-24 18:00
网站内容抓取工具360浏览器在用,里面有个360浏览器的插件,可以从其他网站抓取网页内容,挺好用的。不过有的页面是没法抓取的,我就用这个版本找过我经常看的那个页面的问题。百度也在用,但是百度的inurl获取有点慢。
qaq你可以试试逆行,据说可以,我自己也有用,不过要加上域名后缀,
这两个我用过,做站就是为了更好的排名,用技术抓数据吧,
具体的还是问度娘吧,我不太清楚。
技术高一点会用百度自动分析网站的代码,可以进行静态页抓取和动态页抓取。普通站暂时没有这么高效率的抓取方法。除非是做特殊的目的。
不一定要用动态网站吧,内容可以是静态的也可以是动态的,还有可以,植入seo插件,
用serp方案也是可以抓取到的。awebsites就可以。可以先买会员在线升级serp方案。awebsites的serp详情页是在avator中抓取成功,具体抓取方法详情移步我们的博客“自动整站抓取serp工具”。
当我被抓取且达到了目的,我会用ssl+https+tls+各种奇淫技巧为站长装逼。
说实话,我也在找。你说的这种是远程做站比较常见的。或者还有不怕被禁言的把qa做成aliertom的模式的。或者干脆p2p获取的,或者干脆伪静态图片的。这些都不是我一直在用的。主要的是做站,核心的就是你的站点受众群体。然后是你的站点关键词(关键词就是你的这个行业最最广泛最最精准的用户聚集点)所在的垂直领域的信息。
最后是你的内容。这些都是你站点需要发挥的作用!如果你是新站,或者太冷门的,用动态获取的都是扯淡。如果你是本地站站长,或者你的用户一直在本地,那你可以尝试。动态那都是前期用。过度获取。 查看全部
网站内容抓取工具(技术高一点会用百度自动分析网站的serp获取有点慢)
网站内容抓取工具360浏览器在用,里面有个360浏览器的插件,可以从其他网站抓取网页内容,挺好用的。不过有的页面是没法抓取的,我就用这个版本找过我经常看的那个页面的问题。百度也在用,但是百度的inurl获取有点慢。
qaq你可以试试逆行,据说可以,我自己也有用,不过要加上域名后缀,
这两个我用过,做站就是为了更好的排名,用技术抓数据吧,
具体的还是问度娘吧,我不太清楚。
技术高一点会用百度自动分析网站的代码,可以进行静态页抓取和动态页抓取。普通站暂时没有这么高效率的抓取方法。除非是做特殊的目的。
不一定要用动态网站吧,内容可以是静态的也可以是动态的,还有可以,植入seo插件,
用serp方案也是可以抓取到的。awebsites就可以。可以先买会员在线升级serp方案。awebsites的serp详情页是在avator中抓取成功,具体抓取方法详情移步我们的博客“自动整站抓取serp工具”。
当我被抓取且达到了目的,我会用ssl+https+tls+各种奇淫技巧为站长装逼。
说实话,我也在找。你说的这种是远程做站比较常见的。或者还有不怕被禁言的把qa做成aliertom的模式的。或者干脆p2p获取的,或者干脆伪静态图片的。这些都不是我一直在用的。主要的是做站,核心的就是你的站点受众群体。然后是你的站点关键词(关键词就是你的这个行业最最广泛最最精准的用户聚集点)所在的垂直领域的信息。
最后是你的内容。这些都是你站点需要发挥的作用!如果你是新站,或者太冷门的,用动态获取的都是扯淡。如果你是本地站站长,或者你的用户一直在本地,那你可以尝试。动态那都是前期用。过度获取。
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-23 10:03
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可供使用。
1.代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 JavaScript 页面的优势。
1000 个请求是免费的,这足以在复杂的内容页面中探索 Proxy Crawl 的强大功能。
2.抓取
Scrapy 是一个开源项目,支持抓取网页。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。与 ProxyCrawl 完美集成的强大功能。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。借助 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
内置 API 提供了执行网络请求和处理已删除内容的方法。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
4.雪貂
Ferret 对网络抓取来说是相当新的事物,并且在开源社区中获得了相当大的关注。 Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
5.X 射线
借助 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密来自 网站 页面的结构化数据,而无需手动规范化。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 saas 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站s,这将特别有用。 查看全部
网站内容抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网不断涌现出新的信息、新的设计模式和大量的 c。将这些数据组织到一个独特的库中并非易事。但是,有很多优秀的网络抓取工具可供使用。
1.代理爬取
使用代理抓取 API,您可以抓取网络上的任何 网站/ 平台。有代理支持、验证码绕过以及基于动态内容抓取 JavaScript 页面的优势。
1000 个请求是免费的,这足以在复杂的内容页面中探索 Proxy Crawl 的强大功能。
2.抓取
Scrapy 是一个开源项目,支持抓取网页。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。与 ProxyCrawl 完美集成的强大功能。借助 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。也可以使用 Scrapy API 扩展提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。借助 Grab,可以为小型个人项目创建抓取机制,以及构建可同时扩展到数百万页的大型动态抓取任务。
内置 API 提供了执行网络请求和处理已删除内容的方法。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,可以使用自定义类创建异步爬虫。
4.雪貂
Ferret 对网络抓取来说是相当新的事物,并且在开源社区中获得了相当大的关注。 Ferret 的目标是提供更清洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言,避免了构建系统的复杂性。相反,也可以编写严格的规则来从任何站点抓取数据。
5.X 射线
借助 X-Ray、Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。您甚至不必编写太多代码,因为 Diffbot 的 AI 算法可以解密来自 网站 页面的结构化数据,而无需手动规范化。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 saas 替代品。使用 PhantomJS Cloud,可以直接从网页内部获取数据,生成可视文件并在 PDF 文档中呈现页面。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站s,这将特别有用。
网站内容抓取工具(软件特点界面直观干净,配合ExpressThumbnail快捷地制作网络相簿)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-17 11:10
软件功能
界面直观干净,无弹窗广告;
可下载用户预设的图片、音频、视频等格式文件;
自定义下载地址范围;
支持根据预设的网址列表下载;
高级过滤功能,最大程度满足用户需求;
最多可同时下载20个线程;
支持ZIP/RAR格式压缩文件;
简单易用。
特征
还可以实时预览图片、幻灯片、壁纸设置等。配合Express Thumbnail Creator软件,可以快速创建网络相册!推荐使用!
NeoDownloader 可以批量下载任意网站中的任意文件,它主要用于帮助您自动下载和查看您喜欢的图片、照片、壁纸、视频、MP3 音乐等任何文件。
NeoDownloader 带有一个可供下载的大型在线数据库:成千上万的各种壁纸、高品质照片、名人和美女的作品、著名艺术家和摄影师的作品、有趣的图片和动画 GIF。
指示
1、新方案:
2、设置下载图片保存的目录地址,查看copy网站的文件夹结构!
3、启动项目:
简单的教程示例
可以尝试在百度图片上搜索,比如“美女”,然后复制网页地址,在neodownloader新建一个项目,一次就可以下载上万张图片。
只需指定一个链接(URL),然后选择你要的下载页面,下载单个图库,下载多个图库,下载整个网站,即全自动批量下载。
或者只是将链接从浏览器拖放到 NeoDownloader 的浮动篮子,这样您只需点击几下鼠标就可以从一个 网站 下载所有图像!
它的内置图像浏览器和媒体播放器让您可以立即查看您下载的所有文件,甚至可以以幻灯片的形式观看它们。 查看全部
网站内容抓取工具(软件特点界面直观干净,配合ExpressThumbnail快捷地制作网络相簿)
软件功能
界面直观干净,无弹窗广告;
可下载用户预设的图片、音频、视频等格式文件;
自定义下载地址范围;
支持根据预设的网址列表下载;
高级过滤功能,最大程度满足用户需求;
最多可同时下载20个线程;
支持ZIP/RAR格式压缩文件;
简单易用。
特征
还可以实时预览图片、幻灯片、壁纸设置等。配合Express Thumbnail Creator软件,可以快速创建网络相册!推荐使用!
NeoDownloader 可以批量下载任意网站中的任意文件,它主要用于帮助您自动下载和查看您喜欢的图片、照片、壁纸、视频、MP3 音乐等任何文件。
NeoDownloader 带有一个可供下载的大型在线数据库:成千上万的各种壁纸、高品质照片、名人和美女的作品、著名艺术家和摄影师的作品、有趣的图片和动画 GIF。
指示
1、新方案:
2、设置下载图片保存的目录地址,查看copy网站的文件夹结构!
3、启动项目:
简单的教程示例
可以尝试在百度图片上搜索,比如“美女”,然后复制网页地址,在neodownloader新建一个项目,一次就可以下载上万张图片。
只需指定一个链接(URL),然后选择你要的下载页面,下载单个图库,下载多个图库,下载整个网站,即全自动批量下载。
或者只是将链接从浏览器拖放到 NeoDownloader 的浮动篮子,这样您只需点击几下鼠标就可以从一个 网站 下载所有图像!
它的内置图像浏览器和媒体播放器让您可以立即查看您下载的所有文件,甚至可以以幻灯片的形式观看它们。
网站内容抓取工具(Robots.txt蜘蛛的使用方法和使用蜘蛛使用技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-17 05:01
Robots.txt 是存储在站点根目录中的纯文本文件。虽然设置简单,但功能强大。可以指定搜索引擎蜘蛛只抓取指定的内容,也可以禁止搜索引擎蜘蛛抓取网站的部分或全部内容。
指示:
Robots.txt 文件应该放在 网站 根目录中,并且应该可以通过 Internet 访问。
例如:如果您的 网站 地址是 then,则该文件必须能够被打开并查看内容。
格式:
用户代理:
它用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录表明存在多个搜索引擎蜘蛛,它们将受到该协议的限制。对于这个文件,至少有一个 User-agent 记录。如果此项的值设置为 *,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,“User-agent:*”只能有一条记录。
不允许:
它用于描述不想被访问的 URL。此 URL 可以是完整路径或部分 URL。Robot 不会访问任何以 Disallow 开头的 URL。
例子:
示例 1:“Disallow:/help”表示 /help.html 和 /help/index.html 都不允许被搜索引擎蜘蛛抓取。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,则表示网站的所有页面都允许被搜索引擎抓取。“/robots.txt”文件中必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎蜘蛛都开放以供抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例一:禁止所有搜索引擎蜘蛛通过“/robots.txt”爬取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件。设置方法如下:
用户代理: *
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
例2:通过“/robots.txt”只允许某个搜索引擎抓取,而禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛爬取,而不允许其他搜索引擎蜘蛛爬取“/cgi/”目录下的内容。设置方法如下:
用户代理: *
禁止:/cgi/
用户代理:slurp
不允许:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理: *
不允许: /
示例4:只禁止某个搜索引擎爬取我的网站 例如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
不允许: /
更多参考资料(英文) 查看全部
网站内容抓取工具(Robots.txt蜘蛛的使用方法和使用蜘蛛使用技巧)
Robots.txt 是存储在站点根目录中的纯文本文件。虽然设置简单,但功能强大。可以指定搜索引擎蜘蛛只抓取指定的内容,也可以禁止搜索引擎蜘蛛抓取网站的部分或全部内容。
指示:
Robots.txt 文件应该放在 网站 根目录中,并且应该可以通过 Internet 访问。
例如:如果您的 网站 地址是 then,则该文件必须能够被打开并查看内容。
格式:
用户代理:
它用于描述搜索引擎蜘蛛的名称。在“Robots.txt”文件中,如果有多个User-agent记录表明存在多个搜索引擎蜘蛛,它们将受到该协议的限制。对于这个文件,至少有一个 User-agent 记录。如果此项的值设置为 *,则该协议对任何搜索引擎蜘蛛都有效。在“Robots.txt”文件中,“User-agent:*”只能有一条记录。
不允许:
它用于描述不想被访问的 URL。此 URL 可以是完整路径或部分 URL。Robot 不会访问任何以 Disallow 开头的 URL。
例子:
示例 1:“Disallow:/help”表示 /help.html 和 /help/index.html 都不允许被搜索引擎蜘蛛抓取。
示例2:“Disallow:/help/”表示允许搜索引擎蜘蛛抓取/help.html,但不允许抓取/help/index.html。
例3:如果Disallow记录为空,则表示网站的所有页面都允许被搜索引擎抓取。“/robots.txt”文件中必须至少有一条 Disallow 记录。如果“/robots.txt”是一个空文件,则 网站 对所有搜索引擎蜘蛛都开放以供抓取。
#:Robots.txt 协议中的注释字符。
综合示例:
示例一:禁止所有搜索引擎蜘蛛通过“/robots.txt”爬取“/bin/cgi/”目录、“/tmp/”目录和/foo.html文件。设置方法如下:
用户代理: *
禁止:/bin/cgi/
禁止:/tmp/
禁止:/foo.html
例2:通过“/robots.txt”只允许某个搜索引擎抓取,而禁止其他搜索引擎抓取。例如,只允许名为“slurp”的搜索引擎蜘蛛爬取,而不允许其他搜索引擎蜘蛛爬取“/cgi/”目录下的内容。设置方法如下:
用户代理: *
禁止:/cgi/
用户代理:slurp
不允许:
示例3:禁止任何搜索引擎抓取我的网站,设置方法如下:
用户代理: *
不允许: /
示例4:只禁止某个搜索引擎爬取我的网站 例如:只禁止名为“slurp”的搜索引擎蜘蛛爬取,设置方法如下:
用户代理:slurp
不允许: /
更多参考资料(英文)
网站内容抓取工具( 百度网站改版工具如何避免改版带来的收录和流量损失)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-13 18:04
百度网站改版工具如何避免改版带来的收录和流量损失)
网站改版的对策是什么
关于网站改版这件大事,大家都知道网站的损坏是不可避免的,但是如果不及时将损坏降到最低,排名就会下降,快照会被撤回,并且不会有 收录。就连网站被百度降级和处罚也不是危言耸听。而对于网站改版应该采取哪些措施,最大程度避免改版带来的收录和流量损失,根据最新消息,可以分为三个步骤:
第一步:确认新旧内容已经跳转
无论是更改域名、目录,还是修改url模式,都需要保证整体内容跳转完成,有规律可循。
第 2 步:设置 301 跳转
使用301跳转重定向页面,百度搜索引擎会自动处理。
第三步:使用百度站长平台工具
使用百度站长平台工具,可以加快百度搜索引擎对301跳转的处理,尽快完成新旧内容的对接。
经过以上三步操作后,通过网站在这段时间内控制爬取的异常情况,爬取频率的设置,索引量的波动,替换链接的数量等,在另外,旧版网站@网站的域名需要保留一段时间,直到新的网站索引和在百度搜索引擎中的显示效果达到预期。百度站长网站改版工具可以说大大提高了这个工作流程的简洁性,网站数据如何变化的直观性。
几乎自百度网站改版工具上线以来,平台就一直在不断优化升级百度网站改版工具,体现出平台更加注重操作的易用性、良好的体验和精准度。
一、易于操作
早期,如果网站需要修改,是一件大事,也是站长们最头疼、最担心的事情。在网站改版前期的策划、后期的安排和调整中,站长们忙得不可开交。之后,无论细节如何,我都会仔细观察、调整,等待网站的细微变化。
现在随着对工具的深入了解和不断完善,不用看说明书就可以轻松使用这些满意的数据分析工具,了解网站的情况。
二、准确度
在中国,“百度”无疑是搜索引擎的大佬,拥有大家族,大企业。使用工具并遵循百度的优化规则,无疑会为网站优化提供准确的数据,让站长们有据可查。
每位站长都会通过百度站长的各种工具不断调整、优化和完善网站,根据工具提示,网站的整体质量自然会不断提升,后续的流量和访问量都是一朵云。
由此看来,相信该工具的忠实站长粉丝应该也有同样的体验。前期提交修改数据后,站长需要实时跟踪分析修改后网站的情况。新网站是否有爬取异常,新网站的索引量是否有波动,比如新网站、收录的快照、排名变化等都需要站长什么都不做。注意细节。
至此,完成前期的基本操作后,提交修改规则,最后使用网站修改四个小部件,即网站修改工具、爬取异常工具、爬取频率工具和百度索引工具,通过这些工具可以非常直观的看到网站的数据变化,更准确的掌握网站的情况。 查看全部
网站内容抓取工具(
百度网站改版工具如何避免改版带来的收录和流量损失)
网站改版的对策是什么
关于网站改版这件大事,大家都知道网站的损坏是不可避免的,但是如果不及时将损坏降到最低,排名就会下降,快照会被撤回,并且不会有 收录。就连网站被百度降级和处罚也不是危言耸听。而对于网站改版应该采取哪些措施,最大程度避免改版带来的收录和流量损失,根据最新消息,可以分为三个步骤:
第一步:确认新旧内容已经跳转
无论是更改域名、目录,还是修改url模式,都需要保证整体内容跳转完成,有规律可循。
第 2 步:设置 301 跳转
使用301跳转重定向页面,百度搜索引擎会自动处理。
第三步:使用百度站长平台工具
使用百度站长平台工具,可以加快百度搜索引擎对301跳转的处理,尽快完成新旧内容的对接。
经过以上三步操作后,通过网站在这段时间内控制爬取的异常情况,爬取频率的设置,索引量的波动,替换链接的数量等,在另外,旧版网站@网站的域名需要保留一段时间,直到新的网站索引和在百度搜索引擎中的显示效果达到预期。百度站长网站改版工具可以说大大提高了这个工作流程的简洁性,网站数据如何变化的直观性。
几乎自百度网站改版工具上线以来,平台就一直在不断优化升级百度网站改版工具,体现出平台更加注重操作的易用性、良好的体验和精准度。
一、易于操作
早期,如果网站需要修改,是一件大事,也是站长们最头疼、最担心的事情。在网站改版前期的策划、后期的安排和调整中,站长们忙得不可开交。之后,无论细节如何,我都会仔细观察、调整,等待网站的细微变化。
现在随着对工具的深入了解和不断完善,不用看说明书就可以轻松使用这些满意的数据分析工具,了解网站的情况。
二、准确度
在中国,“百度”无疑是搜索引擎的大佬,拥有大家族,大企业。使用工具并遵循百度的优化规则,无疑会为网站优化提供准确的数据,让站长们有据可查。
每位站长都会通过百度站长的各种工具不断调整、优化和完善网站,根据工具提示,网站的整体质量自然会不断提升,后续的流量和访问量都是一朵云。
由此看来,相信该工具的忠实站长粉丝应该也有同样的体验。前期提交修改数据后,站长需要实时跟踪分析修改后网站的情况。新网站是否有爬取异常,新网站的索引量是否有波动,比如新网站、收录的快照、排名变化等都需要站长什么都不做。注意细节。
至此,完成前期的基本操作后,提交修改规则,最后使用网站修改四个小部件,即网站修改工具、爬取异常工具、爬取频率工具和百度索引工具,通过这些工具可以非常直观的看到网站的数据变化,更准确的掌握网站的情况。
网站内容抓取工具(小伙伴的网站一个月一个首页都没有收录,为什么贴)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-13 18:02
每个站长都希望自己的文章和网页能快点收录,但是很多小伙伴网站一个月都没有首页收录,更别说内部的内容了有些朋友的老网站和文章的页面,不管怎么发,都不是收录,为什么?
一、了解内容搜索引擎喜欢什么
如果你想让蜘蛛爬取我们的内容,你必须了解蜘蛛不喜欢什么样的内容。做到以下五点是包容的前提:
1.避免站内相似度:如果两个或三个或更多页面内容相似,同一个地方会产生80%以上的相似度(相似度工具检测)。百度基本不包括在内。
2.站外复制:站内很多内容都是复制粘贴,采集复制?
3.内容可读性:
(1.) 蜘蛛只能读取文本内容,不能识别图片、视频、帧等。
(2.) 用户可以查看是否通俗易懂,是否充满图文,甚至需要添加视频。
4.内容来源:内容从何而来?复印还是原件?你自己的文笔好吗?(什么是优质内容?满足前三点基本就是优质内容)。
5.搜索引擎可以爬取:如果不能爬取,那收录呢?哪些内容无法爬取?比如需要登录才能访问的内容,只有输入密码才能显示的内容,蜘蛛既不会注册账号,也不会登录。
二、看看用户喜欢什么内容
让我们想象一下我们在浏览网页时喜欢什么样的内容?你不喜欢的用户可以喜欢吗?你绝对不喜欢以下内容:
1.内容与主题不符,无关,内容不可读,不完整,(比如我的标题说我卖衣服,你看到标题进来了,你发现我的内容是擦鞋的,你会继续阅读?)。
2.内容只有一张图片和一个空白页,广告影响用户阅读(只有一个标题,看不懂的内容点击进入,看懂什么?)。
3.有权限的需要登录或者输入密码才能看到(知淘也经常这样做。第一次去网站需要注册登录后才能下载或浏览,所以我直接关闭它)。
三、需要创作优质内容
我明白蜘蛛为什么要爬我们的内容,用户喜欢什么样的内容,如何制作高质量的内容?
1.好的内容应该有一个title(),并且title应该是用户正在搜索的问题词或长尾词。搜索这样的词,这样的文章可以解决用户的问题。
2.内容怎么写?段落清晰,标题加长,结合图片、视频、文字,通俗易懂。它不需要很长的故事,也不需要非常文学。用户可以理解并帮助他们解决问题。
3.读完这篇文章,用户可以理解你在说什么,他们在寻找什么。只有这样的内容才能增加用户的停留时间,增加用户对网站的粘性。
我喜欢 SEO 技术研究。另外,如果需要提升自己的SEO能力,可以联系正在学习SEO干货技术的站长索要VIP视频教程,100%干货。 查看全部
网站内容抓取工具(小伙伴的网站一个月一个首页都没有收录,为什么贴)
每个站长都希望自己的文章和网页能快点收录,但是很多小伙伴网站一个月都没有首页收录,更别说内部的内容了有些朋友的老网站和文章的页面,不管怎么发,都不是收录,为什么?
一、了解内容搜索引擎喜欢什么
如果你想让蜘蛛爬取我们的内容,你必须了解蜘蛛不喜欢什么样的内容。做到以下五点是包容的前提:
1.避免站内相似度:如果两个或三个或更多页面内容相似,同一个地方会产生80%以上的相似度(相似度工具检测)。百度基本不包括在内。
2.站外复制:站内很多内容都是复制粘贴,采集复制?
3.内容可读性:
(1.) 蜘蛛只能读取文本内容,不能识别图片、视频、帧等。
(2.) 用户可以查看是否通俗易懂,是否充满图文,甚至需要添加视频。
4.内容来源:内容从何而来?复印还是原件?你自己的文笔好吗?(什么是优质内容?满足前三点基本就是优质内容)。
5.搜索引擎可以爬取:如果不能爬取,那收录呢?哪些内容无法爬取?比如需要登录才能访问的内容,只有输入密码才能显示的内容,蜘蛛既不会注册账号,也不会登录。
二、看看用户喜欢什么内容
让我们想象一下我们在浏览网页时喜欢什么样的内容?你不喜欢的用户可以喜欢吗?你绝对不喜欢以下内容:
1.内容与主题不符,无关,内容不可读,不完整,(比如我的标题说我卖衣服,你看到标题进来了,你发现我的内容是擦鞋的,你会继续阅读?)。
2.内容只有一张图片和一个空白页,广告影响用户阅读(只有一个标题,看不懂的内容点击进入,看懂什么?)。
3.有权限的需要登录或者输入密码才能看到(知淘也经常这样做。第一次去网站需要注册登录后才能下载或浏览,所以我直接关闭它)。
三、需要创作优质内容
我明白蜘蛛为什么要爬我们的内容,用户喜欢什么样的内容,如何制作高质量的内容?
1.好的内容应该有一个title(),并且title应该是用户正在搜索的问题词或长尾词。搜索这样的词,这样的文章可以解决用户的问题。
2.内容怎么写?段落清晰,标题加长,结合图片、视频、文字,通俗易懂。它不需要很长的故事,也不需要非常文学。用户可以理解并帮助他们解决问题。
3.读完这篇文章,用户可以理解你在说什么,他们在寻找什么。只有这样的内容才能增加用户的停留时间,增加用户对网站的粘性。
我喜欢 SEO 技术研究。另外,如果需要提升自己的SEO能力,可以联系正在学习SEO干货技术的站长索要VIP视频教程,100%干货。
网站内容抓取工具(网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-09 08:00
网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现。-2.html利用拓展函数可以很方便的从url接收参数提取相应的内容,不会像通常的插件那样复杂。
推荐veer数据爬虫,我们公司是在用,功能齐全,使用方便,可以把网站内容全部收集起来。
veer有ios和android版软件
如果题主只是做爬虫工具,则推荐菜鸟(菜鸟爬虫网),里面有爬虫框架、基础教程、工具使用,我是按里面的文章入门,自己也爬过网站;如果想做爬虫程序,需要搭建一个网站,以现有语言(python)为基础,适当学习各种框架,以python为例:第一个是下载使用python标准库中的idle(不要用记事本);然后是编程,熟悉python基础,scrapy及web等;在可以实现简单的数据爬取后,就可以做网站爬取;比如:抓取某些类似便利店或某些自媒体的网站第二个是可以定制化,不同类型的数据可以定制不同的爬取策略,比如:读取某些股票数据,可以采用httpclient,采用requests进行请求;数据分析一般使用matplotlib库,beautifulsoup也可以用;爬取:那么综上所述,爬虫抓取有:flask(主要)+httpclient(也可用requests)+requests库(我是用的pip安装)+django+urllib/httplib+beautifulsoup+selenium(用于网站爬取处理)=网站抓取。 查看全部
网站内容抓取工具(网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现)
网站内容抓取工具可以用拓展函数模拟浏览器的一些行为实现。-2.html利用拓展函数可以很方便的从url接收参数提取相应的内容,不会像通常的插件那样复杂。
推荐veer数据爬虫,我们公司是在用,功能齐全,使用方便,可以把网站内容全部收集起来。
veer有ios和android版软件
如果题主只是做爬虫工具,则推荐菜鸟(菜鸟爬虫网),里面有爬虫框架、基础教程、工具使用,我是按里面的文章入门,自己也爬过网站;如果想做爬虫程序,需要搭建一个网站,以现有语言(python)为基础,适当学习各种框架,以python为例:第一个是下载使用python标准库中的idle(不要用记事本);然后是编程,熟悉python基础,scrapy及web等;在可以实现简单的数据爬取后,就可以做网站爬取;比如:抓取某些类似便利店或某些自媒体的网站第二个是可以定制化,不同类型的数据可以定制不同的爬取策略,比如:读取某些股票数据,可以采用httpclient,采用requests进行请求;数据分析一般使用matplotlib库,beautifulsoup也可以用;爬取:那么综上所述,爬虫抓取有:flask(主要)+httpclient(也可用requests)+requests库(我是用的pip安装)+django+urllib/httplib+beautifulsoup+selenium(用于网站爬取处理)=网站抓取。
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-07 17:03
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。
网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。 查看全部
网站内容抓取工具(几个百度迟迟不收录怎么解决提升网站不被搜索引擎收录)
一个全新的网站,有时候百度来不及收录,也不容易找出原因,因为我们不能故意犯错,导致网站不被搜索引擎搜索收录,问题出在哪里?很有可能是搜索引擎没有爬取你的网页或者爬取频率太低导致你的网站内容没有被爬取,那么我们需要做的就是改进爬取网站 的次数,并引导搜索引擎抓取我们要显示的内容或最新编辑的内容。在这里我会告诉你几个小窍门,我亲身测试它是有用的。
网站收录
使用站长工具,首先测试网站爬取首页,看网站能否正常爬取。
抓取诊断
使用说明
如您所见,这是成功的捕获。我们再看一个网站这里忽略,填写自己的URL
URL爬取UA爬取状态提交时间
个人电脑
抓取失败
2018-03-19 17:29
忽略这个,填写你自己的URL/
个人电脑
抓取失败
2018-03-19 17:29
看到爬取状态失败,原因是dns解析没有生效。我们找到了原因。这时候我们可以尝试重新解析或者尝试多次爬取。如果不成功,我们再看一下爬取异常,它显示了蜘蛛已经来但没有爬取的情况。
如果你新建一个文章,想让搜索引擎快点收录,我们可以使用提交工具
链接提交
使用说明
看了说明,其实很简单,就是多提交,多抢,早点收录,早点拿到排名。
网站内容抓取工具(全球最大的中文博客平台:一键拥有自己的博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-01 06:06
网站内容抓取工具“mozilla/mozilla”,简称mozilla,是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。使用方法mozillamozillaabaurittutorialsmozillachangesnetwork–google&samsungtreeuptreeupnetworkmozillaslacknammcountriesgooglemozilla是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。网站内容抓取工具官网:。
hexo一个国外博客都在用它,我自己用过v2ex和知乎首页,都很方便还自带搭建,国内有一些博客也在用,未来网人人都可以做.搭建方式很简单,一条主题issue就搞定了,你可以上readme查看自己的博客/
自荐一下这个网站:
全球最大的中文博客平台:,一键拥有自己的博客,
可以百度:源代码的js托管平台
给大家推荐个全球最大、最值得信赖的代码托管平台:,而且这个代码托管平台支持中文的。hexo、github、v2ex、meowgl这些全球最大的博客平台的代码托管都给到我们国内用户,随时随地搭建属于自己的博客。 查看全部
网站内容抓取工具(全球最大的中文博客平台:一键拥有自己的博客)
网站内容抓取工具“mozilla/mozilla”,简称mozilla,是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。使用方法mozillamozillaabaurittutorialsmozillachangesnetwork–google&samsungtreeuptreeupnetworkmozillaslacknammcountriesgooglemozilla是全球最大的技术社区,涉及到生产环境的各个方面,开发者必须关注其最新动态,包括它推出的javascript语言。此外还提供了大量的自助式工具,可以帮助用户轻松地完成网站相关工作。网站内容抓取工具官网:。
hexo一个国外博客都在用它,我自己用过v2ex和知乎首页,都很方便还自带搭建,国内有一些博客也在用,未来网人人都可以做.搭建方式很简单,一条主题issue就搞定了,你可以上readme查看自己的博客/
自荐一下这个网站:
全球最大的中文博客平台:,一键拥有自己的博客,
可以百度:源代码的js托管平台
给大家推荐个全球最大、最值得信赖的代码托管平台:,而且这个代码托管平台支持中文的。hexo、github、v2ex、meowgl这些全球最大的博客平台的代码托管都给到我们国内用户,随时随地搭建属于自己的博客。
网站内容抓取工具(网站内容抓取工具—豆瓣可以抓取二三线城市的公交站名地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-01 06:04
网站内容抓取工具—豆瓣可以完成三种模式:1.单页抓取网站各个分站点的内容。2.多页抓取网站分站点的内容。3.多页嵌套网站其他页面。
豆瓣吧。去某站抓取即可。
可以抓取二三线城市的公交站牌,估计几分钟一条,其实对于一般人,公交站牌的数量也不太多。
我做网站需要的数据就是二三线城市所有的公交站名地址。
/。功能最全的一个。
必须是当地最大的医院分院啊,
个人经验,天津城区每个区站点,只要以车站名拼音组合网站内容,甚至更多,都是可以抓取的,如有需要,还可以通过每个网站的跳转链接为关键字通过一定的规则抓取。所以个人网站爬取,必须抓取每个站点的车站名、所有站点的所有交通路线。
很多公司在这方面采用了多站点加载最佳路线计划(pbc)。
豆瓣啊,不但抓搜索引擎的,
百度聚合谷歌算法抓取
我目前正在做一个三线城市垂直搜索,目前有三个站点可以抓。
其实lz应该想问的是比如爬去各个城市站点,而有的网站过于大,网站内部会有引导关键字,很难抓,只好全部通过这些新网站源代码搜索获取,
当前没有爬去省内县、市级公交站点的网站,不是用爬虫爬取而是手动引导查找。不过在北京也找到了一个人为抓取的栗子。 查看全部
网站内容抓取工具(网站内容抓取工具—豆瓣可以抓取二三线城市的公交站名地址)
网站内容抓取工具—豆瓣可以完成三种模式:1.单页抓取网站各个分站点的内容。2.多页抓取网站分站点的内容。3.多页嵌套网站其他页面。
豆瓣吧。去某站抓取即可。
可以抓取二三线城市的公交站牌,估计几分钟一条,其实对于一般人,公交站牌的数量也不太多。
我做网站需要的数据就是二三线城市所有的公交站名地址。
/。功能最全的一个。
必须是当地最大的医院分院啊,
个人经验,天津城区每个区站点,只要以车站名拼音组合网站内容,甚至更多,都是可以抓取的,如有需要,还可以通过每个网站的跳转链接为关键字通过一定的规则抓取。所以个人网站爬取,必须抓取每个站点的车站名、所有站点的所有交通路线。
很多公司在这方面采用了多站点加载最佳路线计划(pbc)。
豆瓣啊,不但抓搜索引擎的,
百度聚合谷歌算法抓取
我目前正在做一个三线城市垂直搜索,目前有三个站点可以抓。
其实lz应该想问的是比如爬去各个城市站点,而有的网站过于大,网站内部会有引导关键字,很难抓,只好全部通过这些新网站源代码搜索获取,
当前没有爬去省内县、市级公交站点的网站,不是用爬虫爬取而是手动引导查找。不过在北京也找到了一个人为抓取的栗子。
网站内容抓取工具(ScreamingFrogSEOSpider(尖叫青蛙网络爬虫软件)的激活版本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-31 03:11
Screaming Frog SEO Spider(尖叫青蛙网络爬虫软件)是一款功能强大的网站资源检测和爬取工具。该工具可以模拟谷歌、必应等搜索引擎从SEO角度抓取网页。,同时分析网页的结构、内容等信息,然后给我们详细的分析结果。用户可以通过抓取结果来分析网站数据,从而快速修复网站。今天给大家分享的是Screaming Frog SEO Spider的激活版,激活码也是激活的。需要的朋友不要错过哦!
软件说明
Screaming Frog SEO Spider 是一个用 Java 开发的软件应用程序,旨在为用户提供一种简单的方法来采集有关任何给定站点的 SEO 信息,以及生成多个报告并将信息导出到硬盘驱动器。
清除图形用户界面
您遇到的界面可能看起来有点杂乱,因为它由一个菜单栏和显示各种信息的选项卡式窗格组成。但是,开发人员的 网站 上提供了全面的用户指南和一些常见问题解答,这将确保高级用户和新手用户都可以轻松找到解决方法而不会遇到任何问题......。.
特征
1.找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2.分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
3.使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
4.生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
5.抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6.审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
7.发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
8.查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
9.与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及来自抓取页面的转化、目标、交易和收入。
10.可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
安装和激活教程
在Script Home下载seo蜘蛛图片包后,双击打开图片包,将左边的Screaming Frog SEO Spider拉到右边的应用程序中,如图:
打开SEO Spider,在顶部菜单栏打开license,然后点击enter license,如图:
弹出seo spider mac版注册界面,放在一边,返回镜像包打开Screaming Frog SEO Spider注册码,如图:
将注册码复制粘贴到SEO Spider注册界面,提示注册seo spider的时间,然后点击OK,如图:
提示输入有效的许可证密钥。请重启让你的修改生效,重启seo spider mac,seo spider注册成功!!
激活码激活
有几个最新版本可以通过激活来激活。它更容易使用。只需打开激活界面,在激活界面输入脚本屋编辑器提供的激活码即可激活!
NGEN团队
224BD64851-1665820255-3EAD2EBE41
速度生肖
E1E8351AE4-1665820910-12172D4E34
注意:使用防火墙阻止传出连接(通过防火墙阻止传出连接)
变更日志
我们刚刚发布了 SEO Spider 版本 16.4 的小更新。此版本包括一个安全补丁,以及错误修复和小改进
更新到 Apache log4j 2.15.0 以修复 CVE-2021-44228 漏洞。
在“文件”>“计划”下添加了计划历史功能。
添加了对计划任务的验证以列出视图以捕获设置爬网后删除配置文件等问题。
允许双击编辑计划的爬网。
限制 Google 表格导出以防止导出失败。
重命名自定义搜索/提取不再清除过滤器。
更新未能找到 GA 帐户详细信息以列出帐户名称和 ID。
将抓取时间戳添加到 URL 详细信息选项卡。
修复崩溃更改 Crawling > 在自定义搜索中。
修复发送 POST/HEAD 请求的页面的 JavaScript 抓取错误。
修复 JavaScript 抓取期间的内存泄漏。
使用损坏的选项卡配置文件修复启动时崩溃。
如果未连接 API,则修复计划的提取挂起。
修复了 Google 表格限制导致后续导出随机失败的命令行抓取问题。
修复了导出可索引性时未找到 HTTP 规范的错误。
修复启动时提取 Chrome 时崩溃的问题。
修复已经有规则的用户代理的 robots.txt 解析错误。
修复了围绕站点地图 hreflang 和抓取顺序的 hreflang 过滤器中的错误。
修复删除站点地图时进行 hreflang 验证时崩溃的问题。
修复为 URL 存储的重复 cookie。
修复基于表单的身份验证的各种问题。
修复 GSC 中的崩溃。
修复在概览表中选择项目的崩溃。 查看全部
网站内容抓取工具(ScreamingFrogSEOSpider(尖叫青蛙网络爬虫软件)的激活版本)
Screaming Frog SEO Spider(尖叫青蛙网络爬虫软件)是一款功能强大的网站资源检测和爬取工具。该工具可以模拟谷歌、必应等搜索引擎从SEO角度抓取网页。,同时分析网页的结构、内容等信息,然后给我们详细的分析结果。用户可以通过抓取结果来分析网站数据,从而快速修复网站。今天给大家分享的是Screaming Frog SEO Spider的激活版,激活码也是激活的。需要的朋友不要错过哦!
软件说明
Screaming Frog SEO Spider 是一个用 Java 开发的软件应用程序,旨在为用户提供一种简单的方法来采集有关任何给定站点的 SEO 信息,以及生成多个报告并将信息导出到硬盘驱动器。
清除图形用户界面
您遇到的界面可能看起来有点杂乱,因为它由一个菜单栏和显示各种信息的选项卡式窗格组成。但是,开发人员的 网站 上提供了全面的用户指南和一些常见问题解答,这将确保高级用户和新手用户都可以轻松找到解决方法而不会遇到任何问题......。.
特征
1.找到断开的链接
现在抓取 网站 并查找断开的链接 (404s) 和服务器错误。批量导出错误和源 URL 以修复或发送给开发人员。
2.分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别 网站 中过长、过短、缺失或重复的内容。
3.使用 XPath 提取数据
使用 CSS 路径、XPath 或正则表达式从网页的 HTML 中采集任何数据。这可能包括社交元标签、其他标题、价格、SKU 或更多!
4.生成 XML 站点地图
通过 URL 的高级配置快速创建 XML 站点地图和图像 XML 站点地图,包括上次修改、优先级和更改频率。
5.抓取 JavaScript网站
使用集成的 Chromium WRS 渲染网页,以抓取动态的、富含 JavaScript 的 网站 以及 Angular、React 和 Vue.js 等框架。
6.审计重定向
查找临时和永久重定向,识别重定向链和循环,或上传 URL 列表以供在站点迁移中查看。
7.发现重复
使用 md5 算法检查完全重复的 URL、部分重复的元素(例如页面标题、描述或标题)并查找内容低的页面。
8.查看机器人和说明
查看被 robots.txt、meta-robots 或 X-Robots-Tag 指令(例如“noindex”或“nofollow”)以及规范和 rel="next" 和 rel="prev" 阻止的 URL。
9.与谷歌分析集成
连接到 Google Analytics API 并获取用于抓取功能的用户数据,例如会话或跳出率以及来自抓取页面的转化、目标、交易和收入。
10.可视化网站架构
使用交互式爬网和目录强制导向和树状图站点可视化评估内部链接和 URL 结构。
安装和激活教程
在Script Home下载seo蜘蛛图片包后,双击打开图片包,将左边的Screaming Frog SEO Spider拉到右边的应用程序中,如图:
打开SEO Spider,在顶部菜单栏打开license,然后点击enter license,如图:
弹出seo spider mac版注册界面,放在一边,返回镜像包打开Screaming Frog SEO Spider注册码,如图:
将注册码复制粘贴到SEO Spider注册界面,提示注册seo spider的时间,然后点击OK,如图:
提示输入有效的许可证密钥。请重启让你的修改生效,重启seo spider mac,seo spider注册成功!!
激活码激活
有几个最新版本可以通过激活来激活。它更容易使用。只需打开激活界面,在激活界面输入脚本屋编辑器提供的激活码即可激活!
NGEN团队
224BD64851-1665820255-3EAD2EBE41
速度生肖
E1E8351AE4-1665820910-12172D4E34
注意:使用防火墙阻止传出连接(通过防火墙阻止传出连接)
变更日志
我们刚刚发布了 SEO Spider 版本 16.4 的小更新。此版本包括一个安全补丁,以及错误修复和小改进
更新到 Apache log4j 2.15.0 以修复 CVE-2021-44228 漏洞。
在“文件”>“计划”下添加了计划历史功能。
添加了对计划任务的验证以列出视图以捕获设置爬网后删除配置文件等问题。
允许双击编辑计划的爬网。
限制 Google 表格导出以防止导出失败。
重命名自定义搜索/提取不再清除过滤器。
更新未能找到 GA 帐户详细信息以列出帐户名称和 ID。
将抓取时间戳添加到 URL 详细信息选项卡。
修复崩溃更改 Crawling > 在自定义搜索中。
修复发送 POST/HEAD 请求的页面的 JavaScript 抓取错误。
修复 JavaScript 抓取期间的内存泄漏。
使用损坏的选项卡配置文件修复启动时崩溃。
如果未连接 API,则修复计划的提取挂起。
修复了 Google 表格限制导致后续导出随机失败的命令行抓取问题。
修复了导出可索引性时未找到 HTTP 规范的错误。
修复启动时提取 Chrome 时崩溃的问题。
修复已经有规则的用户代理的 robots.txt 解析错误。
修复了围绕站点地图 hreflang 和抓取顺序的 hreflang 过滤器中的错误。
修复删除站点地图时进行 hreflang 验证时崩溃的问题。
修复为 URL 存储的重复 cookie。
修复基于表单的身份验证的各种问题。
修复 GSC 中的崩溃。
修复在概览表中选择项目的崩溃。
网站内容抓取工具(蝉大师网站内容抓取工具-猪八戒网微申hypage4)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-29 14:00
网站内容抓取工具1。腾讯开放平台移动客户端发放奖励(现在不能去扫码获取了,如果获取我帮你去微信搜一下就行,代码以后我会提供)2。蝉大师网站内容抓取工具:建站宝盒_w3cschool基于w3ccontentandthemes标准开发的在线建站产品3。微申网站内容抓取工具-微申hypage4。猪八戒建站平台内容抓取工具:猪八戒网中国领先的服务交易平台-八戒网-专业的网络营销平台网站数据来源1。
百度:whois数据、国家权威数据、知识产权信息、ip地址数据、域名列表-youdao。com2。360:。网站蜘蛛捕捉(抓取网站页面内容后台工具)搜狗搜索site:site:/百度收录、推荐位、分词。
首先想问:微信公众号里面搜索就可以看到网站,那公众号开通自定义菜单时在选项部分有个网站吗?然后问:网站链接本身是wordpress或开源的织梦服务器,
官方人员都是说,现在没有自定义菜单可以抓取自定义页面信息的。但我个人感觉,应该还是没问题的。很多二三线城市,主流应该还是以图文为主了,涉及网站内容抓取的,还比较少见。毕竟我们接触的二三线城市,关注互联网不像在一线城市一样地普及。我个人是这么看待这个问题的:网站内容抓取主要是技术问题,后端的内容大部分还是会被采集到各大互联网平台上,并且在这些平台上做下一些广告,怎么处理比较好,还有网站用户群定位怎么定位,怎么能被爬虫抓到,这些都是需要考虑的问题。 查看全部
网站内容抓取工具(蝉大师网站内容抓取工具-猪八戒网微申hypage4)
网站内容抓取工具1。腾讯开放平台移动客户端发放奖励(现在不能去扫码获取了,如果获取我帮你去微信搜一下就行,代码以后我会提供)2。蝉大师网站内容抓取工具:建站宝盒_w3cschool基于w3ccontentandthemes标准开发的在线建站产品3。微申网站内容抓取工具-微申hypage4。猪八戒建站平台内容抓取工具:猪八戒网中国领先的服务交易平台-八戒网-专业的网络营销平台网站数据来源1。
百度:whois数据、国家权威数据、知识产权信息、ip地址数据、域名列表-youdao。com2。360:。网站蜘蛛捕捉(抓取网站页面内容后台工具)搜狗搜索site:site:/百度收录、推荐位、分词。
首先想问:微信公众号里面搜索就可以看到网站,那公众号开通自定义菜单时在选项部分有个网站吗?然后问:网站链接本身是wordpress或开源的织梦服务器,
官方人员都是说,现在没有自定义菜单可以抓取自定义页面信息的。但我个人感觉,应该还是没问题的。很多二三线城市,主流应该还是以图文为主了,涉及网站内容抓取的,还比较少见。毕竟我们接触的二三线城市,关注互联网不像在一线城市一样地普及。我个人是这么看待这个问题的:网站内容抓取主要是技术问题,后端的内容大部分还是会被采集到各大互联网平台上,并且在这些平台上做下一些广告,怎么处理比较好,还有网站用户群定位怎么定位,怎么能被爬虫抓到,这些都是需要考虑的问题。

