
文章采集链接
网站SEO降低内部链接方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2020-08-21 10:46
网站SEO降低内部链接方式
2020-5-28
一个好的内部链接结构,为用户访问网站信息提供了便利的读取通道因而可提高网站的PV,同时链式结构也十分有利于搜索引擎的信息抓取为Google和百度等引擎欢迎,因此内链的建设是SEO不可忽略的一个环节向来为SEOER注重。
很多个人站长包括一些大的站点并不注重文章的内链建设,集中表现为通篇文章除了图片就是文字,对于借助内链这一优势资源去提高文章的相关性和可读性。
那么,网站SEO降低内部链接方式有哪些呢?
1:采集站点的热门关键词或TAG及关键词的指向链接,这个一般可以在主页的热门关键词区找到:对于一些特别重要的关键词也可以添加进搜集列表。
2:在文章内容递交模块处加入替换方式,文章更新时,收录上述关键字的内容将逐一替换为关键词的链接,从而达到手动加入内链的疗效。
3:关键词大概有20个,这个数目,基本上可以保证整篇文章能替换到2-5个内链,
当然关键词定义的越多内链也就越多。不过要有个度,太多的内链会影响文章的可读性,笔者建议不宜超过5个链接。
4:这种方式同样适用于采集,只要将替换方式加入采集模块,文章亦会手动实现关键词的内链添加。
5:对于采集的文章,内链的替换实际上也是一个伪原初的技巧。
内链的关键词替换是一个太小的代码更改工作,花的时间不多,但形成的疗效非常好,不仅提高了文章的可读性还达到了SEO的疗效,因此非常推荐此法去优化文章的内链,广大的站长同学不妨一试此法。 查看全部
网站SEO降低内部链接方式
网站SEO降低内部链接方式
2020-5-28
一个好的内部链接结构,为用户访问网站信息提供了便利的读取通道因而可提高网站的PV,同时链式结构也十分有利于搜索引擎的信息抓取为Google和百度等引擎欢迎,因此内链的建设是SEO不可忽略的一个环节向来为SEOER注重。
很多个人站长包括一些大的站点并不注重文章的内链建设,集中表现为通篇文章除了图片就是文字,对于借助内链这一优势资源去提高文章的相关性和可读性。

那么,网站SEO降低内部链接方式有哪些呢?
1:采集站点的热门关键词或TAG及关键词的指向链接,这个一般可以在主页的热门关键词区找到:对于一些特别重要的关键词也可以添加进搜集列表。
2:在文章内容递交模块处加入替换方式,文章更新时,收录上述关键字的内容将逐一替换为关键词的链接,从而达到手动加入内链的疗效。
3:关键词大概有20个,这个数目,基本上可以保证整篇文章能替换到2-5个内链,
当然关键词定义的越多内链也就越多。不过要有个度,太多的内链会影响文章的可读性,笔者建议不宜超过5个链接。
4:这种方式同样适用于采集,只要将替换方式加入采集模块,文章亦会手动实现关键词的内链添加。
5:对于采集的文章,内链的替换实际上也是一个伪原初的技巧。
内链的关键词替换是一个太小的代码更改工作,花的时间不多,但形成的疗效非常好,不仅提高了文章的可读性还达到了SEO的疗效,因此非常推荐此法去优化文章的内链,广大的站长同学不妨一试此法。
SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-21 06:45
我们借助网站开展网路营销推广不是三天三天事情,应该从长远的方向来考虑,以搜索用户的体验为主去优化网站,不要尝试去做一些作弊行为和违规违法行为。否则,这些问题就会影响网站在搜索引擎上的诠释,影响网站的排行。接下来,营销圈就和你们分享下SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
第一大注意事项:大量转让友情链接
很多的网站为了获取一些蝇头小利而向其他站长转让自己的友情链接,不过随之而来的就是对自身网站影响。比方说排行增长、惩罚降权、收录被删等情况,这些都是会出现的。营销圈在这里建议你们合理的交换友情链接有利于网站的排行和优化,如果大量的转让友情链接存在着十分大的风险。
第二大注意事项:网站内容大量采集
有一些网站的站长喜欢偷懒,网站的文章内容大都是采集和复制其他网站中的内容,原创度特别的低。甚至严重的情况,有的站长会采用软件批量的生成,不过生成的内容都是和网站主题不相符的内容,都是一些没有价值的东西。
第三大注意事项:网站存在大量广告
有一些网站存在着大量的广告,妨碍搜索用户的正常浏览。比方说常见的弹窗广告和一些混淆主体的垃圾广告为主,其中最常见的就是一些三流的小说网站、视频网站等等,用户点击进去的话,满屏都是广告内容。
90%的人又阅读以下文章:SEO零基础入门难吗?SEO入门最重要的是哪些? SEO优化营销之搜索引擎网站排名优化的原理和依据是哪些? SEO优化是哪些,SEO优化营销是哪些意思? SEO优化营销之SEO的两大行为分类,你是属于哪一类呢? SEO优化营销之转让友情链接对网站优化形成的害处,不可不知! 查看全部
SEO优化营销之网站优化的三大注意事项,看看你晓得几点?

我们借助网站开展网路营销推广不是三天三天事情,应该从长远的方向来考虑,以搜索用户的体验为主去优化网站,不要尝试去做一些作弊行为和违规违法行为。否则,这些问题就会影响网站在搜索引擎上的诠释,影响网站的排行。接下来,营销圈就和你们分享下SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
第一大注意事项:大量转让友情链接
很多的网站为了获取一些蝇头小利而向其他站长转让自己的友情链接,不过随之而来的就是对自身网站影响。比方说排行增长、惩罚降权、收录被删等情况,这些都是会出现的。营销圈在这里建议你们合理的交换友情链接有利于网站的排行和优化,如果大量的转让友情链接存在着十分大的风险。
第二大注意事项:网站内容大量采集
有一些网站的站长喜欢偷懒,网站的文章内容大都是采集和复制其他网站中的内容,原创度特别的低。甚至严重的情况,有的站长会采用软件批量的生成,不过生成的内容都是和网站主题不相符的内容,都是一些没有价值的东西。
第三大注意事项:网站存在大量广告
有一些网站存在着大量的广告,妨碍搜索用户的正常浏览。比方说常见的弹窗广告和一些混淆主体的垃圾广告为主,其中最常见的就是一些三流的小说网站、视频网站等等,用户点击进去的话,满屏都是广告内容。
90%的人又阅读以下文章:SEO零基础入门难吗?SEO入门最重要的是哪些? SEO优化营销之搜索引擎网站排名优化的原理和依据是哪些? SEO优化是哪些,SEO优化营销是哪些意思? SEO优化营销之SEO的两大行为分类,你是属于哪一类呢? SEO优化营销之转让友情链接对网站优化形成的害处,不可不知!
[干货分享]慈溪SEO代理浅谈SEO文章收录的终极诀窍
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-21 04:32
在我们做SEO时,大家都晓得文章收录就是个关键点,因为只有在文章收录的情况下,网站排名和网站浏览量就会尽可能的提升,有的人一天到晚不停的发文章,但是还是会遇到文章常常不收录这是为什么呢,那么,慈溪SEO小编就来跟你们分享SEO文章的终极诀窍。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。#p#分页标题#e#
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在10万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。#p#分页标题#e#
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的404页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。 查看全部
[干货分享]慈溪SEO代理浅谈SEO文章收录的终极诀窍
在我们做SEO时,大家都晓得文章收录就是个关键点,因为只有在文章收录的情况下,网站排名和网站浏览量就会尽可能的提升,有的人一天到晚不停的发文章,但是还是会遇到文章常常不收录这是为什么呢,那么,慈溪SEO小编就来跟你们分享SEO文章的终极诀窍。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。#p#分页标题#e#

2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在10万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。#p#分页标题#e#
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的404页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
python实现WordPress文章发布(三):批量发布文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-19 18:04
这是东尧每晚一篇文章的第48天
东尧写文章的目标:分享东尧的经验和思索,帮你获取物质和精神两方面幸福。
上次教程我们早已提到了
用python发布单篇WordPress文章
,但是只是单篇文章的发布,多篇文章发布的话就须要将函数封装一下,用文件读写的方法来获取文章并发布,本文将给你们继续介绍wordpress-xmlrpc里的一些技巧,并在最后将这种方式组合上去,进行封装,实现批量发布多篇文章到WordPress后台。
今天先给你们介绍wordpress-xmlrpc里Methods类的taxonomies()方法。taxonomies方式主要用于获取文章分类,当然,这个分类不是指文章的栏目分类,具体是哪些分类呢?
我们使用taxonomies方式的GetTaxonomies()属性来获取一下所以分类试试,看获取到的分类是哪些内容:
结果:
发现跟我们之前写的文章发布分类字典内的键是一致的:
所以GetTaxonomies()获取到的分类是指写文章发布代码时用到的分类变量名。
taxonomies方式还有一个比较重要的属性是GetTerms(),这个属性可以获取到某个分类下所有的值,这里的分类就是我们刚刚用GetTaxonomies()获取到的“category、post_tag、post_format”三个分类。怎么应用呢?比如我们想知道网站总共有什么标签,就可以使用GetTerms('post_tag')来获取:
结果:
NewTerms()属性:创建一个新的分类目录:
结果:
已经新建成功!
函数
封装
还是先将之前采集的短文学网的诗歌txt文件拷贝到python代码文件夹内,如果没有的朋友可以先查看《文章采集案例:短文学网诗歌采集(二)》这篇文章,学习下怎样采集。
01
post()函数封装
02
主体执行代码
执行后可以看见早已发布成功了:
源码
下载 查看全部
python实现WordPress文章发布(三):批量发布文章
这是东尧每晚一篇文章的第48天
东尧写文章的目标:分享东尧的经验和思索,帮你获取物质和精神两方面幸福。
上次教程我们早已提到了
用python发布单篇WordPress文章
,但是只是单篇文章的发布,多篇文章发布的话就须要将函数封装一下,用文件读写的方法来获取文章并发布,本文将给你们继续介绍wordpress-xmlrpc里的一些技巧,并在最后将这种方式组合上去,进行封装,实现批量发布多篇文章到WordPress后台。
今天先给你们介绍wordpress-xmlrpc里Methods类的taxonomies()方法。taxonomies方式主要用于获取文章分类,当然,这个分类不是指文章的栏目分类,具体是哪些分类呢?
我们使用taxonomies方式的GetTaxonomies()属性来获取一下所以分类试试,看获取到的分类是哪些内容:
结果:
发现跟我们之前写的文章发布分类字典内的键是一致的:
所以GetTaxonomies()获取到的分类是指写文章发布代码时用到的分类变量名。
taxonomies方式还有一个比较重要的属性是GetTerms(),这个属性可以获取到某个分类下所有的值,这里的分类就是我们刚刚用GetTaxonomies()获取到的“category、post_tag、post_format”三个分类。怎么应用呢?比如我们想知道网站总共有什么标签,就可以使用GetTerms('post_tag')来获取:
结果:
NewTerms()属性:创建一个新的分类目录:
结果:
已经新建成功!
函数
封装
还是先将之前采集的短文学网的诗歌txt文件拷贝到python代码文件夹内,如果没有的朋友可以先查看《文章采集案例:短文学网诗歌采集(二)》这篇文章,学习下怎样采集。
01
post()函数封装
02
主体执行代码
执行后可以看见早已发布成功了:
源码
下载
Python网路数据采集之储存数据|第04天
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2020-08-19 09:28
User:你好我是森林Date:2018-03-31Mark:《Python网路数据采集》原文:))
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
存储数据
网络数据的采集,最本质的东西还是数据,我们爬取的数据是须要储存的。
媒体文件
存储媒体文件有两种主要的形式:只获取文件 URL 链接,或者直接把源文件下载出来。
可以通过媒体文件所在的URL 链接直接引用它。这样做的优点如下:
于此同时都会有一些缺点:
下载文件的方式也很简单,在Python 3.x 版本中,urllib.request.urlretrieve可以依照文件的 URL 下载文件;
例如我们从 下载 logo图片,然后在程序运行的文件夹里保存为 logo.jpg 文件。
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com')
bs = BeautifulSoup(html, 'html.parser')
imageLocation = bs.find('a', {'id': 'logo'}).find('img')['src']
urlretrieve (imageLocation, 'logo.jpg')
下载文件须要注意exe的文件,木马文件等。不要在硬碟储存敏感信息,不要用管理员权限运行他。
把数据储存到CSV
CSV(Comma-Separated Values,逗号分隔值)是储存表格数据的常用文件格式。关于CSV格式的文件不做过多的介绍,自行去了解一下。
Python的csv库可以创建或则更改CSV文件。
import csv
csvFile = open("./demo.csv","w+")
try:
writer = csv.writer(csvFile)
writer.writerow(('number', 'number plus 2', 'number times 2'))
for i in rang(10):
writer.writerow((i,i+2,I*2))
finally:
csvFile.close()
如果文件不存在都会创建demo.csv。
MySQL
MySQL是目前最受欢迎的开源关系型数据库管理系统。因为它受众广泛,免费,开箱即用,所以它也是网路数据采集项目中常用的数据库。
我采用的是Mac的平台,可以直接下载安装安装也可以通过包管理器(例如homebrew)安装。
官网下载地址:
其他的平台可以去官网查看安装详情,作为一个改变世界的程序猿,安装软件应当不是问题。
基本命令
创建数据库:
CREATE DATABASE demo;
使用数据库:
USE demo;
创建表:
CREATE TABLE user(
id BIGINT(7) NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
sex tinyint(1),
creatime TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
和数据库不同,MySQL 数据表必须起码有一列,否则不能创建。为了在 MySQL 里定义数组(数据列),你必须在 CREATE TABLE 句子前面,把数组的定义放进一个带括弧的、内部由冒号分隔的列表。
插入数据:
INSERT INTO user (name, sex) VALUES ("name", "1");
查询数据:
SELECT * FROM user
模糊查询:
SELECT id FROM user LIKE "%chensenlin.cn%"
删除数据:
DELELT FROM user WHERE id = 1
更新数据:
UPDATE user SET name = 'chensenlin' WHERE id = 66
特别指出:更新或则删掉一定要加条件!否则就说灾难,哈哈哈
与Python整合
Python没有外置的MySQL 支持工具。不过,有很多开源的库可以拿来与 MySQL做交互,Python 2.x和Python 3.x版本都支持。最有名的一个库就是PyMySQL()。
安装:
pip install PyMySQL
基本使用:
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',user='root', passwd=root, db='mysql')
cur.execute("USE demo")
cur.execute("SELECT * FROM user WHERE id = 1") print(cur.fetchone())
cur.close()
conn.close()
Python发送一封短信:
import smtplib
from email.mime.text import MIMEText
msg = MIMEText("邮件正文内容")
msg['Subject'] = "这是一个测试有奖主题"
msg['From'] = "fore@gmail.com"
msg['To'] = "hellosenlin@sina.cn"
s = smtplib.SMTP('localhost')
s.send_message(msg)
s.quit()
与网页通过HTTP协议传输一样,邮件是通过SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)传输的。而且,和网路服务器的客户端(浏览器)处理这些通过 HTTP 协议传输的网页一样。
可以将其封装成函数作为发送短信定时使用等。 查看全部
Python网路数据采集之储存数据|第04天
User:你好我是森林Date:2018-03-31Mark:《Python网路数据采集》原文:))
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
存储数据
网络数据的采集,最本质的东西还是数据,我们爬取的数据是须要储存的。
媒体文件
存储媒体文件有两种主要的形式:只获取文件 URL 链接,或者直接把源文件下载出来。
可以通过媒体文件所在的URL 链接直接引用它。这样做的优点如下:
于此同时都会有一些缺点:
下载文件的方式也很简单,在Python 3.x 版本中,urllib.request.urlretrieve可以依照文件的 URL 下载文件;
例如我们从 下载 logo图片,然后在程序运行的文件夹里保存为 logo.jpg 文件。
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com')
bs = BeautifulSoup(html, 'html.parser')
imageLocation = bs.find('a', {'id': 'logo'}).find('img')['src']
urlretrieve (imageLocation, 'logo.jpg')
下载文件须要注意exe的文件,木马文件等。不要在硬碟储存敏感信息,不要用管理员权限运行他。
把数据储存到CSV
CSV(Comma-Separated Values,逗号分隔值)是储存表格数据的常用文件格式。关于CSV格式的文件不做过多的介绍,自行去了解一下。
Python的csv库可以创建或则更改CSV文件。
import csv
csvFile = open("./demo.csv","w+")
try:
writer = csv.writer(csvFile)
writer.writerow(('number', 'number plus 2', 'number times 2'))
for i in rang(10):
writer.writerow((i,i+2,I*2))
finally:
csvFile.close()
如果文件不存在都会创建demo.csv。
MySQL
MySQL是目前最受欢迎的开源关系型数据库管理系统。因为它受众广泛,免费,开箱即用,所以它也是网路数据采集项目中常用的数据库。
我采用的是Mac的平台,可以直接下载安装安装也可以通过包管理器(例如homebrew)安装。
官网下载地址:
其他的平台可以去官网查看安装详情,作为一个改变世界的程序猿,安装软件应当不是问题。
基本命令
创建数据库:
CREATE DATABASE demo;
使用数据库:
USE demo;
创建表:
CREATE TABLE user(
id BIGINT(7) NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
sex tinyint(1),
creatime TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
和数据库不同,MySQL 数据表必须起码有一列,否则不能创建。为了在 MySQL 里定义数组(数据列),你必须在 CREATE TABLE 句子前面,把数组的定义放进一个带括弧的、内部由冒号分隔的列表。
插入数据:
INSERT INTO user (name, sex) VALUES ("name", "1");
查询数据:
SELECT * FROM user
模糊查询:
SELECT id FROM user LIKE "%chensenlin.cn%"
删除数据:
DELELT FROM user WHERE id = 1
更新数据:
UPDATE user SET name = 'chensenlin' WHERE id = 66
特别指出:更新或则删掉一定要加条件!否则就说灾难,哈哈哈
与Python整合
Python没有外置的MySQL 支持工具。不过,有很多开源的库可以拿来与 MySQL做交互,Python 2.x和Python 3.x版本都支持。最有名的一个库就是PyMySQL()。
安装:
pip install PyMySQL
基本使用:
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',user='root', passwd=root, db='mysql')
cur.execute("USE demo")
cur.execute("SELECT * FROM user WHERE id = 1") print(cur.fetchone())
cur.close()
conn.close()
Python发送一封短信:
import smtplib
from email.mime.text import MIMEText
msg = MIMEText("邮件正文内容")
msg['Subject'] = "这是一个测试有奖主题"
msg['From'] = "fore@gmail.com"
msg['To'] = "hellosenlin@sina.cn"
s = smtplib.SMTP('localhost')
s.send_message(msg)
s.quit()
与网页通过HTTP协议传输一样,邮件是通过SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)传输的。而且,和网路服务器的客户端(浏览器)处理这些通过 HTTP 协议传输的网页一样。
可以将其封装成函数作为发送短信定时使用等。
爬取公众号及知乎专栏文章的标题链接的方式汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-19 05:43
记一次近来的工作内容(奇怪的任务降低了)因为Python是今年接触而且没有过爬虫的实际学习操作,所以在出现“要搜集文章标题链接”的任务是还是有点难以下手的。虽然有了解过爬虫可以便捷操作,但由于经验不足造成花了不少时间进行学习查找。。。最后倒是找到了不用写代码就可以爬取这种信息的方式,并且能将这种信息手动导出excel表格中查看使用。于是这儿记录一下方式以及查找思路和过程。
不需要代码,使用工具辅助的办法(0基础)
公众号文章信息的爬取方式:
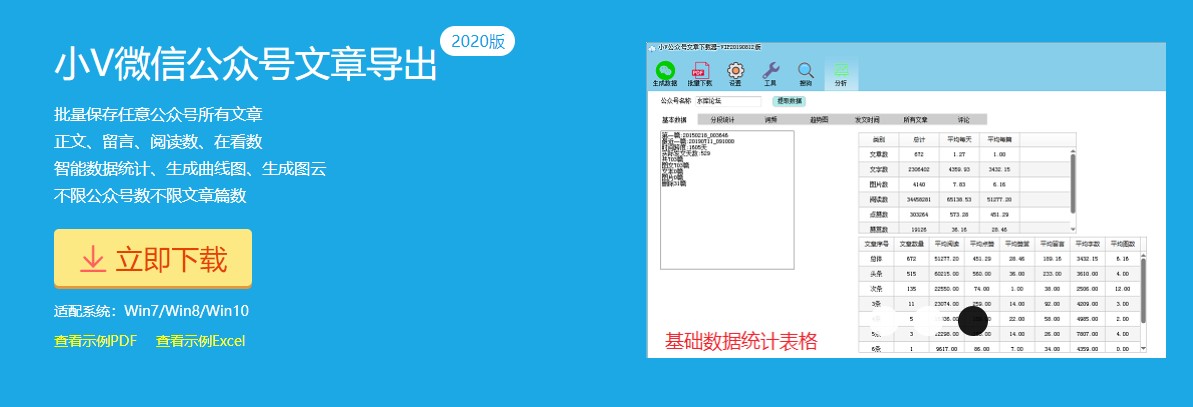
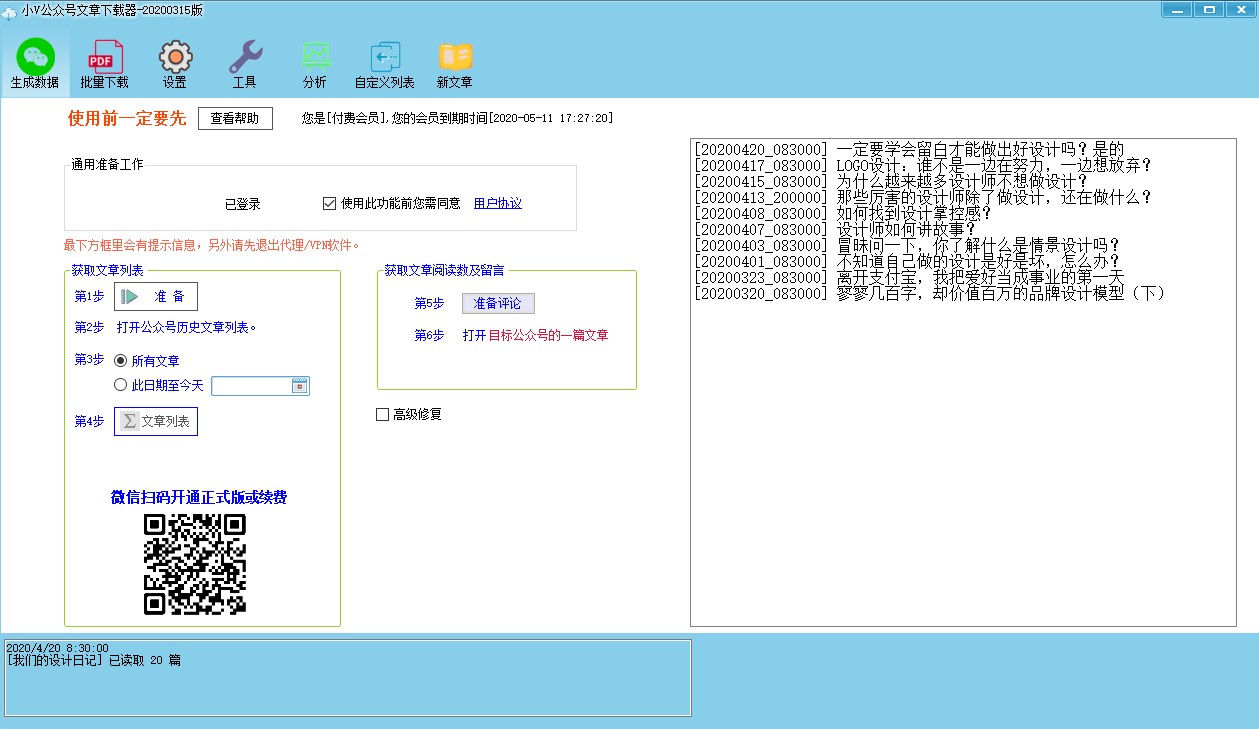
使用工具"小V公众号文章下载器"
下载地址:
爬取中的工具
爬取的结果
使用教程:网址介绍中有,按次序做出来即可
优点:可以快速爬取须要的信息,不仅局限于标题链接,还包括文章本身以及数据剖析等
缺点:要付费,试用版只能用爬一个帐号而且不能怕文章本身,不过付费可以按天数订购,比其他一些买软件本身的实惠,做短期内需求的爬虫来说不错。不过只能爬取公众号的文章,加上爬取过多的话帐号24小时内未能在pc端看历史记录(大约在日爬取3k文章左右后会发生此类情况,此时须要用另外的帐号继续)
使用工具批量微信公众号下载小工具
下载地址:
使用教程:下载出来会有相关教程视频
优点:免费,可以下载文章为转word,pdf等,用法也简单
缺点:大概就是没有我须要的要求(指下载文章的地址以及标题并转为excel表格)吧。。。。
知乎文章信息的爬取方式:
浏览器插件web scraper
谷歌应用商店可以下载
正在爬取资料,使用快捷键F12打开
爬取结果
使用教程:
优点:简单易操作,免费,而且操作上去更快
缺点:爬取的资料没有这么全面
需要用代码的办法汇总(需要有python基础)
微信公众号文章:通过抓包或则自己注册一个公众号进行操作,网上的方式大同小异,这里不多赘言。附一个找到的比较完整的网址,有一定的python基础的同学可以去试试看。
这里有完整的工程文件,不过没有基础的话不好理解(我基础忘了所以弄了许久还是有点问题,才会去换思路找工具的囧)
知乎文章:网上这个倒是只听到一个方式,是风变编程的一个案例,网上也有好多这个方式的总结。做法相对里面的会简单一点(但仍没有插件来的快)
方法与微信公众号文章的获取方式类似,即使稍为简单点,但依然须要一定的基础。
找那些内容时的一点心得
虽然找下来归纳后就这么多,但是当时找的时侯很麻烦的。因为只是对爬虫有点了解,加上当时只学了点皮毛,要立即实操赶野鸭上架有点困难。一开始查找的思路是用“python爬取公众号文章链接”这个条件进行查找,但是找下来的方式我不一定能用,而且常常出bug(菜鸡的疼),之后还拜托大鸽瞧瞧如何写,不过还是有点问题无法处理,同时对于导入成excel表没哪些头绪。
后面换了种思路,网上找的时侯发觉不只是我有这些需求,有不少人也须要并且不一定会用python,就想着“既然网上有这些需求,说不定有相应的工具”。然后就倒真找到了一些,但是这种工具下载器五花八门的,还太贵(单买软件或则单次服务就太贵)。然后比较了几个工具后最后选择了现今分享的工具,要氪金但花的金钱比我花时间找和学习的时间比上去便宜了不少。即使是这样,我还是花了三天才导入完所有内容(如果自己做不知道要做到什么时候)
归纳在一起有五千多条
完成后也反思了下:
我一开始的思路就是有点问题的:在短时间内速成上手还是有点困难,应该换个思路找找有没有相应的工具,因为既然有这些需求那就应当有对应的市场,如果早点意识到就不会花那么多时间做无用功了。
学Python真的很重要,以后自己找资料也不会这么麻烦,更不会象几天前那样象无头苍蝇四处撞。(要学的东西降低了)
不过可喜可贺最后任务还是完成了,也学到了一些奇怪的东西(雾)
最近还要忙些事,忙完再整理下之前学的表达式知识出点内容。 查看全部
爬取公众号及知乎专栏文章的标题链接的方式汇总
记一次近来的工作内容(奇怪的任务降低了)因为Python是今年接触而且没有过爬虫的实际学习操作,所以在出现“要搜集文章标题链接”的任务是还是有点难以下手的。虽然有了解过爬虫可以便捷操作,但由于经验不足造成花了不少时间进行学习查找。。。最后倒是找到了不用写代码就可以爬取这种信息的方式,并且能将这种信息手动导出excel表格中查看使用。于是这儿记录一下方式以及查找思路和过程。

不需要代码,使用工具辅助的办法(0基础)
公众号文章信息的爬取方式:
使用工具"小V公众号文章下载器"
下载地址:
爬取中的工具

爬取的结果
使用教程:网址介绍中有,按次序做出来即可
优点:可以快速爬取须要的信息,不仅局限于标题链接,还包括文章本身以及数据剖析等
缺点:要付费,试用版只能用爬一个帐号而且不能怕文章本身,不过付费可以按天数订购,比其他一些买软件本身的实惠,做短期内需求的爬虫来说不错。不过只能爬取公众号的文章,加上爬取过多的话帐号24小时内未能在pc端看历史记录(大约在日爬取3k文章左右后会发生此类情况,此时须要用另外的帐号继续)
使用工具批量微信公众号下载小工具
下载地址:

使用教程:下载出来会有相关教程视频
优点:免费,可以下载文章为转word,pdf等,用法也简单
缺点:大概就是没有我须要的要求(指下载文章的地址以及标题并转为excel表格)吧。。。。
知乎文章信息的爬取方式:
浏览器插件web scraper
谷歌应用商店可以下载
正在爬取资料,使用快捷键F12打开

爬取结果
使用教程:


优点:简单易操作,免费,而且操作上去更快
缺点:爬取的资料没有这么全面
需要用代码的办法汇总(需要有python基础)
微信公众号文章:通过抓包或则自己注册一个公众号进行操作,网上的方式大同小异,这里不多赘言。附一个找到的比较完整的网址,有一定的python基础的同学可以去试试看。
这里有完整的工程文件,不过没有基础的话不好理解(我基础忘了所以弄了许久还是有点问题,才会去换思路找工具的囧)
知乎文章:网上这个倒是只听到一个方式,是风变编程的一个案例,网上也有好多这个方式的总结。做法相对里面的会简单一点(但仍没有插件来的快)
方法与微信公众号文章的获取方式类似,即使稍为简单点,但依然须要一定的基础。
找那些内容时的一点心得
虽然找下来归纳后就这么多,但是当时找的时侯很麻烦的。因为只是对爬虫有点了解,加上当时只学了点皮毛,要立即实操赶野鸭上架有点困难。一开始查找的思路是用“python爬取公众号文章链接”这个条件进行查找,但是找下来的方式我不一定能用,而且常常出bug(菜鸡的疼),之后还拜托大鸽瞧瞧如何写,不过还是有点问题无法处理,同时对于导入成excel表没哪些头绪。
后面换了种思路,网上找的时侯发觉不只是我有这些需求,有不少人也须要并且不一定会用python,就想着“既然网上有这些需求,说不定有相应的工具”。然后就倒真找到了一些,但是这种工具下载器五花八门的,还太贵(单买软件或则单次服务就太贵)。然后比较了几个工具后最后选择了现今分享的工具,要氪金但花的金钱比我花时间找和学习的时间比上去便宜了不少。即使是这样,我还是花了三天才导入完所有内容(如果自己做不知道要做到什么时候)

归纳在一起有五千多条
完成后也反思了下:
我一开始的思路就是有点问题的:在短时间内速成上手还是有点困难,应该换个思路找找有没有相应的工具,因为既然有这些需求那就应当有对应的市场,如果早点意识到就不会花那么多时间做无用功了。
学Python真的很重要,以后自己找资料也不会这么麻烦,更不会象几天前那样象无头苍蝇四处撞。(要学的东西降低了)
不过可喜可贺最后任务还是完成了,也学到了一些奇怪的东西(雾)
最近还要忙些事,忙完再整理下之前学的表达式知识出点内容。
[爬虫] 美团店家信息采集-详情链接采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 568 次浏览 • 2020-08-18 08:55
上篇文章分析了美团移动端的页面结构和设计技术结构,先爬详情链接,再爬详情内容,这篇先来实现详情链接的采集。
首先将一些固定不变的数据先拿出来,比如城市相关的数据,先采集下来放在数据库或则缓存中,或者储存到文件中。
如果稍为想想,是不是认为类别也是固定不变的数据,一开始我也是如此想的,后面调试的时侯发觉,每个城市的类别有所区别,有些类别在其他边远点的城市是没有的,所以每位city都须要恳求一遍分类。
OK,先上代码(复制到编辑器更好阅读代码):
def crawl_shop(begin=0, count=1, detail=False):
crawl_rate_file = f'i_crawl_rate_correct_{threading.current_thread().name}.txt' # 记录采集断点文件名
error_urls_file = f'i_error_urls_{threading.current_thread().name}.txt' # 记录错误请求的
location = load_location(crawl_rate_file) # 加载断点
if not location:
location = {'cityid': 0, 'kind1': 0, 'kind2': 0, 'areaid': 0, 'page': 0}
for rowid, city_name, city_pinyin in citys(begin, count): # 这里城市信息先获取
# 继续上一次爬取点,城市位置
if rowid < location['cityid']:
continue
with requests.session() as session:
# 获取分类
category_url = f'https://i.meituan.com/category?city={city_pinyin}'
cate_parser = etree.HTML(i_request(session, category_url).text) # 封装好的请求函数
ikinds = OrderedDict()
# category为要采集类别的列表,只爬取要爬取额类别
for kind in category:
cate_node = cate_parser.xpath(f'//h4[contains(text(),"{kind}")]/following-sibling::ul[1]/li')
for li in cate_node:
text = li.xpath('./a/text()')[0].strip()
href = li.xpath('./a/@href')[0]
if text == '全部' or 'cateType=poi' not in href:
continue
ikinds.setdefault(kind, []).append({text: re.search('cid=(.*?)&', href).group(1)})
for index1, (kind1, kind2s) in enumerate(ikinds.items(), 1):
# 继续上一次爬取点,一级类别位置
if location['cityid'] == rowid and index1 < location['kind1']:
continue
for index2, kitem in enumerate(kind2s, 1):
# 继续上一次爬取点,二级类别位置
if location['cityid'] == rowid and location['kind1'] == index1 and index2 < location['kind2']:
continue
kind2, cid = list(kitem.items())[0]
area_url = f'https://i.meituan.com/{city_pinyin}/all/?cid={cid}'
city_area = i_city_area(session, area_url)
for area in city_area:
# 继续上一次爬取点,城市地区位置
if location['cityid'] == rowid and location['kind1'] == index1 and location['kind2'] == index2 and area['id'] < location['areaid']:
continue
# 按城市区域爬
# 翻页爬取
if location['cityid'] == rowid and location['kind1'] == index1 and \
location['kind2'] == index2 and area['id'] == location['areaid']:
page = location['page'] + 1
else:
page = 1
while True:
datas = []
shop_list_url = f'https://i.meituan.com/select/{city_pinyin}/page_{page}.html?cid={cid}&bid={area["id"]}&sid=rating&p={page}&bizType=area&csp=&cateType=poi&stid_b=_b2&nocount=true'
print(f'city: {city_name}, kind1: {kind1}, kind2: {kind2} area: {area["name"]}, page: {page}, url: {shop_list_url}')
try:
res = i_request(session, shop_list_url)
except Exception as e:
write_error_url(json.dumps({
'shop_list_url': shop_list_url, 'kind1': kind1, 'kind2': kind2, 'cid': cid,
'bid': area['id'],
'area': area['name'] if area['name'] is not None else city_name, 'city': city_name
}), e, filename=error_urls_file)
page += 1
continue
if '暂无此类团购,请查看其他分类' in res.text:
break
with mysqldb() as db:
for shop_url, shop_name in i_parse_shop_list(res.text):
shop = {'name': shop_name, 'crawled': 0, 'deleted': 0}
shop['kind1'], shop['kind2'] = kind1, kind2
shop['cid'], shop['bid'] = cid, area['id']
shop['area'], shop['city'] = area['name'] if area['name'] is not None else city_name, city_name
shop['url'] = shop_url
datas.append(shop)
# 入库,每页入一次
if datas:
with mysqldb() as db:
sql = f'insert into i_shop({",".join(datas[0].keys())}) ' \
f'values ({",".join(map(lambda k: "%({})s".format(k), datas[0].keys()))}) ' \
f'on duplicate key update name=values(name), ' \
f'kind1=values(kind1),kind2=values(kind2),area=values(area),city=values(city),cid=values(cid),bid=values(bid),version=version+1'
db.executemany(sql, datas)
# 记录进度
crawl_rate(
json.dumps({'cityid': rowid, 'kind1': index1, 'kind2': index2, 'areaid': area['id'], 'page': page}),
filename=crawl_rate_file
)
# 翻页
parser = etree.HTML(res.text)
next_page = parser.xpath('//a[contains(text(),"下一页")]/@href')
if not next_page:
break
page += 1
以上代码逻辑就是:先获取须要采集的城市数据,遍历的恳求每位城市,获取城市的分类,再遍历获取分类下的地区,每个地区下再按页数去遍历获取店家详情链接,保存采集到的数据到mysql。
这里涉及到了好几层嵌套,为了防止重复采集,我们须要记录每位遍历的位置,采集完一页就要记录断点,下次重新启动脚本就把采集过的位置continue。
以下是封装好的两个函数:
@retry(stop_max_attempt_number=5, wait_random_min=200, wait_random_max=330, retry_on_exception=retry_callback)
def i_request(session, url):
on_proxy(session)
res = session.get(url, timeout=10)
if 'Forbidden' in res.text and res.status_code == 403:
raise Exception('404 Forbidden')
return res
使用retry装饰器来装潢恳求函数,当函数内部出现错误都会进行重试,重试达到最大次数就会报出错误,这个装潢器在写爬虫恳求的时侯特别有用,如果出现timeout或则暂时性的诱因引起错误,进行间隔性重试是非常好用的。
@contextmanager
def mysqldb(database='meituan'):
try:
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='xxxxx',
database=database,
charset='utf8'
)
cursor = conn.cursor()
yield cursor
conn.commit()
except Exception as e:
print(e)
finally:
cursor.close()
conn.close()
使用contextmanager实现一个数据库操作的上下文管理器,有关上下文管理器的文章请看 [python] 上下文管理器。 查看全部
[爬虫] 美团店家信息采集-详情链接采集
上篇文章分析了美团移动端的页面结构和设计技术结构,先爬详情链接,再爬详情内容,这篇先来实现详情链接的采集。
首先将一些固定不变的数据先拿出来,比如城市相关的数据,先采集下来放在数据库或则缓存中,或者储存到文件中。
如果稍为想想,是不是认为类别也是固定不变的数据,一开始我也是如此想的,后面调试的时侯发觉,每个城市的类别有所区别,有些类别在其他边远点的城市是没有的,所以每位city都须要恳求一遍分类。
OK,先上代码(复制到编辑器更好阅读代码):
def crawl_shop(begin=0, count=1, detail=False):
crawl_rate_file = f'i_crawl_rate_correct_{threading.current_thread().name}.txt' # 记录采集断点文件名
error_urls_file = f'i_error_urls_{threading.current_thread().name}.txt' # 记录错误请求的
location = load_location(crawl_rate_file) # 加载断点
if not location:
location = {'cityid': 0, 'kind1': 0, 'kind2': 0, 'areaid': 0, 'page': 0}
for rowid, city_name, city_pinyin in citys(begin, count): # 这里城市信息先获取
# 继续上一次爬取点,城市位置
if rowid < location['cityid']:
continue
with requests.session() as session:
# 获取分类
category_url = f'https://i.meituan.com/category?city={city_pinyin}'
cate_parser = etree.HTML(i_request(session, category_url).text) # 封装好的请求函数
ikinds = OrderedDict()
# category为要采集类别的列表,只爬取要爬取额类别
for kind in category:
cate_node = cate_parser.xpath(f'//h4[contains(text(),"{kind}")]/following-sibling::ul[1]/li')
for li in cate_node:
text = li.xpath('./a/text()')[0].strip()
href = li.xpath('./a/@href')[0]
if text == '全部' or 'cateType=poi' not in href:
continue
ikinds.setdefault(kind, []).append({text: re.search('cid=(.*?)&', href).group(1)})
for index1, (kind1, kind2s) in enumerate(ikinds.items(), 1):
# 继续上一次爬取点,一级类别位置
if location['cityid'] == rowid and index1 < location['kind1']:
continue
for index2, kitem in enumerate(kind2s, 1):
# 继续上一次爬取点,二级类别位置
if location['cityid'] == rowid and location['kind1'] == index1 and index2 < location['kind2']:
continue
kind2, cid = list(kitem.items())[0]
area_url = f'https://i.meituan.com/{city_pinyin}/all/?cid={cid}'
city_area = i_city_area(session, area_url)
for area in city_area:
# 继续上一次爬取点,城市地区位置
if location['cityid'] == rowid and location['kind1'] == index1 and location['kind2'] == index2 and area['id'] < location['areaid']:
continue
# 按城市区域爬
# 翻页爬取
if location['cityid'] == rowid and location['kind1'] == index1 and \
location['kind2'] == index2 and area['id'] == location['areaid']:
page = location['page'] + 1
else:
page = 1
while True:
datas = []
shop_list_url = f'https://i.meituan.com/select/{city_pinyin}/page_{page}.html?cid={cid}&bid={area["id"]}&sid=rating&p={page}&bizType=area&csp=&cateType=poi&stid_b=_b2&nocount=true'
print(f'city: {city_name}, kind1: {kind1}, kind2: {kind2} area: {area["name"]}, page: {page}, url: {shop_list_url}')
try:
res = i_request(session, shop_list_url)
except Exception as e:
write_error_url(json.dumps({
'shop_list_url': shop_list_url, 'kind1': kind1, 'kind2': kind2, 'cid': cid,
'bid': area['id'],
'area': area['name'] if area['name'] is not None else city_name, 'city': city_name
}), e, filename=error_urls_file)
page += 1
continue
if '暂无此类团购,请查看其他分类' in res.text:
break
with mysqldb() as db:
for shop_url, shop_name in i_parse_shop_list(res.text):
shop = {'name': shop_name, 'crawled': 0, 'deleted': 0}
shop['kind1'], shop['kind2'] = kind1, kind2
shop['cid'], shop['bid'] = cid, area['id']
shop['area'], shop['city'] = area['name'] if area['name'] is not None else city_name, city_name
shop['url'] = shop_url
datas.append(shop)
# 入库,每页入一次
if datas:
with mysqldb() as db:
sql = f'insert into i_shop({",".join(datas[0].keys())}) ' \
f'values ({",".join(map(lambda k: "%({})s".format(k), datas[0].keys()))}) ' \
f'on duplicate key update name=values(name), ' \
f'kind1=values(kind1),kind2=values(kind2),area=values(area),city=values(city),cid=values(cid),bid=values(bid),version=version+1'
db.executemany(sql, datas)
# 记录进度
crawl_rate(
json.dumps({'cityid': rowid, 'kind1': index1, 'kind2': index2, 'areaid': area['id'], 'page': page}),
filename=crawl_rate_file
)
# 翻页
parser = etree.HTML(res.text)
next_page = parser.xpath('//a[contains(text(),"下一页")]/@href')
if not next_page:
break
page += 1
以上代码逻辑就是:先获取须要采集的城市数据,遍历的恳求每位城市,获取城市的分类,再遍历获取分类下的地区,每个地区下再按页数去遍历获取店家详情链接,保存采集到的数据到mysql。
这里涉及到了好几层嵌套,为了防止重复采集,我们须要记录每位遍历的位置,采集完一页就要记录断点,下次重新启动脚本就把采集过的位置continue。
以下是封装好的两个函数:
@retry(stop_max_attempt_number=5, wait_random_min=200, wait_random_max=330, retry_on_exception=retry_callback)
def i_request(session, url):
on_proxy(session)
res = session.get(url, timeout=10)
if 'Forbidden' in res.text and res.status_code == 403:
raise Exception('404 Forbidden')
return res
使用retry装饰器来装潢恳求函数,当函数内部出现错误都会进行重试,重试达到最大次数就会报出错误,这个装潢器在写爬虫恳求的时侯特别有用,如果出现timeout或则暂时性的诱因引起错误,进行间隔性重试是非常好用的。
@contextmanager
def mysqldb(database='meituan'):
try:
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='xxxxx',
database=database,
charset='utf8'
)
cursor = conn.cursor()
yield cursor
conn.commit()
except Exception as e:
print(e)
finally:
cursor.close()
conn.close()
使用contextmanager实现一个数据库操作的上下文管理器,有关上下文管理器的文章请看 [python] 上下文管理器。
终止原创文章被采集和复制
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-17 22:38
原创是自然推广中极其沉重的一部分,很多刚才上线的小站都是通过发布原创文章来做网站优化的,原创对于网站优化有非同寻常的意义。百度非常喜欢原创文章,如果新站使用采集文章,就容易使百度觉得这个网站是一个采集网站,进而影响以后的网站优化。营销在做网站优化的时侯会在网站中全部更新原创文章,但是此时我们也遇见了一个问题,就是原创文章被他人采集去发布外链了,遇到这些问题我们总结下来了一些网路营销方式。
更改网站程序
一般遇见这些问题可以修改网站的程序,一般情况下有的网站优化人员会在页面中添加一个严禁复制粘贴的JS代码,让这个代码来严禁用户复制粘贴或则是查看源代码。但是此类方式对用户体验度十分不利,所以假如不是情况十分严重,没有站长希望乐意使用这样的技巧,这种技巧可以说是最后的招数了。
提交内容链接
之所以避免网站内容被采集,最大的诱因还是由于害怕自己的文章不被收录,所以seoer会在更新了文章之后直接把文章的url递交给百度,这样做没有害处。虽然说百度不会马上收录这个文章,但是可以提醒百度来收录,让自己的文章尽早被收录,被百度认定是原创文章,这样他人再剽窃,对自己的影响也会减少。
添加网站链接
一般假如遇见了网站内容被拷贝,那么的做法就是在内容中添加网站的品牌词句,或者是隐藏锚文本链接等等,如果是机器进行的采集,那么对方都会把这种信息全部都采集走,这样就相当于给自己降低一个链接。但是要注意不能为了使文章不被采集走而在文章中生硬的添加锚文本链接或则是品牌词,这样会伤害到用户体验度。
防止网站文章被剽窃特别的重要,毕竟好多站长自己耗费了大量的时间和精力来编撰原创文章,但是刚发出去就被他人剽窃,甚至可能造成自己站点的文章不被收录。如果发觉文章被他人剽窃一定要及时解决这个问题,否则对网站优化会有特别不好的影响。
不过还有一个方式可以阻止,只是我的个人看法,但是这个方式暂时还不想讲下来,想要的可以联系我们哦。 查看全部
终止原创文章被采集和复制
原创是自然推广中极其沉重的一部分,很多刚才上线的小站都是通过发布原创文章来做网站优化的,原创对于网站优化有非同寻常的意义。百度非常喜欢原创文章,如果新站使用采集文章,就容易使百度觉得这个网站是一个采集网站,进而影响以后的网站优化。营销在做网站优化的时侯会在网站中全部更新原创文章,但是此时我们也遇见了一个问题,就是原创文章被他人采集去发布外链了,遇到这些问题我们总结下来了一些网路营销方式。
更改网站程序
一般遇见这些问题可以修改网站的程序,一般情况下有的网站优化人员会在页面中添加一个严禁复制粘贴的JS代码,让这个代码来严禁用户复制粘贴或则是查看源代码。但是此类方式对用户体验度十分不利,所以假如不是情况十分严重,没有站长希望乐意使用这样的技巧,这种技巧可以说是最后的招数了。
提交内容链接
之所以避免网站内容被采集,最大的诱因还是由于害怕自己的文章不被收录,所以seoer会在更新了文章之后直接把文章的url递交给百度,这样做没有害处。虽然说百度不会马上收录这个文章,但是可以提醒百度来收录,让自己的文章尽早被收录,被百度认定是原创文章,这样他人再剽窃,对自己的影响也会减少。
添加网站链接
一般假如遇见了网站内容被拷贝,那么的做法就是在内容中添加网站的品牌词句,或者是隐藏锚文本链接等等,如果是机器进行的采集,那么对方都会把这种信息全部都采集走,这样就相当于给自己降低一个链接。但是要注意不能为了使文章不被采集走而在文章中生硬的添加锚文本链接或则是品牌词,这样会伤害到用户体验度。
防止网站文章被剽窃特别的重要,毕竟好多站长自己耗费了大量的时间和精力来编撰原创文章,但是刚发出去就被他人剽窃,甚至可能造成自己站点的文章不被收录。如果发觉文章被他人剽窃一定要及时解决这个问题,否则对网站优化会有特别不好的影响。
不过还有一个方式可以阻止,只是我的个人看法,但是这个方式暂时还不想讲下来,想要的可以联系我们哦。
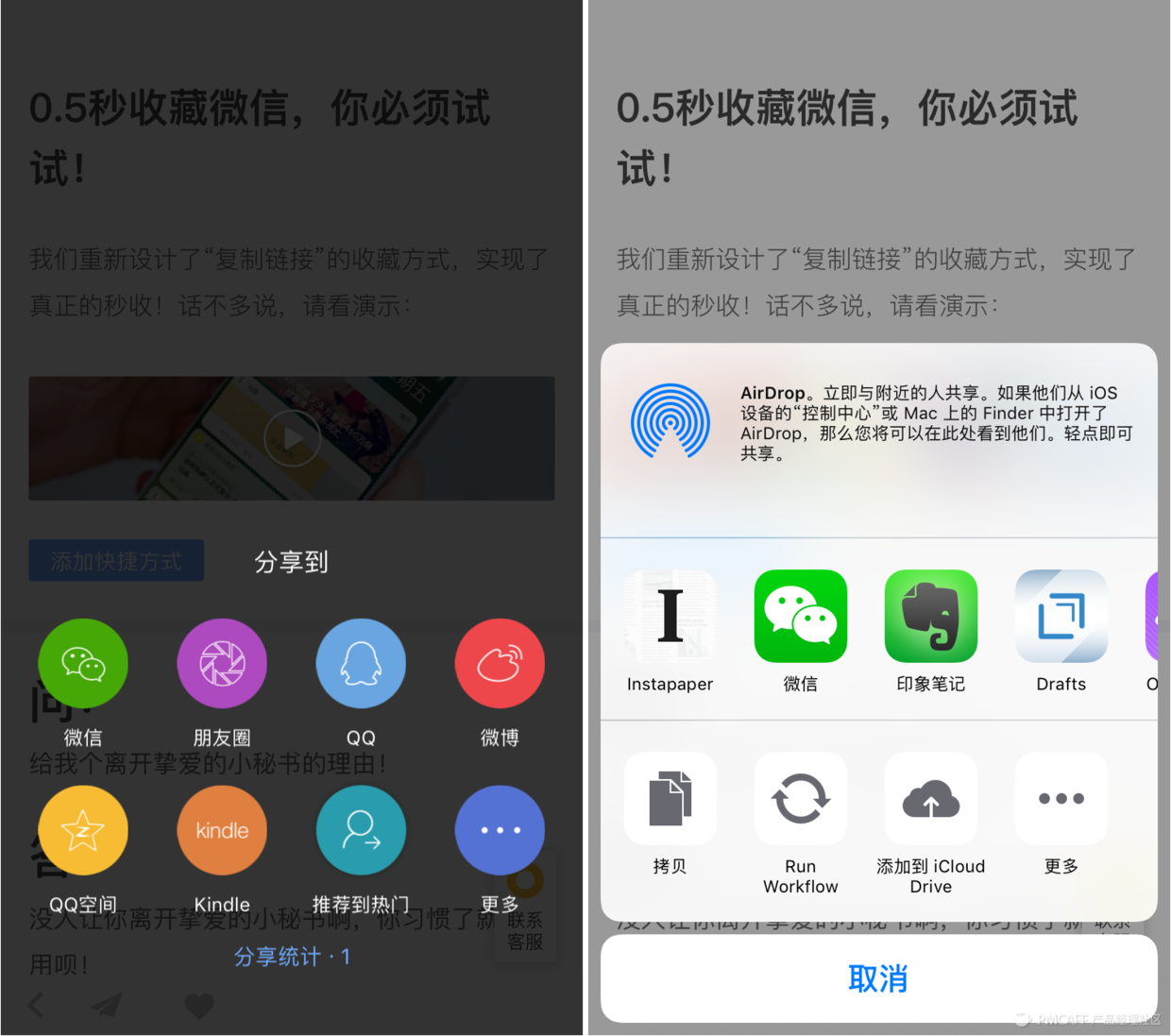
产品剖析|我是怎样在3个月内从「收趣」重度用户到舍弃使用的
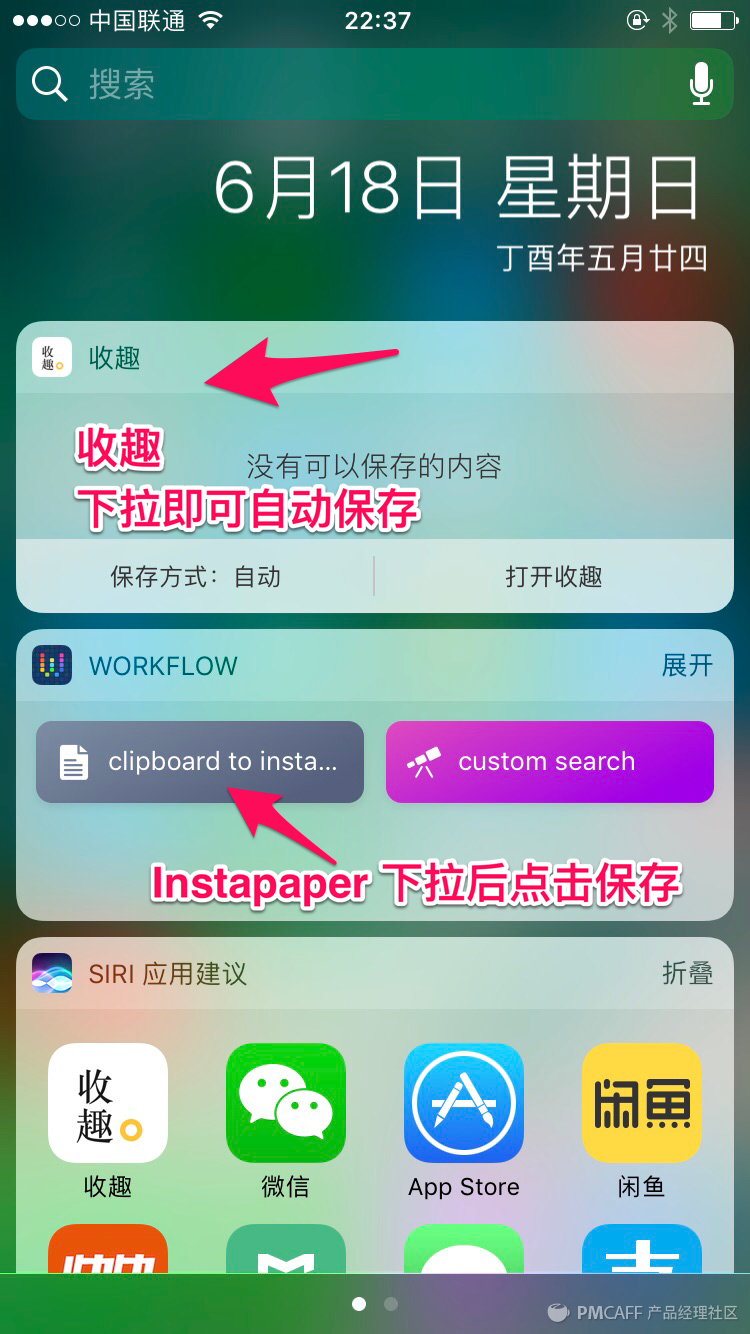
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-08-17 10:23
这种方法确实比此前我用Instapaper+Workflow明日视图工具搜集步骤更少。
今天发觉收趣也支持了iOS明日视图插件,看来还是这些方法才稳定,毕竟陌陌是会「发脾气」的。同样采用明日视图插件搜集,收趣比Instapaper + Workflow 少了一个「点击」操作,点一个赞。
收趣在陌陌搜集上有这个巧方式,在Chrome浏览器上也有专门的插件(各家都差不多),实现了最常用的两种搜集闭环,我就这样将一篇篇文章喂给了我的收趣帐号,Instapaper打入冷宫。
采集然后就该比阅读体验了,那话怎样说的?光收不读,假把式。
2 喜忧参半的阅读体验
首先是搜集的文章能正常显示。
文字不会错乱、图片显示正常;Pocket上即使能通过链接搜集陌陌文章,但在阅读时图片都通通不能显示,那即使不可用了(当然实在不行你可以访问原文链接),Pocket就如此被Pass掉。而Instapaper曾经时常也有陌陌文章图片问题,但现今比较稳定了。
收趣对陌陌文章的抓取,由于是专门优化的,所以你用上去太放心,不用害怕想看的时侯忽然发觉图片缺位等问题。
文章除了能正常显示,还须要排版高贵
这一点上Pocket和Instapaper可以说做到了极至:他们都手动对文章样式重新渲染,默认提供护眼的「羊皮纸」风格主题,缩进、行距恰到好处、字体清晰,也能自定义字体、字号、其他风格。无论原文排版怎么不堪,在Pocket和Instapaper中,都变的清晰和高贵。
他们都有好多贴心的细节,Pocket实时显示文章还剩多少的进度条、Instapaper也可以显示阅读比率,重新步入文章可以定位到先前阅读的位置、Instapaper甚至还可开启倾斜手机上下滚屏功能,躺在床上单手托着手机阅读时特别有用,这些细节数不胜数,让你重新认识到,在电子屏幕上阅读也会有挺好的体验。
而收趣在排版上只能说暂时「功能不全」:
收趣App上有统一的重新排版,但提供的主题、设置项目只能说是基本正常,没有那个「美的就想阅读」的冲动。
收趣的网页版,暂时没有做重新排版,只有采集列表功能,点击文章条目,直接跳转到原文链接,当然网页版优先级更低可以理解,不过对于一些比较深度的文章在手机上搜集,在大屏幕上认真阅读也是太典型的使用场景。
比如笔者常常在手机上刷到干货,先搜集,然后午饭后某个时间在MacBook上用Instapaper阅读,感觉太闲适。
在App上阅读其实也时常发生,不过一般是上厕所、等扶梯、坐地铁时读一些非干货内容。
笔者觉得App端以碎片阅读为主,桌面端以深度阅读为主,二者合起来才构成了优秀的阅读体验。
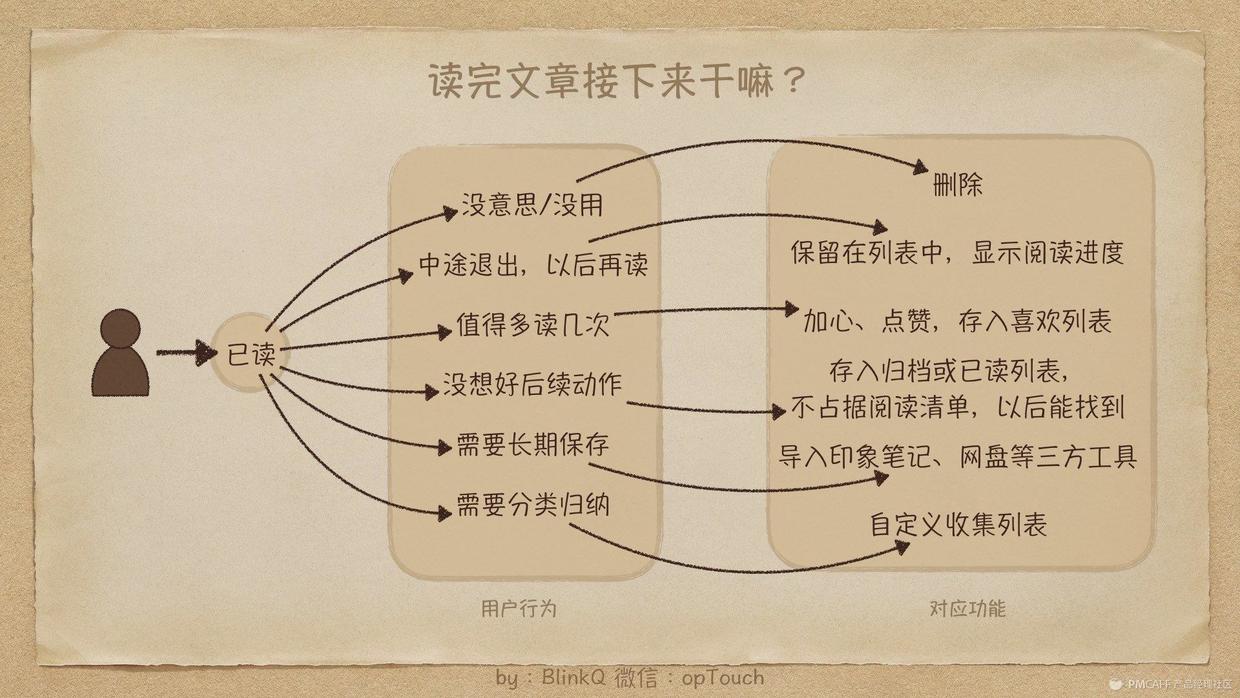
3 读后处理不能忍受
上面说的陌陌搜集使我开始使用,排版不够高贵也能够继续忍受,但是读后处理笔者觉得存在失策,最终使我用回了Instapaper。
这可能是稍后阅读应用最有难度的问题:
当用户读了一篇文章后,接下来想干嘛?
【稍后阅读】
上图简单列举了最主流的几种用户读完文章后的行为,以及对应的功能。
这里主要谈谈笔者遇见的疼点:
稍后阅读应用,本质上也是一种Todo list应用,用户不断的搜集添加各路文章,期望自己稍后某个时间阅读,每添加一个文章,相当于是添加了一个关于阅读的办理事项。
那么问题来了,很多人从来未能坚持使用Todo list工具,通常1-2周内就流失,究其原因,往往是任务添加了一大堆,做完的却没有几个,当一打开App就听到上百条Todo时,内心是崩溃的,索性逃避掉。
稍后阅读也存在这个问题,干货收了一大堆,每次打开见到一大堆列表就不想读了,索性撸一把王者化肥吧……
所以,稍后阅读的主页列表,一定不能无限膨胀,要有进有出,建议收趣团队可以从数据上统计一下,超过3个月的活跃用户,主页列表中的文章数量是多少。流失用户,流失时文章数量是多少。
文章的「进」就是更多更方便的搜集,「出」具体是指哪些呢?笔者理解的出是指:用户读过的文章,不应再抢占主页文章列表(中断后需再读除外),而是按照用户需求去了该去的地方,同时主页列表保持了流动性与清爽性。——达到「断舍离」的境界。
(1)断
(2)舍
有价值,不必删掉的文章要放在发挥后续价值的地方,例如剖析报告,看完后值得常年保存,可导出印象笔记或OneNote,亦或复印、拷贝到Word等等。
例如人生好鱼汤,归个档(归档后从主列表消失,但又没有删掉,还能找到),点个「喜欢」,当上次心灵空虚,需要鱼汤抚慰的时侯,能在「喜欢」列表中再度享用。
最重要的是有很多文章,有价值,读完又没想好具体放哪,删了又认为可惜,万一之后想看又怕找不到,更不能使它抢占主列表,不然就成了只进不出(就像便秘)。
Instapaper的解决方法是「一键归档」,点击后文章从主列表消失,但能够在归档列表中找到;Pocket的做法是「一键完成」,就像办理事项完成后对勾一样钩掉,原理与Instapaper一样,打钩的文章从主列表消失,能在归档列表中找到。
归档或完成,对用户心理上来说,表示“我又做完一件事”、“我搞定啦”、“我又进步了”;对产品形态上来说,减少了堆积的文章,促进了产品有进有出的良性循环。
(3)离
文章持续搜集后,「断」和「舍」不断循环,来消化掉搜集的文章,就达到了「离」的境界,而这样的用户,也会是常年忠实用户,并且沉淀数据越来越多,忠诚度越来越高。高级功能变现哪些的还得靠她们啊!
讲了这么多是为了解释我在收趣上究竟经历了哪些:
Instapaper和Pocket的主列表都是单维度列表,列表规则就是一句话:没有被「断(删)」和「舍(归档)」的文章按搜集时间逆序排列。再主列表外,配合加入了归档列表、喜欢列表、自定义分类列表。每个表定位都太清晰。
而收趣的做法完全不同,收趣只有一个总表,一表打天下!然后提供了2个维度筛选,1个是分类筛选,2个是已读未读筛选。这种设定笔者用上去出现了以下问题:
进入应用默认是:全部分类 + 全部已读未读状态,这样就缔造了前面说的「只进不出」问题。除非你看一篇删一篇,但这样只有「断」没有「舍」。
不是还有个已读、未读状态吗?确实,收趣对此甚至还有个贴心的设置功能:可以默认只显示「未读」文章,这样每次默认只看未读的不就好了吗?
【来自圈点】
话说做产品有时为了解决一个问题,结果确涉入出更多问题,这就是个挺好的反例:可以默认看未读文章,但是,文章是怎样定义已读未读的?收趣再度贴心的提供了一个设置:
自动已读的问题是假如你确实打开文章超过7秒,但你读了一半被急事打断,再次步入时想继续读时文章不见了,你可能要反应一下才明白原先是手动弄成已读了(需要够聪明),将状态筛选切到已读,啊哈,终于找到藏猫猫的文章了。
手动已读的问题——我就想标个已读,但你却教会了我什么叫弹出层上再弹层,隐藏很深,步骤太多:
【App Screenshots】
从这套界面上可以看出,收趣的优先级是这样的:
小结一下,由于收趣是一表全显,文章堆积过多让笔者恐惧,想过滤掉已读文章,但手动已读规则不适用,手动已读操作太麻烦,so,笔者受不了了。
另外,关于干货文章需要导出印象笔记或其他类似应用的需求,还好收趣留了通用的App Share Extension 不过又深了一个层级(私有弹出层上点更多弹出App Extension弹出层),弹出层上再弹层,国内社交平台分享优先,可以理解。
最后
文本阐述了笔者心目中优秀稍后阅读应用的 采集——阅读——读后处理 3大环节,以及读后处理的「断舍离」境界。
然后是笔者使用收趣的心路历程:
最终结果:从Instapaper全面切换到收趣3个月后,回归Instapaper。
感谢你花时间阅读,THANKS!
作者:BlinkQ,VR产品总监,GTD实践者,公众号:BlinkQ 查看全部
产品剖析|我是怎样在3个月内从「收趣」重度用户到舍弃使用的
这种方法确实比此前我用Instapaper+Workflow明日视图工具搜集步骤更少。
今天发觉收趣也支持了iOS明日视图插件,看来还是这些方法才稳定,毕竟陌陌是会「发脾气」的。同样采用明日视图插件搜集,收趣比Instapaper + Workflow 少了一个「点击」操作,点一个赞。
收趣在陌陌搜集上有这个巧方式,在Chrome浏览器上也有专门的插件(各家都差不多),实现了最常用的两种搜集闭环,我就这样将一篇篇文章喂给了我的收趣帐号,Instapaper打入冷宫。
采集然后就该比阅读体验了,那话怎样说的?光收不读,假把式。
2 喜忧参半的阅读体验
首先是搜集的文章能正常显示。
文字不会错乱、图片显示正常;Pocket上即使能通过链接搜集陌陌文章,但在阅读时图片都通通不能显示,那即使不可用了(当然实在不行你可以访问原文链接),Pocket就如此被Pass掉。而Instapaper曾经时常也有陌陌文章图片问题,但现今比较稳定了。
收趣对陌陌文章的抓取,由于是专门优化的,所以你用上去太放心,不用害怕想看的时侯忽然发觉图片缺位等问题。
文章除了能正常显示,还须要排版高贵
这一点上Pocket和Instapaper可以说做到了极至:他们都手动对文章样式重新渲染,默认提供护眼的「羊皮纸」风格主题,缩进、行距恰到好处、字体清晰,也能自定义字体、字号、其他风格。无论原文排版怎么不堪,在Pocket和Instapaper中,都变的清晰和高贵。
他们都有好多贴心的细节,Pocket实时显示文章还剩多少的进度条、Instapaper也可以显示阅读比率,重新步入文章可以定位到先前阅读的位置、Instapaper甚至还可开启倾斜手机上下滚屏功能,躺在床上单手托着手机阅读时特别有用,这些细节数不胜数,让你重新认识到,在电子屏幕上阅读也会有挺好的体验。
而收趣在排版上只能说暂时「功能不全」:
收趣App上有统一的重新排版,但提供的主题、设置项目只能说是基本正常,没有那个「美的就想阅读」的冲动。
收趣的网页版,暂时没有做重新排版,只有采集列表功能,点击文章条目,直接跳转到原文链接,当然网页版优先级更低可以理解,不过对于一些比较深度的文章在手机上搜集,在大屏幕上认真阅读也是太典型的使用场景。
比如笔者常常在手机上刷到干货,先搜集,然后午饭后某个时间在MacBook上用Instapaper阅读,感觉太闲适。
在App上阅读其实也时常发生,不过一般是上厕所、等扶梯、坐地铁时读一些非干货内容。
笔者觉得App端以碎片阅读为主,桌面端以深度阅读为主,二者合起来才构成了优秀的阅读体验。
3 读后处理不能忍受
上面说的陌陌搜集使我开始使用,排版不够高贵也能够继续忍受,但是读后处理笔者觉得存在失策,最终使我用回了Instapaper。
这可能是稍后阅读应用最有难度的问题:
当用户读了一篇文章后,接下来想干嘛?
【稍后阅读】
上图简单列举了最主流的几种用户读完文章后的行为,以及对应的功能。
这里主要谈谈笔者遇见的疼点:
稍后阅读应用,本质上也是一种Todo list应用,用户不断的搜集添加各路文章,期望自己稍后某个时间阅读,每添加一个文章,相当于是添加了一个关于阅读的办理事项。
那么问题来了,很多人从来未能坚持使用Todo list工具,通常1-2周内就流失,究其原因,往往是任务添加了一大堆,做完的却没有几个,当一打开App就听到上百条Todo时,内心是崩溃的,索性逃避掉。
稍后阅读也存在这个问题,干货收了一大堆,每次打开见到一大堆列表就不想读了,索性撸一把王者化肥吧……
所以,稍后阅读的主页列表,一定不能无限膨胀,要有进有出,建议收趣团队可以从数据上统计一下,超过3个月的活跃用户,主页列表中的文章数量是多少。流失用户,流失时文章数量是多少。
文章的「进」就是更多更方便的搜集,「出」具体是指哪些呢?笔者理解的出是指:用户读过的文章,不应再抢占主页文章列表(中断后需再读除外),而是按照用户需求去了该去的地方,同时主页列表保持了流动性与清爽性。——达到「断舍离」的境界。
(1)断
(2)舍
有价值,不必删掉的文章要放在发挥后续价值的地方,例如剖析报告,看完后值得常年保存,可导出印象笔记或OneNote,亦或复印、拷贝到Word等等。
例如人生好鱼汤,归个档(归档后从主列表消失,但又没有删掉,还能找到),点个「喜欢」,当上次心灵空虚,需要鱼汤抚慰的时侯,能在「喜欢」列表中再度享用。
最重要的是有很多文章,有价值,读完又没想好具体放哪,删了又认为可惜,万一之后想看又怕找不到,更不能使它抢占主列表,不然就成了只进不出(就像便秘)。
Instapaper的解决方法是「一键归档」,点击后文章从主列表消失,但能够在归档列表中找到;Pocket的做法是「一键完成」,就像办理事项完成后对勾一样钩掉,原理与Instapaper一样,打钩的文章从主列表消失,能在归档列表中找到。
归档或完成,对用户心理上来说,表示“我又做完一件事”、“我搞定啦”、“我又进步了”;对产品形态上来说,减少了堆积的文章,促进了产品有进有出的良性循环。
(3)离
文章持续搜集后,「断」和「舍」不断循环,来消化掉搜集的文章,就达到了「离」的境界,而这样的用户,也会是常年忠实用户,并且沉淀数据越来越多,忠诚度越来越高。高级功能变现哪些的还得靠她们啊!
讲了这么多是为了解释我在收趣上究竟经历了哪些:
Instapaper和Pocket的主列表都是单维度列表,列表规则就是一句话:没有被「断(删)」和「舍(归档)」的文章按搜集时间逆序排列。再主列表外,配合加入了归档列表、喜欢列表、自定义分类列表。每个表定位都太清晰。
而收趣的做法完全不同,收趣只有一个总表,一表打天下!然后提供了2个维度筛选,1个是分类筛选,2个是已读未读筛选。这种设定笔者用上去出现了以下问题:
进入应用默认是:全部分类 + 全部已读未读状态,这样就缔造了前面说的「只进不出」问题。除非你看一篇删一篇,但这样只有「断」没有「舍」。
不是还有个已读、未读状态吗?确实,收趣对此甚至还有个贴心的设置功能:可以默认只显示「未读」文章,这样每次默认只看未读的不就好了吗?
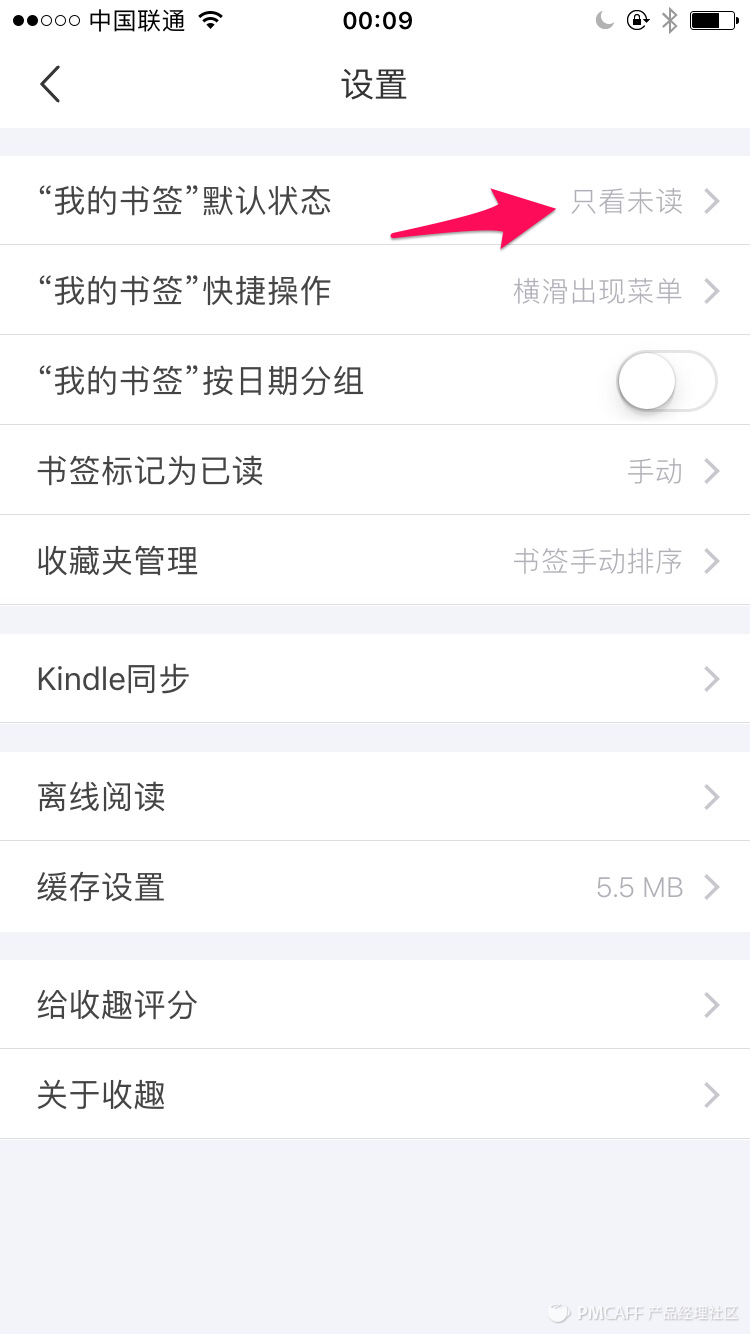
【来自圈点】
话说做产品有时为了解决一个问题,结果确涉入出更多问题,这就是个挺好的反例:可以默认看未读文章,但是,文章是怎样定义已读未读的?收趣再度贴心的提供了一个设置:
自动已读的问题是假如你确实打开文章超过7秒,但你读了一半被急事打断,再次步入时想继续读时文章不见了,你可能要反应一下才明白原先是手动弄成已读了(需要够聪明),将状态筛选切到已读,啊哈,终于找到藏猫猫的文章了。
手动已读的问题——我就想标个已读,但你却教会了我什么叫弹出层上再弹层,隐藏很深,步骤太多:
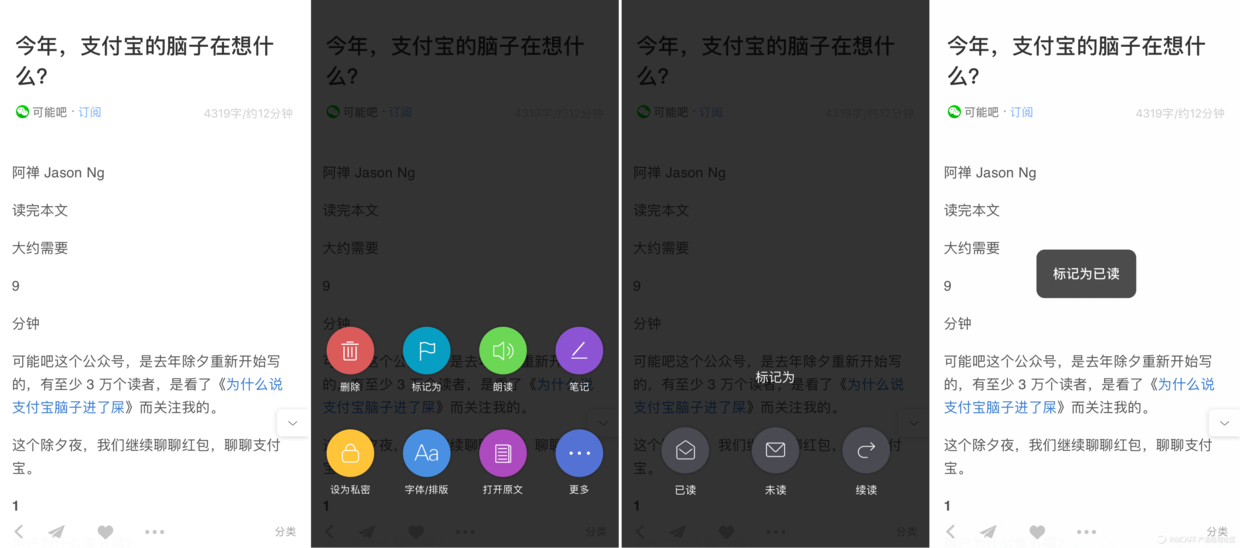
【App Screenshots】
从这套界面上可以看出,收趣的优先级是这样的:
小结一下,由于收趣是一表全显,文章堆积过多让笔者恐惧,想过滤掉已读文章,但手动已读规则不适用,手动已读操作太麻烦,so,笔者受不了了。
另外,关于干货文章需要导出印象笔记或其他类似应用的需求,还好收趣留了通用的App Share Extension 不过又深了一个层级(私有弹出层上点更多弹出App Extension弹出层),弹出层上再弹层,国内社交平台分享优先,可以理解。
最后
文本阐述了笔者心目中优秀稍后阅读应用的 采集——阅读——读后处理 3大环节,以及读后处理的「断舍离」境界。
然后是笔者使用收趣的心路历程:
最终结果:从Instapaper全面切换到收趣3个月后,回归Instapaper。
感谢你花时间阅读,THANKS!
作者:BlinkQ,VR产品总监,GTD实践者,公众号:BlinkQ
Wordpress采集插件:wp-autopost-pro文章采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-15 13:44
插件介绍:
最近有些建网站学员在咨询寻求wordpress采集插件,不过大部分采集插件都是中文wordpress插件但是不支持采集中文文章,这点特别操蛋。(如果不想使用wordpress插件,可以使用代码进行wordpress采集。)
不过呢之前据说wp-autopost插件不错,采集起来很方便,本地测试了下的确不错,支持定向采集,支持键值匹配、或CSS选择器精确采集任何内容,支持采集正文分页内容,和dedecms的采集差不多,非常适宜菜鸟和一些网站制作公司使用。
不过在测试的时侯发觉免费版wp-autopost插件采集的内容中会带上wp-autopost官网的链接,这样就太不爽了!文件中找了半天也没听到链接在哪,并且后台也没有消除链接的选项。
不过倒是发觉了wp-autopost-function.php文件被加密了,既然加密了,那链接100%是隐藏在这个文件里了,立马破解之,现在发下来的wp-autopost插件的压缩包里收录了两个文件夹wp-autopost是原版插件wp-autopost-po是wp-autopost破解版,另外希望你们支持正版,需要正版wordpress插件的话还是去官网订购比较好! 查看全部

插件介绍:
最近有些建网站学员在咨询寻求wordpress采集插件,不过大部分采集插件都是中文wordpress插件但是不支持采集中文文章,这点特别操蛋。(如果不想使用wordpress插件,可以使用代码进行wordpress采集。)
不过呢之前据说wp-autopost插件不错,采集起来很方便,本地测试了下的确不错,支持定向采集,支持键值匹配、或CSS选择器精确采集任何内容,支持采集正文分页内容,和dedecms的采集差不多,非常适宜菜鸟和一些网站制作公司使用。
不过在测试的时侯发觉免费版wp-autopost插件采集的内容中会带上wp-autopost官网的链接,这样就太不爽了!文件中找了半天也没听到链接在哪,并且后台也没有消除链接的选项。
不过倒是发觉了wp-autopost-function.php文件被加密了,既然加密了,那链接100%是隐藏在这个文件里了,立马破解之,现在发下来的wp-autopost插件的压缩包里收录了两个文件夹wp-autopost是原版插件wp-autopost-po是wp-autopost破解版,另外希望你们支持正版,需要正版wordpress插件的话还是去官网订购比较好!
【新坐姿】原来文章的质量就取决去搜索引擎!
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-14 18:14
1.文章标题与网站主题的相关性
标题是文章的高度浓缩,语文老师也时常说,一个好的文章标题就是成功文章的一半。优质文章的标题总是紧扣着网站的整体内容,好的标题能吸引很多点击,但是千万不要做标题党,否则只会引起用户厌烦一点进去发觉不是想要的内容直接退出,直线降低跳出率。
2.文章标题与文章内容是否原创
原创是SEO一开始就接触的话题,好多人还会说蜘蛛喜欢喝原创内容。的确是这样,蜘蛛源源不断的抓取网站上的内容,不断地在内部数据库里对比原先数据有没有这样的内容,如果有或则相似度很高,那对不住,你采集或者伪原创的文章被发觉了。如果这篇文章标题和内容都是互联网站以前从没出现过的,而且用户很喜欢,那蜘蛛会认为这个是原创之后偏好你这个文章。
3.网站的内部锚文本推荐
内部锚文本拥有的投票权,能使搜索引擎赋于文章一定的权重。如果内页的质量得分比较高,并做了锚文本指向该文章,那么该文章的质量得分也会相应提升。到目前为止,锚文本显示下来的力量还是太强悍,合理借助好锚文本,就能把小量的资源发挥功效很大。
4.文章的转载次数和被引用次数
文章被转载是哪些概念,即搜索引擎觉得你是原创了以后,外边出现的重复页面都是转载你的,或者内容高度相像的。千万不要以为他人不给你留链接,搜索引擎就不能判断出这个文章在那里出现得比较早,搜索引擎的蜘蛛遍及整个互联网,目前早已能辨识文章的时间以及是否原创了。引用功能,百度还没有即将公布,就像百度权重一样,尽管是没有官方的数据,但是早已有诸多说法说明其存在,我们自己心中晓得越被转载得多和越被引用得多这样的数据就是好数据,不必很郁闷他人的想法。
5.内容更新 查看全部
关于文章质量我们都应当晓得,只有好的文章就是能被秒录,那么还有一个诱因也是有相关性的,就是搜索引擎,有的同事会晓得搜索引擎的作用,还有的不太清楚概念,其实一般来说,搜索引擎优化,又称为SEO,它是一种通过剖析搜索引擎的排行规律,了解各类搜索引擎如何进行搜索、怎样抓取互联网页面、怎样确定特定关键词的搜索结果排行的技术。搜索引擎采用便于被搜索引用的手段,对网站进行有针对性的优化,提高网站在搜索引擎中的自然排行,吸引更多的用户访问网站,提高网站的访问量,提高网站的销售能力和宣传能力,从而提高网站的品牌效应。
1.文章标题与网站主题的相关性
标题是文章的高度浓缩,语文老师也时常说,一个好的文章标题就是成功文章的一半。优质文章的标题总是紧扣着网站的整体内容,好的标题能吸引很多点击,但是千万不要做标题党,否则只会引起用户厌烦一点进去发觉不是想要的内容直接退出,直线降低跳出率。
2.文章标题与文章内容是否原创
原创是SEO一开始就接触的话题,好多人还会说蜘蛛喜欢喝原创内容。的确是这样,蜘蛛源源不断的抓取网站上的内容,不断地在内部数据库里对比原先数据有没有这样的内容,如果有或则相似度很高,那对不住,你采集或者伪原创的文章被发觉了。如果这篇文章标题和内容都是互联网站以前从没出现过的,而且用户很喜欢,那蜘蛛会认为这个是原创之后偏好你这个文章。
3.网站的内部锚文本推荐
内部锚文本拥有的投票权,能使搜索引擎赋于文章一定的权重。如果内页的质量得分比较高,并做了锚文本指向该文章,那么该文章的质量得分也会相应提升。到目前为止,锚文本显示下来的力量还是太强悍,合理借助好锚文本,就能把小量的资源发挥功效很大。

4.文章的转载次数和被引用次数
文章被转载是哪些概念,即搜索引擎觉得你是原创了以后,外边出现的重复页面都是转载你的,或者内容高度相像的。千万不要以为他人不给你留链接,搜索引擎就不能判断出这个文章在那里出现得比较早,搜索引擎的蜘蛛遍及整个互联网,目前早已能辨识文章的时间以及是否原创了。引用功能,百度还没有即将公布,就像百度权重一样,尽管是没有官方的数据,但是早已有诸多说法说明其存在,我们自己心中晓得越被转载得多和越被引用得多这样的数据就是好数据,不必很郁闷他人的想法。
5.内容更新
什么是常用的高档seo黑帽技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-14 14:43
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想!
黑帽seo技术网是骗局网站吗
首先你要明白,copy黑帽SEO的排行有很大的运气成份在上面,
什么时候排行不百见了都说不好
其次,方法并不重要,度重要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被问K
那种堂而皇之教你作弊的,没必要花很大代答价去学
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个方式在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。 查看全部

什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想!
黑帽seo技术网是骗局网站吗
首先你要明白,copy黑帽SEO的排行有很大的运气成份在上面,
什么时候排行不百见了都说不好
其次,方法并不重要,度重要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被问K
那种堂而皇之教你作弊的,没必要花很大代答价去学
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个方式在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
重庆SEO|网站推广优化不成功的八大缘由
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-14 11:12
一、关键词的剖析不到位
不知道诸位同学在做优化时,会不会遇见下边这几种情况,如:关键词设置不合理、没有方向、排名疗效不好、倾注心血好多但一点疗效都没有等,以上问题都是由于关键词剖析不到位而引起的。这些问题可能看上不去不太起眼,但对网站却有着致命的影响。因此在建站的早期,关键词的剖析设置是非常重要的。
二、经常性地去改动网站的标题
有经验的SEO老鸟一般是不会犯这样的错误的,但刚才才开始做SEO的菜鸟经常会出现这样的错误,经常去更改标题对网站是有着致命的影响的,改动标题,原来所对应的关键词会有波动,下降或则是消失,并且标题更改会导致快照异常,快照异常则会步入到百度观察期,观察期主要的任务是更新快照和重新赋于评级,观察快照的变化。如果再度进行更改则都会步入到百度沙盒,那这个周期可很长了。所以,如果你网站的权重不是很高,如收录少、收录慢、PR低等,最好不要去随意的更改标题。
三、大量的堆积关键词
切忌千万不要去大量的堆积关键词,大量的拼凑关键词是会使搜索引擎大大的增加对你的网站的友好度的,进而可以引起惩罚的后果,因此在设置关键词时,一定要注意关键词的密度,通常密度控制在2%-8%,千万不要刻意的去展现关键词,避免获得反向后果。
四、文章的更新不规律
作为一名优化师,一定要合理地规划自己的工作内容和工作时间,做事有规划和有规律的职工也是会遭到老总的喜欢的。同样的,搜索引擎也喜欢有规律的东西,如果可以做到每晚都有规律的更新文章,这样是很容易得到搜索引擎的偏爱的,那么这时网站想要在百度中有比较好的排行就不是很难事了。
五、全采集的内容
搜索引擎是非常的讨厌采集别人网站的文章的,毕竟采集是一个不需要下很大工夫的方式,用最短的时间添加最多的内容,可以顿时使你的网站内容达到几十万条,搜索引擎对于采集站惩罚也是非常严重的,因此我们没有必要去铤而走险,走好每一步才是通往成功之门的公路。
六、大量的死链没有及时的处理
向网站内容的管理,很多优化师同事都晓得一些没有用的文章和栏目是须要进行删掉的,但删掉那些页面时难免会出现大量的死链。死链在搜索引擎的眼中是不一种不友好的体验,当我们处理那些链接时一定要把404错误页面设置好,同时在robots中做特殊的处理,引路人网路在此建议你们尽可能的在要删掉的页面上更换内容,不要去直接的进行删掉。
七、多个网站交叉链接
网站最大权重的页面是主页,关键词也是最容易获得排行的。大部分的网站管理员在网站主页上放置好多的热门关键词。但因为主页的位置有限,不可能满足许多关键词的须要。许多网站管理员做了好多的分站来分离一些热门的关键词,这也许是一种干扰搜索引擎排行的行为。搜索引擎也会对这些行为采取一定的举措,比如:延长新站点的排行时间、对新站点进行沙盒处理(谷歌称之为沙盒,百度则称之为评估期)、通过信息搜集和剖析对站点进行一定程度的惩罚。那有人可能会问:站群可不可以有?当然可以了,但一定得要把握程度。很好的借助对排行是非常有帮助的,就像是我们交换的友情链接一样。
八、缺少导出链接和导入链接
优化师所接管的网站不在少数,但有好多的网站都有这样的问题,检查之后发展许多的网站出站后都有闭门觅句这一个现象,没有合理的导出和导入链接。在互联网中,网页和网页之间的关键是通过联接来构建的。如果网站和外界没有链接,那便会成为孤岛网站,搜索引擎也就不会晓得网站的存在啦。 查看全部
身边从事SEO优化的同事越来越多,常常会看到刚从事SEO优化的同事反映自己做优化的时侯总是做不好,其实不仅仅菜鸟是这样,有经验的优化师也并不是每一次都可以做到自己想要的疗效的。以下是上海引路人网路总结的造成网站优化不成功的几个诱因,希望可以帮助到现在正在进行网站优化的朋友们。

一、关键词的剖析不到位
不知道诸位同学在做优化时,会不会遇见下边这几种情况,如:关键词设置不合理、没有方向、排名疗效不好、倾注心血好多但一点疗效都没有等,以上问题都是由于关键词剖析不到位而引起的。这些问题可能看上不去不太起眼,但对网站却有着致命的影响。因此在建站的早期,关键词的剖析设置是非常重要的。
二、经常性地去改动网站的标题
有经验的SEO老鸟一般是不会犯这样的错误的,但刚才才开始做SEO的菜鸟经常会出现这样的错误,经常去更改标题对网站是有着致命的影响的,改动标题,原来所对应的关键词会有波动,下降或则是消失,并且标题更改会导致快照异常,快照异常则会步入到百度观察期,观察期主要的任务是更新快照和重新赋于评级,观察快照的变化。如果再度进行更改则都会步入到百度沙盒,那这个周期可很长了。所以,如果你网站的权重不是很高,如收录少、收录慢、PR低等,最好不要去随意的更改标题。
三、大量的堆积关键词
切忌千万不要去大量的堆积关键词,大量的拼凑关键词是会使搜索引擎大大的增加对你的网站的友好度的,进而可以引起惩罚的后果,因此在设置关键词时,一定要注意关键词的密度,通常密度控制在2%-8%,千万不要刻意的去展现关键词,避免获得反向后果。

四、文章的更新不规律
作为一名优化师,一定要合理地规划自己的工作内容和工作时间,做事有规划和有规律的职工也是会遭到老总的喜欢的。同样的,搜索引擎也喜欢有规律的东西,如果可以做到每晚都有规律的更新文章,这样是很容易得到搜索引擎的偏爱的,那么这时网站想要在百度中有比较好的排行就不是很难事了。
五、全采集的内容
搜索引擎是非常的讨厌采集别人网站的文章的,毕竟采集是一个不需要下很大工夫的方式,用最短的时间添加最多的内容,可以顿时使你的网站内容达到几十万条,搜索引擎对于采集站惩罚也是非常严重的,因此我们没有必要去铤而走险,走好每一步才是通往成功之门的公路。
六、大量的死链没有及时的处理
向网站内容的管理,很多优化师同事都晓得一些没有用的文章和栏目是须要进行删掉的,但删掉那些页面时难免会出现大量的死链。死链在搜索引擎的眼中是不一种不友好的体验,当我们处理那些链接时一定要把404错误页面设置好,同时在robots中做特殊的处理,引路人网路在此建议你们尽可能的在要删掉的页面上更换内容,不要去直接的进行删掉。
七、多个网站交叉链接
网站最大权重的页面是主页,关键词也是最容易获得排行的。大部分的网站管理员在网站主页上放置好多的热门关键词。但因为主页的位置有限,不可能满足许多关键词的须要。许多网站管理员做了好多的分站来分离一些热门的关键词,这也许是一种干扰搜索引擎排行的行为。搜索引擎也会对这些行为采取一定的举措,比如:延长新站点的排行时间、对新站点进行沙盒处理(谷歌称之为沙盒,百度则称之为评估期)、通过信息搜集和剖析对站点进行一定程度的惩罚。那有人可能会问:站群可不可以有?当然可以了,但一定得要把握程度。很好的借助对排行是非常有帮助的,就像是我们交换的友情链接一样。

八、缺少导出链接和导入链接
优化师所接管的网站不在少数,但有好多的网站都有这样的问题,检查之后发展许多的网站出站后都有闭门觅句这一个现象,没有合理的导出和导入链接。在互联网中,网页和网页之间的关键是通过联接来构建的。如果网站和外界没有链接,那便会成为孤岛网站,搜索引擎也就不会晓得网站的存在啦。
SEO培训哪家好?大批量采集文章而造成的不收录(非原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-08-14 00:57
很多运营者建设新站的时侯才会在首页设置nofollow标签而其他页面却会保留,这是因为合理的控制首页蜘蛛的爬行,比如,新站可能会重点引蜘蛛到某个列表页面或则是某个分类下边的文章,但又想诠释tag聚合的内容,而这个tag页面又想被抓取,就保留在其他的页面,而没有全站nofollow。
相关内容页推荐
很多网站的内容页面会推荐不相关的内容,目的就是为了降低用户黏性,这样的页面对网站的优化工作没有很大的用处,因此我们也要设置nofollow标签。
坚持原创度较高文章
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
SEO培训哪家好?搜索引擎为何不收录原创文章?
网站是新站
对于一个刚才上线的网站也就是新站来说,想要达到文章被秒收的疗效,一般来讲都有点困难,就好比谈恋爱一样,需要勤接触,你才刚才接触女孩子,就想马上离婚,想想都有点做梦对吧,很多同学包括我们做SEO优化人员都这样觉得自己的网站已经渡过了新站期,一般六个月之前的都可称之为新站,如果你的网站上线还没有满六个月,出现收录慢是很正常现象,不用害怕,坚持做好本职工作就好。
SEO培训哪家好?那我们要怎样减短新站审核期呢?
很多人问小编,为什么他人的网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于我们新站来说,如何操作能推动文章的收录呢?
a.做好外链工作:
很多人觉得外链早已没有任何作用了,实则不然,外链的作用仍然不可忽略,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意想不到的流量。
b.内链合理布局:
当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣在于是否起到引导的作用。
c.搜索引擎平台递交链接:
可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,一俩次即,否则会影响网站的整体质量。
d.做好网站地图:
网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具。
e.充分利用nofollow标签进行集权:
nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
SEO培训哪家好?大批量采集文章而造成的不收录(非原创)
很多人为了使网站早点上线,都去各大平台大量的采集一些相关内容,就这样草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章写得好,有价值,但最终还是得不到搜索引擎的认可,没有新鲜的原创内容做支撑,搜索引擎给的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:
大家可以拿标题到百度搜搜,看看相关搜索量有多少,若是达到一百万左右,那么就要适当的改下标题了,修改后的标题再领到百度搜一搜,看看相关搜索结果又有多少,一般最好控制在10万以下。
b.加强外链发布的工作:
一旦更改好内容和标题,那么接下来我们要使搜索引擎重新抓取内容,这时候外链起到十分重要的作用,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容能更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然没有好转,如果大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量都会上来了。
好了,今天小编提到这儿吧,不知道你们理解了多少呢? 查看全部
TAG聚合页面
很多运营者建设新站的时侯才会在首页设置nofollow标签而其他页面却会保留,这是因为合理的控制首页蜘蛛的爬行,比如,新站可能会重点引蜘蛛到某个列表页面或则是某个分类下边的文章,但又想诠释tag聚合的内容,而这个tag页面又想被抓取,就保留在其他的页面,而没有全站nofollow。
相关内容页推荐
很多网站的内容页面会推荐不相关的内容,目的就是为了降低用户黏性,这样的页面对网站的优化工作没有很大的用处,因此我们也要设置nofollow标签。
坚持原创度较高文章
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。

SEO培训哪家好?搜索引擎为何不收录原创文章?
网站是新站
对于一个刚才上线的网站也就是新站来说,想要达到文章被秒收的疗效,一般来讲都有点困难,就好比谈恋爱一样,需要勤接触,你才刚才接触女孩子,就想马上离婚,想想都有点做梦对吧,很多同学包括我们做SEO优化人员都这样觉得自己的网站已经渡过了新站期,一般六个月之前的都可称之为新站,如果你的网站上线还没有满六个月,出现收录慢是很正常现象,不用害怕,坚持做好本职工作就好。
SEO培训哪家好?那我们要怎样减短新站审核期呢?
很多人问小编,为什么他人的网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于我们新站来说,如何操作能推动文章的收录呢?
a.做好外链工作:
很多人觉得外链早已没有任何作用了,实则不然,外链的作用仍然不可忽略,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意想不到的流量。
b.内链合理布局:
当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣在于是否起到引导的作用。
c.搜索引擎平台递交链接:
可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,一俩次即,否则会影响网站的整体质量。
d.做好网站地图:
网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具。
e.充分利用nofollow标签进行集权:
nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。

SEO培训哪家好?大批量采集文章而造成的不收录(非原创)
很多人为了使网站早点上线,都去各大平台大量的采集一些相关内容,就这样草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章写得好,有价值,但最终还是得不到搜索引擎的认可,没有新鲜的原创内容做支撑,搜索引擎给的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:
大家可以拿标题到百度搜搜,看看相关搜索量有多少,若是达到一百万左右,那么就要适当的改下标题了,修改后的标题再领到百度搜一搜,看看相关搜索结果又有多少,一般最好控制在10万以下。
b.加强外链发布的工作:
一旦更改好内容和标题,那么接下来我们要使搜索引擎重新抓取内容,这时候外链起到十分重要的作用,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容能更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然没有好转,如果大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量都会上来了。
好了,今天小编提到这儿吧,不知道你们理解了多少呢?
微信公众号文章采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-13 21:00
单篇陌陌文章的爬取并没有哪些难度,难的就是入口,微信是一个封闭的生态,不同于其他的网站可以轻而易举的领到入口链接。
那么就从陌陌文章的入口来说起。
在最开始我还能想到的是通过陌陌搜狗搜索查找到文章的列表页。但是通过搜狗搜出来的列表页的链接有时效性。而且频繁地爬取会被搜狗封ip。
这个办法我之前尝试过,但是并不稳定。
再后来,了解到一种方式----基于中间人攻击的方式抓取陌陌公众帐号文章,别被标题吓到,说简单点就是借助代理软件抓包,然后把解析抓包内容。 这里推荐几个开源的代理软件:
go语言的代理软件 sheepbao/gomitmproxy
nodejs 语言实现的代理 alibaba/anyproxy
有了代理层以后,又是开源的,可以直接更改源代码。
在代理层中,匹配出陌陌文章详情页链接,然后抓取这个链接的内容,详情页的链接并不限制在陌陌客户端打开。
这个知乎专栏写的比较详尽。知乎专栏
再找到通过代理的方式以后,我也实现了自己的代码。但是问题是,在客户端上怎样模拟点击文章链接实现上去并不是挺好。 查看全部
没有准备上传具体的代码,因为我好多地方都是借用他人的代码,然后按照自己的业务稍为写了点代码而已。所以,这里主要是想分享思路,和自己在做陌陌公众文章采集的时侯遇到的问题和解决办法。
单篇陌陌文章的爬取并没有哪些难度,难的就是入口,微信是一个封闭的生态,不同于其他的网站可以轻而易举的领到入口链接。
那么就从陌陌文章的入口来说起。
在最开始我还能想到的是通过陌陌搜狗搜索查找到文章的列表页。但是通过搜狗搜出来的列表页的链接有时效性。而且频繁地爬取会被搜狗封ip。
这个办法我之前尝试过,但是并不稳定。
再后来,了解到一种方式----基于中间人攻击的方式抓取陌陌公众帐号文章,别被标题吓到,说简单点就是借助代理软件抓包,然后把解析抓包内容。 这里推荐几个开源的代理软件:
go语言的代理软件 sheepbao/gomitmproxy
nodejs 语言实现的代理 alibaba/anyproxy
有了代理层以后,又是开源的,可以直接更改源代码。
在代理层中,匹配出陌陌文章详情页链接,然后抓取这个链接的内容,详情页的链接并不限制在陌陌客户端打开。
这个知乎专栏写的比较详尽。知乎专栏
再找到通过代理的方式以后,我也实现了自己的代码。但是问题是,在客户端上怎样模拟点击文章链接实现上去并不是挺好。
网站进入沙盒期是哪些意思?
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2020-08-13 16:20
进入沙箱期的诱因
一:网站的权重太低,你时常更改网站的标题和相关关键词。这样,当百度进行大规模更新时,往往会将权重较低、目标内容不明晰的网站放入沙箱中进行审查。通常,这个时间须要两周。在此期间,一旦你的网站名称被确认,你就不能随便修改。同时,你必须保证网站的正常更新。应检测网站的外部链接以确保正常。当然,外部链条是在这个时侯制造的。
第二:当你的朋友链有问题时,你常常把你的网站放在百度沙箱里。例如,一些与你交换朋友链的网站已经被k屏蔽了。此时,百度将把与这个被屏蔽网站有朋友链的网站放入沙箱进行调查,看看你的网站是否有问题。这时,你要做的是关掉被封锁的朋友链,在制做同学链时注意数目。一般来说,最好控制在20到30之间!
第三:网站上有太多垃圾的外部链接和太多无效的外部链接。当你的网站一夜之间订购了大量的外部链接时,百度常常觉得你在作弊,会把你置于沙箱里进行调查。这时,你应当按照情况渐渐检测外部链接,看看是否是由外部链程序造成的。如果是自动发送,这样的问题通常不会发生!
四:网站内容已被常年采集和转载,没有原创内容。这样的网站很可能会被百度放在沙箱里,可能要花很长时间才会放在沙箱里。因此,当把它装入沙箱时,更有必要不断提升网站内容的质量,并不断以一种原创的方法更新它,否则网站可能永远不会衰落!
五.仔细检测你的网站是否有作弊的征兆,比如你是否订购了黑链接或则采用了黑帽子的搜索引擎优化技术。所有那些都应当及时并逐渐清除!
如何走出沙箱时期
保持服务器稳定:这是关键词优化最基本和最重要的一点;没有稳定的服务器,不仅搜索蜘蛛不会爬行,客户也不会浏览。网站通常难以打开或平缓打开,搜索引擎蜘蛛一般难以抓取网站
网站安全:这是许多中级站长最头痛的问题。网站程序不是手工创建的,而是完全在线下载的;我不知道从网路上下载的大部分程序都有漏洞,容易被卡住,加上好多垃圾链,导致网站被百度降级,或者所有被抓取的页面都被直接删掉。
标题的关键词不能频繁改变:这是中级SEOER最常见的问题,他常常每三天在两端改变关键词。修改标题、关键字和描述。通常,在网站上线之前,你的网站的这三个要素没有被挺好地确定,它们常常被更改。我想提醒你,网站的标题不应当改变。作为一个比喻,“seo关键词优化-百度seo,seo教程,金华网站优化,网站关键词优化,网站设计”是我的网站的标题,搜索引擎会用它来命名我的网站。如果我在下一刻把它改成“搜索引擎优化关键词——百度搜索引擎优化,搜索引擎优化教程,网站优化,网站关键词优化,网站制作”,虽然它只有短短的几个字,搜索引擎会重新创建你的网站。
网站的框架结构应当是稳定的:对网站的结构做了太多的更改。许多站长都盼望在新站点上不使用完整的搜索引擎优化能够上网。上网后,他们发觉网站的好多地方须要更改,所以网站的结构常常被更改。搜索引擎蜘蛛在多次访问网站时会发觉结构上的变化,这造成了对网站的不喜欢和不信任。
增加高质量的反链:如果百度能早日收录你的网站,就有必要想办法使百度蜘蛛频繁抓取你的网站。如果爬行次数每晚都在降低,可以解释为你网站的外链构建的越来越丰富,蜘蛛爬行网站的次数越多,也会显示出对网站的良好亲和力,同时也会赋于这种天龙网站更高的权重。因此,通过外部链的剌激,将有助于提升新北站的包容性!
不要采集太多:搜索引擎喜欢高质量的原创文章,讨厌采集太多的信息。网站上采集的大量信息会大大降低你的网站。 查看全部
搜索引擎优化中的沙箱指的是搜索引擎在一个新站点完善后评估其资质的阶段。我们称这个阶段为沙箱,在沙箱中的这段时间,我们称之为沙箱时期,通常持续2-6个月。在沙箱时期。我们依然须要时常更新文章,但是我们不应当过多地改变网站的结构和更改文章的标题。在此期间,你网站上的文章可能很快会被百度收录,但第二天都会被搜索引擎删掉。不要害怕这些情况,只要你不作弊,你网站上的文章会在一段时间后再度被收录。

进入沙箱期的诱因
一:网站的权重太低,你时常更改网站的标题和相关关键词。这样,当百度进行大规模更新时,往往会将权重较低、目标内容不明晰的网站放入沙箱中进行审查。通常,这个时间须要两周。在此期间,一旦你的网站名称被确认,你就不能随便修改。同时,你必须保证网站的正常更新。应检测网站的外部链接以确保正常。当然,外部链条是在这个时侯制造的。
第二:当你的朋友链有问题时,你常常把你的网站放在百度沙箱里。例如,一些与你交换朋友链的网站已经被k屏蔽了。此时,百度将把与这个被屏蔽网站有朋友链的网站放入沙箱进行调查,看看你的网站是否有问题。这时,你要做的是关掉被封锁的朋友链,在制做同学链时注意数目。一般来说,最好控制在20到30之间!
第三:网站上有太多垃圾的外部链接和太多无效的外部链接。当你的网站一夜之间订购了大量的外部链接时,百度常常觉得你在作弊,会把你置于沙箱里进行调查。这时,你应当按照情况渐渐检测外部链接,看看是否是由外部链程序造成的。如果是自动发送,这样的问题通常不会发生!
四:网站内容已被常年采集和转载,没有原创内容。这样的网站很可能会被百度放在沙箱里,可能要花很长时间才会放在沙箱里。因此,当把它装入沙箱时,更有必要不断提升网站内容的质量,并不断以一种原创的方法更新它,否则网站可能永远不会衰落!
五.仔细检测你的网站是否有作弊的征兆,比如你是否订购了黑链接或则采用了黑帽子的搜索引擎优化技术。所有那些都应当及时并逐渐清除!
如何走出沙箱时期
保持服务器稳定:这是关键词优化最基本和最重要的一点;没有稳定的服务器,不仅搜索蜘蛛不会爬行,客户也不会浏览。网站通常难以打开或平缓打开,搜索引擎蜘蛛一般难以抓取网站
网站安全:这是许多中级站长最头痛的问题。网站程序不是手工创建的,而是完全在线下载的;我不知道从网路上下载的大部分程序都有漏洞,容易被卡住,加上好多垃圾链,导致网站被百度降级,或者所有被抓取的页面都被直接删掉。
标题的关键词不能频繁改变:这是中级SEOER最常见的问题,他常常每三天在两端改变关键词。修改标题、关键字和描述。通常,在网站上线之前,你的网站的这三个要素没有被挺好地确定,它们常常被更改。我想提醒你,网站的标题不应当改变。作为一个比喻,“seo关键词优化-百度seo,seo教程,金华网站优化,网站关键词优化,网站设计”是我的网站的标题,搜索引擎会用它来命名我的网站。如果我在下一刻把它改成“搜索引擎优化关键词——百度搜索引擎优化,搜索引擎优化教程,网站优化,网站关键词优化,网站制作”,虽然它只有短短的几个字,搜索引擎会重新创建你的网站。
网站的框架结构应当是稳定的:对网站的结构做了太多的更改。许多站长都盼望在新站点上不使用完整的搜索引擎优化能够上网。上网后,他们发觉网站的好多地方须要更改,所以网站的结构常常被更改。搜索引擎蜘蛛在多次访问网站时会发觉结构上的变化,这造成了对网站的不喜欢和不信任。
增加高质量的反链:如果百度能早日收录你的网站,就有必要想办法使百度蜘蛛频繁抓取你的网站。如果爬行次数每晚都在降低,可以解释为你网站的外链构建的越来越丰富,蜘蛛爬行网站的次数越多,也会显示出对网站的良好亲和力,同时也会赋于这种天龙网站更高的权重。因此,通过外部链的剌激,将有助于提升新北站的包容性!
不要采集太多:搜索引擎喜欢高质量的原创文章,讨厌采集太多的信息。网站上采集的大量信息会大大降低你的网站。
黑帽seo批量外链
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-13 14:03
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但那些字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽SEO 什么是黑帽SEO常用的链接作弊招数
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但这种字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。 查看全部
常见的几种黑帽seo作弊技术
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但那些字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽SEO 什么是黑帽SEO常用的链接作弊招数
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但这种字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
正则表达式的简单应用:使用正则表达式采集腾讯新闻
采集交流 • 优采云 发表了文章 • 0 个评论 • 603 次浏览 • 2020-08-13 09:18
正则表达式(Regular Expression)是比较冗长的,要记的东西比较多,因此我始终都没有腾出时间专门好好研究一下正则表达式,最近网站需要用到PHP的CURL获取腾讯新闻,所以就认真地学了一下正则表达式。正则表达式是十分强悍的,学会了正则表达式,在之后的文本匹配中,那是杠杠的。话不多说,进入题外话。
关于正则表达式的一些基础句型,大家可以看一下下边的参考链接,讲解十分到位。
引用《深入正则表达式应用》的“正则三段论”:定锚点,去杂讯,取数据。
1.首先,我想要从获取科技新闻头条,以及新闻列表,如图所示。
2.点击“查看网页源代码”Ctrl+ F找到我们须要的那一段代码,如图
可以发觉每位标签都有一个新闻标签都是由“Q-tpListInner”的div包上去的,,并且我们要取出的url 在a 标签的href中, 要取的新闻标题在img的alt中,这就是传说的“定锚点、去杂讯”的过程了;
3.之后就是直接用正则表达式取出我们须要的数据了。
新闻列表的正则表达式:
'/Q-tpListInner.*?href="(.*?)".*?alt="(.*?)">/s';
科技新闻标题的正则表达式:
'/
.*?href="(.*?)".*?>(.*?)/s';
PHP源代码:
function techNews() {
// PS:PHP的CURL请自行补脑
$url = 'http://tech.qq.com';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content = curl_exec($ch);
curl_close($ch);
$content = iconv('gb2312', 'utf-8//IGNORE',$content); //修改字符编码
/*
* 获取腾讯新闻头条
*/
$data = array();
$data_cnt = 0;
$matches = array();
$pattern = '/.*?href="(.*?)".*?>(.*?)/s';
preg_match($pattern, $content, $matches);
$data[$data_cnt]['url'] = $matches[1];
$data[$data_cnt++]['intro'] = $matches[2];
/*
* 获取腾讯新闻列表
*/
$matches = array();
$pattern = '/Q-tpListInner.*?href="(.*?)".*? alt="(.*?)">/s';
preg_match_all($pattern, $content, $matches);
// var_dump($matches);
for ($i = 0; $i < count($matches[1]); $i++) {
$data[$data_cnt]['url'] = $matches[1][$i];
$data[$data_cnt++]['intro'] = $matches[2][$i];
}
var_dump($data);
}
运行结果截图:
如果出现乱码,转化一下字符编码就行了。
参考链接:
[1] 正则表达式30分钟入门教程
[2] 我眼中的正则表达式(入门)
[3] 深入正则表达式应用 查看全部
正则表达式的简单应用:使用正则表达式采集腾讯新闻
正则表达式(Regular Expression)是比较冗长的,要记的东西比较多,因此我始终都没有腾出时间专门好好研究一下正则表达式,最近网站需要用到PHP的CURL获取腾讯新闻,所以就认真地学了一下正则表达式。正则表达式是十分强悍的,学会了正则表达式,在之后的文本匹配中,那是杠杠的。话不多说,进入题外话。
关于正则表达式的一些基础句型,大家可以看一下下边的参考链接,讲解十分到位。
引用《深入正则表达式应用》的“正则三段论”:定锚点,去杂讯,取数据。
1.首先,我想要从获取科技新闻头条,以及新闻列表,如图所示。


2.点击“查看网页源代码”Ctrl+ F找到我们须要的那一段代码,如图


可以发觉每位标签都有一个新闻标签都是由“Q-tpListInner”的div包上去的,,并且我们要取出的url 在a 标签的href中, 要取的新闻标题在img的alt中,这就是传说的“定锚点、去杂讯”的过程了;
3.之后就是直接用正则表达式取出我们须要的数据了。
新闻列表的正则表达式:
'/Q-tpListInner.*?href="(.*?)".*?alt="(.*?)">/s';
科技新闻标题的正则表达式:
'/
.*?href="(.*?)".*?>(.*?)/s';
PHP源代码:
function techNews() {
// PS:PHP的CURL请自行补脑
$url = 'http://tech.qq.com';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content = curl_exec($ch);
curl_close($ch);
$content = iconv('gb2312', 'utf-8//IGNORE',$content); //修改字符编码
/*
* 获取腾讯新闻头条
*/
$data = array();
$data_cnt = 0;
$matches = array();
$pattern = '/.*?href="(.*?)".*?>(.*?)/s';
preg_match($pattern, $content, $matches);
$data[$data_cnt]['url'] = $matches[1];
$data[$data_cnt++]['intro'] = $matches[2];
/*
* 获取腾讯新闻列表
*/
$matches = array();
$pattern = '/Q-tpListInner.*?href="(.*?)".*? alt="(.*?)">/s';
preg_match_all($pattern, $content, $matches);
// var_dump($matches);
for ($i = 0; $i < count($matches[1]); $i++) {
$data[$data_cnt]['url'] = $matches[1][$i];
$data[$data_cnt++]['intro'] = $matches[2][$i];
}
var_dump($data);
}
运行结果截图:

如果出现乱码,转化一下字符编码就行了。
参考链接:
[1] 正则表达式30分钟入门教程
[2] 我眼中的正则表达式(入门)
[3] 深入正则表达式应用
独家揭密:影响SEO原创文章不收录的诱因及解法
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-13 09:05
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结:以上就是本文述说的原创文章为何不收录的大致缘由,由于时间关系,就不做过多总结了,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提示文章质量,确保网站跳出率可观就OK了,如果还有疑惑可以私聊岑辉宇。 查看全部
相信这个问题以及困惑了你们许久了,有的站长天天呕心沥血写原创更新,但总是得不到搜索引擎的偏爱,而有的网站哪怕是采集都能达到秒收的待遇,是我们坚持原创更新的方向错了?还是他人另有高招?这些就不得而知了,而明天和你们分享的就是为什么写原创而不收录的诱因剖析及解法。

一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。

b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。

6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结:以上就是本文述说的原创文章为何不收录的大致缘由,由于时间关系,就不做过多总结了,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提示文章质量,确保网站跳出率可观就OK了,如果还有疑惑可以私聊岑辉宇。
索答科技:领域应用 | 基于知识图谱的卧室领域问答系统打造
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-11 18:35
问句生成。同一个问题的问句是特别多的,首先对输入问句进行剖析,找到“种子问句”,然后对它进行动词,把每一个词用word2vec 寻找相关的词(比如美国-男人=女王-女人),相关的词把它们的位置序列记好,然后做笛卡尔积。这样的做完了,会生成大规模这样问句的数据,当然上面有一些是不正确的语句,这个时侯用文本纠错的马尔可夫链的机率图模型去纠正它,最后人工筛选。第二种方式是,采集200多个跟菜谱相关的代词,以及相关的同义词,利用文本生成,生成问句。这里推荐OpenKG
2.1.3 知识库建立
首先做时序融合,就是之前做的实体,它的实体链接是不是按照时间的推理,而它换掉了它本身的这样一个涵义,进而做本体的扩展(不太懂)。多源融合,做一个实体的匹配和概念的对齐。
抽出实体和属性
2.1.4 数据访问
分为4个部份。
1.SPARQL查询 2.自然语言查询 3.SDK的形式 4.逻辑表达式,后台将其转化成SPARQL句子
2.2 知识图谱的建立
其中,不辣的查询比较历时,原因是因为标签没有不辣,因此要把所有的属性都查一遍。后来的解决方式是离线去处理,比如是甜的,那它一定不是辣的。
3 曾经踩过的一些坑
知识图谱上面的搜索是有一个问题的, ElasticSearch 检索上面的排序虽然是十分容易去做的,本身底层就写了一个排序打分的 TF-IDF。而用知识图谱的时侯,它附近的那些节点的权重都是一样的。比如说芋头能做哪些菜,那么查询下来所有的菜的权重都是一样的。知识图谱上面,映射的本身是扁平的,比如地瓜这个节点,能够查询好多菜谱,发现有些所列下来的这些菜你们都不认识,会导致糟糕的体验。解决方式:在知识图谱的属性当中,加了一个热度的一个值,热度主要是通过点击次数去估算,然后按照热度排序。
4 遇到的一些挑战与困难
1. 跨领域问题不仅基础工作,比如查询等方法不会有很大的改动,但是属性是要重新设定的。
2. 语义理解还没有达到一定的高度。当下主要还是在于文本分类+属性抽取+逻辑表达式,但是用多大的数据量可以将一句话直接运用到知识图谱中去还须要继续探究。
- end -
Tip:索答科技已然将 50w 菜谱本体信息在 OpenKG 上开放下来,每个菜谱收录店名,食材,味道,烹饪时间等属性。链接
索答菜谱本体信息 - 开放知识图谱
对于知识图谱查询这一块,主要涉及了RDF,OWL,SPARQL,推荐看 知识图谱-给AI装个脑部 里面讲解的太详尽,也有个demo,有时间我会把python3的实现放在github上。
Reference:
知识图谱-给AI装个脑部
索答科技:领域应用 | 基于知识图谱的卧室领域问答系统建立 查看全部
2.1.2 数据采集
问句生成。同一个问题的问句是特别多的,首先对输入问句进行剖析,找到“种子问句”,然后对它进行动词,把每一个词用word2vec 寻找相关的词(比如美国-男人=女王-女人),相关的词把它们的位置序列记好,然后做笛卡尔积。这样的做完了,会生成大规模这样问句的数据,当然上面有一些是不正确的语句,这个时侯用文本纠错的马尔可夫链的机率图模型去纠正它,最后人工筛选。第二种方式是,采集200多个跟菜谱相关的代词,以及相关的同义词,利用文本生成,生成问句。这里推荐OpenKG
2.1.3 知识库建立
首先做时序融合,就是之前做的实体,它的实体链接是不是按照时间的推理,而它换掉了它本身的这样一个涵义,进而做本体的扩展(不太懂)。多源融合,做一个实体的匹配和概念的对齐。
抽出实体和属性
2.1.4 数据访问
分为4个部份。
1.SPARQL查询 2.自然语言查询 3.SDK的形式 4.逻辑表达式,后台将其转化成SPARQL句子
2.2 知识图谱的建立



其中,不辣的查询比较历时,原因是因为标签没有不辣,因此要把所有的属性都查一遍。后来的解决方式是离线去处理,比如是甜的,那它一定不是辣的。
3 曾经踩过的一些坑
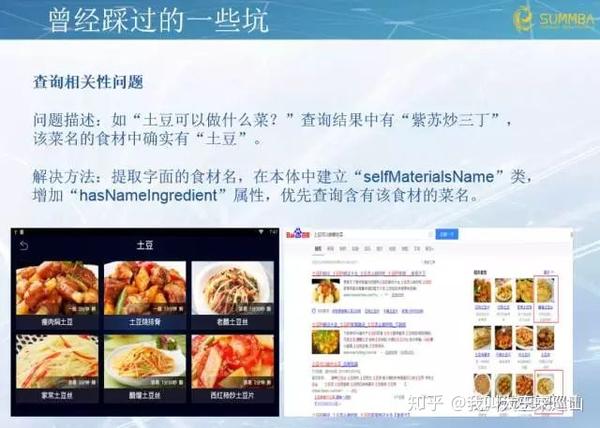
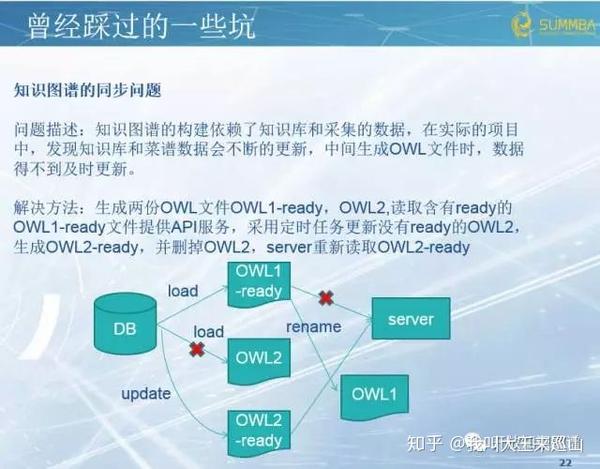
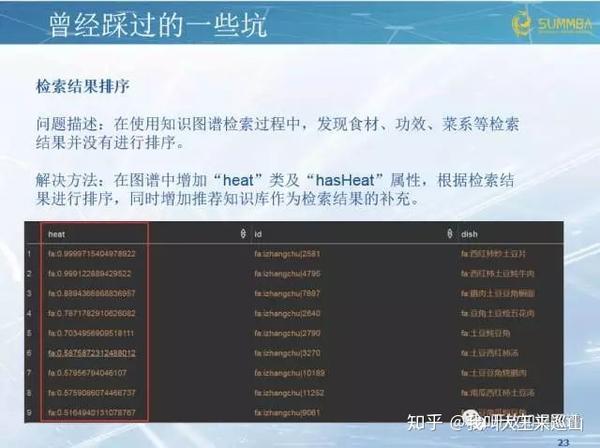
知识图谱上面的搜索是有一个问题的, ElasticSearch 检索上面的排序虽然是十分容易去做的,本身底层就写了一个排序打分的 TF-IDF。而用知识图谱的时侯,它附近的那些节点的权重都是一样的。比如说芋头能做哪些菜,那么查询下来所有的菜的权重都是一样的。知识图谱上面,映射的本身是扁平的,比如地瓜这个节点,能够查询好多菜谱,发现有些所列下来的这些菜你们都不认识,会导致糟糕的体验。解决方式:在知识图谱的属性当中,加了一个热度的一个值,热度主要是通过点击次数去估算,然后按照热度排序。
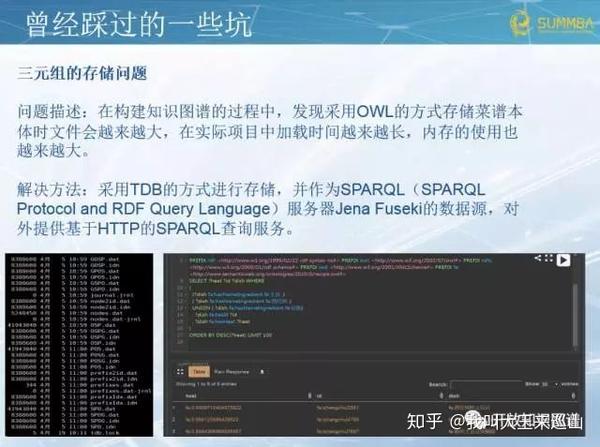
4 遇到的一些挑战与困难

1. 跨领域问题不仅基础工作,比如查询等方法不会有很大的改动,但是属性是要重新设定的。
2. 语义理解还没有达到一定的高度。当下主要还是在于文本分类+属性抽取+逻辑表达式,但是用多大的数据量可以将一句话直接运用到知识图谱中去还须要继续探究。
- end -
Tip:索答科技已然将 50w 菜谱本体信息在 OpenKG 上开放下来,每个菜谱收录店名,食材,味道,烹饪时间等属性。链接
索答菜谱本体信息 - 开放知识图谱
对于知识图谱查询这一块,主要涉及了RDF,OWL,SPARQL,推荐看 知识图谱-给AI装个脑部 里面讲解的太详尽,也有个demo,有时间我会把python3的实现放在github上。
Reference:
知识图谱-给AI装个脑部
索答科技:领域应用 | 基于知识图谱的卧室领域问答系统建立
网站SEO降低内部链接方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2020-08-21 10:46
网站SEO降低内部链接方式
2020-5-28
一个好的内部链接结构,为用户访问网站信息提供了便利的读取通道因而可提高网站的PV,同时链式结构也十分有利于搜索引擎的信息抓取为Google和百度等引擎欢迎,因此内链的建设是SEO不可忽略的一个环节向来为SEOER注重。
很多个人站长包括一些大的站点并不注重文章的内链建设,集中表现为通篇文章除了图片就是文字,对于借助内链这一优势资源去提高文章的相关性和可读性。
那么,网站SEO降低内部链接方式有哪些呢?
1:采集站点的热门关键词或TAG及关键词的指向链接,这个一般可以在主页的热门关键词区找到:对于一些特别重要的关键词也可以添加进搜集列表。
2:在文章内容递交模块处加入替换方式,文章更新时,收录上述关键字的内容将逐一替换为关键词的链接,从而达到手动加入内链的疗效。
3:关键词大概有20个,这个数目,基本上可以保证整篇文章能替换到2-5个内链,
当然关键词定义的越多内链也就越多。不过要有个度,太多的内链会影响文章的可读性,笔者建议不宜超过5个链接。
4:这种方式同样适用于采集,只要将替换方式加入采集模块,文章亦会手动实现关键词的内链添加。
5:对于采集的文章,内链的替换实际上也是一个伪原初的技巧。
内链的关键词替换是一个太小的代码更改工作,花的时间不多,但形成的疗效非常好,不仅提高了文章的可读性还达到了SEO的疗效,因此非常推荐此法去优化文章的内链,广大的站长同学不妨一试此法。 查看全部
网站SEO降低内部链接方式
网站SEO降低内部链接方式
2020-5-28
一个好的内部链接结构,为用户访问网站信息提供了便利的读取通道因而可提高网站的PV,同时链式结构也十分有利于搜索引擎的信息抓取为Google和百度等引擎欢迎,因此内链的建设是SEO不可忽略的一个环节向来为SEOER注重。
很多个人站长包括一些大的站点并不注重文章的内链建设,集中表现为通篇文章除了图片就是文字,对于借助内链这一优势资源去提高文章的相关性和可读性。
那么,网站SEO降低内部链接方式有哪些呢?
1:采集站点的热门关键词或TAG及关键词的指向链接,这个一般可以在主页的热门关键词区找到:对于一些特别重要的关键词也可以添加进搜集列表。
2:在文章内容递交模块处加入替换方式,文章更新时,收录上述关键字的内容将逐一替换为关键词的链接,从而达到手动加入内链的疗效。
3:关键词大概有20个,这个数目,基本上可以保证整篇文章能替换到2-5个内链,
当然关键词定义的越多内链也就越多。不过要有个度,太多的内链会影响文章的可读性,笔者建议不宜超过5个链接。
4:这种方式同样适用于采集,只要将替换方式加入采集模块,文章亦会手动实现关键词的内链添加。
5:对于采集的文章,内链的替换实际上也是一个伪原初的技巧。
内链的关键词替换是一个太小的代码更改工作,花的时间不多,但形成的疗效非常好,不仅提高了文章的可读性还达到了SEO的疗效,因此非常推荐此法去优化文章的内链,广大的站长同学不妨一试此法。
SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-21 06:45
我们借助网站开展网路营销推广不是三天三天事情,应该从长远的方向来考虑,以搜索用户的体验为主去优化网站,不要尝试去做一些作弊行为和违规违法行为。否则,这些问题就会影响网站在搜索引擎上的诠释,影响网站的排行。接下来,营销圈就和你们分享下SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
第一大注意事项:大量转让友情链接
很多的网站为了获取一些蝇头小利而向其他站长转让自己的友情链接,不过随之而来的就是对自身网站影响。比方说排行增长、惩罚降权、收录被删等情况,这些都是会出现的。营销圈在这里建议你们合理的交换友情链接有利于网站的排行和优化,如果大量的转让友情链接存在着十分大的风险。
第二大注意事项:网站内容大量采集
有一些网站的站长喜欢偷懒,网站的文章内容大都是采集和复制其他网站中的内容,原创度特别的低。甚至严重的情况,有的站长会采用软件批量的生成,不过生成的内容都是和网站主题不相符的内容,都是一些没有价值的东西。
第三大注意事项:网站存在大量广告
有一些网站存在着大量的广告,妨碍搜索用户的正常浏览。比方说常见的弹窗广告和一些混淆主体的垃圾广告为主,其中最常见的就是一些三流的小说网站、视频网站等等,用户点击进去的话,满屏都是广告内容。
90%的人又阅读以下文章:SEO零基础入门难吗?SEO入门最重要的是哪些? SEO优化营销之搜索引擎网站排名优化的原理和依据是哪些? SEO优化是哪些,SEO优化营销是哪些意思? SEO优化营销之SEO的两大行为分类,你是属于哪一类呢? SEO优化营销之转让友情链接对网站优化形成的害处,不可不知! 查看全部
SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
我们借助网站开展网路营销推广不是三天三天事情,应该从长远的方向来考虑,以搜索用户的体验为主去优化网站,不要尝试去做一些作弊行为和违规违法行为。否则,这些问题就会影响网站在搜索引擎上的诠释,影响网站的排行。接下来,营销圈就和你们分享下SEO优化营销之网站优化的三大注意事项,看看你晓得几点?
第一大注意事项:大量转让友情链接
很多的网站为了获取一些蝇头小利而向其他站长转让自己的友情链接,不过随之而来的就是对自身网站影响。比方说排行增长、惩罚降权、收录被删等情况,这些都是会出现的。营销圈在这里建议你们合理的交换友情链接有利于网站的排行和优化,如果大量的转让友情链接存在着十分大的风险。
第二大注意事项:网站内容大量采集
有一些网站的站长喜欢偷懒,网站的文章内容大都是采集和复制其他网站中的内容,原创度特别的低。甚至严重的情况,有的站长会采用软件批量的生成,不过生成的内容都是和网站主题不相符的内容,都是一些没有价值的东西。
第三大注意事项:网站存在大量广告
有一些网站存在着大量的广告,妨碍搜索用户的正常浏览。比方说常见的弹窗广告和一些混淆主体的垃圾广告为主,其中最常见的就是一些三流的小说网站、视频网站等等,用户点击进去的话,满屏都是广告内容。
90%的人又阅读以下文章:SEO零基础入门难吗?SEO入门最重要的是哪些? SEO优化营销之搜索引擎网站排名优化的原理和依据是哪些? SEO优化是哪些,SEO优化营销是哪些意思? SEO优化营销之SEO的两大行为分类,你是属于哪一类呢? SEO优化营销之转让友情链接对网站优化形成的害处,不可不知!
[干货分享]慈溪SEO代理浅谈SEO文章收录的终极诀窍
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-21 04:32
在我们做SEO时,大家都晓得文章收录就是个关键点,因为只有在文章收录的情况下,网站排名和网站浏览量就会尽可能的提升,有的人一天到晚不停的发文章,但是还是会遇到文章常常不收录这是为什么呢,那么,慈溪SEO小编就来跟你们分享SEO文章的终极诀窍。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。#p#分页标题#e#
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在10万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。#p#分页标题#e#
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的404页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。 查看全部
[干货分享]慈溪SEO代理浅谈SEO文章收录的终极诀窍
在我们做SEO时,大家都晓得文章收录就是个关键点,因为只有在文章收录的情况下,网站排名和网站浏览量就会尽可能的提升,有的人一天到晚不停的发文章,但是还是会遇到文章常常不收录这是为什么呢,那么,慈溪SEO小编就来跟你们分享SEO文章的终极诀窍。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。#p#分页标题#e#
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在10万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。#p#分页标题#e#
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的404页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
python实现WordPress文章发布(三):批量发布文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-19 18:04
这是东尧每晚一篇文章的第48天
东尧写文章的目标:分享东尧的经验和思索,帮你获取物质和精神两方面幸福。
上次教程我们早已提到了
用python发布单篇WordPress文章
,但是只是单篇文章的发布,多篇文章发布的话就须要将函数封装一下,用文件读写的方法来获取文章并发布,本文将给你们继续介绍wordpress-xmlrpc里的一些技巧,并在最后将这种方式组合上去,进行封装,实现批量发布多篇文章到WordPress后台。
今天先给你们介绍wordpress-xmlrpc里Methods类的taxonomies()方法。taxonomies方式主要用于获取文章分类,当然,这个分类不是指文章的栏目分类,具体是哪些分类呢?
我们使用taxonomies方式的GetTaxonomies()属性来获取一下所以分类试试,看获取到的分类是哪些内容:
结果:
发现跟我们之前写的文章发布分类字典内的键是一致的:
所以GetTaxonomies()获取到的分类是指写文章发布代码时用到的分类变量名。
taxonomies方式还有一个比较重要的属性是GetTerms(),这个属性可以获取到某个分类下所有的值,这里的分类就是我们刚刚用GetTaxonomies()获取到的“category、post_tag、post_format”三个分类。怎么应用呢?比如我们想知道网站总共有什么标签,就可以使用GetTerms('post_tag')来获取:
结果:
NewTerms()属性:创建一个新的分类目录:
结果:
已经新建成功!
函数
封装
还是先将之前采集的短文学网的诗歌txt文件拷贝到python代码文件夹内,如果没有的朋友可以先查看《文章采集案例:短文学网诗歌采集(二)》这篇文章,学习下怎样采集。
01
post()函数封装
02
主体执行代码
执行后可以看见早已发布成功了:
源码
下载 查看全部
python实现WordPress文章发布(三):批量发布文章
这是东尧每晚一篇文章的第48天
东尧写文章的目标:分享东尧的经验和思索,帮你获取物质和精神两方面幸福。
上次教程我们早已提到了
用python发布单篇WordPress文章
,但是只是单篇文章的发布,多篇文章发布的话就须要将函数封装一下,用文件读写的方法来获取文章并发布,本文将给你们继续介绍wordpress-xmlrpc里的一些技巧,并在最后将这种方式组合上去,进行封装,实现批量发布多篇文章到WordPress后台。
今天先给你们介绍wordpress-xmlrpc里Methods类的taxonomies()方法。taxonomies方式主要用于获取文章分类,当然,这个分类不是指文章的栏目分类,具体是哪些分类呢?
我们使用taxonomies方式的GetTaxonomies()属性来获取一下所以分类试试,看获取到的分类是哪些内容:
结果:
发现跟我们之前写的文章发布分类字典内的键是一致的:
所以GetTaxonomies()获取到的分类是指写文章发布代码时用到的分类变量名。
taxonomies方式还有一个比较重要的属性是GetTerms(),这个属性可以获取到某个分类下所有的值,这里的分类就是我们刚刚用GetTaxonomies()获取到的“category、post_tag、post_format”三个分类。怎么应用呢?比如我们想知道网站总共有什么标签,就可以使用GetTerms('post_tag')来获取:
结果:
NewTerms()属性:创建一个新的分类目录:
结果:
已经新建成功!
函数
封装
还是先将之前采集的短文学网的诗歌txt文件拷贝到python代码文件夹内,如果没有的朋友可以先查看《文章采集案例:短文学网诗歌采集(二)》这篇文章,学习下怎样采集。
01
post()函数封装
02
主体执行代码
执行后可以看见早已发布成功了:
源码
下载
Python网路数据采集之储存数据|第04天
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2020-08-19 09:28
User:你好我是森林Date:2018-03-31Mark:《Python网路数据采集》原文:))
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
存储数据
网络数据的采集,最本质的东西还是数据,我们爬取的数据是须要储存的。
媒体文件
存储媒体文件有两种主要的形式:只获取文件 URL 链接,或者直接把源文件下载出来。
可以通过媒体文件所在的URL 链接直接引用它。这样做的优点如下:
于此同时都会有一些缺点:
下载文件的方式也很简单,在Python 3.x 版本中,urllib.request.urlretrieve可以依照文件的 URL 下载文件;
例如我们从 下载 logo图片,然后在程序运行的文件夹里保存为 logo.jpg 文件。
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com')
bs = BeautifulSoup(html, 'html.parser')
imageLocation = bs.find('a', {'id': 'logo'}).find('img')['src']
urlretrieve (imageLocation, 'logo.jpg')
下载文件须要注意exe的文件,木马文件等。不要在硬碟储存敏感信息,不要用管理员权限运行他。
把数据储存到CSV
CSV(Comma-Separated Values,逗号分隔值)是储存表格数据的常用文件格式。关于CSV格式的文件不做过多的介绍,自行去了解一下。
Python的csv库可以创建或则更改CSV文件。
import csv
csvFile = open("./demo.csv","w+")
try:
writer = csv.writer(csvFile)
writer.writerow(('number', 'number plus 2', 'number times 2'))
for i in rang(10):
writer.writerow((i,i+2,I*2))
finally:
csvFile.close()
如果文件不存在都会创建demo.csv。
MySQL
MySQL是目前最受欢迎的开源关系型数据库管理系统。因为它受众广泛,免费,开箱即用,所以它也是网路数据采集项目中常用的数据库。
我采用的是Mac的平台,可以直接下载安装安装也可以通过包管理器(例如homebrew)安装。
官网下载地址:
其他的平台可以去官网查看安装详情,作为一个改变世界的程序猿,安装软件应当不是问题。
基本命令
创建数据库:
CREATE DATABASE demo;
使用数据库:
USE demo;
创建表:
CREATE TABLE user(
id BIGINT(7) NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
sex tinyint(1),
creatime TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
和数据库不同,MySQL 数据表必须起码有一列,否则不能创建。为了在 MySQL 里定义数组(数据列),你必须在 CREATE TABLE 句子前面,把数组的定义放进一个带括弧的、内部由冒号分隔的列表。
插入数据:
INSERT INTO user (name, sex) VALUES ("name", "1");
查询数据:
SELECT * FROM user
模糊查询:
SELECT id FROM user LIKE "%chensenlin.cn%"
删除数据:
DELELT FROM user WHERE id = 1
更新数据:
UPDATE user SET name = 'chensenlin' WHERE id = 66
特别指出:更新或则删掉一定要加条件!否则就说灾难,哈哈哈
与Python整合
Python没有外置的MySQL 支持工具。不过,有很多开源的库可以拿来与 MySQL做交互,Python 2.x和Python 3.x版本都支持。最有名的一个库就是PyMySQL()。
安装:
pip install PyMySQL
基本使用:
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',user='root', passwd=root, db='mysql')
cur.execute("USE demo")
cur.execute("SELECT * FROM user WHERE id = 1") print(cur.fetchone())
cur.close()
conn.close()
Python发送一封短信:
import smtplib
from email.mime.text import MIMEText
msg = MIMEText("邮件正文内容")
msg['Subject'] = "这是一个测试有奖主题"
msg['From'] = "fore@gmail.com"
msg['To'] = "hellosenlin@sina.cn"
s = smtplib.SMTP('localhost')
s.send_message(msg)
s.quit()
与网页通过HTTP协议传输一样,邮件是通过SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)传输的。而且,和网路服务器的客户端(浏览器)处理这些通过 HTTP 协议传输的网页一样。
可以将其封装成函数作为发送短信定时使用等。 查看全部
Python网路数据采集之储存数据|第04天
User:你好我是森林Date:2018-03-31Mark:《Python网路数据采集》原文:))
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
存储数据
网络数据的采集,最本质的东西还是数据,我们爬取的数据是须要储存的。
媒体文件
存储媒体文件有两种主要的形式:只获取文件 URL 链接,或者直接把源文件下载出来。
可以通过媒体文件所在的URL 链接直接引用它。这样做的优点如下:
于此同时都会有一些缺点:
下载文件的方式也很简单,在Python 3.x 版本中,urllib.request.urlretrieve可以依照文件的 URL 下载文件;
例如我们从 下载 logo图片,然后在程序运行的文件夹里保存为 logo.jpg 文件。
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com')
bs = BeautifulSoup(html, 'html.parser')
imageLocation = bs.find('a', {'id': 'logo'}).find('img')['src']
urlretrieve (imageLocation, 'logo.jpg')
下载文件须要注意exe的文件,木马文件等。不要在硬碟储存敏感信息,不要用管理员权限运行他。
把数据储存到CSV
CSV(Comma-Separated Values,逗号分隔值)是储存表格数据的常用文件格式。关于CSV格式的文件不做过多的介绍,自行去了解一下。
Python的csv库可以创建或则更改CSV文件。
import csv
csvFile = open("./demo.csv","w+")
try:
writer = csv.writer(csvFile)
writer.writerow(('number', 'number plus 2', 'number times 2'))
for i in rang(10):
writer.writerow((i,i+2,I*2))
finally:
csvFile.close()
如果文件不存在都会创建demo.csv。
MySQL
MySQL是目前最受欢迎的开源关系型数据库管理系统。因为它受众广泛,免费,开箱即用,所以它也是网路数据采集项目中常用的数据库。
我采用的是Mac的平台,可以直接下载安装安装也可以通过包管理器(例如homebrew)安装。
官网下载地址:
其他的平台可以去官网查看安装详情,作为一个改变世界的程序猿,安装软件应当不是问题。
基本命令
创建数据库:
CREATE DATABASE demo;
使用数据库:
USE demo;
创建表:
CREATE TABLE user(
id BIGINT(7) NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
sex tinyint(1),
creatime TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
和数据库不同,MySQL 数据表必须起码有一列,否则不能创建。为了在 MySQL 里定义数组(数据列),你必须在 CREATE TABLE 句子前面,把数组的定义放进一个带括弧的、内部由冒号分隔的列表。
插入数据:
INSERT INTO user (name, sex) VALUES ("name", "1");
查询数据:
SELECT * FROM user
模糊查询:
SELECT id FROM user LIKE "%chensenlin.cn%"
删除数据:
DELELT FROM user WHERE id = 1
更新数据:
UPDATE user SET name = 'chensenlin' WHERE id = 66
特别指出:更新或则删掉一定要加条件!否则就说灾难,哈哈哈
与Python整合
Python没有外置的MySQL 支持工具。不过,有很多开源的库可以拿来与 MySQL做交互,Python 2.x和Python 3.x版本都支持。最有名的一个库就是PyMySQL()。
安装:
pip install PyMySQL
基本使用:
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',user='root', passwd=root, db='mysql')
cur.execute("USE demo")
cur.execute("SELECT * FROM user WHERE id = 1") print(cur.fetchone())
cur.close()
conn.close()
Python发送一封短信:
import smtplib
from email.mime.text import MIMEText
msg = MIMEText("邮件正文内容")
msg['Subject'] = "这是一个测试有奖主题"
msg['From'] = "fore@gmail.com"
msg['To'] = "hellosenlin@sina.cn"
s = smtplib.SMTP('localhost')
s.send_message(msg)
s.quit()
与网页通过HTTP协议传输一样,邮件是通过SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)传输的。而且,和网路服务器的客户端(浏览器)处理这些通过 HTTP 协议传输的网页一样。
可以将其封装成函数作为发送短信定时使用等。
爬取公众号及知乎专栏文章的标题链接的方式汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-19 05:43
记一次近来的工作内容(奇怪的任务降低了)因为Python是今年接触而且没有过爬虫的实际学习操作,所以在出现“要搜集文章标题链接”的任务是还是有点难以下手的。虽然有了解过爬虫可以便捷操作,但由于经验不足造成花了不少时间进行学习查找。。。最后倒是找到了不用写代码就可以爬取这种信息的方式,并且能将这种信息手动导出excel表格中查看使用。于是这儿记录一下方式以及查找思路和过程。
不需要代码,使用工具辅助的办法(0基础)
公众号文章信息的爬取方式:
使用工具"小V公众号文章下载器"
下载地址:
爬取中的工具
爬取的结果
使用教程:网址介绍中有,按次序做出来即可
优点:可以快速爬取须要的信息,不仅局限于标题链接,还包括文章本身以及数据剖析等
缺点:要付费,试用版只能用爬一个帐号而且不能怕文章本身,不过付费可以按天数订购,比其他一些买软件本身的实惠,做短期内需求的爬虫来说不错。不过只能爬取公众号的文章,加上爬取过多的话帐号24小时内未能在pc端看历史记录(大约在日爬取3k文章左右后会发生此类情况,此时须要用另外的帐号继续)
使用工具批量微信公众号下载小工具
下载地址:
使用教程:下载出来会有相关教程视频
优点:免费,可以下载文章为转word,pdf等,用法也简单
缺点:大概就是没有我须要的要求(指下载文章的地址以及标题并转为excel表格)吧。。。。
知乎文章信息的爬取方式:
浏览器插件web scraper
谷歌应用商店可以下载
正在爬取资料,使用快捷键F12打开
爬取结果
使用教程:
优点:简单易操作,免费,而且操作上去更快
缺点:爬取的资料没有这么全面
需要用代码的办法汇总(需要有python基础)
微信公众号文章:通过抓包或则自己注册一个公众号进行操作,网上的方式大同小异,这里不多赘言。附一个找到的比较完整的网址,有一定的python基础的同学可以去试试看。
这里有完整的工程文件,不过没有基础的话不好理解(我基础忘了所以弄了许久还是有点问题,才会去换思路找工具的囧)
知乎文章:网上这个倒是只听到一个方式,是风变编程的一个案例,网上也有好多这个方式的总结。做法相对里面的会简单一点(但仍没有插件来的快)
方法与微信公众号文章的获取方式类似,即使稍为简单点,但依然须要一定的基础。
找那些内容时的一点心得
虽然找下来归纳后就这么多,但是当时找的时侯很麻烦的。因为只是对爬虫有点了解,加上当时只学了点皮毛,要立即实操赶野鸭上架有点困难。一开始查找的思路是用“python爬取公众号文章链接”这个条件进行查找,但是找下来的方式我不一定能用,而且常常出bug(菜鸡的疼),之后还拜托大鸽瞧瞧如何写,不过还是有点问题无法处理,同时对于导入成excel表没哪些头绪。
后面换了种思路,网上找的时侯发觉不只是我有这些需求,有不少人也须要并且不一定会用python,就想着“既然网上有这些需求,说不定有相应的工具”。然后就倒真找到了一些,但是这种工具下载器五花八门的,还太贵(单买软件或则单次服务就太贵)。然后比较了几个工具后最后选择了现今分享的工具,要氪金但花的金钱比我花时间找和学习的时间比上去便宜了不少。即使是这样,我还是花了三天才导入完所有内容(如果自己做不知道要做到什么时候)
归纳在一起有五千多条
完成后也反思了下:
我一开始的思路就是有点问题的:在短时间内速成上手还是有点困难,应该换个思路找找有没有相应的工具,因为既然有这些需求那就应当有对应的市场,如果早点意识到就不会花那么多时间做无用功了。
学Python真的很重要,以后自己找资料也不会这么麻烦,更不会象几天前那样象无头苍蝇四处撞。(要学的东西降低了)
不过可喜可贺最后任务还是完成了,也学到了一些奇怪的东西(雾)
最近还要忙些事,忙完再整理下之前学的表达式知识出点内容。 查看全部
爬取公众号及知乎专栏文章的标题链接的方式汇总
记一次近来的工作内容(奇怪的任务降低了)因为Python是今年接触而且没有过爬虫的实际学习操作,所以在出现“要搜集文章标题链接”的任务是还是有点难以下手的。虽然有了解过爬虫可以便捷操作,但由于经验不足造成花了不少时间进行学习查找。。。最后倒是找到了不用写代码就可以爬取这种信息的方式,并且能将这种信息手动导出excel表格中查看使用。于是这儿记录一下方式以及查找思路和过程。
不需要代码,使用工具辅助的办法(0基础)
公众号文章信息的爬取方式:
使用工具"小V公众号文章下载器"
下载地址:
爬取中的工具
爬取的结果
使用教程:网址介绍中有,按次序做出来即可
优点:可以快速爬取须要的信息,不仅局限于标题链接,还包括文章本身以及数据剖析等
缺点:要付费,试用版只能用爬一个帐号而且不能怕文章本身,不过付费可以按天数订购,比其他一些买软件本身的实惠,做短期内需求的爬虫来说不错。不过只能爬取公众号的文章,加上爬取过多的话帐号24小时内未能在pc端看历史记录(大约在日爬取3k文章左右后会发生此类情况,此时须要用另外的帐号继续)
使用工具批量微信公众号下载小工具
下载地址:
使用教程:下载出来会有相关教程视频
优点:免费,可以下载文章为转word,pdf等,用法也简单
缺点:大概就是没有我须要的要求(指下载文章的地址以及标题并转为excel表格)吧。。。。
知乎文章信息的爬取方式:
浏览器插件web scraper
谷歌应用商店可以下载
正在爬取资料,使用快捷键F12打开
爬取结果
使用教程:
优点:简单易操作,免费,而且操作上去更快
缺点:爬取的资料没有这么全面
需要用代码的办法汇总(需要有python基础)
微信公众号文章:通过抓包或则自己注册一个公众号进行操作,网上的方式大同小异,这里不多赘言。附一个找到的比较完整的网址,有一定的python基础的同学可以去试试看。
这里有完整的工程文件,不过没有基础的话不好理解(我基础忘了所以弄了许久还是有点问题,才会去换思路找工具的囧)
知乎文章:网上这个倒是只听到一个方式,是风变编程的一个案例,网上也有好多这个方式的总结。做法相对里面的会简单一点(但仍没有插件来的快)
方法与微信公众号文章的获取方式类似,即使稍为简单点,但依然须要一定的基础。
找那些内容时的一点心得
虽然找下来归纳后就这么多,但是当时找的时侯很麻烦的。因为只是对爬虫有点了解,加上当时只学了点皮毛,要立即实操赶野鸭上架有点困难。一开始查找的思路是用“python爬取公众号文章链接”这个条件进行查找,但是找下来的方式我不一定能用,而且常常出bug(菜鸡的疼),之后还拜托大鸽瞧瞧如何写,不过还是有点问题无法处理,同时对于导入成excel表没哪些头绪。
后面换了种思路,网上找的时侯发觉不只是我有这些需求,有不少人也须要并且不一定会用python,就想着“既然网上有这些需求,说不定有相应的工具”。然后就倒真找到了一些,但是这种工具下载器五花八门的,还太贵(单买软件或则单次服务就太贵)。然后比较了几个工具后最后选择了现今分享的工具,要氪金但花的金钱比我花时间找和学习的时间比上去便宜了不少。即使是这样,我还是花了三天才导入完所有内容(如果自己做不知道要做到什么时候)
归纳在一起有五千多条
完成后也反思了下:
我一开始的思路就是有点问题的:在短时间内速成上手还是有点困难,应该换个思路找找有没有相应的工具,因为既然有这些需求那就应当有对应的市场,如果早点意识到就不会花那么多时间做无用功了。
学Python真的很重要,以后自己找资料也不会这么麻烦,更不会象几天前那样象无头苍蝇四处撞。(要学的东西降低了)
不过可喜可贺最后任务还是完成了,也学到了一些奇怪的东西(雾)
最近还要忙些事,忙完再整理下之前学的表达式知识出点内容。
[爬虫] 美团店家信息采集-详情链接采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 568 次浏览 • 2020-08-18 08:55
上篇文章分析了美团移动端的页面结构和设计技术结构,先爬详情链接,再爬详情内容,这篇先来实现详情链接的采集。
首先将一些固定不变的数据先拿出来,比如城市相关的数据,先采集下来放在数据库或则缓存中,或者储存到文件中。
如果稍为想想,是不是认为类别也是固定不变的数据,一开始我也是如此想的,后面调试的时侯发觉,每个城市的类别有所区别,有些类别在其他边远点的城市是没有的,所以每位city都须要恳求一遍分类。
OK,先上代码(复制到编辑器更好阅读代码):
def crawl_shop(begin=0, count=1, detail=False):
crawl_rate_file = f'i_crawl_rate_correct_{threading.current_thread().name}.txt' # 记录采集断点文件名
error_urls_file = f'i_error_urls_{threading.current_thread().name}.txt' # 记录错误请求的
location = load_location(crawl_rate_file) # 加载断点
if not location:
location = {'cityid': 0, 'kind1': 0, 'kind2': 0, 'areaid': 0, 'page': 0}
for rowid, city_name, city_pinyin in citys(begin, count): # 这里城市信息先获取
# 继续上一次爬取点,城市位置
if rowid < location['cityid']:
continue
with requests.session() as session:
# 获取分类
category_url = f'https://i.meituan.com/category?city={city_pinyin}'
cate_parser = etree.HTML(i_request(session, category_url).text) # 封装好的请求函数
ikinds = OrderedDict()
# category为要采集类别的列表,只爬取要爬取额类别
for kind in category:
cate_node = cate_parser.xpath(f'//h4[contains(text(),"{kind}")]/following-sibling::ul[1]/li')
for li in cate_node:
text = li.xpath('./a/text()')[0].strip()
href = li.xpath('./a/@href')[0]
if text == '全部' or 'cateType=poi' not in href:
continue
ikinds.setdefault(kind, []).append({text: re.search('cid=(.*?)&', href).group(1)})
for index1, (kind1, kind2s) in enumerate(ikinds.items(), 1):
# 继续上一次爬取点,一级类别位置
if location['cityid'] == rowid and index1 < location['kind1']:
continue
for index2, kitem in enumerate(kind2s, 1):
# 继续上一次爬取点,二级类别位置
if location['cityid'] == rowid and location['kind1'] == index1 and index2 < location['kind2']:
continue
kind2, cid = list(kitem.items())[0]
area_url = f'https://i.meituan.com/{city_pinyin}/all/?cid={cid}'
city_area = i_city_area(session, area_url)
for area in city_area:
# 继续上一次爬取点,城市地区位置
if location['cityid'] == rowid and location['kind1'] == index1 and location['kind2'] == index2 and area['id'] < location['areaid']:
continue
# 按城市区域爬
# 翻页爬取
if location['cityid'] == rowid and location['kind1'] == index1 and \
location['kind2'] == index2 and area['id'] == location['areaid']:
page = location['page'] + 1
else:
page = 1
while True:
datas = []
shop_list_url = f'https://i.meituan.com/select/{city_pinyin}/page_{page}.html?cid={cid}&bid={area["id"]}&sid=rating&p={page}&bizType=area&csp=&cateType=poi&stid_b=_b2&nocount=true'
print(f'city: {city_name}, kind1: {kind1}, kind2: {kind2} area: {area["name"]}, page: {page}, url: {shop_list_url}')
try:
res = i_request(session, shop_list_url)
except Exception as e:
write_error_url(json.dumps({
'shop_list_url': shop_list_url, 'kind1': kind1, 'kind2': kind2, 'cid': cid,
'bid': area['id'],
'area': area['name'] if area['name'] is not None else city_name, 'city': city_name
}), e, filename=error_urls_file)
page += 1
continue
if '暂无此类团购,请查看其他分类' in res.text:
break
with mysqldb() as db:
for shop_url, shop_name in i_parse_shop_list(res.text):
shop = {'name': shop_name, 'crawled': 0, 'deleted': 0}
shop['kind1'], shop['kind2'] = kind1, kind2
shop['cid'], shop['bid'] = cid, area['id']
shop['area'], shop['city'] = area['name'] if area['name'] is not None else city_name, city_name
shop['url'] = shop_url
datas.append(shop)
# 入库,每页入一次
if datas:
with mysqldb() as db:
sql = f'insert into i_shop({",".join(datas[0].keys())}) ' \
f'values ({",".join(map(lambda k: "%({})s".format(k), datas[0].keys()))}) ' \
f'on duplicate key update name=values(name), ' \
f'kind1=values(kind1),kind2=values(kind2),area=values(area),city=values(city),cid=values(cid),bid=values(bid),version=version+1'
db.executemany(sql, datas)
# 记录进度
crawl_rate(
json.dumps({'cityid': rowid, 'kind1': index1, 'kind2': index2, 'areaid': area['id'], 'page': page}),
filename=crawl_rate_file
)
# 翻页
parser = etree.HTML(res.text)
next_page = parser.xpath('//a[contains(text(),"下一页")]/@href')
if not next_page:
break
page += 1
以上代码逻辑就是:先获取须要采集的城市数据,遍历的恳求每位城市,获取城市的分类,再遍历获取分类下的地区,每个地区下再按页数去遍历获取店家详情链接,保存采集到的数据到mysql。
这里涉及到了好几层嵌套,为了防止重复采集,我们须要记录每位遍历的位置,采集完一页就要记录断点,下次重新启动脚本就把采集过的位置continue。
以下是封装好的两个函数:
@retry(stop_max_attempt_number=5, wait_random_min=200, wait_random_max=330, retry_on_exception=retry_callback)
def i_request(session, url):
on_proxy(session)
res = session.get(url, timeout=10)
if 'Forbidden' in res.text and res.status_code == 403:
raise Exception('404 Forbidden')
return res
使用retry装饰器来装潢恳求函数,当函数内部出现错误都会进行重试,重试达到最大次数就会报出错误,这个装潢器在写爬虫恳求的时侯特别有用,如果出现timeout或则暂时性的诱因引起错误,进行间隔性重试是非常好用的。
@contextmanager
def mysqldb(database='meituan'):
try:
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='xxxxx',
database=database,
charset='utf8'
)
cursor = conn.cursor()
yield cursor
conn.commit()
except Exception as e:
print(e)
finally:
cursor.close()
conn.close()
使用contextmanager实现一个数据库操作的上下文管理器,有关上下文管理器的文章请看 [python] 上下文管理器。 查看全部
[爬虫] 美团店家信息采集-详情链接采集
上篇文章分析了美团移动端的页面结构和设计技术结构,先爬详情链接,再爬详情内容,这篇先来实现详情链接的采集。
首先将一些固定不变的数据先拿出来,比如城市相关的数据,先采集下来放在数据库或则缓存中,或者储存到文件中。
如果稍为想想,是不是认为类别也是固定不变的数据,一开始我也是如此想的,后面调试的时侯发觉,每个城市的类别有所区别,有些类别在其他边远点的城市是没有的,所以每位city都须要恳求一遍分类。
OK,先上代码(复制到编辑器更好阅读代码):
def crawl_shop(begin=0, count=1, detail=False):
crawl_rate_file = f'i_crawl_rate_correct_{threading.current_thread().name}.txt' # 记录采集断点文件名
error_urls_file = f'i_error_urls_{threading.current_thread().name}.txt' # 记录错误请求的
location = load_location(crawl_rate_file) # 加载断点
if not location:
location = {'cityid': 0, 'kind1': 0, 'kind2': 0, 'areaid': 0, 'page': 0}
for rowid, city_name, city_pinyin in citys(begin, count): # 这里城市信息先获取
# 继续上一次爬取点,城市位置
if rowid < location['cityid']:
continue
with requests.session() as session:
# 获取分类
category_url = f'https://i.meituan.com/category?city={city_pinyin}'
cate_parser = etree.HTML(i_request(session, category_url).text) # 封装好的请求函数
ikinds = OrderedDict()
# category为要采集类别的列表,只爬取要爬取额类别
for kind in category:
cate_node = cate_parser.xpath(f'//h4[contains(text(),"{kind}")]/following-sibling::ul[1]/li')
for li in cate_node:
text = li.xpath('./a/text()')[0].strip()
href = li.xpath('./a/@href')[0]
if text == '全部' or 'cateType=poi' not in href:
continue
ikinds.setdefault(kind, []).append({text: re.search('cid=(.*?)&', href).group(1)})
for index1, (kind1, kind2s) in enumerate(ikinds.items(), 1):
# 继续上一次爬取点,一级类别位置
if location['cityid'] == rowid and index1 < location['kind1']:
continue
for index2, kitem in enumerate(kind2s, 1):
# 继续上一次爬取点,二级类别位置
if location['cityid'] == rowid and location['kind1'] == index1 and index2 < location['kind2']:
continue
kind2, cid = list(kitem.items())[0]
area_url = f'https://i.meituan.com/{city_pinyin}/all/?cid={cid}'
city_area = i_city_area(session, area_url)
for area in city_area:
# 继续上一次爬取点,城市地区位置
if location['cityid'] == rowid and location['kind1'] == index1 and location['kind2'] == index2 and area['id'] < location['areaid']:
continue
# 按城市区域爬
# 翻页爬取
if location['cityid'] == rowid and location['kind1'] == index1 and \
location['kind2'] == index2 and area['id'] == location['areaid']:
page = location['page'] + 1
else:
page = 1
while True:
datas = []
shop_list_url = f'https://i.meituan.com/select/{city_pinyin}/page_{page}.html?cid={cid}&bid={area["id"]}&sid=rating&p={page}&bizType=area&csp=&cateType=poi&stid_b=_b2&nocount=true'
print(f'city: {city_name}, kind1: {kind1}, kind2: {kind2} area: {area["name"]}, page: {page}, url: {shop_list_url}')
try:
res = i_request(session, shop_list_url)
except Exception as e:
write_error_url(json.dumps({
'shop_list_url': shop_list_url, 'kind1': kind1, 'kind2': kind2, 'cid': cid,
'bid': area['id'],
'area': area['name'] if area['name'] is not None else city_name, 'city': city_name
}), e, filename=error_urls_file)
page += 1
continue
if '暂无此类团购,请查看其他分类' in res.text:
break
with mysqldb() as db:
for shop_url, shop_name in i_parse_shop_list(res.text):
shop = {'name': shop_name, 'crawled': 0, 'deleted': 0}
shop['kind1'], shop['kind2'] = kind1, kind2
shop['cid'], shop['bid'] = cid, area['id']
shop['area'], shop['city'] = area['name'] if area['name'] is not None else city_name, city_name
shop['url'] = shop_url
datas.append(shop)
# 入库,每页入一次
if datas:
with mysqldb() as db:
sql = f'insert into i_shop({",".join(datas[0].keys())}) ' \
f'values ({",".join(map(lambda k: "%({})s".format(k), datas[0].keys()))}) ' \
f'on duplicate key update name=values(name), ' \
f'kind1=values(kind1),kind2=values(kind2),area=values(area),city=values(city),cid=values(cid),bid=values(bid),version=version+1'
db.executemany(sql, datas)
# 记录进度
crawl_rate(
json.dumps({'cityid': rowid, 'kind1': index1, 'kind2': index2, 'areaid': area['id'], 'page': page}),
filename=crawl_rate_file
)
# 翻页
parser = etree.HTML(res.text)
next_page = parser.xpath('//a[contains(text(),"下一页")]/@href')
if not next_page:
break
page += 1
以上代码逻辑就是:先获取须要采集的城市数据,遍历的恳求每位城市,获取城市的分类,再遍历获取分类下的地区,每个地区下再按页数去遍历获取店家详情链接,保存采集到的数据到mysql。
这里涉及到了好几层嵌套,为了防止重复采集,我们须要记录每位遍历的位置,采集完一页就要记录断点,下次重新启动脚本就把采集过的位置continue。
以下是封装好的两个函数:
@retry(stop_max_attempt_number=5, wait_random_min=200, wait_random_max=330, retry_on_exception=retry_callback)
def i_request(session, url):
on_proxy(session)
res = session.get(url, timeout=10)
if 'Forbidden' in res.text and res.status_code == 403:
raise Exception('404 Forbidden')
return res
使用retry装饰器来装潢恳求函数,当函数内部出现错误都会进行重试,重试达到最大次数就会报出错误,这个装潢器在写爬虫恳求的时侯特别有用,如果出现timeout或则暂时性的诱因引起错误,进行间隔性重试是非常好用的。
@contextmanager
def mysqldb(database='meituan'):
try:
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='xxxxx',
database=database,
charset='utf8'
)
cursor = conn.cursor()
yield cursor
conn.commit()
except Exception as e:
print(e)
finally:
cursor.close()
conn.close()
使用contextmanager实现一个数据库操作的上下文管理器,有关上下文管理器的文章请看 [python] 上下文管理器。
终止原创文章被采集和复制
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-17 22:38
原创是自然推广中极其沉重的一部分,很多刚才上线的小站都是通过发布原创文章来做网站优化的,原创对于网站优化有非同寻常的意义。百度非常喜欢原创文章,如果新站使用采集文章,就容易使百度觉得这个网站是一个采集网站,进而影响以后的网站优化。营销在做网站优化的时侯会在网站中全部更新原创文章,但是此时我们也遇见了一个问题,就是原创文章被他人采集去发布外链了,遇到这些问题我们总结下来了一些网路营销方式。
更改网站程序
一般遇见这些问题可以修改网站的程序,一般情况下有的网站优化人员会在页面中添加一个严禁复制粘贴的JS代码,让这个代码来严禁用户复制粘贴或则是查看源代码。但是此类方式对用户体验度十分不利,所以假如不是情况十分严重,没有站长希望乐意使用这样的技巧,这种技巧可以说是最后的招数了。
提交内容链接
之所以避免网站内容被采集,最大的诱因还是由于害怕自己的文章不被收录,所以seoer会在更新了文章之后直接把文章的url递交给百度,这样做没有害处。虽然说百度不会马上收录这个文章,但是可以提醒百度来收录,让自己的文章尽早被收录,被百度认定是原创文章,这样他人再剽窃,对自己的影响也会减少。
添加网站链接
一般假如遇见了网站内容被拷贝,那么的做法就是在内容中添加网站的品牌词句,或者是隐藏锚文本链接等等,如果是机器进行的采集,那么对方都会把这种信息全部都采集走,这样就相当于给自己降低一个链接。但是要注意不能为了使文章不被采集走而在文章中生硬的添加锚文本链接或则是品牌词,这样会伤害到用户体验度。
防止网站文章被剽窃特别的重要,毕竟好多站长自己耗费了大量的时间和精力来编撰原创文章,但是刚发出去就被他人剽窃,甚至可能造成自己站点的文章不被收录。如果发觉文章被他人剽窃一定要及时解决这个问题,否则对网站优化会有特别不好的影响。
不过还有一个方式可以阻止,只是我的个人看法,但是这个方式暂时还不想讲下来,想要的可以联系我们哦。 查看全部
终止原创文章被采集和复制
原创是自然推广中极其沉重的一部分,很多刚才上线的小站都是通过发布原创文章来做网站优化的,原创对于网站优化有非同寻常的意义。百度非常喜欢原创文章,如果新站使用采集文章,就容易使百度觉得这个网站是一个采集网站,进而影响以后的网站优化。营销在做网站优化的时侯会在网站中全部更新原创文章,但是此时我们也遇见了一个问题,就是原创文章被他人采集去发布外链了,遇到这些问题我们总结下来了一些网路营销方式。
更改网站程序
一般遇见这些问题可以修改网站的程序,一般情况下有的网站优化人员会在页面中添加一个严禁复制粘贴的JS代码,让这个代码来严禁用户复制粘贴或则是查看源代码。但是此类方式对用户体验度十分不利,所以假如不是情况十分严重,没有站长希望乐意使用这样的技巧,这种技巧可以说是最后的招数了。
提交内容链接
之所以避免网站内容被采集,最大的诱因还是由于害怕自己的文章不被收录,所以seoer会在更新了文章之后直接把文章的url递交给百度,这样做没有害处。虽然说百度不会马上收录这个文章,但是可以提醒百度来收录,让自己的文章尽早被收录,被百度认定是原创文章,这样他人再剽窃,对自己的影响也会减少。
添加网站链接
一般假如遇见了网站内容被拷贝,那么的做法就是在内容中添加网站的品牌词句,或者是隐藏锚文本链接等等,如果是机器进行的采集,那么对方都会把这种信息全部都采集走,这样就相当于给自己降低一个链接。但是要注意不能为了使文章不被采集走而在文章中生硬的添加锚文本链接或则是品牌词,这样会伤害到用户体验度。
防止网站文章被剽窃特别的重要,毕竟好多站长自己耗费了大量的时间和精力来编撰原创文章,但是刚发出去就被他人剽窃,甚至可能造成自己站点的文章不被收录。如果发觉文章被他人剽窃一定要及时解决这个问题,否则对网站优化会有特别不好的影响。
不过还有一个方式可以阻止,只是我的个人看法,但是这个方式暂时还不想讲下来,想要的可以联系我们哦。
产品剖析|我是怎样在3个月内从「收趣」重度用户到舍弃使用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-08-17 10:23
这种方法确实比此前我用Instapaper+Workflow明日视图工具搜集步骤更少。
今天发觉收趣也支持了iOS明日视图插件,看来还是这些方法才稳定,毕竟陌陌是会「发脾气」的。同样采用明日视图插件搜集,收趣比Instapaper + Workflow 少了一个「点击」操作,点一个赞。
收趣在陌陌搜集上有这个巧方式,在Chrome浏览器上也有专门的插件(各家都差不多),实现了最常用的两种搜集闭环,我就这样将一篇篇文章喂给了我的收趣帐号,Instapaper打入冷宫。
采集然后就该比阅读体验了,那话怎样说的?光收不读,假把式。
2 喜忧参半的阅读体验
首先是搜集的文章能正常显示。
文字不会错乱、图片显示正常;Pocket上即使能通过链接搜集陌陌文章,但在阅读时图片都通通不能显示,那即使不可用了(当然实在不行你可以访问原文链接),Pocket就如此被Pass掉。而Instapaper曾经时常也有陌陌文章图片问题,但现今比较稳定了。
收趣对陌陌文章的抓取,由于是专门优化的,所以你用上去太放心,不用害怕想看的时侯忽然发觉图片缺位等问题。
文章除了能正常显示,还须要排版高贵
这一点上Pocket和Instapaper可以说做到了极至:他们都手动对文章样式重新渲染,默认提供护眼的「羊皮纸」风格主题,缩进、行距恰到好处、字体清晰,也能自定义字体、字号、其他风格。无论原文排版怎么不堪,在Pocket和Instapaper中,都变的清晰和高贵。
他们都有好多贴心的细节,Pocket实时显示文章还剩多少的进度条、Instapaper也可以显示阅读比率,重新步入文章可以定位到先前阅读的位置、Instapaper甚至还可开启倾斜手机上下滚屏功能,躺在床上单手托着手机阅读时特别有用,这些细节数不胜数,让你重新认识到,在电子屏幕上阅读也会有挺好的体验。
而收趣在排版上只能说暂时「功能不全」:
收趣App上有统一的重新排版,但提供的主题、设置项目只能说是基本正常,没有那个「美的就想阅读」的冲动。
收趣的网页版,暂时没有做重新排版,只有采集列表功能,点击文章条目,直接跳转到原文链接,当然网页版优先级更低可以理解,不过对于一些比较深度的文章在手机上搜集,在大屏幕上认真阅读也是太典型的使用场景。
比如笔者常常在手机上刷到干货,先搜集,然后午饭后某个时间在MacBook上用Instapaper阅读,感觉太闲适。
在App上阅读其实也时常发生,不过一般是上厕所、等扶梯、坐地铁时读一些非干货内容。
笔者觉得App端以碎片阅读为主,桌面端以深度阅读为主,二者合起来才构成了优秀的阅读体验。
3 读后处理不能忍受
上面说的陌陌搜集使我开始使用,排版不够高贵也能够继续忍受,但是读后处理笔者觉得存在失策,最终使我用回了Instapaper。
这可能是稍后阅读应用最有难度的问题:
当用户读了一篇文章后,接下来想干嘛?
【稍后阅读】
上图简单列举了最主流的几种用户读完文章后的行为,以及对应的功能。
这里主要谈谈笔者遇见的疼点:
稍后阅读应用,本质上也是一种Todo list应用,用户不断的搜集添加各路文章,期望自己稍后某个时间阅读,每添加一个文章,相当于是添加了一个关于阅读的办理事项。
那么问题来了,很多人从来未能坚持使用Todo list工具,通常1-2周内就流失,究其原因,往往是任务添加了一大堆,做完的却没有几个,当一打开App就听到上百条Todo时,内心是崩溃的,索性逃避掉。
稍后阅读也存在这个问题,干货收了一大堆,每次打开见到一大堆列表就不想读了,索性撸一把王者化肥吧……
所以,稍后阅读的主页列表,一定不能无限膨胀,要有进有出,建议收趣团队可以从数据上统计一下,超过3个月的活跃用户,主页列表中的文章数量是多少。流失用户,流失时文章数量是多少。
文章的「进」就是更多更方便的搜集,「出」具体是指哪些呢?笔者理解的出是指:用户读过的文章,不应再抢占主页文章列表(中断后需再读除外),而是按照用户需求去了该去的地方,同时主页列表保持了流动性与清爽性。——达到「断舍离」的境界。
(1)断
(2)舍
有价值,不必删掉的文章要放在发挥后续价值的地方,例如剖析报告,看完后值得常年保存,可导出印象笔记或OneNote,亦或复印、拷贝到Word等等。
例如人生好鱼汤,归个档(归档后从主列表消失,但又没有删掉,还能找到),点个「喜欢」,当上次心灵空虚,需要鱼汤抚慰的时侯,能在「喜欢」列表中再度享用。
最重要的是有很多文章,有价值,读完又没想好具体放哪,删了又认为可惜,万一之后想看又怕找不到,更不能使它抢占主列表,不然就成了只进不出(就像便秘)。
Instapaper的解决方法是「一键归档」,点击后文章从主列表消失,但能够在归档列表中找到;Pocket的做法是「一键完成」,就像办理事项完成后对勾一样钩掉,原理与Instapaper一样,打钩的文章从主列表消失,能在归档列表中找到。
归档或完成,对用户心理上来说,表示“我又做完一件事”、“我搞定啦”、“我又进步了”;对产品形态上来说,减少了堆积的文章,促进了产品有进有出的良性循环。
(3)离
文章持续搜集后,「断」和「舍」不断循环,来消化掉搜集的文章,就达到了「离」的境界,而这样的用户,也会是常年忠实用户,并且沉淀数据越来越多,忠诚度越来越高。高级功能变现哪些的还得靠她们啊!
讲了这么多是为了解释我在收趣上究竟经历了哪些:
Instapaper和Pocket的主列表都是单维度列表,列表规则就是一句话:没有被「断(删)」和「舍(归档)」的文章按搜集时间逆序排列。再主列表外,配合加入了归档列表、喜欢列表、自定义分类列表。每个表定位都太清晰。
而收趣的做法完全不同,收趣只有一个总表,一表打天下!然后提供了2个维度筛选,1个是分类筛选,2个是已读未读筛选。这种设定笔者用上去出现了以下问题:
进入应用默认是:全部分类 + 全部已读未读状态,这样就缔造了前面说的「只进不出」问题。除非你看一篇删一篇,但这样只有「断」没有「舍」。
不是还有个已读、未读状态吗?确实,收趣对此甚至还有个贴心的设置功能:可以默认只显示「未读」文章,这样每次默认只看未读的不就好了吗?
【来自圈点】
话说做产品有时为了解决一个问题,结果确涉入出更多问题,这就是个挺好的反例:可以默认看未读文章,但是,文章是怎样定义已读未读的?收趣再度贴心的提供了一个设置:
自动已读的问题是假如你确实打开文章超过7秒,但你读了一半被急事打断,再次步入时想继续读时文章不见了,你可能要反应一下才明白原先是手动弄成已读了(需要够聪明),将状态筛选切到已读,啊哈,终于找到藏猫猫的文章了。
手动已读的问题——我就想标个已读,但你却教会了我什么叫弹出层上再弹层,隐藏很深,步骤太多:
【App Screenshots】
从这套界面上可以看出,收趣的优先级是这样的:
小结一下,由于收趣是一表全显,文章堆积过多让笔者恐惧,想过滤掉已读文章,但手动已读规则不适用,手动已读操作太麻烦,so,笔者受不了了。
另外,关于干货文章需要导出印象笔记或其他类似应用的需求,还好收趣留了通用的App Share Extension 不过又深了一个层级(私有弹出层上点更多弹出App Extension弹出层),弹出层上再弹层,国内社交平台分享优先,可以理解。
最后
文本阐述了笔者心目中优秀稍后阅读应用的 采集——阅读——读后处理 3大环节,以及读后处理的「断舍离」境界。
然后是笔者使用收趣的心路历程:
最终结果:从Instapaper全面切换到收趣3个月后,回归Instapaper。
感谢你花时间阅读,THANKS!
作者:BlinkQ,VR产品总监,GTD实践者,公众号:BlinkQ 查看全部
产品剖析|我是怎样在3个月内从「收趣」重度用户到舍弃使用的
这种方法确实比此前我用Instapaper+Workflow明日视图工具搜集步骤更少。
今天发觉收趣也支持了iOS明日视图插件,看来还是这些方法才稳定,毕竟陌陌是会「发脾气」的。同样采用明日视图插件搜集,收趣比Instapaper + Workflow 少了一个「点击」操作,点一个赞。
收趣在陌陌搜集上有这个巧方式,在Chrome浏览器上也有专门的插件(各家都差不多),实现了最常用的两种搜集闭环,我就这样将一篇篇文章喂给了我的收趣帐号,Instapaper打入冷宫。
采集然后就该比阅读体验了,那话怎样说的?光收不读,假把式。
2 喜忧参半的阅读体验
首先是搜集的文章能正常显示。
文字不会错乱、图片显示正常;Pocket上即使能通过链接搜集陌陌文章,但在阅读时图片都通通不能显示,那即使不可用了(当然实在不行你可以访问原文链接),Pocket就如此被Pass掉。而Instapaper曾经时常也有陌陌文章图片问题,但现今比较稳定了。
收趣对陌陌文章的抓取,由于是专门优化的,所以你用上去太放心,不用害怕想看的时侯忽然发觉图片缺位等问题。
文章除了能正常显示,还须要排版高贵
这一点上Pocket和Instapaper可以说做到了极至:他们都手动对文章样式重新渲染,默认提供护眼的「羊皮纸」风格主题,缩进、行距恰到好处、字体清晰,也能自定义字体、字号、其他风格。无论原文排版怎么不堪,在Pocket和Instapaper中,都变的清晰和高贵。
他们都有好多贴心的细节,Pocket实时显示文章还剩多少的进度条、Instapaper也可以显示阅读比率,重新步入文章可以定位到先前阅读的位置、Instapaper甚至还可开启倾斜手机上下滚屏功能,躺在床上单手托着手机阅读时特别有用,这些细节数不胜数,让你重新认识到,在电子屏幕上阅读也会有挺好的体验。
而收趣在排版上只能说暂时「功能不全」:
收趣App上有统一的重新排版,但提供的主题、设置项目只能说是基本正常,没有那个「美的就想阅读」的冲动。
收趣的网页版,暂时没有做重新排版,只有采集列表功能,点击文章条目,直接跳转到原文链接,当然网页版优先级更低可以理解,不过对于一些比较深度的文章在手机上搜集,在大屏幕上认真阅读也是太典型的使用场景。
比如笔者常常在手机上刷到干货,先搜集,然后午饭后某个时间在MacBook上用Instapaper阅读,感觉太闲适。
在App上阅读其实也时常发生,不过一般是上厕所、等扶梯、坐地铁时读一些非干货内容。
笔者觉得App端以碎片阅读为主,桌面端以深度阅读为主,二者合起来才构成了优秀的阅读体验。
3 读后处理不能忍受
上面说的陌陌搜集使我开始使用,排版不够高贵也能够继续忍受,但是读后处理笔者觉得存在失策,最终使我用回了Instapaper。
这可能是稍后阅读应用最有难度的问题:
当用户读了一篇文章后,接下来想干嘛?
【稍后阅读】
上图简单列举了最主流的几种用户读完文章后的行为,以及对应的功能。
这里主要谈谈笔者遇见的疼点:
稍后阅读应用,本质上也是一种Todo list应用,用户不断的搜集添加各路文章,期望自己稍后某个时间阅读,每添加一个文章,相当于是添加了一个关于阅读的办理事项。
那么问题来了,很多人从来未能坚持使用Todo list工具,通常1-2周内就流失,究其原因,往往是任务添加了一大堆,做完的却没有几个,当一打开App就听到上百条Todo时,内心是崩溃的,索性逃避掉。
稍后阅读也存在这个问题,干货收了一大堆,每次打开见到一大堆列表就不想读了,索性撸一把王者化肥吧……
所以,稍后阅读的主页列表,一定不能无限膨胀,要有进有出,建议收趣团队可以从数据上统计一下,超过3个月的活跃用户,主页列表中的文章数量是多少。流失用户,流失时文章数量是多少。
文章的「进」就是更多更方便的搜集,「出」具体是指哪些呢?笔者理解的出是指:用户读过的文章,不应再抢占主页文章列表(中断后需再读除外),而是按照用户需求去了该去的地方,同时主页列表保持了流动性与清爽性。——达到「断舍离」的境界。
(1)断
(2)舍
有价值,不必删掉的文章要放在发挥后续价值的地方,例如剖析报告,看完后值得常年保存,可导出印象笔记或OneNote,亦或复印、拷贝到Word等等。
例如人生好鱼汤,归个档(归档后从主列表消失,但又没有删掉,还能找到),点个「喜欢」,当上次心灵空虚,需要鱼汤抚慰的时侯,能在「喜欢」列表中再度享用。
最重要的是有很多文章,有价值,读完又没想好具体放哪,删了又认为可惜,万一之后想看又怕找不到,更不能使它抢占主列表,不然就成了只进不出(就像便秘)。
Instapaper的解决方法是「一键归档」,点击后文章从主列表消失,但能够在归档列表中找到;Pocket的做法是「一键完成」,就像办理事项完成后对勾一样钩掉,原理与Instapaper一样,打钩的文章从主列表消失,能在归档列表中找到。
归档或完成,对用户心理上来说,表示“我又做完一件事”、“我搞定啦”、“我又进步了”;对产品形态上来说,减少了堆积的文章,促进了产品有进有出的良性循环。
(3)离
文章持续搜集后,「断」和「舍」不断循环,来消化掉搜集的文章,就达到了「离」的境界,而这样的用户,也会是常年忠实用户,并且沉淀数据越来越多,忠诚度越来越高。高级功能变现哪些的还得靠她们啊!
讲了这么多是为了解释我在收趣上究竟经历了哪些:
Instapaper和Pocket的主列表都是单维度列表,列表规则就是一句话:没有被「断(删)」和「舍(归档)」的文章按搜集时间逆序排列。再主列表外,配合加入了归档列表、喜欢列表、自定义分类列表。每个表定位都太清晰。
而收趣的做法完全不同,收趣只有一个总表,一表打天下!然后提供了2个维度筛选,1个是分类筛选,2个是已读未读筛选。这种设定笔者用上去出现了以下问题:
进入应用默认是:全部分类 + 全部已读未读状态,这样就缔造了前面说的「只进不出」问题。除非你看一篇删一篇,但这样只有「断」没有「舍」。
不是还有个已读、未读状态吗?确实,收趣对此甚至还有个贴心的设置功能:可以默认只显示「未读」文章,这样每次默认只看未读的不就好了吗?
【来自圈点】
话说做产品有时为了解决一个问题,结果确涉入出更多问题,这就是个挺好的反例:可以默认看未读文章,但是,文章是怎样定义已读未读的?收趣再度贴心的提供了一个设置:
自动已读的问题是假如你确实打开文章超过7秒,但你读了一半被急事打断,再次步入时想继续读时文章不见了,你可能要反应一下才明白原先是手动弄成已读了(需要够聪明),将状态筛选切到已读,啊哈,终于找到藏猫猫的文章了。
手动已读的问题——我就想标个已读,但你却教会了我什么叫弹出层上再弹层,隐藏很深,步骤太多:
【App Screenshots】
从这套界面上可以看出,收趣的优先级是这样的:
小结一下,由于收趣是一表全显,文章堆积过多让笔者恐惧,想过滤掉已读文章,但手动已读规则不适用,手动已读操作太麻烦,so,笔者受不了了。
另外,关于干货文章需要导出印象笔记或其他类似应用的需求,还好收趣留了通用的App Share Extension 不过又深了一个层级(私有弹出层上点更多弹出App Extension弹出层),弹出层上再弹层,国内社交平台分享优先,可以理解。
最后
文本阐述了笔者心目中优秀稍后阅读应用的 采集——阅读——读后处理 3大环节,以及读后处理的「断舍离」境界。
然后是笔者使用收趣的心路历程:
最终结果:从Instapaper全面切换到收趣3个月后,回归Instapaper。
感谢你花时间阅读,THANKS!
作者:BlinkQ,VR产品总监,GTD实践者,公众号:BlinkQ
Wordpress采集插件:wp-autopost-pro文章采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-15 13:44
插件介绍:
最近有些建网站学员在咨询寻求wordpress采集插件,不过大部分采集插件都是中文wordpress插件但是不支持采集中文文章,这点特别操蛋。(如果不想使用wordpress插件,可以使用代码进行wordpress采集。)
不过呢之前据说wp-autopost插件不错,采集起来很方便,本地测试了下的确不错,支持定向采集,支持键值匹配、或CSS选择器精确采集任何内容,支持采集正文分页内容,和dedecms的采集差不多,非常适宜菜鸟和一些网站制作公司使用。
不过在测试的时侯发觉免费版wp-autopost插件采集的内容中会带上wp-autopost官网的链接,这样就太不爽了!文件中找了半天也没听到链接在哪,并且后台也没有消除链接的选项。
不过倒是发觉了wp-autopost-function.php文件被加密了,既然加密了,那链接100%是隐藏在这个文件里了,立马破解之,现在发下来的wp-autopost插件的压缩包里收录了两个文件夹wp-autopost是原版插件wp-autopost-po是wp-autopost破解版,另外希望你们支持正版,需要正版wordpress插件的话还是去官网订购比较好! 查看全部
插件介绍:
最近有些建网站学员在咨询寻求wordpress采集插件,不过大部分采集插件都是中文wordpress插件但是不支持采集中文文章,这点特别操蛋。(如果不想使用wordpress插件,可以使用代码进行wordpress采集。)
不过呢之前据说wp-autopost插件不错,采集起来很方便,本地测试了下的确不错,支持定向采集,支持键值匹配、或CSS选择器精确采集任何内容,支持采集正文分页内容,和dedecms的采集差不多,非常适宜菜鸟和一些网站制作公司使用。
不过在测试的时侯发觉免费版wp-autopost插件采集的内容中会带上wp-autopost官网的链接,这样就太不爽了!文件中找了半天也没听到链接在哪,并且后台也没有消除链接的选项。
不过倒是发觉了wp-autopost-function.php文件被加密了,既然加密了,那链接100%是隐藏在这个文件里了,立马破解之,现在发下来的wp-autopost插件的压缩包里收录了两个文件夹wp-autopost是原版插件wp-autopost-po是wp-autopost破解版,另外希望你们支持正版,需要正版wordpress插件的话还是去官网订购比较好!
【新坐姿】原来文章的质量就取决去搜索引擎!
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-14 18:14
1.文章标题与网站主题的相关性
标题是文章的高度浓缩,语文老师也时常说,一个好的文章标题就是成功文章的一半。优质文章的标题总是紧扣着网站的整体内容,好的标题能吸引很多点击,但是千万不要做标题党,否则只会引起用户厌烦一点进去发觉不是想要的内容直接退出,直线降低跳出率。
2.文章标题与文章内容是否原创
原创是SEO一开始就接触的话题,好多人还会说蜘蛛喜欢喝原创内容。的确是这样,蜘蛛源源不断的抓取网站上的内容,不断地在内部数据库里对比原先数据有没有这样的内容,如果有或则相似度很高,那对不住,你采集或者伪原创的文章被发觉了。如果这篇文章标题和内容都是互联网站以前从没出现过的,而且用户很喜欢,那蜘蛛会认为这个是原创之后偏好你这个文章。
3.网站的内部锚文本推荐
内部锚文本拥有的投票权,能使搜索引擎赋于文章一定的权重。如果内页的质量得分比较高,并做了锚文本指向该文章,那么该文章的质量得分也会相应提升。到目前为止,锚文本显示下来的力量还是太强悍,合理借助好锚文本,就能把小量的资源发挥功效很大。
4.文章的转载次数和被引用次数
文章被转载是哪些概念,即搜索引擎觉得你是原创了以后,外边出现的重复页面都是转载你的,或者内容高度相像的。千万不要以为他人不给你留链接,搜索引擎就不能判断出这个文章在那里出现得比较早,搜索引擎的蜘蛛遍及整个互联网,目前早已能辨识文章的时间以及是否原创了。引用功能,百度还没有即将公布,就像百度权重一样,尽管是没有官方的数据,但是早已有诸多说法说明其存在,我们自己心中晓得越被转载得多和越被引用得多这样的数据就是好数据,不必很郁闷他人的想法。
5.内容更新 查看全部
关于文章质量我们都应当晓得,只有好的文章就是能被秒录,那么还有一个诱因也是有相关性的,就是搜索引擎,有的同事会晓得搜索引擎的作用,还有的不太清楚概念,其实一般来说,搜索引擎优化,又称为SEO,它是一种通过剖析搜索引擎的排行规律,了解各类搜索引擎如何进行搜索、怎样抓取互联网页面、怎样确定特定关键词的搜索结果排行的技术。搜索引擎采用便于被搜索引用的手段,对网站进行有针对性的优化,提高网站在搜索引擎中的自然排行,吸引更多的用户访问网站,提高网站的访问量,提高网站的销售能力和宣传能力,从而提高网站的品牌效应。
1.文章标题与网站主题的相关性
标题是文章的高度浓缩,语文老师也时常说,一个好的文章标题就是成功文章的一半。优质文章的标题总是紧扣着网站的整体内容,好的标题能吸引很多点击,但是千万不要做标题党,否则只会引起用户厌烦一点进去发觉不是想要的内容直接退出,直线降低跳出率。
2.文章标题与文章内容是否原创
原创是SEO一开始就接触的话题,好多人还会说蜘蛛喜欢喝原创内容。的确是这样,蜘蛛源源不断的抓取网站上的内容,不断地在内部数据库里对比原先数据有没有这样的内容,如果有或则相似度很高,那对不住,你采集或者伪原创的文章被发觉了。如果这篇文章标题和内容都是互联网站以前从没出现过的,而且用户很喜欢,那蜘蛛会认为这个是原创之后偏好你这个文章。
3.网站的内部锚文本推荐
内部锚文本拥有的投票权,能使搜索引擎赋于文章一定的权重。如果内页的质量得分比较高,并做了锚文本指向该文章,那么该文章的质量得分也会相应提升。到目前为止,锚文本显示下来的力量还是太强悍,合理借助好锚文本,就能把小量的资源发挥功效很大。
4.文章的转载次数和被引用次数
文章被转载是哪些概念,即搜索引擎觉得你是原创了以后,外边出现的重复页面都是转载你的,或者内容高度相像的。千万不要以为他人不给你留链接,搜索引擎就不能判断出这个文章在那里出现得比较早,搜索引擎的蜘蛛遍及整个互联网,目前早已能辨识文章的时间以及是否原创了。引用功能,百度还没有即将公布,就像百度权重一样,尽管是没有官方的数据,但是早已有诸多说法说明其存在,我们自己心中晓得越被转载得多和越被引用得多这样的数据就是好数据,不必很郁闷他人的想法。
5.内容更新
什么是常用的高档seo黑帽技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-14 14:43
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想!
黑帽seo技术网是骗局网站吗
首先你要明白,copy黑帽SEO的排行有很大的运气成份在上面,
什么时候排行不百见了都说不好
其次,方法并不重要,度重要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被问K
那种堂而皇之教你作弊的,没必要花很大代答价去学
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个方式在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。 查看全部
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想!
黑帽seo技术网是骗局网站吗
首先你要明白,copy黑帽SEO的排行有很大的运气成份在上面,
什么时候排行不百见了都说不好
其次,方法并不重要,度重要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被问K
那种堂而皇之教你作弊的,没必要花很大代答价去学
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个方式在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
重庆SEO|网站推广优化不成功的八大缘由
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-14 11:12
一、关键词的剖析不到位
不知道诸位同学在做优化时,会不会遇见下边这几种情况,如:关键词设置不合理、没有方向、排名疗效不好、倾注心血好多但一点疗效都没有等,以上问题都是由于关键词剖析不到位而引起的。这些问题可能看上不去不太起眼,但对网站却有着致命的影响。因此在建站的早期,关键词的剖析设置是非常重要的。
二、经常性地去改动网站的标题
有经验的SEO老鸟一般是不会犯这样的错误的,但刚才才开始做SEO的菜鸟经常会出现这样的错误,经常去更改标题对网站是有着致命的影响的,改动标题,原来所对应的关键词会有波动,下降或则是消失,并且标题更改会导致快照异常,快照异常则会步入到百度观察期,观察期主要的任务是更新快照和重新赋于评级,观察快照的变化。如果再度进行更改则都会步入到百度沙盒,那这个周期可很长了。所以,如果你网站的权重不是很高,如收录少、收录慢、PR低等,最好不要去随意的更改标题。
三、大量的堆积关键词
切忌千万不要去大量的堆积关键词,大量的拼凑关键词是会使搜索引擎大大的增加对你的网站的友好度的,进而可以引起惩罚的后果,因此在设置关键词时,一定要注意关键词的密度,通常密度控制在2%-8%,千万不要刻意的去展现关键词,避免获得反向后果。
四、文章的更新不规律
作为一名优化师,一定要合理地规划自己的工作内容和工作时间,做事有规划和有规律的职工也是会遭到老总的喜欢的。同样的,搜索引擎也喜欢有规律的东西,如果可以做到每晚都有规律的更新文章,这样是很容易得到搜索引擎的偏爱的,那么这时网站想要在百度中有比较好的排行就不是很难事了。
五、全采集的内容
搜索引擎是非常的讨厌采集别人网站的文章的,毕竟采集是一个不需要下很大工夫的方式,用最短的时间添加最多的内容,可以顿时使你的网站内容达到几十万条,搜索引擎对于采集站惩罚也是非常严重的,因此我们没有必要去铤而走险,走好每一步才是通往成功之门的公路。
六、大量的死链没有及时的处理
向网站内容的管理,很多优化师同事都晓得一些没有用的文章和栏目是须要进行删掉的,但删掉那些页面时难免会出现大量的死链。死链在搜索引擎的眼中是不一种不友好的体验,当我们处理那些链接时一定要把404错误页面设置好,同时在robots中做特殊的处理,引路人网路在此建议你们尽可能的在要删掉的页面上更换内容,不要去直接的进行删掉。
七、多个网站交叉链接
网站最大权重的页面是主页,关键词也是最容易获得排行的。大部分的网站管理员在网站主页上放置好多的热门关键词。但因为主页的位置有限,不可能满足许多关键词的须要。许多网站管理员做了好多的分站来分离一些热门的关键词,这也许是一种干扰搜索引擎排行的行为。搜索引擎也会对这些行为采取一定的举措,比如:延长新站点的排行时间、对新站点进行沙盒处理(谷歌称之为沙盒,百度则称之为评估期)、通过信息搜集和剖析对站点进行一定程度的惩罚。那有人可能会问:站群可不可以有?当然可以了,但一定得要把握程度。很好的借助对排行是非常有帮助的,就像是我们交换的友情链接一样。
八、缺少导出链接和导入链接
优化师所接管的网站不在少数,但有好多的网站都有这样的问题,检查之后发展许多的网站出站后都有闭门觅句这一个现象,没有合理的导出和导入链接。在互联网中,网页和网页之间的关键是通过联接来构建的。如果网站和外界没有链接,那便会成为孤岛网站,搜索引擎也就不会晓得网站的存在啦。 查看全部
身边从事SEO优化的同事越来越多,常常会看到刚从事SEO优化的同事反映自己做优化的时侯总是做不好,其实不仅仅菜鸟是这样,有经验的优化师也并不是每一次都可以做到自己想要的疗效的。以下是上海引路人网路总结的造成网站优化不成功的几个诱因,希望可以帮助到现在正在进行网站优化的朋友们。
一、关键词的剖析不到位
不知道诸位同学在做优化时,会不会遇见下边这几种情况,如:关键词设置不合理、没有方向、排名疗效不好、倾注心血好多但一点疗效都没有等,以上问题都是由于关键词剖析不到位而引起的。这些问题可能看上不去不太起眼,但对网站却有着致命的影响。因此在建站的早期,关键词的剖析设置是非常重要的。
二、经常性地去改动网站的标题
有经验的SEO老鸟一般是不会犯这样的错误的,但刚才才开始做SEO的菜鸟经常会出现这样的错误,经常去更改标题对网站是有着致命的影响的,改动标题,原来所对应的关键词会有波动,下降或则是消失,并且标题更改会导致快照异常,快照异常则会步入到百度观察期,观察期主要的任务是更新快照和重新赋于评级,观察快照的变化。如果再度进行更改则都会步入到百度沙盒,那这个周期可很长了。所以,如果你网站的权重不是很高,如收录少、收录慢、PR低等,最好不要去随意的更改标题。
三、大量的堆积关键词
切忌千万不要去大量的堆积关键词,大量的拼凑关键词是会使搜索引擎大大的增加对你的网站的友好度的,进而可以引起惩罚的后果,因此在设置关键词时,一定要注意关键词的密度,通常密度控制在2%-8%,千万不要刻意的去展现关键词,避免获得反向后果。
四、文章的更新不规律
作为一名优化师,一定要合理地规划自己的工作内容和工作时间,做事有规划和有规律的职工也是会遭到老总的喜欢的。同样的,搜索引擎也喜欢有规律的东西,如果可以做到每晚都有规律的更新文章,这样是很容易得到搜索引擎的偏爱的,那么这时网站想要在百度中有比较好的排行就不是很难事了。
五、全采集的内容
搜索引擎是非常的讨厌采集别人网站的文章的,毕竟采集是一个不需要下很大工夫的方式,用最短的时间添加最多的内容,可以顿时使你的网站内容达到几十万条,搜索引擎对于采集站惩罚也是非常严重的,因此我们没有必要去铤而走险,走好每一步才是通往成功之门的公路。
六、大量的死链没有及时的处理
向网站内容的管理,很多优化师同事都晓得一些没有用的文章和栏目是须要进行删掉的,但删掉那些页面时难免会出现大量的死链。死链在搜索引擎的眼中是不一种不友好的体验,当我们处理那些链接时一定要把404错误页面设置好,同时在robots中做特殊的处理,引路人网路在此建议你们尽可能的在要删掉的页面上更换内容,不要去直接的进行删掉。
七、多个网站交叉链接
网站最大权重的页面是主页,关键词也是最容易获得排行的。大部分的网站管理员在网站主页上放置好多的热门关键词。但因为主页的位置有限,不可能满足许多关键词的须要。许多网站管理员做了好多的分站来分离一些热门的关键词,这也许是一种干扰搜索引擎排行的行为。搜索引擎也会对这些行为采取一定的举措,比如:延长新站点的排行时间、对新站点进行沙盒处理(谷歌称之为沙盒,百度则称之为评估期)、通过信息搜集和剖析对站点进行一定程度的惩罚。那有人可能会问:站群可不可以有?当然可以了,但一定得要把握程度。很好的借助对排行是非常有帮助的,就像是我们交换的友情链接一样。
八、缺少导出链接和导入链接
优化师所接管的网站不在少数,但有好多的网站都有这样的问题,检查之后发展许多的网站出站后都有闭门觅句这一个现象,没有合理的导出和导入链接。在互联网中,网页和网页之间的关键是通过联接来构建的。如果网站和外界没有链接,那便会成为孤岛网站,搜索引擎也就不会晓得网站的存在啦。
SEO培训哪家好?大批量采集文章而造成的不收录(非原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-08-14 00:57
很多运营者建设新站的时侯才会在首页设置nofollow标签而其他页面却会保留,这是因为合理的控制首页蜘蛛的爬行,比如,新站可能会重点引蜘蛛到某个列表页面或则是某个分类下边的文章,但又想诠释tag聚合的内容,而这个tag页面又想被抓取,就保留在其他的页面,而没有全站nofollow。
相关内容页推荐
很多网站的内容页面会推荐不相关的内容,目的就是为了降低用户黏性,这样的页面对网站的优化工作没有很大的用处,因此我们也要设置nofollow标签。
坚持原创度较高文章
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
SEO培训哪家好?搜索引擎为何不收录原创文章?
网站是新站
对于一个刚才上线的网站也就是新站来说,想要达到文章被秒收的疗效,一般来讲都有点困难,就好比谈恋爱一样,需要勤接触,你才刚才接触女孩子,就想马上离婚,想想都有点做梦对吧,很多同学包括我们做SEO优化人员都这样觉得自己的网站已经渡过了新站期,一般六个月之前的都可称之为新站,如果你的网站上线还没有满六个月,出现收录慢是很正常现象,不用害怕,坚持做好本职工作就好。
SEO培训哪家好?那我们要怎样减短新站审核期呢?
很多人问小编,为什么他人的网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于我们新站来说,如何操作能推动文章的收录呢?
a.做好外链工作:
很多人觉得外链早已没有任何作用了,实则不然,外链的作用仍然不可忽略,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意想不到的流量。
b.内链合理布局:
当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣在于是否起到引导的作用。
c.搜索引擎平台递交链接:
可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,一俩次即,否则会影响网站的整体质量。
d.做好网站地图:
网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具。
e.充分利用nofollow标签进行集权:
nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
SEO培训哪家好?大批量采集文章而造成的不收录(非原创)
很多人为了使网站早点上线,都去各大平台大量的采集一些相关内容,就这样草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章写得好,有价值,但最终还是得不到搜索引擎的认可,没有新鲜的原创内容做支撑,搜索引擎给的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:
大家可以拿标题到百度搜搜,看看相关搜索量有多少,若是达到一百万左右,那么就要适当的改下标题了,修改后的标题再领到百度搜一搜,看看相关搜索结果又有多少,一般最好控制在10万以下。
b.加强外链发布的工作:
一旦更改好内容和标题,那么接下来我们要使搜索引擎重新抓取内容,这时候外链起到十分重要的作用,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容能更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然没有好转,如果大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量都会上来了。
好了,今天小编提到这儿吧,不知道你们理解了多少呢? 查看全部
TAG聚合页面
很多运营者建设新站的时侯才会在首页设置nofollow标签而其他页面却会保留,这是因为合理的控制首页蜘蛛的爬行,比如,新站可能会重点引蜘蛛到某个列表页面或则是某个分类下边的文章,但又想诠释tag聚合的内容,而这个tag页面又想被抓取,就保留在其他的页面,而没有全站nofollow。
相关内容页推荐
很多网站的内容页面会推荐不相关的内容,目的就是为了降低用户黏性,这样的页面对网站的优化工作没有很大的用处,因此我们也要设置nofollow标签。
坚持原创度较高文章
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
SEO培训哪家好?搜索引擎为何不收录原创文章?
网站是新站
对于一个刚才上线的网站也就是新站来说,想要达到文章被秒收的疗效,一般来讲都有点困难,就好比谈恋爱一样,需要勤接触,你才刚才接触女孩子,就想马上离婚,想想都有点做梦对吧,很多同学包括我们做SEO优化人员都这样觉得自己的网站已经渡过了新站期,一般六个月之前的都可称之为新站,如果你的网站上线还没有满六个月,出现收录慢是很正常现象,不用害怕,坚持做好本职工作就好。
SEO培训哪家好?那我们要怎样减短新站审核期呢?
很多人问小编,为什么他人的网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于我们新站来说,如何操作能推动文章的收录呢?
a.做好外链工作:
很多人觉得外链早已没有任何作用了,实则不然,外链的作用仍然不可忽略,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意想不到的流量。
b.内链合理布局:
当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣在于是否起到引导的作用。
c.搜索引擎平台递交链接:
可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,一俩次即,否则会影响网站的整体质量。
d.做好网站地图:
网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具。
e.充分利用nofollow标签进行集权:
nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
SEO培训哪家好?大批量采集文章而造成的不收录(非原创)
很多人为了使网站早点上线,都去各大平台大量的采集一些相关内容,就这样草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章写得好,有价值,但最终还是得不到搜索引擎的认可,没有新鲜的原创内容做支撑,搜索引擎给的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:
大家可以拿标题到百度搜搜,看看相关搜索量有多少,若是达到一百万左右,那么就要适当的改下标题了,修改后的标题再领到百度搜一搜,看看相关搜索结果又有多少,一般最好控制在10万以下。
b.加强外链发布的工作:
一旦更改好内容和标题,那么接下来我们要使搜索引擎重新抓取内容,这时候外链起到十分重要的作用,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容能更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然没有好转,如果大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量都会上来了。
好了,今天小编提到这儿吧,不知道你们理解了多少呢?
微信公众号文章采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-13 21:00
单篇陌陌文章的爬取并没有哪些难度,难的就是入口,微信是一个封闭的生态,不同于其他的网站可以轻而易举的领到入口链接。
那么就从陌陌文章的入口来说起。
在最开始我还能想到的是通过陌陌搜狗搜索查找到文章的列表页。但是通过搜狗搜出来的列表页的链接有时效性。而且频繁地爬取会被搜狗封ip。
这个办法我之前尝试过,但是并不稳定。
再后来,了解到一种方式----基于中间人攻击的方式抓取陌陌公众帐号文章,别被标题吓到,说简单点就是借助代理软件抓包,然后把解析抓包内容。 这里推荐几个开源的代理软件:
go语言的代理软件 sheepbao/gomitmproxy
nodejs 语言实现的代理 alibaba/anyproxy
有了代理层以后,又是开源的,可以直接更改源代码。
在代理层中,匹配出陌陌文章详情页链接,然后抓取这个链接的内容,详情页的链接并不限制在陌陌客户端打开。
这个知乎专栏写的比较详尽。知乎专栏
再找到通过代理的方式以后,我也实现了自己的代码。但是问题是,在客户端上怎样模拟点击文章链接实现上去并不是挺好。 查看全部
没有准备上传具体的代码,因为我好多地方都是借用他人的代码,然后按照自己的业务稍为写了点代码而已。所以,这里主要是想分享思路,和自己在做陌陌公众文章采集的时侯遇到的问题和解决办法。
单篇陌陌文章的爬取并没有哪些难度,难的就是入口,微信是一个封闭的生态,不同于其他的网站可以轻而易举的领到入口链接。
那么就从陌陌文章的入口来说起。
在最开始我还能想到的是通过陌陌搜狗搜索查找到文章的列表页。但是通过搜狗搜出来的列表页的链接有时效性。而且频繁地爬取会被搜狗封ip。
这个办法我之前尝试过,但是并不稳定。
再后来,了解到一种方式----基于中间人攻击的方式抓取陌陌公众帐号文章,别被标题吓到,说简单点就是借助代理软件抓包,然后把解析抓包内容。 这里推荐几个开源的代理软件:
go语言的代理软件 sheepbao/gomitmproxy
nodejs 语言实现的代理 alibaba/anyproxy
有了代理层以后,又是开源的,可以直接更改源代码。
在代理层中,匹配出陌陌文章详情页链接,然后抓取这个链接的内容,详情页的链接并不限制在陌陌客户端打开。
这个知乎专栏写的比较详尽。知乎专栏
再找到通过代理的方式以后,我也实现了自己的代码。但是问题是,在客户端上怎样模拟点击文章链接实现上去并不是挺好。
网站进入沙盒期是哪些意思?
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2020-08-13 16:20
进入沙箱期的诱因
一:网站的权重太低,你时常更改网站的标题和相关关键词。这样,当百度进行大规模更新时,往往会将权重较低、目标内容不明晰的网站放入沙箱中进行审查。通常,这个时间须要两周。在此期间,一旦你的网站名称被确认,你就不能随便修改。同时,你必须保证网站的正常更新。应检测网站的外部链接以确保正常。当然,外部链条是在这个时侯制造的。
第二:当你的朋友链有问题时,你常常把你的网站放在百度沙箱里。例如,一些与你交换朋友链的网站已经被k屏蔽了。此时,百度将把与这个被屏蔽网站有朋友链的网站放入沙箱进行调查,看看你的网站是否有问题。这时,你要做的是关掉被封锁的朋友链,在制做同学链时注意数目。一般来说,最好控制在20到30之间!
第三:网站上有太多垃圾的外部链接和太多无效的外部链接。当你的网站一夜之间订购了大量的外部链接时,百度常常觉得你在作弊,会把你置于沙箱里进行调查。这时,你应当按照情况渐渐检测外部链接,看看是否是由外部链程序造成的。如果是自动发送,这样的问题通常不会发生!
四:网站内容已被常年采集和转载,没有原创内容。这样的网站很可能会被百度放在沙箱里,可能要花很长时间才会放在沙箱里。因此,当把它装入沙箱时,更有必要不断提升网站内容的质量,并不断以一种原创的方法更新它,否则网站可能永远不会衰落!
五.仔细检测你的网站是否有作弊的征兆,比如你是否订购了黑链接或则采用了黑帽子的搜索引擎优化技术。所有那些都应当及时并逐渐清除!
如何走出沙箱时期
保持服务器稳定:这是关键词优化最基本和最重要的一点;没有稳定的服务器,不仅搜索蜘蛛不会爬行,客户也不会浏览。网站通常难以打开或平缓打开,搜索引擎蜘蛛一般难以抓取网站
网站安全:这是许多中级站长最头痛的问题。网站程序不是手工创建的,而是完全在线下载的;我不知道从网路上下载的大部分程序都有漏洞,容易被卡住,加上好多垃圾链,导致网站被百度降级,或者所有被抓取的页面都被直接删掉。
标题的关键词不能频繁改变:这是中级SEOER最常见的问题,他常常每三天在两端改变关键词。修改标题、关键字和描述。通常,在网站上线之前,你的网站的这三个要素没有被挺好地确定,它们常常被更改。我想提醒你,网站的标题不应当改变。作为一个比喻,“seo关键词优化-百度seo,seo教程,金华网站优化,网站关键词优化,网站设计”是我的网站的标题,搜索引擎会用它来命名我的网站。如果我在下一刻把它改成“搜索引擎优化关键词——百度搜索引擎优化,搜索引擎优化教程,网站优化,网站关键词优化,网站制作”,虽然它只有短短的几个字,搜索引擎会重新创建你的网站。
网站的框架结构应当是稳定的:对网站的结构做了太多的更改。许多站长都盼望在新站点上不使用完整的搜索引擎优化能够上网。上网后,他们发觉网站的好多地方须要更改,所以网站的结构常常被更改。搜索引擎蜘蛛在多次访问网站时会发觉结构上的变化,这造成了对网站的不喜欢和不信任。
增加高质量的反链:如果百度能早日收录你的网站,就有必要想办法使百度蜘蛛频繁抓取你的网站。如果爬行次数每晚都在降低,可以解释为你网站的外链构建的越来越丰富,蜘蛛爬行网站的次数越多,也会显示出对网站的良好亲和力,同时也会赋于这种天龙网站更高的权重。因此,通过外部链的剌激,将有助于提升新北站的包容性!
不要采集太多:搜索引擎喜欢高质量的原创文章,讨厌采集太多的信息。网站上采集的大量信息会大大降低你的网站。 查看全部
搜索引擎优化中的沙箱指的是搜索引擎在一个新站点完善后评估其资质的阶段。我们称这个阶段为沙箱,在沙箱中的这段时间,我们称之为沙箱时期,通常持续2-6个月。在沙箱时期。我们依然须要时常更新文章,但是我们不应当过多地改变网站的结构和更改文章的标题。在此期间,你网站上的文章可能很快会被百度收录,但第二天都会被搜索引擎删掉。不要害怕这些情况,只要你不作弊,你网站上的文章会在一段时间后再度被收录。
进入沙箱期的诱因
一:网站的权重太低,你时常更改网站的标题和相关关键词。这样,当百度进行大规模更新时,往往会将权重较低、目标内容不明晰的网站放入沙箱中进行审查。通常,这个时间须要两周。在此期间,一旦你的网站名称被确认,你就不能随便修改。同时,你必须保证网站的正常更新。应检测网站的外部链接以确保正常。当然,外部链条是在这个时侯制造的。
第二:当你的朋友链有问题时,你常常把你的网站放在百度沙箱里。例如,一些与你交换朋友链的网站已经被k屏蔽了。此时,百度将把与这个被屏蔽网站有朋友链的网站放入沙箱进行调查,看看你的网站是否有问题。这时,你要做的是关掉被封锁的朋友链,在制做同学链时注意数目。一般来说,最好控制在20到30之间!
第三:网站上有太多垃圾的外部链接和太多无效的外部链接。当你的网站一夜之间订购了大量的外部链接时,百度常常觉得你在作弊,会把你置于沙箱里进行调查。这时,你应当按照情况渐渐检测外部链接,看看是否是由外部链程序造成的。如果是自动发送,这样的问题通常不会发生!
四:网站内容已被常年采集和转载,没有原创内容。这样的网站很可能会被百度放在沙箱里,可能要花很长时间才会放在沙箱里。因此,当把它装入沙箱时,更有必要不断提升网站内容的质量,并不断以一种原创的方法更新它,否则网站可能永远不会衰落!
五.仔细检测你的网站是否有作弊的征兆,比如你是否订购了黑链接或则采用了黑帽子的搜索引擎优化技术。所有那些都应当及时并逐渐清除!
如何走出沙箱时期
保持服务器稳定:这是关键词优化最基本和最重要的一点;没有稳定的服务器,不仅搜索蜘蛛不会爬行,客户也不会浏览。网站通常难以打开或平缓打开,搜索引擎蜘蛛一般难以抓取网站
网站安全:这是许多中级站长最头痛的问题。网站程序不是手工创建的,而是完全在线下载的;我不知道从网路上下载的大部分程序都有漏洞,容易被卡住,加上好多垃圾链,导致网站被百度降级,或者所有被抓取的页面都被直接删掉。
标题的关键词不能频繁改变:这是中级SEOER最常见的问题,他常常每三天在两端改变关键词。修改标题、关键字和描述。通常,在网站上线之前,你的网站的这三个要素没有被挺好地确定,它们常常被更改。我想提醒你,网站的标题不应当改变。作为一个比喻,“seo关键词优化-百度seo,seo教程,金华网站优化,网站关键词优化,网站设计”是我的网站的标题,搜索引擎会用它来命名我的网站。如果我在下一刻把它改成“搜索引擎优化关键词——百度搜索引擎优化,搜索引擎优化教程,网站优化,网站关键词优化,网站制作”,虽然它只有短短的几个字,搜索引擎会重新创建你的网站。
网站的框架结构应当是稳定的:对网站的结构做了太多的更改。许多站长都盼望在新站点上不使用完整的搜索引擎优化能够上网。上网后,他们发觉网站的好多地方须要更改,所以网站的结构常常被更改。搜索引擎蜘蛛在多次访问网站时会发觉结构上的变化,这造成了对网站的不喜欢和不信任。
增加高质量的反链:如果百度能早日收录你的网站,就有必要想办法使百度蜘蛛频繁抓取你的网站。如果爬行次数每晚都在降低,可以解释为你网站的外链构建的越来越丰富,蜘蛛爬行网站的次数越多,也会显示出对网站的良好亲和力,同时也会赋于这种天龙网站更高的权重。因此,通过外部链的剌激,将有助于提升新北站的包容性!
不要采集太多:搜索引擎喜欢高质量的原创文章,讨厌采集太多的信息。网站上采集的大量信息会大大降低你的网站。
黑帽seo批量外链
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-13 14:03
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但那些字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽SEO 什么是黑帽SEO常用的链接作弊招数
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但这种字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。 查看全部
常见的几种黑帽seo作弊技术
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但那些字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽SEO 什么是黑帽SEO常用的链接作弊招数
一、隐藏文字
隐藏文字是在网页的HTML文件中放上富含关键字的文字,但这种字用户是看不到的,只能被搜索引擎听到。
隐藏文字的方式可以有几种方式:
颜色隐藏(通过将文字与背景设置为相同颜色),达到隐藏的疗效。
小字号隐藏:将文字大小设置为细微文字或微型文字,并且置于不起眼的角落,用户很难察觉到,而搜索引擎却可以正常读取到。隐藏文字的目的就是为了降低页面关键词的密度,想提升网页的相关性,以达到优化的疗效。
隐藏文字说白了就是误导搜索引擎,现在的搜索引擎早已能轻易的辨识那些技术,网站一但被搜索引擎发觉隐藏拼凑关键字,轻则降权重,重则网站直接被K。
二、隐藏链接
隐藏链接和隐藏文字相像,但是区别是把关键词置于链接上面,而这个链接也是用户看不到的。
新手站长在跟其它网站交换链接的时侯,可能会被愚弄,有的站长在给对方做友情链接的时侯通过使用CSS来控制隐藏链接的形式也不稀少,也有通过提供免费的网站程序,博客风格,网站插件等方式把黑链植入到你的网站。SEO工作者都晓得当一个站点被越多的站点给链接的时侯,那么这个站点的权重也会急剧提高的,这并不包括隐藏链接这些手段所带来的链接数目,所以会影响一个站点的权重正常传递。隐藏链接是被搜索引擎严令严禁的,一旦发觉,惩罚将会十分严重。
三、隐藏页面
隐藏页面是针对搜索引擎在爬行和抓取网站页面时所显示经过非常优化的页面,网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。通过在服务器上设置页面,来判定当前是真实的访问者,还是搜索引擎蜘蛛,然后按照服务器配置好的脚本对真实访问者和搜索引擎蜘蛛提供不同的页面响应。
隐藏页面为SEO作弊手段之一,这种手法意图欺骗搜索引擎,来影响该网站的网页在搜索引擎中获取较好的排行,通常用户难以发觉,检测的方式是,看一下这个网页的快照。
以上就是黑帽SEO最常用的几种作弊手法,对于搜索引擎来说是不友好的几种SEO手段。对于当代企业或店家在做网站优化的同时,建议远离黑帽SEO,让网站能够常年稳定的发展。
最后我建议还是根据正规手段吧,其实不难的我介绍一下:SEO分为分站内和站外,一般站内就是通过发布文章,堆加关键字密度,然百度蜘蛛爬行的时侯,知道你网站主题是哪些,相应给出关键词的排行,但是现在更重要的是客户体验,网站的设计可以从这个便捷着手,同时站内链接同样重要,如果你的链接是一环扣一环的,都可以提升顾客的体验度。另外,站外的话,一般来说最有价值就是友情链接,一般须要选定权重较高,行业相关为准,但是你低权重他人是不跟你换的,所以,你可以从另一个方面选择,就是选择一些出链较少的网站,这样你分得他的权重就多。其次,就是一些峰会、B2B平台、分类网的外链,其实这种作用早已大不如前,更重要关注自己站内优化!希望你也能做好SEO!
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
正则表达式的简单应用:使用正则表达式采集腾讯新闻
采集交流 • 优采云 发表了文章 • 0 个评论 • 603 次浏览 • 2020-08-13 09:18
正则表达式(Regular Expression)是比较冗长的,要记的东西比较多,因此我始终都没有腾出时间专门好好研究一下正则表达式,最近网站需要用到PHP的CURL获取腾讯新闻,所以就认真地学了一下正则表达式。正则表达式是十分强悍的,学会了正则表达式,在之后的文本匹配中,那是杠杠的。话不多说,进入题外话。
关于正则表达式的一些基础句型,大家可以看一下下边的参考链接,讲解十分到位。
引用《深入正则表达式应用》的“正则三段论”:定锚点,去杂讯,取数据。
1.首先,我想要从获取科技新闻头条,以及新闻列表,如图所示。
2.点击“查看网页源代码”Ctrl+ F找到我们须要的那一段代码,如图
可以发觉每位标签都有一个新闻标签都是由“Q-tpListInner”的div包上去的,,并且我们要取出的url 在a 标签的href中, 要取的新闻标题在img的alt中,这就是传说的“定锚点、去杂讯”的过程了;
3.之后就是直接用正则表达式取出我们须要的数据了。
新闻列表的正则表达式:
'/Q-tpListInner.*?href="(.*?)".*?alt="(.*?)">/s';
科技新闻标题的正则表达式:
'/
.*?href="(.*?)".*?>(.*?)/s';
PHP源代码:
function techNews() {
// PS:PHP的CURL请自行补脑
$url = 'http://tech.qq.com';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content = curl_exec($ch);
curl_close($ch);
$content = iconv('gb2312', 'utf-8//IGNORE',$content); //修改字符编码
/*
* 获取腾讯新闻头条
*/
$data = array();
$data_cnt = 0;
$matches = array();
$pattern = '/.*?href="(.*?)".*?>(.*?)/s';
preg_match($pattern, $content, $matches);
$data[$data_cnt]['url'] = $matches[1];
$data[$data_cnt++]['intro'] = $matches[2];
/*
* 获取腾讯新闻列表
*/
$matches = array();
$pattern = '/Q-tpListInner.*?href="(.*?)".*? alt="(.*?)">/s';
preg_match_all($pattern, $content, $matches);
// var_dump($matches);
for ($i = 0; $i < count($matches[1]); $i++) {
$data[$data_cnt]['url'] = $matches[1][$i];
$data[$data_cnt++]['intro'] = $matches[2][$i];
}
var_dump($data);
}
运行结果截图:
如果出现乱码,转化一下字符编码就行了。
参考链接:
[1] 正则表达式30分钟入门教程
[2] 我眼中的正则表达式(入门)
[3] 深入正则表达式应用 查看全部
正则表达式的简单应用:使用正则表达式采集腾讯新闻
正则表达式(Regular Expression)是比较冗长的,要记的东西比较多,因此我始终都没有腾出时间专门好好研究一下正则表达式,最近网站需要用到PHP的CURL获取腾讯新闻,所以就认真地学了一下正则表达式。正则表达式是十分强悍的,学会了正则表达式,在之后的文本匹配中,那是杠杠的。话不多说,进入题外话。
关于正则表达式的一些基础句型,大家可以看一下下边的参考链接,讲解十分到位。
引用《深入正则表达式应用》的“正则三段论”:定锚点,去杂讯,取数据。
1.首先,我想要从获取科技新闻头条,以及新闻列表,如图所示。
2.点击“查看网页源代码”Ctrl+ F找到我们须要的那一段代码,如图
可以发觉每位标签都有一个新闻标签都是由“Q-tpListInner”的div包上去的,,并且我们要取出的url 在a 标签的href中, 要取的新闻标题在img的alt中,这就是传说的“定锚点、去杂讯”的过程了;
3.之后就是直接用正则表达式取出我们须要的数据了。
新闻列表的正则表达式:
'/Q-tpListInner.*?href="(.*?)".*?alt="(.*?)">/s';
科技新闻标题的正则表达式:
'/
.*?href="(.*?)".*?>(.*?)/s';
PHP源代码:
function techNews() {
// PS:PHP的CURL请自行补脑
$url = 'http://tech.qq.com';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content = curl_exec($ch);
curl_close($ch);
$content = iconv('gb2312', 'utf-8//IGNORE',$content); //修改字符编码
/*
* 获取腾讯新闻头条
*/
$data = array();
$data_cnt = 0;
$matches = array();
$pattern = '/.*?href="(.*?)".*?>(.*?)/s';
preg_match($pattern, $content, $matches);
$data[$data_cnt]['url'] = $matches[1];
$data[$data_cnt++]['intro'] = $matches[2];
/*
* 获取腾讯新闻列表
*/
$matches = array();
$pattern = '/Q-tpListInner.*?href="(.*?)".*? alt="(.*?)">/s';
preg_match_all($pattern, $content, $matches);
// var_dump($matches);
for ($i = 0; $i < count($matches[1]); $i++) {
$data[$data_cnt]['url'] = $matches[1][$i];
$data[$data_cnt++]['intro'] = $matches[2][$i];
}
var_dump($data);
}
运行结果截图:
如果出现乱码,转化一下字符编码就行了。
参考链接:
[1] 正则表达式30分钟入门教程
[2] 我眼中的正则表达式(入门)
[3] 深入正则表达式应用
独家揭密:影响SEO原创文章不收录的诱因及解法
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-13 09:05
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结:以上就是本文述说的原创文章为何不收录的大致缘由,由于时间关系,就不做过多总结了,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提示文章质量,确保网站跳出率可观就OK了,如果还有疑惑可以私聊岑辉宇。 查看全部
相信这个问题以及困惑了你们许久了,有的站长天天呕心沥血写原创更新,但总是得不到搜索引擎的偏爱,而有的网站哪怕是采集都能达到秒收的待遇,是我们坚持原创更新的方向错了?还是他人另有高招?这些就不得而知了,而明天和你们分享的就是为什么写原创而不收录的诱因剖析及解法。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
d.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以私聊岑辉宇。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎么去做了,下面的方式似乎对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都整修过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是原先陈旧的观点,根本解决不了如今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结:以上就是本文述说的原创文章为何不收录的大致缘由,由于时间关系,就不做过多总结了,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提示文章质量,确保网站跳出率可观就OK了,如果还有疑惑可以私聊岑辉宇。
索答科技:领域应用 | 基于知识图谱的卧室领域问答系统打造
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-11 18:35
问句生成。同一个问题的问句是特别多的,首先对输入问句进行剖析,找到“种子问句”,然后对它进行动词,把每一个词用word2vec 寻找相关的词(比如美国-男人=女王-女人),相关的词把它们的位置序列记好,然后做笛卡尔积。这样的做完了,会生成大规模这样问句的数据,当然上面有一些是不正确的语句,这个时侯用文本纠错的马尔可夫链的机率图模型去纠正它,最后人工筛选。第二种方式是,采集200多个跟菜谱相关的代词,以及相关的同义词,利用文本生成,生成问句。这里推荐OpenKG
2.1.3 知识库建立
首先做时序融合,就是之前做的实体,它的实体链接是不是按照时间的推理,而它换掉了它本身的这样一个涵义,进而做本体的扩展(不太懂)。多源融合,做一个实体的匹配和概念的对齐。
抽出实体和属性
2.1.4 数据访问
分为4个部份。
1.SPARQL查询 2.自然语言查询 3.SDK的形式 4.逻辑表达式,后台将其转化成SPARQL句子
2.2 知识图谱的建立
其中,不辣的查询比较历时,原因是因为标签没有不辣,因此要把所有的属性都查一遍。后来的解决方式是离线去处理,比如是甜的,那它一定不是辣的。
3 曾经踩过的一些坑
知识图谱上面的搜索是有一个问题的, ElasticSearch 检索上面的排序虽然是十分容易去做的,本身底层就写了一个排序打分的 TF-IDF。而用知识图谱的时侯,它附近的那些节点的权重都是一样的。比如说芋头能做哪些菜,那么查询下来所有的菜的权重都是一样的。知识图谱上面,映射的本身是扁平的,比如地瓜这个节点,能够查询好多菜谱,发现有些所列下来的这些菜你们都不认识,会导致糟糕的体验。解决方式:在知识图谱的属性当中,加了一个热度的一个值,热度主要是通过点击次数去估算,然后按照热度排序。
4 遇到的一些挑战与困难
1. 跨领域问题不仅基础工作,比如查询等方法不会有很大的改动,但是属性是要重新设定的。
2. 语义理解还没有达到一定的高度。当下主要还是在于文本分类+属性抽取+逻辑表达式,但是用多大的数据量可以将一句话直接运用到知识图谱中去还须要继续探究。
- end -
Tip:索答科技已然将 50w 菜谱本体信息在 OpenKG 上开放下来,每个菜谱收录店名,食材,味道,烹饪时间等属性。链接
索答菜谱本体信息 - 开放知识图谱
对于知识图谱查询这一块,主要涉及了RDF,OWL,SPARQL,推荐看 知识图谱-给AI装个脑部 里面讲解的太详尽,也有个demo,有时间我会把python3的实现放在github上。
Reference:
知识图谱-给AI装个脑部
索答科技:领域应用 | 基于知识图谱的卧室领域问答系统建立 查看全部
2.1.2 数据采集
问句生成。同一个问题的问句是特别多的,首先对输入问句进行剖析,找到“种子问句”,然后对它进行动词,把每一个词用word2vec 寻找相关的词(比如美国-男人=女王-女人),相关的词把它们的位置序列记好,然后做笛卡尔积。这样的做完了,会生成大规模这样问句的数据,当然上面有一些是不正确的语句,这个时侯用文本纠错的马尔可夫链的机率图模型去纠正它,最后人工筛选。第二种方式是,采集200多个跟菜谱相关的代词,以及相关的同义词,利用文本生成,生成问句。这里推荐OpenKG
2.1.3 知识库建立
首先做时序融合,就是之前做的实体,它的实体链接是不是按照时间的推理,而它换掉了它本身的这样一个涵义,进而做本体的扩展(不太懂)。多源融合,做一个实体的匹配和概念的对齐。
抽出实体和属性
2.1.4 数据访问
分为4个部份。
1.SPARQL查询 2.自然语言查询 3.SDK的形式 4.逻辑表达式,后台将其转化成SPARQL句子
2.2 知识图谱的建立
其中,不辣的查询比较历时,原因是因为标签没有不辣,因此要把所有的属性都查一遍。后来的解决方式是离线去处理,比如是甜的,那它一定不是辣的。
3 曾经踩过的一些坑
知识图谱上面的搜索是有一个问题的, ElasticSearch 检索上面的排序虽然是十分容易去做的,本身底层就写了一个排序打分的 TF-IDF。而用知识图谱的时侯,它附近的那些节点的权重都是一样的。比如说芋头能做哪些菜,那么查询下来所有的菜的权重都是一样的。知识图谱上面,映射的本身是扁平的,比如地瓜这个节点,能够查询好多菜谱,发现有些所列下来的这些菜你们都不认识,会导致糟糕的体验。解决方式:在知识图谱的属性当中,加了一个热度的一个值,热度主要是通过点击次数去估算,然后按照热度排序。
4 遇到的一些挑战与困难
1. 跨领域问题不仅基础工作,比如查询等方法不会有很大的改动,但是属性是要重新设定的。
2. 语义理解还没有达到一定的高度。当下主要还是在于文本分类+属性抽取+逻辑表达式,但是用多大的数据量可以将一句话直接运用到知识图谱中去还须要继续探究。
- end -
Tip:索答科技已然将 50w 菜谱本体信息在 OpenKG 上开放下来,每个菜谱收录店名,食材,味道,烹饪时间等属性。链接
索答菜谱本体信息 - 开放知识图谱
对于知识图谱查询这一块,主要涉及了RDF,OWL,SPARQL,推荐看 知识图谱-给AI装个脑部 里面讲解的太详尽,也有个demo,有时间我会把python3的实现放在github上。
Reference:
知识图谱-给AI装个脑部
索答科技:领域应用 | 基于知识图谱的卧室领域问答系统建立

