
文章采集链接
拒绝低效!Python教你爬虫公众号文章和链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-11 13:19
前言
上一篇文章整理了的公众号所有文章的导航链接,其实假如自动整理上去的话,是一件太吃力的事情,因为公众号里添加文章的时侯只能一篇篇的选择,是个单选框。
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk姐作为一个 Pythoner,当然不能如此低效,我们用爬虫把文章的标题和链接等信息提取下来。
抓包
我们须要通过抓包提取公众号文章的恳求的 URL,参考之前写过的一篇抓包的文章,pk哥此次直接抓取 PC 端陌陌的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选允许抓取笔记本的恳求,一般是默认就勾选的。
为了过滤掉其他无关恳求,我们在左下方设置下我们要抓取的域名。
打开 PC 端陌陌,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的恳求,找到我们须要的恳求,返回的 JSON 信息里收录了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
这些都是恳求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向下滑动,加载更多文章后发觉链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头收录了 User-Agent、Cookie、Referer。
这些信息都在抓包工具可以看见。
请求数据
通过抓包剖析下来了恳求链接,我们就可以用 requests 库来恳求了,用返回码是否为 200 做一个判定,200 的话说明返回信息正常,我们再构筑一个函数 parse_data() 来解析提取我们须要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过剖析返回的 Json 数据,我们可以看见,我们须要的数据都在 app_msg_ext_info 下面。
我们用 json.loads 解析返回的 Json 信息,把我们须要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果都会以 csv 格式保存上去。
运行代码时,可能会遇见 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应当都晓得,一般写文字就会用 Markdown 的格式来写文章,这样的话,不管置于那个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都晓得新建 Markdown 格式的文件的。
这样,这些导航文章链接整理上去就是分类的事情了。 查看全部
阅读文本大概需要 5 分钟
前言
上一篇文章整理了的公众号所有文章的导航链接,其实假如自动整理上去的话,是一件太吃力的事情,因为公众号里添加文章的时侯只能一篇篇的选择,是个单选框。
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk姐作为一个 Pythoner,当然不能如此低效,我们用爬虫把文章的标题和链接等信息提取下来。
抓包
我们须要通过抓包提取公众号文章的恳求的 URL,参考之前写过的一篇抓包的文章,pk哥此次直接抓取 PC 端陌陌的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选允许抓取笔记本的恳求,一般是默认就勾选的。
为了过滤掉其他无关恳求,我们在左下方设置下我们要抓取的域名。
打开 PC 端陌陌,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的恳求,找到我们须要的恳求,返回的 JSON 信息里收录了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
这些都是恳求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向下滑动,加载更多文章后发觉链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头收录了 User-Agent、Cookie、Referer。
这些信息都在抓包工具可以看见。
请求数据
通过抓包剖析下来了恳求链接,我们就可以用 requests 库来恳求了,用返回码是否为 200 做一个判定,200 的话说明返回信息正常,我们再构筑一个函数 parse_data() 来解析提取我们须要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过剖析返回的 Json 数据,我们可以看见,我们须要的数据都在 app_msg_ext_info 下面。
我们用 json.loads 解析返回的 Json 信息,把我们须要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果都会以 csv 格式保存上去。
运行代码时,可能会遇见 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应当都晓得,一般写文字就会用 Markdown 的格式来写文章,这样的话,不管置于那个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都晓得新建 Markdown 格式的文件的。
这样,这些导航文章链接整理上去就是分类的事情了。
获取微信公众号关注页面链接和历史文章链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-11 12:42
我是这样获取biz值的:分享一篇该公众号的文章到QQ,然后在QQ里点开这篇文章,打开右上角3个点,复制链接,这个链接里就有biz的值了!
最终堆砌成这样子:【复制到陌陌中打开】
https://mp.weixin.qq.com/mp/pr ... irect
根据任一公号文章的链接地址,我们可以获取biz的值(假设为“X”),然后我们可以执行以下动作:
2.获取公众号的历史文章链接:
http://mp.weixin.qq.com/mp/get ... irect
在陌陌环境下(微信客户端或陌陌网页版),点击以上链接可以查看一个公号的历史文章,历史文章的内容会动态更新。
如果你有自定义菜单,设置一个链接,你的订阅用户可以很方便查看历史文章。
3.获取公众号的二维码:
http://mp.weixin.qq.com/mp/qrc ... 3D%3D
在浏览器输入以上地址,可以查看一个公众号的二维码图片。
曾经很难获取他人家公众号的二维码图片,而如今十分简单。
如果你想设置二维码的规格,在里面网址的前面加上“&size=数字”看看有哪些变化。
对于一个公众号而言,历史文章是订阅资源,二维码是对外名片。知道了这种就足够了,你认为呢? 查看全部
1.获取微信公众号关注页面链接
我是这样获取biz值的:分享一篇该公众号的文章到QQ,然后在QQ里点开这篇文章,打开右上角3个点,复制链接,这个链接里就有biz的值了!
最终堆砌成这样子:【复制到陌陌中打开】
https://mp.weixin.qq.com/mp/pr ... irect
根据任一公号文章的链接地址,我们可以获取biz的值(假设为“X”),然后我们可以执行以下动作:
2.获取公众号的历史文章链接:
http://mp.weixin.qq.com/mp/get ... irect
在陌陌环境下(微信客户端或陌陌网页版),点击以上链接可以查看一个公号的历史文章,历史文章的内容会动态更新。
如果你有自定义菜单,设置一个链接,你的订阅用户可以很方便查看历史文章。
3.获取公众号的二维码:
http://mp.weixin.qq.com/mp/qrc ... 3D%3D
在浏览器输入以上地址,可以查看一个公众号的二维码图片。
曾经很难获取他人家公众号的二维码图片,而如今十分简单。
如果你想设置二维码的规格,在里面网址的前面加上“&size=数字”看看有哪些变化。
对于一个公众号而言,历史文章是订阅资源,二维码是对外名片。知道了这种就足够了,你认为呢?
怎么获取唯品会商品链接?唯品会商品链接搜集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-08-10 19:13
唯品会商品链接采集器是一款好用的图片文字辨识工具。我们可以使用唯品会商品链接采集器轻松采集唯品会商品链接;
进入下载
唯品会商品链接采集器 2.0 免费版
大小:603 KB
日期:2018/7/24 11:24:12
环境:WinXP,Win7,
安装软件后双击唯品会商品链接采集器桌面快捷方法打开软件;
极速小编这一次就给你们演示一下如何使用唯品会商品链接采集器的关键词搜索功能搜索唯品会商品吧。点击唯品会商品链接采集器主界面中的关键字输入框,我们就可以直接输入关键字内容。我们还可以指定搜索的网页页脚范围、排序方法;
关键字输入完成、采集范围设置好后,点击开始采集,就可以开始使用唯品会商品链接采集器采集唯品会网页上与关键字吻合的商品链接;
唯品会商品链接采集器正在采集唯品会商城上的商品链接。商品链接采集需要一定的时间,请耐心等待;
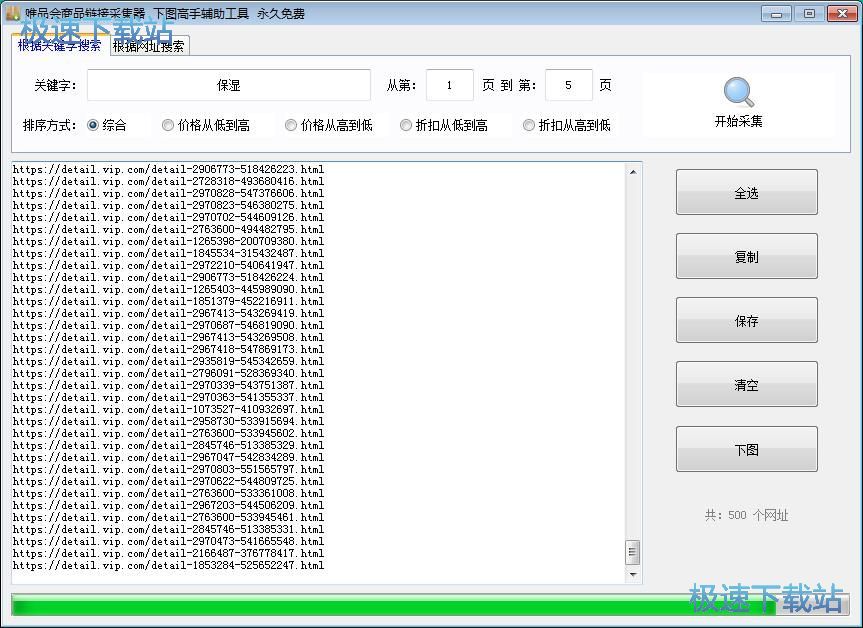
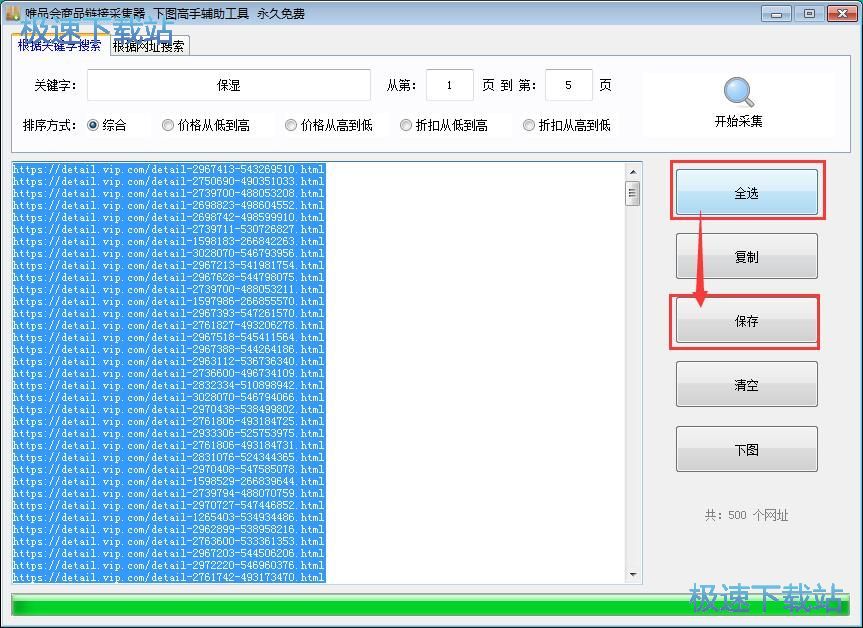
商品链接采集完成,唯品会商品链接采集器共采集了500个网址。点击唯品会商品链接采集器主界面中的全选,就可以将全部链接选中。然后点击保存,就可以将全部采集到的链接保存到笔记本本地;
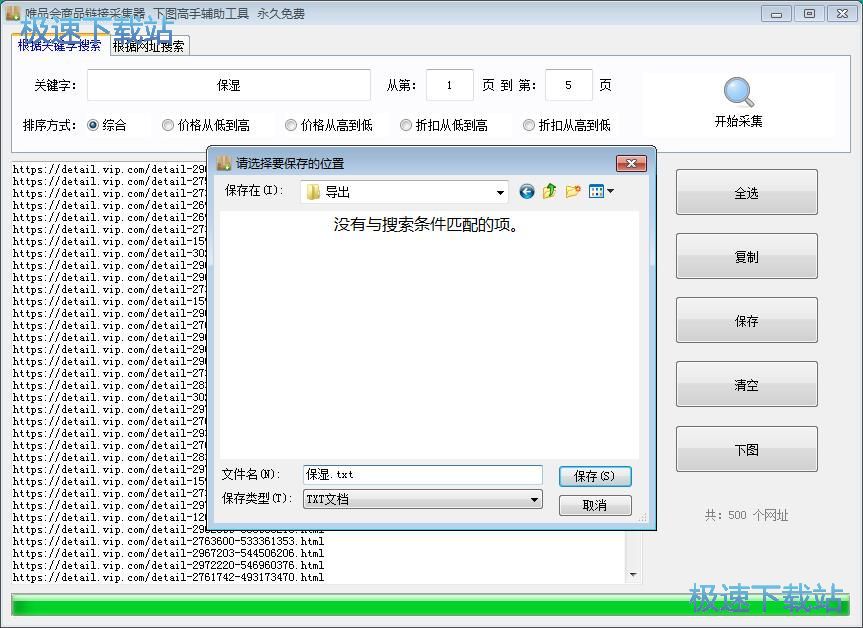
在文件夹选择窗口中,打开想要拿来保存商品链接txt文档的文件夹,对文件进行命名后点击保存,就可以将商品链接保存到笔记本本地;
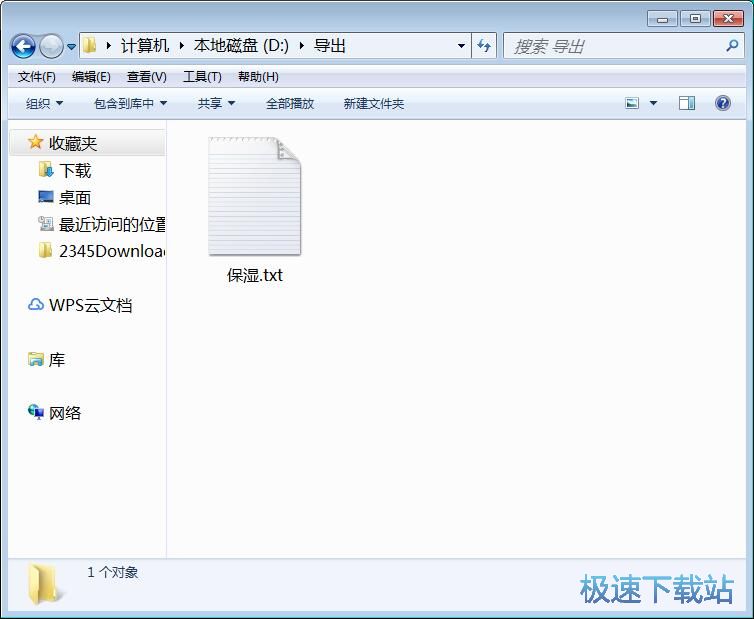
唯品会商品链接保存成功,这时候我们可以在文件夹中找到保存商品链接的txt文件。
唯品会商品链接采集器的使用方式就讲解到这儿,希望对大家有帮助,感谢你对急速下载站的支持!
唯品会商品链接采集器 2.0 免费版 查看全部

唯品会商品链接采集器是一款好用的图片文字辨识工具。我们可以使用唯品会商品链接采集器轻松采集唯品会商品链接;
进入下载
唯品会商品链接采集器 2.0 免费版
大小:603 KB
日期:2018/7/24 11:24:12
环境:WinXP,Win7,
安装软件后双击唯品会商品链接采集器桌面快捷方法打开软件;

极速小编这一次就给你们演示一下如何使用唯品会商品链接采集器的关键词搜索功能搜索唯品会商品吧。点击唯品会商品链接采集器主界面中的关键字输入框,我们就可以直接输入关键字内容。我们还可以指定搜索的网页页脚范围、排序方法;
关键字输入完成、采集范围设置好后,点击开始采集,就可以开始使用唯品会商品链接采集器采集唯品会网页上与关键字吻合的商品链接;
唯品会商品链接采集器正在采集唯品会商城上的商品链接。商品链接采集需要一定的时间,请耐心等待;
商品链接采集完成,唯品会商品链接采集器共采集了500个网址。点击唯品会商品链接采集器主界面中的全选,就可以将全部链接选中。然后点击保存,就可以将全部采集到的链接保存到笔记本本地;
在文件夹选择窗口中,打开想要拿来保存商品链接txt文档的文件夹,对文件进行命名后点击保存,就可以将商品链接保存到笔记本本地;
唯品会商品链接保存成功,这时候我们可以在文件夹中找到保存商品链接的txt文件。
唯品会商品链接采集器的使用方式就讲解到这儿,希望对大家有帮助,感谢你对急速下载站的支持!
唯品会商品链接采集器 2.0 免费版
黑帽seo要具备什么技术 2017年黑帽seo技术快速排行
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-10 17:28
白帽SEO是一种公平的手法,是使用符合主流搜索引擎发行方针规定的seo优化技巧。它是与黑帽seo相反的。白帽SEO仍然被业内觉得是最佳的SEO手法,它是在防止一知切风险的情况下进行操作的,同时也防止了与搜索引擎发道行方针发生任何的冲突,它也是SEOer从业者的最高职业道德标准。
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的版作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
灰帽SEO是介于白帽与黑帽之间的中间地带,相对于白帽而言,会采取一些取巧的方法来操作,这些行为由于不算违法权,但同样也不遵循规则,是为灰色地带。
【一推响工作室】提供
黑帽seo要具备什么技术 2017年黑帽seo技术快速排行
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想! 查看全部
黑帽SEO是指哪些?
白帽SEO是一种公平的手法,是使用符合主流搜索引擎发行方针规定的seo优化技巧。它是与黑帽seo相反的。白帽SEO仍然被业内觉得是最佳的SEO手法,它是在防止一知切风险的情况下进行操作的,同时也防止了与搜索引擎发道行方针发生任何的冲突,它也是SEOer从业者的最高职业道德标准。
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的版作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
灰帽SEO是介于白帽与黑帽之间的中间地带,相对于白帽而言,会采取一些取巧的方法来操作,这些行为由于不算违法权,但同样也不遵循规则,是为灰色地带。
【一推响工作室】提供
黑帽seo要具备什么技术 2017年黑帽seo技术快速排行
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想!
原创文章不如采集文章?来说说百度收录那些事儿! 2019-06
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-10 16:53
一、首先确定网站是刚上线1-3个月的新站,还是半年以上的老网站
对于新网站,上线后首页收录时间大概为一周,大量的内录、收录及被搜索抓取放出收录时间需有10-20天。网站如有好多空白页面,大量的页面内容都非常少,这种情况下,对应的页面不收录,或收录都会特别平缓的。如果网站20天以上,首页都没有收录,网站域名可能有案底被搜索引擎拉黑,如遇这些情况,可通过#1投诉。
老网站不被收录则多为页面质量问题,内页新降低的页面不被搜索,此时若果想要提升收录量,就须要不断强化内容质量。
二、网站不收录常规剖析思路
1、网站的服务器必须稳定。可通百度资源网站管理信息中抓取异常,看出服务器的稳定性,进而剖析网站不收录的具体缘由。
2、检查robots.txt文件是否容许抓取。
3、检查网站各个页面路径是否良好。
4、重要的页面不能写在JS标签内。
5、页面稳定质量良好。网站页面版块链接合理,内容质量良好,并没有频繁改动页面,并非大量内容来自于采集,且无用户搜索需求。
三、分析人为改动诱因
分析近三个月人为操作改动,及内页内容是不内大量采集。大量删掉页面、修改页面标题,程序及网站模块频繁的变更,以至网站被搜索引擎降权引起好多内页内容不收录。又大量的改调内容,内容中植入大量的广告链接弹窗就会引起新增页面不收录。
四、怎么推进网站收录呢?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加快页面的抓取收录。
2、做好网站内容丰富度优化:注意长尾关键词排行布局,多做用户会搜索的内容,文章图文并茂,图片要加ATL关键词,这样搜索引擎才晓得图片的意思是哪些,且内容中要收录用户会搜索的关键词话题。
3、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许优质友链、加快网站抓取收录。 查看全部
很多初涉SEO的小伙伴都有一个问题:为什么我发布的网站文章不被收录呢?甚至有时候发布的原创文章不被收录,而别家网站发布的采集文章却被收录,到底影响文章收录的诱因有什么呢,该如何使网站快速被百度收录呢?接下来为你们来解密这其中的奥秘!

一、首先确定网站是刚上线1-3个月的新站,还是半年以上的老网站
对于新网站,上线后首页收录时间大概为一周,大量的内录、收录及被搜索抓取放出收录时间需有10-20天。网站如有好多空白页面,大量的页面内容都非常少,这种情况下,对应的页面不收录,或收录都会特别平缓的。如果网站20天以上,首页都没有收录,网站域名可能有案底被搜索引擎拉黑,如遇这些情况,可通过#1投诉。
老网站不被收录则多为页面质量问题,内页新降低的页面不被搜索,此时若果想要提升收录量,就须要不断强化内容质量。
二、网站不收录常规剖析思路
1、网站的服务器必须稳定。可通百度资源网站管理信息中抓取异常,看出服务器的稳定性,进而剖析网站不收录的具体缘由。
2、检查robots.txt文件是否容许抓取。
3、检查网站各个页面路径是否良好。
4、重要的页面不能写在JS标签内。
5、页面稳定质量良好。网站页面版块链接合理,内容质量良好,并没有频繁改动页面,并非大量内容来自于采集,且无用户搜索需求。
三、分析人为改动诱因
分析近三个月人为操作改动,及内页内容是不内大量采集。大量删掉页面、修改页面标题,程序及网站模块频繁的变更,以至网站被搜索引擎降权引起好多内页内容不收录。又大量的改调内容,内容中植入大量的广告链接弹窗就会引起新增页面不收录。
四、怎么推进网站收录呢?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加快页面的抓取收录。
2、做好网站内容丰富度优化:注意长尾关键词排行布局,多做用户会搜索的内容,文章图文并茂,图片要加ATL关键词,这样搜索引擎才晓得图片的意思是哪些,且内容中要收录用户会搜索的关键词话题。
3、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许优质友链、加快网站抓取收录。
Python爬虫实现的微信公众号文章下载器
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2020-08-10 10:10
安装python selenium手动模块,通过selenium中的webdriver驱动浏览器获取Cookie登陆微信公众号后台;
使用webdriver功能须要安装对应浏览器的驱动插件
注意:谷歌浏览器版本和chromedriver须要对应,否则会导致启动晨报错。
微信公众号登录地址:
微信公众号文章接口地址可以在微信公众号后台中新建图文消息,超链接功能中获取:
搜索公众号名称
获取要爬取的公众号的fakeid
选定要爬取的公众号,获取文章接口地址
文章列表翻页及内容获取
AnyProxy代理批量采集
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集。
3、本地代理服务器系统:通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。
4、文章列表剖析与入库系统,分析文章列表和完善采集队列实现批量采集内容。
Fiddler设置代理和抓包
通过对多个帐号进行抓包剖析,可以确定:
_biz:这个14位的字符串是每位公众号的“id”,搜狗的陌陌平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1,写按键精灵脚本,在手机上手动点击公号文章列表页,也就是“查看历史消息”;
2,使用fiddler代理绑架手机端的访问,将网址转发到本地用php写的网页;
3,在php网页中将接收到的网址备份到数据库;
4,用python从数据库取出网址,然后进行正常的爬取。
可能存在的问题:
如果只是想爬取文章内容,似乎并没有访问频度限制,但若果想抓取阅读数、点赞数,超过一定频度后,返回都会变为空值。
付费平台
例如清博 新榜,如果只是想看数据的话,直接看每晚的榜单就可以了,还不用花钱,如果须要接入自己的系统的话,他们也提供api接口
3项目步骤
3.1基本原理
目标爬取网站收录了陌陌平台大部分的优质微信公众号文章,会定期更新,经测试发觉对爬虫较为友好。
1、网站页面布局排版规律,不同公众号通过链接中的account分辨
2、一个公众号合辑下的文章翻页也有规律:id号每翻一页+12
所以流程思路就是
获取预查询微信公众号ID(不是直接显示的名称,而是信息名片里的ID号,一般由数字字母组成)
请求html页面,判断是否早已收录改公众号
如果没有收录,则页面显示结果为:404该页面不存在,所以直接使用正则表达式来匹配该提示信息即可
正则匹配,找到目标公众号最大收录文章页数
解析恳求页面,提取文章链接和标题文字
保存信息提取的结果
调用pdfkit和wkhtmltopdf转换网页
3.2环境
win10(64bit)
Spyder(python3.6)
安装转换工具包wkhtmltopdf
requests
pdfkit
3.3公众号信息检索
通过对目标url发起requset恳求,获取页面html信息,然后调用正则方式匹配两条信息
1、该公众号是否存在
2、如果存在,最大的文章收录页数是多少
当公众号存在时,直接调用request解析目标恳求链接。
注意,目标爬虫网站必须要加headers,否则直接拒绝访问
3.4正则解析,提取链接和文章标题
以下代码用于从html文本中解析链接和标题文字信息
3.5手动跳转页面
以下代码通过循环递增形参,改变url中的页脚参数
3.6除去标题中的非法字符
因为windows下文件命令,有些字符是不能用了,所以须要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.8生成的PDF结果
4结果展示
查看全部
selenium爬取流程
安装python selenium手动模块,通过selenium中的webdriver驱动浏览器获取Cookie登陆微信公众号后台;
使用webdriver功能须要安装对应浏览器的驱动插件
注意:谷歌浏览器版本和chromedriver须要对应,否则会导致启动晨报错。
微信公众号登录地址:
微信公众号文章接口地址可以在微信公众号后台中新建图文消息,超链接功能中获取:
搜索公众号名称
获取要爬取的公众号的fakeid
选定要爬取的公众号,获取文章接口地址
文章列表翻页及内容获取
AnyProxy代理批量采集
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集。
3、本地代理服务器系统:通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。
4、文章列表剖析与入库系统,分析文章列表和完善采集队列实现批量采集内容。
Fiddler设置代理和抓包
通过对多个帐号进行抓包剖析,可以确定:
_biz:这个14位的字符串是每位公众号的“id”,搜狗的陌陌平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1,写按键精灵脚本,在手机上手动点击公号文章列表页,也就是“查看历史消息”;
2,使用fiddler代理绑架手机端的访问,将网址转发到本地用php写的网页;
3,在php网页中将接收到的网址备份到数据库;
4,用python从数据库取出网址,然后进行正常的爬取。
可能存在的问题:
如果只是想爬取文章内容,似乎并没有访问频度限制,但若果想抓取阅读数、点赞数,超过一定频度后,返回都会变为空值。
付费平台
例如清博 新榜,如果只是想看数据的话,直接看每晚的榜单就可以了,还不用花钱,如果须要接入自己的系统的话,他们也提供api接口
3项目步骤
3.1基本原理
目标爬取网站收录了陌陌平台大部分的优质微信公众号文章,会定期更新,经测试发觉对爬虫较为友好。
1、网站页面布局排版规律,不同公众号通过链接中的account分辨
2、一个公众号合辑下的文章翻页也有规律:id号每翻一页+12
所以流程思路就是
获取预查询微信公众号ID(不是直接显示的名称,而是信息名片里的ID号,一般由数字字母组成)
请求html页面,判断是否早已收录改公众号
如果没有收录,则页面显示结果为:404该页面不存在,所以直接使用正则表达式来匹配该提示信息即可
正则匹配,找到目标公众号最大收录文章页数
解析恳求页面,提取文章链接和标题文字
保存信息提取的结果
调用pdfkit和wkhtmltopdf转换网页
3.2环境
win10(64bit)
Spyder(python3.6)
安装转换工具包wkhtmltopdf
requests
pdfkit
3.3公众号信息检索
通过对目标url发起requset恳求,获取页面html信息,然后调用正则方式匹配两条信息
1、该公众号是否存在
2、如果存在,最大的文章收录页数是多少

当公众号存在时,直接调用request解析目标恳求链接。

注意,目标爬虫网站必须要加headers,否则直接拒绝访问
3.4正则解析,提取链接和文章标题
以下代码用于从html文本中解析链接和标题文字信息

3.5手动跳转页面
以下代码通过循环递增形参,改变url中的页脚参数

3.6除去标题中的非法字符
因为windows下文件命令,有些字符是不能用了,所以须要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件

3.8生成的PDF结果

4结果展示

网站制作的注意问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-10 06:39
如果不对关键词进行恰当剖析的话,就会导致好多问题,包括:方向不明晰、关键词配置不合理、排名疗效差、ROI低等,所以一定要先对关键词进行剖析。
2、缺少导入链接
很多网站的优化都存在收录问题,检查一下不难发觉,很多都是由于缺乏导出链接。互联网中,网页与网页的关系是通过链接来构建的,如果网站和外界没有链接,没有任何联系的话,就成了一个孤岛型网站,搜索引擎未能晓得网站的存在。
3、采集大量的文章
搜索引擎不会给与互联网中高度重复的文章好的排行的,网站上假如收录大量的采集文章的话,对网站是会有一定的负面影响的。网站建好后,如果没有或则只 有极少的原创的实质内容的话,会给用户带来了不良的浏览体验,也会给搜索引擎留下了不好的印象,为搜索引擎优化带来困难。
4、一味追求网站美观
有些网站一味追求美感:大气、好看、美观,其实对网站来说,这些都不是必需的。用户喜欢简练明了的页面,这样就能带来良好的视觉体验。不要使用大量的 图片和太多的flash,这会导致页面容积过大、页面加载速率慢,大大增加网站的实用性,也不要再导航上使用图片作链接,这会导致搜索引擎辨识网站结构 时有困难。
5、频繁修改网页title
搜索引擎依赖title标签进行切词、分词构建索引,这是最初阶段的搜索引擎排名的核心点,虽然从技术上来说,已经有了突飞猛进的发展,但对 title的依赖还是提升用户体验的一个关键点,如果修改title的话,搜索引擎会把它当成作弊来看待的,所以修改title时一定要谨慎。
6、直接copy网站
为了图省钱省力,很多人在建站时直接胡须眼睛一把抓,把现有的网站程序模板直接套来使用。这样下来的新站都会和之前的站相似度很高,会导致新站很难得到好的排行,老站也会遭到连带影响。 查看全部
1、未进行关键词分析
如果不对关键词进行恰当剖析的话,就会导致好多问题,包括:方向不明晰、关键词配置不合理、排名疗效差、ROI低等,所以一定要先对关键词进行剖析。
2、缺少导入链接
很多网站的优化都存在收录问题,检查一下不难发觉,很多都是由于缺乏导出链接。互联网中,网页与网页的关系是通过链接来构建的,如果网站和外界没有链接,没有任何联系的话,就成了一个孤岛型网站,搜索引擎未能晓得网站的存在。
3、采集大量的文章
搜索引擎不会给与互联网中高度重复的文章好的排行的,网站上假如收录大量的采集文章的话,对网站是会有一定的负面影响的。网站建好后,如果没有或则只 有极少的原创的实质内容的话,会给用户带来了不良的浏览体验,也会给搜索引擎留下了不好的印象,为搜索引擎优化带来困难。
4、一味追求网站美观
有些网站一味追求美感:大气、好看、美观,其实对网站来说,这些都不是必需的。用户喜欢简练明了的页面,这样就能带来良好的视觉体验。不要使用大量的 图片和太多的flash,这会导致页面容积过大、页面加载速率慢,大大增加网站的实用性,也不要再导航上使用图片作链接,这会导致搜索引擎辨识网站结构 时有困难。
5、频繁修改网页title
搜索引擎依赖title标签进行切词、分词构建索引,这是最初阶段的搜索引擎排名的核心点,虽然从技术上来说,已经有了突飞猛进的发展,但对 title的依赖还是提升用户体验的一个关键点,如果修改title的话,搜索引擎会把它当成作弊来看待的,所以修改title时一定要谨慎。
6、直接copy网站
为了图省钱省力,很多人在建站时直接胡须眼睛一把抓,把现有的网站程序模板直接套来使用。这样下来的新站都会和之前的站相似度很高,会导致新站很难得到好的排行,老站也会遭到连带影响。
如何采集微信公众号历史消息页的解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2020-08-10 03:31
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
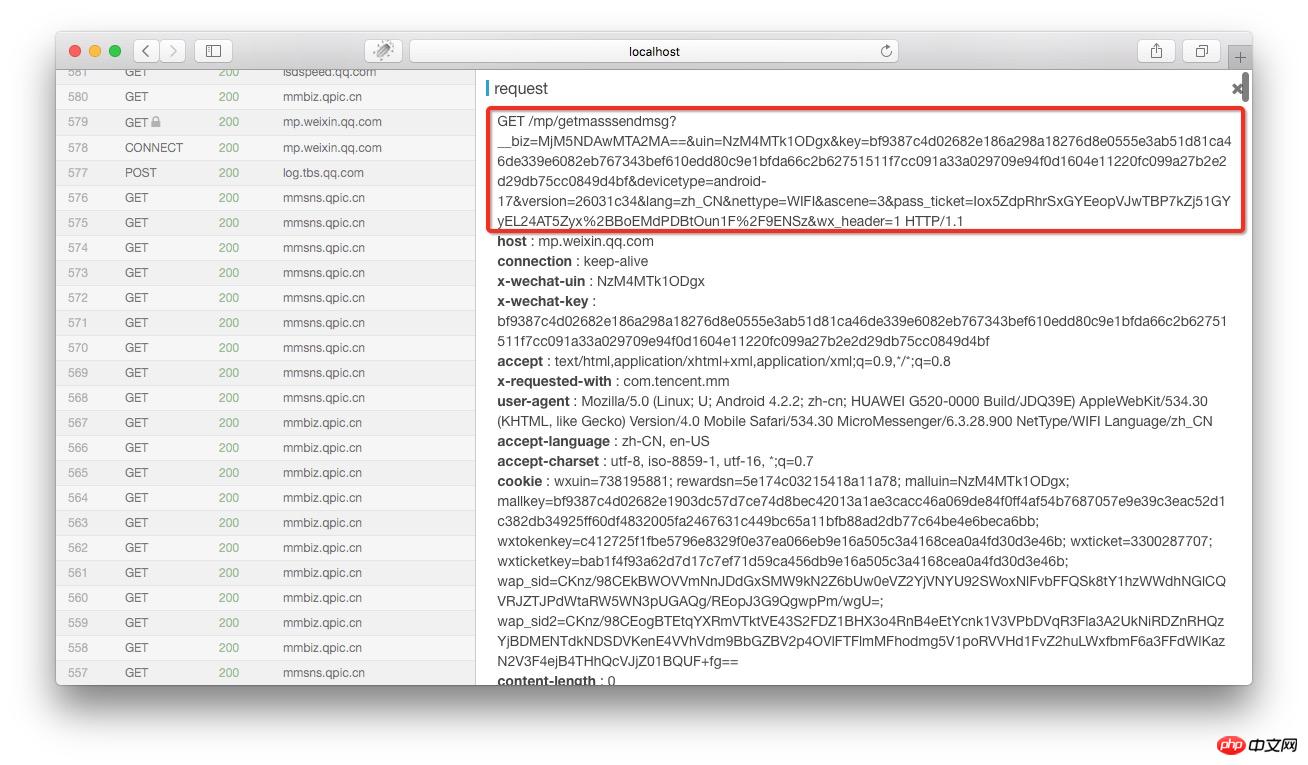
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。 查看全部
给你们讲解了微信公众号文章采集的入口历史消息页信息获取方式,有须要的同事参考一下本内容。
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
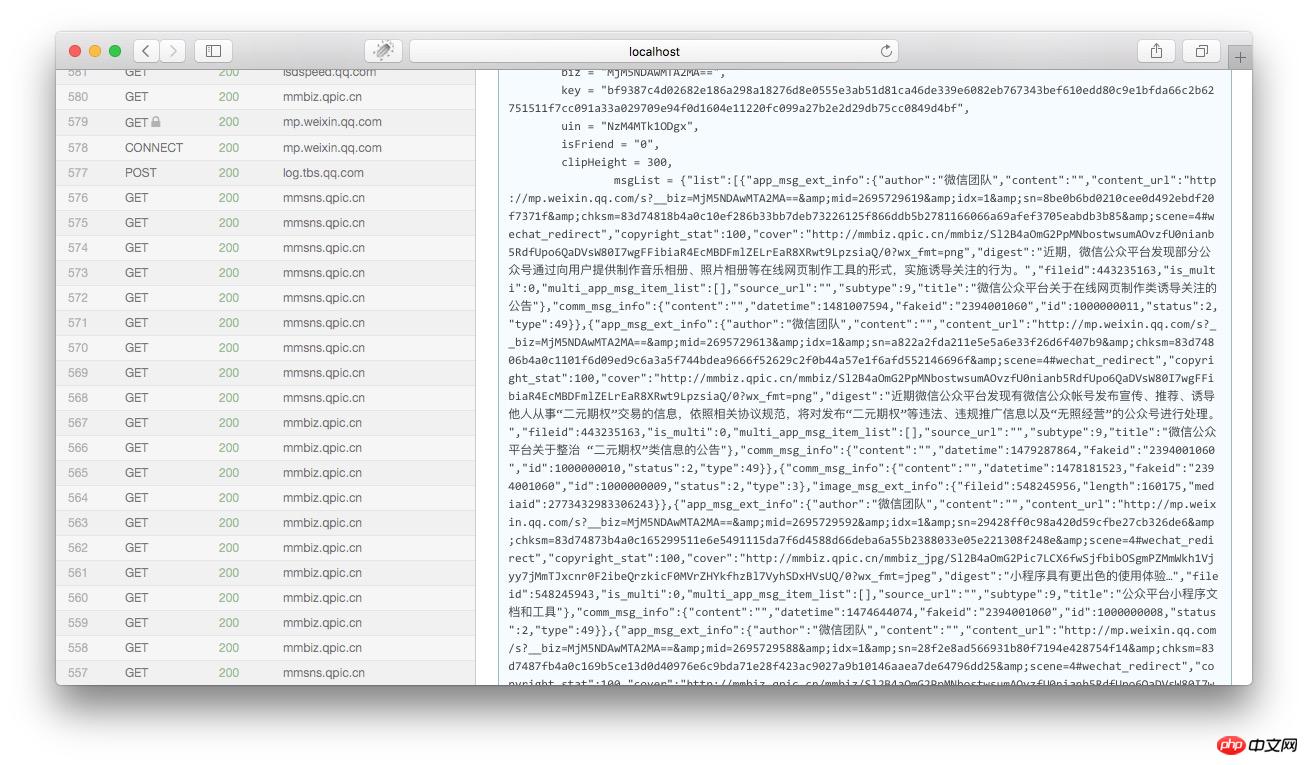
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
【进阶】Python爬虫采集整个网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-08-09 10:14
在之前的文章中,我们实现了在一个网站上随机地从一个链接到另一个链接,但是,如果我们须要系统地把整个网站按目录分类,或者要搜索网站上的每一个页面,我们该如何办?我们须要采集整个网站,但是那是一种十分花费显存资源的过程,尤其是处理小型网站时,比较合适的工具就是用一个数据库来储存采集的资源,之前也说过。下面来说一下怎样做。
网站地图sitemap
网站地图,又称站点地图,它就是一个页面,上面放置了网站上须要搜索引擎抓取的所有页面的链接(注:不是所有页面,一般来说是所有文章链接,比如我的)。大多数人在网站上找不到自己所须要的信息时,可能会将网站地图作为一种补救举措。搜索引擎蜘蛛特别喜欢网站地图。
对于SEO,网站地图的益处:
1.为搜索引擎蜘蛛提供可以浏览整个网站的链接简单的彰显出网站的整体框架下来给搜索引擎看;
2.为搜索引擎蜘蛛提供一些链接,指向动态页面或则采用其他方式比较无法抵达的页面;
3.作为一种潜在的着陆页面,可以为搜索流量进行优化;
4.如果访问者企图访问网站所在域内并不存在的URL,那么这个访问者都会被转入“无法找到文件”的错误页面,而网站地图可以作为该页面的“准”内容。
数据采集
采集网站数据并不难,但是须要爬虫有足够的深度。我们创建一个爬虫,递归地遍历每位网站,只搜集这些网站页面上的数据。一般的比较费时间的网站采集方法从顶尖页面开始(一般是网站主页),然后搜索页面上的所有链接,形成列表,再去采集到的那些链接页面,继续采集每个页面的链接产生新的列表,重复执行。
很明显,这是一个复杂度下降很快的过程。加入每位页面有10个链接,网站上有5个页面深度,如果采集整个网站,一共得采集的网页数目是105,即100000个页面。
因为网站的内链有很多都是重复的,所以为了防止重复采集,必须链接去重,在Python中,去重最常用的方式就是使用自带的set集合方式。只有“新”链接才能被采集。看一下代码实例:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageurl):
globalpages
html= urlopen("" + pageurl)
soup= BeautifulSoup(html)
forlink in soup.findAll("a", href=pile("^(/wiki/)")):
if'href' in link.attrs:
iflink.attrs['href'] not in pages:
#这是新页面
newPage= link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
原理说明:程序执行时,用函数处理一个空URL,其实就是维基百科的主页,然后遍历首页上每位链接,并检测是否早已在全局变量集合pages上面,如果不在,就复印并添加到pages集合,然后递归处理这个链接。
递归警告:Python默认的递归限制是1000次,因为维基百科的链接浩如烟海,所以这个程序达到递归限制后才会停止。如果你不想使它停止,你可以设置一个递归计数器或则其他方式。
采集整个网站数据
为了有效使用爬虫,在用爬虫的时侯我们须要在页面上做一些事情。我们来创建一个爬虫来搜集页面标题、正文的第一个段落,以及编辑页面的链接(如果有的话)这些信息。
第一步,我们须要先观察网站上的页面,然后制订采集模式,通过F12(一般情况下)审查元素,即可见到页面组成。
观察维基百科页面,包括词条和非词条页面,比如隐私策略之类的页面,可以得出下边的规则:
调整一下之前的代码,我们可以构建一个爬虫和数据采集的组合程序,代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("" + pageUrl)
soup = BeautifulSoup(html)
try:
print(soup.h1.get_text())
print(soup.find(id="mw-content-text").findAll("p")[0])
print(soup.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("页面缺乏属性")
for link in soup.findAll("a", href =pile("^(/wiki/)")):
if 'href' in link.attrs:
#这是新页面
newPage = link.attrs['href']
print("------------------\n"+newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
这个for循环和原先的采集程序基本上是一样的,因为不能确定每一页上都有所有类型的数据,所以每位复印句子都是根据数据在页面上出现的可能性从高到低排列的。
数据储存到MySQL
前面早已获取了数据,直接复印下来,查看比较麻烦,所以我们就直接存到MySQL上面吧,这里只存链接没有意义,所以我们就储存页面的标题和内容。前面我有两篇文章已经介绍过怎么储存数据到MySQL,数据表是pages,这里直接给出代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
import pymysql
conn = pymysql.connect(host = '127.0.0.1',port = 3306, user = 'root', passwd = '19930319', db = 'wiki', charset ='utf8mb4')
cur = conn.cursor()
cur.execute("USE wiki")
#随机数种子
random.seed(datetime.datetime.now())
#数据储存
def store(title, content):
cur.execute("INSERT INTO pages(title, content)VALUES(\"%s\", \"%s\")", (title, content))
mit()
def getLinks(articleUrl):
html = urlopen("" + articleUrl)
soup = BeautifulSoup(html)
title = soup.find("h1").get_text()
content =soup.find("div",{"id":"mw-content-text"}).find("p").get_text()
store(title, content)
returnsoup.find("div",{"id":"bodyContent"}).findAll("a",href=pile("^(/wiki/)((?!:).)*$"))
#设置第一页
links =getLinks("/wiki/Kevin_Bacon")
try:
while len(links)>0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print (newArticle)
links = getLinks(newArticle)
finally:
cur.close()
conn.close()
小结
今天主要讲一下Python中遍历采集一个网站的链接,方便下边的学习。
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。 查看全部
前言
在之前的文章中,我们实现了在一个网站上随机地从一个链接到另一个链接,但是,如果我们须要系统地把整个网站按目录分类,或者要搜索网站上的每一个页面,我们该如何办?我们须要采集整个网站,但是那是一种十分花费显存资源的过程,尤其是处理小型网站时,比较合适的工具就是用一个数据库来储存采集的资源,之前也说过。下面来说一下怎样做。
网站地图sitemap
网站地图,又称站点地图,它就是一个页面,上面放置了网站上须要搜索引擎抓取的所有页面的链接(注:不是所有页面,一般来说是所有文章链接,比如我的)。大多数人在网站上找不到自己所须要的信息时,可能会将网站地图作为一种补救举措。搜索引擎蜘蛛特别喜欢网站地图。
对于SEO,网站地图的益处:
1.为搜索引擎蜘蛛提供可以浏览整个网站的链接简单的彰显出网站的整体框架下来给搜索引擎看;
2.为搜索引擎蜘蛛提供一些链接,指向动态页面或则采用其他方式比较无法抵达的页面;
3.作为一种潜在的着陆页面,可以为搜索流量进行优化;
4.如果访问者企图访问网站所在域内并不存在的URL,那么这个访问者都会被转入“无法找到文件”的错误页面,而网站地图可以作为该页面的“准”内容。
数据采集
采集网站数据并不难,但是须要爬虫有足够的深度。我们创建一个爬虫,递归地遍历每位网站,只搜集这些网站页面上的数据。一般的比较费时间的网站采集方法从顶尖页面开始(一般是网站主页),然后搜索页面上的所有链接,形成列表,再去采集到的那些链接页面,继续采集每个页面的链接产生新的列表,重复执行。
很明显,这是一个复杂度下降很快的过程。加入每位页面有10个链接,网站上有5个页面深度,如果采集整个网站,一共得采集的网页数目是105,即100000个页面。
因为网站的内链有很多都是重复的,所以为了防止重复采集,必须链接去重,在Python中,去重最常用的方式就是使用自带的set集合方式。只有“新”链接才能被采集。看一下代码实例:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageurl):
globalpages
html= urlopen("" + pageurl)
soup= BeautifulSoup(html)
forlink in soup.findAll("a", href=pile("^(/wiki/)")):
if'href' in link.attrs:
iflink.attrs['href'] not in pages:
#这是新页面
newPage= link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
原理说明:程序执行时,用函数处理一个空URL,其实就是维基百科的主页,然后遍历首页上每位链接,并检测是否早已在全局变量集合pages上面,如果不在,就复印并添加到pages集合,然后递归处理这个链接。
递归警告:Python默认的递归限制是1000次,因为维基百科的链接浩如烟海,所以这个程序达到递归限制后才会停止。如果你不想使它停止,你可以设置一个递归计数器或则其他方式。
采集整个网站数据
为了有效使用爬虫,在用爬虫的时侯我们须要在页面上做一些事情。我们来创建一个爬虫来搜集页面标题、正文的第一个段落,以及编辑页面的链接(如果有的话)这些信息。
第一步,我们须要先观察网站上的页面,然后制订采集模式,通过F12(一般情况下)审查元素,即可见到页面组成。
观察维基百科页面,包括词条和非词条页面,比如隐私策略之类的页面,可以得出下边的规则:
调整一下之前的代码,我们可以构建一个爬虫和数据采集的组合程序,代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("" + pageUrl)
soup = BeautifulSoup(html)
try:
print(soup.h1.get_text())
print(soup.find(id="mw-content-text").findAll("p")[0])
print(soup.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("页面缺乏属性")
for link in soup.findAll("a", href =pile("^(/wiki/)")):
if 'href' in link.attrs:
#这是新页面
newPage = link.attrs['href']
print("------------------\n"+newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
这个for循环和原先的采集程序基本上是一样的,因为不能确定每一页上都有所有类型的数据,所以每位复印句子都是根据数据在页面上出现的可能性从高到低排列的。
数据储存到MySQL
前面早已获取了数据,直接复印下来,查看比较麻烦,所以我们就直接存到MySQL上面吧,这里只存链接没有意义,所以我们就储存页面的标题和内容。前面我有两篇文章已经介绍过怎么储存数据到MySQL,数据表是pages,这里直接给出代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
import pymysql
conn = pymysql.connect(host = '127.0.0.1',port = 3306, user = 'root', passwd = '19930319', db = 'wiki', charset ='utf8mb4')
cur = conn.cursor()
cur.execute("USE wiki")
#随机数种子
random.seed(datetime.datetime.now())
#数据储存
def store(title, content):
cur.execute("INSERT INTO pages(title, content)VALUES(\"%s\", \"%s\")", (title, content))
mit()
def getLinks(articleUrl):
html = urlopen("" + articleUrl)
soup = BeautifulSoup(html)
title = soup.find("h1").get_text()
content =soup.find("div",{"id":"mw-content-text"}).find("p").get_text()
store(title, content)
returnsoup.find("div",{"id":"bodyContent"}).findAll("a",href=pile("^(/wiki/)((?!:).)*$"))
#设置第一页
links =getLinks("/wiki/Kevin_Bacon")
try:
while len(links)>0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print (newArticle)
links = getLinks(newArticle)
finally:
cur.close()
conn.close()
小结
今天主要讲一下Python中遍历采集一个网站的链接,方便下边的学习。
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。
Xposed实时获取微信公众号推送
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-09 07:59
鸣谢:本项目基于@Gh0u1L5,开源的Xposedhook框架----WechatSpellbook,感谢,很不错的框架,推荐一波(虽然我用的东西都是基于WechatMagician魔改得到的)。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
恰巧此时我正在研究Xposed Hook 微信,所以就准备拿Android版陌陌来试试,需求是怎么样的呢?就是陌陌推送一条公众号消息,我们就接受一条,并且将其发送到对应的插口进行保存,以便于后续浏览。刚打算做的时侯我还认为没啥难度,直接去把陌陌数据库里的东西down下来就可以了嘛,太简单了好吧,然而。
naive.jpg
naive!!!
微信数据表“message”中导入的数据是收录乱码的一堆鬼东西,而且解析下来的url也不全,比如一次推送中的五篇文章,只能取到三篇的url,这就让人觉得太难过。
image.png
但是难过归难过,问题总还是要解决的,怎么解决呢?看源码!
之前我将陌陌的几个dex包的代码分别反编译下来之后放在了一个文件夹下,然后使用VSCode打开,用于平常的查看,
虽然陌陌反编译下来的源码乱七八糟, 但是有的代码能看的。
我们看见前面导下来的数据是存在一些乱码的,那么我猜想陌陌内部实现了一个解码工具,如果我们能否hook到这个解码工具,是不是就可以获取到解码以后的正确数据了呢?
说到解码,根据陌陌往年的数据传输来看,这些数据很有可能是以XML的格式进行传输的,既然涉及到xml,那就一定是通配符对的方式,我们去到的数据中不仅有乱七八糟的方块,还有例如“.msg.appmsg.mmreader.category.item”这类看起来有用的内容。
我打开vscode,全局搜索“.msg.appmsg.mmreader.category.item”,令人高兴的是,搜索下来的结果并不多,这说明这个值确实是有意义的值,挨个查看那些源码,在一个包为:“
com.tencent.mm.plugin.biz;”下中一个名为“a”的类中,我发觉了一些有意思的东西。
image.png
方法名为wS的一个方式,接收了一个String类型的值,且其内部做了一些数据取出的工作。
难道这个str参数就是我想要的标准xml吗?
经过hook验证,打印其参数后发觉,并不是,参数内容的格式和之前数据库中的格式是一致的。
image.png
那么我们就将眼神置于后第一行的Map上,是不是ay.WA(String str)这个方式做了解析操作呢?
我对com.tencent.mm.sdk.platformtools.ay中WA()这个方式进行了hook,取得其返回值,这个返回值是一个Map类型的数据,在复印出其内容后,我的猜测被验证了。
WA()这个方式将昨天的内容解析成了一个以便我们读取的map。其中收录了该条推送收录的图文消息数目,以及公众号的id,名称,对应的文章url,图片url,文章描述等信息。
晚餐终于可以加鸡腿了。啊哈哈哈哈。
本文章只用于研究学习,请正确食用,谢谢。
贴一下相关的hook代码
image.png 查看全部
友情提示:阅读本文须要稍为有一点点Xposed开发基础,一点点Android逆向的基础,以及一点点Kotlin基础
鸣谢:本项目基于@Gh0u1L5,开源的Xposedhook框架----WechatSpellbook,感谢,很不错的框架,推荐一波(虽然我用的东西都是基于WechatMagician魔改得到的)。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
恰巧此时我正在研究Xposed Hook 微信,所以就准备拿Android版陌陌来试试,需求是怎么样的呢?就是陌陌推送一条公众号消息,我们就接受一条,并且将其发送到对应的插口进行保存,以便于后续浏览。刚打算做的时侯我还认为没啥难度,直接去把陌陌数据库里的东西down下来就可以了嘛,太简单了好吧,然而。

naive.jpg
naive!!!
微信数据表“message”中导入的数据是收录乱码的一堆鬼东西,而且解析下来的url也不全,比如一次推送中的五篇文章,只能取到三篇的url,这就让人觉得太难过。

image.png
但是难过归难过,问题总还是要解决的,怎么解决呢?看源码!
之前我将陌陌的几个dex包的代码分别反编译下来之后放在了一个文件夹下,然后使用VSCode打开,用于平常的查看,
虽然陌陌反编译下来的源码乱七八糟, 但是有的代码能看的。
我们看见前面导下来的数据是存在一些乱码的,那么我猜想陌陌内部实现了一个解码工具,如果我们能否hook到这个解码工具,是不是就可以获取到解码以后的正确数据了呢?
说到解码,根据陌陌往年的数据传输来看,这些数据很有可能是以XML的格式进行传输的,既然涉及到xml,那就一定是通配符对的方式,我们去到的数据中不仅有乱七八糟的方块,还有例如“.msg.appmsg.mmreader.category.item”这类看起来有用的内容。
我打开vscode,全局搜索“.msg.appmsg.mmreader.category.item”,令人高兴的是,搜索下来的结果并不多,这说明这个值确实是有意义的值,挨个查看那些源码,在一个包为:“
com.tencent.mm.plugin.biz;”下中一个名为“a”的类中,我发觉了一些有意思的东西。

image.png
方法名为wS的一个方式,接收了一个String类型的值,且其内部做了一些数据取出的工作。
难道这个str参数就是我想要的标准xml吗?
经过hook验证,打印其参数后发觉,并不是,参数内容的格式和之前数据库中的格式是一致的。

image.png
那么我们就将眼神置于后第一行的Map上,是不是ay.WA(String str)这个方式做了解析操作呢?
我对com.tencent.mm.sdk.platformtools.ay中WA()这个方式进行了hook,取得其返回值,这个返回值是一个Map类型的数据,在复印出其内容后,我的猜测被验证了。
WA()这个方式将昨天的内容解析成了一个以便我们读取的map。其中收录了该条推送收录的图文消息数目,以及公众号的id,名称,对应的文章url,图片url,文章描述等信息。
晚餐终于可以加鸡腿了。啊哈哈哈哈。
本文章只用于研究学习,请正确食用,谢谢。
贴一下相关的hook代码

image.png
PHP + fiddler捕获数据包以采集微信文章,阅读和喜欢
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-08 19:07
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求接口以获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”,然后将其添加到OnBeforeRequest(在正式请求之前执行的功能)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果不错,您可以看到该界面已转发
3. 服务器端缓存密钥,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加代码以跳到中间页
效果 查看全部
简介:
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求接口以获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下

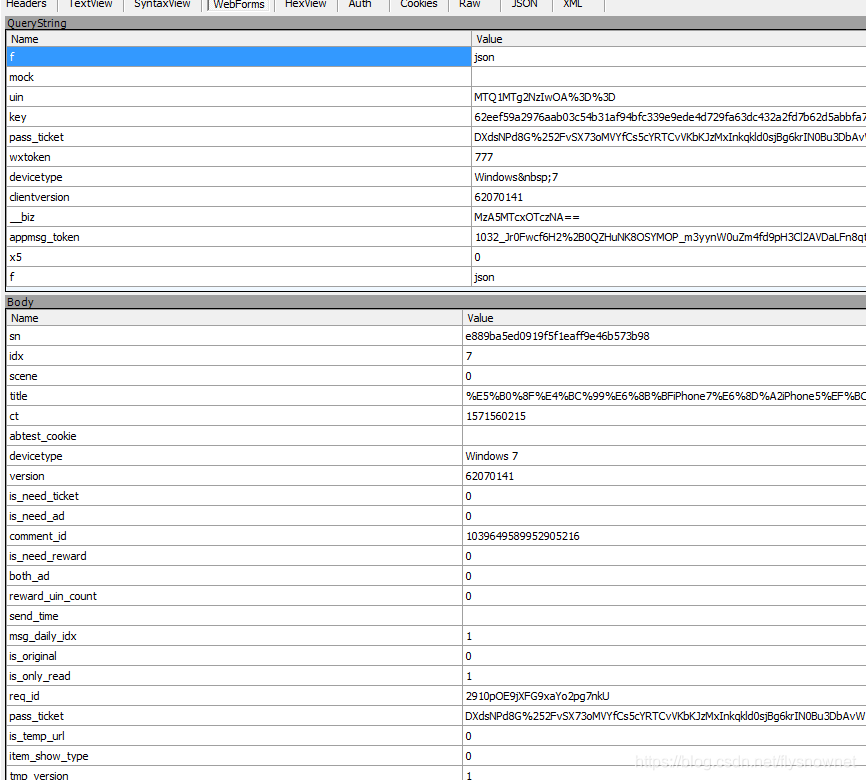
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”,然后将其添加到OnBeforeRequest(在正式请求之前执行的功能)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}

效果不错,您可以看到该界面已转发

3. 服务器端缓存密钥,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加代码以跳到中间页
效果
医院网站的SEO有哪些预防措施?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-08 16:30
1. 避免大量重复的页面标题
标题等同于网页的名称,关键字相对来说是网页的“功能”,“描述”是网页的描述. 网站优化应有助于搜索引擎区分网站的任何两个页面,并减少页面的相似性.
2. 不要在网站上使用大量图片和闪光灯
为了满足医院领导的口味,一些技术人员盲目追求网站的华丽,美观,美观,并使用了大量图片和闪光灯. 这些是医院管理者难以忍受的表现. 简单明了的页面可以为用户带来良好的视觉体验;图片过多,闪烁次数过多,导致页面尺寸太大,页面加载速度慢,大大降低了网站的实用性;导航使用图片作为链接,并且搜索引擎效果不佳. 确定网站结构.
3. 不要采集很多文章
每个人都知道,对于Internet上高度重复的文章,搜索引擎不会给出很好的排名. 大量采集的文章也对整个站点产生相当大的负面影响. 网站建设完成后,大量的没有实质内容的文章被采集起来,给用户带来不好的浏览体验,给搜索引擎留下了不好的印象,给搜索引擎的优化带来了很大的风险. 因此,即使您想采集文章,也要进行伪原创或部分采集.
4. 没有明确的目的和准确的关键字分析就永远不要网站
医院网站的方向不明确,关键字分配不合理,排名效果差,资金投入大,回报率低等都是由于缺乏关键字分析而引起的问题. 这些问题是致命的. 这是浪费金钱,不是太多!
5. 请勿经常更改网页标题
标题是搜索引擎匹配关键字的核心. 搜索引擎依靠标题标签进行单词分割和单词分割以建立索引. 这是原创阶段搜索引擎排名的核心. 尽管搜索引擎在技术上取得了飞速进步,但开发和依赖Title仍然是改善用户体验的关键. 如果您经常更改标题,搜索引擎会将其视为作弊,因此在更改标题时必须谨慎. 幸运的是,该网站已设置为可以上网,并且该网站的标题一次就可以清除!
6. 尽可能少使用或不使用JS和iframe
在Internet的发展过程中,JS和Iframe主要作为在线广告而存在,并且大多数广告管理都是通过JS和Iframe进行管理的. 尽管当前的Web技术允许将广告用作网页内容的补充,但是太多的广告也会对用户浏览页面内容造成干扰. 搜索引擎仍然不“考虑” JS和Iframe中的内容. 将有用的信息放入JS变成无用的信息. 大量JS和iframe会被视为页面上的广告过多.
7. 永远没有网站地图
站点地图也称为站点地图. 它是一个页面,具有指向网站上所有页面的链接. 当大多数人无法在网站上找到所需信息时,他们可以使用网站地图作为补救措施. 搜索引擎蜘蛛非常喜欢站点地图.
8. 永远不要复制别人的网站
为了节省麻烦,有些人只是抓住了胡子,直接使用了现有的网站程序模板. 这导致了两个高度相似的网站. 这样的新网站很难获得良好的排名,旧网站也将受到影响.
9. 不要将多个网站彼此链接
该网站的首页具有很高的权重,并且关键字易于排名. 大多数网站管理员会在网站首页上放置很多热门关键字. 由于首页的位置有限,因此距离许多关键字还很遥远. 需求,许多网站管理员已经建立了许多卫星站点来分隔一些受欢迎的关键字. 这是一种干扰搜索引擎排名的行为. 搜索引擎还针对这种行为采取了某些措施,例如: 龙鑫该站的排名时间被沙箱化为新网站;通过信息采集和分析,站群网站将受到惩罚.
10. 避免频繁删除引起大量无效链接的文章
在医院的内部管理中,经常删除某些网站列,文章等,并且删除的页面将生成大量无效链接. 医院网站必须设置404错误页面,在删除页面时尝试保留页面,在原创页面上进行更改,并在删除后更新网站页面. 本文是由网络营销推广培训教程组织和发布的.
在华旗商城推出更多产品: 快速仿制网站制作,家装和建筑行业php程序开发,企业网站托管和运营 查看全部
医院网站的SEO有哪些预防措施?
1. 避免大量重复的页面标题
标题等同于网页的名称,关键字相对来说是网页的“功能”,“描述”是网页的描述. 网站优化应有助于搜索引擎区分网站的任何两个页面,并减少页面的相似性.
2. 不要在网站上使用大量图片和闪光灯
为了满足医院领导的口味,一些技术人员盲目追求网站的华丽,美观,美观,并使用了大量图片和闪光灯. 这些是医院管理者难以忍受的表现. 简单明了的页面可以为用户带来良好的视觉体验;图片过多,闪烁次数过多,导致页面尺寸太大,页面加载速度慢,大大降低了网站的实用性;导航使用图片作为链接,并且搜索引擎效果不佳. 确定网站结构.
3. 不要采集很多文章
每个人都知道,对于Internet上高度重复的文章,搜索引擎不会给出很好的排名. 大量采集的文章也对整个站点产生相当大的负面影响. 网站建设完成后,大量的没有实质内容的文章被采集起来,给用户带来不好的浏览体验,给搜索引擎留下了不好的印象,给搜索引擎的优化带来了很大的风险. 因此,即使您想采集文章,也要进行伪原创或部分采集.
4. 没有明确的目的和准确的关键字分析就永远不要网站
医院网站的方向不明确,关键字分配不合理,排名效果差,资金投入大,回报率低等都是由于缺乏关键字分析而引起的问题. 这些问题是致命的. 这是浪费金钱,不是太多!
5. 请勿经常更改网页标题
标题是搜索引擎匹配关键字的核心. 搜索引擎依靠标题标签进行单词分割和单词分割以建立索引. 这是原创阶段搜索引擎排名的核心. 尽管搜索引擎在技术上取得了飞速进步,但开发和依赖Title仍然是改善用户体验的关键. 如果您经常更改标题,搜索引擎会将其视为作弊,因此在更改标题时必须谨慎. 幸运的是,该网站已设置为可以上网,并且该网站的标题一次就可以清除!
6. 尽可能少使用或不使用JS和iframe
在Internet的发展过程中,JS和Iframe主要作为在线广告而存在,并且大多数广告管理都是通过JS和Iframe进行管理的. 尽管当前的Web技术允许将广告用作网页内容的补充,但是太多的广告也会对用户浏览页面内容造成干扰. 搜索引擎仍然不“考虑” JS和Iframe中的内容. 将有用的信息放入JS变成无用的信息. 大量JS和iframe会被视为页面上的广告过多.
7. 永远没有网站地图
站点地图也称为站点地图. 它是一个页面,具有指向网站上所有页面的链接. 当大多数人无法在网站上找到所需信息时,他们可以使用网站地图作为补救措施. 搜索引擎蜘蛛非常喜欢站点地图.
8. 永远不要复制别人的网站
为了节省麻烦,有些人只是抓住了胡子,直接使用了现有的网站程序模板. 这导致了两个高度相似的网站. 这样的新网站很难获得良好的排名,旧网站也将受到影响.
9. 不要将多个网站彼此链接
该网站的首页具有很高的权重,并且关键字易于排名. 大多数网站管理员会在网站首页上放置很多热门关键字. 由于首页的位置有限,因此距离许多关键字还很遥远. 需求,许多网站管理员已经建立了许多卫星站点来分隔一些受欢迎的关键字. 这是一种干扰搜索引擎排名的行为. 搜索引擎还针对这种行为采取了某些措施,例如: 龙鑫该站的排名时间被沙箱化为新网站;通过信息采集和分析,站群网站将受到惩罚.
10. 避免频繁删除引起大量无效链接的文章
在医院的内部管理中,经常删除某些网站列,文章等,并且删除的页面将生成大量无效链接. 医院网站必须设置404错误页面,在删除页面时尝试保留页面,在原创页面上进行更改,并在删除后更新网站页面. 本文是由网络营销推广培训教程组织和发布的.
在华旗商城推出更多产品: 快速仿制网站制作,家装和建筑行业php程序开发,企业网站托管和运营
关于采集器采集和重复数据删除的优化
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-08 15:30
首先,对于URL本身的重复数据删除,可以直接处理整个URL. 当提到Internet上的某些文章时,我发现其中大多数使用URL压缩存储. 但是,当数据量很大时,使用这些算法可以大大减少存储空间:
基于磁盘的顺序存储.
基于哈希算法的存储.
基于MD5压缩映射的存储.
基于嵌入式Berkeley DB的存储.
基于Bloom Filter的存储.
URL的直接重复数据删除主要涉及存储优化,这不是本文的重点,因此在这里我将不做详细介绍.
对于URL的逻辑重复数据删除,您需要追求更高的数据可用性,这是进行测试时需要考虑的事情.
这是seay文章中的相似性重复数据删除算法,大致如下:
def urlsimilar(url):
hash_size=199999
tmp=urlparse.urlparse(url)
scheme=tmp[0]
netloc=tmp[1]
path=tmp[2][1:]
query=tmp[4]
#First get tail
if len(path.split('/'))>1:
tail=path.split('/')[-1].split('.')[-1]
#print tail
elif len(path.split('/'))==1:
tail=path
else:
tail='1'
#Second get path_length
path_length=len(path.split('/'))-1
#Third get directy list except last
path_list=path.split('/')[:-1]+[tail]
#Fourth hash
path_value=0
for i in range(path_length+1):
if path_length-i==0:
path_value+=hash(path_list[path_length-i])%98765
else:
path_value+=len(path_list[path_length-i])*(10**(i+1))
#get host hash value
netloc_value=hash(hashlib.new("md5",netloc).hexdigest())%hash_size
url_value=hash(hashlib.new("md5",str(path_value+netloc_value)).hexdigest())%hash_size
return url_value
此函数的一般用途是最终将根据算法返回哈希值,该哈希值也是URL的哈希相似度. 如果两个URL所计算的哈希值最终相等,我们可以判断两个URL具有高度相似性.
但是应该以seay为例来举例说明此功能(在这里强调,以免被喷洒,稍后我将不对其进行详细说明). 这只是一个简单的演示,无需详细检查. 在粗略的情况下,该算法确实可以消除一些简单的参数重复,但是一旦参数复杂或URL不标准化,对于重复数据删除就不是很好.
那么在获取URL的过程中,我们还能进行其他哪些小的优化?
日期和时间命名
首先,我们可以根据日期进行重复数据删除. 我们知道,在爬网博客和门户之类的某些系统时,经常会遇到以日期命名的目录.
这些目录可以粗略地概括,并具有类似于以下内容的形式:
2010-11-11
10-11-11
20101111
当然,有些文件将以时间+随机值命名,或者它们可能以Unix时间戳命名. 这些可以根据上载和编辑时间来定义.
作者的建议是使用缓存数据库(例如redis或memcache)直接存储它;或当数据量很大时,请考虑临时存储它,并在需要时进行比较.
例如,一旦出现以日期和时间命名的目录或静态文件,我们可以考虑以以下格式存储它:
目录级别
姓名格式
URL地址(或压缩的哈希值)
有人可能会说,在seay提到的情况下,似乎日期的相似性可以解决. 让我们首先看下面的例子. 这里的输出仍然基于上述功能:
print urlsimilar('http://www.baidu.com/blog/2010-10-11/')
print urlsimilar('http://www.baidu.com/blog/2010-10-13/')
print urlsimilar('http://www.baidu.com/blog/2010-9-13/')
print urlsimilar('http://www.baidu.com/whisper/2010-10-11/')
输出结果如下:
110086
110086
37294
4842
我们可以看到,在正常情况下,确实在同一父目录中,相似性算法可以判断为正确. 但是,一旦日期格式不统一,或者父目录中存在某些差异,就不是一个很好的判断.
当然,我们还可以使用机器学习来完成重复数据删除的工作. 但是在简化工作方面,您仍然可以根据规则匹配使用一些小技巧来完成它.
删除静态文件
我们知道,在爬网URL的过程中,我们还会遇到许多静态文件,例如shtml,html,css等. 在大多数情况下,这些文件是没有意义的. 除非测试人员倾向于使用完整的采集方法,否则“我宁愿错误地杀死一百个人,也不会错过任何一个. ”
这时,我们可以配置黑名单并创建文件后缀规则库进行过滤.
当然,带有静态后缀的URL链接也可能与参数混淆. 个人建议是,用于回调的json和xml之类的URL可能会存储敏感内容,并尽量不要移动它们. 对于其他类型的静态文件,仍然采用分离参数的方法,最后对URL进行重复数据删除和存储.
针对特定情况进行过滤
在抓取特定网站时,我们可以对其进行预配置并指定过滤某些目录和页面以节省大量时间和资源.
相反,我们还可以指定仅爬网指定目录中的页面,并定位所需的内容.
感知敏感页面
在seay提出的演示算法中,在这种情况下存在某些限制. 例如,我们需要在敏感目录中获取尽可能多的文件信息. 例如,如果我们爬到后台管理目录,则可能会遇到以下情况:
print urlsimilar('http://www.baidu.com/blog/admin/login.php')
print urlsimilar('http://www.baidu.com/blog/admin/manage_index.php')
print urlsimilar('http://www.baidu.com/blog/admin/test.css')
输出结果如下:
40768
40768
40768
显然有问题,不是吗?
我们当然可以监视敏感的页面关键字;或者我们可以指定一个后缀文件来执行白名单监控.
但是一旦您执行了此操作,并且想要使用以前的哈希算法,则您自己定义的过滤器函数的优先级必须大于该算法. 另外,在这样做的过程中,还应考虑过滤成本问题,建议采用选择性激活.
对高频敏感目录的优惠待遇
也许在爬网过程中,某些爬网程序还使用目录爆炸的方法. 如果采用此方法并且匹配成功,则可以对目录中的内容使用单独的过滤规则,以避免误判重复数据删除算法.
过滤响应页面
对于某些网站,由于链接无效,许多页面可能被标记为404页和50x错误. 另外,当您无权访问时,网站可能会进行30倍重定向和403目录限制.
这些页面没有实质性内容,并且在大多数情况下是没有意义的. 我们可以在配置文件中将需要爬网的页面类型列入白名单,例如保留403个页面,或在跳转(之后)页面之前访问30倍.
WAF(警告)页面过滤
某些网站可能已安装WAF. 如果访问频率太快,可能会出现WAF警告页面. 在CMS自身施加限制的情况下,某些不存在的页面将以20x的响应代码显示.
当然,我们可以通过代理的分布式交换来解决其中的一些问题,因此在此不再赘述.
这时,我们可以配置相应的次数阈值. 如果某些页面出现过多次,则可以将它们标记为警告(WAF)页面,然后进行过滤. 在此处可以识别页面,您可以使用黑名单关键字对其进行标记;或尝试计算页面哈希值,例如:
content = urllib2.urlopen('http://www.test.com/').read()
md5_sum = hashlib.md5()
md5_sum.update(content)
print md5_sum.hexdigest()
当然,当我们实际计算页面哈希值并进行关键字监控时,由于存在反爬虫机制(例如,添加随机值). 当然,这也会消耗更多的时间和机器资源. 但是在某些特定情况下,它也可能带来意想不到的收益.
删除无意义的参数页面
在采集页面的过程中,我们可能还会遇到一些无意义的,经常出现的多参数页面. 这样的页面可以是回调页面,也可以是临时呈现的随机页面.
在这里,您可以通过以前的WAF(警告)方法进行过滤. 当然,使用以前的哈希算法也可以应付大多数情况. 毕竟,这种网站的URL是受限制的,并且不需要为多个功能消耗更多的资源,因此收益大于损失.
JS代码中的URL
当我们提取js代码时,也就是说,当我们遇到诸如ajax之类的交互时,我们可能会遇到需要拼接的GET请求或可以直接访问的POST请求.
这种URL地址最好与phantomjs之类的webkit结合使用,以更方便地进行动态拼接.
它们看起来很特殊,可能仅返回状态代码,或者可能返回实质上敏感的内容. 在这种情况下,有必要根据采集器的要求调整搜寻过滤规则.
摘要
此处的作者旨在针对类似URL的重复数据删除提出一些小的优化措施,这些效果可能有限,或者可能不令人满意.
欢迎提出建议. 我希望减少喜欢喷涂的童鞋,并增加讨论和鼓励.
参考文章
如何避免重复抓取同一网页
谈论动态采集器和重复数据删除
Web采集器: 使用BloomFilter进行URL重复数据删除策略
实用科普: 履带技术分析. 编写采集器时的注意事项
Web爬网程序(蜘蛛)URL重复数据删除设计URL重复数据删除设计 查看全部
当我处理漏洞Fuzz采集器时,我曾经从事URL重复数据删除. 当时,我提到了Seay大师的文章以及Internet上的一些零散信息. 我觉得这很简单. 最近遇到了相关的问题,所以我几乎有了重新改进算法的想法.
首先,对于URL本身的重复数据删除,可以直接处理整个URL. 当提到Internet上的某些文章时,我发现其中大多数使用URL压缩存储. 但是,当数据量很大时,使用这些算法可以大大减少存储空间:

基于磁盘的顺序存储.
基于哈希算法的存储.
基于MD5压缩映射的存储.
基于嵌入式Berkeley DB的存储.
基于Bloom Filter的存储.
URL的直接重复数据删除主要涉及存储优化,这不是本文的重点,因此在这里我将不做详细介绍.
对于URL的逻辑重复数据删除,您需要追求更高的数据可用性,这是进行测试时需要考虑的事情.
这是seay文章中的相似性重复数据删除算法,大致如下:
def urlsimilar(url):
hash_size=199999
tmp=urlparse.urlparse(url)
scheme=tmp[0]
netloc=tmp[1]
path=tmp[2][1:]
query=tmp[4]
#First get tail
if len(path.split('/'))>1:
tail=path.split('/')[-1].split('.')[-1]
#print tail
elif len(path.split('/'))==1:
tail=path
else:
tail='1'
#Second get path_length
path_length=len(path.split('/'))-1
#Third get directy list except last
path_list=path.split('/')[:-1]+[tail]
#Fourth hash
path_value=0
for i in range(path_length+1):
if path_length-i==0:
path_value+=hash(path_list[path_length-i])%98765
else:
path_value+=len(path_list[path_length-i])*(10**(i+1))
#get host hash value
netloc_value=hash(hashlib.new("md5",netloc).hexdigest())%hash_size
url_value=hash(hashlib.new("md5",str(path_value+netloc_value)).hexdigest())%hash_size
return url_value
此函数的一般用途是最终将根据算法返回哈希值,该哈希值也是URL的哈希相似度. 如果两个URL所计算的哈希值最终相等,我们可以判断两个URL具有高度相似性.
但是应该以seay为例来举例说明此功能(在这里强调,以免被喷洒,稍后我将不对其进行详细说明). 这只是一个简单的演示,无需详细检查. 在粗略的情况下,该算法确实可以消除一些简单的参数重复,但是一旦参数复杂或URL不标准化,对于重复数据删除就不是很好.
那么在获取URL的过程中,我们还能进行其他哪些小的优化?
日期和时间命名
首先,我们可以根据日期进行重复数据删除. 我们知道,在爬网博客和门户之类的某些系统时,经常会遇到以日期命名的目录.
这些目录可以粗略地概括,并具有类似于以下内容的形式:
2010-11-11
10-11-11
20101111
当然,有些文件将以时间+随机值命名,或者它们可能以Unix时间戳命名. 这些可以根据上载和编辑时间来定义.
作者的建议是使用缓存数据库(例如redis或memcache)直接存储它;或当数据量很大时,请考虑临时存储它,并在需要时进行比较.
例如,一旦出现以日期和时间命名的目录或静态文件,我们可以考虑以以下格式存储它:
目录级别
姓名格式
URL地址(或压缩的哈希值)
有人可能会说,在seay提到的情况下,似乎日期的相似性可以解决. 让我们首先看下面的例子. 这里的输出仍然基于上述功能:
print urlsimilar('http://www.baidu.com/blog/2010-10-11/')
print urlsimilar('http://www.baidu.com/blog/2010-10-13/')
print urlsimilar('http://www.baidu.com/blog/2010-9-13/')
print urlsimilar('http://www.baidu.com/whisper/2010-10-11/')
输出结果如下:
110086
110086
37294
4842
我们可以看到,在正常情况下,确实在同一父目录中,相似性算法可以判断为正确. 但是,一旦日期格式不统一,或者父目录中存在某些差异,就不是一个很好的判断.
当然,我们还可以使用机器学习来完成重复数据删除的工作. 但是在简化工作方面,您仍然可以根据规则匹配使用一些小技巧来完成它.
删除静态文件
我们知道,在爬网URL的过程中,我们还会遇到许多静态文件,例如shtml,html,css等. 在大多数情况下,这些文件是没有意义的. 除非测试人员倾向于使用完整的采集方法,否则“我宁愿错误地杀死一百个人,也不会错过任何一个. ”
这时,我们可以配置黑名单并创建文件后缀规则库进行过滤.
当然,带有静态后缀的URL链接也可能与参数混淆. 个人建议是,用于回调的json和xml之类的URL可能会存储敏感内容,并尽量不要移动它们. 对于其他类型的静态文件,仍然采用分离参数的方法,最后对URL进行重复数据删除和存储.
针对特定情况进行过滤
在抓取特定网站时,我们可以对其进行预配置并指定过滤某些目录和页面以节省大量时间和资源.
相反,我们还可以指定仅爬网指定目录中的页面,并定位所需的内容.
感知敏感页面

在seay提出的演示算法中,在这种情况下存在某些限制. 例如,我们需要在敏感目录中获取尽可能多的文件信息. 例如,如果我们爬到后台管理目录,则可能会遇到以下情况:
print urlsimilar('http://www.baidu.com/blog/admin/login.php')
print urlsimilar('http://www.baidu.com/blog/admin/manage_index.php')
print urlsimilar('http://www.baidu.com/blog/admin/test.css')
输出结果如下:
40768
40768
40768
显然有问题,不是吗?
我们当然可以监视敏感的页面关键字;或者我们可以指定一个后缀文件来执行白名单监控.
但是一旦您执行了此操作,并且想要使用以前的哈希算法,则您自己定义的过滤器函数的优先级必须大于该算法. 另外,在这样做的过程中,还应考虑过滤成本问题,建议采用选择性激活.
对高频敏感目录的优惠待遇
也许在爬网过程中,某些爬网程序还使用目录爆炸的方法. 如果采用此方法并且匹配成功,则可以对目录中的内容使用单独的过滤规则,以避免误判重复数据删除算法.
过滤响应页面
对于某些网站,由于链接无效,许多页面可能被标记为404页和50x错误. 另外,当您无权访问时,网站可能会进行30倍重定向和403目录限制.
这些页面没有实质性内容,并且在大多数情况下是没有意义的. 我们可以在配置文件中将需要爬网的页面类型列入白名单,例如保留403个页面,或在跳转(之后)页面之前访问30倍.
WAF(警告)页面过滤

某些网站可能已安装WAF. 如果访问频率太快,可能会出现WAF警告页面. 在CMS自身施加限制的情况下,某些不存在的页面将以20x的响应代码显示.
当然,我们可以通过代理的分布式交换来解决其中的一些问题,因此在此不再赘述.
这时,我们可以配置相应的次数阈值. 如果某些页面出现过多次,则可以将它们标记为警告(WAF)页面,然后进行过滤. 在此处可以识别页面,您可以使用黑名单关键字对其进行标记;或尝试计算页面哈希值,例如:
content = urllib2.urlopen('http://www.test.com/').read()
md5_sum = hashlib.md5()
md5_sum.update(content)
print md5_sum.hexdigest()
当然,当我们实际计算页面哈希值并进行关键字监控时,由于存在反爬虫机制(例如,添加随机值). 当然,这也会消耗更多的时间和机器资源. 但是在某些特定情况下,它也可能带来意想不到的收益.
删除无意义的参数页面
在采集页面的过程中,我们可能还会遇到一些无意义的,经常出现的多参数页面. 这样的页面可以是回调页面,也可以是临时呈现的随机页面.
在这里,您可以通过以前的WAF(警告)方法进行过滤. 当然,使用以前的哈希算法也可以应付大多数情况. 毕竟,这种网站的URL是受限制的,并且不需要为多个功能消耗更多的资源,因此收益大于损失.
JS代码中的URL
当我们提取js代码时,也就是说,当我们遇到诸如ajax之类的交互时,我们可能会遇到需要拼接的GET请求或可以直接访问的POST请求.
这种URL地址最好与phantomjs之类的webkit结合使用,以更方便地进行动态拼接.
它们看起来很特殊,可能仅返回状态代码,或者可能返回实质上敏感的内容. 在这种情况下,有必要根据采集器的要求调整搜寻过滤规则.
摘要
此处的作者旨在针对类似URL的重复数据删除提出一些小的优化措施,这些效果可能有限,或者可能不令人满意.
欢迎提出建议. 我希望减少喜欢喷涂的童鞋,并增加讨论和鼓励.
参考文章
如何避免重复抓取同一网页
谈论动态采集器和重复数据删除
Web采集器: 使用BloomFilter进行URL重复数据删除策略
实用科普: 履带技术分析. 编写采集器时的注意事项
Web爬网程序(蜘蛛)URL重复数据删除设计URL重复数据删除设计
新知识新闻源文章生成器
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-08 14:52
功能概述:
新知识新闻源文章生成器批量生成新闻源文章,告别了人工新闻源的时代,使用批量上传功能直接发布生成的文章,大大提高了新闻源发布的效率. 采集新闻源文章,采集新闻源文章链接,随机组合本地新闻源段落,替换文章字符,伪原创内容,插入关键字和插入JS脚本.
1该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2该软件适用于具有“批量上传”功能的新闻源平台;
3. 该软件可以从家庭或其他医院网站采集文章,以生成文章作为新闻来源;
4局部模式-段落随机组合模式可以将准备好的文章段落随机组合成完整的文章;
5本地模式-完整文章模式可以通过对网站上准备的完整文章的后续处理来生成新闻组;
6所采集的文章是独立的,包括拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键字等;
7将采集到的文章保存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8采集链接: 批量采集文章链接以准备采集文章;
9保存: 保存商品生成规则的配置,以备下次使用;
10打开: 打开保存的文章生成规则,并继续上一次.
11个视频教程: 这里有一些软件操作视频教程,供新用户学习.
由NSFOCUS 查看全部
该软件需要.net3.5操作环境. 如果在打开软件时报告错误,请下载并安装.net3.5.
功能概述:
新知识新闻源文章生成器批量生成新闻源文章,告别了人工新闻源的时代,使用批量上传功能直接发布生成的文章,大大提高了新闻源发布的效率. 采集新闻源文章,采集新闻源文章链接,随机组合本地新闻源段落,替换文章字符,伪原创内容,插入关键字和插入JS脚本.
1该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2该软件适用于具有“批量上传”功能的新闻源平台;
3. 该软件可以从家庭或其他医院网站采集文章,以生成文章作为新闻来源;
4局部模式-段落随机组合模式可以将准备好的文章段落随机组合成完整的文章;
5本地模式-完整文章模式可以通过对网站上准备的完整文章的后续处理来生成新闻组;
6所采集的文章是独立的,包括拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键字等;
7将采集到的文章保存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8采集链接: 批量采集文章链接以准备采集文章;
9保存: 保存商品生成规则的配置,以备下次使用;
10打开: 打开保存的文章生成规则,并继续上一次.
11个视频教程: 这里有一些软件操作视频教程,供新用户学习.
由NSFOCUS
七个方面可以告诉您不收录原创文章的因素
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-08 02:57
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章?
1. 该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察.
如何解决这个问题?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度.
第二个是更新许多高质量的原创内容. 不管是否包括它,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过.
如果找到大量的无效链接,首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 具体细节不在这里解释.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的境界,则需要继续提高权利,然后提高文章质量,以确保网站的跳出率可观. 组织和发布 查看全部
SEOre问我为什么我的文章是原创的,但仍未包括在内. 实际上,网站的收录不是由原创文章确定的. 我相信这个问题困扰了很长时间的所有人. 一些网站管理员每天都在努力编写原创更新. 但是,它始终不受搜索引擎青睐,某些网站即使被采集也可以在几秒钟内实现接收的处理. 我们坚持以错误的方向进行原创更新的方向吗?还是其他人有其他聪明的把戏?这些未知. 我今天将与您分享的是为什么不包括原创文件的分析和解决方案.
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章?
1. 该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察.
如何解决这个问题?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度.
第二个是更新许多高质量的原创内容. 不管是否包括它,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过.
如果找到大量的无效链接,首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 具体细节不在这里解释.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的境界,则需要继续提高权利,然后提高文章质量,以确保网站的跳出率可观. 组织和发布
SEO的原因和解决方案不包括原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-08 02:10
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章? 1.该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察. 如何解决这个问题呢?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度. 第二是更新许多高质量的原创内容,无论是否收录这些内容,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过. 如果发现大量无效链接,那么首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 这里不解释细节.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的范围,则需要继续提高权利,然后提示文章的质量,以确保网站的跳出率良好. 如有任何疑问,可以咨询Baishang Network下的小偷SEO博客! 查看全部
我认为,“不包括原创物品”的问题困扰了很长时间. 一些网站管理员每天都在努力工作以编写原创更新,但是它们始终不受搜索引擎的青睐,有些网站甚至可以实现原创采集. 第二种采集的处理方式是我们坚持原创更新的错误方向吗?还是其他人有其他聪明的把戏?这些是未知的,今天我将与您分享为什么不包括原创文件的原因分析和解决方案.

1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章? 1.该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察. 如何解决这个问题呢?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度. 第二是更新许多高质量的原创内容,无论是否收录这些内容,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过. 如果发现大量无效链接,那么首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 这里不解释细节.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的范围,则需要继续提高权利,然后提示文章的质量,以确保网站的跳出率良好. 如有任何疑问,可以咨询Baishang Network下的小偷SEO博客!
使用php 优采云采集器捕获当今头条新闻Ajax文章的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-08 00:39
使用Google Chrome浏览器打开链接,右键单击“审阅”,在控制台中切换到网络,然后单击XHR,以便可以过滤不必要的请求(例如图像,文件等),而仅请求查看内容页面
由于页面是由ajax加载的,因此将页面拉到底部,更多文章将自动加载. 目前,控制台捕获的链接是我们真正需要的列表页面的链接:
在优采云采集器中创建任务
创建后,单击“采集器设置”,然后在“起始页面URL”中填写上面爬网的链接
接下来匹配内容页面的URL,标题文章的URL格式为
点击“内容页面网址”以编写“匹配内容网址”规则:
(?+ /)
这是一条常规规则,这意味着将匹配的URL加载到捕获组content1中,然后填写下面的[Content1](与上面的content1相对应)以获取内容页面链接
您可以单击“测试”以查看链接是否成功爬网
获取成功后,您可以开始获取内容
点击“获取内容”以在字段列表的右侧添加默认字段,例如标题,正文等. 可以智能识别,如果需要准确性,则可以自己编辑字段,支持常规, xpath,json和其他匹配内容
我们需要获取文章的标题和正文. 因为它是由Ajax显示的,所以我们需要编写规则以匹配内容,分析文章的源代码: ,找到文章的位置
标题规则: articleInfos: s {stitle: s'[Content1]',
身体规则: content: s'[Content1]',s * groupId
该规则必须唯一,否则它将与其他内容匹配. 将规则添加到字段中,然后为获取方法选择规则匹配:
编写规则后,单击“保存”,然后单击“测试”以查看其工作原理
规则正确,并且爬网是正常的. 捕获的数据也可以发布到cms系统,直接存储在数据库中,另存为excel文件等,只需单击底部导航栏中的“发布设置”即可. 采集在这里,每个人都可以尝试一下! 查看全部
今天的标题数据由Ajax加载并显示. 根据普通URL,无法捕获数据. 有必要分析加载地址. 让我们以示例为例,采集文章列表
使用Google Chrome浏览器打开链接,右键单击“审阅”,在控制台中切换到网络,然后单击XHR,以便可以过滤不必要的请求(例如图像,文件等),而仅请求查看内容页面

由于页面是由ajax加载的,因此将页面拉到底部,更多文章将自动加载. 目前,控制台捕获的链接是我们真正需要的列表页面的链接:
在优采云采集器中创建任务

创建后,单击“采集器设置”,然后在“起始页面URL”中填写上面爬网的链接

接下来匹配内容页面的URL,标题文章的URL格式为
点击“内容页面网址”以编写“匹配内容网址”规则:
(?+ /)
这是一条常规规则,这意味着将匹配的URL加载到捕获组content1中,然后填写下面的[Content1](与上面的content1相对应)以获取内容页面链接

您可以单击“测试”以查看链接是否成功爬网

获取成功后,您可以开始获取内容
点击“获取内容”以在字段列表的右侧添加默认字段,例如标题,正文等. 可以智能识别,如果需要准确性,则可以自己编辑字段,支持常规, xpath,json和其他匹配内容
我们需要获取文章的标题和正文. 因为它是由Ajax显示的,所以我们需要编写规则以匹配内容,分析文章的源代码: ,找到文章的位置

标题规则: articleInfos: s {stitle: s'[Content1]',
身体规则: content: s'[Content1]',s * groupId
该规则必须唯一,否则它将与其他内容匹配. 将规则添加到字段中,然后为获取方法选择规则匹配:


编写规则后,单击“保存”,然后单击“测试”以查看其工作原理

规则正确,并且爬网是正常的. 捕获的数据也可以发布到cms系统,直接存储在数据库中,另存为excel文件等,只需单击底部导航栏中的“发布设置”即可. 采集在这里,每个人都可以尝试一下!
千千: 使用今天的头条自动采集高质量的文章材料实践技能
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2020-08-07 18:55
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于自媒体的运作,无非就是稳定的产值,可以赚很多钱. 对于大多数人来说,他们不知道该值在哪里导入然后输出. 在这里,我将分享头条稳定投入价值的实战游戏玩法,这将帮助更多的人走向自我媒体之路.
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
就像上面的图片一样,一个单独的“种子”文件夹以采集夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
注册或购买标题号码
输入定位标记词以查找文章
按照带有标题词的文章标题
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
已发表的文章数量很少;
刚刚注册的新帐户; 查看全部
在当前的Internet环境中,所谓的营销不再像以前那样容易. 无论是百度,腾讯,阿里,博客,论坛还是视频,许多人都被超越了赚钱门槛. 但是,过去两年中,有一件事情正在如火如荼地发展,那就是自我媒体.

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于自媒体的运作,无非就是稳定的产值,可以赚很多钱. 对于大多数人来说,他们不知道该值在哪里导入然后输出. 在这里,我将分享头条稳定投入价值的实战游戏玩法,这将帮助更多的人走向自我媒体之路.
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
就像上面的图片一样,一个单独的“种子”文件夹以采集夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
注册或购买标题号码
输入定位标记词以查找文章
按照带有标题词的文章标题

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.

uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
已发表的文章数量很少;
刚刚注册的新帐户;
为什么不包括网站优化更新的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 17:13
不收录网站文章的原因
1. 该网站过度优化.
过度优化发生在网站上,这通常表现为关键字和隐藏文本的积累. 如果出现这种情况,我们必须对其进行处理并及时进行调整,以使其缓慢地被百度搜索引擎收录. 即使自己发布的网站文章被搜索引擎收录,百度更新后它们也会消失. 实事求是,进行网站优化.
2. 网站内容采集
几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有价值,则将其丢弃. 网站内容的主要来源已采集. 在这种情况下,有时会不收录网站文章. 即使采集到的文章质量很高,并且被搜索引擎暂时包括在内,经过一段时间后,它们也会逐渐被删除. 文章还将在那时将该网站降级,并在此类步骤中使用百度的算法. 因此,请记住此规则,不要采集更多文章并在您的网站上更新它们.
3. 被阻止的内容出现在网站的主题中
在优化网站时,我们需要检查是否存在任何法律禁止的内容信息. 如果是这样,我们必须将其删除以防止该网站受到搜索引擎的影响. 在制作内容时,必须注意法律所禁止的字眼. 不要触摸它们,也不知道.
4. 网站域名会受到惩罚吗?
注册域名或购买二手域名时,必须检查该域名是否受到搜索引擎的惩罚,以及该域名是否属于灰色行业. 还可以检查域名等的外部链资源.
5. 网站上的无效链接太多
或者由于网站的修订,网站文章的删除等因素,该网站有大量的死链接,而且搜索引擎也很容易找到他们想要的东西. 网站上无效的链接必须提交给搜索引擎.
6. 该网站已修改.
网站修订的内容很长时间以来尚未完善,已提交给百度搜索引擎. 后期的大小变化也会导致网站降级.
7. 被惩罚的网站不在链条之内
已被搜索引擎降级的网站离线资源收录在其自己的网站中,并且您网站上的友好链接已被降级. 如果发生这种情况,应及时清除并添加新的友好链接. 网站上外部链接的减少也是导致搜索引擎爬网程序不收录文章的一个因素. 更多的外部链资源可以驱动更多的采集器来获取数据并提高网站关键字的排名.
8,网站虚拟主机IP被阻止
如果您使用的虚拟主机的IP被阻止,搜索引擎将无法访问您的网站,并且该网站上的内容也不会被抓取.
9. 网站是否存在安全漏洞
定期检查该网站是否可能链接到一匹马,如果有必要及时删除它,搜索引擎不会发现它失去对您网站的信任.
10,网站文章逐步更新
网站需要每天定期且定量地更新文章. 今天不要更新文章,明天也不会更新. 不断更新文章,并改善从伪原创文章到原创文章的转换,从而更好地提高网站的接受率. 查看全部
优化网站时,网站文章收录问题是一个常见问题. 那么,此问题如何导致搜索引擎不对网站文章进行索引?有没有更好的方法让搜索引擎收录您自己的网站?关于此问题的文章,我将与您分享不收录网站文章的主要原因. 具体内容如下:

不收录网站文章的原因
1. 该网站过度优化.
过度优化发生在网站上,这通常表现为关键字和隐藏文本的积累. 如果出现这种情况,我们必须对其进行处理并及时进行调整,以使其缓慢地被百度搜索引擎收录. 即使自己发布的网站文章被搜索引擎收录,百度更新后它们也会消失. 实事求是,进行网站优化.
2. 网站内容采集
几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有价值,则将其丢弃. 网站内容的主要来源已采集. 在这种情况下,有时会不收录网站文章. 即使采集到的文章质量很高,并且被搜索引擎暂时包括在内,经过一段时间后,它们也会逐渐被删除. 文章还将在那时将该网站降级,并在此类步骤中使用百度的算法. 因此,请记住此规则,不要采集更多文章并在您的网站上更新它们.
3. 被阻止的内容出现在网站的主题中
在优化网站时,我们需要检查是否存在任何法律禁止的内容信息. 如果是这样,我们必须将其删除以防止该网站受到搜索引擎的影响. 在制作内容时,必须注意法律所禁止的字眼. 不要触摸它们,也不知道.
4. 网站域名会受到惩罚吗?
注册域名或购买二手域名时,必须检查该域名是否受到搜索引擎的惩罚,以及该域名是否属于灰色行业. 还可以检查域名等的外部链资源.
5. 网站上的无效链接太多
或者由于网站的修订,网站文章的删除等因素,该网站有大量的死链接,而且搜索引擎也很容易找到他们想要的东西. 网站上无效的链接必须提交给搜索引擎.
6. 该网站已修改.
网站修订的内容很长时间以来尚未完善,已提交给百度搜索引擎. 后期的大小变化也会导致网站降级.

7. 被惩罚的网站不在链条之内
已被搜索引擎降级的网站离线资源收录在其自己的网站中,并且您网站上的友好链接已被降级. 如果发生这种情况,应及时清除并添加新的友好链接. 网站上外部链接的减少也是导致搜索引擎爬网程序不收录文章的一个因素. 更多的外部链资源可以驱动更多的采集器来获取数据并提高网站关键字的排名.
8,网站虚拟主机IP被阻止
如果您使用的虚拟主机的IP被阻止,搜索引擎将无法访问您的网站,并且该网站上的内容也不会被抓取.
9. 网站是否存在安全漏洞
定期检查该网站是否可能链接到一匹马,如果有必要及时删除它,搜索引擎不会发现它失去对您网站的信任.
10,网站文章逐步更新
网站需要每天定期且定量地更新文章. 今天不要更新文章,明天也不会更新. 不断更新文章,并改善从伪原创文章到原创文章的转换,从而更好地提高网站的接受率.
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-07 17:11
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?编辑通过他通常的积累总结了以下几点:
原因: 过度优化,例如关键字堆积,隐藏文本等. 如果发生这种情况,即使百度已经收录了您,也不要感谢您被骗了,因为在此过程中它会慢慢被淘汰更新.
解决方案: 当新网站上线时,请勿首先进行过多的SEO操作,不要在标题中重复两次以上关键字;说明中的关键词不要重复三遍以上;不要把它们叠起来;尽量自然地在首页上排列关键词,不要故意堆放在那些重要的地方;尝试将首页的关键字密度控制在3%-4%左右. 标题中的三个或四个关键字就足够了,太多的搜索引擎不喜欢它. 建议设置页面主题+主题名称+网站名称. 至于关键字,是否添加都没关系,但是至少页面上应该有一些相关的内容. 描述设置非常简单,只要语言流利,并且页面的概要,两个或三个关键字就足够了.
2. 网站内容采集
原因: 几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有任何价值,它将被丢弃.
建议的解决方案: 采集完成后,手动添加一些“原创文章”,为什么还要添加引号. 因为独创性不容易写. 教您一个诱骗蜘蛛并找到相关类型文章的简单技巧. 更改标题. 破坏里面的段落格式. 如果您有自己的意见,则可以自己在其中写一个段落. 就产生了这样的“原创文章”. 然后,让您的“原创”文章出现在首页上.
3. 网站域名
原因: 我以前曾被Engine K处罚. 我们可以检查该域名是否曾经被使用过.
建议的解决方案: 在申请域名之前,直接在引擎中输入要注册的域名.
4. 网站结构
原因: 网站结构不清晰,并且存在无效链接,使搜索引擎无法访问网站.
建议的解决方案: 逐一删除无效链接并制作站点地图.
5. 网站修订
原因: 该网站尚未修改,已提交给百度,并且动turn动big. 类别和标题被交换. 有时会有测试或与网站无关的其他内容. 这些是seo的禁忌.
建议的解决方案: 正确放置它并坚持在要停止的位置. 可以添加新的类别和内容. 最好不要随意删除旧内容. 如果更改空间,最好事先进行更改. 确保以前的空间内容在一段时间内继续存在,以防万一.
6. 网站链接
原因: 网站缺少外部链接,或者外部链接逐渐减少. 当然,百度对您网站的关注度也会降低,其内容也会逐渐减少. 链接的质量非常重要. 最好不要使用垃圾链接并删除无效链接. 此外,请检查您的页面,如果存在指向被阻止网站的链接,则您的网站也会在一定程度上受到影响.
建议的解决方案: 检查网站的外部链接,进行交流,如果很少,或者访问一些大型网站和论坛以发布引起他人关注的帖子,并保留链接. 反应的人越多,效果越好. 如果站点中有到被阻止站点的链接,请尽快将其删除. 避免与某些垃圾站建立友谊链接,因为它们会对您的网站造成负面影响.
7. 网站空间
原因: 您使用的虚拟主机的IP被阻止,或者您所涉及的服务器的IP被阻止. 在百度更新期间无法访问您的网站,因此即使搜索引擎想要搜索您的页面,也无法收录该网站.
建议的解决方案: 购买空间时要注意并找到信誉良好的IDC. 不要只是便宜. 如果经常遇到问题,更不用说搜索引擎了,网民负担不起. 因此,您的网站不会吸引搜索引擎的注意. 另外,在购买空间时,请检查虚拟主机IP上的站点,收录状态以及被阻止的站点数.
8. 网站安全性
原因: 如果您添加恶意代码或故意在您的网站上挂马,百度可以对其进行分析. 会减少您的信任. 此外,大多数网页都是那些小黑客使用工具修改或删除的.
建议的解决方案: 定期备份并及时解决问题. 一般来说,百度的更新是在夜间进行的. 每天更新的个人电台很少. 如果异常,请立即进行处理.
总而言之,网站收录量中最重要的因素是网站文章内容的质量. 网站是否被很好地收录在很大程度上取决于文章内容的原创性. 我建议您写这篇文章必须是原创的,至少是伪原创的,以便您的网站的采集情况更快得到改善.
阅读本文的人还阅读:
您如何看待关键字在网站优化中的优化程度?
SEO基层网站管理员新手必须了解并注意的六个问题
新手网站管理员朋友应如何优化公司网站? 查看全部
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?我认为这是所有进行网站SEO优化的人员都更加关心的问题. 如果不包括该网站,则不会有排名,没有排名就不会有流量或流量很小. 是什么原因?对于刚刚从事该行业的小白来说,他此时正处于茫然之中,那么为什么不包括网站上的文章?如何解决网站不收录的问题?今天,小编东莞SEO将与您分享.

如果不收录网站文章,该怎么办?如何解决网站不收录的问题?编辑通过他通常的积累总结了以下几点:
原因: 过度优化,例如关键字堆积,隐藏文本等. 如果发生这种情况,即使百度已经收录了您,也不要感谢您被骗了,因为在此过程中它会慢慢被淘汰更新.
解决方案: 当新网站上线时,请勿首先进行过多的SEO操作,不要在标题中重复两次以上关键字;说明中的关键词不要重复三遍以上;不要把它们叠起来;尽量自然地在首页上排列关键词,不要故意堆放在那些重要的地方;尝试将首页的关键字密度控制在3%-4%左右. 标题中的三个或四个关键字就足够了,太多的搜索引擎不喜欢它. 建议设置页面主题+主题名称+网站名称. 至于关键字,是否添加都没关系,但是至少页面上应该有一些相关的内容. 描述设置非常简单,只要语言流利,并且页面的概要,两个或三个关键字就足够了.
2. 网站内容采集
原因: 几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有任何价值,它将被丢弃.
建议的解决方案: 采集完成后,手动添加一些“原创文章”,为什么还要添加引号. 因为独创性不容易写. 教您一个诱骗蜘蛛并找到相关类型文章的简单技巧. 更改标题. 破坏里面的段落格式. 如果您有自己的意见,则可以自己在其中写一个段落. 就产生了这样的“原创文章”. 然后,让您的“原创”文章出现在首页上.
3. 网站域名
原因: 我以前曾被Engine K处罚. 我们可以检查该域名是否曾经被使用过.
建议的解决方案: 在申请域名之前,直接在引擎中输入要注册的域名.
4. 网站结构
原因: 网站结构不清晰,并且存在无效链接,使搜索引擎无法访问网站.
建议的解决方案: 逐一删除无效链接并制作站点地图.
5. 网站修订
原因: 该网站尚未修改,已提交给百度,并且动turn动big. 类别和标题被交换. 有时会有测试或与网站无关的其他内容. 这些是seo的禁忌.
建议的解决方案: 正确放置它并坚持在要停止的位置. 可以添加新的类别和内容. 最好不要随意删除旧内容. 如果更改空间,最好事先进行更改. 确保以前的空间内容在一段时间内继续存在,以防万一.
6. 网站链接
原因: 网站缺少外部链接,或者外部链接逐渐减少. 当然,百度对您网站的关注度也会降低,其内容也会逐渐减少. 链接的质量非常重要. 最好不要使用垃圾链接并删除无效链接. 此外,请检查您的页面,如果存在指向被阻止网站的链接,则您的网站也会在一定程度上受到影响.
建议的解决方案: 检查网站的外部链接,进行交流,如果很少,或者访问一些大型网站和论坛以发布引起他人关注的帖子,并保留链接. 反应的人越多,效果越好. 如果站点中有到被阻止站点的链接,请尽快将其删除. 避免与某些垃圾站建立友谊链接,因为它们会对您的网站造成负面影响.
7. 网站空间
原因: 您使用的虚拟主机的IP被阻止,或者您所涉及的服务器的IP被阻止. 在百度更新期间无法访问您的网站,因此即使搜索引擎想要搜索您的页面,也无法收录该网站.
建议的解决方案: 购买空间时要注意并找到信誉良好的IDC. 不要只是便宜. 如果经常遇到问题,更不用说搜索引擎了,网民负担不起. 因此,您的网站不会吸引搜索引擎的注意. 另外,在购买空间时,请检查虚拟主机IP上的站点,收录状态以及被阻止的站点数.

8. 网站安全性
原因: 如果您添加恶意代码或故意在您的网站上挂马,百度可以对其进行分析. 会减少您的信任. 此外,大多数网页都是那些小黑客使用工具修改或删除的.
建议的解决方案: 定期备份并及时解决问题. 一般来说,百度的更新是在夜间进行的. 每天更新的个人电台很少. 如果异常,请立即进行处理.
总而言之,网站收录量中最重要的因素是网站文章内容的质量. 网站是否被很好地收录在很大程度上取决于文章内容的原创性. 我建议您写这篇文章必须是原创的,至少是伪原创的,以便您的网站的采集情况更快得到改善.
阅读本文的人还阅读:
您如何看待关键字在网站优化中的优化程度?
SEO基层网站管理员新手必须了解并注意的六个问题
新手网站管理员朋友应如何优化公司网站?
拒绝低效!Python教你爬虫公众号文章和链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-11 13:19
前言
上一篇文章整理了的公众号所有文章的导航链接,其实假如自动整理上去的话,是一件太吃力的事情,因为公众号里添加文章的时侯只能一篇篇的选择,是个单选框。
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk姐作为一个 Pythoner,当然不能如此低效,我们用爬虫把文章的标题和链接等信息提取下来。
抓包
我们须要通过抓包提取公众号文章的恳求的 URL,参考之前写过的一篇抓包的文章,pk哥此次直接抓取 PC 端陌陌的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选允许抓取笔记本的恳求,一般是默认就勾选的。
为了过滤掉其他无关恳求,我们在左下方设置下我们要抓取的域名。
打开 PC 端陌陌,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的恳求,找到我们须要的恳求,返回的 JSON 信息里收录了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
这些都是恳求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向下滑动,加载更多文章后发觉链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头收录了 User-Agent、Cookie、Referer。
这些信息都在抓包工具可以看见。
请求数据
通过抓包剖析下来了恳求链接,我们就可以用 requests 库来恳求了,用返回码是否为 200 做一个判定,200 的话说明返回信息正常,我们再构筑一个函数 parse_data() 来解析提取我们须要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过剖析返回的 Json 数据,我们可以看见,我们须要的数据都在 app_msg_ext_info 下面。
我们用 json.loads 解析返回的 Json 信息,把我们须要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果都会以 csv 格式保存上去。
运行代码时,可能会遇见 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应当都晓得,一般写文字就会用 Markdown 的格式来写文章,这样的话,不管置于那个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都晓得新建 Markdown 格式的文件的。
这样,这些导航文章链接整理上去就是分类的事情了。 查看全部
阅读文本大概需要 5 分钟
前言
上一篇文章整理了的公众号所有文章的导航链接,其实假如自动整理上去的话,是一件太吃力的事情,因为公众号里添加文章的时侯只能一篇篇的选择,是个单选框。
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk姐作为一个 Pythoner,当然不能如此低效,我们用爬虫把文章的标题和链接等信息提取下来。
抓包
我们须要通过抓包提取公众号文章的恳求的 URL,参考之前写过的一篇抓包的文章,pk哥此次直接抓取 PC 端陌陌的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选允许抓取笔记本的恳求,一般是默认就勾选的。
为了过滤掉其他无关恳求,我们在左下方设置下我们要抓取的域名。
打开 PC 端陌陌,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的恳求,找到我们须要的恳求,返回的 JSON 信息里收录了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
这些都是恳求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向下滑动,加载更多文章后发觉链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头收录了 User-Agent、Cookie、Referer。
这些信息都在抓包工具可以看见。
请求数据
通过抓包剖析下来了恳求链接,我们就可以用 requests 库来恳求了,用返回码是否为 200 做一个判定,200 的话说明返回信息正常,我们再构筑一个函数 parse_data() 来解析提取我们须要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过剖析返回的 Json 数据,我们可以看见,我们须要的数据都在 app_msg_ext_info 下面。
我们用 json.loads 解析返回的 Json 信息,把我们须要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果都会以 csv 格式保存上去。
运行代码时,可能会遇见 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应当都晓得,一般写文字就会用 Markdown 的格式来写文章,这样的话,不管置于那个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都晓得新建 Markdown 格式的文件的。
这样,这些导航文章链接整理上去就是分类的事情了。
获取微信公众号关注页面链接和历史文章链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-11 12:42
我是这样获取biz值的:分享一篇该公众号的文章到QQ,然后在QQ里点开这篇文章,打开右上角3个点,复制链接,这个链接里就有biz的值了!
最终堆砌成这样子:【复制到陌陌中打开】
https://mp.weixin.qq.com/mp/pr ... irect
根据任一公号文章的链接地址,我们可以获取biz的值(假设为“X”),然后我们可以执行以下动作:
2.获取公众号的历史文章链接:
http://mp.weixin.qq.com/mp/get ... irect
在陌陌环境下(微信客户端或陌陌网页版),点击以上链接可以查看一个公号的历史文章,历史文章的内容会动态更新。
如果你有自定义菜单,设置一个链接,你的订阅用户可以很方便查看历史文章。
3.获取公众号的二维码:
http://mp.weixin.qq.com/mp/qrc ... 3D%3D
在浏览器输入以上地址,可以查看一个公众号的二维码图片。
曾经很难获取他人家公众号的二维码图片,而如今十分简单。
如果你想设置二维码的规格,在里面网址的前面加上“&size=数字”看看有哪些变化。
对于一个公众号而言,历史文章是订阅资源,二维码是对外名片。知道了这种就足够了,你认为呢? 查看全部
1.获取微信公众号关注页面链接
我是这样获取biz值的:分享一篇该公众号的文章到QQ,然后在QQ里点开这篇文章,打开右上角3个点,复制链接,这个链接里就有biz的值了!
最终堆砌成这样子:【复制到陌陌中打开】
https://mp.weixin.qq.com/mp/pr ... irect
根据任一公号文章的链接地址,我们可以获取biz的值(假设为“X”),然后我们可以执行以下动作:
2.获取公众号的历史文章链接:
http://mp.weixin.qq.com/mp/get ... irect
在陌陌环境下(微信客户端或陌陌网页版),点击以上链接可以查看一个公号的历史文章,历史文章的内容会动态更新。
如果你有自定义菜单,设置一个链接,你的订阅用户可以很方便查看历史文章。
3.获取公众号的二维码:
http://mp.weixin.qq.com/mp/qrc ... 3D%3D
在浏览器输入以上地址,可以查看一个公众号的二维码图片。
曾经很难获取他人家公众号的二维码图片,而如今十分简单。
如果你想设置二维码的规格,在里面网址的前面加上“&size=数字”看看有哪些变化。
对于一个公众号而言,历史文章是订阅资源,二维码是对外名片。知道了这种就足够了,你认为呢?
怎么获取唯品会商品链接?唯品会商品链接搜集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-08-10 19:13
唯品会商品链接采集器是一款好用的图片文字辨识工具。我们可以使用唯品会商品链接采集器轻松采集唯品会商品链接;
进入下载
唯品会商品链接采集器 2.0 免费版
大小:603 KB
日期:2018/7/24 11:24:12
环境:WinXP,Win7,
安装软件后双击唯品会商品链接采集器桌面快捷方法打开软件;
极速小编这一次就给你们演示一下如何使用唯品会商品链接采集器的关键词搜索功能搜索唯品会商品吧。点击唯品会商品链接采集器主界面中的关键字输入框,我们就可以直接输入关键字内容。我们还可以指定搜索的网页页脚范围、排序方法;
关键字输入完成、采集范围设置好后,点击开始采集,就可以开始使用唯品会商品链接采集器采集唯品会网页上与关键字吻合的商品链接;
唯品会商品链接采集器正在采集唯品会商城上的商品链接。商品链接采集需要一定的时间,请耐心等待;
商品链接采集完成,唯品会商品链接采集器共采集了500个网址。点击唯品会商品链接采集器主界面中的全选,就可以将全部链接选中。然后点击保存,就可以将全部采集到的链接保存到笔记本本地;
在文件夹选择窗口中,打开想要拿来保存商品链接txt文档的文件夹,对文件进行命名后点击保存,就可以将商品链接保存到笔记本本地;
唯品会商品链接保存成功,这时候我们可以在文件夹中找到保存商品链接的txt文件。
唯品会商品链接采集器的使用方式就讲解到这儿,希望对大家有帮助,感谢你对急速下载站的支持!
唯品会商品链接采集器 2.0 免费版 查看全部
唯品会商品链接采集器是一款好用的图片文字辨识工具。我们可以使用唯品会商品链接采集器轻松采集唯品会商品链接;
进入下载
唯品会商品链接采集器 2.0 免费版
大小:603 KB
日期:2018/7/24 11:24:12
环境:WinXP,Win7,
安装软件后双击唯品会商品链接采集器桌面快捷方法打开软件;
极速小编这一次就给你们演示一下如何使用唯品会商品链接采集器的关键词搜索功能搜索唯品会商品吧。点击唯品会商品链接采集器主界面中的关键字输入框,我们就可以直接输入关键字内容。我们还可以指定搜索的网页页脚范围、排序方法;
关键字输入完成、采集范围设置好后,点击开始采集,就可以开始使用唯品会商品链接采集器采集唯品会网页上与关键字吻合的商品链接;
唯品会商品链接采集器正在采集唯品会商城上的商品链接。商品链接采集需要一定的时间,请耐心等待;
商品链接采集完成,唯品会商品链接采集器共采集了500个网址。点击唯品会商品链接采集器主界面中的全选,就可以将全部链接选中。然后点击保存,就可以将全部采集到的链接保存到笔记本本地;
在文件夹选择窗口中,打开想要拿来保存商品链接txt文档的文件夹,对文件进行命名后点击保存,就可以将商品链接保存到笔记本本地;
唯品会商品链接保存成功,这时候我们可以在文件夹中找到保存商品链接的txt文件。
唯品会商品链接采集器的使用方式就讲解到这儿,希望对大家有帮助,感谢你对急速下载站的支持!
唯品会商品链接采集器 2.0 免费版
黑帽seo要具备什么技术 2017年黑帽seo技术快速排行
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-10 17:28
白帽SEO是一种公平的手法,是使用符合主流搜索引擎发行方针规定的seo优化技巧。它是与黑帽seo相反的。白帽SEO仍然被业内觉得是最佳的SEO手法,它是在防止一知切风险的情况下进行操作的,同时也防止了与搜索引擎发道行方针发生任何的冲突,它也是SEOer从业者的最高职业道德标准。
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的版作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
灰帽SEO是介于白帽与黑帽之间的中间地带,相对于白帽而言,会采取一些取巧的方法来操作,这些行为由于不算违法权,但同样也不遵循规则,是为灰色地带。
【一推响工作室】提供
黑帽seo要具备什么技术 2017年黑帽seo技术快速排行
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想! 查看全部
黑帽SEO是指哪些?
白帽SEO是一种公平的手法,是使用符合主流搜索引擎发行方针规定的seo优化技巧。它是与黑帽seo相反的。白帽SEO仍然被业内觉得是最佳的SEO手法,它是在防止一知切风险的情况下进行操作的,同时也防止了与搜索引擎发道行方针发生任何的冲突,它也是SEOer从业者的最高职业道德标准。
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的版作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
灰帽SEO是介于白帽与黑帽之间的中间地带,相对于白帽而言,会采取一些取巧的方法来操作,这些行为由于不算违法权,但同样也不遵循规则,是为灰色地带。
【一推响工作室】提供
黑帽seo要具备什么技术 2017年黑帽seo技术快速排行
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
什么是常用的高档seo黑帽技术
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
博客作弊
BLOG是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1、BLOG群发作弊:在国外常见的一些BLOG程序如:wordpress、
ZBLOG、PJBLOG、Bo-blog。早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎还是可以给黑帽子SEO有机可乘的地方。
2、BLOG群作弊:BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
3、BLOG隐藏链接作弊:作弊者通过提供免费的博客风格(Free
Template),在风格文件里降低隐藏链接(HideLinks)以降低网站隐藏链接,达到提升搜索引擎排名的目的。
页面跳转
利用Javascript或则其他技术,使用户在抵达页面然后迅速跳转到另一个页面。
偷换页面
这是为SEO设计的高度优化的网页,当网站在获得理想排行后,用普通页面来替换优化过的页面。
桥页
针对某一个关键字专门做一个优化页面,将链接指向或则重定向到目标页面,而且桥页本身无实际内容,只是针对搜索引擎的关键字拼凑而已。
留言本群发
使用留言本群发软件可以手动发布自己的关键词URL,在短时间内迅速提升外部链接。
链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
网页绑架
网页绑架也就是我们常常所说的Page
Jacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是不耻的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHat
SEO曾广泛应用这项技术作弊,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
挂黑链
扫描FTP或则服务器的弱口令、漏洞,然后黑掉网站,把链接挂进去。这是不合法的手段,这些SEOer也是我厌恶的,国内大有这样的人存在。这些是可以通过SeoQuake插件辅助发觉的。
斗蓬法
斗蓬法(cloaking)简单来讲就是网站站长用了两版不同的网页来达到最佳化的疗效。一个版本只给搜索引擎看,一个版本给自己看。搜索引擎说这类做法是违法的,如果提供给搜索引擎的网站版本不能如实反映网页所收录的真实内容。如被发觉,该网站会永久从搜索引擎名单中被剔除。
关键词堆积
很多站长在优化关键字的时侯,堆积了大量关键字,让搜索引擎以为网页具有相关性,关键词堆积技术借助一长串重复性的关键词来蒙混搜索引擎。而实际上,这些关键词有时候与网页内容相关,有时候则与网页内容无关。这类办法极少奏效,而且,也不太可能在或长或短的时间内将一个网站的排行平抑至很高。
PR劫持
PR劫持的方式是借助跳转。一般搜索引擎在处理301和302转向的时侯,都是把目标URL当成实际应当收录的URL。当然也有特例,不过在大部分情况下是这样处理的。所以假如你从域名A做301或302跳转到域名B,而域名B的PR值比较高,域名A在PR更新后,也会显示域名B的PR值。最简单的就是先做301或302跳转到高PR的域名B,等PR更新之后,立刻取消转向,同时也获得了和B站相同的PR值。这个做假的PR显示值起码维持到下一次PR更新。
细微文字
许多做搜索引擎优化的人士明白隐藏文字可能会受到惩罚,所以就将原本隐藏的文字以细微的字体曝露下来。细微文字虽然是使用微小的字体在网页不醒目的地方书写带有关键词的诗句。一般这种文字是置于网页的最顶端或则最顶部。这些文字的色调其实不是和隐藏文字那样与背景使用相同颜色,但是常常也以特别相仿的颜色出现。
隐藏页面
隐藏页面(cloaked
page)是有的网页使用程序或脚本来测量来访问的是搜索引擎还是普通用户。如果是搜索引擎,网页就返回经过优化的网页版本。如果来访的是普通人,返回的是另外一个版本。这种作弊形式,通常用户难以发觉。因为一旦你的浏览器去看这个网页,无论是在页面上还是在HTML源文件中,你所得到的都早已是与搜索引擎见到的不同的版本。检测的方式是,看一下这个网页的快照。
隐藏文字
隐藏文字(hidden
text)是在网页的HTML文件中放上富含关键词的文字,但这种字不能被用户所见到,只能被搜索引擎见到。可以有几种方式,比如说超小字号的文字,与背景同样颜色的文字,放在评论标签当中的文字,放在表格input标签上面的文字,通过样式表把文字放到不可见的层里面等等。
一推响工作室建议你们不要用黑帽SEO手段,对网站影响特别严重,后果不堪设想!
原创文章不如采集文章?来说说百度收录那些事儿! 2019-06
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-10 16:53
一、首先确定网站是刚上线1-3个月的新站,还是半年以上的老网站
对于新网站,上线后首页收录时间大概为一周,大量的内录、收录及被搜索抓取放出收录时间需有10-20天。网站如有好多空白页面,大量的页面内容都非常少,这种情况下,对应的页面不收录,或收录都会特别平缓的。如果网站20天以上,首页都没有收录,网站域名可能有案底被搜索引擎拉黑,如遇这些情况,可通过#1投诉。
老网站不被收录则多为页面质量问题,内页新降低的页面不被搜索,此时若果想要提升收录量,就须要不断强化内容质量。
二、网站不收录常规剖析思路
1、网站的服务器必须稳定。可通百度资源网站管理信息中抓取异常,看出服务器的稳定性,进而剖析网站不收录的具体缘由。
2、检查robots.txt文件是否容许抓取。
3、检查网站各个页面路径是否良好。
4、重要的页面不能写在JS标签内。
5、页面稳定质量良好。网站页面版块链接合理,内容质量良好,并没有频繁改动页面,并非大量内容来自于采集,且无用户搜索需求。
三、分析人为改动诱因
分析近三个月人为操作改动,及内页内容是不内大量采集。大量删掉页面、修改页面标题,程序及网站模块频繁的变更,以至网站被搜索引擎降权引起好多内页内容不收录。又大量的改调内容,内容中植入大量的广告链接弹窗就会引起新增页面不收录。
四、怎么推进网站收录呢?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加快页面的抓取收录。
2、做好网站内容丰富度优化:注意长尾关键词排行布局,多做用户会搜索的内容,文章图文并茂,图片要加ATL关键词,这样搜索引擎才晓得图片的意思是哪些,且内容中要收录用户会搜索的关键词话题。
3、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许优质友链、加快网站抓取收录。 查看全部
很多初涉SEO的小伙伴都有一个问题:为什么我发布的网站文章不被收录呢?甚至有时候发布的原创文章不被收录,而别家网站发布的采集文章却被收录,到底影响文章收录的诱因有什么呢,该如何使网站快速被百度收录呢?接下来为你们来解密这其中的奥秘!
一、首先确定网站是刚上线1-3个月的新站,还是半年以上的老网站
对于新网站,上线后首页收录时间大概为一周,大量的内录、收录及被搜索抓取放出收录时间需有10-20天。网站如有好多空白页面,大量的页面内容都非常少,这种情况下,对应的页面不收录,或收录都会特别平缓的。如果网站20天以上,首页都没有收录,网站域名可能有案底被搜索引擎拉黑,如遇这些情况,可通过#1投诉。
老网站不被收录则多为页面质量问题,内页新降低的页面不被搜索,此时若果想要提升收录量,就须要不断强化内容质量。
二、网站不收录常规剖析思路
1、网站的服务器必须稳定。可通百度资源网站管理信息中抓取异常,看出服务器的稳定性,进而剖析网站不收录的具体缘由。
2、检查robots.txt文件是否容许抓取。
3、检查网站各个页面路径是否良好。
4、重要的页面不能写在JS标签内。
5、页面稳定质量良好。网站页面版块链接合理,内容质量良好,并没有频繁改动页面,并非大量内容来自于采集,且无用户搜索需求。
三、分析人为改动诱因
分析近三个月人为操作改动,及内页内容是不内大量采集。大量删掉页面、修改页面标题,程序及网站模块频繁的变更,以至网站被搜索引擎降权引起好多内页内容不收录。又大量的改调内容,内容中植入大量的广告链接弹窗就会引起新增页面不收录。
四、怎么推进网站收录呢?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加快页面的抓取收录。
2、做好网站内容丰富度优化:注意长尾关键词排行布局,多做用户会搜索的内容,文章图文并茂,图片要加ATL关键词,这样搜索引擎才晓得图片的意思是哪些,且内容中要收录用户会搜索的关键词话题。
3、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许优质友链、加快网站抓取收录。
Python爬虫实现的微信公众号文章下载器
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2020-08-10 10:10
安装python selenium手动模块,通过selenium中的webdriver驱动浏览器获取Cookie登陆微信公众号后台;
使用webdriver功能须要安装对应浏览器的驱动插件
注意:谷歌浏览器版本和chromedriver须要对应,否则会导致启动晨报错。
微信公众号登录地址:
微信公众号文章接口地址可以在微信公众号后台中新建图文消息,超链接功能中获取:
搜索公众号名称
获取要爬取的公众号的fakeid
选定要爬取的公众号,获取文章接口地址
文章列表翻页及内容获取
AnyProxy代理批量采集
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集。
3、本地代理服务器系统:通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。
4、文章列表剖析与入库系统,分析文章列表和完善采集队列实现批量采集内容。
Fiddler设置代理和抓包
通过对多个帐号进行抓包剖析,可以确定:
_biz:这个14位的字符串是每位公众号的“id”,搜狗的陌陌平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1,写按键精灵脚本,在手机上手动点击公号文章列表页,也就是“查看历史消息”;
2,使用fiddler代理绑架手机端的访问,将网址转发到本地用php写的网页;
3,在php网页中将接收到的网址备份到数据库;
4,用python从数据库取出网址,然后进行正常的爬取。
可能存在的问题:
如果只是想爬取文章内容,似乎并没有访问频度限制,但若果想抓取阅读数、点赞数,超过一定频度后,返回都会变为空值。
付费平台
例如清博 新榜,如果只是想看数据的话,直接看每晚的榜单就可以了,还不用花钱,如果须要接入自己的系统的话,他们也提供api接口
3项目步骤
3.1基本原理
目标爬取网站收录了陌陌平台大部分的优质微信公众号文章,会定期更新,经测试发觉对爬虫较为友好。
1、网站页面布局排版规律,不同公众号通过链接中的account分辨
2、一个公众号合辑下的文章翻页也有规律:id号每翻一页+12
所以流程思路就是
获取预查询微信公众号ID(不是直接显示的名称,而是信息名片里的ID号,一般由数字字母组成)
请求html页面,判断是否早已收录改公众号
如果没有收录,则页面显示结果为:404该页面不存在,所以直接使用正则表达式来匹配该提示信息即可
正则匹配,找到目标公众号最大收录文章页数
解析恳求页面,提取文章链接和标题文字
保存信息提取的结果
调用pdfkit和wkhtmltopdf转换网页
3.2环境
win10(64bit)
Spyder(python3.6)
安装转换工具包wkhtmltopdf
requests
pdfkit
3.3公众号信息检索
通过对目标url发起requset恳求,获取页面html信息,然后调用正则方式匹配两条信息
1、该公众号是否存在
2、如果存在,最大的文章收录页数是多少
当公众号存在时,直接调用request解析目标恳求链接。
注意,目标爬虫网站必须要加headers,否则直接拒绝访问
3.4正则解析,提取链接和文章标题
以下代码用于从html文本中解析链接和标题文字信息
3.5手动跳转页面
以下代码通过循环递增形参,改变url中的页脚参数
3.6除去标题中的非法字符
因为windows下文件命令,有些字符是不能用了,所以须要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.8生成的PDF结果
4结果展示
查看全部
selenium爬取流程
安装python selenium手动模块,通过selenium中的webdriver驱动浏览器获取Cookie登陆微信公众号后台;
使用webdriver功能须要安装对应浏览器的驱动插件
注意:谷歌浏览器版本和chromedriver须要对应,否则会导致启动晨报错。
微信公众号登录地址:
微信公众号文章接口地址可以在微信公众号后台中新建图文消息,超链接功能中获取:
搜索公众号名称
获取要爬取的公众号的fakeid
选定要爬取的公众号,获取文章接口地址
文章列表翻页及内容获取
AnyProxy代理批量采集
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集。
3、本地代理服务器系统:通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。
4、文章列表剖析与入库系统,分析文章列表和完善采集队列实现批量采集内容。
Fiddler设置代理和抓包
通过对多个帐号进行抓包剖析,可以确定:
_biz:这个14位的字符串是每位公众号的“id”,搜狗的陌陌平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1,写按键精灵脚本,在手机上手动点击公号文章列表页,也就是“查看历史消息”;
2,使用fiddler代理绑架手机端的访问,将网址转发到本地用php写的网页;
3,在php网页中将接收到的网址备份到数据库;
4,用python从数据库取出网址,然后进行正常的爬取。
可能存在的问题:
如果只是想爬取文章内容,似乎并没有访问频度限制,但若果想抓取阅读数、点赞数,超过一定频度后,返回都会变为空值。
付费平台
例如清博 新榜,如果只是想看数据的话,直接看每晚的榜单就可以了,还不用花钱,如果须要接入自己的系统的话,他们也提供api接口
3项目步骤
3.1基本原理
目标爬取网站收录了陌陌平台大部分的优质微信公众号文章,会定期更新,经测试发觉对爬虫较为友好。
1、网站页面布局排版规律,不同公众号通过链接中的account分辨
2、一个公众号合辑下的文章翻页也有规律:id号每翻一页+12
所以流程思路就是
获取预查询微信公众号ID(不是直接显示的名称,而是信息名片里的ID号,一般由数字字母组成)
请求html页面,判断是否早已收录改公众号
如果没有收录,则页面显示结果为:404该页面不存在,所以直接使用正则表达式来匹配该提示信息即可
正则匹配,找到目标公众号最大收录文章页数
解析恳求页面,提取文章链接和标题文字
保存信息提取的结果
调用pdfkit和wkhtmltopdf转换网页
3.2环境
win10(64bit)
Spyder(python3.6)
安装转换工具包wkhtmltopdf
requests
pdfkit
3.3公众号信息检索
通过对目标url发起requset恳求,获取页面html信息,然后调用正则方式匹配两条信息
1、该公众号是否存在
2、如果存在,最大的文章收录页数是多少
当公众号存在时,直接调用request解析目标恳求链接。
注意,目标爬虫网站必须要加headers,否则直接拒绝访问
3.4正则解析,提取链接和文章标题
以下代码用于从html文本中解析链接和标题文字信息
3.5手动跳转页面
以下代码通过循环递增形参,改变url中的页脚参数
3.6除去标题中的非法字符
因为windows下文件命令,有些字符是不能用了,所以须要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.7转换html为PDF
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“链接”,“标题”,“日期”
然后通过调用pdfkit函数转换生成PDF文件
3.8生成的PDF结果
4结果展示
网站制作的注意问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-10 06:39
如果不对关键词进行恰当剖析的话,就会导致好多问题,包括:方向不明晰、关键词配置不合理、排名疗效差、ROI低等,所以一定要先对关键词进行剖析。
2、缺少导入链接
很多网站的优化都存在收录问题,检查一下不难发觉,很多都是由于缺乏导出链接。互联网中,网页与网页的关系是通过链接来构建的,如果网站和外界没有链接,没有任何联系的话,就成了一个孤岛型网站,搜索引擎未能晓得网站的存在。
3、采集大量的文章
搜索引擎不会给与互联网中高度重复的文章好的排行的,网站上假如收录大量的采集文章的话,对网站是会有一定的负面影响的。网站建好后,如果没有或则只 有极少的原创的实质内容的话,会给用户带来了不良的浏览体验,也会给搜索引擎留下了不好的印象,为搜索引擎优化带来困难。
4、一味追求网站美观
有些网站一味追求美感:大气、好看、美观,其实对网站来说,这些都不是必需的。用户喜欢简练明了的页面,这样就能带来良好的视觉体验。不要使用大量的 图片和太多的flash,这会导致页面容积过大、页面加载速率慢,大大增加网站的实用性,也不要再导航上使用图片作链接,这会导致搜索引擎辨识网站结构 时有困难。
5、频繁修改网页title
搜索引擎依赖title标签进行切词、分词构建索引,这是最初阶段的搜索引擎排名的核心点,虽然从技术上来说,已经有了突飞猛进的发展,但对 title的依赖还是提升用户体验的一个关键点,如果修改title的话,搜索引擎会把它当成作弊来看待的,所以修改title时一定要谨慎。
6、直接copy网站
为了图省钱省力,很多人在建站时直接胡须眼睛一把抓,把现有的网站程序模板直接套来使用。这样下来的新站都会和之前的站相似度很高,会导致新站很难得到好的排行,老站也会遭到连带影响。 查看全部
1、未进行关键词分析
如果不对关键词进行恰当剖析的话,就会导致好多问题,包括:方向不明晰、关键词配置不合理、排名疗效差、ROI低等,所以一定要先对关键词进行剖析。
2、缺少导入链接
很多网站的优化都存在收录问题,检查一下不难发觉,很多都是由于缺乏导出链接。互联网中,网页与网页的关系是通过链接来构建的,如果网站和外界没有链接,没有任何联系的话,就成了一个孤岛型网站,搜索引擎未能晓得网站的存在。
3、采集大量的文章
搜索引擎不会给与互联网中高度重复的文章好的排行的,网站上假如收录大量的采集文章的话,对网站是会有一定的负面影响的。网站建好后,如果没有或则只 有极少的原创的实质内容的话,会给用户带来了不良的浏览体验,也会给搜索引擎留下了不好的印象,为搜索引擎优化带来困难。
4、一味追求网站美观
有些网站一味追求美感:大气、好看、美观,其实对网站来说,这些都不是必需的。用户喜欢简练明了的页面,这样就能带来良好的视觉体验。不要使用大量的 图片和太多的flash,这会导致页面容积过大、页面加载速率慢,大大增加网站的实用性,也不要再导航上使用图片作链接,这会导致搜索引擎辨识网站结构 时有困难。
5、频繁修改网页title
搜索引擎依赖title标签进行切词、分词构建索引,这是最初阶段的搜索引擎排名的核心点,虽然从技术上来说,已经有了突飞猛进的发展,但对 title的依赖还是提升用户体验的一个关键点,如果修改title的话,搜索引擎会把它当成作弊来看待的,所以修改title时一定要谨慎。
6、直接copy网站
为了图省钱省力,很多人在建站时直接胡须眼睛一把抓,把现有的网站程序模板直接套来使用。这样下来的新站都会和之前的站相似度很高,会导致新站很难得到好的排行,老站也会遭到连带影响。
如何采集微信公众号历史消息页的解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2020-08-10 03:31
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。 查看全部
给你们讲解了微信公众号文章采集的入口历史消息页信息获取方式,有须要的同事参考一下本内容。
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
%2BBoEMdPDBtOun1F%2F9ENSz&wx_header=1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是:8002 其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
【进阶】Python爬虫采集整个网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-08-09 10:14
在之前的文章中,我们实现了在一个网站上随机地从一个链接到另一个链接,但是,如果我们须要系统地把整个网站按目录分类,或者要搜索网站上的每一个页面,我们该如何办?我们须要采集整个网站,但是那是一种十分花费显存资源的过程,尤其是处理小型网站时,比较合适的工具就是用一个数据库来储存采集的资源,之前也说过。下面来说一下怎样做。
网站地图sitemap
网站地图,又称站点地图,它就是一个页面,上面放置了网站上须要搜索引擎抓取的所有页面的链接(注:不是所有页面,一般来说是所有文章链接,比如我的)。大多数人在网站上找不到自己所须要的信息时,可能会将网站地图作为一种补救举措。搜索引擎蜘蛛特别喜欢网站地图。
对于SEO,网站地图的益处:
1.为搜索引擎蜘蛛提供可以浏览整个网站的链接简单的彰显出网站的整体框架下来给搜索引擎看;
2.为搜索引擎蜘蛛提供一些链接,指向动态页面或则采用其他方式比较无法抵达的页面;
3.作为一种潜在的着陆页面,可以为搜索流量进行优化;
4.如果访问者企图访问网站所在域内并不存在的URL,那么这个访问者都会被转入“无法找到文件”的错误页面,而网站地图可以作为该页面的“准”内容。
数据采集
采集网站数据并不难,但是须要爬虫有足够的深度。我们创建一个爬虫,递归地遍历每位网站,只搜集这些网站页面上的数据。一般的比较费时间的网站采集方法从顶尖页面开始(一般是网站主页),然后搜索页面上的所有链接,形成列表,再去采集到的那些链接页面,继续采集每个页面的链接产生新的列表,重复执行。
很明显,这是一个复杂度下降很快的过程。加入每位页面有10个链接,网站上有5个页面深度,如果采集整个网站,一共得采集的网页数目是105,即100000个页面。
因为网站的内链有很多都是重复的,所以为了防止重复采集,必须链接去重,在Python中,去重最常用的方式就是使用自带的set集合方式。只有“新”链接才能被采集。看一下代码实例:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageurl):
globalpages
html= urlopen("" + pageurl)
soup= BeautifulSoup(html)
forlink in soup.findAll("a", href=pile("^(/wiki/)")):
if'href' in link.attrs:
iflink.attrs['href'] not in pages:
#这是新页面
newPage= link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
原理说明:程序执行时,用函数处理一个空URL,其实就是维基百科的主页,然后遍历首页上每位链接,并检测是否早已在全局变量集合pages上面,如果不在,就复印并添加到pages集合,然后递归处理这个链接。
递归警告:Python默认的递归限制是1000次,因为维基百科的链接浩如烟海,所以这个程序达到递归限制后才会停止。如果你不想使它停止,你可以设置一个递归计数器或则其他方式。
采集整个网站数据
为了有效使用爬虫,在用爬虫的时侯我们须要在页面上做一些事情。我们来创建一个爬虫来搜集页面标题、正文的第一个段落,以及编辑页面的链接(如果有的话)这些信息。
第一步,我们须要先观察网站上的页面,然后制订采集模式,通过F12(一般情况下)审查元素,即可见到页面组成。
观察维基百科页面,包括词条和非词条页面,比如隐私策略之类的页面,可以得出下边的规则:
调整一下之前的代码,我们可以构建一个爬虫和数据采集的组合程序,代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("" + pageUrl)
soup = BeautifulSoup(html)
try:
print(soup.h1.get_text())
print(soup.find(id="mw-content-text").findAll("p")[0])
print(soup.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("页面缺乏属性")
for link in soup.findAll("a", href =pile("^(/wiki/)")):
if 'href' in link.attrs:
#这是新页面
newPage = link.attrs['href']
print("------------------\n"+newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
这个for循环和原先的采集程序基本上是一样的,因为不能确定每一页上都有所有类型的数据,所以每位复印句子都是根据数据在页面上出现的可能性从高到低排列的。
数据储存到MySQL
前面早已获取了数据,直接复印下来,查看比较麻烦,所以我们就直接存到MySQL上面吧,这里只存链接没有意义,所以我们就储存页面的标题和内容。前面我有两篇文章已经介绍过怎么储存数据到MySQL,数据表是pages,这里直接给出代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
import pymysql
conn = pymysql.connect(host = '127.0.0.1',port = 3306, user = 'root', passwd = '19930319', db = 'wiki', charset ='utf8mb4')
cur = conn.cursor()
cur.execute("USE wiki")
#随机数种子
random.seed(datetime.datetime.now())
#数据储存
def store(title, content):
cur.execute("INSERT INTO pages(title, content)VALUES(\"%s\", \"%s\")", (title, content))
mit()
def getLinks(articleUrl):
html = urlopen("" + articleUrl)
soup = BeautifulSoup(html)
title = soup.find("h1").get_text()
content =soup.find("div",{"id":"mw-content-text"}).find("p").get_text()
store(title, content)
returnsoup.find("div",{"id":"bodyContent"}).findAll("a",href=pile("^(/wiki/)((?!:).)*$"))
#设置第一页
links =getLinks("/wiki/Kevin_Bacon")
try:
while len(links)>0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print (newArticle)
links = getLinks(newArticle)
finally:
cur.close()
conn.close()
小结
今天主要讲一下Python中遍历采集一个网站的链接,方便下边的学习。
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。 查看全部
前言
在之前的文章中,我们实现了在一个网站上随机地从一个链接到另一个链接,但是,如果我们须要系统地把整个网站按目录分类,或者要搜索网站上的每一个页面,我们该如何办?我们须要采集整个网站,但是那是一种十分花费显存资源的过程,尤其是处理小型网站时,比较合适的工具就是用一个数据库来储存采集的资源,之前也说过。下面来说一下怎样做。
网站地图sitemap
网站地图,又称站点地图,它就是一个页面,上面放置了网站上须要搜索引擎抓取的所有页面的链接(注:不是所有页面,一般来说是所有文章链接,比如我的)。大多数人在网站上找不到自己所须要的信息时,可能会将网站地图作为一种补救举措。搜索引擎蜘蛛特别喜欢网站地图。
对于SEO,网站地图的益处:
1.为搜索引擎蜘蛛提供可以浏览整个网站的链接简单的彰显出网站的整体框架下来给搜索引擎看;
2.为搜索引擎蜘蛛提供一些链接,指向动态页面或则采用其他方式比较无法抵达的页面;
3.作为一种潜在的着陆页面,可以为搜索流量进行优化;
4.如果访问者企图访问网站所在域内并不存在的URL,那么这个访问者都会被转入“无法找到文件”的错误页面,而网站地图可以作为该页面的“准”内容。
数据采集
采集网站数据并不难,但是须要爬虫有足够的深度。我们创建一个爬虫,递归地遍历每位网站,只搜集这些网站页面上的数据。一般的比较费时间的网站采集方法从顶尖页面开始(一般是网站主页),然后搜索页面上的所有链接,形成列表,再去采集到的那些链接页面,继续采集每个页面的链接产生新的列表,重复执行。
很明显,这是一个复杂度下降很快的过程。加入每位页面有10个链接,网站上有5个页面深度,如果采集整个网站,一共得采集的网页数目是105,即100000个页面。
因为网站的内链有很多都是重复的,所以为了防止重复采集,必须链接去重,在Python中,去重最常用的方式就是使用自带的set集合方式。只有“新”链接才能被采集。看一下代码实例:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageurl):
globalpages
html= urlopen("" + pageurl)
soup= BeautifulSoup(html)
forlink in soup.findAll("a", href=pile("^(/wiki/)")):
if'href' in link.attrs:
iflink.attrs['href'] not in pages:
#这是新页面
newPage= link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
原理说明:程序执行时,用函数处理一个空URL,其实就是维基百科的主页,然后遍历首页上每位链接,并检测是否早已在全局变量集合pages上面,如果不在,就复印并添加到pages集合,然后递归处理这个链接。
递归警告:Python默认的递归限制是1000次,因为维基百科的链接浩如烟海,所以这个程序达到递归限制后才会停止。如果你不想使它停止,你可以设置一个递归计数器或则其他方式。
采集整个网站数据
为了有效使用爬虫,在用爬虫的时侯我们须要在页面上做一些事情。我们来创建一个爬虫来搜集页面标题、正文的第一个段落,以及编辑页面的链接(如果有的话)这些信息。
第一步,我们须要先观察网站上的页面,然后制订采集模式,通过F12(一般情况下)审查元素,即可见到页面组成。
观察维基百科页面,包括词条和非词条页面,比如隐私策略之类的页面,可以得出下边的规则:
调整一下之前的代码,我们可以构建一个爬虫和数据采集的组合程序,代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("" + pageUrl)
soup = BeautifulSoup(html)
try:
print(soup.h1.get_text())
print(soup.find(id="mw-content-text").findAll("p")[0])
print(soup.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("页面缺乏属性")
for link in soup.findAll("a", href =pile("^(/wiki/)")):
if 'href' in link.attrs:
#这是新页面
newPage = link.attrs['href']
print("------------------\n"+newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
这个for循环和原先的采集程序基本上是一样的,因为不能确定每一页上都有所有类型的数据,所以每位复印句子都是根据数据在页面上出现的可能性从高到低排列的。
数据储存到MySQL
前面早已获取了数据,直接复印下来,查看比较麻烦,所以我们就直接存到MySQL上面吧,这里只存链接没有意义,所以我们就储存页面的标题和内容。前面我有两篇文章已经介绍过怎么储存数据到MySQL,数据表是pages,这里直接给出代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
import pymysql
conn = pymysql.connect(host = '127.0.0.1',port = 3306, user = 'root', passwd = '19930319', db = 'wiki', charset ='utf8mb4')
cur = conn.cursor()
cur.execute("USE wiki")
#随机数种子
random.seed(datetime.datetime.now())
#数据储存
def store(title, content):
cur.execute("INSERT INTO pages(title, content)VALUES(\"%s\", \"%s\")", (title, content))
mit()
def getLinks(articleUrl):
html = urlopen("" + articleUrl)
soup = BeautifulSoup(html)
title = soup.find("h1").get_text()
content =soup.find("div",{"id":"mw-content-text"}).find("p").get_text()
store(title, content)
returnsoup.find("div",{"id":"bodyContent"}).findAll("a",href=pile("^(/wiki/)((?!:).)*$"))
#设置第一页
links =getLinks("/wiki/Kevin_Bacon")
try:
while len(links)>0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print (newArticle)
links = getLinks(newArticle)
finally:
cur.close()
conn.close()
小结
今天主要讲一下Python中遍历采集一个网站的链接,方便下边的学习。
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。
Xposed实时获取微信公众号推送
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-09 07:59
鸣谢:本项目基于@Gh0u1L5,开源的Xposedhook框架----WechatSpellbook,感谢,很不错的框架,推荐一波(虽然我用的东西都是基于WechatMagician魔改得到的)。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
恰巧此时我正在研究Xposed Hook 微信,所以就准备拿Android版陌陌来试试,需求是怎么样的呢?就是陌陌推送一条公众号消息,我们就接受一条,并且将其发送到对应的插口进行保存,以便于后续浏览。刚打算做的时侯我还认为没啥难度,直接去把陌陌数据库里的东西down下来就可以了嘛,太简单了好吧,然而。
naive.jpg
naive!!!
微信数据表“message”中导入的数据是收录乱码的一堆鬼东西,而且解析下来的url也不全,比如一次推送中的五篇文章,只能取到三篇的url,这就让人觉得太难过。
image.png
但是难过归难过,问题总还是要解决的,怎么解决呢?看源码!
之前我将陌陌的几个dex包的代码分别反编译下来之后放在了一个文件夹下,然后使用VSCode打开,用于平常的查看,
虽然陌陌反编译下来的源码乱七八糟, 但是有的代码能看的。
我们看见前面导下来的数据是存在一些乱码的,那么我猜想陌陌内部实现了一个解码工具,如果我们能否hook到这个解码工具,是不是就可以获取到解码以后的正确数据了呢?
说到解码,根据陌陌往年的数据传输来看,这些数据很有可能是以XML的格式进行传输的,既然涉及到xml,那就一定是通配符对的方式,我们去到的数据中不仅有乱七八糟的方块,还有例如“.msg.appmsg.mmreader.category.item”这类看起来有用的内容。
我打开vscode,全局搜索“.msg.appmsg.mmreader.category.item”,令人高兴的是,搜索下来的结果并不多,这说明这个值确实是有意义的值,挨个查看那些源码,在一个包为:“
com.tencent.mm.plugin.biz;”下中一个名为“a”的类中,我发觉了一些有意思的东西。
image.png
方法名为wS的一个方式,接收了一个String类型的值,且其内部做了一些数据取出的工作。
难道这个str参数就是我想要的标准xml吗?
经过hook验证,打印其参数后发觉,并不是,参数内容的格式和之前数据库中的格式是一致的。
image.png
那么我们就将眼神置于后第一行的Map上,是不是ay.WA(String str)这个方式做了解析操作呢?
我对com.tencent.mm.sdk.platformtools.ay中WA()这个方式进行了hook,取得其返回值,这个返回值是一个Map类型的数据,在复印出其内容后,我的猜测被验证了。
WA()这个方式将昨天的内容解析成了一个以便我们读取的map。其中收录了该条推送收录的图文消息数目,以及公众号的id,名称,对应的文章url,图片url,文章描述等信息。
晚餐终于可以加鸡腿了。啊哈哈哈哈。
本文章只用于研究学习,请正确食用,谢谢。
贴一下相关的hook代码
image.png 查看全部
友情提示:阅读本文须要稍为有一点点Xposed开发基础,一点点Android逆向的基础,以及一点点Kotlin基础
鸣谢:本项目基于@Gh0u1L5,开源的Xposedhook框架----WechatSpellbook,感谢,很不错的框架,推荐一波(虽然我用的东西都是基于WechatMagician魔改得到的)。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
由于之前的基于itchat开发的微信公众号采集工具使用的帐号被封号了,就很郁闷。
恰巧此时我正在研究Xposed Hook 微信,所以就准备拿Android版陌陌来试试,需求是怎么样的呢?就是陌陌推送一条公众号消息,我们就接受一条,并且将其发送到对应的插口进行保存,以便于后续浏览。刚打算做的时侯我还认为没啥难度,直接去把陌陌数据库里的东西down下来就可以了嘛,太简单了好吧,然而。
naive.jpg
naive!!!
微信数据表“message”中导入的数据是收录乱码的一堆鬼东西,而且解析下来的url也不全,比如一次推送中的五篇文章,只能取到三篇的url,这就让人觉得太难过。
image.png
但是难过归难过,问题总还是要解决的,怎么解决呢?看源码!
之前我将陌陌的几个dex包的代码分别反编译下来之后放在了一个文件夹下,然后使用VSCode打开,用于平常的查看,
虽然陌陌反编译下来的源码乱七八糟, 但是有的代码能看的。
我们看见前面导下来的数据是存在一些乱码的,那么我猜想陌陌内部实现了一个解码工具,如果我们能否hook到这个解码工具,是不是就可以获取到解码以后的正确数据了呢?
说到解码,根据陌陌往年的数据传输来看,这些数据很有可能是以XML的格式进行传输的,既然涉及到xml,那就一定是通配符对的方式,我们去到的数据中不仅有乱七八糟的方块,还有例如“.msg.appmsg.mmreader.category.item”这类看起来有用的内容。
我打开vscode,全局搜索“.msg.appmsg.mmreader.category.item”,令人高兴的是,搜索下来的结果并不多,这说明这个值确实是有意义的值,挨个查看那些源码,在一个包为:“
com.tencent.mm.plugin.biz;”下中一个名为“a”的类中,我发觉了一些有意思的东西。
image.png
方法名为wS的一个方式,接收了一个String类型的值,且其内部做了一些数据取出的工作。
难道这个str参数就是我想要的标准xml吗?
经过hook验证,打印其参数后发觉,并不是,参数内容的格式和之前数据库中的格式是一致的。
image.png
那么我们就将眼神置于后第一行的Map上,是不是ay.WA(String str)这个方式做了解析操作呢?
我对com.tencent.mm.sdk.platformtools.ay中WA()这个方式进行了hook,取得其返回值,这个返回值是一个Map类型的数据,在复印出其内容后,我的猜测被验证了。
WA()这个方式将昨天的内容解析成了一个以便我们读取的map。其中收录了该条推送收录的图文消息数目,以及公众号的id,名称,对应的文章url,图片url,文章描述等信息。
晚餐终于可以加鸡腿了。啊哈哈哈哈。
本文章只用于研究学习,请正确食用,谢谢。
贴一下相关的hook代码
image.png
PHP + fiddler捕获数据包以采集微信文章,阅读和喜欢
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-08 19:07
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求接口以获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”,然后将其添加到OnBeforeRequest(在正式请求之前执行的功能)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果不错,您可以看到该界面已转发
3. 服务器端缓存密钥,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加代码以跳到中间页
效果 查看全部
简介:
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求接口以获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”,然后将其添加到OnBeforeRequest(在正式请求之前执行的功能)
if (oSession.fullUrl.Contains("mp.weixin.qq.com/mp/getappmsgext"))
{
oSession.oRequest["Host"]= 'ccc.aaa.com' ;
}
效果不错,您可以看到该界面已转发
3. 服务器端缓存密钥,代码以PHP为例
public function saveKey(Request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
Cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询API代码
public function getReadNum(Request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = Cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1278.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, $v);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);
$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写入cookie到文件
curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执行的最长秒数
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在OnBeforeResponse(返回客户端之前执行的方法)中,添加代码以跳到中间页
效果
医院网站的SEO有哪些预防措施?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-08 16:30
1. 避免大量重复的页面标题
标题等同于网页的名称,关键字相对来说是网页的“功能”,“描述”是网页的描述. 网站优化应有助于搜索引擎区分网站的任何两个页面,并减少页面的相似性.
2. 不要在网站上使用大量图片和闪光灯
为了满足医院领导的口味,一些技术人员盲目追求网站的华丽,美观,美观,并使用了大量图片和闪光灯. 这些是医院管理者难以忍受的表现. 简单明了的页面可以为用户带来良好的视觉体验;图片过多,闪烁次数过多,导致页面尺寸太大,页面加载速度慢,大大降低了网站的实用性;导航使用图片作为链接,并且搜索引擎效果不佳. 确定网站结构.
3. 不要采集很多文章
每个人都知道,对于Internet上高度重复的文章,搜索引擎不会给出很好的排名. 大量采集的文章也对整个站点产生相当大的负面影响. 网站建设完成后,大量的没有实质内容的文章被采集起来,给用户带来不好的浏览体验,给搜索引擎留下了不好的印象,给搜索引擎的优化带来了很大的风险. 因此,即使您想采集文章,也要进行伪原创或部分采集.
4. 没有明确的目的和准确的关键字分析就永远不要网站
医院网站的方向不明确,关键字分配不合理,排名效果差,资金投入大,回报率低等都是由于缺乏关键字分析而引起的问题. 这些问题是致命的. 这是浪费金钱,不是太多!
5. 请勿经常更改网页标题
标题是搜索引擎匹配关键字的核心. 搜索引擎依靠标题标签进行单词分割和单词分割以建立索引. 这是原创阶段搜索引擎排名的核心. 尽管搜索引擎在技术上取得了飞速进步,但开发和依赖Title仍然是改善用户体验的关键. 如果您经常更改标题,搜索引擎会将其视为作弊,因此在更改标题时必须谨慎. 幸运的是,该网站已设置为可以上网,并且该网站的标题一次就可以清除!
6. 尽可能少使用或不使用JS和iframe
在Internet的发展过程中,JS和Iframe主要作为在线广告而存在,并且大多数广告管理都是通过JS和Iframe进行管理的. 尽管当前的Web技术允许将广告用作网页内容的补充,但是太多的广告也会对用户浏览页面内容造成干扰. 搜索引擎仍然不“考虑” JS和Iframe中的内容. 将有用的信息放入JS变成无用的信息. 大量JS和iframe会被视为页面上的广告过多.
7. 永远没有网站地图
站点地图也称为站点地图. 它是一个页面,具有指向网站上所有页面的链接. 当大多数人无法在网站上找到所需信息时,他们可以使用网站地图作为补救措施. 搜索引擎蜘蛛非常喜欢站点地图.
8. 永远不要复制别人的网站
为了节省麻烦,有些人只是抓住了胡子,直接使用了现有的网站程序模板. 这导致了两个高度相似的网站. 这样的新网站很难获得良好的排名,旧网站也将受到影响.
9. 不要将多个网站彼此链接
该网站的首页具有很高的权重,并且关键字易于排名. 大多数网站管理员会在网站首页上放置很多热门关键字. 由于首页的位置有限,因此距离许多关键字还很遥远. 需求,许多网站管理员已经建立了许多卫星站点来分隔一些受欢迎的关键字. 这是一种干扰搜索引擎排名的行为. 搜索引擎还针对这种行为采取了某些措施,例如: 龙鑫该站的排名时间被沙箱化为新网站;通过信息采集和分析,站群网站将受到惩罚.
10. 避免频繁删除引起大量无效链接的文章
在医院的内部管理中,经常删除某些网站列,文章等,并且删除的页面将生成大量无效链接. 医院网站必须设置404错误页面,在删除页面时尝试保留页面,在原创页面上进行更改,并在删除后更新网站页面. 本文是由网络营销推广培训教程组织和发布的.
在华旗商城推出更多产品: 快速仿制网站制作,家装和建筑行业php程序开发,企业网站托管和运营 查看全部
医院网站的SEO有哪些预防措施?
1. 避免大量重复的页面标题
标题等同于网页的名称,关键字相对来说是网页的“功能”,“描述”是网页的描述. 网站优化应有助于搜索引擎区分网站的任何两个页面,并减少页面的相似性.
2. 不要在网站上使用大量图片和闪光灯
为了满足医院领导的口味,一些技术人员盲目追求网站的华丽,美观,美观,并使用了大量图片和闪光灯. 这些是医院管理者难以忍受的表现. 简单明了的页面可以为用户带来良好的视觉体验;图片过多,闪烁次数过多,导致页面尺寸太大,页面加载速度慢,大大降低了网站的实用性;导航使用图片作为链接,并且搜索引擎效果不佳. 确定网站结构.
3. 不要采集很多文章
每个人都知道,对于Internet上高度重复的文章,搜索引擎不会给出很好的排名. 大量采集的文章也对整个站点产生相当大的负面影响. 网站建设完成后,大量的没有实质内容的文章被采集起来,给用户带来不好的浏览体验,给搜索引擎留下了不好的印象,给搜索引擎的优化带来了很大的风险. 因此,即使您想采集文章,也要进行伪原创或部分采集.
4. 没有明确的目的和准确的关键字分析就永远不要网站
医院网站的方向不明确,关键字分配不合理,排名效果差,资金投入大,回报率低等都是由于缺乏关键字分析而引起的问题. 这些问题是致命的. 这是浪费金钱,不是太多!
5. 请勿经常更改网页标题
标题是搜索引擎匹配关键字的核心. 搜索引擎依靠标题标签进行单词分割和单词分割以建立索引. 这是原创阶段搜索引擎排名的核心. 尽管搜索引擎在技术上取得了飞速进步,但开发和依赖Title仍然是改善用户体验的关键. 如果您经常更改标题,搜索引擎会将其视为作弊,因此在更改标题时必须谨慎. 幸运的是,该网站已设置为可以上网,并且该网站的标题一次就可以清除!
6. 尽可能少使用或不使用JS和iframe
在Internet的发展过程中,JS和Iframe主要作为在线广告而存在,并且大多数广告管理都是通过JS和Iframe进行管理的. 尽管当前的Web技术允许将广告用作网页内容的补充,但是太多的广告也会对用户浏览页面内容造成干扰. 搜索引擎仍然不“考虑” JS和Iframe中的内容. 将有用的信息放入JS变成无用的信息. 大量JS和iframe会被视为页面上的广告过多.
7. 永远没有网站地图
站点地图也称为站点地图. 它是一个页面,具有指向网站上所有页面的链接. 当大多数人无法在网站上找到所需信息时,他们可以使用网站地图作为补救措施. 搜索引擎蜘蛛非常喜欢站点地图.
8. 永远不要复制别人的网站
为了节省麻烦,有些人只是抓住了胡子,直接使用了现有的网站程序模板. 这导致了两个高度相似的网站. 这样的新网站很难获得良好的排名,旧网站也将受到影响.
9. 不要将多个网站彼此链接
该网站的首页具有很高的权重,并且关键字易于排名. 大多数网站管理员会在网站首页上放置很多热门关键字. 由于首页的位置有限,因此距离许多关键字还很遥远. 需求,许多网站管理员已经建立了许多卫星站点来分隔一些受欢迎的关键字. 这是一种干扰搜索引擎排名的行为. 搜索引擎还针对这种行为采取了某些措施,例如: 龙鑫该站的排名时间被沙箱化为新网站;通过信息采集和分析,站群网站将受到惩罚.
10. 避免频繁删除引起大量无效链接的文章
在医院的内部管理中,经常删除某些网站列,文章等,并且删除的页面将生成大量无效链接. 医院网站必须设置404错误页面,在删除页面时尝试保留页面,在原创页面上进行更改,并在删除后更新网站页面. 本文是由网络营销推广培训教程组织和发布的.
在华旗商城推出更多产品: 快速仿制网站制作,家装和建筑行业php程序开发,企业网站托管和运营
关于采集器采集和重复数据删除的优化
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-08 15:30
首先,对于URL本身的重复数据删除,可以直接处理整个URL. 当提到Internet上的某些文章时,我发现其中大多数使用URL压缩存储. 但是,当数据量很大时,使用这些算法可以大大减少存储空间:
基于磁盘的顺序存储.
基于哈希算法的存储.
基于MD5压缩映射的存储.
基于嵌入式Berkeley DB的存储.
基于Bloom Filter的存储.
URL的直接重复数据删除主要涉及存储优化,这不是本文的重点,因此在这里我将不做详细介绍.
对于URL的逻辑重复数据删除,您需要追求更高的数据可用性,这是进行测试时需要考虑的事情.
这是seay文章中的相似性重复数据删除算法,大致如下:
def urlsimilar(url):
hash_size=199999
tmp=urlparse.urlparse(url)
scheme=tmp[0]
netloc=tmp[1]
path=tmp[2][1:]
query=tmp[4]
#First get tail
if len(path.split('/'))>1:
tail=path.split('/')[-1].split('.')[-1]
#print tail
elif len(path.split('/'))==1:
tail=path
else:
tail='1'
#Second get path_length
path_length=len(path.split('/'))-1
#Third get directy list except last
path_list=path.split('/')[:-1]+[tail]
#Fourth hash
path_value=0
for i in range(path_length+1):
if path_length-i==0:
path_value+=hash(path_list[path_length-i])%98765
else:
path_value+=len(path_list[path_length-i])*(10**(i+1))
#get host hash value
netloc_value=hash(hashlib.new("md5",netloc).hexdigest())%hash_size
url_value=hash(hashlib.new("md5",str(path_value+netloc_value)).hexdigest())%hash_size
return url_value
此函数的一般用途是最终将根据算法返回哈希值,该哈希值也是URL的哈希相似度. 如果两个URL所计算的哈希值最终相等,我们可以判断两个URL具有高度相似性.
但是应该以seay为例来举例说明此功能(在这里强调,以免被喷洒,稍后我将不对其进行详细说明). 这只是一个简单的演示,无需详细检查. 在粗略的情况下,该算法确实可以消除一些简单的参数重复,但是一旦参数复杂或URL不标准化,对于重复数据删除就不是很好.
那么在获取URL的过程中,我们还能进行其他哪些小的优化?
日期和时间命名
首先,我们可以根据日期进行重复数据删除. 我们知道,在爬网博客和门户之类的某些系统时,经常会遇到以日期命名的目录.
这些目录可以粗略地概括,并具有类似于以下内容的形式:
2010-11-11
10-11-11
20101111
当然,有些文件将以时间+随机值命名,或者它们可能以Unix时间戳命名. 这些可以根据上载和编辑时间来定义.
作者的建议是使用缓存数据库(例如redis或memcache)直接存储它;或当数据量很大时,请考虑临时存储它,并在需要时进行比较.
例如,一旦出现以日期和时间命名的目录或静态文件,我们可以考虑以以下格式存储它:
目录级别
姓名格式
URL地址(或压缩的哈希值)
有人可能会说,在seay提到的情况下,似乎日期的相似性可以解决. 让我们首先看下面的例子. 这里的输出仍然基于上述功能:
print urlsimilar('http://www.baidu.com/blog/2010-10-11/')
print urlsimilar('http://www.baidu.com/blog/2010-10-13/')
print urlsimilar('http://www.baidu.com/blog/2010-9-13/')
print urlsimilar('http://www.baidu.com/whisper/2010-10-11/')
输出结果如下:
110086
110086
37294
4842
我们可以看到,在正常情况下,确实在同一父目录中,相似性算法可以判断为正确. 但是,一旦日期格式不统一,或者父目录中存在某些差异,就不是一个很好的判断.
当然,我们还可以使用机器学习来完成重复数据删除的工作. 但是在简化工作方面,您仍然可以根据规则匹配使用一些小技巧来完成它.
删除静态文件
我们知道,在爬网URL的过程中,我们还会遇到许多静态文件,例如shtml,html,css等. 在大多数情况下,这些文件是没有意义的. 除非测试人员倾向于使用完整的采集方法,否则“我宁愿错误地杀死一百个人,也不会错过任何一个. ”
这时,我们可以配置黑名单并创建文件后缀规则库进行过滤.
当然,带有静态后缀的URL链接也可能与参数混淆. 个人建议是,用于回调的json和xml之类的URL可能会存储敏感内容,并尽量不要移动它们. 对于其他类型的静态文件,仍然采用分离参数的方法,最后对URL进行重复数据删除和存储.
针对特定情况进行过滤
在抓取特定网站时,我们可以对其进行预配置并指定过滤某些目录和页面以节省大量时间和资源.
相反,我们还可以指定仅爬网指定目录中的页面,并定位所需的内容.
感知敏感页面
在seay提出的演示算法中,在这种情况下存在某些限制. 例如,我们需要在敏感目录中获取尽可能多的文件信息. 例如,如果我们爬到后台管理目录,则可能会遇到以下情况:
print urlsimilar('http://www.baidu.com/blog/admin/login.php')
print urlsimilar('http://www.baidu.com/blog/admin/manage_index.php')
print urlsimilar('http://www.baidu.com/blog/admin/test.css')
输出结果如下:
40768
40768
40768
显然有问题,不是吗?
我们当然可以监视敏感的页面关键字;或者我们可以指定一个后缀文件来执行白名单监控.
但是一旦您执行了此操作,并且想要使用以前的哈希算法,则您自己定义的过滤器函数的优先级必须大于该算法. 另外,在这样做的过程中,还应考虑过滤成本问题,建议采用选择性激活.
对高频敏感目录的优惠待遇
也许在爬网过程中,某些爬网程序还使用目录爆炸的方法. 如果采用此方法并且匹配成功,则可以对目录中的内容使用单独的过滤规则,以避免误判重复数据删除算法.
过滤响应页面
对于某些网站,由于链接无效,许多页面可能被标记为404页和50x错误. 另外,当您无权访问时,网站可能会进行30倍重定向和403目录限制.
这些页面没有实质性内容,并且在大多数情况下是没有意义的. 我们可以在配置文件中将需要爬网的页面类型列入白名单,例如保留403个页面,或在跳转(之后)页面之前访问30倍.
WAF(警告)页面过滤
某些网站可能已安装WAF. 如果访问频率太快,可能会出现WAF警告页面. 在CMS自身施加限制的情况下,某些不存在的页面将以20x的响应代码显示.
当然,我们可以通过代理的分布式交换来解决其中的一些问题,因此在此不再赘述.
这时,我们可以配置相应的次数阈值. 如果某些页面出现过多次,则可以将它们标记为警告(WAF)页面,然后进行过滤. 在此处可以识别页面,您可以使用黑名单关键字对其进行标记;或尝试计算页面哈希值,例如:
content = urllib2.urlopen('http://www.test.com/').read()
md5_sum = hashlib.md5()
md5_sum.update(content)
print md5_sum.hexdigest()
当然,当我们实际计算页面哈希值并进行关键字监控时,由于存在反爬虫机制(例如,添加随机值). 当然,这也会消耗更多的时间和机器资源. 但是在某些特定情况下,它也可能带来意想不到的收益.
删除无意义的参数页面
在采集页面的过程中,我们可能还会遇到一些无意义的,经常出现的多参数页面. 这样的页面可以是回调页面,也可以是临时呈现的随机页面.
在这里,您可以通过以前的WAF(警告)方法进行过滤. 当然,使用以前的哈希算法也可以应付大多数情况. 毕竟,这种网站的URL是受限制的,并且不需要为多个功能消耗更多的资源,因此收益大于损失.
JS代码中的URL
当我们提取js代码时,也就是说,当我们遇到诸如ajax之类的交互时,我们可能会遇到需要拼接的GET请求或可以直接访问的POST请求.
这种URL地址最好与phantomjs之类的webkit结合使用,以更方便地进行动态拼接.
它们看起来很特殊,可能仅返回状态代码,或者可能返回实质上敏感的内容. 在这种情况下,有必要根据采集器的要求调整搜寻过滤规则.
摘要
此处的作者旨在针对类似URL的重复数据删除提出一些小的优化措施,这些效果可能有限,或者可能不令人满意.
欢迎提出建议. 我希望减少喜欢喷涂的童鞋,并增加讨论和鼓励.
参考文章
如何避免重复抓取同一网页
谈论动态采集器和重复数据删除
Web采集器: 使用BloomFilter进行URL重复数据删除策略
实用科普: 履带技术分析. 编写采集器时的注意事项
Web爬网程序(蜘蛛)URL重复数据删除设计URL重复数据删除设计 查看全部
当我处理漏洞Fuzz采集器时,我曾经从事URL重复数据删除. 当时,我提到了Seay大师的文章以及Internet上的一些零散信息. 我觉得这很简单. 最近遇到了相关的问题,所以我几乎有了重新改进算法的想法.
首先,对于URL本身的重复数据删除,可以直接处理整个URL. 当提到Internet上的某些文章时,我发现其中大多数使用URL压缩存储. 但是,当数据量很大时,使用这些算法可以大大减少存储空间:
基于磁盘的顺序存储.
基于哈希算法的存储.
基于MD5压缩映射的存储.
基于嵌入式Berkeley DB的存储.
基于Bloom Filter的存储.
URL的直接重复数据删除主要涉及存储优化,这不是本文的重点,因此在这里我将不做详细介绍.
对于URL的逻辑重复数据删除,您需要追求更高的数据可用性,这是进行测试时需要考虑的事情.
这是seay文章中的相似性重复数据删除算法,大致如下:
def urlsimilar(url):
hash_size=199999
tmp=urlparse.urlparse(url)
scheme=tmp[0]
netloc=tmp[1]
path=tmp[2][1:]
query=tmp[4]
#First get tail
if len(path.split('/'))>1:
tail=path.split('/')[-1].split('.')[-1]
#print tail
elif len(path.split('/'))==1:
tail=path
else:
tail='1'
#Second get path_length
path_length=len(path.split('/'))-1
#Third get directy list except last
path_list=path.split('/')[:-1]+[tail]
#Fourth hash
path_value=0
for i in range(path_length+1):
if path_length-i==0:
path_value+=hash(path_list[path_length-i])%98765
else:
path_value+=len(path_list[path_length-i])*(10**(i+1))
#get host hash value
netloc_value=hash(hashlib.new("md5",netloc).hexdigest())%hash_size
url_value=hash(hashlib.new("md5",str(path_value+netloc_value)).hexdigest())%hash_size
return url_value
此函数的一般用途是最终将根据算法返回哈希值,该哈希值也是URL的哈希相似度. 如果两个URL所计算的哈希值最终相等,我们可以判断两个URL具有高度相似性.
但是应该以seay为例来举例说明此功能(在这里强调,以免被喷洒,稍后我将不对其进行详细说明). 这只是一个简单的演示,无需详细检查. 在粗略的情况下,该算法确实可以消除一些简单的参数重复,但是一旦参数复杂或URL不标准化,对于重复数据删除就不是很好.
那么在获取URL的过程中,我们还能进行其他哪些小的优化?
日期和时间命名
首先,我们可以根据日期进行重复数据删除. 我们知道,在爬网博客和门户之类的某些系统时,经常会遇到以日期命名的目录.
这些目录可以粗略地概括,并具有类似于以下内容的形式:
2010-11-11
10-11-11
20101111
当然,有些文件将以时间+随机值命名,或者它们可能以Unix时间戳命名. 这些可以根据上载和编辑时间来定义.
作者的建议是使用缓存数据库(例如redis或memcache)直接存储它;或当数据量很大时,请考虑临时存储它,并在需要时进行比较.
例如,一旦出现以日期和时间命名的目录或静态文件,我们可以考虑以以下格式存储它:
目录级别
姓名格式
URL地址(或压缩的哈希值)
有人可能会说,在seay提到的情况下,似乎日期的相似性可以解决. 让我们首先看下面的例子. 这里的输出仍然基于上述功能:
print urlsimilar('http://www.baidu.com/blog/2010-10-11/')
print urlsimilar('http://www.baidu.com/blog/2010-10-13/')
print urlsimilar('http://www.baidu.com/blog/2010-9-13/')
print urlsimilar('http://www.baidu.com/whisper/2010-10-11/')
输出结果如下:
110086
110086
37294
4842
我们可以看到,在正常情况下,确实在同一父目录中,相似性算法可以判断为正确. 但是,一旦日期格式不统一,或者父目录中存在某些差异,就不是一个很好的判断.
当然,我们还可以使用机器学习来完成重复数据删除的工作. 但是在简化工作方面,您仍然可以根据规则匹配使用一些小技巧来完成它.
删除静态文件
我们知道,在爬网URL的过程中,我们还会遇到许多静态文件,例如shtml,html,css等. 在大多数情况下,这些文件是没有意义的. 除非测试人员倾向于使用完整的采集方法,否则“我宁愿错误地杀死一百个人,也不会错过任何一个. ”
这时,我们可以配置黑名单并创建文件后缀规则库进行过滤.
当然,带有静态后缀的URL链接也可能与参数混淆. 个人建议是,用于回调的json和xml之类的URL可能会存储敏感内容,并尽量不要移动它们. 对于其他类型的静态文件,仍然采用分离参数的方法,最后对URL进行重复数据删除和存储.
针对特定情况进行过滤
在抓取特定网站时,我们可以对其进行预配置并指定过滤某些目录和页面以节省大量时间和资源.
相反,我们还可以指定仅爬网指定目录中的页面,并定位所需的内容.
感知敏感页面
在seay提出的演示算法中,在这种情况下存在某些限制. 例如,我们需要在敏感目录中获取尽可能多的文件信息. 例如,如果我们爬到后台管理目录,则可能会遇到以下情况:
print urlsimilar('http://www.baidu.com/blog/admin/login.php')
print urlsimilar('http://www.baidu.com/blog/admin/manage_index.php')
print urlsimilar('http://www.baidu.com/blog/admin/test.css')
输出结果如下:
40768
40768
40768
显然有问题,不是吗?
我们当然可以监视敏感的页面关键字;或者我们可以指定一个后缀文件来执行白名单监控.
但是一旦您执行了此操作,并且想要使用以前的哈希算法,则您自己定义的过滤器函数的优先级必须大于该算法. 另外,在这样做的过程中,还应考虑过滤成本问题,建议采用选择性激活.
对高频敏感目录的优惠待遇
也许在爬网过程中,某些爬网程序还使用目录爆炸的方法. 如果采用此方法并且匹配成功,则可以对目录中的内容使用单独的过滤规则,以避免误判重复数据删除算法.
过滤响应页面
对于某些网站,由于链接无效,许多页面可能被标记为404页和50x错误. 另外,当您无权访问时,网站可能会进行30倍重定向和403目录限制.
这些页面没有实质性内容,并且在大多数情况下是没有意义的. 我们可以在配置文件中将需要爬网的页面类型列入白名单,例如保留403个页面,或在跳转(之后)页面之前访问30倍.
WAF(警告)页面过滤
某些网站可能已安装WAF. 如果访问频率太快,可能会出现WAF警告页面. 在CMS自身施加限制的情况下,某些不存在的页面将以20x的响应代码显示.
当然,我们可以通过代理的分布式交换来解决其中的一些问题,因此在此不再赘述.
这时,我们可以配置相应的次数阈值. 如果某些页面出现过多次,则可以将它们标记为警告(WAF)页面,然后进行过滤. 在此处可以识别页面,您可以使用黑名单关键字对其进行标记;或尝试计算页面哈希值,例如:
content = urllib2.urlopen('http://www.test.com/').read()
md5_sum = hashlib.md5()
md5_sum.update(content)
print md5_sum.hexdigest()
当然,当我们实际计算页面哈希值并进行关键字监控时,由于存在反爬虫机制(例如,添加随机值). 当然,这也会消耗更多的时间和机器资源. 但是在某些特定情况下,它也可能带来意想不到的收益.
删除无意义的参数页面
在采集页面的过程中,我们可能还会遇到一些无意义的,经常出现的多参数页面. 这样的页面可以是回调页面,也可以是临时呈现的随机页面.
在这里,您可以通过以前的WAF(警告)方法进行过滤. 当然,使用以前的哈希算法也可以应付大多数情况. 毕竟,这种网站的URL是受限制的,并且不需要为多个功能消耗更多的资源,因此收益大于损失.
JS代码中的URL
当我们提取js代码时,也就是说,当我们遇到诸如ajax之类的交互时,我们可能会遇到需要拼接的GET请求或可以直接访问的POST请求.
这种URL地址最好与phantomjs之类的webkit结合使用,以更方便地进行动态拼接.
它们看起来很特殊,可能仅返回状态代码,或者可能返回实质上敏感的内容. 在这种情况下,有必要根据采集器的要求调整搜寻过滤规则.
摘要
此处的作者旨在针对类似URL的重复数据删除提出一些小的优化措施,这些效果可能有限,或者可能不令人满意.
欢迎提出建议. 我希望减少喜欢喷涂的童鞋,并增加讨论和鼓励.
参考文章
如何避免重复抓取同一网页
谈论动态采集器和重复数据删除
Web采集器: 使用BloomFilter进行URL重复数据删除策略
实用科普: 履带技术分析. 编写采集器时的注意事项
Web爬网程序(蜘蛛)URL重复数据删除设计URL重复数据删除设计
新知识新闻源文章生成器
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-08 14:52
功能概述:
新知识新闻源文章生成器批量生成新闻源文章,告别了人工新闻源的时代,使用批量上传功能直接发布生成的文章,大大提高了新闻源发布的效率. 采集新闻源文章,采集新闻源文章链接,随机组合本地新闻源段落,替换文章字符,伪原创内容,插入关键字和插入JS脚本.
1该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2该软件适用于具有“批量上传”功能的新闻源平台;
3. 该软件可以从家庭或其他医院网站采集文章,以生成文章作为新闻来源;
4局部模式-段落随机组合模式可以将准备好的文章段落随机组合成完整的文章;
5本地模式-完整文章模式可以通过对网站上准备的完整文章的后续处理来生成新闻组;
6所采集的文章是独立的,包括拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键字等;
7将采集到的文章保存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8采集链接: 批量采集文章链接以准备采集文章;
9保存: 保存商品生成规则的配置,以备下次使用;
10打开: 打开保存的文章生成规则,并继续上一次.
11个视频教程: 这里有一些软件操作视频教程,供新用户学习.
由NSFOCUS 查看全部
该软件需要.net3.5操作环境. 如果在打开软件时报告错误,请下载并安装.net3.5.
功能概述:
新知识新闻源文章生成器批量生成新闻源文章,告别了人工新闻源的时代,使用批量上传功能直接发布生成的文章,大大提高了新闻源发布的效率. 采集新闻源文章,采集新闻源文章链接,随机组合本地新闻源段落,替换文章字符,伪原创内容,插入关键字和插入JS脚本.
1该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2该软件适用于具有“批量上传”功能的新闻源平台;
3. 该软件可以从家庭或其他医院网站采集文章,以生成文章作为新闻来源;
4局部模式-段落随机组合模式可以将准备好的文章段落随机组合成完整的文章;
5本地模式-完整文章模式可以通过对网站上准备的完整文章的后续处理来生成新闻组;
6所采集的文章是独立的,包括拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键字等;
7将采集到的文章保存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8采集链接: 批量采集文章链接以准备采集文章;
9保存: 保存商品生成规则的配置,以备下次使用;
10打开: 打开保存的文章生成规则,并继续上一次.
11个视频教程: 这里有一些软件操作视频教程,供新用户学习.
由NSFOCUS
七个方面可以告诉您不收录原创文章的因素
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-08 02:57
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章?
1. 该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察.
如何解决这个问题?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度.
第二个是更新许多高质量的原创内容. 不管是否包括它,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过.
如果找到大量的无效链接,首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 具体细节不在这里解释.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的境界,则需要继续提高权利,然后提高文章质量,以确保网站的跳出率可观. 组织和发布 查看全部
SEOre问我为什么我的文章是原创的,但仍未包括在内. 实际上,网站的收录不是由原创文章确定的. 我相信这个问题困扰了很长时间的所有人. 一些网站管理员每天都在努力编写原创更新. 但是,它始终不受搜索引擎青睐,某些网站即使被采集也可以在几秒钟内实现接收的处理. 我们坚持以错误的方向进行原创更新的方向吗?还是其他人有其他聪明的把戏?这些未知. 我今天将与您分享的是为什么不包括原创文件的分析和解决方案.
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章?
1. 该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察.
如何解决这个问题?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度.
第二个是更新许多高质量的原创内容. 不管是否包括它,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过.
如果找到大量的无效链接,首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 具体细节不在这里解释.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的境界,则需要继续提高权利,然后提高文章质量,以确保网站的跳出率可观. 组织和发布
SEO的原因和解决方案不包括原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-08 02:10
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章? 1.该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察. 如何解决这个问题呢?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度. 第二是更新许多高质量的原创内容,无论是否收录这些内容,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过. 如果发现大量无效链接,那么首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 这里不解释细节.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的范围,则需要继续提高权利,然后提示文章的质量,以确保网站的跳出率良好. 如有任何疑问,可以咨询Baishang Network下的小偷SEO博客! 查看全部
我认为,“不包括原创物品”的问题困扰了很长时间. 一些网站管理员每天都在努力工作以编写原创更新,但是它们始终不受搜索引擎的青睐,有些网站甚至可以实现原创采集. 第二种采集的处理方式是我们坚持原创更新的错误方向吗?还是其他人有其他聪明的把戏?这些是未知的,今天我将与您分享为什么不包括原创文件的原因分析和解决方案.
1. 原创文章的方向仍然占主导地位
许多人在写了原创文章并发现不包括原创文章后放弃了更新原创文章的操作. 实际上,在运行时,原创内容仍然是搜索引擎最喜欢的东西,但是您是否曾想过您的原创内容是否符合要求?互联网用户的胃口正在写自我娱乐或学习内容供用户参考. 主要原因是搜索引擎无法抓取网页,因为内容质量不够好. 稍后将对此进行详细说明.
也有一些网站管理员看到其他网站的内容采集很好,因此他们也自己采集了内容. 最终结果是他们的网站的评估价值大大降低,最终采集成为一个问题,但是原创文章仍在优化中. 毫无疑问.
两个. 为什么搜索引擎不收录原创文章? 1.该网站是一个新网站
对于新电台,通常很难在几秒钟内达到接收效果. 就像坠入爱河. 您刚遇到一个女孩,并且想让某人立即打开房子. 考虑一下这是不可能的. 好吧,很多朋友总是认为他们的网站已经过了新网站的期限,一般六个月之内就可以称为一个新网站,如果您的网站六个月没有上线,那么收录的速度就会很慢,这是正常的,不要太担心了,只是坚持做正确的事.
如何缩短新网站的审核期?许多人经常会问为什么其他人的网站比我晚访问,但比我早. 实际上,这就是其他人在优化方面做得很好的原因. 那么新站点呢?操作可以加快文章的采集速度吗?
a. 正确地进行外部链工作: 许多人认为外部链接不再有用,但不再有用. 外部链接的作用仍然很重要. 在某些相关平台上发布外部链接不仅可以吸引蜘蛛到网站. 对内容的访问也会吸引一些意外的流量.
b. 内部链接结构应合理: 吸引蜘蛛进入后,让它们爬网网站的所有部分. 这时,我们需要进行内部链接工作. 最好避免存在无效链接. 链条的好坏,是否受到指导,只有一点.
c. 通过链接将其提交到搜索引擎平台: 您可以通过将文章链接作为百度网站管理员平台来提交,但请注意不要多次提交,这会影响网站的整体质量.
d. 制作好的站点地图: 站点地图的作用是使搜索引擎蜘蛛能够更好地抓取具有清晰轮廓的站点内容,并且是分配站点权重的重要工具. 网站地图不会这样做. 您可以私下与岑慧玉聊天.
e. 使用nofollow标签集中力量: nofollow标签在预优化中也非常重要. 为了集中某个区域的权重值,通常可以使用此标记来限制不重要的位置,以使搜索引擎蜘蛛更好地识别网站的核心焦点;在基于核心重点撰写文章之后,接受率要高得多.
2. 大量采集引起的未包括在内的文章(非原创)
我相信,为了使该网站更早地在线,许多网站管理员进入主要平台来采集大量内容,然后匆匆上线,而这种懒惰的结果是不包括该文章. 虽然该文章非常有价值,但是未被搜索引擎认可,没有新鲜的内容可以支持,搜索引擎得分也很低,很多网站管理员都遇到这种情况,不知道该怎么办,以下方法可能会有所帮助你.
a. 修改文章标题和内容之前和之后: 您可以将标题带到百度搜索框进行搜索,以查看相关搜索量可以达到多少. 如果达到一百万左右,则必须适当修改标题. 搜索标题,然后查看百度搜索框以查看有多少相关搜索结果. 通常,最好将其控制在100,000以下.
b. 加强外部链发布的工作: 修改内容和标题后,下一步就是让搜索引擎重新爬网内容. 这时,外部连锁工作是必不可少的. 您可以发布外部链将链接链接到本文,然后让搜索引擎重新爬网并进行标识. 建议您修改所有内容. 不要修改文章,也不要发布外部链接,这样,当搜索引擎蜘蛛爬网时,只会找到一页. 如果您发现大部分内容已被修改,则下次更新百度快照时,我认为收录的数量将会增加.
3. 内容值太旧,对用户意义不大
我之前也说过,原创文章注重价值. 许多人可以说,当写原稿时,他们将呕吐血,但其中不包括在内. 实际上,主要原因是文章的质量. 许多文章是古老的. 这种观点根本无法解决当前用户的需求. 那么如何更好地把握商品的价值呢?简而言之,我们需要了解用户最近经常搜索的内容. 您可以根据下拉框和相关搜索对其进行分析. 无需过多解释,您也可以使用QQ社交工具来咨询一些专家,并且综合他们的意见也可以成为不错的文章.
您可以使用百度知道用户在问什么问题,然后寻求同行咨询. 这种效果很好,但是相对有害,有些同事也很聪明,他们经常希望您与我们交谈. 这对我们来说创造价值文章会带来一定的难度,但是这种方法可以用于推论.
4. 网站标题的频繁修改也会影响整体收录
对于网站,如果您经常修改网站的标题,也会导致网站内容的方向发生变化. 网站的整体权重不高,将直接影响网站文章的收录率. 我相信每个人都已经经历过. ,因此,如果您只是修改标题而发现不再收录该文章,则意味着该网站已被搜索引擎重新进入观察期进行观察. 如何解决这个问题呢?首先,我们应该考虑百度快照更新的问题. 只有尽快更新快照,我们才能更好地恢复. 您可以通过百度快照更新投诉渠道进行投诉,以加快快照的更新速度. 第二是更新许多高质量的原创内容,无论是否收录这些内容,定期更新都可以缩短此观察期.
5. 检查robots.txt文件中是否收录禁止搜索引擎的说明
这很简单,但是在很多情况下,这是由robots文件引起的. 许多网站管理员很粗心,禁止搜索引擎抓取文件,从而导致文章采集量急剧下降. 这应该不是粗心的. 您可以使用百度网站管理员平台的抓取工具和机器人检测工具进行测试.
6. 网站上有很多无效链接
网站上存在大量无效链接也是影响页面质量的一个因素. 大量的404页为搜索引擎蜘蛛提供了非常差的爬网体验,从而降低了网站的页面质量. 您可能希望检查您的网站是否存在,如果存在多个无效链接,则可能会出现大量无效链接,即动态路径和伪静态路径不统一,从而导致在大量无效链接中. 每个人都应该经历过. 如果发现大量无效链接,那么首先想到的是如何处理无效链接,以便搜索引擎可以尽快对其进行更新. 您可以使用百度网站管理员工具的无效链接工具修复它们. 这里不解释细节.
7. 网站过度优化会导致权利降级
许多网站都过度优化,并且故意堆积关键字,导致网站延迟. 当发现过度优化时,首先要考虑的是如何减少故意优化的痕迹. 还可以适当减少故意堆积的关键字,以减少重复的时间. 一段时间后,可以用原创质量的文章更新页面的重复率.
摘要: 以上是不包括本文所述原创文章的一般原因. 由于时间限制,我将不做太多总结. 如果您发现您的文章经常不被收录,主要原因是网站的信任价值不足. 其次,这与文章的质量是否符合标准有关. 如果您希望网站达到即时采集的范围,则需要继续提高权利,然后提示文章的质量,以确保网站的跳出率良好. 如有任何疑问,可以咨询Baishang Network下的小偷SEO博客!
使用php 优采云采集器捕获当今头条新闻Ajax文章的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-08 00:39
使用Google Chrome浏览器打开链接,右键单击“审阅”,在控制台中切换到网络,然后单击XHR,以便可以过滤不必要的请求(例如图像,文件等),而仅请求查看内容页面
由于页面是由ajax加载的,因此将页面拉到底部,更多文章将自动加载. 目前,控制台捕获的链接是我们真正需要的列表页面的链接:
在优采云采集器中创建任务
创建后,单击“采集器设置”,然后在“起始页面URL”中填写上面爬网的链接
接下来匹配内容页面的URL,标题文章的URL格式为
点击“内容页面网址”以编写“匹配内容网址”规则:
(?+ /)
这是一条常规规则,这意味着将匹配的URL加载到捕获组content1中,然后填写下面的[Content1](与上面的content1相对应)以获取内容页面链接
您可以单击“测试”以查看链接是否成功爬网
获取成功后,您可以开始获取内容
点击“获取内容”以在字段列表的右侧添加默认字段,例如标题,正文等. 可以智能识别,如果需要准确性,则可以自己编辑字段,支持常规, xpath,json和其他匹配内容
我们需要获取文章的标题和正文. 因为它是由Ajax显示的,所以我们需要编写规则以匹配内容,分析文章的源代码: ,找到文章的位置
标题规则: articleInfos: s {stitle: s'[Content1]',
身体规则: content: s'[Content1]',s * groupId
该规则必须唯一,否则它将与其他内容匹配. 将规则添加到字段中,然后为获取方法选择规则匹配:
编写规则后,单击“保存”,然后单击“测试”以查看其工作原理
规则正确,并且爬网是正常的. 捕获的数据也可以发布到cms系统,直接存储在数据库中,另存为excel文件等,只需单击底部导航栏中的“发布设置”即可. 采集在这里,每个人都可以尝试一下! 查看全部
今天的标题数据由Ajax加载并显示. 根据普通URL,无法捕获数据. 有必要分析加载地址. 让我们以示例为例,采集文章列表
使用Google Chrome浏览器打开链接,右键单击“审阅”,在控制台中切换到网络,然后单击XHR,以便可以过滤不必要的请求(例如图像,文件等),而仅请求查看内容页面
由于页面是由ajax加载的,因此将页面拉到底部,更多文章将自动加载. 目前,控制台捕获的链接是我们真正需要的列表页面的链接:
在优采云采集器中创建任务
创建后,单击“采集器设置”,然后在“起始页面URL”中填写上面爬网的链接
接下来匹配内容页面的URL,标题文章的URL格式为
点击“内容页面网址”以编写“匹配内容网址”规则:
(?+ /)
这是一条常规规则,这意味着将匹配的URL加载到捕获组content1中,然后填写下面的[Content1](与上面的content1相对应)以获取内容页面链接
您可以单击“测试”以查看链接是否成功爬网
获取成功后,您可以开始获取内容
点击“获取内容”以在字段列表的右侧添加默认字段,例如标题,正文等. 可以智能识别,如果需要准确性,则可以自己编辑字段,支持常规, xpath,json和其他匹配内容
我们需要获取文章的标题和正文. 因为它是由Ajax显示的,所以我们需要编写规则以匹配内容,分析文章的源代码: ,找到文章的位置
标题规则: articleInfos: s {stitle: s'[Content1]',
身体规则: content: s'[Content1]',s * groupId
该规则必须唯一,否则它将与其他内容匹配. 将规则添加到字段中,然后为获取方法选择规则匹配:
编写规则后,单击“保存”,然后单击“测试”以查看其工作原理
规则正确,并且爬网是正常的. 捕获的数据也可以发布到cms系统,直接存储在数据库中,另存为excel文件等,只需单击底部导航栏中的“发布设置”即可. 采集在这里,每个人都可以尝试一下!
千千: 使用今天的头条自动采集高质量的文章材料实践技能
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2020-08-07 18:55
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于自媒体的运作,无非就是稳定的产值,可以赚很多钱. 对于大多数人来说,他们不知道该值在哪里导入然后输出. 在这里,我将分享头条稳定投入价值的实战游戏玩法,这将帮助更多的人走向自我媒体之路.
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
就像上面的图片一样,一个单独的“种子”文件夹以采集夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
注册或购买标题号码
输入定位标记词以查找文章
按照带有标题词的文章标题
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
已发表的文章数量很少;
刚刚注册的新帐户; 查看全部
在当前的Internet环境中,所谓的营销不再像以前那样容易. 无论是百度,腾讯,阿里,博客,论坛还是视频,许多人都被超越了赚钱门槛. 但是,过去两年中,有一件事情正在如火如荼地发展,那就是自我媒体.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于自媒体的运作,无非就是稳定的产值,可以赚很多钱. 对于大多数人来说,他们不知道该值在哪里导入然后输出. 在这里,我将分享头条稳定投入价值的实战游戏玩法,这将帮助更多的人走向自我媒体之路.
首先,我们必须了解头条的平台机制. 由于今日头条的推荐机制是基于个人兴趣标签的,因此它的准确性很高. 同样,您喜欢阅读哪种文章,标题将根据您的偏好将标签与您匹配,然后向您推荐标签内容.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
通过这种方式,我们可以使用头条的智能标签推荐来稳定地获取输入值材料,然后编辑和组合这些材料的内容,然后输出到主要平台以吸引粉丝并创造个人IP潜力.
该怎么做?查看实际步骤:
1. 定位字段,找到定位标签词
根据我目前的工作状况或项目领域来定位,例如,我正在做市场营销,那么我可以针对互联网营销,移动互联网营销,百度营销,微信营销等,您可以发掘更多的定位与营销相关的标签.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
如果您在另一个行业或领域,也可以使用类似的方法来确定您所在领域的位置. 然后,根据自己的定位,找出更多的定位标签词. 例如,在定位信用的区域中,则定位标记词可以是信贷,网上贷款,信用卡,快速卡,黑白账户开立,提款等,然后记录定位标记词
2,通过标签词找到重要的种子
在定位和搜索定位标记词的第一步之后,找到材料的来源就足够了,通常称为“种子”. 例如:
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
就像上面的图片一样,一个单独的“种子”文件夹以采集夹的形式列出. 当然,这些“播种”标题并不是凭空出现的,而是由高质量内容产生的标题种子,这些种子通过定位标记词不断进行过滤.
如何开始寻找种子?如下:
注册或购买标题号码
输入定位标记词以查找文章
按照带有标题词的文章标题
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
对于每个定位标记词,您可以搜索许多与定位标记词相关的标题编号. 例如,图中的红色框选择标题编号的名称,单击并跟随另一方.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
我们要做的是遵循这些标题,这些标题是通过逐个放置标签词来查找出来的,并且经常浏览它们的文章.
3,大浪洗沙,质量是从数量中选择的
在放置标记词的第二步之后,我注意了许多与我的行业相关的头条新闻. 同时,由于您经常关注相似字段中的标题并阅读该字段中的文章,因此发送至标题系统的消息是您喜欢该字段中的文章. 将来,将向您推荐相似领域的所有文章,并且您将继续关注. 与该字段相关的标题编号.
uaA Baipai链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
头条新闻的数量随着向您推荐的文章数的增加而增加,因此在相关领域中将有很多头条新闻. 如果您阅读每个标题号码,那将很累人. 因此,我们必须过滤掉这些已经引起注意的标题. 例如:
已发表的文章数量很少;
刚刚注册的新帐户;
为什么不包括网站优化更新的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 17:13
不收录网站文章的原因
1. 该网站过度优化.
过度优化发生在网站上,这通常表现为关键字和隐藏文本的积累. 如果出现这种情况,我们必须对其进行处理并及时进行调整,以使其缓慢地被百度搜索引擎收录. 即使自己发布的网站文章被搜索引擎收录,百度更新后它们也会消失. 实事求是,进行网站优化.
2. 网站内容采集
几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有价值,则将其丢弃. 网站内容的主要来源已采集. 在这种情况下,有时会不收录网站文章. 即使采集到的文章质量很高,并且被搜索引擎暂时包括在内,经过一段时间后,它们也会逐渐被删除. 文章还将在那时将该网站降级,并在此类步骤中使用百度的算法. 因此,请记住此规则,不要采集更多文章并在您的网站上更新它们.
3. 被阻止的内容出现在网站的主题中
在优化网站时,我们需要检查是否存在任何法律禁止的内容信息. 如果是这样,我们必须将其删除以防止该网站受到搜索引擎的影响. 在制作内容时,必须注意法律所禁止的字眼. 不要触摸它们,也不知道.
4. 网站域名会受到惩罚吗?
注册域名或购买二手域名时,必须检查该域名是否受到搜索引擎的惩罚,以及该域名是否属于灰色行业. 还可以检查域名等的外部链资源.
5. 网站上的无效链接太多
或者由于网站的修订,网站文章的删除等因素,该网站有大量的死链接,而且搜索引擎也很容易找到他们想要的东西. 网站上无效的链接必须提交给搜索引擎.
6. 该网站已修改.
网站修订的内容很长时间以来尚未完善,已提交给百度搜索引擎. 后期的大小变化也会导致网站降级.
7. 被惩罚的网站不在链条之内
已被搜索引擎降级的网站离线资源收录在其自己的网站中,并且您网站上的友好链接已被降级. 如果发生这种情况,应及时清除并添加新的友好链接. 网站上外部链接的减少也是导致搜索引擎爬网程序不收录文章的一个因素. 更多的外部链资源可以驱动更多的采集器来获取数据并提高网站关键字的排名.
8,网站虚拟主机IP被阻止
如果您使用的虚拟主机的IP被阻止,搜索引擎将无法访问您的网站,并且该网站上的内容也不会被抓取.
9. 网站是否存在安全漏洞
定期检查该网站是否可能链接到一匹马,如果有必要及时删除它,搜索引擎不会发现它失去对您网站的信任.
10,网站文章逐步更新
网站需要每天定期且定量地更新文章. 今天不要更新文章,明天也不会更新. 不断更新文章,并改善从伪原创文章到原创文章的转换,从而更好地提高网站的接受率. 查看全部
优化网站时,网站文章收录问题是一个常见问题. 那么,此问题如何导致搜索引擎不对网站文章进行索引?有没有更好的方法让搜索引擎收录您自己的网站?关于此问题的文章,我将与您分享不收录网站文章的主要原因. 具体内容如下:
不收录网站文章的原因
1. 该网站过度优化.
过度优化发生在网站上,这通常表现为关键字和隐藏文本的积累. 如果出现这种情况,我们必须对其进行处理并及时进行调整,以使其缓慢地被百度搜索引擎收录. 即使自己发布的网站文章被搜索引擎收录,百度更新后它们也会消失. 实事求是,进行网站优化.
2. 网站内容采集
几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有价值,则将其丢弃. 网站内容的主要来源已采集. 在这种情况下,有时会不收录网站文章. 即使采集到的文章质量很高,并且被搜索引擎暂时包括在内,经过一段时间后,它们也会逐渐被删除. 文章还将在那时将该网站降级,并在此类步骤中使用百度的算法. 因此,请记住此规则,不要采集更多文章并在您的网站上更新它们.
3. 被阻止的内容出现在网站的主题中
在优化网站时,我们需要检查是否存在任何法律禁止的内容信息. 如果是这样,我们必须将其删除以防止该网站受到搜索引擎的影响. 在制作内容时,必须注意法律所禁止的字眼. 不要触摸它们,也不知道.
4. 网站域名会受到惩罚吗?
注册域名或购买二手域名时,必须检查该域名是否受到搜索引擎的惩罚,以及该域名是否属于灰色行业. 还可以检查域名等的外部链资源.
5. 网站上的无效链接太多
或者由于网站的修订,网站文章的删除等因素,该网站有大量的死链接,而且搜索引擎也很容易找到他们想要的东西. 网站上无效的链接必须提交给搜索引擎.
6. 该网站已修改.
网站修订的内容很长时间以来尚未完善,已提交给百度搜索引擎. 后期的大小变化也会导致网站降级.
7. 被惩罚的网站不在链条之内
已被搜索引擎降级的网站离线资源收录在其自己的网站中,并且您网站上的友好链接已被降级. 如果发生这种情况,应及时清除并添加新的友好链接. 网站上外部链接的减少也是导致搜索引擎爬网程序不收录文章的一个因素. 更多的外部链资源可以驱动更多的采集器来获取数据并提高网站关键字的排名.
8,网站虚拟主机IP被阻止
如果您使用的虚拟主机的IP被阻止,搜索引擎将无法访问您的网站,并且该网站上的内容也不会被抓取.
9. 网站是否存在安全漏洞
定期检查该网站是否可能链接到一匹马,如果有必要及时删除它,搜索引擎不会发现它失去对您网站的信任.
10,网站文章逐步更新
网站需要每天定期且定量地更新文章. 今天不要更新文章,明天也不会更新. 不断更新文章,并改善从伪原创文章到原创文章的转换,从而更好地提高网站的接受率.
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-07 17:11
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?编辑通过他通常的积累总结了以下几点:
原因: 过度优化,例如关键字堆积,隐藏文本等. 如果发生这种情况,即使百度已经收录了您,也不要感谢您被骗了,因为在此过程中它会慢慢被淘汰更新.
解决方案: 当新网站上线时,请勿首先进行过多的SEO操作,不要在标题中重复两次以上关键字;说明中的关键词不要重复三遍以上;不要把它们叠起来;尽量自然地在首页上排列关键词,不要故意堆放在那些重要的地方;尝试将首页的关键字密度控制在3%-4%左右. 标题中的三个或四个关键字就足够了,太多的搜索引擎不喜欢它. 建议设置页面主题+主题名称+网站名称. 至于关键字,是否添加都没关系,但是至少页面上应该有一些相关的内容. 描述设置非常简单,只要语言流利,并且页面的概要,两个或三个关键字就足够了.
2. 网站内容采集
原因: 几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有任何价值,它将被丢弃.
建议的解决方案: 采集完成后,手动添加一些“原创文章”,为什么还要添加引号. 因为独创性不容易写. 教您一个诱骗蜘蛛并找到相关类型文章的简单技巧. 更改标题. 破坏里面的段落格式. 如果您有自己的意见,则可以自己在其中写一个段落. 就产生了这样的“原创文章”. 然后,让您的“原创”文章出现在首页上.
3. 网站域名
原因: 我以前曾被Engine K处罚. 我们可以检查该域名是否曾经被使用过.
建议的解决方案: 在申请域名之前,直接在引擎中输入要注册的域名.
4. 网站结构
原因: 网站结构不清晰,并且存在无效链接,使搜索引擎无法访问网站.
建议的解决方案: 逐一删除无效链接并制作站点地图.
5. 网站修订
原因: 该网站尚未修改,已提交给百度,并且动turn动big. 类别和标题被交换. 有时会有测试或与网站无关的其他内容. 这些是seo的禁忌.
建议的解决方案: 正确放置它并坚持在要停止的位置. 可以添加新的类别和内容. 最好不要随意删除旧内容. 如果更改空间,最好事先进行更改. 确保以前的空间内容在一段时间内继续存在,以防万一.
6. 网站链接
原因: 网站缺少外部链接,或者外部链接逐渐减少. 当然,百度对您网站的关注度也会降低,其内容也会逐渐减少. 链接的质量非常重要. 最好不要使用垃圾链接并删除无效链接. 此外,请检查您的页面,如果存在指向被阻止网站的链接,则您的网站也会在一定程度上受到影响.
建议的解决方案: 检查网站的外部链接,进行交流,如果很少,或者访问一些大型网站和论坛以发布引起他人关注的帖子,并保留链接. 反应的人越多,效果越好. 如果站点中有到被阻止站点的链接,请尽快将其删除. 避免与某些垃圾站建立友谊链接,因为它们会对您的网站造成负面影响.
7. 网站空间
原因: 您使用的虚拟主机的IP被阻止,或者您所涉及的服务器的IP被阻止. 在百度更新期间无法访问您的网站,因此即使搜索引擎想要搜索您的页面,也无法收录该网站.
建议的解决方案: 购买空间时要注意并找到信誉良好的IDC. 不要只是便宜. 如果经常遇到问题,更不用说搜索引擎了,网民负担不起. 因此,您的网站不会吸引搜索引擎的注意. 另外,在购买空间时,请检查虚拟主机IP上的站点,收录状态以及被阻止的站点数.
8. 网站安全性
原因: 如果您添加恶意代码或故意在您的网站上挂马,百度可以对其进行分析. 会减少您的信任. 此外,大多数网页都是那些小黑客使用工具修改或删除的.
建议的解决方案: 定期备份并及时解决问题. 一般来说,百度的更新是在夜间进行的. 每天更新的个人电台很少. 如果异常,请立即进行处理.
总而言之,网站收录量中最重要的因素是网站文章内容的质量. 网站是否被很好地收录在很大程度上取决于文章内容的原创性. 我建议您写这篇文章必须是原创的,至少是伪原创的,以便您的网站的采集情况更快得到改善.
阅读本文的人还阅读:
您如何看待关键字在网站优化中的优化程度?
SEO基层网站管理员新手必须了解并注意的六个问题
新手网站管理员朋友应如何优化公司网站? 查看全部
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?我认为这是所有进行网站SEO优化的人员都更加关心的问题. 如果不包括该网站,则不会有排名,没有排名就不会有流量或流量很小. 是什么原因?对于刚刚从事该行业的小白来说,他此时正处于茫然之中,那么为什么不包括网站上的文章?如何解决网站不收录的问题?今天,小编东莞SEO将与您分享.
如果不收录网站文章,该怎么办?如何解决网站不收录的问题?编辑通过他通常的积累总结了以下几点:
原因: 过度优化,例如关键字堆积,隐藏文本等. 如果发生这种情况,即使百度已经收录了您,也不要感谢您被骗了,因为在此过程中它会慢慢被淘汰更新.
解决方案: 当新网站上线时,请勿首先进行过多的SEO操作,不要在标题中重复两次以上关键字;说明中的关键词不要重复三遍以上;不要把它们叠起来;尽量自然地在首页上排列关键词,不要故意堆放在那些重要的地方;尝试将首页的关键字密度控制在3%-4%左右. 标题中的三个或四个关键字就足够了,太多的搜索引擎不喜欢它. 建议设置页面主题+主题名称+网站名称. 至于关键字,是否添加都没关系,但是至少页面上应该有一些相关的内容. 描述设置非常简单,只要语言流利,并且页面的概要,两个或三个关键字就足够了.
2. 网站内容采集
原因: 几乎所有内容都已采集,并且是非常受欢迎的文章的集合. 突然,百度将收录您的数千页,但在收录百度之后,它会在一段时间内被检索. 如果您的内容没有任何价值,它将被丢弃.
建议的解决方案: 采集完成后,手动添加一些“原创文章”,为什么还要添加引号. 因为独创性不容易写. 教您一个诱骗蜘蛛并找到相关类型文章的简单技巧. 更改标题. 破坏里面的段落格式. 如果您有自己的意见,则可以自己在其中写一个段落. 就产生了这样的“原创文章”. 然后,让您的“原创”文章出现在首页上.
3. 网站域名
原因: 我以前曾被Engine K处罚. 我们可以检查该域名是否曾经被使用过.
建议的解决方案: 在申请域名之前,直接在引擎中输入要注册的域名.
4. 网站结构
原因: 网站结构不清晰,并且存在无效链接,使搜索引擎无法访问网站.
建议的解决方案: 逐一删除无效链接并制作站点地图.
5. 网站修订
原因: 该网站尚未修改,已提交给百度,并且动turn动big. 类别和标题被交换. 有时会有测试或与网站无关的其他内容. 这些是seo的禁忌.
建议的解决方案: 正确放置它并坚持在要停止的位置. 可以添加新的类别和内容. 最好不要随意删除旧内容. 如果更改空间,最好事先进行更改. 确保以前的空间内容在一段时间内继续存在,以防万一.
6. 网站链接
原因: 网站缺少外部链接,或者外部链接逐渐减少. 当然,百度对您网站的关注度也会降低,其内容也会逐渐减少. 链接的质量非常重要. 最好不要使用垃圾链接并删除无效链接. 此外,请检查您的页面,如果存在指向被阻止网站的链接,则您的网站也会在一定程度上受到影响.
建议的解决方案: 检查网站的外部链接,进行交流,如果很少,或者访问一些大型网站和论坛以发布引起他人关注的帖子,并保留链接. 反应的人越多,效果越好. 如果站点中有到被阻止站点的链接,请尽快将其删除. 避免与某些垃圾站建立友谊链接,因为它们会对您的网站造成负面影响.
7. 网站空间
原因: 您使用的虚拟主机的IP被阻止,或者您所涉及的服务器的IP被阻止. 在百度更新期间无法访问您的网站,因此即使搜索引擎想要搜索您的页面,也无法收录该网站.
建议的解决方案: 购买空间时要注意并找到信誉良好的IDC. 不要只是便宜. 如果经常遇到问题,更不用说搜索引擎了,网民负担不起. 因此,您的网站不会吸引搜索引擎的注意. 另外,在购买空间时,请检查虚拟主机IP上的站点,收录状态以及被阻止的站点数.
8. 网站安全性
原因: 如果您添加恶意代码或故意在您的网站上挂马,百度可以对其进行分析. 会减少您的信任. 此外,大多数网页都是那些小黑客使用工具修改或删除的.
建议的解决方案: 定期备份并及时解决问题. 一般来说,百度的更新是在夜间进行的. 每天更新的个人电台很少. 如果异常,请立即进行处理.
总而言之,网站收录量中最重要的因素是网站文章内容的质量. 网站是否被很好地收录在很大程度上取决于文章内容的原创性. 我建议您写这篇文章必须是原创的,至少是伪原创的,以便您的网站的采集情况更快得到改善.
阅读本文的人还阅读:
您如何看待关键字在网站优化中的优化程度?
SEO基层网站管理员新手必须了解并注意的六个问题
新手网站管理员朋友应如何优化公司网站?

