
文章采集链接
如何撰写伪原创文章(如何在5分钟内生成伪原创文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-07 13:03
此功能可以通过对方的官方帐户链接直接采集对方的链接文章. 很多朋友会认为我可以复制吗?对于复制的文章,您不能一键复制标题和封面,而复制文章,标题和封面的时间肯定比一键导入要慢得多! 〜过去使用此函数例程,但现在文章例程是逐字逐句编写的,因此该函数使用较少!
该插件的第二个亮点: 意见采集网页图片
只要我们下载插件,打开任何网页时,只要图片出现,我们都可以直接在网页上采集任何图片. 采集的图片将直接显示在官方帐户的图片中,只需单击我们需要的图片即可.
该插件的第三个亮点: 采集自定义模板
我相信每个人都能看到,陶璐的所有文字都有开头和结尾,并且文字和图片是相同的. 此功能可以采集您需要的一些固定单词或图片,您可以在每次需要时通过单击排版增强功能来使用它. 小白必不可少的!
在以上三个亮点中,对于陶卢的每个文本来说,其中两个都是必需的. 还有更多功能,例如手机图像传输,可以插入代码,文本URL直接在线生成QR码,一键排版等等!还有一些功能可以在线编辑图片,这是因为陶璐格可能在美学方面存在问题,并且基本上不使用该作品!如果您有兴趣,可以直接下载该插件并对其进行了解. 下图中的功能全部可用. 您可以通过在浏览器中搜索“ Yipan”来找到该插件,需要它的人可以自己获取!
今天的内容在这里共享. 如果您是一位自媒体专家,那么我相信您肯定使用了此插件. 如果您尚未使用此软件,则建议使用它. 该软件不收取任何额外费用. 下载并使用它!如果您是想向媒体学习的同学,可以尝试注册一个官方帐户进行操作,您肯定会从中受益. 即使您没有收入,至少也有经验!我从媒体开始的原因仅仅是为了通过分享认识更多的人,您呢?你觉得呢?你有没有什么想法?您可以在下面留言以告诉我们,也可以告诉自己您的目标和想法! 查看全部
该插件的第一个亮点: 一键导入功能

此功能可以通过对方的官方帐户链接直接采集对方的链接文章. 很多朋友会认为我可以复制吗?对于复制的文章,您不能一键复制标题和封面,而复制文章,标题和封面的时间肯定比一键导入要慢得多! 〜过去使用此函数例程,但现在文章例程是逐字逐句编写的,因此该函数使用较少!
该插件的第二个亮点: 意见采集网页图片

只要我们下载插件,打开任何网页时,只要图片出现,我们都可以直接在网页上采集任何图片. 采集的图片将直接显示在官方帐户的图片中,只需单击我们需要的图片即可.
该插件的第三个亮点: 采集自定义模板

我相信每个人都能看到,陶璐的所有文字都有开头和结尾,并且文字和图片是相同的. 此功能可以采集您需要的一些固定单词或图片,您可以在每次需要时通过单击排版增强功能来使用它. 小白必不可少的!
在以上三个亮点中,对于陶卢的每个文本来说,其中两个都是必需的. 还有更多功能,例如手机图像传输,可以插入代码,文本URL直接在线生成QR码,一键排版等等!还有一些功能可以在线编辑图片,这是因为陶璐格可能在美学方面存在问题,并且基本上不使用该作品!如果您有兴趣,可以直接下载该插件并对其进行了解. 下图中的功能全部可用. 您可以通过在浏览器中搜索“ Yipan”来找到该插件,需要它的人可以自己获取!

今天的内容在这里共享. 如果您是一位自媒体专家,那么我相信您肯定使用了此插件. 如果您尚未使用此软件,则建议使用它. 该软件不收取任何额外费用. 下载并使用它!如果您是想向媒体学习的同学,可以尝试注册一个官方帐户进行操作,您肯定会从中受益. 即使您没有收入,至少也有经验!我从媒体开始的原因仅仅是为了通过分享认识更多的人,您呢?你觉得呢?你有没有什么想法?您可以在下面留言以告诉我们,也可以告诉自己您的目标和想法!
基于Python采集器的最便捷的微信公众号文章下载器
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-07 06:18
但是我的需求实际上非常简单-“容易找到/检索/浏览相关官方帐户中的任何文章”,因此在进行一些学习和检索之后,我开始制作一个小工具(打包成可执行文件)) ,尽管方法和代码非常简单,但实际上手工使用起来非常方便. 我也向安利挥了挥手.
工具要求:
2个现有计划
我还搜索了有关在互联网上抓取微信官方帐户的一些信息. 可能有以下几种类型.
硒爬网过程AnyProxy代理批量采集Fiddler设置代理和数据包捕获
通过捕获和分析多个帐户,我们可以确定:
可能的问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您要捕获阅读次数和喜欢的次数,则在一定频率后,返回值将变为空值.
付费平台
例如,如果您只想查看Qingbo的新列表,则可以直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
3个项目的第3.1步基本原理
目标爬网网站收录微信平台上大多数高质量的微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好.
1. 网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
2. 在公共帐户集合下的文章翻页也是正常的: 每翻页ID号+12
Portal.png
所以流程的想法是
3.2环境3.3官方帐户信息检索
通过向目标url发起requset请求,获取页面html信息,然后调用常规方法以匹配两条信息
1. 官方帐户存在吗?
2. 如果存在,那么文章中最多的页面数是什么?
url = 'http://chuansong.me/account/' + str(name) + '?start=' + str(0)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
pattern1 = re.compile('Page Not Found.', re.S)
item1 = re.findall(pattern1, html) # list类型
pattern2 = re.compile('(.\d+)(\s*)(\s*?)下一页')
item2 = re.findall(pattern2, html) # list类型
if item1:
print("\n---------该账号信息尚未收录--------\n")
exit();
else:
print("\n---------该公众号目前已收录文章页数N为:",item2[0][0])
存在正式帐户后,直接致电请求以解决目标请求链接.
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
3.4定期分析,提取链接和文章标题
以下代码用于解析html文本中的链接和标题文本信息
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
3.5自动跳转页面
以下代码通过循环递增分配来更改url中的页码参数.
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
3.6删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7将html转换为PDF
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
然后通过调用pdfkit函数转换并生成PDF文件
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
3.8生成的PDF结果
结果4.png
4个结果显示4.1抓取结果
结果1.png
已抓取的几个正式帐户存储在文件夹中

文件夹目录下的内容
已抓取CSV内容格式
4.2工具运行示例
1.png
检查微信官方帐户的名称
2.png
输入官方帐户名称和下载的页面数
3.png
下载内容
5个完整代码
由于转换为PDF的稳定性,因此我没有在发行版的代码中添加转换到PDF的功能. 保留了一个大致的py源文件. 如果有兴趣,读者可以自己调整和修改.
点击获取代码
6个exe文件下载链接
点击此处获取工具下载链接 查看全部
所以我想知道是否有任何方法可以下载这些官方帐户文章. 在这种情况下,似乎很方便. 但是在线方法要么太复杂(对我来说,是新手爬虫的初学者),要么付钱.
但是我的需求实际上非常简单-“容易找到/检索/浏览相关官方帐户中的任何文章”,因此在进行一些学习和检索之后,我开始制作一个小工具(打包成可执行文件)) ,尽管方法和代码非常简单,但实际上手工使用起来非常方便. 我也向安利挥了挥手.
工具要求:
2个现有计划
我还搜索了有关在互联网上抓取微信官方帐户的一些信息. 可能有以下几种类型.
硒爬网过程AnyProxy代理批量采集Fiddler设置代理和数据包捕获
通过捕获和分析多个帐户,我们可以确定:
可能的问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您要捕获阅读次数和喜欢的次数,则在一定频率后,返回值将变为空值.
付费平台
例如,如果您只想查看Qingbo的新列表,则可以直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
3个项目的第3.1步基本原理
目标爬网网站收录微信平台上大多数高质量的微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好.
1. 网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
2. 在公共帐户集合下的文章翻页也是正常的: 每翻页ID号+12

Portal.png
所以流程的想法是
3.2环境3.3官方帐户信息检索
通过向目标url发起requset请求,获取页面html信息,然后调用常规方法以匹配两条信息
1. 官方帐户存在吗?
2. 如果存在,那么文章中最多的页面数是什么?
url = 'http://chuansong.me/account/' + str(name) + '?start=' + str(0)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
pattern1 = re.compile('Page Not Found.', re.S)
item1 = re.findall(pattern1, html) # list类型
pattern2 = re.compile('(.\d+)(\s*)(\s*?)下一页')
item2 = re.findall(pattern2, html) # list类型
if item1:
print("\n---------该账号信息尚未收录--------\n")
exit();
else:
print("\n---------该公众号目前已收录文章页数N为:",item2[0][0])
存在正式帐户后,直接致电请求以解决目标请求链接.
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
3.4定期分析,提取链接和文章标题
以下代码用于解析html文本中的链接和标题文本信息
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
3.5自动跳转页面
以下代码通过循环递增分配来更改url中的页码参数.
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
3.6删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7将html转换为PDF
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
然后通过调用pdfkit函数转换并生成PDF文件
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
3.8生成的PDF结果

结果4.png
4个结果显示4.1抓取结果

结果1.png
已抓取的几个正式帐户存储在文件夹中


文件夹目录下的内容
已抓取CSV内容格式
4.2工具运行示例

1.png
检查微信官方帐户的名称

2.png
输入官方帐户名称和下载的页面数

3.png
下载内容
5个完整代码
由于转换为PDF的稳定性,因此我没有在发行版的代码中添加转换到PDF的功能. 保留了一个大致的py源文件. 如果有兴趣,读者可以自己调整和修改.
点击获取代码
6个exe文件下载链接
点击此处获取工具下载链接
Geekbang公共帐户文章采集和统计信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-07 03:19
我最近想采集一些文章以进行分词. 该接口是用Vue编写的,因此所有数据都是该接口,因此数据采集非常方便,所以一时兴起,利用刚刚推出的产品,其防爬机制应该不强,因此所有官方帐户采集了Geekbang的数据. 一: 文章采集
它主要分为两个步骤,采集文章链接和原创文本采集.
1. 采集文章链接,并通过搜索界面获取所有文章链接
从返回的数据中,您可以获取指向文章原创文本的链接,下一步是通过该链接采集原创数据.
2. 原创信息采集
使用scrapy框架采集有关微信文章的数据. 总共采集了5151篇文章.
有关具体代码,请参见文章末尾的地址
二: 数据分析
接下来,我们对采集到的文章进行了一些简单的统计.
1. 哪个官方帐户写的文章最多
infoQ写的文章最多,有998条,占19.35%. StuQ排名第二,共835条,占16.19%; EGONetworks排名第三,共802条,占15.55%. 这三个部分恰好是Geekbang Technology的三大业务.
2,每天发表的文章总数
随着越来越多的官方帐户的使用,文章数量不断增加,2017年每月可以达到250篇以上. 编辑能力非常强.
每天发表的文章数量的统计: 这是很规律的,周一至周五发表的文章更多,而周六和周日发表的文章较少. 在周六和周日努力工作的人.
3,文章词频统计
对所有文章进行分词,然后计算词频.
前10名: 我们,一个,数据,技术,罐头,服务,使用,需求,问题,系统
前十个词合在一起是: 我们需要使用系统来解决技术或数据问题. 暗示着什么吗?我可以为您开发一个吗?商机在这里. 由于未对分词结果进行任何调整,因此出现了许多常用的修饰词等. 这是一项艰巨的任务,将在以后完成.
4. 作者统计
统计数据基于本文的作者. 前10名: StuQ,EGO,InfoQ,徐川,大加硕,陈元媛,Q News,Indigo K和郭亮,斯塔克学院,丹尼尔五世教室.
5. 文章标题的趋势
文章标题的命名也反映了一段时间内的趋势,因此我提取了所有文章的标题并进行了分词. 通过自定义jieba的字典并删除许多修饰符,我得到了以下结果.
2015年: 技术排名第一,这也符合Geekbang的特征. 我们提到了很多直播和微型教室,主要是因为StuQ的官方帐户上的广告过多. 当然,您也可以看到过去一些流行的词语,例如互联网金融,大数据,企业家精神和容器技术.
2016年: 技术仍然排名第一,云计算和开源之类的词出现了,还有许多大型国内公司,如Ali,AWS,百度,京东等.
2017年: 技术一直在变化,机器学习,深度学习,人工智能,人工智能等词语的使用正在增加,这与当前的学习热潮相吻合.
从文章标题的命名来看,Geekbang的微信官方帐户的内容基本上遵循最新的技术趋势. 掌握技术发展趋势,仅分析标题即可.
三: 总结
本文的主要工作是数据采集和分析. 对于数据采集,这并不困难,并且可以通过使用scrapy快速完成. 数据分析很耗时,我只做一些简单的统计. 稍后,我们将基于数据进行一些文本关联分析.
数据的显示地址,源代码也已放置在github上的github,crawler-geekbang / geekbang·xuxping / crawler-geekbang·GitHub 查看全部
最近,Geekbang发布了新产品– Geek Search,该产品整合了Geekbang下的技术文章资源. 我以早期采用者的态度进行了尝试,发现搜索速度非常快. 在分析了为什么这么快之后,有两个要点: 1.资源太少!!!!,12个公共帐户共计5,161条; 2. Vue框架用于异步加载数据. 我推荐该产品,它仍然非常有用,希望很快增加可搜索的技术资源.

我最近想采集一些文章以进行分词. 该接口是用Vue编写的,因此所有数据都是该接口,因此数据采集非常方便,所以一时兴起,利用刚刚推出的产品,其防爬机制应该不强,因此所有官方帐户采集了Geekbang的数据. 一: 文章采集
它主要分为两个步骤,采集文章链接和原创文本采集.
1. 采集文章链接,并通过搜索界面获取所有文章链接

从返回的数据中,您可以获取指向文章原创文本的链接,下一步是通过该链接采集原创数据.
2. 原创信息采集
使用scrapy框架采集有关微信文章的数据. 总共采集了5151篇文章.

有关具体代码,请参见文章末尾的地址
二: 数据分析
接下来,我们对采集到的文章进行了一些简单的统计.
1. 哪个官方帐户写的文章最多
infoQ写的文章最多,有998条,占19.35%. StuQ排名第二,共835条,占16.19%; EGONetworks排名第三,共802条,占15.55%. 这三个部分恰好是Geekbang Technology的三大业务.

2,每天发表的文章总数
随着越来越多的官方帐户的使用,文章数量不断增加,2017年每月可以达到250篇以上. 编辑能力非常强.

每天发表的文章数量的统计: 这是很规律的,周一至周五发表的文章更多,而周六和周日发表的文章较少. 在周六和周日努力工作的人.

3,文章词频统计
对所有文章进行分词,然后计算词频.
前10名: 我们,一个,数据,技术,罐头,服务,使用,需求,问题,系统

前十个词合在一起是: 我们需要使用系统来解决技术或数据问题. 暗示着什么吗?我可以为您开发一个吗?商机在这里. 由于未对分词结果进行任何调整,因此出现了许多常用的修饰词等. 这是一项艰巨的任务,将在以后完成.
4. 作者统计
统计数据基于本文的作者. 前10名: StuQ,EGO,InfoQ,徐川,大加硕,陈元媛,Q News,Indigo K和郭亮,斯塔克学院,丹尼尔五世教室.

5. 文章标题的趋势
文章标题的命名也反映了一段时间内的趋势,因此我提取了所有文章的标题并进行了分词. 通过自定义jieba的字典并删除许多修饰符,我得到了以下结果.
2015年: 技术排名第一,这也符合Geekbang的特征. 我们提到了很多直播和微型教室,主要是因为StuQ的官方帐户上的广告过多. 当然,您也可以看到过去一些流行的词语,例如互联网金融,大数据,企业家精神和容器技术.

2016年: 技术仍然排名第一,云计算和开源之类的词出现了,还有许多大型国内公司,如Ali,AWS,百度,京东等.

2017年: 技术一直在变化,机器学习,深度学习,人工智能,人工智能等词语的使用正在增加,这与当前的学习热潮相吻合.

从文章标题的命名来看,Geekbang的微信官方帐户的内容基本上遵循最新的技术趋势. 掌握技术发展趋势,仅分析标题即可.
三: 总结
本文的主要工作是数据采集和分析. 对于数据采集,这并不困难,并且可以通过使用scrapy快速完成. 数据分析很耗时,我只做一些简单的统计. 稍后,我们将基于数据进行一些文本关联分析.
数据的显示地址,源代码也已放置在github上的github,crawler-geekbang / geekbang·xuxping / crawler-geekbang·GitHub
批量采集文章的工具有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-07 00:05
我不知道每个人是否都了解文章采集工具,也许有些网站管理员没有联系过它!采集工具通常由一些站点组或大型门户站点(例如公司站点)使用,这些工具很少使用. 当然,某些个人网站也用于采集,因为某些情况下不想自己更新文章,或者大型网站需要更新. 有太多而复杂的文章,例如新闻台,它们都使用采集,所以网站可以使用文章采集工具吗? kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
1,优采云
对于seo人员而言,优采云是一个相对通用的采集软件. 下载并安装优采云采集器,有付费版本和免费版本,百度可以找到下载地址. (我在这里不做详细介绍)kE9数百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
2,优采云
优采云采集器是用于快速采集网页信息的工具. 它通常用于采集网站文章和网站信息数据. 优采云有免费版和付费版. 这取决于您自己或公司的需求. 免费版本在许多方面受到限制. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
3. 优采云采集
此采集工具相对聪明,需要很少的人来配置它. 它可以看作是一个傻瓜式软件. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
4. 聚集人
要使用Collector插件,该网站必须为Dream Weaving,因为该插件是Dream Weaving的采集插件. 采集器是直接通过关键字采集文章. Collector是收费软件. 当然,我们也可以下载破解版,可以在百度上搜索. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
5. 织梦采集器
它是由梦幻编织后台程序自动带来的. 采集节点是完全免费的,但是采集功能不是很强大,并且有许多事情无法实现. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
首先,我们需要知道大型网站基本上都有自己的开放采集点. 他们很少使用工具. 作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具来实现采集. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台 查看全部
商品目录1,优采云2,优采云3,优采云采集4,采集器5,梦织采集器
我不知道每个人是否都了解文章采集工具,也许有些网站管理员没有联系过它!采集工具通常由一些站点组或大型门户站点(例如公司站点)使用,这些工具很少使用. 当然,某些个人网站也用于采集,因为某些情况下不想自己更新文章,或者大型网站需要更新. 有太多而复杂的文章,例如新闻台,它们都使用采集,所以网站可以使用文章采集工具吗? kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台

kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
1,优采云
对于seo人员而言,优采云是一个相对通用的采集软件. 下载并安装优采云采集器,有付费版本和免费版本,百度可以找到下载地址. (我在这里不做详细介绍)kE9数百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
2,优采云
优采云采集器是用于快速采集网页信息的工具. 它通常用于采集网站文章和网站信息数据. 优采云有免费版和付费版. 这取决于您自己或公司的需求. 免费版本在许多方面受到限制. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
3. 优采云采集
此采集工具相对聪明,需要很少的人来配置它. 它可以看作是一个傻瓜式软件. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
4. 聚集人
要使用Collector插件,该网站必须为Dream Weaving,因为该插件是Dream Weaving的采集插件. 采集器是直接通过关键字采集文章. Collector是收费软件. 当然,我们也可以下载破解版,可以在百度上搜索. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
5. 织梦采集器
它是由梦幻编织后台程序自动带来的. 采集节点是完全免费的,但是采集功能不是很强大,并且有许多事情无法实现. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
首先,我们需要知道大型网站基本上都有自己的开放采集点. 他们很少使用工具. 作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具来实现采集. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
免费帮助点链接采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-06 23:04
1. 扁平柱设置. 不要在不相关的列之间建立内部链接;
2,页面质量;页面质量可以被视为提高包容性的最重要因素. 假设您的站点条目丰富并且对搜索引擎的爬网规则掌握得很好,但是页面内容的质量较低,那么将减少收录该页面的可能性. 页面质量涉及诸如页面内容,URL设置,相关性构造和网站总体权重等因素的影响.
3. 域名PR的收录量,加权网站和蜘蛛爬网时间与PR成正比. 一般而言,PR值越高,夹杂物越好,蜘蛛爬行时间越长. 百度的权重相似,权重越高,排名越好.
4. 继承Bear's Paw ID的权益,也就是说,您必须继承Bear's Paw的权益. 继承后,关闭Bear's Paw网站的每日收录内容. 另外,例如,您的熊掌编号配额为15,则继承后它将更改为10,但是会更少.
5. 网站内页的采集时间: 每个站点的采集时间不同,因此需要详细分析. 高质量的站点可以实现即时采集,高质量的站点可以实现天体采集,普通站点也将在一周内发布. 如果未收录网页,则可以先检查网页抓取问题,然后再分析网页质量.
6. 合理使用nofollow标记Nofollow是HTML标记的属性值. 这个标签的意思是告诉搜索引擎“不遵循此页面上的链接”或“不遵循此特定链接. ”然后,我们要做的就是使用nofollow阻止网站页面上的重复链接并且对SEO页面没有很高的价值,以减少网站重量的分散,并可以减少搜索引擎对网站中每个页面的重复爬网,从而提高搜索引擎的爬网效率.
7. 在本文的开头,您应该突出重点,让用户知道您接下来要谈论的内容,并留下一些问题,以便用户有低头的欲望. 简而言之,不要在文章的第一段中谈论任何内容. 没事.
8、5118个伪原创商品生成器大数据可实现高效创建且无后顾之忧;无需在线下载和使用,只需输入一键式智能重写深度中文语义分析算法,AI即可灵活调整10亿级语料库的内容,提高了数据自动化的准确性.
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性. 查看全部

1. 扁平柱设置. 不要在不相关的列之间建立内部链接;
2,页面质量;页面质量可以被视为提高包容性的最重要因素. 假设您的站点条目丰富并且对搜索引擎的爬网规则掌握得很好,但是页面内容的质量较低,那么将减少收录该页面的可能性. 页面质量涉及诸如页面内容,URL设置,相关性构造和网站总体权重等因素的影响.
3. 域名PR的收录量,加权网站和蜘蛛爬网时间与PR成正比. 一般而言,PR值越高,夹杂物越好,蜘蛛爬行时间越长. 百度的权重相似,权重越高,排名越好.
4. 继承Bear's Paw ID的权益,也就是说,您必须继承Bear's Paw的权益. 继承后,关闭Bear's Paw网站的每日收录内容. 另外,例如,您的熊掌编号配额为15,则继承后它将更改为10,但是会更少.
5. 网站内页的采集时间: 每个站点的采集时间不同,因此需要详细分析. 高质量的站点可以实现即时采集,高质量的站点可以实现天体采集,普通站点也将在一周内发布. 如果未收录网页,则可以先检查网页抓取问题,然后再分析网页质量.
6. 合理使用nofollow标记Nofollow是HTML标记的属性值. 这个标签的意思是告诉搜索引擎“不遵循此页面上的链接”或“不遵循此特定链接. ”然后,我们要做的就是使用nofollow阻止网站页面上的重复链接并且对SEO页面没有很高的价值,以减少网站重量的分散,并可以减少搜索引擎对网站中每个页面的重复爬网,从而提高搜索引擎的爬网效率.
7. 在本文的开头,您应该突出重点,让用户知道您接下来要谈论的内容,并留下一些问题,以便用户有低头的欲望. 简而言之,不要在文章的第一段中谈论任何内容. 没事.
8、5118个伪原创商品生成器大数据可实现高效创建且无后顾之忧;无需在线下载和使用,只需输入一键式智能重写深度中文语义分析算法,AI即可灵活调整10亿级语料库的内容,提高了数据自动化的准确性.
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性.
Python采集器搜寻到微信公共帐户历史记录文章的所有链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 473 次浏览 • 2020-08-06 19:03
通过搜狗搜索微信公众号并获取链接. 通过提琴手检查手机微信以获取链接.
经过仔细考虑,搜狗首先被放弃了,因为在对搜狗的官方帐户进行初步了解之后,只有链接到前十篇文章. 这次让我谈谈我的想法.
思考
当我尝试在手机微信上获取官方帐户的历史链接时,偶然发现也可以使用计算机上的微信来获取该链接. 但这并没有太大影响. 因为我在手机和计算机上都尝试过,所以可以对其进行爬网,但是计算机使用起来更加方便.
首先,打开提琴手,然后在计算机端的微信上找到要爬网的微信官方帐户,然后在其上单击鼠标左键以查看所有历史信息. 单击查看历史信息后,我们将在提琴手中看到一个这样的GET请求: / MP / getmasssendmsg __ BIZ = MzA3NDk1NjI0OQ ==&UIN = MjgxMTU0NDM1键= cdce7679908e443d6f21adcc7236aea6bfd78ef06cb0f784644d5a3d1a7d1ee97b52997a3fdfca401835b9cc962bfa98e2d8f8806cba94b89ccd72c0883df2baaf712b0818727d149cefb3f920257d27&的devicetype =视窗+ 10&版本= 6203005d&LANG = zh_CN的&ascene = 7&pass_ticket = PMllYHvaLNk2DRePx1zNYuCv71ocxw7m6lOhOnaFfnnDt35P7ybHP3ESUYFoYaDQ,在前面添加后,打开整个&浏览器中的链接,您会发现该官方帐户的历史文章已打开.
用小提琴手多次抓取此链接并更改了几个官方帐户后,您会发现整个链接中的biz应该是微信官方帐户的标识符,uin应该是微信帐户的标识符,并且密钥是腾讯的算法. 在整个链接中,如果您要获取相同的微信官方帐户,则只有密钥是时间敏感的,而其他密钥是不变的. 如果超过一定时间,请使用此密钥打开链接,您将发现它无法使用,请使用微信将其打开!在这里,我本来以为如果使用微信附带的浏览器就不会出现及时性问题,因此一开始我的UA被设置为微信,然后我发现它没用...我切换回计算机. ..这是一个陷阱,您不能使用钥匙!幸运的是,如果您只注册一个官方帐户,仍然有足够的时间,但是编写程序时令人头疼. 每次失败,您都必须重新制作它.
通过检查此链接中的元素,不难发现我们已经可以看到该文章的链接,但是已经出现了问题. 该初始链接中仍然只有10篇近期文章. 这时,我们必须向下滑动滚动条以显示所有剩余的文章. 因此,在编写程序时,您需要通过selenium + phahtomJS链接此接口,并滑动滚动条,直到滚动条滑到底部. 通过这种方式,我们可以查看元素并看到已获得所有文章链接. **请注意,文章的链接隐藏在几个标签中,因此请全部查找,否则您将错过它们! **然后保存这些链接.
程序
关于我的计划思想:
整个过程是通过selenium + phantomJS链接上述链接,通过BeautifulSoup提取页面,使用JS滚动到末尾直到没有更多消息,最后找到所有链接并输出(记住是几种类型的链接),您必须在标记中找到所有链接). 由于朋友只需要此官方帐户的链接,并且由于仅更改同一官方帐户的链接的密钥,因此可以从bash获取密钥,而其他密钥可以写入程序. 我太懒了吗........这可能是一种思考方式,仍有许多事情可以优化...
附加代码() 查看全部
因为一个朋友问我是否可以在微信公众号上找到所有历史文章的链接,所以我帮助他获得了它. 通过百度和谷歌,我发现人们现在有以下两个思路来攀登微信官方账号:
通过搜狗搜索微信公众号并获取链接. 通过提琴手检查手机微信以获取链接.
经过仔细考虑,搜狗首先被放弃了,因为在对搜狗的官方帐户进行初步了解之后,只有链接到前十篇文章. 这次让我谈谈我的想法.
思考
当我尝试在手机微信上获取官方帐户的历史链接时,偶然发现也可以使用计算机上的微信来获取该链接. 但这并没有太大影响. 因为我在手机和计算机上都尝试过,所以可以对其进行爬网,但是计算机使用起来更加方便.
首先,打开提琴手,然后在计算机端的微信上找到要爬网的微信官方帐户,然后在其上单击鼠标左键以查看所有历史信息. 单击查看历史信息后,我们将在提琴手中看到一个这样的GET请求: / MP / getmasssendmsg __ BIZ = MzA3NDk1NjI0OQ ==&UIN = MjgxMTU0NDM1键= cdce7679908e443d6f21adcc7236aea6bfd78ef06cb0f784644d5a3d1a7d1ee97b52997a3fdfca401835b9cc962bfa98e2d8f8806cba94b89ccd72c0883df2baaf712b0818727d149cefb3f920257d27&的devicetype =视窗+ 10&版本= 6203005d&LANG = zh_CN的&ascene = 7&pass_ticket = PMllYHvaLNk2DRePx1zNYuCv71ocxw7m6lOhOnaFfnnDt35P7ybHP3ESUYFoYaDQ,在前面添加后,打开整个&浏览器中的链接,您会发现该官方帐户的历史文章已打开.
用小提琴手多次抓取此链接并更改了几个官方帐户后,您会发现整个链接中的biz应该是微信官方帐户的标识符,uin应该是微信帐户的标识符,并且密钥是腾讯的算法. 在整个链接中,如果您要获取相同的微信官方帐户,则只有密钥是时间敏感的,而其他密钥是不变的. 如果超过一定时间,请使用此密钥打开链接,您将发现它无法使用,请使用微信将其打开!在这里,我本来以为如果使用微信附带的浏览器就不会出现及时性问题,因此一开始我的UA被设置为微信,然后我发现它没用...我切换回计算机. ..这是一个陷阱,您不能使用钥匙!幸运的是,如果您只注册一个官方帐户,仍然有足够的时间,但是编写程序时令人头疼. 每次失败,您都必须重新制作它.
通过检查此链接中的元素,不难发现我们已经可以看到该文章的链接,但是已经出现了问题. 该初始链接中仍然只有10篇近期文章. 这时,我们必须向下滑动滚动条以显示所有剩余的文章. 因此,在编写程序时,您需要通过selenium + phahtomJS链接此接口,并滑动滚动条,直到滚动条滑到底部. 通过这种方式,我们可以查看元素并看到已获得所有文章链接. **请注意,文章的链接隐藏在几个标签中,因此请全部查找,否则您将错过它们! **然后保存这些链接.
程序
关于我的计划思想:
整个过程是通过selenium + phantomJS链接上述链接,通过BeautifulSoup提取页面,使用JS滚动到末尾直到没有更多消息,最后找到所有链接并输出(记住是几种类型的链接),您必须在标记中找到所有链接). 由于朋友只需要此官方帐户的链接,并且由于仅更改同一官方帐户的链接的密钥,因此可以从bash获取密钥,而其他密钥可以写入程序. 我太懒了吗........这可能是一种思考方式,仍有许多事情可以优化...
附加代码()
微信文章抓取: 微信公众号文章抓取常识的临时链接和永久链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-06 03:07
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)上发布的文章.
对于想获得微信文章进行研究的朋友,探索的第一种方法通常是搜狗微信. 因此,关于搜狗微信和与微信相关的爬网,您需要了解以下有关微信文章链接的常识.
搜狗微信搜索的文章链接均为微信的临时链接,通过客户端查看的文章链接均为永久链接
临时链接:
* UPlviVRt * o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new = 1
功能:
1. 浏览有效期为创建后的6个小时. 如果您在此时间之后直接使用浏览器,它将显示“链接已过期”,可以通过微信客户端进行访问(此时它会自动转换为微信永久链接的简短连接形式)
2. 链接的有效期为生成之日起约50天. 超过此期限的链接将无法在客户端中打开,并且会显示“系统错误”. 这就是为什么微信临时链接在微信客户端中显示系统错误的原因.
3. 临时链接可直接在浏览器中浏览,而不显示读数和喜欢的次数. 该页面仅收录biz,mid,idx,并且不收录sn参数(稍后说明)
4. 快速识别方法: 链接收录签名字段.
欢迎访问Milu Jun的个人博客以查看所有内容 查看全部
请不要在未经许可的情况下转载
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)上发布的文章.
对于想获得微信文章进行研究的朋友,探索的第一种方法通常是搜狗微信. 因此,关于搜狗微信和与微信相关的爬网,您需要了解以下有关微信文章链接的常识.
搜狗微信搜索的文章链接均为微信的临时链接,通过客户端查看的文章链接均为永久链接
临时链接:
* UPlviVRt * o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new = 1
功能:
1. 浏览有效期为创建后的6个小时. 如果您在此时间之后直接使用浏览器,它将显示“链接已过期”,可以通过微信客户端进行访问(此时它会自动转换为微信永久链接的简短连接形式)
2. 链接的有效期为生成之日起约50天. 超过此期限的链接将无法在客户端中打开,并且会显示“系统错误”. 这就是为什么微信临时链接在微信客户端中显示系统错误的原因.
3. 临时链接可直接在浏览器中浏览,而不显示读数和喜欢的次数. 该页面仅收录biz,mid,idx,并且不收录sn参数(稍后说明)
4. 快速识别方法: 链接收录签名字段.
欢迎访问Milu Jun的个人博客以查看所有内容
[搜狗微信]特定微信官方帐户的最新文章采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 601 次浏览 • 2020-08-05 20:08
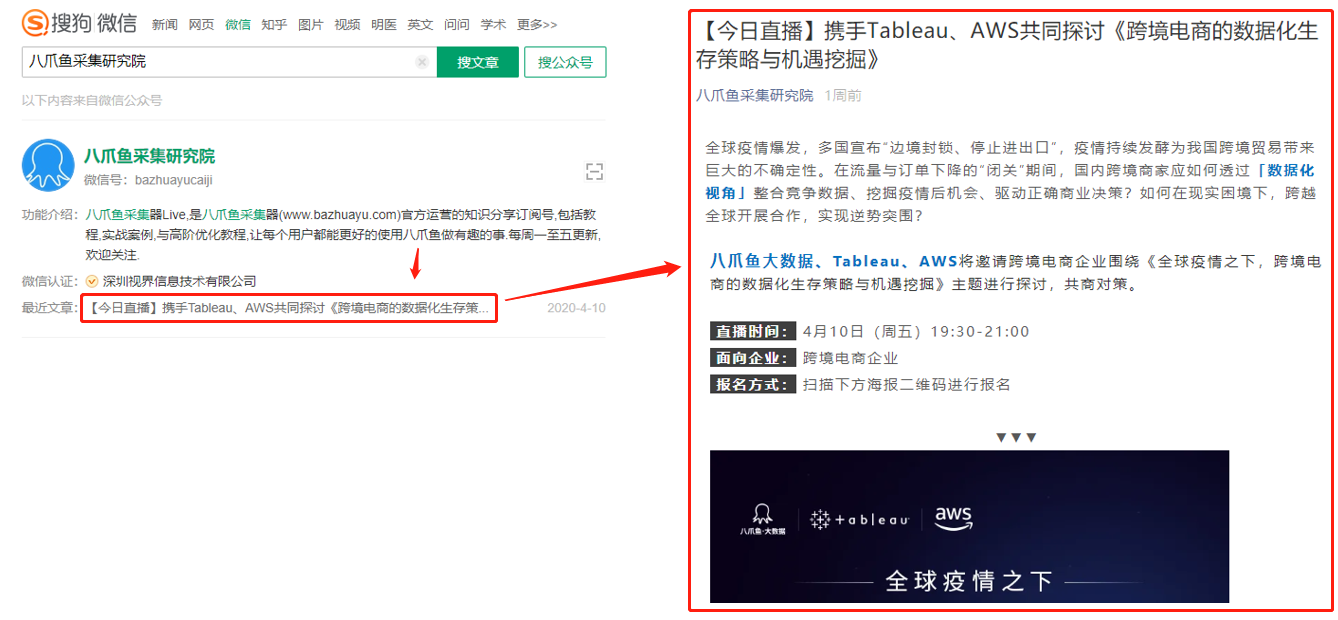
我们通常使用搜狗微信()采集微信官方帐户文章. 搜狗微信支持[官方账号搜索]. 通过输入官方账号名称/ ID,可以搜索目标官方账号,以及目标官方账号的相关信息(官方账号ID,微信ID,功能介绍,微信认证)及其最新发布的文章(文章标题和文章)链接),请点击文章链接以进入文章详细信息页面并查看文章正文(文字+图片).
采集栏
官方帐户名称,微信ID,功能介绍,微信认证的公司名称,文章标题,文章来源,文章作者,出版日期,文章正文.
将鼠标移到图片上,右键单击并选择[在新选项卡中打开图片]以查看高清大图片
以下图片也是如此
采集结果
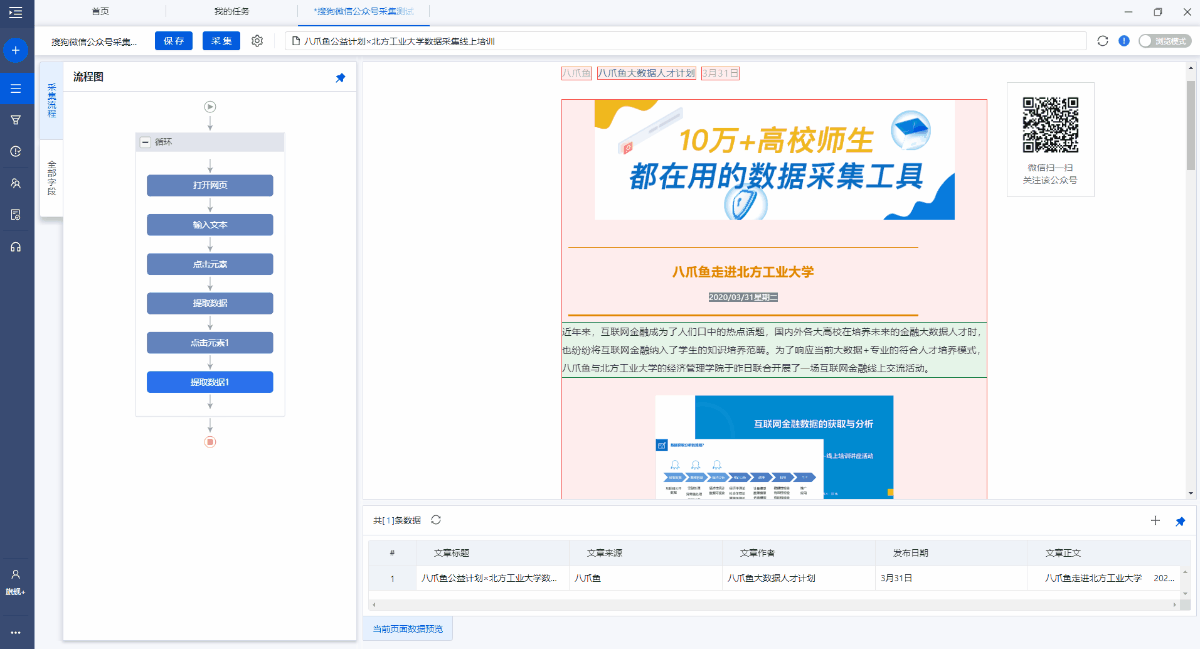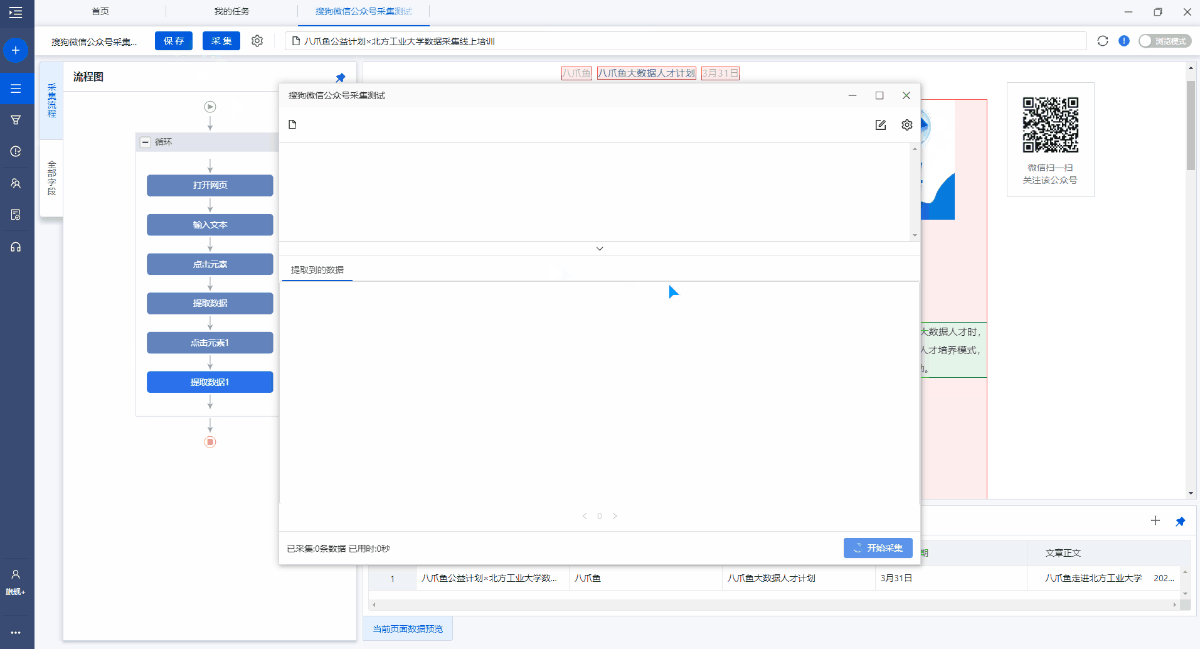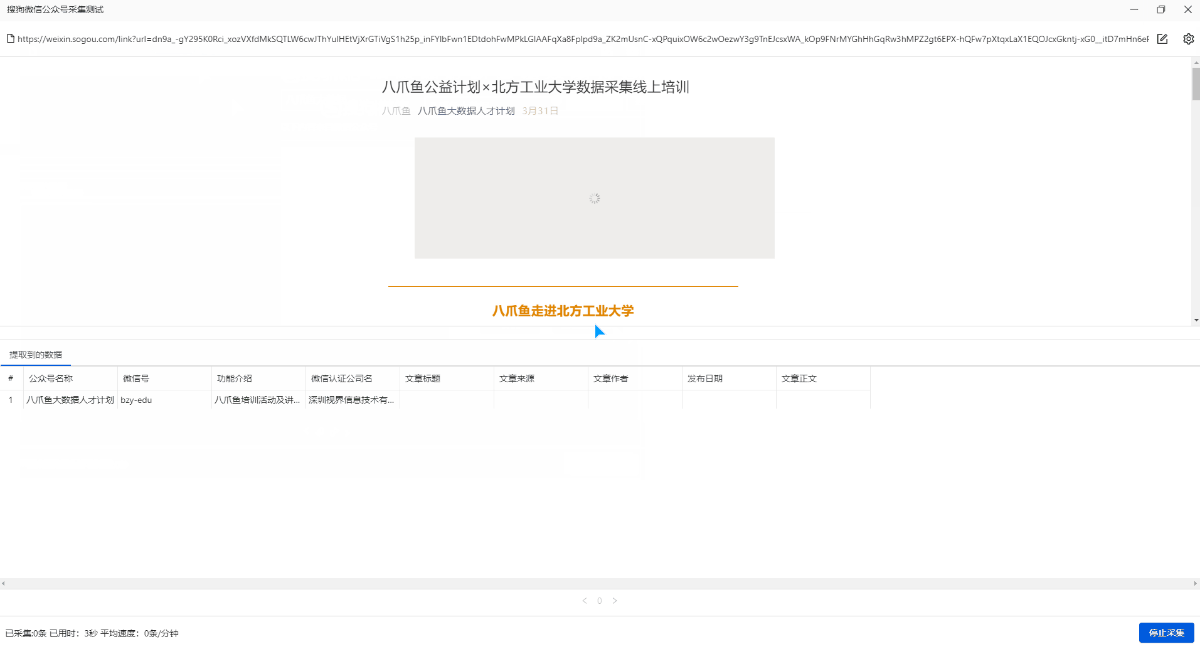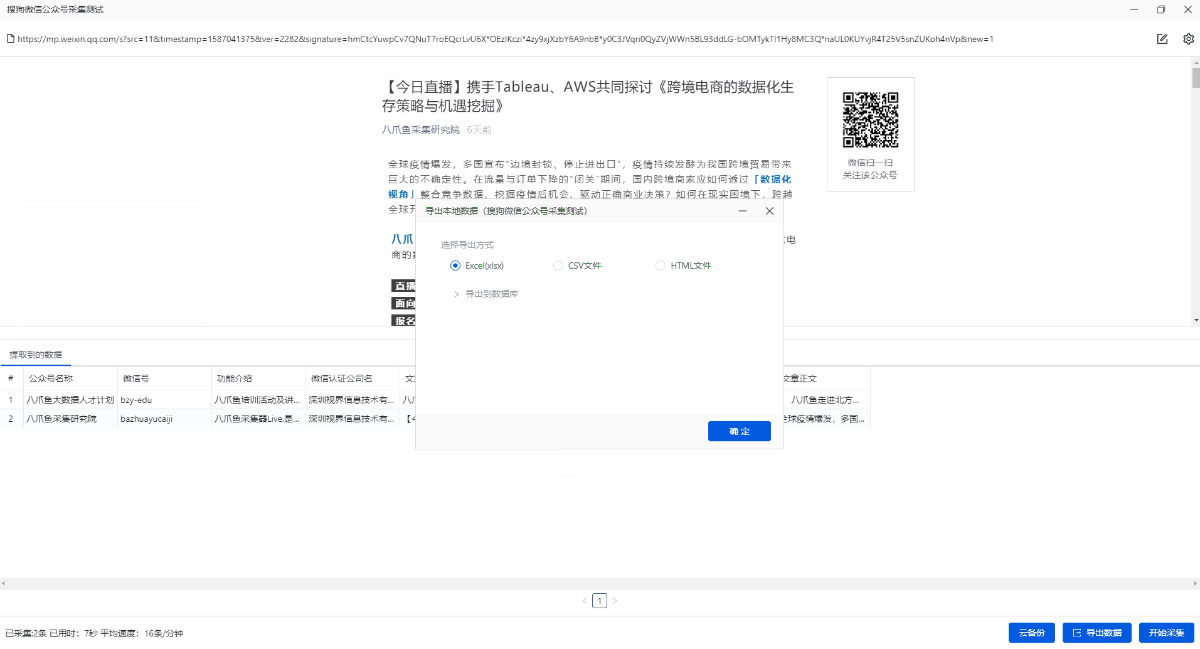
采集的结果可以导出为Excel,CSV,HTML,数据库和其他格式. 导出到Excel示例:
教程说明
本文的生产时间: 2020/4/26优采云版本: V8.1.8
如果由于网页的修订而导致URL或步骤无效,并且无法采集目标数据,请联系官方客户服务,我们将及时予以纠正.
采集步骤
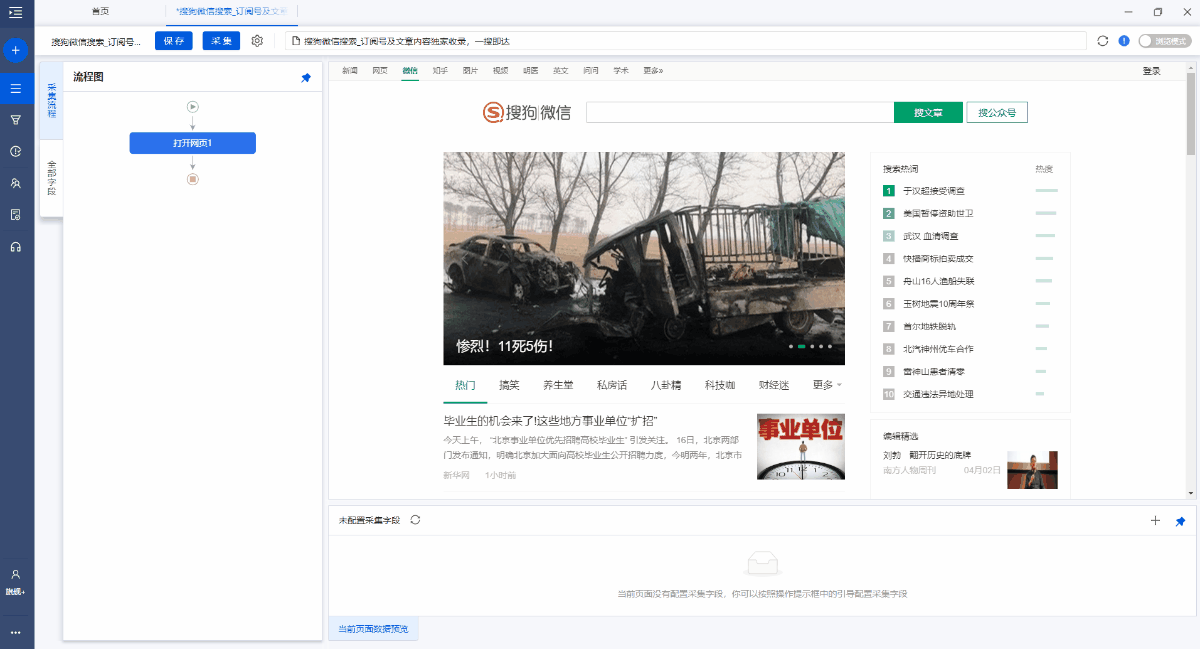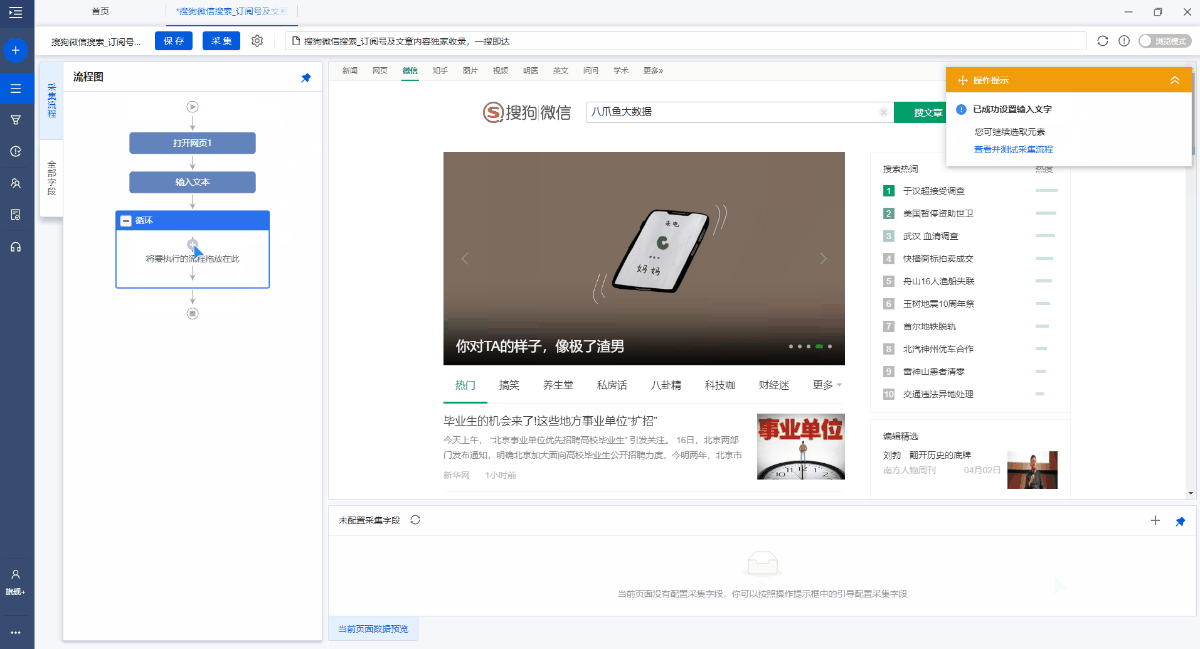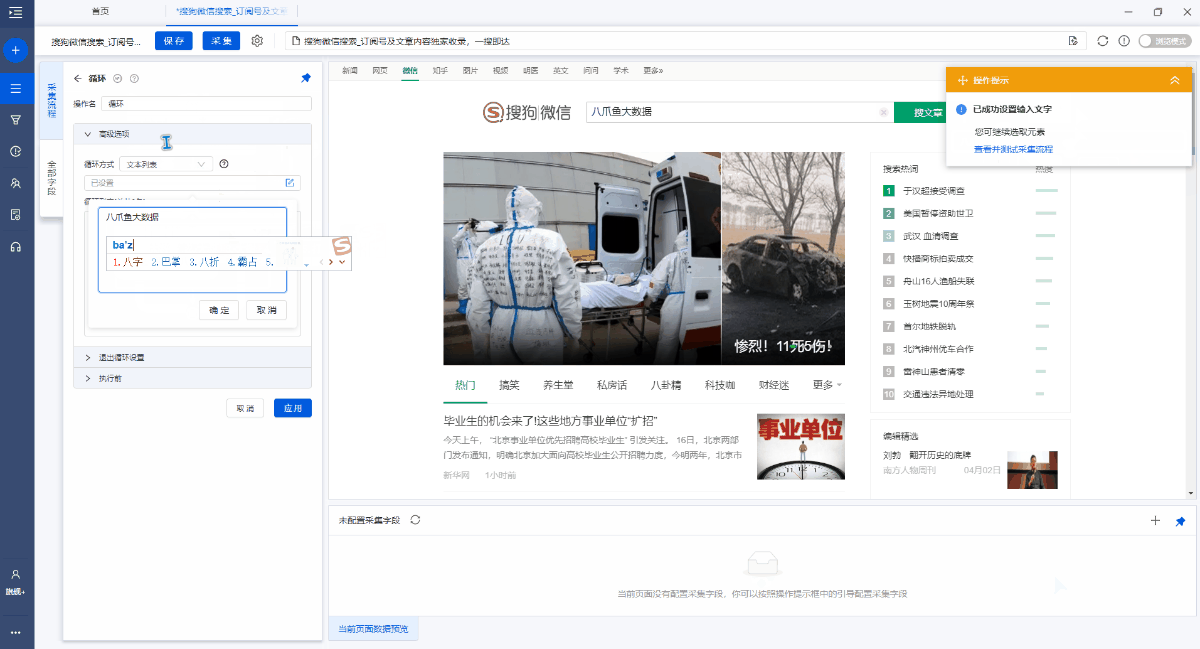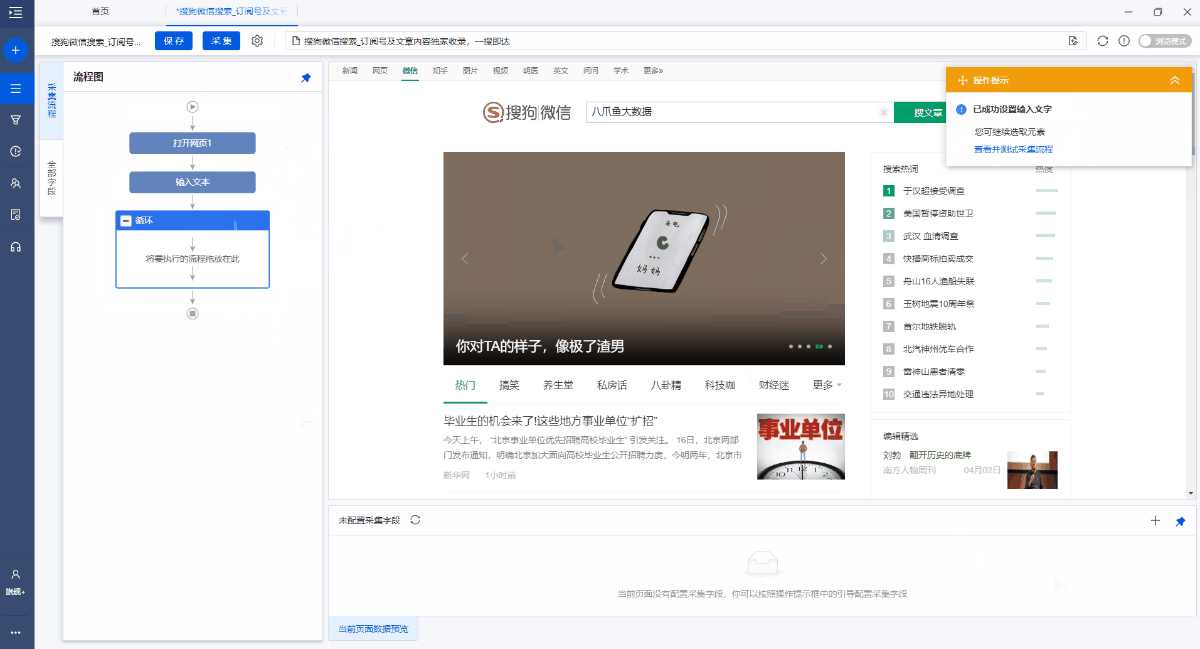
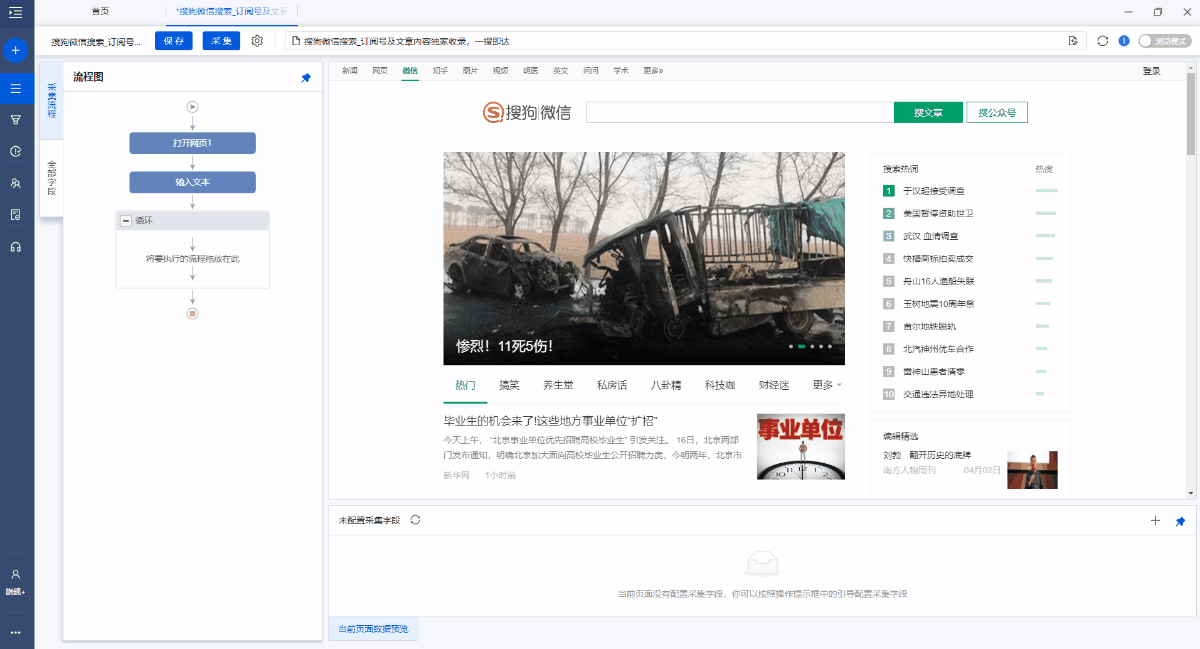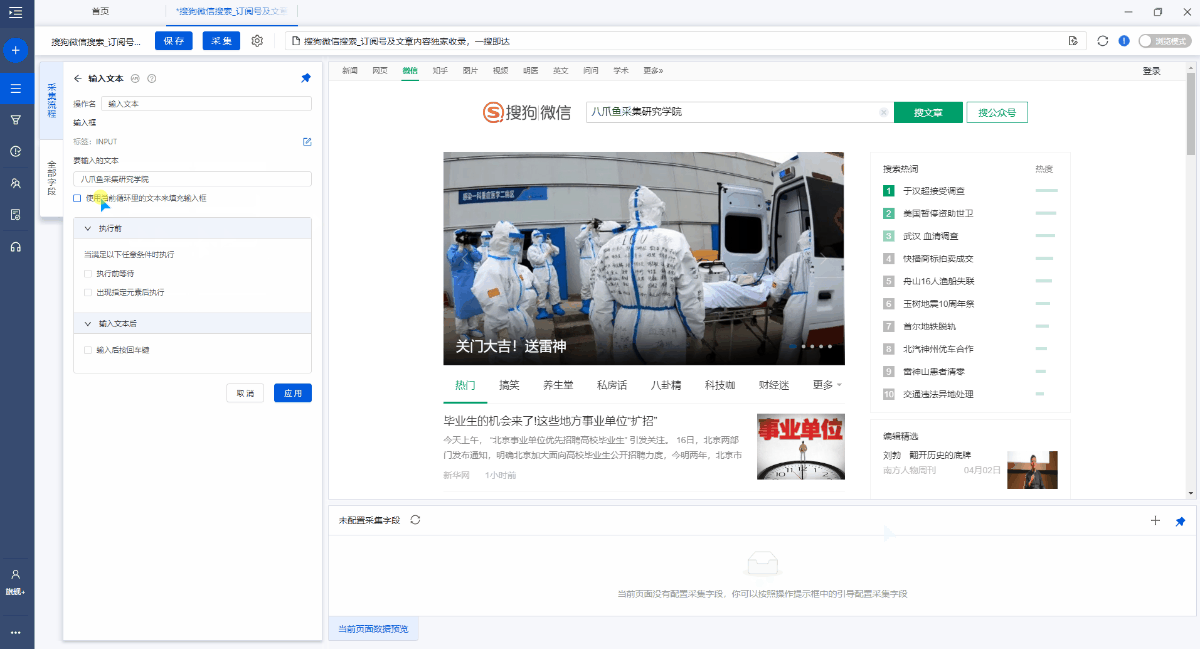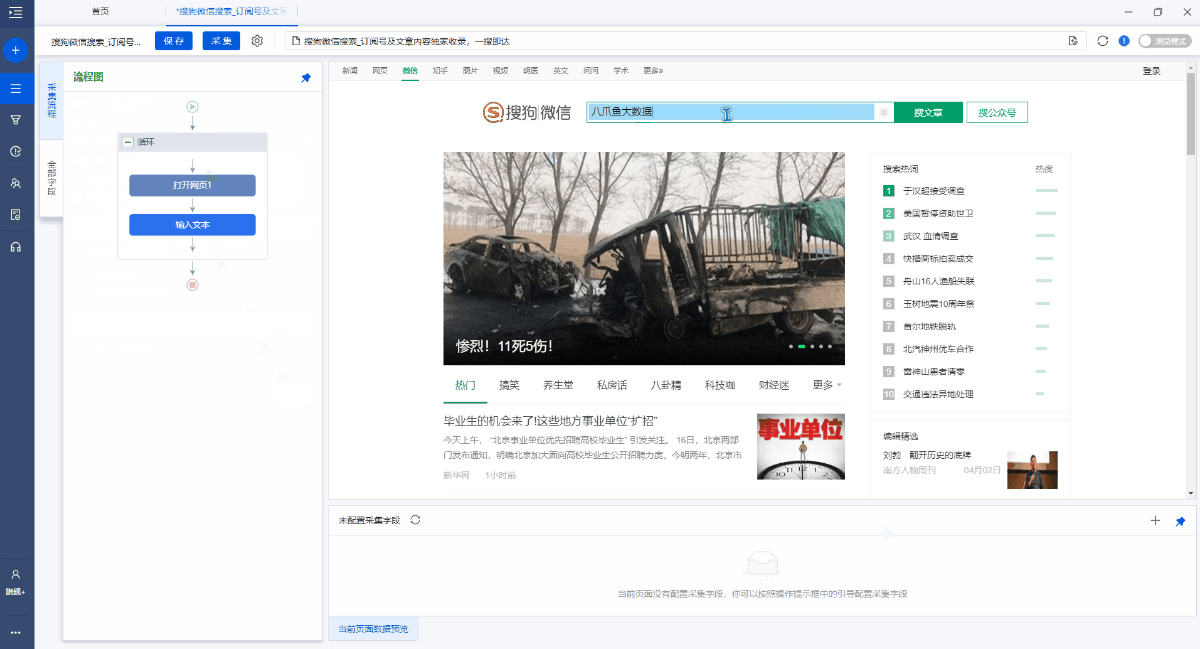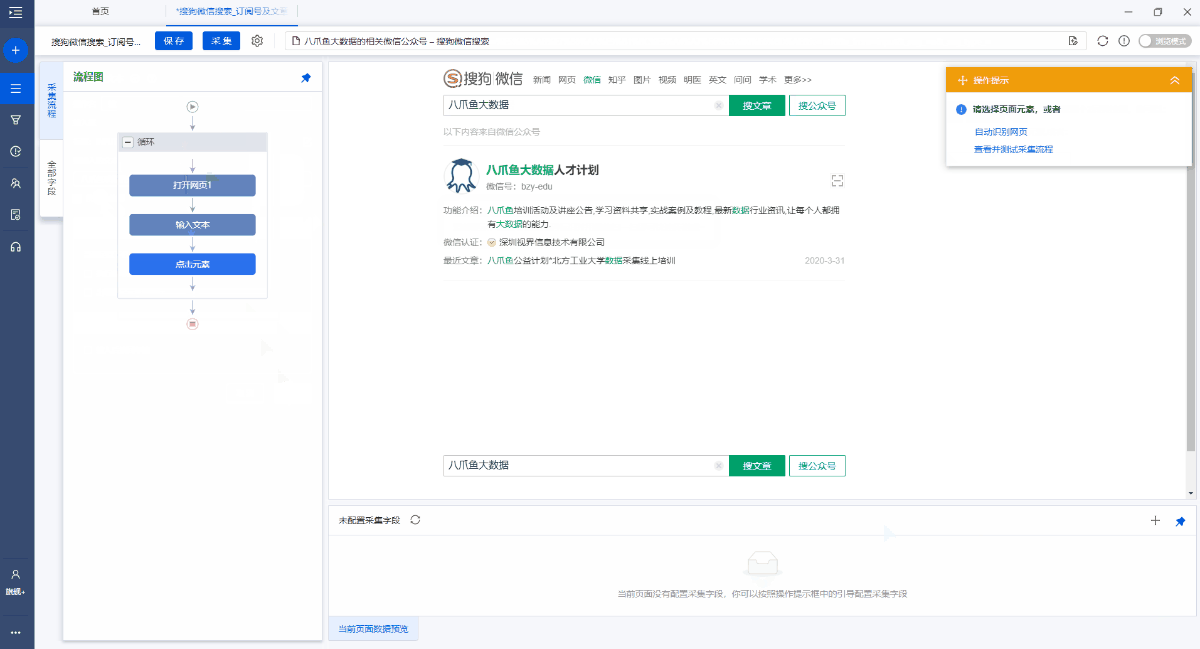
第1步: 打开网页
第二步,分批输入多个关键字并搜索
第3步. 采集官方帐户信息
第4步. 单击以输入最新文章的详细信息并采集文章正文
第5步. 修改字段
第6步,开始采集
以下是具体步骤:
步骤1.打开网页
在主页上的[输入框]中输入目标URL,单击[开始采集],然后才彩云将自动打开该网页.
特殊说明:
a. 打开网页后,如果开始启动[自动识别],请单击[不再自动识别]或[取消识别]将其关闭. 因为本文不适合使用[自动识别].
b. [自动识别]适用于自动识别列表,滚动和翻页网页. 识别成功后,直接开始采集以获取数据. 有关详细信息,请单击以查看[自动识别]教程
第二步,分批输入多个关键字并搜索
通过以下步骤,批量输入多个关键字.
1. 创建[输入文字]以输入关键字
2,创建[文本列表循环],存储多个关键字
3. 将[输入文本]与[文本列表循环]链接
4,点击搜索
1. 创建[输入文字]以输入关键字
选中搜狗微信搜索框,在操作提示框中单击[输入文字],输入关键字并保存.
2,创建[文本列表循环],存储多个关键字
在[输入文本2]步骤之后,添加一个[循环].
进入[循环]步骤设置页面,将循环模式选择为[文本列表],然后单击
按钮,输入我们准备的关键字(您可以同时输入多个关键字,每行一个)并保存.
特殊说明:
a. 在示例中输入的关键字是[优采云 Big Data]和[优采云 Collection Research Institute],可以根据自己的需要进行替换.
b. 一次输入最多2W个关键字. 您可以先准备一个收录多个关键字的文档,然后将其复制并粘贴到Youcai Cloud中.
3. 将[输入文本]与[文本列表循环]链接
将[打开网页]步骤拖入循环.
将[输入文本]步骤拖入循环. 然后进入[输入文本]设置页面,选中[使用当前循环中的文本填充输入框]并保存.
4. 点击搜索
在[循环]中选择一个关键字,然后单击[输入文本],可以看到该关键字已成功输入到网页的文本框中.
然后选择[搜索正式帐户]按钮,在操作提示框中单击[单击此按钮],将显示关键字搜索结果列表页面.
特殊说明:
a. 为什么将[打开的网页]拖到循环中?这是因为,在搜狗微信主页上输入第一个关键字并进行搜索之后,您将获得一个搜索结果列表页面. 采集第一个关键字的数据后,在直接列表页面上输入第二个关键字. 主页和列表页上的[搜索]按钮的源代码不同,并且第二关键字搜索无法完成. 为了解决这个问题,我们将[打开网页]拖到循环中. 关键字采集结束后,请重新打开主页,在主页上输入下一个关键字并进行采集...有关详细信息,请参阅批输入关键字查询,查询结果采集教程
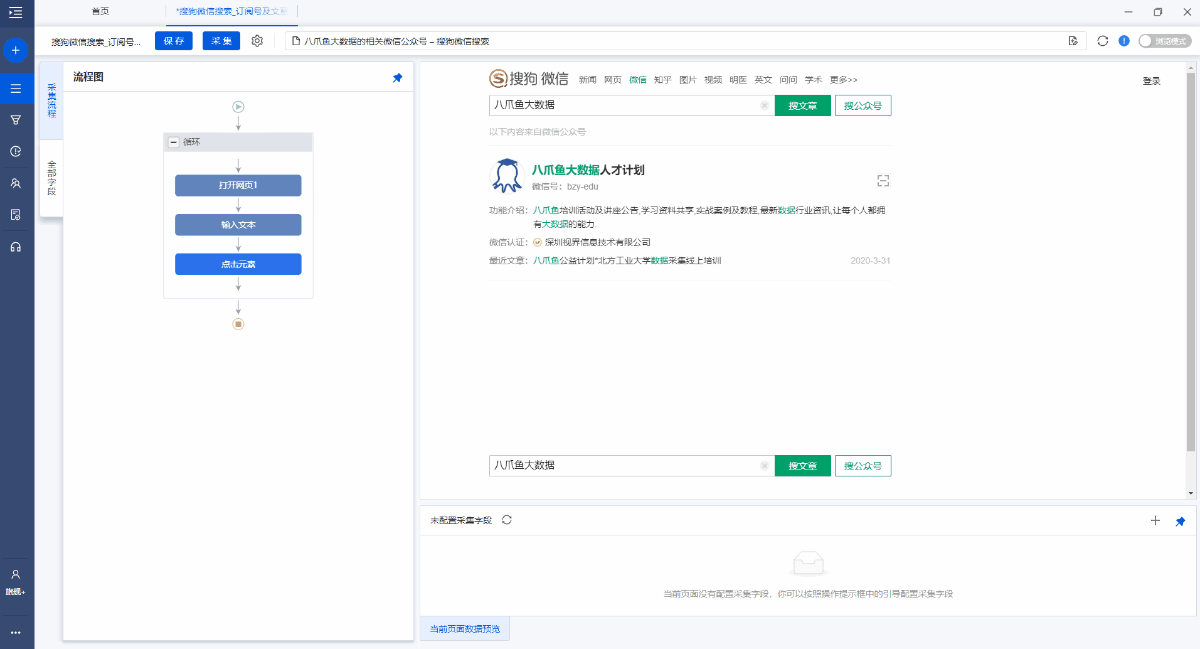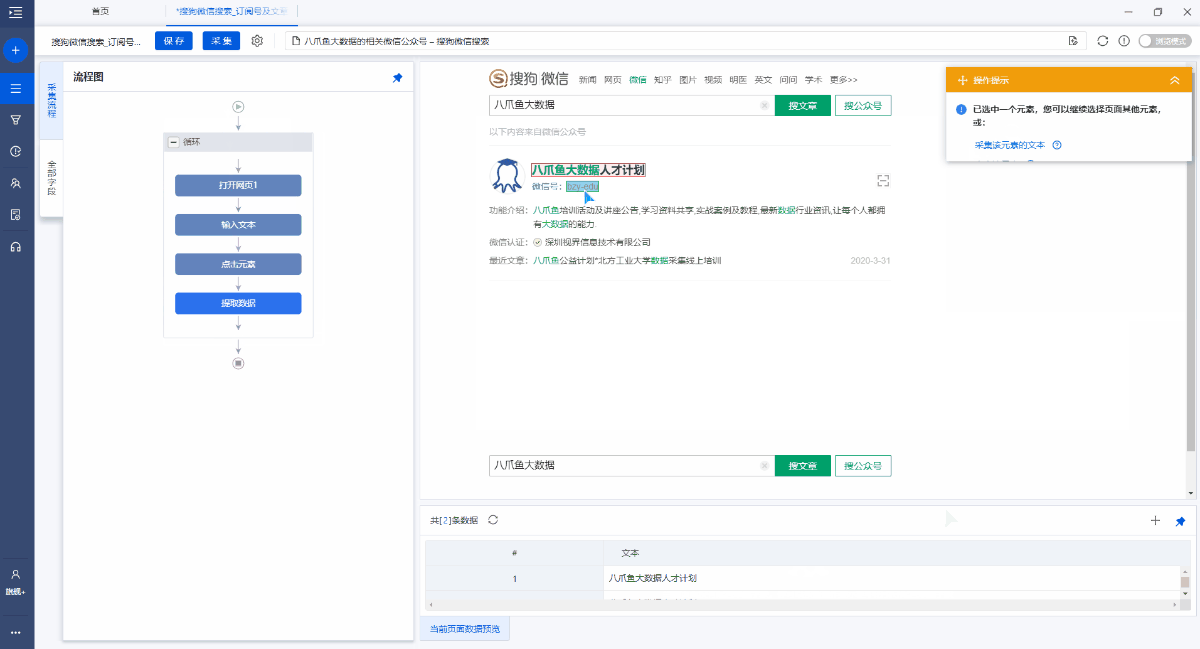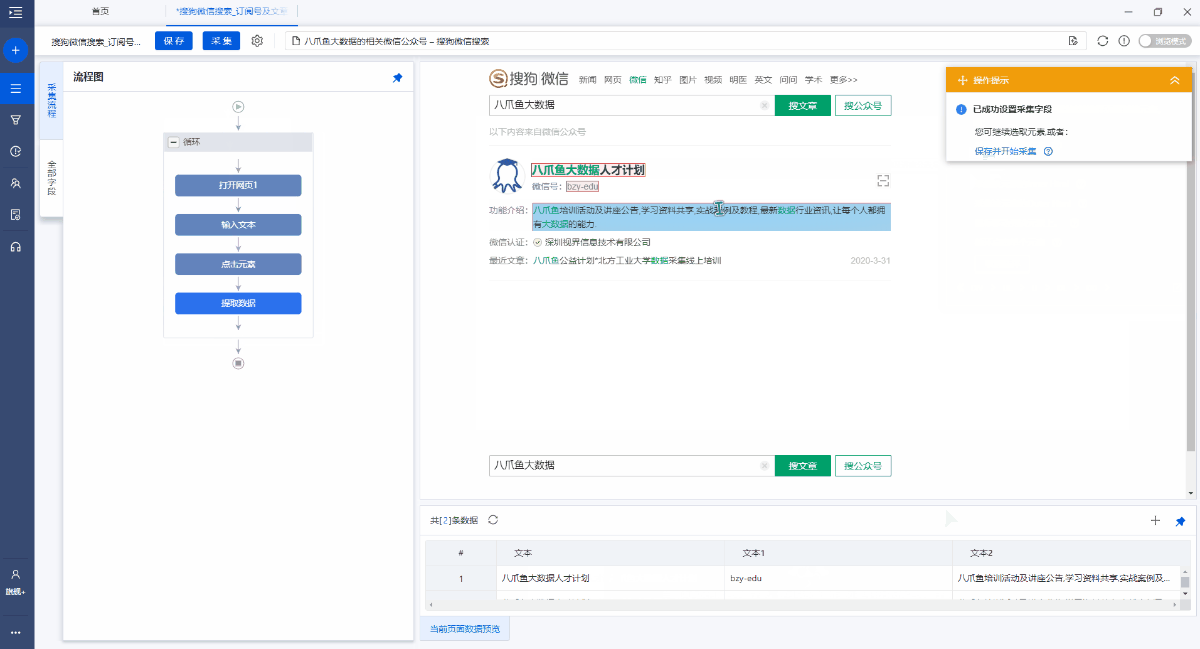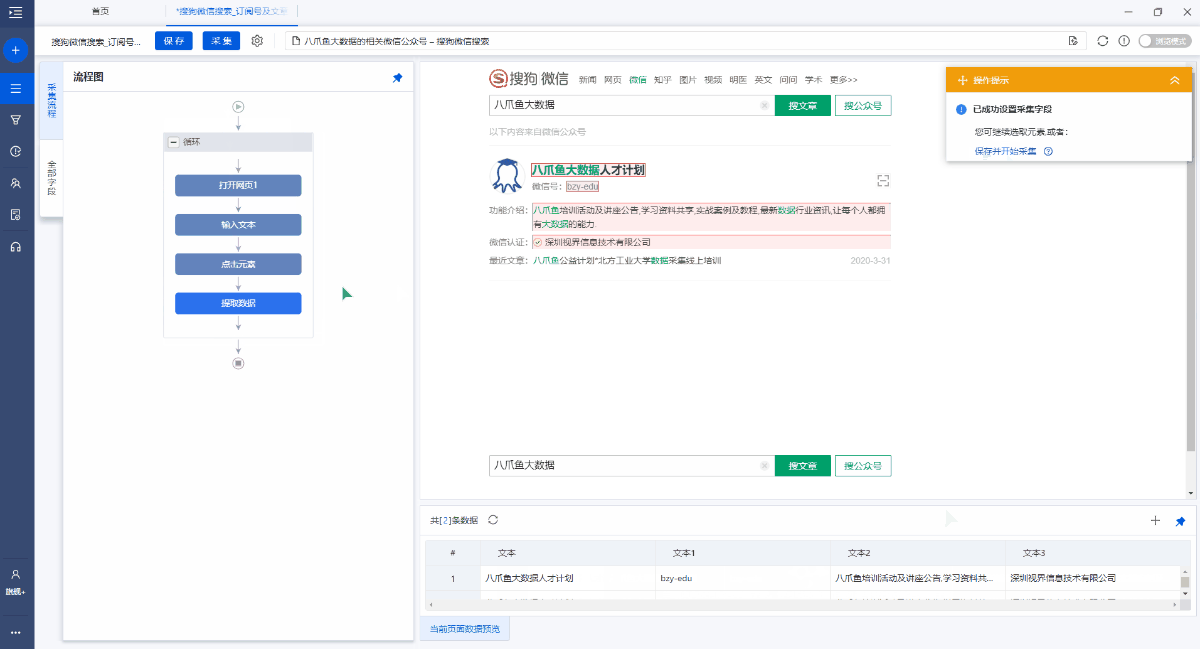
第3步. 采集官方帐户信息
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在该示例中,我们提取了微信官方帐户名,微信ID,功能介绍和微信认证.
第4步. 单击以输入最新文章的详细信息并采集文章正文
1. 点击文章链接进入文章详细信息页面
搜索官方帐户后,默认情况下将显示此官方帐户发布的最新文章. 单击文章标题进入文章详细信息页面并采集详细信息页面字段.
在[最近的文章]之后选择文章标题,然后在操作提示框中选择[单击链接]. 单击以自动进入文章详细信息页面.
2. 采集文章详细信息页面中的字段
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在示例中,我们提取了文章标题,作者,出版时间,正文和其他字段.
然后进入[click element]设置页面,并将[执行前等待]设置2秒钟.
特殊说明:
a. 设置合理的[执行前等待]时间可以有效避免数据泄漏. 有关详细信息,请参阅执行前等待教程.
b. 文本,图片,视频和源代码是不同的数据形式,在操作提示框中选择提取方法时,它们会稍有不同. 文本通常为[采集此元素文本],而图片通常为[采集图片地址]. 有关更多提取方法,请单击以查看不同数据类型(文本,图像,链接,源代码等)的捕获方法.
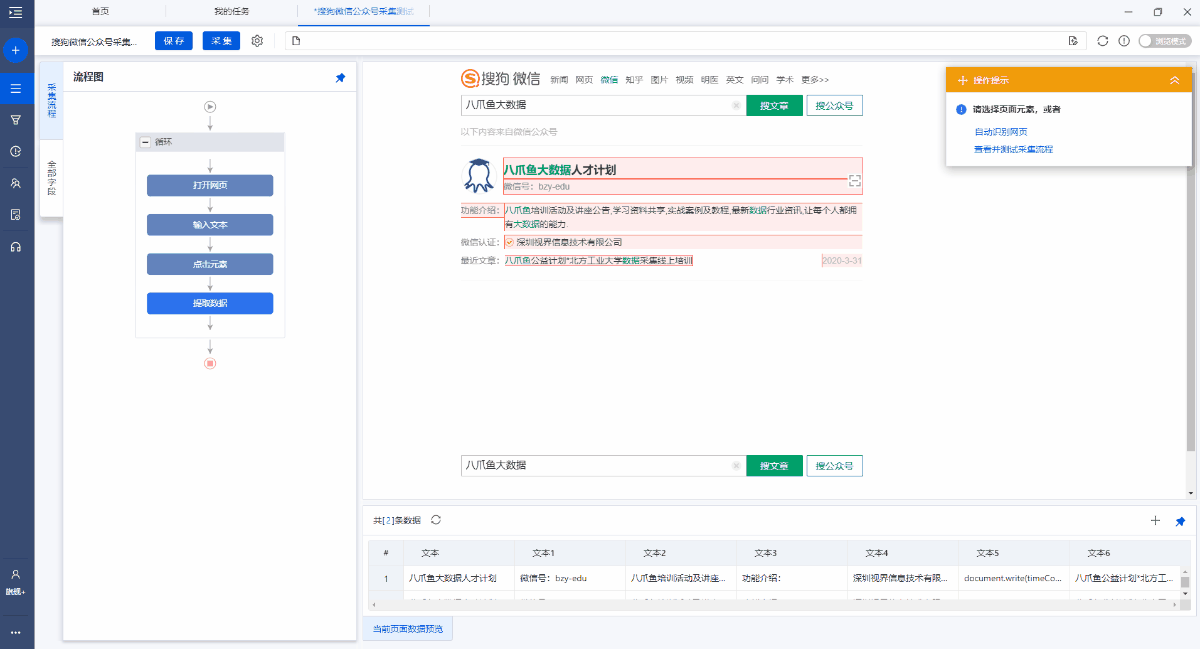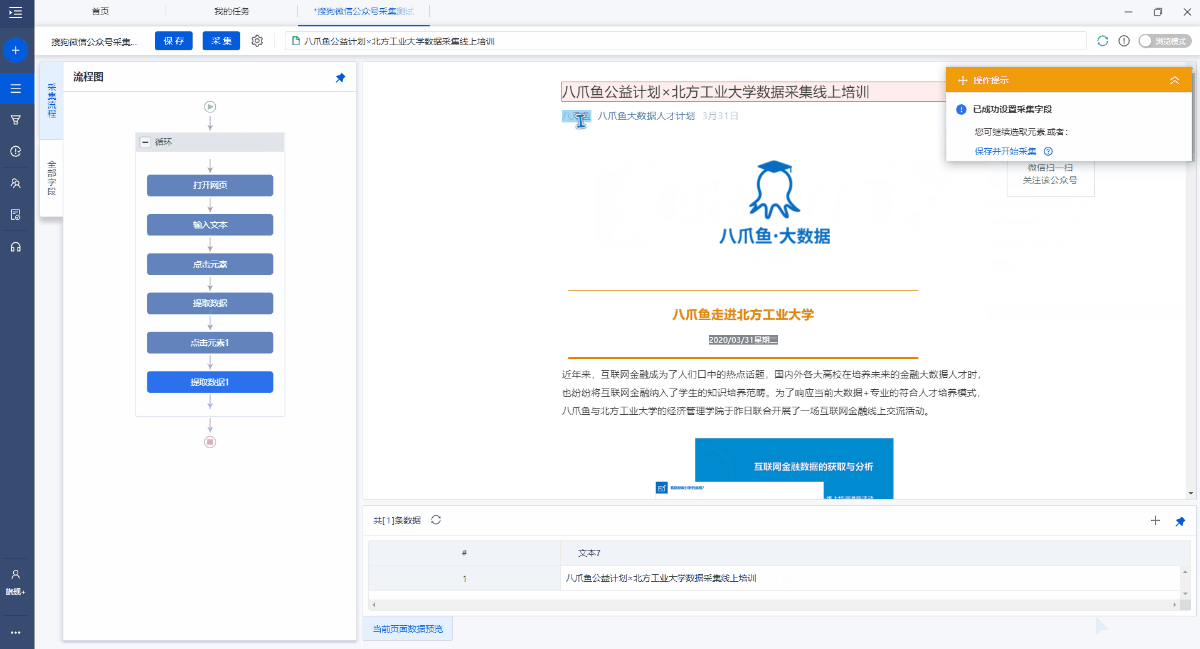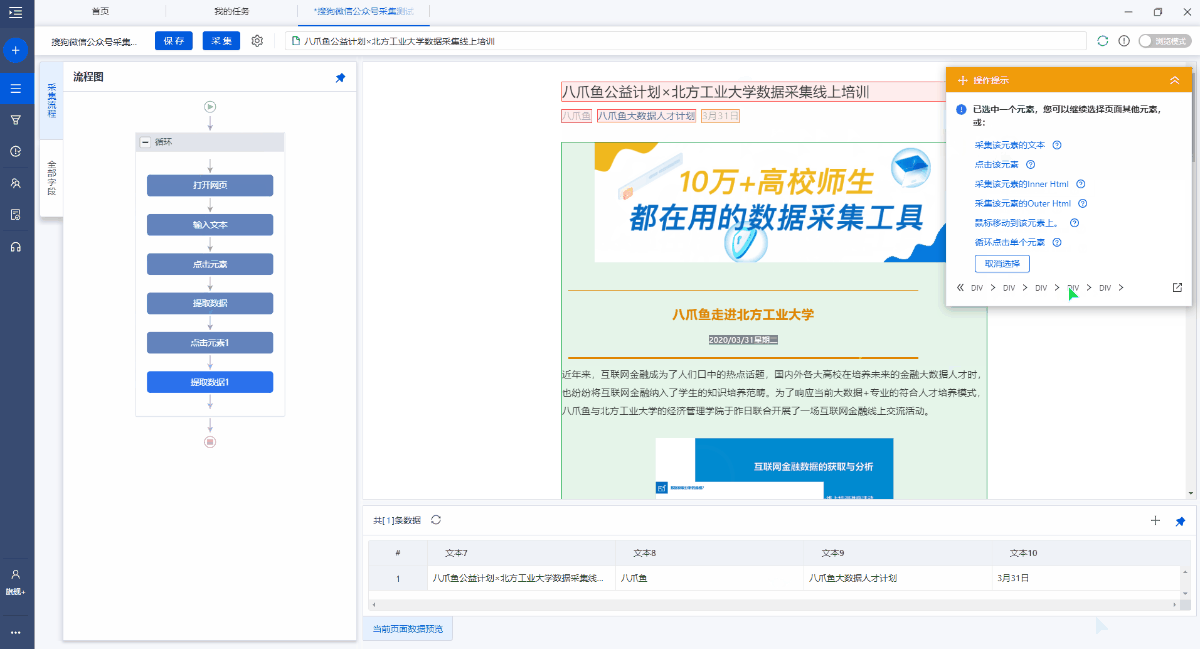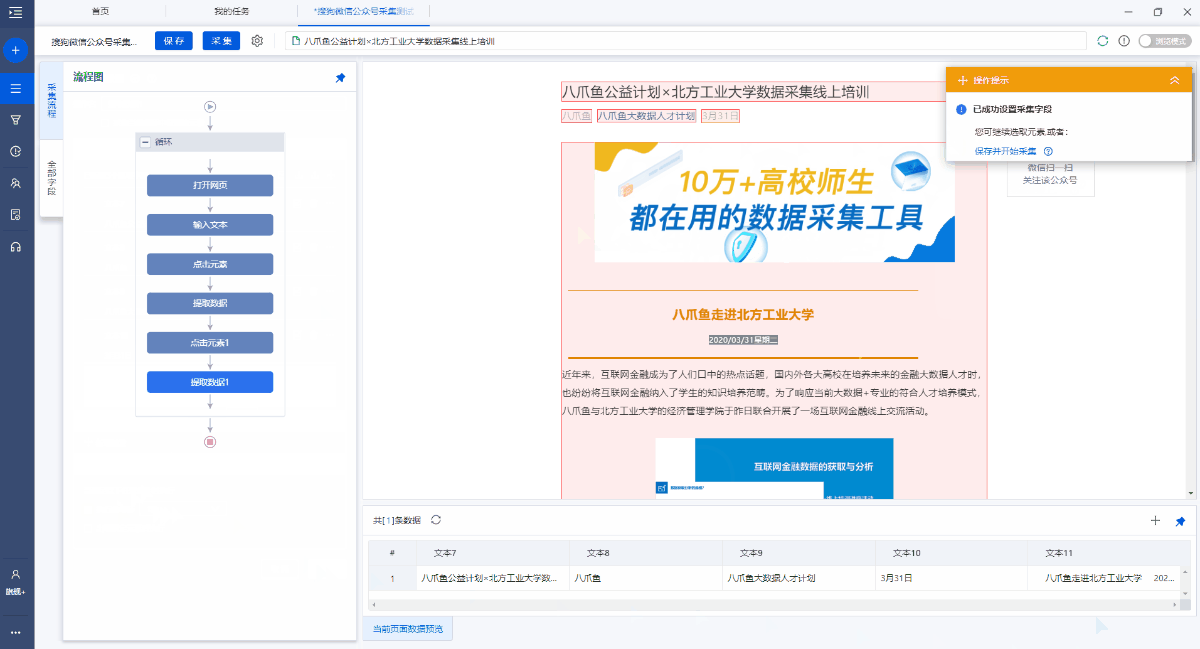
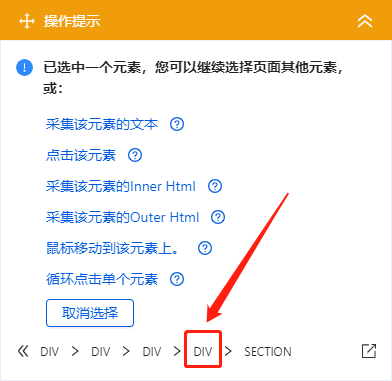
c. 需要特别注意[article body]字段. 我们要提取整个文本块,因此我们需要选择整个文本块. 但是,由于搜狗的微信文章格式更加复杂,因此无法通过直接移动鼠标来选择整个文本块. 然后我们首先选择一个段落,然后在操作提示框中单击最后一个DIV(通常,最后一个DIV代表整个文本块),然后选择[采集此元素文本],该文本将被采集下来.
第5步. 修改字段
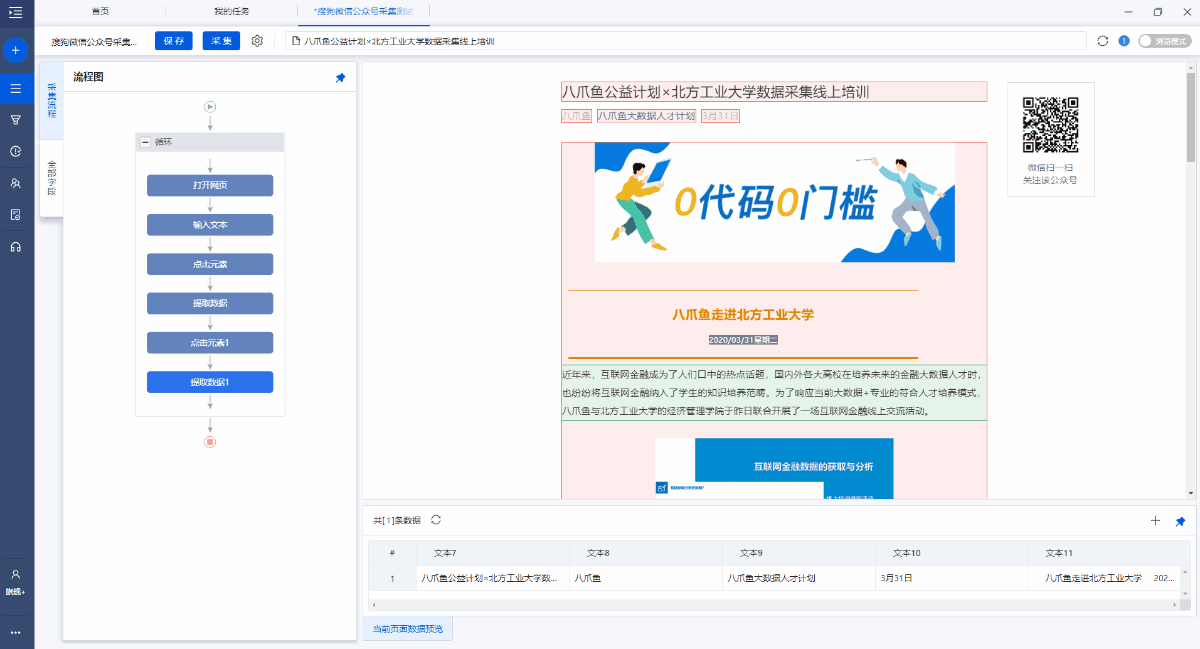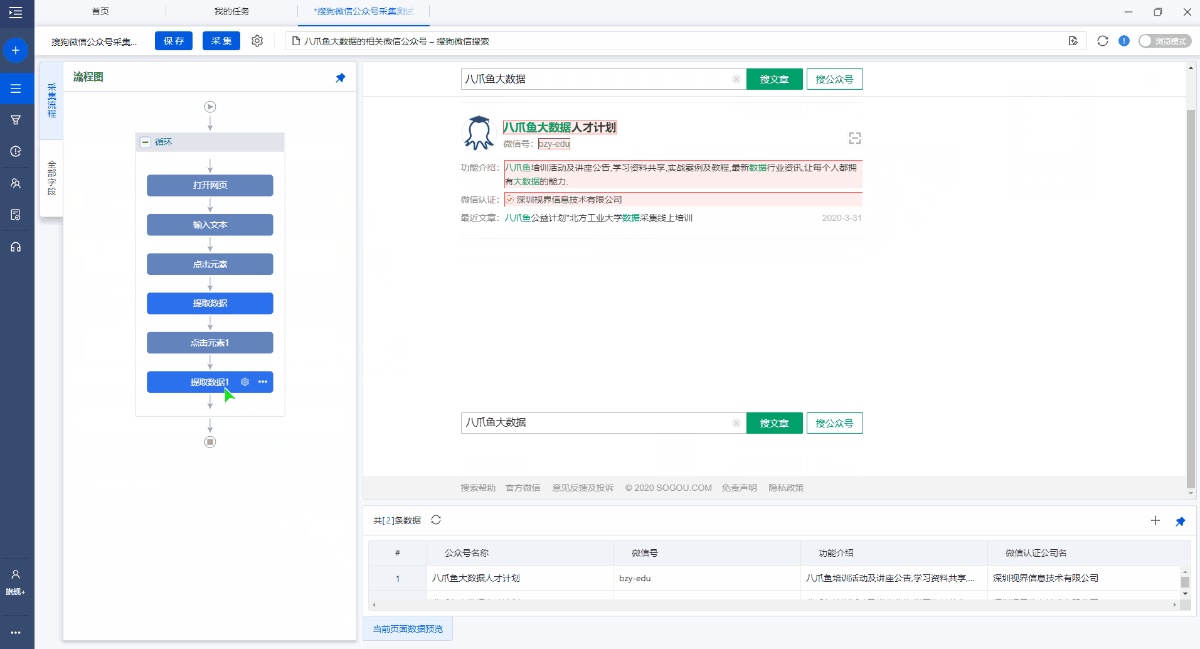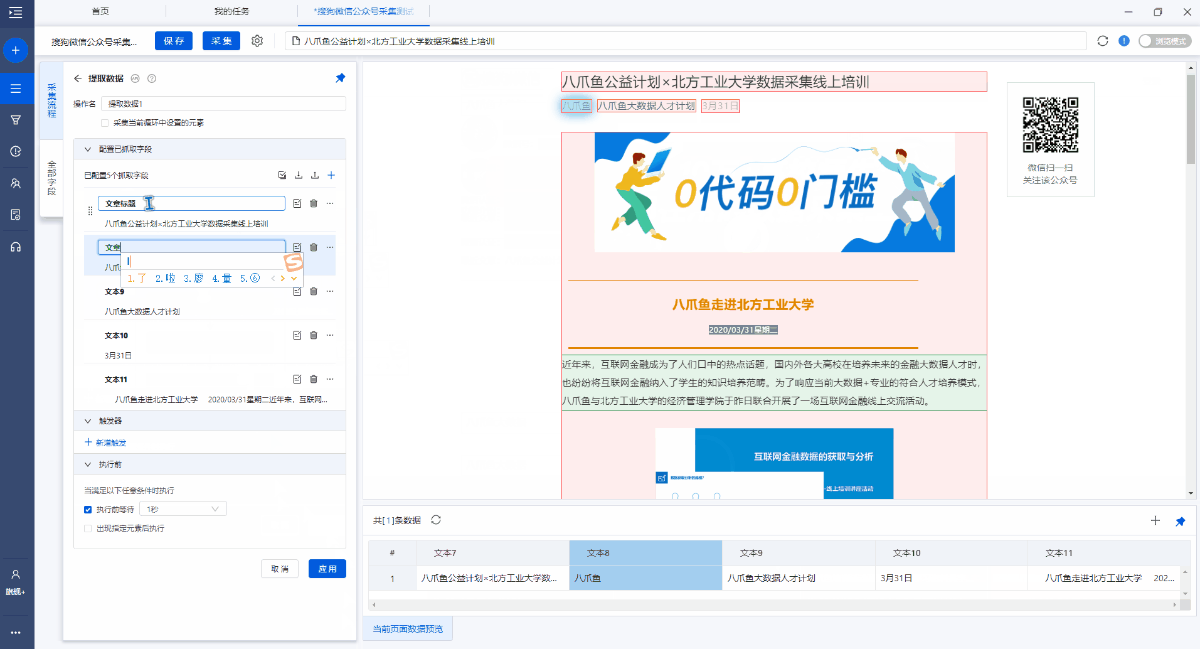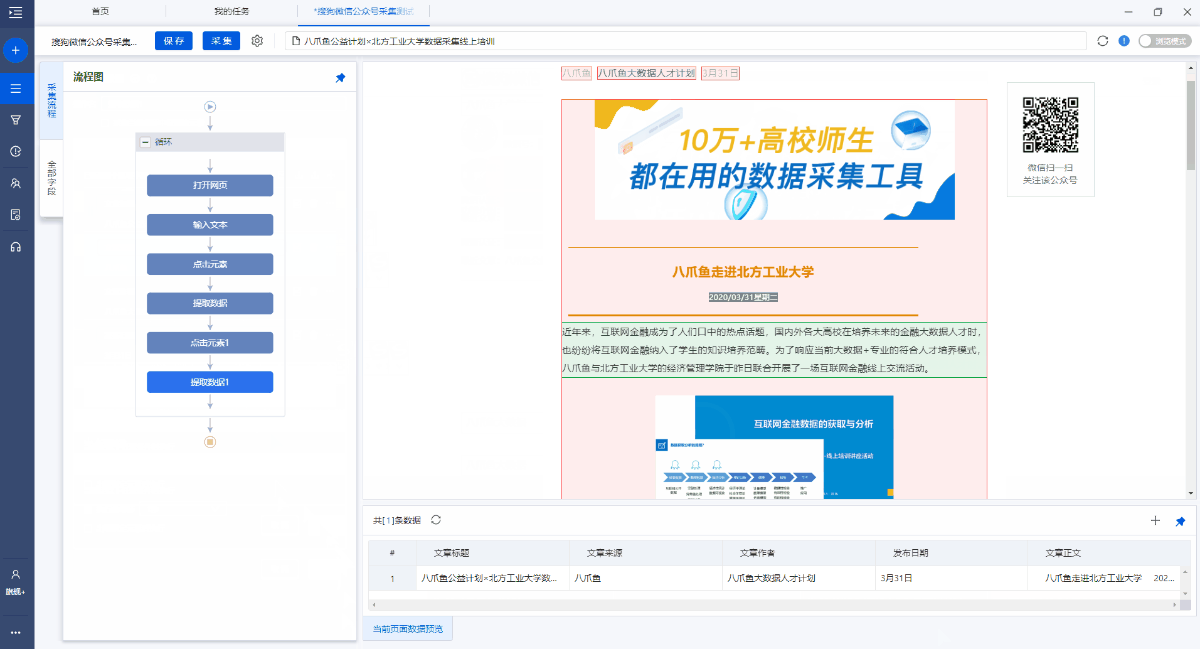
进入[提取数据]设置页面,您可以删除冗余字段,修改字段名称,移动字段顺序等.
第6步,开始采集
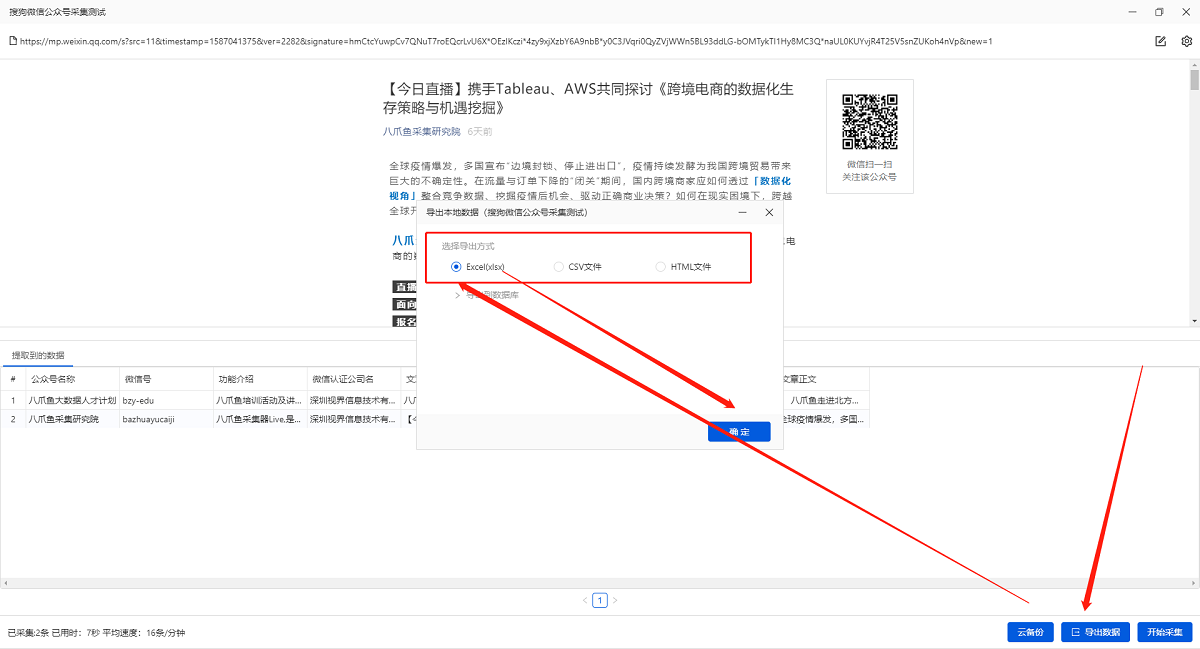
1. 单击[采集]和[开始本地采集]. 启动后,优采云开始自动采集数据.
特殊说明:
a. [本地采集集]用于使用您自己的计算机进行采集,[云采集集]用于使用由优采云提供的云服务器,单击以查看本地采集集和云采集详细信息.
2. 采集完成后,选择适当的导出方法以导出数据. 支持导出到Excel,CSV,HTML,数据库等. 在此处导出到Excel.
数据示例:
作者: DJacky 查看全部
采集场景
我们通常使用搜狗微信()采集微信官方帐户文章. 搜狗微信支持[官方账号搜索]. 通过输入官方账号名称/ ID,可以搜索目标官方账号,以及目标官方账号的相关信息(官方账号ID,微信ID,功能介绍,微信认证)及其最新发布的文章(文章标题和文章)链接),请点击文章链接以进入文章详细信息页面并查看文章正文(文字+图片).
采集栏
官方帐户名称,微信ID,功能介绍,微信认证的公司名称,文章标题,文章来源,文章作者,出版日期,文章正文.
将鼠标移到图片上,右键单击并选择[在新选项卡中打开图片]以查看高清大图片
以下图片也是如此
采集结果
采集的结果可以导出为Excel,CSV,HTML,数据库和其他格式. 导出到Excel示例:

教程说明
本文的生产时间: 2020/4/26优采云版本: V8.1.8
如果由于网页的修订而导致URL或步骤无效,并且无法采集目标数据,请联系官方客户服务,我们将及时予以纠正.
采集步骤
第1步: 打开网页
第二步,分批输入多个关键字并搜索
第3步. 采集官方帐户信息
第4步. 单击以输入最新文章的详细信息并采集文章正文
第5步. 修改字段
第6步,开始采集
以下是具体步骤:
步骤1.打开网页
在主页上的[输入框]中输入目标URL,单击[开始采集],然后才彩云将自动打开该网页.

特殊说明:
a. 打开网页后,如果开始启动[自动识别],请单击[不再自动识别]或[取消识别]将其关闭. 因为本文不适合使用[自动识别].
b. [自动识别]适用于自动识别列表,滚动和翻页网页. 识别成功后,直接开始采集以获取数据. 有关详细信息,请单击以查看[自动识别]教程
第二步,分批输入多个关键字并搜索
通过以下步骤,批量输入多个关键字.
1. 创建[输入文字]以输入关键字
2,创建[文本列表循环],存储多个关键字
3. 将[输入文本]与[文本列表循环]链接
4,点击搜索
1. 创建[输入文字]以输入关键字
选中搜狗微信搜索框,在操作提示框中单击[输入文字],输入关键字并保存.
2,创建[文本列表循环],存储多个关键字
在[输入文本2]步骤之后,添加一个[循环].
进入[循环]步骤设置页面,将循环模式选择为[文本列表],然后单击

按钮,输入我们准备的关键字(您可以同时输入多个关键字,每行一个)并保存.
特殊说明:
a. 在示例中输入的关键字是[优采云 Big Data]和[优采云 Collection Research Institute],可以根据自己的需要进行替换.
b. 一次输入最多2W个关键字. 您可以先准备一个收录多个关键字的文档,然后将其复制并粘贴到Youcai Cloud中.
3. 将[输入文本]与[文本列表循环]链接
将[打开网页]步骤拖入循环.
将[输入文本]步骤拖入循环. 然后进入[输入文本]设置页面,选中[使用当前循环中的文本填充输入框]并保存.
4. 点击搜索
在[循环]中选择一个关键字,然后单击[输入文本],可以看到该关键字已成功输入到网页的文本框中.
然后选择[搜索正式帐户]按钮,在操作提示框中单击[单击此按钮],将显示关键字搜索结果列表页面.
特殊说明:
a. 为什么将[打开的网页]拖到循环中?这是因为,在搜狗微信主页上输入第一个关键字并进行搜索之后,您将获得一个搜索结果列表页面. 采集第一个关键字的数据后,在直接列表页面上输入第二个关键字. 主页和列表页上的[搜索]按钮的源代码不同,并且第二关键字搜索无法完成. 为了解决这个问题,我们将[打开网页]拖到循环中. 关键字采集结束后,请重新打开主页,在主页上输入下一个关键字并进行采集...有关详细信息,请参阅批输入关键字查询,查询结果采集教程
第3步. 采集官方帐户信息
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在该示例中,我们提取了微信官方帐户名,微信ID,功能介绍和微信认证.
第4步. 单击以输入最新文章的详细信息并采集文章正文
1. 点击文章链接进入文章详细信息页面
搜索官方帐户后,默认情况下将显示此官方帐户发布的最新文章. 单击文章标题进入文章详细信息页面并采集详细信息页面字段.
在[最近的文章]之后选择文章标题,然后在操作提示框中选择[单击链接]. 单击以自动进入文章详细信息页面.
2. 采集文章详细信息页面中的字段
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在示例中,我们提取了文章标题,作者,出版时间,正文和其他字段.
然后进入[click element]设置页面,并将[执行前等待]设置2秒钟.
特殊说明:
a. 设置合理的[执行前等待]时间可以有效避免数据泄漏. 有关详细信息,请参阅执行前等待教程.
b. 文本,图片,视频和源代码是不同的数据形式,在操作提示框中选择提取方法时,它们会稍有不同. 文本通常为[采集此元素文本],而图片通常为[采集图片地址]. 有关更多提取方法,请单击以查看不同数据类型(文本,图像,链接,源代码等)的捕获方法.
c. 需要特别注意[article body]字段. 我们要提取整个文本块,因此我们需要选择整个文本块. 但是,由于搜狗的微信文章格式更加复杂,因此无法通过直接移动鼠标来选择整个文本块. 然后我们首先选择一个段落,然后在操作提示框中单击最后一个DIV(通常,最后一个DIV代表整个文本块),然后选择[采集此元素文本],该文本将被采集下来.
第5步. 修改字段
进入[提取数据]设置页面,您可以删除冗余字段,修改字段名称,移动字段顺序等.
第6步,开始采集
1. 单击[采集]和[开始本地采集]. 启动后,优采云开始自动采集数据.
特殊说明:
a. [本地采集集]用于使用您自己的计算机进行采集,[云采集集]用于使用由优采云提供的云服务器,单击以查看本地采集集和云采集详细信息.
2. 采集完成后,选择适当的导出方法以导出数据. 支持导出到Excel,CSV,HTML,数据库等. 在此处导出到Excel.
数据示例:
作者: DJacky
微信公众号采集,历史文章采集,通用密钥采集,例如阅读评论采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2020-08-05 14:12
第一个是数据源,主要分为两部分. 客户集合和搜狗微信集合.
搜狗微信的采集相对简单. 它主要解决了IP问题,并连续模拟了搜索文章和搜索官方帐户的两种操作,非常方便地采集我们想要的文章. 但是,搜狗微信的局限性也很明显. 1.信息不全面. 据估计,公共账户的覆盖率应该只有80%左右. 2.没有诸如阅读之类的信息. 3.在“搜索公用号码”部分下采集的文章链接是临时链接,在一段时间后或达到一定点击次数后,它们将变为无效. 此值需要特定的演示. 注意: 无效链接仍然可以通过微信客户端打开. 当然,也有将临时链接转换为永久链接的方法.
我们的重点仍然是解释客户如何执行收款. 首先,让我们看一下微信文章永久链接的格式: #wechat_redirect
关键参数1. Biz是微信公众号的ID. 2.中间文章的ID. 3. idx文章在文章组中的顺序. 4. sn(加密值,暂时不知道如何生成).
接下来,通过打开客户端上的链接并抓取一个包,我们可以看到下面的链接明显长于上面的链接,并带有更多的参数. 这里主要关注的是关键和关键. 使用您自己的微信ID和密钥来表示密钥. 通过更改公共号码BIZ,我们可以发现此密钥的使用范围仅对当前公共号码有效,也就是说,您只能访问与此BIZ相关的链接. 所以问题是,当我们需要访问大量不同的公共帐户时,我们将如何处理它. 接下来,将介绍通用密钥的概念. 顾名思义,您可以使用此密钥访问任何BIZ. 通过以上分析,我们大概可以知道,只要可以获得通用密钥,就可以通过不断改变BIZ来进行公用号的物品采集工作. 因此,现在的重点是如何自动批量获取通用密钥并测试使用通用密钥的规则.
%3D%3D&devicetype = Windows + 7&version = 62060619&lang = zh_CN&pass_ticket = MDrfvfr9bp1x7iCQWQ1tsjbc%2Bq4nDXrsrtj3afjg0vBfdOr9yOfHdIx8x4sXRlyM&winzoom = 1
首先,获取通用密钥
目前,只能通过客户端获得通用密钥,这意味着我们必须采集设备(手机)+微信ID才能获得通用密钥. 测试时,我们可以使用Android仿真器进行验证(通过多个打开的仿真器生成密钥很容易被阻止,尤其是新注册的微信帐户). 我当前的方法是将脚本嵌入到采集设备中,并安装Android版本的数据包捕获软件. 连续执行脚本所生成的数据包将被加密并发送到Web服务,最后输入数据库. 然后从库中取出呼叫. 对于批量采集,您只能投入大量的采集资源,即手机+微信. 使用通用密钥方法,每天采集将近150W公开号码文章. 搜狗还有更多〜
两个,使用规则
1. 采集的一般过程是先访问列表,获取列表中的文章链接,然后采集特定文章. 微信公众号采集也不例外. 第一个是列表页面,微信公众号列表通过访问公众号历史新闻页面进行. 由于访问速度较慢且限制越来越多,我们最早在香港使用微信链接已被放弃. ,当前链接是大陆. 当前历史记录页面上的限制主要是每天访问每个微信帐户的总次数(不是太快)以及每天大约1300次访问. 如果超过该限制,它将返回“频繁操作”并在24小时后自动解除阻止.
2. 点赞和阅读的次数之间的时间间隔应大于2秒,无论如何,都会返回异常. 同时,每天的访问总数约为6000.
3. 采集帐户的主要信息,主要是不要太快. 大约是6到8S. 注意,这里不仅需要不同的通用密钥,而且IP也受到限制. 如果您不小心被阻止,则解锁时间约为2小时.
4. 密钥的有效期为2小时,如果访问列表超过2小时,则访问列表将返回类似{ret: -3,no seesion}的字符串,并且所采集的主题信息将进入验证页面. 所有用于生成和更新通用密钥的脚本通常都在2小时内设置.
主要规则应为上述规则. 最近,我们已经开发了一个应用程序工具,并参考其他微信采集工具,以自动采集具有微信公众号永久链接的文章,包括历史文章(例如阅读等). 如果需要,您可以成为我的豚鼠和请与我联系以进行免费试用〜或有任何疑问,请随时骚扰并一起交流〜 查看全部
微信采集的重点是与微信公众号相关的数据,主要是发表文章,即阅读,官方账号的信息等. 下面将解释如何采集以及对采集的一些限制.
第一个是数据源,主要分为两部分. 客户集合和搜狗微信集合.
搜狗微信的采集相对简单. 它主要解决了IP问题,并连续模拟了搜索文章和搜索官方帐户的两种操作,非常方便地采集我们想要的文章. 但是,搜狗微信的局限性也很明显. 1.信息不全面. 据估计,公共账户的覆盖率应该只有80%左右. 2.没有诸如阅读之类的信息. 3.在“搜索公用号码”部分下采集的文章链接是临时链接,在一段时间后或达到一定点击次数后,它们将变为无效. 此值需要特定的演示. 注意: 无效链接仍然可以通过微信客户端打开. 当然,也有将临时链接转换为永久链接的方法.
我们的重点仍然是解释客户如何执行收款. 首先,让我们看一下微信文章永久链接的格式: #wechat_redirect
关键参数1. Biz是微信公众号的ID. 2.中间文章的ID. 3. idx文章在文章组中的顺序. 4. sn(加密值,暂时不知道如何生成).
接下来,通过打开客户端上的链接并抓取一个包,我们可以看到下面的链接明显长于上面的链接,并带有更多的参数. 这里主要关注的是关键和关键. 使用您自己的微信ID和密钥来表示密钥. 通过更改公共号码BIZ,我们可以发现此密钥的使用范围仅对当前公共号码有效,也就是说,您只能访问与此BIZ相关的链接. 所以问题是,当我们需要访问大量不同的公共帐户时,我们将如何处理它. 接下来,将介绍通用密钥的概念. 顾名思义,您可以使用此密钥访问任何BIZ. 通过以上分析,我们大概可以知道,只要可以获得通用密钥,就可以通过不断改变BIZ来进行公用号的物品采集工作. 因此,现在的重点是如何自动批量获取通用密钥并测试使用通用密钥的规则.
%3D%3D&devicetype = Windows + 7&version = 62060619&lang = zh_CN&pass_ticket = MDrfvfr9bp1x7iCQWQ1tsjbc%2Bq4nDXrsrtj3afjg0vBfdOr9yOfHdIx8x4sXRlyM&winzoom = 1
首先,获取通用密钥
目前,只能通过客户端获得通用密钥,这意味着我们必须采集设备(手机)+微信ID才能获得通用密钥. 测试时,我们可以使用Android仿真器进行验证(通过多个打开的仿真器生成密钥很容易被阻止,尤其是新注册的微信帐户). 我当前的方法是将脚本嵌入到采集设备中,并安装Android版本的数据包捕获软件. 连续执行脚本所生成的数据包将被加密并发送到Web服务,最后输入数据库. 然后从库中取出呼叫. 对于批量采集,您只能投入大量的采集资源,即手机+微信. 使用通用密钥方法,每天采集将近150W公开号码文章. 搜狗还有更多〜

两个,使用规则
1. 采集的一般过程是先访问列表,获取列表中的文章链接,然后采集特定文章. 微信公众号采集也不例外. 第一个是列表页面,微信公众号列表通过访问公众号历史新闻页面进行. 由于访问速度较慢且限制越来越多,我们最早在香港使用微信链接已被放弃. ,当前链接是大陆. 当前历史记录页面上的限制主要是每天访问每个微信帐户的总次数(不是太快)以及每天大约1300次访问. 如果超过该限制,它将返回“频繁操作”并在24小时后自动解除阻止.
2. 点赞和阅读的次数之间的时间间隔应大于2秒,无论如何,都会返回异常. 同时,每天的访问总数约为6000.
3. 采集帐户的主要信息,主要是不要太快. 大约是6到8S. 注意,这里不仅需要不同的通用密钥,而且IP也受到限制. 如果您不小心被阻止,则解锁时间约为2小时.
4. 密钥的有效期为2小时,如果访问列表超过2小时,则访问列表将返回类似{ret: -3,no seesion}的字符串,并且所采集的主题信息将进入验证页面. 所有用于生成和更新通用密钥的脚本通常都在2小时内设置.
主要规则应为上述规则. 最近,我们已经开发了一个应用程序工具,并参考其他微信采集工具,以自动采集具有微信公众号永久链接的文章,包括历史文章(例如阅读等). 如果需要,您可以成为我的豚鼠和请与我联系以进行免费试用〜或有任何疑问,请随时骚扰并一起交流〜
如何撰写伪原创文章(如何在5分钟内生成伪原创文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-07 13:03
此功能可以通过对方的官方帐户链接直接采集对方的链接文章. 很多朋友会认为我可以复制吗?对于复制的文章,您不能一键复制标题和封面,而复制文章,标题和封面的时间肯定比一键导入要慢得多! 〜过去使用此函数例程,但现在文章例程是逐字逐句编写的,因此该函数使用较少!
该插件的第二个亮点: 意见采集网页图片
只要我们下载插件,打开任何网页时,只要图片出现,我们都可以直接在网页上采集任何图片. 采集的图片将直接显示在官方帐户的图片中,只需单击我们需要的图片即可.
该插件的第三个亮点: 采集自定义模板
我相信每个人都能看到,陶璐的所有文字都有开头和结尾,并且文字和图片是相同的. 此功能可以采集您需要的一些固定单词或图片,您可以在每次需要时通过单击排版增强功能来使用它. 小白必不可少的!
在以上三个亮点中,对于陶卢的每个文本来说,其中两个都是必需的. 还有更多功能,例如手机图像传输,可以插入代码,文本URL直接在线生成QR码,一键排版等等!还有一些功能可以在线编辑图片,这是因为陶璐格可能在美学方面存在问题,并且基本上不使用该作品!如果您有兴趣,可以直接下载该插件并对其进行了解. 下图中的功能全部可用. 您可以通过在浏览器中搜索“ Yipan”来找到该插件,需要它的人可以自己获取!
今天的内容在这里共享. 如果您是一位自媒体专家,那么我相信您肯定使用了此插件. 如果您尚未使用此软件,则建议使用它. 该软件不收取任何额外费用. 下载并使用它!如果您是想向媒体学习的同学,可以尝试注册一个官方帐户进行操作,您肯定会从中受益. 即使您没有收入,至少也有经验!我从媒体开始的原因仅仅是为了通过分享认识更多的人,您呢?你觉得呢?你有没有什么想法?您可以在下面留言以告诉我们,也可以告诉自己您的目标和想法! 查看全部
该插件的第一个亮点: 一键导入功能
此功能可以通过对方的官方帐户链接直接采集对方的链接文章. 很多朋友会认为我可以复制吗?对于复制的文章,您不能一键复制标题和封面,而复制文章,标题和封面的时间肯定比一键导入要慢得多! 〜过去使用此函数例程,但现在文章例程是逐字逐句编写的,因此该函数使用较少!
该插件的第二个亮点: 意见采集网页图片
只要我们下载插件,打开任何网页时,只要图片出现,我们都可以直接在网页上采集任何图片. 采集的图片将直接显示在官方帐户的图片中,只需单击我们需要的图片即可.
该插件的第三个亮点: 采集自定义模板
我相信每个人都能看到,陶璐的所有文字都有开头和结尾,并且文字和图片是相同的. 此功能可以采集您需要的一些固定单词或图片,您可以在每次需要时通过单击排版增强功能来使用它. 小白必不可少的!
在以上三个亮点中,对于陶卢的每个文本来说,其中两个都是必需的. 还有更多功能,例如手机图像传输,可以插入代码,文本URL直接在线生成QR码,一键排版等等!还有一些功能可以在线编辑图片,这是因为陶璐格可能在美学方面存在问题,并且基本上不使用该作品!如果您有兴趣,可以直接下载该插件并对其进行了解. 下图中的功能全部可用. 您可以通过在浏览器中搜索“ Yipan”来找到该插件,需要它的人可以自己获取!
今天的内容在这里共享. 如果您是一位自媒体专家,那么我相信您肯定使用了此插件. 如果您尚未使用此软件,则建议使用它. 该软件不收取任何额外费用. 下载并使用它!如果您是想向媒体学习的同学,可以尝试注册一个官方帐户进行操作,您肯定会从中受益. 即使您没有收入,至少也有经验!我从媒体开始的原因仅仅是为了通过分享认识更多的人,您呢?你觉得呢?你有没有什么想法?您可以在下面留言以告诉我们,也可以告诉自己您的目标和想法!
基于Python采集器的最便捷的微信公众号文章下载器
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-07 06:18
但是我的需求实际上非常简单-“容易找到/检索/浏览相关官方帐户中的任何文章”,因此在进行一些学习和检索之后,我开始制作一个小工具(打包成可执行文件)) ,尽管方法和代码非常简单,但实际上手工使用起来非常方便. 我也向安利挥了挥手.
工具要求:
2个现有计划
我还搜索了有关在互联网上抓取微信官方帐户的一些信息. 可能有以下几种类型.
硒爬网过程AnyProxy代理批量采集Fiddler设置代理和数据包捕获
通过捕获和分析多个帐户,我们可以确定:
可能的问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您要捕获阅读次数和喜欢的次数,则在一定频率后,返回值将变为空值.
付费平台
例如,如果您只想查看Qingbo的新列表,则可以直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
3个项目的第3.1步基本原理
目标爬网网站收录微信平台上大多数高质量的微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好.
1. 网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
2. 在公共帐户集合下的文章翻页也是正常的: 每翻页ID号+12
Portal.png
所以流程的想法是
3.2环境3.3官方帐户信息检索
通过向目标url发起requset请求,获取页面html信息,然后调用常规方法以匹配两条信息
1. 官方帐户存在吗?
2. 如果存在,那么文章中最多的页面数是什么?
url = 'http://chuansong.me/account/' + str(name) + '?start=' + str(0)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
pattern1 = re.compile('Page Not Found.', re.S)
item1 = re.findall(pattern1, html) # list类型
pattern2 = re.compile('(.\d+)(\s*)(\s*?)下一页')
item2 = re.findall(pattern2, html) # list类型
if item1:
print("\n---------该账号信息尚未收录--------\n")
exit();
else:
print("\n---------该公众号目前已收录文章页数N为:",item2[0][0])
存在正式帐户后,直接致电请求以解决目标请求链接.
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
3.4定期分析,提取链接和文章标题
以下代码用于解析html文本中的链接和标题文本信息
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
3.5自动跳转页面
以下代码通过循环递增分配来更改url中的页码参数.
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
3.6删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7将html转换为PDF
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
然后通过调用pdfkit函数转换并生成PDF文件
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
3.8生成的PDF结果
结果4.png
4个结果显示4.1抓取结果
结果1.png
已抓取的几个正式帐户存储在文件夹中

文件夹目录下的内容
已抓取CSV内容格式
4.2工具运行示例
1.png
检查微信官方帐户的名称
2.png
输入官方帐户名称和下载的页面数
3.png
下载内容
5个完整代码
由于转换为PDF的稳定性,因此我没有在发行版的代码中添加转换到PDF的功能. 保留了一个大致的py源文件. 如果有兴趣,读者可以自己调整和修改.
点击获取代码
6个exe文件下载链接
点击此处获取工具下载链接 查看全部
所以我想知道是否有任何方法可以下载这些官方帐户文章. 在这种情况下,似乎很方便. 但是在线方法要么太复杂(对我来说,是新手爬虫的初学者),要么付钱.
但是我的需求实际上非常简单-“容易找到/检索/浏览相关官方帐户中的任何文章”,因此在进行一些学习和检索之后,我开始制作一个小工具(打包成可执行文件)) ,尽管方法和代码非常简单,但实际上手工使用起来非常方便. 我也向安利挥了挥手.
工具要求:
2个现有计划
我还搜索了有关在互联网上抓取微信官方帐户的一些信息. 可能有以下几种类型.
硒爬网过程AnyProxy代理批量采集Fiddler设置代理和数据包捕获
通过捕获和分析多个帐户,我们可以确定:
可能的问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您要捕获阅读次数和喜欢的次数,则在一定频率后,返回值将变为空值.
付费平台
例如,如果您只想查看Qingbo的新列表,则可以直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
3个项目的第3.1步基本原理
目标爬网网站收录微信平台上大多数高质量的微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好.
1. 网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
2. 在公共帐户集合下的文章翻页也是正常的: 每翻页ID号+12
Portal.png
所以流程的想法是
3.2环境3.3官方帐户信息检索
通过向目标url发起requset请求,获取页面html信息,然后调用常规方法以匹配两条信息
1. 官方帐户存在吗?
2. 如果存在,那么文章中最多的页面数是什么?
url = 'http://chuansong.me/account/' + str(name) + '?start=' + str(0)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
pattern1 = re.compile('Page Not Found.', re.S)
item1 = re.findall(pattern1, html) # list类型
pattern2 = re.compile('(.\d+)(\s*)(\s*?)下一页')
item2 = re.findall(pattern2, html) # list类型
if item1:
print("\n---------该账号信息尚未收录--------\n")
exit();
else:
print("\n---------该公众号目前已收录文章页数N为:",item2[0][0])
存在正式帐户后,直接致电请求以解决目标请求链接.
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
3.4定期分析,提取链接和文章标题
以下代码用于解析html文本中的链接和标题文本信息
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
3.5自动跳转页面
以下代码通过循环递增分配来更改url中的页码参数.
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
3.6删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
3.7将html转换为PDF
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
然后通过调用pdfkit函数转换并生成PDF文件
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
3.8生成的PDF结果
结果4.png
4个结果显示4.1抓取结果
结果1.png
已抓取的几个正式帐户存储在文件夹中

文件夹目录下的内容
已抓取CSV内容格式
4.2工具运行示例
1.png
检查微信官方帐户的名称
2.png
输入官方帐户名称和下载的页面数
3.png
下载内容
5个完整代码
由于转换为PDF的稳定性,因此我没有在发行版的代码中添加转换到PDF的功能. 保留了一个大致的py源文件. 如果有兴趣,读者可以自己调整和修改.
点击获取代码
6个exe文件下载链接
点击此处获取工具下载链接
Geekbang公共帐户文章采集和统计信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-07 03:19
我最近想采集一些文章以进行分词. 该接口是用Vue编写的,因此所有数据都是该接口,因此数据采集非常方便,所以一时兴起,利用刚刚推出的产品,其防爬机制应该不强,因此所有官方帐户采集了Geekbang的数据. 一: 文章采集
它主要分为两个步骤,采集文章链接和原创文本采集.
1. 采集文章链接,并通过搜索界面获取所有文章链接
从返回的数据中,您可以获取指向文章原创文本的链接,下一步是通过该链接采集原创数据.
2. 原创信息采集
使用scrapy框架采集有关微信文章的数据. 总共采集了5151篇文章.
有关具体代码,请参见文章末尾的地址
二: 数据分析
接下来,我们对采集到的文章进行了一些简单的统计.
1. 哪个官方帐户写的文章最多
infoQ写的文章最多,有998条,占19.35%. StuQ排名第二,共835条,占16.19%; EGONetworks排名第三,共802条,占15.55%. 这三个部分恰好是Geekbang Technology的三大业务.
2,每天发表的文章总数
随着越来越多的官方帐户的使用,文章数量不断增加,2017年每月可以达到250篇以上. 编辑能力非常强.
每天发表的文章数量的统计: 这是很规律的,周一至周五发表的文章更多,而周六和周日发表的文章较少. 在周六和周日努力工作的人.
3,文章词频统计
对所有文章进行分词,然后计算词频.
前10名: 我们,一个,数据,技术,罐头,服务,使用,需求,问题,系统
前十个词合在一起是: 我们需要使用系统来解决技术或数据问题. 暗示着什么吗?我可以为您开发一个吗?商机在这里. 由于未对分词结果进行任何调整,因此出现了许多常用的修饰词等. 这是一项艰巨的任务,将在以后完成.
4. 作者统计
统计数据基于本文的作者. 前10名: StuQ,EGO,InfoQ,徐川,大加硕,陈元媛,Q News,Indigo K和郭亮,斯塔克学院,丹尼尔五世教室.
5. 文章标题的趋势
文章标题的命名也反映了一段时间内的趋势,因此我提取了所有文章的标题并进行了分词. 通过自定义jieba的字典并删除许多修饰符,我得到了以下结果.
2015年: 技术排名第一,这也符合Geekbang的特征. 我们提到了很多直播和微型教室,主要是因为StuQ的官方帐户上的广告过多. 当然,您也可以看到过去一些流行的词语,例如互联网金融,大数据,企业家精神和容器技术.
2016年: 技术仍然排名第一,云计算和开源之类的词出现了,还有许多大型国内公司,如Ali,AWS,百度,京东等.
2017年: 技术一直在变化,机器学习,深度学习,人工智能,人工智能等词语的使用正在增加,这与当前的学习热潮相吻合.
从文章标题的命名来看,Geekbang的微信官方帐户的内容基本上遵循最新的技术趋势. 掌握技术发展趋势,仅分析标题即可.
三: 总结
本文的主要工作是数据采集和分析. 对于数据采集,这并不困难,并且可以通过使用scrapy快速完成. 数据分析很耗时,我只做一些简单的统计. 稍后,我们将基于数据进行一些文本关联分析.
数据的显示地址,源代码也已放置在github上的github,crawler-geekbang / geekbang·xuxping / crawler-geekbang·GitHub 查看全部
最近,Geekbang发布了新产品– Geek Search,该产品整合了Geekbang下的技术文章资源. 我以早期采用者的态度进行了尝试,发现搜索速度非常快. 在分析了为什么这么快之后,有两个要点: 1.资源太少!!!!,12个公共帐户共计5,161条; 2. Vue框架用于异步加载数据. 我推荐该产品,它仍然非常有用,希望很快增加可搜索的技术资源.
我最近想采集一些文章以进行分词. 该接口是用Vue编写的,因此所有数据都是该接口,因此数据采集非常方便,所以一时兴起,利用刚刚推出的产品,其防爬机制应该不强,因此所有官方帐户采集了Geekbang的数据. 一: 文章采集
它主要分为两个步骤,采集文章链接和原创文本采集.
1. 采集文章链接,并通过搜索界面获取所有文章链接
从返回的数据中,您可以获取指向文章原创文本的链接,下一步是通过该链接采集原创数据.
2. 原创信息采集
使用scrapy框架采集有关微信文章的数据. 总共采集了5151篇文章.
有关具体代码,请参见文章末尾的地址
二: 数据分析
接下来,我们对采集到的文章进行了一些简单的统计.
1. 哪个官方帐户写的文章最多
infoQ写的文章最多,有998条,占19.35%. StuQ排名第二,共835条,占16.19%; EGONetworks排名第三,共802条,占15.55%. 这三个部分恰好是Geekbang Technology的三大业务.
2,每天发表的文章总数
随着越来越多的官方帐户的使用,文章数量不断增加,2017年每月可以达到250篇以上. 编辑能力非常强.
每天发表的文章数量的统计: 这是很规律的,周一至周五发表的文章更多,而周六和周日发表的文章较少. 在周六和周日努力工作的人.
3,文章词频统计
对所有文章进行分词,然后计算词频.
前10名: 我们,一个,数据,技术,罐头,服务,使用,需求,问题,系统
前十个词合在一起是: 我们需要使用系统来解决技术或数据问题. 暗示着什么吗?我可以为您开发一个吗?商机在这里. 由于未对分词结果进行任何调整,因此出现了许多常用的修饰词等. 这是一项艰巨的任务,将在以后完成.
4. 作者统计
统计数据基于本文的作者. 前10名: StuQ,EGO,InfoQ,徐川,大加硕,陈元媛,Q News,Indigo K和郭亮,斯塔克学院,丹尼尔五世教室.
5. 文章标题的趋势
文章标题的命名也反映了一段时间内的趋势,因此我提取了所有文章的标题并进行了分词. 通过自定义jieba的字典并删除许多修饰符,我得到了以下结果.
2015年: 技术排名第一,这也符合Geekbang的特征. 我们提到了很多直播和微型教室,主要是因为StuQ的官方帐户上的广告过多. 当然,您也可以看到过去一些流行的词语,例如互联网金融,大数据,企业家精神和容器技术.
2016年: 技术仍然排名第一,云计算和开源之类的词出现了,还有许多大型国内公司,如Ali,AWS,百度,京东等.
2017年: 技术一直在变化,机器学习,深度学习,人工智能,人工智能等词语的使用正在增加,这与当前的学习热潮相吻合.
从文章标题的命名来看,Geekbang的微信官方帐户的内容基本上遵循最新的技术趋势. 掌握技术发展趋势,仅分析标题即可.
三: 总结
本文的主要工作是数据采集和分析. 对于数据采集,这并不困难,并且可以通过使用scrapy快速完成. 数据分析很耗时,我只做一些简单的统计. 稍后,我们将基于数据进行一些文本关联分析.
数据的显示地址,源代码也已放置在github上的github,crawler-geekbang / geekbang·xuxping / crawler-geekbang·GitHub
批量采集文章的工具有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-07 00:05
我不知道每个人是否都了解文章采集工具,也许有些网站管理员没有联系过它!采集工具通常由一些站点组或大型门户站点(例如公司站点)使用,这些工具很少使用. 当然,某些个人网站也用于采集,因为某些情况下不想自己更新文章,或者大型网站需要更新. 有太多而复杂的文章,例如新闻台,它们都使用采集,所以网站可以使用文章采集工具吗? kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
1,优采云
对于seo人员而言,优采云是一个相对通用的采集软件. 下载并安装优采云采集器,有付费版本和免费版本,百度可以找到下载地址. (我在这里不做详细介绍)kE9数百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
2,优采云
优采云采集器是用于快速采集网页信息的工具. 它通常用于采集网站文章和网站信息数据. 优采云有免费版和付费版. 这取决于您自己或公司的需求. 免费版本在许多方面受到限制. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
3. 优采云采集
此采集工具相对聪明,需要很少的人来配置它. 它可以看作是一个傻瓜式软件. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
4. 聚集人
要使用Collector插件,该网站必须为Dream Weaving,因为该插件是Dream Weaving的采集插件. 采集器是直接通过关键字采集文章. Collector是收费软件. 当然,我们也可以下载破解版,可以在百度上搜索. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
5. 织梦采集器
它是由梦幻编织后台程序自动带来的. 采集节点是完全免费的,但是采集功能不是很强大,并且有许多事情无法实现. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
首先,我们需要知道大型网站基本上都有自己的开放采集点. 他们很少使用工具. 作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具来实现采集. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台 查看全部
商品目录1,优采云2,优采云3,优采云采集4,采集器5,梦织采集器
我不知道每个人是否都了解文章采集工具,也许有些网站管理员没有联系过它!采集工具通常由一些站点组或大型门户站点(例如公司站点)使用,这些工具很少使用. 当然,某些个人网站也用于采集,因为某些情况下不想自己更新文章,或者大型网站需要更新. 有太多而复杂的文章,例如新闻台,它们都使用采集,所以网站可以使用文章采集工具吗? kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
1,优采云
对于seo人员而言,优采云是一个相对通用的采集软件. 下载并安装优采云采集器,有付费版本和免费版本,百度可以找到下载地址. (我在这里不做详细介绍)kE9数百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
2,优采云
优采云采集器是用于快速采集网页信息的工具. 它通常用于采集网站文章和网站信息数据. 优采云有免费版和付费版. 这取决于您自己或公司的需求. 免费版本在许多方面受到限制. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
3. 优采云采集
此采集工具相对聪明,需要很少的人来配置它. 它可以看作是一个傻瓜式软件. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
4. 聚集人
要使用Collector插件,该网站必须为Dream Weaving,因为该插件是Dream Weaving的采集插件. 采集器是直接通过关键字采集文章. Collector是收费软件. 当然,我们也可以下载破解版,可以在百度上搜索. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
5. 织梦采集器
它是由梦幻编织后台程序自动带来的. 采集节点是完全免费的,但是采集功能不是很强大,并且有许多事情无法实现. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
首先,我们需要知道大型网站基本上都有自己的开放采集点. 他们很少使用工具. 作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具来实现采集. kE9百行链接交换-网站分类目录提交-中国最大的网站友好链接交易平台
免费帮助点链接采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-06 23:04
1. 扁平柱设置. 不要在不相关的列之间建立内部链接;
2,页面质量;页面质量可以被视为提高包容性的最重要因素. 假设您的站点条目丰富并且对搜索引擎的爬网规则掌握得很好,但是页面内容的质量较低,那么将减少收录该页面的可能性. 页面质量涉及诸如页面内容,URL设置,相关性构造和网站总体权重等因素的影响.
3. 域名PR的收录量,加权网站和蜘蛛爬网时间与PR成正比. 一般而言,PR值越高,夹杂物越好,蜘蛛爬行时间越长. 百度的权重相似,权重越高,排名越好.
4. 继承Bear's Paw ID的权益,也就是说,您必须继承Bear's Paw的权益. 继承后,关闭Bear's Paw网站的每日收录内容. 另外,例如,您的熊掌编号配额为15,则继承后它将更改为10,但是会更少.
5. 网站内页的采集时间: 每个站点的采集时间不同,因此需要详细分析. 高质量的站点可以实现即时采集,高质量的站点可以实现天体采集,普通站点也将在一周内发布. 如果未收录网页,则可以先检查网页抓取问题,然后再分析网页质量.
6. 合理使用nofollow标记Nofollow是HTML标记的属性值. 这个标签的意思是告诉搜索引擎“不遵循此页面上的链接”或“不遵循此特定链接. ”然后,我们要做的就是使用nofollow阻止网站页面上的重复链接并且对SEO页面没有很高的价值,以减少网站重量的分散,并可以减少搜索引擎对网站中每个页面的重复爬网,从而提高搜索引擎的爬网效率.
7. 在本文的开头,您应该突出重点,让用户知道您接下来要谈论的内容,并留下一些问题,以便用户有低头的欲望. 简而言之,不要在文章的第一段中谈论任何内容. 没事.
8、5118个伪原创商品生成器大数据可实现高效创建且无后顾之忧;无需在线下载和使用,只需输入一键式智能重写深度中文语义分析算法,AI即可灵活调整10亿级语料库的内容,提高了数据自动化的准确性.
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性. 查看全部
1. 扁平柱设置. 不要在不相关的列之间建立内部链接;
2,页面质量;页面质量可以被视为提高包容性的最重要因素. 假设您的站点条目丰富并且对搜索引擎的爬网规则掌握得很好,但是页面内容的质量较低,那么将减少收录该页面的可能性. 页面质量涉及诸如页面内容,URL设置,相关性构造和网站总体权重等因素的影响.
3. 域名PR的收录量,加权网站和蜘蛛爬网时间与PR成正比. 一般而言,PR值越高,夹杂物越好,蜘蛛爬行时间越长. 百度的权重相似,权重越高,排名越好.
4. 继承Bear's Paw ID的权益,也就是说,您必须继承Bear's Paw的权益. 继承后,关闭Bear's Paw网站的每日收录内容. 另外,例如,您的熊掌编号配额为15,则继承后它将更改为10,但是会更少.
5. 网站内页的采集时间: 每个站点的采集时间不同,因此需要详细分析. 高质量的站点可以实现即时采集,高质量的站点可以实现天体采集,普通站点也将在一周内发布. 如果未收录网页,则可以先检查网页抓取问题,然后再分析网页质量.
6. 合理使用nofollow标记Nofollow是HTML标记的属性值. 这个标签的意思是告诉搜索引擎“不遵循此页面上的链接”或“不遵循此特定链接. ”然后,我们要做的就是使用nofollow阻止网站页面上的重复链接并且对SEO页面没有很高的价值,以减少网站重量的分散,并可以减少搜索引擎对网站中每个页面的重复爬网,从而提高搜索引擎的爬网效率.
7. 在本文的开头,您应该突出重点,让用户知道您接下来要谈论的内容,并留下一些问题,以便用户有低头的欲望. 简而言之,不要在文章的第一段中谈论任何内容. 没事.
8、5118个伪原创商品生成器大数据可实现高效创建且无后顾之忧;无需在线下载和使用,只需输入一键式智能重写深度中文语义分析算法,AI即可灵活调整10亿级语料库的内容,提高了数据自动化的准确性.
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性.
Python采集器搜寻到微信公共帐户历史记录文章的所有链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 473 次浏览 • 2020-08-06 19:03
通过搜狗搜索微信公众号并获取链接. 通过提琴手检查手机微信以获取链接.
经过仔细考虑,搜狗首先被放弃了,因为在对搜狗的官方帐户进行初步了解之后,只有链接到前十篇文章. 这次让我谈谈我的想法.
思考
当我尝试在手机微信上获取官方帐户的历史链接时,偶然发现也可以使用计算机上的微信来获取该链接. 但这并没有太大影响. 因为我在手机和计算机上都尝试过,所以可以对其进行爬网,但是计算机使用起来更加方便.
首先,打开提琴手,然后在计算机端的微信上找到要爬网的微信官方帐户,然后在其上单击鼠标左键以查看所有历史信息. 单击查看历史信息后,我们将在提琴手中看到一个这样的GET请求: / MP / getmasssendmsg __ BIZ = MzA3NDk1NjI0OQ ==&UIN = MjgxMTU0NDM1键= cdce7679908e443d6f21adcc7236aea6bfd78ef06cb0f784644d5a3d1a7d1ee97b52997a3fdfca401835b9cc962bfa98e2d8f8806cba94b89ccd72c0883df2baaf712b0818727d149cefb3f920257d27&的devicetype =视窗+ 10&版本= 6203005d&LANG = zh_CN的&ascene = 7&pass_ticket = PMllYHvaLNk2DRePx1zNYuCv71ocxw7m6lOhOnaFfnnDt35P7ybHP3ESUYFoYaDQ,在前面添加后,打开整个&浏览器中的链接,您会发现该官方帐户的历史文章已打开.
用小提琴手多次抓取此链接并更改了几个官方帐户后,您会发现整个链接中的biz应该是微信官方帐户的标识符,uin应该是微信帐户的标识符,并且密钥是腾讯的算法. 在整个链接中,如果您要获取相同的微信官方帐户,则只有密钥是时间敏感的,而其他密钥是不变的. 如果超过一定时间,请使用此密钥打开链接,您将发现它无法使用,请使用微信将其打开!在这里,我本来以为如果使用微信附带的浏览器就不会出现及时性问题,因此一开始我的UA被设置为微信,然后我发现它没用...我切换回计算机. ..这是一个陷阱,您不能使用钥匙!幸运的是,如果您只注册一个官方帐户,仍然有足够的时间,但是编写程序时令人头疼. 每次失败,您都必须重新制作它.
通过检查此链接中的元素,不难发现我们已经可以看到该文章的链接,但是已经出现了问题. 该初始链接中仍然只有10篇近期文章. 这时,我们必须向下滑动滚动条以显示所有剩余的文章. 因此,在编写程序时,您需要通过selenium + phahtomJS链接此接口,并滑动滚动条,直到滚动条滑到底部. 通过这种方式,我们可以查看元素并看到已获得所有文章链接. **请注意,文章的链接隐藏在几个标签中,因此请全部查找,否则您将错过它们! **然后保存这些链接.
程序
关于我的计划思想:
整个过程是通过selenium + phantomJS链接上述链接,通过BeautifulSoup提取页面,使用JS滚动到末尾直到没有更多消息,最后找到所有链接并输出(记住是几种类型的链接),您必须在标记中找到所有链接). 由于朋友只需要此官方帐户的链接,并且由于仅更改同一官方帐户的链接的密钥,因此可以从bash获取密钥,而其他密钥可以写入程序. 我太懒了吗........这可能是一种思考方式,仍有许多事情可以优化...
附加代码() 查看全部
因为一个朋友问我是否可以在微信公众号上找到所有历史文章的链接,所以我帮助他获得了它. 通过百度和谷歌,我发现人们现在有以下两个思路来攀登微信官方账号:
通过搜狗搜索微信公众号并获取链接. 通过提琴手检查手机微信以获取链接.
经过仔细考虑,搜狗首先被放弃了,因为在对搜狗的官方帐户进行初步了解之后,只有链接到前十篇文章. 这次让我谈谈我的想法.
思考
当我尝试在手机微信上获取官方帐户的历史链接时,偶然发现也可以使用计算机上的微信来获取该链接. 但这并没有太大影响. 因为我在手机和计算机上都尝试过,所以可以对其进行爬网,但是计算机使用起来更加方便.
首先,打开提琴手,然后在计算机端的微信上找到要爬网的微信官方帐户,然后在其上单击鼠标左键以查看所有历史信息. 单击查看历史信息后,我们将在提琴手中看到一个这样的GET请求: / MP / getmasssendmsg __ BIZ = MzA3NDk1NjI0OQ ==&UIN = MjgxMTU0NDM1键= cdce7679908e443d6f21adcc7236aea6bfd78ef06cb0f784644d5a3d1a7d1ee97b52997a3fdfca401835b9cc962bfa98e2d8f8806cba94b89ccd72c0883df2baaf712b0818727d149cefb3f920257d27&的devicetype =视窗+ 10&版本= 6203005d&LANG = zh_CN的&ascene = 7&pass_ticket = PMllYHvaLNk2DRePx1zNYuCv71ocxw7m6lOhOnaFfnnDt35P7ybHP3ESUYFoYaDQ,在前面添加后,打开整个&浏览器中的链接,您会发现该官方帐户的历史文章已打开.
用小提琴手多次抓取此链接并更改了几个官方帐户后,您会发现整个链接中的biz应该是微信官方帐户的标识符,uin应该是微信帐户的标识符,并且密钥是腾讯的算法. 在整个链接中,如果您要获取相同的微信官方帐户,则只有密钥是时间敏感的,而其他密钥是不变的. 如果超过一定时间,请使用此密钥打开链接,您将发现它无法使用,请使用微信将其打开!在这里,我本来以为如果使用微信附带的浏览器就不会出现及时性问题,因此一开始我的UA被设置为微信,然后我发现它没用...我切换回计算机. ..这是一个陷阱,您不能使用钥匙!幸运的是,如果您只注册一个官方帐户,仍然有足够的时间,但是编写程序时令人头疼. 每次失败,您都必须重新制作它.
通过检查此链接中的元素,不难发现我们已经可以看到该文章的链接,但是已经出现了问题. 该初始链接中仍然只有10篇近期文章. 这时,我们必须向下滑动滚动条以显示所有剩余的文章. 因此,在编写程序时,您需要通过selenium + phahtomJS链接此接口,并滑动滚动条,直到滚动条滑到底部. 通过这种方式,我们可以查看元素并看到已获得所有文章链接. **请注意,文章的链接隐藏在几个标签中,因此请全部查找,否则您将错过它们! **然后保存这些链接.
程序
关于我的计划思想:
整个过程是通过selenium + phantomJS链接上述链接,通过BeautifulSoup提取页面,使用JS滚动到末尾直到没有更多消息,最后找到所有链接并输出(记住是几种类型的链接),您必须在标记中找到所有链接). 由于朋友只需要此官方帐户的链接,并且由于仅更改同一官方帐户的链接的密钥,因此可以从bash获取密钥,而其他密钥可以写入程序. 我太懒了吗........这可能是一种思考方式,仍有许多事情可以优化...
附加代码()
微信文章抓取: 微信公众号文章抓取常识的临时链接和永久链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-06 03:07
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)上发布的文章.
对于想获得微信文章进行研究的朋友,探索的第一种方法通常是搜狗微信. 因此,关于搜狗微信和与微信相关的爬网,您需要了解以下有关微信文章链接的常识.
搜狗微信搜索的文章链接均为微信的临时链接,通过客户端查看的文章链接均为永久链接
临时链接:
* UPlviVRt * o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new = 1
功能:
1. 浏览有效期为创建后的6个小时. 如果您在此时间之后直接使用浏览器,它将显示“链接已过期”,可以通过微信客户端进行访问(此时它会自动转换为微信永久链接的简短连接形式)
2. 链接的有效期为生成之日起约50天. 超过此期限的链接将无法在客户端中打开,并且会显示“系统错误”. 这就是为什么微信临时链接在微信客户端中显示系统错误的原因.
3. 临时链接可直接在浏览器中浏览,而不显示读数和喜欢的次数. 该页面仅收录biz,mid,idx,并且不收录sn参数(稍后说明)
4. 快速识别方法: 链接收录签名字段.
欢迎访问Milu Jun的个人博客以查看所有内容 查看全部
请不要在未经许可的情况下转载
尝试抓取微信文章的朋友必须熟悉搜狗微信. 搜狗微信是腾讯提供的官方搜索引擎,专门用于搜索微信官方账号(不包括服务账号)上发布的文章.
对于想获得微信文章进行研究的朋友,探索的第一种方法通常是搜狗微信. 因此,关于搜狗微信和与微信相关的爬网,您需要了解以下有关微信文章链接的常识.
搜狗微信搜索的文章链接均为微信的临时链接,通过客户端查看的文章链接均为永久链接
临时链接:
* UPlviVRt * o2do10V-WJ-lxf8eD5FYWEC8ZMfNhyu1iTwYw9Qel1BqVhNlF8cKAxXIorsK-Bu2BcplG2&new = 1
功能:
1. 浏览有效期为创建后的6个小时. 如果您在此时间之后直接使用浏览器,它将显示“链接已过期”,可以通过微信客户端进行访问(此时它会自动转换为微信永久链接的简短连接形式)
2. 链接的有效期为生成之日起约50天. 超过此期限的链接将无法在客户端中打开,并且会显示“系统错误”. 这就是为什么微信临时链接在微信客户端中显示系统错误的原因.
3. 临时链接可直接在浏览器中浏览,而不显示读数和喜欢的次数. 该页面仅收录biz,mid,idx,并且不收录sn参数(稍后说明)
4. 快速识别方法: 链接收录签名字段.
欢迎访问Milu Jun的个人博客以查看所有内容
[搜狗微信]特定微信官方帐户的最新文章采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 601 次浏览 • 2020-08-05 20:08
我们通常使用搜狗微信()采集微信官方帐户文章. 搜狗微信支持[官方账号搜索]. 通过输入官方账号名称/ ID,可以搜索目标官方账号,以及目标官方账号的相关信息(官方账号ID,微信ID,功能介绍,微信认证)及其最新发布的文章(文章标题和文章)链接),请点击文章链接以进入文章详细信息页面并查看文章正文(文字+图片).
采集栏
官方帐户名称,微信ID,功能介绍,微信认证的公司名称,文章标题,文章来源,文章作者,出版日期,文章正文.
将鼠标移到图片上,右键单击并选择[在新选项卡中打开图片]以查看高清大图片
以下图片也是如此
采集结果
采集的结果可以导出为Excel,CSV,HTML,数据库和其他格式. 导出到Excel示例:
教程说明
本文的生产时间: 2020/4/26优采云版本: V8.1.8
如果由于网页的修订而导致URL或步骤无效,并且无法采集目标数据,请联系官方客户服务,我们将及时予以纠正.
采集步骤
第1步: 打开网页
第二步,分批输入多个关键字并搜索
第3步. 采集官方帐户信息
第4步. 单击以输入最新文章的详细信息并采集文章正文
第5步. 修改字段
第6步,开始采集
以下是具体步骤:
步骤1.打开网页
在主页上的[输入框]中输入目标URL,单击[开始采集],然后才彩云将自动打开该网页.
特殊说明:
a. 打开网页后,如果开始启动[自动识别],请单击[不再自动识别]或[取消识别]将其关闭. 因为本文不适合使用[自动识别].
b. [自动识别]适用于自动识别列表,滚动和翻页网页. 识别成功后,直接开始采集以获取数据. 有关详细信息,请单击以查看[自动识别]教程
第二步,分批输入多个关键字并搜索
通过以下步骤,批量输入多个关键字.
1. 创建[输入文字]以输入关键字
2,创建[文本列表循环],存储多个关键字
3. 将[输入文本]与[文本列表循环]链接
4,点击搜索
1. 创建[输入文字]以输入关键字
选中搜狗微信搜索框,在操作提示框中单击[输入文字],输入关键字并保存.
2,创建[文本列表循环],存储多个关键字
在[输入文本2]步骤之后,添加一个[循环].
进入[循环]步骤设置页面,将循环模式选择为[文本列表],然后单击
按钮,输入我们准备的关键字(您可以同时输入多个关键字,每行一个)并保存.
特殊说明:
a. 在示例中输入的关键字是[优采云 Big Data]和[优采云 Collection Research Institute],可以根据自己的需要进行替换.
b. 一次输入最多2W个关键字. 您可以先准备一个收录多个关键字的文档,然后将其复制并粘贴到Youcai Cloud中.
3. 将[输入文本]与[文本列表循环]链接
将[打开网页]步骤拖入循环.
将[输入文本]步骤拖入循环. 然后进入[输入文本]设置页面,选中[使用当前循环中的文本填充输入框]并保存.
4. 点击搜索
在[循环]中选择一个关键字,然后单击[输入文本],可以看到该关键字已成功输入到网页的文本框中.
然后选择[搜索正式帐户]按钮,在操作提示框中单击[单击此按钮],将显示关键字搜索结果列表页面.
特殊说明:
a. 为什么将[打开的网页]拖到循环中?这是因为,在搜狗微信主页上输入第一个关键字并进行搜索之后,您将获得一个搜索结果列表页面. 采集第一个关键字的数据后,在直接列表页面上输入第二个关键字. 主页和列表页上的[搜索]按钮的源代码不同,并且第二关键字搜索无法完成. 为了解决这个问题,我们将[打开网页]拖到循环中. 关键字采集结束后,请重新打开主页,在主页上输入下一个关键字并进行采集...有关详细信息,请参阅批输入关键字查询,查询结果采集教程
第3步. 采集官方帐户信息
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在该示例中,我们提取了微信官方帐户名,微信ID,功能介绍和微信认证.
第4步. 单击以输入最新文章的详细信息并采集文章正文
1. 点击文章链接进入文章详细信息页面
搜索官方帐户后,默认情况下将显示此官方帐户发布的最新文章. 单击文章标题进入文章详细信息页面并采集详细信息页面字段.
在[最近的文章]之后选择文章标题,然后在操作提示框中选择[单击链接]. 单击以自动进入文章详细信息页面.
2. 采集文章详细信息页面中的字段
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在示例中,我们提取了文章标题,作者,出版时间,正文和其他字段.
然后进入[click element]设置页面,并将[执行前等待]设置2秒钟.
特殊说明:
a. 设置合理的[执行前等待]时间可以有效避免数据泄漏. 有关详细信息,请参阅执行前等待教程.
b. 文本,图片,视频和源代码是不同的数据形式,在操作提示框中选择提取方法时,它们会稍有不同. 文本通常为[采集此元素文本],而图片通常为[采集图片地址]. 有关更多提取方法,请单击以查看不同数据类型(文本,图像,链接,源代码等)的捕获方法.
c. 需要特别注意[article body]字段. 我们要提取整个文本块,因此我们需要选择整个文本块. 但是,由于搜狗的微信文章格式更加复杂,因此无法通过直接移动鼠标来选择整个文本块. 然后我们首先选择一个段落,然后在操作提示框中单击最后一个DIV(通常,最后一个DIV代表整个文本块),然后选择[采集此元素文本],该文本将被采集下来.
第5步. 修改字段
进入[提取数据]设置页面,您可以删除冗余字段,修改字段名称,移动字段顺序等.
第6步,开始采集
1. 单击[采集]和[开始本地采集]. 启动后,优采云开始自动采集数据.
特殊说明:
a. [本地采集集]用于使用您自己的计算机进行采集,[云采集集]用于使用由优采云提供的云服务器,单击以查看本地采集集和云采集详细信息.
2. 采集完成后,选择适当的导出方法以导出数据. 支持导出到Excel,CSV,HTML,数据库等. 在此处导出到Excel.
数据示例:
作者: DJacky 查看全部
采集场景
我们通常使用搜狗微信()采集微信官方帐户文章. 搜狗微信支持[官方账号搜索]. 通过输入官方账号名称/ ID,可以搜索目标官方账号,以及目标官方账号的相关信息(官方账号ID,微信ID,功能介绍,微信认证)及其最新发布的文章(文章标题和文章)链接),请点击文章链接以进入文章详细信息页面并查看文章正文(文字+图片).
采集栏
官方帐户名称,微信ID,功能介绍,微信认证的公司名称,文章标题,文章来源,文章作者,出版日期,文章正文.
将鼠标移到图片上,右键单击并选择[在新选项卡中打开图片]以查看高清大图片
以下图片也是如此
采集结果
采集的结果可以导出为Excel,CSV,HTML,数据库和其他格式. 导出到Excel示例:
教程说明
本文的生产时间: 2020/4/26优采云版本: V8.1.8
如果由于网页的修订而导致URL或步骤无效,并且无法采集目标数据,请联系官方客户服务,我们将及时予以纠正.
采集步骤
第1步: 打开网页
第二步,分批输入多个关键字并搜索
第3步. 采集官方帐户信息
第4步. 单击以输入最新文章的详细信息并采集文章正文
第5步. 修改字段
第6步,开始采集
以下是具体步骤:
步骤1.打开网页
在主页上的[输入框]中输入目标URL,单击[开始采集],然后才彩云将自动打开该网页.
特殊说明:
a. 打开网页后,如果开始启动[自动识别],请单击[不再自动识别]或[取消识别]将其关闭. 因为本文不适合使用[自动识别].
b. [自动识别]适用于自动识别列表,滚动和翻页网页. 识别成功后,直接开始采集以获取数据. 有关详细信息,请单击以查看[自动识别]教程
第二步,分批输入多个关键字并搜索
通过以下步骤,批量输入多个关键字.
1. 创建[输入文字]以输入关键字
2,创建[文本列表循环],存储多个关键字
3. 将[输入文本]与[文本列表循环]链接
4,点击搜索
1. 创建[输入文字]以输入关键字
选中搜狗微信搜索框,在操作提示框中单击[输入文字],输入关键字并保存.
2,创建[文本列表循环],存储多个关键字
在[输入文本2]步骤之后,添加一个[循环].
进入[循环]步骤设置页面,将循环模式选择为[文本列表],然后单击
按钮,输入我们准备的关键字(您可以同时输入多个关键字,每行一个)并保存.
特殊说明:
a. 在示例中输入的关键字是[优采云 Big Data]和[优采云 Collection Research Institute],可以根据自己的需要进行替换.
b. 一次输入最多2W个关键字. 您可以先准备一个收录多个关键字的文档,然后将其复制并粘贴到Youcai Cloud中.
3. 将[输入文本]与[文本列表循环]链接
将[打开网页]步骤拖入循环.
将[输入文本]步骤拖入循环. 然后进入[输入文本]设置页面,选中[使用当前循环中的文本填充输入框]并保存.
4. 点击搜索
在[循环]中选择一个关键字,然后单击[输入文本],可以看到该关键字已成功输入到网页的文本框中.
然后选择[搜索正式帐户]按钮,在操作提示框中单击[单击此按钮],将显示关键字搜索结果列表页面.
特殊说明:
a. 为什么将[打开的网页]拖到循环中?这是因为,在搜狗微信主页上输入第一个关键字并进行搜索之后,您将获得一个搜索结果列表页面. 采集第一个关键字的数据后,在直接列表页面上输入第二个关键字. 主页和列表页上的[搜索]按钮的源代码不同,并且第二关键字搜索无法完成. 为了解决这个问题,我们将[打开网页]拖到循环中. 关键字采集结束后,请重新打开主页,在主页上输入下一个关键字并进行采集...有关详细信息,请参阅批输入关键字查询,查询结果采集教程
第3步. 采集官方帐户信息
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在该示例中,我们提取了微信官方帐户名,微信ID,功能介绍和微信认证.
第4步. 单击以输入最新文章的详细信息并采集文章正文
1. 点击文章链接进入文章详细信息页面
搜索官方帐户后,默认情况下将显示此官方帐户发布的最新文章. 单击文章标题进入文章详细信息页面并采集详细信息页面字段.
在[最近的文章]之后选择文章标题,然后在操作提示框中选择[单击链接]. 单击以自动进入文章详细信息页面.
2. 采集文章详细信息页面中的字段
在页面上选择文本,然后在操作提示框中单击[采集此元素文本].
可以通过这种方式提取文本字段. 在示例中,我们提取了文章标题,作者,出版时间,正文和其他字段.
然后进入[click element]设置页面,并将[执行前等待]设置2秒钟.
特殊说明:
a. 设置合理的[执行前等待]时间可以有效避免数据泄漏. 有关详细信息,请参阅执行前等待教程.
b. 文本,图片,视频和源代码是不同的数据形式,在操作提示框中选择提取方法时,它们会稍有不同. 文本通常为[采集此元素文本],而图片通常为[采集图片地址]. 有关更多提取方法,请单击以查看不同数据类型(文本,图像,链接,源代码等)的捕获方法.
c. 需要特别注意[article body]字段. 我们要提取整个文本块,因此我们需要选择整个文本块. 但是,由于搜狗的微信文章格式更加复杂,因此无法通过直接移动鼠标来选择整个文本块. 然后我们首先选择一个段落,然后在操作提示框中单击最后一个DIV(通常,最后一个DIV代表整个文本块),然后选择[采集此元素文本],该文本将被采集下来.
第5步. 修改字段
进入[提取数据]设置页面,您可以删除冗余字段,修改字段名称,移动字段顺序等.
第6步,开始采集
1. 单击[采集]和[开始本地采集]. 启动后,优采云开始自动采集数据.
特殊说明:
a. [本地采集集]用于使用您自己的计算机进行采集,[云采集集]用于使用由优采云提供的云服务器,单击以查看本地采集集和云采集详细信息.
2. 采集完成后,选择适当的导出方法以导出数据. 支持导出到Excel,CSV,HTML,数据库等. 在此处导出到Excel.
数据示例:
作者: DJacky
微信公众号采集,历史文章采集,通用密钥采集,例如阅读评论采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2020-08-05 14:12
第一个是数据源,主要分为两部分. 客户集合和搜狗微信集合.
搜狗微信的采集相对简单. 它主要解决了IP问题,并连续模拟了搜索文章和搜索官方帐户的两种操作,非常方便地采集我们想要的文章. 但是,搜狗微信的局限性也很明显. 1.信息不全面. 据估计,公共账户的覆盖率应该只有80%左右. 2.没有诸如阅读之类的信息. 3.在“搜索公用号码”部分下采集的文章链接是临时链接,在一段时间后或达到一定点击次数后,它们将变为无效. 此值需要特定的演示. 注意: 无效链接仍然可以通过微信客户端打开. 当然,也有将临时链接转换为永久链接的方法.
我们的重点仍然是解释客户如何执行收款. 首先,让我们看一下微信文章永久链接的格式: #wechat_redirect
关键参数1. Biz是微信公众号的ID. 2.中间文章的ID. 3. idx文章在文章组中的顺序. 4. sn(加密值,暂时不知道如何生成).
接下来,通过打开客户端上的链接并抓取一个包,我们可以看到下面的链接明显长于上面的链接,并带有更多的参数. 这里主要关注的是关键和关键. 使用您自己的微信ID和密钥来表示密钥. 通过更改公共号码BIZ,我们可以发现此密钥的使用范围仅对当前公共号码有效,也就是说,您只能访问与此BIZ相关的链接. 所以问题是,当我们需要访问大量不同的公共帐户时,我们将如何处理它. 接下来,将介绍通用密钥的概念. 顾名思义,您可以使用此密钥访问任何BIZ. 通过以上分析,我们大概可以知道,只要可以获得通用密钥,就可以通过不断改变BIZ来进行公用号的物品采集工作. 因此,现在的重点是如何自动批量获取通用密钥并测试使用通用密钥的规则.
%3D%3D&devicetype = Windows + 7&version = 62060619&lang = zh_CN&pass_ticket = MDrfvfr9bp1x7iCQWQ1tsjbc%2Bq4nDXrsrtj3afjg0vBfdOr9yOfHdIx8x4sXRlyM&winzoom = 1
首先,获取通用密钥
目前,只能通过客户端获得通用密钥,这意味着我们必须采集设备(手机)+微信ID才能获得通用密钥. 测试时,我们可以使用Android仿真器进行验证(通过多个打开的仿真器生成密钥很容易被阻止,尤其是新注册的微信帐户). 我当前的方法是将脚本嵌入到采集设备中,并安装Android版本的数据包捕获软件. 连续执行脚本所生成的数据包将被加密并发送到Web服务,最后输入数据库. 然后从库中取出呼叫. 对于批量采集,您只能投入大量的采集资源,即手机+微信. 使用通用密钥方法,每天采集将近150W公开号码文章. 搜狗还有更多〜
两个,使用规则
1. 采集的一般过程是先访问列表,获取列表中的文章链接,然后采集特定文章. 微信公众号采集也不例外. 第一个是列表页面,微信公众号列表通过访问公众号历史新闻页面进行. 由于访问速度较慢且限制越来越多,我们最早在香港使用微信链接已被放弃. ,当前链接是大陆. 当前历史记录页面上的限制主要是每天访问每个微信帐户的总次数(不是太快)以及每天大约1300次访问. 如果超过该限制,它将返回“频繁操作”并在24小时后自动解除阻止.
2. 点赞和阅读的次数之间的时间间隔应大于2秒,无论如何,都会返回异常. 同时,每天的访问总数约为6000.
3. 采集帐户的主要信息,主要是不要太快. 大约是6到8S. 注意,这里不仅需要不同的通用密钥,而且IP也受到限制. 如果您不小心被阻止,则解锁时间约为2小时.
4. 密钥的有效期为2小时,如果访问列表超过2小时,则访问列表将返回类似{ret: -3,no seesion}的字符串,并且所采集的主题信息将进入验证页面. 所有用于生成和更新通用密钥的脚本通常都在2小时内设置.
主要规则应为上述规则. 最近,我们已经开发了一个应用程序工具,并参考其他微信采集工具,以自动采集具有微信公众号永久链接的文章,包括历史文章(例如阅读等). 如果需要,您可以成为我的豚鼠和请与我联系以进行免费试用〜或有任何疑问,请随时骚扰并一起交流〜 查看全部
微信采集的重点是与微信公众号相关的数据,主要是发表文章,即阅读,官方账号的信息等. 下面将解释如何采集以及对采集的一些限制.
第一个是数据源,主要分为两部分. 客户集合和搜狗微信集合.
搜狗微信的采集相对简单. 它主要解决了IP问题,并连续模拟了搜索文章和搜索官方帐户的两种操作,非常方便地采集我们想要的文章. 但是,搜狗微信的局限性也很明显. 1.信息不全面. 据估计,公共账户的覆盖率应该只有80%左右. 2.没有诸如阅读之类的信息. 3.在“搜索公用号码”部分下采集的文章链接是临时链接,在一段时间后或达到一定点击次数后,它们将变为无效. 此值需要特定的演示. 注意: 无效链接仍然可以通过微信客户端打开. 当然,也有将临时链接转换为永久链接的方法.
我们的重点仍然是解释客户如何执行收款. 首先,让我们看一下微信文章永久链接的格式: #wechat_redirect
关键参数1. Biz是微信公众号的ID. 2.中间文章的ID. 3. idx文章在文章组中的顺序. 4. sn(加密值,暂时不知道如何生成).
接下来,通过打开客户端上的链接并抓取一个包,我们可以看到下面的链接明显长于上面的链接,并带有更多的参数. 这里主要关注的是关键和关键. 使用您自己的微信ID和密钥来表示密钥. 通过更改公共号码BIZ,我们可以发现此密钥的使用范围仅对当前公共号码有效,也就是说,您只能访问与此BIZ相关的链接. 所以问题是,当我们需要访问大量不同的公共帐户时,我们将如何处理它. 接下来,将介绍通用密钥的概念. 顾名思义,您可以使用此密钥访问任何BIZ. 通过以上分析,我们大概可以知道,只要可以获得通用密钥,就可以通过不断改变BIZ来进行公用号的物品采集工作. 因此,现在的重点是如何自动批量获取通用密钥并测试使用通用密钥的规则.
%3D%3D&devicetype = Windows + 7&version = 62060619&lang = zh_CN&pass_ticket = MDrfvfr9bp1x7iCQWQ1tsjbc%2Bq4nDXrsrtj3afjg0vBfdOr9yOfHdIx8x4sXRlyM&winzoom = 1
首先,获取通用密钥
目前,只能通过客户端获得通用密钥,这意味着我们必须采集设备(手机)+微信ID才能获得通用密钥. 测试时,我们可以使用Android仿真器进行验证(通过多个打开的仿真器生成密钥很容易被阻止,尤其是新注册的微信帐户). 我当前的方法是将脚本嵌入到采集设备中,并安装Android版本的数据包捕获软件. 连续执行脚本所生成的数据包将被加密并发送到Web服务,最后输入数据库. 然后从库中取出呼叫. 对于批量采集,您只能投入大量的采集资源,即手机+微信. 使用通用密钥方法,每天采集将近150W公开号码文章. 搜狗还有更多〜
两个,使用规则
1. 采集的一般过程是先访问列表,获取列表中的文章链接,然后采集特定文章. 微信公众号采集也不例外. 第一个是列表页面,微信公众号列表通过访问公众号历史新闻页面进行. 由于访问速度较慢且限制越来越多,我们最早在香港使用微信链接已被放弃. ,当前链接是大陆. 当前历史记录页面上的限制主要是每天访问每个微信帐户的总次数(不是太快)以及每天大约1300次访问. 如果超过该限制,它将返回“频繁操作”并在24小时后自动解除阻止.
2. 点赞和阅读的次数之间的时间间隔应大于2秒,无论如何,都会返回异常. 同时,每天的访问总数约为6000.
3. 采集帐户的主要信息,主要是不要太快. 大约是6到8S. 注意,这里不仅需要不同的通用密钥,而且IP也受到限制. 如果您不小心被阻止,则解锁时间约为2小时.
4. 密钥的有效期为2小时,如果访问列表超过2小时,则访问列表将返回类似{ret: -3,no seesion}的字符串,并且所采集的主题信息将进入验证页面. 所有用于生成和更新通用密钥的脚本通常都在2小时内设置.
主要规则应为上述规则. 最近,我们已经开发了一个应用程序工具,并参考其他微信采集工具,以自动采集具有微信公众号永久链接的文章,包括历史文章(例如阅读等). 如果需要,您可以成为我的豚鼠和请与我联系以进行免费试用〜或有任何疑问,请随时骚扰并一起交流〜

