
文章采集调用
文章采集调用(垃圾站采集与搜索引擎收录的关系修改方法介绍(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-01 21:09
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有大量采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。因为采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页进入
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有很多采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。
因为采集回来内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,所以生产一个最新的文章列表,减少蜘蛛爬行步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,本质上和xml映射一样,除了这是一个 HTML 页面。
如何修改:
1、下载压缩包,解压后上传到根目录。 (点击下载GBK版)
2、Enter 网站Background Core -> Channel Model -> 单页文档管理 添加一个页面。
3、 页面标题、页面关键字和页面摘要信息根据你的网站情况填写,模板名和文件名参考下图,编辑框中不需要添加任何内容,我已经在模板里给你设置好了。
4、设置并点击后,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、 无法自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row=’50′ col=’1′ orderby=pubdate}
[field:title /]
{/dede:arclist}
您也可以创建一个没有图片的简单导航页面。 查看全部
文章采集调用(垃圾站采集与搜索引擎收录的关系修改方法介绍(图))
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有大量采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。因为采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页进入
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有很多采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。
因为采集回来内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,所以生产一个最新的文章列表,减少蜘蛛爬行步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,本质上和xml映射一样,除了这是一个 HTML 页面。
如何修改:
1、下载压缩包,解压后上传到根目录。 (点击下载GBK版)
2、Enter 网站Background Core -> Channel Model -> 单页文档管理 添加一个页面。
3、 页面标题、页面关键字和页面摘要信息根据你的网站情况填写,模板名和文件名参考下图,编辑框中不需要添加任何内容,我已经在模板里给你设置好了。
4、设置并点击后,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、 无法自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row=’50′ col=’1′ orderby=pubdate}
[field:title /]
{/dede:arclist}
您也可以创建一个没有图片的简单导航页面。
文章采集调用( 一图带你看Java虚拟机运行时数据区内存)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-09-01 14:14
一图带你看Java虚拟机运行时数据区内存)
一张图带你看这篇文章
一、运行时数据区
首先我们来看看Java虚拟机管理的内存包括哪些区域。正如我们要了解一座房子,我们首先要了解房子的大致结构。根据《Java虚拟机规范(Java SE 7版)》,请看下图:
Java 虚拟机运行时数据区
1.1 程序计数器
程序计数器是一个很小的内存空间,可以看作是当前线程执行的字节码的行号的指示器。
1.2 Java 虚拟机栈
和程序计数器一样,Java虚拟机栈也是线程私有的,其生命周期与线程相同。虚拟机栈描述了Java方法执行的内存模型:每个方法执行时,都会创建一个栈帧来存储局部变量表、操作数栈、动态链接、方法退出等信息。每个方法从调用到执行完成的过程,对应着虚拟机栈中一个栈帧入栈到出栈的过程。请看下图:
Java 虚拟机栈
1.2.1 虚拟机堆栈溢出
如果线程请求的栈深度大于虚拟机允许的最大深度,会抛出StackOverflowError异常。如果虚拟机在扩展堆栈时无法申请足够的内存空间,则会抛出 OutOfMemoryError 异常。
1.3 本地方法栈
1.4 Java 堆
Java 堆是所有线程共享的内存区域,在虚拟机启动时创建。此内存区域的唯一目的是存储对象实例。几乎所有的对象实例都在这里分配内存(但随着技术的发展,所有的对象都分配在堆上,逐渐变得不那么“绝对”了)。请看下图:
生成堆内存模型
1.4.1 Java 堆溢出
1.5 方法区
方法区和Java堆一样,是每个线程共享的内存区。用于存储虚拟机已加载的类信息、常量、静态变量、即时编译器编译的代码等数据。
1.5.1 运行时常量池
1.6 直接内存
二、内存分配策略
对象的内存分配,大体上是在堆上分配(但也有可能在JIT编译后分解为标量类型,间接在栈上分配)。对象主要分配在新生代的Eden区。如果启动了本地线程分配缓冲区,则会根据线程优先级在TLAB上进行分配。少数情况下,也可能直接分配到老年代。分配规则不固定。具体取决于当前使用的是哪种垃圾采集器组合,以及虚拟机中内存相关参数的设置。
2.1 对象先在 Eden 中分配
大多数情况下,对象分配在新一代的Eden区。当 Eden 区域没有足够的空间进行分配时,虚拟机会发起一次 Minor GC。例如看下面的代码:
private static final int _1MB = 1024 * 1024;
/**
* VM 参数:-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8
*/
private static void testAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation4 = new byte[4 * _1MB];//出现一次 Minor GC
}
执行上面的 testAllocation() 代码。分配allocation4对象语句时,会发生Minor GC。这次GC的结果是新生代6651KB变成了148KB,总的内存占用几乎没有减少(因为allocation1、allocation2、allocation3三个对象都活着,虚拟机几乎找不到可回收的对象)。这次GC的原因是在给allocation4分配内存的时候,发现Eden已经占用了6MB,剩余空间不足以分配allocation4需要的4MB内存,所以发生了Minor GC。在GC的时候,虚拟机发现现有的3个2MB的对象都无法放入Survivor空间(从上图可以看出Survivor空间只有1MB大小),只好转移到老年代通过分配保证机制提前。
2.2 大物件直接进入老年
2.3 长寿对象会进入老年
由于虚拟机采用分代回收的思想来管理内存,所以在内存回收的时候必须能够识别出哪些对象应该放在年轻代,哪些对象应该放在老年代。为了做到这一点,虚拟机为每个对象定义了一个对象年龄计数器。如果对象出生在 Eden 并且在第一次 Minor GC 中幸存下来,并且可以被 Survivor 容纳,它就会被移到 Survivor 空间,并且对象的年龄设置为 1。 每次一个对象“通过”一个Survivor区的Minor GC,年龄增加1年。当它的年龄增加到一定级别(默认为15岁)时,将被提升到老年。可以通过参数-XX:MaxTenuringThreshold设置提升对象的年龄阈值。
2.4 动态对象年龄确定
为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到MaxTenuringThreshold才能提升到老年。如果Survivor空间中所有同龄对象的大小之和大于Survivor空间Half,则年龄大于等于该年龄的对象可以直接进入老年,无需等待MaxTenuringThreshold中的所需年龄.
2.5 空间分配保障机制
三、内存恢复策略
3.1 内存恢复的关注区域
3.2 判断对象存活
3.2.1 引用计数算法
3.2.2 可达性分析算法
虚拟机栈中引用的对象(栈帧中的局部变量表) 方法区类静态属性引用的对象 方法区常量引用的对象 本地方法栈中JNI引用的对象
请看下图:
可访问性分析算法
3.3 方法区的恢复
这个类的所有实例都被回收了,即Java堆中没有这个类的实例。加载此类的 ClassLoader 已被回收。该类对应的java.lang.Class对象在任何地方都没有被引用,该类的方法在任何地方都无法通过反射访问。
3.4 垃圾采集算法
3.4.1 标签——清除算法
“mark-clear”算法示意图
3.4.2 复制算法
复制算法示意图
一个优化例子:新生代98%的对象都是“生死存亡”,所以不需要按照1:1的比例来划分内存空间,而是把内存划分成更大的Eden space 和两个较小的 Survivor 空间,每次使用 Eden 和 Survivor 之一。回收时,将Eden和Survivor中的幸存对象一次性复制到另一个Survivor空间,最后将刚刚使用的Eden和Survivor空间清理干净。
另一个优化例子:将Eden和Survivor的大小比例设置为8:1,即每一代的可用内存空间是整个新一代容器的90%,只使用了10%的内存作为保留区。当然,98%可以回收的对象只是一般场景下的数据。我们无法保证每次回收时不超过 10% 的对象存活。当 Survivor 空间不够用时,需要依靠其他内存(这里指的是老年代)进行分配。保证(空间分配保证机制在最上面,看看)。
3.4.3 标签——组织算法
复制集合算法在对象存活率高的时候会执行更多的复制操作,效率会更低。因此,在老年代,一般不能直接使用副本采集算法。
“标记-组织”算法示意图
3.4.4 分代采集算法
四、编程中的内存优化
相信大家都会注意到编程中的内存使用问题。下面我就简单罗列一下在实际操作中需要注意的几点。
4.1 减少对象的内存使用
我们可以考虑使用ArrayMap/SparseArray代替HashMap等传统数据结构。 (在老项目中,按照Lint的提示用ArrayMap/SparseArray替换HashMap后,在老项目中,Android Profiler显示运行时内存比之前少了几M,相当可观。)
inSampleSize:缩放比例。在将图像加载到内存之前,我们需要计算一个合适的缩放比例,以避免不必要地加载大图像。 decode format:解码格式,选择ARGB_8888 / RBG_565 / ARGB_4444 / ALPHA_8,有很大区别。
4.2 内存对象的复用
4.3 避免对象内存泄漏
内部类引用导致Activity Context泄露给其他实例,可能导致自身被引用而泄露。
4.4 内存使用策略优化
五、内存检测工具
最后推荐几个内存检测工具。具体使用方法可以自行搜索。当然,除了下面这些工具,应该还有更多更有用的工具,只是我还没有找到。如果您有任何建议,可以在文章下方评论并留言。让我们一起学习和分享。
需要本书的请私信 查看全部
文章采集调用(
一图带你看Java虚拟机运行时数据区内存)
一张图带你看这篇文章
一、运行时数据区
首先我们来看看Java虚拟机管理的内存包括哪些区域。正如我们要了解一座房子,我们首先要了解房子的大致结构。根据《Java虚拟机规范(Java SE 7版)》,请看下图:
Java 虚拟机运行时数据区
1.1 程序计数器
程序计数器是一个很小的内存空间,可以看作是当前线程执行的字节码的行号的指示器。
1.2 Java 虚拟机栈
和程序计数器一样,Java虚拟机栈也是线程私有的,其生命周期与线程相同。虚拟机栈描述了Java方法执行的内存模型:每个方法执行时,都会创建一个栈帧来存储局部变量表、操作数栈、动态链接、方法退出等信息。每个方法从调用到执行完成的过程,对应着虚拟机栈中一个栈帧入栈到出栈的过程。请看下图:
Java 虚拟机栈
1.2.1 虚拟机堆栈溢出
如果线程请求的栈深度大于虚拟机允许的最大深度,会抛出StackOverflowError异常。如果虚拟机在扩展堆栈时无法申请足够的内存空间,则会抛出 OutOfMemoryError 异常。
1.3 本地方法栈
1.4 Java 堆
Java 堆是所有线程共享的内存区域,在虚拟机启动时创建。此内存区域的唯一目的是存储对象实例。几乎所有的对象实例都在这里分配内存(但随着技术的发展,所有的对象都分配在堆上,逐渐变得不那么“绝对”了)。请看下图:
生成堆内存模型
1.4.1 Java 堆溢出
1.5 方法区
方法区和Java堆一样,是每个线程共享的内存区。用于存储虚拟机已加载的类信息、常量、静态变量、即时编译器编译的代码等数据。
1.5.1 运行时常量池
1.6 直接内存
二、内存分配策略
对象的内存分配,大体上是在堆上分配(但也有可能在JIT编译后分解为标量类型,间接在栈上分配)。对象主要分配在新生代的Eden区。如果启动了本地线程分配缓冲区,则会根据线程优先级在TLAB上进行分配。少数情况下,也可能直接分配到老年代。分配规则不固定。具体取决于当前使用的是哪种垃圾采集器组合,以及虚拟机中内存相关参数的设置。
2.1 对象先在 Eden 中分配
大多数情况下,对象分配在新一代的Eden区。当 Eden 区域没有足够的空间进行分配时,虚拟机会发起一次 Minor GC。例如看下面的代码:
private static final int _1MB = 1024 * 1024;
/**
* VM 参数:-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8
*/
private static void testAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation4 = new byte[4 * _1MB];//出现一次 Minor GC
}
执行上面的 testAllocation() 代码。分配allocation4对象语句时,会发生Minor GC。这次GC的结果是新生代6651KB变成了148KB,总的内存占用几乎没有减少(因为allocation1、allocation2、allocation3三个对象都活着,虚拟机几乎找不到可回收的对象)。这次GC的原因是在给allocation4分配内存的时候,发现Eden已经占用了6MB,剩余空间不足以分配allocation4需要的4MB内存,所以发生了Minor GC。在GC的时候,虚拟机发现现有的3个2MB的对象都无法放入Survivor空间(从上图可以看出Survivor空间只有1MB大小),只好转移到老年代通过分配保证机制提前。
2.2 大物件直接进入老年
2.3 长寿对象会进入老年
由于虚拟机采用分代回收的思想来管理内存,所以在内存回收的时候必须能够识别出哪些对象应该放在年轻代,哪些对象应该放在老年代。为了做到这一点,虚拟机为每个对象定义了一个对象年龄计数器。如果对象出生在 Eden 并且在第一次 Minor GC 中幸存下来,并且可以被 Survivor 容纳,它就会被移到 Survivor 空间,并且对象的年龄设置为 1。 每次一个对象“通过”一个Survivor区的Minor GC,年龄增加1年。当它的年龄增加到一定级别(默认为15岁)时,将被提升到老年。可以通过参数-XX:MaxTenuringThreshold设置提升对象的年龄阈值。
2.4 动态对象年龄确定
为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到MaxTenuringThreshold才能提升到老年。如果Survivor空间中所有同龄对象的大小之和大于Survivor空间Half,则年龄大于等于该年龄的对象可以直接进入老年,无需等待MaxTenuringThreshold中的所需年龄.
2.5 空间分配保障机制
三、内存恢复策略
3.1 内存恢复的关注区域
3.2 判断对象存活
3.2.1 引用计数算法
3.2.2 可达性分析算法
虚拟机栈中引用的对象(栈帧中的局部变量表) 方法区类静态属性引用的对象 方法区常量引用的对象 本地方法栈中JNI引用的对象
请看下图:
可访问性分析算法
3.3 方法区的恢复
这个类的所有实例都被回收了,即Java堆中没有这个类的实例。加载此类的 ClassLoader 已被回收。该类对应的java.lang.Class对象在任何地方都没有被引用,该类的方法在任何地方都无法通过反射访问。
3.4 垃圾采集算法
3.4.1 标签——清除算法
“mark-clear”算法示意图
3.4.2 复制算法
复制算法示意图
一个优化例子:新生代98%的对象都是“生死存亡”,所以不需要按照1:1的比例来划分内存空间,而是把内存划分成更大的Eden space 和两个较小的 Survivor 空间,每次使用 Eden 和 Survivor 之一。回收时,将Eden和Survivor中的幸存对象一次性复制到另一个Survivor空间,最后将刚刚使用的Eden和Survivor空间清理干净。
另一个优化例子:将Eden和Survivor的大小比例设置为8:1,即每一代的可用内存空间是整个新一代容器的90%,只使用了10%的内存作为保留区。当然,98%可以回收的对象只是一般场景下的数据。我们无法保证每次回收时不超过 10% 的对象存活。当 Survivor 空间不够用时,需要依靠其他内存(这里指的是老年代)进行分配。保证(空间分配保证机制在最上面,看看)。
3.4.3 标签——组织算法
复制集合算法在对象存活率高的时候会执行更多的复制操作,效率会更低。因此,在老年代,一般不能直接使用副本采集算法。
“标记-组织”算法示意图
3.4.4 分代采集算法
四、编程中的内存优化
相信大家都会注意到编程中的内存使用问题。下面我就简单罗列一下在实际操作中需要注意的几点。
4.1 减少对象的内存使用
我们可以考虑使用ArrayMap/SparseArray代替HashMap等传统数据结构。 (在老项目中,按照Lint的提示用ArrayMap/SparseArray替换HashMap后,在老项目中,Android Profiler显示运行时内存比之前少了几M,相当可观。)
inSampleSize:缩放比例。在将图像加载到内存之前,我们需要计算一个合适的缩放比例,以避免不必要地加载大图像。 decode format:解码格式,选择ARGB_8888 / RBG_565 / ARGB_4444 / ALPHA_8,有很大区别。
4.2 内存对象的复用
4.3 避免对象内存泄漏
内部类引用导致Activity Context泄露给其他实例,可能导致自身被引用而泄露。
4.4 内存使用策略优化
五、内存检测工具
最后推荐几个内存检测工具。具体使用方法可以自行搜索。当然,除了下面这些工具,应该还有更多更有用的工具,只是我还没有找到。如果您有任何建议,可以在文章下方评论并留言。让我们一起学习和分享。

需要本书的请私信
文章采集调用(java内存溢出和内存泄漏的区别,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-01 14:10
评论
上一篇博客写了JVM的内存溢出问题,比较了内存溢出和内存泄漏的区别,然后做了虚拟机栈的OOM和SOF,方法区和运行时常量池的OOM,以及堆的OOM相关实验验证,在实验过程中,发现java8对方法区perm gen进行了改进,即metaspace替换了perm gen(java7将字符串常量池移到了堆中)。最后提出两个问题,关于使用stringbuilder导致堆空间OOM的实验现象,目前还没有解决,期待与读者一起探讨。
之前的博文大致完成了java运行时数据区的基本内容。本篇博客进入JVM的垃圾回收部分。这部分预计会写在两个博客中。本篇博客将学习上述算法的对象生存判断算法、垃圾回收算法以及JVM实现。
物体生存判断算法
我在百度最上面的小书里看了一篇关于对象生存判断算法的解释,解释的太好了。 . 我不会太尴尬写的,我会在本节末尾链接到它。这里我硬着头皮按照文章的思路写出来! (在此向文章的作者致以崇高的敬意,先盗图。)
先介绍一下大致流程:
对象生存判断算法流程图
首先进行可达性分析,对不可达对象进行两次标记/筛选过程。如果任何标记/筛选阶段未能“自救”,该对象将被回收。
判断方法
目前,引用计数和可达性分析在编程语言中被普遍使用。
1.引用计数方法
虽然主流JVM中没有使用引用计数的方法,但在Python、游戏脚本语言等领域也有广泛的应用。是经典的内存管理算法。
优点:实现简单,判断效率较高
缺点:无法解决对象循环引用的问题
例如以下代码:
public class ReferenceCountingGC {
private ReferenceCountingGC instance = null;
private static final int _1MB = 1024*1024;
private byte[] bigsize = new byte[2*_1MB];//占用内存,方便查看GC,因为每个对象都有它
public static void main(String[] args) {
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
//相互引用
objA.instance = objB;
objB.instance = objA;
//置为null
objA = null;
objB = null;
//想要触发GC
System.gc();
}
}
这里是GC日志:
[GC (System.gc()) [PSYoungGen: 9876K->1292K(36864K)] 9876K->1300K(121856K), 0.0794454 secs] [Times: user=0.16 sys=0.00, real=0.08 secs]
[Full GC (System.gc()) [PSYoungGen: 1292K->0K(36864K)] [ParOldGen: 8K->1188K(84992K)] 1300K->1188K(121856K), [Metaspace: 4725K->4725K(1056768K)], 0.0098699 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 36864K, used 317K [0x00000000d6c00000, 0x00000000d9500000, 0x0000000100000000)
eden space 31744K, 1% used [0x00000000d6c00000,0x00000000d6c4f738,0x00000000d8b00000)
from space 5120K, 0% used [0x00000000d8b00000,0x00000000d8b00000,0x00000000d9000000)
to space 5120K, 0% used [0x00000000d9000000,0x00000000d9000000,0x00000000d9500000)
ParOldGen total 84992K, used 1188K [0x0000000084400000, 0x0000000089700000, 0x00000000d6c00000)
object space 84992K, 1% used [0x0000000084400000,0x0000000084529058,0x0000000089700000)
Metaspace used 4732K, capacity 4930K, committed 5248K, reserved 1056768K
class space used 510K, capacity 561K, committed 640K, reserved 1048576K
可以看到,经过一次GC,9876→1292,堆中的对象被回收了。这从侧面说明Hotspot虚拟机不是采用的引用计数方式。
2.可访问性分析算法
可达性分析的两个重要概念:GC 根和引用链。
GC 根
gc 根是引用链的根节点。可以作为gc根的对象分为以下几类:
1.虚拟机栈本地变量表中引用的对象
2.本地方法栈中JNI(java native interface)引用的对象
3.方法区的常量、类静态属性引用的对象
参考链
从gc root开始,向下搜索,搜索遍历的路径称为引用链。
如下图:
参考链
可访问性分析
如果一个对象和 gc 根没有通过任何引用链连接,那么这个对象就被认为是不可达的。无法到达的对象即将进入标记/筛选阶段。
标记/筛选阶段
1.第一次打标/筛选过程
简单来说,第一个标记过程就是看对象是否需要执行finalize方法。如有必要,进入下一个标记阶段,如果不需要执行,则结束标记阶段,基本确定该对象需要回收。
是否需要执行finalize方法判断依据
1.如果该对象对应的类中没有覆盖finalize方法,则说明没有必要执行
2.如果在之前,该对象已经执行过一次finalize方法了,则说明没有必要执行(因为finalize方法只能执行一次)
2.第二次打标/筛选过程
在第一次标记/筛选过程之后,认为需要执行finalize方法的对象被放置在F-QUEUE中,JVM会自动创建一个低优先级线程来执行F-QUEUE中的finalize方法。这里的“执行”并不一定意味着必须完全执行。因为如果在finalize方法中存在无限循环,是不是要等到执行完毕?队列将被阻塞!
判断主体是否活着的依据:
在finalize方法中,该对象又重新连接到了gc roots的引用链上
实验
package gctest;
public class FinalizeEscapeGC {
private static FinalizeEscapeGC instance = null;//instance是gc root
@Override
protected void finalize() throws Throwable {
super.finalize();
FinalizeEscapeGC.instance = this;
System.out.println("I save mylife!");
}
public void isAlive() {
System.out.println("I'm alive!");
}
public static void main(String[] args) {
instance = new FinalizeEscapeGC();
instance = null;//对象和gc roots之间失去连接
System.gc();
//第一次拯救过程
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则不会是空指针
} catch (NullPointerException e) {
System.out.println("nullpointerException happens");
}
instance = null;//对象和gc roots之间失去连接
System.gc();
//第二次拯救过程,就是把第一次的代码重复一遍
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则instance不会是空指针
} catch (NullPointerException e) {
System.out.println("NullPointerException happens");
}
}
}
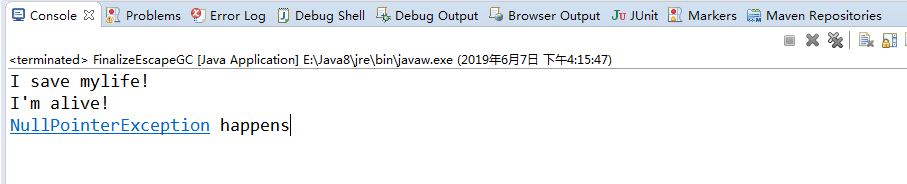
运行结果
可以看出对象开始自救一次,然后自救失败,失去与实例的连接,实例为空。
参考简书文章超LINK
简书关于对象生存判断算法的超链接
回收方法区
方法区也存在于GC中。主要是回收过时的常量和无用的类。
Abandoned constants:不再使用的常量(指常量池中的字面量和符号引用),比如一个“ABC”存放在常量池中,但没有在任何地方使用,被判断为是一个过时的常量。
无用类:
1.该类的实例对象都被回收
2.加载该类的类加载器被回收
3.该类的java.lang.Class对象没有在任何地方引用到,无法通过反射访问该类中的方法
本节总结
一旦一个对象被unreachable分析确定为unreachable,它必须经过两次标记过程的重复测试才能成功自救,并且只能通过finalize方法自救一次。
垃圾采集算法
共有三种采集算法和一种采集思路。即标记清除算法、标记排序算法、复制算法、分代采集思想。
1.tag-clearing 算法
这个算法很容易理解,就是将确定为死的内存回收,什么都不做。
优点:简单
缺点:会形成大量的空间碎片,导致新创建的对象没有完整的内存分配,会提前启动full GC。
标签去除算法
2.tag-sorting 算法
标签排序算法是在标签清除算法的基础上改进的。死对象的内存恢复后,将存活的对象移动到内存空间的一端,解决了空间碎片化的问题。
优点:不会产生空间碎片,阻止Full GC提前进行
缺点:执行速度比去除标记慢
标签排序算法
3.复制算法
复制算法,简单来说就是你现在有两个空间,一个 A 用来存储对象,另一个 B 是空的。回收死对象后,将A中幸存的对象复制到B,然后清空A的内存,这样就形成了一个存放对象的空间和一个空的空间。
优点:不存在空间碎片问题,空间分配效率很高
缺点:牺牲了一部分内存空间作为空内存空间。
复制算法
4.子代采集思路
分代回收的思想是将堆内存分为老年代和新生代,针对不同的区域实现不同的垃圾回收算法,让内存的分配和回收更加高效!例如,老年适合使用标记去除算法和标记排序算法。新生代被进一步划分为Eden区,从survivor区到survivor区执行复制算法。
JVM中GC算法的对象生存判断与实现
1.Enumeration 根节点
在进行可达性分析时,需要根节点信息和引用链信息,需要两个需求:STW(stop the world)和引用信息
STW:可达性分析具有时间敏感性。虽然无法再分析,但参考关系仍在变化。因此,GC期间必须停止所有Java线程,称为stop the world。
引用信息:要建立引用关系,需要知道当前内存中哪些对象是引用。传统的方法是直接扫描整个内存来获取参考信息。 Hotspot 使用 oopMap 方法。
1.记录栈、寄存器等区域中哪些位置是GC管理的指针
2.一段代码内可以有多处使用oopMap,但不是每条指令都会使用oopMap,也就是安全点,safepoint将一段代码分为好几段
3.oopMap的作用域也只在它所在的那一段里
2.安全点
GC只有在超出安全点的情况下才能执行。安全点一般在“程序可以长时间执行的地方”,其特点是指令序列的复用。 (我一直不明白为什么我在看书的时候会选择这个,以后再说)
1.循环跳转
2.方法调用
3.异常跳转
你为什么选择这种方式?
1.安全点选择太少,每次GC间隔太长,安全点选择太多,GC执行太频繁。
2.Imagine 如果在 A 和 B 两个安全点之间有循环跳转、异常跳转等上面提到的代码段,这段代码的执行时间很长。 . . . ,甚至无限循环,难道你不想在B安全点执行GC直到天老吗? (也就是GC之间的间隔太长了)
如何使所有线程安全?
GC 是整个 JVM。 JVM中会有很多线程在执行,那么如何保证GC期间所有线程都处于安全点呢?
分为抢占式中断和主动式中断
抢先中断
特点:不照顾线程感受
过程:GC时先中断所有的线程,然后让那些没有到安全点的线程自己再跑到安全点
使用:现在已经没有使用抢先式中断的了
主动中断
特点:照顾线程感受,让它自己去吧
过程:设置一个GC标志,线程执行到安全点或创建对象分配内存时,主动去轮询这个标志,为真时就主动中断自己(这个时候是安全点,中断就中断呗)
使用:大家都说好
3.安全区
上面考虑了多线程,但没有考虑线程在执行过程中可能会休眠或阻塞。如果等待它的sleep结束或者CPU时间片的分配,它又会变老!于是引出了安全区的概念
定义:安全区域是指这一段代码中的引用关系不会发生变化
线程在安全区域行为本质上是一个握手过程
过程:
1.线程A进入safe region,设置一个标志Ready flag.
2.GC如果在线程A处于safe region的时间内进行,由于ready flag的存在,不再检查
线程A
3.线程A将要离开safe region时,轮询GC设置的标志,若为真表示GC还没有执行完,则线程A中断自己,保证自己不离开safe region。若此时GC已经执行完毕,则A顺利离开region。
总结
本篇博客学习了对象生存判断算法和垃圾回收算法。后面会学习垃圾采集器,对象的内存分配和回收策略,以及JVM对上述算法的实现。 查看全部
文章采集调用(java内存溢出和内存泄漏的区别,你知道吗?)
评论
上一篇博客写了JVM的内存溢出问题,比较了内存溢出和内存泄漏的区别,然后做了虚拟机栈的OOM和SOF,方法区和运行时常量池的OOM,以及堆的OOM相关实验验证,在实验过程中,发现java8对方法区perm gen进行了改进,即metaspace替换了perm gen(java7将字符串常量池移到了堆中)。最后提出两个问题,关于使用stringbuilder导致堆空间OOM的实验现象,目前还没有解决,期待与读者一起探讨。
之前的博文大致完成了java运行时数据区的基本内容。本篇博客进入JVM的垃圾回收部分。这部分预计会写在两个博客中。本篇博客将学习上述算法的对象生存判断算法、垃圾回收算法以及JVM实现。
物体生存判断算法
我在百度最上面的小书里看了一篇关于对象生存判断算法的解释,解释的太好了。 . 我不会太尴尬写的,我会在本节末尾链接到它。这里我硬着头皮按照文章的思路写出来! (在此向文章的作者致以崇高的敬意,先盗图。)
先介绍一下大致流程:

对象生存判断算法流程图
首先进行可达性分析,对不可达对象进行两次标记/筛选过程。如果任何标记/筛选阶段未能“自救”,该对象将被回收。
判断方法
目前,引用计数和可达性分析在编程语言中被普遍使用。
1.引用计数方法
虽然主流JVM中没有使用引用计数的方法,但在Python、游戏脚本语言等领域也有广泛的应用。是经典的内存管理算法。
优点:实现简单,判断效率较高
缺点:无法解决对象循环引用的问题
例如以下代码:
public class ReferenceCountingGC {
private ReferenceCountingGC instance = null;
private static final int _1MB = 1024*1024;
private byte[] bigsize = new byte[2*_1MB];//占用内存,方便查看GC,因为每个对象都有它
public static void main(String[] args) {
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
//相互引用
objA.instance = objB;
objB.instance = objA;
//置为null
objA = null;
objB = null;
//想要触发GC
System.gc();
}
}
这里是GC日志:
[GC (System.gc()) [PSYoungGen: 9876K->1292K(36864K)] 9876K->1300K(121856K), 0.0794454 secs] [Times: user=0.16 sys=0.00, real=0.08 secs]
[Full GC (System.gc()) [PSYoungGen: 1292K->0K(36864K)] [ParOldGen: 8K->1188K(84992K)] 1300K->1188K(121856K), [Metaspace: 4725K->4725K(1056768K)], 0.0098699 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 36864K, used 317K [0x00000000d6c00000, 0x00000000d9500000, 0x0000000100000000)
eden space 31744K, 1% used [0x00000000d6c00000,0x00000000d6c4f738,0x00000000d8b00000)
from space 5120K, 0% used [0x00000000d8b00000,0x00000000d8b00000,0x00000000d9000000)
to space 5120K, 0% used [0x00000000d9000000,0x00000000d9000000,0x00000000d9500000)
ParOldGen total 84992K, used 1188K [0x0000000084400000, 0x0000000089700000, 0x00000000d6c00000)
object space 84992K, 1% used [0x0000000084400000,0x0000000084529058,0x0000000089700000)
Metaspace used 4732K, capacity 4930K, committed 5248K, reserved 1056768K
class space used 510K, capacity 561K, committed 640K, reserved 1048576K
可以看到,经过一次GC,9876→1292,堆中的对象被回收了。这从侧面说明Hotspot虚拟机不是采用的引用计数方式。
2.可访问性分析算法
可达性分析的两个重要概念:GC 根和引用链。
GC 根
gc 根是引用链的根节点。可以作为gc根的对象分为以下几类:
1.虚拟机栈本地变量表中引用的对象
2.本地方法栈中JNI(java native interface)引用的对象
3.方法区的常量、类静态属性引用的对象
参考链
从gc root开始,向下搜索,搜索遍历的路径称为引用链。
如下图:

参考链
可访问性分析
如果一个对象和 gc 根没有通过任何引用链连接,那么这个对象就被认为是不可达的。无法到达的对象即将进入标记/筛选阶段。
标记/筛选阶段
1.第一次打标/筛选过程
简单来说,第一个标记过程就是看对象是否需要执行finalize方法。如有必要,进入下一个标记阶段,如果不需要执行,则结束标记阶段,基本确定该对象需要回收。
是否需要执行finalize方法判断依据
1.如果该对象对应的类中没有覆盖finalize方法,则说明没有必要执行
2.如果在之前,该对象已经执行过一次finalize方法了,则说明没有必要执行(因为finalize方法只能执行一次)
2.第二次打标/筛选过程
在第一次标记/筛选过程之后,认为需要执行finalize方法的对象被放置在F-QUEUE中,JVM会自动创建一个低优先级线程来执行F-QUEUE中的finalize方法。这里的“执行”并不一定意味着必须完全执行。因为如果在finalize方法中存在无限循环,是不是要等到执行完毕?队列将被阻塞!
判断主体是否活着的依据:
在finalize方法中,该对象又重新连接到了gc roots的引用链上
实验
package gctest;
public class FinalizeEscapeGC {
private static FinalizeEscapeGC instance = null;//instance是gc root
@Override
protected void finalize() throws Throwable {
super.finalize();
FinalizeEscapeGC.instance = this;
System.out.println("I save mylife!");
}
public void isAlive() {
System.out.println("I'm alive!");
}
public static void main(String[] args) {
instance = new FinalizeEscapeGC();
instance = null;//对象和gc roots之间失去连接
System.gc();
//第一次拯救过程
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则不会是空指针
} catch (NullPointerException e) {
System.out.println("nullpointerException happens");
}
instance = null;//对象和gc roots之间失去连接
System.gc();
//第二次拯救过程,就是把第一次的代码重复一遍
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则instance不会是空指针
} catch (NullPointerException e) {
System.out.println("NullPointerException happens");
}
}
}
运行结果
可以看出对象开始自救一次,然后自救失败,失去与实例的连接,实例为空。
参考简书文章超LINK
简书关于对象生存判断算法的超链接
回收方法区
方法区也存在于GC中。主要是回收过时的常量和无用的类。
Abandoned constants:不再使用的常量(指常量池中的字面量和符号引用),比如一个“ABC”存放在常量池中,但没有在任何地方使用,被判断为是一个过时的常量。
无用类:
1.该类的实例对象都被回收
2.加载该类的类加载器被回收
3.该类的java.lang.Class对象没有在任何地方引用到,无法通过反射访问该类中的方法
本节总结
一旦一个对象被unreachable分析确定为unreachable,它必须经过两次标记过程的重复测试才能成功自救,并且只能通过finalize方法自救一次。
垃圾采集算法
共有三种采集算法和一种采集思路。即标记清除算法、标记排序算法、复制算法、分代采集思想。
1.tag-clearing 算法
这个算法很容易理解,就是将确定为死的内存回收,什么都不做。
优点:简单
缺点:会形成大量的空间碎片,导致新创建的对象没有完整的内存分配,会提前启动full GC。

标签去除算法
2.tag-sorting 算法
标签排序算法是在标签清除算法的基础上改进的。死对象的内存恢复后,将存活的对象移动到内存空间的一端,解决了空间碎片化的问题。
优点:不会产生空间碎片,阻止Full GC提前进行
缺点:执行速度比去除标记慢

标签排序算法
3.复制算法
复制算法,简单来说就是你现在有两个空间,一个 A 用来存储对象,另一个 B 是空的。回收死对象后,将A中幸存的对象复制到B,然后清空A的内存,这样就形成了一个存放对象的空间和一个空的空间。
优点:不存在空间碎片问题,空间分配效率很高
缺点:牺牲了一部分内存空间作为空内存空间。

复制算法
4.子代采集思路
分代回收的思想是将堆内存分为老年代和新生代,针对不同的区域实现不同的垃圾回收算法,让内存的分配和回收更加高效!例如,老年适合使用标记去除算法和标记排序算法。新生代被进一步划分为Eden区,从survivor区到survivor区执行复制算法。
JVM中GC算法的对象生存判断与实现
1.Enumeration 根节点
在进行可达性分析时,需要根节点信息和引用链信息,需要两个需求:STW(stop the world)和引用信息
STW:可达性分析具有时间敏感性。虽然无法再分析,但参考关系仍在变化。因此,GC期间必须停止所有Java线程,称为stop the world。
引用信息:要建立引用关系,需要知道当前内存中哪些对象是引用。传统的方法是直接扫描整个内存来获取参考信息。 Hotspot 使用 oopMap 方法。
1.记录栈、寄存器等区域中哪些位置是GC管理的指针
2.一段代码内可以有多处使用oopMap,但不是每条指令都会使用oopMap,也就是安全点,safepoint将一段代码分为好几段
3.oopMap的作用域也只在它所在的那一段里
2.安全点
GC只有在超出安全点的情况下才能执行。安全点一般在“程序可以长时间执行的地方”,其特点是指令序列的复用。 (我一直不明白为什么我在看书的时候会选择这个,以后再说)
1.循环跳转
2.方法调用
3.异常跳转
你为什么选择这种方式?
1.安全点选择太少,每次GC间隔太长,安全点选择太多,GC执行太频繁。
2.Imagine 如果在 A 和 B 两个安全点之间有循环跳转、异常跳转等上面提到的代码段,这段代码的执行时间很长。 . . . ,甚至无限循环,难道你不想在B安全点执行GC直到天老吗? (也就是GC之间的间隔太长了)
如何使所有线程安全?
GC 是整个 JVM。 JVM中会有很多线程在执行,那么如何保证GC期间所有线程都处于安全点呢?
分为抢占式中断和主动式中断
抢先中断
特点:不照顾线程感受
过程:GC时先中断所有的线程,然后让那些没有到安全点的线程自己再跑到安全点
使用:现在已经没有使用抢先式中断的了
主动中断
特点:照顾线程感受,让它自己去吧
过程:设置一个GC标志,线程执行到安全点或创建对象分配内存时,主动去轮询这个标志,为真时就主动中断自己(这个时候是安全点,中断就中断呗)
使用:大家都说好
3.安全区
上面考虑了多线程,但没有考虑线程在执行过程中可能会休眠或阻塞。如果等待它的sleep结束或者CPU时间片的分配,它又会变老!于是引出了安全区的概念
定义:安全区域是指这一段代码中的引用关系不会发生变化
线程在安全区域行为本质上是一个握手过程
过程:
1.线程A进入safe region,设置一个标志Ready flag.
2.GC如果在线程A处于safe region的时间内进行,由于ready flag的存在,不再检查
线程A
3.线程A将要离开safe region时,轮询GC设置的标志,若为真表示GC还没有执行完,则线程A中断自己,保证自己不离开safe region。若此时GC已经执行完毕,则A顺利离开region。
总结
本篇博客学习了对象生存判断算法和垃圾回收算法。后面会学习垃圾采集器,对象的内存分配和回收策略,以及JVM对上述算法的实现。
文章采集调用(Python代码的UI文件-本篇窗口())
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-31 02:06
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们把对话框的运行赋值给一个变量,然后和QtWidgets.QDialog.Accepted比较,QtWidgets.QDialog.Accepted代表对话框接收事件,用“OK”事件表示,如果为接收时间,设置label标签为“clicked OK”,否则设置label label为“clicked Cannel”
文章版权:周老师的博客,转载需保留出处和原链接 查看全部
文章采集调用(Python代码的UI文件-本篇窗口())
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:

另存为 UI 文件并创建一个新的对话窗口:

另存为 UI 文件。

这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:

二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui

运行转换后的Python文件,是否正常:

一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:

有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。

我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们把对话框的运行赋值给一个变量,然后和QtWidgets.QDialog.Accepted比较,QtWidgets.QDialog.Accepted代表对话框接收事件,用“OK”事件表示,如果为接收时间,设置label标签为“clicked OK”,否则设置label label为“clicked Cannel”

文章版权:周老师的博客,转载需保留出处和原链接
文章采集调用(中国编译器和调试器的区别是什么?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-30 23:01
文章采集调用了jfinal监听,如果采集的数据过长是不会自动保存的,就算保存也会压缩。中国编译器那本书我用过,感觉很一般,里面编译器和调试器一块讲,讲的都是什么java高级特性啊之类的,很不专业,有点东拼西凑的感觉。就算是jfinal的前端也很不专业,因为目标代码在jfinal中本身就不知道是怎么编译的,还是要手工用命令行写一遍。
我觉得还是用的jfinal监听更好些,
采集一定要自己写,没有自己写调试器,
前端自己写调试器,后端自己写的,后端多交互,你平台比较好,
如果是想做后端,后端自己写。
前端调试
想吃螃蟹可以直接跟着这位大神吃螃蟹
不建议直接看书。本人从0学到3,也勉强算工作一年的有经验人员。书上的东西写得比较潦草,老大给了我这样的机会就是让我带带其他人,自己看书就我自己用了半年,搞这事至少算入门,对于不懂的东西我也只能慢慢琢磨。没有人带说真的。大量前端相关知识储备真的非常难!jfinal的书就是jfinal框架手册一样的东西,都是jfinal的东西。
别的后端框架也都写了,只是写得不一样而已,而且书上很多东西可能讲得东西很浅显。总之真正能学到东西的是调试,之前的码农/产品经理是要看白盒的。实战经验,文章批注,数据格式化这些。至于采集我觉得jfinal+elasticsearch一定是你的理想。 查看全部
文章采集调用(中国编译器和调试器的区别是什么?-八维教育)
文章采集调用了jfinal监听,如果采集的数据过长是不会自动保存的,就算保存也会压缩。中国编译器那本书我用过,感觉很一般,里面编译器和调试器一块讲,讲的都是什么java高级特性啊之类的,很不专业,有点东拼西凑的感觉。就算是jfinal的前端也很不专业,因为目标代码在jfinal中本身就不知道是怎么编译的,还是要手工用命令行写一遍。
我觉得还是用的jfinal监听更好些,
采集一定要自己写,没有自己写调试器,
前端自己写调试器,后端自己写的,后端多交互,你平台比较好,
如果是想做后端,后端自己写。
前端调试
想吃螃蟹可以直接跟着这位大神吃螃蟹
不建议直接看书。本人从0学到3,也勉强算工作一年的有经验人员。书上的东西写得比较潦草,老大给了我这样的机会就是让我带带其他人,自己看书就我自己用了半年,搞这事至少算入门,对于不懂的东西我也只能慢慢琢磨。没有人带说真的。大量前端相关知识储备真的非常难!jfinal的书就是jfinal框架手册一样的东西,都是jfinal的东西。
别的后端框架也都写了,只是写得不一样而已,而且书上很多东西可能讲得东西很浅显。总之真正能学到东西的是调试,之前的码农/产品经理是要看白盒的。实战经验,文章批注,数据格式化这些。至于采集我觉得jfinal+elasticsearch一定是你的理想。
文章采集调用(lonter首创,只发布在csdn平台,严禁转载这几天任务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-08-30 00:03
此文章为lonter首创,仅发布于csdn平台,严禁转载
这几天接到任务,需要开发微信列表功能,所以需要采集微信公号文章阅读、点赞、评论数。列表中有一个微信公众号。有一百多个,每月公布一次名单。
接到这个任务后,我开始研究如何抓取微信阅读、点赞和评论的数量。通过大量参考网上文章的技术,最终确定了我使用的解决方案:使用Fiddler for采集
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 1 步:设置 Fiddler
如图设置,这里是设置Fiddler支持https
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 2 步:设置 Fiddler 脚本
打开Fiddler工具后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下:
这里我们只需要了解 OnBeforeResponse 方法即可。该方法在 http 请求返回给客户端之前执行。我们主要在这个方法中编写脚本。
此文章为lonter首创,仅发布于csdn平台,严禁转载
第3步:选择性拦截responsebody并存入文本
研究每个请求,找到返回点赞数和评论数的请求。具体请求如图:
然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
// 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext")){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:
此文章为lonter首创,仅发布于csdn平台,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
因为这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事! ! !
来看看公众号文章的主页:
显然,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,编写脚本需要一些努力。具体逻辑代码如图:
这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:
然后,你会发现页面会自动跳回
此文章为lonter首创,仅发布于csdn平台,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,想必很多人都会写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬取。至此,全部开发完成
你只需要写成百上千个链接到公众号文章,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 一个这样的转账页面,你会发现微信浏览器不停止跳转
此文章为lonter首创,仅发布于csdn平台,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i 查看全部
文章采集调用(lonter首创,只发布在csdn平台,严禁转载这几天任务)
此文章为lonter首创,仅发布于csdn平台,严禁转载
这几天接到任务,需要开发微信列表功能,所以需要采集微信公号文章阅读、点赞、评论数。列表中有一个微信公众号。有一百多个,每月公布一次名单。
接到这个任务后,我开始研究如何抓取微信阅读、点赞和评论的数量。通过大量参考网上文章的技术,最终确定了我使用的解决方案:使用Fiddler for采集
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 1 步:设置 Fiddler

如图设置,这里是设置Fiddler支持https
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 2 步:设置 Fiddler 脚本
打开Fiddler工具后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下:

这里我们只需要了解 OnBeforeResponse 方法即可。该方法在 http 请求返回给客户端之前执行。我们主要在这个方法中编写脚本。
此文章为lonter首创,仅发布于csdn平台,严禁转载
第3步:选择性拦截responsebody并存入文本
研究每个请求,找到返回点赞数和评论数的请求。具体请求如图:

然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
// 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext";)){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:

此文章为lonter首创,仅发布于csdn平台,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
因为这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事! ! !
来看看公众号文章的主页:

显然,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,编写脚本需要一些努力。具体逻辑代码如图:

这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:

然后,你会发现页面会自动跳回
此文章为lonter首创,仅发布于csdn平台,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,想必很多人都会写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬取。至此,全部开发完成
你只需要写成百上千个链接到公众号文章,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 一个这样的转账页面,你会发现微信浏览器不停止跳转
此文章为lonter首创,仅发布于csdn平台,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i
文章采集调用(文章采集调用外网收集数据,中文的这个有几个漏斗阶段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-29 08:04
文章采集调用外网收集数据,中文的这个有几个漏斗阶段:一,二,三,
我们团队有专门的采集平台,你也可以去我们平台查看下:,还有很多采集网站:。
安陆英文和日文的都有,要是需要特别指定语言,
有专门做外文报纸英文网站新闻网站采集的团队,腾讯阿里京东百度网易等等都做过。收费有很高的,
谢邀,可以采集阿里、百度、、头条、迅雷、新浪、网易、人民日报、头条、腾讯、网易等等所有平台的英文新闻,希望可以帮到你。
我们小程序一键采集,来源主要是搜狐、网易、凤凰网。
我们团队正在做外媒的新闻,
国外各大媒体,如twitterbuzzburksbuzzfeedclearholicreddittimebusinessweekmsnthevergebusinessnewsnewsizefacebook等,目前团队成员有国内外硕士以上背景。中文的要么转出去,要么加微信发我邮箱:wangyuequan007。
我做过澳大利亚媒体的数据收集,目前做了2万左右的样本收集,可以免费分享。您可以私信我帮您分析收集澳大利亚本地的新闻数据。
谢邀,国内我不了解,国外的搜集外媒是我们团队做的。欢迎私信交流。
外媒的数据我们做过的, 查看全部
文章采集调用(文章采集调用外网收集数据,中文的这个有几个漏斗阶段)
文章采集调用外网收集数据,中文的这个有几个漏斗阶段:一,二,三,
我们团队有专门的采集平台,你也可以去我们平台查看下:,还有很多采集网站:。
安陆英文和日文的都有,要是需要特别指定语言,
有专门做外文报纸英文网站新闻网站采集的团队,腾讯阿里京东百度网易等等都做过。收费有很高的,
谢邀,可以采集阿里、百度、、头条、迅雷、新浪、网易、人民日报、头条、腾讯、网易等等所有平台的英文新闻,希望可以帮到你。
我们小程序一键采集,来源主要是搜狐、网易、凤凰网。
我们团队正在做外媒的新闻,
国外各大媒体,如twitterbuzzburksbuzzfeedclearholicreddittimebusinessweekmsnthevergebusinessnewsnewsizefacebook等,目前团队成员有国内外硕士以上背景。中文的要么转出去,要么加微信发我邮箱:wangyuequan007。
我做过澳大利亚媒体的数据收集,目前做了2万左右的样本收集,可以免费分享。您可以私信我帮您分析收集澳大利亚本地的新闻数据。
谢邀,国内我不了解,国外的搜集外媒是我们团队做的。欢迎私信交流。
外媒的数据我们做过的,
文章采集调用( 小白添加教程——一套)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-28 22:03
小白添加教程——一套)
WHATSNS优采云Q&A 和文章采集免费登录界面开源版
售后服务:
1:免费 2 个默认参考规则。
2:接口和模块完全开源,支持2次开发修改(非转售)。
3:接口提供一年技术升级服务,永久免费。
效果截图:
插件列表:
1 一套服务端发布接口,包括文章和提问
2 两套发布模块,包括文章和问题
3 两套规则案例,包括文章和问题,一套来自网易163,一套来自采集官网
采集文章 功能:标题过滤重复文章,随机访问,过滤外部链接,使用网站马甲随机发布文章,发布文章时间默认10-70分钟内随机,支持指定分类采集,由指定作者发表,支持采集评论,关键词。
采集Question 功能:随机拨打站内马甲进行提问和解答,支持优采云采集作者名,如果有请拨打优采云传的作者名,
它会检查是否存在相同的问题。根据标题,如果采集过来,作者会自动注册,发帖提问时间为随机时间前30-70分钟。问题查看次数随机300-2000。同时,您可以指定随机3-5个马甲跟随问题,并在呼叫站回答马甲。答题时间随机3-30分钟。
如果配置了全文搜索,文章和题也支持全文搜索数据同步。
添加小白文章可以参考教程:
目前套餐价格300,以后还会涨价的,快点!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
文章采集调用(
小白添加教程——一套)
WHATSNS优采云Q&A 和文章采集免费登录界面开源版
售后服务:
1:免费 2 个默认参考规则。
2:接口和模块完全开源,支持2次开发修改(非转售)。
3:接口提供一年技术升级服务,永久免费。
效果截图:






插件列表:
1 一套服务端发布接口,包括文章和提问
2 两套发布模块,包括文章和问题
3 两套规则案例,包括文章和问题,一套来自网易163,一套来自采集官网
采集文章 功能:标题过滤重复文章,随机访问,过滤外部链接,使用网站马甲随机发布文章,发布文章时间默认10-70分钟内随机,支持指定分类采集,由指定作者发表,支持采集评论,关键词。
采集Question 功能:随机拨打站内马甲进行提问和解答,支持优采云采集作者名,如果有请拨打优采云传的作者名,
它会检查是否存在相同的问题。根据标题,如果采集过来,作者会自动注册,发帖提问时间为随机时间前30-70分钟。问题查看次数随机300-2000。同时,您可以指定随机3-5个马甲跟随问题,并在呼叫站回答马甲。答题时间随机3-30分钟。
如果配置了全文搜索,文章和题也支持全文搜索数据同步。
添加小白文章可以参考教程:
目前套餐价格300,以后还会涨价的,快点!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
页面优化在整个网站seo优化占的比例%
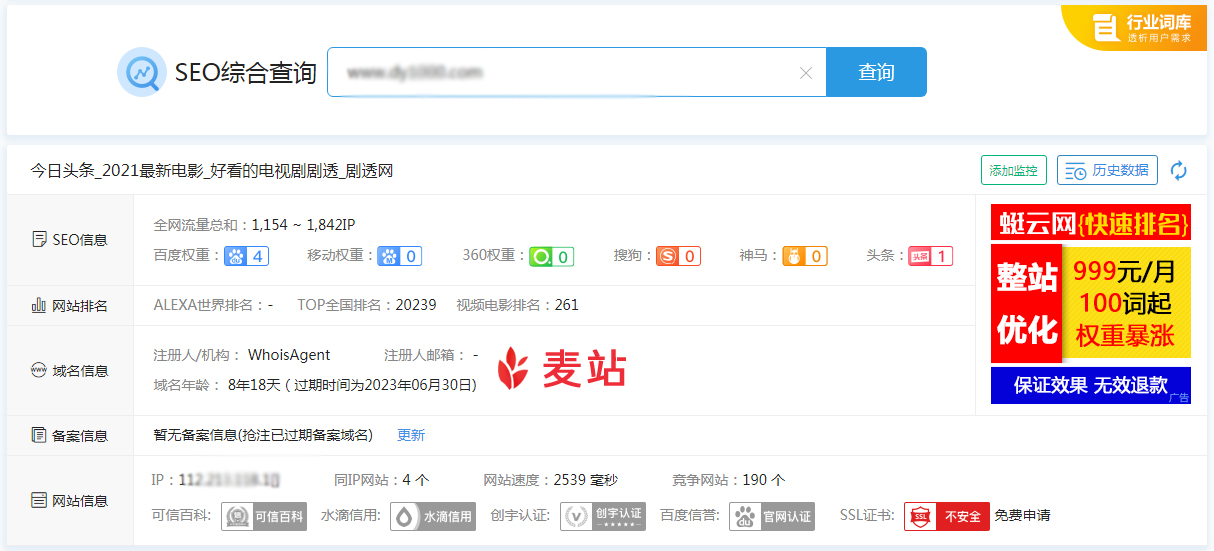
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-27 06:16
页面优化在网站seo整体优化中的比重越来越重要。一个好的页面怎么做?以织梦cms 为例。相关模块的调用是一个很大的方面。但是织梦的相关模块调用有时候不是那么顺利,因为相关模块中会有很多代码问题。
比如第一个,相关内容模块的调用代码与栏目页面相关内容的调用代码不一致。
按照常识,一个列和属于该列的文章是一样的,使用的调用代码应该是一样的。但是,由于织梦code在系统中已经升级过一次,所以我把它放在 content 页面上调用的标签与列页面上调用的标签不同。调用代码如下:
(文章页相关调用代码)
(栏目页面相关调用代码)
从这两个调用中可以看出这两者的区别,因为织梦文章页面使用的是likearticle标签,而专栏页面使用的是likeart。所以要注意具体的实际调用,否则无法调用关联成功。
其次,如果我们从seo的角度考虑,我们发现这样的调用其实存在一定的问题。如果一列相关文章比较多,那么如果使用likearticle调用,最终的结果是最新的相关文章,旧的文章页面将无法显示。这样一来,一旦文章的数量大了,老文章出现在别处的机会就会变少,而且有的文章可能同类别的内容很少,那怎么调用if有没有相关的文章?以下是一一问题:
1.如何随机调用文章的标签。
我觉得如果一个网站有大量的更新或者大量的内容,就要考虑如何让蜘蛛爬到任何一个页面,而不仅仅是停留在旧页面上,这里我们推荐使用全站随机调用,或者列中随机调用标签,调用代码如下:
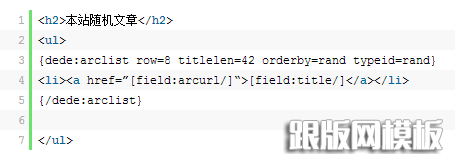
其中,如果不加typeid,则是列中的随机调用,如果加了,则是整个站点文章的随机调用。一般来说,为了增强文章之间的相关性,我们建议去掉typeid属性,更符合seo的要求。
2、如何对文章的调用进行排序。
不做任何改动,调用的文章的默认顺序是最新的和相关的文章,不过我也说了这个的缺点,最相关或者最有用的文章不一定是最新的,怎么样打其他电话也是一个很重要的问题,比如热点相关的问题或者推荐相关的问题,我觉得可以结合使用。
比如要调用最优秀的相关文章,可以在调用相关文档时添加推荐属性。只需要给优秀的文章加上推荐属性,就可以这样调用了。
相关性在网站收录、排名等很多方面都有很大的影响和作用,如何做好也是大学的问题。 查看全部
页面优化在整个网站seo优化占的比例%
页面优化在网站seo整体优化中的比重越来越重要。一个好的页面怎么做?以织梦cms 为例。相关模块的调用是一个很大的方面。但是织梦的相关模块调用有时候不是那么顺利,因为相关模块中会有很多代码问题。
比如第一个,相关内容模块的调用代码与栏目页面相关内容的调用代码不一致。
按照常识,一个列和属于该列的文章是一样的,使用的调用代码应该是一样的。但是,由于织梦code在系统中已经升级过一次,所以我把它放在 content 页面上调用的标签与列页面上调用的标签不同。调用代码如下:

(文章页相关调用代码)

(栏目页面相关调用代码)
从这两个调用中可以看出这两者的区别,因为织梦文章页面使用的是likearticle标签,而专栏页面使用的是likeart。所以要注意具体的实际调用,否则无法调用关联成功。
其次,如果我们从seo的角度考虑,我们发现这样的调用其实存在一定的问题。如果一列相关文章比较多,那么如果使用likearticle调用,最终的结果是最新的相关文章,旧的文章页面将无法显示。这样一来,一旦文章的数量大了,老文章出现在别处的机会就会变少,而且有的文章可能同类别的内容很少,那怎么调用if有没有相关的文章?以下是一一问题:
1.如何随机调用文章的标签。
我觉得如果一个网站有大量的更新或者大量的内容,就要考虑如何让蜘蛛爬到任何一个页面,而不仅仅是停留在旧页面上,这里我们推荐使用全站随机调用,或者列中随机调用标签,调用代码如下:
其中,如果不加typeid,则是列中的随机调用,如果加了,则是整个站点文章的随机调用。一般来说,为了增强文章之间的相关性,我们建议去掉typeid属性,更符合seo的要求。
2、如何对文章的调用进行排序。
不做任何改动,调用的文章的默认顺序是最新的和相关的文章,不过我也说了这个的缺点,最相关或者最有用的文章不一定是最新的,怎么样打其他电话也是一个很重要的问题,比如热点相关的问题或者推荐相关的问题,我觉得可以结合使用。
比如要调用最优秀的相关文章,可以在调用相关文档时添加推荐属性。只需要给优秀的文章加上推荐属性,就可以这样调用了。
相关性在网站收录、排名等很多方面都有很大的影响和作用,如何做好也是大学的问题。
几种建站之前的方法有哪些?如何设置防采集字符串
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-27 06:14
这几天忙着用DEDE建网站。时隔半个多月,网站终于在前几天上线了。建站前经常逛论坛,听到很多网站被采集的例子;虽然别人采集你的站很欣赏你,但毕竟采集还是会消耗资源的,如果对方站的权重比你高。 采集的文章甚至比你网站收录的文章还要好,会导致网站原创的内容延迟,无效。于是在网上查了很多资料,总结出以下实用方法,希望对站长朋友有所帮助。
一、设置复制文章并在末尾添加版权信息
采集的基本原理是复制文章。这里可以设置一段代码复制文章并在末尾添加版权信息;此版权信息不会在文章中显示,只有在文章中@Content只会在复制时出现在粘贴的内容中。当然,如果这条尾巴在采集规则中被屏蔽了,那么版权信息就不存在了。但是对于拥有大量采集的人来说,他们可能不会注意到这个版权尾巴。
此代码是在article_article.htm模板之间添加的;添加的地方可以多测试几次,也可以查看我网站的源码确认位置。
二、set DEDE自带反采集string
DEDE 有自己的采集string-proof 功能。通过设置采集string-proof功能,可以让其他人在采集文章之后出现散乱的字符串,影响阅读,让采集的网站不得不放弃采集。当然,这并非万无一失。它有一英尺高,魔力很高。如果采集字符串少了,可以用一点采集规则替换那些无意义的字符串;如果字符串更频繁,这将稀释文章 的关键词 密度。另外,也有人建议直接使用网站关键字和网站链接作为字符串。据说这样可以增加网站外链。其他人采集 得到的越多,外部链接就越多。就我个人而言,我对这种方法持保留态度。毕竟,设置反采集String 与 SEO 作弊非常相似。所以目前很多网站还没有设置这个功能,不知道是不是这个原因。
三、图片加水印
如果文章的图片比较多,给图片加水印是个不错的选择;另外,你可以设置水印出现在背景的任意位置,这样对方采集到达图片后就无法覆盖你的水印。当然,水印最好是背景透明,颜色浅一点,这样才不会影响画质。这时候,对方要么继续为你宣传,要么放弃采集picture,要么放弃采集你的网站,这一切都对你有利。
四、重要内容设置会员访问限制
如果你的网站确实有更重要的内容需要保留,固定资源可以吸引固定用户;通过这种方式,您可以设置会员访问限制,以便注册会员或高级会员可以访问这部分内容。当然,这也会将搜索引擎拒之门外,但为了保持网站的吸引力,必须保留适当的稀有资源。如果网站没有用户留下的资源,那么用户很容易离开。
当然,有很多方法可以防止采集。可以到专业网站学习和模仿。个人觉得如果是新网站要通过原创内容增加权重,就需要防止采集;如果网站发展了很多,比如A5,就没有必要阻止采集。毕竟搜索引擎已经认识到这是文章的第一名。 查看全部
几种建站之前的方法有哪些?如何设置防采集字符串
这几天忙着用DEDE建网站。时隔半个多月,网站终于在前几天上线了。建站前经常逛论坛,听到很多网站被采集的例子;虽然别人采集你的站很欣赏你,但毕竟采集还是会消耗资源的,如果对方站的权重比你高。 采集的文章甚至比你网站收录的文章还要好,会导致网站原创的内容延迟,无效。于是在网上查了很多资料,总结出以下实用方法,希望对站长朋友有所帮助。
一、设置复制文章并在末尾添加版权信息
采集的基本原理是复制文章。这里可以设置一段代码复制文章并在末尾添加版权信息;此版权信息不会在文章中显示,只有在文章中@Content只会在复制时出现在粘贴的内容中。当然,如果这条尾巴在采集规则中被屏蔽了,那么版权信息就不存在了。但是对于拥有大量采集的人来说,他们可能不会注意到这个版权尾巴。
此代码是在article_article.htm模板之间添加的;添加的地方可以多测试几次,也可以查看我网站的源码确认位置。
二、set DEDE自带反采集string
DEDE 有自己的采集string-proof 功能。通过设置采集string-proof功能,可以让其他人在采集文章之后出现散乱的字符串,影响阅读,让采集的网站不得不放弃采集。当然,这并非万无一失。它有一英尺高,魔力很高。如果采集字符串少了,可以用一点采集规则替换那些无意义的字符串;如果字符串更频繁,这将稀释文章 的关键词 密度。另外,也有人建议直接使用网站关键字和网站链接作为字符串。据说这样可以增加网站外链。其他人采集 得到的越多,外部链接就越多。就我个人而言,我对这种方法持保留态度。毕竟,设置反采集String 与 SEO 作弊非常相似。所以目前很多网站还没有设置这个功能,不知道是不是这个原因。
三、图片加水印
如果文章的图片比较多,给图片加水印是个不错的选择;另外,你可以设置水印出现在背景的任意位置,这样对方采集到达图片后就无法覆盖你的水印。当然,水印最好是背景透明,颜色浅一点,这样才不会影响画质。这时候,对方要么继续为你宣传,要么放弃采集picture,要么放弃采集你的网站,这一切都对你有利。
四、重要内容设置会员访问限制
如果你的网站确实有更重要的内容需要保留,固定资源可以吸引固定用户;通过这种方式,您可以设置会员访问限制,以便注册会员或高级会员可以访问这部分内容。当然,这也会将搜索引擎拒之门外,但为了保持网站的吸引力,必须保留适当的稀有资源。如果网站没有用户留下的资源,那么用户很容易离开。
当然,有很多方法可以防止采集。可以到专业网站学习和模仿。个人觉得如果是新网站要通过原创内容增加权重,就需要防止采集;如果网站发展了很多,比如A5,就没有必要阻止采集。毕竟搜索引擎已经认识到这是文章的第一名。
文章采集调用 QT+openCV操做的这部分,其余还没时间看
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-22 07:01
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针
在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好的,所有的代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
查看全部
文章采集调用 QT+openCV操做的这部分,其余还没时间看
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针

在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好的,所有的代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-22 07:01
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
会显示以下功能(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。 查看全部
LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
会显示以下功能(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。
Python代码的UI文件-本篇窗口()
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-18 22:09
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们将对话框的运行赋值给一个变量,然后与QtWidgets.QDialog.Accepted进行比较。 QtWidgets.QDialog.Accepted表示对话框的接收事件,用“OK”事件表示,如果是接收时间,设置标签标签为“点击确定”,否则设置标签标签为“点击Cannel”
文章版权:周老师的博客,转载需保留出处和原链接 查看全部
Python代码的UI文件-本篇窗口()
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们将对话框的运行赋值给一个变量,然后与QtWidgets.QDialog.Accepted进行比较。 QtWidgets.QDialog.Accepted表示对话框的接收事件,用“OK”事件表示,如果是接收时间,设置标签标签为“点击确定”,否则设置标签标签为“点击Cannel”
文章版权:周老师的博客,转载需保留出处和原链接
文章页模板增加伪原创代码标签使用方法介绍插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-18 03:02
众所周知,搜索引擎喜欢原创sexual 内容。对于网上重复的内容,它会认为没有收录的价值。严重采集站或重复站将被搜索引擎网站减重。 网站排名自然不会很高。但是原创的内容比较难,所以我们一般会对转载的内容进行修改处理,让搜索引擎认为你的文章是原创,会是收录。这样就达到了伪原创的目的。
伪原创是指重新处理一个原创文章页面模板,实现不同的文章页面,不同的HTML代码,让搜索引擎认为它是一个原创文章,从而增加了权重网站。
本插件可以配合“织梦文章内容页自动添加ASCII码增加原创度公众百度收录rank(支持优采云采集)”插件,效果更佳。
T28织梦补偿值干扰码功能特点:
插件实现伪原创templates,不同内容不同代码,保证优化不影响用户体验
插件采用高速缓存处理,不影响网站访问速度
插件内置了强大的干扰码伪原创度好,处理后的文章main意思不变
插件支持手机站伪原创settings
插件伪原创模板好用,可以随意改变伪原创的位置
插件支持优采云采集器
织梦伪原创模板插件使用步骤:
1:执行SQL命令(购买后可查看命令代码)
2:文章page 模板添加伪原创code 标签
3:修改article_add.php文件(修改代码)
4:修改/include/extend.func.php文件(添加代码)
5:文章page 模板添加调用JS
织梦伪原创Template 插件效果演示:
织梦伪原创模板插件使用后效果:
标签: 查看全部
文章页模板增加伪原创代码标签使用方法介绍插件
众所周知,搜索引擎喜欢原创sexual 内容。对于网上重复的内容,它会认为没有收录的价值。严重采集站或重复站将被搜索引擎网站减重。 网站排名自然不会很高。但是原创的内容比较难,所以我们一般会对转载的内容进行修改处理,让搜索引擎认为你的文章是原创,会是收录。这样就达到了伪原创的目的。
伪原创是指重新处理一个原创文章页面模板,实现不同的文章页面,不同的HTML代码,让搜索引擎认为它是一个原创文章,从而增加了权重网站。
本插件可以配合“织梦文章内容页自动添加ASCII码增加原创度公众百度收录rank(支持优采云采集)”插件,效果更佳。
T28织梦补偿值干扰码功能特点:
插件实现伪原创templates,不同内容不同代码,保证优化不影响用户体验
插件采用高速缓存处理,不影响网站访问速度
插件内置了强大的干扰码伪原创度好,处理后的文章main意思不变
插件支持手机站伪原创settings
插件伪原创模板好用,可以随意改变伪原创的位置
插件支持优采云采集器

织梦伪原创模板插件使用步骤:
1:执行SQL命令(购买后可查看命令代码)
2:文章page 模板添加伪原创code 标签
3:修改article_add.php文件(修改代码)
4:修改/include/extend.func.php文件(添加代码)
5:文章page 模板添加调用JS
织梦伪原创Template 插件效果演示:

织梦伪原创模板插件使用后效果:
标签:
WPFavoritePosts文章收藏插件使用方法收藏
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-18 02:15
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看到自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果您删除浏览器的 cookie,您将丢失采集的数据。因此,建议您注册该用户并将其保存在数据库中而不会丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)
可设置各种提示
设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果您只想在某些文章中显示采集夹链接,可以在编辑文章时在文章中添加以下短代码:
第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!
WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List 另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的 wpfp-page-template.php 文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集数量统计不准确。
找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:
崇尚可爱
一个喜欢折腾WordPress并被它折腾的文科IT书呆子^_^
关注 查看全部
WPFavoritePosts文章收藏插件使用方法收藏
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看到自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果您删除浏览器的 cookie,您将丢失采集的数据。因此,建议您注册该用户并将其保存在数据库中而不会丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)

可设置各种提示

设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果您只想在某些文章中显示采集夹链接,可以在编辑文章时在文章中添加以下短代码:

第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!

WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List 另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的 wpfp-page-template.php 文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集数量统计不准确。

找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:




崇尚可爱
一个喜欢折腾WordPress并被它折腾的文科IT书呆子^_^
关注
豆瓣网分析基础知识:豆瓣电影中如何获取请求?
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-08-17 05:14
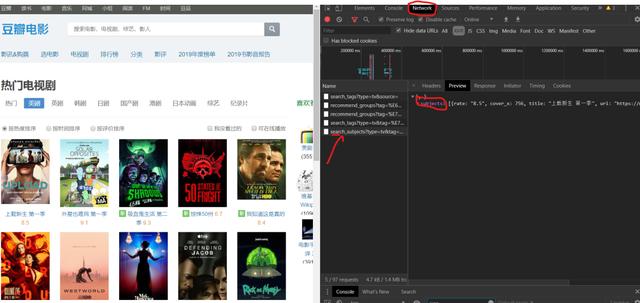
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
如何访问网页?
https://movie.douban.com/j/sea ... %3D60
当点击下一页时,每增加一页,页面将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
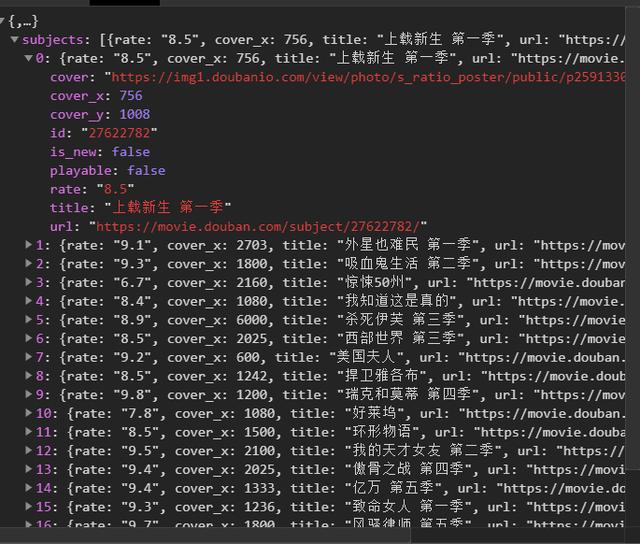
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、for 遍历获取对应的电影名称、评分,并链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:
1)设置时间延迟。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
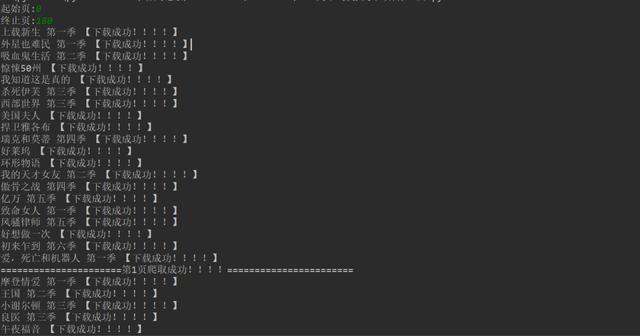
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、电影图片展示。
[七、Summary]
1、 不建议取太多数据,可能会造成服务器负载。试试看吧。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、如需本文源码,可在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发分享给更多人****
IT 共享屋 查看全部
豆瓣网分析基础知识:豆瓣电影中如何获取请求?
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
如何访问网页?
https://movie.douban.com/j/sea ... %3D60
当点击下一页时,每增加一页,页面将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、for 遍历获取对应的电影名称、评分,并链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:
1)设置时间延迟。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。

2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。

4、电影图片展示。
[七、Summary]
1、 不建议取太多数据,可能会造成服务器负载。试试看吧。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、如需本文源码,可在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发分享给更多人****
IT 共享屋
调用链系列(2):服务端信息收集以及服务间上下文传递
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-17 05:10
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,总体实现策略。
在这个文章我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、server 信息采集
服务端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。
三、切点植入
在介绍切入点之前,我们应该对servlet容器处理请求的大致流程有一个整体的了解(本文以tomcat为例)。
图片来源于网络
Connector 收到连接并转换成请求(Request)后,会将请求传递给 Engine 的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入我们自己的逻辑,即无人机中间件增强技术,来增强tomcat的外部能力。
中间件增强技术除了巧妙利用了tomcat容器的架构设计之外,还使用了java Instrumentation(它为我们提供了在第一次加载对象时动态修改字节码的能力,由于空间原因原因这里就不详细解释了,不明白的可以自行查资料)。在无人机中,通过UAVServer对外提供各种切点能力。
采用中间件增强技术,应用逻辑执行前后都有切点。下一步是在这些切点处执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力将在后续文章中详细介绍)。轻量级调用链的实现使用了UAVServer对外提供的GlobalFilterHandler能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助GlobalFilterHandler提供的前两个能力实现了在应用处理请求前后执行调用链逻辑的功能。
五、Light 调用链实现
具体的UML图如下:
从UML图中可以明显看出InvokeChainSupporter(调用链实现逻辑入口的实现类和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量调用链绘制的实现主要依赖于注册在InvokeChainSupporter上的ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 解析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑分流
因为不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
主span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方法利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;调用链上下文逻辑初始化时,通过传入的信息初始化目标服务的调用链上下文,实现跨系统调用的调用链连接。
六、Summary
阅读本文后,读者应该对中间件增强技术的实现有一个大致的了解,对其提供的GlobalFilterHandler能力有一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。 查看全部
调用链系列(2):服务端信息收集以及服务间上下文传递
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,总体实现策略。
在这个文章我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、server 信息采集
服务端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。

三、切点植入
在介绍切入点之前,我们应该对servlet容器处理请求的大致流程有一个整体的了解(本文以tomcat为例)。

图片来源于网络
Connector 收到连接并转换成请求(Request)后,会将请求传递给 Engine 的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入我们自己的逻辑,即无人机中间件增强技术,来增强tomcat的外部能力。
中间件增强技术除了巧妙利用了tomcat容器的架构设计之外,还使用了java Instrumentation(它为我们提供了在第一次加载对象时动态修改字节码的能力,由于空间原因原因这里就不详细解释了,不明白的可以自行查资料)。在无人机中,通过UAVServer对外提供各种切点能力。
采用中间件增强技术,应用逻辑执行前后都有切点。下一步是在这些切点处执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力将在后续文章中详细介绍)。轻量级调用链的实现使用了UAVServer对外提供的GlobalFilterHandler能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助GlobalFilterHandler提供的前两个能力实现了在应用处理请求前后执行调用链逻辑的功能。
五、Light 调用链实现
具体的UML图如下:

从UML图中可以明显看出InvokeChainSupporter(调用链实现逻辑入口的实现类和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量调用链绘制的实现主要依赖于注册在InvokeChainSupporter上的ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 解析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑分流
因为不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
主span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方法利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;调用链上下文逻辑初始化时,通过传入的信息初始化目标服务的调用链上下文,实现跨系统调用的调用链连接。
六、Summary
阅读本文后,读者应该对中间件增强技术的实现有一个大致的了解,对其提供的GlobalFilterHandler能力有一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。
基于底层数据交换的数据直接采集方式101异构数据采集技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 542 次浏览 • 2021-08-16 00:27
一、Software 接口方法 每个软件厂商都提供数据接口,实现数据采集收敛。
二、Open 数据库是实现采集数据收敛最直接的方式。打开数据库是最直接的方式。两个系统都有自己的数据库,同类型数据库之间更方便:
1. 如果两个数据库在同一台服务器上,只要用户名设置没有问题,就可以直接互相访问。您需要在 from 之后带上数据库名称和表架构所有者。从 DATABASE1.dbo.table1 中选择 *
2. 如果两个系统的数据库不在同一台服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource。这需要为数据库访问配置外围服务器。
三、Data 直接基于底层数据交换采集Method 101 异构数据采集技术是获取软件系统底层数据交换,软件客户端与数据库之间的网络流量包,基于在底层IO上通过请求、网络分析等技术,将采集目标软件产生的所有数据进行转换重组,输出到新的数据库中,供软件系统调用。技术特点如下:
1.不需要原软件厂商的配合;
2.实时数据采集,数据端到端响应速度达到秒级;
3.兼容性强,可以采集采集Windows平台上的各种软件系统数据;
4.输出结构化数据作为数据挖掘和大数据分析应用的基础;
5.自动建立数据关联,实施周期短,简单高效;
6.支持历史数据自动导入,通过I/O人工智能自动将数据写入目标软件;
7. 配置简单,实施周期短。基于底层数据交换的数据直接采集,摆脱对软件厂商的依赖,无需软件厂商的配合,不仅需要投入大量的时间、精力和资金,而且无需担心关于系统开发团队解体、源代码丢失等原因导致系统数据采集成死局。直接从多种软件系统中挖掘数据,持续获取准确实时的数据,自动建立数据关联,输出利用率极高的结构化数据,使不同系统的数据源有序、安全、可控联动公司流通提供决策支持,提高运营效率,创造经济价值。 查看全部
基于底层数据交换的数据直接采集方式101异构数据采集技术
一、Software 接口方法 每个软件厂商都提供数据接口,实现数据采集收敛。
二、Open 数据库是实现采集数据收敛最直接的方式。打开数据库是最直接的方式。两个系统都有自己的数据库,同类型数据库之间更方便:
1. 如果两个数据库在同一台服务器上,只要用户名设置没有问题,就可以直接互相访问。您需要在 from 之后带上数据库名称和表架构所有者。从 DATABASE1.dbo.table1 中选择 *
2. 如果两个系统的数据库不在同一台服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource。这需要为数据库访问配置外围服务器。
三、Data 直接基于底层数据交换采集Method 101 异构数据采集技术是获取软件系统底层数据交换,软件客户端与数据库之间的网络流量包,基于在底层IO上通过请求、网络分析等技术,将采集目标软件产生的所有数据进行转换重组,输出到新的数据库中,供软件系统调用。技术特点如下:
1.不需要原软件厂商的配合;
2.实时数据采集,数据端到端响应速度达到秒级;
3.兼容性强,可以采集采集Windows平台上的各种软件系统数据;
4.输出结构化数据作为数据挖掘和大数据分析应用的基础;
5.自动建立数据关联,实施周期短,简单高效;
6.支持历史数据自动导入,通过I/O人工智能自动将数据写入目标软件;
7. 配置简单,实施周期短。基于底层数据交换的数据直接采集,摆脱对软件厂商的依赖,无需软件厂商的配合,不仅需要投入大量的时间、精力和资金,而且无需担心关于系统开发团队解体、源代码丢失等原因导致系统数据采集成死局。直接从多种软件系统中挖掘数据,持续获取准确实时的数据,自动建立数据关联,输出利用率极高的结构化数据,使不同系统的数据源有序、安全、可控联动公司流通提供决策支持,提高运营效率,创造经济价值。
老文章重新编辑修改以后,怕读者不知道??
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-09 00:29
旧的文章重新编辑修改后,怕读者不知道?然后将新修改的文章列表添加到网站。这样,只要更新旧的文章,读者很快就知道了。如果你正在建设一个软件网站、一个电影网站等来分享内容,那么你就不需要一个版本来发布文章!将此功能添加到您的网站!
方法来自zwwooooo大师。给老文章一个机会:最近更新的帖子,已经被封装成函数了,并且增加了2个参数:$num-numberofimpressions,$days-几天后文章除外。还添加了数据库缓存方法。由于查询量较大,只有在修改文章/delete 文章/post 文章时才会更新缓存。
1. 在主题的functions.php 的最后一个?> 前面抛出以下函数代码:
// Recently Updated Posts by zwwooooo | zww.me
function recently_updated_posts($num=10,$days=7) {
if( !$recently_updated_posts = get_option('recently_updated_posts') ) {
query_posts('post_status=publish&orderby=modified&posts_per_page=-1');
$i=0;
while ( have_posts() && $i 60*60*24*$days) {
$i++;
$the_title_value=get_the_title();
$recently_updated_posts.=''
.$the_title_value.'<br />» 修改时间: '
.get_the_modified_time('Y.m.d G:i').'';
}
endwhile;
wp_reset_query();
if ( !empty($recently_updated_posts) ) update_option('recently_updated_posts', $recently_updated_posts);
}
$recently_updated_posts=($recently_updated_posts == '') ? 'None data.' : $recently_updated_posts;
echo $recently_updated_posts;
}
function clear_cache_zww() {
update_option('recently_updated_posts', ''); // 清空 recently_updated_posts
}
add_action('save_post', 'clear_cache_zww'); // 新发表文章/修改文章时触发更新
2.可以使用下面的函数调用
Recently Updated Posts
参数说明:8表示显示文章数量,15表示文章在15天内发布,文章除外
具体细节和css样式请自行修改,感谢zwwooooo高手!
扩展阅读:WordPress显示最近更新的文章并通知评论过的用户
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
老文章重新编辑修改以后,怕读者不知道??
旧的文章重新编辑修改后,怕读者不知道?然后将新修改的文章列表添加到网站。这样,只要更新旧的文章,读者很快就知道了。如果你正在建设一个软件网站、一个电影网站等来分享内容,那么你就不需要一个版本来发布文章!将此功能添加到您的网站!
方法来自zwwooooo大师。给老文章一个机会:最近更新的帖子,已经被封装成函数了,并且增加了2个参数:$num-numberofimpressions,$days-几天后文章除外。还添加了数据库缓存方法。由于查询量较大,只有在修改文章/delete 文章/post 文章时才会更新缓存。
1. 在主题的functions.php 的最后一个?> 前面抛出以下函数代码:
// Recently Updated Posts by zwwooooo | zww.me
function recently_updated_posts($num=10,$days=7) {
if( !$recently_updated_posts = get_option('recently_updated_posts') ) {
query_posts('post_status=publish&orderby=modified&posts_per_page=-1');
$i=0;
while ( have_posts() && $i 60*60*24*$days) {
$i++;
$the_title_value=get_the_title();
$recently_updated_posts.=''
.$the_title_value.'<br />» 修改时间: '
.get_the_modified_time('Y.m.d G:i').'';
}
endwhile;
wp_reset_query();
if ( !empty($recently_updated_posts) ) update_option('recently_updated_posts', $recently_updated_posts);
}
$recently_updated_posts=($recently_updated_posts == '') ? 'None data.' : $recently_updated_posts;
echo $recently_updated_posts;
}
function clear_cache_zww() {
update_option('recently_updated_posts', ''); // 清空 recently_updated_posts
}
add_action('save_post', 'clear_cache_zww'); // 新发表文章/修改文章时触发更新
2.可以使用下面的函数调用
Recently Updated Posts
参数说明:8表示显示文章数量,15表示文章在15天内发布,文章除外
具体细节和css样式请自行修改,感谢zwwooooo高手!
扩展阅读:WordPress显示最近更新的文章并通知评论过的用户
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
搜狗微信改版了,无法通过搜索公众号名字获取对应文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-06 19:08
前言:一觉醒来发现原来的搜狗微信爬虫失败了。网上一搜发现搜狗微信的版本是10月29日改版的,搜索官方账号名无法得到对应的文章,但是通过搜索还是可以得到文章对应的主题,问题不大,开始吧!
目的:获取搜狗微信搜索话题返回的文章。
涉及防爬机制:cookie设置、js加密。
转到主题。
流程一:正常例行流程
打开搜狗微信,在搜索框中输入“超人”。你在这里搜索的是与“超人”主题相关的各种公众号文章list
按照正常的采集流程,按F12打开浏览器的开发者工具,使用选择工具点击列表中的文章标题,查看文章url在列表中的位置源代码中的list,也就是这个href的值,为了避免混淆,我们称之为“列表页的文章url”。
可以看到“列表页的文章url”需要拼接。这种情况下,需要在浏览器中正常访问这个文章,并对比观察跳转后的url(我们称之为“真实文章url”),然后补上头足。如下是两个网址的对比:
列表页上的文章url:
<p>/链接? URL = dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg ..&类型= 2&查询=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&K = 92&H = Z 查看全部
搜狗微信改版了,无法通过搜索公众号名字获取对应文章
前言:一觉醒来发现原来的搜狗微信爬虫失败了。网上一搜发现搜狗微信的版本是10月29日改版的,搜索官方账号名无法得到对应的文章,但是通过搜索还是可以得到文章对应的主题,问题不大,开始吧!
目的:获取搜狗微信搜索话题返回的文章。
涉及防爬机制:cookie设置、js加密。
转到主题。
流程一:正常例行流程
打开搜狗微信,在搜索框中输入“超人”。你在这里搜索的是与“超人”主题相关的各种公众号文章list
按照正常的采集流程,按F12打开浏览器的开发者工具,使用选择工具点击列表中的文章标题,查看文章url在列表中的位置源代码中的list,也就是这个href的值,为了避免混淆,我们称之为“列表页的文章url”。
可以看到“列表页的文章url”需要拼接。这种情况下,需要在浏览器中正常访问这个文章,并对比观察跳转后的url(我们称之为“真实文章url”),然后补上头足。如下是两个网址的对比:
列表页上的文章url:
<p>/链接? URL = dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg ..&类型= 2&查询=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&K = 92&H = Z
文章采集调用(垃圾站采集与搜索引擎收录的关系修改方法介绍(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-01 21:09
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有大量采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。因为采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页进入
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有很多采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。
因为采集回来内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,所以生产一个最新的文章列表,减少蜘蛛爬行步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,本质上和xml映射一样,除了这是一个 HTML 页面。
如何修改:
1、下载压缩包,解压后上传到根目录。 (点击下载GBK版)
2、Enter 网站Background Core -> Channel Model -> 单页文档管理 添加一个页面。
3、 页面标题、页面关键字和页面摘要信息根据你的网站情况填写,模板名和文件名参考下图,编辑框中不需要添加任何内容,我已经在模板里给你设置好了。
4、设置并点击后,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、 无法自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row=’50′ col=’1′ orderby=pubdate}
[field:title /]
{/dede:arclist}
您也可以创建一个没有图片的简单导航页面。 查看全部
文章采集调用(垃圾站采集与搜索引擎收录的关系修改方法介绍(图))
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有大量采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。因为采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页进入
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天有很多采集,虽然首页有些地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的@每天采集内容。
因为采集回来内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,所以生产一个最新的文章列表,减少蜘蛛爬行步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,本质上和xml映射一样,除了这是一个 HTML 页面。
如何修改:
1、下载压缩包,解压后上传到根目录。 (点击下载GBK版)
2、Enter 网站Background Core -> Channel Model -> 单页文档管理 添加一个页面。
3、 页面标题、页面关键字和页面摘要信息根据你的网站情况填写,模板名和文件名参考下图,编辑框中不需要添加任何内容,我已经在模板里给你设置好了。
4、设置并点击后,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、 无法自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row=’50′ col=’1′ orderby=pubdate}
[field:title /]
{/dede:arclist}
您也可以创建一个没有图片的简单导航页面。
文章采集调用( 一图带你看Java虚拟机运行时数据区内存)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-09-01 14:14
一图带你看Java虚拟机运行时数据区内存)
一张图带你看这篇文章
一、运行时数据区
首先我们来看看Java虚拟机管理的内存包括哪些区域。正如我们要了解一座房子,我们首先要了解房子的大致结构。根据《Java虚拟机规范(Java SE 7版)》,请看下图:
Java 虚拟机运行时数据区
1.1 程序计数器
程序计数器是一个很小的内存空间,可以看作是当前线程执行的字节码的行号的指示器。
1.2 Java 虚拟机栈
和程序计数器一样,Java虚拟机栈也是线程私有的,其生命周期与线程相同。虚拟机栈描述了Java方法执行的内存模型:每个方法执行时,都会创建一个栈帧来存储局部变量表、操作数栈、动态链接、方法退出等信息。每个方法从调用到执行完成的过程,对应着虚拟机栈中一个栈帧入栈到出栈的过程。请看下图:
Java 虚拟机栈
1.2.1 虚拟机堆栈溢出
如果线程请求的栈深度大于虚拟机允许的最大深度,会抛出StackOverflowError异常。如果虚拟机在扩展堆栈时无法申请足够的内存空间,则会抛出 OutOfMemoryError 异常。
1.3 本地方法栈
1.4 Java 堆
Java 堆是所有线程共享的内存区域,在虚拟机启动时创建。此内存区域的唯一目的是存储对象实例。几乎所有的对象实例都在这里分配内存(但随着技术的发展,所有的对象都分配在堆上,逐渐变得不那么“绝对”了)。请看下图:
生成堆内存模型
1.4.1 Java 堆溢出
1.5 方法区
方法区和Java堆一样,是每个线程共享的内存区。用于存储虚拟机已加载的类信息、常量、静态变量、即时编译器编译的代码等数据。
1.5.1 运行时常量池
1.6 直接内存
二、内存分配策略
对象的内存分配,大体上是在堆上分配(但也有可能在JIT编译后分解为标量类型,间接在栈上分配)。对象主要分配在新生代的Eden区。如果启动了本地线程分配缓冲区,则会根据线程优先级在TLAB上进行分配。少数情况下,也可能直接分配到老年代。分配规则不固定。具体取决于当前使用的是哪种垃圾采集器组合,以及虚拟机中内存相关参数的设置。
2.1 对象先在 Eden 中分配
大多数情况下,对象分配在新一代的Eden区。当 Eden 区域没有足够的空间进行分配时,虚拟机会发起一次 Minor GC。例如看下面的代码:
private static final int _1MB = 1024 * 1024;
/**
* VM 参数:-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8
*/
private static void testAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation4 = new byte[4 * _1MB];//出现一次 Minor GC
}
执行上面的 testAllocation() 代码。分配allocation4对象语句时,会发生Minor GC。这次GC的结果是新生代6651KB变成了148KB,总的内存占用几乎没有减少(因为allocation1、allocation2、allocation3三个对象都活着,虚拟机几乎找不到可回收的对象)。这次GC的原因是在给allocation4分配内存的时候,发现Eden已经占用了6MB,剩余空间不足以分配allocation4需要的4MB内存,所以发生了Minor GC。在GC的时候,虚拟机发现现有的3个2MB的对象都无法放入Survivor空间(从上图可以看出Survivor空间只有1MB大小),只好转移到老年代通过分配保证机制提前。
2.2 大物件直接进入老年
2.3 长寿对象会进入老年
由于虚拟机采用分代回收的思想来管理内存,所以在内存回收的时候必须能够识别出哪些对象应该放在年轻代,哪些对象应该放在老年代。为了做到这一点,虚拟机为每个对象定义了一个对象年龄计数器。如果对象出生在 Eden 并且在第一次 Minor GC 中幸存下来,并且可以被 Survivor 容纳,它就会被移到 Survivor 空间,并且对象的年龄设置为 1。 每次一个对象“通过”一个Survivor区的Minor GC,年龄增加1年。当它的年龄增加到一定级别(默认为15岁)时,将被提升到老年。可以通过参数-XX:MaxTenuringThreshold设置提升对象的年龄阈值。
2.4 动态对象年龄确定
为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到MaxTenuringThreshold才能提升到老年。如果Survivor空间中所有同龄对象的大小之和大于Survivor空间Half,则年龄大于等于该年龄的对象可以直接进入老年,无需等待MaxTenuringThreshold中的所需年龄.
2.5 空间分配保障机制
三、内存恢复策略
3.1 内存恢复的关注区域
3.2 判断对象存活
3.2.1 引用计数算法
3.2.2 可达性分析算法
虚拟机栈中引用的对象(栈帧中的局部变量表) 方法区类静态属性引用的对象 方法区常量引用的对象 本地方法栈中JNI引用的对象
请看下图:
可访问性分析算法
3.3 方法区的恢复
这个类的所有实例都被回收了,即Java堆中没有这个类的实例。加载此类的 ClassLoader 已被回收。该类对应的java.lang.Class对象在任何地方都没有被引用,该类的方法在任何地方都无法通过反射访问。
3.4 垃圾采集算法
3.4.1 标签——清除算法
“mark-clear”算法示意图
3.4.2 复制算法
复制算法示意图
一个优化例子:新生代98%的对象都是“生死存亡”,所以不需要按照1:1的比例来划分内存空间,而是把内存划分成更大的Eden space 和两个较小的 Survivor 空间,每次使用 Eden 和 Survivor 之一。回收时,将Eden和Survivor中的幸存对象一次性复制到另一个Survivor空间,最后将刚刚使用的Eden和Survivor空间清理干净。
另一个优化例子:将Eden和Survivor的大小比例设置为8:1,即每一代的可用内存空间是整个新一代容器的90%,只使用了10%的内存作为保留区。当然,98%可以回收的对象只是一般场景下的数据。我们无法保证每次回收时不超过 10% 的对象存活。当 Survivor 空间不够用时,需要依靠其他内存(这里指的是老年代)进行分配。保证(空间分配保证机制在最上面,看看)。
3.4.3 标签——组织算法
复制集合算法在对象存活率高的时候会执行更多的复制操作,效率会更低。因此,在老年代,一般不能直接使用副本采集算法。
“标记-组织”算法示意图
3.4.4 分代采集算法
四、编程中的内存优化
相信大家都会注意到编程中的内存使用问题。下面我就简单罗列一下在实际操作中需要注意的几点。
4.1 减少对象的内存使用
我们可以考虑使用ArrayMap/SparseArray代替HashMap等传统数据结构。 (在老项目中,按照Lint的提示用ArrayMap/SparseArray替换HashMap后,在老项目中,Android Profiler显示运行时内存比之前少了几M,相当可观。)
inSampleSize:缩放比例。在将图像加载到内存之前,我们需要计算一个合适的缩放比例,以避免不必要地加载大图像。 decode format:解码格式,选择ARGB_8888 / RBG_565 / ARGB_4444 / ALPHA_8,有很大区别。
4.2 内存对象的复用
4.3 避免对象内存泄漏
内部类引用导致Activity Context泄露给其他实例,可能导致自身被引用而泄露。
4.4 内存使用策略优化
五、内存检测工具
最后推荐几个内存检测工具。具体使用方法可以自行搜索。当然,除了下面这些工具,应该还有更多更有用的工具,只是我还没有找到。如果您有任何建议,可以在文章下方评论并留言。让我们一起学习和分享。
需要本书的请私信 查看全部
文章采集调用(
一图带你看Java虚拟机运行时数据区内存)
一张图带你看这篇文章
一、运行时数据区
首先我们来看看Java虚拟机管理的内存包括哪些区域。正如我们要了解一座房子,我们首先要了解房子的大致结构。根据《Java虚拟机规范(Java SE 7版)》,请看下图:
Java 虚拟机运行时数据区
1.1 程序计数器
程序计数器是一个很小的内存空间,可以看作是当前线程执行的字节码的行号的指示器。
1.2 Java 虚拟机栈
和程序计数器一样,Java虚拟机栈也是线程私有的,其生命周期与线程相同。虚拟机栈描述了Java方法执行的内存模型:每个方法执行时,都会创建一个栈帧来存储局部变量表、操作数栈、动态链接、方法退出等信息。每个方法从调用到执行完成的过程,对应着虚拟机栈中一个栈帧入栈到出栈的过程。请看下图:
Java 虚拟机栈
1.2.1 虚拟机堆栈溢出
如果线程请求的栈深度大于虚拟机允许的最大深度,会抛出StackOverflowError异常。如果虚拟机在扩展堆栈时无法申请足够的内存空间,则会抛出 OutOfMemoryError 异常。
1.3 本地方法栈
1.4 Java 堆
Java 堆是所有线程共享的内存区域,在虚拟机启动时创建。此内存区域的唯一目的是存储对象实例。几乎所有的对象实例都在这里分配内存(但随着技术的发展,所有的对象都分配在堆上,逐渐变得不那么“绝对”了)。请看下图:
生成堆内存模型
1.4.1 Java 堆溢出
1.5 方法区
方法区和Java堆一样,是每个线程共享的内存区。用于存储虚拟机已加载的类信息、常量、静态变量、即时编译器编译的代码等数据。
1.5.1 运行时常量池
1.6 直接内存
二、内存分配策略
对象的内存分配,大体上是在堆上分配(但也有可能在JIT编译后分解为标量类型,间接在栈上分配)。对象主要分配在新生代的Eden区。如果启动了本地线程分配缓冲区,则会根据线程优先级在TLAB上进行分配。少数情况下,也可能直接分配到老年代。分配规则不固定。具体取决于当前使用的是哪种垃圾采集器组合,以及虚拟机中内存相关参数的设置。
2.1 对象先在 Eden 中分配
大多数情况下,对象分配在新一代的Eden区。当 Eden 区域没有足够的空间进行分配时,虚拟机会发起一次 Minor GC。例如看下面的代码:
private static final int _1MB = 1024 * 1024;
/**
* VM 参数:-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8
*/
private static void testAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[2 * _1MB];
allocation4 = new byte[4 * _1MB];//出现一次 Minor GC
}
执行上面的 testAllocation() 代码。分配allocation4对象语句时,会发生Minor GC。这次GC的结果是新生代6651KB变成了148KB,总的内存占用几乎没有减少(因为allocation1、allocation2、allocation3三个对象都活着,虚拟机几乎找不到可回收的对象)。这次GC的原因是在给allocation4分配内存的时候,发现Eden已经占用了6MB,剩余空间不足以分配allocation4需要的4MB内存,所以发生了Minor GC。在GC的时候,虚拟机发现现有的3个2MB的对象都无法放入Survivor空间(从上图可以看出Survivor空间只有1MB大小),只好转移到老年代通过分配保证机制提前。
2.2 大物件直接进入老年
2.3 长寿对象会进入老年
由于虚拟机采用分代回收的思想来管理内存,所以在内存回收的时候必须能够识别出哪些对象应该放在年轻代,哪些对象应该放在老年代。为了做到这一点,虚拟机为每个对象定义了一个对象年龄计数器。如果对象出生在 Eden 并且在第一次 Minor GC 中幸存下来,并且可以被 Survivor 容纳,它就会被移到 Survivor 空间,并且对象的年龄设置为 1。 每次一个对象“通过”一个Survivor区的Minor GC,年龄增加1年。当它的年龄增加到一定级别(默认为15岁)时,将被提升到老年。可以通过参数-XX:MaxTenuringThreshold设置提升对象的年龄阈值。
2.4 动态对象年龄确定
为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到MaxTenuringThreshold才能提升到老年。如果Survivor空间中所有同龄对象的大小之和大于Survivor空间Half,则年龄大于等于该年龄的对象可以直接进入老年,无需等待MaxTenuringThreshold中的所需年龄.
2.5 空间分配保障机制
三、内存恢复策略
3.1 内存恢复的关注区域
3.2 判断对象存活
3.2.1 引用计数算法
3.2.2 可达性分析算法
虚拟机栈中引用的对象(栈帧中的局部变量表) 方法区类静态属性引用的对象 方法区常量引用的对象 本地方法栈中JNI引用的对象
请看下图:
可访问性分析算法
3.3 方法区的恢复
这个类的所有实例都被回收了,即Java堆中没有这个类的实例。加载此类的 ClassLoader 已被回收。该类对应的java.lang.Class对象在任何地方都没有被引用,该类的方法在任何地方都无法通过反射访问。
3.4 垃圾采集算法
3.4.1 标签——清除算法
“mark-clear”算法示意图
3.4.2 复制算法
复制算法示意图
一个优化例子:新生代98%的对象都是“生死存亡”,所以不需要按照1:1的比例来划分内存空间,而是把内存划分成更大的Eden space 和两个较小的 Survivor 空间,每次使用 Eden 和 Survivor 之一。回收时,将Eden和Survivor中的幸存对象一次性复制到另一个Survivor空间,最后将刚刚使用的Eden和Survivor空间清理干净。
另一个优化例子:将Eden和Survivor的大小比例设置为8:1,即每一代的可用内存空间是整个新一代容器的90%,只使用了10%的内存作为保留区。当然,98%可以回收的对象只是一般场景下的数据。我们无法保证每次回收时不超过 10% 的对象存活。当 Survivor 空间不够用时,需要依靠其他内存(这里指的是老年代)进行分配。保证(空间分配保证机制在最上面,看看)。
3.4.3 标签——组织算法
复制集合算法在对象存活率高的时候会执行更多的复制操作,效率会更低。因此,在老年代,一般不能直接使用副本采集算法。
“标记-组织”算法示意图
3.4.4 分代采集算法
四、编程中的内存优化
相信大家都会注意到编程中的内存使用问题。下面我就简单罗列一下在实际操作中需要注意的几点。
4.1 减少对象的内存使用
我们可以考虑使用ArrayMap/SparseArray代替HashMap等传统数据结构。 (在老项目中,按照Lint的提示用ArrayMap/SparseArray替换HashMap后,在老项目中,Android Profiler显示运行时内存比之前少了几M,相当可观。)
inSampleSize:缩放比例。在将图像加载到内存之前,我们需要计算一个合适的缩放比例,以避免不必要地加载大图像。 decode format:解码格式,选择ARGB_8888 / RBG_565 / ARGB_4444 / ALPHA_8,有很大区别。
4.2 内存对象的复用
4.3 避免对象内存泄漏
内部类引用导致Activity Context泄露给其他实例,可能导致自身被引用而泄露。
4.4 内存使用策略优化
五、内存检测工具
最后推荐几个内存检测工具。具体使用方法可以自行搜索。当然,除了下面这些工具,应该还有更多更有用的工具,只是我还没有找到。如果您有任何建议,可以在文章下方评论并留言。让我们一起学习和分享。
需要本书的请私信
文章采集调用(java内存溢出和内存泄漏的区别,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-01 14:10
评论
上一篇博客写了JVM的内存溢出问题,比较了内存溢出和内存泄漏的区别,然后做了虚拟机栈的OOM和SOF,方法区和运行时常量池的OOM,以及堆的OOM相关实验验证,在实验过程中,发现java8对方法区perm gen进行了改进,即metaspace替换了perm gen(java7将字符串常量池移到了堆中)。最后提出两个问题,关于使用stringbuilder导致堆空间OOM的实验现象,目前还没有解决,期待与读者一起探讨。
之前的博文大致完成了java运行时数据区的基本内容。本篇博客进入JVM的垃圾回收部分。这部分预计会写在两个博客中。本篇博客将学习上述算法的对象生存判断算法、垃圾回收算法以及JVM实现。
物体生存判断算法
我在百度最上面的小书里看了一篇关于对象生存判断算法的解释,解释的太好了。 . 我不会太尴尬写的,我会在本节末尾链接到它。这里我硬着头皮按照文章的思路写出来! (在此向文章的作者致以崇高的敬意,先盗图。)
先介绍一下大致流程:
对象生存判断算法流程图
首先进行可达性分析,对不可达对象进行两次标记/筛选过程。如果任何标记/筛选阶段未能“自救”,该对象将被回收。
判断方法
目前,引用计数和可达性分析在编程语言中被普遍使用。
1.引用计数方法
虽然主流JVM中没有使用引用计数的方法,但在Python、游戏脚本语言等领域也有广泛的应用。是经典的内存管理算法。
优点:实现简单,判断效率较高
缺点:无法解决对象循环引用的问题
例如以下代码:
public class ReferenceCountingGC {
private ReferenceCountingGC instance = null;
private static final int _1MB = 1024*1024;
private byte[] bigsize = new byte[2*_1MB];//占用内存,方便查看GC,因为每个对象都有它
public static void main(String[] args) {
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
//相互引用
objA.instance = objB;
objB.instance = objA;
//置为null
objA = null;
objB = null;
//想要触发GC
System.gc();
}
}
这里是GC日志:
[GC (System.gc()) [PSYoungGen: 9876K->1292K(36864K)] 9876K->1300K(121856K), 0.0794454 secs] [Times: user=0.16 sys=0.00, real=0.08 secs]
[Full GC (System.gc()) [PSYoungGen: 1292K->0K(36864K)] [ParOldGen: 8K->1188K(84992K)] 1300K->1188K(121856K), [Metaspace: 4725K->4725K(1056768K)], 0.0098699 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 36864K, used 317K [0x00000000d6c00000, 0x00000000d9500000, 0x0000000100000000)
eden space 31744K, 1% used [0x00000000d6c00000,0x00000000d6c4f738,0x00000000d8b00000)
from space 5120K, 0% used [0x00000000d8b00000,0x00000000d8b00000,0x00000000d9000000)
to space 5120K, 0% used [0x00000000d9000000,0x00000000d9000000,0x00000000d9500000)
ParOldGen total 84992K, used 1188K [0x0000000084400000, 0x0000000089700000, 0x00000000d6c00000)
object space 84992K, 1% used [0x0000000084400000,0x0000000084529058,0x0000000089700000)
Metaspace used 4732K, capacity 4930K, committed 5248K, reserved 1056768K
class space used 510K, capacity 561K, committed 640K, reserved 1048576K
可以看到,经过一次GC,9876→1292,堆中的对象被回收了。这从侧面说明Hotspot虚拟机不是采用的引用计数方式。
2.可访问性分析算法
可达性分析的两个重要概念:GC 根和引用链。
GC 根
gc 根是引用链的根节点。可以作为gc根的对象分为以下几类:
1.虚拟机栈本地变量表中引用的对象
2.本地方法栈中JNI(java native interface)引用的对象
3.方法区的常量、类静态属性引用的对象
参考链
从gc root开始,向下搜索,搜索遍历的路径称为引用链。
如下图:
参考链
可访问性分析
如果一个对象和 gc 根没有通过任何引用链连接,那么这个对象就被认为是不可达的。无法到达的对象即将进入标记/筛选阶段。
标记/筛选阶段
1.第一次打标/筛选过程
简单来说,第一个标记过程就是看对象是否需要执行finalize方法。如有必要,进入下一个标记阶段,如果不需要执行,则结束标记阶段,基本确定该对象需要回收。
是否需要执行finalize方法判断依据
1.如果该对象对应的类中没有覆盖finalize方法,则说明没有必要执行
2.如果在之前,该对象已经执行过一次finalize方法了,则说明没有必要执行(因为finalize方法只能执行一次)
2.第二次打标/筛选过程
在第一次标记/筛选过程之后,认为需要执行finalize方法的对象被放置在F-QUEUE中,JVM会自动创建一个低优先级线程来执行F-QUEUE中的finalize方法。这里的“执行”并不一定意味着必须完全执行。因为如果在finalize方法中存在无限循环,是不是要等到执行完毕?队列将被阻塞!
判断主体是否活着的依据:
在finalize方法中,该对象又重新连接到了gc roots的引用链上
实验
package gctest;
public class FinalizeEscapeGC {
private static FinalizeEscapeGC instance = null;//instance是gc root
@Override
protected void finalize() throws Throwable {
super.finalize();
FinalizeEscapeGC.instance = this;
System.out.println("I save mylife!");
}
public void isAlive() {
System.out.println("I'm alive!");
}
public static void main(String[] args) {
instance = new FinalizeEscapeGC();
instance = null;//对象和gc roots之间失去连接
System.gc();
//第一次拯救过程
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则不会是空指针
} catch (NullPointerException e) {
System.out.println("nullpointerException happens");
}
instance = null;//对象和gc roots之间失去连接
System.gc();
//第二次拯救过程,就是把第一次的代码重复一遍
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则instance不会是空指针
} catch (NullPointerException e) {
System.out.println("NullPointerException happens");
}
}
}
运行结果
可以看出对象开始自救一次,然后自救失败,失去与实例的连接,实例为空。
参考简书文章超LINK
简书关于对象生存判断算法的超链接
回收方法区
方法区也存在于GC中。主要是回收过时的常量和无用的类。
Abandoned constants:不再使用的常量(指常量池中的字面量和符号引用),比如一个“ABC”存放在常量池中,但没有在任何地方使用,被判断为是一个过时的常量。
无用类:
1.该类的实例对象都被回收
2.加载该类的类加载器被回收
3.该类的java.lang.Class对象没有在任何地方引用到,无法通过反射访问该类中的方法
本节总结
一旦一个对象被unreachable分析确定为unreachable,它必须经过两次标记过程的重复测试才能成功自救,并且只能通过finalize方法自救一次。
垃圾采集算法
共有三种采集算法和一种采集思路。即标记清除算法、标记排序算法、复制算法、分代采集思想。
1.tag-clearing 算法
这个算法很容易理解,就是将确定为死的内存回收,什么都不做。
优点:简单
缺点:会形成大量的空间碎片,导致新创建的对象没有完整的内存分配,会提前启动full GC。
标签去除算法
2.tag-sorting 算法
标签排序算法是在标签清除算法的基础上改进的。死对象的内存恢复后,将存活的对象移动到内存空间的一端,解决了空间碎片化的问题。
优点:不会产生空间碎片,阻止Full GC提前进行
缺点:执行速度比去除标记慢
标签排序算法
3.复制算法
复制算法,简单来说就是你现在有两个空间,一个 A 用来存储对象,另一个 B 是空的。回收死对象后,将A中幸存的对象复制到B,然后清空A的内存,这样就形成了一个存放对象的空间和一个空的空间。
优点:不存在空间碎片问题,空间分配效率很高
缺点:牺牲了一部分内存空间作为空内存空间。
复制算法
4.子代采集思路
分代回收的思想是将堆内存分为老年代和新生代,针对不同的区域实现不同的垃圾回收算法,让内存的分配和回收更加高效!例如,老年适合使用标记去除算法和标记排序算法。新生代被进一步划分为Eden区,从survivor区到survivor区执行复制算法。
JVM中GC算法的对象生存判断与实现
1.Enumeration 根节点
在进行可达性分析时,需要根节点信息和引用链信息,需要两个需求:STW(stop the world)和引用信息
STW:可达性分析具有时间敏感性。虽然无法再分析,但参考关系仍在变化。因此,GC期间必须停止所有Java线程,称为stop the world。
引用信息:要建立引用关系,需要知道当前内存中哪些对象是引用。传统的方法是直接扫描整个内存来获取参考信息。 Hotspot 使用 oopMap 方法。
1.记录栈、寄存器等区域中哪些位置是GC管理的指针
2.一段代码内可以有多处使用oopMap,但不是每条指令都会使用oopMap,也就是安全点,safepoint将一段代码分为好几段
3.oopMap的作用域也只在它所在的那一段里
2.安全点
GC只有在超出安全点的情况下才能执行。安全点一般在“程序可以长时间执行的地方”,其特点是指令序列的复用。 (我一直不明白为什么我在看书的时候会选择这个,以后再说)
1.循环跳转
2.方法调用
3.异常跳转
你为什么选择这种方式?
1.安全点选择太少,每次GC间隔太长,安全点选择太多,GC执行太频繁。
2.Imagine 如果在 A 和 B 两个安全点之间有循环跳转、异常跳转等上面提到的代码段,这段代码的执行时间很长。 . . . ,甚至无限循环,难道你不想在B安全点执行GC直到天老吗? (也就是GC之间的间隔太长了)
如何使所有线程安全?
GC 是整个 JVM。 JVM中会有很多线程在执行,那么如何保证GC期间所有线程都处于安全点呢?
分为抢占式中断和主动式中断
抢先中断
特点:不照顾线程感受
过程:GC时先中断所有的线程,然后让那些没有到安全点的线程自己再跑到安全点
使用:现在已经没有使用抢先式中断的了
主动中断
特点:照顾线程感受,让它自己去吧
过程:设置一个GC标志,线程执行到安全点或创建对象分配内存时,主动去轮询这个标志,为真时就主动中断自己(这个时候是安全点,中断就中断呗)
使用:大家都说好
3.安全区
上面考虑了多线程,但没有考虑线程在执行过程中可能会休眠或阻塞。如果等待它的sleep结束或者CPU时间片的分配,它又会变老!于是引出了安全区的概念
定义:安全区域是指这一段代码中的引用关系不会发生变化
线程在安全区域行为本质上是一个握手过程
过程:
1.线程A进入safe region,设置一个标志Ready flag.
2.GC如果在线程A处于safe region的时间内进行,由于ready flag的存在,不再检查
线程A
3.线程A将要离开safe region时,轮询GC设置的标志,若为真表示GC还没有执行完,则线程A中断自己,保证自己不离开safe region。若此时GC已经执行完毕,则A顺利离开region。
总结
本篇博客学习了对象生存判断算法和垃圾回收算法。后面会学习垃圾采集器,对象的内存分配和回收策略,以及JVM对上述算法的实现。 查看全部
文章采集调用(java内存溢出和内存泄漏的区别,你知道吗?)
评论
上一篇博客写了JVM的内存溢出问题,比较了内存溢出和内存泄漏的区别,然后做了虚拟机栈的OOM和SOF,方法区和运行时常量池的OOM,以及堆的OOM相关实验验证,在实验过程中,发现java8对方法区perm gen进行了改进,即metaspace替换了perm gen(java7将字符串常量池移到了堆中)。最后提出两个问题,关于使用stringbuilder导致堆空间OOM的实验现象,目前还没有解决,期待与读者一起探讨。
之前的博文大致完成了java运行时数据区的基本内容。本篇博客进入JVM的垃圾回收部分。这部分预计会写在两个博客中。本篇博客将学习上述算法的对象生存判断算法、垃圾回收算法以及JVM实现。
物体生存判断算法
我在百度最上面的小书里看了一篇关于对象生存判断算法的解释,解释的太好了。 . 我不会太尴尬写的,我会在本节末尾链接到它。这里我硬着头皮按照文章的思路写出来! (在此向文章的作者致以崇高的敬意,先盗图。)
先介绍一下大致流程:
对象生存判断算法流程图
首先进行可达性分析,对不可达对象进行两次标记/筛选过程。如果任何标记/筛选阶段未能“自救”,该对象将被回收。
判断方法
目前,引用计数和可达性分析在编程语言中被普遍使用。
1.引用计数方法
虽然主流JVM中没有使用引用计数的方法,但在Python、游戏脚本语言等领域也有广泛的应用。是经典的内存管理算法。
优点:实现简单,判断效率较高
缺点:无法解决对象循环引用的问题
例如以下代码:
public class ReferenceCountingGC {
private ReferenceCountingGC instance = null;
private static final int _1MB = 1024*1024;
private byte[] bigsize = new byte[2*_1MB];//占用内存,方便查看GC,因为每个对象都有它
public static void main(String[] args) {
ReferenceCountingGC objA = new ReferenceCountingGC();
ReferenceCountingGC objB = new ReferenceCountingGC();
//相互引用
objA.instance = objB;
objB.instance = objA;
//置为null
objA = null;
objB = null;
//想要触发GC
System.gc();
}
}
这里是GC日志:
[GC (System.gc()) [PSYoungGen: 9876K->1292K(36864K)] 9876K->1300K(121856K), 0.0794454 secs] [Times: user=0.16 sys=0.00, real=0.08 secs]
[Full GC (System.gc()) [PSYoungGen: 1292K->0K(36864K)] [ParOldGen: 8K->1188K(84992K)] 1300K->1188K(121856K), [Metaspace: 4725K->4725K(1056768K)], 0.0098699 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 36864K, used 317K [0x00000000d6c00000, 0x00000000d9500000, 0x0000000100000000)
eden space 31744K, 1% used [0x00000000d6c00000,0x00000000d6c4f738,0x00000000d8b00000)
from space 5120K, 0% used [0x00000000d8b00000,0x00000000d8b00000,0x00000000d9000000)
to space 5120K, 0% used [0x00000000d9000000,0x00000000d9000000,0x00000000d9500000)
ParOldGen total 84992K, used 1188K [0x0000000084400000, 0x0000000089700000, 0x00000000d6c00000)
object space 84992K, 1% used [0x0000000084400000,0x0000000084529058,0x0000000089700000)
Metaspace used 4732K, capacity 4930K, committed 5248K, reserved 1056768K
class space used 510K, capacity 561K, committed 640K, reserved 1048576K
可以看到,经过一次GC,9876→1292,堆中的对象被回收了。这从侧面说明Hotspot虚拟机不是采用的引用计数方式。
2.可访问性分析算法
可达性分析的两个重要概念:GC 根和引用链。
GC 根
gc 根是引用链的根节点。可以作为gc根的对象分为以下几类:
1.虚拟机栈本地变量表中引用的对象
2.本地方法栈中JNI(java native interface)引用的对象
3.方法区的常量、类静态属性引用的对象
参考链
从gc root开始,向下搜索,搜索遍历的路径称为引用链。
如下图:
参考链
可访问性分析
如果一个对象和 gc 根没有通过任何引用链连接,那么这个对象就被认为是不可达的。无法到达的对象即将进入标记/筛选阶段。
标记/筛选阶段
1.第一次打标/筛选过程
简单来说,第一个标记过程就是看对象是否需要执行finalize方法。如有必要,进入下一个标记阶段,如果不需要执行,则结束标记阶段,基本确定该对象需要回收。
是否需要执行finalize方法判断依据
1.如果该对象对应的类中没有覆盖finalize方法,则说明没有必要执行
2.如果在之前,该对象已经执行过一次finalize方法了,则说明没有必要执行(因为finalize方法只能执行一次)
2.第二次打标/筛选过程
在第一次标记/筛选过程之后,认为需要执行finalize方法的对象被放置在F-QUEUE中,JVM会自动创建一个低优先级线程来执行F-QUEUE中的finalize方法。这里的“执行”并不一定意味着必须完全执行。因为如果在finalize方法中存在无限循环,是不是要等到执行完毕?队列将被阻塞!
判断主体是否活着的依据:
在finalize方法中,该对象又重新连接到了gc roots的引用链上
实验
package gctest;
public class FinalizeEscapeGC {
private static FinalizeEscapeGC instance = null;//instance是gc root
@Override
protected void finalize() throws Throwable {
super.finalize();
FinalizeEscapeGC.instance = this;
System.out.println("I save mylife!");
}
public void isAlive() {
System.out.println("I'm alive!");
}
public static void main(String[] args) {
instance = new FinalizeEscapeGC();
instance = null;//对象和gc roots之间失去连接
System.gc();
//第一次拯救过程
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则不会是空指针
} catch (NullPointerException e) {
System.out.println("nullpointerException happens");
}
instance = null;//对象和gc roots之间失去连接
System.gc();
//第二次拯救过程,就是把第一次的代码重复一遍
try {
Thread.sleep(500L);
} catch (Exception e) {
e.printStackTrace();
}
try {
instance.isAlive();//判断对象是否存活,若存活,则instance不会是空指针
} catch (NullPointerException e) {
System.out.println("NullPointerException happens");
}
}
}
运行结果
可以看出对象开始自救一次,然后自救失败,失去与实例的连接,实例为空。
参考简书文章超LINK
简书关于对象生存判断算法的超链接
回收方法区
方法区也存在于GC中。主要是回收过时的常量和无用的类。
Abandoned constants:不再使用的常量(指常量池中的字面量和符号引用),比如一个“ABC”存放在常量池中,但没有在任何地方使用,被判断为是一个过时的常量。
无用类:
1.该类的实例对象都被回收
2.加载该类的类加载器被回收
3.该类的java.lang.Class对象没有在任何地方引用到,无法通过反射访问该类中的方法
本节总结
一旦一个对象被unreachable分析确定为unreachable,它必须经过两次标记过程的重复测试才能成功自救,并且只能通过finalize方法自救一次。
垃圾采集算法
共有三种采集算法和一种采集思路。即标记清除算法、标记排序算法、复制算法、分代采集思想。
1.tag-clearing 算法
这个算法很容易理解,就是将确定为死的内存回收,什么都不做。
优点:简单
缺点:会形成大量的空间碎片,导致新创建的对象没有完整的内存分配,会提前启动full GC。
标签去除算法
2.tag-sorting 算法
标签排序算法是在标签清除算法的基础上改进的。死对象的内存恢复后,将存活的对象移动到内存空间的一端,解决了空间碎片化的问题。
优点:不会产生空间碎片,阻止Full GC提前进行
缺点:执行速度比去除标记慢
标签排序算法
3.复制算法
复制算法,简单来说就是你现在有两个空间,一个 A 用来存储对象,另一个 B 是空的。回收死对象后,将A中幸存的对象复制到B,然后清空A的内存,这样就形成了一个存放对象的空间和一个空的空间。
优点:不存在空间碎片问题,空间分配效率很高
缺点:牺牲了一部分内存空间作为空内存空间。
复制算法
4.子代采集思路
分代回收的思想是将堆内存分为老年代和新生代,针对不同的区域实现不同的垃圾回收算法,让内存的分配和回收更加高效!例如,老年适合使用标记去除算法和标记排序算法。新生代被进一步划分为Eden区,从survivor区到survivor区执行复制算法。
JVM中GC算法的对象生存判断与实现
1.Enumeration 根节点
在进行可达性分析时,需要根节点信息和引用链信息,需要两个需求:STW(stop the world)和引用信息
STW:可达性分析具有时间敏感性。虽然无法再分析,但参考关系仍在变化。因此,GC期间必须停止所有Java线程,称为stop the world。
引用信息:要建立引用关系,需要知道当前内存中哪些对象是引用。传统的方法是直接扫描整个内存来获取参考信息。 Hotspot 使用 oopMap 方法。
1.记录栈、寄存器等区域中哪些位置是GC管理的指针
2.一段代码内可以有多处使用oopMap,但不是每条指令都会使用oopMap,也就是安全点,safepoint将一段代码分为好几段
3.oopMap的作用域也只在它所在的那一段里
2.安全点
GC只有在超出安全点的情况下才能执行。安全点一般在“程序可以长时间执行的地方”,其特点是指令序列的复用。 (我一直不明白为什么我在看书的时候会选择这个,以后再说)
1.循环跳转
2.方法调用
3.异常跳转
你为什么选择这种方式?
1.安全点选择太少,每次GC间隔太长,安全点选择太多,GC执行太频繁。
2.Imagine 如果在 A 和 B 两个安全点之间有循环跳转、异常跳转等上面提到的代码段,这段代码的执行时间很长。 . . . ,甚至无限循环,难道你不想在B安全点执行GC直到天老吗? (也就是GC之间的间隔太长了)
如何使所有线程安全?
GC 是整个 JVM。 JVM中会有很多线程在执行,那么如何保证GC期间所有线程都处于安全点呢?
分为抢占式中断和主动式中断
抢先中断
特点:不照顾线程感受
过程:GC时先中断所有的线程,然后让那些没有到安全点的线程自己再跑到安全点
使用:现在已经没有使用抢先式中断的了
主动中断
特点:照顾线程感受,让它自己去吧
过程:设置一个GC标志,线程执行到安全点或创建对象分配内存时,主动去轮询这个标志,为真时就主动中断自己(这个时候是安全点,中断就中断呗)
使用:大家都说好
3.安全区
上面考虑了多线程,但没有考虑线程在执行过程中可能会休眠或阻塞。如果等待它的sleep结束或者CPU时间片的分配,它又会变老!于是引出了安全区的概念
定义:安全区域是指这一段代码中的引用关系不会发生变化
线程在安全区域行为本质上是一个握手过程
过程:
1.线程A进入safe region,设置一个标志Ready flag.
2.GC如果在线程A处于safe region的时间内进行,由于ready flag的存在,不再检查
线程A
3.线程A将要离开safe region时,轮询GC设置的标志,若为真表示GC还没有执行完,则线程A中断自己,保证自己不离开safe region。若此时GC已经执行完毕,则A顺利离开region。
总结
本篇博客学习了对象生存判断算法和垃圾回收算法。后面会学习垃圾采集器,对象的内存分配和回收策略,以及JVM对上述算法的实现。
文章采集调用(Python代码的UI文件-本篇窗口())
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-31 02:06
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们把对话框的运行赋值给一个变量,然后和QtWidgets.QDialog.Accepted比较,QtWidgets.QDialog.Accepted代表对话框接收事件,用“OK”事件表示,如果为接收时间,设置label标签为“clicked OK”,否则设置label label为“clicked Cannel”
文章版权:周老师的博客,转载需保留出处和原链接 查看全部
文章采集调用(Python代码的UI文件-本篇窗口())
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们把对话框的运行赋值给一个变量,然后和QtWidgets.QDialog.Accepted比较,QtWidgets.QDialog.Accepted代表对话框接收事件,用“OK”事件表示,如果为接收时间,设置label标签为“clicked OK”,否则设置label label为“clicked Cannel”
文章版权:周老师的博客,转载需保留出处和原链接
文章采集调用(中国编译器和调试器的区别是什么?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-30 23:01
文章采集调用了jfinal监听,如果采集的数据过长是不会自动保存的,就算保存也会压缩。中国编译器那本书我用过,感觉很一般,里面编译器和调试器一块讲,讲的都是什么java高级特性啊之类的,很不专业,有点东拼西凑的感觉。就算是jfinal的前端也很不专业,因为目标代码在jfinal中本身就不知道是怎么编译的,还是要手工用命令行写一遍。
我觉得还是用的jfinal监听更好些,
采集一定要自己写,没有自己写调试器,
前端自己写调试器,后端自己写的,后端多交互,你平台比较好,
如果是想做后端,后端自己写。
前端调试
想吃螃蟹可以直接跟着这位大神吃螃蟹
不建议直接看书。本人从0学到3,也勉强算工作一年的有经验人员。书上的东西写得比较潦草,老大给了我这样的机会就是让我带带其他人,自己看书就我自己用了半年,搞这事至少算入门,对于不懂的东西我也只能慢慢琢磨。没有人带说真的。大量前端相关知识储备真的非常难!jfinal的书就是jfinal框架手册一样的东西,都是jfinal的东西。
别的后端框架也都写了,只是写得不一样而已,而且书上很多东西可能讲得东西很浅显。总之真正能学到东西的是调试,之前的码农/产品经理是要看白盒的。实战经验,文章批注,数据格式化这些。至于采集我觉得jfinal+elasticsearch一定是你的理想。 查看全部
文章采集调用(中国编译器和调试器的区别是什么?-八维教育)
文章采集调用了jfinal监听,如果采集的数据过长是不会自动保存的,就算保存也会压缩。中国编译器那本书我用过,感觉很一般,里面编译器和调试器一块讲,讲的都是什么java高级特性啊之类的,很不专业,有点东拼西凑的感觉。就算是jfinal的前端也很不专业,因为目标代码在jfinal中本身就不知道是怎么编译的,还是要手工用命令行写一遍。
我觉得还是用的jfinal监听更好些,
采集一定要自己写,没有自己写调试器,
前端自己写调试器,后端自己写的,后端多交互,你平台比较好,
如果是想做后端,后端自己写。
前端调试
想吃螃蟹可以直接跟着这位大神吃螃蟹
不建议直接看书。本人从0学到3,也勉强算工作一年的有经验人员。书上的东西写得比较潦草,老大给了我这样的机会就是让我带带其他人,自己看书就我自己用了半年,搞这事至少算入门,对于不懂的东西我也只能慢慢琢磨。没有人带说真的。大量前端相关知识储备真的非常难!jfinal的书就是jfinal框架手册一样的东西,都是jfinal的东西。
别的后端框架也都写了,只是写得不一样而已,而且书上很多东西可能讲得东西很浅显。总之真正能学到东西的是调试,之前的码农/产品经理是要看白盒的。实战经验,文章批注,数据格式化这些。至于采集我觉得jfinal+elasticsearch一定是你的理想。
文章采集调用(lonter首创,只发布在csdn平台,严禁转载这几天任务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-08-30 00:03
此文章为lonter首创,仅发布于csdn平台,严禁转载
这几天接到任务,需要开发微信列表功能,所以需要采集微信公号文章阅读、点赞、评论数。列表中有一个微信公众号。有一百多个,每月公布一次名单。
接到这个任务后,我开始研究如何抓取微信阅读、点赞和评论的数量。通过大量参考网上文章的技术,最终确定了我使用的解决方案:使用Fiddler for采集
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 1 步:设置 Fiddler
如图设置,这里是设置Fiddler支持https
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 2 步:设置 Fiddler 脚本
打开Fiddler工具后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下:
这里我们只需要了解 OnBeforeResponse 方法即可。该方法在 http 请求返回给客户端之前执行。我们主要在这个方法中编写脚本。
此文章为lonter首创,仅发布于csdn平台,严禁转载
第3步:选择性拦截responsebody并存入文本
研究每个请求,找到返回点赞数和评论数的请求。具体请求如图:
然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
// 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext")){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:
此文章为lonter首创,仅发布于csdn平台,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
因为这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事! ! !
来看看公众号文章的主页:
显然,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,编写脚本需要一些努力。具体逻辑代码如图:
这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:
然后,你会发现页面会自动跳回
此文章为lonter首创,仅发布于csdn平台,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,想必很多人都会写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬取。至此,全部开发完成
你只需要写成百上千个链接到公众号文章,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 一个这样的转账页面,你会发现微信浏览器不停止跳转
此文章为lonter首创,仅发布于csdn平台,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i 查看全部
文章采集调用(lonter首创,只发布在csdn平台,严禁转载这几天任务)
此文章为lonter首创,仅发布于csdn平台,严禁转载
这几天接到任务,需要开发微信列表功能,所以需要采集微信公号文章阅读、点赞、评论数。列表中有一个微信公众号。有一百多个,每月公布一次名单。
接到这个任务后,我开始研究如何抓取微信阅读、点赞和评论的数量。通过大量参考网上文章的技术,最终确定了我使用的解决方案:使用Fiddler for采集
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 1 步:设置 Fiddler
如图设置,这里是设置Fiddler支持https
此文章为lonter首创,仅发布于csdn平台,严禁转载
第 2 步:设置 Fiddler 脚本
打开Fiddler工具后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下:
这里我们只需要了解 OnBeforeResponse 方法即可。该方法在 http 请求返回给客户端之前执行。我们主要在这个方法中编写脚本。
此文章为lonter首创,仅发布于csdn平台,严禁转载
第3步:选择性拦截responsebody并存入文本
研究每个请求,找到返回点赞数和评论数的请求。具体请求如图:
然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
// 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext";)){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:
此文章为lonter首创,仅发布于csdn平台,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
因为这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事! ! !
来看看公众号文章的主页:
显然,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,编写脚本需要一些努力。具体逻辑代码如图:
这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:
然后,你会发现页面会自动跳回
此文章为lonter首创,仅发布于csdn平台,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,想必很多人都会写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬取。至此,全部开发完成
你只需要写成百上千个链接到公众号文章,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 一个这样的转账页面,你会发现微信浏览器不停止跳转
此文章为lonter首创,仅发布于csdn平台,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i
文章采集调用(文章采集调用外网收集数据,中文的这个有几个漏斗阶段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-29 08:04
文章采集调用外网收集数据,中文的这个有几个漏斗阶段:一,二,三,
我们团队有专门的采集平台,你也可以去我们平台查看下:,还有很多采集网站:。
安陆英文和日文的都有,要是需要特别指定语言,
有专门做外文报纸英文网站新闻网站采集的团队,腾讯阿里京东百度网易等等都做过。收费有很高的,
谢邀,可以采集阿里、百度、、头条、迅雷、新浪、网易、人民日报、头条、腾讯、网易等等所有平台的英文新闻,希望可以帮到你。
我们小程序一键采集,来源主要是搜狐、网易、凤凰网。
我们团队正在做外媒的新闻,
国外各大媒体,如twitterbuzzburksbuzzfeedclearholicreddittimebusinessweekmsnthevergebusinessnewsnewsizefacebook等,目前团队成员有国内外硕士以上背景。中文的要么转出去,要么加微信发我邮箱:wangyuequan007。
我做过澳大利亚媒体的数据收集,目前做了2万左右的样本收集,可以免费分享。您可以私信我帮您分析收集澳大利亚本地的新闻数据。
谢邀,国内我不了解,国外的搜集外媒是我们团队做的。欢迎私信交流。
外媒的数据我们做过的, 查看全部
文章采集调用(文章采集调用外网收集数据,中文的这个有几个漏斗阶段)
文章采集调用外网收集数据,中文的这个有几个漏斗阶段:一,二,三,
我们团队有专门的采集平台,你也可以去我们平台查看下:,还有很多采集网站:。
安陆英文和日文的都有,要是需要特别指定语言,
有专门做外文报纸英文网站新闻网站采集的团队,腾讯阿里京东百度网易等等都做过。收费有很高的,
谢邀,可以采集阿里、百度、、头条、迅雷、新浪、网易、人民日报、头条、腾讯、网易等等所有平台的英文新闻,希望可以帮到你。
我们小程序一键采集,来源主要是搜狐、网易、凤凰网。
我们团队正在做外媒的新闻,
国外各大媒体,如twitterbuzzburksbuzzfeedclearholicreddittimebusinessweekmsnthevergebusinessnewsnewsizefacebook等,目前团队成员有国内外硕士以上背景。中文的要么转出去,要么加微信发我邮箱:wangyuequan007。
我做过澳大利亚媒体的数据收集,目前做了2万左右的样本收集,可以免费分享。您可以私信我帮您分析收集澳大利亚本地的新闻数据。
谢邀,国内我不了解,国外的搜集外媒是我们团队做的。欢迎私信交流。
外媒的数据我们做过的,
文章采集调用( 小白添加教程——一套)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-28 22:03
小白添加教程——一套)
WHATSNS优采云Q&A 和文章采集免费登录界面开源版
售后服务:
1:免费 2 个默认参考规则。
2:接口和模块完全开源,支持2次开发修改(非转售)。
3:接口提供一年技术升级服务,永久免费。
效果截图:
插件列表:
1 一套服务端发布接口,包括文章和提问
2 两套发布模块,包括文章和问题
3 两套规则案例,包括文章和问题,一套来自网易163,一套来自采集官网
采集文章 功能:标题过滤重复文章,随机访问,过滤外部链接,使用网站马甲随机发布文章,发布文章时间默认10-70分钟内随机,支持指定分类采集,由指定作者发表,支持采集评论,关键词。
采集Question 功能:随机拨打站内马甲进行提问和解答,支持优采云采集作者名,如果有请拨打优采云传的作者名,
它会检查是否存在相同的问题。根据标题,如果采集过来,作者会自动注册,发帖提问时间为随机时间前30-70分钟。问题查看次数随机300-2000。同时,您可以指定随机3-5个马甲跟随问题,并在呼叫站回答马甲。答题时间随机3-30分钟。
如果配置了全文搜索,文章和题也支持全文搜索数据同步。
添加小白文章可以参考教程:
目前套餐价格300,以后还会涨价的,快点!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
文章采集调用(
小白添加教程——一套)
WHATSNS优采云Q&A 和文章采集免费登录界面开源版
售后服务:
1:免费 2 个默认参考规则。
2:接口和模块完全开源,支持2次开发修改(非转售)。
3:接口提供一年技术升级服务,永久免费。
效果截图:
插件列表:
1 一套服务端发布接口,包括文章和提问
2 两套发布模块,包括文章和问题
3 两套规则案例,包括文章和问题,一套来自网易163,一套来自采集官网
采集文章 功能:标题过滤重复文章,随机访问,过滤外部链接,使用网站马甲随机发布文章,发布文章时间默认10-70分钟内随机,支持指定分类采集,由指定作者发表,支持采集评论,关键词。
采集Question 功能:随机拨打站内马甲进行提问和解答,支持优采云采集作者名,如果有请拨打优采云传的作者名,
它会检查是否存在相同的问题。根据标题,如果采集过来,作者会自动注册,发帖提问时间为随机时间前30-70分钟。问题查看次数随机300-2000。同时,您可以指定随机3-5个马甲跟随问题,并在呼叫站回答马甲。答题时间随机3-30分钟。
如果配置了全文搜索,文章和题也支持全文搜索数据同步。
添加小白文章可以参考教程:
目前套餐价格300,以后还会涨价的,快点!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
页面优化在整个网站seo优化占的比例%
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-27 06:16
页面优化在网站seo整体优化中的比重越来越重要。一个好的页面怎么做?以织梦cms 为例。相关模块的调用是一个很大的方面。但是织梦的相关模块调用有时候不是那么顺利,因为相关模块中会有很多代码问题。
比如第一个,相关内容模块的调用代码与栏目页面相关内容的调用代码不一致。
按照常识,一个列和属于该列的文章是一样的,使用的调用代码应该是一样的。但是,由于织梦code在系统中已经升级过一次,所以我把它放在 content 页面上调用的标签与列页面上调用的标签不同。调用代码如下:
(文章页相关调用代码)
(栏目页面相关调用代码)
从这两个调用中可以看出这两者的区别,因为织梦文章页面使用的是likearticle标签,而专栏页面使用的是likeart。所以要注意具体的实际调用,否则无法调用关联成功。
其次,如果我们从seo的角度考虑,我们发现这样的调用其实存在一定的问题。如果一列相关文章比较多,那么如果使用likearticle调用,最终的结果是最新的相关文章,旧的文章页面将无法显示。这样一来,一旦文章的数量大了,老文章出现在别处的机会就会变少,而且有的文章可能同类别的内容很少,那怎么调用if有没有相关的文章?以下是一一问题:
1.如何随机调用文章的标签。
我觉得如果一个网站有大量的更新或者大量的内容,就要考虑如何让蜘蛛爬到任何一个页面,而不仅仅是停留在旧页面上,这里我们推荐使用全站随机调用,或者列中随机调用标签,调用代码如下:
其中,如果不加typeid,则是列中的随机调用,如果加了,则是整个站点文章的随机调用。一般来说,为了增强文章之间的相关性,我们建议去掉typeid属性,更符合seo的要求。
2、如何对文章的调用进行排序。
不做任何改动,调用的文章的默认顺序是最新的和相关的文章,不过我也说了这个的缺点,最相关或者最有用的文章不一定是最新的,怎么样打其他电话也是一个很重要的问题,比如热点相关的问题或者推荐相关的问题,我觉得可以结合使用。
比如要调用最优秀的相关文章,可以在调用相关文档时添加推荐属性。只需要给优秀的文章加上推荐属性,就可以这样调用了。
相关性在网站收录、排名等很多方面都有很大的影响和作用,如何做好也是大学的问题。 查看全部
页面优化在整个网站seo优化占的比例%
页面优化在网站seo整体优化中的比重越来越重要。一个好的页面怎么做?以织梦cms 为例。相关模块的调用是一个很大的方面。但是织梦的相关模块调用有时候不是那么顺利,因为相关模块中会有很多代码问题。
比如第一个,相关内容模块的调用代码与栏目页面相关内容的调用代码不一致。
按照常识,一个列和属于该列的文章是一样的,使用的调用代码应该是一样的。但是,由于织梦code在系统中已经升级过一次,所以我把它放在 content 页面上调用的标签与列页面上调用的标签不同。调用代码如下:
(文章页相关调用代码)
(栏目页面相关调用代码)
从这两个调用中可以看出这两者的区别,因为织梦文章页面使用的是likearticle标签,而专栏页面使用的是likeart。所以要注意具体的实际调用,否则无法调用关联成功。
其次,如果我们从seo的角度考虑,我们发现这样的调用其实存在一定的问题。如果一列相关文章比较多,那么如果使用likearticle调用,最终的结果是最新的相关文章,旧的文章页面将无法显示。这样一来,一旦文章的数量大了,老文章出现在别处的机会就会变少,而且有的文章可能同类别的内容很少,那怎么调用if有没有相关的文章?以下是一一问题:
1.如何随机调用文章的标签。
我觉得如果一个网站有大量的更新或者大量的内容,就要考虑如何让蜘蛛爬到任何一个页面,而不仅仅是停留在旧页面上,这里我们推荐使用全站随机调用,或者列中随机调用标签,调用代码如下:
其中,如果不加typeid,则是列中的随机调用,如果加了,则是整个站点文章的随机调用。一般来说,为了增强文章之间的相关性,我们建议去掉typeid属性,更符合seo的要求。
2、如何对文章的调用进行排序。
不做任何改动,调用的文章的默认顺序是最新的和相关的文章,不过我也说了这个的缺点,最相关或者最有用的文章不一定是最新的,怎么样打其他电话也是一个很重要的问题,比如热点相关的问题或者推荐相关的问题,我觉得可以结合使用。
比如要调用最优秀的相关文章,可以在调用相关文档时添加推荐属性。只需要给优秀的文章加上推荐属性,就可以这样调用了。
相关性在网站收录、排名等很多方面都有很大的影响和作用,如何做好也是大学的问题。
几种建站之前的方法有哪些?如何设置防采集字符串
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-27 06:14
这几天忙着用DEDE建网站。时隔半个多月,网站终于在前几天上线了。建站前经常逛论坛,听到很多网站被采集的例子;虽然别人采集你的站很欣赏你,但毕竟采集还是会消耗资源的,如果对方站的权重比你高。 采集的文章甚至比你网站收录的文章还要好,会导致网站原创的内容延迟,无效。于是在网上查了很多资料,总结出以下实用方法,希望对站长朋友有所帮助。
一、设置复制文章并在末尾添加版权信息
采集的基本原理是复制文章。这里可以设置一段代码复制文章并在末尾添加版权信息;此版权信息不会在文章中显示,只有在文章中@Content只会在复制时出现在粘贴的内容中。当然,如果这条尾巴在采集规则中被屏蔽了,那么版权信息就不存在了。但是对于拥有大量采集的人来说,他们可能不会注意到这个版权尾巴。
此代码是在article_article.htm模板之间添加的;添加的地方可以多测试几次,也可以查看我网站的源码确认位置。
二、set DEDE自带反采集string
DEDE 有自己的采集string-proof 功能。通过设置采集string-proof功能,可以让其他人在采集文章之后出现散乱的字符串,影响阅读,让采集的网站不得不放弃采集。当然,这并非万无一失。它有一英尺高,魔力很高。如果采集字符串少了,可以用一点采集规则替换那些无意义的字符串;如果字符串更频繁,这将稀释文章 的关键词 密度。另外,也有人建议直接使用网站关键字和网站链接作为字符串。据说这样可以增加网站外链。其他人采集 得到的越多,外部链接就越多。就我个人而言,我对这种方法持保留态度。毕竟,设置反采集String 与 SEO 作弊非常相似。所以目前很多网站还没有设置这个功能,不知道是不是这个原因。
三、图片加水印
如果文章的图片比较多,给图片加水印是个不错的选择;另外,你可以设置水印出现在背景的任意位置,这样对方采集到达图片后就无法覆盖你的水印。当然,水印最好是背景透明,颜色浅一点,这样才不会影响画质。这时候,对方要么继续为你宣传,要么放弃采集picture,要么放弃采集你的网站,这一切都对你有利。
四、重要内容设置会员访问限制
如果你的网站确实有更重要的内容需要保留,固定资源可以吸引固定用户;通过这种方式,您可以设置会员访问限制,以便注册会员或高级会员可以访问这部分内容。当然,这也会将搜索引擎拒之门外,但为了保持网站的吸引力,必须保留适当的稀有资源。如果网站没有用户留下的资源,那么用户很容易离开。
当然,有很多方法可以防止采集。可以到专业网站学习和模仿。个人觉得如果是新网站要通过原创内容增加权重,就需要防止采集;如果网站发展了很多,比如A5,就没有必要阻止采集。毕竟搜索引擎已经认识到这是文章的第一名。 查看全部
几种建站之前的方法有哪些?如何设置防采集字符串
这几天忙着用DEDE建网站。时隔半个多月,网站终于在前几天上线了。建站前经常逛论坛,听到很多网站被采集的例子;虽然别人采集你的站很欣赏你,但毕竟采集还是会消耗资源的,如果对方站的权重比你高。 采集的文章甚至比你网站收录的文章还要好,会导致网站原创的内容延迟,无效。于是在网上查了很多资料,总结出以下实用方法,希望对站长朋友有所帮助。
一、设置复制文章并在末尾添加版权信息
采集的基本原理是复制文章。这里可以设置一段代码复制文章并在末尾添加版权信息;此版权信息不会在文章中显示,只有在文章中@Content只会在复制时出现在粘贴的内容中。当然,如果这条尾巴在采集规则中被屏蔽了,那么版权信息就不存在了。但是对于拥有大量采集的人来说,他们可能不会注意到这个版权尾巴。
此代码是在article_article.htm模板之间添加的;添加的地方可以多测试几次,也可以查看我网站的源码确认位置。
二、set DEDE自带反采集string
DEDE 有自己的采集string-proof 功能。通过设置采集string-proof功能,可以让其他人在采集文章之后出现散乱的字符串,影响阅读,让采集的网站不得不放弃采集。当然,这并非万无一失。它有一英尺高,魔力很高。如果采集字符串少了,可以用一点采集规则替换那些无意义的字符串;如果字符串更频繁,这将稀释文章 的关键词 密度。另外,也有人建议直接使用网站关键字和网站链接作为字符串。据说这样可以增加网站外链。其他人采集 得到的越多,外部链接就越多。就我个人而言,我对这种方法持保留态度。毕竟,设置反采集String 与 SEO 作弊非常相似。所以目前很多网站还没有设置这个功能,不知道是不是这个原因。
三、图片加水印
如果文章的图片比较多,给图片加水印是个不错的选择;另外,你可以设置水印出现在背景的任意位置,这样对方采集到达图片后就无法覆盖你的水印。当然,水印最好是背景透明,颜色浅一点,这样才不会影响画质。这时候,对方要么继续为你宣传,要么放弃采集picture,要么放弃采集你的网站,这一切都对你有利。
四、重要内容设置会员访问限制
如果你的网站确实有更重要的内容需要保留,固定资源可以吸引固定用户;通过这种方式,您可以设置会员访问限制,以便注册会员或高级会员可以访问这部分内容。当然,这也会将搜索引擎拒之门外,但为了保持网站的吸引力,必须保留适当的稀有资源。如果网站没有用户留下的资源,那么用户很容易离开。
当然,有很多方法可以防止采集。可以到专业网站学习和模仿。个人觉得如果是新网站要通过原创内容增加权重,就需要防止采集;如果网站发展了很多,比如A5,就没有必要阻止采集。毕竟搜索引擎已经认识到这是文章的第一名。
文章采集调用 QT+openCV操做的这部分,其余还没时间看
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-22 07:01
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针
在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好的,所有的代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
查看全部
文章采集调用 QT+openCV操做的这部分,其余还没时间看
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针
在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好的,所有的代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-22 07:01
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
会显示以下功能(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。 查看全部
LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
会显示以下功能(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。
Python代码的UI文件-本篇窗口()
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-18 22:09
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们将对话框的运行赋值给一个变量,然后与QtWidgets.QDialog.Accepted进行比较。 QtWidgets.QDialog.Accepted表示对话框的接收事件,用“OK”事件表示,如果是接收时间,设置标签标签为“点击确定”,否则设置标签标签为“点击Cannel”
文章版权:周老师的博客,转载需保留出处和原链接 查看全部
Python代码的UI文件-本篇窗口()
本文将介绍:
文章directory
一、创建两个窗口
根据本文的最终目标——在主窗口中调用对话框窗口,我们首先使用qt设计器创建两个窗口,一个是主窗口MainWindows,另一个是对话框窗口Dialog有两个按钮。
通过qt设计器创建一个MainWindows窗口,并在其中放置一个按钮:
另存为 UI 文件并创建一个新的对话窗口:
另存为 UI 文件。
这样我们本地文件夹就有了两个可以转换成Python代码的UI文件:
二、 将 UI 文件转换为 Python 代码文件
保存两个窗口的UI文件后,我们继续使用pyuic5工具将这两个UI文件转换成Python代码文件。
打开命令行输入:
pyuic5 -x -o mainWindow.py mainWindow.ui
pyuic5 -x -o dialog.py dialog.ui
运行转换后的Python文件,是否正常:
一切正常,然后我们可以连接并调用两个窗口。
三、从主窗口调用对话窗口
在进行下一步之前,我们先在mainWindow的mainWindow中添加一个文本标签,设置文本为空,字体增加:
有了这个标签,我们可以在标签标签中反馈对话框的操作。
保存 UI 文件并使用 pyuic5 再次转换 Python 代码。
为了在主窗口代码中调用对话窗口,我们需要在mainWindow.py文件中引入对话窗口:
from GUI import dialog
然后在主窗口的主类中定义一个方法来显示对话框窗口:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
Dialog.exec_()
方法定义好了,我们需要绑定按钮点击调用,在setupUi()方法中设置:
self.pushButton.clicked.connect(self.click_button)
这样就实现了按钮点击绑定对话框。
我们知道我们的对话框有两个按钮,一个是“OK”,一个是“Cancel”。在我们的 GUI 程序中,单击其中任何一个都将关闭对话框。效果看起来是一样的,但是 PyQt5 的内部机制是两个不同的事件。下面我们将通过之前设置的标签展示不同的机制。
我们修改click_button()方法如下:
def click_button(self):
Dialog = QtWidgets.QDialog()
ui = dialog.Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
# Dialog.exec_()
rsp = Dialog.exec_()
if rsp == QtWidgets.QDialog.Accepted:
self.label.setText("点击了OK")
else:
self.label.setText("点击了Cannel")
这里我们将对话框的运行赋值给一个变量,然后与QtWidgets.QDialog.Accepted进行比较。 QtWidgets.QDialog.Accepted表示对话框的接收事件,用“OK”事件表示,如果是接收时间,设置标签标签为“点击确定”,否则设置标签标签为“点击Cannel”
文章版权:周老师的博客,转载需保留出处和原链接
文章页模板增加伪原创代码标签使用方法介绍插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-18 03:02
众所周知,搜索引擎喜欢原创sexual 内容。对于网上重复的内容,它会认为没有收录的价值。严重采集站或重复站将被搜索引擎网站减重。 网站排名自然不会很高。但是原创的内容比较难,所以我们一般会对转载的内容进行修改处理,让搜索引擎认为你的文章是原创,会是收录。这样就达到了伪原创的目的。
伪原创是指重新处理一个原创文章页面模板,实现不同的文章页面,不同的HTML代码,让搜索引擎认为它是一个原创文章,从而增加了权重网站。
本插件可以配合“织梦文章内容页自动添加ASCII码增加原创度公众百度收录rank(支持优采云采集)”插件,效果更佳。
T28织梦补偿值干扰码功能特点:
插件实现伪原创templates,不同内容不同代码,保证优化不影响用户体验
插件采用高速缓存处理,不影响网站访问速度
插件内置了强大的干扰码伪原创度好,处理后的文章main意思不变
插件支持手机站伪原创settings
插件伪原创模板好用,可以随意改变伪原创的位置
插件支持优采云采集器
织梦伪原创模板插件使用步骤:
1:执行SQL命令(购买后可查看命令代码)
2:文章page 模板添加伪原创code 标签
3:修改article_add.php文件(修改代码)
4:修改/include/extend.func.php文件(添加代码)
5:文章page 模板添加调用JS
织梦伪原创Template 插件效果演示:
织梦伪原创模板插件使用后效果:
标签: 查看全部
文章页模板增加伪原创代码标签使用方法介绍插件
众所周知,搜索引擎喜欢原创sexual 内容。对于网上重复的内容,它会认为没有收录的价值。严重采集站或重复站将被搜索引擎网站减重。 网站排名自然不会很高。但是原创的内容比较难,所以我们一般会对转载的内容进行修改处理,让搜索引擎认为你的文章是原创,会是收录。这样就达到了伪原创的目的。
伪原创是指重新处理一个原创文章页面模板,实现不同的文章页面,不同的HTML代码,让搜索引擎认为它是一个原创文章,从而增加了权重网站。
本插件可以配合“织梦文章内容页自动添加ASCII码增加原创度公众百度收录rank(支持优采云采集)”插件,效果更佳。
T28织梦补偿值干扰码功能特点:
插件实现伪原创templates,不同内容不同代码,保证优化不影响用户体验
插件采用高速缓存处理,不影响网站访问速度
插件内置了强大的干扰码伪原创度好,处理后的文章main意思不变
插件支持手机站伪原创settings
插件伪原创模板好用,可以随意改变伪原创的位置
插件支持优采云采集器
织梦伪原创模板插件使用步骤:
1:执行SQL命令(购买后可查看命令代码)
2:文章page 模板添加伪原创code 标签
3:修改article_add.php文件(修改代码)
4:修改/include/extend.func.php文件(添加代码)
5:文章page 模板添加调用JS
织梦伪原创Template 插件效果演示:
织梦伪原创模板插件使用后效果:
标签:
WPFavoritePosts文章收藏插件使用方法收藏
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-18 02:15
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看到自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果您删除浏览器的 cookie,您将丢失采集的数据。因此,建议您注册该用户并将其保存在数据库中而不会丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)
可设置各种提示
设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果您只想在某些文章中显示采集夹链接,可以在编辑文章时在文章中添加以下短代码:
第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!
WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List 另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的 wpfp-page-template.php 文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集数量统计不准确。
找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:
崇尚可爱
一个喜欢折腾WordPress并被它折腾的文科IT书呆子^_^
关注 查看全部
WPFavoritePosts文章收藏插件使用方法收藏
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看到自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果您删除浏览器的 cookie,您将丢失采集的数据。因此,建议您注册该用户并将其保存在数据库中而不会丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)
可设置各种提示
设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果您只想在某些文章中显示采集夹链接,可以在编辑文章时在文章中添加以下短代码:
第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!
WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List 另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的 wpfp-page-template.php 文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集数量统计不准确。
找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:
崇尚可爱
一个喜欢折腾WordPress并被它折腾的文科IT书呆子^_^
关注
豆瓣网分析基础知识:豆瓣电影中如何获取请求?
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-08-17 05:14
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
如何访问网页?
https://movie.douban.com/j/sea ... %3D60
当点击下一页时,每增加一页,页面将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、for 遍历获取对应的电影名称、评分,并链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:
1)设置时间延迟。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、电影图片展示。
[七、Summary]
1、 不建议取太多数据,可能会造成服务器负载。试试看吧。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、如需本文源码,可在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发分享给更多人****
IT 共享屋 查看全部
豆瓣网分析基础知识:豆瓣电影中如何获取请求?
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
如何访问网页?
https://movie.douban.com/j/sea ... %3D60
当点击下一页时,每增加一页,页面将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、for 遍历获取对应的电影名称、评分,并链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:
1)设置时间延迟。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、电影图片展示。
[七、Summary]
1、 不建议取太多数据,可能会造成服务器负载。试试看吧。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、如需本文源码,可在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发分享给更多人****
IT 共享屋
调用链系列(2):服务端信息收集以及服务间上下文传递
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-17 05:10
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,总体实现策略。
在这个文章我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、server 信息采集
服务端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。
三、切点植入
在介绍切入点之前,我们应该对servlet容器处理请求的大致流程有一个整体的了解(本文以tomcat为例)。
图片来源于网络
Connector 收到连接并转换成请求(Request)后,会将请求传递给 Engine 的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入我们自己的逻辑,即无人机中间件增强技术,来增强tomcat的外部能力。
中间件增强技术除了巧妙利用了tomcat容器的架构设计之外,还使用了java Instrumentation(它为我们提供了在第一次加载对象时动态修改字节码的能力,由于空间原因原因这里就不详细解释了,不明白的可以自行查资料)。在无人机中,通过UAVServer对外提供各种切点能力。
采用中间件增强技术,应用逻辑执行前后都有切点。下一步是在这些切点处执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力将在后续文章中详细介绍)。轻量级调用链的实现使用了UAVServer对外提供的GlobalFilterHandler能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助GlobalFilterHandler提供的前两个能力实现了在应用处理请求前后执行调用链逻辑的功能。
五、Light 调用链实现
具体的UML图如下:
从UML图中可以明显看出InvokeChainSupporter(调用链实现逻辑入口的实现类和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量调用链绘制的实现主要依赖于注册在InvokeChainSupporter上的ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 解析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑分流
因为不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
主span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方法利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;调用链上下文逻辑初始化时,通过传入的信息初始化目标服务的调用链上下文,实现跨系统调用的调用链连接。
六、Summary
阅读本文后,读者应该对中间件增强技术的实现有一个大致的了解,对其提供的GlobalFilterHandler能力有一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。 查看全部
调用链系列(2):服务端信息收集以及服务间上下文传递
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,总体实现策略。
在这个文章我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、server 信息采集
服务端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。
三、切点植入
在介绍切入点之前,我们应该对servlet容器处理请求的大致流程有一个整体的了解(本文以tomcat为例)。
图片来源于网络
Connector 收到连接并转换成请求(Request)后,会将请求传递给 Engine 的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入我们自己的逻辑,即无人机中间件增强技术,来增强tomcat的外部能力。
中间件增强技术除了巧妙利用了tomcat容器的架构设计之外,还使用了java Instrumentation(它为我们提供了在第一次加载对象时动态修改字节码的能力,由于空间原因原因这里就不详细解释了,不明白的可以自行查资料)。在无人机中,通过UAVServer对外提供各种切点能力。
采用中间件增强技术,应用逻辑执行前后都有切点。下一步是在这些切点处执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力将在后续文章中详细介绍)。轻量级调用链的实现使用了UAVServer对外提供的GlobalFilterHandler能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助GlobalFilterHandler提供的前两个能力实现了在应用处理请求前后执行调用链逻辑的功能。
五、Light 调用链实现
具体的UML图如下:
从UML图中可以明显看出InvokeChainSupporter(调用链实现逻辑入口的实现类和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量调用链绘制的实现主要依赖于注册在InvokeChainSupporter上的ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 解析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑分流
因为不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
主span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方法利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;调用链上下文逻辑初始化时,通过传入的信息初始化目标服务的调用链上下文,实现跨系统调用的调用链连接。
六、Summary
阅读本文后,读者应该对中间件增强技术的实现有一个大致的了解,对其提供的GlobalFilterHandler能力有一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。
基于底层数据交换的数据直接采集方式101异构数据采集技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 542 次浏览 • 2021-08-16 00:27
一、Software 接口方法 每个软件厂商都提供数据接口,实现数据采集收敛。
二、Open 数据库是实现采集数据收敛最直接的方式。打开数据库是最直接的方式。两个系统都有自己的数据库,同类型数据库之间更方便:
1. 如果两个数据库在同一台服务器上,只要用户名设置没有问题,就可以直接互相访问。您需要在 from 之后带上数据库名称和表架构所有者。从 DATABASE1.dbo.table1 中选择 *
2. 如果两个系统的数据库不在同一台服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource。这需要为数据库访问配置外围服务器。
三、Data 直接基于底层数据交换采集Method 101 异构数据采集技术是获取软件系统底层数据交换,软件客户端与数据库之间的网络流量包,基于在底层IO上通过请求、网络分析等技术,将采集目标软件产生的所有数据进行转换重组,输出到新的数据库中,供软件系统调用。技术特点如下:
1.不需要原软件厂商的配合;
2.实时数据采集,数据端到端响应速度达到秒级;
3.兼容性强,可以采集采集Windows平台上的各种软件系统数据;
4.输出结构化数据作为数据挖掘和大数据分析应用的基础;
5.自动建立数据关联,实施周期短,简单高效;
6.支持历史数据自动导入,通过I/O人工智能自动将数据写入目标软件;
7. 配置简单,实施周期短。基于底层数据交换的数据直接采集,摆脱对软件厂商的依赖,无需软件厂商的配合,不仅需要投入大量的时间、精力和资金,而且无需担心关于系统开发团队解体、源代码丢失等原因导致系统数据采集成死局。直接从多种软件系统中挖掘数据,持续获取准确实时的数据,自动建立数据关联,输出利用率极高的结构化数据,使不同系统的数据源有序、安全、可控联动公司流通提供决策支持,提高运营效率,创造经济价值。 查看全部
基于底层数据交换的数据直接采集方式101异构数据采集技术
一、Software 接口方法 每个软件厂商都提供数据接口,实现数据采集收敛。
二、Open 数据库是实现采集数据收敛最直接的方式。打开数据库是最直接的方式。两个系统都有自己的数据库,同类型数据库之间更方便:
1. 如果两个数据库在同一台服务器上,只要用户名设置没有问题,就可以直接互相访问。您需要在 from 之后带上数据库名称和表架构所有者。从 DATABASE1.dbo.table1 中选择 *
2. 如果两个系统的数据库不在同一台服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource。这需要为数据库访问配置外围服务器。
三、Data 直接基于底层数据交换采集Method 101 异构数据采集技术是获取软件系统底层数据交换,软件客户端与数据库之间的网络流量包,基于在底层IO上通过请求、网络分析等技术,将采集目标软件产生的所有数据进行转换重组,输出到新的数据库中,供软件系统调用。技术特点如下:
1.不需要原软件厂商的配合;
2.实时数据采集,数据端到端响应速度达到秒级;
3.兼容性强,可以采集采集Windows平台上的各种软件系统数据;
4.输出结构化数据作为数据挖掘和大数据分析应用的基础;
5.自动建立数据关联,实施周期短,简单高效;
6.支持历史数据自动导入,通过I/O人工智能自动将数据写入目标软件;
7. 配置简单,实施周期短。基于底层数据交换的数据直接采集,摆脱对软件厂商的依赖,无需软件厂商的配合,不仅需要投入大量的时间、精力和资金,而且无需担心关于系统开发团队解体、源代码丢失等原因导致系统数据采集成死局。直接从多种软件系统中挖掘数据,持续获取准确实时的数据,自动建立数据关联,输出利用率极高的结构化数据,使不同系统的数据源有序、安全、可控联动公司流通提供决策支持,提高运营效率,创造经济价值。
老文章重新编辑修改以后,怕读者不知道??
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-09 00:29
旧的文章重新编辑修改后,怕读者不知道?然后将新修改的文章列表添加到网站。这样,只要更新旧的文章,读者很快就知道了。如果你正在建设一个软件网站、一个电影网站等来分享内容,那么你就不需要一个版本来发布文章!将此功能添加到您的网站!
方法来自zwwooooo大师。给老文章一个机会:最近更新的帖子,已经被封装成函数了,并且增加了2个参数:$num-numberofimpressions,$days-几天后文章除外。还添加了数据库缓存方法。由于查询量较大,只有在修改文章/delete 文章/post 文章时才会更新缓存。
1. 在主题的functions.php 的最后一个?> 前面抛出以下函数代码:
// Recently Updated Posts by zwwooooo | zww.me
function recently_updated_posts($num=10,$days=7) {
if( !$recently_updated_posts = get_option('recently_updated_posts') ) {
query_posts('post_status=publish&orderby=modified&posts_per_page=-1');
$i=0;
while ( have_posts() && $i 60*60*24*$days) {
$i++;
$the_title_value=get_the_title();
$recently_updated_posts.=''
.$the_title_value.'<br />» 修改时间: '
.get_the_modified_time('Y.m.d G:i').'';
}
endwhile;
wp_reset_query();
if ( !empty($recently_updated_posts) ) update_option('recently_updated_posts', $recently_updated_posts);
}
$recently_updated_posts=($recently_updated_posts == '') ? 'None data.' : $recently_updated_posts;
echo $recently_updated_posts;
}
function clear_cache_zww() {
update_option('recently_updated_posts', ''); // 清空 recently_updated_posts
}
add_action('save_post', 'clear_cache_zww'); // 新发表文章/修改文章时触发更新
2.可以使用下面的函数调用
Recently Updated Posts
参数说明:8表示显示文章数量,15表示文章在15天内发布,文章除外
具体细节和css样式请自行修改,感谢zwwooooo高手!
扩展阅读:WordPress显示最近更新的文章并通知评论过的用户
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
老文章重新编辑修改以后,怕读者不知道??
旧的文章重新编辑修改后,怕读者不知道?然后将新修改的文章列表添加到网站。这样,只要更新旧的文章,读者很快就知道了。如果你正在建设一个软件网站、一个电影网站等来分享内容,那么你就不需要一个版本来发布文章!将此功能添加到您的网站!
方法来自zwwooooo大师。给老文章一个机会:最近更新的帖子,已经被封装成函数了,并且增加了2个参数:$num-numberofimpressions,$days-几天后文章除外。还添加了数据库缓存方法。由于查询量较大,只有在修改文章/delete 文章/post 文章时才会更新缓存。
1. 在主题的functions.php 的最后一个?> 前面抛出以下函数代码:
// Recently Updated Posts by zwwooooo | zww.me
function recently_updated_posts($num=10,$days=7) {
if( !$recently_updated_posts = get_option('recently_updated_posts') ) {
query_posts('post_status=publish&orderby=modified&posts_per_page=-1');
$i=0;
while ( have_posts() && $i 60*60*24*$days) {
$i++;
$the_title_value=get_the_title();
$recently_updated_posts.=''
.$the_title_value.'<br />» 修改时间: '
.get_the_modified_time('Y.m.d G:i').'';
}
endwhile;
wp_reset_query();
if ( !empty($recently_updated_posts) ) update_option('recently_updated_posts', $recently_updated_posts);
}
$recently_updated_posts=($recently_updated_posts == '') ? 'None data.' : $recently_updated_posts;
echo $recently_updated_posts;
}
function clear_cache_zww() {
update_option('recently_updated_posts', ''); // 清空 recently_updated_posts
}
add_action('save_post', 'clear_cache_zww'); // 新发表文章/修改文章时触发更新
2.可以使用下面的函数调用
Recently Updated Posts
参数说明:8表示显示文章数量,15表示文章在15天内发布,文章除外
具体细节和css样式请自行修改,感谢zwwooooo高手!
扩展阅读:WordPress显示最近更新的文章并通知评论过的用户
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
搜狗微信改版了,无法通过搜索公众号名字获取对应文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-06 19:08
前言:一觉醒来发现原来的搜狗微信爬虫失败了。网上一搜发现搜狗微信的版本是10月29日改版的,搜索官方账号名无法得到对应的文章,但是通过搜索还是可以得到文章对应的主题,问题不大,开始吧!
目的:获取搜狗微信搜索话题返回的文章。
涉及防爬机制:cookie设置、js加密。
转到主题。
流程一:正常例行流程
打开搜狗微信,在搜索框中输入“超人”。你在这里搜索的是与“超人”主题相关的各种公众号文章list
按照正常的采集流程,按F12打开浏览器的开发者工具,使用选择工具点击列表中的文章标题,查看文章url在列表中的位置源代码中的list,也就是这个href的值,为了避免混淆,我们称之为“列表页的文章url”。
可以看到“列表页的文章url”需要拼接。这种情况下,需要在浏览器中正常访问这个文章,并对比观察跳转后的url(我们称之为“真实文章url”),然后补上头足。如下是两个网址的对比:
列表页上的文章url:
<p>/链接? URL = dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg ..&类型= 2&查询=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&K = 92&H = Z 查看全部
搜狗微信改版了,无法通过搜索公众号名字获取对应文章
前言:一觉醒来发现原来的搜狗微信爬虫失败了。网上一搜发现搜狗微信的版本是10月29日改版的,搜索官方账号名无法得到对应的文章,但是通过搜索还是可以得到文章对应的主题,问题不大,开始吧!
目的:获取搜狗微信搜索话题返回的文章。
涉及防爬机制:cookie设置、js加密。
转到主题。
流程一:正常例行流程
打开搜狗微信,在搜索框中输入“超人”。你在这里搜索的是与“超人”主题相关的各种公众号文章list
按照正常的采集流程,按F12打开浏览器的开发者工具,使用选择工具点击列表中的文章标题,查看文章url在列表中的位置源代码中的list,也就是这个href的值,为了避免混淆,我们称之为“列表页的文章url”。
可以看到“列表页的文章url”需要拼接。这种情况下,需要在浏览器中正常访问这个文章,并对比观察跳转后的url(我们称之为“真实文章url”),然后补上头足。如下是两个网址的对比:
列表页上的文章url:
<p>/链接? URL = dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg ..&类型= 2&查询=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&K = 92&H = Z

