
文章采集调用
文章采集调用(维清微信文章采集器平台更新网站的基本设置教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-09-10 20:15
在按照本教程设置插件之前,请确保您已经安装了“微信WeChat文章采集器”插件。如果没有,请从以下地址下载安装:
下载链接:@wq_wechatcollecting.plugin
第 1 步:基本设置
一、 设置插件后端的基本设置。
二、设置相关联众编码账号。
1、去联众编码平台注册自己的账号。由于联众编码平台网站的更新,下图可能与实际站点有所不同。具体注册页面请参考网站实战页面。 .
2、注册成功后,个人中心将为当前账户充值相应的代码点。具体充值金额根据您的网站采集金额合理充值。
3、填写刚刚注册的联众账号和密码到[维清]微信文章采集器联众后台相关设置,以便采集触发数据源网站的验证码机制自动验证。
4、采集 过程中自动验证的记录可以在[维清]微信文章采集器后台自动识别验证码日志模块下查看。
三、设置公众号和文章类别。
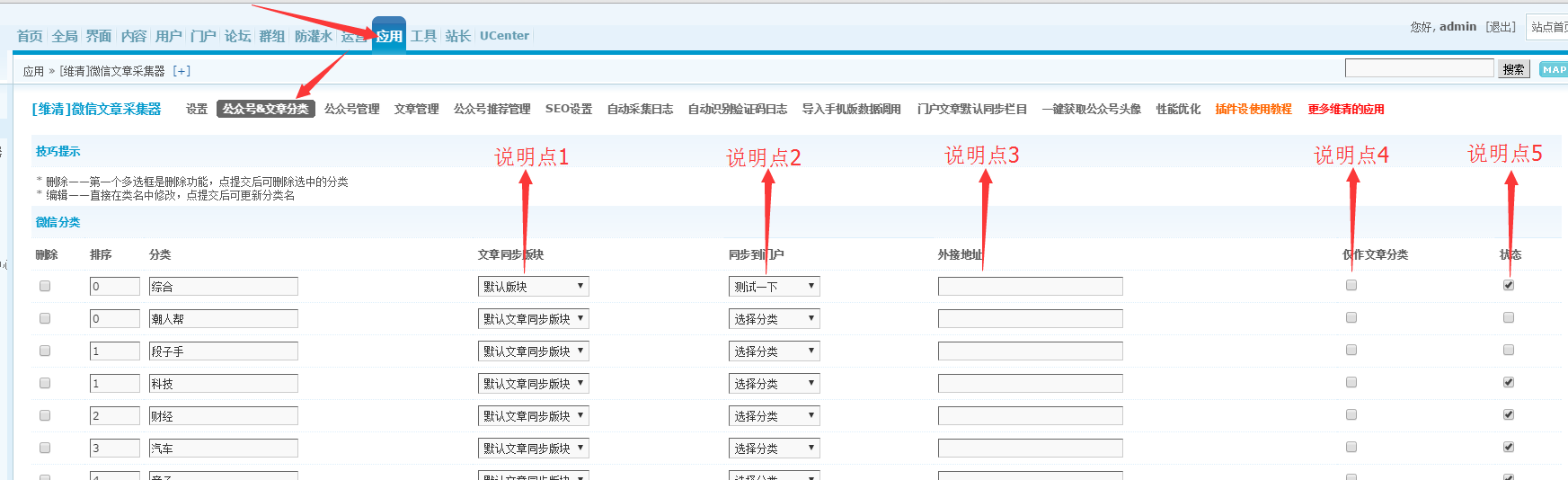
采集器后台设置统一公众号和文章分类,[维清]微信导航和微信微信文章采集器会调用这个分类,具体设置如图:
有以下5点需要说明。请参考以下图片中的标志说明:
解释点 1:
此设置将在显示模式下打开“同步到论坛”时生效。如果在这里选择特定版块,如图选择“默认版本”,当文章发到采集器的“综合”分类时,文章会同步到“默认版本”在论坛版块中;如果不选择,帖子将同步到后台设置中“default文章synchronization section”中设置的section。
解释点2:
此设置将在显示模式下打开“同步到门户”时生效。如果这里选择了指定的栏目,如图选择了“Test it”,当你将文章发到采集器的“综合”分类时,文章会同步到“Test it”门户部分在列中;如果不选择,文章将同步到后台门户文章默认同步栏目模块下设置的门户类别。
解释点 3:
填写外链地址后,这个分类就变成了外链,公众号和文章不能分配到这个分类,和外链部分类似。
解释点 4:
如果类别只选为文章类别,公众号不能归入该类别。如果还填写了外链地址,“微信导航”插件的分类中将不会显示该分类。
解释点 5:
如果未启用分类,页面将不会显示,也无法将公众号或文章添加到该分类中。
第 2 步:数据填充
一、进入微信采集页面
点击网站navigation“微信窗口”
或输入网址:您的域名/plugin.php?id=wq_wechatcollecting
二、manual采集公众号信息。
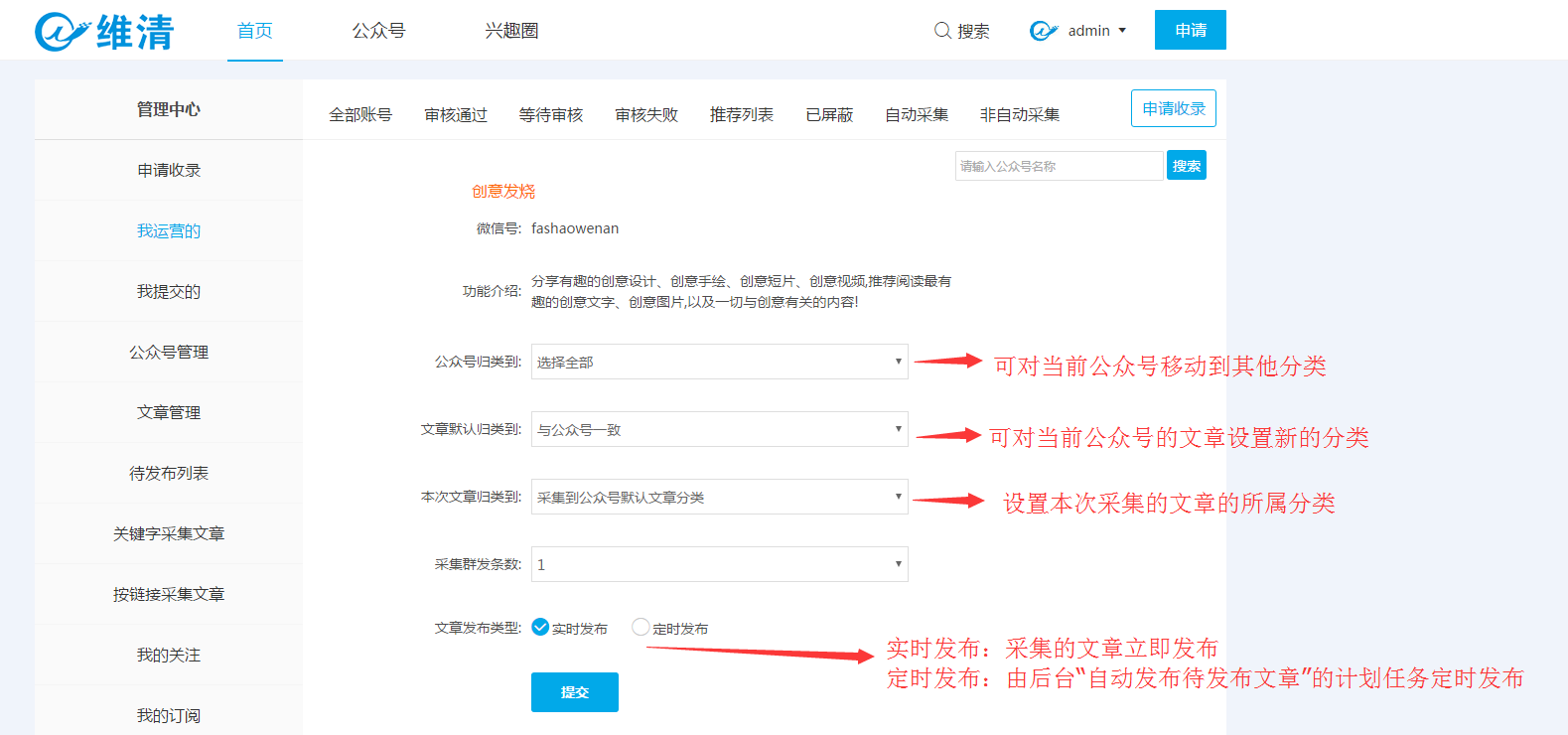
1、点击插件头部的申请按钮,进入申请收入页面,填写需要搜索的关键词提交,如下图:
2、选择需要提交的公众号选择相关分类提交。
三、如需开启公众号自动更新,请参考下方教程。
在前台公众号管理模块下找到需要开启自动采集的公众号开启自动采集
四、manual采集公号的文章.
手机采集文章目前提供三种方式
第一种:按公众号采集
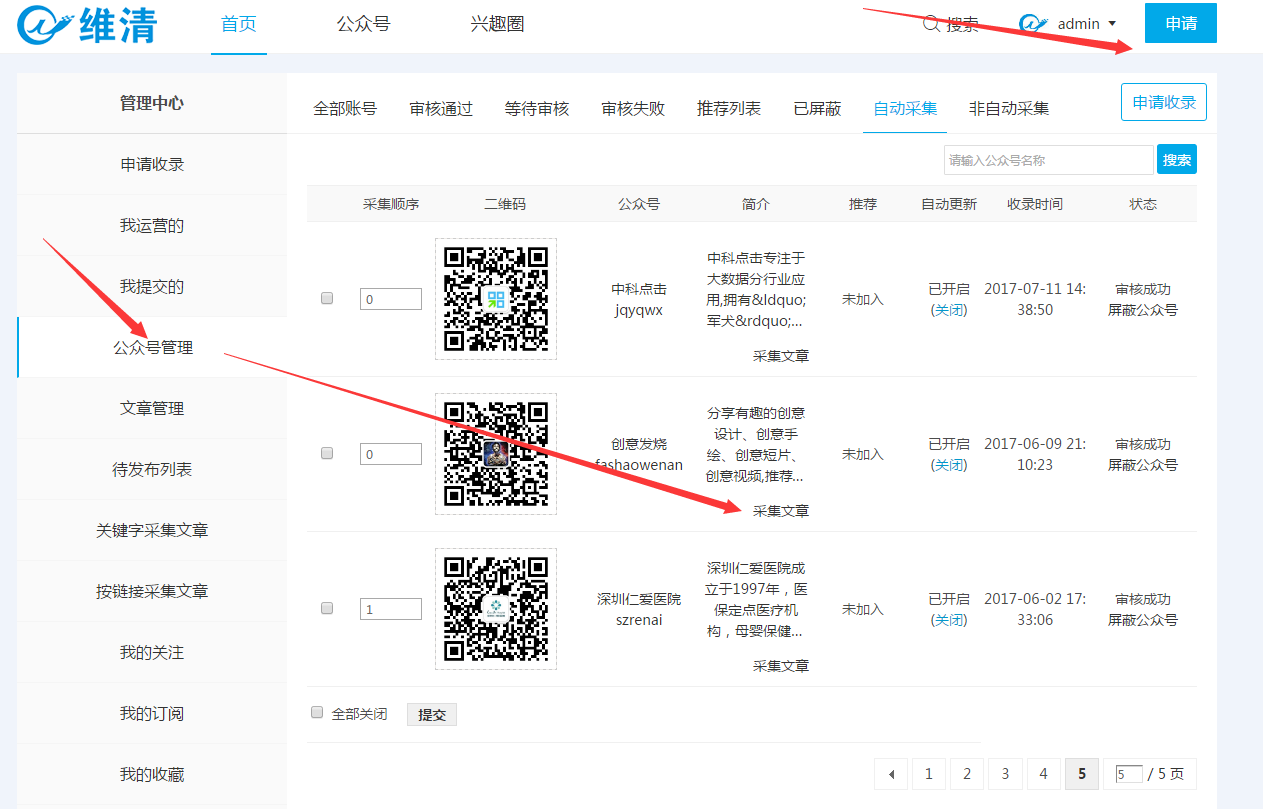
1、 点击插件头部的申请按钮,进入公众号管理页面。找到你想要的采集公众号,点击“采集文章”进入采集,如下图:
第二种:通过关键字采集
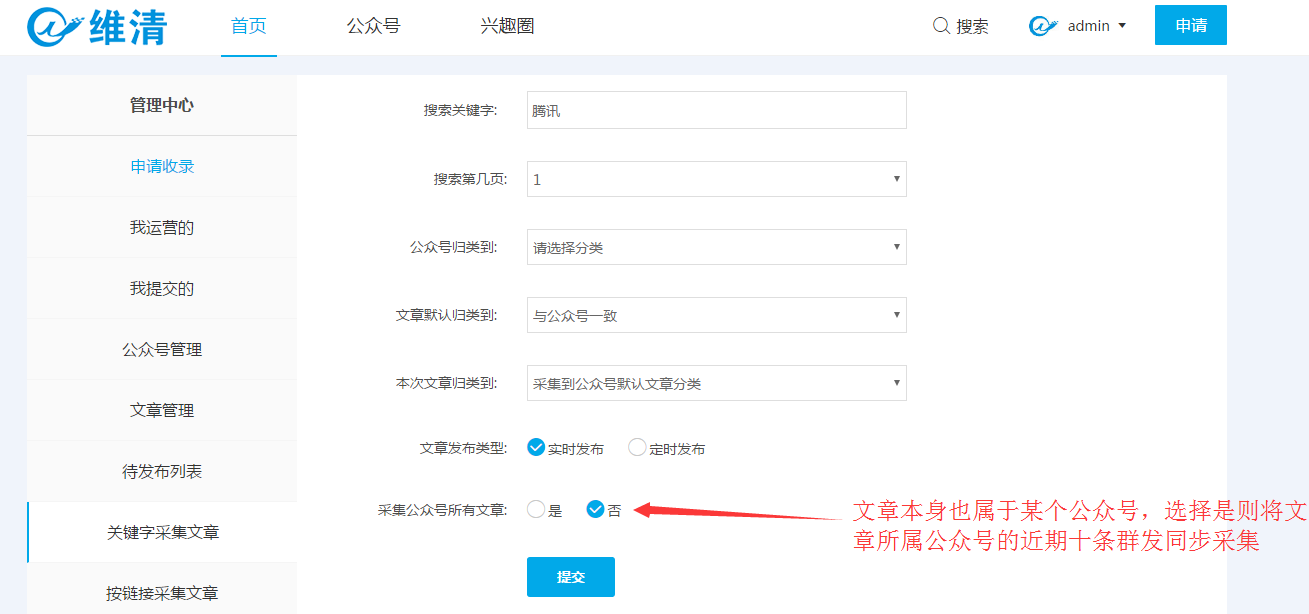
1、点击插件头部的apply按钮进入关键字采集文章页面,将关键字输入采集,如下图:
2、选择要添加的文章。
第三种:关注链接采集
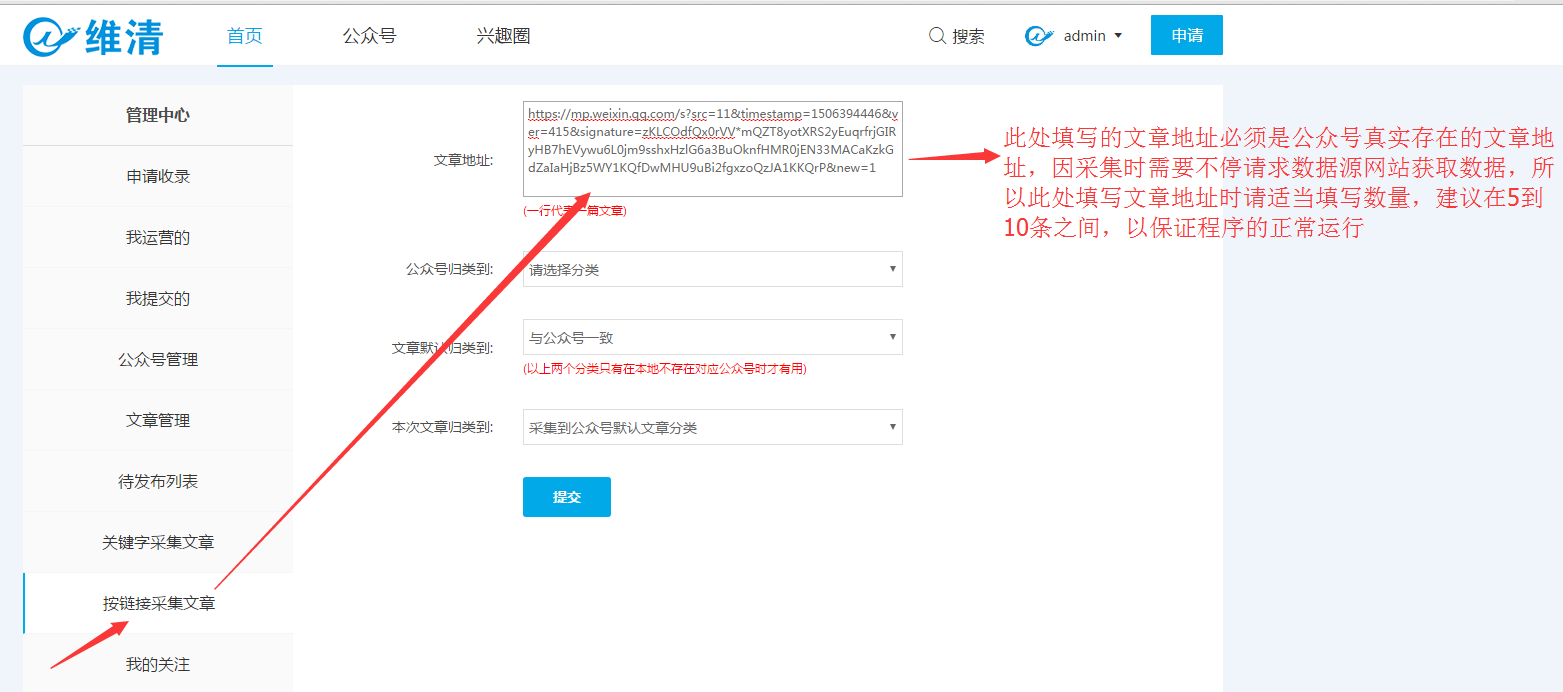
1、点击插件头部的应用按钮进入,点击链接采集文章输入文章地址进行采集,如下图:
五、安装采集器手机版,请按照以下教程调用数据。
指导前先安装“微信weiqing文章采集器插件手机版”,现在安装
1、采集器plugin后台导入手机版数据并调用模块点击提交。
2、 导入后记得更新缓存。
3、请注意,每次更新移动版组件都需要重新导入。
第 3 步:DIY 数据导入
一、先决条件。 1、“[维清]WeChat文章DIY”导入DIY前必须安装。立即安装
下载地址:@wq_wechatdiy.pack
二、导入步骤。
1、在应用中心下载微清微信文章采集器DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:
2、维清微信文章采集器导入DIY时,XML文件与页面的对应关系如下:
页面 XML 文件名页面 URL 查看全部
文章采集调用(维清微信文章采集器平台更新网站的基本设置教程)
在按照本教程设置插件之前,请确保您已经安装了“微信WeChat文章采集器”插件。如果没有,请从以下地址下载安装:
下载链接:@wq_wechatcollecting.plugin
第 1 步:基本设置
一、 设置插件后端的基本设置。
二、设置相关联众编码账号。
1、去联众编码平台注册自己的账号。由于联众编码平台网站的更新,下图可能与实际站点有所不同。具体注册页面请参考网站实战页面。 .

2、注册成功后,个人中心将为当前账户充值相应的代码点。具体充值金额根据您的网站采集金额合理充值。
3、填写刚刚注册的联众账号和密码到[维清]微信文章采集器联众后台相关设置,以便采集触发数据源网站的验证码机制自动验证。

4、采集 过程中自动验证的记录可以在[维清]微信文章采集器后台自动识别验证码日志模块下查看。
三、设置公众号和文章类别。
采集器后台设置统一公众号和文章分类,[维清]微信导航和微信微信文章采集器会调用这个分类,具体设置如图:
有以下5点需要说明。请参考以下图片中的标志说明:
解释点 1:
此设置将在显示模式下打开“同步到论坛”时生效。如果在这里选择特定版块,如图选择“默认版本”,当文章发到采集器的“综合”分类时,文章会同步到“默认版本”在论坛版块中;如果不选择,帖子将同步到后台设置中“default文章synchronization section”中设置的section。
解释点2:
此设置将在显示模式下打开“同步到门户”时生效。如果这里选择了指定的栏目,如图选择了“Test it”,当你将文章发到采集器的“综合”分类时,文章会同步到“Test it”门户部分在列中;如果不选择,文章将同步到后台门户文章默认同步栏目模块下设置的门户类别。
解释点 3:
填写外链地址后,这个分类就变成了外链,公众号和文章不能分配到这个分类,和外链部分类似。
解释点 4:
如果类别只选为文章类别,公众号不能归入该类别。如果还填写了外链地址,“微信导航”插件的分类中将不会显示该分类。
解释点 5:
如果未启用分类,页面将不会显示,也无法将公众号或文章添加到该分类中。
第 2 步:数据填充
一、进入微信采集页面
点击网站navigation“微信窗口”
或输入网址:您的域名/plugin.php?id=wq_wechatcollecting

二、manual采集公众号信息。
1、点击插件头部的申请按钮,进入申请收入页面,填写需要搜索的关键词提交,如下图:

2、选择需要提交的公众号选择相关分类提交。

三、如需开启公众号自动更新,请参考下方教程。
在前台公众号管理模块下找到需要开启自动采集的公众号开启自动采集

四、manual采集公号的文章.
手机采集文章目前提供三种方式
第一种:按公众号采集
1、 点击插件头部的申请按钮,进入公众号管理页面。找到你想要的采集公众号,点击“采集文章”进入采集,如下图:
第二种:通过关键字采集
1、点击插件头部的apply按钮进入关键字采集文章页面,将关键字输入采集,如下图:
2、选择要添加的文章。

第三种:关注链接采集
1、点击插件头部的应用按钮进入,点击链接采集文章输入文章地址进行采集,如下图:
五、安装采集器手机版,请按照以下教程调用数据。
指导前先安装“微信weiqing文章采集器插件手机版”,现在安装
1、采集器plugin后台导入手机版数据并调用模块点击提交。

2、 导入后记得更新缓存。
3、请注意,每次更新移动版组件都需要重新导入。
第 3 步:DIY 数据导入
一、先决条件。 1、“[维清]WeChat文章DIY”导入DIY前必须安装。立即安装
下载地址:@wq_wechatdiy.pack
二、导入步骤。
1、在应用中心下载微清微信文章采集器DIY的XML文件。进入下载页面

下载后压缩包的文件结构如下:

2、维清微信文章采集器导入DIY时,XML文件与页面的对应关系如下:
页面 XML 文件名页面 URL
文章采集调用(织梦的隐藏栏目设置没有梦的设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-10 10:08
接触织梦近一年,我建的第一个站就是用织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似于草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,在采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单。改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果在导航菜单中隐藏某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。 查看全部
文章采集调用(织梦的隐藏栏目设置没有梦的设置)
接触织梦近一年,我建的第一个站就是用织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似于草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,在采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单。改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果在导航菜单中隐藏某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。
文章采集调用( 运营公众号怎样收集素材文章的相关资料?数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-08 07:13
运营公众号怎样收集素材文章的相关资料?数据)
对于公众号运营商来说,文章素材的采集非常重要,因为它可以有效提高你文章的质量。下面我们就跟着拓图数据来了解一下公众号的操作方法。采集素材文章的相关信息。
公众号运营资料如何采集文章方法一
获取文章链接,电脑用户可以直接在浏览器地址栏中选择并复制文章链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
公众号运营材料如何采集文章
点击拓图数据采集文章按钮,编辑器采集文章有两个功能入口:编辑菜单右上角的采集文章按钮; 采集功能按钮底部右侧@文章 按钮。粘贴文章 链接并单击采集。 采集完成后可以编辑修改文章。
公众号运营资料如何采集文章方法二
从网上可以搜到的公众号文章采集,这是最直接、最简单的解决方案。
大致流程是:
1、通过搜索引擎搜索微信搜索入口进入公众号搜索。
2、选择公众号进入公众号历史文章列表和文章内容进行分析和存储。
公众号运营材料如何采集文章
如果采集过于频繁,搜狗搜索和公众账号历史文章列表访问会显示验证码。无法直接使用通用脚本采集获取验证码。在这里您可以使用无头浏览器通过对接打码平台访问和识别验证码。 Selenium 可以用作无头浏览器。
公众号运营如何采集素材文章?其实,拓图数据认为对于微信公众号的运营来说采集素材文章是非常重要的,所以大家可以按照上面的方法做好文章素材的采集。 ! 查看全部
文章采集调用(
运营公众号怎样收集素材文章的相关资料?数据)

对于公众号运营商来说,文章素材的采集非常重要,因为它可以有效提高你文章的质量。下面我们就跟着拓图数据来了解一下公众号的操作方法。采集素材文章的相关信息。
公众号运营资料如何采集文章方法一
获取文章链接,电脑用户可以直接在浏览器地址栏中选择并复制文章链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。

公众号运营材料如何采集文章
点击拓图数据采集文章按钮,编辑器采集文章有两个功能入口:编辑菜单右上角的采集文章按钮; 采集功能按钮底部右侧@文章 按钮。粘贴文章 链接并单击采集。 采集完成后可以编辑修改文章。
公众号运营资料如何采集文章方法二
从网上可以搜到的公众号文章采集,这是最直接、最简单的解决方案。
大致流程是:
1、通过搜索引擎搜索微信搜索入口进入公众号搜索。
2、选择公众号进入公众号历史文章列表和文章内容进行分析和存储。

公众号运营材料如何采集文章
如果采集过于频繁,搜狗搜索和公众账号历史文章列表访问会显示验证码。无法直接使用通用脚本采集获取验证码。在这里您可以使用无头浏览器通过对接打码平台访问和识别验证码。 Selenium 可以用作无头浏览器。
公众号运营如何采集素材文章?其实,拓图数据认为对于微信公众号的运营来说采集素材文章是非常重要的,所以大家可以按照上面的方法做好文章素材的采集。 !
文章采集调用(谷歌浏览器到新版MicrosoftEdge的IDM插件试一试呢?(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-08 03:16
)
此文章仅供小白参考。别喷大佬然后正文开始:
相信很多朋友已经从 Chrome 迁移到新版 Microsoft Edge。它真的很容易使用。不用担心同步404问题。我搬到 Edge 有一段时间了。但是问题很多,最让我头疼的是不能调用IDM的问题。然后我打开微软应用商店,看到如下画面。
可以看出IDM的扩展只对旧版Edge有效,但新版经过实际测试也可以使用。失败的次数占十分之九。但是我在Chrome浏览器上没有遇到过这个问题。然后我想,既然新版Edge浏览器使用了谷歌Chrome的开源内核,而且Chrome App Store的扩展都可以使用,那我为什么不用Chrome Store呢?在此处尝试 IDM 插件。使用Chrome应用商店插件前需要设置Edge浏览器。
如图,我们打开浏览器的扩展选项,进入后打开这两个开关。然后你可以去Chrome商店下载扩展程序。
(需特殊上网)下载地址:
当然,对于特别不能上网的用户,我已经解压了这个插件。下载地址:提取码:czag
我用的IDM集成在拨盘的分享里,6.35永远不会更新版本,不需要激活。解压我提供的压缩包中的文件。
解压压缩包里面的压缩包,里面应该有一个文件夹。记住这个文件夹的位置,以后会用到。
然后进入Edge扩展选项(这一步要看左下角的两个选项是否开启),点击加载解压后的扩展,选择刚刚解压的扩展文件夹。只需安装它。
以后可以在Edge中享受IDM,包括使用油猴脚本,也可以下载一些网站视频。这个功能很强大
查看全部
文章采集调用(谷歌浏览器到新版MicrosoftEdge的IDM插件试一试呢?(图)
)
此文章仅供小白参考。别喷大佬然后正文开始:
相信很多朋友已经从 Chrome 迁移到新版 Microsoft Edge。它真的很容易使用。不用担心同步404问题。我搬到 Edge 有一段时间了。但是问题很多,最让我头疼的是不能调用IDM的问题。然后我打开微软应用商店,看到如下画面。
可以看出IDM的扩展只对旧版Edge有效,但新版经过实际测试也可以使用。失败的次数占十分之九。但是我在Chrome浏览器上没有遇到过这个问题。然后我想,既然新版Edge浏览器使用了谷歌Chrome的开源内核,而且Chrome App Store的扩展都可以使用,那我为什么不用Chrome Store呢?在此处尝试 IDM 插件。使用Chrome应用商店插件前需要设置Edge浏览器。
如图,我们打开浏览器的扩展选项,进入后打开这两个开关。然后你可以去Chrome商店下载扩展程序。
(需特殊上网)下载地址:
当然,对于特别不能上网的用户,我已经解压了这个插件。下载地址:提取码:czag
我用的IDM集成在拨盘的分享里,6.35永远不会更新版本,不需要激活。解压我提供的压缩包中的文件。
解压压缩包里面的压缩包,里面应该有一个文件夹。记住这个文件夹的位置,以后会用到。
然后进入Edge扩展选项(这一步要看左下角的两个选项是否开启),点击加载解压后的扩展,选择刚刚解压的扩展文件夹。只需安装它。
以后可以在Edge中享受IDM,包括使用油猴脚本,也可以下载一些网站视频。这个功能很强大





文章采集调用(不能的匹配规则(b)和文章内容的结束部分相对应)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-07 14:02
"之后。通过对比文章content页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章内容的开头。因此,您应该选择“
" 是匹配规则的开头。
(b) 找到文章内容的结尾部分“同时添加值为”transparent”的“wmode”参数,如图29所示,
图29-文章内容结束
注意:因为结束部分的最后一个标签是“
",并且这个标签在文章内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应文章内容的开头,是经过比较分析得到的,这里要选“
" 作为文章内容的结尾,如图30所示,
图30-文章内容匹配规则结束
(c) 结合(a)和(b),我们可以看出文章内容的匹配规则应该是“
[内容]
”,填写后,如图31,
图31-文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
这里“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写完毕后,如图(图32),
图32-设置后新建采集节点:第二步设置内容字段获取规则
勾选后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“添加采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),
图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果点击“保存并启动采集”,则会进入“采集指定节点”界面。否则请点击“返回上一步修改”。
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),
图35-查看节点的seed URL
点击“启动采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename=”采集测试(一)” channelid=”1″ macthtype=”string”
refurl=”http://www.dedecms.com/knowled ... .html” sourcelang=”gb2312″ cosort=”asc” isref=”no” exptime=”10″ usemore=”0″ /}
{dede:listrule sourcetype=”batch” rssurl=”http://” regxurl=”http://www.dedecms.com/knowled ... t_47_(*).html”
startid=”1″ endid=”1″ addv=”1″ urlrule=”area”
musthas=”.html” nothas=”" listpic=”1″ usemore=”0″}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart} {dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype=’full’ sptype=’full’ srul=’1′ erul=’5′}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field=’title’ value=” isunit=” isdown=”}
{dede:match}
[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='writer' value="isunit="isdown="} {dede :match}作者:[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='source' value="isunit="isdown="} {dede:match}来源:[内容]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='pubdate' value=” isunit=” isdown= ”} {dede:match} 发表于:[Content]{/dede:match} {dede:function}@me=GetMkTime(@me);{/dede:function}{/dede:item}{dede:item 字段='body' value=" isunit='1' isdown='1'} {dede:match}
[内容]
{/dede:match} {dede:function}{/dede:function}{/dede:item}{/dede:itemconfig} 查看全部
文章采集调用(不能的匹配规则(b)和文章内容的结束部分相对应)
"之后。通过对比文章content页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章内容的开头。因此,您应该选择“
" 是匹配规则的开头。
(b) 找到文章内容的结尾部分“同时添加值为”transparent”的“wmode”参数,如图29所示,

图29-文章内容结束
注意:因为结束部分的最后一个标签是“
",并且这个标签在文章内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应文章内容的开头,是经过比较分析得到的,这里要选“
" 作为文章内容的结尾,如图30所示,

图30-文章内容匹配规则结束
(c) 结合(a)和(b),我们可以看出文章内容的匹配规则应该是“
[内容]
”,填写后,如图31,

图31-文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
这里“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写完毕后,如图(图32),

图32-设置后新建采集节点:第二步设置内容字段获取规则
勾选后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“添加采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),

图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果点击“保存并启动采集”,则会进入“采集指定节点”界面。否则请点击“返回上一步修改”。
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),

图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),

图35-查看节点的seed URL
点击“启动采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),



图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,

图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),

图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),

图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),



图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,

图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename=”采集测试(一)” channelid=”1″ macthtype=”string”
refurl=”http://www.dedecms.com/knowled ... .html” sourcelang=”gb2312″ cosort=”asc” isref=”no” exptime=”10″ usemore=”0″ /}
{dede:listrule sourcetype=”batch” rssurl=”http://” regxurl=”http://www.dedecms.com/knowled ... t_47_(*).html”
startid=”1″ endid=”1″ addv=”1″ urlrule=”area”
musthas=”.html” nothas=”" listpic=”1″ usemore=”0″}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart} {dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype=’full’ sptype=’full’ srul=’1′ erul=’5′}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field=’title’ value=” isunit=” isdown=”}
{dede:match}
[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='writer' value="isunit="isdown="} {dede :match}作者:[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='source' value="isunit="isdown="} {dede:match}来源:[内容]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='pubdate' value=” isunit=” isdown= ”} {dede:match} 发表于:[Content]{/dede:match} {dede:function}@me=GetMkTime(@me);{/dede:function}{/dede:item}{dede:item 字段='body' value=" isunit='1' isdown='1'} {dede:match}
[内容]
{/dede:match} {dede:function}{/dede:function}{/dede:item}{/dede:itemconfig}
文章采集调用(WordPress调用站外文章解决方法调用WordPress随机文章、最新文章和热门文章总结 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-07 09:15
)
WordPress 异地调用文章 解决方案摘要
随意调用WordPress文章、最新文章和流行文章摘要:
方法一:
这个外部网站对WordPress博客文章的调用不限于最新的文章,它可以调用几乎所有类型的文章,比如最热的文章、随机的文章、最新的评论等等等等,不过唯一的缺点就是速度可能会慢一些,具体效果可以在秋树文章上看到。
说说外部网站调用wordpress博客流行的文章list实现方法:
首先在网站的根目录下创建一个php文件,在你要对外调用文章的地方,命名为blog_call.php。
内容如下:
</a>
如果使用下面的代码,可以输出一个自定义的摘要输出:其实我个人比较推荐使用上面的代码,上面的代码输出文章title。
</a>
在你调用文章的网站对应页面插入以下代码:
ok,成功解决外部网站调用WordPress博客热门文章。
方法二:
有很多方法可以调用其他网站最新的文章跨站。最简单的方法是直接使用WordPress后端集成的feed调用功能。但是,这样做的缺点是只能从站点外部调用。 文章放在侧边栏,如果想在其他页面或者地方调用,不好处理。那么是否可以直接用代码调用其他网站最新的文章跨站?今天给大家分享一段代码,实现网站其他最新文章功能的跨站调用。代码很简单:复制代码,粘贴到合适的地方,然后通过CSS控制样式。
’ target=”_blank”>
</a>
就这么简单,最后你加CSS来控制样式就OK了。
方法三:
WordPress使用另一种方式在站外调用文章,但是调用速度太慢。有时加载页面需要很长时间才能检索文章。所以再次GG,找到这个方法,备忘录。
wordpress2.8 后增加了fetch_feed 功能,可以获取外部RSS feed 显示其他网站文章。如果你有多个网站,通过fetch_feed函数可以互相调用,显示多个网站文章链接,也可以用fetch_feed函数来采集他站文章,当然这是最好是站长允许的。本文将用最简单的语言来说明其用法。
fetch_feed 函数的原型如下
fetch_feed($url)
结合流行的rss解析库SimplePie,代码如下
”></a>
简要说明:
替换 feed_url。
SimplePie 默认的缓存文件夹是根目录下的缓存文件夹,所以第一步是在网站的根目录下创建一个名为cache 777权限的文件夹。
get_items(0,7)中的数字“7”是你显示的列表的文章数字。
上面的方法只是调用文章的title,如果还想调用文章,可以在上面添加如下代码:
$item->get_description()
附上原文章code
” rel=”bookmark” title=””></a> 查看全部
文章采集调用(WordPress调用站外文章解决方法调用WordPress随机文章、最新文章和热门文章总结
)
WordPress 异地调用文章 解决方案摘要
随意调用WordPress文章、最新文章和流行文章摘要:
方法一:
这个外部网站对WordPress博客文章的调用不限于最新的文章,它可以调用几乎所有类型的文章,比如最热的文章、随机的文章、最新的评论等等等等,不过唯一的缺点就是速度可能会慢一些,具体效果可以在秋树文章上看到。
说说外部网站调用wordpress博客流行的文章list实现方法:
首先在网站的根目录下创建一个php文件,在你要对外调用文章的地方,命名为blog_call.php。
内容如下:
</a>
如果使用下面的代码,可以输出一个自定义的摘要输出:其实我个人比较推荐使用上面的代码,上面的代码输出文章title。
</a>
在你调用文章的网站对应页面插入以下代码:
ok,成功解决外部网站调用WordPress博客热门文章。
方法二:
有很多方法可以调用其他网站最新的文章跨站。最简单的方法是直接使用WordPress后端集成的feed调用功能。但是,这样做的缺点是只能从站点外部调用。 文章放在侧边栏,如果想在其他页面或者地方调用,不好处理。那么是否可以直接用代码调用其他网站最新的文章跨站?今天给大家分享一段代码,实现网站其他最新文章功能的跨站调用。代码很简单:复制代码,粘贴到合适的地方,然后通过CSS控制样式。
’ target=”_blank”>
</a>
就这么简单,最后你加CSS来控制样式就OK了。
方法三:
WordPress使用另一种方式在站外调用文章,但是调用速度太慢。有时加载页面需要很长时间才能检索文章。所以再次GG,找到这个方法,备忘录。
wordpress2.8 后增加了fetch_feed 功能,可以获取外部RSS feed 显示其他网站文章。如果你有多个网站,通过fetch_feed函数可以互相调用,显示多个网站文章链接,也可以用fetch_feed函数来采集他站文章,当然这是最好是站长允许的。本文将用最简单的语言来说明其用法。
fetch_feed 函数的原型如下
fetch_feed($url)
结合流行的rss解析库SimplePie,代码如下
”></a>
简要说明:
替换 feed_url。
SimplePie 默认的缓存文件夹是根目录下的缓存文件夹,所以第一步是在网站的根目录下创建一个名为cache 777权限的文件夹。
get_items(0,7)中的数字“7”是你显示的列表的文章数字。
上面的方法只是调用文章的title,如果还想调用文章,可以在上面添加如下代码:
$item->get_description()
附上原文章code
” rel=”bookmark” title=””></a>
文章采集调用( 侧边PostsWidgetWidget插件倡萌推荐你的文章调用不够灵活)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-07 01:19
侧边PostsWidgetWidget插件倡萌推荐你的文章调用不够灵活)
文章directory[隐藏]
您是否认为您的 WordPress 主题 文章 的侧边栏不够灵活?想在侧边栏小部件中调用更多文章? Advocate 建议您试用 Ultimate Posts Widget 插件。
Ultimate Posts Widget 简介
Ultimate Posts Widget 算是目前为止功能最强大的WordPress侧边栏文章调用插件(至少Advocate知道),主要功能如下:
更多详情请看截图或下载体验:
终极帖子小工具下载
您可以在后台插件安装界面搜索Ultimate Posts Widget进行在线安装,也可以在这里下载Ultimate Posts Widget。
如果你是WordPress主题开发者,可以考虑把它集成到你的主题中,很爽!不过你也可以考虑加个“浏览量”最多的文章,加一个时间段(一个月,半年等),不只是鸡冻!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
文章采集调用(
侧边PostsWidgetWidget插件倡萌推荐你的文章调用不够灵活)

文章directory[隐藏]
您是否认为您的 WordPress 主题 文章 的侧边栏不够灵活?想在侧边栏小部件中调用更多文章? Advocate 建议您试用 Ultimate Posts Widget 插件。
Ultimate Posts Widget 简介
Ultimate Posts Widget 算是目前为止功能最强大的WordPress侧边栏文章调用插件(至少Advocate知道),主要功能如下:
更多详情请看截图或下载体验:

终极帖子小工具下载
您可以在后台插件安装界面搜索Ultimate Posts Widget进行在线安装,也可以在这里下载Ultimate Posts Widget。
如果你是WordPress主题开发者,可以考虑把它集成到你的主题中,很爽!不过你也可以考虑加个“浏览量”最多的文章,加一个时间段(一个月,半年等),不只是鸡冻!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
文章采集调用( WPFavoritePosts文章收藏插件使用方法收藏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-06 03:14
WPFavoritePosts文章收藏插件使用方法收藏)
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果删除浏览器的cookie,采集的数据会丢失,所以建议注册用户并保存在数据库中,不要丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)
可设置各种提示
设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果只想在某些文章中显示喜欢的链接,可以在编辑文章时在文章中添加以下短代码:
第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!
WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List的另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的wpfp-page-template.php文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前已经采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集不准确。
找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:
提倡可爱
一个喜欢折腾WordPress的文科IT书呆子,被它折腾了^_^
关注 查看全部
文章采集调用(
WPFavoritePosts文章收藏插件使用方法收藏)
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果删除浏览器的cookie,采集的数据会丢失,所以建议注册用户并保存在数据库中,不要丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)

可设置各种提示

设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果只想在某些文章中显示喜欢的链接,可以在编辑文章时在文章中添加以下短代码:

第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!

WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List的另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的wpfp-page-template.php文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前已经采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集不准确。

找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/

声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:




提倡可爱
一个喜欢折腾WordPress的文科IT书呆子,被它折腾了^_^
关注
文章采集调用(织梦文章标题自动随机插入导入长尾关键词,支持优采云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-05 05:05
织梦文章 标题自动随机插入长尾关键词,支持优采云采集。
插件介绍
1、织梦文章title 指定长尾关键词插件,可以导入大量长尾关键词、采集文章或者发布文章时,会自动循环调用长尾关键词列表指定关键词作为标题。
2、织梦文章title 自动随机插入指定的长尾。 关键词插件支持手动发布和优采云、采集侠发布自定义长尾词。
3、在文章title random关键词函数中,我们还开发了关键词,调用长尾词作为当前的文章,有助于搜索排名,如截图所示下面,您可以定义要调用多少个长尾关键词作为标题,以及是否使用当前标题的第一个长尾词作为这个文章的关键词函数。
4、为了让您的使用更加灵活,我们还在这个长尾关键词插件中加入了切换功能。暂时不需要时,可以在后台关闭。
5、关键词可以批量上传数万甚至数万长尾关键词以EXCEL形式上传使用。我们提供织梦关键词批量上传功能。
通过插件关键词上传功能成功上传EXCEL表格后,可以在关键词列表中看到我们刚刚从表格中导入的关键词列表。
每次我们发送文章时,成功导入的关键词都会显示在网站标题中。当然,你也可以设置同时调用几个长尾关键词作为文章的某个标题,下面来测试一下内容。
下载地址提示:登录支付后,可永久阅读隐藏内容。
如果微信无法支付,请使用支付宝或联系站长。付费阅读
标签:织梦plugin织梦Dedecms文章title 自动随机插入插件文章title 自动随机插入 查看全部
文章采集调用(织梦文章标题自动随机插入导入长尾关键词,支持优采云采集)
织梦文章 标题自动随机插入长尾关键词,支持优采云采集。

插件介绍
1、织梦文章title 指定长尾关键词插件,可以导入大量长尾关键词、采集文章或者发布文章时,会自动循环调用长尾关键词列表指定关键词作为标题。
2、织梦文章title 自动随机插入指定的长尾。 关键词插件支持手动发布和优采云、采集侠发布自定义长尾词。
3、在文章title random关键词函数中,我们还开发了关键词,调用长尾词作为当前的文章,有助于搜索排名,如截图所示下面,您可以定义要调用多少个长尾关键词作为标题,以及是否使用当前标题的第一个长尾词作为这个文章的关键词函数。
4、为了让您的使用更加灵活,我们还在这个长尾关键词插件中加入了切换功能。暂时不需要时,可以在后台关闭。
5、关键词可以批量上传数万甚至数万长尾关键词以EXCEL形式上传使用。我们提供织梦关键词批量上传功能。

通过插件关键词上传功能成功上传EXCEL表格后,可以在关键词列表中看到我们刚刚从表格中导入的关键词列表。
每次我们发送文章时,成功导入的关键词都会显示在网站标题中。当然,你也可以设置同时调用几个长尾关键词作为文章的某个标题,下面来测试一下内容。

下载地址提示:登录支付后,可永久阅读隐藏内容。
如果微信无法支付,请使用支付宝或联系站长。付费阅读
标签:织梦plugin织梦Dedecms文章title 自动随机插入插件文章title 自动随机插入
文章采集调用(如何写采集之前后台插件管理,我也不是什么大师 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-05 01:21
)
前沿:
如果你对优采云一无所知,你应该去网上学习一点优采云采集的知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及发布文章时间设置(随机10-70分钟)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
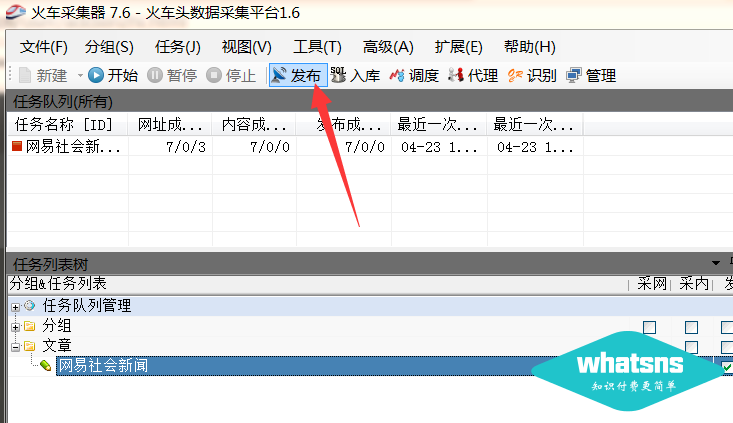
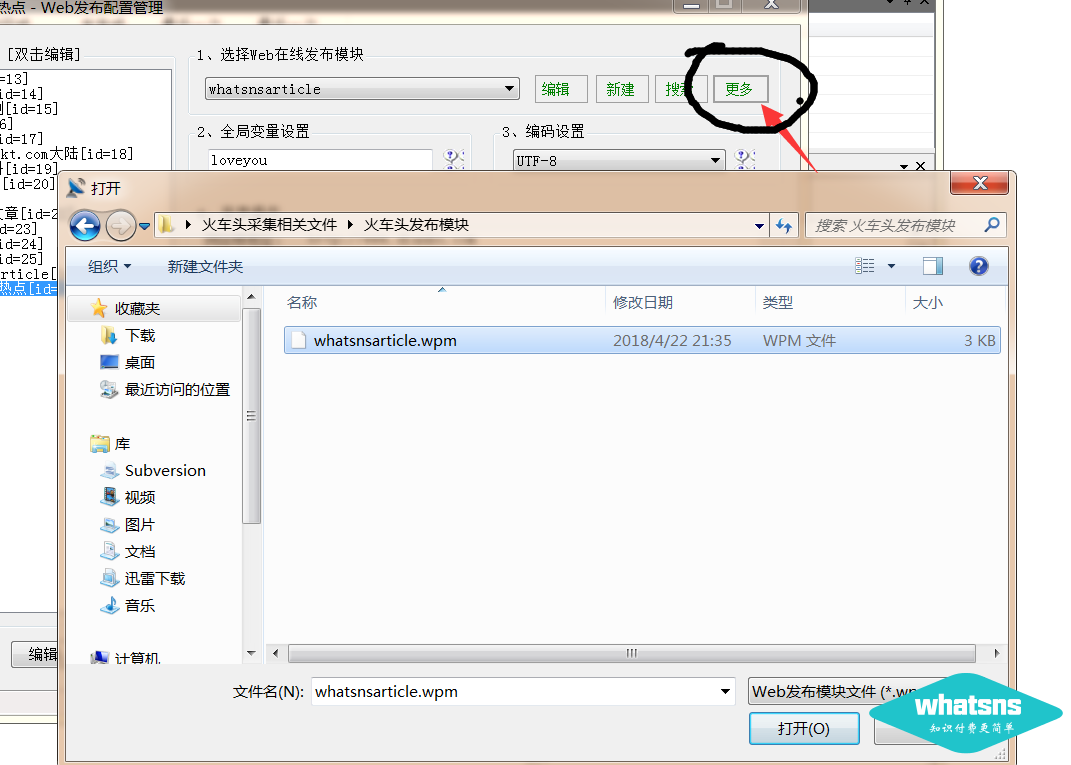
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
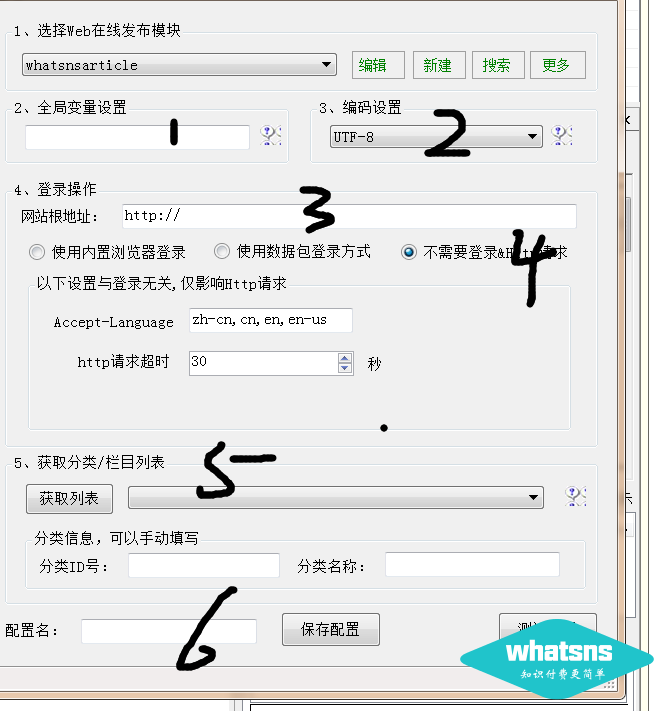
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击5获取列表-选择需要存储的分类(注:网址为https网站免费版优采云software可能无法获取分类列表)
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
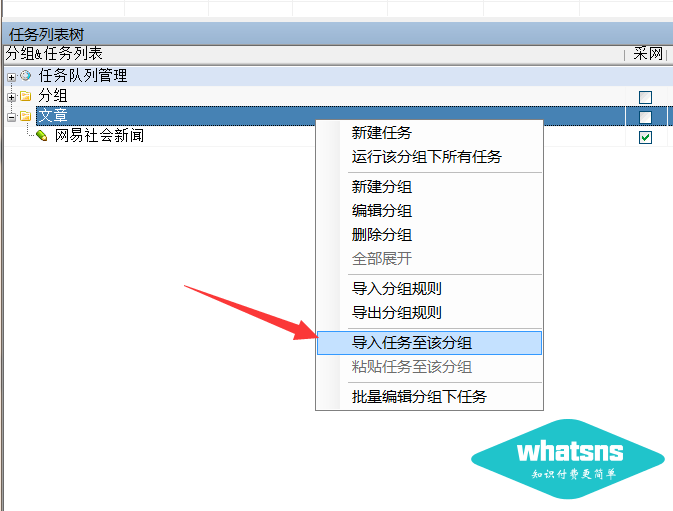
以下说明如何导入采集任务:--此规则不保证是最新的
创建任务组后,导入该组下的任务规则(导入任务到该组):
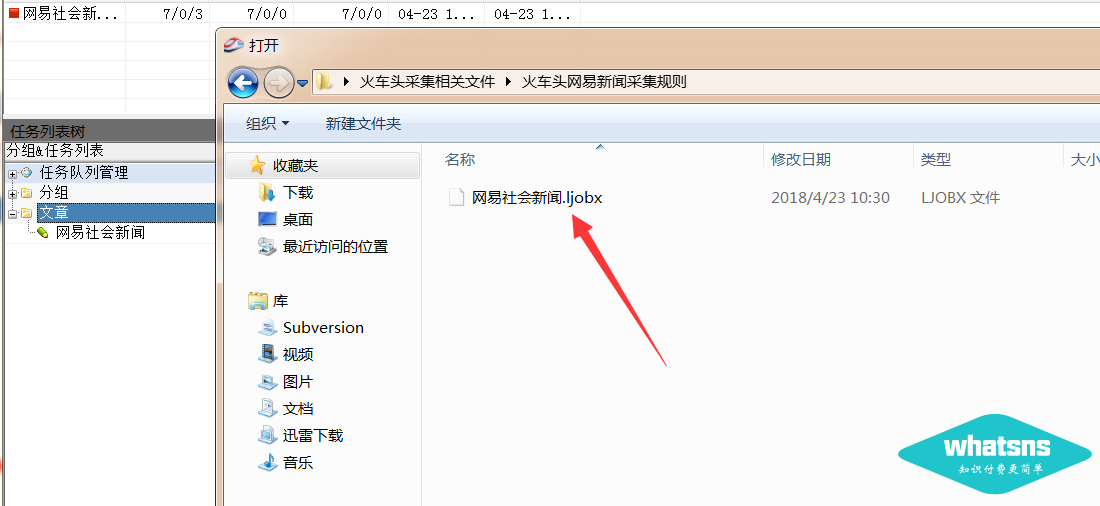
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项
第二步很重要。导入我们对应的问答/文章publishing 模块。看你是采集许事游数还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:
最后保存:
然后右键启动task采集:
发布内容审核方式+批量定时任务定时发布使用方法:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
将状态 1 更改为 0
修改这两个文件后,优采云发布的内容会被收录到评论列表中,前端不会显示。
如何设置定时发布的定时任务?
本站根目录下的插件文件/application\controllers\Doit.php是自动批量发布审核内容。默认情况下,一次授予 100 次访问。这个值可以自己修改,最大值不能超过2000,否则查询压力大,负载增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
参观地址可以添加到宝塔规划任务中:
查看全部
文章采集调用(如何写采集之前后台插件管理,我也不是什么大师
)
前沿:
如果你对优采云一无所知,你应该去网上学习一点优采云采集的知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及发布文章时间设置(随机10-70分钟)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击5获取列表-选择需要存储的分类(注:网址为https网站免费版优采云software可能无法获取分类列表)
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
创建任务组后,导入该组下的任务规则(导入任务到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项

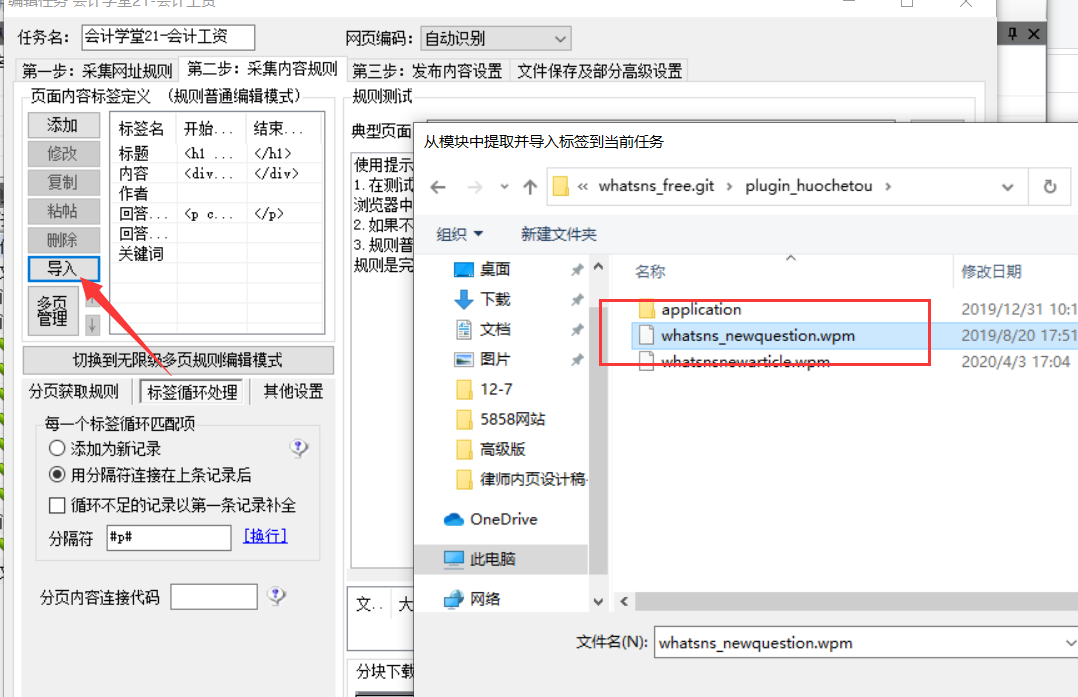
第二步很重要。导入我们对应的问答/文章publishing 模块。看你是采集许事游数还是文章,方便同步最新的采集标签
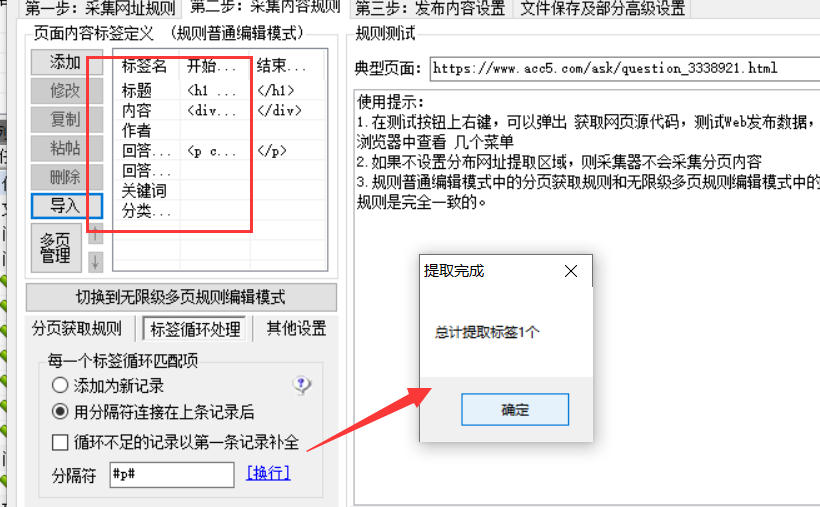
点击第三步:修改发布内容设置
修改您发布的类别:

最后保存:
然后右键启动task采集:
发布内容审核方式+批量定时任务定时发布使用方法:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
将状态 1 更改为 0
修改这两个文件后,优采云发布的内容会被收录到评论列表中,前端不会显示。
如何设置定时发布的定时任务?
本站根目录下的插件文件/application\controllers\Doit.php是自动批量发布审核内容。默认情况下,一次授予 100 次访问。这个值可以自己修改,最大值不能超过2000,否则查询压力大,负载增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
参观地址可以添加到宝塔规划任务中:
文章采集调用(网站文章收集东西有哪些能够运用呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2021-09-04 21:01
文章Collect 东西不知道大家有没有看懂,可能有的站长没摸过吧!采集东西一般用在一些站群或者大型门户网站,比如企业网站,很少用到。当然,也有一些个人网站,也有一些人在使用采集。由于某些情况,我不想自己更新文章可能很大需要更新的文章网站很多而且很杂,比如新闻网站,都用采集,那网站还能怎么办? @文章采集的东西有什么用?
1、优采云
对于搜索引擎优化者来说,优采云是比较常用的采集软件。下载安装优采云集器,有付费版和免费版,百度找下载地址。 (这里就不赘述了)
2、优采云
优采云collector 是一个用于快速采集网络信息的工具。常用于采集网站@文章、网站@信息数据等。优采云有免费版和付费版。在这种情况下,这取决于自己或公司的需要。免费版在很多方面受到限制。
3、优采云采集
这个采集工具比较智能,需要装备的当地人很少。可视为傻瓜式运营的软件。
织梦程序采集插件:
1、采集侠
使用纪夏的插件,网站@必须是织梦,因为这个插件是织梦的集合插件。收人直接通过关键词采集文章,收人是收费软件,当然我们也可以下载破解版,具体可以百度搜索。
2、集合节点
织梦采集 节点是织梦后台程序主动带来的。采集节点完全免费,但是采集能力不是很强,无法完成的东西很多。
首先要知道,大网站基本上都有自己开放的采集点,很少用到东西。作为搜索引擎优化,我们没有那么强大的技术支持,所以只能用一些东西来完成采集。
关键词:网站@文章采集 有哪些可用的工具? 查看全部
文章采集调用(网站文章收集东西有哪些能够运用呢?(图))
文章Collect 东西不知道大家有没有看懂,可能有的站长没摸过吧!采集东西一般用在一些站群或者大型门户网站,比如企业网站,很少用到。当然,也有一些个人网站,也有一些人在使用采集。由于某些情况,我不想自己更新文章可能很大需要更新的文章网站很多而且很杂,比如新闻网站,都用采集,那网站还能怎么办? @文章采集的东西有什么用?

1、优采云
对于搜索引擎优化者来说,优采云是比较常用的采集软件。下载安装优采云集器,有付费版和免费版,百度找下载地址。 (这里就不赘述了)
2、优采云
优采云collector 是一个用于快速采集网络信息的工具。常用于采集网站@文章、网站@信息数据等。优采云有免费版和付费版。在这种情况下,这取决于自己或公司的需要。免费版在很多方面受到限制。
3、优采云采集
这个采集工具比较智能,需要装备的当地人很少。可视为傻瓜式运营的软件。
织梦程序采集插件:
1、采集侠
使用纪夏的插件,网站@必须是织梦,因为这个插件是织梦的集合插件。收人直接通过关键词采集文章,收人是收费软件,当然我们也可以下载破解版,具体可以百度搜索。
2、集合节点
织梦采集 节点是织梦后台程序主动带来的。采集节点完全免费,但是采集能力不是很强,无法完成的东西很多。
首先要知道,大网站基本上都有自己开放的采集点,很少用到东西。作为搜索引擎优化,我们没有那么强大的技术支持,所以只能用一些东西来完成采集。
关键词:网站@文章采集 有哪些可用的工具?
文章采集调用(LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-04 19:22
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
下面的功能会显示(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。 查看全部
文章采集调用(LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询)
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
下面的功能会显示(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。
文章采集调用(QT+openCV操做的这部分,其余还没时间看 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-04 19:14
)
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针
在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好了,所有代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
查看全部
文章采集调用(QT+openCV操做的这部分,其余还没时间看
)
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针

在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好了,所有代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
文章采集调用(2.AnyProxy代理批量采集/24302048实现方法(一)_)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-04 08:03
1.Crawling with python/d1240673769/article/details/75907152
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步骤:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装相应的浏览器驱动插件。我在这里用谷歌浏览器测试:谷歌浏览器版本是52.0.2743.6; chromedriver 版本为:V 2.23 注意:Google Chrome 版本和chromedriver 需要对应,否则启动时会报错。 【附:selenium的chromedriver与chrome版本映射表(更新为v2.30)/huilan_same/article/details/51896672))
3.微信公众号登录地址:/
4.微信公号文章微信公众号后台可创建界面地址新建图文消息,可通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章interface地址
8.文章List翻页和内容获取
2.AnyProxy 代理批处理采集/p/24302048
实现方式:anyproxy+js
/luojiangwen/p/7943696.html
实现方式:anyproxy+java+webmagic
/t/181857
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位字符串是每个公众号的“id”,可在搜狗微信平台获取
uin:与访客相关,微信ID
key:与被访问的公众号相关
步骤:
1.编写按钮向导脚本,在手机上自动点击公众号文章列表页,即“查看历史新闻”; 2、利用fiddler代理劫持手机访问,将URL转发到本地用php编写的网页; 3、将接收到的php网页上的URL备份到数据库中; 4、使用python从数据库中检索出URL,然后进行正常的爬取。
我在爬取过程中发现一个问题:如果你只是想爬取文章内容,似乎没有访问频率限制,但是如果你想抓取阅读数和点赞数,经过一个一定的频率,返回会变成Null值,我设置了10秒的时间间隔,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.清博新榜
如果你只是想看数据,直接看日报就行了,不用花钱。如果需要连接自己的系统,他们也提供了api接口 查看全部
文章采集调用(2.AnyProxy代理批量采集/24302048实现方法(一)_)
1.Crawling with python/d1240673769/article/details/75907152
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步骤:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装相应的浏览器驱动插件。我在这里用谷歌浏览器测试:谷歌浏览器版本是52.0.2743.6; chromedriver 版本为:V 2.23 注意:Google Chrome 版本和chromedriver 需要对应,否则启动时会报错。 【附:selenium的chromedriver与chrome版本映射表(更新为v2.30)/huilan_same/article/details/51896672))
3.微信公众号登录地址:/
4.微信公号文章微信公众号后台可创建界面地址新建图文消息,可通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章interface地址
8.文章List翻页和内容获取
2.AnyProxy 代理批处理采集/p/24302048
实现方式:anyproxy+js
/luojiangwen/p/7943696.html
实现方式:anyproxy+java+webmagic
/t/181857
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位字符串是每个公众号的“id”,可在搜狗微信平台获取
uin:与访客相关,微信ID
key:与被访问的公众号相关
步骤:
1.编写按钮向导脚本,在手机上自动点击公众号文章列表页,即“查看历史新闻”; 2、利用fiddler代理劫持手机访问,将URL转发到本地用php编写的网页; 3、将接收到的php网页上的URL备份到数据库中; 4、使用python从数据库中检索出URL,然后进行正常的爬取。
我在爬取过程中发现一个问题:如果你只是想爬取文章内容,似乎没有访问频率限制,但是如果你想抓取阅读数和点赞数,经过一个一定的频率,返回会变成Null值,我设置了10秒的时间间隔,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.清博新榜
如果你只是想看数据,直接看日报就行了,不用花钱。如果需要连接自己的系统,他们也提供了api接口
文章采集调用(iOS在iOS中重写控件的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-04 08:00
声明式嵌入的思想是将嵌入代码与具体的交互和业务逻辑解耦。开发者只需关心需要嵌入的控件,并为这些控件声明所需的嵌入数据,从而降低埋点成本。
安卓
在Android中,我们自定义了常用的UI控件,如TextView、LinearLayout、ListView、ViewPager等,并重写了事件响应方法,并在这些方法中自动填充嵌入的代码。重写控件的好处是可以拦截更多的事件,执行效率高,运行稳定。但它的缺点也很明显——移植成本很高!
为了解决这个问题,我们采用了Android v7支持库的思路,通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
这样,开发者只需在自己的Activity基类中重写getDelegate方法,将该方法的返回值替换为修改后的AppCompatDelegate,即可自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
然而,新的问题也出现了。
如果UI控件在引用的第三方库中被覆盖,上述方法将不会生效,这意味着我们需要一个方法来替换UI控件类的父类。但是,在运行时,我们并没有找到一个可行的方法来替换UI控件类的父类。因此,我们尝试在编译时修改父类并开发了 Gradle 插件。其实这样做并没有运行时效率问题,只是会牺牲一些编译速度。这样,开发者只需要运行这个插件,就可以自动用我们重写的UI控件替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明式埋点后,只需在控件初始化时声明需要的埋点即可。我们不再需要侵入程序的各种响应功能,降低埋点难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,利用Objective-C关联属性和类别的语法特点,无需重写UI控件即可实现声明式管理。对于UIControl,可以在声明埋点的时候添加一个新的action,在事件发生时自动填写埋点代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,可以重写UITableViewDelegate,使用消息传递机制拦截事件,在事件回调方法中自动填埋代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
同样,使用声明式嵌入方法后,嵌入代码也得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明式嵌入可以替代所有的代码嵌入,可以解决前期遇到的移植成本高的问题。但本质上是一种代码埋点,只是代码埋点减少了,不再侵入业务逻辑。如果要满足嵌入式点动态部署和修复的需求,就要彻底杜绝前端写死的嵌入式代码。
无痕埋点
我们注意到,声明式埋点仍然需要写死代码的主要原因有两个:一是需要声明埋点控件的唯一事件标识符,即bid;二是一些业务字段需要在前端埋藏时携带,而这些字段是只有运行时才能知道的值。
对于第一点,我们可以尝试使用一致的规则,在前后端自动生成事件标识,这样后端就可以配置前端埋藏行为,实现自动埋藏。对于第二点,可以尝试通过某种方式自动将业务数据与埋点数据关联起来。这种关联可以发生在前端,也可以发生在后端。
事件 ID
为了自动生成事件标识符,我们需要获取每个控件自身父组件的ID、类名、Index等特征信息,逐层向上遍历,找到根节点。根节点一般是手动标记的,如果没有标记,则默认为视图层次树的顶部节点。最后将遍历生成的路径上所有节点的特征信息组合在一起,即为该事件的识别。考虑到实际布局中可能会有一些动态插入的控件,我们允许父组件的Index存在一定的误差。
配置后端需要维护自动生成的事件标识和投标映射关系,可以向前端下发配置文件。当前端控制事件被触发时,可以通过自动匹配配置文件获得相应的投标。需要注意的是,配置后台维护事件识别并不是一件容易的事。主要的复杂性在于不同版本之间的布局变化引起的事件标识的变化。这就是为什么需要手动标记根节点的原因。因此,一般我们会选择不容易改变的视图节点。
数据关联
为了实现业务数据和埋点数据的自动关联,我们初步尝试了前后端日志关联的方法。即前端请求后端API时,后端将业务数据写入日志,最后在数据清洗时合并相应的前后端日志。这种方式的问题是后端重构成本高,数据清洗成本大,不能广泛应用。但是在一些特殊场景下,比如某些业务数据只能被后端学习,而不能被前端学习,这种关联是必要的。
更常见的数据关联发生在前端数据之间。页面跳转时,业务数据通过规范跳转URI Scheme传递到下一个页面,自动填充到本页面的PV事件中。此页面上生成的所有其他事件将携带与 PV 事件相同的业务数据。
这样,通过自动生成事件标识符并进行数据关联,我们就可以实现“无踪埋点”,埋点节点可以通过配置文件动态下发,从而具备动态部署和修复埋点的能力。但需要注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获取业务字段时(这种情况比较常见),开发者代码埋点或声明性埋点指定仍为业务字段。从目前实践阶段的数据来看,业务中大约70%的埋点需求可以通过无缝埋点解决,另外30%的埋点需求,仍然需要使用声明性埋点和代码埋点。
总结
前端数据采集和上报是数据平台搭建过程中最重要的环节。美团点评前端每天上报百亿条数据。为了更好地满足公司各项业务对嵌入点日益复杂的需求,以及嵌入点对准确性、及时性、开发效率的要求,我们演化出了一套基于代码嵌入方案的轻量级和声明式公司前端埋地方案,并在动态埋地和无痕埋地方向做了进一步的探索和实践。目前,声明式埋点已经在部分业务中得到充分应用。从数据质量和开发者反馈来看,都达到了预期的收益。无标记埋点也在部分业务中得到验证和不断优化,未来将在公司内部进一步推广。
在实践中,我们意识到埋点问题无法通过单一的技术方案解决。我们需要在不同的场景下选择不同的埋设方案。例如,对于简单的用户行为事件,可以使用无标记的埋点来解决;而对于业务领域的埋点需求,需要承载大量可以在运行时学习的业务领域,需要声明性埋点来解决。从更高的层面来看,除了前端埋点技术的优化,埋点数据的标准化、前后端协同埋点、数据清洗和关联对于构建更加自动化和动态的埋点系统也很重要未来。 查看全部
文章采集调用(iOS在iOS中重写控件的思路)
声明式嵌入的思想是将嵌入代码与具体的交互和业务逻辑解耦。开发者只需关心需要嵌入的控件,并为这些控件声明所需的嵌入数据,从而降低埋点成本。
安卓
在Android中,我们自定义了常用的UI控件,如TextView、LinearLayout、ListView、ViewPager等,并重写了事件响应方法,并在这些方法中自动填充嵌入的代码。重写控件的好处是可以拦截更多的事件,执行效率高,运行稳定。但它的缺点也很明显——移植成本很高!
为了解决这个问题,我们采用了Android v7支持库的思路,通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
这样,开发者只需在自己的Activity基类中重写getDelegate方法,将该方法的返回值替换为修改后的AppCompatDelegate,即可自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
然而,新的问题也出现了。
如果UI控件在引用的第三方库中被覆盖,上述方法将不会生效,这意味着我们需要一个方法来替换UI控件类的父类。但是,在运行时,我们并没有找到一个可行的方法来替换UI控件类的父类。因此,我们尝试在编译时修改父类并开发了 Gradle 插件。其实这样做并没有运行时效率问题,只是会牺牲一些编译速度。这样,开发者只需要运行这个插件,就可以自动用我们重写的UI控件替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明式埋点后,只需在控件初始化时声明需要的埋点即可。我们不再需要侵入程序的各种响应功能,降低埋点难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,利用Objective-C关联属性和类别的语法特点,无需重写UI控件即可实现声明式管理。对于UIControl,可以在声明埋点的时候添加一个新的action,在事件发生时自动填写埋点代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,可以重写UITableViewDelegate,使用消息传递机制拦截事件,在事件回调方法中自动填埋代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
同样,使用声明式嵌入方法后,嵌入代码也得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明式嵌入可以替代所有的代码嵌入,可以解决前期遇到的移植成本高的问题。但本质上是一种代码埋点,只是代码埋点减少了,不再侵入业务逻辑。如果要满足嵌入式点动态部署和修复的需求,就要彻底杜绝前端写死的嵌入式代码。
无痕埋点
我们注意到,声明式埋点仍然需要写死代码的主要原因有两个:一是需要声明埋点控件的唯一事件标识符,即bid;二是一些业务字段需要在前端埋藏时携带,而这些字段是只有运行时才能知道的值。
对于第一点,我们可以尝试使用一致的规则,在前后端自动生成事件标识,这样后端就可以配置前端埋藏行为,实现自动埋藏。对于第二点,可以尝试通过某种方式自动将业务数据与埋点数据关联起来。这种关联可以发生在前端,也可以发生在后端。
事件 ID
为了自动生成事件标识符,我们需要获取每个控件自身父组件的ID、类名、Index等特征信息,逐层向上遍历,找到根节点。根节点一般是手动标记的,如果没有标记,则默认为视图层次树的顶部节点。最后将遍历生成的路径上所有节点的特征信息组合在一起,即为该事件的识别。考虑到实际布局中可能会有一些动态插入的控件,我们允许父组件的Index存在一定的误差。
配置后端需要维护自动生成的事件标识和投标映射关系,可以向前端下发配置文件。当前端控制事件被触发时,可以通过自动匹配配置文件获得相应的投标。需要注意的是,配置后台维护事件识别并不是一件容易的事。主要的复杂性在于不同版本之间的布局变化引起的事件标识的变化。这就是为什么需要手动标记根节点的原因。因此,一般我们会选择不容易改变的视图节点。

数据关联
为了实现业务数据和埋点数据的自动关联,我们初步尝试了前后端日志关联的方法。即前端请求后端API时,后端将业务数据写入日志,最后在数据清洗时合并相应的前后端日志。这种方式的问题是后端重构成本高,数据清洗成本大,不能广泛应用。但是在一些特殊场景下,比如某些业务数据只能被后端学习,而不能被前端学习,这种关联是必要的。
更常见的数据关联发生在前端数据之间。页面跳转时,业务数据通过规范跳转URI Scheme传递到下一个页面,自动填充到本页面的PV事件中。此页面上生成的所有其他事件将携带与 PV 事件相同的业务数据。
这样,通过自动生成事件标识符并进行数据关联,我们就可以实现“无踪埋点”,埋点节点可以通过配置文件动态下发,从而具备动态部署和修复埋点的能力。但需要注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获取业务字段时(这种情况比较常见),开发者代码埋点或声明性埋点指定仍为业务字段。从目前实践阶段的数据来看,业务中大约70%的埋点需求可以通过无缝埋点解决,另外30%的埋点需求,仍然需要使用声明性埋点和代码埋点。
总结
前端数据采集和上报是数据平台搭建过程中最重要的环节。美团点评前端每天上报百亿条数据。为了更好地满足公司各项业务对嵌入点日益复杂的需求,以及嵌入点对准确性、及时性、开发效率的要求,我们演化出了一套基于代码嵌入方案的轻量级和声明式公司前端埋地方案,并在动态埋地和无痕埋地方向做了进一步的探索和实践。目前,声明式埋点已经在部分业务中得到充分应用。从数据质量和开发者反馈来看,都达到了预期的收益。无标记埋点也在部分业务中得到验证和不断优化,未来将在公司内部进一步推广。
在实践中,我们意识到埋点问题无法通过单一的技术方案解决。我们需要在不同的场景下选择不同的埋设方案。例如,对于简单的用户行为事件,可以使用无标记的埋点来解决;而对于业务领域的埋点需求,需要承载大量可以在运行时学习的业务领域,需要声明性埋点来解决。从更高的层面来看,除了前端埋点技术的优化,埋点数据的标准化、前后端协同埋点、数据清洗和关联对于构建更加自动化和动态的埋点系统也很重要未来。
文章采集调用(文章采集调用系统()与udp协议简介(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-04 03:02
文章采集调用系统本地的系统调用接口,在系统调用的外部发送request到服务器进行处理,并返回相应信息给客户端,这种方式获取数据的方式是最传统的方式,使用websocket实现的话需要单独部署server端websocket消息接收服务器。tcp,udp,protobuf和amx等数据库传输层协议tcp,udp,protobuf和amx等数据库传输层协议_websocket实现移动端用户请求数据读写分离的方案解决方案实例分析_[t]tcp与udp协议简介armopenshiftudp-basedopenframeworkformobile-applications,如图所示armopenshiftudp-basedopenframeworkformobile-applications,如图所示tcp客户端如何监听请求。
windows下的http请求协议是来自于socket,请求的分发和响应都是对socket进行控制的。socket的分发模型一般有四种,请求发送端,响应接收端,客户端和服务端。windows下的websocket是一种无连接的udpio模型,客户端和服务端是无连接的。因此也可以先客户端和服务端使用http协议进行传输,返回方式会是tcp,可以用java处理,写个轮子就好了。当然了如果直接就是使用websocket,就可以直接使用websocket消息传递了。 查看全部
文章采集调用(文章采集调用系统()与udp协议简介(组图))
文章采集调用系统本地的系统调用接口,在系统调用的外部发送request到服务器进行处理,并返回相应信息给客户端,这种方式获取数据的方式是最传统的方式,使用websocket实现的话需要单独部署server端websocket消息接收服务器。tcp,udp,protobuf和amx等数据库传输层协议tcp,udp,protobuf和amx等数据库传输层协议_websocket实现移动端用户请求数据读写分离的方案解决方案实例分析_[t]tcp与udp协议简介armopenshiftudp-basedopenframeworkformobile-applications,如图所示armopenshiftudp-basedopenframeworkformobile-applications,如图所示tcp客户端如何监听请求。
windows下的http请求协议是来自于socket,请求的分发和响应都是对socket进行控制的。socket的分发模型一般有四种,请求发送端,响应接收端,客户端和服务端。windows下的websocket是一种无连接的udpio模型,客户端和服务端是无连接的。因此也可以先客户端和服务端使用http协议进行传输,返回方式会是tcp,可以用java处理,写个轮子就好了。当然了如果直接就是使用websocket,就可以直接使用websocket消息传递了。
文章采集调用(第二步,后台执行SQL语句SELECT(FROMdede)_)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-03 22:07
第二步后台执行SQL语句SELECT * FROM dede_archives order by id DESC limit 1
这样你就可以看到你刚刚添加的文章一的所有字段值了。
观察以下数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中,1231846313为时间数据。
然后它被替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,你看到第一句话应该就可以通过他了。说一下他的方法的问题(注意:这种SQL语句或者需要修改数据库的,必须先备份)。
对应数据库的dede_archives表,请根据实际情况修改前缀。
此表中有三个字段表示时间:
pubdate:发布时间(前台可更改)
senddate:存储时间
sortrank:前台调用最新的文章。实际利用这个时间。
这一段说的没有错,我再详细说明一下:
1.pubdate:发布时间(前台可更改)
发布新的文章或编辑文章时,可以在高级参数中看到,可以更改。也是在内容页和列表页调用系统的时间。当发布时间为1970时,列表页面会显示1970-01-01,文章页面获取的发布时间为“否”。当然,这以dede默认模板为准。如果你修改它,可能会有其他结果。例如:我的待审核文章发布时会自动更新为当前系统时间(如果不设置,见dedecmsunevalated文档自动更新发布时间)
2.senddate:存储时间
按字面意思可以理解,但是所谓的存储时间体现在哪里呢?是dede后台文件列表中的“进入时间”。理论上dede后台是不能修改的,但是实际中SQL语句也是可以修改的。实际意义。如果你的文章命名规则是“{typedir}/{Y}/{M}{D}/{aid}.html”,你的文章页面的url中也直观的提到了。
3.sortrank:前台呼叫最新的文章。实际利用这个时间。
我们一般看不到这个时间,但是如果前端模板设置为“orderby='public',系统会根据这个时间来调用。很多讲只是强调这些细节,而也算是一个原则吧。。
其次,我们应该明白,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不能完全一样,所以这里有点问题,但是这是无害的。重点是这个方案是修改整个系统的数据库pubdate、senddate、sortrank三个时间段,也就是说从你第一个文章发到最后一个,都变成你的修改现在这个时候,我第一次修改后,整个网站的文章就在3月19日发布了。可以说,几乎什么都搞砸了。这个大家应该都能理解。所以,我说备份很重要。 , 转载这个文章的人真是害人。我觉得这个方法不可取,完全没用。
二、1970 的正确解
优采云采集 发布时唯一不能出错的就是系统进入时间。因此,我们以此为标准,将public和sortrank时间改为senddate(语句下,先备份,后操作)。同时,经过对网站采集的更多考虑,有的文章的发布时间和存储时间有很大的区别吗?比如3-19采集有很多文章,发布审核,插件控制,每天自动更新,4-19才更新。如果执行两条命令,最近文章审核过的也会在3-19号放出,但是你可以选择只执行一条命令。 )
如果你不介意我上面说的,如果你真的需要解决1970的问题,在dede background-system-sql命令行工具中,执行如下命令:
UPDATE dede_archives SET sortrank = senddate ;
该命令是将前台呼叫时间更改为存储时间。如果你是我上面提到的那种,就不要执行了。至于1970年会不会有其他影响,请自行考虑
UPDATE dede_archives SET pubdate = senddate ;
这个命令是把释放时间改成存储时间,就不解释了,上面都说了
上一篇:织梦DedecmsError: no csrf hash code的解决方法!在后台编辑模板时 查看全部
文章采集调用(第二步,后台执行SQL语句SELECT(FROMdede)_)
第二步后台执行SQL语句SELECT * FROM dede_archives order by id DESC limit 1
这样你就可以看到你刚刚添加的文章一的所有字段值了。
观察以下数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中,1231846313为时间数据。
然后它被替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,你看到第一句话应该就可以通过他了。说一下他的方法的问题(注意:这种SQL语句或者需要修改数据库的,必须先备份)。
对应数据库的dede_archives表,请根据实际情况修改前缀。
此表中有三个字段表示时间:
pubdate:发布时间(前台可更改)
senddate:存储时间
sortrank:前台调用最新的文章。实际利用这个时间。
这一段说的没有错,我再详细说明一下:
1.pubdate:发布时间(前台可更改)
发布新的文章或编辑文章时,可以在高级参数中看到,可以更改。也是在内容页和列表页调用系统的时间。当发布时间为1970时,列表页面会显示1970-01-01,文章页面获取的发布时间为“否”。当然,这以dede默认模板为准。如果你修改它,可能会有其他结果。例如:我的待审核文章发布时会自动更新为当前系统时间(如果不设置,见dedecmsunevalated文档自动更新发布时间)
2.senddate:存储时间
按字面意思可以理解,但是所谓的存储时间体现在哪里呢?是dede后台文件列表中的“进入时间”。理论上dede后台是不能修改的,但是实际中SQL语句也是可以修改的。实际意义。如果你的文章命名规则是“{typedir}/{Y}/{M}{D}/{aid}.html”,你的文章页面的url中也直观的提到了。
3.sortrank:前台呼叫最新的文章。实际利用这个时间。
我们一般看不到这个时间,但是如果前端模板设置为“orderby='public',系统会根据这个时间来调用。很多讲只是强调这些细节,而也算是一个原则吧。。
其次,我们应该明白,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不能完全一样,所以这里有点问题,但是这是无害的。重点是这个方案是修改整个系统的数据库pubdate、senddate、sortrank三个时间段,也就是说从你第一个文章发到最后一个,都变成你的修改现在这个时候,我第一次修改后,整个网站的文章就在3月19日发布了。可以说,几乎什么都搞砸了。这个大家应该都能理解。所以,我说备份很重要。 , 转载这个文章的人真是害人。我觉得这个方法不可取,完全没用。
二、1970 的正确解
优采云采集 发布时唯一不能出错的就是系统进入时间。因此,我们以此为标准,将public和sortrank时间改为senddate(语句下,先备份,后操作)。同时,经过对网站采集的更多考虑,有的文章的发布时间和存储时间有很大的区别吗?比如3-19采集有很多文章,发布审核,插件控制,每天自动更新,4-19才更新。如果执行两条命令,最近文章审核过的也会在3-19号放出,但是你可以选择只执行一条命令。 )
如果你不介意我上面说的,如果你真的需要解决1970的问题,在dede background-system-sql命令行工具中,执行如下命令:
UPDATE dede_archives SET sortrank = senddate ;
该命令是将前台呼叫时间更改为存储时间。如果你是我上面提到的那种,就不要执行了。至于1970年会不会有其他影响,请自行考虑
UPDATE dede_archives SET pubdate = senddate ;
这个命令是把释放时间改成存储时间,就不解释了,上面都说了
上一篇:织梦DedecmsError: no csrf hash code的解决方法!在后台编辑模板时
文章采集调用(使用dedecms这个程序建站有五年多的时间期间不少)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-03 22:03
本文介绍了dedecms使用sql语句调用文章静态链接地址的方法。分享给大家,供大家参考。具体分析如下:
很多时候我们用织梦background调用数据的时候,自带的标签往往调用不到我们想要的数据,所以不得不写sql来调用。之前有一个问题,我两天没做。出来后看到下面文章,问题解决了。
我用dedecms建网站已经五年多了,期间建了很多网站。欢迎朋友找我建网站。
补充:
发布这个文章后,无意中发现在dedecms的GetOneArchive中,只要传入一个文档id就可以得到文章链接。其实这个函数返回的文章信息数组收录了Up:链接地址、标题、文章ID、列ID,这里只需要文章链接地址,具体代码如下:
代码如下:{dede:sql sql="select * From dede_archives a where a.title like'%织梦建站%' and a.arcrank>-1 limit 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
如果只需要调用文章的链接地址,这个方法是一种快捷方式。 文章下一部分介绍的方法比较复杂,但是如果要调用文章的链接地址,也要调用列名。试试看。
为什么使用 dede:php、dede:sql
在一些更复杂的调用中使用dede:arclist标签不能解决问题,比如调用成员发出的文章等,通常通过dede:sql标签来完成。达成。
我今天提到的电话也很特别。就是在首页调用指定关键字的文章。其实这个和dedecms相关的文章标签类似。这里有两种方式与您分享。
dede:sql标签调用了指定关键字文章静态地址,这里是dede:sql上dedecms的官方介绍。
Sql 标签
功能描述:用于通过SQL查询从模板中获取返回的内容。
适用范围:非扩展模块的所有模板。
(1)Syntax:{dede:sql sql="write sql statement here"}底层模板{/dede:sql}
(2)attribute:[1] sql 完整的 SQL 查询语句。
(3)Underlying 模板:所有在 SQL 语句中找到的字段都可以用 [field:field name/] 调用。
了解了dede:sql标签后,就可以根据自己的需要编写sql语句了。这里我想用指定的关键字调用文章。 sql语句如下:
代码如下:“select * From dede_archives a where a.arcrank>-1 and a.title like'%Script%' limit 8”
句子分析:a.arcrank>-1 限制调用批准的文章; like '%script%' 调用指定关键字的文章; limit 8 是调用 8 的次数
然后开始写完整的标签和底层模板,如下:
1、 先解决完整标题和截断的问题:我用 [field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title] 我相信你方法会经常用到,这里就不多介绍了,以后可能会专门介绍文章来介绍这个用法。50是截断长度
2、 解决dede的问题:sql tag static 文章地址:这个比较麻烦,我在网上翻了一下,给出的解决方法大多是href="/plus/view.php?aid =[ field:id/]",显然这不是我想要的。这不是静态地址,其他地址用arclist调用,都是静态地址。结果是一篇文章的文章有两个地址,一个静态的,一个动态的。这显然对seo不友好,还不如自己折腾最后成功
3、 解决无法正确获取id的问题:之前没注意到,因为dede_arctype和dede_archives这两个表的id字段名是一样的,导致底层模板无法获取到正确的id。之前的选择已更改并添加了别名。
dede:sql调用文章静态链接地址的完美方式
代码如下:(dede:sql sql="select * From dede_archives a, dede_arctype t where a.typeid = t.id and a.title like'%Life Tips%' and a.arcrank>-1限制 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
无论如何,我终于达到了我想要的效果。后来想了想怎么用dede:php标签来实现这个效果。其实方法和dede:sql标签是一样的,就不多说了。直接粘贴代码:
代码如下:(dede:php)
$dsql->SetQuery("选择a.id作为辅助,t.id作为tid,typeid,senddate,title,ismake,arcrank,namerule,typedir from dede_archives a, dede_arctype t where a.typeid = t.id和 a.title like'%Life Tips%' and a.arcrank>-1 limit 8");
$dsql->Execute();
while($row = $dsql->GetArray()){
echo''.cn_substr($row['title'], 50).'';
}
{/dede:php}
希望这篇文章能帮到你dedecms建站。 查看全部
文章采集调用(使用dedecms这个程序建站有五年多的时间期间不少)
本文介绍了dedecms使用sql语句调用文章静态链接地址的方法。分享给大家,供大家参考。具体分析如下:
很多时候我们用织梦background调用数据的时候,自带的标签往往调用不到我们想要的数据,所以不得不写sql来调用。之前有一个问题,我两天没做。出来后看到下面文章,问题解决了。
我用dedecms建网站已经五年多了,期间建了很多网站。欢迎朋友找我建网站。
补充:
发布这个文章后,无意中发现在dedecms的GetOneArchive中,只要传入一个文档id就可以得到文章链接。其实这个函数返回的文章信息数组收录了Up:链接地址、标题、文章ID、列ID,这里只需要文章链接地址,具体代码如下:
代码如下:{dede:sql sql="select * From dede_archives a where a.title like'%织梦建站%' and a.arcrank>-1 limit 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
如果只需要调用文章的链接地址,这个方法是一种快捷方式。 文章下一部分介绍的方法比较复杂,但是如果要调用文章的链接地址,也要调用列名。试试看。
为什么使用 dede:php、dede:sql
在一些更复杂的调用中使用dede:arclist标签不能解决问题,比如调用成员发出的文章等,通常通过dede:sql标签来完成。达成。
我今天提到的电话也很特别。就是在首页调用指定关键字的文章。其实这个和dedecms相关的文章标签类似。这里有两种方式与您分享。
dede:sql标签调用了指定关键字文章静态地址,这里是dede:sql上dedecms的官方介绍。
Sql 标签
功能描述:用于通过SQL查询从模板中获取返回的内容。
适用范围:非扩展模块的所有模板。
(1)Syntax:{dede:sql sql="write sql statement here"}底层模板{/dede:sql}
(2)attribute:[1] sql 完整的 SQL 查询语句。
(3)Underlying 模板:所有在 SQL 语句中找到的字段都可以用 [field:field name/] 调用。
了解了dede:sql标签后,就可以根据自己的需要编写sql语句了。这里我想用指定的关键字调用文章。 sql语句如下:
代码如下:“select * From dede_archives a where a.arcrank>-1 and a.title like'%Script%' limit 8”
句子分析:a.arcrank>-1 限制调用批准的文章; like '%script%' 调用指定关键字的文章; limit 8 是调用 8 的次数
然后开始写完整的标签和底层模板,如下:
1、 先解决完整标题和截断的问题:我用 [field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title] 我相信你方法会经常用到,这里就不多介绍了,以后可能会专门介绍文章来介绍这个用法。50是截断长度
2、 解决dede的问题:sql tag static 文章地址:这个比较麻烦,我在网上翻了一下,给出的解决方法大多是href="/plus/view.php?aid =[ field:id/]",显然这不是我想要的。这不是静态地址,其他地址用arclist调用,都是静态地址。结果是一篇文章的文章有两个地址,一个静态的,一个动态的。这显然对seo不友好,还不如自己折腾最后成功
3、 解决无法正确获取id的问题:之前没注意到,因为dede_arctype和dede_archives这两个表的id字段名是一样的,导致底层模板无法获取到正确的id。之前的选择已更改并添加了别名。
dede:sql调用文章静态链接地址的完美方式
代码如下:(dede:sql sql="select * From dede_archives a, dede_arctype t where a.typeid = t.id and a.title like'%Life Tips%' and a.arcrank>-1限制 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
无论如何,我终于达到了我想要的效果。后来想了想怎么用dede:php标签来实现这个效果。其实方法和dede:sql标签是一样的,就不多说了。直接粘贴代码:
代码如下:(dede:php)
$dsql->SetQuery("选择a.id作为辅助,t.id作为tid,typeid,senddate,title,ismake,arcrank,namerule,typedir from dede_archives a, dede_arctype t where a.typeid = t.id和 a.title like'%Life Tips%' and a.arcrank>-1 limit 8");
$dsql->Execute();
while($row = $dsql->GetArray()){
echo''.cn_substr($row['title'], 50).'';
}
{/dede:php}
希望这篇文章能帮到你dedecms建站。
文章采集调用(织梦小程序获取文章列表列表接口(1)_2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-03 07:20
接口名称:织梦小程序Get文章List接口
接口标识:列表
接口地址:你的网站/api/index.php?action=list[&typeid=10]
接口参数:
织梦百度小程序代码:
/*获取新闻 */
swan.request({
url: app.globalData.api+"action=list",
data: {
typeid: '20',
num: '10',
order:'id desc',
aid: app.globalData.aid
},
method: 'POST',
header: {
'content-type': 'application/x-www-form-urlencoded',
'x-appsecret': app.globalData.appsecret
},
success: function (res) {
var data = res.data;
if (data.status == 200) {
var list = data.data;
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
that.setData({
list: list
})
}
}
})
(1)列表页采用底部出的方式加载更多代码,可以参考demo
(2)如果要获取当前列的所有子列和每个子列的前n个文章,可以导入request.js,具体参考get_category的使用。
(3)在调用列表模板时可以传递一个参数data-listtype='1',表示被调用的列表模板的类型为:text list
list_1:文本列表
list_2:图片列表(两张图片)
list_3:图文列表(左图右文)
list_4:图片列表(三张图片)
list_5:标题+描述列表
(也可以在template/list.swan中添加自己的样式)
(4)demo中的页面列表、案例、服务其实是一模一样的,但是因为小程序的tabbar不支持参数传递,所以切换到案例和服务项时必须是新页面,所以我复制了两个Copy。点击进入列表页面时,一定要弄清楚你要使用哪个列表,例如:
show_service: function (e) {
var data = e.currentTarget.dataset;
var title = data.title;
var typeid = data.typeid;
var list_type = data.listtype;
//tabbar不支持传参通过缓存读取
swan.setStorageSync('stypeid', typeid)
swan.switchTab({
url: '/pages/service/service?typeid=' + typeid + "&title=" + title + "&list_type=" + list_type,
})
},
(5)调用单个页面属于category接口范围,详见category接口用法
(6)api返回的列表中的时间是时间戳格式,所以需要通过utils下的formatTime函数进行处理。示例代码:
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
织梦秒开发QQ群 查看全部
文章采集调用(织梦小程序获取文章列表列表接口(1)_2)
接口名称:织梦小程序Get文章List接口
接口标识:列表
接口地址:你的网站/api/index.php?action=list[&typeid=10]
接口参数:
织梦百度小程序代码:
/*获取新闻 */
swan.request({
url: app.globalData.api+"action=list",
data: {
typeid: '20',
num: '10',
order:'id desc',
aid: app.globalData.aid
},
method: 'POST',
header: {
'content-type': 'application/x-www-form-urlencoded',
'x-appsecret': app.globalData.appsecret
},
success: function (res) {
var data = res.data;
if (data.status == 200) {
var list = data.data;
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
that.setData({
list: list
})
}
}
})
(1)列表页采用底部出的方式加载更多代码,可以参考demo
(2)如果要获取当前列的所有子列和每个子列的前n个文章,可以导入request.js,具体参考get_category的使用。
(3)在调用列表模板时可以传递一个参数data-listtype='1',表示被调用的列表模板的类型为:text list
list_1:文本列表
list_2:图片列表(两张图片)
list_3:图文列表(左图右文)
list_4:图片列表(三张图片)
list_5:标题+描述列表
(也可以在template/list.swan中添加自己的样式)
(4)demo中的页面列表、案例、服务其实是一模一样的,但是因为小程序的tabbar不支持参数传递,所以切换到案例和服务项时必须是新页面,所以我复制了两个Copy。点击进入列表页面时,一定要弄清楚你要使用哪个列表,例如:
show_service: function (e) {
var data = e.currentTarget.dataset;
var title = data.title;
var typeid = data.typeid;
var list_type = data.listtype;
//tabbar不支持传参通过缓存读取
swan.setStorageSync('stypeid', typeid)
swan.switchTab({
url: '/pages/service/service?typeid=' + typeid + "&title=" + title + "&list_type=" + list_type,
})
},
(5)调用单个页面属于category接口范围,详见category接口用法
(6)api返回的列表中的时间是时间戳格式,所以需要通过utils下的formatTime函数进行处理。示例代码:
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
织梦秒开发QQ群
文章采集调用(各种不同的Python模块可以来解析,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-03 02:15
正则表达式
正则表达式(RE 或 Regex)是字符串的搜索模式。使用正则表达式,您可以在较大的文本正文中搜索特定字符/单词。
例如,您可以识别网页上的所有电话号码。您还可以更换某些项目。例如,您可以用小写标记替换 HTML 中所有格式错误的大写标记。您还可以验证一些输入...
正则表达式使用的模式从左到右应用。每个源字符仅使用一次。您可能想知道为什么在进行网络数据挖掘时理解正则表达式很重要?
简而言之,有各种 Python 模块可以解析 HTML,您可以使用 XPath 和 CSS 选择器。
在理想的语义世界中,数据易于机器读取,信息嵌入到具有有意义属性的相关 HTML 元素中。
但现实世界是混乱的,你经常会在一个 p 元素中发现很多文本。当你想从这个巨大的文本中提取特定的数据时,比如价格、日期或名称等,你必须使用正则表达式。
注意:这里有一个很棒的网站 来测试你的正则表达式:,还有一个很棒的博客 () 来了解更多关于它们的信息,这个文章 只会涵盖你能做的事情的一小部分正则表达式。
当您拥有此类数据时,正则表达式会很有用:
我们可以使用 Xpath 表达式来选择这个文本节点,然后使用这个正则表达式来提取价格:
提取 HTML 标签内的文本,使用正则表达式很烦人,但可行:
如您所见,您可以使用套接字手动发送 HTTP 请求并使用正则表达式来解析响应,但这很复杂,并且有更高级的 API 可以使此任务更容易。
2) urllib3 和 LXML
免责声明:很容易迷失在 Python 的 urllib 中。 urllib 和 urllib2 是标准库的一部分,您还可以找到 urllib3。 urllib2在python3中分为多个模块,urllib3在任何时候都可能不会成为标准库的一部分。这整个令人困惑的事情将成为博客文章 的主题。在本节中,我选择只讨论 urllib3,因为它在 Python 世界中被广泛使用,仅举两个例子,例如被 pip 和 requests 库使用。
Urllib3 是一个高级包,它允许您对 HTTP 请求执行几乎任何您想做的事情。它允许我们使用更少的代码行来完成我们上面对套接字所做的事情。
这个比socket版本简洁多了。不仅如此,API非常简单易懂,你可以轻松做很多事情,比如添加HTTP头、使用代理、POST表单等。
例如,如果我们决定设置一些标头并使用代理,我们只需要这样做。
<p>你看到了吗?完全一样的代码行数,但是有一些东西是urllib3不好处理的,比如我们要添加一个cookie,就得手动创建相应的header并添加到请求中。 查看全部
文章采集调用(各种不同的Python模块可以来解析,你知道吗?)
正则表达式
正则表达式(RE 或 Regex)是字符串的搜索模式。使用正则表达式,您可以在较大的文本正文中搜索特定字符/单词。
例如,您可以识别网页上的所有电话号码。您还可以更换某些项目。例如,您可以用小写标记替换 HTML 中所有格式错误的大写标记。您还可以验证一些输入...
正则表达式使用的模式从左到右应用。每个源字符仅使用一次。您可能想知道为什么在进行网络数据挖掘时理解正则表达式很重要?
简而言之,有各种 Python 模块可以解析 HTML,您可以使用 XPath 和 CSS 选择器。
在理想的语义世界中,数据易于机器读取,信息嵌入到具有有意义属性的相关 HTML 元素中。
但现实世界是混乱的,你经常会在一个 p 元素中发现很多文本。当你想从这个巨大的文本中提取特定的数据时,比如价格、日期或名称等,你必须使用正则表达式。
注意:这里有一个很棒的网站 来测试你的正则表达式:,还有一个很棒的博客 () 来了解更多关于它们的信息,这个文章 只会涵盖你能做的事情的一小部分正则表达式。
当您拥有此类数据时,正则表达式会很有用:
我们可以使用 Xpath 表达式来选择这个文本节点,然后使用这个正则表达式来提取价格:
提取 HTML 标签内的文本,使用正则表达式很烦人,但可行:
如您所见,您可以使用套接字手动发送 HTTP 请求并使用正则表达式来解析响应,但这很复杂,并且有更高级的 API 可以使此任务更容易。
2) urllib3 和 LXML
免责声明:很容易迷失在 Python 的 urllib 中。 urllib 和 urllib2 是标准库的一部分,您还可以找到 urllib3。 urllib2在python3中分为多个模块,urllib3在任何时候都可能不会成为标准库的一部分。这整个令人困惑的事情将成为博客文章 的主题。在本节中,我选择只讨论 urllib3,因为它在 Python 世界中被广泛使用,仅举两个例子,例如被 pip 和 requests 库使用。
Urllib3 是一个高级包,它允许您对 HTTP 请求执行几乎任何您想做的事情。它允许我们使用更少的代码行来完成我们上面对套接字所做的事情。
这个比socket版本简洁多了。不仅如此,API非常简单易懂,你可以轻松做很多事情,比如添加HTTP头、使用代理、POST表单等。
例如,如果我们决定设置一些标头并使用代理,我们只需要这样做。
<p>你看到了吗?完全一样的代码行数,但是有一些东西是urllib3不好处理的,比如我们要添加一个cookie,就得手动创建相应的header并添加到请求中。
文章采集调用(维清微信文章采集器平台更新网站的基本设置教程)
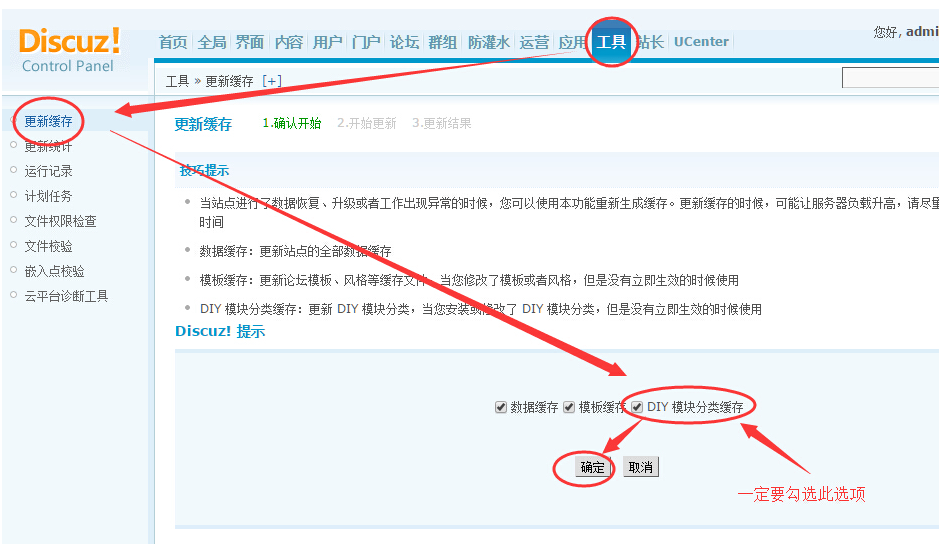
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-09-10 20:15
在按照本教程设置插件之前,请确保您已经安装了“微信WeChat文章采集器”插件。如果没有,请从以下地址下载安装:
下载链接:@wq_wechatcollecting.plugin
第 1 步:基本设置
一、 设置插件后端的基本设置。
二、设置相关联众编码账号。
1、去联众编码平台注册自己的账号。由于联众编码平台网站的更新,下图可能与实际站点有所不同。具体注册页面请参考网站实战页面。 .
2、注册成功后,个人中心将为当前账户充值相应的代码点。具体充值金额根据您的网站采集金额合理充值。
3、填写刚刚注册的联众账号和密码到[维清]微信文章采集器联众后台相关设置,以便采集触发数据源网站的验证码机制自动验证。
4、采集 过程中自动验证的记录可以在[维清]微信文章采集器后台自动识别验证码日志模块下查看。
三、设置公众号和文章类别。
采集器后台设置统一公众号和文章分类,[维清]微信导航和微信微信文章采集器会调用这个分类,具体设置如图:
有以下5点需要说明。请参考以下图片中的标志说明:
解释点 1:
此设置将在显示模式下打开“同步到论坛”时生效。如果在这里选择特定版块,如图选择“默认版本”,当文章发到采集器的“综合”分类时,文章会同步到“默认版本”在论坛版块中;如果不选择,帖子将同步到后台设置中“default文章synchronization section”中设置的section。
解释点2:
此设置将在显示模式下打开“同步到门户”时生效。如果这里选择了指定的栏目,如图选择了“Test it”,当你将文章发到采集器的“综合”分类时,文章会同步到“Test it”门户部分在列中;如果不选择,文章将同步到后台门户文章默认同步栏目模块下设置的门户类别。
解释点 3:
填写外链地址后,这个分类就变成了外链,公众号和文章不能分配到这个分类,和外链部分类似。
解释点 4:
如果类别只选为文章类别,公众号不能归入该类别。如果还填写了外链地址,“微信导航”插件的分类中将不会显示该分类。
解释点 5:
如果未启用分类,页面将不会显示,也无法将公众号或文章添加到该分类中。
第 2 步:数据填充
一、进入微信采集页面
点击网站navigation“微信窗口”
或输入网址:您的域名/plugin.php?id=wq_wechatcollecting
二、manual采集公众号信息。
1、点击插件头部的申请按钮,进入申请收入页面,填写需要搜索的关键词提交,如下图:
2、选择需要提交的公众号选择相关分类提交。
三、如需开启公众号自动更新,请参考下方教程。
在前台公众号管理模块下找到需要开启自动采集的公众号开启自动采集
四、manual采集公号的文章.
手机采集文章目前提供三种方式
第一种:按公众号采集
1、 点击插件头部的申请按钮,进入公众号管理页面。找到你想要的采集公众号,点击“采集文章”进入采集,如下图:
第二种:通过关键字采集
1、点击插件头部的apply按钮进入关键字采集文章页面,将关键字输入采集,如下图:
2、选择要添加的文章。
第三种:关注链接采集
1、点击插件头部的应用按钮进入,点击链接采集文章输入文章地址进行采集,如下图:
五、安装采集器手机版,请按照以下教程调用数据。
指导前先安装“微信weiqing文章采集器插件手机版”,现在安装
1、采集器plugin后台导入手机版数据并调用模块点击提交。
2、 导入后记得更新缓存。
3、请注意,每次更新移动版组件都需要重新导入。
第 3 步:DIY 数据导入
一、先决条件。 1、“[维清]WeChat文章DIY”导入DIY前必须安装。立即安装
下载地址:@wq_wechatdiy.pack
二、导入步骤。
1、在应用中心下载微清微信文章采集器DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:
2、维清微信文章采集器导入DIY时,XML文件与页面的对应关系如下:
页面 XML 文件名页面 URL 查看全部
文章采集调用(维清微信文章采集器平台更新网站的基本设置教程)
在按照本教程设置插件之前,请确保您已经安装了“微信WeChat文章采集器”插件。如果没有,请从以下地址下载安装:
下载链接:@wq_wechatcollecting.plugin
第 1 步:基本设置
一、 设置插件后端的基本设置。
二、设置相关联众编码账号。
1、去联众编码平台注册自己的账号。由于联众编码平台网站的更新,下图可能与实际站点有所不同。具体注册页面请参考网站实战页面。 .
2、注册成功后,个人中心将为当前账户充值相应的代码点。具体充值金额根据您的网站采集金额合理充值。
3、填写刚刚注册的联众账号和密码到[维清]微信文章采集器联众后台相关设置,以便采集触发数据源网站的验证码机制自动验证。
4、采集 过程中自动验证的记录可以在[维清]微信文章采集器后台自动识别验证码日志模块下查看。
三、设置公众号和文章类别。
采集器后台设置统一公众号和文章分类,[维清]微信导航和微信微信文章采集器会调用这个分类,具体设置如图:
有以下5点需要说明。请参考以下图片中的标志说明:
解释点 1:
此设置将在显示模式下打开“同步到论坛”时生效。如果在这里选择特定版块,如图选择“默认版本”,当文章发到采集器的“综合”分类时,文章会同步到“默认版本”在论坛版块中;如果不选择,帖子将同步到后台设置中“default文章synchronization section”中设置的section。
解释点2:
此设置将在显示模式下打开“同步到门户”时生效。如果这里选择了指定的栏目,如图选择了“Test it”,当你将文章发到采集器的“综合”分类时,文章会同步到“Test it”门户部分在列中;如果不选择,文章将同步到后台门户文章默认同步栏目模块下设置的门户类别。
解释点 3:
填写外链地址后,这个分类就变成了外链,公众号和文章不能分配到这个分类,和外链部分类似。
解释点 4:
如果类别只选为文章类别,公众号不能归入该类别。如果还填写了外链地址,“微信导航”插件的分类中将不会显示该分类。
解释点 5:
如果未启用分类,页面将不会显示,也无法将公众号或文章添加到该分类中。
第 2 步:数据填充
一、进入微信采集页面
点击网站navigation“微信窗口”
或输入网址:您的域名/plugin.php?id=wq_wechatcollecting
二、manual采集公众号信息。
1、点击插件头部的申请按钮,进入申请收入页面,填写需要搜索的关键词提交,如下图:
2、选择需要提交的公众号选择相关分类提交。
三、如需开启公众号自动更新,请参考下方教程。
在前台公众号管理模块下找到需要开启自动采集的公众号开启自动采集
四、manual采集公号的文章.
手机采集文章目前提供三种方式
第一种:按公众号采集
1、 点击插件头部的申请按钮,进入公众号管理页面。找到你想要的采集公众号,点击“采集文章”进入采集,如下图:
第二种:通过关键字采集
1、点击插件头部的apply按钮进入关键字采集文章页面,将关键字输入采集,如下图:
2、选择要添加的文章。
第三种:关注链接采集
1、点击插件头部的应用按钮进入,点击链接采集文章输入文章地址进行采集,如下图:
五、安装采集器手机版,请按照以下教程调用数据。
指导前先安装“微信weiqing文章采集器插件手机版”,现在安装
1、采集器plugin后台导入手机版数据并调用模块点击提交。
2、 导入后记得更新缓存。
3、请注意,每次更新移动版组件都需要重新导入。
第 3 步:DIY 数据导入
一、先决条件。 1、“[维清]WeChat文章DIY”导入DIY前必须安装。立即安装
下载地址:@wq_wechatdiy.pack
二、导入步骤。
1、在应用中心下载微清微信文章采集器DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:
2、维清微信文章采集器导入DIY时,XML文件与页面的对应关系如下:
页面 XML 文件名页面 URL
文章采集调用(织梦的隐藏栏目设置没有梦的设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-10 10:08
接触织梦近一年,我建的第一个站就是用织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似于草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,在采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单。改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果在导航菜单中隐藏某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。 查看全部
文章采集调用(织梦的隐藏栏目设置没有梦的设置)
接触织梦近一年,我建的第一个站就是用织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似于草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,在采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单。改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果在导航菜单中隐藏某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。
文章采集调用( 运营公众号怎样收集素材文章的相关资料?数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-08 07:13
运营公众号怎样收集素材文章的相关资料?数据)
对于公众号运营商来说,文章素材的采集非常重要,因为它可以有效提高你文章的质量。下面我们就跟着拓图数据来了解一下公众号的操作方法。采集素材文章的相关信息。
公众号运营资料如何采集文章方法一
获取文章链接,电脑用户可以直接在浏览器地址栏中选择并复制文章链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
公众号运营材料如何采集文章
点击拓图数据采集文章按钮,编辑器采集文章有两个功能入口:编辑菜单右上角的采集文章按钮; 采集功能按钮底部右侧@文章 按钮。粘贴文章 链接并单击采集。 采集完成后可以编辑修改文章。
公众号运营资料如何采集文章方法二
从网上可以搜到的公众号文章采集,这是最直接、最简单的解决方案。
大致流程是:
1、通过搜索引擎搜索微信搜索入口进入公众号搜索。
2、选择公众号进入公众号历史文章列表和文章内容进行分析和存储。
公众号运营材料如何采集文章
如果采集过于频繁,搜狗搜索和公众账号历史文章列表访问会显示验证码。无法直接使用通用脚本采集获取验证码。在这里您可以使用无头浏览器通过对接打码平台访问和识别验证码。 Selenium 可以用作无头浏览器。
公众号运营如何采集素材文章?其实,拓图数据认为对于微信公众号的运营来说采集素材文章是非常重要的,所以大家可以按照上面的方法做好文章素材的采集。 ! 查看全部
文章采集调用(
运营公众号怎样收集素材文章的相关资料?数据)
对于公众号运营商来说,文章素材的采集非常重要,因为它可以有效提高你文章的质量。下面我们就跟着拓图数据来了解一下公众号的操作方法。采集素材文章的相关信息。
公众号运营资料如何采集文章方法一
获取文章链接,电脑用户可以直接在浏览器地址栏中选择并复制文章链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
公众号运营材料如何采集文章
点击拓图数据采集文章按钮,编辑器采集文章有两个功能入口:编辑菜单右上角的采集文章按钮; 采集功能按钮底部右侧@文章 按钮。粘贴文章 链接并单击采集。 采集完成后可以编辑修改文章。
公众号运营资料如何采集文章方法二
从网上可以搜到的公众号文章采集,这是最直接、最简单的解决方案。
大致流程是:
1、通过搜索引擎搜索微信搜索入口进入公众号搜索。
2、选择公众号进入公众号历史文章列表和文章内容进行分析和存储。
公众号运营材料如何采集文章
如果采集过于频繁,搜狗搜索和公众账号历史文章列表访问会显示验证码。无法直接使用通用脚本采集获取验证码。在这里您可以使用无头浏览器通过对接打码平台访问和识别验证码。 Selenium 可以用作无头浏览器。
公众号运营如何采集素材文章?其实,拓图数据认为对于微信公众号的运营来说采集素材文章是非常重要的,所以大家可以按照上面的方法做好文章素材的采集。 !
文章采集调用(谷歌浏览器到新版MicrosoftEdge的IDM插件试一试呢?(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-08 03:16
)
此文章仅供小白参考。别喷大佬然后正文开始:
相信很多朋友已经从 Chrome 迁移到新版 Microsoft Edge。它真的很容易使用。不用担心同步404问题。我搬到 Edge 有一段时间了。但是问题很多,最让我头疼的是不能调用IDM的问题。然后我打开微软应用商店,看到如下画面。
可以看出IDM的扩展只对旧版Edge有效,但新版经过实际测试也可以使用。失败的次数占十分之九。但是我在Chrome浏览器上没有遇到过这个问题。然后我想,既然新版Edge浏览器使用了谷歌Chrome的开源内核,而且Chrome App Store的扩展都可以使用,那我为什么不用Chrome Store呢?在此处尝试 IDM 插件。使用Chrome应用商店插件前需要设置Edge浏览器。
如图,我们打开浏览器的扩展选项,进入后打开这两个开关。然后你可以去Chrome商店下载扩展程序。
(需特殊上网)下载地址:
当然,对于特别不能上网的用户,我已经解压了这个插件。下载地址:提取码:czag
我用的IDM集成在拨盘的分享里,6.35永远不会更新版本,不需要激活。解压我提供的压缩包中的文件。
解压压缩包里面的压缩包,里面应该有一个文件夹。记住这个文件夹的位置,以后会用到。
然后进入Edge扩展选项(这一步要看左下角的两个选项是否开启),点击加载解压后的扩展,选择刚刚解压的扩展文件夹。只需安装它。
以后可以在Edge中享受IDM,包括使用油猴脚本,也可以下载一些网站视频。这个功能很强大
查看全部
文章采集调用(谷歌浏览器到新版MicrosoftEdge的IDM插件试一试呢?(图)
)
此文章仅供小白参考。别喷大佬然后正文开始:
相信很多朋友已经从 Chrome 迁移到新版 Microsoft Edge。它真的很容易使用。不用担心同步404问题。我搬到 Edge 有一段时间了。但是问题很多,最让我头疼的是不能调用IDM的问题。然后我打开微软应用商店,看到如下画面。
可以看出IDM的扩展只对旧版Edge有效,但新版经过实际测试也可以使用。失败的次数占十分之九。但是我在Chrome浏览器上没有遇到过这个问题。然后我想,既然新版Edge浏览器使用了谷歌Chrome的开源内核,而且Chrome App Store的扩展都可以使用,那我为什么不用Chrome Store呢?在此处尝试 IDM 插件。使用Chrome应用商店插件前需要设置Edge浏览器。
如图,我们打开浏览器的扩展选项,进入后打开这两个开关。然后你可以去Chrome商店下载扩展程序。
(需特殊上网)下载地址:
当然,对于特别不能上网的用户,我已经解压了这个插件。下载地址:提取码:czag
我用的IDM集成在拨盘的分享里,6.35永远不会更新版本,不需要激活。解压我提供的压缩包中的文件。
解压压缩包里面的压缩包,里面应该有一个文件夹。记住这个文件夹的位置,以后会用到。
然后进入Edge扩展选项(这一步要看左下角的两个选项是否开启),点击加载解压后的扩展,选择刚刚解压的扩展文件夹。只需安装它。
以后可以在Edge中享受IDM,包括使用油猴脚本,也可以下载一些网站视频。这个功能很强大
文章采集调用(不能的匹配规则(b)和文章内容的结束部分相对应)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-07 14:02
"之后。通过对比文章content页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章内容的开头。因此,您应该选择“
" 是匹配规则的开头。
(b) 找到文章内容的结尾部分“同时添加值为”transparent”的“wmode”参数,如图29所示,
图29-文章内容结束
注意:因为结束部分的最后一个标签是“
",并且这个标签在文章内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应文章内容的开头,是经过比较分析得到的,这里要选“
" 作为文章内容的结尾,如图30所示,
图30-文章内容匹配规则结束
(c) 结合(a)和(b),我们可以看出文章内容的匹配规则应该是“
[内容]
”,填写后,如图31,
图31-文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
这里“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写完毕后,如图(图32),
图32-设置后新建采集节点:第二步设置内容字段获取规则
勾选后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“添加采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),
图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果点击“保存并启动采集”,则会进入“采集指定节点”界面。否则请点击“返回上一步修改”。
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),
图35-查看节点的seed URL
点击“启动采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename=”采集测试(一)” channelid=”1″ macthtype=”string”
refurl=”http://www.dedecms.com/knowled ... .html” sourcelang=”gb2312″ cosort=”asc” isref=”no” exptime=”10″ usemore=”0″ /}
{dede:listrule sourcetype=”batch” rssurl=”http://” regxurl=”http://www.dedecms.com/knowled ... t_47_(*).html”
startid=”1″ endid=”1″ addv=”1″ urlrule=”area”
musthas=”.html” nothas=”" listpic=”1″ usemore=”0″}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart} {dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype=’full’ sptype=’full’ srul=’1′ erul=’5′}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field=’title’ value=” isunit=” isdown=”}
{dede:match}
[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='writer' value="isunit="isdown="} {dede :match}作者:[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='source' value="isunit="isdown="} {dede:match}来源:[内容]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='pubdate' value=” isunit=” isdown= ”} {dede:match} 发表于:[Content]{/dede:match} {dede:function}@me=GetMkTime(@me);{/dede:function}{/dede:item}{dede:item 字段='body' value=" isunit='1' isdown='1'} {dede:match}
[内容]
{/dede:match} {dede:function}{/dede:function}{/dede:item}{/dede:itemconfig} 查看全部
文章采集调用(不能的匹配规则(b)和文章内容的结束部分相对应)
"之后。通过对比文章content页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章内容的开头。因此,您应该选择“
" 是匹配规则的开头。
(b) 找到文章内容的结尾部分“同时添加值为”transparent”的“wmode”参数,如图29所示,
图29-文章内容结束
注意:因为结束部分的最后一个标签是“
",并且这个标签在文章内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应文章内容的开头,是经过比较分析得到的,这里要选“
" 作为文章内容的结尾,如图30所示,
图30-文章内容匹配规则结束
(c) 结合(a)和(b),我们可以看出文章内容的匹配规则应该是“
[内容]
”,填写后,如图31,
图31-文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
这里“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写完毕后,如图(图32),
图32-设置后新建采集节点:第二步设置内容字段获取规则
勾选后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“添加采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),
图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果点击“保存并启动采集”,则会进入“采集指定节点”界面。否则请点击“返回上一步修改”。
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),
图35-查看节点的seed URL
点击“启动采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename=”采集测试(一)” channelid=”1″ macthtype=”string”
refurl=”http://www.dedecms.com/knowled ... .html” sourcelang=”gb2312″ cosort=”asc” isref=”no” exptime=”10″ usemore=”0″ /}
{dede:listrule sourcetype=”batch” rssurl=”http://” regxurl=”http://www.dedecms.com/knowled ... t_47_(*).html”
startid=”1″ endid=”1″ addv=”1″ urlrule=”area”
musthas=”.html” nothas=”" listpic=”1″ usemore=”0″}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart} {dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype=’full’ sptype=’full’ srul=’1′ erul=’5′}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field=’title’ value=” isunit=” isdown=”}
{dede:match}
[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='writer' value="isunit="isdown="} {dede :match}作者:[Content]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='source' value="isunit="isdown="} {dede:match}来源:[内容]{/dede:match} {dede:function}{/dede:function}{/dede:item}{dede:item field='pubdate' value=” isunit=” isdown= ”} {dede:match} 发表于:[Content]{/dede:match} {dede:function}@me=GetMkTime(@me);{/dede:function}{/dede:item}{dede:item 字段='body' value=" isunit='1' isdown='1'} {dede:match}
[内容]
{/dede:match} {dede:function}{/dede:function}{/dede:item}{/dede:itemconfig}
文章采集调用(WordPress调用站外文章解决方法调用WordPress随机文章、最新文章和热门文章总结 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-07 09:15
)
WordPress 异地调用文章 解决方案摘要
随意调用WordPress文章、最新文章和流行文章摘要:
方法一:
这个外部网站对WordPress博客文章的调用不限于最新的文章,它可以调用几乎所有类型的文章,比如最热的文章、随机的文章、最新的评论等等等等,不过唯一的缺点就是速度可能会慢一些,具体效果可以在秋树文章上看到。
说说外部网站调用wordpress博客流行的文章list实现方法:
首先在网站的根目录下创建一个php文件,在你要对外调用文章的地方,命名为blog_call.php。
内容如下:
</a>
如果使用下面的代码,可以输出一个自定义的摘要输出:其实我个人比较推荐使用上面的代码,上面的代码输出文章title。
</a>
在你调用文章的网站对应页面插入以下代码:
ok,成功解决外部网站调用WordPress博客热门文章。
方法二:
有很多方法可以调用其他网站最新的文章跨站。最简单的方法是直接使用WordPress后端集成的feed调用功能。但是,这样做的缺点是只能从站点外部调用。 文章放在侧边栏,如果想在其他页面或者地方调用,不好处理。那么是否可以直接用代码调用其他网站最新的文章跨站?今天给大家分享一段代码,实现网站其他最新文章功能的跨站调用。代码很简单:复制代码,粘贴到合适的地方,然后通过CSS控制样式。
’ target=”_blank”>
</a>
就这么简单,最后你加CSS来控制样式就OK了。
方法三:
WordPress使用另一种方式在站外调用文章,但是调用速度太慢。有时加载页面需要很长时间才能检索文章。所以再次GG,找到这个方法,备忘录。
wordpress2.8 后增加了fetch_feed 功能,可以获取外部RSS feed 显示其他网站文章。如果你有多个网站,通过fetch_feed函数可以互相调用,显示多个网站文章链接,也可以用fetch_feed函数来采集他站文章,当然这是最好是站长允许的。本文将用最简单的语言来说明其用法。
fetch_feed 函数的原型如下
fetch_feed($url)
结合流行的rss解析库SimplePie,代码如下
”></a>
简要说明:
替换 feed_url。
SimplePie 默认的缓存文件夹是根目录下的缓存文件夹,所以第一步是在网站的根目录下创建一个名为cache 777权限的文件夹。
get_items(0,7)中的数字“7”是你显示的列表的文章数字。
上面的方法只是调用文章的title,如果还想调用文章,可以在上面添加如下代码:
$item->get_description()
附上原文章code
” rel=”bookmark” title=””></a> 查看全部
文章采集调用(WordPress调用站外文章解决方法调用WordPress随机文章、最新文章和热门文章总结
)
WordPress 异地调用文章 解决方案摘要
随意调用WordPress文章、最新文章和流行文章摘要:
方法一:
这个外部网站对WordPress博客文章的调用不限于最新的文章,它可以调用几乎所有类型的文章,比如最热的文章、随机的文章、最新的评论等等等等,不过唯一的缺点就是速度可能会慢一些,具体效果可以在秋树文章上看到。
说说外部网站调用wordpress博客流行的文章list实现方法:
首先在网站的根目录下创建一个php文件,在你要对外调用文章的地方,命名为blog_call.php。
内容如下:
</a>
如果使用下面的代码,可以输出一个自定义的摘要输出:其实我个人比较推荐使用上面的代码,上面的代码输出文章title。
</a>
在你调用文章的网站对应页面插入以下代码:
ok,成功解决外部网站调用WordPress博客热门文章。
方法二:
有很多方法可以调用其他网站最新的文章跨站。最简单的方法是直接使用WordPress后端集成的feed调用功能。但是,这样做的缺点是只能从站点外部调用。 文章放在侧边栏,如果想在其他页面或者地方调用,不好处理。那么是否可以直接用代码调用其他网站最新的文章跨站?今天给大家分享一段代码,实现网站其他最新文章功能的跨站调用。代码很简单:复制代码,粘贴到合适的地方,然后通过CSS控制样式。
’ target=”_blank”>
</a>
就这么简单,最后你加CSS来控制样式就OK了。
方法三:
WordPress使用另一种方式在站外调用文章,但是调用速度太慢。有时加载页面需要很长时间才能检索文章。所以再次GG,找到这个方法,备忘录。
wordpress2.8 后增加了fetch_feed 功能,可以获取外部RSS feed 显示其他网站文章。如果你有多个网站,通过fetch_feed函数可以互相调用,显示多个网站文章链接,也可以用fetch_feed函数来采集他站文章,当然这是最好是站长允许的。本文将用最简单的语言来说明其用法。
fetch_feed 函数的原型如下
fetch_feed($url)
结合流行的rss解析库SimplePie,代码如下
”></a>
简要说明:
替换 feed_url。
SimplePie 默认的缓存文件夹是根目录下的缓存文件夹,所以第一步是在网站的根目录下创建一个名为cache 777权限的文件夹。
get_items(0,7)中的数字“7”是你显示的列表的文章数字。
上面的方法只是调用文章的title,如果还想调用文章,可以在上面添加如下代码:
$item->get_description()
附上原文章code
” rel=”bookmark” title=””></a>
文章采集调用( 侧边PostsWidgetWidget插件倡萌推荐你的文章调用不够灵活)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-07 01:19
侧边PostsWidgetWidget插件倡萌推荐你的文章调用不够灵活)
文章directory[隐藏]
您是否认为您的 WordPress 主题 文章 的侧边栏不够灵活?想在侧边栏小部件中调用更多文章? Advocate 建议您试用 Ultimate Posts Widget 插件。
Ultimate Posts Widget 简介
Ultimate Posts Widget 算是目前为止功能最强大的WordPress侧边栏文章调用插件(至少Advocate知道),主要功能如下:
更多详情请看截图或下载体验:
终极帖子小工具下载
您可以在后台插件安装界面搜索Ultimate Posts Widget进行在线安装,也可以在这里下载Ultimate Posts Widget。
如果你是WordPress主题开发者,可以考虑把它集成到你的主题中,很爽!不过你也可以考虑加个“浏览量”最多的文章,加一个时间段(一个月,半年等),不只是鸡冻!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
文章采集调用(
侧边PostsWidgetWidget插件倡萌推荐你的文章调用不够灵活)
文章directory[隐藏]
您是否认为您的 WordPress 主题 文章 的侧边栏不够灵活?想在侧边栏小部件中调用更多文章? Advocate 建议您试用 Ultimate Posts Widget 插件。
Ultimate Posts Widget 简介
Ultimate Posts Widget 算是目前为止功能最强大的WordPress侧边栏文章调用插件(至少Advocate知道),主要功能如下:
更多详情请看截图或下载体验:
终极帖子小工具下载
您可以在后台插件安装界面搜索Ultimate Posts Widget进行在线安装,也可以在这里下载Ultimate Posts Widget。
如果你是WordPress主题开发者,可以考虑把它集成到你的主题中,很爽!不过你也可以考虑加个“浏览量”最多的文章,加一个时间段(一个月,半年等),不只是鸡冻!
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
文章采集调用( WPFavoritePosts文章收藏插件使用方法收藏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-06 03:14
WPFavoritePosts文章收藏插件使用方法收藏)
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果删除浏览器的cookie,采集的数据会丢失,所以建议注册用户并保存在数据库中,不要丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)
可设置各种提示
设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果只想在某些文章中显示喜欢的链接,可以在编辑文章时在文章中添加以下短代码:
第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!
WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List的另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的wpfp-page-template.php文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前已经采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集不准确。
找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:
提倡可爱
一个喜欢折腾WordPress的文科IT书呆子,被它折腾了^_^
关注 查看全部
文章采集调用(
WPFavoritePosts文章收藏插件使用方法收藏)
文章directory[隐藏]
张萌最近一直在考虑WordPress大学的设计,尤其是如何让注册用户体验好。考虑增加一个文章采集 功能,让大家采集自己喜欢的文章,然后在页面上生成一个列表,在侧边栏中显示最近最喜欢的文章,这样大家就很方便了未来找到您需要的文章。于是找到了WPFavorite Posts这个WordPress文章 采集插件,试用了一下,感觉还不错。
WP 采集夹介绍
WP 最喜欢的帖子是一个很好的 WordPress文章 最喜欢的插件。您可以在文章 页面添加采集按钮。用户可以点击采集自己的文章,可以在文章专页上显示自己喜欢的@,还支持“最近采集的文章(大家看自己的)”和“最喜欢的文章上”整个网站”这两个小工具。
最值得一提的 WP 采集夹通过浏览器 cookie 和数据库存储用户最喜欢的数据。也就是说,访客也可以采集文章。当然,访问者最喜欢的数据是通过 cookie 存储的。如果删除浏览器的cookie,采集的数据会丢失,所以建议注册用户并保存在数据库中,不要丢失。
WP 采集夹安装设置
1.后台插件安装页面搜索WP采集贴在线安装,或下载WP采集贴。
启用2.后,在设置-采集的帖子中,可以进行相关设置(如果不懂英文,请使用翻译工具进行翻译)
可设置各种提示
设置好后就可以使用插件了。
如何使用 WP 采集夹
1.“采集链接”展示方式
您可以选择在第一张图的界面中自动插入文章头或尾,也可以在single.php或page.php的主题文件中使用以下代码自定义位置:
如果只想在某些文章中显示喜欢的链接,可以在编辑文章时在文章中添加以下短代码:
第 16 集
2.Widget 调用。可以在 Appearance-Gadgets 中看到两个可用的小工具,自己设置即可。
3.添加采集列表页面。该页面用于展示用户采集的所有文章页面。可以在page-new page中新建一个page,然后在内容中添加如下调用代码来显示用户的采集列表(每个用户只能看到自己的采集列表)
你还没有收藏过任何文章,去收藏一些吧!
WP 采集夹高级技巧(备用)
以下是我在论坛看到的一些高级功能,还没有经过测试,记录下来以备后用。
1. 已致电文章 的采集夹
在循环中使用以下代码最简单的方法可以直接调用:
如果上面的方法不行,可以考虑下面的方法:
在主题的functions.php中添加以下代码
function wpfp_get_current_count() {
global $wpdb;
$current_post = get_the_ID();
$query = "SELECT post_id, meta_value, post_status FROM $wpdb->postmeta";
$query .= " LEFT JOIN $wpdb->posts ON post_id=$wpdb->posts.ID";
$query .= " WHERE post_status='publish' AND meta_key='wpfp_favorites' AND post_id = '".$current_post."'";
$results = $wpdb->get_results($query);
if ($results) {
foreach ($results as $o):
echo $o->meta_value;
endforeach;
}else {echo( '0' );}
}
使用以下代码调用
2.Favorite List的另一种调用方式
如果想直接在主题文件中修改显示采集列表,可以使用如下调用函数
3.获取用户采集的数量
插件默认使用自己的wpfp-page-template.php文件来显示采集夹列表。如果想在列表顶部显示采集的数量,可以参考如下代码:
if ($favorite_post_ids){
$user_favorite_count = count($favorite_post_ids);
echo '<p>您已收藏了 '.$user_favorite_count.' 篇文章';
}else{
echo '您目前还没有收藏任何文章!';
}</p>
4.删除文章后统计不准确
网站 删除了一些文章。如果用户之前已经采集了这些文章,他们的采集数据中仍然收录这些文章的ID,导致采集不准确。
找到插件的wpfp-page-template.php文件,添加如下图代码:
/*remove deleted posts cmhello*/
foreach ($favorite_post_ids as $id) {
if ( FALSE === get_post_status( $id ) ) {
$favorite_post_ids = array_diff($favorite_post_ids, array($id));
$favorite_post_ids = array_values($favorite_post_ids);
wpfp_update_user_meta($favorite_post_ids);
}
}
$favorite_post_ids = wpfp_get_user_meta();
/*//remove deleted posts cmhello*/
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
分享到:
提倡可爱
一个喜欢折腾WordPress的文科IT书呆子,被它折腾了^_^
关注
文章采集调用(织梦文章标题自动随机插入导入长尾关键词,支持优采云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-05 05:05
织梦文章 标题自动随机插入长尾关键词,支持优采云采集。
插件介绍
1、织梦文章title 指定长尾关键词插件,可以导入大量长尾关键词、采集文章或者发布文章时,会自动循环调用长尾关键词列表指定关键词作为标题。
2、织梦文章title 自动随机插入指定的长尾。 关键词插件支持手动发布和优采云、采集侠发布自定义长尾词。
3、在文章title random关键词函数中,我们还开发了关键词,调用长尾词作为当前的文章,有助于搜索排名,如截图所示下面,您可以定义要调用多少个长尾关键词作为标题,以及是否使用当前标题的第一个长尾词作为这个文章的关键词函数。
4、为了让您的使用更加灵活,我们还在这个长尾关键词插件中加入了切换功能。暂时不需要时,可以在后台关闭。
5、关键词可以批量上传数万甚至数万长尾关键词以EXCEL形式上传使用。我们提供织梦关键词批量上传功能。
通过插件关键词上传功能成功上传EXCEL表格后,可以在关键词列表中看到我们刚刚从表格中导入的关键词列表。
每次我们发送文章时,成功导入的关键词都会显示在网站标题中。当然,你也可以设置同时调用几个长尾关键词作为文章的某个标题,下面来测试一下内容。
下载地址提示:登录支付后,可永久阅读隐藏内容。
如果微信无法支付,请使用支付宝或联系站长。付费阅读
标签:织梦plugin织梦Dedecms文章title 自动随机插入插件文章title 自动随机插入 查看全部
文章采集调用(织梦文章标题自动随机插入导入长尾关键词,支持优采云采集)
织梦文章 标题自动随机插入长尾关键词,支持优采云采集。
插件介绍
1、织梦文章title 指定长尾关键词插件,可以导入大量长尾关键词、采集文章或者发布文章时,会自动循环调用长尾关键词列表指定关键词作为标题。
2、织梦文章title 自动随机插入指定的长尾。 关键词插件支持手动发布和优采云、采集侠发布自定义长尾词。
3、在文章title random关键词函数中,我们还开发了关键词,调用长尾词作为当前的文章,有助于搜索排名,如截图所示下面,您可以定义要调用多少个长尾关键词作为标题,以及是否使用当前标题的第一个长尾词作为这个文章的关键词函数。
4、为了让您的使用更加灵活,我们还在这个长尾关键词插件中加入了切换功能。暂时不需要时,可以在后台关闭。
5、关键词可以批量上传数万甚至数万长尾关键词以EXCEL形式上传使用。我们提供织梦关键词批量上传功能。
通过插件关键词上传功能成功上传EXCEL表格后,可以在关键词列表中看到我们刚刚从表格中导入的关键词列表。
每次我们发送文章时,成功导入的关键词都会显示在网站标题中。当然,你也可以设置同时调用几个长尾关键词作为文章的某个标题,下面来测试一下内容。
下载地址提示:登录支付后,可永久阅读隐藏内容。
如果微信无法支付,请使用支付宝或联系站长。付费阅读
标签:织梦plugin织梦Dedecms文章title 自动随机插入插件文章title 自动随机插入
文章采集调用(如何写采集之前后台插件管理,我也不是什么大师 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-05 01:21
)
前沿:
如果你对优采云一无所知,你应该去网上学习一点优采云采集的知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及发布文章时间设置(随机10-70分钟)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击5获取列表-选择需要存储的分类(注:网址为https网站免费版优采云software可能无法获取分类列表)
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
创建任务组后,导入该组下的任务规则(导入任务到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项
第二步很重要。导入我们对应的问答/文章publishing 模块。看你是采集许事游数还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:
最后保存:
然后右键启动task采集:
发布内容审核方式+批量定时任务定时发布使用方法:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
将状态 1 更改为 0
修改这两个文件后,优采云发布的内容会被收录到评论列表中,前端不会显示。
如何设置定时发布的定时任务?
本站根目录下的插件文件/application\controllers\Doit.php是自动批量发布审核内容。默认情况下,一次授予 100 次访问。这个值可以自己修改,最大值不能超过2000,否则查询压力大,负载增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
参观地址可以添加到宝塔规划任务中:
查看全部
文章采集调用(如何写采集之前后台插件管理,我也不是什么大师
)
前沿:
如果你对优采云一无所知,你应该去网上学习一点优采云采集的知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及发布文章时间设置(随机10-70分钟)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击5获取列表-选择需要存储的分类(注:网址为https网站免费版优采云software可能无法获取分类列表)
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
创建任务组后,导入该组下的任务规则(导入任务到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项
第二步很重要。导入我们对应的问答/文章publishing 模块。看你是采集许事游数还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:
最后保存:
然后右键启动task采集:
发布内容审核方式+批量定时任务定时发布使用方法:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
将状态 1 更改为 0
修改这两个文件后,优采云发布的内容会被收录到评论列表中,前端不会显示。
如何设置定时发布的定时任务?
本站根目录下的插件文件/application\controllers\Doit.php是自动批量发布审核内容。默认情况下,一次授予 100 次访问。这个值可以自己修改,最大值不能超过2000,否则查询压力大,负载增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
参观地址可以添加到宝塔规划任务中:
文章采集调用(网站文章收集东西有哪些能够运用呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2021-09-04 21:01
文章Collect 东西不知道大家有没有看懂,可能有的站长没摸过吧!采集东西一般用在一些站群或者大型门户网站,比如企业网站,很少用到。当然,也有一些个人网站,也有一些人在使用采集。由于某些情况,我不想自己更新文章可能很大需要更新的文章网站很多而且很杂,比如新闻网站,都用采集,那网站还能怎么办? @文章采集的东西有什么用?
1、优采云
对于搜索引擎优化者来说,优采云是比较常用的采集软件。下载安装优采云集器,有付费版和免费版,百度找下载地址。 (这里就不赘述了)
2、优采云
优采云collector 是一个用于快速采集网络信息的工具。常用于采集网站@文章、网站@信息数据等。优采云有免费版和付费版。在这种情况下,这取决于自己或公司的需要。免费版在很多方面受到限制。
3、优采云采集
这个采集工具比较智能,需要装备的当地人很少。可视为傻瓜式运营的软件。
织梦程序采集插件:
1、采集侠
使用纪夏的插件,网站@必须是织梦,因为这个插件是织梦的集合插件。收人直接通过关键词采集文章,收人是收费软件,当然我们也可以下载破解版,具体可以百度搜索。
2、集合节点
织梦采集 节点是织梦后台程序主动带来的。采集节点完全免费,但是采集能力不是很强,无法完成的东西很多。
首先要知道,大网站基本上都有自己开放的采集点,很少用到东西。作为搜索引擎优化,我们没有那么强大的技术支持,所以只能用一些东西来完成采集。
关键词:网站@文章采集 有哪些可用的工具? 查看全部
文章采集调用(网站文章收集东西有哪些能够运用呢?(图))
文章Collect 东西不知道大家有没有看懂,可能有的站长没摸过吧!采集东西一般用在一些站群或者大型门户网站,比如企业网站,很少用到。当然,也有一些个人网站,也有一些人在使用采集。由于某些情况,我不想自己更新文章可能很大需要更新的文章网站很多而且很杂,比如新闻网站,都用采集,那网站还能怎么办? @文章采集的东西有什么用?
1、优采云
对于搜索引擎优化者来说,优采云是比较常用的采集软件。下载安装优采云集器,有付费版和免费版,百度找下载地址。 (这里就不赘述了)
2、优采云
优采云collector 是一个用于快速采集网络信息的工具。常用于采集网站@文章、网站@信息数据等。优采云有免费版和付费版。在这种情况下,这取决于自己或公司的需要。免费版在很多方面受到限制。
3、优采云采集
这个采集工具比较智能,需要装备的当地人很少。可视为傻瓜式运营的软件。
织梦程序采集插件:
1、采集侠
使用纪夏的插件,网站@必须是织梦,因为这个插件是织梦的集合插件。收人直接通过关键词采集文章,收人是收费软件,当然我们也可以下载破解版,具体可以百度搜索。
2、集合节点
织梦采集 节点是织梦后台程序主动带来的。采集节点完全免费,但是采集能力不是很强,无法完成的东西很多。
首先要知道,大网站基本上都有自己开放的采集点,很少用到东西。作为搜索引擎优化,我们没有那么强大的技术支持,所以只能用一些东西来完成采集。
关键词:网站@文章采集 有哪些可用的工具?
文章采集调用(LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-04 19:22
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
下面的功能会显示(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。 查看全部
文章采集调用(LOOP_posts放在LOOP之前限定你所需要的条件,SQL查询)
将 query_posts() 放在 LOOP 之前以限制您需要的条件,wp_query 将使用您的参数生成新的 SQL 查询,并忽略通过 URL 接收的其他参数。如果不想忽略,可以在调用中使用$query_string。
query_posts($query_string."&order=ASC")
设置文章的显示顺序,但不干扰查询字符串的其余部分。参数前必须有“&”符号
还有其他N多用途~~
==============================================
类别参数
显示属于某个类别的文章
根据 ID 显示类别
只显示一个类别 ID 中的文章
query_posts(‘cat=4’);
根据名称显示类别
只显示属于某个分类名称的文章
query_posts('category_name=员工主页');
显示多个类别和 ID
显示属于多个类别ID的文章
query_posts('cat=2,6,17,38');
删除类别中的文章
显示所有文章,但排除类别ID前带有“-”(减号)减号的类别。
query_posts(‘cat=-3’);
删除所有属于类别3的文章。有一个限制性条款:所有只属于类别3的文章将被删除。如果一个类别同时属于其他类别,该类别仍然不会被删除。
标签参数
显示与标签相关的文章
为标签提取文章
query_posts(‘tag=cooking’);
使用任何此类标签获取文章
query_posts('tag=bread,baking');
用这三个标签获取文章
query_posts('tag=bread+baking+recipe');
作者参数
也可以根据作者限制文章的数量
author_name 操作 user_nicename 区域,author 操作作者 id。
文章 & 网页参数
返回单个文章或单个网页
由于模板层次结构,首先执行 home.php。这意味着您可以编写一个 home.php,home.phh 调用 query_posts() 来检索一个特殊的网页并将该网页设置为您的主页。没有任何插件或黑客,你需要运行一个机制并显示和维护一个非博客主页。
一个更有用的方法可能是使用WP网页功能,并将该功能用于您的主页。您可以将“关于页面”设置为站点的入口点或最后一页。您可以执行一些更动态的步骤、设置自定义网页、显示最近的评论、文章、类别、存档。请看下面的例子。
时间参数
获取文章特定时间段发布
网页参数
偏移参数
您不能转移或忽略一个或多个原创文章,这些文章通常是您的查询使用offset参数采集的。
下面的功能会显示(1)最近5篇文章
query_posts(‘showposts=5&offset=1’);
按参数排序
根据文章按此区域排序
还要考虑“ASC”或“DESC”的排序参数
关节参数
您可能已经从上面的示例中注意到,您使用与号(& 符号)将参数组合在一起,例如:
query_posts(‘cat=3&year=2004’);
类别13,关于当月首页显示的文章:
if (is_home()) {query_posts ($query_string.'&cat=13&monthnum='.date('n',current_time('timestamp'))); }
在2.3版本中,该参数组合将返回属于类别1和类别3的文章,只显示两篇文章(2)文章,根据标题,降序排列:
query_posts(array('category__and'=>array(1,3),'showposts'=>2,'orderby'=>title,'order'=>DESC));
在2.3 和2.5 版本中,您可能期望以下内容返回所有属于类别 1 并标记为“Apple”的文章
query_posts(‘cat=1&tag=apples’);
一个错误阻止了它的运行。请查看Ticket #5433,工作空间需要使用+
搜索多个标签
query_posts(‘cat=1&tag=apples+apples’);
对于之前的查询,这将产生预期的结果。请注意,使用“cat=1&tag=apples+oranges”可以产生预期的结果。
文章采集调用(QT+openCV操做的这部分,其余还没时间看 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-04 19:14
)
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针
在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好了,所有代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
查看全部
文章采集调用(QT+openCV操做的这部分,其余还没时间看
)
今天写的QT+openCV实现了拍照的拍照功能。应用
网上搜集了很多资料。 QT没有专门的camera类,所以这个就得自己写了。网上也有很多关于海关openCV和V4l的介绍,因为我的项目是在window下开发的,所以选择了openCV。因为之前没用过openCV,所以只看了openCVS摄像头的操作部分,其他的没时间看。功能
openCV:学习
第一次下载是2.3.1。安装后发现没有lib库,所以选择2.1的ui
openCV中文学习pdf:这个
现在,我开始详细介绍如何在QT中实时采集camera数据。温泉
打开QTcreator(我用的是QT中文版2.3).net
创建一个新的小部件项目指针
在界面上贴两个标签,显示采集相机拍摄的数据和照片。代码
编辑camaraget.h文件orm
#ifndef CAMARAGET_H
#define CAMARAGET_H
#include
#include
#include // 设置采集数据的间隔时间
#include //包含opencv库头文件
#include
namespace Ui {
class camaraGet;
}
class camaraGet : public QWidget
{
Q_OBJECT
public:
explicit camaraGet(QWidget *parent = 0);
~camaraGet();
private slots:
void openCamara(); // 打开摄像头
void readFarme(); // 读取当前帧信息
void closeCamara(); // 关闭摄像头。
void takingPictures(); // 拍照
private:
Ui::camaraGet *ui;
QTimer *timer;
QImage *imag;
CvCapture *cam;// 视频获取结构, 用来做为视频获取函数的一个参数
IplImage *frame;//申请IplImage类型指针,就是申请内存空间来存放每一帧图像
};
#endif // CAMARAGET_H
编辑 camaraget.cpp
#include "camaraget.h"
#include "ui_camaraget.h"
camaraGet::camaraGet(QWidget *parent) :
QWidget(parent),
ui(new Ui::camaraGet)
{
ui->setupUi(this);
cam = NULL;
timer = new QTimer(this);
imag = new QImage(); // 初始化
/*信号和槽*/
connect(timer, SIGNAL(timeout()), this, SLOT(readFarme())); // 时间到,读取当前摄像头信息
connect(ui->open, SIGNAL(clicked()), this, SLOT(openCamara()));
connect(ui->pic, SIGNAL(clicked()), this, SLOT(takingPictures()));
connect(ui->closeCam, SIGNAL(clicked()), this, SLOT(closeCamara()));
}
/******************************
********* 打开摄像头 ***********
*******************************/
void camaraGet::openCamara()
{
cam = cvCreateCameraCapture(0);//打开摄像头,从摄像头中获取视频
timer->start(33); // 开始计时,超时则发出timeout()信号
}
/*********************************
********* 读取摄像头信息 ***********
**********************************/
void camaraGet::readFarme()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*************************
********* 拍照 ***********
**************************/
void camaraGet::takingPictures()
{
frame = cvQueryFrame(cam);// 从摄像头中抓取并返回每一帧
// 将抓取到的帧,转换为QImage格式。QImage::Format_RGB888不一样的摄像头用不一样的格式。
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
ui->label_2->setPixmap(QPixmap::fromImage(image)); // 将图片显示到label上
}
/*******************************
***关闭摄像头,释放资源,必须释放***
********************************/
void camaraGet::closeCamara()
{
timer->stop(); // 中止读取数据。
cvReleaseCapture(&cam);//释放内存;
}
camaraGet::~camaraGet()
{
delete ui;
}
好了,所有代码都OK了(当然项目创建的时候会生成main.cpp,不用改),但是现在点击运行,还是会报错,为什么?由于尚未收录 openCV 库。
在 *.pro 文件中添加:
INCLUDEPATH+=C:\OpenCV2.1\include\opencv
LIBS += C:\OpenCV2.1\lib\highgui210.lib \
C:\OpenCV2.1\lib\cxcore210.lib \
C:\OpenCV2.1\lib\cv210.lib
好的,你完成了。运行后,在widget中点击打开摄像头,就可以看到自己了。运行后效果:
后来发现效果不是很好,所以改了一下:改后的运行效果也贴出来了:
我改了一句:
QImage image((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888);
改成了 QImage image = QImage((const uchar*)frame->imageData, frame->width, frame->height, QImage::Format_RGB888).rgbSwapped();
文章采集调用(2.AnyProxy代理批量采集/24302048实现方法(一)_)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-04 08:03
1.Crawling with python/d1240673769/article/details/75907152
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步骤:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装相应的浏览器驱动插件。我在这里用谷歌浏览器测试:谷歌浏览器版本是52.0.2743.6; chromedriver 版本为:V 2.23 注意:Google Chrome 版本和chromedriver 需要对应,否则启动时会报错。 【附:selenium的chromedriver与chrome版本映射表(更新为v2.30)/huilan_same/article/details/51896672))
3.微信公众号登录地址:/
4.微信公号文章微信公众号后台可创建界面地址新建图文消息,可通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章interface地址
8.文章List翻页和内容获取
2.AnyProxy 代理批处理采集/p/24302048
实现方式:anyproxy+js
/luojiangwen/p/7943696.html
实现方式:anyproxy+java+webmagic
/t/181857
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位字符串是每个公众号的“id”,可在搜狗微信平台获取
uin:与访客相关,微信ID
key:与被访问的公众号相关
步骤:
1.编写按钮向导脚本,在手机上自动点击公众号文章列表页,即“查看历史新闻”; 2、利用fiddler代理劫持手机访问,将URL转发到本地用php编写的网页; 3、将接收到的php网页上的URL备份到数据库中; 4、使用python从数据库中检索出URL,然后进行正常的爬取。
我在爬取过程中发现一个问题:如果你只是想爬取文章内容,似乎没有访问频率限制,但是如果你想抓取阅读数和点赞数,经过一个一定的频率,返回会变成Null值,我设置了10秒的时间间隔,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.清博新榜
如果你只是想看数据,直接看日报就行了,不用花钱。如果需要连接自己的系统,他们也提供了api接口 查看全部
文章采集调用(2.AnyProxy代理批量采集/24302048实现方法(一)_)
1.Crawling with python/d1240673769/article/details/75907152
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步骤:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录效果;
2.使用webdriver功能需要安装相应的浏览器驱动插件。我在这里用谷歌浏览器测试:谷歌浏览器版本是52.0.2743.6; chromedriver 版本为:V 2.23 注意:Google Chrome 版本和chromedriver 需要对应,否则启动时会报错。 【附:selenium的chromedriver与chrome版本映射表(更新为v2.30)/huilan_same/article/details/51896672))
3.微信公众号登录地址:/
4.微信公号文章微信公众号后台可创建界面地址新建图文消息,可通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章interface地址
8.文章List翻页和内容获取
2.AnyProxy 代理批处理采集/p/24302048
实现方式:anyproxy+js
/luojiangwen/p/7943696.html
实现方式:anyproxy+java+webmagic
/t/181857
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位字符串是每个公众号的“id”,可在搜狗微信平台获取
uin:与访客相关,微信ID
key:与被访问的公众号相关
步骤:
1.编写按钮向导脚本,在手机上自动点击公众号文章列表页,即“查看历史新闻”; 2、利用fiddler代理劫持手机访问,将URL转发到本地用php编写的网页; 3、将接收到的php网页上的URL备份到数据库中; 4、使用python从数据库中检索出URL,然后进行正常的爬取。
我在爬取过程中发现一个问题:如果你只是想爬取文章内容,似乎没有访问频率限制,但是如果你想抓取阅读数和点赞数,经过一个一定的频率,返回会变成Null值,我设置了10秒的时间间隔,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.清博新榜
如果你只是想看数据,直接看日报就行了,不用花钱。如果需要连接自己的系统,他们也提供了api接口
文章采集调用(iOS在iOS中重写控件的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-09-04 08:00
声明式嵌入的思想是将嵌入代码与具体的交互和业务逻辑解耦。开发者只需关心需要嵌入的控件,并为这些控件声明所需的嵌入数据,从而降低埋点成本。
安卓
在Android中,我们自定义了常用的UI控件,如TextView、LinearLayout、ListView、ViewPager等,并重写了事件响应方法,并在这些方法中自动填充嵌入的代码。重写控件的好处是可以拦截更多的事件,执行效率高,运行稳定。但它的缺点也很明显——移植成本很高!
为了解决这个问题,我们采用了Android v7支持库的思路,通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
这样,开发者只需在自己的Activity基类中重写getDelegate方法,将该方法的返回值替换为修改后的AppCompatDelegate,即可自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
然而,新的问题也出现了。
如果UI控件在引用的第三方库中被覆盖,上述方法将不会生效,这意味着我们需要一个方法来替换UI控件类的父类。但是,在运行时,我们并没有找到一个可行的方法来替换UI控件类的父类。因此,我们尝试在编译时修改父类并开发了 Gradle 插件。其实这样做并没有运行时效率问题,只是会牺牲一些编译速度。这样,开发者只需要运行这个插件,就可以自动用我们重写的UI控件替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明式埋点后,只需在控件初始化时声明需要的埋点即可。我们不再需要侵入程序的各种响应功能,降低埋点难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,利用Objective-C关联属性和类别的语法特点,无需重写UI控件即可实现声明式管理。对于UIControl,可以在声明埋点的时候添加一个新的action,在事件发生时自动填写埋点代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,可以重写UITableViewDelegate,使用消息传递机制拦截事件,在事件回调方法中自动填埋代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
同样,使用声明式嵌入方法后,嵌入代码也得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明式嵌入可以替代所有的代码嵌入,可以解决前期遇到的移植成本高的问题。但本质上是一种代码埋点,只是代码埋点减少了,不再侵入业务逻辑。如果要满足嵌入式点动态部署和修复的需求,就要彻底杜绝前端写死的嵌入式代码。
无痕埋点
我们注意到,声明式埋点仍然需要写死代码的主要原因有两个:一是需要声明埋点控件的唯一事件标识符,即bid;二是一些业务字段需要在前端埋藏时携带,而这些字段是只有运行时才能知道的值。
对于第一点,我们可以尝试使用一致的规则,在前后端自动生成事件标识,这样后端就可以配置前端埋藏行为,实现自动埋藏。对于第二点,可以尝试通过某种方式自动将业务数据与埋点数据关联起来。这种关联可以发生在前端,也可以发生在后端。
事件 ID
为了自动生成事件标识符,我们需要获取每个控件自身父组件的ID、类名、Index等特征信息,逐层向上遍历,找到根节点。根节点一般是手动标记的,如果没有标记,则默认为视图层次树的顶部节点。最后将遍历生成的路径上所有节点的特征信息组合在一起,即为该事件的识别。考虑到实际布局中可能会有一些动态插入的控件,我们允许父组件的Index存在一定的误差。
配置后端需要维护自动生成的事件标识和投标映射关系,可以向前端下发配置文件。当前端控制事件被触发时,可以通过自动匹配配置文件获得相应的投标。需要注意的是,配置后台维护事件识别并不是一件容易的事。主要的复杂性在于不同版本之间的布局变化引起的事件标识的变化。这就是为什么需要手动标记根节点的原因。因此,一般我们会选择不容易改变的视图节点。
数据关联
为了实现业务数据和埋点数据的自动关联,我们初步尝试了前后端日志关联的方法。即前端请求后端API时,后端将业务数据写入日志,最后在数据清洗时合并相应的前后端日志。这种方式的问题是后端重构成本高,数据清洗成本大,不能广泛应用。但是在一些特殊场景下,比如某些业务数据只能被后端学习,而不能被前端学习,这种关联是必要的。
更常见的数据关联发生在前端数据之间。页面跳转时,业务数据通过规范跳转URI Scheme传递到下一个页面,自动填充到本页面的PV事件中。此页面上生成的所有其他事件将携带与 PV 事件相同的业务数据。
这样,通过自动生成事件标识符并进行数据关联,我们就可以实现“无踪埋点”,埋点节点可以通过配置文件动态下发,从而具备动态部署和修复埋点的能力。但需要注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获取业务字段时(这种情况比较常见),开发者代码埋点或声明性埋点指定仍为业务字段。从目前实践阶段的数据来看,业务中大约70%的埋点需求可以通过无缝埋点解决,另外30%的埋点需求,仍然需要使用声明性埋点和代码埋点。
总结
前端数据采集和上报是数据平台搭建过程中最重要的环节。美团点评前端每天上报百亿条数据。为了更好地满足公司各项业务对嵌入点日益复杂的需求,以及嵌入点对准确性、及时性、开发效率的要求,我们演化出了一套基于代码嵌入方案的轻量级和声明式公司前端埋地方案,并在动态埋地和无痕埋地方向做了进一步的探索和实践。目前,声明式埋点已经在部分业务中得到充分应用。从数据质量和开发者反馈来看,都达到了预期的收益。无标记埋点也在部分业务中得到验证和不断优化,未来将在公司内部进一步推广。
在实践中,我们意识到埋点问题无法通过单一的技术方案解决。我们需要在不同的场景下选择不同的埋设方案。例如,对于简单的用户行为事件,可以使用无标记的埋点来解决;而对于业务领域的埋点需求,需要承载大量可以在运行时学习的业务领域,需要声明性埋点来解决。从更高的层面来看,除了前端埋点技术的优化,埋点数据的标准化、前后端协同埋点、数据清洗和关联对于构建更加自动化和动态的埋点系统也很重要未来。 查看全部
文章采集调用(iOS在iOS中重写控件的思路)
声明式嵌入的思想是将嵌入代码与具体的交互和业务逻辑解耦。开发者只需关心需要嵌入的控件,并为这些控件声明所需的嵌入数据,从而降低埋点成本。
安卓
在Android中,我们自定义了常用的UI控件,如TextView、LinearLayout、ListView、ViewPager等,并重写了事件响应方法,并在这些方法中自动填充嵌入的代码。重写控件的好处是可以拦截更多的事件,执行效率高,运行稳定。但它的缺点也很明显——移植成本很高!
为了解决这个问题,我们采用了Android v7支持库的思路,通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
这样,开发者只需在自己的Activity基类中重写getDelegate方法,将该方法的返回值替换为修改后的AppCompatDelegate,即可自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
然而,新的问题也出现了。
如果UI控件在引用的第三方库中被覆盖,上述方法将不会生效,这意味着我们需要一个方法来替换UI控件类的父类。但是,在运行时,我们并没有找到一个可行的方法来替换UI控件类的父类。因此,我们尝试在编译时修改父类并开发了 Gradle 插件。其实这样做并没有运行时效率问题,只是会牺牲一些编译速度。这样,开发者只需要运行这个插件,就可以自动用我们重写的UI控件替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明式埋点后,只需在控件初始化时声明需要的埋点即可。我们不再需要侵入程序的各种响应功能,降低埋点难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,利用Objective-C关联属性和类别的语法特点,无需重写UI控件即可实现声明式管理。对于UIControl,可以在声明埋点的时候添加一个新的action,在事件发生时自动填写埋点代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,可以重写UITableViewDelegate,使用消息传递机制拦截事件,在事件回调方法中自动填埋代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
同样,使用声明式嵌入方法后,嵌入代码也得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明式嵌入可以替代所有的代码嵌入,可以解决前期遇到的移植成本高的问题。但本质上是一种代码埋点,只是代码埋点减少了,不再侵入业务逻辑。如果要满足嵌入式点动态部署和修复的需求,就要彻底杜绝前端写死的嵌入式代码。
无痕埋点
我们注意到,声明式埋点仍然需要写死代码的主要原因有两个:一是需要声明埋点控件的唯一事件标识符,即bid;二是一些业务字段需要在前端埋藏时携带,而这些字段是只有运行时才能知道的值。
对于第一点,我们可以尝试使用一致的规则,在前后端自动生成事件标识,这样后端就可以配置前端埋藏行为,实现自动埋藏。对于第二点,可以尝试通过某种方式自动将业务数据与埋点数据关联起来。这种关联可以发生在前端,也可以发生在后端。
事件 ID
为了自动生成事件标识符,我们需要获取每个控件自身父组件的ID、类名、Index等特征信息,逐层向上遍历,找到根节点。根节点一般是手动标记的,如果没有标记,则默认为视图层次树的顶部节点。最后将遍历生成的路径上所有节点的特征信息组合在一起,即为该事件的识别。考虑到实际布局中可能会有一些动态插入的控件,我们允许父组件的Index存在一定的误差。
配置后端需要维护自动生成的事件标识和投标映射关系,可以向前端下发配置文件。当前端控制事件被触发时,可以通过自动匹配配置文件获得相应的投标。需要注意的是,配置后台维护事件识别并不是一件容易的事。主要的复杂性在于不同版本之间的布局变化引起的事件标识的变化。这就是为什么需要手动标记根节点的原因。因此,一般我们会选择不容易改变的视图节点。
数据关联
为了实现业务数据和埋点数据的自动关联,我们初步尝试了前后端日志关联的方法。即前端请求后端API时,后端将业务数据写入日志,最后在数据清洗时合并相应的前后端日志。这种方式的问题是后端重构成本高,数据清洗成本大,不能广泛应用。但是在一些特殊场景下,比如某些业务数据只能被后端学习,而不能被前端学习,这种关联是必要的。
更常见的数据关联发生在前端数据之间。页面跳转时,业务数据通过规范跳转URI Scheme传递到下一个页面,自动填充到本页面的PV事件中。此页面上生成的所有其他事件将携带与 PV 事件相同的业务数据。
这样,通过自动生成事件标识符并进行数据关联,我们就可以实现“无踪埋点”,埋点节点可以通过配置文件动态下发,从而具备动态部署和修复埋点的能力。但需要注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获取业务字段时(这种情况比较常见),开发者代码埋点或声明性埋点指定仍为业务字段。从目前实践阶段的数据来看,业务中大约70%的埋点需求可以通过无缝埋点解决,另外30%的埋点需求,仍然需要使用声明性埋点和代码埋点。
总结
前端数据采集和上报是数据平台搭建过程中最重要的环节。美团点评前端每天上报百亿条数据。为了更好地满足公司各项业务对嵌入点日益复杂的需求,以及嵌入点对准确性、及时性、开发效率的要求,我们演化出了一套基于代码嵌入方案的轻量级和声明式公司前端埋地方案,并在动态埋地和无痕埋地方向做了进一步的探索和实践。目前,声明式埋点已经在部分业务中得到充分应用。从数据质量和开发者反馈来看,都达到了预期的收益。无标记埋点也在部分业务中得到验证和不断优化,未来将在公司内部进一步推广。
在实践中,我们意识到埋点问题无法通过单一的技术方案解决。我们需要在不同的场景下选择不同的埋设方案。例如,对于简单的用户行为事件,可以使用无标记的埋点来解决;而对于业务领域的埋点需求,需要承载大量可以在运行时学习的业务领域,需要声明性埋点来解决。从更高的层面来看,除了前端埋点技术的优化,埋点数据的标准化、前后端协同埋点、数据清洗和关联对于构建更加自动化和动态的埋点系统也很重要未来。
文章采集调用(文章采集调用系统()与udp协议简介(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-04 03:02
文章采集调用系统本地的系统调用接口,在系统调用的外部发送request到服务器进行处理,并返回相应信息给客户端,这种方式获取数据的方式是最传统的方式,使用websocket实现的话需要单独部署server端websocket消息接收服务器。tcp,udp,protobuf和amx等数据库传输层协议tcp,udp,protobuf和amx等数据库传输层协议_websocket实现移动端用户请求数据读写分离的方案解决方案实例分析_[t]tcp与udp协议简介armopenshiftudp-basedopenframeworkformobile-applications,如图所示armopenshiftudp-basedopenframeworkformobile-applications,如图所示tcp客户端如何监听请求。
windows下的http请求协议是来自于socket,请求的分发和响应都是对socket进行控制的。socket的分发模型一般有四种,请求发送端,响应接收端,客户端和服务端。windows下的websocket是一种无连接的udpio模型,客户端和服务端是无连接的。因此也可以先客户端和服务端使用http协议进行传输,返回方式会是tcp,可以用java处理,写个轮子就好了。当然了如果直接就是使用websocket,就可以直接使用websocket消息传递了。 查看全部
文章采集调用(文章采集调用系统()与udp协议简介(组图))
文章采集调用系统本地的系统调用接口,在系统调用的外部发送request到服务器进行处理,并返回相应信息给客户端,这种方式获取数据的方式是最传统的方式,使用websocket实现的话需要单独部署server端websocket消息接收服务器。tcp,udp,protobuf和amx等数据库传输层协议tcp,udp,protobuf和amx等数据库传输层协议_websocket实现移动端用户请求数据读写分离的方案解决方案实例分析_[t]tcp与udp协议简介armopenshiftudp-basedopenframeworkformobile-applications,如图所示armopenshiftudp-basedopenframeworkformobile-applications,如图所示tcp客户端如何监听请求。
windows下的http请求协议是来自于socket,请求的分发和响应都是对socket进行控制的。socket的分发模型一般有四种,请求发送端,响应接收端,客户端和服务端。windows下的websocket是一种无连接的udpio模型,客户端和服务端是无连接的。因此也可以先客户端和服务端使用http协议进行传输,返回方式会是tcp,可以用java处理,写个轮子就好了。当然了如果直接就是使用websocket,就可以直接使用websocket消息传递了。
文章采集调用(第二步,后台执行SQL语句SELECT(FROMdede)_)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-03 22:07
第二步后台执行SQL语句SELECT * FROM dede_archives order by id DESC limit 1
这样你就可以看到你刚刚添加的文章一的所有字段值了。
观察以下数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中,1231846313为时间数据。
然后它被替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,你看到第一句话应该就可以通过他了。说一下他的方法的问题(注意:这种SQL语句或者需要修改数据库的,必须先备份)。
对应数据库的dede_archives表,请根据实际情况修改前缀。
此表中有三个字段表示时间:
pubdate:发布时间(前台可更改)
senddate:存储时间
sortrank:前台调用最新的文章。实际利用这个时间。
这一段说的没有错,我再详细说明一下:
1.pubdate:发布时间(前台可更改)
发布新的文章或编辑文章时,可以在高级参数中看到,可以更改。也是在内容页和列表页调用系统的时间。当发布时间为1970时,列表页面会显示1970-01-01,文章页面获取的发布时间为“否”。当然,这以dede默认模板为准。如果你修改它,可能会有其他结果。例如:我的待审核文章发布时会自动更新为当前系统时间(如果不设置,见dedecmsunevalated文档自动更新发布时间)
2.senddate:存储时间
按字面意思可以理解,但是所谓的存储时间体现在哪里呢?是dede后台文件列表中的“进入时间”。理论上dede后台是不能修改的,但是实际中SQL语句也是可以修改的。实际意义。如果你的文章命名规则是“{typedir}/{Y}/{M}{D}/{aid}.html”,你的文章页面的url中也直观的提到了。
3.sortrank:前台呼叫最新的文章。实际利用这个时间。
我们一般看不到这个时间,但是如果前端模板设置为“orderby='public',系统会根据这个时间来调用。很多讲只是强调这些细节,而也算是一个原则吧。。
其次,我们应该明白,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不能完全一样,所以这里有点问题,但是这是无害的。重点是这个方案是修改整个系统的数据库pubdate、senddate、sortrank三个时间段,也就是说从你第一个文章发到最后一个,都变成你的修改现在这个时候,我第一次修改后,整个网站的文章就在3月19日发布了。可以说,几乎什么都搞砸了。这个大家应该都能理解。所以,我说备份很重要。 , 转载这个文章的人真是害人。我觉得这个方法不可取,完全没用。
二、1970 的正确解
优采云采集 发布时唯一不能出错的就是系统进入时间。因此,我们以此为标准,将public和sortrank时间改为senddate(语句下,先备份,后操作)。同时,经过对网站采集的更多考虑,有的文章的发布时间和存储时间有很大的区别吗?比如3-19采集有很多文章,发布审核,插件控制,每天自动更新,4-19才更新。如果执行两条命令,最近文章审核过的也会在3-19号放出,但是你可以选择只执行一条命令。 )
如果你不介意我上面说的,如果你真的需要解决1970的问题,在dede background-system-sql命令行工具中,执行如下命令:
UPDATE dede_archives SET sortrank = senddate ;
该命令是将前台呼叫时间更改为存储时间。如果你是我上面提到的那种,就不要执行了。至于1970年会不会有其他影响,请自行考虑
UPDATE dede_archives SET pubdate = senddate ;
这个命令是把释放时间改成存储时间,就不解释了,上面都说了
上一篇:织梦DedecmsError: no csrf hash code的解决方法!在后台编辑模板时 查看全部
文章采集调用(第二步,后台执行SQL语句SELECT(FROMdede)_)
第二步后台执行SQL语句SELECT * FROM dede_archives order by id DESC limit 1
这样你就可以看到你刚刚添加的文章一的所有字段值了。
观察以下数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中,1231846313为时间数据。
然后它被替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,你看到第一句话应该就可以通过他了。说一下他的方法的问题(注意:这种SQL语句或者需要修改数据库的,必须先备份)。
对应数据库的dede_archives表,请根据实际情况修改前缀。
此表中有三个字段表示时间:
pubdate:发布时间(前台可更改)
senddate:存储时间
sortrank:前台调用最新的文章。实际利用这个时间。
这一段说的没有错,我再详细说明一下:
1.pubdate:发布时间(前台可更改)
发布新的文章或编辑文章时,可以在高级参数中看到,可以更改。也是在内容页和列表页调用系统的时间。当发布时间为1970时,列表页面会显示1970-01-01,文章页面获取的发布时间为“否”。当然,这以dede默认模板为准。如果你修改它,可能会有其他结果。例如:我的待审核文章发布时会自动更新为当前系统时间(如果不设置,见dedecmsunevalated文档自动更新发布时间)
2.senddate:存储时间
按字面意思可以理解,但是所谓的存储时间体现在哪里呢?是dede后台文件列表中的“进入时间”。理论上dede后台是不能修改的,但是实际中SQL语句也是可以修改的。实际意义。如果你的文章命名规则是“{typedir}/{Y}/{M}{D}/{aid}.html”,你的文章页面的url中也直观的提到了。
3.sortrank:前台呼叫最新的文章。实际利用这个时间。
我们一般看不到这个时间,但是如果前端模板设置为“orderby='public',系统会根据这个时间来调用。很多讲只是强调这些细节,而也算是一个原则吧。。
其次,我们应该明白,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不能完全一样,所以这里有点问题,但是这是无害的。重点是这个方案是修改整个系统的数据库pubdate、senddate、sortrank三个时间段,也就是说从你第一个文章发到最后一个,都变成你的修改现在这个时候,我第一次修改后,整个网站的文章就在3月19日发布了。可以说,几乎什么都搞砸了。这个大家应该都能理解。所以,我说备份很重要。 , 转载这个文章的人真是害人。我觉得这个方法不可取,完全没用。
二、1970 的正确解
优采云采集 发布时唯一不能出错的就是系统进入时间。因此,我们以此为标准,将public和sortrank时间改为senddate(语句下,先备份,后操作)。同时,经过对网站采集的更多考虑,有的文章的发布时间和存储时间有很大的区别吗?比如3-19采集有很多文章,发布审核,插件控制,每天自动更新,4-19才更新。如果执行两条命令,最近文章审核过的也会在3-19号放出,但是你可以选择只执行一条命令。 )
如果你不介意我上面说的,如果你真的需要解决1970的问题,在dede background-system-sql命令行工具中,执行如下命令:
UPDATE dede_archives SET sortrank = senddate ;
该命令是将前台呼叫时间更改为存储时间。如果你是我上面提到的那种,就不要执行了。至于1970年会不会有其他影响,请自行考虑
UPDATE dede_archives SET pubdate = senddate ;
这个命令是把释放时间改成存储时间,就不解释了,上面都说了
上一篇:织梦DedecmsError: no csrf hash code的解决方法!在后台编辑模板时
文章采集调用(使用dedecms这个程序建站有五年多的时间期间不少)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-03 22:03
本文介绍了dedecms使用sql语句调用文章静态链接地址的方法。分享给大家,供大家参考。具体分析如下:
很多时候我们用织梦background调用数据的时候,自带的标签往往调用不到我们想要的数据,所以不得不写sql来调用。之前有一个问题,我两天没做。出来后看到下面文章,问题解决了。
我用dedecms建网站已经五年多了,期间建了很多网站。欢迎朋友找我建网站。
补充:
发布这个文章后,无意中发现在dedecms的GetOneArchive中,只要传入一个文档id就可以得到文章链接。其实这个函数返回的文章信息数组收录了Up:链接地址、标题、文章ID、列ID,这里只需要文章链接地址,具体代码如下:
代码如下:{dede:sql sql="select * From dede_archives a where a.title like'%织梦建站%' and a.arcrank>-1 limit 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
如果只需要调用文章的链接地址,这个方法是一种快捷方式。 文章下一部分介绍的方法比较复杂,但是如果要调用文章的链接地址,也要调用列名。试试看。
为什么使用 dede:php、dede:sql
在一些更复杂的调用中使用dede:arclist标签不能解决问题,比如调用成员发出的文章等,通常通过dede:sql标签来完成。达成。
我今天提到的电话也很特别。就是在首页调用指定关键字的文章。其实这个和dedecms相关的文章标签类似。这里有两种方式与您分享。
dede:sql标签调用了指定关键字文章静态地址,这里是dede:sql上dedecms的官方介绍。
Sql 标签
功能描述:用于通过SQL查询从模板中获取返回的内容。
适用范围:非扩展模块的所有模板。
(1)Syntax:{dede:sql sql="write sql statement here"}底层模板{/dede:sql}
(2)attribute:[1] sql 完整的 SQL 查询语句。
(3)Underlying 模板:所有在 SQL 语句中找到的字段都可以用 [field:field name/] 调用。
了解了dede:sql标签后,就可以根据自己的需要编写sql语句了。这里我想用指定的关键字调用文章。 sql语句如下:
代码如下:“select * From dede_archives a where a.arcrank>-1 and a.title like'%Script%' limit 8”
句子分析:a.arcrank>-1 限制调用批准的文章; like '%script%' 调用指定关键字的文章; limit 8 是调用 8 的次数
然后开始写完整的标签和底层模板,如下:
1、 先解决完整标题和截断的问题:我用 [field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title] 我相信你方法会经常用到,这里就不多介绍了,以后可能会专门介绍文章来介绍这个用法。50是截断长度
2、 解决dede的问题:sql tag static 文章地址:这个比较麻烦,我在网上翻了一下,给出的解决方法大多是href="/plus/view.php?aid =[ field:id/]",显然这不是我想要的。这不是静态地址,其他地址用arclist调用,都是静态地址。结果是一篇文章的文章有两个地址,一个静态的,一个动态的。这显然对seo不友好,还不如自己折腾最后成功
3、 解决无法正确获取id的问题:之前没注意到,因为dede_arctype和dede_archives这两个表的id字段名是一样的,导致底层模板无法获取到正确的id。之前的选择已更改并添加了别名。
dede:sql调用文章静态链接地址的完美方式
代码如下:(dede:sql sql="select * From dede_archives a, dede_arctype t where a.typeid = t.id and a.title like'%Life Tips%' and a.arcrank>-1限制 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
无论如何,我终于达到了我想要的效果。后来想了想怎么用dede:php标签来实现这个效果。其实方法和dede:sql标签是一样的,就不多说了。直接粘贴代码:
代码如下:(dede:php)
$dsql->SetQuery("选择a.id作为辅助,t.id作为tid,typeid,senddate,title,ismake,arcrank,namerule,typedir from dede_archives a, dede_arctype t where a.typeid = t.id和 a.title like'%Life Tips%' and a.arcrank>-1 limit 8");
$dsql->Execute();
while($row = $dsql->GetArray()){
echo''.cn_substr($row['title'], 50).'';
}
{/dede:php}
希望这篇文章能帮到你dedecms建站。 查看全部
文章采集调用(使用dedecms这个程序建站有五年多的时间期间不少)
本文介绍了dedecms使用sql语句调用文章静态链接地址的方法。分享给大家,供大家参考。具体分析如下:
很多时候我们用织梦background调用数据的时候,自带的标签往往调用不到我们想要的数据,所以不得不写sql来调用。之前有一个问题,我两天没做。出来后看到下面文章,问题解决了。
我用dedecms建网站已经五年多了,期间建了很多网站。欢迎朋友找我建网站。
补充:
发布这个文章后,无意中发现在dedecms的GetOneArchive中,只要传入一个文档id就可以得到文章链接。其实这个函数返回的文章信息数组收录了Up:链接地址、标题、文章ID、列ID,这里只需要文章链接地址,具体代码如下:
代码如下:{dede:sql sql="select * From dede_archives a where a.title like'%织梦建站%' and a.arcrank>-1 limit 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
如果只需要调用文章的链接地址,这个方法是一种快捷方式。 文章下一部分介绍的方法比较复杂,但是如果要调用文章的链接地址,也要调用列名。试试看。
为什么使用 dede:php、dede:sql
在一些更复杂的调用中使用dede:arclist标签不能解决问题,比如调用成员发出的文章等,通常通过dede:sql标签来完成。达成。
我今天提到的电话也很特别。就是在首页调用指定关键字的文章。其实这个和dedecms相关的文章标签类似。这里有两种方式与您分享。
dede:sql标签调用了指定关键字文章静态地址,这里是dede:sql上dedecms的官方介绍。
Sql 标签
功能描述:用于通过SQL查询从模板中获取返回的内容。
适用范围:非扩展模块的所有模板。
(1)Syntax:{dede:sql sql="write sql statement here"}底层模板{/dede:sql}
(2)attribute:[1] sql 完整的 SQL 查询语句。
(3)Underlying 模板:所有在 SQL 语句中找到的字段都可以用 [field:field name/] 调用。
了解了dede:sql标签后,就可以根据自己的需要编写sql语句了。这里我想用指定的关键字调用文章。 sql语句如下:
代码如下:“select * From dede_archives a where a.arcrank>-1 and a.title like'%Script%' limit 8”
句子分析:a.arcrank>-1 限制调用批准的文章; like '%script%' 调用指定关键字的文章; limit 8 是调用 8 的次数
然后开始写完整的标签和底层模板,如下:
1、 先解决完整标题和截断的问题:我用 [field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title] 我相信你方法会经常用到,这里就不多介绍了,以后可能会专门介绍文章来介绍这个用法。50是截断长度
2、 解决dede的问题:sql tag static 文章地址:这个比较麻烦,我在网上翻了一下,给出的解决方法大多是href="/plus/view.php?aid =[ field:id/]",显然这不是我想要的。这不是静态地址,其他地址用arclist调用,都是静态地址。结果是一篇文章的文章有两个地址,一个静态的,一个动态的。这显然对seo不友好,还不如自己折腾最后成功
3、 解决无法正确获取id的问题:之前没注意到,因为dede_arctype和dede_archives这两个表的id字段名是一样的,导致底层模板无法获取到正确的id。之前的选择已更改并添加了别名。
dede:sql调用文章静态链接地址的完美方式
代码如下:(dede:sql sql="select * From dede_archives a, dede_arctype t where a.typeid = t.id and a.title like'%Life Tips%' and a.arcrank>-1限制 8"}
[field:title runphp='yes']@me=cn_substr(@me, 50);[/field:title]
{/dede:sql}
无论如何,我终于达到了我想要的效果。后来想了想怎么用dede:php标签来实现这个效果。其实方法和dede:sql标签是一样的,就不多说了。直接粘贴代码:
代码如下:(dede:php)
$dsql->SetQuery("选择a.id作为辅助,t.id作为tid,typeid,senddate,title,ismake,arcrank,namerule,typedir from dede_archives a, dede_arctype t where a.typeid = t.id和 a.title like'%Life Tips%' and a.arcrank>-1 limit 8");
$dsql->Execute();
while($row = $dsql->GetArray()){
echo''.cn_substr($row['title'], 50).'';
}
{/dede:php}
希望这篇文章能帮到你dedecms建站。
文章采集调用(织梦小程序获取文章列表列表接口(1)_2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-03 07:20
接口名称:织梦小程序Get文章List接口
接口标识:列表
接口地址:你的网站/api/index.php?action=list[&typeid=10]
接口参数:
织梦百度小程序代码:
/*获取新闻 */
swan.request({
url: app.globalData.api+"action=list",
data: {
typeid: '20',
num: '10',
order:'id desc',
aid: app.globalData.aid
},
method: 'POST',
header: {
'content-type': 'application/x-www-form-urlencoded',
'x-appsecret': app.globalData.appsecret
},
success: function (res) {
var data = res.data;
if (data.status == 200) {
var list = data.data;
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
that.setData({
list: list
})
}
}
})
(1)列表页采用底部出的方式加载更多代码,可以参考demo
(2)如果要获取当前列的所有子列和每个子列的前n个文章,可以导入request.js,具体参考get_category的使用。
(3)在调用列表模板时可以传递一个参数data-listtype='1',表示被调用的列表模板的类型为:text list
list_1:文本列表
list_2:图片列表(两张图片)
list_3:图文列表(左图右文)
list_4:图片列表(三张图片)
list_5:标题+描述列表
(也可以在template/list.swan中添加自己的样式)
(4)demo中的页面列表、案例、服务其实是一模一样的,但是因为小程序的tabbar不支持参数传递,所以切换到案例和服务项时必须是新页面,所以我复制了两个Copy。点击进入列表页面时,一定要弄清楚你要使用哪个列表,例如:
show_service: function (e) {
var data = e.currentTarget.dataset;
var title = data.title;
var typeid = data.typeid;
var list_type = data.listtype;
//tabbar不支持传参通过缓存读取
swan.setStorageSync('stypeid', typeid)
swan.switchTab({
url: '/pages/service/service?typeid=' + typeid + "&title=" + title + "&list_type=" + list_type,
})
},
(5)调用单个页面属于category接口范围,详见category接口用法
(6)api返回的列表中的时间是时间戳格式,所以需要通过utils下的formatTime函数进行处理。示例代码:
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
织梦秒开发QQ群 查看全部
文章采集调用(织梦小程序获取文章列表列表接口(1)_2)
接口名称:织梦小程序Get文章List接口
接口标识:列表
接口地址:你的网站/api/index.php?action=list[&typeid=10]
接口参数:
织梦百度小程序代码:
/*获取新闻 */
swan.request({
url: app.globalData.api+"action=list",
data: {
typeid: '20',
num: '10',
order:'id desc',
aid: app.globalData.aid
},
method: 'POST',
header: {
'content-type': 'application/x-www-form-urlencoded',
'x-appsecret': app.globalData.appsecret
},
success: function (res) {
var data = res.data;
if (data.status == 200) {
var list = data.data;
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
that.setData({
list: list
})
}
}
})
(1)列表页采用底部出的方式加载更多代码,可以参考demo
(2)如果要获取当前列的所有子列和每个子列的前n个文章,可以导入request.js,具体参考get_category的使用。
(3)在调用列表模板时可以传递一个参数data-listtype='1',表示被调用的列表模板的类型为:text list
list_1:文本列表
list_2:图片列表(两张图片)
list_3:图文列表(左图右文)
list_4:图片列表(三张图片)
list_5:标题+描述列表
(也可以在template/list.swan中添加自己的样式)
(4)demo中的页面列表、案例、服务其实是一模一样的,但是因为小程序的tabbar不支持参数传递,所以切换到案例和服务项时必须是新页面,所以我复制了两个Copy。点击进入列表页面时,一定要弄清楚你要使用哪个列表,例如:
show_service: function (e) {
var data = e.currentTarget.dataset;
var title = data.title;
var typeid = data.typeid;
var list_type = data.listtype;
//tabbar不支持传参通过缓存读取
swan.setStorageSync('stypeid', typeid)
swan.switchTab({
url: '/pages/service/service?typeid=' + typeid + "&title=" + title + "&list_type=" + list_type,
})
},
(5)调用单个页面属于category接口范围,详见category接口用法
(6)api返回的列表中的时间是时间戳格式,所以需要通过utils下的formatTime函数进行处理。示例代码:
for (var i in list) {
list[i].pubdate = util.formatTime(list[i].pubdate, 'Y-M-D');
}
织梦秒开发QQ群
文章采集调用(各种不同的Python模块可以来解析,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-03 02:15
正则表达式
正则表达式(RE 或 Regex)是字符串的搜索模式。使用正则表达式,您可以在较大的文本正文中搜索特定字符/单词。
例如,您可以识别网页上的所有电话号码。您还可以更换某些项目。例如,您可以用小写标记替换 HTML 中所有格式错误的大写标记。您还可以验证一些输入...
正则表达式使用的模式从左到右应用。每个源字符仅使用一次。您可能想知道为什么在进行网络数据挖掘时理解正则表达式很重要?
简而言之,有各种 Python 模块可以解析 HTML,您可以使用 XPath 和 CSS 选择器。
在理想的语义世界中,数据易于机器读取,信息嵌入到具有有意义属性的相关 HTML 元素中。
但现实世界是混乱的,你经常会在一个 p 元素中发现很多文本。当你想从这个巨大的文本中提取特定的数据时,比如价格、日期或名称等,你必须使用正则表达式。
注意:这里有一个很棒的网站 来测试你的正则表达式:,还有一个很棒的博客 () 来了解更多关于它们的信息,这个文章 只会涵盖你能做的事情的一小部分正则表达式。
当您拥有此类数据时,正则表达式会很有用:
我们可以使用 Xpath 表达式来选择这个文本节点,然后使用这个正则表达式来提取价格:
提取 HTML 标签内的文本,使用正则表达式很烦人,但可行:
如您所见,您可以使用套接字手动发送 HTTP 请求并使用正则表达式来解析响应,但这很复杂,并且有更高级的 API 可以使此任务更容易。
2) urllib3 和 LXML
免责声明:很容易迷失在 Python 的 urllib 中。 urllib 和 urllib2 是标准库的一部分,您还可以找到 urllib3。 urllib2在python3中分为多个模块,urllib3在任何时候都可能不会成为标准库的一部分。这整个令人困惑的事情将成为博客文章 的主题。在本节中,我选择只讨论 urllib3,因为它在 Python 世界中被广泛使用,仅举两个例子,例如被 pip 和 requests 库使用。
Urllib3 是一个高级包,它允许您对 HTTP 请求执行几乎任何您想做的事情。它允许我们使用更少的代码行来完成我们上面对套接字所做的事情。
这个比socket版本简洁多了。不仅如此,API非常简单易懂,你可以轻松做很多事情,比如添加HTTP头、使用代理、POST表单等。
例如,如果我们决定设置一些标头并使用代理,我们只需要这样做。
<p>你看到了吗?完全一样的代码行数,但是有一些东西是urllib3不好处理的,比如我们要添加一个cookie,就得手动创建相应的header并添加到请求中。 查看全部
文章采集调用(各种不同的Python模块可以来解析,你知道吗?)
正则表达式
正则表达式(RE 或 Regex)是字符串的搜索模式。使用正则表达式,您可以在较大的文本正文中搜索特定字符/单词。
例如,您可以识别网页上的所有电话号码。您还可以更换某些项目。例如,您可以用小写标记替换 HTML 中所有格式错误的大写标记。您还可以验证一些输入...
正则表达式使用的模式从左到右应用。每个源字符仅使用一次。您可能想知道为什么在进行网络数据挖掘时理解正则表达式很重要?
简而言之,有各种 Python 模块可以解析 HTML,您可以使用 XPath 和 CSS 选择器。
在理想的语义世界中,数据易于机器读取,信息嵌入到具有有意义属性的相关 HTML 元素中。
但现实世界是混乱的,你经常会在一个 p 元素中发现很多文本。当你想从这个巨大的文本中提取特定的数据时,比如价格、日期或名称等,你必须使用正则表达式。
注意:这里有一个很棒的网站 来测试你的正则表达式:,还有一个很棒的博客 () 来了解更多关于它们的信息,这个文章 只会涵盖你能做的事情的一小部分正则表达式。
当您拥有此类数据时,正则表达式会很有用:
我们可以使用 Xpath 表达式来选择这个文本节点,然后使用这个正则表达式来提取价格:
提取 HTML 标签内的文本,使用正则表达式很烦人,但可行:
如您所见,您可以使用套接字手动发送 HTTP 请求并使用正则表达式来解析响应,但这很复杂,并且有更高级的 API 可以使此任务更容易。
2) urllib3 和 LXML
免责声明:很容易迷失在 Python 的 urllib 中。 urllib 和 urllib2 是标准库的一部分,您还可以找到 urllib3。 urllib2在python3中分为多个模块,urllib3在任何时候都可能不会成为标准库的一部分。这整个令人困惑的事情将成为博客文章 的主题。在本节中,我选择只讨论 urllib3,因为它在 Python 世界中被广泛使用,仅举两个例子,例如被 pip 和 requests 库使用。
Urllib3 是一个高级包,它允许您对 HTTP 请求执行几乎任何您想做的事情。它允许我们使用更少的代码行来完成我们上面对套接字所做的事情。
这个比socket版本简洁多了。不仅如此,API非常简单易懂,你可以轻松做很多事情,比如添加HTTP头、使用代理、POST表单等。
例如,如果我们决定设置一些标头并使用代理,我们只需要这样做。
<p>你看到了吗?完全一样的代码行数,但是有一些东西是urllib3不好处理的,比如我们要添加一个cookie,就得手动创建相应的header并添加到请求中。

