
文章采集调用
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统),还是在易用性方面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-26 10:17
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户是个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_template,最灵活的应该是系统提供的,这里我们可以将我们的页面编辑成模板,然后调用...这里需要强调一下,这里涉及到缓存的东西,我们需要使用:一键更新网站-->更新一切...因为我在做的时候遇到了缓存问题,所以不敢相信自己哪里出错了...
1.2K 查看全部
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统),还是在易用性方面)
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户是个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_template,最灵活的应该是系统提供的,这里我们可以将我们的页面编辑成模板,然后调用...这里需要强调一下,这里涉及到缓存的东西,我们需要使用:一键更新网站-->更新一切...因为我在做的时候遇到了缓存问题,所以不敢相信自己哪里出错了...
1.2K
文章采集调用(最好调用二级目录(二级)、微博客和“教育频道”,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-26 08:08
在我的博客中,我建立了“励志故事”、“微博”和“教育频道”三个二级目录,以提高百度蜘蛛的抓取速度和全面抓取,促进网站< @收录,最好能实现zblog博客根目录与二级目录、二级目录与根目录、二级目录与二级目录之间的顺畅调用。
网上搜集了一些互相调用的方法。很多方法漏洞百出或者不够全面,无法说明zblog博客目录之间如何相互调用。我在这里果断写一篇文章文章,同时纠正各种错误,为博主提供正确的调用方法。
根目录调用二级目录,二级目录调用根目录,二级目录和二级目录可以相互调用,方法相同。
1.zblog根目录调用二级目录中最新的文章。
①在本地新建一个t_previous.asp文件(新建一个t_previous.txt文件并将扩展名改为asp),将该文件上传到zblog博客根目录下的include文件中。t_previous.asp 主要用于存储从二级目录调用的内容。
②在你要使用的二级目录的FUNCTION文件夹中找到c_system_base.asp文件,通过ftp软件下载到本地以txt文件格式打开,使用搜索工具找到
调用 SaveToFile(BlogPath & “/include/previous.asp”,strPrevious,”utf-8”,True)
在代码下方添加以下代码:
调用 SaveToFile(Left(BlogPath,len(BlogPath)-7) & “/include/t_previous.asp”,strPrevious,”utf-8″,True)
注:7为“jiaoyu/”的字符长度。如果要调用“微博/”的内容,改成6,自己用的时候一定要注意这一点。因为很多博文都说文章的数量显示为7,表示这是完全错误的。未经大脑或实践检验的废话。
③上传c_system_base.asp文件到你的二级目录,重建文章就OK了!
④在你要调用的地方,比如文章的首页侧边栏,你要在你的zblog采用的样式中default.html对应位置添加如下代码: 查看全部
文章采集调用(最好调用二级目录(二级)、微博客和“教育频道”,)
在我的博客中,我建立了“励志故事”、“微博”和“教育频道”三个二级目录,以提高百度蜘蛛的抓取速度和全面抓取,促进网站< @收录,最好能实现zblog博客根目录与二级目录、二级目录与根目录、二级目录与二级目录之间的顺畅调用。
网上搜集了一些互相调用的方法。很多方法漏洞百出或者不够全面,无法说明zblog博客目录之间如何相互调用。我在这里果断写一篇文章文章,同时纠正各种错误,为博主提供正确的调用方法。
根目录调用二级目录,二级目录调用根目录,二级目录和二级目录可以相互调用,方法相同。
1.zblog根目录调用二级目录中最新的文章。
①在本地新建一个t_previous.asp文件(新建一个t_previous.txt文件并将扩展名改为asp),将该文件上传到zblog博客根目录下的include文件中。t_previous.asp 主要用于存储从二级目录调用的内容。
②在你要使用的二级目录的FUNCTION文件夹中找到c_system_base.asp文件,通过ftp软件下载到本地以txt文件格式打开,使用搜索工具找到
调用 SaveToFile(BlogPath & “/include/previous.asp”,strPrevious,”utf-8”,True)
在代码下方添加以下代码:
调用 SaveToFile(Left(BlogPath,len(BlogPath)-7) & “/include/t_previous.asp”,strPrevious,”utf-8″,True)
注:7为“jiaoyu/”的字符长度。如果要调用“微博/”的内容,改成6,自己用的时候一定要注意这一点。因为很多博文都说文章的数量显示为7,表示这是完全错误的。未经大脑或实践检验的废话。
③上传c_system_base.asp文件到你的二级目录,重建文章就OK了!
④在你要调用的地方,比如文章的首页侧边栏,你要在你的zblog采用的样式中default.html对应位置添加如下代码:
文章采集调用(Dedecms采集节点管理界面1.2.增加新节点在采集指定节点和网址索引页规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-25 00:14
前言:这篇文章是写给刚接触德德的朋友cms采集的。选择的目标站点是德德cms官方网站的dreameaver栏目文章,其内容页面不收录分页。以图文形式详细讲解了如何创建一个Basic 采集规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二节,主要是引入新的采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定节点以及如何导出采集的内容。现在进入第一部分。
1.1进入采集节点管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集节点管理”进入采集节点管理界面,如图(图2).
(本图来源于网络,如有侵权请联系删除!)
图1-后台管理界面
(本图来源于网络,如有侵权请联系删除!)
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以进入“选择内容”模型”界面,如(如图3),
(本图来源于网络,如有侵权请联系删除!)
图3-选择内容模型界面
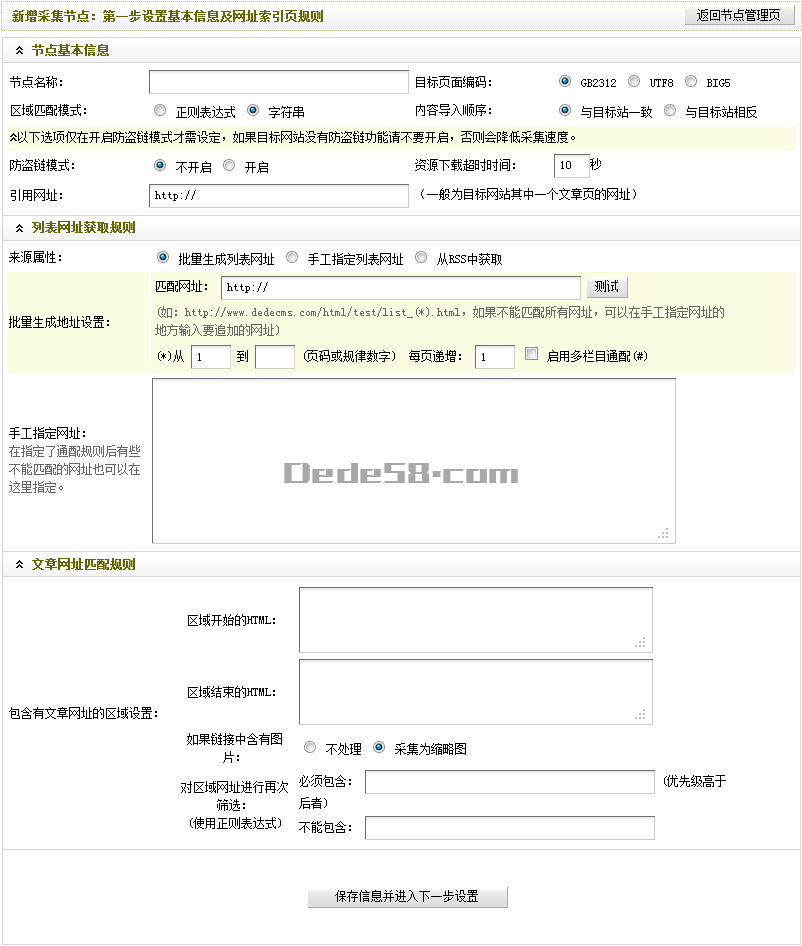
在“选择内容模型”界面的下拉列表框中,有“常用文章”和“图片集”可供选择。根据页面类型为采集,选择对应的内容模型。本文选择“普通文章”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图文章4)显示,
(本图来源于网络,如有侵权请联系删除!)
图4-新建采集节点:第一步是设置基本信息和URL索引页面规则
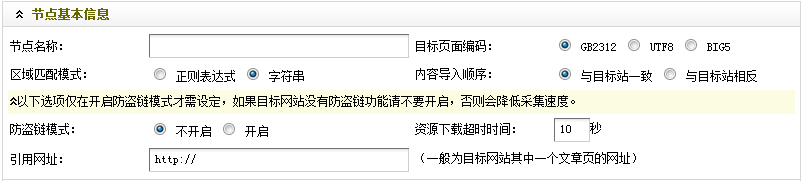
1.2.1 设置基本节点信息
(本图来源于网络,如有侵权请联系删除!)
图5-基本节点信息
如图(图5),
节点名称:给新创建的节点起一个名字,填写“采集Test(一)”;
目标页面编码:通过采集设置目标页面的编码格式。共有三种类型:GB2312、UTF8 和 BIG5。在采集的目标页面右击,选择“查看源文件”即可获得。
脚步:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),
(本图来源于网络,如有侵权请联系删除!)
图6-查看源文件
等号后面的代码就是需要的“编码格式”,这里是“gb2312”。
“区域匹配方式”:设置如何匹配所需采集的内容部分,可以是字符串,也可以是正则表达式。系统默认模式为字符串。如果您对正则表达式有更多的了解,可以在这里选择正则表达式模式。
“内容导入顺序”:指定导入文章列表时的顺序。可以选择“与目标站一致”或“反向到目标站”。
“防盗链模式”:目标站点是否有刷新限制采集。一开始很难说,你需要测试才能知道。如果是这样,您需要在此处设置“资源下载超时时间”。
“引用网址”:填写任意文章内容页面的网址,即采集。
具体步骤:
(a) 在打开的文章列表页面,点击第一篇文章
标题为“在Dreamweaver中为插入的Flash添加透明度”打开文章内容页面,如图(图7),
(本图来源于网络,如有侵权请联系删除!)
图7-文章内容页面
(b)此时浏览器的URL地址栏显示的URL就是“引用URL”处需要填写的URL,如图(图8),
(本图来源于网络,如有侵权请联系删除!)
图8-浏览器的URL地址栏
至此,“节点基本信息”就设置好了。最终结果,如图(图9),
(本图来源于网络,如有侵权请联系删除!)
图9-设置后节点的基本信息
检查无误后,进入下一步。
1.2.2 设置获取列表URL的规则
如图(图10),
(本图来源于网络,如有侵权请联系删除!)
图10-列出URL获取规则
这里是设置采集的文章列表页的匹配规则。如果采集的文章的列表页面有一定的样式,可以选择“批量生成列表URL”;如果采集的文章的列表页面完全没有规则,那么可以选择“手动指定列表URL”;如果采集的站点提供RSS,您可以选择“从RSS获取”。对于特殊情况,例如:列表页面部分规则,其余部分不规则,您可以在“匹配URL”中填写规则部分,然后在“手动指定URL”中填写不规则部分。
具体步骤:
(a) 首先回到打开的文章列表页面,找到浏览器URL地址栏中显示的URL(图片8)和页面底部的换页部分。对于示例(如图11),
(本图来源于网络,如有侵权请联系删除!)
图11-页面变化
(b) 点击“2”打开文章列表页的第二页。这时浏览器的URL地址栏中显示的URL和页面底部的页面变化部分,如(图12)和(图13),
(本图来源于网络,如有侵权请联系删除!)
图12-第二页的URL
(本图来源于网络,如有侵权请联系删除!)
图13-page feed部分第二页
(c) 在打开的文章列表页的第二页,点击(1)打开文章列表页的第一页,底部的换页部分页面如下图11相同,只是浏览器的URL地址栏显示的URL与之前的图8不同,如下图(图14),
(本图来源于网络,如有侵权请联系删除!)
图14-第一页的URL
(d) 由(b)和(c)推断,采集的文章列表页的URL遵循如下规律:
(*).html。为安全起见,请自行测试更多列表页面。确定规则后,在“匹配URL”中填写规则后跟文章列表页。
(e) 最后,指定需要采集的页码或正则数,并设置递增的正则。
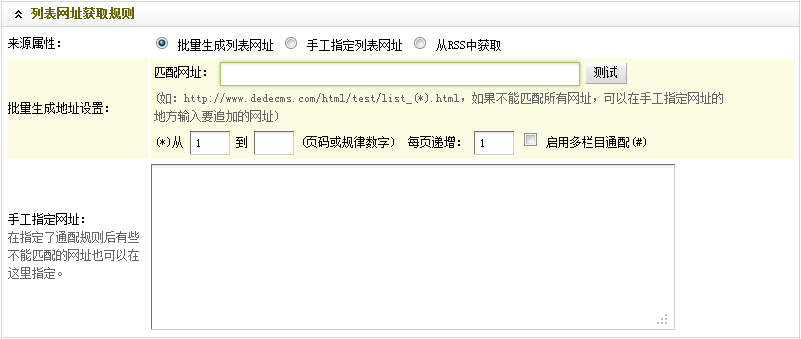
至此,“列表URL获取规则”部分的设置就结束了。最终结果,如图(图15),
(本图来源于网络,如有侵权请联系删除!)
图15-设置后的URL获取规则列表
确认无误后,进行下一步设置。
1.2.3 设置文章 URL匹配规则
如图(图16),
(本图来源于网络,如有侵权请联系删除!)
图16-文章 URL匹配规则
这里是设置采集文章列表页的匹配规则。
具体步骤:
(a)对于“区域开头的HTML”,可以在打开的文章列表首页右击,选择“查看源文件”。在源文件中,找到第一篇文章的标题《在Dreamweaver中为插入的Flash添加透明度》,如图(图17),
(本图来源于网络,如有侵权请联系删除!)
图17-查看源文件中第一篇文章文章的标题
通过观察,不难看出“
”这是整个文章列表的开头。因此,在“HTML开头的区域”中,填写“
”。
(b) 在源文件中找到上一篇文章的文章《通过Dreamweaver设计网页时组织CSS的建议》,如图(图18),
(本图来源于网络,如有侵权请联系删除!)
图18-查看源文件中上一篇文章的标题
结合文章列表的开头并观察,第一个"
“这是整个文章列表的结尾。因此,在“区域末尾的HTML”中,您应该填写“
”。
“如果链接收录图片”:设置收录图片的链接的处理方式,是否不处理,缩略图可选采集。可根据实际需要选择。
“重新过滤区域URL”:可以使用正则表达式再次过滤区域网站。这是针对一些需要保留或者过滤掉的内容,尤其是混合列表页面,通过使用“必须收录”或者“不能收录”过滤掉你想要获取的文章内容页面的URL或者不想得到。
具体步骤:
回到正在打开的文章列表首页的源文件,通过观察可以看出,每个文章内容页地址的扩展名都是.html。因此,您可以在“必须收录”中填写“.html”。
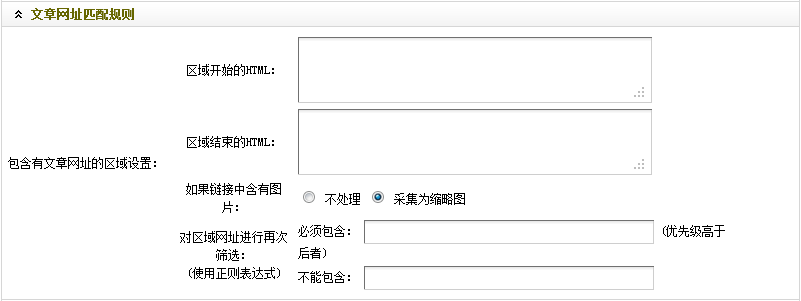
至此,“文章URL匹配规则”的设置就结束了。最终结果,如图(图19),
(本图来源于网络,如有侵权请联系删除!)
图19-文章 设置后的URL匹配规则
通过1.2.1子节,1.2.2子节和1.2.3子节,采集节点的节添加 一步完成设置。设置后的结果,如图(图20),
(本图来源于网络,如有侵权请联系删除!)
图20-设置后新增的采集节点:第一步是设置基本信息和URL索引页面规则
一切都完成并检查后,单击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置URL获取规则测试”页面,看到对应的文章列表地址. 如图(图21),
(本图来源于网络,如有侵权请联系删除!)
图21-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
免责声明:本站所有文章及图片均来自用户分享和网络采集。文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
有问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群 查看全部
文章采集调用(Dedecms采集节点管理界面1.2.增加新节点在采集指定节点和网址索引页规则)
前言:这篇文章是写给刚接触德德的朋友cms采集的。选择的目标站点是德德cms官方网站的dreameaver栏目文章,其内容页面不收录分页。以图文形式详细讲解了如何创建一个Basic 采集规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二节,主要是引入新的采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定节点以及如何导出采集的内容。现在进入第一部分。
1.1进入采集节点管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集节点管理”进入采集节点管理界面,如图(图2).
(本图来源于网络,如有侵权请联系删除!)
图1-后台管理界面

(本图来源于网络,如有侵权请联系删除!)
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以进入“选择内容”模型”界面,如(如图3),

(本图来源于网络,如有侵权请联系删除!)
图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“常用文章”和“图片集”可供选择。根据页面类型为采集,选择对应的内容模型。本文选择“普通文章”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图文章4)显示,
(本图来源于网络,如有侵权请联系删除!)
图4-新建采集节点:第一步是设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息
(本图来源于网络,如有侵权请联系删除!)
图5-基本节点信息
如图(图5),
节点名称:给新创建的节点起一个名字,填写“采集Test(一)”;
目标页面编码:通过采集设置目标页面的编码格式。共有三种类型:GB2312、UTF8 和 BIG5。在采集的目标页面右击,选择“查看源文件”即可获得。
脚步:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),

(本图来源于网络,如有侵权请联系删除!)
图6-查看源文件
等号后面的代码就是需要的“编码格式”,这里是“gb2312”。
“区域匹配方式”:设置如何匹配所需采集的内容部分,可以是字符串,也可以是正则表达式。系统默认模式为字符串。如果您对正则表达式有更多的了解,可以在这里选择正则表达式模式。
“内容导入顺序”:指定导入文章列表时的顺序。可以选择“与目标站一致”或“反向到目标站”。
“防盗链模式”:目标站点是否有刷新限制采集。一开始很难说,你需要测试才能知道。如果是这样,您需要在此处设置“资源下载超时时间”。
“引用网址”:填写任意文章内容页面的网址,即采集。
具体步骤:
(a) 在打开的文章列表页面,点击第一篇文章
标题为“在Dreamweaver中为插入的Flash添加透明度”打开文章内容页面,如图(图7),
(本图来源于网络,如有侵权请联系删除!)
图7-文章内容页面
(b)此时浏览器的URL地址栏显示的URL就是“引用URL”处需要填写的URL,如图(图8),

(本图来源于网络,如有侵权请联系删除!)
图8-浏览器的URL地址栏
至此,“节点基本信息”就设置好了。最终结果,如图(图9),
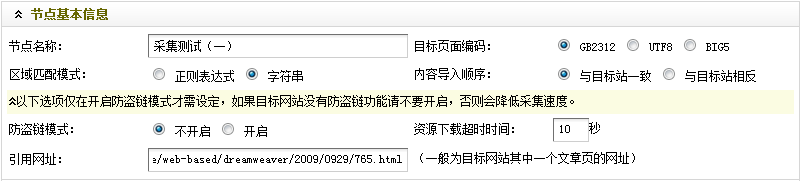
(本图来源于网络,如有侵权请联系删除!)
图9-设置后节点的基本信息
检查无误后,进入下一步。
1.2.2 设置获取列表URL的规则
如图(图10),
(本图来源于网络,如有侵权请联系删除!)
图10-列出URL获取规则
这里是设置采集的文章列表页的匹配规则。如果采集的文章的列表页面有一定的样式,可以选择“批量生成列表URL”;如果采集的文章的列表页面完全没有规则,那么可以选择“手动指定列表URL”;如果采集的站点提供RSS,您可以选择“从RSS获取”。对于特殊情况,例如:列表页面部分规则,其余部分不规则,您可以在“匹配URL”中填写规则部分,然后在“手动指定URL”中填写不规则部分。
具体步骤:
(a) 首先回到打开的文章列表页面,找到浏览器URL地址栏中显示的URL(图片8)和页面底部的换页部分。对于示例(如图11),

(本图来源于网络,如有侵权请联系删除!)
图11-页面变化
(b) 点击“2”打开文章列表页的第二页。这时浏览器的URL地址栏中显示的URL和页面底部的页面变化部分,如(图12)和(图13),

(本图来源于网络,如有侵权请联系删除!)
图12-第二页的URL

(本图来源于网络,如有侵权请联系删除!)
图13-page feed部分第二页
(c) 在打开的文章列表页的第二页,点击(1)打开文章列表页的第一页,底部的换页部分页面如下图11相同,只是浏览器的URL地址栏显示的URL与之前的图8不同,如下图(图14),

(本图来源于网络,如有侵权请联系删除!)
图14-第一页的URL
(d) 由(b)和(c)推断,采集的文章列表页的URL遵循如下规律:
(*).html。为安全起见,请自行测试更多列表页面。确定规则后,在“匹配URL”中填写规则后跟文章列表页。
(e) 最后,指定需要采集的页码或正则数,并设置递增的正则。
至此,“列表URL获取规则”部分的设置就结束了。最终结果,如图(图15),
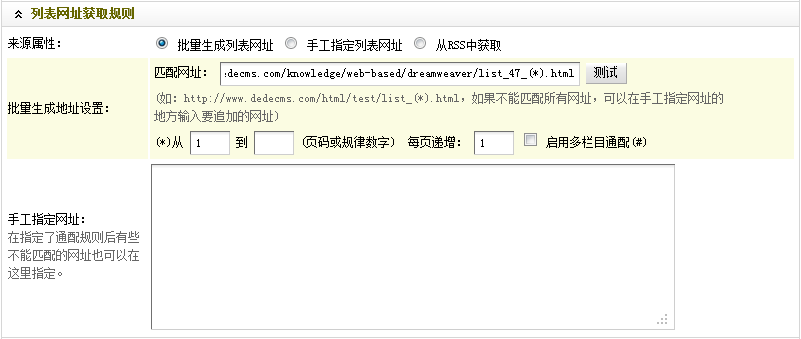
(本图来源于网络,如有侵权请联系删除!)
图15-设置后的URL获取规则列表
确认无误后,进行下一步设置。
1.2.3 设置文章 URL匹配规则
如图(图16),
(本图来源于网络,如有侵权请联系删除!)
图16-文章 URL匹配规则
这里是设置采集文章列表页的匹配规则。
具体步骤:
(a)对于“区域开头的HTML”,可以在打开的文章列表首页右击,选择“查看源文件”。在源文件中,找到第一篇文章的标题《在Dreamweaver中为插入的Flash添加透明度》,如图(图17),

(本图来源于网络,如有侵权请联系删除!)
图17-查看源文件中第一篇文章文章的标题
通过观察,不难看出“
”这是整个文章列表的开头。因此,在“HTML开头的区域”中,填写“
”。
(b) 在源文件中找到上一篇文章的文章《通过Dreamweaver设计网页时组织CSS的建议》,如图(图18),

(本图来源于网络,如有侵权请联系删除!)
图18-查看源文件中上一篇文章的标题
结合文章列表的开头并观察,第一个"
“这是整个文章列表的结尾。因此,在“区域末尾的HTML”中,您应该填写“
”。
“如果链接收录图片”:设置收录图片的链接的处理方式,是否不处理,缩略图可选采集。可根据实际需要选择。
“重新过滤区域URL”:可以使用正则表达式再次过滤区域网站。这是针对一些需要保留或者过滤掉的内容,尤其是混合列表页面,通过使用“必须收录”或者“不能收录”过滤掉你想要获取的文章内容页面的URL或者不想得到。
具体步骤:
回到正在打开的文章列表首页的源文件,通过观察可以看出,每个文章内容页地址的扩展名都是.html。因此,您可以在“必须收录”中填写“.html”。
至此,“文章URL匹配规则”的设置就结束了。最终结果,如图(图19),
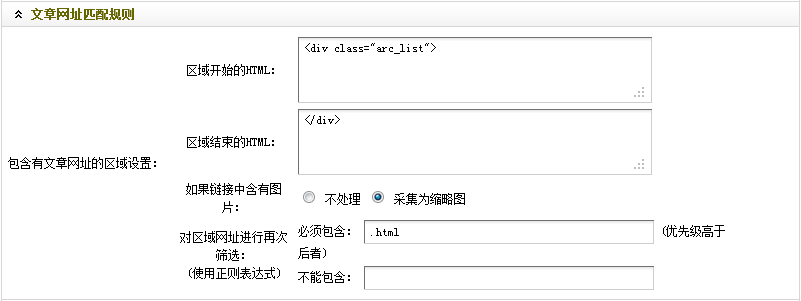
(本图来源于网络,如有侵权请联系删除!)
图19-文章 设置后的URL匹配规则
通过1.2.1子节,1.2.2子节和1.2.3子节,采集节点的节添加 一步完成设置。设置后的结果,如图(图20),
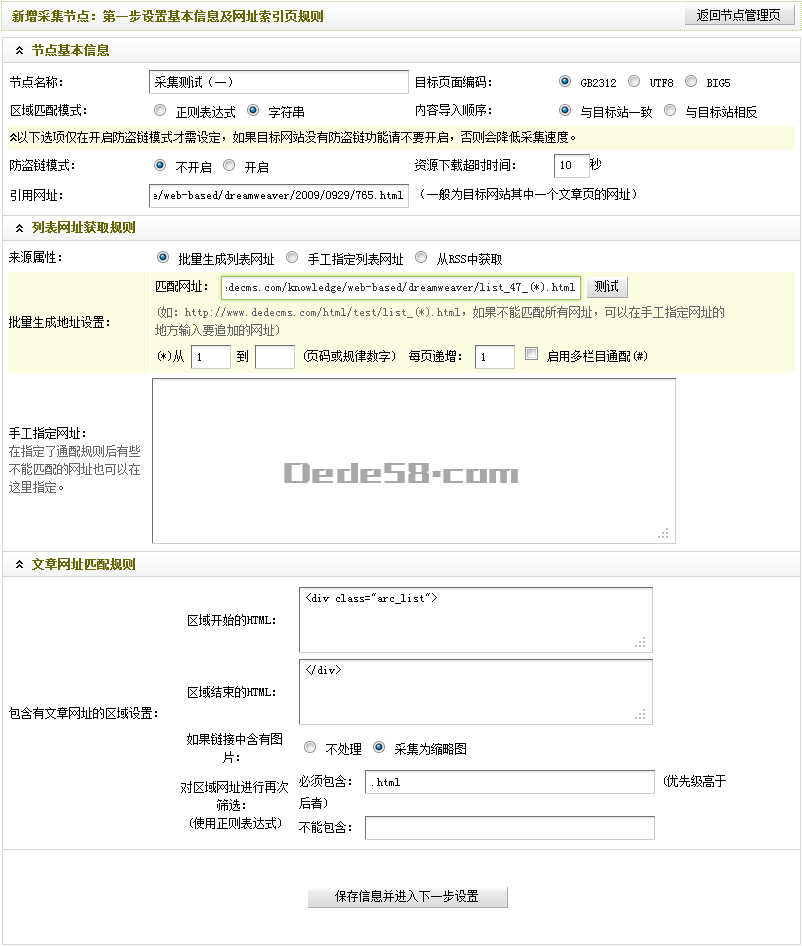
(本图来源于网络,如有侵权请联系删除!)
图20-设置后新增的采集节点:第一步是设置基本信息和URL索引页面规则
一切都完成并检查后,单击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置URL获取规则测试”页面,看到对应的文章列表地址. 如图(图21),

(本图来源于网络,如有侵权请联系删除!)
图21-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
免责声明:本站所有文章及图片均来自用户分享和网络采集。文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
有问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群
文章采集调用(,ajax动态加载的网页并提取网页信息(需进行) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-24 23:29
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$ 查看全部
文章采集调用(,ajax动态加载的网页并提取网页信息(需进行)
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$
文章采集调用(本文对使用到的技术仅做简单的介绍(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-24 23:25
)
本文仅简单介绍所使用的技术。如果想了解更多,请到相应官网网站学习。
本文适合对爬虫相关知识接触较少的新手,主要是普及Selenium是如何做爬虫的,请跳过。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!
QQ群:701698587
1.硒简介
1.简介
Selenium 是一个用于测试网站的自动化测试工具,支持各种主流界面浏览器。
总之,Selenium是一个网站自动化测试的库,它的定位是做自动化测试。我们也可以将其作为爬虫来获取一些网页信息,这个爬虫模拟了真实浏览器的操作,更加实用。
Selenium 是市场上唯一可以与付费产品竞争的自动化测试工具。
如果想了解更多可以到Selenium中文网学习:戳我去Selenium中文网
2.安装
要使用Selenium,首先必须在python中安装相关的库:
pip install Selenium
安装对应浏览器的webdricer驱动文件,这里有chrome的链接,其他浏览器可以网上搜索。戳我下载chrome webdriver驱动文件。选择合适的版本,我选择了2.23。
下载解压后得到exe文件,将此文件复制到chrom安装文件夹中:
通常它是 C:\Program Files (x86)\Google\Chrome\Application, 或 C:\Program Files\Google\Chrome\Application.
然后配置环境变量的路径:
最后写一段代码进行测试:
from selenium import webdriverdriver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
如果看到打开了一个浏览器窗口就成功了,否则下面会出现相应的错误提示,需要查看前面的步骤。
3. 简单介绍
1. 元素定位方法:
基本上前几种方式就可以拿到需要的元素了,需要判断结果是否唯一来选择对应的选择器。
通过驱动对象调用此方法会返回一个标签对象或标签对象列表。标签下的文本可以通过.text获取,标签的其他属性值可以通过get_attribute()获取。
分享一个快速定位元素的小妙招:查看所需信息所在标签的id、class、name是否与标签下信息的语义相关。一般来说,相关的都是唯一的。(从开发者的角度考虑)如果当前标签不能唯一定位,考虑父标签。以此类推,你总能找到一种定位方法。
2.鼠标事件(模拟鼠标操作)
可以通过标签对象调用。
3.键盘事件(模拟键盘操作)
4.其他操作
其他操作包括控制浏览器的操作、获取断言信息、表单切换、多窗口切换、警告框处理、下拉框处理、文件上传操作、cookie操作、调用js代码、截图、关闭浏览器等操作,因为这里我用的不多,就不一一列举了,自己去官网学习吧。
2.爬取目标
本次实战爬虫主要完成以下目标:
在QQ音乐官网爬取指定歌手的前5首歌曲基本信息和前500名流行评论。
1.获取前五首歌曲的url
分析这个页面的代码,我们知道包裹所有歌曲信息的tag的class是唯一的,我们可以拿到它,然后遍历所有的子标签,或者一次性获取所有包裹歌曲信息的div,并且然后获取里面的 a 标签。
2.获取歌曲基本信息
可以看出,基本信息标签中的类名有一部分语义,所以可以通过css选择器来唯一确定。
3.获取歌词
页面上的歌词不完整,貌似需要点击展开,其实所有的歌词都已经在标签里了,只是显示问题。
查看全部
文章采集调用(本文对使用到的技术仅做简单的介绍(组图)
)
本文仅简单介绍所使用的技术。如果想了解更多,请到相应官网网站学习。
本文适合对爬虫相关知识接触较少的新手,主要是普及Selenium是如何做爬虫的,请跳过。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!
QQ群:701698587
1.硒简介
1.简介
Selenium 是一个用于测试网站的自动化测试工具,支持各种主流界面浏览器。
总之,Selenium是一个网站自动化测试的库,它的定位是做自动化测试。我们也可以将其作为爬虫来获取一些网页信息,这个爬虫模拟了真实浏览器的操作,更加实用。
Selenium 是市场上唯一可以与付费产品竞争的自动化测试工具。
如果想了解更多可以到Selenium中文网学习:戳我去Selenium中文网
2.安装
要使用Selenium,首先必须在python中安装相关的库:
pip install Selenium
安装对应浏览器的webdricer驱动文件,这里有chrome的链接,其他浏览器可以网上搜索。戳我下载chrome webdriver驱动文件。选择合适的版本,我选择了2.23。
下载解压后得到exe文件,将此文件复制到chrom安装文件夹中:
通常它是 C:\Program Files (x86)\Google\Chrome\Application, 或 C:\Program Files\Google\Chrome\Application.
然后配置环境变量的路径:
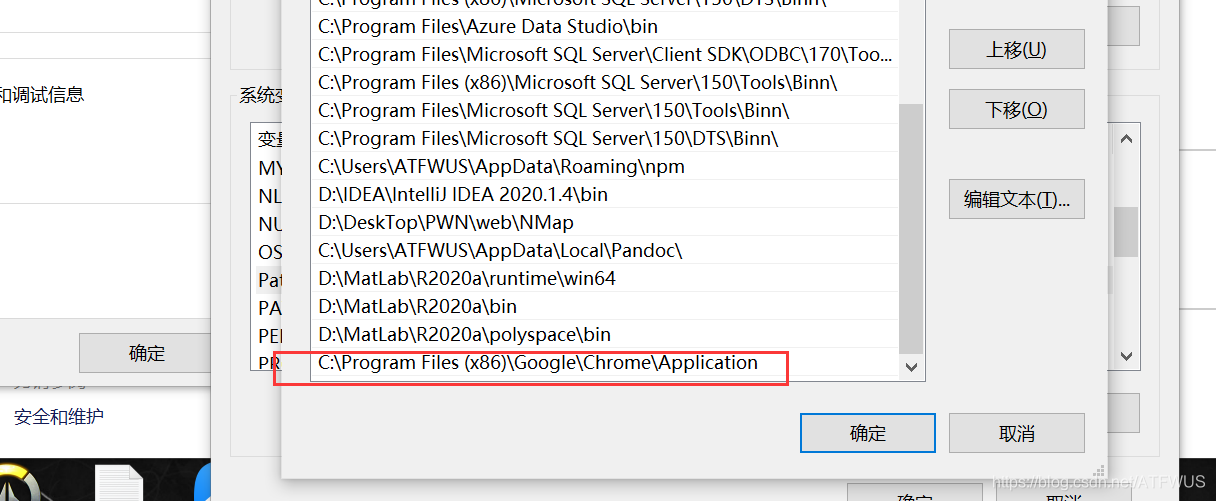
最后写一段代码进行测试:
from selenium import webdriverdriver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
如果看到打开了一个浏览器窗口就成功了,否则下面会出现相应的错误提示,需要查看前面的步骤。
3. 简单介绍
1. 元素定位方法:
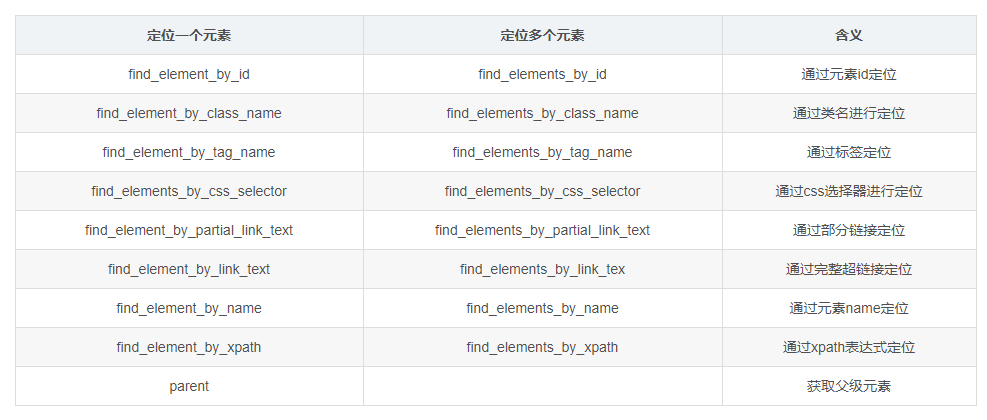
基本上前几种方式就可以拿到需要的元素了,需要判断结果是否唯一来选择对应的选择器。
通过驱动对象调用此方法会返回一个标签对象或标签对象列表。标签下的文本可以通过.text获取,标签的其他属性值可以通过get_attribute()获取。
分享一个快速定位元素的小妙招:查看所需信息所在标签的id、class、name是否与标签下信息的语义相关。一般来说,相关的都是唯一的。(从开发者的角度考虑)如果当前标签不能唯一定位,考虑父标签。以此类推,你总能找到一种定位方法。
2.鼠标事件(模拟鼠标操作)
可以通过标签对象调用。
3.键盘事件(模拟键盘操作)
4.其他操作
其他操作包括控制浏览器的操作、获取断言信息、表单切换、多窗口切换、警告框处理、下拉框处理、文件上传操作、cookie操作、调用js代码、截图、关闭浏览器等操作,因为这里我用的不多,就不一一列举了,自己去官网学习吧。
2.爬取目标
本次实战爬虫主要完成以下目标:
在QQ音乐官网爬取指定歌手的前5首歌曲基本信息和前500名流行评论。
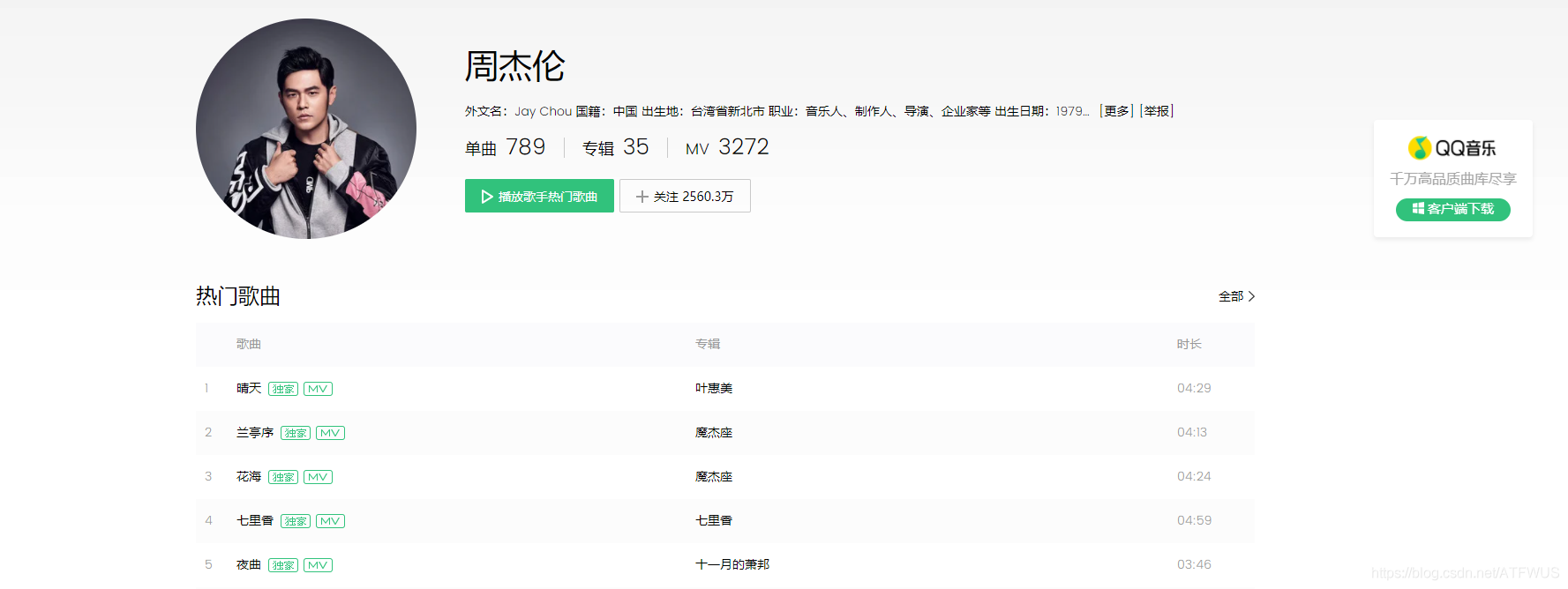
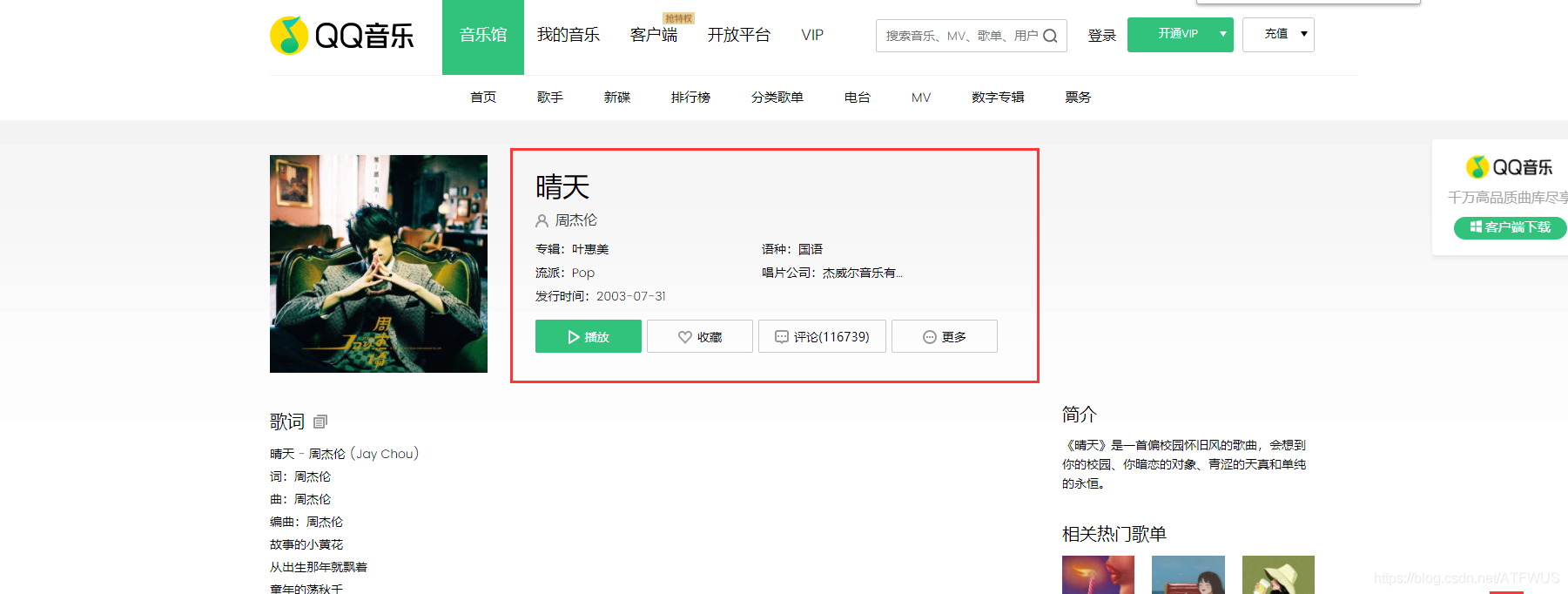
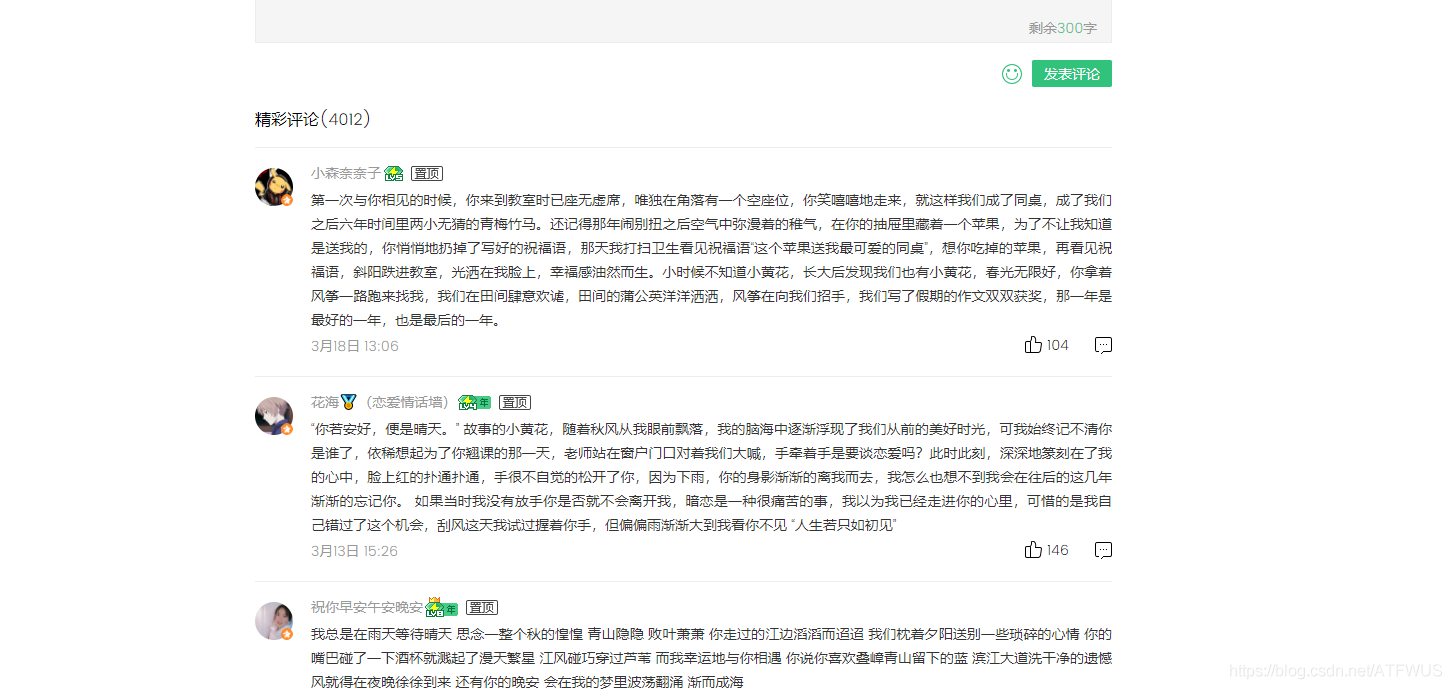
1.获取前五首歌曲的url
分析这个页面的代码,我们知道包裹所有歌曲信息的tag的class是唯一的,我们可以拿到它,然后遍历所有的子标签,或者一次性获取所有包裹歌曲信息的div,并且然后获取里面的 a 标签。
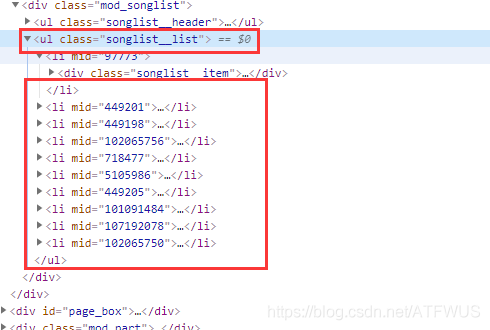
2.获取歌曲基本信息
可以看出,基本信息标签中的类名有一部分语义,所以可以通过css选择器来唯一确定。
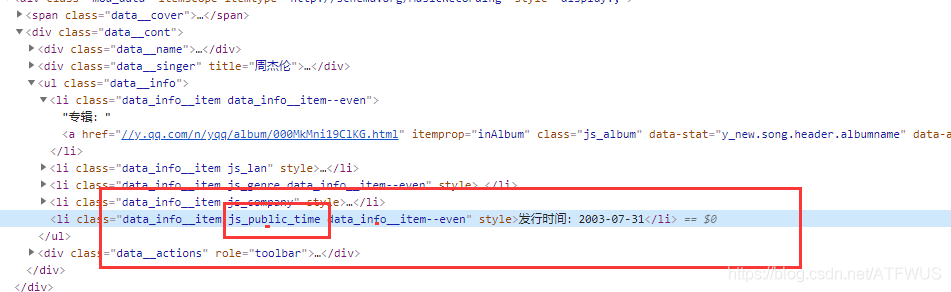
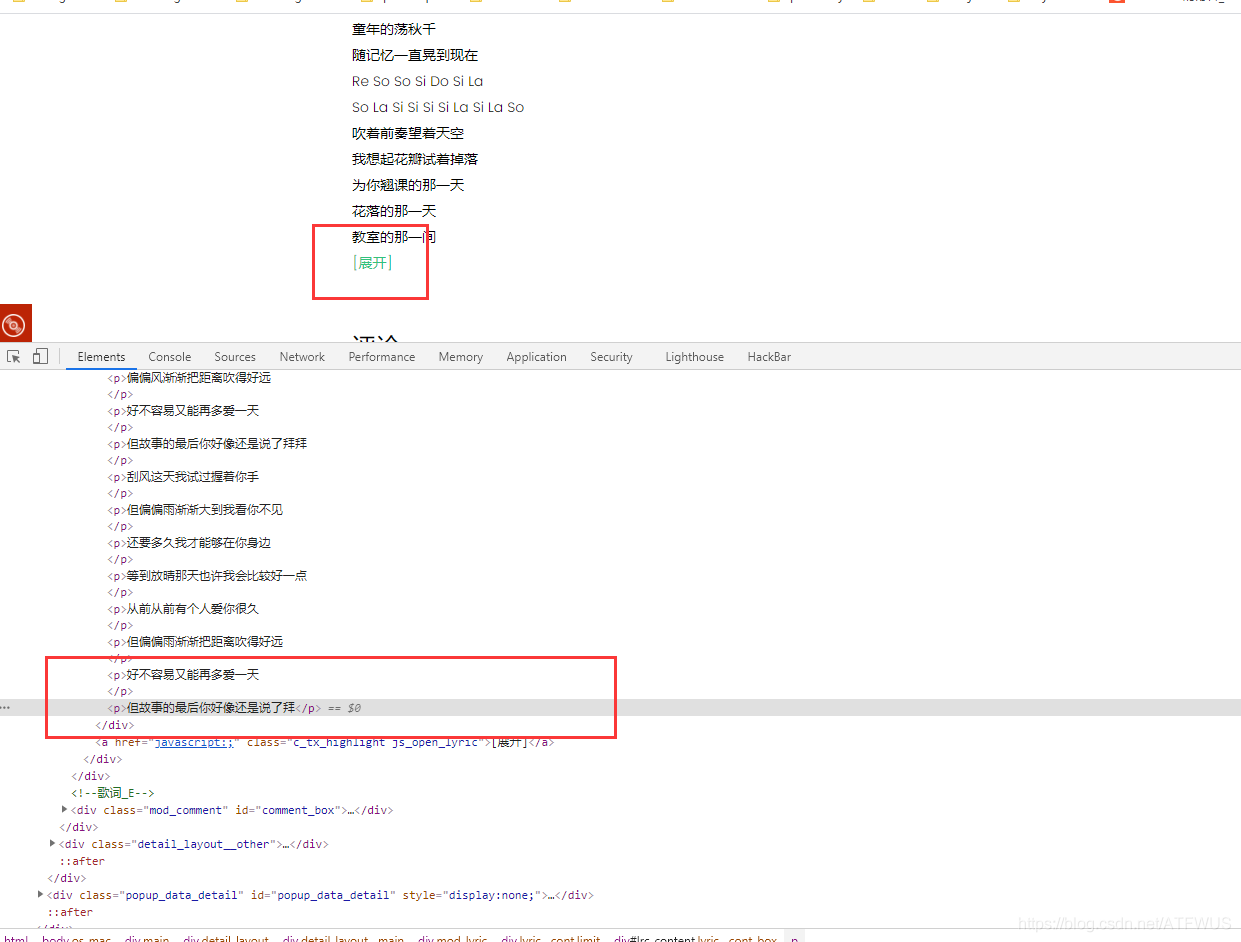
3.获取歌词
页面上的歌词不完整,貌似需要点击展开,其实所有的歌词都已经在标签里了,只是显示问题。
文章采集调用(中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-24 12:01
文章采集调用了爬虫服务器爬取信息,返回json数据以支持后面自动化推荐,爬虫服务器可自动获取文章pdf的内容,如链接,评论,新增收藏,删除收藏,位置,描述,评分,星级评价,评论等等,更重要的是可以向爬虫服务器导出点击数据和爬虫过程显示数据。
我们是做推荐系统的,和小鸟推荐系统比,neilinks绝对算是最先进的,我们开始的时候是想做中文世界的自动化推荐,后来架构考虑后,干脆直接把数据进行一定量的汇聚,编码成数据库里面的形式,用sql实现。国内真正有这个需求的企业不多,不过国内的小平台起来的有好几家,小鸟推荐也算是比较成熟的一个产品。
小鸟实时推荐系统是基于实时大数据的消息推荐。中文自适应推荐系统的模式,我们团队已经提出了很多年了,实际上确有一些难度,由于目前中文在大数据的分析理解上还存在不少技术挑战。希望以下这些讨论,对大家有所帮助。中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐从大数据到实时数据推荐用户行为大数据推荐平台使用什么类型的数据对于信息推荐和推荐系统,本文主要讨论基于用户行为大数据的推荐技术。
这里先聊聊中文市场有关推荐系统的部分。我们将推荐系统描述为:对已被使用过的信息与未被使用过的信息进行有针对性地推荐。根据公众对目标内容的偏好,用户产生的对目标内容的搜索可用于推荐,直接提供给用户。1.中文市场的推荐系统已经存在多年,但依然非常不理想推荐系统的推荐已经持续了漫长的时间,当我们考虑推荐时,技术选型要关注信息的来源,由于中文市场存在太多的没有被使用过的信息。
依赖于这些来源的推荐系统有以下缺点:缺乏技术门槛,缺乏工程实现,上手非常难。缺乏人才保障,人才和工具缺乏。上述的推荐问题会影响很多人加入推荐系统领域,形成恶性循环。2.推荐系统存在的痛点对于每一个信息都能推荐,这可能吗?对于最终用户的需求,是不是存在的推荐呢?用户并不知道哪些信息是最终的用户需求,但是信息至少用于推荐。
根据用户的搜索记录进行推荐可以吗?只需要几秒钟就能做一个最终用户页面的推荐。即使能做,其推荐也是靠计算机实现的,并且推荐效率很低。使用人工审核进行推荐有困难吗?有技术实现难度,人工审核靠人工,效率低的问题。即使人工审核,也有审核人员的个人偏好问题。目前专业的人员个人偏好也不理想。但是,所有能够提供推荐的信息确实都被已经使用过了,没有被使用过的信息,用户是不愿意去触碰,也不感兴趣的。为什么使用新闻、订阅、社交网络等推荐系统?新闻这些信息的推。 查看全部
文章采集调用(中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐)
文章采集调用了爬虫服务器爬取信息,返回json数据以支持后面自动化推荐,爬虫服务器可自动获取文章pdf的内容,如链接,评论,新增收藏,删除收藏,位置,描述,评分,星级评价,评论等等,更重要的是可以向爬虫服务器导出点击数据和爬虫过程显示数据。
我们是做推荐系统的,和小鸟推荐系统比,neilinks绝对算是最先进的,我们开始的时候是想做中文世界的自动化推荐,后来架构考虑后,干脆直接把数据进行一定量的汇聚,编码成数据库里面的形式,用sql实现。国内真正有这个需求的企业不多,不过国内的小平台起来的有好几家,小鸟推荐也算是比较成熟的一个产品。
小鸟实时推荐系统是基于实时大数据的消息推荐。中文自适应推荐系统的模式,我们团队已经提出了很多年了,实际上确有一些难度,由于目前中文在大数据的分析理解上还存在不少技术挑战。希望以下这些讨论,对大家有所帮助。中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐从大数据到实时数据推荐用户行为大数据推荐平台使用什么类型的数据对于信息推荐和推荐系统,本文主要讨论基于用户行为大数据的推荐技术。
这里先聊聊中文市场有关推荐系统的部分。我们将推荐系统描述为:对已被使用过的信息与未被使用过的信息进行有针对性地推荐。根据公众对目标内容的偏好,用户产生的对目标内容的搜索可用于推荐,直接提供给用户。1.中文市场的推荐系统已经存在多年,但依然非常不理想推荐系统的推荐已经持续了漫长的时间,当我们考虑推荐时,技术选型要关注信息的来源,由于中文市场存在太多的没有被使用过的信息。
依赖于这些来源的推荐系统有以下缺点:缺乏技术门槛,缺乏工程实现,上手非常难。缺乏人才保障,人才和工具缺乏。上述的推荐问题会影响很多人加入推荐系统领域,形成恶性循环。2.推荐系统存在的痛点对于每一个信息都能推荐,这可能吗?对于最终用户的需求,是不是存在的推荐呢?用户并不知道哪些信息是最终的用户需求,但是信息至少用于推荐。
根据用户的搜索记录进行推荐可以吗?只需要几秒钟就能做一个最终用户页面的推荐。即使能做,其推荐也是靠计算机实现的,并且推荐效率很低。使用人工审核进行推荐有困难吗?有技术实现难度,人工审核靠人工,效率低的问题。即使人工审核,也有审核人员的个人偏好问题。目前专业的人员个人偏好也不理想。但是,所有能够提供推荐的信息确实都被已经使用过了,没有被使用过的信息,用户是不愿意去触碰,也不感兴趣的。为什么使用新闻、订阅、社交网络等推荐系统?新闻这些信息的推。
文章采集调用( DedeCMS跳转链接实际指向是哪里呢?秀站网秀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-23 18:07
DedeCMS跳转链接实际指向是哪里呢?秀站网秀)
在Dedecms中,文章模型经常使用jump[j]属性,但是前台显示的链接是动态的URL地址,搜索引擎会跟着爬,而是跳转发送。这个链接实际上指向哪里?王秀展 王秀展做了一个实验。这个链接返回的HTTP状态码是302,是临时跳转。这个跳转链接其实很不友好。对于站点,页面上有多个指向实际 URL 的 URL;如果是站外链接,很容易分散权重。
调用文章的一般方法如下,不修改源文件。
{dede:arclist addfields='redirecturl' channelid='1'}
][field:title/]
{/dede:arclist}
这里的链接修改为站内和站外直接调用Jump[j]引用的URL,站外调用nofollow。
需要用到的是通用的[field:array]标签,可以用在任何Dedecms默认标签中,特别适合多条件判断。
{dede:arclist addfields='redirecturl' channelid='1'}
[field:array runphp='yes']
if(@me['redirecturl'] !=''){
@me = ' . ']' . @me['title'] . '';
}else{
@me = ' . ']' . @me['title'] . '';
};
[/field:array]
{/dede:arclist}
dedecms的{dede:list}标签不能直接调用redirecturl字段,需要修改源程序
打开/include/arc.listview.class.php,找到(复制时请删除分隔符)
//如果不用默认的sortrank或id排序,使用联合查询(数据量大时非常缓慢)
if(preg_match('/hot|click|lastpost/', $orderby))
{
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.isdefault,tp.defaultname,
tp.namerule,tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
$addField
FROM `#分隔符@__archives` arc
LEFT JOIN `#分隔符@__arctype` tp ON arc.typeid=tp.id
$addJoin
WHERE {$this->addSql} $ordersql LIMIT $limitstart,$row";
}
在这段代码之前,添加
$addField .= ','.$addtable.'.redirecturl';
调用方法
{dede:list row='1' addfields='redirecturl' orderby='pubdate'}
][field:title/]
{/dede:list}
也可以增加该字段的判断,调用跳转地址,不再赘述。 查看全部
文章采集调用(
DedeCMS跳转链接实际指向是哪里呢?秀站网秀)

在Dedecms中,文章模型经常使用jump[j]属性,但是前台显示的链接是动态的URL地址,搜索引擎会跟着爬,而是跳转发送。这个链接实际上指向哪里?王秀展 王秀展做了一个实验。这个链接返回的HTTP状态码是302,是临时跳转。这个跳转链接其实很不友好。对于站点,页面上有多个指向实际 URL 的 URL;如果是站外链接,很容易分散权重。
调用文章的一般方法如下,不修改源文件。
{dede:arclist addfields='redirecturl' channelid='1'}
][field:title/]
{/dede:arclist}
这里的链接修改为站内和站外直接调用Jump[j]引用的URL,站外调用nofollow。
需要用到的是通用的[field:array]标签,可以用在任何Dedecms默认标签中,特别适合多条件判断。
{dede:arclist addfields='redirecturl' channelid='1'}
[field:array runphp='yes']
if(@me['redirecturl'] !=''){
@me = ' . ']' . @me['title'] . '';
}else{
@me = ' . ']' . @me['title'] . '';
};
[/field:array]
{/dede:arclist}
dedecms的{dede:list}标签不能直接调用redirecturl字段,需要修改源程序
打开/include/arc.listview.class.php,找到(复制时请删除分隔符)
//如果不用默认的sortrank或id排序,使用联合查询(数据量大时非常缓慢)
if(preg_match('/hot|click|lastpost/', $orderby))
{
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.isdefault,tp.defaultname,
tp.namerule,tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
$addField
FROM `#分隔符@__archives` arc
LEFT JOIN `#分隔符@__arctype` tp ON arc.typeid=tp.id
$addJoin
WHERE {$this->addSql} $ordersql LIMIT $limitstart,$row";
}
在这段代码之前,添加
$addField .= ','.$addtable.'.redirecturl';
调用方法
{dede:list row='1' addfields='redirecturl' orderby='pubdate'}
][field:title/]
{/dede:list}
也可以增加该字段的判断,调用跳转地址,不再赘述。
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-22 18:09
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的 Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那么我们在java项目中如何控制camera capture呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。web程序调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,其中收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的 Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那么我们在java项目中如何控制camera capture呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。web程序调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,其中收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
文章采集调用(第二个降低写作启动成本的大招:建立写作素材库有了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-22 01:14
以后只要掌握了两个能力,自己不创业也能活的很好。
第一个是写 第二个是说
只要掌握了这些能力中的任何一项,就可以立于不败之地。
和我一样,我更喜欢写作!
每天写一篇文章来创建自己的个人品牌。写文章其实没有想象的那么难。关键是要降低写入的启动成本。
简单来说,你什么都不用想,直接开始写作。这个我在之前的文章中已经详细介绍过了。
今天分享第二大降低写作启动成本的方法:搭建写作素材库
有了这个写作素材库,再也不用为文章的写作发愁了。
一、什么是文具库
写作素材库是一个灵感参考库,可以让你降低思考成本。
例如,厨师就像烹饪一样需要各种配料和调味品。没有这些,厨师就无法烹饪出美味的菜肴。
图片来自简书App
各种难懂的食材和调味品,都是厨师的素材库。有了这些,依靠我多年积累的经验,我可以轻松地立即烹饪出各种美味佳肴。
编写 文章 也是如此。
而且我在写作过程中也需要经常使用素材库(我的第二大脑)
图片来自简书App
不同的分类下有不同的内容素材,方便我每次调用。
比如今天我要写一篇关于时间管理的文章文章。直接在软件里面搜索时间管理,1秒参考资料很多。
图片来自简书App
这些都是我平时看的很好的文章,采集了。写文章时可以快速参考。
二、为什么要建写作材料库
在我的任务中拥有一个写作材料库的最大好处是我可以随时用一些经典的思维来证明我的一些观点。
例如:
比如我想写一篇关于竞争力的文章。我提出的核心理念是专注做事,建立自己的影响圈。我说的话可能不会立刻引起大家的共鸣,所以我必须借用一些名人。祝福我的想法。
我使用了写作材料库中“Working with a System”的作者 Sam Carpenter 来祝福我的想法。
图片来自简书App
如果你没有素材库,即使你记忆力很好,你也不会长时间记住它。
在我的写作素材库中,专门设置了一个分类,用来保存阅读时的一些经典句子。
图片来自简书App
这是3本不合理的书
图片来自简书App
在这里很容易找到一些经典的参考句子。
写作素材库最大的好处就是可以随时调用,无论身在何处,只要输入相关关键词,就可以立即找到我想要的素材,给写作带来了极大的便利< @文章。
三、如何搭建写作素材库
写作素材库的建立其实很简单,分为三个步骤:
第 1 步:采集材料
在采集资料方面,其实有两种采集方式:
1、碎片采集
我们每天看大量的公众号文章、知乎文章或网站文章,感觉好的文章可以被采集。
这是通过碎片时间采集的,文章 永远不会太多。
图片来自简书App
Fragments 文章,我把它们都放在我的收件箱里。
好像很清楚,我采集了多少文章,有空就读。
2、固定主题合集
有时,我们可能会做一些项目,我们需要一个明确的方向来采集知识。
例如:
我媳妇现在主要卖玫瑰,所以她每天都需要出口玫瑰文章,打造个人品牌,创造价值,增加销量。
我的做法是通过百度知乎、知乎、公众号直接采集玫瑰素材
图片来自简书App
通过搜索,马上有数百条写作方向和材料,百度知道。
使用文章搜索微信公众号,上千条素材
图片来自简书App
看,有6000多篇文案,自己写就够了。
问答平台知乎、公众号文章,这三个地方足以让你采集上万条固定主题的写作素材。
第 2 步:保存材料
采集的最终目的是为了方便调用,所以尝试了很多工具,最后决定使用印象笔记作为载体工具。原因很明显:
1、全平台支持2、强大的搜索功能
全平台的优势在于,无论是手机还是电脑,都可以轻松采集保存。
尤其是有时候出去看到一些有启发性的东西,就直接打开印象笔记拍张照片,然后把这个时候的灵感写下来。
这是之后的想法。
但是,要保持一个好的材料库,就必须建立一个完整的分类体系。
图片来自简书App
以上是我自己的分类系统,主要由收件箱、主题知识库、存档知识库组成
收件箱:用于临时存放刚刚采集到的分片信息。你可能没有仔细阅读它,但感觉这是一个很好的材料。先存起来,有时间再读。
知识主题库:我把它分为工作、学习、生活、兴趣四大类,基本涵盖了方方面面。有了对应的分类,我以后只需要按照知识的类型来分类就可以了。
例如
图片来自简书App
对于这一类阅读,我专门存储电子书和经典句子的摘录。
在例如
图片来自简书App
平时看到一些好的文案,我会放到存档类
合理的分类可以让我快速找到相关的素材位置。
分类很重要。
只要仔细观察,一些大的网站都有非常详细的分类导航。
图片来自简书App
这是京东的网站品类,人们一看就知道应该点击商品,才能找到自己想要的商品。
第 3 步:检索材料
材料的采集是为了最后的快速调用,所以以前的分类工作体现了价值。
通过印象笔记有两种调用方式
第一种:使用搜索功能
Evernote 使用了强大的搜索功能。只要学会了搜索命令,不管怎么找都可以快速调出素材。
Plus+:多个关键词 搜索
减号-:不收录某个关键词
双引号"":精确搜索
notebook:在 notebook 内搜索
Intitle:标题搜索
例如:
intitle:seo 该命令用于搜索标题中收录seo的信息
图片来自简书App
标题是否收录seo的信息知识。
双引号“促销”来促进关键词搜索
图片来自简书App
结果是title收录promotion关键词,content收录promotion关键词信息,可以搜索到,调用起来很方便。
第二种:按类别搜索
合理的分类也可以让你找到相关的信息,就像我的学习分类一样
图片来自简书App
根据分类结构,我可以快速找到我想要的材料,比如时间管理。我只是点击这个类别,它是所有时间管理材料。
请记住,创建材料库是为了快速回忆,找不到它就意味着没有它。
如果你想每天写文章来打造个人品牌,那你就需要一个属于自己的写作素材库。
知道方法和方法并不意味着你已经学会了。只有自己实践和应用,才能取得更大的进步。
版权归周振兴作者所有,希望能帮到你! 查看全部
文章采集调用(第二个降低写作启动成本的大招:建立写作素材库有了)
以后只要掌握了两个能力,自己不创业也能活的很好。
第一个是写 第二个是说
只要掌握了这些能力中的任何一项,就可以立于不败之地。
和我一样,我更喜欢写作!
每天写一篇文章来创建自己的个人品牌。写文章其实没有想象的那么难。关键是要降低写入的启动成本。
简单来说,你什么都不用想,直接开始写作。这个我在之前的文章中已经详细介绍过了。
今天分享第二大降低写作启动成本的方法:搭建写作素材库
有了这个写作素材库,再也不用为文章的写作发愁了。
一、什么是文具库
写作素材库是一个灵感参考库,可以让你降低思考成本。
例如,厨师就像烹饪一样需要各种配料和调味品。没有这些,厨师就无法烹饪出美味的菜肴。

图片来自简书App
各种难懂的食材和调味品,都是厨师的素材库。有了这些,依靠我多年积累的经验,我可以轻松地立即烹饪出各种美味佳肴。
编写 文章 也是如此。
而且我在写作过程中也需要经常使用素材库(我的第二大脑)
图片来自简书App
不同的分类下有不同的内容素材,方便我每次调用。
比如今天我要写一篇关于时间管理的文章文章。直接在软件里面搜索时间管理,1秒参考资料很多。
图片来自简书App
这些都是我平时看的很好的文章,采集了。写文章时可以快速参考。
二、为什么要建写作材料库
在我的任务中拥有一个写作材料库的最大好处是我可以随时用一些经典的思维来证明我的一些观点。
例如:
比如我想写一篇关于竞争力的文章。我提出的核心理念是专注做事,建立自己的影响圈。我说的话可能不会立刻引起大家的共鸣,所以我必须借用一些名人。祝福我的想法。
我使用了写作材料库中“Working with a System”的作者 Sam Carpenter 来祝福我的想法。
图片来自简书App
如果你没有素材库,即使你记忆力很好,你也不会长时间记住它。
在我的写作素材库中,专门设置了一个分类,用来保存阅读时的一些经典句子。
图片来自简书App
这是3本不合理的书
图片来自简书App
在这里很容易找到一些经典的参考句子。
写作素材库最大的好处就是可以随时调用,无论身在何处,只要输入相关关键词,就可以立即找到我想要的素材,给写作带来了极大的便利< @文章。
三、如何搭建写作素材库
写作素材库的建立其实很简单,分为三个步骤:
第 1 步:采集材料
在采集资料方面,其实有两种采集方式:
1、碎片采集
我们每天看大量的公众号文章、知乎文章或网站文章,感觉好的文章可以被采集。
这是通过碎片时间采集的,文章 永远不会太多。
图片来自简书App
Fragments 文章,我把它们都放在我的收件箱里。
好像很清楚,我采集了多少文章,有空就读。
2、固定主题合集
有时,我们可能会做一些项目,我们需要一个明确的方向来采集知识。
例如:
我媳妇现在主要卖玫瑰,所以她每天都需要出口玫瑰文章,打造个人品牌,创造价值,增加销量。
我的做法是通过百度知乎、知乎、公众号直接采集玫瑰素材
图片来自简书App
通过搜索,马上有数百条写作方向和材料,百度知道。
使用文章搜索微信公众号,上千条素材
图片来自简书App
看,有6000多篇文案,自己写就够了。
问答平台知乎、公众号文章,这三个地方足以让你采集上万条固定主题的写作素材。
第 2 步:保存材料
采集的最终目的是为了方便调用,所以尝试了很多工具,最后决定使用印象笔记作为载体工具。原因很明显:
1、全平台支持2、强大的搜索功能
全平台的优势在于,无论是手机还是电脑,都可以轻松采集保存。
尤其是有时候出去看到一些有启发性的东西,就直接打开印象笔记拍张照片,然后把这个时候的灵感写下来。
这是之后的想法。
但是,要保持一个好的材料库,就必须建立一个完整的分类体系。
图片来自简书App
以上是我自己的分类系统,主要由收件箱、主题知识库、存档知识库组成
收件箱:用于临时存放刚刚采集到的分片信息。你可能没有仔细阅读它,但感觉这是一个很好的材料。先存起来,有时间再读。
知识主题库:我把它分为工作、学习、生活、兴趣四大类,基本涵盖了方方面面。有了对应的分类,我以后只需要按照知识的类型来分类就可以了。
例如
图片来自简书App
对于这一类阅读,我专门存储电子书和经典句子的摘录。
在例如
图片来自简书App
平时看到一些好的文案,我会放到存档类
合理的分类可以让我快速找到相关的素材位置。
分类很重要。
只要仔细观察,一些大的网站都有非常详细的分类导航。
图片来自简书App
这是京东的网站品类,人们一看就知道应该点击商品,才能找到自己想要的商品。
第 3 步:检索材料
材料的采集是为了最后的快速调用,所以以前的分类工作体现了价值。
通过印象笔记有两种调用方式
第一种:使用搜索功能
Evernote 使用了强大的搜索功能。只要学会了搜索命令,不管怎么找都可以快速调出素材。
Plus+:多个关键词 搜索
减号-:不收录某个关键词
双引号"":精确搜索
notebook:在 notebook 内搜索
Intitle:标题搜索
例如:
intitle:seo 该命令用于搜索标题中收录seo的信息
图片来自简书App
标题是否收录seo的信息知识。
双引号“促销”来促进关键词搜索
图片来自简书App
结果是title收录promotion关键词,content收录promotion关键词信息,可以搜索到,调用起来很方便。
第二种:按类别搜索
合理的分类也可以让你找到相关的信息,就像我的学习分类一样
图片来自简书App
根据分类结构,我可以快速找到我想要的材料,比如时间管理。我只是点击这个类别,它是所有时间管理材料。
请记住,创建材料库是为了快速回忆,找不到它就意味着没有它。
如果你想每天写文章来打造个人品牌,那你就需要一个属于自己的写作素材库。
知道方法和方法并不意味着你已经学会了。只有自己实践和应用,才能取得更大的进步。
版权归周振兴作者所有,希望能帮到你!
文章采集调用(5.5新版本的+30联络651606775830元功能形容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-11-22 01:09
)
(需5.5新版+30联系6516067758)需加30元
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能详情、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与百万订阅账号分享优质内容,每天大量升级可以快速提升网站的权重和排名。
功能亮点:
1、可以自己设置插件名称:
可以在后台面包屑导航上修改插件名称。如果不设置,则默认为微信窗口。
2、您可以自己设置SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你要采集的公众号,提交。一次最多可以采集 10个公众号信息。
4、批量提供采集公众号文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、介绍页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只需安装diy扩展,即可拥有强大的DIY机制,可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、介绍页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、 可以灵活设置信息是否需要审核:
客户提交的内容公众号和文章信息是否需要审核,可以通过后台的开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只要安装相应的手机版组件,就可以轻松打开手机版。
查看全部
文章采集调用(5.5新版本的+30联络651606775830元功能形容
)
(需5.5新版+30联系6516067758)需加30元

功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能详情、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与百万订阅账号分享优质内容,每天大量升级可以快速提升网站的权重和排名。
功能亮点:
1、可以自己设置插件名称:
可以在后台面包屑导航上修改插件名称。如果不设置,则默认为微信窗口。
2、您可以自己设置SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你要采集的公众号,提交。一次最多可以采集 10个公众号信息。
4、批量提供采集公众号文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、介绍页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只需安装diy扩展,即可拥有强大的DIY机制,可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、介绍页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、 可以灵活设置信息是否需要审核:
客户提交的内容公众号和文章信息是否需要审核,可以通过后台的开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只要安装相应的手机版组件,就可以轻松打开手机版。



文章采集调用(DedeCMSV5.7sp2网站漏洞如何修复dedecms)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-19 17:12
如何修复Dedecms V5.7sp2网站漏洞
织梦dedecms,在整个互联网中,很多企业网站、个人网站、优化网站都在用dede作为整个网站的发展@>架构,dedecms采用php+mysql数据库架构来承载整个网站的操作和用户访问。首页和专栏页面生成了织梦漏洞的详细信息,我们来一步步分析:首先介绍一下parse_str函数的机制和作用。简单来说就是解析网站传递过来的字符串,将字符串的值转换成一个固有的变量值。这个函数是传入进来的,当有改动的时候,不会验证当前变量网站的值是否收录在buy_action中。最新版dedecms中的php代码。存在一个网站漏洞,dedecms针对之前更新修复的文件网站漏洞,在代码中加入了很多功能的安全过滤,但是传入的值在过滤的同时解码编码函数时没有严格过滤掉。网站漏洞的产生和dedecms的利用非常简单,但是在实际的利用过程中,我们发现实现起来还是比较困难的。最重要的是mchStrCode的功能是在整个网站编码中控制前端用户提交的值中的参数。dedecms网站 漏洞修复建议:关于dedecms parse_str函数SQL注入漏洞,需要修复的是变量覆盖修复,对前端输入的值进行安全判断。, 确认变量值是否存在,如果存在则不会被覆盖,防止变量覆盖导致恶意结构的掺入
726 查看全部
文章采集调用(DedeCMSV5.7sp2网站漏洞如何修复dedecms)
如何修复Dedecms V5.7sp2网站漏洞
织梦dedecms,在整个互联网中,很多企业网站、个人网站、优化网站都在用dede作为整个网站的发展@>架构,dedecms采用php+mysql数据库架构来承载整个网站的操作和用户访问。首页和专栏页面生成了织梦漏洞的详细信息,我们来一步步分析:首先介绍一下parse_str函数的机制和作用。简单来说就是解析网站传递过来的字符串,将字符串的值转换成一个固有的变量值。这个函数是传入进来的,当有改动的时候,不会验证当前变量网站的值是否收录在buy_action中。最新版dedecms中的php代码。存在一个网站漏洞,dedecms针对之前更新修复的文件网站漏洞,在代码中加入了很多功能的安全过滤,但是传入的值在过滤的同时解码编码函数时没有严格过滤掉。网站漏洞的产生和dedecms的利用非常简单,但是在实际的利用过程中,我们发现实现起来还是比较困难的。最重要的是mchStrCode的功能是在整个网站编码中控制前端用户提交的值中的参数。dedecms网站 漏洞修复建议:关于dedecms parse_str函数SQL注入漏洞,需要修复的是变量覆盖修复,对前端输入的值进行安全判断。, 确认变量值是否存在,如果存在则不会被覆盖,防止变量覆盖导致恶意结构的掺入
726
文章采集调用(几款调用最新或是随机文章的标签是哪几种? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-19 09:16
)
目前国内流行的几个开源程序包括Empirecms、织梦cms、WordPress等,这些对于建网站做seo的站长来说肯定不陌生优化。一般有在首页或内页调用最新的或随机的文章的爱好。如果这些文章是同一个开源程序,调用起来相对容易一些。如果它们不一样怎么办?接下来我讲一下帝国cms如何调用WordPress博客的最新或随机文章,仅供参考。
1、 Empirecms 最常用的信息调用标签是(ecmsinfo),如下图,就是ecmsinfo调用标签
格式主要是列/主题ID和模板ID这两个参数。操作系统的默认 ID 为 24。
例如:如[ecmsinfo] 10, 5, 36, 1, 24, 20, 0 [/ecmsinfo]
“10”表示“管理栏”中标识的对应栏的ID
“20”表示“管理标签模板”中的标签模板ID
整个代码的意思是按照标签模板ID(20))的规则调用列ID(10))中5篇文章的标题文章,并调用文章标题前不显示列名和图片。
2、根据上面的例子,Empire cms随机调用WordPress博客文章,标签如下:
[ecmsinfo]"选择 post_title 作为标题,id 作为 id from wp_posts order by rand() desc limit 5",5,36,1,24,29,0[/ecms信息]
说明:“select post_title as title, id as id from wp_posts order by rand() desc limit 5”本段表示用SQL语句调用WordPress博客数据库的字段命令。
(1) post_title 对应 WordPress 博客的 文章 标题。
(2) id 对应标题号。
(3) wp_posts 是存放 WordPress 文章 的数据表,如果帝国cms 和 WordPress 博客是
不同的数据库,那么,上面的“wp_posts”改为“博客数据库名.wp_posts”。因为是调用WordPress博客的URL地址,所以必须单独自定义一个标签模板。进入帝国cms后台“模板管理”——“管理标签模板”——“添加模板”如下图:
模板名称,只写一个好记的名字,比如“首页调用WordPress博客文章模板”
(4)在页面模板内容中输入以下代码
[!–empirenews.listtemp–]
[!–empirenews.listtemp–]
(5)列表内容模板list.var输入如下:
[!–title–]
注意,如果WordPress的相对地址是/blog/?p=*,则使用/blog/?p=[! –Id–]
伪静态地址 blog/*.html 是 /blog/ [! –Id–].html(*代表一个数字)
当然最好使用绝对地址。其他的URL地址可以类推。
然后点击“保存模板”,对应的图如下,29为标签模板的ID。
(6)"order by rand() desc"这段代码的意思是随机排序,如果调用最新的文章,对应的是"order by id desc"
(7)limt 5 表示5次文章调用的次数。如果是5,后面的第一个数字也必须是5(见ecmsinfo标签写法)
好的,然后把ecmsinfo标签代码放到一些你要调用的Empirecms模板中就OK了
最后附上效果图:
文章 的 WordPress 博客:
Empirecms随意调用一个WordPress博客文章:
查看全部
文章采集调用(几款调用最新或是随机文章的标签是哪几种?
)
目前国内流行的几个开源程序包括Empirecms、织梦cms、WordPress等,这些对于建网站做seo的站长来说肯定不陌生优化。一般有在首页或内页调用最新的或随机的文章的爱好。如果这些文章是同一个开源程序,调用起来相对容易一些。如果它们不一样怎么办?接下来我讲一下帝国cms如何调用WordPress博客的最新或随机文章,仅供参考。

1、 Empirecms 最常用的信息调用标签是(ecmsinfo),如下图,就是ecmsinfo调用标签
格式主要是列/主题ID和模板ID这两个参数。操作系统的默认 ID 为 24。
例如:如[ecmsinfo] 10, 5, 36, 1, 24, 20, 0 [/ecmsinfo]
“10”表示“管理栏”中标识的对应栏的ID
“20”表示“管理标签模板”中的标签模板ID
整个代码的意思是按照标签模板ID(20))的规则调用列ID(10))中5篇文章的标题文章,并调用文章标题前不显示列名和图片。
2、根据上面的例子,Empire cms随机调用WordPress博客文章,标签如下:
[ecmsinfo]"选择 post_title 作为标题,id 作为 id from wp_posts order by rand() desc limit 5",5,36,1,24,29,0[/ecms信息]
说明:“select post_title as title, id as id from wp_posts order by rand() desc limit 5”本段表示用SQL语句调用WordPress博客数据库的字段命令。

(1) post_title 对应 WordPress 博客的 文章 标题。
(2) id 对应标题号。
(3) wp_posts 是存放 WordPress 文章 的数据表,如果帝国cms 和 WordPress 博客是
不同的数据库,那么,上面的“wp_posts”改为“博客数据库名.wp_posts”。因为是调用WordPress博客的URL地址,所以必须单独自定义一个标签模板。进入帝国cms后台“模板管理”——“管理标签模板”——“添加模板”如下图:


模板名称,只写一个好记的名字,比如“首页调用WordPress博客文章模板”
(4)在页面模板内容中输入以下代码
[!–empirenews.listtemp–]
[!–empirenews.listtemp–]
(5)列表内容模板list.var输入如下:
[!–title–]
注意,如果WordPress的相对地址是/blog/?p=*,则使用/blog/?p=[! –Id–]
伪静态地址 blog/*.html 是 /blog/ [! –Id–].html(*代表一个数字)
当然最好使用绝对地址。其他的URL地址可以类推。
然后点击“保存模板”,对应的图如下,29为标签模板的ID。

(6)"order by rand() desc"这段代码的意思是随机排序,如果调用最新的文章,对应的是"order by id desc"
(7)limt 5 表示5次文章调用的次数。如果是5,后面的第一个数字也必须是5(见ecmsinfo标签写法)
好的,然后把ecmsinfo标签代码放到一些你要调用的Empirecms模板中就OK了
最后附上效果图:
文章 的 WordPress 博客:

Empirecms随意调用一个WordPress博客文章:

文章采集调用( Typechotypecho分类调用代码放到模板的相关位置即可(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-19 09:14
Typechotypecho分类调用代码放到模板的相关位置即可(图))
【使用指南】可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是找到了typecho调用某个类的实现。文章的方法很简单。只需要使用一段typecho分类调用代码,放在模板的相关位置即可。
可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是我找到了typecho调用一个类别目录的实现文章 方法很简单,只需要使用一段typecho分类调用代码就可以了在模板的相关位置。
下面是这个类的调用代码的使用方法。
$this->widget('Widget_Archive@index', 'pageSize=6&type=category', 'mid=3')
->parse('{title}');
其中,pageSize代表输出的数量,mid代表一个类别的类别id。
为了移植方便,可以将mid=3改为slug=your_shot_name,其中your_shot_name代表某类的缩写名称。
其中,permalink表示文章的链接,title表示文章的标题。 查看全部
文章采集调用(
Typechotypecho分类调用代码放到模板的相关位置即可(图))

【使用指南】可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是找到了typecho调用某个类的实现。文章的方法很简单。只需要使用一段typecho分类调用代码,放在模板的相关位置即可。
可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是我找到了typecho调用一个类别目录的实现文章 方法很简单,只需要使用一段typecho分类调用代码就可以了在模板的相关位置。
下面是这个类的调用代码的使用方法。
$this->widget('Widget_Archive@index', 'pageSize=6&type=category', 'mid=3')
->parse('{title}');
其中,pageSize代表输出的数量,mid代表一个类别的类别id。
为了移植方便,可以将mid=3改为slug=your_shot_name,其中your_shot_name代表某类的缩写名称。
其中,permalink表示文章的链接,title表示文章的标题。
文章采集调用(一个网站的采集规则/article/collectsite.php)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-14 16:13
首先登录后台,点击上方菜单“模块管理”-“小说连载”,然后点击左侧菜单“采集配置”链接,会显示当前所有采集@ > 规则,每一行代表一个网站。 1、“单篇采集规则”指的是一篇采集文章文章所需的规则配置,主要内容包括网站名称、网站@ > 地址、文章标题、作者等基本信息,以及本文章的章节结构和章节内容,可以点击编辑配置修改采集规则。
2、“Batch采集”是在单个采集的基础上进行的,比如采集一个文章所有文章在列表页@>,这个列表可以是最近更新、排行榜或文章的一个类别。批量采集的规则主要是获取列表页的文章名称和文章序号,然后将单个采集调用到采集,如果需要获取列表的第二页、第三页等内容,则需要设置翻页的参数解析规则。
注意:所有采集规则都生成了相应的配置文件,允许网站配置在:configs/article/collectsite.php中的采集,某个网站的规则配置文件为:configs/article/site_网站英文logo.php,所以网站英文logo不允许重复。例如:在configs/article/collectsite.php中配置起点中文网站的采集:
$jieqiCollectsite['1']['name'] ='起点中文网';$jieqiCollectsite['1']['config'] ='cmfu_com';$jieqiCollectsite['1']['url ' ] ='';$jieqiCollectsite['1']['subarticleid'] ='';$jieqiCollectsite['1']['enable'] = '1';
那么起点采集规则配置文件是configs/article/site_cmfu_com.php。 查看全部
文章采集调用(一个网站的采集规则/article/collectsite.php)
首先登录后台,点击上方菜单“模块管理”-“小说连载”,然后点击左侧菜单“采集配置”链接,会显示当前所有采集@ > 规则,每一行代表一个网站。 1、“单篇采集规则”指的是一篇采集文章文章所需的规则配置,主要内容包括网站名称、网站@ > 地址、文章标题、作者等基本信息,以及本文章的章节结构和章节内容,可以点击编辑配置修改采集规则。
2、“Batch采集”是在单个采集的基础上进行的,比如采集一个文章所有文章在列表页@>,这个列表可以是最近更新、排行榜或文章的一个类别。批量采集的规则主要是获取列表页的文章名称和文章序号,然后将单个采集调用到采集,如果需要获取列表的第二页、第三页等内容,则需要设置翻页的参数解析规则。
注意:所有采集规则都生成了相应的配置文件,允许网站配置在:configs/article/collectsite.php中的采集,某个网站的规则配置文件为:configs/article/site_网站英文logo.php,所以网站英文logo不允许重复。例如:在configs/article/collectsite.php中配置起点中文网站的采集:
$jieqiCollectsite['1']['name'] ='起点中文网';$jieqiCollectsite['1']['config'] ='cmfu_com';$jieqiCollectsite['1']['url ' ] ='';$jieqiCollectsite['1']['subarticleid'] ='';$jieqiCollectsite['1']['enable'] = '1';
那么起点采集规则配置文件是configs/article/site_cmfu_com.php。
文章采集调用( 使用SQL调用当前文章链接的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-14 16:11
使用SQL调用当前文章链接的方法,你知道吗?)
很多时候在使用织梦cms的时候,想在文章页面的最后加上当前的文章链接(url),这样别人复制文章的时候@>,添加链接,这相当于做了一个外链(虽然这个概率很低)。下面,老米将介绍三种调用当前文章链接的方法。您可以根据自己的需要进行选择。
第一种方法:
这是最简单的方法,只需在相应位置添加标签即可。代码显示如下:
{dede:field name='arcurl'/}
添加完成后,保存文章模板并上传服务器重新生成页面。
第二种方法:
只需使用织梦cms本身的一个全局函数,并以标签的形式在前台调用即可。代码显示如下:
{dede:geturl runphp='yes'}
@me = GetCurUrl();
{/dede:geturl}
将上述代码插入需要显示当前文章 URL地址的位置,然后生成文章内容页面。
第三种方法:
使用 SQL 语句调用静态文档地址。代码显示如下:
{dede:field.id runphp='yes'}
$id=@me;
@我='';
$url=GetOneArchive($id);
@me=$url['arcurl'];
{/dede:field.id}
织梦文章 介绍了调用当前页面末尾的文章链接(url)的三种方法。如果你对织梦不熟悉或者有一点了解,可以使用第一种和第二种方法。比如老米技术有限,说到数据库,他不喜欢操作,所以不会优先考虑第三个。使用哪种方法可以根据自己的情况来决定。
原创文章, title: 织梦文章 页面末尾调用当前文章链接(url)的三种方法,如转载请注明出处: 查看全部
文章采集调用(
使用SQL调用当前文章链接的方法,你知道吗?)

很多时候在使用织梦cms的时候,想在文章页面的最后加上当前的文章链接(url),这样别人复制文章的时候@>,添加链接,这相当于做了一个外链(虽然这个概率很低)。下面,老米将介绍三种调用当前文章链接的方法。您可以根据自己的需要进行选择。
第一种方法:
这是最简单的方法,只需在相应位置添加标签即可。代码显示如下:
{dede:field name='arcurl'/}
添加完成后,保存文章模板并上传服务器重新生成页面。
第二种方法:
只需使用织梦cms本身的一个全局函数,并以标签的形式在前台调用即可。代码显示如下:
{dede:geturl runphp='yes'}
@me = GetCurUrl();
{/dede:geturl}
将上述代码插入需要显示当前文章 URL地址的位置,然后生成文章内容页面。
第三种方法:
使用 SQL 语句调用静态文档地址。代码显示如下:
{dede:field.id runphp='yes'}
$id=@me;
@我='';
$url=GetOneArchive($id);
@me=$url['arcurl'];
{/dede:field.id}
织梦文章 介绍了调用当前页面末尾的文章链接(url)的三种方法。如果你对织梦不熟悉或者有一点了解,可以使用第一种和第二种方法。比如老米技术有限,说到数据库,他不喜欢操作,所以不会优先考虑第三个。使用哪种方法可以根据自己的情况来决定。
原创文章, title: 织梦文章 页面末尾调用当前文章链接(url)的三种方法,如转载请注明出处:
文章采集调用(忘记WordPress后台密码怎么办?WordPress网站PHP纯代码生成文章海报图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-12 07:11
猜猜你在找什么 wordpress文章
Typecho 到 WordPress 的迁移插件:ByeTyp
Typecho 是轻量级的,但是已经好几年没有更新了。插件和模板支持一直非常困难。越来越多的人退出了 Typecho,转而使用 WordPress。
WordPress 如何隐藏后台登录地址
隐藏WordPress后台登录地址是保证网站安全的方法之一。在隐藏它的同时,删除指向后端网站的链接。
如果忘记了 WordPress 后台密码怎么办? WordPress后台找回密码方法
我昨天忘记了后台网站的密码。 网站用WordPress搭建,忘记后台密码怎么办?
WordPress网站PHP 纯代码生成文章海报图片
要实现这个功能,需要依赖PHP的GD库。如果您没有它,它将无法工作。虚拟主机用户请看是否支持。
Wordpress 作者判断调用不同的模板显示在作者页面上
如果网站开放注册和投稿功能,将会有作者、编辑、订阅者和管理员。页面显示不同的模板需要单独调用。
wordpress 不同类别调用不同模板的方法
之前介绍了在WordPress不同类别中调用不同文章模板的方法。今天给大家分享一下如何调用不同类别的不同模板。
为WordPress页面添加自定义汇总功能
我们在做 WordPress网站 的时候,经常需要调用首页或者分类页上的摘要,并在分类列表中展示。
WordPress上传附件提示“上级目录没有写权限”的解决方法
WordPress用户在后台上传附件提示“上级目录没有写权限”一般出现在网站迁移到新站点后,如果用户在WordPress后台上传图片附件,或者在工具import网站遇到数据时,遇到如下提示: 查看全部
文章采集调用(忘记WordPress后台密码怎么办?WordPress网站PHP纯代码生成文章海报图片)
猜猜你在找什么 wordpress文章
Typecho 到 WordPress 的迁移插件:ByeTyp
Typecho 是轻量级的,但是已经好几年没有更新了。插件和模板支持一直非常困难。越来越多的人退出了 Typecho,转而使用 WordPress。
WordPress 如何隐藏后台登录地址
隐藏WordPress后台登录地址是保证网站安全的方法之一。在隐藏它的同时,删除指向后端网站的链接。
如果忘记了 WordPress 后台密码怎么办? WordPress后台找回密码方法
我昨天忘记了后台网站的密码。 网站用WordPress搭建,忘记后台密码怎么办?
WordPress网站PHP 纯代码生成文章海报图片
要实现这个功能,需要依赖PHP的GD库。如果您没有它,它将无法工作。虚拟主机用户请看是否支持。
Wordpress 作者判断调用不同的模板显示在作者页面上
如果网站开放注册和投稿功能,将会有作者、编辑、订阅者和管理员。页面显示不同的模板需要单独调用。
wordpress 不同类别调用不同模板的方法
之前介绍了在WordPress不同类别中调用不同文章模板的方法。今天给大家分享一下如何调用不同类别的不同模板。
为WordPress页面添加自定义汇总功能
我们在做 WordPress网站 的时候,经常需要调用首页或者分类页上的摘要,并在分类列表中展示。
WordPress上传附件提示“上级目录没有写权限”的解决方法
WordPress用户在后台上传附件提示“上级目录没有写权限”一般出现在网站迁移到新站点后,如果用户在WordPress后台上传图片附件,或者在工具import网站遇到数据时,遇到如下提示:
文章采集调用(1.用python爬取实现方法:anyproxy+java+webmagic3.FiddlerCore)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-11-10 11:06
微信公众号文章爬取方法用python组织1.爬取
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是谷歌浏览器:
谷歌浏览器版本为 52.0.2743.6;
chromedriver 版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver与chrome版本映射表(更新为v2.30))】
3. 微信公众号登录地址:
4.微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章接口地址
8.文章 列表翻页和内容获取
2.AnyProxy 代理批处理采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,您可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,自动点击手机公众号文章列表页,即“查看历史消息”;
2、利用fiddler代理劫持手机访问,将URL转发到本地php编写的网页;
3、将接收到的php网页上的URL备份到数据库中;
4、使用python从数据库中获取URL,然后进行正常爬取。
爬取过程中发现一个问题:
如果只是抓取文章的内容,好像没有访问频率限制,但是如果要抓取阅读数和点赞数,达到一定频率后,返回就会变成一个空值,我设置的时间间隔是10秒,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.青波新名单
如果你只是想看数据,直接看日单就行了,不用花钱。如果您需要访问自己的系统,他们还提供了一个 api 接口。 查看全部
文章采集调用(1.用python爬取实现方法:anyproxy+java+webmagic3.FiddlerCore)
微信公众号文章爬取方法用python组织1.爬取
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是谷歌浏览器:
谷歌浏览器版本为 52.0.2743.6;
chromedriver 版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver与chrome版本映射表(更新为v2.30))】
3. 微信公众号登录地址:
4.微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章接口地址
8.文章 列表翻页和内容获取
2.AnyProxy 代理批处理采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,您可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,自动点击手机公众号文章列表页,即“查看历史消息”;
2、利用fiddler代理劫持手机访问,将URL转发到本地php编写的网页;
3、将接收到的php网页上的URL备份到数据库中;
4、使用python从数据库中获取URL,然后进行正常爬取。
爬取过程中发现一个问题:
如果只是抓取文章的内容,好像没有访问频率限制,但是如果要抓取阅读数和点赞数,达到一定频率后,返回就会变成一个空值,我设置的时间间隔是10秒,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.青波新名单
如果你只是想看数据,直接看日单就行了,不用花钱。如果您需要访问自己的系统,他们还提供了一个 api 接口。
文章采集调用(梦dedecms(V5.7版)调用相似文章中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-10 10:15
当我们发布文章文章时,一般情况下,为了增加用户的停留时间,我们会在文章的末尾或者在为了再次赢得用户点击,在织梦dedecms(V5.7版)调用类似文章,实际调用代码为{dede:likearticle} ,这段代码的原理是通过识别文章的title、category、关键词等来判断相似度,从而做出推荐。后台调用代码如下/include/taglib/likearticle.lib.php,打开文件找到如下这段代码:
/**************************************************** ****************************************************** ****/
if($keyword !='')
{
if(!empty($typeid)) {
$typeid ="AND arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
where arc.arcrank>-1AND ($keyword) $typeid$orderquery limit 0, $row";
}
其他
{
if(!empty($typeid)) {
$typeid = "arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
WHERE arc.arcrank>-1AND $typeid$orderquery limit 0, $row";
}
<p>/**************************************************** ****************************************************/ 查看全部
文章采集调用(梦dedecms(V5.7版)调用相似文章中)
当我们发布文章文章时,一般情况下,为了增加用户的停留时间,我们会在文章的末尾或者在为了再次赢得用户点击,在织梦dedecms(V5.7版)调用类似文章,实际调用代码为{dede:likearticle} ,这段代码的原理是通过识别文章的title、category、关键词等来判断相似度,从而做出推荐。后台调用代码如下/include/taglib/likearticle.lib.php,打开文件找到如下这段代码:
/**************************************************** ****************************************************** ****/
if($keyword !='')
{
if(!empty($typeid)) {
$typeid ="AND arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
where arc.arcrank>-1AND ($keyword) $typeid$orderquery limit 0, $row";
}
其他
{
if(!empty($typeid)) {
$typeid = "arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
WHERE arc.arcrank>-1AND $typeid$orderquery limit 0, $row";
}
<p>/**************************************************** ****************************************************/
文章采集调用(如何网页访问?豆瓣网教你如何获取真正请求的地址?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-11-10 00:07
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何访问网页?
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
导入请求,json
从 fake_useragent 导入 UserAgent
导入 csv
类多班(对象):
def __init__(self):
self.url = ";tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
定义主(自我):
经过
如果 __name__ =='__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
对于范围内的 i(1, 50):
self.headers = {
'用户代理':ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
返回 html
4、json 解析页面数据,获取对应的字典。
数据 = json.loads(html)['主题']
#打印(数据[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
打印(名称,妖精赫夫)
html2 = self.get_page(goblin_herf) # 第二个请求发生
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建一个用于写入的csv文件
csv_file = open('scr.csv','a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题内容
csv_writerr.writerow(['电影','评级',"详细页面"])
#数据输入
csv_writer.writerow([id, rate, url])
7、图片地址提出请求。定义图片的名称并保存文档。
html2 = requests.get(url=url, headers=self.headers).content
目录名 = "./图片/" + id + ".jpg"
with open(dirname,'wb') as f:
f.write(html2)
print("%s [下载成功!!!]"% id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享之家 查看全部
文章采集调用(如何网页访问?豆瓣网教你如何获取真正请求的地址?(图))
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何访问网页?
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
导入请求,json
从 fake_useragent 导入 UserAgent
导入 csv
类多班(对象):
def __init__(self):
self.url = ";tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
定义主(自我):
经过
如果 __name__ =='__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
对于范围内的 i(1, 50):
self.headers = {
'用户代理':ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
返回 html
4、json 解析页面数据,获取对应的字典。
数据 = json.loads(html)['主题']
#打印(数据[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
打印(名称,妖精赫夫)
html2 = self.get_page(goblin_herf) # 第二个请求发生
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建一个用于写入的csv文件
csv_file = open('scr.csv','a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题内容
csv_writerr.writerow(['电影','评级',"详细页面"])
#数据输入
csv_writer.writerow([id, rate, url])
7、图片地址提出请求。定义图片的名称并保存文档。
html2 = requests.get(url=url, headers=self.headers).content
目录名 = "./图片/" + id + ".jpg"
with open(dirname,'wb') as f:
f.write(html2)
print("%s [下载成功!!!]"% id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。

2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享之家
文章采集调用(WordPress每页文章固定内容的侧边栏看多了很枯燥,怎么添加侧边栏?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-08 06:24
WordPress
在文章的每一页上看到太多固定内容侧边栏很无聊。如何添加侧边栏并使每个 文章 调用不同的侧边栏?本文文章不需要任何基础,按照我的方法一步步完成即可。原因自然是不同的侧边栏可以让用户体验和SEO效果更好。
一、添加侧边栏
参考资料:
如何在wordpress中添加侧边栏并不只是上传代码那么简单,为了方便,放在wp的后台部分是更好的选择。说一下流程
首先我们找到主题的functions.php文件,打开编辑functions.php,找到侧边栏的代码,直接复制。
function twentysixteen_widgets_init() {
register_sidebar( array(
'name' => __( 'Sidebar', 'twentysixteen' ),
'id' => 'sidebar-1',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
}
说说基本参数:
我们只需要参考原创代码进行更改以用于特定用途。例如,我在 now 之后添加了一个段落
register_sidebar( array(
'name' => __( 'Sidebar4', 'twentysixteen' ),
'id' => 'sidebar-4',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
这时候打开小工具,发现后面有一个侧边栏,叫做sidebar4。您可以添加您想要的侧边栏效果工具。
如下图,我添加了三个“文章Measure column 1,文章Measure column 2,文章Measure column 3”。
注意这里id的区别
保存后返回wp背景的widget选项。打开后,我们发现页面上多了三个新的侧边栏。
二、如何让文章调用侧边栏
参考资料:
%e4%b8%8d%e5%90%8c%e6%96%87%e7%ab%a0%e6%98%be%e7%a4%ba%e4%b8%8d%e5%90%8c%e7 %9a%84%e4%be%a7%e8%be%b9%e6%a0%8f.html
首先是添加文章需要绑定的代码文件。
主题根目录对应新建三个文件,如下图所示。
以第一个文件为例,我这里的名字是side1.php
内容是:
修改functions.php文件和side1.php文件后。
如何将 文章 绑定到侧边栏?使用自定义字段是一个不错的选择。具体使用方法是打开文章编辑界面的显示选项,然后输入参数和数值。
要使自定义字段起作用,您必须首先使 文章 能够识别自定义字段的作用。我们编辑 single.php 文件。找到 get_sidebar() 函数:
替换为:
更新后,文章会根据我们输入的自定义字段的值改变侧边栏。我在这里输入:
对应我刚刚测试的文件名。最后更新文章后,发现侧边栏变成了我们刚刚添加的侧边栏sid1的侧边栏。
ps:注意标点符号,容易出错。我花了很长时间才发现。
如果文章图片、下载链接等信息有误,请在评论区留言,博主会第一时间更新!如果喜欢,请打赏支持本站,谢谢大家! 查看全部
文章采集调用(WordPress每页文章固定内容的侧边栏看多了很枯燥,怎么添加侧边栏?)
WordPress
在文章的每一页上看到太多固定内容侧边栏很无聊。如何添加侧边栏并使每个 文章 调用不同的侧边栏?本文文章不需要任何基础,按照我的方法一步步完成即可。原因自然是不同的侧边栏可以让用户体验和SEO效果更好。

一、添加侧边栏
参考资料:
如何在wordpress中添加侧边栏并不只是上传代码那么简单,为了方便,放在wp的后台部分是更好的选择。说一下流程
首先我们找到主题的functions.php文件,打开编辑functions.php,找到侧边栏的代码,直接复制。
function twentysixteen_widgets_init() {
register_sidebar( array(
'name' => __( 'Sidebar', 'twentysixteen' ),
'id' => 'sidebar-1',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
}
说说基本参数:
我们只需要参考原创代码进行更改以用于特定用途。例如,我在 now 之后添加了一个段落
register_sidebar( array(
'name' => __( 'Sidebar4', 'twentysixteen' ),
'id' => 'sidebar-4',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
这时候打开小工具,发现后面有一个侧边栏,叫做sidebar4。您可以添加您想要的侧边栏效果工具。
如下图,我添加了三个“文章Measure column 1,文章Measure column 2,文章Measure column 3”。
注意这里id的区别

保存后返回wp背景的widget选项。打开后,我们发现页面上多了三个新的侧边栏。
二、如何让文章调用侧边栏
参考资料:
%e4%b8%8d%e5%90%8c%e6%96%87%e7%ab%a0%e6%98%be%e7%a4%ba%e4%b8%8d%e5%90%8c%e7 %9a%84%e4%be%a7%e8%be%b9%e6%a0%8f.html
首先是添加文章需要绑定的代码文件。
主题根目录对应新建三个文件,如下图所示。

以第一个文件为例,我这里的名字是side1.php
内容是:
修改functions.php文件和side1.php文件后。
如何将 文章 绑定到侧边栏?使用自定义字段是一个不错的选择。具体使用方法是打开文章编辑界面的显示选项,然后输入参数和数值。
要使自定义字段起作用,您必须首先使 文章 能够识别自定义字段的作用。我们编辑 single.php 文件。找到 get_sidebar() 函数:
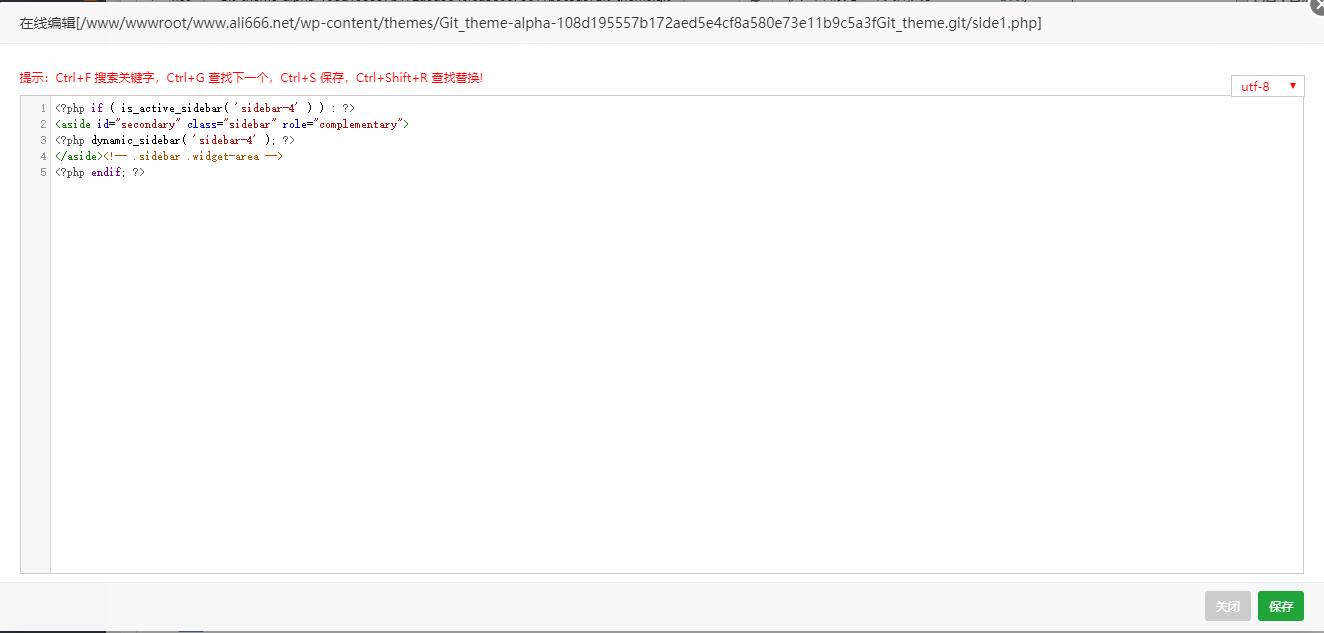
替换为:
更新后,文章会根据我们输入的自定义字段的值改变侧边栏。我在这里输入:
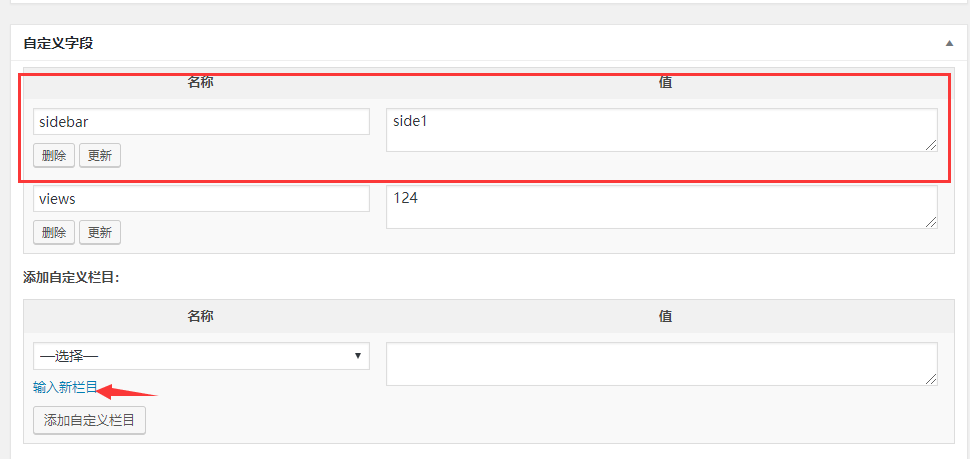
对应我刚刚测试的文件名。最后更新文章后,发现侧边栏变成了我们刚刚添加的侧边栏sid1的侧边栏。
ps:注意标点符号,容易出错。我花了很长时间才发现。
如果文章图片、下载链接等信息有误,请在评论区留言,博主会第一时间更新!如果喜欢,请打赏支持本站,谢谢大家!
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统),还是在易用性方面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-26 10:17
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户是个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_template,最灵活的应该是系统提供的,这里我们可以将我们的页面编辑成模板,然后调用...这里需要强调一下,这里涉及到缓存的东西,我们需要使用:一键更新网站-->更新一切...因为我在做的时候遇到了缓存问题,所以不敢相信自己哪里出错了...
1.2K 查看全部
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统),还是在易用性方面)
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户是个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_template,最灵活的应该是系统提供的,这里我们可以将我们的页面编辑成模板,然后调用...这里需要强调一下,这里涉及到缓存的东西,我们需要使用:一键更新网站-->更新一切...因为我在做的时候遇到了缓存问题,所以不敢相信自己哪里出错了...
1.2K
文章采集调用(最好调用二级目录(二级)、微博客和“教育频道”,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-26 08:08
在我的博客中,我建立了“励志故事”、“微博”和“教育频道”三个二级目录,以提高百度蜘蛛的抓取速度和全面抓取,促进网站< @收录,最好能实现zblog博客根目录与二级目录、二级目录与根目录、二级目录与二级目录之间的顺畅调用。
网上搜集了一些互相调用的方法。很多方法漏洞百出或者不够全面,无法说明zblog博客目录之间如何相互调用。我在这里果断写一篇文章文章,同时纠正各种错误,为博主提供正确的调用方法。
根目录调用二级目录,二级目录调用根目录,二级目录和二级目录可以相互调用,方法相同。
1.zblog根目录调用二级目录中最新的文章。
①在本地新建一个t_previous.asp文件(新建一个t_previous.txt文件并将扩展名改为asp),将该文件上传到zblog博客根目录下的include文件中。t_previous.asp 主要用于存储从二级目录调用的内容。
②在你要使用的二级目录的FUNCTION文件夹中找到c_system_base.asp文件,通过ftp软件下载到本地以txt文件格式打开,使用搜索工具找到
调用 SaveToFile(BlogPath & “/include/previous.asp”,strPrevious,”utf-8”,True)
在代码下方添加以下代码:
调用 SaveToFile(Left(BlogPath,len(BlogPath)-7) & “/include/t_previous.asp”,strPrevious,”utf-8″,True)
注:7为“jiaoyu/”的字符长度。如果要调用“微博/”的内容,改成6,自己用的时候一定要注意这一点。因为很多博文都说文章的数量显示为7,表示这是完全错误的。未经大脑或实践检验的废话。
③上传c_system_base.asp文件到你的二级目录,重建文章就OK了!
④在你要调用的地方,比如文章的首页侧边栏,你要在你的zblog采用的样式中default.html对应位置添加如下代码: 查看全部
文章采集调用(最好调用二级目录(二级)、微博客和“教育频道”,)
在我的博客中,我建立了“励志故事”、“微博”和“教育频道”三个二级目录,以提高百度蜘蛛的抓取速度和全面抓取,促进网站< @收录,最好能实现zblog博客根目录与二级目录、二级目录与根目录、二级目录与二级目录之间的顺畅调用。
网上搜集了一些互相调用的方法。很多方法漏洞百出或者不够全面,无法说明zblog博客目录之间如何相互调用。我在这里果断写一篇文章文章,同时纠正各种错误,为博主提供正确的调用方法。
根目录调用二级目录,二级目录调用根目录,二级目录和二级目录可以相互调用,方法相同。
1.zblog根目录调用二级目录中最新的文章。
①在本地新建一个t_previous.asp文件(新建一个t_previous.txt文件并将扩展名改为asp),将该文件上传到zblog博客根目录下的include文件中。t_previous.asp 主要用于存储从二级目录调用的内容。
②在你要使用的二级目录的FUNCTION文件夹中找到c_system_base.asp文件,通过ftp软件下载到本地以txt文件格式打开,使用搜索工具找到
调用 SaveToFile(BlogPath & “/include/previous.asp”,strPrevious,”utf-8”,True)
在代码下方添加以下代码:
调用 SaveToFile(Left(BlogPath,len(BlogPath)-7) & “/include/t_previous.asp”,strPrevious,”utf-8″,True)
注:7为“jiaoyu/”的字符长度。如果要调用“微博/”的内容,改成6,自己用的时候一定要注意这一点。因为很多博文都说文章的数量显示为7,表示这是完全错误的。未经大脑或实践检验的废话。
③上传c_system_base.asp文件到你的二级目录,重建文章就OK了!
④在你要调用的地方,比如文章的首页侧边栏,你要在你的zblog采用的样式中default.html对应位置添加如下代码:
文章采集调用(Dedecms采集节点管理界面1.2.增加新节点在采集指定节点和网址索引页规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-25 00:14
前言:这篇文章是写给刚接触德德的朋友cms采集的。选择的目标站点是德德cms官方网站的dreameaver栏目文章,其内容页面不收录分页。以图文形式详细讲解了如何创建一个Basic 采集规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二节,主要是引入新的采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定节点以及如何导出采集的内容。现在进入第一部分。
1.1进入采集节点管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集节点管理”进入采集节点管理界面,如图(图2).
(本图来源于网络,如有侵权请联系删除!)
图1-后台管理界面
(本图来源于网络,如有侵权请联系删除!)
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以进入“选择内容”模型”界面,如(如图3),
(本图来源于网络,如有侵权请联系删除!)
图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“常用文章”和“图片集”可供选择。根据页面类型为采集,选择对应的内容模型。本文选择“普通文章”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图文章4)显示,
(本图来源于网络,如有侵权请联系删除!)
图4-新建采集节点:第一步是设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息
(本图来源于网络,如有侵权请联系删除!)
图5-基本节点信息
如图(图5),
节点名称:给新创建的节点起一个名字,填写“采集Test(一)”;
目标页面编码:通过采集设置目标页面的编码格式。共有三种类型:GB2312、UTF8 和 BIG5。在采集的目标页面右击,选择“查看源文件”即可获得。
脚步:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),
(本图来源于网络,如有侵权请联系删除!)
图6-查看源文件
等号后面的代码就是需要的“编码格式”,这里是“gb2312”。
“区域匹配方式”:设置如何匹配所需采集的内容部分,可以是字符串,也可以是正则表达式。系统默认模式为字符串。如果您对正则表达式有更多的了解,可以在这里选择正则表达式模式。
“内容导入顺序”:指定导入文章列表时的顺序。可以选择“与目标站一致”或“反向到目标站”。
“防盗链模式”:目标站点是否有刷新限制采集。一开始很难说,你需要测试才能知道。如果是这样,您需要在此处设置“资源下载超时时间”。
“引用网址”:填写任意文章内容页面的网址,即采集。
具体步骤:
(a) 在打开的文章列表页面,点击第一篇文章
标题为“在Dreamweaver中为插入的Flash添加透明度”打开文章内容页面,如图(图7),
(本图来源于网络,如有侵权请联系删除!)
图7-文章内容页面
(b)此时浏览器的URL地址栏显示的URL就是“引用URL”处需要填写的URL,如图(图8),
(本图来源于网络,如有侵权请联系删除!)
图8-浏览器的URL地址栏
至此,“节点基本信息”就设置好了。最终结果,如图(图9),
(本图来源于网络,如有侵权请联系删除!)
图9-设置后节点的基本信息
检查无误后,进入下一步。
1.2.2 设置获取列表URL的规则
如图(图10),
(本图来源于网络,如有侵权请联系删除!)
图10-列出URL获取规则
这里是设置采集的文章列表页的匹配规则。如果采集的文章的列表页面有一定的样式,可以选择“批量生成列表URL”;如果采集的文章的列表页面完全没有规则,那么可以选择“手动指定列表URL”;如果采集的站点提供RSS,您可以选择“从RSS获取”。对于特殊情况,例如:列表页面部分规则,其余部分不规则,您可以在“匹配URL”中填写规则部分,然后在“手动指定URL”中填写不规则部分。
具体步骤:
(a) 首先回到打开的文章列表页面,找到浏览器URL地址栏中显示的URL(图片8)和页面底部的换页部分。对于示例(如图11),
(本图来源于网络,如有侵权请联系删除!)
图11-页面变化
(b) 点击“2”打开文章列表页的第二页。这时浏览器的URL地址栏中显示的URL和页面底部的页面变化部分,如(图12)和(图13),
(本图来源于网络,如有侵权请联系删除!)
图12-第二页的URL
(本图来源于网络,如有侵权请联系删除!)
图13-page feed部分第二页
(c) 在打开的文章列表页的第二页,点击(1)打开文章列表页的第一页,底部的换页部分页面如下图11相同,只是浏览器的URL地址栏显示的URL与之前的图8不同,如下图(图14),
(本图来源于网络,如有侵权请联系删除!)
图14-第一页的URL
(d) 由(b)和(c)推断,采集的文章列表页的URL遵循如下规律:
(*).html。为安全起见,请自行测试更多列表页面。确定规则后,在“匹配URL”中填写规则后跟文章列表页。
(e) 最后,指定需要采集的页码或正则数,并设置递增的正则。
至此,“列表URL获取规则”部分的设置就结束了。最终结果,如图(图15),
(本图来源于网络,如有侵权请联系删除!)
图15-设置后的URL获取规则列表
确认无误后,进行下一步设置。
1.2.3 设置文章 URL匹配规则
如图(图16),
(本图来源于网络,如有侵权请联系删除!)
图16-文章 URL匹配规则
这里是设置采集文章列表页的匹配规则。
具体步骤:
(a)对于“区域开头的HTML”,可以在打开的文章列表首页右击,选择“查看源文件”。在源文件中,找到第一篇文章的标题《在Dreamweaver中为插入的Flash添加透明度》,如图(图17),
(本图来源于网络,如有侵权请联系删除!)
图17-查看源文件中第一篇文章文章的标题
通过观察,不难看出“
”这是整个文章列表的开头。因此,在“HTML开头的区域”中,填写“
”。
(b) 在源文件中找到上一篇文章的文章《通过Dreamweaver设计网页时组织CSS的建议》,如图(图18),
(本图来源于网络,如有侵权请联系删除!)
图18-查看源文件中上一篇文章的标题
结合文章列表的开头并观察,第一个"
“这是整个文章列表的结尾。因此,在“区域末尾的HTML”中,您应该填写“
”。
“如果链接收录图片”:设置收录图片的链接的处理方式,是否不处理,缩略图可选采集。可根据实际需要选择。
“重新过滤区域URL”:可以使用正则表达式再次过滤区域网站。这是针对一些需要保留或者过滤掉的内容,尤其是混合列表页面,通过使用“必须收录”或者“不能收录”过滤掉你想要获取的文章内容页面的URL或者不想得到。
具体步骤:
回到正在打开的文章列表首页的源文件,通过观察可以看出,每个文章内容页地址的扩展名都是.html。因此,您可以在“必须收录”中填写“.html”。
至此,“文章URL匹配规则”的设置就结束了。最终结果,如图(图19),
(本图来源于网络,如有侵权请联系删除!)
图19-文章 设置后的URL匹配规则
通过1.2.1子节,1.2.2子节和1.2.3子节,采集节点的节添加 一步完成设置。设置后的结果,如图(图20),
(本图来源于网络,如有侵权请联系删除!)
图20-设置后新增的采集节点:第一步是设置基本信息和URL索引页面规则
一切都完成并检查后,单击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置URL获取规则测试”页面,看到对应的文章列表地址. 如图(图21),
(本图来源于网络,如有侵权请联系删除!)
图21-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
免责声明:本站所有文章及图片均来自用户分享和网络采集。文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
有问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群 查看全部
文章采集调用(Dedecms采集节点管理界面1.2.增加新节点在采集指定节点和网址索引页规则)
前言:这篇文章是写给刚接触德德的朋友cms采集的。选择的目标站点是德德cms官方网站的dreameaver栏目文章,其内容页面不收录分页。以图文形式详细讲解了如何创建一个Basic 采集规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加采集节点的第一步:设置基本信息和URL索引页面规则;第二节,主要是引入新的采集节点的第二步:设置字段获取规则;第三部分主要介绍如何采集指定节点以及如何导出采集的内容。现在进入第一部分。
1.1进入采集节点管理界面
如图(图1),在后台管理界面主菜单中点击“采集”,然后点击“采集节点管理”进入采集节点管理界面,如图(图2).
(本图来源于网络,如有侵权请联系删除!)
图1-后台管理界面
(本图来源于网络,如有侵权请联系删除!)
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以进入“选择内容”模型”界面,如(如图3),
(本图来源于网络,如有侵权请联系删除!)
图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“常用文章”和“图片集”可供选择。根据页面类型为采集,选择对应的内容模型。本文选择“普通文章”,点击确定,进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图文章4)显示,
(本图来源于网络,如有侵权请联系删除!)
图4-新建采集节点:第一步是设置基本信息和URL索引页面规则
1.2.1 设置基本节点信息
(本图来源于网络,如有侵权请联系删除!)
图5-基本节点信息
如图(图5),
节点名称:给新创建的节点起一个名字,填写“采集Test(一)”;
目标页面编码:通过采集设置目标页面的编码格式。共有三种类型:GB2312、UTF8 和 BIG5。在采集的目标页面右击,选择“查看源文件”即可获得。
脚步:
(a) 打开采集的目标页面:;
(b) 右击选择“查看源文件”,找到“字符集”,如图(图6),
(本图来源于网络,如有侵权请联系删除!)
图6-查看源文件
等号后面的代码就是需要的“编码格式”,这里是“gb2312”。
“区域匹配方式”:设置如何匹配所需采集的内容部分,可以是字符串,也可以是正则表达式。系统默认模式为字符串。如果您对正则表达式有更多的了解,可以在这里选择正则表达式模式。
“内容导入顺序”:指定导入文章列表时的顺序。可以选择“与目标站一致”或“反向到目标站”。
“防盗链模式”:目标站点是否有刷新限制采集。一开始很难说,你需要测试才能知道。如果是这样,您需要在此处设置“资源下载超时时间”。
“引用网址”:填写任意文章内容页面的网址,即采集。
具体步骤:
(a) 在打开的文章列表页面,点击第一篇文章
标题为“在Dreamweaver中为插入的Flash添加透明度”打开文章内容页面,如图(图7),
(本图来源于网络,如有侵权请联系删除!)
图7-文章内容页面
(b)此时浏览器的URL地址栏显示的URL就是“引用URL”处需要填写的URL,如图(图8),
(本图来源于网络,如有侵权请联系删除!)
图8-浏览器的URL地址栏
至此,“节点基本信息”就设置好了。最终结果,如图(图9),
(本图来源于网络,如有侵权请联系删除!)
图9-设置后节点的基本信息
检查无误后,进入下一步。
1.2.2 设置获取列表URL的规则
如图(图10),
(本图来源于网络,如有侵权请联系删除!)
图10-列出URL获取规则
这里是设置采集的文章列表页的匹配规则。如果采集的文章的列表页面有一定的样式,可以选择“批量生成列表URL”;如果采集的文章的列表页面完全没有规则,那么可以选择“手动指定列表URL”;如果采集的站点提供RSS,您可以选择“从RSS获取”。对于特殊情况,例如:列表页面部分规则,其余部分不规则,您可以在“匹配URL”中填写规则部分,然后在“手动指定URL”中填写不规则部分。
具体步骤:
(a) 首先回到打开的文章列表页面,找到浏览器URL地址栏中显示的URL(图片8)和页面底部的换页部分。对于示例(如图11),
(本图来源于网络,如有侵权请联系删除!)
图11-页面变化
(b) 点击“2”打开文章列表页的第二页。这时浏览器的URL地址栏中显示的URL和页面底部的页面变化部分,如(图12)和(图13),
(本图来源于网络,如有侵权请联系删除!)
图12-第二页的URL
(本图来源于网络,如有侵权请联系删除!)
图13-page feed部分第二页
(c) 在打开的文章列表页的第二页,点击(1)打开文章列表页的第一页,底部的换页部分页面如下图11相同,只是浏览器的URL地址栏显示的URL与之前的图8不同,如下图(图14),
(本图来源于网络,如有侵权请联系删除!)
图14-第一页的URL
(d) 由(b)和(c)推断,采集的文章列表页的URL遵循如下规律:
(*).html。为安全起见,请自行测试更多列表页面。确定规则后,在“匹配URL”中填写规则后跟文章列表页。
(e) 最后,指定需要采集的页码或正则数,并设置递增的正则。
至此,“列表URL获取规则”部分的设置就结束了。最终结果,如图(图15),
(本图来源于网络,如有侵权请联系删除!)
图15-设置后的URL获取规则列表
确认无误后,进行下一步设置。
1.2.3 设置文章 URL匹配规则
如图(图16),
(本图来源于网络,如有侵权请联系删除!)
图16-文章 URL匹配规则
这里是设置采集文章列表页的匹配规则。
具体步骤:
(a)对于“区域开头的HTML”,可以在打开的文章列表首页右击,选择“查看源文件”。在源文件中,找到第一篇文章的标题《在Dreamweaver中为插入的Flash添加透明度》,如图(图17),
(本图来源于网络,如有侵权请联系删除!)
图17-查看源文件中第一篇文章文章的标题
通过观察,不难看出“
”这是整个文章列表的开头。因此,在“HTML开头的区域”中,填写“
”。
(b) 在源文件中找到上一篇文章的文章《通过Dreamweaver设计网页时组织CSS的建议》,如图(图18),
(本图来源于网络,如有侵权请联系删除!)
图18-查看源文件中上一篇文章的标题
结合文章列表的开头并观察,第一个"
“这是整个文章列表的结尾。因此,在“区域末尾的HTML”中,您应该填写“
”。
“如果链接收录图片”:设置收录图片的链接的处理方式,是否不处理,缩略图可选采集。可根据实际需要选择。
“重新过滤区域URL”:可以使用正则表达式再次过滤区域网站。这是针对一些需要保留或者过滤掉的内容,尤其是混合列表页面,通过使用“必须收录”或者“不能收录”过滤掉你想要获取的文章内容页面的URL或者不想得到。
具体步骤:
回到正在打开的文章列表首页的源文件,通过观察可以看出,每个文章内容页地址的扩展名都是.html。因此,您可以在“必须收录”中填写“.html”。
至此,“文章URL匹配规则”的设置就结束了。最终结果,如图(图19),
(本图来源于网络,如有侵权请联系删除!)
图19-文章 设置后的URL匹配规则
通过1.2.1子节,1.2.2子节和1.2.3子节,采集节点的节添加 一步完成设置。设置后的结果,如图(图20),
(本图来源于网络,如有侵权请联系删除!)
图20-设置后新增的采集节点:第一步是设置基本信息和URL索引页面规则
一切都完成并检查后,单击“保存信息并进入下一步设置”。如果之前的设置正确,点击后会进入“新建采集节点:测试基本信息和URL索引页面规则设置URL获取规则测试”页面,看到对应的文章列表地址. 如图(图21),
(本图来源于网络,如有侵权请联系删除!)
图21-URL获取规则测试
确认无误后,点击“保存信息,进入下一步设置”。否则请点击“返回上一步修改”。
免责声明:本站所有文章及图片均来自用户分享和网络采集。文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
有问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群
文章采集调用(,ajax动态加载的网页并提取网页信息(需进行) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-24 23:29
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$ 查看全部
文章采集调用(,ajax动态加载的网页并提取网页信息(需进行)
)
网页有几种类型的采集:
1.静态网页
2.动态网页(需要js、ajax动态加载数据的网页)
3.采集的网页前需要模拟登录
4.加密网页
3、4个解决方案和想法会在后续博客中说明
目前,只有 1、2 的解决方案和想法:
一.静态网页
解析静态网页的方法有很多很多采集! java和python都提供了很多工具包或者框架,比如java httpclient、Htmlunit、Jsoup、HtmlParser等,Python urllib、urllib2、BeautifulSoup、Scrapy等,不详,网上有很多资料。
二.动态网页
对于采集来说,动态网页就是那些需要js和ajax动态加载获取数据的网页。 采集 有两个数据计划:
1.通过抓包工具分析js、ajax的请求,模拟js加载后获取数据的请求。
2.调用浏览器内核,获取加载网页的源码,然后解析源码
研究爬虫的人一定对js有所了解。网上学习资料很多,不做声明,本文仅为文章
的完整性
调用浏览器内核的工具包也有几个,不过不是今天的重点。今天的重点是文章的标题。 Scrapy框架结合Spynner采集需要动态加载js、ajax并提取页面信息(以采集微信公众号文章列表为例)
开始...
1.创建微信公众号文章list采集项目(以下简称微采集)
scrapy startproject weixin
2.在spider目录下创建一个采集spider文件
vim weixinlist.py
编写如下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'http://weixin.sogou.com/gzh?openid=oIWsFt5QBSP8mn4Jx2WSGw_rCNzQ',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3.在items.py中添加WeixinItem类
4.在items.py的同级目录下创建一个下载中间件downloadwebkit.py,写入如下代码:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
这段代码是在网页加载完成后调用浏览器内核获取源码
5.在setting.py文件中配置并声明下载使用下载中间件
在底部添加以下代码:
#which spider should use WEBKIT
WEBKIT_DOWNLOADER=['weixinlist']
DOWNLOADER_MIDDLEWARES = {
'weixin.downloadwebkit.WebkitDownloaderTest': 543,
}
import os
os.environ["DISPLAY"] = ":0"
6.运行程序:
运行命令:
scrapy crawl weixinlist
运行结果:
kevinflynndeMacBook-Pro:spiders kevinflynn$ scrapy crawl weixinlist
start init....
2015-07-28 21:13:55 [scrapy] INFO: Scrapy 1.0.1 started (bot: weixin)
2015-07-28 21:13:55 [scrapy] INFO: Optional features available: ssl, http11
2015-07-28 21:13:55 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'weixin.spiders', 'SPIDER_MODULES': ['weixin.spiders'], 'BOT_NAME': 'weixin'}
2015-07-28 21:13:55 [py.warnings] WARNING: :0: UserWarning: You do not have a working installation of the service_identity module: 'No module named service_identity'. Please install it from and make sure all of its dependencies are satisfied. Without the service_identity module and a recent enough pyOpenSSL to support it, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.
2015-07-28 21:13:55 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-07-28 21:13:55 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, WebkitDownloaderTest, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-07-28 21:13:55 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-07-28 21:13:55 [scrapy] INFO: Enabled item pipelines:
2015-07-28 21:13:55 [scrapy] INFO: Spider opened
2015-07-28 21:13:55 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-07-28 21:13:55 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
QFont::setPixelSize: Pixel size
互联网协议入门
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210032701&idx=1&sn=6b1fc2bc5d4eb0f87513751e4ccf610c&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
自己动手写贝叶斯分类器给图书分类
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=210013947&idx=1&sn=1f36ba5794e22d0fb94a9900230e74ca&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
不当免费技术支持的10种方法
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=1&sn=216106034a3b4afea6e67f813ce1971f&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
以 Python 为实例,介绍贝叶斯理论
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209998175&idx=2&sn=2f3dee873d7350dfe9546ab4a9323c05&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
我从腾讯那“偷了”3000万QQ用户数据,出了份很有趣的...
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209980651&idx=1&sn=11fd40a2dee5132b0de8d4c79a97dac2&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
如何用 Spark 快速开发应用?
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209820653&idx=2&sn=23712b78d82fb412e960c6aa1e361dd3&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
一起来写个简单的解释器(1)
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209797651&idx=1&sn=15073e27080e6b637c8d24b6bb815417&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
那个直接在机器码中改 Bug 的家伙
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=1&sn=04ae1bc3a366d358f474ac3e9a85fb60&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
把一个库开源,你该做些什么
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209762756&idx=2&sn=0ac961ffd82ead6078a60f25fed3c2c4&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
程序员的困境
[u'http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=209696436&idx=1&sn=8cb55b03c8b95586ba4498c64fa54513&3rd=MzA3MDU4NTYzMw==&scene=6#rd']
2015-07-28 21:14:08 [scrapy] INFO: Closing spider (finished)
2015-07-28 21:14:08 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 131181,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 7, 28, 13, 14, 8, 958071),
'log_count/DEBUG': 2,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2015, 7, 28, 13, 13, 55, 688111)}
2015-07-28 21:14:08 [scrapy] INFO: Spider closed (finished)
QThread: Destroyed while thread is still running
kevinflynndeMacBook-Pro:spiders kevinflynn$
文章采集调用(本文对使用到的技术仅做简单的介绍(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-24 23:25
)
本文仅简单介绍所使用的技术。如果想了解更多,请到相应官网网站学习。
本文适合对爬虫相关知识接触较少的新手,主要是普及Selenium是如何做爬虫的,请跳过。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!
QQ群:701698587
1.硒简介
1.简介
Selenium 是一个用于测试网站的自动化测试工具,支持各种主流界面浏览器。
总之,Selenium是一个网站自动化测试的库,它的定位是做自动化测试。我们也可以将其作为爬虫来获取一些网页信息,这个爬虫模拟了真实浏览器的操作,更加实用。
Selenium 是市场上唯一可以与付费产品竞争的自动化测试工具。
如果想了解更多可以到Selenium中文网学习:戳我去Selenium中文网
2.安装
要使用Selenium,首先必须在python中安装相关的库:
pip install Selenium
安装对应浏览器的webdricer驱动文件,这里有chrome的链接,其他浏览器可以网上搜索。戳我下载chrome webdriver驱动文件。选择合适的版本,我选择了2.23。
下载解压后得到exe文件,将此文件复制到chrom安装文件夹中:
通常它是 C:\Program Files (x86)\Google\Chrome\Application, 或 C:\Program Files\Google\Chrome\Application.
然后配置环境变量的路径:
最后写一段代码进行测试:
from selenium import webdriverdriver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
如果看到打开了一个浏览器窗口就成功了,否则下面会出现相应的错误提示,需要查看前面的步骤。
3. 简单介绍
1. 元素定位方法:
基本上前几种方式就可以拿到需要的元素了,需要判断结果是否唯一来选择对应的选择器。
通过驱动对象调用此方法会返回一个标签对象或标签对象列表。标签下的文本可以通过.text获取,标签的其他属性值可以通过get_attribute()获取。
分享一个快速定位元素的小妙招:查看所需信息所在标签的id、class、name是否与标签下信息的语义相关。一般来说,相关的都是唯一的。(从开发者的角度考虑)如果当前标签不能唯一定位,考虑父标签。以此类推,你总能找到一种定位方法。
2.鼠标事件(模拟鼠标操作)
可以通过标签对象调用。
3.键盘事件(模拟键盘操作)
4.其他操作
其他操作包括控制浏览器的操作、获取断言信息、表单切换、多窗口切换、警告框处理、下拉框处理、文件上传操作、cookie操作、调用js代码、截图、关闭浏览器等操作,因为这里我用的不多,就不一一列举了,自己去官网学习吧。
2.爬取目标
本次实战爬虫主要完成以下目标:
在QQ音乐官网爬取指定歌手的前5首歌曲基本信息和前500名流行评论。
1.获取前五首歌曲的url
分析这个页面的代码,我们知道包裹所有歌曲信息的tag的class是唯一的,我们可以拿到它,然后遍历所有的子标签,或者一次性获取所有包裹歌曲信息的div,并且然后获取里面的 a 标签。
2.获取歌曲基本信息
可以看出,基本信息标签中的类名有一部分语义,所以可以通过css选择器来唯一确定。
3.获取歌词
页面上的歌词不完整,貌似需要点击展开,其实所有的歌词都已经在标签里了,只是显示问题。
查看全部
文章采集调用(本文对使用到的技术仅做简单的介绍(组图)
)
本文仅简单介绍所使用的技术。如果想了解更多,请到相应官网网站学习。
本文适合对爬虫相关知识接触较少的新手,主要是普及Selenium是如何做爬虫的,请跳过。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!
QQ群:701698587
1.硒简介
1.简介
Selenium 是一个用于测试网站的自动化测试工具,支持各种主流界面浏览器。
总之,Selenium是一个网站自动化测试的库,它的定位是做自动化测试。我们也可以将其作为爬虫来获取一些网页信息,这个爬虫模拟了真实浏览器的操作,更加实用。
Selenium 是市场上唯一可以与付费产品竞争的自动化测试工具。
如果想了解更多可以到Selenium中文网学习:戳我去Selenium中文网
2.安装
要使用Selenium,首先必须在python中安装相关的库:
pip install Selenium
安装对应浏览器的webdricer驱动文件,这里有chrome的链接,其他浏览器可以网上搜索。戳我下载chrome webdriver驱动文件。选择合适的版本,我选择了2.23。
下载解压后得到exe文件,将此文件复制到chrom安装文件夹中:
通常它是 C:\Program Files (x86)\Google\Chrome\Application, 或 C:\Program Files\Google\Chrome\Application.
然后配置环境变量的路径:
最后写一段代码进行测试:
from selenium import webdriverdriver=webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
如果看到打开了一个浏览器窗口就成功了,否则下面会出现相应的错误提示,需要查看前面的步骤。
3. 简单介绍
1. 元素定位方法:
基本上前几种方式就可以拿到需要的元素了,需要判断结果是否唯一来选择对应的选择器。
通过驱动对象调用此方法会返回一个标签对象或标签对象列表。标签下的文本可以通过.text获取,标签的其他属性值可以通过get_attribute()获取。
分享一个快速定位元素的小妙招:查看所需信息所在标签的id、class、name是否与标签下信息的语义相关。一般来说,相关的都是唯一的。(从开发者的角度考虑)如果当前标签不能唯一定位,考虑父标签。以此类推,你总能找到一种定位方法。
2.鼠标事件(模拟鼠标操作)
可以通过标签对象调用。
3.键盘事件(模拟键盘操作)
4.其他操作
其他操作包括控制浏览器的操作、获取断言信息、表单切换、多窗口切换、警告框处理、下拉框处理、文件上传操作、cookie操作、调用js代码、截图、关闭浏览器等操作,因为这里我用的不多,就不一一列举了,自己去官网学习吧。
2.爬取目标
本次实战爬虫主要完成以下目标:
在QQ音乐官网爬取指定歌手的前5首歌曲基本信息和前500名流行评论。
1.获取前五首歌曲的url
分析这个页面的代码,我们知道包裹所有歌曲信息的tag的class是唯一的,我们可以拿到它,然后遍历所有的子标签,或者一次性获取所有包裹歌曲信息的div,并且然后获取里面的 a 标签。
2.获取歌曲基本信息
可以看出,基本信息标签中的类名有一部分语义,所以可以通过css选择器来唯一确定。
3.获取歌词
页面上的歌词不完整,貌似需要点击展开,其实所有的歌词都已经在标签里了,只是显示问题。
文章采集调用(中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-24 12:01
文章采集调用了爬虫服务器爬取信息,返回json数据以支持后面自动化推荐,爬虫服务器可自动获取文章pdf的内容,如链接,评论,新增收藏,删除收藏,位置,描述,评分,星级评价,评论等等,更重要的是可以向爬虫服务器导出点击数据和爬虫过程显示数据。
我们是做推荐系统的,和小鸟推荐系统比,neilinks绝对算是最先进的,我们开始的时候是想做中文世界的自动化推荐,后来架构考虑后,干脆直接把数据进行一定量的汇聚,编码成数据库里面的形式,用sql实现。国内真正有这个需求的企业不多,不过国内的小平台起来的有好几家,小鸟推荐也算是比较成熟的一个产品。
小鸟实时推荐系统是基于实时大数据的消息推荐。中文自适应推荐系统的模式,我们团队已经提出了很多年了,实际上确有一些难度,由于目前中文在大数据的分析理解上还存在不少技术挑战。希望以下这些讨论,对大家有所帮助。中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐从大数据到实时数据推荐用户行为大数据推荐平台使用什么类型的数据对于信息推荐和推荐系统,本文主要讨论基于用户行为大数据的推荐技术。
这里先聊聊中文市场有关推荐系统的部分。我们将推荐系统描述为:对已被使用过的信息与未被使用过的信息进行有针对性地推荐。根据公众对目标内容的偏好,用户产生的对目标内容的搜索可用于推荐,直接提供给用户。1.中文市场的推荐系统已经存在多年,但依然非常不理想推荐系统的推荐已经持续了漫长的时间,当我们考虑推荐时,技术选型要关注信息的来源,由于中文市场存在太多的没有被使用过的信息。
依赖于这些来源的推荐系统有以下缺点:缺乏技术门槛,缺乏工程实现,上手非常难。缺乏人才保障,人才和工具缺乏。上述的推荐问题会影响很多人加入推荐系统领域,形成恶性循环。2.推荐系统存在的痛点对于每一个信息都能推荐,这可能吗?对于最终用户的需求,是不是存在的推荐呢?用户并不知道哪些信息是最终的用户需求,但是信息至少用于推荐。
根据用户的搜索记录进行推荐可以吗?只需要几秒钟就能做一个最终用户页面的推荐。即使能做,其推荐也是靠计算机实现的,并且推荐效率很低。使用人工审核进行推荐有困难吗?有技术实现难度,人工审核靠人工,效率低的问题。即使人工审核,也有审核人员的个人偏好问题。目前专业的人员个人偏好也不理想。但是,所有能够提供推荐的信息确实都被已经使用过了,没有被使用过的信息,用户是不愿意去触碰,也不感兴趣的。为什么使用新闻、订阅、社交网络等推荐系统?新闻这些信息的推。 查看全部
文章采集调用(中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐)
文章采集调用了爬虫服务器爬取信息,返回json数据以支持后面自动化推荐,爬虫服务器可自动获取文章pdf的内容,如链接,评论,新增收藏,删除收藏,位置,描述,评分,星级评价,评论等等,更重要的是可以向爬虫服务器导出点击数据和爬虫过程显示数据。
我们是做推荐系统的,和小鸟推荐系统比,neilinks绝对算是最先进的,我们开始的时候是想做中文世界的自动化推荐,后来架构考虑后,干脆直接把数据进行一定量的汇聚,编码成数据库里面的形式,用sql实现。国内真正有这个需求的企业不多,不过国内的小平台起来的有好几家,小鸟推荐也算是比较成熟的一个产品。
小鸟实时推荐系统是基于实时大数据的消息推荐。中文自适应推荐系统的模式,我们团队已经提出了很多年了,实际上确有一些难度,由于目前中文在大数据的分析理解上还存在不少技术挑战。希望以下这些讨论,对大家有所帮助。中文自适应推荐系统最终靠什么技术实现从实时分析到离线实时推荐从大数据到实时数据推荐用户行为大数据推荐平台使用什么类型的数据对于信息推荐和推荐系统,本文主要讨论基于用户行为大数据的推荐技术。
这里先聊聊中文市场有关推荐系统的部分。我们将推荐系统描述为:对已被使用过的信息与未被使用过的信息进行有针对性地推荐。根据公众对目标内容的偏好,用户产生的对目标内容的搜索可用于推荐,直接提供给用户。1.中文市场的推荐系统已经存在多年,但依然非常不理想推荐系统的推荐已经持续了漫长的时间,当我们考虑推荐时,技术选型要关注信息的来源,由于中文市场存在太多的没有被使用过的信息。
依赖于这些来源的推荐系统有以下缺点:缺乏技术门槛,缺乏工程实现,上手非常难。缺乏人才保障,人才和工具缺乏。上述的推荐问题会影响很多人加入推荐系统领域,形成恶性循环。2.推荐系统存在的痛点对于每一个信息都能推荐,这可能吗?对于最终用户的需求,是不是存在的推荐呢?用户并不知道哪些信息是最终的用户需求,但是信息至少用于推荐。
根据用户的搜索记录进行推荐可以吗?只需要几秒钟就能做一个最终用户页面的推荐。即使能做,其推荐也是靠计算机实现的,并且推荐效率很低。使用人工审核进行推荐有困难吗?有技术实现难度,人工审核靠人工,效率低的问题。即使人工审核,也有审核人员的个人偏好问题。目前专业的人员个人偏好也不理想。但是,所有能够提供推荐的信息确实都被已经使用过了,没有被使用过的信息,用户是不愿意去触碰,也不感兴趣的。为什么使用新闻、订阅、社交网络等推荐系统?新闻这些信息的推。
文章采集调用( DedeCMS跳转链接实际指向是哪里呢?秀站网秀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-23 18:07
DedeCMS跳转链接实际指向是哪里呢?秀站网秀)
在Dedecms中,文章模型经常使用jump[j]属性,但是前台显示的链接是动态的URL地址,搜索引擎会跟着爬,而是跳转发送。这个链接实际上指向哪里?王秀展 王秀展做了一个实验。这个链接返回的HTTP状态码是302,是临时跳转。这个跳转链接其实很不友好。对于站点,页面上有多个指向实际 URL 的 URL;如果是站外链接,很容易分散权重。
调用文章的一般方法如下,不修改源文件。
{dede:arclist addfields='redirecturl' channelid='1'}
][field:title/]
{/dede:arclist}
这里的链接修改为站内和站外直接调用Jump[j]引用的URL,站外调用nofollow。
需要用到的是通用的[field:array]标签,可以用在任何Dedecms默认标签中,特别适合多条件判断。
{dede:arclist addfields='redirecturl' channelid='1'}
[field:array runphp='yes']
if(@me['redirecturl'] !=''){
@me = ' . ']' . @me['title'] . '';
}else{
@me = ' . ']' . @me['title'] . '';
};
[/field:array]
{/dede:arclist}
dedecms的{dede:list}标签不能直接调用redirecturl字段,需要修改源程序
打开/include/arc.listview.class.php,找到(复制时请删除分隔符)
//如果不用默认的sortrank或id排序,使用联合查询(数据量大时非常缓慢)
if(preg_match('/hot|click|lastpost/', $orderby))
{
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.isdefault,tp.defaultname,
tp.namerule,tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
$addField
FROM `#分隔符@__archives` arc
LEFT JOIN `#分隔符@__arctype` tp ON arc.typeid=tp.id
$addJoin
WHERE {$this->addSql} $ordersql LIMIT $limitstart,$row";
}
在这段代码之前,添加
$addField .= ','.$addtable.'.redirecturl';
调用方法
{dede:list row='1' addfields='redirecturl' orderby='pubdate'}
][field:title/]
{/dede:list}
也可以增加该字段的判断,调用跳转地址,不再赘述。 查看全部
文章采集调用(
DedeCMS跳转链接实际指向是哪里呢?秀站网秀)
在Dedecms中,文章模型经常使用jump[j]属性,但是前台显示的链接是动态的URL地址,搜索引擎会跟着爬,而是跳转发送。这个链接实际上指向哪里?王秀展 王秀展做了一个实验。这个链接返回的HTTP状态码是302,是临时跳转。这个跳转链接其实很不友好。对于站点,页面上有多个指向实际 URL 的 URL;如果是站外链接,很容易分散权重。
调用文章的一般方法如下,不修改源文件。
{dede:arclist addfields='redirecturl' channelid='1'}
][field:title/]
{/dede:arclist}
这里的链接修改为站内和站外直接调用Jump[j]引用的URL,站外调用nofollow。
需要用到的是通用的[field:array]标签,可以用在任何Dedecms默认标签中,特别适合多条件判断。
{dede:arclist addfields='redirecturl' channelid='1'}
[field:array runphp='yes']
if(@me['redirecturl'] !=''){
@me = ' . ']' . @me['title'] . '';
}else{
@me = ' . ']' . @me['title'] . '';
};
[/field:array]
{/dede:arclist}
dedecms的{dede:list}标签不能直接调用redirecturl字段,需要修改源程序
打开/include/arc.listview.class.php,找到(复制时请删除分隔符)
//如果不用默认的sortrank或id排序,使用联合查询(数据量大时非常缓慢)
if(preg_match('/hot|click|lastpost/', $orderby))
{
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.isdefault,tp.defaultname,
tp.namerule,tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
$addField
FROM `#分隔符@__archives` arc
LEFT JOIN `#分隔符@__arctype` tp ON arc.typeid=tp.id
$addJoin
WHERE {$this->addSql} $ordersql LIMIT $limitstart,$row";
}
在这段代码之前,添加
$addField .= ','.$addtable.'.redirecturl';
调用方法
{dede:list row='1' addfields='redirecturl' orderby='pubdate'}
][field:title/]
{/dede:list}
也可以增加该字段的判断,调用跳转地址,不再赘述。
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-22 18:09
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的 Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那么我们在java项目中如何控制camera capture呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。web程序调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,其中收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的 Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那么我们在java项目中如何控制camera capture呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。web程序调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,其中收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
文章采集调用(第二个降低写作启动成本的大招:建立写作素材库有了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-22 01:14
以后只要掌握了两个能力,自己不创业也能活的很好。
第一个是写 第二个是说
只要掌握了这些能力中的任何一项,就可以立于不败之地。
和我一样,我更喜欢写作!
每天写一篇文章来创建自己的个人品牌。写文章其实没有想象的那么难。关键是要降低写入的启动成本。
简单来说,你什么都不用想,直接开始写作。这个我在之前的文章中已经详细介绍过了。
今天分享第二大降低写作启动成本的方法:搭建写作素材库
有了这个写作素材库,再也不用为文章的写作发愁了。
一、什么是文具库
写作素材库是一个灵感参考库,可以让你降低思考成本。
例如,厨师就像烹饪一样需要各种配料和调味品。没有这些,厨师就无法烹饪出美味的菜肴。
图片来自简书App
各种难懂的食材和调味品,都是厨师的素材库。有了这些,依靠我多年积累的经验,我可以轻松地立即烹饪出各种美味佳肴。
编写 文章 也是如此。
而且我在写作过程中也需要经常使用素材库(我的第二大脑)
图片来自简书App
不同的分类下有不同的内容素材,方便我每次调用。
比如今天我要写一篇关于时间管理的文章文章。直接在软件里面搜索时间管理,1秒参考资料很多。
图片来自简书App
这些都是我平时看的很好的文章,采集了。写文章时可以快速参考。
二、为什么要建写作材料库
在我的任务中拥有一个写作材料库的最大好处是我可以随时用一些经典的思维来证明我的一些观点。
例如:
比如我想写一篇关于竞争力的文章。我提出的核心理念是专注做事,建立自己的影响圈。我说的话可能不会立刻引起大家的共鸣,所以我必须借用一些名人。祝福我的想法。
我使用了写作材料库中“Working with a System”的作者 Sam Carpenter 来祝福我的想法。
图片来自简书App
如果你没有素材库,即使你记忆力很好,你也不会长时间记住它。
在我的写作素材库中,专门设置了一个分类,用来保存阅读时的一些经典句子。
图片来自简书App
这是3本不合理的书
图片来自简书App
在这里很容易找到一些经典的参考句子。
写作素材库最大的好处就是可以随时调用,无论身在何处,只要输入相关关键词,就可以立即找到我想要的素材,给写作带来了极大的便利< @文章。
三、如何搭建写作素材库
写作素材库的建立其实很简单,分为三个步骤:
第 1 步:采集材料
在采集资料方面,其实有两种采集方式:
1、碎片采集
我们每天看大量的公众号文章、知乎文章或网站文章,感觉好的文章可以被采集。
这是通过碎片时间采集的,文章 永远不会太多。
图片来自简书App
Fragments 文章,我把它们都放在我的收件箱里。
好像很清楚,我采集了多少文章,有空就读。
2、固定主题合集
有时,我们可能会做一些项目,我们需要一个明确的方向来采集知识。
例如:
我媳妇现在主要卖玫瑰,所以她每天都需要出口玫瑰文章,打造个人品牌,创造价值,增加销量。
我的做法是通过百度知乎、知乎、公众号直接采集玫瑰素材
图片来自简书App
通过搜索,马上有数百条写作方向和材料,百度知道。
使用文章搜索微信公众号,上千条素材
图片来自简书App
看,有6000多篇文案,自己写就够了。
问答平台知乎、公众号文章,这三个地方足以让你采集上万条固定主题的写作素材。
第 2 步:保存材料
采集的最终目的是为了方便调用,所以尝试了很多工具,最后决定使用印象笔记作为载体工具。原因很明显:
1、全平台支持2、强大的搜索功能
全平台的优势在于,无论是手机还是电脑,都可以轻松采集保存。
尤其是有时候出去看到一些有启发性的东西,就直接打开印象笔记拍张照片,然后把这个时候的灵感写下来。
这是之后的想法。
但是,要保持一个好的材料库,就必须建立一个完整的分类体系。
图片来自简书App
以上是我自己的分类系统,主要由收件箱、主题知识库、存档知识库组成
收件箱:用于临时存放刚刚采集到的分片信息。你可能没有仔细阅读它,但感觉这是一个很好的材料。先存起来,有时间再读。
知识主题库:我把它分为工作、学习、生活、兴趣四大类,基本涵盖了方方面面。有了对应的分类,我以后只需要按照知识的类型来分类就可以了。
例如
图片来自简书App
对于这一类阅读,我专门存储电子书和经典句子的摘录。
在例如
图片来自简书App
平时看到一些好的文案,我会放到存档类
合理的分类可以让我快速找到相关的素材位置。
分类很重要。
只要仔细观察,一些大的网站都有非常详细的分类导航。
图片来自简书App
这是京东的网站品类,人们一看就知道应该点击商品,才能找到自己想要的商品。
第 3 步:检索材料
材料的采集是为了最后的快速调用,所以以前的分类工作体现了价值。
通过印象笔记有两种调用方式
第一种:使用搜索功能
Evernote 使用了强大的搜索功能。只要学会了搜索命令,不管怎么找都可以快速调出素材。
Plus+:多个关键词 搜索
减号-:不收录某个关键词
双引号"":精确搜索
notebook:在 notebook 内搜索
Intitle:标题搜索
例如:
intitle:seo 该命令用于搜索标题中收录seo的信息
图片来自简书App
标题是否收录seo的信息知识。
双引号“促销”来促进关键词搜索
图片来自简书App
结果是title收录promotion关键词,content收录promotion关键词信息,可以搜索到,调用起来很方便。
第二种:按类别搜索
合理的分类也可以让你找到相关的信息,就像我的学习分类一样
图片来自简书App
根据分类结构,我可以快速找到我想要的材料,比如时间管理。我只是点击这个类别,它是所有时间管理材料。
请记住,创建材料库是为了快速回忆,找不到它就意味着没有它。
如果你想每天写文章来打造个人品牌,那你就需要一个属于自己的写作素材库。
知道方法和方法并不意味着你已经学会了。只有自己实践和应用,才能取得更大的进步。
版权归周振兴作者所有,希望能帮到你! 查看全部
文章采集调用(第二个降低写作启动成本的大招:建立写作素材库有了)
以后只要掌握了两个能力,自己不创业也能活的很好。
第一个是写 第二个是说
只要掌握了这些能力中的任何一项,就可以立于不败之地。
和我一样,我更喜欢写作!
每天写一篇文章来创建自己的个人品牌。写文章其实没有想象的那么难。关键是要降低写入的启动成本。
简单来说,你什么都不用想,直接开始写作。这个我在之前的文章中已经详细介绍过了。
今天分享第二大降低写作启动成本的方法:搭建写作素材库
有了这个写作素材库,再也不用为文章的写作发愁了。
一、什么是文具库
写作素材库是一个灵感参考库,可以让你降低思考成本。
例如,厨师就像烹饪一样需要各种配料和调味品。没有这些,厨师就无法烹饪出美味的菜肴。
图片来自简书App
各种难懂的食材和调味品,都是厨师的素材库。有了这些,依靠我多年积累的经验,我可以轻松地立即烹饪出各种美味佳肴。
编写 文章 也是如此。
而且我在写作过程中也需要经常使用素材库(我的第二大脑)
图片来自简书App
不同的分类下有不同的内容素材,方便我每次调用。
比如今天我要写一篇关于时间管理的文章文章。直接在软件里面搜索时间管理,1秒参考资料很多。
图片来自简书App
这些都是我平时看的很好的文章,采集了。写文章时可以快速参考。
二、为什么要建写作材料库
在我的任务中拥有一个写作材料库的最大好处是我可以随时用一些经典的思维来证明我的一些观点。
例如:
比如我想写一篇关于竞争力的文章。我提出的核心理念是专注做事,建立自己的影响圈。我说的话可能不会立刻引起大家的共鸣,所以我必须借用一些名人。祝福我的想法。
我使用了写作材料库中“Working with a System”的作者 Sam Carpenter 来祝福我的想法。
图片来自简书App
如果你没有素材库,即使你记忆力很好,你也不会长时间记住它。
在我的写作素材库中,专门设置了一个分类,用来保存阅读时的一些经典句子。
图片来自简书App
这是3本不合理的书
图片来自简书App
在这里很容易找到一些经典的参考句子。
写作素材库最大的好处就是可以随时调用,无论身在何处,只要输入相关关键词,就可以立即找到我想要的素材,给写作带来了极大的便利< @文章。
三、如何搭建写作素材库
写作素材库的建立其实很简单,分为三个步骤:
第 1 步:采集材料
在采集资料方面,其实有两种采集方式:
1、碎片采集
我们每天看大量的公众号文章、知乎文章或网站文章,感觉好的文章可以被采集。
这是通过碎片时间采集的,文章 永远不会太多。
图片来自简书App
Fragments 文章,我把它们都放在我的收件箱里。
好像很清楚,我采集了多少文章,有空就读。
2、固定主题合集
有时,我们可能会做一些项目,我们需要一个明确的方向来采集知识。
例如:
我媳妇现在主要卖玫瑰,所以她每天都需要出口玫瑰文章,打造个人品牌,创造价值,增加销量。
我的做法是通过百度知乎、知乎、公众号直接采集玫瑰素材
图片来自简书App
通过搜索,马上有数百条写作方向和材料,百度知道。
使用文章搜索微信公众号,上千条素材
图片来自简书App
看,有6000多篇文案,自己写就够了。
问答平台知乎、公众号文章,这三个地方足以让你采集上万条固定主题的写作素材。
第 2 步:保存材料
采集的最终目的是为了方便调用,所以尝试了很多工具,最后决定使用印象笔记作为载体工具。原因很明显:
1、全平台支持2、强大的搜索功能
全平台的优势在于,无论是手机还是电脑,都可以轻松采集保存。
尤其是有时候出去看到一些有启发性的东西,就直接打开印象笔记拍张照片,然后把这个时候的灵感写下来。
这是之后的想法。
但是,要保持一个好的材料库,就必须建立一个完整的分类体系。
图片来自简书App
以上是我自己的分类系统,主要由收件箱、主题知识库、存档知识库组成
收件箱:用于临时存放刚刚采集到的分片信息。你可能没有仔细阅读它,但感觉这是一个很好的材料。先存起来,有时间再读。
知识主题库:我把它分为工作、学习、生活、兴趣四大类,基本涵盖了方方面面。有了对应的分类,我以后只需要按照知识的类型来分类就可以了。
例如
图片来自简书App
对于这一类阅读,我专门存储电子书和经典句子的摘录。
在例如
图片来自简书App
平时看到一些好的文案,我会放到存档类
合理的分类可以让我快速找到相关的素材位置。
分类很重要。
只要仔细观察,一些大的网站都有非常详细的分类导航。
图片来自简书App
这是京东的网站品类,人们一看就知道应该点击商品,才能找到自己想要的商品。
第 3 步:检索材料
材料的采集是为了最后的快速调用,所以以前的分类工作体现了价值。
通过印象笔记有两种调用方式
第一种:使用搜索功能
Evernote 使用了强大的搜索功能。只要学会了搜索命令,不管怎么找都可以快速调出素材。
Plus+:多个关键词 搜索
减号-:不收录某个关键词
双引号"":精确搜索
notebook:在 notebook 内搜索
Intitle:标题搜索
例如:
intitle:seo 该命令用于搜索标题中收录seo的信息
图片来自简书App
标题是否收录seo的信息知识。
双引号“促销”来促进关键词搜索
图片来自简书App
结果是title收录promotion关键词,content收录promotion关键词信息,可以搜索到,调用起来很方便。
第二种:按类别搜索
合理的分类也可以让你找到相关的信息,就像我的学习分类一样
图片来自简书App
根据分类结构,我可以快速找到我想要的材料,比如时间管理。我只是点击这个类别,它是所有时间管理材料。
请记住,创建材料库是为了快速回忆,找不到它就意味着没有它。
如果你想每天写文章来打造个人品牌,那你就需要一个属于自己的写作素材库。
知道方法和方法并不意味着你已经学会了。只有自己实践和应用,才能取得更大的进步。
版权归周振兴作者所有,希望能帮到你!
文章采集调用(5.5新版本的+30联络651606775830元功能形容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-11-22 01:09
)
(需5.5新版+30联系6516067758)需加30元
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能详情、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与百万订阅账号分享优质内容,每天大量升级可以快速提升网站的权重和排名。
功能亮点:
1、可以自己设置插件名称:
可以在后台面包屑导航上修改插件名称。如果不设置,则默认为微信窗口。
2、您可以自己设置SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你要采集的公众号,提交。一次最多可以采集 10个公众号信息。
4、批量提供采集公众号文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、介绍页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只需安装diy扩展,即可拥有强大的DIY机制,可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、介绍页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、 可以灵活设置信息是否需要审核:
客户提交的内容公众号和文章信息是否需要审核,可以通过后台的开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只要安装相应的手机版组件,就可以轻松打开手机版。
查看全部
文章采集调用(5.5新版本的+30联络651606775830元功能形容
)
(需5.5新版+30联系6516067758)需加30元
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能详情、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与百万订阅账号分享优质内容,每天大量升级可以快速提升网站的权重和排名。
功能亮点:
1、可以自己设置插件名称:
可以在后台面包屑导航上修改插件名称。如果不设置,则默认为微信窗口。
2、您可以自己设置SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、批量提供采集官方账号信息:
输入微信公众号昵称点击搜索,选择你要采集的公众号,提交。一次最多可以采集 10个公众号信息。
4、批量提供采集公众号文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,即可批量采集文章信息,一次至少可以使用采集篇文章文章,文章的内容也是本地化的。
5、文章可以完美显示信息:
插件自建首页、列表页、介绍页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只需安装diy扩展,即可拥有强大的DIY机制,可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(首页、列表页、介绍页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、 可以灵活设置信息是否需要审核:
客户提交的内容公众号和文章信息是否需要审核,可以通过后台的开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、完全支持手机版:
只要安装相应的手机版组件,就可以轻松打开手机版。
文章采集调用(DedeCMSV5.7sp2网站漏洞如何修复dedecms)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-19 17:12
如何修复Dedecms V5.7sp2网站漏洞
织梦dedecms,在整个互联网中,很多企业网站、个人网站、优化网站都在用dede作为整个网站的发展@>架构,dedecms采用php+mysql数据库架构来承载整个网站的操作和用户访问。首页和专栏页面生成了织梦漏洞的详细信息,我们来一步步分析:首先介绍一下parse_str函数的机制和作用。简单来说就是解析网站传递过来的字符串,将字符串的值转换成一个固有的变量值。这个函数是传入进来的,当有改动的时候,不会验证当前变量网站的值是否收录在buy_action中。最新版dedecms中的php代码。存在一个网站漏洞,dedecms针对之前更新修复的文件网站漏洞,在代码中加入了很多功能的安全过滤,但是传入的值在过滤的同时解码编码函数时没有严格过滤掉。网站漏洞的产生和dedecms的利用非常简单,但是在实际的利用过程中,我们发现实现起来还是比较困难的。最重要的是mchStrCode的功能是在整个网站编码中控制前端用户提交的值中的参数。dedecms网站 漏洞修复建议:关于dedecms parse_str函数SQL注入漏洞,需要修复的是变量覆盖修复,对前端输入的值进行安全判断。, 确认变量值是否存在,如果存在则不会被覆盖,防止变量覆盖导致恶意结构的掺入
726 查看全部
文章采集调用(DedeCMSV5.7sp2网站漏洞如何修复dedecms)
如何修复Dedecms V5.7sp2网站漏洞
织梦dedecms,在整个互联网中,很多企业网站、个人网站、优化网站都在用dede作为整个网站的发展@>架构,dedecms采用php+mysql数据库架构来承载整个网站的操作和用户访问。首页和专栏页面生成了织梦漏洞的详细信息,我们来一步步分析:首先介绍一下parse_str函数的机制和作用。简单来说就是解析网站传递过来的字符串,将字符串的值转换成一个固有的变量值。这个函数是传入进来的,当有改动的时候,不会验证当前变量网站的值是否收录在buy_action中。最新版dedecms中的php代码。存在一个网站漏洞,dedecms针对之前更新修复的文件网站漏洞,在代码中加入了很多功能的安全过滤,但是传入的值在过滤的同时解码编码函数时没有严格过滤掉。网站漏洞的产生和dedecms的利用非常简单,但是在实际的利用过程中,我们发现实现起来还是比较困难的。最重要的是mchStrCode的功能是在整个网站编码中控制前端用户提交的值中的参数。dedecms网站 漏洞修复建议:关于dedecms parse_str函数SQL注入漏洞,需要修复的是变量覆盖修复,对前端输入的值进行安全判断。, 确认变量值是否存在,如果存在则不会被覆盖,防止变量覆盖导致恶意结构的掺入
726
文章采集调用(几款调用最新或是随机文章的标签是哪几种? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-19 09:16
)
目前国内流行的几个开源程序包括Empirecms、织梦cms、WordPress等,这些对于建网站做seo的站长来说肯定不陌生优化。一般有在首页或内页调用最新的或随机的文章的爱好。如果这些文章是同一个开源程序,调用起来相对容易一些。如果它们不一样怎么办?接下来我讲一下帝国cms如何调用WordPress博客的最新或随机文章,仅供参考。
1、 Empirecms 最常用的信息调用标签是(ecmsinfo),如下图,就是ecmsinfo调用标签
格式主要是列/主题ID和模板ID这两个参数。操作系统的默认 ID 为 24。
例如:如[ecmsinfo] 10, 5, 36, 1, 24, 20, 0 [/ecmsinfo]
“10”表示“管理栏”中标识的对应栏的ID
“20”表示“管理标签模板”中的标签模板ID
整个代码的意思是按照标签模板ID(20))的规则调用列ID(10))中5篇文章的标题文章,并调用文章标题前不显示列名和图片。
2、根据上面的例子,Empire cms随机调用WordPress博客文章,标签如下:
[ecmsinfo]"选择 post_title 作为标题,id 作为 id from wp_posts order by rand() desc limit 5",5,36,1,24,29,0[/ecms信息]
说明:“select post_title as title, id as id from wp_posts order by rand() desc limit 5”本段表示用SQL语句调用WordPress博客数据库的字段命令。
(1) post_title 对应 WordPress 博客的 文章 标题。
(2) id 对应标题号。
(3) wp_posts 是存放 WordPress 文章 的数据表,如果帝国cms 和 WordPress 博客是
不同的数据库,那么,上面的“wp_posts”改为“博客数据库名.wp_posts”。因为是调用WordPress博客的URL地址,所以必须单独自定义一个标签模板。进入帝国cms后台“模板管理”——“管理标签模板”——“添加模板”如下图:
模板名称,只写一个好记的名字,比如“首页调用WordPress博客文章模板”
(4)在页面模板内容中输入以下代码
[!–empirenews.listtemp–]
[!–empirenews.listtemp–]
(5)列表内容模板list.var输入如下:
[!–title–]
注意,如果WordPress的相对地址是/blog/?p=*,则使用/blog/?p=[! –Id–]
伪静态地址 blog/*.html 是 /blog/ [! –Id–].html(*代表一个数字)
当然最好使用绝对地址。其他的URL地址可以类推。
然后点击“保存模板”,对应的图如下,29为标签模板的ID。
(6)"order by rand() desc"这段代码的意思是随机排序,如果调用最新的文章,对应的是"order by id desc"
(7)limt 5 表示5次文章调用的次数。如果是5,后面的第一个数字也必须是5(见ecmsinfo标签写法)
好的,然后把ecmsinfo标签代码放到一些你要调用的Empirecms模板中就OK了
最后附上效果图:
文章 的 WordPress 博客:
Empirecms随意调用一个WordPress博客文章:
查看全部
文章采集调用(几款调用最新或是随机文章的标签是哪几种?
)
目前国内流行的几个开源程序包括Empirecms、织梦cms、WordPress等,这些对于建网站做seo的站长来说肯定不陌生优化。一般有在首页或内页调用最新的或随机的文章的爱好。如果这些文章是同一个开源程序,调用起来相对容易一些。如果它们不一样怎么办?接下来我讲一下帝国cms如何调用WordPress博客的最新或随机文章,仅供参考。
1、 Empirecms 最常用的信息调用标签是(ecmsinfo),如下图,就是ecmsinfo调用标签
格式主要是列/主题ID和模板ID这两个参数。操作系统的默认 ID 为 24。
例如:如[ecmsinfo] 10, 5, 36, 1, 24, 20, 0 [/ecmsinfo]
“10”表示“管理栏”中标识的对应栏的ID
“20”表示“管理标签模板”中的标签模板ID
整个代码的意思是按照标签模板ID(20))的规则调用列ID(10))中5篇文章的标题文章,并调用文章标题前不显示列名和图片。
2、根据上面的例子,Empire cms随机调用WordPress博客文章,标签如下:
[ecmsinfo]"选择 post_title 作为标题,id 作为 id from wp_posts order by rand() desc limit 5",5,36,1,24,29,0[/ecms信息]
说明:“select post_title as title, id as id from wp_posts order by rand() desc limit 5”本段表示用SQL语句调用WordPress博客数据库的字段命令。
(1) post_title 对应 WordPress 博客的 文章 标题。
(2) id 对应标题号。
(3) wp_posts 是存放 WordPress 文章 的数据表,如果帝国cms 和 WordPress 博客是
不同的数据库,那么,上面的“wp_posts”改为“博客数据库名.wp_posts”。因为是调用WordPress博客的URL地址,所以必须单独自定义一个标签模板。进入帝国cms后台“模板管理”——“管理标签模板”——“添加模板”如下图:
模板名称,只写一个好记的名字,比如“首页调用WordPress博客文章模板”
(4)在页面模板内容中输入以下代码
[!–empirenews.listtemp–]
[!–empirenews.listtemp–]
(5)列表内容模板list.var输入如下:
[!–title–]
注意,如果WordPress的相对地址是/blog/?p=*,则使用/blog/?p=[! –Id–]
伪静态地址 blog/*.html 是 /blog/ [! –Id–].html(*代表一个数字)
当然最好使用绝对地址。其他的URL地址可以类推。
然后点击“保存模板”,对应的图如下,29为标签模板的ID。
(6)"order by rand() desc"这段代码的意思是随机排序,如果调用最新的文章,对应的是"order by id desc"
(7)limt 5 表示5次文章调用的次数。如果是5,后面的第一个数字也必须是5(见ecmsinfo标签写法)
好的,然后把ecmsinfo标签代码放到一些你要调用的Empirecms模板中就OK了
最后附上效果图:
文章 的 WordPress 博客:
Empirecms随意调用一个WordPress博客文章:
文章采集调用( Typechotypecho分类调用代码放到模板的相关位置即可(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-19 09:14
Typechotypecho分类调用代码放到模板的相关位置即可(图))
【使用指南】可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是找到了typecho调用某个类的实现。文章的方法很简单。只需要使用一段typecho分类调用代码,放在模板的相关位置即可。
可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是我找到了typecho调用一个类别目录的实现文章 方法很简单,只需要使用一段typecho分类调用代码就可以了在模板的相关位置。
下面是这个类的调用代码的使用方法。
$this->widget('Widget_Archive@index', 'pageSize=6&type=category', 'mid=3')
->parse('{title}');
其中,pageSize代表输出的数量,mid代表一个类别的类别id。
为了移植方便,可以将mid=3改为slug=your_shot_name,其中your_shot_name代表某类的缩写名称。
其中,permalink表示文章的链接,title表示文章的标题。 查看全部
文章采集调用(
Typechotypecho分类调用代码放到模板的相关位置即可(图))
【使用指南】可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是找到了typecho调用某个类的实现。文章的方法很简单。只需要使用一段typecho分类调用代码,放在模板的相关位置即可。
可能是Typecho博客模板的布局原因,需要单独调用某类typecho的文章列表。目前还没有找到相关的typecho插件,但是我找到了typecho调用一个类别目录的实现文章 方法很简单,只需要使用一段typecho分类调用代码就可以了在模板的相关位置。
下面是这个类的调用代码的使用方法。
$this->widget('Widget_Archive@index', 'pageSize=6&type=category', 'mid=3')
->parse('{title}');
其中,pageSize代表输出的数量,mid代表一个类别的类别id。
为了移植方便,可以将mid=3改为slug=your_shot_name,其中your_shot_name代表某类的缩写名称。
其中,permalink表示文章的链接,title表示文章的标题。
文章采集调用(一个网站的采集规则/article/collectsite.php)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-14 16:13
首先登录后台,点击上方菜单“模块管理”-“小说连载”,然后点击左侧菜单“采集配置”链接,会显示当前所有采集@ > 规则,每一行代表一个网站。 1、“单篇采集规则”指的是一篇采集文章文章所需的规则配置,主要内容包括网站名称、网站@ > 地址、文章标题、作者等基本信息,以及本文章的章节结构和章节内容,可以点击编辑配置修改采集规则。
2、“Batch采集”是在单个采集的基础上进行的,比如采集一个文章所有文章在列表页@>,这个列表可以是最近更新、排行榜或文章的一个类别。批量采集的规则主要是获取列表页的文章名称和文章序号,然后将单个采集调用到采集,如果需要获取列表的第二页、第三页等内容,则需要设置翻页的参数解析规则。
注意:所有采集规则都生成了相应的配置文件,允许网站配置在:configs/article/collectsite.php中的采集,某个网站的规则配置文件为:configs/article/site_网站英文logo.php,所以网站英文logo不允许重复。例如:在configs/article/collectsite.php中配置起点中文网站的采集:
$jieqiCollectsite['1']['name'] ='起点中文网';$jieqiCollectsite['1']['config'] ='cmfu_com';$jieqiCollectsite['1']['url ' ] ='';$jieqiCollectsite['1']['subarticleid'] ='';$jieqiCollectsite['1']['enable'] = '1';
那么起点采集规则配置文件是configs/article/site_cmfu_com.php。 查看全部
文章采集调用(一个网站的采集规则/article/collectsite.php)
首先登录后台,点击上方菜单“模块管理”-“小说连载”,然后点击左侧菜单“采集配置”链接,会显示当前所有采集@ > 规则,每一行代表一个网站。 1、“单篇采集规则”指的是一篇采集文章文章所需的规则配置,主要内容包括网站名称、网站@ > 地址、文章标题、作者等基本信息,以及本文章的章节结构和章节内容,可以点击编辑配置修改采集规则。
2、“Batch采集”是在单个采集的基础上进行的,比如采集一个文章所有文章在列表页@>,这个列表可以是最近更新、排行榜或文章的一个类别。批量采集的规则主要是获取列表页的文章名称和文章序号,然后将单个采集调用到采集,如果需要获取列表的第二页、第三页等内容,则需要设置翻页的参数解析规则。
注意:所有采集规则都生成了相应的配置文件,允许网站配置在:configs/article/collectsite.php中的采集,某个网站的规则配置文件为:configs/article/site_网站英文logo.php,所以网站英文logo不允许重复。例如:在configs/article/collectsite.php中配置起点中文网站的采集:
$jieqiCollectsite['1']['name'] ='起点中文网';$jieqiCollectsite['1']['config'] ='cmfu_com';$jieqiCollectsite['1']['url ' ] ='';$jieqiCollectsite['1']['subarticleid'] ='';$jieqiCollectsite['1']['enable'] = '1';
那么起点采集规则配置文件是configs/article/site_cmfu_com.php。
文章采集调用( 使用SQL调用当前文章链接的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-14 16:11
使用SQL调用当前文章链接的方法,你知道吗?)
很多时候在使用织梦cms的时候,想在文章页面的最后加上当前的文章链接(url),这样别人复制文章的时候@>,添加链接,这相当于做了一个外链(虽然这个概率很低)。下面,老米将介绍三种调用当前文章链接的方法。您可以根据自己的需要进行选择。
第一种方法:
这是最简单的方法,只需在相应位置添加标签即可。代码显示如下:
{dede:field name='arcurl'/}
添加完成后,保存文章模板并上传服务器重新生成页面。
第二种方法:
只需使用织梦cms本身的一个全局函数,并以标签的形式在前台调用即可。代码显示如下:
{dede:geturl runphp='yes'}
@me = GetCurUrl();
{/dede:geturl}
将上述代码插入需要显示当前文章 URL地址的位置,然后生成文章内容页面。
第三种方法:
使用 SQL 语句调用静态文档地址。代码显示如下:
{dede:field.id runphp='yes'}
$id=@me;
@我='';
$url=GetOneArchive($id);
@me=$url['arcurl'];
{/dede:field.id}
织梦文章 介绍了调用当前页面末尾的文章链接(url)的三种方法。如果你对织梦不熟悉或者有一点了解,可以使用第一种和第二种方法。比如老米技术有限,说到数据库,他不喜欢操作,所以不会优先考虑第三个。使用哪种方法可以根据自己的情况来决定。
原创文章, title: 织梦文章 页面末尾调用当前文章链接(url)的三种方法,如转载请注明出处: 查看全部
文章采集调用(
使用SQL调用当前文章链接的方法,你知道吗?)
很多时候在使用织梦cms的时候,想在文章页面的最后加上当前的文章链接(url),这样别人复制文章的时候@>,添加链接,这相当于做了一个外链(虽然这个概率很低)。下面,老米将介绍三种调用当前文章链接的方法。您可以根据自己的需要进行选择。
第一种方法:
这是最简单的方法,只需在相应位置添加标签即可。代码显示如下:
{dede:field name='arcurl'/}
添加完成后,保存文章模板并上传服务器重新生成页面。
第二种方法:
只需使用织梦cms本身的一个全局函数,并以标签的形式在前台调用即可。代码显示如下:
{dede:geturl runphp='yes'}
@me = GetCurUrl();
{/dede:geturl}
将上述代码插入需要显示当前文章 URL地址的位置,然后生成文章内容页面。
第三种方法:
使用 SQL 语句调用静态文档地址。代码显示如下:
{dede:field.id runphp='yes'}
$id=@me;
@我='';
$url=GetOneArchive($id);
@me=$url['arcurl'];
{/dede:field.id}
织梦文章 介绍了调用当前页面末尾的文章链接(url)的三种方法。如果你对织梦不熟悉或者有一点了解,可以使用第一种和第二种方法。比如老米技术有限,说到数据库,他不喜欢操作,所以不会优先考虑第三个。使用哪种方法可以根据自己的情况来决定。
原创文章, title: 织梦文章 页面末尾调用当前文章链接(url)的三种方法,如转载请注明出处:
文章采集调用(忘记WordPress后台密码怎么办?WordPress网站PHP纯代码生成文章海报图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-12 07:11
猜猜你在找什么 wordpress文章
Typecho 到 WordPress 的迁移插件:ByeTyp
Typecho 是轻量级的,但是已经好几年没有更新了。插件和模板支持一直非常困难。越来越多的人退出了 Typecho,转而使用 WordPress。
WordPress 如何隐藏后台登录地址
隐藏WordPress后台登录地址是保证网站安全的方法之一。在隐藏它的同时,删除指向后端网站的链接。
如果忘记了 WordPress 后台密码怎么办? WordPress后台找回密码方法
我昨天忘记了后台网站的密码。 网站用WordPress搭建,忘记后台密码怎么办?
WordPress网站PHP 纯代码生成文章海报图片
要实现这个功能,需要依赖PHP的GD库。如果您没有它,它将无法工作。虚拟主机用户请看是否支持。
Wordpress 作者判断调用不同的模板显示在作者页面上
如果网站开放注册和投稿功能,将会有作者、编辑、订阅者和管理员。页面显示不同的模板需要单独调用。
wordpress 不同类别调用不同模板的方法
之前介绍了在WordPress不同类别中调用不同文章模板的方法。今天给大家分享一下如何调用不同类别的不同模板。
为WordPress页面添加自定义汇总功能
我们在做 WordPress网站 的时候,经常需要调用首页或者分类页上的摘要,并在分类列表中展示。
WordPress上传附件提示“上级目录没有写权限”的解决方法
WordPress用户在后台上传附件提示“上级目录没有写权限”一般出现在网站迁移到新站点后,如果用户在WordPress后台上传图片附件,或者在工具import网站遇到数据时,遇到如下提示: 查看全部
文章采集调用(忘记WordPress后台密码怎么办?WordPress网站PHP纯代码生成文章海报图片)
猜猜你在找什么 wordpress文章
Typecho 到 WordPress 的迁移插件:ByeTyp
Typecho 是轻量级的,但是已经好几年没有更新了。插件和模板支持一直非常困难。越来越多的人退出了 Typecho,转而使用 WordPress。
WordPress 如何隐藏后台登录地址
隐藏WordPress后台登录地址是保证网站安全的方法之一。在隐藏它的同时,删除指向后端网站的链接。
如果忘记了 WordPress 后台密码怎么办? WordPress后台找回密码方法
我昨天忘记了后台网站的密码。 网站用WordPress搭建,忘记后台密码怎么办?
WordPress网站PHP 纯代码生成文章海报图片
要实现这个功能,需要依赖PHP的GD库。如果您没有它,它将无法工作。虚拟主机用户请看是否支持。
Wordpress 作者判断调用不同的模板显示在作者页面上
如果网站开放注册和投稿功能,将会有作者、编辑、订阅者和管理员。页面显示不同的模板需要单独调用。
wordpress 不同类别调用不同模板的方法
之前介绍了在WordPress不同类别中调用不同文章模板的方法。今天给大家分享一下如何调用不同类别的不同模板。
为WordPress页面添加自定义汇总功能
我们在做 WordPress网站 的时候,经常需要调用首页或者分类页上的摘要,并在分类列表中展示。
WordPress上传附件提示“上级目录没有写权限”的解决方法
WordPress用户在后台上传附件提示“上级目录没有写权限”一般出现在网站迁移到新站点后,如果用户在WordPress后台上传图片附件,或者在工具import网站遇到数据时,遇到如下提示:
文章采集调用(1.用python爬取实现方法:anyproxy+java+webmagic3.FiddlerCore)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-11-10 11:06
微信公众号文章爬取方法用python组织1.爬取
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是谷歌浏览器:
谷歌浏览器版本为 52.0.2743.6;
chromedriver 版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver与chrome版本映射表(更新为v2.30))】
3. 微信公众号登录地址:
4.微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章接口地址
8.文章 列表翻页和内容获取
2.AnyProxy 代理批处理采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,您可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,自动点击手机公众号文章列表页,即“查看历史消息”;
2、利用fiddler代理劫持手机访问,将URL转发到本地php编写的网页;
3、将接收到的php网页上的URL备份到数据库中;
4、使用python从数据库中获取URL,然后进行正常爬取。
爬取过程中发现一个问题:
如果只是抓取文章的内容,好像没有访问频率限制,但是如果要抓取阅读数和点赞数,达到一定频率后,返回就会变成一个空值,我设置的时间间隔是10秒,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.青波新名单
如果你只是想看数据,直接看日单就行了,不用花钱。如果您需要访问自己的系统,他们还提供了一个 api 接口。 查看全部
文章采集调用(1.用python爬取实现方法:anyproxy+java+webmagic3.FiddlerCore)
微信公众号文章爬取方法用python组织1.爬取
实现方法:通过微信提供的公众号文章调用接口,实现爬取公众号文章的功能
步:
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2.使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是谷歌浏览器:
谷歌浏览器版本为 52.0.2743.6;
chromedriver 版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver与chrome版本映射表(更新为v2.30))】
3. 微信公众号登录地址:
4.微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取:
5.搜索公众号
6.获取要爬取的公众号的fakeid
7.选择要爬取的公众号,获取文章接口地址
8.文章 列表翻页和内容获取
2.AnyProxy 代理批处理采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个帐户,您可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,自动点击手机公众号文章列表页,即“查看历史消息”;
2、利用fiddler代理劫持手机访问,将URL转发到本地php编写的网页;
3、将接收到的php网页上的URL备份到数据库中;
4、使用python从数据库中获取URL,然后进行正常爬取。
爬取过程中发现一个问题:
如果只是抓取文章的内容,好像没有访问频率限制,但是如果要抓取阅读数和点赞数,达到一定频率后,返回就会变成一个空值,我设置的时间间隔是10秒,可以正常爬取。在这个频率下,一个小时只能抓取360条,没有实际意义。
4.青波新名单
如果你只是想看数据,直接看日单就行了,不用花钱。如果您需要访问自己的系统,他们还提供了一个 api 接口。
文章采集调用(梦dedecms(V5.7版)调用相似文章中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-10 10:15
当我们发布文章文章时,一般情况下,为了增加用户的停留时间,我们会在文章的末尾或者在为了再次赢得用户点击,在织梦dedecms(V5.7版)调用类似文章,实际调用代码为{dede:likearticle} ,这段代码的原理是通过识别文章的title、category、关键词等来判断相似度,从而做出推荐。后台调用代码如下/include/taglib/likearticle.lib.php,打开文件找到如下这段代码:
/**************************************************** ****************************************************** ****/
if($keyword !='')
{
if(!empty($typeid)) {
$typeid ="AND arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
where arc.arcrank>-1AND ($keyword) $typeid$orderquery limit 0, $row";
}
其他
{
if(!empty($typeid)) {
$typeid = "arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
WHERE arc.arcrank>-1AND $typeid$orderquery limit 0, $row";
}
<p>/**************************************************** ****************************************************/ 查看全部
文章采集调用(梦dedecms(V5.7版)调用相似文章中)
当我们发布文章文章时,一般情况下,为了增加用户的停留时间,我们会在文章的末尾或者在为了再次赢得用户点击,在织梦dedecms(V5.7版)调用类似文章,实际调用代码为{dede:likearticle} ,这段代码的原理是通过识别文章的title、category、关键词等来判断相似度,从而做出推荐。后台调用代码如下/include/taglib/likearticle.lib.php,打开文件找到如下这段代码:
/**************************************************** ****************************************************** ****/
if($keyword !='')
{
if(!empty($typeid)) {
$typeid ="AND arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
where arc.arcrank>-1AND ($keyword) $typeid$orderquery limit 0, $row";
}
其他
{
if(!empty($typeid)) {
$typeid = "arc.typeid IN($typeid) AND arc.id'$aid'";
}
$query = "SELECT arc.*,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM `dede_archives` arc LEFT JOIN `dede_arctype` tp ON arc.typeid=tp.id
WHERE arc.arcrank>-1AND $typeid$orderquery limit 0, $row";
}
<p>/**************************************************** ****************************************************/
文章采集调用(如何网页访问?豆瓣网教你如何获取真正请求的地址?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-11-10 00:07
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何访问网页?
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
导入请求,json
从 fake_useragent 导入 UserAgent
导入 csv
类多班(对象):
def __init__(self):
self.url = ";tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
定义主(自我):
经过
如果 __name__ =='__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
对于范围内的 i(1, 50):
self.headers = {
'用户代理':ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
返回 html
4、json 解析页面数据,获取对应的字典。
数据 = json.loads(html)['主题']
#打印(数据[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
打印(名称,妖精赫夫)
html2 = self.get_page(goblin_herf) # 第二个请求发生
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建一个用于写入的csv文件
csv_file = open('scr.csv','a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题内容
csv_writerr.writerow(['电影','评级',"详细页面"])
#数据输入
csv_writer.writerow([id, rate, url])
7、图片地址提出请求。定义图片的名称并保存文档。
html2 = requests.get(url=url, headers=self.headers).content
目录名 = "./图片/" + id + ".jpg"
with open(dirname,'wb') as f:
f.write(html2)
print("%s [下载成功!!!]"% id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享之家 查看全部
文章采集调用(如何网页访问?豆瓣网教你如何获取真正请求的地址?(图))
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,Name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何访问网页?
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40
%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
导入请求,json
从 fake_useragent 导入 UserAgent
导入 csv
类多班(对象):
def __init__(self):
self.url = ";tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
定义主(自我):
经过
如果 __name__ =='__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
对于范围内的 i(1, 50):
self.headers = {
'用户代理':ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
返回 html
4、json 解析页面数据,获取对应的字典。
数据 = json.loads(html)['主题']
#打印(数据[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
打印(名称,妖精赫夫)
html2 = self.get_page(goblin_herf) # 第二个请求发生
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建一个用于写入的csv文件
csv_file = open('scr.csv','a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题内容
csv_writerr.writerow(['电影','评级',"详细页面"])
#数据输入
csv_writer.writerow([id, rate, url])
7、图片地址提出请求。定义图片的名称并保存文档。
html2 = requests.get(url=url, headers=self.headers).content
目录名 = "./图片/" + id + ".jpg"
with open(dirname,'wb') as f:
f.write(html2)
print("%s [下载成功!!!]"% id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享之家
文章采集调用(WordPress每页文章固定内容的侧边栏看多了很枯燥,怎么添加侧边栏?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-08 06:24
WordPress
在文章的每一页上看到太多固定内容侧边栏很无聊。如何添加侧边栏并使每个 文章 调用不同的侧边栏?本文文章不需要任何基础,按照我的方法一步步完成即可。原因自然是不同的侧边栏可以让用户体验和SEO效果更好。
一、添加侧边栏
参考资料:
如何在wordpress中添加侧边栏并不只是上传代码那么简单,为了方便,放在wp的后台部分是更好的选择。说一下流程
首先我们找到主题的functions.php文件,打开编辑functions.php,找到侧边栏的代码,直接复制。
function twentysixteen_widgets_init() {
register_sidebar( array(
'name' => __( 'Sidebar', 'twentysixteen' ),
'id' => 'sidebar-1',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
}
说说基本参数:
我们只需要参考原创代码进行更改以用于特定用途。例如,我在 now 之后添加了一个段落
register_sidebar( array(
'name' => __( 'Sidebar4', 'twentysixteen' ),
'id' => 'sidebar-4',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
这时候打开小工具,发现后面有一个侧边栏,叫做sidebar4。您可以添加您想要的侧边栏效果工具。
如下图,我添加了三个“文章Measure column 1,文章Measure column 2,文章Measure column 3”。
注意这里id的区别
保存后返回wp背景的widget选项。打开后,我们发现页面上多了三个新的侧边栏。
二、如何让文章调用侧边栏
参考资料:
%e4%b8%8d%e5%90%8c%e6%96%87%e7%ab%a0%e6%98%be%e7%a4%ba%e4%b8%8d%e5%90%8c%e7 %9a%84%e4%be%a7%e8%be%b9%e6%a0%8f.html
首先是添加文章需要绑定的代码文件。
主题根目录对应新建三个文件,如下图所示。
以第一个文件为例,我这里的名字是side1.php
内容是:
修改functions.php文件和side1.php文件后。
如何将 文章 绑定到侧边栏?使用自定义字段是一个不错的选择。具体使用方法是打开文章编辑界面的显示选项,然后输入参数和数值。
要使自定义字段起作用,您必须首先使 文章 能够识别自定义字段的作用。我们编辑 single.php 文件。找到 get_sidebar() 函数:
替换为:
更新后,文章会根据我们输入的自定义字段的值改变侧边栏。我在这里输入:
对应我刚刚测试的文件名。最后更新文章后,发现侧边栏变成了我们刚刚添加的侧边栏sid1的侧边栏。
ps:注意标点符号,容易出错。我花了很长时间才发现。
如果文章图片、下载链接等信息有误,请在评论区留言,博主会第一时间更新!如果喜欢,请打赏支持本站,谢谢大家! 查看全部
文章采集调用(WordPress每页文章固定内容的侧边栏看多了很枯燥,怎么添加侧边栏?)
WordPress
在文章的每一页上看到太多固定内容侧边栏很无聊。如何添加侧边栏并使每个 文章 调用不同的侧边栏?本文文章不需要任何基础,按照我的方法一步步完成即可。原因自然是不同的侧边栏可以让用户体验和SEO效果更好。
一、添加侧边栏
参考资料:
如何在wordpress中添加侧边栏并不只是上传代码那么简单,为了方便,放在wp的后台部分是更好的选择。说一下流程
首先我们找到主题的functions.php文件,打开编辑functions.php,找到侧边栏的代码,直接复制。
function twentysixteen_widgets_init() {
register_sidebar( array(
'name' => __( 'Sidebar', 'twentysixteen' ),
'id' => 'sidebar-1',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
}
说说基本参数:
我们只需要参考原创代码进行更改以用于特定用途。例如,我在 now 之后添加了一个段落
register_sidebar( array(
'name' => __( 'Sidebar4', 'twentysixteen' ),
'id' => 'sidebar-4',
'description' => __( 'Add widgets here to appear in your sidebar.', 'twentysixteen' ),
'before_widget' => '',
'after_widget' => '',
'before_title' => '',
'after_title' => '',
) );
这时候打开小工具,发现后面有一个侧边栏,叫做sidebar4。您可以添加您想要的侧边栏效果工具。
如下图,我添加了三个“文章Measure column 1,文章Measure column 2,文章Measure column 3”。
注意这里id的区别
保存后返回wp背景的widget选项。打开后,我们发现页面上多了三个新的侧边栏。
二、如何让文章调用侧边栏
参考资料:
%e4%b8%8d%e5%90%8c%e6%96%87%e7%ab%a0%e6%98%be%e7%a4%ba%e4%b8%8d%e5%90%8c%e7 %9a%84%e4%be%a7%e8%be%b9%e6%a0%8f.html
首先是添加文章需要绑定的代码文件。
主题根目录对应新建三个文件,如下图所示。
以第一个文件为例,我这里的名字是side1.php
内容是:
修改functions.php文件和side1.php文件后。
如何将 文章 绑定到侧边栏?使用自定义字段是一个不错的选择。具体使用方法是打开文章编辑界面的显示选项,然后输入参数和数值。
要使自定义字段起作用,您必须首先使 文章 能够识别自定义字段的作用。我们编辑 single.php 文件。找到 get_sidebar() 函数:
替换为:
更新后,文章会根据我们输入的自定义字段的值改变侧边栏。我在这里输入:
对应我刚刚测试的文件名。最后更新文章后,发现侧边栏变成了我们刚刚添加的侧边栏sid1的侧边栏。
ps:注意标点符号,容易出错。我花了很长时间才发现。
如果文章图片、下载链接等信息有误,请在评论区留言,博主会第一时间更新!如果喜欢,请打赏支持本站,谢谢大家!

