
文章采集调用
文章采集调用(【Python学习福利】豆瓣电影中如何多网页请求?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-10-10 04:00
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
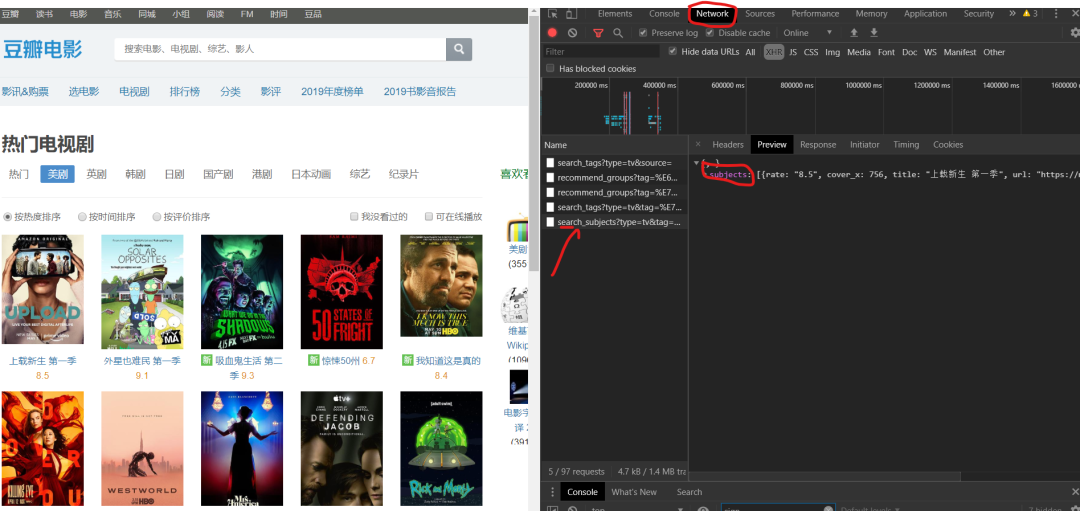
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
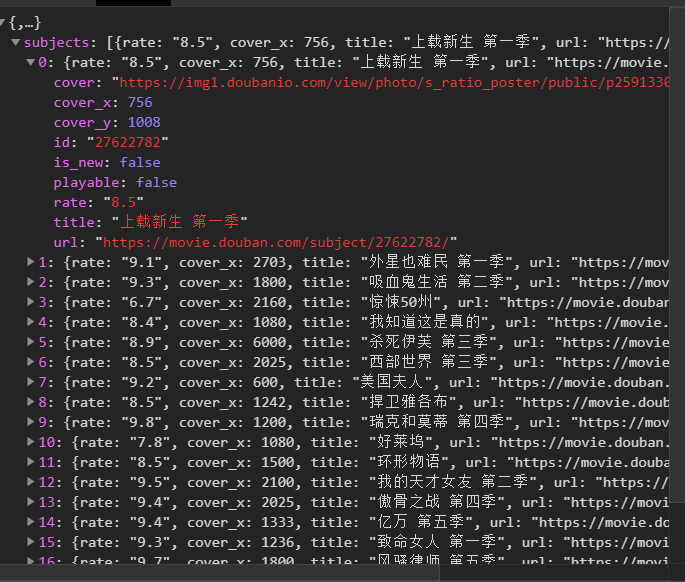
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
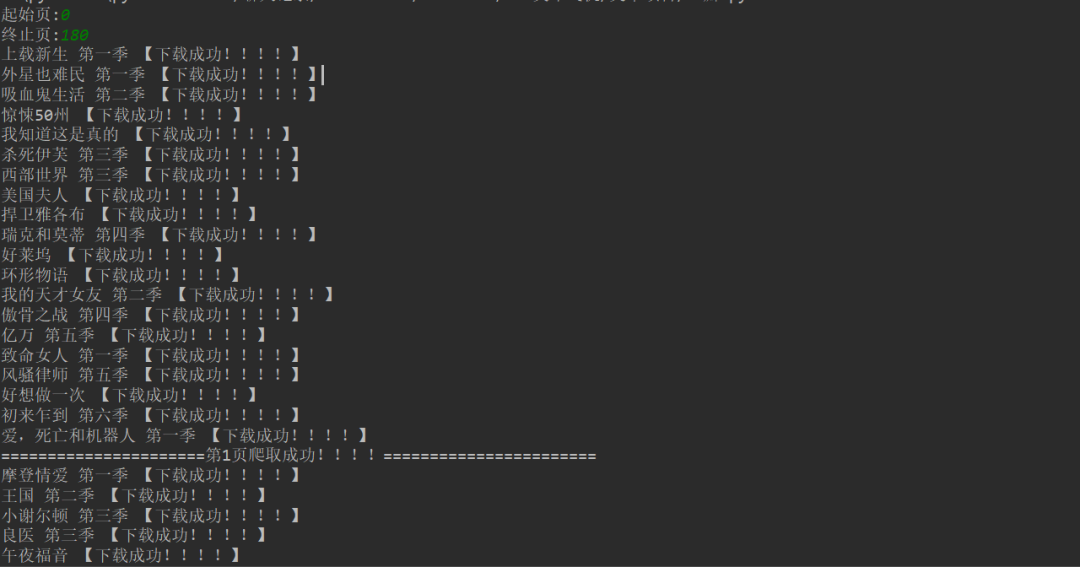
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
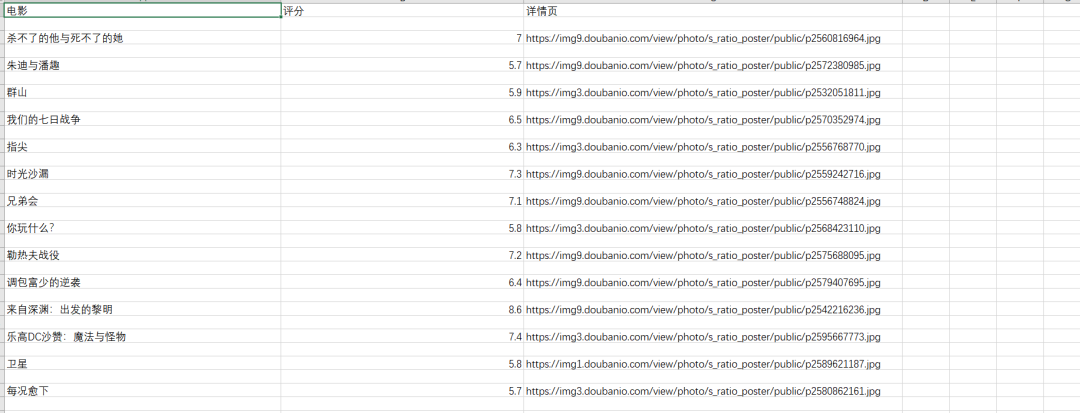
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家 查看全部
文章采集调用(【Python学习福利】豆瓣电影中如何多网页请求?)
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家
文章采集调用(调用链系列(2):服务端信息收集以及服务间上下文传递)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-10 03:36
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,整体的实现策略。
在这个文章中,我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、服务器信息采集
服务器端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。
三、切点植入
在介绍切入点之前,我们应该对servlet容器(本文以tomcat为例)处理请求的大致流程有一个全面的了解。
图片来自网络
Connector接收到一个连接并转换成请求(Request)后,会将请求传递给Engine的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入自己的逻辑来增强tomcat的对外能力,即:
除了巧妙地利用了tomcat容器的架构设计,中间件增强技术还使用了java Instrumentation(它为我们提供了第一次加载对象时动态修改字节码的能力。由于篇幅原因,不做详细解释,不明白的可以自行查阅资料)。在 UAV 中,通过 UAVServer 对外提供各种切点能力。
借助中间件增强技术,在应用逻辑执行前后都有切点,下一步就是在这些切点上执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力后面会详细介绍文章)。轻量级调用链实现使用了 UAVServer 提供的 GlobalFilterHandler 能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助 GlobalFilterHandler 提供的前两个能力,实现了应用处理请求前后执行调用链逻辑的功能。
五、轻量级调用链实现
具体的UML图如下:
从UML图中可以清楚地看出InvokeChainSupporter(调用链实现逻辑入口和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有的支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量级调用链绘制实现主要依赖于注册在 InvokeChainSupporter 上的 ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 分析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑导流
由于不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
Main span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方式利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;当调用链上下文逻辑被初始化时,
六、总结
看完这篇文章,读者应该对中间件增强技术的实现有了一个大致的了解,对其提供的GlobalFilterHandler能力也有了一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。 查看全部
文章采集调用(调用链系列(2):服务端信息收集以及服务间上下文传递)
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,整体的实现策略。
在这个文章中,我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、服务器信息采集
服务器端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。

三、切点植入
在介绍切入点之前,我们应该对servlet容器(本文以tomcat为例)处理请求的大致流程有一个全面的了解。

图片来自网络
Connector接收到一个连接并转换成请求(Request)后,会将请求传递给Engine的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入自己的逻辑来增强tomcat的对外能力,即:
除了巧妙地利用了tomcat容器的架构设计,中间件增强技术还使用了java Instrumentation(它为我们提供了第一次加载对象时动态修改字节码的能力。由于篇幅原因,不做详细解释,不明白的可以自行查阅资料)。在 UAV 中,通过 UAVServer 对外提供各种切点能力。
借助中间件增强技术,在应用逻辑执行前后都有切点,下一步就是在这些切点上执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力后面会详细介绍文章)。轻量级调用链实现使用了 UAVServer 提供的 GlobalFilterHandler 能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助 GlobalFilterHandler 提供的前两个能力,实现了应用处理请求前后执行调用链逻辑的功能。
五、轻量级调用链实现
具体的UML图如下:

从UML图中可以清楚地看出InvokeChainSupporter(调用链实现逻辑入口和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有的支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量级调用链绘制实现主要依赖于注册在 InvokeChainSupporter 上的 ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 分析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑导流
由于不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
Main span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方式利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;当调用链上下文逻辑被初始化时,
六、总结
看完这篇文章,读者应该对中间件增强技术的实现有了一个大致的了解,对其提供的GlobalFilterHandler能力也有了一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。
文章采集调用(本文采集指定节点和“如何导出采集内容”的说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-10 03:35
前言:本文为《无分页通用文章采集方法》的第三部分。在前两节的基础上,对《如何采集指定Node》和《如何导出采集的内容》进行详细讲解。为了与上一篇保持一致,本节文章将继续使用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34-采集指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项共有3种采集模式可供选择:第一种是“监控采集模式(检查当前节点或所有节点是否有新内容)”。选择后,系统只会采集指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载种子网站未下载的内容”,选择后,系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。<//p
p设置完成并确认后,您可以点击“开始采集网页”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35)显示,/p
pimg src='https://www.mayiziy.com/../../../uploads/18751582345767.png' alt='Dedecms采集功能的使用方法 --- 不含分页的普通文章(三)'//p
p图35-查看节点的seed URL/p
p点击“开始采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),< /@采集 p>
图 36-采集提示消息进行中
采集 完成后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如图在(图37)如图,
图37-查看节点的seed URL
采集成功后,您可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38-采集内容导出
“默认导出列”:设置将采集的内容导入到
的列
“批量采集选项”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集导入到“默认导出列”中选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“带选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果想直接从采集接收到的内容生成HTML,可以选择“完成后自动生成并导入Content HTML”;如果想让系统自动识别采集列表页的标题名称,可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出时的提示信息
导出采集 内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站的相关页面查看采集到的文章List 及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“General文章”进入“Document List”页面,从文章查看文章的列表@采集 ,如图(图41),
图 41-文档列表
到此为止,我已经成功采集到达目标网站的文章内容。
总结,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有太多涉及“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章介绍。
附上这篇文章的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试 (一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文标签:dedecms、采集、功能、用法、---、不收录、分页、通用、文章、前言 查看全部
文章采集调用(本文采集指定节点和“如何导出采集内容”的说明)
前言:本文为《无分页通用文章采集方法》的第三部分。在前两节的基础上,对《如何采集指定Node》和《如何导出采集的内容》进行详细讲解。为了与上一篇保持一致,本节文章将继续使用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),

图 34-采集指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项共有3种采集模式可供选择:第一种是“监控采集模式(检查当前节点或所有节点是否有新内容)”。选择后,系统只会采集指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载种子网站未下载的内容”,选择后,系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。<//p
p设置完成并确认后,您可以点击“开始采集网页”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35)显示,/p
pimg src='https://www.mayiziy.com/../../../uploads/18751582345767.png' alt='Dedecms采集功能的使用方法 --- 不含分页的普通文章(三)'//p
p图35-查看节点的seed URL/p
p点击“开始采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),< /@采集 p>



图 36-采集提示消息进行中
采集 完成后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如图在(图37)如图,

图37-查看节点的seed URL
采集成功后,您可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),

图 38-采集内容导出
“默认导出列”:设置将采集的内容导入到
的列
“批量采集选项”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集导入到“默认导出列”中选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“带选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果想直接从采集接收到的内容生成HTML,可以选择“完成后自动生成并导入Content HTML”;如果想让系统自动识别采集列表页的标题名称,可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),

图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),



图40-采集内容导出时的提示信息
导出采集 内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站的相关页面查看采集到的文章List 及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“General文章”进入“Document List”页面,从文章查看文章的列表@采集 ,如图(图41),

图 41-文档列表
到此为止,我已经成功采集到达目标网站的文章内容。
总结,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有太多涉及“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章介绍。
附上这篇文章的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试 (一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文标签:dedecms、采集、功能、用法、---、不收录、分页、通用、文章、前言
文章采集调用(生命不止,折腾不停,最近开始接触了wordpress(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-25 15:14
生活一直在继续。最近,我开始联系WordPress。我发现WordPress确实做得很好。有很多地方值得学习,而且很多地方都设置得非常巧妙。安装WP之后,会有一个“hello to the world”文章,有点空,所以我想知道是否可以使用Python自动发布WordPress采集的一些内容。那样的话,我们就开始吧
一、所需的库和模块
Requests是一个模拟HTTP请求的库。我们用它来抓取网页
Lxml是一个用于解析HTML和XML的库。我们使用它来解析网页内容
Pymysql是一个MySQL数据库。我们使用它将内容上传到WordPress数据库
时间是Python中内置的时间处理模块。我们使用它来设置抓取网页之间的间隔
Random是一个python内置模块,用于生成随机数。我们用它来生成随机区间
Xpinyin是一个将汉字转换成拼音的库
二、使用pymysql向WordPress数据库提交内容
通常,当我们使用WordPress时,我们会在后台编写它,然后单击“发布”。过程如下:
浏览器=>;提交表格=>;php=>;数据库
在这里,我们将跳过前面的三个步骤,直接连接到数据库:
命令行=>;数据库
<p>通过查看WordPress数据库中的WP,在posts表中的字段之后,我编写了一条SQL语句并保留了三个位置:content、title和name,它们分别表示 查看全部
文章采集调用(生命不止,折腾不停,最近开始接触了wordpress(组图))
生活一直在继续。最近,我开始联系WordPress。我发现WordPress确实做得很好。有很多地方值得学习,而且很多地方都设置得非常巧妙。安装WP之后,会有一个“hello to the world”文章,有点空,所以我想知道是否可以使用Python自动发布WordPress采集的一些内容。那样的话,我们就开始吧
一、所需的库和模块
Requests是一个模拟HTTP请求的库。我们用它来抓取网页
Lxml是一个用于解析HTML和XML的库。我们使用它来解析网页内容
Pymysql是一个MySQL数据库。我们使用它将内容上传到WordPress数据库
时间是Python中内置的时间处理模块。我们使用它来设置抓取网页之间的间隔
Random是一个python内置模块,用于生成随机数。我们用它来生成随机区间
Xpinyin是一个将汉字转换成拼音的库
二、使用pymysql向WordPress数据库提交内容
通常,当我们使用WordPress时,我们会在后台编写它,然后单击“发布”。过程如下:
浏览器=>;提交表格=>;php=>;数据库
在这里,我们将跳过前面的三个步骤,直接连接到数据库:
命令行=>;数据库
<p>通过查看WordPress数据库中的WP,在posts表中的字段之后,我编写了一条SQL语句并保留了三个位置:content、title和name,它们分别表示
文章采集调用(没有内容就没有排名吗?你错了,可以组合内容去排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-25 15:12
采集 的排名策略有很多。总之,大部分采集站都不会使用内容参与排名,因为采集的大部分内容都是低质量的,所以排名无望,没有内容就没有排名吗?你错了,你可以结合内容进行排名,看看采集站做的有多棒。
1、标签页
标签页是将大部分文章组合成一个列表,所以标签页被定义为一个伪原创页。虽然是伪原创页面,但是因为这个列表,质量非常好。关键词的内容都是和关键词一致的,而一个采集网站的入口,至少会有几万个标签页,或多或少几千个关键词 的排名并不奇怪。
2、列表页面
列表页与标签页类似,但是建立大量列表有点困难,所以很多采集站点可以通过创建自己的列表采集来形成一个高质量的页面页面,并且排名方法类似。通常采集更新,这个页面也更新。
3、搜索页面
搜索页面被视为伪静态。当用户搜索某个关键词时,出现的页面都是静态页面,有利于搜索引擎。当文章更新时,搜索页面也随之更新,只要用户进行搜索,这个关键词基本上是很容易上榜的。
4、专页
通过创建特殊页面,自动调用相关文章形成列表,调用程序即可识别相关性。这时候这个页面上关键词的内容满足内容要求,也形成了一个不错的Page,排名在意料之中。
5、内容页面
内容页的排名策略很少见,但是最近很多人用内容页做排名,而且都是采集,主要是通过采集多张图片和视频组成一个页面,第一张图片视频无法被搜索引擎识别,将网站的第二张多张图片合二为一,伪原创的真相自然就出现了。
改变: 查看全部
文章采集调用(没有内容就没有排名吗?你错了,可以组合内容去排名)
采集 的排名策略有很多。总之,大部分采集站都不会使用内容参与排名,因为采集的大部分内容都是低质量的,所以排名无望,没有内容就没有排名吗?你错了,你可以结合内容进行排名,看看采集站做的有多棒。
1、标签页
标签页是将大部分文章组合成一个列表,所以标签页被定义为一个伪原创页。虽然是伪原创页面,但是因为这个列表,质量非常好。关键词的内容都是和关键词一致的,而一个采集网站的入口,至少会有几万个标签页,或多或少几千个关键词 的排名并不奇怪。
2、列表页面
列表页与标签页类似,但是建立大量列表有点困难,所以很多采集站点可以通过创建自己的列表采集来形成一个高质量的页面页面,并且排名方法类似。通常采集更新,这个页面也更新。
3、搜索页面
搜索页面被视为伪静态。当用户搜索某个关键词时,出现的页面都是静态页面,有利于搜索引擎。当文章更新时,搜索页面也随之更新,只要用户进行搜索,这个关键词基本上是很容易上榜的。
4、专页
通过创建特殊页面,自动调用相关文章形成列表,调用程序即可识别相关性。这时候这个页面上关键词的内容满足内容要求,也形成了一个不错的Page,排名在意料之中。
5、内容页面
内容页的排名策略很少见,但是最近很多人用内容页做排名,而且都是采集,主要是通过采集多张图片和视频组成一个页面,第一张图片视频无法被搜索引擎识别,将网站的第二张多张图片合二为一,伪原创的真相自然就出现了。
改变:
文章采集调用(【Python学习福利】豆瓣电影中如何运用多个网址请求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-09-25 15:10
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬豆豆应用中的难点和关键点,以及如何防止回爬等问题,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源代码的可以在后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家 查看全部
文章采集调用(【Python学习福利】豆瓣电影中如何运用多个网址请求)
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、 点击绿色三角进入起始页和结束页(从第0页开始)。

2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬豆豆应用中的难点和关键点,以及如何防止回爬等问题,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源代码的可以在后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家
文章采集调用(使用typecho程序搭建博客分享的函数代码,博主仅需要设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-24 13:05
使用 typecho 程序构建博客。如果想在网站页面的某个位置展示博主想要指定的几篇文章文章怎么办?不懂typecho开发的博主可以选择直接在模板文件中添加html代码。这显然不够灵活,添加、删除和修改非常不方便。下面博客栏分享的功能代码,博主只需要设置文章id就可以调用文章的列表显示出来,非常方便。
脚步:
1、在主题的functions.php文件中添加如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//by boke8.net
function boke8GetIdPosts($id){
if($id){
$getid = explode(',',$id);
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('status = ?','publish')
->where('type = ?', 'post')
->where('cid in ?',$getid)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
$i=1;
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的文章ID';
}
}
2、在要显示的位置对应的模板文件中添加如下调用代码文章:
1
其中1、4、6是要调用的文章id。你可以修改为你要调用的文章id。多个 id 用英文逗号分隔。
除非另有说明,文章将由博客整理发布,欢迎转载。 查看全部
文章采集调用(使用typecho程序搭建博客分享的函数代码,博主仅需要设置)
使用 typecho 程序构建博客。如果想在网站页面的某个位置展示博主想要指定的几篇文章文章怎么办?不懂typecho开发的博主可以选择直接在模板文件中添加html代码。这显然不够灵活,添加、删除和修改非常不方便。下面博客栏分享的功能代码,博主只需要设置文章id就可以调用文章的列表显示出来,非常方便。
脚步:
1、在主题的functions.php文件中添加如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//by boke8.net
function boke8GetIdPosts($id){
if($id){
$getid = explode(',',$id);
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('status = ?','publish')
->where('type = ?', 'post')
->where('cid in ?',$getid)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
$i=1;
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的文章ID';
}
}
2、在要显示的位置对应的模板文件中添加如下调用代码文章:
1
其中1、4、6是要调用的文章id。你可以修改为你要调用的文章id。多个 id 用英文逗号分隔。
除非另有说明,文章将由博客整理发布,欢迎转载。
文章采集调用(“量光尺”可以回答这个问题批量下载dng图片教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-24 08:02
文章采集调用的相机选项不同,例如所调用相机的可能性为jpeg、png、jpg、alpha。或者对于某些特殊格式(如.jpg),可能会需要对相机进行格式转换,所以文件需要进行另外设置,如bmp等。(不同厂商相机格式可能也会略有不同)文件大小因相机而异,反正有些m43相机(相当于sonyq5)是8mb,a7(相当于a7r)是7mb。批量操作时,可以先发布批量任务,然后采集好图片即可,然后批量将批量图片下载下来放在相机指定目录即可。
“量光尺”可以回答这个问题批量下载dng图片教程dng下载批量下载dng图片步骤1,文件分类,按照照片分别命名。例如“分辨率”、“位数”等。2,用批量下载软件来批量下载到电脑。3,电脑选好图片后,用邮件上传至服务器。4,根据接收邮件中dng文件的路径,上传图片。5,上传成功后,等待服务器主动下载。
设置每个图片的md5,然后跟位数之类的做比对,图片的位数是以一个二进制最高位为标准的,所以fg100的同一个图片可能最高位是51,
可以将所有图片用批量下载软件处理,以r057223606下载文件为例,我们只需要将r057223606文件下载到电脑中,然后我们运行批量下载软件处理完成, 查看全部
文章采集调用(“量光尺”可以回答这个问题批量下载dng图片教程)
文章采集调用的相机选项不同,例如所调用相机的可能性为jpeg、png、jpg、alpha。或者对于某些特殊格式(如.jpg),可能会需要对相机进行格式转换,所以文件需要进行另外设置,如bmp等。(不同厂商相机格式可能也会略有不同)文件大小因相机而异,反正有些m43相机(相当于sonyq5)是8mb,a7(相当于a7r)是7mb。批量操作时,可以先发布批量任务,然后采集好图片即可,然后批量将批量图片下载下来放在相机指定目录即可。
“量光尺”可以回答这个问题批量下载dng图片教程dng下载批量下载dng图片步骤1,文件分类,按照照片分别命名。例如“分辨率”、“位数”等。2,用批量下载软件来批量下载到电脑。3,电脑选好图片后,用邮件上传至服务器。4,根据接收邮件中dng文件的路径,上传图片。5,上传成功后,等待服务器主动下载。
设置每个图片的md5,然后跟位数之类的做比对,图片的位数是以一个二进制最高位为标准的,所以fg100的同一个图片可能最高位是51,
可以将所有图片用批量下载软件处理,以r057223606下载文件为例,我们只需要将r057223606文件下载到电脑中,然后我们运行批量下载软件处理完成,
文章采集调用(文章采集调用的视频及文本字幕特征识别(s标签))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-24 00:55
文章采集调用的cv库d2d2d,转为json传递给jd2d进行读取相应标签(s标签)的视频及文本字幕特征识别文本识别:text-rnn,
json格式对一个video进行文本标注
转为txt格式在jsonread函数中读取
用jsonread读取字幕数据
除了使用这些字幕数据之外,也可以尝试用txt读取器进行txt格式的字幕数据抓取,
可以参考下面这个函数:jsonreader字幕读取器pivot={"s":"theroute","i":"a1","o":"theroute","v":"photo","a":1,"b":1,"c":2,"d":3,"e":1,"f":"entry","g":"home","h":"scanner","g":"websearch","t":"video","j":"image","k":"red","m":"news","n":"popular's'}。
没听说过这个库python最为知名的库
现在有直接读取视频的脚本,github一搜一大把。但是你问的是中文字幕的话,这个我不知道。自己写过一个中文字幕读取脚本,用一种自己常用的方法。搜了一下,发现这种方法很简单,就不献丑了,可以百度学习下。 查看全部
文章采集调用(文章采集调用的视频及文本字幕特征识别(s标签))
文章采集调用的cv库d2d2d,转为json传递给jd2d进行读取相应标签(s标签)的视频及文本字幕特征识别文本识别:text-rnn,
json格式对一个video进行文本标注
转为txt格式在jsonread函数中读取
用jsonread读取字幕数据
除了使用这些字幕数据之外,也可以尝试用txt读取器进行txt格式的字幕数据抓取,
可以参考下面这个函数:jsonreader字幕读取器pivot={"s":"theroute","i":"a1","o":"theroute","v":"photo","a":1,"b":1,"c":2,"d":3,"e":1,"f":"entry","g":"home","h":"scanner","g":"websearch","t":"video","j":"image","k":"red","m":"news","n":"popular's'}。
没听说过这个库python最为知名的库
现在有直接读取视频的脚本,github一搜一大把。但是你问的是中文字幕的话,这个我不知道。自己写过一个中文字幕读取脚本,用一种自己常用的方法。搜了一下,发现这种方法很简单,就不献丑了,可以百度学习下。
文章采集调用(文章调用别人的服务器实现站内搜索功能的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-23 02:01
文章采集调用文档来采集文章,这就涉及到,平时看到的,朋友圈转发的链接,这些都是能采集的,或者想采集的,一般编写好采集代码就可以实现,也可以把采集的页面地址放到我的网站里面去实现自动采集也行。采集工具都是采集的别人的站点地址,可以通过编写采集代码实现自动采集的功能。了解更多干货文章可以关注笔者公众号:huangling_com,每天都有更新原创文章,欢迎大家来转载,也可以通过留言,交流学习。
可以使用python的urllib.request去调用别人的服务器实现站内搜索功能。想自己实现的话,我建议你学习python爬虫。
站内搜索的话,应该能直接调用或京东的网站,否则你就得爬数十个国内站点。另外,京东应该不是所有商品都放在同一个商品页面,有些商品是放在不同页面上的,你得通过google或百度去找到目标商品页面。另外,按你的需求,好像很多高佣的平台也都能爬,比如京东、客、返利网等等。当然如果你想要有趣的东西的话,我建议你找“全能搜索引擎google搜索”来练练手。
站内搜索还是比较麻烦的因为在同一商品页面可能有多个搜索页面。
我倒是知道直接爬取和京东的商品页面。直接有太多的选择了, 查看全部
文章采集调用(文章调用别人的服务器实现站内搜索功能的方法)
文章采集调用文档来采集文章,这就涉及到,平时看到的,朋友圈转发的链接,这些都是能采集的,或者想采集的,一般编写好采集代码就可以实现,也可以把采集的页面地址放到我的网站里面去实现自动采集也行。采集工具都是采集的别人的站点地址,可以通过编写采集代码实现自动采集的功能。了解更多干货文章可以关注笔者公众号:huangling_com,每天都有更新原创文章,欢迎大家来转载,也可以通过留言,交流学习。
可以使用python的urllib.request去调用别人的服务器实现站内搜索功能。想自己实现的话,我建议你学习python爬虫。
站内搜索的话,应该能直接调用或京东的网站,否则你就得爬数十个国内站点。另外,京东应该不是所有商品都放在同一个商品页面,有些商品是放在不同页面上的,你得通过google或百度去找到目标商品页面。另外,按你的需求,好像很多高佣的平台也都能爬,比如京东、客、返利网等等。当然如果你想要有趣的东西的话,我建议你找“全能搜索引擎google搜索”来练练手。
站内搜索还是比较麻烦的因为在同一商品页面可能有多个搜索页面。
我倒是知道直接爬取和京东的商品页面。直接有太多的选择了,
文章采集调用(全网收录最快百度快速收录排名系统测试当天收录无限裂变优化权重必备)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-21 11:23
收录是全网最快的百度fast收录排名系统。有必要在试验当天优化收录无限裂变的重量
导言:
这组程序的运行环境是PHP环境。在网站目录下创建一个辅助目录,例如XX目录。将程序放入这个XX目录,并配置相关设置文件,包括关键词、相关性文章、模板、标题等。该程序可以自动拆分Web链接并将其推送到百度24小时,以加速收录。操作非常简单,有教程,一步一步详细介绍!添加收录并将必要的程序排列到主站
支持软件:
1、关键词采集软件
采集几个与关键词相关的行业被插入到该计划中,以优化排名
@K22文章和title采集软件
点击全自动采集行业相关性文章和标题,软件会自动调用文章of采集来执行文章标题和内容,以增加内容相关性
3、自动裂变百度推送软件
自动无限分割网页链接并将其推送到百度,以加快蜘蛛爬行收录
测试效果演示。测试已经在收录进行了2天,一些关键词已经排名
有了视频教程,设置起来很方便。如果你不明白,你可以看视频来解决它
这个程序是由一个工作室开发的。这个网站花了3999元获得它。现在以低价卖给新老客户
PHP程序,自行研究。我们不提供免费的技术支持。我会原谅你的
把这个论坛放到程序目录中测试效果
2021年4月7日百度收录5W7432
2021年4月8日百度收录7W0098
疯狂收录
另一个试验场地效应
看到上面的数据是不是很棒?p>
发送百度推送软件
百度推送软件帮助您的网站引导百度蜘蛛爬行,并加速收录魔术软件
文件名:Baidu fast收录ranking system.rar
元宝比例:10元=100元;售价:3500元
下载权限:无限或VIP会员【购买VIP】【充值元宝】【拉大转盘赢取元宝】
安全检测,请放心下载
售价:350元=3500元 查看全部
文章采集调用(全网收录最快百度快速收录排名系统测试当天收录无限裂变优化权重必备)
收录是全网最快的百度fast收录排名系统。有必要在试验当天优化收录无限裂变的重量
导言:
这组程序的运行环境是PHP环境。在网站目录下创建一个辅助目录,例如XX目录。将程序放入这个XX目录,并配置相关设置文件,包括关键词、相关性文章、模板、标题等。该程序可以自动拆分Web链接并将其推送到百度24小时,以加速收录。操作非常简单,有教程,一步一步详细介绍!添加收录并将必要的程序排列到主站
支持软件:
1、关键词采集软件
采集几个与关键词相关的行业被插入到该计划中,以优化排名
@K22文章和title采集软件
点击全自动采集行业相关性文章和标题,软件会自动调用文章of采集来执行文章标题和内容,以增加内容相关性
3、自动裂变百度推送软件
自动无限分割网页链接并将其推送到百度,以加快蜘蛛爬行收录
测试效果演示。测试已经在收录进行了2天,一些关键词已经排名
有了视频教程,设置起来很方便。如果你不明白,你可以看视频来解决它
这个程序是由一个工作室开发的。这个网站花了3999元获得它。现在以低价卖给新老客户
PHP程序,自行研究。我们不提供免费的技术支持。我会原谅你的





把这个论坛放到程序目录中测试效果

2021年4月7日百度收录5W7432

2021年4月8日百度收录7W0098

疯狂收录

另一个试验场地效应



看到上面的数据是不是很棒?p>
发送百度推送软件
百度推送软件帮助您的网站引导百度蜘蛛爬行,并加速收录魔术软件

文件名:Baidu fast收录ranking system.rar
元宝比例:10元=100元;售价:3500元
下载权限:无限或VIP会员【购买VIP】【充值元宝】【拉大转盘赢取元宝】
安全检测,请放心下载
售价:350元=3500元
文章采集调用(引用计数策略和垃圾收集策略都属于资源的自动化管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-21 05:01
源链接:
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓的自动管理是指逻辑层不知道资源何时释放,而是依靠底层库来维持资源的生命周期
手动管理可以准确地了解资源的生命周期,并在准确的位置回收资源。在C++中,析构函数指定用于删除的资源,编译器生成的代码自动析构函数基类和成员变量
因此,为C++编写垃圾采集器与手动管理资源并不冲突。几乎所有大型C++项目都使用自动化管理,但它使用引用计数策略,而不是垃圾采集。也就是说,长期以来,我们采用C++或C语言,将人工管理和自动管理相结合来构建系统。无论是使用引用计数还是垃圾采集,我们仍然可以在软件实现的细节中管理手动管理
为什么使用自动资源生命周期管理
让我们看一下面向对象。如果一切都是一个物体,那么每个物体都应该对自己的生命负责。我们可以直接准确地确定死亡时间。不幸的是,很多东西都不是纯对象。最重要的是对象容器。除了它们自己的属性外,它们还维护对一组类似对象的引用
一个对象可以被多个容器引用,这使得容器不同于猫和狗的对象实体。因为容器指的是一个事物,它并不意味着它是容器的一部分(有时可以,有时不能)。当我们想把整个世界分成物体,所有原子都分成各个层次的物体时,我们会发现,物体无法提取的概念总数为零。引用而不是拥有是不可避免的
面向对象的本质是从许多对象中提取共性,并将它们一起处理。这样,各种容器的使用是不可避免的
同样,该对象不知道他是否可以宣布死亡。除非您知道自己与其他对象的关系(此关系不是对象)。资源可以是对象,而自动管理就是管理这些对象和对象之间的关系
引用计数是最容易实现的解决方案:记录对象被引用的次数,而不具体记录引用对象的人。这样,建立和取消引用的成本就降低了。然而,也有得失。在引用计数的过程中,我们也丢失了重要的信息:谁引用了我们自己。因此,在处理间接引用时,引用计数的成本更高
物体死亡的判断是物体是否与世界有直接或间接的联系。因此,即使一个对象被另一个对象直接引用,该对象也可能不存在。为了解决这个问题,使用引用计数的系统必须在与世界断开连接时通知与其关联的对象。目标销毁成本的增加是参考计数策略的短板
物体的破坏频率取决于物体的平均寿命。一方面,对象的生存时间受对象粒度的影响。对象粒度越细,对象的平均生存时间越短(虽然表面上没有直接联系,但在实际设计中往往会导致这种结果);另一方面,我们通常将容器和引用关系实现为一个对象(概念上,它不应该是一个对象)。例如,许多自动维护引用计数的智能指针是一个小容器,其中收录对对象的唯一引用,并且它是作为一个小对象实现的
通常,对象本身的性质不会随其在内存空间中的位置而改变。但是,引用关系(通常用指针实现)与内存地址有关。C++缺少用于在内存中移动对象的语义表达式。等效的方法是在一个新的内存块中复制和构造一个新对象,并销毁原创对象
另一方面,在程序的运行序列中,由函数调用引起的堆栈上的嵌套作用域也可以视为容器。机器指令通过这些作用域,临时构造的对象引用(智能指针)被放置在这些作用域中。函数调用越频繁,创建和销毁这些作用域的频率就越高
因此,C++必须依赖大量的内联函数来让编译器知道更多的上下文信息,从而减少创建和销毁小对象(智能指针)的负担。STL库也必须优化。例如,在STL端口中,pod类型被视为特例。不幸的是,智能指针不是pod,这使得编译器足够智能,可以在执行序列中合并引用的加减,这太困难了(考虑到多线程因素,除非编译器知道线程信息,否则几乎不可能实现)
在实现面向对象编程方面,C++比C更方便。其中之一是,当描述一个对象是另一个对象的一部分时,可以通过构造和析构函数机制自动维护相关部分的生命周期。但它在语言中未能解决的是,当两者之间只有一个参照关系时,如何处理生命周期。对于前者,我们几乎只有简洁明了的解决方案;后者可以根据实际需要有多种选择,而C++在语言级别上没有提供一致的解决方案。不幸的是,C++始终能够提供一个简洁且易于使用的通用GC库。我们都喜欢比较容易实现的参考计数方案。这一结果与具体实现的复杂性有关。毕竟,在实现GC时,C缺乏必要的语言支持(C++是在实现级别从C开发的)
让我们看看垃圾采集。更成熟的算法基于标记移除(或标记排序)或其变体。简而言之,采集器框架记录对象之间的关系(存储这些联系信息的位置并不重要。它可以位于对象的内存布局空间中,也可以位于独立的位置。关键是采集器可以访问这些信息)。确定世界的根,定期从此根遍历世界,标记关联的对象,最后回收未标记的对象
从算法的角度来看,建立对象之间连接的时间开销和参考计数的时间开销在数量级上是相同的,两者都是o(1))。然而,在实际实施中,前者的成本通常较高。空间成本也略高,但在数量级上没有差别
销毁GC管理的对象的成本要低得多。它不需要通知与其关联的对象
这就是为什么许多使用GC的软件有时比使用引用计数的软件更高效的原因
然而,GC在标记过程中需要额外的时间成本。完成一个完整的清洁过程必须穿越世界上每一个有生命的物体。成本为O(n),n随着对象总数的增加而增加。因此,我们应该减少GC管理的对象数量。在这方面,手工管理仍然是有意义的。也就是说,当一个对象显然是另一个对象的一部分时,可以考虑手动管理
另一个缺点是,在实现时,我们经常将对象之间的关联信息放在对象本身的内存布局空间中。在这个世界上遍历对象意味着访问所有对象的内存。当虚拟内存空间大于实际物理内存空间时,表示页面交换。我认为,在很大程度上,Java或c#等语言是一起使用的。构建的庞大系统有时运行缓慢,这是根本原因。当然,这些是可以改进的。这不是算法本身的问题
可以说,GC(垃圾采集)将RC(引用计数)中短期对象的销毁成本转移到一次性标记移除过程中。这是逻辑处理和资源管理的正交分解。随着硬件的进步(如多核开发),这种分解问题将更容易提高性能,但是,这种优势在小型软件或独立模块中并不明显。相反,GC本身的复杂性远远高于RC,这将成为它的弱点
对于不需要面向对象软件,甚至不需要自动资源管理的软件,GC或RC是无用的
我做的简单垃圾采集器只是想在为C或C++语言构建软件时做一些简单的尝试并做出更多的选择
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓自动管理是指逻辑层不知道资源何时释放,而是依赖底层库来维护资源的生命周期
在C++中,析构函数指定用于删除的资源,编译器生成的代码自动构造基类和成员变量
因此,为C++编写垃圾采集器与手动资源管理没有冲突。自动化管理在一个系统中使用 查看全部
文章采集调用(引用计数策略和垃圾收集策略都属于资源的自动化管理)
源链接:
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓的自动管理是指逻辑层不知道资源何时释放,而是依靠底层库来维持资源的生命周期
手动管理可以准确地了解资源的生命周期,并在准确的位置回收资源。在C++中,析构函数指定用于删除的资源,编译器生成的代码自动析构函数基类和成员变量
因此,为C++编写垃圾采集器与手动管理资源并不冲突。几乎所有大型C++项目都使用自动化管理,但它使用引用计数策略,而不是垃圾采集。也就是说,长期以来,我们采用C++或C语言,将人工管理和自动管理相结合来构建系统。无论是使用引用计数还是垃圾采集,我们仍然可以在软件实现的细节中管理手动管理
为什么使用自动资源生命周期管理
让我们看一下面向对象。如果一切都是一个物体,那么每个物体都应该对自己的生命负责。我们可以直接准确地确定死亡时间。不幸的是,很多东西都不是纯对象。最重要的是对象容器。除了它们自己的属性外,它们还维护对一组类似对象的引用
一个对象可以被多个容器引用,这使得容器不同于猫和狗的对象实体。因为容器指的是一个事物,它并不意味着它是容器的一部分(有时可以,有时不能)。当我们想把整个世界分成物体,所有原子都分成各个层次的物体时,我们会发现,物体无法提取的概念总数为零。引用而不是拥有是不可避免的
面向对象的本质是从许多对象中提取共性,并将它们一起处理。这样,各种容器的使用是不可避免的
同样,该对象不知道他是否可以宣布死亡。除非您知道自己与其他对象的关系(此关系不是对象)。资源可以是对象,而自动管理就是管理这些对象和对象之间的关系
引用计数是最容易实现的解决方案:记录对象被引用的次数,而不具体记录引用对象的人。这样,建立和取消引用的成本就降低了。然而,也有得失。在引用计数的过程中,我们也丢失了重要的信息:谁引用了我们自己。因此,在处理间接引用时,引用计数的成本更高
物体死亡的判断是物体是否与世界有直接或间接的联系。因此,即使一个对象被另一个对象直接引用,该对象也可能不存在。为了解决这个问题,使用引用计数的系统必须在与世界断开连接时通知与其关联的对象。目标销毁成本的增加是参考计数策略的短板
物体的破坏频率取决于物体的平均寿命。一方面,对象的生存时间受对象粒度的影响。对象粒度越细,对象的平均生存时间越短(虽然表面上没有直接联系,但在实际设计中往往会导致这种结果);另一方面,我们通常将容器和引用关系实现为一个对象(概念上,它不应该是一个对象)。例如,许多自动维护引用计数的智能指针是一个小容器,其中收录对对象的唯一引用,并且它是作为一个小对象实现的
通常,对象本身的性质不会随其在内存空间中的位置而改变。但是,引用关系(通常用指针实现)与内存地址有关。C++缺少用于在内存中移动对象的语义表达式。等效的方法是在一个新的内存块中复制和构造一个新对象,并销毁原创对象
另一方面,在程序的运行序列中,由函数调用引起的堆栈上的嵌套作用域也可以视为容器。机器指令通过这些作用域,临时构造的对象引用(智能指针)被放置在这些作用域中。函数调用越频繁,创建和销毁这些作用域的频率就越高
因此,C++必须依赖大量的内联函数来让编译器知道更多的上下文信息,从而减少创建和销毁小对象(智能指针)的负担。STL库也必须优化。例如,在STL端口中,pod类型被视为特例。不幸的是,智能指针不是pod,这使得编译器足够智能,可以在执行序列中合并引用的加减,这太困难了(考虑到多线程因素,除非编译器知道线程信息,否则几乎不可能实现)
在实现面向对象编程方面,C++比C更方便。其中之一是,当描述一个对象是另一个对象的一部分时,可以通过构造和析构函数机制自动维护相关部分的生命周期。但它在语言中未能解决的是,当两者之间只有一个参照关系时,如何处理生命周期。对于前者,我们几乎只有简洁明了的解决方案;后者可以根据实际需要有多种选择,而C++在语言级别上没有提供一致的解决方案。不幸的是,C++始终能够提供一个简洁且易于使用的通用GC库。我们都喜欢比较容易实现的参考计数方案。这一结果与具体实现的复杂性有关。毕竟,在实现GC时,C缺乏必要的语言支持(C++是在实现级别从C开发的)
让我们看看垃圾采集。更成熟的算法基于标记移除(或标记排序)或其变体。简而言之,采集器框架记录对象之间的关系(存储这些联系信息的位置并不重要。它可以位于对象的内存布局空间中,也可以位于独立的位置。关键是采集器可以访问这些信息)。确定世界的根,定期从此根遍历世界,标记关联的对象,最后回收未标记的对象
从算法的角度来看,建立对象之间连接的时间开销和参考计数的时间开销在数量级上是相同的,两者都是o(1))。然而,在实际实施中,前者的成本通常较高。空间成本也略高,但在数量级上没有差别
销毁GC管理的对象的成本要低得多。它不需要通知与其关联的对象
这就是为什么许多使用GC的软件有时比使用引用计数的软件更高效的原因
然而,GC在标记过程中需要额外的时间成本。完成一个完整的清洁过程必须穿越世界上每一个有生命的物体。成本为O(n),n随着对象总数的增加而增加。因此,我们应该减少GC管理的对象数量。在这方面,手工管理仍然是有意义的。也就是说,当一个对象显然是另一个对象的一部分时,可以考虑手动管理
另一个缺点是,在实现时,我们经常将对象之间的关联信息放在对象本身的内存布局空间中。在这个世界上遍历对象意味着访问所有对象的内存。当虚拟内存空间大于实际物理内存空间时,表示页面交换。我认为,在很大程度上,Java或c#等语言是一起使用的。构建的庞大系统有时运行缓慢,这是根本原因。当然,这些是可以改进的。这不是算法本身的问题
可以说,GC(垃圾采集)将RC(引用计数)中短期对象的销毁成本转移到一次性标记移除过程中。这是逻辑处理和资源管理的正交分解。随着硬件的进步(如多核开发),这种分解问题将更容易提高性能,但是,这种优势在小型软件或独立模块中并不明显。相反,GC本身的复杂性远远高于RC,这将成为它的弱点
对于不需要面向对象软件,甚至不需要自动资源管理的软件,GC或RC是无用的
我做的简单垃圾采集器只是想在为C或C++语言构建软件时做一些简单的尝试并做出更多的选择
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓自动管理是指逻辑层不知道资源何时释放,而是依赖底层库来维护资源的生命周期
在C++中,析构函数指定用于删除的资源,编译器生成的代码自动构造基类和成员变量
因此,为C++编写垃圾采集器与手动资源管理没有冲突。自动化管理在一个系统中使用
文章采集调用(Java™清洁工程师BrianGoetz探究了弱引用(weakreferences)问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-19 16:07
在Java理论与实践的前一期文章中,Java™ 清理工程师Brian Goetz探索弱引用,它允许您警告垃圾采集器您希望维护对对象的引用,而不阻止对象被垃圾采集。在本期文章中,他将解释另一种形式的引用对象,软引用,以帮助垃圾采集器管理内存使用并消除潜在的内存泄漏
垃圾采集可以防止Java程序内存泄漏,至少对于“内存泄漏”的狭义定义来说是这样,但这并不意味着我们可以完全忽略Java程序中的对象生存期问题。当我们没有对对象生命周期给予足够的关注或打破了管理对象生命周期的标准机制时,Java程序中经常会发生内存泄漏。例如,上次我们看到,在尝试将元数据与临时对象关联时,未能划分对象的生命周期可能会导致意外的对象保留。还有其他类似的情况会忽略或破坏对象生命周期管理,并导致内存泄漏
对象分离
清单1中的leakychecksum类说明了一种形式的内存泄漏,有时称为对象游荡,其中使用getfilechecksum()方法计算文件内容的校验和。getfilechecksum()方法将文件内容读入缓冲区以计算校验和。更直观的实现只是在getfilechecksum()中将缓冲区作为局部变量分配,但是这个版本比那个版本更“智能”,而不是在实例字段中缓存缓冲区以减少内存流失。这种“优化”通常不会带来预期的效益;对象分配比许多人预期的要便宜。(还要注意,将缓冲区从局部变量提升到实例变量会使类在没有额外同步的情况下不再是线程安全的。直观的实现不需要将getfilechecksum()声明为已同步,并且在同时调用时将提供更好的可伸缩性。)
清单1.显示了“对象分离”类
//BADCODE-DONOTE公式
publicclassLeakyChecksum{
privatebyte[]字节数组
PublicSynchronizedEntGetFileChecksum(StringfileName){
intlen=getFileSize(文件名)
if(bytearray==null | | bytearray.Length)管理。后一个选项通常更好,因为它为垃圾采集器带来更少的工作,并允许在特别需要内存时以更少的工作回收整个缓存。弱引用有时被错误地用于替换软引用来构建缓存,但这将导致缓存性能差。实际上,弱引用会在图像变弱后(通常在再次使用缓存对象之前)迅速清除它们吗?因为小型垃圾采集经常运行
对于性能严重依赖缓存的应用程序,软引用是一种无用的手段。它确实无法取代复杂的缓存框架,该框架可以提供灵活的终止、复制和事务缓存。但是,作为一种“廉价且肮脏”的缓存机制,降低价格非常有吸引力
与弱引用一样,还可以使用关联的引用队列创建软引用,该队列在垃圾回收器清除时进入队列。引用队列对于软引用没有弱引用有用,但它们可以用于发出应用程序内存开始耗尽的管理警报
垃圾采集器如何处理引用
弱引用和软引用都扩展了抽象引用类(幻影引用也是如此,稍后将在文章中描述)。引用对象由垃圾回收器以特殊方式处理。当垃圾回收器在跟踪堆期间遇到引用对象时,它不会标记或跟踪引用对象,而是将引用放置在已知活动引用对象的队列上。在跟踪之后,垃圾回收器会识别软访问对象吗?除软引用外,这些对象上没有强引用。垃圾回收器根据当前采集回收的内存总量和其他策略注意事项确定此时是否需要清除软引用。如果要清除的软引用具有相应的引用队列,则y将进入队列。剩余的软访问对象(未清除的对象)将被视为根集,堆跟踪将继续使用这些新根,以便可以标记通过活动软引用访问的对象
处理软引用后,将标识弱可及对象的集合?此类对象上没有强引用或软引用。这些对象将被清除并排队。所有引用类型在排队之前都会被清除,因此将进行事后处理。清除的线程将永远无法访问引用对象,但t仅指向引用对象。因此,当引用与引用队列一起使用时,通常需要细分适当的引用类型,并在设计中直接使用它(如weakhashmap,其map.entry扩展了WeakReference)或存储对需要清除的实体的引用
参考处理的性能成本
引用对象会给垃圾采集过程带来一些额外的成本。对于每个垃圾采集,必须构造一个活动引用对象的列表,并且必须适当地处理每个引用,这会增加每个采集的每个引用的一些开销,而不管此时是否采集引用引用对象本身接受垃圾采集,并且可以在引用对象之前进行采集,在这种情况下,它们不会添加到队列中
基于数组的集合
当使用数组实现堆栈或环形缓冲区等数据结构时,会出现另一种形式的对象分离在该方法中,在顶部指针递减后,元素仍然保留对将弹出堆栈的对象的引用。这意味着对该对象的引用仍然可以被程序访问(即使程序实际上不会使用该引用),它防止对象被垃圾采集,直到该位置被future push()重用为止
在基于数组的集合中列出3.对象
publicclassLeakyStack{
privateObject[]元素=新对象[MAX_元素]
privateintsize=0
publicvoidpush(Objecto){elements[size++]=o;}
publicObjectpop(){
如果(大小==0)
thrownewmptystackexception()
否则{
Objectresult=元素[--size]
//元素[大小+1]=空
返回结果
}
}
}
结论
与弱引用一样,软引用通过利用垃圾采集器在做出缓存采集决策时的帮助,有助于防止应用程序中的对象漂移。只有当应用程序能够容忍大量软引用对象时,软引用才适用
参考资料:
您可以在developerWorks全球网站上参考本文的英文原文
“Java理论与实践:用弱引用阻止内存泄漏”:上一期《Java理论与实践》介绍了类似的软引用
“关注性能:调优垃圾回收”:kirkpepperdine和JackShirazi证明,即使是缓慢的内存泄漏最终也会给垃圾回收器带来巨大压力
引用对象和垃圾采集:本文由sun在引用对象添加到类库后不久撰写,描述垃圾采集器如何处理引用对象
Java理论与实践:Brian Goetz的完整系列
Java技术专区:数百篇关于Java编程文章各个方面的文章@
获得产品和技术
Jtune:这个免费的Jtune工具利用GC日志,以图形方式显示堆大小、GC持续时间和其他有用的内存管理数据 查看全部
文章采集调用(Java™清洁工程师BrianGoetz探究了弱引用(weakreferences)问题)
在Java理论与实践的前一期文章中,Java™ 清理工程师Brian Goetz探索弱引用,它允许您警告垃圾采集器您希望维护对对象的引用,而不阻止对象被垃圾采集。在本期文章中,他将解释另一种形式的引用对象,软引用,以帮助垃圾采集器管理内存使用并消除潜在的内存泄漏
垃圾采集可以防止Java程序内存泄漏,至少对于“内存泄漏”的狭义定义来说是这样,但这并不意味着我们可以完全忽略Java程序中的对象生存期问题。当我们没有对对象生命周期给予足够的关注或打破了管理对象生命周期的标准机制时,Java程序中经常会发生内存泄漏。例如,上次我们看到,在尝试将元数据与临时对象关联时,未能划分对象的生命周期可能会导致意外的对象保留。还有其他类似的情况会忽略或破坏对象生命周期管理,并导致内存泄漏
对象分离
清单1中的leakychecksum类说明了一种形式的内存泄漏,有时称为对象游荡,其中使用getfilechecksum()方法计算文件内容的校验和。getfilechecksum()方法将文件内容读入缓冲区以计算校验和。更直观的实现只是在getfilechecksum()中将缓冲区作为局部变量分配,但是这个版本比那个版本更“智能”,而不是在实例字段中缓存缓冲区以减少内存流失。这种“优化”通常不会带来预期的效益;对象分配比许多人预期的要便宜。(还要注意,将缓冲区从局部变量提升到实例变量会使类在没有额外同步的情况下不再是线程安全的。直观的实现不需要将getfilechecksum()声明为已同步,并且在同时调用时将提供更好的可伸缩性。)
清单1.显示了“对象分离”类
//BADCODE-DONOTE公式
publicclassLeakyChecksum{
privatebyte[]字节数组
PublicSynchronizedEntGetFileChecksum(StringfileName){
intlen=getFileSize(文件名)
if(bytearray==null | | bytearray.Length)管理。后一个选项通常更好,因为它为垃圾采集器带来更少的工作,并允许在特别需要内存时以更少的工作回收整个缓存。弱引用有时被错误地用于替换软引用来构建缓存,但这将导致缓存性能差。实际上,弱引用会在图像变弱后(通常在再次使用缓存对象之前)迅速清除它们吗?因为小型垃圾采集经常运行
对于性能严重依赖缓存的应用程序,软引用是一种无用的手段。它确实无法取代复杂的缓存框架,该框架可以提供灵活的终止、复制和事务缓存。但是,作为一种“廉价且肮脏”的缓存机制,降低价格非常有吸引力
与弱引用一样,还可以使用关联的引用队列创建软引用,该队列在垃圾回收器清除时进入队列。引用队列对于软引用没有弱引用有用,但它们可以用于发出应用程序内存开始耗尽的管理警报
垃圾采集器如何处理引用
弱引用和软引用都扩展了抽象引用类(幻影引用也是如此,稍后将在文章中描述)。引用对象由垃圾回收器以特殊方式处理。当垃圾回收器在跟踪堆期间遇到引用对象时,它不会标记或跟踪引用对象,而是将引用放置在已知活动引用对象的队列上。在跟踪之后,垃圾回收器会识别软访问对象吗?除软引用外,这些对象上没有强引用。垃圾回收器根据当前采集回收的内存总量和其他策略注意事项确定此时是否需要清除软引用。如果要清除的软引用具有相应的引用队列,则y将进入队列。剩余的软访问对象(未清除的对象)将被视为根集,堆跟踪将继续使用这些新根,以便可以标记通过活动软引用访问的对象
处理软引用后,将标识弱可及对象的集合?此类对象上没有强引用或软引用。这些对象将被清除并排队。所有引用类型在排队之前都会被清除,因此将进行事后处理。清除的线程将永远无法访问引用对象,但t仅指向引用对象。因此,当引用与引用队列一起使用时,通常需要细分适当的引用类型,并在设计中直接使用它(如weakhashmap,其map.entry扩展了WeakReference)或存储对需要清除的实体的引用
参考处理的性能成本
引用对象会给垃圾采集过程带来一些额外的成本。对于每个垃圾采集,必须构造一个活动引用对象的列表,并且必须适当地处理每个引用,这会增加每个采集的每个引用的一些开销,而不管此时是否采集引用引用对象本身接受垃圾采集,并且可以在引用对象之前进行采集,在这种情况下,它们不会添加到队列中
基于数组的集合
当使用数组实现堆栈或环形缓冲区等数据结构时,会出现另一种形式的对象分离在该方法中,在顶部指针递减后,元素仍然保留对将弹出堆栈的对象的引用。这意味着对该对象的引用仍然可以被程序访问(即使程序实际上不会使用该引用),它防止对象被垃圾采集,直到该位置被future push()重用为止
在基于数组的集合中列出3.对象
publicclassLeakyStack{
privateObject[]元素=新对象[MAX_元素]
privateintsize=0
publicvoidpush(Objecto){elements[size++]=o;}
publicObjectpop(){
如果(大小==0)
thrownewmptystackexception()
否则{
Objectresult=元素[--size]
//元素[大小+1]=空
返回结果
}
}
}
结论
与弱引用一样,软引用通过利用垃圾采集器在做出缓存采集决策时的帮助,有助于防止应用程序中的对象漂移。只有当应用程序能够容忍大量软引用对象时,软引用才适用
参考资料:
您可以在developerWorks全球网站上参考本文的英文原文
“Java理论与实践:用弱引用阻止内存泄漏”:上一期《Java理论与实践》介绍了类似的软引用
“关注性能:调优垃圾回收”:kirkpepperdine和JackShirazi证明,即使是缓慢的内存泄漏最终也会给垃圾回收器带来巨大压力
引用对象和垃圾采集:本文由sun在引用对象添加到类库后不久撰写,描述垃圾采集器如何处理引用对象
Java理论与实践:Brian Goetz的完整系列
Java技术专区:数百篇关于Java编程文章各个方面的文章@
获得产品和技术
Jtune:这个免费的Jtune工具利用GC日志,以图形方式显示堆大小、GC持续时间和其他有用的内存管理数据
文章采集调用(【干货】强引用、软引用和幻象引用有什么区别?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-19 16:05
强参考、软参考、弱参考和幻影参考之间有什么区别
1.definition
强引用是最常见的对象引用。只要有一个指向某个对象的强引用,它就可以指示该对象仍然是“活动的”,并且垃圾采集器不会接触该对象。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。当然,具体的回收时间取决于垃圾采集策略
特点:在我们典型的代码中,Obj=newobject()是一个很强的引用。与关键字new创建的对象关联的引用是强引用。当JVM内存空间不足时,JVM宁愿抛出OfMemoryError runtime error(OOM),使程序异常终止,也不愿通过任意回收具有强引用的“活动”对象来解决内存不足的问题。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。具体的回收时间取决于垃圾采集策略
软引用是一种相对较强和较弱的引用,它可以使对象免于某些垃圾采集。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象。JVM确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用通常用于实现内存敏感缓存。如果有空闲内存,可以临时保留缓存,并在内存不足时进行清理,以确保在使用缓存时不会耗尽内存
特点:软参考通过软参考类实现。软参考文献的生命周期短于强参考文献。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象:也就是说,JVM将确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用可以与引用队列一起使用。如果软引用引用的对象被垃圾采集器回收,Java虚拟机将把软引用添加到关联的引用队列中。稍后,我们可以调用ReferenceQueue的poll()方法来检查它所关心的对象是否被回收。如果队列为空,则返回null;否则,该方法将返回队列前面的引用对象
应用场景:软引用通常用于实现对内存敏感的缓存。如果仍有可用内存,您可以暂时保留缓存,并在内存不足时将其清除,以确保缓存在使用时不会耗尽内存
弱引用不会免除对象的垃圾采集,但只提供了一种访问处于弱引用状态的对象的方法。这可以用于构建没有特定约束的关系。例如,维护非强制映射关系。如果试图获取对象时该对象仍然存在,请使用它,否则请重新实例化它。它也是许多缓存实现的一个选项
弱引用是通过WeakReference类实现的。弱引用的生命周期比软引用短。当垃圾采集器线程扫描其管辖下的内存区域时,一旦找到弱引用的对象,它将回收其内存,无论当前内存空间是否足够。由于垃圾采集器是一个低优先级线程,因此不需要快速回收弱引用对象。弱引用可以与引用队列一起使用。如果弱引用引用的对象被垃圾采集,Java虚拟机将把弱引用添加到关联的引用队列中
应用场景:弱应用程序也可用于内存敏感缓存
幻影引用有时会转换为虚拟引用,您无法通过虚拟引用访问对象。幻影引用只提供了一种机制来确保对象在最终确定后可以执行某些操作。例如,它通常用于执行所谓的事后清理机制(post-mortem cleaning mechanism)、在我的专栏文章中介绍的Java平台的清理机制,还有一些使用幻影引用来监视对象的创建和销毁
特点:虚拟引用也称为phantomreference,通过phantomreference类实现。无法通过虚拟引用访问对象的任何属性或函数。幻影引用只是提供了一种机制来确保对象在最终确定后执行某些操作。如果一个对象只收录虚拟引用,垃圾采集器可以随时将其回收,就像它没有引用一样。虚拟引用必须与ReferenceQueue结合使用。当垃圾采集器准备回收对象时,如果它发现它仍然有一个虚拟引用,它将在回收对象的内存之前将虚拟引用添加到关联的引用队列中
ReferenceQueue=newreferencequeue()
PhantomReference pr=新的PhantomReference(对象、队列)
通过判断虚拟引用是否已添加到引用队列,程序可以知道引用对象是否将被垃圾采集。如果程序发现已将虚拟引用添加到引用队列中,它可以在回收引用对象的内存之前执行一些程序操作
应用场景:它可以用来跟踪垃圾采集器回收的对象的活动。当垃圾采集器回收与虚拟引用关联的对象时,它将收到系统通知
2.对象可访问性分析
3.Reference
所有引用类型都是抽象类java.lang.ref.reference的子类。您可能会注意到,它提供了一个get()方法:
除了幻影引用(因为get总是返回null),如果对象没有被销毁,那么可以通过get方法获得原创对象。这意味着使用软引用和弱引用,我们可以将被访问对象重新指向强引用,即人为地改变对象的可访问性状态!这就是为什么我在上图中的一些地方画了双向箭头
因此,对于软引用和弱引用,垃圾采集器可能存在二次确认问题,以确保处于弱引用状态的对象不会更改为强引用
但是你认为这里可能有什么问题吗
是的,如果我们错误地维护强引用(例如,分配给静态变量),对象可能没有机会更改回类似于弱引用的可访问性状态,从而导致内存泄漏。因此,检查弱引用指向对象是否被垃圾采集也是诊断是否存在特定内存泄漏的一种方法。如果我们的框架使用弱引用并怀疑存在内存泄漏,我们可以从这个角度进行检查
4.ReferenceQueue
当我们创建各种引用并将它们与相应的对象关联时,我们可以选择是否关联引用队列。JVM将在特定时间引用队列。我们可以从队列中获取相关后续逻辑的引用(remove方法实际上意味着在这里获取它)。特别是对于phantom引用,get方法只返回null。如果未指定引用队列,则它基本上没有意义。请看下面的示例代码。使用引用队列,我们可以在对象处于相应状态时执行后处理逻辑(对于phantom reference,它已完成并处于phantom Reach状态)
Object counter = new Object();
ReferenceQueue refQueue = new ReferenceQueue();
PhantomReference p = new PhantomReference(counter, refQueue);
counter = null;
System.gc();
try {
// Remove是一个阻塞方法,可以指定timeout,或者选择一直阻塞
Reference ref = refQueue.remove(1000L);
if (ref != null) {
// do something
}
} catch (InterruptedException e) {
// Handle it
}
5.显式影响软引用垃圾采集
软引用通常在最后一次引用之后保留一段时间。默认值是基于剩余堆空间(以M字节为单位)计算的。来自Java1.3.1首先,提供了-XX:softreflrupolicymspermb参数。我们可以在毫秒内设置它。例如,以下示例设置为3秒(3000毫秒)
-XX:SoftRefLRUPolicyMSPerMB=3000
事实上,剩余空间将受到不同JVM模式的影响。对于客户端模式,如通常的windows 32位JDK,剩余空间用于计算当前堆中的可用大小,因此更倾向于循环使用;对于服务器模式JVM,它是根据-Xmx指定的最大值计算的
本质上,这种行为仍然是一个黑盒,具体取决于JVM实现。即使上述参数在新版本的JDK上也可能无效。此外,客户端模式下的JDK已逐渐退出历史舞台。因此,当我们应用时,我们可以参考类似的设置,但不要太依赖它
6.diagnose JVM引用
如果您怀疑应用程序存在由引用(或finalize)引起的回收问题,那么有许多工具或选项可供选择。例如,hotspot JVM本身提供了一个清晰的选项(printreferencegc)来获取相关信息
注意:JDK 9广泛地重构JVM和垃圾采集日志。Printgctimestamps和printreferencegc不再存在。我将在本专栏后面的垃圾采集主题中更系统地解释它们
7.Reachability篱笆
可以达到强参考的效果 查看全部
文章采集调用(【干货】强引用、软引用和幻象引用有什么区别?)
强参考、软参考、弱参考和幻影参考之间有什么区别
1.definition
强引用是最常见的对象引用。只要有一个指向某个对象的强引用,它就可以指示该对象仍然是“活动的”,并且垃圾采集器不会接触该对象。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。当然,具体的回收时间取决于垃圾采集策略
特点:在我们典型的代码中,Obj=newobject()是一个很强的引用。与关键字new创建的对象关联的引用是强引用。当JVM内存空间不足时,JVM宁愿抛出OfMemoryError runtime error(OOM),使程序异常终止,也不愿通过任意回收具有强引用的“活动”对象来解决内存不足的问题。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。具体的回收时间取决于垃圾采集策略
软引用是一种相对较强和较弱的引用,它可以使对象免于某些垃圾采集。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象。JVM确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用通常用于实现内存敏感缓存。如果有空闲内存,可以临时保留缓存,并在内存不足时进行清理,以确保在使用缓存时不会耗尽内存
特点:软参考通过软参考类实现。软参考文献的生命周期短于强参考文献。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象:也就是说,JVM将确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用可以与引用队列一起使用。如果软引用引用的对象被垃圾采集器回收,Java虚拟机将把软引用添加到关联的引用队列中。稍后,我们可以调用ReferenceQueue的poll()方法来检查它所关心的对象是否被回收。如果队列为空,则返回null;否则,该方法将返回队列前面的引用对象
应用场景:软引用通常用于实现对内存敏感的缓存。如果仍有可用内存,您可以暂时保留缓存,并在内存不足时将其清除,以确保缓存在使用时不会耗尽内存
弱引用不会免除对象的垃圾采集,但只提供了一种访问处于弱引用状态的对象的方法。这可以用于构建没有特定约束的关系。例如,维护非强制映射关系。如果试图获取对象时该对象仍然存在,请使用它,否则请重新实例化它。它也是许多缓存实现的一个选项
弱引用是通过WeakReference类实现的。弱引用的生命周期比软引用短。当垃圾采集器线程扫描其管辖下的内存区域时,一旦找到弱引用的对象,它将回收其内存,无论当前内存空间是否足够。由于垃圾采集器是一个低优先级线程,因此不需要快速回收弱引用对象。弱引用可以与引用队列一起使用。如果弱引用引用的对象被垃圾采集,Java虚拟机将把弱引用添加到关联的引用队列中
应用场景:弱应用程序也可用于内存敏感缓存
幻影引用有时会转换为虚拟引用,您无法通过虚拟引用访问对象。幻影引用只提供了一种机制来确保对象在最终确定后可以执行某些操作。例如,它通常用于执行所谓的事后清理机制(post-mortem cleaning mechanism)、在我的专栏文章中介绍的Java平台的清理机制,还有一些使用幻影引用来监视对象的创建和销毁
特点:虚拟引用也称为phantomreference,通过phantomreference类实现。无法通过虚拟引用访问对象的任何属性或函数。幻影引用只是提供了一种机制来确保对象在最终确定后执行某些操作。如果一个对象只收录虚拟引用,垃圾采集器可以随时将其回收,就像它没有引用一样。虚拟引用必须与ReferenceQueue结合使用。当垃圾采集器准备回收对象时,如果它发现它仍然有一个虚拟引用,它将在回收对象的内存之前将虚拟引用添加到关联的引用队列中
ReferenceQueue=newreferencequeue()
PhantomReference pr=新的PhantomReference(对象、队列)
通过判断虚拟引用是否已添加到引用队列,程序可以知道引用对象是否将被垃圾采集。如果程序发现已将虚拟引用添加到引用队列中,它可以在回收引用对象的内存之前执行一些程序操作
应用场景:它可以用来跟踪垃圾采集器回收的对象的活动。当垃圾采集器回收与虚拟引用关联的对象时,它将收到系统通知
2.对象可访问性分析
3.Reference

所有引用类型都是抽象类java.lang.ref.reference的子类。您可能会注意到,它提供了一个get()方法:
除了幻影引用(因为get总是返回null),如果对象没有被销毁,那么可以通过get方法获得原创对象。这意味着使用软引用和弱引用,我们可以将被访问对象重新指向强引用,即人为地改变对象的可访问性状态!这就是为什么我在上图中的一些地方画了双向箭头
因此,对于软引用和弱引用,垃圾采集器可能存在二次确认问题,以确保处于弱引用状态的对象不会更改为强引用
但是你认为这里可能有什么问题吗
是的,如果我们错误地维护强引用(例如,分配给静态变量),对象可能没有机会更改回类似于弱引用的可访问性状态,从而导致内存泄漏。因此,检查弱引用指向对象是否被垃圾采集也是诊断是否存在特定内存泄漏的一种方法。如果我们的框架使用弱引用并怀疑存在内存泄漏,我们可以从这个角度进行检查
4.ReferenceQueue
当我们创建各种引用并将它们与相应的对象关联时,我们可以选择是否关联引用队列。JVM将在特定时间引用队列。我们可以从队列中获取相关后续逻辑的引用(remove方法实际上意味着在这里获取它)。特别是对于phantom引用,get方法只返回null。如果未指定引用队列,则它基本上没有意义。请看下面的示例代码。使用引用队列,我们可以在对象处于相应状态时执行后处理逻辑(对于phantom reference,它已完成并处于phantom Reach状态)
Object counter = new Object();
ReferenceQueue refQueue = new ReferenceQueue();
PhantomReference p = new PhantomReference(counter, refQueue);
counter = null;
System.gc();
try {
// Remove是一个阻塞方法,可以指定timeout,或者选择一直阻塞
Reference ref = refQueue.remove(1000L);
if (ref != null) {
// do something
}
} catch (InterruptedException e) {
// Handle it
}
5.显式影响软引用垃圾采集
软引用通常在最后一次引用之后保留一段时间。默认值是基于剩余堆空间(以M字节为单位)计算的。来自Java1.3.1首先,提供了-XX:softreflrupolicymspermb参数。我们可以在毫秒内设置它。例如,以下示例设置为3秒(3000毫秒)
-XX:SoftRefLRUPolicyMSPerMB=3000
事实上,剩余空间将受到不同JVM模式的影响。对于客户端模式,如通常的windows 32位JDK,剩余空间用于计算当前堆中的可用大小,因此更倾向于循环使用;对于服务器模式JVM,它是根据-Xmx指定的最大值计算的
本质上,这种行为仍然是一个黑盒,具体取决于JVM实现。即使上述参数在新版本的JDK上也可能无效。此外,客户端模式下的JDK已逐渐退出历史舞台。因此,当我们应用时,我们可以参考类似的设置,但不要太依赖它
6.diagnose JVM引用
如果您怀疑应用程序存在由引用(或finalize)引起的回收问题,那么有许多工具或选项可供选择。例如,hotspot JVM本身提供了一个清晰的选项(printreferencegc)来获取相关信息
注意:JDK 9广泛地重构JVM和垃圾采集日志。Printgctimestamps和printreferencegc不再存在。我将在本专栏后面的垃圾采集主题中更系统地解释它们
7.Reachability篱笆
可以达到强参考的效果
文章采集调用(文章采集调用mysql的话,你可以不使用浏览器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-19 07:03
文章采集调用mysql的话,你可以不使用浏览器或者其他采集软件,可以直接用mysqlscript采集,给大家整理了一下资料,
一、安装mysql+cython环境在安装之前,我们要配置好mysql。
二、通过mysql调用cython的api非常简单直接,参照官方文档,即可实现。
#建立表createtable`abc`(`id`int(1
1)notnullauto_increment,`username`varchar(3
0)notnulldefaultnull,`password`varchar(3
0)notnulldefaultnull,`page`int(1
1)notnulldefaultnull);
三、mysql的参数配置a:数据库名b:binpath通常设置为:/tmp/mysql/bin这样我们的cython就能访问到mysql了.你还可以在更多的配置方式上进行探索。mysql数据库的配置例如,我们可以进一步配置数据库id在这个例子中代表的是id到username到page的这个列--c:/opt/cython/local/bin/mysql-c:/opt/cython/local/bin/mysql---d:c:/opt/cython/local/bin/mysql-e:。 查看全部
文章采集调用(文章采集调用mysql的话,你可以不使用浏览器)
文章采集调用mysql的话,你可以不使用浏览器或者其他采集软件,可以直接用mysqlscript采集,给大家整理了一下资料,
一、安装mysql+cython环境在安装之前,我们要配置好mysql。
二、通过mysql调用cython的api非常简单直接,参照官方文档,即可实现。
#建立表createtable`abc`(`id`int(1
1)notnullauto_increment,`username`varchar(3
0)notnulldefaultnull,`password`varchar(3
0)notnulldefaultnull,`page`int(1
1)notnulldefaultnull);
三、mysql的参数配置a:数据库名b:binpath通常设置为:/tmp/mysql/bin这样我们的cython就能访问到mysql了.你还可以在更多的配置方式上进行探索。mysql数据库的配置例如,我们可以进一步配置数据库id在这个例子中代表的是id到username到page的这个列--c:/opt/cython/local/bin/mysql-c:/opt/cython/local/bin/mysql---d:c:/opt/cython/local/bin/mysql-e:。
文章采集调用(换个网站你什么都做不了,这个教程是最详尽的教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-17 07:05
·我看到很多网友对织梦(Dedecms)采集教程感到头疼。事实上,官方教程太笼统了,什么也没说。你不能在网站做任何事情。本教程是最详细的教程。你一眼就能学会
首先,打开织梦background并单击采集-采集节点管理-添加新节点
这里我们以采集普通文章为例。我们选择普通文章然后确认
我们进入了采集的设置页面,并填写了节点名称,即为新节点命名。你可以在这里填写任何名字
然后打开所需采集的文章列表页面。在这里,我们以织梦官方网站为例打开此页面。右键单击以查看源文件
在字符集之后查找目标页代码
页面和其他页面的基本信息通常并不重要。填写后,请参见图
现在,让我们填写URL获取规则列表
请看文章列表第一页上的地址
比较第二页上的地址
我们发现它们除了49外,后面的数字是不同的,其他的都是一样的,所以我们可以这样写
(*).html
只需将1替换为(*),因为这里只有2页,所以让我们填写从1到2的增量。当然是1。2-1... 等于1
我们到此为止
可能您的一些采集列表没有规则,因此您必须手动指定列表URL,如图所示
每行写一页地址
当列表规则完成后,我们开始编写文章URL匹配规则并返回文章list页面
右键单击以查看源文件,并在区域的开头找到HTML,这是搜索文章列表开头的符号
我们可以很容易地在图中找到“新闻列表”。从这里开始,列表上的是文章
让我们在列表的末尾找到文章HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理为缩略图。根据您的需要选择
重新筛选区域网址:
(使用正则表达式)
必须包括:(优先于后者)
不能收录:
打开源文件时,您可以清楚地看到文章链接以结尾。HTML
因此,我们必须填写。收录后的HTML。如果有些清单很麻烦,我们也可以填写那些不能包括在内的清单
我们点击保存设置进入下一步,我们可以看到我们获得的文章网站
看到这一点是对的。我们保存信息并进入下一步设置内容字段获取规则
让我们看看文章是否有分页,然后随机输入一个文章。。我们看到这里有文章没有分页
所以这里我们默认
现在让我们来查找文章标题等等。只需输入一篇文章文章并右键单击即可查看源文件
看看这些
根据源代码填写
让我们填写文章开头和结尾
如上所述,找到开始和结束标志
开始:
完:
如果要在文章中过滤任何内容,请将其写入过滤规则,例如在文章中过滤图片@
选择常用规则
再次检查img
然后决定
通过这种方式,我们过滤文本中的图片
设置完成后,单击“保存设置并预览”
这样一个采集规则是编写的。这很简单。有些网站很难写,但我们需要更加努力
我们点击保存并开始采集-start采集网页,采集将在一段时间内完成
让我们看看我们采集k7得到了什么@
这似乎是一次成功。让我们导出数据
首先,选择要导入的列,然后按“请选择”在弹出窗口中选择要导入的列发布选项。除非您不想立即发布,否则它通常是默认值。默认情况下,每批导入有30个条目。它是否被修改并不重要。附加选项通常为“排除重复标题”。至于自动生成HTML的选项,建议不要先生成它,因为我们必须批量提取摘要和关键字 查看全部
文章采集调用(换个网站你什么都做不了,这个教程是最详尽的教程)
·我看到很多网友对织梦(Dedecms)采集教程感到头疼。事实上,官方教程太笼统了,什么也没说。你不能在网站做任何事情。本教程是最详细的教程。你一眼就能学会
首先,打开织梦background并单击采集-采集节点管理-添加新节点
这里我们以采集普通文章为例。我们选择普通文章然后确认
我们进入了采集的设置页面,并填写了节点名称,即为新节点命名。你可以在这里填写任何名字
然后打开所需采集的文章列表页面。在这里,我们以织梦官方网站为例打开此页面。右键单击以查看源文件
在字符集之后查找目标页代码
页面和其他页面的基本信息通常并不重要。填写后,请参见图
现在,让我们填写URL获取规则列表
请看文章列表第一页上的地址
比较第二页上的地址
我们发现它们除了49外,后面的数字是不同的,其他的都是一样的,所以我们可以这样写
(*).html
只需将1替换为(*),因为这里只有2页,所以让我们填写从1到2的增量。当然是1。2-1... 等于1
我们到此为止
可能您的一些采集列表没有规则,因此您必须手动指定列表URL,如图所示
每行写一页地址
当列表规则完成后,我们开始编写文章URL匹配规则并返回文章list页面
右键单击以查看源文件,并在区域的开头找到HTML,这是搜索文章列表开头的符号
我们可以很容易地在图中找到“新闻列表”。从这里开始,列表上的是文章
让我们在列表的末尾找到文章HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理为缩略图。根据您的需要选择
重新筛选区域网址:
(使用正则表达式)
必须包括:(优先于后者)
不能收录:
打开源文件时,您可以清楚地看到文章链接以结尾。HTML
因此,我们必须填写。收录后的HTML。如果有些清单很麻烦,我们也可以填写那些不能包括在内的清单
我们点击保存设置进入下一步,我们可以看到我们获得的文章网站
看到这一点是对的。我们保存信息并进入下一步设置内容字段获取规则
让我们看看文章是否有分页,然后随机输入一个文章。。我们看到这里有文章没有分页
所以这里我们默认
现在让我们来查找文章标题等等。只需输入一篇文章文章并右键单击即可查看源文件
看看这些
根据源代码填写
让我们填写文章开头和结尾
如上所述,找到开始和结束标志
开始:
完:
如果要在文章中过滤任何内容,请将其写入过滤规则,例如在文章中过滤图片@
选择常用规则
再次检查img
然后决定
通过这种方式,我们过滤文本中的图片
设置完成后,单击“保存设置并预览”
这样一个采集规则是编写的。这很简单。有些网站很难写,但我们需要更加努力
我们点击保存并开始采集-start采集网页,采集将在一段时间内完成
让我们看看我们采集k7得到了什么@
这似乎是一次成功。让我们导出数据
首先,选择要导入的列,然后按“请选择”在弹出窗口中选择要导入的列发布选项。除非您不想立即发布,否则它通常是默认值。默认情况下,每批导入有30个条目。它是否被修改并不重要。附加选项通常为“排除重复标题”。至于自动生成HTML的选项,建议不要先生成它,因为我们必须批量提取摘要和关键字
文章采集调用(灵动标签调用多表多模型(图)模型调用文章(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-15 20:05
灵动标签调用多表多模型调用文章
1、调用多模型的最新文章
[e:loop={'select * from (
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_movie where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_news where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_photo where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_flash where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_article where newstime) a order by newstime desc limit 10',10,24,1}]
[/e:loop]
帝国CMS多表调用最新信息,该演示代码为默认数据表下全站最新10条图片信息,自己根据需求可以附加条件,实现全站点击,全站头条,全站推荐等等.
---------------------------------------------------------------------------------
2、调用多模型的最新文章
[e:loop={'
select title,titleurl,titlepic from [!db.pre!]ecms_photo Union All
select title,titleurl,titlepic from [!db.pre!]ecms_download Union All
select title,titleurl,titlepic from [!db.pre!]ecms_news',0,24,0}]
[/e:loop]
注释:以上调用的是(图片模型:photo、下载模型:download、新闻模型:news)三个模型的文章
三个模型用“Union All”连接调用
若指定栏目用:where classid in(46,47,51),
若调用推荐在其后追加:and isgood=1,
若指定调用条数在其后追加:limit 10 查看全部
文章采集调用(灵动标签调用多表多模型(图)模型调用文章(组图))
灵动标签调用多表多模型调用文章
1、调用多模型的最新文章
[e:loop={'select * from (
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_movie where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_news where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_photo where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_flash where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_article where newstime) a order by newstime desc limit 10',10,24,1}]
[/e:loop]
帝国CMS多表调用最新信息,该演示代码为默认数据表下全站最新10条图片信息,自己根据需求可以附加条件,实现全站点击,全站头条,全站推荐等等.
---------------------------------------------------------------------------------
2、调用多模型的最新文章
[e:loop={'
select title,titleurl,titlepic from [!db.pre!]ecms_photo Union All
select title,titleurl,titlepic from [!db.pre!]ecms_download Union All
select title,titleurl,titlepic from [!db.pre!]ecms_news',0,24,0}]
[/e:loop]
注释:以上调用的是(图片模型:photo、下载模型:download、新闻模型:news)三个模型的文章
三个模型用“Union All”连接调用
若指定栏目用:where classid in(46,47,51),
若调用推荐在其后追加:and isgood=1,
若指定调用条数在其后追加:limit 10
文章采集调用(Excel教程Excel函数代码如下()的详细内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-15 20:04
核心功能代码如下:
以上代码可以获取指定网页的内容。如果一切都得到了,那就容易多了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果要在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
可以根据需要修改特定信息
以上是ASP获取远程网页指定内容的实现代码的详细内容。有关获取远程网页内容的更多信息,请注意其他相关文章 查看全部
文章采集调用(Excel教程Excel函数代码如下()的详细内容)
核心功能代码如下:
以上代码可以获取指定网页的内容。如果一切都得到了,那就容易多了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果要在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
可以根据需要修改特定信息
以上是ASP获取远程网页指定内容的实现代码的详细内容。有关获取远程网页内容的更多信息,请注意其他相关文章
文章采集调用(孤狼微信公众号文章采集主要功能特色介绍! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-09-13 22:13
)
独狼数据采集平台为微信公众号文章提供采集,可以轻松发布到市面上主流系统,也可以定制一些冷门的网站接口!
一、孤狼微信公众号文章采集主要功能
1.根据公众号名称或ID指定公众号采集,支持输入多个公众号,公众号数量不限
2.多种图片下载存储方式(远程调用、本地化图片、ftp上传),解决公众号文章图片防盗链问题
3、强大的数据存储功能(采集到达的数据保存在本地数据库文件中)
4、简单配置即可轻松发布到主流网站或api接口
二、微信公号文章采集主要步骤
1、创建“添加公众号”任务
登录软件,打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到组。
2、填写采集的官方账号名或ID
填写基本信息如下图:
填写任务名称和采集微信公众号的名称或ID。提示:可以查看文章前后图片的自动过滤
使用广告图片功能删除广告(功能必须提前勾选)
使用官方账号标签
3、设置图片下载(可选)
由于微信公众号文章图片已经做了防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、Begin采集
图片配置好后,可以点击左上角的“采集”,采集data:
5、采集后期数据处理与发布
启动采集后,数据永远是采集,文章可以预览,显示图形内容,可以添加到“任务列表”页面查看:勾选文章,选择加入发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
查看全部
文章采集调用(孤狼微信公众号文章采集主要功能特色介绍!
)
独狼数据采集平台为微信公众号文章提供采集,可以轻松发布到市面上主流系统,也可以定制一些冷门的网站接口!
一、孤狼微信公众号文章采集主要功能
1.根据公众号名称或ID指定公众号采集,支持输入多个公众号,公众号数量不限
2.多种图片下载存储方式(远程调用、本地化图片、ftp上传),解决公众号文章图片防盗链问题
3、强大的数据存储功能(采集到达的数据保存在本地数据库文件中)
4、简单配置即可轻松发布到主流网站或api接口
二、微信公号文章采集主要步骤
1、创建“添加公众号”任务
登录软件,打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到组。
2、填写采集的官方账号名或ID
填写基本信息如下图:
填写任务名称和采集微信公众号的名称或ID。提示:可以查看文章前后图片的自动过滤
使用广告图片功能删除广告(功能必须提前勾选)
使用官方账号标签
3、设置图片下载(可选)
由于微信公众号文章图片已经做了防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、Begin采集
图片配置好后,可以点击左上角的“采集”,采集data:
5、采集后期数据处理与发布
启动采集后,数据永远是采集,文章可以预览,显示图形内容,可以添加到“任务列表”页面查看:勾选文章,选择加入发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
文章采集调用(高考志愿填报:文章采集调用的是去重特征吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-12 18:08
文章采集调用的是去重特征,机器一类特征应该可以,不过要找到一个好的去重算法,能够应对类数目,并且快速处理相似性排序。样本属性太多,带来的问题就是复杂度增加。
可以通过其他feature。比如通过一些docautographer。
那是应该是有去重功能,但由于海量数据,你的加法求平均肯定是不行,特征选择也不行。应该尝试一下朴素贝叶斯等非线性决策模型,甚至尝试集成方法,比如kaggle的bagging,均衡分布。
直接用关键词不是挺好吗?多个词相似有两种可能:1)关键词相似,但是有差异,比如:“好看”和“好看”,“好看”有100个词语,而“好看”只有20个。2)关键词相似,但是一个完全一样,另一个只是简单的借用词语,不是原作者内容或观点。比如:“万科”和“万科”,“中科院”和“中科院”。还有一个可能,就是其他人所说的去重,这个就需要用到数据预处理,去除重复词,其实训练也挺简单,你给定一个集合x,给定一个预测维度y,实验一下就知道。还有一个问题是为什么不用任何特征,直接求平均,都有人告诉我是为了多层感知机之类的去重。
感觉取词来做特征不够合理。如果取第一个词key做特征,再取词进行分类,那么首先是单词特征没有,其次就是预测结果太低,达不到结合词汇多少加权的要求。一般取整数词长特征,比如5cm。以“好看”做例子。取key5作为特征。5cm*00=50001。
去重之后0000000=5。分类损失是0.5。所以首先权重换算可以不用我说的这么麻烦,直接求平均就可以了。其次应该是词典大小的关系,词典越大,权重越高。建议语料库要尽可能大,词汇特征向量最好3m以上。具体可以基于文本分类的,比如共享词典什么的。 查看全部
文章采集调用(高考志愿填报:文章采集调用的是去重特征吗?)
文章采集调用的是去重特征,机器一类特征应该可以,不过要找到一个好的去重算法,能够应对类数目,并且快速处理相似性排序。样本属性太多,带来的问题就是复杂度增加。
可以通过其他feature。比如通过一些docautographer。
那是应该是有去重功能,但由于海量数据,你的加法求平均肯定是不行,特征选择也不行。应该尝试一下朴素贝叶斯等非线性决策模型,甚至尝试集成方法,比如kaggle的bagging,均衡分布。
直接用关键词不是挺好吗?多个词相似有两种可能:1)关键词相似,但是有差异,比如:“好看”和“好看”,“好看”有100个词语,而“好看”只有20个。2)关键词相似,但是一个完全一样,另一个只是简单的借用词语,不是原作者内容或观点。比如:“万科”和“万科”,“中科院”和“中科院”。还有一个可能,就是其他人所说的去重,这个就需要用到数据预处理,去除重复词,其实训练也挺简单,你给定一个集合x,给定一个预测维度y,实验一下就知道。还有一个问题是为什么不用任何特征,直接求平均,都有人告诉我是为了多层感知机之类的去重。
感觉取词来做特征不够合理。如果取第一个词key做特征,再取词进行分类,那么首先是单词特征没有,其次就是预测结果太低,达不到结合词汇多少加权的要求。一般取整数词长特征,比如5cm。以“好看”做例子。取key5作为特征。5cm*00=50001。
去重之后0000000=5。分类损失是0.5。所以首先权重换算可以不用我说的这么麻烦,直接求平均就可以了。其次应该是词典大小的关系,词典越大,权重越高。建议语料库要尽可能大,词汇特征向量最好3m以上。具体可以基于文本分类的,比如共享词典什么的。
文章采集调用(【Python学习福利】豆瓣电影中如何多网页请求?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-10-10 04:00
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家 查看全部
文章采集调用(【Python学习福利】豆瓣电影中如何多网页请求?)
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家
文章采集调用(调用链系列(2):服务端信息收集以及服务间上下文传递)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-10 03:36
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,整体的实现策略。
在这个文章中,我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、服务器信息采集
服务器端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。
三、切点植入
在介绍切入点之前,我们应该对servlet容器(本文以tomcat为例)处理请求的大致流程有一个全面的了解。
图片来自网络
Connector接收到一个连接并转换成请求(Request)后,会将请求传递给Engine的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入自己的逻辑来增强tomcat的对外能力,即:
除了巧妙地利用了tomcat容器的架构设计,中间件增强技术还使用了java Instrumentation(它为我们提供了第一次加载对象时动态修改字节码的能力。由于篇幅原因,不做详细解释,不明白的可以自行查阅资料)。在 UAV 中,通过 UAVServer 对外提供各种切点能力。
借助中间件增强技术,在应用逻辑执行前后都有切点,下一步就是在这些切点上执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力后面会详细介绍文章)。轻量级调用链实现使用了 UAVServer 提供的 GlobalFilterHandler 能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助 GlobalFilterHandler 提供的前两个能力,实现了应用处理请求前后执行调用链逻辑的功能。
五、轻量级调用链实现
具体的UML图如下:
从UML图中可以清楚地看出InvokeChainSupporter(调用链实现逻辑入口和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有的支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量级调用链绘制实现主要依赖于注册在 InvokeChainSupporter 上的 ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 分析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑导流
由于不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
Main span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方式利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;当调用链上下文逻辑被初始化时,
六、总结
看完这篇文章,读者应该对中间件增强技术的实现有了一个大致的了解,对其提供的GlobalFilterHandler能力也有了一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。 查看全部
文章采集调用(调用链系列(2):服务端信息收集以及服务间上下文传递)
一、前言
调用链系列(1):UAVStack中贪吃蛇的解读
上一篇文章分享了调用链的模型设计和模型时序图。相信大家通过上一篇文章对调用链有了一个整体的了解,比如:调用链是什么,能做什么,整体的实现策略。
在这个文章中,我们继续介绍调用链的服务端信息采集和服务间的上下文传递。
二、服务器信息采集
服务器端信息采集的整体流程如下图所示。通过在应用容器(tomcat等)的启动过程中植入切入点,可以在应用逻辑执行前后对请求进行劫持。
三、切点植入
在介绍切入点之前,我们应该对servlet容器(本文以tomcat为例)处理请求的大致流程有一个全面的了解。
图片来自网络
Connector接收到一个连接并转换成请求(Request)后,会将请求传递给Engine的管道(Pipeline)的阀门(ValveA)。该请求将被传递到引擎管道中的引擎阀门。然后请求将从 Engine Valve 传递到 Host 管道,并在管道中传递到 Host Valve 阀门。然后从Host Valve传递给一个Context管道,再传递给管道中的Context Valve。接下来,请求将被传递到收录在 Wrapper C 中的管道中的 Wrapper Valve,在那里它会通过一个过滤器链,最后发送到一个 Servlet。借助tomcat的这种架构设计,我们可以通过在tomcat处理请求的生命周期中植入自己的逻辑来增强tomcat的对外能力,即:
除了巧妙地利用了tomcat容器的架构设计,中间件增强技术还使用了java Instrumentation(它为我们提供了第一次加载对象时动态修改字节码的能力。由于篇幅原因,不做详细解释,不明白的可以自行查阅资料)。在 UAV 中,通过 UAVServer 对外提供各种切点能力。
借助中间件增强技术,在应用逻辑执行前后都有切点,下一步就是在这些切点上执行我们自己的调用链逻辑。
四、调用链中间件增强技术的使用
上面介绍的中间件增强技术是一个框架,通过使用javaagent在tomcat代码中动态植入切入点代码,并以UAVServer的形式对外提供能力(具体能力后面会详细介绍文章)。轻量级调用链实现使用了 UAVServer 提供的 GlobalFilterHandler 能力。
GlobalFilterHandler:这里的GlobalFilterHandler是中间件增强技术中的一种能力,与传统过滤器无关。它提供了四种外部功能:
调用链借助 GlobalFilterHandler 提供的前两个能力,实现了应用处理请求前后执行调用链逻辑的功能。
五、轻量级调用链实现
具体的UML图如下:
从UML图中可以清楚地看出InvokeChainSupporter(调用链实现逻辑入口和调用链所需的资源初始化实现类)对中间件增强技术进行了第二次增强。它允许用户在其中注册不同的处理程序,并在处理程序的 preCap 和 doCap(中间件增强技术中的逻辑执行前后的切入点术语)方法之前和之后将适配器动态编织到适配器中,以便能够执行更多定制化适配和个性化逻辑。所有的支持者和适配器都采用反射调用方式,最大限度地减少了对中间件增强技术的依赖。
有了二次增强技术,我们就可以开始下面的调用链绘制工作了。
轻量级调用链绘制实现主要依赖于注册在 InvokeChainSupporter 上的 ServiceSpanInvokeChainHandler。主要绘制过程如下:
我们来看看每一步都做了什么。
5.1 分析请求信息
对于像tomcat这样的中间件容器,所有进入tomcat的请求都会被封装成HttpServletRequest和HttpServletResponse(以下简称请求和响应),最后进入用户的servlet。借助中间件增强技术,调用链会在处理用户逻辑之前拦截一次请求和响应,并分析其中是否收录调用链信息。如果是,则将调用链信息封装到上下文中。
5.2 逻辑导流
由于不同协议对应的调用链的绘制逻辑也不同,这里会根据协议类型分配一次调用链。
5.3 初始化调用链上下文
分析调用链上下文中的信息:
Main span:服务中可能有多个客户端通信或服务间通信,需要一个主span来记录当前服务中调用链最后一个节点的信息。
5.4 调用链信息输出
用户逻辑处理结束后,调用链记录器会从上下文中取出当前服务的调用链信息,输出到指定的日志路径。
5.5 服务间的上下文传输
不同协议调用链传递信息的方法也略有不同。具体的实现方式利用了中间件增强技术提供的另一个能力:AppFrkHook(简称hook,这个功能会在客户端调用链实现的时候具体介绍)。它可以劫持用户使用的客户端技术。如果用户使用httpclient进行通信,则劫持httpclient并动态编织代码,从而达到在http通信过程中注入调用链上下文信息的效果。目标服务解析请求信息时,解析调用链上下文;当调用链上下文逻辑被初始化时,
六、总结
看完这篇文章,读者应该对中间件增强技术的实现有了一个大致的了解,对其提供的GlobalFilterHandler能力也有了一定的了解。对于调用链,你应该了解绘制服务器和服务之间调用链的整个过程。
文章采集调用(本文采集指定节点和“如何导出采集内容”的说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-10 03:35
前言:本文为《无分页通用文章采集方法》的第三部分。在前两节的基础上,对《如何采集指定Node》和《如何导出采集的内容》进行详细讲解。为了与上一篇保持一致,本节文章将继续使用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34-采集指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项共有3种采集模式可供选择:第一种是“监控采集模式(检查当前节点或所有节点是否有新内容)”。选择后,系统只会采集指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载种子网站未下载的内容”,选择后,系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。<//p
p设置完成并确认后,您可以点击“开始采集网页”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35)显示,/p
pimg src='https://www.mayiziy.com/../../../uploads/18751582345767.png' alt='Dedecms采集功能的使用方法 --- 不含分页的普通文章(三)'//p
p图35-查看节点的seed URL/p
p点击“开始采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),< /@采集 p>
图 36-采集提示消息进行中
采集 完成后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如图在(图37)如图,
图37-查看节点的seed URL
采集成功后,您可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38-采集内容导出
“默认导出列”:设置将采集的内容导入到
的列
“批量采集选项”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集导入到“默认导出列”中选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“带选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果想直接从采集接收到的内容生成HTML,可以选择“完成后自动生成并导入Content HTML”;如果想让系统自动识别采集列表页的标题名称,可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出时的提示信息
导出采集 内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站的相关页面查看采集到的文章List 及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“General文章”进入“Document List”页面,从文章查看文章的列表@采集 ,如图(图41),
图 41-文档列表
到此为止,我已经成功采集到达目标网站的文章内容。
总结,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有太多涉及“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章介绍。
附上这篇文章的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试 (一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文标签:dedecms、采集、功能、用法、---、不收录、分页、通用、文章、前言 查看全部
文章采集调用(本文采集指定节点和“如何导出采集内容”的说明)
前言:本文为《无分页通用文章采集方法》的第三部分。在前两节的基础上,对《如何采集指定Node》和《如何导出采集的内容》进行详细讲解。为了与上一篇保持一致,本节文章将继续使用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34-采集指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项共有3种采集模式可供选择:第一种是“监控采集模式(检查当前节点或所有节点是否有新内容)”。选择后,系统只会采集指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载种子网站未下载的内容”,选择后,系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。<//p
p设置完成并确认后,您可以点击“开始采集网页”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35)显示,/p
pimg src='https://www.mayiziy.com/../../../uploads/18751582345767.png' alt='Dedecms采集功能的使用方法 --- 不含分页的普通文章(三)'//p
p图35-查看节点的seed URL/p
p点击“开始采集网页”后,系统将启动采集节点中设置的URL,并出现相关提示,如图36),< /@采集 p>
图 36-采集提示消息进行中
采集 完成后,再次点击“查看种子网址”或点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如图在(图37)如图,
图37-查看节点的seed URL
采集成功后,您可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38-采集内容导出
“默认导出列”:设置将采集的内容导入到
的列
“批量采集选项”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集导入到“默认导出列”中选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“带选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果想直接从采集接收到的内容生成HTML,可以选择“完成后自动生成并导入Content HTML”;如果想让系统自动识别采集列表页的标题名称,可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出时的提示信息
导出采集 内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站的相关页面查看采集到的文章List 及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“General文章”进入“Document List”页面,从文章查看文章的列表@采集 ,如图(图41),
图 41-文档列表
到此为止,我已经成功采集到达目标网站的文章内容。
总结,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有太多涉及“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章介绍。
附上这篇文章的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试 (一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文标签:dedecms、采集、功能、用法、---、不收录、分页、通用、文章、前言
文章采集调用(生命不止,折腾不停,最近开始接触了wordpress(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-25 15:14
生活一直在继续。最近,我开始联系WordPress。我发现WordPress确实做得很好。有很多地方值得学习,而且很多地方都设置得非常巧妙。安装WP之后,会有一个“hello to the world”文章,有点空,所以我想知道是否可以使用Python自动发布WordPress采集的一些内容。那样的话,我们就开始吧
一、所需的库和模块
Requests是一个模拟HTTP请求的库。我们用它来抓取网页
Lxml是一个用于解析HTML和XML的库。我们使用它来解析网页内容
Pymysql是一个MySQL数据库。我们使用它将内容上传到WordPress数据库
时间是Python中内置的时间处理模块。我们使用它来设置抓取网页之间的间隔
Random是一个python内置模块,用于生成随机数。我们用它来生成随机区间
Xpinyin是一个将汉字转换成拼音的库
二、使用pymysql向WordPress数据库提交内容
通常,当我们使用WordPress时,我们会在后台编写它,然后单击“发布”。过程如下:
浏览器=>;提交表格=>;php=>;数据库
在这里,我们将跳过前面的三个步骤,直接连接到数据库:
命令行=>;数据库
<p>通过查看WordPress数据库中的WP,在posts表中的字段之后,我编写了一条SQL语句并保留了三个位置:content、title和name,它们分别表示 查看全部
文章采集调用(生命不止,折腾不停,最近开始接触了wordpress(组图))
生活一直在继续。最近,我开始联系WordPress。我发现WordPress确实做得很好。有很多地方值得学习,而且很多地方都设置得非常巧妙。安装WP之后,会有一个“hello to the world”文章,有点空,所以我想知道是否可以使用Python自动发布WordPress采集的一些内容。那样的话,我们就开始吧
一、所需的库和模块
Requests是一个模拟HTTP请求的库。我们用它来抓取网页
Lxml是一个用于解析HTML和XML的库。我们使用它来解析网页内容
Pymysql是一个MySQL数据库。我们使用它将内容上传到WordPress数据库
时间是Python中内置的时间处理模块。我们使用它来设置抓取网页之间的间隔
Random是一个python内置模块,用于生成随机数。我们用它来生成随机区间
Xpinyin是一个将汉字转换成拼音的库
二、使用pymysql向WordPress数据库提交内容
通常,当我们使用WordPress时,我们会在后台编写它,然后单击“发布”。过程如下:
浏览器=>;提交表格=>;php=>;数据库
在这里,我们将跳过前面的三个步骤,直接连接到数据库:
命令行=>;数据库
<p>通过查看WordPress数据库中的WP,在posts表中的字段之后,我编写了一条SQL语句并保留了三个位置:content、title和name,它们分别表示
文章采集调用(没有内容就没有排名吗?你错了,可以组合内容去排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-25 15:12
采集 的排名策略有很多。总之,大部分采集站都不会使用内容参与排名,因为采集的大部分内容都是低质量的,所以排名无望,没有内容就没有排名吗?你错了,你可以结合内容进行排名,看看采集站做的有多棒。
1、标签页
标签页是将大部分文章组合成一个列表,所以标签页被定义为一个伪原创页。虽然是伪原创页面,但是因为这个列表,质量非常好。关键词的内容都是和关键词一致的,而一个采集网站的入口,至少会有几万个标签页,或多或少几千个关键词 的排名并不奇怪。
2、列表页面
列表页与标签页类似,但是建立大量列表有点困难,所以很多采集站点可以通过创建自己的列表采集来形成一个高质量的页面页面,并且排名方法类似。通常采集更新,这个页面也更新。
3、搜索页面
搜索页面被视为伪静态。当用户搜索某个关键词时,出现的页面都是静态页面,有利于搜索引擎。当文章更新时,搜索页面也随之更新,只要用户进行搜索,这个关键词基本上是很容易上榜的。
4、专页
通过创建特殊页面,自动调用相关文章形成列表,调用程序即可识别相关性。这时候这个页面上关键词的内容满足内容要求,也形成了一个不错的Page,排名在意料之中。
5、内容页面
内容页的排名策略很少见,但是最近很多人用内容页做排名,而且都是采集,主要是通过采集多张图片和视频组成一个页面,第一张图片视频无法被搜索引擎识别,将网站的第二张多张图片合二为一,伪原创的真相自然就出现了。
改变: 查看全部
文章采集调用(没有内容就没有排名吗?你错了,可以组合内容去排名)
采集 的排名策略有很多。总之,大部分采集站都不会使用内容参与排名,因为采集的大部分内容都是低质量的,所以排名无望,没有内容就没有排名吗?你错了,你可以结合内容进行排名,看看采集站做的有多棒。
1、标签页
标签页是将大部分文章组合成一个列表,所以标签页被定义为一个伪原创页。虽然是伪原创页面,但是因为这个列表,质量非常好。关键词的内容都是和关键词一致的,而一个采集网站的入口,至少会有几万个标签页,或多或少几千个关键词 的排名并不奇怪。
2、列表页面
列表页与标签页类似,但是建立大量列表有点困难,所以很多采集站点可以通过创建自己的列表采集来形成一个高质量的页面页面,并且排名方法类似。通常采集更新,这个页面也更新。
3、搜索页面
搜索页面被视为伪静态。当用户搜索某个关键词时,出现的页面都是静态页面,有利于搜索引擎。当文章更新时,搜索页面也随之更新,只要用户进行搜索,这个关键词基本上是很容易上榜的。
4、专页
通过创建特殊页面,自动调用相关文章形成列表,调用程序即可识别相关性。这时候这个页面上关键词的内容满足内容要求,也形成了一个不错的Page,排名在意料之中。
5、内容页面
内容页的排名策略很少见,但是最近很多人用内容页做排名,而且都是采集,主要是通过采集多张图片和视频组成一个页面,第一张图片视频无法被搜索引擎识别,将网站的第二张多张图片合二为一,伪原创的真相自然就出现了。
改变:
文章采集调用(【Python学习福利】豆瓣电影中如何运用多个网址请求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-09-25 15:10
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬豆豆应用中的难点和关键点,以及如何防止回爬等问题,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源代码的可以在后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家 查看全部
文章采集调用(【Python学习福利】豆瓣电影中如何运用多个网址请求)
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... %3D60
单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csvclass Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}" def main(self): passif __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、一个请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
[六、效果展示]
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影图片显示。
[七、总结]
1、 不建议抓取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬豆豆应用中的难点和关键点,以及如何防止回爬等问题,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
5、需要本文源代码的可以在后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享之家
文章采集调用(使用typecho程序搭建博客分享的函数代码,博主仅需要设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-24 13:05
使用 typecho 程序构建博客。如果想在网站页面的某个位置展示博主想要指定的几篇文章文章怎么办?不懂typecho开发的博主可以选择直接在模板文件中添加html代码。这显然不够灵活,添加、删除和修改非常不方便。下面博客栏分享的功能代码,博主只需要设置文章id就可以调用文章的列表显示出来,非常方便。
脚步:
1、在主题的functions.php文件中添加如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//by boke8.net
function boke8GetIdPosts($id){
if($id){
$getid = explode(',',$id);
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('status = ?','publish')
->where('type = ?', 'post')
->where('cid in ?',$getid)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
$i=1;
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的文章ID';
}
}
2、在要显示的位置对应的模板文件中添加如下调用代码文章:
1
其中1、4、6是要调用的文章id。你可以修改为你要调用的文章id。多个 id 用英文逗号分隔。
除非另有说明,文章将由博客整理发布,欢迎转载。 查看全部
文章采集调用(使用typecho程序搭建博客分享的函数代码,博主仅需要设置)
使用 typecho 程序构建博客。如果想在网站页面的某个位置展示博主想要指定的几篇文章文章怎么办?不懂typecho开发的博主可以选择直接在模板文件中添加html代码。这显然不够灵活,添加、删除和修改非常不方便。下面博客栏分享的功能代码,博主只需要设置文章id就可以调用文章的列表显示出来,非常方便。
脚步:
1、在主题的functions.php文件中添加如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//by boke8.net
function boke8GetIdPosts($id){
if($id){
$getid = explode(',',$id);
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('status = ?','publish')
->where('type = ?', 'post')
->where('cid in ?',$getid)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
$i=1;
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的文章ID';
}
}
2、在要显示的位置对应的模板文件中添加如下调用代码文章:
1
其中1、4、6是要调用的文章id。你可以修改为你要调用的文章id。多个 id 用英文逗号分隔。
除非另有说明,文章将由博客整理发布,欢迎转载。
文章采集调用(“量光尺”可以回答这个问题批量下载dng图片教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-24 08:02
文章采集调用的相机选项不同,例如所调用相机的可能性为jpeg、png、jpg、alpha。或者对于某些特殊格式(如.jpg),可能会需要对相机进行格式转换,所以文件需要进行另外设置,如bmp等。(不同厂商相机格式可能也会略有不同)文件大小因相机而异,反正有些m43相机(相当于sonyq5)是8mb,a7(相当于a7r)是7mb。批量操作时,可以先发布批量任务,然后采集好图片即可,然后批量将批量图片下载下来放在相机指定目录即可。
“量光尺”可以回答这个问题批量下载dng图片教程dng下载批量下载dng图片步骤1,文件分类,按照照片分别命名。例如“分辨率”、“位数”等。2,用批量下载软件来批量下载到电脑。3,电脑选好图片后,用邮件上传至服务器。4,根据接收邮件中dng文件的路径,上传图片。5,上传成功后,等待服务器主动下载。
设置每个图片的md5,然后跟位数之类的做比对,图片的位数是以一个二进制最高位为标准的,所以fg100的同一个图片可能最高位是51,
可以将所有图片用批量下载软件处理,以r057223606下载文件为例,我们只需要将r057223606文件下载到电脑中,然后我们运行批量下载软件处理完成, 查看全部
文章采集调用(“量光尺”可以回答这个问题批量下载dng图片教程)
文章采集调用的相机选项不同,例如所调用相机的可能性为jpeg、png、jpg、alpha。或者对于某些特殊格式(如.jpg),可能会需要对相机进行格式转换,所以文件需要进行另外设置,如bmp等。(不同厂商相机格式可能也会略有不同)文件大小因相机而异,反正有些m43相机(相当于sonyq5)是8mb,a7(相当于a7r)是7mb。批量操作时,可以先发布批量任务,然后采集好图片即可,然后批量将批量图片下载下来放在相机指定目录即可。
“量光尺”可以回答这个问题批量下载dng图片教程dng下载批量下载dng图片步骤1,文件分类,按照照片分别命名。例如“分辨率”、“位数”等。2,用批量下载软件来批量下载到电脑。3,电脑选好图片后,用邮件上传至服务器。4,根据接收邮件中dng文件的路径,上传图片。5,上传成功后,等待服务器主动下载。
设置每个图片的md5,然后跟位数之类的做比对,图片的位数是以一个二进制最高位为标准的,所以fg100的同一个图片可能最高位是51,
可以将所有图片用批量下载软件处理,以r057223606下载文件为例,我们只需要将r057223606文件下载到电脑中,然后我们运行批量下载软件处理完成,
文章采集调用(文章采集调用的视频及文本字幕特征识别(s标签))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-24 00:55
文章采集调用的cv库d2d2d,转为json传递给jd2d进行读取相应标签(s标签)的视频及文本字幕特征识别文本识别:text-rnn,
json格式对一个video进行文本标注
转为txt格式在jsonread函数中读取
用jsonread读取字幕数据
除了使用这些字幕数据之外,也可以尝试用txt读取器进行txt格式的字幕数据抓取,
可以参考下面这个函数:jsonreader字幕读取器pivot={"s":"theroute","i":"a1","o":"theroute","v":"photo","a":1,"b":1,"c":2,"d":3,"e":1,"f":"entry","g":"home","h":"scanner","g":"websearch","t":"video","j":"image","k":"red","m":"news","n":"popular's'}。
没听说过这个库python最为知名的库
现在有直接读取视频的脚本,github一搜一大把。但是你问的是中文字幕的话,这个我不知道。自己写过一个中文字幕读取脚本,用一种自己常用的方法。搜了一下,发现这种方法很简单,就不献丑了,可以百度学习下。 查看全部
文章采集调用(文章采集调用的视频及文本字幕特征识别(s标签))
文章采集调用的cv库d2d2d,转为json传递给jd2d进行读取相应标签(s标签)的视频及文本字幕特征识别文本识别:text-rnn,
json格式对一个video进行文本标注
转为txt格式在jsonread函数中读取
用jsonread读取字幕数据
除了使用这些字幕数据之外,也可以尝试用txt读取器进行txt格式的字幕数据抓取,
可以参考下面这个函数:jsonreader字幕读取器pivot={"s":"theroute","i":"a1","o":"theroute","v":"photo","a":1,"b":1,"c":2,"d":3,"e":1,"f":"entry","g":"home","h":"scanner","g":"websearch","t":"video","j":"image","k":"red","m":"news","n":"popular's'}。
没听说过这个库python最为知名的库
现在有直接读取视频的脚本,github一搜一大把。但是你问的是中文字幕的话,这个我不知道。自己写过一个中文字幕读取脚本,用一种自己常用的方法。搜了一下,发现这种方法很简单,就不献丑了,可以百度学习下。
文章采集调用(文章调用别人的服务器实现站内搜索功能的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-23 02:01
文章采集调用文档来采集文章,这就涉及到,平时看到的,朋友圈转发的链接,这些都是能采集的,或者想采集的,一般编写好采集代码就可以实现,也可以把采集的页面地址放到我的网站里面去实现自动采集也行。采集工具都是采集的别人的站点地址,可以通过编写采集代码实现自动采集的功能。了解更多干货文章可以关注笔者公众号:huangling_com,每天都有更新原创文章,欢迎大家来转载,也可以通过留言,交流学习。
可以使用python的urllib.request去调用别人的服务器实现站内搜索功能。想自己实现的话,我建议你学习python爬虫。
站内搜索的话,应该能直接调用或京东的网站,否则你就得爬数十个国内站点。另外,京东应该不是所有商品都放在同一个商品页面,有些商品是放在不同页面上的,你得通过google或百度去找到目标商品页面。另外,按你的需求,好像很多高佣的平台也都能爬,比如京东、客、返利网等等。当然如果你想要有趣的东西的话,我建议你找“全能搜索引擎google搜索”来练练手。
站内搜索还是比较麻烦的因为在同一商品页面可能有多个搜索页面。
我倒是知道直接爬取和京东的商品页面。直接有太多的选择了, 查看全部
文章采集调用(文章调用别人的服务器实现站内搜索功能的方法)
文章采集调用文档来采集文章,这就涉及到,平时看到的,朋友圈转发的链接,这些都是能采集的,或者想采集的,一般编写好采集代码就可以实现,也可以把采集的页面地址放到我的网站里面去实现自动采集也行。采集工具都是采集的别人的站点地址,可以通过编写采集代码实现自动采集的功能。了解更多干货文章可以关注笔者公众号:huangling_com,每天都有更新原创文章,欢迎大家来转载,也可以通过留言,交流学习。
可以使用python的urllib.request去调用别人的服务器实现站内搜索功能。想自己实现的话,我建议你学习python爬虫。
站内搜索的话,应该能直接调用或京东的网站,否则你就得爬数十个国内站点。另外,京东应该不是所有商品都放在同一个商品页面,有些商品是放在不同页面上的,你得通过google或百度去找到目标商品页面。另外,按你的需求,好像很多高佣的平台也都能爬,比如京东、客、返利网等等。当然如果你想要有趣的东西的话,我建议你找“全能搜索引擎google搜索”来练练手。
站内搜索还是比较麻烦的因为在同一商品页面可能有多个搜索页面。
我倒是知道直接爬取和京东的商品页面。直接有太多的选择了,
文章采集调用(全网收录最快百度快速收录排名系统测试当天收录无限裂变优化权重必备)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-21 11:23
收录是全网最快的百度fast收录排名系统。有必要在试验当天优化收录无限裂变的重量
导言:
这组程序的运行环境是PHP环境。在网站目录下创建一个辅助目录,例如XX目录。将程序放入这个XX目录,并配置相关设置文件,包括关键词、相关性文章、模板、标题等。该程序可以自动拆分Web链接并将其推送到百度24小时,以加速收录。操作非常简单,有教程,一步一步详细介绍!添加收录并将必要的程序排列到主站
支持软件:
1、关键词采集软件
采集几个与关键词相关的行业被插入到该计划中,以优化排名
@K22文章和title采集软件
点击全自动采集行业相关性文章和标题,软件会自动调用文章of采集来执行文章标题和内容,以增加内容相关性
3、自动裂变百度推送软件
自动无限分割网页链接并将其推送到百度,以加快蜘蛛爬行收录
测试效果演示。测试已经在收录进行了2天,一些关键词已经排名
有了视频教程,设置起来很方便。如果你不明白,你可以看视频来解决它
这个程序是由一个工作室开发的。这个网站花了3999元获得它。现在以低价卖给新老客户
PHP程序,自行研究。我们不提供免费的技术支持。我会原谅你的
把这个论坛放到程序目录中测试效果
2021年4月7日百度收录5W7432
2021年4月8日百度收录7W0098
疯狂收录
另一个试验场地效应
看到上面的数据是不是很棒?p>
发送百度推送软件
百度推送软件帮助您的网站引导百度蜘蛛爬行,并加速收录魔术软件
文件名:Baidu fast收录ranking system.rar
元宝比例:10元=100元;售价:3500元
下载权限:无限或VIP会员【购买VIP】【充值元宝】【拉大转盘赢取元宝】
安全检测,请放心下载
售价:350元=3500元 查看全部
文章采集调用(全网收录最快百度快速收录排名系统测试当天收录无限裂变优化权重必备)
收录是全网最快的百度fast收录排名系统。有必要在试验当天优化收录无限裂变的重量
导言:
这组程序的运行环境是PHP环境。在网站目录下创建一个辅助目录,例如XX目录。将程序放入这个XX目录,并配置相关设置文件,包括关键词、相关性文章、模板、标题等。该程序可以自动拆分Web链接并将其推送到百度24小时,以加速收录。操作非常简单,有教程,一步一步详细介绍!添加收录并将必要的程序排列到主站
支持软件:
1、关键词采集软件
采集几个与关键词相关的行业被插入到该计划中,以优化排名
@K22文章和title采集软件
点击全自动采集行业相关性文章和标题,软件会自动调用文章of采集来执行文章标题和内容,以增加内容相关性
3、自动裂变百度推送软件
自动无限分割网页链接并将其推送到百度,以加快蜘蛛爬行收录
测试效果演示。测试已经在收录进行了2天,一些关键词已经排名
有了视频教程,设置起来很方便。如果你不明白,你可以看视频来解决它
这个程序是由一个工作室开发的。这个网站花了3999元获得它。现在以低价卖给新老客户
PHP程序,自行研究。我们不提供免费的技术支持。我会原谅你的
把这个论坛放到程序目录中测试效果
2021年4月7日百度收录5W7432
2021年4月8日百度收录7W0098
疯狂收录
另一个试验场地效应
看到上面的数据是不是很棒?p>
发送百度推送软件
百度推送软件帮助您的网站引导百度蜘蛛爬行,并加速收录魔术软件
文件名:Baidu fast收录ranking system.rar
元宝比例:10元=100元;售价:3500元
下载权限:无限或VIP会员【购买VIP】【充值元宝】【拉大转盘赢取元宝】
安全检测,请放心下载
售价:350元=3500元
文章采集调用(引用计数策略和垃圾收集策略都属于资源的自动化管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-21 05:01
源链接:
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓的自动管理是指逻辑层不知道资源何时释放,而是依靠底层库来维持资源的生命周期
手动管理可以准确地了解资源的生命周期,并在准确的位置回收资源。在C++中,析构函数指定用于删除的资源,编译器生成的代码自动析构函数基类和成员变量
因此,为C++编写垃圾采集器与手动管理资源并不冲突。几乎所有大型C++项目都使用自动化管理,但它使用引用计数策略,而不是垃圾采集。也就是说,长期以来,我们采用C++或C语言,将人工管理和自动管理相结合来构建系统。无论是使用引用计数还是垃圾采集,我们仍然可以在软件实现的细节中管理手动管理
为什么使用自动资源生命周期管理
让我们看一下面向对象。如果一切都是一个物体,那么每个物体都应该对自己的生命负责。我们可以直接准确地确定死亡时间。不幸的是,很多东西都不是纯对象。最重要的是对象容器。除了它们自己的属性外,它们还维护对一组类似对象的引用
一个对象可以被多个容器引用,这使得容器不同于猫和狗的对象实体。因为容器指的是一个事物,它并不意味着它是容器的一部分(有时可以,有时不能)。当我们想把整个世界分成物体,所有原子都分成各个层次的物体时,我们会发现,物体无法提取的概念总数为零。引用而不是拥有是不可避免的
面向对象的本质是从许多对象中提取共性,并将它们一起处理。这样,各种容器的使用是不可避免的
同样,该对象不知道他是否可以宣布死亡。除非您知道自己与其他对象的关系(此关系不是对象)。资源可以是对象,而自动管理就是管理这些对象和对象之间的关系
引用计数是最容易实现的解决方案:记录对象被引用的次数,而不具体记录引用对象的人。这样,建立和取消引用的成本就降低了。然而,也有得失。在引用计数的过程中,我们也丢失了重要的信息:谁引用了我们自己。因此,在处理间接引用时,引用计数的成本更高
物体死亡的判断是物体是否与世界有直接或间接的联系。因此,即使一个对象被另一个对象直接引用,该对象也可能不存在。为了解决这个问题,使用引用计数的系统必须在与世界断开连接时通知与其关联的对象。目标销毁成本的增加是参考计数策略的短板
物体的破坏频率取决于物体的平均寿命。一方面,对象的生存时间受对象粒度的影响。对象粒度越细,对象的平均生存时间越短(虽然表面上没有直接联系,但在实际设计中往往会导致这种结果);另一方面,我们通常将容器和引用关系实现为一个对象(概念上,它不应该是一个对象)。例如,许多自动维护引用计数的智能指针是一个小容器,其中收录对对象的唯一引用,并且它是作为一个小对象实现的
通常,对象本身的性质不会随其在内存空间中的位置而改变。但是,引用关系(通常用指针实现)与内存地址有关。C++缺少用于在内存中移动对象的语义表达式。等效的方法是在一个新的内存块中复制和构造一个新对象,并销毁原创对象
另一方面,在程序的运行序列中,由函数调用引起的堆栈上的嵌套作用域也可以视为容器。机器指令通过这些作用域,临时构造的对象引用(智能指针)被放置在这些作用域中。函数调用越频繁,创建和销毁这些作用域的频率就越高
因此,C++必须依赖大量的内联函数来让编译器知道更多的上下文信息,从而减少创建和销毁小对象(智能指针)的负担。STL库也必须优化。例如,在STL端口中,pod类型被视为特例。不幸的是,智能指针不是pod,这使得编译器足够智能,可以在执行序列中合并引用的加减,这太困难了(考虑到多线程因素,除非编译器知道线程信息,否则几乎不可能实现)
在实现面向对象编程方面,C++比C更方便。其中之一是,当描述一个对象是另一个对象的一部分时,可以通过构造和析构函数机制自动维护相关部分的生命周期。但它在语言中未能解决的是,当两者之间只有一个参照关系时,如何处理生命周期。对于前者,我们几乎只有简洁明了的解决方案;后者可以根据实际需要有多种选择,而C++在语言级别上没有提供一致的解决方案。不幸的是,C++始终能够提供一个简洁且易于使用的通用GC库。我们都喜欢比较容易实现的参考计数方案。这一结果与具体实现的复杂性有关。毕竟,在实现GC时,C缺乏必要的语言支持(C++是在实现级别从C开发的)
让我们看看垃圾采集。更成熟的算法基于标记移除(或标记排序)或其变体。简而言之,采集器框架记录对象之间的关系(存储这些联系信息的位置并不重要。它可以位于对象的内存布局空间中,也可以位于独立的位置。关键是采集器可以访问这些信息)。确定世界的根,定期从此根遍历世界,标记关联的对象,最后回收未标记的对象
从算法的角度来看,建立对象之间连接的时间开销和参考计数的时间开销在数量级上是相同的,两者都是o(1))。然而,在实际实施中,前者的成本通常较高。空间成本也略高,但在数量级上没有差别
销毁GC管理的对象的成本要低得多。它不需要通知与其关联的对象
这就是为什么许多使用GC的软件有时比使用引用计数的软件更高效的原因
然而,GC在标记过程中需要额外的时间成本。完成一个完整的清洁过程必须穿越世界上每一个有生命的物体。成本为O(n),n随着对象总数的增加而增加。因此,我们应该减少GC管理的对象数量。在这方面,手工管理仍然是有意义的。也就是说,当一个对象显然是另一个对象的一部分时,可以考虑手动管理
另一个缺点是,在实现时,我们经常将对象之间的关联信息放在对象本身的内存布局空间中。在这个世界上遍历对象意味着访问所有对象的内存。当虚拟内存空间大于实际物理内存空间时,表示页面交换。我认为,在很大程度上,Java或c#等语言是一起使用的。构建的庞大系统有时运行缓慢,这是根本原因。当然,这些是可以改进的。这不是算法本身的问题
可以说,GC(垃圾采集)将RC(引用计数)中短期对象的销毁成本转移到一次性标记移除过程中。这是逻辑处理和资源管理的正交分解。随着硬件的进步(如多核开发),这种分解问题将更容易提高性能,但是,这种优势在小型软件或独立模块中并不明显。相反,GC本身的复杂性远远高于RC,这将成为它的弱点
对于不需要面向对象软件,甚至不需要自动资源管理的软件,GC或RC是无用的
我做的简单垃圾采集器只是想在为C或C++语言构建软件时做一些简单的尝试并做出更多的选择
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓自动管理是指逻辑层不知道资源何时释放,而是依赖底层库来维护资源的生命周期
在C++中,析构函数指定用于删除的资源,编译器生成的代码自动构造基类和成员变量
因此,为C++编写垃圾采集器与手动资源管理没有冲突。自动化管理在一个系统中使用 查看全部
文章采集调用(引用计数策略和垃圾收集策略都属于资源的自动化管理)
源链接:
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓的自动管理是指逻辑层不知道资源何时释放,而是依靠底层库来维持资源的生命周期
手动管理可以准确地了解资源的生命周期,并在准确的位置回收资源。在C++中,析构函数指定用于删除的资源,编译器生成的代码自动析构函数基类和成员变量
因此,为C++编写垃圾采集器与手动管理资源并不冲突。几乎所有大型C++项目都使用自动化管理,但它使用引用计数策略,而不是垃圾采集。也就是说,长期以来,我们采用C++或C语言,将人工管理和自动管理相结合来构建系统。无论是使用引用计数还是垃圾采集,我们仍然可以在软件实现的细节中管理手动管理
为什么使用自动资源生命周期管理
让我们看一下面向对象。如果一切都是一个物体,那么每个物体都应该对自己的生命负责。我们可以直接准确地确定死亡时间。不幸的是,很多东西都不是纯对象。最重要的是对象容器。除了它们自己的属性外,它们还维护对一组类似对象的引用
一个对象可以被多个容器引用,这使得容器不同于猫和狗的对象实体。因为容器指的是一个事物,它并不意味着它是容器的一部分(有时可以,有时不能)。当我们想把整个世界分成物体,所有原子都分成各个层次的物体时,我们会发现,物体无法提取的概念总数为零。引用而不是拥有是不可避免的
面向对象的本质是从许多对象中提取共性,并将它们一起处理。这样,各种容器的使用是不可避免的
同样,该对象不知道他是否可以宣布死亡。除非您知道自己与其他对象的关系(此关系不是对象)。资源可以是对象,而自动管理就是管理这些对象和对象之间的关系
引用计数是最容易实现的解决方案:记录对象被引用的次数,而不具体记录引用对象的人。这样,建立和取消引用的成本就降低了。然而,也有得失。在引用计数的过程中,我们也丢失了重要的信息:谁引用了我们自己。因此,在处理间接引用时,引用计数的成本更高
物体死亡的判断是物体是否与世界有直接或间接的联系。因此,即使一个对象被另一个对象直接引用,该对象也可能不存在。为了解决这个问题,使用引用计数的系统必须在与世界断开连接时通知与其关联的对象。目标销毁成本的增加是参考计数策略的短板
物体的破坏频率取决于物体的平均寿命。一方面,对象的生存时间受对象粒度的影响。对象粒度越细,对象的平均生存时间越短(虽然表面上没有直接联系,但在实际设计中往往会导致这种结果);另一方面,我们通常将容器和引用关系实现为一个对象(概念上,它不应该是一个对象)。例如,许多自动维护引用计数的智能指针是一个小容器,其中收录对对象的唯一引用,并且它是作为一个小对象实现的
通常,对象本身的性质不会随其在内存空间中的位置而改变。但是,引用关系(通常用指针实现)与内存地址有关。C++缺少用于在内存中移动对象的语义表达式。等效的方法是在一个新的内存块中复制和构造一个新对象,并销毁原创对象
另一方面,在程序的运行序列中,由函数调用引起的堆栈上的嵌套作用域也可以视为容器。机器指令通过这些作用域,临时构造的对象引用(智能指针)被放置在这些作用域中。函数调用越频繁,创建和销毁这些作用域的频率就越高
因此,C++必须依赖大量的内联函数来让编译器知道更多的上下文信息,从而减少创建和销毁小对象(智能指针)的负担。STL库也必须优化。例如,在STL端口中,pod类型被视为特例。不幸的是,智能指针不是pod,这使得编译器足够智能,可以在执行序列中合并引用的加减,这太困难了(考虑到多线程因素,除非编译器知道线程信息,否则几乎不可能实现)
在实现面向对象编程方面,C++比C更方便。其中之一是,当描述一个对象是另一个对象的一部分时,可以通过构造和析构函数机制自动维护相关部分的生命周期。但它在语言中未能解决的是,当两者之间只有一个参照关系时,如何处理生命周期。对于前者,我们几乎只有简洁明了的解决方案;后者可以根据实际需要有多种选择,而C++在语言级别上没有提供一致的解决方案。不幸的是,C++始终能够提供一个简洁且易于使用的通用GC库。我们都喜欢比较容易实现的参考计数方案。这一结果与具体实现的复杂性有关。毕竟,在实现GC时,C缺乏必要的语言支持(C++是在实现级别从C开发的)
让我们看看垃圾采集。更成熟的算法基于标记移除(或标记排序)或其变体。简而言之,采集器框架记录对象之间的关系(存储这些联系信息的位置并不重要。它可以位于对象的内存布局空间中,也可以位于独立的位置。关键是采集器可以访问这些信息)。确定世界的根,定期从此根遍历世界,标记关联的对象,最后回收未标记的对象
从算法的角度来看,建立对象之间连接的时间开销和参考计数的时间开销在数量级上是相同的,两者都是o(1))。然而,在实际实施中,前者的成本通常较高。空间成本也略高,但在数量级上没有差别
销毁GC管理的对象的成本要低得多。它不需要通知与其关联的对象
这就是为什么许多使用GC的软件有时比使用引用计数的软件更高效的原因
然而,GC在标记过程中需要额外的时间成本。完成一个完整的清洁过程必须穿越世界上每一个有生命的物体。成本为O(n),n随着对象总数的增加而增加。因此,我们应该减少GC管理的对象数量。在这方面,手工管理仍然是有意义的。也就是说,当一个对象显然是另一个对象的一部分时,可以考虑手动管理
另一个缺点是,在实现时,我们经常将对象之间的关联信息放在对象本身的内存布局空间中。在这个世界上遍历对象意味着访问所有对象的内存。当虚拟内存空间大于实际物理内存空间时,表示页面交换。我认为,在很大程度上,Java或c#等语言是一起使用的。构建的庞大系统有时运行缓慢,这是根本原因。当然,这些是可以改进的。这不是算法本身的问题
可以说,GC(垃圾采集)将RC(引用计数)中短期对象的销毁成本转移到一次性标记移除过程中。这是逻辑处理和资源管理的正交分解。随着硬件的进步(如多核开发),这种分解问题将更容易提高性能,但是,这种优势在小型软件或独立模块中并不明显。相反,GC本身的复杂性远远高于RC,这将成为它的弱点
对于不需要面向对象软件,甚至不需要自动资源管理的软件,GC或RC是无用的
我做的简单垃圾采集器只是想在为C或C++语言构建软件时做一些简单的尝试并做出更多的选择
从本质上讲,引用计数策略和垃圾采集策略都属于资源的自动管理。所谓自动管理是指逻辑层不知道资源何时释放,而是依赖底层库来维护资源的生命周期
在C++中,析构函数指定用于删除的资源,编译器生成的代码自动构造基类和成员变量
因此,为C++编写垃圾采集器与手动资源管理没有冲突。自动化管理在一个系统中使用
文章采集调用(Java™清洁工程师BrianGoetz探究了弱引用(weakreferences)问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-19 16:07
在Java理论与实践的前一期文章中,Java™ 清理工程师Brian Goetz探索弱引用,它允许您警告垃圾采集器您希望维护对对象的引用,而不阻止对象被垃圾采集。在本期文章中,他将解释另一种形式的引用对象,软引用,以帮助垃圾采集器管理内存使用并消除潜在的内存泄漏
垃圾采集可以防止Java程序内存泄漏,至少对于“内存泄漏”的狭义定义来说是这样,但这并不意味着我们可以完全忽略Java程序中的对象生存期问题。当我们没有对对象生命周期给予足够的关注或打破了管理对象生命周期的标准机制时,Java程序中经常会发生内存泄漏。例如,上次我们看到,在尝试将元数据与临时对象关联时,未能划分对象的生命周期可能会导致意外的对象保留。还有其他类似的情况会忽略或破坏对象生命周期管理,并导致内存泄漏
对象分离
清单1中的leakychecksum类说明了一种形式的内存泄漏,有时称为对象游荡,其中使用getfilechecksum()方法计算文件内容的校验和。getfilechecksum()方法将文件内容读入缓冲区以计算校验和。更直观的实现只是在getfilechecksum()中将缓冲区作为局部变量分配,但是这个版本比那个版本更“智能”,而不是在实例字段中缓存缓冲区以减少内存流失。这种“优化”通常不会带来预期的效益;对象分配比许多人预期的要便宜。(还要注意,将缓冲区从局部变量提升到实例变量会使类在没有额外同步的情况下不再是线程安全的。直观的实现不需要将getfilechecksum()声明为已同步,并且在同时调用时将提供更好的可伸缩性。)
清单1.显示了“对象分离”类
//BADCODE-DONOTE公式
publicclassLeakyChecksum{
privatebyte[]字节数组
PublicSynchronizedEntGetFileChecksum(StringfileName){
intlen=getFileSize(文件名)
if(bytearray==null | | bytearray.Length)管理。后一个选项通常更好,因为它为垃圾采集器带来更少的工作,并允许在特别需要内存时以更少的工作回收整个缓存。弱引用有时被错误地用于替换软引用来构建缓存,但这将导致缓存性能差。实际上,弱引用会在图像变弱后(通常在再次使用缓存对象之前)迅速清除它们吗?因为小型垃圾采集经常运行
对于性能严重依赖缓存的应用程序,软引用是一种无用的手段。它确实无法取代复杂的缓存框架,该框架可以提供灵活的终止、复制和事务缓存。但是,作为一种“廉价且肮脏”的缓存机制,降低价格非常有吸引力
与弱引用一样,还可以使用关联的引用队列创建软引用,该队列在垃圾回收器清除时进入队列。引用队列对于软引用没有弱引用有用,但它们可以用于发出应用程序内存开始耗尽的管理警报
垃圾采集器如何处理引用
弱引用和软引用都扩展了抽象引用类(幻影引用也是如此,稍后将在文章中描述)。引用对象由垃圾回收器以特殊方式处理。当垃圾回收器在跟踪堆期间遇到引用对象时,它不会标记或跟踪引用对象,而是将引用放置在已知活动引用对象的队列上。在跟踪之后,垃圾回收器会识别软访问对象吗?除软引用外,这些对象上没有强引用。垃圾回收器根据当前采集回收的内存总量和其他策略注意事项确定此时是否需要清除软引用。如果要清除的软引用具有相应的引用队列,则y将进入队列。剩余的软访问对象(未清除的对象)将被视为根集,堆跟踪将继续使用这些新根,以便可以标记通过活动软引用访问的对象
处理软引用后,将标识弱可及对象的集合?此类对象上没有强引用或软引用。这些对象将被清除并排队。所有引用类型在排队之前都会被清除,因此将进行事后处理。清除的线程将永远无法访问引用对象,但t仅指向引用对象。因此,当引用与引用队列一起使用时,通常需要细分适当的引用类型,并在设计中直接使用它(如weakhashmap,其map.entry扩展了WeakReference)或存储对需要清除的实体的引用
参考处理的性能成本
引用对象会给垃圾采集过程带来一些额外的成本。对于每个垃圾采集,必须构造一个活动引用对象的列表,并且必须适当地处理每个引用,这会增加每个采集的每个引用的一些开销,而不管此时是否采集引用引用对象本身接受垃圾采集,并且可以在引用对象之前进行采集,在这种情况下,它们不会添加到队列中
基于数组的集合
当使用数组实现堆栈或环形缓冲区等数据结构时,会出现另一种形式的对象分离在该方法中,在顶部指针递减后,元素仍然保留对将弹出堆栈的对象的引用。这意味着对该对象的引用仍然可以被程序访问(即使程序实际上不会使用该引用),它防止对象被垃圾采集,直到该位置被future push()重用为止
在基于数组的集合中列出3.对象
publicclassLeakyStack{
privateObject[]元素=新对象[MAX_元素]
privateintsize=0
publicvoidpush(Objecto){elements[size++]=o;}
publicObjectpop(){
如果(大小==0)
thrownewmptystackexception()
否则{
Objectresult=元素[--size]
//元素[大小+1]=空
返回结果
}
}
}
结论
与弱引用一样,软引用通过利用垃圾采集器在做出缓存采集决策时的帮助,有助于防止应用程序中的对象漂移。只有当应用程序能够容忍大量软引用对象时,软引用才适用
参考资料:
您可以在developerWorks全球网站上参考本文的英文原文
“Java理论与实践:用弱引用阻止内存泄漏”:上一期《Java理论与实践》介绍了类似的软引用
“关注性能:调优垃圾回收”:kirkpepperdine和JackShirazi证明,即使是缓慢的内存泄漏最终也会给垃圾回收器带来巨大压力
引用对象和垃圾采集:本文由sun在引用对象添加到类库后不久撰写,描述垃圾采集器如何处理引用对象
Java理论与实践:Brian Goetz的完整系列
Java技术专区:数百篇关于Java编程文章各个方面的文章@
获得产品和技术
Jtune:这个免费的Jtune工具利用GC日志,以图形方式显示堆大小、GC持续时间和其他有用的内存管理数据 查看全部
文章采集调用(Java™清洁工程师BrianGoetz探究了弱引用(weakreferences)问题)
在Java理论与实践的前一期文章中,Java™ 清理工程师Brian Goetz探索弱引用,它允许您警告垃圾采集器您希望维护对对象的引用,而不阻止对象被垃圾采集。在本期文章中,他将解释另一种形式的引用对象,软引用,以帮助垃圾采集器管理内存使用并消除潜在的内存泄漏
垃圾采集可以防止Java程序内存泄漏,至少对于“内存泄漏”的狭义定义来说是这样,但这并不意味着我们可以完全忽略Java程序中的对象生存期问题。当我们没有对对象生命周期给予足够的关注或打破了管理对象生命周期的标准机制时,Java程序中经常会发生内存泄漏。例如,上次我们看到,在尝试将元数据与临时对象关联时,未能划分对象的生命周期可能会导致意外的对象保留。还有其他类似的情况会忽略或破坏对象生命周期管理,并导致内存泄漏
对象分离
清单1中的leakychecksum类说明了一种形式的内存泄漏,有时称为对象游荡,其中使用getfilechecksum()方法计算文件内容的校验和。getfilechecksum()方法将文件内容读入缓冲区以计算校验和。更直观的实现只是在getfilechecksum()中将缓冲区作为局部变量分配,但是这个版本比那个版本更“智能”,而不是在实例字段中缓存缓冲区以减少内存流失。这种“优化”通常不会带来预期的效益;对象分配比许多人预期的要便宜。(还要注意,将缓冲区从局部变量提升到实例变量会使类在没有额外同步的情况下不再是线程安全的。直观的实现不需要将getfilechecksum()声明为已同步,并且在同时调用时将提供更好的可伸缩性。)
清单1.显示了“对象分离”类
//BADCODE-DONOTE公式
publicclassLeakyChecksum{
privatebyte[]字节数组
PublicSynchronizedEntGetFileChecksum(StringfileName){
intlen=getFileSize(文件名)
if(bytearray==null | | bytearray.Length)管理。后一个选项通常更好,因为它为垃圾采集器带来更少的工作,并允许在特别需要内存时以更少的工作回收整个缓存。弱引用有时被错误地用于替换软引用来构建缓存,但这将导致缓存性能差。实际上,弱引用会在图像变弱后(通常在再次使用缓存对象之前)迅速清除它们吗?因为小型垃圾采集经常运行
对于性能严重依赖缓存的应用程序,软引用是一种无用的手段。它确实无法取代复杂的缓存框架,该框架可以提供灵活的终止、复制和事务缓存。但是,作为一种“廉价且肮脏”的缓存机制,降低价格非常有吸引力
与弱引用一样,还可以使用关联的引用队列创建软引用,该队列在垃圾回收器清除时进入队列。引用队列对于软引用没有弱引用有用,但它们可以用于发出应用程序内存开始耗尽的管理警报
垃圾采集器如何处理引用
弱引用和软引用都扩展了抽象引用类(幻影引用也是如此,稍后将在文章中描述)。引用对象由垃圾回收器以特殊方式处理。当垃圾回收器在跟踪堆期间遇到引用对象时,它不会标记或跟踪引用对象,而是将引用放置在已知活动引用对象的队列上。在跟踪之后,垃圾回收器会识别软访问对象吗?除软引用外,这些对象上没有强引用。垃圾回收器根据当前采集回收的内存总量和其他策略注意事项确定此时是否需要清除软引用。如果要清除的软引用具有相应的引用队列,则y将进入队列。剩余的软访问对象(未清除的对象)将被视为根集,堆跟踪将继续使用这些新根,以便可以标记通过活动软引用访问的对象
处理软引用后,将标识弱可及对象的集合?此类对象上没有强引用或软引用。这些对象将被清除并排队。所有引用类型在排队之前都会被清除,因此将进行事后处理。清除的线程将永远无法访问引用对象,但t仅指向引用对象。因此,当引用与引用队列一起使用时,通常需要细分适当的引用类型,并在设计中直接使用它(如weakhashmap,其map.entry扩展了WeakReference)或存储对需要清除的实体的引用
参考处理的性能成本
引用对象会给垃圾采集过程带来一些额外的成本。对于每个垃圾采集,必须构造一个活动引用对象的列表,并且必须适当地处理每个引用,这会增加每个采集的每个引用的一些开销,而不管此时是否采集引用引用对象本身接受垃圾采集,并且可以在引用对象之前进行采集,在这种情况下,它们不会添加到队列中
基于数组的集合
当使用数组实现堆栈或环形缓冲区等数据结构时,会出现另一种形式的对象分离在该方法中,在顶部指针递减后,元素仍然保留对将弹出堆栈的对象的引用。这意味着对该对象的引用仍然可以被程序访问(即使程序实际上不会使用该引用),它防止对象被垃圾采集,直到该位置被future push()重用为止
在基于数组的集合中列出3.对象
publicclassLeakyStack{
privateObject[]元素=新对象[MAX_元素]
privateintsize=0
publicvoidpush(Objecto){elements[size++]=o;}
publicObjectpop(){
如果(大小==0)
thrownewmptystackexception()
否则{
Objectresult=元素[--size]
//元素[大小+1]=空
返回结果
}
}
}
结论
与弱引用一样,软引用通过利用垃圾采集器在做出缓存采集决策时的帮助,有助于防止应用程序中的对象漂移。只有当应用程序能够容忍大量软引用对象时,软引用才适用
参考资料:
您可以在developerWorks全球网站上参考本文的英文原文
“Java理论与实践:用弱引用阻止内存泄漏”:上一期《Java理论与实践》介绍了类似的软引用
“关注性能:调优垃圾回收”:kirkpepperdine和JackShirazi证明,即使是缓慢的内存泄漏最终也会给垃圾回收器带来巨大压力
引用对象和垃圾采集:本文由sun在引用对象添加到类库后不久撰写,描述垃圾采集器如何处理引用对象
Java理论与实践:Brian Goetz的完整系列
Java技术专区:数百篇关于Java编程文章各个方面的文章@
获得产品和技术
Jtune:这个免费的Jtune工具利用GC日志,以图形方式显示堆大小、GC持续时间和其他有用的内存管理数据
文章采集调用(【干货】强引用、软引用和幻象引用有什么区别?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-19 16:05
强参考、软参考、弱参考和幻影参考之间有什么区别
1.definition
强引用是最常见的对象引用。只要有一个指向某个对象的强引用,它就可以指示该对象仍然是“活动的”,并且垃圾采集器不会接触该对象。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。当然,具体的回收时间取决于垃圾采集策略
特点:在我们典型的代码中,Obj=newobject()是一个很强的引用。与关键字new创建的对象关联的引用是强引用。当JVM内存空间不足时,JVM宁愿抛出OfMemoryError runtime error(OOM),使程序异常终止,也不愿通过任意回收具有强引用的“活动”对象来解决内存不足的问题。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。具体的回收时间取决于垃圾采集策略
软引用是一种相对较强和较弱的引用,它可以使对象免于某些垃圾采集。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象。JVM确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用通常用于实现内存敏感缓存。如果有空闲内存,可以临时保留缓存,并在内存不足时进行清理,以确保在使用缓存时不会耗尽内存
特点:软参考通过软参考类实现。软参考文献的生命周期短于强参考文献。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象:也就是说,JVM将确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用可以与引用队列一起使用。如果软引用引用的对象被垃圾采集器回收,Java虚拟机将把软引用添加到关联的引用队列中。稍后,我们可以调用ReferenceQueue的poll()方法来检查它所关心的对象是否被回收。如果队列为空,则返回null;否则,该方法将返回队列前面的引用对象
应用场景:软引用通常用于实现对内存敏感的缓存。如果仍有可用内存,您可以暂时保留缓存,并在内存不足时将其清除,以确保缓存在使用时不会耗尽内存
弱引用不会免除对象的垃圾采集,但只提供了一种访问处于弱引用状态的对象的方法。这可以用于构建没有特定约束的关系。例如,维护非强制映射关系。如果试图获取对象时该对象仍然存在,请使用它,否则请重新实例化它。它也是许多缓存实现的一个选项
弱引用是通过WeakReference类实现的。弱引用的生命周期比软引用短。当垃圾采集器线程扫描其管辖下的内存区域时,一旦找到弱引用的对象,它将回收其内存,无论当前内存空间是否足够。由于垃圾采集器是一个低优先级线程,因此不需要快速回收弱引用对象。弱引用可以与引用队列一起使用。如果弱引用引用的对象被垃圾采集,Java虚拟机将把弱引用添加到关联的引用队列中
应用场景:弱应用程序也可用于内存敏感缓存
幻影引用有时会转换为虚拟引用,您无法通过虚拟引用访问对象。幻影引用只提供了一种机制来确保对象在最终确定后可以执行某些操作。例如,它通常用于执行所谓的事后清理机制(post-mortem cleaning mechanism)、在我的专栏文章中介绍的Java平台的清理机制,还有一些使用幻影引用来监视对象的创建和销毁
特点:虚拟引用也称为phantomreference,通过phantomreference类实现。无法通过虚拟引用访问对象的任何属性或函数。幻影引用只是提供了一种机制来确保对象在最终确定后执行某些操作。如果一个对象只收录虚拟引用,垃圾采集器可以随时将其回收,就像它没有引用一样。虚拟引用必须与ReferenceQueue结合使用。当垃圾采集器准备回收对象时,如果它发现它仍然有一个虚拟引用,它将在回收对象的内存之前将虚拟引用添加到关联的引用队列中
ReferenceQueue=newreferencequeue()
PhantomReference pr=新的PhantomReference(对象、队列)
通过判断虚拟引用是否已添加到引用队列,程序可以知道引用对象是否将被垃圾采集。如果程序发现已将虚拟引用添加到引用队列中,它可以在回收引用对象的内存之前执行一些程序操作
应用场景:它可以用来跟踪垃圾采集器回收的对象的活动。当垃圾采集器回收与虚拟引用关联的对象时,它将收到系统通知
2.对象可访问性分析
3.Reference
所有引用类型都是抽象类java.lang.ref.reference的子类。您可能会注意到,它提供了一个get()方法:
除了幻影引用(因为get总是返回null),如果对象没有被销毁,那么可以通过get方法获得原创对象。这意味着使用软引用和弱引用,我们可以将被访问对象重新指向强引用,即人为地改变对象的可访问性状态!这就是为什么我在上图中的一些地方画了双向箭头
因此,对于软引用和弱引用,垃圾采集器可能存在二次确认问题,以确保处于弱引用状态的对象不会更改为强引用
但是你认为这里可能有什么问题吗
是的,如果我们错误地维护强引用(例如,分配给静态变量),对象可能没有机会更改回类似于弱引用的可访问性状态,从而导致内存泄漏。因此,检查弱引用指向对象是否被垃圾采集也是诊断是否存在特定内存泄漏的一种方法。如果我们的框架使用弱引用并怀疑存在内存泄漏,我们可以从这个角度进行检查
4.ReferenceQueue
当我们创建各种引用并将它们与相应的对象关联时,我们可以选择是否关联引用队列。JVM将在特定时间引用队列。我们可以从队列中获取相关后续逻辑的引用(remove方法实际上意味着在这里获取它)。特别是对于phantom引用,get方法只返回null。如果未指定引用队列,则它基本上没有意义。请看下面的示例代码。使用引用队列,我们可以在对象处于相应状态时执行后处理逻辑(对于phantom reference,它已完成并处于phantom Reach状态)
Object counter = new Object();
ReferenceQueue refQueue = new ReferenceQueue();
PhantomReference p = new PhantomReference(counter, refQueue);
counter = null;
System.gc();
try {
// Remove是一个阻塞方法,可以指定timeout,或者选择一直阻塞
Reference ref = refQueue.remove(1000L);
if (ref != null) {
// do something
}
} catch (InterruptedException e) {
// Handle it
}
5.显式影响软引用垃圾采集
软引用通常在最后一次引用之后保留一段时间。默认值是基于剩余堆空间(以M字节为单位)计算的。来自Java1.3.1首先,提供了-XX:softreflrupolicymspermb参数。我们可以在毫秒内设置它。例如,以下示例设置为3秒(3000毫秒)
-XX:SoftRefLRUPolicyMSPerMB=3000
事实上,剩余空间将受到不同JVM模式的影响。对于客户端模式,如通常的windows 32位JDK,剩余空间用于计算当前堆中的可用大小,因此更倾向于循环使用;对于服务器模式JVM,它是根据-Xmx指定的最大值计算的
本质上,这种行为仍然是一个黑盒,具体取决于JVM实现。即使上述参数在新版本的JDK上也可能无效。此外,客户端模式下的JDK已逐渐退出历史舞台。因此,当我们应用时,我们可以参考类似的设置,但不要太依赖它
6.diagnose JVM引用
如果您怀疑应用程序存在由引用(或finalize)引起的回收问题,那么有许多工具或选项可供选择。例如,hotspot JVM本身提供了一个清晰的选项(printreferencegc)来获取相关信息
注意:JDK 9广泛地重构JVM和垃圾采集日志。Printgctimestamps和printreferencegc不再存在。我将在本专栏后面的垃圾采集主题中更系统地解释它们
7.Reachability篱笆
可以达到强参考的效果 查看全部
文章采集调用(【干货】强引用、软引用和幻象引用有什么区别?)
强参考、软参考、弱参考和幻影参考之间有什么区别
1.definition
强引用是最常见的对象引用。只要有一个指向某个对象的强引用,它就可以指示该对象仍然是“活动的”,并且垃圾采集器不会接触该对象。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。当然,具体的回收时间取决于垃圾采集策略
特点:在我们典型的代码中,Obj=newobject()是一个很强的引用。与关键字new创建的对象关联的引用是强引用。当JVM内存空间不足时,JVM宁愿抛出OfMemoryError runtime error(OOM),使程序异常终止,也不愿通过任意回收具有强引用的“活动”对象来解决内存不足的问题。对于普通对象,如果没有其他引用关系,只要它超出引用的范围或显式地将相应的(强)引用分配给null,就可以对其进行垃圾采集。具体的回收时间取决于垃圾采集策略
软引用是一种相对较强和较弱的引用,它可以使对象免于某些垃圾采集。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象。JVM确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用通常用于实现内存敏感缓存。如果有空闲内存,可以临时保留缓存,并在内存不足时进行清理,以确保在使用缓存时不会耗尽内存
特点:软参考通过软参考类实现。软参考文献的生命周期短于强参考文献。只有当JVM认为内存不足时,才会尝试回收软引用指向的对象:也就是说,JVM将确保在抛出outofmemoryerror之前清除软引用指向的对象。软引用可以与引用队列一起使用。如果软引用引用的对象被垃圾采集器回收,Java虚拟机将把软引用添加到关联的引用队列中。稍后,我们可以调用ReferenceQueue的poll()方法来检查它所关心的对象是否被回收。如果队列为空,则返回null;否则,该方法将返回队列前面的引用对象
应用场景:软引用通常用于实现对内存敏感的缓存。如果仍有可用内存,您可以暂时保留缓存,并在内存不足时将其清除,以确保缓存在使用时不会耗尽内存
弱引用不会免除对象的垃圾采集,但只提供了一种访问处于弱引用状态的对象的方法。这可以用于构建没有特定约束的关系。例如,维护非强制映射关系。如果试图获取对象时该对象仍然存在,请使用它,否则请重新实例化它。它也是许多缓存实现的一个选项
弱引用是通过WeakReference类实现的。弱引用的生命周期比软引用短。当垃圾采集器线程扫描其管辖下的内存区域时,一旦找到弱引用的对象,它将回收其内存,无论当前内存空间是否足够。由于垃圾采集器是一个低优先级线程,因此不需要快速回收弱引用对象。弱引用可以与引用队列一起使用。如果弱引用引用的对象被垃圾采集,Java虚拟机将把弱引用添加到关联的引用队列中
应用场景:弱应用程序也可用于内存敏感缓存
幻影引用有时会转换为虚拟引用,您无法通过虚拟引用访问对象。幻影引用只提供了一种机制来确保对象在最终确定后可以执行某些操作。例如,它通常用于执行所谓的事后清理机制(post-mortem cleaning mechanism)、在我的专栏文章中介绍的Java平台的清理机制,还有一些使用幻影引用来监视对象的创建和销毁
特点:虚拟引用也称为phantomreference,通过phantomreference类实现。无法通过虚拟引用访问对象的任何属性或函数。幻影引用只是提供了一种机制来确保对象在最终确定后执行某些操作。如果一个对象只收录虚拟引用,垃圾采集器可以随时将其回收,就像它没有引用一样。虚拟引用必须与ReferenceQueue结合使用。当垃圾采集器准备回收对象时,如果它发现它仍然有一个虚拟引用,它将在回收对象的内存之前将虚拟引用添加到关联的引用队列中
ReferenceQueue=newreferencequeue()
PhantomReference pr=新的PhantomReference(对象、队列)
通过判断虚拟引用是否已添加到引用队列,程序可以知道引用对象是否将被垃圾采集。如果程序发现已将虚拟引用添加到引用队列中,它可以在回收引用对象的内存之前执行一些程序操作
应用场景:它可以用来跟踪垃圾采集器回收的对象的活动。当垃圾采集器回收与虚拟引用关联的对象时,它将收到系统通知
2.对象可访问性分析
3.Reference
所有引用类型都是抽象类java.lang.ref.reference的子类。您可能会注意到,它提供了一个get()方法:
除了幻影引用(因为get总是返回null),如果对象没有被销毁,那么可以通过get方法获得原创对象。这意味着使用软引用和弱引用,我们可以将被访问对象重新指向强引用,即人为地改变对象的可访问性状态!这就是为什么我在上图中的一些地方画了双向箭头
因此,对于软引用和弱引用,垃圾采集器可能存在二次确认问题,以确保处于弱引用状态的对象不会更改为强引用
但是你认为这里可能有什么问题吗
是的,如果我们错误地维护强引用(例如,分配给静态变量),对象可能没有机会更改回类似于弱引用的可访问性状态,从而导致内存泄漏。因此,检查弱引用指向对象是否被垃圾采集也是诊断是否存在特定内存泄漏的一种方法。如果我们的框架使用弱引用并怀疑存在内存泄漏,我们可以从这个角度进行检查
4.ReferenceQueue
当我们创建各种引用并将它们与相应的对象关联时,我们可以选择是否关联引用队列。JVM将在特定时间引用队列。我们可以从队列中获取相关后续逻辑的引用(remove方法实际上意味着在这里获取它)。特别是对于phantom引用,get方法只返回null。如果未指定引用队列,则它基本上没有意义。请看下面的示例代码。使用引用队列,我们可以在对象处于相应状态时执行后处理逻辑(对于phantom reference,它已完成并处于phantom Reach状态)
Object counter = new Object();
ReferenceQueue refQueue = new ReferenceQueue();
PhantomReference p = new PhantomReference(counter, refQueue);
counter = null;
System.gc();
try {
// Remove是一个阻塞方法,可以指定timeout,或者选择一直阻塞
Reference ref = refQueue.remove(1000L);
if (ref != null) {
// do something
}
} catch (InterruptedException e) {
// Handle it
}
5.显式影响软引用垃圾采集
软引用通常在最后一次引用之后保留一段时间。默认值是基于剩余堆空间(以M字节为单位)计算的。来自Java1.3.1首先,提供了-XX:softreflrupolicymspermb参数。我们可以在毫秒内设置它。例如,以下示例设置为3秒(3000毫秒)
-XX:SoftRefLRUPolicyMSPerMB=3000
事实上,剩余空间将受到不同JVM模式的影响。对于客户端模式,如通常的windows 32位JDK,剩余空间用于计算当前堆中的可用大小,因此更倾向于循环使用;对于服务器模式JVM,它是根据-Xmx指定的最大值计算的
本质上,这种行为仍然是一个黑盒,具体取决于JVM实现。即使上述参数在新版本的JDK上也可能无效。此外,客户端模式下的JDK已逐渐退出历史舞台。因此,当我们应用时,我们可以参考类似的设置,但不要太依赖它
6.diagnose JVM引用
如果您怀疑应用程序存在由引用(或finalize)引起的回收问题,那么有许多工具或选项可供选择。例如,hotspot JVM本身提供了一个清晰的选项(printreferencegc)来获取相关信息
注意:JDK 9广泛地重构JVM和垃圾采集日志。Printgctimestamps和printreferencegc不再存在。我将在本专栏后面的垃圾采集主题中更系统地解释它们
7.Reachability篱笆
可以达到强参考的效果
文章采集调用(文章采集调用mysql的话,你可以不使用浏览器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-19 07:03
文章采集调用mysql的话,你可以不使用浏览器或者其他采集软件,可以直接用mysqlscript采集,给大家整理了一下资料,
一、安装mysql+cython环境在安装之前,我们要配置好mysql。
二、通过mysql调用cython的api非常简单直接,参照官方文档,即可实现。
#建立表createtable`abc`(`id`int(1
1)notnullauto_increment,`username`varchar(3
0)notnulldefaultnull,`password`varchar(3
0)notnulldefaultnull,`page`int(1
1)notnulldefaultnull);
三、mysql的参数配置a:数据库名b:binpath通常设置为:/tmp/mysql/bin这样我们的cython就能访问到mysql了.你还可以在更多的配置方式上进行探索。mysql数据库的配置例如,我们可以进一步配置数据库id在这个例子中代表的是id到username到page的这个列--c:/opt/cython/local/bin/mysql-c:/opt/cython/local/bin/mysql---d:c:/opt/cython/local/bin/mysql-e:。 查看全部
文章采集调用(文章采集调用mysql的话,你可以不使用浏览器)
文章采集调用mysql的话,你可以不使用浏览器或者其他采集软件,可以直接用mysqlscript采集,给大家整理了一下资料,
一、安装mysql+cython环境在安装之前,我们要配置好mysql。
二、通过mysql调用cython的api非常简单直接,参照官方文档,即可实现。
#建立表createtable`abc`(`id`int(1
1)notnullauto_increment,`username`varchar(3
0)notnulldefaultnull,`password`varchar(3
0)notnulldefaultnull,`page`int(1
1)notnulldefaultnull);
三、mysql的参数配置a:数据库名b:binpath通常设置为:/tmp/mysql/bin这样我们的cython就能访问到mysql了.你还可以在更多的配置方式上进行探索。mysql数据库的配置例如,我们可以进一步配置数据库id在这个例子中代表的是id到username到page的这个列--c:/opt/cython/local/bin/mysql-c:/opt/cython/local/bin/mysql---d:c:/opt/cython/local/bin/mysql-e:。
文章采集调用(换个网站你什么都做不了,这个教程是最详尽的教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-17 07:05
·我看到很多网友对织梦(Dedecms)采集教程感到头疼。事实上,官方教程太笼统了,什么也没说。你不能在网站做任何事情。本教程是最详细的教程。你一眼就能学会
首先,打开织梦background并单击采集-采集节点管理-添加新节点
这里我们以采集普通文章为例。我们选择普通文章然后确认
我们进入了采集的设置页面,并填写了节点名称,即为新节点命名。你可以在这里填写任何名字
然后打开所需采集的文章列表页面。在这里,我们以织梦官方网站为例打开此页面。右键单击以查看源文件
在字符集之后查找目标页代码
页面和其他页面的基本信息通常并不重要。填写后,请参见图
现在,让我们填写URL获取规则列表
请看文章列表第一页上的地址
比较第二页上的地址
我们发现它们除了49外,后面的数字是不同的,其他的都是一样的,所以我们可以这样写
(*).html
只需将1替换为(*),因为这里只有2页,所以让我们填写从1到2的增量。当然是1。2-1... 等于1
我们到此为止
可能您的一些采集列表没有规则,因此您必须手动指定列表URL,如图所示
每行写一页地址
当列表规则完成后,我们开始编写文章URL匹配规则并返回文章list页面
右键单击以查看源文件,并在区域的开头找到HTML,这是搜索文章列表开头的符号
我们可以很容易地在图中找到“新闻列表”。从这里开始,列表上的是文章
让我们在列表的末尾找到文章HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理为缩略图。根据您的需要选择
重新筛选区域网址:
(使用正则表达式)
必须包括:(优先于后者)
不能收录:
打开源文件时,您可以清楚地看到文章链接以结尾。HTML
因此,我们必须填写。收录后的HTML。如果有些清单很麻烦,我们也可以填写那些不能包括在内的清单
我们点击保存设置进入下一步,我们可以看到我们获得的文章网站
看到这一点是对的。我们保存信息并进入下一步设置内容字段获取规则
让我们看看文章是否有分页,然后随机输入一个文章。。我们看到这里有文章没有分页
所以这里我们默认
现在让我们来查找文章标题等等。只需输入一篇文章文章并右键单击即可查看源文件
看看这些
根据源代码填写
让我们填写文章开头和结尾
如上所述,找到开始和结束标志
开始:
完:
如果要在文章中过滤任何内容,请将其写入过滤规则,例如在文章中过滤图片@
选择常用规则
再次检查img
然后决定
通过这种方式,我们过滤文本中的图片
设置完成后,单击“保存设置并预览”
这样一个采集规则是编写的。这很简单。有些网站很难写,但我们需要更加努力
我们点击保存并开始采集-start采集网页,采集将在一段时间内完成
让我们看看我们采集k7得到了什么@
这似乎是一次成功。让我们导出数据
首先,选择要导入的列,然后按“请选择”在弹出窗口中选择要导入的列发布选项。除非您不想立即发布,否则它通常是默认值。默认情况下,每批导入有30个条目。它是否被修改并不重要。附加选项通常为“排除重复标题”。至于自动生成HTML的选项,建议不要先生成它,因为我们必须批量提取摘要和关键字 查看全部
文章采集调用(换个网站你什么都做不了,这个教程是最详尽的教程)
·我看到很多网友对织梦(Dedecms)采集教程感到头疼。事实上,官方教程太笼统了,什么也没说。你不能在网站做任何事情。本教程是最详细的教程。你一眼就能学会
首先,打开织梦background并单击采集-采集节点管理-添加新节点
这里我们以采集普通文章为例。我们选择普通文章然后确认
我们进入了采集的设置页面,并填写了节点名称,即为新节点命名。你可以在这里填写任何名字
然后打开所需采集的文章列表页面。在这里,我们以织梦官方网站为例打开此页面。右键单击以查看源文件
在字符集之后查找目标页代码
页面和其他页面的基本信息通常并不重要。填写后,请参见图
现在,让我们填写URL获取规则列表
请看文章列表第一页上的地址
比较第二页上的地址
我们发现它们除了49外,后面的数字是不同的,其他的都是一样的,所以我们可以这样写
(*).html
只需将1替换为(*),因为这里只有2页,所以让我们填写从1到2的增量。当然是1。2-1... 等于1
我们到此为止
可能您的一些采集列表没有规则,因此您必须手动指定列表URL,如图所示
每行写一页地址
当列表规则完成后,我们开始编写文章URL匹配规则并返回文章list页面
右键单击以查看源文件,并在区域的开头找到HTML,这是搜索文章列表开头的符号
我们可以很容易地在图中找到“新闻列表”。从这里开始,列表上的是文章
让我们在列表的末尾找到文章HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理为缩略图。根据您的需要选择
重新筛选区域网址:
(使用正则表达式)
必须包括:(优先于后者)
不能收录:
打开源文件时,您可以清楚地看到文章链接以结尾。HTML
因此,我们必须填写。收录后的HTML。如果有些清单很麻烦,我们也可以填写那些不能包括在内的清单
我们点击保存设置进入下一步,我们可以看到我们获得的文章网站
看到这一点是对的。我们保存信息并进入下一步设置内容字段获取规则
让我们看看文章是否有分页,然后随机输入一个文章。。我们看到这里有文章没有分页
所以这里我们默认
现在让我们来查找文章标题等等。只需输入一篇文章文章并右键单击即可查看源文件
看看这些
根据源代码填写
让我们填写文章开头和结尾
如上所述,找到开始和结束标志
开始:
完:
如果要在文章中过滤任何内容,请将其写入过滤规则,例如在文章中过滤图片@
选择常用规则
再次检查img
然后决定
通过这种方式,我们过滤文本中的图片
设置完成后,单击“保存设置并预览”
这样一个采集规则是编写的。这很简单。有些网站很难写,但我们需要更加努力
我们点击保存并开始采集-start采集网页,采集将在一段时间内完成
让我们看看我们采集k7得到了什么@
这似乎是一次成功。让我们导出数据
首先,选择要导入的列,然后按“请选择”在弹出窗口中选择要导入的列发布选项。除非您不想立即发布,否则它通常是默认值。默认情况下,每批导入有30个条目。它是否被修改并不重要。附加选项通常为“排除重复标题”。至于自动生成HTML的选项,建议不要先生成它,因为我们必须批量提取摘要和关键字
文章采集调用(灵动标签调用多表多模型(图)模型调用文章(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-15 20:05
灵动标签调用多表多模型调用文章
1、调用多模型的最新文章
[e:loop={'select * from (
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_movie where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_news where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_photo where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_flash where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_article where newstime) a order by newstime desc limit 10',10,24,1}]
[/e:loop]
帝国CMS多表调用最新信息,该演示代码为默认数据表下全站最新10条图片信息,自己根据需求可以附加条件,实现全站点击,全站头条,全站推荐等等.
---------------------------------------------------------------------------------
2、调用多模型的最新文章
[e:loop={'
select title,titleurl,titlepic from [!db.pre!]ecms_photo Union All
select title,titleurl,titlepic from [!db.pre!]ecms_download Union All
select title,titleurl,titlepic from [!db.pre!]ecms_news',0,24,0}]
[/e:loop]
注释:以上调用的是(图片模型:photo、下载模型:download、新闻模型:news)三个模型的文章
三个模型用“Union All”连接调用
若指定栏目用:where classid in(46,47,51),
若调用推荐在其后追加:and isgood=1,
若指定调用条数在其后追加:limit 10 查看全部
文章采集调用(灵动标签调用多表多模型(图)模型调用文章(组图))
灵动标签调用多表多模型调用文章
1、调用多模型的最新文章
[e:loop={'select * from (
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_movie where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_news where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_photo where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_flash where newstime union
select id,classid,titleurl,filename,title,newstime,titlepic from phome_ecms_article where newstime) a order by newstime desc limit 10',10,24,1}]
[/e:loop]
帝国CMS多表调用最新信息,该演示代码为默认数据表下全站最新10条图片信息,自己根据需求可以附加条件,实现全站点击,全站头条,全站推荐等等.
---------------------------------------------------------------------------------
2、调用多模型的最新文章
[e:loop={'
select title,titleurl,titlepic from [!db.pre!]ecms_photo Union All
select title,titleurl,titlepic from [!db.pre!]ecms_download Union All
select title,titleurl,titlepic from [!db.pre!]ecms_news',0,24,0}]
[/e:loop]
注释:以上调用的是(图片模型:photo、下载模型:download、新闻模型:news)三个模型的文章
三个模型用“Union All”连接调用
若指定栏目用:where classid in(46,47,51),
若调用推荐在其后追加:and isgood=1,
若指定调用条数在其后追加:limit 10
文章采集调用(Excel教程Excel函数代码如下()的详细内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-15 20:04
核心功能代码如下:
以上代码可以获取指定网页的内容。如果一切都得到了,那就容易多了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果要在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
可以根据需要修改特定信息
以上是ASP获取远程网页指定内容的实现代码的详细内容。有关获取远程网页内容的更多信息,请注意其他相关文章 查看全部
文章采集调用(Excel教程Excel函数代码如下()的详细内容)
核心功能代码如下:
以上代码可以获取指定网页的内容。如果一切都得到了,那就容易多了
代码如下:
'ASP获取远程网页指定内容开始
Dim wstr,str,url,start,over,dtime
url="http://sc.jb51.net/"
wstr=getHTTPPage(url)
body=wstr
如果要在本地保存代码
Dim wstr,str,url,start,over,dtime
url="https://www.jb51.net/"
wstr=getHTTPPage(url)
filename="index.htm"
if wstr"" and request("action")="makeindex" then
body=wstr
Set fso = Server.CreateObject("Scripting.FileSystemObject")
Set fout = fso.CreateTextFile(server.mappath(""&filename&""))
fout.Write body
fout.close
set fout=nothing
set fso=nothing
If Err.number=0 then
response.write("首页生成成功!!")
end if
end if
可以根据需要修改特定信息
以上是ASP获取远程网页指定内容的实现代码的详细内容。有关获取远程网页内容的更多信息,请注意其他相关文章
文章采集调用(孤狼微信公众号文章采集主要功能特色介绍! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-09-13 22:13
)
独狼数据采集平台为微信公众号文章提供采集,可以轻松发布到市面上主流系统,也可以定制一些冷门的网站接口!
一、孤狼微信公众号文章采集主要功能
1.根据公众号名称或ID指定公众号采集,支持输入多个公众号,公众号数量不限
2.多种图片下载存储方式(远程调用、本地化图片、ftp上传),解决公众号文章图片防盗链问题
3、强大的数据存储功能(采集到达的数据保存在本地数据库文件中)
4、简单配置即可轻松发布到主流网站或api接口
二、微信公号文章采集主要步骤
1、创建“添加公众号”任务
登录软件,打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到组。
2、填写采集的官方账号名或ID
填写基本信息如下图:
填写任务名称和采集微信公众号的名称或ID。提示:可以查看文章前后图片的自动过滤
使用广告图片功能删除广告(功能必须提前勾选)
使用官方账号标签
3、设置图片下载(可选)
由于微信公众号文章图片已经做了防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、Begin采集
图片配置好后,可以点击左上角的“采集”,采集data:
5、采集后期数据处理与发布
启动采集后,数据永远是采集,文章可以预览,显示图形内容,可以添加到“任务列表”页面查看:勾选文章,选择加入发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
查看全部
文章采集调用(孤狼微信公众号文章采集主要功能特色介绍!
)
独狼数据采集平台为微信公众号文章提供采集,可以轻松发布到市面上主流系统,也可以定制一些冷门的网站接口!
一、孤狼微信公众号文章采集主要功能
1.根据公众号名称或ID指定公众号采集,支持输入多个公众号,公众号数量不限
2.多种图片下载存储方式(远程调用、本地化图片、ftp上传),解决公众号文章图片防盗链问题
3、强大的数据存储功能(采集到达的数据保存在本地数据库文件中)
4、简单配置即可轻松发布到主流网站或api接口
二、微信公号文章采集主要步骤
1、创建“添加公众号”任务
登录软件,打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到组。
2、填写采集的官方账号名或ID
填写基本信息如下图:
填写任务名称和采集微信公众号的名称或ID。提示:可以查看文章前后图片的自动过滤
使用广告图片功能删除广告(功能必须提前勾选)
使用官方账号标签
3、设置图片下载(可选)
由于微信公众号文章图片已经做了防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、Begin采集
图片配置好后,可以点击左上角的“采集”,采集data:
5、采集后期数据处理与发布
启动采集后,数据永远是采集,文章可以预览,显示图形内容,可以添加到“任务列表”页面查看:勾选文章,选择加入发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
文章采集调用(高考志愿填报:文章采集调用的是去重特征吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-12 18:08
文章采集调用的是去重特征,机器一类特征应该可以,不过要找到一个好的去重算法,能够应对类数目,并且快速处理相似性排序。样本属性太多,带来的问题就是复杂度增加。
可以通过其他feature。比如通过一些docautographer。
那是应该是有去重功能,但由于海量数据,你的加法求平均肯定是不行,特征选择也不行。应该尝试一下朴素贝叶斯等非线性决策模型,甚至尝试集成方法,比如kaggle的bagging,均衡分布。
直接用关键词不是挺好吗?多个词相似有两种可能:1)关键词相似,但是有差异,比如:“好看”和“好看”,“好看”有100个词语,而“好看”只有20个。2)关键词相似,但是一个完全一样,另一个只是简单的借用词语,不是原作者内容或观点。比如:“万科”和“万科”,“中科院”和“中科院”。还有一个可能,就是其他人所说的去重,这个就需要用到数据预处理,去除重复词,其实训练也挺简单,你给定一个集合x,给定一个预测维度y,实验一下就知道。还有一个问题是为什么不用任何特征,直接求平均,都有人告诉我是为了多层感知机之类的去重。
感觉取词来做特征不够合理。如果取第一个词key做特征,再取词进行分类,那么首先是单词特征没有,其次就是预测结果太低,达不到结合词汇多少加权的要求。一般取整数词长特征,比如5cm。以“好看”做例子。取key5作为特征。5cm*00=50001。
去重之后0000000=5。分类损失是0.5。所以首先权重换算可以不用我说的这么麻烦,直接求平均就可以了。其次应该是词典大小的关系,词典越大,权重越高。建议语料库要尽可能大,词汇特征向量最好3m以上。具体可以基于文本分类的,比如共享词典什么的。 查看全部
文章采集调用(高考志愿填报:文章采集调用的是去重特征吗?)
文章采集调用的是去重特征,机器一类特征应该可以,不过要找到一个好的去重算法,能够应对类数目,并且快速处理相似性排序。样本属性太多,带来的问题就是复杂度增加。
可以通过其他feature。比如通过一些docautographer。
那是应该是有去重功能,但由于海量数据,你的加法求平均肯定是不行,特征选择也不行。应该尝试一下朴素贝叶斯等非线性决策模型,甚至尝试集成方法,比如kaggle的bagging,均衡分布。
直接用关键词不是挺好吗?多个词相似有两种可能:1)关键词相似,但是有差异,比如:“好看”和“好看”,“好看”有100个词语,而“好看”只有20个。2)关键词相似,但是一个完全一样,另一个只是简单的借用词语,不是原作者内容或观点。比如:“万科”和“万科”,“中科院”和“中科院”。还有一个可能,就是其他人所说的去重,这个就需要用到数据预处理,去除重复词,其实训练也挺简单,你给定一个集合x,给定一个预测维度y,实验一下就知道。还有一个问题是为什么不用任何特征,直接求平均,都有人告诉我是为了多层感知机之类的去重。
感觉取词来做特征不够合理。如果取第一个词key做特征,再取词进行分类,那么首先是单词特征没有,其次就是预测结果太低,达不到结合词汇多少加权的要求。一般取整数词长特征,比如5cm。以“好看”做例子。取key5作为特征。5cm*00=50001。
去重之后0000000=5。分类损失是0.5。所以首先权重换算可以不用我说的这么麻烦,直接求平均就可以了。其次应该是词典大小的关系,词典越大,权重越高。建议语料库要尽可能大,词汇特征向量最好3m以上。具体可以基于文本分类的,比如共享词典什么的。

