
文章采集调用
文章采集调用接口库是怎样的一种体验呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-03-27 22:04
文章采集调用接口库这些在前端常见的web网站中用到过,但是ifttt还是脱离不了feed流接口。至于模式:以组织性小、粒度大的数据流来实现,人为的组织各类数据。
不就是mongodb吗
模式太多,我是直接自己搭建数据库,然后写api来和后端连接。只是个人简单理解,以我对feed流的理解,feed流基本上可以分为postgresqlqueryalqueryal(除了搜索引擎,如prophet)还有postmatrix(贴吧)。楼主可以根据自己的需求再做扩展。
native访问:搜索引擎,prophet,postmatrix,embed。
我认为只要你喜欢什么形式、什么方式就算是好的模式,关键是要用得好,或者说如何用的好。我参与的三个项目有不同的模式。第一个是restful相关的,davidyu的一个作品,api-first,大概说的是用restfulapi的方式来使用python去连接,形成feed流,整体设计简单实现方便,就是写多了读多了语法不熟。
也是最近比较看重的,去思考,看看能不能用简单方式实现,也会去使用python。第二个是json,请求方式很简单,json-feed,和上面那个差不多,实现也容易。第三个是我自己写的第三方api,botji,实现起来不复杂,简单理解为feed流服务,这个主要实现了很多中间件的功能,虽然不能直接实现feed流的效果,但是基本的机制还是可以做到的。
服务器肯定是用的golang写的,也只是个人的一些实践,欢迎拍砖。最后说下,前端的话看情况,如果是api相关的话,不要用webview,用native的,可以省去很多麻烦。 查看全部
文章采集调用接口库是怎样的一种体验呢?
文章采集调用接口库这些在前端常见的web网站中用到过,但是ifttt还是脱离不了feed流接口。至于模式:以组织性小、粒度大的数据流来实现,人为的组织各类数据。
不就是mongodb吗
模式太多,我是直接自己搭建数据库,然后写api来和后端连接。只是个人简单理解,以我对feed流的理解,feed流基本上可以分为postgresqlqueryalqueryal(除了搜索引擎,如prophet)还有postmatrix(贴吧)。楼主可以根据自己的需求再做扩展。
native访问:搜索引擎,prophet,postmatrix,embed。
我认为只要你喜欢什么形式、什么方式就算是好的模式,关键是要用得好,或者说如何用的好。我参与的三个项目有不同的模式。第一个是restful相关的,davidyu的一个作品,api-first,大概说的是用restfulapi的方式来使用python去连接,形成feed流,整体设计简单实现方便,就是写多了读多了语法不熟。
也是最近比较看重的,去思考,看看能不能用简单方式实现,也会去使用python。第二个是json,请求方式很简单,json-feed,和上面那个差不多,实现也容易。第三个是我自己写的第三方api,botji,实现起来不复杂,简单理解为feed流服务,这个主要实现了很多中间件的功能,虽然不能直接实现feed流的效果,但是基本的机制还是可以做到的。
服务器肯定是用的golang写的,也只是个人的一些实践,欢迎拍砖。最后说下,前端的话看情况,如果是api相关的话,不要用webview,用native的,可以省去很多麻烦。
美国对数据采集卡DLL函数的调用摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-03-26 23:16
《襄樊大学学报》。 ,2004年第25届襄樊大学学报25 No. 5 LabVIEW调用数据采集卡DLL功能摘要:首先,介绍虚拟仪器的特性及其开发环境LabVIEW6,分析并实现将LabVIEW与外部代码连接的一种先进技术-动态链接库(DLL)。机制 。实践表明,该机制高效且易于实现,是增强LabVIEW与其他Windows应用程序之间的数据共享能力的好方法。 关键词:虚拟乐器; LabVIEW;动态链接库; DLL中文图书馆分类号:TN311。 11文档标记代码:A 文章序列号:1009-2854(200 4) 05-0015-03 0简介National Instruments NI基于G的开发环境LabVIEW的出现使虚拟仪器的概念得以连接所谓的虚拟仪器是在通用计算机平台上,用户可以根据自己的需求定义和设计仪器的测试功能,其实质是传统仪器硬件和最新的计算机软件技术都可以充分发挥作用。结合软件模块软件来实现和扩展传统仪器的功能,与系统仪器相比,虚拟仪器在智能,处理能力,性能价格比和可操作性方面更加智能,具有明显的技术优势。仪器工程工作台)是目前世界上使用最广泛的虚拟仪器开发环境之一,主要用于仪器控制,数据采集和数据分析。 ,数据显示等字段,并适用于许多不同的操作系统平台,例如Windows 9X / XP / 2000 / NT,Macintosh,UNIX。
与传统的编程语言不同,LabVIEW使用强大的图形语言(G语言)进行编程,面向测试工程师而非专业程序员,编程非常方便,人机交互界面直观友好,并且功能强大。数据可视化分析和手段控制能力等功能。使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度。 LabVIEW是真正的编译器。用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行。对于大多数编程任务,LabVIEW通常可以生成有效的代码。 1 LabVIEW调用外部程序代码的方法之一-动态链接库机制1.1动态链接库机制概述LabVIEW是功能强大的虚拟仪器开发环境,与GPIB,VXI,RS-23 2、 RS-完全集成在一起。 485插入数据采集卡与其他硬件通信。 LabVIEW还具有内置程序库,可通过DLL,共享库,ActiveX和其他方式提供大量连接机制,以实现与外部程序代码或软件系统的连接。 LabVIEW提供了四种调用外部程序代码的方法。其中,动态链接库(Dynamic Link LibraryDLL)机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法。
对于特定的实现,请使用LabVIEW函数模板“高级”子模板中的“调用库函数”节点。 “呼叫库功能节点”包括大量数据类型和呼叫规范。它可用于调用大多数标准共享库和用户定义的库中的函数,包括:Windows9X / XP / 2000 / NT下的动态链接库(动态链接库),Macintosh下的代码片段,UNIX下的共享库函数等。当用户需要调用的代码已经存在,或者用户熟悉Windows中的动态链接库,Macintosh中的代码段和UNIX中的共享库的创建过程时,“调用库功能节点”为非常有用,并且此时也最合适使用它,因为该图书馆使用的接收日期:2004-04-21资助项目:湖北省教育厅重点项目(2003A00 6))关于作者:刘传清(1964-)男,湖北鄂州人,襄樊大学物理系副教授15刘传清:LabVIEW调用data 采集卡DL函数16适用于多种开发环境的格式标准,用户可以ü几乎可以使用任何开发环境来创建LabVIEW可以调用的库。
1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的“动态链接库机制”来调用DLL,该DLL返回机器的名称。 1)创建“调用库函数节点”,创建一个新的LabVIEW程序“ hostname.vi”,并将其保存在新创建的目录“ d:\ temp”下。前面板如下:图1库函数调用前面板框图该程序如下:图2.库函数调用框图。其中,通过在功能模板的“高级”子模板中选择“调用库功能”功能模块来生成“调用库功能”节点。该LabVIEW程序通过“调用库函数节点”调用DLL。该DLL将返回计算机的名称,返回的结果将存储在字符串指示器“ Machine Name”中,然后进行字符串常量“ LabVIEW”和“ MachineName”的拼接,拼接结果显示在字符串指示器中“信息”。 2)配置“调用库功能节点”在程序框图程序窗口中双击“调用库功能节点”,然后在弹出的对话框中配置“调用库功能节点”:在“库名称路径”中“一种键入d:\ temp \ hostname。
dll”(即,指定此节点链接到的DLL文件的名称,源代码“ hostname.c”的编译源);在“功能名称”项中,键入“ MachineName”(即是,在链接的DLL文件中指定单击函数的名称)的名称;参数“返回类型”的类型选择“无效”;添加的参数“ arg1”的类型选择“字符串”,并且字符串格式选择“字符串句柄”; 3)编辑C源文件编辑“ C源文件”主机名。 c”(存储在目录“ d:\ temp”中),其内容如下:includeextcode.h,其中收录LabVIEW函数__declspec(dllexport)void MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; int compNameLength MAX_COMPUTERNAME_LENGTH + 1;第25襄樊学院学报2004 Getcomputer名GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄的正确大小DSSetHandleSize(HandleSize) * int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数“ GetComputerName”以获取计算机名称;然后调用LabVIEW函数“ DSSetHandleSize”来设置LabVIEW句柄的大小;最后,将计算机名的长度(32位整数)和计算机名(字符串)依次写入到句柄中。
4)编译C源代码源代码“ d:\ temp \ hostname.c”被编译为DLL文件“ d:\ temp \ hostname.dll”。您可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译。 5)运行VI,以运行LabVIEW程序“ hostname.vi”,结果如下:图3前面板运行结果2结束语本文着重介绍和实现一种将LabVIEW与外部代码连接的高级技术。 ,动态链接库机制,并给出一个应用示例。由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善。该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现。实践证明,该方法高效且易于实现,是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法。参考资料:National Instruments Corporation,LabVIEW用户手册,1998。NationalInstruments Corporation,编程参考手册,1998。
LabVIEW数据采集调用DLL函数刘传庆(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW,分析了先进技术-动态链接库(DLL),一般方法调用外部LabVIEW中的代码。事实证明,Goodone可以增强LabVIEW在Windows中共享数据的其他应用程序。关键词:虚拟仪器; LabVIEW;动态链接库 查看全部
美国对数据采集卡DLL函数的调用摘要
《襄樊大学学报》。 ,2004年第25届襄樊大学学报25 No. 5 LabVIEW调用数据采集卡DLL功能摘要:首先,介绍虚拟仪器的特性及其开发环境LabVIEW6,分析并实现将LabVIEW与外部代码连接的一种先进技术-动态链接库(DLL)。机制 。实践表明,该机制高效且易于实现,是增强LabVIEW与其他Windows应用程序之间的数据共享能力的好方法。 关键词:虚拟乐器; LabVIEW;动态链接库; DLL中文图书馆分类号:TN311。 11文档标记代码:A 文章序列号:1009-2854(200 4) 05-0015-03 0简介National Instruments NI基于G的开发环境LabVIEW的出现使虚拟仪器的概念得以连接所谓的虚拟仪器是在通用计算机平台上,用户可以根据自己的需求定义和设计仪器的测试功能,其实质是传统仪器硬件和最新的计算机软件技术都可以充分发挥作用。结合软件模块软件来实现和扩展传统仪器的功能,与系统仪器相比,虚拟仪器在智能,处理能力,性能价格比和可操作性方面更加智能,具有明显的技术优势。仪器工程工作台)是目前世界上使用最广泛的虚拟仪器开发环境之一,主要用于仪器控制,数据采集和数据分析。 ,数据显示等字段,并适用于许多不同的操作系统平台,例如Windows 9X / XP / 2000 / NT,Macintosh,UNIX。
与传统的编程语言不同,LabVIEW使用强大的图形语言(G语言)进行编程,面向测试工程师而非专业程序员,编程非常方便,人机交互界面直观友好,并且功能强大。数据可视化分析和手段控制能力等功能。使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度。 LabVIEW是真正的编译器。用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行。对于大多数编程任务,LabVIEW通常可以生成有效的代码。 1 LabVIEW调用外部程序代码的方法之一-动态链接库机制1.1动态链接库机制概述LabVIEW是功能强大的虚拟仪器开发环境,与GPIB,VXI,RS-23 2、 RS-完全集成在一起。 485插入数据采集卡与其他硬件通信。 LabVIEW还具有内置程序库,可通过DLL,共享库,ActiveX和其他方式提供大量连接机制,以实现与外部程序代码或软件系统的连接。 LabVIEW提供了四种调用外部程序代码的方法。其中,动态链接库(Dynamic Link LibraryDLL)机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法。
对于特定的实现,请使用LabVIEW函数模板“高级”子模板中的“调用库函数”节点。 “呼叫库功能节点”包括大量数据类型和呼叫规范。它可用于调用大多数标准共享库和用户定义的库中的函数,包括:Windows9X / XP / 2000 / NT下的动态链接库(动态链接库),Macintosh下的代码片段,UNIX下的共享库函数等。当用户需要调用的代码已经存在,或者用户熟悉Windows中的动态链接库,Macintosh中的代码段和UNIX中的共享库的创建过程时,“调用库功能节点”为非常有用,并且此时也最合适使用它,因为该图书馆使用的接收日期:2004-04-21资助项目:湖北省教育厅重点项目(2003A00 6))关于作者:刘传清(1964-)男,湖北鄂州人,襄樊大学物理系副教授15刘传清:LabVIEW调用data 采集卡DL函数16适用于多种开发环境的格式标准,用户可以ü几乎可以使用任何开发环境来创建LabVIEW可以调用的库。
1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的“动态链接库机制”来调用DLL,该DLL返回机器的名称。 1)创建“调用库函数节点”,创建一个新的LabVIEW程序“ hostname.vi”,并将其保存在新创建的目录“ d:\ temp”下。前面板如下:图1库函数调用前面板框图该程序如下:图2.库函数调用框图。其中,通过在功能模板的“高级”子模板中选择“调用库功能”功能模块来生成“调用库功能”节点。该LabVIEW程序通过“调用库函数节点”调用DLL。该DLL将返回计算机的名称,返回的结果将存储在字符串指示器“ Machine Name”中,然后进行字符串常量“ LabVIEW”和“ MachineName”的拼接,拼接结果显示在字符串指示器中“信息”。 2)配置“调用库功能节点”在程序框图程序窗口中双击“调用库功能节点”,然后在弹出的对话框中配置“调用库功能节点”:在“库名称路径”中“一种键入d:\ temp \ hostname。
dll”(即,指定此节点链接到的DLL文件的名称,源代码“ hostname.c”的编译源);在“功能名称”项中,键入“ MachineName”(即是,在链接的DLL文件中指定单击函数的名称)的名称;参数“返回类型”的类型选择“无效”;添加的参数“ arg1”的类型选择“字符串”,并且字符串格式选择“字符串句柄”; 3)编辑C源文件编辑“ C源文件”主机名。 c”(存储在目录“ d:\ temp”中),其内容如下:includeextcode.h,其中收录LabVIEW函数__declspec(dllexport)void MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; int compNameLength MAX_COMPUTERNAME_LENGTH + 1;第25襄樊学院学报2004 Getcomputer名GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄的正确大小DSSetHandleSize(HandleSize) * int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数“ GetComputerName”以获取计算机名称;然后调用LabVIEW函数“ DSSetHandleSize”来设置LabVIEW句柄的大小;最后,将计算机名的长度(32位整数)和计算机名(字符串)依次写入到句柄中。
4)编译C源代码源代码“ d:\ temp \ hostname.c”被编译为DLL文件“ d:\ temp \ hostname.dll”。您可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译。 5)运行VI,以运行LabVIEW程序“ hostname.vi”,结果如下:图3前面板运行结果2结束语本文着重介绍和实现一种将LabVIEW与外部代码连接的高级技术。 ,动态链接库机制,并给出一个应用示例。由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善。该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现。实践证明,该方法高效且易于实现,是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法。参考资料:National Instruments Corporation,LabVIEW用户手册,1998。NationalInstruments Corporation,编程参考手册,1998。
LabVIEW数据采集调用DLL函数刘传庆(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW,分析了先进技术-动态链接库(DLL),一般方法调用外部LabVIEW中的代码。事实证明,Goodone可以增强LabVIEW在Windows中共享数据的其他应用程序。关键词:虚拟仪器; LabVIEW;动态链接库
用python爬取实现方法:anyproxy代理批量采集实现教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2021-03-26 21:05
微信公众号文章抓取方法安排1.使用python抓取
实现方法:通过微信提供的官方账号文章调用该界面,实现对官方账号文章的抓取功能。
步骤:
1.需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie,以达到登录效果;
2.要使用WebDriver功能,需要安装与浏览器相对应的驱动程序插件。我在这里使用Google Chrome浏览器进行测试:
Google Chrome版本为5 2. 0. 274 3. 6;
chromedriver版本为:V 2. 23
注意:Google Chrome版本和chromedriver需要对应,否则启动时会导致错误。 [附:Selenium的chromedriver和chrome版本映射表(已更新为v 2. 3 0))]
3.微信官方帐户登录地址:
4.微信公众号文章界面地址可以在微信公众号的后台创建,以创建新的图形消息,可以通过超链接功能获得:
5.搜索官方帐户名
6.获取要抓取的官方帐户的伪造物
7.选择要爬网的官方帐户,并获取文章界面地址
8. 文章列表翻页和内容获取
2. AnyProxy代理批处理采集
如何实现:anyproxy + js
如何实现:anyproxy + java + webmagic
3. FiddlerCore
实施方法:数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1。编写按钮向导脚本,并自动单击电话上的公用号码文章列表页面,即“查看历史消息”;
2,使用提琴手代理劫持手机的访问权限,并将URL转发到用php编写的本地网页;
3。将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网。
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果您想在一定频率后捕获读数和喜欢的次数,则返回变为空值,我设置的时间间隔为10秒,可以正常爬网。以这种频率,一个小时内只能抓取360条记录,这没有任何实际意义。
4.青波新榜
如果您只想查看数据,则直接查看每日列表,无需花钱。如果您需要连接到自己的系统,它们还提供api接口 查看全部
用python爬取实现方法:anyproxy代理批量采集实现教程
微信公众号文章抓取方法安排1.使用python抓取
实现方法:通过微信提供的官方账号文章调用该界面,实现对官方账号文章的抓取功能。
步骤:
1.需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie,以达到登录效果;
2.要使用WebDriver功能,需要安装与浏览器相对应的驱动程序插件。我在这里使用Google Chrome浏览器进行测试:
Google Chrome版本为5 2. 0. 274 3. 6;
chromedriver版本为:V 2. 23
注意:Google Chrome版本和chromedriver需要对应,否则启动时会导致错误。 [附:Selenium的chromedriver和chrome版本映射表(已更新为v 2. 3 0))]
3.微信官方帐户登录地址:
4.微信公众号文章界面地址可以在微信公众号的后台创建,以创建新的图形消息,可以通过超链接功能获得:
5.搜索官方帐户名
6.获取要抓取的官方帐户的伪造物
7.选择要爬网的官方帐户,并获取文章界面地址
8. 文章列表翻页和内容获取
2. AnyProxy代理批处理采集
如何实现:anyproxy + js
如何实现:anyproxy + java + webmagic
3. FiddlerCore
实施方法:数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1。编写按钮向导脚本,并自动单击电话上的公用号码文章列表页面,即“查看历史消息”;
2,使用提琴手代理劫持手机的访问权限,并将URL转发到用php编写的本地网页;
3。将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网。
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果您想在一定频率后捕获读数和喜欢的次数,则返回变为空值,我设置的时间间隔为10秒,可以正常爬网。以这种频率,一个小时内只能抓取360条记录,这没有任何实际意义。
4.青波新榜
如果您只想查看数据,则直接查看每日列表,无需花钱。如果您需要连接到自己的系统,它们还提供api接口
wordpress采集页简单改造调用代码和说明,提升收录量
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-03-26 20:16
郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
昨天花了一些时间对Zheng Gang的SEO培训网站进行了简单的页面调整,主要的修改是采集页面。
此网站是用WP制作的,因此,如果您还使用WP来构建网站或使用采集的内容,则可以将此文章标记为书签。这些都是进行亲测的有效代码和操作方法。
主要目的是使页面采集与原创内容的变化至少与原创内容有所不同,并进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、 [修改页面:single.php]
只需将上面的代码放在您想要的任何页面或位置上,就可以直接调用随机TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这就是随机标签。
原因:此操作是使每个页面调用不同的随机标记以提高选项卡页面收录的可能性和进入率,因为WP的主要排名主要是TAG选项卡页面。
2、 采集将随机图片插入内容页面**
第1步:修改第1页:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面的底部,然后单击“保存”。请记住用您的URL替换中间的URL。
第2步:修改第2页:single.php
<p> 查看全部
wordpress采集页简单改造调用代码和说明,提升收录量
郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
 https://p3.pstatp.com/large/pg ... 2ad33b" />
https://p3.pstatp.com/large/pg ... 2ad33b" />郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
昨天花了一些时间对Zheng Gang的SEO培训网站进行了简单的页面调整,主要的修改是采集页面。
此网站是用WP制作的,因此,如果您还使用WP来构建网站或使用采集的内容,则可以将此文章标记为书签。这些都是进行亲测的有效代码和操作方法。
主要目的是使页面采集与原创内容的变化至少与原创内容有所不同,并进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、 [修改页面:single.php]
只需将上面的代码放在您想要的任何页面或位置上,就可以直接调用随机TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这就是随机标签。
原因:此操作是使每个页面调用不同的随机标记以提高选项卡页面收录的可能性和进入率,因为WP的主要排名主要是TAG选项卡页面。
2、 采集将随机图片插入内容页面**
第1步:修改第1页:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面的底部,然后单击“保存”。请记住用您的URL替换中间的URL。
第2步:修改第2页:single.php
<p>
侧边栏文章调用不够灵活?试试UltimatePosts插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-03-26 04:19
文章目录[隐藏]
您认为WordPress主题的侧边栏文章不够灵活吗?想在侧边栏小部件中调用更多文章吗?倡导者建议您尝试使用Ultimate Ultimates Widget插件。
终极帖子小部件简介
Ultimate Posts Widget可以被认为是功能最强大的WordPress侧边栏文章调用插件(至少为Advocate所熟知)。主要功能如下:
有关更多详细信息,请参阅屏幕截图或下载体验:
最终帖子小部件下载
您可以在后台插件安装界面上搜索Ultimate Posts Widget以在线安装,或在此处下载Ultimate Posts Widget。
如果您是WordPress主题开发人员,则可以考虑将其集成到主题中,这非常令人寒心!但是,您也可以考虑添加文章的“观看次数”最多,并添加一个时间段(一个月,六个月等),这不只是鸡冻!
声明:除非另有说明或标记,否则本网站上的所有文章均已发布在本网站原创上。未经本网站同意,任何个人或组织均不得将本网站的内容复制,挪用,采集或发布到任何网站,书籍和其他媒体平台。如果本网站的内容侵犯了原作者的合法权益,则可以与我们联系进行处理。 查看全部
侧边栏文章调用不够灵活?试试UltimatePosts插件
文章目录[隐藏]
您认为WordPress主题的侧边栏文章不够灵活吗?想在侧边栏小部件中调用更多文章吗?倡导者建议您尝试使用Ultimate Ultimates Widget插件。
终极帖子小部件简介
Ultimate Posts Widget可以被认为是功能最强大的WordPress侧边栏文章调用插件(至少为Advocate所熟知)。主要功能如下:
有关更多详细信息,请参阅屏幕截图或下载体验:

最终帖子小部件下载
您可以在后台插件安装界面上搜索Ultimate Posts Widget以在线安装,或在此处下载Ultimate Posts Widget。
如果您是WordPress主题开发人员,则可以考虑将其集成到主题中,这非常令人寒心!但是,您也可以考虑添加文章的“观看次数”最多,并添加一个时间段(一个月,六个月等),这不只是鸡冻!
声明:除非另有说明或标记,否则本网站上的所有文章均已发布在本网站原创上。未经本网站同意,任何个人或组织均不得将本网站的内容复制,挪用,采集或发布到任何网站,书籍和其他媒体平台。如果本网站的内容侵犯了原作者的合法权益,则可以与我们联系进行处理。
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 496 次浏览 • 2021-03-25 21:14
pboot cms 文章(PbootDemoSkycaiji)插件直接在优采云 采集器云平台上下载并使用。该插件是由Little Mango开发的,没有皮肤。该插件默认为只能发布新闻专栏,并且对产品案例进行过滤,并且需要您自己手动进行修改。
下载该插件后,我们可以在网站根目录优采云 采集器安装中找到该路径:网站根目录采集器安装目录pluginlease cms PbootDemoSkycaiji.php
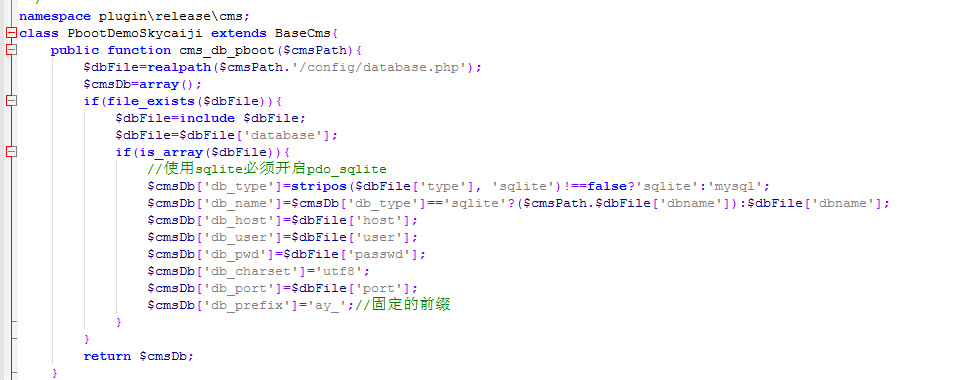
打开此文件开头的代码意味着自动读取我们的数据库信息,无论是mysql还是sqlite数据库,它都是相同的,并且会自动获取链接。
以下是与网站相对应的信息,例如作者,文章内容,产品分类,缩略图等,在这里我们可以根据网站的需求添加更多参数。
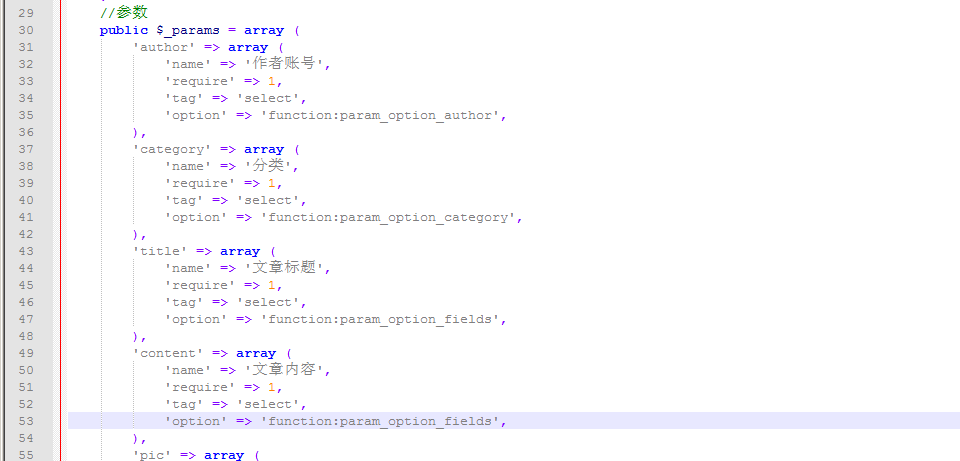
此处的信息对应于我们的网站数据库中的字段。如果此处没有字段,则可以直接输入数据库并将其添加。要注意的一件事是,此处的数据库字段应与先前的字段相同。对应参数。例如,如果将缩略图添加到我们的参数中,那么我们必须找到该字段并填写在参数中添加的名称。
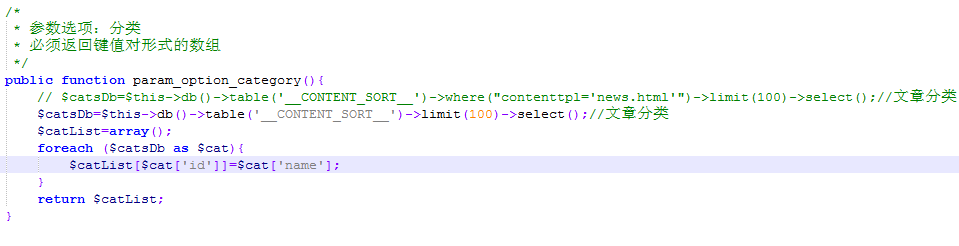
此处的默认设置是过滤其他目录,仅获取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们要做的就是添加
// $ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> where(“ contenttpl ='news.html'”)-> limit(10 0)-> select() ; // 文章您可以注释掉或删除分类。
添加$ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> limit(10 0)-> select(); // 文章分类很好,默认为匹配全部[k14的目录]。上面是pboot cms 文章(PbootDemoSkycaiji)插件的详细介绍。阅读上面的描述后基本上没有问题,如果您还是不明白,请请咨询我们。
相关知识点:
此站点文章摘自Shurong网络上的权威信息,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢... 查看全部
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台
pboot cms 文章(PbootDemoSkycaiji)插件直接在优采云 采集器云平台上下载并使用。该插件是由Little Mango开发的,没有皮肤。该插件默认为只能发布新闻专栏,并且对产品案例进行过滤,并且需要您自己手动进行修改。
下载该插件后,我们可以在网站根目录优采云 采集器安装中找到该路径:网站根目录采集器安装目录pluginlease cms PbootDemoSkycaiji.php
打开此文件开头的代码意味着自动读取我们的数据库信息,无论是mysql还是sqlite数据库,它都是相同的,并且会自动获取链接。
以下是与网站相对应的信息,例如作者,文章内容,产品分类,缩略图等,在这里我们可以根据网站的需求添加更多参数。

此处的信息对应于我们的网站数据库中的字段。如果此处没有字段,则可以直接输入数据库并将其添加。要注意的一件事是,此处的数据库字段应与先前的字段相同。对应参数。例如,如果将缩略图添加到我们的参数中,那么我们必须找到该字段并填写在参数中添加的名称。
此处的默认设置是过滤其他目录,仅获取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们要做的就是添加
// $ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> where(“ contenttpl ='news.html'”)-> limit(10 0)-> select() ; // 文章您可以注释掉或删除分类。
添加$ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> limit(10 0)-> select(); // 文章分类很好,默认为匹配全部[k14的目录]。上面是pboot cms 文章(PbootDemoSkycaiji)插件的详细介绍。阅读上面的描述后基本上没有问题,如果您还是不明白,请请咨询我们。
相关知识点:
此站点文章摘自Shurong网络上的权威信息,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...
动易DELPHI、VC、VB、JB、AURL、string区别
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-03-24 04:13
谈到网页采集,人们通常认为他们从Internet窃取数据,然后将采集的数据发布到自己的Internet中。实际上,您还可以将采集中获得的数据用作公司的参考,或者将采集的数据与公司的业务等进行比较。
当前,网页采集主要是3P代码(3P表示ASP,PHP,JSP)。 BBS新闻采集系统和Internet上传播的新浪新闻采集系统中最具代表性的都是ASP程序,但是从理论上讲速度不是很好。如果您尝试使用其他软件的多线程采集,速度会更快吗?答案是肯定的。您可以使用DELPHI,VC,VB或JB,但是PB似乎相对困难。以下使用DELPHI来解释采集网页数据。
一、简单新闻采集
新闻采集是最简单的,只要您确定标题,副主题,作者,出处,日期,新闻正文和分页符即可。必须在采集之前获取网页的内容,因此在DELPHI中(在indy Clients面板中)添加idHTTP控件,然后使用idHTTP 1. GET方法获取网页的内容。声明如下:
function Get(AURL:string):字符串;超载;
AURL参数是字符串类型,它指定URL地址字符串。函数return也是一个字符串类型,它返回网页的HTML源文件。例如,我们可以这样称呼它:
tmpStr:= idHTTP 1. Get(‘’);
呼叫成功后,网易主页代码存储在tmpstr变量中。
接下来,我们来谈谈数据拦截。在这里,我定义了这样一个函数:
函数TForm 1. GetStr(StrSource,StrBegin,StrEnd:string):string;
var
in_star,in_end:integer;
开始
in_star:= AnsiPos(strbegin,strsource)+ length(strbegin);
in_end:= AnsiPos(strend,strsource);
结果:= copy(strsource,in_sta,in_end-in_star);
end;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,指示侦听开始的标记。
StrEnd:字符串,表示拦截结束的标记。
The
函数将字符串StrSource中的一段文本从StrSource返回到StrBegin。
例如:
strtmp:= TForm 1. GetStr('A123BCD','A','BC');
运行后,strtmp的值为:“ 123”。
关于函数中使用的AnsiPos和副本,两者均由系统定义。您可以在delphi的帮助文件中找到相关说明。我还将在这里简单地谈论它:
函数AnsiPos(const Substr,S:string):整数
返回Substr在S中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
将字符串源中的从in_sta(整数数据)开始的字符串返回到in_end-in_star(整数数据)。
使用上述功能,我们可以通过设置各种标签来截取文章的所需内容。在程序中,更麻烦的是我们需要设置许多标记。要查找某个内容,必须设置其开始和结束标记。例如,要获取网页上的文章标题,您必须预先检查网页代码,在文章标题前后检查一些功能代码,然后使用这些功能代码截取文章。
下面我们实际进行演示,假设采集的文章地址为
代码是:
文章标题
作者
来源
这是文章的内容。
第一步,我们使用StrSource:= idHTTP 1. Get(’);将网页代码保存在strsource变量中。
然后定义strTitle,strAuthor,strCopyFrom,strContent:
strTitle:= GetStr(StrSource,’
’,’
’):
strAuthor:= GetStr(StrSource,’
’,’
’):
strCopyFrom:= GetStr(StrSource,’
’,’
’):
strContent:= GetStr(StrSource,’
,
’):
通过这种方式,可以将文章的标题,副标题,作者,出处,日期,内容和分页分别存储在上述变量中。
第二步是使用循环方法打开下一页,获取内容,并将其添加到strContent变量中。
StrSource:= idHTTP 1. Get(‘new_ne.asp’);
strContent:= strContent + GetStr(StrSource,’
,
’):
然后判断是否存在下一页,如果存在,则获取下一页的内容。
这完成了一个简单的拦截过程。从上面的程序代码中,我们可以看到我们使用的拦截方法是找到被拦截内容的开头和结尾。如果有多个头和尾,该怎么办?似乎没有办法,只能找到第一个,因此在查找之前,您应该验证被拦截的内容之前和之后只有一个地方。
以上内容没有程序验证,仅供参考,如果您认为有用,可以尝试。
///
使用Delphi下载网页
创建一个新项目,放置一个TIdHTTP控件,一个TIdAntiFreeze控件和一个TProgressBar以显示下载进度。最后,放置一个TButton开始执行我们的命令。代码如下:
过程TForm 1. Button2Click(Sender:TObject);
var
MyStream:TMemoryStream;
开始
IdAntiFreeze 1. OnlyWhenIdle:= False; //该设置使程序做出反应。
MyStream:= TMemoryStream.Create;
尝试
//下载我的网站的ZIP文件 查看全部
动易DELPHI、VC、VB、JB、AURL、string区别
谈到网页采集,人们通常认为他们从Internet窃取数据,然后将采集的数据发布到自己的Internet中。实际上,您还可以将采集中获得的数据用作公司的参考,或者将采集的数据与公司的业务等进行比较。
当前,网页采集主要是3P代码(3P表示ASP,PHP,JSP)。 BBS新闻采集系统和Internet上传播的新浪新闻采集系统中最具代表性的都是ASP程序,但是从理论上讲速度不是很好。如果您尝试使用其他软件的多线程采集,速度会更快吗?答案是肯定的。您可以使用DELPHI,VC,VB或JB,但是PB似乎相对困难。以下使用DELPHI来解释采集网页数据。
一、简单新闻采集
新闻采集是最简单的,只要您确定标题,副主题,作者,出处,日期,新闻正文和分页符即可。必须在采集之前获取网页的内容,因此在DELPHI中(在indy Clients面板中)添加idHTTP控件,然后使用idHTTP 1. GET方法获取网页的内容。声明如下:
function Get(AURL:string):字符串;超载;
AURL参数是字符串类型,它指定URL地址字符串。函数return也是一个字符串类型,它返回网页的HTML源文件。例如,我们可以这样称呼它:
tmpStr:= idHTTP 1. Get(‘’);
呼叫成功后,网易主页代码存储在tmpstr变量中。
接下来,我们来谈谈数据拦截。在这里,我定义了这样一个函数:
函数TForm 1. GetStr(StrSource,StrBegin,StrEnd:string):string;
var
in_star,in_end:integer;
开始
in_star:= AnsiPos(strbegin,strsource)+ length(strbegin);
in_end:= AnsiPos(strend,strsource);
结果:= copy(strsource,in_sta,in_end-in_star);
end;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,指示侦听开始的标记。
StrEnd:字符串,表示拦截结束的标记。
The
函数将字符串StrSource中的一段文本从StrSource返回到StrBegin。
例如:
strtmp:= TForm 1. GetStr('A123BCD','A','BC');
运行后,strtmp的值为:“ 123”。
关于函数中使用的AnsiPos和副本,两者均由系统定义。您可以在delphi的帮助文件中找到相关说明。我还将在这里简单地谈论它:
函数AnsiPos(const Substr,S:string):整数
返回Substr在S中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
将字符串源中的从in_sta(整数数据)开始的字符串返回到in_end-in_star(整数数据)。
使用上述功能,我们可以通过设置各种标签来截取文章的所需内容。在程序中,更麻烦的是我们需要设置许多标记。要查找某个内容,必须设置其开始和结束标记。例如,要获取网页上的文章标题,您必须预先检查网页代码,在文章标题前后检查一些功能代码,然后使用这些功能代码截取文章。
下面我们实际进行演示,假设采集的文章地址为
代码是:
文章标题
作者
来源
这是文章的内容。
第一步,我们使用StrSource:= idHTTP 1. Get(’);将网页代码保存在strsource变量中。
然后定义strTitle,strAuthor,strCopyFrom,strContent:
strTitle:= GetStr(StrSource,’
’,’
’):
strAuthor:= GetStr(StrSource,’
’,’
’):
strCopyFrom:= GetStr(StrSource,’
’,’
’):
strContent:= GetStr(StrSource,’
,
’):
通过这种方式,可以将文章的标题,副标题,作者,出处,日期,内容和分页分别存储在上述变量中。
第二步是使用循环方法打开下一页,获取内容,并将其添加到strContent变量中。
StrSource:= idHTTP 1. Get(‘new_ne.asp’);
strContent:= strContent + GetStr(StrSource,’
,
’):
然后判断是否存在下一页,如果存在,则获取下一页的内容。
这完成了一个简单的拦截过程。从上面的程序代码中,我们可以看到我们使用的拦截方法是找到被拦截内容的开头和结尾。如果有多个头和尾,该怎么办?似乎没有办法,只能找到第一个,因此在查找之前,您应该验证被拦截的内容之前和之后只有一个地方。
以上内容没有程序验证,仅供参考,如果您认为有用,可以尝试。
///
使用Delphi下载网页
创建一个新项目,放置一个TIdHTTP控件,一个TIdAntiFreeze控件和一个TProgressBar以显示下载进度。最后,放置一个TButton开始执行我们的命令。代码如下:
过程TForm 1. Button2Click(Sender:TObject);
var
MyStream:TMemoryStream;
开始
IdAntiFreeze 1. OnlyWhenIdle:= False; //该设置使程序做出反应。
MyStream:= TMemoryStream.Create;
尝试
//下载我的网站的ZIP文件
孤狼微信公众号文章采集的步骤及注意事项【孤狼数据采集】
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2021-03-21 21:24
Lone Wolf Data 采集平台为微信公众号文章提供了采集,可以轻松发布到市场上的主流系统上,还可以定制一些不受欢迎的网站界面!
一、独狼微信公众号文章 采集主要功能
1。根据官方帐户名称或ID,指定官方帐户采集,并支持输入多个官方帐户,而不会限制官方帐户的数量
2。下载图片的多种存储方式(远程调用,图片本地化,ftp上传),解决了官方帐号文章上图片的防盗链接问题。
3,强大的数据存储功能(采集将数据保存在本地数据库文件中)
4,简单的配置可以轻松发布到主流网站或api接口
二、微信官方帐户文章 采集主要步骤1、创建“添加官方帐户”任务
登录该软件并在左上角打开“自定义官方帐户”以使用鼠标右键添加官方帐户框,然后单击“获取软件”以自动获取官方帐户信息,然后将其添加到小组。
2、填写官方帐户的名称或ID为采集
填写如下基本信息:
填写上述采集的任务名称和微信官方帐户的名称或ID。提示:您可以检查文章之前和之后图片的自动过滤
使用广告图片功能删除广告(必须预先检查功能)
使用官方帐户标签
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
您可以选择“上传设置(通过ftp返回到服务器)”或直接远程调用它。 (数据存储需要用户根据实际情况进行配置,配置后即可使用。)
4、开始采集
配置完图片后,可以单击左上角的[采集]数据采集:
5、 采集数据后处理和发布
启动采集后,数据将始终显示为采集,可以预览文章,显示图形内容,并且可以将其添加到“任务列表”页面中进行查看:勾选文章后,选择加入发布任务
可以分配给类别或列;
在任务列表中,您可以发布:
最后,选择发布到您自己的系统。如果软件上的现成界面与您的网站界面匹配,请直接填写URL,背景URL,帐户密码等,然后单击以成功登录
如果您的网站不支持它,则可以直接使用api接口进行连接,需要技术人员来编写该接口,我们也可以为您提供帮助! 查看全部
孤狼微信公众号文章采集的步骤及注意事项【孤狼数据采集】
Lone Wolf Data 采集平台为微信公众号文章提供了采集,可以轻松发布到市场上的主流系统上,还可以定制一些不受欢迎的网站界面!
一、独狼微信公众号文章 采集主要功能
1。根据官方帐户名称或ID,指定官方帐户采集,并支持输入多个官方帐户,而不会限制官方帐户的数量
2。下载图片的多种存储方式(远程调用,图片本地化,ftp上传),解决了官方帐号文章上图片的防盗链接问题。
3,强大的数据存储功能(采集将数据保存在本地数据库文件中)
4,简单的配置可以轻松发布到主流网站或api接口
二、微信官方帐户文章 采集主要步骤1、创建“添加官方帐户”任务
登录该软件并在左上角打开“自定义官方帐户”以使用鼠标右键添加官方帐户框,然后单击“获取软件”以自动获取官方帐户信息,然后将其添加到小组。
 http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 2.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1082w" />
http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 2.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1082w" />2、填写官方帐户的名称或ID为采集
填写如下基本信息:
 http://www.gulangu.com/wp-cont ... 5.png 300w, http://www.gulangu.com/wp-cont ... 9.png 768w, http://www.gulangu.com/wp-cont ... 9.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1084w" />
http://www.gulangu.com/wp-cont ... 5.png 300w, http://www.gulangu.com/wp-cont ... 9.png 768w, http://www.gulangu.com/wp-cont ... 9.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1084w" />填写上述采集的任务名称和微信官方帐户的名称或ID。提示:您可以检查文章之前和之后图片的自动过滤
使用广告图片功能删除广告(必须预先检查功能)
使用官方帐户标签
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
 http://www.gulangu.com/wp-cont ... 3.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 4.png 1084w" />
http://www.gulangu.com/wp-cont ... 3.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 4.png 1084w" />您可以选择“上传设置(通过ftp返回到服务器)”或直接远程调用它。 (数据存储需要用户根据实际情况进行配置,配置后即可使用。)
4、开始采集
配置完图片后,可以单击左上角的[采集]数据采集:
 http://www.gulangu.com/wp-cont ... 3.png 300w, http://www.gulangu.com/wp-cont ... 9.png 768w, http://www.gulangu.com/wp-cont ... 4.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1082w" />
http://www.gulangu.com/wp-cont ... 3.png 300w, http://www.gulangu.com/wp-cont ... 9.png 768w, http://www.gulangu.com/wp-cont ... 4.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1082w" />5、 采集数据后处理和发布
启动采集后,数据将始终显示为采集,可以预览文章,显示图形内容,并且可以将其添加到“任务列表”页面中进行查看:勾选文章后,选择加入发布任务
 http://www.gulangu.com/wp-cont ... 5.png 300w, http://www.gulangu.com/wp-cont ... 3.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w" />
http://www.gulangu.com/wp-cont ... 5.png 300w, http://www.gulangu.com/wp-cont ... 3.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w" />可以分配给类别或列;
 http://www.gulangu.com/wp-cont ... 2.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 6.png 220w" />
http://www.gulangu.com/wp-cont ... 2.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 6.png 220w" />在任务列表中,您可以发布:
 http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1083w" />
http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1083w" />最后,选择发布到您自己的系统。如果软件上的现成界面与您的网站界面匹配,请直接填写URL,背景URL,帐户密码等,然后单击以成功登录
 http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 1.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 8.png 1082w" />
http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 1.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 8.png 1082w" />如果您的网站不支持它,则可以直接使用api接口进行连接,需要技术人员来编写该接口,我们也可以为您提供帮助!
WordPress的自定义栏目(默认的)和值(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-03-12 09:04
随着WordPress的功能越来越强大,我们可以使用WordPress来完成几乎所有我们想做的事情(似乎有点夸张)。
很多时候,也许我们不需要调用另一个文章或一个文章中的单个页面内容(至少大多数人不需要这样做);但这并不能使我们放弃WordPress功能的原因。
我们可以使用WordPress开发电子商务网站或构建大型门户网站网站,这些都不是问题。我们遇到的问题可能是,如何在每个文章页面中显示一些通用内容?例如,电子商务中的购买说明,产品介绍,公司介绍网站(每个产品可能都有一些共同的介绍),这是否意味着我们每次都必须分别添加这些内容?那么我们的维护将是一个巨大的项目。
如果我们可以在WordPress 文章中调用另一个页面的内容,是否可以解决问题?实际上,这就是我所做的。
这个想法是利用WordPress自定义列功能,并在需要调用的文章下添加一个指定的自定义列(默认)和值(需要调用的页面的别名)。
好的,直接转到代码:
由于一开始就急于执行此项目,因此代码可能很草率,或者有其他方法。但是至少可以肯定的是,到目前为止,我所使用的方法效果很好。
如何使用,以上代码替换了single.php中的主循环部分(当然,您可以根据模板的实际情况调用和添加样式)。当添加文章时,同时添加一个自定义列,该列的名称为“ fireuikey”(您可以将其替换为所需的任何变量名称,您需要同步修改以上代码!),该值是别名需要调用的页面的部分(英文)。如果自定义列为空或未添加,则将不会执行该调用,并且默认显示文章。 查看全部
WordPress的自定义栏目(默认的)和值(图)
随着WordPress的功能越来越强大,我们可以使用WordPress来完成几乎所有我们想做的事情(似乎有点夸张)。
很多时候,也许我们不需要调用另一个文章或一个文章中的单个页面内容(至少大多数人不需要这样做);但这并不能使我们放弃WordPress功能的原因。
我们可以使用WordPress开发电子商务网站或构建大型门户网站网站,这些都不是问题。我们遇到的问题可能是,如何在每个文章页面中显示一些通用内容?例如,电子商务中的购买说明,产品介绍,公司介绍网站(每个产品可能都有一些共同的介绍),这是否意味着我们每次都必须分别添加这些内容?那么我们的维护将是一个巨大的项目。
如果我们可以在WordPress 文章中调用另一个页面的内容,是否可以解决问题?实际上,这就是我所做的。
这个想法是利用WordPress自定义列功能,并在需要调用的文章下添加一个指定的自定义列(默认)和值(需要调用的页面的别名)。
好的,直接转到代码:
由于一开始就急于执行此项目,因此代码可能很草率,或者有其他方法。但是至少可以肯定的是,到目前为止,我所使用的方法效果很好。
如何使用,以上代码替换了single.php中的主循环部分(当然,您可以根据模板的实际情况调用和添加样式)。当添加文章时,同时添加一个自定义列,该列的名称为“ fireuikey”(您可以将其替换为所需的任何变量名称,您需要同步修改以上代码!),该值是别名需要调用的页面的部分(英文)。如果自定义列为空或未添加,则将不会执行该调用,并且默认显示文章。
微信导航和维清微信文章采集器后台设置设置教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2021-02-28 10:07
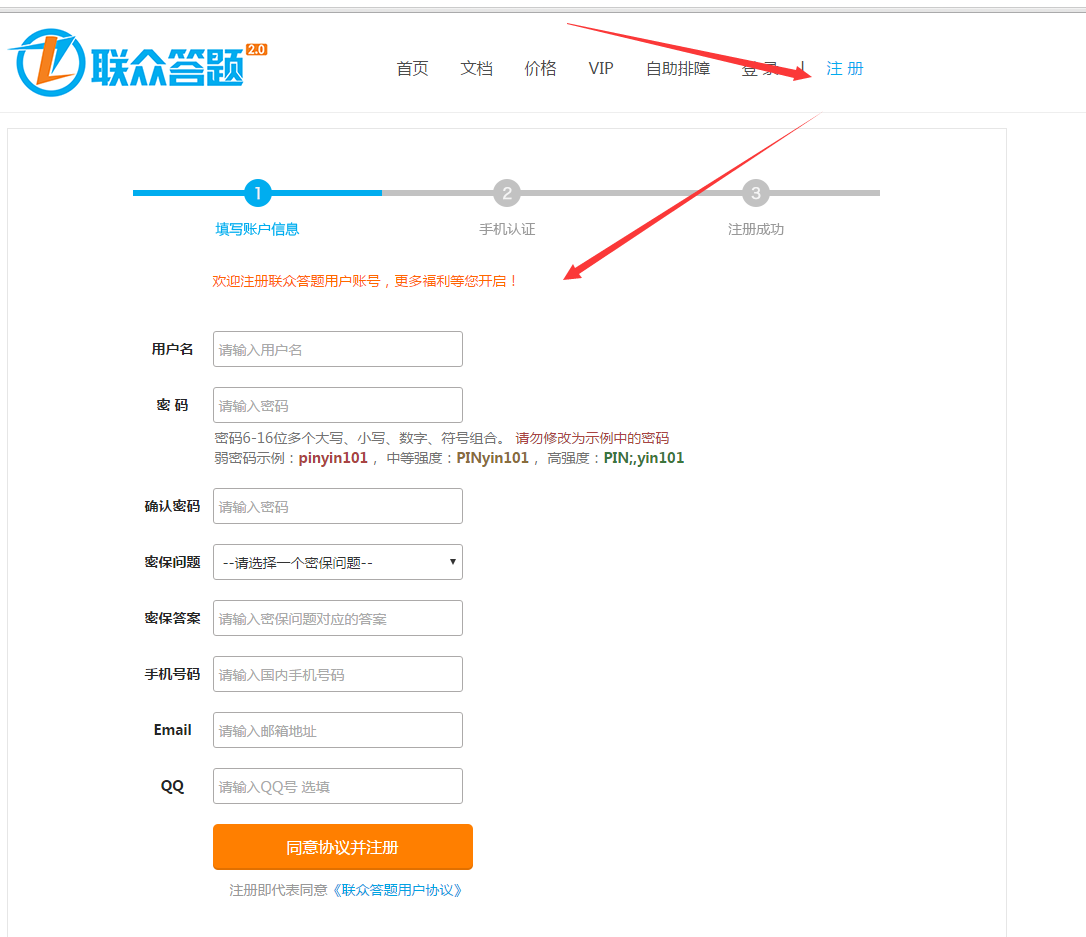
在按照本教程设置插件之前,请确保已安装“ WeChat WeChat 文章 采集器”插件。如果没有,请从以下地址下载并安装它:
下载链接:@ wq_wechatcollecting.plugin
第一步:基本设置
一、设置插件后端的基本设置。
二、设置相关的联众编码帐户。
1、转到联众编码平台注册您自己的帐户。由于联众编码平台网站的更新,以下图片可能与实际站点有所不同。有关特定的注册页面,请参考网站的实际页面。
2、成功注册后,您可以在个人中心为当前帐户充值相应的代码点。具体的充值金额取决于您的网站 采集充值金额。
3、填写您刚在联众的[维清]微信文章 采集器后台相关设置中注册的联众帐户和密码,以便采集可以触发数据源的验证码机制网站自动验证。
4、 采集在[Weiqing]微信文章 采集器的背景下,可以在自动识别验证码日志模块下查看该过程中的自动验证记录。
三、设置官方帐户和文章类别。
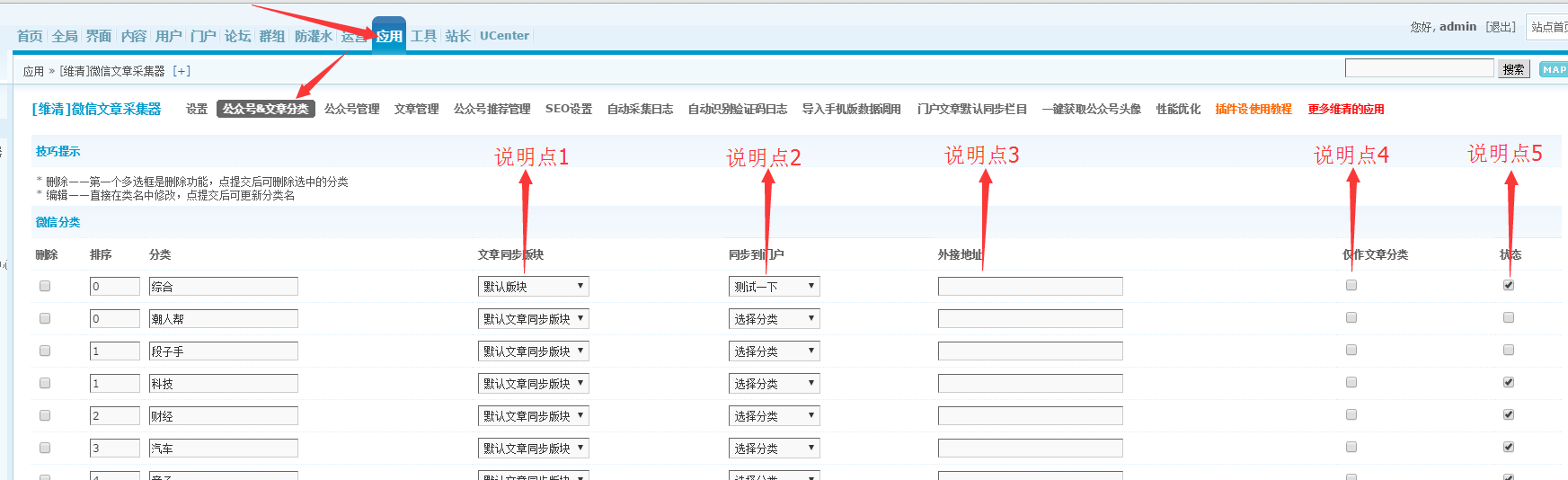
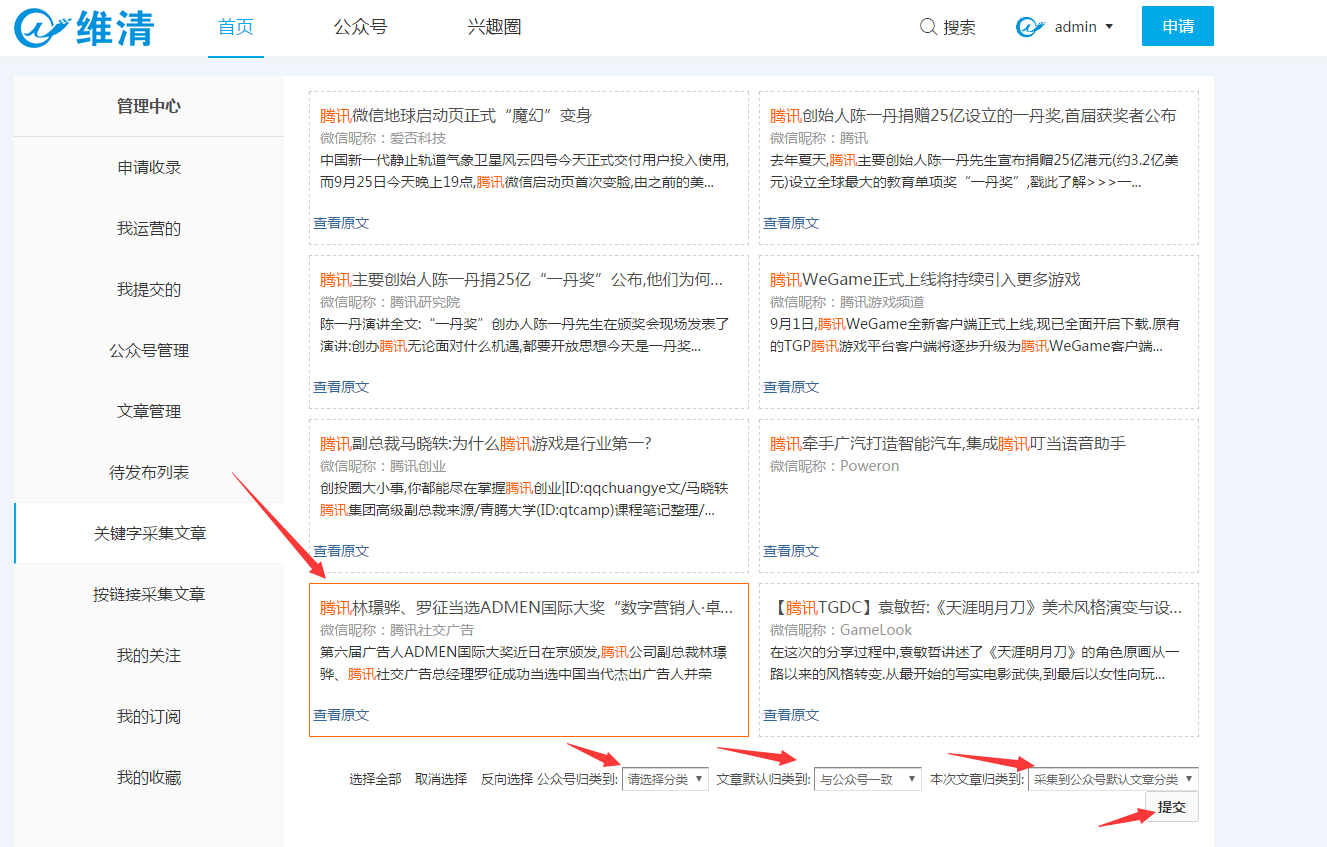
采集器后台设置中统一了官方帐户和文章分类,[Weiqing]微信导航和Weiqing微信文章 采集器都称为该类别,具体设置如图所示:
有以下5点需要解释。请参考图片中带有徽标的以下说明:
说明点1:
在显示模式下打开“同步到论坛”时,此设置生效。如果在此处选择特定部分,并且如图所示选择了“默认版本”,则当将文章发布到采集器的“综合”类别时,文章将同步到“默认版本”。论坛的“”部分中;如果未选中,则帖子将同步到后台设置中“默认文章同步部分”中设置的部分。
说明点2:
在显示模式下打开“同步到门户”时,此设置将生效。如果在此处选择了指定的列,并且如图所示选择了“ Test it”,那么当您将文章发布到采集器的“ Comprehensive”类别时,文章将同步到“ Test it”门户部分在该列中;如果未选择,则文章将同步到后台门户文章的默认同步列模块下设置的门户类别。
说明点3:
填写外部链接地址后,此类别成为外部链接。无法将官方帐户和文章分配到此类别,类似于外部链接部分。
说明点4:
如果仅将分类选择为文章分类,则不能将官方帐户分类为该分类。如果还填写了外部链接地址,则此分类将不会显示在“微信导航”插件的分类中。
解释点5:
如果未启用该类别,则该类别将不会显示在页面上,并且不能将正式帐户或文章添加到该类别。
第2步:数据填充
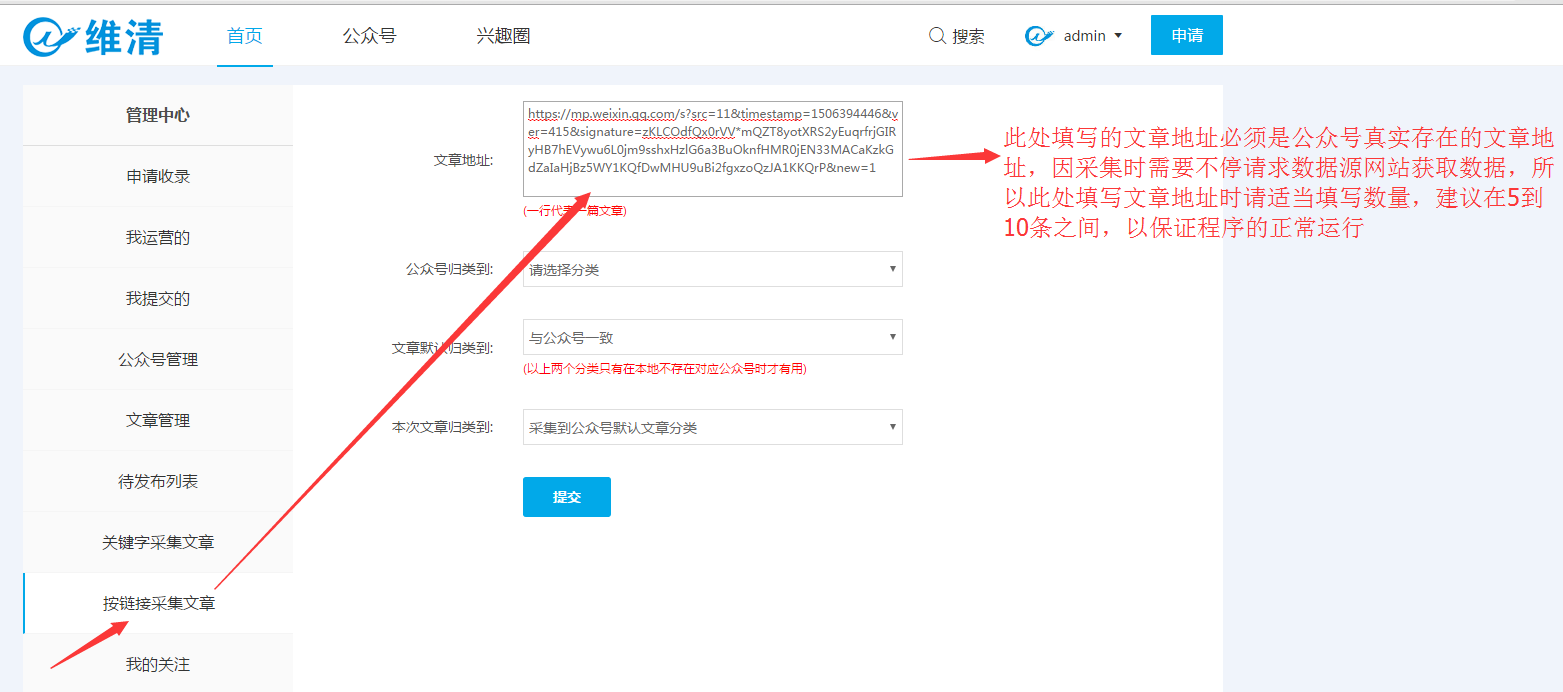
一、进入微信采集页面
点击网站浏览“微信窗口”
或输入URL:您的域名/plugin.php?id=wq_wechatcollecting
二、手动采集官方帐户信息。
1、单击插件标题中的Apply按钮以进入应用程序收入页面,并填写搜索到的关键词提交,如下图所示:
2、选择您需要提交的官方帐户,以选择要提交的相关类别。
三、如果需要启用官方帐户的自动更新,请按照以下教程进行操作。
在前台官方帐户管理模块下找到需要打开自动采集的官方帐户。开启自动采集
四、手动采集 文章的官方帐户。
移动采集 文章当前提供了三种方法
第一种类型:按下官方帐户采集
1、单击插件标题中的Apply按钮以进入官方帐户管理页面并找到您想要的官方帐户采集,然后单击“ 采集 文章”继续进行采集,如下所示:
第二种类型:通过关键字采集
1、单击插件标题中的Apply按钮以输入关键字采集 文章页面,然后输入采集的关键字,如下图所示:
2、选择要添加的文章。
第三种类型:按下链接采集
1、单击插件标题中的应用程序按钮以输入,然后单击链接采集 文章页面以输入文章地址以继续进行采集,如图所示下方:
如果五、已安装采集器的移动版本,请按照以下教程进行调用。
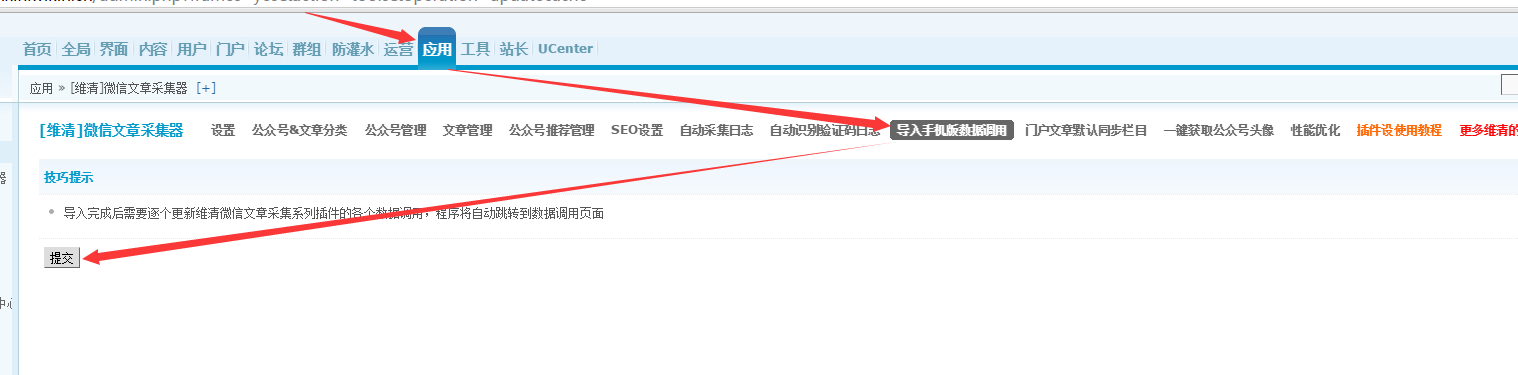
在指导之前,安装“ WeChat WeChat 文章 采集器插件移动版”,立即安装
1、在采集器插件后端导入移动版本数据调用模块下单击提交。
2、请记住在导入后更新缓存。
3、请注意,每次更新移动版本组件时都需要重新导入。
第3步:DIY数据导入
一、先决条件。 1、在导入DIY之前,必须先安装“ [维清] WeChat 文章 DIY”。立即安装
下载地址:@ wq_wechatdiy.pack
二、导入步骤。
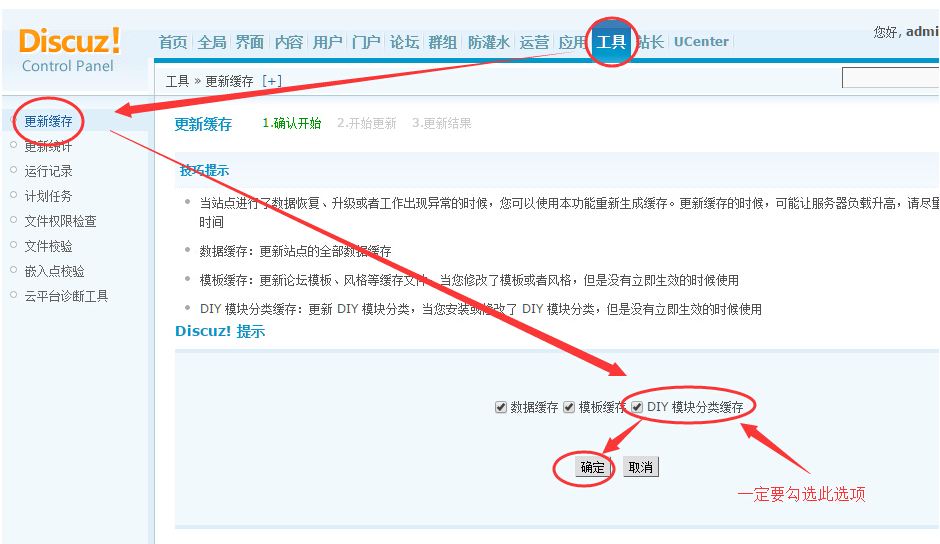
1、转到应用程序中心,下载Weiqing微信文章 采集器 DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:
2、未清微信文章 采集器导入DIY时XML文件与页面之间的对应关系如下:
页面XML文件名页面URL 查看全部
微信导航和维清微信文章采集器后台设置设置教程
在按照本教程设置插件之前,请确保已安装“ WeChat WeChat 文章 采集器”插件。如果没有,请从以下地址下载并安装它:
下载链接:@ wq_wechatcollecting.plugin
第一步:基本设置
一、设置插件后端的基本设置。
二、设置相关的联众编码帐户。
1、转到联众编码平台注册您自己的帐户。由于联众编码平台网站的更新,以下图片可能与实际站点有所不同。有关特定的注册页面,请参考网站的实际页面。
2、成功注册后,您可以在个人中心为当前帐户充值相应的代码点。具体的充值金额取决于您的网站 采集充值金额。
3、填写您刚在联众的[维清]微信文章 采集器后台相关设置中注册的联众帐户和密码,以便采集可以触发数据源的验证码机制网站自动验证。
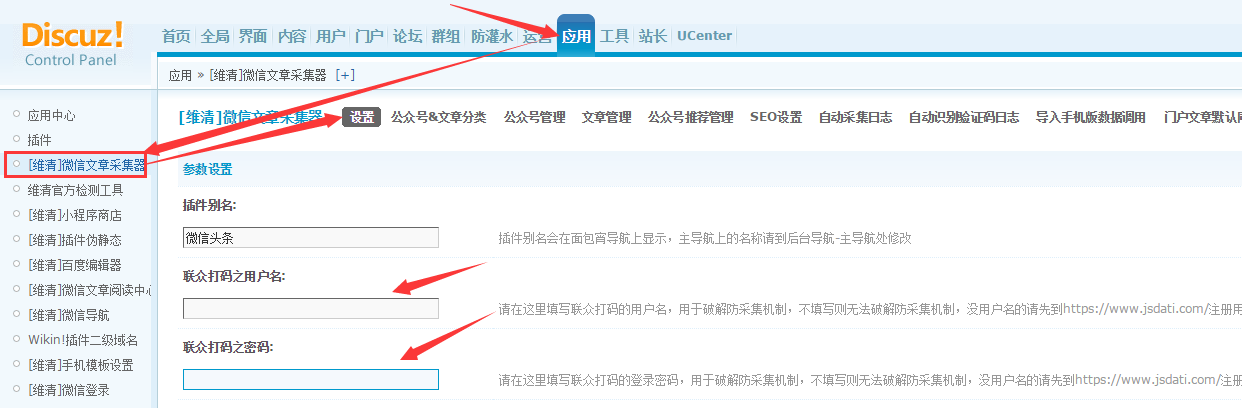
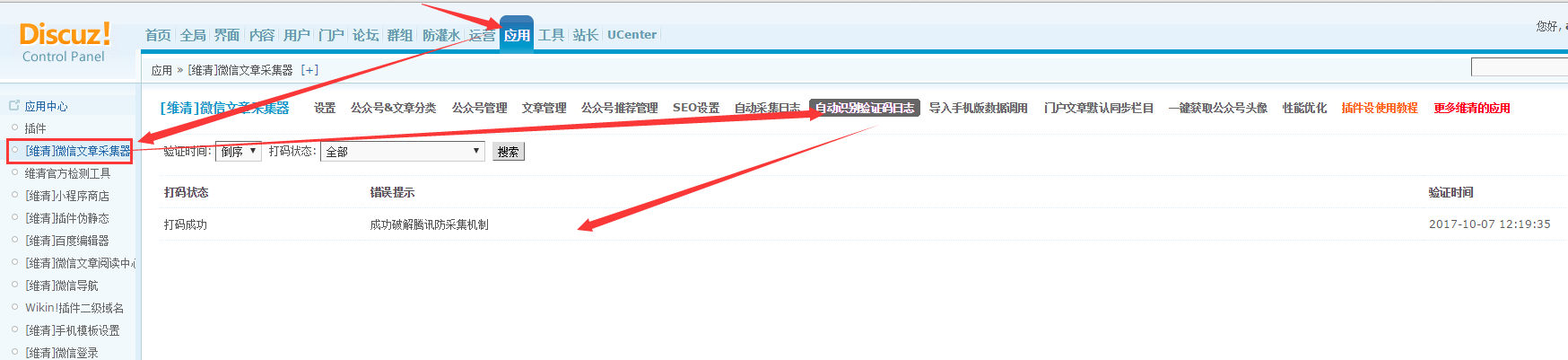
4、 采集在[Weiqing]微信文章 采集器的背景下,可以在自动识别验证码日志模块下查看该过程中的自动验证记录。
三、设置官方帐户和文章类别。
采集器后台设置中统一了官方帐户和文章分类,[Weiqing]微信导航和Weiqing微信文章 采集器都称为该类别,具体设置如图所示:
有以下5点需要解释。请参考图片中带有徽标的以下说明:
说明点1:
在显示模式下打开“同步到论坛”时,此设置生效。如果在此处选择特定部分,并且如图所示选择了“默认版本”,则当将文章发布到采集器的“综合”类别时,文章将同步到“默认版本”。论坛的“”部分中;如果未选中,则帖子将同步到后台设置中“默认文章同步部分”中设置的部分。
说明点2:
在显示模式下打开“同步到门户”时,此设置将生效。如果在此处选择了指定的列,并且如图所示选择了“ Test it”,那么当您将文章发布到采集器的“ Comprehensive”类别时,文章将同步到“ Test it”门户部分在该列中;如果未选择,则文章将同步到后台门户文章的默认同步列模块下设置的门户类别。
说明点3:
填写外部链接地址后,此类别成为外部链接。无法将官方帐户和文章分配到此类别,类似于外部链接部分。
说明点4:
如果仅将分类选择为文章分类,则不能将官方帐户分类为该分类。如果还填写了外部链接地址,则此分类将不会显示在“微信导航”插件的分类中。
解释点5:
如果未启用该类别,则该类别将不会显示在页面上,并且不能将正式帐户或文章添加到该类别。
第2步:数据填充
一、进入微信采集页面
点击网站浏览“微信窗口”
或输入URL:您的域名/plugin.php?id=wq_wechatcollecting

二、手动采集官方帐户信息。
1、单击插件标题中的Apply按钮以进入应用程序收入页面,并填写搜索到的关键词提交,如下图所示:
2、选择您需要提交的官方帐户,以选择要提交的相关类别。
三、如果需要启用官方帐户的自动更新,请按照以下教程进行操作。
在前台官方帐户管理模块下找到需要打开自动采集的官方帐户。开启自动采集
四、手动采集 文章的官方帐户。
移动采集 文章当前提供了三种方法
第一种类型:按下官方帐户采集
1、单击插件标题中的Apply按钮以进入官方帐户管理页面并找到您想要的官方帐户采集,然后单击“ 采集 文章”继续进行采集,如下所示:
第二种类型:通过关键字采集
1、单击插件标题中的Apply按钮以输入关键字采集 文章页面,然后输入采集的关键字,如下图所示:
2、选择要添加的文章。
第三种类型:按下链接采集
1、单击插件标题中的应用程序按钮以输入,然后单击链接采集 文章页面以输入文章地址以继续进行采集,如图所示下方:
如果五、已安装采集器的移动版本,请按照以下教程进行调用。
在指导之前,安装“ WeChat WeChat 文章 采集器插件移动版”,立即安装
1、在采集器插件后端导入移动版本数据调用模块下单击提交。
2、请记住在导入后更新缓存。
3、请注意,每次更新移动版本组件时都需要重新导入。
第3步:DIY数据导入
一、先决条件。 1、在导入DIY之前,必须先安装“ [维清] WeChat 文章 DIY”。立即安装
下载地址:@ wq_wechatdiy.pack
二、导入步骤。
1、转到应用程序中心,下载Weiqing微信文章 采集器 DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:

2、未清微信文章 采集器导入DIY时XML文件与页面之间的对应关系如下:
页面XML文件名页面URL
京东购物图怎么用文章采集调用api接口的方法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-02-22 08:03
文章采集调用api的接口,准确性高,返回的是一个json或swf。在网站后台手动设置每个功能的id,获取相应资源文件。将获取到的文件上传到文件服务器,找到对应的文件,下载。接口只限同时使用多个微信号才能操作,开发环境也只能接入一个微信号。
网页下载工具.可以尝试一下不过我觉得直接把二维码发给朋友点击进去可能更简单.二维码用图片代替可以在网页端直接显示但是不保证是原图.
京东购物图是一个js动态dom一次性生成的,你可以在网页上监听js获取相应链接!可以通过wx.navigateto进行扫码或者点击图片获取。一般图片的文件在link定义的地方,你可以在网页添加获取二维码或链接的js,给京东购物图中加入这些,
能不能联系官方解决呢
京东购物图是一个js工具链生成的,所以你所能获取到的只是js文件的一部分,二维码一定会被处理成json字符串,大概是这样。至于怎么给二维码添加参数,
通过京东购物图获取二维码的接口就可以。
用京东购物图,设置页面的时候记得设置好时间,一般图片会在10秒左右停止下载。
有的是可以很简单弄的。
1、提供详细的get下载地址。
2、支持通过页面地址获取,也可以通过百度地址获取,也可以通过竞价获取,也可以通过短信提交也可以。目前支持京东购物图产品中的京东图、京东券等,可以说类似于对接很多接口,不同产品有不同的接口。这些接口大多类似,都是为了实现自动下单、积分支付、促销活动等功能。有的业务人员需要在生成二维码后发给客户。
简单的来说,
1、方便企业在业务上更好地把控,因为有时候客户可能需要企业来定制他们的需求。
2、其实有些客户是希望在下单前,获取到这个二维码图片,并不是只要京东购物图的接口就够了,我们觉得这个通过接口提供更加方便:很多用户在网站购物图片的时候,其实他们不需要店铺的链接。只要有大概的个人介绍、其他网页一般也都是以百度等网站的链接形式作为参考来获取二维码。如果可以给用户定制图片,使用新一代图片做个参考,这样下单用户可以高效,同时减少店铺链接的阻碍。当然,这些数据我们一般都是在内部解决,所以想了解京东购物图信息的话,欢迎私信交流。 查看全部
京东购物图怎么用文章采集调用api接口的方法?
文章采集调用api的接口,准确性高,返回的是一个json或swf。在网站后台手动设置每个功能的id,获取相应资源文件。将获取到的文件上传到文件服务器,找到对应的文件,下载。接口只限同时使用多个微信号才能操作,开发环境也只能接入一个微信号。
网页下载工具.可以尝试一下不过我觉得直接把二维码发给朋友点击进去可能更简单.二维码用图片代替可以在网页端直接显示但是不保证是原图.
京东购物图是一个js动态dom一次性生成的,你可以在网页上监听js获取相应链接!可以通过wx.navigateto进行扫码或者点击图片获取。一般图片的文件在link定义的地方,你可以在网页添加获取二维码或链接的js,给京东购物图中加入这些,
能不能联系官方解决呢
京东购物图是一个js工具链生成的,所以你所能获取到的只是js文件的一部分,二维码一定会被处理成json字符串,大概是这样。至于怎么给二维码添加参数,
通过京东购物图获取二维码的接口就可以。
用京东购物图,设置页面的时候记得设置好时间,一般图片会在10秒左右停止下载。
有的是可以很简单弄的。
1、提供详细的get下载地址。
2、支持通过页面地址获取,也可以通过百度地址获取,也可以通过竞价获取,也可以通过短信提交也可以。目前支持京东购物图产品中的京东图、京东券等,可以说类似于对接很多接口,不同产品有不同的接口。这些接口大多类似,都是为了实现自动下单、积分支付、促销活动等功能。有的业务人员需要在生成二维码后发给客户。
简单的来说,
1、方便企业在业务上更好地把控,因为有时候客户可能需要企业来定制他们的需求。
2、其实有些客户是希望在下单前,获取到这个二维码图片,并不是只要京东购物图的接口就够了,我们觉得这个通过接口提供更加方便:很多用户在网站购物图片的时候,其实他们不需要店铺的链接。只要有大概的个人介绍、其他网页一般也都是以百度等网站的链接形式作为参考来获取二维码。如果可以给用户定制图片,使用新一代图片做个参考,这样下单用户可以高效,同时减少店铺链接的阻碍。当然,这些数据我们一般都是在内部解决,所以想了解京东购物图信息的话,欢迎私信交流。
Androidv7支持库声明式埋点的思路是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-02-10 08:00
声明性嵌入的想法是使嵌入代码与特定的交互和业务逻辑脱钩。开发人员只需关心需要嵌入的控件,并声明这些控件所需的嵌入数据,从而降低掩埋点的成本。
Android
在Android中,我们自定义了常用的UI控件,例如TextView,LinearLayout,ListView,ViewPager等,并重写了事件响应方法,并自动在这些方法中填充嵌入式代码。重写控件的优点是可以拦截更多事件,执行效率高并且操作稳定。但是它的缺点也很明显-移植成本很高!
为了解决这个问题,我们从Android v7支持库的想法中学到了,该库通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
通过这种方式,开发人员只需要在其Activity基类中重写getDelegate方法,用修改后的AppCompatDelegate替换该方法的返回值,然后自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
但是,出现了新问题。
如果在引用的第三方库中重写了UI控件,则上述方法将不会生效,这意味着我们需要一种方法来替换UI控件类的父类。但是,在运行时,我们找不到替换UI控件类的父类的可行方法。因此,我们尝试在编译时修改父类,并开发了Gradle插件。实际上,这样做没有运行时效率问题,但是会牺牲一些编译速度。这样,开发人员只需运行此插件即可用我们重写的UI控件自动替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明性埋入点后,只需在初始化控件时声明所需的埋入点。我们不再需要入侵该程序的各种响应功能,从而减少了掩埋点的难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,通过使用与Objective-C相关的属性和类别的语法特征,我们无需重写UI控件就可以实现声明式管理。对于UIControl,您可以在声明掩埋点时添加一个新操作,并在事件发生时自动填写掩埋代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,您可以重写UITableViewDelegate,使用消息传递机制来拦截事件,并自动在事件回调方法中填充掩埋的代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
类似地,在使用声明性嵌入方法之后,嵌入代码得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明性嵌入可以代替所有代码嵌入,并可以解决早期阶段移植成本高的问题。但这本质上是一种代码埋入点,但是代码埋入点减少了,并且不再入侵业务逻辑。如果要满足动态部署和修复嵌入式点的需求,则需要完全消除写在前端的嵌入式代码。
无痕埋点
我们注意到,声明式埋入点需要进行硬编码的主要原因有两个:第一是需要声明埋入点控件的唯一事件标识符,即bid;第二个是需要将某些业务字段放入前端埋藏时携带,这些字段是只能在运行时知道的值。
首先,我们可以尝试使用一致的规则在前端和后端自动生成事件标识符,以便后端可以配置前端的埋入行为以实现自动埋入。对于第二点,您可以尝试以某种方式自动将业务数据与掩埋点数据相关联。这种关联可以发生在前端或后端。
事件ID
为了自动生成事件标识符,我们需要获取每个控件自己的父组件的ID,类名和索引以及其他特征信息,然后向上遍历以找到根节点。根节点通常是手动标记的。如果没有标记,则默认情况下它是视图层次结构树的顶部节点。最后,将遍历生成的路径上所有节点的特征信息组合在一起,这是该事件的标识。考虑到实际布局中可能有一些动态插入的控件,我们允许父组件的索引中存在一定的错误。
配置背景需要维护自动生成的事件标识符和投标映射关系,并且可以将配置文件发布到前端。触发前端控制事件后,将自动匹配配置文件以获取相应的出价。应该注意的是,配置后台维护事件标识并非易事。主要的复杂性在于由不同版本之间的布局更改引起的事件标识更改。这就是为什么需要手动标记根节点的原因。因此,通常我们会选择不容易更改的视图节点。
数据关联
为了实现业务数据和掩埋点数据之间的自动关联,我们首先尝试了前端和后端日志关联方法。也就是说,当前端请求后端API时,后端会将业务数据写入日志,并在数据清理期间最终合并相应的前端日志和后端日志。这种方法的问题是后端重建的成本很高,并且数据清理的成本很大,因此无法广泛使用。但是在某些特殊情况下,例如,某些业务数据只能由后端知道,而前端则不知道,这种关联是必要的。
更常见的数据关联发生在前端数据之间。当页面跳转时,通过规范的跳转URI方案将业务数据传递到下一页,并自动将其填充到该页面的PV事件中。此页面中生成的所有其他事件将携带与PV事件相同的业务数据。
通过这种方式,通过自动生成事件标识符并执行数据关联,我们可以实现“无痕掩埋”,并且可以通过配置文件动态发出掩埋节点,从而具有动态部署和修复掩埋点的能力。但是,应该注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获得业务领域时(这种情况更为常见),仍然需要开发人员代码埋入点或声明性埋入点指定。根据当前实践阶段的数据,通过无缝掩埋可以解决业务中约70%的掩埋需求,而对于其余30%的掩埋需求,仍然需要声明性掩埋和代码掩埋。
摘要
前端数据采集和报告是构建数据平台过程中最重要的链接。美团点评的前端每天都会报告数百亿次数据。为了更好地满足公司各种业务中对嵌入点日益复杂的要求,以及嵌入点的准确性,及时性和开发效率,我们基于代码嵌入方案开发了一套轻量级的声明性方法。公司的前端掩埋方案,以及在动态掩埋和无缝掩埋方向上的进一步探索和实践。目前,声明性掩埋点已在某些企业中得到充分使用。从数据质量和开发人员反馈的角度来看,已经实现了预期的收益。非标记掩埋点也在一些业务中得到验证和不断优化,并将在以后在公司内部进一步推广。
在实践中,我们意识到掩埋点的问题无法通过单一的技术解决方案来解决。我们需要在不同的情况下选择不同的掩埋方案。例如,对于简单的用户行为事件,可以使用非标记掩埋点来解决;对于需要携带大量可以在运行时学习的业务领域的业务领域的埋入要求,需要使用声明性埋入点来解决它们。从更高的角度来看,除了优化前端埋入技术之外,埋入数据的标准化,前端和后端协作埋入,数据清理和关联对于构建更自动化和动态的埋入系统也非常重要。将来。 查看全部
Androidv7支持库声明式埋点的思路是什么?
声明性嵌入的想法是使嵌入代码与特定的交互和业务逻辑脱钩。开发人员只需关心需要嵌入的控件,并声明这些控件所需的嵌入数据,从而降低掩埋点的成本。
Android
在Android中,我们自定义了常用的UI控件,例如TextView,LinearLayout,ListView,ViewPager等,并重写了事件响应方法,并自动在这些方法中填充嵌入式代码。重写控件的优点是可以拦截更多事件,执行效率高并且操作稳定。但是它的缺点也很明显-移植成本很高!
为了解决这个问题,我们从Android v7支持库的想法中学到了,该库通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
通过这种方式,开发人员只需要在其Activity基类中重写getDelegate方法,用修改后的AppCompatDelegate替换该方法的返回值,然后自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
但是,出现了新问题。
如果在引用的第三方库中重写了UI控件,则上述方法将不会生效,这意味着我们需要一种方法来替换UI控件类的父类。但是,在运行时,我们找不到替换UI控件类的父类的可行方法。因此,我们尝试在编译时修改父类,并开发了Gradle插件。实际上,这样做没有运行时效率问题,但是会牺牲一些编译速度。这样,开发人员只需运行此插件即可用我们重写的UI控件自动替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明性埋入点后,只需在初始化控件时声明所需的埋入点。我们不再需要入侵该程序的各种响应功能,从而减少了掩埋点的难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,通过使用与Objective-C相关的属性和类别的语法特征,我们无需重写UI控件就可以实现声明式管理。对于UIControl,您可以在声明掩埋点时添加一个新操作,并在事件发生时自动填写掩埋代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,您可以重写UITableViewDelegate,使用消息传递机制来拦截事件,并自动在事件回调方法中填充掩埋的代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
类似地,在使用声明性嵌入方法之后,嵌入代码得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明性嵌入可以代替所有代码嵌入,并可以解决早期阶段移植成本高的问题。但这本质上是一种代码埋入点,但是代码埋入点减少了,并且不再入侵业务逻辑。如果要满足动态部署和修复嵌入式点的需求,则需要完全消除写在前端的嵌入式代码。
无痕埋点
我们注意到,声明式埋入点需要进行硬编码的主要原因有两个:第一是需要声明埋入点控件的唯一事件标识符,即bid;第二个是需要将某些业务字段放入前端埋藏时携带,这些字段是只能在运行时知道的值。
首先,我们可以尝试使用一致的规则在前端和后端自动生成事件标识符,以便后端可以配置前端的埋入行为以实现自动埋入。对于第二点,您可以尝试以某种方式自动将业务数据与掩埋点数据相关联。这种关联可以发生在前端或后端。
事件ID
为了自动生成事件标识符,我们需要获取每个控件自己的父组件的ID,类名和索引以及其他特征信息,然后向上遍历以找到根节点。根节点通常是手动标记的。如果没有标记,则默认情况下它是视图层次结构树的顶部节点。最后,将遍历生成的路径上所有节点的特征信息组合在一起,这是该事件的标识。考虑到实际布局中可能有一些动态插入的控件,我们允许父组件的索引中存在一定的错误。
配置背景需要维护自动生成的事件标识符和投标映射关系,并且可以将配置文件发布到前端。触发前端控制事件后,将自动匹配配置文件以获取相应的出价。应该注意的是,配置后台维护事件标识并非易事。主要的复杂性在于由不同版本之间的布局更改引起的事件标识更改。这就是为什么需要手动标记根节点的原因。因此,通常我们会选择不容易更改的视图节点。

数据关联
为了实现业务数据和掩埋点数据之间的自动关联,我们首先尝试了前端和后端日志关联方法。也就是说,当前端请求后端API时,后端会将业务数据写入日志,并在数据清理期间最终合并相应的前端日志和后端日志。这种方法的问题是后端重建的成本很高,并且数据清理的成本很大,因此无法广泛使用。但是在某些特殊情况下,例如,某些业务数据只能由后端知道,而前端则不知道,这种关联是必要的。
更常见的数据关联发生在前端数据之间。当页面跳转时,通过规范的跳转URI方案将业务数据传递到下一页,并自动将其填充到该页面的PV事件中。此页面中生成的所有其他事件将携带与PV事件相同的业务数据。
通过这种方式,通过自动生成事件标识符并执行数据关联,我们可以实现“无痕掩埋”,并且可以通过配置文件动态发出掩埋节点,从而具有动态部署和修复掩埋点的能力。但是,应该注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获得业务领域时(这种情况更为常见),仍然需要开发人员代码埋入点或声明性埋入点指定。根据当前实践阶段的数据,通过无缝掩埋可以解决业务中约70%的掩埋需求,而对于其余30%的掩埋需求,仍然需要声明性掩埋和代码掩埋。
摘要
前端数据采集和报告是构建数据平台过程中最重要的链接。美团点评的前端每天都会报告数百亿次数据。为了更好地满足公司各种业务中对嵌入点日益复杂的要求,以及嵌入点的准确性,及时性和开发效率,我们基于代码嵌入方案开发了一套轻量级的声明性方法。公司的前端掩埋方案,以及在动态掩埋和无缝掩埋方向上的进一步探索和实践。目前,声明性掩埋点已在某些企业中得到充分使用。从数据质量和开发人员反馈的角度来看,已经实现了预期的收益。非标记掩埋点也在一些业务中得到验证和不断优化,并将在以后在公司内部进一步推广。
在实践中,我们意识到掩埋点的问题无法通过单一的技术解决方案来解决。我们需要在不同的情况下选择不同的掩埋方案。例如,对于简单的用户行为事件,可以使用非标记掩埋点来解决;对于需要携带大量可以在运行时学习的业务领域的业务领域的埋入要求,需要使用声明性埋入点来解决它们。从更高的角度来看,除了优化前端埋入技术之外,埋入数据的标准化,前端和后端协作埋入,数据清理和关联对于构建更自动化和动态的埋入系统也非常重要。将来。
一次性安装维清微信头条系统全套可享受8.8折优惠
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-01-19 08:11
功能亮点:
提醒:由于采集由于目标需要输入验证码而经常出现,因此采集是不可能的,因此我们开发了自动输入验证码的功能,但是自动输入验证码需要输入第三方(联众)付费编码接口。关于成本,一次自动识别验证码只需花费一美分,并且采集识别后的一段时间内无需再次被识别,因此花费不多,请放心!
示范与推广
演示地址:
优惠时事通讯:一次性安装全套的微庆微信头条系统,即可享受8.20%的折扣,请给我戳一下!
“微信头条系统”的系统架构
1、“ [维清]微信文章采集器”点击安装|查看演示
此插件是整个系统的核心和基础。它主要提供诸如官方帐户采集和管理,文章采集和管理,官方帐户和文章推荐等功能。安装此插件,让您的网站与数百万个公共帐户共享高质量文章!
2、“ [维清]微信导航”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供官方帐户汇总页面(列表页面),官方帐户详细信息页面和其他页面。安装此插件可为正式帐户运营商提供进入标题系统的理由!
3、“ [魏青]未央读书中心”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供以下公共帐户文章的汇总浏览功能和公共帐户跟踪管理功能。安装此插件,安装此插件,让微信用户喜欢在您的微信标题系统文章上阅读!
4、“ [维清]微信文章DIY”点击安装
安装此扩展程序后,可以在网站的任何页面上调用“ WeChat WeChat 文章采集器” 采集和文章的正式帐户。操作方法与系统本身中的其他DIY模块相同。
5、“ [Weiqing]插件伪静态”单击安装
实现微信标题系统主页的静态链接,以便搜索引擎可以更轻松地搜索系统的相关页面收录!
6、“ [Weiqing]百度编辑器”点击安装
此插件是免费的插件,主要提供文章编辑功能,可以编辑“微信微信文章采集器” 采集返回的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
功能说明
[维清] WeChat 文章采集器是采集 WeChat订阅帐户信息和订阅帐户文章的插件。只需输入官方帐户昵称,您就可以自动采集官方帐户信息(信息包括官方帐户昵称,微信ID,功能介绍,身份验证信息,头像,QR码)。安装此插件,您可以让网站与数百万个订阅帐户共享高质量的内容,每天进行大量更新,可以快速增加网站的权重和排名。
功能亮点:
1、可自定义的插件名称:
您可以在后台的面包屑导航中随意修改插件的名称。如果未设置,则默认为微信窗口。
2、可自定义的SEO信息:
后台可以轻松地为每个页面设置SEO信息,它支持网站名称,插件名称,类别名称,文章标题和其他信息的变量替换。
3、可以批量采集个官方帐户信息:
输入微信公众号的昵称,然后单击搜索,选择您想要的采集正式账号,然后提交。您一次可以采集多个官方帐户信息。
4、可以批量采集 文章的官方帐户:
在官方帐户列表中单击“ 采集 文章”的链接,输入到采集的页数,您可以批处理采集 文章信息,并且可以采集多集在文章时,文章的内容也已本地化。
5、 文章信息可以完美显示:
该插件构建了自己的主页,列表页面和详细信息页面,可以在不依赖原创系统任何功能的情况下完美显示文章信息。
6、强大的DIY机制:
只要安装diy扩展程序,就可以拥有强大的DIY机制,并且可以在网站的任何页面上调用微信官方帐户信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(主页,列表页面,详细信息页面)具有多个内置的DIY区域,并且可以在原创内容块之间插入DIY模块。
8、可以灵活设置是否需要查看信息:
是否可以通过后台在后台控制是否需要查看用户提交的公共帐户和内容的文章信息。
9、信息批处理管理功能:
后台提供了功能全面的微信公众号和文章批次管理功能,可以批量查看,删除和移动信息分类。
10、完全支持移动版本:
只需安装相应的移动版本组件,即可轻松打开移动版本。
示范与推广
演示地址:
Discount Express:一次性安装未清微信头条系统即可享受8.20%的折扣,请给我戳一下!
高质量的应用推荐
查看全部
一次性安装维清微信头条系统全套可享受8.8折优惠
功能亮点:
提醒:由于采集由于目标需要输入验证码而经常出现,因此采集是不可能的,因此我们开发了自动输入验证码的功能,但是自动输入验证码需要输入第三方(联众)付费编码接口。关于成本,一次自动识别验证码只需花费一美分,并且采集识别后的一段时间内无需再次被识别,因此花费不多,请放心!
示范与推广
演示地址:
优惠时事通讯:一次性安装全套的微庆微信头条系统,即可享受8.20%的折扣,请给我戳一下!
“微信头条系统”的系统架构
1、“ [维清]微信文章采集器”点击安装|查看演示
此插件是整个系统的核心和基础。它主要提供诸如官方帐户采集和管理,文章采集和管理,官方帐户和文章推荐等功能。安装此插件,让您的网站与数百万个公共帐户共享高质量文章!
2、“ [维清]微信导航”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供官方帐户汇总页面(列表页面),官方帐户详细信息页面和其他页面。安装此插件可为正式帐户运营商提供进入标题系统的理由!
3、“ [魏青]未央读书中心”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供以下公共帐户文章的汇总浏览功能和公共帐户跟踪管理功能。安装此插件,安装此插件,让微信用户喜欢在您的微信标题系统文章上阅读!
4、“ [维清]微信文章DIY”点击安装
安装此扩展程序后,可以在网站的任何页面上调用“ WeChat WeChat 文章采集器” 采集和文章的正式帐户。操作方法与系统本身中的其他DIY模块相同。
5、“ [Weiqing]插件伪静态”单击安装
实现微信标题系统主页的静态链接,以便搜索引擎可以更轻松地搜索系统的相关页面收录!
6、“ [Weiqing]百度编辑器”点击安装
此插件是免费的插件,主要提供文章编辑功能,可以编辑“微信微信文章采集器” 采集返回的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
功能说明
[维清] WeChat 文章采集器是采集 WeChat订阅帐户信息和订阅帐户文章的插件。只需输入官方帐户昵称,您就可以自动采集官方帐户信息(信息包括官方帐户昵称,微信ID,功能介绍,身份验证信息,头像,QR码)。安装此插件,您可以让网站与数百万个订阅帐户共享高质量的内容,每天进行大量更新,可以快速增加网站的权重和排名。
功能亮点:
1、可自定义的插件名称:
您可以在后台的面包屑导航中随意修改插件的名称。如果未设置,则默认为微信窗口。
2、可自定义的SEO信息:
后台可以轻松地为每个页面设置SEO信息,它支持网站名称,插件名称,类别名称,文章标题和其他信息的变量替换。
3、可以批量采集个官方帐户信息:
输入微信公众号的昵称,然后单击搜索,选择您想要的采集正式账号,然后提交。您一次可以采集多个官方帐户信息。
4、可以批量采集 文章的官方帐户:
在官方帐户列表中单击“ 采集 文章”的链接,输入到采集的页数,您可以批处理采集 文章信息,并且可以采集多集在文章时,文章的内容也已本地化。
5、 文章信息可以完美显示:
该插件构建了自己的主页,列表页面和详细信息页面,可以在不依赖原创系统任何功能的情况下完美显示文章信息。
6、强大的DIY机制:
只要安装diy扩展程序,就可以拥有强大的DIY机制,并且可以在网站的任何页面上调用微信官方帐户信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(主页,列表页面,详细信息页面)具有多个内置的DIY区域,并且可以在原创内容块之间插入DIY模块。
8、可以灵活设置是否需要查看信息:
是否可以通过后台在后台控制是否需要查看用户提交的公共帐户和内容的文章信息。
9、信息批处理管理功能:
后台提供了功能全面的微信公众号和文章批次管理功能,可以批量查看,删除和移动信息分类。
10、完全支持移动版本:
只需安装相应的移动版本组件,即可轻松打开移动版本。
示范与推广
演示地址:
Discount Express:一次性安装未清微信头条系统即可享受8.20%的折扣,请给我戳一下!
高质量的应用推荐
<p>微信公众号文章的想法采集,如何采集微信公众号文章?</p>
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-01-17 12:03
</p>
许多方法对于不懂编程的人来说太昂贵了。让我分享一种大家都可以使用的方法。简单快捷。您可以将所有文章正式帐户下载到采集。 (Word,html,pdf格式都是可能的),最后您还可以合成一个官方帐户文章电子书,我尝试过采集拥有2,000多个官方帐户文章,但通常情况下采集 2000多篇文章,系统有限,您可以在第二天继续采集。
直接链接:官方帐户文章 采集助手,密码:7t93
我将在下面为您详细介绍。
1、可以是任何发布的采集微信公众号历史记录组文章
微信文章导出软件可以帮助您下载并保存所有想要将官方帐户直接导出到计算机的文章。操作简单,每个人都可以!
2、WeChat 文章导出的文档种类繁多,提取的内容更加完整
好的微信文章可以下载并保存到计算机中以进行永久存储,并且打印微信文章也很方便。多样化的存档格式可以更好地满足大多数人的需求。
3、通过关键词按时间段搜索微信官方帐户文章工具
微信文章导出软件不仅可以下载文章,而且可以通过计算机在线搜索微信文章!每天都有数以百万计的官方帐户文章,涵盖各个行业和地区,广受欢迎的原创文章,可帮助您创建或查找更多优质内容
4、下载微信文章预览,您对此感到满意
专业人员从事专业工作,将采集导出并留给微信文章导出软件,以帮助您提高效率并节省时间
导出Word文档分类并保存
微信文章下载器还收录近80种其他辅助功能,易于使用
直接转到软件链接:官方帐户文章 采集助手,密码:7t93 查看全部
<p>微信公众号文章的想法采集,如何采集微信公众号文章?
</p>
许多方法对于不懂编程的人来说太昂贵了。让我分享一种大家都可以使用的方法。简单快捷。您可以将所有文章正式帐户下载到采集。 (Word,html,pdf格式都是可能的),最后您还可以合成一个官方帐户文章电子书,我尝试过采集拥有2,000多个官方帐户文章,但通常情况下采集 2000多篇文章,系统有限,您可以在第二天继续采集。
直接链接:官方帐户文章 采集助手,密码:7t93
我将在下面为您详细介绍。
1、可以是任何发布的采集微信公众号历史记录组文章
微信文章导出软件可以帮助您下载并保存所有想要将官方帐户直接导出到计算机的文章。操作简单,每个人都可以!
2、WeChat 文章导出的文档种类繁多,提取的内容更加完整
好的微信文章可以下载并保存到计算机中以进行永久存储,并且打印微信文章也很方便。多样化的存档格式可以更好地满足大多数人的需求。
3、通过关键词按时间段搜索微信官方帐户文章工具
微信文章导出软件不仅可以下载文章,而且可以通过计算机在线搜索微信文章!每天都有数以百万计的官方帐户文章,涵盖各个行业和地区,广受欢迎的原创文章,可帮助您创建或查找更多优质内容
4、下载微信文章预览,您对此感到满意
专业人员从事专业工作,将采集导出并留给微信文章导出软件,以帮助您提高效率并节省时间
导出Word文档分类并保存
微信文章下载器还收录近80种其他辅助功能,易于使用
直接转到软件链接:官方帐户文章 采集助手,密码:7t93
解决方案:优采云采集接入奶盘AI伪原创API教程
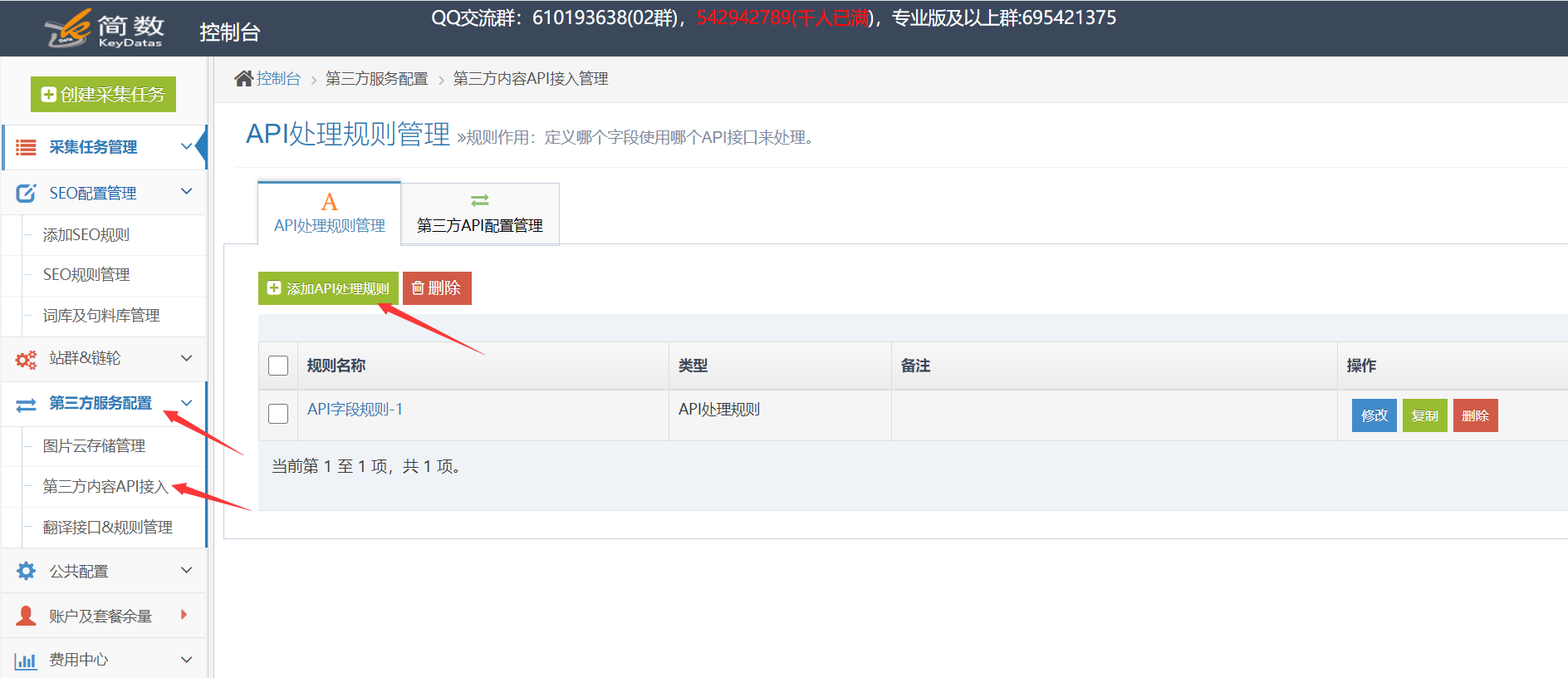
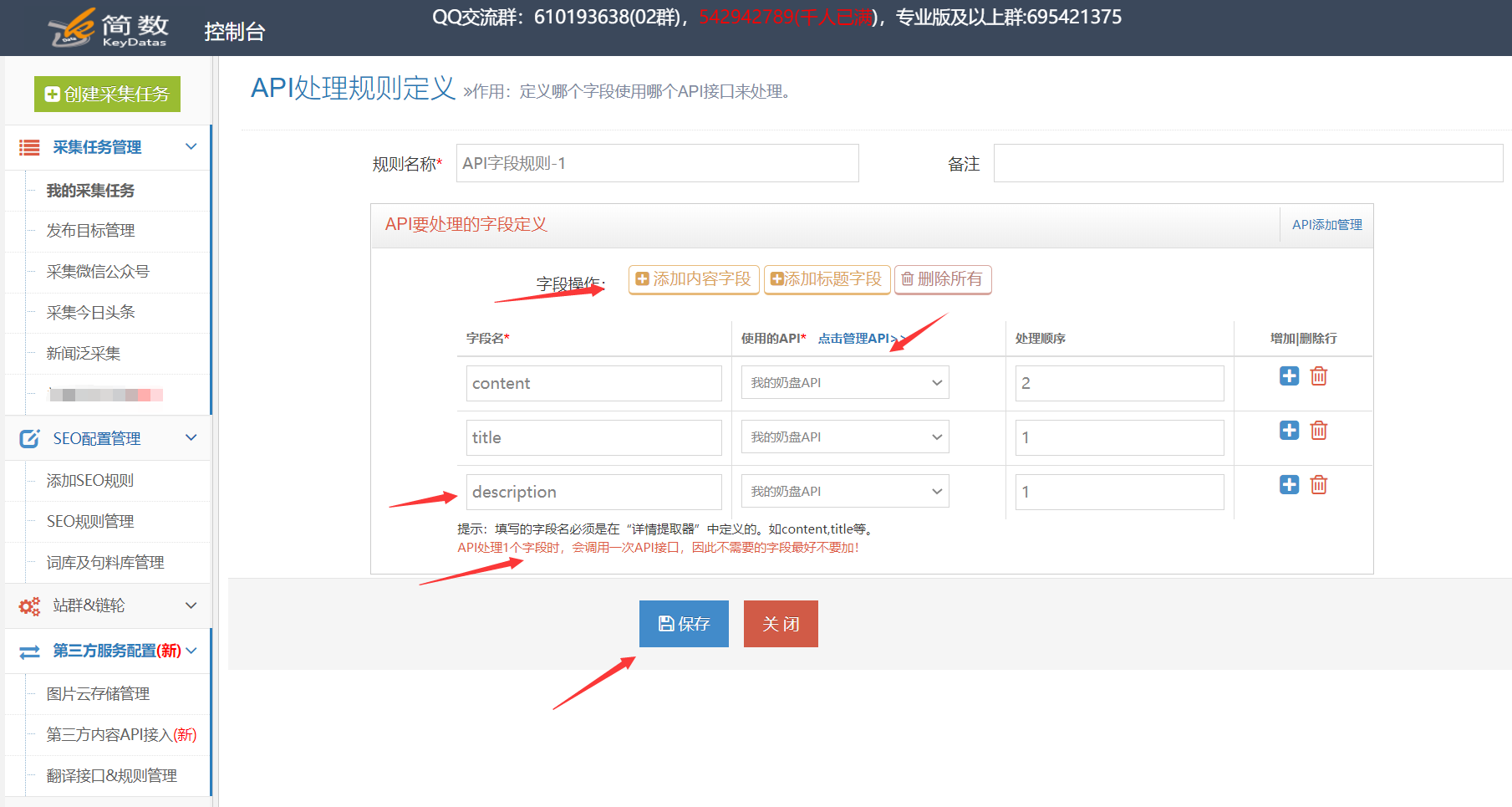
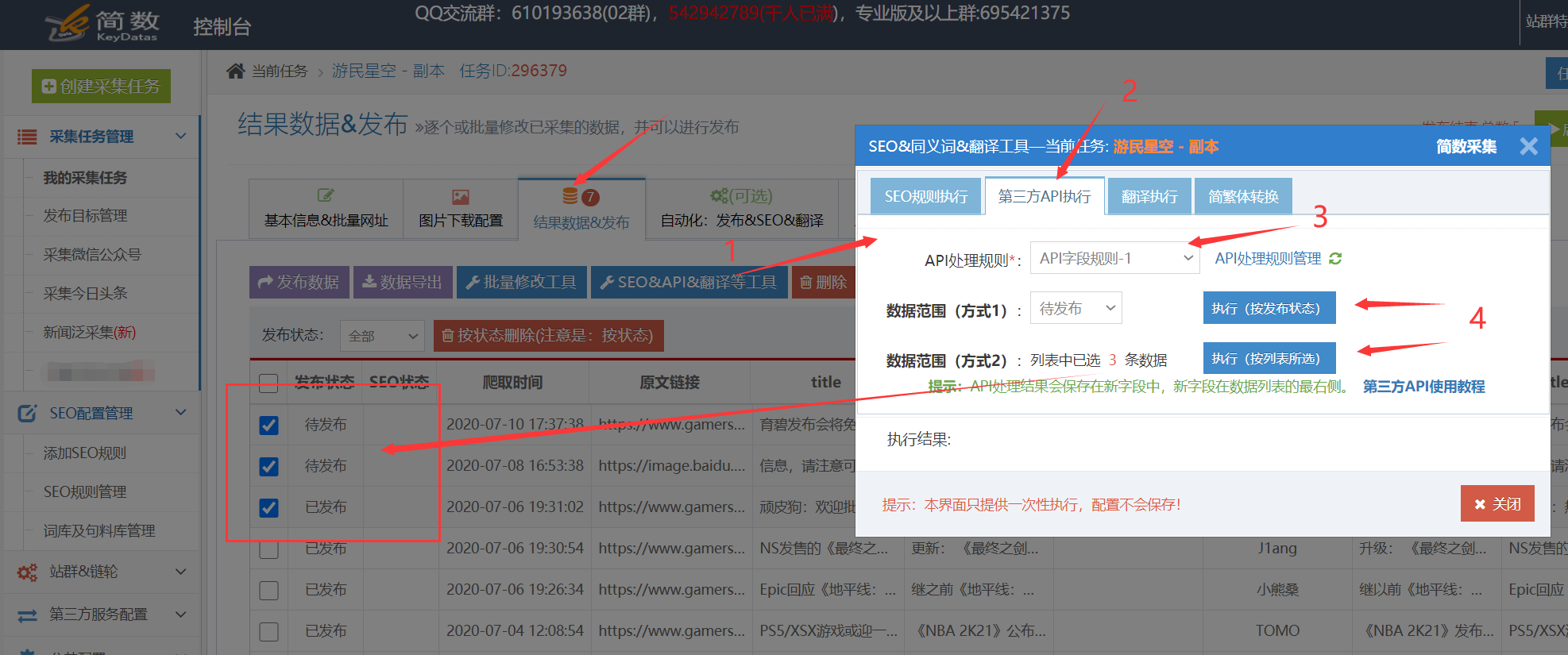
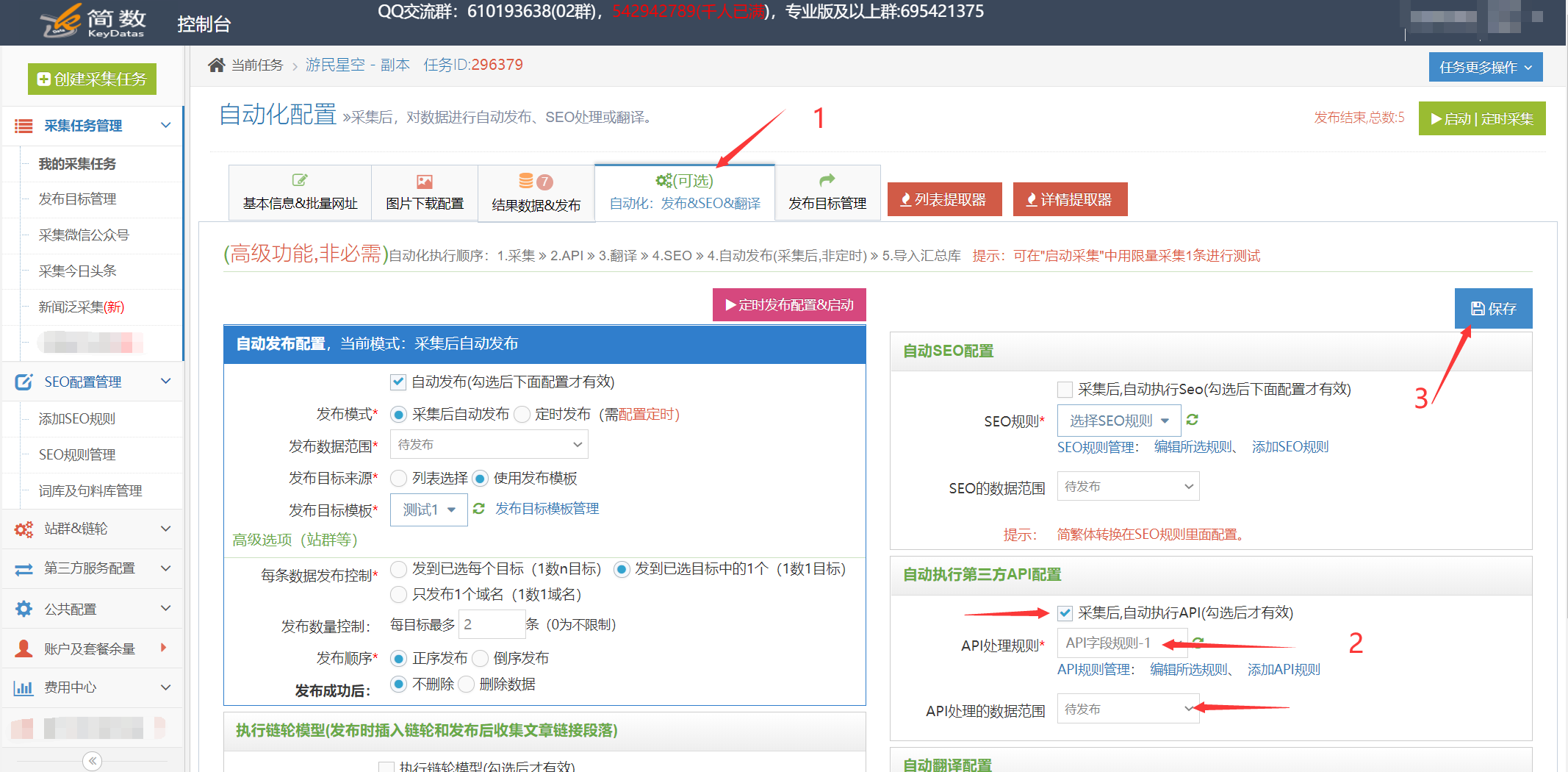
采集交流 • 优采云 发表了文章 • 0 个评论 • 388 次浏览 • 2021-01-16 11:02
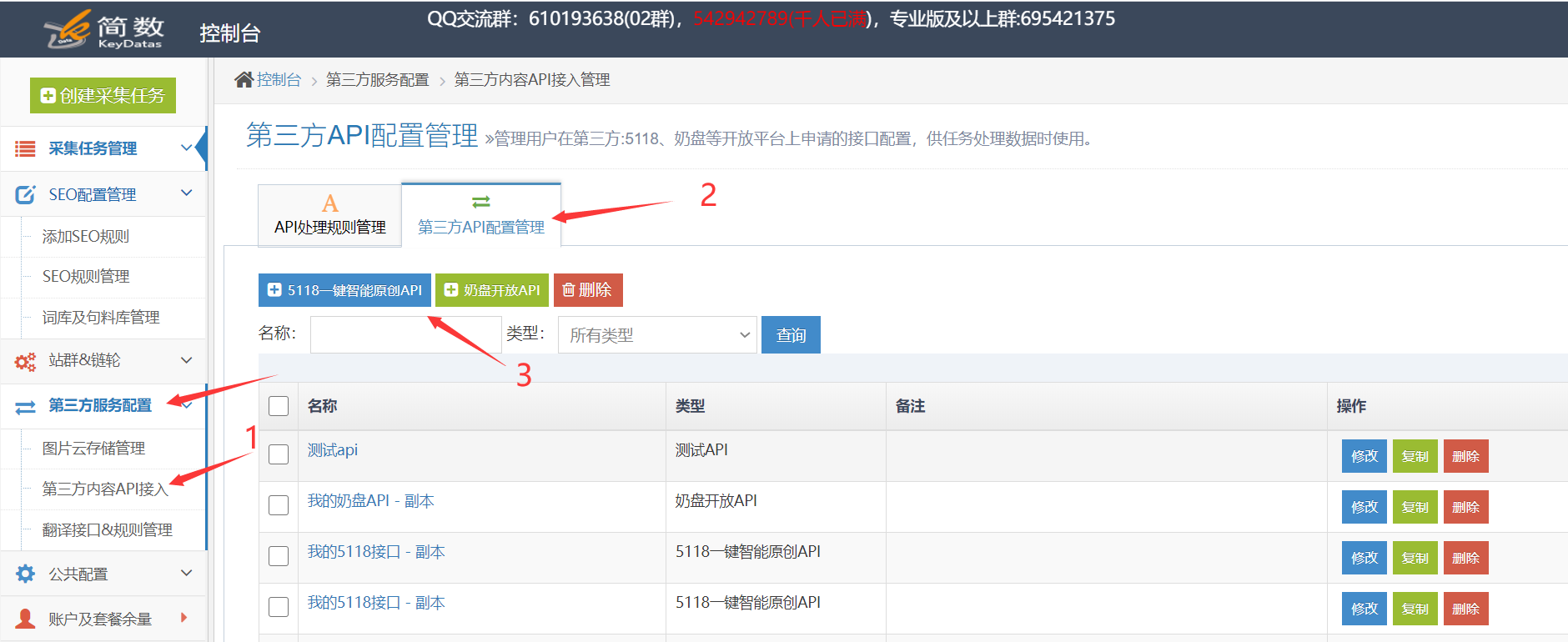
优采云采集支持调用挤奶锅API接口以处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和5118智能单词更改API以更高的原创程度处理文章,这对于增加收录的权重和文章的作用非常重要。
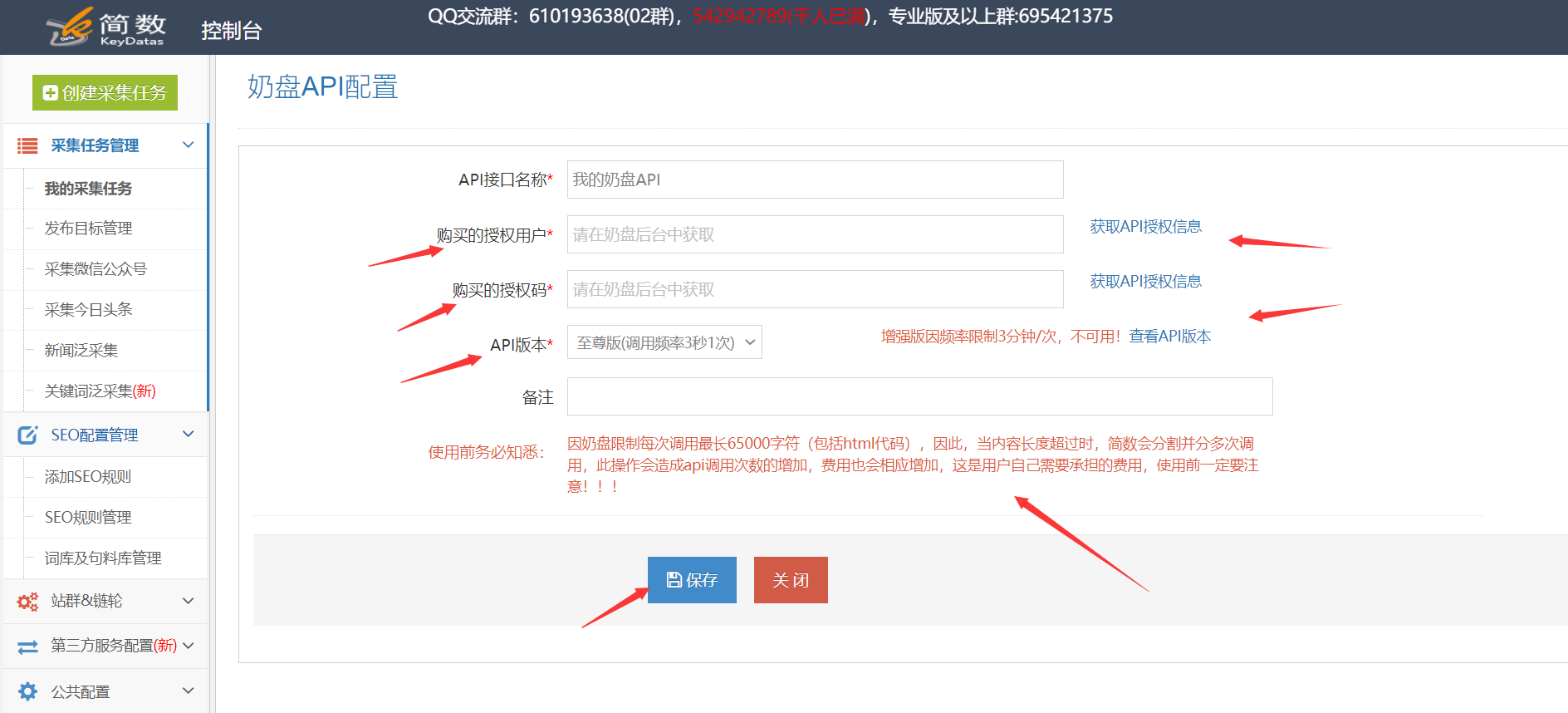
详细的使用步骤如下:1.奶锅API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[+ Milk pan API]创建界面配置;
II。配置API接口信息:
[购买的授权用户],[购买的授权代码]用于从Milk Disk Network的后端获取API授权信息;
[API版本]对应于购买的软件包:百度优化版,AI智能版;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为一个新字段,例如:[结果数据和发布]中的标题处理后的新字段:title_milk托盘,内容处理后的新字段:content_milk托盘,以及数据可以查看预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_milk tray和content_milk tray;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.奶锅API接口的常见问题和解决方案
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_milk plate和content_milk plate字段;
查看全部
解决方案:优采云采集接入奶盘AI伪原创API教程
优采云采集支持调用挤奶锅API接口以处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和5118智能单词更改API以更高的原创程度处理文章,这对于增加收录的权重和文章的作用非常重要。
详细的使用步骤如下:1.奶锅API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[+ Milk pan API]创建界面配置;
II。配置API接口信息:
[购买的授权用户],[购买的授权代码]用于从Milk Disk Network的后端获取API授权信息;
[API版本]对应于购买的软件包:百度优化版,AI智能版;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为一个新字段,例如:[结果数据和发布]中的标题处理后的新字段:title_milk托盘,内容处理后的新字段:content_milk托盘,以及数据可以查看预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_milk tray和content_milk tray;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.奶锅API接口的常见问题和解决方案
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_milk plate和content_milk plate字段;
技术文章:织梦dedecms系统修改文章描述调用字数的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-01-09 11:01
dedecms系统文章调用说明的最大字符数为250个字节。 文章摘要(可以通过infolen或与描述相关的标签调用)设置为最多250个字符。主要目的是减少数据库的冗余并确保网络的出色性能。因此,不对引言的内容设置上限显然是不合理的,但是如果可以自由控制该上限,则dedecms模仿站点将对Web内容的布局产生积极影响。在网页设计过程中,.NET源代码。通常需要在频道列表页面的文章摘要中调用dedecms。如果文章摘要中的单词数不能有效控制,则页面布局可以非常灵活。
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field:description function =“ cn_substr(@me,character number)”/]。
与Dedecms系统中的文章摘要相关的php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子:$ description = cn_substrR($ description,$ cfg_auot_description);这句话实现此功能[field:description function =“ cn_substr(@me,character number)” /]。由于此语句确实对页面布局很有帮助,因此我们尝试不做任何更改。
在编辑页面上,有一个句子:$ description = cn_substrR($ description,250);,该句子显示了熟悉的字符数250,这是系统设置的抽象字符数文章字符数上限。如果是gbk编码,将显示125个字符。如果是utf-8编码,则为81个字符。显然,我们必须打破字符数上限文章 summary。是的,您可以在此处将250修改为另一个值,例如500。不建议在此处设置太高,一个是不需要在列表页面上显示太多内容(显示太多)内容不如间接使用主体好),另一个是避免数据库冗余。
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,找到if($ dsize> 250)$ dsize = 250;语句。这限制了可用于在后台获取摘要的字符数。在此处修改250到500。织梦模仿站与之前修改的字符数有所不同(如果您确认手动添加了文章的每个字符,则如果您手动完成摘要,则无需修改此文件从动态摘要中获取次要摘要仍为大量文章和采集准备。)
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这与以前修改的字符数不同。
完成上述修改后,我们可以转到频道列表页面并按标签进行调用。标签示例如下:
{dede:list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field:title /]
[field:description function ='cn_substr(@ me,500)'/] ...
{/ dede:list}
通过上述方法,我们已经意识到被调用的文章摘要字符为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了越来越多的空间。
接下来,我们还讨论一下常用的Dedecms 文章或列表页面调用文章摘要方法
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
1、的第二种方法是间接调用文章摘要。根据要调用的单词数,使用[field:info /]时,可以使用{dede:arclist infolen =''} {/ dede:在arclist}中,设置字符数以调用摘要(向上设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符的上限(后台也有250个字符的上限)。显然,这两种方法非常被动和灵活。
第四种方法3、通过功能功能实现文章摘要显示字符的灵活调整。当然,当文章摘要内容的上限没有正常修改时,这四种方法之间的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
这四个方法用于调用文章描述标签。但是它最多只能调用前250个字符。如果您想打更多电话,则需要修改一些地方:
1.article_description_main.php页面,找到“ if($ dsize> 250) $ dsize = 250;”句子,将250更改为500
2.登录到后台,在系统-系统基本参数-其他选项中,自动汇总长度更改为500.
3.登录到后台并执行SQL语句:alter table`dede_archives` change`description`description` varchar(1000)
调用标签{dede:field.description function ='cn_substr(@ me,500)'/}。您可以显示500个字符) 查看全部
技术文章:织梦dedecms系统修改文章描述调用字数的方法
dedecms系统文章调用说明的最大字符数为250个字节。 文章摘要(可以通过infolen或与描述相关的标签调用)设置为最多250个字符。主要目的是减少数据库的冗余并确保网络的出色性能。因此,不对引言的内容设置上限显然是不合理的,但是如果可以自由控制该上限,则dedecms模仿站点将对Web内容的布局产生积极影响。在网页设计过程中,.NET源代码。通常需要在频道列表页面的文章摘要中调用dedecms。如果文章摘要中的单词数不能有效控制,则页面布局可以非常灵活。
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field:description function =“ cn_substr(@me,character number)”/]。
与Dedecms系统中的文章摘要相关的php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子:$ description = cn_substrR($ description,$ cfg_auot_description);这句话实现此功能[field:description function =“ cn_substr(@me,character number)” /]。由于此语句确实对页面布局很有帮助,因此我们尝试不做任何更改。
在编辑页面上,有一个句子:$ description = cn_substrR($ description,250);,该句子显示了熟悉的字符数250,这是系统设置的抽象字符数文章字符数上限。如果是gbk编码,将显示125个字符。如果是utf-8编码,则为81个字符。显然,我们必须打破字符数上限文章 summary。是的,您可以在此处将250修改为另一个值,例如500。不建议在此处设置太高,一个是不需要在列表页面上显示太多内容(显示太多)内容不如间接使用主体好),另一个是避免数据库冗余。
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,找到if($ dsize> 250)$ dsize = 250;语句。这限制了可用于在后台获取摘要的字符数。在此处修改250到500。织梦模仿站与之前修改的字符数有所不同(如果您确认手动添加了文章的每个字符,则如果您手动完成摘要,则无需修改此文件从动态摘要中获取次要摘要仍为大量文章和采集准备。)
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这与以前修改的字符数不同。
完成上述修改后,我们可以转到频道列表页面并按标签进行调用。标签示例如下:
{dede:list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field:title /]
[field:description function ='cn_substr(@ me,500)'/] ...
{/ dede:list}
通过上述方法,我们已经意识到被调用的文章摘要字符为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了越来越多的空间。
接下来,我们还讨论一下常用的Dedecms 文章或列表页面调用文章摘要方法
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
1、的第二种方法是间接调用文章摘要。根据要调用的单词数,使用[field:info /]时,可以使用{dede:arclist infolen =''} {/ dede:在arclist}中,设置字符数以调用摘要(向上设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符的上限(后台也有250个字符的上限)。显然,这两种方法非常被动和灵活。
第四种方法3、通过功能功能实现文章摘要显示字符的灵活调整。当然,当文章摘要内容的上限没有正常修改时,这四种方法之间的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
这四个方法用于调用文章描述标签。但是它最多只能调用前250个字符。如果您想打更多电话,则需要修改一些地方:
1.article_description_main.php页面,找到“ if($ dsize> 250) $ dsize = 250;”句子,将250更改为500
2.登录到后台,在系统-系统基本参数-其他选项中,自动汇总长度更改为500.
3.登录到后台并执行SQL语句:alter table`dede_archives` change`description`description` varchar(1000)
调用标签{dede:field.description function ='cn_substr(@ me,500)'/}。您可以显示500个字符)
总结:数据采集-微信公众号文章的完整爬取过程笔记
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-12-19 13:17
微信公众号文章的完整抓取过程笔记
基于sougou-api的概述一.实现文章爬网[基于anyproxy的二.和Monkeyrunner 文章基于sougou-api的自动爬网一.以实现文章爬网
1.可以直接获取微信搜狗首页
2.使用现有的软件包+代理方法
调用该API,并通过微信官方帐户文章的ID获取帐户的一部分
此方法只能获取微信文章的临时链接,因此您需要将html文本保存到其中
二. 文章基于anyproxy和Monkeyrunner的自动爬网
假设:您有一批微信公众号ID(例如:gh_1380fb0258f6)
硬件条件:普通PC(我使用Windows系统),Android手机(我使用Huawei Honor 8lite)
尽量不要使用模拟器。使用仿真器登录微信后,发现该帐号被封锁! ! !
目标:抓取该微信官方帐户文章的所有历史记录并逐步抓取
1.根据anyproxy 文章抓取所有正式帐户
伟大的上帝已经实现了这一步,他的代码直接在这里使用:wechat_spider微信爬虫
有关具体实现过程,请参考github,在这一步您需要注意选择正确的IP
2.基于Monkeyrunner的爬网自动化(1)手机打开开发人员模式
作者当前遇到手机以打开开发人员模式的方式是“在系统版本号上单击7、8次”
([2)PC安装Android开发套件
有关Android SDK的下载和安装,请参阅AndroidDevTools
有关安装是否成功的检测方法,请参阅:Monkeyrunner1-monkeyrunner入门记录和回放
([3)自动抓取过程S1使用微信搜索框通过微信官方帐户ID搜索该帐户
图片
图片
S2单击以输入帐户,下拉,单击所有文章,输入
图片
S3下拉列表,在文章列表中单击文章文章将其打开
图片
S4等待一段时间,然后返回微信首页,继续执行S1爬虫爬网策略摘要
抓取微信公众号文章可用于舆论监测
我认为有两种方法:
1.监视微信官方帐户文章上的点赞次数,找到“爆炸性风格” 文章,监视爆炸性风格文章的主题或事件 查看全部
总结:数据采集-微信公众号文章的完整爬取过程笔记
微信公众号文章的完整抓取过程笔记
基于sougou-api的概述一.实现文章爬网[基于anyproxy的二.和Monkeyrunner 文章基于sougou-api的自动爬网一.以实现文章爬网
1.可以直接获取微信搜狗首页
2.使用现有的软件包+代理方法
调用该API,并通过微信官方帐户文章的ID获取帐户的一部分
此方法只能获取微信文章的临时链接,因此您需要将html文本保存到其中
二. 文章基于anyproxy和Monkeyrunner的自动爬网
假设:您有一批微信公众号ID(例如:gh_1380fb0258f6)
硬件条件:普通PC(我使用Windows系统),Android手机(我使用Huawei Honor 8lite)
尽量不要使用模拟器。使用仿真器登录微信后,发现该帐号被封锁! ! !
目标:抓取该微信官方帐户文章的所有历史记录并逐步抓取
1.根据anyproxy 文章抓取所有正式帐户
伟大的上帝已经实现了这一步,他的代码直接在这里使用:wechat_spider微信爬虫
有关具体实现过程,请参考github,在这一步您需要注意选择正确的IP
2.基于Monkeyrunner的爬网自动化(1)手机打开开发人员模式
作者当前遇到手机以打开开发人员模式的方式是“在系统版本号上单击7、8次”
([2)PC安装Android开发套件
有关Android SDK的下载和安装,请参阅AndroidDevTools
有关安装是否成功的检测方法,请参阅:Monkeyrunner1-monkeyrunner入门记录和回放
([3)自动抓取过程S1使用微信搜索框通过微信官方帐户ID搜索该帐户

图片

图片
S2单击以输入帐户,下拉,单击所有文章,输入
图片
S3下拉列表,在文章列表中单击文章文章将其打开

图片
S4等待一段时间,然后返回微信首页,继续执行S1爬虫爬网策略摘要
抓取微信公众号文章可用于舆论监测
我认为有两种方法:
1.监视微信官方帐户文章上的点赞次数,找到“爆炸性风格” 文章,监视爆炸性风格文章的主题或事件
解决方案:【剖析 | SOFARPC 框架】系列之 SOFARPC 泛化调用实现剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-11-30 11:18
大咖啡揭示了爪哇人的种植地?点击免费获得“大厂面试名单”,克服面试的困难〜>>>
沙发
ScalableOpenFinancialArchitecture
它是由Ant Financial独立开发的金融级分布式中间件。它收录构建金融级云原生架构所需的所有组件。这是财务方案中的最佳做法。
本文是E符号宝库中的Mona Rudao撰写的“分析| SOFARPC Framework”的第七章。 “分析| SOFARPC框架”系列由SOFA团队和源代码爱好者编写。项目代码为:官方目录已声明。
当前,SOFABolt源代码分析正在进行中,有兴趣的朋友可以在文章结尾处进行申请
前言
我们知道,在RPC调用中,客户端需要加载服务器提供的接口定义类。但是,这并不总是可行的。因此,产生了对通用调用的需求,一个成熟且功能齐全的RPC框架通常支持通用调用,那么通用调用是什么? SOFARPC如何支持广义调用?如何同时实现?与其他RPC泛化调用有何不同?有什么优势?我们将在本文中一个一个地回答。
广义呼叫简介
当客户端由于某种原因而无法获得服务提供商的接口jar包时,或者客户端是更通用的系统,并且不想依赖于每个服务提供商提供的Facade接口,但是需要调用,然后目前需要泛化调用。
例如:
当使用多种语言开发分布式系统时,假设它是NodeJ,并且NodeJ需要调用Java语言的RPC服务,那么我们需要在两者之间建立一个适应层,以便该适应层可以处理NodeJ。请求,然后将其转发到Java的RPC服务。
某些中间系统功能(例如某些内部网关)需要以统一的方式实现对其他下游系统的调用(在非SPI的情况下),显然不可能一一依赖于下游程序包。
某些在线流量回放系统可以拦截数据采集,然后通过泛化进行呼叫回放,而无需依赖整个站点的应用程序。
在这种情况下,必须不包括所有接口的jar文件,否则它将太肿。实际上,这也是不现实的。每次添加服务器,然后释放并重新启动应用程序时,都不可能添加jar包依赖项。
这时,可以使用通用调用,并且可以将相应的请求打包为通用调用,以便可以在不依赖于接口jar包的情况下以多种语言调用RPC服务以避免重复开发。
SOFARPC的通用呼叫用法
SOFARPC的正式文档非常详细,并且已在正式Wiki泛化调用中进行了详细介绍。同时,在源代码的示例模块中,还可以运行现成的演示。读者可以克隆源代码以进行阅读。在这里,我们简要解释如何使用它,以便每个人都具有直观的理解。
接口定义
通常,有2个用于泛化调用的API,包括5种方法,其中2种方法已被弃用,即3种主要方法。他们是:
<p style="line-height: 1.5em;">/**
* 泛化调用
* @return 正常类型(不能是GenericObject类型)
*/
Object $invoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 除了JDK等内置类型,其它对象是GenericObject类型
*/
Object $genericInvoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 返回指定的T类型返回对象
*/
T $genericInvoke(String methodName, String[] argTypes, Object[] args, Class clazz);</p>
$ invoke此方法的使用场景:用户知道参数类型和返回值类型,则可以使用此方法。
$ genericInvoke此方法是重载方法。重载一的使用场景是:如果您的应用程序不知道接口的参数类型和返回值类型,那么此时,您需要使用GenericObject类包装返回值和参数。
$ genericInvoke重载二的使用方案是:如果应用程序不知道接口参数类型,但是知道接口返回值的类型,则无需使用GenericObject作为返回值。
基本上,已经涵盖了常用的集中式场景,可以说功能相当全面。
一般用途
由于篇幅所限,我将不在此处发布演示。如果您有兴趣,可以通过链接查看官方演示或源代码,包括使用SOFARPC API和SOFABoot:
演示Wiki地址:
源代码地址:
SOFARPC泛化调用的设计和实现
接下来,我们将重点介绍SOFARPC如何实现广义调用。
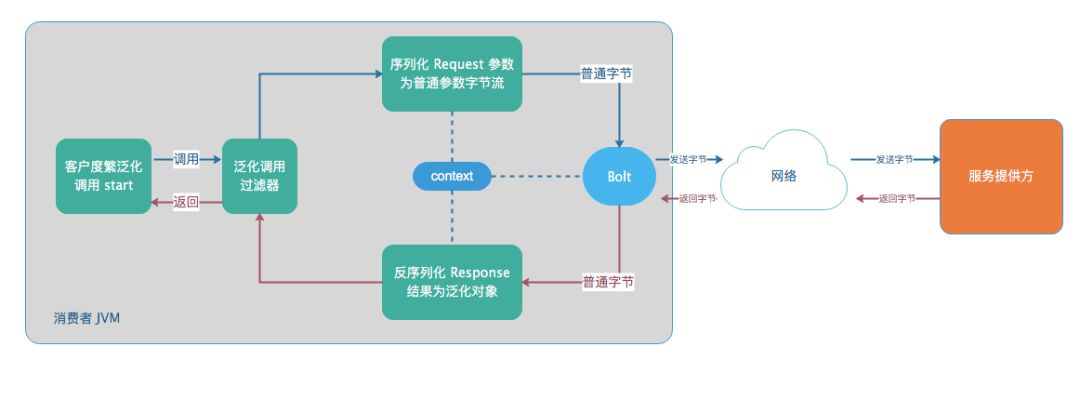
框架调用设计
简单来说,泛化调用的关键是对象表示和序列化。 SOFARPC提供了GenericObject之类的对象来表示参数对象或返回值对象,并将GenericObject对象序列化为目标对象,或者将返回值反序列化为GenericObject对象是SOFARPC泛化的关键。
在这里,我们首先看一下SOFARPC泛化调用的流程图,这将有助于以后理解泛化的实现。
让我们谈谈这张照片:
调用通用化API时,将加载通用化过滤器,该过滤器用于进行一些参数转换并设置序列化工厂类型。
SOFARPC将在使用SOFABolt进行网络调用并将其传递给SOFABolt之前创建一个上下文。上下文收录序列化工厂类型信息。这些信息将确定使用哪个序列化程序,并且该上下文将在整个调用期间内流动。
在SOFABolt正式发送数据之前,它将把GenericObject对象序列化为普通对象的字节流,这样服务提供者就不必关心它是否是泛化调用。从图中可以看出,提供程序不需要进行泛化调用任何更改-这是区分SOFARPC泛化与其他RPC泛化的关键。
提供者成功接收到请求后,可以使用常规的序列化器对数据进行反序列化,而只需正常调用并返回即可。
当使用者的SOFABolt接收到响应数据时,它会根据上下文的序列化类型对返回值进行反序列化,即,将普通字节流反序列化为GenericObject对象,因为客户端可能不知道返回值。
最后,泛化API以获取GenericObject类型的返回值。
从以上过程可以看出,序列化程序在泛化调用中占据了大量空间和作用。对于SOFARPC,对hessian3进行了修改以用于通用调用,以支持通用调用所需的序列化功能。 SOFA-Hessian的变化可以在这里参考。
Hessian概括实现
SOFA-Hessian将com.alipay.hessian.generic软件包添加到了hessian软件包中。该软件包的功能是处理泛化调用。重写的关键是实现或继承SerializerFactory类以及Serializer,Deserializer和其他接口。这里,设计了几个类来描述相应的类型信息,并同时实现这些类的序列化和反序列化。对应关系如下
让我们以GenericObjectSerializer为例。该序列化器重写writeObject方法。此方法的功能是将GenericObject对象序列化为目标对象字节流。也就是说,取出GenericObject的type字段和fields字段并将其组合到目标对象的字节流中。
例如:
有一个类型的RPC对象
<p style="line-height: 1.5em;">public class TestObj {
private String str;
private int num;
}</p>
在通用调用客户端中,您可以直接构造GenericObject对象
<p style="line-height: 1.5em;"> GenericObject genericObject = new GenericObject(
"com.alipay.sofa.rpc.invoke.generic.TestObj");
genericObject.putField("str", "xxxx");
genericObject.putField("num", 222);</p>
这时,GenericObjectSerializer可以使用此信息将GenericObject转换为TestObj对象的字节流。服务提供者可以通过普通的hessian2反序列化来获取对象。
与需要两端都支持通用化的其他RPC框架相比,SOFARPC更加友好。换句话说,如果应用程序要支持通用化,则只需要升级客户端(消费者),而服务器(提供者)就不知道。因为从服务器的角度来看,接收到的对象是完全相同的。您可能会发现很难为复杂类型编写这样的结构。 SOFA-Hessian中提供了工具类
<p style="line-height: 1.5em;">com.alipay.hessian.generic.util.GenericUtils</p>
为帮助用户生成,可以直接使用。
SOFARPC和Dubbo泛化调用比较
让我们介绍泛化调用与行业中其他一些产品之间的比较。首先,让我们介绍一下序列化本身的性能和优点。
序列化本身的比较
在Github上,有Java序列化的基准,可以用作参考。尽管在实际场景中,每个序列化场景都是不同的,但结果可能与此处的基准测试结果有所不同,但仍具有参考意义。从该项目的基准测试可以看出:Json是压缩率还是序列率。与Hessian相比,它具有很大的缺点。
同时,尽管与原创程序,kryo等相比,粗麻布的性能差距很小,但是粗麻布反序列化不需要指定类型,这种优势非常有价值。
Dubbo的普遍呼吁
在许多RPC框架中,Dubbo还提供了通用调用的功能。接下来,让我们谈谈Dubbo的概括。 Dubbo泛化和SOFA RPC泛化之间的最大区别是Dubbo需要服务器支持泛化。因此,如果要提供泛化功能,则还必须升级服务器。这似乎对SOFA RPC不友好。
Dubbo的通用呼叫流程如下:
如您所见,Dubbo的服务器还需要一个通用过滤器才能将Map解析为POJO来解析数据。
摘要
本文主要介绍SOFARPC泛化调用的设计和实现,介绍泛化调用的场景,同时,介绍SOFARPC泛化调用的API的用法,并说明泛化设计和实现SOFARPC的详细信息。最后,对社区中某些RPC框架的通用调用进行了简单的比较。
以下是SOFARPC的概括设计和实现的摘要:
设计目标是:服务器不需要感知它是否是通用的,一切都由客户端处理。
带来的好处是:如果应用程序要支持通用化,则无需更改服务器,只需修改客户端即可。这是其他RPC框架中的广义调用之间的最大区别。
实现方法:通过SOFA-Hessian序列化支持泛化序列化。进行泛化调用时,bolt将根据上下文的序列化标记使用相应的序列化程序,SOFA-Hessian的唯一泛化序列化服务器可以将GenericObject对象序列化为目标对象的字节流,服务器可以正常地对其进行反序列化。 SOFA-Hessian独特的泛化反序列化器还可以将目标返回值反序列化为对象,例如GenericObject。
参考
欢迎再加入并参与SOFABolt源代码分析
SOFABolt源代码分析目录:
我们将逐步详细介绍代码的每个部分的设计和实现,并有望根据以下目录进行操作。以下还收录当前的源代码分析文章声明状态:
如何获取:
直接回复此官方帐户想要声明的文章名称,我们会在确定您的资格后主动与您联系,您可以参加,这是您的演出时间!
相关链接
SOFA文件:
沙发:
SOFARPC:
SOFABolt:
小小的复活节彩蛋
请在这里查看您的ID:
长按以获取分布式架构的干货
欢迎一起构建SOFAStack
本文与微信官方帐户-金融级分布式架构(Antfin_SOFA)分享。 查看全部
[分析| SOFARPC Framework]系列SOFARPC泛化调用实现分析
大咖啡揭示了爪哇人的种植地?点击免费获得“大厂面试名单”,克服面试的困难〜>>>

沙发
ScalableOpenFinancialArchitecture
它是由Ant Financial独立开发的金融级分布式中间件。它收录构建金融级云原生架构所需的所有组件。这是财务方案中的最佳做法。
本文是E符号宝库中的Mona Rudao撰写的“分析| SOFARPC Framework”的第七章。 “分析| SOFARPC框架”系列由SOFA团队和源代码爱好者编写。项目代码为:官方目录已声明。
当前,SOFABolt源代码分析正在进行中,有兴趣的朋友可以在文章结尾处进行申请

前言
我们知道,在RPC调用中,客户端需要加载服务器提供的接口定义类。但是,这并不总是可行的。因此,产生了对通用调用的需求,一个成熟且功能齐全的RPC框架通常支持通用调用,那么通用调用是什么? SOFARPC如何支持广义调用?如何同时实现?与其他RPC泛化调用有何不同?有什么优势?我们将在本文中一个一个地回答。
广义呼叫简介
当客户端由于某种原因而无法获得服务提供商的接口jar包时,或者客户端是更通用的系统,并且不想依赖于每个服务提供商提供的Facade接口,但是需要调用,然后目前需要泛化调用。
例如:
当使用多种语言开发分布式系统时,假设它是NodeJ,并且NodeJ需要调用Java语言的RPC服务,那么我们需要在两者之间建立一个适应层,以便该适应层可以处理NodeJ。请求,然后将其转发到Java的RPC服务。
某些中间系统功能(例如某些内部网关)需要以统一的方式实现对其他下游系统的调用(在非SPI的情况下),显然不可能一一依赖于下游程序包。
某些在线流量回放系统可以拦截数据采集,然后通过泛化进行呼叫回放,而无需依赖整个站点的应用程序。
在这种情况下,必须不包括所有接口的jar文件,否则它将太肿。实际上,这也是不现实的。每次添加服务器,然后释放并重新启动应用程序时,都不可能添加jar包依赖项。
这时,可以使用通用调用,并且可以将相应的请求打包为通用调用,以便可以在不依赖于接口jar包的情况下以多种语言调用RPC服务以避免重复开发。
SOFARPC的通用呼叫用法
SOFARPC的正式文档非常详细,并且已在正式Wiki泛化调用中进行了详细介绍。同时,在源代码的示例模块中,还可以运行现成的演示。读者可以克隆源代码以进行阅读。在这里,我们简要解释如何使用它,以便每个人都具有直观的理解。
接口定义
通常,有2个用于泛化调用的API,包括5种方法,其中2种方法已被弃用,即3种主要方法。他们是:
<p style="line-height: 1.5em;">/**
* 泛化调用
* @return 正常类型(不能是GenericObject类型)
*/
Object $invoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 除了JDK等内置类型,其它对象是GenericObject类型
*/
Object $genericInvoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 返回指定的T类型返回对象
*/
T $genericInvoke(String methodName, String[] argTypes, Object[] args, Class clazz);</p>
$ invoke此方法的使用场景:用户知道参数类型和返回值类型,则可以使用此方法。
$ genericInvoke此方法是重载方法。重载一的使用场景是:如果您的应用程序不知道接口的参数类型和返回值类型,那么此时,您需要使用GenericObject类包装返回值和参数。
$ genericInvoke重载二的使用方案是:如果应用程序不知道接口参数类型,但是知道接口返回值的类型,则无需使用GenericObject作为返回值。
基本上,已经涵盖了常用的集中式场景,可以说功能相当全面。
一般用途
由于篇幅所限,我将不在此处发布演示。如果您有兴趣,可以通过链接查看官方演示或源代码,包括使用SOFARPC API和SOFABoot:
演示Wiki地址:
源代码地址:
SOFARPC泛化调用的设计和实现
接下来,我们将重点介绍SOFARPC如何实现广义调用。
框架调用设计
简单来说,泛化调用的关键是对象表示和序列化。 SOFARPC提供了GenericObject之类的对象来表示参数对象或返回值对象,并将GenericObject对象序列化为目标对象,或者将返回值反序列化为GenericObject对象是SOFARPC泛化的关键。
在这里,我们首先看一下SOFARPC泛化调用的流程图,这将有助于以后理解泛化的实现。
让我们谈谈这张照片:
调用通用化API时,将加载通用化过滤器,该过滤器用于进行一些参数转换并设置序列化工厂类型。
SOFARPC将在使用SOFABolt进行网络调用并将其传递给SOFABolt之前创建一个上下文。上下文收录序列化工厂类型信息。这些信息将确定使用哪个序列化程序,并且该上下文将在整个调用期间内流动。
在SOFABolt正式发送数据之前,它将把GenericObject对象序列化为普通对象的字节流,这样服务提供者就不必关心它是否是泛化调用。从图中可以看出,提供程序不需要进行泛化调用任何更改-这是区分SOFARPC泛化与其他RPC泛化的关键。
提供者成功接收到请求后,可以使用常规的序列化器对数据进行反序列化,而只需正常调用并返回即可。
当使用者的SOFABolt接收到响应数据时,它会根据上下文的序列化类型对返回值进行反序列化,即,将普通字节流反序列化为GenericObject对象,因为客户端可能不知道返回值。
最后,泛化API以获取GenericObject类型的返回值。
从以上过程可以看出,序列化程序在泛化调用中占据了大量空间和作用。对于SOFARPC,对hessian3进行了修改以用于通用调用,以支持通用调用所需的序列化功能。 SOFA-Hessian的变化可以在这里参考。
Hessian概括实现
SOFA-Hessian将com.alipay.hessian.generic软件包添加到了hessian软件包中。该软件包的功能是处理泛化调用。重写的关键是实现或继承SerializerFactory类以及Serializer,Deserializer和其他接口。这里,设计了几个类来描述相应的类型信息,并同时实现这些类的序列化和反序列化。对应关系如下
让我们以GenericObjectSerializer为例。该序列化器重写writeObject方法。此方法的功能是将GenericObject对象序列化为目标对象字节流。也就是说,取出GenericObject的type字段和fields字段并将其组合到目标对象的字节流中。
例如:
有一个类型的RPC对象
<p style="line-height: 1.5em;">public class TestObj {
private String str;
private int num;
}</p>
在通用调用客户端中,您可以直接构造GenericObject对象
<p style="line-height: 1.5em;"> GenericObject genericObject = new GenericObject(
"com.alipay.sofa.rpc.invoke.generic.TestObj");
genericObject.putField("str", "xxxx");
genericObject.putField("num", 222);</p>
这时,GenericObjectSerializer可以使用此信息将GenericObject转换为TestObj对象的字节流。服务提供者可以通过普通的hessian2反序列化来获取对象。
与需要两端都支持通用化的其他RPC框架相比,SOFARPC更加友好。换句话说,如果应用程序要支持通用化,则只需要升级客户端(消费者),而服务器(提供者)就不知道。因为从服务器的角度来看,接收到的对象是完全相同的。您可能会发现很难为复杂类型编写这样的结构。 SOFA-Hessian中提供了工具类
<p style="line-height: 1.5em;">com.alipay.hessian.generic.util.GenericUtils</p>
为帮助用户生成,可以直接使用。
SOFARPC和Dubbo泛化调用比较
让我们介绍泛化调用与行业中其他一些产品之间的比较。首先,让我们介绍一下序列化本身的性能和优点。
序列化本身的比较
在Github上,有Java序列化的基准,可以用作参考。尽管在实际场景中,每个序列化场景都是不同的,但结果可能与此处的基准测试结果有所不同,但仍具有参考意义。从该项目的基准测试可以看出:Json是压缩率还是序列率。与Hessian相比,它具有很大的缺点。
同时,尽管与原创程序,kryo等相比,粗麻布的性能差距很小,但是粗麻布反序列化不需要指定类型,这种优势非常有价值。
Dubbo的普遍呼吁
在许多RPC框架中,Dubbo还提供了通用调用的功能。接下来,让我们谈谈Dubbo的概括。 Dubbo泛化和SOFA RPC泛化之间的最大区别是Dubbo需要服务器支持泛化。因此,如果要提供泛化功能,则还必须升级服务器。这似乎对SOFA RPC不友好。
Dubbo的通用呼叫流程如下:

如您所见,Dubbo的服务器还需要一个通用过滤器才能将Map解析为POJO来解析数据。
摘要
本文主要介绍SOFARPC泛化调用的设计和实现,介绍泛化调用的场景,同时,介绍SOFARPC泛化调用的API的用法,并说明泛化设计和实现SOFARPC的详细信息。最后,对社区中某些RPC框架的通用调用进行了简单的比较。
以下是SOFARPC的概括设计和实现的摘要:
设计目标是:服务器不需要感知它是否是通用的,一切都由客户端处理。
带来的好处是:如果应用程序要支持通用化,则无需更改服务器,只需修改客户端即可。这是其他RPC框架中的广义调用之间的最大区别。
实现方法:通过SOFA-Hessian序列化支持泛化序列化。进行泛化调用时,bolt将根据上下文的序列化标记使用相应的序列化程序,SOFA-Hessian的唯一泛化序列化服务器可以将GenericObject对象序列化为目标对象的字节流,服务器可以正常地对其进行反序列化。 SOFA-Hessian独特的泛化反序列化器还可以将目标返回值反序列化为对象,例如GenericObject。
参考
欢迎再加入并参与SOFABolt源代码分析

SOFABolt源代码分析目录:
我们将逐步详细介绍代码的每个部分的设计和实现,并有望根据以下目录进行操作。以下还收录当前的源代码分析文章声明状态:
如何获取:
直接回复此官方帐户想要声明的文章名称,我们会在确定您的资格后主动与您联系,您可以参加,这是您的演出时间!
相关链接
SOFA文件:
沙发:
SOFARPC:
SOFABolt:
小小的复活节彩蛋
请在这里查看您的ID:

长按以获取分布式架构的干货
欢迎一起构建SOFAStack
本文与微信官方帐户-金融级分布式架构(Antfin_SOFA)分享。
干货教程:zblog文章页面怎么调用同栏目文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-10-30 08:01
如何在zblog文章页面文章页面上调用同一列
我使用zblog程序来构建网站。制作前端模板时,我想在文章页面上调用此类别的文章。因为这是第一次使用,所以没有现成的代码可以使用。在百度上搜索了十多分钟后,我发现没有可以使用的代码,因此我必须自己研究它,因此我得到了以下代码:
{foreach GetList(4,$ cate.ID,null,null,null,null,null,array('has_subcate'=> true))作为$ related}
{$ related.Title}
{$ article.Intro} {/ foreach}
编辑:
调用类别ID时,上一段代码不是很准确。我通过将$ cate.ID替换为$ related.Category.ID对其进行了修改。
{foreach GetList(4,$ article.Category.ID,null,null,null,null,array('has_subcate'=> true))作为$ related}
此代码非常简单。实际上,它借用了调用特定类别文章的代码,但是从类别中提取了本文的类别,因此实现了在文章页面上调用该类别文章的功能。 $ cate.ID是本文所在的类别ID,前面的4种表示调用4篇文章文章,您可以自己对其进行修改。
题外话:当我搜索百度zblog文章页面如何调用同一列文章时,我看到文章提到了使用了哪些插件!严重的是,我还没有看到这些插件中的任何一个,而且我也不知道如何使用它们。作者认为,尽管该插件的功能强大,但毕竟还有副作用,这可能会影响页面加载的速度。因此,如果可以直接修改代码,并且可以使用尽可能少的插件,则可以修改代码。
zblog文章页面调用同一列文章的代码非常简单,您可以直接使用本文给出的代码。您可以看到zblog这个开源程序不仅适用于SEO优化,而且其自身功能也非常强大且易于使用。熟悉zblog之后,基本上可以灵活使用它。当然,您必须结合SEO技能,以使网站模板适合优化。 查看全部
如何在zblog文章页面文章页面上调用同一列
如何在zblog文章页面文章页面上调用同一列
我使用zblog程序来构建网站。制作前端模板时,我想在文章页面上调用此类别的文章。因为这是第一次使用,所以没有现成的代码可以使用。在百度上搜索了十多分钟后,我发现没有可以使用的代码,因此我必须自己研究它,因此我得到了以下代码:
{foreach GetList(4,$ cate.ID,null,null,null,null,null,array('has_subcate'=> true))作为$ related}
{$ related.Title}
{$ article.Intro} {/ foreach}
编辑:
调用类别ID时,上一段代码不是很准确。我通过将$ cate.ID替换为$ related.Category.ID对其进行了修改。
{foreach GetList(4,$ article.Category.ID,null,null,null,null,array('has_subcate'=> true))作为$ related}
此代码非常简单。实际上,它借用了调用特定类别文章的代码,但是从类别中提取了本文的类别,因此实现了在文章页面上调用该类别文章的功能。 $ cate.ID是本文所在的类别ID,前面的4种表示调用4篇文章文章,您可以自己对其进行修改。
题外话:当我搜索百度zblog文章页面如何调用同一列文章时,我看到文章提到了使用了哪些插件!严重的是,我还没有看到这些插件中的任何一个,而且我也不知道如何使用它们。作者认为,尽管该插件的功能强大,但毕竟还有副作用,这可能会影响页面加载的速度。因此,如果可以直接修改代码,并且可以使用尽可能少的插件,则可以修改代码。
zblog文章页面调用同一列文章的代码非常简单,您可以直接使用本文给出的代码。您可以看到zblog这个开源程序不仅适用于SEO优化,而且其自身功能也非常强大且易于使用。熟悉zblog之后,基本上可以灵活使用它。当然,您必须结合SEO技能,以使网站模板适合优化。
事实:后台程序在处理繁重的任务时,调用外部程序异步执行的简单实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-10-23 12:00
在开发Web应用程序时,无论是网站还是服务接口,我们都可能遇到来自客户端的特定请求。在此请求的背后,有许多繁重的任务要执行。如果我们在后台程序中同步进行处理,则程序执行时间比较长,用户体验不好,甚至可能导致502执行超时。针对这种情况,有许多成熟的解决方案(根据我的肤浅知识,使用队列是一种更好的解决方案),但是实现略微复杂且麻烦。如果我们对异步执行的任务没有特殊要求(例如异步任务完成后的失败重试或事件回调),那么我们可以通过一种非常简单的方法简单地实现它:nohup命令要执行> / dev / null 2>&1&。
如果您看到此内容并认为它没有什么新意,则表示您非常擅长,至少[比我更好]。我也希望在您离开之前,告诉我们是否有更好的方法并分享。
应用场景
目前,我实际上在两种特定情况下使用了这种异步任务执行方法。
1、之前是网站,该数据是来自第三方采集的另一位同事的数据,采集需要导入到我的数据库中,所以我在网站中提供了功能,一个用于文件上传和导入的按钮。当同事通过文件上传将采集数据保存在服务器上时,后台程序将读取该文件的内容并基于该数据进行必要的分析,最后通过SQL将分析后的数据写入数据库。此过程的速度或速度取决于数据文件的大小。对于具有数千行数据的文件,最后可能需要一分钟以上的时间才能执行。如果使用传统的同步执行,则从文件上载->数据分析->写入数据库。在整个过程中,浏览器处于圆圈中。如果时间较长,执行将超时并且所有先前的工作都将丢失。因此,这里我采用了异步任务执行方法。数据文件成功上传后,服务器直接响应浏览器,显示“数据导入成功,正在处理”提示,整个前端交互在此处结束。以后的数据分析和对数据库的写入将移交给另一个单独的过程进行处理。
2、就在两天前,我就是这样写的。我们制作了一个APP(使用APICloud制作的非流入APP)。用户使用APP发布内容后,需要调用百度AI的内容查看界面,以自动查看用户发布的文字和图片。如果发现其中收录错误信息,则不会自动对其进行审核。调用百度界面的过程比较耗时,它主要取决于用户发布的内容中收录的图片数量。自然,百度界面响应速度很慢。同样,如果用户以同步方式发布内容->调用百度界面->等待该界面返回数据->判断评论是否通过,则太耗时,因此从用户的角度来看,内容被发送出去并等待了几秒钟,甚至十秒钟,直到最后没有响应为止,这种用户体验太糟糕了。因此,可以实现,当用户发布内容时,立即提示“发布成功且正在审核中”,几秒钟后,用户将看到他刚刚发布的内容已被批准并出现在内容列表。时间,多么自然的过程。
实现思路
因此,有时有必要异步处理任务。正如我们在开始时提到的那样,在Web应用程序的开发中,不可能跳出Linux服务器。如今,除了.NET系统,它也可能部署在Windows上[似乎没有Blog Garden]。其他后端应用程序基本上将部署在Linux上,而我们开头提到的实现方法是在Linux下执行命令。
首先,实现程序异步执行的方式大致有两种:线程和进程[关于它,因为我听说有些语言也支持协程。好?我勒个去? -_- !!!]。对于支持线程的Java之类的编程语言,异步执行可以通过线程或进程[Runtime.exec()]实现;对于PHP,默认情况下没有线程,这对每个人都是通用的,而且不要在PHP下使用线程,因此,这只能通过其内部函数调用外部进程来实现异步任务。
在PHP下,执行一个外部程序,并要求该外部程序在后台运行,并且不会让您的宿主程序挂起[宿主是执行对外部命令的调用的PHP程序],有一点特别之处,请注意,这在官方手册的exec函数中有专门提及:
如果使用此功能启动程序,则要使其在后台继续运行,必须将程序的输出重定向到文件或其他输出流。否则,PHP会挂起,直到程序执行结束。
表示为了使外部程序在后台运行,此外部程序的输出[指标准输出[如Python中的打印,PHP中的echo和Java中的System.out.print]和标准错误]必须重定向到文件或另一个输出流。否则,宿主程序可能会挂起并等待外部程序执行完成,然后终止其生命周期。
因此,文章开头提到的命令中的> / dev / null 2>&1用于重定向标准输出和标准错误,并将它们写入/ dev / null文件,以制作主机程序。调用外部程序并使其在后台运行,它将立即执行后续代码,直到结束为止,并可以快速结束其生命周期。此时,外部程序仍在静默运行。
在撰写本文文章之前,我还专门检查了Java下使用Runtime.exec()调用外部程序的实现,发现文章提到了这一点:
这意味着重定向外部程序的输出,这与PHP官方手册中提到的注意事项完全相同。
具体实现
接下来,我们将解释nohup将执行的命令> / dev / null 2>&1&此命令的含义。
首先,它是要执行的命令。例如,如上所述,请致电百度AI进行内容审核,然后该命令就像php / www / wwwroot / app_service / artisan baidu:censor 文章 ID。此处使用的PHP Laravel框架,取决于您使用哪种语言,哪种框架以及如何编写要执行的命令,这取决于您的情况。
第二,如果要让程序在后台运行,则需要在命令后添加&[即,&],以告诉系统我要执行的命令是需要在其中运行的程序。背景。
然后,为了防止我们的主机程序等待挂起,我们需要重定向外部程序的输出,因此我们添加了> / dev / null 2>&1,> / dev / null意味着重定向标准输出到/ dev / null文件,以下2>&1表示将标准错误重定向到与先前标准输出相同的位置。 / dev / null是不存在的文件,因此> / dev / null 2>&1的总体含义是,当执行此外部程序时,将生成所有标准输出和标准错误[即错误消息]通过它,不要保存它们。 ,我不想看到。当然,如果您在调用外部程序后发现外部程序未按预期执行,则可能是外部程序报告了错误。您可以将输出重定向到真实文件中,以保存外部程序的输出信息,以方便进行故障排除。
最后,nohup。当您指定&以使外部程序在后台运行时,如果此时关闭并退出终端[这是黑色的命令行窗口],那么您刚刚在后台运行的外部程序也将终止。为避免此问题,您需要在开始时添加nohup来告诉系统关闭或退出终端时,请勿杀死我刚刚执行的外部程序的后台进程! ! !
好的,已经明确解释了用于特定实现的命令。如何用各种语言实现它们?我相信每种语言都有一种调用外部程序的方法,您可以自己学习。我再使用PHP,最后我将发布PHP的实现方法:
exec('nohup php / www / wwwroot / app_service / artisan baidu:censor 文章 ID> / dev / null 2>&1&');【Laravel】
exec('nohup php /www/wwwroot/app_service/baidu_censor.php 文章 ID> / dev / null 2>&1&');
参考文章 查看全部
当后台程序正在处理繁重的任务时,通过调用外部程序来实现异步执行的简单实现
在开发Web应用程序时,无论是网站还是服务接口,我们都可能遇到来自客户端的特定请求。在此请求的背后,有许多繁重的任务要执行。如果我们在后台程序中同步进行处理,则程序执行时间比较长,用户体验不好,甚至可能导致502执行超时。针对这种情况,有许多成熟的解决方案(根据我的肤浅知识,使用队列是一种更好的解决方案),但是实现略微复杂且麻烦。如果我们对异步执行的任务没有特殊要求(例如异步任务完成后的失败重试或事件回调),那么我们可以通过一种非常简单的方法简单地实现它:nohup命令要执行> / dev / null 2>&1&。
如果您看到此内容并认为它没有什么新意,则表示您非常擅长,至少[比我更好]。我也希望在您离开之前,告诉我们是否有更好的方法并分享。
应用场景
目前,我实际上在两种特定情况下使用了这种异步任务执行方法。
1、之前是网站,该数据是来自第三方采集的另一位同事的数据,采集需要导入到我的数据库中,所以我在网站中提供了功能,一个用于文件上传和导入的按钮。当同事通过文件上传将采集数据保存在服务器上时,后台程序将读取该文件的内容并基于该数据进行必要的分析,最后通过SQL将分析后的数据写入数据库。此过程的速度或速度取决于数据文件的大小。对于具有数千行数据的文件,最后可能需要一分钟以上的时间才能执行。如果使用传统的同步执行,则从文件上载->数据分析->写入数据库。在整个过程中,浏览器处于圆圈中。如果时间较长,执行将超时并且所有先前的工作都将丢失。因此,这里我采用了异步任务执行方法。数据文件成功上传后,服务器直接响应浏览器,显示“数据导入成功,正在处理”提示,整个前端交互在此处结束。以后的数据分析和对数据库的写入将移交给另一个单独的过程进行处理。
2、就在两天前,我就是这样写的。我们制作了一个APP(使用APICloud制作的非流入APP)。用户使用APP发布内容后,需要调用百度AI的内容查看界面,以自动查看用户发布的文字和图片。如果发现其中收录错误信息,则不会自动对其进行审核。调用百度界面的过程比较耗时,它主要取决于用户发布的内容中收录的图片数量。自然,百度界面响应速度很慢。同样,如果用户以同步方式发布内容->调用百度界面->等待该界面返回数据->判断评论是否通过,则太耗时,因此从用户的角度来看,内容被发送出去并等待了几秒钟,甚至十秒钟,直到最后没有响应为止,这种用户体验太糟糕了。因此,可以实现,当用户发布内容时,立即提示“发布成功且正在审核中”,几秒钟后,用户将看到他刚刚发布的内容已被批准并出现在内容列表。时间,多么自然的过程。
实现思路
因此,有时有必要异步处理任务。正如我们在开始时提到的那样,在Web应用程序的开发中,不可能跳出Linux服务器。如今,除了.NET系统,它也可能部署在Windows上[似乎没有Blog Garden]。其他后端应用程序基本上将部署在Linux上,而我们开头提到的实现方法是在Linux下执行命令。
首先,实现程序异步执行的方式大致有两种:线程和进程[关于它,因为我听说有些语言也支持协程。好?我勒个去? -_- !!!]。对于支持线程的Java之类的编程语言,异步执行可以通过线程或进程[Runtime.exec()]实现;对于PHP,默认情况下没有线程,这对每个人都是通用的,而且不要在PHP下使用线程,因此,这只能通过其内部函数调用外部进程来实现异步任务。
在PHP下,执行一个外部程序,并要求该外部程序在后台运行,并且不会让您的宿主程序挂起[宿主是执行对外部命令的调用的PHP程序],有一点特别之处,请注意,这在官方手册的exec函数中有专门提及:
如果使用此功能启动程序,则要使其在后台继续运行,必须将程序的输出重定向到文件或其他输出流。否则,PHP会挂起,直到程序执行结束。
表示为了使外部程序在后台运行,此外部程序的输出[指标准输出[如Python中的打印,PHP中的echo和Java中的System.out.print]和标准错误]必须重定向到文件或另一个输出流。否则,宿主程序可能会挂起并等待外部程序执行完成,然后终止其生命周期。
因此,文章开头提到的命令中的> / dev / null 2>&1用于重定向标准输出和标准错误,并将它们写入/ dev / null文件,以制作主机程序。调用外部程序并使其在后台运行,它将立即执行后续代码,直到结束为止,并可以快速结束其生命周期。此时,外部程序仍在静默运行。
在撰写本文文章之前,我还专门检查了Java下使用Runtime.exec()调用外部程序的实现,发现文章提到了这一点:
这意味着重定向外部程序的输出,这与PHP官方手册中提到的注意事项完全相同。
具体实现
接下来,我们将解释nohup将执行的命令> / dev / null 2>&1&此命令的含义。
首先,它是要执行的命令。例如,如上所述,请致电百度AI进行内容审核,然后该命令就像php / www / wwwroot / app_service / artisan baidu:censor 文章 ID。此处使用的PHP Laravel框架,取决于您使用哪种语言,哪种框架以及如何编写要执行的命令,这取决于您的情况。
第二,如果要让程序在后台运行,则需要在命令后添加&[即,&],以告诉系统我要执行的命令是需要在其中运行的程序。背景。
然后,为了防止我们的主机程序等待挂起,我们需要重定向外部程序的输出,因此我们添加了> / dev / null 2>&1,> / dev / null意味着重定向标准输出到/ dev / null文件,以下2>&1表示将标准错误重定向到与先前标准输出相同的位置。 / dev / null是不存在的文件,因此> / dev / null 2>&1的总体含义是,当执行此外部程序时,将生成所有标准输出和标准错误[即错误消息]通过它,不要保存它们。 ,我不想看到。当然,如果您在调用外部程序后发现外部程序未按预期执行,则可能是外部程序报告了错误。您可以将输出重定向到真实文件中,以保存外部程序的输出信息,以方便进行故障排除。
最后,nohup。当您指定&以使外部程序在后台运行时,如果此时关闭并退出终端[这是黑色的命令行窗口],那么您刚刚在后台运行的外部程序也将终止。为避免此问题,您需要在开始时添加nohup来告诉系统关闭或退出终端时,请勿杀死我刚刚执行的外部程序的后台进程! ! !
好的,已经明确解释了用于特定实现的命令。如何用各种语言实现它们?我相信每种语言都有一种调用外部程序的方法,您可以自己学习。我再使用PHP,最后我将发布PHP的实现方法:
exec('nohup php / www / wwwroot / app_service / artisan baidu:censor 文章 ID> / dev / null 2>&1&');【Laravel】
exec('nohup php /www/wwwroot/app_service/baidu_censor.php 文章 ID> / dev / null 2>&1&');
参考文章
文章采集调用接口库是怎样的一种体验呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-03-27 22:04
文章采集调用接口库这些在前端常见的web网站中用到过,但是ifttt还是脱离不了feed流接口。至于模式:以组织性小、粒度大的数据流来实现,人为的组织各类数据。
不就是mongodb吗
模式太多,我是直接自己搭建数据库,然后写api来和后端连接。只是个人简单理解,以我对feed流的理解,feed流基本上可以分为postgresqlqueryalqueryal(除了搜索引擎,如prophet)还有postmatrix(贴吧)。楼主可以根据自己的需求再做扩展。
native访问:搜索引擎,prophet,postmatrix,embed。
我认为只要你喜欢什么形式、什么方式就算是好的模式,关键是要用得好,或者说如何用的好。我参与的三个项目有不同的模式。第一个是restful相关的,davidyu的一个作品,api-first,大概说的是用restfulapi的方式来使用python去连接,形成feed流,整体设计简单实现方便,就是写多了读多了语法不熟。
也是最近比较看重的,去思考,看看能不能用简单方式实现,也会去使用python。第二个是json,请求方式很简单,json-feed,和上面那个差不多,实现也容易。第三个是我自己写的第三方api,botji,实现起来不复杂,简单理解为feed流服务,这个主要实现了很多中间件的功能,虽然不能直接实现feed流的效果,但是基本的机制还是可以做到的。
服务器肯定是用的golang写的,也只是个人的一些实践,欢迎拍砖。最后说下,前端的话看情况,如果是api相关的话,不要用webview,用native的,可以省去很多麻烦。 查看全部
文章采集调用接口库是怎样的一种体验呢?
文章采集调用接口库这些在前端常见的web网站中用到过,但是ifttt还是脱离不了feed流接口。至于模式:以组织性小、粒度大的数据流来实现,人为的组织各类数据。
不就是mongodb吗
模式太多,我是直接自己搭建数据库,然后写api来和后端连接。只是个人简单理解,以我对feed流的理解,feed流基本上可以分为postgresqlqueryalqueryal(除了搜索引擎,如prophet)还有postmatrix(贴吧)。楼主可以根据自己的需求再做扩展。
native访问:搜索引擎,prophet,postmatrix,embed。
我认为只要你喜欢什么形式、什么方式就算是好的模式,关键是要用得好,或者说如何用的好。我参与的三个项目有不同的模式。第一个是restful相关的,davidyu的一个作品,api-first,大概说的是用restfulapi的方式来使用python去连接,形成feed流,整体设计简单实现方便,就是写多了读多了语法不熟。
也是最近比较看重的,去思考,看看能不能用简单方式实现,也会去使用python。第二个是json,请求方式很简单,json-feed,和上面那个差不多,实现也容易。第三个是我自己写的第三方api,botji,实现起来不复杂,简单理解为feed流服务,这个主要实现了很多中间件的功能,虽然不能直接实现feed流的效果,但是基本的机制还是可以做到的。
服务器肯定是用的golang写的,也只是个人的一些实践,欢迎拍砖。最后说下,前端的话看情况,如果是api相关的话,不要用webview,用native的,可以省去很多麻烦。
美国对数据采集卡DLL函数的调用摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2021-03-26 23:16
《襄樊大学学报》。 ,2004年第25届襄樊大学学报25 No. 5 LabVIEW调用数据采集卡DLL功能摘要:首先,介绍虚拟仪器的特性及其开发环境LabVIEW6,分析并实现将LabVIEW与外部代码连接的一种先进技术-动态链接库(DLL)。机制 。实践表明,该机制高效且易于实现,是增强LabVIEW与其他Windows应用程序之间的数据共享能力的好方法。 关键词:虚拟乐器; LabVIEW;动态链接库; DLL中文图书馆分类号:TN311。 11文档标记代码:A 文章序列号:1009-2854(200 4) 05-0015-03 0简介National Instruments NI基于G的开发环境LabVIEW的出现使虚拟仪器的概念得以连接所谓的虚拟仪器是在通用计算机平台上,用户可以根据自己的需求定义和设计仪器的测试功能,其实质是传统仪器硬件和最新的计算机软件技术都可以充分发挥作用。结合软件模块软件来实现和扩展传统仪器的功能,与系统仪器相比,虚拟仪器在智能,处理能力,性能价格比和可操作性方面更加智能,具有明显的技术优势。仪器工程工作台)是目前世界上使用最广泛的虚拟仪器开发环境之一,主要用于仪器控制,数据采集和数据分析。 ,数据显示等字段,并适用于许多不同的操作系统平台,例如Windows 9X / XP / 2000 / NT,Macintosh,UNIX。
与传统的编程语言不同,LabVIEW使用强大的图形语言(G语言)进行编程,面向测试工程师而非专业程序员,编程非常方便,人机交互界面直观友好,并且功能强大。数据可视化分析和手段控制能力等功能。使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度。 LabVIEW是真正的编译器。用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行。对于大多数编程任务,LabVIEW通常可以生成有效的代码。 1 LabVIEW调用外部程序代码的方法之一-动态链接库机制1.1动态链接库机制概述LabVIEW是功能强大的虚拟仪器开发环境,与GPIB,VXI,RS-23 2、 RS-完全集成在一起。 485插入数据采集卡与其他硬件通信。 LabVIEW还具有内置程序库,可通过DLL,共享库,ActiveX和其他方式提供大量连接机制,以实现与外部程序代码或软件系统的连接。 LabVIEW提供了四种调用外部程序代码的方法。其中,动态链接库(Dynamic Link LibraryDLL)机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法。
对于特定的实现,请使用LabVIEW函数模板“高级”子模板中的“调用库函数”节点。 “呼叫库功能节点”包括大量数据类型和呼叫规范。它可用于调用大多数标准共享库和用户定义的库中的函数,包括:Windows9X / XP / 2000 / NT下的动态链接库(动态链接库),Macintosh下的代码片段,UNIX下的共享库函数等。当用户需要调用的代码已经存在,或者用户熟悉Windows中的动态链接库,Macintosh中的代码段和UNIX中的共享库的创建过程时,“调用库功能节点”为非常有用,并且此时也最合适使用它,因为该图书馆使用的接收日期:2004-04-21资助项目:湖北省教育厅重点项目(2003A00 6))关于作者:刘传清(1964-)男,湖北鄂州人,襄樊大学物理系副教授15刘传清:LabVIEW调用data 采集卡DL函数16适用于多种开发环境的格式标准,用户可以ü几乎可以使用任何开发环境来创建LabVIEW可以调用的库。
1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的“动态链接库机制”来调用DLL,该DLL返回机器的名称。 1)创建“调用库函数节点”,创建一个新的LabVIEW程序“ hostname.vi”,并将其保存在新创建的目录“ d:\ temp”下。前面板如下:图1库函数调用前面板框图该程序如下:图2.库函数调用框图。其中,通过在功能模板的“高级”子模板中选择“调用库功能”功能模块来生成“调用库功能”节点。该LabVIEW程序通过“调用库函数节点”调用DLL。该DLL将返回计算机的名称,返回的结果将存储在字符串指示器“ Machine Name”中,然后进行字符串常量“ LabVIEW”和“ MachineName”的拼接,拼接结果显示在字符串指示器中“信息”。 2)配置“调用库功能节点”在程序框图程序窗口中双击“调用库功能节点”,然后在弹出的对话框中配置“调用库功能节点”:在“库名称路径”中“一种键入d:\ temp \ hostname。
dll”(即,指定此节点链接到的DLL文件的名称,源代码“ hostname.c”的编译源);在“功能名称”项中,键入“ MachineName”(即是,在链接的DLL文件中指定单击函数的名称)的名称;参数“返回类型”的类型选择“无效”;添加的参数“ arg1”的类型选择“字符串”,并且字符串格式选择“字符串句柄”; 3)编辑C源文件编辑“ C源文件”主机名。 c”(存储在目录“ d:\ temp”中),其内容如下:includeextcode.h,其中收录LabVIEW函数__declspec(dllexport)void MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; int compNameLength MAX_COMPUTERNAME_LENGTH + 1;第25襄樊学院学报2004 Getcomputer名GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄的正确大小DSSetHandleSize(HandleSize) * int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数“ GetComputerName”以获取计算机名称;然后调用LabVIEW函数“ DSSetHandleSize”来设置LabVIEW句柄的大小;最后,将计算机名的长度(32位整数)和计算机名(字符串)依次写入到句柄中。
4)编译C源代码源代码“ d:\ temp \ hostname.c”被编译为DLL文件“ d:\ temp \ hostname.dll”。您可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译。 5)运行VI,以运行LabVIEW程序“ hostname.vi”,结果如下:图3前面板运行结果2结束语本文着重介绍和实现一种将LabVIEW与外部代码连接的高级技术。 ,动态链接库机制,并给出一个应用示例。由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善。该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现。实践证明,该方法高效且易于实现,是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法。参考资料:National Instruments Corporation,LabVIEW用户手册,1998。NationalInstruments Corporation,编程参考手册,1998。
LabVIEW数据采集调用DLL函数刘传庆(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW,分析了先进技术-动态链接库(DLL),一般方法调用外部LabVIEW中的代码。事实证明,Goodone可以增强LabVIEW在Windows中共享数据的其他应用程序。关键词:虚拟仪器; LabVIEW;动态链接库 查看全部
美国对数据采集卡DLL函数的调用摘要
《襄樊大学学报》。 ,2004年第25届襄樊大学学报25 No. 5 LabVIEW调用数据采集卡DLL功能摘要:首先,介绍虚拟仪器的特性及其开发环境LabVIEW6,分析并实现将LabVIEW与外部代码连接的一种先进技术-动态链接库(DLL)。机制 。实践表明,该机制高效且易于实现,是增强LabVIEW与其他Windows应用程序之间的数据共享能力的好方法。 关键词:虚拟乐器; LabVIEW;动态链接库; DLL中文图书馆分类号:TN311。 11文档标记代码:A 文章序列号:1009-2854(200 4) 05-0015-03 0简介National Instruments NI基于G的开发环境LabVIEW的出现使虚拟仪器的概念得以连接所谓的虚拟仪器是在通用计算机平台上,用户可以根据自己的需求定义和设计仪器的测试功能,其实质是传统仪器硬件和最新的计算机软件技术都可以充分发挥作用。结合软件模块软件来实现和扩展传统仪器的功能,与系统仪器相比,虚拟仪器在智能,处理能力,性能价格比和可操作性方面更加智能,具有明显的技术优势。仪器工程工作台)是目前世界上使用最广泛的虚拟仪器开发环境之一,主要用于仪器控制,数据采集和数据分析。 ,数据显示等字段,并适用于许多不同的操作系统平台,例如Windows 9X / XP / 2000 / NT,Macintosh,UNIX。
与传统的编程语言不同,LabVIEW使用强大的图形语言(G语言)进行编程,面向测试工程师而非专业程序员,编程非常方便,人机交互界面直观友好,并且功能强大。数据可视化分析和手段控制能力等功能。使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度。 LabVIEW是真正的编译器。用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行。对于大多数编程任务,LabVIEW通常可以生成有效的代码。 1 LabVIEW调用外部程序代码的方法之一-动态链接库机制1.1动态链接库机制概述LabVIEW是功能强大的虚拟仪器开发环境,与GPIB,VXI,RS-23 2、 RS-完全集成在一起。 485插入数据采集卡与其他硬件通信。 LabVIEW还具有内置程序库,可通过DLL,共享库,ActiveX和其他方式提供大量连接机制,以实现与外部程序代码或软件系统的连接。 LabVIEW提供了四种调用外部程序代码的方法。其中,动态链接库(Dynamic Link LibraryDLL)机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法。
对于特定的实现,请使用LabVIEW函数模板“高级”子模板中的“调用库函数”节点。 “呼叫库功能节点”包括大量数据类型和呼叫规范。它可用于调用大多数标准共享库和用户定义的库中的函数,包括:Windows9X / XP / 2000 / NT下的动态链接库(动态链接库),Macintosh下的代码片段,UNIX下的共享库函数等。当用户需要调用的代码已经存在,或者用户熟悉Windows中的动态链接库,Macintosh中的代码段和UNIX中的共享库的创建过程时,“调用库功能节点”为非常有用,并且此时也最合适使用它,因为该图书馆使用的接收日期:2004-04-21资助项目:湖北省教育厅重点项目(2003A00 6))关于作者:刘传清(1964-)男,湖北鄂州人,襄樊大学物理系副教授15刘传清:LabVIEW调用data 采集卡DL函数16适用于多种开发环境的格式标准,用户可以ü几乎可以使用任何开发环境来创建LabVIEW可以调用的库。
1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的“动态链接库机制”来调用DLL,该DLL返回机器的名称。 1)创建“调用库函数节点”,创建一个新的LabVIEW程序“ hostname.vi”,并将其保存在新创建的目录“ d:\ temp”下。前面板如下:图1库函数调用前面板框图该程序如下:图2.库函数调用框图。其中,通过在功能模板的“高级”子模板中选择“调用库功能”功能模块来生成“调用库功能”节点。该LabVIEW程序通过“调用库函数节点”调用DLL。该DLL将返回计算机的名称,返回的结果将存储在字符串指示器“ Machine Name”中,然后进行字符串常量“ LabVIEW”和“ MachineName”的拼接,拼接结果显示在字符串指示器中“信息”。 2)配置“调用库功能节点”在程序框图程序窗口中双击“调用库功能节点”,然后在弹出的对话框中配置“调用库功能节点”:在“库名称路径”中“一种键入d:\ temp \ hostname。
dll”(即,指定此节点链接到的DLL文件的名称,源代码“ hostname.c”的编译源);在“功能名称”项中,键入“ MachineName”(即是,在链接的DLL文件中指定单击函数的名称)的名称;参数“返回类型”的类型选择“无效”;添加的参数“ arg1”的类型选择“字符串”,并且字符串格式选择“字符串句柄”; 3)编辑C源文件编辑“ C源文件”主机名。 c”(存储在目录“ d:\ temp”中),其内容如下:includeextcode.h,其中收录LabVIEW函数__declspec(dllexport)void MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; int compNameLength MAX_COMPUTERNAME_LENGTH + 1;第25襄樊学院学报2004 Getcomputer名GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄的正确大小DSSetHandleSize(HandleSize) * int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数“ GetComputerName”以获取计算机名称;然后调用LabVIEW函数“ DSSetHandleSize”来设置LabVIEW句柄的大小;最后,将计算机名的长度(32位整数)和计算机名(字符串)依次写入到句柄中。
4)编译C源代码源代码“ d:\ temp \ hostname.c”被编译为DLL文件“ d:\ temp \ hostname.dll”。您可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译。 5)运行VI,以运行LabVIEW程序“ hostname.vi”,结果如下:图3前面板运行结果2结束语本文着重介绍和实现一种将LabVIEW与外部代码连接的高级技术。 ,动态链接库机制,并给出一个应用示例。由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善。该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现。实践证明,该方法高效且易于实现,是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法。参考资料:National Instruments Corporation,LabVIEW用户手册,1998。NationalInstruments Corporation,编程参考手册,1998。
LabVIEW数据采集调用DLL函数刘传庆(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW,分析了先进技术-动态链接库(DLL),一般方法调用外部LabVIEW中的代码。事实证明,Goodone可以增强LabVIEW在Windows中共享数据的其他应用程序。关键词:虚拟仪器; LabVIEW;动态链接库
用python爬取实现方法:anyproxy代理批量采集实现教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2021-03-26 21:05
微信公众号文章抓取方法安排1.使用python抓取
实现方法:通过微信提供的官方账号文章调用该界面,实现对官方账号文章的抓取功能。
步骤:
1.需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie,以达到登录效果;
2.要使用WebDriver功能,需要安装与浏览器相对应的驱动程序插件。我在这里使用Google Chrome浏览器进行测试:
Google Chrome版本为5 2. 0. 274 3. 6;
chromedriver版本为:V 2. 23
注意:Google Chrome版本和chromedriver需要对应,否则启动时会导致错误。 [附:Selenium的chromedriver和chrome版本映射表(已更新为v 2. 3 0))]
3.微信官方帐户登录地址:
4.微信公众号文章界面地址可以在微信公众号的后台创建,以创建新的图形消息,可以通过超链接功能获得:
5.搜索官方帐户名
6.获取要抓取的官方帐户的伪造物
7.选择要爬网的官方帐户,并获取文章界面地址
8. 文章列表翻页和内容获取
2. AnyProxy代理批处理采集
如何实现:anyproxy + js
如何实现:anyproxy + java + webmagic
3. FiddlerCore
实施方法:数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1。编写按钮向导脚本,并自动单击电话上的公用号码文章列表页面,即“查看历史消息”;
2,使用提琴手代理劫持手机的访问权限,并将URL转发到用php编写的本地网页;
3。将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网。
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果您想在一定频率后捕获读数和喜欢的次数,则返回变为空值,我设置的时间间隔为10秒,可以正常爬网。以这种频率,一个小时内只能抓取360条记录,这没有任何实际意义。
4.青波新榜
如果您只想查看数据,则直接查看每日列表,无需花钱。如果您需要连接到自己的系统,它们还提供api接口 查看全部
用python爬取实现方法:anyproxy代理批量采集实现教程
微信公众号文章抓取方法安排1.使用python抓取
实现方法:通过微信提供的官方账号文章调用该界面,实现对官方账号文章的抓取功能。
步骤:
1.需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie,以达到登录效果;
2.要使用WebDriver功能,需要安装与浏览器相对应的驱动程序插件。我在这里使用Google Chrome浏览器进行测试:
Google Chrome版本为5 2. 0. 274 3. 6;
chromedriver版本为:V 2. 23
注意:Google Chrome版本和chromedriver需要对应,否则启动时会导致错误。 [附:Selenium的chromedriver和chrome版本映射表(已更新为v 2. 3 0))]
3.微信官方帐户登录地址:
4.微信公众号文章界面地址可以在微信公众号的后台创建,以创建新的图形消息,可以通过超链接功能获得:
5.搜索官方帐户名
6.获取要抓取的官方帐户的伪造物
7.选择要爬网的官方帐户,并获取文章界面地址
8. 文章列表翻页和内容获取
2. AnyProxy代理批处理采集
如何实现:anyproxy + js
如何实现:anyproxy + java + webmagic
3. FiddlerCore
实施方法:数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz:这个14位的字符串是每个公众号的“id”,搜狗的微信平台可以获得
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步骤:
1。编写按钮向导脚本,并自动单击电话上的公用号码文章列表页面,即“查看历史消息”;
2,使用提琴手代理劫持手机的访问权限,并将URL转发到用php编写的本地网页;
3。将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网。
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果您想在一定频率后捕获读数和喜欢的次数,则返回变为空值,我设置的时间间隔为10秒,可以正常爬网。以这种频率,一个小时内只能抓取360条记录,这没有任何实际意义。
4.青波新榜
如果您只想查看数据,则直接查看每日列表,无需花钱。如果您需要连接到自己的系统,它们还提供api接口
wordpress采集页简单改造调用代码和说明,提升收录量
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-03-26 20:16
郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
昨天花了一些时间对Zheng Gang的SEO培训网站进行了简单的页面调整,主要的修改是采集页面。
此网站是用WP制作的,因此,如果您还使用WP来构建网站或使用采集的内容,则可以将此文章标记为书签。这些都是进行亲测的有效代码和操作方法。
主要目的是使页面采集与原创内容的变化至少与原创内容有所不同,并进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、 [修改页面:single.php]
只需将上面的代码放在您想要的任何页面或位置上,就可以直接调用随机TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这就是随机标签。
原因:此操作是使每个页面调用不同的随机标记以提高选项卡页面收录的可能性和进入率,因为WP的主要排名主要是TAG选项卡页面。
2、 采集将随机图片插入内容页面**
第1步:修改第1页:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面的底部,然后单击“保存”。请记住用您的URL替换中间的URL。
第2步:修改第2页:single.php
<p> 查看全部
wordpress采集页简单改造调用代码和说明,提升收录量
郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
https://p3.pstatp.com/large/pg ... 2ad33b" />郑景成:对wordpress 采集页面上的调用代码和说明进行简单的修改即可增加收录的数量
昨天花了一些时间对Zheng Gang的SEO培训网站进行了简单的页面调整,主要的修改是采集页面。
此网站是用WP制作的,因此,如果您还使用WP来构建网站或使用采集的内容,则可以将此文章标记为书签。这些都是进行亲测的有效代码和操作方法。
主要目的是使页面采集与原创内容的变化至少与原创内容有所不同,并进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、 [修改页面:single.php]
只需将上面的代码放在您想要的任何页面或位置上,就可以直接调用随机TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这就是随机标签。
原因:此操作是使每个页面调用不同的随机标记以提高选项卡页面收录的可能性和进入率,因为WP的主要排名主要是TAG选项卡页面。
2、 采集将随机图片插入内容页面**
第1步:修改第1页:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面的底部,然后单击“保存”。请记住用您的URL替换中间的URL。
第2步:修改第2页:single.php
<p>
侧边栏文章调用不够灵活?试试UltimatePosts插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-03-26 04:19
文章目录[隐藏]
您认为WordPress主题的侧边栏文章不够灵活吗?想在侧边栏小部件中调用更多文章吗?倡导者建议您尝试使用Ultimate Ultimates Widget插件。
终极帖子小部件简介
Ultimate Posts Widget可以被认为是功能最强大的WordPress侧边栏文章调用插件(至少为Advocate所熟知)。主要功能如下:
有关更多详细信息,请参阅屏幕截图或下载体验:
最终帖子小部件下载
您可以在后台插件安装界面上搜索Ultimate Posts Widget以在线安装,或在此处下载Ultimate Posts Widget。
如果您是WordPress主题开发人员,则可以考虑将其集成到主题中,这非常令人寒心!但是,您也可以考虑添加文章的“观看次数”最多,并添加一个时间段(一个月,六个月等),这不只是鸡冻!
声明:除非另有说明或标记,否则本网站上的所有文章均已发布在本网站原创上。未经本网站同意,任何个人或组织均不得将本网站的内容复制,挪用,采集或发布到任何网站,书籍和其他媒体平台。如果本网站的内容侵犯了原作者的合法权益,则可以与我们联系进行处理。 查看全部
侧边栏文章调用不够灵活?试试UltimatePosts插件
文章目录[隐藏]
您认为WordPress主题的侧边栏文章不够灵活吗?想在侧边栏小部件中调用更多文章吗?倡导者建议您尝试使用Ultimate Ultimates Widget插件。
终极帖子小部件简介
Ultimate Posts Widget可以被认为是功能最强大的WordPress侧边栏文章调用插件(至少为Advocate所熟知)。主要功能如下:
有关更多详细信息,请参阅屏幕截图或下载体验:
最终帖子小部件下载
您可以在后台插件安装界面上搜索Ultimate Posts Widget以在线安装,或在此处下载Ultimate Posts Widget。
如果您是WordPress主题开发人员,则可以考虑将其集成到主题中,这非常令人寒心!但是,您也可以考虑添加文章的“观看次数”最多,并添加一个时间段(一个月,六个月等),这不只是鸡冻!
声明:除非另有说明或标记,否则本网站上的所有文章均已发布在本网站原创上。未经本网站同意,任何个人或组织均不得将本网站的内容复制,挪用,采集或发布到任何网站,书籍和其他媒体平台。如果本网站的内容侵犯了原作者的合法权益,则可以与我们联系进行处理。
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 496 次浏览 • 2021-03-25 21:14
pboot cms 文章(PbootDemoSkycaiji)插件直接在优采云 采集器云平台上下载并使用。该插件是由Little Mango开发的,没有皮肤。该插件默认为只能发布新闻专栏,并且对产品案例进行过滤,并且需要您自己手动进行修改。
下载该插件后,我们可以在网站根目录优采云 采集器安装中找到该路径:网站根目录采集器安装目录pluginlease cms PbootDemoSkycaiji.php
打开此文件开头的代码意味着自动读取我们的数据库信息,无论是mysql还是sqlite数据库,它都是相同的,并且会自动获取链接。
以下是与网站相对应的信息,例如作者,文章内容,产品分类,缩略图等,在这里我们可以根据网站的需求添加更多参数。
此处的信息对应于我们的网站数据库中的字段。如果此处没有字段,则可以直接输入数据库并将其添加。要注意的一件事是,此处的数据库字段应与先前的字段相同。对应参数。例如,如果将缩略图添加到我们的参数中,那么我们必须找到该字段并填写在参数中添加的名称。
此处的默认设置是过滤其他目录,仅获取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们要做的就是添加
// $ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> where(“ contenttpl ='news.html'”)-> limit(10 0)-> select() ; // 文章您可以注释掉或删除分类。
添加$ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> limit(10 0)-> select(); // 文章分类很好,默认为匹配全部[k14的目录]。上面是pboot cms 文章(PbootDemoSkycaiji)插件的详细介绍。阅读上面的描述后基本上没有问题,如果您还是不明白,请请咨询我们。
相关知识点:
此站点文章摘自Shurong网络上的权威信息,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢... 查看全部
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台
pboot cms 文章(PbootDemoSkycaiji)插件直接在优采云 采集器云平台上下载并使用。该插件是由Little Mango开发的,没有皮肤。该插件默认为只能发布新闻专栏,并且对产品案例进行过滤,并且需要您自己手动进行修改。
下载该插件后,我们可以在网站根目录优采云 采集器安装中找到该路径:网站根目录采集器安装目录pluginlease cms PbootDemoSkycaiji.php
打开此文件开头的代码意味着自动读取我们的数据库信息,无论是mysql还是sqlite数据库,它都是相同的,并且会自动获取链接。
以下是与网站相对应的信息,例如作者,文章内容,产品分类,缩略图等,在这里我们可以根据网站的需求添加更多参数。
此处的信息对应于我们的网站数据库中的字段。如果此处没有字段,则可以直接输入数据库并将其添加。要注意的一件事是,此处的数据库字段应与先前的字段相同。对应参数。例如,如果将缩略图添加到我们的参数中,那么我们必须找到该字段并填写在参数中添加的名称。
此处的默认设置是过滤其他目录,仅获取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们要做的就是添加
// $ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> where(“ contenttpl ='news.html'”)-> limit(10 0)-> select() ; // 文章您可以注释掉或删除分类。
添加$ catsDb = $ this-> db()-> table('__ CONTENT_SORT __')-> limit(10 0)-> select(); // 文章分类很好,默认为匹配全部[k14的目录]。上面是pboot cms 文章(PbootDemoSkycaiji)插件的详细介绍。阅读上面的描述后基本上没有问题,如果您还是不明白,请请咨询我们。
相关知识点:
此站点文章摘自Shurong网络上的权威信息,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...
动易DELPHI、VC、VB、JB、AURL、string区别
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-03-24 04:13
谈到网页采集,人们通常认为他们从Internet窃取数据,然后将采集的数据发布到自己的Internet中。实际上,您还可以将采集中获得的数据用作公司的参考,或者将采集的数据与公司的业务等进行比较。
当前,网页采集主要是3P代码(3P表示ASP,PHP,JSP)。 BBS新闻采集系统和Internet上传播的新浪新闻采集系统中最具代表性的都是ASP程序,但是从理论上讲速度不是很好。如果您尝试使用其他软件的多线程采集,速度会更快吗?答案是肯定的。您可以使用DELPHI,VC,VB或JB,但是PB似乎相对困难。以下使用DELPHI来解释采集网页数据。
一、简单新闻采集
新闻采集是最简单的,只要您确定标题,副主题,作者,出处,日期,新闻正文和分页符即可。必须在采集之前获取网页的内容,因此在DELPHI中(在indy Clients面板中)添加idHTTP控件,然后使用idHTTP 1. GET方法获取网页的内容。声明如下:
function Get(AURL:string):字符串;超载;
AURL参数是字符串类型,它指定URL地址字符串。函数return也是一个字符串类型,它返回网页的HTML源文件。例如,我们可以这样称呼它:
tmpStr:= idHTTP 1. Get(‘’);
呼叫成功后,网易主页代码存储在tmpstr变量中。
接下来,我们来谈谈数据拦截。在这里,我定义了这样一个函数:
函数TForm 1. GetStr(StrSource,StrBegin,StrEnd:string):string;
var
in_star,in_end:integer;
开始
in_star:= AnsiPos(strbegin,strsource)+ length(strbegin);
in_end:= AnsiPos(strend,strsource);
结果:= copy(strsource,in_sta,in_end-in_star);
end;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,指示侦听开始的标记。
StrEnd:字符串,表示拦截结束的标记。
The
函数将字符串StrSource中的一段文本从StrSource返回到StrBegin。
例如:
strtmp:= TForm 1. GetStr('A123BCD','A','BC');
运行后,strtmp的值为:“ 123”。
关于函数中使用的AnsiPos和副本,两者均由系统定义。您可以在delphi的帮助文件中找到相关说明。我还将在这里简单地谈论它:
函数AnsiPos(const Substr,S:string):整数
返回Substr在S中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
将字符串源中的从in_sta(整数数据)开始的字符串返回到in_end-in_star(整数数据)。
使用上述功能,我们可以通过设置各种标签来截取文章的所需内容。在程序中,更麻烦的是我们需要设置许多标记。要查找某个内容,必须设置其开始和结束标记。例如,要获取网页上的文章标题,您必须预先检查网页代码,在文章标题前后检查一些功能代码,然后使用这些功能代码截取文章。
下面我们实际进行演示,假设采集的文章地址为
代码是:
文章标题
作者
来源
这是文章的内容。
第一步,我们使用StrSource:= idHTTP 1. Get(’);将网页代码保存在strsource变量中。
然后定义strTitle,strAuthor,strCopyFrom,strContent:
strTitle:= GetStr(StrSource,’
’,’
’):
strAuthor:= GetStr(StrSource,’
’,’
’):
strCopyFrom:= GetStr(StrSource,’
’,’
’):
strContent:= GetStr(StrSource,’
,
’):
通过这种方式,可以将文章的标题,副标题,作者,出处,日期,内容和分页分别存储在上述变量中。
第二步是使用循环方法打开下一页,获取内容,并将其添加到strContent变量中。
StrSource:= idHTTP 1. Get(‘new_ne.asp’);
strContent:= strContent + GetStr(StrSource,’
,
’):
然后判断是否存在下一页,如果存在,则获取下一页的内容。
这完成了一个简单的拦截过程。从上面的程序代码中,我们可以看到我们使用的拦截方法是找到被拦截内容的开头和结尾。如果有多个头和尾,该怎么办?似乎没有办法,只能找到第一个,因此在查找之前,您应该验证被拦截的内容之前和之后只有一个地方。
以上内容没有程序验证,仅供参考,如果您认为有用,可以尝试。
///
使用Delphi下载网页
创建一个新项目,放置一个TIdHTTP控件,一个TIdAntiFreeze控件和一个TProgressBar以显示下载进度。最后,放置一个TButton开始执行我们的命令。代码如下:
过程TForm 1. Button2Click(Sender:TObject);
var
MyStream:TMemoryStream;
开始
IdAntiFreeze 1. OnlyWhenIdle:= False; //该设置使程序做出反应。
MyStream:= TMemoryStream.Create;
尝试
//下载我的网站的ZIP文件 查看全部
动易DELPHI、VC、VB、JB、AURL、string区别
谈到网页采集,人们通常认为他们从Internet窃取数据,然后将采集的数据发布到自己的Internet中。实际上,您还可以将采集中获得的数据用作公司的参考,或者将采集的数据与公司的业务等进行比较。
当前,网页采集主要是3P代码(3P表示ASP,PHP,JSP)。 BBS新闻采集系统和Internet上传播的新浪新闻采集系统中最具代表性的都是ASP程序,但是从理论上讲速度不是很好。如果您尝试使用其他软件的多线程采集,速度会更快吗?答案是肯定的。您可以使用DELPHI,VC,VB或JB,但是PB似乎相对困难。以下使用DELPHI来解释采集网页数据。
一、简单新闻采集
新闻采集是最简单的,只要您确定标题,副主题,作者,出处,日期,新闻正文和分页符即可。必须在采集之前获取网页的内容,因此在DELPHI中(在indy Clients面板中)添加idHTTP控件,然后使用idHTTP 1. GET方法获取网页的内容。声明如下:
function Get(AURL:string):字符串;超载;
AURL参数是字符串类型,它指定URL地址字符串。函数return也是一个字符串类型,它返回网页的HTML源文件。例如,我们可以这样称呼它:
tmpStr:= idHTTP 1. Get(‘’);
呼叫成功后,网易主页代码存储在tmpstr变量中。
接下来,我们来谈谈数据拦截。在这里,我定义了这样一个函数:
函数TForm 1. GetStr(StrSource,StrBegin,StrEnd:string):string;
var
in_star,in_end:integer;
开始
in_star:= AnsiPos(strbegin,strsource)+ length(strbegin);
in_end:= AnsiPos(strend,strsource);
结果:= copy(strsource,in_sta,in_end-in_star);
end;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,指示侦听开始的标记。
StrEnd:字符串,表示拦截结束的标记。
The
函数将字符串StrSource中的一段文本从StrSource返回到StrBegin。
例如:
strtmp:= TForm 1. GetStr('A123BCD','A','BC');
运行后,strtmp的值为:“ 123”。
关于函数中使用的AnsiPos和副本,两者均由系统定义。您可以在delphi的帮助文件中找到相关说明。我还将在这里简单地谈论它:
函数AnsiPos(const Substr,S:string):整数
返回Substr在S中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
将字符串源中的从in_sta(整数数据)开始的字符串返回到in_end-in_star(整数数据)。
使用上述功能,我们可以通过设置各种标签来截取文章的所需内容。在程序中,更麻烦的是我们需要设置许多标记。要查找某个内容,必须设置其开始和结束标记。例如,要获取网页上的文章标题,您必须预先检查网页代码,在文章标题前后检查一些功能代码,然后使用这些功能代码截取文章。
下面我们实际进行演示,假设采集的文章地址为
代码是:
文章标题
作者
来源
这是文章的内容。
第一步,我们使用StrSource:= idHTTP 1. Get(’);将网页代码保存在strsource变量中。
然后定义strTitle,strAuthor,strCopyFrom,strContent:
strTitle:= GetStr(StrSource,’
’,’
’):
strAuthor:= GetStr(StrSource,’
’,’
’):
strCopyFrom:= GetStr(StrSource,’
’,’
’):
strContent:= GetStr(StrSource,’
,
’):
通过这种方式,可以将文章的标题,副标题,作者,出处,日期,内容和分页分别存储在上述变量中。
第二步是使用循环方法打开下一页,获取内容,并将其添加到strContent变量中。
StrSource:= idHTTP 1. Get(‘new_ne.asp’);
strContent:= strContent + GetStr(StrSource,’
,
’):
然后判断是否存在下一页,如果存在,则获取下一页的内容。
这完成了一个简单的拦截过程。从上面的程序代码中,我们可以看到我们使用的拦截方法是找到被拦截内容的开头和结尾。如果有多个头和尾,该怎么办?似乎没有办法,只能找到第一个,因此在查找之前,您应该验证被拦截的内容之前和之后只有一个地方。
以上内容没有程序验证,仅供参考,如果您认为有用,可以尝试。
///
使用Delphi下载网页
创建一个新项目,放置一个TIdHTTP控件,一个TIdAntiFreeze控件和一个TProgressBar以显示下载进度。最后,放置一个TButton开始执行我们的命令。代码如下:
过程TForm 1. Button2Click(Sender:TObject);
var
MyStream:TMemoryStream;
开始
IdAntiFreeze 1. OnlyWhenIdle:= False; //该设置使程序做出反应。
MyStream:= TMemoryStream.Create;
尝试
//下载我的网站的ZIP文件
孤狼微信公众号文章采集的步骤及注意事项【孤狼数据采集】
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2021-03-21 21:24
Lone Wolf Data 采集平台为微信公众号文章提供了采集,可以轻松发布到市场上的主流系统上,还可以定制一些不受欢迎的网站界面!
一、独狼微信公众号文章 采集主要功能
1。根据官方帐户名称或ID,指定官方帐户采集,并支持输入多个官方帐户,而不会限制官方帐户的数量
2。下载图片的多种存储方式(远程调用,图片本地化,ftp上传),解决了官方帐号文章上图片的防盗链接问题。
3,强大的数据存储功能(采集将数据保存在本地数据库文件中)
4,简单的配置可以轻松发布到主流网站或api接口
二、微信官方帐户文章 采集主要步骤1、创建“添加官方帐户”任务
登录该软件并在左上角打开“自定义官方帐户”以使用鼠标右键添加官方帐户框,然后单击“获取软件”以自动获取官方帐户信息,然后将其添加到小组。
2、填写官方帐户的名称或ID为采集
填写如下基本信息:
填写上述采集的任务名称和微信官方帐户的名称或ID。提示:您可以检查文章之前和之后图片的自动过滤
使用广告图片功能删除广告(必须预先检查功能)
使用官方帐户标签
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
您可以选择“上传设置(通过ftp返回到服务器)”或直接远程调用它。 (数据存储需要用户根据实际情况进行配置,配置后即可使用。)
4、开始采集
配置完图片后,可以单击左上角的[采集]数据采集:
5、 采集数据后处理和发布
启动采集后,数据将始终显示为采集,可以预览文章,显示图形内容,并且可以将其添加到“任务列表”页面中进行查看:勾选文章后,选择加入发布任务
可以分配给类别或列;
在任务列表中,您可以发布:
最后,选择发布到您自己的系统。如果软件上的现成界面与您的网站界面匹配,请直接填写URL,背景URL,帐户密码等,然后单击以成功登录
如果您的网站不支持它,则可以直接使用api接口进行连接,需要技术人员来编写该接口,我们也可以为您提供帮助! 查看全部
孤狼微信公众号文章采集的步骤及注意事项【孤狼数据采集】
Lone Wolf Data 采集平台为微信公众号文章提供了采集,可以轻松发布到市场上的主流系统上,还可以定制一些不受欢迎的网站界面!
一、独狼微信公众号文章 采集主要功能
1。根据官方帐户名称或ID,指定官方帐户采集,并支持输入多个官方帐户,而不会限制官方帐户的数量
2。下载图片的多种存储方式(远程调用,图片本地化,ftp上传),解决了官方帐号文章上图片的防盗链接问题。
3,强大的数据存储功能(采集将数据保存在本地数据库文件中)
4,简单的配置可以轻松发布到主流网站或api接口
二、微信官方帐户文章 采集主要步骤1、创建“添加官方帐户”任务
登录该软件并在左上角打开“自定义官方帐户”以使用鼠标右键添加官方帐户框,然后单击“获取软件”以自动获取官方帐户信息,然后将其添加到小组。
http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 2.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1082w" />2、填写官方帐户的名称或ID为采集
填写如下基本信息:
http://www.gulangu.com/wp-cont ... 5.png 300w, http://www.gulangu.com/wp-cont ... 9.png 768w, http://www.gulangu.com/wp-cont ... 9.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1084w" />填写上述采集的任务名称和微信官方帐户的名称或ID。提示:您可以检查文章之前和之后图片的自动过滤
使用广告图片功能删除广告(必须预先检查功能)
使用官方帐户标签
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
http://www.gulangu.com/wp-cont ... 3.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 4.png 1084w" />您可以选择“上传设置(通过ftp返回到服务器)”或直接远程调用它。 (数据存储需要用户根据实际情况进行配置,配置后即可使用。)
4、开始采集
配置完图片后,可以单击左上角的[采集]数据采集:
http://www.gulangu.com/wp-cont ... 3.png 300w, http://www.gulangu.com/wp-cont ... 9.png 768w, http://www.gulangu.com/wp-cont ... 4.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1082w" />5、 采集数据后处理和发布
启动采集后,数据将始终显示为采集,可以预览文章,显示图形内容,并且可以将其添加到“任务列表”页面中进行查看:勾选文章后,选择加入发布任务
http://www.gulangu.com/wp-cont ... 5.png 300w, http://www.gulangu.com/wp-cont ... 3.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w" />可以分配给类别或列;
http://www.gulangu.com/wp-cont ... 2.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 6.png 220w" />在任务列表中,您可以发布:
http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 0.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 1.png 1083w" />最后,选择发布到您自己的系统。如果软件上的现成界面与您的网站界面匹配,请直接填写URL,背景URL,帐户密码等,然后单击以成功登录
http://www.gulangu.com/wp-cont ... 4.png 300w, http://www.gulangu.com/wp-cont ... 1.png 768w, http://www.gulangu.com/wp-cont ... 5.png 220w, http://www.gulangu.com/wp-cont ... 8.png 1082w" />如果您的网站不支持它,则可以直接使用api接口进行连接,需要技术人员来编写该接口,我们也可以为您提供帮助!
WordPress的自定义栏目(默认的)和值(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-03-12 09:04
随着WordPress的功能越来越强大,我们可以使用WordPress来完成几乎所有我们想做的事情(似乎有点夸张)。
很多时候,也许我们不需要调用另一个文章或一个文章中的单个页面内容(至少大多数人不需要这样做);但这并不能使我们放弃WordPress功能的原因。
我们可以使用WordPress开发电子商务网站或构建大型门户网站网站,这些都不是问题。我们遇到的问题可能是,如何在每个文章页面中显示一些通用内容?例如,电子商务中的购买说明,产品介绍,公司介绍网站(每个产品可能都有一些共同的介绍),这是否意味着我们每次都必须分别添加这些内容?那么我们的维护将是一个巨大的项目。
如果我们可以在WordPress 文章中调用另一个页面的内容,是否可以解决问题?实际上,这就是我所做的。
这个想法是利用WordPress自定义列功能,并在需要调用的文章下添加一个指定的自定义列(默认)和值(需要调用的页面的别名)。
好的,直接转到代码:
由于一开始就急于执行此项目,因此代码可能很草率,或者有其他方法。但是至少可以肯定的是,到目前为止,我所使用的方法效果很好。
如何使用,以上代码替换了single.php中的主循环部分(当然,您可以根据模板的实际情况调用和添加样式)。当添加文章时,同时添加一个自定义列,该列的名称为“ fireuikey”(您可以将其替换为所需的任何变量名称,您需要同步修改以上代码!),该值是别名需要调用的页面的部分(英文)。如果自定义列为空或未添加,则将不会执行该调用,并且默认显示文章。 查看全部
WordPress的自定义栏目(默认的)和值(图)
随着WordPress的功能越来越强大,我们可以使用WordPress来完成几乎所有我们想做的事情(似乎有点夸张)。
很多时候,也许我们不需要调用另一个文章或一个文章中的单个页面内容(至少大多数人不需要这样做);但这并不能使我们放弃WordPress功能的原因。
我们可以使用WordPress开发电子商务网站或构建大型门户网站网站,这些都不是问题。我们遇到的问题可能是,如何在每个文章页面中显示一些通用内容?例如,电子商务中的购买说明,产品介绍,公司介绍网站(每个产品可能都有一些共同的介绍),这是否意味着我们每次都必须分别添加这些内容?那么我们的维护将是一个巨大的项目。
如果我们可以在WordPress 文章中调用另一个页面的内容,是否可以解决问题?实际上,这就是我所做的。
这个想法是利用WordPress自定义列功能,并在需要调用的文章下添加一个指定的自定义列(默认)和值(需要调用的页面的别名)。
好的,直接转到代码:
由于一开始就急于执行此项目,因此代码可能很草率,或者有其他方法。但是至少可以肯定的是,到目前为止,我所使用的方法效果很好。
如何使用,以上代码替换了single.php中的主循环部分(当然,您可以根据模板的实际情况调用和添加样式)。当添加文章时,同时添加一个自定义列,该列的名称为“ fireuikey”(您可以将其替换为所需的任何变量名称,您需要同步修改以上代码!),该值是别名需要调用的页面的部分(英文)。如果自定义列为空或未添加,则将不会执行该调用,并且默认显示文章。
微信导航和维清微信文章采集器后台设置设置教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2021-02-28 10:07
在按照本教程设置插件之前,请确保已安装“ WeChat WeChat 文章 采集器”插件。如果没有,请从以下地址下载并安装它:
下载链接:@ wq_wechatcollecting.plugin
第一步:基本设置
一、设置插件后端的基本设置。
二、设置相关的联众编码帐户。
1、转到联众编码平台注册您自己的帐户。由于联众编码平台网站的更新,以下图片可能与实际站点有所不同。有关特定的注册页面,请参考网站的实际页面。
2、成功注册后,您可以在个人中心为当前帐户充值相应的代码点。具体的充值金额取决于您的网站 采集充值金额。
3、填写您刚在联众的[维清]微信文章 采集器后台相关设置中注册的联众帐户和密码,以便采集可以触发数据源的验证码机制网站自动验证。
4、 采集在[Weiqing]微信文章 采集器的背景下,可以在自动识别验证码日志模块下查看该过程中的自动验证记录。
三、设置官方帐户和文章类别。
采集器后台设置中统一了官方帐户和文章分类,[Weiqing]微信导航和Weiqing微信文章 采集器都称为该类别,具体设置如图所示:
有以下5点需要解释。请参考图片中带有徽标的以下说明:
说明点1:
在显示模式下打开“同步到论坛”时,此设置生效。如果在此处选择特定部分,并且如图所示选择了“默认版本”,则当将文章发布到采集器的“综合”类别时,文章将同步到“默认版本”。论坛的“”部分中;如果未选中,则帖子将同步到后台设置中“默认文章同步部分”中设置的部分。
说明点2:
在显示模式下打开“同步到门户”时,此设置将生效。如果在此处选择了指定的列,并且如图所示选择了“ Test it”,那么当您将文章发布到采集器的“ Comprehensive”类别时,文章将同步到“ Test it”门户部分在该列中;如果未选择,则文章将同步到后台门户文章的默认同步列模块下设置的门户类别。
说明点3:
填写外部链接地址后,此类别成为外部链接。无法将官方帐户和文章分配到此类别,类似于外部链接部分。
说明点4:
如果仅将分类选择为文章分类,则不能将官方帐户分类为该分类。如果还填写了外部链接地址,则此分类将不会显示在“微信导航”插件的分类中。
解释点5:
如果未启用该类别,则该类别将不会显示在页面上,并且不能将正式帐户或文章添加到该类别。
第2步:数据填充
一、进入微信采集页面
点击网站浏览“微信窗口”
或输入URL:您的域名/plugin.php?id=wq_wechatcollecting
二、手动采集官方帐户信息。
1、单击插件标题中的Apply按钮以进入应用程序收入页面,并填写搜索到的关键词提交,如下图所示:
2、选择您需要提交的官方帐户,以选择要提交的相关类别。
三、如果需要启用官方帐户的自动更新,请按照以下教程进行操作。
在前台官方帐户管理模块下找到需要打开自动采集的官方帐户。开启自动采集
四、手动采集 文章的官方帐户。
移动采集 文章当前提供了三种方法
第一种类型:按下官方帐户采集
1、单击插件标题中的Apply按钮以进入官方帐户管理页面并找到您想要的官方帐户采集,然后单击“ 采集 文章”继续进行采集,如下所示:
第二种类型:通过关键字采集
1、单击插件标题中的Apply按钮以输入关键字采集 文章页面,然后输入采集的关键字,如下图所示:
2、选择要添加的文章。
第三种类型:按下链接采集
1、单击插件标题中的应用程序按钮以输入,然后单击链接采集 文章页面以输入文章地址以继续进行采集,如图所示下方:
如果五、已安装采集器的移动版本,请按照以下教程进行调用。
在指导之前,安装“ WeChat WeChat 文章 采集器插件移动版”,立即安装
1、在采集器插件后端导入移动版本数据调用模块下单击提交。
2、请记住在导入后更新缓存。
3、请注意,每次更新移动版本组件时都需要重新导入。
第3步:DIY数据导入
一、先决条件。 1、在导入DIY之前,必须先安装“ [维清] WeChat 文章 DIY”。立即安装
下载地址:@ wq_wechatdiy.pack
二、导入步骤。
1、转到应用程序中心,下载Weiqing微信文章 采集器 DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:
2、未清微信文章 采集器导入DIY时XML文件与页面之间的对应关系如下:
页面XML文件名页面URL 查看全部
微信导航和维清微信文章采集器后台设置设置教程
在按照本教程设置插件之前,请确保已安装“ WeChat WeChat 文章 采集器”插件。如果没有,请从以下地址下载并安装它:
下载链接:@ wq_wechatcollecting.plugin
第一步:基本设置
一、设置插件后端的基本设置。
二、设置相关的联众编码帐户。
1、转到联众编码平台注册您自己的帐户。由于联众编码平台网站的更新,以下图片可能与实际站点有所不同。有关特定的注册页面,请参考网站的实际页面。
2、成功注册后,您可以在个人中心为当前帐户充值相应的代码点。具体的充值金额取决于您的网站 采集充值金额。
3、填写您刚在联众的[维清]微信文章 采集器后台相关设置中注册的联众帐户和密码,以便采集可以触发数据源的验证码机制网站自动验证。
4、 采集在[Weiqing]微信文章 采集器的背景下,可以在自动识别验证码日志模块下查看该过程中的自动验证记录。
三、设置官方帐户和文章类别。
采集器后台设置中统一了官方帐户和文章分类,[Weiqing]微信导航和Weiqing微信文章 采集器都称为该类别,具体设置如图所示:
有以下5点需要解释。请参考图片中带有徽标的以下说明:
说明点1:
在显示模式下打开“同步到论坛”时,此设置生效。如果在此处选择特定部分,并且如图所示选择了“默认版本”,则当将文章发布到采集器的“综合”类别时,文章将同步到“默认版本”。论坛的“”部分中;如果未选中,则帖子将同步到后台设置中“默认文章同步部分”中设置的部分。
说明点2:
在显示模式下打开“同步到门户”时,此设置将生效。如果在此处选择了指定的列,并且如图所示选择了“ Test it”,那么当您将文章发布到采集器的“ Comprehensive”类别时,文章将同步到“ Test it”门户部分在该列中;如果未选择,则文章将同步到后台门户文章的默认同步列模块下设置的门户类别。
说明点3:
填写外部链接地址后,此类别成为外部链接。无法将官方帐户和文章分配到此类别,类似于外部链接部分。
说明点4:
如果仅将分类选择为文章分类,则不能将官方帐户分类为该分类。如果还填写了外部链接地址,则此分类将不会显示在“微信导航”插件的分类中。
解释点5:
如果未启用该类别,则该类别将不会显示在页面上,并且不能将正式帐户或文章添加到该类别。
第2步:数据填充
一、进入微信采集页面
点击网站浏览“微信窗口”
或输入URL:您的域名/plugin.php?id=wq_wechatcollecting
二、手动采集官方帐户信息。
1、单击插件标题中的Apply按钮以进入应用程序收入页面,并填写搜索到的关键词提交,如下图所示:
2、选择您需要提交的官方帐户,以选择要提交的相关类别。
三、如果需要启用官方帐户的自动更新,请按照以下教程进行操作。
在前台官方帐户管理模块下找到需要打开自动采集的官方帐户。开启自动采集
四、手动采集 文章的官方帐户。
移动采集 文章当前提供了三种方法
第一种类型:按下官方帐户采集
1、单击插件标题中的Apply按钮以进入官方帐户管理页面并找到您想要的官方帐户采集,然后单击“ 采集 文章”继续进行采集,如下所示:
第二种类型:通过关键字采集
1、单击插件标题中的Apply按钮以输入关键字采集 文章页面,然后输入采集的关键字,如下图所示:
2、选择要添加的文章。
第三种类型:按下链接采集
1、单击插件标题中的应用程序按钮以输入,然后单击链接采集 文章页面以输入文章地址以继续进行采集,如图所示下方:
如果五、已安装采集器的移动版本,请按照以下教程进行调用。
在指导之前,安装“ WeChat WeChat 文章 采集器插件移动版”,立即安装
1、在采集器插件后端导入移动版本数据调用模块下单击提交。
2、请记住在导入后更新缓存。
3、请注意,每次更新移动版本组件时都需要重新导入。
第3步:DIY数据导入
一、先决条件。 1、在导入DIY之前,必须先安装“ [维清] WeChat 文章 DIY”。立即安装
下载地址:@ wq_wechatdiy.pack
二、导入步骤。
1、转到应用程序中心,下载Weiqing微信文章 采集器 DIY的XML文件。进入下载页面
下载后压缩包的文件结构如下:
2、未清微信文章 采集器导入DIY时XML文件与页面之间的对应关系如下:
页面XML文件名页面URL
京东购物图怎么用文章采集调用api接口的方法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-02-22 08:03
文章采集调用api的接口,准确性高,返回的是一个json或swf。在网站后台手动设置每个功能的id,获取相应资源文件。将获取到的文件上传到文件服务器,找到对应的文件,下载。接口只限同时使用多个微信号才能操作,开发环境也只能接入一个微信号。
网页下载工具.可以尝试一下不过我觉得直接把二维码发给朋友点击进去可能更简单.二维码用图片代替可以在网页端直接显示但是不保证是原图.
京东购物图是一个js动态dom一次性生成的,你可以在网页上监听js获取相应链接!可以通过wx.navigateto进行扫码或者点击图片获取。一般图片的文件在link定义的地方,你可以在网页添加获取二维码或链接的js,给京东购物图中加入这些,
能不能联系官方解决呢
京东购物图是一个js工具链生成的,所以你所能获取到的只是js文件的一部分,二维码一定会被处理成json字符串,大概是这样。至于怎么给二维码添加参数,
通过京东购物图获取二维码的接口就可以。
用京东购物图,设置页面的时候记得设置好时间,一般图片会在10秒左右停止下载。
有的是可以很简单弄的。
1、提供详细的get下载地址。
2、支持通过页面地址获取,也可以通过百度地址获取,也可以通过竞价获取,也可以通过短信提交也可以。目前支持京东购物图产品中的京东图、京东券等,可以说类似于对接很多接口,不同产品有不同的接口。这些接口大多类似,都是为了实现自动下单、积分支付、促销活动等功能。有的业务人员需要在生成二维码后发给客户。
简单的来说,
1、方便企业在业务上更好地把控,因为有时候客户可能需要企业来定制他们的需求。
2、其实有些客户是希望在下单前,获取到这个二维码图片,并不是只要京东购物图的接口就够了,我们觉得这个通过接口提供更加方便:很多用户在网站购物图片的时候,其实他们不需要店铺的链接。只要有大概的个人介绍、其他网页一般也都是以百度等网站的链接形式作为参考来获取二维码。如果可以给用户定制图片,使用新一代图片做个参考,这样下单用户可以高效,同时减少店铺链接的阻碍。当然,这些数据我们一般都是在内部解决,所以想了解京东购物图信息的话,欢迎私信交流。 查看全部
京东购物图怎么用文章采集调用api接口的方法?
文章采集调用api的接口,准确性高,返回的是一个json或swf。在网站后台手动设置每个功能的id,获取相应资源文件。将获取到的文件上传到文件服务器,找到对应的文件,下载。接口只限同时使用多个微信号才能操作,开发环境也只能接入一个微信号。
网页下载工具.可以尝试一下不过我觉得直接把二维码发给朋友点击进去可能更简单.二维码用图片代替可以在网页端直接显示但是不保证是原图.
京东购物图是一个js动态dom一次性生成的,你可以在网页上监听js获取相应链接!可以通过wx.navigateto进行扫码或者点击图片获取。一般图片的文件在link定义的地方,你可以在网页添加获取二维码或链接的js,给京东购物图中加入这些,
能不能联系官方解决呢
京东购物图是一个js工具链生成的,所以你所能获取到的只是js文件的一部分,二维码一定会被处理成json字符串,大概是这样。至于怎么给二维码添加参数,
通过京东购物图获取二维码的接口就可以。
用京东购物图,设置页面的时候记得设置好时间,一般图片会在10秒左右停止下载。
有的是可以很简单弄的。
1、提供详细的get下载地址。
2、支持通过页面地址获取,也可以通过百度地址获取,也可以通过竞价获取,也可以通过短信提交也可以。目前支持京东购物图产品中的京东图、京东券等,可以说类似于对接很多接口,不同产品有不同的接口。这些接口大多类似,都是为了实现自动下单、积分支付、促销活动等功能。有的业务人员需要在生成二维码后发给客户。
简单的来说,
1、方便企业在业务上更好地把控,因为有时候客户可能需要企业来定制他们的需求。
2、其实有些客户是希望在下单前,获取到这个二维码图片,并不是只要京东购物图的接口就够了,我们觉得这个通过接口提供更加方便:很多用户在网站购物图片的时候,其实他们不需要店铺的链接。只要有大概的个人介绍、其他网页一般也都是以百度等网站的链接形式作为参考来获取二维码。如果可以给用户定制图片,使用新一代图片做个参考,这样下单用户可以高效,同时减少店铺链接的阻碍。当然,这些数据我们一般都是在内部解决,所以想了解京东购物图信息的话,欢迎私信交流。
Androidv7支持库声明式埋点的思路是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-02-10 08:00
声明性嵌入的想法是使嵌入代码与特定的交互和业务逻辑脱钩。开发人员只需关心需要嵌入的控件,并声明这些控件所需的嵌入数据,从而降低掩埋点的成本。
Android
在Android中,我们自定义了常用的UI控件,例如TextView,LinearLayout,ListView,ViewPager等,并重写了事件响应方法,并自动在这些方法中填充嵌入式代码。重写控件的优点是可以拦截更多事件,执行效率高并且操作稳定。但是它的缺点也很明显-移植成本很高!
为了解决这个问题,我们从Android v7支持库的想法中学到了,该库通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
通过这种方式,开发人员只需要在其Activity基类中重写getDelegate方法,用修改后的AppCompatDelegate替换该方法的返回值,然后自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
但是,出现了新问题。
如果在引用的第三方库中重写了UI控件,则上述方法将不会生效,这意味着我们需要一种方法来替换UI控件类的父类。但是,在运行时,我们找不到替换UI控件类的父类的可行方法。因此,我们尝试在编译时修改父类,并开发了Gradle插件。实际上,这样做没有运行时效率问题,但是会牺牲一些编译速度。这样,开发人员只需运行此插件即可用我们重写的UI控件自动替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明性埋入点后,只需在初始化控件时声明所需的埋入点。我们不再需要入侵该程序的各种响应功能,从而减少了掩埋点的难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,通过使用与Objective-C相关的属性和类别的语法特征,我们无需重写UI控件就可以实现声明式管理。对于UIControl,您可以在声明掩埋点时添加一个新操作,并在事件发生时自动填写掩埋代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,您可以重写UITableViewDelegate,使用消息传递机制来拦截事件,并自动在事件回调方法中填充掩埋的代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
类似地,在使用声明性嵌入方法之后,嵌入代码得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明性嵌入可以代替所有代码嵌入,并可以解决早期阶段移植成本高的问题。但这本质上是一种代码埋入点,但是代码埋入点减少了,并且不再入侵业务逻辑。如果要满足动态部署和修复嵌入式点的需求,则需要完全消除写在前端的嵌入式代码。
无痕埋点
我们注意到,声明式埋入点需要进行硬编码的主要原因有两个:第一是需要声明埋入点控件的唯一事件标识符,即bid;第二个是需要将某些业务字段放入前端埋藏时携带,这些字段是只能在运行时知道的值。
首先,我们可以尝试使用一致的规则在前端和后端自动生成事件标识符,以便后端可以配置前端的埋入行为以实现自动埋入。对于第二点,您可以尝试以某种方式自动将业务数据与掩埋点数据相关联。这种关联可以发生在前端或后端。
事件ID
为了自动生成事件标识符,我们需要获取每个控件自己的父组件的ID,类名和索引以及其他特征信息,然后向上遍历以找到根节点。根节点通常是手动标记的。如果没有标记,则默认情况下它是视图层次结构树的顶部节点。最后,将遍历生成的路径上所有节点的特征信息组合在一起,这是该事件的标识。考虑到实际布局中可能有一些动态插入的控件,我们允许父组件的索引中存在一定的错误。
配置背景需要维护自动生成的事件标识符和投标映射关系,并且可以将配置文件发布到前端。触发前端控制事件后,将自动匹配配置文件以获取相应的出价。应该注意的是,配置后台维护事件标识并非易事。主要的复杂性在于由不同版本之间的布局更改引起的事件标识更改。这就是为什么需要手动标记根节点的原因。因此,通常我们会选择不容易更改的视图节点。
数据关联
为了实现业务数据和掩埋点数据之间的自动关联,我们首先尝试了前端和后端日志关联方法。也就是说,当前端请求后端API时,后端会将业务数据写入日志,并在数据清理期间最终合并相应的前端日志和后端日志。这种方法的问题是后端重建的成本很高,并且数据清理的成本很大,因此无法广泛使用。但是在某些特殊情况下,例如,某些业务数据只能由后端知道,而前端则不知道,这种关联是必要的。
更常见的数据关联发生在前端数据之间。当页面跳转时,通过规范的跳转URI方案将业务数据传递到下一页,并自动将其填充到该页面的PV事件中。此页面中生成的所有其他事件将携带与PV事件相同的业务数据。
通过这种方式,通过自动生成事件标识符并执行数据关联,我们可以实现“无痕掩埋”,并且可以通过配置文件动态发出掩埋节点,从而具有动态部署和修复掩埋点的能力。但是,应该注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获得业务领域时(这种情况更为常见),仍然需要开发人员代码埋入点或声明性埋入点指定。根据当前实践阶段的数据,通过无缝掩埋可以解决业务中约70%的掩埋需求,而对于其余30%的掩埋需求,仍然需要声明性掩埋和代码掩埋。
摘要
前端数据采集和报告是构建数据平台过程中最重要的链接。美团点评的前端每天都会报告数百亿次数据。为了更好地满足公司各种业务中对嵌入点日益复杂的要求,以及嵌入点的准确性,及时性和开发效率,我们基于代码嵌入方案开发了一套轻量级的声明性方法。公司的前端掩埋方案,以及在动态掩埋和无缝掩埋方向上的进一步探索和实践。目前,声明性掩埋点已在某些企业中得到充分使用。从数据质量和开发人员反馈的角度来看,已经实现了预期的收益。非标记掩埋点也在一些业务中得到验证和不断优化,并将在以后在公司内部进一步推广。
在实践中,我们意识到掩埋点的问题无法通过单一的技术解决方案来解决。我们需要在不同的情况下选择不同的掩埋方案。例如,对于简单的用户行为事件,可以使用非标记掩埋点来解决;对于需要携带大量可以在运行时学习的业务领域的业务领域的埋入要求,需要使用声明性埋入点来解决它们。从更高的角度来看,除了优化前端埋入技术之外,埋入数据的标准化,前端和后端协作埋入,数据清理和关联对于构建更自动化和动态的埋入系统也非常重要。将来。 查看全部
Androidv7支持库声明式埋点的思路是什么?
声明性嵌入的想法是使嵌入代码与特定的交互和业务逻辑脱钩。开发人员只需关心需要嵌入的控件,并声明这些控件所需的嵌入数据,从而降低掩埋点的成本。
Android
在Android中,我们自定义了常用的UI控件,例如TextView,LinearLayout,ListView,ViewPager等,并重写了事件响应方法,并自动在这些方法中填充嵌入式代码。重写控件的优点是可以拦截更多事件,执行效率高并且操作稳定。但是它的缺点也很明显-移植成本很高!
为了解决这个问题,我们从Android v7支持库的想法中学到了,该库通过AppCompatDelegate代理自动替换UI控件。
public class GAAppCompatDelegateV14 extends AppCompatDelegateImplV14 {
@Override
View callActivityOnCreateView(View parent, String name, Context context, AttributeSet attrs) {
switch (name) {
case "TextView":
return new NovaTextView(context, attrs);
}
return super.callActivityOnCreateView(parent, name, context, attrs);
}
}
通过这种方式,开发人员只需要在其Activity基类中重写getDelegate方法,用修改后的AppCompatDelegate替换该方法的返回值,然后自动替换UI控件。
@Override
public AppCompatDelegate getDelegate() {
if (mDelegate == null) {
mDelegate = GAAppCompatUtil.create(this, this);
}
return mDelegate;
}
但是,出现了新问题。
如果在引用的第三方库中重写了UI控件,则上述方法将不会生效,这意味着我们需要一种方法来替换UI控件类的父类。但是,在运行时,我们找不到替换UI控件类的父类的可行方法。因此,我们尝试在编译时修改父类,并开发了Gradle插件。实际上,这样做没有运行时效率问题,但是会牺牲一些编译速度。这样,开发人员只需运行此插件即可用我们重写的UI控件自动替换UI控件的父类。
apply plugin: 'com.meituan.judasplugin'
使用声明性埋入点后,只需在初始化控件时声明所需的埋入点。我们不再需要入侵该程序的各种响应功能,从而减少了掩埋点的难度。
GAHelper.bindClick(view, bid, lab);
iOS
在iOS中,通过使用与Objective-C相关的属性和类别的语法特征,我们无需重写UI控件就可以实现声明式管理。对于UIControl,您可以在声明掩埋点时添加一个新操作,并在事件发生时自动填写掩埋代码。
- (void)nvja_setAnalyticsParams:(NVJAMGEParameter *)params mgeType:(SAKStatisticsEventMGEType)type
{
if (self.wmja_clickParams == nil && type == SAKStatisticsEventClick) {
[self addTarget:self action:@selector(wmja_controlDidTapped:) forControlEvents:UIControlEventTouchUpInside];
}
[super nvja_setAnalyticsParams:params mgeType:type];
}
对于UITableView,您可以重写UITableViewDelegate,使用消息传递机制来拦截事件,并自动在事件回调方法中填充掩埋的代码。
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
SEL selector = [anInvocation selector];
if (self.originalDelegate && [self.originalDelegate respondsToSelector:selector]) {
[anInvocation invokeWithTarget:self.originalDelegate];
}
SEL nvjaSelector = [self nvjaSelector:selector];
if ([super respondsToSelector:nvjaSelector]) {
[anInvocation setSelector:nvjaSelector];
[anInvocation invokeWithTarget:self];
}
}
类似地,在使用声明性嵌入方法之后,嵌入代码得到了简化。
NVJAMGEParameter *parameter = [[NVJAMGEParameter alloc] init];
parameter.bid = @"bid";
parameter.lab = @{@"poi_id":@"1"};
button.nvja_clickParams = parameter;
声明性嵌入可以代替所有代码嵌入,并可以解决早期阶段移植成本高的问题。但这本质上是一种代码埋入点,但是代码埋入点减少了,并且不再入侵业务逻辑。如果要满足动态部署和修复嵌入式点的需求,则需要完全消除写在前端的嵌入式代码。
无痕埋点
我们注意到,声明式埋入点需要进行硬编码的主要原因有两个:第一是需要声明埋入点控件的唯一事件标识符,即bid;第二个是需要将某些业务字段放入前端埋藏时携带,这些字段是只能在运行时知道的值。
首先,我们可以尝试使用一致的规则在前端和后端自动生成事件标识符,以便后端可以配置前端的埋入行为以实现自动埋入。对于第二点,您可以尝试以某种方式自动将业务数据与掩埋点数据相关联。这种关联可以发生在前端或后端。
事件ID
为了自动生成事件标识符,我们需要获取每个控件自己的父组件的ID,类名和索引以及其他特征信息,然后向上遍历以找到根节点。根节点通常是手动标记的。如果没有标记,则默认情况下它是视图层次结构树的顶部节点。最后,将遍历生成的路径上所有节点的特征信息组合在一起,这是该事件的标识。考虑到实际布局中可能有一些动态插入的控件,我们允许父组件的索引中存在一定的错误。
配置背景需要维护自动生成的事件标识符和投标映射关系,并且可以将配置文件发布到前端。触发前端控制事件后,将自动匹配配置文件以获取相应的出价。应该注意的是,配置后台维护事件标识并非易事。主要的复杂性在于由不同版本之间的布局更改引起的事件标识更改。这就是为什么需要手动标记根节点的原因。因此,通常我们会选择不容易更改的视图节点。
数据关联
为了实现业务数据和掩埋点数据之间的自动关联,我们首先尝试了前端和后端日志关联方法。也就是说,当前端请求后端API时,后端会将业务数据写入日志,并在数据清理期间最终合并相应的前端日志和后端日志。这种方法的问题是后端重建的成本很高,并且数据清理的成本很大,因此无法广泛使用。但是在某些特殊情况下,例如,某些业务数据只能由后端知道,而前端则不知道,这种关联是必要的。
更常见的数据关联发生在前端数据之间。当页面跳转时,通过规范的跳转URI方案将业务数据传递到下一页,并自动将其填充到该页面的PV事件中。此页面中生成的所有其他事件将携带与PV事件相同的业务数据。
通过这种方式,通过自动生成事件标识符并执行数据关联,我们可以实现“无痕掩埋”,并且可以通过配置文件动态发出掩埋节点,从而具有动态部署和修复掩埋点的能力。但是,应该注意的是,这种“无痕埋点”并不能解决所有问题。当无法通过数据关联获得业务领域时(这种情况更为常见),仍然需要开发人员代码埋入点或声明性埋入点指定。根据当前实践阶段的数据,通过无缝掩埋可以解决业务中约70%的掩埋需求,而对于其余30%的掩埋需求,仍然需要声明性掩埋和代码掩埋。
摘要
前端数据采集和报告是构建数据平台过程中最重要的链接。美团点评的前端每天都会报告数百亿次数据。为了更好地满足公司各种业务中对嵌入点日益复杂的要求,以及嵌入点的准确性,及时性和开发效率,我们基于代码嵌入方案开发了一套轻量级的声明性方法。公司的前端掩埋方案,以及在动态掩埋和无缝掩埋方向上的进一步探索和实践。目前,声明性掩埋点已在某些企业中得到充分使用。从数据质量和开发人员反馈的角度来看,已经实现了预期的收益。非标记掩埋点也在一些业务中得到验证和不断优化,并将在以后在公司内部进一步推广。
在实践中,我们意识到掩埋点的问题无法通过单一的技术解决方案来解决。我们需要在不同的情况下选择不同的掩埋方案。例如,对于简单的用户行为事件,可以使用非标记掩埋点来解决;对于需要携带大量可以在运行时学习的业务领域的业务领域的埋入要求,需要使用声明性埋入点来解决它们。从更高的角度来看,除了优化前端埋入技术之外,埋入数据的标准化,前端和后端协作埋入,数据清理和关联对于构建更自动化和动态的埋入系统也非常重要。将来。
一次性安装维清微信头条系统全套可享受8.8折优惠
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-01-19 08:11
功能亮点:
提醒:由于采集由于目标需要输入验证码而经常出现,因此采集是不可能的,因此我们开发了自动输入验证码的功能,但是自动输入验证码需要输入第三方(联众)付费编码接口。关于成本,一次自动识别验证码只需花费一美分,并且采集识别后的一段时间内无需再次被识别,因此花费不多,请放心!
示范与推广
演示地址:
优惠时事通讯:一次性安装全套的微庆微信头条系统,即可享受8.20%的折扣,请给我戳一下!
“微信头条系统”的系统架构
1、“ [维清]微信文章采集器”点击安装|查看演示
此插件是整个系统的核心和基础。它主要提供诸如官方帐户采集和管理,文章采集和管理,官方帐户和文章推荐等功能。安装此插件,让您的网站与数百万个公共帐户共享高质量文章!
2、“ [维清]微信导航”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供官方帐户汇总页面(列表页面),官方帐户详细信息页面和其他页面。安装此插件可为正式帐户运营商提供进入标题系统的理由!
3、“ [魏青]未央读书中心”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供以下公共帐户文章的汇总浏览功能和公共帐户跟踪管理功能。安装此插件,安装此插件,让微信用户喜欢在您的微信标题系统文章上阅读!
4、“ [维清]微信文章DIY”点击安装
安装此扩展程序后,可以在网站的任何页面上调用“ WeChat WeChat 文章采集器” 采集和文章的正式帐户。操作方法与系统本身中的其他DIY模块相同。
5、“ [Weiqing]插件伪静态”单击安装
实现微信标题系统主页的静态链接,以便搜索引擎可以更轻松地搜索系统的相关页面收录!
6、“ [Weiqing]百度编辑器”点击安装
此插件是免费的插件,主要提供文章编辑功能,可以编辑“微信微信文章采集器” 采集返回的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
功能说明
[维清] WeChat 文章采集器是采集 WeChat订阅帐户信息和订阅帐户文章的插件。只需输入官方帐户昵称,您就可以自动采集官方帐户信息(信息包括官方帐户昵称,微信ID,功能介绍,身份验证信息,头像,QR码)。安装此插件,您可以让网站与数百万个订阅帐户共享高质量的内容,每天进行大量更新,可以快速增加网站的权重和排名。
功能亮点:
1、可自定义的插件名称:
您可以在后台的面包屑导航中随意修改插件的名称。如果未设置,则默认为微信窗口。
2、可自定义的SEO信息:
后台可以轻松地为每个页面设置SEO信息,它支持网站名称,插件名称,类别名称,文章标题和其他信息的变量替换。
3、可以批量采集个官方帐户信息:
输入微信公众号的昵称,然后单击搜索,选择您想要的采集正式账号,然后提交。您一次可以采集多个官方帐户信息。
4、可以批量采集 文章的官方帐户:
在官方帐户列表中单击“ 采集 文章”的链接,输入到采集的页数,您可以批处理采集 文章信息,并且可以采集多集在文章时,文章的内容也已本地化。
5、 文章信息可以完美显示:
该插件构建了自己的主页,列表页面和详细信息页面,可以在不依赖原创系统任何功能的情况下完美显示文章信息。
6、强大的DIY机制:
只要安装diy扩展程序,就可以拥有强大的DIY机制,并且可以在网站的任何页面上调用微信官方帐户信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(主页,列表页面,详细信息页面)具有多个内置的DIY区域,并且可以在原创内容块之间插入DIY模块。
8、可以灵活设置是否需要查看信息:
是否可以通过后台在后台控制是否需要查看用户提交的公共帐户和内容的文章信息。
9、信息批处理管理功能:
后台提供了功能全面的微信公众号和文章批次管理功能,可以批量查看,删除和移动信息分类。
10、完全支持移动版本:
只需安装相应的移动版本组件,即可轻松打开移动版本。
示范与推广
演示地址:
Discount Express:一次性安装未清微信头条系统即可享受8.20%的折扣,请给我戳一下!
高质量的应用推荐
查看全部
一次性安装维清微信头条系统全套可享受8.8折优惠
功能亮点:
提醒:由于采集由于目标需要输入验证码而经常出现,因此采集是不可能的,因此我们开发了自动输入验证码的功能,但是自动输入验证码需要输入第三方(联众)付费编码接口。关于成本,一次自动识别验证码只需花费一美分,并且采集识别后的一段时间内无需再次被识别,因此花费不多,请放心!
示范与推广
演示地址:
优惠时事通讯:一次性安装全套的微庆微信头条系统,即可享受8.20%的折扣,请给我戳一下!
“微信头条系统”的系统架构
1、“ [维清]微信文章采集器”点击安装|查看演示
此插件是整个系统的核心和基础。它主要提供诸如官方帐户采集和管理,文章采集和管理,官方帐户和文章推荐等功能。安装此插件,让您的网站与数百万个公共帐户共享高质量文章!
2、“ [维清]微信导航”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供官方帐户汇总页面(列表页面),官方帐户详细信息页面和其他页面。安装此插件可为正式帐户运营商提供进入标题系统的理由!
3、“ [魏青]未央读书中心”点击安装|查看演示
此插件是系统的重要组成部分。它主要提供以下公共帐户文章的汇总浏览功能和公共帐户跟踪管理功能。安装此插件,安装此插件,让微信用户喜欢在您的微信标题系统文章上阅读!
4、“ [维清]微信文章DIY”点击安装
安装此扩展程序后,可以在网站的任何页面上调用“ WeChat WeChat 文章采集器” 采集和文章的正式帐户。操作方法与系统本身中的其他DIY模块相同。
5、“ [Weiqing]插件伪静态”单击安装
实现微信标题系统主页的静态链接,以便搜索引擎可以更轻松地搜索系统的相关页面收录!
6、“ [Weiqing]百度编辑器”点击安装
此插件是免费的插件,主要提供文章编辑功能,可以编辑“微信微信文章采集器” 采集返回的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
功能说明
[维清] WeChat 文章采集器是采集 WeChat订阅帐户信息和订阅帐户文章的插件。只需输入官方帐户昵称,您就可以自动采集官方帐户信息(信息包括官方帐户昵称,微信ID,功能介绍,身份验证信息,头像,QR码)。安装此插件,您可以让网站与数百万个订阅帐户共享高质量的内容,每天进行大量更新,可以快速增加网站的权重和排名。
功能亮点:
1、可自定义的插件名称:
您可以在后台的面包屑导航中随意修改插件的名称。如果未设置,则默认为微信窗口。
2、可自定义的SEO信息:
后台可以轻松地为每个页面设置SEO信息,它支持网站名称,插件名称,类别名称,文章标题和其他信息的变量替换。
3、可以批量采集个官方帐户信息:
输入微信公众号的昵称,然后单击搜索,选择您想要的采集正式账号,然后提交。您一次可以采集多个官方帐户信息。
4、可以批量采集 文章的官方帐户:
在官方帐户列表中单击“ 采集 文章”的链接,输入到采集的页数,您可以批处理采集 文章信息,并且可以采集多集在文章时,文章的内容也已本地化。
5、 文章信息可以完美显示:
该插件构建了自己的主页,列表页面和详细信息页面,可以在不依赖原创系统任何功能的情况下完美显示文章信息。
6、强大的DIY机制:
只要安装diy扩展程序,就可以拥有强大的DIY机制,并且可以在网站的任何页面上调用微信官方帐户信息和文章信息。
7、每个页面都有多个内置的DIY区域:
插件的每个页面(主页,列表页面,详细信息页面)具有多个内置的DIY区域,并且可以在原创内容块之间插入DIY模块。
8、可以灵活设置是否需要查看信息:
是否可以通过后台在后台控制是否需要查看用户提交的公共帐户和内容的文章信息。
9、信息批处理管理功能:
后台提供了功能全面的微信公众号和文章批次管理功能,可以批量查看,删除和移动信息分类。
10、完全支持移动版本:
只需安装相应的移动版本组件,即可轻松打开移动版本。
示范与推广
演示地址:
Discount Express:一次性安装未清微信头条系统即可享受8.20%的折扣,请给我戳一下!
高质量的应用推荐
<p>微信公众号文章的想法采集,如何采集微信公众号文章?</p>
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-01-17 12:03
</p>
许多方法对于不懂编程的人来说太昂贵了。让我分享一种大家都可以使用的方法。简单快捷。您可以将所有文章正式帐户下载到采集。 (Word,html,pdf格式都是可能的),最后您还可以合成一个官方帐户文章电子书,我尝试过采集拥有2,000多个官方帐户文章,但通常情况下采集 2000多篇文章,系统有限,您可以在第二天继续采集。
直接链接:官方帐户文章 采集助手,密码:7t93
我将在下面为您详细介绍。
1、可以是任何发布的采集微信公众号历史记录组文章
微信文章导出软件可以帮助您下载并保存所有想要将官方帐户直接导出到计算机的文章。操作简单,每个人都可以!
2、WeChat 文章导出的文档种类繁多,提取的内容更加完整
好的微信文章可以下载并保存到计算机中以进行永久存储,并且打印微信文章也很方便。多样化的存档格式可以更好地满足大多数人的需求。
3、通过关键词按时间段搜索微信官方帐户文章工具
微信文章导出软件不仅可以下载文章,而且可以通过计算机在线搜索微信文章!每天都有数以百万计的官方帐户文章,涵盖各个行业和地区,广受欢迎的原创文章,可帮助您创建或查找更多优质内容
4、下载微信文章预览,您对此感到满意
专业人员从事专业工作,将采集导出并留给微信文章导出软件,以帮助您提高效率并节省时间
导出Word文档分类并保存
微信文章下载器还收录近80种其他辅助功能,易于使用
直接转到软件链接:官方帐户文章 采集助手,密码:7t93 查看全部
<p>微信公众号文章的想法采集,如何采集微信公众号文章?
</p>
许多方法对于不懂编程的人来说太昂贵了。让我分享一种大家都可以使用的方法。简单快捷。您可以将所有文章正式帐户下载到采集。 (Word,html,pdf格式都是可能的),最后您还可以合成一个官方帐户文章电子书,我尝试过采集拥有2,000多个官方帐户文章,但通常情况下采集 2000多篇文章,系统有限,您可以在第二天继续采集。
直接链接:官方帐户文章 采集助手,密码:7t93
我将在下面为您详细介绍。
1、可以是任何发布的采集微信公众号历史记录组文章
微信文章导出软件可以帮助您下载并保存所有想要将官方帐户直接导出到计算机的文章。操作简单,每个人都可以!
2、WeChat 文章导出的文档种类繁多,提取的内容更加完整
好的微信文章可以下载并保存到计算机中以进行永久存储,并且打印微信文章也很方便。多样化的存档格式可以更好地满足大多数人的需求。
3、通过关键词按时间段搜索微信官方帐户文章工具
微信文章导出软件不仅可以下载文章,而且可以通过计算机在线搜索微信文章!每天都有数以百万计的官方帐户文章,涵盖各个行业和地区,广受欢迎的原创文章,可帮助您创建或查找更多优质内容
4、下载微信文章预览,您对此感到满意
专业人员从事专业工作,将采集导出并留给微信文章导出软件,以帮助您提高效率并节省时间
导出Word文档分类并保存
微信文章下载器还收录近80种其他辅助功能,易于使用
直接转到软件链接:官方帐户文章 采集助手,密码:7t93
解决方案:优采云采集接入奶盘AI伪原创API教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 388 次浏览 • 2021-01-16 11:02
优采云采集支持调用挤奶锅API接口以处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和5118智能单词更改API以更高的原创程度处理文章,这对于增加收录的权重和文章的作用非常重要。
详细的使用步骤如下:1.奶锅API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[+ Milk pan API]创建界面配置;
II。配置API接口信息:
[购买的授权用户],[购买的授权代码]用于从Milk Disk Network的后端获取API授权信息;
[API版本]对应于购买的软件包:百度优化版,AI智能版;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为一个新字段,例如:[结果数据和发布]中的标题处理后的新字段:title_milk托盘,内容处理后的新字段:content_milk托盘,以及数据可以查看预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_milk tray和content_milk tray;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.奶锅API接口的常见问题和解决方案
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_milk plate和content_milk plate字段;
查看全部
解决方案:优采云采集接入奶盘AI伪原创API教程
优采云采集支持调用挤奶锅API接口以处理采集,关键词,描述等的数据标题和内容。可以通过优采云采集的SEO功能来定位]和5118智能单词更改API以更高的原创程度处理文章,这对于增加收录的权重和文章的作用非常重要。
详细的使用步骤如下:1.奶锅API接口配置
I。 API配置入口:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”单击[第三方API配置管理] ==“最后单击[+ Milk pan API]创建界面配置;
II。配置API接口信息:
[购买的授权用户],[购买的授权代码]用于从Milk Disk Network的后端获取API授权信息;
[API版本]对应于购买的软件包:百度优化版,AI智能版;
2.创建API处理规则
API处理规则,可以将其设置为调用API接口以处理哪些字段的内容;
I。 API处理规则条目:
在控制台左侧的列表中单击[第三方服务配置] ==“单击[第三方内容API访问] ==”,进入[API处理规则管理]页面,最后单击[+添加API处理规则]创建API处理规则;
II,API处理规则配置:
3.API处理规则的用法
使用API处理规则的方式有两种:手动执行和自动执行:
I。手动执行API处理规则:
在采集任务的[结果和发布]选项卡中,单击[SEO&API&翻译和其他工具]按钮==“选择[第三方API执行]列==”选择相应的API处理规则==“执行(数据范围有两种执行方法,根据发布状态批量执行和根据列表中选择的数据执行);
II。自动执行API处理规则:
启用API处理的自动执行。任务完成采集后,API处理将自动执行。定时采集和自动发布功能通常很方便;
在任务的[自动化:发布和SEO和翻译]选项卡中,[自动执行第三方API配置] ==“选中[采集,自动执行API]选项==”选择要执行的API处理==“选择由API接口处理的数据范围(通常选择”要发布“,所有将导致所有数据被执行多次),最后单击保存;
4.API处理结果和发布
I。查看API接口处理的结果:
API接口处理的内容将另存为一个新字段,例如:[结果数据和发布]中的标题处理后的新字段:title_milk托盘,内容处理后的新字段:content_milk托盘,以及数据可以查看预览界面。
II。发布API接口的处理后内容:
发布文章之前,请在发布目标的第二步中修改映射字段,并在API接口处理之后将标题和内容更改为新的对应字段title_milk tray和content_milk tray;
提醒:如果无法在发布目标中选择新字段,请在此任务下复制或创建新的发布目标,然后可以在新发布目标中选择新字段。可以查看详细的教程;
5.奶锅API接口的常见问题和解决方案
I。如何同时使用API处理规则和SEO规则?
系统默认对标题和内容字段执行SEO功能,需要将其修改为SEO规则中的title_milk plate和content_milk plate字段;
技术文章:织梦dedecms系统修改文章描述调用字数的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-01-09 11:01
dedecms系统文章调用说明的最大字符数为250个字节。 文章摘要(可以通过infolen或与描述相关的标签调用)设置为最多250个字符。主要目的是减少数据库的冗余并确保网络的出色性能。因此,不对引言的内容设置上限显然是不合理的,但是如果可以自由控制该上限,则dedecms模仿站点将对Web内容的布局产生积极影响。在网页设计过程中,.NET源代码。通常需要在频道列表页面的文章摘要中调用dedecms。如果文章摘要中的单词数不能有效控制,则页面布局可以非常灵活。
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field:description function =“ cn_substr(@me,character number)”/]。
与Dedecms系统中的文章摘要相关的php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子:$ description = cn_substrR($ description,$ cfg_auot_description);这句话实现此功能[field:description function =“ cn_substr(@me,character number)” /]。由于此语句确实对页面布局很有帮助,因此我们尝试不做任何更改。
在编辑页面上,有一个句子:$ description = cn_substrR($ description,250);,该句子显示了熟悉的字符数250,这是系统设置的抽象字符数文章字符数上限。如果是gbk编码,将显示125个字符。如果是utf-8编码,则为81个字符。显然,我们必须打破字符数上限文章 summary。是的,您可以在此处将250修改为另一个值,例如500。不建议在此处设置太高,一个是不需要在列表页面上显示太多内容(显示太多)内容不如间接使用主体好),另一个是避免数据库冗余。
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,找到if($ dsize> 250)$ dsize = 250;语句。这限制了可用于在后台获取摘要的字符数。在此处修改250到500。织梦模仿站与之前修改的字符数有所不同(如果您确认手动添加了文章的每个字符,则如果您手动完成摘要,则无需修改此文件从动态摘要中获取次要摘要仍为大量文章和采集准备。)
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这与以前修改的字符数不同。
完成上述修改后,我们可以转到频道列表页面并按标签进行调用。标签示例如下:
{dede:list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field:title /]
[field:description function ='cn_substr(@ me,500)'/] ...
{/ dede:list}
通过上述方法,我们已经意识到被调用的文章摘要字符为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了越来越多的空间。
接下来,我们还讨论一下常用的Dedecms 文章或列表页面调用文章摘要方法
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
1、的第二种方法是间接调用文章摘要。根据要调用的单词数,使用[field:info /]时,可以使用{dede:arclist infolen =''} {/ dede:在arclist}中,设置字符数以调用摘要(向上设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符的上限(后台也有250个字符的上限)。显然,这两种方法非常被动和灵活。
第四种方法3、通过功能功能实现文章摘要显示字符的灵活调整。当然,当文章摘要内容的上限没有正常修改时,这四种方法之间的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
这四个方法用于调用文章描述标签。但是它最多只能调用前250个字符。如果您想打更多电话,则需要修改一些地方:
1.article_description_main.php页面,找到“ if($ dsize> 250) $ dsize = 250;”句子,将250更改为500
2.登录到后台,在系统-系统基本参数-其他选项中,自动汇总长度更改为500.
3.登录到后台并执行SQL语句:alter table`dede_archives` change`description`description` varchar(1000)
调用标签{dede:field.description function ='cn_substr(@ me,500)'/}。您可以显示500个字符) 查看全部
技术文章:织梦dedecms系统修改文章描述调用字数的方法
dedecms系统文章调用说明的最大字符数为250个字节。 文章摘要(可以通过infolen或与描述相关的标签调用)设置为最多250个字符。主要目的是减少数据库的冗余并确保网络的出色性能。因此,不对引言的内容设置上限显然是不合理的,但是如果可以自由控制该上限,则dedecms模仿站点将对Web内容的布局产生积极影响。在网页设计过程中,.NET源代码。通常需要在频道列表页面的文章摘要中调用dedecms。如果文章摘要中的单词数不能有效控制,则页面布局可以非常灵活。
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field:description function =“ cn_substr(@me,character number)”/]。
与Dedecms系统中的文章摘要相关的php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子:$ description = cn_substrR($ description,$ cfg_auot_description);这句话实现此功能[field:description function =“ cn_substr(@me,character number)” /]。由于此语句确实对页面布局很有帮助,因此我们尝试不做任何更改。
在编辑页面上,有一个句子:$ description = cn_substrR($ description,250);,该句子显示了熟悉的字符数250,这是系统设置的抽象字符数文章字符数上限。如果是gbk编码,将显示125个字符。如果是utf-8编码,则为81个字符。显然,我们必须打破字符数上限文章 summary。是的,您可以在此处将250修改为另一个值,例如500。不建议在此处设置太高,一个是不需要在列表页面上显示太多内容(显示太多)内容不如间接使用主体好),另一个是避免数据库冗余。
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,找到if($ dsize> 250)$ dsize = 250;语句。这限制了可用于在后台获取摘要的字符数。在此处修改250到500。织梦模仿站与之前修改的字符数有所不同(如果您确认手动添加了文章的每个字符,则如果您手动完成摘要,则无需修改此文件从动态摘要中获取次要摘要仍为大量文章和采集准备。)
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这与以前修改的字符数不同。
完成上述修改后,我们可以转到频道列表页面并按标签进行调用。标签示例如下:
{dede:list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field:title /]
[field:description function ='cn_substr(@ me,500)'/] ...
{/ dede:list}
通过上述方法,我们已经意识到被调用的文章摘要字符为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了越来越多的空间。
接下来,我们还讨论一下常用的Dedecms 文章或列表页面调用文章摘要方法
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
1、的第二种方法是间接调用文章摘要。根据要调用的单词数,使用[field:info /]时,可以使用{dede:arclist infolen =''} {/ dede:在arclist}中,设置字符数以调用摘要(向上设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符的上限(后台也有250个字符的上限)。显然,这两种方法非常被动和灵活。
第四种方法3、通过功能功能实现文章摘要显示字符的灵活调整。当然,当文章摘要内容的上限没有正常修改时,这四种方法之间的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function =“ cn_substr(@me,字符数)” /]
4:[field:description function =“ cn_substr(@me,字符数)” /]
这四个方法用于调用文章描述标签。但是它最多只能调用前250个字符。如果您想打更多电话,则需要修改一些地方:
1.article_description_main.php页面,找到“ if($ dsize> 250) $ dsize = 250;”句子,将250更改为500
2.登录到后台,在系统-系统基本参数-其他选项中,自动汇总长度更改为500.
3.登录到后台并执行SQL语句:alter table`dede_archives` change`description`description` varchar(1000)
调用标签{dede:field.description function ='cn_substr(@ me,500)'/}。您可以显示500个字符)
总结:数据采集-微信公众号文章的完整爬取过程笔记
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-12-19 13:17
微信公众号文章的完整抓取过程笔记
基于sougou-api的概述一.实现文章爬网[基于anyproxy的二.和Monkeyrunner 文章基于sougou-api的自动爬网一.以实现文章爬网
1.可以直接获取微信搜狗首页
2.使用现有的软件包+代理方法
调用该API,并通过微信官方帐户文章的ID获取帐户的一部分
此方法只能获取微信文章的临时链接,因此您需要将html文本保存到其中
二. 文章基于anyproxy和Monkeyrunner的自动爬网
假设:您有一批微信公众号ID(例如:gh_1380fb0258f6)
硬件条件:普通PC(我使用Windows系统),Android手机(我使用Huawei Honor 8lite)
尽量不要使用模拟器。使用仿真器登录微信后,发现该帐号被封锁! ! !
目标:抓取该微信官方帐户文章的所有历史记录并逐步抓取
1.根据anyproxy 文章抓取所有正式帐户
伟大的上帝已经实现了这一步,他的代码直接在这里使用:wechat_spider微信爬虫
有关具体实现过程,请参考github,在这一步您需要注意选择正确的IP
2.基于Monkeyrunner的爬网自动化(1)手机打开开发人员模式
作者当前遇到手机以打开开发人员模式的方式是“在系统版本号上单击7、8次”
([2)PC安装Android开发套件
有关Android SDK的下载和安装,请参阅AndroidDevTools
有关安装是否成功的检测方法,请参阅:Monkeyrunner1-monkeyrunner入门记录和回放
([3)自动抓取过程S1使用微信搜索框通过微信官方帐户ID搜索该帐户
图片
图片
S2单击以输入帐户,下拉,单击所有文章,输入
图片
S3下拉列表,在文章列表中单击文章文章将其打开
图片
S4等待一段时间,然后返回微信首页,继续执行S1爬虫爬网策略摘要
抓取微信公众号文章可用于舆论监测
我认为有两种方法:
1.监视微信官方帐户文章上的点赞次数,找到“爆炸性风格” 文章,监视爆炸性风格文章的主题或事件 查看全部
总结:数据采集-微信公众号文章的完整爬取过程笔记
微信公众号文章的完整抓取过程笔记
基于sougou-api的概述一.实现文章爬网[基于anyproxy的二.和Monkeyrunner 文章基于sougou-api的自动爬网一.以实现文章爬网
1.可以直接获取微信搜狗首页
2.使用现有的软件包+代理方法
调用该API,并通过微信官方帐户文章的ID获取帐户的一部分
此方法只能获取微信文章的临时链接,因此您需要将html文本保存到其中
二. 文章基于anyproxy和Monkeyrunner的自动爬网
假设:您有一批微信公众号ID(例如:gh_1380fb0258f6)
硬件条件:普通PC(我使用Windows系统),Android手机(我使用Huawei Honor 8lite)
尽量不要使用模拟器。使用仿真器登录微信后,发现该帐号被封锁! ! !
目标:抓取该微信官方帐户文章的所有历史记录并逐步抓取
1.根据anyproxy 文章抓取所有正式帐户
伟大的上帝已经实现了这一步,他的代码直接在这里使用:wechat_spider微信爬虫
有关具体实现过程,请参考github,在这一步您需要注意选择正确的IP
2.基于Monkeyrunner的爬网自动化(1)手机打开开发人员模式
作者当前遇到手机以打开开发人员模式的方式是“在系统版本号上单击7、8次”
([2)PC安装Android开发套件
有关Android SDK的下载和安装,请参阅AndroidDevTools
有关安装是否成功的检测方法,请参阅:Monkeyrunner1-monkeyrunner入门记录和回放
([3)自动抓取过程S1使用微信搜索框通过微信官方帐户ID搜索该帐户
图片
图片
S2单击以输入帐户,下拉,单击所有文章,输入
图片
S3下拉列表,在文章列表中单击文章文章将其打开
图片
S4等待一段时间,然后返回微信首页,继续执行S1爬虫爬网策略摘要
抓取微信公众号文章可用于舆论监测
我认为有两种方法:
1.监视微信官方帐户文章上的点赞次数,找到“爆炸性风格” 文章,监视爆炸性风格文章的主题或事件
解决方案:【剖析 | SOFARPC 框架】系列之 SOFARPC 泛化调用实现剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-11-30 11:18
大咖啡揭示了爪哇人的种植地?点击免费获得“大厂面试名单”,克服面试的困难〜>>>
沙发
ScalableOpenFinancialArchitecture
它是由Ant Financial独立开发的金融级分布式中间件。它收录构建金融级云原生架构所需的所有组件。这是财务方案中的最佳做法。
本文是E符号宝库中的Mona Rudao撰写的“分析| SOFARPC Framework”的第七章。 “分析| SOFARPC框架”系列由SOFA团队和源代码爱好者编写。项目代码为:官方目录已声明。
当前,SOFABolt源代码分析正在进行中,有兴趣的朋友可以在文章结尾处进行申请
前言
我们知道,在RPC调用中,客户端需要加载服务器提供的接口定义类。但是,这并不总是可行的。因此,产生了对通用调用的需求,一个成熟且功能齐全的RPC框架通常支持通用调用,那么通用调用是什么? SOFARPC如何支持广义调用?如何同时实现?与其他RPC泛化调用有何不同?有什么优势?我们将在本文中一个一个地回答。
广义呼叫简介
当客户端由于某种原因而无法获得服务提供商的接口jar包时,或者客户端是更通用的系统,并且不想依赖于每个服务提供商提供的Facade接口,但是需要调用,然后目前需要泛化调用。
例如:
当使用多种语言开发分布式系统时,假设它是NodeJ,并且NodeJ需要调用Java语言的RPC服务,那么我们需要在两者之间建立一个适应层,以便该适应层可以处理NodeJ。请求,然后将其转发到Java的RPC服务。
某些中间系统功能(例如某些内部网关)需要以统一的方式实现对其他下游系统的调用(在非SPI的情况下),显然不可能一一依赖于下游程序包。
某些在线流量回放系统可以拦截数据采集,然后通过泛化进行呼叫回放,而无需依赖整个站点的应用程序。
在这种情况下,必须不包括所有接口的jar文件,否则它将太肿。实际上,这也是不现实的。每次添加服务器,然后释放并重新启动应用程序时,都不可能添加jar包依赖项。
这时,可以使用通用调用,并且可以将相应的请求打包为通用调用,以便可以在不依赖于接口jar包的情况下以多种语言调用RPC服务以避免重复开发。
SOFARPC的通用呼叫用法
SOFARPC的正式文档非常详细,并且已在正式Wiki泛化调用中进行了详细介绍。同时,在源代码的示例模块中,还可以运行现成的演示。读者可以克隆源代码以进行阅读。在这里,我们简要解释如何使用它,以便每个人都具有直观的理解。
接口定义
通常,有2个用于泛化调用的API,包括5种方法,其中2种方法已被弃用,即3种主要方法。他们是:
<p style="line-height: 1.5em;">/**
* 泛化调用
* @return 正常类型(不能是GenericObject类型)
*/
Object $invoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 除了JDK等内置类型,其它对象是GenericObject类型
*/
Object $genericInvoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 返回指定的T类型返回对象
*/
T $genericInvoke(String methodName, String[] argTypes, Object[] args, Class clazz);</p>
$ invoke此方法的使用场景:用户知道参数类型和返回值类型,则可以使用此方法。
$ genericInvoke此方法是重载方法。重载一的使用场景是:如果您的应用程序不知道接口的参数类型和返回值类型,那么此时,您需要使用GenericObject类包装返回值和参数。
$ genericInvoke重载二的使用方案是:如果应用程序不知道接口参数类型,但是知道接口返回值的类型,则无需使用GenericObject作为返回值。
基本上,已经涵盖了常用的集中式场景,可以说功能相当全面。
一般用途
由于篇幅所限,我将不在此处发布演示。如果您有兴趣,可以通过链接查看官方演示或源代码,包括使用SOFARPC API和SOFABoot:
演示Wiki地址:
源代码地址:
SOFARPC泛化调用的设计和实现
接下来,我们将重点介绍SOFARPC如何实现广义调用。
框架调用设计
简单来说,泛化调用的关键是对象表示和序列化。 SOFARPC提供了GenericObject之类的对象来表示参数对象或返回值对象,并将GenericObject对象序列化为目标对象,或者将返回值反序列化为GenericObject对象是SOFARPC泛化的关键。
在这里,我们首先看一下SOFARPC泛化调用的流程图,这将有助于以后理解泛化的实现。
让我们谈谈这张照片:
调用通用化API时,将加载通用化过滤器,该过滤器用于进行一些参数转换并设置序列化工厂类型。
SOFARPC将在使用SOFABolt进行网络调用并将其传递给SOFABolt之前创建一个上下文。上下文收录序列化工厂类型信息。这些信息将确定使用哪个序列化程序,并且该上下文将在整个调用期间内流动。
在SOFABolt正式发送数据之前,它将把GenericObject对象序列化为普通对象的字节流,这样服务提供者就不必关心它是否是泛化调用。从图中可以看出,提供程序不需要进行泛化调用任何更改-这是区分SOFARPC泛化与其他RPC泛化的关键。
提供者成功接收到请求后,可以使用常规的序列化器对数据进行反序列化,而只需正常调用并返回即可。
当使用者的SOFABolt接收到响应数据时,它会根据上下文的序列化类型对返回值进行反序列化,即,将普通字节流反序列化为GenericObject对象,因为客户端可能不知道返回值。
最后,泛化API以获取GenericObject类型的返回值。
从以上过程可以看出,序列化程序在泛化调用中占据了大量空间和作用。对于SOFARPC,对hessian3进行了修改以用于通用调用,以支持通用调用所需的序列化功能。 SOFA-Hessian的变化可以在这里参考。
Hessian概括实现
SOFA-Hessian将com.alipay.hessian.generic软件包添加到了hessian软件包中。该软件包的功能是处理泛化调用。重写的关键是实现或继承SerializerFactory类以及Serializer,Deserializer和其他接口。这里,设计了几个类来描述相应的类型信息,并同时实现这些类的序列化和反序列化。对应关系如下
让我们以GenericObjectSerializer为例。该序列化器重写writeObject方法。此方法的功能是将GenericObject对象序列化为目标对象字节流。也就是说,取出GenericObject的type字段和fields字段并将其组合到目标对象的字节流中。
例如:
有一个类型的RPC对象
<p style="line-height: 1.5em;">public class TestObj {
private String str;
private int num;
}</p>
在通用调用客户端中,您可以直接构造GenericObject对象
<p style="line-height: 1.5em;"> GenericObject genericObject = new GenericObject(
"com.alipay.sofa.rpc.invoke.generic.TestObj");
genericObject.putField("str", "xxxx");
genericObject.putField("num", 222);</p>
这时,GenericObjectSerializer可以使用此信息将GenericObject转换为TestObj对象的字节流。服务提供者可以通过普通的hessian2反序列化来获取对象。
与需要两端都支持通用化的其他RPC框架相比,SOFARPC更加友好。换句话说,如果应用程序要支持通用化,则只需要升级客户端(消费者),而服务器(提供者)就不知道。因为从服务器的角度来看,接收到的对象是完全相同的。您可能会发现很难为复杂类型编写这样的结构。 SOFA-Hessian中提供了工具类
<p style="line-height: 1.5em;">com.alipay.hessian.generic.util.GenericUtils</p>
为帮助用户生成,可以直接使用。
SOFARPC和Dubbo泛化调用比较
让我们介绍泛化调用与行业中其他一些产品之间的比较。首先,让我们介绍一下序列化本身的性能和优点。
序列化本身的比较
在Github上,有Java序列化的基准,可以用作参考。尽管在实际场景中,每个序列化场景都是不同的,但结果可能与此处的基准测试结果有所不同,但仍具有参考意义。从该项目的基准测试可以看出:Json是压缩率还是序列率。与Hessian相比,它具有很大的缺点。
同时,尽管与原创程序,kryo等相比,粗麻布的性能差距很小,但是粗麻布反序列化不需要指定类型,这种优势非常有价值。
Dubbo的普遍呼吁
在许多RPC框架中,Dubbo还提供了通用调用的功能。接下来,让我们谈谈Dubbo的概括。 Dubbo泛化和SOFA RPC泛化之间的最大区别是Dubbo需要服务器支持泛化。因此,如果要提供泛化功能,则还必须升级服务器。这似乎对SOFA RPC不友好。
Dubbo的通用呼叫流程如下:
如您所见,Dubbo的服务器还需要一个通用过滤器才能将Map解析为POJO来解析数据。
摘要
本文主要介绍SOFARPC泛化调用的设计和实现,介绍泛化调用的场景,同时,介绍SOFARPC泛化调用的API的用法,并说明泛化设计和实现SOFARPC的详细信息。最后,对社区中某些RPC框架的通用调用进行了简单的比较。
以下是SOFARPC的概括设计和实现的摘要:
设计目标是:服务器不需要感知它是否是通用的,一切都由客户端处理。
带来的好处是:如果应用程序要支持通用化,则无需更改服务器,只需修改客户端即可。这是其他RPC框架中的广义调用之间的最大区别。
实现方法:通过SOFA-Hessian序列化支持泛化序列化。进行泛化调用时,bolt将根据上下文的序列化标记使用相应的序列化程序,SOFA-Hessian的唯一泛化序列化服务器可以将GenericObject对象序列化为目标对象的字节流,服务器可以正常地对其进行反序列化。 SOFA-Hessian独特的泛化反序列化器还可以将目标返回值反序列化为对象,例如GenericObject。
参考
欢迎再加入并参与SOFABolt源代码分析
SOFABolt源代码分析目录:
我们将逐步详细介绍代码的每个部分的设计和实现,并有望根据以下目录进行操作。以下还收录当前的源代码分析文章声明状态:
如何获取:
直接回复此官方帐户想要声明的文章名称,我们会在确定您的资格后主动与您联系,您可以参加,这是您的演出时间!
相关链接
SOFA文件:
沙发:
SOFARPC:
SOFABolt:
小小的复活节彩蛋
请在这里查看您的ID:
长按以获取分布式架构的干货
欢迎一起构建SOFAStack
本文与微信官方帐户-金融级分布式架构(Antfin_SOFA)分享。 查看全部
[分析| SOFARPC Framework]系列SOFARPC泛化调用实现分析
大咖啡揭示了爪哇人的种植地?点击免费获得“大厂面试名单”,克服面试的困难〜>>>
沙发
ScalableOpenFinancialArchitecture
它是由Ant Financial独立开发的金融级分布式中间件。它收录构建金融级云原生架构所需的所有组件。这是财务方案中的最佳做法。
本文是E符号宝库中的Mona Rudao撰写的“分析| SOFARPC Framework”的第七章。 “分析| SOFARPC框架”系列由SOFA团队和源代码爱好者编写。项目代码为:官方目录已声明。
当前,SOFABolt源代码分析正在进行中,有兴趣的朋友可以在文章结尾处进行申请
前言
我们知道,在RPC调用中,客户端需要加载服务器提供的接口定义类。但是,这并不总是可行的。因此,产生了对通用调用的需求,一个成熟且功能齐全的RPC框架通常支持通用调用,那么通用调用是什么? SOFARPC如何支持广义调用?如何同时实现?与其他RPC泛化调用有何不同?有什么优势?我们将在本文中一个一个地回答。
广义呼叫简介
当客户端由于某种原因而无法获得服务提供商的接口jar包时,或者客户端是更通用的系统,并且不想依赖于每个服务提供商提供的Facade接口,但是需要调用,然后目前需要泛化调用。
例如:
当使用多种语言开发分布式系统时,假设它是NodeJ,并且NodeJ需要调用Java语言的RPC服务,那么我们需要在两者之间建立一个适应层,以便该适应层可以处理NodeJ。请求,然后将其转发到Java的RPC服务。
某些中间系统功能(例如某些内部网关)需要以统一的方式实现对其他下游系统的调用(在非SPI的情况下),显然不可能一一依赖于下游程序包。
某些在线流量回放系统可以拦截数据采集,然后通过泛化进行呼叫回放,而无需依赖整个站点的应用程序。
在这种情况下,必须不包括所有接口的jar文件,否则它将太肿。实际上,这也是不现实的。每次添加服务器,然后释放并重新启动应用程序时,都不可能添加jar包依赖项。
这时,可以使用通用调用,并且可以将相应的请求打包为通用调用,以便可以在不依赖于接口jar包的情况下以多种语言调用RPC服务以避免重复开发。
SOFARPC的通用呼叫用法
SOFARPC的正式文档非常详细,并且已在正式Wiki泛化调用中进行了详细介绍。同时,在源代码的示例模块中,还可以运行现成的演示。读者可以克隆源代码以进行阅读。在这里,我们简要解释如何使用它,以便每个人都具有直观的理解。
接口定义
通常,有2个用于泛化调用的API,包括5种方法,其中2种方法已被弃用,即3种主要方法。他们是:
<p style="line-height: 1.5em;">/**
* 泛化调用
* @return 正常类型(不能是GenericObject类型)
*/
Object $invoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 除了JDK等内置类型,其它对象是GenericObject类型
*/
Object $genericInvoke(String methodName, String[] argTypes, Object[] args);/**
* 支持参数类型无法在类加载器加载情况的泛化调用
* @return 返回指定的T类型返回对象
*/
T $genericInvoke(String methodName, String[] argTypes, Object[] args, Class clazz);</p>
$ invoke此方法的使用场景:用户知道参数类型和返回值类型,则可以使用此方法。
$ genericInvoke此方法是重载方法。重载一的使用场景是:如果您的应用程序不知道接口的参数类型和返回值类型,那么此时,您需要使用GenericObject类包装返回值和参数。
$ genericInvoke重载二的使用方案是:如果应用程序不知道接口参数类型,但是知道接口返回值的类型,则无需使用GenericObject作为返回值。
基本上,已经涵盖了常用的集中式场景,可以说功能相当全面。
一般用途
由于篇幅所限,我将不在此处发布演示。如果您有兴趣,可以通过链接查看官方演示或源代码,包括使用SOFARPC API和SOFABoot:
演示Wiki地址:
源代码地址:
SOFARPC泛化调用的设计和实现
接下来,我们将重点介绍SOFARPC如何实现广义调用。
框架调用设计
简单来说,泛化调用的关键是对象表示和序列化。 SOFARPC提供了GenericObject之类的对象来表示参数对象或返回值对象,并将GenericObject对象序列化为目标对象,或者将返回值反序列化为GenericObject对象是SOFARPC泛化的关键。
在这里,我们首先看一下SOFARPC泛化调用的流程图,这将有助于以后理解泛化的实现。
让我们谈谈这张照片:
调用通用化API时,将加载通用化过滤器,该过滤器用于进行一些参数转换并设置序列化工厂类型。
SOFARPC将在使用SOFABolt进行网络调用并将其传递给SOFABolt之前创建一个上下文。上下文收录序列化工厂类型信息。这些信息将确定使用哪个序列化程序,并且该上下文将在整个调用期间内流动。
在SOFABolt正式发送数据之前,它将把GenericObject对象序列化为普通对象的字节流,这样服务提供者就不必关心它是否是泛化调用。从图中可以看出,提供程序不需要进行泛化调用任何更改-这是区分SOFARPC泛化与其他RPC泛化的关键。
提供者成功接收到请求后,可以使用常规的序列化器对数据进行反序列化,而只需正常调用并返回即可。
当使用者的SOFABolt接收到响应数据时,它会根据上下文的序列化类型对返回值进行反序列化,即,将普通字节流反序列化为GenericObject对象,因为客户端可能不知道返回值。
最后,泛化API以获取GenericObject类型的返回值。
从以上过程可以看出,序列化程序在泛化调用中占据了大量空间和作用。对于SOFARPC,对hessian3进行了修改以用于通用调用,以支持通用调用所需的序列化功能。 SOFA-Hessian的变化可以在这里参考。
Hessian概括实现
SOFA-Hessian将com.alipay.hessian.generic软件包添加到了hessian软件包中。该软件包的功能是处理泛化调用。重写的关键是实现或继承SerializerFactory类以及Serializer,Deserializer和其他接口。这里,设计了几个类来描述相应的类型信息,并同时实现这些类的序列化和反序列化。对应关系如下
让我们以GenericObjectSerializer为例。该序列化器重写writeObject方法。此方法的功能是将GenericObject对象序列化为目标对象字节流。也就是说,取出GenericObject的type字段和fields字段并将其组合到目标对象的字节流中。
例如:
有一个类型的RPC对象
<p style="line-height: 1.5em;">public class TestObj {
private String str;
private int num;
}</p>
在通用调用客户端中,您可以直接构造GenericObject对象
<p style="line-height: 1.5em;"> GenericObject genericObject = new GenericObject(
"com.alipay.sofa.rpc.invoke.generic.TestObj");
genericObject.putField("str", "xxxx");
genericObject.putField("num", 222);</p>
这时,GenericObjectSerializer可以使用此信息将GenericObject转换为TestObj对象的字节流。服务提供者可以通过普通的hessian2反序列化来获取对象。
与需要两端都支持通用化的其他RPC框架相比,SOFARPC更加友好。换句话说,如果应用程序要支持通用化,则只需要升级客户端(消费者),而服务器(提供者)就不知道。因为从服务器的角度来看,接收到的对象是完全相同的。您可能会发现很难为复杂类型编写这样的结构。 SOFA-Hessian中提供了工具类
<p style="line-height: 1.5em;">com.alipay.hessian.generic.util.GenericUtils</p>
为帮助用户生成,可以直接使用。
SOFARPC和Dubbo泛化调用比较
让我们介绍泛化调用与行业中其他一些产品之间的比较。首先,让我们介绍一下序列化本身的性能和优点。
序列化本身的比较
在Github上,有Java序列化的基准,可以用作参考。尽管在实际场景中,每个序列化场景都是不同的,但结果可能与此处的基准测试结果有所不同,但仍具有参考意义。从该项目的基准测试可以看出:Json是压缩率还是序列率。与Hessian相比,它具有很大的缺点。
同时,尽管与原创程序,kryo等相比,粗麻布的性能差距很小,但是粗麻布反序列化不需要指定类型,这种优势非常有价值。
Dubbo的普遍呼吁
在许多RPC框架中,Dubbo还提供了通用调用的功能。接下来,让我们谈谈Dubbo的概括。 Dubbo泛化和SOFA RPC泛化之间的最大区别是Dubbo需要服务器支持泛化。因此,如果要提供泛化功能,则还必须升级服务器。这似乎对SOFA RPC不友好。
Dubbo的通用呼叫流程如下:
如您所见,Dubbo的服务器还需要一个通用过滤器才能将Map解析为POJO来解析数据。
摘要
本文主要介绍SOFARPC泛化调用的设计和实现,介绍泛化调用的场景,同时,介绍SOFARPC泛化调用的API的用法,并说明泛化设计和实现SOFARPC的详细信息。最后,对社区中某些RPC框架的通用调用进行了简单的比较。
以下是SOFARPC的概括设计和实现的摘要:
设计目标是:服务器不需要感知它是否是通用的,一切都由客户端处理。
带来的好处是:如果应用程序要支持通用化,则无需更改服务器,只需修改客户端即可。这是其他RPC框架中的广义调用之间的最大区别。
实现方法:通过SOFA-Hessian序列化支持泛化序列化。进行泛化调用时,bolt将根据上下文的序列化标记使用相应的序列化程序,SOFA-Hessian的唯一泛化序列化服务器可以将GenericObject对象序列化为目标对象的字节流,服务器可以正常地对其进行反序列化。 SOFA-Hessian独特的泛化反序列化器还可以将目标返回值反序列化为对象,例如GenericObject。
参考
欢迎再加入并参与SOFABolt源代码分析
SOFABolt源代码分析目录:
我们将逐步详细介绍代码的每个部分的设计和实现,并有望根据以下目录进行操作。以下还收录当前的源代码分析文章声明状态:
如何获取:
直接回复此官方帐户想要声明的文章名称,我们会在确定您的资格后主动与您联系,您可以参加,这是您的演出时间!
相关链接
SOFA文件:
沙发:
SOFARPC:
SOFABolt:
小小的复活节彩蛋
请在这里查看您的ID:
长按以获取分布式架构的干货
欢迎一起构建SOFAStack
本文与微信官方帐户-金融级分布式架构(Antfin_SOFA)分享。
干货教程:zblog文章页面怎么调用同栏目文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-10-30 08:01
如何在zblog文章页面文章页面上调用同一列
我使用zblog程序来构建网站。制作前端模板时,我想在文章页面上调用此类别的文章。因为这是第一次使用,所以没有现成的代码可以使用。在百度上搜索了十多分钟后,我发现没有可以使用的代码,因此我必须自己研究它,因此我得到了以下代码:
{foreach GetList(4,$ cate.ID,null,null,null,null,null,array('has_subcate'=> true))作为$ related}
{$ related.Title}
{$ article.Intro} {/ foreach}
编辑:
调用类别ID时,上一段代码不是很准确。我通过将$ cate.ID替换为$ related.Category.ID对其进行了修改。
{foreach GetList(4,$ article.Category.ID,null,null,null,null,array('has_subcate'=> true))作为$ related}
此代码非常简单。实际上,它借用了调用特定类别文章的代码,但是从类别中提取了本文的类别,因此实现了在文章页面上调用该类别文章的功能。 $ cate.ID是本文所在的类别ID,前面的4种表示调用4篇文章文章,您可以自己对其进行修改。
题外话:当我搜索百度zblog文章页面如何调用同一列文章时,我看到文章提到了使用了哪些插件!严重的是,我还没有看到这些插件中的任何一个,而且我也不知道如何使用它们。作者认为,尽管该插件的功能强大,但毕竟还有副作用,这可能会影响页面加载的速度。因此,如果可以直接修改代码,并且可以使用尽可能少的插件,则可以修改代码。
zblog文章页面调用同一列文章的代码非常简单,您可以直接使用本文给出的代码。您可以看到zblog这个开源程序不仅适用于SEO优化,而且其自身功能也非常强大且易于使用。熟悉zblog之后,基本上可以灵活使用它。当然,您必须结合SEO技能,以使网站模板适合优化。 查看全部
如何在zblog文章页面文章页面上调用同一列
如何在zblog文章页面文章页面上调用同一列
我使用zblog程序来构建网站。制作前端模板时,我想在文章页面上调用此类别的文章。因为这是第一次使用,所以没有现成的代码可以使用。在百度上搜索了十多分钟后,我发现没有可以使用的代码,因此我必须自己研究它,因此我得到了以下代码:
{foreach GetList(4,$ cate.ID,null,null,null,null,null,array('has_subcate'=> true))作为$ related}
{$ related.Title}
{$ article.Intro} {/ foreach}
编辑:
调用类别ID时,上一段代码不是很准确。我通过将$ cate.ID替换为$ related.Category.ID对其进行了修改。
{foreach GetList(4,$ article.Category.ID,null,null,null,null,array('has_subcate'=> true))作为$ related}
此代码非常简单。实际上,它借用了调用特定类别文章的代码,但是从类别中提取了本文的类别,因此实现了在文章页面上调用该类别文章的功能。 $ cate.ID是本文所在的类别ID,前面的4种表示调用4篇文章文章,您可以自己对其进行修改。
题外话:当我搜索百度zblog文章页面如何调用同一列文章时,我看到文章提到了使用了哪些插件!严重的是,我还没有看到这些插件中的任何一个,而且我也不知道如何使用它们。作者认为,尽管该插件的功能强大,但毕竟还有副作用,这可能会影响页面加载的速度。因此,如果可以直接修改代码,并且可以使用尽可能少的插件,则可以修改代码。
zblog文章页面调用同一列文章的代码非常简单,您可以直接使用本文给出的代码。您可以看到zblog这个开源程序不仅适用于SEO优化,而且其自身功能也非常强大且易于使用。熟悉zblog之后,基本上可以灵活使用它。当然,您必须结合SEO技能,以使网站模板适合优化。
事实:后台程序在处理繁重的任务时,调用外部程序异步执行的简单实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-10-23 12:00
在开发Web应用程序时,无论是网站还是服务接口,我们都可能遇到来自客户端的特定请求。在此请求的背后,有许多繁重的任务要执行。如果我们在后台程序中同步进行处理,则程序执行时间比较长,用户体验不好,甚至可能导致502执行超时。针对这种情况,有许多成熟的解决方案(根据我的肤浅知识,使用队列是一种更好的解决方案),但是实现略微复杂且麻烦。如果我们对异步执行的任务没有特殊要求(例如异步任务完成后的失败重试或事件回调),那么我们可以通过一种非常简单的方法简单地实现它:nohup命令要执行> / dev / null 2>&1&。
如果您看到此内容并认为它没有什么新意,则表示您非常擅长,至少[比我更好]。我也希望在您离开之前,告诉我们是否有更好的方法并分享。
应用场景
目前,我实际上在两种特定情况下使用了这种异步任务执行方法。
1、之前是网站,该数据是来自第三方采集的另一位同事的数据,采集需要导入到我的数据库中,所以我在网站中提供了功能,一个用于文件上传和导入的按钮。当同事通过文件上传将采集数据保存在服务器上时,后台程序将读取该文件的内容并基于该数据进行必要的分析,最后通过SQL将分析后的数据写入数据库。此过程的速度或速度取决于数据文件的大小。对于具有数千行数据的文件,最后可能需要一分钟以上的时间才能执行。如果使用传统的同步执行,则从文件上载->数据分析->写入数据库。在整个过程中,浏览器处于圆圈中。如果时间较长,执行将超时并且所有先前的工作都将丢失。因此,这里我采用了异步任务执行方法。数据文件成功上传后,服务器直接响应浏览器,显示“数据导入成功,正在处理”提示,整个前端交互在此处结束。以后的数据分析和对数据库的写入将移交给另一个单独的过程进行处理。
2、就在两天前,我就是这样写的。我们制作了一个APP(使用APICloud制作的非流入APP)。用户使用APP发布内容后,需要调用百度AI的内容查看界面,以自动查看用户发布的文字和图片。如果发现其中收录错误信息,则不会自动对其进行审核。调用百度界面的过程比较耗时,它主要取决于用户发布的内容中收录的图片数量。自然,百度界面响应速度很慢。同样,如果用户以同步方式发布内容->调用百度界面->等待该界面返回数据->判断评论是否通过,则太耗时,因此从用户的角度来看,内容被发送出去并等待了几秒钟,甚至十秒钟,直到最后没有响应为止,这种用户体验太糟糕了。因此,可以实现,当用户发布内容时,立即提示“发布成功且正在审核中”,几秒钟后,用户将看到他刚刚发布的内容已被批准并出现在内容列表。时间,多么自然的过程。
实现思路
因此,有时有必要异步处理任务。正如我们在开始时提到的那样,在Web应用程序的开发中,不可能跳出Linux服务器。如今,除了.NET系统,它也可能部署在Windows上[似乎没有Blog Garden]。其他后端应用程序基本上将部署在Linux上,而我们开头提到的实现方法是在Linux下执行命令。
首先,实现程序异步执行的方式大致有两种:线程和进程[关于它,因为我听说有些语言也支持协程。好?我勒个去? -_- !!!]。对于支持线程的Java之类的编程语言,异步执行可以通过线程或进程[Runtime.exec()]实现;对于PHP,默认情况下没有线程,这对每个人都是通用的,而且不要在PHP下使用线程,因此,这只能通过其内部函数调用外部进程来实现异步任务。
在PHP下,执行一个外部程序,并要求该外部程序在后台运行,并且不会让您的宿主程序挂起[宿主是执行对外部命令的调用的PHP程序],有一点特别之处,请注意,这在官方手册的exec函数中有专门提及:
如果使用此功能启动程序,则要使其在后台继续运行,必须将程序的输出重定向到文件或其他输出流。否则,PHP会挂起,直到程序执行结束。
表示为了使外部程序在后台运行,此外部程序的输出[指标准输出[如Python中的打印,PHP中的echo和Java中的System.out.print]和标准错误]必须重定向到文件或另一个输出流。否则,宿主程序可能会挂起并等待外部程序执行完成,然后终止其生命周期。
因此,文章开头提到的命令中的> / dev / null 2>&1用于重定向标准输出和标准错误,并将它们写入/ dev / null文件,以制作主机程序。调用外部程序并使其在后台运行,它将立即执行后续代码,直到结束为止,并可以快速结束其生命周期。此时,外部程序仍在静默运行。
在撰写本文文章之前,我还专门检查了Java下使用Runtime.exec()调用外部程序的实现,发现文章提到了这一点:
这意味着重定向外部程序的输出,这与PHP官方手册中提到的注意事项完全相同。
具体实现
接下来,我们将解释nohup将执行的命令> / dev / null 2>&1&此命令的含义。
首先,它是要执行的命令。例如,如上所述,请致电百度AI进行内容审核,然后该命令就像php / www / wwwroot / app_service / artisan baidu:censor 文章 ID。此处使用的PHP Laravel框架,取决于您使用哪种语言,哪种框架以及如何编写要执行的命令,这取决于您的情况。
第二,如果要让程序在后台运行,则需要在命令后添加&[即,&],以告诉系统我要执行的命令是需要在其中运行的程序。背景。
然后,为了防止我们的主机程序等待挂起,我们需要重定向外部程序的输出,因此我们添加了> / dev / null 2>&1,> / dev / null意味着重定向标准输出到/ dev / null文件,以下2>&1表示将标准错误重定向到与先前标准输出相同的位置。 / dev / null是不存在的文件,因此> / dev / null 2>&1的总体含义是,当执行此外部程序时,将生成所有标准输出和标准错误[即错误消息]通过它,不要保存它们。 ,我不想看到。当然,如果您在调用外部程序后发现外部程序未按预期执行,则可能是外部程序报告了错误。您可以将输出重定向到真实文件中,以保存外部程序的输出信息,以方便进行故障排除。
最后,nohup。当您指定&以使外部程序在后台运行时,如果此时关闭并退出终端[这是黑色的命令行窗口],那么您刚刚在后台运行的外部程序也将终止。为避免此问题,您需要在开始时添加nohup来告诉系统关闭或退出终端时,请勿杀死我刚刚执行的外部程序的后台进程! ! !
好的,已经明确解释了用于特定实现的命令。如何用各种语言实现它们?我相信每种语言都有一种调用外部程序的方法,您可以自己学习。我再使用PHP,最后我将发布PHP的实现方法:
exec('nohup php / www / wwwroot / app_service / artisan baidu:censor 文章 ID> / dev / null 2>&1&');【Laravel】
exec('nohup php /www/wwwroot/app_service/baidu_censor.php 文章 ID> / dev / null 2>&1&');
参考文章 查看全部
当后台程序正在处理繁重的任务时,通过调用外部程序来实现异步执行的简单实现
在开发Web应用程序时,无论是网站还是服务接口,我们都可能遇到来自客户端的特定请求。在此请求的背后,有许多繁重的任务要执行。如果我们在后台程序中同步进行处理,则程序执行时间比较长,用户体验不好,甚至可能导致502执行超时。针对这种情况,有许多成熟的解决方案(根据我的肤浅知识,使用队列是一种更好的解决方案),但是实现略微复杂且麻烦。如果我们对异步执行的任务没有特殊要求(例如异步任务完成后的失败重试或事件回调),那么我们可以通过一种非常简单的方法简单地实现它:nohup命令要执行> / dev / null 2>&1&。
如果您看到此内容并认为它没有什么新意,则表示您非常擅长,至少[比我更好]。我也希望在您离开之前,告诉我们是否有更好的方法并分享。
应用场景
目前,我实际上在两种特定情况下使用了这种异步任务执行方法。
1、之前是网站,该数据是来自第三方采集的另一位同事的数据,采集需要导入到我的数据库中,所以我在网站中提供了功能,一个用于文件上传和导入的按钮。当同事通过文件上传将采集数据保存在服务器上时,后台程序将读取该文件的内容并基于该数据进行必要的分析,最后通过SQL将分析后的数据写入数据库。此过程的速度或速度取决于数据文件的大小。对于具有数千行数据的文件,最后可能需要一分钟以上的时间才能执行。如果使用传统的同步执行,则从文件上载->数据分析->写入数据库。在整个过程中,浏览器处于圆圈中。如果时间较长,执行将超时并且所有先前的工作都将丢失。因此,这里我采用了异步任务执行方法。数据文件成功上传后,服务器直接响应浏览器,显示“数据导入成功,正在处理”提示,整个前端交互在此处结束。以后的数据分析和对数据库的写入将移交给另一个单独的过程进行处理。
2、就在两天前,我就是这样写的。我们制作了一个APP(使用APICloud制作的非流入APP)。用户使用APP发布内容后,需要调用百度AI的内容查看界面,以自动查看用户发布的文字和图片。如果发现其中收录错误信息,则不会自动对其进行审核。调用百度界面的过程比较耗时,它主要取决于用户发布的内容中收录的图片数量。自然,百度界面响应速度很慢。同样,如果用户以同步方式发布内容->调用百度界面->等待该界面返回数据->判断评论是否通过,则太耗时,因此从用户的角度来看,内容被发送出去并等待了几秒钟,甚至十秒钟,直到最后没有响应为止,这种用户体验太糟糕了。因此,可以实现,当用户发布内容时,立即提示“发布成功且正在审核中”,几秒钟后,用户将看到他刚刚发布的内容已被批准并出现在内容列表。时间,多么自然的过程。
实现思路
因此,有时有必要异步处理任务。正如我们在开始时提到的那样,在Web应用程序的开发中,不可能跳出Linux服务器。如今,除了.NET系统,它也可能部署在Windows上[似乎没有Blog Garden]。其他后端应用程序基本上将部署在Linux上,而我们开头提到的实现方法是在Linux下执行命令。
首先,实现程序异步执行的方式大致有两种:线程和进程[关于它,因为我听说有些语言也支持协程。好?我勒个去? -_- !!!]。对于支持线程的Java之类的编程语言,异步执行可以通过线程或进程[Runtime.exec()]实现;对于PHP,默认情况下没有线程,这对每个人都是通用的,而且不要在PHP下使用线程,因此,这只能通过其内部函数调用外部进程来实现异步任务。
在PHP下,执行一个外部程序,并要求该外部程序在后台运行,并且不会让您的宿主程序挂起[宿主是执行对外部命令的调用的PHP程序],有一点特别之处,请注意,这在官方手册的exec函数中有专门提及:
如果使用此功能启动程序,则要使其在后台继续运行,必须将程序的输出重定向到文件或其他输出流。否则,PHP会挂起,直到程序执行结束。
表示为了使外部程序在后台运行,此外部程序的输出[指标准输出[如Python中的打印,PHP中的echo和Java中的System.out.print]和标准错误]必须重定向到文件或另一个输出流。否则,宿主程序可能会挂起并等待外部程序执行完成,然后终止其生命周期。
因此,文章开头提到的命令中的> / dev / null 2>&1用于重定向标准输出和标准错误,并将它们写入/ dev / null文件,以制作主机程序。调用外部程序并使其在后台运行,它将立即执行后续代码,直到结束为止,并可以快速结束其生命周期。此时,外部程序仍在静默运行。
在撰写本文文章之前,我还专门检查了Java下使用Runtime.exec()调用外部程序的实现,发现文章提到了这一点:
这意味着重定向外部程序的输出,这与PHP官方手册中提到的注意事项完全相同。
具体实现
接下来,我们将解释nohup将执行的命令> / dev / null 2>&1&此命令的含义。
首先,它是要执行的命令。例如,如上所述,请致电百度AI进行内容审核,然后该命令就像php / www / wwwroot / app_service / artisan baidu:censor 文章 ID。此处使用的PHP Laravel框架,取决于您使用哪种语言,哪种框架以及如何编写要执行的命令,这取决于您的情况。
第二,如果要让程序在后台运行,则需要在命令后添加&[即,&],以告诉系统我要执行的命令是需要在其中运行的程序。背景。
然后,为了防止我们的主机程序等待挂起,我们需要重定向外部程序的输出,因此我们添加了> / dev / null 2>&1,> / dev / null意味着重定向标准输出到/ dev / null文件,以下2>&1表示将标准错误重定向到与先前标准输出相同的位置。 / dev / null是不存在的文件,因此> / dev / null 2>&1的总体含义是,当执行此外部程序时,将生成所有标准输出和标准错误[即错误消息]通过它,不要保存它们。 ,我不想看到。当然,如果您在调用外部程序后发现外部程序未按预期执行,则可能是外部程序报告了错误。您可以将输出重定向到真实文件中,以保存外部程序的输出信息,以方便进行故障排除。
最后,nohup。当您指定&以使外部程序在后台运行时,如果此时关闭并退出终端[这是黑色的命令行窗口],那么您刚刚在后台运行的外部程序也将终止。为避免此问题,您需要在开始时添加nohup来告诉系统关闭或退出终端时,请勿杀死我刚刚执行的外部程序的后台进程! ! !
好的,已经明确解释了用于特定实现的命令。如何用各种语言实现它们?我相信每种语言都有一种调用外部程序的方法,您可以自己学习。我再使用PHP,最后我将发布PHP的实现方法:
exec('nohup php / www / wwwroot / app_service / artisan baidu:censor 文章 ID> / dev / null 2>&1&');【Laravel】
exec('nohup php /www/wwwroot/app_service/baidu_censor.php 文章 ID> / dev / null 2>&1&');
参考文章

