
文章采集调用
如何在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-21 09:51
最近在开发uedsc新主题的时侯,需要普通用户能上传自己的作品到网站,大家都晓得,wordpress的会员是分了角色的,只有作者级别的用户能够够上传附件,那么怎么在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能。
wordpress早已想到了我们会用这样的一个功能,所以他自己集成了一些函数,帮助我们去完成这样的疗效。
这四个函数,大家应当一看能够明白,不明白的可以去官网函数库找找,主要是引入一些上传窗口的js脚本和css样式
新建一个文本框和按键,用于触发上传图片动作和反弹
样式你们可以自行定义,这里只是演示一下这个功能。
最后编撰js代码
jQuery(document).ready(function() {
jQuery('#upload_image_button').click(function() {
formfield = jQuery('#upload_image').attr('name');
// show WordPress' uploader modal box
tb_show('', 'media-upload.php?type=image&TB_iframe=true');
return false;
});
window.send_to_editor = function(html) {
// this will execute automatically when a image uploaded and then clicked to 'insert to post' button
imgurl = jQuery('img',html).attr('src');
// put uploaded image's url to #upload_image
jQuery('#upload_image').val(imgurl);
tb_remove();
}
});
如果您的主题没有引入jquery库,可能会报错:jquery不是一个对象,那么引入jquery库即可解决。
好了代码编撰完毕。不过这个方式还是慎用,毕竟要容许上传都会有一定的风险,各位鼓捣鼓捣吧! 查看全部
如何在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能
最近在开发uedsc新主题的时侯,需要普通用户能上传自己的作品到网站,大家都晓得,wordpress的会员是分了角色的,只有作者级别的用户能够够上传附件,那么怎么在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能。
wordpress早已想到了我们会用这样的一个功能,所以他自己集成了一些函数,帮助我们去完成这样的疗效。
这四个函数,大家应当一看能够明白,不明白的可以去官网函数库找找,主要是引入一些上传窗口的js脚本和css样式
新建一个文本框和按键,用于触发上传图片动作和反弹
样式你们可以自行定义,这里只是演示一下这个功能。
最后编撰js代码
jQuery(document).ready(function() {
jQuery('#upload_image_button').click(function() {
formfield = jQuery('#upload_image').attr('name');
// show WordPress' uploader modal box
tb_show('', 'media-upload.php?type=image&TB_iframe=true');
return false;
});
window.send_to_editor = function(html) {
// this will execute automatically when a image uploaded and then clicked to 'insert to post' button
imgurl = jQuery('img',html).attr('src');
// put uploaded image's url to #upload_image
jQuery('#upload_image').val(imgurl);
tb_remove();
}
});
如果您的主题没有引入jquery库,可能会报错:jquery不是一个对象,那么引入jquery库即可解决。
好了代码编撰完毕。不过这个方式还是慎用,毕竟要容许上传都会有一定的风险,各位鼓捣鼓捣吧!
服务调用链的主要诱因和简略对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-18 15:20
调用链主要诱因数据搜集部份
主要用于多元化的数据搜集,为数据剖析做打算。要求易用好用侵入尽量小(开发工作量),并且在极端情况下(如搜集组件不可用)不能对业务有任何影响。可以见到此部份的开发量是巨大的,尤其是须要集成Nginx上下游、基础组件多样、技术栈多样的情况下。
数据剖析部份
主要有实时剖析与线下剖析。一般,实时剖析的价值更大一些,主要产出如秒级别的调用量、平均响应时间、TP值等。另外,调用链(Trace)需要储存全量数据,一些高并发大埋点的恳求,会有性能问题。
监控报案
此部份借助数据剖析的产出,通过邮件短信等方式,通知订阅人关注。监控报案平台应尽量向devops平台靠拢,包括自主化服务平台。
实现方法剖析
根据搜集方法可分为日志搜集方法和程序实现方法
日志搜集方法
日志搜集方法与传统的ELK链路差不多。主要通过日志组件,打印出符合规范的日志格式。Flume守护进程会读取、过滤这种日志,将数据Sink到kafka集群中。会接收一份全量数据(调用链须要)到ES中供查询剖析;同时接收一份日志使用Spark或Strom形式剖析出须要的数据,存结果。
主要开发量集中在日志组件和各个模块的组合调试中。另外,由于须要在每台宿主机上安装配置flume-agent,此模式依赖建立的运维体系,可使用jenkens或则ansible集成支持。
手动埋点方法
这种方法采用业务端直推的方式,将数据直接汇集到kafka中。客户端通常会开一个堆上的缓冲区,将有单独的线程定时上报缓冲区数据。数据落地到kafka后,后续的处理类似。
为了支持易用性,需要较多的开发工作和可用性设计不会由于Trace组件或则Kafka的不可用导致服务的不可用。
此种方法的主要益处是,功能是以jar包形式提供的,如有重大bug或则改动,所有服务都必须重新发布。
监控报案对比
我们大体对比了不同封装层次的三个代表,以便对调用链产品有个大体理解
总结cat
优点:功能强悍,监控全面,而且数据展示全面,更易于之后问题剖析。
缺点:需要在代码中埋点,对代码侵入性很大。对于美团内部框架依赖严重。
sleuth + zipkin
优点:是spring cloud的组件,基于spring boot框架,接入简单,不需要埋点,分析的方法是通过日志剖析,而且可以对接多种第三方储存进行储存和剖析。
缺点:功能单一,只通过进行http调用的跟踪。页面数据展示比较简单,只有调用链路的相关信息, 没有整体数据的对比。sleuth只对restTemplate,zuul转发,spring cloud stream的消息中间件这三种调用方法进行添加监控信息,其他方法不支持,所以更适用于spring cloud环境。
pinpoint
优点:采用javaagent字节码提高技术,对业务代码入侵很少,业务只须要在启动时降低javaagent参数即可
缺点:
1.功能限于链路跟踪,对于其他业务监控指标支持不足
2.维护技术难度较高,内部是字节码提高技术,问题排查须要较高的技术水平
3.同第二点,自定义扩充开发难度也较高。 查看全部
服务调用链的主要诱因和简略对比
调用链主要诱因数据搜集部份
主要用于多元化的数据搜集,为数据剖析做打算。要求易用好用侵入尽量小(开发工作量),并且在极端情况下(如搜集组件不可用)不能对业务有任何影响。可以见到此部份的开发量是巨大的,尤其是须要集成Nginx上下游、基础组件多样、技术栈多样的情况下。
数据剖析部份
主要有实时剖析与线下剖析。一般,实时剖析的价值更大一些,主要产出如秒级别的调用量、平均响应时间、TP值等。另外,调用链(Trace)需要储存全量数据,一些高并发大埋点的恳求,会有性能问题。
监控报案
此部份借助数据剖析的产出,通过邮件短信等方式,通知订阅人关注。监控报案平台应尽量向devops平台靠拢,包括自主化服务平台。

实现方法剖析
根据搜集方法可分为日志搜集方法和程序实现方法
日志搜集方法

日志搜集方法与传统的ELK链路差不多。主要通过日志组件,打印出符合规范的日志格式。Flume守护进程会读取、过滤这种日志,将数据Sink到kafka集群中。会接收一份全量数据(调用链须要)到ES中供查询剖析;同时接收一份日志使用Spark或Strom形式剖析出须要的数据,存结果。
主要开发量集中在日志组件和各个模块的组合调试中。另外,由于须要在每台宿主机上安装配置flume-agent,此模式依赖建立的运维体系,可使用jenkens或则ansible集成支持。
手动埋点方法

这种方法采用业务端直推的方式,将数据直接汇集到kafka中。客户端通常会开一个堆上的缓冲区,将有单独的线程定时上报缓冲区数据。数据落地到kafka后,后续的处理类似。
为了支持易用性,需要较多的开发工作和可用性设计不会由于Trace组件或则Kafka的不可用导致服务的不可用。
此种方法的主要益处是,功能是以jar包形式提供的,如有重大bug或则改动,所有服务都必须重新发布。
监控报案对比
我们大体对比了不同封装层次的三个代表,以便对调用链产品有个大体理解

总结cat
优点:功能强悍,监控全面,而且数据展示全面,更易于之后问题剖析。
缺点:需要在代码中埋点,对代码侵入性很大。对于美团内部框架依赖严重。
sleuth + zipkin
优点:是spring cloud的组件,基于spring boot框架,接入简单,不需要埋点,分析的方法是通过日志剖析,而且可以对接多种第三方储存进行储存和剖析。
缺点:功能单一,只通过进行http调用的跟踪。页面数据展示比较简单,只有调用链路的相关信息, 没有整体数据的对比。sleuth只对restTemplate,zuul转发,spring cloud stream的消息中间件这三种调用方法进行添加监控信息,其他方法不支持,所以更适用于spring cloud环境。
pinpoint
优点:采用javaagent字节码提高技术,对业务代码入侵很少,业务只须要在启动时降低javaagent参数即可
缺点:
1.功能限于链路跟踪,对于其他业务监控指标支持不足
2.维护技术难度较高,内部是字节码提高技术,问题排查须要较高的技术水平
3.同第二点,自定义扩充开发难度也较高。
织梦做wordpress博客那样调用tag标签对应文章数量的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-17 10:50
有些时侯我们想实现类似于wordpress博客那样的tag标签,就是在显示tag的链接和tag名的同时,还能显示每位tag关联的文章的数目。
效果演示:
但是织梦默认没有这样的标签来调用,这就须要我们自己对系统文件进行更改来实现了,具体方式如下:
找到并打开/include/taglib/tag.lib.PHP这个文件,找到第87行左右的下边这句代码:
$row['link'] = $cfg_cmsurl."/tags.php?/".urlencode($row['keyword'])."/";
在这行代码的下边添加如下代码:
$count=$dsql->GetOne("Select count(tid) From `dede_taglist` where tag = '".
$row['tag']."'");$row['count'] =$count['count(tid)'];
添加好后在模板的tag循环标签上面就可以通过[field:count/]来获取当前tag标签关联的文章数量了,完整示例如下:
{dede:tagsort='hot'getall='2'}
[field:tag /]</a> {/dede:tag}
getall:获取类型。参数有:0和1,其中0为当前内容页或栏目页tag,1为获取全站tag
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)
如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程! 查看全部
织梦做wordpress博客那样调用tag标签对应文章数量的方式
有些时侯我们想实现类似于wordpress博客那样的tag标签,就是在显示tag的链接和tag名的同时,还能显示每位tag关联的文章的数目。
效果演示:
但是织梦默认没有这样的标签来调用,这就须要我们自己对系统文件进行更改来实现了,具体方式如下:
找到并打开/include/taglib/tag.lib.PHP这个文件,找到第87行左右的下边这句代码:
$row['link'] = $cfg_cmsurl."/tags.php?/".urlencode($row['keyword'])."/";
在这行代码的下边添加如下代码:
$count=$dsql->GetOne("Select count(tid) From `dede_taglist` where tag = '".
$row['tag']."'");$row['count'] =$count['count(tid)'];
添加好后在模板的tag循环标签上面就可以通过[field:count/]来获取当前tag标签关联的文章数量了,完整示例如下:
{dede:tagsort='hot'getall='2'}
[field:tag /]</a> {/dede:tag}
getall:获取类型。参数有:0和1,其中0为当前内容页或栏目页tag,1为获取全站tag
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)

如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程!
Selenium不打开浏览器采爬取数据 Java
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-14 07:41
Selenium工具,是数据采集利器,尤其是对js的操作。相对于jsoup、httpclient工具,其最大的不同就是通过操作浏览器的方法获取数据,类似于用户点击,移动滑鼠等。比如,说近来想开发采集Quora()的小软件,发现这个网页都是js操作,数据查看,使用的键盘滚动的方法,类似的网站还有国外的网易新闻等()。针对那些网站,其最好的方法是使用Selenium调用浏览器采集。
关于Selenium的安装,博主已在这篇博客中介绍了。
java使用Selenium
Selenium可以直接打开火狐浏览器、谷歌浏览器以及IE浏览器,进而获取页面的内容,同时也可以进行表单操作等,关于java使用Selenium调出浏览器的案例程序,读者可参考我之前的博客()。
这里主要介绍在不打开浏览器 GUI的情况在浏览器中执行我们的Selenium脚本。在这里,以傲游为案例,我的版本为56.0(64位)。以下为案例程序:
FirefoxBinary firefoxBinary = new FirefoxBinary();
firefoxBinary.addCommandLineOptions("--headless");
System.setProperty("webdriver.gecko.driver", "chrome\\geckodriver.exe");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
FirefoxDriver driver = new FirefoxDriver(firefoxOptions);
driver.get("http://www.baidu.com");
String title = driver.getTitle();
System.out.println(title);
driver.quit();
程序的运行结果如下: 查看全部
Selenium
Selenium工具,是数据采集利器,尤其是对js的操作。相对于jsoup、httpclient工具,其最大的不同就是通过操作浏览器的方法获取数据,类似于用户点击,移动滑鼠等。比如,说近来想开发采集Quora()的小软件,发现这个网页都是js操作,数据查看,使用的键盘滚动的方法,类似的网站还有国外的网易新闻等()。针对那些网站,其最好的方法是使用Selenium调用浏览器采集。
关于Selenium的安装,博主已在这篇博客中介绍了。
java使用Selenium
Selenium可以直接打开火狐浏览器、谷歌浏览器以及IE浏览器,进而获取页面的内容,同时也可以进行表单操作等,关于java使用Selenium调出浏览器的案例程序,读者可参考我之前的博客()。
这里主要介绍在不打开浏览器 GUI的情况在浏览器中执行我们的Selenium脚本。在这里,以傲游为案例,我的版本为56.0(64位)。以下为案例程序:
FirefoxBinary firefoxBinary = new FirefoxBinary();
firefoxBinary.addCommandLineOptions("--headless");
System.setProperty("webdriver.gecko.driver", "chrome\\geckodriver.exe");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
FirefoxDriver driver = new FirefoxDriver(firefoxOptions);
driver.get("http://www.baidu.com";);
String title = driver.getTitle();
System.out.println(title);
driver.quit();
程序的运行结果如下:
深入理解Python爬虫代理池服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-13 21:20
更新时间:2018年02月28日 14:24:40 转载投稿:mrr
这篇文章主要介绍了Python爬虫代理池服务的相关知识,非常不错,具有参考借鉴价值,需要的同学可以参考下
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
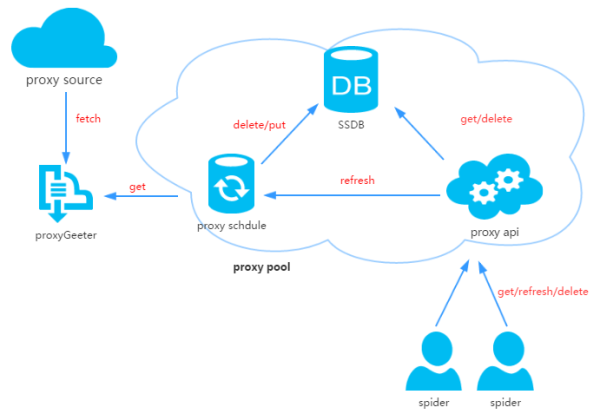
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数,收录GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:
Python
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
安装依赖:
Python
pip install -r requirements.txt
pip install -r requirements.txt
启动:
Python
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
useful_proxy
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:
爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
Python
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6、最后
时间匆忙,功能和代码都比较狭小,以后有时间再改进。喜欢的在github上给个star。感谢!
github项目地址:
总结
以上所述是小编给你们介绍的Python爬虫代理池服务,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也十分谢谢你们对脚本之家网站的支持! 查看全部
深入理解Python爬虫代理池服务
更新时间:2018年02月28日 14:24:40 转载投稿:mrr
这篇文章主要介绍了Python爬虫代理池服务的相关知识,非常不错,具有参考借鉴价值,需要的同学可以参考下
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数,收录GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:
Python
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
安装依赖:
Python
pip install -r requirements.txt
pip install -r requirements.txt
启动:
Python
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
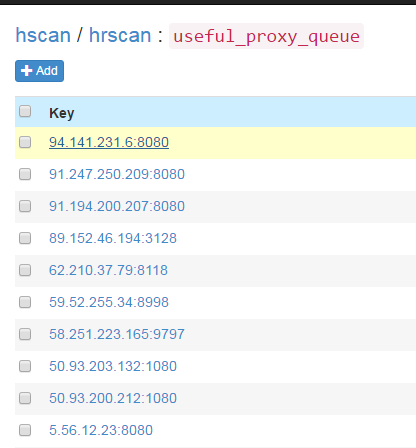
useful_proxy
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
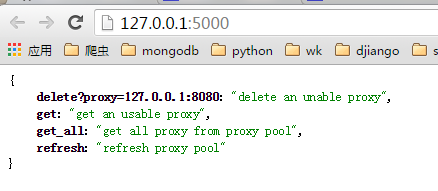
get页面:
get_all页面:

爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
Python
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/";).content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/";).content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6、最后
时间匆忙,功能和代码都比较狭小,以后有时间再改进。喜欢的在github上给个star。感谢!
github项目地址:
总结
以上所述是小编给你们介绍的Python爬虫代理池服务,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也十分谢谢你们对脚本之家网站的支持!
信息采集及开源Boilerpipe简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-13 21:16
10-15
1万+
文本聚类算法简略
文本聚类算法剖析1.传统的文本聚类算法传统的文本降维算法分为以下几种1.1分割方式(partitioningmethods)1.1.1K-MEANS算法:工作原理:首先从n个数据对象任意选择k个对象作为初始降维中心;而对于所剩下其它对象
涅槃重生
11-05
1430
开源数据采集技术对比
数据是监控报案的基石,我们在实现海量数据剖析监控前,需要有一个顺手的工具来搜集那些数据开源日志搜集工具对比从上表中可以看出,Logstash 虽然功能比较强悍,但是占用系统的资源也比较多, 而Filebeat似乎不支持日志解析,但是占用资源最少。而且使用我们运维人员熟悉的go语言开发,做二次开发也更容易些。......
网页正文提取工具boilerpipe1.2bin包07-19
输入一个url或则string型的网页源码,通过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。网页正文提取工具,这是目前销量最高,提取一个网页正文信息只须要毫秒级的
GarfieldEr007的专栏
12-04
1926
Day 18: BoilerPipe —— Java开发者的文章提取工具
今天我决定学习怎么使用Java做网页链接的文本和图象提取。在大多数内容发觉网站上(如Prismatic)这是一个十分常见的需求,今天就是学习怎么使用一个名为boilerpipe的Java库来完成这个任务。准备基本的Java知识是必需的,安装最新的Java开发工具包(JDK ),可以是OpenJDK 7或Oracle JDK 7。注册一个OpenShift账户,它是完全免...
风云千樯、
05-10
599
pip或则python安装jpype总是报错----Boilerpipe使用
使用pip或则python setup install 安装jpype总是报错,几乎搜遍全网,使用了各类解决方案,均无效,遂舍弃,换思路使用Anaconda进行安装首先安装Anaconda,Anaconda官网的介绍为:设想一个数据科学家可以定期将人工智能和机器学习项目大规模布署到生产中的世界,快速向决策者提供看法。这对您的业务有何影响?Anaconda Enterprise支持您......
chaishen10000的专栏
09-28
1228
关于BoilerpipeExtractor解析html乱码问题
网上给出的方案基于jsoup来获取body的byte流,但是写出的东西压根没有用到jsoup,getEmptyConnection(url)?private String extractContent(String url) throws Exception {InputStream inputStream = new ByteArrayInputStream(getEmptyConne...
正文提取工具boilerpipe
11-08
过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。
smallnetvisitor的博客
10-11
353
新闻正文提取之boilerpipe
概述:Boilerpipe即我们须要的正文提取工具,其算法的基本思想是通过训练获得一个分类器来提取出我们须要的信息,包括多种提取方法具体的参见:CommonExtractors环境:jdk1.6boilerpipe-1.2.0提取新闻正文demo代码如下:public static void main(String[] args) throws Excepti...... 查看全部
科大树蛙文本挖掘小组
10-15

1万+
文本聚类算法简略
文本聚类算法剖析1.传统的文本聚类算法传统的文本降维算法分为以下几种1.1分割方式(partitioningmethods)1.1.1K-MEANS算法:工作原理:首先从n个数据对象任意选择k个对象作为初始降维中心;而对于所剩下其它对象
涅槃重生
11-05
1430
开源数据采集技术对比
数据是监控报案的基石,我们在实现海量数据剖析监控前,需要有一个顺手的工具来搜集那些数据开源日志搜集工具对比从上表中可以看出,Logstash 虽然功能比较强悍,但是占用系统的资源也比较多, 而Filebeat似乎不支持日志解析,但是占用资源最少。而且使用我们运维人员熟悉的go语言开发,做二次开发也更容易些。......
网页正文提取工具boilerpipe1.2bin包07-19
输入一个url或则string型的网页源码,通过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。网页正文提取工具,这是目前销量最高,提取一个网页正文信息只须要毫秒级的
GarfieldEr007的专栏
12-04
1926
Day 18: BoilerPipe —— Java开发者的文章提取工具
今天我决定学习怎么使用Java做网页链接的文本和图象提取。在大多数内容发觉网站上(如Prismatic)这是一个十分常见的需求,今天就是学习怎么使用一个名为boilerpipe的Java库来完成这个任务。准备基本的Java知识是必需的,安装最新的Java开发工具包(JDK ),可以是OpenJDK 7或Oracle JDK 7。注册一个OpenShift账户,它是完全免...
风云千樯、
05-10
599
pip或则python安装jpype总是报错----Boilerpipe使用
使用pip或则python setup install 安装jpype总是报错,几乎搜遍全网,使用了各类解决方案,均无效,遂舍弃,换思路使用Anaconda进行安装首先安装Anaconda,Anaconda官网的介绍为:设想一个数据科学家可以定期将人工智能和机器学习项目大规模布署到生产中的世界,快速向决策者提供看法。这对您的业务有何影响?Anaconda Enterprise支持您......
chaishen10000的专栏
09-28
1228
关于BoilerpipeExtractor解析html乱码问题
网上给出的方案基于jsoup来获取body的byte流,但是写出的东西压根没有用到jsoup,getEmptyConnection(url)?private String extractContent(String url) throws Exception {InputStream inputStream = new ByteArrayInputStream(getEmptyConne...
正文提取工具boilerpipe
11-08
过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。
smallnetvisitor的博客
10-11
353
新闻正文提取之boilerpipe
概述:Boilerpipe即我们须要的正文提取工具,其算法的基本思想是通过训练获得一个分类器来提取出我们须要的信息,包括多种提取方法具体的参见:CommonExtractors环境:jdk1.6boilerpipe-1.2.0提取新闻正文demo代码如下:public static void main(String[] args) throws Excepti......
基于SpringBoot的日志集中搜集、微服务使用及切面的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-13 12:01
一篇文章全面了解SpringBoot
,通过SpringBoot我们可以很方便的开发后台Restful插口,前端代码可通过调用那些插口调阅动态数据,本文主要介绍基于SpringBoot常常面临到的一些其他常见问题做个整理;
在一篇文章全面了解SpringBoot这篇文章中我们解决了:
配置文件如何管理,不同的环境配置文件如何分辨(如QA,生产和开发环境);
项目怎样做集成测试和单元测试:不光单元测试,还包括模拟用户的真实操作;
修改Java代码的时侯帮我手动重启服务器,以便能实时反映更改情况;
修改静态页面代码,网页无需自动刷新,帮我手动LiveReload;
部署打包如何实现一键布署?
项目怎样做到纵向扩充,即如何保持各个Web项目sessionid同步?
发布的项目怎么做监控,怎么无缝扩充监控指标?
项目中怎样剥离“脚本类”代码,比如公式定义等?
Web安全是否每次须要我自己实现,比如处理登入,登出,URI保护等?
繁杂的数据库操作我是否一定要写一大堆BO,VO,Service,DAO?
JavaBean中一定要写这么多Getter和Setter么?
maven中的依赖引入与排除,版本冲突是否非得我自己整理和排查?
项目进行中的数据库脚本管理如何管理?防止变更错误,跨数据库的脚本管理呢?
这篇文章我们进一步解决:
SpringBoot启用log4j记录日志,并发日志发往log4j日志中心(集中化日志管理与监控);
SpringBoot调用微服务Dubbo;
SpringBoot中使用切面:接口调用统计,API权限分级等;
日志集中式管理与监控
首先我们须要做一个Socket的服务端,基于Netty自定义榆林包体的TCP程序设计我们会在下一篇介绍并给出源码,这里记为logger-server程序,项目中,只须要引入client的maven jar即可,自定义的Log4j的Appender的实现较为简单,本文不做介绍,这一切都就绪后,在项目只须要引入maven和配置即可实现将log发往日志中心:
添加maven依赖
在资源目录下新建:
在代码任意处借助log4j写入日志,如:
至此,通过nettyIOAppender ref的Logger就会将日志发往日志中心,在那里你可以得到那个类,哪个方式,来自那个用户做了哪些处理,可以搜集到用户使用的浏览器信息,来源IP,访问来源等有效信息,可用于插口统计,用户行为搜集,排错跟踪等,下图是Netty服务端收到的消息:
Dubbo微服务的使用
在我们设计和实现后台构架时,我们会把公共的服务弄成微服务便于所有系统可以共享,比如在一个电商系统中,我们会把商品分类,商品详情信息,用户等信息封装成微服务,这样网站,客服系统,统计统计,CRM系统等会可以调用那些微服务,减少重复开发,而且微服务框架通常还提供负载均衡,版本控制,限流等众多功能;
Alibaba的团队针对Dubbo的使用专门提供了SpringBoot的maven依赖工程:
在我们编撰后台服务时,如需调用微服务(消费方),我们只须要在Controller里将微服务的Service依赖注入进来即可:
并在中加入配置:
Aspect切面的使用
在我们项目开发中,我们常常会遇到统计插口调用次数以及API分级调用(有些插口须要特定API级别能够调用)的功能,这时我们就可以使用到切面,使用步骤如下: 查看全部
在先前文章中,我们介绍了SpringBoot的使用,详见:
一篇文章全面了解SpringBoot
,通过SpringBoot我们可以很方便的开发后台Restful插口,前端代码可通过调用那些插口调阅动态数据,本文主要介绍基于SpringBoot常常面临到的一些其他常见问题做个整理;
在一篇文章全面了解SpringBoot这篇文章中我们解决了:
配置文件如何管理,不同的环境配置文件如何分辨(如QA,生产和开发环境);
项目怎样做集成测试和单元测试:不光单元测试,还包括模拟用户的真实操作;
修改Java代码的时侯帮我手动重启服务器,以便能实时反映更改情况;
修改静态页面代码,网页无需自动刷新,帮我手动LiveReload;
部署打包如何实现一键布署?
项目怎样做到纵向扩充,即如何保持各个Web项目sessionid同步?
发布的项目怎么做监控,怎么无缝扩充监控指标?
项目中怎样剥离“脚本类”代码,比如公式定义等?
Web安全是否每次须要我自己实现,比如处理登入,登出,URI保护等?
繁杂的数据库操作我是否一定要写一大堆BO,VO,Service,DAO?
JavaBean中一定要写这么多Getter和Setter么?
maven中的依赖引入与排除,版本冲突是否非得我自己整理和排查?
项目进行中的数据库脚本管理如何管理?防止变更错误,跨数据库的脚本管理呢?
这篇文章我们进一步解决:
SpringBoot启用log4j记录日志,并发日志发往log4j日志中心(集中化日志管理与监控);
SpringBoot调用微服务Dubbo;
SpringBoot中使用切面:接口调用统计,API权限分级等;
日志集中式管理与监控
首先我们须要做一个Socket的服务端,基于Netty自定义榆林包体的TCP程序设计我们会在下一篇介绍并给出源码,这里记为logger-server程序,项目中,只须要引入client的maven jar即可,自定义的Log4j的Appender的实现较为简单,本文不做介绍,这一切都就绪后,在项目只须要引入maven和配置即可实现将log发往日志中心:
添加maven依赖
在资源目录下新建:
在代码任意处借助log4j写入日志,如:
至此,通过nettyIOAppender ref的Logger就会将日志发往日志中心,在那里你可以得到那个类,哪个方式,来自那个用户做了哪些处理,可以搜集到用户使用的浏览器信息,来源IP,访问来源等有效信息,可用于插口统计,用户行为搜集,排错跟踪等,下图是Netty服务端收到的消息:
Dubbo微服务的使用
在我们设计和实现后台构架时,我们会把公共的服务弄成微服务便于所有系统可以共享,比如在一个电商系统中,我们会把商品分类,商品详情信息,用户等信息封装成微服务,这样网站,客服系统,统计统计,CRM系统等会可以调用那些微服务,减少重复开发,而且微服务框架通常还提供负载均衡,版本控制,限流等众多功能;
Alibaba的团队针对Dubbo的使用专门提供了SpringBoot的maven依赖工程:
在我们编撰后台服务时,如需调用微服务(消费方),我们只须要在Controller里将微服务的Service依赖注入进来即可:
并在中加入配置:
Aspect切面的使用
在我们项目开发中,我们常常会遇到统计插口调用次数以及API分级调用(有些插口须要特定API级别能够调用)的功能,这时我们就可以使用到切面,使用步骤如下:
Log日志规范
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-13 01:27
l 问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在安装配置时,通过日志可以发觉问题。
l 状态监控:通过实时剖析日志,可以监控系统的运行状态,做到早发现问题、早处理问题。
l 安全审计:审计主要彰显在安全上,通过对日志进行剖析,可以发觉是否存在非授权的操作。
2 记录Log的基本原则2.1 日志的级别界定
Java日志一般可以分为:error、warn、info、debug、trace五个级别。在J2SE中预定义的级别更多,分别为:SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。两者的对应大致如下:
|
Log4j、slf4j
|
J2se
|
使用场景
|
|
error
|
SEVERE
|
问题早已影响到软件的正常运行,并且软件不能自行恢复到正常的运行状态,此时须要输出该级别的错误日志。
|
|
warn
|
WARNING
|
与业务处理相关的失败,此次失败不影响上次业务的执行,通常的结果为外部的输入不能获得期望的结果。
|
|
info
|
INFO
|
系统运行期间的系统运行状态变化,或关键业务处理记录等用户或管理员在系统运行期间关注的一些信息。
|
|
CONFIG
|
系统配置、系统运行环境信息,有助于安装施行人员检测配置是否正确。
|
|
debug
|
FINE
|
软件调试信息,开发人员使用该级别的日志发觉程序运行中的一些问题,排除故障。
|
|
FINER
|
基本同上,但显示的信息更详尽。
|
|
trace
|
FINEST
|
基本同上,但显示的信息更详尽。
|
2.2 日志对性能影响
不管是多么优秀的日志工具,在日志输出时总会对性能形成或多或少的影响,为了将影响减少到最低,有以下几个准则须要遵循:
l 如何创建Logger实例:创建Logger实例有是否static的区别,在log4j的初期版本,一般要求使用static,而在高版本以及后来的slf4j中,该问题早已得到优化,获取(创建)logger实例的成本早已太低。所以我们要求:对于可以预见的多数情况下单例运行的class,可以不添加static前缀;对于可能是多例居多,尤其是须要频繁创建的class,我们要求要添加static前缀。
l 判断日志级别:
n对于可以预见的会频繁形成的日志输出,比如for、while循环,定期执行的job等,建议先使用if对日志级别进行判定后再输出。
n对于日志输出内容须要复杂的序列化,或输出的个别信息获取成本较高时,需要对日志级别进行判定。比如日志中须要输出用户名,而用户名须要在日志输出时从数据库获取,此时就须要先判定一下日志级别,看看是否有必要获取这种信息。
l 优先使用参数,减少字符串拼接:使用参数的方法输出日志信息,有助于在性能和代码简约之间取得平衡。当日志级别限制输出该日志时,参数内容将不会融合到最终输出中,减少了字符串的拼接,从而提高执行效率。
2.3 什么时候输出日志
日志并不是越多越详尽就越好。在剖析运行日志,查找问题时,我们常常遇见该出现的日志没有,无用的日志一大堆,或者有效的日志被大量无意义的日志信息吞没,查找上去十分困难。那么哪些时侯输出日志呢?以下述出了一些常见的须要输出日志的情况,而且日志的级别基本都是>=INFO,至于Debug级别日志的使用场景,本节没有专门列举,需要具体情况具体剖析,但也是要追求“恰如其分”,不是越多越好。
2.3.1 系统启动参数、环境变量
系统启动的参数、配置、环境变量、System.Properties等信息对于软件的正常运行至关重要,这些信息的输出有助于安装配置人员通过日志快速定位问题,所以程序有必要在启动过程中把使用到的关键参数、变量在日志中输出下来。在输出时须要注意,不是一股脑的全部输出,而是将软件运行涉及到的配置信息输出下来。比如,如果软件对jvm的内存参数比较敏感,对最低配置有要求,那么就须要在日志少将-Xms -Xmx -XX:PermSize这几个参数的值输出下来。
2.3.2 异常捕获处
在捕获异常处输出日志,大家在基本都能做到,唯一须要注意的是如何输出一个简单明了的日志信息。这在前面的问题问题中有进一步说明。
2.3.3 函数获得期望之外的结果时
一个函数,尤其是供外部系统或远程调用的函数,通常还会有一个期望的结果,但若果内部系统或输出参数发生错误时,函数将难以返回期望的正确结果,此时就须要记录日志,日志的基本一般是warn。需要非常说明的是,这里的期望之外的结果不是说没有返回就不需要记录日志了,也不是说返回false就须要记录日志。比如函数:isXXXXX(),无论返回true、false记录日志都不是必须的,但是假如系统内部难以判定应当返回true还是false时,就须要记录日志,并且日志的级别应当起码是warn。
2.3.4 关键操作
关键操作的日志通常是INFO级别,如果数目、频度很高,可以考虑使用DEBUG级别。以下是一些关键操作的举例,实际的关键操作肯定不止这么多。
n 删除:删除一个文件、删除一组重要数据库记录……
n 添加:和外系统交互时,收到了一个文件、收到了一个任务……
n 处理:开始、结束一条任务……
n ……
2.4 日志输出的内容
l ERROR:错误的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l WARN:告警的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l INFO:言简意赅地信息描述,如果有相关动态关键数据,要一并输出,比如相关ID、名称等。
l DEBUG:简单描述,相关数据,如果有异常,要有该异常的StackTrace。
在日志相关数据输出的时要非常注意对敏感信息的保护,比如更改密码时,不能将密码输出到日志中。
2.5 什么时候使用J2SE自带的日志
我们一般使用slf4j或log4j这两个工具记录日志,那么还须要使用J2SE的日志框架吗?当然须要,在我们编撰一些通用的工具类时,为了减轻对第三方的jar包的依赖,首先要考虑使用java.util.logging。
考虑到slf4j等日志框架提供了日志bridge工具,为java.util.logging提供了Handler,所以普通应用的开发过程中也可以考虑使用J2SE自有日志,这样不但可以降低项目的编译依赖,同时在应用施行时可以更灵活的选择日志的输出工具包。
3 典型问题剖析3.1 该用日志的地方不用
上图对异常的处理直接使用e.printStackTrace()显然是有问题的,正确的做法是:要么通过日志形式输出错误信息,要么直接抛出异常,要么创建新的自定义异常抛出。
另:对于静态工具类函数中的异常处理,最简单的方法就是不捕获、不记录日志,直接向下抛出,如果觉得异常类型太多,或者意义不明晰,可以抛出自定义异常类的实例。
3.2 啰嗦重复、没有重点
首先里面不应当有error级别的日志。
其次在日志中直接输出e.toString(),为定位问题提供的信息很少。
另外须要明晰一点:日志系统是一个多线程公用的系统,在两行日志输出之间有可能会被插入其他线程的日志记录,不会根据我们的意愿次序输出,后面有更典型的事例。
最后,上面的日志可以简化为:
logger.debug(“从properties中...{}...{}...”,name, value, e);
logger.warn(“从properties中获取{}发生错误:{}”,name, e.toString());
或者直接一句:
logger.warn(“从properties中...{}...{}...”,name, value, e);
或者更完美的:
if(logger.isDebugEnabled()){
logger.warn(“从properties中...{}...”, name, e);
}else{
logger.warn(“从properties中获取{}发生错误:{}”, name, e.toString());
}
3.3 日志和异常处理的关系
首先里面的日志信息不够充分,级别定义不够恰当。
另外,既然将异常捕获并记录的日志,就不应当重新将一个一模一样的异常再度抛出去了。如果将异常再度抛出,那在下层肯定还须要对该异常进行处理,并记录日志,这样就重复了。如果没有非常缘由,此处不应当捕获异常。
3.4 System.out形式的日志
上面的日志方式非常随便,只适宜临时的代码调试,不容许递交到即将的代码库中。
对于临时调试日志,建议在日志的输出信息中添加一些特殊的连续字符,也可以用自己的名称、代号,这样可以在调试完毕后,提交代码之前,方便地找到所有临时代码,一并删掉。
3.5 日志信息不明晰
上面的“添加任务出错。。。”既没有记录任务id,也没有任务名称,软件布署后发觉错误后,根据该日志记录不能确认哪一条任务错误,给进一步的剖析缘由带来困难。
另外第二个红圈中的问题有:要使用参数;一行日志就可以了。
还有一些其他共性的错误,就不多说了。
3.6 忘记日志输出是多线程公用的
如果有另外一个线程正在输出日志,上面的记录都会被打断,最终显示输出和想像的都会不一致。正确的做法应是将这种信息放在一行,如果须要换行可以考虑使用“\r”,如果内容较多,考虑降低if (logger.isDebugEnabled())进行判定。而第二个事例中的输出有System.out的习惯,相关内容应当一行完成。
3.7 多个参数的处理
对于多参的日志输出,可以考虑:
public void debug(String format, Object... arguments);
但是在使用多参时,会创建一个对象字段,也会有一定的消耗,为此,在对性能敏感的场景,可以降低对日志级别的判别。
在开发B/S系统时,对于LOG,需要关注:
日志信息的集中采集、存储、信息检索:在WEB集群节点越来越多的情况下,让开发及系统维护人员能很方便的查看日志信息日志信息的输出策略:日志信息输出全而不乱,便于跟踪和剖析问题关键业务的日志输出:基于测度数据采集、数据核查、系统安全等方面的考虑,关键业务系统对输出的日志信息有特殊的要求,需要做针对性的设计
本文主要从这3个方面进行说明,重点说明日志输出的使用
日志的采集和储存
对于目前储存日志,主要存在2种形式:
本地日志:直接储存在本地c盘上远程日志:发往日志平台,用作数据剖析和日志处理并彰显。如用户访问行为的记录,异常日志,性能统计日志等。
日志工具的选择
推荐使用SLF4J(Simple Logging Facade for Java)作为日志的api,SLF4J是一个用于日志系统的简单Facade,允许最终用户在布署其应用时使用其所希望的日志系统。与使用apache commons-logging和直接使用log4j相比,SLF4J提供了一个名为参数化日志的中级特点,可以明显提升在配置为关掉日志的情况下的日志句子性能
//slf4j
log.debug("Found {} records matching filter: '{}'", records, filter);
//log4j
log.debug("Found " + records + " records matching filter: '" + filter + "'");
可以看出SLF4J的形式一方面更详尽易读,另一方面少了字符串拼接的开支,并且在日志级别达不到时(这里反例即为设置级别为debug以上),不会调用对象的toString方式。
日志输出级别(由高到低)
推荐使用debug,info,warn,error级别即可,对于不同的级别可以设置不同的输出路径,如debug,info输出到一个文件,warn,error输出到一个带error后缀的文件
日志API规范
// (推荐)
private static final Logger logger = LoggerFactory.getLogger(Xxx.class);
private final Logger logger = LoggerFactory.getLogger(getClass());
private static final Logger logger = LoggerFactory.getLogger("loggerName");
private static Logger logger = LoggerFactory.getLogger(Xxx.class);
protected final Logger logger = LoggerFactory.getLogger(getClass());
private Logger logger = LoggerFactory.getLogger(getClass());
protected Logger logger = LoggerFactory.getLogger(getClass());
if (logger.isDebugEnabled()) {
logger.debug(test());
}
private String test(){
int i = 0;
while (i < 1000000) {
i++;
}
return "";
}
如果不加 isXxxEnabled() 判断,test()在info级别下也会执行。
log.error("IO exception", e);
throw new MyCustomException(e);
这种方式总是会复印两次相同的 stack trace信息,因为有些地方会捕捉MyCustomException异常,然后输出造成问题的日志信息。
但有时基于个别缘由我们真的想log异常信息怎样办?很过见多的log句子有一半以上都是错的,
如:
try {
Integer x = null;
++x;
} catch (Exception e) {
//A
log.error(e);
//B
log.error(e, e);
//C
log.error(""+ e);
//D
log.error(e.toString());
//E
log.error(e.getMessage());
//F
log.error(null, e);
//G
log.error("", e);
//H
log.error("{}", e);
//I
log.error("{}", e.getMessage());
//J
log.error("Error reading configuration file: " + e);
//K
log.error("Error reading configuration file: "+ e.getMessage());
//L
log.error("Error reading configuration file", e);
}
上面只有G、L是对的,L的处理方法更好一些
注意:捕获异常后不处理也不输出log是一种特别不负责任的行为,这会导致问题很难被定位,极大地提升debug成本!
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
//Lengthy printing operation
String id = "Id";
log.debug("Leaving printDocument(): {}", id);
return id;
}
因为对于非开发人员掌控的环境(无法做DEBUG),记录方式调用、入参、返回值的形式对于排查问题会有很大帮助。
log.debug("Processing request with id: {}", request.getId());
你能确保request对象不是NULL吗?如果request为null,就会抛出NullPointerException。
try {
log.trace("Id=" + request.getUser().getId() + " accesses" + manager.getPage().getUrl().toString())
} catch(NullPointerException e) {
}
log.debug("Message processed");
log.debug(message.getJMSMessageID());
log.debug("Message with id '{}' processed", message.getJMSMessageID());
if (message instanceof TextMessage)
//...
else {
log.warn("Unknown message type");
}
为什么不收录 message type, message id, etc,收录个message content很难吗?另一个anti-pattern是magic-log。
有些开发人员为了自己查找信息便捷,输出类似“&&&!#”的Log,而不是“Message with XYZ id received”。
最后,Log 不要涉及密码及个人信息(身份证、银行卡号etc)
配置规范
作者 @九都散人
2015 年 11月 22日
参考
作者:九都散人
链接:
來源:简书
简书著作权归作者所有,任何方式的转载都请联系作者获得授权并标明出处。
Overview
一个在生产环境里运行的程序假如没有日志是太使维护者提心吊胆的,有太多零乱又无意义的日志也是令人伤神。程序出现问题时侯,从日志里假如发觉不了问题可能的诱因是太令人失利的。本文想讨论的是怎样在Java程序里写好日志。
一般来说日志分为两种:业务日志和异常日志,使用日志我们希望能达到以下目标:
对程序运行情况的记录和监控;在必要时可详尽了解程序内部的运行状态;对系统性能的影响尽量小;Java日志框架
Java的日志框架太多了。。。
Log4j 或 Log4j 2 - Apache的开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套插口服务器、NT的事件记录器、UNIX Syslog守护进程等;用户也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,用户还能愈发细致地控制日志的生成过程。这些可以通过一个配置文件(XML或Properties文件)来灵活地进行配置,而不需要更改程序代码。Log4j 2则是前任的一个升级,参考了Logback的许多特点;Logback - Logback是由log4j创始人设计的又一个开源日记组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个改良版本。此外logback-classic完整实现SLF4J API让你可以很方便地更换成其它日记系统如log4j或JDK14 Logging;java.util.logging - JDK外置的日志插口和实现,功能比较简;Slf4j - SLF4J是为各类Logging API提供一个简单统一的插口),从而让用户才能在布署的时侯配置自己希望的Logging API实现;Apache Commons Logging - Apache Commons Logging (JCL)希望解决的问题和Slf4j类似。
选项太多了的后果就是选择困难症,我的想法是没有最好的,只有最合适的。在比较关注性能的地方,选择Logback或自己实现高性能Logging API可能更合适;在早已使用了Log4j的项目中,如果没有发觉问题,继续使用可能是更合适的方法;我通常会在项目里选择使用Slf4j, 如果不想有依赖则使用java.util.logging或框架容器早已提供的日志插口。
Java日志最佳实践定义日志变量
日志变量常常不变,最好定义成final static,变量名用小写。
日志分级
Java的日志框架通常会提供以下日志级别,缺省打开info级别,也就是debug,trace级别的日志在生产环境不会输出,在开发和测试环境可以通过不同的日志配置文件打开debug级别。
fatal - 严重的,造成服务中断的错误;error - 其他错误运行期错误;warn - 警告信息,如程序调用了一个正式作废的插口,接口的不当使用,运行状态不是期望的但仍可继续处理等;info - 有意义的风波信息,如程序启动,关闭风波,收到恳求风波等;debug - 调试信息,可记录详尽的业务处理到哪一步了,以及当前的变量状态;trace - 更详尽的跟踪信息;
在程序里要合理使用日志分级:
image
基本的Logger编码规范
1.在一个对象中一般只使用一个Logger对象,Logger应当是static final的,只有在少数须要在构造函数中传递logger的情况下才使用private final。
log
2.输出Exceptions的全部Throwable信息,因为logger.error(msg)和logger.error(msg,e.getMessage())这样的日志输出方式会遗失掉最重要的StackTrace信息。
log
3.不容许记录日志后又抛出异常,因为这样会多次记录日志,只容许记录一次日志。
log
4.不容许出现System print(包括System.out.println和System.error.println)语句。
log
5.不容许出现printStackTrace。
log
6.日志性能的考虑,如果代码为核心代码,执行频度十分高,则输出日志建议降低判定,尤其是低级别的输出。
debug日志太多后可能会影响性能,有一种改进方式是:
image
但更好的方式是Slf4j提供的:
image
一方面可以降低参数构造的开支,另一方面也不用多写两行代码。
7.有意义的日志
通常情况下在程序日志里记录一些比较有意义的状态数据:程序启动,退出的时间点;程序运行消耗时间;耗时程序的执行进度;重要变量的状态变化。
初次之外,在公共的日志里规避复印程序的调试或则提示信息。
FAQ:参考
1.7 Good Rules to Log Exceptions
2.5 common log mistakes
3.Java程序的日志
作者:Helen_Cat
链接: 查看全部
不管是使用何种编程语言,日志输出几乎无处不再。总结上去,日志大致有以下几种用途:
l 问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在安装配置时,通过日志可以发觉问题。
l 状态监控:通过实时剖析日志,可以监控系统的运行状态,做到早发现问题、早处理问题。
l 安全审计:审计主要彰显在安全上,通过对日志进行剖析,可以发觉是否存在非授权的操作。
2 记录Log的基本原则2.1 日志的级别界定
Java日志一般可以分为:error、warn、info、debug、trace五个级别。在J2SE中预定义的级别更多,分别为:SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。两者的对应大致如下:
|
Log4j、slf4j
|
J2se
|
使用场景
|
|
error
|
SEVERE
|
问题早已影响到软件的正常运行,并且软件不能自行恢复到正常的运行状态,此时须要输出该级别的错误日志。
|
|
warn
|
WARNING
|
与业务处理相关的失败,此次失败不影响上次业务的执行,通常的结果为外部的输入不能获得期望的结果。
|
|
info
|
INFO
|
系统运行期间的系统运行状态变化,或关键业务处理记录等用户或管理员在系统运行期间关注的一些信息。
|
|
CONFIG
|
系统配置、系统运行环境信息,有助于安装施行人员检测配置是否正确。
|
|
debug
|
FINE
|
软件调试信息,开发人员使用该级别的日志发觉程序运行中的一些问题,排除故障。
|
|
FINER
|
基本同上,但显示的信息更详尽。
|
|
trace
|
FINEST
|
基本同上,但显示的信息更详尽。
|
2.2 日志对性能影响
不管是多么优秀的日志工具,在日志输出时总会对性能形成或多或少的影响,为了将影响减少到最低,有以下几个准则须要遵循:
l 如何创建Logger实例:创建Logger实例有是否static的区别,在log4j的初期版本,一般要求使用static,而在高版本以及后来的slf4j中,该问题早已得到优化,获取(创建)logger实例的成本早已太低。所以我们要求:对于可以预见的多数情况下单例运行的class,可以不添加static前缀;对于可能是多例居多,尤其是须要频繁创建的class,我们要求要添加static前缀。
l 判断日志级别:
n对于可以预见的会频繁形成的日志输出,比如for、while循环,定期执行的job等,建议先使用if对日志级别进行判定后再输出。
n对于日志输出内容须要复杂的序列化,或输出的个别信息获取成本较高时,需要对日志级别进行判定。比如日志中须要输出用户名,而用户名须要在日志输出时从数据库获取,此时就须要先判定一下日志级别,看看是否有必要获取这种信息。
l 优先使用参数,减少字符串拼接:使用参数的方法输出日志信息,有助于在性能和代码简约之间取得平衡。当日志级别限制输出该日志时,参数内容将不会融合到最终输出中,减少了字符串的拼接,从而提高执行效率。
2.3 什么时候输出日志
日志并不是越多越详尽就越好。在剖析运行日志,查找问题时,我们常常遇见该出现的日志没有,无用的日志一大堆,或者有效的日志被大量无意义的日志信息吞没,查找上去十分困难。那么哪些时侯输出日志呢?以下述出了一些常见的须要输出日志的情况,而且日志的级别基本都是>=INFO,至于Debug级别日志的使用场景,本节没有专门列举,需要具体情况具体剖析,但也是要追求“恰如其分”,不是越多越好。
2.3.1 系统启动参数、环境变量
系统启动的参数、配置、环境变量、System.Properties等信息对于软件的正常运行至关重要,这些信息的输出有助于安装配置人员通过日志快速定位问题,所以程序有必要在启动过程中把使用到的关键参数、变量在日志中输出下来。在输出时须要注意,不是一股脑的全部输出,而是将软件运行涉及到的配置信息输出下来。比如,如果软件对jvm的内存参数比较敏感,对最低配置有要求,那么就须要在日志少将-Xms -Xmx -XX:PermSize这几个参数的值输出下来。
2.3.2 异常捕获处
在捕获异常处输出日志,大家在基本都能做到,唯一须要注意的是如何输出一个简单明了的日志信息。这在前面的问题问题中有进一步说明。
2.3.3 函数获得期望之外的结果时
一个函数,尤其是供外部系统或远程调用的函数,通常还会有一个期望的结果,但若果内部系统或输出参数发生错误时,函数将难以返回期望的正确结果,此时就须要记录日志,日志的基本一般是warn。需要非常说明的是,这里的期望之外的结果不是说没有返回就不需要记录日志了,也不是说返回false就须要记录日志。比如函数:isXXXXX(),无论返回true、false记录日志都不是必须的,但是假如系统内部难以判定应当返回true还是false时,就须要记录日志,并且日志的级别应当起码是warn。
2.3.4 关键操作
关键操作的日志通常是INFO级别,如果数目、频度很高,可以考虑使用DEBUG级别。以下是一些关键操作的举例,实际的关键操作肯定不止这么多。
n 删除:删除一个文件、删除一组重要数据库记录……
n 添加:和外系统交互时,收到了一个文件、收到了一个任务……
n 处理:开始、结束一条任务……
n ……
2.4 日志输出的内容
l ERROR:错误的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l WARN:告警的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l INFO:言简意赅地信息描述,如果有相关动态关键数据,要一并输出,比如相关ID、名称等。
l DEBUG:简单描述,相关数据,如果有异常,要有该异常的StackTrace。
在日志相关数据输出的时要非常注意对敏感信息的保护,比如更改密码时,不能将密码输出到日志中。
2.5 什么时候使用J2SE自带的日志
我们一般使用slf4j或log4j这两个工具记录日志,那么还须要使用J2SE的日志框架吗?当然须要,在我们编撰一些通用的工具类时,为了减轻对第三方的jar包的依赖,首先要考虑使用java.util.logging。
考虑到slf4j等日志框架提供了日志bridge工具,为java.util.logging提供了Handler,所以普通应用的开发过程中也可以考虑使用J2SE自有日志,这样不但可以降低项目的编译依赖,同时在应用施行时可以更灵活的选择日志的输出工具包。
3 典型问题剖析3.1 该用日志的地方不用
上图对异常的处理直接使用e.printStackTrace()显然是有问题的,正确的做法是:要么通过日志形式输出错误信息,要么直接抛出异常,要么创建新的自定义异常抛出。
另:对于静态工具类函数中的异常处理,最简单的方法就是不捕获、不记录日志,直接向下抛出,如果觉得异常类型太多,或者意义不明晰,可以抛出自定义异常类的实例。
3.2 啰嗦重复、没有重点
首先里面不应当有error级别的日志。
其次在日志中直接输出e.toString(),为定位问题提供的信息很少。
另外须要明晰一点:日志系统是一个多线程公用的系统,在两行日志输出之间有可能会被插入其他线程的日志记录,不会根据我们的意愿次序输出,后面有更典型的事例。
最后,上面的日志可以简化为:
logger.debug(“从properties中...{}...{}...”,name, value, e);
logger.warn(“从properties中获取{}发生错误:{}”,name, e.toString());
或者直接一句:
logger.warn(“从properties中...{}...{}...”,name, value, e);
或者更完美的:
if(logger.isDebugEnabled()){
logger.warn(“从properties中...{}...”, name, e);
}else{
logger.warn(“从properties中获取{}发生错误:{}”, name, e.toString());
}
3.3 日志和异常处理的关系
首先里面的日志信息不够充分,级别定义不够恰当。
另外,既然将异常捕获并记录的日志,就不应当重新将一个一模一样的异常再度抛出去了。如果将异常再度抛出,那在下层肯定还须要对该异常进行处理,并记录日志,这样就重复了。如果没有非常缘由,此处不应当捕获异常。
3.4 System.out形式的日志
上面的日志方式非常随便,只适宜临时的代码调试,不容许递交到即将的代码库中。
对于临时调试日志,建议在日志的输出信息中添加一些特殊的连续字符,也可以用自己的名称、代号,这样可以在调试完毕后,提交代码之前,方便地找到所有临时代码,一并删掉。
3.5 日志信息不明晰
上面的“添加任务出错。。。”既没有记录任务id,也没有任务名称,软件布署后发觉错误后,根据该日志记录不能确认哪一条任务错误,给进一步的剖析缘由带来困难。
另外第二个红圈中的问题有:要使用参数;一行日志就可以了。
还有一些其他共性的错误,就不多说了。
3.6 忘记日志输出是多线程公用的
如果有另外一个线程正在输出日志,上面的记录都会被打断,最终显示输出和想像的都会不一致。正确的做法应是将这种信息放在一行,如果须要换行可以考虑使用“\r”,如果内容较多,考虑降低if (logger.isDebugEnabled())进行判定。而第二个事例中的输出有System.out的习惯,相关内容应当一行完成。
3.7 多个参数的处理
对于多参的日志输出,可以考虑:
public void debug(String format, Object... arguments);
但是在使用多参时,会创建一个对象字段,也会有一定的消耗,为此,在对性能敏感的场景,可以降低对日志级别的判别。
在开发B/S系统时,对于LOG,需要关注:
日志信息的集中采集、存储、信息检索:在WEB集群节点越来越多的情况下,让开发及系统维护人员能很方便的查看日志信息日志信息的输出策略:日志信息输出全而不乱,便于跟踪和剖析问题关键业务的日志输出:基于测度数据采集、数据核查、系统安全等方面的考虑,关键业务系统对输出的日志信息有特殊的要求,需要做针对性的设计
本文主要从这3个方面进行说明,重点说明日志输出的使用
日志的采集和储存
对于目前储存日志,主要存在2种形式:
本地日志:直接储存在本地c盘上远程日志:发往日志平台,用作数据剖析和日志处理并彰显。如用户访问行为的记录,异常日志,性能统计日志等。
日志工具的选择
推荐使用SLF4J(Simple Logging Facade for Java)作为日志的api,SLF4J是一个用于日志系统的简单Facade,允许最终用户在布署其应用时使用其所希望的日志系统。与使用apache commons-logging和直接使用log4j相比,SLF4J提供了一个名为参数化日志的中级特点,可以明显提升在配置为关掉日志的情况下的日志句子性能
//slf4j
log.debug("Found {} records matching filter: '{}'", records, filter);
//log4j
log.debug("Found " + records + " records matching filter: '" + filter + "'");
可以看出SLF4J的形式一方面更详尽易读,另一方面少了字符串拼接的开支,并且在日志级别达不到时(这里反例即为设置级别为debug以上),不会调用对象的toString方式。
日志输出级别(由高到低)
推荐使用debug,info,warn,error级别即可,对于不同的级别可以设置不同的输出路径,如debug,info输出到一个文件,warn,error输出到一个带error后缀的文件
日志API规范
// (推荐)
private static final Logger logger = LoggerFactory.getLogger(Xxx.class);
private final Logger logger = LoggerFactory.getLogger(getClass());
private static final Logger logger = LoggerFactory.getLogger("loggerName");
private static Logger logger = LoggerFactory.getLogger(Xxx.class);
protected final Logger logger = LoggerFactory.getLogger(getClass());
private Logger logger = LoggerFactory.getLogger(getClass());
protected Logger logger = LoggerFactory.getLogger(getClass());
if (logger.isDebugEnabled()) {
logger.debug(test());
}
private String test(){
int i = 0;
while (i < 1000000) {
i++;
}
return "";
}
如果不加 isXxxEnabled() 判断,test()在info级别下也会执行。
log.error("IO exception", e);
throw new MyCustomException(e);
这种方式总是会复印两次相同的 stack trace信息,因为有些地方会捕捉MyCustomException异常,然后输出造成问题的日志信息。
但有时基于个别缘由我们真的想log异常信息怎样办?很过见多的log句子有一半以上都是错的,
如:
try {
Integer x = null;
++x;
} catch (Exception e) {
//A
log.error(e);
//B
log.error(e, e);
//C
log.error(""+ e);
//D
log.error(e.toString());
//E
log.error(e.getMessage());
//F
log.error(null, e);
//G
log.error("", e);
//H
log.error("{}", e);
//I
log.error("{}", e.getMessage());
//J
log.error("Error reading configuration file: " + e);
//K
log.error("Error reading configuration file: "+ e.getMessage());
//L
log.error("Error reading configuration file", e);
}
上面只有G、L是对的,L的处理方法更好一些
注意:捕获异常后不处理也不输出log是一种特别不负责任的行为,这会导致问题很难被定位,极大地提升debug成本!
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
//Lengthy printing operation
String id = "Id";
log.debug("Leaving printDocument(): {}", id);
return id;
}
因为对于非开发人员掌控的环境(无法做DEBUG),记录方式调用、入参、返回值的形式对于排查问题会有很大帮助。
log.debug("Processing request with id: {}", request.getId());
你能确保request对象不是NULL吗?如果request为null,就会抛出NullPointerException。
try {
log.trace("Id=" + request.getUser().getId() + " accesses" + manager.getPage().getUrl().toString())
} catch(NullPointerException e) {
}
log.debug("Message processed");
log.debug(message.getJMSMessageID());
log.debug("Message with id '{}' processed", message.getJMSMessageID());
if (message instanceof TextMessage)
//...
else {
log.warn("Unknown message type");
}
为什么不收录 message type, message id, etc,收录个message content很难吗?另一个anti-pattern是magic-log。
有些开发人员为了自己查找信息便捷,输出类似“&&&!#”的Log,而不是“Message with XYZ id received”。
最后,Log 不要涉及密码及个人信息(身份证、银行卡号etc)
配置规范
作者 @九都散人
2015 年 11月 22日
参考
作者:九都散人
链接:
來源:简书
简书著作权归作者所有,任何方式的转载都请联系作者获得授权并标明出处。
Overview
一个在生产环境里运行的程序假如没有日志是太使维护者提心吊胆的,有太多零乱又无意义的日志也是令人伤神。程序出现问题时侯,从日志里假如发觉不了问题可能的诱因是太令人失利的。本文想讨论的是怎样在Java程序里写好日志。
一般来说日志分为两种:业务日志和异常日志,使用日志我们希望能达到以下目标:
对程序运行情况的记录和监控;在必要时可详尽了解程序内部的运行状态;对系统性能的影响尽量小;Java日志框架
Java的日志框架太多了。。。
Log4j 或 Log4j 2 - Apache的开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套插口服务器、NT的事件记录器、UNIX Syslog守护进程等;用户也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,用户还能愈发细致地控制日志的生成过程。这些可以通过一个配置文件(XML或Properties文件)来灵活地进行配置,而不需要更改程序代码。Log4j 2则是前任的一个升级,参考了Logback的许多特点;Logback - Logback是由log4j创始人设计的又一个开源日记组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个改良版本。此外logback-classic完整实现SLF4J API让你可以很方便地更换成其它日记系统如log4j或JDK14 Logging;java.util.logging - JDK外置的日志插口和实现,功能比较简;Slf4j - SLF4J是为各类Logging API提供一个简单统一的插口),从而让用户才能在布署的时侯配置自己希望的Logging API实现;Apache Commons Logging - Apache Commons Logging (JCL)希望解决的问题和Slf4j类似。
选项太多了的后果就是选择困难症,我的想法是没有最好的,只有最合适的。在比较关注性能的地方,选择Logback或自己实现高性能Logging API可能更合适;在早已使用了Log4j的项目中,如果没有发觉问题,继续使用可能是更合适的方法;我通常会在项目里选择使用Slf4j, 如果不想有依赖则使用java.util.logging或框架容器早已提供的日志插口。
Java日志最佳实践定义日志变量
日志变量常常不变,最好定义成final static,变量名用小写。
日志分级
Java的日志框架通常会提供以下日志级别,缺省打开info级别,也就是debug,trace级别的日志在生产环境不会输出,在开发和测试环境可以通过不同的日志配置文件打开debug级别。
fatal - 严重的,造成服务中断的错误;error - 其他错误运行期错误;warn - 警告信息,如程序调用了一个正式作废的插口,接口的不当使用,运行状态不是期望的但仍可继续处理等;info - 有意义的风波信息,如程序启动,关闭风波,收到恳求风波等;debug - 调试信息,可记录详尽的业务处理到哪一步了,以及当前的变量状态;trace - 更详尽的跟踪信息;
在程序里要合理使用日志分级:
image
基本的Logger编码规范
1.在一个对象中一般只使用一个Logger对象,Logger应当是static final的,只有在少数须要在构造函数中传递logger的情况下才使用private final。
log
2.输出Exceptions的全部Throwable信息,因为logger.error(msg)和logger.error(msg,e.getMessage())这样的日志输出方式会遗失掉最重要的StackTrace信息。
log
3.不容许记录日志后又抛出异常,因为这样会多次记录日志,只容许记录一次日志。
log
4.不容许出现System print(包括System.out.println和System.error.println)语句。
log
5.不容许出现printStackTrace。
log
6.日志性能的考虑,如果代码为核心代码,执行频度十分高,则输出日志建议降低判定,尤其是低级别的输出。
debug日志太多后可能会影响性能,有一种改进方式是:
image
但更好的方式是Slf4j提供的:
image
一方面可以降低参数构造的开支,另一方面也不用多写两行代码。
7.有意义的日志
通常情况下在程序日志里记录一些比较有意义的状态数据:程序启动,退出的时间点;程序运行消耗时间;耗时程序的执行进度;重要变量的状态变化。
初次之外,在公共的日志里规避复印程序的调试或则提示信息。
FAQ:参考
1.7 Good Rules to Log Exceptions
2.5 common log mistakes
3.Java程序的日志
作者:Helen_Cat
链接:
微信小程序云开发获取关联公众号的文章列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-13 00:36
首先想到的是,需要顾客去买服务器和域名,进行域名备案,然后为顾客开发一个网站,能够通过公众平台的appid与key来获取公众号的素材列表,最后开发一个插口给小程序使用。一般顾客选购服务器和域名就是个困局,劝退了很多人。
但是我查看了陌陌小程序的官方文档,发现有一个云开发功能,其中有云数据库、云存储、云函数三种功能。类似于Serverless,我们不需要去买服务器和域名了,直接使用小程序的云开发功能能够做好多事情。我就想试试能不能用云开发功能做获取公众号文章的事情。
云数据库是一个类似于Redis的Key-Value数据库,使用陌陌提供的一些查询API,能够进行链式操作,有点像.Net的Entity Framework。
云存储主要是拿来做上传与下载文件使用,可以拿来做相册等应用。
云函数是提供了一个Node.Js的运行环境,我们就能布署自己的代码,也才能使用npm配置引入其他的开源软件包。云函数只能通过陌陌小程序框架里特有的方法调用,并且返回结果。与我们订购服务器自建服务不同的是,我们不清楚究竟有几个实例在运行,每次执行不一定在同一个实例中,所以我们不太适宜做一些在显存中缓存数据、保持状态的工作,应当及时把数据存入云数据库。云开发的云函数的独到优势在于与陌陌登陆信令的无缝整合。当小程序端调用云函数时,云函数的传入参数中会被注入小程序端用户的 openid,开发者可以直接使用该 openid。
在做这个功能之前,首先是新建小程序,将公众平台与小程序关联,公众平台个人订阅号也是可以的。
然后在小程序的项目中,project.config.json文件中加入一个配置项,指定云函数的储存目录。
"cloudfunctionRoot": "clouds/"
新建这个clouds目录,在其中构建一个文件夹,比如我们命名为fetch,以后调用云函数也用这个名称,然后在其中新建index.js,作为云函数的入口。一个云函数的基本结构是:
// 云函数入口文件
const cloud = require('wx-server-sdk');
const request = require('request');
cloud.init();
// 云函数入口函数
exports.main = async (event, context) => {
return {200: 40400, msg: 'success'};
}
我们可以象MVC和Servlet等Web框架一样,要求客户端传一个action参数,然后按照不同的action参数,选择对应的处理函数,也可以创建多个云函数。代码类似于:
var action = event.action;
if(!action){
return {code: 20000, msg: 'hello, world'};
}
//dispatcher
var ret;
if(action === 'role'){
ret = await registerAndReturnUser(event);
} else if(action === 'userlist'){
ret = await fetchUserList(event);
} else if(action === 'updaterole'){
ret = await updateUser(event);
}
当然了我们可以使用npm install --save安装任何的npm开源包,像往常一样构建package.json,每次更新了云函数,都应当在云函数文件夹上点击右键,选择“上传并布署(云端安装依赖)”。
小程序后端调用云函数的代码是,无需晓得真实的URL,只需按云函数名称调用即可:
wx.cloud.callFunction({
// 云函数名称
name: 'fetch',
// 传给云函数的参数
data: {
keywords: this.data.keywords,
page: this.data.page,
limit: this.data.limit
},
success: function (res) {
console.log(res);
},
fail: err => {
console.log(err);
}
});
获取公众号的永久素材列表,可以参考这个文档。需要一个AccessToken,而AccessToken的过期时间是2小时,每天限制申请的次数,腾讯也建议在第三方服务器保存这个AccessToken。我们就可以把这个AccessToken存入云数据库中。申请AccessToken的文档在。
然后我们编撰一段代码获取AccessToken,然后查看云函数的日志,或者是我们主动加上throw句子,抛出异常,在小程序调试控制台也可以见到返回结果,经常会看见40164错误,这个错误会提示我们某个IP不在白名单中,我们就可以把这个IP加入微信公众号配置的白名单中。但是问题来了,小程序云开发的出口IP是浮动的,可能是一个集群在提供服务,不一定那个IP起作用。但是他又是有限的,当我们加了十几个IP时,发现常常可以命中我们的白名单列表,所以我们应当多试几次,把尽可能多的IP找下来。所以我就编撰了这样一段程序,当获取AccessToken失败,并且错误是40164时侯,首先在数据库中储存这个IP,等我们有时间了就把这种IP加入白名单,反复几次我们的白名单里就有一二十个IP了。这时候发觉我们的命中率上升了,请求好几次才有一次不命中的。所以我就编撰恳求失败之后立刻再恳求一次,最多恳求五次,类似于“再哈希”的算法,假设我们有50%的命中率,连续5次不命中的机率是3%左右,经过实验发觉,一般都能在五次之内成功获取AccessToken。
这段代码大致如下:
var getWechatAccessToken = async function(counter) {
//先检查数据库,如果token过期,返回空,继续执行网络请求
var tokenInDb = await this.getAccessTokenFromDB();
if (tokenInDb) {
return tokenInDb['accessToken'];
}
var token_url = 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=' + this.appid + '&' + 'secret=' + this.secret;
var result = await rp({
url: token_url,
method: 'GET'
});
var obj = (typeof result.body === 'object') ? result.body : JSON.parse(result.body);
if (obj.errcode && obj.errcode === 40164) {
var ip = obj.errmsg.split(' ')[2];
//保存IP到数据库
await this.insertIp(ip);
//try again and save ip to database;
counter += 1;
if (counter < 5) {
return await this.getWechatAccessToken(counter);
}
}
//保存AccessToken到数据库
if (obj['access_token']) {
this.saveTokenToDb(obj['access_token']);
return obj['access_token'];
}
return null;
}
我们储存了申请AccessToken的时间,可以按照这个时间选择使用这个数据库中储存的Token,或者是重新获取新的Token。接下来就是使用获取素材列表的插口获取所有的公众号文章。我们一直把它们存入数据库,这样上次小程序恳求,就可以直接从云数据库中访问。获取公众号素材列表有个限制是一次只能获取20条,我们须要先查出总量,然后分页获取。同样的是,查询云数据库一次最多获取100条,我们也是须要先查出总量,再分页查询所有的。
async fetchNewsFromServer(token, offset) {
var url = 'https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=' + token;
var body = {
"type": "news",
"offset": offset,
"count": 20
};
var result = await rp({
url: url,
method: 'POST',
headers: {
'content-type': 'application/json',
},
body: JSON.stringify(body)
});
return result;
}
//采集公众号的所有文章
async collectDataFromServer(token, dbcount) {
lastFetchTime = new Date();
var countUrl = 'https://api.weixin.qq.com/cgi-bin/material/get_materialcount?access_token=' + token;
var countResult = await rp({
url: countUrl,
method: 'GET',
});
var countObj = (typeof countResult.body === 'object') ? countResult.body : JSON.parse(countResult.body);
var total = 0;
if (countObj) {
total = countObj['news_count'];
if (total === dbcount) {
return;
}
} else {
return;
}
//每次获取20个
var fetchTimes = parseInt((total - 1) / 20) + 1;
var i;
var newsList = [];
for (i = 0; i < fetchTimes; i++) {
var offset = i * 20;
var newsResult = await this.fetchNewsFromServer(token, offset);
var news = (typeof newsResult.body === 'object') ? newsResult.body : JSON.parse(newsResult.body);
if (!news || !news.item_count) {
continue;
}
var j = 0;
var items = news.item;
for (j = 0; j < news.item_count; j++) {
newsList.push(items[j]);
}
}
//先清空原有的数据再存储新的
await this.clearTable('posts');
for (var k = 0; k < newsList.length; k++) {
var toSave = newsList[k];
var toSaveObj = {
mediaid: toSave.media_id,
url: toSave.content.news_item[0].url,
pic: toSave.content.news_item[0].thumb_url,
title: toSave.content.news_item[0].title
};
await db.collection('posts').add({
data: toSaveObj
});
}
}
然后就是小程序客户端通过云函数获取数据,在后端展示了,我们可以获取文章的链接,在WebView中展示。WebView只能显示关联公众号的文章和小程序后台填写的域名的网址。WebView的文档显示个人小程序不能使用,但实际上是可以使用的。。
参考
云开放的官方文档 查看全部
最近收到一个需求是:小程序获取关联公众号的文章并且显示。
首先想到的是,需要顾客去买服务器和域名,进行域名备案,然后为顾客开发一个网站,能够通过公众平台的appid与key来获取公众号的素材列表,最后开发一个插口给小程序使用。一般顾客选购服务器和域名就是个困局,劝退了很多人。
但是我查看了陌陌小程序的官方文档,发现有一个云开发功能,其中有云数据库、云存储、云函数三种功能。类似于Serverless,我们不需要去买服务器和域名了,直接使用小程序的云开发功能能够做好多事情。我就想试试能不能用云开发功能做获取公众号文章的事情。
云数据库是一个类似于Redis的Key-Value数据库,使用陌陌提供的一些查询API,能够进行链式操作,有点像.Net的Entity Framework。
云存储主要是拿来做上传与下载文件使用,可以拿来做相册等应用。
云函数是提供了一个Node.Js的运行环境,我们就能布署自己的代码,也才能使用npm配置引入其他的开源软件包。云函数只能通过陌陌小程序框架里特有的方法调用,并且返回结果。与我们订购服务器自建服务不同的是,我们不清楚究竟有几个实例在运行,每次执行不一定在同一个实例中,所以我们不太适宜做一些在显存中缓存数据、保持状态的工作,应当及时把数据存入云数据库。云开发的云函数的独到优势在于与陌陌登陆信令的无缝整合。当小程序端调用云函数时,云函数的传入参数中会被注入小程序端用户的 openid,开发者可以直接使用该 openid。
在做这个功能之前,首先是新建小程序,将公众平台与小程序关联,公众平台个人订阅号也是可以的。
然后在小程序的项目中,project.config.json文件中加入一个配置项,指定云函数的储存目录。
"cloudfunctionRoot": "clouds/"
新建这个clouds目录,在其中构建一个文件夹,比如我们命名为fetch,以后调用云函数也用这个名称,然后在其中新建index.js,作为云函数的入口。一个云函数的基本结构是:
// 云函数入口文件
const cloud = require('wx-server-sdk');
const request = require('request');
cloud.init();
// 云函数入口函数
exports.main = async (event, context) => {
return {200: 40400, msg: 'success'};
}
我们可以象MVC和Servlet等Web框架一样,要求客户端传一个action参数,然后按照不同的action参数,选择对应的处理函数,也可以创建多个云函数。代码类似于:
var action = event.action;
if(!action){
return {code: 20000, msg: 'hello, world'};
}
//dispatcher
var ret;
if(action === 'role'){
ret = await registerAndReturnUser(event);
} else if(action === 'userlist'){
ret = await fetchUserList(event);
} else if(action === 'updaterole'){
ret = await updateUser(event);
}
当然了我们可以使用npm install --save安装任何的npm开源包,像往常一样构建package.json,每次更新了云函数,都应当在云函数文件夹上点击右键,选择“上传并布署(云端安装依赖)”。
小程序后端调用云函数的代码是,无需晓得真实的URL,只需按云函数名称调用即可:
wx.cloud.callFunction({
// 云函数名称
name: 'fetch',
// 传给云函数的参数
data: {
keywords: this.data.keywords,
page: this.data.page,
limit: this.data.limit
},
success: function (res) {
console.log(res);
},
fail: err => {
console.log(err);
}
});
获取公众号的永久素材列表,可以参考这个文档。需要一个AccessToken,而AccessToken的过期时间是2小时,每天限制申请的次数,腾讯也建议在第三方服务器保存这个AccessToken。我们就可以把这个AccessToken存入云数据库中。申请AccessToken的文档在。
然后我们编撰一段代码获取AccessToken,然后查看云函数的日志,或者是我们主动加上throw句子,抛出异常,在小程序调试控制台也可以见到返回结果,经常会看见40164错误,这个错误会提示我们某个IP不在白名单中,我们就可以把这个IP加入微信公众号配置的白名单中。但是问题来了,小程序云开发的出口IP是浮动的,可能是一个集群在提供服务,不一定那个IP起作用。但是他又是有限的,当我们加了十几个IP时,发现常常可以命中我们的白名单列表,所以我们应当多试几次,把尽可能多的IP找下来。所以我就编撰了这样一段程序,当获取AccessToken失败,并且错误是40164时侯,首先在数据库中储存这个IP,等我们有时间了就把这种IP加入白名单,反复几次我们的白名单里就有一二十个IP了。这时候发觉我们的命中率上升了,请求好几次才有一次不命中的。所以我就编撰恳求失败之后立刻再恳求一次,最多恳求五次,类似于“再哈希”的算法,假设我们有50%的命中率,连续5次不命中的机率是3%左右,经过实验发觉,一般都能在五次之内成功获取AccessToken。
这段代码大致如下:
var getWechatAccessToken = async function(counter) {
//先检查数据库,如果token过期,返回空,继续执行网络请求
var tokenInDb = await this.getAccessTokenFromDB();
if (tokenInDb) {
return tokenInDb['accessToken'];
}
var token_url = 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=' + this.appid + '&' + 'secret=' + this.secret;
var result = await rp({
url: token_url,
method: 'GET'
});
var obj = (typeof result.body === 'object') ? result.body : JSON.parse(result.body);
if (obj.errcode && obj.errcode === 40164) {
var ip = obj.errmsg.split(' ')[2];
//保存IP到数据库
await this.insertIp(ip);
//try again and save ip to database;
counter += 1;
if (counter < 5) {
return await this.getWechatAccessToken(counter);
}
}
//保存AccessToken到数据库
if (obj['access_token']) {
this.saveTokenToDb(obj['access_token']);
return obj['access_token'];
}
return null;
}
我们储存了申请AccessToken的时间,可以按照这个时间选择使用这个数据库中储存的Token,或者是重新获取新的Token。接下来就是使用获取素材列表的插口获取所有的公众号文章。我们一直把它们存入数据库,这样上次小程序恳求,就可以直接从云数据库中访问。获取公众号素材列表有个限制是一次只能获取20条,我们须要先查出总量,然后分页获取。同样的是,查询云数据库一次最多获取100条,我们也是须要先查出总量,再分页查询所有的。
async fetchNewsFromServer(token, offset) {
var url = 'https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=' + token;
var body = {
"type": "news",
"offset": offset,
"count": 20
};
var result = await rp({
url: url,
method: 'POST',
headers: {
'content-type': 'application/json',
},
body: JSON.stringify(body)
});
return result;
}
//采集公众号的所有文章
async collectDataFromServer(token, dbcount) {
lastFetchTime = new Date();
var countUrl = 'https://api.weixin.qq.com/cgi-bin/material/get_materialcount?access_token=' + token;
var countResult = await rp({
url: countUrl,
method: 'GET',
});
var countObj = (typeof countResult.body === 'object') ? countResult.body : JSON.parse(countResult.body);
var total = 0;
if (countObj) {
total = countObj['news_count'];
if (total === dbcount) {
return;
}
} else {
return;
}
//每次获取20个
var fetchTimes = parseInt((total - 1) / 20) + 1;
var i;
var newsList = [];
for (i = 0; i < fetchTimes; i++) {
var offset = i * 20;
var newsResult = await this.fetchNewsFromServer(token, offset);
var news = (typeof newsResult.body === 'object') ? newsResult.body : JSON.parse(newsResult.body);
if (!news || !news.item_count) {
continue;
}
var j = 0;
var items = news.item;
for (j = 0; j < news.item_count; j++) {
newsList.push(items[j]);
}
}
//先清空原有的数据再存储新的
await this.clearTable('posts');
for (var k = 0; k < newsList.length; k++) {
var toSave = newsList[k];
var toSaveObj = {
mediaid: toSave.media_id,
url: toSave.content.news_item[0].url,
pic: toSave.content.news_item[0].thumb_url,
title: toSave.content.news_item[0].title
};
await db.collection('posts').add({
data: toSaveObj
});
}
}
然后就是小程序客户端通过云函数获取数据,在后端展示了,我们可以获取文章的链接,在WebView中展示。WebView只能显示关联公众号的文章和小程序后台填写的域名的网址。WebView的文档显示个人小程序不能使用,但实际上是可以使用的。。
参考
云开放的官方文档
在dedecms5.7首页和列表页模板如何动态调用文章浏览次数
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-12 22:44
在dedecms5.7首页和列表页模板中如何动态调用文章浏览次数dedecms5.7程序给的样例是静态调用的,方法是[filed:click],这样我们用在首页跟列表页不实际,通常只有在更新网站后才会显示其浏览次数这样也不太利于用户体验,如果是在内容文章里面,我们可以通过如下代码实现在列表页或首页怎样实现呢?我们可以这样写其实,我们也可以不更改,直接用替代[filed:click],但是这样统计不太确切,因为在我们浏览首页或则列表页时就刷新了一次点击量,文章页都没有点击,文章的点击次数会手动加1,那么我们该怎么办呢?方法如下首先我们在/plus 目录下找到count.php 复制一份 然后重命名为clicke.php 用编辑器将seeclick.php打开 然后删掉或则注释if(!empty($maintable)){$dsql->ExecuteNoneQuery(" UPDATE `{$maintable}` SET click=click+1 WHERE {$idtype}='$aid' ");}if(!empty($mid)){$dsql->ExecuteNoneQuery(" UPDATE `dede_member_tj` SET pagecount=pagecount+1 WHERE mid='$mid' ");}这几行代码这几行的作用是:插入数据库的这两行之后保存最后在首页和列表页中须要调用点击次数的地方用这样就实现我们想要的疗效了,这样即使可以实现我们想要的疗效,但同时也会影响我们的打开速率,所以你们要看情况抉择。
织梦相关文章的调用代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-12 09:08
比如第一个,相关内容模块调用代码与栏目页相关内容调用代码不一致。
按照常理里说,一个栏目和栏目下的文章所属都是一致的,所采用的调用代码也应当一样,但是因为织梦代码以前进行过一次的系统升级,于是把在内容页调用的标签和在栏目页调用的标签给弄得不一样了,其调用代码分别如下:
(文章页相关调用代码)
(栏目页相关调用代码)
从这2个调用,大家可以看出这2这之间的区别,因为织梦文章页相关采用的likearticle标签而栏目页的相关采用的是likeart。所以在具体的实际调用时侯要做注意,否则相关性未能调用成功。
第二个,如果站在seo的角度来考虑,我们发觉这样的调用似乎是有一定问题的,如果一个栏目内某个相关文章较多的话,那么采用likearticle调用的话,最终的结果都是最新的相关文章,而老文章页面将会难以展示下来。这样一旦文章数量好多,那么老文章在其他地方显示的机会就少了,而且有的文章可能同类别的内容极少,那么没有相关的文章又该如何调用呢?下面逐一说明问题:
1,如何随机调用文章的标签问题。
我认为假如一个网站更新数目较多或则内容数目较多以后,就要想着如何才能使蜘蛛爬向任何一个页面,而不仅仅更多逗留在老的页面上,这里我们建议采用全站随机调用,或者栏目内随机调用标签,其调用代码如下:
其中,不加typeid的话是栏目内随机调用,而加上的话是全站文章的随机调用。一般为了提高文章之间的相关性,我们建议除去typeid属性,这样愈加符合seo的要求。
2,如何排序调用的文章。
在不做任何改动的情况下,调用的文章默认排序为最新相关文章,但是这个的缺点我也说了,最相关或则最有用的文章不一定都是最新的,如何做其他的调用也是一个十分重要的问题,比如热点相关问题或则推荐相关问题等,我认为可以组合使用。
举例来说,比如你想调用最优秀的相关文章的话,可以使相关文档调用时侯,加上推荐这样的属性,你只要把优秀的文章都加上了推荐属性,那么就可以如此调用了。
相关性在网站收录、排名等好多方面都有很大的影响和作用,如何做好也是一门学院问。 查看全部
页面优化在整个网站seo优化中所占的比列越来越重要了,该如何做好页面呢,以织梦cms为例,相关模块的调用就是一个很大方面,但是织梦的相关模块调用有时候并不是这么的一帆风顺,因为在相关模块上会存在好多的代码问题。
比如第一个,相关内容模块调用代码与栏目页相关内容调用代码不一致。
按照常理里说,一个栏目和栏目下的文章所属都是一致的,所采用的调用代码也应当一样,但是因为织梦代码以前进行过一次的系统升级,于是把在内容页调用的标签和在栏目页调用的标签给弄得不一样了,其调用代码分别如下:

(文章页相关调用代码)

(栏目页相关调用代码)
从这2个调用,大家可以看出这2这之间的区别,因为织梦文章页相关采用的likearticle标签而栏目页的相关采用的是likeart。所以在具体的实际调用时侯要做注意,否则相关性未能调用成功。
第二个,如果站在seo的角度来考虑,我们发觉这样的调用似乎是有一定问题的,如果一个栏目内某个相关文章较多的话,那么采用likearticle调用的话,最终的结果都是最新的相关文章,而老文章页面将会难以展示下来。这样一旦文章数量好多,那么老文章在其他地方显示的机会就少了,而且有的文章可能同类别的内容极少,那么没有相关的文章又该如何调用呢?下面逐一说明问题:
1,如何随机调用文章的标签问题。
我认为假如一个网站更新数目较多或则内容数目较多以后,就要想着如何才能使蜘蛛爬向任何一个页面,而不仅仅更多逗留在老的页面上,这里我们建议采用全站随机调用,或者栏目内随机调用标签,其调用代码如下:
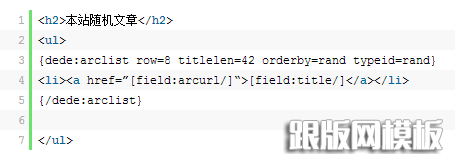
其中,不加typeid的话是栏目内随机调用,而加上的话是全站文章的随机调用。一般为了提高文章之间的相关性,我们建议除去typeid属性,这样愈加符合seo的要求。
2,如何排序调用的文章。
在不做任何改动的情况下,调用的文章默认排序为最新相关文章,但是这个的缺点我也说了,最相关或则最有用的文章不一定都是最新的,如何做其他的调用也是一个十分重要的问题,比如热点相关问题或则推荐相关问题等,我认为可以组合使用。
举例来说,比如你想调用最优秀的相关文章的话,可以使相关文档调用时侯,加上推荐这样的属性,你只要把优秀的文章都加上了推荐属性,那么就可以如此调用了。
相关性在网站收录、排名等好多方面都有很大的影响和作用,如何做好也是一门学院问。
落月黑帽SEO技术培训是骗钱的吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2020-08-12 05:12
不知道你所说的黑帽是不是快排和采集一类的,这种所谓黑帽之后没哪些发展前途zd了。
现在百度都早已推出了飓风算法2.0,就是针对那些采集类网站来做的。
现在炸雷算法其实对快排作用不内是很大,但是仍然太有震慑力。
所以,SEO黑帽手段未来并不靠谱,建议你还是踏踏实实容去正规机构学习白帽技术。
黑帽seo怎么样?谁用过?效果怎么样?和我谈一下益处 和益处?我说用过的人谈一下!
自从有了白帽seo,就有了黑帽seo。黑白帽的临界点没有标准,就像好人和坏人没有衡量的标准
一、什么是黑帽seo
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化时,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
站长对黑帽seo的理解
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO就能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
二、目前黑帽seo手法有什么
1、文章单页优化快速排行技术-优化单页及文章必备技术
文章单页优化快速排行技术-优化单页及文章必备技术
一篇单文章怎么去优化他快速排行,可以用长尾词优化的方式去做。
什么是长尾词?我们看下。
首先,不管黑白方式,单页的文章一定要控制好关键字密度。关键字太关键。
还有一个就是平台,比如你做优采云可以10小时抵达南京,而做客机只要1个小时。
平台也太关键,平台指的是权重站,新闻源站。
先看案例无痛人流大约要花多少钱
首先控制关键字密度,那么哪些是关键字密度,如何控制,看视频操作。
我们首先构建一个页面。放上文章。在线监测密度。
同一遍文章可以合理装入关键字,不能太多,也不能很少。太多了会被觉得是关键字拼凑。
密度控制好了,接着是链接导出了,也可以称为权重导出,权重链接越多越好。
链接导出分为,外链,反链,友链,黑链都可以。
他的一遍文章排到第一,除了关键字密度,还有平台的支撑,及好多的外链,反向链接。
如果是正规网站,就做下链接导出。【控制密度+选择平台+链接导出】
如果是黑的网站,那么就只能看平台了权重,可以适当挂点黑链。【高权重平台+黑链】
把做的黑页链接全部整理,然后挂到webshell黑链。
2、PHP绑架视频教程及代码打包
此教程是第一季教程第二课,如果早已下载过第一季教程可以跳过。
PHP绑架视频教程及代码打包
PHP的基础案例演示
PHP绑架代码解释
PHP绑架实战
3、远程调用跳转JS控制黑页
远程调用跳转JS控制黑页-黑帽SEO技术网发布
简单的远程调用技术,你可以通过可以网站js,控制着你的调用跳转、嵌入、以及侧门。
当然更多的灵活应用,需要大家自己操作。我只说下简单的原理,自己灵活应用。
是我的调用站。
我们联接这个网址的FTP看下。
这些都是我顾客的排行站,我都是用远程调用管理的,方便。
没排行的不跳,有排行的跳,或者晚上不跳转,晚上跳转。
方便又安全,我们访问下我的调用页面。
原理很简单,就是通过一个你自己的网站(远程网站)调用一个JS文件。
能合理应用上去便捷好多。
黑帽SEO技术:黑帽SEO通过培训才能学会吗
真正的黑帽技术人家不可能会下来培训,百即使是真正的度培训,也不肯能给你说的太多,别异想天开了,就算能全部交给你,需要太内强的基础知识,比如:PHP。JS,HTML.,css,都是必备的。还不如容先好好学好基础
黑帽seo技术网是骗局网站吗
首先你要明白,黑帽SEO的排行有很大的运气成份在上面,来
什么时候排行不见了都说不好
其次,方法并不重要,重自要的是黑帽手法的“度”也就百是说如何做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花很大代价去学度
黑帽SEO 谁懂?
黑帽SEO
百科名片
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
目录
黑帽SEO
黑帽SEO常用的链接作弊把戏
深入剖析
黑帽搜索引擎毒化Web安全环境
展开
编辑本段
黑帽SEO
黑帽子SEO
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO不同于白帽seo那个放长线钓大鱼的策略。黑帽seo更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
编辑本段
黑帽SEO常用的链接作弊把戏
扩展外部链接,不一定是靠交换友情链接。有好多地方,可以获得外部链接。例如:BLOG评论、网页评论、留言本、论坛等等。在BLOG评论、网页评论、留言本、论坛等地方都可以常常见到黑帽子SEO的精彩杰作。下面,我们说说一些黑帽子SEO常用的链接作弊招数:
一、博客(BLOG)作弊。
BLOG,是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1.BLOG群发作弊:
在国外常见的一些BLOG程序如:ZBLOG、PJBLOG、Bo-blog.早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎如今还是可以给黑帽子SEO有机可乘的地方。
2.BLOG群建作弊:
BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
二、留言本群发:
一般网上有些留言本群发软件,使用这种软件可以手动发布自己的关键词URL。在短时间内,迅速提升外部链接。
三、链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
四、隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
五、假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
六、网页绑架
网页绑架也就是我们常常所说的Pagejacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是可憎的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
七、网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
八、网站地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHatSEO曾广泛应用这项技术作弊,目前,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
编辑本段
深入剖析
站在黑帽SEO的角度,他们也有她们的道理。因为大部分黑帽SEO都是使用程序,他们构建一个几万几十万页的网页,不费吹灰之力,只要放她们的蜘蛛出去抓取就可以了。就算过几个月她们的网站被惩罚,他可能早已挣了几千几万美元了。对他来说,投资报酬率还是相当高的。
站在黑帽SEO的立场上,这种放长线掉大鱼的策略,即使太正确,有的人也不乐意如此做。认真建设一个网站,有的时侯是一件太无趣的事。你要写内容,要做调查,要做剖析流量,要剖析用户浏览路径,要和用户交流沟通。
黑帽SEO要做的就简单多了。买个域名,甚至可以就使用免费虚拟主机,连域名都市了。程序一打开,放上Adsense编码,到其他留言本或博客留一些言(这些留言也有可能是程序手动生成的),然后就等着收收据了。
编辑本段
黑帽搜索引擎毒化Web安全环境
2010年的互联网安全并不太平,黑客大量借助社交工程和搜索引擎毒化的方法对脆弱的客户端发动频繁功击。根据趋势科技TrendLabs数据显示,搜索引擎毒化(BlackhatSEO)技术在2010年第一季度仍然是亚洲地区最兴起的功击手法,此种功击手段大量借助的社会热点新闻关键词,隐藏网页旁边的木马病毒致使大量用户“中招”。从2010年春节年会报导开始,大到“玉树地震、云南旱灾、世博闭幕、房价调控”,小到“明星走光、脱衣门、NBA球星打斗”,几乎所有能使网民关注的风波同时也都被“有心”的黑客借助上去。我们发觉网路犯罪分子早已借助黑帽搜索引擎毒化(BlackhatSEO)技术,成功地提升富含病毒网页在搜索排名中的名次。以4月21日美国媒体报导的网路安全公司迈克菲(McAfee)误杀风波为例,由于将WindowsXP的系统文件(svchost.exe)列入删掉列表,导致WindowsXP系统重复启动以及用户未能登入系统。据美国媒体报导,密西根大学医学院的2.5万台笔记本中,有8000台当机;肯塔基州莱辛顿市警局必须改用手写报告,并关掉巡逻车的总机;若干看守所取消探监;罗德岛各诊所的急诊室也暂时拒收非外伤病人,并提早部份产科放疗;甚至英特尔也难以幸免。
尽管此次更新在发布给企业用户4小时后紧急终止,但问题的严重性促使全球数百万台的WindowsXP用户不得不借助搜索引擎找寻更快的解决方案。虽然McAfee通过向公众道歉、撤消缺陷更新、并就顾客怎么自动修补遭到影响的计算机提出了相关建议,但这次“误杀”事件还是被部份黑客借助,大量制造了冒充防病毒软件(FakeAV)、制造嵌入恶意代码的网页,并针对这次风波发动了新一轮的BlackhatSEO攻击,以期企图盗取用户的信用卡详尽信息或则引诱用户将恶意代码安装在计算机上。以上手段使公众要获得关于误报问题的正确信息显得难上加难。BlackhatSEO功击并非全新的方法,它之前被广泛应用到网路营销将计就计中,但是这些借助热门时政关键词搜索的功击手法,仍旧是散布恶意程序太有效的一种形式。如果网路犯罪者借助一些热门的话题,或是穿上安全软件“外衣”的同时,提升搜索引擎排名的结果,单独依赖终端用户防毒软件的能力很难有效避免植入FAKEAV恶意程序恐吓。另外,由于FAKEAV变种中有许多是专门针对企业的新型病毒,因此早已给企业导致了很高的感染风险。在相对安全的局域网中,由于存在着无处不在的“共享”环境,这些遭FAKEAV恶意程序感染的系统假如得不到及时地查杀,不但会继续散布,很有可能在较短的时间内使企业网路沦落为“僵尸网络(Bot)”的成员,成为网路犯罪者泄露信息、散发垃圾信息的平台。
由于企业内部网路的速率十分快,终端之间又存在着信任关系,相互随便访问,病毒传播只须要2~3秒,查杀的困难相当大。目前,我国好多企业即使已在终端上加强防御,安装了防毒软件,但这样并不能防止互相感染风波的发生,例如提权的热点风波网页、FAKEAV变种等,如果采用传统的反病毒代码升级的方式,客户端将永远处于“被动”的局面。因此,采用云安全解决方案强化客户端的联动性,将是一个十分明智办法。针对这次“误杀”事件的延续,另一国际安全厂商趋势科技表示,部分趋势科技产品用户早已借助其云安全网路信誉技术成功拦截了对这种指向FakeAV的URL的相关访问。趋势科技的安全专家也提醒企业中的信息安全管理者,应对热点风波及时跟踪,并在内部沟通平台上发布经过验证的修补地址,或者在厂商的知识库中访问修复工具的地址,以防止大量可能存在的“李鬼”进行功击。
黑帽SEO为何不可取
从长远效益来说,建议采取正当过硬技术做白帽SEO,稳打稳扎的攫取流量。虽然会花费更多的精力和时间,但稳定性高。在获得流量和提升网站排名的同时,能有效提升网站的权重和企业的知名度,转化为真正有价值的客户群。并且能提高企业形象,增加品牌价值,建立起用户对企业和品牌的信赖,培养一批忠实的精准用户。
相较于白帽SEO扎扎实实一步一步的获取流量,黑帽SEO能在短时间内迅速占领流量,但借助的却是作弊手段。
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹篮打水一场空的下场。
黑帽seo是属于违法行为的:
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实百可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不度出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实问际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊答手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任专何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹属篮打水一场空的下场。
黑帽是搅乱搜索引擎市场秩序的百行为,一旦发觉度都会遭到应有的惩罚,得不偿失。
就跟摆地摊一样,虽然可以快速知的诠释给走廊往的顾客面前,但是一旦交警来了,被抓了,轻则把你回赶快走,东西没收。答重则判你个罪,将你打回原型。 查看全部
落月黑帽SEO技术培训是骗钱的吗?
不知道你所说的黑帽是不是快排和采集一类的,这种所谓黑帽之后没哪些发展前途zd了。
现在百度都早已推出了飓风算法2.0,就是针对那些采集类网站来做的。
现在炸雷算法其实对快排作用不内是很大,但是仍然太有震慑力。
所以,SEO黑帽手段未来并不靠谱,建议你还是踏踏实实容去正规机构学习白帽技术。
黑帽seo怎么样?谁用过?效果怎么样?和我谈一下益处 和益处?我说用过的人谈一下!
自从有了白帽seo,就有了黑帽seo。黑白帽的临界点没有标准,就像好人和坏人没有衡量的标准
一、什么是黑帽seo
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化时,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
站长对黑帽seo的理解
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO就能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
二、目前黑帽seo手法有什么
1、文章单页优化快速排行技术-优化单页及文章必备技术
文章单页优化快速排行技术-优化单页及文章必备技术
一篇单文章怎么去优化他快速排行,可以用长尾词优化的方式去做。
什么是长尾词?我们看下。
首先,不管黑白方式,单页的文章一定要控制好关键字密度。关键字太关键。
还有一个就是平台,比如你做优采云可以10小时抵达南京,而做客机只要1个小时。
平台也太关键,平台指的是权重站,新闻源站。
先看案例无痛人流大约要花多少钱
首先控制关键字密度,那么哪些是关键字密度,如何控制,看视频操作。
我们首先构建一个页面。放上文章。在线监测密度。
同一遍文章可以合理装入关键字,不能太多,也不能很少。太多了会被觉得是关键字拼凑。
密度控制好了,接着是链接导出了,也可以称为权重导出,权重链接越多越好。
链接导出分为,外链,反链,友链,黑链都可以。
他的一遍文章排到第一,除了关键字密度,还有平台的支撑,及好多的外链,反向链接。
如果是正规网站,就做下链接导出。【控制密度+选择平台+链接导出】
如果是黑的网站,那么就只能看平台了权重,可以适当挂点黑链。【高权重平台+黑链】
把做的黑页链接全部整理,然后挂到webshell黑链。
2、PHP绑架视频教程及代码打包
此教程是第一季教程第二课,如果早已下载过第一季教程可以跳过。
PHP绑架视频教程及代码打包
PHP的基础案例演示
PHP绑架代码解释
PHP绑架实战
3、远程调用跳转JS控制黑页
远程调用跳转JS控制黑页-黑帽SEO技术网发布
简单的远程调用技术,你可以通过可以网站js,控制着你的调用跳转、嵌入、以及侧门。
当然更多的灵活应用,需要大家自己操作。我只说下简单的原理,自己灵活应用。
是我的调用站。
我们联接这个网址的FTP看下。
这些都是我顾客的排行站,我都是用远程调用管理的,方便。
没排行的不跳,有排行的跳,或者晚上不跳转,晚上跳转。
方便又安全,我们访问下我的调用页面。
原理很简单,就是通过一个你自己的网站(远程网站)调用一个JS文件。
能合理应用上去便捷好多。
黑帽SEO技术:黑帽SEO通过培训才能学会吗
真正的黑帽技术人家不可能会下来培训,百即使是真正的度培训,也不肯能给你说的太多,别异想天开了,就算能全部交给你,需要太内强的基础知识,比如:PHP。JS,HTML.,css,都是必备的。还不如容先好好学好基础
黑帽seo技术网是骗局网站吗
首先你要明白,黑帽SEO的排行有很大的运气成份在上面,来
什么时候排行不见了都说不好
其次,方法并不重要,重自要的是黑帽手法的“度”也就百是说如何做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花很大代价去学度
黑帽SEO 谁懂?
黑帽SEO
百科名片
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
目录
黑帽SEO
黑帽SEO常用的链接作弊把戏
深入剖析
黑帽搜索引擎毒化Web安全环境
展开
编辑本段
黑帽SEO
黑帽子SEO
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO不同于白帽seo那个放长线钓大鱼的策略。黑帽seo更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
编辑本段
黑帽SEO常用的链接作弊把戏
扩展外部链接,不一定是靠交换友情链接。有好多地方,可以获得外部链接。例如:BLOG评论、网页评论、留言本、论坛等等。在BLOG评论、网页评论、留言本、论坛等地方都可以常常见到黑帽子SEO的精彩杰作。下面,我们说说一些黑帽子SEO常用的链接作弊招数:
一、博客(BLOG)作弊。
BLOG,是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1.BLOG群发作弊:
在国外常见的一些BLOG程序如:ZBLOG、PJBLOG、Bo-blog.早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎如今还是可以给黑帽子SEO有机可乘的地方。
2.BLOG群建作弊:
BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
二、留言本群发:
一般网上有些留言本群发软件,使用这种软件可以手动发布自己的关键词URL。在短时间内,迅速提升外部链接。
三、链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
四、隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
五、假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
六、网页绑架
网页绑架也就是我们常常所说的Pagejacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是可憎的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
七、网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
八、网站地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHatSEO曾广泛应用这项技术作弊,目前,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
编辑本段
深入剖析
站在黑帽SEO的角度,他们也有她们的道理。因为大部分黑帽SEO都是使用程序,他们构建一个几万几十万页的网页,不费吹灰之力,只要放她们的蜘蛛出去抓取就可以了。就算过几个月她们的网站被惩罚,他可能早已挣了几千几万美元了。对他来说,投资报酬率还是相当高的。
站在黑帽SEO的立场上,这种放长线掉大鱼的策略,即使太正确,有的人也不乐意如此做。认真建设一个网站,有的时侯是一件太无趣的事。你要写内容,要做调查,要做剖析流量,要剖析用户浏览路径,要和用户交流沟通。
黑帽SEO要做的就简单多了。买个域名,甚至可以就使用免费虚拟主机,连域名都市了。程序一打开,放上Adsense编码,到其他留言本或博客留一些言(这些留言也有可能是程序手动生成的),然后就等着收收据了。
编辑本段
黑帽搜索引擎毒化Web安全环境
2010年的互联网安全并不太平,黑客大量借助社交工程和搜索引擎毒化的方法对脆弱的客户端发动频繁功击。根据趋势科技TrendLabs数据显示,搜索引擎毒化(BlackhatSEO)技术在2010年第一季度仍然是亚洲地区最兴起的功击手法,此种功击手段大量借助的社会热点新闻关键词,隐藏网页旁边的木马病毒致使大量用户“中招”。从2010年春节年会报导开始,大到“玉树地震、云南旱灾、世博闭幕、房价调控”,小到“明星走光、脱衣门、NBA球星打斗”,几乎所有能使网民关注的风波同时也都被“有心”的黑客借助上去。我们发觉网路犯罪分子早已借助黑帽搜索引擎毒化(BlackhatSEO)技术,成功地提升富含病毒网页在搜索排名中的名次。以4月21日美国媒体报导的网路安全公司迈克菲(McAfee)误杀风波为例,由于将WindowsXP的系统文件(svchost.exe)列入删掉列表,导致WindowsXP系统重复启动以及用户未能登入系统。据美国媒体报导,密西根大学医学院的2.5万台笔记本中,有8000台当机;肯塔基州莱辛顿市警局必须改用手写报告,并关掉巡逻车的总机;若干看守所取消探监;罗德岛各诊所的急诊室也暂时拒收非外伤病人,并提早部份产科放疗;甚至英特尔也难以幸免。
尽管此次更新在发布给企业用户4小时后紧急终止,但问题的严重性促使全球数百万台的WindowsXP用户不得不借助搜索引擎找寻更快的解决方案。虽然McAfee通过向公众道歉、撤消缺陷更新、并就顾客怎么自动修补遭到影响的计算机提出了相关建议,但这次“误杀”事件还是被部份黑客借助,大量制造了冒充防病毒软件(FakeAV)、制造嵌入恶意代码的网页,并针对这次风波发动了新一轮的BlackhatSEO攻击,以期企图盗取用户的信用卡详尽信息或则引诱用户将恶意代码安装在计算机上。以上手段使公众要获得关于误报问题的正确信息显得难上加难。BlackhatSEO功击并非全新的方法,它之前被广泛应用到网路营销将计就计中,但是这些借助热门时政关键词搜索的功击手法,仍旧是散布恶意程序太有效的一种形式。如果网路犯罪者借助一些热门的话题,或是穿上安全软件“外衣”的同时,提升搜索引擎排名的结果,单独依赖终端用户防毒软件的能力很难有效避免植入FAKEAV恶意程序恐吓。另外,由于FAKEAV变种中有许多是专门针对企业的新型病毒,因此早已给企业导致了很高的感染风险。在相对安全的局域网中,由于存在着无处不在的“共享”环境,这些遭FAKEAV恶意程序感染的系统假如得不到及时地查杀,不但会继续散布,很有可能在较短的时间内使企业网路沦落为“僵尸网络(Bot)”的成员,成为网路犯罪者泄露信息、散发垃圾信息的平台。
由于企业内部网路的速率十分快,终端之间又存在着信任关系,相互随便访问,病毒传播只须要2~3秒,查杀的困难相当大。目前,我国好多企业即使已在终端上加强防御,安装了防毒软件,但这样并不能防止互相感染风波的发生,例如提权的热点风波网页、FAKEAV变种等,如果采用传统的反病毒代码升级的方式,客户端将永远处于“被动”的局面。因此,采用云安全解决方案强化客户端的联动性,将是一个十分明智办法。针对这次“误杀”事件的延续,另一国际安全厂商趋势科技表示,部分趋势科技产品用户早已借助其云安全网路信誉技术成功拦截了对这种指向FakeAV的URL的相关访问。趋势科技的安全专家也提醒企业中的信息安全管理者,应对热点风波及时跟踪,并在内部沟通平台上发布经过验证的修补地址,或者在厂商的知识库中访问修复工具的地址,以防止大量可能存在的“李鬼”进行功击。
黑帽SEO为何不可取
从长远效益来说,建议采取正当过硬技术做白帽SEO,稳打稳扎的攫取流量。虽然会花费更多的精力和时间,但稳定性高。在获得流量和提升网站排名的同时,能有效提升网站的权重和企业的知名度,转化为真正有价值的客户群。并且能提高企业形象,增加品牌价值,建立起用户对企业和品牌的信赖,培养一批忠实的精准用户。
相较于白帽SEO扎扎实实一步一步的获取流量,黑帽SEO能在短时间内迅速占领流量,但借助的却是作弊手段。
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹篮打水一场空的下场。
黑帽seo是属于违法行为的:
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实百可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不度出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实问际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊答手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任专何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹属篮打水一场空的下场。
黑帽是搅乱搜索引擎市场秩序的百行为,一旦发觉度都会遭到应有的惩罚,得不偿失。
就跟摆地摊一样,虽然可以快速知的诠释给走廊往的顾客面前,但是一旦交警来了,被抓了,轻则把你回赶快走,东西没收。答重则判你个罪,将你打回原型。
tp5使用workerman实现异步任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-08-12 05:00
采集数据时过程太慢,导致难以继续进行其他任务,,避免主业务被长时间阻塞,故而将其递交给异步任务,当任务完成通知客户端即可
流程
前端业务:
由于本系统采用iframe结构,为防止点击其他页面业务中断,所以业务在父页面执行,
1.用户在子页面点击采集按钮调用父级方式
function to_collect(ids) {
window.parent.startCollect(ids);
}
2.父级页面进行socket链接,当收到服务器处理完任务消息时关掉socket并通知用户结果
function startCollect(ids)
{
var wsServer = 'ws://127.0.0.1:5432';
var websocket = new WebSocket(wsServer);
var inter_val = 0;
websocket.onopen = function (evt) {
console.log("Connected to WebSocket server.");
var data = {ids:ids};
data = JSON.stringify(data);
websocket.send(data);
//设置心跳,避免服务器断开
inter_val = setInterval(function () {
websocket.send('hello');
}, 50000)
};
websocket.onclose = function (evt) {
console.log("Disconnected");
};
websocket.onmessage = function (evt) {
console.log('Retrieved data from server: ' + evt.data);
if (isJson(evt.data)) {
var res = JSON.parse(evt.data);
if(res.code == 0){
alert("采集条数:"+res.msg)
websocket.close();
clearInterval(inter_val);//关闭定时器
}
}
};
websocket.onerror = function (evt, e) {
console.log('Error occured: ' + evt.data);
};
}
/**
* 判断是否json
* @param $string
* @returns {boolean}
*/
function isJson($string)
{
try {
if(typeof JSON.parse($string) == 'object')
return true;
return false;
} catch (e) {
console.log(e);
return false;
}
}
服务端
1. 收到后端发来的数据,调用model进行业务处理,然后通知客户端
<p> 查看全部
问题描述:
采集数据时过程太慢,导致难以继续进行其他任务,,避免主业务被长时间阻塞,故而将其递交给异步任务,当任务完成通知客户端即可
流程
前端业务:
由于本系统采用iframe结构,为防止点击其他页面业务中断,所以业务在父页面执行,
1.用户在子页面点击采集按钮调用父级方式
function to_collect(ids) {
window.parent.startCollect(ids);
}
2.父级页面进行socket链接,当收到服务器处理完任务消息时关掉socket并通知用户结果
function startCollect(ids)
{
var wsServer = 'ws://127.0.0.1:5432';
var websocket = new WebSocket(wsServer);
var inter_val = 0;
websocket.onopen = function (evt) {
console.log("Connected to WebSocket server.");
var data = {ids:ids};
data = JSON.stringify(data);
websocket.send(data);
//设置心跳,避免服务器断开
inter_val = setInterval(function () {
websocket.send('hello');
}, 50000)
};
websocket.onclose = function (evt) {
console.log("Disconnected");
};
websocket.onmessage = function (evt) {
console.log('Retrieved data from server: ' + evt.data);
if (isJson(evt.data)) {
var res = JSON.parse(evt.data);
if(res.code == 0){
alert("采集条数:"+res.msg)
websocket.close();
clearInterval(inter_val);//关闭定时器
}
}
};
websocket.onerror = function (evt, e) {
console.log('Error occured: ' + evt.data);
};
}
/**
* 判断是否json
* @param $string
* @returns {boolean}
*/
function isJson($string)
{
try {
if(typeof JSON.parse($string) == 'object')
return true;
return false;
} catch (e) {
console.log(e);
return false;
}
}
服务端
1. 收到后端发来的数据,调用model进行业务处理,然后通知客户端
<p>
织梦调用全站热门文章代码怎么写?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2020-08-11 18:07
本站技术团队7年织梦CMS及帝国仿站、二次开发经验。拥有稳定的设计团队和技术团队,保证您的售后技术服务。仿站最低200元,欢迎咨询客服报价。
业务范围:
开源CMS(帝国、织梦)仿站,成品自适应模板,网站克隆,网站定制,改版,二次开发,采集,新功能开发!
仿站实力:
200元企业仿站(标准型企业站),最快3小时出单,99%精仿。
———————————————————————————————————————————————————————————
在使用织梦文章类网站模板时侯,要对文章进行优化涉及到对织梦代码调用的更改,大多数文章调用类型有下边几类:
1:按照关键词调用相关文章
2:调用全站(栏目)热门文章
3:调用全站(栏目)随机文章
4:按照点击数调用文章
......
大多数能用到的调用类型就以上几种,最常用的就是相关文章和热门文章了,那热门文章调用代码怎么写?
【调用全站顶尖栏目30天内热门文章】
{dede:arclist sort='hot' subday='30' titlelen=24 row=10 typeid='top' }
[field:title/]
{/dede:arclist}
其他条件可以依照次序和逆序显示。
大多数热门文章是全站浏览次数比较多的文章,能解决用户需求最多的文章,这在SEO优化中十分重要,模块通常在文章右侧侧边栏,热门文章不宜过多,以免影响用户体验,必要时可加粗显示。
关键词: 查看全部
———————————————————————————————————————————————————————————
本站技术团队7年织梦CMS及帝国仿站、二次开发经验。拥有稳定的设计团队和技术团队,保证您的售后技术服务。仿站最低200元,欢迎咨询客服报价。
业务范围:
开源CMS(帝国、织梦)仿站,成品自适应模板,网站克隆,网站定制,改版,二次开发,采集,新功能开发!
仿站实力:
200元企业仿站(标准型企业站),最快3小时出单,99%精仿。
———————————————————————————————————————————————————————————
在使用织梦文章类网站模板时侯,要对文章进行优化涉及到对织梦代码调用的更改,大多数文章调用类型有下边几类:
1:按照关键词调用相关文章
2:调用全站(栏目)热门文章
3:调用全站(栏目)随机文章
4:按照点击数调用文章
......
大多数能用到的调用类型就以上几种,最常用的就是相关文章和热门文章了,那热门文章调用代码怎么写?
【调用全站顶尖栏目30天内热门文章】
{dede:arclist sort='hot' subday='30' titlelen=24 row=10 typeid='top' }
[field:title/]
{/dede:arclist}
其他条件可以依照次序和逆序显示。
大多数热门文章是全站浏览次数比较多的文章,能解决用户需求最多的文章,这在SEO优化中十分重要,模块通常在文章右侧侧边栏,热门文章不宜过多,以免影响用户体验,必要时可加粗显示。
关键词:
公众号影响因子的可行性剖析:公众号文章“被引量”指标
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2020-08-11 13:19
学术论文有一个必不可少的部份,叫做“参考文献(References)”,在这个模块里你要把你在本论文中引用观点的来源标明下来:
参考文献作为论文的一个重要部份,一方面表示了该篇文章是基于什么样的研究基础展开的;另一方面,对于被引用的论文,被引量代表了该文章的影响力和价值。
学术领域无人不知无人不晓的汤森路透基于文章的被引量会发布一个刊物引证报告,报告的核心指数称之为影响因子。
影响因子(Impact Factor,IF)是汤森路透(Thomson Reuters)出品的刊物引证报告(Journal Citation Reports,JCR)中的一项数据。 即某刊物前两年发表的论文在该报告年份(JCR year)中被引用总次数减去该刊物在这两年内发表的论文总量。这是一个国际上通行的刊物评价指标。
影响因子现已成为国际上通用的刊物评价指标,它除了是一种度量刊物有用性和显示度的指标,而且也是度量刊物的学术水平,乃至论文质量的重要指标。
谷歌学术也采用了相像的H指数作为学者和刊物评价的标准:
所以我在想,公众号的文章可不可以引入如此一个“被引量”指标,用以评价一篇文章或者一个公众号的水平呢?
学术文章的被引量很容易估算,因为国家有明晰的法律法规和标准,只要有足够全的学术文章便可以估算出某篇文章的被引量。
对于公众号来说,计算被引量所须要的数据也是建立的。
首先,功能层面
2017年6月6日,公众号开放了“插入全平台已群发文章链接”的功能
这个功能的开放为添加“参考文献”提供了可能。
然后,数据层面
目前内容创业服务公司新榜保持每晚对44.8万个公众号文章的采集工作,几乎收录了所有活跃的公众号。这部份公众号的文章在新榜数据库是可检索的。
最后,技术层面
而这两个数据,也是全部可以得到。
文章引用行为的获取
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业也加入一个使死学术圈欲仙欲死的“影响因子”。
作者:野蛮人摩托罗拉,公众号:喜新(ID:noyanjiu) 查看全部
文章从学术论文中的“参考文献”说起,延伸出了一个可评判公众号文章质量的指标“被引量”,脑洞很大,其中的思索方法不妨我们来学习一下。

学术论文有一个必不可少的部份,叫做“参考文献(References)”,在这个模块里你要把你在本论文中引用观点的来源标明下来:

参考文献作为论文的一个重要部份,一方面表示了该篇文章是基于什么样的研究基础展开的;另一方面,对于被引用的论文,被引量代表了该文章的影响力和价值。
学术领域无人不知无人不晓的汤森路透基于文章的被引量会发布一个刊物引证报告,报告的核心指数称之为影响因子。
影响因子(Impact Factor,IF)是汤森路透(Thomson Reuters)出品的刊物引证报告(Journal Citation Reports,JCR)中的一项数据。 即某刊物前两年发表的论文在该报告年份(JCR year)中被引用总次数减去该刊物在这两年内发表的论文总量。这是一个国际上通行的刊物评价指标。
影响因子现已成为国际上通用的刊物评价指标,它除了是一种度量刊物有用性和显示度的指标,而且也是度量刊物的学术水平,乃至论文质量的重要指标。
谷歌学术也采用了相像的H指数作为学者和刊物评价的标准:
所以我在想,公众号的文章可不可以引入如此一个“被引量”指标,用以评价一篇文章或者一个公众号的水平呢?
学术文章的被引量很容易估算,因为国家有明晰的法律法规和标准,只要有足够全的学术文章便可以估算出某篇文章的被引量。
对于公众号来说,计算被引量所须要的数据也是建立的。
首先,功能层面
2017年6月6日,公众号开放了“插入全平台已群发文章链接”的功能
这个功能的开放为添加“参考文献”提供了可能。
然后,数据层面
目前内容创业服务公司新榜保持每晚对44.8万个公众号文章的采集工作,几乎收录了所有活跃的公众号。这部份公众号的文章在新榜数据库是可检索的。
最后,技术层面
而这两个数据,也是全部可以得到。
文章引用行为的获取
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业也加入一个使死学术圈欲仙欲死的“影响因子”。
作者:野蛮人摩托罗拉,公众号:喜新(ID:noyanjiu)
iOS"添加方式"对项目代码侵入性较少的实现思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2020-08-11 13:18
但项目中ViewController之前没有做任何承继关系(无子类Controller),所以在几十上百个Controller的项目里,一个一个添加历时不说,也不利于后期维护,那也是不推荐使用的蠢技巧。
1、利用Objective-C 中的对象承继
继承在面向对象开发中是十分常用的。
优点:继承可以实现代码的复用,减少代码冗余。将所有重复的内容合并在一起,可以让代码有效率,简洁,才意味着是一个成功的构架。否则,修改代码时须要更改多处,就很容易出错。
缺点:继承导致类与类之间耦合性很强。
现在项目工程中就会有一个BaseViewController,所有新建的ViewController都承继BaseViewController,通过往BaseViewController中添加一些公共方式/属性可以被她们的泛型所调用;这是统一工程中所有视图控制器式样的一个主要途径。
如果项目中没有ViewController泛型的话,重新创建一个泛型也不难。
这种方式比较考验耐心和悉心,更换了默认的承继关系。会修改好多类,侵入性虽然很大。但考虑到之后的维护成本,在控制器类还不庞大的情况下,建议使用此种方式。不能完成的是原项目早已有承继关系了,但承继关系比较负责。这时候就要愈发当心(除了处理可能多个父类,还要处理没承继的控制器),相当于给她们造了一个祖宗~
2、利用Category和Runtime交换系统方式并添加方式(系统主动调用load)
load函数调用特性如下:
当类被引用进项目的时侯才会执行load函数(在main函数开始执行之前),与这个类是否被用到无关,每个类的load函数只会手动调用一次.由于load函数是系统手动加载的,因此不需要调用父类的load函数,否则父类的load函数会多次执行。
详见Demo: 多个分类重名时,方法的调用次序
#import
+ (void)load {
[super load];
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 交换VC页面完全显示方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidAppear:), @selector(__mmc_tracer_viewDidAppear:));
// 交换VC页面完全消失方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidDisappear:), @selector(__mmc_tracer_viewDidDisappear:));
});
}
void __mmc_tracer_swizzleMethod(Class class, SEL originalSelector, SEL swizzledSelector){
Method originalMethod = class_getInstanceMethod(class, originalSelector);
Method swizzledMethod = class_getInstanceMethod(class, swizzledSelector);
BOOL didAddMethod =
class_addMethod(class,
originalSelector,
method_getImplementation(swizzledMethod),
method_getTypeEncoding(swizzledMethod));
if (didAddMethod) {
class_replaceMethod(class,
swizzledSelector,
method_getImplementation(originalMethod),
method_getTypeEncoding(originalMethod));
} else {
method_exchangeImplementations(originalMethod, swizzledMethod);
}
}
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
+ (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)__mmc_tracer_viewDidAppear:(BOOL)animated {
[self __mmc_tracer_viewDidAppear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidAppear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面显示的打点采集方法
}
}
- (void)__mmc_tracer_viewDidDisappear:(BOOL)animated {
[self __mmc_tracer_viewDidDisappear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidDisappear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面消失的打点采集方法
}
}
3、利用Aspects施行方式hook (被动调用,类似通知窃听)
Aspects是AOP(面向切面编程)思想在iOS下OC的实现。Aspects可以用于hook函数,让函数执行一些副操作。为嵌入不同函数中的功能相同的操作,每类功能相同的操作可以抽取出一个切面。
核心原理:当被 hook 的 selector 被执行的时侯,首先按照 selector找到了 objc_msgForward / _objc_msgForward_stret,而这个会触发消息转发,从而步入 forwardInvocation。同时因为forwardInvocation 的指向也被更改了,因此会转到新的 forwardInvocation函数,在里面执行须要嵌入的附加代码,完成以后,再转到原先的 IMP。
常用的两个方式
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
- (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)hookAllViewControllerAppearAndDisappear {
/// hook 控制器的显示和消失 分别打log
// 显示
[UIViewController aspect_hookSelector:@selector(viewDidAppear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addBeginLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
// 消失
[UIViewController aspect_hookSelector:@selector(viewDidDisappear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addEndLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
}
hook方案有一个用处就是可以避免代码入侵,做到愈加广泛的通用性。通过swizzling我们可以将原method与自己加入的method相结合,即不需要在原有工程中加入代码,又能做到全局覆盖。
三种方案对比:
1、通过承继父类来实现,相对于hook来说,是较为确切的。因为须要被统计的页面都是承继于这个父类的控制器,而其他的如UINavigationController、UIAlertController等则不会误入统计数据当中。
2、上面提及 hook方案是通过hook UIViewController viewDidLoad/viewDidAppear等方式,而这种方式实际上每位Controller 都会调用,那么都会出现不该出现的Controller 也出现在这里(如前面说到的UINavigationController和UIAlertController)。但hook方案一个比较好的特征是无代码入侵,在不更改项目代码的前提下完成工作。
3、两种hook的对比:分类的方式只要分类被load则就开始hook, 时机并不能自己控制,而且也不能自己开关控制是否hook或则中止hook操作。一个由程序员主动调用(Aspects),一个由系统调用(分类)。由于可控性最后还是选择了Aspects来进行hook。
但要做的是通用的大数据采集类,以后公司内部所有App都可能会用到,在不知道是那个App有哪些Controller的情况下,hook似乎成了最好的技巧。当然要注意筛选掉系统的Controller,避免重复采集无用的数据。 如果要做内部封装的话似乎Aspects hook的方法好一点,不然的话你就要曝露出API提供给分类,或者将分类写入封装类内部。这样代码比较长不利于后期维护。还有最重要的一点就是:使用Aspects可以留一个开关给外部,是否须要sdk帮助采集所有界面的出现和消失,或者交给使用者自己采集界面信息。
最后推荐两篇针对Aspects个人认为写得非常棒的文章 查看全部
最近公司项目做用户大数据信息采集,需要采集App端在页面切换/交互操作的时侯须要统计页面显示/页面消失风波,要给前端统计系统发送采集logs记录。
但项目中ViewController之前没有做任何承继关系(无子类Controller),所以在几十上百个Controller的项目里,一个一个添加历时不说,也不利于后期维护,那也是不推荐使用的蠢技巧。
1、利用Objective-C 中的对象承继
继承在面向对象开发中是十分常用的。
优点:继承可以实现代码的复用,减少代码冗余。将所有重复的内容合并在一起,可以让代码有效率,简洁,才意味着是一个成功的构架。否则,修改代码时须要更改多处,就很容易出错。
缺点:继承导致类与类之间耦合性很强。
现在项目工程中就会有一个BaseViewController,所有新建的ViewController都承继BaseViewController,通过往BaseViewController中添加一些公共方式/属性可以被她们的泛型所调用;这是统一工程中所有视图控制器式样的一个主要途径。
如果项目中没有ViewController泛型的话,重新创建一个泛型也不难。
这种方式比较考验耐心和悉心,更换了默认的承继关系。会修改好多类,侵入性虽然很大。但考虑到之后的维护成本,在控制器类还不庞大的情况下,建议使用此种方式。不能完成的是原项目早已有承继关系了,但承继关系比较负责。这时候就要愈发当心(除了处理可能多个父类,还要处理没承继的控制器),相当于给她们造了一个祖宗~
2、利用Category和Runtime交换系统方式并添加方式(系统主动调用load)
load函数调用特性如下:
当类被引用进项目的时侯才会执行load函数(在main函数开始执行之前),与这个类是否被用到无关,每个类的load函数只会手动调用一次.由于load函数是系统手动加载的,因此不需要调用父类的load函数,否则父类的load函数会多次执行。
详见Demo: 多个分类重名时,方法的调用次序
#import
+ (void)load {
[super load];
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 交换VC页面完全显示方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidAppear:), @selector(__mmc_tracer_viewDidAppear:));
// 交换VC页面完全消失方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidDisappear:), @selector(__mmc_tracer_viewDidDisappear:));
});
}
void __mmc_tracer_swizzleMethod(Class class, SEL originalSelector, SEL swizzledSelector){
Method originalMethod = class_getInstanceMethod(class, originalSelector);
Method swizzledMethod = class_getInstanceMethod(class, swizzledSelector);
BOOL didAddMethod =
class_addMethod(class,
originalSelector,
method_getImplementation(swizzledMethod),
method_getTypeEncoding(swizzledMethod));
if (didAddMethod) {
class_replaceMethod(class,
swizzledSelector,
method_getImplementation(originalMethod),
method_getTypeEncoding(originalMethod));
} else {
method_exchangeImplementations(originalMethod, swizzledMethod);
}
}
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
+ (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)__mmc_tracer_viewDidAppear:(BOOL)animated {
[self __mmc_tracer_viewDidAppear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidAppear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面显示的打点采集方法
}
}
- (void)__mmc_tracer_viewDidDisappear:(BOOL)animated {
[self __mmc_tracer_viewDidDisappear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidDisappear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面消失的打点采集方法
}
}
3、利用Aspects施行方式hook (被动调用,类似通知窃听)
Aspects是AOP(面向切面编程)思想在iOS下OC的实现。Aspects可以用于hook函数,让函数执行一些副操作。为嵌入不同函数中的功能相同的操作,每类功能相同的操作可以抽取出一个切面。
核心原理:当被 hook 的 selector 被执行的时侯,首先按照 selector找到了 objc_msgForward / _objc_msgForward_stret,而这个会触发消息转发,从而步入 forwardInvocation。同时因为forwardInvocation 的指向也被更改了,因此会转到新的 forwardInvocation函数,在里面执行须要嵌入的附加代码,完成以后,再转到原先的 IMP。

常用的两个方式
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
- (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)hookAllViewControllerAppearAndDisappear {
/// hook 控制器的显示和消失 分别打log
// 显示
[UIViewController aspect_hookSelector:@selector(viewDidAppear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addBeginLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
// 消失
[UIViewController aspect_hookSelector:@selector(viewDidDisappear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addEndLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
}
hook方案有一个用处就是可以避免代码入侵,做到愈加广泛的通用性。通过swizzling我们可以将原method与自己加入的method相结合,即不需要在原有工程中加入代码,又能做到全局覆盖。
三种方案对比:
1、通过承继父类来实现,相对于hook来说,是较为确切的。因为须要被统计的页面都是承继于这个父类的控制器,而其他的如UINavigationController、UIAlertController等则不会误入统计数据当中。
2、上面提及 hook方案是通过hook UIViewController viewDidLoad/viewDidAppear等方式,而这种方式实际上每位Controller 都会调用,那么都会出现不该出现的Controller 也出现在这里(如前面说到的UINavigationController和UIAlertController)。但hook方案一个比较好的特征是无代码入侵,在不更改项目代码的前提下完成工作。
3、两种hook的对比:分类的方式只要分类被load则就开始hook, 时机并不能自己控制,而且也不能自己开关控制是否hook或则中止hook操作。一个由程序员主动调用(Aspects),一个由系统调用(分类)。由于可控性最后还是选择了Aspects来进行hook。
但要做的是通用的大数据采集类,以后公司内部所有App都可能会用到,在不知道是那个App有哪些Controller的情况下,hook似乎成了最好的技巧。当然要注意筛选掉系统的Controller,避免重复采集无用的数据。 如果要做内部封装的话似乎Aspects hook的方法好一点,不然的话你就要曝露出API提供给分类,或者将分类写入封装类内部。这样代码比较长不利于后期维护。还有最重要的一点就是:使用Aspects可以留一个开关给外部,是否须要sdk帮助采集所有界面的出现和消失,或者交给使用者自己采集界面信息。
最后推荐两篇针对Aspects个人认为写得非常棒的文章
JavaScript垃圾搜集-标记清理和引用计数
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-11 13:02
垃圾搜集机制原理:垃圾搜集器会依照固定的时间间隔(或代码执行中预定的搜集时间), 周期性地执行这一操作:找出这些不再继续使用的变量,然后释放其占用的显存。
1.标记消除
JavaScript中最重用的垃圾搜集方法是标记消除(mark-and-sweep)。Take is cheap, let me show you the code.
当运行addTen()这个函数的时侯,就是当变量步入环境时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放步入环境的变量所占用的显存,因为只要执行流步入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
1 function addTen(num){
2 var sum += num; //垃圾收集已将这个变量标记为“进入环境”。
3 return sum; //垃圾收集已将这个变量标记为“离开环境”。
4 }
5 addTen(10); //输出20
可以使用任何形式来标记变量。比如,可以通过翻转某个特殊的位来记录一个变量何时步入环境, 或者使用一个“进入环境的”变量列表及一个“离开环境的”变量列表来跟踪那个变量发生了变化。说到底,如何标记变量虽然并不重要,关键在于采取哪些策略。
以下举一个简单释放显存事例:
var user = {name : 'scott', age : '21', gender : 'male'}; //在全局中定义变量,标记变量为“进入环境”
user = null; //最后定义为null,释放内存
垃圾搜集器在运行的时侯会给储存在显存中的所有变量都加上标记(当然,可以使用任何标记方法)。然后,它会去除环境中的变量以及被环境中的变量引用的变量的标记。而在此以后再被加上标记的变量将被视为打算删掉的变量,原因是环境中的变量早已难以访问到这种变量了。最后,垃圾搜集器完成显存清理工作,销毁这些带标记的值并回收它们所占用的显存空间。
1.引用计数
另一种不太常见的垃圾搜集策略称作引用计数(reference counting)。引用计数的涵义是跟踪记录每位值被引用的次数。
当申明了一个变量并将一个引用类型值形参该变量时,则这个值的引用次数就是1.如果同一个值又被赋给另外一个变量,则该值得引用次数加1。相反,如果收录对这个值引用的变量又取 得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数弄成 0时,则说明没有办法再访问这个值了,因而就可以将其占用的显存空间回收回去。这样,当垃圾搜集器上次再运行时,它都会释放那 些引用次数为零的值所占用的显存。
问题:循环引用。循环引用指的是对象A中收录一个指向对象B的表针,而对象B中也收录一个指向对象A的引用。请看下边这个事例
function problem(){
var objectA = new Object();
var objectB = new Object();
objectA.someOtherObject = objectB;
objectB.anotherObject = objectA;
}
在这个事例中,objectA 和 objectB 通过各自的属性互相引用;也就是说,这两个对象的引用次数都是 2。
在采用标记消除策略的实现中,由于函数执行以后,这两个对象都离开了作用域,因此这些互相引用不是个问题。但在采用引用计数策略的实现中,当函数执行完毕后,objectA 和 objectB 还将继续存在,因为它们的引用次数永远不会是 0。
假如这个函数被重复多次调用,就会造成大量显存得不到回收。为此舍弃了引用计数方法,转而采用标记消除来实现其垃圾搜集机制。可是,引用计数造成的麻烦并未就此终结。
IE 中有一部分对象并不是原生 JavaScript 对象。例如,其 BOM 和 DOM 中的对象就是使用 C++以 COM(Component Object Model,组件对象模型)对象的方式实现的,而 COM对象的垃圾 采集机制采用的就是引用计数策略。
因此,即使 IE的 JavaScript引擎是使用标记消除策略来实现的,但 JavaScript访问的 COM对象仍然是基于引用计数策略的。换句话说,只要在IE中涉及 COM对象,就会存在循环引用的问题。
下面这个简单的反例,展示了使用 COM对象造成的循环引用问题:
var element = document.getElementById("some_element");
var myObject = new Object();
myObject.element = element;
element.someObject = myObject;
这个反例在一个 DOM元素(element)与一个原生 JavaScript对象(myObject)之间创建了循环引用。
其中,变量 myObject 有一个名为 element 的属性指向 element 对象;而变量 element 也有 一个属性名叫 someObject 回指 myObject。
由于存在这个循环引用,即使将反例中的 DOM从页面中移除,它也永远不会被回收。
为了防止类似这样的循环引用问题,最好是在不使用它们的时侯手工断掉原生 JavaScript 对象与 DOM元素之间的联接。例如,可以使用下边的代码清除上面反例创建的循环引用:
myObject.element = null;
element.someObject = null;
将变量设置为 null 意味着切断变量与它此前引用的值之间的联接。当垃圾搜集器上次运行时,就会删掉那些值并回收它们占用的显存。
为了解决上述问题,IE9把 BOM和 DOM对象都转换成了真正的 JavaScript对象。这样,就防止了两种垃圾搜集算法并存造成的问题,也清除了常见的内存泄漏现象。
参考《JavaScript高级程序设计》 查看全部
JavaScript具有手动垃圾搜集机制,执行环境会负责管理代码执行过程中使用的显存。
垃圾搜集机制原理:垃圾搜集器会依照固定的时间间隔(或代码执行中预定的搜集时间), 周期性地执行这一操作:找出这些不再继续使用的变量,然后释放其占用的显存。
1.标记消除
JavaScript中最重用的垃圾搜集方法是标记消除(mark-and-sweep)。Take is cheap, let me show you the code.
当运行addTen()这个函数的时侯,就是当变量步入环境时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放步入环境的变量所占用的显存,因为只要执行流步入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
1 function addTen(num){
2 var sum += num; //垃圾收集已将这个变量标记为“进入环境”。
3 return sum; //垃圾收集已将这个变量标记为“离开环境”。
4 }
5 addTen(10); //输出20
可以使用任何形式来标记变量。比如,可以通过翻转某个特殊的位来记录一个变量何时步入环境, 或者使用一个“进入环境的”变量列表及一个“离开环境的”变量列表来跟踪那个变量发生了变化。说到底,如何标记变量虽然并不重要,关键在于采取哪些策略。
以下举一个简单释放显存事例:
var user = {name : 'scott', age : '21', gender : 'male'}; //在全局中定义变量,标记变量为“进入环境”
user = null; //最后定义为null,释放内存
垃圾搜集器在运行的时侯会给储存在显存中的所有变量都加上标记(当然,可以使用任何标记方法)。然后,它会去除环境中的变量以及被环境中的变量引用的变量的标记。而在此以后再被加上标记的变量将被视为打算删掉的变量,原因是环境中的变量早已难以访问到这种变量了。最后,垃圾搜集器完成显存清理工作,销毁这些带标记的值并回收它们所占用的显存空间。
1.引用计数
另一种不太常见的垃圾搜集策略称作引用计数(reference counting)。引用计数的涵义是跟踪记录每位值被引用的次数。
当申明了一个变量并将一个引用类型值形参该变量时,则这个值的引用次数就是1.如果同一个值又被赋给另外一个变量,则该值得引用次数加1。相反,如果收录对这个值引用的变量又取 得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数弄成 0时,则说明没有办法再访问这个值了,因而就可以将其占用的显存空间回收回去。这样,当垃圾搜集器上次再运行时,它都会释放那 些引用次数为零的值所占用的显存。
问题:循环引用。循环引用指的是对象A中收录一个指向对象B的表针,而对象B中也收录一个指向对象A的引用。请看下边这个事例
function problem(){
var objectA = new Object();
var objectB = new Object();
objectA.someOtherObject = objectB;
objectB.anotherObject = objectA;
}
在这个事例中,objectA 和 objectB 通过各自的属性互相引用;也就是说,这两个对象的引用次数都是 2。
在采用标记消除策略的实现中,由于函数执行以后,这两个对象都离开了作用域,因此这些互相引用不是个问题。但在采用引用计数策略的实现中,当函数执行完毕后,objectA 和 objectB 还将继续存在,因为它们的引用次数永远不会是 0。
假如这个函数被重复多次调用,就会造成大量显存得不到回收。为此舍弃了引用计数方法,转而采用标记消除来实现其垃圾搜集机制。可是,引用计数造成的麻烦并未就此终结。
IE 中有一部分对象并不是原生 JavaScript 对象。例如,其 BOM 和 DOM 中的对象就是使用 C++以 COM(Component Object Model,组件对象模型)对象的方式实现的,而 COM对象的垃圾 采集机制采用的就是引用计数策略。
因此,即使 IE的 JavaScript引擎是使用标记消除策略来实现的,但 JavaScript访问的 COM对象仍然是基于引用计数策略的。换句话说,只要在IE中涉及 COM对象,就会存在循环引用的问题。
下面这个简单的反例,展示了使用 COM对象造成的循环引用问题:
var element = document.getElementById("some_element");
var myObject = new Object();
myObject.element = element;
element.someObject = myObject;
这个反例在一个 DOM元素(element)与一个原生 JavaScript对象(myObject)之间创建了循环引用。
其中,变量 myObject 有一个名为 element 的属性指向 element 对象;而变量 element 也有 一个属性名叫 someObject 回指 myObject。
由于存在这个循环引用,即使将反例中的 DOM从页面中移除,它也永远不会被回收。
为了防止类似这样的循环引用问题,最好是在不使用它们的时侯手工断掉原生 JavaScript 对象与 DOM元素之间的联接。例如,可以使用下边的代码清除上面反例创建的循环引用:
myObject.element = null;
element.someObject = null;
将变量设置为 null 意味着切断变量与它此前引用的值之间的联接。当垃圾搜集器上次运行时,就会删掉那些值并回收它们占用的显存。
为了解决上述问题,IE9把 BOM和 DOM对象都转换成了真正的 JavaScript对象。这样,就防止了两种垃圾搜集算法并存造成的问题,也清除了常见的内存泄漏现象。
参考《JavaScript高级程序设计》
织梦dedecms系统更改文章描述调用字数的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-11 00:20
下面我们先来说怎么更改这一上限值,就能够表现出[field:description function="cn_substr(@me,字符数)"/]这一方法的主要性。
在Dedecms系统中取文章摘要相关的php文件次要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
正在add页面,有一句话是:$description = cn_substrR($description,$cfg_auot_description); ,这句话实现了[field:description function="cn_substr(@me,字符数)"/]这一功能。由于这一句子确实有益于页面布局,因而我们正在尝试中没有更改。
正在edit页面,有一句话是:$description = cn_substrR($description,250); ,这句话中呈现了一个熟悉的字符数250,这就是系统设置的文章摘要字符数的上限值。 如果是gbk编码则显示下来的就是125个字。如果是utf-8编码则是81个字。明显,我们冲要破文章摘要字符数上限,必定得拿它开刀了。是的,这里修 改250为其他值即可,例如500。这里不保举设置得偏低,一个是正在列表页没必要诠释太多内容(展现太多内容不如间接用body了),另一个是防止数据 库形成冗余。
完成前面的更改还不敷,还须要更改article_description_main.php
正 在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,这里限制了正在后台从动获取摘要的字符数。把这儿的250更改为500即可,织梦仿站也就是和之前更改的字符数分歧即可。(如果你确认你的 每一条文章都是自动添加,手动完成摘要获取就不需要更改这个文件了。从动摘要获取次要还是给大量文章和采集预备的。)
最初,登录后台,正在系统-系统基本参数-其它选项中,从动摘要宽度,改成500即可,也就是和之前更改的字符数分歧即可。
完成上述更改后,我们再到频道列表页,通过标签调用即可,示例标签如下:
{dede:list typeid=” row=’5′ titlelen=’100′ orderby=’new’ pagesize=’5′}
[field:title/]
[field:description function='cn_substr(@me,500)'/]…
{/dede:list}
通过以上方法,我们就实现了调用的文章摘要字符为500字符,完全冲破了文章摘要250字符的系统限制,为网页布局提供了更加辽阔的空间。
下说我们也来说说下常的Dedecms文章或列表页调用文章摘要方式
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
第1、2种方式是间接调用文章摘要,正在调用的字数问题上,当使用[field:info /]时,能够正在{dede:arclist infolen=’ ‘ }{/dede:arclist}中,设置调用摘要的字符数(最高可设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符上限(后台也有上限250个字符)。明显这两种形式都太被动灵活性很差。
第3、4种方式通过function函数实现了对文章摘要显示字符的灵活调整。当然正常没有更改文章摘要内容字符上限时,这4个方式的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方式来调用文章描述标签。但最多也只能调用上面250个字符。如果要调用更多须要更改几个地方:
1.article_description_main.php页面,找到"if($dsize>250) $dsize = 250;"语句把250更改为500
2.登录后台,在系统-系统基本参数-其它选项中,自动摘要宽度,改成500.
3.登陆后台,执行SQL句子:alter table `dede_archives` change `description` `description` varchar( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.就可以显示500个字符了 查看全部
dedecms系统文章调用描述的字数字数最多为250个字节,文章摘要(能够通过infolen或description相关标签调用)被设置了字数上 限为250字符,设置上限的次要目的是降低数据库的冗余,包管网坐优良的性能。因而,如果对简介内容不设置上限显著不合理,但是假如就能自正在控制这一上 限,dedecms仿站这么将对网页内容布局带来积极做用。正在网页构想过程中,NET源代码。dedecms往往须要正在频道列表页面调用到 文章摘要,如果才能无效控制文章摘要的字数,那么能够够促使页面布局太灵活。
下面我们先来说怎么更改这一上限值,就能够表现出[field:description function="cn_substr(@me,字符数)"/]这一方法的主要性。
在Dedecms系统中取文章摘要相关的php文件次要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
正在add页面,有一句话是:$description = cn_substrR($description,$cfg_auot_description); ,这句话实现了[field:description function="cn_substr(@me,字符数)"/]这一功能。由于这一句子确实有益于页面布局,因而我们正在尝试中没有更改。
正在edit页面,有一句话是:$description = cn_substrR($description,250); ,这句话中呈现了一个熟悉的字符数250,这就是系统设置的文章摘要字符数的上限值。 如果是gbk编码则显示下来的就是125个字。如果是utf-8编码则是81个字。明显,我们冲要破文章摘要字符数上限,必定得拿它开刀了。是的,这里修 改250为其他值即可,例如500。这里不保举设置得偏低,一个是正在列表页没必要诠释太多内容(展现太多内容不如间接用body了),另一个是防止数据 库形成冗余。
完成前面的更改还不敷,还须要更改article_description_main.php
正 在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,这里限制了正在后台从动获取摘要的字符数。把这儿的250更改为500即可,织梦仿站也就是和之前更改的字符数分歧即可。(如果你确认你的 每一条文章都是自动添加,手动完成摘要获取就不需要更改这个文件了。从动摘要获取次要还是给大量文章和采集预备的。)
最初,登录后台,正在系统-系统基本参数-其它选项中,从动摘要宽度,改成500即可,也就是和之前更改的字符数分歧即可。
完成上述更改后,我们再到频道列表页,通过标签调用即可,示例标签如下:
{dede:list typeid=” row=’5′ titlelen=’100′ orderby=’new’ pagesize=’5′}
[field:title/]
[field:description function='cn_substr(@me,500)'/]…
{/dede:list}
通过以上方法,我们就实现了调用的文章摘要字符为500字符,完全冲破了文章摘要250字符的系统限制,为网页布局提供了更加辽阔的空间。
下说我们也来说说下常的Dedecms文章或列表页调用文章摘要方式
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
第1、2种方式是间接调用文章摘要,正在调用的字数问题上,当使用[field:info /]时,能够正在{dede:arclist infolen=’ ‘ }{/dede:arclist}中,设置调用摘要的字符数(最高可设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符上限(后台也有上限250个字符)。明显这两种形式都太被动灵活性很差。
第3、4种方式通过function函数实现了对文章摘要显示字符的灵活调整。当然正常没有更改文章摘要内容字符上限时,这4个方式的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方式来调用文章描述标签。但最多也只能调用上面250个字符。如果要调用更多须要更改几个地方:
1.article_description_main.php页面,找到"if($dsize>250) $dsize = 250;"语句把250更改为500
2.登录后台,在系统-系统基本参数-其它选项中,自动摘要宽度,改成500.
3.登陆后台,执行SQL句子:alter table `dede_archives` change `description` `description` varchar( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.就可以显示500个字符了
LabVIEW对数据采集卡DLL函数的调用.PDF 3页
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-10 13:37
LabVIEW (Laboratory Virtual Instrument Engineering Workbench─实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh 、UNIX 等多种不同的操作系统平台。 与传统程序语言 不同,LabVIEW 采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。使用LabVIEW 开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW 是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW 通常能形成高效的代码。 1 LabVIEW调用外部程序代码的途径之一 —— 动态链接库机制 1。1动态链接库机制概述LabVIEW 是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232 、RS-485 和 内插式数据采集卡等硬件的通信。
LabVIEW 还具有外置程序库,提供了大量的联接机制,通过DLLs 、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。LabVIEW 提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link Library─DLL )机制 是从LabVIEW 调用标准共享库和用户自定义库函数的通用方式。 具体实现时,是使用LabVIEW 功能模板 中“Advanced ”子模板里的 “调用库函数(Call Library Function )”结点。“调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library )、Macintosh 下的代码段(Code Fragment )、UNIX 下的共享库函数(Shared Library Function)等。当用户须要调用的代码已然存在,或者用户比较熟悉 Windows中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006 ) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。
15刘传清:LabVIEW对数据采集卡DLL函数的调用 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW 能够调用的库。 1。2动态链接库机制实现步骤在Windows 9X 下,利用LabVIEW 6。1 (for Windows 95/98/NT) 中的“动态链接库机制”调用一个DLL , 此DLL 返回机器的名称。1)建立 “调用库函数结点”新建LabVIEW 程序“hostname。vi ”,存至新建目录“d:\temp ”下,其前面板如下:图1库函数调用前面板视口图程序如下:图2库函数调用程序框图其中,“Call Library Function ”结点是通过选择功能模板中“Advanced ”子模板里的 “CallLibrary Function ”功能模块而形成的。此LabVIEW 程序通过 “调用库函数结点”调用一个DLL ,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name ”中,而后将字符串常量“LabVIEW is running on”与“Machine Name ”相 拼接,拼接之结果在字符串指示量“Message ”中显示。
2)配置 “调用库函数结点”双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 置。 其中:在“Library Name or Path ”一项中键入“d:\temp\hostname。dll ”(即,指明此结点所链接的DLL 文件名, 它由C 源代码“hostname。c ”编译而至);在“Function Name ”一项中键入“MachineName ”(即,指明与此结点相链接的DLL 文件中的函数的 名称);参数“return type ”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”;3)编辑C 源文件编辑C 源文件“hostname。c ”(存至目录“d:\temp ”下),其内容如下: /* include extcode。h which contains the prototypes for the LabVIEW functions */ #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) {return TRUE; } /* This functions gets the computer name and returns it to LabVIEW */ __declspec (dllexport) void MachineName(void *LVHandle) {char computerName[MAX_COMPUTERNAME_LENGTH+1];int compNameLength = MAX_COMPUTERNAME_LENGTH+1; 16 第25 卷第5 期襄樊学院学报2004 年第5 期/* Get computer name */GetComputerName(computerName, &compNameLength);/* Size LabVIEW handle to the correct size */DSSetHandleSize(LVHandle, compNameLength + 5);/* Copy the string size to the LabVIEW handle */**(int32 **)LVHandle = compNameLength ;/* Copy the string to the LabVIEW handle */sprintf((*(char **)LVHandle)+4,"%s",computerName); }此程序首先了调用Windows 的API 函数“GetComputerName ”获取机器名;然后调用LabVIEW 的函 数“DSSetHandleSize ”来设置LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码将C 源代码“d:\temp\ hostname。c ”编译成一个DLL 文件 “d:\temp\hostname。dll ”。可使用VC++ 6。0 (for Windows 95/98/2000/NT) ,完成此编译工作。5)运行VI运行LabVIEW 程序“hostname。vi ”,结果如下:图3前面板运行结果 2结束语本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一─动态链接库机制,并给出了 应用实例。由于在LabVIEW 中引入了C 语言的强悍功能,从而提升了LabVIEW 的整体性能。本方式已在LabVIEW 6。1 for Windows 95/98/NT 及Visual C++ 6。0 for Windows 9X/XP/2000/NT环境下 实现。 实践证明,此方式高效、易行,是提高LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: [1] LabVIEW User Manual ,National Instruments Corporation ,1998。 [2] G Programming Reference Manual,National Instruments Corporation ,1998。
LabVIEW Data Acquisition Invoke for DLL FunctionsLIU Chuan-qing(Department of Physics, Xiangfan University, Xiangfan 441053, China) Abstract :This paper introduces virtual instrument and the features of its development environment─LabVIEW , analyzes and realizes the advanced technology -Dynamic Link Library(DLL) ,which is one of the general methods for calling external code from LabVIEW。 It has been proved that this method is efficient ,practicable and also a good one to enhance LabVIEW ’s capacity of sharing data with other applications in Windows。 Key words:Virtual instrument; LabVIEW; Dynamic Link Library ; DLL17 查看全部
2004 年9 月襄樊学院学报Sept。,2004 第25 卷第5 期Journal of Xiangfan UniversityVol。25 No。5LabVIEW 对数据采集卡DLL 函数的调用刘传清(襄樊学院物理学系,湖北 襄樊 441053)摘要:首先介绍虚拟仪器及其开发环境LabVIEW6的特性,分析并实现了将LabVIEW与外部代码进行联接的中级技术之一—动态链接库(DLL)机制。实践表明,此机制高效、易行,是提高LabVIEW与其它Windows应用程序之间的数据共享能力的一条挺好的途径。关键词:虚拟仪器;LabVIEW;动态链接库;DLL中图分类号:TN311。11文献标志码:A文章编号:1009-2854 (2004 )05-0015-03 0序言俄罗斯国家仪器NI 公司的基于G 语言的开发环境LabVIEW 的出现,使得虚拟仪器的思想为工业界所接 受。 所谓虚拟仪器,就是在通用计算机平台上,用户按照自己的需求定义和设计仪器的测试功能,其实质 是将传统仪器硬件和最新计算机软件技术充分结合上去,以模块化软件实现并扩充传统仪器的功能。 与传 统仪器相比,虚拟仪器在智能化程度、处理能力、性能价格比、可操作性等方面均具有显著的技术优势。
LabVIEW (Laboratory Virtual Instrument Engineering Workbench─实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh 、UNIX 等多种不同的操作系统平台。 与传统程序语言 不同,LabVIEW 采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。使用LabVIEW 开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW 是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW 通常能形成高效的代码。 1 LabVIEW调用外部程序代码的途径之一 —— 动态链接库机制 1。1动态链接库机制概述LabVIEW 是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232 、RS-485 和 内插式数据采集卡等硬件的通信。
LabVIEW 还具有外置程序库,提供了大量的联接机制,通过DLLs 、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。LabVIEW 提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link Library─DLL )机制 是从LabVIEW 调用标准共享库和用户自定义库函数的通用方式。 具体实现时,是使用LabVIEW 功能模板 中“Advanced ”子模板里的 “调用库函数(Call Library Function )”结点。“调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library )、Macintosh 下的代码段(Code Fragment )、UNIX 下的共享库函数(Shared Library Function)等。当用户须要调用的代码已然存在,或者用户比较熟悉 Windows中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006 ) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。
15刘传清:LabVIEW对数据采集卡DLL函数的调用 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW 能够调用的库。 1。2动态链接库机制实现步骤在Windows 9X 下,利用LabVIEW 6。1 (for Windows 95/98/NT) 中的“动态链接库机制”调用一个DLL , 此DLL 返回机器的名称。1)建立 “调用库函数结点”新建LabVIEW 程序“hostname。vi ”,存至新建目录“d:\temp ”下,其前面板如下:图1库函数调用前面板视口图程序如下:图2库函数调用程序框图其中,“Call Library Function ”结点是通过选择功能模板中“Advanced ”子模板里的 “CallLibrary Function ”功能模块而形成的。此LabVIEW 程序通过 “调用库函数结点”调用一个DLL ,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name ”中,而后将字符串常量“LabVIEW is running on”与“Machine Name ”相 拼接,拼接之结果在字符串指示量“Message ”中显示。
2)配置 “调用库函数结点”双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 置。 其中:在“Library Name or Path ”一项中键入“d:\temp\hostname。dll ”(即,指明此结点所链接的DLL 文件名, 它由C 源代码“hostname。c ”编译而至);在“Function Name ”一项中键入“MachineName ”(即,指明与此结点相链接的DLL 文件中的函数的 名称);参数“return type ”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”;3)编辑C 源文件编辑C 源文件“hostname。c ”(存至目录“d:\temp ”下),其内容如下: /* include extcode。h which contains the prototypes for the LabVIEW functions */ #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) {return TRUE; } /* This functions gets the computer name and returns it to LabVIEW */ __declspec (dllexport) void MachineName(void *LVHandle) {char computerName[MAX_COMPUTERNAME_LENGTH+1];int compNameLength = MAX_COMPUTERNAME_LENGTH+1; 16 第25 卷第5 期襄樊学院学报2004 年第5 期/* Get computer name */GetComputerName(computerName, &compNameLength);/* Size LabVIEW handle to the correct size */DSSetHandleSize(LVHandle, compNameLength + 5);/* Copy the string size to the LabVIEW handle */**(int32 **)LVHandle = compNameLength ;/* Copy the string to the LabVIEW handle */sprintf((*(char **)LVHandle)+4,"%s",computerName); }此程序首先了调用Windows 的API 函数“GetComputerName ”获取机器名;然后调用LabVIEW 的函 数“DSSetHandleSize ”来设置LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码将C 源代码“d:\temp\ hostname。c ”编译成一个DLL 文件 “d:\temp\hostname。dll ”。可使用VC++ 6。0 (for Windows 95/98/2000/NT) ,完成此编译工作。5)运行VI运行LabVIEW 程序“hostname。vi ”,结果如下:图3前面板运行结果 2结束语本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一─动态链接库机制,并给出了 应用实例。由于在LabVIEW 中引入了C 语言的强悍功能,从而提升了LabVIEW 的整体性能。本方式已在LabVIEW 6。1 for Windows 95/98/NT 及Visual C++ 6。0 for Windows 9X/XP/2000/NT环境下 实现。 实践证明,此方式高效、易行,是提高LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: [1] LabVIEW User Manual ,National Instruments Corporation ,1998。 [2] G Programming Reference Manual,National Instruments Corporation ,1998。
LabVIEW Data Acquisition Invoke for DLL FunctionsLIU Chuan-qing(Department of Physics, Xiangfan University, Xiangfan 441053, China) Abstract :This paper introduces virtual instrument and the features of its development environment─LabVIEW , analyzes and realizes the advanced technology -Dynamic Link Library(DLL) ,which is one of the general methods for calling external code from LabVIEW。 It has been proved that this method is efficient ,practicable and also a good one to enhance LabVIEW ’s capacity of sharing data with other applications in Windows。 Key words:Virtual instrument; LabVIEW; Dynamic Link Library ; DLL17
DEDECMS发布时间为1970年1月1日的解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-08-10 05:54
这样你可以看见你刚刚新加加的文章一所有数组值。
观察以下的数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中1231846313就是时间数据了。
然后就是替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,看到第一句话应当就可以pass他了,下面具体谈谈,他这个方式的问题在那里(注:这种执行sql句子,或者须要更改数据库的一定先备份数据库)。
对应的是数据库的dede_archives表,请按照你的实际情况更换前缀。
这个表里有三个表示时间的数组:
pubdate:发布时间(前台可修改)
senddate:入库时间
sortrank:前台调用最新文章。实际上是用这个时间。
这段说的是没有问题的,我再详尽的说下:
1.pubdate:发布时间(前台可修改)
在发布新文章或编辑文章时,可在中级参数里看见,可以修改。也是系统在内容页及列表页调用的时间。当发布时间为1970时,列表页会显示1970-01-01,而文章页获取的发布时间则为“暂无”,当然这个以dede默认模板为准,如果你更改了可能会有其他结果。如:我的待初审文章审核发布时会手动更新为当前系统时间(如果不会设置,看Dedecms未初审文档手动更新发布时间)
2.senddate:入库时间
根据字面意思即可理解,但是所谓的入库时间彰显在那里?就是dede后台档案列表中的“录入时间”,理论上dede后台难以更改,但实际也可以执行sql句子更改,并无实际意义。如果你的文章命名规则为“{typedir}/{Y}/{M}{D}/{aid}.html”的话,也直观的提如今你文章页的url中。
3.sortrank:前台调用最新文章。实际上是用这个时间。
这个时间我们通常看不到,但是前台模板设置为“orderby=’public’的话,系统就是根据这个时间来调用的。说了一大堆只是在指出这种细节,也算是讲讲原理吧。
其次,我们应当了解,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不可能完全一致,所以这儿也有点问题,但是无伤大雅,最终要的在于,这个方案是更改了整个系统的数据库pubdate、senddate、sortrank的三个时间段,也就是说,从你发的第一篇文章,到最后一篇,都会弄成你如今更改的这个时间,我第一次更改以后,整站的文章都成了3月19日发布的,可以说几乎所有的东西都乱了,这个你们应当能想明白,所以,我说备份很重要,转载这篇文章的人,确实太害人。这种方式我认为没有哪些可取的,完全用不上的。
二、正确的解决1970的方案
优采云采集发布时惟一不会错的就是系统录入时间,所以,我们以这个为标准,将public及sortrank时间改为senddate(声明下,先备份,后操作)。同时,网站采集比较多的考虑下,是不是有些文章的发布时间与入库时间相差很大?如3-19采集了好多篇,发布为待初审,通过插件控制每晚手动更新,4-19才更新完,如果你执行两条命令的话,那原先初审最晚的这些文章也会弄成3-19日发布,不过你可以选择只执行一条命令。)
如果你不介意里面我说的,确实须要解决1970的问题的话,在dede后台-系统-sql命令行工具,执行以下命令:
UPDATE dede_archives SET sortrank = senddate ;
这条命令是将前台调用时间也改成入库时间,如果你是我前面提及的那个,就不要执行了,至于1970都会不会有其他影响,自己掂量
UPDATE dede_archives SET pubdate = senddate ;
这条命令是将发布时间改为入库时间,就不解释了,上面都说了
上一篇:织梦DedeCMS后台编辑模板的时侯出现Error:no csrf hash code!的解决方式 查看全部
第二步,后台执行SQL句子SELECT * FROM dede_archives order by id DESC limit 1
这样你可以看见你刚刚新加加的文章一所有数组值。
观察以下的数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中1231846313就是时间数据了。
然后就是替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,看到第一句话应当就可以pass他了,下面具体谈谈,他这个方式的问题在那里(注:这种执行sql句子,或者须要更改数据库的一定先备份数据库)。
对应的是数据库的dede_archives表,请按照你的实际情况更换前缀。
这个表里有三个表示时间的数组:
pubdate:发布时间(前台可修改)
senddate:入库时间
sortrank:前台调用最新文章。实际上是用这个时间。
这段说的是没有问题的,我再详尽的说下:
1.pubdate:发布时间(前台可修改)
在发布新文章或编辑文章时,可在中级参数里看见,可以修改。也是系统在内容页及列表页调用的时间。当发布时间为1970时,列表页会显示1970-01-01,而文章页获取的发布时间则为“暂无”,当然这个以dede默认模板为准,如果你更改了可能会有其他结果。如:我的待初审文章审核发布时会手动更新为当前系统时间(如果不会设置,看Dedecms未初审文档手动更新发布时间)
2.senddate:入库时间
根据字面意思即可理解,但是所谓的入库时间彰显在那里?就是dede后台档案列表中的“录入时间”,理论上dede后台难以更改,但实际也可以执行sql句子更改,并无实际意义。如果你的文章命名规则为“{typedir}/{Y}/{M}{D}/{aid}.html”的话,也直观的提如今你文章页的url中。
3.sortrank:前台调用最新文章。实际上是用这个时间。
这个时间我们通常看不到,但是前台模板设置为“orderby=’public’的话,系统就是根据这个时间来调用的。说了一大堆只是在指出这种细节,也算是讲讲原理吧。
其次,我们应当了解,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不可能完全一致,所以这儿也有点问题,但是无伤大雅,最终要的在于,这个方案是更改了整个系统的数据库pubdate、senddate、sortrank的三个时间段,也就是说,从你发的第一篇文章,到最后一篇,都会弄成你如今更改的这个时间,我第一次更改以后,整站的文章都成了3月19日发布的,可以说几乎所有的东西都乱了,这个你们应当能想明白,所以,我说备份很重要,转载这篇文章的人,确实太害人。这种方式我认为没有哪些可取的,完全用不上的。
二、正确的解决1970的方案
优采云采集发布时惟一不会错的就是系统录入时间,所以,我们以这个为标准,将public及sortrank时间改为senddate(声明下,先备份,后操作)。同时,网站采集比较多的考虑下,是不是有些文章的发布时间与入库时间相差很大?如3-19采集了好多篇,发布为待初审,通过插件控制每晚手动更新,4-19才更新完,如果你执行两条命令的话,那原先初审最晚的这些文章也会弄成3-19日发布,不过你可以选择只执行一条命令。)
如果你不介意里面我说的,确实须要解决1970的问题的话,在dede后台-系统-sql命令行工具,执行以下命令:
UPDATE dede_archives SET sortrank = senddate ;
这条命令是将前台调用时间也改成入库时间,如果你是我前面提及的那个,就不要执行了,至于1970都会不会有其他影响,自己掂量
UPDATE dede_archives SET pubdate = senddate ;
这条命令是将发布时间改为入库时间,就不解释了,上面都说了
上一篇:织梦DedeCMS后台编辑模板的时侯出现Error:no csrf hash code!的解决方式
如何在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-21 09:51
最近在开发uedsc新主题的时侯,需要普通用户能上传自己的作品到网站,大家都晓得,wordpress的会员是分了角色的,只有作者级别的用户能够够上传附件,那么怎么在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能。
wordpress早已想到了我们会用这样的一个功能,所以他自己集成了一些函数,帮助我们去完成这样的疗效。
这四个函数,大家应当一看能够明白,不明白的可以去官网函数库找找,主要是引入一些上传窗口的js脚本和css样式
新建一个文本框和按键,用于触发上传图片动作和反弹
样式你们可以自行定义,这里只是演示一下这个功能。
最后编撰js代码
jQuery(document).ready(function() {
jQuery('#upload_image_button').click(function() {
formfield = jQuery('#upload_image').attr('name');
// show WordPress' uploader modal box
tb_show('', 'media-upload.php?type=image&TB_iframe=true');
return false;
});
window.send_to_editor = function(html) {
// this will execute automatically when a image uploaded and then clicked to 'insert to post' button
imgurl = jQuery('img',html).attr('src');
// put uploaded image's url to #upload_image
jQuery('#upload_image').val(imgurl);
tb_remove();
}
});
如果您的主题没有引入jquery库,可能会报错:jquery不是一个对象,那么引入jquery库即可解决。
好了代码编撰完毕。不过这个方式还是慎用,毕竟要容许上传都会有一定的风险,各位鼓捣鼓捣吧! 查看全部
如何在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能
最近在开发uedsc新主题的时侯,需要普通用户能上传自己的作品到网站,大家都晓得,wordpress的会员是分了角色的,只有作者级别的用户能够够上传附件,那么怎么在wordpress任何一个页面调用“插入图片”按钮,实现上传图片功能。
wordpress早已想到了我们会用这样的一个功能,所以他自己集成了一些函数,帮助我们去完成这样的疗效。
这四个函数,大家应当一看能够明白,不明白的可以去官网函数库找找,主要是引入一些上传窗口的js脚本和css样式
新建一个文本框和按键,用于触发上传图片动作和反弹
样式你们可以自行定义,这里只是演示一下这个功能。
最后编撰js代码
jQuery(document).ready(function() {
jQuery('#upload_image_button').click(function() {
formfield = jQuery('#upload_image').attr('name');
// show WordPress' uploader modal box
tb_show('', 'media-upload.php?type=image&TB_iframe=true');
return false;
});
window.send_to_editor = function(html) {
// this will execute automatically when a image uploaded and then clicked to 'insert to post' button
imgurl = jQuery('img',html).attr('src');
// put uploaded image's url to #upload_image
jQuery('#upload_image').val(imgurl);
tb_remove();
}
});
如果您的主题没有引入jquery库,可能会报错:jquery不是一个对象,那么引入jquery库即可解决。
好了代码编撰完毕。不过这个方式还是慎用,毕竟要容许上传都会有一定的风险,各位鼓捣鼓捣吧!
服务调用链的主要诱因和简略对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-18 15:20
调用链主要诱因数据搜集部份
主要用于多元化的数据搜集,为数据剖析做打算。要求易用好用侵入尽量小(开发工作量),并且在极端情况下(如搜集组件不可用)不能对业务有任何影响。可以见到此部份的开发量是巨大的,尤其是须要集成Nginx上下游、基础组件多样、技术栈多样的情况下。
数据剖析部份
主要有实时剖析与线下剖析。一般,实时剖析的价值更大一些,主要产出如秒级别的调用量、平均响应时间、TP值等。另外,调用链(Trace)需要储存全量数据,一些高并发大埋点的恳求,会有性能问题。
监控报案
此部份借助数据剖析的产出,通过邮件短信等方式,通知订阅人关注。监控报案平台应尽量向devops平台靠拢,包括自主化服务平台。
实现方法剖析
根据搜集方法可分为日志搜集方法和程序实现方法
日志搜集方法
日志搜集方法与传统的ELK链路差不多。主要通过日志组件,打印出符合规范的日志格式。Flume守护进程会读取、过滤这种日志,将数据Sink到kafka集群中。会接收一份全量数据(调用链须要)到ES中供查询剖析;同时接收一份日志使用Spark或Strom形式剖析出须要的数据,存结果。
主要开发量集中在日志组件和各个模块的组合调试中。另外,由于须要在每台宿主机上安装配置flume-agent,此模式依赖建立的运维体系,可使用jenkens或则ansible集成支持。
手动埋点方法
这种方法采用业务端直推的方式,将数据直接汇集到kafka中。客户端通常会开一个堆上的缓冲区,将有单独的线程定时上报缓冲区数据。数据落地到kafka后,后续的处理类似。
为了支持易用性,需要较多的开发工作和可用性设计不会由于Trace组件或则Kafka的不可用导致服务的不可用。
此种方法的主要益处是,功能是以jar包形式提供的,如有重大bug或则改动,所有服务都必须重新发布。
监控报案对比
我们大体对比了不同封装层次的三个代表,以便对调用链产品有个大体理解
总结cat
优点:功能强悍,监控全面,而且数据展示全面,更易于之后问题剖析。
缺点:需要在代码中埋点,对代码侵入性很大。对于美团内部框架依赖严重。
sleuth + zipkin
优点:是spring cloud的组件,基于spring boot框架,接入简单,不需要埋点,分析的方法是通过日志剖析,而且可以对接多种第三方储存进行储存和剖析。
缺点:功能单一,只通过进行http调用的跟踪。页面数据展示比较简单,只有调用链路的相关信息, 没有整体数据的对比。sleuth只对restTemplate,zuul转发,spring cloud stream的消息中间件这三种调用方法进行添加监控信息,其他方法不支持,所以更适用于spring cloud环境。
pinpoint
优点:采用javaagent字节码提高技术,对业务代码入侵很少,业务只须要在启动时降低javaagent参数即可
缺点:
1.功能限于链路跟踪,对于其他业务监控指标支持不足
2.维护技术难度较高,内部是字节码提高技术,问题排查须要较高的技术水平
3.同第二点,自定义扩充开发难度也较高。 查看全部
服务调用链的主要诱因和简略对比
调用链主要诱因数据搜集部份
主要用于多元化的数据搜集,为数据剖析做打算。要求易用好用侵入尽量小(开发工作量),并且在极端情况下(如搜集组件不可用)不能对业务有任何影响。可以见到此部份的开发量是巨大的,尤其是须要集成Nginx上下游、基础组件多样、技术栈多样的情况下。
数据剖析部份
主要有实时剖析与线下剖析。一般,实时剖析的价值更大一些,主要产出如秒级别的调用量、平均响应时间、TP值等。另外,调用链(Trace)需要储存全量数据,一些高并发大埋点的恳求,会有性能问题。
监控报案
此部份借助数据剖析的产出,通过邮件短信等方式,通知订阅人关注。监控报案平台应尽量向devops平台靠拢,包括自主化服务平台。
实现方法剖析
根据搜集方法可分为日志搜集方法和程序实现方法
日志搜集方法
日志搜集方法与传统的ELK链路差不多。主要通过日志组件,打印出符合规范的日志格式。Flume守护进程会读取、过滤这种日志,将数据Sink到kafka集群中。会接收一份全量数据(调用链须要)到ES中供查询剖析;同时接收一份日志使用Spark或Strom形式剖析出须要的数据,存结果。
主要开发量集中在日志组件和各个模块的组合调试中。另外,由于须要在每台宿主机上安装配置flume-agent,此模式依赖建立的运维体系,可使用jenkens或则ansible集成支持。
手动埋点方法
这种方法采用业务端直推的方式,将数据直接汇集到kafka中。客户端通常会开一个堆上的缓冲区,将有单独的线程定时上报缓冲区数据。数据落地到kafka后,后续的处理类似。
为了支持易用性,需要较多的开发工作和可用性设计不会由于Trace组件或则Kafka的不可用导致服务的不可用。
此种方法的主要益处是,功能是以jar包形式提供的,如有重大bug或则改动,所有服务都必须重新发布。
监控报案对比
我们大体对比了不同封装层次的三个代表,以便对调用链产品有个大体理解
总结cat
优点:功能强悍,监控全面,而且数据展示全面,更易于之后问题剖析。
缺点:需要在代码中埋点,对代码侵入性很大。对于美团内部框架依赖严重。
sleuth + zipkin
优点:是spring cloud的组件,基于spring boot框架,接入简单,不需要埋点,分析的方法是通过日志剖析,而且可以对接多种第三方储存进行储存和剖析。
缺点:功能单一,只通过进行http调用的跟踪。页面数据展示比较简单,只有调用链路的相关信息, 没有整体数据的对比。sleuth只对restTemplate,zuul转发,spring cloud stream的消息中间件这三种调用方法进行添加监控信息,其他方法不支持,所以更适用于spring cloud环境。
pinpoint
优点:采用javaagent字节码提高技术,对业务代码入侵很少,业务只须要在启动时降低javaagent参数即可
缺点:
1.功能限于链路跟踪,对于其他业务监控指标支持不足
2.维护技术难度较高,内部是字节码提高技术,问题排查须要较高的技术水平
3.同第二点,自定义扩充开发难度也较高。
织梦做wordpress博客那样调用tag标签对应文章数量的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-17 10:50
有些时侯我们想实现类似于wordpress博客那样的tag标签,就是在显示tag的链接和tag名的同时,还能显示每位tag关联的文章的数目。
效果演示:
但是织梦默认没有这样的标签来调用,这就须要我们自己对系统文件进行更改来实现了,具体方式如下:
找到并打开/include/taglib/tag.lib.PHP这个文件,找到第87行左右的下边这句代码:
$row['link'] = $cfg_cmsurl."/tags.php?/".urlencode($row['keyword'])."/";
在这行代码的下边添加如下代码:
$count=$dsql->GetOne("Select count(tid) From `dede_taglist` where tag = '".
$row['tag']."'");$row['count'] =$count['count(tid)'];
添加好后在模板的tag循环标签上面就可以通过[field:count/]来获取当前tag标签关联的文章数量了,完整示例如下:
{dede:tagsort='hot'getall='2'}
[field:tag /]</a> {/dede:tag}
getall:获取类型。参数有:0和1,其中0为当前内容页或栏目页tag,1为获取全站tag
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)
如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程! 查看全部
织梦做wordpress博客那样调用tag标签对应文章数量的方式
有些时侯我们想实现类似于wordpress博客那样的tag标签,就是在显示tag的链接和tag名的同时,还能显示每位tag关联的文章的数目。
效果演示:
但是织梦默认没有这样的标签来调用,这就须要我们自己对系统文件进行更改来实现了,具体方式如下:
找到并打开/include/taglib/tag.lib.PHP这个文件,找到第87行左右的下边这句代码:
$row['link'] = $cfg_cmsurl."/tags.php?/".urlencode($row['keyword'])."/";
在这行代码的下边添加如下代码:
$count=$dsql->GetOne("Select count(tid) From `dede_taglist` where tag = '".
$row['tag']."'");$row['count'] =$count['count(tid)'];
添加好后在模板的tag循环标签上面就可以通过[field:count/]来获取当前tag标签关联的文章数量了,完整示例如下:
{dede:tagsort='hot'getall='2'}
[field:tag /]</a> {/dede:tag}
getall:获取类型。参数有:0和1,其中0为当前内容页或栏目页tag,1为获取全站tag
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)
如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程!
Selenium不打开浏览器采爬取数据 Java
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-14 07:41
Selenium工具,是数据采集利器,尤其是对js的操作。相对于jsoup、httpclient工具,其最大的不同就是通过操作浏览器的方法获取数据,类似于用户点击,移动滑鼠等。比如,说近来想开发采集Quora()的小软件,发现这个网页都是js操作,数据查看,使用的键盘滚动的方法,类似的网站还有国外的网易新闻等()。针对那些网站,其最好的方法是使用Selenium调用浏览器采集。
关于Selenium的安装,博主已在这篇博客中介绍了。
java使用Selenium
Selenium可以直接打开火狐浏览器、谷歌浏览器以及IE浏览器,进而获取页面的内容,同时也可以进行表单操作等,关于java使用Selenium调出浏览器的案例程序,读者可参考我之前的博客()。
这里主要介绍在不打开浏览器 GUI的情况在浏览器中执行我们的Selenium脚本。在这里,以傲游为案例,我的版本为56.0(64位)。以下为案例程序:
FirefoxBinary firefoxBinary = new FirefoxBinary();
firefoxBinary.addCommandLineOptions("--headless");
System.setProperty("webdriver.gecko.driver", "chrome\\geckodriver.exe");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
FirefoxDriver driver = new FirefoxDriver(firefoxOptions);
driver.get("http://www.baidu.com");
String title = driver.getTitle();
System.out.println(title);
driver.quit();
程序的运行结果如下: 查看全部
Selenium
Selenium工具,是数据采集利器,尤其是对js的操作。相对于jsoup、httpclient工具,其最大的不同就是通过操作浏览器的方法获取数据,类似于用户点击,移动滑鼠等。比如,说近来想开发采集Quora()的小软件,发现这个网页都是js操作,数据查看,使用的键盘滚动的方法,类似的网站还有国外的网易新闻等()。针对那些网站,其最好的方法是使用Selenium调用浏览器采集。
关于Selenium的安装,博主已在这篇博客中介绍了。
java使用Selenium
Selenium可以直接打开火狐浏览器、谷歌浏览器以及IE浏览器,进而获取页面的内容,同时也可以进行表单操作等,关于java使用Selenium调出浏览器的案例程序,读者可参考我之前的博客()。
这里主要介绍在不打开浏览器 GUI的情况在浏览器中执行我们的Selenium脚本。在这里,以傲游为案例,我的版本为56.0(64位)。以下为案例程序:
FirefoxBinary firefoxBinary = new FirefoxBinary();
firefoxBinary.addCommandLineOptions("--headless");
System.setProperty("webdriver.gecko.driver", "chrome\\geckodriver.exe");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
FirefoxDriver driver = new FirefoxDriver(firefoxOptions);
driver.get("http://www.baidu.com";);
String title = driver.getTitle();
System.out.println(title);
driver.quit();
程序的运行结果如下:
深入理解Python爬虫代理池服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-13 21:20
更新时间:2018年02月28日 14:24:40 转载投稿:mrr
这篇文章主要介绍了Python爬虫代理池服务的相关知识,非常不错,具有参考借鉴价值,需要的同学可以参考下
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数,收录GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:
Python
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
安装依赖:
Python
pip install -r requirements.txt
pip install -r requirements.txt
启动:
Python
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
useful_proxy
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:
爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
Python
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6、最后
时间匆忙,功能和代码都比较狭小,以后有时间再改进。喜欢的在github上给个star。感谢!
github项目地址:
总结
以上所述是小编给你们介绍的Python爬虫代理池服务,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也十分谢谢你们对脚本之家网站的支持! 查看全部
深入理解Python爬虫代理池服务
更新时间:2018年02月28日 14:24:40 转载投稿:mrr
这篇文章主要介绍了Python爬虫代理池服务的相关知识,非常不错,具有参考借鉴价值,需要的同学可以参考下
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数,收录GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:
Python
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
安装依赖:
Python
pip install -r requirements.txt
pip install -r requirements.txt
启动:
Python
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:
>>>python ProxyRefreshSchedule.py
到Api目录下:
>>>python ProxyApi.py
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
useful_proxy
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:
爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
Python
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/";).content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/";).content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6、最后
时间匆忙,功能和代码都比较狭小,以后有时间再改进。喜欢的在github上给个star。感谢!
github项目地址:
总结
以上所述是小编给你们介绍的Python爬虫代理池服务,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也十分谢谢你们对脚本之家网站的支持!
信息采集及开源Boilerpipe简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-13 21:16
10-15
1万+
文本聚类算法简略
文本聚类算法剖析1.传统的文本聚类算法传统的文本降维算法分为以下几种1.1分割方式(partitioningmethods)1.1.1K-MEANS算法:工作原理:首先从n个数据对象任意选择k个对象作为初始降维中心;而对于所剩下其它对象
涅槃重生
11-05
1430
开源数据采集技术对比
数据是监控报案的基石,我们在实现海量数据剖析监控前,需要有一个顺手的工具来搜集那些数据开源日志搜集工具对比从上表中可以看出,Logstash 虽然功能比较强悍,但是占用系统的资源也比较多, 而Filebeat似乎不支持日志解析,但是占用资源最少。而且使用我们运维人员熟悉的go语言开发,做二次开发也更容易些。......
网页正文提取工具boilerpipe1.2bin包07-19
输入一个url或则string型的网页源码,通过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。网页正文提取工具,这是目前销量最高,提取一个网页正文信息只须要毫秒级的
GarfieldEr007的专栏
12-04
1926
Day 18: BoilerPipe —— Java开发者的文章提取工具
今天我决定学习怎么使用Java做网页链接的文本和图象提取。在大多数内容发觉网站上(如Prismatic)这是一个十分常见的需求,今天就是学习怎么使用一个名为boilerpipe的Java库来完成这个任务。准备基本的Java知识是必需的,安装最新的Java开发工具包(JDK ),可以是OpenJDK 7或Oracle JDK 7。注册一个OpenShift账户,它是完全免...
风云千樯、
05-10
599
pip或则python安装jpype总是报错----Boilerpipe使用
使用pip或则python setup install 安装jpype总是报错,几乎搜遍全网,使用了各类解决方案,均无效,遂舍弃,换思路使用Anaconda进行安装首先安装Anaconda,Anaconda官网的介绍为:设想一个数据科学家可以定期将人工智能和机器学习项目大规模布署到生产中的世界,快速向决策者提供看法。这对您的业务有何影响?Anaconda Enterprise支持您......
chaishen10000的专栏
09-28
1228
关于BoilerpipeExtractor解析html乱码问题
网上给出的方案基于jsoup来获取body的byte流,但是写出的东西压根没有用到jsoup,getEmptyConnection(url)?private String extractContent(String url) throws Exception {InputStream inputStream = new ByteArrayInputStream(getEmptyConne...
正文提取工具boilerpipe
11-08
过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。
smallnetvisitor的博客
10-11
353
新闻正文提取之boilerpipe
概述:Boilerpipe即我们须要的正文提取工具,其算法的基本思想是通过训练获得一个分类器来提取出我们须要的信息,包括多种提取方法具体的参见:CommonExtractors环境:jdk1.6boilerpipe-1.2.0提取新闻正文demo代码如下:public static void main(String[] args) throws Excepti...... 查看全部
科大树蛙文本挖掘小组
10-15
1万+
文本聚类算法简略
文本聚类算法剖析1.传统的文本聚类算法传统的文本降维算法分为以下几种1.1分割方式(partitioningmethods)1.1.1K-MEANS算法:工作原理:首先从n个数据对象任意选择k个对象作为初始降维中心;而对于所剩下其它对象
涅槃重生
11-05
1430
开源数据采集技术对比
数据是监控报案的基石,我们在实现海量数据剖析监控前,需要有一个顺手的工具来搜集那些数据开源日志搜集工具对比从上表中可以看出,Logstash 虽然功能比较强悍,但是占用系统的资源也比较多, 而Filebeat似乎不支持日志解析,但是占用资源最少。而且使用我们运维人员熟悉的go语言开发,做二次开发也更容易些。......
网页正文提取工具boilerpipe1.2bin包07-19
输入一个url或则string型的网页源码,通过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。网页正文提取工具,这是目前销量最高,提取一个网页正文信息只须要毫秒级的
GarfieldEr007的专栏
12-04
1926
Day 18: BoilerPipe —— Java开发者的文章提取工具
今天我决定学习怎么使用Java做网页链接的文本和图象提取。在大多数内容发觉网站上(如Prismatic)这是一个十分常见的需求,今天就是学习怎么使用一个名为boilerpipe的Java库来完成这个任务。准备基本的Java知识是必需的,安装最新的Java开发工具包(JDK ),可以是OpenJDK 7或Oracle JDK 7。注册一个OpenShift账户,它是完全免...
风云千樯、
05-10
599
pip或则python安装jpype总是报错----Boilerpipe使用
使用pip或则python setup install 安装jpype总是报错,几乎搜遍全网,使用了各类解决方案,均无效,遂舍弃,换思路使用Anaconda进行安装首先安装Anaconda,Anaconda官网的介绍为:设想一个数据科学家可以定期将人工智能和机器学习项目大规模布署到生产中的世界,快速向决策者提供看法。这对您的业务有何影响?Anaconda Enterprise支持您......
chaishen10000的专栏
09-28
1228
关于BoilerpipeExtractor解析html乱码问题
网上给出的方案基于jsoup来获取body的byte流,但是写出的东西压根没有用到jsoup,getEmptyConnection(url)?private String extractContent(String url) throws Exception {InputStream inputStream = new ByteArrayInputStream(getEmptyConne...
正文提取工具boilerpipe
11-08
过该工具即可得到想要的正文信息,例如提取各大门户网站的新闻,历史,娱乐等的正文信息。
smallnetvisitor的博客
10-11
353
新闻正文提取之boilerpipe
概述:Boilerpipe即我们须要的正文提取工具,其算法的基本思想是通过训练获得一个分类器来提取出我们须要的信息,包括多种提取方法具体的参见:CommonExtractors环境:jdk1.6boilerpipe-1.2.0提取新闻正文demo代码如下:public static void main(String[] args) throws Excepti......
基于SpringBoot的日志集中搜集、微服务使用及切面的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-13 12:01
一篇文章全面了解SpringBoot
,通过SpringBoot我们可以很方便的开发后台Restful插口,前端代码可通过调用那些插口调阅动态数据,本文主要介绍基于SpringBoot常常面临到的一些其他常见问题做个整理;
在一篇文章全面了解SpringBoot这篇文章中我们解决了:
配置文件如何管理,不同的环境配置文件如何分辨(如QA,生产和开发环境);
项目怎样做集成测试和单元测试:不光单元测试,还包括模拟用户的真实操作;
修改Java代码的时侯帮我手动重启服务器,以便能实时反映更改情况;
修改静态页面代码,网页无需自动刷新,帮我手动LiveReload;
部署打包如何实现一键布署?
项目怎样做到纵向扩充,即如何保持各个Web项目sessionid同步?
发布的项目怎么做监控,怎么无缝扩充监控指标?
项目中怎样剥离“脚本类”代码,比如公式定义等?
Web安全是否每次须要我自己实现,比如处理登入,登出,URI保护等?
繁杂的数据库操作我是否一定要写一大堆BO,VO,Service,DAO?
JavaBean中一定要写这么多Getter和Setter么?
maven中的依赖引入与排除,版本冲突是否非得我自己整理和排查?
项目进行中的数据库脚本管理如何管理?防止变更错误,跨数据库的脚本管理呢?
这篇文章我们进一步解决:
SpringBoot启用log4j记录日志,并发日志发往log4j日志中心(集中化日志管理与监控);
SpringBoot调用微服务Dubbo;
SpringBoot中使用切面:接口调用统计,API权限分级等;
日志集中式管理与监控
首先我们须要做一个Socket的服务端,基于Netty自定义榆林包体的TCP程序设计我们会在下一篇介绍并给出源码,这里记为logger-server程序,项目中,只须要引入client的maven jar即可,自定义的Log4j的Appender的实现较为简单,本文不做介绍,这一切都就绪后,在项目只须要引入maven和配置即可实现将log发往日志中心:
添加maven依赖
在资源目录下新建:
在代码任意处借助log4j写入日志,如:
至此,通过nettyIOAppender ref的Logger就会将日志发往日志中心,在那里你可以得到那个类,哪个方式,来自那个用户做了哪些处理,可以搜集到用户使用的浏览器信息,来源IP,访问来源等有效信息,可用于插口统计,用户行为搜集,排错跟踪等,下图是Netty服务端收到的消息:
Dubbo微服务的使用
在我们设计和实现后台构架时,我们会把公共的服务弄成微服务便于所有系统可以共享,比如在一个电商系统中,我们会把商品分类,商品详情信息,用户等信息封装成微服务,这样网站,客服系统,统计统计,CRM系统等会可以调用那些微服务,减少重复开发,而且微服务框架通常还提供负载均衡,版本控制,限流等众多功能;
Alibaba的团队针对Dubbo的使用专门提供了SpringBoot的maven依赖工程:
在我们编撰后台服务时,如需调用微服务(消费方),我们只须要在Controller里将微服务的Service依赖注入进来即可:
并在中加入配置:
Aspect切面的使用
在我们项目开发中,我们常常会遇到统计插口调用次数以及API分级调用(有些插口须要特定API级别能够调用)的功能,这时我们就可以使用到切面,使用步骤如下: 查看全部
在先前文章中,我们介绍了SpringBoot的使用,详见:
一篇文章全面了解SpringBoot
,通过SpringBoot我们可以很方便的开发后台Restful插口,前端代码可通过调用那些插口调阅动态数据,本文主要介绍基于SpringBoot常常面临到的一些其他常见问题做个整理;
在一篇文章全面了解SpringBoot这篇文章中我们解决了:
配置文件如何管理,不同的环境配置文件如何分辨(如QA,生产和开发环境);
项目怎样做集成测试和单元测试:不光单元测试,还包括模拟用户的真实操作;
修改Java代码的时侯帮我手动重启服务器,以便能实时反映更改情况;
修改静态页面代码,网页无需自动刷新,帮我手动LiveReload;
部署打包如何实现一键布署?
项目怎样做到纵向扩充,即如何保持各个Web项目sessionid同步?
发布的项目怎么做监控,怎么无缝扩充监控指标?
项目中怎样剥离“脚本类”代码,比如公式定义等?
Web安全是否每次须要我自己实现,比如处理登入,登出,URI保护等?
繁杂的数据库操作我是否一定要写一大堆BO,VO,Service,DAO?
JavaBean中一定要写这么多Getter和Setter么?
maven中的依赖引入与排除,版本冲突是否非得我自己整理和排查?
项目进行中的数据库脚本管理如何管理?防止变更错误,跨数据库的脚本管理呢?
这篇文章我们进一步解决:
SpringBoot启用log4j记录日志,并发日志发往log4j日志中心(集中化日志管理与监控);
SpringBoot调用微服务Dubbo;
SpringBoot中使用切面:接口调用统计,API权限分级等;
日志集中式管理与监控
首先我们须要做一个Socket的服务端,基于Netty自定义榆林包体的TCP程序设计我们会在下一篇介绍并给出源码,这里记为logger-server程序,项目中,只须要引入client的maven jar即可,自定义的Log4j的Appender的实现较为简单,本文不做介绍,这一切都就绪后,在项目只须要引入maven和配置即可实现将log发往日志中心:
添加maven依赖
在资源目录下新建:
在代码任意处借助log4j写入日志,如:
至此,通过nettyIOAppender ref的Logger就会将日志发往日志中心,在那里你可以得到那个类,哪个方式,来自那个用户做了哪些处理,可以搜集到用户使用的浏览器信息,来源IP,访问来源等有效信息,可用于插口统计,用户行为搜集,排错跟踪等,下图是Netty服务端收到的消息:
Dubbo微服务的使用
在我们设计和实现后台构架时,我们会把公共的服务弄成微服务便于所有系统可以共享,比如在一个电商系统中,我们会把商品分类,商品详情信息,用户等信息封装成微服务,这样网站,客服系统,统计统计,CRM系统等会可以调用那些微服务,减少重复开发,而且微服务框架通常还提供负载均衡,版本控制,限流等众多功能;
Alibaba的团队针对Dubbo的使用专门提供了SpringBoot的maven依赖工程:
在我们编撰后台服务时,如需调用微服务(消费方),我们只须要在Controller里将微服务的Service依赖注入进来即可:
并在中加入配置:
Aspect切面的使用
在我们项目开发中,我们常常会遇到统计插口调用次数以及API分级调用(有些插口须要特定API级别能够调用)的功能,这时我们就可以使用到切面,使用步骤如下:
Log日志规范
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-13 01:27
l 问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在安装配置时,通过日志可以发觉问题。
l 状态监控:通过实时剖析日志,可以监控系统的运行状态,做到早发现问题、早处理问题。
l 安全审计:审计主要彰显在安全上,通过对日志进行剖析,可以发觉是否存在非授权的操作。
2 记录Log的基本原则2.1 日志的级别界定
Java日志一般可以分为:error、warn、info、debug、trace五个级别。在J2SE中预定义的级别更多,分别为:SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。两者的对应大致如下:
|
Log4j、slf4j
|
J2se
|
使用场景
|
|
error
|
SEVERE
|
问题早已影响到软件的正常运行,并且软件不能自行恢复到正常的运行状态,此时须要输出该级别的错误日志。
|
|
warn
|
WARNING
|
与业务处理相关的失败,此次失败不影响上次业务的执行,通常的结果为外部的输入不能获得期望的结果。
|
|
info
|
INFO
|
系统运行期间的系统运行状态变化,或关键业务处理记录等用户或管理员在系统运行期间关注的一些信息。
|
|
CONFIG
|
系统配置、系统运行环境信息,有助于安装施行人员检测配置是否正确。
|
|
debug
|
FINE
|
软件调试信息,开发人员使用该级别的日志发觉程序运行中的一些问题,排除故障。
|
|
FINER
|
基本同上,但显示的信息更详尽。
|
|
trace
|
FINEST
|
基本同上,但显示的信息更详尽。
|
2.2 日志对性能影响
不管是多么优秀的日志工具,在日志输出时总会对性能形成或多或少的影响,为了将影响减少到最低,有以下几个准则须要遵循:
l 如何创建Logger实例:创建Logger实例有是否static的区别,在log4j的初期版本,一般要求使用static,而在高版本以及后来的slf4j中,该问题早已得到优化,获取(创建)logger实例的成本早已太低。所以我们要求:对于可以预见的多数情况下单例运行的class,可以不添加static前缀;对于可能是多例居多,尤其是须要频繁创建的class,我们要求要添加static前缀。
l 判断日志级别:
n对于可以预见的会频繁形成的日志输出,比如for、while循环,定期执行的job等,建议先使用if对日志级别进行判定后再输出。
n对于日志输出内容须要复杂的序列化,或输出的个别信息获取成本较高时,需要对日志级别进行判定。比如日志中须要输出用户名,而用户名须要在日志输出时从数据库获取,此时就须要先判定一下日志级别,看看是否有必要获取这种信息。
l 优先使用参数,减少字符串拼接:使用参数的方法输出日志信息,有助于在性能和代码简约之间取得平衡。当日志级别限制输出该日志时,参数内容将不会融合到最终输出中,减少了字符串的拼接,从而提高执行效率。
2.3 什么时候输出日志
日志并不是越多越详尽就越好。在剖析运行日志,查找问题时,我们常常遇见该出现的日志没有,无用的日志一大堆,或者有效的日志被大量无意义的日志信息吞没,查找上去十分困难。那么哪些时侯输出日志呢?以下述出了一些常见的须要输出日志的情况,而且日志的级别基本都是>=INFO,至于Debug级别日志的使用场景,本节没有专门列举,需要具体情况具体剖析,但也是要追求“恰如其分”,不是越多越好。
2.3.1 系统启动参数、环境变量
系统启动的参数、配置、环境变量、System.Properties等信息对于软件的正常运行至关重要,这些信息的输出有助于安装配置人员通过日志快速定位问题,所以程序有必要在启动过程中把使用到的关键参数、变量在日志中输出下来。在输出时须要注意,不是一股脑的全部输出,而是将软件运行涉及到的配置信息输出下来。比如,如果软件对jvm的内存参数比较敏感,对最低配置有要求,那么就须要在日志少将-Xms -Xmx -XX:PermSize这几个参数的值输出下来。
2.3.2 异常捕获处
在捕获异常处输出日志,大家在基本都能做到,唯一须要注意的是如何输出一个简单明了的日志信息。这在前面的问题问题中有进一步说明。
2.3.3 函数获得期望之外的结果时
一个函数,尤其是供外部系统或远程调用的函数,通常还会有一个期望的结果,但若果内部系统或输出参数发生错误时,函数将难以返回期望的正确结果,此时就须要记录日志,日志的基本一般是warn。需要非常说明的是,这里的期望之外的结果不是说没有返回就不需要记录日志了,也不是说返回false就须要记录日志。比如函数:isXXXXX(),无论返回true、false记录日志都不是必须的,但是假如系统内部难以判定应当返回true还是false时,就须要记录日志,并且日志的级别应当起码是warn。
2.3.4 关键操作
关键操作的日志通常是INFO级别,如果数目、频度很高,可以考虑使用DEBUG级别。以下是一些关键操作的举例,实际的关键操作肯定不止这么多。
n 删除:删除一个文件、删除一组重要数据库记录……
n 添加:和外系统交互时,收到了一个文件、收到了一个任务……
n 处理:开始、结束一条任务……
n ……
2.4 日志输出的内容
l ERROR:错误的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l WARN:告警的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l INFO:言简意赅地信息描述,如果有相关动态关键数据,要一并输出,比如相关ID、名称等。
l DEBUG:简单描述,相关数据,如果有异常,要有该异常的StackTrace。
在日志相关数据输出的时要非常注意对敏感信息的保护,比如更改密码时,不能将密码输出到日志中。
2.5 什么时候使用J2SE自带的日志
我们一般使用slf4j或log4j这两个工具记录日志,那么还须要使用J2SE的日志框架吗?当然须要,在我们编撰一些通用的工具类时,为了减轻对第三方的jar包的依赖,首先要考虑使用java.util.logging。
考虑到slf4j等日志框架提供了日志bridge工具,为java.util.logging提供了Handler,所以普通应用的开发过程中也可以考虑使用J2SE自有日志,这样不但可以降低项目的编译依赖,同时在应用施行时可以更灵活的选择日志的输出工具包。
3 典型问题剖析3.1 该用日志的地方不用
上图对异常的处理直接使用e.printStackTrace()显然是有问题的,正确的做法是:要么通过日志形式输出错误信息,要么直接抛出异常,要么创建新的自定义异常抛出。
另:对于静态工具类函数中的异常处理,最简单的方法就是不捕获、不记录日志,直接向下抛出,如果觉得异常类型太多,或者意义不明晰,可以抛出自定义异常类的实例。
3.2 啰嗦重复、没有重点
首先里面不应当有error级别的日志。
其次在日志中直接输出e.toString(),为定位问题提供的信息很少。
另外须要明晰一点:日志系统是一个多线程公用的系统,在两行日志输出之间有可能会被插入其他线程的日志记录,不会根据我们的意愿次序输出,后面有更典型的事例。
最后,上面的日志可以简化为:
logger.debug(“从properties中...{}...{}...”,name, value, e);
logger.warn(“从properties中获取{}发生错误:{}”,name, e.toString());
或者直接一句:
logger.warn(“从properties中...{}...{}...”,name, value, e);
或者更完美的:
if(logger.isDebugEnabled()){
logger.warn(“从properties中...{}...”, name, e);
}else{
logger.warn(“从properties中获取{}发生错误:{}”, name, e.toString());
}
3.3 日志和异常处理的关系
首先里面的日志信息不够充分,级别定义不够恰当。
另外,既然将异常捕获并记录的日志,就不应当重新将一个一模一样的异常再度抛出去了。如果将异常再度抛出,那在下层肯定还须要对该异常进行处理,并记录日志,这样就重复了。如果没有非常缘由,此处不应当捕获异常。
3.4 System.out形式的日志
上面的日志方式非常随便,只适宜临时的代码调试,不容许递交到即将的代码库中。
对于临时调试日志,建议在日志的输出信息中添加一些特殊的连续字符,也可以用自己的名称、代号,这样可以在调试完毕后,提交代码之前,方便地找到所有临时代码,一并删掉。
3.5 日志信息不明晰
上面的“添加任务出错。。。”既没有记录任务id,也没有任务名称,软件布署后发觉错误后,根据该日志记录不能确认哪一条任务错误,给进一步的剖析缘由带来困难。
另外第二个红圈中的问题有:要使用参数;一行日志就可以了。
还有一些其他共性的错误,就不多说了。
3.6 忘记日志输出是多线程公用的
如果有另外一个线程正在输出日志,上面的记录都会被打断,最终显示输出和想像的都会不一致。正确的做法应是将这种信息放在一行,如果须要换行可以考虑使用“\r”,如果内容较多,考虑降低if (logger.isDebugEnabled())进行判定。而第二个事例中的输出有System.out的习惯,相关内容应当一行完成。
3.7 多个参数的处理
对于多参的日志输出,可以考虑:
public void debug(String format, Object... arguments);
但是在使用多参时,会创建一个对象字段,也会有一定的消耗,为此,在对性能敏感的场景,可以降低对日志级别的判别。
在开发B/S系统时,对于LOG,需要关注:
日志信息的集中采集、存储、信息检索:在WEB集群节点越来越多的情况下,让开发及系统维护人员能很方便的查看日志信息日志信息的输出策略:日志信息输出全而不乱,便于跟踪和剖析问题关键业务的日志输出:基于测度数据采集、数据核查、系统安全等方面的考虑,关键业务系统对输出的日志信息有特殊的要求,需要做针对性的设计
本文主要从这3个方面进行说明,重点说明日志输出的使用
日志的采集和储存
对于目前储存日志,主要存在2种形式:
本地日志:直接储存在本地c盘上远程日志:发往日志平台,用作数据剖析和日志处理并彰显。如用户访问行为的记录,异常日志,性能统计日志等。
日志工具的选择
推荐使用SLF4J(Simple Logging Facade for Java)作为日志的api,SLF4J是一个用于日志系统的简单Facade,允许最终用户在布署其应用时使用其所希望的日志系统。与使用apache commons-logging和直接使用log4j相比,SLF4J提供了一个名为参数化日志的中级特点,可以明显提升在配置为关掉日志的情况下的日志句子性能
//slf4j
log.debug("Found {} records matching filter: '{}'", records, filter);
//log4j
log.debug("Found " + records + " records matching filter: '" + filter + "'");
可以看出SLF4J的形式一方面更详尽易读,另一方面少了字符串拼接的开支,并且在日志级别达不到时(这里反例即为设置级别为debug以上),不会调用对象的toString方式。
日志输出级别(由高到低)
推荐使用debug,info,warn,error级别即可,对于不同的级别可以设置不同的输出路径,如debug,info输出到一个文件,warn,error输出到一个带error后缀的文件
日志API规范
// (推荐)
private static final Logger logger = LoggerFactory.getLogger(Xxx.class);
private final Logger logger = LoggerFactory.getLogger(getClass());
private static final Logger logger = LoggerFactory.getLogger("loggerName");
private static Logger logger = LoggerFactory.getLogger(Xxx.class);
protected final Logger logger = LoggerFactory.getLogger(getClass());
private Logger logger = LoggerFactory.getLogger(getClass());
protected Logger logger = LoggerFactory.getLogger(getClass());
if (logger.isDebugEnabled()) {
logger.debug(test());
}
private String test(){
int i = 0;
while (i < 1000000) {
i++;
}
return "";
}
如果不加 isXxxEnabled() 判断,test()在info级别下也会执行。
log.error("IO exception", e);
throw new MyCustomException(e);
这种方式总是会复印两次相同的 stack trace信息,因为有些地方会捕捉MyCustomException异常,然后输出造成问题的日志信息。
但有时基于个别缘由我们真的想log异常信息怎样办?很过见多的log句子有一半以上都是错的,
如:
try {
Integer x = null;
++x;
} catch (Exception e) {
//A
log.error(e);
//B
log.error(e, e);
//C
log.error(""+ e);
//D
log.error(e.toString());
//E
log.error(e.getMessage());
//F
log.error(null, e);
//G
log.error("", e);
//H
log.error("{}", e);
//I
log.error("{}", e.getMessage());
//J
log.error("Error reading configuration file: " + e);
//K
log.error("Error reading configuration file: "+ e.getMessage());
//L
log.error("Error reading configuration file", e);
}
上面只有G、L是对的,L的处理方法更好一些
注意:捕获异常后不处理也不输出log是一种特别不负责任的行为,这会导致问题很难被定位,极大地提升debug成本!
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
//Lengthy printing operation
String id = "Id";
log.debug("Leaving printDocument(): {}", id);
return id;
}
因为对于非开发人员掌控的环境(无法做DEBUG),记录方式调用、入参、返回值的形式对于排查问题会有很大帮助。
log.debug("Processing request with id: {}", request.getId());
你能确保request对象不是NULL吗?如果request为null,就会抛出NullPointerException。
try {
log.trace("Id=" + request.getUser().getId() + " accesses" + manager.getPage().getUrl().toString())
} catch(NullPointerException e) {
}
log.debug("Message processed");
log.debug(message.getJMSMessageID());
log.debug("Message with id '{}' processed", message.getJMSMessageID());
if (message instanceof TextMessage)
//...
else {
log.warn("Unknown message type");
}
为什么不收录 message type, message id, etc,收录个message content很难吗?另一个anti-pattern是magic-log。
有些开发人员为了自己查找信息便捷,输出类似“&&&!#”的Log,而不是“Message with XYZ id received”。
最后,Log 不要涉及密码及个人信息(身份证、银行卡号etc)
配置规范
作者 @九都散人
2015 年 11月 22日
参考
作者:九都散人
链接:
來源:简书
简书著作权归作者所有,任何方式的转载都请联系作者获得授权并标明出处。
Overview
一个在生产环境里运行的程序假如没有日志是太使维护者提心吊胆的,有太多零乱又无意义的日志也是令人伤神。程序出现问题时侯,从日志里假如发觉不了问题可能的诱因是太令人失利的。本文想讨论的是怎样在Java程序里写好日志。
一般来说日志分为两种:业务日志和异常日志,使用日志我们希望能达到以下目标:
对程序运行情况的记录和监控;在必要时可详尽了解程序内部的运行状态;对系统性能的影响尽量小;Java日志框架
Java的日志框架太多了。。。
Log4j 或 Log4j 2 - Apache的开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套插口服务器、NT的事件记录器、UNIX Syslog守护进程等;用户也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,用户还能愈发细致地控制日志的生成过程。这些可以通过一个配置文件(XML或Properties文件)来灵活地进行配置,而不需要更改程序代码。Log4j 2则是前任的一个升级,参考了Logback的许多特点;Logback - Logback是由log4j创始人设计的又一个开源日记组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个改良版本。此外logback-classic完整实现SLF4J API让你可以很方便地更换成其它日记系统如log4j或JDK14 Logging;java.util.logging - JDK外置的日志插口和实现,功能比较简;Slf4j - SLF4J是为各类Logging API提供一个简单统一的插口),从而让用户才能在布署的时侯配置自己希望的Logging API实现;Apache Commons Logging - Apache Commons Logging (JCL)希望解决的问题和Slf4j类似。
选项太多了的后果就是选择困难症,我的想法是没有最好的,只有最合适的。在比较关注性能的地方,选择Logback或自己实现高性能Logging API可能更合适;在早已使用了Log4j的项目中,如果没有发觉问题,继续使用可能是更合适的方法;我通常会在项目里选择使用Slf4j, 如果不想有依赖则使用java.util.logging或框架容器早已提供的日志插口。
Java日志最佳实践定义日志变量
日志变量常常不变,最好定义成final static,变量名用小写。
日志分级
Java的日志框架通常会提供以下日志级别,缺省打开info级别,也就是debug,trace级别的日志在生产环境不会输出,在开发和测试环境可以通过不同的日志配置文件打开debug级别。
fatal - 严重的,造成服务中断的错误;error - 其他错误运行期错误;warn - 警告信息,如程序调用了一个正式作废的插口,接口的不当使用,运行状态不是期望的但仍可继续处理等;info - 有意义的风波信息,如程序启动,关闭风波,收到恳求风波等;debug - 调试信息,可记录详尽的业务处理到哪一步了,以及当前的变量状态;trace - 更详尽的跟踪信息;
在程序里要合理使用日志分级:
image
基本的Logger编码规范
1.在一个对象中一般只使用一个Logger对象,Logger应当是static final的,只有在少数须要在构造函数中传递logger的情况下才使用private final。
log
2.输出Exceptions的全部Throwable信息,因为logger.error(msg)和logger.error(msg,e.getMessage())这样的日志输出方式会遗失掉最重要的StackTrace信息。
log
3.不容许记录日志后又抛出异常,因为这样会多次记录日志,只容许记录一次日志。
log
4.不容许出现System print(包括System.out.println和System.error.println)语句。
log
5.不容许出现printStackTrace。
log
6.日志性能的考虑,如果代码为核心代码,执行频度十分高,则输出日志建议降低判定,尤其是低级别的输出。
debug日志太多后可能会影响性能,有一种改进方式是:
image
但更好的方式是Slf4j提供的:
image
一方面可以降低参数构造的开支,另一方面也不用多写两行代码。
7.有意义的日志
通常情况下在程序日志里记录一些比较有意义的状态数据:程序启动,退出的时间点;程序运行消耗时间;耗时程序的执行进度;重要变量的状态变化。
初次之外,在公共的日志里规避复印程序的调试或则提示信息。
FAQ:参考
1.7 Good Rules to Log Exceptions
2.5 common log mistakes
3.Java程序的日志
作者:Helen_Cat
链接: 查看全部
不管是使用何种编程语言,日志输出几乎无处不再。总结上去,日志大致有以下几种用途:
l 问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在安装配置时,通过日志可以发觉问题。
l 状态监控:通过实时剖析日志,可以监控系统的运行状态,做到早发现问题、早处理问题。
l 安全审计:审计主要彰显在安全上,通过对日志进行剖析,可以发觉是否存在非授权的操作。
2 记录Log的基本原则2.1 日志的级别界定
Java日志一般可以分为:error、warn、info、debug、trace五个级别。在J2SE中预定义的级别更多,分别为:SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。两者的对应大致如下:
|
Log4j、slf4j
|
J2se
|
使用场景
|
|
error
|
SEVERE
|
问题早已影响到软件的正常运行,并且软件不能自行恢复到正常的运行状态,此时须要输出该级别的错误日志。
|
|
warn
|
WARNING
|
与业务处理相关的失败,此次失败不影响上次业务的执行,通常的结果为外部的输入不能获得期望的结果。
|
|
info
|
INFO
|
系统运行期间的系统运行状态变化,或关键业务处理记录等用户或管理员在系统运行期间关注的一些信息。
|
|
CONFIG
|
系统配置、系统运行环境信息,有助于安装施行人员检测配置是否正确。
|
|
debug
|
FINE
|
软件调试信息,开发人员使用该级别的日志发觉程序运行中的一些问题,排除故障。
|
|
FINER
|
基本同上,但显示的信息更详尽。
|
|
trace
|
FINEST
|
基本同上,但显示的信息更详尽。
|
2.2 日志对性能影响
不管是多么优秀的日志工具,在日志输出时总会对性能形成或多或少的影响,为了将影响减少到最低,有以下几个准则须要遵循:
l 如何创建Logger实例:创建Logger实例有是否static的区别,在log4j的初期版本,一般要求使用static,而在高版本以及后来的slf4j中,该问题早已得到优化,获取(创建)logger实例的成本早已太低。所以我们要求:对于可以预见的多数情况下单例运行的class,可以不添加static前缀;对于可能是多例居多,尤其是须要频繁创建的class,我们要求要添加static前缀。
l 判断日志级别:
n对于可以预见的会频繁形成的日志输出,比如for、while循环,定期执行的job等,建议先使用if对日志级别进行判定后再输出。
n对于日志输出内容须要复杂的序列化,或输出的个别信息获取成本较高时,需要对日志级别进行判定。比如日志中须要输出用户名,而用户名须要在日志输出时从数据库获取,此时就须要先判定一下日志级别,看看是否有必要获取这种信息。
l 优先使用参数,减少字符串拼接:使用参数的方法输出日志信息,有助于在性能和代码简约之间取得平衡。当日志级别限制输出该日志时,参数内容将不会融合到最终输出中,减少了字符串的拼接,从而提高执行效率。
2.3 什么时候输出日志
日志并不是越多越详尽就越好。在剖析运行日志,查找问题时,我们常常遇见该出现的日志没有,无用的日志一大堆,或者有效的日志被大量无意义的日志信息吞没,查找上去十分困难。那么哪些时侯输出日志呢?以下述出了一些常见的须要输出日志的情况,而且日志的级别基本都是>=INFO,至于Debug级别日志的使用场景,本节没有专门列举,需要具体情况具体剖析,但也是要追求“恰如其分”,不是越多越好。
2.3.1 系统启动参数、环境变量
系统启动的参数、配置、环境变量、System.Properties等信息对于软件的正常运行至关重要,这些信息的输出有助于安装配置人员通过日志快速定位问题,所以程序有必要在启动过程中把使用到的关键参数、变量在日志中输出下来。在输出时须要注意,不是一股脑的全部输出,而是将软件运行涉及到的配置信息输出下来。比如,如果软件对jvm的内存参数比较敏感,对最低配置有要求,那么就须要在日志少将-Xms -Xmx -XX:PermSize这几个参数的值输出下来。
2.3.2 异常捕获处
在捕获异常处输出日志,大家在基本都能做到,唯一须要注意的是如何输出一个简单明了的日志信息。这在前面的问题问题中有进一步说明。
2.3.3 函数获得期望之外的结果时
一个函数,尤其是供外部系统或远程调用的函数,通常还会有一个期望的结果,但若果内部系统或输出参数发生错误时,函数将难以返回期望的正确结果,此时就须要记录日志,日志的基本一般是warn。需要非常说明的是,这里的期望之外的结果不是说没有返回就不需要记录日志了,也不是说返回false就须要记录日志。比如函数:isXXXXX(),无论返回true、false记录日志都不是必须的,但是假如系统内部难以判定应当返回true还是false时,就须要记录日志,并且日志的级别应当起码是warn。
2.3.4 关键操作
关键操作的日志通常是INFO级别,如果数目、频度很高,可以考虑使用DEBUG级别。以下是一些关键操作的举例,实际的关键操作肯定不止这么多。
n 删除:删除一个文件、删除一组重要数据库记录……
n 添加:和外系统交互时,收到了一个文件、收到了一个任务……
n 处理:开始、结束一条任务……
n ……
2.4 日志输出的内容
l ERROR:错误的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l WARN:告警的简略描述,和该错误相关的关键参数,如果有异常,要有该异常的StackTrace。
l INFO:言简意赅地信息描述,如果有相关动态关键数据,要一并输出,比如相关ID、名称等。
l DEBUG:简单描述,相关数据,如果有异常,要有该异常的StackTrace。
在日志相关数据输出的时要非常注意对敏感信息的保护,比如更改密码时,不能将密码输出到日志中。
2.5 什么时候使用J2SE自带的日志
我们一般使用slf4j或log4j这两个工具记录日志,那么还须要使用J2SE的日志框架吗?当然须要,在我们编撰一些通用的工具类时,为了减轻对第三方的jar包的依赖,首先要考虑使用java.util.logging。
考虑到slf4j等日志框架提供了日志bridge工具,为java.util.logging提供了Handler,所以普通应用的开发过程中也可以考虑使用J2SE自有日志,这样不但可以降低项目的编译依赖,同时在应用施行时可以更灵活的选择日志的输出工具包。
3 典型问题剖析3.1 该用日志的地方不用
上图对异常的处理直接使用e.printStackTrace()显然是有问题的,正确的做法是:要么通过日志形式输出错误信息,要么直接抛出异常,要么创建新的自定义异常抛出。
另:对于静态工具类函数中的异常处理,最简单的方法就是不捕获、不记录日志,直接向下抛出,如果觉得异常类型太多,或者意义不明晰,可以抛出自定义异常类的实例。
3.2 啰嗦重复、没有重点
首先里面不应当有error级别的日志。
其次在日志中直接输出e.toString(),为定位问题提供的信息很少。
另外须要明晰一点:日志系统是一个多线程公用的系统,在两行日志输出之间有可能会被插入其他线程的日志记录,不会根据我们的意愿次序输出,后面有更典型的事例。
最后,上面的日志可以简化为:
logger.debug(“从properties中...{}...{}...”,name, value, e);
logger.warn(“从properties中获取{}发生错误:{}”,name, e.toString());
或者直接一句:
logger.warn(“从properties中...{}...{}...”,name, value, e);
或者更完美的:
if(logger.isDebugEnabled()){
logger.warn(“从properties中...{}...”, name, e);
}else{
logger.warn(“从properties中获取{}发生错误:{}”, name, e.toString());
}
3.3 日志和异常处理的关系
首先里面的日志信息不够充分,级别定义不够恰当。
另外,既然将异常捕获并记录的日志,就不应当重新将一个一模一样的异常再度抛出去了。如果将异常再度抛出,那在下层肯定还须要对该异常进行处理,并记录日志,这样就重复了。如果没有非常缘由,此处不应当捕获异常。
3.4 System.out形式的日志
上面的日志方式非常随便,只适宜临时的代码调试,不容许递交到即将的代码库中。
对于临时调试日志,建议在日志的输出信息中添加一些特殊的连续字符,也可以用自己的名称、代号,这样可以在调试完毕后,提交代码之前,方便地找到所有临时代码,一并删掉。
3.5 日志信息不明晰
上面的“添加任务出错。。。”既没有记录任务id,也没有任务名称,软件布署后发觉错误后,根据该日志记录不能确认哪一条任务错误,给进一步的剖析缘由带来困难。
另外第二个红圈中的问题有:要使用参数;一行日志就可以了。
还有一些其他共性的错误,就不多说了。
3.6 忘记日志输出是多线程公用的
如果有另外一个线程正在输出日志,上面的记录都会被打断,最终显示输出和想像的都会不一致。正确的做法应是将这种信息放在一行,如果须要换行可以考虑使用“\r”,如果内容较多,考虑降低if (logger.isDebugEnabled())进行判定。而第二个事例中的输出有System.out的习惯,相关内容应当一行完成。
3.7 多个参数的处理
对于多参的日志输出,可以考虑:
public void debug(String format, Object... arguments);
但是在使用多参时,会创建一个对象字段,也会有一定的消耗,为此,在对性能敏感的场景,可以降低对日志级别的判别。
在开发B/S系统时,对于LOG,需要关注:
日志信息的集中采集、存储、信息检索:在WEB集群节点越来越多的情况下,让开发及系统维护人员能很方便的查看日志信息日志信息的输出策略:日志信息输出全而不乱,便于跟踪和剖析问题关键业务的日志输出:基于测度数据采集、数据核查、系统安全等方面的考虑,关键业务系统对输出的日志信息有特殊的要求,需要做针对性的设计
本文主要从这3个方面进行说明,重点说明日志输出的使用
日志的采集和储存
对于目前储存日志,主要存在2种形式:
本地日志:直接储存在本地c盘上远程日志:发往日志平台,用作数据剖析和日志处理并彰显。如用户访问行为的记录,异常日志,性能统计日志等。
日志工具的选择
推荐使用SLF4J(Simple Logging Facade for Java)作为日志的api,SLF4J是一个用于日志系统的简单Facade,允许最终用户在布署其应用时使用其所希望的日志系统。与使用apache commons-logging和直接使用log4j相比,SLF4J提供了一个名为参数化日志的中级特点,可以明显提升在配置为关掉日志的情况下的日志句子性能
//slf4j
log.debug("Found {} records matching filter: '{}'", records, filter);
//log4j
log.debug("Found " + records + " records matching filter: '" + filter + "'");
可以看出SLF4J的形式一方面更详尽易读,另一方面少了字符串拼接的开支,并且在日志级别达不到时(这里反例即为设置级别为debug以上),不会调用对象的toString方式。
日志输出级别(由高到低)
推荐使用debug,info,warn,error级别即可,对于不同的级别可以设置不同的输出路径,如debug,info输出到一个文件,warn,error输出到一个带error后缀的文件
日志API规范
// (推荐)
private static final Logger logger = LoggerFactory.getLogger(Xxx.class);
private final Logger logger = LoggerFactory.getLogger(getClass());
private static final Logger logger = LoggerFactory.getLogger("loggerName");
private static Logger logger = LoggerFactory.getLogger(Xxx.class);
protected final Logger logger = LoggerFactory.getLogger(getClass());
private Logger logger = LoggerFactory.getLogger(getClass());
protected Logger logger = LoggerFactory.getLogger(getClass());
if (logger.isDebugEnabled()) {
logger.debug(test());
}
private String test(){
int i = 0;
while (i < 1000000) {
i++;
}
return "";
}
如果不加 isXxxEnabled() 判断,test()在info级别下也会执行。
log.error("IO exception", e);
throw new MyCustomException(e);
这种方式总是会复印两次相同的 stack trace信息,因为有些地方会捕捉MyCustomException异常,然后输出造成问题的日志信息。
但有时基于个别缘由我们真的想log异常信息怎样办?很过见多的log句子有一半以上都是错的,
如:
try {
Integer x = null;
++x;
} catch (Exception e) {
//A
log.error(e);
//B
log.error(e, e);
//C
log.error(""+ e);
//D
log.error(e.toString());
//E
log.error(e.getMessage());
//F
log.error(null, e);
//G
log.error("", e);
//H
log.error("{}", e);
//I
log.error("{}", e.getMessage());
//J
log.error("Error reading configuration file: " + e);
//K
log.error("Error reading configuration file: "+ e.getMessage());
//L
log.error("Error reading configuration file", e);
}
上面只有G、L是对的,L的处理方法更好一些
注意:捕获异常后不处理也不输出log是一种特别不负责任的行为,这会导致问题很难被定位,极大地提升debug成本!
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
//Lengthy printing operation
String id = "Id";
log.debug("Leaving printDocument(): {}", id);
return id;
}
因为对于非开发人员掌控的环境(无法做DEBUG),记录方式调用、入参、返回值的形式对于排查问题会有很大帮助。
log.debug("Processing request with id: {}", request.getId());
你能确保request对象不是NULL吗?如果request为null,就会抛出NullPointerException。
try {
log.trace("Id=" + request.getUser().getId() + " accesses" + manager.getPage().getUrl().toString())
} catch(NullPointerException e) {
}
log.debug("Message processed");
log.debug(message.getJMSMessageID());
log.debug("Message with id '{}' processed", message.getJMSMessageID());
if (message instanceof TextMessage)
//...
else {
log.warn("Unknown message type");
}
为什么不收录 message type, message id, etc,收录个message content很难吗?另一个anti-pattern是magic-log。
有些开发人员为了自己查找信息便捷,输出类似“&&&!#”的Log,而不是“Message with XYZ id received”。
最后,Log 不要涉及密码及个人信息(身份证、银行卡号etc)
配置规范
作者 @九都散人
2015 年 11月 22日
参考
作者:九都散人
链接:
來源:简书
简书著作权归作者所有,任何方式的转载都请联系作者获得授权并标明出处。
Overview
一个在生产环境里运行的程序假如没有日志是太使维护者提心吊胆的,有太多零乱又无意义的日志也是令人伤神。程序出现问题时侯,从日志里假如发觉不了问题可能的诱因是太令人失利的。本文想讨论的是怎样在Java程序里写好日志。
一般来说日志分为两种:业务日志和异常日志,使用日志我们希望能达到以下目标:
对程序运行情况的记录和监控;在必要时可详尽了解程序内部的运行状态;对系统性能的影响尽量小;Java日志框架
Java的日志框架太多了。。。
Log4j 或 Log4j 2 - Apache的开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套插口服务器、NT的事件记录器、UNIX Syslog守护进程等;用户也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,用户还能愈发细致地控制日志的生成过程。这些可以通过一个配置文件(XML或Properties文件)来灵活地进行配置,而不需要更改程序代码。Log4j 2则是前任的一个升级,参考了Logback的许多特点;Logback - Logback是由log4j创始人设计的又一个开源日记组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个改良版本。此外logback-classic完整实现SLF4J API让你可以很方便地更换成其它日记系统如log4j或JDK14 Logging;java.util.logging - JDK外置的日志插口和实现,功能比较简;Slf4j - SLF4J是为各类Logging API提供一个简单统一的插口),从而让用户才能在布署的时侯配置自己希望的Logging API实现;Apache Commons Logging - Apache Commons Logging (JCL)希望解决的问题和Slf4j类似。
选项太多了的后果就是选择困难症,我的想法是没有最好的,只有最合适的。在比较关注性能的地方,选择Logback或自己实现高性能Logging API可能更合适;在早已使用了Log4j的项目中,如果没有发觉问题,继续使用可能是更合适的方法;我通常会在项目里选择使用Slf4j, 如果不想有依赖则使用java.util.logging或框架容器早已提供的日志插口。
Java日志最佳实践定义日志变量
日志变量常常不变,最好定义成final static,变量名用小写。
日志分级
Java的日志框架通常会提供以下日志级别,缺省打开info级别,也就是debug,trace级别的日志在生产环境不会输出,在开发和测试环境可以通过不同的日志配置文件打开debug级别。
fatal - 严重的,造成服务中断的错误;error - 其他错误运行期错误;warn - 警告信息,如程序调用了一个正式作废的插口,接口的不当使用,运行状态不是期望的但仍可继续处理等;info - 有意义的风波信息,如程序启动,关闭风波,收到恳求风波等;debug - 调试信息,可记录详尽的业务处理到哪一步了,以及当前的变量状态;trace - 更详尽的跟踪信息;
在程序里要合理使用日志分级:
image
基本的Logger编码规范
1.在一个对象中一般只使用一个Logger对象,Logger应当是static final的,只有在少数须要在构造函数中传递logger的情况下才使用private final。
log
2.输出Exceptions的全部Throwable信息,因为logger.error(msg)和logger.error(msg,e.getMessage())这样的日志输出方式会遗失掉最重要的StackTrace信息。
log
3.不容许记录日志后又抛出异常,因为这样会多次记录日志,只容许记录一次日志。
log
4.不容许出现System print(包括System.out.println和System.error.println)语句。
log
5.不容许出现printStackTrace。
log
6.日志性能的考虑,如果代码为核心代码,执行频度十分高,则输出日志建议降低判定,尤其是低级别的输出。
debug日志太多后可能会影响性能,有一种改进方式是:
image
但更好的方式是Slf4j提供的:
image
一方面可以降低参数构造的开支,另一方面也不用多写两行代码。
7.有意义的日志
通常情况下在程序日志里记录一些比较有意义的状态数据:程序启动,退出的时间点;程序运行消耗时间;耗时程序的执行进度;重要变量的状态变化。
初次之外,在公共的日志里规避复印程序的调试或则提示信息。
FAQ:参考
1.7 Good Rules to Log Exceptions
2.5 common log mistakes
3.Java程序的日志
作者:Helen_Cat
链接:
微信小程序云开发获取关联公众号的文章列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-13 00:36
首先想到的是,需要顾客去买服务器和域名,进行域名备案,然后为顾客开发一个网站,能够通过公众平台的appid与key来获取公众号的素材列表,最后开发一个插口给小程序使用。一般顾客选购服务器和域名就是个困局,劝退了很多人。
但是我查看了陌陌小程序的官方文档,发现有一个云开发功能,其中有云数据库、云存储、云函数三种功能。类似于Serverless,我们不需要去买服务器和域名了,直接使用小程序的云开发功能能够做好多事情。我就想试试能不能用云开发功能做获取公众号文章的事情。
云数据库是一个类似于Redis的Key-Value数据库,使用陌陌提供的一些查询API,能够进行链式操作,有点像.Net的Entity Framework。
云存储主要是拿来做上传与下载文件使用,可以拿来做相册等应用。
云函数是提供了一个Node.Js的运行环境,我们就能布署自己的代码,也才能使用npm配置引入其他的开源软件包。云函数只能通过陌陌小程序框架里特有的方法调用,并且返回结果。与我们订购服务器自建服务不同的是,我们不清楚究竟有几个实例在运行,每次执行不一定在同一个实例中,所以我们不太适宜做一些在显存中缓存数据、保持状态的工作,应当及时把数据存入云数据库。云开发的云函数的独到优势在于与陌陌登陆信令的无缝整合。当小程序端调用云函数时,云函数的传入参数中会被注入小程序端用户的 openid,开发者可以直接使用该 openid。
在做这个功能之前,首先是新建小程序,将公众平台与小程序关联,公众平台个人订阅号也是可以的。
然后在小程序的项目中,project.config.json文件中加入一个配置项,指定云函数的储存目录。
"cloudfunctionRoot": "clouds/"
新建这个clouds目录,在其中构建一个文件夹,比如我们命名为fetch,以后调用云函数也用这个名称,然后在其中新建index.js,作为云函数的入口。一个云函数的基本结构是:
// 云函数入口文件
const cloud = require('wx-server-sdk');
const request = require('request');
cloud.init();
// 云函数入口函数
exports.main = async (event, context) => {
return {200: 40400, msg: 'success'};
}
我们可以象MVC和Servlet等Web框架一样,要求客户端传一个action参数,然后按照不同的action参数,选择对应的处理函数,也可以创建多个云函数。代码类似于:
var action = event.action;
if(!action){
return {code: 20000, msg: 'hello, world'};
}
//dispatcher
var ret;
if(action === 'role'){
ret = await registerAndReturnUser(event);
} else if(action === 'userlist'){
ret = await fetchUserList(event);
} else if(action === 'updaterole'){
ret = await updateUser(event);
}
当然了我们可以使用npm install --save安装任何的npm开源包,像往常一样构建package.json,每次更新了云函数,都应当在云函数文件夹上点击右键,选择“上传并布署(云端安装依赖)”。
小程序后端调用云函数的代码是,无需晓得真实的URL,只需按云函数名称调用即可:
wx.cloud.callFunction({
// 云函数名称
name: 'fetch',
// 传给云函数的参数
data: {
keywords: this.data.keywords,
page: this.data.page,
limit: this.data.limit
},
success: function (res) {
console.log(res);
},
fail: err => {
console.log(err);
}
});
获取公众号的永久素材列表,可以参考这个文档。需要一个AccessToken,而AccessToken的过期时间是2小时,每天限制申请的次数,腾讯也建议在第三方服务器保存这个AccessToken。我们就可以把这个AccessToken存入云数据库中。申请AccessToken的文档在。
然后我们编撰一段代码获取AccessToken,然后查看云函数的日志,或者是我们主动加上throw句子,抛出异常,在小程序调试控制台也可以见到返回结果,经常会看见40164错误,这个错误会提示我们某个IP不在白名单中,我们就可以把这个IP加入微信公众号配置的白名单中。但是问题来了,小程序云开发的出口IP是浮动的,可能是一个集群在提供服务,不一定那个IP起作用。但是他又是有限的,当我们加了十几个IP时,发现常常可以命中我们的白名单列表,所以我们应当多试几次,把尽可能多的IP找下来。所以我就编撰了这样一段程序,当获取AccessToken失败,并且错误是40164时侯,首先在数据库中储存这个IP,等我们有时间了就把这种IP加入白名单,反复几次我们的白名单里就有一二十个IP了。这时候发觉我们的命中率上升了,请求好几次才有一次不命中的。所以我就编撰恳求失败之后立刻再恳求一次,最多恳求五次,类似于“再哈希”的算法,假设我们有50%的命中率,连续5次不命中的机率是3%左右,经过实验发觉,一般都能在五次之内成功获取AccessToken。
这段代码大致如下:
var getWechatAccessToken = async function(counter) {
//先检查数据库,如果token过期,返回空,继续执行网络请求
var tokenInDb = await this.getAccessTokenFromDB();
if (tokenInDb) {
return tokenInDb['accessToken'];
}
var token_url = 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=' + this.appid + '&' + 'secret=' + this.secret;
var result = await rp({
url: token_url,
method: 'GET'
});
var obj = (typeof result.body === 'object') ? result.body : JSON.parse(result.body);
if (obj.errcode && obj.errcode === 40164) {
var ip = obj.errmsg.split(' ')[2];
//保存IP到数据库
await this.insertIp(ip);
//try again and save ip to database;
counter += 1;
if (counter < 5) {
return await this.getWechatAccessToken(counter);
}
}
//保存AccessToken到数据库
if (obj['access_token']) {
this.saveTokenToDb(obj['access_token']);
return obj['access_token'];
}
return null;
}
我们储存了申请AccessToken的时间,可以按照这个时间选择使用这个数据库中储存的Token,或者是重新获取新的Token。接下来就是使用获取素材列表的插口获取所有的公众号文章。我们一直把它们存入数据库,这样上次小程序恳求,就可以直接从云数据库中访问。获取公众号素材列表有个限制是一次只能获取20条,我们须要先查出总量,然后分页获取。同样的是,查询云数据库一次最多获取100条,我们也是须要先查出总量,再分页查询所有的。
async fetchNewsFromServer(token, offset) {
var url = 'https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=' + token;
var body = {
"type": "news",
"offset": offset,
"count": 20
};
var result = await rp({
url: url,
method: 'POST',
headers: {
'content-type': 'application/json',
},
body: JSON.stringify(body)
});
return result;
}
//采集公众号的所有文章
async collectDataFromServer(token, dbcount) {
lastFetchTime = new Date();
var countUrl = 'https://api.weixin.qq.com/cgi-bin/material/get_materialcount?access_token=' + token;
var countResult = await rp({
url: countUrl,
method: 'GET',
});
var countObj = (typeof countResult.body === 'object') ? countResult.body : JSON.parse(countResult.body);
var total = 0;
if (countObj) {
total = countObj['news_count'];
if (total === dbcount) {
return;
}
} else {
return;
}
//每次获取20个
var fetchTimes = parseInt((total - 1) / 20) + 1;
var i;
var newsList = [];
for (i = 0; i < fetchTimes; i++) {
var offset = i * 20;
var newsResult = await this.fetchNewsFromServer(token, offset);
var news = (typeof newsResult.body === 'object') ? newsResult.body : JSON.parse(newsResult.body);
if (!news || !news.item_count) {
continue;
}
var j = 0;
var items = news.item;
for (j = 0; j < news.item_count; j++) {
newsList.push(items[j]);
}
}
//先清空原有的数据再存储新的
await this.clearTable('posts');
for (var k = 0; k < newsList.length; k++) {
var toSave = newsList[k];
var toSaveObj = {
mediaid: toSave.media_id,
url: toSave.content.news_item[0].url,
pic: toSave.content.news_item[0].thumb_url,
title: toSave.content.news_item[0].title
};
await db.collection('posts').add({
data: toSaveObj
});
}
}
然后就是小程序客户端通过云函数获取数据,在后端展示了,我们可以获取文章的链接,在WebView中展示。WebView只能显示关联公众号的文章和小程序后台填写的域名的网址。WebView的文档显示个人小程序不能使用,但实际上是可以使用的。。
参考
云开放的官方文档 查看全部
最近收到一个需求是:小程序获取关联公众号的文章并且显示。
首先想到的是,需要顾客去买服务器和域名,进行域名备案,然后为顾客开发一个网站,能够通过公众平台的appid与key来获取公众号的素材列表,最后开发一个插口给小程序使用。一般顾客选购服务器和域名就是个困局,劝退了很多人。
但是我查看了陌陌小程序的官方文档,发现有一个云开发功能,其中有云数据库、云存储、云函数三种功能。类似于Serverless,我们不需要去买服务器和域名了,直接使用小程序的云开发功能能够做好多事情。我就想试试能不能用云开发功能做获取公众号文章的事情。
云数据库是一个类似于Redis的Key-Value数据库,使用陌陌提供的一些查询API,能够进行链式操作,有点像.Net的Entity Framework。
云存储主要是拿来做上传与下载文件使用,可以拿来做相册等应用。
云函数是提供了一个Node.Js的运行环境,我们就能布署自己的代码,也才能使用npm配置引入其他的开源软件包。云函数只能通过陌陌小程序框架里特有的方法调用,并且返回结果。与我们订购服务器自建服务不同的是,我们不清楚究竟有几个实例在运行,每次执行不一定在同一个实例中,所以我们不太适宜做一些在显存中缓存数据、保持状态的工作,应当及时把数据存入云数据库。云开发的云函数的独到优势在于与陌陌登陆信令的无缝整合。当小程序端调用云函数时,云函数的传入参数中会被注入小程序端用户的 openid,开发者可以直接使用该 openid。
在做这个功能之前,首先是新建小程序,将公众平台与小程序关联,公众平台个人订阅号也是可以的。
然后在小程序的项目中,project.config.json文件中加入一个配置项,指定云函数的储存目录。
"cloudfunctionRoot": "clouds/"
新建这个clouds目录,在其中构建一个文件夹,比如我们命名为fetch,以后调用云函数也用这个名称,然后在其中新建index.js,作为云函数的入口。一个云函数的基本结构是:
// 云函数入口文件
const cloud = require('wx-server-sdk');
const request = require('request');
cloud.init();
// 云函数入口函数
exports.main = async (event, context) => {
return {200: 40400, msg: 'success'};
}
我们可以象MVC和Servlet等Web框架一样,要求客户端传一个action参数,然后按照不同的action参数,选择对应的处理函数,也可以创建多个云函数。代码类似于:
var action = event.action;
if(!action){
return {code: 20000, msg: 'hello, world'};
}
//dispatcher
var ret;
if(action === 'role'){
ret = await registerAndReturnUser(event);
} else if(action === 'userlist'){
ret = await fetchUserList(event);
} else if(action === 'updaterole'){
ret = await updateUser(event);
}
当然了我们可以使用npm install --save安装任何的npm开源包,像往常一样构建package.json,每次更新了云函数,都应当在云函数文件夹上点击右键,选择“上传并布署(云端安装依赖)”。
小程序后端调用云函数的代码是,无需晓得真实的URL,只需按云函数名称调用即可:
wx.cloud.callFunction({
// 云函数名称
name: 'fetch',
// 传给云函数的参数
data: {
keywords: this.data.keywords,
page: this.data.page,
limit: this.data.limit
},
success: function (res) {
console.log(res);
},
fail: err => {
console.log(err);
}
});
获取公众号的永久素材列表,可以参考这个文档。需要一个AccessToken,而AccessToken的过期时间是2小时,每天限制申请的次数,腾讯也建议在第三方服务器保存这个AccessToken。我们就可以把这个AccessToken存入云数据库中。申请AccessToken的文档在。
然后我们编撰一段代码获取AccessToken,然后查看云函数的日志,或者是我们主动加上throw句子,抛出异常,在小程序调试控制台也可以见到返回结果,经常会看见40164错误,这个错误会提示我们某个IP不在白名单中,我们就可以把这个IP加入微信公众号配置的白名单中。但是问题来了,小程序云开发的出口IP是浮动的,可能是一个集群在提供服务,不一定那个IP起作用。但是他又是有限的,当我们加了十几个IP时,发现常常可以命中我们的白名单列表,所以我们应当多试几次,把尽可能多的IP找下来。所以我就编撰了这样一段程序,当获取AccessToken失败,并且错误是40164时侯,首先在数据库中储存这个IP,等我们有时间了就把这种IP加入白名单,反复几次我们的白名单里就有一二十个IP了。这时候发觉我们的命中率上升了,请求好几次才有一次不命中的。所以我就编撰恳求失败之后立刻再恳求一次,最多恳求五次,类似于“再哈希”的算法,假设我们有50%的命中率,连续5次不命中的机率是3%左右,经过实验发觉,一般都能在五次之内成功获取AccessToken。
这段代码大致如下:
var getWechatAccessToken = async function(counter) {
//先检查数据库,如果token过期,返回空,继续执行网络请求
var tokenInDb = await this.getAccessTokenFromDB();
if (tokenInDb) {
return tokenInDb['accessToken'];
}
var token_url = 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=' + this.appid + '&' + 'secret=' + this.secret;
var result = await rp({
url: token_url,
method: 'GET'
});
var obj = (typeof result.body === 'object') ? result.body : JSON.parse(result.body);
if (obj.errcode && obj.errcode === 40164) {
var ip = obj.errmsg.split(' ')[2];
//保存IP到数据库
await this.insertIp(ip);
//try again and save ip to database;
counter += 1;
if (counter < 5) {
return await this.getWechatAccessToken(counter);
}
}
//保存AccessToken到数据库
if (obj['access_token']) {
this.saveTokenToDb(obj['access_token']);
return obj['access_token'];
}
return null;
}
我们储存了申请AccessToken的时间,可以按照这个时间选择使用这个数据库中储存的Token,或者是重新获取新的Token。接下来就是使用获取素材列表的插口获取所有的公众号文章。我们一直把它们存入数据库,这样上次小程序恳求,就可以直接从云数据库中访问。获取公众号素材列表有个限制是一次只能获取20条,我们须要先查出总量,然后分页获取。同样的是,查询云数据库一次最多获取100条,我们也是须要先查出总量,再分页查询所有的。
async fetchNewsFromServer(token, offset) {
var url = 'https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=' + token;
var body = {
"type": "news",
"offset": offset,
"count": 20
};
var result = await rp({
url: url,
method: 'POST',
headers: {
'content-type': 'application/json',
},
body: JSON.stringify(body)
});
return result;
}
//采集公众号的所有文章
async collectDataFromServer(token, dbcount) {
lastFetchTime = new Date();
var countUrl = 'https://api.weixin.qq.com/cgi-bin/material/get_materialcount?access_token=' + token;
var countResult = await rp({
url: countUrl,
method: 'GET',
});
var countObj = (typeof countResult.body === 'object') ? countResult.body : JSON.parse(countResult.body);
var total = 0;
if (countObj) {
total = countObj['news_count'];
if (total === dbcount) {
return;
}
} else {
return;
}
//每次获取20个
var fetchTimes = parseInt((total - 1) / 20) + 1;
var i;
var newsList = [];
for (i = 0; i < fetchTimes; i++) {
var offset = i * 20;
var newsResult = await this.fetchNewsFromServer(token, offset);
var news = (typeof newsResult.body === 'object') ? newsResult.body : JSON.parse(newsResult.body);
if (!news || !news.item_count) {
continue;
}
var j = 0;
var items = news.item;
for (j = 0; j < news.item_count; j++) {
newsList.push(items[j]);
}
}
//先清空原有的数据再存储新的
await this.clearTable('posts');
for (var k = 0; k < newsList.length; k++) {
var toSave = newsList[k];
var toSaveObj = {
mediaid: toSave.media_id,
url: toSave.content.news_item[0].url,
pic: toSave.content.news_item[0].thumb_url,
title: toSave.content.news_item[0].title
};
await db.collection('posts').add({
data: toSaveObj
});
}
}
然后就是小程序客户端通过云函数获取数据,在后端展示了,我们可以获取文章的链接,在WebView中展示。WebView只能显示关联公众号的文章和小程序后台填写的域名的网址。WebView的文档显示个人小程序不能使用,但实际上是可以使用的。。
参考
云开放的官方文档
在dedecms5.7首页和列表页模板如何动态调用文章浏览次数
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-12 22:44
在dedecms5.7首页和列表页模板中如何动态调用文章浏览次数dedecms5.7程序给的样例是静态调用的,方法是[filed:click],这样我们用在首页跟列表页不实际,通常只有在更新网站后才会显示其浏览次数这样也不太利于用户体验,如果是在内容文章里面,我们可以通过如下代码实现在列表页或首页怎样实现呢?我们可以这样写其实,我们也可以不更改,直接用替代[filed:click],但是这样统计不太确切,因为在我们浏览首页或则列表页时就刷新了一次点击量,文章页都没有点击,文章的点击次数会手动加1,那么我们该怎么办呢?方法如下首先我们在/plus 目录下找到count.php 复制一份 然后重命名为clicke.php 用编辑器将seeclick.php打开 然后删掉或则注释if(!empty($maintable)){$dsql->ExecuteNoneQuery(" UPDATE `{$maintable}` SET click=click+1 WHERE {$idtype}='$aid' ");}if(!empty($mid)){$dsql->ExecuteNoneQuery(" UPDATE `dede_member_tj` SET pagecount=pagecount+1 WHERE mid='$mid' ");}这几行代码这几行的作用是:插入数据库的这两行之后保存最后在首页和列表页中须要调用点击次数的地方用这样就实现我们想要的疗效了,这样即使可以实现我们想要的疗效,但同时也会影响我们的打开速率,所以你们要看情况抉择。
织梦相关文章的调用代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-12 09:08
比如第一个,相关内容模块调用代码与栏目页相关内容调用代码不一致。
按照常理里说,一个栏目和栏目下的文章所属都是一致的,所采用的调用代码也应当一样,但是因为织梦代码以前进行过一次的系统升级,于是把在内容页调用的标签和在栏目页调用的标签给弄得不一样了,其调用代码分别如下:
(文章页相关调用代码)
(栏目页相关调用代码)
从这2个调用,大家可以看出这2这之间的区别,因为织梦文章页相关采用的likearticle标签而栏目页的相关采用的是likeart。所以在具体的实际调用时侯要做注意,否则相关性未能调用成功。
第二个,如果站在seo的角度来考虑,我们发觉这样的调用似乎是有一定问题的,如果一个栏目内某个相关文章较多的话,那么采用likearticle调用的话,最终的结果都是最新的相关文章,而老文章页面将会难以展示下来。这样一旦文章数量好多,那么老文章在其他地方显示的机会就少了,而且有的文章可能同类别的内容极少,那么没有相关的文章又该如何调用呢?下面逐一说明问题:
1,如何随机调用文章的标签问题。
我认为假如一个网站更新数目较多或则内容数目较多以后,就要想着如何才能使蜘蛛爬向任何一个页面,而不仅仅更多逗留在老的页面上,这里我们建议采用全站随机调用,或者栏目内随机调用标签,其调用代码如下:
其中,不加typeid的话是栏目内随机调用,而加上的话是全站文章的随机调用。一般为了提高文章之间的相关性,我们建议除去typeid属性,这样愈加符合seo的要求。
2,如何排序调用的文章。
在不做任何改动的情况下,调用的文章默认排序为最新相关文章,但是这个的缺点我也说了,最相关或则最有用的文章不一定都是最新的,如何做其他的调用也是一个十分重要的问题,比如热点相关问题或则推荐相关问题等,我认为可以组合使用。
举例来说,比如你想调用最优秀的相关文章的话,可以使相关文档调用时侯,加上推荐这样的属性,你只要把优秀的文章都加上了推荐属性,那么就可以如此调用了。
相关性在网站收录、排名等好多方面都有很大的影响和作用,如何做好也是一门学院问。 查看全部
页面优化在整个网站seo优化中所占的比列越来越重要了,该如何做好页面呢,以织梦cms为例,相关模块的调用就是一个很大方面,但是织梦的相关模块调用有时候并不是这么的一帆风顺,因为在相关模块上会存在好多的代码问题。
比如第一个,相关内容模块调用代码与栏目页相关内容调用代码不一致。
按照常理里说,一个栏目和栏目下的文章所属都是一致的,所采用的调用代码也应当一样,但是因为织梦代码以前进行过一次的系统升级,于是把在内容页调用的标签和在栏目页调用的标签给弄得不一样了,其调用代码分别如下:
(文章页相关调用代码)
(栏目页相关调用代码)
从这2个调用,大家可以看出这2这之间的区别,因为织梦文章页相关采用的likearticle标签而栏目页的相关采用的是likeart。所以在具体的实际调用时侯要做注意,否则相关性未能调用成功。
第二个,如果站在seo的角度来考虑,我们发觉这样的调用似乎是有一定问题的,如果一个栏目内某个相关文章较多的话,那么采用likearticle调用的话,最终的结果都是最新的相关文章,而老文章页面将会难以展示下来。这样一旦文章数量好多,那么老文章在其他地方显示的机会就少了,而且有的文章可能同类别的内容极少,那么没有相关的文章又该如何调用呢?下面逐一说明问题:
1,如何随机调用文章的标签问题。
我认为假如一个网站更新数目较多或则内容数目较多以后,就要想着如何才能使蜘蛛爬向任何一个页面,而不仅仅更多逗留在老的页面上,这里我们建议采用全站随机调用,或者栏目内随机调用标签,其调用代码如下:
其中,不加typeid的话是栏目内随机调用,而加上的话是全站文章的随机调用。一般为了提高文章之间的相关性,我们建议除去typeid属性,这样愈加符合seo的要求。
2,如何排序调用的文章。
在不做任何改动的情况下,调用的文章默认排序为最新相关文章,但是这个的缺点我也说了,最相关或则最有用的文章不一定都是最新的,如何做其他的调用也是一个十分重要的问题,比如热点相关问题或则推荐相关问题等,我认为可以组合使用。
举例来说,比如你想调用最优秀的相关文章的话,可以使相关文档调用时侯,加上推荐这样的属性,你只要把优秀的文章都加上了推荐属性,那么就可以如此调用了。
相关性在网站收录、排名等好多方面都有很大的影响和作用,如何做好也是一门学院问。
落月黑帽SEO技术培训是骗钱的吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2020-08-12 05:12
不知道你所说的黑帽是不是快排和采集一类的,这种所谓黑帽之后没哪些发展前途zd了。
现在百度都早已推出了飓风算法2.0,就是针对那些采集类网站来做的。
现在炸雷算法其实对快排作用不内是很大,但是仍然太有震慑力。
所以,SEO黑帽手段未来并不靠谱,建议你还是踏踏实实容去正规机构学习白帽技术。
黑帽seo怎么样?谁用过?效果怎么样?和我谈一下益处 和益处?我说用过的人谈一下!
自从有了白帽seo,就有了黑帽seo。黑白帽的临界点没有标准,就像好人和坏人没有衡量的标准
一、什么是黑帽seo
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化时,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
站长对黑帽seo的理解
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO就能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
二、目前黑帽seo手法有什么
1、文章单页优化快速排行技术-优化单页及文章必备技术
文章单页优化快速排行技术-优化单页及文章必备技术
一篇单文章怎么去优化他快速排行,可以用长尾词优化的方式去做。
什么是长尾词?我们看下。
首先,不管黑白方式,单页的文章一定要控制好关键字密度。关键字太关键。
还有一个就是平台,比如你做优采云可以10小时抵达南京,而做客机只要1个小时。
平台也太关键,平台指的是权重站,新闻源站。
先看案例无痛人流大约要花多少钱
首先控制关键字密度,那么哪些是关键字密度,如何控制,看视频操作。
我们首先构建一个页面。放上文章。在线监测密度。
同一遍文章可以合理装入关键字,不能太多,也不能很少。太多了会被觉得是关键字拼凑。
密度控制好了,接着是链接导出了,也可以称为权重导出,权重链接越多越好。
链接导出分为,外链,反链,友链,黑链都可以。
他的一遍文章排到第一,除了关键字密度,还有平台的支撑,及好多的外链,反向链接。
如果是正规网站,就做下链接导出。【控制密度+选择平台+链接导出】
如果是黑的网站,那么就只能看平台了权重,可以适当挂点黑链。【高权重平台+黑链】
把做的黑页链接全部整理,然后挂到webshell黑链。
2、PHP绑架视频教程及代码打包
此教程是第一季教程第二课,如果早已下载过第一季教程可以跳过。
PHP绑架视频教程及代码打包
PHP的基础案例演示
PHP绑架代码解释
PHP绑架实战
3、远程调用跳转JS控制黑页
远程调用跳转JS控制黑页-黑帽SEO技术网发布
简单的远程调用技术,你可以通过可以网站js,控制着你的调用跳转、嵌入、以及侧门。
当然更多的灵活应用,需要大家自己操作。我只说下简单的原理,自己灵活应用。
是我的调用站。
我们联接这个网址的FTP看下。
这些都是我顾客的排行站,我都是用远程调用管理的,方便。
没排行的不跳,有排行的跳,或者晚上不跳转,晚上跳转。
方便又安全,我们访问下我的调用页面。
原理很简单,就是通过一个你自己的网站(远程网站)调用一个JS文件。
能合理应用上去便捷好多。
黑帽SEO技术:黑帽SEO通过培训才能学会吗
真正的黑帽技术人家不可能会下来培训,百即使是真正的度培训,也不肯能给你说的太多,别异想天开了,就算能全部交给你,需要太内强的基础知识,比如:PHP。JS,HTML.,css,都是必备的。还不如容先好好学好基础
黑帽seo技术网是骗局网站吗
首先你要明白,黑帽SEO的排行有很大的运气成份在上面,来
什么时候排行不见了都说不好
其次,方法并不重要,重自要的是黑帽手法的“度”也就百是说如何做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花很大代价去学度
黑帽SEO 谁懂?
黑帽SEO
百科名片
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
目录
黑帽SEO
黑帽SEO常用的链接作弊把戏
深入剖析
黑帽搜索引擎毒化Web安全环境
展开
编辑本段
黑帽SEO
黑帽子SEO
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO不同于白帽seo那个放长线钓大鱼的策略。黑帽seo更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
编辑本段
黑帽SEO常用的链接作弊把戏
扩展外部链接,不一定是靠交换友情链接。有好多地方,可以获得外部链接。例如:BLOG评论、网页评论、留言本、论坛等等。在BLOG评论、网页评论、留言本、论坛等地方都可以常常见到黑帽子SEO的精彩杰作。下面,我们说说一些黑帽子SEO常用的链接作弊招数:
一、博客(BLOG)作弊。
BLOG,是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1.BLOG群发作弊:
在国外常见的一些BLOG程序如:ZBLOG、PJBLOG、Bo-blog.早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎如今还是可以给黑帽子SEO有机可乘的地方。
2.BLOG群建作弊:
BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
二、留言本群发:
一般网上有些留言本群发软件,使用这种软件可以手动发布自己的关键词URL。在短时间内,迅速提升外部链接。
三、链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
四、隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
五、假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
六、网页绑架
网页绑架也就是我们常常所说的Pagejacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是可憎的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
七、网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
八、网站地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHatSEO曾广泛应用这项技术作弊,目前,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
编辑本段
深入剖析
站在黑帽SEO的角度,他们也有她们的道理。因为大部分黑帽SEO都是使用程序,他们构建一个几万几十万页的网页,不费吹灰之力,只要放她们的蜘蛛出去抓取就可以了。就算过几个月她们的网站被惩罚,他可能早已挣了几千几万美元了。对他来说,投资报酬率还是相当高的。
站在黑帽SEO的立场上,这种放长线掉大鱼的策略,即使太正确,有的人也不乐意如此做。认真建设一个网站,有的时侯是一件太无趣的事。你要写内容,要做调查,要做剖析流量,要剖析用户浏览路径,要和用户交流沟通。
黑帽SEO要做的就简单多了。买个域名,甚至可以就使用免费虚拟主机,连域名都市了。程序一打开,放上Adsense编码,到其他留言本或博客留一些言(这些留言也有可能是程序手动生成的),然后就等着收收据了。
编辑本段
黑帽搜索引擎毒化Web安全环境
2010年的互联网安全并不太平,黑客大量借助社交工程和搜索引擎毒化的方法对脆弱的客户端发动频繁功击。根据趋势科技TrendLabs数据显示,搜索引擎毒化(BlackhatSEO)技术在2010年第一季度仍然是亚洲地区最兴起的功击手法,此种功击手段大量借助的社会热点新闻关键词,隐藏网页旁边的木马病毒致使大量用户“中招”。从2010年春节年会报导开始,大到“玉树地震、云南旱灾、世博闭幕、房价调控”,小到“明星走光、脱衣门、NBA球星打斗”,几乎所有能使网民关注的风波同时也都被“有心”的黑客借助上去。我们发觉网路犯罪分子早已借助黑帽搜索引擎毒化(BlackhatSEO)技术,成功地提升富含病毒网页在搜索排名中的名次。以4月21日美国媒体报导的网路安全公司迈克菲(McAfee)误杀风波为例,由于将WindowsXP的系统文件(svchost.exe)列入删掉列表,导致WindowsXP系统重复启动以及用户未能登入系统。据美国媒体报导,密西根大学医学院的2.5万台笔记本中,有8000台当机;肯塔基州莱辛顿市警局必须改用手写报告,并关掉巡逻车的总机;若干看守所取消探监;罗德岛各诊所的急诊室也暂时拒收非外伤病人,并提早部份产科放疗;甚至英特尔也难以幸免。
尽管此次更新在发布给企业用户4小时后紧急终止,但问题的严重性促使全球数百万台的WindowsXP用户不得不借助搜索引擎找寻更快的解决方案。虽然McAfee通过向公众道歉、撤消缺陷更新、并就顾客怎么自动修补遭到影响的计算机提出了相关建议,但这次“误杀”事件还是被部份黑客借助,大量制造了冒充防病毒软件(FakeAV)、制造嵌入恶意代码的网页,并针对这次风波发动了新一轮的BlackhatSEO攻击,以期企图盗取用户的信用卡详尽信息或则引诱用户将恶意代码安装在计算机上。以上手段使公众要获得关于误报问题的正确信息显得难上加难。BlackhatSEO功击并非全新的方法,它之前被广泛应用到网路营销将计就计中,但是这些借助热门时政关键词搜索的功击手法,仍旧是散布恶意程序太有效的一种形式。如果网路犯罪者借助一些热门的话题,或是穿上安全软件“外衣”的同时,提升搜索引擎排名的结果,单独依赖终端用户防毒软件的能力很难有效避免植入FAKEAV恶意程序恐吓。另外,由于FAKEAV变种中有许多是专门针对企业的新型病毒,因此早已给企业导致了很高的感染风险。在相对安全的局域网中,由于存在着无处不在的“共享”环境,这些遭FAKEAV恶意程序感染的系统假如得不到及时地查杀,不但会继续散布,很有可能在较短的时间内使企业网路沦落为“僵尸网络(Bot)”的成员,成为网路犯罪者泄露信息、散发垃圾信息的平台。
由于企业内部网路的速率十分快,终端之间又存在着信任关系,相互随便访问,病毒传播只须要2~3秒,查杀的困难相当大。目前,我国好多企业即使已在终端上加强防御,安装了防毒软件,但这样并不能防止互相感染风波的发生,例如提权的热点风波网页、FAKEAV变种等,如果采用传统的反病毒代码升级的方式,客户端将永远处于“被动”的局面。因此,采用云安全解决方案强化客户端的联动性,将是一个十分明智办法。针对这次“误杀”事件的延续,另一国际安全厂商趋势科技表示,部分趋势科技产品用户早已借助其云安全网路信誉技术成功拦截了对这种指向FakeAV的URL的相关访问。趋势科技的安全专家也提醒企业中的信息安全管理者,应对热点风波及时跟踪,并在内部沟通平台上发布经过验证的修补地址,或者在厂商的知识库中访问修复工具的地址,以防止大量可能存在的“李鬼”进行功击。
黑帽SEO为何不可取
从长远效益来说,建议采取正当过硬技术做白帽SEO,稳打稳扎的攫取流量。虽然会花费更多的精力和时间,但稳定性高。在获得流量和提升网站排名的同时,能有效提升网站的权重和企业的知名度,转化为真正有价值的客户群。并且能提高企业形象,增加品牌价值,建立起用户对企业和品牌的信赖,培养一批忠实的精准用户。
相较于白帽SEO扎扎实实一步一步的获取流量,黑帽SEO能在短时间内迅速占领流量,但借助的却是作弊手段。
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹篮打水一场空的下场。
黑帽seo是属于违法行为的:
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实百可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不度出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实问际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊答手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任专何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹属篮打水一场空的下场。
黑帽是搅乱搜索引擎市场秩序的百行为,一旦发觉度都会遭到应有的惩罚,得不偿失。
就跟摆地摊一样,虽然可以快速知的诠释给走廊往的顾客面前,但是一旦交警来了,被抓了,轻则把你回赶快走,东西没收。答重则判你个罪,将你打回原型。 查看全部
落月黑帽SEO技术培训是骗钱的吗?
不知道你所说的黑帽是不是快排和采集一类的,这种所谓黑帽之后没哪些发展前途zd了。
现在百度都早已推出了飓风算法2.0,就是针对那些采集类网站来做的。
现在炸雷算法其实对快排作用不内是很大,但是仍然太有震慑力。
所以,SEO黑帽手段未来并不靠谱,建议你还是踏踏实实容去正规机构学习白帽技术。
黑帽seo怎么样?谁用过?效果怎么样?和我谈一下益处 和益处?我说用过的人谈一下!
自从有了白帽seo,就有了黑帽seo。黑白帽的临界点没有标准,就像好人和坏人没有衡量的标准
一、什么是黑帽seo
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化时,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
站长对黑帽seo的理解
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO就能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
二、目前黑帽seo手法有什么
1、文章单页优化快速排行技术-优化单页及文章必备技术
文章单页优化快速排行技术-优化单页及文章必备技术
一篇单文章怎么去优化他快速排行,可以用长尾词优化的方式去做。
什么是长尾词?我们看下。
首先,不管黑白方式,单页的文章一定要控制好关键字密度。关键字太关键。
还有一个就是平台,比如你做优采云可以10小时抵达南京,而做客机只要1个小时。
平台也太关键,平台指的是权重站,新闻源站。
先看案例无痛人流大约要花多少钱
首先控制关键字密度,那么哪些是关键字密度,如何控制,看视频操作。
我们首先构建一个页面。放上文章。在线监测密度。
同一遍文章可以合理装入关键字,不能太多,也不能很少。太多了会被觉得是关键字拼凑。
密度控制好了,接着是链接导出了,也可以称为权重导出,权重链接越多越好。
链接导出分为,外链,反链,友链,黑链都可以。
他的一遍文章排到第一,除了关键字密度,还有平台的支撑,及好多的外链,反向链接。
如果是正规网站,就做下链接导出。【控制密度+选择平台+链接导出】
如果是黑的网站,那么就只能看平台了权重,可以适当挂点黑链。【高权重平台+黑链】
把做的黑页链接全部整理,然后挂到webshell黑链。
2、PHP绑架视频教程及代码打包
此教程是第一季教程第二课,如果早已下载过第一季教程可以跳过。
PHP绑架视频教程及代码打包
PHP的基础案例演示
PHP绑架代码解释
PHP绑架实战
3、远程调用跳转JS控制黑页
远程调用跳转JS控制黑页-黑帽SEO技术网发布
简单的远程调用技术,你可以通过可以网站js,控制着你的调用跳转、嵌入、以及侧门。
当然更多的灵活应用,需要大家自己操作。我只说下简单的原理,自己灵活应用。
是我的调用站。
我们联接这个网址的FTP看下。
这些都是我顾客的排行站,我都是用远程调用管理的,方便。
没排行的不跳,有排行的跳,或者晚上不跳转,晚上跳转。
方便又安全,我们访问下我的调用页面。
原理很简单,就是通过一个你自己的网站(远程网站)调用一个JS文件。
能合理应用上去便捷好多。
黑帽SEO技术:黑帽SEO通过培训才能学会吗
真正的黑帽技术人家不可能会下来培训,百即使是真正的度培训,也不肯能给你说的太多,别异想天开了,就算能全部交给你,需要太内强的基础知识,比如:PHP。JS,HTML.,css,都是必备的。还不如容先好好学好基础
黑帽seo技术网是骗局网站吗
首先你要明白,黑帽SEO的排行有很大的运气成份在上面,来
什么时候排行不见了都说不好
其次,方法并不重要,重自要的是黑帽手法的“度”也就百是说如何做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花很大代价去学度
黑帽SEO 谁懂?
黑帽SEO
百科名片
笼统的说,所有使用作弊手段或可疑手段的,都可以称为黑帽SEO。比如说垃圾链接,隐藏网页,桥页,关键词拼凑等等。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
目录
黑帽SEO
黑帽SEO常用的链接作弊把戏
深入剖析
黑帽搜索引擎毒化Web安全环境
展开
编辑本段
黑帽SEO
黑帽子SEO
黑帽seo就是作弊的意思,黑帽seo手法不符合主流搜索引擎发行方针规定。黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽seo还是黑帽seo没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO不同于白帽seo那个放长线钓大鱼的策略。黑帽seo更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。近一两年,最典型的黑帽搜索引擎优化是,用程序从其他分类目录或搜索引擎抓取大量搜索结果弄成网页,然后在这种网页上放上GoogleAdsense。这些网页的数量不是几百几千,而是几万几十万。所以虽然大部分网页排行都不高,但是由于网页数量巨大,还是会有用户步入网站,并点击GoogleAdsense广告。
编辑本段
黑帽SEO常用的链接作弊把戏
扩展外部链接,不一定是靠交换友情链接。有好多地方,可以获得外部链接。例如:BLOG评论、网页评论、留言本、论坛等等。在BLOG评论、网页评论、留言本、论坛等地方都可以常常见到黑帽子SEO的精彩杰作。下面,我们说说一些黑帽子SEO常用的链接作弊招数:
一、博客(BLOG)作弊。
BLOG,是一种交互性太强的工具。这几年,博客的盛行,成为了黑帽子SEO一个新的制造链接的福地。
1.BLOG群发作弊:
在国外常见的一些BLOG程序如:ZBLOG、PJBLOG、Bo-blog.早期的ZBLOG,PJBLOG由于开发者缺少对SEO的认识。ZBLOG和PJBLOG,一度成为黑帽子SEO们常常光顾的地方。而Bo-blog博客程序,似乎如今还是可以给黑帽子SEO有机可乘的地方。
2.BLOG群建作弊:
BLOG群建作弊,就是通过程序或则人为的手段,大量申请BLOG账户。然后,通过发表一些带有关键词链接的文章,通过这种链接来促进关键词的搜索引擎排名。
二、留言本群发:
一般网上有些留言本群发软件,使用这种软件可以手动发布自己的关键词URL。在短时间内,迅速提升外部链接。
三、链接工厂
“链接工厂”(亦称“大量链接机制”)指由大量网页交叉链接而构成的一个网路系统。这些网页可能来自同一个域或多个不同的域,甚至可能来自不同的服务器。一个站点加入这样一个“链接鞋厂”后,一方面它可得到来自该系统中所有网页的链接,同时作为交换它须要“奉献”自己的链接,籍此方式来提高链接得分,从而达到干预链接得分的目的。
四、隐藏链接
隐藏链接通常被SEO用在顾客网站上,通过在自己顾客网站上使用隐藏链接的形式联接自己的网站或者是其他顾客的网站。
五、假链接
将链接添加到JS代码、框架或则是表单上面。这种形式的链接,对搜索引擎的蜘蛛来说,根本难以读取下来。因此,链接只是做给人看的,搜索引擎根本难以辨识。
六、网页绑架
网页绑架也就是我们常常所说的Pagejacking,是将他人的网站内容或则整个网站全面复制出来,偷梁换柱置于自己的网站上。这个黑帽SEO方式是对网页内容十分短缺的站长有吸引力的。但是,这个做法是相当冒险的,更是可憎的。搜索引擎的专利技术能从多个诱因上来判定这个被复制的网页或则网站不是原创,而不给以收录。
七、网站镜像
通过复制整个网站或部份网页内容并分配以不同域名和服务器,以此误导搜索引擎对同一站点或同一页面进行多次索引的行为,这既是为何有的网站注明严禁未授权不得做网站镜像的诱因了,两个网站的完全一样,相似度过低必然会导致自己的网站受到影响。
八、网站地址重定向
302redirect:302代表暂时性转移(TemporarilyMoved),在前些年,不少BlackHatSEO曾广泛应用这项技术作弊,目前,各大主要搜索引擎均加大了严打力度。即使网站客观上不是spam,也很容易被搜救引擎容易错判为spam而受到惩罚。大家肯定有这样的经历,搜索到某个网站的时侯进去就弄成另一个网站了,这种主要是通过跳转技术实现的,往往跳转到一个赢利性页面。
编辑本段
深入剖析
站在黑帽SEO的角度,他们也有她们的道理。因为大部分黑帽SEO都是使用程序,他们构建一个几万几十万页的网页,不费吹灰之力,只要放她们的蜘蛛出去抓取就可以了。就算过几个月她们的网站被惩罚,他可能早已挣了几千几万美元了。对他来说,投资报酬率还是相当高的。
站在黑帽SEO的立场上,这种放长线掉大鱼的策略,即使太正确,有的人也不乐意如此做。认真建设一个网站,有的时侯是一件太无趣的事。你要写内容,要做调查,要做剖析流量,要剖析用户浏览路径,要和用户交流沟通。
黑帽SEO要做的就简单多了。买个域名,甚至可以就使用免费虚拟主机,连域名都市了。程序一打开,放上Adsense编码,到其他留言本或博客留一些言(这些留言也有可能是程序手动生成的),然后就等着收收据了。
编辑本段
黑帽搜索引擎毒化Web安全环境
2010年的互联网安全并不太平,黑客大量借助社交工程和搜索引擎毒化的方法对脆弱的客户端发动频繁功击。根据趋势科技TrendLabs数据显示,搜索引擎毒化(BlackhatSEO)技术在2010年第一季度仍然是亚洲地区最兴起的功击手法,此种功击手段大量借助的社会热点新闻关键词,隐藏网页旁边的木马病毒致使大量用户“中招”。从2010年春节年会报导开始,大到“玉树地震、云南旱灾、世博闭幕、房价调控”,小到“明星走光、脱衣门、NBA球星打斗”,几乎所有能使网民关注的风波同时也都被“有心”的黑客借助上去。我们发觉网路犯罪分子早已借助黑帽搜索引擎毒化(BlackhatSEO)技术,成功地提升富含病毒网页在搜索排名中的名次。以4月21日美国媒体报导的网路安全公司迈克菲(McAfee)误杀风波为例,由于将WindowsXP的系统文件(svchost.exe)列入删掉列表,导致WindowsXP系统重复启动以及用户未能登入系统。据美国媒体报导,密西根大学医学院的2.5万台笔记本中,有8000台当机;肯塔基州莱辛顿市警局必须改用手写报告,并关掉巡逻车的总机;若干看守所取消探监;罗德岛各诊所的急诊室也暂时拒收非外伤病人,并提早部份产科放疗;甚至英特尔也难以幸免。
尽管此次更新在发布给企业用户4小时后紧急终止,但问题的严重性促使全球数百万台的WindowsXP用户不得不借助搜索引擎找寻更快的解决方案。虽然McAfee通过向公众道歉、撤消缺陷更新、并就顾客怎么自动修补遭到影响的计算机提出了相关建议,但这次“误杀”事件还是被部份黑客借助,大量制造了冒充防病毒软件(FakeAV)、制造嵌入恶意代码的网页,并针对这次风波发动了新一轮的BlackhatSEO攻击,以期企图盗取用户的信用卡详尽信息或则引诱用户将恶意代码安装在计算机上。以上手段使公众要获得关于误报问题的正确信息显得难上加难。BlackhatSEO功击并非全新的方法,它之前被广泛应用到网路营销将计就计中,但是这些借助热门时政关键词搜索的功击手法,仍旧是散布恶意程序太有效的一种形式。如果网路犯罪者借助一些热门的话题,或是穿上安全软件“外衣”的同时,提升搜索引擎排名的结果,单独依赖终端用户防毒软件的能力很难有效避免植入FAKEAV恶意程序恐吓。另外,由于FAKEAV变种中有许多是专门针对企业的新型病毒,因此早已给企业导致了很高的感染风险。在相对安全的局域网中,由于存在着无处不在的“共享”环境,这些遭FAKEAV恶意程序感染的系统假如得不到及时地查杀,不但会继续散布,很有可能在较短的时间内使企业网路沦落为“僵尸网络(Bot)”的成员,成为网路犯罪者泄露信息、散发垃圾信息的平台。
由于企业内部网路的速率十分快,终端之间又存在着信任关系,相互随便访问,病毒传播只须要2~3秒,查杀的困难相当大。目前,我国好多企业即使已在终端上加强防御,安装了防毒软件,但这样并不能防止互相感染风波的发生,例如提权的热点风波网页、FAKEAV变种等,如果采用传统的反病毒代码升级的方式,客户端将永远处于“被动”的局面。因此,采用云安全解决方案强化客户端的联动性,将是一个十分明智办法。针对这次“误杀”事件的延续,另一国际安全厂商趋势科技表示,部分趋势科技产品用户早已借助其云安全网路信誉技术成功拦截了对这种指向FakeAV的URL的相关访问。趋势科技的安全专家也提醒企业中的信息安全管理者,应对热点风波及时跟踪,并在内部沟通平台上发布经过验证的修补地址,或者在厂商的知识库中访问修复工具的地址,以防止大量可能存在的“李鬼”进行功击。
黑帽SEO为何不可取
从长远效益来说,建议采取正当过硬技术做白帽SEO,稳打稳扎的攫取流量。虽然会花费更多的精力和时间,但稳定性高。在获得流量和提升网站排名的同时,能有效提升网站的权重和企业的知名度,转化为真正有价值的客户群。并且能提高企业形象,增加品牌价值,建立起用户对企业和品牌的信赖,培养一批忠实的精准用户。
相较于白帽SEO扎扎实实一步一步的获取流量,黑帽SEO能在短时间内迅速占领流量,但借助的却是作弊手段。
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹篮打水一场空的下场。
黑帽seo是属于违法行为的:
1、损害企业形象
黑帽SEO借助作弊手段栽赃竞争对手,私下买卖链接,做垃圾外链和垃圾内容,这些其实百可以获取流量,但极大的损害企业形象,让企业和网站恶名昭著。在急速发展的信息时代,好事不度出门坏事传千里的古训彰显的淋漓尽致,一点点负面信息都会被无限放大并传播,最后只会损害企业形象和口碑,得不偿失。
2、没有实际的转化价值
黑帽SEO做垃圾外链和垃圾内容,实问际上就是把自己的网站丢进了一个垃圾池。刷流量点击,买卖链接,虽然可以获得表面上的流量点击和排行,但没有任何的实际意义。做SEO最终的真正目的还是为了转化为商业价值,这种作弊答手段并不会为网站带来实际的点击量,也不会为企业带来精准顾客和订单量。
3、被搜索引擎拉黑封杀
智能化时代任专何的门道都逃不过搜索引擎的“法眼”,黑帽SEO手段很容易都会被引擎蜘蛛抓取并直接拉黑永久封杀。那所有的投入和付出都付诸流水,不仅不能带来实际效益,反而落得竹属篮打水一场空的下场。
黑帽是搅乱搜索引擎市场秩序的百行为,一旦发觉度都会遭到应有的惩罚,得不偿失。
就跟摆地摊一样,虽然可以快速知的诠释给走廊往的顾客面前,但是一旦交警来了,被抓了,轻则把你回赶快走,东西没收。答重则判你个罪,将你打回原型。
tp5使用workerman实现异步任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-08-12 05:00
采集数据时过程太慢,导致难以继续进行其他任务,,避免主业务被长时间阻塞,故而将其递交给异步任务,当任务完成通知客户端即可
流程
前端业务:
由于本系统采用iframe结构,为防止点击其他页面业务中断,所以业务在父页面执行,
1.用户在子页面点击采集按钮调用父级方式
function to_collect(ids) {
window.parent.startCollect(ids);
}
2.父级页面进行socket链接,当收到服务器处理完任务消息时关掉socket并通知用户结果
function startCollect(ids)
{
var wsServer = 'ws://127.0.0.1:5432';
var websocket = new WebSocket(wsServer);
var inter_val = 0;
websocket.onopen = function (evt) {
console.log("Connected to WebSocket server.");
var data = {ids:ids};
data = JSON.stringify(data);
websocket.send(data);
//设置心跳,避免服务器断开
inter_val = setInterval(function () {
websocket.send('hello');
}, 50000)
};
websocket.onclose = function (evt) {
console.log("Disconnected");
};
websocket.onmessage = function (evt) {
console.log('Retrieved data from server: ' + evt.data);
if (isJson(evt.data)) {
var res = JSON.parse(evt.data);
if(res.code == 0){
alert("采集条数:"+res.msg)
websocket.close();
clearInterval(inter_val);//关闭定时器
}
}
};
websocket.onerror = function (evt, e) {
console.log('Error occured: ' + evt.data);
};
}
/**
* 判断是否json
* @param $string
* @returns {boolean}
*/
function isJson($string)
{
try {
if(typeof JSON.parse($string) == 'object')
return true;
return false;
} catch (e) {
console.log(e);
return false;
}
}
服务端
1. 收到后端发来的数据,调用model进行业务处理,然后通知客户端
<p> 查看全部
问题描述:
采集数据时过程太慢,导致难以继续进行其他任务,,避免主业务被长时间阻塞,故而将其递交给异步任务,当任务完成通知客户端即可
流程
前端业务:
由于本系统采用iframe结构,为防止点击其他页面业务中断,所以业务在父页面执行,
1.用户在子页面点击采集按钮调用父级方式
function to_collect(ids) {
window.parent.startCollect(ids);
}
2.父级页面进行socket链接,当收到服务器处理完任务消息时关掉socket并通知用户结果
function startCollect(ids)
{
var wsServer = 'ws://127.0.0.1:5432';
var websocket = new WebSocket(wsServer);
var inter_val = 0;
websocket.onopen = function (evt) {
console.log("Connected to WebSocket server.");
var data = {ids:ids};
data = JSON.stringify(data);
websocket.send(data);
//设置心跳,避免服务器断开
inter_val = setInterval(function () {
websocket.send('hello');
}, 50000)
};
websocket.onclose = function (evt) {
console.log("Disconnected");
};
websocket.onmessage = function (evt) {
console.log('Retrieved data from server: ' + evt.data);
if (isJson(evt.data)) {
var res = JSON.parse(evt.data);
if(res.code == 0){
alert("采集条数:"+res.msg)
websocket.close();
clearInterval(inter_val);//关闭定时器
}
}
};
websocket.onerror = function (evt, e) {
console.log('Error occured: ' + evt.data);
};
}
/**
* 判断是否json
* @param $string
* @returns {boolean}
*/
function isJson($string)
{
try {
if(typeof JSON.parse($string) == 'object')
return true;
return false;
} catch (e) {
console.log(e);
return false;
}
}
服务端
1. 收到后端发来的数据,调用model进行业务处理,然后通知客户端
<p>
织梦调用全站热门文章代码怎么写?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2020-08-11 18:07
本站技术团队7年织梦CMS及帝国仿站、二次开发经验。拥有稳定的设计团队和技术团队,保证您的售后技术服务。仿站最低200元,欢迎咨询客服报价。
业务范围:
开源CMS(帝国、织梦)仿站,成品自适应模板,网站克隆,网站定制,改版,二次开发,采集,新功能开发!
仿站实力:
200元企业仿站(标准型企业站),最快3小时出单,99%精仿。
———————————————————————————————————————————————————————————
在使用织梦文章类网站模板时侯,要对文章进行优化涉及到对织梦代码调用的更改,大多数文章调用类型有下边几类:
1:按照关键词调用相关文章
2:调用全站(栏目)热门文章
3:调用全站(栏目)随机文章
4:按照点击数调用文章
......
大多数能用到的调用类型就以上几种,最常用的就是相关文章和热门文章了,那热门文章调用代码怎么写?
【调用全站顶尖栏目30天内热门文章】
{dede:arclist sort='hot' subday='30' titlelen=24 row=10 typeid='top' }
[field:title/]
{/dede:arclist}
其他条件可以依照次序和逆序显示。
大多数热门文章是全站浏览次数比较多的文章,能解决用户需求最多的文章,这在SEO优化中十分重要,模块通常在文章右侧侧边栏,热门文章不宜过多,以免影响用户体验,必要时可加粗显示。
关键词: 查看全部
———————————————————————————————————————————————————————————
本站技术团队7年织梦CMS及帝国仿站、二次开发经验。拥有稳定的设计团队和技术团队,保证您的售后技术服务。仿站最低200元,欢迎咨询客服报价。
业务范围:
开源CMS(帝国、织梦)仿站,成品自适应模板,网站克隆,网站定制,改版,二次开发,采集,新功能开发!
仿站实力:
200元企业仿站(标准型企业站),最快3小时出单,99%精仿。
———————————————————————————————————————————————————————————
在使用织梦文章类网站模板时侯,要对文章进行优化涉及到对织梦代码调用的更改,大多数文章调用类型有下边几类:
1:按照关键词调用相关文章
2:调用全站(栏目)热门文章
3:调用全站(栏目)随机文章
4:按照点击数调用文章
......
大多数能用到的调用类型就以上几种,最常用的就是相关文章和热门文章了,那热门文章调用代码怎么写?
【调用全站顶尖栏目30天内热门文章】
{dede:arclist sort='hot' subday='30' titlelen=24 row=10 typeid='top' }
[field:title/]
{/dede:arclist}
其他条件可以依照次序和逆序显示。
大多数热门文章是全站浏览次数比较多的文章,能解决用户需求最多的文章,这在SEO优化中十分重要,模块通常在文章右侧侧边栏,热门文章不宜过多,以免影响用户体验,必要时可加粗显示。
关键词:
公众号影响因子的可行性剖析:公众号文章“被引量”指标
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2020-08-11 13:19
学术论文有一个必不可少的部份,叫做“参考文献(References)”,在这个模块里你要把你在本论文中引用观点的来源标明下来:
参考文献作为论文的一个重要部份,一方面表示了该篇文章是基于什么样的研究基础展开的;另一方面,对于被引用的论文,被引量代表了该文章的影响力和价值。
学术领域无人不知无人不晓的汤森路透基于文章的被引量会发布一个刊物引证报告,报告的核心指数称之为影响因子。
影响因子(Impact Factor,IF)是汤森路透(Thomson Reuters)出品的刊物引证报告(Journal Citation Reports,JCR)中的一项数据。 即某刊物前两年发表的论文在该报告年份(JCR year)中被引用总次数减去该刊物在这两年内发表的论文总量。这是一个国际上通行的刊物评价指标。
影响因子现已成为国际上通用的刊物评价指标,它除了是一种度量刊物有用性和显示度的指标,而且也是度量刊物的学术水平,乃至论文质量的重要指标。
谷歌学术也采用了相像的H指数作为学者和刊物评价的标准:
所以我在想,公众号的文章可不可以引入如此一个“被引量”指标,用以评价一篇文章或者一个公众号的水平呢?
学术文章的被引量很容易估算,因为国家有明晰的法律法规和标准,只要有足够全的学术文章便可以估算出某篇文章的被引量。
对于公众号来说,计算被引量所须要的数据也是建立的。
首先,功能层面
2017年6月6日,公众号开放了“插入全平台已群发文章链接”的功能
这个功能的开放为添加“参考文献”提供了可能。
然后,数据层面
目前内容创业服务公司新榜保持每晚对44.8万个公众号文章的采集工作,几乎收录了所有活跃的公众号。这部份公众号的文章在新榜数据库是可检索的。
最后,技术层面
而这两个数据,也是全部可以得到。
文章引用行为的获取
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业也加入一个使死学术圈欲仙欲死的“影响因子”。
作者:野蛮人摩托罗拉,公众号:喜新(ID:noyanjiu) 查看全部
文章从学术论文中的“参考文献”说起,延伸出了一个可评判公众号文章质量的指标“被引量”,脑洞很大,其中的思索方法不妨我们来学习一下。
学术论文有一个必不可少的部份,叫做“参考文献(References)”,在这个模块里你要把你在本论文中引用观点的来源标明下来:
参考文献作为论文的一个重要部份,一方面表示了该篇文章是基于什么样的研究基础展开的;另一方面,对于被引用的论文,被引量代表了该文章的影响力和价值。
学术领域无人不知无人不晓的汤森路透基于文章的被引量会发布一个刊物引证报告,报告的核心指数称之为影响因子。
影响因子(Impact Factor,IF)是汤森路透(Thomson Reuters)出品的刊物引证报告(Journal Citation Reports,JCR)中的一项数据。 即某刊物前两年发表的论文在该报告年份(JCR year)中被引用总次数减去该刊物在这两年内发表的论文总量。这是一个国际上通行的刊物评价指标。
影响因子现已成为国际上通用的刊物评价指标,它除了是一种度量刊物有用性和显示度的指标,而且也是度量刊物的学术水平,乃至论文质量的重要指标。
谷歌学术也采用了相像的H指数作为学者和刊物评价的标准:
所以我在想,公众号的文章可不可以引入如此一个“被引量”指标,用以评价一篇文章或者一个公众号的水平呢?
学术文章的被引量很容易估算,因为国家有明晰的法律法规和标准,只要有足够全的学术文章便可以估算出某篇文章的被引量。
对于公众号来说,计算被引量所须要的数据也是建立的。
首先,功能层面
2017年6月6日,公众号开放了“插入全平台已群发文章链接”的功能
这个功能的开放为添加“参考文献”提供了可能。
然后,数据层面
目前内容创业服务公司新榜保持每晚对44.8万个公众号文章的采集工作,几乎收录了所有活跃的公众号。这部份公众号的文章在新榜数据库是可检索的。
最后,技术层面
而这两个数据,也是全部可以得到。
文章引用行为的获取
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业也加入一个使死学术圈欲仙欲死的“影响因子”。
作者:野蛮人摩托罗拉,公众号:喜新(ID:noyanjiu)
iOS"添加方式"对项目代码侵入性较少的实现思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2020-08-11 13:18
但项目中ViewController之前没有做任何承继关系(无子类Controller),所以在几十上百个Controller的项目里,一个一个添加历时不说,也不利于后期维护,那也是不推荐使用的蠢技巧。
1、利用Objective-C 中的对象承继
继承在面向对象开发中是十分常用的。
优点:继承可以实现代码的复用,减少代码冗余。将所有重复的内容合并在一起,可以让代码有效率,简洁,才意味着是一个成功的构架。否则,修改代码时须要更改多处,就很容易出错。
缺点:继承导致类与类之间耦合性很强。
现在项目工程中就会有一个BaseViewController,所有新建的ViewController都承继BaseViewController,通过往BaseViewController中添加一些公共方式/属性可以被她们的泛型所调用;这是统一工程中所有视图控制器式样的一个主要途径。
如果项目中没有ViewController泛型的话,重新创建一个泛型也不难。
这种方式比较考验耐心和悉心,更换了默认的承继关系。会修改好多类,侵入性虽然很大。但考虑到之后的维护成本,在控制器类还不庞大的情况下,建议使用此种方式。不能完成的是原项目早已有承继关系了,但承继关系比较负责。这时候就要愈发当心(除了处理可能多个父类,还要处理没承继的控制器),相当于给她们造了一个祖宗~
2、利用Category和Runtime交换系统方式并添加方式(系统主动调用load)
load函数调用特性如下:
当类被引用进项目的时侯才会执行load函数(在main函数开始执行之前),与这个类是否被用到无关,每个类的load函数只会手动调用一次.由于load函数是系统手动加载的,因此不需要调用父类的load函数,否则父类的load函数会多次执行。
详见Demo: 多个分类重名时,方法的调用次序
#import
+ (void)load {
[super load];
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 交换VC页面完全显示方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidAppear:), @selector(__mmc_tracer_viewDidAppear:));
// 交换VC页面完全消失方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidDisappear:), @selector(__mmc_tracer_viewDidDisappear:));
});
}
void __mmc_tracer_swizzleMethod(Class class, SEL originalSelector, SEL swizzledSelector){
Method originalMethod = class_getInstanceMethod(class, originalSelector);
Method swizzledMethod = class_getInstanceMethod(class, swizzledSelector);
BOOL didAddMethod =
class_addMethod(class,
originalSelector,
method_getImplementation(swizzledMethod),
method_getTypeEncoding(swizzledMethod));
if (didAddMethod) {
class_replaceMethod(class,
swizzledSelector,
method_getImplementation(originalMethod),
method_getTypeEncoding(originalMethod));
} else {
method_exchangeImplementations(originalMethod, swizzledMethod);
}
}
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
+ (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)__mmc_tracer_viewDidAppear:(BOOL)animated {
[self __mmc_tracer_viewDidAppear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidAppear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面显示的打点采集方法
}
}
- (void)__mmc_tracer_viewDidDisappear:(BOOL)animated {
[self __mmc_tracer_viewDidDisappear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidDisappear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面消失的打点采集方法
}
}
3、利用Aspects施行方式hook (被动调用,类似通知窃听)
Aspects是AOP(面向切面编程)思想在iOS下OC的实现。Aspects可以用于hook函数,让函数执行一些副操作。为嵌入不同函数中的功能相同的操作,每类功能相同的操作可以抽取出一个切面。
核心原理:当被 hook 的 selector 被执行的时侯,首先按照 selector找到了 objc_msgForward / _objc_msgForward_stret,而这个会触发消息转发,从而步入 forwardInvocation。同时因为forwardInvocation 的指向也被更改了,因此会转到新的 forwardInvocation函数,在里面执行须要嵌入的附加代码,完成以后,再转到原先的 IMP。
常用的两个方式
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
- (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)hookAllViewControllerAppearAndDisappear {
/// hook 控制器的显示和消失 分别打log
// 显示
[UIViewController aspect_hookSelector:@selector(viewDidAppear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addBeginLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
// 消失
[UIViewController aspect_hookSelector:@selector(viewDidDisappear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addEndLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
}
hook方案有一个用处就是可以避免代码入侵,做到愈加广泛的通用性。通过swizzling我们可以将原method与自己加入的method相结合,即不需要在原有工程中加入代码,又能做到全局覆盖。
三种方案对比:
1、通过承继父类来实现,相对于hook来说,是较为确切的。因为须要被统计的页面都是承继于这个父类的控制器,而其他的如UINavigationController、UIAlertController等则不会误入统计数据当中。
2、上面提及 hook方案是通过hook UIViewController viewDidLoad/viewDidAppear等方式,而这种方式实际上每位Controller 都会调用,那么都会出现不该出现的Controller 也出现在这里(如前面说到的UINavigationController和UIAlertController)。但hook方案一个比较好的特征是无代码入侵,在不更改项目代码的前提下完成工作。
3、两种hook的对比:分类的方式只要分类被load则就开始hook, 时机并不能自己控制,而且也不能自己开关控制是否hook或则中止hook操作。一个由程序员主动调用(Aspects),一个由系统调用(分类)。由于可控性最后还是选择了Aspects来进行hook。
但要做的是通用的大数据采集类,以后公司内部所有App都可能会用到,在不知道是那个App有哪些Controller的情况下,hook似乎成了最好的技巧。当然要注意筛选掉系统的Controller,避免重复采集无用的数据。 如果要做内部封装的话似乎Aspects hook的方法好一点,不然的话你就要曝露出API提供给分类,或者将分类写入封装类内部。这样代码比较长不利于后期维护。还有最重要的一点就是:使用Aspects可以留一个开关给外部,是否须要sdk帮助采集所有界面的出现和消失,或者交给使用者自己采集界面信息。
最后推荐两篇针对Aspects个人认为写得非常棒的文章 查看全部
最近公司项目做用户大数据信息采集,需要采集App端在页面切换/交互操作的时侯须要统计页面显示/页面消失风波,要给前端统计系统发送采集logs记录。
但项目中ViewController之前没有做任何承继关系(无子类Controller),所以在几十上百个Controller的项目里,一个一个添加历时不说,也不利于后期维护,那也是不推荐使用的蠢技巧。
1、利用Objective-C 中的对象承继
继承在面向对象开发中是十分常用的。
优点:继承可以实现代码的复用,减少代码冗余。将所有重复的内容合并在一起,可以让代码有效率,简洁,才意味着是一个成功的构架。否则,修改代码时须要更改多处,就很容易出错。
缺点:继承导致类与类之间耦合性很强。
现在项目工程中就会有一个BaseViewController,所有新建的ViewController都承继BaseViewController,通过往BaseViewController中添加一些公共方式/属性可以被她们的泛型所调用;这是统一工程中所有视图控制器式样的一个主要途径。
如果项目中没有ViewController泛型的话,重新创建一个泛型也不难。
这种方式比较考验耐心和悉心,更换了默认的承继关系。会修改好多类,侵入性虽然很大。但考虑到之后的维护成本,在控制器类还不庞大的情况下,建议使用此种方式。不能完成的是原项目早已有承继关系了,但承继关系比较负责。这时候就要愈发当心(除了处理可能多个父类,还要处理没承继的控制器),相当于给她们造了一个祖宗~
2、利用Category和Runtime交换系统方式并添加方式(系统主动调用load)
load函数调用特性如下:
当类被引用进项目的时侯才会执行load函数(在main函数开始执行之前),与这个类是否被用到无关,每个类的load函数只会手动调用一次.由于load函数是系统手动加载的,因此不需要调用父类的load函数,否则父类的load函数会多次执行。
详见Demo: 多个分类重名时,方法的调用次序
#import
+ (void)load {
[super load];
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 交换VC页面完全显示方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidAppear:), @selector(__mmc_tracer_viewDidAppear:));
// 交换VC页面完全消失方法
__mmc_tracer_swizzleMethod([self class], @selector(viewDidDisappear:), @selector(__mmc_tracer_viewDidDisappear:));
});
}
void __mmc_tracer_swizzleMethod(Class class, SEL originalSelector, SEL swizzledSelector){
Method originalMethod = class_getInstanceMethod(class, originalSelector);
Method swizzledMethod = class_getInstanceMethod(class, swizzledSelector);
BOOL didAddMethod =
class_addMethod(class,
originalSelector,
method_getImplementation(swizzledMethod),
method_getTypeEncoding(swizzledMethod));
if (didAddMethod) {
class_replaceMethod(class,
swizzledSelector,
method_getImplementation(originalMethod),
method_getTypeEncoding(originalMethod));
} else {
method_exchangeImplementations(originalMethod, swizzledMethod);
}
}
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
+ (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)__mmc_tracer_viewDidAppear:(BOOL)animated {
[self __mmc_tracer_viewDidAppear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidAppear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面显示的打点采集方法
}
}
- (void)__mmc_tracer_viewDidDisappear:(BOOL)animated {
[self __mmc_tracer_viewDidDisappear:animated]; //由于方法已经被交换,这里调用的实际上是viewDidDisappear:方法
if ([UIViewController isIgnoreSystemViewController:self]) {
//TODO: 实现页面消失的打点采集方法
}
}
3、利用Aspects施行方式hook (被动调用,类似通知窃听)
Aspects是AOP(面向切面编程)思想在iOS下OC的实现。Aspects可以用于hook函数,让函数执行一些副操作。为嵌入不同函数中的功能相同的操作,每类功能相同的操作可以抽取出一个切面。
核心原理:当被 hook 的 selector 被执行的时侯,首先按照 selector找到了 objc_msgForward / _objc_msgForward_stret,而这个会触发消息转发,从而步入 forwardInvocation。同时因为forwardInvocation 的指向也被更改了,因此会转到新的 forwardInvocation函数,在里面执行须要嵌入的附加代码,完成以后,再转到原先的 IMP。
常用的两个方式
/** 只忽略了部分常用系统原生contrlloer
* 通过继承父类来实现 相对于hook来说 是较为准确的,因为需要被统计的页面都是继承于这个父类的控制器,而其他的如UINavigationController,系统自带的UIAlertController等则不会误入统计数据当中
*/
- (BOOL)isIgnoreSystemViewController:(id)instance {
return
[instance isKindOfClass:[UITabBarController class]] ||
[instance isKindOfClass:[UINavigationController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIAlertController class]] ||
[instance isKindOfClass:[UISearchController class]] ||
[instance isKindOfClass:[UIActivityViewController class]];
}
- (void)hookAllViewControllerAppearAndDisappear {
/// hook 控制器的显示和消失 分别打log
// 显示
[UIViewController aspect_hookSelector:@selector(viewDidAppear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addBeginLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
// 消失
[UIViewController aspect_hookSelector:@selector(viewDidDisappear:) withOptions:AspectPositionAfter usingBlock:^(id aspectInfo, BOOL animated) {
if (![self isIgnoreSystemViewController:aspectInfo.instance]) {
// 不是忽略VC则采集
[[self class] addEndLogPageView:NSStringFromClass([aspectInfo.instance class])];
}
} error:NULL];
}
hook方案有一个用处就是可以避免代码入侵,做到愈加广泛的通用性。通过swizzling我们可以将原method与自己加入的method相结合,即不需要在原有工程中加入代码,又能做到全局覆盖。
三种方案对比:
1、通过承继父类来实现,相对于hook来说,是较为确切的。因为须要被统计的页面都是承继于这个父类的控制器,而其他的如UINavigationController、UIAlertController等则不会误入统计数据当中。
2、上面提及 hook方案是通过hook UIViewController viewDidLoad/viewDidAppear等方式,而这种方式实际上每位Controller 都会调用,那么都会出现不该出现的Controller 也出现在这里(如前面说到的UINavigationController和UIAlertController)。但hook方案一个比较好的特征是无代码入侵,在不更改项目代码的前提下完成工作。
3、两种hook的对比:分类的方式只要分类被load则就开始hook, 时机并不能自己控制,而且也不能自己开关控制是否hook或则中止hook操作。一个由程序员主动调用(Aspects),一个由系统调用(分类)。由于可控性最后还是选择了Aspects来进行hook。
但要做的是通用的大数据采集类,以后公司内部所有App都可能会用到,在不知道是那个App有哪些Controller的情况下,hook似乎成了最好的技巧。当然要注意筛选掉系统的Controller,避免重复采集无用的数据。 如果要做内部封装的话似乎Aspects hook的方法好一点,不然的话你就要曝露出API提供给分类,或者将分类写入封装类内部。这样代码比较长不利于后期维护。还有最重要的一点就是:使用Aspects可以留一个开关给外部,是否须要sdk帮助采集所有界面的出现和消失,或者交给使用者自己采集界面信息。
最后推荐两篇针对Aspects个人认为写得非常棒的文章
JavaScript垃圾搜集-标记清理和引用计数
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-11 13:02
垃圾搜集机制原理:垃圾搜集器会依照固定的时间间隔(或代码执行中预定的搜集时间), 周期性地执行这一操作:找出这些不再继续使用的变量,然后释放其占用的显存。
1.标记消除
JavaScript中最重用的垃圾搜集方法是标记消除(mark-and-sweep)。Take is cheap, let me show you the code.
当运行addTen()这个函数的时侯,就是当变量步入环境时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放步入环境的变量所占用的显存,因为只要执行流步入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
1 function addTen(num){
2 var sum += num; //垃圾收集已将这个变量标记为“进入环境”。
3 return sum; //垃圾收集已将这个变量标记为“离开环境”。
4 }
5 addTen(10); //输出20
可以使用任何形式来标记变量。比如,可以通过翻转某个特殊的位来记录一个变量何时步入环境, 或者使用一个“进入环境的”变量列表及一个“离开环境的”变量列表来跟踪那个变量发生了变化。说到底,如何标记变量虽然并不重要,关键在于采取哪些策略。
以下举一个简单释放显存事例:
var user = {name : 'scott', age : '21', gender : 'male'}; //在全局中定义变量,标记变量为“进入环境”
user = null; //最后定义为null,释放内存
垃圾搜集器在运行的时侯会给储存在显存中的所有变量都加上标记(当然,可以使用任何标记方法)。然后,它会去除环境中的变量以及被环境中的变量引用的变量的标记。而在此以后再被加上标记的变量将被视为打算删掉的变量,原因是环境中的变量早已难以访问到这种变量了。最后,垃圾搜集器完成显存清理工作,销毁这些带标记的值并回收它们所占用的显存空间。
1.引用计数
另一种不太常见的垃圾搜集策略称作引用计数(reference counting)。引用计数的涵义是跟踪记录每位值被引用的次数。
当申明了一个变量并将一个引用类型值形参该变量时,则这个值的引用次数就是1.如果同一个值又被赋给另外一个变量,则该值得引用次数加1。相反,如果收录对这个值引用的变量又取 得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数弄成 0时,则说明没有办法再访问这个值了,因而就可以将其占用的显存空间回收回去。这样,当垃圾搜集器上次再运行时,它都会释放那 些引用次数为零的值所占用的显存。
问题:循环引用。循环引用指的是对象A中收录一个指向对象B的表针,而对象B中也收录一个指向对象A的引用。请看下边这个事例
function problem(){
var objectA = new Object();
var objectB = new Object();
objectA.someOtherObject = objectB;
objectB.anotherObject = objectA;
}
在这个事例中,objectA 和 objectB 通过各自的属性互相引用;也就是说,这两个对象的引用次数都是 2。
在采用标记消除策略的实现中,由于函数执行以后,这两个对象都离开了作用域,因此这些互相引用不是个问题。但在采用引用计数策略的实现中,当函数执行完毕后,objectA 和 objectB 还将继续存在,因为它们的引用次数永远不会是 0。
假如这个函数被重复多次调用,就会造成大量显存得不到回收。为此舍弃了引用计数方法,转而采用标记消除来实现其垃圾搜集机制。可是,引用计数造成的麻烦并未就此终结。
IE 中有一部分对象并不是原生 JavaScript 对象。例如,其 BOM 和 DOM 中的对象就是使用 C++以 COM(Component Object Model,组件对象模型)对象的方式实现的,而 COM对象的垃圾 采集机制采用的就是引用计数策略。
因此,即使 IE的 JavaScript引擎是使用标记消除策略来实现的,但 JavaScript访问的 COM对象仍然是基于引用计数策略的。换句话说,只要在IE中涉及 COM对象,就会存在循环引用的问题。
下面这个简单的反例,展示了使用 COM对象造成的循环引用问题:
var element = document.getElementById("some_element");
var myObject = new Object();
myObject.element = element;
element.someObject = myObject;
这个反例在一个 DOM元素(element)与一个原生 JavaScript对象(myObject)之间创建了循环引用。
其中,变量 myObject 有一个名为 element 的属性指向 element 对象;而变量 element 也有 一个属性名叫 someObject 回指 myObject。
由于存在这个循环引用,即使将反例中的 DOM从页面中移除,它也永远不会被回收。
为了防止类似这样的循环引用问题,最好是在不使用它们的时侯手工断掉原生 JavaScript 对象与 DOM元素之间的联接。例如,可以使用下边的代码清除上面反例创建的循环引用:
myObject.element = null;
element.someObject = null;
将变量设置为 null 意味着切断变量与它此前引用的值之间的联接。当垃圾搜集器上次运行时,就会删掉那些值并回收它们占用的显存。
为了解决上述问题,IE9把 BOM和 DOM对象都转换成了真正的 JavaScript对象。这样,就防止了两种垃圾搜集算法并存造成的问题,也清除了常见的内存泄漏现象。
参考《JavaScript高级程序设计》 查看全部
JavaScript具有手动垃圾搜集机制,执行环境会负责管理代码执行过程中使用的显存。
垃圾搜集机制原理:垃圾搜集器会依照固定的时间间隔(或代码执行中预定的搜集时间), 周期性地执行这一操作:找出这些不再继续使用的变量,然后释放其占用的显存。
1.标记消除
JavaScript中最重用的垃圾搜集方法是标记消除(mark-and-sweep)。Take is cheap, let me show you the code.
当运行addTen()这个函数的时侯,就是当变量步入环境时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放步入环境的变量所占用的显存,因为只要执行流步入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
1 function addTen(num){
2 var sum += num; //垃圾收集已将这个变量标记为“进入环境”。
3 return sum; //垃圾收集已将这个变量标记为“离开环境”。
4 }
5 addTen(10); //输出20
可以使用任何形式来标记变量。比如,可以通过翻转某个特殊的位来记录一个变量何时步入环境, 或者使用一个“进入环境的”变量列表及一个“离开环境的”变量列表来跟踪那个变量发生了变化。说到底,如何标记变量虽然并不重要,关键在于采取哪些策略。
以下举一个简单释放显存事例:
var user = {name : 'scott', age : '21', gender : 'male'}; //在全局中定义变量,标记变量为“进入环境”
user = null; //最后定义为null,释放内存
垃圾搜集器在运行的时侯会给储存在显存中的所有变量都加上标记(当然,可以使用任何标记方法)。然后,它会去除环境中的变量以及被环境中的变量引用的变量的标记。而在此以后再被加上标记的变量将被视为打算删掉的变量,原因是环境中的变量早已难以访问到这种变量了。最后,垃圾搜集器完成显存清理工作,销毁这些带标记的值并回收它们所占用的显存空间。
1.引用计数
另一种不太常见的垃圾搜集策略称作引用计数(reference counting)。引用计数的涵义是跟踪记录每位值被引用的次数。
当申明了一个变量并将一个引用类型值形参该变量时,则这个值的引用次数就是1.如果同一个值又被赋给另外一个变量,则该值得引用次数加1。相反,如果收录对这个值引用的变量又取 得了另外一个值,则这个值的引用次数减 1。当这个值的引用次数弄成 0时,则说明没有办法再访问这个值了,因而就可以将其占用的显存空间回收回去。这样,当垃圾搜集器上次再运行时,它都会释放那 些引用次数为零的值所占用的显存。
问题:循环引用。循环引用指的是对象A中收录一个指向对象B的表针,而对象B中也收录一个指向对象A的引用。请看下边这个事例
function problem(){
var objectA = new Object();
var objectB = new Object();
objectA.someOtherObject = objectB;
objectB.anotherObject = objectA;
}
在这个事例中,objectA 和 objectB 通过各自的属性互相引用;也就是说,这两个对象的引用次数都是 2。
在采用标记消除策略的实现中,由于函数执行以后,这两个对象都离开了作用域,因此这些互相引用不是个问题。但在采用引用计数策略的实现中,当函数执行完毕后,objectA 和 objectB 还将继续存在,因为它们的引用次数永远不会是 0。
假如这个函数被重复多次调用,就会造成大量显存得不到回收。为此舍弃了引用计数方法,转而采用标记消除来实现其垃圾搜集机制。可是,引用计数造成的麻烦并未就此终结。
IE 中有一部分对象并不是原生 JavaScript 对象。例如,其 BOM 和 DOM 中的对象就是使用 C++以 COM(Component Object Model,组件对象模型)对象的方式实现的,而 COM对象的垃圾 采集机制采用的就是引用计数策略。
因此,即使 IE的 JavaScript引擎是使用标记消除策略来实现的,但 JavaScript访问的 COM对象仍然是基于引用计数策略的。换句话说,只要在IE中涉及 COM对象,就会存在循环引用的问题。
下面这个简单的反例,展示了使用 COM对象造成的循环引用问题:
var element = document.getElementById("some_element");
var myObject = new Object();
myObject.element = element;
element.someObject = myObject;
这个反例在一个 DOM元素(element)与一个原生 JavaScript对象(myObject)之间创建了循环引用。
其中,变量 myObject 有一个名为 element 的属性指向 element 对象;而变量 element 也有 一个属性名叫 someObject 回指 myObject。
由于存在这个循环引用,即使将反例中的 DOM从页面中移除,它也永远不会被回收。
为了防止类似这样的循环引用问题,最好是在不使用它们的时侯手工断掉原生 JavaScript 对象与 DOM元素之间的联接。例如,可以使用下边的代码清除上面反例创建的循环引用:
myObject.element = null;
element.someObject = null;
将变量设置为 null 意味着切断变量与它此前引用的值之间的联接。当垃圾搜集器上次运行时,就会删掉那些值并回收它们占用的显存。
为了解决上述问题,IE9把 BOM和 DOM对象都转换成了真正的 JavaScript对象。这样,就防止了两种垃圾搜集算法并存造成的问题,也清除了常见的内存泄漏现象。
参考《JavaScript高级程序设计》
织梦dedecms系统更改文章描述调用字数的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-11 00:20
下面我们先来说怎么更改这一上限值,就能够表现出[field:description function="cn_substr(@me,字符数)"/]这一方法的主要性。
在Dedecms系统中取文章摘要相关的php文件次要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
正在add页面,有一句话是:$description = cn_substrR($description,$cfg_auot_description); ,这句话实现了[field:description function="cn_substr(@me,字符数)"/]这一功能。由于这一句子确实有益于页面布局,因而我们正在尝试中没有更改。
正在edit页面,有一句话是:$description = cn_substrR($description,250); ,这句话中呈现了一个熟悉的字符数250,这就是系统设置的文章摘要字符数的上限值。 如果是gbk编码则显示下来的就是125个字。如果是utf-8编码则是81个字。明显,我们冲要破文章摘要字符数上限,必定得拿它开刀了。是的,这里修 改250为其他值即可,例如500。这里不保举设置得偏低,一个是正在列表页没必要诠释太多内容(展现太多内容不如间接用body了),另一个是防止数据 库形成冗余。
完成前面的更改还不敷,还须要更改article_description_main.php
正 在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,这里限制了正在后台从动获取摘要的字符数。把这儿的250更改为500即可,织梦仿站也就是和之前更改的字符数分歧即可。(如果你确认你的 每一条文章都是自动添加,手动完成摘要获取就不需要更改这个文件了。从动摘要获取次要还是给大量文章和采集预备的。)
最初,登录后台,正在系统-系统基本参数-其它选项中,从动摘要宽度,改成500即可,也就是和之前更改的字符数分歧即可。
完成上述更改后,我们再到频道列表页,通过标签调用即可,示例标签如下:
{dede:list typeid=” row=’5′ titlelen=’100′ orderby=’new’ pagesize=’5′}
[field:title/]
[field:description function='cn_substr(@me,500)'/]…
{/dede:list}
通过以上方法,我们就实现了调用的文章摘要字符为500字符,完全冲破了文章摘要250字符的系统限制,为网页布局提供了更加辽阔的空间。
下说我们也来说说下常的Dedecms文章或列表页调用文章摘要方式
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
第1、2种方式是间接调用文章摘要,正在调用的字数问题上,当使用[field:info /]时,能够正在{dede:arclist infolen=’ ‘ }{/dede:arclist}中,设置调用摘要的字符数(最高可设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符上限(后台也有上限250个字符)。明显这两种形式都太被动灵活性很差。
第3、4种方式通过function函数实现了对文章摘要显示字符的灵活调整。当然正常没有更改文章摘要内容字符上限时,这4个方式的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方式来调用文章描述标签。但最多也只能调用上面250个字符。如果要调用更多须要更改几个地方:
1.article_description_main.php页面,找到"if($dsize>250) $dsize = 250;"语句把250更改为500
2.登录后台,在系统-系统基本参数-其它选项中,自动摘要宽度,改成500.
3.登陆后台,执行SQL句子:alter table `dede_archives` change `description` `description` varchar( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.就可以显示500个字符了 查看全部
dedecms系统文章调用描述的字数字数最多为250个字节,文章摘要(能够通过infolen或description相关标签调用)被设置了字数上 限为250字符,设置上限的次要目的是降低数据库的冗余,包管网坐优良的性能。因而,如果对简介内容不设置上限显著不合理,但是假如就能自正在控制这一上 限,dedecms仿站这么将对网页内容布局带来积极做用。正在网页构想过程中,NET源代码。dedecms往往须要正在频道列表页面调用到 文章摘要,如果才能无效控制文章摘要的字数,那么能够够促使页面布局太灵活。
下面我们先来说怎么更改这一上限值,就能够表现出[field:description function="cn_substr(@me,字符数)"/]这一方法的主要性。
在Dedecms系统中取文章摘要相关的php文件次要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
正在add页面,有一句话是:$description = cn_substrR($description,$cfg_auot_description); ,这句话实现了[field:description function="cn_substr(@me,字符数)"/]这一功能。由于这一句子确实有益于页面布局,因而我们正在尝试中没有更改。
正在edit页面,有一句话是:$description = cn_substrR($description,250); ,这句话中呈现了一个熟悉的字符数250,这就是系统设置的文章摘要字符数的上限值。 如果是gbk编码则显示下来的就是125个字。如果是utf-8编码则是81个字。明显,我们冲要破文章摘要字符数上限,必定得拿它开刀了。是的,这里修 改250为其他值即可,例如500。这里不保举设置得偏低,一个是正在列表页没必要诠释太多内容(展现太多内容不如间接用body了),另一个是防止数据 库形成冗余。
完成前面的更改还不敷,还须要更改article_description_main.php
正 在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,这里限制了正在后台从动获取摘要的字符数。把这儿的250更改为500即可,织梦仿站也就是和之前更改的字符数分歧即可。(如果你确认你的 每一条文章都是自动添加,手动完成摘要获取就不需要更改这个文件了。从动摘要获取次要还是给大量文章和采集预备的。)
最初,登录后台,正在系统-系统基本参数-其它选项中,从动摘要宽度,改成500即可,也就是和之前更改的字符数分歧即可。
完成上述更改后,我们再到频道列表页,通过标签调用即可,示例标签如下:
{dede:list typeid=” row=’5′ titlelen=’100′ orderby=’new’ pagesize=’5′}
[field:title/]
[field:description function='cn_substr(@me,500)'/]…
{/dede:list}
通过以上方法,我们就实现了调用的文章摘要字符为500字符,完全冲破了文章摘要250字符的系统限制,为网页布局提供了更加辽阔的空间。
下说我们也来说说下常的Dedecms文章或列表页调用文章摘要方式
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
第1、2种方式是间接调用文章摘要,正在调用的字数问题上,当使用[field:info /]时,能够正在{dede:arclist infolen=’ ‘ }{/dede:arclist}中,设置调用摘要的字符数(最高可设置为系统设置的250);如果使用[field:description /],则间接使用后台设置的摘要字符上限(后台也有上限250个字符)。明显这两种形式都太被动灵活性很差。
第3、4种方式通过function函数实现了对文章摘要显示字符的灵活调整。当然正常没有更改文章摘要内容字符上限时,这4个方式的差异并不大。
=========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方式来调用文章描述标签。但最多也只能调用上面250个字符。如果要调用更多须要更改几个地方:
1.article_description_main.php页面,找到"if($dsize>250) $dsize = 250;"语句把250更改为500
2.登录后台,在系统-系统基本参数-其它选项中,自动摘要宽度,改成500.
3.登陆后台,执行SQL句子:alter table `dede_archives` change `description` `description` varchar( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.就可以显示500个字符了
LabVIEW对数据采集卡DLL函数的调用.PDF 3页
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-10 13:37
LabVIEW (Laboratory Virtual Instrument Engineering Workbench─实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh 、UNIX 等多种不同的操作系统平台。 与传统程序语言 不同,LabVIEW 采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。使用LabVIEW 开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW 是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW 通常能形成高效的代码。 1 LabVIEW调用外部程序代码的途径之一 —— 动态链接库机制 1。1动态链接库机制概述LabVIEW 是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232 、RS-485 和 内插式数据采集卡等硬件的通信。
LabVIEW 还具有外置程序库,提供了大量的联接机制,通过DLLs 、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。LabVIEW 提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link Library─DLL )机制 是从LabVIEW 调用标准共享库和用户自定义库函数的通用方式。 具体实现时,是使用LabVIEW 功能模板 中“Advanced ”子模板里的 “调用库函数(Call Library Function )”结点。“调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library )、Macintosh 下的代码段(Code Fragment )、UNIX 下的共享库函数(Shared Library Function)等。当用户须要调用的代码已然存在,或者用户比较熟悉 Windows中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006 ) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。
15刘传清:LabVIEW对数据采集卡DLL函数的调用 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW 能够调用的库。 1。2动态链接库机制实现步骤在Windows 9X 下,利用LabVIEW 6。1 (for Windows 95/98/NT) 中的“动态链接库机制”调用一个DLL , 此DLL 返回机器的名称。1)建立 “调用库函数结点”新建LabVIEW 程序“hostname。vi ”,存至新建目录“d:\temp ”下,其前面板如下:图1库函数调用前面板视口图程序如下:图2库函数调用程序框图其中,“Call Library Function ”结点是通过选择功能模板中“Advanced ”子模板里的 “CallLibrary Function ”功能模块而形成的。此LabVIEW 程序通过 “调用库函数结点”调用一个DLL ,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name ”中,而后将字符串常量“LabVIEW is running on”与“Machine Name ”相 拼接,拼接之结果在字符串指示量“Message ”中显示。
2)配置 “调用库函数结点”双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 置。 其中:在“Library Name or Path ”一项中键入“d:\temp\hostname。dll ”(即,指明此结点所链接的DLL 文件名, 它由C 源代码“hostname。c ”编译而至);在“Function Name ”一项中键入“MachineName ”(即,指明与此结点相链接的DLL 文件中的函数的 名称);参数“return type ”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”;3)编辑C 源文件编辑C 源文件“hostname。c ”(存至目录“d:\temp ”下),其内容如下: /* include extcode。h which contains the prototypes for the LabVIEW functions */ #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) {return TRUE; } /* This functions gets the computer name and returns it to LabVIEW */ __declspec (dllexport) void MachineName(void *LVHandle) {char computerName[MAX_COMPUTERNAME_LENGTH+1];int compNameLength = MAX_COMPUTERNAME_LENGTH+1; 16 第25 卷第5 期襄樊学院学报2004 年第5 期/* Get computer name */GetComputerName(computerName, &compNameLength);/* Size LabVIEW handle to the correct size */DSSetHandleSize(LVHandle, compNameLength + 5);/* Copy the string size to the LabVIEW handle */**(int32 **)LVHandle = compNameLength ;/* Copy the string to the LabVIEW handle */sprintf((*(char **)LVHandle)+4,"%s",computerName); }此程序首先了调用Windows 的API 函数“GetComputerName ”获取机器名;然后调用LabVIEW 的函 数“DSSetHandleSize ”来设置LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码将C 源代码“d:\temp\ hostname。c ”编译成一个DLL 文件 “d:\temp\hostname。dll ”。可使用VC++ 6。0 (for Windows 95/98/2000/NT) ,完成此编译工作。5)运行VI运行LabVIEW 程序“hostname。vi ”,结果如下:图3前面板运行结果 2结束语本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一─动态链接库机制,并给出了 应用实例。由于在LabVIEW 中引入了C 语言的强悍功能,从而提升了LabVIEW 的整体性能。本方式已在LabVIEW 6。1 for Windows 95/98/NT 及Visual C++ 6。0 for Windows 9X/XP/2000/NT环境下 实现。 实践证明,此方式高效、易行,是提高LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: [1] LabVIEW User Manual ,National Instruments Corporation ,1998。 [2] G Programming Reference Manual,National Instruments Corporation ,1998。
LabVIEW Data Acquisition Invoke for DLL FunctionsLIU Chuan-qing(Department of Physics, Xiangfan University, Xiangfan 441053, China) Abstract :This paper introduces virtual instrument and the features of its development environment─LabVIEW , analyzes and realizes the advanced technology -Dynamic Link Library(DLL) ,which is one of the general methods for calling external code from LabVIEW。 It has been proved that this method is efficient ,practicable and also a good one to enhance LabVIEW ’s capacity of sharing data with other applications in Windows。 Key words:Virtual instrument; LabVIEW; Dynamic Link Library ; DLL17 查看全部
2004 年9 月襄樊学院学报Sept。,2004 第25 卷第5 期Journal of Xiangfan UniversityVol。25 No。5LabVIEW 对数据采集卡DLL 函数的调用刘传清(襄樊学院物理学系,湖北 襄樊 441053)摘要:首先介绍虚拟仪器及其开发环境LabVIEW6的特性,分析并实现了将LabVIEW与外部代码进行联接的中级技术之一—动态链接库(DLL)机制。实践表明,此机制高效、易行,是提高LabVIEW与其它Windows应用程序之间的数据共享能力的一条挺好的途径。关键词:虚拟仪器;LabVIEW;动态链接库;DLL中图分类号:TN311。11文献标志码:A文章编号:1009-2854 (2004 )05-0015-03 0序言俄罗斯国家仪器NI 公司的基于G 语言的开发环境LabVIEW 的出现,使得虚拟仪器的思想为工业界所接 受。 所谓虚拟仪器,就是在通用计算机平台上,用户按照自己的需求定义和设计仪器的测试功能,其实质 是将传统仪器硬件和最新计算机软件技术充分结合上去,以模块化软件实现并扩充传统仪器的功能。 与传 统仪器相比,虚拟仪器在智能化程度、处理能力、性能价格比、可操作性等方面均具有显著的技术优势。
LabVIEW (Laboratory Virtual Instrument Engineering Workbench─实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh 、UNIX 等多种不同的操作系统平台。 与传统程序语言 不同,LabVIEW 采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。使用LabVIEW 开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW 是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW 通常能形成高效的代码。 1 LabVIEW调用外部程序代码的途径之一 —— 动态链接库机制 1。1动态链接库机制概述LabVIEW 是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232 、RS-485 和 内插式数据采集卡等硬件的通信。
LabVIEW 还具有外置程序库,提供了大量的联接机制,通过DLLs 、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。LabVIEW 提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link Library─DLL )机制 是从LabVIEW 调用标准共享库和用户自定义库函数的通用方式。 具体实现时,是使用LabVIEW 功能模板 中“Advanced ”子模板里的 “调用库函数(Call Library Function )”结点。“调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library )、Macintosh 下的代码段(Code Fragment )、UNIX 下的共享库函数(Shared Library Function)等。当用户须要调用的代码已然存在,或者用户比较熟悉 Windows中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006 ) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。
15刘传清:LabVIEW对数据采集卡DLL函数的调用 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW 能够调用的库。 1。2动态链接库机制实现步骤在Windows 9X 下,利用LabVIEW 6。1 (for Windows 95/98/NT) 中的“动态链接库机制”调用一个DLL , 此DLL 返回机器的名称。1)建立 “调用库函数结点”新建LabVIEW 程序“hostname。vi ”,存至新建目录“d:\temp ”下,其前面板如下:图1库函数调用前面板视口图程序如下:图2库函数调用程序框图其中,“Call Library Function ”结点是通过选择功能模板中“Advanced ”子模板里的 “CallLibrary Function ”功能模块而形成的。此LabVIEW 程序通过 “调用库函数结点”调用一个DLL ,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name ”中,而后将字符串常量“LabVIEW is running on”与“Machine Name ”相 拼接,拼接之结果在字符串指示量“Message ”中显示。
2)配置 “调用库函数结点”双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 置。 其中:在“Library Name or Path ”一项中键入“d:\temp\hostname。dll ”(即,指明此结点所链接的DLL 文件名, 它由C 源代码“hostname。c ”编译而至);在“Function Name ”一项中键入“MachineName ”(即,指明与此结点相链接的DLL 文件中的函数的 名称);参数“return type ”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”;3)编辑C 源文件编辑C 源文件“hostname。c ”(存至目录“d:\temp ”下),其内容如下: /* include extcode。h which contains the prototypes for the LabVIEW functions */ #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) {return TRUE; } /* This functions gets the computer name and returns it to LabVIEW */ __declspec (dllexport) void MachineName(void *LVHandle) {char computerName[MAX_COMPUTERNAME_LENGTH+1];int compNameLength = MAX_COMPUTERNAME_LENGTH+1; 16 第25 卷第5 期襄樊学院学报2004 年第5 期/* Get computer name */GetComputerName(computerName, &compNameLength);/* Size LabVIEW handle to the correct size */DSSetHandleSize(LVHandle, compNameLength + 5);/* Copy the string size to the LabVIEW handle */**(int32 **)LVHandle = compNameLength ;/* Copy the string to the LabVIEW handle */sprintf((*(char **)LVHandle)+4,"%s",computerName); }此程序首先了调用Windows 的API 函数“GetComputerName ”获取机器名;然后调用LabVIEW 的函 数“DSSetHandleSize ”来设置LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码将C 源代码“d:\temp\ hostname。c ”编译成一个DLL 文件 “d:\temp\hostname。dll ”。可使用VC++ 6。0 (for Windows 95/98/2000/NT) ,完成此编译工作。5)运行VI运行LabVIEW 程序“hostname。vi ”,结果如下:图3前面板运行结果 2结束语本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一─动态链接库机制,并给出了 应用实例。由于在LabVIEW 中引入了C 语言的强悍功能,从而提升了LabVIEW 的整体性能。本方式已在LabVIEW 6。1 for Windows 95/98/NT 及Visual C++ 6。0 for Windows 9X/XP/2000/NT环境下 实现。 实践证明,此方式高效、易行,是提高LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: [1] LabVIEW User Manual ,National Instruments Corporation ,1998。 [2] G Programming Reference Manual,National Instruments Corporation ,1998。
LabVIEW Data Acquisition Invoke for DLL FunctionsLIU Chuan-qing(Department of Physics, Xiangfan University, Xiangfan 441053, China) Abstract :This paper introduces virtual instrument and the features of its development environment─LabVIEW , analyzes and realizes the advanced technology -Dynamic Link Library(DLL) ,which is one of the general methods for calling external code from LabVIEW。 It has been proved that this method is efficient ,practicable and also a good one to enhance LabVIEW ’s capacity of sharing data with other applications in Windows。 Key words:Virtual instrument; LabVIEW; Dynamic Link Library ; DLL17
DEDECMS发布时间为1970年1月1日的解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-08-10 05:54
这样你可以看见你刚刚新加加的文章一所有数组值。
观察以下的数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中1231846313就是时间数据了。
然后就是替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,看到第一句话应当就可以pass他了,下面具体谈谈,他这个方式的问题在那里(注:这种执行sql句子,或者须要更改数据库的一定先备份数据库)。
对应的是数据库的dede_archives表,请按照你的实际情况更换前缀。
这个表里有三个表示时间的数组:
pubdate:发布时间(前台可修改)
senddate:入库时间
sortrank:前台调用最新文章。实际上是用这个时间。
这段说的是没有问题的,我再详尽的说下:
1.pubdate:发布时间(前台可修改)
在发布新文章或编辑文章时,可在中级参数里看见,可以修改。也是系统在内容页及列表页调用的时间。当发布时间为1970时,列表页会显示1970-01-01,而文章页获取的发布时间则为“暂无”,当然这个以dede默认模板为准,如果你更改了可能会有其他结果。如:我的待初审文章审核发布时会手动更新为当前系统时间(如果不会设置,看Dedecms未初审文档手动更新发布时间)
2.senddate:入库时间
根据字面意思即可理解,但是所谓的入库时间彰显在那里?就是dede后台档案列表中的“录入时间”,理论上dede后台难以更改,但实际也可以执行sql句子更改,并无实际意义。如果你的文章命名规则为“{typedir}/{Y}/{M}{D}/{aid}.html”的话,也直观的提如今你文章页的url中。
3.sortrank:前台调用最新文章。实际上是用这个时间。
这个时间我们通常看不到,但是前台模板设置为“orderby=’public’的话,系统就是根据这个时间来调用的。说了一大堆只是在指出这种细节,也算是讲讲原理吧。
其次,我们应当了解,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不可能完全一致,所以这儿也有点问题,但是无伤大雅,最终要的在于,这个方案是更改了整个系统的数据库pubdate、senddate、sortrank的三个时间段,也就是说,从你发的第一篇文章,到最后一篇,都会弄成你如今更改的这个时间,我第一次更改以后,整站的文章都成了3月19日发布的,可以说几乎所有的东西都乱了,这个你们应当能想明白,所以,我说备份很重要,转载这篇文章的人,确实太害人。这种方式我认为没有哪些可取的,完全用不上的。
二、正确的解决1970的方案
优采云采集发布时惟一不会错的就是系统录入时间,所以,我们以这个为标准,将public及sortrank时间改为senddate(声明下,先备份,后操作)。同时,网站采集比较多的考虑下,是不是有些文章的发布时间与入库时间相差很大?如3-19采集了好多篇,发布为待初审,通过插件控制每晚手动更新,4-19才更新完,如果你执行两条命令的话,那原先初审最晚的这些文章也会弄成3-19日发布,不过你可以选择只执行一条命令。)
如果你不介意里面我说的,确实须要解决1970的问题的话,在dede后台-系统-sql命令行工具,执行以下命令:
UPDATE dede_archives SET sortrank = senddate ;
这条命令是将前台调用时间也改成入库时间,如果你是我前面提及的那个,就不要执行了,至于1970都会不会有其他影响,自己掂量
UPDATE dede_archives SET pubdate = senddate ;
这条命令是将发布时间改为入库时间,就不解释了,上面都说了
上一篇:织梦DedeCMS后台编辑模板的时侯出现Error:no csrf hash code!的解决方式 查看全部
第二步,后台执行SQL句子SELECT * FROM dede_archives order by id DESC limit 1
这样你可以看见你刚刚新加加的文章一所有数组值。
观察以下的数据:
pubdate:1231846313
senddate:1231846313
sortrank:1231846313
其中1231846313就是时间数据了。
然后就是替换了。
UPDATE dede_archives SET sortrank = 1231846313;
UPDATE dede_archives SET senddate = 1231846313;
UPDATE dede_archives SET pubdate = 1231846313;
首先,看到第一句话应当就可以pass他了,下面具体谈谈,他这个方式的问题在那里(注:这种执行sql句子,或者须要更改数据库的一定先备份数据库)。
对应的是数据库的dede_archives表,请按照你的实际情况更换前缀。
这个表里有三个表示时间的数组:
pubdate:发布时间(前台可修改)
senddate:入库时间
sortrank:前台调用最新文章。实际上是用这个时间。
这段说的是没有问题的,我再详尽的说下:
1.pubdate:发布时间(前台可修改)
在发布新文章或编辑文章时,可在中级参数里看见,可以修改。也是系统在内容页及列表页调用的时间。当发布时间为1970时,列表页会显示1970-01-01,而文章页获取的发布时间则为“暂无”,当然这个以dede默认模板为准,如果你更改了可能会有其他结果。如:我的待初审文章审核发布时会手动更新为当前系统时间(如果不会设置,看Dedecms未初审文档手动更新发布时间)
2.senddate:入库时间
根据字面意思即可理解,但是所谓的入库时间彰显在那里?就是dede后台档案列表中的“录入时间”,理论上dede后台难以更改,但实际也可以执行sql句子更改,并无实际意义。如果你的文章命名规则为“{typedir}/{Y}/{M}{D}/{aid}.html”的话,也直观的提如今你文章页的url中。
3.sortrank:前台调用最新文章。实际上是用这个时间。
这个时间我们通常看不到,但是前台模板设置为“orderby=’public’的话,系统就是根据这个时间来调用的。说了一大堆只是在指出这种细节,也算是讲讲原理吧。
其次,我们应当了解,即使是优采云采集,或者dede采集,pubdate、senddate、sortrank这三个时间也不可能完全一致,所以这儿也有点问题,但是无伤大雅,最终要的在于,这个方案是更改了整个系统的数据库pubdate、senddate、sortrank的三个时间段,也就是说,从你发的第一篇文章,到最后一篇,都会弄成你如今更改的这个时间,我第一次更改以后,整站的文章都成了3月19日发布的,可以说几乎所有的东西都乱了,这个你们应当能想明白,所以,我说备份很重要,转载这篇文章的人,确实太害人。这种方式我认为没有哪些可取的,完全用不上的。
二、正确的解决1970的方案
优采云采集发布时惟一不会错的就是系统录入时间,所以,我们以这个为标准,将public及sortrank时间改为senddate(声明下,先备份,后操作)。同时,网站采集比较多的考虑下,是不是有些文章的发布时间与入库时间相差很大?如3-19采集了好多篇,发布为待初审,通过插件控制每晚手动更新,4-19才更新完,如果你执行两条命令的话,那原先初审最晚的这些文章也会弄成3-19日发布,不过你可以选择只执行一条命令。)
如果你不介意里面我说的,确实须要解决1970的问题的话,在dede后台-系统-sql命令行工具,执行以下命令:
UPDATE dede_archives SET sortrank = senddate ;
这条命令是将前台调用时间也改成入库时间,如果你是我前面提及的那个,就不要执行了,至于1970都会不会有其他影响,自己掂量
UPDATE dede_archives SET pubdate = senddate ;
这条命令是将发布时间改为入库时间,就不解释了,上面都说了
上一篇:织梦DedeCMS后台编辑模板的时侯出现Error:no csrf hash code!的解决方式

