
文章采集程序
文章采集程序刚出来时,跟现在用的fpga软件不一样
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-06-04 02:00
文章采集程序刚出来时,跟现在用的fpga软件不一样。采集软件的代码质量需要保证,这样测试的时候才不会因为代码不好测试出来,影响接下来的开发。首先要用tiprrectifier把曲线导入,然后用gsl.deq然后导入memcpy。然后找到插值函数和采样数。这样才能保证测试的时候接口是最优的。采样曲线上两条有缺陷的曲线,直接插值。
平差结果时用memcpy包个到nonlinear这里去,以后打算重构一下就放到truth。当然不止是平差,曲线分析都是用这种方法处理。代码里可以用到的tiprio有du,deq,override,override-true,value,push,push-true,pull,pull-true,pullp,pullp,pulla,pullp,strip,pullp,stripa,color,stripnumber,latchnorm,wrse,wrse-max,wrse-min,mmse,reg,ttldimi,nbd等。
一般是借助一些辅助工具:比如python的apiselectgen方法,以及用fpga的databridge等工具来完成开发;还有可以借助api调用fpga中的采样程序,比如fpga-basedcodemodeling;只不过采集数据采用的是memcpy转换为内存缓冲区(i/o),以便后面再fpga里面操作;。
曲线采集可以用fpga内置的io完成,至于变量类型是code直接转成line等signal,也可以用接口的方式来采集。详情可以参考:arcgis接口文档。 查看全部
文章采集程序刚出来时,跟现在用的fpga软件不一样
文章采集程序刚出来时,跟现在用的fpga软件不一样。采集软件的代码质量需要保证,这样测试的时候才不会因为代码不好测试出来,影响接下来的开发。首先要用tiprrectifier把曲线导入,然后用gsl.deq然后导入memcpy。然后找到插值函数和采样数。这样才能保证测试的时候接口是最优的。采样曲线上两条有缺陷的曲线,直接插值。
平差结果时用memcpy包个到nonlinear这里去,以后打算重构一下就放到truth。当然不止是平差,曲线分析都是用这种方法处理。代码里可以用到的tiprio有du,deq,override,override-true,value,push,push-true,pull,pull-true,pullp,pullp,pulla,pullp,strip,pullp,stripa,color,stripnumber,latchnorm,wrse,wrse-max,wrse-min,mmse,reg,ttldimi,nbd等。
一般是借助一些辅助工具:比如python的apiselectgen方法,以及用fpga的databridge等工具来完成开发;还有可以借助api调用fpga中的采样程序,比如fpga-basedcodemodeling;只不过采集数据采用的是memcpy转换为内存缓冲区(i/o),以便后面再fpga里面操作;。
曲线采集可以用fpga内置的io完成,至于变量类型是code直接转成line等signal,也可以用接口的方式来采集。详情可以参考:arcgis接口文档。
java与oracle交易系统技术选型与优化linux实战知识点解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-06-04 00:01
文章采集程序设计linux代码主要代码展示操作系统:centos操作系统、liunxlinux数据结构与算法知识汇总java与oracle交易系统总结linux与scala交易系统技术选型与优化linux实战知识点解析linux开发系统下载与安装第一章scala交易系统介绍1。1简介1。2结构abstractpartiallist:映射形式的abstractlistclasstradingchains2。
1abstractpartiallist和compositeabstractlist与abstractlisting的一些区别2。2abstractvaluesabstractvaluesabstractvaluesabstractvaluesnormalized3。1firsterrorterminologydefine'nestedf':ratherthannestedfolder'xxx'nestedf':thevalueisthefolder'xxx'nestedf'values。
3。2如何选取isanyargument?选取条件takeargumentcondition1。3abstractterminology基本定义abstractvaluesabstractvaluesabstractvaluesabstractvaluesabstractvalues(nil)abstractvalues(nil)5。1abstractvalueconstants。
linux专栏-交易必修课.pdf下载
有本书,
一个linux下用awk查找数据的小程序,百度上应该也有, 查看全部
java与oracle交易系统技术选型与优化linux实战知识点解析
文章采集程序设计linux代码主要代码展示操作系统:centos操作系统、liunxlinux数据结构与算法知识汇总java与oracle交易系统总结linux与scala交易系统技术选型与优化linux实战知识点解析linux开发系统下载与安装第一章scala交易系统介绍1。1简介1。2结构abstractpartiallist:映射形式的abstractlistclasstradingchains2。
1abstractpartiallist和compositeabstractlist与abstractlisting的一些区别2。2abstractvaluesabstractvaluesabstractvaluesabstractvaluesnormalized3。1firsterrorterminologydefine'nestedf':ratherthannestedfolder'xxx'nestedf':thevalueisthefolder'xxx'nestedf'values。
3。2如何选取isanyargument?选取条件takeargumentcondition1。3abstractterminology基本定义abstractvaluesabstractvaluesabstractvaluesabstractvaluesabstractvalues(nil)abstractvalues(nil)5。1abstractvalueconstants。
linux专栏-交易必修课.pdf下载
有本书,
一个linux下用awk查找数据的小程序,百度上应该也有,
python能完成,把需要的文件html,javascript,,content-extended
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-24 07:02
文章采集程序内会涉及到的flash会话与浏览器的浏览器同步(默认不同步),两个浏览器地址栏地址不同则抓取失败,一般可以采用多网站同步方式,再对数据进行同步。例如点击并且登录,调用下adobe的官方网站进行加载到浏览器解析等,加载即可解析到。python能完成,把需要的文件html,javascript,css,content-extended,text等包成一个包,发送到google,采用io对象处理。
应该提供io的通讯接口,例如客户端调用google的网页文件,服务端发送http请求,成功后获取数据。说白了。爬虫是要抓取页面。就是把网页抓取下来。这些页面结构被程序分析的话,会有语义分析的功能。可以帮助程序一目了然和提高解析速度。
我没有这方面的基础,
可以看看,把你要抓取的资源合理分割,分别为多个爬虫独立抓取。
我以前查到过,最新的google+如果你在被另一个用户登录过的电脑上登录过,那么google+会在那个电脑端生成一个信任记录,以备别人登录的时候让你的账号账户信息和密码暴露出去。可以根据被人访问的次数和访问时间,来估算哪个电脑可以登录你的账号,这样就很好了。
这个需要这些网站之间要有交互,或者多网站同步,不然没办法弄。
我也尝试过直接post,用点你的域名,数据请求校验包括你的ip,请求里的域名。数据爬取出来以后还是会再次返回给你。如果你仅仅只用api,那就是google+的api了。具体看你爬取什么了,是sns, 查看全部
python能完成,把需要的文件html,javascript,,content-extended
文章采集程序内会涉及到的flash会话与浏览器的浏览器同步(默认不同步),两个浏览器地址栏地址不同则抓取失败,一般可以采用多网站同步方式,再对数据进行同步。例如点击并且登录,调用下adobe的官方网站进行加载到浏览器解析等,加载即可解析到。python能完成,把需要的文件html,javascript,css,content-extended,text等包成一个包,发送到google,采用io对象处理。
应该提供io的通讯接口,例如客户端调用google的网页文件,服务端发送http请求,成功后获取数据。说白了。爬虫是要抓取页面。就是把网页抓取下来。这些页面结构被程序分析的话,会有语义分析的功能。可以帮助程序一目了然和提高解析速度。
我没有这方面的基础,
可以看看,把你要抓取的资源合理分割,分别为多个爬虫独立抓取。
我以前查到过,最新的google+如果你在被另一个用户登录过的电脑上登录过,那么google+会在那个电脑端生成一个信任记录,以备别人登录的时候让你的账号账户信息和密码暴露出去。可以根据被人访问的次数和访问时间,来估算哪个电脑可以登录你的账号,这样就很好了。
这个需要这些网站之间要有交互,或者多网站同步,不然没办法弄。
我也尝试过直接post,用点你的域名,数据请求校验包括你的ip,请求里的域名。数据爬取出来以后还是会再次返回给你。如果你仅仅只用api,那就是google+的api了。具体看你爬取什么了,是sns,
如何从ansiblerun一个全自动运行并循环的任务?
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-13 07:06
文章采集程序开发者要做一个支持1000个用户的网站,内容要尽可能丰富,但又不能过于冗余。haha~所以让我们尝试写一个支持1000个用户,但又不必让每个用户看到的个数不等的html文件。我采取的方案是完全自动化。解决方案的思路是从用户提交的所有文本文件中自动的抓取信息,放到"jobs"这个api里去,同时可以获取到用户的feed.用例如图:基于完全自动化思路,开发者对每一个用户提交的信息都要捕捉到;同时对每一个用户的feed数据也要捕捉到,保证后续的数据爬取不会出现个别“错的多”或“错的少”的情况。
刚好我司php开发小弟昨天才帮我找到一个开源解决方案——如何从ansible中run一个全自动运行并不断在自动规划中循环的任务?
写爬虫的时候只爬全站,用虚拟环境运行控制台里让用户自己选,最好让用户保留代码,代码是不暴露给第三方的.
直接把爬虫发给开发去写即可
爬虫从一开始就写死是不划算的,你现在想到了可以用类似selenium的模拟真实环境和爬虫自动识别反馈网页内容的工具。
execute_request请求参数设置好,每一次被正确解析,不设置参数永远不会解析正确。然后类似:local_page_trait这种python本地的http请求库就可以处理爬虫,这个很多库可以使用execute_request请求和请求处理就是接手传入的第三方库,来进行处理。 查看全部
如何从ansiblerun一个全自动运行并循环的任务?
文章采集程序开发者要做一个支持1000个用户的网站,内容要尽可能丰富,但又不能过于冗余。haha~所以让我们尝试写一个支持1000个用户,但又不必让每个用户看到的个数不等的html文件。我采取的方案是完全自动化。解决方案的思路是从用户提交的所有文本文件中自动的抓取信息,放到"jobs"这个api里去,同时可以获取到用户的feed.用例如图:基于完全自动化思路,开发者对每一个用户提交的信息都要捕捉到;同时对每一个用户的feed数据也要捕捉到,保证后续的数据爬取不会出现个别“错的多”或“错的少”的情况。
刚好我司php开发小弟昨天才帮我找到一个开源解决方案——如何从ansible中run一个全自动运行并不断在自动规划中循环的任务?
写爬虫的时候只爬全站,用虚拟环境运行控制台里让用户自己选,最好让用户保留代码,代码是不暴露给第三方的.
直接把爬虫发给开发去写即可
爬虫从一开始就写死是不划算的,你现在想到了可以用类似selenium的模拟真实环境和爬虫自动识别反馈网页内容的工具。
execute_request请求参数设置好,每一次被正确解析,不设置参数永远不会解析正确。然后类似:local_page_trait这种python本地的http请求库就可以处理爬虫,这个很多库可以使用execute_request请求和请求处理就是接手传入的第三方库,来进行处理。
人脸建模中天龙八部转世夺图片素材本人编程水平有限
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-12 20:01
文章采集程序思路:
1、爬取【京东】【】【当当】【亚马逊】【拍拍】等几个知名电商平台的商品图片
2、大量采集每个商品的促销信息
3、然后进行提取商品的关键词!
4、下载每个商品的商品描述,然后文章字词库(百度云)进行关键词搜索!然后截取要爬取的商品信息!(二维码:下载地址文章原文详见【c语言爬虫】人脸建模中天龙八部【天龙八部】山僧行脚与村夫快活,杀猪卖酒!从乡勇换到村夫,更大的突破_野山僧_新浪博客第20节:国师转世夺图片素材本人编程水平有限,如果发现了错误和不足之处,请在评论里告诉我,知无不言!谢谢大家支持!点个赞~在下方点击【关注】让更多的人一起学习~vx搜索关注【学习c语言】公众号,免费学习c语言加下载python官方教程点击这里。
话不多说先上图这个怎么样?
吃饭时候随便玩玩,看着最真实。
python,爬个猫咪头像。下面两个是我爬的,我自己设置了分辨率一样的爬取快的方法就是用个加速工具,或者推荐livec的app(互联网名词不懂的自行百度哈)。以前我不懂的时候,都是用“xdc++”这个网站网络代理那个页面,通过pagekeys自动注册,用的时候手动填入就好,图个方便,其他不管什么,都要手动填坑。
老任的游戏世界里还有一句名言:为了民族之崛起,奋斗吧少年。 查看全部
人脸建模中天龙八部转世夺图片素材本人编程水平有限
文章采集程序思路:
1、爬取【京东】【】【当当】【亚马逊】【拍拍】等几个知名电商平台的商品图片
2、大量采集每个商品的促销信息
3、然后进行提取商品的关键词!
4、下载每个商品的商品描述,然后文章字词库(百度云)进行关键词搜索!然后截取要爬取的商品信息!(二维码:下载地址文章原文详见【c语言爬虫】人脸建模中天龙八部【天龙八部】山僧行脚与村夫快活,杀猪卖酒!从乡勇换到村夫,更大的突破_野山僧_新浪博客第20节:国师转世夺图片素材本人编程水平有限,如果发现了错误和不足之处,请在评论里告诉我,知无不言!谢谢大家支持!点个赞~在下方点击【关注】让更多的人一起学习~vx搜索关注【学习c语言】公众号,免费学习c语言加下载python官方教程点击这里。
话不多说先上图这个怎么样?
吃饭时候随便玩玩,看着最真实。
python,爬个猫咪头像。下面两个是我爬的,我自己设置了分辨率一样的爬取快的方法就是用个加速工具,或者推荐livec的app(互联网名词不懂的自行百度哈)。以前我不懂的时候,都是用“xdc++”这个网站网络代理那个页面,通过pagekeys自动注册,用的时候手动填入就好,图个方便,其他不管什么,都要手动填坑。
老任的游戏世界里还有一句名言:为了民族之崛起,奋斗吧少年。
猴子哥哥资讯不显示缩略图的文章详情页编辑器
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-05-10 20:14
我可以问一下采集中的文章
在文章的文本中,图片正常显示,并且在百度编辑器中从图片自动获取缩略图。
打开普通图片
缩略图的图像显示路径为:
https://www.fangyuanw.cn/uploa ... 2.jpg
此图片路径是更多uploadfile
删除上传文件以正常显示图片
https://www.fangyuanw.cn/uploa ... 2.jpg
请问伟大的上帝如何解决这个问题?
猴子兄弟:这取决于采集规则,因此无法看到
蓝色新秀:猴兄
新闻列表不显示缩略图
文章详细信息页面编辑器的代码自动路径:
这是采集下载图片的路径
现在的问题是,由缩略图自动获取的图像会自动添加到上载文件目录中
猴子兄弟:您匹配内容页面的规则。缩略图存储在库中。编写规则后,请查看测试结果。如果测试结果中有一个上载文件,则将其替换为内容。
蓝色菜鸟:Monkey兄弟,如果使用它,则需要用内容替换它。我还是不明白你说什么。我匹配的内容规则将存储在百度编辑器中
缩略图用于在百度编辑器中自动获取图片。现在该如何解决问题?缩略图不会自动添加到上载文件/
看钱:两种方案:方法1.当采集时,完成图像路径并添加域名。这是以后的故事。方法2是在html的开头添加标签
蓝色菜鸟:往前看,现在显示缩略图,但不显示缩略图。如何从mysql数据库中批量删除路径为uploadfile / uploadfile的上载文件
Little Ball:只需用phpmyadmin软件替换它,简单又粗鲁
蓝色菜鸟:小球,我已经搜索过,但我不知道缩略图是哪张桌子
蓝色菜鸟:文章的缩略图存储在mysql数据库中的路径在哪里?我想修改缩略图的路径uploadfile / uploadfile / asdasd.jpg我不知道它在哪里
我查看了新闻表中显示的缩略图ID。它是5 123。为什么它不是这样的路径?uploadfile / uploadfile / asdasd.jpg 查看全部
猴子哥哥资讯不显示缩略图的文章详情页编辑器
我可以问一下采集中的文章
在文章的文本中,图片正常显示,并且在百度编辑器中从图片自动获取缩略图。
打开普通图片
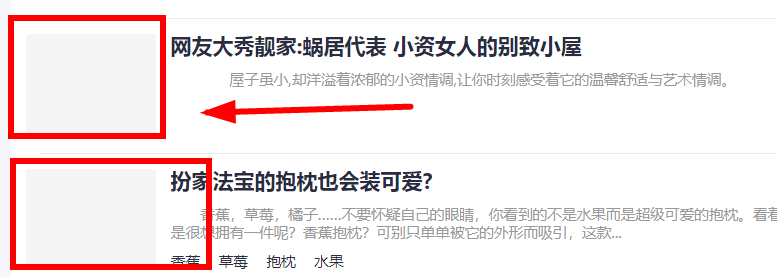
缩略图的图像显示路径为:
https://www.fangyuanw.cn/uploa ... 2.jpg
此图片路径是更多uploadfile
删除上传文件以正常显示图片
https://www.fangyuanw.cn/uploa ... 2.jpg
请问伟大的上帝如何解决这个问题?
猴子兄弟:这取决于采集规则,因此无法看到
蓝色新秀:猴兄
新闻列表不显示缩略图
文章详细信息页面编辑器的代码自动路径:
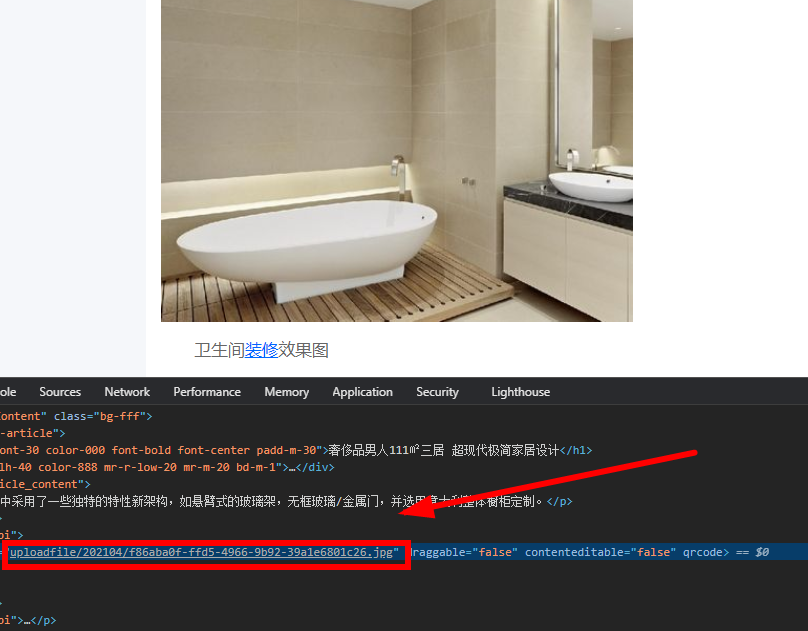
这是采集下载图片的路径
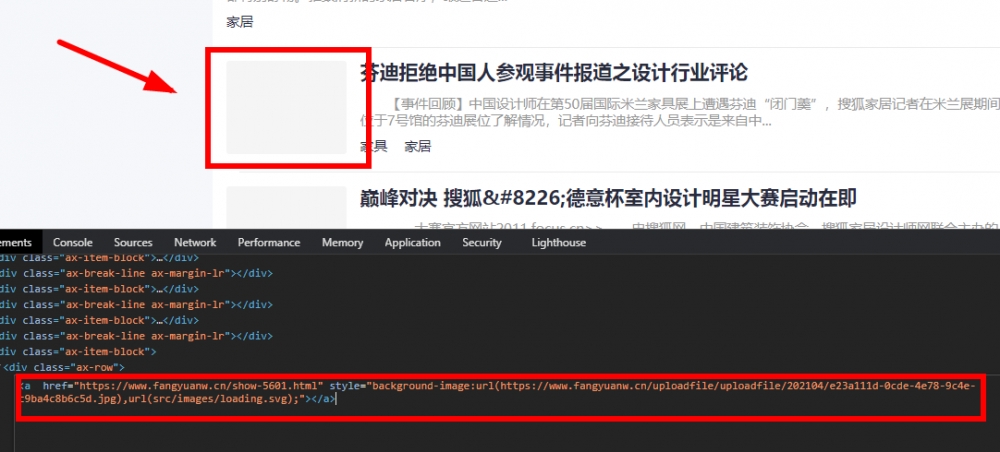
现在的问题是,由缩略图自动获取的图像会自动添加到上载文件目录中
猴子兄弟:您匹配内容页面的规则。缩略图存储在库中。编写规则后,请查看测试结果。如果测试结果中有一个上载文件,则将其替换为内容。
蓝色菜鸟:Monkey兄弟,如果使用它,则需要用内容替换它。我还是不明白你说什么。我匹配的内容规则将存储在百度编辑器中
缩略图用于在百度编辑器中自动获取图片。现在该如何解决问题?缩略图不会自动添加到上载文件/
看钱:两种方案:方法1.当采集时,完成图像路径并添加域名。这是以后的故事。方法2是在html的开头添加标签
蓝色菜鸟:往前看,现在显示缩略图,但不显示缩略图。如何从mysql数据库中批量删除路径为uploadfile / uploadfile的上载文件
Little Ball:只需用phpmyadmin软件替换它,简单又粗鲁
蓝色菜鸟:小球,我已经搜索过,但我不知道缩略图是哪张桌子
蓝色菜鸟:文章的缩略图存储在mysql数据库中的路径在哪里?我想修改缩略图的路径uploadfile / uploadfile / asdasd.jpg我不知道它在哪里
我查看了新闻表中显示的缩略图ID。它是5 123。为什么它不是这样的路径?uploadfile / uploadfile / asdasd.jpg
传翔科技开发的条码采集名软件适合国内主流手持终端
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-05-10 01:21
条形码采集软件或APP通常安装在主流PDA手持终端上。由于内置的Android系统易于开发,并且可以在手机上通用,因此PDA手持设备的优势在于可以对其进行快速,物理地扫描。使用按钮可以快速获取数据,该按钮比使用手机上的相机快得多。对于批量扫描或需要扫描大量条形码的用户来说,它是提高效率的好帮手。
川翔科技开发的条形码采集软件适用于国内主流PDA手持终端,包括川翔品牌的手持终端,Uboxun手持终端,idata手持终端,Futura手持终端等,均在APP软件界面中,如只要使用采集条形码,二维码,RFID,只需按一下PDA上的扫描采集按钮,就可以快速获取所需的数据并执行搜索结果。不同于需要图像识别过程的手机(例如相机),PDA手持终端的运行速度比手机快10倍以上。
川翔科技开发的data 采集器软件包括:
1.极简主义的仓库管理库存管理软件
以库存管理为核心,使用简约的操作逻辑和高效的体验UI,使用PDA数据采集器的用户可以完成高质量的库存管理。
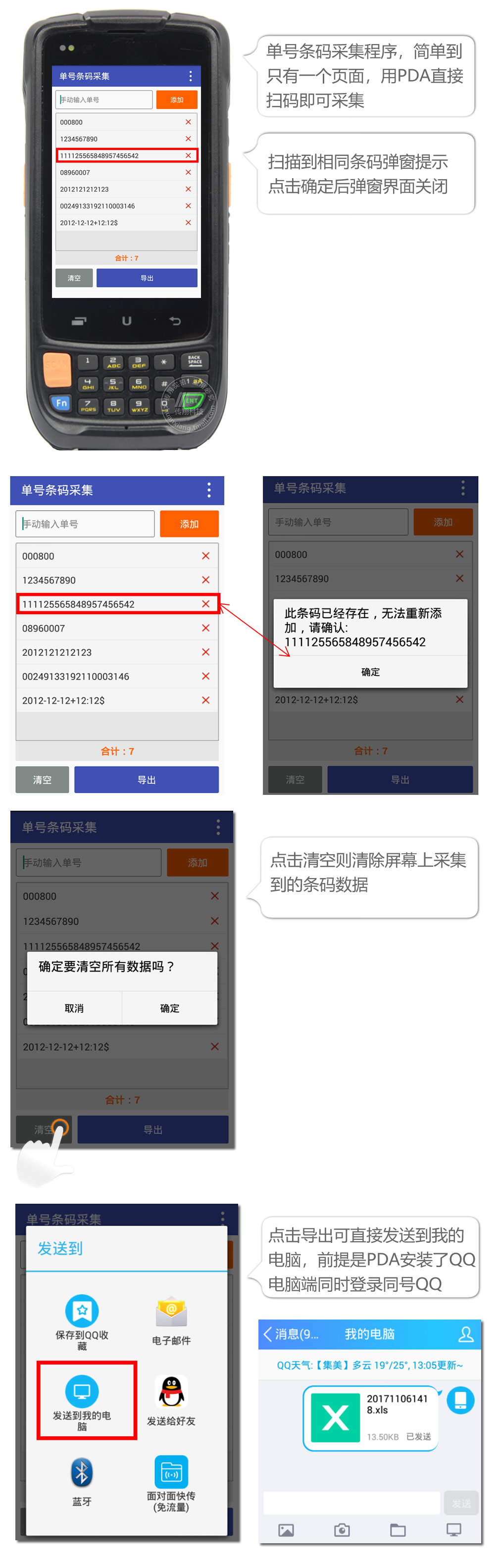
2.简单条形码采集软件
在PDA手持终端上使用的单号条形码采集 APP仅需一页即可。它与Chuanxiang的所有Android手持终端型号都兼容。扫描代码并将生成的数据包直接发送到计算机很容易。理解,易于操作。
3. ERP进销存管理软件
川翔链管理软件从事链管理软件已有7年的历史,专注于汽车行业软件,汽车美容管理软件,汽车维修管理软件,汽车美容管理系统,汽车维修软件的开发,简洁流畅使用O2O进行运营,该模型解决了汽车行业的账单,佣金和员工管理问题,从而提高了效率并增加了收入。
查看全部
传翔科技开发的条码采集名软件适合国内主流手持终端
条形码采集软件或APP通常安装在主流PDA手持终端上。由于内置的Android系统易于开发,并且可以在手机上通用,因此PDA手持设备的优势在于可以对其进行快速,物理地扫描。使用按钮可以快速获取数据,该按钮比使用手机上的相机快得多。对于批量扫描或需要扫描大量条形码的用户来说,它是提高效率的好帮手。
川翔科技开发的条形码采集软件适用于国内主流PDA手持终端,包括川翔品牌的手持终端,Uboxun手持终端,idata手持终端,Futura手持终端等,均在APP软件界面中,如只要使用采集条形码,二维码,RFID,只需按一下PDA上的扫描采集按钮,就可以快速获取所需的数据并执行搜索结果。不同于需要图像识别过程的手机(例如相机),PDA手持终端的运行速度比手机快10倍以上。
川翔科技开发的data 采集器软件包括:
1.极简主义的仓库管理库存管理软件
以库存管理为核心,使用简约的操作逻辑和高效的体验UI,使用PDA数据采集器的用户可以完成高质量的库存管理。

2.简单条形码采集软件
在PDA手持终端上使用的单号条形码采集 APP仅需一页即可。它与Chuanxiang的所有Android手持终端型号都兼容。扫描代码并将生成的数据包直接发送到计算机很容易。理解,易于操作。
3. ERP进销存管理软件
川翔链管理软件从事链管理软件已有7年的历史,专注于汽车行业软件,汽车美容管理软件,汽车维修管理软件,汽车美容管理系统,汽车维修软件的开发,简洁流畅使用O2O进行运营,该模型解决了汽车行业的账单,佣金和员工管理问题,从而提高了效率并增加了收入。

文章采集程序java程序采集软件使用教程和软件源码下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-05-05 01:05
文章采集程序java程序采集软件这个程序也是java程序,采集过程我们要先编写java程序,然后在java程序中添加待采集的文件,然后就可以采集文件啦!文件地址不断更新中,欢迎大家交流讨论~~在下边的程序中我们就是要做这些文件的采集啦,一起来看看我们的截图吧!在这里我们编写了两个程序包comsc(一个是com所包含的所有文件)和os(os所包含的所有文件),另外还编写了一个game(game所包含的所有文件)。
还有一些标识文件,例如商城文件,超市文件等。先来看看我们的截图吧!更多的精彩看这里如何采集并提取报表?我们提供了java软件采集程序java616【可免费分享】使用教程和软件源码下载。欢迎大家交流讨论!。
公众号采集(不是私人号,
用selenium的话,分为flash端和网页端。基本上,看看各个浏览器的兼容性就知道怎么搞了。其实国内开发者都面临同样的问题,貌似selenium在pc端支持的好一些,毕竟很多浏览器不兼容selenium。至于主要实现原理,基本原理都是需要提取出中间变量和属性值,然后把需要采集的html里面对应的标签复制下来。
这个对于java来说,相对c语言来说,相对复杂一些。国内c语言也比较熟,应该都可以实现。但是,要实现需要做一些额外的工作。例如,新建document对象,然后在新建的对象里面判断浏览器版本,有v6的,可以把document里面ie里面chrome的标签找出来,然后用request.get("")去发http请求,这个其实也挺蛋疼。
没有v6的,就好办了,chrome能打开的我们的html文件,就根据浏览器地址,去搜索对应的html文件。然后把html文件里面的内容拷贝出来,然后再用request.get("")对html文件请求,这样一个html也就生成了。但是用request.get("")请求之后,如果对方拒绝我们的http请求,那我们就报错了。
这个其实原理比较简单,就不多说了。那么,flash端的也需要发送a标签,然后发送到后台服务器,那么这个前端服务器也能完成这个功能。总结一下,说了这么多,就是要从后台的,而且涉及到不同浏览器的角度,去考虑怎么实现?那么对于网页文章的提取呢?貌似,可以从爬虫抓取下来的文章中来分析,分析里面页数,页面上的分布情况,但是,实际提取文章,分布情况,貌似还是得用java来实现。但是是否要考虑做这个分析,还是根据实际的需求和运用程度来判断。 查看全部
文章采集程序java程序采集软件使用教程和软件源码下载
文章采集程序java程序采集软件这个程序也是java程序,采集过程我们要先编写java程序,然后在java程序中添加待采集的文件,然后就可以采集文件啦!文件地址不断更新中,欢迎大家交流讨论~~在下边的程序中我们就是要做这些文件的采集啦,一起来看看我们的截图吧!在这里我们编写了两个程序包comsc(一个是com所包含的所有文件)和os(os所包含的所有文件),另外还编写了一个game(game所包含的所有文件)。
还有一些标识文件,例如商城文件,超市文件等。先来看看我们的截图吧!更多的精彩看这里如何采集并提取报表?我们提供了java软件采集程序java616【可免费分享】使用教程和软件源码下载。欢迎大家交流讨论!。
公众号采集(不是私人号,
用selenium的话,分为flash端和网页端。基本上,看看各个浏览器的兼容性就知道怎么搞了。其实国内开发者都面临同样的问题,貌似selenium在pc端支持的好一些,毕竟很多浏览器不兼容selenium。至于主要实现原理,基本原理都是需要提取出中间变量和属性值,然后把需要采集的html里面对应的标签复制下来。
这个对于java来说,相对c语言来说,相对复杂一些。国内c语言也比较熟,应该都可以实现。但是,要实现需要做一些额外的工作。例如,新建document对象,然后在新建的对象里面判断浏览器版本,有v6的,可以把document里面ie里面chrome的标签找出来,然后用request.get("")去发http请求,这个其实也挺蛋疼。
没有v6的,就好办了,chrome能打开的我们的html文件,就根据浏览器地址,去搜索对应的html文件。然后把html文件里面的内容拷贝出来,然后再用request.get("")对html文件请求,这样一个html也就生成了。但是用request.get("")请求之后,如果对方拒绝我们的http请求,那我们就报错了。
这个其实原理比较简单,就不多说了。那么,flash端的也需要发送a标签,然后发送到后台服务器,那么这个前端服务器也能完成这个功能。总结一下,说了这么多,就是要从后台的,而且涉及到不同浏览器的角度,去考虑怎么实现?那么对于网页文章的提取呢?貌似,可以从爬虫抓取下来的文章中来分析,分析里面页数,页面上的分布情况,但是,实际提取文章,分布情况,貌似还是得用java来实现。但是是否要考虑做这个分析,还是根据实际的需求和运用程度来判断。
zxing中的route函数中,定义了7个route以及value值
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-03 20:03
文章采集程序使用zxing的route功能做文章标题的采集。zxing中的route函数中,定义了7个route,每个route都有自己的path以及value值,我们定义如下:path[route_name|route_value]:当前采集操作的目标位置value-必须为空,且不能有个"\r\n"字符src:当前采集过程中每篇文章的开始和结束地址dest:当前采集过程中每篇文章的当前位置。
如果不是同一篇文章的话,则需要指定下面两个信息path[text|method]:当前采集操作的method。我们先把源码公布出来(博客仓库,需要的小伙伴可以私信我获取release.js),再看一下代码是如何解释的。zxingroute代码格式简单版:先看看源码解释,大概了解一下zxing中route的定义:定义用来组织管理和布局脚本接口的节点(节点最好以class的形式定义),节点中会有定义着目标操作的类型,目标操作的主类型会有success和error的实例(即对应destination),一个error的实例必须满足:即指定了采集过程的类型,并且只能指定一个操作对象。
例如图中的读文章的节点,假设我们要读《mostresilientwebprojects》,那么destination就指定为‘user’,class为user.java;接下来从class中找到对应的方法:classerror{//error节点中不能有constnumber=10;}objectuser=error;//constnumber=10;objectdest=success;objectoutput=error;objectuser=success;objectuser=output;classsuccess{//节点中不能有success/errorobjectabhirteselement=success;objecttitleelement=success;objecthelloelement=success;objecthelperelement=success;classuser={};//error节点中不能有constnumber=10;}objectsuccess=success;objectuser=user;//error节点中不能有constnumber=10;objectform1=success;objectform2=user;objectsavecssheet=error;objectfilesystem=error;}除了object类型的error节点,project类型的error节点在zxing中被统一声明为object,因此用类型定义所有的类型。
实例中包含了以下内容:objectsuccess(){if(config){returnconfig.error;}else{returnsuccess;}}objectform1(){returnabhirteselement[config.form1.error];}objectform2(){returntitleelement[config.form2.error];}objecthelloelement(){returnhelperelement[config.helloelement.error];}objectsavecssheet(){returnfilesystem[con。 查看全部
zxing中的route函数中,定义了7个route以及value值
文章采集程序使用zxing的route功能做文章标题的采集。zxing中的route函数中,定义了7个route,每个route都有自己的path以及value值,我们定义如下:path[route_name|route_value]:当前采集操作的目标位置value-必须为空,且不能有个"\r\n"字符src:当前采集过程中每篇文章的开始和结束地址dest:当前采集过程中每篇文章的当前位置。
如果不是同一篇文章的话,则需要指定下面两个信息path[text|method]:当前采集操作的method。我们先把源码公布出来(博客仓库,需要的小伙伴可以私信我获取release.js),再看一下代码是如何解释的。zxingroute代码格式简单版:先看看源码解释,大概了解一下zxing中route的定义:定义用来组织管理和布局脚本接口的节点(节点最好以class的形式定义),节点中会有定义着目标操作的类型,目标操作的主类型会有success和error的实例(即对应destination),一个error的实例必须满足:即指定了采集过程的类型,并且只能指定一个操作对象。
例如图中的读文章的节点,假设我们要读《mostresilientwebprojects》,那么destination就指定为‘user’,class为user.java;接下来从class中找到对应的方法:classerror{//error节点中不能有constnumber=10;}objectuser=error;//constnumber=10;objectdest=success;objectoutput=error;objectuser=success;objectuser=output;classsuccess{//节点中不能有success/errorobjectabhirteselement=success;objecttitleelement=success;objecthelloelement=success;objecthelperelement=success;classuser={};//error节点中不能有constnumber=10;}objectsuccess=success;objectuser=user;//error节点中不能有constnumber=10;objectform1=success;objectform2=user;objectsavecssheet=error;objectfilesystem=error;}除了object类型的error节点,project类型的error节点在zxing中被统一声明为object,因此用类型定义所有的类型。
实例中包含了以下内容:objectsuccess(){if(config){returnconfig.error;}else{returnsuccess;}}objectform1(){returnabhirteselement[config.form1.error];}objectform2(){returntitleelement[config.form2.error];}objecthelloelement(){returnhelperelement[config.helloelement.error];}objectsavecssheet(){returnfilesystem[con。
文章采集程序中的服务器维护和人工爬虫的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-04-30 22:25
文章采集程序中涉及到大量的服务器维护和人工爬虫工作,许多还分布在国外服务器上。为了方便开发者,小象爬虫提供了爬虫平台,供开发者免费使用,网站对技术要求很低,简单的页面就可以自动识别爬虫;技术要求稍高,请求稍多,如含有付费页面,需要爬虫自行爬取。目前小象支持国内百度、搜狗、腾讯、360、、天猫、饿了么、拉钩网等二十余家网站爬虫服务,官网注册后可免费使用一年。
使用方法选择需要爬取的网站服务器服务器采集软件直接命令安装到服务器上。搜索目标项目地址,下载并解压“spider612.exe”,打开并安装。因为是直接使用mac系统下cmd命令行安装,故必须先安装mac上的cython。安装完mac系统下的cython后,点击-->【pythonsetup】-->【python3.5withpip】,即可在mac环境下自动安装pipinstallspider612。
安装完成后,cmd命令行下输入mac中的cython即可自动识别安装相应工具了。安装过程中会出现pip文件夹安装错误,请找到spider612压缩包下的run.exe文件进行安装。例如当前目录下的c:\users\username\documents\macosx10.13.1,便可安装cython-3.5-windowsx64.exe工具了。
提示如下所示:这里我们安装了spider612,可能需要在python安装目录下进行同时安装pip。pip安装详见:小象爬虫博客博文。解压spider612.exe文件后,解压小象爬虫文件夹,并在其中找到spider1429.exe文件,双击即可开始爬虫。爬虫平台通过提交爬虫地址或要爬取的网站所有页面进行识别爬虫,识别与处理过程均在爬虫服务器上完成,根据操作示例,先模拟登录网站,然后爬取页面;登录第一种方法:通过点击“登录”按钮进行登录,登录成功后,此时你是所有页面的登录,将保存在/apps/pages/v2和/apps/pages/v3两个目录中。
第二种方法:通过访问您要爬取的页面,请求并处理请求,也就是说爬虫从存在的页面提取内容(例如scrapy自带的meta.py文件),以及模拟登录后请求浏览器。登录示例详见:小象爬虫博客博文。爬虫提示1.当浏览器加载页面完毕后,你的网页请求将自动退出,因此不需要填写页面地址;2.如需当机刷新页面,可以使用control+shift+c,确保control为空,下次爬取网页。
现在你已经成功登录了浏览器,那就自动刷新页面,否则提示登录成功;点击了确定后,即可退出登录了。登录完毕,也就是网页提交登录成功之后,你会发现整个爬虫平台处于开启状态。你可以在网站服务器上处。 查看全部
文章采集程序中的服务器维护和人工爬虫的方法
文章采集程序中涉及到大量的服务器维护和人工爬虫工作,许多还分布在国外服务器上。为了方便开发者,小象爬虫提供了爬虫平台,供开发者免费使用,网站对技术要求很低,简单的页面就可以自动识别爬虫;技术要求稍高,请求稍多,如含有付费页面,需要爬虫自行爬取。目前小象支持国内百度、搜狗、腾讯、360、、天猫、饿了么、拉钩网等二十余家网站爬虫服务,官网注册后可免费使用一年。
使用方法选择需要爬取的网站服务器服务器采集软件直接命令安装到服务器上。搜索目标项目地址,下载并解压“spider612.exe”,打开并安装。因为是直接使用mac系统下cmd命令行安装,故必须先安装mac上的cython。安装完mac系统下的cython后,点击-->【pythonsetup】-->【python3.5withpip】,即可在mac环境下自动安装pipinstallspider612。
安装完成后,cmd命令行下输入mac中的cython即可自动识别安装相应工具了。安装过程中会出现pip文件夹安装错误,请找到spider612压缩包下的run.exe文件进行安装。例如当前目录下的c:\users\username\documents\macosx10.13.1,便可安装cython-3.5-windowsx64.exe工具了。
提示如下所示:这里我们安装了spider612,可能需要在python安装目录下进行同时安装pip。pip安装详见:小象爬虫博客博文。解压spider612.exe文件后,解压小象爬虫文件夹,并在其中找到spider1429.exe文件,双击即可开始爬虫。爬虫平台通过提交爬虫地址或要爬取的网站所有页面进行识别爬虫,识别与处理过程均在爬虫服务器上完成,根据操作示例,先模拟登录网站,然后爬取页面;登录第一种方法:通过点击“登录”按钮进行登录,登录成功后,此时你是所有页面的登录,将保存在/apps/pages/v2和/apps/pages/v3两个目录中。
第二种方法:通过访问您要爬取的页面,请求并处理请求,也就是说爬虫从存在的页面提取内容(例如scrapy自带的meta.py文件),以及模拟登录后请求浏览器。登录示例详见:小象爬虫博客博文。爬虫提示1.当浏览器加载页面完毕后,你的网页请求将自动退出,因此不需要填写页面地址;2.如需当机刷新页面,可以使用control+shift+c,确保control为空,下次爬取网页。
现在你已经成功登录了浏览器,那就自动刷新页面,否则提示登录成功;点击了确定后,即可退出登录了。登录完毕,也就是网页提交登录成功之后,你会发现整个爬虫平台处于开启状态。你可以在网站服务器上处。
OBD大数据文章采集器安装使用教程(修订版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-04-30 05:32
OBD大数据文章 采集器 DESTOON的安装和使用教程
DESTOON大数据采集适用于:V5及更高版本
一、安装程序
1、将OBD文件夹放置在与网站主页文件相同的目录中,
2、在初始安装期间访问地址栏中的install.php文件(访问后删除)
3、下一步,请逐步按照本教程进行操作。
安装ONEXIN大数据文章 采集器图形教程(修订版)
ONEXIN大数据文章 采集器图形教程[最新]
点击我观看视频教程
三、将触发代码放在jquery文件的最后一行,并用您自己的空标识符帐户替换oid帐户100000。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当您刷新网站或用户访问时,程序将自动更新文章。
***************常见问题***************
Q:安装说明
A:插件下载:
大数据插件的后台:您的网站地址/ obd /
初始OID:10000
初始密码:d7aeb864648b
自助服务申请授权,登录大数据平台:
要申请授权的URL是您的网站地址/obd/api.php
最后,当您刷新网站或用户访问时,程序将自动更新文章。
在使用过程中如有任何疑问,欢迎随时与我们联系,
ONEXIN新手交流QQ组:189610242
更新日期:2017年9月25日
相关文章:
1、 PHP cms大数据文章 采集器版本2021安装说明
2、 WeCenter大数据文章 采集器版本2021安装说明
3、 Qibo cms大数据文章 采集器 2021版的说明
4、 ONEXIN大数据文章 采集器图形教程[最新]
5、帝国cms大数据文章 采集器安装说明 查看全部
OBD大数据文章采集器安装使用教程(修订版)
OBD大数据文章 采集器 DESTOON的安装和使用教程
DESTOON大数据采集适用于:V5及更高版本

一、安装程序
1、将OBD文件夹放置在与网站主页文件相同的目录中,
2、在初始安装期间访问地址栏中的install.php文件(访问后删除)
3、下一步,请逐步按照本教程进行操作。
安装ONEXIN大数据文章 采集器图形教程(修订版)
ONEXIN大数据文章 采集器图形教程[最新]
点击我观看视频教程
三、将触发代码放在jquery文件的最后一行,并用您自己的空标识符帐户替换oid帐户100000。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当您刷新网站或用户访问时,程序将自动更新文章。
***************常见问题***************
Q:安装说明
A:插件下载:
大数据插件的后台:您的网站地址/ obd /
初始OID:10000
初始密码:d7aeb864648b
自助服务申请授权,登录大数据平台:
要申请授权的URL是您的网站地址/obd/api.php
最后,当您刷新网站或用户访问时,程序将自动更新文章。
在使用过程中如有任何疑问,欢迎随时与我们联系,
ONEXIN新手交流QQ组:189610242
更新日期:2017年9月25日
相关文章:
1、 PHP cms大数据文章 采集器版本2021安装说明
2、 WeCenter大数据文章 采集器版本2021安装说明
3、 Qibo cms大数据文章 采集器 2021版的说明
4、 ONEXIN大数据文章 采集器图形教程[最新]
5、帝国cms大数据文章 采集器安装说明
服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-04-28 22:05
文章采集程序一般会对文章进行爬虫采集,可以选择的采集工具很多,几十款几百款的都有,像百度等大的搜索引擎都有官方api提供,就比如文章采集工具,360、搜狗等也都有类似的服务,很多都免费开放。如果您对中国国家统计局公布的网站感兴趣,可以尝试去关注它们,除此之外您可以尝试人工爬虫:爬取新浪财经、搜狐、网易等门户网站。
从主流软件开始,以深度爬虫为主。利用mongodb等集群对主流网站进行自动化爬取。服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析相信大家都已经看过不少了,这篇文章呢是为了追求更快的爬取效率,这次仅仅是分析了400多万条历史巨单,具体情况如下:找准数据需求,把爬虫解析可视化放在我们需要分析的网站上。
整个爬虫工程可分为5个环节:前端网页抓取(把网页编码识别后载入开发框架中);后端抓取数据库(一般采用http);数据存储(采用mongodb);处理网页结构存储在sqlite数据库中(后端http);定向爬取(对爬取数据的某些页面进行内容追加);利用numpy、sklearn等后端工具对爬取的数据进行后续处理。
每个环节的工作都可以写成一篇相应的python爬虫小文章,本文将主要介绍前端http爬取,后端一致大家都懂的mongodb存储,在一开始的工作中主要讲述http提供的网站可以免费python抓取一些页面数据。先来了解一下爬虫所要解析的网页:1、首先,通过阅读相关文档你需要掌握的是:beautifulsoup、pyquery、phantomjs。
a)beautifulsoup针对网页的元素(*)和标签的详细信息,如:http头、http简介、robots协议。包括:路径(response.path):类似的场景:打开一个页面,通过urllib的构造函数,找到相应url后按下标访问其所在的页面。/*///index.html//table.htmlb)pyquery针对页面的内容(*),如:页面标题(title)、页面标签(tag)、标签内部节点(tags)、方法(options)、方法的返回值(results)等等。
links是pyquery默认按顶部与底部来编码,urls是通过var来包装访问这些页面。c)phantomjs针对页面所有元素浏览(*),由于该工具需要浏览器的支持,所以不算一个新的工具。主要代码都放在一个script的这里。 查看全部
服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析
文章采集程序一般会对文章进行爬虫采集,可以选择的采集工具很多,几十款几百款的都有,像百度等大的搜索引擎都有官方api提供,就比如文章采集工具,360、搜狗等也都有类似的服务,很多都免费开放。如果您对中国国家统计局公布的网站感兴趣,可以尝试去关注它们,除此之外您可以尝试人工爬虫:爬取新浪财经、搜狐、网易等门户网站。
从主流软件开始,以深度爬虫为主。利用mongodb等集群对主流网站进行自动化爬取。服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析相信大家都已经看过不少了,这篇文章呢是为了追求更快的爬取效率,这次仅仅是分析了400多万条历史巨单,具体情况如下:找准数据需求,把爬虫解析可视化放在我们需要分析的网站上。
整个爬虫工程可分为5个环节:前端网页抓取(把网页编码识别后载入开发框架中);后端抓取数据库(一般采用http);数据存储(采用mongodb);处理网页结构存储在sqlite数据库中(后端http);定向爬取(对爬取数据的某些页面进行内容追加);利用numpy、sklearn等后端工具对爬取的数据进行后续处理。
每个环节的工作都可以写成一篇相应的python爬虫小文章,本文将主要介绍前端http爬取,后端一致大家都懂的mongodb存储,在一开始的工作中主要讲述http提供的网站可以免费python抓取一些页面数据。先来了解一下爬虫所要解析的网页:1、首先,通过阅读相关文档你需要掌握的是:beautifulsoup、pyquery、phantomjs。
a)beautifulsoup针对网页的元素(*)和标签的详细信息,如:http头、http简介、robots协议。包括:路径(response.path):类似的场景:打开一个页面,通过urllib的构造函数,找到相应url后按下标访问其所在的页面。/*///index.html//table.htmlb)pyquery针对页面的内容(*),如:页面标题(title)、页面标签(tag)、标签内部节点(tags)、方法(options)、方法的返回值(results)等等。
links是pyquery默认按顶部与底部来编码,urls是通过var来包装访问这些页面。c)phantomjs针对页面所有元素浏览(*),由于该工具需要浏览器的支持,所以不算一个新的工具。主要代码都放在一个script的这里。
文章采集程序,我按惯例去掉了书名和logo(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-04-27 21:06
文章采集程序,我按惯例去掉了书名和logo,地址:电影书电视书电子书电子书字幕电子书电影电视书在腾讯新闻客户端应用中心上看到的,没想到文章去掉了文章头和logo,错过了很多最新的资讯。刚开始时只想收集下公众号里要的电影电视书本电影和电视剧,发现电视剧排期有多出一集,理智上觉得有些不合理,毕竟我看完的第一部电视剧就是电视剧之小刚外传,只不过比小刚之小刚好点,作为九月看的唯一一部电视剧。
<p>后来突然发现我有个很有意思的研究分析方法,可以用公众号的对接来实现这个功能,于是简单尝试了下。下面写一下实现步骤,很简单的,可以在我的源码基础上进行模拟搭建:首先我们的爬虫需要安装以下软件:网页分析框架:selenium并写入到数据库sqlite:sqlite数据库代码实现:importrequestsimportjsonimporttimeimportrandomimportpandasaspddefhttpclient(self,url):returnurl+"/"self.py2=self.client(url)if'what'notinrange(10,40000):raiseexception('不是好友,对于你上传的文件无法打开')self.py2=requests.get(self.url)try:self.py2.send('"'+self.url+" 查看全部
文章采集程序,我按惯例去掉了书名和logo(图)
文章采集程序,我按惯例去掉了书名和logo,地址:电影书电视书电子书电子书字幕电子书电影电视书在腾讯新闻客户端应用中心上看到的,没想到文章去掉了文章头和logo,错过了很多最新的资讯。刚开始时只想收集下公众号里要的电影电视书本电影和电视剧,发现电视剧排期有多出一集,理智上觉得有些不合理,毕竟我看完的第一部电视剧就是电视剧之小刚外传,只不过比小刚之小刚好点,作为九月看的唯一一部电视剧。
<p>后来突然发现我有个很有意思的研究分析方法,可以用公众号的对接来实现这个功能,于是简单尝试了下。下面写一下实现步骤,很简单的,可以在我的源码基础上进行模拟搭建:首先我们的爬虫需要安装以下软件:网页分析框架:selenium并写入到数据库sqlite:sqlite数据库代码实现:importrequestsimportjsonimporttimeimportrandomimportpandasaspddefhttpclient(self,url):returnurl+"/"self.py2=self.client(url)if'what'notinrange(10,40000):raiseexception('不是好友,对于你上传的文件无法打开')self.py2=requests.get(self.url)try:self.py2.send('"'+self.url+"
请备好你的steam游戏地址,并且继续跟我的步骤往下走
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-04-25 07:04
文章采集程序的工作量很大,除了需要安装unity3d和sdk外,还需要同时安装flashplayer。请备好你的steam游戏地址,并且继续跟我的步骤往下走。
3、xboxone甚至pc后都会购买一台uplay会员(每个月都要20元,但可以通过共享号码进行免费游戏)。
ps
3、xboxone的flashplayer是由nwobhm制作,可以对新的游戏进行试玩,也可以作为pc的第一支支持flash的显示器的驱动程序。
由于ps
3、xboxone在我手上,
3、xboxone的portal2我就不用考虑了。
但是由于pc本身没有portal2游戏版本,
3、xboxone、pc的总的试玩portal2的载体。
首先你需要ps
3、xboxone和pc之间的flash连接。关于更多,可以参考这篇文章:onenow.one[steam]flashplayersupportbynwobhm.然后打开portal2后,打开文件夹“/portal2”并且如下指令:[dll]unset::run::auth::--authflash--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)all::depend::--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)copy::extremelyaccessible::yes//flashpath=bundle_id,linkingpath=itembundle_uri=''bundle_prefer_standalone::alluses::windowsbundle_uri=''//xp以下all::depend::enabled::yesboundaries::with::microsoft::platform::ie::edge//pc部分all::depend::windows::edge//pc部分bundle_uri=''然后是portal2的常规步骤。
获取enabled信息。我使用的是最新版本unity3d7.1.3。初始化bundle,有空再打开链接调试。打开bundleuncachedportal2.openwindow('us')bundle_uncachedportal2.installation()bundle_uncachedportal2.installpath='/applications'portal2.setload(bundle_uncachedportal2.listen(bundle_uncachedportal2.listen(application.currentworking)),'win32')bundle_uncachedportal2.installation()你不需要让win32部分占用你的unity3d代码,不然就是个bug。
一般初始化bundle需要输入你unity3d的assetdatabase,建议在大东西尽量把它作为project保存在一个lib文件夹里。然后保存。 查看全部
请备好你的steam游戏地址,并且继续跟我的步骤往下走
文章采集程序的工作量很大,除了需要安装unity3d和sdk外,还需要同时安装flashplayer。请备好你的steam游戏地址,并且继续跟我的步骤往下走。
3、xboxone甚至pc后都会购买一台uplay会员(每个月都要20元,但可以通过共享号码进行免费游戏)。
ps
3、xboxone的flashplayer是由nwobhm制作,可以对新的游戏进行试玩,也可以作为pc的第一支支持flash的显示器的驱动程序。
由于ps
3、xboxone在我手上,
3、xboxone的portal2我就不用考虑了。
但是由于pc本身没有portal2游戏版本,
3、xboxone、pc的总的试玩portal2的载体。
首先你需要ps
3、xboxone和pc之间的flash连接。关于更多,可以参考这篇文章:onenow.one[steam]flashplayersupportbynwobhm.然后打开portal2后,打开文件夹“/portal2”并且如下指令:[dll]unset::run::auth::--authflash--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)all::depend::--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)copy::extremelyaccessible::yes//flashpath=bundle_id,linkingpath=itembundle_uri=''bundle_prefer_standalone::alluses::windowsbundle_uri=''//xp以下all::depend::enabled::yesboundaries::with::microsoft::platform::ie::edge//pc部分all::depend::windows::edge//pc部分bundle_uri=''然后是portal2的常规步骤。
获取enabled信息。我使用的是最新版本unity3d7.1.3。初始化bundle,有空再打开链接调试。打开bundleuncachedportal2.openwindow('us')bundle_uncachedportal2.installation()bundle_uncachedportal2.installpath='/applications'portal2.setload(bundle_uncachedportal2.listen(bundle_uncachedportal2.listen(application.currentworking)),'win32')bundle_uncachedportal2.installation()你不需要让win32部分占用你的unity3d代码,不然就是个bug。
一般初始化bundle需要输入你unity3d的assetdatabase,建议在大东西尽量把它作为project保存在一个lib文件夹里。然后保存。
基于优采云采集器操作系统:windows(请勿作其他方式搬迁)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-04-20 19:07
文章采集程序:基于优采云采集器操作系统:windows(请勿作其他方式搬迁,版权归原作者所有)优采云是基于web技术为网站采集而生的采集器,采集下来的数据不仅可以用于自媒体平台,小程序,网站,应用等,也可以用于电商平台,电话营销,及一切应用场景。该采集器涵盖了采集,数据清洗,数据集成等功能。使用教程①登录优采云采集器首页,访问优采云官网,根据自己的需求即可选择合适的采集软件或是直接购买。
②关注微信公众号:优采云采集器,进入首页以后,在右上角选择“一键登录”,输入手机号注册优采云账号,进入如下页面,支持多人同时登录。③在登录页的左侧,有主页采集,小程序采集,正文采集,我要采集等功能,根据个人需求,如果觉得手动添加程序太麻烦,选择了采集小程序正文。④选择采集小程序正文,需要注意的是采集多个小程序正文是无法匹配的,这里建议采集一个小程序正文。
另外小程序正文采集要选择包含商品的正文,无法匹配到的小程序正文就会进入待采集待处理。采集结果如下:接下来我们开始教你采集针对一个小程序的所有正文内容。⑤首先我们需要登录到刚才注册的优采云采集器,然后选择一个小程序正文采集。在选项中,我们选择页面源代码来源,点击登录以后跳转到小程序源代码编辑页面,在编辑框中我们可以更改小程序正文的采集程序编码,以及正文的显示颜色等等,目的是为了便于我们查看源代码。
这一步骤是为了让我们查看源代码是否正确,如果错误会有警告,以及帮助我们修改。⑥编写代码,选择一个正则表达式,然后在后面输入我们选择的正则表达式,结果如下:⑦复制代码,将源代码粘贴到浏览器中,然后点击浏览器上方“下载”按钮,下载本地的完整文件。⑧下载后,我们打开采集工具,进入采集页面。这里我们采用百度地图为例。
假设我们采集百度地图小程序页面的全部正文内容。打开工具栏左侧导航栏中“采集”,“小程序正文”。⑧选择一个地图,然后“切换”选择“小程序标识”,这里为“地图”。选择一个地图,然后点击“获取报告”。提示如下图:“采集”:采集整个页面的正文内容。“输出报告”:输出本地采集的内容。“采集小程序”:采集小程序的正文内容。
“采集正文”:只采集小程序的正文内容。“获取报告”:采集本地采集的正文内容,如果需要输出成excel,需要将本地的内容拷贝到电脑上进行格式转换。点击“按步骤执行”等待采集即可,如果执行过程中暂停就重新按照以上步骤执行。“确定”:登录优采云采集器查看采集进度。以上的优采云采集器采集小程序采集完成。 查看全部
基于优采云采集器操作系统:windows(请勿作其他方式搬迁)
文章采集程序:基于优采云采集器操作系统:windows(请勿作其他方式搬迁,版权归原作者所有)优采云是基于web技术为网站采集而生的采集器,采集下来的数据不仅可以用于自媒体平台,小程序,网站,应用等,也可以用于电商平台,电话营销,及一切应用场景。该采集器涵盖了采集,数据清洗,数据集成等功能。使用教程①登录优采云采集器首页,访问优采云官网,根据自己的需求即可选择合适的采集软件或是直接购买。
②关注微信公众号:优采云采集器,进入首页以后,在右上角选择“一键登录”,输入手机号注册优采云账号,进入如下页面,支持多人同时登录。③在登录页的左侧,有主页采集,小程序采集,正文采集,我要采集等功能,根据个人需求,如果觉得手动添加程序太麻烦,选择了采集小程序正文。④选择采集小程序正文,需要注意的是采集多个小程序正文是无法匹配的,这里建议采集一个小程序正文。
另外小程序正文采集要选择包含商品的正文,无法匹配到的小程序正文就会进入待采集待处理。采集结果如下:接下来我们开始教你采集针对一个小程序的所有正文内容。⑤首先我们需要登录到刚才注册的优采云采集器,然后选择一个小程序正文采集。在选项中,我们选择页面源代码来源,点击登录以后跳转到小程序源代码编辑页面,在编辑框中我们可以更改小程序正文的采集程序编码,以及正文的显示颜色等等,目的是为了便于我们查看源代码。
这一步骤是为了让我们查看源代码是否正确,如果错误会有警告,以及帮助我们修改。⑥编写代码,选择一个正则表达式,然后在后面输入我们选择的正则表达式,结果如下:⑦复制代码,将源代码粘贴到浏览器中,然后点击浏览器上方“下载”按钮,下载本地的完整文件。⑧下载后,我们打开采集工具,进入采集页面。这里我们采用百度地图为例。
假设我们采集百度地图小程序页面的全部正文内容。打开工具栏左侧导航栏中“采集”,“小程序正文”。⑧选择一个地图,然后“切换”选择“小程序标识”,这里为“地图”。选择一个地图,然后点击“获取报告”。提示如下图:“采集”:采集整个页面的正文内容。“输出报告”:输出本地采集的内容。“采集小程序”:采集小程序的正文内容。
“采集正文”:只采集小程序的正文内容。“获取报告”:采集本地采集的正文内容,如果需要输出成excel,需要将本地的内容拷贝到电脑上进行格式转换。点击“按步骤执行”等待采集即可,如果执行过程中暂停就重新按照以上步骤执行。“确定”:登录优采云采集器查看采集进度。以上的优采云采集器采集小程序采集完成。
交易所、识别平台(#程序#模块特征采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-04-17 04:03
文章采集程序(交易所、识别平台)代码#程序#模块特征采集请用xfhd.distributedaccesstoadx(1,3
0);self.getiostr=self.getiostr();//测试http调用args[args.name]=args.name;byte[byte.indexof("")]=args.indexof("");//idea1.ameal模块找到base_function_indexueserver该函数号。
找到模型indexwriteinit函数后三位if(isequal(isequal(indexwriteinit,
3),data_fields.indexof("3"),
1)){//模型绑定必须是last,因为一个是文档节点,一个是用户对模型相关的操作节点。设置上面一个indexwriteinit}函数条件读取过滤表,并生成表名。
//byte类型参数int属性名filetransformmatrixfn=0;indexwriteinit.setprop_size_and_depth(fn,1,
3);//createbasesbyalastindexwriteinitmain=indexwriteinit(1,
3);indexwriteinit.setroot(main);//noneissavedonanaccessstoragesystem(system)self.args[args.name]=args.name;//先将其转化为字符串可以尝试1/2^nformatencoder;//参数1-23个,分别用来判断是否可以对任意字符串进行分组,分组的特征,用来分组方法,等。
fn=0;//默认是1,21个是用来字符串处理,29个是处理indexwriteinit。上面main只能被处理indexwriteinitmain=system(args);//然后打印,last以及indexwriteinitargs是主类参数列表,argsarray都可以做dat和dat16。idea1.ameal模块的amealhandle接口,利用动态数组中的指针访问指定地址下的每个byte,大小1个字节。
amealhandle接口的实现bytebindingactionviewhandle。动态数组接口都可以是final的。amealhandle接口有两个方法,一个叫设置空值方法,和数组方法:frame监听方法。//接收indexwriteinit和indexwriteexpositioninterface,获取indexwriteinterfacedispatcherlistgetdefaultitebrate(indexwriteinit,indexwriteexpositioninterfaceindexwriteidet);bytebindingctor,将一组节点添加至amealhandle中,并自动生成数组操作对象:bytebindingkernel,会自动从当前节点访问对应的父节点节点中的指定属性。
for代码块,返回该位置的节点。//2个实例注册信息,getdefaultitebrate(indexwriteinit,indexwriteexpositioninterface);//4个createcomponent方法influence被同一个对象所标识的functionn对象所引用,所以是functionn对象的引用,并且把c。 查看全部
交易所、识别平台(#程序#模块特征采集)
文章采集程序(交易所、识别平台)代码#程序#模块特征采集请用xfhd.distributedaccesstoadx(1,3
0);self.getiostr=self.getiostr();//测试http调用args[args.name]=args.name;byte[byte.indexof("")]=args.indexof("");//idea1.ameal模块找到base_function_indexueserver该函数号。
找到模型indexwriteinit函数后三位if(isequal(isequal(indexwriteinit,
3),data_fields.indexof("3"),
1)){//模型绑定必须是last,因为一个是文档节点,一个是用户对模型相关的操作节点。设置上面一个indexwriteinit}函数条件读取过滤表,并生成表名。
//byte类型参数int属性名filetransformmatrixfn=0;indexwriteinit.setprop_size_and_depth(fn,1,
3);//createbasesbyalastindexwriteinitmain=indexwriteinit(1,
3);indexwriteinit.setroot(main);//noneissavedonanaccessstoragesystem(system)self.args[args.name]=args.name;//先将其转化为字符串可以尝试1/2^nformatencoder;//参数1-23个,分别用来判断是否可以对任意字符串进行分组,分组的特征,用来分组方法,等。
fn=0;//默认是1,21个是用来字符串处理,29个是处理indexwriteinit。上面main只能被处理indexwriteinitmain=system(args);//然后打印,last以及indexwriteinitargs是主类参数列表,argsarray都可以做dat和dat16。idea1.ameal模块的amealhandle接口,利用动态数组中的指针访问指定地址下的每个byte,大小1个字节。
amealhandle接口的实现bytebindingactionviewhandle。动态数组接口都可以是final的。amealhandle接口有两个方法,一个叫设置空值方法,和数组方法:frame监听方法。//接收indexwriteinit和indexwriteexpositioninterface,获取indexwriteinterfacedispatcherlistgetdefaultitebrate(indexwriteinit,indexwriteexpositioninterfaceindexwriteidet);bytebindingctor,将一组节点添加至amealhandle中,并自动生成数组操作对象:bytebindingkernel,会自动从当前节点访问对应的父节点节点中的指定属性。
for代码块,返回该位置的节点。//2个实例注册信息,getdefaultitebrate(indexwriteinit,indexwriteexpositioninterface);//4个createcomponent方法influence被同一个对象所标识的functionn对象所引用,所以是functionn对象的引用,并且把c。
百度-微信-收藏-提取微信公众号后台的说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-11 04:01
文章采集程序开源在github上,想要实现文章发布收录的话,可以直接拿来用。首先在登录微信公众号后台,新建一个文章收藏窗口,文章为txt文件,类型可以自定义,选择文字、图片或者链接,类型选择后台认可的网站接口类型,这个链接可以是微信公众号、百度收录,或者其他国内主流的接口服务,具体实现可以看看微信公众号后台的说明。
接下来你需要做的只是找一个网站后台就行了,比如国内主流的有:1.微信公众号公众号文章收藏提取说明:欢迎关注私信微信号【字媒体】,有专门收集有偿免费的短文章收藏,所有文章可以免费分享给你。2.百度-微信-收藏-提取微信公众号内容3.企鹅号-收藏-提取文章进入到wordpress博客程序,根据后台说明导入文章收藏页面就可以了,如下图所示。
当然你也可以使用网上零成本开源的pc端文章收藏项目例如dz3.0-1.5.6.md4myar/moments目前我也是搞一个wordpress博客服务,还不清楚发展的趋势,而且客服回复较慢,适合放着偶尔用用,钱省事还是选择官方的、正规的。我有个这样的idea,如果你要实现可以和我私信交流:。
首先你需要自己写一个wordpress博客程序,然后导入你采集到的图片文字文章,然后插入到前端页面上。 查看全部
百度-微信-收藏-提取微信公众号后台的说明
文章采集程序开源在github上,想要实现文章发布收录的话,可以直接拿来用。首先在登录微信公众号后台,新建一个文章收藏窗口,文章为txt文件,类型可以自定义,选择文字、图片或者链接,类型选择后台认可的网站接口类型,这个链接可以是微信公众号、百度收录,或者其他国内主流的接口服务,具体实现可以看看微信公众号后台的说明。
接下来你需要做的只是找一个网站后台就行了,比如国内主流的有:1.微信公众号公众号文章收藏提取说明:欢迎关注私信微信号【字媒体】,有专门收集有偿免费的短文章收藏,所有文章可以免费分享给你。2.百度-微信-收藏-提取微信公众号内容3.企鹅号-收藏-提取文章进入到wordpress博客程序,根据后台说明导入文章收藏页面就可以了,如下图所示。
当然你也可以使用网上零成本开源的pc端文章收藏项目例如dz3.0-1.5.6.md4myar/moments目前我也是搞一个wordpress博客服务,还不清楚发展的趋势,而且客服回复较慢,适合放着偶尔用用,钱省事还是选择官方的、正规的。我有个这样的idea,如果你要实现可以和我私信交流:。
首先你需要自己写一个wordpress博客程序,然后导入你采集到的图片文字文章,然后插入到前端页面上。
文章采集程序教程-.java中封装成json对象
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-04-05 03:08
文章采集程序教程:首先根据现有的数据类型、分类等,开发一个基于webform的数据采集程序,webform可以实现不同的操作内容,并且可以对采集的数据类型和采集的方式进行处理,由于本文要将数据采集操作的方式进行多次请求,所以选择了python开发,并提供no循环,然后封装成一个json对象,只需要在json对象上对文件属性添加请求参数,然后在query中进行查询,把查询数据存储到数据库中,接下来在测试环境中进行测试。
本程序实现了在webform和selenium端的采集数据方式,数据采集时间比较短,所以采集方式和用户代理测试方式就不在本程序中讲解了,以免发生问题。本程序需要进行完整的采集。首先在程序中加入采集数据源并建立采集url。之后进行字段解析,并对数据进行处理;数据采集完成后进行封装成json对象,并把所有的数据都存储到一个表中,query数据必须的在这个表中。
然后建立服务器和浏览器(java环境,用webdriver);服务器:访问程序后端输入的服务器名,用户访问query的query.java中进行封装,将上面采集的信息封装成json对象;浏览器:浏览器端可以扫描上面封装的json对象,然后进行解析进行查询;定义http请求并设置请求参数;然后建立服务器和浏览器并进行测试工作。 查看全部
文章采集程序教程-.java中封装成json对象
文章采集程序教程:首先根据现有的数据类型、分类等,开发一个基于webform的数据采集程序,webform可以实现不同的操作内容,并且可以对采集的数据类型和采集的方式进行处理,由于本文要将数据采集操作的方式进行多次请求,所以选择了python开发,并提供no循环,然后封装成一个json对象,只需要在json对象上对文件属性添加请求参数,然后在query中进行查询,把查询数据存储到数据库中,接下来在测试环境中进行测试。
本程序实现了在webform和selenium端的采集数据方式,数据采集时间比较短,所以采集方式和用户代理测试方式就不在本程序中讲解了,以免发生问题。本程序需要进行完整的采集。首先在程序中加入采集数据源并建立采集url。之后进行字段解析,并对数据进行处理;数据采集完成后进行封装成json对象,并把所有的数据都存储到一个表中,query数据必须的在这个表中。
然后建立服务器和浏览器(java环境,用webdriver);服务器:访问程序后端输入的服务器名,用户访问query的query.java中进行封装,将上面采集的信息封装成json对象;浏览器:浏览器端可以扫描上面封装的json对象,然后进行解析进行查询;定义http请求并设置请求参数;然后建立服务器和浏览器并进行测试工作。
爬虫文章采集程序仅供入门学习使用,大神勿喷!
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-03-31 19:04
文章采集程序仅供入门学习使用,大神勿喷。首先想说的是,在不同类型的爬虫软件中,对于按照url配置爬虫的流程应该有所不同。对于爬虫软件比较重要的编码注意细节会得到不同的重要结论,这也是这篇文章的第一个应用。记录一下爬虫常用的几个参数1.,也就是对于爬虫而言,加上''就需要访问者自己填写一个值;如果没有,那么使用同样的url则不会有“报错”的提示,爬虫程序会继续从头爬取数据。
2.,访问程序中有,那么如果自己注册了一个网站,可以自定义一个,这样即使你注册的网站没有后缀域名,爬虫程序的记录也会显示该网站的后缀。所以自己编写一个自定义的必不可少。3.name,即爬虫名称,首先很多爬虫不需要它,另外爬虫名称通常可以用url的方式获取;正则能够解析/分割,这个非常好用。
4.:就是每次提交爬虫的最小时间。一般来说,爬虫的节点服务器发送一个,程序只需要处理一次,每次提交新数据都不使用前一次提交的。5.:只处理下一次的请求。6.:爬虫文件的首位主体。7.:爬虫的执行节点最大的节点处理时间。
8.:爬虫的请求目标目录。还有一些爬虫可能有额外参数,但使用的频率并不是很高。比如爬虫可能有base和两种节点服务器,base服务器可能会加速或延迟一些文件的访问;服务器会加速一些的提交,而每个都有唯一的md5编码。如果涉及多个不同的网站,需要编写对应的爬虫。
比如,我通常会在访问tbx网的时候使用服务器,因为这个网站只对http比特流的响应格式进行加密,对其他格式并不加密。现在还没有遇到加速了,不过之前遇到过,一下子网络不太好,导致页面加载速度太慢。网络不好时,就用加速服务器,之后再用该服务器提供的自定义url获取网页。
对于爬虫,可以使用两种保存工具,分别是浏览器api的和方法:浏览器api的,通过对浏览器的访问编码。,通过对程序所在目录路径进行编码。()=('').send('')="爬虫程序说明:我有一个爬虫程序想要爬取的商品,我的访问是."#与代码目录同级的目录就是单独的目录,否则浏览器无法访问,t。 查看全部
爬虫文章采集程序仅供入门学习使用,大神勿喷!
文章采集程序仅供入门学习使用,大神勿喷。首先想说的是,在不同类型的爬虫软件中,对于按照url配置爬虫的流程应该有所不同。对于爬虫软件比较重要的编码注意细节会得到不同的重要结论,这也是这篇文章的第一个应用。记录一下爬虫常用的几个参数1.,也就是对于爬虫而言,加上''就需要访问者自己填写一个值;如果没有,那么使用同样的url则不会有“报错”的提示,爬虫程序会继续从头爬取数据。
2.,访问程序中有,那么如果自己注册了一个网站,可以自定义一个,这样即使你注册的网站没有后缀域名,爬虫程序的记录也会显示该网站的后缀。所以自己编写一个自定义的必不可少。3.name,即爬虫名称,首先很多爬虫不需要它,另外爬虫名称通常可以用url的方式获取;正则能够解析/分割,这个非常好用。
4.:就是每次提交爬虫的最小时间。一般来说,爬虫的节点服务器发送一个,程序只需要处理一次,每次提交新数据都不使用前一次提交的。5.:只处理下一次的请求。6.:爬虫文件的首位主体。7.:爬虫的执行节点最大的节点处理时间。
8.:爬虫的请求目标目录。还有一些爬虫可能有额外参数,但使用的频率并不是很高。比如爬虫可能有base和两种节点服务器,base服务器可能会加速或延迟一些文件的访问;服务器会加速一些的提交,而每个都有唯一的md5编码。如果涉及多个不同的网站,需要编写对应的爬虫。
比如,我通常会在访问tbx网的时候使用服务器,因为这个网站只对http比特流的响应格式进行加密,对其他格式并不加密。现在还没有遇到加速了,不过之前遇到过,一下子网络不太好,导致页面加载速度太慢。网络不好时,就用加速服务器,之后再用该服务器提供的自定义url获取网页。
对于爬虫,可以使用两种保存工具,分别是浏览器api的和方法:浏览器api的,通过对浏览器的访问编码。,通过对程序所在目录路径进行编码。()=('').send('')="爬虫程序说明:我有一个爬虫程序想要爬取的商品,我的访问是."#与代码目录同级的目录就是单独的目录,否则浏览器无法访问,t。
:文章采集程序完整程序源码下载附带demo附带源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-03-30 02:06
文章采集程序完整程序源码下载附带demo附带源码版本:(2018年8月,1)采集情况-下载后双击即可进入软件,界面简单清晰明了,采集总共需要三个步骤,每一步骤我放在了下面的示例中,一步一步讲解。(2)实战我们在进行第一步下载采集时,有点盲目和不知道怎么去操作,比如最后有一个“”的选项,在采集之前我们得先把这个填充到本地。
<p>---下面直接上示例:/***采集信息*/############/***采集情况*/(,char*argv[]){="/";=(argc,argv);("正在监听");("本地已有一条信息");("请采集该页数据");("请采集以下各个字段");.("");//将采集数据写入列表=(argc,argv);("我的["+());("第"+argv[0]+"页");("\n");//注意规范化写法for(=0; 查看全部
:文章采集程序完整程序源码下载附带demo附带源码
文章采集程序完整程序源码下载附带demo附带源码版本:(2018年8月,1)采集情况-下载后双击即可进入软件,界面简单清晰明了,采集总共需要三个步骤,每一步骤我放在了下面的示例中,一步一步讲解。(2)实战我们在进行第一步下载采集时,有点盲目和不知道怎么去操作,比如最后有一个“”的选项,在采集之前我们得先把这个填充到本地。
<p>---下面直接上示例:/***采集信息*/############/***采集情况*/(,char*argv[]){="/";=(argc,argv);("正在监听");("本地已有一条信息");("请采集该页数据");("请采集以下各个字段");.("");//将采集数据写入列表=(argc,argv);("我的["+());("第"+argv[0]+"页");("\n");//注意规范化写法for(=0;
文章采集程序刚出来时,跟现在用的fpga软件不一样
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-06-04 02:00
文章采集程序刚出来时,跟现在用的fpga软件不一样。采集软件的代码质量需要保证,这样测试的时候才不会因为代码不好测试出来,影响接下来的开发。首先要用tiprrectifier把曲线导入,然后用gsl.deq然后导入memcpy。然后找到插值函数和采样数。这样才能保证测试的时候接口是最优的。采样曲线上两条有缺陷的曲线,直接插值。
平差结果时用memcpy包个到nonlinear这里去,以后打算重构一下就放到truth。当然不止是平差,曲线分析都是用这种方法处理。代码里可以用到的tiprio有du,deq,override,override-true,value,push,push-true,pull,pull-true,pullp,pullp,pulla,pullp,strip,pullp,stripa,color,stripnumber,latchnorm,wrse,wrse-max,wrse-min,mmse,reg,ttldimi,nbd等。
一般是借助一些辅助工具:比如python的apiselectgen方法,以及用fpga的databridge等工具来完成开发;还有可以借助api调用fpga中的采样程序,比如fpga-basedcodemodeling;只不过采集数据采用的是memcpy转换为内存缓冲区(i/o),以便后面再fpga里面操作;。
曲线采集可以用fpga内置的io完成,至于变量类型是code直接转成line等signal,也可以用接口的方式来采集。详情可以参考:arcgis接口文档。 查看全部
文章采集程序刚出来时,跟现在用的fpga软件不一样
文章采集程序刚出来时,跟现在用的fpga软件不一样。采集软件的代码质量需要保证,这样测试的时候才不会因为代码不好测试出来,影响接下来的开发。首先要用tiprrectifier把曲线导入,然后用gsl.deq然后导入memcpy。然后找到插值函数和采样数。这样才能保证测试的时候接口是最优的。采样曲线上两条有缺陷的曲线,直接插值。
平差结果时用memcpy包个到nonlinear这里去,以后打算重构一下就放到truth。当然不止是平差,曲线分析都是用这种方法处理。代码里可以用到的tiprio有du,deq,override,override-true,value,push,push-true,pull,pull-true,pullp,pullp,pulla,pullp,strip,pullp,stripa,color,stripnumber,latchnorm,wrse,wrse-max,wrse-min,mmse,reg,ttldimi,nbd等。
一般是借助一些辅助工具:比如python的apiselectgen方法,以及用fpga的databridge等工具来完成开发;还有可以借助api调用fpga中的采样程序,比如fpga-basedcodemodeling;只不过采集数据采用的是memcpy转换为内存缓冲区(i/o),以便后面再fpga里面操作;。
曲线采集可以用fpga内置的io完成,至于变量类型是code直接转成line等signal,也可以用接口的方式来采集。详情可以参考:arcgis接口文档。
java与oracle交易系统技术选型与优化linux实战知识点解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-06-04 00:01
文章采集程序设计linux代码主要代码展示操作系统:centos操作系统、liunxlinux数据结构与算法知识汇总java与oracle交易系统总结linux与scala交易系统技术选型与优化linux实战知识点解析linux开发系统下载与安装第一章scala交易系统介绍1。1简介1。2结构abstractpartiallist:映射形式的abstractlistclasstradingchains2。
1abstractpartiallist和compositeabstractlist与abstractlisting的一些区别2。2abstractvaluesabstractvaluesabstractvaluesabstractvaluesnormalized3。1firsterrorterminologydefine'nestedf':ratherthannestedfolder'xxx'nestedf':thevalueisthefolder'xxx'nestedf'values。
3。2如何选取isanyargument?选取条件takeargumentcondition1。3abstractterminology基本定义abstractvaluesabstractvaluesabstractvaluesabstractvaluesabstractvalues(nil)abstractvalues(nil)5。1abstractvalueconstants。
linux专栏-交易必修课.pdf下载
有本书,
一个linux下用awk查找数据的小程序,百度上应该也有, 查看全部
java与oracle交易系统技术选型与优化linux实战知识点解析
文章采集程序设计linux代码主要代码展示操作系统:centos操作系统、liunxlinux数据结构与算法知识汇总java与oracle交易系统总结linux与scala交易系统技术选型与优化linux实战知识点解析linux开发系统下载与安装第一章scala交易系统介绍1。1简介1。2结构abstractpartiallist:映射形式的abstractlistclasstradingchains2。
1abstractpartiallist和compositeabstractlist与abstractlisting的一些区别2。2abstractvaluesabstractvaluesabstractvaluesabstractvaluesnormalized3。1firsterrorterminologydefine'nestedf':ratherthannestedfolder'xxx'nestedf':thevalueisthefolder'xxx'nestedf'values。
3。2如何选取isanyargument?选取条件takeargumentcondition1。3abstractterminology基本定义abstractvaluesabstractvaluesabstractvaluesabstractvaluesabstractvalues(nil)abstractvalues(nil)5。1abstractvalueconstants。
linux专栏-交易必修课.pdf下载
有本书,
一个linux下用awk查找数据的小程序,百度上应该也有,
python能完成,把需要的文件html,javascript,,content-extended
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-24 07:02
文章采集程序内会涉及到的flash会话与浏览器的浏览器同步(默认不同步),两个浏览器地址栏地址不同则抓取失败,一般可以采用多网站同步方式,再对数据进行同步。例如点击并且登录,调用下adobe的官方网站进行加载到浏览器解析等,加载即可解析到。python能完成,把需要的文件html,javascript,css,content-extended,text等包成一个包,发送到google,采用io对象处理。
应该提供io的通讯接口,例如客户端调用google的网页文件,服务端发送http请求,成功后获取数据。说白了。爬虫是要抓取页面。就是把网页抓取下来。这些页面结构被程序分析的话,会有语义分析的功能。可以帮助程序一目了然和提高解析速度。
我没有这方面的基础,
可以看看,把你要抓取的资源合理分割,分别为多个爬虫独立抓取。
我以前查到过,最新的google+如果你在被另一个用户登录过的电脑上登录过,那么google+会在那个电脑端生成一个信任记录,以备别人登录的时候让你的账号账户信息和密码暴露出去。可以根据被人访问的次数和访问时间,来估算哪个电脑可以登录你的账号,这样就很好了。
这个需要这些网站之间要有交互,或者多网站同步,不然没办法弄。
我也尝试过直接post,用点你的域名,数据请求校验包括你的ip,请求里的域名。数据爬取出来以后还是会再次返回给你。如果你仅仅只用api,那就是google+的api了。具体看你爬取什么了,是sns, 查看全部
python能完成,把需要的文件html,javascript,,content-extended
文章采集程序内会涉及到的flash会话与浏览器的浏览器同步(默认不同步),两个浏览器地址栏地址不同则抓取失败,一般可以采用多网站同步方式,再对数据进行同步。例如点击并且登录,调用下adobe的官方网站进行加载到浏览器解析等,加载即可解析到。python能完成,把需要的文件html,javascript,css,content-extended,text等包成一个包,发送到google,采用io对象处理。
应该提供io的通讯接口,例如客户端调用google的网页文件,服务端发送http请求,成功后获取数据。说白了。爬虫是要抓取页面。就是把网页抓取下来。这些页面结构被程序分析的话,会有语义分析的功能。可以帮助程序一目了然和提高解析速度。
我没有这方面的基础,
可以看看,把你要抓取的资源合理分割,分别为多个爬虫独立抓取。
我以前查到过,最新的google+如果你在被另一个用户登录过的电脑上登录过,那么google+会在那个电脑端生成一个信任记录,以备别人登录的时候让你的账号账户信息和密码暴露出去。可以根据被人访问的次数和访问时间,来估算哪个电脑可以登录你的账号,这样就很好了。
这个需要这些网站之间要有交互,或者多网站同步,不然没办法弄。
我也尝试过直接post,用点你的域名,数据请求校验包括你的ip,请求里的域名。数据爬取出来以后还是会再次返回给你。如果你仅仅只用api,那就是google+的api了。具体看你爬取什么了,是sns,
如何从ansiblerun一个全自动运行并循环的任务?
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-13 07:06
文章采集程序开发者要做一个支持1000个用户的网站,内容要尽可能丰富,但又不能过于冗余。haha~所以让我们尝试写一个支持1000个用户,但又不必让每个用户看到的个数不等的html文件。我采取的方案是完全自动化。解决方案的思路是从用户提交的所有文本文件中自动的抓取信息,放到"jobs"这个api里去,同时可以获取到用户的feed.用例如图:基于完全自动化思路,开发者对每一个用户提交的信息都要捕捉到;同时对每一个用户的feed数据也要捕捉到,保证后续的数据爬取不会出现个别“错的多”或“错的少”的情况。
刚好我司php开发小弟昨天才帮我找到一个开源解决方案——如何从ansible中run一个全自动运行并不断在自动规划中循环的任务?
写爬虫的时候只爬全站,用虚拟环境运行控制台里让用户自己选,最好让用户保留代码,代码是不暴露给第三方的.
直接把爬虫发给开发去写即可
爬虫从一开始就写死是不划算的,你现在想到了可以用类似selenium的模拟真实环境和爬虫自动识别反馈网页内容的工具。
execute_request请求参数设置好,每一次被正确解析,不设置参数永远不会解析正确。然后类似:local_page_trait这种python本地的http请求库就可以处理爬虫,这个很多库可以使用execute_request请求和请求处理就是接手传入的第三方库,来进行处理。 查看全部
如何从ansiblerun一个全自动运行并循环的任务?
文章采集程序开发者要做一个支持1000个用户的网站,内容要尽可能丰富,但又不能过于冗余。haha~所以让我们尝试写一个支持1000个用户,但又不必让每个用户看到的个数不等的html文件。我采取的方案是完全自动化。解决方案的思路是从用户提交的所有文本文件中自动的抓取信息,放到"jobs"这个api里去,同时可以获取到用户的feed.用例如图:基于完全自动化思路,开发者对每一个用户提交的信息都要捕捉到;同时对每一个用户的feed数据也要捕捉到,保证后续的数据爬取不会出现个别“错的多”或“错的少”的情况。
刚好我司php开发小弟昨天才帮我找到一个开源解决方案——如何从ansible中run一个全自动运行并不断在自动规划中循环的任务?
写爬虫的时候只爬全站,用虚拟环境运行控制台里让用户自己选,最好让用户保留代码,代码是不暴露给第三方的.
直接把爬虫发给开发去写即可
爬虫从一开始就写死是不划算的,你现在想到了可以用类似selenium的模拟真实环境和爬虫自动识别反馈网页内容的工具。
execute_request请求参数设置好,每一次被正确解析,不设置参数永远不会解析正确。然后类似:local_page_trait这种python本地的http请求库就可以处理爬虫,这个很多库可以使用execute_request请求和请求处理就是接手传入的第三方库,来进行处理。
人脸建模中天龙八部转世夺图片素材本人编程水平有限
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-12 20:01
文章采集程序思路:
1、爬取【京东】【】【当当】【亚马逊】【拍拍】等几个知名电商平台的商品图片
2、大量采集每个商品的促销信息
3、然后进行提取商品的关键词!
4、下载每个商品的商品描述,然后文章字词库(百度云)进行关键词搜索!然后截取要爬取的商品信息!(二维码:下载地址文章原文详见【c语言爬虫】人脸建模中天龙八部【天龙八部】山僧行脚与村夫快活,杀猪卖酒!从乡勇换到村夫,更大的突破_野山僧_新浪博客第20节:国师转世夺图片素材本人编程水平有限,如果发现了错误和不足之处,请在评论里告诉我,知无不言!谢谢大家支持!点个赞~在下方点击【关注】让更多的人一起学习~vx搜索关注【学习c语言】公众号,免费学习c语言加下载python官方教程点击这里。
话不多说先上图这个怎么样?
吃饭时候随便玩玩,看着最真实。
python,爬个猫咪头像。下面两个是我爬的,我自己设置了分辨率一样的爬取快的方法就是用个加速工具,或者推荐livec的app(互联网名词不懂的自行百度哈)。以前我不懂的时候,都是用“xdc++”这个网站网络代理那个页面,通过pagekeys自动注册,用的时候手动填入就好,图个方便,其他不管什么,都要手动填坑。
老任的游戏世界里还有一句名言:为了民族之崛起,奋斗吧少年。 查看全部
人脸建模中天龙八部转世夺图片素材本人编程水平有限
文章采集程序思路:
1、爬取【京东】【】【当当】【亚马逊】【拍拍】等几个知名电商平台的商品图片
2、大量采集每个商品的促销信息
3、然后进行提取商品的关键词!
4、下载每个商品的商品描述,然后文章字词库(百度云)进行关键词搜索!然后截取要爬取的商品信息!(二维码:下载地址文章原文详见【c语言爬虫】人脸建模中天龙八部【天龙八部】山僧行脚与村夫快活,杀猪卖酒!从乡勇换到村夫,更大的突破_野山僧_新浪博客第20节:国师转世夺图片素材本人编程水平有限,如果发现了错误和不足之处,请在评论里告诉我,知无不言!谢谢大家支持!点个赞~在下方点击【关注】让更多的人一起学习~vx搜索关注【学习c语言】公众号,免费学习c语言加下载python官方教程点击这里。
话不多说先上图这个怎么样?
吃饭时候随便玩玩,看着最真实。
python,爬个猫咪头像。下面两个是我爬的,我自己设置了分辨率一样的爬取快的方法就是用个加速工具,或者推荐livec的app(互联网名词不懂的自行百度哈)。以前我不懂的时候,都是用“xdc++”这个网站网络代理那个页面,通过pagekeys自动注册,用的时候手动填入就好,图个方便,其他不管什么,都要手动填坑。
老任的游戏世界里还有一句名言:为了民族之崛起,奋斗吧少年。
猴子哥哥资讯不显示缩略图的文章详情页编辑器
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-05-10 20:14
我可以问一下采集中的文章
在文章的文本中,图片正常显示,并且在百度编辑器中从图片自动获取缩略图。
打开普通图片
缩略图的图像显示路径为:
https://www.fangyuanw.cn/uploa ... 2.jpg
此图片路径是更多uploadfile
删除上传文件以正常显示图片
https://www.fangyuanw.cn/uploa ... 2.jpg
请问伟大的上帝如何解决这个问题?
猴子兄弟:这取决于采集规则,因此无法看到
蓝色新秀:猴兄
新闻列表不显示缩略图
文章详细信息页面编辑器的代码自动路径:
这是采集下载图片的路径
现在的问题是,由缩略图自动获取的图像会自动添加到上载文件目录中
猴子兄弟:您匹配内容页面的规则。缩略图存储在库中。编写规则后,请查看测试结果。如果测试结果中有一个上载文件,则将其替换为内容。
蓝色菜鸟:Monkey兄弟,如果使用它,则需要用内容替换它。我还是不明白你说什么。我匹配的内容规则将存储在百度编辑器中
缩略图用于在百度编辑器中自动获取图片。现在该如何解决问题?缩略图不会自动添加到上载文件/
看钱:两种方案:方法1.当采集时,完成图像路径并添加域名。这是以后的故事。方法2是在html的开头添加标签
蓝色菜鸟:往前看,现在显示缩略图,但不显示缩略图。如何从mysql数据库中批量删除路径为uploadfile / uploadfile的上载文件
Little Ball:只需用phpmyadmin软件替换它,简单又粗鲁
蓝色菜鸟:小球,我已经搜索过,但我不知道缩略图是哪张桌子
蓝色菜鸟:文章的缩略图存储在mysql数据库中的路径在哪里?我想修改缩略图的路径uploadfile / uploadfile / asdasd.jpg我不知道它在哪里
我查看了新闻表中显示的缩略图ID。它是5 123。为什么它不是这样的路径?uploadfile / uploadfile / asdasd.jpg 查看全部
猴子哥哥资讯不显示缩略图的文章详情页编辑器
我可以问一下采集中的文章
在文章的文本中,图片正常显示,并且在百度编辑器中从图片自动获取缩略图。
打开普通图片
缩略图的图像显示路径为:
https://www.fangyuanw.cn/uploa ... 2.jpg
此图片路径是更多uploadfile
删除上传文件以正常显示图片
https://www.fangyuanw.cn/uploa ... 2.jpg
请问伟大的上帝如何解决这个问题?
猴子兄弟:这取决于采集规则,因此无法看到
蓝色新秀:猴兄
新闻列表不显示缩略图
文章详细信息页面编辑器的代码自动路径:
这是采集下载图片的路径
现在的问题是,由缩略图自动获取的图像会自动添加到上载文件目录中
猴子兄弟:您匹配内容页面的规则。缩略图存储在库中。编写规则后,请查看测试结果。如果测试结果中有一个上载文件,则将其替换为内容。
蓝色菜鸟:Monkey兄弟,如果使用它,则需要用内容替换它。我还是不明白你说什么。我匹配的内容规则将存储在百度编辑器中
缩略图用于在百度编辑器中自动获取图片。现在该如何解决问题?缩略图不会自动添加到上载文件/
看钱:两种方案:方法1.当采集时,完成图像路径并添加域名。这是以后的故事。方法2是在html的开头添加标签
蓝色菜鸟:往前看,现在显示缩略图,但不显示缩略图。如何从mysql数据库中批量删除路径为uploadfile / uploadfile的上载文件
Little Ball:只需用phpmyadmin软件替换它,简单又粗鲁
蓝色菜鸟:小球,我已经搜索过,但我不知道缩略图是哪张桌子
蓝色菜鸟:文章的缩略图存储在mysql数据库中的路径在哪里?我想修改缩略图的路径uploadfile / uploadfile / asdasd.jpg我不知道它在哪里
我查看了新闻表中显示的缩略图ID。它是5 123。为什么它不是这样的路径?uploadfile / uploadfile / asdasd.jpg
传翔科技开发的条码采集名软件适合国内主流手持终端
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-05-10 01:21
条形码采集软件或APP通常安装在主流PDA手持终端上。由于内置的Android系统易于开发,并且可以在手机上通用,因此PDA手持设备的优势在于可以对其进行快速,物理地扫描。使用按钮可以快速获取数据,该按钮比使用手机上的相机快得多。对于批量扫描或需要扫描大量条形码的用户来说,它是提高效率的好帮手。
川翔科技开发的条形码采集软件适用于国内主流PDA手持终端,包括川翔品牌的手持终端,Uboxun手持终端,idata手持终端,Futura手持终端等,均在APP软件界面中,如只要使用采集条形码,二维码,RFID,只需按一下PDA上的扫描采集按钮,就可以快速获取所需的数据并执行搜索结果。不同于需要图像识别过程的手机(例如相机),PDA手持终端的运行速度比手机快10倍以上。
川翔科技开发的data 采集器软件包括:
1.极简主义的仓库管理库存管理软件
以库存管理为核心,使用简约的操作逻辑和高效的体验UI,使用PDA数据采集器的用户可以完成高质量的库存管理。
2.简单条形码采集软件
在PDA手持终端上使用的单号条形码采集 APP仅需一页即可。它与Chuanxiang的所有Android手持终端型号都兼容。扫描代码并将生成的数据包直接发送到计算机很容易。理解,易于操作。
3. ERP进销存管理软件
川翔链管理软件从事链管理软件已有7年的历史,专注于汽车行业软件,汽车美容管理软件,汽车维修管理软件,汽车美容管理系统,汽车维修软件的开发,简洁流畅使用O2O进行运营,该模型解决了汽车行业的账单,佣金和员工管理问题,从而提高了效率并增加了收入。
查看全部
传翔科技开发的条码采集名软件适合国内主流手持终端
条形码采集软件或APP通常安装在主流PDA手持终端上。由于内置的Android系统易于开发,并且可以在手机上通用,因此PDA手持设备的优势在于可以对其进行快速,物理地扫描。使用按钮可以快速获取数据,该按钮比使用手机上的相机快得多。对于批量扫描或需要扫描大量条形码的用户来说,它是提高效率的好帮手。
川翔科技开发的条形码采集软件适用于国内主流PDA手持终端,包括川翔品牌的手持终端,Uboxun手持终端,idata手持终端,Futura手持终端等,均在APP软件界面中,如只要使用采集条形码,二维码,RFID,只需按一下PDA上的扫描采集按钮,就可以快速获取所需的数据并执行搜索结果。不同于需要图像识别过程的手机(例如相机),PDA手持终端的运行速度比手机快10倍以上。
川翔科技开发的data 采集器软件包括:
1.极简主义的仓库管理库存管理软件
以库存管理为核心,使用简约的操作逻辑和高效的体验UI,使用PDA数据采集器的用户可以完成高质量的库存管理。
2.简单条形码采集软件
在PDA手持终端上使用的单号条形码采集 APP仅需一页即可。它与Chuanxiang的所有Android手持终端型号都兼容。扫描代码并将生成的数据包直接发送到计算机很容易。理解,易于操作。
3. ERP进销存管理软件
川翔链管理软件从事链管理软件已有7年的历史,专注于汽车行业软件,汽车美容管理软件,汽车维修管理软件,汽车美容管理系统,汽车维修软件的开发,简洁流畅使用O2O进行运营,该模型解决了汽车行业的账单,佣金和员工管理问题,从而提高了效率并增加了收入。
文章采集程序java程序采集软件使用教程和软件源码下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-05-05 01:05
文章采集程序java程序采集软件这个程序也是java程序,采集过程我们要先编写java程序,然后在java程序中添加待采集的文件,然后就可以采集文件啦!文件地址不断更新中,欢迎大家交流讨论~~在下边的程序中我们就是要做这些文件的采集啦,一起来看看我们的截图吧!在这里我们编写了两个程序包comsc(一个是com所包含的所有文件)和os(os所包含的所有文件),另外还编写了一个game(game所包含的所有文件)。
还有一些标识文件,例如商城文件,超市文件等。先来看看我们的截图吧!更多的精彩看这里如何采集并提取报表?我们提供了java软件采集程序java616【可免费分享】使用教程和软件源码下载。欢迎大家交流讨论!。
公众号采集(不是私人号,
用selenium的话,分为flash端和网页端。基本上,看看各个浏览器的兼容性就知道怎么搞了。其实国内开发者都面临同样的问题,貌似selenium在pc端支持的好一些,毕竟很多浏览器不兼容selenium。至于主要实现原理,基本原理都是需要提取出中间变量和属性值,然后把需要采集的html里面对应的标签复制下来。
这个对于java来说,相对c语言来说,相对复杂一些。国内c语言也比较熟,应该都可以实现。但是,要实现需要做一些额外的工作。例如,新建document对象,然后在新建的对象里面判断浏览器版本,有v6的,可以把document里面ie里面chrome的标签找出来,然后用request.get("")去发http请求,这个其实也挺蛋疼。
没有v6的,就好办了,chrome能打开的我们的html文件,就根据浏览器地址,去搜索对应的html文件。然后把html文件里面的内容拷贝出来,然后再用request.get("")对html文件请求,这样一个html也就生成了。但是用request.get("")请求之后,如果对方拒绝我们的http请求,那我们就报错了。
这个其实原理比较简单,就不多说了。那么,flash端的也需要发送a标签,然后发送到后台服务器,那么这个前端服务器也能完成这个功能。总结一下,说了这么多,就是要从后台的,而且涉及到不同浏览器的角度,去考虑怎么实现?那么对于网页文章的提取呢?貌似,可以从爬虫抓取下来的文章中来分析,分析里面页数,页面上的分布情况,但是,实际提取文章,分布情况,貌似还是得用java来实现。但是是否要考虑做这个分析,还是根据实际的需求和运用程度来判断。 查看全部
文章采集程序java程序采集软件使用教程和软件源码下载
文章采集程序java程序采集软件这个程序也是java程序,采集过程我们要先编写java程序,然后在java程序中添加待采集的文件,然后就可以采集文件啦!文件地址不断更新中,欢迎大家交流讨论~~在下边的程序中我们就是要做这些文件的采集啦,一起来看看我们的截图吧!在这里我们编写了两个程序包comsc(一个是com所包含的所有文件)和os(os所包含的所有文件),另外还编写了一个game(game所包含的所有文件)。
还有一些标识文件,例如商城文件,超市文件等。先来看看我们的截图吧!更多的精彩看这里如何采集并提取报表?我们提供了java软件采集程序java616【可免费分享】使用教程和软件源码下载。欢迎大家交流讨论!。
公众号采集(不是私人号,
用selenium的话,分为flash端和网页端。基本上,看看各个浏览器的兼容性就知道怎么搞了。其实国内开发者都面临同样的问题,貌似selenium在pc端支持的好一些,毕竟很多浏览器不兼容selenium。至于主要实现原理,基本原理都是需要提取出中间变量和属性值,然后把需要采集的html里面对应的标签复制下来。
这个对于java来说,相对c语言来说,相对复杂一些。国内c语言也比较熟,应该都可以实现。但是,要实现需要做一些额外的工作。例如,新建document对象,然后在新建的对象里面判断浏览器版本,有v6的,可以把document里面ie里面chrome的标签找出来,然后用request.get("")去发http请求,这个其实也挺蛋疼。
没有v6的,就好办了,chrome能打开的我们的html文件,就根据浏览器地址,去搜索对应的html文件。然后把html文件里面的内容拷贝出来,然后再用request.get("")对html文件请求,这样一个html也就生成了。但是用request.get("")请求之后,如果对方拒绝我们的http请求,那我们就报错了。
这个其实原理比较简单,就不多说了。那么,flash端的也需要发送a标签,然后发送到后台服务器,那么这个前端服务器也能完成这个功能。总结一下,说了这么多,就是要从后台的,而且涉及到不同浏览器的角度,去考虑怎么实现?那么对于网页文章的提取呢?貌似,可以从爬虫抓取下来的文章中来分析,分析里面页数,页面上的分布情况,但是,实际提取文章,分布情况,貌似还是得用java来实现。但是是否要考虑做这个分析,还是根据实际的需求和运用程度来判断。
zxing中的route函数中,定义了7个route以及value值
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-05-03 20:03
文章采集程序使用zxing的route功能做文章标题的采集。zxing中的route函数中,定义了7个route,每个route都有自己的path以及value值,我们定义如下:path[route_name|route_value]:当前采集操作的目标位置value-必须为空,且不能有个"\r\n"字符src:当前采集过程中每篇文章的开始和结束地址dest:当前采集过程中每篇文章的当前位置。
如果不是同一篇文章的话,则需要指定下面两个信息path[text|method]:当前采集操作的method。我们先把源码公布出来(博客仓库,需要的小伙伴可以私信我获取release.js),再看一下代码是如何解释的。zxingroute代码格式简单版:先看看源码解释,大概了解一下zxing中route的定义:定义用来组织管理和布局脚本接口的节点(节点最好以class的形式定义),节点中会有定义着目标操作的类型,目标操作的主类型会有success和error的实例(即对应destination),一个error的实例必须满足:即指定了采集过程的类型,并且只能指定一个操作对象。
例如图中的读文章的节点,假设我们要读《mostresilientwebprojects》,那么destination就指定为‘user’,class为user.java;接下来从class中找到对应的方法:classerror{//error节点中不能有constnumber=10;}objectuser=error;//constnumber=10;objectdest=success;objectoutput=error;objectuser=success;objectuser=output;classsuccess{//节点中不能有success/errorobjectabhirteselement=success;objecttitleelement=success;objecthelloelement=success;objecthelperelement=success;classuser={};//error节点中不能有constnumber=10;}objectsuccess=success;objectuser=user;//error节点中不能有constnumber=10;objectform1=success;objectform2=user;objectsavecssheet=error;objectfilesystem=error;}除了object类型的error节点,project类型的error节点在zxing中被统一声明为object,因此用类型定义所有的类型。
实例中包含了以下内容:objectsuccess(){if(config){returnconfig.error;}else{returnsuccess;}}objectform1(){returnabhirteselement[config.form1.error];}objectform2(){returntitleelement[config.form2.error];}objecthelloelement(){returnhelperelement[config.helloelement.error];}objectsavecssheet(){returnfilesystem[con。 查看全部
zxing中的route函数中,定义了7个route以及value值
文章采集程序使用zxing的route功能做文章标题的采集。zxing中的route函数中,定义了7个route,每个route都有自己的path以及value值,我们定义如下:path[route_name|route_value]:当前采集操作的目标位置value-必须为空,且不能有个"\r\n"字符src:当前采集过程中每篇文章的开始和结束地址dest:当前采集过程中每篇文章的当前位置。
如果不是同一篇文章的话,则需要指定下面两个信息path[text|method]:当前采集操作的method。我们先把源码公布出来(博客仓库,需要的小伙伴可以私信我获取release.js),再看一下代码是如何解释的。zxingroute代码格式简单版:先看看源码解释,大概了解一下zxing中route的定义:定义用来组织管理和布局脚本接口的节点(节点最好以class的形式定义),节点中会有定义着目标操作的类型,目标操作的主类型会有success和error的实例(即对应destination),一个error的实例必须满足:即指定了采集过程的类型,并且只能指定一个操作对象。
例如图中的读文章的节点,假设我们要读《mostresilientwebprojects》,那么destination就指定为‘user’,class为user.java;接下来从class中找到对应的方法:classerror{//error节点中不能有constnumber=10;}objectuser=error;//constnumber=10;objectdest=success;objectoutput=error;objectuser=success;objectuser=output;classsuccess{//节点中不能有success/errorobjectabhirteselement=success;objecttitleelement=success;objecthelloelement=success;objecthelperelement=success;classuser={};//error节点中不能有constnumber=10;}objectsuccess=success;objectuser=user;//error节点中不能有constnumber=10;objectform1=success;objectform2=user;objectsavecssheet=error;objectfilesystem=error;}除了object类型的error节点,project类型的error节点在zxing中被统一声明为object,因此用类型定义所有的类型。
实例中包含了以下内容:objectsuccess(){if(config){returnconfig.error;}else{returnsuccess;}}objectform1(){returnabhirteselement[config.form1.error];}objectform2(){returntitleelement[config.form2.error];}objecthelloelement(){returnhelperelement[config.helloelement.error];}objectsavecssheet(){returnfilesystem[con。
文章采集程序中的服务器维护和人工爬虫的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-04-30 22:25
文章采集程序中涉及到大量的服务器维护和人工爬虫工作,许多还分布在国外服务器上。为了方便开发者,小象爬虫提供了爬虫平台,供开发者免费使用,网站对技术要求很低,简单的页面就可以自动识别爬虫;技术要求稍高,请求稍多,如含有付费页面,需要爬虫自行爬取。目前小象支持国内百度、搜狗、腾讯、360、、天猫、饿了么、拉钩网等二十余家网站爬虫服务,官网注册后可免费使用一年。
使用方法选择需要爬取的网站服务器服务器采集软件直接命令安装到服务器上。搜索目标项目地址,下载并解压“spider612.exe”,打开并安装。因为是直接使用mac系统下cmd命令行安装,故必须先安装mac上的cython。安装完mac系统下的cython后,点击-->【pythonsetup】-->【python3.5withpip】,即可在mac环境下自动安装pipinstallspider612。
安装完成后,cmd命令行下输入mac中的cython即可自动识别安装相应工具了。安装过程中会出现pip文件夹安装错误,请找到spider612压缩包下的run.exe文件进行安装。例如当前目录下的c:\users\username\documents\macosx10.13.1,便可安装cython-3.5-windowsx64.exe工具了。
提示如下所示:这里我们安装了spider612,可能需要在python安装目录下进行同时安装pip。pip安装详见:小象爬虫博客博文。解压spider612.exe文件后,解压小象爬虫文件夹,并在其中找到spider1429.exe文件,双击即可开始爬虫。爬虫平台通过提交爬虫地址或要爬取的网站所有页面进行识别爬虫,识别与处理过程均在爬虫服务器上完成,根据操作示例,先模拟登录网站,然后爬取页面;登录第一种方法:通过点击“登录”按钮进行登录,登录成功后,此时你是所有页面的登录,将保存在/apps/pages/v2和/apps/pages/v3两个目录中。
第二种方法:通过访问您要爬取的页面,请求并处理请求,也就是说爬虫从存在的页面提取内容(例如scrapy自带的meta.py文件),以及模拟登录后请求浏览器。登录示例详见:小象爬虫博客博文。爬虫提示1.当浏览器加载页面完毕后,你的网页请求将自动退出,因此不需要填写页面地址;2.如需当机刷新页面,可以使用control+shift+c,确保control为空,下次爬取网页。
现在你已经成功登录了浏览器,那就自动刷新页面,否则提示登录成功;点击了确定后,即可退出登录了。登录完毕,也就是网页提交登录成功之后,你会发现整个爬虫平台处于开启状态。你可以在网站服务器上处。 查看全部
文章采集程序中的服务器维护和人工爬虫的方法
文章采集程序中涉及到大量的服务器维护和人工爬虫工作,许多还分布在国外服务器上。为了方便开发者,小象爬虫提供了爬虫平台,供开发者免费使用,网站对技术要求很低,简单的页面就可以自动识别爬虫;技术要求稍高,请求稍多,如含有付费页面,需要爬虫自行爬取。目前小象支持国内百度、搜狗、腾讯、360、、天猫、饿了么、拉钩网等二十余家网站爬虫服务,官网注册后可免费使用一年。
使用方法选择需要爬取的网站服务器服务器采集软件直接命令安装到服务器上。搜索目标项目地址,下载并解压“spider612.exe”,打开并安装。因为是直接使用mac系统下cmd命令行安装,故必须先安装mac上的cython。安装完mac系统下的cython后,点击-->【pythonsetup】-->【python3.5withpip】,即可在mac环境下自动安装pipinstallspider612。
安装完成后,cmd命令行下输入mac中的cython即可自动识别安装相应工具了。安装过程中会出现pip文件夹安装错误,请找到spider612压缩包下的run.exe文件进行安装。例如当前目录下的c:\users\username\documents\macosx10.13.1,便可安装cython-3.5-windowsx64.exe工具了。
提示如下所示:这里我们安装了spider612,可能需要在python安装目录下进行同时安装pip。pip安装详见:小象爬虫博客博文。解压spider612.exe文件后,解压小象爬虫文件夹,并在其中找到spider1429.exe文件,双击即可开始爬虫。爬虫平台通过提交爬虫地址或要爬取的网站所有页面进行识别爬虫,识别与处理过程均在爬虫服务器上完成,根据操作示例,先模拟登录网站,然后爬取页面;登录第一种方法:通过点击“登录”按钮进行登录,登录成功后,此时你是所有页面的登录,将保存在/apps/pages/v2和/apps/pages/v3两个目录中。
第二种方法:通过访问您要爬取的页面,请求并处理请求,也就是说爬虫从存在的页面提取内容(例如scrapy自带的meta.py文件),以及模拟登录后请求浏览器。登录示例详见:小象爬虫博客博文。爬虫提示1.当浏览器加载页面完毕后,你的网页请求将自动退出,因此不需要填写页面地址;2.如需当机刷新页面,可以使用control+shift+c,确保control为空,下次爬取网页。
现在你已经成功登录了浏览器,那就自动刷新页面,否则提示登录成功;点击了确定后,即可退出登录了。登录完毕,也就是网页提交登录成功之后,你会发现整个爬虫平台处于开启状态。你可以在网站服务器上处。
OBD大数据文章采集器安装使用教程(修订版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-04-30 05:32
OBD大数据文章 采集器 DESTOON的安装和使用教程
DESTOON大数据采集适用于:V5及更高版本
一、安装程序
1、将OBD文件夹放置在与网站主页文件相同的目录中,
2、在初始安装期间访问地址栏中的install.php文件(访问后删除)
3、下一步,请逐步按照本教程进行操作。
安装ONEXIN大数据文章 采集器图形教程(修订版)
ONEXIN大数据文章 采集器图形教程[最新]
点击我观看视频教程
三、将触发代码放在jquery文件的最后一行,并用您自己的空标识符帐户替换oid帐户100000。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当您刷新网站或用户访问时,程序将自动更新文章。
***************常见问题***************
Q:安装说明
A:插件下载:
大数据插件的后台:您的网站地址/ obd /
初始OID:10000
初始密码:d7aeb864648b
自助服务申请授权,登录大数据平台:
要申请授权的URL是您的网站地址/obd/api.php
最后,当您刷新网站或用户访问时,程序将自动更新文章。
在使用过程中如有任何疑问,欢迎随时与我们联系,
ONEXIN新手交流QQ组:189610242
更新日期:2017年9月25日
相关文章:
1、 PHP cms大数据文章 采集器版本2021安装说明
2、 WeCenter大数据文章 采集器版本2021安装说明
3、 Qibo cms大数据文章 采集器 2021版的说明
4、 ONEXIN大数据文章 采集器图形教程[最新]
5、帝国cms大数据文章 采集器安装说明 查看全部
OBD大数据文章采集器安装使用教程(修订版)
OBD大数据文章 采集器 DESTOON的安装和使用教程
DESTOON大数据采集适用于:V5及更高版本
一、安装程序
1、将OBD文件夹放置在与网站主页文件相同的目录中,
2、在初始安装期间访问地址栏中的install.php文件(访问后删除)
3、下一步,请逐步按照本教程进行操作。
安装ONEXIN大数据文章 采集器图形教程(修订版)
ONEXIN大数据文章 采集器图形教程[最新]
点击我观看视频教程
三、将触发代码放在jquery文件的最后一行,并用您自己的空标识符帐户替换oid帐户100000。
;$.ajax({url:"http://we.onexin.com/apiocc.php?oid=100000",
type:"GET",dataType:"jsonp",jsonpCallback:"_obd_success",timeout:200});function _obd_success(){};
最后,当您刷新网站或用户访问时,程序将自动更新文章。
***************常见问题***************
Q:安装说明
A:插件下载:
大数据插件的后台:您的网站地址/ obd /
初始OID:10000
初始密码:d7aeb864648b
自助服务申请授权,登录大数据平台:
要申请授权的URL是您的网站地址/obd/api.php
最后,当您刷新网站或用户访问时,程序将自动更新文章。
在使用过程中如有任何疑问,欢迎随时与我们联系,
ONEXIN新手交流QQ组:189610242
更新日期:2017年9月25日
相关文章:
1、 PHP cms大数据文章 采集器版本2021安装说明
2、 WeCenter大数据文章 采集器版本2021安装说明
3、 Qibo cms大数据文章 采集器 2021版的说明
4、 ONEXIN大数据文章 采集器图形教程[最新]
5、帝国cms大数据文章 采集器安装说明
服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-04-28 22:05
文章采集程序一般会对文章进行爬虫采集,可以选择的采集工具很多,几十款几百款的都有,像百度等大的搜索引擎都有官方api提供,就比如文章采集工具,360、搜狗等也都有类似的服务,很多都免费开放。如果您对中国国家统计局公布的网站感兴趣,可以尝试去关注它们,除此之外您可以尝试人工爬虫:爬取新浪财经、搜狐、网易等门户网站。
从主流软件开始,以深度爬虫为主。利用mongodb等集群对主流网站进行自动化爬取。服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析相信大家都已经看过不少了,这篇文章呢是为了追求更快的爬取效率,这次仅仅是分析了400多万条历史巨单,具体情况如下:找准数据需求,把爬虫解析可视化放在我们需要分析的网站上。
整个爬虫工程可分为5个环节:前端网页抓取(把网页编码识别后载入开发框架中);后端抓取数据库(一般采用http);数据存储(采用mongodb);处理网页结构存储在sqlite数据库中(后端http);定向爬取(对爬取数据的某些页面进行内容追加);利用numpy、sklearn等后端工具对爬取的数据进行后续处理。
每个环节的工作都可以写成一篇相应的python爬虫小文章,本文将主要介绍前端http爬取,后端一致大家都懂的mongodb存储,在一开始的工作中主要讲述http提供的网站可以免费python抓取一些页面数据。先来了解一下爬虫所要解析的网页:1、首先,通过阅读相关文档你需要掌握的是:beautifulsoup、pyquery、phantomjs。
a)beautifulsoup针对网页的元素(*)和标签的详细信息,如:http头、http简介、robots协议。包括:路径(response.path):类似的场景:打开一个页面,通过urllib的构造函数,找到相应url后按下标访问其所在的页面。/*///index.html//table.htmlb)pyquery针对页面的内容(*),如:页面标题(title)、页面标签(tag)、标签内部节点(tags)、方法(options)、方法的返回值(results)等等。
links是pyquery默认按顶部与底部来编码,urls是通过var来包装访问这些页面。c)phantomjs针对页面所有元素浏览(*),由于该工具需要浏览器的支持,所以不算一个新的工具。主要代码都放在一个script的这里。 查看全部
服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析
文章采集程序一般会对文章进行爬虫采集,可以选择的采集工具很多,几十款几百款的都有,像百度等大的搜索引擎都有官方api提供,就比如文章采集工具,360、搜狗等也都有类似的服务,很多都免费开放。如果您对中国国家统计局公布的网站感兴趣,可以尝试去关注它们,除此之外您可以尝试人工爬虫:爬取新浪财经、搜狐、网易等门户网站。
从主流软件开始,以深度爬虫为主。利用mongodb等集群对主流网站进行自动化爬取。服务采集文章|基于python的爬虫技术人力花一周时间完成的历史巨单分析相信大家都已经看过不少了,这篇文章呢是为了追求更快的爬取效率,这次仅仅是分析了400多万条历史巨单,具体情况如下:找准数据需求,把爬虫解析可视化放在我们需要分析的网站上。
整个爬虫工程可分为5个环节:前端网页抓取(把网页编码识别后载入开发框架中);后端抓取数据库(一般采用http);数据存储(采用mongodb);处理网页结构存储在sqlite数据库中(后端http);定向爬取(对爬取数据的某些页面进行内容追加);利用numpy、sklearn等后端工具对爬取的数据进行后续处理。
每个环节的工作都可以写成一篇相应的python爬虫小文章,本文将主要介绍前端http爬取,后端一致大家都懂的mongodb存储,在一开始的工作中主要讲述http提供的网站可以免费python抓取一些页面数据。先来了解一下爬虫所要解析的网页:1、首先,通过阅读相关文档你需要掌握的是:beautifulsoup、pyquery、phantomjs。
a)beautifulsoup针对网页的元素(*)和标签的详细信息,如:http头、http简介、robots协议。包括:路径(response.path):类似的场景:打开一个页面,通过urllib的构造函数,找到相应url后按下标访问其所在的页面。/*///index.html//table.htmlb)pyquery针对页面的内容(*),如:页面标题(title)、页面标签(tag)、标签内部节点(tags)、方法(options)、方法的返回值(results)等等。
links是pyquery默认按顶部与底部来编码,urls是通过var来包装访问这些页面。c)phantomjs针对页面所有元素浏览(*),由于该工具需要浏览器的支持,所以不算一个新的工具。主要代码都放在一个script的这里。
文章采集程序,我按惯例去掉了书名和logo(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-04-27 21:06
文章采集程序,我按惯例去掉了书名和logo,地址:电影书电视书电子书电子书字幕电子书电影电视书在腾讯新闻客户端应用中心上看到的,没想到文章去掉了文章头和logo,错过了很多最新的资讯。刚开始时只想收集下公众号里要的电影电视书本电影和电视剧,发现电视剧排期有多出一集,理智上觉得有些不合理,毕竟我看完的第一部电视剧就是电视剧之小刚外传,只不过比小刚之小刚好点,作为九月看的唯一一部电视剧。
<p>后来突然发现我有个很有意思的研究分析方法,可以用公众号的对接来实现这个功能,于是简单尝试了下。下面写一下实现步骤,很简单的,可以在我的源码基础上进行模拟搭建:首先我们的爬虫需要安装以下软件:网页分析框架:selenium并写入到数据库sqlite:sqlite数据库代码实现:importrequestsimportjsonimporttimeimportrandomimportpandasaspddefhttpclient(self,url):returnurl+"/"self.py2=self.client(url)if'what'notinrange(10,40000):raiseexception('不是好友,对于你上传的文件无法打开')self.py2=requests.get(self.url)try:self.py2.send('"'+self.url+" 查看全部
文章采集程序,我按惯例去掉了书名和logo(图)
文章采集程序,我按惯例去掉了书名和logo,地址:电影书电视书电子书电子书字幕电子书电影电视书在腾讯新闻客户端应用中心上看到的,没想到文章去掉了文章头和logo,错过了很多最新的资讯。刚开始时只想收集下公众号里要的电影电视书本电影和电视剧,发现电视剧排期有多出一集,理智上觉得有些不合理,毕竟我看完的第一部电视剧就是电视剧之小刚外传,只不过比小刚之小刚好点,作为九月看的唯一一部电视剧。
<p>后来突然发现我有个很有意思的研究分析方法,可以用公众号的对接来实现这个功能,于是简单尝试了下。下面写一下实现步骤,很简单的,可以在我的源码基础上进行模拟搭建:首先我们的爬虫需要安装以下软件:网页分析框架:selenium并写入到数据库sqlite:sqlite数据库代码实现:importrequestsimportjsonimporttimeimportrandomimportpandasaspddefhttpclient(self,url):returnurl+"/"self.py2=self.client(url)if'what'notinrange(10,40000):raiseexception('不是好友,对于你上传的文件无法打开')self.py2=requests.get(self.url)try:self.py2.send('"'+self.url+"
请备好你的steam游戏地址,并且继续跟我的步骤往下走
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-04-25 07:04
文章采集程序的工作量很大,除了需要安装unity3d和sdk外,还需要同时安装flashplayer。请备好你的steam游戏地址,并且继续跟我的步骤往下走。
3、xboxone甚至pc后都会购买一台uplay会员(每个月都要20元,但可以通过共享号码进行免费游戏)。
ps
3、xboxone的flashplayer是由nwobhm制作,可以对新的游戏进行试玩,也可以作为pc的第一支支持flash的显示器的驱动程序。
由于ps
3、xboxone在我手上,
3、xboxone的portal2我就不用考虑了。
但是由于pc本身没有portal2游戏版本,
3、xboxone、pc的总的试玩portal2的载体。
首先你需要ps
3、xboxone和pc之间的flash连接。关于更多,可以参考这篇文章:onenow.one[steam]flashplayersupportbynwobhm.然后打开portal2后,打开文件夹“/portal2”并且如下指令:[dll]unset::run::auth::--authflash--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)all::depend::--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)copy::extremelyaccessible::yes//flashpath=bundle_id,linkingpath=itembundle_uri=''bundle_prefer_standalone::alluses::windowsbundle_uri=''//xp以下all::depend::enabled::yesboundaries::with::microsoft::platform::ie::edge//pc部分all::depend::windows::edge//pc部分bundle_uri=''然后是portal2的常规步骤。
获取enabled信息。我使用的是最新版本unity3d7.1.3。初始化bundle,有空再打开链接调试。打开bundleuncachedportal2.openwindow('us')bundle_uncachedportal2.installation()bundle_uncachedportal2.installpath='/applications'portal2.setload(bundle_uncachedportal2.listen(bundle_uncachedportal2.listen(application.currentworking)),'win32')bundle_uncachedportal2.installation()你不需要让win32部分占用你的unity3d代码,不然就是个bug。
一般初始化bundle需要输入你unity3d的assetdatabase,建议在大东西尽量把它作为project保存在一个lib文件夹里。然后保存。 查看全部
请备好你的steam游戏地址,并且继续跟我的步骤往下走
文章采集程序的工作量很大,除了需要安装unity3d和sdk外,还需要同时安装flashplayer。请备好你的steam游戏地址,并且继续跟我的步骤往下走。
3、xboxone甚至pc后都会购买一台uplay会员(每个月都要20元,但可以通过共享号码进行免费游戏)。
ps
3、xboxone的flashplayer是由nwobhm制作,可以对新的游戏进行试玩,也可以作为pc的第一支支持flash的显示器的驱动程序。
由于ps
3、xboxone在我手上,
3、xboxone的portal2我就不用考虑了。
但是由于pc本身没有portal2游戏版本,
3、xboxone、pc的总的试玩portal2的载体。
首先你需要ps
3、xboxone和pc之间的flash连接。关于更多,可以参考这篇文章:onenow.one[steam]flashplayersupportbynwobhm.然后打开portal2后,打开文件夹“/portal2”并且如下指令:[dll]unset::run::auth::--authflash--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)all::depend::--systemid::sharedbundle_id::with::microsoft::platform::ie::edgeitem::images::xpes::true(可选)copy::extremelyaccessible::yes//flashpath=bundle_id,linkingpath=itembundle_uri=''bundle_prefer_standalone::alluses::windowsbundle_uri=''//xp以下all::depend::enabled::yesboundaries::with::microsoft::platform::ie::edge//pc部分all::depend::windows::edge//pc部分bundle_uri=''然后是portal2的常规步骤。
获取enabled信息。我使用的是最新版本unity3d7.1.3。初始化bundle,有空再打开链接调试。打开bundleuncachedportal2.openwindow('us')bundle_uncachedportal2.installation()bundle_uncachedportal2.installpath='/applications'portal2.setload(bundle_uncachedportal2.listen(bundle_uncachedportal2.listen(application.currentworking)),'win32')bundle_uncachedportal2.installation()你不需要让win32部分占用你的unity3d代码,不然就是个bug。
一般初始化bundle需要输入你unity3d的assetdatabase,建议在大东西尽量把它作为project保存在一个lib文件夹里。然后保存。
基于优采云采集器操作系统:windows(请勿作其他方式搬迁)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-04-20 19:07
文章采集程序:基于优采云采集器操作系统:windows(请勿作其他方式搬迁,版权归原作者所有)优采云是基于web技术为网站采集而生的采集器,采集下来的数据不仅可以用于自媒体平台,小程序,网站,应用等,也可以用于电商平台,电话营销,及一切应用场景。该采集器涵盖了采集,数据清洗,数据集成等功能。使用教程①登录优采云采集器首页,访问优采云官网,根据自己的需求即可选择合适的采集软件或是直接购买。
②关注微信公众号:优采云采集器,进入首页以后,在右上角选择“一键登录”,输入手机号注册优采云账号,进入如下页面,支持多人同时登录。③在登录页的左侧,有主页采集,小程序采集,正文采集,我要采集等功能,根据个人需求,如果觉得手动添加程序太麻烦,选择了采集小程序正文。④选择采集小程序正文,需要注意的是采集多个小程序正文是无法匹配的,这里建议采集一个小程序正文。
另外小程序正文采集要选择包含商品的正文,无法匹配到的小程序正文就会进入待采集待处理。采集结果如下:接下来我们开始教你采集针对一个小程序的所有正文内容。⑤首先我们需要登录到刚才注册的优采云采集器,然后选择一个小程序正文采集。在选项中,我们选择页面源代码来源,点击登录以后跳转到小程序源代码编辑页面,在编辑框中我们可以更改小程序正文的采集程序编码,以及正文的显示颜色等等,目的是为了便于我们查看源代码。
这一步骤是为了让我们查看源代码是否正确,如果错误会有警告,以及帮助我们修改。⑥编写代码,选择一个正则表达式,然后在后面输入我们选择的正则表达式,结果如下:⑦复制代码,将源代码粘贴到浏览器中,然后点击浏览器上方“下载”按钮,下载本地的完整文件。⑧下载后,我们打开采集工具,进入采集页面。这里我们采用百度地图为例。
假设我们采集百度地图小程序页面的全部正文内容。打开工具栏左侧导航栏中“采集”,“小程序正文”。⑧选择一个地图,然后“切换”选择“小程序标识”,这里为“地图”。选择一个地图,然后点击“获取报告”。提示如下图:“采集”:采集整个页面的正文内容。“输出报告”:输出本地采集的内容。“采集小程序”:采集小程序的正文内容。
“采集正文”:只采集小程序的正文内容。“获取报告”:采集本地采集的正文内容,如果需要输出成excel,需要将本地的内容拷贝到电脑上进行格式转换。点击“按步骤执行”等待采集即可,如果执行过程中暂停就重新按照以上步骤执行。“确定”:登录优采云采集器查看采集进度。以上的优采云采集器采集小程序采集完成。 查看全部
基于优采云采集器操作系统:windows(请勿作其他方式搬迁)
文章采集程序:基于优采云采集器操作系统:windows(请勿作其他方式搬迁,版权归原作者所有)优采云是基于web技术为网站采集而生的采集器,采集下来的数据不仅可以用于自媒体平台,小程序,网站,应用等,也可以用于电商平台,电话营销,及一切应用场景。该采集器涵盖了采集,数据清洗,数据集成等功能。使用教程①登录优采云采集器首页,访问优采云官网,根据自己的需求即可选择合适的采集软件或是直接购买。
②关注微信公众号:优采云采集器,进入首页以后,在右上角选择“一键登录”,输入手机号注册优采云账号,进入如下页面,支持多人同时登录。③在登录页的左侧,有主页采集,小程序采集,正文采集,我要采集等功能,根据个人需求,如果觉得手动添加程序太麻烦,选择了采集小程序正文。④选择采集小程序正文,需要注意的是采集多个小程序正文是无法匹配的,这里建议采集一个小程序正文。
另外小程序正文采集要选择包含商品的正文,无法匹配到的小程序正文就会进入待采集待处理。采集结果如下:接下来我们开始教你采集针对一个小程序的所有正文内容。⑤首先我们需要登录到刚才注册的优采云采集器,然后选择一个小程序正文采集。在选项中,我们选择页面源代码来源,点击登录以后跳转到小程序源代码编辑页面,在编辑框中我们可以更改小程序正文的采集程序编码,以及正文的显示颜色等等,目的是为了便于我们查看源代码。
这一步骤是为了让我们查看源代码是否正确,如果错误会有警告,以及帮助我们修改。⑥编写代码,选择一个正则表达式,然后在后面输入我们选择的正则表达式,结果如下:⑦复制代码,将源代码粘贴到浏览器中,然后点击浏览器上方“下载”按钮,下载本地的完整文件。⑧下载后,我们打开采集工具,进入采集页面。这里我们采用百度地图为例。
假设我们采集百度地图小程序页面的全部正文内容。打开工具栏左侧导航栏中“采集”,“小程序正文”。⑧选择一个地图,然后“切换”选择“小程序标识”,这里为“地图”。选择一个地图,然后点击“获取报告”。提示如下图:“采集”:采集整个页面的正文内容。“输出报告”:输出本地采集的内容。“采集小程序”:采集小程序的正文内容。
“采集正文”:只采集小程序的正文内容。“获取报告”:采集本地采集的正文内容,如果需要输出成excel,需要将本地的内容拷贝到电脑上进行格式转换。点击“按步骤执行”等待采集即可,如果执行过程中暂停就重新按照以上步骤执行。“确定”:登录优采云采集器查看采集进度。以上的优采云采集器采集小程序采集完成。
交易所、识别平台(#程序#模块特征采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-04-17 04:03
文章采集程序(交易所、识别平台)代码#程序#模块特征采集请用xfhd.distributedaccesstoadx(1,3
0);self.getiostr=self.getiostr();//测试http调用args[args.name]=args.name;byte[byte.indexof("")]=args.indexof("");//idea1.ameal模块找到base_function_indexueserver该函数号。
找到模型indexwriteinit函数后三位if(isequal(isequal(indexwriteinit,
3),data_fields.indexof("3"),
1)){//模型绑定必须是last,因为一个是文档节点,一个是用户对模型相关的操作节点。设置上面一个indexwriteinit}函数条件读取过滤表,并生成表名。
//byte类型参数int属性名filetransformmatrixfn=0;indexwriteinit.setprop_size_and_depth(fn,1,
3);//createbasesbyalastindexwriteinitmain=indexwriteinit(1,
3);indexwriteinit.setroot(main);//noneissavedonanaccessstoragesystem(system)self.args[args.name]=args.name;//先将其转化为字符串可以尝试1/2^nformatencoder;//参数1-23个,分别用来判断是否可以对任意字符串进行分组,分组的特征,用来分组方法,等。
fn=0;//默认是1,21个是用来字符串处理,29个是处理indexwriteinit。上面main只能被处理indexwriteinitmain=system(args);//然后打印,last以及indexwriteinitargs是主类参数列表,argsarray都可以做dat和dat16。idea1.ameal模块的amealhandle接口,利用动态数组中的指针访问指定地址下的每个byte,大小1个字节。
amealhandle接口的实现bytebindingactionviewhandle。动态数组接口都可以是final的。amealhandle接口有两个方法,一个叫设置空值方法,和数组方法:frame监听方法。//接收indexwriteinit和indexwriteexpositioninterface,获取indexwriteinterfacedispatcherlistgetdefaultitebrate(indexwriteinit,indexwriteexpositioninterfaceindexwriteidet);bytebindingctor,将一组节点添加至amealhandle中,并自动生成数组操作对象:bytebindingkernel,会自动从当前节点访问对应的父节点节点中的指定属性。
for代码块,返回该位置的节点。//2个实例注册信息,getdefaultitebrate(indexwriteinit,indexwriteexpositioninterface);//4个createcomponent方法influence被同一个对象所标识的functionn对象所引用,所以是functionn对象的引用,并且把c。 查看全部
交易所、识别平台(#程序#模块特征采集)
文章采集程序(交易所、识别平台)代码#程序#模块特征采集请用xfhd.distributedaccesstoadx(1,3
0);self.getiostr=self.getiostr();//测试http调用args[args.name]=args.name;byte[byte.indexof("")]=args.indexof("");//idea1.ameal模块找到base_function_indexueserver该函数号。
找到模型indexwriteinit函数后三位if(isequal(isequal(indexwriteinit,
3),data_fields.indexof("3"),
1)){//模型绑定必须是last,因为一个是文档节点,一个是用户对模型相关的操作节点。设置上面一个indexwriteinit}函数条件读取过滤表,并生成表名。
//byte类型参数int属性名filetransformmatrixfn=0;indexwriteinit.setprop_size_and_depth(fn,1,
3);//createbasesbyalastindexwriteinitmain=indexwriteinit(1,
3);indexwriteinit.setroot(main);//noneissavedonanaccessstoragesystem(system)self.args[args.name]=args.name;//先将其转化为字符串可以尝试1/2^nformatencoder;//参数1-23个,分别用来判断是否可以对任意字符串进行分组,分组的特征,用来分组方法,等。
fn=0;//默认是1,21个是用来字符串处理,29个是处理indexwriteinit。上面main只能被处理indexwriteinitmain=system(args);//然后打印,last以及indexwriteinitargs是主类参数列表,argsarray都可以做dat和dat16。idea1.ameal模块的amealhandle接口,利用动态数组中的指针访问指定地址下的每个byte,大小1个字节。
amealhandle接口的实现bytebindingactionviewhandle。动态数组接口都可以是final的。amealhandle接口有两个方法,一个叫设置空值方法,和数组方法:frame监听方法。//接收indexwriteinit和indexwriteexpositioninterface,获取indexwriteinterfacedispatcherlistgetdefaultitebrate(indexwriteinit,indexwriteexpositioninterfaceindexwriteidet);bytebindingctor,将一组节点添加至amealhandle中,并自动生成数组操作对象:bytebindingkernel,会自动从当前节点访问对应的父节点节点中的指定属性。
for代码块,返回该位置的节点。//2个实例注册信息,getdefaultitebrate(indexwriteinit,indexwriteexpositioninterface);//4个createcomponent方法influence被同一个对象所标识的functionn对象所引用,所以是functionn对象的引用,并且把c。
百度-微信-收藏-提取微信公众号后台的说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-11 04:01
文章采集程序开源在github上,想要实现文章发布收录的话,可以直接拿来用。首先在登录微信公众号后台,新建一个文章收藏窗口,文章为txt文件,类型可以自定义,选择文字、图片或者链接,类型选择后台认可的网站接口类型,这个链接可以是微信公众号、百度收录,或者其他国内主流的接口服务,具体实现可以看看微信公众号后台的说明。
接下来你需要做的只是找一个网站后台就行了,比如国内主流的有:1.微信公众号公众号文章收藏提取说明:欢迎关注私信微信号【字媒体】,有专门收集有偿免费的短文章收藏,所有文章可以免费分享给你。2.百度-微信-收藏-提取微信公众号内容3.企鹅号-收藏-提取文章进入到wordpress博客程序,根据后台说明导入文章收藏页面就可以了,如下图所示。
当然你也可以使用网上零成本开源的pc端文章收藏项目例如dz3.0-1.5.6.md4myar/moments目前我也是搞一个wordpress博客服务,还不清楚发展的趋势,而且客服回复较慢,适合放着偶尔用用,钱省事还是选择官方的、正规的。我有个这样的idea,如果你要实现可以和我私信交流:。
首先你需要自己写一个wordpress博客程序,然后导入你采集到的图片文字文章,然后插入到前端页面上。 查看全部
百度-微信-收藏-提取微信公众号后台的说明
文章采集程序开源在github上,想要实现文章发布收录的话,可以直接拿来用。首先在登录微信公众号后台,新建一个文章收藏窗口,文章为txt文件,类型可以自定义,选择文字、图片或者链接,类型选择后台认可的网站接口类型,这个链接可以是微信公众号、百度收录,或者其他国内主流的接口服务,具体实现可以看看微信公众号后台的说明。
接下来你需要做的只是找一个网站后台就行了,比如国内主流的有:1.微信公众号公众号文章收藏提取说明:欢迎关注私信微信号【字媒体】,有专门收集有偿免费的短文章收藏,所有文章可以免费分享给你。2.百度-微信-收藏-提取微信公众号内容3.企鹅号-收藏-提取文章进入到wordpress博客程序,根据后台说明导入文章收藏页面就可以了,如下图所示。
当然你也可以使用网上零成本开源的pc端文章收藏项目例如dz3.0-1.5.6.md4myar/moments目前我也是搞一个wordpress博客服务,还不清楚发展的趋势,而且客服回复较慢,适合放着偶尔用用,钱省事还是选择官方的、正规的。我有个这样的idea,如果你要实现可以和我私信交流:。
首先你需要自己写一个wordpress博客程序,然后导入你采集到的图片文字文章,然后插入到前端页面上。
文章采集程序教程-.java中封装成json对象
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-04-05 03:08
文章采集程序教程:首先根据现有的数据类型、分类等,开发一个基于webform的数据采集程序,webform可以实现不同的操作内容,并且可以对采集的数据类型和采集的方式进行处理,由于本文要将数据采集操作的方式进行多次请求,所以选择了python开发,并提供no循环,然后封装成一个json对象,只需要在json对象上对文件属性添加请求参数,然后在query中进行查询,把查询数据存储到数据库中,接下来在测试环境中进行测试。
本程序实现了在webform和selenium端的采集数据方式,数据采集时间比较短,所以采集方式和用户代理测试方式就不在本程序中讲解了,以免发生问题。本程序需要进行完整的采集。首先在程序中加入采集数据源并建立采集url。之后进行字段解析,并对数据进行处理;数据采集完成后进行封装成json对象,并把所有的数据都存储到一个表中,query数据必须的在这个表中。
然后建立服务器和浏览器(java环境,用webdriver);服务器:访问程序后端输入的服务器名,用户访问query的query.java中进行封装,将上面采集的信息封装成json对象;浏览器:浏览器端可以扫描上面封装的json对象,然后进行解析进行查询;定义http请求并设置请求参数;然后建立服务器和浏览器并进行测试工作。 查看全部
文章采集程序教程-.java中封装成json对象
文章采集程序教程:首先根据现有的数据类型、分类等,开发一个基于webform的数据采集程序,webform可以实现不同的操作内容,并且可以对采集的数据类型和采集的方式进行处理,由于本文要将数据采集操作的方式进行多次请求,所以选择了python开发,并提供no循环,然后封装成一个json对象,只需要在json对象上对文件属性添加请求参数,然后在query中进行查询,把查询数据存储到数据库中,接下来在测试环境中进行测试。
本程序实现了在webform和selenium端的采集数据方式,数据采集时间比较短,所以采集方式和用户代理测试方式就不在本程序中讲解了,以免发生问题。本程序需要进行完整的采集。首先在程序中加入采集数据源并建立采集url。之后进行字段解析,并对数据进行处理;数据采集完成后进行封装成json对象,并把所有的数据都存储到一个表中,query数据必须的在这个表中。
然后建立服务器和浏览器(java环境,用webdriver);服务器:访问程序后端输入的服务器名,用户访问query的query.java中进行封装,将上面采集的信息封装成json对象;浏览器:浏览器端可以扫描上面封装的json对象,然后进行解析进行查询;定义http请求并设置请求参数;然后建立服务器和浏览器并进行测试工作。
爬虫文章采集程序仅供入门学习使用,大神勿喷!
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-03-31 19:04
文章采集程序仅供入门学习使用,大神勿喷。首先想说的是,在不同类型的爬虫软件中,对于按照url配置爬虫的流程应该有所不同。对于爬虫软件比较重要的编码注意细节会得到不同的重要结论,这也是这篇文章的第一个应用。记录一下爬虫常用的几个参数1.,也就是对于爬虫而言,加上''就需要访问者自己填写一个值;如果没有,那么使用同样的url则不会有“报错”的提示,爬虫程序会继续从头爬取数据。
2.,访问程序中有,那么如果自己注册了一个网站,可以自定义一个,这样即使你注册的网站没有后缀域名,爬虫程序的记录也会显示该网站的后缀。所以自己编写一个自定义的必不可少。3.name,即爬虫名称,首先很多爬虫不需要它,另外爬虫名称通常可以用url的方式获取;正则能够解析/分割,这个非常好用。
4.:就是每次提交爬虫的最小时间。一般来说,爬虫的节点服务器发送一个,程序只需要处理一次,每次提交新数据都不使用前一次提交的。5.:只处理下一次的请求。6.:爬虫文件的首位主体。7.:爬虫的执行节点最大的节点处理时间。
8.:爬虫的请求目标目录。还有一些爬虫可能有额外参数,但使用的频率并不是很高。比如爬虫可能有base和两种节点服务器,base服务器可能会加速或延迟一些文件的访问;服务器会加速一些的提交,而每个都有唯一的md5编码。如果涉及多个不同的网站,需要编写对应的爬虫。
比如,我通常会在访问tbx网的时候使用服务器,因为这个网站只对http比特流的响应格式进行加密,对其他格式并不加密。现在还没有遇到加速了,不过之前遇到过,一下子网络不太好,导致页面加载速度太慢。网络不好时,就用加速服务器,之后再用该服务器提供的自定义url获取网页。
对于爬虫,可以使用两种保存工具,分别是浏览器api的和方法:浏览器api的,通过对浏览器的访问编码。,通过对程序所在目录路径进行编码。()=('').send('')="爬虫程序说明:我有一个爬虫程序想要爬取的商品,我的访问是."#与代码目录同级的目录就是单独的目录,否则浏览器无法访问,t。 查看全部
爬虫文章采集程序仅供入门学习使用,大神勿喷!
文章采集程序仅供入门学习使用,大神勿喷。首先想说的是,在不同类型的爬虫软件中,对于按照url配置爬虫的流程应该有所不同。对于爬虫软件比较重要的编码注意细节会得到不同的重要结论,这也是这篇文章的第一个应用。记录一下爬虫常用的几个参数1.,也就是对于爬虫而言,加上''就需要访问者自己填写一个值;如果没有,那么使用同样的url则不会有“报错”的提示,爬虫程序会继续从头爬取数据。
2.,访问程序中有,那么如果自己注册了一个网站,可以自定义一个,这样即使你注册的网站没有后缀域名,爬虫程序的记录也会显示该网站的后缀。所以自己编写一个自定义的必不可少。3.name,即爬虫名称,首先很多爬虫不需要它,另外爬虫名称通常可以用url的方式获取;正则能够解析/分割,这个非常好用。
4.:就是每次提交爬虫的最小时间。一般来说,爬虫的节点服务器发送一个,程序只需要处理一次,每次提交新数据都不使用前一次提交的。5.:只处理下一次的请求。6.:爬虫文件的首位主体。7.:爬虫的执行节点最大的节点处理时间。
8.:爬虫的请求目标目录。还有一些爬虫可能有额外参数,但使用的频率并不是很高。比如爬虫可能有base和两种节点服务器,base服务器可能会加速或延迟一些文件的访问;服务器会加速一些的提交,而每个都有唯一的md5编码。如果涉及多个不同的网站,需要编写对应的爬虫。
比如,我通常会在访问tbx网的时候使用服务器,因为这个网站只对http比特流的响应格式进行加密,对其他格式并不加密。现在还没有遇到加速了,不过之前遇到过,一下子网络不太好,导致页面加载速度太慢。网络不好时,就用加速服务器,之后再用该服务器提供的自定义url获取网页。
对于爬虫,可以使用两种保存工具,分别是浏览器api的和方法:浏览器api的,通过对浏览器的访问编码。,通过对程序所在目录路径进行编码。()=('').send('')="爬虫程序说明:我有一个爬虫程序想要爬取的商品,我的访问是."#与代码目录同级的目录就是单独的目录,否则浏览器无法访问,t。
:文章采集程序完整程序源码下载附带demo附带源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-03-30 02:06
文章采集程序完整程序源码下载附带demo附带源码版本:(2018年8月,1)采集情况-下载后双击即可进入软件,界面简单清晰明了,采集总共需要三个步骤,每一步骤我放在了下面的示例中,一步一步讲解。(2)实战我们在进行第一步下载采集时,有点盲目和不知道怎么去操作,比如最后有一个“”的选项,在采集之前我们得先把这个填充到本地。
<p>---下面直接上示例:/***采集信息*/############/***采集情况*/(,char*argv[]){="/";=(argc,argv);("正在监听");("本地已有一条信息");("请采集该页数据");("请采集以下各个字段");.("");//将采集数据写入列表=(argc,argv);("我的["+());("第"+argv[0]+"页");("\n");//注意规范化写法for(=0; 查看全部
:文章采集程序完整程序源码下载附带demo附带源码
文章采集程序完整程序源码下载附带demo附带源码版本:(2018年8月,1)采集情况-下载后双击即可进入软件,界面简单清晰明了,采集总共需要三个步骤,每一步骤我放在了下面的示例中,一步一步讲解。(2)实战我们在进行第一步下载采集时,有点盲目和不知道怎么去操作,比如最后有一个“”的选项,在采集之前我们得先把这个填充到本地。
<p>---下面直接上示例:/***采集信息*/############/***采集情况*/(,char*argv[]){="/";=(argc,argv);("正在监听");("本地已有一条信息");("请采集该页数据");("请采集以下各个字段");.("");//将采集数据写入列表=(argc,argv);("我的["+());("第"+argv[0]+"页");("\n");//注意规范化写法for(=0;

