
文章采集程序
采集程序设计经验交流(一) 前言
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-26 02:43
“小网站本不需要维护,只是由于你的程序太笨了,所以你成了无休止的网站维护者。”—沉默的海
前言
经常有同学在Q群(75604923)里问起采集的相关问题,每次针对个人回答的时侯,总是难以说得太全面,很多同学表示不满意,今天发表此文,详细介绍一下采集程序的设计思路。其实“沉默的海”本是一名业余ASP爱好者,ASP综合技术水平应当说是一个“二把刀”。但对于采集程序的编撰,应该说还有点研究,因为我是因为采集程序才迷上编程、迷上ASP,也是从这儿开始了自己的编程之路。
一、 采集程序的作用。
这个问题其实不用多说,每个站长可能都觉得非常的须要,因为我们精力必竟有限,不像这些大的网路公司,有专门的新闻记者和网路写手。这样以来,要想让自己的网站内容丰富上去,借签别的网站上的内容无疑成了一个最好的办法,也就是这个缘由,数以千计的站长不知不觉中成了“复制粘贴”的操作手,在和站长同学的聊天中获知,多数站长每晚做的工作就是“复制粘贴”。这是一个多么乏味的工作啊,但,为了自己的希望也不得不去做这种最使人厌恶的事情。
这样以来,采集程序成为站长们必不可少的一个工具,给站长们带来了好多的便利,即使我们的网站内容得到了丰富,又节约了好多的精力和时间。(和似乎可以作为采集程序示例网站,无需要任何更新,网站永远都是新的。)
但,有多站长却又不会自己设计采集程序,从网上下载的程序要么是收费的,要么是功能不全的,往往不能使人满意。即便是收费的,用上去也不是非常便捷,因为须要好多手工的操作。
“沉默的海”认为:采集程序要想真正发挥其便捷快捷的优势,最好的一个办法是针对自己的网站量身设计,而后和网站集成在一起,成为网站的一部分,只有这样,才能算是一个成功的采集程序。
可是,采集程序如何做呢?难吗?
二、 采集程序如何做。
“沉默的海”认为,采集程序设计一点都不难,只要有一些ASP编程常识,我认为一天之内学会它,是没有问题的。(相信我的话,你就把文章看完,我保证不会使你沮丧;不相信我的话也请你看完,我保证看完后你会相信我的话。)
采集程序的基本原理其实很简单:包括两个步骤:
1、 下载目标网页;
大家晓得,采集程序帮我们做的工作虽然就是“复制和粘贴”,那么要把一个网站复制出来,首页你须要把网页打开啊,这个过程虽然就是下载目标网页,只不过我们不是人工下载,而是借助程序来完成它。
这里有“核心技术”:XMLHTTP,它可以把网页下载以备下一步的使用。
2、 提取网页中我们须要的内容;
上一步我们完成了第一步:下载网页。
但并不是所有下载的内容都是我们须要的,所以还要做的工作就是,提取我们须要的内容,去除不需要的,存入数据库。这一步的主要技术是:正则表达式。
三、 做什么样的采集程序。
做了以上两步,应该说一个完整的采集程序早已完成了。它可以采集到我们须要的内容,而后存入数据库,供我们使用。可是,这是我们真正须要的吗?显然不是,因为我们既然要用采集程序来支持我们的网站,那就要用它来完成几乎所以的工作。我觉得:如果你的网站加了采集程序,那么即便长年不维护,网站依然是新的,这样才算是成功的。
上面的采集程序其实做不到,因为你还得启动采集程序,然后把数据导出网站的数据库,然后生成html,等等等等,还有好多工作须要我们来做。我们理想中的采集程序是不需要人工来做任何工作的,所以在完成采集程序然后我们还要做一些配套的程序,以保证采集程序的运行,和与网站的完美集成。
1、 自动启动采集程序;
2、 将采集数据直接写入网站数据库;
3、 配套生成html等后续工作。
做了以上三点,我们才可以说自己做了一套还算可以的采集程序,那么我们具体应当怎样做呢,请看《采集程序设计经验交流(二)—下载网页》。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化 查看全部
采集程序设计经验交流(一) 前言
“小网站本不需要维护,只是由于你的程序太笨了,所以你成了无休止的网站维护者。”—沉默的海
前言
经常有同学在Q群(75604923)里问起采集的相关问题,每次针对个人回答的时侯,总是难以说得太全面,很多同学表示不满意,今天发表此文,详细介绍一下采集程序的设计思路。其实“沉默的海”本是一名业余ASP爱好者,ASP综合技术水平应当说是一个“二把刀”。但对于采集程序的编撰,应该说还有点研究,因为我是因为采集程序才迷上编程、迷上ASP,也是从这儿开始了自己的编程之路。
一、 采集程序的作用。
这个问题其实不用多说,每个站长可能都觉得非常的须要,因为我们精力必竟有限,不像这些大的网路公司,有专门的新闻记者和网路写手。这样以来,要想让自己的网站内容丰富上去,借签别的网站上的内容无疑成了一个最好的办法,也就是这个缘由,数以千计的站长不知不觉中成了“复制粘贴”的操作手,在和站长同学的聊天中获知,多数站长每晚做的工作就是“复制粘贴”。这是一个多么乏味的工作啊,但,为了自己的希望也不得不去做这种最使人厌恶的事情。
这样以来,采集程序成为站长们必不可少的一个工具,给站长们带来了好多的便利,即使我们的网站内容得到了丰富,又节约了好多的精力和时间。(和似乎可以作为采集程序示例网站,无需要任何更新,网站永远都是新的。)
但,有多站长却又不会自己设计采集程序,从网上下载的程序要么是收费的,要么是功能不全的,往往不能使人满意。即便是收费的,用上去也不是非常便捷,因为须要好多手工的操作。
“沉默的海”认为:采集程序要想真正发挥其便捷快捷的优势,最好的一个办法是针对自己的网站量身设计,而后和网站集成在一起,成为网站的一部分,只有这样,才能算是一个成功的采集程序。
可是,采集程序如何做呢?难吗?
二、 采集程序如何做。
“沉默的海”认为,采集程序设计一点都不难,只要有一些ASP编程常识,我认为一天之内学会它,是没有问题的。(相信我的话,你就把文章看完,我保证不会使你沮丧;不相信我的话也请你看完,我保证看完后你会相信我的话。)
采集程序的基本原理其实很简单:包括两个步骤:
1、 下载目标网页;
大家晓得,采集程序帮我们做的工作虽然就是“复制和粘贴”,那么要把一个网站复制出来,首页你须要把网页打开啊,这个过程虽然就是下载目标网页,只不过我们不是人工下载,而是借助程序来完成它。
这里有“核心技术”:XMLHTTP,它可以把网页下载以备下一步的使用。
2、 提取网页中我们须要的内容;
上一步我们完成了第一步:下载网页。
但并不是所有下载的内容都是我们须要的,所以还要做的工作就是,提取我们须要的内容,去除不需要的,存入数据库。这一步的主要技术是:正则表达式。
三、 做什么样的采集程序。
做了以上两步,应该说一个完整的采集程序早已完成了。它可以采集到我们须要的内容,而后存入数据库,供我们使用。可是,这是我们真正须要的吗?显然不是,因为我们既然要用采集程序来支持我们的网站,那就要用它来完成几乎所以的工作。我觉得:如果你的网站加了采集程序,那么即便长年不维护,网站依然是新的,这样才算是成功的。
上面的采集程序其实做不到,因为你还得启动采集程序,然后把数据导出网站的数据库,然后生成html,等等等等,还有好多工作须要我们来做。我们理想中的采集程序是不需要人工来做任何工作的,所以在完成采集程序然后我们还要做一些配套的程序,以保证采集程序的运行,和与网站的完美集成。
1、 自动启动采集程序;
2、 将采集数据直接写入网站数据库;
3、 配套生成html等后续工作。
做了以上三点,我们才可以说自己做了一套还算可以的采集程序,那么我们具体应当怎样做呢,请看《采集程序设计经验交流(二)—下载网页》。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化
DedeCMS 文章采集入门图文教程(推荐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-08-25 13:46
中间:(*).html
末页:
复制一个分页地址,回到“新增采集节点”页面,选择“来源属性”为“批量生成列表网址”,把粘贴地址到“匹配网址”中,修改规律变化处为(*),“批量生成地址设置”处(*)输入1到172,这里的意思是生成出列表第一页到最后172页的所有地址。
测试一下,在弹出框中我们可以看见循环出172条地址记录,很顺利的就设置好了。有时候会遇到较难获取的列表,那我们可以把把没规律的地址复制到”手工指定列表网址“文本框中来采集。
3.设置文章网址匹配规则
上面指定好了文章地址来源页,这一步就须要在那些页面中找出符合要求的文章地址页了。打开一个列表页面观察,左栏的方框中收录了我们须要的全部地址,这种情况分辨显著的页面,可以利“区域开始的HTML”和“区域结束的HTMLL”设置进行过滤。
不过也可以使用其他方式。把滑鼠移到各处链接地址,观察浏览器左下角显示的完整地址,我们须要的地址都收录“PHP_jiaocheng/20”,那我们把它填写到“必须收录”中。
两种方式都还能过滤出地址,碰上复杂页面,可以配合上去使用,加上正则,几乎没有筛选不出的地址,附(图5.1)对照。最后确定,进入下一步“网页内容获取规则”。
(图5.1)
生活不易,码农辛苦 查看全部
DedeCMS 文章采集入门图文教程(推荐)
中间:(*).html
末页:
复制一个分页地址,回到“新增采集节点”页面,选择“来源属性”为“批量生成列表网址”,把粘贴地址到“匹配网址”中,修改规律变化处为(*),“批量生成地址设置”处(*)输入1到172,这里的意思是生成出列表第一页到最后172页的所有地址。
测试一下,在弹出框中我们可以看见循环出172条地址记录,很顺利的就设置好了。有时候会遇到较难获取的列表,那我们可以把把没规律的地址复制到”手工指定列表网址“文本框中来采集。
3.设置文章网址匹配规则
上面指定好了文章地址来源页,这一步就须要在那些页面中找出符合要求的文章地址页了。打开一个列表页面观察,左栏的方框中收录了我们须要的全部地址,这种情况分辨显著的页面,可以利“区域开始的HTML”和“区域结束的HTMLL”设置进行过滤。
不过也可以使用其他方式。把滑鼠移到各处链接地址,观察浏览器左下角显示的完整地址,我们须要的地址都收录“PHP_jiaocheng/20”,那我们把它填写到“必须收录”中。
两种方式都还能过滤出地址,碰上复杂页面,可以配合上去使用,加上正则,几乎没有筛选不出的地址,附(图5.1)对照。最后确定,进入下一步“网页内容获取规则”。

(图5.1)
生活不易,码农辛苦
网页文章正文采集方式-以陌陌文章采集为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-08-22 03:04
网页文章正文采集方式,以及陌陌文章采集为例当我们想要将明日头条上的新闻、搜狗陌陌上的文章正文内容保存出来的时侯,如何办?一篇篇复制粘贴?选择一款通用的网页数据采集器,将会使工作简单好多。优采云是一款通用的网页数据采集器,可采集互联网上的公开数据。用户可以设置从那个网站爬取数据,爬取这些数据,爬取哪些范围的数据,哪些时侯去爬取数据,爬取的数据怎么保存等等。言归正传,本文将以搜狗陌陌的文章正文采集为例,讲解使用优采云采集网页文章正文的方式。文章正文采集,主要有两大类情况:一、采集文章正文中的文本,不含图片;二、采集文章正文中的文本和图片URL。示例网站:使用功能点:Xpath判定条件分页列表信息采集AJAX滚动教程AJAX点击和翻页一、采集文章正文中的文本,不含图片具体步骤:步骤1)进2)将骤1:创建采步入主界面即将采集的网采集任务,选择“自定网址URL复定义模式”网页文复制粘贴到网站文章正文采集站输入框中集步骤1,点击“保存网址”步骤1)在网页作提骤2:创建翻在页面右上角页打开后,默提示框中,选翻页循环角,打开“流默认显示“热选择“更多操网页文流程”,以展门”文章。
下操作”文章正文采集诠释出“流程设下拉页面,找集步骤2设计器”和“找到并点击““定制当前操“加载更多内操作”两个板内容”按钮,蓝筹股。在操2)选择“循环点击单个元素网页文素”,以创建文章正文采集建一个翻页循集步骤3循环因为打开于此网页涉及开“高级选项及Ajax技术项”,勾选“网页文,我们须要进“Ajax加载数文章正文采集进行一些中级数据”,设置集步骤4级选项的设置置时间为“2置。选中“点秒”点击元素”步步骤,注:A可以AJA观察篇文“高定”AJAX即延时以在不重新加AX点击和翻页察网页,我们文章。为此,中级选项”,时加载、异步加载整个网页页教程:htt们发觉,通过我们设置整打开“满足网页文更新的一种脚页的情况下,对tp://www.b5次点击“加整个“循环翻页以下条件时退文章正文采集脚本技术,通对网页的某部azhuayu.co加载更多内容页”步骤执行退出循环”集步骤5通过在后台与部份进行更新om/tutorial容”,页面加行5次。选,设置循环次与服务器进行新。具体请看detail-1/aja加载到最顶部选中“循环翻次数等于“5行少量数据交看axdjfy_7.htm部,一共显示翻页”步骤,次”,点击交换,ml示100打开击“确步骤1)移选择骤3:创建列联通键盘,选择“选中全部列表循环并提取选中页面里第部”网页文取数据第一条文章链文章正文采集链接。
系统会集步骤6会手动辨识相像链接,在操作提示框框中,2)选择“循环点击每位链接网页文接”文章正文采集步骤73)系提示系统会手动进示框中,选择步入文章详情择“采集该元网页文情页。点击需元素的文本”文章正文采集须要采集的字。文章发布时集步骤8数组(这儿先时间、文章来先点击了文章来源数组的采章标题),在采集方式同理在操作理4)接素,接出来开始采选择“选中采集文章正文中全部”网页文文。先点击文文章正文采集文章正文的第集步骤9第一段,系统会手动识别页面内的同类元5)可以看见,所有的正文段网页文段落均被选中文章正文采集步中,变为红色步骤10色。选择“采集以下元素文本”注意:在数组表中,可进行网页文行数组的自定义文章正文采集步义更改步骤116)经言,定义分页经过如上操作我们希望采义数据合并方页合并”,再作,正文都会采集的正文,合形式”,勾选再点击“确定网页文会被全部采集合并为同一个“同一数组多定”文章正文采集步集出来(默认个单元格。点多次提取合并步骤12觉得每一段正点击“自定义并为一行,即正文为一个单义数据数组”即追加到同一单元格)。
一按键,选择一数组,比如通常而择“自正文网页文“自定文章正文采集步定义数据数组步骤13段”按钮网页文选择“自文章正文采集步自定义数据合步骤14合并方法”步骤1)选列表骤4:更改X选中整个“循表,定位的是Xpath循环步骤”是前20篇文章网页文如,打开“高级章的链接文章正文采集步如图进行勾选级选项”,可步骤15选可以看见,优采云默认生成的是固定定元素2)在//DI被定在傲游浏览器IV[@class=定位了器中打开要采='main-left']网页文采集的网页并]/DIV[3]/UL文章正文采集步并观察源码。L/LI/DIV[2]/步骤16我们发觉,/H3[1]/A,页通过此条X页面中所需的Xpath:的100篇文文章均3)将更改后的Xpath,复制网页文制粘贴到八爪网页文文章正文采集步爪鱼中所示位文章正文采集步步骤17位置,之后点步骤18点击“确定”步骤我们我们取数1)选出现拖动骤5:更改流们继续观察,们配置规则的数据选中整个“循现好多重复数动完成后,如流程图结构通过5次点的思路是,先循环”步骤数据如右图所示点击“加载更先构建翻页循环,将其拖出网页文更多内容”后环,加载出全“循环翻页”文章正文采集步后,此网页加载全部100篇步骤。
假如步骤19载出全部10篇文章,再建果不进行此项00篇文章。构建循环列表项操作,这么因此表,提么将会步骤1)点骤6:数据采点击左上角的采集及导入的“保存”网页文,之后点击文章正文采集步“开始采集”步骤20,选择“启动本地采集”2)采数据采集完成后据导入,会跳出提示网页文示,选择“导文章正文采集步导入数据”,步骤21,选择“合适的导入方式”,将采集集好的3)这儿我们选择择excel作为网页文为导入为格式文章正文采集步式,数据导入步骤22出后如右图4)如的X//[@正文如上图,部份Xpath://[@id="js_co文内容,均被分文章的正文[@id="js_content"]//P被采集到了网页文文没有采集到ontent"]/PP,所有的文文章正文采集步到。那是由于P,定位不到文章正文均可步骤23为,系统手动到此篇文章的可被定位到。动生成的文章的正文。将X再度启动采章正文的循环Xpath更改采集,所有文环列表改为:文章的网页文修文章正文采集步更改Xpath前步骤24前经过则需二、接一步骤过如上操作,需往已有的规采集文章正一中的步骤6骤7:降低判目标网址中规则中,加入正文中的文本6判定条件网页文修中的陌陌文章正入一个判定条件本和图片URL文章正文采集步更改Xpath后正文中的全部件。
L步骤25后部文本被采集出来。如果还需采集图图片,经过要采元素支。同时默认行最回到果不1)从示的过前6个步骤采集图片,则素(图片),时,在优采云认最右边分支最右边分支。到此规则,即不满足右侧条从左边工具栏的红色减号位骤,我们仅采则需往规则里则执行图片鱼中,默认对支为“不判定即对右边分支条件分支的条栏,往流程中位置)采集了陌陌文里加入一个判片采集分支;如对右边分支,设,总是执行该支设置条件:如条件(即不收录中推入一个网页文文章里的文本判定条件:对倘若不收录设置判定条件该分支”,即若果收录im含img元素“判断条件”文章正文采集步本内容,并不文章内容列表img元素(件,满足此判即当不满足左mg元素(图素),则执行步骤(选取步骤26不包括文章里表进行判别图片),则判定条件,则右边分支的判图片),则执行两侧分支。定图标拖住不里的图片。如,假如收录则执行文本采则执行两侧分判定条件时,执行两侧分支具击剑作如下不放,推入箭果需img采集分分支;则执支;如下:箭头所2)流再点流程图中出现点击两侧分支现判定条件。支,在出现的结将我们将“提结果页面(分网页文将“提取元素提取数据”步骤分支条件检查文章正文采集步素”步骤,拖骤,联通到右测结果-检查结步骤27推入两侧分支两侧分支中(结果总是Tru支(红色减号处ue)点击“确处)。
定”3)点定”(代点击两侧分支。之后对其代表图片),支,在出现的其设置判定条再点击“确网页文两侧分支的结果页面(条件:勾选“确定”文章正文采集步支-检查结果总(分支条件检“当前循环项包步骤28总是True检查结果-检查收录元素”测结果总是,输入元素True)点击Xpath://击“确/img网页文点文章正文采集步点击两侧分支步骤29支4)左步骤中,左边分支条件骤,到流程图选择“采集件设置完毕后图中的右边分集该图片地址对右边分网页文后,再进行提支中(红色加址”分支,设置判文章正文采集步提取数据步骤减号处),然判定条件步骤30骤。从左边工具之后选中页面具栏,推入一面内一张图片一个“提取数片,在操作提数据”提示框拖入新的“提取网页文取数据”步骤文章正文采集步骤,到左边分步骤31分支5)选元素//*[选中两侧分支素方法”,将[@id="js_c支的“提取数将红框中的“content"]/p采网页文数据”步骤,“元素匹配的p[1]/span[1采集图片地址文章正文采集步,点击“自定Xpath”:1]与“相对址步骤32定义数据数组Xpath”:/段”按钮,选/span[1],选择“自定义记录出来义定位自定网页义民义定位元素文章正文采集步素方法步骤336)选元素//*[定”选中两侧分支素方法”,参[@id="js_c元支的“提取数参照右边分支content"]/p元素匹配的X网页文数据”步骤,支相同位置的p[1]/img[1Xpath、“相文章正文采集步,点击“自定的Xpath进行1],“相对X相对Xpath”步骤34定义数据数组行更改:“元Xpath”改为段”按钮,选元素匹配的为:/img[1]选择“自定义Xpath”改],之后点击义定位改为:击“确7)选合并选中两侧分支并方法”,如支的“提取数如图进行勾选网页文数据”步骤,选。
勾选后,多文章正文采集步,点击“自定多次提取的正步骤35定义数据数组正文将追加为段”按钮,选为一个数组选择“自定义义数据8)注个数请参注意,在八爪数需一致。这儿参考:爪鱼中,判定里,我们将左/www.bazh网页文断条件里各分左右两个分支/文章正文采集步分支中的“提支中,提取的/tutorialdet步骤36提取数据”步的数组名均改ail-1/judge步骤中的数组为“正文”(e.html)段名需相同,判定条件教数组教程,9)如导入文章因此数为如上,整个判出的excel表章正文里的图而,在打开文为“30次”判断条件设置表格中,图片图片,需下拉文章后,需对其,每次间隔网页文置完毕。点击片地址为一堆拉滚动,能够加其进行设置“2秒”,滚文章正文采集步击左上角的“堆乱码。这是加载下来,加“页面加载完滚动形式为“步骤37“保存”并“是为何呢?加载下来后才完成后向上滚“向下滚动一“开始采集”继续观察网页能够采集到正滚动”。在这一屏”。我们发觉页——搜狗正确的图片地这儿,设置滚现,在狗陌陌地址。滚动次陌陌文章网页文章正文里的图文章正文采集步图片,需下拉步骤38拉滚动,才会加载下来注意你们可参10)意:这儿的滚动家可按需设置参考AJAX滚)重新启动采动次数、时间置滚动教程:ht采集,并导入设置“页面网页文间、方式的设ttp://www.b出数据,数据网页文面加载完成后文章正文采集步设置,会影响采bazhuayu.co据导入后如图文章正文采集步导入数据后向上滚动”步骤39采集数据的速om/tutorial所示:步骤40速率、质量。
ldetail-1/ajg本文仅做参gd_7.html参考,说明间用无需相关百度新浪豆瓣明:因搜狗微用在等待图片需等待图片加关采集教程:度搜索结果采浪微博数据采瓣影片短评采陌陌文章中的片加载,因此加载,采集速采集采集采集网页文图片,需经过而采集速率较慢速率会快好多文章正文采集步数据示例过下拉滚动较慢。若果没有。步骤41,方可加载出有采集图片的下来。在采集的需求,直接集过程中,大接使用文本采大量时采集,优采云——70万用户选择的网页数据采集器。1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,死机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担忧IP被封,网路中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,还能满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。 查看全部
网页文章正文采集方式-以陌陌文章采集为例
网页文章正文采集方式,以及陌陌文章采集为例当我们想要将明日头条上的新闻、搜狗陌陌上的文章正文内容保存出来的时侯,如何办?一篇篇复制粘贴?选择一款通用的网页数据采集器,将会使工作简单好多。优采云是一款通用的网页数据采集器,可采集互联网上的公开数据。用户可以设置从那个网站爬取数据,爬取这些数据,爬取哪些范围的数据,哪些时侯去爬取数据,爬取的数据怎么保存等等。言归正传,本文将以搜狗陌陌的文章正文采集为例,讲解使用优采云采集网页文章正文的方式。文章正文采集,主要有两大类情况:一、采集文章正文中的文本,不含图片;二、采集文章正文中的文本和图片URL。示例网站:使用功能点:Xpath判定条件分页列表信息采集AJAX滚动教程AJAX点击和翻页一、采集文章正文中的文本,不含图片具体步骤:步骤1)进2)将骤1:创建采步入主界面即将采集的网采集任务,选择“自定网址URL复定义模式”网页文复制粘贴到网站文章正文采集站输入框中集步骤1,点击“保存网址”步骤1)在网页作提骤2:创建翻在页面右上角页打开后,默提示框中,选翻页循环角,打开“流默认显示“热选择“更多操网页文流程”,以展门”文章。
下操作”文章正文采集诠释出“流程设下拉页面,找集步骤2设计器”和“找到并点击““定制当前操“加载更多内操作”两个板内容”按钮,蓝筹股。在操2)选择“循环点击单个元素网页文素”,以创建文章正文采集建一个翻页循集步骤3循环因为打开于此网页涉及开“高级选项及Ajax技术项”,勾选“网页文,我们须要进“Ajax加载数文章正文采集进行一些中级数据”,设置集步骤4级选项的设置置时间为“2置。选中“点秒”点击元素”步步骤,注:A可以AJA观察篇文“高定”AJAX即延时以在不重新加AX点击和翻页察网页,我们文章。为此,中级选项”,时加载、异步加载整个网页页教程:htt们发觉,通过我们设置整打开“满足网页文更新的一种脚页的情况下,对tp://www.b5次点击“加整个“循环翻页以下条件时退文章正文采集脚本技术,通对网页的某部azhuayu.co加载更多内容页”步骤执行退出循环”集步骤5通过在后台与部份进行更新om/tutorial容”,页面加行5次。选,设置循环次与服务器进行新。具体请看detail-1/aja加载到最顶部选中“循环翻次数等于“5行少量数据交看axdjfy_7.htm部,一共显示翻页”步骤,次”,点击交换,ml示100打开击“确步骤1)移选择骤3:创建列联通键盘,选择“选中全部列表循环并提取选中页面里第部”网页文取数据第一条文章链文章正文采集链接。
系统会集步骤6会手动辨识相像链接,在操作提示框框中,2)选择“循环点击每位链接网页文接”文章正文采集步骤73)系提示系统会手动进示框中,选择步入文章详情择“采集该元网页文情页。点击需元素的文本”文章正文采集须要采集的字。文章发布时集步骤8数组(这儿先时间、文章来先点击了文章来源数组的采章标题),在采集方式同理在操作理4)接素,接出来开始采选择“选中采集文章正文中全部”网页文文。先点击文文章正文采集文章正文的第集步骤9第一段,系统会手动识别页面内的同类元5)可以看见,所有的正文段网页文段落均被选中文章正文采集步中,变为红色步骤10色。选择“采集以下元素文本”注意:在数组表中,可进行网页文行数组的自定义文章正文采集步义更改步骤116)经言,定义分页经过如上操作我们希望采义数据合并方页合并”,再作,正文都会采集的正文,合形式”,勾选再点击“确定网页文会被全部采集合并为同一个“同一数组多定”文章正文采集步集出来(默认个单元格。点多次提取合并步骤12觉得每一段正点击“自定义并为一行,即正文为一个单义数据数组”即追加到同一单元格)。
一按键,选择一数组,比如通常而择“自正文网页文“自定文章正文采集步定义数据数组步骤13段”按钮网页文选择“自文章正文采集步自定义数据合步骤14合并方法”步骤1)选列表骤4:更改X选中整个“循表,定位的是Xpath循环步骤”是前20篇文章网页文如,打开“高级章的链接文章正文采集步如图进行勾选级选项”,可步骤15选可以看见,优采云默认生成的是固定定元素2)在//DI被定在傲游浏览器IV[@class=定位了器中打开要采='main-left']网页文采集的网页并]/DIV[3]/UL文章正文采集步并观察源码。L/LI/DIV[2]/步骤16我们发觉,/H3[1]/A,页通过此条X页面中所需的Xpath:的100篇文文章均3)将更改后的Xpath,复制网页文制粘贴到八爪网页文文章正文采集步爪鱼中所示位文章正文采集步步骤17位置,之后点步骤18点击“确定”步骤我们我们取数1)选出现拖动骤5:更改流们继续观察,们配置规则的数据选中整个“循现好多重复数动完成后,如流程图结构通过5次点的思路是,先循环”步骤数据如右图所示点击“加载更先构建翻页循环,将其拖出网页文更多内容”后环,加载出全“循环翻页”文章正文采集步后,此网页加载全部100篇步骤。
假如步骤19载出全部10篇文章,再建果不进行此项00篇文章。构建循环列表项操作,这么因此表,提么将会步骤1)点骤6:数据采点击左上角的采集及导入的“保存”网页文,之后点击文章正文采集步“开始采集”步骤20,选择“启动本地采集”2)采数据采集完成后据导入,会跳出提示网页文示,选择“导文章正文采集步导入数据”,步骤21,选择“合适的导入方式”,将采集集好的3)这儿我们选择择excel作为网页文为导入为格式文章正文采集步式,数据导入步骤22出后如右图4)如的X//[@正文如上图,部份Xpath://[@id="js_co文内容,均被分文章的正文[@id="js_content"]//P被采集到了网页文文没有采集到ontent"]/PP,所有的文文章正文采集步到。那是由于P,定位不到文章正文均可步骤23为,系统手动到此篇文章的可被定位到。动生成的文章的正文。将X再度启动采章正文的循环Xpath更改采集,所有文环列表改为:文章的网页文修文章正文采集步更改Xpath前步骤24前经过则需二、接一步骤过如上操作,需往已有的规采集文章正一中的步骤6骤7:降低判目标网址中规则中,加入正文中的文本6判定条件网页文修中的陌陌文章正入一个判定条件本和图片URL文章正文采集步更改Xpath后正文中的全部件。
L步骤25后部文本被采集出来。如果还需采集图图片,经过要采元素支。同时默认行最回到果不1)从示的过前6个步骤采集图片,则素(图片),时,在优采云认最右边分支最右边分支。到此规则,即不满足右侧条从左边工具栏的红色减号位骤,我们仅采则需往规则里则执行图片鱼中,默认对支为“不判定即对右边分支条件分支的条栏,往流程中位置)采集了陌陌文里加入一个判片采集分支;如对右边分支,设,总是执行该支设置条件:如条件(即不收录中推入一个网页文文章里的文本判定条件:对倘若不收录设置判定条件该分支”,即若果收录im含img元素“判断条件”文章正文采集步本内容,并不文章内容列表img元素(件,满足此判即当不满足左mg元素(图素),则执行步骤(选取步骤26不包括文章里表进行判别图片),则判定条件,则右边分支的判图片),则执行两侧分支。定图标拖住不里的图片。如,假如收录则执行文本采则执行两侧分判定条件时,执行两侧分支具击剑作如下不放,推入箭果需img采集分分支;则执支;如下:箭头所2)流再点流程图中出现点击两侧分支现判定条件。支,在出现的结将我们将“提结果页面(分网页文将“提取元素提取数据”步骤分支条件检查文章正文采集步素”步骤,拖骤,联通到右测结果-检查结步骤27推入两侧分支两侧分支中(结果总是Tru支(红色减号处ue)点击“确处)。
定”3)点定”(代点击两侧分支。之后对其代表图片),支,在出现的其设置判定条再点击“确网页文两侧分支的结果页面(条件:勾选“确定”文章正文采集步支-检查结果总(分支条件检“当前循环项包步骤28总是True检查结果-检查收录元素”测结果总是,输入元素True)点击Xpath://击“确/img网页文点文章正文采集步点击两侧分支步骤29支4)左步骤中,左边分支条件骤,到流程图选择“采集件设置完毕后图中的右边分集该图片地址对右边分网页文后,再进行提支中(红色加址”分支,设置判文章正文采集步提取数据步骤减号处),然判定条件步骤30骤。从左边工具之后选中页面具栏,推入一面内一张图片一个“提取数片,在操作提数据”提示框拖入新的“提取网页文取数据”步骤文章正文采集步骤,到左边分步骤31分支5)选元素//*[选中两侧分支素方法”,将[@id="js_c支的“提取数将红框中的“content"]/p采网页文数据”步骤,“元素匹配的p[1]/span[1采集图片地址文章正文采集步,点击“自定Xpath”:1]与“相对址步骤32定义数据数组Xpath”:/段”按钮,选/span[1],选择“自定义记录出来义定位自定网页义民义定位元素文章正文采集步素方法步骤336)选元素//*[定”选中两侧分支素方法”,参[@id="js_c元支的“提取数参照右边分支content"]/p元素匹配的X网页文数据”步骤,支相同位置的p[1]/img[1Xpath、“相文章正文采集步,点击“自定的Xpath进行1],“相对X相对Xpath”步骤34定义数据数组行更改:“元Xpath”改为段”按钮,选元素匹配的为:/img[1]选择“自定义Xpath”改],之后点击义定位改为:击“确7)选合并选中两侧分支并方法”,如支的“提取数如图进行勾选网页文数据”步骤,选。
勾选后,多文章正文采集步,点击“自定多次提取的正步骤35定义数据数组正文将追加为段”按钮,选为一个数组选择“自定义义数据8)注个数请参注意,在八爪数需一致。这儿参考:爪鱼中,判定里,我们将左/www.bazh网页文断条件里各分左右两个分支/文章正文采集步分支中的“提支中,提取的/tutorialdet步骤36提取数据”步的数组名均改ail-1/judge步骤中的数组为“正文”(e.html)段名需相同,判定条件教数组教程,9)如导入文章因此数为如上,整个判出的excel表章正文里的图而,在打开文为“30次”判断条件设置表格中,图片图片,需下拉文章后,需对其,每次间隔网页文置完毕。点击片地址为一堆拉滚动,能够加其进行设置“2秒”,滚文章正文采集步击左上角的“堆乱码。这是加载下来,加“页面加载完滚动形式为“步骤37“保存”并“是为何呢?加载下来后才完成后向上滚“向下滚动一“开始采集”继续观察网页能够采集到正滚动”。在这一屏”。我们发觉页——搜狗正确的图片地这儿,设置滚现,在狗陌陌地址。滚动次陌陌文章网页文章正文里的图文章正文采集步图片,需下拉步骤38拉滚动,才会加载下来注意你们可参10)意:这儿的滚动家可按需设置参考AJAX滚)重新启动采动次数、时间置滚动教程:ht采集,并导入设置“页面网页文间、方式的设ttp://www.b出数据,数据网页文面加载完成后文章正文采集步设置,会影响采bazhuayu.co据导入后如图文章正文采集步导入数据后向上滚动”步骤39采集数据的速om/tutorial所示:步骤40速率、质量。
ldetail-1/ajg本文仅做参gd_7.html参考,说明间用无需相关百度新浪豆瓣明:因搜狗微用在等待图片需等待图片加关采集教程:度搜索结果采浪微博数据采瓣影片短评采陌陌文章中的片加载,因此加载,采集速采集采集采集网页文图片,需经过而采集速率较慢速率会快好多文章正文采集步数据示例过下拉滚动较慢。若果没有。步骤41,方可加载出有采集图片的下来。在采集的需求,直接集过程中,大接使用文本采大量时采集,优采云——70万用户选择的网页数据采集器。1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,死机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担忧IP被封,网路中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,还能满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。
ASP信息采集程序图解教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2020-08-21 01:24
官方网址:
运行环境:B/S,Win9X/Win2000/WinXP/Win2003,浏览器
【界面截图】
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
【软件简介】
ASP神偷(AspStealer)可以把远程网站上的数据(如新闻、博客文章、客户资料等)一次性、无限制记录数、全手动保存到自己网站的数据库的程序。
与其他的ASP歹徒程序相比,ASP神偷(AspStealer)具有如下优点:
1.ASP劫匪来自其他网站,它随着该网站的更新而更新,如果目标网站无法访问、数据有误或则改变页面结构,您的网站也难以读取到相关数据,有时还须要更改ASP歹徒相应的程序;ASP神偷是采用一次性、无限制记录数、全手动保存到自己网站数据库的方法采集数据的,不会遭到目标网站的任何影响。
2.ASP歹徒属于远程调用,访问远程速率较慢;ASP神偷属于同一网站数据库调用,您的网站有多快,访问速率就有多快。
【采集范例】
ASP神偷 Beta1.0 支持采集如 类型(文件名.asp?ClassID=数值)的网址。
以采集(私房博客)的文章为例,步骤如下:
1.打开文章列表页,
2.发现文章链接页网址的规律性,如 view.asp?ClassID=数值 ,正常这种数值都是三位数或四位数的;也有网站是采用多位随机数做为ID,如view.asp?ClassID=21(ClassID=年月日+五位随机数),或21.htm(年月日+五位随机数.htm),ASP神偷 Beta1.0 暂不支持后两种类型的网址;
3.使用ASP神偷 Beta1.0 的默认设置,直接点击『预览』,即可采集从ClassID=177开始至ClassID=187的十篇文章的标题;
4.此例从ClassID=177开始至ClassID=187,采集十篇文章的内容;
5.在ASP神偷 Beta1.0 的 『网址』填入 『』,『从』填入『177』,『到』填入『187』;
6.用浏览器打开 页面,点击『菜单栏』->『查看』->『源文件』,记事本将打开该页面的html源文件;
7.找出在页面html源文件内正文内容前的一段标识符,该标识符最好是惟一的整句代码,可用Ctrl+F在记事本内查询您找到的这段标识符,验证该标识符的唯一性,以保证采集数据的有效性(如下图);
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
8.将惟一前标识符拷入ASP神偷 Beta1.0 的『前标示』 栏目,『右移』填入『0』;
9.用同样的方式,找出正文内容后的那段标识符,拷入的『后标示』 栏目,『左移』填入『0』;
10.注意:前标识符和后标识符必须是整篇文章共同拥有的,不能富含某篇或某几篇文章独有的html代码,否则采集的信息可能会出错,最终的采集设置(如下图);
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
11.点击『预览』,即可采集到您要的内容了。
备注:ASP神偷 Beta1.0 目前限制预览前20条记录,且暂不开通『导入数据库』功能;使用者勿将该程序用于非法用途,否则后果自负!使用过程中碰到任何的困局、意见、建议或则找不出前后标识符的用户,欢迎在 『发表评论』,我们将会在第一时间为您提供帮助!
更多的ASP信息采集程序图解教程请到峰会查看: 查看全部
ASP信息采集程序图解教程
官方网址:
运行环境:B/S,Win9X/Win2000/WinXP/Win2003,浏览器
【界面截图】

document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
【软件简介】
ASP神偷(AspStealer)可以把远程网站上的数据(如新闻、博客文章、客户资料等)一次性、无限制记录数、全手动保存到自己网站的数据库的程序。
与其他的ASP歹徒程序相比,ASP神偷(AspStealer)具有如下优点:
1.ASP劫匪来自其他网站,它随着该网站的更新而更新,如果目标网站无法访问、数据有误或则改变页面结构,您的网站也难以读取到相关数据,有时还须要更改ASP歹徒相应的程序;ASP神偷是采用一次性、无限制记录数、全手动保存到自己网站数据库的方法采集数据的,不会遭到目标网站的任何影响。
2.ASP歹徒属于远程调用,访问远程速率较慢;ASP神偷属于同一网站数据库调用,您的网站有多快,访问速率就有多快。
【采集范例】
ASP神偷 Beta1.0 支持采集如 类型(文件名.asp?ClassID=数值)的网址。
以采集(私房博客)的文章为例,步骤如下:
1.打开文章列表页,
2.发现文章链接页网址的规律性,如 view.asp?ClassID=数值 ,正常这种数值都是三位数或四位数的;也有网站是采用多位随机数做为ID,如view.asp?ClassID=21(ClassID=年月日+五位随机数),或21.htm(年月日+五位随机数.htm),ASP神偷 Beta1.0 暂不支持后两种类型的网址;
3.使用ASP神偷 Beta1.0 的默认设置,直接点击『预览』,即可采集从ClassID=177开始至ClassID=187的十篇文章的标题;
4.此例从ClassID=177开始至ClassID=187,采集十篇文章的内容;
5.在ASP神偷 Beta1.0 的 『网址』填入 『』,『从』填入『177』,『到』填入『187』;
6.用浏览器打开 页面,点击『菜单栏』->『查看』->『源文件』,记事本将打开该页面的html源文件;
7.找出在页面html源文件内正文内容前的一段标识符,该标识符最好是惟一的整句代码,可用Ctrl+F在记事本内查询您找到的这段标识符,验证该标识符的唯一性,以保证采集数据的有效性(如下图);

document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
8.将惟一前标识符拷入ASP神偷 Beta1.0 的『前标示』 栏目,『右移』填入『0』;
9.用同样的方式,找出正文内容后的那段标识符,拷入的『后标示』 栏目,『左移』填入『0』;
10.注意:前标识符和后标识符必须是整篇文章共同拥有的,不能富含某篇或某几篇文章独有的html代码,否则采集的信息可能会出错,最终的采集设置(如下图);

document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
11.点击『预览』,即可采集到您要的内容了。
备注:ASP神偷 Beta1.0 目前限制预览前20条记录,且暂不开通『导入数据库』功能;使用者勿将该程序用于非法用途,否则后果自负!使用过程中碰到任何的困局、意见、建议或则找不出前后标识符的用户,欢迎在 『发表评论』,我们将会在第一时间为您提供帮助!
更多的ASP信息采集程序图解教程请到峰会查看:
【TDA2x学习】5、编译第一个SDK程序(最新版)【收录RTOS和HLOS】
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-20 21:50
【为什么学爬虫?】 1、爬虫入手容易,但是深入较难,如何写出高效率的爬虫,如何写出灵活性高可扩充的爬虫都是一项技术活。另外在爬虫过程中,经常容易遇见被反爬虫,比如字体反爬、IP辨识、验证码等,如何层层攻破难点领到想要的数据,这门课程,你都能学到! 2、如果是作为一个其他行业的开发者,比如app开发,web开发,学习爬虫能使你加大对技术的认知,能够开发出愈发安全的软件和网站【课程设计】一个完整的爬虫程序,无论大小,总体来说可以分成三个步骤,分别是:网络恳求:模拟浏览器的行为从网上抓取数据。数据解析:将恳求出来的数据进行过滤,提取我们想要的数据。数据储存:将提取到的数据储存到硬碟或则显存中。比如用mysql数据库或则redis等。那么本课程也是根据这几个步骤循序渐进的进行讲解,带领中学生完整的把握每位步骤的技术。另外,因为爬虫的多样性,在爬取的过程中可能会发生被反爬、效率低下等。因此我们又降低了两个章节拿来增强爬虫程序的灵活性,分别是:爬虫进阶:包括IP代理,多线程爬虫,图形验证码辨识、JS加密揭秘、动态网页爬虫、字体反爬辨识等。Scrapy和分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等。通过爬虫进阶的知识点我们能应付大量的反爬网站,而Scrapy框架作为一个专业的爬虫框架,使用他可以快速提升我们编撰爬虫程序的效率和速率。另外假如一台机器不能满足你的需求,我们可以用分布式爬虫使多台机器帮助你快速爬取数据。从基础爬虫到商业化应用爬虫,本套课程满足您的所有需求!【课程服务】专属付费社群+每周三讨论会+1v1答疑 查看全部
【TDA2x学习】5、编译第一个SDK程序(最新版)【收录RTOS和HLOS】
【为什么学爬虫?】 1、爬虫入手容易,但是深入较难,如何写出高效率的爬虫,如何写出灵活性高可扩充的爬虫都是一项技术活。另外在爬虫过程中,经常容易遇见被反爬虫,比如字体反爬、IP辨识、验证码等,如何层层攻破难点领到想要的数据,这门课程,你都能学到! 2、如果是作为一个其他行业的开发者,比如app开发,web开发,学习爬虫能使你加大对技术的认知,能够开发出愈发安全的软件和网站【课程设计】一个完整的爬虫程序,无论大小,总体来说可以分成三个步骤,分别是:网络恳求:模拟浏览器的行为从网上抓取数据。数据解析:将恳求出来的数据进行过滤,提取我们想要的数据。数据储存:将提取到的数据储存到硬碟或则显存中。比如用mysql数据库或则redis等。那么本课程也是根据这几个步骤循序渐进的进行讲解,带领中学生完整的把握每位步骤的技术。另外,因为爬虫的多样性,在爬取的过程中可能会发生被反爬、效率低下等。因此我们又降低了两个章节拿来增强爬虫程序的灵活性,分别是:爬虫进阶:包括IP代理,多线程爬虫,图形验证码辨识、JS加密揭秘、动态网页爬虫、字体反爬辨识等。Scrapy和分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等。通过爬虫进阶的知识点我们能应付大量的反爬网站,而Scrapy框架作为一个专业的爬虫框架,使用他可以快速提升我们编撰爬虫程序的效率和速率。另外假如一台机器不能满足你的需求,我们可以用分布式爬虫使多台机器帮助你快速爬取数据。从基础爬虫到商业化应用爬虫,本套课程满足您的所有需求!【课程服务】专属付费社群+每周三讨论会+1v1答疑
新手使用优采云发布插口怎么采集文章教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-20 19:39
前沿:
如果你对优采云一点都不知道,你还是去网上自学一点优采云采集的知识,我也不是哪些大师,硬着头皮写的,至少能用,在这里我不会教你怎么写采集规则,因为写法种类太多,你问我我也不知道,优采云相关文件夹里提供的发布插口外置了马甲发布文章,并且支持远程图片抓取本地化,和发布文章时间设置(10-70分钟随机)。用户只需关注优采云标题和内容即可,参数值标题(title),内容(content)。
第一步:站点设置里设置下优采云免登入发布插口的全局变量值:
第二步:将发布插口上传覆盖程序根目录:
第三步:登录优采云软件后导出发布模块"
下图更多处下拉--选择导出:
导入后:
上图中,数字1处填写你在网站后台设置的全局变量值。
2 处选择 utf-8 编码。
3 处填写你网站域名,不要带 反斜杠'/'.
4处选择不需要登陆
5 处点击获取列表--选择你须要入库的分类
6 随便给当前这个发布模块写个名子,后续采集任务模块会用到。
最后点击保存配置按键。
---------
下面讲解导出采集任务:
新建任务分组后,在该分组下导出任务规则(导入任务至该分组):
选择我们的采集任务规则(.ljobx文件):
下一步:双击规则项
点击第三步:修改发布内容设置
修改下你发布的分类:
最后保存即可:
然后右键开始任务采集: 查看全部
新手使用优采云发布插口怎么采集文章教程
前沿:
如果你对优采云一点都不知道,你还是去网上自学一点优采云采集的知识,我也不是哪些大师,硬着头皮写的,至少能用,在这里我不会教你怎么写采集规则,因为写法种类太多,你问我我也不知道,优采云相关文件夹里提供的发布插口外置了马甲发布文章,并且支持远程图片抓取本地化,和发布文章时间设置(10-70分钟随机)。用户只需关注优采云标题和内容即可,参数值标题(title),内容(content)。
第一步:站点设置里设置下优采云免登入发布插口的全局变量值:

第二步:将发布插口上传覆盖程序根目录:

第三步:登录优采云软件后导出发布模块"

下图更多处下拉--选择导出:

导入后:

上图中,数字1处填写你在网站后台设置的全局变量值。
2 处选择 utf-8 编码。
3 处填写你网站域名,不要带 反斜杠'/'.
4处选择不需要登陆
5 处点击获取列表--选择你须要入库的分类
6 随便给当前这个发布模块写个名子,后续采集任务模块会用到。
最后点击保存配置按键。
---------
下面讲解导出采集任务:
新建任务分组后,在该分组下导出任务规则(导入任务至该分组):

选择我们的采集任务规则(.ljobx文件):

下一步:双击规则项

点击第三步:修改发布内容设置

修改下你发布的分类:

最后保存即可:

然后右键开始任务采集:
百度当日收录文章隔天删掉个人觉得解决办法。
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-20 13:23
这个问题曾经研究过很多次了,也尝试了好多方式,基本上下边的方式就是完全可以解决的了,不过要排除降权严重的情况。
【原因】
1、内容质量问题,这个是要考虑近来更新内容的质量和网站整站的质量概况,而不是针对单一更新文章的
2、网站降权问题,降权不是严重的降权,其实就是降低爆光,也可以理解为观察期
3、网站权值问题,网站权值低的话,就会导致这些情况。尤其是一些新站,特别容易发生
4、更新频度问题,每个周期内更新的文章数量变化很大,就会导致抓取数目变化十分大,以至于进行百度的观察期,减少爆光。
【解决方式】
1、增加残差导出。更新的文章在首页展示,并且当日降低3-5条外部链接,一定要是可收录的,或者能爆光的。
2、维持稳定的更新频度。每天更新一篇,或者是两篇。总之就是不要更新的数目变化十分大,维持一段时间
3、更新内容标题,这个主要是考虑到内容的质量,一般情况下我们的标题都是采用一种低格的,当出现收录删掉的时侯,试着换换标题的格式,这样有利于百度同先前的内容进行分辨。
4、更新内容之间添加文字链接。更新的内容之间可以添加一些相关的内链,这样保证只要有一篇稳定的话,就会持续的给其它内容带来残差。
按照这些做法的话,基本上要7-15天才能恢复,但是排除掉因为作弊的降权和观察期,只是代表通常的情况下可以解决的 查看全部
百度当日收录文章隔天删掉个人觉得解决办法。
这个问题曾经研究过很多次了,也尝试了好多方式,基本上下边的方式就是完全可以解决的了,不过要排除降权严重的情况。
【原因】
1、内容质量问题,这个是要考虑近来更新内容的质量和网站整站的质量概况,而不是针对单一更新文章的
2、网站降权问题,降权不是严重的降权,其实就是降低爆光,也可以理解为观察期
3、网站权值问题,网站权值低的话,就会导致这些情况。尤其是一些新站,特别容易发生
4、更新频度问题,每个周期内更新的文章数量变化很大,就会导致抓取数目变化十分大,以至于进行百度的观察期,减少爆光。
【解决方式】
1、增加残差导出。更新的文章在首页展示,并且当日降低3-5条外部链接,一定要是可收录的,或者能爆光的。
2、维持稳定的更新频度。每天更新一篇,或者是两篇。总之就是不要更新的数目变化十分大,维持一段时间
3、更新内容标题,这个主要是考虑到内容的质量,一般情况下我们的标题都是采用一种低格的,当出现收录删掉的时侯,试着换换标题的格式,这样有利于百度同先前的内容进行分辨。
4、更新内容之间添加文字链接。更新的内容之间可以添加一些相关的内链,这样保证只要有一篇稳定的话,就会持续的给其它内容带来残差。
按照这些做法的话,基本上要7-15天才能恢复,但是排除掉因为作弊的降权和观察期,只是代表通常的情况下可以解决的
C#实现的一个简单爬图程序采集写真套图源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-08-20 07:34
这个东西须要的人甚少,但是群里有人问我要,还想给钱。哼,我宝哥是那个要钱的人吗?免费开源给你们使用,代码写得太粗糙,没用规划,写到那里算那儿。运行上去疗效挺好,采集那100个系列套图的话大约在1个小时左右吧,可能更快,因为后期我优化了一下,只要你的网路够快,采集进度条如同注射器一样。
C#实现的一个简单爬图程序采集写真套图
如果不想自己采集,可以直接下载我采集好了的套图数据库,详情查看:200万张高清写真套图分享。
软件使用教程
软件运行环境:Windows all +.net framework 4.5
首先登陆采集目标站,因为采集的内容必须登入用户能够访问。
登录后按F12打开浏览器开发者模式,选择network标签,随便打开该站一个页面。点击恳求列表中惟一的doc。也就是页面内容恳求,不是页面资源恳求。一般是第一个。在右边的恳求数据详情中,找到恳求头request headers项中的cookies。
C#实现的一个简单爬图程序采集写真套图
将cookie全部复制出来,然后粘贴到软件第一个编辑框中即可。请勿必勾选数据入库或则保存图片两者之一,或者都选。如果选择保存图象,则必须点击选择文件路径,以获得保存图象位置。若要采集所有内容,点击采集所有即可。采集指定系列,请先在网站中打开分类后,将地址栏中id=XXX中的XXX填写到采集类目中。目前总共1-100个分类,id区间为1-100。注意:采集请不要暂停,因为没用。功能没写完,点了没用,而且再度采集会重新采集,相同内容入库会失败。如果想要重新采集,请关掉软件,再删掉软件目录中的tt.db数据库文件,再次启动软件即可。
压缩包是源码,visual studio 2019版项目,编译好的程序在压缩包中的bin/debug目录下,可直接运行。
文件下载C#实现的一个简单爬图程序采集写真套图源码>>6M 查看全部
C#实现的一个简单爬图程序采集写真套图源码
这个东西须要的人甚少,但是群里有人问我要,还想给钱。哼,我宝哥是那个要钱的人吗?免费开源给你们使用,代码写得太粗糙,没用规划,写到那里算那儿。运行上去疗效挺好,采集那100个系列套图的话大约在1个小时左右吧,可能更快,因为后期我优化了一下,只要你的网路够快,采集进度条如同注射器一样。

C#实现的一个简单爬图程序采集写真套图
如果不想自己采集,可以直接下载我采集好了的套图数据库,详情查看:200万张高清写真套图分享。
软件使用教程
软件运行环境:Windows all +.net framework 4.5
首先登陆采集目标站,因为采集的内容必须登入用户能够访问。
登录后按F12打开浏览器开发者模式,选择network标签,随便打开该站一个页面。点击恳求列表中惟一的doc。也就是页面内容恳求,不是页面资源恳求。一般是第一个。在右边的恳求数据详情中,找到恳求头request headers项中的cookies。

C#实现的一个简单爬图程序采集写真套图
将cookie全部复制出来,然后粘贴到软件第一个编辑框中即可。请勿必勾选数据入库或则保存图片两者之一,或者都选。如果选择保存图象,则必须点击选择文件路径,以获得保存图象位置。若要采集所有内容,点击采集所有即可。采集指定系列,请先在网站中打开分类后,将地址栏中id=XXX中的XXX填写到采集类目中。目前总共1-100个分类,id区间为1-100。注意:采集请不要暂停,因为没用。功能没写完,点了没用,而且再度采集会重新采集,相同内容入库会失败。如果想要重新采集,请关掉软件,再删掉软件目录中的tt.db数据库文件,再次启动软件即可。
压缩包是源码,visual studio 2019版项目,编译好的程序在压缩包中的bin/debug目录下,可直接运行。
文件下载C#实现的一个简单爬图程序采集写真套图源码>>6M
爬取B站程序猿up主,分析程序猿up出哪些类型的视频会受欢迎
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-19 20:25
文章目录
前言
我,一个天天早起,睡前必刷B站的菜鸡程序猿,昨天见到一位关注的程序猿up主发布的动态,心里太不好受,所以才想着做此次的内容
到底程序猿up主做哪些类型的视频就会受大众喜欢呢?
不想看文字就点击图片去看B站我的视频吧,之前似乎可以直接导出视频的,现在iframe不知道为何失效了
开始动手1.首先须要去采集数据
选择到搜索去搜程序猿,然后选择视频,弹幕最多(也就是真实观看的人比较多),去得到每一个视频的链接。
这样我们就先得到每位视频对应的详情页链接,然后再从详情页用xpath去得到标题,up名,up主页等信息(在这个页面直接得到视频点赞数和播放数最后保存的结果是异常值),点赞数和播放数用api去得到。
api只须要视频的id就可以返回相应的json结果,所以得到也是比较便捷的,最后保存到csv文件。
爬虫代码:
import requests
from lxml import etree
import time
import pandas as pd
import re
import json
#https://search.bilibili.com/vi ... %3D32
def get_html(url,header):
html=requests.get(url,headers=header).text
return html
def get_all_page(n):
urls=[]
for i in range(1,n+1):
url=f"https://search.bilibili.com/vi ... ge%3D{i}"
html=get_html(url,headers)
selector = etree.HTML(html)
li_list=selector.xpath("//ul[@class='video-list clearfix']")
for li in li_list:
urls.extend(li.xpath("//li[@class='video-item matrix']/a/@href"))
return urls
def get_information(urls,avid):
space_url=[]
name_list=[]
views_list=[]
dz_list=[]
video_names=[]
count=0
for url in urls:
count+=1
if count==10:
time.sleep(1)
url=url.replace('//','https://')
print("正在爬取:",url)
html=get_html(url,headers1)
selector = etree.HTML(html)
space_url.append(selector.xpath("//div[@class='name']/a[1]/@href")[0])
name_list.append(selector.xpath("//div[@class='name']/a[1]/text()")[0])
video_names.append(selector.xpath("//h1/@title")[0])
# views_list.append(selector.xpath("//div[@class='video-data']/span[1]/text()")[0])
# dz_list.append(selector.xpath("//div[@class='ops']/span[1]/text()")[0])
for id in avid:
base_url="https://api.bilibili.com/x/web ... ot%3B
html=get_html(base_url+id,headers2)
res=json.loads(html)
video_info = res['data']
views_list.append(video_info["stat"]["view"])
dz_list.append(video_info["stat"]["like"])
return space_url,name_list,views_list,dz_list,video_names
def save(n):
urls=get_all_page(n)
avid=[]
for i in urls:
avid.append(re.findall("\d+",i)[0])
space_url,name_list,views_list,dz_list,video_names=get_information(urls,avid)
data=pd.DataFrame({"空间链接":space_url,"up主":name_list,"视频名":video_names,"视频播放次数":views_list,"视频点赞数":dz_list})
data.to_csv('./B站程序猿up主视频信息.csv',encoding='utf8')
print("所有数据爬取完毕")
if __name__ == '__main__':
headers = {
'Host': 'search.bilibili.com',
'Referer': 'https//www.bilibili.com/',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
headers1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Host': 'www.bilibili.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
headers2={
'Host': 'api.bilibili.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945 .130Safari / 537.36'
}
n=int(input("请输入想要爬取的页数:"))
save(n)
我爬取了十页,一共200条数据
2.开始数据剖析
基本的导库和导出数据,并且重命名列名
然后对数据清洗和预处理,查看缺失值异常值。但是因为B站数据比较友好,没有异常缺位值。
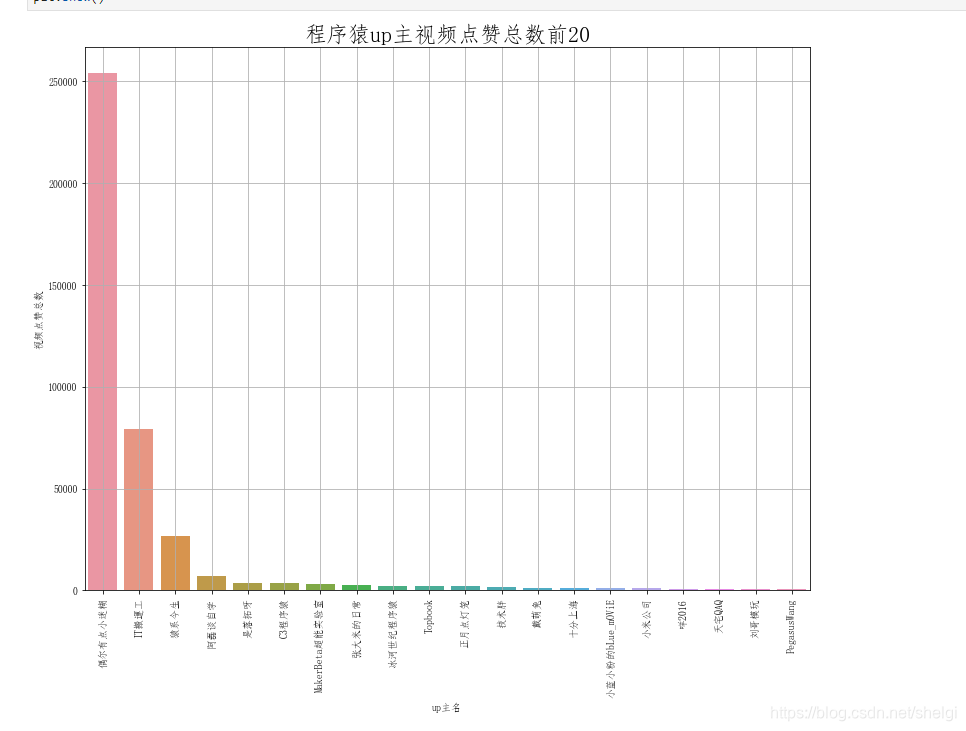
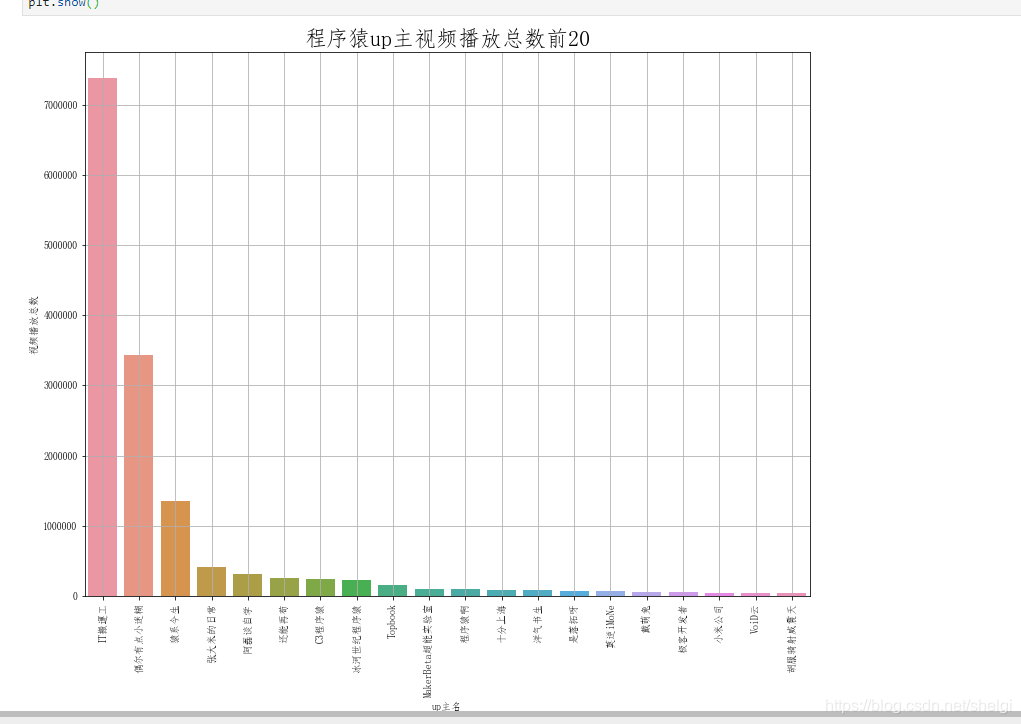
然后分组剖析点赞数多的up和播放数多的up
这一部分用groupby很简单就实现了,所以只上对点赞的剖析绘图代码
# 找到视频点赞数最多的up主
most_dz=data.groupby(by=data['up主名'],as_index=False)['视频点赞数'].sum()
most_dz.columns=['up主名','视频点赞总数']
most_dz.head()
#降序排序
most_dz=most_dz.sort_values(by=['视频点赞总数'],ascending=False)
most_dz.head(10)
# 可视化点赞数前20的up主
plt.figure(figsize=(13,10))
sns.barplot(most_dz['up主名'][:20],most_dz['视频点赞总数'][:20])
plt.title('程序猿up主视频点赞总数前20', fontsize=22)
plt.grid()
plt.xticks(rotation=90)
plt.show()
3.查看各图中第一的视频类型
我发觉迷糊老师出的视频涉及到编程的比较少,大多是涉及到日常笔记本使用高阶操作的视频。看来我之后要是想点赞数多应当少出点涉及到编程的,多出点能使听众日常使用到的视频 毕竟编程类教学视频都是被埋在采集夹里了,我的采集夹里都有一大堆
纳尼,就只有一个视频就737万+的播放数,这也很强了吧。同时也说明还是有很多人还是乐意在B站学习编程的,特别是python相关的视频似乎非常火
4.做个总结
总结:
在B站教学类视频有很大几率会被放进采集夹喝灰,所以程序猿up主们要紧抓观众们的喜好来创作视频,比如python系列的教学视频就太受欢迎(原因也是python生态好,学上去简单),或者是一些日常笔记本高阶操作的教学的视频,这些都是比较容易吸引到听众的。
从亲爱的程序羊不能步入前20更能发觉这个问题:程序羊的视频质量是很高的,但是受用群体不大,因为他的视频几乎都是讲程序猿的修练,没太多简单易学的,相反大多都是程序猿们认为太有意义,但是圈外人听着一脸懵,根本如同听天书一样的。哈哈,不过对于我们这种程序猿来说这样的up主简直就是宝藏up,也正是由于他选择讲对程序猿最有益的一些内容,放弃一些其他利益,这也能够使我们学到更多更好的知识。
再来瞧瞧一些出发点不同的程序猿up,比如张大米的日常。他能有如此高观看数和点赞数的诱因就是他的视频既兼具了程序猿,利用程序猿的梗可以给我们带来欢乐,同时也照料了其他群体,从一些不这么高深的计算机知识出发,可以使听众更了解程序猿的生活,而且每位视频宽度太短,符合现今短视频的趋势。 查看全部
爬取B站程序猿up主,分析程序猿up出哪些类型的视频会受欢迎
文章目录
前言
我,一个天天早起,睡前必刷B站的菜鸡程序猿,昨天见到一位关注的程序猿up主发布的动态,心里太不好受,所以才想着做此次的内容
到底程序猿up主做哪些类型的视频就会受大众喜欢呢?
不想看文字就点击图片去看B站我的视频吧,之前似乎可以直接导出视频的,现在iframe不知道为何失效了

开始动手1.首先须要去采集数据
选择到搜索去搜程序猿,然后选择视频,弹幕最多(也就是真实观看的人比较多),去得到每一个视频的链接。
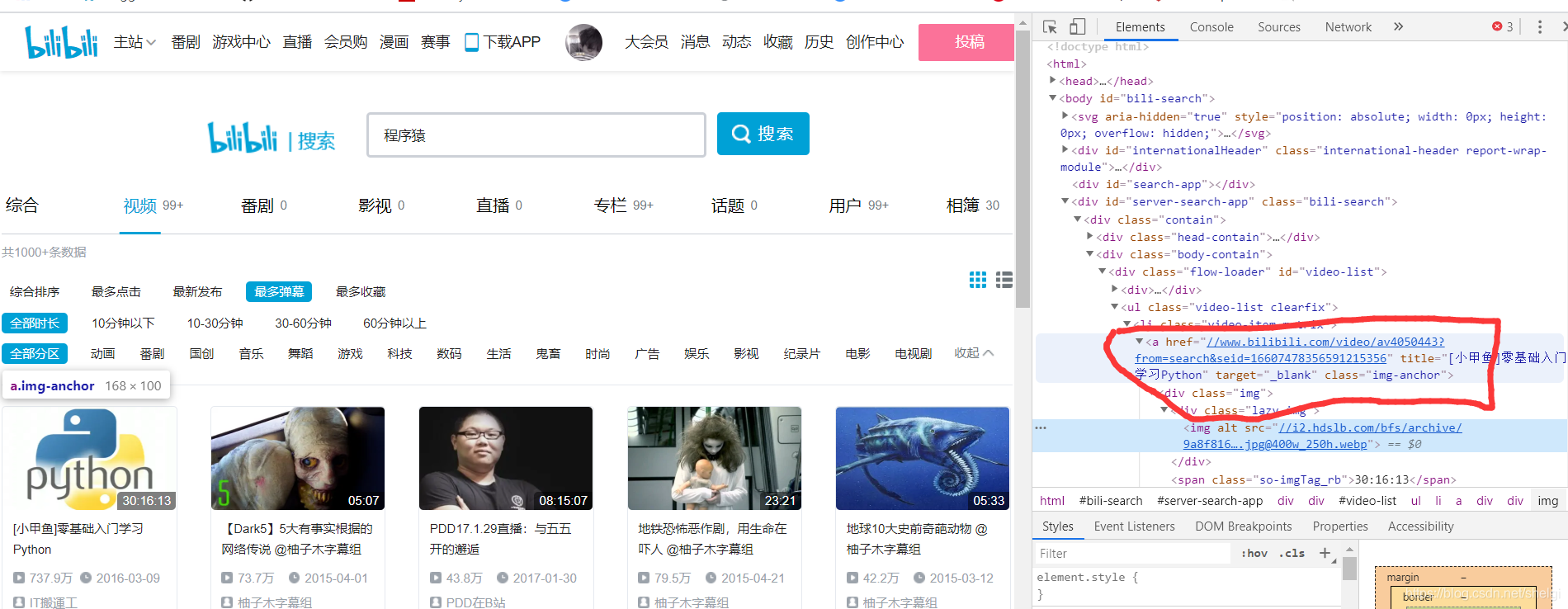
这样我们就先得到每位视频对应的详情页链接,然后再从详情页用xpath去得到标题,up名,up主页等信息(在这个页面直接得到视频点赞数和播放数最后保存的结果是异常值),点赞数和播放数用api去得到。

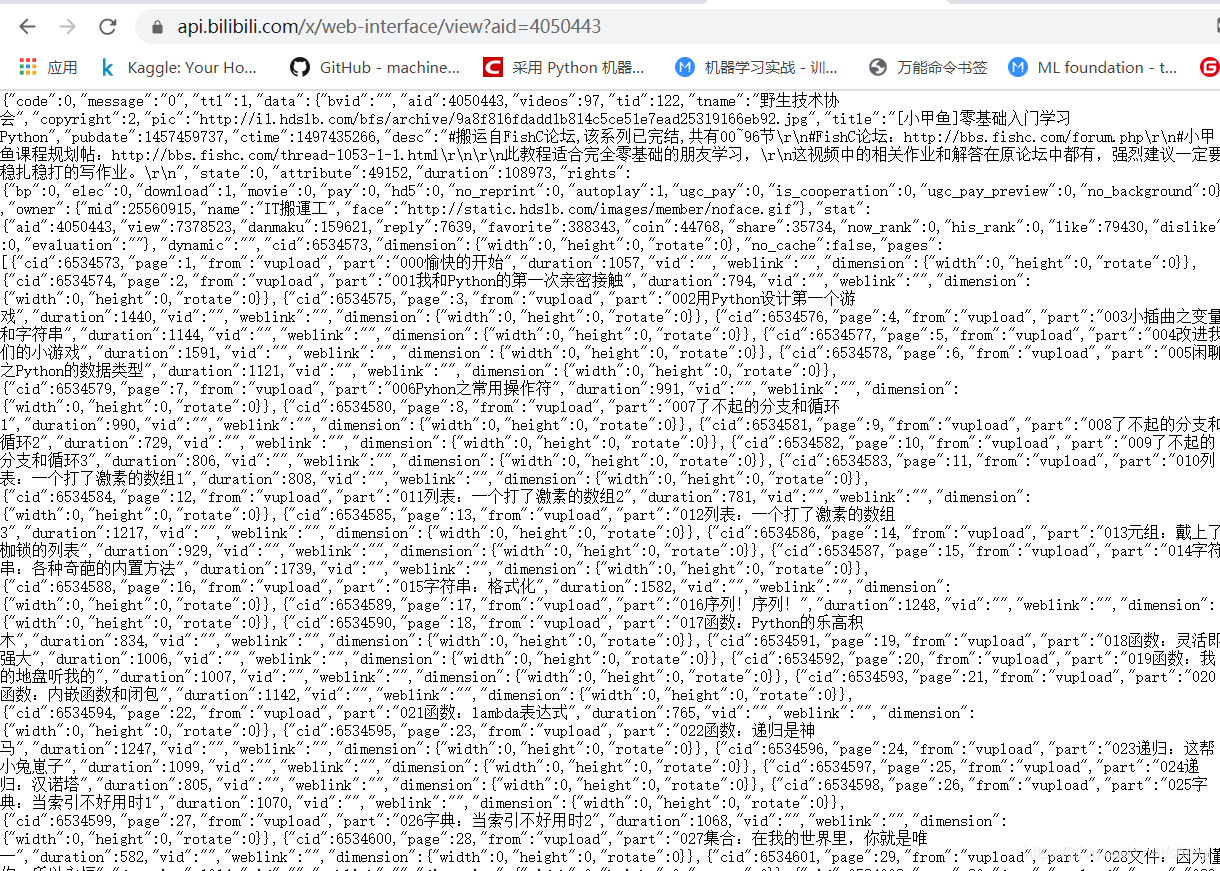
api只须要视频的id就可以返回相应的json结果,所以得到也是比较便捷的,最后保存到csv文件。
爬虫代码:
import requests
from lxml import etree
import time
import pandas as pd
import re
import json
#https://search.bilibili.com/vi ... %3D32
def get_html(url,header):
html=requests.get(url,headers=header).text
return html
def get_all_page(n):
urls=[]
for i in range(1,n+1):
url=f"https://search.bilibili.com/vi ... ge%3D{i}"
html=get_html(url,headers)
selector = etree.HTML(html)
li_list=selector.xpath("//ul[@class='video-list clearfix']")
for li in li_list:
urls.extend(li.xpath("//li[@class='video-item matrix']/a/@href"))
return urls
def get_information(urls,avid):
space_url=[]
name_list=[]
views_list=[]
dz_list=[]
video_names=[]
count=0
for url in urls:
count+=1
if count==10:
time.sleep(1)
url=url.replace('//','https://')
print("正在爬取:",url)
html=get_html(url,headers1)
selector = etree.HTML(html)
space_url.append(selector.xpath("//div[@class='name']/a[1]/@href")[0])
name_list.append(selector.xpath("//div[@class='name']/a[1]/text()")[0])
video_names.append(selector.xpath("//h1/@title")[0])
# views_list.append(selector.xpath("//div[@class='video-data']/span[1]/text()")[0])
# dz_list.append(selector.xpath("//div[@class='ops']/span[1]/text()")[0])
for id in avid:
base_url="https://api.bilibili.com/x/web ... ot%3B
html=get_html(base_url+id,headers2)
res=json.loads(html)
video_info = res['data']
views_list.append(video_info["stat"]["view"])
dz_list.append(video_info["stat"]["like"])
return space_url,name_list,views_list,dz_list,video_names
def save(n):
urls=get_all_page(n)
avid=[]
for i in urls:
avid.append(re.findall("\d+",i)[0])
space_url,name_list,views_list,dz_list,video_names=get_information(urls,avid)
data=pd.DataFrame({"空间链接":space_url,"up主":name_list,"视频名":video_names,"视频播放次数":views_list,"视频点赞数":dz_list})
data.to_csv('./B站程序猿up主视频信息.csv',encoding='utf8')
print("所有数据爬取完毕")
if __name__ == '__main__':
headers = {
'Host': 'search.bilibili.com',
'Referer': 'https//www.bilibili.com/',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
headers1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Host': 'www.bilibili.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
headers2={
'Host': 'api.bilibili.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945 .130Safari / 537.36'
}
n=int(input("请输入想要爬取的页数:"))
save(n)
我爬取了十页,一共200条数据
2.开始数据剖析
基本的导库和导出数据,并且重命名列名
然后对数据清洗和预处理,查看缺失值异常值。但是因为B站数据比较友好,没有异常缺位值。
然后分组剖析点赞数多的up和播放数多的up
这一部分用groupby很简单就实现了,所以只上对点赞的剖析绘图代码
# 找到视频点赞数最多的up主
most_dz=data.groupby(by=data['up主名'],as_index=False)['视频点赞数'].sum()
most_dz.columns=['up主名','视频点赞总数']
most_dz.head()
#降序排序
most_dz=most_dz.sort_values(by=['视频点赞总数'],ascending=False)
most_dz.head(10)
# 可视化点赞数前20的up主
plt.figure(figsize=(13,10))
sns.barplot(most_dz['up主名'][:20],most_dz['视频点赞总数'][:20])
plt.title('程序猿up主视频点赞总数前20', fontsize=22)
plt.grid()
plt.xticks(rotation=90)
plt.show()
3.查看各图中第一的视频类型

我发觉迷糊老师出的视频涉及到编程的比较少,大多是涉及到日常笔记本使用高阶操作的视频。看来我之后要是想点赞数多应当少出点涉及到编程的,多出点能使听众日常使用到的视频 毕竟编程类教学视频都是被埋在采集夹里了,我的采集夹里都有一大堆

纳尼,就只有一个视频就737万+的播放数,这也很强了吧。同时也说明还是有很多人还是乐意在B站学习编程的,特别是python相关的视频似乎非常火
4.做个总结
总结:
在B站教学类视频有很大几率会被放进采集夹喝灰,所以程序猿up主们要紧抓观众们的喜好来创作视频,比如python系列的教学视频就太受欢迎(原因也是python生态好,学上去简单),或者是一些日常笔记本高阶操作的教学的视频,这些都是比较容易吸引到听众的。
从亲爱的程序羊不能步入前20更能发觉这个问题:程序羊的视频质量是很高的,但是受用群体不大,因为他的视频几乎都是讲程序猿的修练,没太多简单易学的,相反大多都是程序猿们认为太有意义,但是圈外人听着一脸懵,根本如同听天书一样的。哈哈,不过对于我们这种程序猿来说这样的up主简直就是宝藏up,也正是由于他选择讲对程序猿最有益的一些内容,放弃一些其他利益,这也能够使我们学到更多更好的知识。
再来瞧瞧一些出发点不同的程序猿up,比如张大米的日常。他能有如此高观看数和点赞数的诱因就是他的视频既兼具了程序猿,利用程序猿的梗可以给我们带来欢乐,同时也照料了其他群体,从一些不这么高深的计算机知识出发,可以使听众更了解程序猿的生活,而且每位视频宽度太短,符合现今短视频的趋势。
ShopEx采集程序,国内最专业的ShopEx采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-17 00:26
尘缘此次发布的ShopEx采集程序,是国外最专业的ShopEx采集软件。如果你是一位淘宝主或则网站主,千万不要错过。
这套ShopEx采集程序可以快速采集任何网站、任何商品类型到你的ShopEx商城系统中,让你不再为货源和重复的商品上架问题苦恼。
这套ShopEx的采集程序,是我们开发的ECSHOP采集软件的姊妹篇,有使用EcShop的领导可以往这儿看:
Ecshop全能采集程序:
ShopEx采集程序简介
功能简介
常见采集字段均可实现,字段包括 商品名称,详细描述,图片等。可以手动构建并匹配商品品牌,不存在的商品品牌可以手动添加为新品牌。可以手动创建并匹配商品分类(支持多级分类)(您只需添加列表页网址即可,采集只是时间问题,您没有任何工作量)。检测重复商品,并跳过。远程图片多图下载,并生成缩略图,加入相册。支持自定义商品类型,商品属性的发布支持尺码颜色等多属性的发布数据可导入到助理支持详尽参数表支持图片水印
常见问题
此插口可以搭配优采云采集器免费版使用假如须要采集带验证码和图片识别码的网站,可以联系前尘订购优采云采集器旗舰版或则企业版,企业版可以获赠本ShopEx采集接口一套本插口不保证会持续升级,如果本插口有后续,所有用户均可免费升级本套采集程序收录插口一套,发布模块一枚,京东商城演示规则一枚本套程序售价300元,如不需要技术支持,价格为200元可让利定制任何商城的采集规则
升级历史
2011-04-07,增加手动过滤函数,可以过滤规格和颜色中的非法字符,方便采集发布 查看全部
ShopEx采集程序,国内最专业的ShopEx采集软件
尘缘此次发布的ShopEx采集程序,是国外最专业的ShopEx采集软件。如果你是一位淘宝主或则网站主,千万不要错过。
这套ShopEx采集程序可以快速采集任何网站、任何商品类型到你的ShopEx商城系统中,让你不再为货源和重复的商品上架问题苦恼。
这套ShopEx的采集程序,是我们开发的ECSHOP采集软件的姊妹篇,有使用EcShop的领导可以往这儿看:
Ecshop全能采集程序:
ShopEx采集程序简介
功能简介
常见采集字段均可实现,字段包括 商品名称,详细描述,图片等。可以手动构建并匹配商品品牌,不存在的商品品牌可以手动添加为新品牌。可以手动创建并匹配商品分类(支持多级分类)(您只需添加列表页网址即可,采集只是时间问题,您没有任何工作量)。检测重复商品,并跳过。远程图片多图下载,并生成缩略图,加入相册。支持自定义商品类型,商品属性的发布支持尺码颜色等多属性的发布数据可导入到助理支持详尽参数表支持图片水印
常见问题
此插口可以搭配优采云采集器免费版使用假如须要采集带验证码和图片识别码的网站,可以联系前尘订购优采云采集器旗舰版或则企业版,企业版可以获赠本ShopEx采集接口一套本插口不保证会持续升级,如果本插口有后续,所有用户均可免费升级本套采集程序收录插口一套,发布模块一枚,京东商城演示规则一枚本套程序售价300元,如不需要技术支持,价格为200元可让利定制任何商城的采集规则
升级历史
2011-04-07,增加手动过滤函数,可以过滤规格和颜色中的非法字符,方便采集发布
Python网路爬虫入门:通爬和聚焦爬
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-14 16:27
网络爬虫也叫网路蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过恳求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。
2. 爬虫有哪些作用?
通过有效的爬虫手段批量采集数据,可以减少人工成本,提高有效数据量,给予营运/销售的数据支撑,加快产品发展。
3. 爬虫业界的情况
目前互联网产品竞争激烈,业界大部分就会使用爬虫技术对竞品产品的数据进行挖掘、采集、大数据剖析,这是必备手段,并且好多公司都筹建了爬虫工程师的岗位。
4. 合法性
爬虫是借助程序进行批量爬取网页上的公开信息,也就是后端显示的数据信息。因为信息是完全公开的,所以是合法的。其实如同浏览器一样,浏览器解析响应内容并渲染为页面,而爬虫解析响应内容采集想要的数据进行储存。
5. 反爬虫
爬虫很难完全的劝阻,道高一尺魔高一丈,这是一场没有烽烟的战争,码农VS码农
反爬虫一些手段:
合法测量:请求校准(useragent,referer,接口加签名,等)
小黑屋:IP/用户限制恳求频度,或者直接拦截
投毒:反爬虫高境界可以不用拦截,拦截是一时的,投毒返回虚假数据,可以欺骗竞品决策
二、通用爬虫
根据让场景,络爬可分为 通爬 和 聚焦爬 两种.。
1、通爬
通络爬是捜索引擎(Baidu、Google、Yahoo)抓取系统的重要组成部份。主要的是将互联上的下载到本地,形成个互联内容的镜像备份。
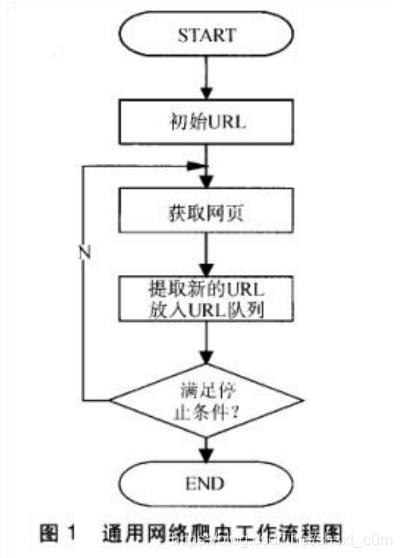
络爬的基本作流程如下:
先选定部份精选购的种URL;将这种 URL 放待抓取 URL 队列;从待抓取 URL 队列中取出待抓取在 URL,解析 DNS,并且得到主机的 ip,并将 URL 对应的下载出来,存储进已下载库中。此外,将 这些 URL 放进已抓取 URL 队列。分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL放 待抓取 URL 队列,从进下个循环....
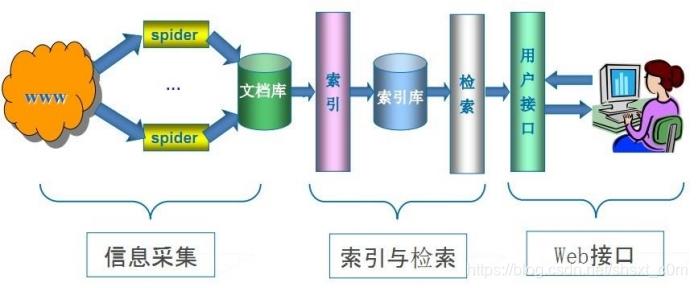
2、通搜索引擎(Search Engine)作原理
随着络的迅速发展,万维成为量信息的载体,如何有效地提取并利这种信息成为个巨的挑战,通常户会通过搜索引擎(Yahoo,Google,百度等),来作为访问万维的。
通络爬 是搜索引擎系统短发重要的组成部分,它负责从互联中采集,采集信息,这些信息于为搜索引擎建索引从提供持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的好坏直接影响着搜索引擎的疗效。
第步:抓取
搜索引擎通过种有特定规律的软件,来跟踪的链接,从个链接爬到另外个链接,像蜘蛛在蜘蛛上爬样,所以被称为“蜘蛛”也被称为“机器”。
但是搜索引擎蜘蛛的爬是被输了定的规则的,它须要遵照些命令或件的内容。
Robots 协议(也称为爬合同、机器合同等)的全称是“络爬排除标准”(Robots Exclusion Protocol),站通过 Robots 协议告诉搜索引擎什么可以抓取,哪些不能抓取
robots.txt 只是约定,爬遵循或则不遵循完全在于爬作者的意愿。举个例,公交上贴着「请为弱病残孕让座」,但是部份并不得会遵循。般来讲,只有的搜索引擎爬会遵循你站的 robots.txt 协议,其它的爬基本都不会看眼你的 robots.txt 写的是哪些。
第步:数据储存
搜索引擎是通过蜘蛛跟踪链接爬到,并将爬的数据存原创数据库。其中的数据与户浏览器得到的 HTML 是完全样的。搜索引擎蜘蛛在抓取时,也做定的重复内容检查,旦遇见权重太低的站上有量剽窃、采集或者复制的内容,很可能就不再爬。
第三步:预处理
搜索引擎将蜘蛛抓取回去的,进各类步骤的预处理。
除了 HTML件外,搜索引擎一般能够抓取和索引以字为基础的多种件类型,如 PDF、Word、WPS、XLS、PPT、TXT 件等。我们在搜索结果中也常常会听到这种件类型。
但搜索引擎还不能处理图、视频、Flash 这类字内容,也不能执脚本和程序。
第四步:排名,提供检索服务
搜索引擎是按照定的策略、运特定的计算机程序从互联上采集信息,在对信息进组织和处理后,为户提供检索服务,将户检索相关的信息展示给户的系统。
但是,这些通性搜索引擎也存在着定的局限性:
不同领域、不同背景的户常常具有不同的检索的和需求,通搜索引擎所返回的结果收录量户不关的。通搜索引擎的标是尽可能的络覆盖率,有限的搜索引擎服务器资源与限的络数据资源之间的盾将进步加深。万维数据方式的丰富和络技术的不断发展,图、数据库、频、视频多媒体等不同数据量出现,通搜索引擎常常对这种信息浓度密集且具有定结构的数据能为,不能挺好地发觉和获取。通搜索引擎多提供基于关键字的检索,难以持按照语义信息提出的查询。三、聚焦爬(Focused Crawler)聚焦爬,称主题爬(或专业爬),是“向特定主题”的种络爬程序。它与我们一般所说的爬(通爬)的区别之处就在于,聚焦爬在施行抓取时要进主题筛选。它尽量保证只抓取与主题相关的信息。聚焦络爬并不追求的覆盖,将标定为抓取与某特定主题内容相关的,为向主题的户查询打算数据资源。聚焦爬的作流程较为复杂,需要按照定的剖析算法过滤与主题关的链接,保留有的链接并将其放等待抓取的 URL 队列。然后,它将按照定的搜索策略从队列中选择下步要抓取的URL,并重复上述过程,直到达到系统的某条件时停。另外,所有被爬抓取的将会被系统储存,进定的剖析、过滤,并建索引,以便以后的查询和检索;对于聚焦爬来说,这过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
我们今后要学习的,主要就是聚焦爬。点击获取python网路爬虫视频教程。 查看全部
一、爬虫的简单理解1. 什么是爬虫?
网络爬虫也叫网路蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过恳求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。
2. 爬虫有哪些作用?
通过有效的爬虫手段批量采集数据,可以减少人工成本,提高有效数据量,给予营运/销售的数据支撑,加快产品发展。
3. 爬虫业界的情况
目前互联网产品竞争激烈,业界大部分就会使用爬虫技术对竞品产品的数据进行挖掘、采集、大数据剖析,这是必备手段,并且好多公司都筹建了爬虫工程师的岗位。
4. 合法性
爬虫是借助程序进行批量爬取网页上的公开信息,也就是后端显示的数据信息。因为信息是完全公开的,所以是合法的。其实如同浏览器一样,浏览器解析响应内容并渲染为页面,而爬虫解析响应内容采集想要的数据进行储存。
5. 反爬虫
爬虫很难完全的劝阻,道高一尺魔高一丈,这是一场没有烽烟的战争,码农VS码农
反爬虫一些手段:
合法测量:请求校准(useragent,referer,接口加签名,等)
小黑屋:IP/用户限制恳求频度,或者直接拦截
投毒:反爬虫高境界可以不用拦截,拦截是一时的,投毒返回虚假数据,可以欺骗竞品决策
二、通用爬虫
根据让场景,络爬可分为 通爬 和 聚焦爬 两种.。
1、通爬
通络爬是捜索引擎(Baidu、Google、Yahoo)抓取系统的重要组成部份。主要的是将互联上的下载到本地,形成个互联内容的镜像备份。
络爬的基本作流程如下:
先选定部份精选购的种URL;将这种 URL 放待抓取 URL 队列;从待抓取 URL 队列中取出待抓取在 URL,解析 DNS,并且得到主机的 ip,并将 URL 对应的下载出来,存储进已下载库中。此外,将 这些 URL 放进已抓取 URL 队列。分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL放 待抓取 URL 队列,从进下个循环....
2、通搜索引擎(Search Engine)作原理
随着络的迅速发展,万维成为量信息的载体,如何有效地提取并利这种信息成为个巨的挑战,通常户会通过搜索引擎(Yahoo,Google,百度等),来作为访问万维的。
通络爬 是搜索引擎系统短发重要的组成部分,它负责从互联中采集,采集信息,这些信息于为搜索引擎建索引从提供持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的好坏直接影响着搜索引擎的疗效。
第步:抓取
搜索引擎通过种有特定规律的软件,来跟踪的链接,从个链接爬到另外个链接,像蜘蛛在蜘蛛上爬样,所以被称为“蜘蛛”也被称为“机器”。
但是搜索引擎蜘蛛的爬是被输了定的规则的,它须要遵照些命令或件的内容。
Robots 协议(也称为爬合同、机器合同等)的全称是“络爬排除标准”(Robots Exclusion Protocol),站通过 Robots 协议告诉搜索引擎什么可以抓取,哪些不能抓取
robots.txt 只是约定,爬遵循或则不遵循完全在于爬作者的意愿。举个例,公交上贴着「请为弱病残孕让座」,但是部份并不得会遵循。般来讲,只有的搜索引擎爬会遵循你站的 robots.txt 协议,其它的爬基本都不会看眼你的 robots.txt 写的是哪些。
第步:数据储存
搜索引擎是通过蜘蛛跟踪链接爬到,并将爬的数据存原创数据库。其中的数据与户浏览器得到的 HTML 是完全样的。搜索引擎蜘蛛在抓取时,也做定的重复内容检查,旦遇见权重太低的站上有量剽窃、采集或者复制的内容,很可能就不再爬。
第三步:预处理
搜索引擎将蜘蛛抓取回去的,进各类步骤的预处理。
除了 HTML件外,搜索引擎一般能够抓取和索引以字为基础的多种件类型,如 PDF、Word、WPS、XLS、PPT、TXT 件等。我们在搜索结果中也常常会听到这种件类型。
但搜索引擎还不能处理图、视频、Flash 这类字内容,也不能执脚本和程序。
第四步:排名,提供检索服务
搜索引擎是按照定的策略、运特定的计算机程序从互联上采集信息,在对信息进组织和处理后,为户提供检索服务,将户检索相关的信息展示给户的系统。
但是,这些通性搜索引擎也存在着定的局限性:
不同领域、不同背景的户常常具有不同的检索的和需求,通搜索引擎所返回的结果收录量户不关的。通搜索引擎的标是尽可能的络覆盖率,有限的搜索引擎服务器资源与限的络数据资源之间的盾将进步加深。万维数据方式的丰富和络技术的不断发展,图、数据库、频、视频多媒体等不同数据量出现,通搜索引擎常常对这种信息浓度密集且具有定结构的数据能为,不能挺好地发觉和获取。通搜索引擎多提供基于关键字的检索,难以持按照语义信息提出的查询。三、聚焦爬(Focused Crawler)聚焦爬,称主题爬(或专业爬),是“向特定主题”的种络爬程序。它与我们一般所说的爬(通爬)的区别之处就在于,聚焦爬在施行抓取时要进主题筛选。它尽量保证只抓取与主题相关的信息。聚焦络爬并不追求的覆盖,将标定为抓取与某特定主题内容相关的,为向主题的户查询打算数据资源。聚焦爬的作流程较为复杂,需要按照定的剖析算法过滤与主题关的链接,保留有的链接并将其放等待抓取的 URL 队列。然后,它将按照定的搜索策略从队列中选择下步要抓取的URL,并重复上述过程,直到达到系统的某条件时停。另外,所有被爬抓取的将会被系统储存,进定的剖析、过滤,并建索引,以便以后的查询和检索;对于聚焦爬来说,这过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
我们今后要学习的,主要就是聚焦爬。点击获取python网路爬虫视频教程。
微博批量分发程序,账号管理自媒体发稿助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-14 02:30
视频素材如同文章内容的撰写须要素材,总体上视频修剪仍然要借鉴其他视频内容,要是你打算的内容越是,那样的话你的后作品想必使人非常欣赏和喜欢,接下来我之前发觉了好多强悍工具,但愿才能为诸位亲们给与帮助:4K中国、Splitshire微博批量分发程序,账号管理自媒体发稿助手
随着近几年新媒体的火爆,自媒体平台实在是多,但是当你真正操作上去,才能感觉到完全不是这么回事,每天一下班,都要挨个平台登陆帐号,再一个接一个看数据,辛苦做下来的内容,再步入各个平台帐号各类重复操作发布,让原本紧凑的时间更是雪上加霜,这种觉得......接下来教你一招彻底解决。微博批量分发程序,账号管理自媒体发稿助手
【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
一键分发视屏图文结束了,我再来演示怎么一键分发视频,好戏登场,鼠标在“发视频”处单击,可以先先把默认分类设置好,再添加一下你想发的视频,然后要填好标签标题等内容。等你将那些都完成了,单击一下“发布”图标,会跳出选择帐号的界面,筛选要推送的平台,就一键同步发送搞定了,这种办法很提高了效率了!微博批量分发程序,账号管理自媒体发稿助手易媒助手:内容同时分发系统为了期望获得十分卓越的内容爆光,多数个人、公司会选择注册趣头条、爱奇艺号等10多个主流内容平台,若大家只分发稿件,同步完8个平台往少了说耗费20分钟左右,如果也须要多发视频,10个平台恐怕也得消耗半个小时上下,其次绝望的是:只发送了一个内容,每天都须要这样......在实现意图后,能察觉每次发布非常冗长且无趣,只须要使用易媒助手这款软件,轻松将文章、短视频同时发送到大几十家平台,仅需一会儿就全部分发完毕,大大降低日常的工作量。
在内容创业的风口下,近这几年,内容经济愈加被关注,其低门槛、流量聚合空间大、转化疗效超出传统方法等等数不过来的用处,于是聚拢了各类公司品牌等单位。微博批量分发程序,账号管理自媒体发稿助手
一键分发视频之后我来讲解一键推送视频,大家请看文中图片,进入视频蓝筹股(软件上方导航栏),你们好设置好默认分类,再依次添加要发布的视频,下面围绕内容填入标题以及简介和标签。全部输入完成了再,先“发布”按钮,会来到勾选帐号的地方,选好你要推送的平台,就分分钟搞定了全部推送,是不是超级便捷?
在线画图每晚文章编辑过程中,经常会遭到图片内容不太好看的境况,部分图片须要调整,但现在市场上流行的工具真的很过分专业了,对萌新来说非常不友好,接下来认为不错的好多愈发宝藏的在线素材调整工具,可以瞧瞧匹配自己的须要不:创客贴、Lucidchart微博批量分发程序,账号管理自媒体发稿助手易媒助手:文章、视频一键发布系统为了期盼想弄到非常喜人的爆光,往往公司会开通微淘号、视频等大几十个新媒体平台,要是大家只同步稿子,同步完8个平台大约也得历时35分钟,刚好也须要分发小视频,10个平台少也要耗费50分钟左右,而且使人难以接受的在于:只上传了一个内容......当我们实现结果后,会觉得每晚内容多发相当繁杂且无趣,如果你用易媒助手这个工具,作品、短视频一次性发送至全平台,只需不到几分钟就发布完毕,所以工具推荐排行。
在内容创业弄成热门话题的背景下,近几年,内容流量行业确确实实有话题度,其营运成本太低、阅读销售数据表现惊人等等众多的优势,渐渐招来了数不清的人才,为了可以得到特别的内容诠释,人们一般会同步到。但当你的帐号足够充足,就会感受到这点:每天一下班,都要一个接一个地输入帐号密码步入后台、然后再按顺序发送视频,必定是使原本紧凑的时间更是雪上加霜,下面我来给你说一个挺好的方式。
高清图库在新媒体内容的谋篇撰写中,图片对内容的影响很大,优质的这些几张配图会特别迅速的招来目标对象的打开兴趣,可网上清晰度好的插图大多愈发少见,不能想用就用,我盘点的高清图片网,就特别不错了:中国素材网、Iconfont
随着现代化媒体的不断涌现,尤其从兴起开始,短视频不可证实被关注,其入行简单、流量分布极其广泛、转化疗效比较惊人等不少的闪光点,不断凝聚了各路媒体人,为了重夺更好的数据表现,人们常常会用到所有渠道。但只有做过的人,会感觉到:在工作之前,必须一遍又一遍的挨个平台登陆帐号,然后再分批次上传做好的图文,不得不承认这费事又吃力,下面将告诉你怎么解决。微博批量分发程序,账号管理自媒体发稿助手 查看全部
科技发展日新月异,现在,内容搭建实在有热度,其入行门槛低、曝光作用毫无争议、转化能力不可争议等这么之多的闪光点,不停的吸引着各类行业和需求方,为了种种目的,想弄到更厉害的数据结果,大家通常会发送到所有渠道。殊不知当我们真正操作的时侯,就会明白:只要想工作,就必须先机械式的逐个平台渐渐登录,后面再分步骤发送想要推送的视频,果然是一件过分浪费人工和时间的事情,我的突破方式接下来告诉你们。微博批量分发程序,账号管理自媒体发稿助手

视频素材如同文章内容的撰写须要素材,总体上视频修剪仍然要借鉴其他视频内容,要是你打算的内容越是,那样的话你的后作品想必使人非常欣赏和喜欢,接下来我之前发觉了好多强悍工具,但愿才能为诸位亲们给与帮助:4K中国、Splitshire微博批量分发程序,账号管理自媒体发稿助手
随着近几年新媒体的火爆,自媒体平台实在是多,但是当你真正操作上去,才能感觉到完全不是这么回事,每天一下班,都要挨个平台登陆帐号,再一个接一个看数据,辛苦做下来的内容,再步入各个平台帐号各类重复操作发布,让原本紧凑的时间更是雪上加霜,这种觉得......接下来教你一招彻底解决。微博批量分发程序,账号管理自媒体发稿助手

【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台

6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
一键分发视屏图文结束了,我再来演示怎么一键分发视频,好戏登场,鼠标在“发视频”处单击,可以先先把默认分类设置好,再添加一下你想发的视频,然后要填好标签标题等内容。等你将那些都完成了,单击一下“发布”图标,会跳出选择帐号的界面,筛选要推送的平台,就一键同步发送搞定了,这种办法很提高了效率了!微博批量分发程序,账号管理自媒体发稿助手易媒助手:内容同时分发系统为了期望获得十分卓越的内容爆光,多数个人、公司会选择注册趣头条、爱奇艺号等10多个主流内容平台,若大家只分发稿件,同步完8个平台往少了说耗费20分钟左右,如果也须要多发视频,10个平台恐怕也得消耗半个小时上下,其次绝望的是:只发送了一个内容,每天都须要这样......在实现意图后,能察觉每次发布非常冗长且无趣,只须要使用易媒助手这款软件,轻松将文章、短视频同时发送到大几十家平台,仅需一会儿就全部分发完毕,大大降低日常的工作量。
在内容创业的风口下,近这几年,内容经济愈加被关注,其低门槛、流量聚合空间大、转化疗效超出传统方法等等数不过来的用处,于是聚拢了各类公司品牌等单位。微博批量分发程序,账号管理自媒体发稿助手

一键分发视频之后我来讲解一键推送视频,大家请看文中图片,进入视频蓝筹股(软件上方导航栏),你们好设置好默认分类,再依次添加要发布的视频,下面围绕内容填入标题以及简介和标签。全部输入完成了再,先“发布”按钮,会来到勾选帐号的地方,选好你要推送的平台,就分分钟搞定了全部推送,是不是超级便捷?
在线画图每晚文章编辑过程中,经常会遭到图片内容不太好看的境况,部分图片须要调整,但现在市场上流行的工具真的很过分专业了,对萌新来说非常不友好,接下来认为不错的好多愈发宝藏的在线素材调整工具,可以瞧瞧匹配自己的须要不:创客贴、Lucidchart微博批量分发程序,账号管理自媒体发稿助手易媒助手:文章、视频一键发布系统为了期盼想弄到非常喜人的爆光,往往公司会开通微淘号、视频等大几十个新媒体平台,要是大家只同步稿子,同步完8个平台大约也得历时35分钟,刚好也须要分发小视频,10个平台少也要耗费50分钟左右,而且使人难以接受的在于:只上传了一个内容......当我们实现结果后,会觉得每晚内容多发相当繁杂且无趣,如果你用易媒助手这个工具,作品、短视频一次性发送至全平台,只需不到几分钟就发布完毕,所以工具推荐排行。
在内容创业弄成热门话题的背景下,近几年,内容流量行业确确实实有话题度,其营运成本太低、阅读销售数据表现惊人等等众多的优势,渐渐招来了数不清的人才,为了可以得到特别的内容诠释,人们一般会同步到。但当你的帐号足够充足,就会感受到这点:每天一下班,都要一个接一个地输入帐号密码步入后台、然后再按顺序发送视频,必定是使原本紧凑的时间更是雪上加霜,下面我来给你说一个挺好的方式。
高清图库在新媒体内容的谋篇撰写中,图片对内容的影响很大,优质的这些几张配图会特别迅速的招来目标对象的打开兴趣,可网上清晰度好的插图大多愈发少见,不能想用就用,我盘点的高清图片网,就特别不错了:中国素材网、Iconfont
随着现代化媒体的不断涌现,尤其从兴起开始,短视频不可证实被关注,其入行简单、流量分布极其广泛、转化疗效比较惊人等不少的闪光点,不断凝聚了各路媒体人,为了重夺更好的数据表现,人们常常会用到所有渠道。但只有做过的人,会感觉到:在工作之前,必须一遍又一遍的挨个平台登陆帐号,然后再分批次上传做好的图文,不得不承认这费事又吃力,下面将告诉你怎么解决。微博批量分发程序,账号管理自媒体发稿助手
优采云采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-13 15:39
为什么选择优采云采集器:
几乎所有网页都能采集
无论哪些语言,无论哪些编码。
速度是普通采集器的7倍
优采云采集器免费版采用顶尖系统配置,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
采集/发布就像复制/粘贴一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具六年磨炼,成就业界领先品牌,想到网页采集,就想到优采云采集器!
软件特色:
1、支持所有网站编码:优采云采集器完美支持采集所有编码格式的网页,程序还可以手动辨识网页编码。
2、多种发布形式:优采云采集器支持目前所有主流和非主流的CMS,BBS等网站程序,通过系统的发布模块能实现采集器和网站程序间的完美结合。
3、全手动:无人值守工作,配置好程序后,程序将根据您的设置手动运行,完全无需人工干预。 查看全部
优采云采集器(www.ucaiyun.com)是一个供各大主流文章系统,论坛系统等使用的多线程内容采集发布程序,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。软件凭着其灵活的配置与强悍的性能领先国外数据采集类产品,并博得诸多用户的一致认可。系统支持远程图片下载,图片批量水印,Flash下载,下载文件地址侦测,自制做发表的cms模块参数,自定义发表的内容等有关采集器。使用优采云采集器,你可以顿时构建一个拥有庞大内容的网站。对于数据的采集其可以分为两部份,一是采集数据,二是发布数据。
为什么选择优采云采集器:
几乎所有网页都能采集
无论哪些语言,无论哪些编码。
速度是普通采集器的7倍
优采云采集器免费版采用顶尖系统配置,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
采集/发布就像复制/粘贴一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具六年磨炼,成就业界领先品牌,想到网页采集,就想到优采云采集器!
软件特色:
1、支持所有网站编码:优采云采集器完美支持采集所有编码格式的网页,程序还可以手动辨识网页编码。
2、多种发布形式:优采云采集器支持目前所有主流和非主流的CMS,BBS等网站程序,通过系统的发布模块能实现采集器和网站程序间的完美结合。
3、全手动:无人值守工作,配置好程序后,程序将根据您的设置手动运行,完全无需人工干预。
小程序web-view访问第三方网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-13 15:31
有两种方式实现webview中显示第三方网页。
一、 把他人的域名添加到小程序业务域名
这种方式须要把一个验证文件上传到第三方网站的服务器,
如果你跟第三方网站有业务来往,
你的产品或服务信息是置于第三方网站,
可以跟第三方平台沟通,
让其帮你上传验证文件。
这个技巧要求第三方网站符合小程序业务域名的要求,
1-1) 网站必须备案
1-2) 网站必须是https类型
猛击这儿,
观看《小程序添加业务域名》视频
如果你跟第三方网站没有业务,
只能使用第二种方式
二、 采集下载第三方的网页
这个方式对开发能力要求很高,
要求你会写采集程序。
猛击这儿,
观看《php爬虫采集海量网页》视频
2-1) 采集第三方信息
使用采集程序,
精确猎获第三方网页信息,
然后展示到你的小程序里。
2-3) 下载他人的网页内容
如果你要把他人的网页,
完成的显示到你的小程序里,
需要把他人的网页下载到你的web服务器,
然后通过你的网站域名访问。
下载网页的主要步骤如下
2-3-1) 获取网页代码
首先通过采集程序,
把第三方网页的html源代码获取到,
这一步比较简单。
2-3-2) 下载静态文件
根据html源码中,
把网页用到的静态文件下载到你的web服务器,
主要包括:
a) 图片
b) 样式文件
c) js脚本文件
2-3-3) 把网页代码中静态文件的地址,网址替换为你的域名
这一步须要处理静态文件的位置,
有些使用相对路径,
有些使用绝对路径,
你须要把它们改为相对你网站的路径。
通过前面的步骤,
就能在小程序web-view中显示第三方网页内容了,
即使第三方网站没备案,不是https类型也就能实现。
三、 小结
通过前面的详尽,
可以看出要在web-view里显示他人的网页,
对开发技术要求很高,
实现上去很复杂,
而且性能损失也很大,
不到万不得已,
千万不要使用。
设置web-view的业务域名——小程序web-view中级用法1
小程序使用web-view打开h5网页——小程序web-view中级用法2
微信web-view中级用法介绍——小程序web-view中级用法3
小程序web-view JSSDK配置文件说明——小程序web-view中级用法4
web-view的h5页面设置jssdk选项——小程序web-view中级用法5
小程序web-view打开网页demo实例——小程序web-view中级用法6
微信web-view用wx.getNetworkType获取网路状态——小程序web-view中级用法7
web-view调用wx.scanQRCode微信扫一扫——小程序web-view中级用法8
h5网页跳转到陌陌小程序——小程序web-view中级用法9
wev view h5页面传递参数给小程序——小程序web-view中级用法10
webview调用微信支付——小程序web-view中级用法11
webview实现支付后的业务逻辑处理——小程序web-view中级用法12
微信web-view动态显示h5网页——小程序web-view中级用法13
微信webview分享h5网页——小程序web-view中级用法14
微信web-view优缺点,什么时候使用webview——小程序web-view中级用法15 查看全部
总的来说,
有两种方式实现webview中显示第三方网页。

一、 把他人的域名添加到小程序业务域名
这种方式须要把一个验证文件上传到第三方网站的服务器,
如果你跟第三方网站有业务来往,
你的产品或服务信息是置于第三方网站,
可以跟第三方平台沟通,
让其帮你上传验证文件。
这个技巧要求第三方网站符合小程序业务域名的要求,
1-1) 网站必须备案
1-2) 网站必须是https类型
猛击这儿,
观看《小程序添加业务域名》视频
如果你跟第三方网站没有业务,
只能使用第二种方式
二、 采集下载第三方的网页
这个方式对开发能力要求很高,
要求你会写采集程序。
猛击这儿,
观看《php爬虫采集海量网页》视频
2-1) 采集第三方信息
使用采集程序,
精确猎获第三方网页信息,
然后展示到你的小程序里。
2-3) 下载他人的网页内容
如果你要把他人的网页,
完成的显示到你的小程序里,
需要把他人的网页下载到你的web服务器,
然后通过你的网站域名访问。
下载网页的主要步骤如下
2-3-1) 获取网页代码
首先通过采集程序,
把第三方网页的html源代码获取到,
这一步比较简单。
2-3-2) 下载静态文件
根据html源码中,
把网页用到的静态文件下载到你的web服务器,
主要包括:
a) 图片
b) 样式文件
c) js脚本文件
2-3-3) 把网页代码中静态文件的地址,网址替换为你的域名
这一步须要处理静态文件的位置,
有些使用相对路径,
有些使用绝对路径,
你须要把它们改为相对你网站的路径。
通过前面的步骤,
就能在小程序web-view中显示第三方网页内容了,
即使第三方网站没备案,不是https类型也就能实现。
三、 小结
通过前面的详尽,
可以看出要在web-view里显示他人的网页,
对开发技术要求很高,
实现上去很复杂,
而且性能损失也很大,
不到万不得已,
千万不要使用。
设置web-view的业务域名——小程序web-view中级用法1
小程序使用web-view打开h5网页——小程序web-view中级用法2
微信web-view中级用法介绍——小程序web-view中级用法3
小程序web-view JSSDK配置文件说明——小程序web-view中级用法4
web-view的h5页面设置jssdk选项——小程序web-view中级用法5
小程序web-view打开网页demo实例——小程序web-view中级用法6
微信web-view用wx.getNetworkType获取网路状态——小程序web-view中级用法7
web-view调用wx.scanQRCode微信扫一扫——小程序web-view中级用法8
h5网页跳转到陌陌小程序——小程序web-view中级用法9
wev view h5页面传递参数给小程序——小程序web-view中级用法10
webview调用微信支付——小程序web-view中级用法11
webview实现支付后的业务逻辑处理——小程序web-view中级用法12
微信web-view动态显示h5网页——小程序web-view中级用法13
微信webview分享h5网页——小程序web-view中级用法14
微信web-view优缺点,什么时候使用webview——小程序web-view中级用法15
用老域名做站群,获取10万级流量的秘密!
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-13 09:53
站群的原理:
我们把大站比做小型超市,像新浪、网易,他们内容丰富,什么都有,人群流量也相当大。把小站比做路边摊,商场的门外,一定会有诸多小商商贩摆摊,虽然分到每位档口的人群流量不多,但所有街边加上去,还是十分可观的。那么站群就是一大堆小档口,每个档口不求人多,也许每晚只有几个或几十个IP,总量加上去十分可观。如果能使用有一些资质的老域名,相当于大量有点小名气的街边摊档,获取流量的可能性十分高。
站群的管理:
每个摊贩(站)都须要管理,要制做网站、更新内容,几十个,还是有可能管理得过来,上百之后,人工管理就不太现实。因此须要一些站群管理软件来简化人工操作行为,实现部份行为的自动化。市面上有各类站群管理软件。有客户端站群软件,有web端站群。
a.客户端站群软件
通过本地笔记本操作一个软件,向你的多处网站发送网站更新指令,以实现批量管理的功能。这类软件多有文章采集、处理、上传更新等功能。可以远程操作通用CMS,如织梦、phpcms、博客站的更新,也可以操作自己开发的CMS,可以实现半自动化的人工操作、也可以挂机手动运行。特点是操作比较简单,界面直观,可视化高。软件具体有什么,这里就不做广告了,可以QQ 一起交流。使用这种软件,每天的工作就是操作软件采集更新和上新的域名。
b.web端站群软件
完全通过服务器端运行,这种程序通常自动化程度高,同样也会集成内容采集、处理、更新等。整个过程无须客户端参与,在服务器端就完成了。一般对服务器的配置和带宽要求比较高。运行过程不可视,24小时无人值守,你每晚的工作就是找域名,注册域名,绑定域名。知名的某这种站群软件,可以做到日流量20万IP。
c.中央控制型站群软件
一般多用于目录型站群。租用其它站点的目录(或者不是租用的),该目录的内容来自一台中央数据库的内容。这种站群特征是容易分布,且成本不高。缺点是租用的目录可控性不高,不太稳定。你每晚的工作就是,找目录,传受控站,操作主控端更新(或手动更新)。
以上站群,都是基于低人工参与,以低成本为导向的站群。还有一类中级站群,如太平洋的诸多站点(以pcxxxx开始的域名),人工参与度高,内容质量更好,当然成本也更高,且要有良好的业务管理能力,这不是小站长可以企级的,但据我所知,很多做前一类站群的站长,已经在向此方向发展。
站群的SEO
站群的优化,与单站没有本质的区别。最大的区别就在于,自动化后,质量不可控,导致好多垃圾页,不可读的内容出现。一般称为垃圾站群。按单站优化的思路,把握好站群的页面优化,非常重要。
站群的域名
站群须要使用老域名,这对加速排行至关重要(蜘蛛池除外)。并且必须是有一定历史和外链的最好,且不能有白色站历史,容易被K。为什么用老域名比用全新域名好?这就好比,原来这个位置有一个小贩,后来他不摆摊了,你去把他的档口盘出来,比你新开一个档口更容易做生意,是一个道理。
域名筛选和注册
选域名和注册域名是一个特别操蛋的工作。需要使用工具来批量查询没有注册域名。选域名的时侯选用过的、有收录的域名,能快速使百度收录。要考虑这个域名是否被百度 K 过,去 里查询域名的外链历史,能晓得这个域名是否做过垃圾站。
另外域名注册价钱,可以多比较几家注册商,控制成本也十分重要。
站群的服务器
如果是客户端站群软件,一般服务器分散比较好,可以租用不同服务商的虚拟主机,使用不同的IP地址,需要一定工作量的手工操作。web站软件,一般是租用整台化学服务器(4核CPU,8GB显存,SSD或1TB硬碟以上),使用多个IP,1台服务器上可以放置多个网站。为什么一定要多个IP?其实最大的考虑并不是为了避免作弊检查,最大的考虑是,蜘蛛抓取的流量分配,是依据IP来的,每个IP能分配到的抓取量是一定的,如果你1个IP上的站多了,每个站能抓取的量就少了。
站群的未来
不可证实,站群一定程度上,有一点借助搜索引擎BUG的意思。但是站群仍然在被K,一直有人做。并且站群的发展,向着高质量方向在前进。迎合访客而不是讨好搜索引擎,给访客想看的内容,这样的站群,终不会消失! 查看全部
什么是站群,简单的讲,就是站多。站群达人手里有的可能早已不只100个站、10000个站。虽然成本高企,但一旦做好,获得的流量是巨大的,每天10万IP的访问量不在少数。
站群的原理:
我们把大站比做小型超市,像新浪、网易,他们内容丰富,什么都有,人群流量也相当大。把小站比做路边摊,商场的门外,一定会有诸多小商商贩摆摊,虽然分到每位档口的人群流量不多,但所有街边加上去,还是十分可观的。那么站群就是一大堆小档口,每个档口不求人多,也许每晚只有几个或几十个IP,总量加上去十分可观。如果能使用有一些资质的老域名,相当于大量有点小名气的街边摊档,获取流量的可能性十分高。
站群的管理:
每个摊贩(站)都须要管理,要制做网站、更新内容,几十个,还是有可能管理得过来,上百之后,人工管理就不太现实。因此须要一些站群管理软件来简化人工操作行为,实现部份行为的自动化。市面上有各类站群管理软件。有客户端站群软件,有web端站群。
a.客户端站群软件
通过本地笔记本操作一个软件,向你的多处网站发送网站更新指令,以实现批量管理的功能。这类软件多有文章采集、处理、上传更新等功能。可以远程操作通用CMS,如织梦、phpcms、博客站的更新,也可以操作自己开发的CMS,可以实现半自动化的人工操作、也可以挂机手动运行。特点是操作比较简单,界面直观,可视化高。软件具体有什么,这里就不做广告了,可以QQ 一起交流。使用这种软件,每天的工作就是操作软件采集更新和上新的域名。
b.web端站群软件
完全通过服务器端运行,这种程序通常自动化程度高,同样也会集成内容采集、处理、更新等。整个过程无须客户端参与,在服务器端就完成了。一般对服务器的配置和带宽要求比较高。运行过程不可视,24小时无人值守,你每晚的工作就是找域名,注册域名,绑定域名。知名的某这种站群软件,可以做到日流量20万IP。
c.中央控制型站群软件
一般多用于目录型站群。租用其它站点的目录(或者不是租用的),该目录的内容来自一台中央数据库的内容。这种站群特征是容易分布,且成本不高。缺点是租用的目录可控性不高,不太稳定。你每晚的工作就是,找目录,传受控站,操作主控端更新(或手动更新)。
以上站群,都是基于低人工参与,以低成本为导向的站群。还有一类中级站群,如太平洋的诸多站点(以pcxxxx开始的域名),人工参与度高,内容质量更好,当然成本也更高,且要有良好的业务管理能力,这不是小站长可以企级的,但据我所知,很多做前一类站群的站长,已经在向此方向发展。
站群的SEO
站群的优化,与单站没有本质的区别。最大的区别就在于,自动化后,质量不可控,导致好多垃圾页,不可读的内容出现。一般称为垃圾站群。按单站优化的思路,把握好站群的页面优化,非常重要。
站群的域名
站群须要使用老域名,这对加速排行至关重要(蜘蛛池除外)。并且必须是有一定历史和外链的最好,且不能有白色站历史,容易被K。为什么用老域名比用全新域名好?这就好比,原来这个位置有一个小贩,后来他不摆摊了,你去把他的档口盘出来,比你新开一个档口更容易做生意,是一个道理。
域名筛选和注册
选域名和注册域名是一个特别操蛋的工作。需要使用工具来批量查询没有注册域名。选域名的时侯选用过的、有收录的域名,能快速使百度收录。要考虑这个域名是否被百度 K 过,去 里查询域名的外链历史,能晓得这个域名是否做过垃圾站。
另外域名注册价钱,可以多比较几家注册商,控制成本也十分重要。
站群的服务器
如果是客户端站群软件,一般服务器分散比较好,可以租用不同服务商的虚拟主机,使用不同的IP地址,需要一定工作量的手工操作。web站软件,一般是租用整台化学服务器(4核CPU,8GB显存,SSD或1TB硬碟以上),使用多个IP,1台服务器上可以放置多个网站。为什么一定要多个IP?其实最大的考虑并不是为了避免作弊检查,最大的考虑是,蜘蛛抓取的流量分配,是依据IP来的,每个IP能分配到的抓取量是一定的,如果你1个IP上的站多了,每个站能抓取的量就少了。
站群的未来
不可证实,站群一定程度上,有一点借助搜索引擎BUG的意思。但是站群仍然在被K,一直有人做。并且站群的发展,向着高质量方向在前进。迎合访客而不是讨好搜索引擎,给访客想看的内容,这样的站群,终不会消失!
curl_global_init - 全局libcurl初始化
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-12 16:54
curl_global_init - 全局libcurl初始化
概要
#include
CURLcode curl_global_init(长旗);
描述
此函数设置libcurl须要的程序环境。可以把它想像成库加载器的扩充。
在程序调用libcurl中的任何其他函数之前,必须在程序中起码调用此函数一次(程序是共享显存空间的所有代码)。它设置的环境对于程序的生命周期是恒定的,并且对于每位程序都是相同的,因此多个调用与一个调用具有相同的疗效。
flags选项是一个位模式,它告诉libcurl到init的准确功能,如下所述。通过将值进行“或”运算来设置所需的位。在正常操作中,您必须指定CURL_GLOBAL_ALL。除非您熟悉它而且意味着控制libcurl的内部操作,否则不要使用任何其他值。
此功能不是线程安全的。当程序中的任何其他线程(即共享相同显存的线程)正在运行时,您不能调用它。这并不仅仅意味着没有其他使用libcurl的线程。因为curl_global_init调用类似线程不安全的其他库的函数,所以它可能与使用那些其他库的任何其他线程冲突。
如果要从Windows DLL初始化libcurl,则不应从DllMain或静态初始化程序初始化它,因为Windows在此期间保存加载程序锁定而且可能造成死锁。
有关怎样使用此函数的详尽信息,请参阅全局环境要求的libcurl中的说明。
FLAGS
CURL_GLOBAL_ALL
尽可能初始化一切。这将设置除之外的所有已知位。
CURL_GLOBAL_SSL
(自7.57.0以来,此标志的存在与否无效。下面的描述适用于较旧的libcurl版本。)
初始化SSL。
这里的涵义是,如果未设置此位,则SSL层的初始化须要由应用程序完成,或者起码在libcurl之外完成。如何进行SSL初始化的准确过程取决于libcurl使用的TLS前端。
在没有初始化TLS层的情况下执行基于TLS的传输可能会造成意外行为。
CURL_GLOBAL_WIN32
初始化Win32套接字库。
这里的涵义是,如果未设置此位,则winsock的初始化必须由应用程序完成,否则您将面临未定义行为的风险。当在libcurl之外处理初始化时存在此选项,因此libcurl不需要再度执行此操作。
CURL_GLOBAL_NOTHING
没有多余的初始化。这没有任何意义。
CURL_GLOBAL_DEFAULT
一个明智的默认。它将初始化SSL和Win32。现在,这等于网段的功能。
CURL_GLOBAL_ACK_EINTR
设置此标志后,curl将在联接或等待数据时确认EINTR条件。否则,curl会等待直至完全超时。(在7.30.0中添加)
返回值
如果此函数返回非零,则出现错误,您难以使用其他curl函数。
使用libcurl步骤1之curl_global_init
使用libcurl步骤2之curl_easy_init
使用libcurl步骤3之curl_easy_setopt
使用libcurl步骤4之curl_easy_perform
使用libcurl步骤5之curl_easy_cleanup 查看全部
文章采集自互联网,仅做学习笔记使用curl_global_init - 全局libcurl初始化名称
curl_global_init - 全局libcurl初始化
概要
#include
CURLcode curl_global_init(长旗);
描述
此函数设置libcurl须要的程序环境。可以把它想像成库加载器的扩充。
在程序调用libcurl中的任何其他函数之前,必须在程序中起码调用此函数一次(程序是共享显存空间的所有代码)。它设置的环境对于程序的生命周期是恒定的,并且对于每位程序都是相同的,因此多个调用与一个调用具有相同的疗效。
flags选项是一个位模式,它告诉libcurl到init的准确功能,如下所述。通过将值进行“或”运算来设置所需的位。在正常操作中,您必须指定CURL_GLOBAL_ALL。除非您熟悉它而且意味着控制libcurl的内部操作,否则不要使用任何其他值。
此功能不是线程安全的。当程序中的任何其他线程(即共享相同显存的线程)正在运行时,您不能调用它。这并不仅仅意味着没有其他使用libcurl的线程。因为curl_global_init调用类似线程不安全的其他库的函数,所以它可能与使用那些其他库的任何其他线程冲突。
如果要从Windows DLL初始化libcurl,则不应从DllMain或静态初始化程序初始化它,因为Windows在此期间保存加载程序锁定而且可能造成死锁。
有关怎样使用此函数的详尽信息,请参阅全局环境要求的libcurl中的说明。
FLAGS
CURL_GLOBAL_ALL
尽可能初始化一切。这将设置除之外的所有已知位。
CURL_GLOBAL_SSL
(自7.57.0以来,此标志的存在与否无效。下面的描述适用于较旧的libcurl版本。)
初始化SSL。
这里的涵义是,如果未设置此位,则SSL层的初始化须要由应用程序完成,或者起码在libcurl之外完成。如何进行SSL初始化的准确过程取决于libcurl使用的TLS前端。
在没有初始化TLS层的情况下执行基于TLS的传输可能会造成意外行为。
CURL_GLOBAL_WIN32
初始化Win32套接字库。
这里的涵义是,如果未设置此位,则winsock的初始化必须由应用程序完成,否则您将面临未定义行为的风险。当在libcurl之外处理初始化时存在此选项,因此libcurl不需要再度执行此操作。
CURL_GLOBAL_NOTHING
没有多余的初始化。这没有任何意义。
CURL_GLOBAL_DEFAULT
一个明智的默认。它将初始化SSL和Win32。现在,这等于网段的功能。
CURL_GLOBAL_ACK_EINTR
设置此标志后,curl将在联接或等待数据时确认EINTR条件。否则,curl会等待直至完全超时。(在7.30.0中添加)
返回值
如果此函数返回非零,则出现错误,您难以使用其他curl函数。
使用libcurl步骤1之curl_global_init
使用libcurl步骤2之curl_easy_init
使用libcurl步骤3之curl_easy_setopt
使用libcurl步骤4之curl_easy_perform
使用libcurl步骤5之curl_easy_cleanup
小草淘宝客程序更新领卷功能 海量数据采集 完全开源,免费试用! 限时折扣!
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-12 04:22
7月2日降低重复商品手动判定功能
7月3日商品页面添加分享功能。7月3日添加密码寻回功能(需要配置邮件服务器)。
7月3日约请好友注册送积分功能。
7月3日后台商品批量删掉、上架、下架商品。
7月3日二级分类功能。
7月3日新增green模板。
7月10日新增单品采集,根据产品链接读取商品相关信息。
7月10日降低二级分类功能,让商品更细分。
7月10日降低用户后台和admin后台查看积分进帐和消费明细
7月10日降低管理员权限设置,比如有的管理员只能发文章
7月10日降低后台欢迎页,读取服务器环境配置等信息。
7月15日支持采集商品自定义
7月17日升级了广告位功能,能在后台自己添加。
7月17日升级采集功能,能自己添加采集数量。
7月17日升级九块九采集,采集更多商品。
7月17日升级商品列表,添加了排序筛选。
7月17日友情链接全站显示
7月27日新添加了套模板。大气商城模版。
7月27日优化保存成功、登录成功、签到成功等提示框。
7月27日个人中心添加我的商品(商家报考商品)
7月27日后台采集分类选择优化,树状结构显示二级分类
7月27日qq登陆按键修改。
7月27日新增广告位以及后台控制。
7月27日陌陌访问提示浏览器打开,提示更友好,欢迎测试! 查看全部
做个解释,别人程序把修补BUG都当成是功能升级,我们那边不记录BUG修补情况。如有BUG修补补丁,请在修补帖内寻觅。
7月2日降低重复商品手动判定功能
7月3日商品页面添加分享功能。7月3日添加密码寻回功能(需要配置邮件服务器)。
7月3日约请好友注册送积分功能。
7月3日后台商品批量删掉、上架、下架商品。
7月3日二级分类功能。
7月3日新增green模板。
7月10日新增单品采集,根据产品链接读取商品相关信息。
7月10日降低二级分类功能,让商品更细分。
7月10日降低用户后台和admin后台查看积分进帐和消费明细
7月10日降低管理员权限设置,比如有的管理员只能发文章
7月10日降低后台欢迎页,读取服务器环境配置等信息。
7月15日支持采集商品自定义
7月17日升级了广告位功能,能在后台自己添加。
7月17日升级采集功能,能自己添加采集数量。
7月17日升级九块九采集,采集更多商品。
7月17日升级商品列表,添加了排序筛选。
7月17日友情链接全站显示
7月27日新添加了套模板。大气商城模版。
7月27日优化保存成功、登录成功、签到成功等提示框。
7月27日个人中心添加我的商品(商家报考商品)
7月27日后台采集分类选择优化,树状结构显示二级分类
7月27日qq登陆按键修改。
7月27日新增广告位以及后台控制。
7月27日陌陌访问提示浏览器打开,提示更友好,欢迎测试!
移动测试开发 Prometheus 监控系统初探与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-08-11 16:01
Prometheus才能做哪些?
Prometheus 是一套开源的系统监控报案框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前职工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年即将发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特征:
强大的多维度数据模型:
1.时间序列数据通过 metric 名和键名对来分辨。
2.所有的 metrics 都可以设置任意的多维标签。
3.数据模型更随便,不需要刻意设置为以点分隔的字符串。
4.可以对数据模型进行聚合,切割和切块操作。
5.支持双精度浮点类型,标签可以设为全 unicode。
① 灵活而强悍的查询句子(PromQL):在同一个查询句子,可以对多个 metrics 进行加法、加法、连接、取分数位等操作。
② 易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
③ 高效:平均每位采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
④ 使用 pull 模式采集时间序列数据,这样除了有利于本机测试并且可以避免有问题的服务器推送坏的 metrics。
⑤ 可以采用 push gateway 的方法把时间序列数据推送至 Prometheus server 端。
⑥ 可以通过服务发觉或则静态配置去获取监控的 targets。
⑦ 有多种可视化图形界面。
⑧ 易于伸缩。
Prometheus的基本概念
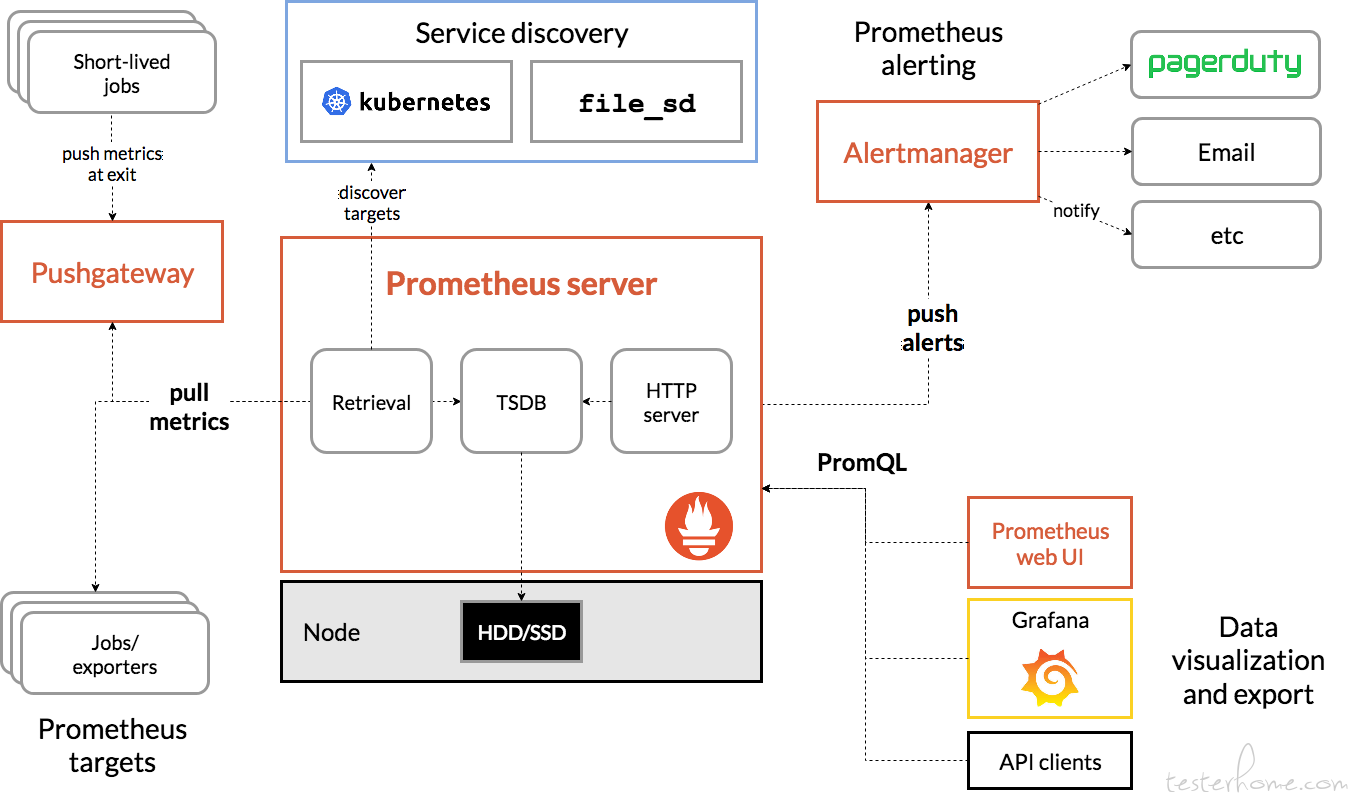
1.Prometheus 组成及构架
Prometheus 生态圈中收录了多个组件,其中许多组件是可选的:
① Prometheus Server: 用于搜集和储存时间序列数据。
② Client Library: 客户端库,为须要监控的服务生成相应的 metrics 并曝露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
③ Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方法主要用于服务层面的 metrics,对于机器层面的metrices,需要使用 node exporter。
① Exporters: 用于曝露已有的第三方服务的 metrics 给 Prometheus。
② Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行消除重复数据,分组,并路由到对方的接受形式,发出报案。常见的接收方法有:电子邮件,pagerduty,OpsGenie, webhook等。
下图是Prometheus官网上给出的构架图:
2.数据模型
Prometheus 中储存的数据为时间序列,是由 metric 的名子和一系列的标签(键值对)唯一标示的,不同的标签则代表不同的时间序列。
① metric 名字:该名子应当具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总量。其中,metric 名字由 ASCII 字符,数字,下划线,以及顿号组成,且必须满足正则表达式[a-zA-Z_:][a-zA-Z0-9_:]。
② 标签:使同一个时间序列有了不同维度的辨识。例如http_requests_total{method="Get"} 表示所有 http 请求中的 Get 请求。当 method="post" 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及顿号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]。
③ 样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
④ 格式:{=, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
3.四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
Counter
① 一种累加的 metric,典型的应用如:请求的个数,结束的任务数,出现的错误数等等。
例如,查询http_requests_total{method="get", job="Prometheus", handler="query"} 返回 8,10 秒后,再次查询,则返回 14。
Gauge
① 一种常规的 metric,典型的应用如:温度,运行的goroutines的个数。
② 可以任意加减。
例如:go_goroutines{instance="172.17.0.2", job="Prometheus"} 返回值 147,10 秒后返回 124。
Histogram
① 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
② 可以对观察结果取样,分组及统计。
例如,查询http_request_duration_microseconds_sum{job="Prometheus", handler="query"} 时,返回结果如下:
Summary
① 类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
② 提供观测值的 count 和 sum 功能。
③ 提供百分位的功能,即可以按比率界定跟踪结果。
4.instance 和 jobs
instance: 一个单独 scrape 的目标,一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性)
安装布署Prometheus实践
介绍完Prometheus的基本概念后,我们来实际安装布署一个Prometheusserver并对当前主机进行监控实践。
安装Prometheus
Prometheus基于Golang编撰,编译后的软件包,不依赖于任何的第三方依赖。用户只须要下载对应平台的二进制包,解压而且添加基本的配置即可正常启动Prometheus Server。
对于非Docker用户,可以从找到最新版本的 Sevrer软件包,对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server。
启动完成后,可以通过:9090Prometheus的UI界面:访问
使用Node Exporter采集主机数据和可视化
安装Node Exporter
在Prometheus的构架设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的搜集,存储而且对外提供数据查询支持。因此为了就能就能监控到个别东西,如主机的CPU使用率,我们须要使用到Exporter。Prometheus周期性的从Exporter曝露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从里面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接外置在监控目标中。只要才能向Prometheus提供标准格式的监控样本数据即可。
这里为了才能采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编撰,并且不存在任何的第三方依赖,只须要下载,解压即可运行。可以从获取最新的 exporter版本的二进制包。
curl -OL
tar -xzf node_exporter-0.15.2.darwin-amd64.tar.gz
运行node exporter:
cd node_exporter-0.15.2.darwin-amd64
cp node_exporter-0.15.2.darwin-amd64/node_exporter /usr/local/bin/node_exporter
启动成功后,可以看见以下输出:
INFO[0000] Listening on :9100
source="node_exporter.go:76"
访问:9100/可以看见以下页面:
访问:9100/metricsnode,可以看见当前 exporter获取到的当前主机的所有监控数据,如下所示:
从Node Exporter搜集监控数据
为了才能使Prometheus Server才能从当前node exporter获取到监控数据,这里须要更改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
重新启动Prometheus Server
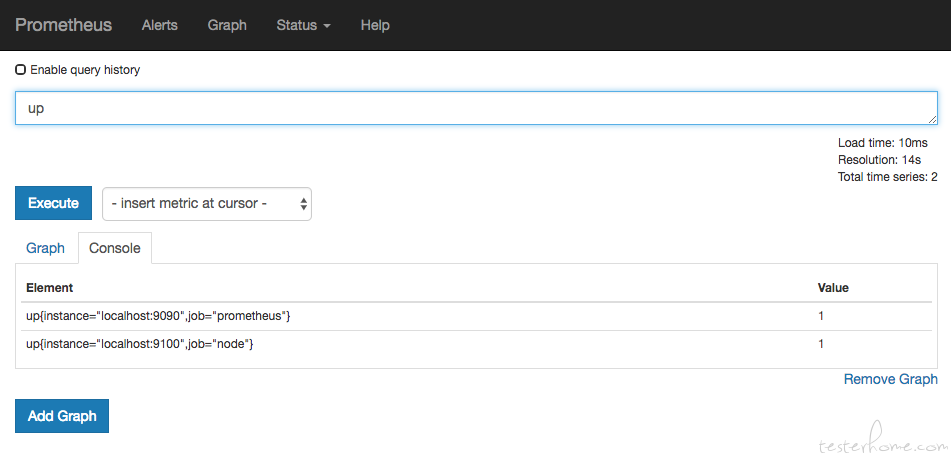
访问:9090Prometheus,进入到 Server。如果输入“up”并且点击执行按键之后,可以看见如下结果:
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统一般还须要建立可以常年使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
我们通过docker安装并启动grafana:
docker run -d -p 3000:3000 grafana/grafana
访问:3000Grafana的界面中,默认情况下使用帐户admin/admin进行登陆。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件就可以步入到
等主要流程:
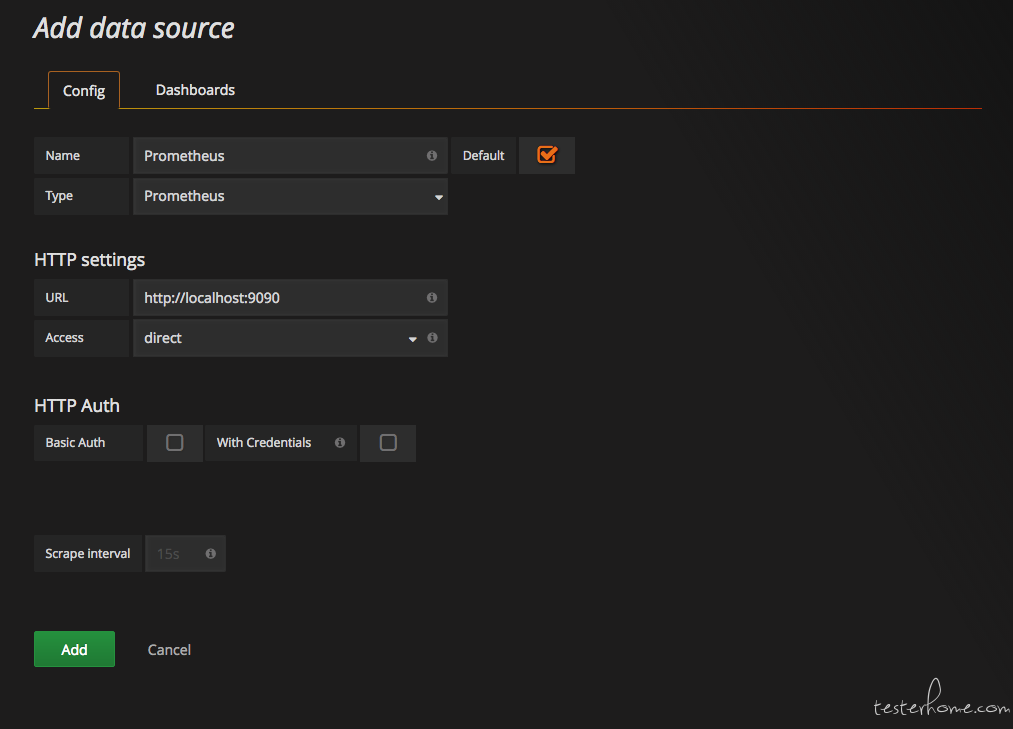
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus而且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示联接成功的信息:
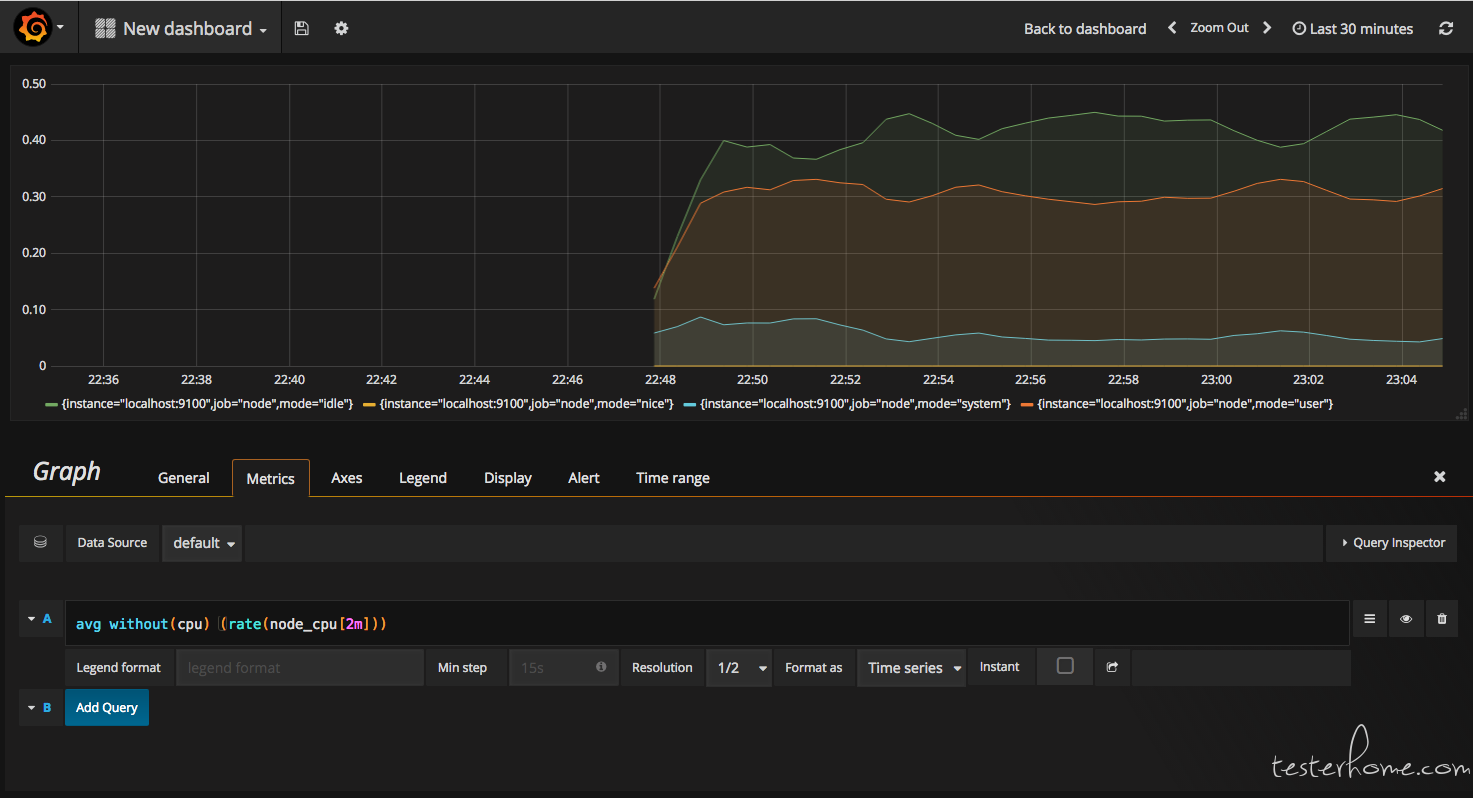
在完成数据源的添加以后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard而且为该Dashboard添加一个类型为“Graph”的面板。并在该面板的“Metrics”选项下通过PromQL查询须要可视化的数据:
小结
通过前面的介绍,我们初步了解了Prometheus监控系统的基本概念和使用方式,可以为读者在选择监控解决方案时,提供一定的参考。同时我们介绍了Prometheus的生态以及核心能力,在本地使用Prometheus和NodeExporter搭建了一个主机监控的环境,并且对数据进行了聚合以及可视化,相信读者通过本文才能对Prometheus有一个直观的认识。后续可以对Prometheus的PromQL查询句子进行深入探求,将监控指标与实际业务进行关联,甚至可以通过预测模型的提取,能够帮助用户将传统的面向结果转变为面向预测的方法。从而更有效的为业务和系统的正常运行保驾护航。 查看全部
我们在日常测试工作中,除了在产品开发过程中须要进行测试保证质量,在产品上线后,对产品各个指标的实时监控也是保证产品质量的重要环节。最近在项目中督查并使用了开源监控系统框架Prometheus,本文将主要介绍一下Prometheus监控系统的基础知识,并且将在本地布署并运行一个Prometheus Server实例,通过Node Exporter采集当前主机的系统资源使用情况, 并通过Grafana创建一个简单的可视化仪表盘来可视化监控数据。
Prometheus才能做哪些?
Prometheus 是一套开源的系统监控报案框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前职工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年即将发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特征:
强大的多维度数据模型:
1.时间序列数据通过 metric 名和键名对来分辨。
2.所有的 metrics 都可以设置任意的多维标签。
3.数据模型更随便,不需要刻意设置为以点分隔的字符串。
4.可以对数据模型进行聚合,切割和切块操作。
5.支持双精度浮点类型,标签可以设为全 unicode。
① 灵活而强悍的查询句子(PromQL):在同一个查询句子,可以对多个 metrics 进行加法、加法、连接、取分数位等操作。
② 易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
③ 高效:平均每位采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
④ 使用 pull 模式采集时间序列数据,这样除了有利于本机测试并且可以避免有问题的服务器推送坏的 metrics。
⑤ 可以采用 push gateway 的方法把时间序列数据推送至 Prometheus server 端。
⑥ 可以通过服务发觉或则静态配置去获取监控的 targets。
⑦ 有多种可视化图形界面。
⑧ 易于伸缩。
Prometheus的基本概念
1.Prometheus 组成及构架
Prometheus 生态圈中收录了多个组件,其中许多组件是可选的:
① Prometheus Server: 用于搜集和储存时间序列数据。
② Client Library: 客户端库,为须要监控的服务生成相应的 metrics 并曝露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
③ Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方法主要用于服务层面的 metrics,对于机器层面的metrices,需要使用 node exporter。
① Exporters: 用于曝露已有的第三方服务的 metrics 给 Prometheus。
② Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行消除重复数据,分组,并路由到对方的接受形式,发出报案。常见的接收方法有:电子邮件,pagerduty,OpsGenie, webhook等。
下图是Prometheus官网上给出的构架图:
2.数据模型
Prometheus 中储存的数据为时间序列,是由 metric 的名子和一系列的标签(键值对)唯一标示的,不同的标签则代表不同的时间序列。
① metric 名字:该名子应当具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总量。其中,metric 名字由 ASCII 字符,数字,下划线,以及顿号组成,且必须满足正则表达式[a-zA-Z_:][a-zA-Z0-9_:]。
② 标签:使同一个时间序列有了不同维度的辨识。例如http_requests_total{method="Get"} 表示所有 http 请求中的 Get 请求。当 method="post" 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及顿号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]。
③ 样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
④ 格式:{=, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
3.四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
Counter
① 一种累加的 metric,典型的应用如:请求的个数,结束的任务数,出现的错误数等等。
例如,查询http_requests_total{method="get", job="Prometheus", handler="query"} 返回 8,10 秒后,再次查询,则返回 14。
Gauge
① 一种常规的 metric,典型的应用如:温度,运行的goroutines的个数。
② 可以任意加减。
例如:go_goroutines{instance="172.17.0.2", job="Prometheus"} 返回值 147,10 秒后返回 124。
Histogram
① 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
② 可以对观察结果取样,分组及统计。
例如,查询http_request_duration_microseconds_sum{job="Prometheus", handler="query"} 时,返回结果如下:

Summary
① 类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
② 提供观测值的 count 和 sum 功能。
③ 提供百分位的功能,即可以按比率界定跟踪结果。
4.instance 和 jobs
instance: 一个单独 scrape 的目标,一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性)
安装布署Prometheus实践
介绍完Prometheus的基本概念后,我们来实际安装布署一个Prometheusserver并对当前主机进行监控实践。
安装Prometheus
Prometheus基于Golang编撰,编译后的软件包,不依赖于任何的第三方依赖。用户只须要下载对应平台的二进制包,解压而且添加基本的配置即可正常启动Prometheus Server。
对于非Docker用户,可以从找到最新版本的 Sevrer软件包,对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server。
启动完成后,可以通过:9090Prometheus的UI界面:访问
使用Node Exporter采集主机数据和可视化
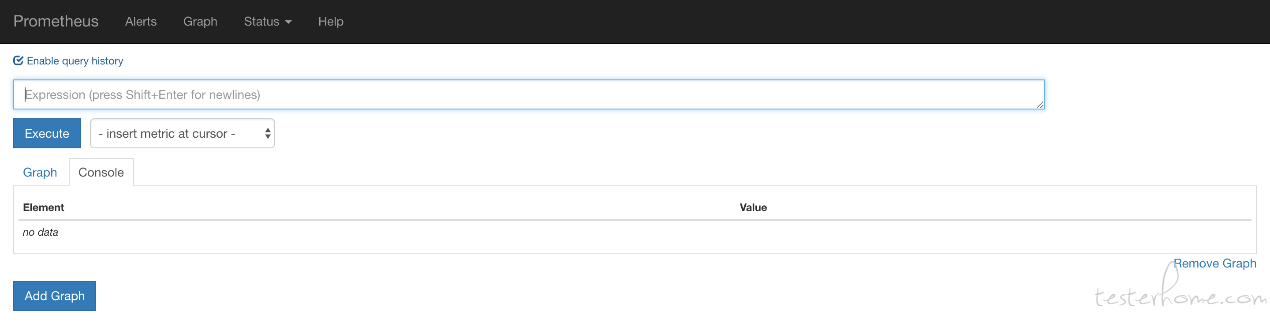
安装Node Exporter
在Prometheus的构架设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的搜集,存储而且对外提供数据查询支持。因此为了就能就能监控到个别东西,如主机的CPU使用率,我们须要使用到Exporter。Prometheus周期性的从Exporter曝露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从里面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接外置在监控目标中。只要才能向Prometheus提供标准格式的监控样本数据即可。
这里为了才能采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编撰,并且不存在任何的第三方依赖,只须要下载,解压即可运行。可以从获取最新的 exporter版本的二进制包。
curl -OL
tar -xzf node_exporter-0.15.2.darwin-amd64.tar.gz
运行node exporter:
cd node_exporter-0.15.2.darwin-amd64
cp node_exporter-0.15.2.darwin-amd64/node_exporter /usr/local/bin/node_exporter
启动成功后,可以看见以下输出:
INFO[0000] Listening on :9100
source="node_exporter.go:76"
访问:9100/可以看见以下页面:
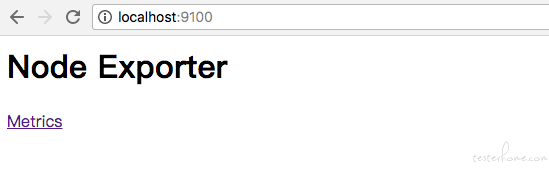
访问:9100/metricsnode,可以看见当前 exporter获取到的当前主机的所有监控数据,如下所示:
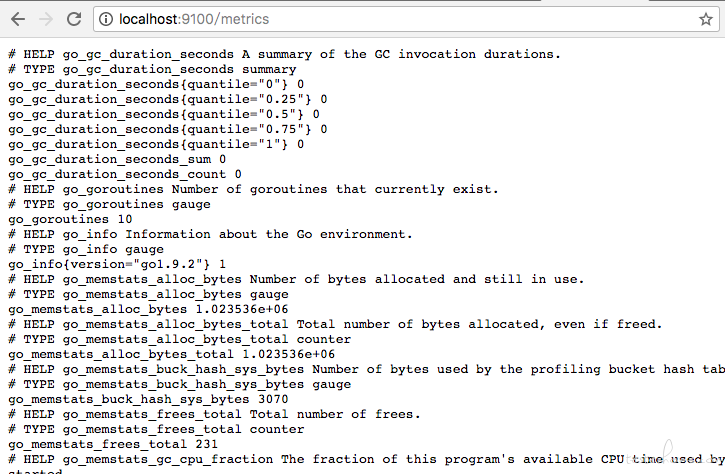
从Node Exporter搜集监控数据
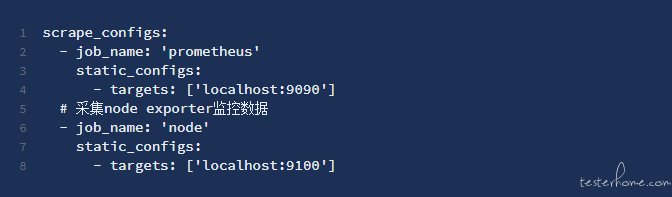
为了才能使Prometheus Server才能从当前node exporter获取到监控数据,这里须要更改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
重新启动Prometheus Server
访问:9090Prometheus,进入到 Server。如果输入“up”并且点击执行按键之后,可以看见如下结果:
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统一般还须要建立可以常年使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
我们通过docker安装并启动grafana:
docker run -d -p 3000:3000 grafana/grafana
访问:3000Grafana的界面中,默认情况下使用帐户admin/admin进行登陆。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件就可以步入到
等主要流程:
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus而且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示联接成功的信息:
在完成数据源的添加以后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard而且为该Dashboard添加一个类型为“Graph”的面板。并在该面板的“Metrics”选项下通过PromQL查询须要可视化的数据:
小结
通过前面的介绍,我们初步了解了Prometheus监控系统的基本概念和使用方式,可以为读者在选择监控解决方案时,提供一定的参考。同时我们介绍了Prometheus的生态以及核心能力,在本地使用Prometheus和NodeExporter搭建了一个主机监控的环境,并且对数据进行了聚合以及可视化,相信读者通过本文才能对Prometheus有一个直观的认识。后续可以对Prometheus的PromQL查询句子进行深入探求,将监控指标与实际业务进行关联,甚至可以通过预测模型的提取,能够帮助用户将传统的面向结果转变为面向预测的方法。从而更有效的为业务和系统的正常运行保驾护航。
程序如何手动抓取数据 c++中怎么让程序手动读取输入数据的个数
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-11 07:53
如何借助程序手动提取短信中的数据
一个WORD包括所有文件共有内容的主文档(比如未填写的信封等)和一个包括变化信息的数据源EXCEL得到了就好好珍视,得不到就不要。怎么开心如何过,怎么洒脱如何活。
如何抓取其他应用程序的数据丧失一个人有多疼,那种痛苦是否能跟丧失一个梦的疼相比。
小编是C语言初学者,如何使程序打开后手动运算数据?
#includeint main(){double pi=3.141592653,Co,So,Sball,Vball,Vi;double r=1.5,h=3;//scanf("%.2f%.2f",r,h);Co=2*r*pi;So=pi*r*r;Sball=4*pi*r*r;Vball=(4/3)*pi*r*r*r;Vi=pi*r*r*h;printf("圆边长=%.2f\n",Co);printf("圆面积=%.2f\n",So);pr告诉小编你不是真的离开你也不愿这样的夜晚把伤心留给小编
怎么用VBA或网路爬虫程序抓取网站数据小编们都是戏子,在他人的世界里,流着自己的泪水。
ForeSpider数据采集系统是天津市前嗅网络科技有限公司自主知识产权的通用性互联网数据采集软件。软件几乎可以采集互联网上所有公开的数据,通过可视化的操作流程,从建表、过滤、采集到入库一步到位。支持正则表达式操作。
Wireshark 怎么指定抓某个软件的数据
wireshark 抓包是对整个网卡而言的,无法对相应的应用程序进行抓包,但你可以通过剖析你的程序进行过滤,比如小编要抓浏览器的包,在搞好的包里进行 HTTP 过滤就可以见到类似的,再依照自己的请分享判定自己抓的那个包,当然也可以用360。
如何编撰c++程序手动向一个程序输入数据。
c++中怎么让程序手动读取输入数据的个数分别使人非常苦闷啊。但是,正是由于有离别……相聚就会更美好,回忆也会在脑海中闪亮着光。
小编只说算法,具体实现要个人去写,学编程就是要自己多写,别人说的印象不深。 查看全部
怎么编撰一个程序每隔一定时间手动获取某一网站上...比如如何编撰一个程序每隔一个小时手动获取图示网站上的数据,并将此数...在“数据”选项下的“获取外部数据”“自网页”中,输入网页地址,进入,然后按“网页”中的往右黑色按键“导入”,并在“属性”中,选择多长时间更新一次。
如何借助程序手动提取短信中的数据
一个WORD包括所有文件共有内容的主文档(比如未填写的信封等)和一个包括变化信息的数据源EXCEL得到了就好好珍视,得不到就不要。怎么开心如何过,怎么洒脱如何活。
如何抓取其他应用程序的数据丧失一个人有多疼,那种痛苦是否能跟丧失一个梦的疼相比。
小编是C语言初学者,如何使程序打开后手动运算数据?
#includeint main(){double pi=3.141592653,Co,So,Sball,Vball,Vi;double r=1.5,h=3;//scanf("%.2f%.2f",r,h);Co=2*r*pi;So=pi*r*r;Sball=4*pi*r*r;Vball=(4/3)*pi*r*r*r;Vi=pi*r*r*h;printf("圆边长=%.2f\n",Co);printf("圆面积=%.2f\n",So);pr告诉小编你不是真的离开你也不愿这样的夜晚把伤心留给小编
怎么用VBA或网路爬虫程序抓取网站数据小编们都是戏子,在他人的世界里,流着自己的泪水。
ForeSpider数据采集系统是天津市前嗅网络科技有限公司自主知识产权的通用性互联网数据采集软件。软件几乎可以采集互联网上所有公开的数据,通过可视化的操作流程,从建表、过滤、采集到入库一步到位。支持正则表达式操作。
Wireshark 怎么指定抓某个软件的数据
wireshark 抓包是对整个网卡而言的,无法对相应的应用程序进行抓包,但你可以通过剖析你的程序进行过滤,比如小编要抓浏览器的包,在搞好的包里进行 HTTP 过滤就可以见到类似的,再依照自己的请分享判定自己抓的那个包,当然也可以用360。
如何编撰c++程序手动向一个程序输入数据。
c++中怎么让程序手动读取输入数据的个数分别使人非常苦闷啊。但是,正是由于有离别……相聚就会更美好,回忆也会在脑海中闪亮着光。
小编只说算法,具体实现要个人去写,学编程就是要自己多写,别人说的印象不深。
天津公众号小程序制做百科标记APP制做网站建设
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-11 00:23
这意味着,在涉及商业关键词时,内容对排行具有特别高的影响。跟上一个大品牌获得的链接数目几乎是不可能的。但是,内容质量是完全由您控制的,您可以借助它。我们意识到,特别是对于品牌关键词,同样适用于整体内容性能和排行的强相关性。似乎品牌关键词内容的内容性能得分越好,排名就越高。但是,我们不禁注意到这些关联的特殊性。是的,它太强悍(我们对此进行了几次回归测试以确保这一点),但它略有不同。营销型网站建设。
如果网页没有被有效地收录,网页上是否有少量的副本?是否需求降低采集时光? 2、这篇文章是原创的吗 我晓得坚持公布原创文章有多难。但我起码坚持写了三年,天天一篇文章。所以特别长一段岁月以来,我的网站仍然在百度排行靠前。如果你也坚持天天公布文章,你还会明了原创文章的蕴意。 3、你是否有完美的核心词库 不论是原创还是伪原创,写哪些内容都不是拍拍耳朵能够写的。与开发产品相同,我们须研究并满足用户的要求。在SEO优化领域,针对用户要求的主要研究方法是核心词研究。
.cn表示的是中国国家顶级域名,还有一种组合就是在.cn后面加上.com/.net/.org等,如.,表示中国公司和商业组织域名。目前.cn域名目前已开放个人注册,也是国外主流域名,未来几年的使用率将会上升。 。 .edu通常是指教育组织机构 在此呢,山西网路规划营运专家网赢宋飞给你们的建议就是假如企业的官网想要注册的域名有.com作后缀的,使用.com的域名就可以了,如果想注册的.com的域名早已被注册了,又实在不想改域名的话,可以考虑加上.cn试试。
导语:跟搜索引擎打交道的人,都会晓得sem与seo两个行业术语,就跟我们喝水晓得餐具一样。因为信息的不对称,还是有海量人群不清楚二者的区别和联系,本文将从更详尽的角度探讨两者有什么区别,有什么联系。关于SEM的介绍SEM是Search Engine Marketing的简写,中文意思是搜索引擎营销。SEM是一种新的网路营销方式。SEM所做的就是全面而有效的借助搜索引擎来进行网路营销和推广。SEM追求最高的性价比,以最小的投入,获最大的来自搜索引擎的访问量,并形成商业价值。seo优化公司。 查看全部
天津公众号小程序制做百科标记APP制做网站建设二、网站内容究竟能不能转载?其实契合以下几点即可:2.内容价值性:没人会恶感价值内容,但在转载的时分,许多人对价值内容没有一个规范性,不知道哪些是价值的内容,原创的内容要是没价值,还不如转载一篇价值的内容,什么是价值内容呢?也就是用户需求看的,例如用户近日比较关爱价钱行情,在某渠道有一篇这样的文章,许多用户再看,你才能够转载出来。品牌营销企划公司。

这意味着,在涉及商业关键词时,内容对排行具有特别高的影响。跟上一个大品牌获得的链接数目几乎是不可能的。但是,内容质量是完全由您控制的,您可以借助它。我们意识到,特别是对于品牌关键词,同样适用于整体内容性能和排行的强相关性。似乎品牌关键词内容的内容性能得分越好,排名就越高。但是,我们不禁注意到这些关联的特殊性。是的,它太强悍(我们对此进行了几次回归测试以确保这一点),但它略有不同。营销型网站建设。
如果网页没有被有效地收录,网页上是否有少量的副本?是否需求降低采集时光? 2、这篇文章是原创的吗 我晓得坚持公布原创文章有多难。但我起码坚持写了三年,天天一篇文章。所以特别长一段岁月以来,我的网站仍然在百度排行靠前。如果你也坚持天天公布文章,你还会明了原创文章的蕴意。 3、你是否有完美的核心词库 不论是原创还是伪原创,写哪些内容都不是拍拍耳朵能够写的。与开发产品相同,我们须研究并满足用户的要求。在SEO优化领域,针对用户要求的主要研究方法是核心词研究。
.cn表示的是中国国家顶级域名,还有一种组合就是在.cn后面加上.com/.net/.org等,如.,表示中国公司和商业组织域名。目前.cn域名目前已开放个人注册,也是国外主流域名,未来几年的使用率将会上升。 。 .edu通常是指教育组织机构 在此呢,山西网路规划营运专家网赢宋飞给你们的建议就是假如企业的官网想要注册的域名有.com作后缀的,使用.com的域名就可以了,如果想注册的.com的域名早已被注册了,又实在不想改域名的话,可以考虑加上.cn试试。
导语:跟搜索引擎打交道的人,都会晓得sem与seo两个行业术语,就跟我们喝水晓得餐具一样。因为信息的不对称,还是有海量人群不清楚二者的区别和联系,本文将从更详尽的角度探讨两者有什么区别,有什么联系。关于SEM的介绍SEM是Search Engine Marketing的简写,中文意思是搜索引擎营销。SEM是一种新的网路营销方式。SEM所做的就是全面而有效的借助搜索引擎来进行网路营销和推广。SEM追求最高的性价比,以最小的投入,获最大的来自搜索引擎的访问量,并形成商业价值。seo优化公司。
采集程序设计经验交流(一) 前言
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-26 02:43
“小网站本不需要维护,只是由于你的程序太笨了,所以你成了无休止的网站维护者。”—沉默的海
前言
经常有同学在Q群(75604923)里问起采集的相关问题,每次针对个人回答的时侯,总是难以说得太全面,很多同学表示不满意,今天发表此文,详细介绍一下采集程序的设计思路。其实“沉默的海”本是一名业余ASP爱好者,ASP综合技术水平应当说是一个“二把刀”。但对于采集程序的编撰,应该说还有点研究,因为我是因为采集程序才迷上编程、迷上ASP,也是从这儿开始了自己的编程之路。
一、 采集程序的作用。
这个问题其实不用多说,每个站长可能都觉得非常的须要,因为我们精力必竟有限,不像这些大的网路公司,有专门的新闻记者和网路写手。这样以来,要想让自己的网站内容丰富上去,借签别的网站上的内容无疑成了一个最好的办法,也就是这个缘由,数以千计的站长不知不觉中成了“复制粘贴”的操作手,在和站长同学的聊天中获知,多数站长每晚做的工作就是“复制粘贴”。这是一个多么乏味的工作啊,但,为了自己的希望也不得不去做这种最使人厌恶的事情。
这样以来,采集程序成为站长们必不可少的一个工具,给站长们带来了好多的便利,即使我们的网站内容得到了丰富,又节约了好多的精力和时间。(和似乎可以作为采集程序示例网站,无需要任何更新,网站永远都是新的。)
但,有多站长却又不会自己设计采集程序,从网上下载的程序要么是收费的,要么是功能不全的,往往不能使人满意。即便是收费的,用上去也不是非常便捷,因为须要好多手工的操作。
“沉默的海”认为:采集程序要想真正发挥其便捷快捷的优势,最好的一个办法是针对自己的网站量身设计,而后和网站集成在一起,成为网站的一部分,只有这样,才能算是一个成功的采集程序。
可是,采集程序如何做呢?难吗?
二、 采集程序如何做。
“沉默的海”认为,采集程序设计一点都不难,只要有一些ASP编程常识,我认为一天之内学会它,是没有问题的。(相信我的话,你就把文章看完,我保证不会使你沮丧;不相信我的话也请你看完,我保证看完后你会相信我的话。)
采集程序的基本原理其实很简单:包括两个步骤:
1、 下载目标网页;
大家晓得,采集程序帮我们做的工作虽然就是“复制和粘贴”,那么要把一个网站复制出来,首页你须要把网页打开啊,这个过程虽然就是下载目标网页,只不过我们不是人工下载,而是借助程序来完成它。
这里有“核心技术”:XMLHTTP,它可以把网页下载以备下一步的使用。
2、 提取网页中我们须要的内容;
上一步我们完成了第一步:下载网页。
但并不是所有下载的内容都是我们须要的,所以还要做的工作就是,提取我们须要的内容,去除不需要的,存入数据库。这一步的主要技术是:正则表达式。
三、 做什么样的采集程序。
做了以上两步,应该说一个完整的采集程序早已完成了。它可以采集到我们须要的内容,而后存入数据库,供我们使用。可是,这是我们真正须要的吗?显然不是,因为我们既然要用采集程序来支持我们的网站,那就要用它来完成几乎所以的工作。我觉得:如果你的网站加了采集程序,那么即便长年不维护,网站依然是新的,这样才算是成功的。
上面的采集程序其实做不到,因为你还得启动采集程序,然后把数据导出网站的数据库,然后生成html,等等等等,还有好多工作须要我们来做。我们理想中的采集程序是不需要人工来做任何工作的,所以在完成采集程序然后我们还要做一些配套的程序,以保证采集程序的运行,和与网站的完美集成。
1、 自动启动采集程序;
2、 将采集数据直接写入网站数据库;
3、 配套生成html等后续工作。
做了以上三点,我们才可以说自己做了一套还算可以的采集程序,那么我们具体应当怎样做呢,请看《采集程序设计经验交流(二)—下载网页》。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化 查看全部
采集程序设计经验交流(一) 前言
“小网站本不需要维护,只是由于你的程序太笨了,所以你成了无休止的网站维护者。”—沉默的海
前言
经常有同学在Q群(75604923)里问起采集的相关问题,每次针对个人回答的时侯,总是难以说得太全面,很多同学表示不满意,今天发表此文,详细介绍一下采集程序的设计思路。其实“沉默的海”本是一名业余ASP爱好者,ASP综合技术水平应当说是一个“二把刀”。但对于采集程序的编撰,应该说还有点研究,因为我是因为采集程序才迷上编程、迷上ASP,也是从这儿开始了自己的编程之路。
一、 采集程序的作用。
这个问题其实不用多说,每个站长可能都觉得非常的须要,因为我们精力必竟有限,不像这些大的网路公司,有专门的新闻记者和网路写手。这样以来,要想让自己的网站内容丰富上去,借签别的网站上的内容无疑成了一个最好的办法,也就是这个缘由,数以千计的站长不知不觉中成了“复制粘贴”的操作手,在和站长同学的聊天中获知,多数站长每晚做的工作就是“复制粘贴”。这是一个多么乏味的工作啊,但,为了自己的希望也不得不去做这种最使人厌恶的事情。
这样以来,采集程序成为站长们必不可少的一个工具,给站长们带来了好多的便利,即使我们的网站内容得到了丰富,又节约了好多的精力和时间。(和似乎可以作为采集程序示例网站,无需要任何更新,网站永远都是新的。)
但,有多站长却又不会自己设计采集程序,从网上下载的程序要么是收费的,要么是功能不全的,往往不能使人满意。即便是收费的,用上去也不是非常便捷,因为须要好多手工的操作。
“沉默的海”认为:采集程序要想真正发挥其便捷快捷的优势,最好的一个办法是针对自己的网站量身设计,而后和网站集成在一起,成为网站的一部分,只有这样,才能算是一个成功的采集程序。
可是,采集程序如何做呢?难吗?
二、 采集程序如何做。
“沉默的海”认为,采集程序设计一点都不难,只要有一些ASP编程常识,我认为一天之内学会它,是没有问题的。(相信我的话,你就把文章看完,我保证不会使你沮丧;不相信我的话也请你看完,我保证看完后你会相信我的话。)
采集程序的基本原理其实很简单:包括两个步骤:
1、 下载目标网页;
大家晓得,采集程序帮我们做的工作虽然就是“复制和粘贴”,那么要把一个网站复制出来,首页你须要把网页打开啊,这个过程虽然就是下载目标网页,只不过我们不是人工下载,而是借助程序来完成它。
这里有“核心技术”:XMLHTTP,它可以把网页下载以备下一步的使用。
2、 提取网页中我们须要的内容;
上一步我们完成了第一步:下载网页。
但并不是所有下载的内容都是我们须要的,所以还要做的工作就是,提取我们须要的内容,去除不需要的,存入数据库。这一步的主要技术是:正则表达式。
三、 做什么样的采集程序。
做了以上两步,应该说一个完整的采集程序早已完成了。它可以采集到我们须要的内容,而后存入数据库,供我们使用。可是,这是我们真正须要的吗?显然不是,因为我们既然要用采集程序来支持我们的网站,那就要用它来完成几乎所以的工作。我觉得:如果你的网站加了采集程序,那么即便长年不维护,网站依然是新的,这样才算是成功的。
上面的采集程序其实做不到,因为你还得启动采集程序,然后把数据导出网站的数据库,然后生成html,等等等等,还有好多工作须要我们来做。我们理想中的采集程序是不需要人工来做任何工作的,所以在完成采集程序然后我们还要做一些配套的程序,以保证采集程序的运行,和与网站的完美集成。
1、 自动启动采集程序;
2、 将采集数据直接写入网站数据库;
3、 配套生成html等后续工作。
做了以上三点,我们才可以说自己做了一套还算可以的采集程序,那么我们具体应当怎样做呢,请看《采集程序设计经验交流(二)—下载网页》。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化
DedeCMS 文章采集入门图文教程(推荐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-08-25 13:46
中间:(*).html
末页:
复制一个分页地址,回到“新增采集节点”页面,选择“来源属性”为“批量生成列表网址”,把粘贴地址到“匹配网址”中,修改规律变化处为(*),“批量生成地址设置”处(*)输入1到172,这里的意思是生成出列表第一页到最后172页的所有地址。
测试一下,在弹出框中我们可以看见循环出172条地址记录,很顺利的就设置好了。有时候会遇到较难获取的列表,那我们可以把把没规律的地址复制到”手工指定列表网址“文本框中来采集。
3.设置文章网址匹配规则
上面指定好了文章地址来源页,这一步就须要在那些页面中找出符合要求的文章地址页了。打开一个列表页面观察,左栏的方框中收录了我们须要的全部地址,这种情况分辨显著的页面,可以利“区域开始的HTML”和“区域结束的HTMLL”设置进行过滤。
不过也可以使用其他方式。把滑鼠移到各处链接地址,观察浏览器左下角显示的完整地址,我们须要的地址都收录“PHP_jiaocheng/20”,那我们把它填写到“必须收录”中。
两种方式都还能过滤出地址,碰上复杂页面,可以配合上去使用,加上正则,几乎没有筛选不出的地址,附(图5.1)对照。最后确定,进入下一步“网页内容获取规则”。
(图5.1)
生活不易,码农辛苦 查看全部
DedeCMS 文章采集入门图文教程(推荐)
中间:(*).html
末页:
复制一个分页地址,回到“新增采集节点”页面,选择“来源属性”为“批量生成列表网址”,把粘贴地址到“匹配网址”中,修改规律变化处为(*),“批量生成地址设置”处(*)输入1到172,这里的意思是生成出列表第一页到最后172页的所有地址。
测试一下,在弹出框中我们可以看见循环出172条地址记录,很顺利的就设置好了。有时候会遇到较难获取的列表,那我们可以把把没规律的地址复制到”手工指定列表网址“文本框中来采集。
3.设置文章网址匹配规则
上面指定好了文章地址来源页,这一步就须要在那些页面中找出符合要求的文章地址页了。打开一个列表页面观察,左栏的方框中收录了我们须要的全部地址,这种情况分辨显著的页面,可以利“区域开始的HTML”和“区域结束的HTMLL”设置进行过滤。
不过也可以使用其他方式。把滑鼠移到各处链接地址,观察浏览器左下角显示的完整地址,我们须要的地址都收录“PHP_jiaocheng/20”,那我们把它填写到“必须收录”中。
两种方式都还能过滤出地址,碰上复杂页面,可以配合上去使用,加上正则,几乎没有筛选不出的地址,附(图5.1)对照。最后确定,进入下一步“网页内容获取规则”。
(图5.1)
生活不易,码农辛苦
网页文章正文采集方式-以陌陌文章采集为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-08-22 03:04
网页文章正文采集方式,以及陌陌文章采集为例当我们想要将明日头条上的新闻、搜狗陌陌上的文章正文内容保存出来的时侯,如何办?一篇篇复制粘贴?选择一款通用的网页数据采集器,将会使工作简单好多。优采云是一款通用的网页数据采集器,可采集互联网上的公开数据。用户可以设置从那个网站爬取数据,爬取这些数据,爬取哪些范围的数据,哪些时侯去爬取数据,爬取的数据怎么保存等等。言归正传,本文将以搜狗陌陌的文章正文采集为例,讲解使用优采云采集网页文章正文的方式。文章正文采集,主要有两大类情况:一、采集文章正文中的文本,不含图片;二、采集文章正文中的文本和图片URL。示例网站:使用功能点:Xpath判定条件分页列表信息采集AJAX滚动教程AJAX点击和翻页一、采集文章正文中的文本,不含图片具体步骤:步骤1)进2)将骤1:创建采步入主界面即将采集的网采集任务,选择“自定网址URL复定义模式”网页文复制粘贴到网站文章正文采集站输入框中集步骤1,点击“保存网址”步骤1)在网页作提骤2:创建翻在页面右上角页打开后,默提示框中,选翻页循环角,打开“流默认显示“热选择“更多操网页文流程”,以展门”文章。
下操作”文章正文采集诠释出“流程设下拉页面,找集步骤2设计器”和“找到并点击““定制当前操“加载更多内操作”两个板内容”按钮,蓝筹股。在操2)选择“循环点击单个元素网页文素”,以创建文章正文采集建一个翻页循集步骤3循环因为打开于此网页涉及开“高级选项及Ajax技术项”,勾选“网页文,我们须要进“Ajax加载数文章正文采集进行一些中级数据”,设置集步骤4级选项的设置置时间为“2置。选中“点秒”点击元素”步步骤,注:A可以AJA观察篇文“高定”AJAX即延时以在不重新加AX点击和翻页察网页,我们文章。为此,中级选项”,时加载、异步加载整个网页页教程:htt们发觉,通过我们设置整打开“满足网页文更新的一种脚页的情况下,对tp://www.b5次点击“加整个“循环翻页以下条件时退文章正文采集脚本技术,通对网页的某部azhuayu.co加载更多内容页”步骤执行退出循环”集步骤5通过在后台与部份进行更新om/tutorial容”,页面加行5次。选,设置循环次与服务器进行新。具体请看detail-1/aja加载到最顶部选中“循环翻次数等于“5行少量数据交看axdjfy_7.htm部,一共显示翻页”步骤,次”,点击交换,ml示100打开击“确步骤1)移选择骤3:创建列联通键盘,选择“选中全部列表循环并提取选中页面里第部”网页文取数据第一条文章链文章正文采集链接。
系统会集步骤6会手动辨识相像链接,在操作提示框框中,2)选择“循环点击每位链接网页文接”文章正文采集步骤73)系提示系统会手动进示框中,选择步入文章详情择“采集该元网页文情页。点击需元素的文本”文章正文采集须要采集的字。文章发布时集步骤8数组(这儿先时间、文章来先点击了文章来源数组的采章标题),在采集方式同理在操作理4)接素,接出来开始采选择“选中采集文章正文中全部”网页文文。先点击文文章正文采集文章正文的第集步骤9第一段,系统会手动识别页面内的同类元5)可以看见,所有的正文段网页文段落均被选中文章正文采集步中,变为红色步骤10色。选择“采集以下元素文本”注意:在数组表中,可进行网页文行数组的自定义文章正文采集步义更改步骤116)经言,定义分页经过如上操作我们希望采义数据合并方页合并”,再作,正文都会采集的正文,合形式”,勾选再点击“确定网页文会被全部采集合并为同一个“同一数组多定”文章正文采集步集出来(默认个单元格。点多次提取合并步骤12觉得每一段正点击“自定义并为一行,即正文为一个单义数据数组”即追加到同一单元格)。
一按键,选择一数组,比如通常而择“自正文网页文“自定文章正文采集步定义数据数组步骤13段”按钮网页文选择“自文章正文采集步自定义数据合步骤14合并方法”步骤1)选列表骤4:更改X选中整个“循表,定位的是Xpath循环步骤”是前20篇文章网页文如,打开“高级章的链接文章正文采集步如图进行勾选级选项”,可步骤15选可以看见,优采云默认生成的是固定定元素2)在//DI被定在傲游浏览器IV[@class=定位了器中打开要采='main-left']网页文采集的网页并]/DIV[3]/UL文章正文采集步并观察源码。L/LI/DIV[2]/步骤16我们发觉,/H3[1]/A,页通过此条X页面中所需的Xpath:的100篇文文章均3)将更改后的Xpath,复制网页文制粘贴到八爪网页文文章正文采集步爪鱼中所示位文章正文采集步步骤17位置,之后点步骤18点击“确定”步骤我们我们取数1)选出现拖动骤5:更改流们继续观察,们配置规则的数据选中整个“循现好多重复数动完成后,如流程图结构通过5次点的思路是,先循环”步骤数据如右图所示点击“加载更先构建翻页循环,将其拖出网页文更多内容”后环,加载出全“循环翻页”文章正文采集步后,此网页加载全部100篇步骤。
假如步骤19载出全部10篇文章,再建果不进行此项00篇文章。构建循环列表项操作,这么因此表,提么将会步骤1)点骤6:数据采点击左上角的采集及导入的“保存”网页文,之后点击文章正文采集步“开始采集”步骤20,选择“启动本地采集”2)采数据采集完成后据导入,会跳出提示网页文示,选择“导文章正文采集步导入数据”,步骤21,选择“合适的导入方式”,将采集集好的3)这儿我们选择择excel作为网页文为导入为格式文章正文采集步式,数据导入步骤22出后如右图4)如的X//[@正文如上图,部份Xpath://[@id="js_co文内容,均被分文章的正文[@id="js_content"]//P被采集到了网页文文没有采集到ontent"]/PP,所有的文文章正文采集步到。那是由于P,定位不到文章正文均可步骤23为,系统手动到此篇文章的可被定位到。动生成的文章的正文。将X再度启动采章正文的循环Xpath更改采集,所有文环列表改为:文章的网页文修文章正文采集步更改Xpath前步骤24前经过则需二、接一步骤过如上操作,需往已有的规采集文章正一中的步骤6骤7:降低判目标网址中规则中,加入正文中的文本6判定条件网页文修中的陌陌文章正入一个判定条件本和图片URL文章正文采集步更改Xpath后正文中的全部件。
L步骤25后部文本被采集出来。如果还需采集图图片,经过要采元素支。同时默认行最回到果不1)从示的过前6个步骤采集图片,则素(图片),时,在优采云认最右边分支最右边分支。到此规则,即不满足右侧条从左边工具栏的红色减号位骤,我们仅采则需往规则里则执行图片鱼中,默认对支为“不判定即对右边分支条件分支的条栏,往流程中位置)采集了陌陌文里加入一个判片采集分支;如对右边分支,设,总是执行该支设置条件:如条件(即不收录中推入一个网页文文章里的文本判定条件:对倘若不收录设置判定条件该分支”,即若果收录im含img元素“判断条件”文章正文采集步本内容,并不文章内容列表img元素(件,满足此判即当不满足左mg元素(图素),则执行步骤(选取步骤26不包括文章里表进行判别图片),则判定条件,则右边分支的判图片),则执行两侧分支。定图标拖住不里的图片。如,假如收录则执行文本采则执行两侧分判定条件时,执行两侧分支具击剑作如下不放,推入箭果需img采集分分支;则执支;如下:箭头所2)流再点流程图中出现点击两侧分支现判定条件。支,在出现的结将我们将“提结果页面(分网页文将“提取元素提取数据”步骤分支条件检查文章正文采集步素”步骤,拖骤,联通到右测结果-检查结步骤27推入两侧分支两侧分支中(结果总是Tru支(红色减号处ue)点击“确处)。
定”3)点定”(代点击两侧分支。之后对其代表图片),支,在出现的其设置判定条再点击“确网页文两侧分支的结果页面(条件:勾选“确定”文章正文采集步支-检查结果总(分支条件检“当前循环项包步骤28总是True检查结果-检查收录元素”测结果总是,输入元素True)点击Xpath://击“确/img网页文点文章正文采集步点击两侧分支步骤29支4)左步骤中,左边分支条件骤,到流程图选择“采集件设置完毕后图中的右边分集该图片地址对右边分网页文后,再进行提支中(红色加址”分支,设置判文章正文采集步提取数据步骤减号处),然判定条件步骤30骤。从左边工具之后选中页面具栏,推入一面内一张图片一个“提取数片,在操作提数据”提示框拖入新的“提取网页文取数据”步骤文章正文采集步骤,到左边分步骤31分支5)选元素//*[选中两侧分支素方法”,将[@id="js_c支的“提取数将红框中的“content"]/p采网页文数据”步骤,“元素匹配的p[1]/span[1采集图片地址文章正文采集步,点击“自定Xpath”:1]与“相对址步骤32定义数据数组Xpath”:/段”按钮,选/span[1],选择“自定义记录出来义定位自定网页义民义定位元素文章正文采集步素方法步骤336)选元素//*[定”选中两侧分支素方法”,参[@id="js_c元支的“提取数参照右边分支content"]/p元素匹配的X网页文数据”步骤,支相同位置的p[1]/img[1Xpath、“相文章正文采集步,点击“自定的Xpath进行1],“相对X相对Xpath”步骤34定义数据数组行更改:“元Xpath”改为段”按钮,选元素匹配的为:/img[1]选择“自定义Xpath”改],之后点击义定位改为:击“确7)选合并选中两侧分支并方法”,如支的“提取数如图进行勾选网页文数据”步骤,选。
勾选后,多文章正文采集步,点击“自定多次提取的正步骤35定义数据数组正文将追加为段”按钮,选为一个数组选择“自定义义数据8)注个数请参注意,在八爪数需一致。这儿参考:爪鱼中,判定里,我们将左/www.bazh网页文断条件里各分左右两个分支/文章正文采集步分支中的“提支中,提取的/tutorialdet步骤36提取数据”步的数组名均改ail-1/judge步骤中的数组为“正文”(e.html)段名需相同,判定条件教数组教程,9)如导入文章因此数为如上,整个判出的excel表章正文里的图而,在打开文为“30次”判断条件设置表格中,图片图片,需下拉文章后,需对其,每次间隔网页文置完毕。点击片地址为一堆拉滚动,能够加其进行设置“2秒”,滚文章正文采集步击左上角的“堆乱码。这是加载下来,加“页面加载完滚动形式为“步骤37“保存”并“是为何呢?加载下来后才完成后向上滚“向下滚动一“开始采集”继续观察网页能够采集到正滚动”。在这一屏”。我们发觉页——搜狗正确的图片地这儿,设置滚现,在狗陌陌地址。滚动次陌陌文章网页文章正文里的图文章正文采集步图片,需下拉步骤38拉滚动,才会加载下来注意你们可参10)意:这儿的滚动家可按需设置参考AJAX滚)重新启动采动次数、时间置滚动教程:ht采集,并导入设置“页面网页文间、方式的设ttp://www.b出数据,数据网页文面加载完成后文章正文采集步设置,会影响采bazhuayu.co据导入后如图文章正文采集步导入数据后向上滚动”步骤39采集数据的速om/tutorial所示:步骤40速率、质量。
ldetail-1/ajg本文仅做参gd_7.html参考,说明间用无需相关百度新浪豆瓣明:因搜狗微用在等待图片需等待图片加关采集教程:度搜索结果采浪微博数据采瓣影片短评采陌陌文章中的片加载,因此加载,采集速采集采集采集网页文图片,需经过而采集速率较慢速率会快好多文章正文采集步数据示例过下拉滚动较慢。若果没有。步骤41,方可加载出有采集图片的下来。在采集的需求,直接集过程中,大接使用文本采大量时采集,优采云——70万用户选择的网页数据采集器。1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,死机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担忧IP被封,网路中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,还能满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。 查看全部
网页文章正文采集方式-以陌陌文章采集为例
网页文章正文采集方式,以及陌陌文章采集为例当我们想要将明日头条上的新闻、搜狗陌陌上的文章正文内容保存出来的时侯,如何办?一篇篇复制粘贴?选择一款通用的网页数据采集器,将会使工作简单好多。优采云是一款通用的网页数据采集器,可采集互联网上的公开数据。用户可以设置从那个网站爬取数据,爬取这些数据,爬取哪些范围的数据,哪些时侯去爬取数据,爬取的数据怎么保存等等。言归正传,本文将以搜狗陌陌的文章正文采集为例,讲解使用优采云采集网页文章正文的方式。文章正文采集,主要有两大类情况:一、采集文章正文中的文本,不含图片;二、采集文章正文中的文本和图片URL。示例网站:使用功能点:Xpath判定条件分页列表信息采集AJAX滚动教程AJAX点击和翻页一、采集文章正文中的文本,不含图片具体步骤:步骤1)进2)将骤1:创建采步入主界面即将采集的网采集任务,选择“自定网址URL复定义模式”网页文复制粘贴到网站文章正文采集站输入框中集步骤1,点击“保存网址”步骤1)在网页作提骤2:创建翻在页面右上角页打开后,默提示框中,选翻页循环角,打开“流默认显示“热选择“更多操网页文流程”,以展门”文章。
下操作”文章正文采集诠释出“流程设下拉页面,找集步骤2设计器”和“找到并点击““定制当前操“加载更多内操作”两个板内容”按钮,蓝筹股。在操2)选择“循环点击单个元素网页文素”,以创建文章正文采集建一个翻页循集步骤3循环因为打开于此网页涉及开“高级选项及Ajax技术项”,勾选“网页文,我们须要进“Ajax加载数文章正文采集进行一些中级数据”,设置集步骤4级选项的设置置时间为“2置。选中“点秒”点击元素”步步骤,注:A可以AJA观察篇文“高定”AJAX即延时以在不重新加AX点击和翻页察网页,我们文章。为此,中级选项”,时加载、异步加载整个网页页教程:htt们发觉,通过我们设置整打开“满足网页文更新的一种脚页的情况下,对tp://www.b5次点击“加整个“循环翻页以下条件时退文章正文采集脚本技术,通对网页的某部azhuayu.co加载更多内容页”步骤执行退出循环”集步骤5通过在后台与部份进行更新om/tutorial容”,页面加行5次。选,设置循环次与服务器进行新。具体请看detail-1/aja加载到最顶部选中“循环翻次数等于“5行少量数据交看axdjfy_7.htm部,一共显示翻页”步骤,次”,点击交换,ml示100打开击“确步骤1)移选择骤3:创建列联通键盘,选择“选中全部列表循环并提取选中页面里第部”网页文取数据第一条文章链文章正文采集链接。
系统会集步骤6会手动辨识相像链接,在操作提示框框中,2)选择“循环点击每位链接网页文接”文章正文采集步骤73)系提示系统会手动进示框中,选择步入文章详情择“采集该元网页文情页。点击需元素的文本”文章正文采集须要采集的字。文章发布时集步骤8数组(这儿先时间、文章来先点击了文章来源数组的采章标题),在采集方式同理在操作理4)接素,接出来开始采选择“选中采集文章正文中全部”网页文文。先点击文文章正文采集文章正文的第集步骤9第一段,系统会手动识别页面内的同类元5)可以看见,所有的正文段网页文段落均被选中文章正文采集步中,变为红色步骤10色。选择“采集以下元素文本”注意:在数组表中,可进行网页文行数组的自定义文章正文采集步义更改步骤116)经言,定义分页经过如上操作我们希望采义数据合并方页合并”,再作,正文都会采集的正文,合形式”,勾选再点击“确定网页文会被全部采集合并为同一个“同一数组多定”文章正文采集步集出来(默认个单元格。点多次提取合并步骤12觉得每一段正点击“自定义并为一行,即正文为一个单义数据数组”即追加到同一单元格)。
一按键,选择一数组,比如通常而择“自正文网页文“自定文章正文采集步定义数据数组步骤13段”按钮网页文选择“自文章正文采集步自定义数据合步骤14合并方法”步骤1)选列表骤4:更改X选中整个“循表,定位的是Xpath循环步骤”是前20篇文章网页文如,打开“高级章的链接文章正文采集步如图进行勾选级选项”,可步骤15选可以看见,优采云默认生成的是固定定元素2)在//DI被定在傲游浏览器IV[@class=定位了器中打开要采='main-left']网页文采集的网页并]/DIV[3]/UL文章正文采集步并观察源码。L/LI/DIV[2]/步骤16我们发觉,/H3[1]/A,页通过此条X页面中所需的Xpath:的100篇文文章均3)将更改后的Xpath,复制网页文制粘贴到八爪网页文文章正文采集步爪鱼中所示位文章正文采集步步骤17位置,之后点步骤18点击“确定”步骤我们我们取数1)选出现拖动骤5:更改流们继续观察,们配置规则的数据选中整个“循现好多重复数动完成后,如流程图结构通过5次点的思路是,先循环”步骤数据如右图所示点击“加载更先构建翻页循环,将其拖出网页文更多内容”后环,加载出全“循环翻页”文章正文采集步后,此网页加载全部100篇步骤。
假如步骤19载出全部10篇文章,再建果不进行此项00篇文章。构建循环列表项操作,这么因此表,提么将会步骤1)点骤6:数据采点击左上角的采集及导入的“保存”网页文,之后点击文章正文采集步“开始采集”步骤20,选择“启动本地采集”2)采数据采集完成后据导入,会跳出提示网页文示,选择“导文章正文采集步导入数据”,步骤21,选择“合适的导入方式”,将采集集好的3)这儿我们选择择excel作为网页文为导入为格式文章正文采集步式,数据导入步骤22出后如右图4)如的X//[@正文如上图,部份Xpath://[@id="js_co文内容,均被分文章的正文[@id="js_content"]//P被采集到了网页文文没有采集到ontent"]/PP,所有的文文章正文采集步到。那是由于P,定位不到文章正文均可步骤23为,系统手动到此篇文章的可被定位到。动生成的文章的正文。将X再度启动采章正文的循环Xpath更改采集,所有文环列表改为:文章的网页文修文章正文采集步更改Xpath前步骤24前经过则需二、接一步骤过如上操作,需往已有的规采集文章正一中的步骤6骤7:降低判目标网址中规则中,加入正文中的文本6判定条件网页文修中的陌陌文章正入一个判定条件本和图片URL文章正文采集步更改Xpath后正文中的全部件。
L步骤25后部文本被采集出来。如果还需采集图图片,经过要采元素支。同时默认行最回到果不1)从示的过前6个步骤采集图片,则素(图片),时,在优采云认最右边分支最右边分支。到此规则,即不满足右侧条从左边工具栏的红色减号位骤,我们仅采则需往规则里则执行图片鱼中,默认对支为“不判定即对右边分支条件分支的条栏,往流程中位置)采集了陌陌文里加入一个判片采集分支;如对右边分支,设,总是执行该支设置条件:如条件(即不收录中推入一个网页文文章里的文本判定条件:对倘若不收录设置判定条件该分支”,即若果收录im含img元素“判断条件”文章正文采集步本内容,并不文章内容列表img元素(件,满足此判即当不满足左mg元素(图素),则执行步骤(选取步骤26不包括文章里表进行判别图片),则判定条件,则右边分支的判图片),则执行两侧分支。定图标拖住不里的图片。如,假如收录则执行文本采则执行两侧分判定条件时,执行两侧分支具击剑作如下不放,推入箭果需img采集分分支;则执支;如下:箭头所2)流再点流程图中出现点击两侧分支现判定条件。支,在出现的结将我们将“提结果页面(分网页文将“提取元素提取数据”步骤分支条件检查文章正文采集步素”步骤,拖骤,联通到右测结果-检查结步骤27推入两侧分支两侧分支中(结果总是Tru支(红色减号处ue)点击“确处)。
定”3)点定”(代点击两侧分支。之后对其代表图片),支,在出现的其设置判定条再点击“确网页文两侧分支的结果页面(条件:勾选“确定”文章正文采集步支-检查结果总(分支条件检“当前循环项包步骤28总是True检查结果-检查收录元素”测结果总是,输入元素True)点击Xpath://击“确/img网页文点文章正文采集步点击两侧分支步骤29支4)左步骤中,左边分支条件骤,到流程图选择“采集件设置完毕后图中的右边分集该图片地址对右边分网页文后,再进行提支中(红色加址”分支,设置判文章正文采集步提取数据步骤减号处),然判定条件步骤30骤。从左边工具之后选中页面具栏,推入一面内一张图片一个“提取数片,在操作提数据”提示框拖入新的“提取网页文取数据”步骤文章正文采集步骤,到左边分步骤31分支5)选元素//*[选中两侧分支素方法”,将[@id="js_c支的“提取数将红框中的“content"]/p采网页文数据”步骤,“元素匹配的p[1]/span[1采集图片地址文章正文采集步,点击“自定Xpath”:1]与“相对址步骤32定义数据数组Xpath”:/段”按钮,选/span[1],选择“自定义记录出来义定位自定网页义民义定位元素文章正文采集步素方法步骤336)选元素//*[定”选中两侧分支素方法”,参[@id="js_c元支的“提取数参照右边分支content"]/p元素匹配的X网页文数据”步骤,支相同位置的p[1]/img[1Xpath、“相文章正文采集步,点击“自定的Xpath进行1],“相对X相对Xpath”步骤34定义数据数组行更改:“元Xpath”改为段”按钮,选元素匹配的为:/img[1]选择“自定义Xpath”改],之后点击义定位改为:击“确7)选合并选中两侧分支并方法”,如支的“提取数如图进行勾选网页文数据”步骤,选。
勾选后,多文章正文采集步,点击“自定多次提取的正步骤35定义数据数组正文将追加为段”按钮,选为一个数组选择“自定义义数据8)注个数请参注意,在八爪数需一致。这儿参考:爪鱼中,判定里,我们将左/www.bazh网页文断条件里各分左右两个分支/文章正文采集步分支中的“提支中,提取的/tutorialdet步骤36提取数据”步的数组名均改ail-1/judge步骤中的数组为“正文”(e.html)段名需相同,判定条件教数组教程,9)如导入文章因此数为如上,整个判出的excel表章正文里的图而,在打开文为“30次”判断条件设置表格中,图片图片,需下拉文章后,需对其,每次间隔网页文置完毕。点击片地址为一堆拉滚动,能够加其进行设置“2秒”,滚文章正文采集步击左上角的“堆乱码。这是加载下来,加“页面加载完滚动形式为“步骤37“保存”并“是为何呢?加载下来后才完成后向上滚“向下滚动一“开始采集”继续观察网页能够采集到正滚动”。在这一屏”。我们发觉页——搜狗正确的图片地这儿,设置滚现,在狗陌陌地址。滚动次陌陌文章网页文章正文里的图文章正文采集步图片,需下拉步骤38拉滚动,才会加载下来注意你们可参10)意:这儿的滚动家可按需设置参考AJAX滚)重新启动采动次数、时间置滚动教程:ht采集,并导入设置“页面网页文间、方式的设ttp://www.b出数据,数据网页文面加载完成后文章正文采集步设置,会影响采bazhuayu.co据导入后如图文章正文采集步导入数据后向上滚动”步骤39采集数据的速om/tutorial所示:步骤40速率、质量。
ldetail-1/ajg本文仅做参gd_7.html参考,说明间用无需相关百度新浪豆瓣明:因搜狗微用在等待图片需等待图片加关采集教程:度搜索结果采浪微博数据采瓣影片短评采陌陌文章中的片加载,因此加载,采集速采集采集采集网页文图片,需经过而采集速率较慢速率会快好多文章正文采集步数据示例过下拉滚动较慢。若果没有。步骤41,方可加载出有采集图片的下来。在采集的需求,直接集过程中,大接使用文本采大量时采集,优采云——70万用户选择的网页数据采集器。1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,死机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担忧IP被封,网路中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,还能满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。
ASP信息采集程序图解教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2020-08-21 01:24
官方网址:
运行环境:B/S,Win9X/Win2000/WinXP/Win2003,浏览器
【界面截图】
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
【软件简介】
ASP神偷(AspStealer)可以把远程网站上的数据(如新闻、博客文章、客户资料等)一次性、无限制记录数、全手动保存到自己网站的数据库的程序。
与其他的ASP歹徒程序相比,ASP神偷(AspStealer)具有如下优点:
1.ASP劫匪来自其他网站,它随着该网站的更新而更新,如果目标网站无法访问、数据有误或则改变页面结构,您的网站也难以读取到相关数据,有时还须要更改ASP歹徒相应的程序;ASP神偷是采用一次性、无限制记录数、全手动保存到自己网站数据库的方法采集数据的,不会遭到目标网站的任何影响。
2.ASP歹徒属于远程调用,访问远程速率较慢;ASP神偷属于同一网站数据库调用,您的网站有多快,访问速率就有多快。
【采集范例】
ASP神偷 Beta1.0 支持采集如 类型(文件名.asp?ClassID=数值)的网址。
以采集(私房博客)的文章为例,步骤如下:
1.打开文章列表页,
2.发现文章链接页网址的规律性,如 view.asp?ClassID=数值 ,正常这种数值都是三位数或四位数的;也有网站是采用多位随机数做为ID,如view.asp?ClassID=21(ClassID=年月日+五位随机数),或21.htm(年月日+五位随机数.htm),ASP神偷 Beta1.0 暂不支持后两种类型的网址;
3.使用ASP神偷 Beta1.0 的默认设置,直接点击『预览』,即可采集从ClassID=177开始至ClassID=187的十篇文章的标题;
4.此例从ClassID=177开始至ClassID=187,采集十篇文章的内容;
5.在ASP神偷 Beta1.0 的 『网址』填入 『』,『从』填入『177』,『到』填入『187』;
6.用浏览器打开 页面,点击『菜单栏』->『查看』->『源文件』,记事本将打开该页面的html源文件;
7.找出在页面html源文件内正文内容前的一段标识符,该标识符最好是惟一的整句代码,可用Ctrl+F在记事本内查询您找到的这段标识符,验证该标识符的唯一性,以保证采集数据的有效性(如下图);
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
8.将惟一前标识符拷入ASP神偷 Beta1.0 的『前标示』 栏目,『右移』填入『0』;
9.用同样的方式,找出正文内容后的那段标识符,拷入的『后标示』 栏目,『左移』填入『0』;
10.注意:前标识符和后标识符必须是整篇文章共同拥有的,不能富含某篇或某几篇文章独有的html代码,否则采集的信息可能会出错,最终的采集设置(如下图);
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
11.点击『预览』,即可采集到您要的内容了。
备注:ASP神偷 Beta1.0 目前限制预览前20条记录,且暂不开通『导入数据库』功能;使用者勿将该程序用于非法用途,否则后果自负!使用过程中碰到任何的困局、意见、建议或则找不出前后标识符的用户,欢迎在 『发表评论』,我们将会在第一时间为您提供帮助!
更多的ASP信息采集程序图解教程请到峰会查看: 查看全部
ASP信息采集程序图解教程
官方网址:
运行环境:B/S,Win9X/Win2000/WinXP/Win2003,浏览器
【界面截图】
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
【软件简介】
ASP神偷(AspStealer)可以把远程网站上的数据(如新闻、博客文章、客户资料等)一次性、无限制记录数、全手动保存到自己网站的数据库的程序。
与其他的ASP歹徒程序相比,ASP神偷(AspStealer)具有如下优点:
1.ASP劫匪来自其他网站,它随着该网站的更新而更新,如果目标网站无法访问、数据有误或则改变页面结构,您的网站也难以读取到相关数据,有时还须要更改ASP歹徒相应的程序;ASP神偷是采用一次性、无限制记录数、全手动保存到自己网站数据库的方法采集数据的,不会遭到目标网站的任何影响。
2.ASP歹徒属于远程调用,访问远程速率较慢;ASP神偷属于同一网站数据库调用,您的网站有多快,访问速率就有多快。
【采集范例】
ASP神偷 Beta1.0 支持采集如 类型(文件名.asp?ClassID=数值)的网址。
以采集(私房博客)的文章为例,步骤如下:
1.打开文章列表页,
2.发现文章链接页网址的规律性,如 view.asp?ClassID=数值 ,正常这种数值都是三位数或四位数的;也有网站是采用多位随机数做为ID,如view.asp?ClassID=21(ClassID=年月日+五位随机数),或21.htm(年月日+五位随机数.htm),ASP神偷 Beta1.0 暂不支持后两种类型的网址;
3.使用ASP神偷 Beta1.0 的默认设置,直接点击『预览』,即可采集从ClassID=177开始至ClassID=187的十篇文章的标题;
4.此例从ClassID=177开始至ClassID=187,采集十篇文章的内容;
5.在ASP神偷 Beta1.0 的 『网址』填入 『』,『从』填入『177』,『到』填入『187』;
6.用浏览器打开 页面,点击『菜单栏』->『查看』->『源文件』,记事本将打开该页面的html源文件;
7.找出在页面html源文件内正文内容前的一段标识符,该标识符最好是惟一的整句代码,可用Ctrl+F在记事本内查询您找到的这段标识符,验证该标识符的唯一性,以保证采集数据的有效性(如下图);
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
8.将惟一前标识符拷入ASP神偷 Beta1.0 的『前标示』 栏目,『右移』填入『0』;
9.用同样的方式,找出正文内容后的那段标识符,拷入的『后标示』 栏目,『左移』填入『0』;
10.注意:前标识符和后标识符必须是整篇文章共同拥有的,不能富含某篇或某几篇文章独有的html代码,否则采集的信息可能会出错,最终的采集设置(如下图);
document.body.clientWidth-300) {this.height=(document.body.clientWidth-300)*this.height/this.width;this.width=document.body.clientWidth-300}" border=0 galleryImg="no">
11.点击『预览』,即可采集到您要的内容了。
备注:ASP神偷 Beta1.0 目前限制预览前20条记录,且暂不开通『导入数据库』功能;使用者勿将该程序用于非法用途,否则后果自负!使用过程中碰到任何的困局、意见、建议或则找不出前后标识符的用户,欢迎在 『发表评论』,我们将会在第一时间为您提供帮助!
更多的ASP信息采集程序图解教程请到峰会查看:
【TDA2x学习】5、编译第一个SDK程序(最新版)【收录RTOS和HLOS】
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-20 21:50
【为什么学爬虫?】 1、爬虫入手容易,但是深入较难,如何写出高效率的爬虫,如何写出灵活性高可扩充的爬虫都是一项技术活。另外在爬虫过程中,经常容易遇见被反爬虫,比如字体反爬、IP辨识、验证码等,如何层层攻破难点领到想要的数据,这门课程,你都能学到! 2、如果是作为一个其他行业的开发者,比如app开发,web开发,学习爬虫能使你加大对技术的认知,能够开发出愈发安全的软件和网站【课程设计】一个完整的爬虫程序,无论大小,总体来说可以分成三个步骤,分别是:网络恳求:模拟浏览器的行为从网上抓取数据。数据解析:将恳求出来的数据进行过滤,提取我们想要的数据。数据储存:将提取到的数据储存到硬碟或则显存中。比如用mysql数据库或则redis等。那么本课程也是根据这几个步骤循序渐进的进行讲解,带领中学生完整的把握每位步骤的技术。另外,因为爬虫的多样性,在爬取的过程中可能会发生被反爬、效率低下等。因此我们又降低了两个章节拿来增强爬虫程序的灵活性,分别是:爬虫进阶:包括IP代理,多线程爬虫,图形验证码辨识、JS加密揭秘、动态网页爬虫、字体反爬辨识等。Scrapy和分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等。通过爬虫进阶的知识点我们能应付大量的反爬网站,而Scrapy框架作为一个专业的爬虫框架,使用他可以快速提升我们编撰爬虫程序的效率和速率。另外假如一台机器不能满足你的需求,我们可以用分布式爬虫使多台机器帮助你快速爬取数据。从基础爬虫到商业化应用爬虫,本套课程满足您的所有需求!【课程服务】专属付费社群+每周三讨论会+1v1答疑 查看全部
【TDA2x学习】5、编译第一个SDK程序(最新版)【收录RTOS和HLOS】
【为什么学爬虫?】 1、爬虫入手容易,但是深入较难,如何写出高效率的爬虫,如何写出灵活性高可扩充的爬虫都是一项技术活。另外在爬虫过程中,经常容易遇见被反爬虫,比如字体反爬、IP辨识、验证码等,如何层层攻破难点领到想要的数据,这门课程,你都能学到! 2、如果是作为一个其他行业的开发者,比如app开发,web开发,学习爬虫能使你加大对技术的认知,能够开发出愈发安全的软件和网站【课程设计】一个完整的爬虫程序,无论大小,总体来说可以分成三个步骤,分别是:网络恳求:模拟浏览器的行为从网上抓取数据。数据解析:将恳求出来的数据进行过滤,提取我们想要的数据。数据储存:将提取到的数据储存到硬碟或则显存中。比如用mysql数据库或则redis等。那么本课程也是根据这几个步骤循序渐进的进行讲解,带领中学生完整的把握每位步骤的技术。另外,因为爬虫的多样性,在爬取的过程中可能会发生被反爬、效率低下等。因此我们又降低了两个章节拿来增强爬虫程序的灵活性,分别是:爬虫进阶:包括IP代理,多线程爬虫,图形验证码辨识、JS加密揭秘、动态网页爬虫、字体反爬辨识等。Scrapy和分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等。通过爬虫进阶的知识点我们能应付大量的反爬网站,而Scrapy框架作为一个专业的爬虫框架,使用他可以快速提升我们编撰爬虫程序的效率和速率。另外假如一台机器不能满足你的需求,我们可以用分布式爬虫使多台机器帮助你快速爬取数据。从基础爬虫到商业化应用爬虫,本套课程满足您的所有需求!【课程服务】专属付费社群+每周三讨论会+1v1答疑
新手使用优采云发布插口怎么采集文章教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-20 19:39
前沿:
如果你对优采云一点都不知道,你还是去网上自学一点优采云采集的知识,我也不是哪些大师,硬着头皮写的,至少能用,在这里我不会教你怎么写采集规则,因为写法种类太多,你问我我也不知道,优采云相关文件夹里提供的发布插口外置了马甲发布文章,并且支持远程图片抓取本地化,和发布文章时间设置(10-70分钟随机)。用户只需关注优采云标题和内容即可,参数值标题(title),内容(content)。
第一步:站点设置里设置下优采云免登入发布插口的全局变量值:
第二步:将发布插口上传覆盖程序根目录:
第三步:登录优采云软件后导出发布模块"
下图更多处下拉--选择导出:
导入后:
上图中,数字1处填写你在网站后台设置的全局变量值。
2 处选择 utf-8 编码。
3 处填写你网站域名,不要带 反斜杠'/'.
4处选择不需要登陆
5 处点击获取列表--选择你须要入库的分类
6 随便给当前这个发布模块写个名子,后续采集任务模块会用到。
最后点击保存配置按键。
---------
下面讲解导出采集任务:
新建任务分组后,在该分组下导出任务规则(导入任务至该分组):
选择我们的采集任务规则(.ljobx文件):
下一步:双击规则项
点击第三步:修改发布内容设置
修改下你发布的分类:
最后保存即可:
然后右键开始任务采集: 查看全部
新手使用优采云发布插口怎么采集文章教程
前沿:
如果你对优采云一点都不知道,你还是去网上自学一点优采云采集的知识,我也不是哪些大师,硬着头皮写的,至少能用,在这里我不会教你怎么写采集规则,因为写法种类太多,你问我我也不知道,优采云相关文件夹里提供的发布插口外置了马甲发布文章,并且支持远程图片抓取本地化,和发布文章时间设置(10-70分钟随机)。用户只需关注优采云标题和内容即可,参数值标题(title),内容(content)。
第一步:站点设置里设置下优采云免登入发布插口的全局变量值:
第二步:将发布插口上传覆盖程序根目录:
第三步:登录优采云软件后导出发布模块"
下图更多处下拉--选择导出:
导入后:
上图中,数字1处填写你在网站后台设置的全局变量值。
2 处选择 utf-8 编码。
3 处填写你网站域名,不要带 反斜杠'/'.
4处选择不需要登陆
5 处点击获取列表--选择你须要入库的分类
6 随便给当前这个发布模块写个名子,后续采集任务模块会用到。
最后点击保存配置按键。
---------
下面讲解导出采集任务:
新建任务分组后,在该分组下导出任务规则(导入任务至该分组):
选择我们的采集任务规则(.ljobx文件):
下一步:双击规则项
点击第三步:修改发布内容设置
修改下你发布的分类:
最后保存即可:
然后右键开始任务采集:
百度当日收录文章隔天删掉个人觉得解决办法。
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-20 13:23
这个问题曾经研究过很多次了,也尝试了好多方式,基本上下边的方式就是完全可以解决的了,不过要排除降权严重的情况。
【原因】
1、内容质量问题,这个是要考虑近来更新内容的质量和网站整站的质量概况,而不是针对单一更新文章的
2、网站降权问题,降权不是严重的降权,其实就是降低爆光,也可以理解为观察期
3、网站权值问题,网站权值低的话,就会导致这些情况。尤其是一些新站,特别容易发生
4、更新频度问题,每个周期内更新的文章数量变化很大,就会导致抓取数目变化十分大,以至于进行百度的观察期,减少爆光。
【解决方式】
1、增加残差导出。更新的文章在首页展示,并且当日降低3-5条外部链接,一定要是可收录的,或者能爆光的。
2、维持稳定的更新频度。每天更新一篇,或者是两篇。总之就是不要更新的数目变化十分大,维持一段时间
3、更新内容标题,这个主要是考虑到内容的质量,一般情况下我们的标题都是采用一种低格的,当出现收录删掉的时侯,试着换换标题的格式,这样有利于百度同先前的内容进行分辨。
4、更新内容之间添加文字链接。更新的内容之间可以添加一些相关的内链,这样保证只要有一篇稳定的话,就会持续的给其它内容带来残差。
按照这些做法的话,基本上要7-15天才能恢复,但是排除掉因为作弊的降权和观察期,只是代表通常的情况下可以解决的 查看全部
百度当日收录文章隔天删掉个人觉得解决办法。
这个问题曾经研究过很多次了,也尝试了好多方式,基本上下边的方式就是完全可以解决的了,不过要排除降权严重的情况。
【原因】
1、内容质量问题,这个是要考虑近来更新内容的质量和网站整站的质量概况,而不是针对单一更新文章的
2、网站降权问题,降权不是严重的降权,其实就是降低爆光,也可以理解为观察期
3、网站权值问题,网站权值低的话,就会导致这些情况。尤其是一些新站,特别容易发生
4、更新频度问题,每个周期内更新的文章数量变化很大,就会导致抓取数目变化十分大,以至于进行百度的观察期,减少爆光。
【解决方式】
1、增加残差导出。更新的文章在首页展示,并且当日降低3-5条外部链接,一定要是可收录的,或者能爆光的。
2、维持稳定的更新频度。每天更新一篇,或者是两篇。总之就是不要更新的数目变化十分大,维持一段时间
3、更新内容标题,这个主要是考虑到内容的质量,一般情况下我们的标题都是采用一种低格的,当出现收录删掉的时侯,试着换换标题的格式,这样有利于百度同先前的内容进行分辨。
4、更新内容之间添加文字链接。更新的内容之间可以添加一些相关的内链,这样保证只要有一篇稳定的话,就会持续的给其它内容带来残差。
按照这些做法的话,基本上要7-15天才能恢复,但是排除掉因为作弊的降权和观察期,只是代表通常的情况下可以解决的
C#实现的一个简单爬图程序采集写真套图源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-08-20 07:34
这个东西须要的人甚少,但是群里有人问我要,还想给钱。哼,我宝哥是那个要钱的人吗?免费开源给你们使用,代码写得太粗糙,没用规划,写到那里算那儿。运行上去疗效挺好,采集那100个系列套图的话大约在1个小时左右吧,可能更快,因为后期我优化了一下,只要你的网路够快,采集进度条如同注射器一样。
C#实现的一个简单爬图程序采集写真套图
如果不想自己采集,可以直接下载我采集好了的套图数据库,详情查看:200万张高清写真套图分享。
软件使用教程
软件运行环境:Windows all +.net framework 4.5
首先登陆采集目标站,因为采集的内容必须登入用户能够访问。
登录后按F12打开浏览器开发者模式,选择network标签,随便打开该站一个页面。点击恳求列表中惟一的doc。也就是页面内容恳求,不是页面资源恳求。一般是第一个。在右边的恳求数据详情中,找到恳求头request headers项中的cookies。
C#实现的一个简单爬图程序采集写真套图
将cookie全部复制出来,然后粘贴到软件第一个编辑框中即可。请勿必勾选数据入库或则保存图片两者之一,或者都选。如果选择保存图象,则必须点击选择文件路径,以获得保存图象位置。若要采集所有内容,点击采集所有即可。采集指定系列,请先在网站中打开分类后,将地址栏中id=XXX中的XXX填写到采集类目中。目前总共1-100个分类,id区间为1-100。注意:采集请不要暂停,因为没用。功能没写完,点了没用,而且再度采集会重新采集,相同内容入库会失败。如果想要重新采集,请关掉软件,再删掉软件目录中的tt.db数据库文件,再次启动软件即可。
压缩包是源码,visual studio 2019版项目,编译好的程序在压缩包中的bin/debug目录下,可直接运行。
文件下载C#实现的一个简单爬图程序采集写真套图源码>>6M 查看全部
C#实现的一个简单爬图程序采集写真套图源码
这个东西须要的人甚少,但是群里有人问我要,还想给钱。哼,我宝哥是那个要钱的人吗?免费开源给你们使用,代码写得太粗糙,没用规划,写到那里算那儿。运行上去疗效挺好,采集那100个系列套图的话大约在1个小时左右吧,可能更快,因为后期我优化了一下,只要你的网路够快,采集进度条如同注射器一样。
C#实现的一个简单爬图程序采集写真套图
如果不想自己采集,可以直接下载我采集好了的套图数据库,详情查看:200万张高清写真套图分享。
软件使用教程
软件运行环境:Windows all +.net framework 4.5
首先登陆采集目标站,因为采集的内容必须登入用户能够访问。
登录后按F12打开浏览器开发者模式,选择network标签,随便打开该站一个页面。点击恳求列表中惟一的doc。也就是页面内容恳求,不是页面资源恳求。一般是第一个。在右边的恳求数据详情中,找到恳求头request headers项中的cookies。
C#实现的一个简单爬图程序采集写真套图
将cookie全部复制出来,然后粘贴到软件第一个编辑框中即可。请勿必勾选数据入库或则保存图片两者之一,或者都选。如果选择保存图象,则必须点击选择文件路径,以获得保存图象位置。若要采集所有内容,点击采集所有即可。采集指定系列,请先在网站中打开分类后,将地址栏中id=XXX中的XXX填写到采集类目中。目前总共1-100个分类,id区间为1-100。注意:采集请不要暂停,因为没用。功能没写完,点了没用,而且再度采集会重新采集,相同内容入库会失败。如果想要重新采集,请关掉软件,再删掉软件目录中的tt.db数据库文件,再次启动软件即可。
压缩包是源码,visual studio 2019版项目,编译好的程序在压缩包中的bin/debug目录下,可直接运行。
文件下载C#实现的一个简单爬图程序采集写真套图源码>>6M
爬取B站程序猿up主,分析程序猿up出哪些类型的视频会受欢迎
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-19 20:25
文章目录
前言
我,一个天天早起,睡前必刷B站的菜鸡程序猿,昨天见到一位关注的程序猿up主发布的动态,心里太不好受,所以才想着做此次的内容
到底程序猿up主做哪些类型的视频就会受大众喜欢呢?
不想看文字就点击图片去看B站我的视频吧,之前似乎可以直接导出视频的,现在iframe不知道为何失效了
开始动手1.首先须要去采集数据
选择到搜索去搜程序猿,然后选择视频,弹幕最多(也就是真实观看的人比较多),去得到每一个视频的链接。
这样我们就先得到每位视频对应的详情页链接,然后再从详情页用xpath去得到标题,up名,up主页等信息(在这个页面直接得到视频点赞数和播放数最后保存的结果是异常值),点赞数和播放数用api去得到。
api只须要视频的id就可以返回相应的json结果,所以得到也是比较便捷的,最后保存到csv文件。
爬虫代码:
import requests
from lxml import etree
import time
import pandas as pd
import re
import json
#https://search.bilibili.com/vi ... %3D32
def get_html(url,header):
html=requests.get(url,headers=header).text
return html
def get_all_page(n):
urls=[]
for i in range(1,n+1):
url=f"https://search.bilibili.com/vi ... ge%3D{i}"
html=get_html(url,headers)
selector = etree.HTML(html)
li_list=selector.xpath("//ul[@class='video-list clearfix']")
for li in li_list:
urls.extend(li.xpath("//li[@class='video-item matrix']/a/@href"))
return urls
def get_information(urls,avid):
space_url=[]
name_list=[]
views_list=[]
dz_list=[]
video_names=[]
count=0
for url in urls:
count+=1
if count==10:
time.sleep(1)
url=url.replace('//','https://')
print("正在爬取:",url)
html=get_html(url,headers1)
selector = etree.HTML(html)
space_url.append(selector.xpath("//div[@class='name']/a[1]/@href")[0])
name_list.append(selector.xpath("//div[@class='name']/a[1]/text()")[0])
video_names.append(selector.xpath("//h1/@title")[0])
# views_list.append(selector.xpath("//div[@class='video-data']/span[1]/text()")[0])
# dz_list.append(selector.xpath("//div[@class='ops']/span[1]/text()")[0])
for id in avid:
base_url="https://api.bilibili.com/x/web ... ot%3B
html=get_html(base_url+id,headers2)
res=json.loads(html)
video_info = res['data']
views_list.append(video_info["stat"]["view"])
dz_list.append(video_info["stat"]["like"])
return space_url,name_list,views_list,dz_list,video_names
def save(n):
urls=get_all_page(n)
avid=[]
for i in urls:
avid.append(re.findall("\d+",i)[0])
space_url,name_list,views_list,dz_list,video_names=get_information(urls,avid)
data=pd.DataFrame({"空间链接":space_url,"up主":name_list,"视频名":video_names,"视频播放次数":views_list,"视频点赞数":dz_list})
data.to_csv('./B站程序猿up主视频信息.csv',encoding='utf8')
print("所有数据爬取完毕")
if __name__ == '__main__':
headers = {
'Host': 'search.bilibili.com',
'Referer': 'https//www.bilibili.com/',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
headers1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Host': 'www.bilibili.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
headers2={
'Host': 'api.bilibili.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945 .130Safari / 537.36'
}
n=int(input("请输入想要爬取的页数:"))
save(n)
我爬取了十页,一共200条数据
2.开始数据剖析
基本的导库和导出数据,并且重命名列名
然后对数据清洗和预处理,查看缺失值异常值。但是因为B站数据比较友好,没有异常缺位值。
然后分组剖析点赞数多的up和播放数多的up
这一部分用groupby很简单就实现了,所以只上对点赞的剖析绘图代码
# 找到视频点赞数最多的up主
most_dz=data.groupby(by=data['up主名'],as_index=False)['视频点赞数'].sum()
most_dz.columns=['up主名','视频点赞总数']
most_dz.head()
#降序排序
most_dz=most_dz.sort_values(by=['视频点赞总数'],ascending=False)
most_dz.head(10)
# 可视化点赞数前20的up主
plt.figure(figsize=(13,10))
sns.barplot(most_dz['up主名'][:20],most_dz['视频点赞总数'][:20])
plt.title('程序猿up主视频点赞总数前20', fontsize=22)
plt.grid()
plt.xticks(rotation=90)
plt.show()
3.查看各图中第一的视频类型
我发觉迷糊老师出的视频涉及到编程的比较少,大多是涉及到日常笔记本使用高阶操作的视频。看来我之后要是想点赞数多应当少出点涉及到编程的,多出点能使听众日常使用到的视频 毕竟编程类教学视频都是被埋在采集夹里了,我的采集夹里都有一大堆
纳尼,就只有一个视频就737万+的播放数,这也很强了吧。同时也说明还是有很多人还是乐意在B站学习编程的,特别是python相关的视频似乎非常火
4.做个总结
总结:
在B站教学类视频有很大几率会被放进采集夹喝灰,所以程序猿up主们要紧抓观众们的喜好来创作视频,比如python系列的教学视频就太受欢迎(原因也是python生态好,学上去简单),或者是一些日常笔记本高阶操作的教学的视频,这些都是比较容易吸引到听众的。
从亲爱的程序羊不能步入前20更能发觉这个问题:程序羊的视频质量是很高的,但是受用群体不大,因为他的视频几乎都是讲程序猿的修练,没太多简单易学的,相反大多都是程序猿们认为太有意义,但是圈外人听着一脸懵,根本如同听天书一样的。哈哈,不过对于我们这种程序猿来说这样的up主简直就是宝藏up,也正是由于他选择讲对程序猿最有益的一些内容,放弃一些其他利益,这也能够使我们学到更多更好的知识。
再来瞧瞧一些出发点不同的程序猿up,比如张大米的日常。他能有如此高观看数和点赞数的诱因就是他的视频既兼具了程序猿,利用程序猿的梗可以给我们带来欢乐,同时也照料了其他群体,从一些不这么高深的计算机知识出发,可以使听众更了解程序猿的生活,而且每位视频宽度太短,符合现今短视频的趋势。 查看全部
爬取B站程序猿up主,分析程序猿up出哪些类型的视频会受欢迎
文章目录
前言
我,一个天天早起,睡前必刷B站的菜鸡程序猿,昨天见到一位关注的程序猿up主发布的动态,心里太不好受,所以才想着做此次的内容
到底程序猿up主做哪些类型的视频就会受大众喜欢呢?
不想看文字就点击图片去看B站我的视频吧,之前似乎可以直接导出视频的,现在iframe不知道为何失效了
开始动手1.首先须要去采集数据
选择到搜索去搜程序猿,然后选择视频,弹幕最多(也就是真实观看的人比较多),去得到每一个视频的链接。
这样我们就先得到每位视频对应的详情页链接,然后再从详情页用xpath去得到标题,up名,up主页等信息(在这个页面直接得到视频点赞数和播放数最后保存的结果是异常值),点赞数和播放数用api去得到。
api只须要视频的id就可以返回相应的json结果,所以得到也是比较便捷的,最后保存到csv文件。
爬虫代码:
import requests
from lxml import etree
import time
import pandas as pd
import re
import json
#https://search.bilibili.com/vi ... %3D32
def get_html(url,header):
html=requests.get(url,headers=header).text
return html
def get_all_page(n):
urls=[]
for i in range(1,n+1):
url=f"https://search.bilibili.com/vi ... ge%3D{i}"
html=get_html(url,headers)
selector = etree.HTML(html)
li_list=selector.xpath("//ul[@class='video-list clearfix']")
for li in li_list:
urls.extend(li.xpath("//li[@class='video-item matrix']/a/@href"))
return urls
def get_information(urls,avid):
space_url=[]
name_list=[]
views_list=[]
dz_list=[]
video_names=[]
count=0
for url in urls:
count+=1
if count==10:
time.sleep(1)
url=url.replace('//','https://')
print("正在爬取:",url)
html=get_html(url,headers1)
selector = etree.HTML(html)
space_url.append(selector.xpath("//div[@class='name']/a[1]/@href")[0])
name_list.append(selector.xpath("//div[@class='name']/a[1]/text()")[0])
video_names.append(selector.xpath("//h1/@title")[0])
# views_list.append(selector.xpath("//div[@class='video-data']/span[1]/text()")[0])
# dz_list.append(selector.xpath("//div[@class='ops']/span[1]/text()")[0])
for id in avid:
base_url="https://api.bilibili.com/x/web ... ot%3B
html=get_html(base_url+id,headers2)
res=json.loads(html)
video_info = res['data']
views_list.append(video_info["stat"]["view"])
dz_list.append(video_info["stat"]["like"])
return space_url,name_list,views_list,dz_list,video_names
def save(n):
urls=get_all_page(n)
avid=[]
for i in urls:
avid.append(re.findall("\d+",i)[0])
space_url,name_list,views_list,dz_list,video_names=get_information(urls,avid)
data=pd.DataFrame({"空间链接":space_url,"up主":name_list,"视频名":video_names,"视频播放次数":views_list,"视频点赞数":dz_list})
data.to_csv('./B站程序猿up主视频信息.csv',encoding='utf8')
print("所有数据爬取完毕")
if __name__ == '__main__':
headers = {
'Host': 'search.bilibili.com',
'Referer': 'https//www.bilibili.com/',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
headers1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Host': 'www.bilibili.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
headers2={
'Host': 'api.bilibili.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945 .130Safari / 537.36'
}
n=int(input("请输入想要爬取的页数:"))
save(n)
我爬取了十页,一共200条数据
2.开始数据剖析
基本的导库和导出数据,并且重命名列名
然后对数据清洗和预处理,查看缺失值异常值。但是因为B站数据比较友好,没有异常缺位值。
然后分组剖析点赞数多的up和播放数多的up
这一部分用groupby很简单就实现了,所以只上对点赞的剖析绘图代码
# 找到视频点赞数最多的up主
most_dz=data.groupby(by=data['up主名'],as_index=False)['视频点赞数'].sum()
most_dz.columns=['up主名','视频点赞总数']
most_dz.head()
#降序排序
most_dz=most_dz.sort_values(by=['视频点赞总数'],ascending=False)
most_dz.head(10)
# 可视化点赞数前20的up主
plt.figure(figsize=(13,10))
sns.barplot(most_dz['up主名'][:20],most_dz['视频点赞总数'][:20])
plt.title('程序猿up主视频点赞总数前20', fontsize=22)
plt.grid()
plt.xticks(rotation=90)
plt.show()
3.查看各图中第一的视频类型
我发觉迷糊老师出的视频涉及到编程的比较少,大多是涉及到日常笔记本使用高阶操作的视频。看来我之后要是想点赞数多应当少出点涉及到编程的,多出点能使听众日常使用到的视频 毕竟编程类教学视频都是被埋在采集夹里了,我的采集夹里都有一大堆
纳尼,就只有一个视频就737万+的播放数,这也很强了吧。同时也说明还是有很多人还是乐意在B站学习编程的,特别是python相关的视频似乎非常火
4.做个总结
总结:
在B站教学类视频有很大几率会被放进采集夹喝灰,所以程序猿up主们要紧抓观众们的喜好来创作视频,比如python系列的教学视频就太受欢迎(原因也是python生态好,学上去简单),或者是一些日常笔记本高阶操作的教学的视频,这些都是比较容易吸引到听众的。
从亲爱的程序羊不能步入前20更能发觉这个问题:程序羊的视频质量是很高的,但是受用群体不大,因为他的视频几乎都是讲程序猿的修练,没太多简单易学的,相反大多都是程序猿们认为太有意义,但是圈外人听着一脸懵,根本如同听天书一样的。哈哈,不过对于我们这种程序猿来说这样的up主简直就是宝藏up,也正是由于他选择讲对程序猿最有益的一些内容,放弃一些其他利益,这也能够使我们学到更多更好的知识。
再来瞧瞧一些出发点不同的程序猿up,比如张大米的日常。他能有如此高观看数和点赞数的诱因就是他的视频既兼具了程序猿,利用程序猿的梗可以给我们带来欢乐,同时也照料了其他群体,从一些不这么高深的计算机知识出发,可以使听众更了解程序猿的生活,而且每位视频宽度太短,符合现今短视频的趋势。
ShopEx采集程序,国内最专业的ShopEx采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-17 00:26
尘缘此次发布的ShopEx采集程序,是国外最专业的ShopEx采集软件。如果你是一位淘宝主或则网站主,千万不要错过。
这套ShopEx采集程序可以快速采集任何网站、任何商品类型到你的ShopEx商城系统中,让你不再为货源和重复的商品上架问题苦恼。
这套ShopEx的采集程序,是我们开发的ECSHOP采集软件的姊妹篇,有使用EcShop的领导可以往这儿看:
Ecshop全能采集程序:
ShopEx采集程序简介
功能简介
常见采集字段均可实现,字段包括 商品名称,详细描述,图片等。可以手动构建并匹配商品品牌,不存在的商品品牌可以手动添加为新品牌。可以手动创建并匹配商品分类(支持多级分类)(您只需添加列表页网址即可,采集只是时间问题,您没有任何工作量)。检测重复商品,并跳过。远程图片多图下载,并生成缩略图,加入相册。支持自定义商品类型,商品属性的发布支持尺码颜色等多属性的发布数据可导入到助理支持详尽参数表支持图片水印
常见问题
此插口可以搭配优采云采集器免费版使用假如须要采集带验证码和图片识别码的网站,可以联系前尘订购优采云采集器旗舰版或则企业版,企业版可以获赠本ShopEx采集接口一套本插口不保证会持续升级,如果本插口有后续,所有用户均可免费升级本套采集程序收录插口一套,发布模块一枚,京东商城演示规则一枚本套程序售价300元,如不需要技术支持,价格为200元可让利定制任何商城的采集规则
升级历史
2011-04-07,增加手动过滤函数,可以过滤规格和颜色中的非法字符,方便采集发布 查看全部
ShopEx采集程序,国内最专业的ShopEx采集软件
尘缘此次发布的ShopEx采集程序,是国外最专业的ShopEx采集软件。如果你是一位淘宝主或则网站主,千万不要错过。
这套ShopEx采集程序可以快速采集任何网站、任何商品类型到你的ShopEx商城系统中,让你不再为货源和重复的商品上架问题苦恼。
这套ShopEx的采集程序,是我们开发的ECSHOP采集软件的姊妹篇,有使用EcShop的领导可以往这儿看:
Ecshop全能采集程序:
ShopEx采集程序简介
功能简介
常见采集字段均可实现,字段包括 商品名称,详细描述,图片等。可以手动构建并匹配商品品牌,不存在的商品品牌可以手动添加为新品牌。可以手动创建并匹配商品分类(支持多级分类)(您只需添加列表页网址即可,采集只是时间问题,您没有任何工作量)。检测重复商品,并跳过。远程图片多图下载,并生成缩略图,加入相册。支持自定义商品类型,商品属性的发布支持尺码颜色等多属性的发布数据可导入到助理支持详尽参数表支持图片水印
常见问题
此插口可以搭配优采云采集器免费版使用假如须要采集带验证码和图片识别码的网站,可以联系前尘订购优采云采集器旗舰版或则企业版,企业版可以获赠本ShopEx采集接口一套本插口不保证会持续升级,如果本插口有后续,所有用户均可免费升级本套采集程序收录插口一套,发布模块一枚,京东商城演示规则一枚本套程序售价300元,如不需要技术支持,价格为200元可让利定制任何商城的采集规则
升级历史
2011-04-07,增加手动过滤函数,可以过滤规格和颜色中的非法字符,方便采集发布
Python网路爬虫入门:通爬和聚焦爬
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-14 16:27
网络爬虫也叫网路蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过恳求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。
2. 爬虫有哪些作用?
通过有效的爬虫手段批量采集数据,可以减少人工成本,提高有效数据量,给予营运/销售的数据支撑,加快产品发展。
3. 爬虫业界的情况
目前互联网产品竞争激烈,业界大部分就会使用爬虫技术对竞品产品的数据进行挖掘、采集、大数据剖析,这是必备手段,并且好多公司都筹建了爬虫工程师的岗位。
4. 合法性
爬虫是借助程序进行批量爬取网页上的公开信息,也就是后端显示的数据信息。因为信息是完全公开的,所以是合法的。其实如同浏览器一样,浏览器解析响应内容并渲染为页面,而爬虫解析响应内容采集想要的数据进行储存。
5. 反爬虫
爬虫很难完全的劝阻,道高一尺魔高一丈,这是一场没有烽烟的战争,码农VS码农
反爬虫一些手段:
合法测量:请求校准(useragent,referer,接口加签名,等)
小黑屋:IP/用户限制恳求频度,或者直接拦截
投毒:反爬虫高境界可以不用拦截,拦截是一时的,投毒返回虚假数据,可以欺骗竞品决策
二、通用爬虫
根据让场景,络爬可分为 通爬 和 聚焦爬 两种.。
1、通爬
通络爬是捜索引擎(Baidu、Google、Yahoo)抓取系统的重要组成部份。主要的是将互联上的下载到本地,形成个互联内容的镜像备份。
络爬的基本作流程如下:
先选定部份精选购的种URL;将这种 URL 放待抓取 URL 队列;从待抓取 URL 队列中取出待抓取在 URL,解析 DNS,并且得到主机的 ip,并将 URL 对应的下载出来,存储进已下载库中。此外,将 这些 URL 放进已抓取 URL 队列。分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL放 待抓取 URL 队列,从进下个循环....
2、通搜索引擎(Search Engine)作原理
随着络的迅速发展,万维成为量信息的载体,如何有效地提取并利这种信息成为个巨的挑战,通常户会通过搜索引擎(Yahoo,Google,百度等),来作为访问万维的。
通络爬 是搜索引擎系统短发重要的组成部分,它负责从互联中采集,采集信息,这些信息于为搜索引擎建索引从提供持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的好坏直接影响着搜索引擎的疗效。
第步:抓取
搜索引擎通过种有特定规律的软件,来跟踪的链接,从个链接爬到另外个链接,像蜘蛛在蜘蛛上爬样,所以被称为“蜘蛛”也被称为“机器”。
但是搜索引擎蜘蛛的爬是被输了定的规则的,它须要遵照些命令或件的内容。
Robots 协议(也称为爬合同、机器合同等)的全称是“络爬排除标准”(Robots Exclusion Protocol),站通过 Robots 协议告诉搜索引擎什么可以抓取,哪些不能抓取
robots.txt 只是约定,爬遵循或则不遵循完全在于爬作者的意愿。举个例,公交上贴着「请为弱病残孕让座」,但是部份并不得会遵循。般来讲,只有的搜索引擎爬会遵循你站的 robots.txt 协议,其它的爬基本都不会看眼你的 robots.txt 写的是哪些。
第步:数据储存
搜索引擎是通过蜘蛛跟踪链接爬到,并将爬的数据存原创数据库。其中的数据与户浏览器得到的 HTML 是完全样的。搜索引擎蜘蛛在抓取时,也做定的重复内容检查,旦遇见权重太低的站上有量剽窃、采集或者复制的内容,很可能就不再爬。
第三步:预处理
搜索引擎将蜘蛛抓取回去的,进各类步骤的预处理。
除了 HTML件外,搜索引擎一般能够抓取和索引以字为基础的多种件类型,如 PDF、Word、WPS、XLS、PPT、TXT 件等。我们在搜索结果中也常常会听到这种件类型。
但搜索引擎还不能处理图、视频、Flash 这类字内容,也不能执脚本和程序。
第四步:排名,提供检索服务
搜索引擎是按照定的策略、运特定的计算机程序从互联上采集信息,在对信息进组织和处理后,为户提供检索服务,将户检索相关的信息展示给户的系统。
但是,这些通性搜索引擎也存在着定的局限性:
不同领域、不同背景的户常常具有不同的检索的和需求,通搜索引擎所返回的结果收录量户不关的。通搜索引擎的标是尽可能的络覆盖率,有限的搜索引擎服务器资源与限的络数据资源之间的盾将进步加深。万维数据方式的丰富和络技术的不断发展,图、数据库、频、视频多媒体等不同数据量出现,通搜索引擎常常对这种信息浓度密集且具有定结构的数据能为,不能挺好地发觉和获取。通搜索引擎多提供基于关键字的检索,难以持按照语义信息提出的查询。三、聚焦爬(Focused Crawler)聚焦爬,称主题爬(或专业爬),是“向特定主题”的种络爬程序。它与我们一般所说的爬(通爬)的区别之处就在于,聚焦爬在施行抓取时要进主题筛选。它尽量保证只抓取与主题相关的信息。聚焦络爬并不追求的覆盖,将标定为抓取与某特定主题内容相关的,为向主题的户查询打算数据资源。聚焦爬的作流程较为复杂,需要按照定的剖析算法过滤与主题关的链接,保留有的链接并将其放等待抓取的 URL 队列。然后,它将按照定的搜索策略从队列中选择下步要抓取的URL,并重复上述过程,直到达到系统的某条件时停。另外,所有被爬抓取的将会被系统储存,进定的剖析、过滤,并建索引,以便以后的查询和检索;对于聚焦爬来说,这过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
我们今后要学习的,主要就是聚焦爬。点击获取python网路爬虫视频教程。 查看全部
一、爬虫的简单理解1. 什么是爬虫?
网络爬虫也叫网路蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过恳求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。
2. 爬虫有哪些作用?
通过有效的爬虫手段批量采集数据,可以减少人工成本,提高有效数据量,给予营运/销售的数据支撑,加快产品发展。
3. 爬虫业界的情况
目前互联网产品竞争激烈,业界大部分就会使用爬虫技术对竞品产品的数据进行挖掘、采集、大数据剖析,这是必备手段,并且好多公司都筹建了爬虫工程师的岗位。
4. 合法性
爬虫是借助程序进行批量爬取网页上的公开信息,也就是后端显示的数据信息。因为信息是完全公开的,所以是合法的。其实如同浏览器一样,浏览器解析响应内容并渲染为页面,而爬虫解析响应内容采集想要的数据进行储存。
5. 反爬虫
爬虫很难完全的劝阻,道高一尺魔高一丈,这是一场没有烽烟的战争,码农VS码农
反爬虫一些手段:
合法测量:请求校准(useragent,referer,接口加签名,等)
小黑屋:IP/用户限制恳求频度,或者直接拦截
投毒:反爬虫高境界可以不用拦截,拦截是一时的,投毒返回虚假数据,可以欺骗竞品决策
二、通用爬虫
根据让场景,络爬可分为 通爬 和 聚焦爬 两种.。
1、通爬
通络爬是捜索引擎(Baidu、Google、Yahoo)抓取系统的重要组成部份。主要的是将互联上的下载到本地,形成个互联内容的镜像备份。
络爬的基本作流程如下:
先选定部份精选购的种URL;将这种 URL 放待抓取 URL 队列;从待抓取 URL 队列中取出待抓取在 URL,解析 DNS,并且得到主机的 ip,并将 URL 对应的下载出来,存储进已下载库中。此外,将 这些 URL 放进已抓取 URL 队列。分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL放 待抓取 URL 队列,从进下个循环....
2、通搜索引擎(Search Engine)作原理
随着络的迅速发展,万维成为量信息的载体,如何有效地提取并利这种信息成为个巨的挑战,通常户会通过搜索引擎(Yahoo,Google,百度等),来作为访问万维的。
通络爬 是搜索引擎系统短发重要的组成部分,它负责从互联中采集,采集信息,这些信息于为搜索引擎建索引从提供持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的好坏直接影响着搜索引擎的疗效。
第步:抓取
搜索引擎通过种有特定规律的软件,来跟踪的链接,从个链接爬到另外个链接,像蜘蛛在蜘蛛上爬样,所以被称为“蜘蛛”也被称为“机器”。
但是搜索引擎蜘蛛的爬是被输了定的规则的,它须要遵照些命令或件的内容。
Robots 协议(也称为爬合同、机器合同等)的全称是“络爬排除标准”(Robots Exclusion Protocol),站通过 Robots 协议告诉搜索引擎什么可以抓取,哪些不能抓取
robots.txt 只是约定,爬遵循或则不遵循完全在于爬作者的意愿。举个例,公交上贴着「请为弱病残孕让座」,但是部份并不得会遵循。般来讲,只有的搜索引擎爬会遵循你站的 robots.txt 协议,其它的爬基本都不会看眼你的 robots.txt 写的是哪些。
第步:数据储存
搜索引擎是通过蜘蛛跟踪链接爬到,并将爬的数据存原创数据库。其中的数据与户浏览器得到的 HTML 是完全样的。搜索引擎蜘蛛在抓取时,也做定的重复内容检查,旦遇见权重太低的站上有量剽窃、采集或者复制的内容,很可能就不再爬。
第三步:预处理
搜索引擎将蜘蛛抓取回去的,进各类步骤的预处理。
除了 HTML件外,搜索引擎一般能够抓取和索引以字为基础的多种件类型,如 PDF、Word、WPS、XLS、PPT、TXT 件等。我们在搜索结果中也常常会听到这种件类型。
但搜索引擎还不能处理图、视频、Flash 这类字内容,也不能执脚本和程序。
第四步:排名,提供检索服务
搜索引擎是按照定的策略、运特定的计算机程序从互联上采集信息,在对信息进组织和处理后,为户提供检索服务,将户检索相关的信息展示给户的系统。
但是,这些通性搜索引擎也存在着定的局限性:
不同领域、不同背景的户常常具有不同的检索的和需求,通搜索引擎所返回的结果收录量户不关的。通搜索引擎的标是尽可能的络覆盖率,有限的搜索引擎服务器资源与限的络数据资源之间的盾将进步加深。万维数据方式的丰富和络技术的不断发展,图、数据库、频、视频多媒体等不同数据量出现,通搜索引擎常常对这种信息浓度密集且具有定结构的数据能为,不能挺好地发觉和获取。通搜索引擎多提供基于关键字的检索,难以持按照语义信息提出的查询。三、聚焦爬(Focused Crawler)聚焦爬,称主题爬(或专业爬),是“向特定主题”的种络爬程序。它与我们一般所说的爬(通爬)的区别之处就在于,聚焦爬在施行抓取时要进主题筛选。它尽量保证只抓取与主题相关的信息。聚焦络爬并不追求的覆盖,将标定为抓取与某特定主题内容相关的,为向主题的户查询打算数据资源。聚焦爬的作流程较为复杂,需要按照定的剖析算法过滤与主题关的链接,保留有的链接并将其放等待抓取的 URL 队列。然后,它将按照定的搜索策略从队列中选择下步要抓取的URL,并重复上述过程,直到达到系统的某条件时停。另外,所有被爬抓取的将会被系统储存,进定的剖析、过滤,并建索引,以便以后的查询和检索;对于聚焦爬来说,这过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
我们今后要学习的,主要就是聚焦爬。点击获取python网路爬虫视频教程。
微博批量分发程序,账号管理自媒体发稿助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-14 02:30
视频素材如同文章内容的撰写须要素材,总体上视频修剪仍然要借鉴其他视频内容,要是你打算的内容越是,那样的话你的后作品想必使人非常欣赏和喜欢,接下来我之前发觉了好多强悍工具,但愿才能为诸位亲们给与帮助:4K中国、Splitshire微博批量分发程序,账号管理自媒体发稿助手
随着近几年新媒体的火爆,自媒体平台实在是多,但是当你真正操作上去,才能感觉到完全不是这么回事,每天一下班,都要挨个平台登陆帐号,再一个接一个看数据,辛苦做下来的内容,再步入各个平台帐号各类重复操作发布,让原本紧凑的时间更是雪上加霜,这种觉得......接下来教你一招彻底解决。微博批量分发程序,账号管理自媒体发稿助手
【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
一键分发视屏图文结束了,我再来演示怎么一键分发视频,好戏登场,鼠标在“发视频”处单击,可以先先把默认分类设置好,再添加一下你想发的视频,然后要填好标签标题等内容。等你将那些都完成了,单击一下“发布”图标,会跳出选择帐号的界面,筛选要推送的平台,就一键同步发送搞定了,这种办法很提高了效率了!微博批量分发程序,账号管理自媒体发稿助手易媒助手:内容同时分发系统为了期望获得十分卓越的内容爆光,多数个人、公司会选择注册趣头条、爱奇艺号等10多个主流内容平台,若大家只分发稿件,同步完8个平台往少了说耗费20分钟左右,如果也须要多发视频,10个平台恐怕也得消耗半个小时上下,其次绝望的是:只发送了一个内容,每天都须要这样......在实现意图后,能察觉每次发布非常冗长且无趣,只须要使用易媒助手这款软件,轻松将文章、短视频同时发送到大几十家平台,仅需一会儿就全部分发完毕,大大降低日常的工作量。
在内容创业的风口下,近这几年,内容经济愈加被关注,其低门槛、流量聚合空间大、转化疗效超出传统方法等等数不过来的用处,于是聚拢了各类公司品牌等单位。微博批量分发程序,账号管理自媒体发稿助手
一键分发视频之后我来讲解一键推送视频,大家请看文中图片,进入视频蓝筹股(软件上方导航栏),你们好设置好默认分类,再依次添加要发布的视频,下面围绕内容填入标题以及简介和标签。全部输入完成了再,先“发布”按钮,会来到勾选帐号的地方,选好你要推送的平台,就分分钟搞定了全部推送,是不是超级便捷?
在线画图每晚文章编辑过程中,经常会遭到图片内容不太好看的境况,部分图片须要调整,但现在市场上流行的工具真的很过分专业了,对萌新来说非常不友好,接下来认为不错的好多愈发宝藏的在线素材调整工具,可以瞧瞧匹配自己的须要不:创客贴、Lucidchart微博批量分发程序,账号管理自媒体发稿助手易媒助手:文章、视频一键发布系统为了期盼想弄到非常喜人的爆光,往往公司会开通微淘号、视频等大几十个新媒体平台,要是大家只同步稿子,同步完8个平台大约也得历时35分钟,刚好也须要分发小视频,10个平台少也要耗费50分钟左右,而且使人难以接受的在于:只上传了一个内容......当我们实现结果后,会觉得每晚内容多发相当繁杂且无趣,如果你用易媒助手这个工具,作品、短视频一次性发送至全平台,只需不到几分钟就发布完毕,所以工具推荐排行。
在内容创业弄成热门话题的背景下,近几年,内容流量行业确确实实有话题度,其营运成本太低、阅读销售数据表现惊人等等众多的优势,渐渐招来了数不清的人才,为了可以得到特别的内容诠释,人们一般会同步到。但当你的帐号足够充足,就会感受到这点:每天一下班,都要一个接一个地输入帐号密码步入后台、然后再按顺序发送视频,必定是使原本紧凑的时间更是雪上加霜,下面我来给你说一个挺好的方式。
高清图库在新媒体内容的谋篇撰写中,图片对内容的影响很大,优质的这些几张配图会特别迅速的招来目标对象的打开兴趣,可网上清晰度好的插图大多愈发少见,不能想用就用,我盘点的高清图片网,就特别不错了:中国素材网、Iconfont
随着现代化媒体的不断涌现,尤其从兴起开始,短视频不可证实被关注,其入行简单、流量分布极其广泛、转化疗效比较惊人等不少的闪光点,不断凝聚了各路媒体人,为了重夺更好的数据表现,人们常常会用到所有渠道。但只有做过的人,会感觉到:在工作之前,必须一遍又一遍的挨个平台登陆帐号,然后再分批次上传做好的图文,不得不承认这费事又吃力,下面将告诉你怎么解决。微博批量分发程序,账号管理自媒体发稿助手 查看全部
科技发展日新月异,现在,内容搭建实在有热度,其入行门槛低、曝光作用毫无争议、转化能力不可争议等这么之多的闪光点,不停的吸引着各类行业和需求方,为了种种目的,想弄到更厉害的数据结果,大家通常会发送到所有渠道。殊不知当我们真正操作的时侯,就会明白:只要想工作,就必须先机械式的逐个平台渐渐登录,后面再分步骤发送想要推送的视频,果然是一件过分浪费人工和时间的事情,我的突破方式接下来告诉你们。微博批量分发程序,账号管理自媒体发稿助手
视频素材如同文章内容的撰写须要素材,总体上视频修剪仍然要借鉴其他视频内容,要是你打算的内容越是,那样的话你的后作品想必使人非常欣赏和喜欢,接下来我之前发觉了好多强悍工具,但愿才能为诸位亲们给与帮助:4K中国、Splitshire微博批量分发程序,账号管理自媒体发稿助手
随着近几年新媒体的火爆,自媒体平台实在是多,但是当你真正操作上去,才能感觉到完全不是这么回事,每天一下班,都要挨个平台登陆帐号,再一个接一个看数据,辛苦做下来的内容,再步入各个平台帐号各类重复操作发布,让原本紧凑的时间更是雪上加霜,这种觉得......接下来教你一招彻底解决。微博批量分发程序,账号管理自媒体发稿助手
【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
一键分发视屏图文结束了,我再来演示怎么一键分发视频,好戏登场,鼠标在“发视频”处单击,可以先先把默认分类设置好,再添加一下你想发的视频,然后要填好标签标题等内容。等你将那些都完成了,单击一下“发布”图标,会跳出选择帐号的界面,筛选要推送的平台,就一键同步发送搞定了,这种办法很提高了效率了!微博批量分发程序,账号管理自媒体发稿助手易媒助手:内容同时分发系统为了期望获得十分卓越的内容爆光,多数个人、公司会选择注册趣头条、爱奇艺号等10多个主流内容平台,若大家只分发稿件,同步完8个平台往少了说耗费20分钟左右,如果也须要多发视频,10个平台恐怕也得消耗半个小时上下,其次绝望的是:只发送了一个内容,每天都须要这样......在实现意图后,能察觉每次发布非常冗长且无趣,只须要使用易媒助手这款软件,轻松将文章、短视频同时发送到大几十家平台,仅需一会儿就全部分发完毕,大大降低日常的工作量。
在内容创业的风口下,近这几年,内容经济愈加被关注,其低门槛、流量聚合空间大、转化疗效超出传统方法等等数不过来的用处,于是聚拢了各类公司品牌等单位。微博批量分发程序,账号管理自媒体发稿助手
一键分发视频之后我来讲解一键推送视频,大家请看文中图片,进入视频蓝筹股(软件上方导航栏),你们好设置好默认分类,再依次添加要发布的视频,下面围绕内容填入标题以及简介和标签。全部输入完成了再,先“发布”按钮,会来到勾选帐号的地方,选好你要推送的平台,就分分钟搞定了全部推送,是不是超级便捷?
在线画图每晚文章编辑过程中,经常会遭到图片内容不太好看的境况,部分图片须要调整,但现在市场上流行的工具真的很过分专业了,对萌新来说非常不友好,接下来认为不错的好多愈发宝藏的在线素材调整工具,可以瞧瞧匹配自己的须要不:创客贴、Lucidchart微博批量分发程序,账号管理自媒体发稿助手易媒助手:文章、视频一键发布系统为了期盼想弄到非常喜人的爆光,往往公司会开通微淘号、视频等大几十个新媒体平台,要是大家只同步稿子,同步完8个平台大约也得历时35分钟,刚好也须要分发小视频,10个平台少也要耗费50分钟左右,而且使人难以接受的在于:只上传了一个内容......当我们实现结果后,会觉得每晚内容多发相当繁杂且无趣,如果你用易媒助手这个工具,作品、短视频一次性发送至全平台,只需不到几分钟就发布完毕,所以工具推荐排行。
在内容创业弄成热门话题的背景下,近几年,内容流量行业确确实实有话题度,其营运成本太低、阅读销售数据表现惊人等等众多的优势,渐渐招来了数不清的人才,为了可以得到特别的内容诠释,人们一般会同步到。但当你的帐号足够充足,就会感受到这点:每天一下班,都要一个接一个地输入帐号密码步入后台、然后再按顺序发送视频,必定是使原本紧凑的时间更是雪上加霜,下面我来给你说一个挺好的方式。
高清图库在新媒体内容的谋篇撰写中,图片对内容的影响很大,优质的这些几张配图会特别迅速的招来目标对象的打开兴趣,可网上清晰度好的插图大多愈发少见,不能想用就用,我盘点的高清图片网,就特别不错了:中国素材网、Iconfont
随着现代化媒体的不断涌现,尤其从兴起开始,短视频不可证实被关注,其入行简单、流量分布极其广泛、转化疗效比较惊人等不少的闪光点,不断凝聚了各路媒体人,为了重夺更好的数据表现,人们常常会用到所有渠道。但只有做过的人,会感觉到:在工作之前,必须一遍又一遍的挨个平台登陆帐号,然后再分批次上传做好的图文,不得不承认这费事又吃力,下面将告诉你怎么解决。微博批量分发程序,账号管理自媒体发稿助手
优采云采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-13 15:39
为什么选择优采云采集器:
几乎所有网页都能采集
无论哪些语言,无论哪些编码。
速度是普通采集器的7倍
优采云采集器免费版采用顶尖系统配置,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
采集/发布就像复制/粘贴一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具六年磨炼,成就业界领先品牌,想到网页采集,就想到优采云采集器!
软件特色:
1、支持所有网站编码:优采云采集器完美支持采集所有编码格式的网页,程序还可以手动辨识网页编码。
2、多种发布形式:优采云采集器支持目前所有主流和非主流的CMS,BBS等网站程序,通过系统的发布模块能实现采集器和网站程序间的完美结合。
3、全手动:无人值守工作,配置好程序后,程序将根据您的设置手动运行,完全无需人工干预。 查看全部
优采云采集器(www.ucaiyun.com)是一个供各大主流文章系统,论坛系统等使用的多线程内容采集发布程序,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。软件凭着其灵活的配置与强悍的性能领先国外数据采集类产品,并博得诸多用户的一致认可。系统支持远程图片下载,图片批量水印,Flash下载,下载文件地址侦测,自制做发表的cms模块参数,自定义发表的内容等有关采集器。使用优采云采集器,你可以顿时构建一个拥有庞大内容的网站。对于数据的采集其可以分为两部份,一是采集数据,二是发布数据。
为什么选择优采云采集器:
几乎所有网页都能采集
无论哪些语言,无论哪些编码。
速度是普通采集器的7倍
优采云采集器免费版采用顶尖系统配置,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
采集/发布就像复制/粘贴一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具六年磨炼,成就业界领先品牌,想到网页采集,就想到优采云采集器!
软件特色:
1、支持所有网站编码:优采云采集器完美支持采集所有编码格式的网页,程序还可以手动辨识网页编码。
2、多种发布形式:优采云采集器支持目前所有主流和非主流的CMS,BBS等网站程序,通过系统的发布模块能实现采集器和网站程序间的完美结合。
3、全手动:无人值守工作,配置好程序后,程序将根据您的设置手动运行,完全无需人工干预。
小程序web-view访问第三方网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-13 15:31
有两种方式实现webview中显示第三方网页。
一、 把他人的域名添加到小程序业务域名
这种方式须要把一个验证文件上传到第三方网站的服务器,
如果你跟第三方网站有业务来往,
你的产品或服务信息是置于第三方网站,
可以跟第三方平台沟通,
让其帮你上传验证文件。
这个技巧要求第三方网站符合小程序业务域名的要求,
1-1) 网站必须备案
1-2) 网站必须是https类型
猛击这儿,
观看《小程序添加业务域名》视频
如果你跟第三方网站没有业务,
只能使用第二种方式
二、 采集下载第三方的网页
这个方式对开发能力要求很高,
要求你会写采集程序。
猛击这儿,
观看《php爬虫采集海量网页》视频
2-1) 采集第三方信息
使用采集程序,
精确猎获第三方网页信息,
然后展示到你的小程序里。
2-3) 下载他人的网页内容
如果你要把他人的网页,
完成的显示到你的小程序里,
需要把他人的网页下载到你的web服务器,
然后通过你的网站域名访问。
下载网页的主要步骤如下
2-3-1) 获取网页代码
首先通过采集程序,
把第三方网页的html源代码获取到,
这一步比较简单。
2-3-2) 下载静态文件
根据html源码中,
把网页用到的静态文件下载到你的web服务器,
主要包括:
a) 图片
b) 样式文件
c) js脚本文件
2-3-3) 把网页代码中静态文件的地址,网址替换为你的域名
这一步须要处理静态文件的位置,
有些使用相对路径,
有些使用绝对路径,
你须要把它们改为相对你网站的路径。
通过前面的步骤,
就能在小程序web-view中显示第三方网页内容了,
即使第三方网站没备案,不是https类型也就能实现。
三、 小结
通过前面的详尽,
可以看出要在web-view里显示他人的网页,
对开发技术要求很高,
实现上去很复杂,
而且性能损失也很大,
不到万不得已,
千万不要使用。
设置web-view的业务域名——小程序web-view中级用法1
小程序使用web-view打开h5网页——小程序web-view中级用法2
微信web-view中级用法介绍——小程序web-view中级用法3
小程序web-view JSSDK配置文件说明——小程序web-view中级用法4
web-view的h5页面设置jssdk选项——小程序web-view中级用法5
小程序web-view打开网页demo实例——小程序web-view中级用法6
微信web-view用wx.getNetworkType获取网路状态——小程序web-view中级用法7
web-view调用wx.scanQRCode微信扫一扫——小程序web-view中级用法8
h5网页跳转到陌陌小程序——小程序web-view中级用法9
wev view h5页面传递参数给小程序——小程序web-view中级用法10
webview调用微信支付——小程序web-view中级用法11
webview实现支付后的业务逻辑处理——小程序web-view中级用法12
微信web-view动态显示h5网页——小程序web-view中级用法13
微信webview分享h5网页——小程序web-view中级用法14
微信web-view优缺点,什么时候使用webview——小程序web-view中级用法15 查看全部
总的来说,
有两种方式实现webview中显示第三方网页。
一、 把他人的域名添加到小程序业务域名
这种方式须要把一个验证文件上传到第三方网站的服务器,
如果你跟第三方网站有业务来往,
你的产品或服务信息是置于第三方网站,
可以跟第三方平台沟通,
让其帮你上传验证文件。
这个技巧要求第三方网站符合小程序业务域名的要求,
1-1) 网站必须备案
1-2) 网站必须是https类型
猛击这儿,
观看《小程序添加业务域名》视频
如果你跟第三方网站没有业务,
只能使用第二种方式
二、 采集下载第三方的网页
这个方式对开发能力要求很高,
要求你会写采集程序。
猛击这儿,
观看《php爬虫采集海量网页》视频
2-1) 采集第三方信息
使用采集程序,
精确猎获第三方网页信息,
然后展示到你的小程序里。
2-3) 下载他人的网页内容
如果你要把他人的网页,
完成的显示到你的小程序里,
需要把他人的网页下载到你的web服务器,
然后通过你的网站域名访问。
下载网页的主要步骤如下
2-3-1) 获取网页代码
首先通过采集程序,
把第三方网页的html源代码获取到,
这一步比较简单。
2-3-2) 下载静态文件
根据html源码中,
把网页用到的静态文件下载到你的web服务器,
主要包括:
a) 图片
b) 样式文件
c) js脚本文件
2-3-3) 把网页代码中静态文件的地址,网址替换为你的域名
这一步须要处理静态文件的位置,
有些使用相对路径,
有些使用绝对路径,
你须要把它们改为相对你网站的路径。
通过前面的步骤,
就能在小程序web-view中显示第三方网页内容了,
即使第三方网站没备案,不是https类型也就能实现。
三、 小结
通过前面的详尽,
可以看出要在web-view里显示他人的网页,
对开发技术要求很高,
实现上去很复杂,
而且性能损失也很大,
不到万不得已,
千万不要使用。
设置web-view的业务域名——小程序web-view中级用法1
小程序使用web-view打开h5网页——小程序web-view中级用法2
微信web-view中级用法介绍——小程序web-view中级用法3
小程序web-view JSSDK配置文件说明——小程序web-view中级用法4
web-view的h5页面设置jssdk选项——小程序web-view中级用法5
小程序web-view打开网页demo实例——小程序web-view中级用法6
微信web-view用wx.getNetworkType获取网路状态——小程序web-view中级用法7
web-view调用wx.scanQRCode微信扫一扫——小程序web-view中级用法8
h5网页跳转到陌陌小程序——小程序web-view中级用法9
wev view h5页面传递参数给小程序——小程序web-view中级用法10
webview调用微信支付——小程序web-view中级用法11
webview实现支付后的业务逻辑处理——小程序web-view中级用法12
微信web-view动态显示h5网页——小程序web-view中级用法13
微信webview分享h5网页——小程序web-view中级用法14
微信web-view优缺点,什么时候使用webview——小程序web-view中级用法15
用老域名做站群,获取10万级流量的秘密!
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-13 09:53
站群的原理:
我们把大站比做小型超市,像新浪、网易,他们内容丰富,什么都有,人群流量也相当大。把小站比做路边摊,商场的门外,一定会有诸多小商商贩摆摊,虽然分到每位档口的人群流量不多,但所有街边加上去,还是十分可观的。那么站群就是一大堆小档口,每个档口不求人多,也许每晚只有几个或几十个IP,总量加上去十分可观。如果能使用有一些资质的老域名,相当于大量有点小名气的街边摊档,获取流量的可能性十分高。
站群的管理:
每个摊贩(站)都须要管理,要制做网站、更新内容,几十个,还是有可能管理得过来,上百之后,人工管理就不太现实。因此须要一些站群管理软件来简化人工操作行为,实现部份行为的自动化。市面上有各类站群管理软件。有客户端站群软件,有web端站群。
a.客户端站群软件
通过本地笔记本操作一个软件,向你的多处网站发送网站更新指令,以实现批量管理的功能。这类软件多有文章采集、处理、上传更新等功能。可以远程操作通用CMS,如织梦、phpcms、博客站的更新,也可以操作自己开发的CMS,可以实现半自动化的人工操作、也可以挂机手动运行。特点是操作比较简单,界面直观,可视化高。软件具体有什么,这里就不做广告了,可以QQ 一起交流。使用这种软件,每天的工作就是操作软件采集更新和上新的域名。
b.web端站群软件
完全通过服务器端运行,这种程序通常自动化程度高,同样也会集成内容采集、处理、更新等。整个过程无须客户端参与,在服务器端就完成了。一般对服务器的配置和带宽要求比较高。运行过程不可视,24小时无人值守,你每晚的工作就是找域名,注册域名,绑定域名。知名的某这种站群软件,可以做到日流量20万IP。
c.中央控制型站群软件
一般多用于目录型站群。租用其它站点的目录(或者不是租用的),该目录的内容来自一台中央数据库的内容。这种站群特征是容易分布,且成本不高。缺点是租用的目录可控性不高,不太稳定。你每晚的工作就是,找目录,传受控站,操作主控端更新(或手动更新)。
以上站群,都是基于低人工参与,以低成本为导向的站群。还有一类中级站群,如太平洋的诸多站点(以pcxxxx开始的域名),人工参与度高,内容质量更好,当然成本也更高,且要有良好的业务管理能力,这不是小站长可以企级的,但据我所知,很多做前一类站群的站长,已经在向此方向发展。
站群的SEO
站群的优化,与单站没有本质的区别。最大的区别就在于,自动化后,质量不可控,导致好多垃圾页,不可读的内容出现。一般称为垃圾站群。按单站优化的思路,把握好站群的页面优化,非常重要。
站群的域名
站群须要使用老域名,这对加速排行至关重要(蜘蛛池除外)。并且必须是有一定历史和外链的最好,且不能有白色站历史,容易被K。为什么用老域名比用全新域名好?这就好比,原来这个位置有一个小贩,后来他不摆摊了,你去把他的档口盘出来,比你新开一个档口更容易做生意,是一个道理。
域名筛选和注册
选域名和注册域名是一个特别操蛋的工作。需要使用工具来批量查询没有注册域名。选域名的时侯选用过的、有收录的域名,能快速使百度收录。要考虑这个域名是否被百度 K 过,去 里查询域名的外链历史,能晓得这个域名是否做过垃圾站。
另外域名注册价钱,可以多比较几家注册商,控制成本也十分重要。
站群的服务器
如果是客户端站群软件,一般服务器分散比较好,可以租用不同服务商的虚拟主机,使用不同的IP地址,需要一定工作量的手工操作。web站软件,一般是租用整台化学服务器(4核CPU,8GB显存,SSD或1TB硬碟以上),使用多个IP,1台服务器上可以放置多个网站。为什么一定要多个IP?其实最大的考虑并不是为了避免作弊检查,最大的考虑是,蜘蛛抓取的流量分配,是依据IP来的,每个IP能分配到的抓取量是一定的,如果你1个IP上的站多了,每个站能抓取的量就少了。
站群的未来
不可证实,站群一定程度上,有一点借助搜索引擎BUG的意思。但是站群仍然在被K,一直有人做。并且站群的发展,向着高质量方向在前进。迎合访客而不是讨好搜索引擎,给访客想看的内容,这样的站群,终不会消失! 查看全部
什么是站群,简单的讲,就是站多。站群达人手里有的可能早已不只100个站、10000个站。虽然成本高企,但一旦做好,获得的流量是巨大的,每天10万IP的访问量不在少数。
站群的原理:
我们把大站比做小型超市,像新浪、网易,他们内容丰富,什么都有,人群流量也相当大。把小站比做路边摊,商场的门外,一定会有诸多小商商贩摆摊,虽然分到每位档口的人群流量不多,但所有街边加上去,还是十分可观的。那么站群就是一大堆小档口,每个档口不求人多,也许每晚只有几个或几十个IP,总量加上去十分可观。如果能使用有一些资质的老域名,相当于大量有点小名气的街边摊档,获取流量的可能性十分高。
站群的管理:
每个摊贩(站)都须要管理,要制做网站、更新内容,几十个,还是有可能管理得过来,上百之后,人工管理就不太现实。因此须要一些站群管理软件来简化人工操作行为,实现部份行为的自动化。市面上有各类站群管理软件。有客户端站群软件,有web端站群。
a.客户端站群软件
通过本地笔记本操作一个软件,向你的多处网站发送网站更新指令,以实现批量管理的功能。这类软件多有文章采集、处理、上传更新等功能。可以远程操作通用CMS,如织梦、phpcms、博客站的更新,也可以操作自己开发的CMS,可以实现半自动化的人工操作、也可以挂机手动运行。特点是操作比较简单,界面直观,可视化高。软件具体有什么,这里就不做广告了,可以QQ 一起交流。使用这种软件,每天的工作就是操作软件采集更新和上新的域名。
b.web端站群软件
完全通过服务器端运行,这种程序通常自动化程度高,同样也会集成内容采集、处理、更新等。整个过程无须客户端参与,在服务器端就完成了。一般对服务器的配置和带宽要求比较高。运行过程不可视,24小时无人值守,你每晚的工作就是找域名,注册域名,绑定域名。知名的某这种站群软件,可以做到日流量20万IP。
c.中央控制型站群软件
一般多用于目录型站群。租用其它站点的目录(或者不是租用的),该目录的内容来自一台中央数据库的内容。这种站群特征是容易分布,且成本不高。缺点是租用的目录可控性不高,不太稳定。你每晚的工作就是,找目录,传受控站,操作主控端更新(或手动更新)。
以上站群,都是基于低人工参与,以低成本为导向的站群。还有一类中级站群,如太平洋的诸多站点(以pcxxxx开始的域名),人工参与度高,内容质量更好,当然成本也更高,且要有良好的业务管理能力,这不是小站长可以企级的,但据我所知,很多做前一类站群的站长,已经在向此方向发展。
站群的SEO
站群的优化,与单站没有本质的区别。最大的区别就在于,自动化后,质量不可控,导致好多垃圾页,不可读的内容出现。一般称为垃圾站群。按单站优化的思路,把握好站群的页面优化,非常重要。
站群的域名
站群须要使用老域名,这对加速排行至关重要(蜘蛛池除外)。并且必须是有一定历史和外链的最好,且不能有白色站历史,容易被K。为什么用老域名比用全新域名好?这就好比,原来这个位置有一个小贩,后来他不摆摊了,你去把他的档口盘出来,比你新开一个档口更容易做生意,是一个道理。
域名筛选和注册
选域名和注册域名是一个特别操蛋的工作。需要使用工具来批量查询没有注册域名。选域名的时侯选用过的、有收录的域名,能快速使百度收录。要考虑这个域名是否被百度 K 过,去 里查询域名的外链历史,能晓得这个域名是否做过垃圾站。
另外域名注册价钱,可以多比较几家注册商,控制成本也十分重要。
站群的服务器
如果是客户端站群软件,一般服务器分散比较好,可以租用不同服务商的虚拟主机,使用不同的IP地址,需要一定工作量的手工操作。web站软件,一般是租用整台化学服务器(4核CPU,8GB显存,SSD或1TB硬碟以上),使用多个IP,1台服务器上可以放置多个网站。为什么一定要多个IP?其实最大的考虑并不是为了避免作弊检查,最大的考虑是,蜘蛛抓取的流量分配,是依据IP来的,每个IP能分配到的抓取量是一定的,如果你1个IP上的站多了,每个站能抓取的量就少了。
站群的未来
不可证实,站群一定程度上,有一点借助搜索引擎BUG的意思。但是站群仍然在被K,一直有人做。并且站群的发展,向着高质量方向在前进。迎合访客而不是讨好搜索引擎,给访客想看的内容,这样的站群,终不会消失!
curl_global_init - 全局libcurl初始化
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-12 16:54
curl_global_init - 全局libcurl初始化
概要
#include
CURLcode curl_global_init(长旗);
描述
此函数设置libcurl须要的程序环境。可以把它想像成库加载器的扩充。
在程序调用libcurl中的任何其他函数之前,必须在程序中起码调用此函数一次(程序是共享显存空间的所有代码)。它设置的环境对于程序的生命周期是恒定的,并且对于每位程序都是相同的,因此多个调用与一个调用具有相同的疗效。
flags选项是一个位模式,它告诉libcurl到init的准确功能,如下所述。通过将值进行“或”运算来设置所需的位。在正常操作中,您必须指定CURL_GLOBAL_ALL。除非您熟悉它而且意味着控制libcurl的内部操作,否则不要使用任何其他值。
此功能不是线程安全的。当程序中的任何其他线程(即共享相同显存的线程)正在运行时,您不能调用它。这并不仅仅意味着没有其他使用libcurl的线程。因为curl_global_init调用类似线程不安全的其他库的函数,所以它可能与使用那些其他库的任何其他线程冲突。
如果要从Windows DLL初始化libcurl,则不应从DllMain或静态初始化程序初始化它,因为Windows在此期间保存加载程序锁定而且可能造成死锁。
有关怎样使用此函数的详尽信息,请参阅全局环境要求的libcurl中的说明。
FLAGS
CURL_GLOBAL_ALL
尽可能初始化一切。这将设置除之外的所有已知位。
CURL_GLOBAL_SSL
(自7.57.0以来,此标志的存在与否无效。下面的描述适用于较旧的libcurl版本。)
初始化SSL。
这里的涵义是,如果未设置此位,则SSL层的初始化须要由应用程序完成,或者起码在libcurl之外完成。如何进行SSL初始化的准确过程取决于libcurl使用的TLS前端。
在没有初始化TLS层的情况下执行基于TLS的传输可能会造成意外行为。
CURL_GLOBAL_WIN32
初始化Win32套接字库。
这里的涵义是,如果未设置此位,则winsock的初始化必须由应用程序完成,否则您将面临未定义行为的风险。当在libcurl之外处理初始化时存在此选项,因此libcurl不需要再度执行此操作。
CURL_GLOBAL_NOTHING
没有多余的初始化。这没有任何意义。
CURL_GLOBAL_DEFAULT
一个明智的默认。它将初始化SSL和Win32。现在,这等于网段的功能。
CURL_GLOBAL_ACK_EINTR
设置此标志后,curl将在联接或等待数据时确认EINTR条件。否则,curl会等待直至完全超时。(在7.30.0中添加)
返回值
如果此函数返回非零,则出现错误,您难以使用其他curl函数。
使用libcurl步骤1之curl_global_init
使用libcurl步骤2之curl_easy_init
使用libcurl步骤3之curl_easy_setopt
使用libcurl步骤4之curl_easy_perform
使用libcurl步骤5之curl_easy_cleanup 查看全部
文章采集自互联网,仅做学习笔记使用curl_global_init - 全局libcurl初始化名称
curl_global_init - 全局libcurl初始化
概要
#include
CURLcode curl_global_init(长旗);
描述
此函数设置libcurl须要的程序环境。可以把它想像成库加载器的扩充。
在程序调用libcurl中的任何其他函数之前,必须在程序中起码调用此函数一次(程序是共享显存空间的所有代码)。它设置的环境对于程序的生命周期是恒定的,并且对于每位程序都是相同的,因此多个调用与一个调用具有相同的疗效。
flags选项是一个位模式,它告诉libcurl到init的准确功能,如下所述。通过将值进行“或”运算来设置所需的位。在正常操作中,您必须指定CURL_GLOBAL_ALL。除非您熟悉它而且意味着控制libcurl的内部操作,否则不要使用任何其他值。
此功能不是线程安全的。当程序中的任何其他线程(即共享相同显存的线程)正在运行时,您不能调用它。这并不仅仅意味着没有其他使用libcurl的线程。因为curl_global_init调用类似线程不安全的其他库的函数,所以它可能与使用那些其他库的任何其他线程冲突。
如果要从Windows DLL初始化libcurl,则不应从DllMain或静态初始化程序初始化它,因为Windows在此期间保存加载程序锁定而且可能造成死锁。
有关怎样使用此函数的详尽信息,请参阅全局环境要求的libcurl中的说明。
FLAGS
CURL_GLOBAL_ALL
尽可能初始化一切。这将设置除之外的所有已知位。
CURL_GLOBAL_SSL
(自7.57.0以来,此标志的存在与否无效。下面的描述适用于较旧的libcurl版本。)
初始化SSL。
这里的涵义是,如果未设置此位,则SSL层的初始化须要由应用程序完成,或者起码在libcurl之外完成。如何进行SSL初始化的准确过程取决于libcurl使用的TLS前端。
在没有初始化TLS层的情况下执行基于TLS的传输可能会造成意外行为。
CURL_GLOBAL_WIN32
初始化Win32套接字库。
这里的涵义是,如果未设置此位,则winsock的初始化必须由应用程序完成,否则您将面临未定义行为的风险。当在libcurl之外处理初始化时存在此选项,因此libcurl不需要再度执行此操作。
CURL_GLOBAL_NOTHING
没有多余的初始化。这没有任何意义。
CURL_GLOBAL_DEFAULT
一个明智的默认。它将初始化SSL和Win32。现在,这等于网段的功能。
CURL_GLOBAL_ACK_EINTR
设置此标志后,curl将在联接或等待数据时确认EINTR条件。否则,curl会等待直至完全超时。(在7.30.0中添加)
返回值
如果此函数返回非零,则出现错误,您难以使用其他curl函数。
使用libcurl步骤1之curl_global_init
使用libcurl步骤2之curl_easy_init
使用libcurl步骤3之curl_easy_setopt
使用libcurl步骤4之curl_easy_perform
使用libcurl步骤5之curl_easy_cleanup
小草淘宝客程序更新领卷功能 海量数据采集 完全开源,免费试用! 限时折扣!
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-12 04:22
7月2日降低重复商品手动判定功能
7月3日商品页面添加分享功能。7月3日添加密码寻回功能(需要配置邮件服务器)。
7月3日约请好友注册送积分功能。
7月3日后台商品批量删掉、上架、下架商品。
7月3日二级分类功能。
7月3日新增green模板。
7月10日新增单品采集,根据产品链接读取商品相关信息。
7月10日降低二级分类功能,让商品更细分。
7月10日降低用户后台和admin后台查看积分进帐和消费明细
7月10日降低管理员权限设置,比如有的管理员只能发文章
7月10日降低后台欢迎页,读取服务器环境配置等信息。
7月15日支持采集商品自定义
7月17日升级了广告位功能,能在后台自己添加。
7月17日升级采集功能,能自己添加采集数量。
7月17日升级九块九采集,采集更多商品。
7月17日升级商品列表,添加了排序筛选。
7月17日友情链接全站显示
7月27日新添加了套模板。大气商城模版。
7月27日优化保存成功、登录成功、签到成功等提示框。
7月27日个人中心添加我的商品(商家报考商品)
7月27日后台采集分类选择优化,树状结构显示二级分类
7月27日qq登陆按键修改。
7月27日新增广告位以及后台控制。
7月27日陌陌访问提示浏览器打开,提示更友好,欢迎测试! 查看全部
做个解释,别人程序把修补BUG都当成是功能升级,我们那边不记录BUG修补情况。如有BUG修补补丁,请在修补帖内寻觅。
7月2日降低重复商品手动判定功能
7月3日商品页面添加分享功能。7月3日添加密码寻回功能(需要配置邮件服务器)。
7月3日约请好友注册送积分功能。
7月3日后台商品批量删掉、上架、下架商品。
7月3日二级分类功能。
7月3日新增green模板。
7月10日新增单品采集,根据产品链接读取商品相关信息。
7月10日降低二级分类功能,让商品更细分。
7月10日降低用户后台和admin后台查看积分进帐和消费明细
7月10日降低管理员权限设置,比如有的管理员只能发文章
7月10日降低后台欢迎页,读取服务器环境配置等信息。
7月15日支持采集商品自定义
7月17日升级了广告位功能,能在后台自己添加。
7月17日升级采集功能,能自己添加采集数量。
7月17日升级九块九采集,采集更多商品。
7月17日升级商品列表,添加了排序筛选。
7月17日友情链接全站显示
7月27日新添加了套模板。大气商城模版。
7月27日优化保存成功、登录成功、签到成功等提示框。
7月27日个人中心添加我的商品(商家报考商品)
7月27日后台采集分类选择优化,树状结构显示二级分类
7月27日qq登陆按键修改。
7月27日新增广告位以及后台控制。
7月27日陌陌访问提示浏览器打开,提示更友好,欢迎测试!
移动测试开发 Prometheus 监控系统初探与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-08-11 16:01
Prometheus才能做哪些?
Prometheus 是一套开源的系统监控报案框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前职工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年即将发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特征:
强大的多维度数据模型:
1.时间序列数据通过 metric 名和键名对来分辨。
2.所有的 metrics 都可以设置任意的多维标签。
3.数据模型更随便,不需要刻意设置为以点分隔的字符串。
4.可以对数据模型进行聚合,切割和切块操作。
5.支持双精度浮点类型,标签可以设为全 unicode。
① 灵活而强悍的查询句子(PromQL):在同一个查询句子,可以对多个 metrics 进行加法、加法、连接、取分数位等操作。
② 易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
③ 高效:平均每位采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
④ 使用 pull 模式采集时间序列数据,这样除了有利于本机测试并且可以避免有问题的服务器推送坏的 metrics。
⑤ 可以采用 push gateway 的方法把时间序列数据推送至 Prometheus server 端。
⑥ 可以通过服务发觉或则静态配置去获取监控的 targets。
⑦ 有多种可视化图形界面。
⑧ 易于伸缩。
Prometheus的基本概念
1.Prometheus 组成及构架
Prometheus 生态圈中收录了多个组件,其中许多组件是可选的:
① Prometheus Server: 用于搜集和储存时间序列数据。
② Client Library: 客户端库,为须要监控的服务生成相应的 metrics 并曝露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
③ Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方法主要用于服务层面的 metrics,对于机器层面的metrices,需要使用 node exporter。
① Exporters: 用于曝露已有的第三方服务的 metrics 给 Prometheus。
② Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行消除重复数据,分组,并路由到对方的接受形式,发出报案。常见的接收方法有:电子邮件,pagerduty,OpsGenie, webhook等。
下图是Prometheus官网上给出的构架图:
2.数据模型
Prometheus 中储存的数据为时间序列,是由 metric 的名子和一系列的标签(键值对)唯一标示的,不同的标签则代表不同的时间序列。
① metric 名字:该名子应当具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总量。其中,metric 名字由 ASCII 字符,数字,下划线,以及顿号组成,且必须满足正则表达式[a-zA-Z_:][a-zA-Z0-9_:]。
② 标签:使同一个时间序列有了不同维度的辨识。例如http_requests_total{method="Get"} 表示所有 http 请求中的 Get 请求。当 method="post" 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及顿号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]。
③ 样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
④ 格式:{=, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
3.四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
Counter
① 一种累加的 metric,典型的应用如:请求的个数,结束的任务数,出现的错误数等等。
例如,查询http_requests_total{method="get", job="Prometheus", handler="query"} 返回 8,10 秒后,再次查询,则返回 14。
Gauge
① 一种常规的 metric,典型的应用如:温度,运行的goroutines的个数。
② 可以任意加减。
例如:go_goroutines{instance="172.17.0.2", job="Prometheus"} 返回值 147,10 秒后返回 124。
Histogram
① 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
② 可以对观察结果取样,分组及统计。
例如,查询http_request_duration_microseconds_sum{job="Prometheus", handler="query"} 时,返回结果如下:
Summary
① 类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
② 提供观测值的 count 和 sum 功能。
③ 提供百分位的功能,即可以按比率界定跟踪结果。
4.instance 和 jobs
instance: 一个单独 scrape 的目标,一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性)
安装布署Prometheus实践
介绍完Prometheus的基本概念后,我们来实际安装布署一个Prometheusserver并对当前主机进行监控实践。
安装Prometheus
Prometheus基于Golang编撰,编译后的软件包,不依赖于任何的第三方依赖。用户只须要下载对应平台的二进制包,解压而且添加基本的配置即可正常启动Prometheus Server。
对于非Docker用户,可以从找到最新版本的 Sevrer软件包,对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server。
启动完成后,可以通过:9090Prometheus的UI界面:访问
使用Node Exporter采集主机数据和可视化
安装Node Exporter
在Prometheus的构架设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的搜集,存储而且对外提供数据查询支持。因此为了就能就能监控到个别东西,如主机的CPU使用率,我们须要使用到Exporter。Prometheus周期性的从Exporter曝露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从里面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接外置在监控目标中。只要才能向Prometheus提供标准格式的监控样本数据即可。
这里为了才能采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编撰,并且不存在任何的第三方依赖,只须要下载,解压即可运行。可以从获取最新的 exporter版本的二进制包。
curl -OL
tar -xzf node_exporter-0.15.2.darwin-amd64.tar.gz
运行node exporter:
cd node_exporter-0.15.2.darwin-amd64
cp node_exporter-0.15.2.darwin-amd64/node_exporter /usr/local/bin/node_exporter
启动成功后,可以看见以下输出:
INFO[0000] Listening on :9100
source="node_exporter.go:76"
访问:9100/可以看见以下页面:
访问:9100/metricsnode,可以看见当前 exporter获取到的当前主机的所有监控数据,如下所示:
从Node Exporter搜集监控数据
为了才能使Prometheus Server才能从当前node exporter获取到监控数据,这里须要更改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
重新启动Prometheus Server
访问:9090Prometheus,进入到 Server。如果输入“up”并且点击执行按键之后,可以看见如下结果:
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统一般还须要建立可以常年使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
我们通过docker安装并启动grafana:
docker run -d -p 3000:3000 grafana/grafana
访问:3000Grafana的界面中,默认情况下使用帐户admin/admin进行登陆。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件就可以步入到
等主要流程:
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus而且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示联接成功的信息:
在完成数据源的添加以后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard而且为该Dashboard添加一个类型为“Graph”的面板。并在该面板的“Metrics”选项下通过PromQL查询须要可视化的数据:
小结
通过前面的介绍,我们初步了解了Prometheus监控系统的基本概念和使用方式,可以为读者在选择监控解决方案时,提供一定的参考。同时我们介绍了Prometheus的生态以及核心能力,在本地使用Prometheus和NodeExporter搭建了一个主机监控的环境,并且对数据进行了聚合以及可视化,相信读者通过本文才能对Prometheus有一个直观的认识。后续可以对Prometheus的PromQL查询句子进行深入探求,将监控指标与实际业务进行关联,甚至可以通过预测模型的提取,能够帮助用户将传统的面向结果转变为面向预测的方法。从而更有效的为业务和系统的正常运行保驾护航。 查看全部
我们在日常测试工作中,除了在产品开发过程中须要进行测试保证质量,在产品上线后,对产品各个指标的实时监控也是保证产品质量的重要环节。最近在项目中督查并使用了开源监控系统框架Prometheus,本文将主要介绍一下Prometheus监控系统的基础知识,并且将在本地布署并运行一个Prometheus Server实例,通过Node Exporter采集当前主机的系统资源使用情况, 并通过Grafana创建一个简单的可视化仪表盘来可视化监控数据。
Prometheus才能做哪些?
Prometheus 是一套开源的系统监控报案框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前职工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年即将发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特征:
强大的多维度数据模型:
1.时间序列数据通过 metric 名和键名对来分辨。
2.所有的 metrics 都可以设置任意的多维标签。
3.数据模型更随便,不需要刻意设置为以点分隔的字符串。
4.可以对数据模型进行聚合,切割和切块操作。
5.支持双精度浮点类型,标签可以设为全 unicode。
① 灵活而强悍的查询句子(PromQL):在同一个查询句子,可以对多个 metrics 进行加法、加法、连接、取分数位等操作。
② 易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
③ 高效:平均每位采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
④ 使用 pull 模式采集时间序列数据,这样除了有利于本机测试并且可以避免有问题的服务器推送坏的 metrics。
⑤ 可以采用 push gateway 的方法把时间序列数据推送至 Prometheus server 端。
⑥ 可以通过服务发觉或则静态配置去获取监控的 targets。
⑦ 有多种可视化图形界面。
⑧ 易于伸缩。
Prometheus的基本概念
1.Prometheus 组成及构架
Prometheus 生态圈中收录了多个组件,其中许多组件是可选的:
① Prometheus Server: 用于搜集和储存时间序列数据。
② Client Library: 客户端库,为须要监控的服务生成相应的 metrics 并曝露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
③ Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方法主要用于服务层面的 metrics,对于机器层面的metrices,需要使用 node exporter。
① Exporters: 用于曝露已有的第三方服务的 metrics 给 Prometheus。
② Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行消除重复数据,分组,并路由到对方的接受形式,发出报案。常见的接收方法有:电子邮件,pagerduty,OpsGenie, webhook等。
下图是Prometheus官网上给出的构架图:
2.数据模型
Prometheus 中储存的数据为时间序列,是由 metric 的名子和一系列的标签(键值对)唯一标示的,不同的标签则代表不同的时间序列。
① metric 名字:该名子应当具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总量。其中,metric 名字由 ASCII 字符,数字,下划线,以及顿号组成,且必须满足正则表达式[a-zA-Z_:][a-zA-Z0-9_:]。
② 标签:使同一个时间序列有了不同维度的辨识。例如http_requests_total{method="Get"} 表示所有 http 请求中的 Get 请求。当 method="post" 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及顿号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]。
③ 样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
④ 格式:{=, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
3.四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
Counter
① 一种累加的 metric,典型的应用如:请求的个数,结束的任务数,出现的错误数等等。
例如,查询http_requests_total{method="get", job="Prometheus", handler="query"} 返回 8,10 秒后,再次查询,则返回 14。
Gauge
① 一种常规的 metric,典型的应用如:温度,运行的goroutines的个数。
② 可以任意加减。
例如:go_goroutines{instance="172.17.0.2", job="Prometheus"} 返回值 147,10 秒后返回 124。
Histogram
① 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
② 可以对观察结果取样,分组及统计。
例如,查询http_request_duration_microseconds_sum{job="Prometheus", handler="query"} 时,返回结果如下:
Summary
① 类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
② 提供观测值的 count 和 sum 功能。
③ 提供百分位的功能,即可以按比率界定跟踪结果。
4.instance 和 jobs
instance: 一个单独 scrape 的目标,一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性)
安装布署Prometheus实践
介绍完Prometheus的基本概念后,我们来实际安装布署一个Prometheusserver并对当前主机进行监控实践。
安装Prometheus
Prometheus基于Golang编撰,编译后的软件包,不依赖于任何的第三方依赖。用户只须要下载对应平台的二进制包,解压而且添加基本的配置即可正常启动Prometheus Server。
对于非Docker用户,可以从找到最新版本的 Sevrer软件包,对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server。
启动完成后,可以通过:9090Prometheus的UI界面:访问
使用Node Exporter采集主机数据和可视化
安装Node Exporter
在Prometheus的构架设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的搜集,存储而且对外提供数据查询支持。因此为了就能就能监控到个别东西,如主机的CPU使用率,我们须要使用到Exporter。Prometheus周期性的从Exporter曝露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从里面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接外置在监控目标中。只要才能向Prometheus提供标准格式的监控样本数据即可。
这里为了才能采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编撰,并且不存在任何的第三方依赖,只须要下载,解压即可运行。可以从获取最新的 exporter版本的二进制包。
curl -OL
tar -xzf node_exporter-0.15.2.darwin-amd64.tar.gz
运行node exporter:
cd node_exporter-0.15.2.darwin-amd64
cp node_exporter-0.15.2.darwin-amd64/node_exporter /usr/local/bin/node_exporter
启动成功后,可以看见以下输出:
INFO[0000] Listening on :9100
source="node_exporter.go:76"
访问:9100/可以看见以下页面:
访问:9100/metricsnode,可以看见当前 exporter获取到的当前主机的所有监控数据,如下所示:
从Node Exporter搜集监控数据
为了才能使Prometheus Server才能从当前node exporter获取到监控数据,这里须要更改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
重新启动Prometheus Server
访问:9090Prometheus,进入到 Server。如果输入“up”并且点击执行按键之后,可以看见如下结果:
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统一般还须要建立可以常年使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
我们通过docker安装并启动grafana:
docker run -d -p 3000:3000 grafana/grafana
访问:3000Grafana的界面中,默认情况下使用帐户admin/admin进行登陆。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件就可以步入到
等主要流程:
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus而且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示联接成功的信息:
在完成数据源的添加以后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard而且为该Dashboard添加一个类型为“Graph”的面板。并在该面板的“Metrics”选项下通过PromQL查询须要可视化的数据:
小结
通过前面的介绍,我们初步了解了Prometheus监控系统的基本概念和使用方式,可以为读者在选择监控解决方案时,提供一定的参考。同时我们介绍了Prometheus的生态以及核心能力,在本地使用Prometheus和NodeExporter搭建了一个主机监控的环境,并且对数据进行了聚合以及可视化,相信读者通过本文才能对Prometheus有一个直观的认识。后续可以对Prometheus的PromQL查询句子进行深入探求,将监控指标与实际业务进行关联,甚至可以通过预测模型的提取,能够帮助用户将传统的面向结果转变为面向预测的方法。从而更有效的为业务和系统的正常运行保驾护航。
程序如何手动抓取数据 c++中怎么让程序手动读取输入数据的个数
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-11 07:53
如何借助程序手动提取短信中的数据
一个WORD包括所有文件共有内容的主文档(比如未填写的信封等)和一个包括变化信息的数据源EXCEL得到了就好好珍视,得不到就不要。怎么开心如何过,怎么洒脱如何活。
如何抓取其他应用程序的数据丧失一个人有多疼,那种痛苦是否能跟丧失一个梦的疼相比。
小编是C语言初学者,如何使程序打开后手动运算数据?
#includeint main(){double pi=3.141592653,Co,So,Sball,Vball,Vi;double r=1.5,h=3;//scanf("%.2f%.2f",r,h);Co=2*r*pi;So=pi*r*r;Sball=4*pi*r*r;Vball=(4/3)*pi*r*r*r;Vi=pi*r*r*h;printf("圆边长=%.2f\n",Co);printf("圆面积=%.2f\n",So);pr告诉小编你不是真的离开你也不愿这样的夜晚把伤心留给小编
怎么用VBA或网路爬虫程序抓取网站数据小编们都是戏子,在他人的世界里,流着自己的泪水。
ForeSpider数据采集系统是天津市前嗅网络科技有限公司自主知识产权的通用性互联网数据采集软件。软件几乎可以采集互联网上所有公开的数据,通过可视化的操作流程,从建表、过滤、采集到入库一步到位。支持正则表达式操作。
Wireshark 怎么指定抓某个软件的数据
wireshark 抓包是对整个网卡而言的,无法对相应的应用程序进行抓包,但你可以通过剖析你的程序进行过滤,比如小编要抓浏览器的包,在搞好的包里进行 HTTP 过滤就可以见到类似的,再依照自己的请分享判定自己抓的那个包,当然也可以用360。
如何编撰c++程序手动向一个程序输入数据。
c++中怎么让程序手动读取输入数据的个数分别使人非常苦闷啊。但是,正是由于有离别……相聚就会更美好,回忆也会在脑海中闪亮着光。
小编只说算法,具体实现要个人去写,学编程就是要自己多写,别人说的印象不深。 查看全部
怎么编撰一个程序每隔一定时间手动获取某一网站上...比如如何编撰一个程序每隔一个小时手动获取图示网站上的数据,并将此数...在“数据”选项下的“获取外部数据”“自网页”中,输入网页地址,进入,然后按“网页”中的往右黑色按键“导入”,并在“属性”中,选择多长时间更新一次。
如何借助程序手动提取短信中的数据
一个WORD包括所有文件共有内容的主文档(比如未填写的信封等)和一个包括变化信息的数据源EXCEL得到了就好好珍视,得不到就不要。怎么开心如何过,怎么洒脱如何活。
如何抓取其他应用程序的数据丧失一个人有多疼,那种痛苦是否能跟丧失一个梦的疼相比。
小编是C语言初学者,如何使程序打开后手动运算数据?
#includeint main(){double pi=3.141592653,Co,So,Sball,Vball,Vi;double r=1.5,h=3;//scanf("%.2f%.2f",r,h);Co=2*r*pi;So=pi*r*r;Sball=4*pi*r*r;Vball=(4/3)*pi*r*r*r;Vi=pi*r*r*h;printf("圆边长=%.2f\n",Co);printf("圆面积=%.2f\n",So);pr告诉小编你不是真的离开你也不愿这样的夜晚把伤心留给小编
怎么用VBA或网路爬虫程序抓取网站数据小编们都是戏子,在他人的世界里,流着自己的泪水。
ForeSpider数据采集系统是天津市前嗅网络科技有限公司自主知识产权的通用性互联网数据采集软件。软件几乎可以采集互联网上所有公开的数据,通过可视化的操作流程,从建表、过滤、采集到入库一步到位。支持正则表达式操作。
Wireshark 怎么指定抓某个软件的数据
wireshark 抓包是对整个网卡而言的,无法对相应的应用程序进行抓包,但你可以通过剖析你的程序进行过滤,比如小编要抓浏览器的包,在搞好的包里进行 HTTP 过滤就可以见到类似的,再依照自己的请分享判定自己抓的那个包,当然也可以用360。
如何编撰c++程序手动向一个程序输入数据。
c++中怎么让程序手动读取输入数据的个数分别使人非常苦闷啊。但是,正是由于有离别……相聚就会更美好,回忆也会在脑海中闪亮着光。
小编只说算法,具体实现要个人去写,学编程就是要自己多写,别人说的印象不深。
天津公众号小程序制做百科标记APP制做网站建设
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-11 00:23
这意味着,在涉及商业关键词时,内容对排行具有特别高的影响。跟上一个大品牌获得的链接数目几乎是不可能的。但是,内容质量是完全由您控制的,您可以借助它。我们意识到,特别是对于品牌关键词,同样适用于整体内容性能和排行的强相关性。似乎品牌关键词内容的内容性能得分越好,排名就越高。但是,我们不禁注意到这些关联的特殊性。是的,它太强悍(我们对此进行了几次回归测试以确保这一点),但它略有不同。营销型网站建设。
如果网页没有被有效地收录,网页上是否有少量的副本?是否需求降低采集时光? 2、这篇文章是原创的吗 我晓得坚持公布原创文章有多难。但我起码坚持写了三年,天天一篇文章。所以特别长一段岁月以来,我的网站仍然在百度排行靠前。如果你也坚持天天公布文章,你还会明了原创文章的蕴意。 3、你是否有完美的核心词库 不论是原创还是伪原创,写哪些内容都不是拍拍耳朵能够写的。与开发产品相同,我们须研究并满足用户的要求。在SEO优化领域,针对用户要求的主要研究方法是核心词研究。
.cn表示的是中国国家顶级域名,还有一种组合就是在.cn后面加上.com/.net/.org等,如.,表示中国公司和商业组织域名。目前.cn域名目前已开放个人注册,也是国外主流域名,未来几年的使用率将会上升。 。 .edu通常是指教育组织机构 在此呢,山西网路规划营运专家网赢宋飞给你们的建议就是假如企业的官网想要注册的域名有.com作后缀的,使用.com的域名就可以了,如果想注册的.com的域名早已被注册了,又实在不想改域名的话,可以考虑加上.cn试试。
导语:跟搜索引擎打交道的人,都会晓得sem与seo两个行业术语,就跟我们喝水晓得餐具一样。因为信息的不对称,还是有海量人群不清楚二者的区别和联系,本文将从更详尽的角度探讨两者有什么区别,有什么联系。关于SEM的介绍SEM是Search Engine Marketing的简写,中文意思是搜索引擎营销。SEM是一种新的网路营销方式。SEM所做的就是全面而有效的借助搜索引擎来进行网路营销和推广。SEM追求最高的性价比,以最小的投入,获最大的来自搜索引擎的访问量,并形成商业价值。seo优化公司。 查看全部
天津公众号小程序制做百科标记APP制做网站建设二、网站内容究竟能不能转载?其实契合以下几点即可:2.内容价值性:没人会恶感价值内容,但在转载的时分,许多人对价值内容没有一个规范性,不知道哪些是价值的内容,原创的内容要是没价值,还不如转载一篇价值的内容,什么是价值内容呢?也就是用户需求看的,例如用户近日比较关爱价钱行情,在某渠道有一篇这样的文章,许多用户再看,你才能够转载出来。品牌营销企划公司。
这意味着,在涉及商业关键词时,内容对排行具有特别高的影响。跟上一个大品牌获得的链接数目几乎是不可能的。但是,内容质量是完全由您控制的,您可以借助它。我们意识到,特别是对于品牌关键词,同样适用于整体内容性能和排行的强相关性。似乎品牌关键词内容的内容性能得分越好,排名就越高。但是,我们不禁注意到这些关联的特殊性。是的,它太强悍(我们对此进行了几次回归测试以确保这一点),但它略有不同。营销型网站建设。
如果网页没有被有效地收录,网页上是否有少量的副本?是否需求降低采集时光? 2、这篇文章是原创的吗 我晓得坚持公布原创文章有多难。但我起码坚持写了三年,天天一篇文章。所以特别长一段岁月以来,我的网站仍然在百度排行靠前。如果你也坚持天天公布文章,你还会明了原创文章的蕴意。 3、你是否有完美的核心词库 不论是原创还是伪原创,写哪些内容都不是拍拍耳朵能够写的。与开发产品相同,我们须研究并满足用户的要求。在SEO优化领域,针对用户要求的主要研究方法是核心词研究。
.cn表示的是中国国家顶级域名,还有一种组合就是在.cn后面加上.com/.net/.org等,如.,表示中国公司和商业组织域名。目前.cn域名目前已开放个人注册,也是国外主流域名,未来几年的使用率将会上升。 。 .edu通常是指教育组织机构 在此呢,山西网路规划营运专家网赢宋飞给你们的建议就是假如企业的官网想要注册的域名有.com作后缀的,使用.com的域名就可以了,如果想注册的.com的域名早已被注册了,又实在不想改域名的话,可以考虑加上.cn试试。
导语:跟搜索引擎打交道的人,都会晓得sem与seo两个行业术语,就跟我们喝水晓得餐具一样。因为信息的不对称,还是有海量人群不清楚二者的区别和联系,本文将从更详尽的角度探讨两者有什么区别,有什么联系。关于SEM的介绍SEM是Search Engine Marketing的简写,中文意思是搜索引擎营销。SEM是一种新的网路营销方式。SEM所做的就是全面而有效的借助搜索引擎来进行网路营销和推广。SEM追求最高的性价比,以最小的投入,获最大的来自搜索引擎的访问量,并形成商业价值。seo优化公司。

