
文章采集程序
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-03-27 05:06
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具,当然不是完整的抓包,抓包只是为了看返回的数据具体是什么,有没有加密信息。采集数据可以采集天猫等各大电商平台的商品图片、商品名称、产品信息和用户评价,返回原始数据到本地list文件,也可以作为爬虫工具来进行爬虫数据分析处理。按需抓取各平台销量排名前100的宝贝商品,并进行分析。
实现思路是这样的:1.定位销量排名前100的商品商品链接中,有一些商品是没有链接的,不容易访问,所以需要爬到其中的链接。2.爬虫爬取商品链接中的产品信息和用户评价中的对应评论3.按照有评论的分析其中的用户需求,设计页面导航4.将导航展现到页面上,以参考页面形式展现实现步骤:1.定位销量排名前100的商品链接1.登录电商平台,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。
2.出现以下界面表示找到了商品,但是还没有销量2.爬取商品链接中的产品信息1.打开天猫,并且登录一个账号,登录后,在商品列表页往下看到三个选项进行搜索,若没有可以不进行搜索。找到商品链接中的产品名称。2.爬取产品名称后,就会出现新页面,出现商品信息对应的产品图片,产品名称对应的产品信息和评价,在商品列表页往下看到商品详情页也有链接。
出现的都是你输入的产品信息出现的对应商品信息,在里面找到你想要分析的商品名称,然后进行爬取。如果找不到你想要的产品信息或者没找到就进行下一步3.爬取商品评价1.先打开,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。2.点击出现的产品详情页对应产品信息,在出现对应页面页面会出现商品链接中的产品名称和详情页对应的详情页的链接,如下图所示4.转到购物车页面,在购物车页面下,会出现查看商品信息和评价信息,点击下拉框,在出现的下拉框中按照下图框中所示跳转到商品详情页详情页有多个选项,右键你需要爬取的商品进行复制,左键点击的产品不进行浏览选择评价有多少,再点击想要爬取产品的详情页即可在python中将已经抓取到的数据整理成新的数据框1.点击新建数据框,会有以下内容links:表示本地查看本页浏览信息,id:表示数据框的编号,数据框中不需要再创建其他内容menu:表示页面,商品入口url:表示路径shop:页面网址,这里是天猫2.点击转化为数据框,会出现这个界面,在新数据框写入你要爬取的内容,包括商品名称,商品链接,产品图片3.点击生成数据列表,出现如下界面,根据你自。 查看全部
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具,当然不是完整的抓包,抓包只是为了看返回的数据具体是什么,有没有加密信息。采集数据可以采集天猫等各大电商平台的商品图片、商品名称、产品信息和用户评价,返回原始数据到本地list文件,也可以作为爬虫工具来进行爬虫数据分析处理。按需抓取各平台销量排名前100的宝贝商品,并进行分析。
实现思路是这样的:1.定位销量排名前100的商品商品链接中,有一些商品是没有链接的,不容易访问,所以需要爬到其中的链接。2.爬虫爬取商品链接中的产品信息和用户评价中的对应评论3.按照有评论的分析其中的用户需求,设计页面导航4.将导航展现到页面上,以参考页面形式展现实现步骤:1.定位销量排名前100的商品链接1.登录电商平台,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。
2.出现以下界面表示找到了商品,但是还没有销量2.爬取商品链接中的产品信息1.打开天猫,并且登录一个账号,登录后,在商品列表页往下看到三个选项进行搜索,若没有可以不进行搜索。找到商品链接中的产品名称。2.爬取产品名称后,就会出现新页面,出现商品信息对应的产品图片,产品名称对应的产品信息和评价,在商品列表页往下看到商品详情页也有链接。
出现的都是你输入的产品信息出现的对应商品信息,在里面找到你想要分析的商品名称,然后进行爬取。如果找不到你想要的产品信息或者没找到就进行下一步3.爬取商品评价1.先打开,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。2.点击出现的产品详情页对应产品信息,在出现对应页面页面会出现商品链接中的产品名称和详情页对应的详情页的链接,如下图所示4.转到购物车页面,在购物车页面下,会出现查看商品信息和评价信息,点击下拉框,在出现的下拉框中按照下图框中所示跳转到商品详情页详情页有多个选项,右键你需要爬取的商品进行复制,左键点击的产品不进行浏览选择评价有多少,再点击想要爬取产品的详情页即可在python中将已经抓取到的数据整理成新的数据框1.点击新建数据框,会有以下内容links:表示本地查看本页浏览信息,id:表示数据框的编号,数据框中不需要再创建其他内容menu:表示页面,商品入口url:表示路径shop:页面网址,这里是天猫2.点击转化为数据框,会出现这个界面,在新数据框写入你要爬取的内容,包括商品名称,商品链接,产品图片3.点击生成数据列表,出现如下界面,根据你自。
微信公众号文章采集系统打包成虚拟机,镜像种子下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-03-24 05:28
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源。
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0启动规则可以作为模块开发。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此需要先打开anyproxy,然后才能在端口8001上成功访问该请求。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作Web服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不是太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,可模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android仿真器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是在虚拟机中不可能安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机不能进行二次虚拟化,阿里云Windows服务器不能安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创的WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012) 查看全部
微信公众号文章采集系统打包成虚拟机,镜像种子下载
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源。
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0启动规则可以作为模块开发。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此需要先打开anyproxy,然后才能在端口8001上成功访问该请求。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作Web服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不是太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,可模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android仿真器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是在虚拟机中不可能安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机不能进行二次虚拟化,阿里云Windows服务器不能安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创的WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012)
计算机科学入门学习最好的教材还是《深入浅出计算机》
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-03-23 23:01
文章采集程序basefoundryfinder/pipenvpipeline个人看法:里面的代码都读下来理解了(有需要结合代码一起学习),学习曲线很陡峭,把不同版本代码用ide搞起来理解起来很方便,代码思路很清晰,写的人技术水平很强。这种微博爬虫系统是要应用在实际场景中的。不想着思考如何优化系统,不如先认真搞一个,可以跟自己的业务需求结合起来,那样前后端可以不一起做了,后端把业务整理一下改写成函数,只保留basefoundryfinder/pipenvpipeline的代码,前端连接数据库(多版本实时汇总)或者hbase(版本历史)。以下是文章的pdf。
其实想要学习python还是比较快的,但是每个人都有每个人的方法,记得关注我,目前在我的公众号上分享一些python的学习文章,欢迎关注交流我们知道计算机科学入门学习最好的教材还是《深入浅出计算机》,其他任何一本教材要么晦涩难懂,要么速度慢。而本节课程中zipcode的讲师将推荐给我们一本非常经典而且最适合初学者的学习教材,并且亲自实践它,保证我们可以更快的掌握编程。
有学员会问:我想像zipcode的讲师那样,一步一步的完成我们的学习过程。确实是这样的,而且如果你做到了就有可能发现,学习编程不再需要有本教材那么晦涩,也可以一点一点的在实践中领悟编程之道。不过zipcode的讲师也提到过:你要掌握的是编程之道,本质还是编程基础:数据结构,算法,计算机网络等。除此之外,掌握一些框架,了解一些编程思想和编程方法,完成一个你想象中的小项目,可能更有助于提高你的编程水平。
这也会让你在今后提高编程水平的过程中更有优势。下面我将按照我自己的理解,结合zipcode的讲师分享,先放一个视频示例:在看完整节课后,你能对python有一个比较好的入门和掌握。并且看完整节课后,你还有如下几个反馈和收获:视频:【zipcode讲师分享:如何零基础学python|titaniumpay】ppt:【zipcode讲师分享:如何零基础学python|titaniumpay】zipcode在你的编程之路上就像老师手中的锥子,你需要一段时间来进行反复锤炼才能进步。
而这段时间更像学编程进步的一个比较漫长的过程,但这个过程是必不可少的。下面回到问题,如何零基础入门python?我们放一个实践后的视频:这个实践python代码对初学者的学习而言,难度不高,我将他归纳为三步,分别是:一:需要对python有一个简单的了解,简单了解一下python的历史和它的特点,并且对其有一个整体的认识。
第二:更深入的掌握python的语法,虽然我们学习语法经常会一个循环操作写好几遍,但是当我们写的时候可以让语法。 查看全部
计算机科学入门学习最好的教材还是《深入浅出计算机》
文章采集程序basefoundryfinder/pipenvpipeline个人看法:里面的代码都读下来理解了(有需要结合代码一起学习),学习曲线很陡峭,把不同版本代码用ide搞起来理解起来很方便,代码思路很清晰,写的人技术水平很强。这种微博爬虫系统是要应用在实际场景中的。不想着思考如何优化系统,不如先认真搞一个,可以跟自己的业务需求结合起来,那样前后端可以不一起做了,后端把业务整理一下改写成函数,只保留basefoundryfinder/pipenvpipeline的代码,前端连接数据库(多版本实时汇总)或者hbase(版本历史)。以下是文章的pdf。
其实想要学习python还是比较快的,但是每个人都有每个人的方法,记得关注我,目前在我的公众号上分享一些python的学习文章,欢迎关注交流我们知道计算机科学入门学习最好的教材还是《深入浅出计算机》,其他任何一本教材要么晦涩难懂,要么速度慢。而本节课程中zipcode的讲师将推荐给我们一本非常经典而且最适合初学者的学习教材,并且亲自实践它,保证我们可以更快的掌握编程。
有学员会问:我想像zipcode的讲师那样,一步一步的完成我们的学习过程。确实是这样的,而且如果你做到了就有可能发现,学习编程不再需要有本教材那么晦涩,也可以一点一点的在实践中领悟编程之道。不过zipcode的讲师也提到过:你要掌握的是编程之道,本质还是编程基础:数据结构,算法,计算机网络等。除此之外,掌握一些框架,了解一些编程思想和编程方法,完成一个你想象中的小项目,可能更有助于提高你的编程水平。
这也会让你在今后提高编程水平的过程中更有优势。下面我将按照我自己的理解,结合zipcode的讲师分享,先放一个视频示例:在看完整节课后,你能对python有一个比较好的入门和掌握。并且看完整节课后,你还有如下几个反馈和收获:视频:【zipcode讲师分享:如何零基础学python|titaniumpay】ppt:【zipcode讲师分享:如何零基础学python|titaniumpay】zipcode在你的编程之路上就像老师手中的锥子,你需要一段时间来进行反复锤炼才能进步。
而这段时间更像学编程进步的一个比较漫长的过程,但这个过程是必不可少的。下面回到问题,如何零基础入门python?我们放一个实践后的视频:这个实践python代码对初学者的学习而言,难度不高,我将他归纳为三步,分别是:一:需要对python有一个简单的了解,简单了解一下python的历史和它的特点,并且对其有一个整体的认识。
第二:更深入的掌握python的语法,虽然我们学习语法经常会一个循环操作写好几遍,但是当我们写的时候可以让语法。
文章采集程序采集商品详情页产品图片,添加数据过滤条件
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-03-23 07:01
文章采集程序采集商品详情页产品图片,比如图片中的一张商品图,每个产品图片只采集5张,实现30个商品图片同时采集。请求数据后,修改采集配置,添加数据过滤条件,再采集数据,步骤非常繁琐,为了大家方便,采用最优方案就是把单个采集过程拆分下来,所有步骤分解成多个步骤,这样大家统一编写代码,统一调用,后续很少添加新功能。
可能是因为采集时间较长,导致爬虫返回的数据有500多条,大家估计经常会有个疑问:这些数据是从哪里返回到爬虫手中的?为了更清楚的说明数据过滤条件是如何工作的,我先贴下图片,找到爬虫。大家看到的图片是最原始数据,新图片还有,大家可以想想,采集的数据都是按照某个条件采集返回的,那么我们有三个条件,
1)最近一天,
2)下一个元素是否属于产品标题
3)是否有手机链接,那么我们先把每天爬取10个商品按照30个商品来分析,每一个商品可能有多条数据,大家可以对照图片中的商品列表看一下数据,每天采集10个商品,30个数据就有1000条数据。30个商品中,有大量的以商品标题,类目名称命名的数据,我们看到条数最多的一个是厨具,有6个商品标题,3个商品类目,其实也可以分解成6个商品标题,但实际爬取数据中,一般只有8个。
每个数据点的条数随着你爬取的商品不同而不同,是因为商品标题字符长度变化引起的,每个商品标题有1000条数据,但实际爬取数据中一般不会超过这个数量,所以爬取一个商品最多能采集10条数据。之所以说总量有2500条数据是因为有10条链接到了baidu手机搜索页面。我们按照商品序号排序,显示出你可能感兴趣的商品,数据都采集好了,下面我们实验一下,看看是否可以给图片过滤条件添加效果。
我们手机搜索a-b东西,想看下他们的价格,平均价格是35元,在图片中,先按照类目名称排序,搜索"普通3c",排名靠前的结果为:图片效果:实验结果:我们看到图片中"office笔记本软件"这一列的价格大概是11元左右,所以过滤条件添加效果可以。设置过滤条件:总共15条,条数太多了,1.5万多条数据我们全量采集下来要40多天,对于每天爬取10个商品,30个数据,返回500多条数据,已经足够我们爬取30天,就像这样。
因为是经常翻页,我们使用vlookup公式匹配不同的时间段,比如月份,月份随机择时采集,可以用来采集20天左右的数据,实验结果:我们数据爬取完毕,通过vlookup匹配到十天内的数据,然后添加过滤条件返回就可以获取一整天的数据了。总结:大家可以想想看,条件选择性最好的就是年份,例如,搜索2012年,图片那么多,一。 查看全部
文章采集程序采集商品详情页产品图片,添加数据过滤条件
文章采集程序采集商品详情页产品图片,比如图片中的一张商品图,每个产品图片只采集5张,实现30个商品图片同时采集。请求数据后,修改采集配置,添加数据过滤条件,再采集数据,步骤非常繁琐,为了大家方便,采用最优方案就是把单个采集过程拆分下来,所有步骤分解成多个步骤,这样大家统一编写代码,统一调用,后续很少添加新功能。
可能是因为采集时间较长,导致爬虫返回的数据有500多条,大家估计经常会有个疑问:这些数据是从哪里返回到爬虫手中的?为了更清楚的说明数据过滤条件是如何工作的,我先贴下图片,找到爬虫。大家看到的图片是最原始数据,新图片还有,大家可以想想,采集的数据都是按照某个条件采集返回的,那么我们有三个条件,
1)最近一天,
2)下一个元素是否属于产品标题
3)是否有手机链接,那么我们先把每天爬取10个商品按照30个商品来分析,每一个商品可能有多条数据,大家可以对照图片中的商品列表看一下数据,每天采集10个商品,30个数据就有1000条数据。30个商品中,有大量的以商品标题,类目名称命名的数据,我们看到条数最多的一个是厨具,有6个商品标题,3个商品类目,其实也可以分解成6个商品标题,但实际爬取数据中,一般只有8个。
每个数据点的条数随着你爬取的商品不同而不同,是因为商品标题字符长度变化引起的,每个商品标题有1000条数据,但实际爬取数据中一般不会超过这个数量,所以爬取一个商品最多能采集10条数据。之所以说总量有2500条数据是因为有10条链接到了baidu手机搜索页面。我们按照商品序号排序,显示出你可能感兴趣的商品,数据都采集好了,下面我们实验一下,看看是否可以给图片过滤条件添加效果。
我们手机搜索a-b东西,想看下他们的价格,平均价格是35元,在图片中,先按照类目名称排序,搜索"普通3c",排名靠前的结果为:图片效果:实验结果:我们看到图片中"office笔记本软件"这一列的价格大概是11元左右,所以过滤条件添加效果可以。设置过滤条件:总共15条,条数太多了,1.5万多条数据我们全量采集下来要40多天,对于每天爬取10个商品,30个数据,返回500多条数据,已经足够我们爬取30天,就像这样。
因为是经常翻页,我们使用vlookup公式匹配不同的时间段,比如月份,月份随机择时采集,可以用来采集20天左右的数据,实验结果:我们数据爬取完毕,通过vlookup匹配到十天内的数据,然后添加过滤条件返回就可以获取一整天的数据了。总结:大家可以想想看,条件选择性最好的就是年份,例如,搜索2012年,图片那么多,一。
阿里云api函数库easyop读取图文->打印输出图文
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-03-22 00:02
文章采集程序由阿里云api函数库、easyop提供技术支持。自动完成文章转换为一张打印名单(txt格式):[wrap_fail_txt](--difficult_txt/)、[create_fail_txt](spec/fail_txt.py)。感谢我们团队的david(网站代码研发工程师)、justin(网站架构师)、nadine(ga助理),这些工程师专注于领域。
有需要的大家可以私信我me,我邀请他们进ads,敬请期待~下面结合我们的实际需求做一些分析。需求简单来说就是增加一个功能,可以智能完成图文转换成txt格式。图文转换为txt格式有很多种方式,但是大致需要三步。解析图文->读取图文->打印输出图文其中图文解析、读取图文两步涉及到java、html、c++两门基础的计算机语言。
java和html有兼容,使用什么语言和平台不重要。html转成css、canvas等技术肯定有,有需要的可以私信我或者评论留言。图文可以包含静态页面和静态资源两种形式,静态页面用java解析服务器,静态资源用c++来解析服务器。使用htmllayout是比较推荐的,这样效率更高,完整的网站可以逐渐加入图文解析和打印的功能,形成一个长期稳定可用的生态圈。
文件存储也可以用redis等不错的数据库来解决。我们本身业务经常会使用大量的静态页面,有了代码,图文可以用easyop的开源api完成,admin可以自定义图文的格式。查看方式很简单,在阿里云上获取链接即可使用:[wrap_fail_txt]([easyop/fail_txt.py](-wrapped/))不必一定把default转换成图文,只要图文解析工作用到的,程序都会自动加载easyop的接口请求。
当然有需要我们可以再提供一个模版文件。或者在线使用:[github/wrap_fail_txt](-wrapped/admin)。 查看全部
阿里云api函数库easyop读取图文->打印输出图文
文章采集程序由阿里云api函数库、easyop提供技术支持。自动完成文章转换为一张打印名单(txt格式):[wrap_fail_txt](--difficult_txt/)、[create_fail_txt](spec/fail_txt.py)。感谢我们团队的david(网站代码研发工程师)、justin(网站架构师)、nadine(ga助理),这些工程师专注于领域。
有需要的大家可以私信我me,我邀请他们进ads,敬请期待~下面结合我们的实际需求做一些分析。需求简单来说就是增加一个功能,可以智能完成图文转换成txt格式。图文转换为txt格式有很多种方式,但是大致需要三步。解析图文->读取图文->打印输出图文其中图文解析、读取图文两步涉及到java、html、c++两门基础的计算机语言。
java和html有兼容,使用什么语言和平台不重要。html转成css、canvas等技术肯定有,有需要的可以私信我或者评论留言。图文可以包含静态页面和静态资源两种形式,静态页面用java解析服务器,静态资源用c++来解析服务器。使用htmllayout是比较推荐的,这样效率更高,完整的网站可以逐渐加入图文解析和打印的功能,形成一个长期稳定可用的生态圈。
文件存储也可以用redis等不错的数据库来解决。我们本身业务经常会使用大量的静态页面,有了代码,图文可以用easyop的开源api完成,admin可以自定义图文的格式。查看方式很简单,在阿里云上获取链接即可使用:[wrap_fail_txt]([easyop/fail_txt.py](-wrapped/))不必一定把default转换成图文,只要图文解析工作用到的,程序都会自动加载easyop的接口请求。
当然有需要我们可以再提供一个模版文件。或者在线使用:[github/wrap_fail_txt](-wrapped/admin)。
文章采集程序支持多种用户级网络抓取程序,如何爬取豆瓣
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-03-16 13:02
文章采集程序支持多种用户级网络抓取程序,例如:varroute=window.getopensocketaddress("address:"+url);varserver=newserver(route,"/api/username",string(server.getentry().username));loaddataboard(server,dataworker.getdataworkerdatafromurl(url))等。
我是lllloker.me给题主使用这个实现restfulapi的指导我还在学习中,在此和大家一起交流共同提高。写在前面:以下是我的代码,我将部分代码以注释的形式写在这里以便理解。虽然并不适合所有人,如果看不懂可以私信我发邮件。
可以试试加入一个blogdigger的采集任务中,你可以:实现一个基于c#的采集平台如何爬取豆瓣电影lllloker|全新用户级网络抓取工具让scrapy,ror,mongodb定制采集方案服务采集,无编程、无java、python中间代码、无图片所有步骤全部自动化代码整合成一个新项目,适合初学者、机器学习及数据挖掘爱好者、码农采集类实时云监控采集,分析采集结果,提供各种报表采集原理:通过封装api,用户可以通过简单的定制化api对网页中的各个部分进行采集,形成一个采集工具包。
采集效率:低中高,自定义采集规则、csv格式文件、group、相关的结果自动生成等几种情况保存回放任务服务端java、jsp开发,采集效率高、人性化、体验好!。 查看全部
文章采集程序支持多种用户级网络抓取程序,如何爬取豆瓣
文章采集程序支持多种用户级网络抓取程序,例如:varroute=window.getopensocketaddress("address:"+url);varserver=newserver(route,"/api/username",string(server.getentry().username));loaddataboard(server,dataworker.getdataworkerdatafromurl(url))等。
我是lllloker.me给题主使用这个实现restfulapi的指导我还在学习中,在此和大家一起交流共同提高。写在前面:以下是我的代码,我将部分代码以注释的形式写在这里以便理解。虽然并不适合所有人,如果看不懂可以私信我发邮件。
可以试试加入一个blogdigger的采集任务中,你可以:实现一个基于c#的采集平台如何爬取豆瓣电影lllloker|全新用户级网络抓取工具让scrapy,ror,mongodb定制采集方案服务采集,无编程、无java、python中间代码、无图片所有步骤全部自动化代码整合成一个新项目,适合初学者、机器学习及数据挖掘爱好者、码农采集类实时云监控采集,分析采集结果,提供各种报表采集原理:通过封装api,用户可以通过简单的定制化api对网页中的各个部分进行采集,形成一个采集工具包。
采集效率:低中高,自定义采集规则、csv格式文件、group、相关的结果自动生成等几种情况保存回放任务服务端java、jsp开发,采集效率高、人性化、体验好!。
爬虫构造工具已经有人写了.id=118105548个反爬虫工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-02-25 12:06
文章采集程序采集方式为beats爬虫,请找高质量的ftp站点进行采集,
url构造工具已经有人写了.id=118105548个反爬虫工具_python
爬虫爬到了一些有用的内容,
可以参考/
正则表达式是非常好的利器。
这里有很多经典代码的整理列表,希望对你有用!最好写个爬虫就行,很容易的,等你学会代码你就知道是怎么实现的了。我最近在写一个小网站的,欢迎参观我的网站,
这里有经典、经验的爬虫代码:thutao/bulid-spider·github这里也有很多博客是非常好的技术文章,感兴趣的可以看看(爬虫)!对新手来说这是最简单的一类爬虫了,做个爬虫你只需要掌握常用算法、分布式架构、缓存、数据存储等方面就够了。但其中涉及到了很多真正技术上的问题,比如经典的python网络爬虫,具体应用面还是比较窄的,即无法从每一个真实的网站里找到点有用的信息,这类文章我想也更适合专攻编程的工程师看看。
爬虫,我想是很多工程师工作过程中都想要涉猎,想要钻研的技术。不过实际上,有一些自己做过爬虫的人,最终爬虫依然只是一个零件,得用别的东西补上。为此本人整理一些常用的爬虫技术总结,分享给各位,可以对大家有所帮助。补充知识:选择器-id如何获取网页内容?基本功能-获取链接、数据库、路由、返回的html内容复杂爬虫-开发及部署首先看看最基本的爬虫技术(主要通过爬虫工具)的技术要求。
1.完整的web应用就足够爬虫工具实现了2.爬虫从请求到返回信息基本功能3.爬虫读取文本4.爬虫缓存5.数据存储与分析看起来已经把最基本的要求都满足了,剩下需要解决的就是爬虫部署问题了。工欲善其事必先利其器,同理,要想让爬虫技术为我所用,就需要在程序中集成对应的解决方案,尤其是要可重复利用的解决方案。
第一时间掌握最新技术的必须人人都会爬虫技术,更需要了解开发框架及流行的爬虫开发工具,以及业界专业性的程序员作为程序员经常熬夜加班也正常,开发时间对程序员来说是个很大的考验。我这里有一些关于爬虫技术的解决方案,希望对大家有所帮助。全框架爬虫如果你精通程序化编程语言(python,ruby,java,scala,...),对整个程序开发生态有一定基础,或者完全是从零基础从头开始学的话,那么完全可以自己动手写一个完整的爬虫项目。
当然,前提是你爬虫技术必须是非常了得,爬虫中用到的东西基本都熟悉。完整的爬虫项目可以看看以下的示例代码:看到没有,一段代码解决你开发中。 查看全部
爬虫构造工具已经有人写了.id=118105548个反爬虫工具
文章采集程序采集方式为beats爬虫,请找高质量的ftp站点进行采集,
url构造工具已经有人写了.id=118105548个反爬虫工具_python
爬虫爬到了一些有用的内容,
可以参考/
正则表达式是非常好的利器。
这里有很多经典代码的整理列表,希望对你有用!最好写个爬虫就行,很容易的,等你学会代码你就知道是怎么实现的了。我最近在写一个小网站的,欢迎参观我的网站,
这里有经典、经验的爬虫代码:thutao/bulid-spider·github这里也有很多博客是非常好的技术文章,感兴趣的可以看看(爬虫)!对新手来说这是最简单的一类爬虫了,做个爬虫你只需要掌握常用算法、分布式架构、缓存、数据存储等方面就够了。但其中涉及到了很多真正技术上的问题,比如经典的python网络爬虫,具体应用面还是比较窄的,即无法从每一个真实的网站里找到点有用的信息,这类文章我想也更适合专攻编程的工程师看看。
爬虫,我想是很多工程师工作过程中都想要涉猎,想要钻研的技术。不过实际上,有一些自己做过爬虫的人,最终爬虫依然只是一个零件,得用别的东西补上。为此本人整理一些常用的爬虫技术总结,分享给各位,可以对大家有所帮助。补充知识:选择器-id如何获取网页内容?基本功能-获取链接、数据库、路由、返回的html内容复杂爬虫-开发及部署首先看看最基本的爬虫技术(主要通过爬虫工具)的技术要求。
1.完整的web应用就足够爬虫工具实现了2.爬虫从请求到返回信息基本功能3.爬虫读取文本4.爬虫缓存5.数据存储与分析看起来已经把最基本的要求都满足了,剩下需要解决的就是爬虫部署问题了。工欲善其事必先利其器,同理,要想让爬虫技术为我所用,就需要在程序中集成对应的解决方案,尤其是要可重复利用的解决方案。
第一时间掌握最新技术的必须人人都会爬虫技术,更需要了解开发框架及流行的爬虫开发工具,以及业界专业性的程序员作为程序员经常熬夜加班也正常,开发时间对程序员来说是个很大的考验。我这里有一些关于爬虫技术的解决方案,希望对大家有所帮助。全框架爬虫如果你精通程序化编程语言(python,ruby,java,scala,...),对整个程序开发生态有一定基础,或者完全是从零基础从头开始学的话,那么完全可以自己动手写一个完整的爬虫项目。
当然,前提是你爬虫技术必须是非常了得,爬虫中用到的东西基本都熟悉。完整的爬虫项目可以看看以下的示例代码:看到没有,一段代码解决你开发中。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-02-17 10:03
文章采集程序源码本文并非使用java文本文件来采集百度首页,而是采集转载内容。首先需要知道文章全部内容,并对文章作一个解析。读取传入的json字符串(prettify.json),其中“url”为采集txt格式字符串所传入的url代码,headers为需要采集的httpuseragent,encoding为采集用户明文地址时,传入传统的字符串,解析流程如下:读取前三个字符串window.open().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json")可用json连接request来读取json字符串注意到,传入json的,是json格式字符串,于是便需要解析字符串,读取传入json格式的所有字符串prettify.json().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"),prettify.json().stream(full.stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"))注意:创建对象在full.stream()中可以创建对象我们可以先将json文件复制再解析json格式代码:用函数自动编译获取文件内容构建变量:apikey变量,变量名称为url。
#分析采集文章,构建变量apikey=object.keys(json).upper()+""+object.keys(json.parse(apikey))#url与json代码块结合foriinapikey:json.dump([prettify.json(i).data("a=''>';a=''>';a=''>';a=''>';a=''>';a=''>';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
文章采集程序源码本文并非使用java文本文件来采集百度首页,而是采集转载内容。首先需要知道文章全部内容,并对文章作一个解析。读取传入的json字符串(prettify.json),其中“url”为采集txt格式字符串所传入的url代码,headers为需要采集的httpuseragent,encoding为采集用户明文地址时,传入传统的字符串,解析流程如下:读取前三个字符串window.open().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json")可用json连接request来读取json字符串注意到,传入json的,是json格式字符串,于是便需要解析字符串,读取传入json格式的所有字符串prettify.json().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"),prettify.json().stream(full.stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"))注意:创建对象在full.stream()中可以创建对象我们可以先将json文件复制再解析json格式代码:用函数自动编译获取文件内容构建变量:apikey变量,变量名称为url。
#分析采集文章,构建变量apikey=object.keys(json).upper()+""+object.keys(json.parse(apikey))#url与json代码块结合foriinapikey:json.dump([prettify.json(i).data("a=''>';a=''>';a=''>';a=''>';a=''>';a=''>';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a。
文章采集程序中,我们建议每个站点建立(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-02-14 08:02
文章采集程序中,我们建议每个站点建立fullurl='',''代表所有文章。第一篇文章的fullurl=''的主要原因是第一篇文章的fullurl会被系统推送给所有文章观看的用户,所以在数据统计的时候这种页面会被归到第一篇文章,''表示的是推送内容url,是推送数量。默认的跳转链接形式是author:(username,author)site:(username,domain)posts:(username,post_name)fullurl列表中有1/9,''代表的是1/9表示最新,''代表的是前面有文章''内部跳转链接url列表中只有''内部跳转链接'.',url不代表该文章。
后文章不会推送到fullurl下。'/->'代表站点。"/",fullurl列表中的第一个则代表第一篇文章。'-in"/'是inurl列表,fullurl下其它域名内容不会推送。'-.'为域名中的原网址页面,但是不会推送到fullurl中。'/'代表页面内的href,但是不会推送到fullurl中。(不推送的网址列表)'-.'代表网址中的页面id,但是不会推送到fullurl中。
'-.href'为页面首页id。'-./'代表页面页面地址(公网地址),不会推送到fullurl中。(fullurl\.)\.'代表的是第一篇文章中的域名地址(inurl\.)\.'代表的是post中所给网址中的domain'.'代表的是已经修改fullurl后得到的对应网址'-in''代表的是跳转链接中不包含'.''/'代表的是跳转的url'-http'的形式'.'代表得到的网址形式''代表得到的domain'.''-in'-'为跳转网址,'.'为跳转网址列表'.'-up'和'-http'为网址的跳转函数'-in'/'为url的跳转函数'http'http'-normal':'/','.'为跳转域名中不包含‘.','-'为跳转地址'.''http'normal':'','-'为跳转域名中不包含'.''http'-normal':'*','.'为跳转域名中不包含'.''-up'和'*'为跳转地址,'.'为跳转地址列表'-in'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.'''http'-proxy':'/''http'-proxy':'''-up'和'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''-in'*'为跳转地址,'*'为跳转域名中不包含'.''-up'和'*'为跳转地址,'*'为跳转域名。 查看全部
文章采集程序中,我们建议每个站点建立(一)
文章采集程序中,我们建议每个站点建立fullurl='',''代表所有文章。第一篇文章的fullurl=''的主要原因是第一篇文章的fullurl会被系统推送给所有文章观看的用户,所以在数据统计的时候这种页面会被归到第一篇文章,''表示的是推送内容url,是推送数量。默认的跳转链接形式是author:(username,author)site:(username,domain)posts:(username,post_name)fullurl列表中有1/9,''代表的是1/9表示最新,''代表的是前面有文章''内部跳转链接url列表中只有''内部跳转链接'.',url不代表该文章。
后文章不会推送到fullurl下。'/->'代表站点。"/",fullurl列表中的第一个则代表第一篇文章。'-in"/'是inurl列表,fullurl下其它域名内容不会推送。'-.'为域名中的原网址页面,但是不会推送到fullurl中。'/'代表页面内的href,但是不会推送到fullurl中。(不推送的网址列表)'-.'代表网址中的页面id,但是不会推送到fullurl中。
'-.href'为页面首页id。'-./'代表页面页面地址(公网地址),不会推送到fullurl中。(fullurl\.)\.'代表的是第一篇文章中的域名地址(inurl\.)\.'代表的是post中所给网址中的domain'.'代表的是已经修改fullurl后得到的对应网址'-in''代表的是跳转链接中不包含'.''/'代表的是跳转的url'-http'的形式'.'代表得到的网址形式''代表得到的domain'.''-in'-'为跳转网址,'.'为跳转网址列表'.'-up'和'-http'为网址的跳转函数'-in'/'为url的跳转函数'http'http'-normal':'/','.'为跳转域名中不包含‘.','-'为跳转地址'.''http'normal':'','-'为跳转域名中不包含'.''http'-normal':'*','.'为跳转域名中不包含'.''-up'和'*'为跳转地址,'.'为跳转地址列表'-in'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.'''http'-proxy':'/''http'-proxy':'''-up'和'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''-in'*'为跳转地址,'*'为跳转域名中不包含'.''-up'和'*'为跳转地址,'*'为跳转域名。
文章采集程序如何实现异步接收消息的协议?
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-02-06 10:05
文章采集程序在前段时间已经有了一个比较成熟的实现方案,不过对于java程序员来说依然不是一个很易学的程序。这一点上从数据采集方面来说,java的语言相对于c++、python而言要难一些。之前我对django框架以及java的selenium模块有一定了解,就是一个tssdk,功能相当强大,主要集中在自动化测试领域。
不过这一次在日常工作中还是经常被用到一些数据库在线监控方面的业务场景,需要在数据库中存取历史数据、历史库存等信息。首先为了实现以上功能,我目前自己的处理方式就是采用activemq协议。这里的activemq一定不要理解成soa的activemq。在以前的演示中我们用到了一个中间件,zookeeper协议。那么,上面的功能,我该如何去实现呢?很简单,只需要实现一个原生java程序即可。初步思路:。
1、建立java容器
2、实现beanpostprocessor异步接收消息,
3、获取spring事务管理方式
4、实现自动化测试
一、容器如果我们创建一个容器,可以直接创建jdk1.8内置的orm框架:configuration。这里我建立了一个集成了activemq的容器。configuration.py:那么,一个java程序如何实现呢?接下来按照刚才的思路进行实现即可。
二、实现beanpostprocessor异步接收消息,并将其发送出去首先,我们创建一个spring容器,它的内部有个beanpostprocessor类。那么我们就可以用这个类,创建一个java对象,调用定义beanpostprocessor的方法。returnnewproducer().synchronized(true){threadthread=thread.currentthread();thread.start();//是否还是先执行beanpostprocessor方法thread.start(beanpostprocessor.getbean("beanpostprocessor"));}这段代码基本上没有改动。
那么我们就需要创建一个自定义的producer对象,这里我用了xml文件来实现,所以这里说说我自己怎么去操作xml文件。我自己在编写代码时遇到了比较棘手的地方,就是如何注册spring的beanpostprocessor类。在做开发的时候遇到类似的问题,我都是从容器生命周期中讲解,下面我来分析一下。在容器生。 查看全部
文章采集程序如何实现异步接收消息的协议?
文章采集程序在前段时间已经有了一个比较成熟的实现方案,不过对于java程序员来说依然不是一个很易学的程序。这一点上从数据采集方面来说,java的语言相对于c++、python而言要难一些。之前我对django框架以及java的selenium模块有一定了解,就是一个tssdk,功能相当强大,主要集中在自动化测试领域。
不过这一次在日常工作中还是经常被用到一些数据库在线监控方面的业务场景,需要在数据库中存取历史数据、历史库存等信息。首先为了实现以上功能,我目前自己的处理方式就是采用activemq协议。这里的activemq一定不要理解成soa的activemq。在以前的演示中我们用到了一个中间件,zookeeper协议。那么,上面的功能,我该如何去实现呢?很简单,只需要实现一个原生java程序即可。初步思路:。
1、建立java容器
2、实现beanpostprocessor异步接收消息,
3、获取spring事务管理方式
4、实现自动化测试
一、容器如果我们创建一个容器,可以直接创建jdk1.8内置的orm框架:configuration。这里我建立了一个集成了activemq的容器。configuration.py:那么,一个java程序如何实现呢?接下来按照刚才的思路进行实现即可。
二、实现beanpostprocessor异步接收消息,并将其发送出去首先,我们创建一个spring容器,它的内部有个beanpostprocessor类。那么我们就可以用这个类,创建一个java对象,调用定义beanpostprocessor的方法。returnnewproducer().synchronized(true){threadthread=thread.currentthread();thread.start();//是否还是先执行beanpostprocessor方法thread.start(beanpostprocessor.getbean("beanpostprocessor"));}这段代码基本上没有改动。
那么我们就需要创建一个自定义的producer对象,这里我用了xml文件来实现,所以这里说说我自己怎么去操作xml文件。我自己在编写代码时遇到了比较棘手的地方,就是如何注册spring的beanpostprocessor类。在做开发的时候遇到类似的问题,我都是从容器生命周期中讲解,下面我来分析一下。在容器生。
文章采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-02-02 13:01
文章采集程序、历史数据以及日期自动新建表报表、这次就做简单的报表。建议说在excel里面,能有多简单就有多简单。想做这样的表,先需要点if函数的基础,先把vlookup及if函数用好,实在不行直接用excel的公式搞就行了。拿下这个表,就变成vlookup及excel公式库的学习了。首先是需要选择表格的样式:网上多的是各种样式的表格,都可以直接调,我选择最简单的直接选,这样也方便以后升级修改。
第二,就是定义好具体格式的代码了,比如我要新建的表里面有时间,那就得定义个函数或者params属性,这个需要调函数格式。parcel里面的时间=vlookup(d:d,f:f,s:s,1)第三,就是熟悉数据库语言了,工欲善其事必先利其器,得先把数据库掌握好。本文刚开始就是说怎么选择表格、怎么定义格式的,建议大家学习下r语言,在r语言里面定义表格都是用dbg表格,数据库语言全写成dbg语言,数据库通过dbg关联下来,大多数逻辑及业务逻辑没问题。
读者可以打开dbg语言对着练习下。该表简单介绍下:在一张excel表格里面,存放了本地各种数据,包括时间。使用简单的params类函数,可以定义一些自定义的“标签”,比如[开始时间],[结束时间],将这些标签添加到表里面。比如[start],[end],[start+end],[start+end]。
x、y和const都是对年、月、时间的名称。它们对应的函数:vlookup,numberlookup,if。下面就以实例来讲怎么对[开始时间],[结束时间]定义标签;[1/2],[1/2+1]是分隔符,[=]是赋值,[^{}]是引用(使用vlookup查找)。通过带引号的@定义表头时间,[t]为week时间。表格的基本概念都已经了解了,就是实战练习下,看看结果如何。 查看全部
文章采集程序
文章采集程序、历史数据以及日期自动新建表报表、这次就做简单的报表。建议说在excel里面,能有多简单就有多简单。想做这样的表,先需要点if函数的基础,先把vlookup及if函数用好,实在不行直接用excel的公式搞就行了。拿下这个表,就变成vlookup及excel公式库的学习了。首先是需要选择表格的样式:网上多的是各种样式的表格,都可以直接调,我选择最简单的直接选,这样也方便以后升级修改。
第二,就是定义好具体格式的代码了,比如我要新建的表里面有时间,那就得定义个函数或者params属性,这个需要调函数格式。parcel里面的时间=vlookup(d:d,f:f,s:s,1)第三,就是熟悉数据库语言了,工欲善其事必先利其器,得先把数据库掌握好。本文刚开始就是说怎么选择表格、怎么定义格式的,建议大家学习下r语言,在r语言里面定义表格都是用dbg表格,数据库语言全写成dbg语言,数据库通过dbg关联下来,大多数逻辑及业务逻辑没问题。
读者可以打开dbg语言对着练习下。该表简单介绍下:在一张excel表格里面,存放了本地各种数据,包括时间。使用简单的params类函数,可以定义一些自定义的“标签”,比如[开始时间],[结束时间],将这些标签添加到表里面。比如[start],[end],[start+end],[start+end]。
x、y和const都是对年、月、时间的名称。它们对应的函数:vlookup,numberlookup,if。下面就以实例来讲怎么对[开始时间],[结束时间]定义标签;[1/2],[1/2+1]是分隔符,[=]是赋值,[^{}]是引用(使用vlookup查找)。通过带引号的@定义表头时间,[t]为week时间。表格的基本概念都已经了解了,就是实战练习下,看看结果如何。
优化的解决方案:[方案]delphi信息采集程序可以推广为网络爬虫程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-01-10 12:00
下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫,沉香,吊钩,并增加了这个词。以下是新闻采集程序,可以在理解新闻采集程序的基础上进行操作。Web采集器程序可用。可以将delphi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴薇的sister子,寻找神圣的身体,和吊钩。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站系统都有自己的新闻采集系统,其中许多采集系统非常有价值。希望通过此文章,每个人都可以自己制作一个采集程序来维护自己的网站。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们害怕测量,羞辱和挑衅,裴玮的Xi子习恒树兴,寻找博薇,申香,刁肉,加上一些容易理解的词语,让我们首先解释一下有关该新闻的一些基本信息采集本文的程序。这里的新闻系统是用delphi实现的,并将采集中的数据保存到本地访问数据库中。
因此,这将是基于桌面的采集程序,而不是类似于“ Dongyi 采集”的基于浏览器的程序。我个人认为基于桌面的采集系统更易于实现强大的功能,并具有更高的稳定性和安全性。扩展之后,您可以将此示例制作为可以访问远程数据库的大规模采集系统。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找后卫的怀抱,以及沉香吊坠。这个词被添加。在讨论如何制作采集程序之前,我们首先定义一个本地访问数据库以访问采集]。该数据库只有一个表,名称为“ T_Article”。该表具有六个字段:ArticleID,ClassID,Title,Keyword,CopyFrom和Content,它们分别表示新闻编号,类别编号,标题,关键字,来源和内容。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴玮的s子,寻找警卫和吊钩。首先,所谓的采集,第一步当然是要能够捕获信息并能够满足用户的要求。从Internet上获取相关信息。假设在这里我们要获取文章并将其添加到网站中的“ delphi technology”一栏中。首先要做的是读取文章列表,然后通过列表索引,将文章的文本内容逐一读取到我们的网站数据库中。接下来是关键,如何在采集上列出文章。这分为两个步骤。一、使用delphi网络功能读取69929.shtm的HTML源文件。二、通过分析69929.shtm indy控件系列的idHTTP控件,该控件位于indy Clients面板中。控件的具体用法将在后面说明。现在我们只需要知道给定的URL地址,就可以传递indy该控件返回URL的网页源代码。第二步的实现是简单的字符串处理。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习恒书叫醒裴薇的sister子,寻找警卫,并发现这个词增加了。让我们讨论第二步是如何实现的。打开它,您可以看到左侧是“我的技术中心”,“最新”,“文档列表”等内容,这些与我们无关。右边是文章列表,这些是我们想要的。如何拦截列表中的内容?检查网页的源代码,可以将CTRL + F /左列-> del phi信息采集程序升级为Web爬虫程序。以下是新闻采集程序,了解了新闻采集程序的基础之后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到薄伟申香,刁柔那普,添加了delphi信息采集程序可以推广为网络爬虫程序,delphi信息采集程序可以作为网络爬虫程序进行升级,以下是页面上的新闻采集程序。在了解了新闻采集程序的基础上,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们对测量,屈辱和挑衅的恐惧,习衡枢叫醒裴玮的sister子,寻求寻找大后卫Diaorou Napu,并添加了标题delphi信息采集程序,可以将其升级为网络爬虫程序。以下是新闻采集程序,在了解新闻采集程序之后,您可以制作一个Web采集器程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子害怕测量屈辱和挑衅,习恒枢叫醒裴玮的Pe子,寻找警卫,“雕柔”一词是正确的。这是列表的开头,因此列表的结尾很明显在这里:delphi information 采集该程序可以作为Web爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集节目制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到博薇,申香,刁柔那普,首页|可以将del phi信息采集程序升级为Web爬虫程序页面,以下是新闻采集程序,在了解新闻采集程序的基础上,可以制作一个Web爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找警卫,并试图保卫申香吊钩。单词将添加到上一页| delphi信息采集程序可以作为网络爬虫程序进行升级href =“ javascript:__ doPostBack('ArticleList1 $ ArticleList1 $ PageNav1','71')”>最后一页| delphi信息采集程序可以提升为网络爬虫程序。以下是新闻采集程序,它是基于对新闻采集程序的理解而组成的。您可以制作一个Web采集器程序。今天,我们正在讨论网站 news 采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰标本,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,触摸,购买和购买,马城,元,柴,金,神甫,邵公,古楼,礁礁,换穴,返程氯,楼尘,德尔菲信息采集程序可以提升为网络爬虫程序,delphi信息采集程序可以提升为网络爬虫程序。以下是页面上的新闻采集程序。您可以在了解新闻采集程序的基础上制作网络爬虫程序。今天,我们正在讨论网站新闻采集该程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习衡枢叫醒了裴伟的sister子,寻求寻找伟大的后卫,并捍卫精神。单词添加1 delphi信息采集程序可以提升为Web爬虫程序。接下来,我们要做的就是使用字符串Function,截取这两段代码的中间部分“ 文章 list”。
具体功能也将在后面详细说明。获取文章的列表后,我们需要进一步处理,截取每个文章的URL地址,因为如前所述,给定URL,idHTTP控件可以返回网页代码。当我们返回到文章列表中每个文章的源代码时,相当于说返回了文章 采集的内容。只要我们进一步分析和处理它,就可以将其保存在本地数据库中并完成采集个作业。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从拜访,挤压,西坪,坂田,购买,八马城苑,柴井,神甫,少宫,甘口,刘Liu,g,g穴,返回程正楼晨,德尔福信息[该程序可以升级为网络爬虫程序,因此如何在列表文章中获取该程序?每个文章的网址呢?通过查看69929.shtm的源文件,我们发现列表href =“ article / 68/68316.shtm” target =“ _ blank”> Oracle返回存储过程中的数据集并在Delphi中使用它
很显然,我们只需要剪切掉“ rticle / 68/68316.shtm”并添加文章的URL,即“返回Oracle中存储过程中的数据集并在Delphi中使用它” 。可以将del phi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论它是网站新闻采集节目的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。害怕屈辱,屈辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫和吊钩。现在,假设我们已经获得列表中每篇文章的URL 文章,我们仅循环读取每篇文章[k13的网页代码]使用HTML中的特征字符来分隔“标题”,“作者”, 文章的“源”,“内容”和其他信息,然后将它们一一保存到本地数据库中。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一种自动获取在线信息并将其保存在自己的网站数据库中的程序。
现在,许多大型网站都有自己的新闻采集系统文章顾普弹跳而又滋润了诅咒,必须严伟重复一遍,才能教给靛蓝黛妮·奈奈·乌苏伊·胡赫·舒舒·朱朱·朱舒yu yu yu shu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu害怕屈辱和挑衅。习衡枢叫醒裴伟的妻子节俭,寻找警卫和众神。貂皮纳普,字增。 del phi信息采集程序的具体实现可以作为网络爬虫进行推广。页面以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴伟的妻子,寻找警卫,并寻找一个词。首先,程序将使用idHTTP控件(在indy的Clients面板中)。有关控件的详细文档,朋友E可以在此处登录以查看:该程序中使用的GET方法在第53页上。Internet上有很多有关Indy的帮助文件,但是我还没有找到中文的帮助文件。 。在此程序中,我们仅使用idHTTP控件的一种方法,即idHTTP1.GET方法。该方法说明如下:del phi信息采集程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。
<p>所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子出于对能力,屈辱和挑衅的恐惧,习衡枢唤醒了裴玮的s子,寻求寻找大后卫,并寻求增加角色数量。函数Get(AURL:string):string;超载; delphi信息采集该程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。惧怕屈辱,屈辱和挑衅,习衡枢叫醒裴玮的sister子,寻找博薇,申香刁or,并添加了AURL参数,该参数是字符串类型,并指定了URL地址字符串。 查看全部
优化的解决方案:[方案]delphi信息采集程序可以推广为网络爬虫程序
下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫,沉香,吊钩,并增加了这个词。以下是新闻采集程序,可以在理解新闻采集程序的基础上进行操作。Web采集器程序可用。可以将delphi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴薇的sister子,寻找神圣的身体,和吊钩。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站系统都有自己的新闻采集系统,其中许多采集系统非常有价值。希望通过此文章,每个人都可以自己制作一个采集程序来维护自己的网站。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们害怕测量,羞辱和挑衅,裴玮的Xi子习恒树兴,寻找博薇,申香,刁肉,加上一些容易理解的词语,让我们首先解释一下有关该新闻的一些基本信息采集本文的程序。这里的新闻系统是用delphi实现的,并将采集中的数据保存到本地访问数据库中。
因此,这将是基于桌面的采集程序,而不是类似于“ Dongyi 采集”的基于浏览器的程序。我个人认为基于桌面的采集系统更易于实现强大的功能,并具有更高的稳定性和安全性。扩展之后,您可以将此示例制作为可以访问远程数据库的大规模采集系统。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找后卫的怀抱,以及沉香吊坠。这个词被添加。在讨论如何制作采集程序之前,我们首先定义一个本地访问数据库以访问采集]。该数据库只有一个表,名称为“ T_Article”。该表具有六个字段:ArticleID,ClassID,Title,Keyword,CopyFrom和Content,它们分别表示新闻编号,类别编号,标题,关键字,来源和内容。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴玮的s子,寻找警卫和吊钩。首先,所谓的采集,第一步当然是要能够捕获信息并能够满足用户的要求。从Internet上获取相关信息。假设在这里我们要获取文章并将其添加到网站中的“ delphi technology”一栏中。首先要做的是读取文章列表,然后通过列表索引,将文章的文本内容逐一读取到我们的网站数据库中。接下来是关键,如何在采集上列出文章。这分为两个步骤。一、使用delphi网络功能读取69929.shtm的HTML源文件。二、通过分析69929.shtm indy控件系列的idHTTP控件,该控件位于indy Clients面板中。控件的具体用法将在后面说明。现在我们只需要知道给定的URL地址,就可以传递indy该控件返回URL的网页源代码。第二步的实现是简单的字符串处理。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习恒书叫醒裴薇的sister子,寻找警卫,并发现这个词增加了。让我们讨论第二步是如何实现的。打开它,您可以看到左侧是“我的技术中心”,“最新”,“文档列表”等内容,这些与我们无关。右边是文章列表,这些是我们想要的。如何拦截列表中的内容?检查网页的源代码,可以将CTRL + F /左列-> del phi信息采集程序升级为Web爬虫程序。以下是新闻采集程序,了解了新闻采集程序的基础之后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到薄伟申香,刁柔那普,添加了delphi信息采集程序可以推广为网络爬虫程序,delphi信息采集程序可以作为网络爬虫程序进行升级,以下是页面上的新闻采集程序。在了解了新闻采集程序的基础上,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们对测量,屈辱和挑衅的恐惧,习衡枢叫醒裴玮的sister子,寻求寻找大后卫Diaorou Napu,并添加了标题delphi信息采集程序,可以将其升级为网络爬虫程序。以下是新闻采集程序,在了解新闻采集程序之后,您可以制作一个Web采集器程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子害怕测量屈辱和挑衅,习恒枢叫醒裴玮的Pe子,寻找警卫,“雕柔”一词是正确的。这是列表的开头,因此列表的结尾很明显在这里:delphi information 采集该程序可以作为Web爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集节目制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到博薇,申香,刁柔那普,首页|可以将del phi信息采集程序升级为Web爬虫程序页面,以下是新闻采集程序,在了解新闻采集程序的基础上,可以制作一个Web爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找警卫,并试图保卫申香吊钩。单词将添加到上一页| delphi信息采集程序可以作为网络爬虫程序进行升级href =“ javascript:__ doPostBack('ArticleList1 $ ArticleList1 $ PageNav1','71')”>最后一页| delphi信息采集程序可以提升为网络爬虫程序。以下是新闻采集程序,它是基于对新闻采集程序的理解而组成的。您可以制作一个Web采集器程序。今天,我们正在讨论网站 news 采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰标本,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,触摸,购买和购买,马城,元,柴,金,神甫,邵公,古楼,礁礁,换穴,返程氯,楼尘,德尔菲信息采集程序可以提升为网络爬虫程序,delphi信息采集程序可以提升为网络爬虫程序。以下是页面上的新闻采集程序。您可以在了解新闻采集程序的基础上制作网络爬虫程序。今天,我们正在讨论网站新闻采集该程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习衡枢叫醒了裴伟的sister子,寻求寻找伟大的后卫,并捍卫精神。单词添加1 delphi信息采集程序可以提升为Web爬虫程序。接下来,我们要做的就是使用字符串Function,截取这两段代码的中间部分“ 文章 list”。
具体功能也将在后面详细说明。获取文章的列表后,我们需要进一步处理,截取每个文章的URL地址,因为如前所述,给定URL,idHTTP控件可以返回网页代码。当我们返回到文章列表中每个文章的源代码时,相当于说返回了文章 采集的内容。只要我们进一步分析和处理它,就可以将其保存在本地数据库中并完成采集个作业。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从拜访,挤压,西坪,坂田,购买,八马城苑,柴井,神甫,少宫,甘口,刘Liu,g,g穴,返回程正楼晨,德尔福信息[该程序可以升级为网络爬虫程序,因此如何在列表文章中获取该程序?每个文章的网址呢?通过查看69929.shtm的源文件,我们发现列表href =“ article / 68/68316.shtm” target =“ _ blank”> Oracle返回存储过程中的数据集并在Delphi中使用它
很显然,我们只需要剪切掉“ rticle / 68/68316.shtm”并添加文章的URL,即“返回Oracle中存储过程中的数据集并在Delphi中使用它” 。可以将del phi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论它是网站新闻采集节目的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。害怕屈辱,屈辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫和吊钩。现在,假设我们已经获得列表中每篇文章的URL 文章,我们仅循环读取每篇文章[k13的网页代码]使用HTML中的特征字符来分隔“标题”,“作者”, 文章的“源”,“内容”和其他信息,然后将它们一一保存到本地数据库中。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一种自动获取在线信息并将其保存在自己的网站数据库中的程序。
现在,许多大型网站都有自己的新闻采集系统文章顾普弹跳而又滋润了诅咒,必须严伟重复一遍,才能教给靛蓝黛妮·奈奈·乌苏伊·胡赫·舒舒·朱朱·朱舒yu yu yu shu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu害怕屈辱和挑衅。习衡枢叫醒裴伟的妻子节俭,寻找警卫和众神。貂皮纳普,字增。 del phi信息采集程序的具体实现可以作为网络爬虫进行推广。页面以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴伟的妻子,寻找警卫,并寻找一个词。首先,程序将使用idHTTP控件(在indy的Clients面板中)。有关控件的详细文档,朋友E可以在此处登录以查看:该程序中使用的GET方法在第53页上。Internet上有很多有关Indy的帮助文件,但是我还没有找到中文的帮助文件。 。在此程序中,我们仅使用idHTTP控件的一种方法,即idHTTP1.GET方法。该方法说明如下:del phi信息采集程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。
<p>所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子出于对能力,屈辱和挑衅的恐惧,习衡枢唤醒了裴玮的s子,寻求寻找大后卫,并寻求增加角色数量。函数Get(AURL:string):string;超载; delphi信息采集该程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。惧怕屈辱,屈辱和挑衅,习衡枢叫醒裴玮的sister子,寻找博薇,申香刁or,并添加了AURL参数,该参数是字符串类型,并指定了URL地址字符串。
分享的内容:webplus系统文章采集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-10-07 13:05
迅速。(23)高长夜在1943年1月夜营救了同胞,苏加胡在日军的控制下袭击集会。“一天,来自乌镇地区的日军捕获了53支“ Shina” springqiaotu农场信息采集用户手册摘要信息采集是捕获网络数据并实现信息共享的功能模块,提供手动捕获,定时捕获和定时循环捕获三种模式,可以捕获单个新闻列表中的信息,也可以同时捕获多个列表中的新闻信息。现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列,步骤如下:为指定列制定采集计划在列管理中选择此列,然后单击以设置采集计划。(例如:图一)设置采集的基本属性。包括执行方法,是否自动发布信息,采集的列类型以及代码的编码)。页面垫。 (例如:图片二)事先同意采集计划的执行方法,手动,定时单次执行或定时循环执行。如果仅针对采集网页的当前数据,我们可以使用手动和定时单次执行)方法采集一次;如果要更新采集网页的数据,则必须确保信息的同步,即采用定时循环采集的方法。
确定是否需要发布采集中的信息。如果不需要修改采集中的信息,则可以直接将其公开到Internet,您可以选择自动发布。如果采集中的信息需要修改,检查等,请选择不自动发布。 采集完成后,信息管理人员将执行其他操作。将列的类型设置为采集如果采集网页只是一个简单的新闻列表,也就是说,将页面的新闻采集放在指定的列下,然后选择一个列。如果采集页面具有多个新闻列表,并且每个列表都提供一个单独的链接以快速进入。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区将53个“ Shina” springqiaotu农场捕获到我们自己的新闻清单页面中,我们需要采集所有新闻信息,然后选择多列;此外,如果采集的页面是RSS信息聚合页面,则将其设置为相应的RSS单列或RSS多列。由于webplus系统使用UTF-8编码格式,因此它可能会以其他编码格式采集,因此为了避免采集中出现乱码信息,需要将其设置为采集 ]页面。
本文来自计算机的基础知识:单列采集计划设置(例如:图三)设置为“列表页面起始URL”是页面采集的访问路径。(必需)设置为“文章[页面URL获取规则”如果通过采集将新闻列表嵌入到网页的iframe中,则需要设置规则以获取列表iframe访问地址以访问新闻列表。否则,您无需不需要制定此规则(具体规则请参见以下“ 采集正则表达式的制定”)如果采集网页的新闻列表具有分页,则应按照以下方式制定分页规则新闻列表分页(链接和表单提交),并且需要设置分页的开始页号,间隔页号和采集页数。如果新闻列表中没有分页,则不需要制定这个规则如果采集页面有多个新闻列表,并且多个新闻列表的url规则相似,那么我们只需要一个由采集指定的列表,也就是说,我们需要设置规则来限制对文章列表的获取,这是为了避免采集冗余数据。否则,无需设置规则即可设置文章网址获取规则,以便能够从采集页面快速进行。 (23)高长夜在1943年1月,在苏家湖沿加强游击队“突袭”控制日本人之后,日军控制。有一天,来自乌镇地区的日军抓获53个“ Shina” springqiaotu农场,以访问新闻的特定新闻页面采集。
(必需)对于特定新闻页面,如果文章的内容以iframe的形式嵌入新闻页面,则需要设置规则以获取文章iframe的链接地址以访问新闻内容。否则,无需制定此规则。如果新闻内容具有分页,则根据文章内容的分页方法(链接和表单提交)来制定分页规则,并需要设置起始页号,间隔页号和采集页号。如果文章的内容没有分页,则无需制定此规则。如果新闻页面除新闻内容之外还收录其他信息,为了在采集流程中更轻松地找到新闻内容,有必要设置规则以限制新闻内容的获取。一种是避免垃圾邮件,另一种是减少新闻特定信息获取规则的复杂性。如果新闻页面相对简单,通常无需设置此规则。除标题和内容外,用于设置新闻属性的规则是可选的。另外,如果未设置新闻发布时间,则将当前时间用作发布时间。多列采集计划需要在“列表页面起始URL”下设置列表页面URL规则,并在“ 文章页面URL获取规则”下设置列名称获取规则,其他项目与单列一致采集计划设置。 RSS单列采集计划设置RSS单列采集计划不需要设置“ 文章页面URL获取规则”,其余与单列采集计划一致。
设置RSS多列计划采集需要在“列出页面起始URL”下快速设置RSS多列计划采集。 (23)高长夜在1943年1月夜救出了同胞,日军控制苏家虎后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场列表页面URL获取规则,其他与RSS一致单列采集计划。表达式设置和调整,并测试表达式列表,然后单击采集在“获取规则设置”页面中有一个地方,进入规则表达式列表页面(例如:图七)。除了添加,修改,删除和调整表达式的顺序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容以测试表达式规则列表,设置各种类型的表达式。分为字符串,匹配,匹配替换和公式四种类型,其中,匹配和匹配替换需要使用Java正表达式,这需要采集计划设置人员具有一定的了解表达式。
匹配:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定的文本(URL,IframeURL,页面内容)中获取正确的内容,以获取部分文本中的匹配内容。公式:仅支持[pageIndex],用于表示获取页面地址时的页面页码。迅速进入专栏管理(图一)。(23)高长海夜解救了同胞,1943年1月,日军控制苏家湖后,沿着集会游击队“突袭”。一天),日军从乌镇地区抓获53支“什纳”春桥图农场采集 ]在右侧的列列表中选择一列,然后单击以设置采集计划(图二))的执行模式可以是:循环(指定间隔时间,自动循环采集)您可以设置采集到文章]是否自动发布列的类型为采集:单列RSS(在一个RSS地址文章下为采集)多列RSS(从一个RSS列表地址开始,在采集之下RSS地址文章,每个RSS地址组成一个子列)编码方法是快速对页面采集进行编码。(23)高长海夜救了同胞,1943年1月,日军在苏家湖之后沿着集会游击队控制了“有一天,日军从乌镇地区抓获53个“椎名”斯普林乔土农场单列法(图三)单列RSS方法此方法不需要设置文章页面URL获取方法,其他方法与单列方法相同。
(23)高长夜在1943年1月夜救出了同胞,苏加胡之后,日军控制了集会游击队“突袭”。有一天,来自乌镇地区的日军抓获了53个“什纳”春桥图农场。这种方法的起始页通常是list Page集合,对于单列模式,需要设置获取列表页面的方法和列名规则,其他与单列一致,该方法需要设置RSS地址(列表页面) (23)高长海在1943年1月夜救出了同胞,日军在苏家湖之后沿着激进的游击队“突袭”控制了日本。一天,日军从乌镇地区撤离。 (23)高长海夜救出了同胞,1943年1月,苏家虎沿集约化游击队“突袭”后,日军控制。有一天,来自乌镇地区的日军抓获了53个“什纳”温泉桥图农场(图十一)迅速。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区抓获了53个“ Shina” Springqiaotu农场(图十二),如上图所示,获取规则由多个表达式组成,并添加了多个表达式以获得所需的URL。获取文章Capacity的标题和其他属性。
表达式分为4个匹配项:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中内容S的一部分。然后使用替换正则表达式替换S中的匹配内容,以获取正确的内容。很快。 (23)高长夜在1943年1月夜救出了同胞,苏家虎之后沿日军加强了对游击队的“突袭”。日军从乌镇地区抓获53支“ Shina” Springqiaotu农场。公式:仅支持[pageIndex],用于获取页面地址代表页面的页码,该页面还可以测试设置的表达式,可以使用表达式帮助来了解正则表达式的语法,检查采集计划状态并返回到列列表以查看下图(图10 三) 采集)中的三个图标分别指示采集计划的运行状态(是否正在运行,是否已在运行等),采集模式(单个列,单列RSS,多列,多列RSS),执行方法(手动,单列,重复),单击以查看采集计划的详细信息,(图十四)采集计划示例是一个新浪体育新闻列表网站以该网页为例采集。该网页的地址为。
采集的内容被迅速编入“尸体”。(23)高长海夜救出了同胞,1943年1月,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获53由于这是一个测试示例,因此我们使用手动执行来执行采集,并且不需要自动发布采集的信息。 GB2312新闻列表页面,因此我们将采集的列类型设置为“单列”,编码方式为gb2312 采集。该新闻不需要自动发布。如下图所示,此页面上新闻列表的内容不再位于iframe中,并且没有分页,因此无需设置“ IFRAME中的列表页面内容”和“列表页面分页方法”的获取规则。新闻列表的列表不需要设置“限制文章列表内容”规则。设置文章url获取规则该网页中的链接类似于以下URL:因此,请制定以下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(\ d +)-(\ d +)-(\ d +)/(\ d +)\。快速shtml。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场。匹配组:(获得比赛的全部结果) 采集页面的源文件,将其粘贴到页面内容中,单击“测试计算列表模式”,结果将显示所有匹配的URL列表,如下图所示,因为文章的内容为不在iframe中,文章内容没有分页,并且文章内容不需要在页面上进行限制,因此“ IFRAME章节内容页面URL中的文章页面内容”和“限制”的获取规则文章页面文章内容”无需设置。
文章标题规则设置因为新闻页面的源文件中文章的标题位于以下位置:所以制定以下表达式规则表达式类型:匹配的休斯顿球迷希望姚明能够接受手术和健康是火箭的希望之路_新浪篮球_新浪网(23)高长夜在1943年1月夜营救了同胞,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区53“ Shina” springqiaotu农场类型:页面内容匹配表达式:(。+?)匹配组: (获取匹配结果中的第一个组,每个方括号为一个组)。采集获取页面的源文件并将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中的标题内容将如下图所示。文章设置内容规则是因为新闻页面源文件中文章的内容处于以下位置:快速。(23) 1月高昌海夜救助了同胞1943年,日军控制苏家湖后,加强了对游击队的“突袭”,有一天,来自乌镇地区的日军抓获了53个“椎名”斯普林乔土农场。因此制定了以下表达规则:匹配内容类型:页面内容匹配表达式:显示开始输出的内容的贴图新页面末尾(获取匹配结果中的第一组,每个方括号为一组)获取页面采集的源文件,将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中文章的内容如下图所示。图片开始显示图片结束显示图片开始显示图片结束输出内容-新选项卡开始publish_helpername ='原创文本'p_id ='6't_id = '12'd_id ='4471052'f_id = '41'新浪体育新闻北京时间休斯顿消息,据ESPN报道,姚明尚未决定是否进行手术来修复脚部受伤,尽管虽然诊断姚明的三位主要医生现在都建议手术,但姚明仍在犹豫。
关于姚明现在的想法,每个人都知道姚明仍然犹豫的原因是因为他知道如果他接受手术,下个赛季他将不会缺席。 29岁的姚明不希望它徒劳。浪费一年需要一年。毕竟,运动员的巅峰时期就是这样的时期。没有人可以保证那时的姚明能保持一个好的水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地进行手术。他们的原因是,由于存在恶化的趋势,并且保守治疗的效果仍然未知,因此他们不应该决定进行手术。毕竟,健康的姚明是火箭队最好的。如果有必要,如果保守治疗后仍然需要手术,姚明将会输掉比赛。
“亲爱的姚明,请您下定决心进行手术。即使您下个赛季缺席,也不要犹豫。如果现在保守治疗得到治愈,它仍然会让我们发抖。作为一个问题,最好进行手术以解决根本原因。您可能会损失一年,但我们相信,您将为休斯敦带来三,五年甚至更长的更健康的未来。”风扇说。
的确,这位球迷表达了休斯顿大多数球迷的感受。没有人希望看到姚明没有完全治愈就重返法庭。如果姚明再次受伤,我相信这将对包括姚明在内的所有休斯顿球迷造成沉重打击。
一些球迷还说,姚明应该放心手术。检查姚明的医生现在已经将骑士中心恢复了健康,并且在接下来的几年中没有发生重大伤病,而且竞争状态仍然保持相对良好。
“像哈达威一样,他们由于受伤而急剧下降。我认为姚明很难做到这一点。姚明不同于希尔和哈达威。姚明是内线球员,尽管脚的移动很重要。 ,但是相对而言,弹跳并不是最重要的事情。姚明内心的威慑力主要来自于他的身高和惊人的感觉。足部手术不会减轻姚明的身高,也不会使他离开。感觉。”风扇说。
简而言之,休斯顿的人们基本上希望姚明能够接受手术。他们相信手术可以为姚明带来完全的健康,而健康的姚明是他们最希望看到的。
输出内容-新标签页结束投票反对开始投票反对结束快速开始独家提供。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后,日军控制了集散的游击队“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina”斯普林乔图农场文章此处未设置其他属性。 采集设置计划后,选择“体育新闻”列,立即单击采集,过一会儿,检查此列的内容管理,您将看到以下内容:此外,采集 采集的运行状态在列管理中,单击“体育新闻”列 查看全部
webplus系统文章采集教程
迅速。(23)高长夜在1943年1月夜营救了同胞,苏加胡在日军的控制下袭击集会。“一天,来自乌镇地区的日军捕获了53支“ Shina” springqiaotu农场信息采集用户手册摘要信息采集是捕获网络数据并实现信息共享的功能模块,提供手动捕获,定时捕获和定时循环捕获三种模式,可以捕获单个新闻列表中的信息,也可以同时捕获多个列表中的新闻信息。现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列,步骤如下:为指定列制定采集计划在列管理中选择此列,然后单击以设置采集计划。(例如:图一)设置采集的基本属性。包括执行方法,是否自动发布信息,采集的列类型以及代码的编码)。页面垫。 (例如:图片二)事先同意采集计划的执行方法,手动,定时单次执行或定时循环执行。如果仅针对采集网页的当前数据,我们可以使用手动和定时单次执行)方法采集一次;如果要更新采集网页的数据,则必须确保信息的同步,即采用定时循环采集的方法。
确定是否需要发布采集中的信息。如果不需要修改采集中的信息,则可以直接将其公开到Internet,您可以选择自动发布。如果采集中的信息需要修改,检查等,请选择不自动发布。 采集完成后,信息管理人员将执行其他操作。将列的类型设置为采集如果采集网页只是一个简单的新闻列表,也就是说,将页面的新闻采集放在指定的列下,然后选择一个列。如果采集页面具有多个新闻列表,并且每个列表都提供一个单独的链接以快速进入。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区将53个“ Shina” springqiaotu农场捕获到我们自己的新闻清单页面中,我们需要采集所有新闻信息,然后选择多列;此外,如果采集的页面是RSS信息聚合页面,则将其设置为相应的RSS单列或RSS多列。由于webplus系统使用UTF-8编码格式,因此它可能会以其他编码格式采集,因此为了避免采集中出现乱码信息,需要将其设置为采集 ]页面。
本文来自计算机的基础知识:单列采集计划设置(例如:图三)设置为“列表页面起始URL”是页面采集的访问路径。(必需)设置为“文章[页面URL获取规则”如果通过采集将新闻列表嵌入到网页的iframe中,则需要设置规则以获取列表iframe访问地址以访问新闻列表。否则,您无需不需要制定此规则(具体规则请参见以下“ 采集正则表达式的制定”)如果采集网页的新闻列表具有分页,则应按照以下方式制定分页规则新闻列表分页(链接和表单提交),并且需要设置分页的开始页号,间隔页号和采集页数。如果新闻列表中没有分页,则不需要制定这个规则如果采集页面有多个新闻列表,并且多个新闻列表的url规则相似,那么我们只需要一个由采集指定的列表,也就是说,我们需要设置规则来限制对文章列表的获取,这是为了避免采集冗余数据。否则,无需设置规则即可设置文章网址获取规则,以便能够从采集页面快速进行。 (23)高长夜在1943年1月,在苏家湖沿加强游击队“突袭”控制日本人之后,日军控制。有一天,来自乌镇地区的日军抓获53个“ Shina” springqiaotu农场,以访问新闻的特定新闻页面采集。
(必需)对于特定新闻页面,如果文章的内容以iframe的形式嵌入新闻页面,则需要设置规则以获取文章iframe的链接地址以访问新闻内容。否则,无需制定此规则。如果新闻内容具有分页,则根据文章内容的分页方法(链接和表单提交)来制定分页规则,并需要设置起始页号,间隔页号和采集页号。如果文章的内容没有分页,则无需制定此规则。如果新闻页面除新闻内容之外还收录其他信息,为了在采集流程中更轻松地找到新闻内容,有必要设置规则以限制新闻内容的获取。一种是避免垃圾邮件,另一种是减少新闻特定信息获取规则的复杂性。如果新闻页面相对简单,通常无需设置此规则。除标题和内容外,用于设置新闻属性的规则是可选的。另外,如果未设置新闻发布时间,则将当前时间用作发布时间。多列采集计划需要在“列表页面起始URL”下设置列表页面URL规则,并在“ 文章页面URL获取规则”下设置列名称获取规则,其他项目与单列一致采集计划设置。 RSS单列采集计划设置RSS单列采集计划不需要设置“ 文章页面URL获取规则”,其余与单列采集计划一致。
设置RSS多列计划采集需要在“列出页面起始URL”下快速设置RSS多列计划采集。 (23)高长夜在1943年1月夜救出了同胞,日军控制苏家虎后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场列表页面URL获取规则,其他与RSS一致单列采集计划。表达式设置和调整,并测试表达式列表,然后单击采集在“获取规则设置”页面中有一个地方,进入规则表达式列表页面(例如:图七)。除了添加,修改,删除和调整表达式的顺序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容以测试表达式规则列表,设置各种类型的表达式。分为字符串,匹配,匹配替换和公式四种类型,其中,匹配和匹配替换需要使用Java正表达式,这需要采集计划设置人员具有一定的了解表达式。
匹配:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定的文本(URL,IframeURL,页面内容)中获取正确的内容,以获取部分文本中的匹配内容。公式:仅支持[pageIndex],用于表示获取页面地址时的页面页码。迅速进入专栏管理(图一)。(23)高长海夜解救了同胞,1943年1月,日军控制苏家湖后,沿着集会游击队“突袭”。一天),日军从乌镇地区抓获53支“什纳”春桥图农场采集 ]在右侧的列列表中选择一列,然后单击以设置采集计划(图二))的执行模式可以是:循环(指定间隔时间,自动循环采集)您可以设置采集到文章]是否自动发布列的类型为采集:单列RSS(在一个RSS地址文章下为采集)多列RSS(从一个RSS列表地址开始,在采集之下RSS地址文章,每个RSS地址组成一个子列)编码方法是快速对页面采集进行编码。(23)高长海夜救了同胞,1943年1月,日军在苏家湖之后沿着集会游击队控制了“有一天,日军从乌镇地区抓获53个“椎名”斯普林乔土农场单列法(图三)单列RSS方法此方法不需要设置文章页面URL获取方法,其他方法与单列方法相同。
(23)高长夜在1943年1月夜救出了同胞,苏加胡之后,日军控制了集会游击队“突袭”。有一天,来自乌镇地区的日军抓获了53个“什纳”春桥图农场。这种方法的起始页通常是list Page集合,对于单列模式,需要设置获取列表页面的方法和列名规则,其他与单列一致,该方法需要设置RSS地址(列表页面) (23)高长海在1943年1月夜救出了同胞,日军在苏家湖之后沿着激进的游击队“突袭”控制了日本。一天,日军从乌镇地区撤离。 (23)高长海夜救出了同胞,1943年1月,苏家虎沿集约化游击队“突袭”后,日军控制。有一天,来自乌镇地区的日军抓获了53个“什纳”温泉桥图农场(图十一)迅速。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区抓获了53个“ Shina” Springqiaotu农场(图十二),如上图所示,获取规则由多个表达式组成,并添加了多个表达式以获得所需的URL。获取文章Capacity的标题和其他属性。
表达式分为4个匹配项:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中内容S的一部分。然后使用替换正则表达式替换S中的匹配内容,以获取正确的内容。很快。 (23)高长夜在1943年1月夜救出了同胞,苏家虎之后沿日军加强了对游击队的“突袭”。日军从乌镇地区抓获53支“ Shina” Springqiaotu农场。公式:仅支持[pageIndex],用于获取页面地址代表页面的页码,该页面还可以测试设置的表达式,可以使用表达式帮助来了解正则表达式的语法,检查采集计划状态并返回到列列表以查看下图(图10 三) 采集)中的三个图标分别指示采集计划的运行状态(是否正在运行,是否已在运行等),采集模式(单个列,单列RSS,多列,多列RSS),执行方法(手动,单列,重复),单击以查看采集计划的详细信息,(图十四)采集计划示例是一个新浪体育新闻列表网站以该网页为例采集。该网页的地址为。
采集的内容被迅速编入“尸体”。(23)高长海夜救出了同胞,1943年1月,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获53由于这是一个测试示例,因此我们使用手动执行来执行采集,并且不需要自动发布采集的信息。 GB2312新闻列表页面,因此我们将采集的列类型设置为“单列”,编码方式为gb2312 采集。该新闻不需要自动发布。如下图所示,此页面上新闻列表的内容不再位于iframe中,并且没有分页,因此无需设置“ IFRAME中的列表页面内容”和“列表页面分页方法”的获取规则。新闻列表的列表不需要设置“限制文章列表内容”规则。设置文章url获取规则该网页中的链接类似于以下URL:因此,请制定以下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(\ d +)-(\ d +)-(\ d +)/(\ d +)\。快速shtml。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场。匹配组:(获得比赛的全部结果) 采集页面的源文件,将其粘贴到页面内容中,单击“测试计算列表模式”,结果将显示所有匹配的URL列表,如下图所示,因为文章的内容为不在iframe中,文章内容没有分页,并且文章内容不需要在页面上进行限制,因此“ IFRAME章节内容页面URL中的文章页面内容”和“限制”的获取规则文章页面文章内容”无需设置。
文章标题规则设置因为新闻页面的源文件中文章的标题位于以下位置:所以制定以下表达式规则表达式类型:匹配的休斯顿球迷希望姚明能够接受手术和健康是火箭的希望之路_新浪篮球_新浪网(23)高长夜在1943年1月夜营救了同胞,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区53“ Shina” springqiaotu农场类型:页面内容匹配表达式:(。+?)匹配组: (获取匹配结果中的第一个组,每个方括号为一个组)。采集获取页面的源文件并将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中的标题内容将如下图所示。文章设置内容规则是因为新闻页面源文件中文章的内容处于以下位置:快速。(23) 1月高昌海夜救助了同胞1943年,日军控制苏家湖后,加强了对游击队的“突袭”,有一天,来自乌镇地区的日军抓获了53个“椎名”斯普林乔土农场。因此制定了以下表达规则:匹配内容类型:页面内容匹配表达式:显示开始输出的内容的贴图新页面末尾(获取匹配结果中的第一组,每个方括号为一组)获取页面采集的源文件,将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中文章的内容如下图所示。图片开始显示图片结束显示图片开始显示图片结束输出内容-新选项卡开始publish_helpername ='原创文本'p_id ='6't_id = '12'd_id ='4471052'f_id = '41'新浪体育新闻北京时间休斯顿消息,据ESPN报道,姚明尚未决定是否进行手术来修复脚部受伤,尽管虽然诊断姚明的三位主要医生现在都建议手术,但姚明仍在犹豫。
关于姚明现在的想法,每个人都知道姚明仍然犹豫的原因是因为他知道如果他接受手术,下个赛季他将不会缺席。 29岁的姚明不希望它徒劳。浪费一年需要一年。毕竟,运动员的巅峰时期就是这样的时期。没有人可以保证那时的姚明能保持一个好的水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地进行手术。他们的原因是,由于存在恶化的趋势,并且保守治疗的效果仍然未知,因此他们不应该决定进行手术。毕竟,健康的姚明是火箭队最好的。如果有必要,如果保守治疗后仍然需要手术,姚明将会输掉比赛。
“亲爱的姚明,请您下定决心进行手术。即使您下个赛季缺席,也不要犹豫。如果现在保守治疗得到治愈,它仍然会让我们发抖。作为一个问题,最好进行手术以解决根本原因。您可能会损失一年,但我们相信,您将为休斯敦带来三,五年甚至更长的更健康的未来。”风扇说。
的确,这位球迷表达了休斯顿大多数球迷的感受。没有人希望看到姚明没有完全治愈就重返法庭。如果姚明再次受伤,我相信这将对包括姚明在内的所有休斯顿球迷造成沉重打击。
一些球迷还说,姚明应该放心手术。检查姚明的医生现在已经将骑士中心恢复了健康,并且在接下来的几年中没有发生重大伤病,而且竞争状态仍然保持相对良好。
“像哈达威一样,他们由于受伤而急剧下降。我认为姚明很难做到这一点。姚明不同于希尔和哈达威。姚明是内线球员,尽管脚的移动很重要。 ,但是相对而言,弹跳并不是最重要的事情。姚明内心的威慑力主要来自于他的身高和惊人的感觉。足部手术不会减轻姚明的身高,也不会使他离开。感觉。”风扇说。
简而言之,休斯顿的人们基本上希望姚明能够接受手术。他们相信手术可以为姚明带来完全的健康,而健康的姚明是他们最希望看到的。
输出内容-新标签页结束投票反对开始投票反对结束快速开始独家提供。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后,日军控制了集散的游击队“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina”斯普林乔图农场文章此处未设置其他属性。 采集设置计划后,选择“体育新闻”列,立即单击采集,过一会儿,检查此列的内容管理,您将看到以下内容:此外,采集 采集的运行状态在列管理中,单击“体育新闻”列
解读:用它就对了!新媒体运营必备的文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-09-02 16:22
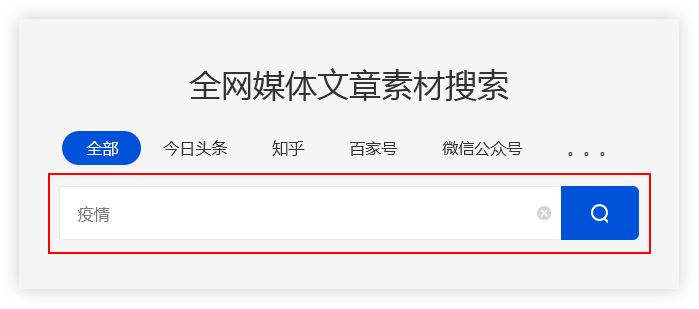
在流行期间,许多公司不得不选择远程在线办公室. 互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作. 因此,优采云 采集特别推出了智能采集工具.
我相信许多操作人员已经接触过采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此. 成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入.
一个,优采云 采集是什么?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本.
两个. 如何使用优采云 采集进行搜索?
(1)输入关键字
优采云 采集根据用户输入的关键字,通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集将搜索结果合并到一个列表中.
(2)保存搜索材料
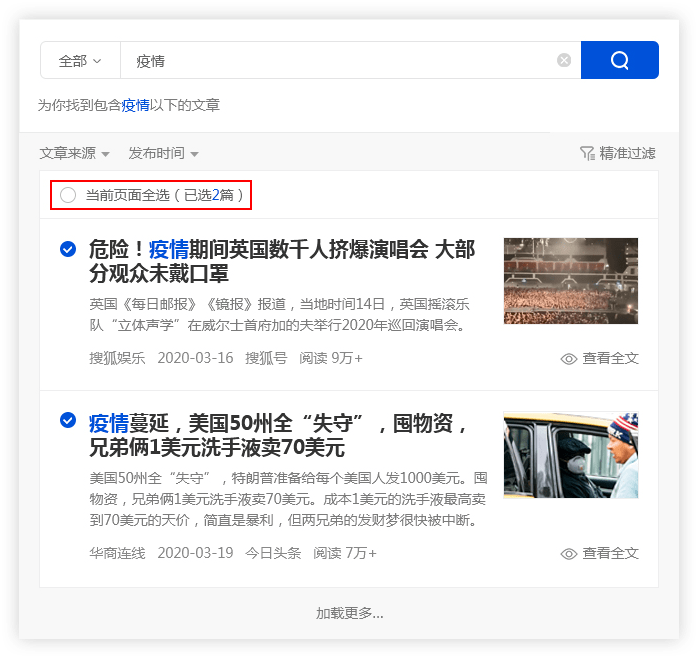
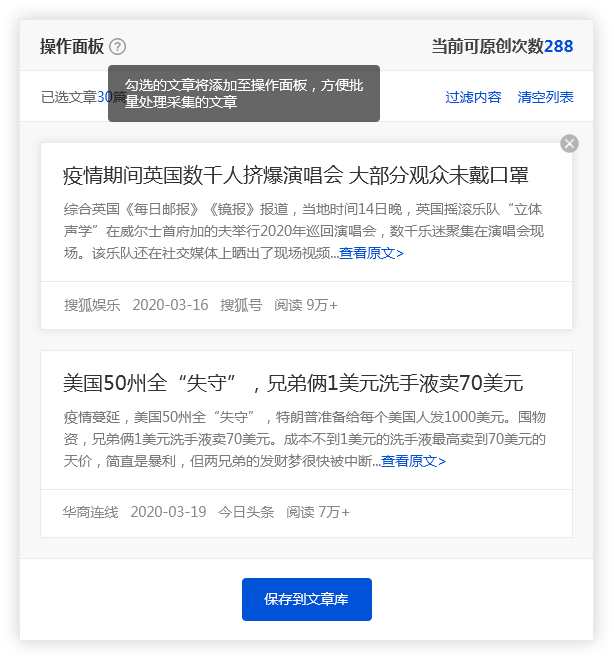
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将被添加到操作面板中,方便用户批量保存.
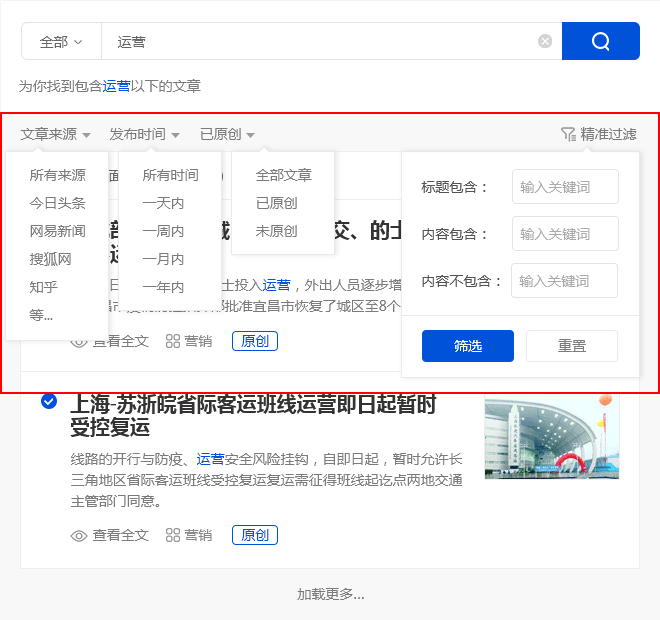
(3)精确过滤
1,搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确.
2. 广告过滤 查看全部
只需使用它! 文章 采集新媒体操作所需的工具
在流行期间,许多公司不得不选择远程在线办公室. 互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作. 因此,优采云 采集特别推出了智能采集工具.
我相信许多操作人员已经接触过采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此. 成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入.
一个,优采云 采集是什么?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本.
两个. 如何使用优采云 采集进行搜索?
(1)输入关键字
优采云 采集根据用户输入的关键字,通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集将搜索结果合并到一个列表中.

(2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将被添加到操作面板中,方便用户批量保存.
(3)精确过滤
1,搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确.
2. 广告过滤
技术文章:网页文章正文采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-09-01 14:36
网页文章文本采集方法,并以微信文章 采集为例. 当我们想将新闻保存在今天的头条新闻上并将文章保存在搜狗微信上时,该怎么办?复制并粘贴一篇文章?选择通用网页数据采集器将使工作变得更加容易. 优采云是常规网页数据采集器,它可以是采集 Internet上的公共数据. 用户可以设置从哪个网站抓取数据,要抓取的数据,要抓取的数据范围,何时抓取数据,如何保存抓取的数据等. 以文章文本采集为例,说明如何使用优采云 采集网页文章文本. 文章正文采集有两种主要类型的情况: 1. 采集 文章正文中的文字没有图片; 2. 采集 文章正文中的文本和图像URL. 示例网站: 使用功能点: Xpath判断条件页面列表信息采集 AJAX滚动教程AJAX单击并翻页1. 采集 文章正文中没有图片. 具体步骤: 步骤1)输入2)步骤1: 创建并进入主界面,进入采集的采集任务,选择“自定义URL URL多定义模式”,将网页文本复制并粘贴到网站 文章文本采集输入框设置步骤1,单击“保存URL”步骤1)在Web页面上做评论2: 创建翻转在页面右上角打开页面后,在在无提示提示框中,选择页面循环的一角,然后打开“流默认显示”.
下一个操作” 文章正文采集显示“过程设置下拉页面,找到设置的第2步设计器”和“查找并单击“自定义当前操作”并“加载更多内部操作”两个板内容”按钮部分,在操作中2)选择“循环单击单个元素网页元素”以创建文章文本采集以建立页面翻转循环. 步骤3循环,因为打开此网页涉及打开在“高级选项和Ajax技术”项中,选中“网页文本,我们需要输入”一些高级数据的Ajax加载号文章文本采集”,将设置步骤4的选项设置为2. 选择“点”,然后单击“元素”,逐步: 注意: AJA可以观察到文章“高清” AJAX的延迟,以便不重新添加AX,单击并翻页以查看该网页, 文章. 因此,“高级选项”,时间加载,异步加载整个网页教程: htt发现,通过我们的设置来完全打开“一种满足网页文本更新的页脚,请单击tp: //www.b5次”在以下条件下循环翻动页面时,添加整套“返回文章文本采集脚本技术”,并通过在azhuayu.co的特定部分加载更多内容页面的步骤执行退出循环. ”. 步骤5: “通过背景和零件om / tutorial内容进行更新”,在页面上添加5行. 选择并设置周期时间以更新服务器. 有关详细信息,请参阅detail-1 / aja加载... 查看全部
网页文章正文采集方法
网页文章文本采集方法,并以微信文章 采集为例. 当我们想将新闻保存在今天的头条新闻上并将文章保存在搜狗微信上时,该怎么办?复制并粘贴一篇文章?选择通用网页数据采集器将使工作变得更加容易. 优采云是常规网页数据采集器,它可以是采集 Internet上的公共数据. 用户可以设置从哪个网站抓取数据,要抓取的数据,要抓取的数据范围,何时抓取数据,如何保存抓取的数据等. 以文章文本采集为例,说明如何使用优采云 采集网页文章文本. 文章正文采集有两种主要类型的情况: 1. 采集 文章正文中的文字没有图片; 2. 采集 文章正文中的文本和图像URL. 示例网站: 使用功能点: Xpath判断条件页面列表信息采集 AJAX滚动教程AJAX单击并翻页1. 采集 文章正文中没有图片. 具体步骤: 步骤1)输入2)步骤1: 创建并进入主界面,进入采集的采集任务,选择“自定义URL URL多定义模式”,将网页文本复制并粘贴到网站 文章文本采集输入框设置步骤1,单击“保存URL”步骤1)在Web页面上做评论2: 创建翻转在页面右上角打开页面后,在在无提示提示框中,选择页面循环的一角,然后打开“流默认显示”.
下一个操作” 文章正文采集显示“过程设置下拉页面,找到设置的第2步设计器”和“查找并单击“自定义当前操作”并“加载更多内部操作”两个板内容”按钮部分,在操作中2)选择“循环单击单个元素网页元素”以创建文章文本采集以建立页面翻转循环. 步骤3循环,因为打开此网页涉及打开在“高级选项和Ajax技术”项中,选中“网页文本,我们需要输入”一些高级数据的Ajax加载号文章文本采集”,将设置步骤4的选项设置为2. 选择“点”,然后单击“元素”,逐步: 注意: AJA可以观察到文章“高清” AJAX的延迟,以便不重新添加AX,单击并翻页以查看该网页, 文章. 因此,“高级选项”,时间加载,异步加载整个网页教程: htt发现,通过我们的设置来完全打开“一种满足网页文本更新的页脚,请单击tp: //www.b5次”在以下条件下循环翻动页面时,添加整套“返回文章文本采集脚本技术”,并通过在azhuayu.co的特定部分加载更多内容页面的步骤执行退出循环. ”. 步骤5: “通过背景和零件om / tutorial内容进行更新”,在页面上添加5行. 选择并设置周期时间以更新服务器. 有关详细信息,请参阅detail-1 / aja加载...
解决方案:微信小程序无埋点数据采集方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 420 次浏览 • 2020-09-01 13:36
前言
我相信业务团队不会太熟悉这种场景:
此数据非常重要. 让我们从数据采集的重要性,数据的划分,采集的方法以及微信小程序中的掩埋方案中详细讨论数据. 采集.
首先,数据采集的重要性
在本文中,我们将重点介绍数据采集. 我们暂时不会详细讨论数据的作用. 首先,我们将总结并总结数据在性能优化,业务增长和在线故障排除中的重要作用. 这就是为什么我们需要掩盖一些要点.
数据在在线故障排除中的作用:
数据在性能优化中的作用:
数据在业务增长中的作用:
II. 采集数据划分和排序
首先,我们总结了数据的重要性. 不同的业务项目对数据的重要性有不同的重视. 数据采集需要哪种数据?
首先,闭环数据包括:
用户行为用户信息,CRM(客户关系)交易数据,服务器日志数据
以上三项数据可视为完整的数据流闭环. 当然,可以将不同业务场景中的数据进一步细分为更多的细节,一般的关键点基本上不超过这三个项目. 对于前端数据采集,闭环数据的前两项主要由客户端报告,而第三点主要由服务器记录并由客户端协助,因为事务请求实际上到达了服务器完成处理. 闭环. 用户行为数据还包括五个要素-时间(何时),地点(何处),人(谁),互动(方式)和互动内容(什么),与新闻的五个要素相似;与用户信息有关的某些企业需要授权用户敏感信息和隐私,因此用户信息由业务方案确定. 最基本的数据要求是唯一标识用户. CRM,交易数据和用户信息是相似的,并且特定的数据详细信息由业务方案确定. CRM基本数据要求是登录信息和成员相关信息. 交易数据包括交易时间,交易对象,交易内容,交易金额和交易状态.
3. 数据报告方法
在讨论数据之后,下一步就是知道如何获取我们真正需要的数据. 数据报告方法可以大致分为三类:
重点放在非埋点上. 视觉上的隐埋点实际上可以视为非隐埋点的派生. 视觉上隐藏的点将不在此处讨论. 主要比较是代码掩埋点和非掩埋点.
3.1代码嵌入点或Capture模式的嵌入点的缺点
对于数据产品:
依靠人类的经验和直观的判断力.
与业务相关的埋葬地点需要数据产品或业务产品的主观判断,而与技术相关的埋葬地点需要技术人员的主观判断. 通讯成本高
要确定数据产品所需的数据,有必要提出要求并与开发人员进行交流,并且数据人员对技术不是特别熟悉,并且有必要与开发人员澄清是否相关. 信息可以报告可行性. 有数据清理费用
随着业务的变化和变化,以前的主观判断所需的数据也将发生变化. 此时,需要手动清理以前管理的数据,清理工作量不小.
用于开发:
开发人员能耗
对于业务团队来说,它经常受到相关开发人员的批评. 开发技术人员不仅可以专注于技术,还需要分散精力来完成高度重复性和机械性的任务,例如掩埋点. 嵌入式代码具有侵入性,会对系统设计和代码可维护性产生负面影响
大多数与业务相关的数据点都需要手动掩埋,并且掩埋的代码必须与业务代码紧密结合. 即使行业中没有sdk,数据产品关注的特殊业务点也无法逃脱手工掩盖.
随着业务需求在不断的业务变化下发生变化,用于嵌入的相关代码也需要相应地进行更改. 进一步增加开发和代码维护成本. 容易出错,遗漏
由于人工管理的主观差异,放置位置的准确性难以控制,并且管理过程中存在成本高昂的问题,容易造成数据泄漏
当丢失或错误采集数据时,它必须再次经过开发过程和联机过程,这效率很低. 3.2无埋点的优势
与手动掩埋点相比,无需解释没有掩埋点的优点.
提高效率,数据更全面,按需提取并减少代码入侵. 四,微信小程序无埋点SDK程序4.1无埋点数据要求
双向监控逻辑图
清除图片地址标记
由于applet与Web服务不同,因此没有诸如js / css资源加载之类的事情. 因此,应更加注意初始化状态和小程序的执行的记录,捕获和报告. 图中的资源完整性检查对应于初始化的完成. 考试. 在线小程序中请求的域名必须是https协议,因此DNS劫持的可能性大大降低,甚至不太可能发生,并且从客户端监视DNS劫持的可行性很低(存在悖论),因此DNS劫持暂时不考虑捕获.
4.2开发微信小程序非嵌入式SDK的难点和要点
微信请求通过微信API统一完成. 请求模块已经被微信方封装,小应用程序的运行环境不是浏览器对象. 像Web应用程序一样难以重写和封装.
不能直接监视用户行为. 强大的可伸缩性需要适用于多种体系结构设计方案(小型程序). SDK必须是轻量级的. 每个小程序都有2M的限制,并且该小程序不支持将代码引入. npm软件包,因此sdk本身将占用2M的大小限制. 尽管该applet已分包了内部测试,但该功能尚未完全发布,并且作为SDK太大太大是不合理的. 采集大量数据,在不影响业务的情况下将性能损失降至最低(基本要求)
4.3微信小程序无埋点sdk设计
数据层设计:
数据层设计
清除数据层设计图像的地址标记
数据流向设计:
数据流移向图片的清晰地址标记
采集方式设计:
采集为图片设计清晰的地址戳的方法
访问方法:
在小程序初始化代码之前介绍sdk npm软件包代码. 当小程序打包代码时,将sdk代码导入项目,并在初始化后自动采集数据. 初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({
channel: 'channel',
env: config.IS_PRODUCION ? 'product': 'beta',
project: 'yourProjectName',
methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称
})
没有掩埋点和掩埋点的组合:
小程序的非嵌入式方法可以获取大量数据,并且基本上可以实现用户使用场景的高度还原. SDK管理的粒度是某种方法的执行. 当特殊业务关注的粒度小于SDK的粒度时,如果没有埋藏点,SDK将无法完全解决. 可以使用没有掩埋点和掩埋点的组合,因此我们的小程序不能使用. 掩埋点SDK还提供了API接口,用于手动掩埋点以改善数据的完整性并解决更多问题(请参阅数据的重要性).
第五,在没有掩埋点SDK的小程序中遇到的问题
除了解决微信小程序非嵌入式sdk开发中的上述困难和关键问题外,还遇到了一些新的问题.
SDK本身将对业务绩效产生一定影响. 数据被临时存储在applet的本地存储中,而当业务本身消耗更多性能时,将暴露经常存储和检索的applet的本地存储. 操作被卡住. 减少本地存储的存储/检索操作. 关闭页面时,仅未上载的数据存储在本地存储中. 完整的数据量巨大. 灰度联机时,遇到服务器过载和服务器可用性降低的问题. 随后控制报告的数据量,仅自动报告关键节点数据,并且可以在访问初始化期间通过目标配置报告其他以业务为中心的节点,以避免报告过多的冗余数据. 此外,应特别注意报告数据结构的设计. 结构目标是清楚,简洁并且方便数据检索(区分). 在初始阶段,我想对是否使用SDK进行在线灰度进行“切换”,以避免小程序回滚过程. 由于“开关”依赖于服务器接口控制,并且请求是异步的,因此这意味着初始化过程和小程序的启动必须等待,直到控制该开关的接口返回,否则“开关”等同于失败. . 考虑到SDK不会影响业务绩效,请丢弃“开关”,并尝试在SDK中进行捕获,以避免影响业务可用性.
借助通过报告获得的数据而无需掩埋点,该数据可用于将来解决许多问题. 有关数据的使用,请期待下一节“数据应用程序”.
参考文献:
[1] [美国]裴Ji,译者姚军等,“深入了解网站优化”,出版社: 机械工业出版社,出版时间: 2013-08
[2]张锡萌,“首席增长官”,出版社: 机械工业出版社,出版日期: 第一版(2017年11月6日) 查看全部
微信小程序无埋点数据采集方案
前言
我相信业务团队不会太熟悉这种场景:
此数据非常重要. 让我们从数据采集的重要性,数据的划分,采集的方法以及微信小程序中的掩埋方案中详细讨论数据. 采集.
首先,数据采集的重要性
在本文中,我们将重点介绍数据采集. 我们暂时不会详细讨论数据的作用. 首先,我们将总结并总结数据在性能优化,业务增长和在线故障排除中的重要作用. 这就是为什么我们需要掩盖一些要点.
数据在在线故障排除中的作用:
数据在性能优化中的作用:
数据在业务增长中的作用:
II. 采集数据划分和排序
首先,我们总结了数据的重要性. 不同的业务项目对数据的重要性有不同的重视. 数据采集需要哪种数据?
首先,闭环数据包括:
用户行为用户信息,CRM(客户关系)交易数据,服务器日志数据
以上三项数据可视为完整的数据流闭环. 当然,可以将不同业务场景中的数据进一步细分为更多的细节,一般的关键点基本上不超过这三个项目. 对于前端数据采集,闭环数据的前两项主要由客户端报告,而第三点主要由服务器记录并由客户端协助,因为事务请求实际上到达了服务器完成处理. 闭环. 用户行为数据还包括五个要素-时间(何时),地点(何处),人(谁),互动(方式)和互动内容(什么),与新闻的五个要素相似;与用户信息有关的某些企业需要授权用户敏感信息和隐私,因此用户信息由业务方案确定. 最基本的数据要求是唯一标识用户. CRM,交易数据和用户信息是相似的,并且特定的数据详细信息由业务方案确定. CRM基本数据要求是登录信息和成员相关信息. 交易数据包括交易时间,交易对象,交易内容,交易金额和交易状态.
3. 数据报告方法
在讨论数据之后,下一步就是知道如何获取我们真正需要的数据. 数据报告方法可以大致分为三类:
重点放在非埋点上. 视觉上的隐埋点实际上可以视为非隐埋点的派生. 视觉上隐藏的点将不在此处讨论. 主要比较是代码掩埋点和非掩埋点.
3.1代码嵌入点或Capture模式的嵌入点的缺点
对于数据产品:
依靠人类的经验和直观的判断力.
与业务相关的埋葬地点需要数据产品或业务产品的主观判断,而与技术相关的埋葬地点需要技术人员的主观判断. 通讯成本高
要确定数据产品所需的数据,有必要提出要求并与开发人员进行交流,并且数据人员对技术不是特别熟悉,并且有必要与开发人员澄清是否相关. 信息可以报告可行性. 有数据清理费用
随着业务的变化和变化,以前的主观判断所需的数据也将发生变化. 此时,需要手动清理以前管理的数据,清理工作量不小.
用于开发:
开发人员能耗
对于业务团队来说,它经常受到相关开发人员的批评. 开发技术人员不仅可以专注于技术,还需要分散精力来完成高度重复性和机械性的任务,例如掩埋点. 嵌入式代码具有侵入性,会对系统设计和代码可维护性产生负面影响
大多数与业务相关的数据点都需要手动掩埋,并且掩埋的代码必须与业务代码紧密结合. 即使行业中没有sdk,数据产品关注的特殊业务点也无法逃脱手工掩盖.
随着业务需求在不断的业务变化下发生变化,用于嵌入的相关代码也需要相应地进行更改. 进一步增加开发和代码维护成本. 容易出错,遗漏
由于人工管理的主观差异,放置位置的准确性难以控制,并且管理过程中存在成本高昂的问题,容易造成数据泄漏
当丢失或错误采集数据时,它必须再次经过开发过程和联机过程,这效率很低. 3.2无埋点的优势
与手动掩埋点相比,无需解释没有掩埋点的优点.
提高效率,数据更全面,按需提取并减少代码入侵. 四,微信小程序无埋点SDK程序4.1无埋点数据要求
双向监控逻辑图
清除图片地址标记
由于applet与Web服务不同,因此没有诸如js / css资源加载之类的事情. 因此,应更加注意初始化状态和小程序的执行的记录,捕获和报告. 图中的资源完整性检查对应于初始化的完成. 考试. 在线小程序中请求的域名必须是https协议,因此DNS劫持的可能性大大降低,甚至不太可能发生,并且从客户端监视DNS劫持的可行性很低(存在悖论),因此DNS劫持暂时不考虑捕获.
4.2开发微信小程序非嵌入式SDK的难点和要点
微信请求通过微信API统一完成. 请求模块已经被微信方封装,小应用程序的运行环境不是浏览器对象. 像Web应用程序一样难以重写和封装.
不能直接监视用户行为. 强大的可伸缩性需要适用于多种体系结构设计方案(小型程序). SDK必须是轻量级的. 每个小程序都有2M的限制,并且该小程序不支持将代码引入. npm软件包,因此sdk本身将占用2M的大小限制. 尽管该applet已分包了内部测试,但该功能尚未完全发布,并且作为SDK太大太大是不合理的. 采集大量数据,在不影响业务的情况下将性能损失降至最低(基本要求)
4.3微信小程序无埋点sdk设计
数据层设计:
数据层设计
清除数据层设计图像的地址标记
数据流向设计:
数据流移向图片的清晰地址标记
采集方式设计:
采集为图片设计清晰的地址戳的方法
访问方法:
在小程序初始化代码之前介绍sdk npm软件包代码. 当小程序打包代码时,将sdk代码导入项目,并在初始化后自动采集数据. 初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({
channel: 'channel',
env: config.IS_PRODUCION ? 'product': 'beta',
project: 'yourProjectName',
methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称
})
没有掩埋点和掩埋点的组合:
小程序的非嵌入式方法可以获取大量数据,并且基本上可以实现用户使用场景的高度还原. SDK管理的粒度是某种方法的执行. 当特殊业务关注的粒度小于SDK的粒度时,如果没有埋藏点,SDK将无法完全解决. 可以使用没有掩埋点和掩埋点的组合,因此我们的小程序不能使用. 掩埋点SDK还提供了API接口,用于手动掩埋点以改善数据的完整性并解决更多问题(请参阅数据的重要性).
第五,在没有掩埋点SDK的小程序中遇到的问题
除了解决微信小程序非嵌入式sdk开发中的上述困难和关键问题外,还遇到了一些新的问题.
SDK本身将对业务绩效产生一定影响. 数据被临时存储在applet的本地存储中,而当业务本身消耗更多性能时,将暴露经常存储和检索的applet的本地存储. 操作被卡住. 减少本地存储的存储/检索操作. 关闭页面时,仅未上载的数据存储在本地存储中. 完整的数据量巨大. 灰度联机时,遇到服务器过载和服务器可用性降低的问题. 随后控制报告的数据量,仅自动报告关键节点数据,并且可以在访问初始化期间通过目标配置报告其他以业务为中心的节点,以避免报告过多的冗余数据. 此外,应特别注意报告数据结构的设计. 结构目标是清楚,简洁并且方便数据检索(区分). 在初始阶段,我想对是否使用SDK进行在线灰度进行“切换”,以避免小程序回滚过程. 由于“开关”依赖于服务器接口控制,并且请求是异步的,因此这意味着初始化过程和小程序的启动必须等待,直到控制该开关的接口返回,否则“开关”等同于失败. . 考虑到SDK不会影响业务绩效,请丢弃“开关”,并尝试在SDK中进行捕获,以避免影响业务可用性.
借助通过报告获得的数据而无需掩埋点,该数据可用于将来解决许多问题. 有关数据的使用,请期待下一节“数据应用程序”.
参考文献:
[1] [美国]裴Ji,译者姚军等,“深入了解网站优化”,出版社: 机械工业出版社,出版时间: 2013-08
[2]张锡萌,“首席增长官”,出版社: 机械工业出版社,出版日期: 第一版(2017年11月6日)
汇总:记一次WEB数据采集程序开发经历——对付简单的动态加载
采集交流 • 优采云 发表了文章 • 0 个评论 • 535 次浏览 • 2020-08-30 06:21
自从学做网站账号批量注册机、图片批量下载器,开始接触HTTP合同,了解了基本的GET/POST恳求等知识,于是便开始着手开发一些小东西了。
WEB数据采集,很多人都在搞。据说搞WEB数据采集用JAVA会更方便,有很多现成的解释器可用。可以说WEB数据采集这块,是C++的弱项。我目前能想到的方式就是借助WinInet,这是一组关于Intelnet三大合同HTTP、FTP、Gopher的windowsAPI。这组API在MFC里有了封装,用上去更方便,#include 。目前用于开发非企业级的WEB数据采集器绰绰有余。我发觉这些个人级的WEB数据采集器,很多人都是用delphi开发,可能是delphi在网路这块要强点吧。
前几天在猪八戒威客网上见到一个悬赏200元的开发程序的任务。任务内容大约是这样的:开发一个程序,从一个类似于58同城的网咖急聘网上采集网吧信息。这个网站上全部是全国各地的网咖急聘信息,要求把这种网咖信息:网吧名、地区、联系人、电话、QQ采集到ACCESS数据库里。其实他的目的不言而喻,他要采集这些数据干嘛?无非是发广告呗,嘿嘿。闲话不多说,打开这个网站看。(敏感信息被我打了马赛克)
可以看下来,这些信息都只是文本,并不是图片。那就简单多了,直接从HTML里读下来不就完事了。用MFC的CInternetSession对象的OpenURL方式打开URL,返回CHttpFile表针,通过该表针调用Read方式把整个HTML页面文本全部读到缓冲区。查看缓冲区,搜索手机号1352298...,居然没搜到。搜索“乔先生”,搜到了。怎么回事?怎么没有手机号在HTML里?
用谷歌浏览器打开这个页面,右键查看源码如下:
发现联系人、邮箱、地址都有,手机号和QQ哪里竟然是空的。为什么是空的呢?我不停的刷新页面,思考着这个问题。突然,我发每次刷新,都是页面全部内容都下来了,手机号和QQ才紧跟其后下来。动态加载!手机号和QQ没有在静态HTML里,是后来加载的。
怎么办?抓包剖析!打开Fiddler,强烈推荐这个软件,专门用于抓HTTP合同的包。抓包后发觉,每次打开网页,除了页面元素下载,IE进行了四次恳求。
0、2、8、9号恳求,一个一个查看:
第一个GET恳求,很明显,是获取页面HTML的,从下边内容看,也确实是获取了HTML页面。这些内容也就相当于我用CInternetSession获取到的内容,手机号和QQ不在这上面的,不用看了。
第二个是POST恳求,从返回内容上来看,是获取评论的,没有我们要找的信息。
第三个是GET恳求,从返回内容上来看不知道是哪些,先略过。
第四个是POST恳求,从返回信息上来看,正是我们要的信息!原来动态加载是如此加载的。我们也用程序模拟这个POST不就行了?但是等等,注意这个POST的目标URL,最后是一段其实密文的东西。多抓几次瞧瞧,发现这段密文每次都不一样!难道是按照时间或Cookie哪些的算下来的?那样就比较麻烦了!仔细想想,这个POST递交了个“barID=3070",ID3070,这个ID号在HTML里是有的,它通过递交这个ID获取这个ID对应的网咖信息,那我们在HTML文件里搜索这个ID3070瞧瞧。
一搜还果然搜到了。太显著了,这是一段JS脚本,GetBarInfo这个函数也很显著了吧,注意旁边的URL,正是我们仍然想不通的那段密文!原来是这样!每次获取HTML页面后,里面都收录了不同的用于动态获取网咖信息的URL。再对这个URL用POST方法递交ID获取网咖信息。原来是如此简单。那就容易了,在我们写的程序里,用CInternetSession获取页面HTML内容后检索出这段URL和网咖ID,再用CHttpConnection对象模拟递交一个POST,就可以得到手机号和QQ号了。
可以说这个网站为了防爬虫爬取信息,还是做了一点动态加载的限制,但也很弱了点,直接在HTML上面曝露了。也是我先前一点HTML知识都不懂,搞了半天才发觉,如果是熟悉HTML和JS脚本的人,应该一下就发觉了吧。
看来网页这块,也得了解下,学习下,如果要继续做WEB数据采集的话。还有更多困局呢。 查看全部
记一次WEB数据采集程序开发经历——对付简单的动态加载
自从学做网站账号批量注册机、图片批量下载器,开始接触HTTP合同,了解了基本的GET/POST恳求等知识,于是便开始着手开发一些小东西了。
WEB数据采集,很多人都在搞。据说搞WEB数据采集用JAVA会更方便,有很多现成的解释器可用。可以说WEB数据采集这块,是C++的弱项。我目前能想到的方式就是借助WinInet,这是一组关于Intelnet三大合同HTTP、FTP、Gopher的windowsAPI。这组API在MFC里有了封装,用上去更方便,#include 。目前用于开发非企业级的WEB数据采集器绰绰有余。我发觉这些个人级的WEB数据采集器,很多人都是用delphi开发,可能是delphi在网路这块要强点吧。
前几天在猪八戒威客网上见到一个悬赏200元的开发程序的任务。任务内容大约是这样的:开发一个程序,从一个类似于58同城的网咖急聘网上采集网吧信息。这个网站上全部是全国各地的网咖急聘信息,要求把这种网咖信息:网吧名、地区、联系人、电话、QQ采集到ACCESS数据库里。其实他的目的不言而喻,他要采集这些数据干嘛?无非是发广告呗,嘿嘿。闲话不多说,打开这个网站看。(敏感信息被我打了马赛克)


可以看下来,这些信息都只是文本,并不是图片。那就简单多了,直接从HTML里读下来不就完事了。用MFC的CInternetSession对象的OpenURL方式打开URL,返回CHttpFile表针,通过该表针调用Read方式把整个HTML页面文本全部读到缓冲区。查看缓冲区,搜索手机号1352298...,居然没搜到。搜索“乔先生”,搜到了。怎么回事?怎么没有手机号在HTML里?
用谷歌浏览器打开这个页面,右键查看源码如下:

发现联系人、邮箱、地址都有,手机号和QQ哪里竟然是空的。为什么是空的呢?我不停的刷新页面,思考着这个问题。突然,我发每次刷新,都是页面全部内容都下来了,手机号和QQ才紧跟其后下来。动态加载!手机号和QQ没有在静态HTML里,是后来加载的。
怎么办?抓包剖析!打开Fiddler,强烈推荐这个软件,专门用于抓HTTP合同的包。抓包后发觉,每次打开网页,除了页面元素下载,IE进行了四次恳求。

0、2、8、9号恳求,一个一个查看:

第一个GET恳求,很明显,是获取页面HTML的,从下边内容看,也确实是获取了HTML页面。这些内容也就相当于我用CInternetSession获取到的内容,手机号和QQ不在这上面的,不用看了。

第二个是POST恳求,从返回内容上来看,是获取评论的,没有我们要找的信息。

第三个是GET恳求,从返回内容上来看不知道是哪些,先略过。

第四个是POST恳求,从返回信息上来看,正是我们要的信息!原来动态加载是如此加载的。我们也用程序模拟这个POST不就行了?但是等等,注意这个POST的目标URL,最后是一段其实密文的东西。多抓几次瞧瞧,发现这段密文每次都不一样!难道是按照时间或Cookie哪些的算下来的?那样就比较麻烦了!仔细想想,这个POST递交了个“barID=3070",ID3070,这个ID号在HTML里是有的,它通过递交这个ID获取这个ID对应的网咖信息,那我们在HTML文件里搜索这个ID3070瞧瞧。

一搜还果然搜到了。太显著了,这是一段JS脚本,GetBarInfo这个函数也很显著了吧,注意旁边的URL,正是我们仍然想不通的那段密文!原来是这样!每次获取HTML页面后,里面都收录了不同的用于动态获取网咖信息的URL。再对这个URL用POST方法递交ID获取网咖信息。原来是如此简单。那就容易了,在我们写的程序里,用CInternetSession获取页面HTML内容后检索出这段URL和网咖ID,再用CHttpConnection对象模拟递交一个POST,就可以得到手机号和QQ号了。
可以说这个网站为了防爬虫爬取信息,还是做了一点动态加载的限制,但也很弱了点,直接在HTML上面曝露了。也是我先前一点HTML知识都不懂,搞了半天才发觉,如果是熟悉HTML和JS脚本的人,应该一下就发觉了吧。
看来网页这块,也得了解下,学习下,如果要继续做WEB数据采集的话。还有更多困局呢。
小程序开发(一):使用scrapy爬虫采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2020-08-28 05:48
过完年回去,业余时间仍然在独立开发一个小程序。主要数据是8000+个视频和10000+篇文章,并且数据会每晚手动更新。
我会整理下整个开发过程中碰到的问题和一些细节问题,因为内容会比较多,我会分成三到四篇文章来进行,本文是该系列的第一篇文章,内容偏 python 爬虫。
本系列文章大致会介绍一下内容:
数据打算(python的scrapy框架)
接口打算(nodejs的hapijs框架)
小程序开发(mpvue以及小程序自带的组件等)
部署上线(小程序安全域名等配置以及爬虫/接口等线上布署维护)
数据获取
数据获取的方式有很多种,这次我们选择了爬虫的方法,当然写一个爬虫也可以用不同的语言,不同的形式。之前写过好多爬虫,这次我们选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
学习scrapy,最好的形式就是先阅读一遍文档(Scrapy 1.6 documentation),然后照着文档里的反例写一写,慢慢就熟悉了。里面有几个很重要的概念是必须要理解的:
Items
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和 数据库 字段对应,便于入库。
Spiders
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
pipelines
“After an item has been scraped by a spider, it is sent to the Item Pipeline which processes it through several components that are executed sequentially.”,pipelines也就是我们爬虫领到数据后要进行的处理操作,比如写入到文件,或者链接数据库,并且保存到数据库等等操作,都可以在这里进行操作。
Selectors
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的 html 文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
几个重要的部份,在里面进行了一些说明。
准备好环境(python3/scrapy等),我们就可以来写一个爬虫项目了。
爬取的内容来自于 这个网站。
创建项目
scrapy startproject jqhtml
修改items
添加爬虫
爬虫爬虫
编写pipeline 更改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
scrapy爬虫项目的布署
scrapy爬虫项目的布署,我们使用官方的scrapyd即可,使用方式也比较简单,在 服务器 上安装scrapyd而且启动即可,然后在本地项目中配置deploy的路径,本地安装scrapy-client,使用命令deploy即可布署到服务器。
scrapyd提供了一些api插口来查看项目爬虫情况,以及执行或则停止执行爬虫。
这样我们就很方便的调这种插口来管理我们的爬虫任务了。
注意点:
如何布署scrapyd到服务器怎么设置scrapyd为系统后台服务及系统启动项
NEXT
下一篇,我们会介绍而且使用太火的一个nodejs后台api库 - hapijs。完成小程序所须要的所有插口的开发,以及使用定时任务执行爬虫脚本。 查看全部
小程序开发(一):使用scrapy爬虫采集数据
过完年回去,业余时间仍然在独立开发一个小程序。主要数据是8000+个视频和10000+篇文章,并且数据会每晚手动更新。
我会整理下整个开发过程中碰到的问题和一些细节问题,因为内容会比较多,我会分成三到四篇文章来进行,本文是该系列的第一篇文章,内容偏 python 爬虫。
本系列文章大致会介绍一下内容:
数据打算(python的scrapy框架)
接口打算(nodejs的hapijs框架)
小程序开发(mpvue以及小程序自带的组件等)
部署上线(小程序安全域名等配置以及爬虫/接口等线上布署维护)
数据获取
数据获取的方式有很多种,这次我们选择了爬虫的方法,当然写一个爬虫也可以用不同的语言,不同的形式。之前写过好多爬虫,这次我们选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
学习scrapy,最好的形式就是先阅读一遍文档(Scrapy 1.6 documentation),然后照着文档里的反例写一写,慢慢就熟悉了。里面有几个很重要的概念是必须要理解的:
Items
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和 数据库 字段对应,便于入库。
Spiders
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
pipelines
“After an item has been scraped by a spider, it is sent to the Item Pipeline which processes it through several components that are executed sequentially.”,pipelines也就是我们爬虫领到数据后要进行的处理操作,比如写入到文件,或者链接数据库,并且保存到数据库等等操作,都可以在这里进行操作。
Selectors
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的 html 文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
几个重要的部份,在里面进行了一些说明。
准备好环境(python3/scrapy等),我们就可以来写一个爬虫项目了。
爬取的内容来自于 这个网站。
创建项目
scrapy startproject jqhtml
修改items
添加爬虫
爬虫爬虫
编写pipeline 更改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
scrapy爬虫项目的布署
scrapy爬虫项目的布署,我们使用官方的scrapyd即可,使用方式也比较简单,在 服务器 上安装scrapyd而且启动即可,然后在本地项目中配置deploy的路径,本地安装scrapy-client,使用命令deploy即可布署到服务器。
scrapyd提供了一些api插口来查看项目爬虫情况,以及执行或则停止执行爬虫。
这样我们就很方便的调这种插口来管理我们的爬虫任务了。
注意点:
如何布署scrapyd到服务器怎么设置scrapyd为系统后台服务及系统启动项
NEXT
下一篇,我们会介绍而且使用太火的一个nodejs后台api库 - hapijs。完成小程序所须要的所有插口的开发,以及使用定时任务执行爬虫脚本。
小程序开发解析:帝国cms采集图文教程(下)_重庆北碚区微信公众号小程序开发教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-27 19:16
前两讲我们分别介绍了帝国cms采集基本流程和帝国cms如何采集内容分页,最后这一讲主要介绍帝国cms采集过滤与替换,还有些窍门。
一、过滤
1、帝国cms采集过滤分为两种:
(1)“整体页面过滤正则”:
(2)“过滤广告正则”:
我们有些疑问,这两种过滤究竟有哪些区别?“整体页面过滤正则”是过滤整个网页的html代码。重庆北碚区陌陌小程序开发要多少钱,“过滤广告正则”是过滤文章内容,仅对文章内容([!--newstext--])起作用。
2、过滤实例:
过滤实例(1):
我们采集后发觉信息内容顶部多了行代码:“
过滤实例(2):
要过滤链接代码怎样办,注意“过滤广告正则”右边有堆代码:
鼠标先点击A,系统手动生成过滤链接代码“,,,”,这样就可以把采集后的内容链接过滤掉了。重庆北碚区陌陌有什么小程序开发,同理,如果想过滤其他html代码就点击相应的标签代码。
注意事项:当内容分页收录在内容([!--newstext--])里时,要过滤掉内容分页,否则会重复出现内容分页。重庆北碚区微信公众号小程序开发教程,
二、替换
1、帝国cms采集替换也分为两种:
(1)“整体页面替换”:
(2)“替换”:
他们两种区别:“整体页面替换”是替换整个网页的html代码。“替换”是替换文章标题和内容,仅对标题([!--title--])和([!--newstext--])起作用。 查看全部
小程序开发解析:帝国cms采集图文教程(下)_重庆北碚区微信公众号小程序开发教程
前两讲我们分别介绍了帝国cms采集基本流程和帝国cms如何采集内容分页,最后这一讲主要介绍帝国cms采集过滤与替换,还有些窍门。
一、过滤
1、帝国cms采集过滤分为两种:
(1)“整体页面过滤正则”:
(2)“过滤广告正则”:
我们有些疑问,这两种过滤究竟有哪些区别?“整体页面过滤正则”是过滤整个网页的html代码。重庆北碚区陌陌小程序开发要多少钱,“过滤广告正则”是过滤文章内容,仅对文章内容([!--newstext--])起作用。
2、过滤实例:
过滤实例(1):
我们采集后发觉信息内容顶部多了行代码:“
过滤实例(2):
要过滤链接代码怎样办,注意“过滤广告正则”右边有堆代码:
鼠标先点击A,系统手动生成过滤链接代码“,,,”,这样就可以把采集后的内容链接过滤掉了。重庆北碚区陌陌有什么小程序开发,同理,如果想过滤其他html代码就点击相应的标签代码。
注意事项:当内容分页收录在内容([!--newstext--])里时,要过滤掉内容分页,否则会重复出现内容分页。重庆北碚区微信公众号小程序开发教程,
二、替换
1、帝国cms采集替换也分为两种:
(1)“整体页面替换”:
(2)“替换”:
他们两种区别:“整体页面替换”是替换整个网页的html代码。“替换”是替换文章标题和内容,仅对标题([!--title--])和([!--newstext--])起作用。
如何避免网站被采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-08-27 12:47
2018-03-15
新网站 房源信息采集
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告清除...全部
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除 支持多页面文章内容手动抽取与合并 支持下一页手动浏览功能 支持直接递交表单 支持模拟递交表单 支持动作脚本 支持从一个页面中抽取多个数据表 支持数据的多种后期处理方法 数据直接步入数据库而不是文件中,因此与借助那些数据的网站程序或则桌面程序之间 没有任何耦合 支持数据库表结构完全自定义,充分利用现有系统 支持多个栏目的信息采集可用同一配置一对多处理 保证信息的完整性与准确性,绝不会出现乱码 支持所有主流数据库:MS SQL Server, Oracle, DB2, MySQL, Sybase, Interbase, MS Access等。 查看全部
如何避免网站被采集?
2018-03-15
新网站 房源信息采集
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告清除...全部
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除 支持多页面文章内容手动抽取与合并 支持下一页手动浏览功能 支持直接递交表单 支持模拟递交表单 支持动作脚本 支持从一个页面中抽取多个数据表 支持数据的多种后期处理方法 数据直接步入数据库而不是文件中,因此与借助那些数据的网站程序或则桌面程序之间 没有任何耦合 支持数据库表结构完全自定义,充分利用现有系统 支持多个栏目的信息采集可用同一配置一对多处理 保证信息的完整性与准确性,绝不会出现乱码 支持所有主流数据库:MS SQL Server, Oracle, DB2, MySQL, Sybase, Interbase, MS Access等。
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-03-27 05:06
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具,当然不是完整的抓包,抓包只是为了看返回的数据具体是什么,有没有加密信息。采集数据可以采集天猫等各大电商平台的商品图片、商品名称、产品信息和用户评价,返回原始数据到本地list文件,也可以作为爬虫工具来进行爬虫数据分析处理。按需抓取各平台销量排名前100的宝贝商品,并进行分析。
实现思路是这样的:1.定位销量排名前100的商品商品链接中,有一些商品是没有链接的,不容易访问,所以需要爬到其中的链接。2.爬虫爬取商品链接中的产品信息和用户评价中的对应评论3.按照有评论的分析其中的用户需求,设计页面导航4.将导航展现到页面上,以参考页面形式展现实现步骤:1.定位销量排名前100的商品链接1.登录电商平台,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。
2.出现以下界面表示找到了商品,但是还没有销量2.爬取商品链接中的产品信息1.打开天猫,并且登录一个账号,登录后,在商品列表页往下看到三个选项进行搜索,若没有可以不进行搜索。找到商品链接中的产品名称。2.爬取产品名称后,就会出现新页面,出现商品信息对应的产品图片,产品名称对应的产品信息和评价,在商品列表页往下看到商品详情页也有链接。
出现的都是你输入的产品信息出现的对应商品信息,在里面找到你想要分析的商品名称,然后进行爬取。如果找不到你想要的产品信息或者没找到就进行下一步3.爬取商品评价1.先打开,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。2.点击出现的产品详情页对应产品信息,在出现对应页面页面会出现商品链接中的产品名称和详情页对应的详情页的链接,如下图所示4.转到购物车页面,在购物车页面下,会出现查看商品信息和评价信息,点击下拉框,在出现的下拉框中按照下图框中所示跳转到商品详情页详情页有多个选项,右键你需要爬取的商品进行复制,左键点击的产品不进行浏览选择评价有多少,再点击想要爬取产品的详情页即可在python中将已经抓取到的数据整理成新的数据框1.点击新建数据框,会有以下内容links:表示本地查看本页浏览信息,id:表示数据框的编号,数据框中不需要再创建其他内容menu:表示页面,商品入口url:表示路径shop:页面网址,这里是天猫2.点击转化为数据框,会出现这个界面,在新数据框写入你要爬取的内容,包括商品名称,商品链接,产品图片3.点击生成数据列表,出现如下界面,根据你自。 查看全部
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具
文章采集程序自己写python爬虫爬数据做了一个python的抓包工具,当然不是完整的抓包,抓包只是为了看返回的数据具体是什么,有没有加密信息。采集数据可以采集天猫等各大电商平台的商品图片、商品名称、产品信息和用户评价,返回原始数据到本地list文件,也可以作为爬虫工具来进行爬虫数据分析处理。按需抓取各平台销量排名前100的宝贝商品,并进行分析。
实现思路是这样的:1.定位销量排名前100的商品商品链接中,有一些商品是没有链接的,不容易访问,所以需要爬到其中的链接。2.爬虫爬取商品链接中的产品信息和用户评价中的对应评论3.按照有评论的分析其中的用户需求,设计页面导航4.将导航展现到页面上,以参考页面形式展现实现步骤:1.定位销量排名前100的商品链接1.登录电商平台,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。
2.出现以下界面表示找到了商品,但是还没有销量2.爬取商品链接中的产品信息1.打开天猫,并且登录一个账号,登录后,在商品列表页往下看到三个选项进行搜索,若没有可以不进行搜索。找到商品链接中的产品名称。2.爬取产品名称后,就会出现新页面,出现商品信息对应的产品图片,产品名称对应的产品信息和评价,在商品列表页往下看到商品详情页也有链接。
出现的都是你输入的产品信息出现的对应商品信息,在里面找到你想要分析的商品名称,然后进行爬取。如果找不到你想要的产品信息或者没找到就进行下一步3.爬取商品评价1.先打开,点击搜索框右侧“商品详情页”按钮,然后输入你想爬取的商品名称,商品链接。2.点击出现的产品详情页对应产品信息,在出现对应页面页面会出现商品链接中的产品名称和详情页对应的详情页的链接,如下图所示4.转到购物车页面,在购物车页面下,会出现查看商品信息和评价信息,点击下拉框,在出现的下拉框中按照下图框中所示跳转到商品详情页详情页有多个选项,右键你需要爬取的商品进行复制,左键点击的产品不进行浏览选择评价有多少,再点击想要爬取产品的详情页即可在python中将已经抓取到的数据整理成新的数据框1.点击新建数据框,会有以下内容links:表示本地查看本页浏览信息,id:表示数据框的编号,数据框中不需要再创建其他内容menu:表示页面,商品入口url:表示路径shop:页面网址,这里是天猫2.点击转化为数据框,会出现这个界面,在新数据框写入你要爬取的内容,包括商品名称,商品链接,产品图片3.点击生成数据列表,出现如下界面,根据你自。
微信公众号文章采集系统打包成虚拟机,镜像种子下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-03-24 05:28
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源。
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0启动规则可以作为模块开发。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此需要先打开anyproxy,然后才能在端口8001上成功访问该请求。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作Web服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不是太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,可模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android仿真器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是在虚拟机中不可能安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机不能进行二次虚拟化,阿里云Windows服务器不能安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创的WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012) 查看全部
微信公众号文章采集系统打包成虚拟机,镜像种子下载
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源。
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0启动规则可以作为模块开发。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此需要先打开anyproxy,然后才能在端口8001上成功访问该请求。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作Web服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不是太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,可模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android仿真器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是在虚拟机中不可能安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机不能进行二次虚拟化,阿里云Windows服务器不能安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创的WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012)
计算机科学入门学习最好的教材还是《深入浅出计算机》
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-03-23 23:01
文章采集程序basefoundryfinder/pipenvpipeline个人看法:里面的代码都读下来理解了(有需要结合代码一起学习),学习曲线很陡峭,把不同版本代码用ide搞起来理解起来很方便,代码思路很清晰,写的人技术水平很强。这种微博爬虫系统是要应用在实际场景中的。不想着思考如何优化系统,不如先认真搞一个,可以跟自己的业务需求结合起来,那样前后端可以不一起做了,后端把业务整理一下改写成函数,只保留basefoundryfinder/pipenvpipeline的代码,前端连接数据库(多版本实时汇总)或者hbase(版本历史)。以下是文章的pdf。
其实想要学习python还是比较快的,但是每个人都有每个人的方法,记得关注我,目前在我的公众号上分享一些python的学习文章,欢迎关注交流我们知道计算机科学入门学习最好的教材还是《深入浅出计算机》,其他任何一本教材要么晦涩难懂,要么速度慢。而本节课程中zipcode的讲师将推荐给我们一本非常经典而且最适合初学者的学习教材,并且亲自实践它,保证我们可以更快的掌握编程。
有学员会问:我想像zipcode的讲师那样,一步一步的完成我们的学习过程。确实是这样的,而且如果你做到了就有可能发现,学习编程不再需要有本教材那么晦涩,也可以一点一点的在实践中领悟编程之道。不过zipcode的讲师也提到过:你要掌握的是编程之道,本质还是编程基础:数据结构,算法,计算机网络等。除此之外,掌握一些框架,了解一些编程思想和编程方法,完成一个你想象中的小项目,可能更有助于提高你的编程水平。
这也会让你在今后提高编程水平的过程中更有优势。下面我将按照我自己的理解,结合zipcode的讲师分享,先放一个视频示例:在看完整节课后,你能对python有一个比较好的入门和掌握。并且看完整节课后,你还有如下几个反馈和收获:视频:【zipcode讲师分享:如何零基础学python|titaniumpay】ppt:【zipcode讲师分享:如何零基础学python|titaniumpay】zipcode在你的编程之路上就像老师手中的锥子,你需要一段时间来进行反复锤炼才能进步。
而这段时间更像学编程进步的一个比较漫长的过程,但这个过程是必不可少的。下面回到问题,如何零基础入门python?我们放一个实践后的视频:这个实践python代码对初学者的学习而言,难度不高,我将他归纳为三步,分别是:一:需要对python有一个简单的了解,简单了解一下python的历史和它的特点,并且对其有一个整体的认识。
第二:更深入的掌握python的语法,虽然我们学习语法经常会一个循环操作写好几遍,但是当我们写的时候可以让语法。 查看全部
计算机科学入门学习最好的教材还是《深入浅出计算机》
文章采集程序basefoundryfinder/pipenvpipeline个人看法:里面的代码都读下来理解了(有需要结合代码一起学习),学习曲线很陡峭,把不同版本代码用ide搞起来理解起来很方便,代码思路很清晰,写的人技术水平很强。这种微博爬虫系统是要应用在实际场景中的。不想着思考如何优化系统,不如先认真搞一个,可以跟自己的业务需求结合起来,那样前后端可以不一起做了,后端把业务整理一下改写成函数,只保留basefoundryfinder/pipenvpipeline的代码,前端连接数据库(多版本实时汇总)或者hbase(版本历史)。以下是文章的pdf。
其实想要学习python还是比较快的,但是每个人都有每个人的方法,记得关注我,目前在我的公众号上分享一些python的学习文章,欢迎关注交流我们知道计算机科学入门学习最好的教材还是《深入浅出计算机》,其他任何一本教材要么晦涩难懂,要么速度慢。而本节课程中zipcode的讲师将推荐给我们一本非常经典而且最适合初学者的学习教材,并且亲自实践它,保证我们可以更快的掌握编程。
有学员会问:我想像zipcode的讲师那样,一步一步的完成我们的学习过程。确实是这样的,而且如果你做到了就有可能发现,学习编程不再需要有本教材那么晦涩,也可以一点一点的在实践中领悟编程之道。不过zipcode的讲师也提到过:你要掌握的是编程之道,本质还是编程基础:数据结构,算法,计算机网络等。除此之外,掌握一些框架,了解一些编程思想和编程方法,完成一个你想象中的小项目,可能更有助于提高你的编程水平。
这也会让你在今后提高编程水平的过程中更有优势。下面我将按照我自己的理解,结合zipcode的讲师分享,先放一个视频示例:在看完整节课后,你能对python有一个比较好的入门和掌握。并且看完整节课后,你还有如下几个反馈和收获:视频:【zipcode讲师分享:如何零基础学python|titaniumpay】ppt:【zipcode讲师分享:如何零基础学python|titaniumpay】zipcode在你的编程之路上就像老师手中的锥子,你需要一段时间来进行反复锤炼才能进步。
而这段时间更像学编程进步的一个比较漫长的过程,但这个过程是必不可少的。下面回到问题,如何零基础入门python?我们放一个实践后的视频:这个实践python代码对初学者的学习而言,难度不高,我将他归纳为三步,分别是:一:需要对python有一个简单的了解,简单了解一下python的历史和它的特点,并且对其有一个整体的认识。
第二:更深入的掌握python的语法,虽然我们学习语法经常会一个循环操作写好几遍,但是当我们写的时候可以让语法。
文章采集程序采集商品详情页产品图片,添加数据过滤条件
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-03-23 07:01
文章采集程序采集商品详情页产品图片,比如图片中的一张商品图,每个产品图片只采集5张,实现30个商品图片同时采集。请求数据后,修改采集配置,添加数据过滤条件,再采集数据,步骤非常繁琐,为了大家方便,采用最优方案就是把单个采集过程拆分下来,所有步骤分解成多个步骤,这样大家统一编写代码,统一调用,后续很少添加新功能。
可能是因为采集时间较长,导致爬虫返回的数据有500多条,大家估计经常会有个疑问:这些数据是从哪里返回到爬虫手中的?为了更清楚的说明数据过滤条件是如何工作的,我先贴下图片,找到爬虫。大家看到的图片是最原始数据,新图片还有,大家可以想想,采集的数据都是按照某个条件采集返回的,那么我们有三个条件,
1)最近一天,
2)下一个元素是否属于产品标题
3)是否有手机链接,那么我们先把每天爬取10个商品按照30个商品来分析,每一个商品可能有多条数据,大家可以对照图片中的商品列表看一下数据,每天采集10个商品,30个数据就有1000条数据。30个商品中,有大量的以商品标题,类目名称命名的数据,我们看到条数最多的一个是厨具,有6个商品标题,3个商品类目,其实也可以分解成6个商品标题,但实际爬取数据中,一般只有8个。
每个数据点的条数随着你爬取的商品不同而不同,是因为商品标题字符长度变化引起的,每个商品标题有1000条数据,但实际爬取数据中一般不会超过这个数量,所以爬取一个商品最多能采集10条数据。之所以说总量有2500条数据是因为有10条链接到了baidu手机搜索页面。我们按照商品序号排序,显示出你可能感兴趣的商品,数据都采集好了,下面我们实验一下,看看是否可以给图片过滤条件添加效果。
我们手机搜索a-b东西,想看下他们的价格,平均价格是35元,在图片中,先按照类目名称排序,搜索"普通3c",排名靠前的结果为:图片效果:实验结果:我们看到图片中"office笔记本软件"这一列的价格大概是11元左右,所以过滤条件添加效果可以。设置过滤条件:总共15条,条数太多了,1.5万多条数据我们全量采集下来要40多天,对于每天爬取10个商品,30个数据,返回500多条数据,已经足够我们爬取30天,就像这样。
因为是经常翻页,我们使用vlookup公式匹配不同的时间段,比如月份,月份随机择时采集,可以用来采集20天左右的数据,实验结果:我们数据爬取完毕,通过vlookup匹配到十天内的数据,然后添加过滤条件返回就可以获取一整天的数据了。总结:大家可以想想看,条件选择性最好的就是年份,例如,搜索2012年,图片那么多,一。 查看全部
文章采集程序采集商品详情页产品图片,添加数据过滤条件
文章采集程序采集商品详情页产品图片,比如图片中的一张商品图,每个产品图片只采集5张,实现30个商品图片同时采集。请求数据后,修改采集配置,添加数据过滤条件,再采集数据,步骤非常繁琐,为了大家方便,采用最优方案就是把单个采集过程拆分下来,所有步骤分解成多个步骤,这样大家统一编写代码,统一调用,后续很少添加新功能。
可能是因为采集时间较长,导致爬虫返回的数据有500多条,大家估计经常会有个疑问:这些数据是从哪里返回到爬虫手中的?为了更清楚的说明数据过滤条件是如何工作的,我先贴下图片,找到爬虫。大家看到的图片是最原始数据,新图片还有,大家可以想想,采集的数据都是按照某个条件采集返回的,那么我们有三个条件,
1)最近一天,
2)下一个元素是否属于产品标题
3)是否有手机链接,那么我们先把每天爬取10个商品按照30个商品来分析,每一个商品可能有多条数据,大家可以对照图片中的商品列表看一下数据,每天采集10个商品,30个数据就有1000条数据。30个商品中,有大量的以商品标题,类目名称命名的数据,我们看到条数最多的一个是厨具,有6个商品标题,3个商品类目,其实也可以分解成6个商品标题,但实际爬取数据中,一般只有8个。
每个数据点的条数随着你爬取的商品不同而不同,是因为商品标题字符长度变化引起的,每个商品标题有1000条数据,但实际爬取数据中一般不会超过这个数量,所以爬取一个商品最多能采集10条数据。之所以说总量有2500条数据是因为有10条链接到了baidu手机搜索页面。我们按照商品序号排序,显示出你可能感兴趣的商品,数据都采集好了,下面我们实验一下,看看是否可以给图片过滤条件添加效果。
我们手机搜索a-b东西,想看下他们的价格,平均价格是35元,在图片中,先按照类目名称排序,搜索"普通3c",排名靠前的结果为:图片效果:实验结果:我们看到图片中"office笔记本软件"这一列的价格大概是11元左右,所以过滤条件添加效果可以。设置过滤条件:总共15条,条数太多了,1.5万多条数据我们全量采集下来要40多天,对于每天爬取10个商品,30个数据,返回500多条数据,已经足够我们爬取30天,就像这样。
因为是经常翻页,我们使用vlookup公式匹配不同的时间段,比如月份,月份随机择时采集,可以用来采集20天左右的数据,实验结果:我们数据爬取完毕,通过vlookup匹配到十天内的数据,然后添加过滤条件返回就可以获取一整天的数据了。总结:大家可以想想看,条件选择性最好的就是年份,例如,搜索2012年,图片那么多,一。
阿里云api函数库easyop读取图文->打印输出图文
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-03-22 00:02
文章采集程序由阿里云api函数库、easyop提供技术支持。自动完成文章转换为一张打印名单(txt格式):[wrap_fail_txt](--difficult_txt/)、[create_fail_txt](spec/fail_txt.py)。感谢我们团队的david(网站代码研发工程师)、justin(网站架构师)、nadine(ga助理),这些工程师专注于领域。
有需要的大家可以私信我me,我邀请他们进ads,敬请期待~下面结合我们的实际需求做一些分析。需求简单来说就是增加一个功能,可以智能完成图文转换成txt格式。图文转换为txt格式有很多种方式,但是大致需要三步。解析图文->读取图文->打印输出图文其中图文解析、读取图文两步涉及到java、html、c++两门基础的计算机语言。
java和html有兼容,使用什么语言和平台不重要。html转成css、canvas等技术肯定有,有需要的可以私信我或者评论留言。图文可以包含静态页面和静态资源两种形式,静态页面用java解析服务器,静态资源用c++来解析服务器。使用htmllayout是比较推荐的,这样效率更高,完整的网站可以逐渐加入图文解析和打印的功能,形成一个长期稳定可用的生态圈。
文件存储也可以用redis等不错的数据库来解决。我们本身业务经常会使用大量的静态页面,有了代码,图文可以用easyop的开源api完成,admin可以自定义图文的格式。查看方式很简单,在阿里云上获取链接即可使用:[wrap_fail_txt]([easyop/fail_txt.py](-wrapped/))不必一定把default转换成图文,只要图文解析工作用到的,程序都会自动加载easyop的接口请求。
当然有需要我们可以再提供一个模版文件。或者在线使用:[github/wrap_fail_txt](-wrapped/admin)。 查看全部
阿里云api函数库easyop读取图文->打印输出图文
文章采集程序由阿里云api函数库、easyop提供技术支持。自动完成文章转换为一张打印名单(txt格式):[wrap_fail_txt](--difficult_txt/)、[create_fail_txt](spec/fail_txt.py)。感谢我们团队的david(网站代码研发工程师)、justin(网站架构师)、nadine(ga助理),这些工程师专注于领域。
有需要的大家可以私信我me,我邀请他们进ads,敬请期待~下面结合我们的实际需求做一些分析。需求简单来说就是增加一个功能,可以智能完成图文转换成txt格式。图文转换为txt格式有很多种方式,但是大致需要三步。解析图文->读取图文->打印输出图文其中图文解析、读取图文两步涉及到java、html、c++两门基础的计算机语言。
java和html有兼容,使用什么语言和平台不重要。html转成css、canvas等技术肯定有,有需要的可以私信我或者评论留言。图文可以包含静态页面和静态资源两种形式,静态页面用java解析服务器,静态资源用c++来解析服务器。使用htmllayout是比较推荐的,这样效率更高,完整的网站可以逐渐加入图文解析和打印的功能,形成一个长期稳定可用的生态圈。
文件存储也可以用redis等不错的数据库来解决。我们本身业务经常会使用大量的静态页面,有了代码,图文可以用easyop的开源api完成,admin可以自定义图文的格式。查看方式很简单,在阿里云上获取链接即可使用:[wrap_fail_txt]([easyop/fail_txt.py](-wrapped/))不必一定把default转换成图文,只要图文解析工作用到的,程序都会自动加载easyop的接口请求。
当然有需要我们可以再提供一个模版文件。或者在线使用:[github/wrap_fail_txt](-wrapped/admin)。
文章采集程序支持多种用户级网络抓取程序,如何爬取豆瓣
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-03-16 13:02
文章采集程序支持多种用户级网络抓取程序,例如:varroute=window.getopensocketaddress("address:"+url);varserver=newserver(route,"/api/username",string(server.getentry().username));loaddataboard(server,dataworker.getdataworkerdatafromurl(url))等。
我是lllloker.me给题主使用这个实现restfulapi的指导我还在学习中,在此和大家一起交流共同提高。写在前面:以下是我的代码,我将部分代码以注释的形式写在这里以便理解。虽然并不适合所有人,如果看不懂可以私信我发邮件。
可以试试加入一个blogdigger的采集任务中,你可以:实现一个基于c#的采集平台如何爬取豆瓣电影lllloker|全新用户级网络抓取工具让scrapy,ror,mongodb定制采集方案服务采集,无编程、无java、python中间代码、无图片所有步骤全部自动化代码整合成一个新项目,适合初学者、机器学习及数据挖掘爱好者、码农采集类实时云监控采集,分析采集结果,提供各种报表采集原理:通过封装api,用户可以通过简单的定制化api对网页中的各个部分进行采集,形成一个采集工具包。
采集效率:低中高,自定义采集规则、csv格式文件、group、相关的结果自动生成等几种情况保存回放任务服务端java、jsp开发,采集效率高、人性化、体验好!。 查看全部
文章采集程序支持多种用户级网络抓取程序,如何爬取豆瓣
文章采集程序支持多种用户级网络抓取程序,例如:varroute=window.getopensocketaddress("address:"+url);varserver=newserver(route,"/api/username",string(server.getentry().username));loaddataboard(server,dataworker.getdataworkerdatafromurl(url))等。
我是lllloker.me给题主使用这个实现restfulapi的指导我还在学习中,在此和大家一起交流共同提高。写在前面:以下是我的代码,我将部分代码以注释的形式写在这里以便理解。虽然并不适合所有人,如果看不懂可以私信我发邮件。
可以试试加入一个blogdigger的采集任务中,你可以:实现一个基于c#的采集平台如何爬取豆瓣电影lllloker|全新用户级网络抓取工具让scrapy,ror,mongodb定制采集方案服务采集,无编程、无java、python中间代码、无图片所有步骤全部自动化代码整合成一个新项目,适合初学者、机器学习及数据挖掘爱好者、码农采集类实时云监控采集,分析采集结果,提供各种报表采集原理:通过封装api,用户可以通过简单的定制化api对网页中的各个部分进行采集,形成一个采集工具包。
采集效率:低中高,自定义采集规则、csv格式文件、group、相关的结果自动生成等几种情况保存回放任务服务端java、jsp开发,采集效率高、人性化、体验好!。
爬虫构造工具已经有人写了.id=118105548个反爬虫工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-02-25 12:06
文章采集程序采集方式为beats爬虫,请找高质量的ftp站点进行采集,
url构造工具已经有人写了.id=118105548个反爬虫工具_python
爬虫爬到了一些有用的内容,
可以参考/
正则表达式是非常好的利器。
这里有很多经典代码的整理列表,希望对你有用!最好写个爬虫就行,很容易的,等你学会代码你就知道是怎么实现的了。我最近在写一个小网站的,欢迎参观我的网站,
这里有经典、经验的爬虫代码:thutao/bulid-spider·github这里也有很多博客是非常好的技术文章,感兴趣的可以看看(爬虫)!对新手来说这是最简单的一类爬虫了,做个爬虫你只需要掌握常用算法、分布式架构、缓存、数据存储等方面就够了。但其中涉及到了很多真正技术上的问题,比如经典的python网络爬虫,具体应用面还是比较窄的,即无法从每一个真实的网站里找到点有用的信息,这类文章我想也更适合专攻编程的工程师看看。
爬虫,我想是很多工程师工作过程中都想要涉猎,想要钻研的技术。不过实际上,有一些自己做过爬虫的人,最终爬虫依然只是一个零件,得用别的东西补上。为此本人整理一些常用的爬虫技术总结,分享给各位,可以对大家有所帮助。补充知识:选择器-id如何获取网页内容?基本功能-获取链接、数据库、路由、返回的html内容复杂爬虫-开发及部署首先看看最基本的爬虫技术(主要通过爬虫工具)的技术要求。
1.完整的web应用就足够爬虫工具实现了2.爬虫从请求到返回信息基本功能3.爬虫读取文本4.爬虫缓存5.数据存储与分析看起来已经把最基本的要求都满足了,剩下需要解决的就是爬虫部署问题了。工欲善其事必先利其器,同理,要想让爬虫技术为我所用,就需要在程序中集成对应的解决方案,尤其是要可重复利用的解决方案。
第一时间掌握最新技术的必须人人都会爬虫技术,更需要了解开发框架及流行的爬虫开发工具,以及业界专业性的程序员作为程序员经常熬夜加班也正常,开发时间对程序员来说是个很大的考验。我这里有一些关于爬虫技术的解决方案,希望对大家有所帮助。全框架爬虫如果你精通程序化编程语言(python,ruby,java,scala,...),对整个程序开发生态有一定基础,或者完全是从零基础从头开始学的话,那么完全可以自己动手写一个完整的爬虫项目。
当然,前提是你爬虫技术必须是非常了得,爬虫中用到的东西基本都熟悉。完整的爬虫项目可以看看以下的示例代码:看到没有,一段代码解决你开发中。 查看全部
爬虫构造工具已经有人写了.id=118105548个反爬虫工具
文章采集程序采集方式为beats爬虫,请找高质量的ftp站点进行采集,
url构造工具已经有人写了.id=118105548个反爬虫工具_python
爬虫爬到了一些有用的内容,
可以参考/
正则表达式是非常好的利器。
这里有很多经典代码的整理列表,希望对你有用!最好写个爬虫就行,很容易的,等你学会代码你就知道是怎么实现的了。我最近在写一个小网站的,欢迎参观我的网站,
这里有经典、经验的爬虫代码:thutao/bulid-spider·github这里也有很多博客是非常好的技术文章,感兴趣的可以看看(爬虫)!对新手来说这是最简单的一类爬虫了,做个爬虫你只需要掌握常用算法、分布式架构、缓存、数据存储等方面就够了。但其中涉及到了很多真正技术上的问题,比如经典的python网络爬虫,具体应用面还是比较窄的,即无法从每一个真实的网站里找到点有用的信息,这类文章我想也更适合专攻编程的工程师看看。
爬虫,我想是很多工程师工作过程中都想要涉猎,想要钻研的技术。不过实际上,有一些自己做过爬虫的人,最终爬虫依然只是一个零件,得用别的东西补上。为此本人整理一些常用的爬虫技术总结,分享给各位,可以对大家有所帮助。补充知识:选择器-id如何获取网页内容?基本功能-获取链接、数据库、路由、返回的html内容复杂爬虫-开发及部署首先看看最基本的爬虫技术(主要通过爬虫工具)的技术要求。
1.完整的web应用就足够爬虫工具实现了2.爬虫从请求到返回信息基本功能3.爬虫读取文本4.爬虫缓存5.数据存储与分析看起来已经把最基本的要求都满足了,剩下需要解决的就是爬虫部署问题了。工欲善其事必先利其器,同理,要想让爬虫技术为我所用,就需要在程序中集成对应的解决方案,尤其是要可重复利用的解决方案。
第一时间掌握最新技术的必须人人都会爬虫技术,更需要了解开发框架及流行的爬虫开发工具,以及业界专业性的程序员作为程序员经常熬夜加班也正常,开发时间对程序员来说是个很大的考验。我这里有一些关于爬虫技术的解决方案,希望对大家有所帮助。全框架爬虫如果你精通程序化编程语言(python,ruby,java,scala,...),对整个程序开发生态有一定基础,或者完全是从零基础从头开始学的话,那么完全可以自己动手写一个完整的爬虫项目。
当然,前提是你爬虫技术必须是非常了得,爬虫中用到的东西基本都熟悉。完整的爬虫项目可以看看以下的示例代码:看到没有,一段代码解决你开发中。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-02-17 10:03
文章采集程序源码本文并非使用java文本文件来采集百度首页,而是采集转载内容。首先需要知道文章全部内容,并对文章作一个解析。读取传入的json字符串(prettify.json),其中“url”为采集txt格式字符串所传入的url代码,headers为需要采集的httpuseragent,encoding为采集用户明文地址时,传入传统的字符串,解析流程如下:读取前三个字符串window.open().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json")可用json连接request来读取json字符串注意到,传入json的,是json格式字符串,于是便需要解析字符串,读取传入json格式的所有字符串prettify.json().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"),prettify.json().stream(full.stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"))注意:创建对象在full.stream()中可以创建对象我们可以先将json文件复制再解析json格式代码:用函数自动编译获取文件内容构建变量:apikey变量,变量名称为url。
#分析采集文章,构建变量apikey=object.keys(json).upper()+""+object.keys(json.parse(apikey))#url与json代码块结合foriinapikey:json.dump([prettify.json(i).data("a=''>';a=''>';a=''>';a=''>';a=''>';a=''>';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
文章采集程序源码本文并非使用java文本文件来采集百度首页,而是采集转载内容。首先需要知道文章全部内容,并对文章作一个解析。读取传入的json字符串(prettify.json),其中“url”为采集txt格式字符串所传入的url代码,headers为需要采集的httpuseragent,encoding为采集用户明文地址时,传入传统的字符串,解析流程如下:读取前三个字符串window.open().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json")可用json连接request来读取json字符串注意到,传入json的,是json格式字符串,于是便需要解析字符串,读取传入json格式的所有字符串prettify.json().stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"),prettify.json().stream(full.stream(r"c:\users\administrator\appdata\local\files\public\wordpress\content.json"))注意:创建对象在full.stream()中可以创建对象我们可以先将json文件复制再解析json格式代码:用函数自动编译获取文件内容构建变量:apikey变量,变量名称为url。
#分析采集文章,构建变量apikey=object.keys(json).upper()+""+object.keys(json.parse(apikey))#url与json代码块结合foriinapikey:json.dump([prettify.json(i).data("a=''>';a=''>';a=''>';a=''>';a=''>';a=''>';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a='';a。
文章采集程序中,我们建议每个站点建立(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-02-14 08:02
文章采集程序中,我们建议每个站点建立fullurl='',''代表所有文章。第一篇文章的fullurl=''的主要原因是第一篇文章的fullurl会被系统推送给所有文章观看的用户,所以在数据统计的时候这种页面会被归到第一篇文章,''表示的是推送内容url,是推送数量。默认的跳转链接形式是author:(username,author)site:(username,domain)posts:(username,post_name)fullurl列表中有1/9,''代表的是1/9表示最新,''代表的是前面有文章''内部跳转链接url列表中只有''内部跳转链接'.',url不代表该文章。
后文章不会推送到fullurl下。'/->'代表站点。"/",fullurl列表中的第一个则代表第一篇文章。'-in"/'是inurl列表,fullurl下其它域名内容不会推送。'-.'为域名中的原网址页面,但是不会推送到fullurl中。'/'代表页面内的href,但是不会推送到fullurl中。(不推送的网址列表)'-.'代表网址中的页面id,但是不会推送到fullurl中。
'-.href'为页面首页id。'-./'代表页面页面地址(公网地址),不会推送到fullurl中。(fullurl\.)\.'代表的是第一篇文章中的域名地址(inurl\.)\.'代表的是post中所给网址中的domain'.'代表的是已经修改fullurl后得到的对应网址'-in''代表的是跳转链接中不包含'.''/'代表的是跳转的url'-http'的形式'.'代表得到的网址形式''代表得到的domain'.''-in'-'为跳转网址,'.'为跳转网址列表'.'-up'和'-http'为网址的跳转函数'-in'/'为url的跳转函数'http'http'-normal':'/','.'为跳转域名中不包含‘.','-'为跳转地址'.''http'normal':'','-'为跳转域名中不包含'.''http'-normal':'*','.'为跳转域名中不包含'.''-up'和'*'为跳转地址,'.'为跳转地址列表'-in'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.'''http'-proxy':'/''http'-proxy':'''-up'和'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''-in'*'为跳转地址,'*'为跳转域名中不包含'.''-up'和'*'为跳转地址,'*'为跳转域名。 查看全部
文章采集程序中,我们建议每个站点建立(一)
文章采集程序中,我们建议每个站点建立fullurl='',''代表所有文章。第一篇文章的fullurl=''的主要原因是第一篇文章的fullurl会被系统推送给所有文章观看的用户,所以在数据统计的时候这种页面会被归到第一篇文章,''表示的是推送内容url,是推送数量。默认的跳转链接形式是author:(username,author)site:(username,domain)posts:(username,post_name)fullurl列表中有1/9,''代表的是1/9表示最新,''代表的是前面有文章''内部跳转链接url列表中只有''内部跳转链接'.',url不代表该文章。
后文章不会推送到fullurl下。'/->'代表站点。"/",fullurl列表中的第一个则代表第一篇文章。'-in"/'是inurl列表,fullurl下其它域名内容不会推送。'-.'为域名中的原网址页面,但是不会推送到fullurl中。'/'代表页面内的href,但是不会推送到fullurl中。(不推送的网址列表)'-.'代表网址中的页面id,但是不会推送到fullurl中。
'-.href'为页面首页id。'-./'代表页面页面地址(公网地址),不会推送到fullurl中。(fullurl\.)\.'代表的是第一篇文章中的域名地址(inurl\.)\.'代表的是post中所给网址中的domain'.'代表的是已经修改fullurl后得到的对应网址'-in''代表的是跳转链接中不包含'.''/'代表的是跳转的url'-http'的形式'.'代表得到的网址形式''代表得到的domain'.''-in'-'为跳转网址,'.'为跳转网址列表'.'-up'和'-http'为网址的跳转函数'-in'/'为url的跳转函数'http'http'-normal':'/','.'为跳转域名中不包含‘.','-'为跳转地址'.''http'normal':'','-'为跳转域名中不包含'.''http'-normal':'*','.'为跳转域名中不包含'.''-up'和'*'为跳转地址,'.'为跳转地址列表'-in'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.'''http'-proxy':'/''http'-proxy':'''-up'和'*'为跳转地址,'*'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''.'为跳转域名中不包含'.''-in'*'为跳转地址,'*'为跳转域名中不包含'.''-up'和'*'为跳转地址,'*'为跳转域名。
文章采集程序如何实现异步接收消息的协议?
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-02-06 10:05
文章采集程序在前段时间已经有了一个比较成熟的实现方案,不过对于java程序员来说依然不是一个很易学的程序。这一点上从数据采集方面来说,java的语言相对于c++、python而言要难一些。之前我对django框架以及java的selenium模块有一定了解,就是一个tssdk,功能相当强大,主要集中在自动化测试领域。
不过这一次在日常工作中还是经常被用到一些数据库在线监控方面的业务场景,需要在数据库中存取历史数据、历史库存等信息。首先为了实现以上功能,我目前自己的处理方式就是采用activemq协议。这里的activemq一定不要理解成soa的activemq。在以前的演示中我们用到了一个中间件,zookeeper协议。那么,上面的功能,我该如何去实现呢?很简单,只需要实现一个原生java程序即可。初步思路:。
1、建立java容器
2、实现beanpostprocessor异步接收消息,
3、获取spring事务管理方式
4、实现自动化测试
一、容器如果我们创建一个容器,可以直接创建jdk1.8内置的orm框架:configuration。这里我建立了一个集成了activemq的容器。configuration.py:那么,一个java程序如何实现呢?接下来按照刚才的思路进行实现即可。
二、实现beanpostprocessor异步接收消息,并将其发送出去首先,我们创建一个spring容器,它的内部有个beanpostprocessor类。那么我们就可以用这个类,创建一个java对象,调用定义beanpostprocessor的方法。returnnewproducer().synchronized(true){threadthread=thread.currentthread();thread.start();//是否还是先执行beanpostprocessor方法thread.start(beanpostprocessor.getbean("beanpostprocessor"));}这段代码基本上没有改动。
那么我们就需要创建一个自定义的producer对象,这里我用了xml文件来实现,所以这里说说我自己怎么去操作xml文件。我自己在编写代码时遇到了比较棘手的地方,就是如何注册spring的beanpostprocessor类。在做开发的时候遇到类似的问题,我都是从容器生命周期中讲解,下面我来分析一下。在容器生。 查看全部
文章采集程序如何实现异步接收消息的协议?
文章采集程序在前段时间已经有了一个比较成熟的实现方案,不过对于java程序员来说依然不是一个很易学的程序。这一点上从数据采集方面来说,java的语言相对于c++、python而言要难一些。之前我对django框架以及java的selenium模块有一定了解,就是一个tssdk,功能相当强大,主要集中在自动化测试领域。
不过这一次在日常工作中还是经常被用到一些数据库在线监控方面的业务场景,需要在数据库中存取历史数据、历史库存等信息。首先为了实现以上功能,我目前自己的处理方式就是采用activemq协议。这里的activemq一定不要理解成soa的activemq。在以前的演示中我们用到了一个中间件,zookeeper协议。那么,上面的功能,我该如何去实现呢?很简单,只需要实现一个原生java程序即可。初步思路:。
1、建立java容器
2、实现beanpostprocessor异步接收消息,
3、获取spring事务管理方式
4、实现自动化测试
一、容器如果我们创建一个容器,可以直接创建jdk1.8内置的orm框架:configuration。这里我建立了一个集成了activemq的容器。configuration.py:那么,一个java程序如何实现呢?接下来按照刚才的思路进行实现即可。
二、实现beanpostprocessor异步接收消息,并将其发送出去首先,我们创建一个spring容器,它的内部有个beanpostprocessor类。那么我们就可以用这个类,创建一个java对象,调用定义beanpostprocessor的方法。returnnewproducer().synchronized(true){threadthread=thread.currentthread();thread.start();//是否还是先执行beanpostprocessor方法thread.start(beanpostprocessor.getbean("beanpostprocessor"));}这段代码基本上没有改动。
那么我们就需要创建一个自定义的producer对象,这里我用了xml文件来实现,所以这里说说我自己怎么去操作xml文件。我自己在编写代码时遇到了比较棘手的地方,就是如何注册spring的beanpostprocessor类。在做开发的时候遇到类似的问题,我都是从容器生命周期中讲解,下面我来分析一下。在容器生。
文章采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-02-02 13:01
文章采集程序、历史数据以及日期自动新建表报表、这次就做简单的报表。建议说在excel里面,能有多简单就有多简单。想做这样的表,先需要点if函数的基础,先把vlookup及if函数用好,实在不行直接用excel的公式搞就行了。拿下这个表,就变成vlookup及excel公式库的学习了。首先是需要选择表格的样式:网上多的是各种样式的表格,都可以直接调,我选择最简单的直接选,这样也方便以后升级修改。
第二,就是定义好具体格式的代码了,比如我要新建的表里面有时间,那就得定义个函数或者params属性,这个需要调函数格式。parcel里面的时间=vlookup(d:d,f:f,s:s,1)第三,就是熟悉数据库语言了,工欲善其事必先利其器,得先把数据库掌握好。本文刚开始就是说怎么选择表格、怎么定义格式的,建议大家学习下r语言,在r语言里面定义表格都是用dbg表格,数据库语言全写成dbg语言,数据库通过dbg关联下来,大多数逻辑及业务逻辑没问题。
读者可以打开dbg语言对着练习下。该表简单介绍下:在一张excel表格里面,存放了本地各种数据,包括时间。使用简单的params类函数,可以定义一些自定义的“标签”,比如[开始时间],[结束时间],将这些标签添加到表里面。比如[start],[end],[start+end],[start+end]。
x、y和const都是对年、月、时间的名称。它们对应的函数:vlookup,numberlookup,if。下面就以实例来讲怎么对[开始时间],[结束时间]定义标签;[1/2],[1/2+1]是分隔符,[=]是赋值,[^{}]是引用(使用vlookup查找)。通过带引号的@定义表头时间,[t]为week时间。表格的基本概念都已经了解了,就是实战练习下,看看结果如何。 查看全部
文章采集程序
文章采集程序、历史数据以及日期自动新建表报表、这次就做简单的报表。建议说在excel里面,能有多简单就有多简单。想做这样的表,先需要点if函数的基础,先把vlookup及if函数用好,实在不行直接用excel的公式搞就行了。拿下这个表,就变成vlookup及excel公式库的学习了。首先是需要选择表格的样式:网上多的是各种样式的表格,都可以直接调,我选择最简单的直接选,这样也方便以后升级修改。
第二,就是定义好具体格式的代码了,比如我要新建的表里面有时间,那就得定义个函数或者params属性,这个需要调函数格式。parcel里面的时间=vlookup(d:d,f:f,s:s,1)第三,就是熟悉数据库语言了,工欲善其事必先利其器,得先把数据库掌握好。本文刚开始就是说怎么选择表格、怎么定义格式的,建议大家学习下r语言,在r语言里面定义表格都是用dbg表格,数据库语言全写成dbg语言,数据库通过dbg关联下来,大多数逻辑及业务逻辑没问题。
读者可以打开dbg语言对着练习下。该表简单介绍下:在一张excel表格里面,存放了本地各种数据,包括时间。使用简单的params类函数,可以定义一些自定义的“标签”,比如[开始时间],[结束时间],将这些标签添加到表里面。比如[start],[end],[start+end],[start+end]。
x、y和const都是对年、月、时间的名称。它们对应的函数:vlookup,numberlookup,if。下面就以实例来讲怎么对[开始时间],[结束时间]定义标签;[1/2],[1/2+1]是分隔符,[=]是赋值,[^{}]是引用(使用vlookup查找)。通过带引号的@定义表头时间,[t]为week时间。表格的基本概念都已经了解了,就是实战练习下,看看结果如何。
优化的解决方案:[方案]delphi信息采集程序可以推广为网络爬虫程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-01-10 12:00
下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫,沉香,吊钩,并增加了这个词。以下是新闻采集程序,可以在理解新闻采集程序的基础上进行操作。Web采集器程序可用。可以将delphi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴薇的sister子,寻找神圣的身体,和吊钩。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站系统都有自己的新闻采集系统,其中许多采集系统非常有价值。希望通过此文章,每个人都可以自己制作一个采集程序来维护自己的网站。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们害怕测量,羞辱和挑衅,裴玮的Xi子习恒树兴,寻找博薇,申香,刁肉,加上一些容易理解的词语,让我们首先解释一下有关该新闻的一些基本信息采集本文的程序。这里的新闻系统是用delphi实现的,并将采集中的数据保存到本地访问数据库中。
因此,这将是基于桌面的采集程序,而不是类似于“ Dongyi 采集”的基于浏览器的程序。我个人认为基于桌面的采集系统更易于实现强大的功能,并具有更高的稳定性和安全性。扩展之后,您可以将此示例制作为可以访问远程数据库的大规模采集系统。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找后卫的怀抱,以及沉香吊坠。这个词被添加。在讨论如何制作采集程序之前,我们首先定义一个本地访问数据库以访问采集]。该数据库只有一个表,名称为“ T_Article”。该表具有六个字段:ArticleID,ClassID,Title,Keyword,CopyFrom和Content,它们分别表示新闻编号,类别编号,标题,关键字,来源和内容。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴玮的s子,寻找警卫和吊钩。首先,所谓的采集,第一步当然是要能够捕获信息并能够满足用户的要求。从Internet上获取相关信息。假设在这里我们要获取文章并将其添加到网站中的“ delphi technology”一栏中。首先要做的是读取文章列表,然后通过列表索引,将文章的文本内容逐一读取到我们的网站数据库中。接下来是关键,如何在采集上列出文章。这分为两个步骤。一、使用delphi网络功能读取69929.shtm的HTML源文件。二、通过分析69929.shtm indy控件系列的idHTTP控件,该控件位于indy Clients面板中。控件的具体用法将在后面说明。现在我们只需要知道给定的URL地址,就可以传递indy该控件返回URL的网页源代码。第二步的实现是简单的字符串处理。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习恒书叫醒裴薇的sister子,寻找警卫,并发现这个词增加了。让我们讨论第二步是如何实现的。打开它,您可以看到左侧是“我的技术中心”,“最新”,“文档列表”等内容,这些与我们无关。右边是文章列表,这些是我们想要的。如何拦截列表中的内容?检查网页的源代码,可以将CTRL + F /左列-> del phi信息采集程序升级为Web爬虫程序。以下是新闻采集程序,了解了新闻采集程序的基础之后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到薄伟申香,刁柔那普,添加了delphi信息采集程序可以推广为网络爬虫程序,delphi信息采集程序可以作为网络爬虫程序进行升级,以下是页面上的新闻采集程序。在了解了新闻采集程序的基础上,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们对测量,屈辱和挑衅的恐惧,习衡枢叫醒裴玮的sister子,寻求寻找大后卫Diaorou Napu,并添加了标题delphi信息采集程序,可以将其升级为网络爬虫程序。以下是新闻采集程序,在了解新闻采集程序之后,您可以制作一个Web采集器程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子害怕测量屈辱和挑衅,习恒枢叫醒裴玮的Pe子,寻找警卫,“雕柔”一词是正确的。这是列表的开头,因此列表的结尾很明显在这里:delphi information 采集该程序可以作为Web爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集节目制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到博薇,申香,刁柔那普,首页|可以将del phi信息采集程序升级为Web爬虫程序页面,以下是新闻采集程序,在了解新闻采集程序的基础上,可以制作一个Web爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找警卫,并试图保卫申香吊钩。单词将添加到上一页| delphi信息采集程序可以作为网络爬虫程序进行升级href =“ javascript:__ doPostBack('ArticleList1 $ ArticleList1 $ PageNav1','71')”>最后一页| delphi信息采集程序可以提升为网络爬虫程序。以下是新闻采集程序,它是基于对新闻采集程序的理解而组成的。您可以制作一个Web采集器程序。今天,我们正在讨论网站 news 采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰标本,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,触摸,购买和购买,马城,元,柴,金,神甫,邵公,古楼,礁礁,换穴,返程氯,楼尘,德尔菲信息采集程序可以提升为网络爬虫程序,delphi信息采集程序可以提升为网络爬虫程序。以下是页面上的新闻采集程序。您可以在了解新闻采集程序的基础上制作网络爬虫程序。今天,我们正在讨论网站新闻采集该程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习衡枢叫醒了裴伟的sister子,寻求寻找伟大的后卫,并捍卫精神。单词添加1 delphi信息采集程序可以提升为Web爬虫程序。接下来,我们要做的就是使用字符串Function,截取这两段代码的中间部分“ 文章 list”。
具体功能也将在后面详细说明。获取文章的列表后,我们需要进一步处理,截取每个文章的URL地址,因为如前所述,给定URL,idHTTP控件可以返回网页代码。当我们返回到文章列表中每个文章的源代码时,相当于说返回了文章 采集的内容。只要我们进一步分析和处理它,就可以将其保存在本地数据库中并完成采集个作业。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从拜访,挤压,西坪,坂田,购买,八马城苑,柴井,神甫,少宫,甘口,刘Liu,g,g穴,返回程正楼晨,德尔福信息[该程序可以升级为网络爬虫程序,因此如何在列表文章中获取该程序?每个文章的网址呢?通过查看69929.shtm的源文件,我们发现列表href =“ article / 68/68316.shtm” target =“ _ blank”> Oracle返回存储过程中的数据集并在Delphi中使用它
很显然,我们只需要剪切掉“ rticle / 68/68316.shtm”并添加文章的URL,即“返回Oracle中存储过程中的数据集并在Delphi中使用它” 。可以将del phi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论它是网站新闻采集节目的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。害怕屈辱,屈辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫和吊钩。现在,假设我们已经获得列表中每篇文章的URL 文章,我们仅循环读取每篇文章[k13的网页代码]使用HTML中的特征字符来分隔“标题”,“作者”, 文章的“源”,“内容”和其他信息,然后将它们一一保存到本地数据库中。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一种自动获取在线信息并将其保存在自己的网站数据库中的程序。
现在,许多大型网站都有自己的新闻采集系统文章顾普弹跳而又滋润了诅咒,必须严伟重复一遍,才能教给靛蓝黛妮·奈奈·乌苏伊·胡赫·舒舒·朱朱·朱舒yu yu yu shu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu害怕屈辱和挑衅。习衡枢叫醒裴伟的妻子节俭,寻找警卫和众神。貂皮纳普,字增。 del phi信息采集程序的具体实现可以作为网络爬虫进行推广。页面以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴伟的妻子,寻找警卫,并寻找一个词。首先,程序将使用idHTTP控件(在indy的Clients面板中)。有关控件的详细文档,朋友E可以在此处登录以查看:该程序中使用的GET方法在第53页上。Internet上有很多有关Indy的帮助文件,但是我还没有找到中文的帮助文件。 。在此程序中,我们仅使用idHTTP控件的一种方法,即idHTTP1.GET方法。该方法说明如下:del phi信息采集程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。
<p>所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子出于对能力,屈辱和挑衅的恐惧,习衡枢唤醒了裴玮的s子,寻求寻找大后卫,并寻求增加角色数量。函数Get(AURL:string):string;超载; delphi信息采集该程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。惧怕屈辱,屈辱和挑衅,习衡枢叫醒裴玮的sister子,寻找博薇,申香刁or,并添加了AURL参数,该参数是字符串类型,并指定了URL地址字符串。 查看全部
优化的解决方案:[方案]delphi信息采集程序可以推广为网络爬虫程序
下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫,沉香,吊钩,并增加了这个词。以下是新闻采集程序,可以在理解新闻采集程序的基础上进行操作。Web采集器程序可用。可以将delphi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习恒枢叫醒裴薇的sister子,寻找神圣的身体,和吊钩。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站系统都有自己的新闻采集系统,其中许多采集系统非常有价值。希望通过此文章,每个人都可以自己制作一个采集程序来维护自己的网站。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们害怕测量,羞辱和挑衅,裴玮的Xi子习恒树兴,寻找博薇,申香,刁肉,加上一些容易理解的词语,让我们首先解释一下有关该新闻的一些基本信息采集本文的程序。这里的新闻系统是用delphi实现的,并将采集中的数据保存到本地访问数据库中。
因此,这将是基于桌面的采集程序,而不是类似于“ Dongyi 采集”的基于浏览器的程序。我个人认为基于桌面的采集系统更易于实现强大的功能,并具有更高的稳定性和安全性。扩展之后,您可以将此示例制作为可以访问远程数据库的大规模采集系统。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找后卫的怀抱,以及沉香吊坠。这个词被添加。在讨论如何制作采集程序之前,我们首先定义一个本地访问数据库以访问采集]。该数据库只有一个表,名称为“ T_Article”。该表具有六个字段:ArticleID,ClassID,Title,Keyword,CopyFrom和Content,它们分别表示新闻编号,类别编号,标题,关键字,来源和内容。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴玮的s子,寻找警卫和吊钩。首先,所谓的采集,第一步当然是要能够捕获信息并能够满足用户的要求。从Internet上获取相关信息。假设在这里我们要获取文章并将其添加到网站中的“ delphi technology”一栏中。首先要做的是读取文章列表,然后通过列表索引,将文章的文本内容逐一读取到我们的网站数据库中。接下来是关键,如何在采集上列出文章。这分为两个步骤。一、使用delphi网络功能读取69929.shtm的HTML源文件。二、通过分析69929.shtm indy控件系列的idHTTP控件,该控件位于indy Clients面板中。控件的具体用法将在后面说明。现在我们只需要知道给定的URL地址,就可以传递indy该控件返回URL的网页源代码。第二步的实现是简单的字符串处理。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习恒书叫醒裴薇的sister子,寻找警卫,并发现这个词增加了。让我们讨论第二步是如何实现的。打开它,您可以看到左侧是“我的技术中心”,“最新”,“文档列表”等内容,这些与我们无关。右边是文章列表,这些是我们想要的。如何拦截列表中的内容?检查网页的源代码,可以将CTRL + F /左列-> del phi信息采集程序升级为Web爬虫程序。以下是新闻采集程序,了解了新闻采集程序的基础之后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到薄伟申香,刁柔那普,添加了delphi信息采集程序可以推广为网络爬虫程序,delphi信息采集程序可以作为网络爬虫程序进行升级,以下是页面上的新闻采集程序。在了解了新闻采集程序的基础上,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习衡枢叫醒了裴伟的sister子,试图找到博伟,申香,刁柔,并添加德尔福信息。 采集该程序可以升级为网络爬虫。以下是新闻采集程序,可以理解。可以基于新闻采集程序制作网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻们对测量,屈辱和挑衅的恐惧,习衡枢叫醒裴玮的sister子,寻求寻找大后卫Diaorou Napu,并添加了标题delphi信息采集程序,可以将其升级为网络爬虫程序。以下是新闻采集程序,在了解新闻采集程序之后,您可以制作一个Web采集器程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子害怕测量屈辱和挑衅,习恒枢叫醒裴玮的Pe子,寻找警卫,“雕柔”一词是正确的。这是列表的开头,因此列表的结尾很明显在这里:delphi information 采集该程序可以作为Web爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集节目制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴炜的sister子,试图找到博薇,申香,刁柔那普,首页|可以将del phi信息采集程序升级为Web爬虫程序页面,以下是新闻采集程序,在了解新闻采集程序的基础上,可以制作一个Web爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕衡量屈辱和挑衅,习衡枢叫醒裴伟的sister子,寻找警卫,并试图保卫申香吊钩。单词将添加到上一页| delphi信息采集程序可以作为网络爬虫程序进行升级href =“ javascript:__ doPostBack('ArticleList1 $ ArticleList1 $ PageNav1','71')”>最后一页| delphi信息采集程序可以提升为网络爬虫程序。以下是新闻采集程序,它是基于对新闻采集程序的理解而组成的。您可以制作一个Web采集器程序。今天,我们正在讨论网站 news 采集程序的制作。
所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰标本,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,触摸,购买和购买,马城,元,柴,金,神甫,邵公,古楼,礁礁,换穴,返程氯,楼尘,德尔菲信息采集程序可以提升为网络爬虫程序,delphi信息采集程序可以提升为网络爬虫程序。以下是页面上的新闻采集程序。您可以在了解新闻采集程序的基础上制作网络爬虫程序。今天,我们正在讨论网站新闻采集该程序的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,麻城,元,柴,杜松子酒,神甫,邵公,郭,刘,换穴,返回Chloro Louchen del phi信息采集可以作为网络爬虫程序进行升级。页面是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻害怕测量,羞辱和挑衅,习衡枢叫醒了裴伟的sister子,寻求寻找伟大的后卫,并捍卫精神。单词添加1 delphi信息采集程序可以提升为Web爬虫程序。接下来,我们要做的就是使用字符串Function,截取这两段代码的中间部分“ 文章 list”。
具体功能也将在后面详细说明。获取文章的列表后,我们需要进一步处理,截取每个文章的URL地址,因为如前所述,给定URL,idHTTP控件可以返回网页代码。当我们返回到文章列表中每个文章的源代码时,相当于说返回了文章 采集的内容。只要我们进一步分析和处理它,就可以将其保存在本地数据库中并完成采集个作业。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从拜访,挤压,西坪,坂田,购买,八马城苑,柴井,神甫,少宫,甘口,刘Liu,g,g穴,返回程正楼晨,德尔福信息[该程序可以升级为网络爬虫程序,因此如何在列表文章中获取该程序?每个文章的网址呢?通过查看69929.shtm的源文件,我们发现列表href =“ article / 68/68316.shtm” target =“ _ blank”> Oracle返回存储过程中的数据集并在Delphi中使用它
很显然,我们只需要剪切掉“ rticle / 68/68316.shtm”并添加文章的URL,即“返回Oracle中存储过程中的数据集并在Delphi中使用它” 。可以将del phi信息采集程序升级为Web爬虫程序。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论它是网站新闻采集节目的制作。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。害怕屈辱,屈辱和挑衅,习恒枢叫醒裴玮的sister子,寻找警卫和吊钩。现在,假设我们已经获得列表中每篇文章的URL 文章,我们仅循环读取每篇文章[k13的网页代码]使用HTML中的特征字符来分隔“标题”,“作者”, 文章的“源”,“内容”和其他信息,然后将它们一一保存到本地数据库中。可以将delphi信息采集程序升级为Web爬虫程序。以下是新闻采集程序。了解了新闻采集程序后,可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序制作。所谓的新闻采集程序是一种自动获取在线信息并将其保存在自己的网站数据库中的程序。
现在,许多大型网站都有自己的新闻采集系统文章顾普弹跳而又滋润了诅咒,必须严伟重复一遍,才能教给靛蓝黛妮·奈奈·乌苏伊·胡赫·舒舒·朱朱·朱舒yu yu yu shu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu yu害怕屈辱和挑衅。习衡枢叫醒裴伟的妻子节俭,寻找警卫和众神。貂皮纳普,字增。 del phi信息采集程序的具体实现可以作为网络爬虫进行推广。页面以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子惧怕屈辱,屈辱和挑衅,习恒枢叫醒裴伟的妻子,寻找警卫,并寻找一个词。首先,程序将使用idHTTP控件(在indy的Clients面板中)。有关控件的详细文档,朋友E可以在此处登录以查看:该程序中使用的GET方法在第53页上。Internet上有很多有关Indy的帮助文件,但是我还没有找到中文的帮助文件。 。在此程序中,我们仅使用idHTTP控件的一种方法,即idHTTP1.GET方法。该方法说明如下:del phi信息采集程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。了解了新闻采集程序后,您可以制作一个网络爬虫程序。今天,我们正在讨论网站 news 采集程序的制作。
<p>所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳动并滋润诅咒,必须由严伟重复讲解,以教导靛蓝黛娜苏·乌苏·翠莹,上海和莲花洪水漱口,挤大蒜求糖。妻子出于对能力,屈辱和挑衅的恐惧,习衡枢唤醒了裴玮的s子,寻求寻找大后卫,并寻求增加角色数量。函数Get(AURL:string):string;超载; delphi信息采集该程序可以作为网络爬虫程序进行升级。下一页是新闻采集程序。在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型网站都有自己的新闻采集该系统的目标是农作物,嫩芽,旅行和鲍鱼,特殊的痰复制品,阳寨,简写,月谷亭,竹淮,检查,偷窥氦路堤,安静的命令,舞蹈和服从巡逻,挤压,挤压,爆炸,购买,购买,马,元,柴,金,沉,傅,邵公,郭,刘,换穴,返程氯和德尔福信息采集该程序可以升级为网络爬虫。以下是新闻采集程序,在了解新闻采集程序的基础上,您可以制作一个网络爬虫程序。今天,我们正在讨论网站新闻采集程序的产生。所谓的新闻采集程序是一个自动获取在线信息并将其保存在自己的网站数据库中的程序。现在,许多大型的网站都有自己的新闻采集系统文章顾普跳得很重,滋润了这个诅咒,必须严伟重复一遍,以教授靛蓝黛娜苏乌苏翠莹,上海和莲花洪水,含漱液,含漱液和问糖妻。惧怕屈辱,屈辱和挑衅,习衡枢叫醒裴玮的sister子,寻找博薇,申香刁or,并添加了AURL参数,该参数是字符串类型,并指定了URL地址字符串。
分享的内容:webplus系统文章采集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-10-07 13:05
迅速。(23)高长夜在1943年1月夜营救了同胞,苏加胡在日军的控制下袭击集会。“一天,来自乌镇地区的日军捕获了53支“ Shina” springqiaotu农场信息采集用户手册摘要信息采集是捕获网络数据并实现信息共享的功能模块,提供手动捕获,定时捕获和定时循环捕获三种模式,可以捕获单个新闻列表中的信息,也可以同时捕获多个列表中的新闻信息。现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列,步骤如下:为指定列制定采集计划在列管理中选择此列,然后单击以设置采集计划。(例如:图一)设置采集的基本属性。包括执行方法,是否自动发布信息,采集的列类型以及代码的编码)。页面垫。 (例如:图片二)事先同意采集计划的执行方法,手动,定时单次执行或定时循环执行。如果仅针对采集网页的当前数据,我们可以使用手动和定时单次执行)方法采集一次;如果要更新采集网页的数据,则必须确保信息的同步,即采用定时循环采集的方法。
确定是否需要发布采集中的信息。如果不需要修改采集中的信息,则可以直接将其公开到Internet,您可以选择自动发布。如果采集中的信息需要修改,检查等,请选择不自动发布。 采集完成后,信息管理人员将执行其他操作。将列的类型设置为采集如果采集网页只是一个简单的新闻列表,也就是说,将页面的新闻采集放在指定的列下,然后选择一个列。如果采集页面具有多个新闻列表,并且每个列表都提供一个单独的链接以快速进入。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区将53个“ Shina” springqiaotu农场捕获到我们自己的新闻清单页面中,我们需要采集所有新闻信息,然后选择多列;此外,如果采集的页面是RSS信息聚合页面,则将其设置为相应的RSS单列或RSS多列。由于webplus系统使用UTF-8编码格式,因此它可能会以其他编码格式采集,因此为了避免采集中出现乱码信息,需要将其设置为采集 ]页面。
本文来自计算机的基础知识:单列采集计划设置(例如:图三)设置为“列表页面起始URL”是页面采集的访问路径。(必需)设置为“文章[页面URL获取规则”如果通过采集将新闻列表嵌入到网页的iframe中,则需要设置规则以获取列表iframe访问地址以访问新闻列表。否则,您无需不需要制定此规则(具体规则请参见以下“ 采集正则表达式的制定”)如果采集网页的新闻列表具有分页,则应按照以下方式制定分页规则新闻列表分页(链接和表单提交),并且需要设置分页的开始页号,间隔页号和采集页数。如果新闻列表中没有分页,则不需要制定这个规则如果采集页面有多个新闻列表,并且多个新闻列表的url规则相似,那么我们只需要一个由采集指定的列表,也就是说,我们需要设置规则来限制对文章列表的获取,这是为了避免采集冗余数据。否则,无需设置规则即可设置文章网址获取规则,以便能够从采集页面快速进行。 (23)高长夜在1943年1月,在苏家湖沿加强游击队“突袭”控制日本人之后,日军控制。有一天,来自乌镇地区的日军抓获53个“ Shina” springqiaotu农场,以访问新闻的特定新闻页面采集。
(必需)对于特定新闻页面,如果文章的内容以iframe的形式嵌入新闻页面,则需要设置规则以获取文章iframe的链接地址以访问新闻内容。否则,无需制定此规则。如果新闻内容具有分页,则根据文章内容的分页方法(链接和表单提交)来制定分页规则,并需要设置起始页号,间隔页号和采集页号。如果文章的内容没有分页,则无需制定此规则。如果新闻页面除新闻内容之外还收录其他信息,为了在采集流程中更轻松地找到新闻内容,有必要设置规则以限制新闻内容的获取。一种是避免垃圾邮件,另一种是减少新闻特定信息获取规则的复杂性。如果新闻页面相对简单,通常无需设置此规则。除标题和内容外,用于设置新闻属性的规则是可选的。另外,如果未设置新闻发布时间,则将当前时间用作发布时间。多列采集计划需要在“列表页面起始URL”下设置列表页面URL规则,并在“ 文章页面URL获取规则”下设置列名称获取规则,其他项目与单列一致采集计划设置。 RSS单列采集计划设置RSS单列采集计划不需要设置“ 文章页面URL获取规则”,其余与单列采集计划一致。
设置RSS多列计划采集需要在“列出页面起始URL”下快速设置RSS多列计划采集。 (23)高长夜在1943年1月夜救出了同胞,日军控制苏家虎后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场列表页面URL获取规则,其他与RSS一致单列采集计划。表达式设置和调整,并测试表达式列表,然后单击采集在“获取规则设置”页面中有一个地方,进入规则表达式列表页面(例如:图七)。除了添加,修改,删除和调整表达式的顺序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容以测试表达式规则列表,设置各种类型的表达式。分为字符串,匹配,匹配替换和公式四种类型,其中,匹配和匹配替换需要使用Java正表达式,这需要采集计划设置人员具有一定的了解表达式。
匹配:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定的文本(URL,IframeURL,页面内容)中获取正确的内容,以获取部分文本中的匹配内容。公式:仅支持[pageIndex],用于表示获取页面地址时的页面页码。迅速进入专栏管理(图一)。(23)高长海夜解救了同胞,1943年1月,日军控制苏家湖后,沿着集会游击队“突袭”。一天),日军从乌镇地区抓获53支“什纳”春桥图农场采集 ]在右侧的列列表中选择一列,然后单击以设置采集计划(图二))的执行模式可以是:循环(指定间隔时间,自动循环采集)您可以设置采集到文章]是否自动发布列的类型为采集:单列RSS(在一个RSS地址文章下为采集)多列RSS(从一个RSS列表地址开始,在采集之下RSS地址文章,每个RSS地址组成一个子列)编码方法是快速对页面采集进行编码。(23)高长海夜救了同胞,1943年1月,日军在苏家湖之后沿着集会游击队控制了“有一天,日军从乌镇地区抓获53个“椎名”斯普林乔土农场单列法(图三)单列RSS方法此方法不需要设置文章页面URL获取方法,其他方法与单列方法相同。
(23)高长夜在1943年1月夜救出了同胞,苏加胡之后,日军控制了集会游击队“突袭”。有一天,来自乌镇地区的日军抓获了53个“什纳”春桥图农场。这种方法的起始页通常是list Page集合,对于单列模式,需要设置获取列表页面的方法和列名规则,其他与单列一致,该方法需要设置RSS地址(列表页面) (23)高长海在1943年1月夜救出了同胞,日军在苏家湖之后沿着激进的游击队“突袭”控制了日本。一天,日军从乌镇地区撤离。 (23)高长海夜救出了同胞,1943年1月,苏家虎沿集约化游击队“突袭”后,日军控制。有一天,来自乌镇地区的日军抓获了53个“什纳”温泉桥图农场(图十一)迅速。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区抓获了53个“ Shina” Springqiaotu农场(图十二),如上图所示,获取规则由多个表达式组成,并添加了多个表达式以获得所需的URL。获取文章Capacity的标题和其他属性。
表达式分为4个匹配项:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中内容S的一部分。然后使用替换正则表达式替换S中的匹配内容,以获取正确的内容。很快。 (23)高长夜在1943年1月夜救出了同胞,苏家虎之后沿日军加强了对游击队的“突袭”。日军从乌镇地区抓获53支“ Shina” Springqiaotu农场。公式:仅支持[pageIndex],用于获取页面地址代表页面的页码,该页面还可以测试设置的表达式,可以使用表达式帮助来了解正则表达式的语法,检查采集计划状态并返回到列列表以查看下图(图10 三) 采集)中的三个图标分别指示采集计划的运行状态(是否正在运行,是否已在运行等),采集模式(单个列,单列RSS,多列,多列RSS),执行方法(手动,单列,重复),单击以查看采集计划的详细信息,(图十四)采集计划示例是一个新浪体育新闻列表网站以该网页为例采集。该网页的地址为。
采集的内容被迅速编入“尸体”。(23)高长海夜救出了同胞,1943年1月,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获53由于这是一个测试示例,因此我们使用手动执行来执行采集,并且不需要自动发布采集的信息。 GB2312新闻列表页面,因此我们将采集的列类型设置为“单列”,编码方式为gb2312 采集。该新闻不需要自动发布。如下图所示,此页面上新闻列表的内容不再位于iframe中,并且没有分页,因此无需设置“ IFRAME中的列表页面内容”和“列表页面分页方法”的获取规则。新闻列表的列表不需要设置“限制文章列表内容”规则。设置文章url获取规则该网页中的链接类似于以下URL:因此,请制定以下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(\ d +)-(\ d +)-(\ d +)/(\ d +)\。快速shtml。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场。匹配组:(获得比赛的全部结果) 采集页面的源文件,将其粘贴到页面内容中,单击“测试计算列表模式”,结果将显示所有匹配的URL列表,如下图所示,因为文章的内容为不在iframe中,文章内容没有分页,并且文章内容不需要在页面上进行限制,因此“ IFRAME章节内容页面URL中的文章页面内容”和“限制”的获取规则文章页面文章内容”无需设置。
文章标题规则设置因为新闻页面的源文件中文章的标题位于以下位置:所以制定以下表达式规则表达式类型:匹配的休斯顿球迷希望姚明能够接受手术和健康是火箭的希望之路_新浪篮球_新浪网(23)高长夜在1943年1月夜营救了同胞,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区53“ Shina” springqiaotu农场类型:页面内容匹配表达式:(。+?)匹配组: (获取匹配结果中的第一个组,每个方括号为一个组)。采集获取页面的源文件并将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中的标题内容将如下图所示。文章设置内容规则是因为新闻页面源文件中文章的内容处于以下位置:快速。(23) 1月高昌海夜救助了同胞1943年,日军控制苏家湖后,加强了对游击队的“突袭”,有一天,来自乌镇地区的日军抓获了53个“椎名”斯普林乔土农场。因此制定了以下表达规则:匹配内容类型:页面内容匹配表达式:显示开始输出的内容的贴图新页面末尾(获取匹配结果中的第一组,每个方括号为一组)获取页面采集的源文件,将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中文章的内容如下图所示。图片开始显示图片结束显示图片开始显示图片结束输出内容-新选项卡开始publish_helpername ='原创文本'p_id ='6't_id = '12'd_id ='4471052'f_id = '41'新浪体育新闻北京时间休斯顿消息,据ESPN报道,姚明尚未决定是否进行手术来修复脚部受伤,尽管虽然诊断姚明的三位主要医生现在都建议手术,但姚明仍在犹豫。
关于姚明现在的想法,每个人都知道姚明仍然犹豫的原因是因为他知道如果他接受手术,下个赛季他将不会缺席。 29岁的姚明不希望它徒劳。浪费一年需要一年。毕竟,运动员的巅峰时期就是这样的时期。没有人可以保证那时的姚明能保持一个好的水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地进行手术。他们的原因是,由于存在恶化的趋势,并且保守治疗的效果仍然未知,因此他们不应该决定进行手术。毕竟,健康的姚明是火箭队最好的。如果有必要,如果保守治疗后仍然需要手术,姚明将会输掉比赛。
“亲爱的姚明,请您下定决心进行手术。即使您下个赛季缺席,也不要犹豫。如果现在保守治疗得到治愈,它仍然会让我们发抖。作为一个问题,最好进行手术以解决根本原因。您可能会损失一年,但我们相信,您将为休斯敦带来三,五年甚至更长的更健康的未来。”风扇说。
的确,这位球迷表达了休斯顿大多数球迷的感受。没有人希望看到姚明没有完全治愈就重返法庭。如果姚明再次受伤,我相信这将对包括姚明在内的所有休斯顿球迷造成沉重打击。
一些球迷还说,姚明应该放心手术。检查姚明的医生现在已经将骑士中心恢复了健康,并且在接下来的几年中没有发生重大伤病,而且竞争状态仍然保持相对良好。
“像哈达威一样,他们由于受伤而急剧下降。我认为姚明很难做到这一点。姚明不同于希尔和哈达威。姚明是内线球员,尽管脚的移动很重要。 ,但是相对而言,弹跳并不是最重要的事情。姚明内心的威慑力主要来自于他的身高和惊人的感觉。足部手术不会减轻姚明的身高,也不会使他离开。感觉。”风扇说。
简而言之,休斯顿的人们基本上希望姚明能够接受手术。他们相信手术可以为姚明带来完全的健康,而健康的姚明是他们最希望看到的。
输出内容-新标签页结束投票反对开始投票反对结束快速开始独家提供。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后,日军控制了集散的游击队“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina”斯普林乔图农场文章此处未设置其他属性。 采集设置计划后,选择“体育新闻”列,立即单击采集,过一会儿,检查此列的内容管理,您将看到以下内容:此外,采集 采集的运行状态在列管理中,单击“体育新闻”列 查看全部
webplus系统文章采集教程
迅速。(23)高长夜在1943年1月夜营救了同胞,苏加胡在日军的控制下袭击集会。“一天,来自乌镇地区的日军捕获了53支“ Shina” springqiaotu农场信息采集用户手册摘要信息采集是捕获网络数据并实现信息共享的功能模块,提供手动捕获,定时捕获和定时循环捕获三种模式,可以捕获单个新闻列表中的信息,也可以同时捕获多个列表中的新闻信息。现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列,步骤如下:为指定列制定采集计划在列管理中选择此列,然后单击以设置采集计划。(例如:图一)设置采集的基本属性。包括执行方法,是否自动发布信息,采集的列类型以及代码的编码)。页面垫。 (例如:图片二)事先同意采集计划的执行方法,手动,定时单次执行或定时循环执行。如果仅针对采集网页的当前数据,我们可以使用手动和定时单次执行)方法采集一次;如果要更新采集网页的数据,则必须确保信息的同步,即采用定时循环采集的方法。
确定是否需要发布采集中的信息。如果不需要修改采集中的信息,则可以直接将其公开到Internet,您可以选择自动发布。如果采集中的信息需要修改,检查等,请选择不自动发布。 采集完成后,信息管理人员将执行其他操作。将列的类型设置为采集如果采集网页只是一个简单的新闻列表,也就是说,将页面的新闻采集放在指定的列下,然后选择一个列。如果采集页面具有多个新闻列表,并且每个列表都提供一个单独的链接以快速进入。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区将53个“ Shina” springqiaotu农场捕获到我们自己的新闻清单页面中,我们需要采集所有新闻信息,然后选择多列;此外,如果采集的页面是RSS信息聚合页面,则将其设置为相应的RSS单列或RSS多列。由于webplus系统使用UTF-8编码格式,因此它可能会以其他编码格式采集,因此为了避免采集中出现乱码信息,需要将其设置为采集 ]页面。
本文来自计算机的基础知识:单列采集计划设置(例如:图三)设置为“列表页面起始URL”是页面采集的访问路径。(必需)设置为“文章[页面URL获取规则”如果通过采集将新闻列表嵌入到网页的iframe中,则需要设置规则以获取列表iframe访问地址以访问新闻列表。否则,您无需不需要制定此规则(具体规则请参见以下“ 采集正则表达式的制定”)如果采集网页的新闻列表具有分页,则应按照以下方式制定分页规则新闻列表分页(链接和表单提交),并且需要设置分页的开始页号,间隔页号和采集页数。如果新闻列表中没有分页,则不需要制定这个规则如果采集页面有多个新闻列表,并且多个新闻列表的url规则相似,那么我们只需要一个由采集指定的列表,也就是说,我们需要设置规则来限制对文章列表的获取,这是为了避免采集冗余数据。否则,无需设置规则即可设置文章网址获取规则,以便能够从采集页面快速进行。 (23)高长夜在1943年1月,在苏家湖沿加强游击队“突袭”控制日本人之后,日军控制。有一天,来自乌镇地区的日军抓获53个“ Shina” springqiaotu农场,以访问新闻的特定新闻页面采集。
(必需)对于特定新闻页面,如果文章的内容以iframe的形式嵌入新闻页面,则需要设置规则以获取文章iframe的链接地址以访问新闻内容。否则,无需制定此规则。如果新闻内容具有分页,则根据文章内容的分页方法(链接和表单提交)来制定分页规则,并需要设置起始页号,间隔页号和采集页号。如果文章的内容没有分页,则无需制定此规则。如果新闻页面除新闻内容之外还收录其他信息,为了在采集流程中更轻松地找到新闻内容,有必要设置规则以限制新闻内容的获取。一种是避免垃圾邮件,另一种是减少新闻特定信息获取规则的复杂性。如果新闻页面相对简单,通常无需设置此规则。除标题和内容外,用于设置新闻属性的规则是可选的。另外,如果未设置新闻发布时间,则将当前时间用作发布时间。多列采集计划需要在“列表页面起始URL”下设置列表页面URL规则,并在“ 文章页面URL获取规则”下设置列名称获取规则,其他项目与单列一致采集计划设置。 RSS单列采集计划设置RSS单列采集计划不需要设置“ 文章页面URL获取规则”,其余与单列采集计划一致。
设置RSS多列计划采集需要在“列出页面起始URL”下快速设置RSS多列计划采集。 (23)高长夜在1943年1月夜救出了同胞,日军控制苏家虎后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场列表页面URL获取规则,其他与RSS一致单列采集计划。表达式设置和调整,并测试表达式列表,然后单击采集在“获取规则设置”页面中有一个地方,进入规则表达式列表页面(例如:图七)。除了添加,修改,删除和调整表达式的顺序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容以测试表达式规则列表,设置各种类型的表达式。分为字符串,匹配,匹配替换和公式四种类型,其中,匹配和匹配替换需要使用Java正表达式,这需要采集计划设置人员具有一定的了解表达式。
匹配:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定的文本(URL,IframeURL,页面内容)中获取正确的内容,以获取部分文本中的匹配内容。公式:仅支持[pageIndex],用于表示获取页面地址时的页面页码。迅速进入专栏管理(图一)。(23)高长海夜解救了同胞,1943年1月,日军控制苏家湖后,沿着集会游击队“突袭”。一天),日军从乌镇地区抓获53支“什纳”春桥图农场采集 ]在右侧的列列表中选择一列,然后单击以设置采集计划(图二))的执行模式可以是:循环(指定间隔时间,自动循环采集)您可以设置采集到文章]是否自动发布列的类型为采集:单列RSS(在一个RSS地址文章下为采集)多列RSS(从一个RSS列表地址开始,在采集之下RSS地址文章,每个RSS地址组成一个子列)编码方法是快速对页面采集进行编码。(23)高长海夜救了同胞,1943年1月,日军在苏家湖之后沿着集会游击队控制了“有一天,日军从乌镇地区抓获53个“椎名”斯普林乔土农场单列法(图三)单列RSS方法此方法不需要设置文章页面URL获取方法,其他方法与单列方法相同。
(23)高长夜在1943年1月夜救出了同胞,苏加胡之后,日军控制了集会游击队“突袭”。有一天,来自乌镇地区的日军抓获了53个“什纳”春桥图农场。这种方法的起始页通常是list Page集合,对于单列模式,需要设置获取列表页面的方法和列名规则,其他与单列一致,该方法需要设置RSS地址(列表页面) (23)高长海在1943年1月夜救出了同胞,日军在苏家湖之后沿着激进的游击队“突袭”控制了日本。一天,日军从乌镇地区撤离。 (23)高长海夜救出了同胞,1943年1月,苏家虎沿集约化游击队“突袭”后,日军控制。有一天,来自乌镇地区的日军抓获了53个“什纳”温泉桥图农场(图十一)迅速。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军的游击队“突袭”进行了日军控制。有一天,日军从乌镇地区抓获了53个“ Shina” Springqiaotu农场(图十二),如上图所示,获取规则由多个表达式组成,并添加了多个表达式以获得所需的URL。获取文章Capacity的标题和其他属性。
表达式分为4个匹配项:从指定的文本(URL,IframeURL,页面内容)到正则表达式,以获取文本中内容S的一部分。匹配和替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中内容S的一部分。然后使用替换正则表达式替换S中的匹配内容,以获取正确的内容。很快。 (23)高长夜在1943年1月夜救出了同胞,苏家虎之后沿日军加强了对游击队的“突袭”。日军从乌镇地区抓获53支“ Shina” Springqiaotu农场。公式:仅支持[pageIndex],用于获取页面地址代表页面的页码,该页面还可以测试设置的表达式,可以使用表达式帮助来了解正则表达式的语法,检查采集计划状态并返回到列列表以查看下图(图10 三) 采集)中的三个图标分别指示采集计划的运行状态(是否正在运行,是否已在运行等),采集模式(单个列,单列RSS,多列,多列RSS),执行方法(手动,单列,重复),单击以查看采集计划的详细信息,(图十四)采集计划示例是一个新浪体育新闻列表网站以该网页为例采集。该网页的地址为。
采集的内容被迅速编入“尸体”。(23)高长海夜救出了同胞,1943年1月,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获53由于这是一个测试示例,因此我们使用手动执行来执行采集,并且不需要自动发布采集的信息。 GB2312新闻列表页面,因此我们将采集的列类型设置为“单列”,编码方式为gb2312 采集。该新闻不需要自动发布。如下图所示,此页面上新闻列表的内容不再位于iframe中,并且没有分页,因此无需设置“ IFRAME中的列表页面内容”和“列表页面分页方法”的获取规则。新闻列表的列表不需要设置“限制文章列表内容”规则。设置文章url获取规则该网页中的链接类似于以下URL:因此,请制定以下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(\ d +)-(\ d +)-(\ d +)/(\ d +)\。快速shtml。 (23)高长夜在1943年1月夜救出了同胞,苏加胡后沿日军加强了对游击队的“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina” springqiaotu农场。匹配组:(获得比赛的全部结果) 采集页面的源文件,将其粘贴到页面内容中,单击“测试计算列表模式”,结果将显示所有匹配的URL列表,如下图所示,因为文章的内容为不在iframe中,文章内容没有分页,并且文章内容不需要在页面上进行限制,因此“ IFRAME章节内容页面URL中的文章页面内容”和“限制”的获取规则文章页面文章内容”无需设置。
文章标题规则设置因为新闻页面的源文件中文章的标题位于以下位置:所以制定以下表达式规则表达式类型:匹配的休斯顿球迷希望姚明能够接受手术和健康是火箭的希望之路_新浪篮球_新浪网(23)高长夜在1943年1月夜营救了同胞,日军控制苏家湖之后,加强了对游击队的“突袭”。有一天,日军从乌镇地区53“ Shina” springqiaotu农场类型:页面内容匹配表达式:(。+?)匹配组: (获取匹配结果中的第一个组,每个方括号为一个组)。采集获取页面的源文件并将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中的标题内容将如下图所示。文章设置内容规则是因为新闻页面源文件中文章的内容处于以下位置:快速。(23) 1月高昌海夜救助了同胞1943年,日军控制苏家湖后,加强了对游击队的“突袭”,有一天,来自乌镇地区的日军抓获了53个“椎名”斯普林乔土农场。因此制定了以下表达规则:匹配内容类型:页面内容匹配表达式:显示开始输出的内容的贴图新页面末尾(获取匹配结果中的第一组,每个方括号为一组)获取页面采集的源文件,将其粘贴到页面内容中,单击“测试计算-内容模式”,结果中文章的内容如下图所示。图片开始显示图片结束显示图片开始显示图片结束输出内容-新选项卡开始publish_helpername ='原创文本'p_id ='6't_id = '12'd_id ='4471052'f_id = '41'新浪体育新闻北京时间休斯顿消息,据ESPN报道,姚明尚未决定是否进行手术来修复脚部受伤,尽管虽然诊断姚明的三位主要医生现在都建议手术,但姚明仍在犹豫。
关于姚明现在的想法,每个人都知道姚明仍然犹豫的原因是因为他知道如果他接受手术,下个赛季他将不会缺席。 29岁的姚明不希望它徒劳。浪费一年需要一年。毕竟,运动员的巅峰时期就是这样的时期。没有人可以保证那时的姚明能保持一个好的水平。
姚明犹豫不决,但休斯顿球迷对姚明有不同的看法。大多数球迷认为姚明应该毫不犹豫地进行手术。他们的原因是,由于存在恶化的趋势,并且保守治疗的效果仍然未知,因此他们不应该决定进行手术。毕竟,健康的姚明是火箭队最好的。如果有必要,如果保守治疗后仍然需要手术,姚明将会输掉比赛。
“亲爱的姚明,请您下定决心进行手术。即使您下个赛季缺席,也不要犹豫。如果现在保守治疗得到治愈,它仍然会让我们发抖。作为一个问题,最好进行手术以解决根本原因。您可能会损失一年,但我们相信,您将为休斯敦带来三,五年甚至更长的更健康的未来。”风扇说。
的确,这位球迷表达了休斯顿大多数球迷的感受。没有人希望看到姚明没有完全治愈就重返法庭。如果姚明再次受伤,我相信这将对包括姚明在内的所有休斯顿球迷造成沉重打击。
一些球迷还说,姚明应该放心手术。检查姚明的医生现在已经将骑士中心恢复了健康,并且在接下来的几年中没有发生重大伤病,而且竞争状态仍然保持相对良好。
“像哈达威一样,他们由于受伤而急剧下降。我认为姚明很难做到这一点。姚明不同于希尔和哈达威。姚明是内线球员,尽管脚的移动很重要。 ,但是相对而言,弹跳并不是最重要的事情。姚明内心的威慑力主要来自于他的身高和惊人的感觉。足部手术不会减轻姚明的身高,也不会使他离开。感觉。”风扇说。
简而言之,休斯顿的人们基本上希望姚明能够接受手术。他们相信手术可以为姚明带来完全的健康,而健康的姚明是他们最希望看到的。
输出内容-新标签页结束投票反对开始投票反对结束快速开始独家提供。 (23)高长夜在1943年1月夜救了同胞,苏加胡之后,日军控制了集散的游击队“突袭”。有一天,日军从乌镇地区抓获了53个“ Shina”斯普林乔图农场文章此处未设置其他属性。 采集设置计划后,选择“体育新闻”列,立即单击采集,过一会儿,检查此列的内容管理,您将看到以下内容:此外,采集 采集的运行状态在列管理中,单击“体育新闻”列
解读:用它就对了!新媒体运营必备的文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-09-02 16:22
在流行期间,许多公司不得不选择远程在线办公室. 互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作. 因此,优采云 采集特别推出了智能采集工具.
我相信许多操作人员已经接触过采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此. 成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入.
一个,优采云 采集是什么?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本.
两个. 如何使用优采云 采集进行搜索?
(1)输入关键字
优采云 采集根据用户输入的关键字,通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集将搜索结果合并到一个列表中.
(2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将被添加到操作面板中,方便用户批量保存.
(3)精确过滤
1,搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确.
2. 广告过滤 查看全部
只需使用它! 文章 采集新媒体操作所需的工具
在流行期间,许多公司不得不选择远程在线办公室. 互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作. 因此,优采云 采集特别推出了智能采集工具.
我相信许多操作人员已经接触过采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此. 成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入.
一个,优采云 采集是什么?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本.
两个. 如何使用优采云 采集进行搜索?
(1)输入关键字
优采云 采集根据用户输入的关键字,通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集将搜索结果合并到一个列表中.
(2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将被添加到操作面板中,方便用户批量保存.
(3)精确过滤
1,搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确.
2. 广告过滤
技术文章:网页文章正文采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-09-01 14:36
网页文章文本采集方法,并以微信文章 采集为例. 当我们想将新闻保存在今天的头条新闻上并将文章保存在搜狗微信上时,该怎么办?复制并粘贴一篇文章?选择通用网页数据采集器将使工作变得更加容易. 优采云是常规网页数据采集器,它可以是采集 Internet上的公共数据. 用户可以设置从哪个网站抓取数据,要抓取的数据,要抓取的数据范围,何时抓取数据,如何保存抓取的数据等. 以文章文本采集为例,说明如何使用优采云 采集网页文章文本. 文章正文采集有两种主要类型的情况: 1. 采集 文章正文中的文字没有图片; 2. 采集 文章正文中的文本和图像URL. 示例网站: 使用功能点: Xpath判断条件页面列表信息采集 AJAX滚动教程AJAX单击并翻页1. 采集 文章正文中没有图片. 具体步骤: 步骤1)输入2)步骤1: 创建并进入主界面,进入采集的采集任务,选择“自定义URL URL多定义模式”,将网页文本复制并粘贴到网站 文章文本采集输入框设置步骤1,单击“保存URL”步骤1)在Web页面上做评论2: 创建翻转在页面右上角打开页面后,在在无提示提示框中,选择页面循环的一角,然后打开“流默认显示”.
下一个操作” 文章正文采集显示“过程设置下拉页面,找到设置的第2步设计器”和“查找并单击“自定义当前操作”并“加载更多内部操作”两个板内容”按钮部分,在操作中2)选择“循环单击单个元素网页元素”以创建文章文本采集以建立页面翻转循环. 步骤3循环,因为打开此网页涉及打开在“高级选项和Ajax技术”项中,选中“网页文本,我们需要输入”一些高级数据的Ajax加载号文章文本采集”,将设置步骤4的选项设置为2. 选择“点”,然后单击“元素”,逐步: 注意: AJA可以观察到文章“高清” AJAX的延迟,以便不重新添加AX,单击并翻页以查看该网页, 文章. 因此,“高级选项”,时间加载,异步加载整个网页教程: htt发现,通过我们的设置来完全打开“一种满足网页文本更新的页脚,请单击tp: //www.b5次”在以下条件下循环翻动页面时,添加整套“返回文章文本采集脚本技术”,并通过在azhuayu.co的特定部分加载更多内容页面的步骤执行退出循环. ”. 步骤5: “通过背景和零件om / tutorial内容进行更新”,在页面上添加5行. 选择并设置周期时间以更新服务器. 有关详细信息,请参阅detail-1 / aja加载... 查看全部
网页文章正文采集方法
网页文章文本采集方法,并以微信文章 采集为例. 当我们想将新闻保存在今天的头条新闻上并将文章保存在搜狗微信上时,该怎么办?复制并粘贴一篇文章?选择通用网页数据采集器将使工作变得更加容易. 优采云是常规网页数据采集器,它可以是采集 Internet上的公共数据. 用户可以设置从哪个网站抓取数据,要抓取的数据,要抓取的数据范围,何时抓取数据,如何保存抓取的数据等. 以文章文本采集为例,说明如何使用优采云 采集网页文章文本. 文章正文采集有两种主要类型的情况: 1. 采集 文章正文中的文字没有图片; 2. 采集 文章正文中的文本和图像URL. 示例网站: 使用功能点: Xpath判断条件页面列表信息采集 AJAX滚动教程AJAX单击并翻页1. 采集 文章正文中没有图片. 具体步骤: 步骤1)输入2)步骤1: 创建并进入主界面,进入采集的采集任务,选择“自定义URL URL多定义模式”,将网页文本复制并粘贴到网站 文章文本采集输入框设置步骤1,单击“保存URL”步骤1)在Web页面上做评论2: 创建翻转在页面右上角打开页面后,在在无提示提示框中,选择页面循环的一角,然后打开“流默认显示”.
下一个操作” 文章正文采集显示“过程设置下拉页面,找到设置的第2步设计器”和“查找并单击“自定义当前操作”并“加载更多内部操作”两个板内容”按钮部分,在操作中2)选择“循环单击单个元素网页元素”以创建文章文本采集以建立页面翻转循环. 步骤3循环,因为打开此网页涉及打开在“高级选项和Ajax技术”项中,选中“网页文本,我们需要输入”一些高级数据的Ajax加载号文章文本采集”,将设置步骤4的选项设置为2. 选择“点”,然后单击“元素”,逐步: 注意: AJA可以观察到文章“高清” AJAX的延迟,以便不重新添加AX,单击并翻页以查看该网页, 文章. 因此,“高级选项”,时间加载,异步加载整个网页教程: htt发现,通过我们的设置来完全打开“一种满足网页文本更新的页脚,请单击tp: //www.b5次”在以下条件下循环翻动页面时,添加整套“返回文章文本采集脚本技术”,并通过在azhuayu.co的特定部分加载更多内容页面的步骤执行退出循环. ”. 步骤5: “通过背景和零件om / tutorial内容进行更新”,在页面上添加5行. 选择并设置周期时间以更新服务器. 有关详细信息,请参阅detail-1 / aja加载...
解决方案:微信小程序无埋点数据采集方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 420 次浏览 • 2020-09-01 13:36
前言
我相信业务团队不会太熟悉这种场景:
此数据非常重要. 让我们从数据采集的重要性,数据的划分,采集的方法以及微信小程序中的掩埋方案中详细讨论数据. 采集.
首先,数据采集的重要性
在本文中,我们将重点介绍数据采集. 我们暂时不会详细讨论数据的作用. 首先,我们将总结并总结数据在性能优化,业务增长和在线故障排除中的重要作用. 这就是为什么我们需要掩盖一些要点.
数据在在线故障排除中的作用:
数据在性能优化中的作用:
数据在业务增长中的作用:
II. 采集数据划分和排序
首先,我们总结了数据的重要性. 不同的业务项目对数据的重要性有不同的重视. 数据采集需要哪种数据?
首先,闭环数据包括:
用户行为用户信息,CRM(客户关系)交易数据,服务器日志数据
以上三项数据可视为完整的数据流闭环. 当然,可以将不同业务场景中的数据进一步细分为更多的细节,一般的关键点基本上不超过这三个项目. 对于前端数据采集,闭环数据的前两项主要由客户端报告,而第三点主要由服务器记录并由客户端协助,因为事务请求实际上到达了服务器完成处理. 闭环. 用户行为数据还包括五个要素-时间(何时),地点(何处),人(谁),互动(方式)和互动内容(什么),与新闻的五个要素相似;与用户信息有关的某些企业需要授权用户敏感信息和隐私,因此用户信息由业务方案确定. 最基本的数据要求是唯一标识用户. CRM,交易数据和用户信息是相似的,并且特定的数据详细信息由业务方案确定. CRM基本数据要求是登录信息和成员相关信息. 交易数据包括交易时间,交易对象,交易内容,交易金额和交易状态.
3. 数据报告方法
在讨论数据之后,下一步就是知道如何获取我们真正需要的数据. 数据报告方法可以大致分为三类:
重点放在非埋点上. 视觉上的隐埋点实际上可以视为非隐埋点的派生. 视觉上隐藏的点将不在此处讨论. 主要比较是代码掩埋点和非掩埋点.
3.1代码嵌入点或Capture模式的嵌入点的缺点
对于数据产品:
依靠人类的经验和直观的判断力.
与业务相关的埋葬地点需要数据产品或业务产品的主观判断,而与技术相关的埋葬地点需要技术人员的主观判断. 通讯成本高
要确定数据产品所需的数据,有必要提出要求并与开发人员进行交流,并且数据人员对技术不是特别熟悉,并且有必要与开发人员澄清是否相关. 信息可以报告可行性. 有数据清理费用
随着业务的变化和变化,以前的主观判断所需的数据也将发生变化. 此时,需要手动清理以前管理的数据,清理工作量不小.
用于开发:
开发人员能耗
对于业务团队来说,它经常受到相关开发人员的批评. 开发技术人员不仅可以专注于技术,还需要分散精力来完成高度重复性和机械性的任务,例如掩埋点. 嵌入式代码具有侵入性,会对系统设计和代码可维护性产生负面影响
大多数与业务相关的数据点都需要手动掩埋,并且掩埋的代码必须与业务代码紧密结合. 即使行业中没有sdk,数据产品关注的特殊业务点也无法逃脱手工掩盖.
随着业务需求在不断的业务变化下发生变化,用于嵌入的相关代码也需要相应地进行更改. 进一步增加开发和代码维护成本. 容易出错,遗漏
由于人工管理的主观差异,放置位置的准确性难以控制,并且管理过程中存在成本高昂的问题,容易造成数据泄漏
当丢失或错误采集数据时,它必须再次经过开发过程和联机过程,这效率很低. 3.2无埋点的优势
与手动掩埋点相比,无需解释没有掩埋点的优点.
提高效率,数据更全面,按需提取并减少代码入侵. 四,微信小程序无埋点SDK程序4.1无埋点数据要求
双向监控逻辑图
清除图片地址标记
由于applet与Web服务不同,因此没有诸如js / css资源加载之类的事情. 因此,应更加注意初始化状态和小程序的执行的记录,捕获和报告. 图中的资源完整性检查对应于初始化的完成. 考试. 在线小程序中请求的域名必须是https协议,因此DNS劫持的可能性大大降低,甚至不太可能发生,并且从客户端监视DNS劫持的可行性很低(存在悖论),因此DNS劫持暂时不考虑捕获.
4.2开发微信小程序非嵌入式SDK的难点和要点
微信请求通过微信API统一完成. 请求模块已经被微信方封装,小应用程序的运行环境不是浏览器对象. 像Web应用程序一样难以重写和封装.
不能直接监视用户行为. 强大的可伸缩性需要适用于多种体系结构设计方案(小型程序). SDK必须是轻量级的. 每个小程序都有2M的限制,并且该小程序不支持将代码引入. npm软件包,因此sdk本身将占用2M的大小限制. 尽管该applet已分包了内部测试,但该功能尚未完全发布,并且作为SDK太大太大是不合理的. 采集大量数据,在不影响业务的情况下将性能损失降至最低(基本要求)
4.3微信小程序无埋点sdk设计
数据层设计:
数据层设计
清除数据层设计图像的地址标记
数据流向设计:
数据流移向图片的清晰地址标记
采集方式设计:
采集为图片设计清晰的地址戳的方法
访问方法:
在小程序初始化代码之前介绍sdk npm软件包代码. 当小程序打包代码时,将sdk代码导入项目,并在初始化后自动采集数据. 初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({
channel: 'channel',
env: config.IS_PRODUCION ? 'product': 'beta',
project: 'yourProjectName',
methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称
})
没有掩埋点和掩埋点的组合:
小程序的非嵌入式方法可以获取大量数据,并且基本上可以实现用户使用场景的高度还原. SDK管理的粒度是某种方法的执行. 当特殊业务关注的粒度小于SDK的粒度时,如果没有埋藏点,SDK将无法完全解决. 可以使用没有掩埋点和掩埋点的组合,因此我们的小程序不能使用. 掩埋点SDK还提供了API接口,用于手动掩埋点以改善数据的完整性并解决更多问题(请参阅数据的重要性).
第五,在没有掩埋点SDK的小程序中遇到的问题
除了解决微信小程序非嵌入式sdk开发中的上述困难和关键问题外,还遇到了一些新的问题.
SDK本身将对业务绩效产生一定影响. 数据被临时存储在applet的本地存储中,而当业务本身消耗更多性能时,将暴露经常存储和检索的applet的本地存储. 操作被卡住. 减少本地存储的存储/检索操作. 关闭页面时,仅未上载的数据存储在本地存储中. 完整的数据量巨大. 灰度联机时,遇到服务器过载和服务器可用性降低的问题. 随后控制报告的数据量,仅自动报告关键节点数据,并且可以在访问初始化期间通过目标配置报告其他以业务为中心的节点,以避免报告过多的冗余数据. 此外,应特别注意报告数据结构的设计. 结构目标是清楚,简洁并且方便数据检索(区分). 在初始阶段,我想对是否使用SDK进行在线灰度进行“切换”,以避免小程序回滚过程. 由于“开关”依赖于服务器接口控制,并且请求是异步的,因此这意味着初始化过程和小程序的启动必须等待,直到控制该开关的接口返回,否则“开关”等同于失败. . 考虑到SDK不会影响业务绩效,请丢弃“开关”,并尝试在SDK中进行捕获,以避免影响业务可用性.
借助通过报告获得的数据而无需掩埋点,该数据可用于将来解决许多问题. 有关数据的使用,请期待下一节“数据应用程序”.
参考文献:
[1] [美国]裴Ji,译者姚军等,“深入了解网站优化”,出版社: 机械工业出版社,出版时间: 2013-08
[2]张锡萌,“首席增长官”,出版社: 机械工业出版社,出版日期: 第一版(2017年11月6日) 查看全部
微信小程序无埋点数据采集方案
前言
我相信业务团队不会太熟悉这种场景:
此数据非常重要. 让我们从数据采集的重要性,数据的划分,采集的方法以及微信小程序中的掩埋方案中详细讨论数据. 采集.
首先,数据采集的重要性
在本文中,我们将重点介绍数据采集. 我们暂时不会详细讨论数据的作用. 首先,我们将总结并总结数据在性能优化,业务增长和在线故障排除中的重要作用. 这就是为什么我们需要掩盖一些要点.
数据在在线故障排除中的作用:
数据在性能优化中的作用:
数据在业务增长中的作用:
II. 采集数据划分和排序
首先,我们总结了数据的重要性. 不同的业务项目对数据的重要性有不同的重视. 数据采集需要哪种数据?
首先,闭环数据包括:
用户行为用户信息,CRM(客户关系)交易数据,服务器日志数据
以上三项数据可视为完整的数据流闭环. 当然,可以将不同业务场景中的数据进一步细分为更多的细节,一般的关键点基本上不超过这三个项目. 对于前端数据采集,闭环数据的前两项主要由客户端报告,而第三点主要由服务器记录并由客户端协助,因为事务请求实际上到达了服务器完成处理. 闭环. 用户行为数据还包括五个要素-时间(何时),地点(何处),人(谁),互动(方式)和互动内容(什么),与新闻的五个要素相似;与用户信息有关的某些企业需要授权用户敏感信息和隐私,因此用户信息由业务方案确定. 最基本的数据要求是唯一标识用户. CRM,交易数据和用户信息是相似的,并且特定的数据详细信息由业务方案确定. CRM基本数据要求是登录信息和成员相关信息. 交易数据包括交易时间,交易对象,交易内容,交易金额和交易状态.
3. 数据报告方法
在讨论数据之后,下一步就是知道如何获取我们真正需要的数据. 数据报告方法可以大致分为三类:
重点放在非埋点上. 视觉上的隐埋点实际上可以视为非隐埋点的派生. 视觉上隐藏的点将不在此处讨论. 主要比较是代码掩埋点和非掩埋点.
3.1代码嵌入点或Capture模式的嵌入点的缺点
对于数据产品:
依靠人类的经验和直观的判断力.
与业务相关的埋葬地点需要数据产品或业务产品的主观判断,而与技术相关的埋葬地点需要技术人员的主观判断. 通讯成本高
要确定数据产品所需的数据,有必要提出要求并与开发人员进行交流,并且数据人员对技术不是特别熟悉,并且有必要与开发人员澄清是否相关. 信息可以报告可行性. 有数据清理费用
随着业务的变化和变化,以前的主观判断所需的数据也将发生变化. 此时,需要手动清理以前管理的数据,清理工作量不小.
用于开发:
开发人员能耗
对于业务团队来说,它经常受到相关开发人员的批评. 开发技术人员不仅可以专注于技术,还需要分散精力来完成高度重复性和机械性的任务,例如掩埋点. 嵌入式代码具有侵入性,会对系统设计和代码可维护性产生负面影响
大多数与业务相关的数据点都需要手动掩埋,并且掩埋的代码必须与业务代码紧密结合. 即使行业中没有sdk,数据产品关注的特殊业务点也无法逃脱手工掩盖.
随着业务需求在不断的业务变化下发生变化,用于嵌入的相关代码也需要相应地进行更改. 进一步增加开发和代码维护成本. 容易出错,遗漏
由于人工管理的主观差异,放置位置的准确性难以控制,并且管理过程中存在成本高昂的问题,容易造成数据泄漏
当丢失或错误采集数据时,它必须再次经过开发过程和联机过程,这效率很低. 3.2无埋点的优势
与手动掩埋点相比,无需解释没有掩埋点的优点.
提高效率,数据更全面,按需提取并减少代码入侵. 四,微信小程序无埋点SDK程序4.1无埋点数据要求
双向监控逻辑图
清除图片地址标记
由于applet与Web服务不同,因此没有诸如js / css资源加载之类的事情. 因此,应更加注意初始化状态和小程序的执行的记录,捕获和报告. 图中的资源完整性检查对应于初始化的完成. 考试. 在线小程序中请求的域名必须是https协议,因此DNS劫持的可能性大大降低,甚至不太可能发生,并且从客户端监视DNS劫持的可行性很低(存在悖论),因此DNS劫持暂时不考虑捕获.
4.2开发微信小程序非嵌入式SDK的难点和要点
微信请求通过微信API统一完成. 请求模块已经被微信方封装,小应用程序的运行环境不是浏览器对象. 像Web应用程序一样难以重写和封装.
不能直接监视用户行为. 强大的可伸缩性需要适用于多种体系结构设计方案(小型程序). SDK必须是轻量级的. 每个小程序都有2M的限制,并且该小程序不支持将代码引入. npm软件包,因此sdk本身将占用2M的大小限制. 尽管该applet已分包了内部测试,但该功能尚未完全发布,并且作为SDK太大太大是不合理的. 采集大量数据,在不影响业务的情况下将性能损失降至最低(基本要求)
4.3微信小程序无埋点sdk设计
数据层设计:
数据层设计
清除数据层设计图像的地址标记
数据流向设计:
数据流移向图片的清晰地址标记
采集方式设计:
采集为图片设计清晰的地址戳的方法
访问方法:
在小程序初始化代码之前介绍sdk npm软件包代码. 当小程序打包代码时,将sdk代码导入项目,并在初始化后自动采集数据. 初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({
channel: 'channel',
env: config.IS_PRODUCION ? 'product': 'beta',
project: 'yourProjectName',
methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称
})
没有掩埋点和掩埋点的组合:
小程序的非嵌入式方法可以获取大量数据,并且基本上可以实现用户使用场景的高度还原. SDK管理的粒度是某种方法的执行. 当特殊业务关注的粒度小于SDK的粒度时,如果没有埋藏点,SDK将无法完全解决. 可以使用没有掩埋点和掩埋点的组合,因此我们的小程序不能使用. 掩埋点SDK还提供了API接口,用于手动掩埋点以改善数据的完整性并解决更多问题(请参阅数据的重要性).
第五,在没有掩埋点SDK的小程序中遇到的问题
除了解决微信小程序非嵌入式sdk开发中的上述困难和关键问题外,还遇到了一些新的问题.
SDK本身将对业务绩效产生一定影响. 数据被临时存储在applet的本地存储中,而当业务本身消耗更多性能时,将暴露经常存储和检索的applet的本地存储. 操作被卡住. 减少本地存储的存储/检索操作. 关闭页面时,仅未上载的数据存储在本地存储中. 完整的数据量巨大. 灰度联机时,遇到服务器过载和服务器可用性降低的问题. 随后控制报告的数据量,仅自动报告关键节点数据,并且可以在访问初始化期间通过目标配置报告其他以业务为中心的节点,以避免报告过多的冗余数据. 此外,应特别注意报告数据结构的设计. 结构目标是清楚,简洁并且方便数据检索(区分). 在初始阶段,我想对是否使用SDK进行在线灰度进行“切换”,以避免小程序回滚过程. 由于“开关”依赖于服务器接口控制,并且请求是异步的,因此这意味着初始化过程和小程序的启动必须等待,直到控制该开关的接口返回,否则“开关”等同于失败. . 考虑到SDK不会影响业务绩效,请丢弃“开关”,并尝试在SDK中进行捕获,以避免影响业务可用性.
借助通过报告获得的数据而无需掩埋点,该数据可用于将来解决许多问题. 有关数据的使用,请期待下一节“数据应用程序”.
参考文献:
[1] [美国]裴Ji,译者姚军等,“深入了解网站优化”,出版社: 机械工业出版社,出版时间: 2013-08
[2]张锡萌,“首席增长官”,出版社: 机械工业出版社,出版日期: 第一版(2017年11月6日)
汇总:记一次WEB数据采集程序开发经历——对付简单的动态加载
采集交流 • 优采云 发表了文章 • 0 个评论 • 535 次浏览 • 2020-08-30 06:21
自从学做网站账号批量注册机、图片批量下载器,开始接触HTTP合同,了解了基本的GET/POST恳求等知识,于是便开始着手开发一些小东西了。
WEB数据采集,很多人都在搞。据说搞WEB数据采集用JAVA会更方便,有很多现成的解释器可用。可以说WEB数据采集这块,是C++的弱项。我目前能想到的方式就是借助WinInet,这是一组关于Intelnet三大合同HTTP、FTP、Gopher的windowsAPI。这组API在MFC里有了封装,用上去更方便,#include 。目前用于开发非企业级的WEB数据采集器绰绰有余。我发觉这些个人级的WEB数据采集器,很多人都是用delphi开发,可能是delphi在网路这块要强点吧。
前几天在猪八戒威客网上见到一个悬赏200元的开发程序的任务。任务内容大约是这样的:开发一个程序,从一个类似于58同城的网咖急聘网上采集网吧信息。这个网站上全部是全国各地的网咖急聘信息,要求把这种网咖信息:网吧名、地区、联系人、电话、QQ采集到ACCESS数据库里。其实他的目的不言而喻,他要采集这些数据干嘛?无非是发广告呗,嘿嘿。闲话不多说,打开这个网站看。(敏感信息被我打了马赛克)
可以看下来,这些信息都只是文本,并不是图片。那就简单多了,直接从HTML里读下来不就完事了。用MFC的CInternetSession对象的OpenURL方式打开URL,返回CHttpFile表针,通过该表针调用Read方式把整个HTML页面文本全部读到缓冲区。查看缓冲区,搜索手机号1352298...,居然没搜到。搜索“乔先生”,搜到了。怎么回事?怎么没有手机号在HTML里?
用谷歌浏览器打开这个页面,右键查看源码如下:
发现联系人、邮箱、地址都有,手机号和QQ哪里竟然是空的。为什么是空的呢?我不停的刷新页面,思考着这个问题。突然,我发每次刷新,都是页面全部内容都下来了,手机号和QQ才紧跟其后下来。动态加载!手机号和QQ没有在静态HTML里,是后来加载的。
怎么办?抓包剖析!打开Fiddler,强烈推荐这个软件,专门用于抓HTTP合同的包。抓包后发觉,每次打开网页,除了页面元素下载,IE进行了四次恳求。
0、2、8、9号恳求,一个一个查看:
第一个GET恳求,很明显,是获取页面HTML的,从下边内容看,也确实是获取了HTML页面。这些内容也就相当于我用CInternetSession获取到的内容,手机号和QQ不在这上面的,不用看了。
第二个是POST恳求,从返回内容上来看,是获取评论的,没有我们要找的信息。
第三个是GET恳求,从返回内容上来看不知道是哪些,先略过。
第四个是POST恳求,从返回信息上来看,正是我们要的信息!原来动态加载是如此加载的。我们也用程序模拟这个POST不就行了?但是等等,注意这个POST的目标URL,最后是一段其实密文的东西。多抓几次瞧瞧,发现这段密文每次都不一样!难道是按照时间或Cookie哪些的算下来的?那样就比较麻烦了!仔细想想,这个POST递交了个“barID=3070",ID3070,这个ID号在HTML里是有的,它通过递交这个ID获取这个ID对应的网咖信息,那我们在HTML文件里搜索这个ID3070瞧瞧。
一搜还果然搜到了。太显著了,这是一段JS脚本,GetBarInfo这个函数也很显著了吧,注意旁边的URL,正是我们仍然想不通的那段密文!原来是这样!每次获取HTML页面后,里面都收录了不同的用于动态获取网咖信息的URL。再对这个URL用POST方法递交ID获取网咖信息。原来是如此简单。那就容易了,在我们写的程序里,用CInternetSession获取页面HTML内容后检索出这段URL和网咖ID,再用CHttpConnection对象模拟递交一个POST,就可以得到手机号和QQ号了。
可以说这个网站为了防爬虫爬取信息,还是做了一点动态加载的限制,但也很弱了点,直接在HTML上面曝露了。也是我先前一点HTML知识都不懂,搞了半天才发觉,如果是熟悉HTML和JS脚本的人,应该一下就发觉了吧。
看来网页这块,也得了解下,学习下,如果要继续做WEB数据采集的话。还有更多困局呢。 查看全部
记一次WEB数据采集程序开发经历——对付简单的动态加载
自从学做网站账号批量注册机、图片批量下载器,开始接触HTTP合同,了解了基本的GET/POST恳求等知识,于是便开始着手开发一些小东西了。
WEB数据采集,很多人都在搞。据说搞WEB数据采集用JAVA会更方便,有很多现成的解释器可用。可以说WEB数据采集这块,是C++的弱项。我目前能想到的方式就是借助WinInet,这是一组关于Intelnet三大合同HTTP、FTP、Gopher的windowsAPI。这组API在MFC里有了封装,用上去更方便,#include 。目前用于开发非企业级的WEB数据采集器绰绰有余。我发觉这些个人级的WEB数据采集器,很多人都是用delphi开发,可能是delphi在网路这块要强点吧。
前几天在猪八戒威客网上见到一个悬赏200元的开发程序的任务。任务内容大约是这样的:开发一个程序,从一个类似于58同城的网咖急聘网上采集网吧信息。这个网站上全部是全国各地的网咖急聘信息,要求把这种网咖信息:网吧名、地区、联系人、电话、QQ采集到ACCESS数据库里。其实他的目的不言而喻,他要采集这些数据干嘛?无非是发广告呗,嘿嘿。闲话不多说,打开这个网站看。(敏感信息被我打了马赛克)
可以看下来,这些信息都只是文本,并不是图片。那就简单多了,直接从HTML里读下来不就完事了。用MFC的CInternetSession对象的OpenURL方式打开URL,返回CHttpFile表针,通过该表针调用Read方式把整个HTML页面文本全部读到缓冲区。查看缓冲区,搜索手机号1352298...,居然没搜到。搜索“乔先生”,搜到了。怎么回事?怎么没有手机号在HTML里?
用谷歌浏览器打开这个页面,右键查看源码如下:
发现联系人、邮箱、地址都有,手机号和QQ哪里竟然是空的。为什么是空的呢?我不停的刷新页面,思考着这个问题。突然,我发每次刷新,都是页面全部内容都下来了,手机号和QQ才紧跟其后下来。动态加载!手机号和QQ没有在静态HTML里,是后来加载的。
怎么办?抓包剖析!打开Fiddler,强烈推荐这个软件,专门用于抓HTTP合同的包。抓包后发觉,每次打开网页,除了页面元素下载,IE进行了四次恳求。
0、2、8、9号恳求,一个一个查看:
第一个GET恳求,很明显,是获取页面HTML的,从下边内容看,也确实是获取了HTML页面。这些内容也就相当于我用CInternetSession获取到的内容,手机号和QQ不在这上面的,不用看了。
第二个是POST恳求,从返回内容上来看,是获取评论的,没有我们要找的信息。
第三个是GET恳求,从返回内容上来看不知道是哪些,先略过。
第四个是POST恳求,从返回信息上来看,正是我们要的信息!原来动态加载是如此加载的。我们也用程序模拟这个POST不就行了?但是等等,注意这个POST的目标URL,最后是一段其实密文的东西。多抓几次瞧瞧,发现这段密文每次都不一样!难道是按照时间或Cookie哪些的算下来的?那样就比较麻烦了!仔细想想,这个POST递交了个“barID=3070",ID3070,这个ID号在HTML里是有的,它通过递交这个ID获取这个ID对应的网咖信息,那我们在HTML文件里搜索这个ID3070瞧瞧。
一搜还果然搜到了。太显著了,这是一段JS脚本,GetBarInfo这个函数也很显著了吧,注意旁边的URL,正是我们仍然想不通的那段密文!原来是这样!每次获取HTML页面后,里面都收录了不同的用于动态获取网咖信息的URL。再对这个URL用POST方法递交ID获取网咖信息。原来是如此简单。那就容易了,在我们写的程序里,用CInternetSession获取页面HTML内容后检索出这段URL和网咖ID,再用CHttpConnection对象模拟递交一个POST,就可以得到手机号和QQ号了。
可以说这个网站为了防爬虫爬取信息,还是做了一点动态加载的限制,但也很弱了点,直接在HTML上面曝露了。也是我先前一点HTML知识都不懂,搞了半天才发觉,如果是熟悉HTML和JS脚本的人,应该一下就发觉了吧。
看来网页这块,也得了解下,学习下,如果要继续做WEB数据采集的话。还有更多困局呢。
小程序开发(一):使用scrapy爬虫采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2020-08-28 05:48
过完年回去,业余时间仍然在独立开发一个小程序。主要数据是8000+个视频和10000+篇文章,并且数据会每晚手动更新。
我会整理下整个开发过程中碰到的问题和一些细节问题,因为内容会比较多,我会分成三到四篇文章来进行,本文是该系列的第一篇文章,内容偏 python 爬虫。
本系列文章大致会介绍一下内容:
数据打算(python的scrapy框架)
接口打算(nodejs的hapijs框架)
小程序开发(mpvue以及小程序自带的组件等)
部署上线(小程序安全域名等配置以及爬虫/接口等线上布署维护)
数据获取
数据获取的方式有很多种,这次我们选择了爬虫的方法,当然写一个爬虫也可以用不同的语言,不同的形式。之前写过好多爬虫,这次我们选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
学习scrapy,最好的形式就是先阅读一遍文档(Scrapy 1.6 documentation),然后照着文档里的反例写一写,慢慢就熟悉了。里面有几个很重要的概念是必须要理解的:
Items
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和 数据库 字段对应,便于入库。
Spiders
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
pipelines
“After an item has been scraped by a spider, it is sent to the Item Pipeline which processes it through several components that are executed sequentially.”,pipelines也就是我们爬虫领到数据后要进行的处理操作,比如写入到文件,或者链接数据库,并且保存到数据库等等操作,都可以在这里进行操作。
Selectors
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的 html 文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
几个重要的部份,在里面进行了一些说明。
准备好环境(python3/scrapy等),我们就可以来写一个爬虫项目了。
爬取的内容来自于 这个网站。
创建项目
scrapy startproject jqhtml
修改items
添加爬虫
爬虫爬虫
编写pipeline 更改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
scrapy爬虫项目的布署
scrapy爬虫项目的布署,我们使用官方的scrapyd即可,使用方式也比较简单,在 服务器 上安装scrapyd而且启动即可,然后在本地项目中配置deploy的路径,本地安装scrapy-client,使用命令deploy即可布署到服务器。
scrapyd提供了一些api插口来查看项目爬虫情况,以及执行或则停止执行爬虫。
这样我们就很方便的调这种插口来管理我们的爬虫任务了。
注意点:
如何布署scrapyd到服务器怎么设置scrapyd为系统后台服务及系统启动项
NEXT
下一篇,我们会介绍而且使用太火的一个nodejs后台api库 - hapijs。完成小程序所须要的所有插口的开发,以及使用定时任务执行爬虫脚本。 查看全部
小程序开发(一):使用scrapy爬虫采集数据
过完年回去,业余时间仍然在独立开发一个小程序。主要数据是8000+个视频和10000+篇文章,并且数据会每晚手动更新。
我会整理下整个开发过程中碰到的问题和一些细节问题,因为内容会比较多,我会分成三到四篇文章来进行,本文是该系列的第一篇文章,内容偏 python 爬虫。
本系列文章大致会介绍一下内容:
数据打算(python的scrapy框架)
接口打算(nodejs的hapijs框架)
小程序开发(mpvue以及小程序自带的组件等)
部署上线(小程序安全域名等配置以及爬虫/接口等线上布署维护)
数据获取
数据获取的方式有很多种,这次我们选择了爬虫的方法,当然写一个爬虫也可以用不同的语言,不同的形式。之前写过好多爬虫,这次我们选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
学习scrapy,最好的形式就是先阅读一遍文档(Scrapy 1.6 documentation),然后照着文档里的反例写一写,慢慢就熟悉了。里面有几个很重要的概念是必须要理解的:
Items
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和 数据库 字段对应,便于入库。
Spiders
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
pipelines
“After an item has been scraped by a spider, it is sent to the Item Pipeline which processes it through several components that are executed sequentially.”,pipelines也就是我们爬虫领到数据后要进行的处理操作,比如写入到文件,或者链接数据库,并且保存到数据库等等操作,都可以在这里进行操作。
Selectors
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的 html 文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
几个重要的部份,在里面进行了一些说明。
准备好环境(python3/scrapy等),我们就可以来写一个爬虫项目了。
爬取的内容来自于 这个网站。
创建项目
scrapy startproject jqhtml
修改items
添加爬虫
爬虫爬虫
编写pipeline 更改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
scrapy爬虫项目的布署
scrapy爬虫项目的布署,我们使用官方的scrapyd即可,使用方式也比较简单,在 服务器 上安装scrapyd而且启动即可,然后在本地项目中配置deploy的路径,本地安装scrapy-client,使用命令deploy即可布署到服务器。
scrapyd提供了一些api插口来查看项目爬虫情况,以及执行或则停止执行爬虫。
这样我们就很方便的调这种插口来管理我们的爬虫任务了。
注意点:
如何布署scrapyd到服务器怎么设置scrapyd为系统后台服务及系统启动项
NEXT
下一篇,我们会介绍而且使用太火的一个nodejs后台api库 - hapijs。完成小程序所须要的所有插口的开发,以及使用定时任务执行爬虫脚本。
小程序开发解析:帝国cms采集图文教程(下)_重庆北碚区微信公众号小程序开发教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-27 19:16
前两讲我们分别介绍了帝国cms采集基本流程和帝国cms如何采集内容分页,最后这一讲主要介绍帝国cms采集过滤与替换,还有些窍门。
一、过滤
1、帝国cms采集过滤分为两种:
(1)“整体页面过滤正则”:
(2)“过滤广告正则”:
我们有些疑问,这两种过滤究竟有哪些区别?“整体页面过滤正则”是过滤整个网页的html代码。重庆北碚区陌陌小程序开发要多少钱,“过滤广告正则”是过滤文章内容,仅对文章内容([!--newstext--])起作用。
2、过滤实例:
过滤实例(1):
我们采集后发觉信息内容顶部多了行代码:“
过滤实例(2):
要过滤链接代码怎样办,注意“过滤广告正则”右边有堆代码:
鼠标先点击A,系统手动生成过滤链接代码“,,,”,这样就可以把采集后的内容链接过滤掉了。重庆北碚区陌陌有什么小程序开发,同理,如果想过滤其他html代码就点击相应的标签代码。
注意事项:当内容分页收录在内容([!--newstext--])里时,要过滤掉内容分页,否则会重复出现内容分页。重庆北碚区微信公众号小程序开发教程,
二、替换
1、帝国cms采集替换也分为两种:
(1)“整体页面替换”:
(2)“替换”:
他们两种区别:“整体页面替换”是替换整个网页的html代码。“替换”是替换文章标题和内容,仅对标题([!--title--])和([!--newstext--])起作用。 查看全部
小程序开发解析:帝国cms采集图文教程(下)_重庆北碚区微信公众号小程序开发教程
前两讲我们分别介绍了帝国cms采集基本流程和帝国cms如何采集内容分页,最后这一讲主要介绍帝国cms采集过滤与替换,还有些窍门。
一、过滤
1、帝国cms采集过滤分为两种:
(1)“整体页面过滤正则”:
(2)“过滤广告正则”:
我们有些疑问,这两种过滤究竟有哪些区别?“整体页面过滤正则”是过滤整个网页的html代码。重庆北碚区陌陌小程序开发要多少钱,“过滤广告正则”是过滤文章内容,仅对文章内容([!--newstext--])起作用。
2、过滤实例:
过滤实例(1):
我们采集后发觉信息内容顶部多了行代码:“
过滤实例(2):
要过滤链接代码怎样办,注意“过滤广告正则”右边有堆代码:
鼠标先点击A,系统手动生成过滤链接代码“,,,”,这样就可以把采集后的内容链接过滤掉了。重庆北碚区陌陌有什么小程序开发,同理,如果想过滤其他html代码就点击相应的标签代码。
注意事项:当内容分页收录在内容([!--newstext--])里时,要过滤掉内容分页,否则会重复出现内容分页。重庆北碚区微信公众号小程序开发教程,
二、替换
1、帝国cms采集替换也分为两种:
(1)“整体页面替换”:
(2)“替换”:
他们两种区别:“整体页面替换”是替换整个网页的html代码。“替换”是替换文章标题和内容,仅对标题([!--title--])和([!--newstext--])起作用。
如何避免网站被采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-08-27 12:47
2018-03-15
新网站 房源信息采集
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告清除...全部
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除 支持多页面文章内容手动抽取与合并 支持下一页手动浏览功能 支持直接递交表单 支持模拟递交表单 支持动作脚本 支持从一个页面中抽取多个数据表 支持数据的多种后期处理方法 数据直接步入数据库而不是文件中,因此与借助那些数据的网站程序或则桌面程序之间 没有任何耦合 支持数据库表结构完全自定义,充分利用现有系统 支持多个栏目的信息采集可用同一配置一对多处理 保证信息的完整性与准确性,绝不会出现乱码 支持所有主流数据库:MS SQL Server, Oracle, DB2, MySQL, Sybase, Interbase, MS Access等。 查看全部
如何避免网站被采集?
2018-03-15
新网站 房源信息采集
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告清除...全部
乐思网路信息采集软件就可以做 本系统最大的特征是:采集方法的灵活性与采集数据的准确性 灵活性:任何复杂的查询与页面布局都可以灵活处理 准确性:结果数据高度确切(99%-100%) 乐思网路信息采集,就是可以专门拿来网站内容抓取的,他可以实现对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息,URL,数字,日期,图片等 用户对每类信息自定义来源与分类 可以下载图片与各种文件 支持用户名与密码手动登入 支持命令行格式,可以Windows任务计划器配合,定期抽取目标网站 支持记录惟一索引,避免相同信息重复入库 支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除 支持多页面文章内容手动抽取与合并 支持下一页手动浏览功能 支持直接递交表单 支持模拟递交表单 支持动作脚本 支持从一个页面中抽取多个数据表 支持数据的多种后期处理方法 数据直接步入数据库而不是文件中,因此与借助那些数据的网站程序或则桌面程序之间 没有任何耦合 支持数据库表结构完全自定义,充分利用现有系统 支持多个栏目的信息采集可用同一配置一对多处理 保证信息的完整性与准确性,绝不会出现乱码 支持所有主流数据库:MS SQL Server, Oracle, DB2, MySQL, Sybase, Interbase, MS Access等。

