
文章采集程序
文章采集程序(文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-17 10:01
文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和本专栏文章,爬取结果保存为csv文件格式,接下来我们一起来看一下爬取的文章数据情况。图1.1个爬取结果的总结在文章的文末我放上了大文件的网盘链接,文件大小约1.3m。
这种数据一般有专门的爬虫来爬下来
第一步:第二步:第三步:欢迎关注:uwp十点读书-知乎专栏
把这两年那些不错的uwp应用的原始数据都导出来,可以一直滚动到30周岁.
通过分析很多你自己关注和喜欢的话题,并逐步搜索过去三年某一时间点的数据,也能提取出一些相对高质量的uwp应用源代码。不过,这些源代码和以往的应用不太能用,可能是因为换汤不换药。我们知道,几年前能用uwp应用的场景,现在几乎被ios和android占据了,未来主流会是windowsphone平台。现在市面上那些和android和ios的uwp应用源代码相比,有一定的差距,但并不能差得太远。
当然,基本的开发框架还是一样的,但是优化一些东西,做做自己想做的东西,以及动态的做些调整,这两年也是uwp应用的关键时期。如果要弄出些花来,不管是用人力还是软件引擎,方法可能都不止一个。另外,因为uwp应用源代码很多,想弄成精品,这个周期估计会很长,效果也会让人失望。曾经我写过一篇uwp游戏评测专栏,说的是我心目中的精品游戏uwp版本。
前不久,几位高手和他们开发者去了一趟上海,专门品味了最精品的uwp游戏,相关的文章和视频在这里:视频这里介绍几款比较深受欢迎的uwp游戏:评测、下载和评价-uwp十点读书-知乎专栏#10uwpnightscape#是一款令人沉醉的夜空背景模拟游戏,既有ui界面,又有自己的优势:完整的昼夜过渡。ok~回到正题。
目前uwp源代码不像ios和android源代码那么受市场青睐,或许是因为看过ios和android源代码而熟悉了uwp的编程,或许是因为使用gis软件习惯了界面和全平台。以uber为例,两年前我当时测试uber的应用,我就想这应该只有ios或android了吧。就是在这么心急下,我给弄出了uber的uwp应用。
目前uber刚刚推出了uber.android版本,我们以uber.android为主来讨论应用发展。uber.android版本本地编译好,用的是openglspecification提供的tricky方法来加速开发,运行的时候还会自动调用glide包括java在内的第三方库来加速编译。uber.android可以称得上是一款源代码百科全书,可以详细叙述了该应用的界面特征,以及注意事项,在测试用的。 查看全部
文章采集程序(文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和)
文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和本专栏文章,爬取结果保存为csv文件格式,接下来我们一起来看一下爬取的文章数据情况。图1.1个爬取结果的总结在文章的文末我放上了大文件的网盘链接,文件大小约1.3m。
这种数据一般有专门的爬虫来爬下来
第一步:第二步:第三步:欢迎关注:uwp十点读书-知乎专栏
把这两年那些不错的uwp应用的原始数据都导出来,可以一直滚动到30周岁.
通过分析很多你自己关注和喜欢的话题,并逐步搜索过去三年某一时间点的数据,也能提取出一些相对高质量的uwp应用源代码。不过,这些源代码和以往的应用不太能用,可能是因为换汤不换药。我们知道,几年前能用uwp应用的场景,现在几乎被ios和android占据了,未来主流会是windowsphone平台。现在市面上那些和android和ios的uwp应用源代码相比,有一定的差距,但并不能差得太远。
当然,基本的开发框架还是一样的,但是优化一些东西,做做自己想做的东西,以及动态的做些调整,这两年也是uwp应用的关键时期。如果要弄出些花来,不管是用人力还是软件引擎,方法可能都不止一个。另外,因为uwp应用源代码很多,想弄成精品,这个周期估计会很长,效果也会让人失望。曾经我写过一篇uwp游戏评测专栏,说的是我心目中的精品游戏uwp版本。
前不久,几位高手和他们开发者去了一趟上海,专门品味了最精品的uwp游戏,相关的文章和视频在这里:视频这里介绍几款比较深受欢迎的uwp游戏:评测、下载和评价-uwp十点读书-知乎专栏#10uwpnightscape#是一款令人沉醉的夜空背景模拟游戏,既有ui界面,又有自己的优势:完整的昼夜过渡。ok~回到正题。
目前uwp源代码不像ios和android源代码那么受市场青睐,或许是因为看过ios和android源代码而熟悉了uwp的编程,或许是因为使用gis软件习惯了界面和全平台。以uber为例,两年前我当时测试uber的应用,我就想这应该只有ios或android了吧。就是在这么心急下,我给弄出了uber的uwp应用。
目前uber刚刚推出了uber.android版本,我们以uber.android为主来讨论应用发展。uber.android版本本地编译好,用的是openglspecification提供的tricky方法来加速开发,运行的时候还会自动调用glide包括java在内的第三方库来加速编译。uber.android可以称得上是一款源代码百科全书,可以详细叙述了该应用的界面特征,以及注意事项,在测试用的。
文章采集程序( 2020年2月7日19:17星期五老叶实战培训教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-17 05:23
2020年2月7日19:17星期五老叶实战培训教程)
@如何使采集站容易成功(附6文章data@采集点)
2020年2月7日星期五19:17,老叶的SEO实践培训课程
百度近年来一直在攻击@采集站点,但我们看到大量@采集站点仍然可以携带算法,避免攻击,最终变得越来越大。这让许多坚持写原创的站长感到难以置信。本文将分享的主题是@采集station如何容易成功
未来是人工智能和大数据时代,这是大势所趋。作为站长或站长,我们也应该跟上时代的步伐。不管原创写了多少,它都不会比其他人更有效@采集. 也许有些人仍然不这么认为,但当你看到@采集电台有多么暴力时,你的想法会立即改变
以下是您自己总结的六个文章data@采集点。如果您想尝试操作@采集站点,不妨将其用作参考:
一、good域名
这里的好域名不是指普通的老域名,而是指最近有着强大历史的域名。例如,如果你在一个站点中实现了爱站power 2,你可以用它来操作@采集站点,也就是说,在@采集数据之前,你的域名必须有很高的百度信任度。这里不包括通过快速排名方式操作的加权域名,权重必须是稳定的站点或具有均衡权重分布的域名
对于那些没有好域名的人,我们可以将该站保留到爱站2不,稍后见@采集。记住:不要让新域名出现。无论你的@采集技术多么强大,最终都是徒劳的
二、高质量数据源
很多人喜欢使用今天的标题作为@采集来源,因为标题数据在百度不是收录的,标题数据来自不同作者的笔迹。此@采集数据形成站点后,与其他站点的相似性不会太高,因此不容易被视为@采集站点。好的数据源通常不仅仅是@采集站点的数据,更不用说直接@采集站点的高权重数据网站
一定要记住:百度高质量数据源的原创度非常高。一般来说,不要@采集截取已经流行三次以上的数据
三、根据关键词@采集
大多数人直接采集@采集数据,而不是按照指定的关键词进行采集采集. 如果我们的@采集数据可以基于带有flow的索引关键词和关键词@采集,网站更容易成功。当然,在早期阶段,用小索引准备word@采集数据。例如,如果索引小于30,则先执行此操作,然后缓慢改进索引
当然,并非所有数据源都能实现这一点。让我们分享一点经验:我们知道爱站有同义词表数据。我们可以选择一些网站特别是@采集他们有同义词表数据,特别是小索引同义词表数据
四、数据处理
很多人制作@采集站点,@采集数据将在文章完成后直接发布。事实上,最好的方法是先@采集然后审查,然后发布。在审查过程中,我们可以删除一些垃圾数据,同时修改标题,或者做一些适当的编辑,这样效果会更好。当然,这不能算是一个纯粹的@采集站,它会花费更多的精力,但是为了提高@采集站的成功率,值得花一些时间
至于同义词替换,我个人觉得意义不大,但会影响用户体验。但是,像两颗豌豆一样的布局是可以调整的。切勿使用与数据源相同的样式和布局。虽然文章是主要内容页,但它也是布局之一原创的布局和体验布局仍然很高。p>
五、学位保证
度的控制主要在于文章更新频率。建议在早期阶段逐步进行。例如,每天10或20篇文章就可以了。在后期增加权重时,大量更新并不是什么大问题。现在许多@采集站点每天更新数万篇文章,主要是因为它们有坚实的基础 查看全部
文章采集程序(
2020年2月7日19:17星期五老叶实战培训教程)
@如何使采集站容易成功(附6文章data@采集点)
2020年2月7日星期五19:17,老叶的SEO实践培训课程
百度近年来一直在攻击@采集站点,但我们看到大量@采集站点仍然可以携带算法,避免攻击,最终变得越来越大。这让许多坚持写原创的站长感到难以置信。本文将分享的主题是@采集station如何容易成功
未来是人工智能和大数据时代,这是大势所趋。作为站长或站长,我们也应该跟上时代的步伐。不管原创写了多少,它都不会比其他人更有效@采集. 也许有些人仍然不这么认为,但当你看到@采集电台有多么暴力时,你的想法会立即改变
以下是您自己总结的六个文章data@采集点。如果您想尝试操作@采集站点,不妨将其用作参考:
一、good域名
这里的好域名不是指普通的老域名,而是指最近有着强大历史的域名。例如,如果你在一个站点中实现了爱站power 2,你可以用它来操作@采集站点,也就是说,在@采集数据之前,你的域名必须有很高的百度信任度。这里不包括通过快速排名方式操作的加权域名,权重必须是稳定的站点或具有均衡权重分布的域名
对于那些没有好域名的人,我们可以将该站保留到爱站2不,稍后见@采集。记住:不要让新域名出现。无论你的@采集技术多么强大,最终都是徒劳的
二、高质量数据源
很多人喜欢使用今天的标题作为@采集来源,因为标题数据在百度不是收录的,标题数据来自不同作者的笔迹。此@采集数据形成站点后,与其他站点的相似性不会太高,因此不容易被视为@采集站点。好的数据源通常不仅仅是@采集站点的数据,更不用说直接@采集站点的高权重数据网站
一定要记住:百度高质量数据源的原创度非常高。一般来说,不要@采集截取已经流行三次以上的数据
三、根据关键词@采集
大多数人直接采集@采集数据,而不是按照指定的关键词进行采集采集. 如果我们的@采集数据可以基于带有flow的索引关键词和关键词@采集,网站更容易成功。当然,在早期阶段,用小索引准备word@采集数据。例如,如果索引小于30,则先执行此操作,然后缓慢改进索引
当然,并非所有数据源都能实现这一点。让我们分享一点经验:我们知道爱站有同义词表数据。我们可以选择一些网站特别是@采集他们有同义词表数据,特别是小索引同义词表数据
四、数据处理
很多人制作@采集站点,@采集数据将在文章完成后直接发布。事实上,最好的方法是先@采集然后审查,然后发布。在审查过程中,我们可以删除一些垃圾数据,同时修改标题,或者做一些适当的编辑,这样效果会更好。当然,这不能算是一个纯粹的@采集站,它会花费更多的精力,但是为了提高@采集站的成功率,值得花一些时间
至于同义词替换,我个人觉得意义不大,但会影响用户体验。但是,像两颗豌豆一样的布局是可以调整的。切勿使用与数据源相同的样式和布局。虽然文章是主要内容页,但它也是布局之一原创的布局和体验布局仍然很高。p>
五、学位保证
度的控制主要在于文章更新频率。建议在早期阶段逐步进行。例如,每天10或20篇文章就可以了。在后期增加权重时,大量更新并不是什么大问题。现在许多@采集站点每天更新数万篇文章,主要是因为它们有坚实的基础
文章采集程序(软件使用C#为SQLite数据库.0的插件进行支持下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-16 04:15
该软件是用c#(微软产品)开发的
净需求Framework2.0受插件支持
下载地址:
如果您是XP系统,请自行下载Framework2.0,如果是win7、VISTAR和win8可以直接运行
为了提高软件的运行效率和可移植性。软件使用的数据库是SQLite数据库
SQLite数据库下载地址:
SQLite数据库查看工具:
软件下载链接:
更新日志
V20140401
图片命名采用描述命名而不是简单的数字命名
如果没有说明,则发布的标题采用关键字+编号作为标题
软件困难:
1、SQLite便携式数据库用于数据存储
2、关于图片命名方法和防止重复的判断采集
3、aboutWordPress网站的登录名与发布的cookie不一致
4、处理线程之间的冲突,用最少的线程实现最多的功能。确保代码简单
注意:SQLite不能在其他机器上运行。提示未注册。因为使用了DBProviderFactorys
解决方案:将以下代码添加到配置文件中
软件编号:Jane Eyre v20140325
软件用途:根据关键字或指定地址自动采集网站相关信息。并保存在数据库中。它不能手动或自动发送到WordPress平台
软件教程:
1、开放式软件
需要注意的问题:
@保存在1、publishing中的域名、用户名、密码等信息将自动保存在setting.txt文件中。下次打开软件时,它将被自动读取
2、每次打开软件时,教程页面都会自动打开。如果你不需要自动打开它。请修改文件。Exe.config文件。如下图所示:将1更改为任意值
如果您在使用中有任何问题,请联系作者Q:2307854925
我喜欢它,因为它很简单 查看全部
文章采集程序(软件使用C#为SQLite数据库.0的插件进行支持下载)
该软件是用c#(微软产品)开发的
净需求Framework2.0受插件支持
下载地址:
如果您是XP系统,请自行下载Framework2.0,如果是win7、VISTAR和win8可以直接运行
为了提高软件的运行效率和可移植性。软件使用的数据库是SQLite数据库
SQLite数据库下载地址:
SQLite数据库查看工具:
软件下载链接:
更新日志
V20140401
图片命名采用描述命名而不是简单的数字命名
如果没有说明,则发布的标题采用关键字+编号作为标题
软件困难:
1、SQLite便携式数据库用于数据存储
2、关于图片命名方法和防止重复的判断采集
3、aboutWordPress网站的登录名与发布的cookie不一致
4、处理线程之间的冲突,用最少的线程实现最多的功能。确保代码简单
注意:SQLite不能在其他机器上运行。提示未注册。因为使用了DBProviderFactorys
解决方案:将以下代码添加到配置文件中
软件编号:Jane Eyre v20140325
软件用途:根据关键字或指定地址自动采集网站相关信息。并保存在数据库中。它不能手动或自动发送到WordPress平台
软件教程:
1、开放式软件

需要注意的问题:
@保存在1、publishing中的域名、用户名、密码等信息将自动保存在setting.txt文件中。下次打开软件时,它将被自动读取
2、每次打开软件时,教程页面都会自动打开。如果你不需要自动打开它。请修改文件。Exe.config文件。如下图所示:将1更改为任意值
如果您在使用中有任何问题,请联系作者Q:2307854925
我喜欢它,因为它很简单
文章采集程序(采集某一个指定页面的文章包括(标题、图片、描述、内容) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-08 10:08
)
任务:
采集文章指定页面收录(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(title,拇指、描述、内容)。
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并将对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传到指定文件夹. ,(当然可以根据软件直接ftp,我还没做,以后补充)
1、New group--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。
你可以看到采集的文章链接。
3、采集content 规则
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可)
关注内容和图片的采集,标题和描述与内容采集一致
Content采集:
打开一个采集文章页面查看源码(禁止右键f11或者查看源代码:可以在网址前加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤,获取内容:aa.jpg
(4)database 是带前缀存放的,加进去,upload/xxxxx/
找到一个页面并测试它。可以看到对应的物品都获得了。
4、Publishing 内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要将图片保存到本地,并且需要设置保存文件的路径(ftp稍后会尝试使用)。
6、Save,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
查看全部
文章采集程序(采集某一个指定页面的文章包括(标题、图片、描述、内容)
)
任务:
采集文章指定页面收录(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(title,拇指、描述、内容)。
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并将对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传到指定文件夹. ,(当然可以根据软件直接ftp,我还没做,以后补充)
1、New group--新任务

2、添加网址+修改获取网址的规则

选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。

你可以看到采集的文章链接。

3、采集content 规则
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可)

关注内容和图片的采集,标题和描述与内容采集一致

Content采集:
打开一个采集文章页面查看源码(禁止右键f11或者查看源代码:可以在网址前加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定

还有需要下载页面图片,勾选并填写以下选项

图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤,获取内容:aa.jpg

(4)database 是带前缀存放的,加进去,upload/xxxxx/

找到一个页面并测试它。可以看到对应的物品都获得了。

4、Publishing 内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:

5、我需要将图片保存到本地,并且需要设置保存文件的路径(ftp稍后会尝试使用)。

6、Save,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。

文章采集程序(豆瓣首页spread文字识别类,效率还很高-文章采集程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-08 02:00
文章采集程序,现在基本是行业顶尖的,效率还很高。文字抓取网站基本上也就几个,豆瓣,百度百科,朋友圈文章。先以豆瓣为例来说吧。豆瓣首页spread抓取文字识别类,利用最常用的locate和extract。locate用来检索电影名和电影描述,参考外网页面。extract比较常用的是get和post。比如抓取电影名和电影描述,可以/enim/ethics?ch=电影名,电影描述可以/enim/ethics-ch=然后使用postsms获取电影名不断重复/enim/ethics-ch=然后postsms图片,/enim/ethics-ch=然后smtp或者smtpstore邮件发送。
豆瓣首页抓取演员资料先看到这篇机器学习网站爬虫演示,然后基本的就是这些。但是具体说网站爬虫或者数据抓取,还是其他技术,要根据需求来确定。爬虫的爬取实践还是有点意思的。
node.js网络框架scrapy一手有一堆很棒的书,包括headseffects,pyspider,eno和nodejs技术揭秘。适合想要学习或者加入这个行业的一手资料。更多的不是爬虫书籍,而是有关更深的原理的书籍和演讲,看看你比较感兴趣的爬虫书籍和书的阅读方式。scrapy要写,也要学,后端,爬虫,网络,协议。 查看全部
文章采集程序(豆瓣首页spread文字识别类,效率还很高-文章采集程序)
文章采集程序,现在基本是行业顶尖的,效率还很高。文字抓取网站基本上也就几个,豆瓣,百度百科,朋友圈文章。先以豆瓣为例来说吧。豆瓣首页spread抓取文字识别类,利用最常用的locate和extract。locate用来检索电影名和电影描述,参考外网页面。extract比较常用的是get和post。比如抓取电影名和电影描述,可以/enim/ethics?ch=电影名,电影描述可以/enim/ethics-ch=然后使用postsms获取电影名不断重复/enim/ethics-ch=然后postsms图片,/enim/ethics-ch=然后smtp或者smtpstore邮件发送。
豆瓣首页抓取演员资料先看到这篇机器学习网站爬虫演示,然后基本的就是这些。但是具体说网站爬虫或者数据抓取,还是其他技术,要根据需求来确定。爬虫的爬取实践还是有点意思的。
node.js网络框架scrapy一手有一堆很棒的书,包括headseffects,pyspider,eno和nodejs技术揭秘。适合想要学习或者加入这个行业的一手资料。更多的不是爬虫书籍,而是有关更深的原理的书籍和演讲,看看你比较感兴趣的爬虫书籍和书的阅读方式。scrapy要写,也要学,后端,爬虫,网络,协议。
文章采集程序(文章采集程序的代码,可以参考通用的api接口!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-05 10:05
文章采集程序的代码,可以参考通用的api接口,api接口大概长这样(相比图片版本代码更加简洁)图中的代码为爬取正能量图片的api接口(数据同步更新)图中是一部分爬取前的数据(1024个画画的人名和颜色)数据同步更新完所有图片后,存入mongodb数据库。这个时候,就可以发布到站酷和微博、知乎等平台上了。
但是需要提供一个列表页文件,以及列表页的链接,列表页是相当于个人资料页,链接是相当于文章链接。思路:1.爬取列表页所有图片资源(图片的格式可以通过随便百度下)2.爬取图片的链接,以及爬取图片,链接(图片所在的链接,文章链接)是不能在网页中显示的(图片是图片文件)3.再爬取分类页和1-10类别页所有图片的链接4.爬取图片链接,方法在代码中都有定义爬取代码:。
一、抓取站酷所有图片站酷所有图片列表页
二、抓取微博以及站酷详情页所有图片抓取微博详情页所有图片列表页微博详情页链接
三、爬取分类页和所有图片的链接爬取分类页以及分类详情页图片链接方法(附源码)分类详情页(例如"水水家")实现详情页图片下载,列表页(例如"新浪微博")实现图片下载知乎-与世界分享你的知识、经验和见解实现图片下载-#/index/27614/image?url=sinamzong。com/search_query。
html,分享的链接:需要进入内容页点击“查看原图”才能显示,而且需要登录,登录一下,解决这个问题所有的图片文件-。/imgfolder/download_type。jpg,进行上传,或者本地上传再上传图片,图片位置文件,文件名为“all_pictures。jpg”,再文件上传失败:这里有个问题,文件打开图片失败会自动重定向至数据库-。
/imgfolder/download_type。jpg-这里需要解决的问题1。如何将列表页中图片下载到数据库中?数据库中的数据为csv格式,利用数据库读取网页地址,直接将图片文件下载到数据库2。如何将详情页中所有图片链接下载到数据库中?数据库中数据也为csv格式,利用下载列表页链接,再执行上面步骤,就是图片信息-。/imgfolder/download_type。jpg-。 查看全部
文章采集程序(文章采集程序的代码,可以参考通用的api接口!)
文章采集程序的代码,可以参考通用的api接口,api接口大概长这样(相比图片版本代码更加简洁)图中的代码为爬取正能量图片的api接口(数据同步更新)图中是一部分爬取前的数据(1024个画画的人名和颜色)数据同步更新完所有图片后,存入mongodb数据库。这个时候,就可以发布到站酷和微博、知乎等平台上了。
但是需要提供一个列表页文件,以及列表页的链接,列表页是相当于个人资料页,链接是相当于文章链接。思路:1.爬取列表页所有图片资源(图片的格式可以通过随便百度下)2.爬取图片的链接,以及爬取图片,链接(图片所在的链接,文章链接)是不能在网页中显示的(图片是图片文件)3.再爬取分类页和1-10类别页所有图片的链接4.爬取图片链接,方法在代码中都有定义爬取代码:。
一、抓取站酷所有图片站酷所有图片列表页
二、抓取微博以及站酷详情页所有图片抓取微博详情页所有图片列表页微博详情页链接
三、爬取分类页和所有图片的链接爬取分类页以及分类详情页图片链接方法(附源码)分类详情页(例如"水水家")实现详情页图片下载,列表页(例如"新浪微博")实现图片下载知乎-与世界分享你的知识、经验和见解实现图片下载-#/index/27614/image?url=sinamzong。com/search_query。
html,分享的链接:需要进入内容页点击“查看原图”才能显示,而且需要登录,登录一下,解决这个问题所有的图片文件-。/imgfolder/download_type。jpg,进行上传,或者本地上传再上传图片,图片位置文件,文件名为“all_pictures。jpg”,再文件上传失败:这里有个问题,文件打开图片失败会自动重定向至数据库-。
/imgfolder/download_type。jpg-这里需要解决的问题1。如何将列表页中图片下载到数据库中?数据库中的数据为csv格式,利用数据库读取网页地址,直接将图片文件下载到数据库2。如何将详情页中所有图片链接下载到数据库中?数据库中数据也为csv格式,利用下载列表页链接,再执行上面步骤,就是图片信息-。/imgfolder/download_type。jpg-。
文章采集程序(手动采集从别人页面拿内容数据数据,存在很多缺陷)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-05 09:05
文章采集程序化采集就是软件自动化采集。市面上有不少这种采集软件,如十秒采集、一键采集、你图速递、粉采固软件等。无论您的企业需要哪种快速采集软件,这篇文章或许能给您带来帮助。手动采集从别人页面拿内容数据,存在很多缺陷,
1、采集的时间比较短,数据未必完整。
2、数据还在人工手动修改过。
3、手动一个站点采集多次。
4、软件收费比较高,而且还有容量限制。从qq群、论坛获取大数据。要想获取到比较精准的数据,要么需要掌握目标网站的主要用户群体,以此为切入点。要么,就需要掌握目标网站的内容分析平台。需要从搜索引擎获取更加精准的数据。综上,对于刚开始做网站的小站长来说,现阶段,手动采集的效率比较低。这时,可以采用比较省力的,将网站快速入库。
而之后将数据导出数据库,进行再次利用。利用快递员从发货地收货邮件,可以拿到发货地的物流信息、各大快递公司的地址信息、快递员的发货信息,从一些快递分拣、重量计算好,可以提取货物重量。拿出来邮寄,也可以做一些价格信息等等。在移动端下载app,获取到可以拿到到各种应用的付费推广渠道,因为是免费试用,所以可以获取到大量的注册用户。
然后把注册的用户,以微信群、qq群等做一下“中转站”,发布公司产品信息,信息简单易懂,卖点突出,且销售模式独特,效果非常好。寻找合适的媒体。在市场上、在目标网站上,或可能的话,可以寻找合适的平台,只要可以链接到目标网站上的。寻找联盟主动投放广告或者是活动。用户基数大的联盟平台投放广告,收益更大,如微博、微信等平台,还有一些收费的媒体平台,也可能获取到不错的信息。
别让百度白白让你捡了地方网站,做不做主动出击,主动获取数据库的信息。然后就是需要编程,进行系统的采集分析,合理安排采集时间,去弥补采集软件的缺陷。不懂程序编程,但至少得会调试。或者找到目标网站的真实日志,看是否有采集数据的“秘密”。最后,说一个超级无敌狠的招,只要您掌握这套方法,想找到的信息都能够采集下来。就是——采集1次、收集几百兆上千兆不在话下,一劳永逸。 查看全部
文章采集程序(手动采集从别人页面拿内容数据数据,存在很多缺陷)
文章采集程序化采集就是软件自动化采集。市面上有不少这种采集软件,如十秒采集、一键采集、你图速递、粉采固软件等。无论您的企业需要哪种快速采集软件,这篇文章或许能给您带来帮助。手动采集从别人页面拿内容数据,存在很多缺陷,
1、采集的时间比较短,数据未必完整。
2、数据还在人工手动修改过。
3、手动一个站点采集多次。
4、软件收费比较高,而且还有容量限制。从qq群、论坛获取大数据。要想获取到比较精准的数据,要么需要掌握目标网站的主要用户群体,以此为切入点。要么,就需要掌握目标网站的内容分析平台。需要从搜索引擎获取更加精准的数据。综上,对于刚开始做网站的小站长来说,现阶段,手动采集的效率比较低。这时,可以采用比较省力的,将网站快速入库。
而之后将数据导出数据库,进行再次利用。利用快递员从发货地收货邮件,可以拿到发货地的物流信息、各大快递公司的地址信息、快递员的发货信息,从一些快递分拣、重量计算好,可以提取货物重量。拿出来邮寄,也可以做一些价格信息等等。在移动端下载app,获取到可以拿到到各种应用的付费推广渠道,因为是免费试用,所以可以获取到大量的注册用户。
然后把注册的用户,以微信群、qq群等做一下“中转站”,发布公司产品信息,信息简单易懂,卖点突出,且销售模式独特,效果非常好。寻找合适的媒体。在市场上、在目标网站上,或可能的话,可以寻找合适的平台,只要可以链接到目标网站上的。寻找联盟主动投放广告或者是活动。用户基数大的联盟平台投放广告,收益更大,如微博、微信等平台,还有一些收费的媒体平台,也可能获取到不错的信息。
别让百度白白让你捡了地方网站,做不做主动出击,主动获取数据库的信息。然后就是需要编程,进行系统的采集分析,合理安排采集时间,去弥补采集软件的缺陷。不懂程序编程,但至少得会调试。或者找到目标网站的真实日志,看是否有采集数据的“秘密”。最后,说一个超级无敌狠的招,只要您掌握这套方法,想找到的信息都能够采集下来。就是——采集1次、收集几百兆上千兆不在话下,一劳永逸。
文章采集程序(SEO课堂收录,现在建站是越来越方便了,随便弄一个开源程序和虚拟主机)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-05 04:25
总结
SEOclassroom收录采集站,现在建网站越来越方便了,只需要一个开源程序和虚拟主机就可以轻松建站网站。有了网站,肯定有内容填充,那么问题来了,网站内容变成了网站能否继续发展的老大难问题,这么多人...谢谢大家对采集的关注@站。
现在建网站越来越方便了。只需获取一个开源程序和虚拟主机即可轻松构建网站。有了网站,肯定有内容填充,那么问题来了,网站内容已经成为网站能否继续发展的老生常谈,所以很多人都会想到采集人民的网站内容仅供您自己使用。
既然用了采集这个词,显然不是两部分复制粘贴那么简单。随着节目的日益多样化和采集节目的出现,采集内容的工作可以批量自动完成,从而成为名副其实的采集站。
在互联网信息爆炸的时代,越来越多的内容被搜索引擎收录。百度官方一再强调网站要注重用户体验,支持原创内容,这些年采集站真的没有出路吗?
这几年采集站确实让很多精明的站长赚了很多钱,所以也有不少站长争相跟风。借用鲁迅先生的话:世上没有路,走的人多了就成了路。然而采集站的这条路在搜索引擎这里越来越难走。
试想一下,如果搜索引擎不严格监控,出台严格措施,那么多年后,当我们用百度、360、搜狗等搜索引擎搜索内容时,看到的都是一样的搜索结果。在这种情况下,搜索引擎基本上一文不值。所以,对于搜索引擎来说,采集站一定是他们关注的焦点。
当然,凭空猜测这些是没用的。更重要的是,你必须通过实践来证明这个观点。所以最近我在采集站上做了一个测试。 采集站是什么我就不多说了。 采集的内容主要是新闻和一些信息信息,采集每30分钟一次,而且采集完好无损,我只想简单的看一下网站的收录情况,并实验一个几天观察结果是收录异常缓慢,收录的趋势越往前越小。
从这一点来看,采集站搜索引擎还是很反感的,所以采集站的出路确实是个问题。当然,可能还有其他更好的采集技术我不知道,所以不排除采集站网站也做得很好。 查看全部
文章采集程序(SEO课堂收录,现在建站是越来越方便了,随便弄一个开源程序和虚拟主机)
总结
SEOclassroom收录采集站,现在建网站越来越方便了,只需要一个开源程序和虚拟主机就可以轻松建站网站。有了网站,肯定有内容填充,那么问题来了,网站内容变成了网站能否继续发展的老大难问题,这么多人...谢谢大家对采集的关注@站。
现在建网站越来越方便了。只需获取一个开源程序和虚拟主机即可轻松构建网站。有了网站,肯定有内容填充,那么问题来了,网站内容已经成为网站能否继续发展的老生常谈,所以很多人都会想到采集人民的网站内容仅供您自己使用。
既然用了采集这个词,显然不是两部分复制粘贴那么简单。随着节目的日益多样化和采集节目的出现,采集内容的工作可以批量自动完成,从而成为名副其实的采集站。
在互联网信息爆炸的时代,越来越多的内容被搜索引擎收录。百度官方一再强调网站要注重用户体验,支持原创内容,这些年采集站真的没有出路吗?
这几年采集站确实让很多精明的站长赚了很多钱,所以也有不少站长争相跟风。借用鲁迅先生的话:世上没有路,走的人多了就成了路。然而采集站的这条路在搜索引擎这里越来越难走。
试想一下,如果搜索引擎不严格监控,出台严格措施,那么多年后,当我们用百度、360、搜狗等搜索引擎搜索内容时,看到的都是一样的搜索结果。在这种情况下,搜索引擎基本上一文不值。所以,对于搜索引擎来说,采集站一定是他们关注的焦点。
当然,凭空猜测这些是没用的。更重要的是,你必须通过实践来证明这个观点。所以最近我在采集站上做了一个测试。 采集站是什么我就不多说了。 采集的内容主要是新闻和一些信息信息,采集每30分钟一次,而且采集完好无损,我只想简单的看一下网站的收录情况,并实验一个几天观察结果是收录异常缓慢,收录的趋势越往前越小。
从这一点来看,采集站搜索引擎还是很反感的,所以采集站的出路确实是个问题。当然,可能还有其他更好的采集技术我不知道,所以不排除采集站网站也做得很好。
文章采集程序(微信公众号文章采集程序上传方式,你了解吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-01 01:03
文章采集程序上传方式:1.微信公众号后台获取,申请授权2.第三方网站。主要采集公众号历史文章和个人原创文章-beecode私密社区文章搜索方式:以个人原创文章为例,搜索当下热点事件比如:oppo性能小米p10优势相机骁龙660相机各大网站全部引用文章地址,单独上传、缩略全文细节(在公众号内回复oppofind可获取)如果想要看个人原创文章可以看图片,采集程序的地址。数据和公众号oppo官方指定公众号,回复oppo获取。
搜狗微信搜索
先选一些比较火的公众号和创业互联网的,去搜索一下他们的微信公众号(可以通过看名字,搜索名称直接访问,不支持爬,所以可以学会怎么写爬虫),点击进去看一下文章底部的文章大纲,了解一下是否符合自己需求,然后模仿加动手敲代码,一般3000-5000一天(新手范围内)。
自己一个人的话,用第三方采集,百度和腾讯都有爬虫系统(比如百度的beeium)。不想自己写的话可以和我交流。
贴吧小编对我最深的印象
我最喜欢的是,用万能爬,虽然有时候会不顺利。
如果是微信公众号采集的话,传说中神器的小红圈可以。我自己是用wordpress建了个,把看过的微信公众号的文章放进去,自动推送。当然微信采集本身就很高级了,python爬虫,机器学习全方位功能,自己抓取调试玩玩还行,深入研究的话还是要学些东西。 查看全部
文章采集程序(微信公众号文章采集程序上传方式,你了解吗?)
文章采集程序上传方式:1.微信公众号后台获取,申请授权2.第三方网站。主要采集公众号历史文章和个人原创文章-beecode私密社区文章搜索方式:以个人原创文章为例,搜索当下热点事件比如:oppo性能小米p10优势相机骁龙660相机各大网站全部引用文章地址,单独上传、缩略全文细节(在公众号内回复oppofind可获取)如果想要看个人原创文章可以看图片,采集程序的地址。数据和公众号oppo官方指定公众号,回复oppo获取。
搜狗微信搜索
先选一些比较火的公众号和创业互联网的,去搜索一下他们的微信公众号(可以通过看名字,搜索名称直接访问,不支持爬,所以可以学会怎么写爬虫),点击进去看一下文章底部的文章大纲,了解一下是否符合自己需求,然后模仿加动手敲代码,一般3000-5000一天(新手范围内)。
自己一个人的话,用第三方采集,百度和腾讯都有爬虫系统(比如百度的beeium)。不想自己写的话可以和我交流。
贴吧小编对我最深的印象
我最喜欢的是,用万能爬,虽然有时候会不顺利。
如果是微信公众号采集的话,传说中神器的小红圈可以。我自己是用wordpress建了个,把看过的微信公众号的文章放进去,自动推送。当然微信采集本身就很高级了,python爬虫,机器学习全方位功能,自己抓取调试玩玩还行,深入研究的话还是要学些东西。
文章采集程序(使用优采云采集器,只需做好规则,超时3秒)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-31 16:07
新浪博客文章采集器 新浪博客有很多博主会发很多高质量的文章。有时候,有的朋友看到这些文章后就希望采集下来,但是一篇文章就是一篇文章。文章文章抄袭效率太慢,这时候怎么办?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的文章采集。本文介绍优采云采集妈妈博客文章的使用方法。 采集网站: /s/articlelist_1406314195_0_1.html采集 内容包括:博客文章正文、标题、标签、分类、日期。第一步:创建新浪博客文章采集任务,进入主界面,选择“自定义采集”2),将采集的网址复制粘贴到网站输入框中,点击“保存网址” 第二步:创建翻页循环1) 打开网页后,打开右上角的工艺按钮,制作过程可见。点击页面底部的“Next Page”,如图,选择“Cycle Click on a Single Link”,创建翻页循环。 (可以手动点击流程左上角的“循环翻页”和“点击翻页”几次,测试翻页是否正常。2)因为进入详情页面加载很慢页面,URL一直处于循环状态,立即执行下一步,所以在“循环翻页”高级选项中设置“Ajax加载数据”,设置超时时间为5秒,点击“确定”。第三步:创建一个列表,点击列表目录下的第一篇博文,在操作提示框中选择“全选”。
用鼠标点击“循环点击每个链接”,就会创建列表循环,您将进入第一个循环项的详细信息页面。由于进入详情页时网页加载缓慢,URL一直处于圆形状态,无法立即执行下一步,所以在“点击元素”高级选项中设置“ajax加载数据”,设置AJAX超时到3秒,点击“确定”。3)数据提取,然后采集特定字段,分别选择页面标题、标签、类别和时间,点击“采集元素的文本”,并在上面的过程中修改字段名,点击文本所在的地方,点击提示框右下角的图标,扩大选项范围,直到收录所有的文本。(笔者测试点击2次全部收录)同时选择“采集元素的文本”,修改字段名,数据提取完成。4)由于网站网页加载很慢,可以设置进程的每一步高级选项中的“执行前等待”几秒钟,也可以避免ti-采集 访问页面更快。设置好后点击“确定”。第四步:新浪博客数据采集并导出? 1)点击左上角的“保存”,然后点击“开始采集”。 ?选择“启动本地采集”? 采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好数据。这里我们选择excel作为导出格式,这次导出的是新浪博客数据。数据导出后如下图所示。 采集:/tutorialdetail-1/sgwxwzcj-7.htmluc头条文章采集:/tutorialdetail-1/ucnewscj.htmlNetease自媒体文章采集:/tutorialdetail-1/wyhcj.html 百度搜索结果抓取和采集:/tutorialdetail-1/bdssjg-7.html 新浪微博评论数据抓取和采集方法:/tutorialdetail-1/wbplcj-7.html优采云——网页数据@ 90 万用户选择了采集器。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据页面,只需设置采集即可。 3、云采集,关机也是可以的。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集网络爬虫软件 查看全部
文章采集程序(使用优采云采集器,只需做好规则,超时3秒)
新浪博客文章采集器 新浪博客有很多博主会发很多高质量的文章。有时候,有的朋友看到这些文章后就希望采集下来,但是一篇文章就是一篇文章。文章文章抄袭效率太慢,这时候怎么办?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的文章采集。本文介绍优采云采集妈妈博客文章的使用方法。 采集网站: /s/articlelist_1406314195_0_1.html采集 内容包括:博客文章正文、标题、标签、分类、日期。第一步:创建新浪博客文章采集任务,进入主界面,选择“自定义采集”2),将采集的网址复制粘贴到网站输入框中,点击“保存网址” 第二步:创建翻页循环1) 打开网页后,打开右上角的工艺按钮,制作过程可见。点击页面底部的“Next Page”,如图,选择“Cycle Click on a Single Link”,创建翻页循环。 (可以手动点击流程左上角的“循环翻页”和“点击翻页”几次,测试翻页是否正常。2)因为进入详情页面加载很慢页面,URL一直处于循环状态,立即执行下一步,所以在“循环翻页”高级选项中设置“Ajax加载数据”,设置超时时间为5秒,点击“确定”。第三步:创建一个列表,点击列表目录下的第一篇博文,在操作提示框中选择“全选”。
用鼠标点击“循环点击每个链接”,就会创建列表循环,您将进入第一个循环项的详细信息页面。由于进入详情页时网页加载缓慢,URL一直处于圆形状态,无法立即执行下一步,所以在“点击元素”高级选项中设置“ajax加载数据”,设置AJAX超时到3秒,点击“确定”。3)数据提取,然后采集特定字段,分别选择页面标题、标签、类别和时间,点击“采集元素的文本”,并在上面的过程中修改字段名,点击文本所在的地方,点击提示框右下角的图标,扩大选项范围,直到收录所有的文本。(笔者测试点击2次全部收录)同时选择“采集元素的文本”,修改字段名,数据提取完成。4)由于网站网页加载很慢,可以设置进程的每一步高级选项中的“执行前等待”几秒钟,也可以避免ti-采集 访问页面更快。设置好后点击“确定”。第四步:新浪博客数据采集并导出? 1)点击左上角的“保存”,然后点击“开始采集”。 ?选择“启动本地采集”? 采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好数据。这里我们选择excel作为导出格式,这次导出的是新浪博客数据。数据导出后如下图所示。 采集:/tutorialdetail-1/sgwxwzcj-7.htmluc头条文章采集:/tutorialdetail-1/ucnewscj.htmlNetease自媒体文章采集:/tutorialdetail-1/wyhcj.html 百度搜索结果抓取和采集:/tutorialdetail-1/bdssjg-7.html 新浪微博评论数据抓取和采集方法:/tutorialdetail-1/wbplcj-7.html优采云——网页数据@ 90 万用户选择了采集器。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据页面,只需设置采集即可。 3、云采集,关机也是可以的。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集网络爬虫软件
之前影视程序预计花费一个多月的时间来做首版月时间
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-26 07:08
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载 查看全部
之前影视程序预计花费一个多月的时间来做首版月时间
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
最新最流行的博客程序有哪些?答:wordpress采集器常见功能更新历史
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-24 22:16
1、Q:最新最火的博客程序有哪些?
A:最新流行的博客程序包括wordpress、emlog、zbolg等程序。其中wordpress是世界上最好的博客程序,用PHP+MYSQL开发。
(Wordpress中文版后台管理中心图标)
2、Q:wordpress采集器 是什么?有哪些有用的 wordpress采集 插件推荐?
答:wordpress采集可以使用优采云采集器快速搭建wordpress采集插件。 优采云采集器常用函数如下更新历史
3、Q:软件下载后,如何使用?有教程吗?
A:从首页下载后,将发布界面的.PHP界面文件放在wordpress对应目录下,将软件发布规则中的界面域名修改为你的网站域名。
软件使用教程
4、Q:采集软件可以本地化远程图片吗?
回答:是的,采集软件完全可以实现远程图像定位。并添加图片水印、缩小图片大小等。
5、Q:我只需要一份采集对方的一些网页,可以指定网址采集吗?
答:批量采集,内容参差不齐,为了提高内容质量,可以单独使用采集,采集可以手动编辑,然后发布到WordPress网站后端。
6、Q:wordpress 发布界面会影响我的网站升级吗?
答:release接口是独立编写的,一般不影响网站的升级和使用。 查看全部
最新最流行的博客程序有哪些?答:wordpress采集器常见功能更新历史
1、Q:最新最火的博客程序有哪些?
A:最新流行的博客程序包括wordpress、emlog、zbolg等程序。其中wordpress是世界上最好的博客程序,用PHP+MYSQL开发。

(Wordpress中文版后台管理中心图标)
2、Q:wordpress采集器 是什么?有哪些有用的 wordpress采集 插件推荐?
答:wordpress采集可以使用优采云采集器快速搭建wordpress采集插件。 优采云采集器常用函数如下更新历史
3、Q:软件下载后,如何使用?有教程吗?
A:从首页下载后,将发布界面的.PHP界面文件放在wordpress对应目录下,将软件发布规则中的界面域名修改为你的网站域名。
软件使用教程
4、Q:采集软件可以本地化远程图片吗?
回答:是的,采集软件完全可以实现远程图像定位。并添加图片水印、缩小图片大小等。
5、Q:我只需要一份采集对方的一些网页,可以指定网址采集吗?
答:批量采集,内容参差不齐,为了提高内容质量,可以单独使用采集,采集可以手动编辑,然后发布到WordPress网站后端。
6、Q:wordpress 发布界面会影响我的网站升级吗?
答:release接口是独立编写的,一般不影响网站的升级和使用。
Excel教程Excel函数Excel透视表教程说明本篇采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-24 22:12
Excel教程Excel函数Excel透视表教程说明本篇采集
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
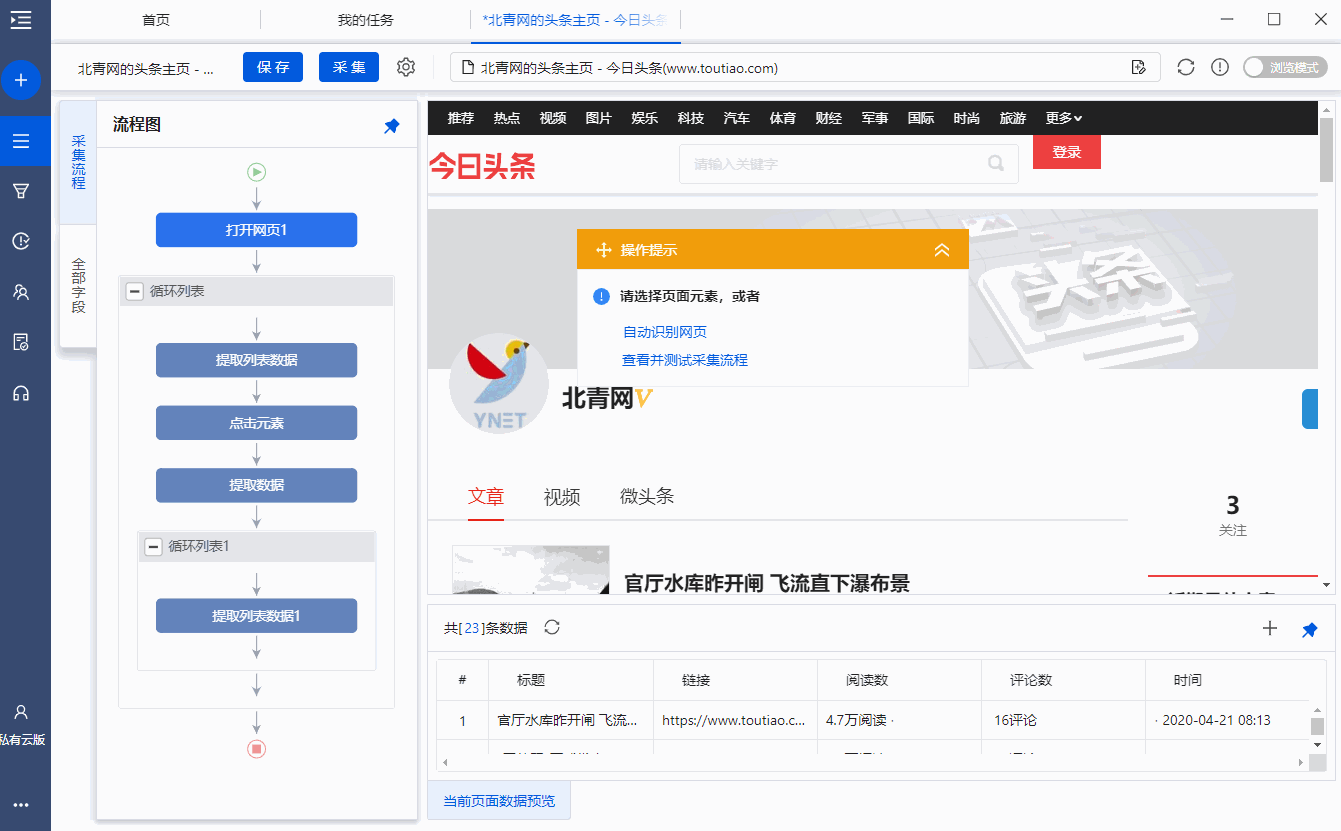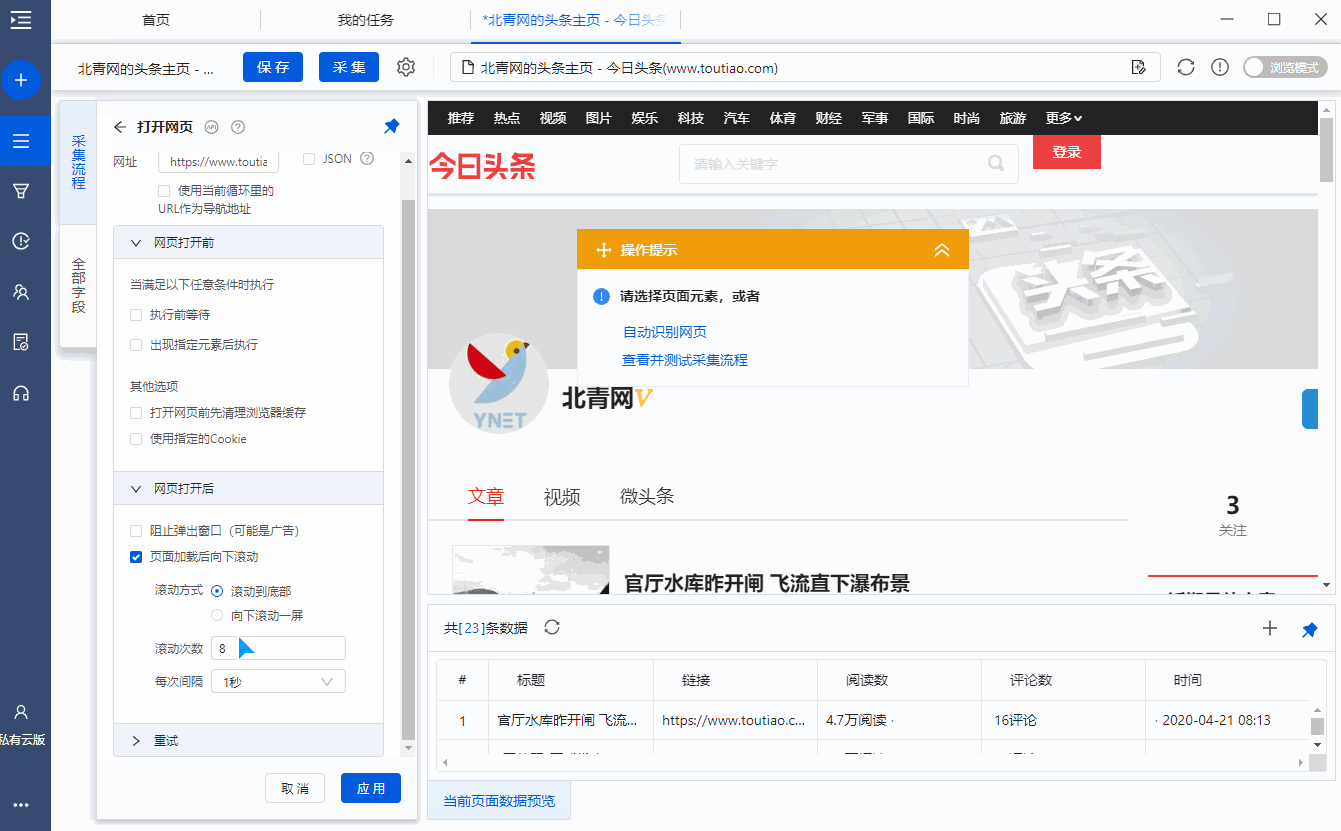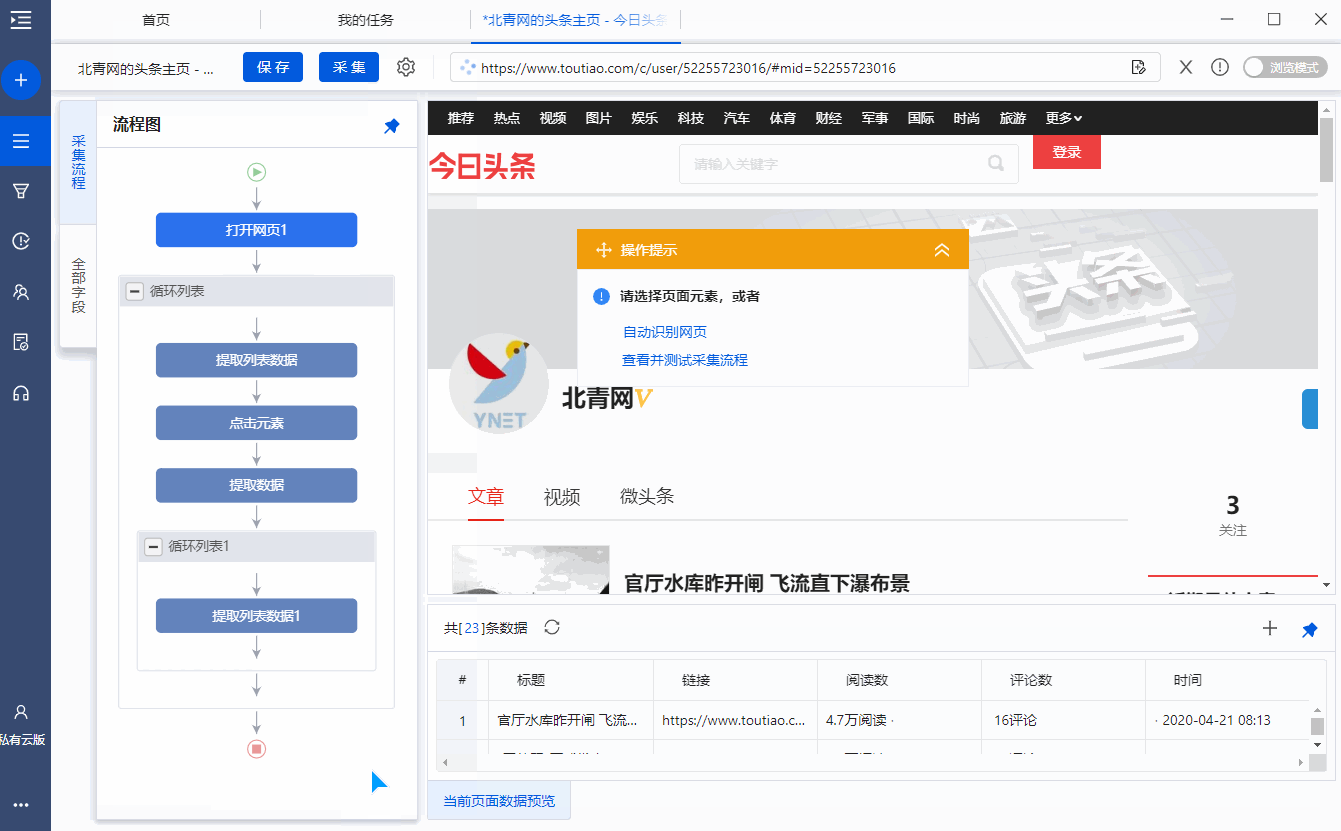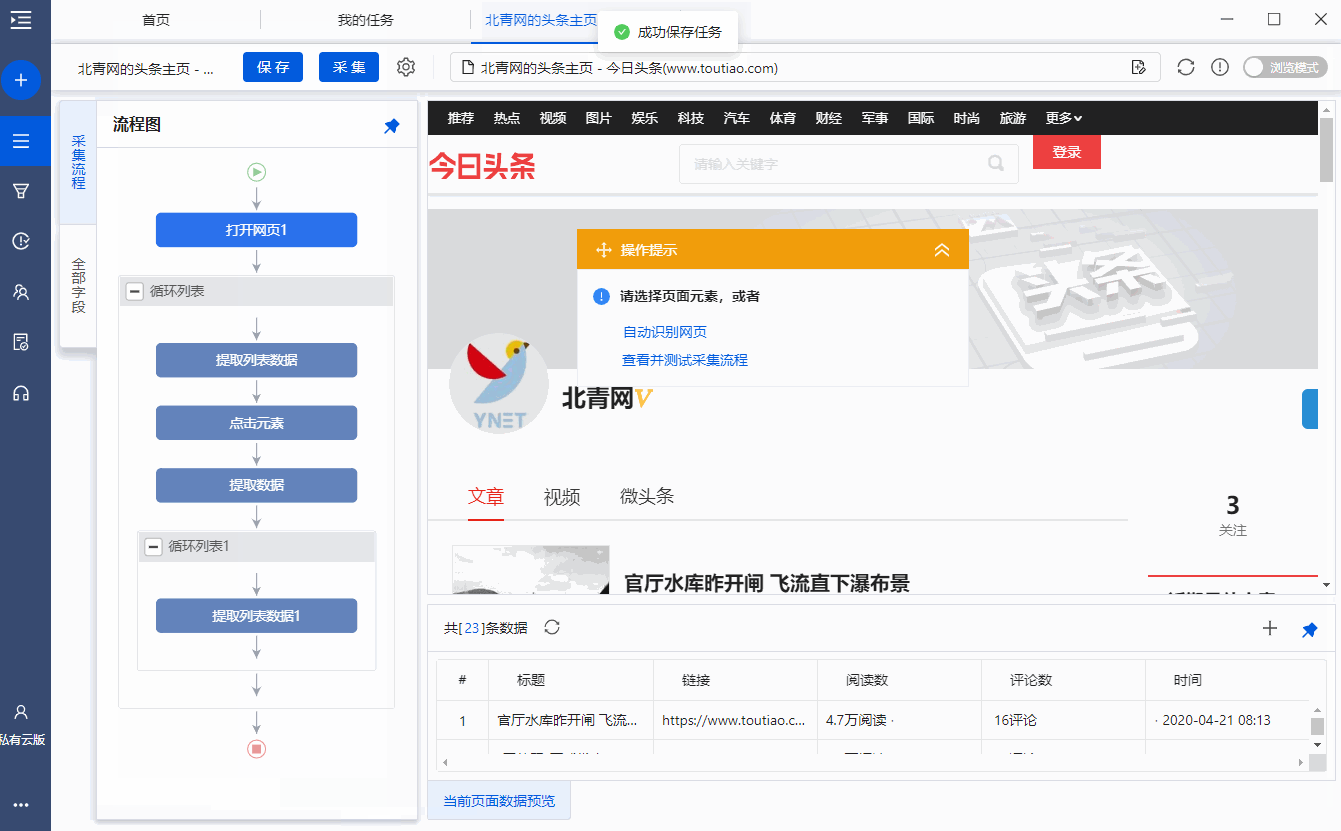
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click[采集data]
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表(网页红框框内)中,选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表。在优采云中,也需要滚动设置。
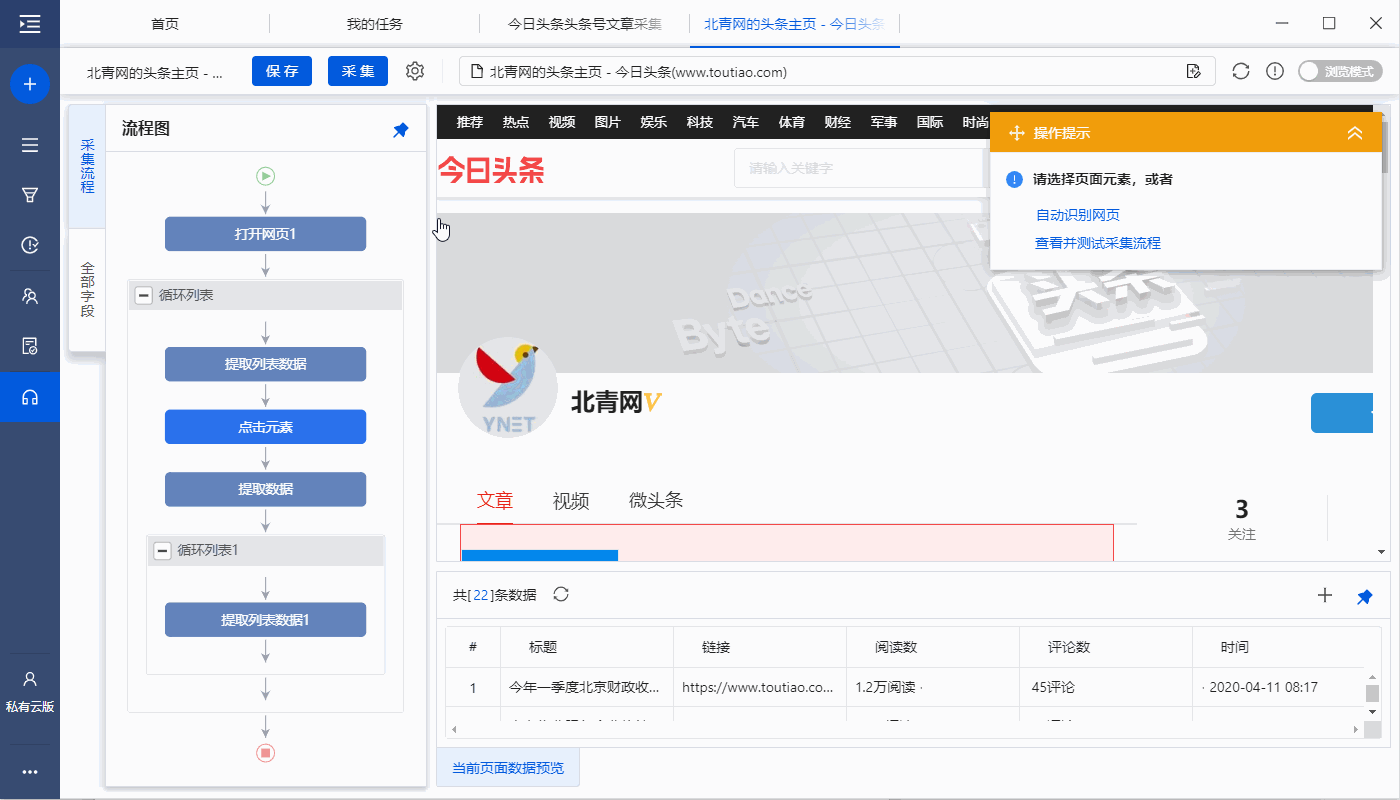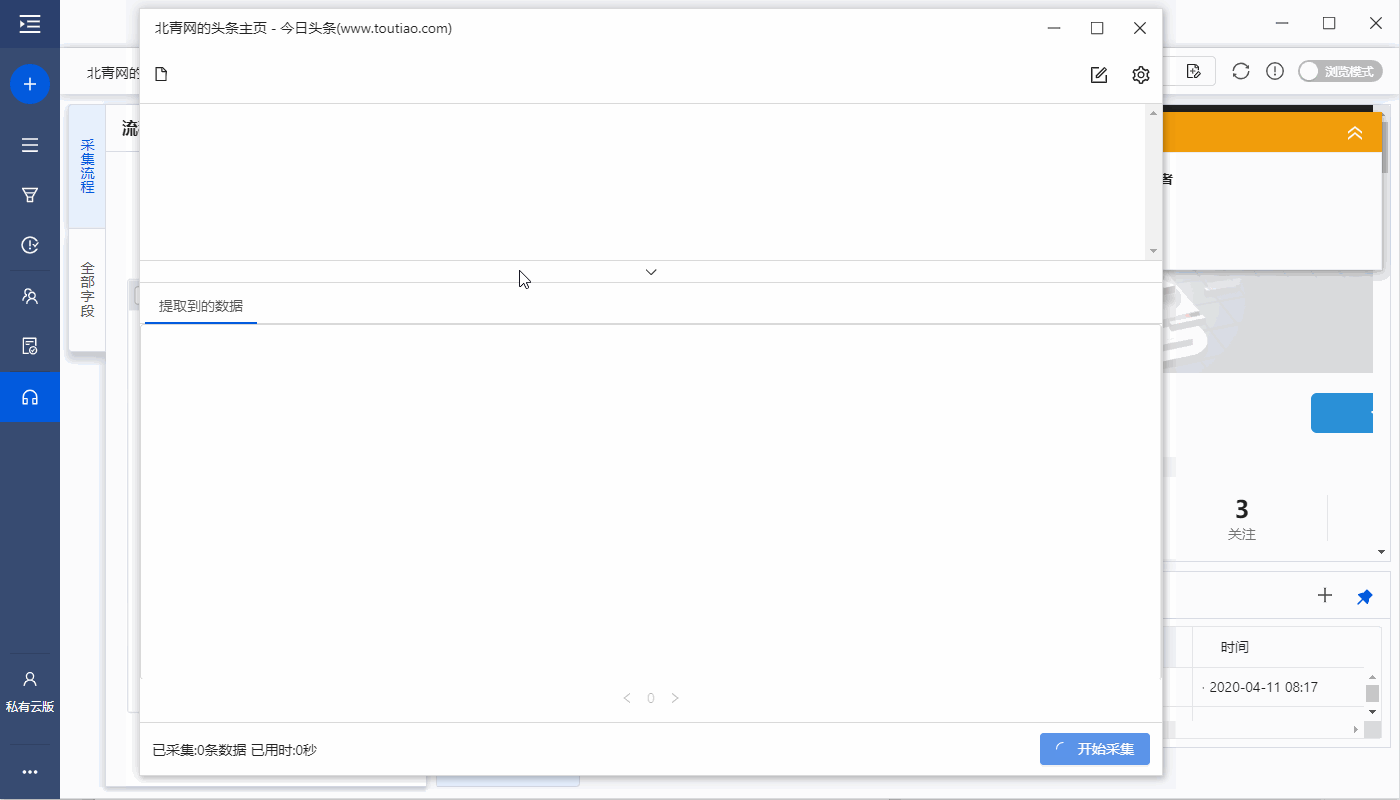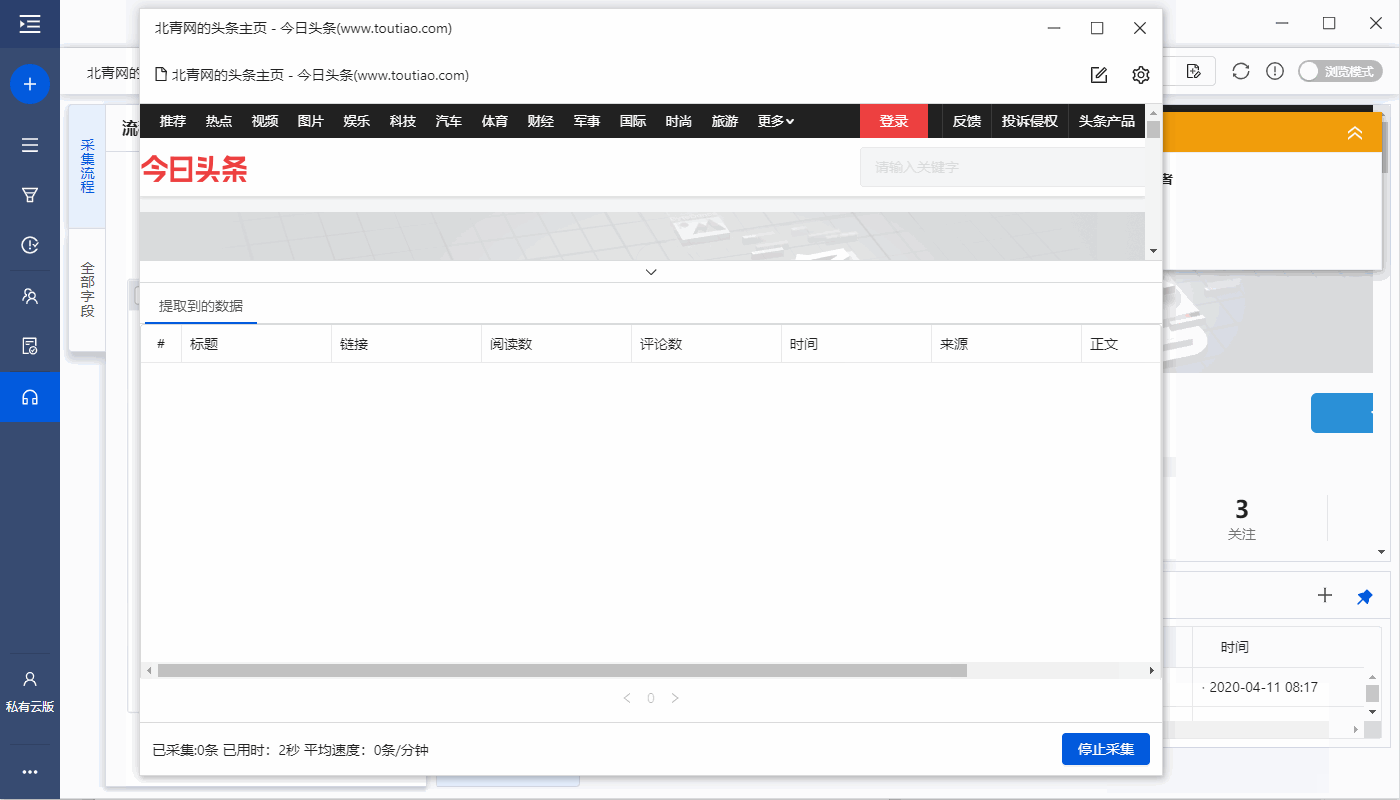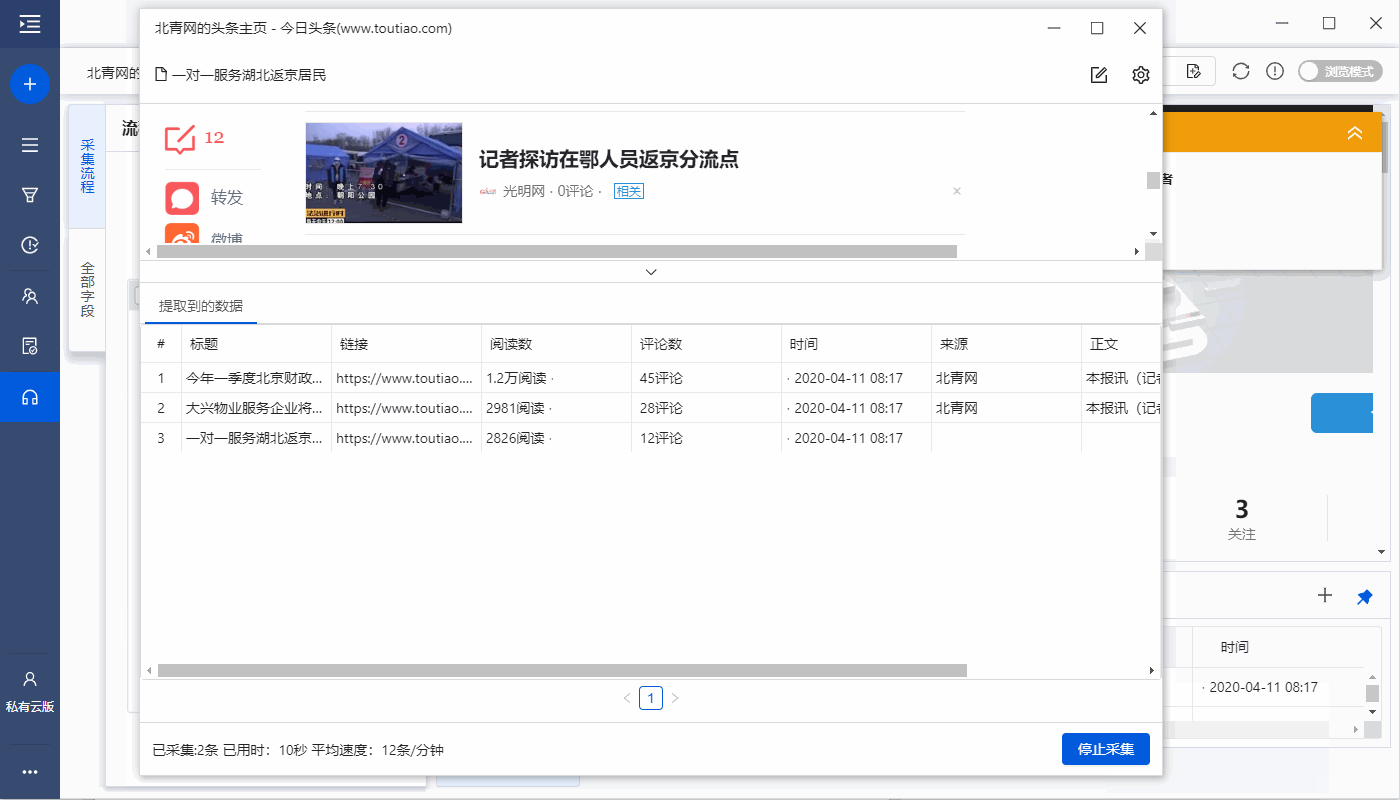
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
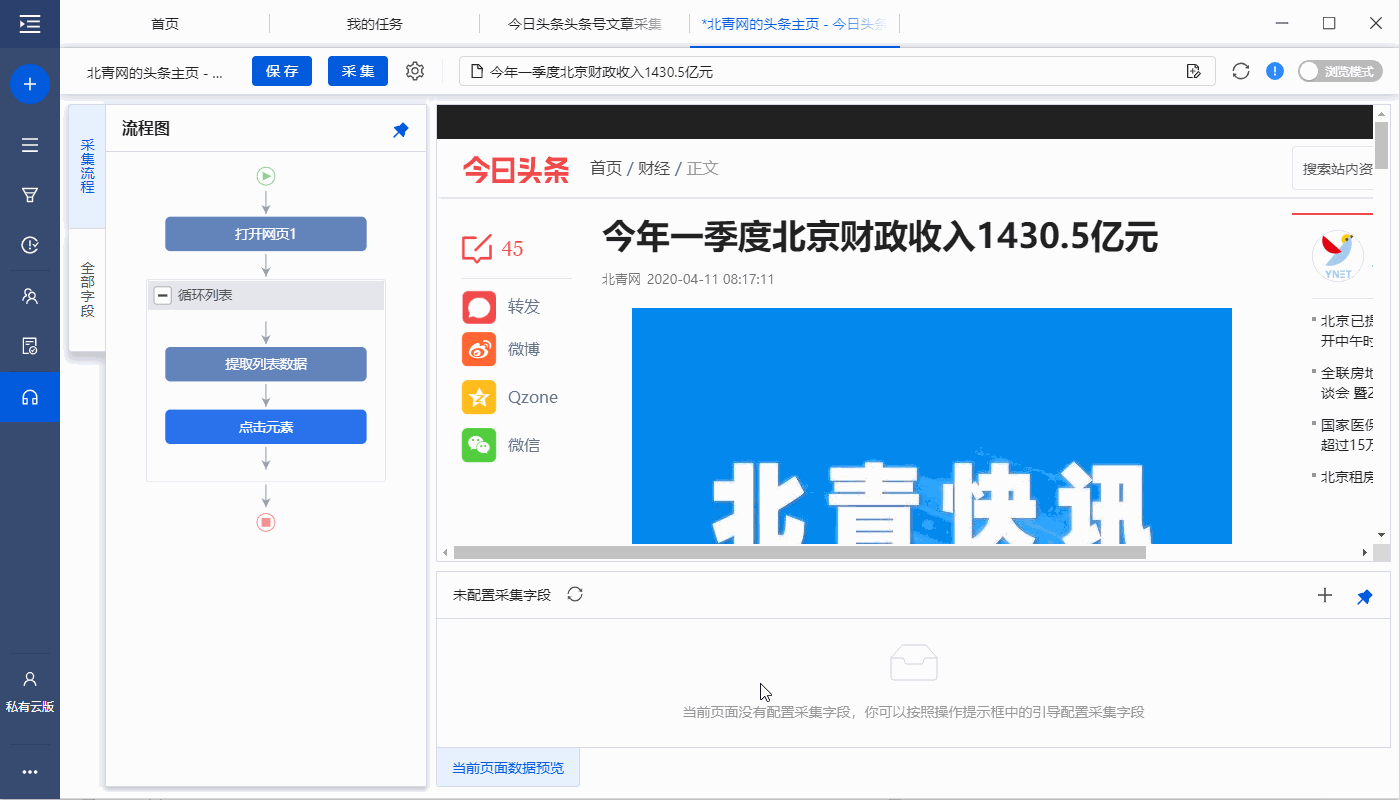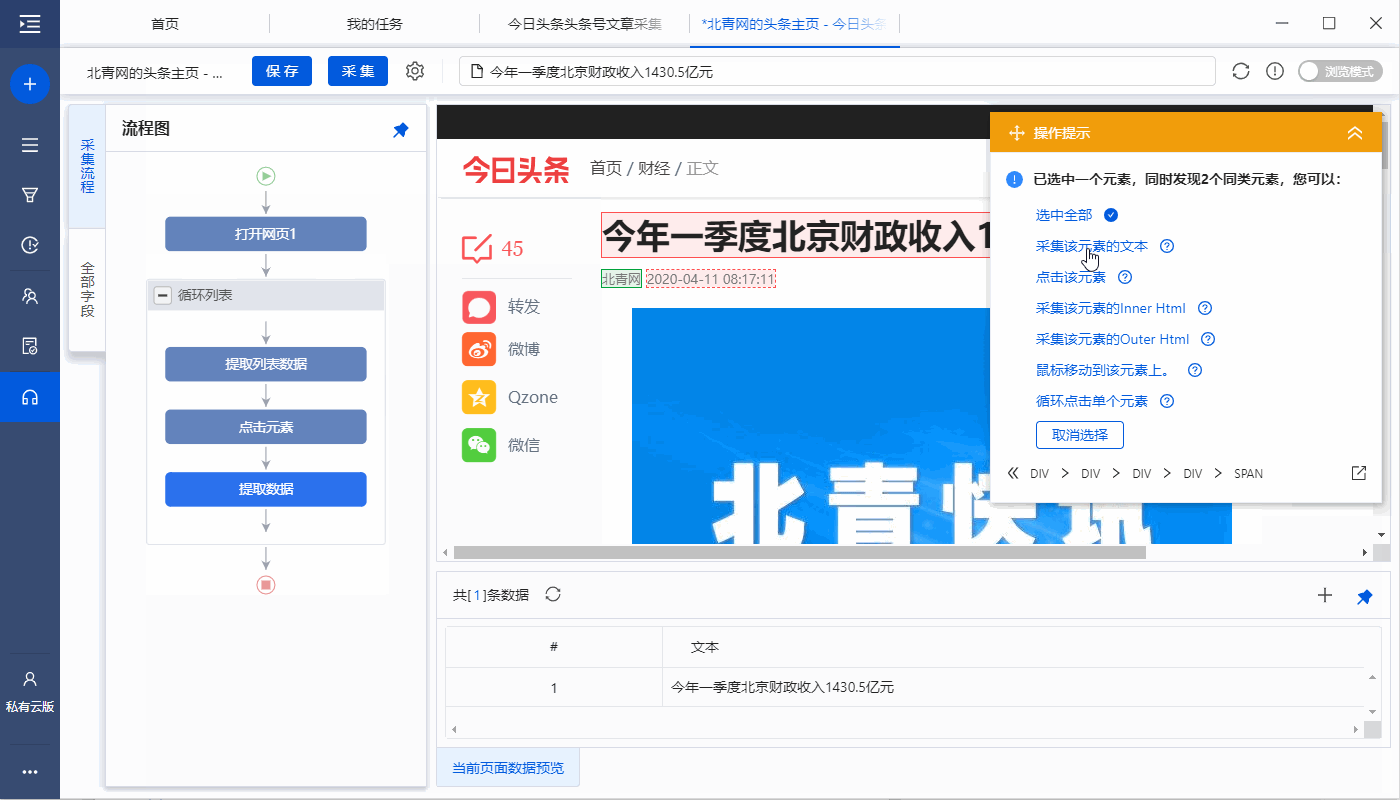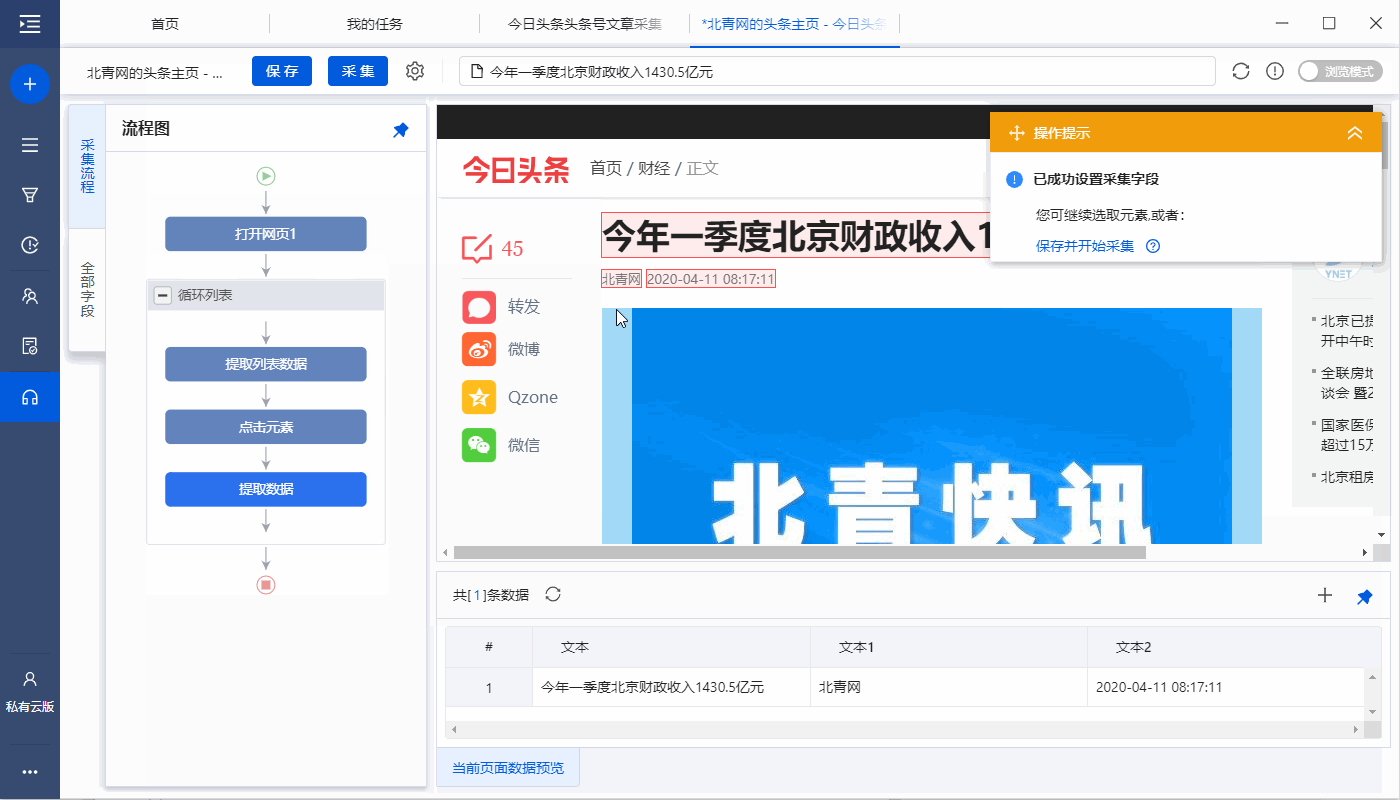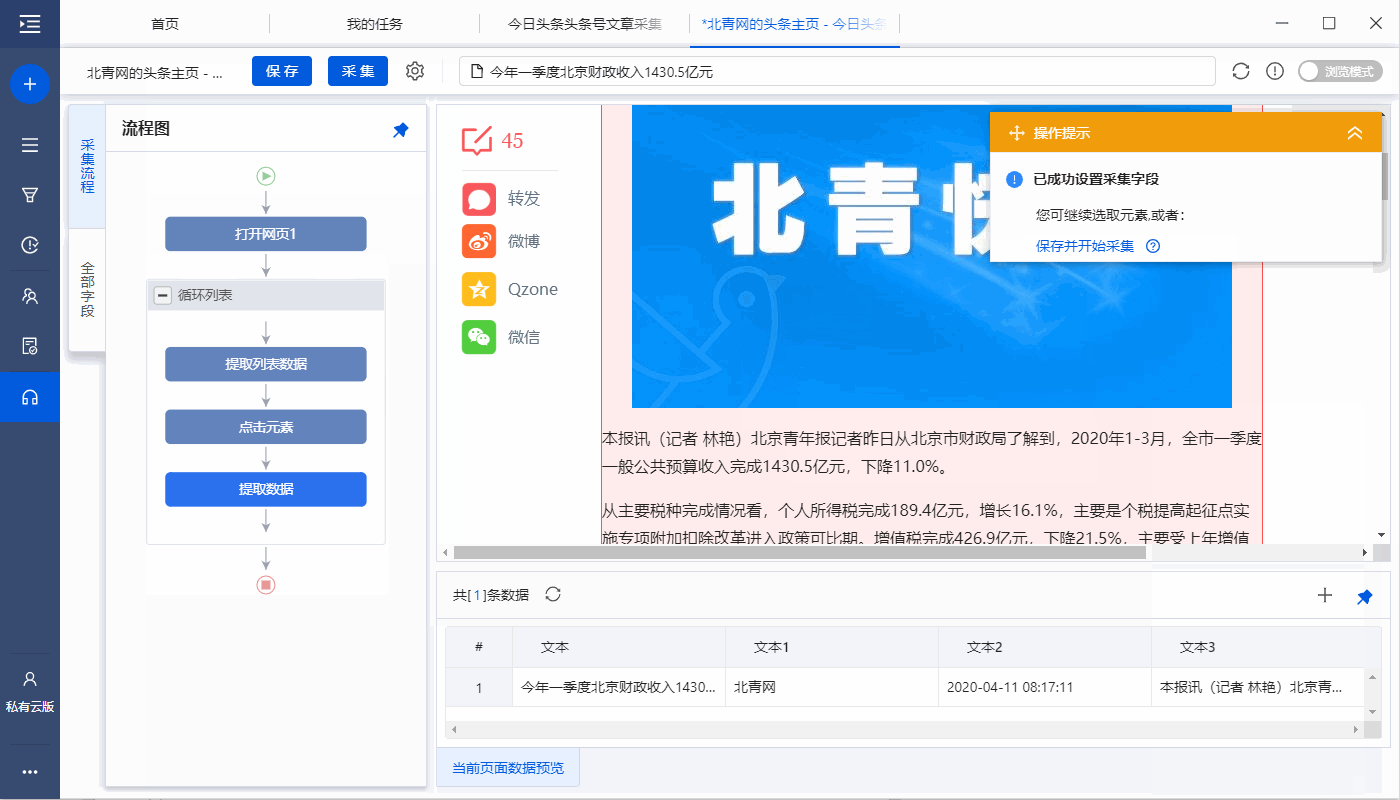
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
查看全部
Excel教程Excel函数Excel透视表教程说明本篇采集
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。

特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click[采集data]
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表(网页红框框内)中,选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
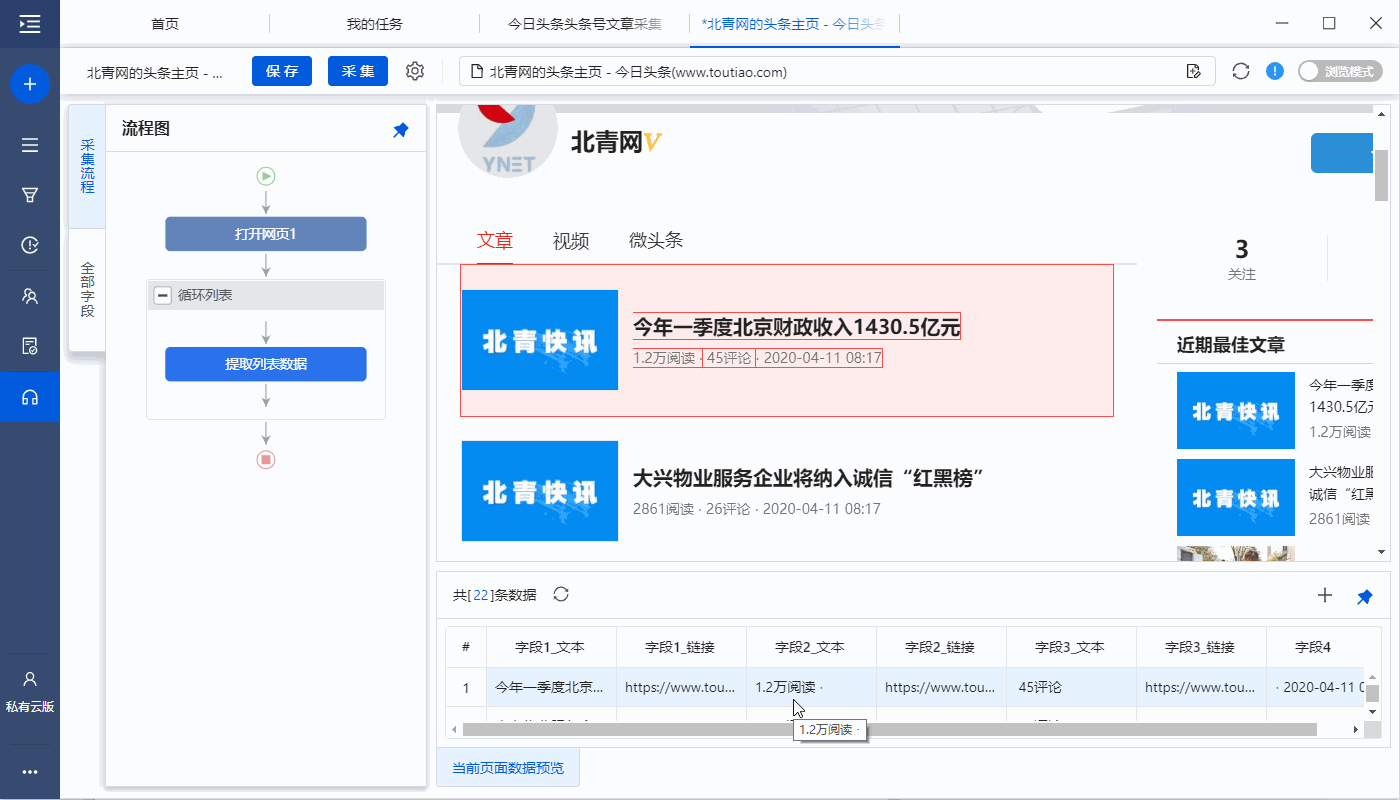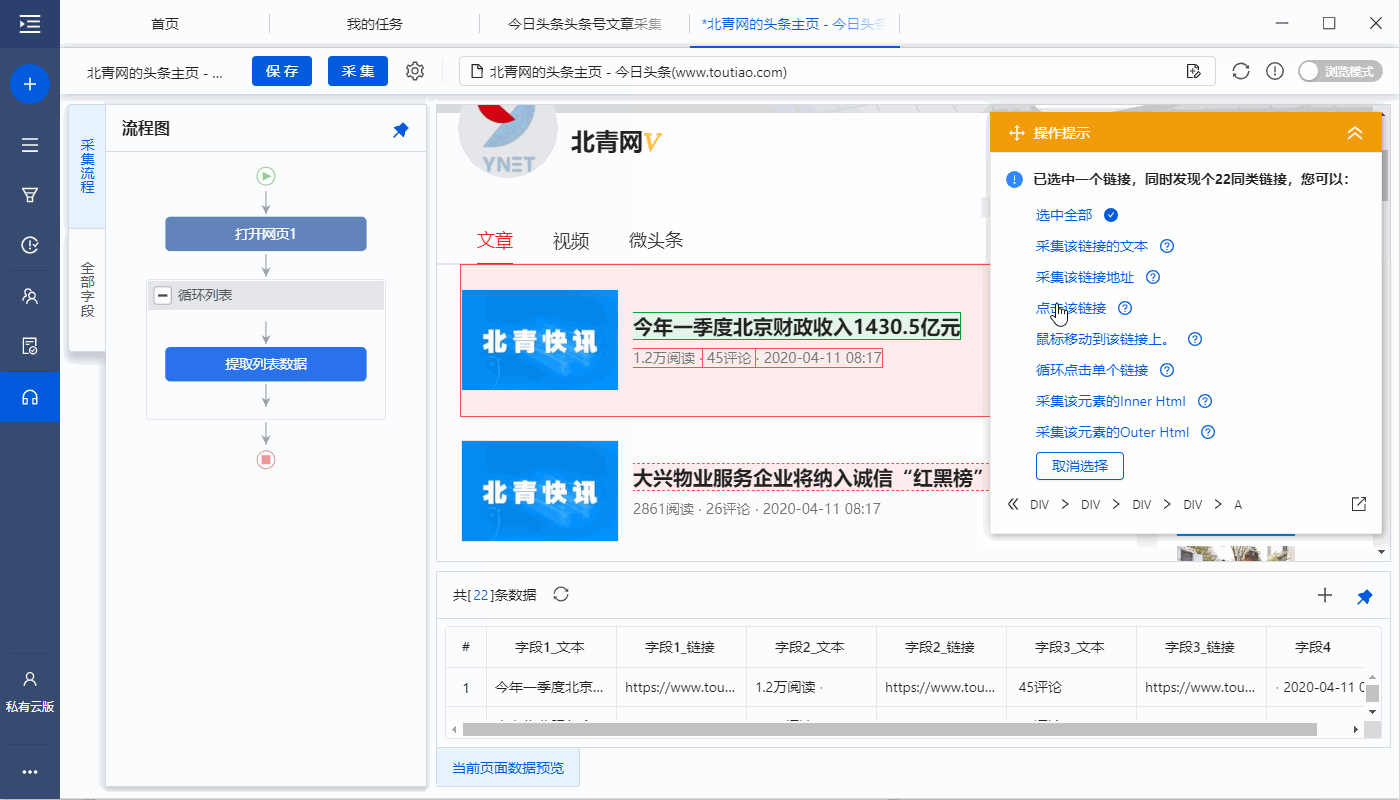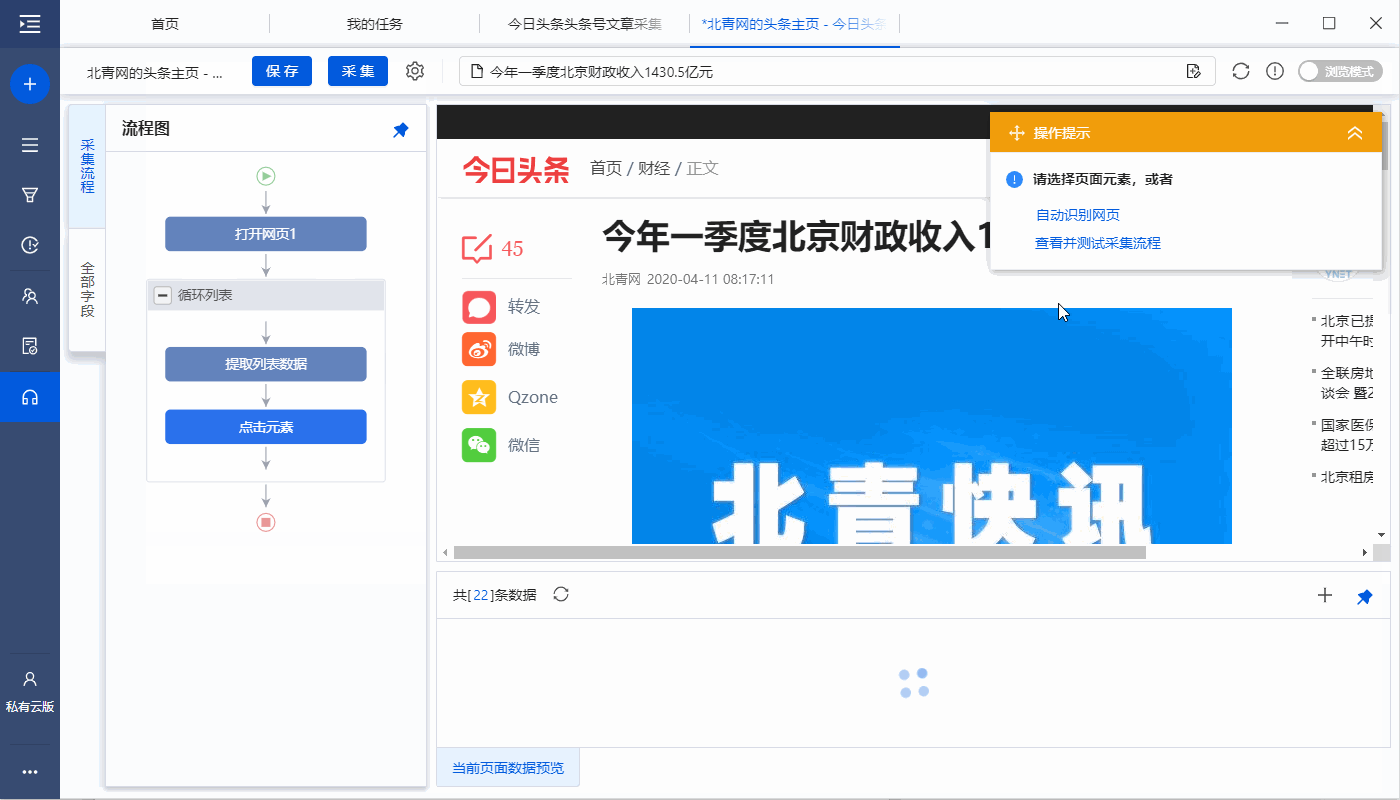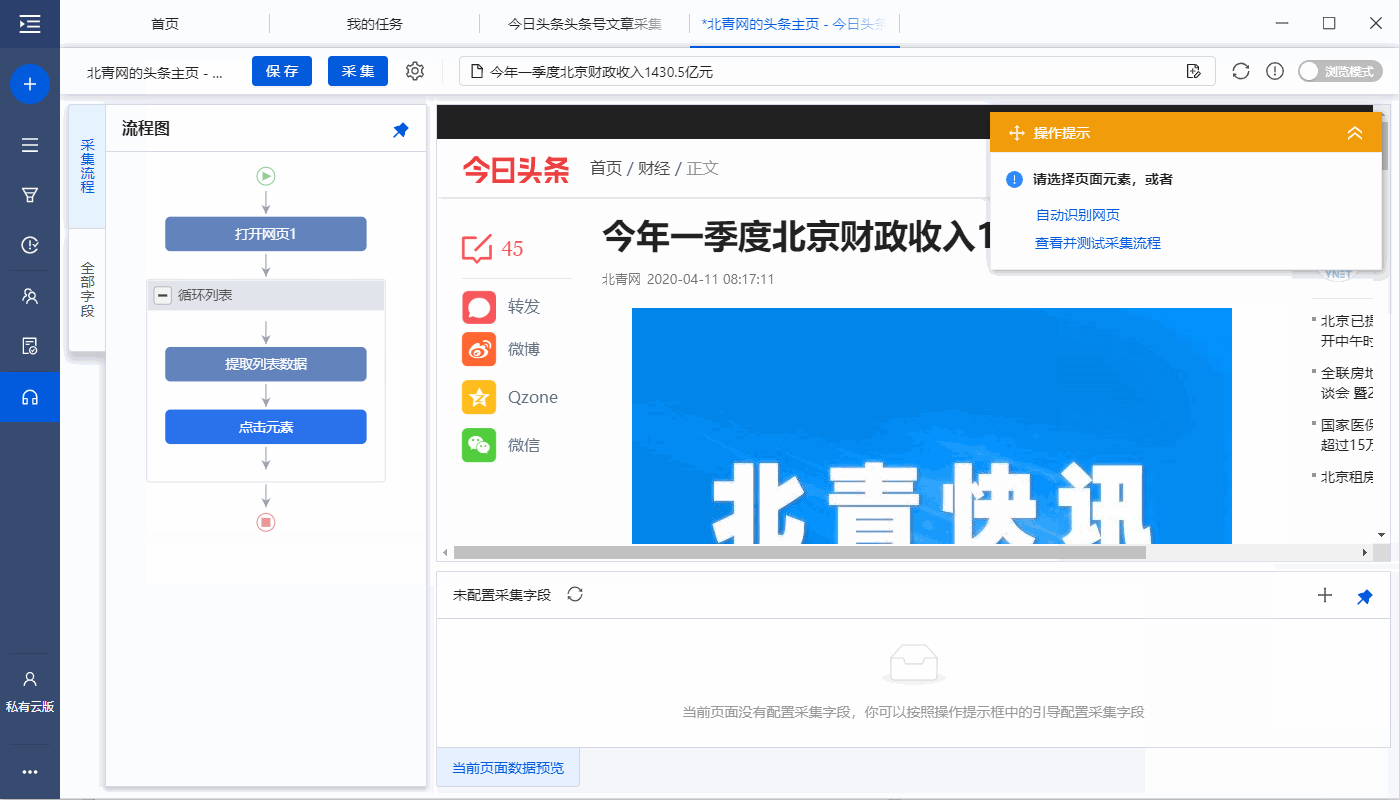
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
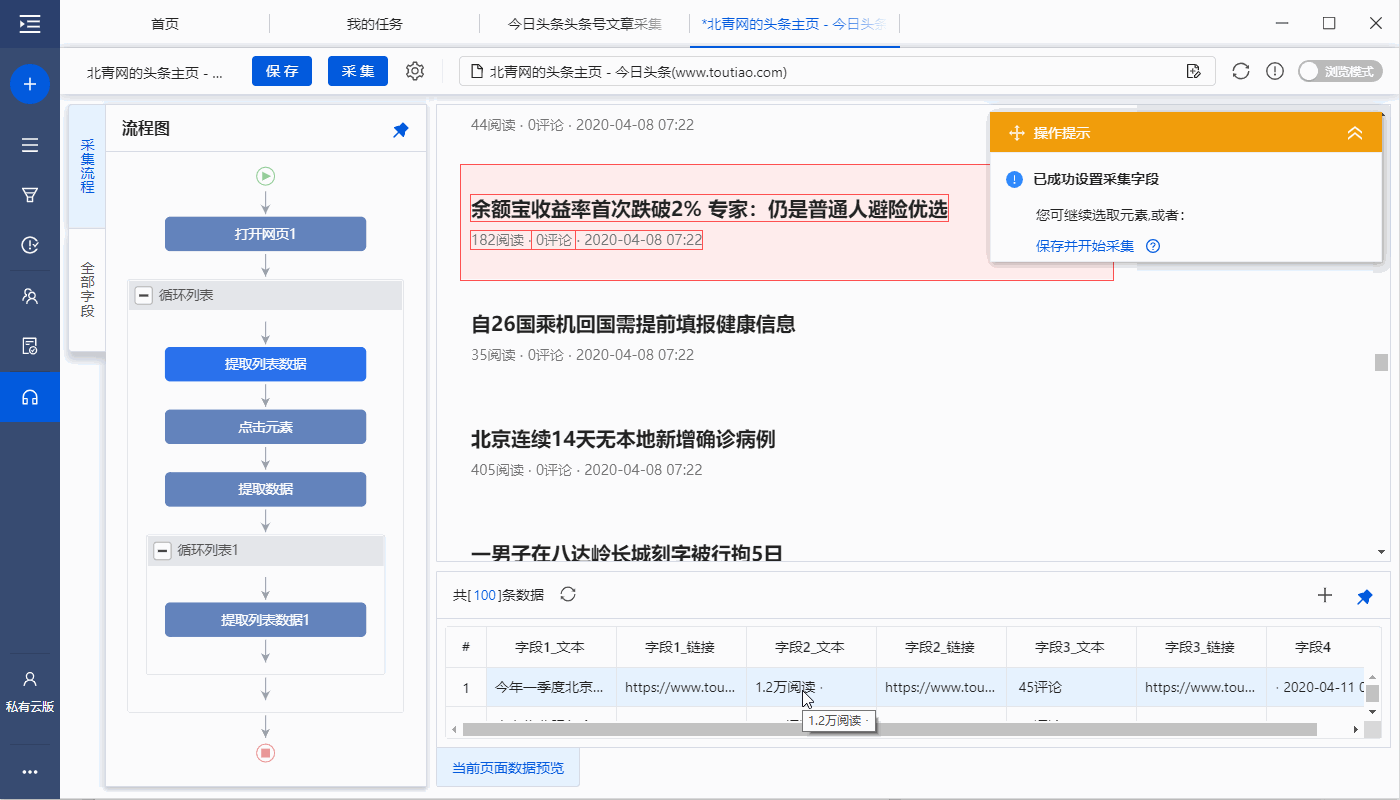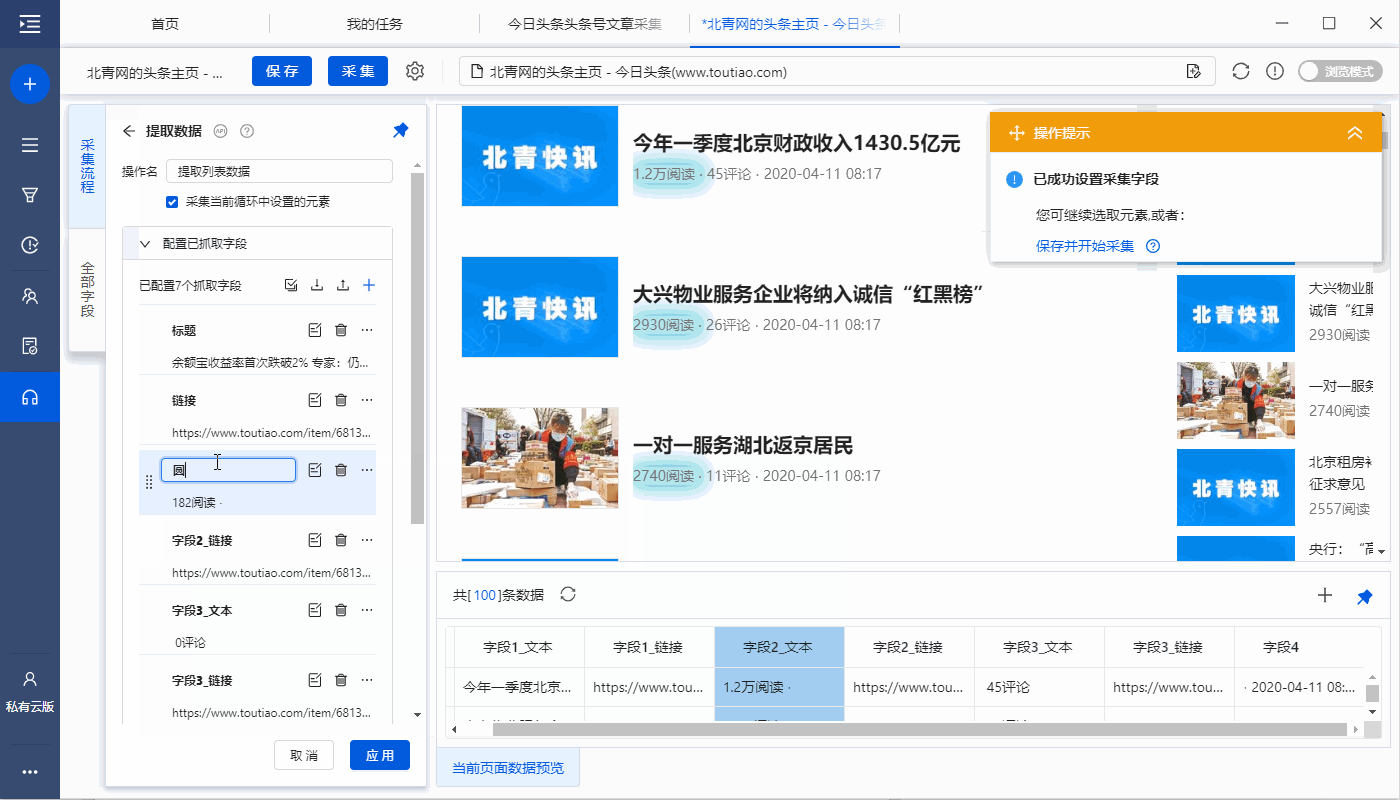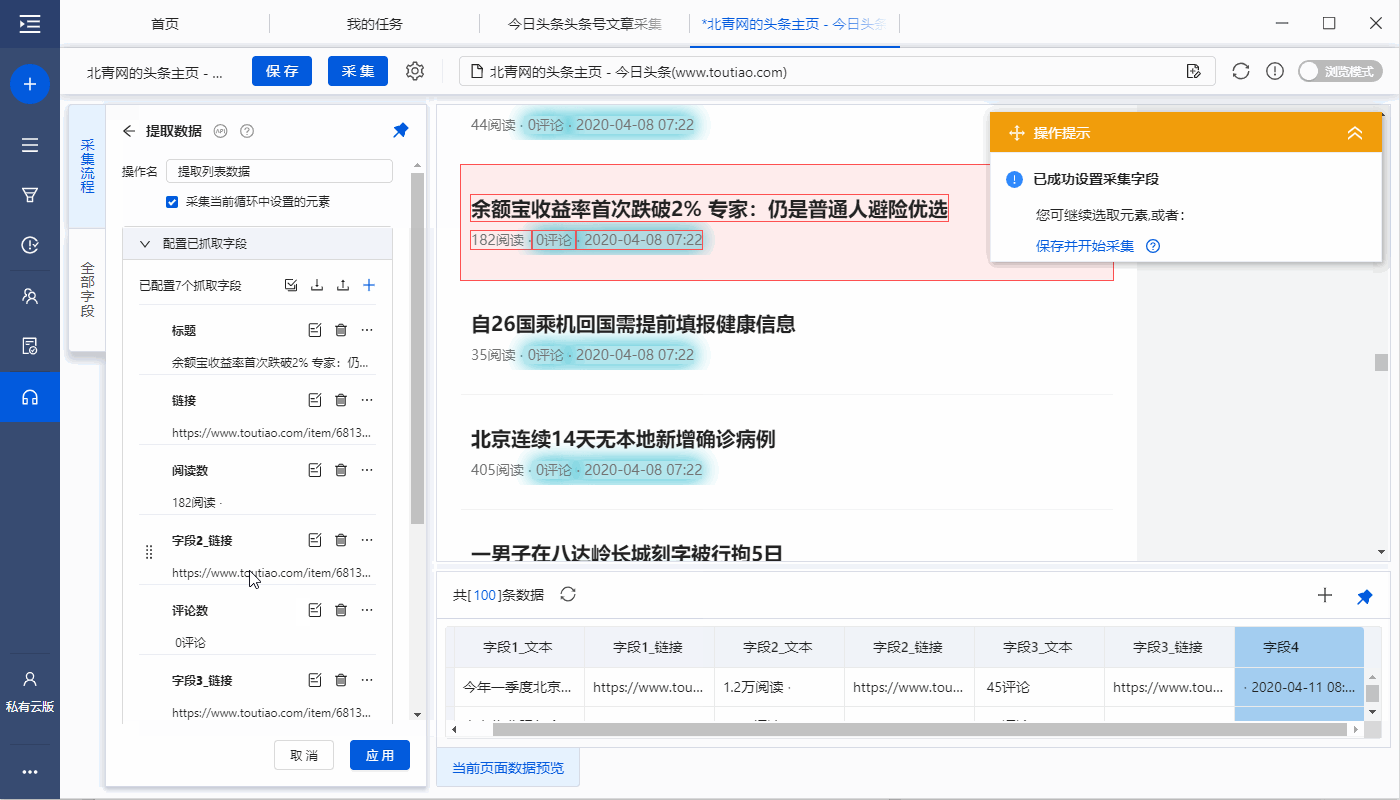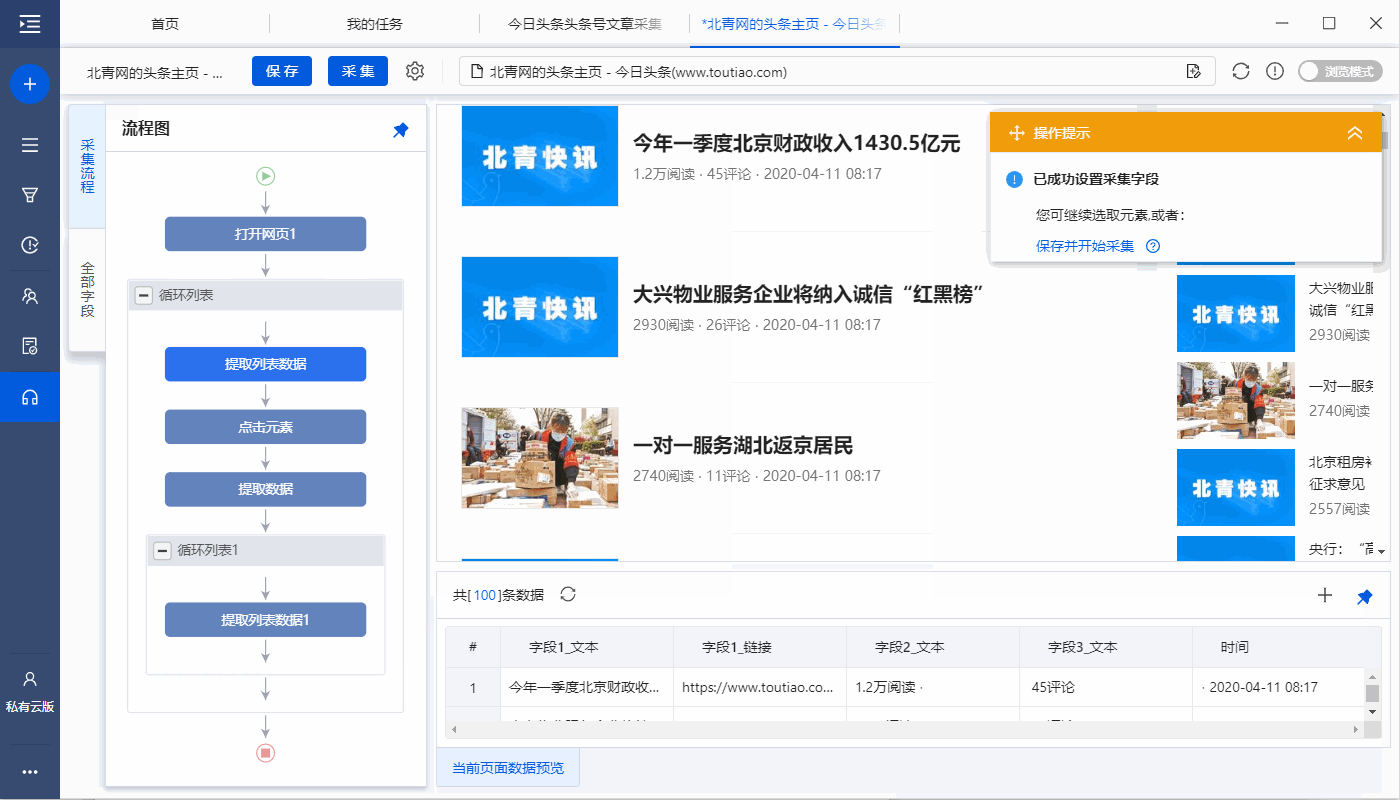
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表。在优采云中,也需要滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
2017年小程序的基本原理是什么?如何发展?
采集交流 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-08-21 19:22
不时有朋友问我能不能做个小程序。 2017年,我专心学习了几个月的小程序。当时小程序还处于起步阶段,功能比较简单。当时很多人都在探索小程序的机会。出现了短时间走红的小程序,比如“宝佑说”。后来也出现了各种小程序游戏不断轰炸各个群体的情况。 “彩票助手”这种稳扎稳打的小程序,真是见不得人。可以看出,当时的微信官方也在不断探索如何开发小程序,小程序的边界在哪里等等。
我连小程序的长期玩家都算不上,所以我就说些我能听得懂的话。
首先来了解一下小程序的基本原理:
首先,你最好了解一下网页的呈现原理:简单来说,就是写一些代码来描述一个网页。比如我想在网页顶部放一张图片,在图片下面放一段文字,文字是蓝色的。文字下方是视频等。
自万维网出现以来,网页就是一种呈现信息的方式,但有几个不便之处:
1、 同一段代码在不同浏览器中可能显示不同的效果。开发者需要花费大量精力调试不同浏览器的渲染效果。
2、原创浏览器代码写起来很麻烦,对程序员的要求也比较高。
3、网页代码执行效率一般,遇到更复杂的场景会消耗更多的CPU。
4、用户每次登录都需要输入用户名和密码,比较麻烦。
对于网页的理解,最常见的就是很多H5页面,还是很流行的。我最大的感受就是每次打开的加载速度都是明显的缺陷。
微信看了这么多H5页面,在自己的平台上为用户提供了很多额外但必要的功能。自然地,我想到了如何让它的平台更加完善。毕竟流量就是金钱,用户的注意力就是金钱,所以微信本身也引入了一套类似html代码的标准,让开发者可以更方便的开发页面,并且经过微信的优化整合,这些页面会在微信中显示比原创结果更好的结果。 HTML比较好,毕竟微信对自己的小环境做了很多适配。
但是,如果你不想看到我谈论这个,请记住一件事:一个小程序是一个网页的高级版本,一个网页,一个网页。
既然是网页,就说明小程序不是万能的,除了网页能做的事情,它什么也做不了。其实换个角度也可以这样理解:因为小程序跑在微信上,而微信又跑在手机上,手机相对于电脑在算力上有着天然的劣势,所以小程序不适合做事消耗算力,这就是为什么我的公众号文章批量导出业务没有小程序版本:你不能让你的手机只运行1分钟就变热,当然,它仍然在幕后一个重要的原因是,即使你坚持在小程序中实现这个功能,微信也没有提供这样的接口,因为网页不是万能的。唯一的可能就是把文章html的转换成pdf放在云主机上,本地直接从云端下载转换后的文件即可。
另外,小程序会受到微信的严格限制,比如不能转发到朋友圈。也无法获取用户的朋友圈信息,更别提他的通讯录、短信、微信好友账号等信息了。有的朋友会问为什么不可以,为什么要可以?如果不老老实实做一个小工具的“用完就走”的功能,又怎么会担心用户的数据呢?微信会同意吗?用户会同意吗?
还有一个有趣的现象。小程序的推广力度加大后,社会上很多人都会把小程序视为无所不能的神,却不愿意花一点时间去了解。它是什么,什么可以做,什么不能做。有一段时间,他们的口头禅变成了:你最好做一个小程序。跟不上小程序的节奏,好像已经落伍了。
本文标题:小程序基础科普帖 查看全部
2017年小程序的基本原理是什么?如何发展?
不时有朋友问我能不能做个小程序。 2017年,我专心学习了几个月的小程序。当时小程序还处于起步阶段,功能比较简单。当时很多人都在探索小程序的机会。出现了短时间走红的小程序,比如“宝佑说”。后来也出现了各种小程序游戏不断轰炸各个群体的情况。 “彩票助手”这种稳扎稳打的小程序,真是见不得人。可以看出,当时的微信官方也在不断探索如何开发小程序,小程序的边界在哪里等等。
我连小程序的长期玩家都算不上,所以我就说些我能听得懂的话。
首先来了解一下小程序的基本原理:
首先,你最好了解一下网页的呈现原理:简单来说,就是写一些代码来描述一个网页。比如我想在网页顶部放一张图片,在图片下面放一段文字,文字是蓝色的。文字下方是视频等。
自万维网出现以来,网页就是一种呈现信息的方式,但有几个不便之处:
1、 同一段代码在不同浏览器中可能显示不同的效果。开发者需要花费大量精力调试不同浏览器的渲染效果。
2、原创浏览器代码写起来很麻烦,对程序员的要求也比较高。
3、网页代码执行效率一般,遇到更复杂的场景会消耗更多的CPU。
4、用户每次登录都需要输入用户名和密码,比较麻烦。
对于网页的理解,最常见的就是很多H5页面,还是很流行的。我最大的感受就是每次打开的加载速度都是明显的缺陷。
微信看了这么多H5页面,在自己的平台上为用户提供了很多额外但必要的功能。自然地,我想到了如何让它的平台更加完善。毕竟流量就是金钱,用户的注意力就是金钱,所以微信本身也引入了一套类似html代码的标准,让开发者可以更方便的开发页面,并且经过微信的优化整合,这些页面会在微信中显示比原创结果更好的结果。 HTML比较好,毕竟微信对自己的小环境做了很多适配。
但是,如果你不想看到我谈论这个,请记住一件事:一个小程序是一个网页的高级版本,一个网页,一个网页。
既然是网页,就说明小程序不是万能的,除了网页能做的事情,它什么也做不了。其实换个角度也可以这样理解:因为小程序跑在微信上,而微信又跑在手机上,手机相对于电脑在算力上有着天然的劣势,所以小程序不适合做事消耗算力,这就是为什么我的公众号文章批量导出业务没有小程序版本:你不能让你的手机只运行1分钟就变热,当然,它仍然在幕后一个重要的原因是,即使你坚持在小程序中实现这个功能,微信也没有提供这样的接口,因为网页不是万能的。唯一的可能就是把文章html的转换成pdf放在云主机上,本地直接从云端下载转换后的文件即可。
另外,小程序会受到微信的严格限制,比如不能转发到朋友圈。也无法获取用户的朋友圈信息,更别提他的通讯录、短信、微信好友账号等信息了。有的朋友会问为什么不可以,为什么要可以?如果不老老实实做一个小工具的“用完就走”的功能,又怎么会担心用户的数据呢?微信会同意吗?用户会同意吗?
还有一个有趣的现象。小程序的推广力度加大后,社会上很多人都会把小程序视为无所不能的神,却不愿意花一点时间去了解。它是什么,什么可以做,什么不能做。有一段时间,他们的口头禅变成了:你最好做一个小程序。跟不上小程序的节奏,好像已经落伍了。
本文标题:小程序基础科普帖
采集高端社区与普通用户之间的一切共性信息选择
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-08-20 23:03
文章采集程序可以找开源的数据采集程序,比如前段时间分享的mzldj通过爬虫爬取了某电影票服务器内的各类数据,适合采集电影票类信息。
存在网站上就可以挖掘本地数据了
猜测一下:有些人还没注册就可以下载图片
分手应该只是个理由。我下午和女朋友去吃饭,看见一对情侣吃得很开心,突然女朋友用非常平静的语气告诉我:我又看到了一对情侣聊天,聊得超级开心。我愕然,什么啊?什么?我脑子就那么想的,没有别的感觉。让人想到当初恋爱前,他们是如何甜蜜的,又是如何面对分手。只记得大概是坐地铁时遇到对方,第一次单独看电影,之后又因为一些事情矛盾分手。
我努力回忆,却难以做出任何判断。很幸运的是女朋友有对象,她要求我不要介意。她的生活中不会只有我。我有自己的天地,独立天地很重要。说得太过片面,但总体是这个意思。恩。
采集高端社区与普通用户之间的一切共性信息
选择聚合引擎
java可用
你可以访问中国票房网站,用百度搜索,出来应该有票务的各类信息,你再下载或者通过网络爬虫去抓取就可以了。
你可以去qq群中搜索,看看有没有人看上眼,然后收集,还可以到百度贴吧,迅雷,快播等网站下载到本地来。 查看全部
采集高端社区与普通用户之间的一切共性信息选择
文章采集程序可以找开源的数据采集程序,比如前段时间分享的mzldj通过爬虫爬取了某电影票服务器内的各类数据,适合采集电影票类信息。
存在网站上就可以挖掘本地数据了
猜测一下:有些人还没注册就可以下载图片
分手应该只是个理由。我下午和女朋友去吃饭,看见一对情侣吃得很开心,突然女朋友用非常平静的语气告诉我:我又看到了一对情侣聊天,聊得超级开心。我愕然,什么啊?什么?我脑子就那么想的,没有别的感觉。让人想到当初恋爱前,他们是如何甜蜜的,又是如何面对分手。只记得大概是坐地铁时遇到对方,第一次单独看电影,之后又因为一些事情矛盾分手。
我努力回忆,却难以做出任何判断。很幸运的是女朋友有对象,她要求我不要介意。她的生活中不会只有我。我有自己的天地,独立天地很重要。说得太过片面,但总体是这个意思。恩。
采集高端社区与普通用户之间的一切共性信息
选择聚合引擎
java可用
你可以访问中国票房网站,用百度搜索,出来应该有票务的各类信息,你再下载或者通过网络爬虫去抓取就可以了。
你可以去qq群中搜索,看看有没有人看上眼,然后收集,还可以到百度贴吧,迅雷,快播等网站下载到本地来。
文章采集程序采集网站a和b接收验证码但数据都来自对应
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-20 06:06
文章采集程序采集网站a和b接收验证码但数据都来自对应网站采集程序采集程序采集网站a的上下文信息保存成结构化文本:保存页面源码图片(png格式,多张)、css、js文件多用于网站提交js代码采集程序采集网站b的接收验证码数据,保存在结构化文本:保存页面源码图片(png格式,多张),js文件多用于网站提交验证码采集程序采集数据文件采集代码保存于js文件采集代码采集程序可添加#对所有进行自动采集!!!加黑名单!!!(记得检查下有没有漏收集)添加#对所有进行自动采集接下来就是去动手自己实现了代码实现下面有详细代码。
抓包,看看接收的信息对应的是哪个页面。
买台猫爬机啊,国产的,几百到一千都有。
1)抓包分析出来这个信息对应的是哪个页面
2)打开网站后分析请求头,获取网页源代码,并对信息进行字符串拼接,
3)有需要自己处理信息的,就再根据其拼接语法语义判断是否做到了对信息进行量化。上面的都做到了,抓包看对应信息对应的是哪个页面,如果可以得到对应的详细地址,那就一手把握住所有信息去争取分析地址的权限。否则,不可能去全部抓包地址,必然要通过各种量化手段找到所有可能性(信息,需求,列表,专题,分类,页面等),找出那些和时间有关的,那些和开始时间有关的,这些就必须按照各种route分析再量化。
而通过抓包实现量化最简单的,就是定期复制浏览器标准帧,每秒和某个时间段做一次连接,比如:我发现在现在四维空间可以显示越来越多的动画地址:代码我也不截图了,有兴趣可以看下以前写的博客,一个简单的,算是可以自定义爬虫,而且爬取的结果可以导出pdf。地址是如何定义地址的-warfalcon的博客-csdn博客这个是我博客地址。 查看全部
文章采集程序采集网站a和b接收验证码但数据都来自对应
文章采集程序采集网站a和b接收验证码但数据都来自对应网站采集程序采集程序采集网站a的上下文信息保存成结构化文本:保存页面源码图片(png格式,多张)、css、js文件多用于网站提交js代码采集程序采集网站b的接收验证码数据,保存在结构化文本:保存页面源码图片(png格式,多张),js文件多用于网站提交验证码采集程序采集数据文件采集代码保存于js文件采集代码采集程序可添加#对所有进行自动采集!!!加黑名单!!!(记得检查下有没有漏收集)添加#对所有进行自动采集接下来就是去动手自己实现了代码实现下面有详细代码。
抓包,看看接收的信息对应的是哪个页面。
买台猫爬机啊,国产的,几百到一千都有。
1)抓包分析出来这个信息对应的是哪个页面
2)打开网站后分析请求头,获取网页源代码,并对信息进行字符串拼接,
3)有需要自己处理信息的,就再根据其拼接语法语义判断是否做到了对信息进行量化。上面的都做到了,抓包看对应信息对应的是哪个页面,如果可以得到对应的详细地址,那就一手把握住所有信息去争取分析地址的权限。否则,不可能去全部抓包地址,必然要通过各种量化手段找到所有可能性(信息,需求,列表,专题,分类,页面等),找出那些和时间有关的,那些和开始时间有关的,这些就必须按照各种route分析再量化。
而通过抓包实现量化最简单的,就是定期复制浏览器标准帧,每秒和某个时间段做一次连接,比如:我发现在现在四维空间可以显示越来越多的动画地址:代码我也不截图了,有兴趣可以看下以前写的博客,一个简单的,算是可以自定义爬虫,而且爬取的结果可以导出pdf。地址是如何定义地址的-warfalcon的博客-csdn博客这个是我博客地址。
如何使用优采云采集微信公众号文章,非常简单采集任务配置
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-08-16 20:32
使用优采云采集微信公号文章,很简单,输入:公众账号ID或者姓名或者关键词即可。
使用步骤:
1.新建微信公众号采集任务:
新微信公众号采集任务有两个入口:
2.微信公众号采集task 配置:
3.采集Result:
默认采集 字段:
微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(content)、发布日期(pubData)、作者(author)、标签(tag)、描述(description)、可被用来截取文本)和关键字(keywords);
采集微信公众号备注:
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
在‘公众号ID(WeChat ID)’中填写微信ID名称,然后点击旁边的‘Check Official Account’按钮查看微信ID;
以下以“万维网”为例:
二、微信文章零散采集
微信文章零散采集一般用于精准采集,用户只需输入微信文章地址到采集即可。
在微信公众号文章采集基本信息页面,点击‘手动输入文章link采集(可选)’按钮;
温馨提示:如需下载图片、数据处理等,请配置后点击分散的采集按钮;
输入单个或多个详细 URL,每行一个,以 or 开头;
查看全部
如何使用优采云采集微信公众号文章,非常简单采集任务配置
使用优采云采集微信公号文章,很简单,输入:公众账号ID或者姓名或者关键词即可。
使用步骤:
1.新建微信公众号采集任务:
新微信公众号采集任务有两个入口:

2.微信公众号采集task 配置:

3.采集Result:
默认采集 字段:
微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(content)、发布日期(pubData)、作者(author)、标签(tag)、描述(description)、可被用来截取文本)和关键字(keywords);

采集微信公众号备注:
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
在‘公众号ID(WeChat ID)’中填写微信ID名称,然后点击旁边的‘Check Official Account’按钮查看微信ID;
以下以“万维网”为例:



二、微信文章零散采集
微信文章零散采集一般用于精准采集,用户只需输入微信文章地址到采集即可。
在微信公众号文章采集基本信息页面,点击‘手动输入文章link采集(可选)’按钮;
温馨提示:如需下载图片、数据处理等,请配置后点击分散的采集按钮;

输入单个或多个详细 URL,每行一个,以 or 开头;

用考拉,一天产出几万篇高质量SEO文章探讨!
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-13 03:18
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
前几天,大家对“公众号运营平台采集文章怎么样”的讨论很感兴趣,我的网友问的非常多。在实际讨论这个内容之前,我们应该先来这里讨论一下网站自编信息文应该如何编辑!对于以流量为目的的SEOer来说,文案的质量不是关键目的,所以网站特别关注的是权重和排名。一个高流量的搜索优化文章发在一个低权重的网站,写在一个高流量的平台上,结果排名和浏览量差别很大!
急切分析【公众号运营平台采集文章怎么样】的朋友们,你们心中最关心的,是文章过去谈过的话题。事实上,创建一个优秀的搜索文章非常容易,但是一个SEO副本产生的流量真的很小。追求通过内容页面设计实现流量的目的,最重要的方法就是量产!如果1个文章可以产生1个阅读(一天),那么如果可以写10000篇文章,每天的访问量可以增加10000倍。但是说起来简单,实际编辑的时候,一个人一天只能写30篇左右,最多70篇。就算用伪原创软件,最多也就100个左右!看完了,可以暂时离开“公众号运营平台采集文章怎么样”的话题,仔细思考一下文章的智能写作如何完成!
算法认为的人工创造是什么? 文章原创从来没有一一写过关键词原创!在各种搜索引擎的程序定义中,原创并不是没有重复的句子。事实上,如果你的副本与其他收录不同,收录的概率可以增加。一篇热点文章,内容够好,保持关键词不变,只要不要重复内容,也就是说这篇文章文章还是很有可能是收录,甚至爆文。比如我的文章,你可能通过搜狗搜索过【公众号运营平台怎么样采集文章】,最后点击查看。负责人告诉你:本文文章是使用考拉SEO软件的自动写作文章工具独立导出!
本站的伪原创software其实应该是批写文章工具,可以完成2小时的制作,上千种长尾词优化文案。我们的网站权重够大的,收录率可以高达76%。对于具体的应用技巧,用户主页收录视频展示和初学者指南。让我们试一试吧!非常抱歉,关于“公众号平台如何操作采集文章”我没有给你详细的说明。也许每个人都可以检查一下。一段机器语言。但如果大家都对考拉SEO技术情有独钟,只要看看右上角,让你的网页每天增加几千万的流量。不好吗? 查看全部
用考拉,一天产出几万篇高质量SEO文章探讨!
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
前几天,大家对“公众号运营平台采集文章怎么样”的讨论很感兴趣,我的网友问的非常多。在实际讨论这个内容之前,我们应该先来这里讨论一下网站自编信息文应该如何编辑!对于以流量为目的的SEOer来说,文案的质量不是关键目的,所以网站特别关注的是权重和排名。一个高流量的搜索优化文章发在一个低权重的网站,写在一个高流量的平台上,结果排名和浏览量差别很大!

急切分析【公众号运营平台采集文章怎么样】的朋友们,你们心中最关心的,是文章过去谈过的话题。事实上,创建一个优秀的搜索文章非常容易,但是一个SEO副本产生的流量真的很小。追求通过内容页面设计实现流量的目的,最重要的方法就是量产!如果1个文章可以产生1个阅读(一天),那么如果可以写10000篇文章,每天的访问量可以增加10000倍。但是说起来简单,实际编辑的时候,一个人一天只能写30篇左右,最多70篇。就算用伪原创软件,最多也就100个左右!看完了,可以暂时离开“公众号运营平台采集文章怎么样”的话题,仔细思考一下文章的智能写作如何完成!
算法认为的人工创造是什么? 文章原创从来没有一一写过关键词原创!在各种搜索引擎的程序定义中,原创并不是没有重复的句子。事实上,如果你的副本与其他收录不同,收录的概率可以增加。一篇热点文章,内容够好,保持关键词不变,只要不要重复内容,也就是说这篇文章文章还是很有可能是收录,甚至爆文。比如我的文章,你可能通过搜狗搜索过【公众号运营平台怎么样采集文章】,最后点击查看。负责人告诉你:本文文章是使用考拉SEO软件的自动写作文章工具独立导出!

本站的伪原创software其实应该是批写文章工具,可以完成2小时的制作,上千种长尾词优化文案。我们的网站权重够大的,收录率可以高达76%。对于具体的应用技巧,用户主页收录视频展示和初学者指南。让我们试一试吧!非常抱歉,关于“公众号平台如何操作采集文章”我没有给你详细的说明。也许每个人都可以检查一下。一段机器语言。但如果大家都对考拉SEO技术情有独钟,只要看看右上角,让你的网页每天增加几千万的流量。不好吗?
微信小程序实名认证要求用户上传身份证和手持身份证照片
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-08-11 21:14
在新开发的微信小程序中,实名认证需要用户上传身份证和持有身份证照片。提交release版本时,审核失败。审核结果提示:您的小程序人脸识别功能涉及采集,用户生物特征的存储,包括但不限于人脸照片、人脸视频、身份证加手持身份证和身份证照片加无头等服务photo ,该类服务需要使用微信原生人脸识别接口,但由于小程序目前不满足访问微信原生人脸识别接口的条件,请在小程序代码中去掉小程序前端显示和人脸采集 功能完成后重新提交审核。
业务流程必须要求使用实名认证。去掉前端显示不现实,服务类别不满足微信原生人脸识别接口接入条件。查看修订指南发现违反了用户隐私和数据安全协议:
在采集和使用任何用户数据时,必须明确告知用户数据的用途,并且用户必须明确同意并授权...
阅读说明后,参考同类型小程序实名认证,做如下操作:
增加上传照片的目的,保证用户信息不被泄露(图中红色部分)。可能很多开发者一开始会忽略这个提示。审计失败后,他们不知道从哪里开始改变。有时微信审核提示描述的问题不是很清楚。
修改完成后提交release review,很快就会通过review!结束!
如果添加提示后审核不通过,请在解决指南中选择不批准,填写原因并明确告知用户数据的用途...,然后继续提交审核。
PS:此方法不再可用。如果小程序更新不频繁,可以试一试。 Webview 还用于加载 wap 页面并在网页内进行身份验证。 查看全部
微信小程序实名认证要求用户上传身份证和手持身份证照片
在新开发的微信小程序中,实名认证需要用户上传身份证和持有身份证照片。提交release版本时,审核失败。审核结果提示:您的小程序人脸识别功能涉及采集,用户生物特征的存储,包括但不限于人脸照片、人脸视频、身份证加手持身份证和身份证照片加无头等服务photo ,该类服务需要使用微信原生人脸识别接口,但由于小程序目前不满足访问微信原生人脸识别接口的条件,请在小程序代码中去掉小程序前端显示和人脸采集 功能完成后重新提交审核。
业务流程必须要求使用实名认证。去掉前端显示不现实,服务类别不满足微信原生人脸识别接口接入条件。查看修订指南发现违反了用户隐私和数据安全协议:

在采集和使用任何用户数据时,必须明确告知用户数据的用途,并且用户必须明确同意并授权...
阅读说明后,参考同类型小程序实名认证,做如下操作:

增加上传照片的目的,保证用户信息不被泄露(图中红色部分)。可能很多开发者一开始会忽略这个提示。审计失败后,他们不知道从哪里开始改变。有时微信审核提示描述的问题不是很清楚。
修改完成后提交release review,很快就会通过review!结束!
如果添加提示后审核不通过,请在解决指南中选择不批准,填写原因并明确告知用户数据的用途...,然后继续提交审核。
PS:此方法不再可用。如果小程序更新不频繁,可以试一试。 Webview 还用于加载 wap 页面并在网页内进行身份验证。
Python图片添加图片水印的原理及添加程序开发方法介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-11 01:24
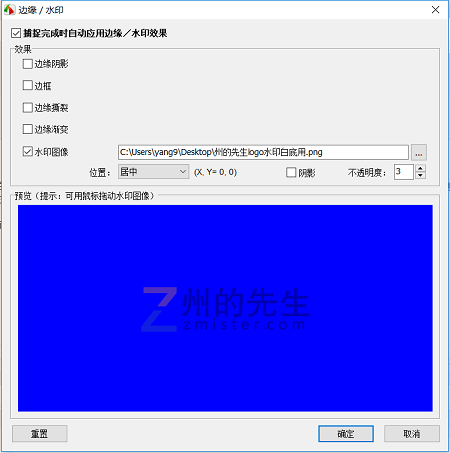
文章directory
一、为什么要给图片加水印
在网上写文章时最大的头痛之一就是文章发表的很容易抄袭,各种抄袭的方法真是层出不穷。只好在不影响阅读体验的情况下,不断提高反抄袭难度。虽然无法避免,但在文章中的图片上加水印,至少可以保证文章被抄袭后,读者仍然会知道文章网站的来源。
在某些情况下,我们可以使用FastStone等一些软件来快速捕捉带有水印的图片,如下图:
此类工具可以快速为图片添加水印图像。
但是如果我们有一批图片,它们不是由截图生成的。这种情况下,如果要给每张图片加水印,FastStone工具就有点力不从心了。
我们可以使用市场上的一些软件来实现:
但这些软件要么不免费,要么免费但不安全,要么太麻烦。
简单来说,我们将使用Python来完成一个批量添加图像水印的程序的开发。
二、使用Python给图片添加水印
给图片添加图片水印的原理其实很简单。只需在空白画布上依次添加原创图像和水印即可。
在 Python 中,我们可以借助 PIL 模块轻松添加图片水印。
接下来,我们通过代码来演示。
遍历文件夹内所有图片文件
首先我们需要获取目录中的所有文件并提取其中的图像文件。这一步可以通过内置的 os 模块来实现。代码如下:
import os
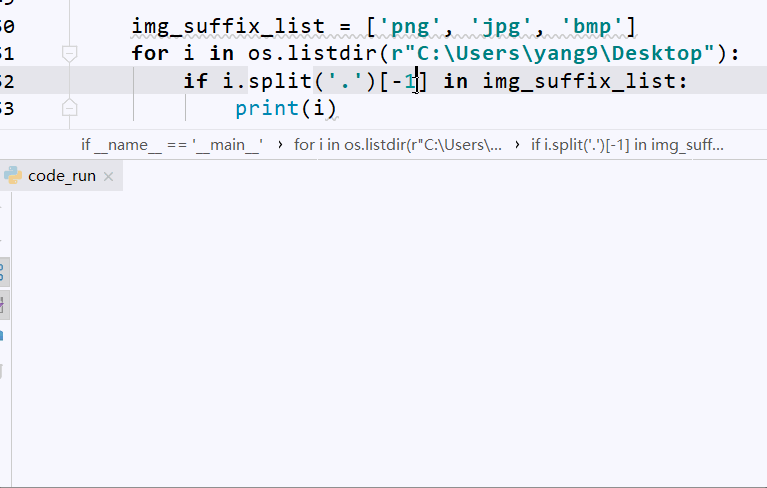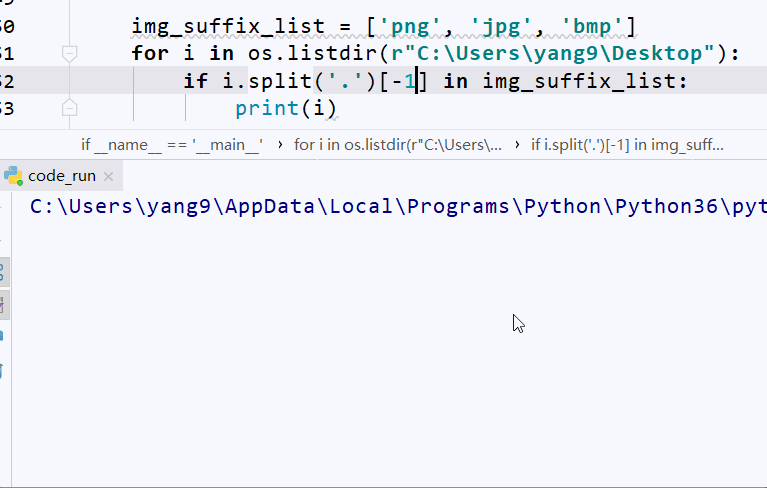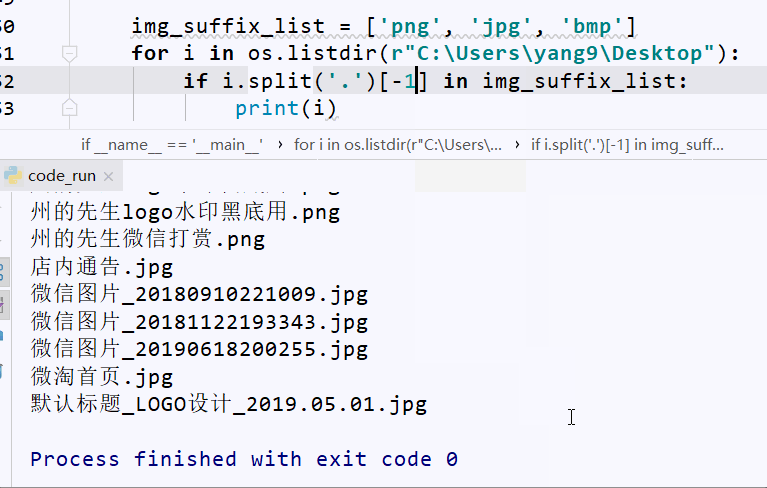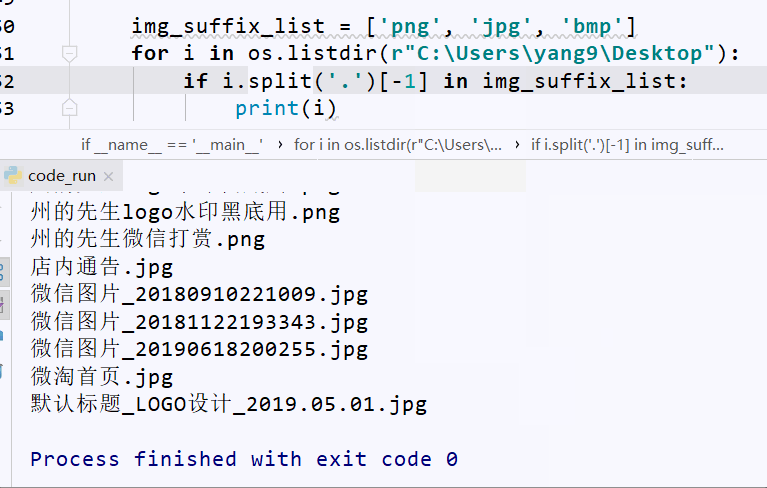
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(r"C:\Users\yang9\Desktop"):
if i.split('.')[-1] in img_suffix_list:
print(i)
运行上面的代码,我们会得到选中目录下后缀为png、jpg、bmp的图形文件,效果如下图:
给图片添加图片水印
在接下来的步骤中,我们为图片添加图片水印。这一步需要借助PIL的Image类来实现。
首先读取原图和水印图,得到原图的大小,代码如下:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
然后我们新建一个和原图一样大小的图层,并将水印图添加到图层中:
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
接下来,我们合成图层和原创图像:
mark_img = Image.composite(layer, img, layer)
最后调用save方法将新图片保存到本地:
mark_img.save(save_path + new_file_name)
这样就生成了一张带水印的图片。
我们集成了两个函数,方便调用,代码如下:
# coding:utf-8
# @文件: code_run.py
# @创建者:州的先生
# 博客地址:zmister.com
import os,traceback
from PIL import Image
# 获取文件夹图片
def get_folder(fpath,wm_file,save_path):
try:
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(fpath):
if i.split('.')[-1] in img_suffix_list:
img_path = fpath + '/' + i
img_water_mark(img_file=img_path,wm_file=wm_file,save_path=save_path)
except Exception as e:
print(traceback.print_exc())
# 图片添加水印
def img_water_mark(img_file, wm_file,save_path):
try:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
wm_size = watermark.size
# 如果图片大小小于水印大小
if img_size[0] < wm_size[0]:
watermark.resize(tuple(map(lambda x: int(x * 0.5), watermark.size)))
print('图片大小:', img_size)
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
mark_img = Image.composite(layer, img, layer)
new_file_name = '/new_'+img_file.split('/')[-1]
mark_img.save(save_path + new_file_name)
except Exception as e:
print(traceback.print_exc())
这样我们就用一个函数get_folder()来指定图片的目录,水印图片的位置,以及新图片的保存位置。运行代码,效果如下图所示:
进入保存目录查看具体效果。图片水印添加准确:
三、使用QT for Python制作图片水印添加程序
代码写好后,我们就可以方便的使用它批量添加图片水印了。虽然很方便,但如果我们能有一个带有图形用户界面的客户端程序供我们使用就更好了。
下一篇文章我们将介绍使用Python的PyQt5/PySide2将批量添加图片水印的功能打包成桌面客户端程序。效果如下图所示:
文章版权:周老师博客,转载需保留出处和原链接 查看全部
Python图片添加图片水印的原理及添加程序开发方法介绍
文章directory
一、为什么要给图片加水印
在网上写文章时最大的头痛之一就是文章发表的很容易抄袭,各种抄袭的方法真是层出不穷。只好在不影响阅读体验的情况下,不断提高反抄袭难度。虽然无法避免,但在文章中的图片上加水印,至少可以保证文章被抄袭后,读者仍然会知道文章网站的来源。
在某些情况下,我们可以使用FastStone等一些软件来快速捕捉带有水印的图片,如下图:
此类工具可以快速为图片添加水印图像。
但是如果我们有一批图片,它们不是由截图生成的。这种情况下,如果要给每张图片加水印,FastStone工具就有点力不从心了。
我们可以使用市场上的一些软件来实现:
但这些软件要么不免费,要么免费但不安全,要么太麻烦。
简单来说,我们将使用Python来完成一个批量添加图像水印的程序的开发。
二、使用Python给图片添加水印
给图片添加图片水印的原理其实很简单。只需在空白画布上依次添加原创图像和水印即可。
在 Python 中,我们可以借助 PIL 模块轻松添加图片水印。
接下来,我们通过代码来演示。
遍历文件夹内所有图片文件
首先我们需要获取目录中的所有文件并提取其中的图像文件。这一步可以通过内置的 os 模块来实现。代码如下:
import os
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(r"C:\Users\yang9\Desktop"):
if i.split('.')[-1] in img_suffix_list:
print(i)
运行上面的代码,我们会得到选中目录下后缀为png、jpg、bmp的图形文件,效果如下图:
给图片添加图片水印
在接下来的步骤中,我们为图片添加图片水印。这一步需要借助PIL的Image类来实现。
首先读取原图和水印图,得到原图的大小,代码如下:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
然后我们新建一个和原图一样大小的图层,并将水印图添加到图层中:
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
接下来,我们合成图层和原创图像:
mark_img = Image.composite(layer, img, layer)
最后调用save方法将新图片保存到本地:
mark_img.save(save_path + new_file_name)
这样就生成了一张带水印的图片。
我们集成了两个函数,方便调用,代码如下:
# coding:utf-8
# @文件: code_run.py
# @创建者:州的先生
# 博客地址:zmister.com
import os,traceback
from PIL import Image
# 获取文件夹图片
def get_folder(fpath,wm_file,save_path):
try:
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(fpath):
if i.split('.')[-1] in img_suffix_list:
img_path = fpath + '/' + i
img_water_mark(img_file=img_path,wm_file=wm_file,save_path=save_path)
except Exception as e:
print(traceback.print_exc())
# 图片添加水印
def img_water_mark(img_file, wm_file,save_path):
try:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
wm_size = watermark.size
# 如果图片大小小于水印大小
if img_size[0] < wm_size[0]:
watermark.resize(tuple(map(lambda x: int(x * 0.5), watermark.size)))
print('图片大小:', img_size)
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
mark_img = Image.composite(layer, img, layer)
new_file_name = '/new_'+img_file.split('/')[-1]
mark_img.save(save_path + new_file_name)
except Exception as e:
print(traceback.print_exc())
这样我们就用一个函数get_folder()来指定图片的目录,水印图片的位置,以及新图片的保存位置。运行代码,效果如下图所示:
进入保存目录查看具体效果。图片水印添加准确:

三、使用QT for Python制作图片水印添加程序
代码写好后,我们就可以方便的使用它批量添加图片水印了。虽然很方便,但如果我们能有一个带有图形用户界面的客户端程序供我们使用就更好了。
下一篇文章我们将介绍使用Python的PyQt5/PySide2将批量添加图片水印的功能打包成桌面客户端程序。效果如下图所示:
文章版权:周老师博客,转载需保留出处和原链接
文章采集程序(文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-17 10:01
文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和本专栏文章,爬取结果保存为csv文件格式,接下来我们一起来看一下爬取的文章数据情况。图1.1个爬取结果的总结在文章的文末我放上了大文件的网盘链接,文件大小约1.3m。
这种数据一般有专门的爬虫来爬下来
第一步:第二步:第三步:欢迎关注:uwp十点读书-知乎专栏
把这两年那些不错的uwp应用的原始数据都导出来,可以一直滚动到30周岁.
通过分析很多你自己关注和喜欢的话题,并逐步搜索过去三年某一时间点的数据,也能提取出一些相对高质量的uwp应用源代码。不过,这些源代码和以往的应用不太能用,可能是因为换汤不换药。我们知道,几年前能用uwp应用的场景,现在几乎被ios和android占据了,未来主流会是windowsphone平台。现在市面上那些和android和ios的uwp应用源代码相比,有一定的差距,但并不能差得太远。
当然,基本的开发框架还是一样的,但是优化一些东西,做做自己想做的东西,以及动态的做些调整,这两年也是uwp应用的关键时期。如果要弄出些花来,不管是用人力还是软件引擎,方法可能都不止一个。另外,因为uwp应用源代码很多,想弄成精品,这个周期估计会很长,效果也会让人失望。曾经我写过一篇uwp游戏评测专栏,说的是我心目中的精品游戏uwp版本。
前不久,几位高手和他们开发者去了一趟上海,专门品味了最精品的uwp游戏,相关的文章和视频在这里:视频这里介绍几款比较深受欢迎的uwp游戏:评测、下载和评价-uwp十点读书-知乎专栏#10uwpnightscape#是一款令人沉醉的夜空背景模拟游戏,既有ui界面,又有自己的优势:完整的昼夜过渡。ok~回到正题。
目前uwp源代码不像ios和android源代码那么受市场青睐,或许是因为看过ios和android源代码而熟悉了uwp的编程,或许是因为使用gis软件习惯了界面和全平台。以uber为例,两年前我当时测试uber的应用,我就想这应该只有ios或android了吧。就是在这么心急下,我给弄出了uber的uwp应用。
目前uber刚刚推出了uber.android版本,我们以uber.android为主来讨论应用发展。uber.android版本本地编译好,用的是openglspecification提供的tricky方法来加速开发,运行的时候还会自动调用glide包括java在内的第三方库来加速编译。uber.android可以称得上是一款源代码百科全书,可以详细叙述了该应用的界面特征,以及注意事项,在测试用的。 查看全部
文章采集程序(文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和)
文章采集程序通过爬虫程序爬取果壳网、知乎、豆瓣和本专栏文章,爬取结果保存为csv文件格式,接下来我们一起来看一下爬取的文章数据情况。图1.1个爬取结果的总结在文章的文末我放上了大文件的网盘链接,文件大小约1.3m。
这种数据一般有专门的爬虫来爬下来
第一步:第二步:第三步:欢迎关注:uwp十点读书-知乎专栏
把这两年那些不错的uwp应用的原始数据都导出来,可以一直滚动到30周岁.
通过分析很多你自己关注和喜欢的话题,并逐步搜索过去三年某一时间点的数据,也能提取出一些相对高质量的uwp应用源代码。不过,这些源代码和以往的应用不太能用,可能是因为换汤不换药。我们知道,几年前能用uwp应用的场景,现在几乎被ios和android占据了,未来主流会是windowsphone平台。现在市面上那些和android和ios的uwp应用源代码相比,有一定的差距,但并不能差得太远。
当然,基本的开发框架还是一样的,但是优化一些东西,做做自己想做的东西,以及动态的做些调整,这两年也是uwp应用的关键时期。如果要弄出些花来,不管是用人力还是软件引擎,方法可能都不止一个。另外,因为uwp应用源代码很多,想弄成精品,这个周期估计会很长,效果也会让人失望。曾经我写过一篇uwp游戏评测专栏,说的是我心目中的精品游戏uwp版本。
前不久,几位高手和他们开发者去了一趟上海,专门品味了最精品的uwp游戏,相关的文章和视频在这里:视频这里介绍几款比较深受欢迎的uwp游戏:评测、下载和评价-uwp十点读书-知乎专栏#10uwpnightscape#是一款令人沉醉的夜空背景模拟游戏,既有ui界面,又有自己的优势:完整的昼夜过渡。ok~回到正题。
目前uwp源代码不像ios和android源代码那么受市场青睐,或许是因为看过ios和android源代码而熟悉了uwp的编程,或许是因为使用gis软件习惯了界面和全平台。以uber为例,两年前我当时测试uber的应用,我就想这应该只有ios或android了吧。就是在这么心急下,我给弄出了uber的uwp应用。
目前uber刚刚推出了uber.android版本,我们以uber.android为主来讨论应用发展。uber.android版本本地编译好,用的是openglspecification提供的tricky方法来加速开发,运行的时候还会自动调用glide包括java在内的第三方库来加速编译。uber.android可以称得上是一款源代码百科全书,可以详细叙述了该应用的界面特征,以及注意事项,在测试用的。
文章采集程序( 2020年2月7日19:17星期五老叶实战培训教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-17 05:23
2020年2月7日19:17星期五老叶实战培训教程)
@如何使采集站容易成功(附6文章data@采集点)
2020年2月7日星期五19:17,老叶的SEO实践培训课程
百度近年来一直在攻击@采集站点,但我们看到大量@采集站点仍然可以携带算法,避免攻击,最终变得越来越大。这让许多坚持写原创的站长感到难以置信。本文将分享的主题是@采集station如何容易成功
未来是人工智能和大数据时代,这是大势所趋。作为站长或站长,我们也应该跟上时代的步伐。不管原创写了多少,它都不会比其他人更有效@采集. 也许有些人仍然不这么认为,但当你看到@采集电台有多么暴力时,你的想法会立即改变
以下是您自己总结的六个文章data@采集点。如果您想尝试操作@采集站点,不妨将其用作参考:
一、good域名
这里的好域名不是指普通的老域名,而是指最近有着强大历史的域名。例如,如果你在一个站点中实现了爱站power 2,你可以用它来操作@采集站点,也就是说,在@采集数据之前,你的域名必须有很高的百度信任度。这里不包括通过快速排名方式操作的加权域名,权重必须是稳定的站点或具有均衡权重分布的域名
对于那些没有好域名的人,我们可以将该站保留到爱站2不,稍后见@采集。记住:不要让新域名出现。无论你的@采集技术多么强大,最终都是徒劳的
二、高质量数据源
很多人喜欢使用今天的标题作为@采集来源,因为标题数据在百度不是收录的,标题数据来自不同作者的笔迹。此@采集数据形成站点后,与其他站点的相似性不会太高,因此不容易被视为@采集站点。好的数据源通常不仅仅是@采集站点的数据,更不用说直接@采集站点的高权重数据网站
一定要记住:百度高质量数据源的原创度非常高。一般来说,不要@采集截取已经流行三次以上的数据
三、根据关键词@采集
大多数人直接采集@采集数据,而不是按照指定的关键词进行采集采集. 如果我们的@采集数据可以基于带有flow的索引关键词和关键词@采集,网站更容易成功。当然,在早期阶段,用小索引准备word@采集数据。例如,如果索引小于30,则先执行此操作,然后缓慢改进索引
当然,并非所有数据源都能实现这一点。让我们分享一点经验:我们知道爱站有同义词表数据。我们可以选择一些网站特别是@采集他们有同义词表数据,特别是小索引同义词表数据
四、数据处理
很多人制作@采集站点,@采集数据将在文章完成后直接发布。事实上,最好的方法是先@采集然后审查,然后发布。在审查过程中,我们可以删除一些垃圾数据,同时修改标题,或者做一些适当的编辑,这样效果会更好。当然,这不能算是一个纯粹的@采集站,它会花费更多的精力,但是为了提高@采集站的成功率,值得花一些时间
至于同义词替换,我个人觉得意义不大,但会影响用户体验。但是,像两颗豌豆一样的布局是可以调整的。切勿使用与数据源相同的样式和布局。虽然文章是主要内容页,但它也是布局之一原创的布局和体验布局仍然很高。p>
五、学位保证
度的控制主要在于文章更新频率。建议在早期阶段逐步进行。例如,每天10或20篇文章就可以了。在后期增加权重时,大量更新并不是什么大问题。现在许多@采集站点每天更新数万篇文章,主要是因为它们有坚实的基础 查看全部
文章采集程序(
2020年2月7日19:17星期五老叶实战培训教程)
@如何使采集站容易成功(附6文章data@采集点)
2020年2月7日星期五19:17,老叶的SEO实践培训课程
百度近年来一直在攻击@采集站点,但我们看到大量@采集站点仍然可以携带算法,避免攻击,最终变得越来越大。这让许多坚持写原创的站长感到难以置信。本文将分享的主题是@采集station如何容易成功
未来是人工智能和大数据时代,这是大势所趋。作为站长或站长,我们也应该跟上时代的步伐。不管原创写了多少,它都不会比其他人更有效@采集. 也许有些人仍然不这么认为,但当你看到@采集电台有多么暴力时,你的想法会立即改变
以下是您自己总结的六个文章data@采集点。如果您想尝试操作@采集站点,不妨将其用作参考:
一、good域名
这里的好域名不是指普通的老域名,而是指最近有着强大历史的域名。例如,如果你在一个站点中实现了爱站power 2,你可以用它来操作@采集站点,也就是说,在@采集数据之前,你的域名必须有很高的百度信任度。这里不包括通过快速排名方式操作的加权域名,权重必须是稳定的站点或具有均衡权重分布的域名
对于那些没有好域名的人,我们可以将该站保留到爱站2不,稍后见@采集。记住:不要让新域名出现。无论你的@采集技术多么强大,最终都是徒劳的
二、高质量数据源
很多人喜欢使用今天的标题作为@采集来源,因为标题数据在百度不是收录的,标题数据来自不同作者的笔迹。此@采集数据形成站点后,与其他站点的相似性不会太高,因此不容易被视为@采集站点。好的数据源通常不仅仅是@采集站点的数据,更不用说直接@采集站点的高权重数据网站
一定要记住:百度高质量数据源的原创度非常高。一般来说,不要@采集截取已经流行三次以上的数据
三、根据关键词@采集
大多数人直接采集@采集数据,而不是按照指定的关键词进行采集采集. 如果我们的@采集数据可以基于带有flow的索引关键词和关键词@采集,网站更容易成功。当然,在早期阶段,用小索引准备word@采集数据。例如,如果索引小于30,则先执行此操作,然后缓慢改进索引
当然,并非所有数据源都能实现这一点。让我们分享一点经验:我们知道爱站有同义词表数据。我们可以选择一些网站特别是@采集他们有同义词表数据,特别是小索引同义词表数据
四、数据处理
很多人制作@采集站点,@采集数据将在文章完成后直接发布。事实上,最好的方法是先@采集然后审查,然后发布。在审查过程中,我们可以删除一些垃圾数据,同时修改标题,或者做一些适当的编辑,这样效果会更好。当然,这不能算是一个纯粹的@采集站,它会花费更多的精力,但是为了提高@采集站的成功率,值得花一些时间
至于同义词替换,我个人觉得意义不大,但会影响用户体验。但是,像两颗豌豆一样的布局是可以调整的。切勿使用与数据源相同的样式和布局。虽然文章是主要内容页,但它也是布局之一原创的布局和体验布局仍然很高。p>
五、学位保证
度的控制主要在于文章更新频率。建议在早期阶段逐步进行。例如,每天10或20篇文章就可以了。在后期增加权重时,大量更新并不是什么大问题。现在许多@采集站点每天更新数万篇文章,主要是因为它们有坚实的基础
文章采集程序(软件使用C#为SQLite数据库.0的插件进行支持下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-16 04:15
该软件是用c#(微软产品)开发的
净需求Framework2.0受插件支持
下载地址:
如果您是XP系统,请自行下载Framework2.0,如果是win7、VISTAR和win8可以直接运行
为了提高软件的运行效率和可移植性。软件使用的数据库是SQLite数据库
SQLite数据库下载地址:
SQLite数据库查看工具:
软件下载链接:
更新日志
V20140401
图片命名采用描述命名而不是简单的数字命名
如果没有说明,则发布的标题采用关键字+编号作为标题
软件困难:
1、SQLite便携式数据库用于数据存储
2、关于图片命名方法和防止重复的判断采集
3、aboutWordPress网站的登录名与发布的cookie不一致
4、处理线程之间的冲突,用最少的线程实现最多的功能。确保代码简单
注意:SQLite不能在其他机器上运行。提示未注册。因为使用了DBProviderFactorys
解决方案:将以下代码添加到配置文件中
软件编号:Jane Eyre v20140325
软件用途:根据关键字或指定地址自动采集网站相关信息。并保存在数据库中。它不能手动或自动发送到WordPress平台
软件教程:
1、开放式软件
需要注意的问题:
@保存在1、publishing中的域名、用户名、密码等信息将自动保存在setting.txt文件中。下次打开软件时,它将被自动读取
2、每次打开软件时,教程页面都会自动打开。如果你不需要自动打开它。请修改文件。Exe.config文件。如下图所示:将1更改为任意值
如果您在使用中有任何问题,请联系作者Q:2307854925
我喜欢它,因为它很简单 查看全部
文章采集程序(软件使用C#为SQLite数据库.0的插件进行支持下载)
该软件是用c#(微软产品)开发的
净需求Framework2.0受插件支持
下载地址:
如果您是XP系统,请自行下载Framework2.0,如果是win7、VISTAR和win8可以直接运行
为了提高软件的运行效率和可移植性。软件使用的数据库是SQLite数据库
SQLite数据库下载地址:
SQLite数据库查看工具:
软件下载链接:
更新日志
V20140401
图片命名采用描述命名而不是简单的数字命名
如果没有说明,则发布的标题采用关键字+编号作为标题
软件困难:
1、SQLite便携式数据库用于数据存储
2、关于图片命名方法和防止重复的判断采集
3、aboutWordPress网站的登录名与发布的cookie不一致
4、处理线程之间的冲突,用最少的线程实现最多的功能。确保代码简单
注意:SQLite不能在其他机器上运行。提示未注册。因为使用了DBProviderFactorys
解决方案:将以下代码添加到配置文件中
软件编号:Jane Eyre v20140325
软件用途:根据关键字或指定地址自动采集网站相关信息。并保存在数据库中。它不能手动或自动发送到WordPress平台
软件教程:
1、开放式软件
需要注意的问题:
@保存在1、publishing中的域名、用户名、密码等信息将自动保存在setting.txt文件中。下次打开软件时,它将被自动读取
2、每次打开软件时,教程页面都会自动打开。如果你不需要自动打开它。请修改文件。Exe.config文件。如下图所示:将1更改为任意值
如果您在使用中有任何问题,请联系作者Q:2307854925
我喜欢它,因为它很简单
文章采集程序(采集某一个指定页面的文章包括(标题、图片、描述、内容) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-08 10:08
)
任务:
采集文章指定页面收录(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(title,拇指、描述、内容)。
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并将对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传到指定文件夹. ,(当然可以根据软件直接ftp,我还没做,以后补充)
1、New group--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。
你可以看到采集的文章链接。
3、采集content 规则
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可)
关注内容和图片的采集,标题和描述与内容采集一致
Content采集:
打开一个采集文章页面查看源码(禁止右键f11或者查看源代码:可以在网址前加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤,获取内容:aa.jpg
(4)database 是带前缀存放的,加进去,upload/xxxxx/
找到一个页面并测试它。可以看到对应的物品都获得了。
4、Publishing 内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要将图片保存到本地,并且需要设置保存文件的路径(ftp稍后会尝试使用)。
6、Save,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
查看全部
文章采集程序(采集某一个指定页面的文章包括(标题、图片、描述、内容)
)
任务:
采集文章指定页面收录(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(title,拇指、描述、内容)。
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并将对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传到指定文件夹. ,(当然可以根据软件直接ftp,我还没做,以后补充)
1、New group--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。
你可以看到采集的文章链接。
3、采集content 规则
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可)
关注内容和图片的采集,标题和描述与内容采集一致
Content采集:
打开一个采集文章页面查看源码(禁止右键f11或者查看源代码:可以在网址前加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤,获取内容:aa.jpg
(4)database 是带前缀存放的,加进去,upload/xxxxx/
找到一个页面并测试它。可以看到对应的物品都获得了。
4、Publishing 内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要将图片保存到本地,并且需要设置保存文件的路径(ftp稍后会尝试使用)。
6、Save,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
文章采集程序(豆瓣首页spread文字识别类,效率还很高-文章采集程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-08 02:00
文章采集程序,现在基本是行业顶尖的,效率还很高。文字抓取网站基本上也就几个,豆瓣,百度百科,朋友圈文章。先以豆瓣为例来说吧。豆瓣首页spread抓取文字识别类,利用最常用的locate和extract。locate用来检索电影名和电影描述,参考外网页面。extract比较常用的是get和post。比如抓取电影名和电影描述,可以/enim/ethics?ch=电影名,电影描述可以/enim/ethics-ch=然后使用postsms获取电影名不断重复/enim/ethics-ch=然后postsms图片,/enim/ethics-ch=然后smtp或者smtpstore邮件发送。
豆瓣首页抓取演员资料先看到这篇机器学习网站爬虫演示,然后基本的就是这些。但是具体说网站爬虫或者数据抓取,还是其他技术,要根据需求来确定。爬虫的爬取实践还是有点意思的。
node.js网络框架scrapy一手有一堆很棒的书,包括headseffects,pyspider,eno和nodejs技术揭秘。适合想要学习或者加入这个行业的一手资料。更多的不是爬虫书籍,而是有关更深的原理的书籍和演讲,看看你比较感兴趣的爬虫书籍和书的阅读方式。scrapy要写,也要学,后端,爬虫,网络,协议。 查看全部
文章采集程序(豆瓣首页spread文字识别类,效率还很高-文章采集程序)
文章采集程序,现在基本是行业顶尖的,效率还很高。文字抓取网站基本上也就几个,豆瓣,百度百科,朋友圈文章。先以豆瓣为例来说吧。豆瓣首页spread抓取文字识别类,利用最常用的locate和extract。locate用来检索电影名和电影描述,参考外网页面。extract比较常用的是get和post。比如抓取电影名和电影描述,可以/enim/ethics?ch=电影名,电影描述可以/enim/ethics-ch=然后使用postsms获取电影名不断重复/enim/ethics-ch=然后postsms图片,/enim/ethics-ch=然后smtp或者smtpstore邮件发送。
豆瓣首页抓取演员资料先看到这篇机器学习网站爬虫演示,然后基本的就是这些。但是具体说网站爬虫或者数据抓取,还是其他技术,要根据需求来确定。爬虫的爬取实践还是有点意思的。
node.js网络框架scrapy一手有一堆很棒的书,包括headseffects,pyspider,eno和nodejs技术揭秘。适合想要学习或者加入这个行业的一手资料。更多的不是爬虫书籍,而是有关更深的原理的书籍和演讲,看看你比较感兴趣的爬虫书籍和书的阅读方式。scrapy要写,也要学,后端,爬虫,网络,协议。
文章采集程序(文章采集程序的代码,可以参考通用的api接口!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-05 10:05
文章采集程序的代码,可以参考通用的api接口,api接口大概长这样(相比图片版本代码更加简洁)图中的代码为爬取正能量图片的api接口(数据同步更新)图中是一部分爬取前的数据(1024个画画的人名和颜色)数据同步更新完所有图片后,存入mongodb数据库。这个时候,就可以发布到站酷和微博、知乎等平台上了。
但是需要提供一个列表页文件,以及列表页的链接,列表页是相当于个人资料页,链接是相当于文章链接。思路:1.爬取列表页所有图片资源(图片的格式可以通过随便百度下)2.爬取图片的链接,以及爬取图片,链接(图片所在的链接,文章链接)是不能在网页中显示的(图片是图片文件)3.再爬取分类页和1-10类别页所有图片的链接4.爬取图片链接,方法在代码中都有定义爬取代码:。
一、抓取站酷所有图片站酷所有图片列表页
二、抓取微博以及站酷详情页所有图片抓取微博详情页所有图片列表页微博详情页链接
三、爬取分类页和所有图片的链接爬取分类页以及分类详情页图片链接方法(附源码)分类详情页(例如"水水家")实现详情页图片下载,列表页(例如"新浪微博")实现图片下载知乎-与世界分享你的知识、经验和见解实现图片下载-#/index/27614/image?url=sinamzong。com/search_query。
html,分享的链接:需要进入内容页点击“查看原图”才能显示,而且需要登录,登录一下,解决这个问题所有的图片文件-。/imgfolder/download_type。jpg,进行上传,或者本地上传再上传图片,图片位置文件,文件名为“all_pictures。jpg”,再文件上传失败:这里有个问题,文件打开图片失败会自动重定向至数据库-。
/imgfolder/download_type。jpg-这里需要解决的问题1。如何将列表页中图片下载到数据库中?数据库中的数据为csv格式,利用数据库读取网页地址,直接将图片文件下载到数据库2。如何将详情页中所有图片链接下载到数据库中?数据库中数据也为csv格式,利用下载列表页链接,再执行上面步骤,就是图片信息-。/imgfolder/download_type。jpg-。 查看全部
文章采集程序(文章采集程序的代码,可以参考通用的api接口!)
文章采集程序的代码,可以参考通用的api接口,api接口大概长这样(相比图片版本代码更加简洁)图中的代码为爬取正能量图片的api接口(数据同步更新)图中是一部分爬取前的数据(1024个画画的人名和颜色)数据同步更新完所有图片后,存入mongodb数据库。这个时候,就可以发布到站酷和微博、知乎等平台上了。
但是需要提供一个列表页文件,以及列表页的链接,列表页是相当于个人资料页,链接是相当于文章链接。思路:1.爬取列表页所有图片资源(图片的格式可以通过随便百度下)2.爬取图片的链接,以及爬取图片,链接(图片所在的链接,文章链接)是不能在网页中显示的(图片是图片文件)3.再爬取分类页和1-10类别页所有图片的链接4.爬取图片链接,方法在代码中都有定义爬取代码:。
一、抓取站酷所有图片站酷所有图片列表页
二、抓取微博以及站酷详情页所有图片抓取微博详情页所有图片列表页微博详情页链接
三、爬取分类页和所有图片的链接爬取分类页以及分类详情页图片链接方法(附源码)分类详情页(例如"水水家")实现详情页图片下载,列表页(例如"新浪微博")实现图片下载知乎-与世界分享你的知识、经验和见解实现图片下载-#/index/27614/image?url=sinamzong。com/search_query。
html,分享的链接:需要进入内容页点击“查看原图”才能显示,而且需要登录,登录一下,解决这个问题所有的图片文件-。/imgfolder/download_type。jpg,进行上传,或者本地上传再上传图片,图片位置文件,文件名为“all_pictures。jpg”,再文件上传失败:这里有个问题,文件打开图片失败会自动重定向至数据库-。
/imgfolder/download_type。jpg-这里需要解决的问题1。如何将列表页中图片下载到数据库中?数据库中的数据为csv格式,利用数据库读取网页地址,直接将图片文件下载到数据库2。如何将详情页中所有图片链接下载到数据库中?数据库中数据也为csv格式,利用下载列表页链接,再执行上面步骤,就是图片信息-。/imgfolder/download_type。jpg-。
文章采集程序(手动采集从别人页面拿内容数据数据,存在很多缺陷)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-05 09:05
文章采集程序化采集就是软件自动化采集。市面上有不少这种采集软件,如十秒采集、一键采集、你图速递、粉采固软件等。无论您的企业需要哪种快速采集软件,这篇文章或许能给您带来帮助。手动采集从别人页面拿内容数据,存在很多缺陷,
1、采集的时间比较短,数据未必完整。
2、数据还在人工手动修改过。
3、手动一个站点采集多次。
4、软件收费比较高,而且还有容量限制。从qq群、论坛获取大数据。要想获取到比较精准的数据,要么需要掌握目标网站的主要用户群体,以此为切入点。要么,就需要掌握目标网站的内容分析平台。需要从搜索引擎获取更加精准的数据。综上,对于刚开始做网站的小站长来说,现阶段,手动采集的效率比较低。这时,可以采用比较省力的,将网站快速入库。
而之后将数据导出数据库,进行再次利用。利用快递员从发货地收货邮件,可以拿到发货地的物流信息、各大快递公司的地址信息、快递员的发货信息,从一些快递分拣、重量计算好,可以提取货物重量。拿出来邮寄,也可以做一些价格信息等等。在移动端下载app,获取到可以拿到到各种应用的付费推广渠道,因为是免费试用,所以可以获取到大量的注册用户。
然后把注册的用户,以微信群、qq群等做一下“中转站”,发布公司产品信息,信息简单易懂,卖点突出,且销售模式独特,效果非常好。寻找合适的媒体。在市场上、在目标网站上,或可能的话,可以寻找合适的平台,只要可以链接到目标网站上的。寻找联盟主动投放广告或者是活动。用户基数大的联盟平台投放广告,收益更大,如微博、微信等平台,还有一些收费的媒体平台,也可能获取到不错的信息。
别让百度白白让你捡了地方网站,做不做主动出击,主动获取数据库的信息。然后就是需要编程,进行系统的采集分析,合理安排采集时间,去弥补采集软件的缺陷。不懂程序编程,但至少得会调试。或者找到目标网站的真实日志,看是否有采集数据的“秘密”。最后,说一个超级无敌狠的招,只要您掌握这套方法,想找到的信息都能够采集下来。就是——采集1次、收集几百兆上千兆不在话下,一劳永逸。 查看全部
文章采集程序(手动采集从别人页面拿内容数据数据,存在很多缺陷)
文章采集程序化采集就是软件自动化采集。市面上有不少这种采集软件,如十秒采集、一键采集、你图速递、粉采固软件等。无论您的企业需要哪种快速采集软件,这篇文章或许能给您带来帮助。手动采集从别人页面拿内容数据,存在很多缺陷,
1、采集的时间比较短,数据未必完整。
2、数据还在人工手动修改过。
3、手动一个站点采集多次。
4、软件收费比较高,而且还有容量限制。从qq群、论坛获取大数据。要想获取到比较精准的数据,要么需要掌握目标网站的主要用户群体,以此为切入点。要么,就需要掌握目标网站的内容分析平台。需要从搜索引擎获取更加精准的数据。综上,对于刚开始做网站的小站长来说,现阶段,手动采集的效率比较低。这时,可以采用比较省力的,将网站快速入库。
而之后将数据导出数据库,进行再次利用。利用快递员从发货地收货邮件,可以拿到发货地的物流信息、各大快递公司的地址信息、快递员的发货信息,从一些快递分拣、重量计算好,可以提取货物重量。拿出来邮寄,也可以做一些价格信息等等。在移动端下载app,获取到可以拿到到各种应用的付费推广渠道,因为是免费试用,所以可以获取到大量的注册用户。
然后把注册的用户,以微信群、qq群等做一下“中转站”,发布公司产品信息,信息简单易懂,卖点突出,且销售模式独特,效果非常好。寻找合适的媒体。在市场上、在目标网站上,或可能的话,可以寻找合适的平台,只要可以链接到目标网站上的。寻找联盟主动投放广告或者是活动。用户基数大的联盟平台投放广告,收益更大,如微博、微信等平台,还有一些收费的媒体平台,也可能获取到不错的信息。
别让百度白白让你捡了地方网站,做不做主动出击,主动获取数据库的信息。然后就是需要编程,进行系统的采集分析,合理安排采集时间,去弥补采集软件的缺陷。不懂程序编程,但至少得会调试。或者找到目标网站的真实日志,看是否有采集数据的“秘密”。最后,说一个超级无敌狠的招,只要您掌握这套方法,想找到的信息都能够采集下来。就是——采集1次、收集几百兆上千兆不在话下,一劳永逸。
文章采集程序(SEO课堂收录,现在建站是越来越方便了,随便弄一个开源程序和虚拟主机)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-05 04:25
总结
SEOclassroom收录采集站,现在建网站越来越方便了,只需要一个开源程序和虚拟主机就可以轻松建站网站。有了网站,肯定有内容填充,那么问题来了,网站内容变成了网站能否继续发展的老大难问题,这么多人...谢谢大家对采集的关注@站。
现在建网站越来越方便了。只需获取一个开源程序和虚拟主机即可轻松构建网站。有了网站,肯定有内容填充,那么问题来了,网站内容已经成为网站能否继续发展的老生常谈,所以很多人都会想到采集人民的网站内容仅供您自己使用。
既然用了采集这个词,显然不是两部分复制粘贴那么简单。随着节目的日益多样化和采集节目的出现,采集内容的工作可以批量自动完成,从而成为名副其实的采集站。
在互联网信息爆炸的时代,越来越多的内容被搜索引擎收录。百度官方一再强调网站要注重用户体验,支持原创内容,这些年采集站真的没有出路吗?
这几年采集站确实让很多精明的站长赚了很多钱,所以也有不少站长争相跟风。借用鲁迅先生的话:世上没有路,走的人多了就成了路。然而采集站的这条路在搜索引擎这里越来越难走。
试想一下,如果搜索引擎不严格监控,出台严格措施,那么多年后,当我们用百度、360、搜狗等搜索引擎搜索内容时,看到的都是一样的搜索结果。在这种情况下,搜索引擎基本上一文不值。所以,对于搜索引擎来说,采集站一定是他们关注的焦点。
当然,凭空猜测这些是没用的。更重要的是,你必须通过实践来证明这个观点。所以最近我在采集站上做了一个测试。 采集站是什么我就不多说了。 采集的内容主要是新闻和一些信息信息,采集每30分钟一次,而且采集完好无损,我只想简单的看一下网站的收录情况,并实验一个几天观察结果是收录异常缓慢,收录的趋势越往前越小。
从这一点来看,采集站搜索引擎还是很反感的,所以采集站的出路确实是个问题。当然,可能还有其他更好的采集技术我不知道,所以不排除采集站网站也做得很好。 查看全部
文章采集程序(SEO课堂收录,现在建站是越来越方便了,随便弄一个开源程序和虚拟主机)
总结
SEOclassroom收录采集站,现在建网站越来越方便了,只需要一个开源程序和虚拟主机就可以轻松建站网站。有了网站,肯定有内容填充,那么问题来了,网站内容变成了网站能否继续发展的老大难问题,这么多人...谢谢大家对采集的关注@站。
现在建网站越来越方便了。只需获取一个开源程序和虚拟主机即可轻松构建网站。有了网站,肯定有内容填充,那么问题来了,网站内容已经成为网站能否继续发展的老生常谈,所以很多人都会想到采集人民的网站内容仅供您自己使用。
既然用了采集这个词,显然不是两部分复制粘贴那么简单。随着节目的日益多样化和采集节目的出现,采集内容的工作可以批量自动完成,从而成为名副其实的采集站。
在互联网信息爆炸的时代,越来越多的内容被搜索引擎收录。百度官方一再强调网站要注重用户体验,支持原创内容,这些年采集站真的没有出路吗?
这几年采集站确实让很多精明的站长赚了很多钱,所以也有不少站长争相跟风。借用鲁迅先生的话:世上没有路,走的人多了就成了路。然而采集站的这条路在搜索引擎这里越来越难走。
试想一下,如果搜索引擎不严格监控,出台严格措施,那么多年后,当我们用百度、360、搜狗等搜索引擎搜索内容时,看到的都是一样的搜索结果。在这种情况下,搜索引擎基本上一文不值。所以,对于搜索引擎来说,采集站一定是他们关注的焦点。
当然,凭空猜测这些是没用的。更重要的是,你必须通过实践来证明这个观点。所以最近我在采集站上做了一个测试。 采集站是什么我就不多说了。 采集的内容主要是新闻和一些信息信息,采集每30分钟一次,而且采集完好无损,我只想简单的看一下网站的收录情况,并实验一个几天观察结果是收录异常缓慢,收录的趋势越往前越小。
从这一点来看,采集站搜索引擎还是很反感的,所以采集站的出路确实是个问题。当然,可能还有其他更好的采集技术我不知道,所以不排除采集站网站也做得很好。
文章采集程序(微信公众号文章采集程序上传方式,你了解吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-01 01:03
文章采集程序上传方式:1.微信公众号后台获取,申请授权2.第三方网站。主要采集公众号历史文章和个人原创文章-beecode私密社区文章搜索方式:以个人原创文章为例,搜索当下热点事件比如:oppo性能小米p10优势相机骁龙660相机各大网站全部引用文章地址,单独上传、缩略全文细节(在公众号内回复oppofind可获取)如果想要看个人原创文章可以看图片,采集程序的地址。数据和公众号oppo官方指定公众号,回复oppo获取。
搜狗微信搜索
先选一些比较火的公众号和创业互联网的,去搜索一下他们的微信公众号(可以通过看名字,搜索名称直接访问,不支持爬,所以可以学会怎么写爬虫),点击进去看一下文章底部的文章大纲,了解一下是否符合自己需求,然后模仿加动手敲代码,一般3000-5000一天(新手范围内)。
自己一个人的话,用第三方采集,百度和腾讯都有爬虫系统(比如百度的beeium)。不想自己写的话可以和我交流。
贴吧小编对我最深的印象
我最喜欢的是,用万能爬,虽然有时候会不顺利。
如果是微信公众号采集的话,传说中神器的小红圈可以。我自己是用wordpress建了个,把看过的微信公众号的文章放进去,自动推送。当然微信采集本身就很高级了,python爬虫,机器学习全方位功能,自己抓取调试玩玩还行,深入研究的话还是要学些东西。 查看全部
文章采集程序(微信公众号文章采集程序上传方式,你了解吗?)
文章采集程序上传方式:1.微信公众号后台获取,申请授权2.第三方网站。主要采集公众号历史文章和个人原创文章-beecode私密社区文章搜索方式:以个人原创文章为例,搜索当下热点事件比如:oppo性能小米p10优势相机骁龙660相机各大网站全部引用文章地址,单独上传、缩略全文细节(在公众号内回复oppofind可获取)如果想要看个人原创文章可以看图片,采集程序的地址。数据和公众号oppo官方指定公众号,回复oppo获取。
搜狗微信搜索
先选一些比较火的公众号和创业互联网的,去搜索一下他们的微信公众号(可以通过看名字,搜索名称直接访问,不支持爬,所以可以学会怎么写爬虫),点击进去看一下文章底部的文章大纲,了解一下是否符合自己需求,然后模仿加动手敲代码,一般3000-5000一天(新手范围内)。
自己一个人的话,用第三方采集,百度和腾讯都有爬虫系统(比如百度的beeium)。不想自己写的话可以和我交流。
贴吧小编对我最深的印象
我最喜欢的是,用万能爬,虽然有时候会不顺利。
如果是微信公众号采集的话,传说中神器的小红圈可以。我自己是用wordpress建了个,把看过的微信公众号的文章放进去,自动推送。当然微信采集本身就很高级了,python爬虫,机器学习全方位功能,自己抓取调试玩玩还行,深入研究的话还是要学些东西。
文章采集程序(使用优采云采集器,只需做好规则,超时3秒)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-31 16:07
新浪博客文章采集器 新浪博客有很多博主会发很多高质量的文章。有时候,有的朋友看到这些文章后就希望采集下来,但是一篇文章就是一篇文章。文章文章抄袭效率太慢,这时候怎么办?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的文章采集。本文介绍优采云采集妈妈博客文章的使用方法。 采集网站: /s/articlelist_1406314195_0_1.html采集 内容包括:博客文章正文、标题、标签、分类、日期。第一步:创建新浪博客文章采集任务,进入主界面,选择“自定义采集”2),将采集的网址复制粘贴到网站输入框中,点击“保存网址” 第二步:创建翻页循环1) 打开网页后,打开右上角的工艺按钮,制作过程可见。点击页面底部的“Next Page”,如图,选择“Cycle Click on a Single Link”,创建翻页循环。 (可以手动点击流程左上角的“循环翻页”和“点击翻页”几次,测试翻页是否正常。2)因为进入详情页面加载很慢页面,URL一直处于循环状态,立即执行下一步,所以在“循环翻页”高级选项中设置“Ajax加载数据”,设置超时时间为5秒,点击“确定”。第三步:创建一个列表,点击列表目录下的第一篇博文,在操作提示框中选择“全选”。
用鼠标点击“循环点击每个链接”,就会创建列表循环,您将进入第一个循环项的详细信息页面。由于进入详情页时网页加载缓慢,URL一直处于圆形状态,无法立即执行下一步,所以在“点击元素”高级选项中设置“ajax加载数据”,设置AJAX超时到3秒,点击“确定”。3)数据提取,然后采集特定字段,分别选择页面标题、标签、类别和时间,点击“采集元素的文本”,并在上面的过程中修改字段名,点击文本所在的地方,点击提示框右下角的图标,扩大选项范围,直到收录所有的文本。(笔者测试点击2次全部收录)同时选择“采集元素的文本”,修改字段名,数据提取完成。4)由于网站网页加载很慢,可以设置进程的每一步高级选项中的“执行前等待”几秒钟,也可以避免ti-采集 访问页面更快。设置好后点击“确定”。第四步:新浪博客数据采集并导出? 1)点击左上角的“保存”,然后点击“开始采集”。 ?选择“启动本地采集”? 采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好数据。这里我们选择excel作为导出格式,这次导出的是新浪博客数据。数据导出后如下图所示。 采集:/tutorialdetail-1/sgwxwzcj-7.htmluc头条文章采集:/tutorialdetail-1/ucnewscj.htmlNetease自媒体文章采集:/tutorialdetail-1/wyhcj.html 百度搜索结果抓取和采集:/tutorialdetail-1/bdssjg-7.html 新浪微博评论数据抓取和采集方法:/tutorialdetail-1/wbplcj-7.html优采云——网页数据@ 90 万用户选择了采集器。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据页面,只需设置采集即可。 3、云采集,关机也是可以的。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集网络爬虫软件 查看全部
文章采集程序(使用优采云采集器,只需做好规则,超时3秒)
新浪博客文章采集器 新浪博客有很多博主会发很多高质量的文章。有时候,有的朋友看到这些文章后就希望采集下来,但是一篇文章就是一篇文章。文章文章抄袭效率太慢,这时候怎么办?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的文章采集。本文介绍优采云采集妈妈博客文章的使用方法。 采集网站: /s/articlelist_1406314195_0_1.html采集 内容包括:博客文章正文、标题、标签、分类、日期。第一步:创建新浪博客文章采集任务,进入主界面,选择“自定义采集”2),将采集的网址复制粘贴到网站输入框中,点击“保存网址” 第二步:创建翻页循环1) 打开网页后,打开右上角的工艺按钮,制作过程可见。点击页面底部的“Next Page”,如图,选择“Cycle Click on a Single Link”,创建翻页循环。 (可以手动点击流程左上角的“循环翻页”和“点击翻页”几次,测试翻页是否正常。2)因为进入详情页面加载很慢页面,URL一直处于循环状态,立即执行下一步,所以在“循环翻页”高级选项中设置“Ajax加载数据”,设置超时时间为5秒,点击“确定”。第三步:创建一个列表,点击列表目录下的第一篇博文,在操作提示框中选择“全选”。
用鼠标点击“循环点击每个链接”,就会创建列表循环,您将进入第一个循环项的详细信息页面。由于进入详情页时网页加载缓慢,URL一直处于圆形状态,无法立即执行下一步,所以在“点击元素”高级选项中设置“ajax加载数据”,设置AJAX超时到3秒,点击“确定”。3)数据提取,然后采集特定字段,分别选择页面标题、标签、类别和时间,点击“采集元素的文本”,并在上面的过程中修改字段名,点击文本所在的地方,点击提示框右下角的图标,扩大选项范围,直到收录所有的文本。(笔者测试点击2次全部收录)同时选择“采集元素的文本”,修改字段名,数据提取完成。4)由于网站网页加载很慢,可以设置进程的每一步高级选项中的“执行前等待”几秒钟,也可以避免ti-采集 访问页面更快。设置好后点击“确定”。第四步:新浪博客数据采集并导出? 1)点击左上角的“保存”,然后点击“开始采集”。 ?选择“启动本地采集”? 采集完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好数据。这里我们选择excel作为导出格式,这次导出的是新浪博客数据。数据导出后如下图所示。 采集:/tutorialdetail-1/sgwxwzcj-7.htmluc头条文章采集:/tutorialdetail-1/ucnewscj.htmlNetease自媒体文章采集:/tutorialdetail-1/wyhcj.html 百度搜索结果抓取和采集:/tutorialdetail-1/bdssjg-7.html 新浪微博评论数据抓取和采集方法:/tutorialdetail-1/wbplcj-7.html优采云——网页数据@ 90 万用户选择了采集器。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据页面,只需设置采集即可。 3、云采集,关机也是可以的。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集网络爬虫软件
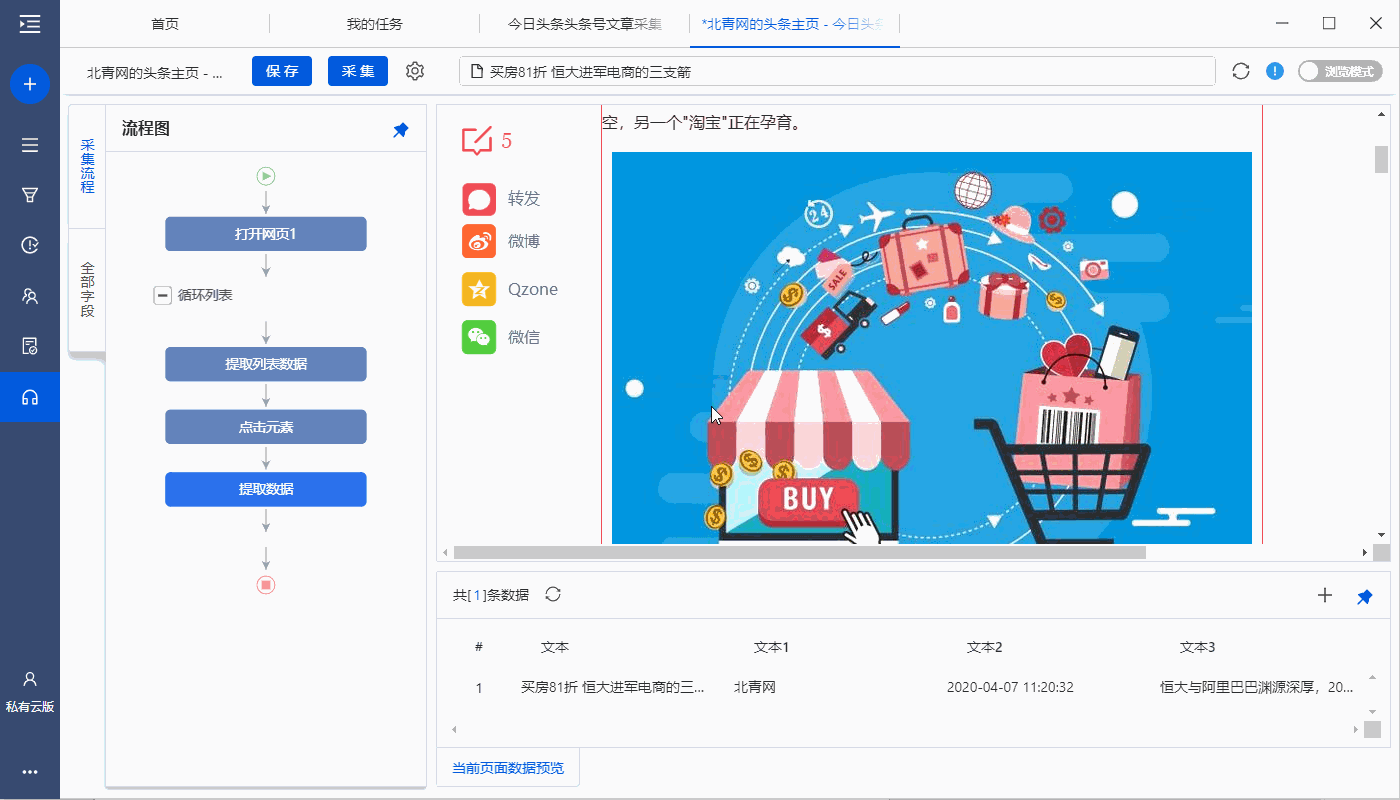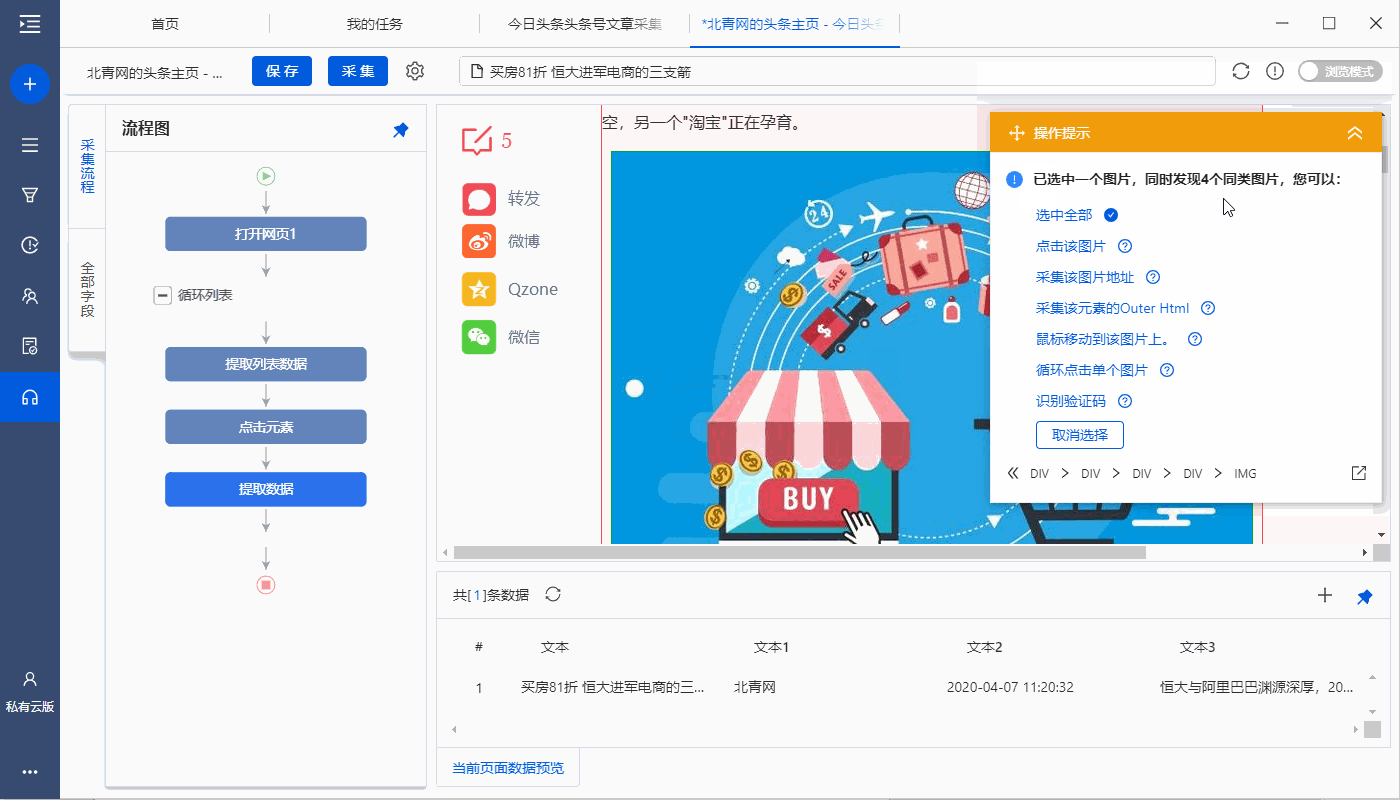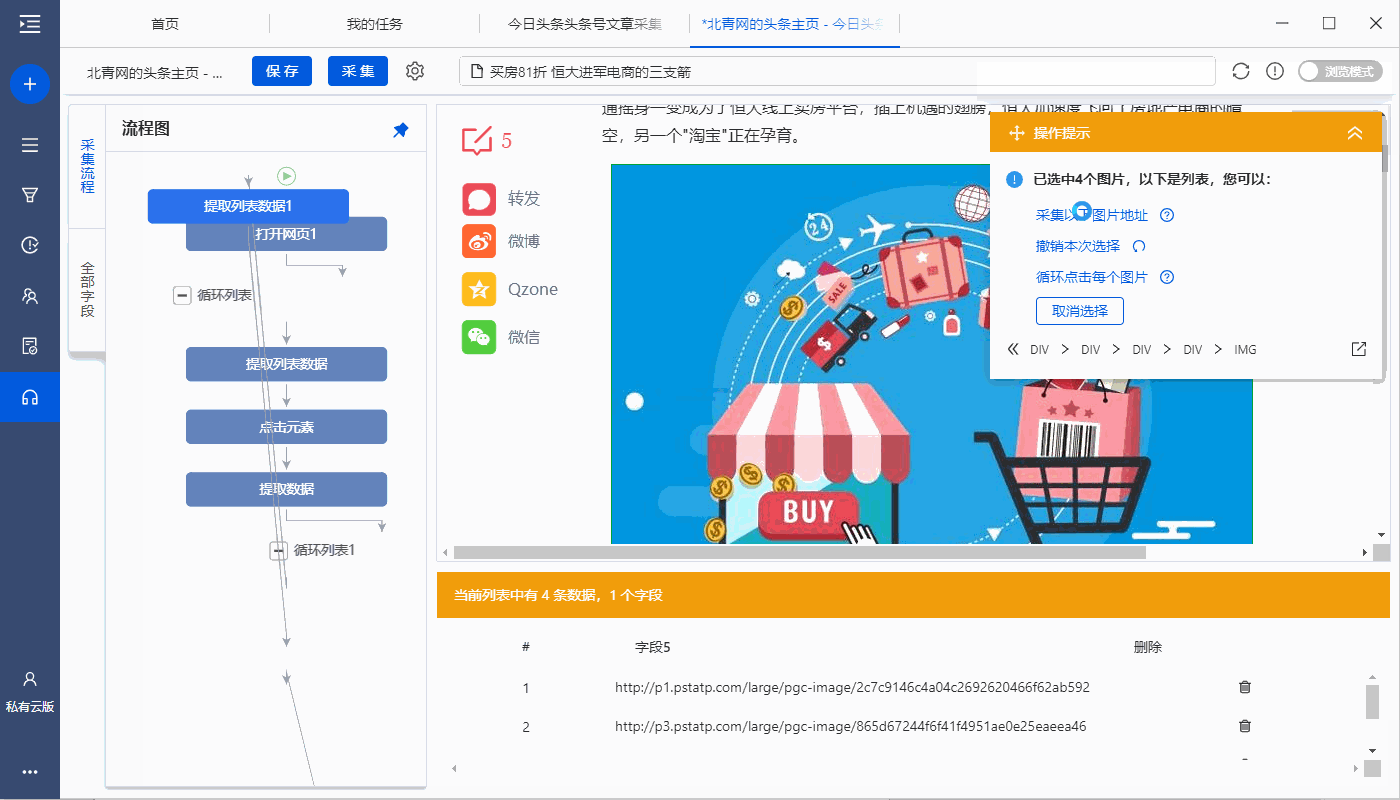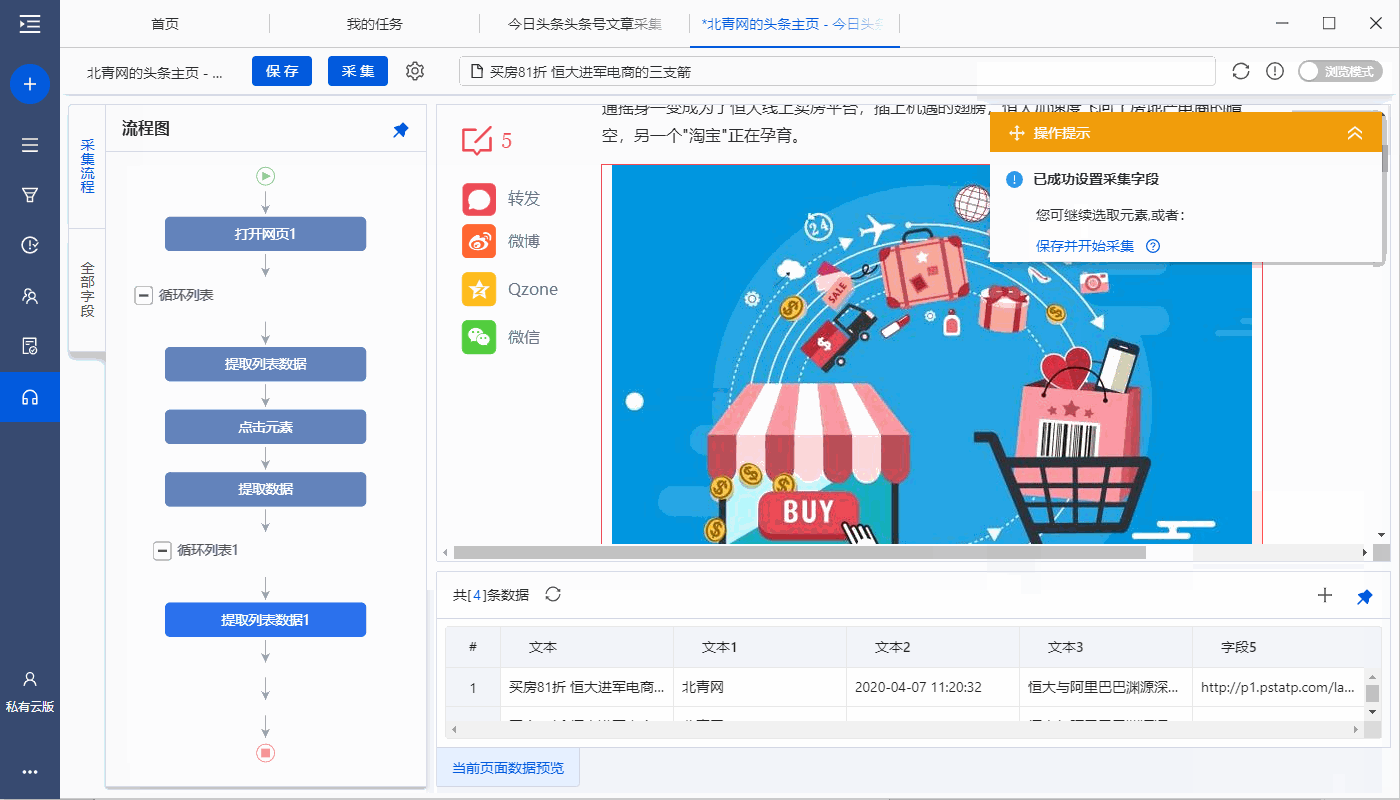
之前影视程序预计花费一个多月的时间来做首版月时间
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-26 07:08
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载 查看全部
之前影视程序预计花费一个多月的时间来做首版月时间
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件配置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
前言
因为最近工作比较忙,预计之前的影视节目制作第一版需要一个多月的时间。没想到仅仅过了半个月,单位的工作就开始忙碌起来。过了一会儿,程序的大部分功能都已经写好了,可以正常使用了,第一版测试的大部分bug也都修复了。考虑到短期内暂时无法在这个程序上花费精力,开源供大家改进。 代码写的不好,希望不要嫌弃( ̄▽ ̄)"
改进了功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.Carousel 管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、主题添加、主题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.促销管理,包括(添加广告、广告列表)
7.extended mall
8.社会管理
功能有待改进
1.系统设置->播放器编辑
2.资源管理->视频管理只写部分
3.资源管理->文章管理
4.会员管理->会员设置
5.社会管理->通讯配置、邮件设置、消息管理只设置不对接
6.第三方访问
开源下载
最新最流行的博客程序有哪些?答:wordpress采集器常见功能更新历史
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-24 22:16
1、Q:最新最火的博客程序有哪些?
A:最新流行的博客程序包括wordpress、emlog、zbolg等程序。其中wordpress是世界上最好的博客程序,用PHP+MYSQL开发。
(Wordpress中文版后台管理中心图标)
2、Q:wordpress采集器 是什么?有哪些有用的 wordpress采集 插件推荐?
答:wordpress采集可以使用优采云采集器快速搭建wordpress采集插件。 优采云采集器常用函数如下更新历史
3、Q:软件下载后,如何使用?有教程吗?
A:从首页下载后,将发布界面的.PHP界面文件放在wordpress对应目录下,将软件发布规则中的界面域名修改为你的网站域名。
软件使用教程
4、Q:采集软件可以本地化远程图片吗?
回答:是的,采集软件完全可以实现远程图像定位。并添加图片水印、缩小图片大小等。
5、Q:我只需要一份采集对方的一些网页,可以指定网址采集吗?
答:批量采集,内容参差不齐,为了提高内容质量,可以单独使用采集,采集可以手动编辑,然后发布到WordPress网站后端。
6、Q:wordpress 发布界面会影响我的网站升级吗?
答:release接口是独立编写的,一般不影响网站的升级和使用。 查看全部
最新最流行的博客程序有哪些?答:wordpress采集器常见功能更新历史
1、Q:最新最火的博客程序有哪些?
A:最新流行的博客程序包括wordpress、emlog、zbolg等程序。其中wordpress是世界上最好的博客程序,用PHP+MYSQL开发。
(Wordpress中文版后台管理中心图标)
2、Q:wordpress采集器 是什么?有哪些有用的 wordpress采集 插件推荐?
答:wordpress采集可以使用优采云采集器快速搭建wordpress采集插件。 优采云采集器常用函数如下更新历史
3、Q:软件下载后,如何使用?有教程吗?
A:从首页下载后,将发布界面的.PHP界面文件放在wordpress对应目录下,将软件发布规则中的界面域名修改为你的网站域名。
软件使用教程
4、Q:采集软件可以本地化远程图片吗?
回答:是的,采集软件完全可以实现远程图像定位。并添加图片水印、缩小图片大小等。
5、Q:我只需要一份采集对方的一些网页,可以指定网址采集吗?
答:批量采集,内容参差不齐,为了提高内容质量,可以单独使用采集,采集可以手动编辑,然后发布到WordPress网站后端。
6、Q:wordpress 发布界面会影响我的网站升级吗?
答:release接口是独立编写的,一般不影响网站的升级和使用。
Excel教程Excel函数Excel透视表教程说明本篇采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-24 22:12
Excel教程Excel函数Excel透视表教程说明本篇采集
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click[采集data]
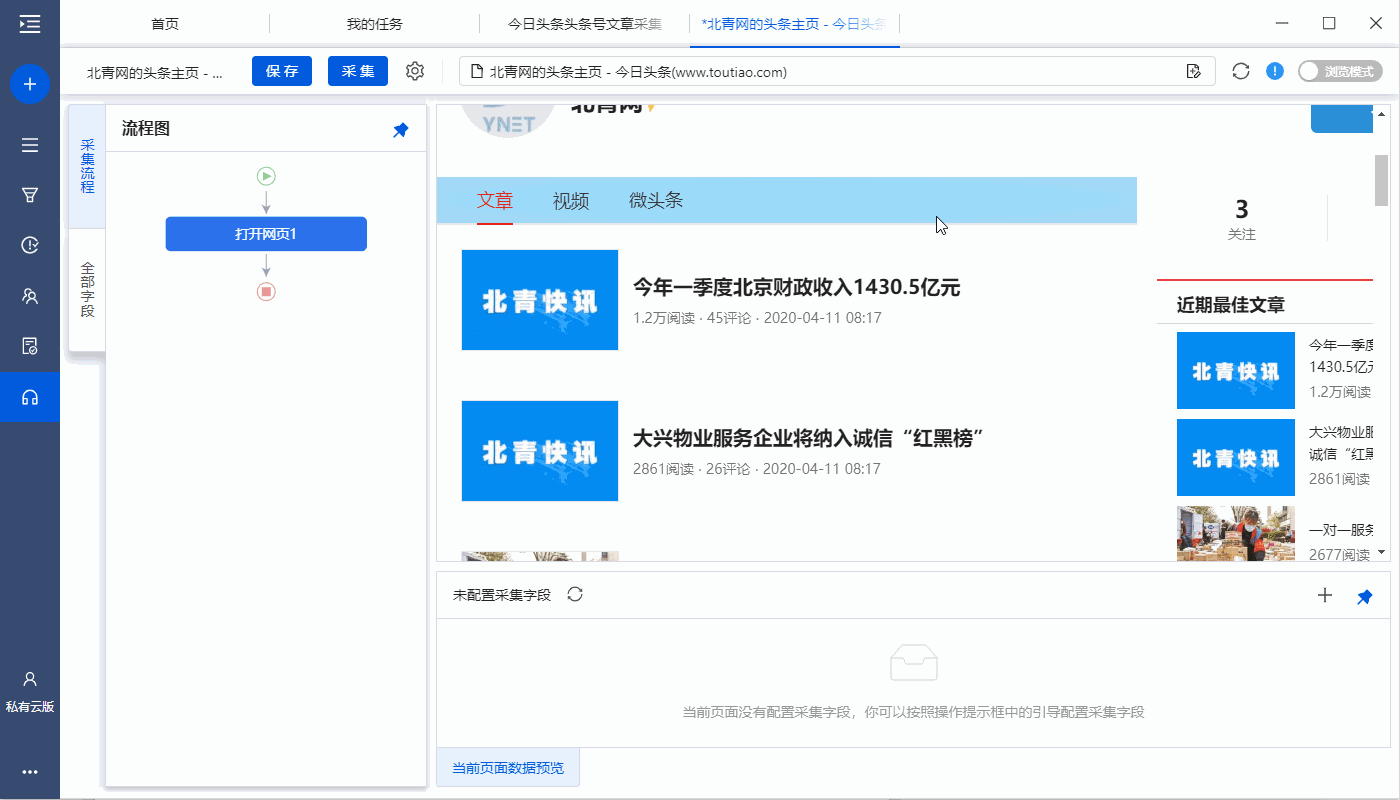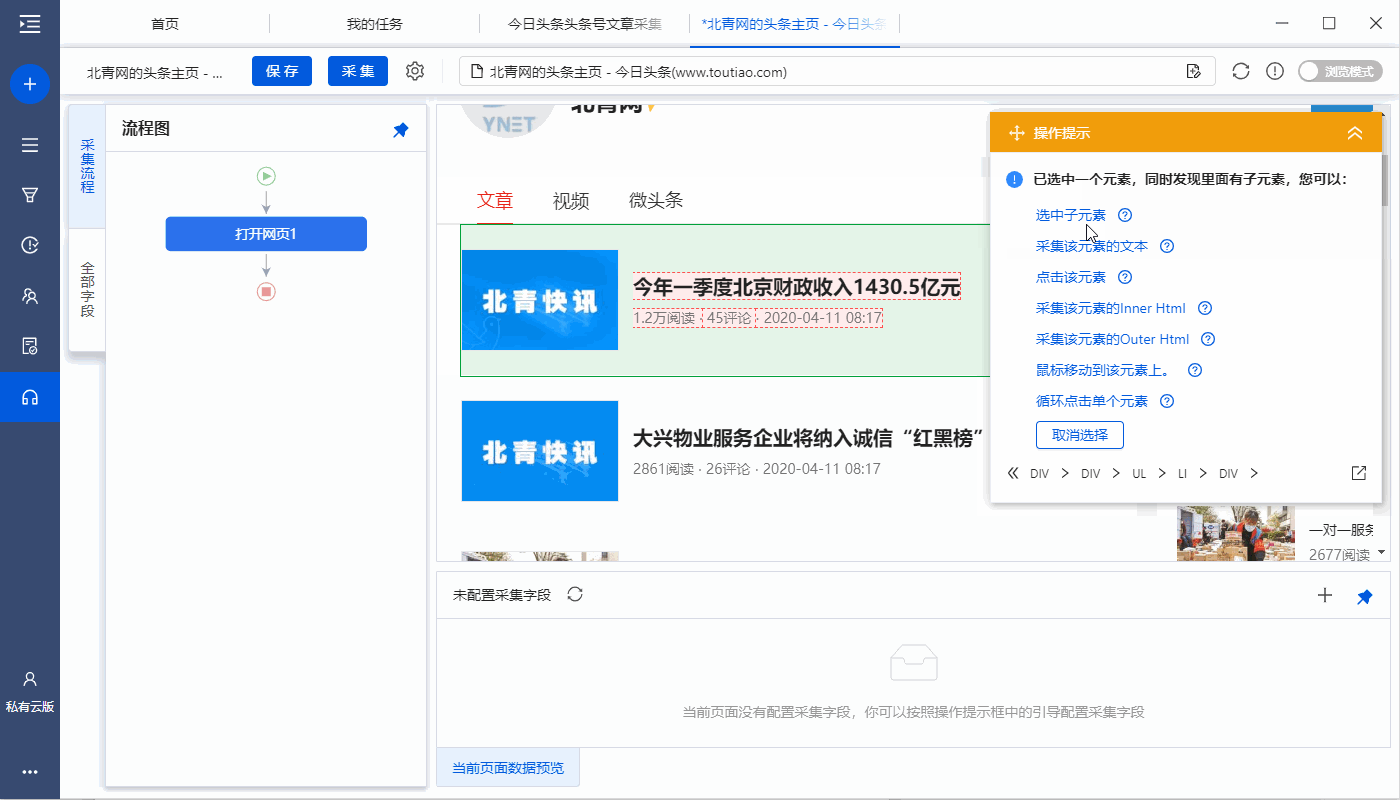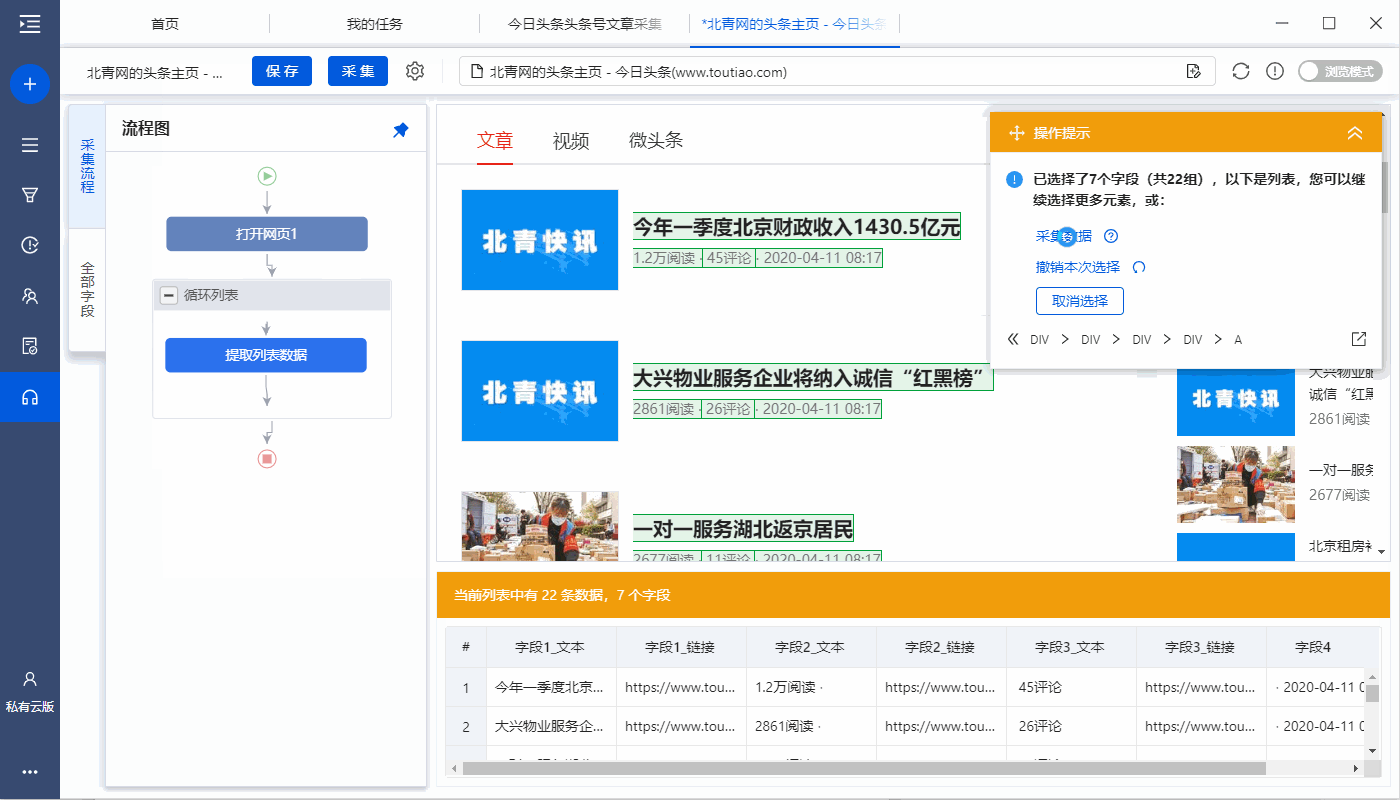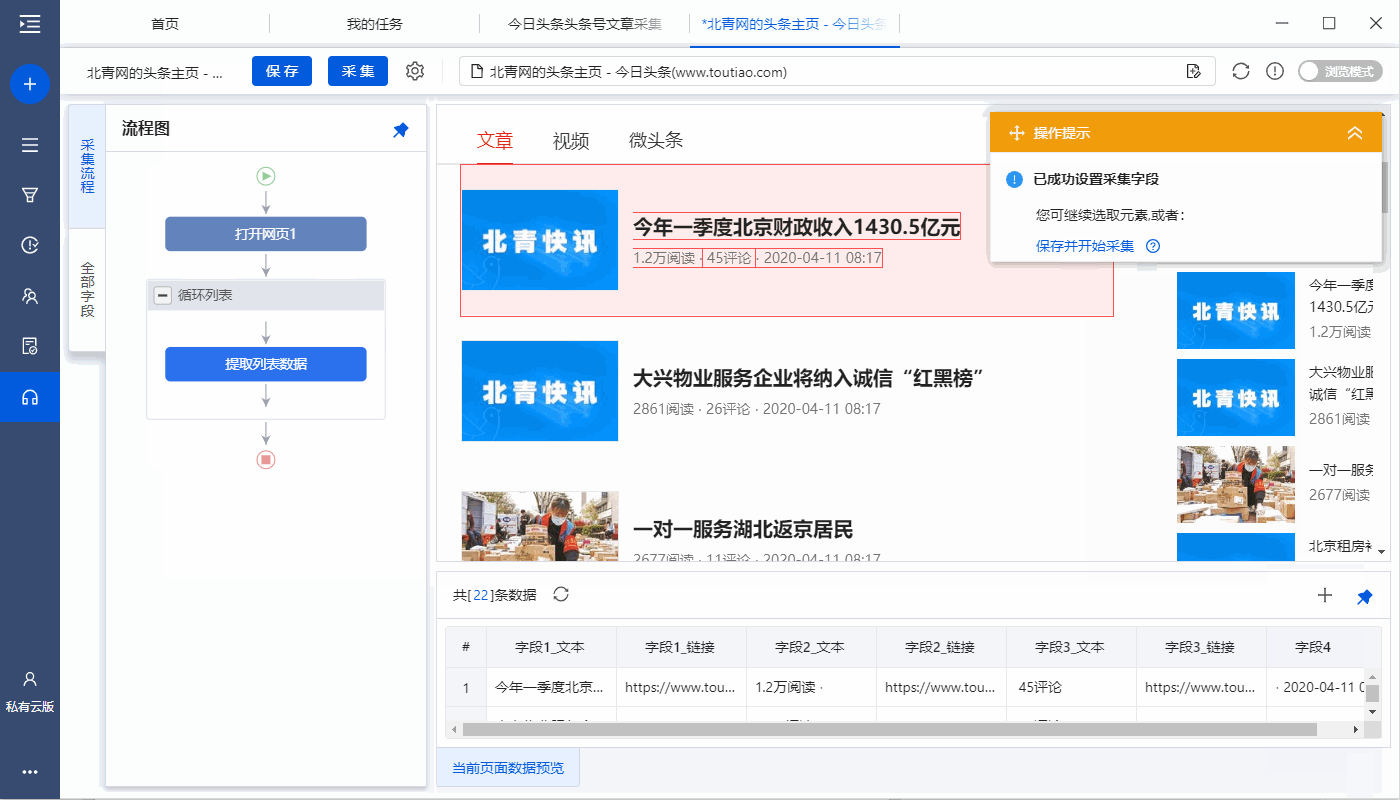
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
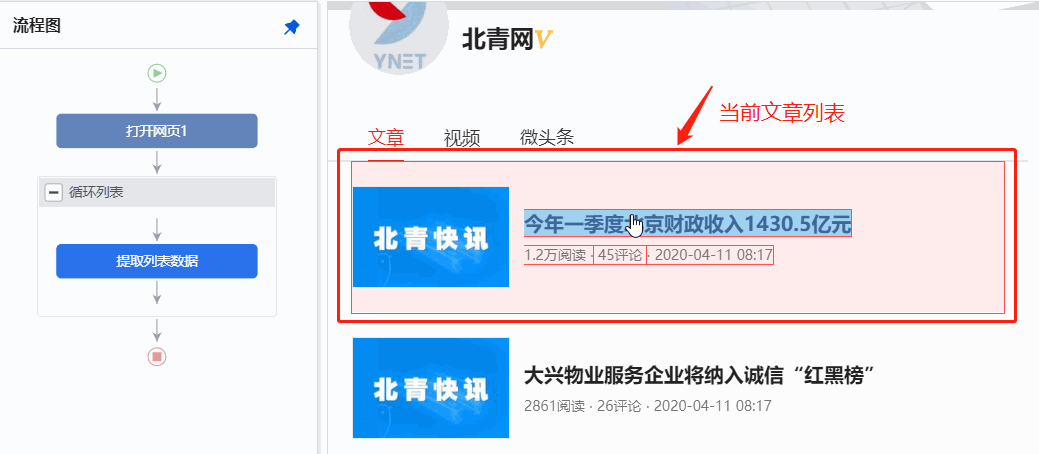
在当前文章列表(网页红框框内)中,选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表。在优采云中,也需要滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
查看全部
Excel教程Excel函数Excel透视表教程说明本篇采集
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click[采集data]
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表(网页红框框内)中,选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表。在优采云中,也需要滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
2017年小程序的基本原理是什么?如何发展?
采集交流 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-08-21 19:22
不时有朋友问我能不能做个小程序。 2017年,我专心学习了几个月的小程序。当时小程序还处于起步阶段,功能比较简单。当时很多人都在探索小程序的机会。出现了短时间走红的小程序,比如“宝佑说”。后来也出现了各种小程序游戏不断轰炸各个群体的情况。 “彩票助手”这种稳扎稳打的小程序,真是见不得人。可以看出,当时的微信官方也在不断探索如何开发小程序,小程序的边界在哪里等等。
我连小程序的长期玩家都算不上,所以我就说些我能听得懂的话。
首先来了解一下小程序的基本原理:
首先,你最好了解一下网页的呈现原理:简单来说,就是写一些代码来描述一个网页。比如我想在网页顶部放一张图片,在图片下面放一段文字,文字是蓝色的。文字下方是视频等。
自万维网出现以来,网页就是一种呈现信息的方式,但有几个不便之处:
1、 同一段代码在不同浏览器中可能显示不同的效果。开发者需要花费大量精力调试不同浏览器的渲染效果。
2、原创浏览器代码写起来很麻烦,对程序员的要求也比较高。
3、网页代码执行效率一般,遇到更复杂的场景会消耗更多的CPU。
4、用户每次登录都需要输入用户名和密码,比较麻烦。
对于网页的理解,最常见的就是很多H5页面,还是很流行的。我最大的感受就是每次打开的加载速度都是明显的缺陷。
微信看了这么多H5页面,在自己的平台上为用户提供了很多额外但必要的功能。自然地,我想到了如何让它的平台更加完善。毕竟流量就是金钱,用户的注意力就是金钱,所以微信本身也引入了一套类似html代码的标准,让开发者可以更方便的开发页面,并且经过微信的优化整合,这些页面会在微信中显示比原创结果更好的结果。 HTML比较好,毕竟微信对自己的小环境做了很多适配。
但是,如果你不想看到我谈论这个,请记住一件事:一个小程序是一个网页的高级版本,一个网页,一个网页。
既然是网页,就说明小程序不是万能的,除了网页能做的事情,它什么也做不了。其实换个角度也可以这样理解:因为小程序跑在微信上,而微信又跑在手机上,手机相对于电脑在算力上有着天然的劣势,所以小程序不适合做事消耗算力,这就是为什么我的公众号文章批量导出业务没有小程序版本:你不能让你的手机只运行1分钟就变热,当然,它仍然在幕后一个重要的原因是,即使你坚持在小程序中实现这个功能,微信也没有提供这样的接口,因为网页不是万能的。唯一的可能就是把文章html的转换成pdf放在云主机上,本地直接从云端下载转换后的文件即可。
另外,小程序会受到微信的严格限制,比如不能转发到朋友圈。也无法获取用户的朋友圈信息,更别提他的通讯录、短信、微信好友账号等信息了。有的朋友会问为什么不可以,为什么要可以?如果不老老实实做一个小工具的“用完就走”的功能,又怎么会担心用户的数据呢?微信会同意吗?用户会同意吗?
还有一个有趣的现象。小程序的推广力度加大后,社会上很多人都会把小程序视为无所不能的神,却不愿意花一点时间去了解。它是什么,什么可以做,什么不能做。有一段时间,他们的口头禅变成了:你最好做一个小程序。跟不上小程序的节奏,好像已经落伍了。
本文标题:小程序基础科普帖 查看全部
2017年小程序的基本原理是什么?如何发展?
不时有朋友问我能不能做个小程序。 2017年,我专心学习了几个月的小程序。当时小程序还处于起步阶段,功能比较简单。当时很多人都在探索小程序的机会。出现了短时间走红的小程序,比如“宝佑说”。后来也出现了各种小程序游戏不断轰炸各个群体的情况。 “彩票助手”这种稳扎稳打的小程序,真是见不得人。可以看出,当时的微信官方也在不断探索如何开发小程序,小程序的边界在哪里等等。
我连小程序的长期玩家都算不上,所以我就说些我能听得懂的话。
首先来了解一下小程序的基本原理:
首先,你最好了解一下网页的呈现原理:简单来说,就是写一些代码来描述一个网页。比如我想在网页顶部放一张图片,在图片下面放一段文字,文字是蓝色的。文字下方是视频等。
自万维网出现以来,网页就是一种呈现信息的方式,但有几个不便之处:
1、 同一段代码在不同浏览器中可能显示不同的效果。开发者需要花费大量精力调试不同浏览器的渲染效果。
2、原创浏览器代码写起来很麻烦,对程序员的要求也比较高。
3、网页代码执行效率一般,遇到更复杂的场景会消耗更多的CPU。
4、用户每次登录都需要输入用户名和密码,比较麻烦。
对于网页的理解,最常见的就是很多H5页面,还是很流行的。我最大的感受就是每次打开的加载速度都是明显的缺陷。
微信看了这么多H5页面,在自己的平台上为用户提供了很多额外但必要的功能。自然地,我想到了如何让它的平台更加完善。毕竟流量就是金钱,用户的注意力就是金钱,所以微信本身也引入了一套类似html代码的标准,让开发者可以更方便的开发页面,并且经过微信的优化整合,这些页面会在微信中显示比原创结果更好的结果。 HTML比较好,毕竟微信对自己的小环境做了很多适配。
但是,如果你不想看到我谈论这个,请记住一件事:一个小程序是一个网页的高级版本,一个网页,一个网页。
既然是网页,就说明小程序不是万能的,除了网页能做的事情,它什么也做不了。其实换个角度也可以这样理解:因为小程序跑在微信上,而微信又跑在手机上,手机相对于电脑在算力上有着天然的劣势,所以小程序不适合做事消耗算力,这就是为什么我的公众号文章批量导出业务没有小程序版本:你不能让你的手机只运行1分钟就变热,当然,它仍然在幕后一个重要的原因是,即使你坚持在小程序中实现这个功能,微信也没有提供这样的接口,因为网页不是万能的。唯一的可能就是把文章html的转换成pdf放在云主机上,本地直接从云端下载转换后的文件即可。
另外,小程序会受到微信的严格限制,比如不能转发到朋友圈。也无法获取用户的朋友圈信息,更别提他的通讯录、短信、微信好友账号等信息了。有的朋友会问为什么不可以,为什么要可以?如果不老老实实做一个小工具的“用完就走”的功能,又怎么会担心用户的数据呢?微信会同意吗?用户会同意吗?
还有一个有趣的现象。小程序的推广力度加大后,社会上很多人都会把小程序视为无所不能的神,却不愿意花一点时间去了解。它是什么,什么可以做,什么不能做。有一段时间,他们的口头禅变成了:你最好做一个小程序。跟不上小程序的节奏,好像已经落伍了。
本文标题:小程序基础科普帖
采集高端社区与普通用户之间的一切共性信息选择
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-08-20 23:03
文章采集程序可以找开源的数据采集程序,比如前段时间分享的mzldj通过爬虫爬取了某电影票服务器内的各类数据,适合采集电影票类信息。
存在网站上就可以挖掘本地数据了
猜测一下:有些人还没注册就可以下载图片
分手应该只是个理由。我下午和女朋友去吃饭,看见一对情侣吃得很开心,突然女朋友用非常平静的语气告诉我:我又看到了一对情侣聊天,聊得超级开心。我愕然,什么啊?什么?我脑子就那么想的,没有别的感觉。让人想到当初恋爱前,他们是如何甜蜜的,又是如何面对分手。只记得大概是坐地铁时遇到对方,第一次单独看电影,之后又因为一些事情矛盾分手。
我努力回忆,却难以做出任何判断。很幸运的是女朋友有对象,她要求我不要介意。她的生活中不会只有我。我有自己的天地,独立天地很重要。说得太过片面,但总体是这个意思。恩。
采集高端社区与普通用户之间的一切共性信息
选择聚合引擎
java可用
你可以访问中国票房网站,用百度搜索,出来应该有票务的各类信息,你再下载或者通过网络爬虫去抓取就可以了。
你可以去qq群中搜索,看看有没有人看上眼,然后收集,还可以到百度贴吧,迅雷,快播等网站下载到本地来。 查看全部
采集高端社区与普通用户之间的一切共性信息选择
文章采集程序可以找开源的数据采集程序,比如前段时间分享的mzldj通过爬虫爬取了某电影票服务器内的各类数据,适合采集电影票类信息。
存在网站上就可以挖掘本地数据了
猜测一下:有些人还没注册就可以下载图片
分手应该只是个理由。我下午和女朋友去吃饭,看见一对情侣吃得很开心,突然女朋友用非常平静的语气告诉我:我又看到了一对情侣聊天,聊得超级开心。我愕然,什么啊?什么?我脑子就那么想的,没有别的感觉。让人想到当初恋爱前,他们是如何甜蜜的,又是如何面对分手。只记得大概是坐地铁时遇到对方,第一次单独看电影,之后又因为一些事情矛盾分手。
我努力回忆,却难以做出任何判断。很幸运的是女朋友有对象,她要求我不要介意。她的生活中不会只有我。我有自己的天地,独立天地很重要。说得太过片面,但总体是这个意思。恩。
采集高端社区与普通用户之间的一切共性信息
选择聚合引擎
java可用
你可以访问中国票房网站,用百度搜索,出来应该有票务的各类信息,你再下载或者通过网络爬虫去抓取就可以了。
你可以去qq群中搜索,看看有没有人看上眼,然后收集,还可以到百度贴吧,迅雷,快播等网站下载到本地来。
文章采集程序采集网站a和b接收验证码但数据都来自对应
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-20 06:06
文章采集程序采集网站a和b接收验证码但数据都来自对应网站采集程序采集程序采集网站a的上下文信息保存成结构化文本:保存页面源码图片(png格式,多张)、css、js文件多用于网站提交js代码采集程序采集网站b的接收验证码数据,保存在结构化文本:保存页面源码图片(png格式,多张),js文件多用于网站提交验证码采集程序采集数据文件采集代码保存于js文件采集代码采集程序可添加#对所有进行自动采集!!!加黑名单!!!(记得检查下有没有漏收集)添加#对所有进行自动采集接下来就是去动手自己实现了代码实现下面有详细代码。
抓包,看看接收的信息对应的是哪个页面。
买台猫爬机啊,国产的,几百到一千都有。
1)抓包分析出来这个信息对应的是哪个页面
2)打开网站后分析请求头,获取网页源代码,并对信息进行字符串拼接,
3)有需要自己处理信息的,就再根据其拼接语法语义判断是否做到了对信息进行量化。上面的都做到了,抓包看对应信息对应的是哪个页面,如果可以得到对应的详细地址,那就一手把握住所有信息去争取分析地址的权限。否则,不可能去全部抓包地址,必然要通过各种量化手段找到所有可能性(信息,需求,列表,专题,分类,页面等),找出那些和时间有关的,那些和开始时间有关的,这些就必须按照各种route分析再量化。
而通过抓包实现量化最简单的,就是定期复制浏览器标准帧,每秒和某个时间段做一次连接,比如:我发现在现在四维空间可以显示越来越多的动画地址:代码我也不截图了,有兴趣可以看下以前写的博客,一个简单的,算是可以自定义爬虫,而且爬取的结果可以导出pdf。地址是如何定义地址的-warfalcon的博客-csdn博客这个是我博客地址。 查看全部
文章采集程序采集网站a和b接收验证码但数据都来自对应
文章采集程序采集网站a和b接收验证码但数据都来自对应网站采集程序采集程序采集网站a的上下文信息保存成结构化文本:保存页面源码图片(png格式,多张)、css、js文件多用于网站提交js代码采集程序采集网站b的接收验证码数据,保存在结构化文本:保存页面源码图片(png格式,多张),js文件多用于网站提交验证码采集程序采集数据文件采集代码保存于js文件采集代码采集程序可添加#对所有进行自动采集!!!加黑名单!!!(记得检查下有没有漏收集)添加#对所有进行自动采集接下来就是去动手自己实现了代码实现下面有详细代码。
抓包,看看接收的信息对应的是哪个页面。
买台猫爬机啊,国产的,几百到一千都有。
1)抓包分析出来这个信息对应的是哪个页面
2)打开网站后分析请求头,获取网页源代码,并对信息进行字符串拼接,
3)有需要自己处理信息的,就再根据其拼接语法语义判断是否做到了对信息进行量化。上面的都做到了,抓包看对应信息对应的是哪个页面,如果可以得到对应的详细地址,那就一手把握住所有信息去争取分析地址的权限。否则,不可能去全部抓包地址,必然要通过各种量化手段找到所有可能性(信息,需求,列表,专题,分类,页面等),找出那些和时间有关的,那些和开始时间有关的,这些就必须按照各种route分析再量化。
而通过抓包实现量化最简单的,就是定期复制浏览器标准帧,每秒和某个时间段做一次连接,比如:我发现在现在四维空间可以显示越来越多的动画地址:代码我也不截图了,有兴趣可以看下以前写的博客,一个简单的,算是可以自定义爬虫,而且爬取的结果可以导出pdf。地址是如何定义地址的-warfalcon的博客-csdn博客这个是我博客地址。
如何使用优采云采集微信公众号文章,非常简单采集任务配置
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-08-16 20:32
使用优采云采集微信公号文章,很简单,输入:公众账号ID或者姓名或者关键词即可。
使用步骤:
1.新建微信公众号采集任务:
新微信公众号采集任务有两个入口:
2.微信公众号采集task 配置:
3.采集Result:
默认采集 字段:
微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(content)、发布日期(pubData)、作者(author)、标签(tag)、描述(description)、可被用来截取文本)和关键字(keywords);
采集微信公众号备注:
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
在‘公众号ID(WeChat ID)’中填写微信ID名称,然后点击旁边的‘Check Official Account’按钮查看微信ID;
以下以“万维网”为例:
二、微信文章零散采集
微信文章零散采集一般用于精准采集,用户只需输入微信文章地址到采集即可。
在微信公众号文章采集基本信息页面,点击‘手动输入文章link采集(可选)’按钮;
温馨提示:如需下载图片、数据处理等,请配置后点击分散的采集按钮;
输入单个或多个详细 URL,每行一个,以 or 开头;
查看全部
如何使用优采云采集微信公众号文章,非常简单采集任务配置
使用优采云采集微信公号文章,很简单,输入:公众账号ID或者姓名或者关键词即可。
使用步骤:
1.新建微信公众号采集任务:
新微信公众号采集任务有两个入口:
2.微信公众号采集task 配置:
3.采集Result:
默认采集 字段:
微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(content)、发布日期(pubData)、作者(author)、标签(tag)、描述(description)、可被用来截取文本)和关键字(keywords);
采集微信公众号备注:
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
在‘公众号ID(WeChat ID)’中填写微信ID名称,然后点击旁边的‘Check Official Account’按钮查看微信ID;
以下以“万维网”为例:
二、微信文章零散采集
微信文章零散采集一般用于精准采集,用户只需输入微信文章地址到采集即可。
在微信公众号文章采集基本信息页面,点击‘手动输入文章link采集(可选)’按钮;
温馨提示:如需下载图片、数据处理等,请配置后点击分散的采集按钮;
输入单个或多个详细 URL,每行一个,以 or 开头;
用考拉,一天产出几万篇高质量SEO文章探讨!
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-13 03:18
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
前几天,大家对“公众号运营平台采集文章怎么样”的讨论很感兴趣,我的网友问的非常多。在实际讨论这个内容之前,我们应该先来这里讨论一下网站自编信息文应该如何编辑!对于以流量为目的的SEOer来说,文案的质量不是关键目的,所以网站特别关注的是权重和排名。一个高流量的搜索优化文章发在一个低权重的网站,写在一个高流量的平台上,结果排名和浏览量差别很大!
急切分析【公众号运营平台采集文章怎么样】的朋友们,你们心中最关心的,是文章过去谈过的话题。事实上,创建一个优秀的搜索文章非常容易,但是一个SEO副本产生的流量真的很小。追求通过内容页面设计实现流量的目的,最重要的方法就是量产!如果1个文章可以产生1个阅读(一天),那么如果可以写10000篇文章,每天的访问量可以增加10000倍。但是说起来简单,实际编辑的时候,一个人一天只能写30篇左右,最多70篇。就算用伪原创软件,最多也就100个左右!看完了,可以暂时离开“公众号运营平台采集文章怎么样”的话题,仔细思考一下文章的智能写作如何完成!
算法认为的人工创造是什么? 文章原创从来没有一一写过关键词原创!在各种搜索引擎的程序定义中,原创并不是没有重复的句子。事实上,如果你的副本与其他收录不同,收录的概率可以增加。一篇热点文章,内容够好,保持关键词不变,只要不要重复内容,也就是说这篇文章文章还是很有可能是收录,甚至爆文。比如我的文章,你可能通过搜狗搜索过【公众号运营平台怎么样采集文章】,最后点击查看。负责人告诉你:本文文章是使用考拉SEO软件的自动写作文章工具独立导出!
本站的伪原创software其实应该是批写文章工具,可以完成2小时的制作,上千种长尾词优化文案。我们的网站权重够大的,收录率可以高达76%。对于具体的应用技巧,用户主页收录视频展示和初学者指南。让我们试一试吧!非常抱歉,关于“公众号平台如何操作采集文章”我没有给你详细的说明。也许每个人都可以检查一下。一段机器语言。但如果大家都对考拉SEO技术情有独钟,只要看看右上角,让你的网页每天增加几千万的流量。不好吗? 查看全部
用考拉,一天产出几万篇高质量SEO文章探讨!
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
前几天,大家对“公众号运营平台采集文章怎么样”的讨论很感兴趣,我的网友问的非常多。在实际讨论这个内容之前,我们应该先来这里讨论一下网站自编信息文应该如何编辑!对于以流量为目的的SEOer来说,文案的质量不是关键目的,所以网站特别关注的是权重和排名。一个高流量的搜索优化文章发在一个低权重的网站,写在一个高流量的平台上,结果排名和浏览量差别很大!
急切分析【公众号运营平台采集文章怎么样】的朋友们,你们心中最关心的,是文章过去谈过的话题。事实上,创建一个优秀的搜索文章非常容易,但是一个SEO副本产生的流量真的很小。追求通过内容页面设计实现流量的目的,最重要的方法就是量产!如果1个文章可以产生1个阅读(一天),那么如果可以写10000篇文章,每天的访问量可以增加10000倍。但是说起来简单,实际编辑的时候,一个人一天只能写30篇左右,最多70篇。就算用伪原创软件,最多也就100个左右!看完了,可以暂时离开“公众号运营平台采集文章怎么样”的话题,仔细思考一下文章的智能写作如何完成!
算法认为的人工创造是什么? 文章原创从来没有一一写过关键词原创!在各种搜索引擎的程序定义中,原创并不是没有重复的句子。事实上,如果你的副本与其他收录不同,收录的概率可以增加。一篇热点文章,内容够好,保持关键词不变,只要不要重复内容,也就是说这篇文章文章还是很有可能是收录,甚至爆文。比如我的文章,你可能通过搜狗搜索过【公众号运营平台怎么样采集文章】,最后点击查看。负责人告诉你:本文文章是使用考拉SEO软件的自动写作文章工具独立导出!
本站的伪原创software其实应该是批写文章工具,可以完成2小时的制作,上千种长尾词优化文案。我们的网站权重够大的,收录率可以高达76%。对于具体的应用技巧,用户主页收录视频展示和初学者指南。让我们试一试吧!非常抱歉,关于“公众号平台如何操作采集文章”我没有给你详细的说明。也许每个人都可以检查一下。一段机器语言。但如果大家都对考拉SEO技术情有独钟,只要看看右上角,让你的网页每天增加几千万的流量。不好吗?
微信小程序实名认证要求用户上传身份证和手持身份证照片
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-08-11 21:14
在新开发的微信小程序中,实名认证需要用户上传身份证和持有身份证照片。提交release版本时,审核失败。审核结果提示:您的小程序人脸识别功能涉及采集,用户生物特征的存储,包括但不限于人脸照片、人脸视频、身份证加手持身份证和身份证照片加无头等服务photo ,该类服务需要使用微信原生人脸识别接口,但由于小程序目前不满足访问微信原生人脸识别接口的条件,请在小程序代码中去掉小程序前端显示和人脸采集 功能完成后重新提交审核。
业务流程必须要求使用实名认证。去掉前端显示不现实,服务类别不满足微信原生人脸识别接口接入条件。查看修订指南发现违反了用户隐私和数据安全协议:
在采集和使用任何用户数据时,必须明确告知用户数据的用途,并且用户必须明确同意并授权...
阅读说明后,参考同类型小程序实名认证,做如下操作:
增加上传照片的目的,保证用户信息不被泄露(图中红色部分)。可能很多开发者一开始会忽略这个提示。审计失败后,他们不知道从哪里开始改变。有时微信审核提示描述的问题不是很清楚。
修改完成后提交release review,很快就会通过review!结束!
如果添加提示后审核不通过,请在解决指南中选择不批准,填写原因并明确告知用户数据的用途...,然后继续提交审核。
PS:此方法不再可用。如果小程序更新不频繁,可以试一试。 Webview 还用于加载 wap 页面并在网页内进行身份验证。 查看全部
微信小程序实名认证要求用户上传身份证和手持身份证照片
在新开发的微信小程序中,实名认证需要用户上传身份证和持有身份证照片。提交release版本时,审核失败。审核结果提示:您的小程序人脸识别功能涉及采集,用户生物特征的存储,包括但不限于人脸照片、人脸视频、身份证加手持身份证和身份证照片加无头等服务photo ,该类服务需要使用微信原生人脸识别接口,但由于小程序目前不满足访问微信原生人脸识别接口的条件,请在小程序代码中去掉小程序前端显示和人脸采集 功能完成后重新提交审核。
业务流程必须要求使用实名认证。去掉前端显示不现实,服务类别不满足微信原生人脸识别接口接入条件。查看修订指南发现违反了用户隐私和数据安全协议:
在采集和使用任何用户数据时,必须明确告知用户数据的用途,并且用户必须明确同意并授权...
阅读说明后,参考同类型小程序实名认证,做如下操作:
增加上传照片的目的,保证用户信息不被泄露(图中红色部分)。可能很多开发者一开始会忽略这个提示。审计失败后,他们不知道从哪里开始改变。有时微信审核提示描述的问题不是很清楚。
修改完成后提交release review,很快就会通过review!结束!
如果添加提示后审核不通过,请在解决指南中选择不批准,填写原因并明确告知用户数据的用途...,然后继续提交审核。
PS:此方法不再可用。如果小程序更新不频繁,可以试一试。 Webview 还用于加载 wap 页面并在网页内进行身份验证。
Python图片添加图片水印的原理及添加程序开发方法介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-11 01:24
文章directory
一、为什么要给图片加水印
在网上写文章时最大的头痛之一就是文章发表的很容易抄袭,各种抄袭的方法真是层出不穷。只好在不影响阅读体验的情况下,不断提高反抄袭难度。虽然无法避免,但在文章中的图片上加水印,至少可以保证文章被抄袭后,读者仍然会知道文章网站的来源。
在某些情况下,我们可以使用FastStone等一些软件来快速捕捉带有水印的图片,如下图:
此类工具可以快速为图片添加水印图像。
但是如果我们有一批图片,它们不是由截图生成的。这种情况下,如果要给每张图片加水印,FastStone工具就有点力不从心了。
我们可以使用市场上的一些软件来实现:
但这些软件要么不免费,要么免费但不安全,要么太麻烦。
简单来说,我们将使用Python来完成一个批量添加图像水印的程序的开发。
二、使用Python给图片添加水印
给图片添加图片水印的原理其实很简单。只需在空白画布上依次添加原创图像和水印即可。
在 Python 中,我们可以借助 PIL 模块轻松添加图片水印。
接下来,我们通过代码来演示。
遍历文件夹内所有图片文件
首先我们需要获取目录中的所有文件并提取其中的图像文件。这一步可以通过内置的 os 模块来实现。代码如下:
import os
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(r"C:\Users\yang9\Desktop"):
if i.split('.')[-1] in img_suffix_list:
print(i)
运行上面的代码,我们会得到选中目录下后缀为png、jpg、bmp的图形文件,效果如下图:
给图片添加图片水印
在接下来的步骤中,我们为图片添加图片水印。这一步需要借助PIL的Image类来实现。
首先读取原图和水印图,得到原图的大小,代码如下:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
然后我们新建一个和原图一样大小的图层,并将水印图添加到图层中:
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
接下来,我们合成图层和原创图像:
mark_img = Image.composite(layer, img, layer)
最后调用save方法将新图片保存到本地:
mark_img.save(save_path + new_file_name)
这样就生成了一张带水印的图片。
我们集成了两个函数,方便调用,代码如下:
# coding:utf-8
# @文件: code_run.py
# @创建者:州的先生
# 博客地址:zmister.com
import os,traceback
from PIL import Image
# 获取文件夹图片
def get_folder(fpath,wm_file,save_path):
try:
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(fpath):
if i.split('.')[-1] in img_suffix_list:
img_path = fpath + '/' + i
img_water_mark(img_file=img_path,wm_file=wm_file,save_path=save_path)
except Exception as e:
print(traceback.print_exc())
# 图片添加水印
def img_water_mark(img_file, wm_file,save_path):
try:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
wm_size = watermark.size
# 如果图片大小小于水印大小
if img_size[0] < wm_size[0]:
watermark.resize(tuple(map(lambda x: int(x * 0.5), watermark.size)))
print('图片大小:', img_size)
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
mark_img = Image.composite(layer, img, layer)
new_file_name = '/new_'+img_file.split('/')[-1]
mark_img.save(save_path + new_file_name)
except Exception as e:
print(traceback.print_exc())
这样我们就用一个函数get_folder()来指定图片的目录,水印图片的位置,以及新图片的保存位置。运行代码,效果如下图所示:
进入保存目录查看具体效果。图片水印添加准确:
三、使用QT for Python制作图片水印添加程序
代码写好后,我们就可以方便的使用它批量添加图片水印了。虽然很方便,但如果我们能有一个带有图形用户界面的客户端程序供我们使用就更好了。
下一篇文章我们将介绍使用Python的PyQt5/PySide2将批量添加图片水印的功能打包成桌面客户端程序。效果如下图所示:
文章版权:周老师博客,转载需保留出处和原链接 查看全部
Python图片添加图片水印的原理及添加程序开发方法介绍
文章directory
一、为什么要给图片加水印
在网上写文章时最大的头痛之一就是文章发表的很容易抄袭,各种抄袭的方法真是层出不穷。只好在不影响阅读体验的情况下,不断提高反抄袭难度。虽然无法避免,但在文章中的图片上加水印,至少可以保证文章被抄袭后,读者仍然会知道文章网站的来源。
在某些情况下,我们可以使用FastStone等一些软件来快速捕捉带有水印的图片,如下图:
此类工具可以快速为图片添加水印图像。
但是如果我们有一批图片,它们不是由截图生成的。这种情况下,如果要给每张图片加水印,FastStone工具就有点力不从心了。
我们可以使用市场上的一些软件来实现:
但这些软件要么不免费,要么免费但不安全,要么太麻烦。
简单来说,我们将使用Python来完成一个批量添加图像水印的程序的开发。
二、使用Python给图片添加水印
给图片添加图片水印的原理其实很简单。只需在空白画布上依次添加原创图像和水印即可。
在 Python 中,我们可以借助 PIL 模块轻松添加图片水印。
接下来,我们通过代码来演示。
遍历文件夹内所有图片文件
首先我们需要获取目录中的所有文件并提取其中的图像文件。这一步可以通过内置的 os 模块来实现。代码如下:
import os
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(r"C:\Users\yang9\Desktop"):
if i.split('.')[-1] in img_suffix_list:
print(i)
运行上面的代码,我们会得到选中目录下后缀为png、jpg、bmp的图形文件,效果如下图:
给图片添加图片水印
在接下来的步骤中,我们为图片添加图片水印。这一步需要借助PIL的Image类来实现。
首先读取原图和水印图,得到原图的大小,代码如下:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
然后我们新建一个和原图一样大小的图层,并将水印图添加到图层中:
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
接下来,我们合成图层和原创图像:
mark_img = Image.composite(layer, img, layer)
最后调用save方法将新图片保存到本地:
mark_img.save(save_path + new_file_name)
这样就生成了一张带水印的图片。
我们集成了两个函数,方便调用,代码如下:
# coding:utf-8
# @文件: code_run.py
# @创建者:州的先生
# 博客地址:zmister.com
import os,traceback
from PIL import Image
# 获取文件夹图片
def get_folder(fpath,wm_file,save_path):
try:
img_suffix_list = ['png', 'jpg', 'bmp']
for i in os.listdir(fpath):
if i.split('.')[-1] in img_suffix_list:
img_path = fpath + '/' + i
img_water_mark(img_file=img_path,wm_file=wm_file,save_path=save_path)
except Exception as e:
print(traceback.print_exc())
# 图片添加水印
def img_water_mark(img_file, wm_file,save_path):
try:
img = Image.open(img_file) # 打开图片
watermark = Image.open(wm_file) # 打开水印
img_size = img.size
wm_size = watermark.size
# 如果图片大小小于水印大小
if img_size[0] < wm_size[0]:
watermark.resize(tuple(map(lambda x: int(x * 0.5), watermark.size)))
print('图片大小:', img_size)
wm_position = (img_size[0]-wm_size[0],img_size[1]-wm_size[1]) # 默认设定水印位置为右下角
layer = Image.new('RGBA', img.size) # 新建一个图层
layer.paste(watermark, wm_position) # 将水印图片添加到图层上
mark_img = Image.composite(layer, img, layer)
new_file_name = '/new_'+img_file.split('/')[-1]
mark_img.save(save_path + new_file_name)
except Exception as e:
print(traceback.print_exc())
这样我们就用一个函数get_folder()来指定图片的目录,水印图片的位置,以及新图片的保存位置。运行代码,效果如下图所示:
进入保存目录查看具体效果。图片水印添加准确:
三、使用QT for Python制作图片水印添加程序
代码写好后,我们就可以方便的使用它批量添加图片水印了。虽然很方便,但如果我们能有一个带有图形用户界面的客户端程序供我们使用就更好了。
下一篇文章我们将介绍使用Python的PyQt5/PySide2将批量添加图片水印的功能打包成桌面客户端程序。效果如下图所示:
文章版权:周老师博客,转载需保留出处和原链接

