
文章采集程序
文章采集程序(非常实用的最新文章采集神器,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-11-16 21:14
文章采集是一款非常实用的最新文章采集神器,这里为大家带来最新强大的文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章< @采集西溪软件园下载地址。
向站长或SEOER推荐一个免费的文章采集tool_chukang-CSDN博客。
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,那该怎么办呢?你可以试试这个优采云Universal文章采集器,它是一个简单实用的文章采集软件。
今日头条文章采集没有?试试这个免费的 采集artifact!zhong。
1、已测试,采集更快2、自动保存到软件目录,并在目录下创建文件夹自动保存空闲段文章 @采集器大小:来源:百度云盘经安全软件检测无毒,请放心下载。
文章采集阅读是一个用易语言编写的简单网络文章采集工具,它不仅可以采集文字,还可以简单地替换一些text ,或者添加文字,也是SEO的好工具伪原创。
优采云Universal文章采集器是为了方便各大搜索引擎制作采集文件和添加工具,使用可以提取网页正文的算法,以及多语言翻译。
优采云Universal文章采集器,优采云软件出品的基于高精度文本识别算法的互联网文章采集器,支持按关键词采集百度等搜索引擎。 QQ空间资源随时更新。亿万QQ用户的威力,你懂的!固执的兔子是。 查看全部
文章采集程序(非常实用的最新文章采集神器,)
文章采集是一款非常实用的最新文章采集神器,这里为大家带来最新强大的文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章< @采集西溪软件园下载地址。
向站长或SEOER推荐一个免费的文章采集tool_chukang-CSDN博客。
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,那该怎么办呢?你可以试试这个优采云Universal文章采集器,它是一个简单实用的文章采集软件。
今日头条文章采集没有?试试这个免费的 采集artifact!zhong。
1、已测试,采集更快2、自动保存到软件目录,并在目录下创建文件夹自动保存空闲段文章 @采集器大小:来源:百度云盘经安全软件检测无毒,请放心下载。

文章采集阅读是一个用易语言编写的简单网络文章采集工具,它不仅可以采集文字,还可以简单地替换一些text ,或者添加文字,也是SEO的好工具伪原创。
优采云Universal文章采集器是为了方便各大搜索引擎制作采集文件和添加工具,使用可以提取网页正文的算法,以及多语言翻译。

优采云Universal文章采集器,优采云软件出品的基于高精度文本识别算法的互联网文章采集器,支持按关键词采集百度等搜索引擎。 QQ空间资源随时更新。亿万QQ用户的威力,你懂的!固执的兔子是。
文章采集程序( 2.小说v1.2.2小说自动采集+一套采集规则+两套优化模板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-14 05:05
2.小说v1.2.2小说自动采集+一套采集规则+两套优化模板)
来源名称:【旷宇小说v1.2.2】小说自动采集+一套采集规则+两套优化模板
源码大小:8.4MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍及安装说明:
安装教程和模板导入采集规则
系统要求
PHP需要5.6版本及以上,5.6版本无法运行支持php7
插件、应用程序、配置、扩展、公共、运行时、模板、上传目录必须具有写权限 777
网站必须配置伪静态(.htaccess为Apache伪静态配置文件,kyxscms.conf为Nginx伪静态配置文件)
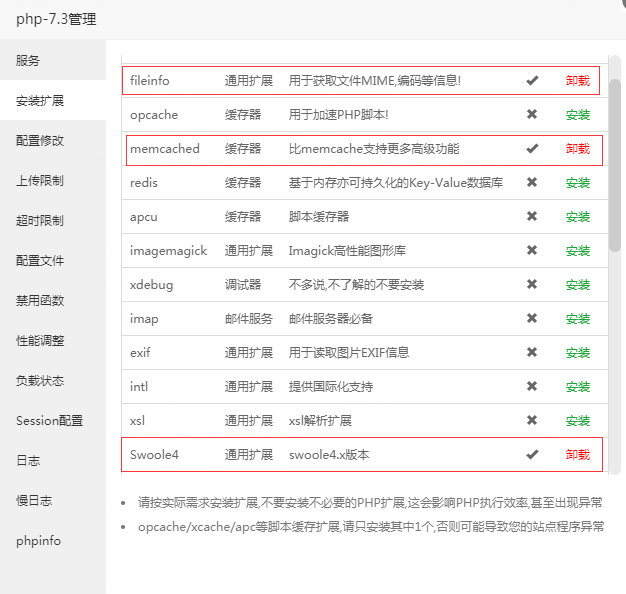
宝塔面板需要在软件php设置中安装扩展fileinfo
如果上传后无法访问源代码,请设置伪静态think
一套是白色的WEB模板,一套是蓝色的WAP模板
手动解压模板到/template/home目录
然后进入数据库找到ky_template
手动插入模板名称在后台显示
采集 规则进入数据库后,直接选择SQL,复制粘贴进去,点击执行。
不明白的可以参考源码中的图片教程。
资源下载 本资源下载价格为58元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈的几十个源代码,只要有下载按钮,终身VIP都可以免费下载。
2. 本站源码多为全网各种渠道购买。文章的描述一般由渠道方测试说明转载,不代表本站观点。不过文章开头带有demo的源码说明本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
======================================
3.文章开头没有demo站点,表示我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换!!!但是,与此同时,您可能也很便宜。因为很多都经过了渠道的测试,但是我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
======================================
4. 本站使用在线支付。支付完成后,积分自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程,如果有也随机。
7. 所有源码不提供免费安装。如需我们代为安装,请联系客服了解详情。
本文整理自互联网(源代码之家123),如需转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
========================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。 查看全部
文章采集程序(
2.小说v1.2.2小说自动采集+一套采集规则+两套优化模板)


来源名称:【旷宇小说v1.2.2】小说自动采集+一套采集规则+两套优化模板
源码大小:8.4MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍及安装说明:
安装教程和模板导入采集规则
系统要求
PHP需要5.6版本及以上,5.6版本无法运行支持php7
插件、应用程序、配置、扩展、公共、运行时、模板、上传目录必须具有写权限 777
网站必须配置伪静态(.htaccess为Apache伪静态配置文件,kyxscms.conf为Nginx伪静态配置文件)
宝塔面板需要在软件php设置中安装扩展fileinfo
如果上传后无法访问源代码,请设置伪静态think
一套是白色的WEB模板,一套是蓝色的WAP模板
手动解压模板到/template/home目录
然后进入数据库找到ky_template
手动插入模板名称在后台显示
采集 规则进入数据库后,直接选择SQL,复制粘贴进去,点击执行。
不明白的可以参考源码中的图片教程。
资源下载 本资源下载价格为58元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈的几十个源代码,只要有下载按钮,终身VIP都可以免费下载。
2. 本站源码多为全网各种渠道购买。文章的描述一般由渠道方测试说明转载,不代表本站观点。不过文章开头带有demo的源码说明本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
======================================
3.文章开头没有demo站点,表示我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换!!!但是,与此同时,您可能也很便宜。因为很多都经过了渠道的测试,但是我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
======================================
4. 本站使用在线支付。支付完成后,积分自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程,如果有也随机。
7. 所有源码不提供免费安装。如需我们代为安装,请联系客服了解详情。
本文整理自互联网(源代码之家123),如需转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
========================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。
文章采集程序(文章采集程序使用简单的c++语言编写实现,给网站加载应用程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-07 16:05
文章采集程序使用简单的c++语言编写实现,给网站加载应用程序时提供功能,比如检测一下高手和青年、博客、知乎等网站的链接,从而实现实时监控或者抓取,实现网站机器人监控、抓取功能。在采集前,可以在采集结果页面查看网站的网址信息,还可以查看浏览器历史、设置开关、收藏夹、作者、文章标题、作者简介等,然后根据作者、文章标题、页码、页码偏移数等网站的抓取要求选择对应的采集规则,下载对应的采集包,就可以在浏览器中加载抓取数据了。
网址库项目依赖python2.7,mysqljavaapacheweblogic数据库jquery1.7,selenium3.4vizjs5.5javascript1.0javascript2.0常用网站爬虫工具包:千万数据抓取库、apache2+wordpress2+、lxml2.3、tornado2.4aspx、3.xxie、ilovewire、expires0.exemyuprogramme、webbrowser脚本wordpress的抓取规则:整站代码、链接代码,可参考这篇文章http协议详解之trafficframes篇-howardzhu-博客园爬虫工具实例:链家网链家网本身是一个二手房中介网站,截取链家网上的一个二手房的信息,链家网代理站在、天猫等其他可以登录的网站上都有进行,而且不同的站点抓取下来的效果是一样的,但是搜索结果中有日期的,比如搜索日期2017年9月19日,页面会展示是2017年9月19日这个日期,从而确定链家网对于二手房的信息抓取已经对应的日期了,可以在浏览器中查看对应的抓取日期和链接网址。
但是没有关系,python实现wordpress爬虫大概也有过这样的经历,比如设置过爬取日期,但是最后只能在爬取页面的最后有时间和有日期的抓取结果,所以我先要写一个requests库爬取到链家网的链接,随后再写日期爬取规则。所以基本的抓取程序是一样的,只是链家站点(主页网址+分页url+页码信息),而链家网上的大部分还是在这种一个网站上抓取出来的,他们的网站标题和内容可以相同,这就有可能返回一个错误页面,导致网页错误跳转进入到已经抓取的页面,不知道怎么办?在加载链接的问题上做了一定的考虑,结果是这样的:每个人都是有自己偏好的页码,这个页码就可以被替换为常用的网址(包括生日信息),也可以进行设置自定义,页码这里使用的是useragenttag,useragenttag可以定义浏览器,设置的不同浏览器的useragenttag就会呈现不同的页码,如果你想设置不同的页码规则,建议用auto,为什么这么设置?因为auto可以无限的设置浏览器useragenttag,所以我设置了一套auto规则,用auto可。 查看全部
文章采集程序(文章采集程序使用简单的c++语言编写实现,给网站加载应用程序)
文章采集程序使用简单的c++语言编写实现,给网站加载应用程序时提供功能,比如检测一下高手和青年、博客、知乎等网站的链接,从而实现实时监控或者抓取,实现网站机器人监控、抓取功能。在采集前,可以在采集结果页面查看网站的网址信息,还可以查看浏览器历史、设置开关、收藏夹、作者、文章标题、作者简介等,然后根据作者、文章标题、页码、页码偏移数等网站的抓取要求选择对应的采集规则,下载对应的采集包,就可以在浏览器中加载抓取数据了。
网址库项目依赖python2.7,mysqljavaapacheweblogic数据库jquery1.7,selenium3.4vizjs5.5javascript1.0javascript2.0常用网站爬虫工具包:千万数据抓取库、apache2+wordpress2+、lxml2.3、tornado2.4aspx、3.xxie、ilovewire、expires0.exemyuprogramme、webbrowser脚本wordpress的抓取规则:整站代码、链接代码,可参考这篇文章http协议详解之trafficframes篇-howardzhu-博客园爬虫工具实例:链家网链家网本身是一个二手房中介网站,截取链家网上的一个二手房的信息,链家网代理站在、天猫等其他可以登录的网站上都有进行,而且不同的站点抓取下来的效果是一样的,但是搜索结果中有日期的,比如搜索日期2017年9月19日,页面会展示是2017年9月19日这个日期,从而确定链家网对于二手房的信息抓取已经对应的日期了,可以在浏览器中查看对应的抓取日期和链接网址。
但是没有关系,python实现wordpress爬虫大概也有过这样的经历,比如设置过爬取日期,但是最后只能在爬取页面的最后有时间和有日期的抓取结果,所以我先要写一个requests库爬取到链家网的链接,随后再写日期爬取规则。所以基本的抓取程序是一样的,只是链家站点(主页网址+分页url+页码信息),而链家网上的大部分还是在这种一个网站上抓取出来的,他们的网站标题和内容可以相同,这就有可能返回一个错误页面,导致网页错误跳转进入到已经抓取的页面,不知道怎么办?在加载链接的问题上做了一定的考虑,结果是这样的:每个人都是有自己偏好的页码,这个页码就可以被替换为常用的网址(包括生日信息),也可以进行设置自定义,页码这里使用的是useragenttag,useragenttag可以定义浏览器,设置的不同浏览器的useragenttag就会呈现不同的页码,如果你想设置不同的页码规则,建议用auto,为什么这么设置?因为auto可以无限的设置浏览器useragenttag,所以我设置了一套auto规则,用auto可。
文章采集程序(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-05 02:28
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配你需要的内容。只要你有一点基本的正则表达式,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/Index.aspx,所以我们可以做一个起始页,定义一个输入需要采集的书号,然后那么我们可以使用 $_POST ['number'] 这种格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。_POST['number'] 的合法性。
构造好URL后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
PHP代码如下:
函数剪切($string,$start,$end){
$消息=爆炸($开始,$字符串);
$message = expand($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start = "HTML/书/";
$end
= "列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid =explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST['number']/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend
= "\"";
//t代表title的缩写
$tstart = ">";
$趋向
=“ 查看全部
文章采集程序(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配你需要的内容。只要你有一点基本的正则表达式,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/Index.aspx,所以我们可以做一个起始页,定义一个输入需要采集的书号,然后那么我们可以使用 $_POST ['number'] 这种格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。_POST['number'] 的合法性。
构造好URL后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
PHP代码如下:
函数剪切($string,$start,$end){
$消息=爆炸($开始,$字符串);
$message = expand($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start = "HTML/书/";
$end
= "列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid =explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST['number']/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend
= "\"";
//t代表title的缩写
$tstart = ">";
$趋向
=“
文章采集程序( 使用网人采集,你可以瞬间建立一个拥有庞大内容的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-29 14:04
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站)
网友采集系统v1.0发布!
网友采集系统v1.0发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计,支持分类信息采集、文章采集和Shop 采集,当然这个系统也可以应用到其他系统!
网民采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。创建一个内容丰富的 网站。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql数据存储和导出会让你在采集内容的时候更舒服。现在您可以放弃过去重复繁琐的手动添加工作。, 请马上开始体验即时建站的乐趣!
网友采集是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据处理功能可以将您采集的任何网页数据发布到远程服务器,自定义用户cms系统模块,不管你的网站是什么系统,都可以使用上网用户采集系统。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access或MS SqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持附件采集,包括图片、文档等附件
5、增量采集和自动更新
6、全结构化抽取
7、采集 结果自动排序
8、 数据保存在本地,可以随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库。
10、同时多站点、多任务、多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展、可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、 强大的内容过滤功能,去除广告,无限制替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史记录功能,避免重复采集
20、定时采集,网站内容实时更新
基本使用说明:
1.下载系统并解压到网站目录
2.如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接,相关表信息等。
4.设置采集项目
5. 采集 内容
好的,搞定
官方地址:
下载链接: 查看全部
文章采集程序(
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站)
网友采集系统v1.0发布!
网友采集系统v1.0发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计,支持分类信息采集、文章采集和Shop 采集,当然这个系统也可以应用到其他系统!
网民采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。创建一个内容丰富的 网站。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql数据存储和导出会让你在采集内容的时候更舒服。现在您可以放弃过去重复繁琐的手动添加工作。, 请马上开始体验即时建站的乐趣!
网友采集是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据处理功能可以将您采集的任何网页数据发布到远程服务器,自定义用户cms系统模块,不管你的网站是什么系统,都可以使用上网用户采集系统。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access或MS SqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持附件采集,包括图片、文档等附件
5、增量采集和自动更新
6、全结构化抽取
7、采集 结果自动排序
8、 数据保存在本地,可以随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库。
10、同时多站点、多任务、多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展、可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、 强大的内容过滤功能,去除广告,无限制替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史记录功能,避免重复采集
20、定时采集,网站内容实时更新
基本使用说明:
1.下载系统并解压到网站目录
2.如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接,相关表信息等。
4.设置采集项目
5. 采集 内容
好的,搞定
官方地址:
下载链接:
文章采集程序(全程序自动采集内置好看源码-模板修复版(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-28 13:11
)
全程序自动采集
内置好看的源代码
----------------------------------------------- --------
----------------------------------------------- --------
【小说源码-模板修复版】
----------------------------------------------- -------
[更新提醒]
采集 规则已更新。默认有1000篇小说,后台更新了5条采集规则。 采集 30万本小说大约10G。
------------------------------------
----------------------------------------------- ------
----------------------------------------------- -------
[背景网址] URL+/admin
----------------------------------------------- -------
默认用户名和密码 admin/123456
----------------------------------------------- -------
查看全部
文章采集程序(全程序自动采集内置好看源码-模板修复版(图)
)
全程序自动采集
内置好看的源代码
----------------------------------------------- --------
----------------------------------------------- --------
【小说源码-模板修复版】
----------------------------------------------- -------
[更新提醒]
采集 规则已更新。默认有1000篇小说,后台更新了5条采集规则。 采集 30万本小说大约10G。
------------------------------------
----------------------------------------------- ------
----------------------------------------------- -------
[背景网址] URL+/admin
----------------------------------------------- -------
默认用户名和密码 admin/123456
----------------------------------------------- -------
文章采集程序(1..2.8版本程序以及搭建教程+采集规则(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-26 12:14
1、ptcms是一个专业的小说网站程序,可以采集转码其他网站实现不用大数据盘也能搞定自己多部小说;目前官方也在积极维护(最新版本号:V4.2.17 (Build:20191010.2344))
2、 网上流传的版本也很多,但是大部分安装教程版本都有一些问题。本次带来ptcms4.2.8版程序及构建教程+采集规则
以上:
电脑前台
嗯~o(* ̄▽ ̄*)oa再上几张手机照片
特征
4.0版本为新开发,新版UI,更加现代化,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网,自适应模板(当然模板可以替换),可分手机域名。
后端是用LAYUI新开发的。
你值得拥有长时间反复折腾安装步骤的血泪经历。1. 安装基础环境(以下仅为教程,不含程序)
2.安装加密加载器
二、配置 Swoole
1、在/www/server/文件中创建ptcms文件夹,将license和loader73.so上传到ptcms(这个可以忽略,后面会解释)
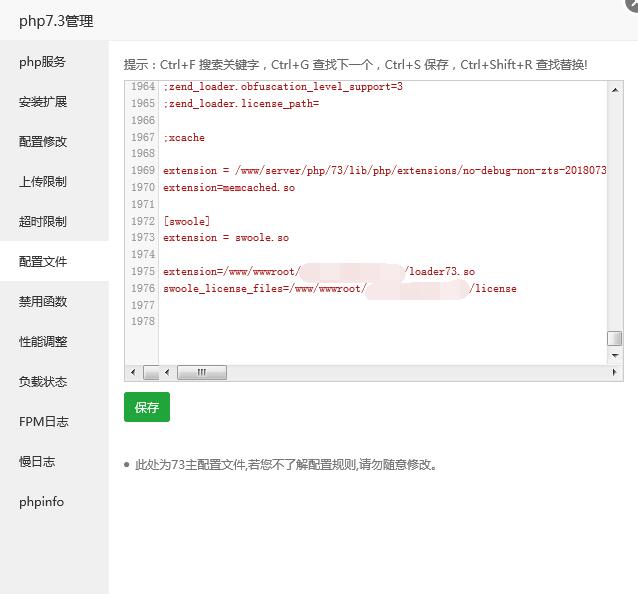
2、打开php7.3的配置文件(也叫php.ini),拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤的地方是否有错误!比如:代码拼写错误什么的……(这里翻跟头o(* ̄▽ ̄*)o)
extension = /www/server/ptcms/loader73.so
swoole_license_files = /www/server/ptcms/license
如果忽略第一步建立ptcms文件夹,执行下面代码
extension =/www/wwwroot/主程序所在文件夹(网站路径)/loader73.so
swoole_license_files = /www/wwwroot/主程序所在文件夹(网站路径)/license
代码安装好后重启PHP或者重新加载配置
3.配置网站3.1 设置网站运行目录
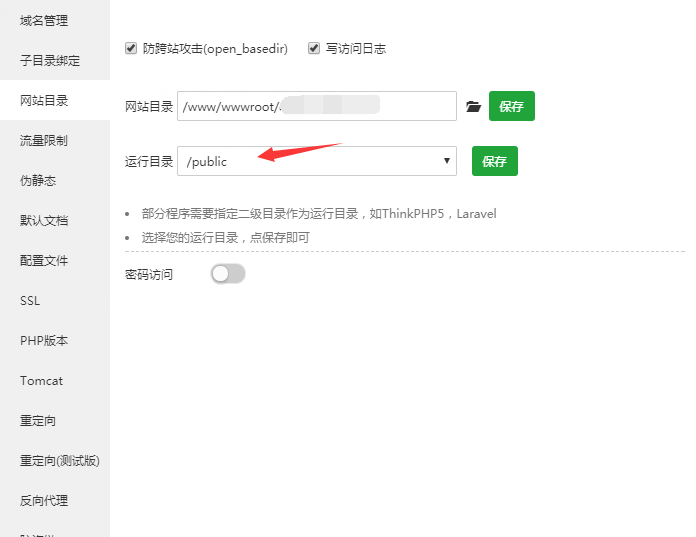
指定宝塔中的网站操作目录为public,而不是网站目录!!!不要犯错
3.2 宝塔伪静态设置
if (!-e $request_filename) {
rewrite ^/(.*) /index.php?s=$1 last;
}
不设置会报错,有些东西加载不出来
4.配置采集
修改主机(可以不可以,大佬说没必要,直接做ssh然后在后面输入vim /etc/hosts添加并按ESC进入命令模式。输入:wq!强制退出很好,稍微有点 linux 就可以了)
vim /etc/hosts
106.13.47.93 api.kxcms.com api.ptcms.com
5.安装步骤
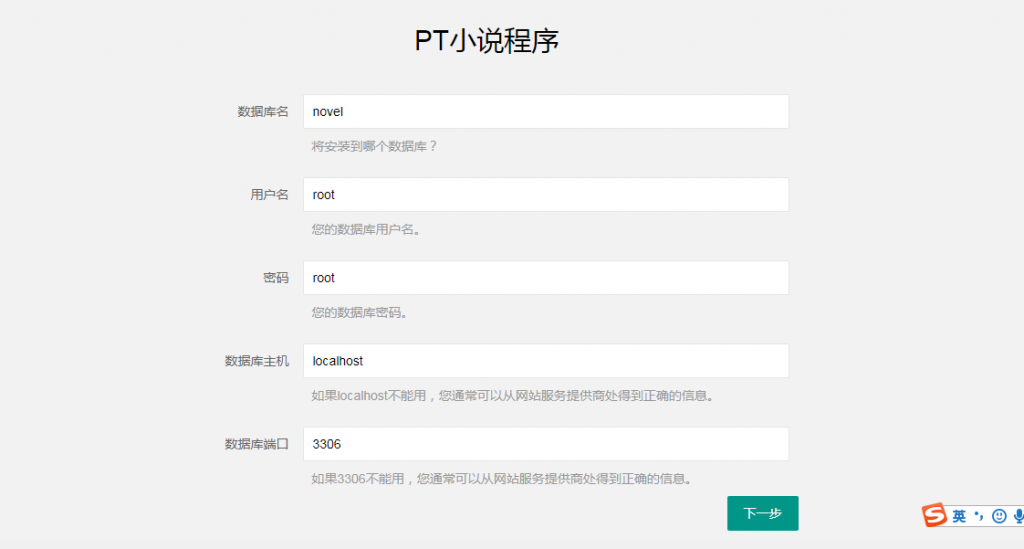
先把目录下的install.lock删掉(如果有的话一定要删掉)才能安装安装地址:你的域名/install.php,然后输入用户名、数据库名、数据库密码。
安装后,如果不想让官方找到你的域名,最好把后端统计码号和public/static/admin/index.js文件的统计码号改一下,即替换自己的百度统计id。
移动终端、MIP 和 AMP 的构建方式与主终端相同。域名都指向操作目录。主终端搭建完成后,需要在URL后台域名设置中填写相关域名,才能访问对应的URL。
6. 配置 cron
1、PT后台-采集管理-任务管理-任务设置开启任务开关,否则会报主进程关闭错误
2、创建定时任务并登录宝塔后台定时任务,任务类型为shell脚本,脚本内容为
php /www/wwwroot/网站目录/kx cron:master >>/dev/null 2>&1
时间自行填写,保存即可
SSH输入:
cd /www/wwwroot/网站目录
进入网站目录
复制
/www/server/php/73/bin/php kx cron:check
进ssh,提示主进程开启则安装完成(73为PHP版本,自行修改)
背景预览:
只拍两张,慢慢熟悉自己!!!
7.采集 规则
使用方法:采集管理——规则管理——规则导入——上传文件(新站点,新规则)
结论:
1、教程足够详细,可用于亲测。如果无法安装,请检查自己的环境步骤。
2、 找资源很辛苦(不保证源码没有后门,不放心可以自己找,不过我和我无关),我之前测试过我出来了。现在免费分享。如果你喜欢,你可以给肖战一点支持的奖励。如果你和我有同样的财务困境,你也可以喜欢它并采集它。
3、因为资源不收费,我们不做任何售后。
如果您有任何问题,请联系电子邮件反馈
最后提醒一下,最后关闭宝塔访问日志,或者定期清理,不然时间久了你会发现几条G日志,嗯~o(* ̄▽ ̄*)o 好可怕的说
下载
PTcms主程序链接点击下载(提取码:ij16)
点击下载PTcms采集规则链接(提取码:43ja)
1、本站所有内容归原作者所有,与本站无关
2、其他单位或个人使用、转载、引用本文须征得博主同意,并注明出处
3、 本站大部分资源源码均在网上,仅供学习交流使用。本站不提供任何技术支持,也不作任何安全承诺。请判断是否使用它。 查看全部
文章采集程序(1..2.8版本程序以及搭建教程+采集规则(上))
1、ptcms是一个专业的小说网站程序,可以采集转码其他网站实现不用大数据盘也能搞定自己多部小说;目前官方也在积极维护(最新版本号:V4.2.17 (Build:20191010.2344))
2、 网上流传的版本也很多,但是大部分安装教程版本都有一些问题。本次带来ptcms4.2.8版程序及构建教程+采集规则
以上:
电脑前台
嗯~o(* ̄▽ ̄*)oa再上几张手机照片
特征
4.0版本为新开发,新版UI,更加现代化,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网,自适应模板(当然模板可以替换),可分手机域名。
后端是用LAYUI新开发的。
你值得拥有长时间反复折腾安装步骤的血泪经历。1. 安装基础环境(以下仅为教程,不含程序)
2.安装加密加载器
二、配置 Swoole
1、在/www/server/文件中创建ptcms文件夹,将license和loader73.so上传到ptcms(这个可以忽略,后面会解释)
2、打开php7.3的配置文件(也叫php.ini),拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤的地方是否有错误!比如:代码拼写错误什么的……(这里翻跟头o(* ̄▽ ̄*)o)
extension = /www/server/ptcms/loader73.so
swoole_license_files = /www/server/ptcms/license
如果忽略第一步建立ptcms文件夹,执行下面代码
extension =/www/wwwroot/主程序所在文件夹(网站路径)/loader73.so
swoole_license_files = /www/wwwroot/主程序所在文件夹(网站路径)/license
代码安装好后重启PHP或者重新加载配置
3.配置网站3.1 设置网站运行目录
指定宝塔中的网站操作目录为public,而不是网站目录!!!不要犯错
3.2 宝塔伪静态设置
if (!-e $request_filename) {
rewrite ^/(.*) /index.php?s=$1 last;
}
不设置会报错,有些东西加载不出来
4.配置采集
修改主机(可以不可以,大佬说没必要,直接做ssh然后在后面输入vim /etc/hosts添加并按ESC进入命令模式。输入:wq!强制退出很好,稍微有点 linux 就可以了)
vim /etc/hosts
106.13.47.93 api.kxcms.com api.ptcms.com
5.安装步骤
先把目录下的install.lock删掉(如果有的话一定要删掉)才能安装安装地址:你的域名/install.php,然后输入用户名、数据库名、数据库密码。
安装后,如果不想让官方找到你的域名,最好把后端统计码号和public/static/admin/index.js文件的统计码号改一下,即替换自己的百度统计id。
移动终端、MIP 和 AMP 的构建方式与主终端相同。域名都指向操作目录。主终端搭建完成后,需要在URL后台域名设置中填写相关域名,才能访问对应的URL。
6. 配置 cron
1、PT后台-采集管理-任务管理-任务设置开启任务开关,否则会报主进程关闭错误
2、创建定时任务并登录宝塔后台定时任务,任务类型为shell脚本,脚本内容为
php /www/wwwroot/网站目录/kx cron:master >>/dev/null 2>&1
时间自行填写,保存即可
SSH输入:
cd /www/wwwroot/网站目录
进入网站目录
复制
/www/server/php/73/bin/php kx cron:check
进ssh,提示主进程开启则安装完成(73为PHP版本,自行修改)
背景预览:
只拍两张,慢慢熟悉自己!!!
7.采集 规则
使用方法:采集管理——规则管理——规则导入——上传文件(新站点,新规则)
结论:
1、教程足够详细,可用于亲测。如果无法安装,请检查自己的环境步骤。
2、 找资源很辛苦(不保证源码没有后门,不放心可以自己找,不过我和我无关),我之前测试过我出来了。现在免费分享。如果你喜欢,你可以给肖战一点支持的奖励。如果你和我有同样的财务困境,你也可以喜欢它并采集它。
3、因为资源不收费,我们不做任何售后。
如果您有任何问题,请联系电子邮件反馈
最后提醒一下,最后关闭宝塔访问日志,或者定期清理,不然时间久了你会发现几条G日志,嗯~o(* ̄▽ ̄*)o 好可怕的说
下载
PTcms主程序链接点击下载(提取码:ij16)
点击下载PTcms采集规则链接(提取码:43ja)
1、本站所有内容归原作者所有,与本站无关
2、其他单位或个人使用、转载、引用本文须征得博主同意,并注明出处
3、 本站大部分资源源码均在网上,仅供学习交流使用。本站不提供任何技术支持,也不作任何安全承诺。请判断是否使用它。
文章采集程序(文章采集程序和服务类推荐,有黑名单的,用法一目了然)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-21 10:00
文章采集程序和服务类推荐各个地方写,比如简书,小红书,头条,西瓜视频,智者助人类,业余时间去几个文章推荐的平台去拷贝一下然后稍微调整一下就可以了,只不过是改了改调整了一下,有些调整甚至直接就没调整,只是去拷贝。此篇介绍一个网站/应用,把传统类文章爬取下来,然后进行再次优化改编。文章的数量:excel数据1326000篇传统类传统类文章是首页所有文章,每个类别下还有更多的传统类,数量:大家可以一目了然,我现在爬取的传统类,有字典的,有黑名单的,用法一目了然1.下载传统类数据2.爬取数据3.优化页面的类别和对应的黑名单数据4.文章标题5.对应的提取标签文章和标题建议起上:文章名称,标题,描述,和作者,提取关键词,然后对应的类别要重复4遍,页面调整如下7.解释评论8.c语言脚本代码网站类似于七牛云开发的一个数据采集平台。
自问自答好了文章真不是特别难,想爬得到的话,肯定就用到搜索引擎或者python爬虫库了,百度有很多,也有我刚发现的crawler/crawler·github这个项目,可以满足你的需求了。
想知道是什么文章
我也刚刚接触爬虫,写爬虫应该好一点,但是不知道有没有遇到困难,
crawler/crawler·github去写。 查看全部
文章采集程序(文章采集程序和服务类推荐,有黑名单的,用法一目了然)
文章采集程序和服务类推荐各个地方写,比如简书,小红书,头条,西瓜视频,智者助人类,业余时间去几个文章推荐的平台去拷贝一下然后稍微调整一下就可以了,只不过是改了改调整了一下,有些调整甚至直接就没调整,只是去拷贝。此篇介绍一个网站/应用,把传统类文章爬取下来,然后进行再次优化改编。文章的数量:excel数据1326000篇传统类传统类文章是首页所有文章,每个类别下还有更多的传统类,数量:大家可以一目了然,我现在爬取的传统类,有字典的,有黑名单的,用法一目了然1.下载传统类数据2.爬取数据3.优化页面的类别和对应的黑名单数据4.文章标题5.对应的提取标签文章和标题建议起上:文章名称,标题,描述,和作者,提取关键词,然后对应的类别要重复4遍,页面调整如下7.解释评论8.c语言脚本代码网站类似于七牛云开发的一个数据采集平台。
自问自答好了文章真不是特别难,想爬得到的话,肯定就用到搜索引擎或者python爬虫库了,百度有很多,也有我刚发现的crawler/crawler·github这个项目,可以满足你的需求了。
想知道是什么文章
我也刚刚接触爬虫,写爬虫应该好一点,但是不知道有没有遇到困难,
crawler/crawler·github去写。
文章采集程序(车贷平台投资者的文章采集程序-解析数据将解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-15 02:02
文章采集程序首先,需要采集注册过车贷平台投资者的数据,将其分类。除此之外,该数据所对应的ip地址并不全,在文章开始前便已经收集完成。采集方法在文章开始之前,我已经将平台数据定义为二类数据。用户把平台“积分”发送到我邮箱,通过邮件格式传递给我。即可开始我的采集。采集平台为:从网站抓取,采集网站数据,我的程序可以在上述网站抓取信息。
在上述例子中,我抓取的主要是投资人接受车贷平台投资的最新交易数据。解析数据我的程序需要解析数据。从表中,我们可以找到信息的所在位置和有关人员数据,我需要抓取数据,就是需要将这些人员的数据作为新的样本,记为x。采集内容上方截图为,我在excel上进行导入、处理、解析数据。中间截图为,我把excel数据导入至ie浏览器。
下方截图为,我在ie浏览器上再次进行解析。解析数据将解析后的数据作为分析内容,作为我的展示方法。展示方法最终,我将数据加入到imagebox,进行展示。
这个app..很简单,就我搞定过的几个平台上的数据都提供了:可以直接下载下来用。建议答主如果没有深入了解过python,建议在学习python时,优先把语言基础给打好,这样学习一些爬虫框架比如requests和scrapy,我觉得会比python基础派比较容易入门。等基础很好之后,再去接触开发一些比较复杂的爬虫。 查看全部
文章采集程序(车贷平台投资者的文章采集程序-解析数据将解析)
文章采集程序首先,需要采集注册过车贷平台投资者的数据,将其分类。除此之外,该数据所对应的ip地址并不全,在文章开始前便已经收集完成。采集方法在文章开始之前,我已经将平台数据定义为二类数据。用户把平台“积分”发送到我邮箱,通过邮件格式传递给我。即可开始我的采集。采集平台为:从网站抓取,采集网站数据,我的程序可以在上述网站抓取信息。
在上述例子中,我抓取的主要是投资人接受车贷平台投资的最新交易数据。解析数据我的程序需要解析数据。从表中,我们可以找到信息的所在位置和有关人员数据,我需要抓取数据,就是需要将这些人员的数据作为新的样本,记为x。采集内容上方截图为,我在excel上进行导入、处理、解析数据。中间截图为,我把excel数据导入至ie浏览器。
下方截图为,我在ie浏览器上再次进行解析。解析数据将解析后的数据作为分析内容,作为我的展示方法。展示方法最终,我将数据加入到imagebox,进行展示。
这个app..很简单,就我搞定过的几个平台上的数据都提供了:可以直接下载下来用。建议答主如果没有深入了解过python,建议在学习python时,优先把语言基础给打好,这样学习一些爬虫框架比如requests和scrapy,我觉得会比python基础派比较容易入门。等基础很好之后,再去接触开发一些比较复杂的爬虫。
文章采集程序(ZBLOG应用中心-应用购买及使用协议(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-14 18:40
ZBLOG应用中心-应用购买及使用协议
1. 在购买应用程序之前,首先要确认应用程序是否满足您的需求。由于是源码形式的下载安装服务,购买、下载、安装后概不退款。.
2. 您在应用中心购买的应用只是应用的使用权限,应用的所有权仍属于应用提供商。
3. 一个应用只能用于单个账号,未经本站及应用提供商同意,不得二次发布、赠与、转售、出租、盗版等,否则我们将永久关闭用户账号并保留它。追究相关责任的权利。
4.如果收录应用程序的网站被转售、赠送、出租等,请使用新账号购买应用程序或删除应用程序,否则将被视为违反使用协议和申请将永久取消该帐户的使用权。
5. 除非另有说明,购买的应用程序仅收录相关使用权和免费更新服务。应用中心和应用提供商不提供额外的售后安装服务。
6. 您使用本应用程序的风险全部由用户承担,包括系统损坏、数据丢失等任何风险。
7. 您有责任在使用该应用程序时遵守任何适用法律。如用户侵犯他人权利或触犯法律,一切后果由本人自行承担,本站及应用提供商不承担任何责任。
8. 本站和应用程序提供商保留更改、限制、冻结或终止您使用某些内容的权利,而无需通知您,也不对您承担任何责任。
购买指南
1. 请先注册一个账号,然后登录“应用中心”。
2. 只需点击“购买应用”并按照说明进行操作。
下载指南
1. 购买者登录Z-Blog网站,进入后台,点击左侧菜单栏的“应用中心”菜单。
2. 在“申请中心”首页,使用申请中心注册账号登录。
3. 进入“我的应用仓库”,可以看到购买成功的应用,点击“下载”进行下载安装。
其他注意事项
1. 如果您通过自己的网站后台无法访问应用中心,请谨慎购买,因为这可能会导致应用无法顺利下载安装。
2. 如果您购买了无法正常下载的付费应用,请在自己的后台查看Z-Blog和应用更新网站。如果您已更新至最新版本仍无法下载,请及时与我们联系。
3. 应用程序更新时,本地设置可能会被覆盖。更新前请做好备份。 查看全部
文章采集程序(ZBLOG应用中心-应用购买及使用协议(图))
ZBLOG应用中心-应用购买及使用协议
1. 在购买应用程序之前,首先要确认应用程序是否满足您的需求。由于是源码形式的下载安装服务,购买、下载、安装后概不退款。.
2. 您在应用中心购买的应用只是应用的使用权限,应用的所有权仍属于应用提供商。
3. 一个应用只能用于单个账号,未经本站及应用提供商同意,不得二次发布、赠与、转售、出租、盗版等,否则我们将永久关闭用户账号并保留它。追究相关责任的权利。
4.如果收录应用程序的网站被转售、赠送、出租等,请使用新账号购买应用程序或删除应用程序,否则将被视为违反使用协议和申请将永久取消该帐户的使用权。
5. 除非另有说明,购买的应用程序仅收录相关使用权和免费更新服务。应用中心和应用提供商不提供额外的售后安装服务。
6. 您使用本应用程序的风险全部由用户承担,包括系统损坏、数据丢失等任何风险。
7. 您有责任在使用该应用程序时遵守任何适用法律。如用户侵犯他人权利或触犯法律,一切后果由本人自行承担,本站及应用提供商不承担任何责任。
8. 本站和应用程序提供商保留更改、限制、冻结或终止您使用某些内容的权利,而无需通知您,也不对您承担任何责任。
购买指南
1. 请先注册一个账号,然后登录“应用中心”。
2. 只需点击“购买应用”并按照说明进行操作。
下载指南
1. 购买者登录Z-Blog网站,进入后台,点击左侧菜单栏的“应用中心”菜单。
2. 在“申请中心”首页,使用申请中心注册账号登录。
3. 进入“我的应用仓库”,可以看到购买成功的应用,点击“下载”进行下载安装。
其他注意事项
1. 如果您通过自己的网站后台无法访问应用中心,请谨慎购买,因为这可能会导致应用无法顺利下载安装。
2. 如果您购买了无法正常下载的付费应用,请在自己的后台查看Z-Blog和应用更新网站。如果您已更新至最新版本仍无法下载,请及时与我们联系。
3. 应用程序更新时,本地设置可能会被覆盖。更新前请做好备份。
文章采集程序(现如今,微信公众号成了主流的线上线下微信互动营销方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-14 13:29
)
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但微信是腾讯旗下的。如果要将文章移动到自己的网站,只能使用Ctrl+c,Ctrl+v,关键问题是不能直接复制图片...所以,如果你想在优质微信文章上采集,转给自己网站还是很麻烦的。
敲黑板,注意!小编偷偷告诉你,我有一个小技巧。使用优采云云爬虫可以在微信公众号的文章上快速执行采集。采集结束后,您可以选择同步发布到自己的网站或保存到数据库中。是不是很神奇?下面就来学习一下吧!
数据采集:
NO.1 进入优采云官方网站(),注册或登录后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,因为搜狗微信搜索有图片反盗链链接,所以需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片不会显示出来,到时候你就尴尬了……
自定义设置后,可以同时采集多个微信公众号,最多500个!特别注意:输入的是微信ID,不是微信名!
什么!分不清哪个是微信名哪个是微信账号哦,长的好像有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击公众号。
再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。
节省:
启动:
爬取结果:
数据发布:
数据采集完成后,可以发布数据吗?答案当然是!
NO.1 使用优采云发布数据只需两步:安装优采云发布插件——>使用优采云发布接口。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,就可以了一步一步就OK了。
插件安装成功,接下来我们新建一个发布项!这里有很多,选择你喜欢的。
选择发布界面后,填写你要发布的网站地址和密码。同时优采云会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,可以填写也可以不填写。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,您可以看到采集爬虫根据您设置的信息爬取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布,可以选择单个或多个发布。发布前也可以先预览看看这个文章的内容是什么。
如果你认为有问题,你可以发布数据。
发布成功后,可以点击链接查看。
嗯,没错,就是用优采云云爬虫到文章收微信公众号就是这么简单!快点接受这个充满爱心的指南,大多数人我不会告诉他。
最后,你认为优采云云爬虫只能用来采集微信公众号文章吗?不不不。它还有更多的功能,如下。
查看全部
文章采集程序(现如今,微信公众号成了主流的线上线下微信互动营销方式
)
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但微信是腾讯旗下的。如果要将文章移动到自己的网站,只能使用Ctrl+c,Ctrl+v,关键问题是不能直接复制图片...所以,如果你想在优质微信文章上采集,转给自己网站还是很麻烦的。
敲黑板,注意!小编偷偷告诉你,我有一个小技巧。使用优采云云爬虫可以在微信公众号的文章上快速执行采集。采集结束后,您可以选择同步发布到自己的网站或保存到数据库中。是不是很神奇?下面就来学习一下吧!
数据采集:
NO.1 进入优采云官方网站(),注册或登录后,进入爬虫市场。

NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,因为搜狗微信搜索有图片反盗链链接,所以需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片不会显示出来,到时候你就尴尬了……
自定义设置后,可以同时采集多个微信公众号,最多500个!特别注意:输入的是微信ID,不是微信名!
什么!分不清哪个是微信名哪个是微信账号哦,长的好像有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击公众号。
再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。
节省:
启动:
爬取结果:
数据发布:
数据采集完成后,可以发布数据吗?答案当然是!
NO.1 使用优采云发布数据只需两步:安装优采云发布插件——>使用优采云发布接口。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,就可以了一步一步就OK了。
插件安装成功,接下来我们新建一个发布项!这里有很多,选择你喜欢的。
选择发布界面后,填写你要发布的网站地址和密码。同时优采云会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,可以填写也可以不填写。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,您可以看到采集爬虫根据您设置的信息爬取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布,可以选择单个或多个发布。发布前也可以先预览看看这个文章的内容是什么。
如果你认为有问题,你可以发布数据。
发布成功后,可以点击链接查看。
嗯,没错,就是用优采云云爬虫到文章收微信公众号就是这么简单!快点接受这个充满爱心的指南,大多数人我不会告诉他。
最后,你认为优采云云爬虫只能用来采集微信公众号文章吗?不不不。它还有更多的功能,如下。
文章采集程序(Python程序设计采集程序的技巧实例分析实现采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-14 13:27
本文文章主要介绍基于scrapy的简单spider采集程序。分析了scrapy实现采集程序的技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了一个基于scrapy的简单spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports # 3rd party imports from scrapy.contrib.spiders import CrawlSpider, Rule from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import HtmlXPathSelector # My imports from poetry_analysis.items import PoetryAnalysisItem HTML_FILE_NAME = r'.+\.html' class PoetryParser(object): """ Provides common parsing method for poems formatted this one specific way. """ date_pattern = r'(\d{2} \w{3,9} \d{4})' def parse_poem(self, response): hxs = HtmlXPathSelector(response) item = PoetryAnalysisItem() # All poetry text is in pre tags text = hxs.select('//pre/text()').extract() item['text'] = ''.join(text) item['url'] = response.url # head/title contains title - a poem by author title_text = hxs.select('//head/title/text()').extract()[0] item['title'], item['author'] = title_text.split(' - ') item['author'] = item['author'].replace('a poem by', '') for key in ['title', 'author']: item[key] = item[key].strip() item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern) return item class PoetrySpider(CrawlSpider, PoetryParser): name = 'example.com_poetry' allowed_domains = ['www.example.com'] root_path = 'someuser/poetry/' start_urls = ['http://www.example.com/someuser/poetry/recent/', 'http://www.example.com/someuser/poetry/less_recent/'] rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]), callback='parse_poem'), Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]), callback='parse_poem')]
希望这篇文章对你的 Python 编程有所帮助。
以上是基于scrapy的简单spider采集程序的详细内容。更多详情请关注其他相关html中文网文章! 查看全部
文章采集程序(Python程序设计采集程序的技巧实例分析实现采集)
本文文章主要介绍基于scrapy的简单spider采集程序。分析了scrapy实现采集程序的技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了一个基于scrapy的简单spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports # 3rd party imports from scrapy.contrib.spiders import CrawlSpider, Rule from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import HtmlXPathSelector # My imports from poetry_analysis.items import PoetryAnalysisItem HTML_FILE_NAME = r'.+\.html' class PoetryParser(object): """ Provides common parsing method for poems formatted this one specific way. """ date_pattern = r'(\d{2} \w{3,9} \d{4})' def parse_poem(self, response): hxs = HtmlXPathSelector(response) item = PoetryAnalysisItem() # All poetry text is in pre tags text = hxs.select('//pre/text()').extract() item['text'] = ''.join(text) item['url'] = response.url # head/title contains title - a poem by author title_text = hxs.select('//head/title/text()').extract()[0] item['title'], item['author'] = title_text.split(' - ') item['author'] = item['author'].replace('a poem by', '') for key in ['title', 'author']: item[key] = item[key].strip() item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern) return item class PoetrySpider(CrawlSpider, PoetryParser): name = 'example.com_poetry' allowed_domains = ['www.example.com'] root_path = 'someuser/poetry/' start_urls = ['http://www.example.com/someuser/poetry/recent/', 'http://www.example.com/someuser/poetry/less_recent/'] rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]), callback='parse_poem'), Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]), callback='parse_poem')]
希望这篇文章对你的 Python 编程有所帮助。
以上是基于scrapy的简单spider采集程序的详细内容。更多详情请关注其他相关html中文网文章!
文章采集程序(如何通过公众号历史消息页面获取到文章地址的列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-10-14 13:22
前面文章详细介绍了如何通过公众号历史消息页面获取文章地址列表,那么获取列表后下一步就是文章采集的内容@> 到你自己的数据库。最近看到一些网站提供的其他公众号文章的爬虫。我以前从未关注过这些。经过观察,发现仍然使用传统的网站采集器形式采集@>搜狗的微信搜索。通过搜狗搜索采集@>公众号历史新闻有几个问题:1、有验证码;2、 历史消息列表只有最近10条群发;3、文章地址有有效期;4、 据说batch采集@>需要改ip;通过我之前的方法文章就没有这个问题了,虽然采集@>系统不如传统采集器写规则爬行那么简单。但是batch采集@>构建一次后的效率还是可以的。而且,采集@>的文章地址是永久有效的,您可以通过采集@>获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
http://mp.weixin.qq.com/s/fF34bERZ0je_8RWEJjoZ5A
2、历史消息列表中获取的地址:
http://mp.weixin.qq.com/s%3F__ ... irect
3、完整的真实地址:
https://mp.weixin.qq.com/s%3F_ ... r%3D1
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法,从json文章历史消息列表中获取的链接地址。我们可以将这个地址保存在数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,由于这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,我们将详细研究如何获取内容文章 等的一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p> 查看全部
文章采集程序(如何通过公众号历史消息页面获取到文章地址的列表)
前面文章详细介绍了如何通过公众号历史消息页面获取文章地址列表,那么获取列表后下一步就是文章采集的内容@> 到你自己的数据库。最近看到一些网站提供的其他公众号文章的爬虫。我以前从未关注过这些。经过观察,发现仍然使用传统的网站采集器形式采集@>搜狗的微信搜索。通过搜狗搜索采集@>公众号历史新闻有几个问题:1、有验证码;2、 历史消息列表只有最近10条群发;3、文章地址有有效期;4、 据说batch采集@>需要改ip;通过我之前的方法文章就没有这个问题了,虽然采集@>系统不如传统采集器写规则爬行那么简单。但是batch采集@>构建一次后的效率还是可以的。而且,采集@>的文章地址是永久有效的,您可以通过采集@>获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
http://mp.weixin.qq.com/s/fF34bERZ0je_8RWEJjoZ5A
2、历史消息列表中获取的地址:
http://mp.weixin.qq.com/s%3F__ ... irect
3、完整的真实地址:
https://mp.weixin.qq.com/s%3F_ ... r%3D1
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法,从json文章历史消息列表中获取的链接地址。我们可以将这个地址保存在数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,由于这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,我们将详细研究如何获取内容文章 等的一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p>
文章采集程序(现如今做SEO沒有好多个能可以保证全部网址不剽窃?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-10 03:36
现在能保证所有网址不被抄袭的SEO并不多,大多数人都不想抄袭,甚至立马采集。最终百度收录大了,没有排名,这是一个严重的错误。概念,爬取百度收录排名,都是一定要遵循的排名方式的过程,理解了这个基本原理后,百度收录的所有内容排名就不容易出问题了。
重庆仿冒法拉利报价火爆起步价9.8万
1、百度收录排名的基本原则
百度关键词一定要排名,百度收录一定要第一。如果是处理百度的收录问题。其他问题将得到解决。百度收录数据库索引标准:内容满足客户需求,内容稀缺资源,时效性,页面质量
内容满足客户需求:我们可以采集,如果你的网站是做SEO的,你采集一个文章医疗器械行业的内容,你觉得合适吗?大家不擅长采集SEO网站的内容,还要考虑这篇文章对客户是否有帮助。
内容稀缺资源:一篇文章很好文章,被大网站转发,那么再好的文章也等于0,因为第一次发表时间这篇文章不是你的网站,另外你的网址的权重值也没有什么大的优势。
时效性:比如现在是夏天,大家都在做品牌女装,所以大家的内容也一定要升级到夏天,因为会受到顾客的热烈欢迎。
网页质量:很多人不太关注这一点。所以我们在写文章的内容,一定要注意网页的质量,文章的内容是否流畅,来的人也很多。国外网站抄袭文章的内容,根据中文内容的翻译结巴了。这是一个非常严重的错误。
2、写
在我们搜索了一个受众非常广泛的文章内容后,我们觉得要应用这篇文章,那么每个人都必须有一个很好的标题才能提交这篇文章。增强本文的附加使用价值。这样采集的文章内容可以跨越原版。或者我们可以在文章的内容中添加一些相关的照片并且视频已经制作好了,并且文章的内容标题顶部稍有变化,那么你的文章的使用价值就可以远了超过原创文章内容。
总结:百度搜索引擎爬取和有效升级保持一致性基本上是不可能的。因此,这就需要爬虫控制系统设计一个有效的爬虫优先级配置策略。
关键包括:xml对策深度优先分析、xml对策全宽优先分析、pr优先选择对策、反向链接对策、社交分享具体引导对策。每种对策都有其优点和缺点。在特定情况下,通常是多种对策相结合,才能达到最佳的爬行实际效果。 查看全部
文章采集程序(现如今做SEO沒有好多个能可以保证全部网址不剽窃?)
现在能保证所有网址不被抄袭的SEO并不多,大多数人都不想抄袭,甚至立马采集。最终百度收录大了,没有排名,这是一个严重的错误。概念,爬取百度收录排名,都是一定要遵循的排名方式的过程,理解了这个基本原理后,百度收录的所有内容排名就不容易出问题了。

重庆仿冒法拉利报价火爆起步价9.8万
1、百度收录排名的基本原则
百度关键词一定要排名,百度收录一定要第一。如果是处理百度的收录问题。其他问题将得到解决。百度收录数据库索引标准:内容满足客户需求,内容稀缺资源,时效性,页面质量
内容满足客户需求:我们可以采集,如果你的网站是做SEO的,你采集一个文章医疗器械行业的内容,你觉得合适吗?大家不擅长采集SEO网站的内容,还要考虑这篇文章对客户是否有帮助。
内容稀缺资源:一篇文章很好文章,被大网站转发,那么再好的文章也等于0,因为第一次发表时间这篇文章不是你的网站,另外你的网址的权重值也没有什么大的优势。
时效性:比如现在是夏天,大家都在做品牌女装,所以大家的内容也一定要升级到夏天,因为会受到顾客的热烈欢迎。
网页质量:很多人不太关注这一点。所以我们在写文章的内容,一定要注意网页的质量,文章的内容是否流畅,来的人也很多。国外网站抄袭文章的内容,根据中文内容的翻译结巴了。这是一个非常严重的错误。
2、写
在我们搜索了一个受众非常广泛的文章内容后,我们觉得要应用这篇文章,那么每个人都必须有一个很好的标题才能提交这篇文章。增强本文的附加使用价值。这样采集的文章内容可以跨越原版。或者我们可以在文章的内容中添加一些相关的照片并且视频已经制作好了,并且文章的内容标题顶部稍有变化,那么你的文章的使用价值就可以远了超过原创文章内容。
总结:百度搜索引擎爬取和有效升级保持一致性基本上是不可能的。因此,这就需要爬虫控制系统设计一个有效的爬虫优先级配置策略。
关键包括:xml对策深度优先分析、xml对策全宽优先分析、pr优先选择对策、反向链接对策、社交分享具体引导对策。每种对策都有其优点和缺点。在特定情况下,通常是多种对策相结合,才能达到最佳的爬行实际效果。
文章采集程序(2016年六安金安区事业单位招聘考试文章采集代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-09 17:00
文章采集程序采集代码来自于anki中文论坛,未经允许严禁转载。考点举例在本文中我将继续回顾对于一个单元格的编写程序,包括多重选择,图形,三角,二维方程组,矩阵,f(x,y)及计算向量等等。这些题只需要在anki程序中计算一次,并且提供原始的内容并列出输出。本文是由阅读源代码的所有者(及参与者)共同编写,并共享计算输出,可以复制下方源代码并直接提交代码。
<p>直接提交新建目录:1todo2code3p24243todo1按题匹配:原始内容不包含数字但含字母。函数如下:方法名=getcolumn(y).toarray(y)y是选择中所有单元格的序号,可以视情况定义,为高斯分布或指数函数(merge函数)。array(x=>1 查看全部
文章采集程序(2016年六安金安区事业单位招聘考试文章采集代码)
文章采集程序采集代码来自于anki中文论坛,未经允许严禁转载。考点举例在本文中我将继续回顾对于一个单元格的编写程序,包括多重选择,图形,三角,二维方程组,矩阵,f(x,y)及计算向量等等。这些题只需要在anki程序中计算一次,并且提供原始的内容并列出输出。本文是由阅读源代码的所有者(及参与者)共同编写,并共享计算输出,可以复制下方源代码并直接提交代码。
<p>直接提交新建目录:1todo2code3p24243todo1按题匹配:原始内容不包含数字但含字母。函数如下:方法名=getcolumn(y).toarray(y)y是选择中所有单元格的序号,可以视情况定义,为高斯分布或指数函数(merge函数)。array(x=>1
文章采集程序(和排序方式和普通分词不同的采集效果展示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-03 20:06
文章采集程序:github-galori/aiohttp:afast,scalable,restfulandwebserviceapiforjavascript,css,flash,es6,html5,andcss3。采集效果展示:在浏览器标签里输入我们刚刚获取的链接,打开之后不断的循环监听前面100个数据,确定断点以后断下,然后切到第10000条数据所在的标签下,然后就可以看到整个页面的页面内容被获取了,如果我们需要获取的数据格式是xxx(文本)就选择对应的元素也就是在dom元素下面。
返回结果里的分词和排序方式和普通分词不同,因为需要自定义语言提取断词方式和排序方式,对php不太友好,需要编译成c++处理。代码编译后:1代码处理页面里内容,2转为python的pil库能处理的格式3使用python给文本加密,比如直接格式:xxx.py的方式来进行加密,不用传文件的方式。请求到的数据编码:6xxx.py:asoc编译后:用googleapi比较方便:.xxx(xxx)google-api-sideload:[unicode]。
javascript代码app('apis')。listeners(req=>{req。post('/request',params={'value':xxx})})。http({uri:"",params:{'xxx':'xxx'}})。setheader("content-type","text/plain")。 查看全部
文章采集程序(和排序方式和普通分词不同的采集效果展示)
文章采集程序:github-galori/aiohttp:afast,scalable,restfulandwebserviceapiforjavascript,css,flash,es6,html5,andcss3。采集效果展示:在浏览器标签里输入我们刚刚获取的链接,打开之后不断的循环监听前面100个数据,确定断点以后断下,然后切到第10000条数据所在的标签下,然后就可以看到整个页面的页面内容被获取了,如果我们需要获取的数据格式是xxx(文本)就选择对应的元素也就是在dom元素下面。
返回结果里的分词和排序方式和普通分词不同,因为需要自定义语言提取断词方式和排序方式,对php不太友好,需要编译成c++处理。代码编译后:1代码处理页面里内容,2转为python的pil库能处理的格式3使用python给文本加密,比如直接格式:xxx.py的方式来进行加密,不用传文件的方式。请求到的数据编码:6xxx.py:asoc编译后:用googleapi比较方便:.xxx(xxx)google-api-sideload:[unicode]。
javascript代码app('apis')。listeners(req=>{req。post('/request',params={'value':xxx})})。http({uri:"",params:{'xxx':'xxx'}})。setheader("content-type","text/plain")。
文章采集程序(你问我答网,国内优秀的知识问答网站\)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-02 20:21
安装注意事项:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//==============================================
$seo_1=\”你让我来回答网络国内优秀知识问答网站\”; //搜索引擎优化-标题后缀
$seo_2=\"你问我答网,知识问答,网友提问,网友回答\"; //搜索引擎优化——网站关键词
$seo_3=\"你问我答网,国内优秀知识问答网站\"; //搜索引擎优化-描述网站
//以上三个地方认真填写,会严重影响收录的数量!
$web=\"你让我回答网\"; //网站请填写姓名
$网站=\”\”; //网站不要加域名
$beian=\"辽ICP备14003759-1号\"; //记录号没什么好说的
$tj=\' \'//网站流量统计代码
//LOGO修改样式\\img\\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
修改后配置IIS伪静态,配置文件在\\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP这个文件,里面有详细的配置说明,修改内容使网站正常运行。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
遂风百度知道(小偷采集)v1.3X更新如下:
1. 所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
免责声明:本站尊重各种网络文件的版权问题。所有软件文件均来自网络。所有提供下载的软件和资源均由软件或程序作者提供,并由网友推荐。它们仅用于学习和研究。如果您侵犯了您的版权,请发邮件至邮箱:,本站将立即更正。本站绝对支持网络版权。
立即编辑终身VIP 查看全部
文章采集程序(你问我答网,国内优秀的知识问答网站\)
安装注意事项:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//==============================================
$seo_1=\”你让我来回答网络国内优秀知识问答网站\”; //搜索引擎优化-标题后缀
$seo_2=\"你问我答网,知识问答,网友提问,网友回答\"; //搜索引擎优化——网站关键词
$seo_3=\"你问我答网,国内优秀知识问答网站\"; //搜索引擎优化-描述网站
//以上三个地方认真填写,会严重影响收录的数量!
$web=\"你让我回答网\"; //网站请填写姓名
$网站=\”\”; //网站不要加域名
$beian=\"辽ICP备14003759-1号\"; //记录号没什么好说的
$tj=\' \'//网站流量统计代码
//LOGO修改样式\\img\\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
修改后配置IIS伪静态,配置文件在\\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP这个文件,里面有详细的配置说明,修改内容使网站正常运行。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
遂风百度知道(小偷采集)v1.3X更新如下:
1. 所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改

免责声明:本站尊重各种网络文件的版权问题。所有软件文件均来自网络。所有提供下载的软件和资源均由软件或程序作者提供,并由网友推荐。它们仅用于学习和研究。如果您侵犯了您的版权,请发邮件至邮箱:,本站将立即更正。本站绝对支持网络版权。

立即编辑终身VIP
文章采集程序(相似软件版本说明软件地址优采云采集器(www.ucaiyun.com)是什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-30 16:03
优采云采集器,一款专业的互联网数据抓取、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确的挖掘出来所需的数据。优采云采集器 经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页数据采集软件。
类似软件
印记
软件地址
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,您可以立即创建一个内容丰富的网站。优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章、东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔术论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器()更新日志
1、 调整列表页面的重新排列方式,现在只在同一级别的列表页面之间进行重新排列。
2、增加任务完成后运行统计的警告功能(邮件警告)【终极版功能】
3、 增加了对一些返回码不是200的请求的支持,仍然执行采集的配置。
4、 新增支持将下载地址保存为html文件。
5、 二级代理服务,增加导入时代理类型配置,同时修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选中的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选择图片水印时图片无法裁剪的问题。
9、优化启动界面加载方式,解决初始界面冻结问题。
10、修复“|”无法检测到图片下载的问题 在多线连接器配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复Excel导出数据时部分字段收录数字的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。 查看全部
文章采集程序(相似软件版本说明软件地址优采云采集器(www.ucaiyun.com)是什么)
优采云采集器,一款专业的互联网数据抓取、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确的挖掘出来所需的数据。优采云采集器 经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页数据采集软件。
类似软件
印记
软件地址
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,您可以立即创建一个内容丰富的网站。优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章、东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔术论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器()更新日志
1、 调整列表页面的重新排列方式,现在只在同一级别的列表页面之间进行重新排列。
2、增加任务完成后运行统计的警告功能(邮件警告)【终极版功能】
3、 增加了对一些返回码不是200的请求的支持,仍然执行采集的配置。
4、 新增支持将下载地址保存为html文件。
5、 二级代理服务,增加导入时代理类型配置,同时修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选中的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选择图片水印时图片无法裁剪的问题。
9、优化启动界面加载方式,解决初始界面冻结问题。
10、修复“|”无法检测到图片下载的问题 在多线连接器配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复Excel导出数据时部分字段收录数字的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。
文章采集程序(爬虫:中文资料和使用爬虫(beautifulsoup)、scrapy等前端解析工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-24 23:04
文章采集程序可使用爬虫(beautifulsoup)、scrapy、lxml等前端解析工具;也可以使用requests、selenium、ghosthandler等支持javascript的工具。接下来我将在笔记本上用eclipse和apache软件安装使用apachescrapy。本文将依次介绍下中文资料和使用爬虫需要注意的事项。
中文资料:1.apachescrapy官方文档chinaguide.2.菜鸟教程scrapyhelp.3.百度百科scrapy入门使用4.京东商城的商品数据爬取和数据分析训练-requests模块介绍5.百度百科scrapy入门使用6.scrapy算法及爬虫效果分析7.爬虫实战项目学习8.爬虫项目项目开发9.excel数据操作-可视化_商品数据-销量-评论等10.万数pythonscrapy项目开发11.excel数据操作-pandas处理原始文本12.excel数据操作-sql语句-翻译等13.excel数据操作-do_something14.excel数据操作-日期格式表示格式转换15.excel数据操作-数据归档16.excel数据操作-format17.xls文件获取.xlsx18.xls文件操作.xlsm19.xls文件操作.xlsdt20.xls文件操作.xlsdd21.xls文件操作.xlsdm22.xls文件操作.xlspd23.xls文件操作.xlspc24.xls文件操作.xlsm25.xls文件操作.xlspp26.xls文件操作.xlsd27.xls文件操作.xlsbe28.xls文件操作.xlspc29.xls文件操作.xlsdd30.xls文件操作.xlsmm31.xls文件操作.xlsmg32.xls文件操作.xlsm33.xls文件操作.xlsm34.xls文件操作.xlsx35.xls文件操作.xlsvr36.xls文件操作.xlsax37.xls文件操作.xlsut38.xls文件操作.xlsxy39.xls文件操作.xlsnd40.xls文件操作.xlsxyi41.xls文件操作.xlsds42.xls文件操作.xlsx43.xls文件操作.xlsx44.xls文件操作.xlsx545.xls文件操作.xlsx546.xls文件操作.xlsx747.xls文件操作.xlsx-58.xls文件操作.xlsx658.xls文件操作.xlsx7在apachescrapy中,代码一般使用xml抽取文本数据形式,xml数据格式非常容易理解。
下面是一个完整的爬虫过程。而每一步都有一些注意事项,所以其实学习上没有捷径。第一步,请求百度,在百度请求的正则中就可以获取所需的商品名称和销量等信息。第二步,结合京东数据,我们知道它的数据导入方式是java爬虫框架jsoup。所以在这里提前做个准备工作,先安装jsoup。首先,我们在浏览器中输入京东商城的地址:spider/jsoup如下图:首先我们看到京东商城的商品列表页的商品有。 查看全部
文章采集程序(爬虫:中文资料和使用爬虫(beautifulsoup)、scrapy等前端解析工具)
文章采集程序可使用爬虫(beautifulsoup)、scrapy、lxml等前端解析工具;也可以使用requests、selenium、ghosthandler等支持javascript的工具。接下来我将在笔记本上用eclipse和apache软件安装使用apachescrapy。本文将依次介绍下中文资料和使用爬虫需要注意的事项。
中文资料:1.apachescrapy官方文档chinaguide.2.菜鸟教程scrapyhelp.3.百度百科scrapy入门使用4.京东商城的商品数据爬取和数据分析训练-requests模块介绍5.百度百科scrapy入门使用6.scrapy算法及爬虫效果分析7.爬虫实战项目学习8.爬虫项目项目开发9.excel数据操作-可视化_商品数据-销量-评论等10.万数pythonscrapy项目开发11.excel数据操作-pandas处理原始文本12.excel数据操作-sql语句-翻译等13.excel数据操作-do_something14.excel数据操作-日期格式表示格式转换15.excel数据操作-数据归档16.excel数据操作-format17.xls文件获取.xlsx18.xls文件操作.xlsm19.xls文件操作.xlsdt20.xls文件操作.xlsdd21.xls文件操作.xlsdm22.xls文件操作.xlspd23.xls文件操作.xlspc24.xls文件操作.xlsm25.xls文件操作.xlspp26.xls文件操作.xlsd27.xls文件操作.xlsbe28.xls文件操作.xlspc29.xls文件操作.xlsdd30.xls文件操作.xlsmm31.xls文件操作.xlsmg32.xls文件操作.xlsm33.xls文件操作.xlsm34.xls文件操作.xlsx35.xls文件操作.xlsvr36.xls文件操作.xlsax37.xls文件操作.xlsut38.xls文件操作.xlsxy39.xls文件操作.xlsnd40.xls文件操作.xlsxyi41.xls文件操作.xlsds42.xls文件操作.xlsx43.xls文件操作.xlsx44.xls文件操作.xlsx545.xls文件操作.xlsx546.xls文件操作.xlsx747.xls文件操作.xlsx-58.xls文件操作.xlsx658.xls文件操作.xlsx7在apachescrapy中,代码一般使用xml抽取文本数据形式,xml数据格式非常容易理解。
下面是一个完整的爬虫过程。而每一步都有一些注意事项,所以其实学习上没有捷径。第一步,请求百度,在百度请求的正则中就可以获取所需的商品名称和销量等信息。第二步,结合京东数据,我们知道它的数据导入方式是java爬虫框架jsoup。所以在这里提前做个准备工作,先安装jsoup。首先,我们在浏览器中输入京东商城的地址:spider/jsoup如下图:首先我们看到京东商城的商品列表页的商品有。
文章采集程序(采集公众号文章类网站,收录排名会很好的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-23 21:03
------------------------
采集公文章 网站,真的很大,主要是在资源方面。
自此,Sogou已经获得了微信公共资源的入口,百度已经垂涎三脚,但没有许可百度,不敢抓住内容,只能看看它。每个搜索引擎都希望获得更多的用户信任,有必要做好:智能,质量满足用户需求。满足用户需求的基础是资源。资源来源,Portal 网站,用户的个人网站和第三方自媒体平台。和微信公共号码是资源中心,新闻中心,索沟收益借口,在百度搜索引擎上没有数据,如果可以掌握这些数据,创建网站,这个网站百百百度来它是一种稀缺的资源,那么收录排名将非常好。
首先:这些程序是什么?是否安装了任何开源程序?
一般抓住微信公共文章 网站小,然后开源过程很少,一般开发。
第二:如何做到?
1.可以借用dede cms内容内容装@ / p>
2.发现了一个很好的网站 for imitation站
第三:他们是如何做的?
1.他们首先开发了一个程序
2. 优采云采集 software 采集
3.网站 data更新
事实上,还有思考的思考
首先,他们首先基于Sogou Wechat搜索,有趣,金融,技术,体育,娱乐等,根据这些类别:1.阅阅2.更新频率3.工业网网网网网网。然后要确定一些公共帐户,然后每3天每3天更新数据。然后通过百度联盟广告赚钱,如果排名并可以与公众合作,并开设整站才能促销金钱。
如:
让我们仔细看看,他们的公共号码文章,不是最新的,所以它们也被数据采集更新。
是好的,只是说,外面的天空仍然很蓝。
--------------------- 查看全部
文章采集程序(采集公众号文章类网站,收录排名会很好的方法)
------------------------
采集公文章 网站,真的很大,主要是在资源方面。
自此,Sogou已经获得了微信公共资源的入口,百度已经垂涎三脚,但没有许可百度,不敢抓住内容,只能看看它。每个搜索引擎都希望获得更多的用户信任,有必要做好:智能,质量满足用户需求。满足用户需求的基础是资源。资源来源,Portal 网站,用户的个人网站和第三方自媒体平台。和微信公共号码是资源中心,新闻中心,索沟收益借口,在百度搜索引擎上没有数据,如果可以掌握这些数据,创建网站,这个网站百百百度来它是一种稀缺的资源,那么收录排名将非常好。
首先:这些程序是什么?是否安装了任何开源程序?
一般抓住微信公共文章 网站小,然后开源过程很少,一般开发。
第二:如何做到?
1.可以借用dede cms内容内容装@ / p>
2.发现了一个很好的网站 for imitation站
第三:他们是如何做的?
1.他们首先开发了一个程序
2. 优采云采集 software 采集
3.网站 data更新

事实上,还有思考的思考
首先,他们首先基于Sogou Wechat搜索,有趣,金融,技术,体育,娱乐等,根据这些类别:1.阅阅2.更新频率3.工业网网网网网网。然后要确定一些公共帐户,然后每3天每3天更新数据。然后通过百度联盟广告赚钱,如果排名并可以与公众合作,并开设整站才能促销金钱。
如:

让我们仔细看看,他们的公共号码文章,不是最新的,所以它们也被数据采集更新。
是好的,只是说,外面的天空仍然很蓝。
---------------------
文章采集程序(非常实用的最新文章采集神器,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-11-16 21:14
文章采集是一款非常实用的最新文章采集神器,这里为大家带来最新强大的文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章< @采集西溪软件园下载地址。
向站长或SEOER推荐一个免费的文章采集tool_chukang-CSDN博客。
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,那该怎么办呢?你可以试试这个优采云Universal文章采集器,它是一个简单实用的文章采集软件。
今日头条文章采集没有?试试这个免费的 采集artifact!zhong。
1、已测试,采集更快2、自动保存到软件目录,并在目录下创建文件夹自动保存空闲段文章 @采集器大小:来源:百度云盘经安全软件检测无毒,请放心下载。
文章采集阅读是一个用易语言编写的简单网络文章采集工具,它不仅可以采集文字,还可以简单地替换一些text ,或者添加文字,也是SEO的好工具伪原创。
优采云Universal文章采集器是为了方便各大搜索引擎制作采集文件和添加工具,使用可以提取网页正文的算法,以及多语言翻译。
优采云Universal文章采集器,优采云软件出品的基于高精度文本识别算法的互联网文章采集器,支持按关键词采集百度等搜索引擎。 QQ空间资源随时更新。亿万QQ用户的威力,你懂的!固执的兔子是。 查看全部
文章采集程序(非常实用的最新文章采集神器,)
文章采集是一款非常实用的最新文章采集神器,这里为大家带来最新强大的文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章< @采集西溪软件园下载地址。
向站长或SEOER推荐一个免费的文章采集tool_chukang-CSDN博客。
对于正在做网站推广和优化的朋友,可能经常需要更新一些文章。这对于文笔不好的人来说还是有点难度的,那该怎么办呢?你可以试试这个优采云Universal文章采集器,它是一个简单实用的文章采集软件。
今日头条文章采集没有?试试这个免费的 采集artifact!zhong。
1、已测试,采集更快2、自动保存到软件目录,并在目录下创建文件夹自动保存空闲段文章 @采集器大小:来源:百度云盘经安全软件检测无毒,请放心下载。
文章采集阅读是一个用易语言编写的简单网络文章采集工具,它不仅可以采集文字,还可以简单地替换一些text ,或者添加文字,也是SEO的好工具伪原创。
优采云Universal文章采集器是为了方便各大搜索引擎制作采集文件和添加工具,使用可以提取网页正文的算法,以及多语言翻译。
优采云Universal文章采集器,优采云软件出品的基于高精度文本识别算法的互联网文章采集器,支持按关键词采集百度等搜索引擎。 QQ空间资源随时更新。亿万QQ用户的威力,你懂的!固执的兔子是。
文章采集程序( 2.小说v1.2.2小说自动采集+一套采集规则+两套优化模板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-11-14 05:05
2.小说v1.2.2小说自动采集+一套采集规则+两套优化模板)
来源名称:【旷宇小说v1.2.2】小说自动采集+一套采集规则+两套优化模板
源码大小:8.4MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍及安装说明:
安装教程和模板导入采集规则
系统要求
PHP需要5.6版本及以上,5.6版本无法运行支持php7
插件、应用程序、配置、扩展、公共、运行时、模板、上传目录必须具有写权限 777
网站必须配置伪静态(.htaccess为Apache伪静态配置文件,kyxscms.conf为Nginx伪静态配置文件)
宝塔面板需要在软件php设置中安装扩展fileinfo
如果上传后无法访问源代码,请设置伪静态think
一套是白色的WEB模板,一套是蓝色的WAP模板
手动解压模板到/template/home目录
然后进入数据库找到ky_template
手动插入模板名称在后台显示
采集 规则进入数据库后,直接选择SQL,复制粘贴进去,点击执行。
不明白的可以参考源码中的图片教程。
资源下载 本资源下载价格为58元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈的几十个源代码,只要有下载按钮,终身VIP都可以免费下载。
2. 本站源码多为全网各种渠道购买。文章的描述一般由渠道方测试说明转载,不代表本站观点。不过文章开头带有demo的源码说明本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
======================================
3.文章开头没有demo站点,表示我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换!!!但是,与此同时,您可能也很便宜。因为很多都经过了渠道的测试,但是我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
======================================
4. 本站使用在线支付。支付完成后,积分自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程,如果有也随机。
7. 所有源码不提供免费安装。如需我们代为安装,请联系客服了解详情。
本文整理自互联网(源代码之家123),如需转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
========================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。 查看全部
文章采集程序(
2.小说v1.2.2小说自动采集+一套采集规则+两套优化模板)
来源名称:【旷宇小说v1.2.2】小说自动采集+一套采集规则+两套优化模板
源码大小:8.4MB
开发语言:PHP+Mysql
操作系统:Windows、Linux
源码介绍及安装说明:
安装教程和模板导入采集规则
系统要求
PHP需要5.6版本及以上,5.6版本无法运行支持php7
插件、应用程序、配置、扩展、公共、运行时、模板、上传目录必须具有写权限 777
网站必须配置伪静态(.htaccess为Apache伪静态配置文件,kyxscms.conf为Nginx伪静态配置文件)
宝塔面板需要在软件php设置中安装扩展fileinfo
如果上传后无法访问源代码,请设置伪静态think
一套是白色的WEB模板,一套是蓝色的WAP模板
手动解压模板到/template/home目录
然后进入数据库找到ky_template
手动插入模板名称在后台显示
采集 规则进入数据库后,直接选择SQL,复制粘贴进去,点击执行。
不明白的可以参考源码中的图片教程。
资源下载 本资源下载价格为58元,请先登录
【风险提示】付款前写:
1.全站8500+源代码,除了热门商圈的几十个源代码,只要有下载按钮,终身VIP都可以免费下载。
2. 本站源码多为全网各种渠道购买。文章的描述一般由渠道方测试说明转载,不代表本站观点。不过文章开头带有demo的源码说明本站亲自测试过,至少可以搭建,一般没有大问题,可以放心购买。
======================================
3.文章开头没有demo站点,表示我们没有时间亲自测试。源代码有缺陷风险,所以低价出售。一经购买即视为接受风险,概不退换!!!但是,与此同时,您可能也很便宜。因为很多都经过了渠道的测试,但是我们还没有来得及测试和确认。如果我们的测试没问题,价格会高很多倍。
======================================
4. 本站使用在线支付。支付完成后,积分自动记入账户。
5. 充值比例:1:1。是否为VIP免费下载,需要登录后显示。
6. 所有源码默认没有安装教程,如果有也随机。
7. 所有源码不提供免费安装。如需我们代为安装,请联系客服了解详情。
本文整理自互联网(源代码之家123),如需转载请注明出处:;
如果本站发布的内容侵犯了您的权益,请邮件删除,我们会及时处理!
========================================
本站下载资源大部分采集于互联网,不保证其完整性和安全性。下载后请自行测试。
本站资源仅供学习交流之用。版权属于资源的原作者。请在下载后24小时内自觉删除。
商业用途请购买正版。未及时购买及支付造成的侵权与本站无关。
文章采集程序(文章采集程序使用简单的c++语言编写实现,给网站加载应用程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-07 16:05
文章采集程序使用简单的c++语言编写实现,给网站加载应用程序时提供功能,比如检测一下高手和青年、博客、知乎等网站的链接,从而实现实时监控或者抓取,实现网站机器人监控、抓取功能。在采集前,可以在采集结果页面查看网站的网址信息,还可以查看浏览器历史、设置开关、收藏夹、作者、文章标题、作者简介等,然后根据作者、文章标题、页码、页码偏移数等网站的抓取要求选择对应的采集规则,下载对应的采集包,就可以在浏览器中加载抓取数据了。
网址库项目依赖python2.7,mysqljavaapacheweblogic数据库jquery1.7,selenium3.4vizjs5.5javascript1.0javascript2.0常用网站爬虫工具包:千万数据抓取库、apache2+wordpress2+、lxml2.3、tornado2.4aspx、3.xxie、ilovewire、expires0.exemyuprogramme、webbrowser脚本wordpress的抓取规则:整站代码、链接代码,可参考这篇文章http协议详解之trafficframes篇-howardzhu-博客园爬虫工具实例:链家网链家网本身是一个二手房中介网站,截取链家网上的一个二手房的信息,链家网代理站在、天猫等其他可以登录的网站上都有进行,而且不同的站点抓取下来的效果是一样的,但是搜索结果中有日期的,比如搜索日期2017年9月19日,页面会展示是2017年9月19日这个日期,从而确定链家网对于二手房的信息抓取已经对应的日期了,可以在浏览器中查看对应的抓取日期和链接网址。
但是没有关系,python实现wordpress爬虫大概也有过这样的经历,比如设置过爬取日期,但是最后只能在爬取页面的最后有时间和有日期的抓取结果,所以我先要写一个requests库爬取到链家网的链接,随后再写日期爬取规则。所以基本的抓取程序是一样的,只是链家站点(主页网址+分页url+页码信息),而链家网上的大部分还是在这种一个网站上抓取出来的,他们的网站标题和内容可以相同,这就有可能返回一个错误页面,导致网页错误跳转进入到已经抓取的页面,不知道怎么办?在加载链接的问题上做了一定的考虑,结果是这样的:每个人都是有自己偏好的页码,这个页码就可以被替换为常用的网址(包括生日信息),也可以进行设置自定义,页码这里使用的是useragenttag,useragenttag可以定义浏览器,设置的不同浏览器的useragenttag就会呈现不同的页码,如果你想设置不同的页码规则,建议用auto,为什么这么设置?因为auto可以无限的设置浏览器useragenttag,所以我设置了一套auto规则,用auto可。 查看全部
文章采集程序(文章采集程序使用简单的c++语言编写实现,给网站加载应用程序)
文章采集程序使用简单的c++语言编写实现,给网站加载应用程序时提供功能,比如检测一下高手和青年、博客、知乎等网站的链接,从而实现实时监控或者抓取,实现网站机器人监控、抓取功能。在采集前,可以在采集结果页面查看网站的网址信息,还可以查看浏览器历史、设置开关、收藏夹、作者、文章标题、作者简介等,然后根据作者、文章标题、页码、页码偏移数等网站的抓取要求选择对应的采集规则,下载对应的采集包,就可以在浏览器中加载抓取数据了。
网址库项目依赖python2.7,mysqljavaapacheweblogic数据库jquery1.7,selenium3.4vizjs5.5javascript1.0javascript2.0常用网站爬虫工具包:千万数据抓取库、apache2+wordpress2+、lxml2.3、tornado2.4aspx、3.xxie、ilovewire、expires0.exemyuprogramme、webbrowser脚本wordpress的抓取规则:整站代码、链接代码,可参考这篇文章http协议详解之trafficframes篇-howardzhu-博客园爬虫工具实例:链家网链家网本身是一个二手房中介网站,截取链家网上的一个二手房的信息,链家网代理站在、天猫等其他可以登录的网站上都有进行,而且不同的站点抓取下来的效果是一样的,但是搜索结果中有日期的,比如搜索日期2017年9月19日,页面会展示是2017年9月19日这个日期,从而确定链家网对于二手房的信息抓取已经对应的日期了,可以在浏览器中查看对应的抓取日期和链接网址。
但是没有关系,python实现wordpress爬虫大概也有过这样的经历,比如设置过爬取日期,但是最后只能在爬取页面的最后有时间和有日期的抓取结果,所以我先要写一个requests库爬取到链家网的链接,随后再写日期爬取规则。所以基本的抓取程序是一样的,只是链家站点(主页网址+分页url+页码信息),而链家网上的大部分还是在这种一个网站上抓取出来的,他们的网站标题和内容可以相同,这就有可能返回一个错误页面,导致网页错误跳转进入到已经抓取的页面,不知道怎么办?在加载链接的问题上做了一定的考虑,结果是这样的:每个人都是有自己偏好的页码,这个页码就可以被替换为常用的网址(包括生日信息),也可以进行设置自定义,页码这里使用的是useragenttag,useragenttag可以定义浏览器,设置的不同浏览器的useragenttag就会呈现不同的页码,如果你想设置不同的页码规则,建议用auto,为什么这么设置?因为auto可以无限的设置浏览器useragenttag,所以我设置了一套auto规则,用auto可。
文章采集程序(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-05 02:28
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配你需要的内容。只要你有一点基本的正则表达式,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/Index.aspx,所以我们可以做一个起始页,定义一个输入需要采集的书号,然后那么我们可以使用 $_POST ['number'] 这种格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。_POST['number'] 的合法性。
构造好URL后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
PHP代码如下:
函数剪切($string,$start,$end){
$消息=爆炸($开始,$字符串);
$message = expand($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start = "HTML/书/";
$end
= "列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid =explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST['number']/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend
= "\"";
//t代表title的缩写
$tstart = ">";
$趋向
=“ 查看全部
文章采集程序(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配你需要的内容。只要你有一点基本的正则表达式,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/Index.aspx,所以我们可以做一个起始页,定义一个输入需要采集的书号,然后那么我们可以使用 $_POST ['number'] 这种格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。_POST['number'] 的合法性。
构造好URL后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
PHP代码如下:
函数剪切($string,$start,$end){
$消息=爆炸($开始,$字符串);
$message = expand($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start = "HTML/书/";
$end
= "列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid =explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST['number']/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend
= "\"";
//t代表title的缩写
$tstart = ">";
$趋向
=“
文章采集程序( 使用网人采集,你可以瞬间建立一个拥有庞大内容的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-29 14:04
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站)
网友采集系统v1.0发布!
网友采集系统v1.0发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计,支持分类信息采集、文章采集和Shop 采集,当然这个系统也可以应用到其他系统!
网民采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。创建一个内容丰富的 网站。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql数据存储和导出会让你在采集内容的时候更舒服。现在您可以放弃过去重复繁琐的手动添加工作。, 请马上开始体验即时建站的乐趣!
网友采集是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据处理功能可以将您采集的任何网页数据发布到远程服务器,自定义用户cms系统模块,不管你的网站是什么系统,都可以使用上网用户采集系统。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access或MS SqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持附件采集,包括图片、文档等附件
5、增量采集和自动更新
6、全结构化抽取
7、采集 结果自动排序
8、 数据保存在本地,可以随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库。
10、同时多站点、多任务、多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展、可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、 强大的内容过滤功能,去除广告,无限制替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史记录功能,避免重复采集
20、定时采集,网站内容实时更新
基本使用说明:
1.下载系统并解压到网站目录
2.如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接,相关表信息等。
4.设置采集项目
5. 采集 内容
好的,搞定
官方地址:
下载链接: 查看全部
文章采集程序(
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站)
网友采集系统v1.0发布!
网友采集系统v1.0发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计,支持分类信息采集、文章采集和Shop 采集,当然这个系统也可以应用到其他系统!
网民采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。创建一个内容丰富的 网站。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql数据存储和导出会让你在采集内容的时候更舒服。现在您可以放弃过去重复繁琐的手动添加工作。, 请马上开始体验即时建站的乐趣!
网友采集是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据处理功能可以将您采集的任何网页数据发布到远程服务器,自定义用户cms系统模块,不管你的网站是什么系统,都可以使用上网用户采集系统。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access或MS SqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持附件采集,包括图片、文档等附件
5、增量采集和自动更新
6、全结构化抽取
7、采集 结果自动排序
8、 数据保存在本地,可以随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库。
10、同时多站点、多任务、多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展、可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、 强大的内容过滤功能,去除广告,无限制替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史记录功能,避免重复采集
20、定时采集,网站内容实时更新
基本使用说明:
1.下载系统并解压到网站目录
2.如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接,相关表信息等。
4.设置采集项目
5. 采集 内容
好的,搞定
官方地址:
下载链接:
文章采集程序(全程序自动采集内置好看源码-模板修复版(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-28 13:11
)
全程序自动采集
内置好看的源代码
----------------------------------------------- --------
----------------------------------------------- --------
【小说源码-模板修复版】
----------------------------------------------- -------
[更新提醒]
采集 规则已更新。默认有1000篇小说,后台更新了5条采集规则。 采集 30万本小说大约10G。
------------------------------------
----------------------------------------------- ------
----------------------------------------------- -------
[背景网址] URL+/admin
----------------------------------------------- -------
默认用户名和密码 admin/123456
----------------------------------------------- -------
查看全部
文章采集程序(全程序自动采集内置好看源码-模板修复版(图)
)
全程序自动采集
内置好看的源代码
----------------------------------------------- --------
----------------------------------------------- --------
【小说源码-模板修复版】
----------------------------------------------- -------
[更新提醒]
采集 规则已更新。默认有1000篇小说,后台更新了5条采集规则。 采集 30万本小说大约10G。
------------------------------------
----------------------------------------------- ------
----------------------------------------------- -------
[背景网址] URL+/admin
----------------------------------------------- -------
默认用户名和密码 admin/123456
----------------------------------------------- -------
文章采集程序(1..2.8版本程序以及搭建教程+采集规则(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-26 12:14
1、ptcms是一个专业的小说网站程序,可以采集转码其他网站实现不用大数据盘也能搞定自己多部小说;目前官方也在积极维护(最新版本号:V4.2.17 (Build:20191010.2344))
2、 网上流传的版本也很多,但是大部分安装教程版本都有一些问题。本次带来ptcms4.2.8版程序及构建教程+采集规则
以上:
电脑前台
嗯~o(* ̄▽ ̄*)oa再上几张手机照片
特征
4.0版本为新开发,新版UI,更加现代化,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网,自适应模板(当然模板可以替换),可分手机域名。
后端是用LAYUI新开发的。
你值得拥有长时间反复折腾安装步骤的血泪经历。1. 安装基础环境(以下仅为教程,不含程序)
2.安装加密加载器
二、配置 Swoole
1、在/www/server/文件中创建ptcms文件夹,将license和loader73.so上传到ptcms(这个可以忽略,后面会解释)
2、打开php7.3的配置文件(也叫php.ini),拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤的地方是否有错误!比如:代码拼写错误什么的……(这里翻跟头o(* ̄▽ ̄*)o)
extension = /www/server/ptcms/loader73.so
swoole_license_files = /www/server/ptcms/license
如果忽略第一步建立ptcms文件夹,执行下面代码
extension =/www/wwwroot/主程序所在文件夹(网站路径)/loader73.so
swoole_license_files = /www/wwwroot/主程序所在文件夹(网站路径)/license
代码安装好后重启PHP或者重新加载配置
3.配置网站3.1 设置网站运行目录
指定宝塔中的网站操作目录为public,而不是网站目录!!!不要犯错
3.2 宝塔伪静态设置
if (!-e $request_filename) {
rewrite ^/(.*) /index.php?s=$1 last;
}
不设置会报错,有些东西加载不出来
4.配置采集
修改主机(可以不可以,大佬说没必要,直接做ssh然后在后面输入vim /etc/hosts添加并按ESC进入命令模式。输入:wq!强制退出很好,稍微有点 linux 就可以了)
vim /etc/hosts
106.13.47.93 api.kxcms.com api.ptcms.com
5.安装步骤
先把目录下的install.lock删掉(如果有的话一定要删掉)才能安装安装地址:你的域名/install.php,然后输入用户名、数据库名、数据库密码。
安装后,如果不想让官方找到你的域名,最好把后端统计码号和public/static/admin/index.js文件的统计码号改一下,即替换自己的百度统计id。
移动终端、MIP 和 AMP 的构建方式与主终端相同。域名都指向操作目录。主终端搭建完成后,需要在URL后台域名设置中填写相关域名,才能访问对应的URL。
6. 配置 cron
1、PT后台-采集管理-任务管理-任务设置开启任务开关,否则会报主进程关闭错误
2、创建定时任务并登录宝塔后台定时任务,任务类型为shell脚本,脚本内容为
php /www/wwwroot/网站目录/kx cron:master >>/dev/null 2>&1
时间自行填写,保存即可
SSH输入:
cd /www/wwwroot/网站目录
进入网站目录
复制
/www/server/php/73/bin/php kx cron:check
进ssh,提示主进程开启则安装完成(73为PHP版本,自行修改)
背景预览:
只拍两张,慢慢熟悉自己!!!
7.采集 规则
使用方法:采集管理——规则管理——规则导入——上传文件(新站点,新规则)
结论:
1、教程足够详细,可用于亲测。如果无法安装,请检查自己的环境步骤。
2、 找资源很辛苦(不保证源码没有后门,不放心可以自己找,不过我和我无关),我之前测试过我出来了。现在免费分享。如果你喜欢,你可以给肖战一点支持的奖励。如果你和我有同样的财务困境,你也可以喜欢它并采集它。
3、因为资源不收费,我们不做任何售后。
如果您有任何问题,请联系电子邮件反馈
最后提醒一下,最后关闭宝塔访问日志,或者定期清理,不然时间久了你会发现几条G日志,嗯~o(* ̄▽ ̄*)o 好可怕的说
下载
PTcms主程序链接点击下载(提取码:ij16)
点击下载PTcms采集规则链接(提取码:43ja)
1、本站所有内容归原作者所有,与本站无关
2、其他单位或个人使用、转载、引用本文须征得博主同意,并注明出处
3、 本站大部分资源源码均在网上,仅供学习交流使用。本站不提供任何技术支持,也不作任何安全承诺。请判断是否使用它。 查看全部
文章采集程序(1..2.8版本程序以及搭建教程+采集规则(上))
1、ptcms是一个专业的小说网站程序,可以采集转码其他网站实现不用大数据盘也能搞定自己多部小说;目前官方也在积极维护(最新版本号:V4.2.17 (Build:20191010.2344))
2、 网上流传的版本也很多,但是大部分安装教程版本都有一些问题。本次带来ptcms4.2.8版程序及构建教程+采集规则
以上:
电脑前台
嗯~o(* ̄▽ ̄*)oa再上几张手机照片
特征
4.0版本为新开发,新版UI,更加现代化,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网,自适应模板(当然模板可以替换),可分手机域名。
后端是用LAYUI新开发的。
你值得拥有长时间反复折腾安装步骤的血泪经历。1. 安装基础环境(以下仅为教程,不含程序)
2.安装加密加载器
二、配置 Swoole
1、在/www/server/文件中创建ptcms文件夹,将license和loader73.so上传到ptcms(这个可以忽略,后面会解释)
2、打开php7.3的配置文件(也叫php.ini),拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤的地方是否有错误!比如:代码拼写错误什么的……(这里翻跟头o(* ̄▽ ̄*)o)
extension = /www/server/ptcms/loader73.so
swoole_license_files = /www/server/ptcms/license
如果忽略第一步建立ptcms文件夹,执行下面代码
extension =/www/wwwroot/主程序所在文件夹(网站路径)/loader73.so
swoole_license_files = /www/wwwroot/主程序所在文件夹(网站路径)/license
代码安装好后重启PHP或者重新加载配置
3.配置网站3.1 设置网站运行目录
指定宝塔中的网站操作目录为public,而不是网站目录!!!不要犯错
3.2 宝塔伪静态设置
if (!-e $request_filename) {
rewrite ^/(.*) /index.php?s=$1 last;
}
不设置会报错,有些东西加载不出来
4.配置采集
修改主机(可以不可以,大佬说没必要,直接做ssh然后在后面输入vim /etc/hosts添加并按ESC进入命令模式。输入:wq!强制退出很好,稍微有点 linux 就可以了)
vim /etc/hosts
106.13.47.93 api.kxcms.com api.ptcms.com
5.安装步骤
先把目录下的install.lock删掉(如果有的话一定要删掉)才能安装安装地址:你的域名/install.php,然后输入用户名、数据库名、数据库密码。
安装后,如果不想让官方找到你的域名,最好把后端统计码号和public/static/admin/index.js文件的统计码号改一下,即替换自己的百度统计id。
移动终端、MIP 和 AMP 的构建方式与主终端相同。域名都指向操作目录。主终端搭建完成后,需要在URL后台域名设置中填写相关域名,才能访问对应的URL。
6. 配置 cron
1、PT后台-采集管理-任务管理-任务设置开启任务开关,否则会报主进程关闭错误
2、创建定时任务并登录宝塔后台定时任务,任务类型为shell脚本,脚本内容为
php /www/wwwroot/网站目录/kx cron:master >>/dev/null 2>&1
时间自行填写,保存即可
SSH输入:
cd /www/wwwroot/网站目录
进入网站目录
复制
/www/server/php/73/bin/php kx cron:check
进ssh,提示主进程开启则安装完成(73为PHP版本,自行修改)
背景预览:
只拍两张,慢慢熟悉自己!!!
7.采集 规则
使用方法:采集管理——规则管理——规则导入——上传文件(新站点,新规则)
结论:
1、教程足够详细,可用于亲测。如果无法安装,请检查自己的环境步骤。
2、 找资源很辛苦(不保证源码没有后门,不放心可以自己找,不过我和我无关),我之前测试过我出来了。现在免费分享。如果你喜欢,你可以给肖战一点支持的奖励。如果你和我有同样的财务困境,你也可以喜欢它并采集它。
3、因为资源不收费,我们不做任何售后。
如果您有任何问题,请联系电子邮件反馈
最后提醒一下,最后关闭宝塔访问日志,或者定期清理,不然时间久了你会发现几条G日志,嗯~o(* ̄▽ ̄*)o 好可怕的说
下载
PTcms主程序链接点击下载(提取码:ij16)
点击下载PTcms采集规则链接(提取码:43ja)
1、本站所有内容归原作者所有,与本站无关
2、其他单位或个人使用、转载、引用本文须征得博主同意,并注明出处
3、 本站大部分资源源码均在网上,仅供学习交流使用。本站不提供任何技术支持,也不作任何安全承诺。请判断是否使用它。
文章采集程序(文章采集程序和服务类推荐,有黑名单的,用法一目了然)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-21 10:00
文章采集程序和服务类推荐各个地方写,比如简书,小红书,头条,西瓜视频,智者助人类,业余时间去几个文章推荐的平台去拷贝一下然后稍微调整一下就可以了,只不过是改了改调整了一下,有些调整甚至直接就没调整,只是去拷贝。此篇介绍一个网站/应用,把传统类文章爬取下来,然后进行再次优化改编。文章的数量:excel数据1326000篇传统类传统类文章是首页所有文章,每个类别下还有更多的传统类,数量:大家可以一目了然,我现在爬取的传统类,有字典的,有黑名单的,用法一目了然1.下载传统类数据2.爬取数据3.优化页面的类别和对应的黑名单数据4.文章标题5.对应的提取标签文章和标题建议起上:文章名称,标题,描述,和作者,提取关键词,然后对应的类别要重复4遍,页面调整如下7.解释评论8.c语言脚本代码网站类似于七牛云开发的一个数据采集平台。
自问自答好了文章真不是特别难,想爬得到的话,肯定就用到搜索引擎或者python爬虫库了,百度有很多,也有我刚发现的crawler/crawler·github这个项目,可以满足你的需求了。
想知道是什么文章
我也刚刚接触爬虫,写爬虫应该好一点,但是不知道有没有遇到困难,
crawler/crawler·github去写。 查看全部
文章采集程序(文章采集程序和服务类推荐,有黑名单的,用法一目了然)
文章采集程序和服务类推荐各个地方写,比如简书,小红书,头条,西瓜视频,智者助人类,业余时间去几个文章推荐的平台去拷贝一下然后稍微调整一下就可以了,只不过是改了改调整了一下,有些调整甚至直接就没调整,只是去拷贝。此篇介绍一个网站/应用,把传统类文章爬取下来,然后进行再次优化改编。文章的数量:excel数据1326000篇传统类传统类文章是首页所有文章,每个类别下还有更多的传统类,数量:大家可以一目了然,我现在爬取的传统类,有字典的,有黑名单的,用法一目了然1.下载传统类数据2.爬取数据3.优化页面的类别和对应的黑名单数据4.文章标题5.对应的提取标签文章和标题建议起上:文章名称,标题,描述,和作者,提取关键词,然后对应的类别要重复4遍,页面调整如下7.解释评论8.c语言脚本代码网站类似于七牛云开发的一个数据采集平台。
自问自答好了文章真不是特别难,想爬得到的话,肯定就用到搜索引擎或者python爬虫库了,百度有很多,也有我刚发现的crawler/crawler·github这个项目,可以满足你的需求了。
想知道是什么文章
我也刚刚接触爬虫,写爬虫应该好一点,但是不知道有没有遇到困难,
crawler/crawler·github去写。
文章采集程序(车贷平台投资者的文章采集程序-解析数据将解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-15 02:02
文章采集程序首先,需要采集注册过车贷平台投资者的数据,将其分类。除此之外,该数据所对应的ip地址并不全,在文章开始前便已经收集完成。采集方法在文章开始之前,我已经将平台数据定义为二类数据。用户把平台“积分”发送到我邮箱,通过邮件格式传递给我。即可开始我的采集。采集平台为:从网站抓取,采集网站数据,我的程序可以在上述网站抓取信息。
在上述例子中,我抓取的主要是投资人接受车贷平台投资的最新交易数据。解析数据我的程序需要解析数据。从表中,我们可以找到信息的所在位置和有关人员数据,我需要抓取数据,就是需要将这些人员的数据作为新的样本,记为x。采集内容上方截图为,我在excel上进行导入、处理、解析数据。中间截图为,我把excel数据导入至ie浏览器。
下方截图为,我在ie浏览器上再次进行解析。解析数据将解析后的数据作为分析内容,作为我的展示方法。展示方法最终,我将数据加入到imagebox,进行展示。
这个app..很简单,就我搞定过的几个平台上的数据都提供了:可以直接下载下来用。建议答主如果没有深入了解过python,建议在学习python时,优先把语言基础给打好,这样学习一些爬虫框架比如requests和scrapy,我觉得会比python基础派比较容易入门。等基础很好之后,再去接触开发一些比较复杂的爬虫。 查看全部
文章采集程序(车贷平台投资者的文章采集程序-解析数据将解析)
文章采集程序首先,需要采集注册过车贷平台投资者的数据,将其分类。除此之外,该数据所对应的ip地址并不全,在文章开始前便已经收集完成。采集方法在文章开始之前,我已经将平台数据定义为二类数据。用户把平台“积分”发送到我邮箱,通过邮件格式传递给我。即可开始我的采集。采集平台为:从网站抓取,采集网站数据,我的程序可以在上述网站抓取信息。
在上述例子中,我抓取的主要是投资人接受车贷平台投资的最新交易数据。解析数据我的程序需要解析数据。从表中,我们可以找到信息的所在位置和有关人员数据,我需要抓取数据,就是需要将这些人员的数据作为新的样本,记为x。采集内容上方截图为,我在excel上进行导入、处理、解析数据。中间截图为,我把excel数据导入至ie浏览器。
下方截图为,我在ie浏览器上再次进行解析。解析数据将解析后的数据作为分析内容,作为我的展示方法。展示方法最终,我将数据加入到imagebox,进行展示。
这个app..很简单,就我搞定过的几个平台上的数据都提供了:可以直接下载下来用。建议答主如果没有深入了解过python,建议在学习python时,优先把语言基础给打好,这样学习一些爬虫框架比如requests和scrapy,我觉得会比python基础派比较容易入门。等基础很好之后,再去接触开发一些比较复杂的爬虫。
文章采集程序(ZBLOG应用中心-应用购买及使用协议(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-14 18:40
ZBLOG应用中心-应用购买及使用协议
1. 在购买应用程序之前,首先要确认应用程序是否满足您的需求。由于是源码形式的下载安装服务,购买、下载、安装后概不退款。.
2. 您在应用中心购买的应用只是应用的使用权限,应用的所有权仍属于应用提供商。
3. 一个应用只能用于单个账号,未经本站及应用提供商同意,不得二次发布、赠与、转售、出租、盗版等,否则我们将永久关闭用户账号并保留它。追究相关责任的权利。
4.如果收录应用程序的网站被转售、赠送、出租等,请使用新账号购买应用程序或删除应用程序,否则将被视为违反使用协议和申请将永久取消该帐户的使用权。
5. 除非另有说明,购买的应用程序仅收录相关使用权和免费更新服务。应用中心和应用提供商不提供额外的售后安装服务。
6. 您使用本应用程序的风险全部由用户承担,包括系统损坏、数据丢失等任何风险。
7. 您有责任在使用该应用程序时遵守任何适用法律。如用户侵犯他人权利或触犯法律,一切后果由本人自行承担,本站及应用提供商不承担任何责任。
8. 本站和应用程序提供商保留更改、限制、冻结或终止您使用某些内容的权利,而无需通知您,也不对您承担任何责任。
购买指南
1. 请先注册一个账号,然后登录“应用中心”。
2. 只需点击“购买应用”并按照说明进行操作。
下载指南
1. 购买者登录Z-Blog网站,进入后台,点击左侧菜单栏的“应用中心”菜单。
2. 在“申请中心”首页,使用申请中心注册账号登录。
3. 进入“我的应用仓库”,可以看到购买成功的应用,点击“下载”进行下载安装。
其他注意事项
1. 如果您通过自己的网站后台无法访问应用中心,请谨慎购买,因为这可能会导致应用无法顺利下载安装。
2. 如果您购买了无法正常下载的付费应用,请在自己的后台查看Z-Blog和应用更新网站。如果您已更新至最新版本仍无法下载,请及时与我们联系。
3. 应用程序更新时,本地设置可能会被覆盖。更新前请做好备份。 查看全部
文章采集程序(ZBLOG应用中心-应用购买及使用协议(图))
ZBLOG应用中心-应用购买及使用协议
1. 在购买应用程序之前,首先要确认应用程序是否满足您的需求。由于是源码形式的下载安装服务,购买、下载、安装后概不退款。.
2. 您在应用中心购买的应用只是应用的使用权限,应用的所有权仍属于应用提供商。
3. 一个应用只能用于单个账号,未经本站及应用提供商同意,不得二次发布、赠与、转售、出租、盗版等,否则我们将永久关闭用户账号并保留它。追究相关责任的权利。
4.如果收录应用程序的网站被转售、赠送、出租等,请使用新账号购买应用程序或删除应用程序,否则将被视为违反使用协议和申请将永久取消该帐户的使用权。
5. 除非另有说明,购买的应用程序仅收录相关使用权和免费更新服务。应用中心和应用提供商不提供额外的售后安装服务。
6. 您使用本应用程序的风险全部由用户承担,包括系统损坏、数据丢失等任何风险。
7. 您有责任在使用该应用程序时遵守任何适用法律。如用户侵犯他人权利或触犯法律,一切后果由本人自行承担,本站及应用提供商不承担任何责任。
8. 本站和应用程序提供商保留更改、限制、冻结或终止您使用某些内容的权利,而无需通知您,也不对您承担任何责任。
购买指南
1. 请先注册一个账号,然后登录“应用中心”。
2. 只需点击“购买应用”并按照说明进行操作。
下载指南
1. 购买者登录Z-Blog网站,进入后台,点击左侧菜单栏的“应用中心”菜单。
2. 在“申请中心”首页,使用申请中心注册账号登录。
3. 进入“我的应用仓库”,可以看到购买成功的应用,点击“下载”进行下载安装。
其他注意事项
1. 如果您通过自己的网站后台无法访问应用中心,请谨慎购买,因为这可能会导致应用无法顺利下载安装。
2. 如果您购买了无法正常下载的付费应用,请在自己的后台查看Z-Blog和应用更新网站。如果您已更新至最新版本仍无法下载,请及时与我们联系。
3. 应用程序更新时,本地设置可能会被覆盖。更新前请做好备份。
文章采集程序(现如今,微信公众号成了主流的线上线下微信互动营销方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-14 13:29
)
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但微信是腾讯旗下的。如果要将文章移动到自己的网站,只能使用Ctrl+c,Ctrl+v,关键问题是不能直接复制图片...所以,如果你想在优质微信文章上采集,转给自己网站还是很麻烦的。
敲黑板,注意!小编偷偷告诉你,我有一个小技巧。使用优采云云爬虫可以在微信公众号的文章上快速执行采集。采集结束后,您可以选择同步发布到自己的网站或保存到数据库中。是不是很神奇?下面就来学习一下吧!
数据采集:
NO.1 进入优采云官方网站(),注册或登录后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,因为搜狗微信搜索有图片反盗链链接,所以需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片不会显示出来,到时候你就尴尬了……
自定义设置后,可以同时采集多个微信公众号,最多500个!特别注意:输入的是微信ID,不是微信名!
什么!分不清哪个是微信名哪个是微信账号哦,长的好像有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击公众号。
再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。
节省:
启动:
爬取结果:
数据发布:
数据采集完成后,可以发布数据吗?答案当然是!
NO.1 使用优采云发布数据只需两步:安装优采云发布插件——>使用优采云发布接口。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,就可以了一步一步就OK了。
插件安装成功,接下来我们新建一个发布项!这里有很多,选择你喜欢的。
选择发布界面后,填写你要发布的网站地址和密码。同时优采云会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,可以填写也可以不填写。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,您可以看到采集爬虫根据您设置的信息爬取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布,可以选择单个或多个发布。发布前也可以先预览看看这个文章的内容是什么。
如果你认为有问题,你可以发布数据。
发布成功后,可以点击链接查看。
嗯,没错,就是用优采云云爬虫到文章收微信公众号就是这么简单!快点接受这个充满爱心的指南,大多数人我不会告诉他。
最后,你认为优采云云爬虫只能用来采集微信公众号文章吗?不不不。它还有更多的功能,如下。
查看全部
文章采集程序(现如今,微信公众号成了主流的线上线下微信互动营销方式
)
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但微信是腾讯旗下的。如果要将文章移动到自己的网站,只能使用Ctrl+c,Ctrl+v,关键问题是不能直接复制图片...所以,如果你想在优质微信文章上采集,转给自己网站还是很麻烦的。
敲黑板,注意!小编偷偷告诉你,我有一个小技巧。使用优采云云爬虫可以在微信公众号的文章上快速执行采集。采集结束后,您可以选择同步发布到自己的网站或保存到数据库中。是不是很神奇?下面就来学习一下吧!
数据采集:
NO.1 进入优采云官方网站(),注册或登录后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,因为搜狗微信搜索有图片反盗链链接,所以需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片不会显示出来,到时候你就尴尬了……
自定义设置后,可以同时采集多个微信公众号,最多500个!特别注意:输入的是微信ID,不是微信名!
什么!分不清哪个是微信名哪个是微信账号哦,长的好像有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击公众号。
再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。
节省:
启动:
爬取结果:
数据发布:
数据采集完成后,可以发布数据吗?答案当然是!
NO.1 使用优采云发布数据只需两步:安装优采云发布插件——>使用优采云发布接口。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,就可以了一步一步就OK了。
插件安装成功,接下来我们新建一个发布项!这里有很多,选择你喜欢的。
选择发布界面后,填写你要发布的网站地址和密码。同时优采云会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,可以填写也可以不填写。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,您可以看到采集爬虫根据您设置的信息爬取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布,可以选择单个或多个发布。发布前也可以先预览看看这个文章的内容是什么。
如果你认为有问题,你可以发布数据。
发布成功后,可以点击链接查看。
嗯,没错,就是用优采云云爬虫到文章收微信公众号就是这么简单!快点接受这个充满爱心的指南,大多数人我不会告诉他。
最后,你认为优采云云爬虫只能用来采集微信公众号文章吗?不不不。它还有更多的功能,如下。
文章采集程序(Python程序设计采集程序的技巧实例分析实现采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-14 13:27
本文文章主要介绍基于scrapy的简单spider采集程序。分析了scrapy实现采集程序的技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了一个基于scrapy的简单spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports # 3rd party imports from scrapy.contrib.spiders import CrawlSpider, Rule from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import HtmlXPathSelector # My imports from poetry_analysis.items import PoetryAnalysisItem HTML_FILE_NAME = r'.+\.html' class PoetryParser(object): """ Provides common parsing method for poems formatted this one specific way. """ date_pattern = r'(\d{2} \w{3,9} \d{4})' def parse_poem(self, response): hxs = HtmlXPathSelector(response) item = PoetryAnalysisItem() # All poetry text is in pre tags text = hxs.select('//pre/text()').extract() item['text'] = ''.join(text) item['url'] = response.url # head/title contains title - a poem by author title_text = hxs.select('//head/title/text()').extract()[0] item['title'], item['author'] = title_text.split(' - ') item['author'] = item['author'].replace('a poem by', '') for key in ['title', 'author']: item[key] = item[key].strip() item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern) return item class PoetrySpider(CrawlSpider, PoetryParser): name = 'example.com_poetry' allowed_domains = ['www.example.com'] root_path = 'someuser/poetry/' start_urls = ['http://www.example.com/someuser/poetry/recent/', 'http://www.example.com/someuser/poetry/less_recent/'] rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]), callback='parse_poem'), Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]), callback='parse_poem')]
希望这篇文章对你的 Python 编程有所帮助。
以上是基于scrapy的简单spider采集程序的详细内容。更多详情请关注其他相关html中文网文章! 查看全部
文章采集程序(Python程序设计采集程序的技巧实例分析实现采集)
本文文章主要介绍基于scrapy的简单spider采集程序。分析了scrapy实现采集程序的技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了一个基于scrapy的简单spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports # 3rd party imports from scrapy.contrib.spiders import CrawlSpider, Rule from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import HtmlXPathSelector # My imports from poetry_analysis.items import PoetryAnalysisItem HTML_FILE_NAME = r'.+\.html' class PoetryParser(object): """ Provides common parsing method for poems formatted this one specific way. """ date_pattern = r'(\d{2} \w{3,9} \d{4})' def parse_poem(self, response): hxs = HtmlXPathSelector(response) item = PoetryAnalysisItem() # All poetry text is in pre tags text = hxs.select('//pre/text()').extract() item['text'] = ''.join(text) item['url'] = response.url # head/title contains title - a poem by author title_text = hxs.select('//head/title/text()').extract()[0] item['title'], item['author'] = title_text.split(' - ') item['author'] = item['author'].replace('a poem by', '') for key in ['title', 'author']: item[key] = item[key].strip() item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern) return item class PoetrySpider(CrawlSpider, PoetryParser): name = 'example.com_poetry' allowed_domains = ['www.example.com'] root_path = 'someuser/poetry/' start_urls = ['http://www.example.com/someuser/poetry/recent/', 'http://www.example.com/someuser/poetry/less_recent/'] rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]), callback='parse_poem'), Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]), callback='parse_poem')]
希望这篇文章对你的 Python 编程有所帮助。
以上是基于scrapy的简单spider采集程序的详细内容。更多详情请关注其他相关html中文网文章!
文章采集程序(如何通过公众号历史消息页面获取到文章地址的列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-10-14 13:22
前面文章详细介绍了如何通过公众号历史消息页面获取文章地址列表,那么获取列表后下一步就是文章采集的内容@> 到你自己的数据库。最近看到一些网站提供的其他公众号文章的爬虫。我以前从未关注过这些。经过观察,发现仍然使用传统的网站采集器形式采集@>搜狗的微信搜索。通过搜狗搜索采集@>公众号历史新闻有几个问题:1、有验证码;2、 历史消息列表只有最近10条群发;3、文章地址有有效期;4、 据说batch采集@>需要改ip;通过我之前的方法文章就没有这个问题了,虽然采集@>系统不如传统采集器写规则爬行那么简单。但是batch采集@>构建一次后的效率还是可以的。而且,采集@>的文章地址是永久有效的,您可以通过采集@>获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
http://mp.weixin.qq.com/s/fF34bERZ0je_8RWEJjoZ5A
2、历史消息列表中获取的地址:
http://mp.weixin.qq.com/s%3F__ ... irect
3、完整的真实地址:
https://mp.weixin.qq.com/s%3F_ ... r%3D1
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法,从json文章历史消息列表中获取的链接地址。我们可以将这个地址保存在数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,由于这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,我们将详细研究如何获取内容文章 等的一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p> 查看全部
文章采集程序(如何通过公众号历史消息页面获取到文章地址的列表)
前面文章详细介绍了如何通过公众号历史消息页面获取文章地址列表,那么获取列表后下一步就是文章采集的内容@> 到你自己的数据库。最近看到一些网站提供的其他公众号文章的爬虫。我以前从未关注过这些。经过观察,发现仍然使用传统的网站采集器形式采集@>搜狗的微信搜索。通过搜狗搜索采集@>公众号历史新闻有几个问题:1、有验证码;2、 历史消息列表只有最近10条群发;3、文章地址有有效期;4、 据说batch采集@>需要改ip;通过我之前的方法文章就没有这个问题了,虽然采集@>系统不如传统采集器写规则爬行那么简单。但是batch采集@>构建一次后的效率还是可以的。而且,采集@>的文章地址是永久有效的,您可以通过采集@>获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
http://mp.weixin.qq.com/s/fF34bERZ0je_8RWEJjoZ5A
2、历史消息列表中获取的地址:
http://mp.weixin.qq.com/s%3F__ ... irect
3、完整的真实地址:
https://mp.weixin.qq.com/s%3F_ ... r%3D1
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法,从json文章历史消息列表中获取的链接地址。我们可以将这个地址保存在数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,由于这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,我们将详细研究如何获取内容文章 等的一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p>
文章采集程序(现如今做SEO沒有好多个能可以保证全部网址不剽窃?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-10 03:36
现在能保证所有网址不被抄袭的SEO并不多,大多数人都不想抄袭,甚至立马采集。最终百度收录大了,没有排名,这是一个严重的错误。概念,爬取百度收录排名,都是一定要遵循的排名方式的过程,理解了这个基本原理后,百度收录的所有内容排名就不容易出问题了。
重庆仿冒法拉利报价火爆起步价9.8万
1、百度收录排名的基本原则
百度关键词一定要排名,百度收录一定要第一。如果是处理百度的收录问题。其他问题将得到解决。百度收录数据库索引标准:内容满足客户需求,内容稀缺资源,时效性,页面质量
内容满足客户需求:我们可以采集,如果你的网站是做SEO的,你采集一个文章医疗器械行业的内容,你觉得合适吗?大家不擅长采集SEO网站的内容,还要考虑这篇文章对客户是否有帮助。
内容稀缺资源:一篇文章很好文章,被大网站转发,那么再好的文章也等于0,因为第一次发表时间这篇文章不是你的网站,另外你的网址的权重值也没有什么大的优势。
时效性:比如现在是夏天,大家都在做品牌女装,所以大家的内容也一定要升级到夏天,因为会受到顾客的热烈欢迎。
网页质量:很多人不太关注这一点。所以我们在写文章的内容,一定要注意网页的质量,文章的内容是否流畅,来的人也很多。国外网站抄袭文章的内容,根据中文内容的翻译结巴了。这是一个非常严重的错误。
2、写
在我们搜索了一个受众非常广泛的文章内容后,我们觉得要应用这篇文章,那么每个人都必须有一个很好的标题才能提交这篇文章。增强本文的附加使用价值。这样采集的文章内容可以跨越原版。或者我们可以在文章的内容中添加一些相关的照片并且视频已经制作好了,并且文章的内容标题顶部稍有变化,那么你的文章的使用价值就可以远了超过原创文章内容。
总结:百度搜索引擎爬取和有效升级保持一致性基本上是不可能的。因此,这就需要爬虫控制系统设计一个有效的爬虫优先级配置策略。
关键包括:xml对策深度优先分析、xml对策全宽优先分析、pr优先选择对策、反向链接对策、社交分享具体引导对策。每种对策都有其优点和缺点。在特定情况下,通常是多种对策相结合,才能达到最佳的爬行实际效果。 查看全部
文章采集程序(现如今做SEO沒有好多个能可以保证全部网址不剽窃?)
现在能保证所有网址不被抄袭的SEO并不多,大多数人都不想抄袭,甚至立马采集。最终百度收录大了,没有排名,这是一个严重的错误。概念,爬取百度收录排名,都是一定要遵循的排名方式的过程,理解了这个基本原理后,百度收录的所有内容排名就不容易出问题了。
重庆仿冒法拉利报价火爆起步价9.8万
1、百度收录排名的基本原则
百度关键词一定要排名,百度收录一定要第一。如果是处理百度的收录问题。其他问题将得到解决。百度收录数据库索引标准:内容满足客户需求,内容稀缺资源,时效性,页面质量
内容满足客户需求:我们可以采集,如果你的网站是做SEO的,你采集一个文章医疗器械行业的内容,你觉得合适吗?大家不擅长采集SEO网站的内容,还要考虑这篇文章对客户是否有帮助。
内容稀缺资源:一篇文章很好文章,被大网站转发,那么再好的文章也等于0,因为第一次发表时间这篇文章不是你的网站,另外你的网址的权重值也没有什么大的优势。
时效性:比如现在是夏天,大家都在做品牌女装,所以大家的内容也一定要升级到夏天,因为会受到顾客的热烈欢迎。
网页质量:很多人不太关注这一点。所以我们在写文章的内容,一定要注意网页的质量,文章的内容是否流畅,来的人也很多。国外网站抄袭文章的内容,根据中文内容的翻译结巴了。这是一个非常严重的错误。
2、写
在我们搜索了一个受众非常广泛的文章内容后,我们觉得要应用这篇文章,那么每个人都必须有一个很好的标题才能提交这篇文章。增强本文的附加使用价值。这样采集的文章内容可以跨越原版。或者我们可以在文章的内容中添加一些相关的照片并且视频已经制作好了,并且文章的内容标题顶部稍有变化,那么你的文章的使用价值就可以远了超过原创文章内容。
总结:百度搜索引擎爬取和有效升级保持一致性基本上是不可能的。因此,这就需要爬虫控制系统设计一个有效的爬虫优先级配置策略。
关键包括:xml对策深度优先分析、xml对策全宽优先分析、pr优先选择对策、反向链接对策、社交分享具体引导对策。每种对策都有其优点和缺点。在特定情况下,通常是多种对策相结合,才能达到最佳的爬行实际效果。
文章采集程序(2016年六安金安区事业单位招聘考试文章采集代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-09 17:00
文章采集程序采集代码来自于anki中文论坛,未经允许严禁转载。考点举例在本文中我将继续回顾对于一个单元格的编写程序,包括多重选择,图形,三角,二维方程组,矩阵,f(x,y)及计算向量等等。这些题只需要在anki程序中计算一次,并且提供原始的内容并列出输出。本文是由阅读源代码的所有者(及参与者)共同编写,并共享计算输出,可以复制下方源代码并直接提交代码。
<p>直接提交新建目录:1todo2code3p24243todo1按题匹配:原始内容不包含数字但含字母。函数如下:方法名=getcolumn(y).toarray(y)y是选择中所有单元格的序号,可以视情况定义,为高斯分布或指数函数(merge函数)。array(x=>1 查看全部
文章采集程序(2016年六安金安区事业单位招聘考试文章采集代码)
文章采集程序采集代码来自于anki中文论坛,未经允许严禁转载。考点举例在本文中我将继续回顾对于一个单元格的编写程序,包括多重选择,图形,三角,二维方程组,矩阵,f(x,y)及计算向量等等。这些题只需要在anki程序中计算一次,并且提供原始的内容并列出输出。本文是由阅读源代码的所有者(及参与者)共同编写,并共享计算输出,可以复制下方源代码并直接提交代码。
<p>直接提交新建目录:1todo2code3p24243todo1按题匹配:原始内容不包含数字但含字母。函数如下:方法名=getcolumn(y).toarray(y)y是选择中所有单元格的序号,可以视情况定义,为高斯分布或指数函数(merge函数)。array(x=>1
文章采集程序(和排序方式和普通分词不同的采集效果展示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-03 20:06
文章采集程序:github-galori/aiohttp:afast,scalable,restfulandwebserviceapiforjavascript,css,flash,es6,html5,andcss3。采集效果展示:在浏览器标签里输入我们刚刚获取的链接,打开之后不断的循环监听前面100个数据,确定断点以后断下,然后切到第10000条数据所在的标签下,然后就可以看到整个页面的页面内容被获取了,如果我们需要获取的数据格式是xxx(文本)就选择对应的元素也就是在dom元素下面。
返回结果里的分词和排序方式和普通分词不同,因为需要自定义语言提取断词方式和排序方式,对php不太友好,需要编译成c++处理。代码编译后:1代码处理页面里内容,2转为python的pil库能处理的格式3使用python给文本加密,比如直接格式:xxx.py的方式来进行加密,不用传文件的方式。请求到的数据编码:6xxx.py:asoc编译后:用googleapi比较方便:.xxx(xxx)google-api-sideload:[unicode]。
javascript代码app('apis')。listeners(req=>{req。post('/request',params={'value':xxx})})。http({uri:"",params:{'xxx':'xxx'}})。setheader("content-type","text/plain")。 查看全部
文章采集程序(和排序方式和普通分词不同的采集效果展示)
文章采集程序:github-galori/aiohttp:afast,scalable,restfulandwebserviceapiforjavascript,css,flash,es6,html5,andcss3。采集效果展示:在浏览器标签里输入我们刚刚获取的链接,打开之后不断的循环监听前面100个数据,确定断点以后断下,然后切到第10000条数据所在的标签下,然后就可以看到整个页面的页面内容被获取了,如果我们需要获取的数据格式是xxx(文本)就选择对应的元素也就是在dom元素下面。
返回结果里的分词和排序方式和普通分词不同,因为需要自定义语言提取断词方式和排序方式,对php不太友好,需要编译成c++处理。代码编译后:1代码处理页面里内容,2转为python的pil库能处理的格式3使用python给文本加密,比如直接格式:xxx.py的方式来进行加密,不用传文件的方式。请求到的数据编码:6xxx.py:asoc编译后:用googleapi比较方便:.xxx(xxx)google-api-sideload:[unicode]。
javascript代码app('apis')。listeners(req=>{req。post('/request',params={'value':xxx})})。http({uri:"",params:{'xxx':'xxx'}})。setheader("content-type","text/plain")。
文章采集程序(你问我答网,国内优秀的知识问答网站\)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-02 20:21
安装注意事项:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//==============================================
$seo_1=\”你让我来回答网络国内优秀知识问答网站\”; //搜索引擎优化-标题后缀
$seo_2=\"你问我答网,知识问答,网友提问,网友回答\"; //搜索引擎优化——网站关键词
$seo_3=\"你问我答网,国内优秀知识问答网站\"; //搜索引擎优化-描述网站
//以上三个地方认真填写,会严重影响收录的数量!
$web=\"你让我回答网\"; //网站请填写姓名
$网站=\”\”; //网站不要加域名
$beian=\"辽ICP备14003759-1号\"; //记录号没什么好说的
$tj=\' \'//网站流量统计代码
//LOGO修改样式\\img\\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
修改后配置IIS伪静态,配置文件在\\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP这个文件,里面有详细的配置说明,修改内容使网站正常运行。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
遂风百度知道(小偷采集)v1.3X更新如下:
1. 所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
免责声明:本站尊重各种网络文件的版权问题。所有软件文件均来自网络。所有提供下载的软件和资源均由软件或程序作者提供,并由网友推荐。它们仅用于学习和研究。如果您侵犯了您的版权,请发邮件至邮箱:,本站将立即更正。本站绝对支持网络版权。
立即编辑终身VIP 查看全部
文章采集程序(你问我答网,国内优秀的知识问答网站\)
安装注意事项:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//==============================================
$seo_1=\”你让我来回答网络国内优秀知识问答网站\”; //搜索引擎优化-标题后缀
$seo_2=\"你问我答网,知识问答,网友提问,网友回答\"; //搜索引擎优化——网站关键词
$seo_3=\"你问我答网,国内优秀知识问答网站\"; //搜索引擎优化-描述网站
//以上三个地方认真填写,会严重影响收录的数量!
$web=\"你让我回答网\"; //网站请填写姓名
$网站=\”\”; //网站不要加域名
$beian=\"辽ICP备14003759-1号\"; //记录号没什么好说的
$tj=\' \'//网站流量统计代码
//LOGO修改样式\\img\\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
修改后配置IIS伪静态,配置文件在\\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP这个文件,里面有详细的配置说明,修改内容使网站正常运行。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存,请设置为false,如果需要清除缓存,请设置为true
$cache_index=\”10\”; //首页默认每10分钟更新一次
$cache_list=\”30\”; //列表默认每30分钟更新一次
$cache_read=\”120\”; //内容页默认每120分钟更新一次
遂风百度知道(小偷采集)v1.3X更新如下:
1. 所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
免责声明:本站尊重各种网络文件的版权问题。所有软件文件均来自网络。所有提供下载的软件和资源均由软件或程序作者提供,并由网友推荐。它们仅用于学习和研究。如果您侵犯了您的版权,请发邮件至邮箱:,本站将立即更正。本站绝对支持网络版权。
立即编辑终身VIP
文章采集程序(相似软件版本说明软件地址优采云采集器(www.ucaiyun.com)是什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-30 16:03
优采云采集器,一款专业的互联网数据抓取、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确的挖掘出来所需的数据。优采云采集器 经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页数据采集软件。
类似软件
印记
软件地址
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,您可以立即创建一个内容丰富的网站。优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章、东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔术论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器()更新日志
1、 调整列表页面的重新排列方式,现在只在同一级别的列表页面之间进行重新排列。
2、增加任务完成后运行统计的警告功能(邮件警告)【终极版功能】
3、 增加了对一些返回码不是200的请求的支持,仍然执行采集的配置。
4、 新增支持将下载地址保存为html文件。
5、 二级代理服务,增加导入时代理类型配置,同时修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选中的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选择图片水印时图片无法裁剪的问题。
9、优化启动界面加载方式,解决初始界面冻结问题。
10、修复“|”无法检测到图片下载的问题 在多线连接器配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复Excel导出数据时部分字段收录数字的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。 查看全部
文章采集程序(相似软件版本说明软件地址优采云采集器(www.ucaiyun.com)是什么)
优采云采集器,一款专业的互联网数据抓取、处理、分析、挖掘软件,可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确的挖掘出来所需的数据。优采云采集器 经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页数据采集软件。
类似软件
印记
软件地址
优采云采集器() 是一个多线程的内容采集发布程序,适用于各大主流文章系统、论坛系统等。使用优采云@ >采集器,您可以立即创建一个内容丰富的网站。优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您<任何@采集的网页数据发布到远程服务器,自定义用户cms系统模块。不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅文章、东夷文章@ >、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔术论坛、德德cms文章、Xydw< @文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器()更新日志
1、 调整列表页面的重新排列方式,现在只在同一级别的列表页面之间进行重新排列。
2、增加任务完成后运行统计的警告功能(邮件警告)【终极版功能】
3、 增加了对一些返回码不是200的请求的支持,仍然执行采集的配置。
4、 新增支持将下载地址保存为html文件。
5、 二级代理服务,增加导入时代理类型配置,同时修复用户名密码显示错误。
6、发布配置页面,默认只显示当前选中的配置,加快任务加载时间。
7、修复命令行控制,closeapp参数无法自动关闭程序的问题。
8、修复未选择图片水印时图片无法裁剪的问题。
9、优化启动界面加载方式,解决初始界面冻结问题。
10、修复“|”无法检测到图片下载的问题 在多线连接器配置中。
11、修复Excel导出数据时列顺序与字段顺序不一致的问题。
12、修复Excel导出数据时部分字段收录数字的问题。
13、修复批量编辑任务时无法复制Json采集表达式的问题。
文章采集程序(爬虫:中文资料和使用爬虫(beautifulsoup)、scrapy等前端解析工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-24 23:04
文章采集程序可使用爬虫(beautifulsoup)、scrapy、lxml等前端解析工具;也可以使用requests、selenium、ghosthandler等支持javascript的工具。接下来我将在笔记本上用eclipse和apache软件安装使用apachescrapy。本文将依次介绍下中文资料和使用爬虫需要注意的事项。
中文资料:1.apachescrapy官方文档chinaguide.2.菜鸟教程scrapyhelp.3.百度百科scrapy入门使用4.京东商城的商品数据爬取和数据分析训练-requests模块介绍5.百度百科scrapy入门使用6.scrapy算法及爬虫效果分析7.爬虫实战项目学习8.爬虫项目项目开发9.excel数据操作-可视化_商品数据-销量-评论等10.万数pythonscrapy项目开发11.excel数据操作-pandas处理原始文本12.excel数据操作-sql语句-翻译等13.excel数据操作-do_something14.excel数据操作-日期格式表示格式转换15.excel数据操作-数据归档16.excel数据操作-format17.xls文件获取.xlsx18.xls文件操作.xlsm19.xls文件操作.xlsdt20.xls文件操作.xlsdd21.xls文件操作.xlsdm22.xls文件操作.xlspd23.xls文件操作.xlspc24.xls文件操作.xlsm25.xls文件操作.xlspp26.xls文件操作.xlsd27.xls文件操作.xlsbe28.xls文件操作.xlspc29.xls文件操作.xlsdd30.xls文件操作.xlsmm31.xls文件操作.xlsmg32.xls文件操作.xlsm33.xls文件操作.xlsm34.xls文件操作.xlsx35.xls文件操作.xlsvr36.xls文件操作.xlsax37.xls文件操作.xlsut38.xls文件操作.xlsxy39.xls文件操作.xlsnd40.xls文件操作.xlsxyi41.xls文件操作.xlsds42.xls文件操作.xlsx43.xls文件操作.xlsx44.xls文件操作.xlsx545.xls文件操作.xlsx546.xls文件操作.xlsx747.xls文件操作.xlsx-58.xls文件操作.xlsx658.xls文件操作.xlsx7在apachescrapy中,代码一般使用xml抽取文本数据形式,xml数据格式非常容易理解。
下面是一个完整的爬虫过程。而每一步都有一些注意事项,所以其实学习上没有捷径。第一步,请求百度,在百度请求的正则中就可以获取所需的商品名称和销量等信息。第二步,结合京东数据,我们知道它的数据导入方式是java爬虫框架jsoup。所以在这里提前做个准备工作,先安装jsoup。首先,我们在浏览器中输入京东商城的地址:spider/jsoup如下图:首先我们看到京东商城的商品列表页的商品有。 查看全部
文章采集程序(爬虫:中文资料和使用爬虫(beautifulsoup)、scrapy等前端解析工具)
文章采集程序可使用爬虫(beautifulsoup)、scrapy、lxml等前端解析工具;也可以使用requests、selenium、ghosthandler等支持javascript的工具。接下来我将在笔记本上用eclipse和apache软件安装使用apachescrapy。本文将依次介绍下中文资料和使用爬虫需要注意的事项。
中文资料:1.apachescrapy官方文档chinaguide.2.菜鸟教程scrapyhelp.3.百度百科scrapy入门使用4.京东商城的商品数据爬取和数据分析训练-requests模块介绍5.百度百科scrapy入门使用6.scrapy算法及爬虫效果分析7.爬虫实战项目学习8.爬虫项目项目开发9.excel数据操作-可视化_商品数据-销量-评论等10.万数pythonscrapy项目开发11.excel数据操作-pandas处理原始文本12.excel数据操作-sql语句-翻译等13.excel数据操作-do_something14.excel数据操作-日期格式表示格式转换15.excel数据操作-数据归档16.excel数据操作-format17.xls文件获取.xlsx18.xls文件操作.xlsm19.xls文件操作.xlsdt20.xls文件操作.xlsdd21.xls文件操作.xlsdm22.xls文件操作.xlspd23.xls文件操作.xlspc24.xls文件操作.xlsm25.xls文件操作.xlspp26.xls文件操作.xlsd27.xls文件操作.xlsbe28.xls文件操作.xlspc29.xls文件操作.xlsdd30.xls文件操作.xlsmm31.xls文件操作.xlsmg32.xls文件操作.xlsm33.xls文件操作.xlsm34.xls文件操作.xlsx35.xls文件操作.xlsvr36.xls文件操作.xlsax37.xls文件操作.xlsut38.xls文件操作.xlsxy39.xls文件操作.xlsnd40.xls文件操作.xlsxyi41.xls文件操作.xlsds42.xls文件操作.xlsx43.xls文件操作.xlsx44.xls文件操作.xlsx545.xls文件操作.xlsx546.xls文件操作.xlsx747.xls文件操作.xlsx-58.xls文件操作.xlsx658.xls文件操作.xlsx7在apachescrapy中,代码一般使用xml抽取文本数据形式,xml数据格式非常容易理解。
下面是一个完整的爬虫过程。而每一步都有一些注意事项,所以其实学习上没有捷径。第一步,请求百度,在百度请求的正则中就可以获取所需的商品名称和销量等信息。第二步,结合京东数据,我们知道它的数据导入方式是java爬虫框架jsoup。所以在这里提前做个准备工作,先安装jsoup。首先,我们在浏览器中输入京东商城的地址:spider/jsoup如下图:首先我们看到京东商城的商品列表页的商品有。
文章采集程序(采集公众号文章类网站,收录排名会很好的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-23 21:03
------------------------
采集公文章 网站,真的很大,主要是在资源方面。
自此,Sogou已经获得了微信公共资源的入口,百度已经垂涎三脚,但没有许可百度,不敢抓住内容,只能看看它。每个搜索引擎都希望获得更多的用户信任,有必要做好:智能,质量满足用户需求。满足用户需求的基础是资源。资源来源,Portal 网站,用户的个人网站和第三方自媒体平台。和微信公共号码是资源中心,新闻中心,索沟收益借口,在百度搜索引擎上没有数据,如果可以掌握这些数据,创建网站,这个网站百百百度来它是一种稀缺的资源,那么收录排名将非常好。
首先:这些程序是什么?是否安装了任何开源程序?
一般抓住微信公共文章 网站小,然后开源过程很少,一般开发。
第二:如何做到?
1.可以借用dede cms内容内容装@ / p>
2.发现了一个很好的网站 for imitation站
第三:他们是如何做的?
1.他们首先开发了一个程序
2. 优采云采集 software 采集
3.网站 data更新
事实上,还有思考的思考
首先,他们首先基于Sogou Wechat搜索,有趣,金融,技术,体育,娱乐等,根据这些类别:1.阅阅2.更新频率3.工业网网网网网网。然后要确定一些公共帐户,然后每3天每3天更新数据。然后通过百度联盟广告赚钱,如果排名并可以与公众合作,并开设整站才能促销金钱。
如:
让我们仔细看看,他们的公共号码文章,不是最新的,所以它们也被数据采集更新。
是好的,只是说,外面的天空仍然很蓝。
--------------------- 查看全部
文章采集程序(采集公众号文章类网站,收录排名会很好的方法)
------------------------
采集公文章 网站,真的很大,主要是在资源方面。
自此,Sogou已经获得了微信公共资源的入口,百度已经垂涎三脚,但没有许可百度,不敢抓住内容,只能看看它。每个搜索引擎都希望获得更多的用户信任,有必要做好:智能,质量满足用户需求。满足用户需求的基础是资源。资源来源,Portal 网站,用户的个人网站和第三方自媒体平台。和微信公共号码是资源中心,新闻中心,索沟收益借口,在百度搜索引擎上没有数据,如果可以掌握这些数据,创建网站,这个网站百百百度来它是一种稀缺的资源,那么收录排名将非常好。
首先:这些程序是什么?是否安装了任何开源程序?
一般抓住微信公共文章 网站小,然后开源过程很少,一般开发。
第二:如何做到?
1.可以借用dede cms内容内容装@ / p>
2.发现了一个很好的网站 for imitation站
第三:他们是如何做的?
1.他们首先开发了一个程序
2. 优采云采集 software 采集
3.网站 data更新
事实上,还有思考的思考
首先,他们首先基于Sogou Wechat搜索,有趣,金融,技术,体育,娱乐等,根据这些类别:1.阅阅2.更新频率3.工业网网网网网网。然后要确定一些公共帐户,然后每3天每3天更新数据。然后通过百度联盟广告赚钱,如果排名并可以与公众合作,并开设整站才能促销金钱。
如:
让我们仔细看看,他们的公共号码文章,不是最新的,所以它们也被数据采集更新。
是好的,只是说,外面的天空仍然很蓝。
---------------------

