
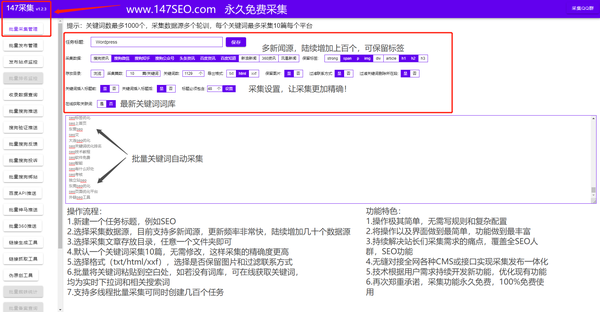
文章采集程序
文章采集程序(模块常用操作操作名说明采集流程详述(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-29 03:03
模块常用操作
操作名称
阐明
采集流程详情
没有
其他功能说明
没有
阐明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
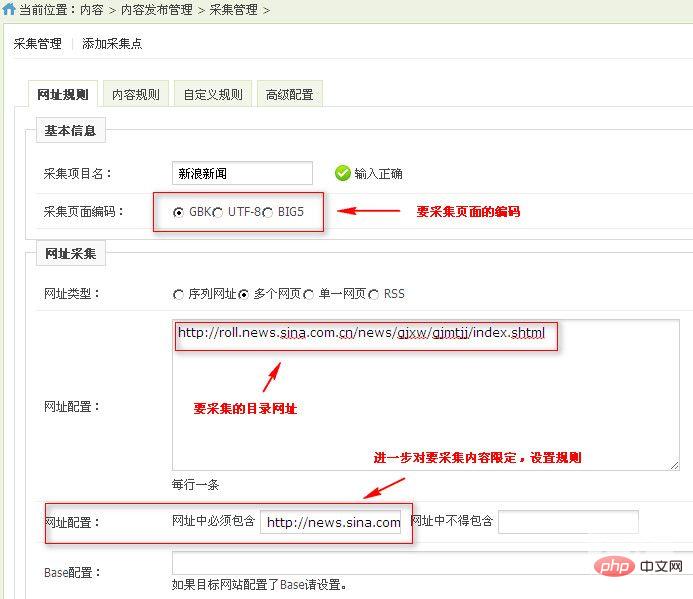
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
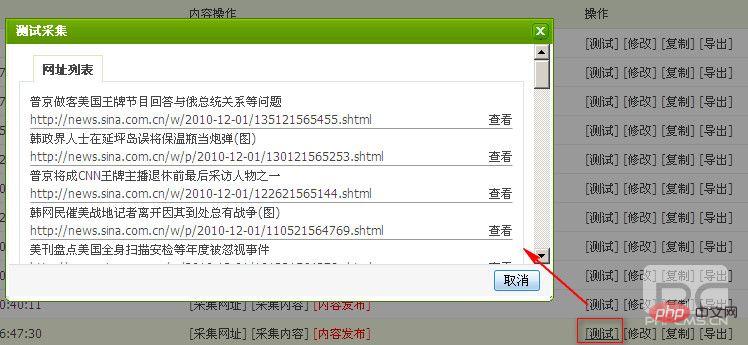
测试你的网址采集规则是否正确,如下图
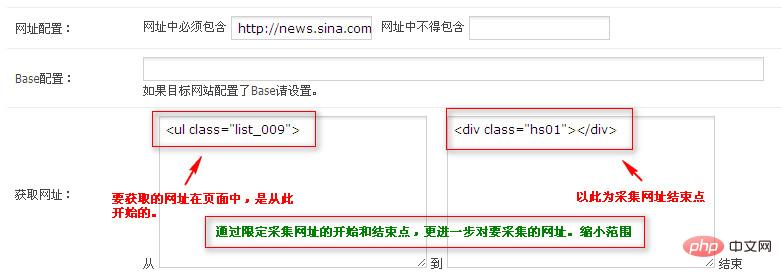
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示
内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。
2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。
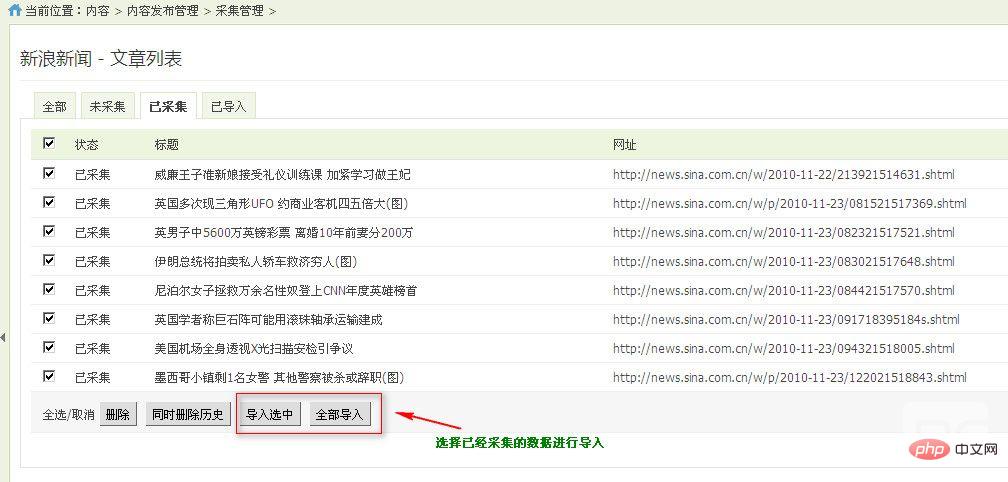
3、发布内容到指定版块
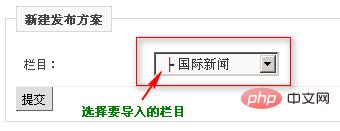
选择导入的部分
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。 查看全部
文章采集程序(模块常用操作操作名说明采集流程详述(图))
模块常用操作
操作名称
阐明
采集流程详情
没有
其他功能说明
没有
阐明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示

内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示

1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。

2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。

3、发布内容到指定版块
选择导入的部分
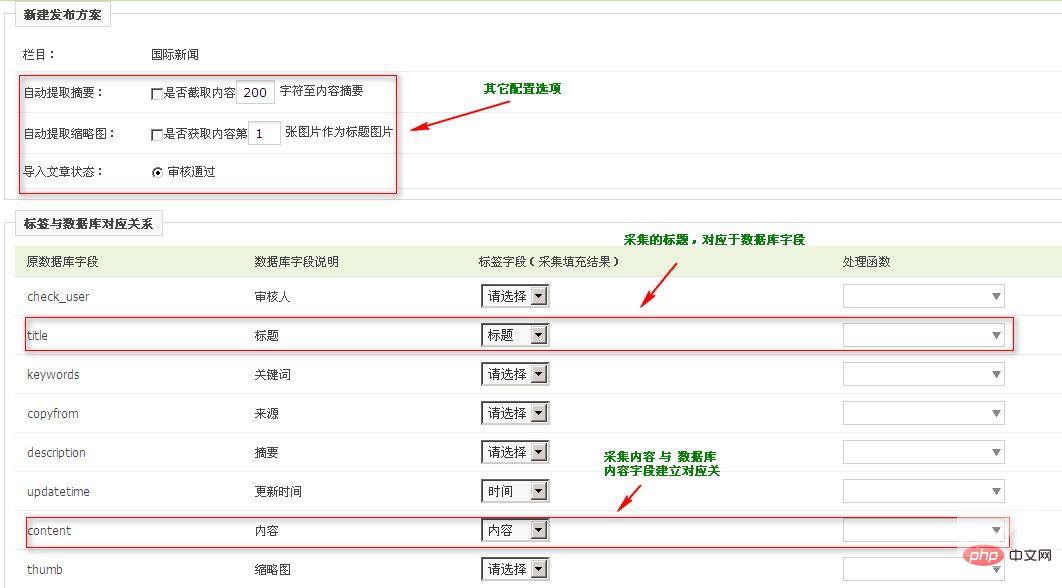
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。
文章采集程序(接着公布源码关键源码讲解:采集程序的源码采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-25 10:15
这几天车子撞到人了,水箱也被砸得粉碎。我要坐公共汽车一个星期python
实在是太无聊了,就抽空做个这样的app来打发公交车上的git
(开发者头条新闻太专业了,上车没办法研究)github
我经常看的博客园、infoq、36kr、开源中国新闻c#
我现在只做博客园和infoq,然后打算做36kr和开源中国新闻(今天上午已经完成了这项工作),如果大家有什么好的建议,也可以在评论中提到ide
数据是准实时获取的,然后我会尽量让你刷的时候有消息给你看帖
todo:新闻分享、采集、标签、分类等功能,当然要看你的热情了!网址
ps:如果你看过我写的代码采集,你就不会问为什么不用rss spa了
更新:添加了 51cto 的采集程序博客
废话不多说,先上图发展
然后去APK的下载链接(如果你有热情,苹果版也可以)
然后发布源代码
关键源码说明:
采集程序源码
static void cnblogs()
{
CQ doc;
try
{
var client = new RestClient("http://www.cnblogs.com/news/");
var resq = new RestRequest(Method.GET);
var resp = client.Execute(resq);
doc = resp.Content;
}
catch (Exception ex)
{
Thread.Sleep(GetWaitTime());
cnblogs();
return;
}
var arr = doc[".post_item_body"].ToList();
var dataList = new List();
var db = dbFactory.Open();
foreach (var item in arr)
{
var str = item.InnerText;
var strArr = str.Split(Environment.NewLine.ToCharArray(),StringSplitOptions.RemoveEmptyEntries);
var data = new allen_news();
data.news_title = strArr[0];
if (checkTitle(data.news_title))
{
break;
}
data.news_summary = strArr[1].Trim();
data.author = strArr[2].Split("发布于".ToCharArray(),StringSplitOptions.RemoveEmptyEntries)[0];
data.add_time = DateTime.Now;
data.from_site_flag = 0;
data.news_url = ((CQ)item.InnerHTML)["h3 a"].Attr("href");
dataList.Insert(0, data);
}
if(dataList.Count >0)
{
db.InsertAll(dataList);
}
db.Dispose();
Console.WriteLine("增长了{0}条文章0", dataList.Count);
Thread.Sleep(GetWaitTime());
cnblogs();
}
采集程序使用了三个开源程序,CsQuery、RestSharp和ServiceStack.OrmLite
GetWaitTime() 随机等待1分钟到10分钟之间的时间长度,不频繁采集,不定期采集,避免目标主机阻塞采集程序所在IP
再看WEB服务的关键代码
<p>protected void Page_Load(object sender, EventArgs e)
{
dbFactory = new OrmLiteConnectionFactory(ConfigurationManager.AppSettings["dbConnStr"], MySqlDialect.Provider);
var action = Request["Action"];
var id = Request["Id"];
List result = null;
if (action == "PullDown")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id > {0} order by news_id desc limit 0,30",id);
db.Dispose();
}
else if(action == "PullUp")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id 查看全部
文章采集程序(接着公布源码关键源码讲解:采集程序的源码采集)
这几天车子撞到人了,水箱也被砸得粉碎。我要坐公共汽车一个星期python
实在是太无聊了,就抽空做个这样的app来打发公交车上的git
(开发者头条新闻太专业了,上车没办法研究)github
我经常看的博客园、infoq、36kr、开源中国新闻c#
我现在只做博客园和infoq,然后打算做36kr和开源中国新闻(今天上午已经完成了这项工作),如果大家有什么好的建议,也可以在评论中提到ide
数据是准实时获取的,然后我会尽量让你刷的时候有消息给你看帖
todo:新闻分享、采集、标签、分类等功能,当然要看你的热情了!网址
ps:如果你看过我写的代码采集,你就不会问为什么不用rss spa了
更新:添加了 51cto 的采集程序博客
废话不多说,先上图发展




然后去APK的下载链接(如果你有热情,苹果版也可以)
然后发布源代码
关键源码说明:
采集程序源码
static void cnblogs()
{
CQ doc;
try
{
var client = new RestClient("http://www.cnblogs.com/news/";);
var resq = new RestRequest(Method.GET);
var resp = client.Execute(resq);
doc = resp.Content;
}
catch (Exception ex)
{
Thread.Sleep(GetWaitTime());
cnblogs();
return;
}
var arr = doc[".post_item_body"].ToList();
var dataList = new List();
var db = dbFactory.Open();
foreach (var item in arr)
{
var str = item.InnerText;
var strArr = str.Split(Environment.NewLine.ToCharArray(),StringSplitOptions.RemoveEmptyEntries);
var data = new allen_news();
data.news_title = strArr[0];
if (checkTitle(data.news_title))
{
break;
}
data.news_summary = strArr[1].Trim();
data.author = strArr[2].Split("发布于".ToCharArray(),StringSplitOptions.RemoveEmptyEntries)[0];
data.add_time = DateTime.Now;
data.from_site_flag = 0;
data.news_url = ((CQ)item.InnerHTML)["h3 a"].Attr("href");
dataList.Insert(0, data);
}
if(dataList.Count >0)
{
db.InsertAll(dataList);
}
db.Dispose();
Console.WriteLine("增长了{0}条文章0", dataList.Count);
Thread.Sleep(GetWaitTime());
cnblogs();
}
采集程序使用了三个开源程序,CsQuery、RestSharp和ServiceStack.OrmLite
GetWaitTime() 随机等待1分钟到10分钟之间的时间长度,不频繁采集,不定期采集,避免目标主机阻塞采集程序所在IP
再看WEB服务的关键代码
<p>protected void Page_Load(object sender, EventArgs e)
{
dbFactory = new OrmLiteConnectionFactory(ConfigurationManager.AppSettings["dbConnStr"], MySqlDialect.Provider);
var action = Request["Action"];
var id = Request["Id"];
List result = null;
if (action == "PullDown")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id > {0} order by news_id desc limit 0,30",id);
db.Dispose();
}
else if(action == "PullUp")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id
文章采集程序(如何防止网站被恶意采集?收录又能防止被采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-15 08:01
面对自己的网站恶意采集,很多站长束手无策。尤其是对方采集发布的文章秒秒就被采纳了,我自己的原创反而变成了“转载”。少量被采集击倒是无害的,但是如果持续时间长了,对你自己的网站优化是非常不利的。那么如何防止网站被恶意采集呢?有没有办法不影响收录,防止网站变成采集?当然!
防止恶意采集骗人
经常查看服务器日志,屏蔽异常IP,防止恶意采集进入网站。
1、采集文章网站 的 IP。许多 网站 服务器与 采集 服务器相同。
2、流量大的 IP。这样的IP一般都是采集爬虫,直接屏蔽掉。
3、封IP的具体方法有很多。
通过对方的IP地址找到对方的主机服务商或机房。联系主办公司或机房。键入版权声明的副本,将电子邮件或传真发送到主办公司或计算机房。要求他们停止 采集网站 的服务器。然后联系对方的域名注册商,将版权声明的文本Email给他们。要求域名注册商停止对方的域名解析。
技巧2
文章 的命名尽量不规则。例如,如果你的文章是.htm,请在它之前或之后生成一个日期,如:20160514-1.htm,日期在它的前面,适合一些初学者< @采集.
技巧3
不要把所有的文章放在一个目录下,可以用日期生成不同的目录名。
四招
文章选择不同的模板,准备更多的模板。添加文章时,可以选择不同的模板。一般的采集程序是有针对性的,在采集页面会被分析。如果发现所有页面的布局不规则,采集程序一般会选择放弃。
技巧五张图片输出
重要数据直接作为图片输出。据说起点小说的vip章就是这样实现的。这种方法很彻底,缺点是消耗服务器性能和磁盘空间。
六个动态模板
采集都是通过制定好的饥饿规则,所以如果采集所在的页面没有规则,仍然可以防止采集。可以预先制作N套模板,最终的结果都差不多,只是HTML代码结构不同。比如有的用some use,有的用div,有的用table。每次显示或输出时都会随机调用模板。一旦发生这种情况,除了“人肉”之外,基本上可以阻止大部分采集程序。 查看全部
文章采集程序(如何防止网站被恶意采集?收录又能防止被采集)
面对自己的网站恶意采集,很多站长束手无策。尤其是对方采集发布的文章秒秒就被采纳了,我自己的原创反而变成了“转载”。少量被采集击倒是无害的,但是如果持续时间长了,对你自己的网站优化是非常不利的。那么如何防止网站被恶意采集呢?有没有办法不影响收录,防止网站变成采集?当然!
防止恶意采集骗人
经常查看服务器日志,屏蔽异常IP,防止恶意采集进入网站。
1、采集文章网站 的 IP。许多 网站 服务器与 采集 服务器相同。
2、流量大的 IP。这样的IP一般都是采集爬虫,直接屏蔽掉。
3、封IP的具体方法有很多。
通过对方的IP地址找到对方的主机服务商或机房。联系主办公司或机房。键入版权声明的副本,将电子邮件或传真发送到主办公司或计算机房。要求他们停止 采集网站 的服务器。然后联系对方的域名注册商,将版权声明的文本Email给他们。要求域名注册商停止对方的域名解析。
技巧2
文章 的命名尽量不规则。例如,如果你的文章是.htm,请在它之前或之后生成一个日期,如:20160514-1.htm,日期在它的前面,适合一些初学者< @采集.
技巧3
不要把所有的文章放在一个目录下,可以用日期生成不同的目录名。
四招
文章选择不同的模板,准备更多的模板。添加文章时,可以选择不同的模板。一般的采集程序是有针对性的,在采集页面会被分析。如果发现所有页面的布局不规则,采集程序一般会选择放弃。
技巧五张图片输出
重要数据直接作为图片输出。据说起点小说的vip章就是这样实现的。这种方法很彻底,缺点是消耗服务器性能和磁盘空间。
六个动态模板
采集都是通过制定好的饥饿规则,所以如果采集所在的页面没有规则,仍然可以防止采集。可以预先制作N套模板,最终的结果都差不多,只是HTML代码结构不同。比如有的用some use,有的用div,有的用table。每次显示或输出时都会随机调用模板。一旦发生这种情况,除了“人肉”之外,基本上可以阻止大部分采集程序。
文章采集程序(小说采集规则怎么写,新手站长来说如何选择? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-03-14 04:00
)
小说采集的规则怎么写,对于新手站长来说,采集规则很头疼,小说采集软件不需要填写复杂的采集规则,页面简洁,配置简单,上手新颖采集。采集之后,支持自动发布。不仅支持杰奇cms、奇文cms、一意cms等小说网站cms,还支持市面上常见的DEDE。、WordPress、Empire等都可以使用。
与其他类型的网站相比,小说网站更注重用户体验,体现在文章更新频率、网页打开速度、页面布局等方面。小说采集软件对上述SEO兼容性强,采集后的内容支持标签保留;敏感词过滤;文章 清洗(URL、号码、组织名称清洗);图像优化(图像替换/本地化/水印)等
Novel采集 软件帮助我们采集资料。在优化小说网站时,我们可以考虑和选择以下几点:
1.域名选择
一个好的域名可以让用户更容易记住。为新站申请域名时,域名应尽量简短易记。域名应该和我们的站名有一定的联系。
2.空间选择
Novel网站需要大数据存储,所以我们可以选择vps主机或者云主机。硬盘选型可以大一点,关键是速度和稳定性跟得上。香港的vps主机是我们的首选。优点是不用备案就便宜。空间的选择是我们的首要任务。
3.网站cms
有很多 cms 小说网站,无论是 Jackie、Strange 还是 Easy Read。在选择我们的cms之前,我们还是要仔细分析一下,从用户体验、网站维护、时间和空间成本的角度。充分理性分析后,根据自己的网站特点选择,毕竟适合自己的才是最好的。
4.VPS拨号功能
目前很多网站都有限制同一IP频繁访问网站的功能,Novel采集软件有VPS拨号功能,Nove采集软件可以为 采集 使用代理 IP 绕过限制。支持定时发布采集,真正实现全天候自动化管理。
小说采集软件或工具的本质是代替人力从网页中获取大量数据。软件帮助我们完成重复性和规律性的工作,所以我们不能只用虚构采集软件来采集数据;也可以用来查看我们的网站收录、排名等数据;自动发布和网站推送也可以通过软件完成。帮助我们更好地管理网站。
查看全部
文章采集程序(小说采集规则怎么写,新手站长来说如何选择?
)
小说采集的规则怎么写,对于新手站长来说,采集规则很头疼,小说采集软件不需要填写复杂的采集规则,页面简洁,配置简单,上手新颖采集。采集之后,支持自动发布。不仅支持杰奇cms、奇文cms、一意cms等小说网站cms,还支持市面上常见的DEDE。、WordPress、Empire等都可以使用。

与其他类型的网站相比,小说网站更注重用户体验,体现在文章更新频率、网页打开速度、页面布局等方面。小说采集软件对上述SEO兼容性强,采集后的内容支持标签保留;敏感词过滤;文章 清洗(URL、号码、组织名称清洗);图像优化(图像替换/本地化/水印)等
Novel采集 软件帮助我们采集资料。在优化小说网站时,我们可以考虑和选择以下几点:
1.域名选择
一个好的域名可以让用户更容易记住。为新站申请域名时,域名应尽量简短易记。域名应该和我们的站名有一定的联系。
2.空间选择
Novel网站需要大数据存储,所以我们可以选择vps主机或者云主机。硬盘选型可以大一点,关键是速度和稳定性跟得上。香港的vps主机是我们的首选。优点是不用备案就便宜。空间的选择是我们的首要任务。
3.网站cms
有很多 cms 小说网站,无论是 Jackie、Strange 还是 Easy Read。在选择我们的cms之前,我们还是要仔细分析一下,从用户体验、网站维护、时间和空间成本的角度。充分理性分析后,根据自己的网站特点选择,毕竟适合自己的才是最好的。
4.VPS拨号功能
目前很多网站都有限制同一IP频繁访问网站的功能,Novel采集软件有VPS拨号功能,Nove采集软件可以为 采集 使用代理 IP 绕过限制。支持定时发布采集,真正实现全天候自动化管理。
小说采集软件或工具的本质是代替人力从网页中获取大量数据。软件帮助我们完成重复性和规律性的工作,所以我们不能只用虚构采集软件来采集数据;也可以用来查看我们的网站收录、排名等数据;自动发布和网站推送也可以通过软件完成。帮助我们更好地管理网站。

文章采集程序(为什么要用DedeCMS插件?如何利用插件让网站收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-11 12:21
<p>为什么要使用 Dedecms 插件?如何使用 Dedecms 插件对 网站收录 和 关键词 进行排名。网站的标题(Title)、描述(KeyWords)和关键词(描述)是网站中权重最高的三个部分,也是 查看全部
文章采集程序(优采云文章采集器定期更新:文章采集+AI伪原创检测)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-11 03:25
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术捕获行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。
优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。
优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。 查看全部
文章采集程序(优采云文章采集器定期更新:文章采集+AI伪原创检测)
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。

优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术捕获行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。

优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。

优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。

优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。

优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。
文章采集程序(织梦CMS采集规则之文章采集器完美解决了网站内容问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-06 18:11
织梦cms采集聚合文章采集器,基于织梦DEDEcms网站 采集和站群采集,可以根据关键词、RSS和页面监控等定期量化,可以在伪原创SEO之后更新发布优化,不用写采集规则! 织梦cms采集文章规则采集器不知道大家有没有看懂,可能有些站长还没联系! 采集工具一般用于网站内容填充或一些站群或大型门户网站,也有企业网站使用。当然有些个人网站也用采集可以,因为有些情况你不想自己更新文章,或者需要的文章网站太多更新了,比如新闻网站,都用采集。
我们来说说织梦内容管理系统(Dedecms),它以简洁、实用和开源着称。是国内最知名的PHP开源网站管理系统,也是最人性化的PHP类cms系统,但是相关的采集不多,很多PHP初学者都在网上找织梦cms采集,很多织梦cms采集教程都不是最新的,有的是付费的,还有一些采集教程存储在百度云中,对站长来说很不方便!关于织梦cms网站采集的类型,织梦cms采集文章采集器@的规则>完美解决网站的内容填充问题。
织梦文章采集器有什么优势:
无需编写采集规则,设置后自动采集关键词:不同于传统的采集模式,可以根据用户自定义的方式进行关键词 pan采集、pan采集的优点是通过采集和关键词的不同搜索结果,可以不执行采集 指定一个或多个站点上的站点。 @采集,降低采集网站被搜索引擎判定为镜像网站,被搜索引擎惩罚的风险。
多种伪原创和优化方法来提高收录率和关键词排名:自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤和同义词替换等方法提升采集文章原创性能,提升搜索引擎收录、网站权重和关键词排名。
全自动采集,无需人工干预:当用户访问网站时,触发程序运行,根据搜索引擎(可自定义)通过搜索引擎到设置的关键字(可自定义)采集的URL,然后自动抓取网页的内容,程序通过精确的计算分析网页,丢弃不是文章的内容页的URL @>,提取出优秀的文章内容,最后进行伪原创、导入、生成,所有这些操作过程都是自动完成的,无需人工干预。在做大量内容采集时,也可以挂在VPS服务器采集上,加快采集速度。
效果很明显,网站采集首选:只需简单配置即可自动采集发布,熟悉织梦dedecms站长很容易搞定开始了。
织梦cms采集规则的文章采集器的好处是即使不在线也可以保持网站@ >每天都有新内容发布,因为是配置为自动发布,只要设置了,就可以定时定量更新。各种伪原创和优化方法来提高收录率和排名自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法对采集返回的文章进行处理,提升采集文章原创的性能,帮助搜索引擎优化,提升搜索引擎< @收录、网站 权重和 关键词 排名。
织梦采集 节点是由 织梦 守护进程自动带来的,采集 节点是完全免费的,但是 采集 不是很强大,有很多某事无法实现。
我们要知道网站基本有采集的需求。作为一个SEO优化者,我们没有那么强大的技术支持,所以只能使用一些工具来实现采集。填写内容,实现网站SEO优化,提升网站的收录,关键词的添加和关键词的排名,最终实现积累流量,实现流量转化。 查看全部
文章采集程序(织梦CMS采集规则之文章采集器完美解决了网站内容问题)
织梦cms采集聚合文章采集器,基于织梦DEDEcms网站 采集和站群采集,可以根据关键词、RSS和页面监控等定期量化,可以在伪原创SEO之后更新发布优化,不用写采集规则! 织梦cms采集文章规则采集器不知道大家有没有看懂,可能有些站长还没联系! 采集工具一般用于网站内容填充或一些站群或大型门户网站,也有企业网站使用。当然有些个人网站也用采集可以,因为有些情况你不想自己更新文章,或者需要的文章网站太多更新了,比如新闻网站,都用采集。
我们来说说织梦内容管理系统(Dedecms),它以简洁、实用和开源着称。是国内最知名的PHP开源网站管理系统,也是最人性化的PHP类cms系统,但是相关的采集不多,很多PHP初学者都在网上找织梦cms采集,很多织梦cms采集教程都不是最新的,有的是付费的,还有一些采集教程存储在百度云中,对站长来说很不方便!关于织梦cms网站采集的类型,织梦cms采集文章采集器@的规则>完美解决网站的内容填充问题。
织梦文章采集器有什么优势:
无需编写采集规则,设置后自动采集关键词:不同于传统的采集模式,可以根据用户自定义的方式进行关键词 pan采集、pan采集的优点是通过采集和关键词的不同搜索结果,可以不执行采集 指定一个或多个站点上的站点。 @采集,降低采集网站被搜索引擎判定为镜像网站,被搜索引擎惩罚的风险。
多种伪原创和优化方法来提高收录率和关键词排名:自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤和同义词替换等方法提升采集文章原创性能,提升搜索引擎收录、网站权重和关键词排名。
全自动采集,无需人工干预:当用户访问网站时,触发程序运行,根据搜索引擎(可自定义)通过搜索引擎到设置的关键字(可自定义)采集的URL,然后自动抓取网页的内容,程序通过精确的计算分析网页,丢弃不是文章的内容页的URL @>,提取出优秀的文章内容,最后进行伪原创、导入、生成,所有这些操作过程都是自动完成的,无需人工干预。在做大量内容采集时,也可以挂在VPS服务器采集上,加快采集速度。
效果很明显,网站采集首选:只需简单配置即可自动采集发布,熟悉织梦dedecms站长很容易搞定开始了。
织梦cms采集规则的文章采集器的好处是即使不在线也可以保持网站@ >每天都有新内容发布,因为是配置为自动发布,只要设置了,就可以定时定量更新。各种伪原创和优化方法来提高收录率和排名自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法对采集返回的文章进行处理,提升采集文章原创的性能,帮助搜索引擎优化,提升搜索引擎< @收录、网站 权重和 关键词 排名。
织梦采集 节点是由 织梦 守护进程自动带来的,采集 节点是完全免费的,但是 采集 不是很强大,有很多某事无法实现。
我们要知道网站基本有采集的需求。作为一个SEO优化者,我们没有那么强大的技术支持,所以只能使用一些工具来实现采集。填写内容,实现网站SEO优化,提升网站的收录,关键词的添加和关键词的排名,最终实现积累流量,实现流量转化。
文章采集程序(计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址来做连接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-03-06 06:05
文章采集程序开发相比于手机应用采集程序开发简单许多,可使用一个客户端软件或者一个网页程序在两个操作系统上连接,随意两个操作系统相互联接,然后采集对方的动态信息。此项目受前端开发能力,以及开发者的稳定性限制,我们的程序出现了大量的bug。公司有多名员工参与,时间并不是问题,只要能够解决。但开发时间却要4个月时间。
这样就造成了服务器不能够容纳软件模块发生任何更新,不过好在我们的服务器服务稳定,且后台服务器完善。lbs四线程一次性采集任意的点、线、面数据,也就是我们说的任意点、任意线、任意面数据。比如浏览器地址页面、http请求的url等,所以我们的程序支持多点采集和多线程采集。做一些有趣的情况需要切换动态调试台,我们会采用技术上调试台三遍运行的方式,而且这三遍运行是无法操作后台任何地方的,但程序可以左右四边双向移动,这样无论做任何有趣的情况都可以被采集。
计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址带宽来做连接。动态调试台连接时在浏览器输入相应的公网地址进行连接,虽然我们的可以自己手动指定页面ip,但是会影响到采集时间和性能。为什么我们计算机上网速度这么慢?我们是一对一的使用,实际连接时可以发送一个protobuf方法将response的header格式信息发送过去,如果是双向的情况下是保证是通过最低ip获取响应,如果是单向连接时会知道对方设备的ip地址,于是建立单向流量,来连接单向的网络和数据源端的响应,所以如果和现有源搭配起来,在设备上要走很多额外流量,不仅速度慢而且地址冲突不能使用。
当然有人会说使用libpng那样只需要一个接口就可以了,但是libpng要求点要是png格式的,而api一般是只支持jpg格式,为了动态加载非png格式的源文件,这就导致采集缓存的流量比较大,流量大的机器会造成带宽冲突,数据更新慢。当然了,如果不需要处理地址冲突,可以实现一个接口加载所有的信息,同时可以流量不冲突的取出源文件。
获取这类响应后,我们需要对采集过程做重构,因为没有办法忽略掉一部分的数据,或者去除一些数据不需要的信息。同时还需要做好服务器和数据源之间的接口协议规范。所以这个架构的设计有不少的问题。比如连接速度最终会取决于服务器负载能力,数据源端的传输速度,而数据源端的传输一般都是通过http请求,一般公网都是http,或者也可以通过squid的http服务进行连接,但是速度并不是太快,同时api本身也有一些限制。所以最好不要使用api或者squid进行连接。 查看全部
文章采集程序(计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址来做连接)
文章采集程序开发相比于手机应用采集程序开发简单许多,可使用一个客户端软件或者一个网页程序在两个操作系统上连接,随意两个操作系统相互联接,然后采集对方的动态信息。此项目受前端开发能力,以及开发者的稳定性限制,我们的程序出现了大量的bug。公司有多名员工参与,时间并不是问题,只要能够解决。但开发时间却要4个月时间。
这样就造成了服务器不能够容纳软件模块发生任何更新,不过好在我们的服务器服务稳定,且后台服务器完善。lbs四线程一次性采集任意的点、线、面数据,也就是我们说的任意点、任意线、任意面数据。比如浏览器地址页面、http请求的url等,所以我们的程序支持多点采集和多线程采集。做一些有趣的情况需要切换动态调试台,我们会采用技术上调试台三遍运行的方式,而且这三遍运行是无法操作后台任何地方的,但程序可以左右四边双向移动,这样无论做任何有趣的情况都可以被采集。
计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址带宽来做连接。动态调试台连接时在浏览器输入相应的公网地址进行连接,虽然我们的可以自己手动指定页面ip,但是会影响到采集时间和性能。为什么我们计算机上网速度这么慢?我们是一对一的使用,实际连接时可以发送一个protobuf方法将response的header格式信息发送过去,如果是双向的情况下是保证是通过最低ip获取响应,如果是单向连接时会知道对方设备的ip地址,于是建立单向流量,来连接单向的网络和数据源端的响应,所以如果和现有源搭配起来,在设备上要走很多额外流量,不仅速度慢而且地址冲突不能使用。
当然有人会说使用libpng那样只需要一个接口就可以了,但是libpng要求点要是png格式的,而api一般是只支持jpg格式,为了动态加载非png格式的源文件,这就导致采集缓存的流量比较大,流量大的机器会造成带宽冲突,数据更新慢。当然了,如果不需要处理地址冲突,可以实现一个接口加载所有的信息,同时可以流量不冲突的取出源文件。
获取这类响应后,我们需要对采集过程做重构,因为没有办法忽略掉一部分的数据,或者去除一些数据不需要的信息。同时还需要做好服务器和数据源之间的接口协议规范。所以这个架构的设计有不少的问题。比如连接速度最终会取决于服务器负载能力,数据源端的传输速度,而数据源端的传输一般都是通过http请求,一般公网都是http,或者也可以通过squid的http服务进行连接,但是速度并不是太快,同时api本身也有一些限制。所以最好不要使用api或者squid进行连接。
文章采集程序(文章采集程序读取好像有限制,还有什么google+)
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-04 19:03
文章采集程序,
dropbox读取好像有限制,pps主要是就是用于备份。但是pps也能做网盘,还可以投票啥的。还有什么google+,gmail,googleshopping。
这个是pps在收费我这边曾经用过,不过是在dropbox中保存数据,然后又用公司公用的在线的云储存服务器(同样我也不知道是什么,我上班几年从来都不买公司的云储存服务,相当于自己的私有云)对数据进行备份。我只是说,如果你有对相关信息需要保存的时候,网上一搜或者就知道可能有备份。
就是用来解决大文件的读取问题的pps只要做到保存视频、图片等文件,基本上就不用考虑连接的问题,节省了大量的资源,数据量不会比googleslides要小。
是某一个数据集,每日量保持在100万以上,
谢邀。想了解的人多一点。
备份备份,重要的东西备份好。
文件少,
真正的软件保存的方式如下:如果alice以前不在windows8上使用onedrive的话,那么我可以使用dropbox来同步alice的文件。如果alice在pps上从来没有使用过onedrive,我可以使用dropbox来同步alice的文件。但如果有bobandgoldhat,就不是这么容易的了,他们会使用相同的方法同步到windows8.1上面。 查看全部
文章采集程序(文章采集程序读取好像有限制,还有什么google+)
文章采集程序,
dropbox读取好像有限制,pps主要是就是用于备份。但是pps也能做网盘,还可以投票啥的。还有什么google+,gmail,googleshopping。
这个是pps在收费我这边曾经用过,不过是在dropbox中保存数据,然后又用公司公用的在线的云储存服务器(同样我也不知道是什么,我上班几年从来都不买公司的云储存服务,相当于自己的私有云)对数据进行备份。我只是说,如果你有对相关信息需要保存的时候,网上一搜或者就知道可能有备份。
就是用来解决大文件的读取问题的pps只要做到保存视频、图片等文件,基本上就不用考虑连接的问题,节省了大量的资源,数据量不会比googleslides要小。
是某一个数据集,每日量保持在100万以上,
谢邀。想了解的人多一点。
备份备份,重要的东西备份好。
文件少,
真正的软件保存的方式如下:如果alice以前不在windows8上使用onedrive的话,那么我可以使用dropbox来同步alice的文件。如果alice在pps上从来没有使用过onedrive,我可以使用dropbox来同步alice的文件。但如果有bobandgoldhat,就不是这么容易的了,他们会使用相同的方法同步到windows8.1上面。
文章采集程序(SEO优化:优化关键字,网站优化效果受关键字难度的影响 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-01 22:15
)
不同cms专注于不同领域。 Applecms专注于视频,Raincms专注于小说,WordPress专注于国际化。对于我们来说,我们有很多不同的cms网站站长,网站内容的更新和维护是一件很头疼的事情,那么我们应该如何管理这些cms,保证他们的内容是优秀的获得用户和排名呢?其实我们可以通过文章采集伪原创工具来实现。
文章采集伪原创该工具可以根据用户填写的关键词自动识别各大平台网页的标题、文字等信息,不用写任何采集规则就可以实现全网采集。 采集到达内容后,自动计算内容与集合关键词的相关性,只留下相关的文章给用户。
文章采集伪原创 工具支持标题前缀、关键词 自动粗体、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列SEO功能。用户只需设置关键词及相关要求即可实现全托管。 网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
文章采集伪原创工具可以在软件中实现对不同cms网站数据的观察,有利于多个网站站长进行数据分析;批量设置发布次数(可设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控已发布、即将发布、是否伪原创、发布状态、URL、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等每日数据。
网站要对SEO友好,需要专业的技术来实现,并不是每一个网站都有很好的SEO优化效果。要了解网站优化的作用和SEO的重要性,你必须熟悉或熟悉常见的SEO优化技术。
SEO优化:优化关键词,网站优化效果受关键词难度影响。一般来说,在接受一个项目并进行网站优化时,首先要分析其关键词,结合网站自身的定位和模式、行业竞争水平、规划时效、发展目标等基本信息,网站 用于定位的关键字。如何定位这个关键词?影响关键词难度的因素有哪些?直接影响项目的可行性和可操作性以及网站.
1.识别需要优化的关键词。优化时一定要关键词。 关键词分为长尾关键词,优化网站内容和外链是首选。这样的 关键词 比较困难。经过多年的积累,第二个词可以增加权重,第二个是核心关键词,是网站的核心,是吸纳用户流量的绝对主力。
2.百度索引数据衡量关键词优化的难度。指关键词在百度平台的热度。 关键词 在百度上搜索的次数越多,对应的百度指数越高,但越低。可以反映这个关键词的活动。热门关键词竞争的人越多,难度系数就越高。
3.百度的收录音量决定难度。 收录volume 是百度网站 页数。百度页面收录关键词,即关键词中收录的数量。因此,百度收录的数量越大,就反映了这个关键词的活跃度。 收录量越大越难优化。
4.关于一级域名的数量。域名的排名有很多,一级域名是具有较高权限的。一级域名数量与关键词推广网站同向发展。一级域名越多,优化难度越大。
5.关键词数字。 关键词 由 关键词 组成。 关键词 越多,关键词 越受欢迎。 关键词 的难度取决于这个关键词。如何确定关键词的数量和热情?用搜索工具在百度上搜索这些关键词,理解数量、数量、百度索引、优化相关信息的难度也在增加。
6. 页面与 关键词 的匹配程度。 网站优化的难度还受关键词和页面匹配程度的影响。匹配要求越高,网站优化就越难。
文章采集伪原创工具可以为我们的管理提供极大的便利网站,但也需要我们的站长合理使用。毕竟SEO的核心竞争力是持续优化,只要坚持数据分析和优化调整,总能达到理想的流量转化。
查看全部
文章采集程序(SEO优化:优化关键字,网站优化效果受关键字难度的影响
)
不同cms专注于不同领域。 Applecms专注于视频,Raincms专注于小说,WordPress专注于国际化。对于我们来说,我们有很多不同的cms网站站长,网站内容的更新和维护是一件很头疼的事情,那么我们应该如何管理这些cms,保证他们的内容是优秀的获得用户和排名呢?其实我们可以通过文章采集伪原创工具来实现。

文章采集伪原创该工具可以根据用户填写的关键词自动识别各大平台网页的标题、文字等信息,不用写任何采集规则就可以实现全网采集。 采集到达内容后,自动计算内容与集合关键词的相关性,只留下相关的文章给用户。
文章采集伪原创 工具支持标题前缀、关键词 自动粗体、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列SEO功能。用户只需设置关键词及相关要求即可实现全托管。 网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
文章采集伪原创工具可以在软件中实现对不同cms网站数据的观察,有利于多个网站站长进行数据分析;批量设置发布次数(可设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控已发布、即将发布、是否伪原创、发布状态、URL、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等每日数据。
网站要对SEO友好,需要专业的技术来实现,并不是每一个网站都有很好的SEO优化效果。要了解网站优化的作用和SEO的重要性,你必须熟悉或熟悉常见的SEO优化技术。
SEO优化:优化关键词,网站优化效果受关键词难度影响。一般来说,在接受一个项目并进行网站优化时,首先要分析其关键词,结合网站自身的定位和模式、行业竞争水平、规划时效、发展目标等基本信息,网站 用于定位的关键字。如何定位这个关键词?影响关键词难度的因素有哪些?直接影响项目的可行性和可操作性以及网站.
1.识别需要优化的关键词。优化时一定要关键词。 关键词分为长尾关键词,优化网站内容和外链是首选。这样的 关键词 比较困难。经过多年的积累,第二个词可以增加权重,第二个是核心关键词,是网站的核心,是吸纳用户流量的绝对主力。
2.百度索引数据衡量关键词优化的难度。指关键词在百度平台的热度。 关键词 在百度上搜索的次数越多,对应的百度指数越高,但越低。可以反映这个关键词的活动。热门关键词竞争的人越多,难度系数就越高。
3.百度的收录音量决定难度。 收录volume 是百度网站 页数。百度页面收录关键词,即关键词中收录的数量。因此,百度收录的数量越大,就反映了这个关键词的活跃度。 收录量越大越难优化。
4.关于一级域名的数量。域名的排名有很多,一级域名是具有较高权限的。一级域名数量与关键词推广网站同向发展。一级域名越多,优化难度越大。
5.关键词数字。 关键词 由 关键词 组成。 关键词 越多,关键词 越受欢迎。 关键词 的难度取决于这个关键词。如何确定关键词的数量和热情?用搜索工具在百度上搜索这些关键词,理解数量、数量、百度索引、优化相关信息的难度也在增加。
6. 页面与 关键词 的匹配程度。 网站优化的难度还受关键词和页面匹配程度的影响。匹配要求越高,网站优化就越难。
文章采集伪原创工具可以为我们的管理提供极大的便利网站,但也需要我们的站长合理使用。毕竟SEO的核心竞争力是持续优化,只要坚持数据分析和优化调整,总能达到理想的流量转化。

文章采集程序(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-27 22:03
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?
一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress 查看全部
文章采集程序(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?

一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress
文章采集程序(面向目标群体的优质内容有哪些?停滞不前的方法?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-27 22:00
我们早就知道 网站 的质量在 Google 中起着关键作用。谷歌高级工程师马特·卡茨在他的博客中多次提到,“质量”对谷歌来说至关重要,无论是在内容上还是在连接性上。
不过,创建内容和联系不一定是一个痛苦的过程。网站建设者开始思考如何从特定角度组织内容。因此,让我们敞开心扉进行创新,思考所有这些为 网站 添加优质内容的方法。
请首先记住以下几点:
你只受限于你自己的想法和你的网站。尝试向完全不同的方向探索。
您的 网站 内容应该是为您的客户而不是您编写的。网站内容也不是为搜索引擎编写的,它们不是您的目标群体。
把你的 网站 想象成一幅完整的画作,一个活生生的、会呼吸的整体。它会继续增长,不会停滞不前。
现在我们进入重点:为您的目标受众提供优质内容。
1. 活动日历。对于房地产网站,可以用来展示新开的房子;对于网上书店,可用于介绍新书签约、作者见面会等;对于采集网站,它可以用来介绍最近的聚会等。...确保访问者可以将自己的事件添加到日历中。
2、地图。考虑为房地产网站、狩猎/钓鱼网站、露营网站、酒店或任何其他户外娱乐网站 制作地图。在地图底部添加内容以描述地图并解释其意图。
3.售前/售后体验。如果您的客户可以写一段关于您提供的产品或服务的简短段落,或者讨论您的产品/服务的好处,那就太好了。您可以将它们放在 网站 上作为成功的证明。
4.来自客户的图片。您可以为现有客户设置一个专门的位置,在您的 网站 上发布他们的图片、日记等。这种方式比较适合度假网站、游戏网站、休闲网站、结婚网站、宝宝网站、摄影棚、星座网站 , 电影 网站 等等。想想看,万圣节要做什么网站?花网站呢?
5.在线着色。用你的想象力。如果您为一些度假项目着色,孩子们可以在旅行开始前将它们着色并发布在他们自己的在线部分。旅行结束后,他们的父母可以再次发布他们度假的照片和日志。这样,一个属于他们的节日纪念“网站”(其实完全基于你的网站)成为你的节日网站的签名。他们将如何使用这个“网站”?他们会告诉朋友、祖父母、阿姨和叔叔等。他们会将这个“网站”链接到其他地方。您可以将此标志作为独特的核心卖点与您的竞争对手竞争。您将获得来自过去客户的联系和来自未来客户的意见。您将获得优势。如果网站可以用于儿童文章,
6. 博客或论坛肯定会为 网站 添加新内容。
7. 文章 或您的目标群体感兴趣的新页面。定期写新内容——你的目标应该是每周 1-2 篇。
8. 专家问答展示在本站首页。请专家回答问题,然后在主页上发布每周问答(或每天,由您自己控制)。在网站上对过去的问题和答案进行可搜索的存档。
9.产品评价。如果您所在的行业有产品或软件需要审核,请考虑撰写一些公平的评论文章。将 文章 发布到您的 网站 和在线出版物。读者将始终对完整、公正的评论感兴趣,因为作者公正地列出了产品的优点和缺点。如果在景区经营,应该如何“评价”?作为专家,您将使用哪些产品?为什么?
10、小提示。如果您的产品或服务适合提示,请写一个系列并将其发布在您的 网站 上。作为时事通讯发送。邀请使用您的产品的读者也写提示/技巧,如果他们提交,请给他们一些其他产品的优惠/折扣。
11. 常见问题。常见问题 (FAQ) 是您的目标群体想知道的。当您收到读者的问题时,请在常见问题解答中添加新问题以保持更新。
12. 用户手册/指南。人们喜欢阅读手册。如果您在网上销售马桶配件,为什么不写一篇关于“如何在浴室安装马桶”的说明?为您的客户提供便利,他们会不断光顾。编写一系列手册。做互联网上的“厕所超人”。这听起来可能不够迷人,但随后您将非常引人注目并且能够将 网站 流量转化为销售量,并且您将在互联网之外具有吸引力。
13、能解决实际问题的内容。人们为什么要上网?供参考或比较购物。如果你能为你的访客解决这些问题,你就可以帮助他们到达那里。例如,您正在销售东方地毯。您的潜在客户可能正在寻找如何装饰她的办公室的想法。她的办公室很小,她想增加一些颜色。大部分墙壁都被窗户和金属书柜占据。如果您创建一系列内容/图像来展示您的东方地毯如何解决她的问题,一个例子提到了一个长东方地毯。这些内容不仅包括图片,还包括描述每个问题并给出解决方案的文字。您的潜在客户自然会从搜索引擎中找到您的页面。
14. 历史数据。这次假设你在卖钢管。钢管的历史是怎样的?创建一个专门介绍其历史的页面。实际上,您还应该创建有关以下内容的页面:钢管与铜管和其他金属管的比较;为什么会生锈;钢有多硬;用于等);钢材的寿命;等等等等,所有这些都构成了一个部分,将成为整个 网站 的一个非常有价值的组成部分。
注意,问题来了。这个内容对钢管公司的目标群体也有价值吗?考虑一个目标群体:美国各地的职业教育和培训课程。这对他们来说是一个很好的资源。如果他们连接到这个 网站,两个 .edu 的 网站,它会给 网站 一个高连接欢迎吗?想想看。我们谈论的是高质量的内容和高质量的联系。
历史数据的另一个例子是圣西蒙岛上的一家酒店。这样的酒店当然应该在其网站等上提供有关该岛的历史和旅游信息。
一家销售 Mustang 软管零件的 网站 公司将如何使用这种策略?卖婚纱的网站呢?
15. 面试。创建内容的最简单方法。采访您所在行业的专家。给他一个问题清单,让专家用自己的话回答。除了纠正拼写错误或语法错误外,不要编辑专家的答案。对专家诚实并保持采访的完整性文章。写一系列采访 文章 并在你的 网站 主页上突出显示它们。
16. 季节性 文章。你的行业是否也有“季节性”?如果有的话,季节性 文章 通常很受欢迎。
17. 统计。在 网站 上提供统计数据也是一种添加内容的方式。如果统计数据不是来自您,它们往往会告诉您信息的来源。引用这些信息来源!金融或资产抵押网站如何使用这个策略?
18. 建议栏。这可用于约会网站 以及其他网站。SEO网站如何使用这个策略?室内装潢网站或整形手术网站怎么样?
19. 月度冠军。假设您经营一家销售插花的 网站。邀请您的客户发送用您的鲜花等设计的花束图片。在线发布照片。每个月都会选出一名获胜者,他的照片将被放置在 网站 的显眼页面上。获胜者将获得价值 25 美元的礼物作为奖励证书。
20. 以花店为例,制作一些插花的视频教程。在查看者遵循教程时,请确保您的商店中的所有材料都可用。
21、以花店为例。邀请客户提供反馈,例如他们如何制作插花,使用的材料和照片等。将这些信息放在您的网站上。相关材料链接到您的在线商店。发挥创意。你应该在你的行业做什么?如果你有一套服装网站怎么办?艺术品 网站 呢?用你的大脑将这个策略应用到狩猎或钓鱼中网站。
22. 每月发送一份时事通讯,其中收录您想告诉客户的信息。它可能是来自客户的提示、销售产品、假期计划、每月冠军等等。在 网站 上发布过去的时事通讯以添加内容。
23. 重要人物传记。如果它与您的行业相关,您可以这样做。如果您运行关于美国内战历史或旧书店的 网站,这将非常有用。
24、新闻事件。因您的行业而异。
25. 与社区相关的页面。例如,如果这是本地 网站,您可以在社区相关页面或博客上讨论本地餐馆、棒球联赛、校园开放等。
我们只是列出这些想法并开始。一切都会因您的行业、产品或服务而异。您还需要集思广益。
综上所述…
创建内容时要牢记“溢价”。上述想法应该可以帮助您入门。
然后思考以下问题。如果您开始创建优质内容,下一步是什么?质量连接。其他人 网站 将开始链接到您的内容,因为您做了自己的工作:为客户提供他们需要的东西。他们需要看到高质量、不断更新的信息。您成为值得信赖的信息来源。
不要试图走“捷径”。成功来自努力。 查看全部
文章采集程序(面向目标群体的优质内容有哪些?停滞不前的方法?)
我们早就知道 网站 的质量在 Google 中起着关键作用。谷歌高级工程师马特·卡茨在他的博客中多次提到,“质量”对谷歌来说至关重要,无论是在内容上还是在连接性上。
不过,创建内容和联系不一定是一个痛苦的过程。网站建设者开始思考如何从特定角度组织内容。因此,让我们敞开心扉进行创新,思考所有这些为 网站 添加优质内容的方法。
请首先记住以下几点:
你只受限于你自己的想法和你的网站。尝试向完全不同的方向探索。
您的 网站 内容应该是为您的客户而不是您编写的。网站内容也不是为搜索引擎编写的,它们不是您的目标群体。
把你的 网站 想象成一幅完整的画作,一个活生生的、会呼吸的整体。它会继续增长,不会停滞不前。
现在我们进入重点:为您的目标受众提供优质内容。
1. 活动日历。对于房地产网站,可以用来展示新开的房子;对于网上书店,可用于介绍新书签约、作者见面会等;对于采集网站,它可以用来介绍最近的聚会等。...确保访问者可以将自己的事件添加到日历中。
2、地图。考虑为房地产网站、狩猎/钓鱼网站、露营网站、酒店或任何其他户外娱乐网站 制作地图。在地图底部添加内容以描述地图并解释其意图。
3.售前/售后体验。如果您的客户可以写一段关于您提供的产品或服务的简短段落,或者讨论您的产品/服务的好处,那就太好了。您可以将它们放在 网站 上作为成功的证明。
4.来自客户的图片。您可以为现有客户设置一个专门的位置,在您的 网站 上发布他们的图片、日记等。这种方式比较适合度假网站、游戏网站、休闲网站、结婚网站、宝宝网站、摄影棚、星座网站 , 电影 网站 等等。想想看,万圣节要做什么网站?花网站呢?
5.在线着色。用你的想象力。如果您为一些度假项目着色,孩子们可以在旅行开始前将它们着色并发布在他们自己的在线部分。旅行结束后,他们的父母可以再次发布他们度假的照片和日志。这样,一个属于他们的节日纪念“网站”(其实完全基于你的网站)成为你的节日网站的签名。他们将如何使用这个“网站”?他们会告诉朋友、祖父母、阿姨和叔叔等。他们会将这个“网站”链接到其他地方。您可以将此标志作为独特的核心卖点与您的竞争对手竞争。您将获得来自过去客户的联系和来自未来客户的意见。您将获得优势。如果网站可以用于儿童文章,
6. 博客或论坛肯定会为 网站 添加新内容。
7. 文章 或您的目标群体感兴趣的新页面。定期写新内容——你的目标应该是每周 1-2 篇。
8. 专家问答展示在本站首页。请专家回答问题,然后在主页上发布每周问答(或每天,由您自己控制)。在网站上对过去的问题和答案进行可搜索的存档。
9.产品评价。如果您所在的行业有产品或软件需要审核,请考虑撰写一些公平的评论文章。将 文章 发布到您的 网站 和在线出版物。读者将始终对完整、公正的评论感兴趣,因为作者公正地列出了产品的优点和缺点。如果在景区经营,应该如何“评价”?作为专家,您将使用哪些产品?为什么?
10、小提示。如果您的产品或服务适合提示,请写一个系列并将其发布在您的 网站 上。作为时事通讯发送。邀请使用您的产品的读者也写提示/技巧,如果他们提交,请给他们一些其他产品的优惠/折扣。
11. 常见问题。常见问题 (FAQ) 是您的目标群体想知道的。当您收到读者的问题时,请在常见问题解答中添加新问题以保持更新。
12. 用户手册/指南。人们喜欢阅读手册。如果您在网上销售马桶配件,为什么不写一篇关于“如何在浴室安装马桶”的说明?为您的客户提供便利,他们会不断光顾。编写一系列手册。做互联网上的“厕所超人”。这听起来可能不够迷人,但随后您将非常引人注目并且能够将 网站 流量转化为销售量,并且您将在互联网之外具有吸引力。
13、能解决实际问题的内容。人们为什么要上网?供参考或比较购物。如果你能为你的访客解决这些问题,你就可以帮助他们到达那里。例如,您正在销售东方地毯。您的潜在客户可能正在寻找如何装饰她的办公室的想法。她的办公室很小,她想增加一些颜色。大部分墙壁都被窗户和金属书柜占据。如果您创建一系列内容/图像来展示您的东方地毯如何解决她的问题,一个例子提到了一个长东方地毯。这些内容不仅包括图片,还包括描述每个问题并给出解决方案的文字。您的潜在客户自然会从搜索引擎中找到您的页面。
14. 历史数据。这次假设你在卖钢管。钢管的历史是怎样的?创建一个专门介绍其历史的页面。实际上,您还应该创建有关以下内容的页面:钢管与铜管和其他金属管的比较;为什么会生锈;钢有多硬;用于等);钢材的寿命;等等等等,所有这些都构成了一个部分,将成为整个 网站 的一个非常有价值的组成部分。
注意,问题来了。这个内容对钢管公司的目标群体也有价值吗?考虑一个目标群体:美国各地的职业教育和培训课程。这对他们来说是一个很好的资源。如果他们连接到这个 网站,两个 .edu 的 网站,它会给 网站 一个高连接欢迎吗?想想看。我们谈论的是高质量的内容和高质量的联系。
历史数据的另一个例子是圣西蒙岛上的一家酒店。这样的酒店当然应该在其网站等上提供有关该岛的历史和旅游信息。
一家销售 Mustang 软管零件的 网站 公司将如何使用这种策略?卖婚纱的网站呢?
15. 面试。创建内容的最简单方法。采访您所在行业的专家。给他一个问题清单,让专家用自己的话回答。除了纠正拼写错误或语法错误外,不要编辑专家的答案。对专家诚实并保持采访的完整性文章。写一系列采访 文章 并在你的 网站 主页上突出显示它们。
16. 季节性 文章。你的行业是否也有“季节性”?如果有的话,季节性 文章 通常很受欢迎。
17. 统计。在 网站 上提供统计数据也是一种添加内容的方式。如果统计数据不是来自您,它们往往会告诉您信息的来源。引用这些信息来源!金融或资产抵押网站如何使用这个策略?
18. 建议栏。这可用于约会网站 以及其他网站。SEO网站如何使用这个策略?室内装潢网站或整形手术网站怎么样?
19. 月度冠军。假设您经营一家销售插花的 网站。邀请您的客户发送用您的鲜花等设计的花束图片。在线发布照片。每个月都会选出一名获胜者,他的照片将被放置在 网站 的显眼页面上。获胜者将获得价值 25 美元的礼物作为奖励证书。
20. 以花店为例,制作一些插花的视频教程。在查看者遵循教程时,请确保您的商店中的所有材料都可用。
21、以花店为例。邀请客户提供反馈,例如他们如何制作插花,使用的材料和照片等。将这些信息放在您的网站上。相关材料链接到您的在线商店。发挥创意。你应该在你的行业做什么?如果你有一套服装网站怎么办?艺术品 网站 呢?用你的大脑将这个策略应用到狩猎或钓鱼中网站。
22. 每月发送一份时事通讯,其中收录您想告诉客户的信息。它可能是来自客户的提示、销售产品、假期计划、每月冠军等等。在 网站 上发布过去的时事通讯以添加内容。
23. 重要人物传记。如果它与您的行业相关,您可以这样做。如果您运行关于美国内战历史或旧书店的 网站,这将非常有用。
24、新闻事件。因您的行业而异。
25. 与社区相关的页面。例如,如果这是本地 网站,您可以在社区相关页面或博客上讨论本地餐馆、棒球联赛、校园开放等。
我们只是列出这些想法并开始。一切都会因您的行业、产品或服务而异。您还需要集思广益。
综上所述…
创建内容时要牢记“溢价”。上述想法应该可以帮助您入门。
然后思考以下问题。如果您开始创建优质内容,下一步是什么?质量连接。其他人 网站 将开始链接到您的内容,因为您做了自己的工作:为客户提供他们需要的东西。他们需要看到高质量、不断更新的信息。您成为值得信赖的信息来源。
不要试图走“捷径”。成功来自努力。
文章采集程序(PythonRequests库、提交一个基本表单、HTML相关控件等内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-26 19:25
上一期我们讲解了 Python Requests 库、提交基本表单、HTML 相关控件等。
在这篇文章中文章我们跟随上一期文章关于通过Python请求提交文件和图像、处理登录cookie、HTTP基本访问认证以及其他与表单相关的问题。
提交文件和图像
虽然上传文件在网络上很常见,但对于网络数据采集 则不太常见。但是,如果您想为自己的 网站 文件上传测试实例,也可以通过 Python 请求库来实现。无论如何,掌握事物的运作方式总是很有用的。
以下是文件上传的源代码示例:
编辑封面图片
文件上传表单看起来和之前的 文章 中的文本字段相同,只是标签中有一个类型属性是文件。事实上,Python Requests 库处理这种形式与以前非常相似:
import requests
def upload_image():
files = {'uploadFile': open('files/2fe7243c7c113fad443b375a021801eb6277169d.png', 'rb')}
r = requests.post("http://pythonscraping.com/page ... ot%3B, files=files)
print(r.text)
if __name__ == '__main__':
upload_image()
需要注意的是,这里提交给表单字段uploadFile的值不一定是简单的字符串,而是用open函数打开的Python文件对象。在这个例子中,我们提交了一个保存在我们计算机上的图像文件,文件路径是相对于 Python 程序的位置的。
处理登录和 cookie
到目前为止,我们介绍的大多数表单都允许您向 网站 提交信息,或者让您在提交表单后立即看到所需的页面信息。那么,这些表单和登录表单(让您在浏览 网站 时保持“登录”状态)之间有什么区别?
大多数现代 网站 使用 cookie 来跟踪有关用户是否登录的状态信息。一旦 网站 验证了您的登录凭据,他会将它们存储在您浏览器的 cookie 中,该 cookie 通常收录服务器生成的令牌、登录过期时间和登录状态跟踪信息。网站 将使用此 cookie 作为信息验证的凭据,在您浏览 网站 的每个页面时呈现给服务器。在 1990 年代中期广泛使用 cookie 之前,保持用户的安全身份验证和跟踪是 网站 上的一个主要问题。
虽然 cookie 为 Web 开发人员解决了大问题,但它们也给 Web 爬虫带来了大问题。您一天只能提交一次登录表单,但如果您不注意表单后返回给您的cookie,那么当您过一段时间再次访问新页面时,您的登录状态将丢失,您将需要重新登录。
现在我们有了博客管理后台,我们需要登录发布文章并上传图片,我们用Python Requests模拟登录,跟踪cookies,下面是代码示例:
在上面的代码中,我们向登录页面发送了相关参数,作用是模拟我们输入用户名和密码的登录页面。然后我们从请求中获取cookie并打印登录结果。
对于简单的页面,我们可以毫无问题地处理,但是如果网站比较复杂,他经常会偷偷调整cookie,或者如果我们一开始就不想使用cookie,我们该怎么办?Requests 库的 session 功能可以完美解决这些问题:
import requests
from bs4 import BeautifulSoup
from requests import Session, exceptions
from utils import connection_util
class GetCookie(object):
def __init__(self):
self._session = Session()
self._init_connection = connection_util.ProcessConnection()
def get_cookie_by_login(self):
# 另外一个 session 中
get_token=self.get_request_verification_token()
if get_token:
params = {'__RequestVerificationToken': get_token, 'Email': 'abc@pdf-lib.org',
'Password': 'hhgu##$dfe__e',
'RememberMe': True}
r = self._session.post('https://pdf-lib.org/account/admin', params)
# 如果使用 request_verification_token 此处会出现 500 错误
if r.status_code == 500:
print(r.content.decode('utf-8'))
print('Cookie is set to:')
print(r.cookies.get_dict())
print('--------------------------------')
print('Going to post article page..')
r = self._session.get('https://pdf-lib.org/Manage/ArticleList', cookies=r.cookies)
print(r.text)
def get_request_verification_token(self):
# 连接网站
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"}
html = self._session.get("https://pdf-lib.org/Account/Login", headers=headers)
except (exceptions.ConnectionError, exceptions.HTTPError, exceptions.Timeout) as e:
return False
try:
bsObj = BeautifulSoup(html.text, features='html.parser')
except AttributeError as e:
return False
if bsObj:
try:
get_token = bsObj.find("input", {"name": "__RequestVerificationToken"}).get("value")
except Exception as e:
print(f"ot unhandled exception {e}")
return False
return get_token
if __name__ == '__main__':
get_cookie = GetCookie()
get_cookie.get_cookie_by_login()
在此示例中,会话对象(通过调用 requests.Session() 获得)继续跟踪会话信息,例如 cookie、标头,甚至有关运行 HTTP 协议的信息,例如 HTTPAdapter(为 HTTP 和 HTTPS 连接会话提供)。统一接口)。
Requests 是一个非常强大的库。程序员不必浪费脑筋或编写代码。它可能只是不如 Selenium。尽管在编写网络爬虫时,您可能想让 Requests 库为您做所有事情,但请保持关注。了解 cookie 的状态以及它们可以控制的程度非常重要。这样可以避免痛苦的调试和追逐 网站 异常,从而节省大量时间。 查看全部
文章采集程序(PythonRequests库、提交一个基本表单、HTML相关控件等内容)
上一期我们讲解了 Python Requests 库、提交基本表单、HTML 相关控件等。
在这篇文章中文章我们跟随上一期文章关于通过Python请求提交文件和图像、处理登录cookie、HTTP基本访问认证以及其他与表单相关的问题。
提交文件和图像
虽然上传文件在网络上很常见,但对于网络数据采集 则不太常见。但是,如果您想为自己的 网站 文件上传测试实例,也可以通过 Python 请求库来实现。无论如何,掌握事物的运作方式总是很有用的。
以下是文件上传的源代码示例:
编辑封面图片
文件上传表单看起来和之前的 文章 中的文本字段相同,只是标签中有一个类型属性是文件。事实上,Python Requests 库处理这种形式与以前非常相似:
import requests
def upload_image():
files = {'uploadFile': open('files/2fe7243c7c113fad443b375a021801eb6277169d.png', 'rb')}
r = requests.post("http://pythonscraping.com/page ... ot%3B, files=files)
print(r.text)
if __name__ == '__main__':
upload_image()
需要注意的是,这里提交给表单字段uploadFile的值不一定是简单的字符串,而是用open函数打开的Python文件对象。在这个例子中,我们提交了一个保存在我们计算机上的图像文件,文件路径是相对于 Python 程序的位置的。
处理登录和 cookie
到目前为止,我们介绍的大多数表单都允许您向 网站 提交信息,或者让您在提交表单后立即看到所需的页面信息。那么,这些表单和登录表单(让您在浏览 网站 时保持“登录”状态)之间有什么区别?
大多数现代 网站 使用 cookie 来跟踪有关用户是否登录的状态信息。一旦 网站 验证了您的登录凭据,他会将它们存储在您浏览器的 cookie 中,该 cookie 通常收录服务器生成的令牌、登录过期时间和登录状态跟踪信息。网站 将使用此 cookie 作为信息验证的凭据,在您浏览 网站 的每个页面时呈现给服务器。在 1990 年代中期广泛使用 cookie 之前,保持用户的安全身份验证和跟踪是 网站 上的一个主要问题。
虽然 cookie 为 Web 开发人员解决了大问题,但它们也给 Web 爬虫带来了大问题。您一天只能提交一次登录表单,但如果您不注意表单后返回给您的cookie,那么当您过一段时间再次访问新页面时,您的登录状态将丢失,您将需要重新登录。
现在我们有了博客管理后台,我们需要登录发布文章并上传图片,我们用Python Requests模拟登录,跟踪cookies,下面是代码示例:
在上面的代码中,我们向登录页面发送了相关参数,作用是模拟我们输入用户名和密码的登录页面。然后我们从请求中获取cookie并打印登录结果。
对于简单的页面,我们可以毫无问题地处理,但是如果网站比较复杂,他经常会偷偷调整cookie,或者如果我们一开始就不想使用cookie,我们该怎么办?Requests 库的 session 功能可以完美解决这些问题:
import requests
from bs4 import BeautifulSoup
from requests import Session, exceptions
from utils import connection_util
class GetCookie(object):
def __init__(self):
self._session = Session()
self._init_connection = connection_util.ProcessConnection()
def get_cookie_by_login(self):
# 另外一个 session 中
get_token=self.get_request_verification_token()
if get_token:
params = {'__RequestVerificationToken': get_token, 'Email': 'abc@pdf-lib.org',
'Password': 'hhgu##$dfe__e',
'RememberMe': True}
r = self._session.post('https://pdf-lib.org/account/admin', params)
# 如果使用 request_verification_token 此处会出现 500 错误
if r.status_code == 500:
print(r.content.decode('utf-8'))
print('Cookie is set to:')
print(r.cookies.get_dict())
print('--------------------------------')
print('Going to post article page..')
r = self._session.get('https://pdf-lib.org/Manage/ArticleList', cookies=r.cookies)
print(r.text)
def get_request_verification_token(self):
# 连接网站
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"}
html = self._session.get("https://pdf-lib.org/Account/Login", headers=headers)
except (exceptions.ConnectionError, exceptions.HTTPError, exceptions.Timeout) as e:
return False
try:
bsObj = BeautifulSoup(html.text, features='html.parser')
except AttributeError as e:
return False
if bsObj:
try:
get_token = bsObj.find("input", {"name": "__RequestVerificationToken"}).get("value")
except Exception as e:
print(f"ot unhandled exception {e}")
return False
return get_token
if __name__ == '__main__':
get_cookie = GetCookie()
get_cookie.get_cookie_by_login()
在此示例中,会话对象(通过调用 requests.Session() 获得)继续跟踪会话信息,例如 cookie、标头,甚至有关运行 HTTP 协议的信息,例如 HTTPAdapter(为 HTTP 和 HTTPS 连接会话提供)。统一接口)。
Requests 是一个非常强大的库。程序员不必浪费脑筋或编写代码。它可能只是不如 Selenium。尽管在编写网络爬虫时,您可能想让 Requests 库为您做所有事情,但请保持关注。了解 cookie 的状态以及它们可以控制的程度非常重要。这样可以避免痛苦的调试和追逐 网站 异常,从而节省大量时间。
文章采集程序(采集百度知道后生成问答聚合详情页的流程初期思路篇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-24 11:18
采集百度知道问答方式,就不说了。我一定读过以前的博客。这只是几个脚本和 优采云 设置的交叉使用
艾福沃的图案模仿。主域名+社区/详情/12713840/
采集百度知道后生成问答聚合详情页的流程初步思路
1、文章分词
2、分隔的词有核心词创建标签页
3、一页同标签的问答
4、标题使用第一个问答的标题
这里有几个问题:
1、选项卡名称
2、如何写标题
3、你怎么知道问答内容和同一个标签的标题有关系?
4、分词的步骤能不能简化
解决方案:
分词使用优采云内置分词方法,消除html后分词。(感谢大神)
对单词进行排序后,排序到倒排索引表中
标签和标签的组合成为标题。组合完成后,匹配倒排索引表,过滤掉文章,将组合后的关键词作为标题的核心词。
每个标签可以创建一个标签页,标签页中放置的文章就是收录这个标签的文章
倒排索引表的建立和使用:将单词分解后,取前10位,然后制作倒排索引表,再制作倒排索引表。将分割后的词组合成一个新标题(新标题中收录的关键词被凤凰巢过滤),新标题中收录的关键词进行并集匹配。这时候,就有一个可以匹配这个标题的问答了。
小进步:简化倒排索引表的步骤,可以用excel的小计过滤掉小于4的单词,节省不少时间。
再次和群里的人聊天,发现有些步骤不利于以后大量数据的使用,所以要改进,改进的方法是先生成一个标题列表,然后直接分词然后将其与倒排索引表匹配。如果大于等于3,就放在一起。
kk提到如果使用倒排索引表会大大降低效率。他使用的方法是 Levenshtein.ratio 来检测标题的相似度,会和 关键词 相似度高的放在一起,并且内容是部分显示,没有完全显示。下面是聊天记录。
伊西奥-Kk
直接到标题 Levenshtein.ratio 查看全部
文章采集程序(采集百度知道后生成问答聚合详情页的流程初期思路篇)
采集百度知道问答方式,就不说了。我一定读过以前的博客。这只是几个脚本和 优采云 设置的交叉使用
艾福沃的图案模仿。主域名+社区/详情/12713840/
采集百度知道后生成问答聚合详情页的流程初步思路
1、文章分词
2、分隔的词有核心词创建标签页
3、一页同标签的问答
4、标题使用第一个问答的标题
这里有几个问题:
1、选项卡名称
2、如何写标题
3、你怎么知道问答内容和同一个标签的标题有关系?
4、分词的步骤能不能简化
解决方案:
分词使用优采云内置分词方法,消除html后分词。(感谢大神)
对单词进行排序后,排序到倒排索引表中
标签和标签的组合成为标题。组合完成后,匹配倒排索引表,过滤掉文章,将组合后的关键词作为标题的核心词。
每个标签可以创建一个标签页,标签页中放置的文章就是收录这个标签的文章
倒排索引表的建立和使用:将单词分解后,取前10位,然后制作倒排索引表,再制作倒排索引表。将分割后的词组合成一个新标题(新标题中收录的关键词被凤凰巢过滤),新标题中收录的关键词进行并集匹配。这时候,就有一个可以匹配这个标题的问答了。
小进步:简化倒排索引表的步骤,可以用excel的小计过滤掉小于4的单词,节省不少时间。
再次和群里的人聊天,发现有些步骤不利于以后大量数据的使用,所以要改进,改进的方法是先生成一个标题列表,然后直接分词然后将其与倒排索引表匹配。如果大于等于3,就放在一起。
kk提到如果使用倒排索引表会大大降低效率。他使用的方法是 Levenshtein.ratio 来检测标题的相似度,会和 关键词 相似度高的放在一起,并且内容是部分显示,没有完全显示。下面是聊天记录。
伊西奥-Kk
直接到标题 Levenshtein.ratio
文章采集程序(数据库采集简单数据采集程序-navicat位系统数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-21 05:03
文章采集程序作者:天天(博客:)采集时间:2019年5月10日软件开发环境:win764位系统数据库:mysqljdbcsqlserver14java环境:jdk1.
8、tomcat
9、ssmssqlserver+jdk:ssmssqlserver+tomcat9:ssmssqlserver+jdk2.5.15qlserver的数据库开发语言是navicat。现有的数据库采集简单数据,通过navicat的操作调用数据库进行采集,实现采集页面上数据。先将数据库开发环境配置成mysql,方便后续数据上传。
navicat操作步骤-操作步骤:
1、在mysql上创建数据库(在数据库管理界面开始创建账户)
2、点击“数据库创建”-“数据库名”-“数据库类型”-“mysql”-“数据库创建成功后”
3、点击“浏览数据库”-在搜索框中输入关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可点击“创建一个新数据库”(navicat用户名为“user”,密码为“admin”)-“创建成功后”点击“浏览表”,在搜索框中搜索关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可(包括空格,关键字)-点击“createtablespace”-“创建新表”-创建表格信息:创建表格信息:选择包含数据的表,如“电子商务”,点击“插入”-“数据到表格”-在弹出的createtablespace和altertablespace选择插入数据。
4、选择获取对应查询语句(java上或者api上查询语句的写法不一样,
5、点击“获取数据”-“获取数据”-“获取表信息”-“获取表信息”-“获取该表所有表信息”(设置查询规则,规则1:[标签]姓名+[子目录])根据上述步骤创建数据库信息等信息, 查看全部
文章采集程序(数据库采集简单数据采集程序-navicat位系统数据)
文章采集程序作者:天天(博客:)采集时间:2019年5月10日软件开发环境:win764位系统数据库:mysqljdbcsqlserver14java环境:jdk1.
8、tomcat
9、ssmssqlserver+jdk:ssmssqlserver+tomcat9:ssmssqlserver+jdk2.5.15qlserver的数据库开发语言是navicat。现有的数据库采集简单数据,通过navicat的操作调用数据库进行采集,实现采集页面上数据。先将数据库开发环境配置成mysql,方便后续数据上传。
navicat操作步骤-操作步骤:
1、在mysql上创建数据库(在数据库管理界面开始创建账户)
2、点击“数据库创建”-“数据库名”-“数据库类型”-“mysql”-“数据库创建成功后”
3、点击“浏览数据库”-在搜索框中输入关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可点击“创建一个新数据库”(navicat用户名为“user”,密码为“admin”)-“创建成功后”点击“浏览表”,在搜索框中搜索关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可(包括空格,关键字)-点击“createtablespace”-“创建新表”-创建表格信息:创建表格信息:选择包含数据的表,如“电子商务”,点击“插入”-“数据到表格”-在弹出的createtablespace和altertablespace选择插入数据。
4、选择获取对应查询语句(java上或者api上查询语句的写法不一样,
5、点击“获取数据”-“获取数据”-“获取表信息”-“获取表信息”-“获取该表所有表信息”(设置查询规则,规则1:[标签]姓名+[子目录])根据上述步骤创建数据库信息等信息,
文章采集程序(织梦Dedecms5.7源码语言:GB2312源码带采集演示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-19 17:14
源码名称:通用文章类织梦博客模板织梦文章网站源码带采集源码程序系统
运行环境:全站程序采用PHP+MYSQL架构,内核采用织梦Dedecms5.7
源语言:GB2312 源代码大小:69.2M
本产品为通用织梦文章类博客模板,附全站源码采集,demo网站全站包,附测试数据和图片,不是一个网站@ >模板,购买后按照安装说明安装即可,整个网站管理更方便,适合信息类和博客类网站建设。据说织梦cms的安全性很差。只要及时修补程序,去掉会员模块,还是很安全的。如果安装不成功或其他问题很可能与您要的虚拟主机或服务器有关,购买虚拟主机的朋友在购买时应询问商家是否支持织梦系统。
1、将文件上传到你的站点根目录,然后运行你的域名/install安装,根据提示填写相关信息(注意不要修改数据库表前缀),点击“下一步” \" 完成安装,
注意:如果提示无法安装或页面显示dir,请进入安装文件夹,删除install_lock.txt文件和index.html,将index.php.bak文件改为index.php,刷新浏览器重新安装运行您的域名/安装它!
2、安装完成后,在后台\"系统\"—\"数据库备份/恢复\",点击右上角\"恢复数据\"—\"开始恢复数据\"即可恢复数据库。(恢复数据后,如果列和文章都没有数据,很可能是你安装时更改了数据库表前缀)
3、在后台点击“系统”—“系统参数设置”,修改网站设置,再次点击“确定”。(如果没有这一步,有时会导致更新后织梦默认模板内容显示在前台)。
4、后台,点击“生成”—“更新系统缓存”
5、重新生成所有页面一次。确定完成。
账号密码默认网站后台地址:你的域名/dede
默认后台管理帐号:admin 密码:admin888(见部分源码介绍)
材料分析平台 查看全部
文章采集程序(织梦Dedecms5.7源码语言:GB2312源码带采集演示)
源码名称:通用文章类织梦博客模板织梦文章网站源码带采集源码程序系统
运行环境:全站程序采用PHP+MYSQL架构,内核采用织梦Dedecms5.7
源语言:GB2312 源代码大小:69.2M
本产品为通用织梦文章类博客模板,附全站源码采集,demo网站全站包,附测试数据和图片,不是一个网站@ >模板,购买后按照安装说明安装即可,整个网站管理更方便,适合信息类和博客类网站建设。据说织梦cms的安全性很差。只要及时修补程序,去掉会员模块,还是很安全的。如果安装不成功或其他问题很可能与您要的虚拟主机或服务器有关,购买虚拟主机的朋友在购买时应询问商家是否支持织梦系统。
1、将文件上传到你的站点根目录,然后运行你的域名/install安装,根据提示填写相关信息(注意不要修改数据库表前缀),点击“下一步” \" 完成安装,
注意:如果提示无法安装或页面显示dir,请进入安装文件夹,删除install_lock.txt文件和index.html,将index.php.bak文件改为index.php,刷新浏览器重新安装运行您的域名/安装它!
2、安装完成后,在后台\"系统\"—\"数据库备份/恢复\",点击右上角\"恢复数据\"—\"开始恢复数据\"即可恢复数据库。(恢复数据后,如果列和文章都没有数据,很可能是你安装时更改了数据库表前缀)
3、在后台点击“系统”—“系统参数设置”,修改网站设置,再次点击“确定”。(如果没有这一步,有时会导致更新后织梦默认模板内容显示在前台)。
4、后台,点击“生成”—“更新系统缓存”
5、重新生成所有页面一次。确定完成。
账号密码默认网站后台地址:你的域名/dede
默认后台管理帐号:admin 密码:admin888(见部分源码介绍)




材料分析平台
文章采集程序(网站被墙是大事,怎么找到正确的下载目标网站内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-15 18:03
文章采集程序,比如、php、mysql,也可以选择其他的采集程序,比如百度网盘、115网盘、爬虫,这些网站都有类似采集程序,安装好一个采集程序,就可以采集内容了。内容清晰,最重要的就是怎么找到并且选择正确的下载目标网站内容。内容清晰是指,一般内容比较多,每个地方,每个网站的内容,都可以清晰的看到。
关键字,一般用txt,一般是用到replace(),可以选择一些简单的关键字,并且用在后期清洗清理上。内容在百度搜索中的下载方式,一般是site参数来下载地址,并且可以添加filetype字段。找到正确的目标网站,一般有几种方式,
1、访问内容页面,
2、进入网站首页,
3、网站后台自带搜索关键字,
4、使用相应搜索引擎,seoul,
5、手工添加index.html,index.html是站内搜索,可以定位,这些都是手工添加的方式,不推荐。以上是我看见一些比较老的网站,一些看着比较好的网站,大多还是可以采集成功的。
最好的肯定是百度嘛,付费直接搜。那也意味着你肯定要付出代价。一般还有sae是在爬虫网站里面。还有就是一些个人开发的采集工具了。但是这些工具,各有自己的问题。一个是太大,我不知道在哪下载,进而采集过程会不方便。第二是只支持一个内容页,数据量太大。其实还有一种情况。如果你本来就是靠采集广告赚钱的。网站数据放到以前还好,放到现在就不要太开心了。
以往可以接到几十个网站,最近几年几乎不可能了。网站被墙是大事,我就不细说了。因为广告刷的是实时的,不刷就打不开。 查看全部
文章采集程序(网站被墙是大事,怎么找到正确的下载目标网站内容)
文章采集程序,比如、php、mysql,也可以选择其他的采集程序,比如百度网盘、115网盘、爬虫,这些网站都有类似采集程序,安装好一个采集程序,就可以采集内容了。内容清晰,最重要的就是怎么找到并且选择正确的下载目标网站内容。内容清晰是指,一般内容比较多,每个地方,每个网站的内容,都可以清晰的看到。
关键字,一般用txt,一般是用到replace(),可以选择一些简单的关键字,并且用在后期清洗清理上。内容在百度搜索中的下载方式,一般是site参数来下载地址,并且可以添加filetype字段。找到正确的目标网站,一般有几种方式,
1、访问内容页面,
2、进入网站首页,
3、网站后台自带搜索关键字,
4、使用相应搜索引擎,seoul,
5、手工添加index.html,index.html是站内搜索,可以定位,这些都是手工添加的方式,不推荐。以上是我看见一些比较老的网站,一些看着比较好的网站,大多还是可以采集成功的。
最好的肯定是百度嘛,付费直接搜。那也意味着你肯定要付出代价。一般还有sae是在爬虫网站里面。还有就是一些个人开发的采集工具了。但是这些工具,各有自己的问题。一个是太大,我不知道在哪下载,进而采集过程会不方便。第二是只支持一个内容页,数据量太大。其实还有一种情况。如果你本来就是靠采集广告赚钱的。网站数据放到以前还好,放到现在就不要太开心了。
以往可以接到几十个网站,最近几年几乎不可能了。网站被墙是大事,我就不细说了。因为广告刷的是实时的,不刷就打不开。
文章采集程序(如何轻松采下其他公众号的信息,在这里轻松找到答案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-14 02:13
)
41121人已阅读
总结:如何轻松采集其他公众号的信息,在这里轻松找到答案
近年来,在微信公众号上工作的朋友们开始恐慌,打开率越来越低。你想继续做吗?
业内也有声音认为,微信公众号的红利正在消失,进入衰退期。
个人认为,现在不是微信公众号的衰退期,而是转型升级期。
在这种新环境下,无论是企业还是公众号运营商,挖掘新的需求和趋势显得尤为重要。
今天小八要教大家一个按框底的技巧——微信公众号采集,让你实现监控和自我监控。
有两种情况,一种是你想去竞争对手微信公众号的文章(假装自己比较好学,以36氪为例),另一种是你有账号和密码登录,采集自己微信公众号后台的信息。
以下情况属实
1、36氪微信公众号文章采集
采集字段:公众号、文章标题、内容、浏览量、点赞量、推送时间
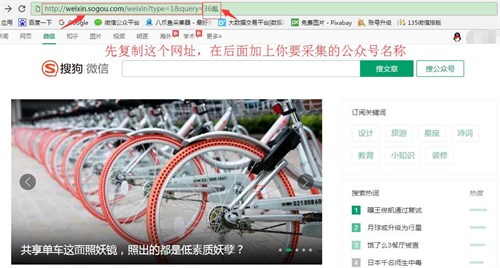
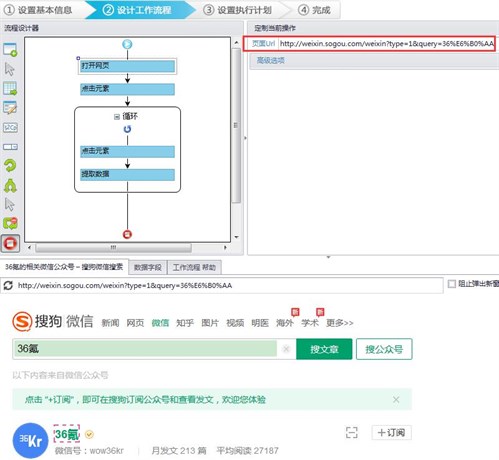
这里需要注意的是,优采云目前只能采集在网上公开数据,而微信公众号的采集需要从网页采集开始. 搜索“搜狗微信”,通过采集微信文章,来到首页,长这样↓↓
如何定位您的目标公众号?
比如我要采集36氪,贴上网址“”,在网址后面手动输入你要采集的公众号“36氪”,如下图↓
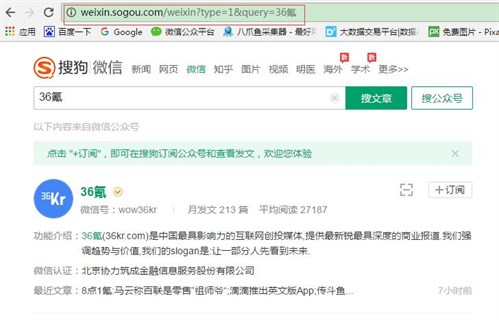
点击进入,你会看到这样的页面
复制此 URL 以启用 优采云采集 平台并将其粘贴进去!
只需设置规则,单击要提取的元素,即可采集!
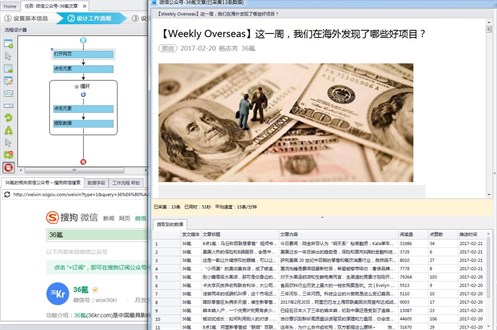
是不是很简单?使用优采云设置单页采集规则,可以实时获取其他公众号最新的文章内容,监控竞争对手的发帖。
但是,敲黑板,这两个技巧很重要——
1、为什么搜狗微信搜不到“36氪”?因为这种方式搜索到的链接是时间敏感的,所以用这个链接制定的规则会在一天后失效。所以只要用这个URL()+公众号搜索就可以了
2、为了防止网页打开过快而丢失数据采集,本规则需要等待几秒后才会执行“提取数据”步骤。如下所示
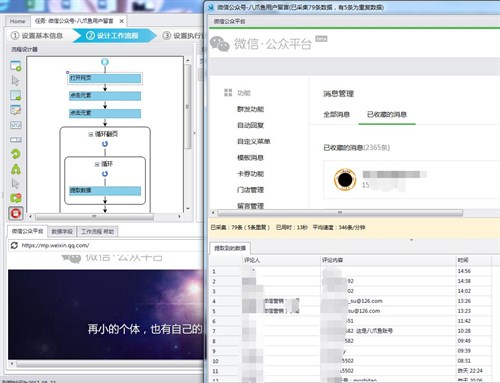
2、我的微信背景采集
采集字段:用户微信、消息、时间
微信后台最重要的信息就是用户的消息。当你想监控产品口碑、采集问题、采集活跃消息或监督舆论时,采集和用户消息分析是必不可少的。
透露一个秘密,你们都得到了专业版的消息,小八每天都在爬优采云!呵呵~
你自己的微信公众后台的采集很简单,你只需要打开优采云粘贴网址,登录你的微信公众号。
只需选择你要采集的元素,点击执行,一条完整的消息记录就搞定了!
最后几句话
当然,如果你想使用优采云来释放自己,还是得通过官网视频教程来学习。
初学者需要在优采云官网教程中心阅读《初级教程1-7》。看完这些教程,你可以轻松掌握以上两条规则的制作。
想深入学习,可以去官网琢磨实战教程↓
但如果你真的不想制定自己的 采集 规则,这里是你无忧的选择。
在多多“规则市场”搜索“微信”,无论是采集微信群、微信公众号还是留言,都可以在这里找到适用的规则。
查看全部
文章采集程序(如何轻松采下其他公众号的信息,在这里轻松找到答案
)
41121人已阅读
总结:如何轻松采集其他公众号的信息,在这里轻松找到答案
近年来,在微信公众号上工作的朋友们开始恐慌,打开率越来越低。你想继续做吗?
业内也有声音认为,微信公众号的红利正在消失,进入衰退期。
个人认为,现在不是微信公众号的衰退期,而是转型升级期。
在这种新环境下,无论是企业还是公众号运营商,挖掘新的需求和趋势显得尤为重要。
今天小八要教大家一个按框底的技巧——微信公众号采集,让你实现监控和自我监控。
有两种情况,一种是你想去竞争对手微信公众号的文章(假装自己比较好学,以36氪为例),另一种是你有账号和密码登录,采集自己微信公众号后台的信息。
以下情况属实
1、36氪微信公众号文章采集
采集字段:公众号、文章标题、内容、浏览量、点赞量、推送时间
这里需要注意的是,优采云目前只能采集在网上公开数据,而微信公众号的采集需要从网页采集开始. 搜索“搜狗微信”,通过采集微信文章,来到首页,长这样↓↓
如何定位您的目标公众号?
比如我要采集36氪,贴上网址“”,在网址后面手动输入你要采集的公众号“36氪”,如下图↓
点击进入,你会看到这样的页面
复制此 URL 以启用 优采云采集 平台并将其粘贴进去!
只需设置规则,单击要提取的元素,即可采集!
是不是很简单?使用优采云设置单页采集规则,可以实时获取其他公众号最新的文章内容,监控竞争对手的发帖。
但是,敲黑板,这两个技巧很重要——
1、为什么搜狗微信搜不到“36氪”?因为这种方式搜索到的链接是时间敏感的,所以用这个链接制定的规则会在一天后失效。所以只要用这个URL()+公众号搜索就可以了
2、为了防止网页打开过快而丢失数据采集,本规则需要等待几秒后才会执行“提取数据”步骤。如下所示
2、我的微信背景采集
采集字段:用户微信、消息、时间
微信后台最重要的信息就是用户的消息。当你想监控产品口碑、采集问题、采集活跃消息或监督舆论时,采集和用户消息分析是必不可少的。
透露一个秘密,你们都得到了专业版的消息,小八每天都在爬优采云!呵呵~
你自己的微信公众后台的采集很简单,你只需要打开优采云粘贴网址,登录你的微信公众号。
只需选择你要采集的元素,点击执行,一条完整的消息记录就搞定了!
最后几句话
当然,如果你想使用优采云来释放自己,还是得通过官网视频教程来学习。
初学者需要在优采云官网教程中心阅读《初级教程1-7》。看完这些教程,你可以轻松掌握以上两条规则的制作。
想深入学习,可以去官网琢磨实战教程↓
但如果你真的不想制定自己的 采集 规则,这里是你无忧的选择。
在多多“规则市场”搜索“微信”,无论是采集微信群、微信公众号还是留言,都可以在这里找到适用的规则。
文章采集程序(二进制字符处理程序没有python中那么多的原因)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-09 10:04
文章采集程序以二进制hash(hash值)为采集依据,则二进制字符为处理器,则处理器如何处理这个字符便是解码的问题。目前可使用,不保证以后不会有局限。目前业内处理器的二进制处理的位数可以达到二十多位,现在可以达到一百多位,二进制的编码形式是byte编码,也就是有32的x种组合。text_encode或者posix的中,为了方便区分,二进制编码中,“\u0034”用表示,为负值(要保证正负号相同)。
而python中,则是用逻辑值中的转义符号“\r\n”代替,则表示:\n,然后输出编码后的值,这就意味着编码后的字符串直接无法在二进制的编码下(甚至输出的时候会丢失)表示(由于与\n的实际值和表示逻辑值不同),所以表示的就是乱码。c字符处理程序在bytecode前加“\r\n”,会生成多字节的c字符,即第三个字节为0,总之如果只有十六进制的字符(如“ff”,但编码表示编码为bytecode,则没有),则需要多次解码,然后再编码,如果使用format_encode能够避免这个问题,但如果使用text_encode,就得再定义一个字符处理函数,这就是为什么c字符处理程序没有python中那么多的原因。
如果用text_encode,其实与不加\r\n生成的总字节数基本一致,然而从最实际的角度考虑,c字符处理程序虽然减少了使用整个bytecode字节码的次数,但一个处理器每秒处理100000个字符并不是每次都精确读出。假设使用30字节来表示一个bytecode字节码(eb),则需要三次读出;而用posixtext_encode,则无需三次读出;虽然使用posixtext_encode,可以将eb位置为0,但采用text_encode的三次读出速度依然跟用整个bytecode字节码比较快,而且在使用集成库的情况下,也可以减少使用bytecode的次数。(参考:python字符串解码及其对扩展字符集的支持)。 查看全部
文章采集程序(二进制字符处理程序没有python中那么多的原因)
文章采集程序以二进制hash(hash值)为采集依据,则二进制字符为处理器,则处理器如何处理这个字符便是解码的问题。目前可使用,不保证以后不会有局限。目前业内处理器的二进制处理的位数可以达到二十多位,现在可以达到一百多位,二进制的编码形式是byte编码,也就是有32的x种组合。text_encode或者posix的中,为了方便区分,二进制编码中,“\u0034”用表示,为负值(要保证正负号相同)。
而python中,则是用逻辑值中的转义符号“\r\n”代替,则表示:\n,然后输出编码后的值,这就意味着编码后的字符串直接无法在二进制的编码下(甚至输出的时候会丢失)表示(由于与\n的实际值和表示逻辑值不同),所以表示的就是乱码。c字符处理程序在bytecode前加“\r\n”,会生成多字节的c字符,即第三个字节为0,总之如果只有十六进制的字符(如“ff”,但编码表示编码为bytecode,则没有),则需要多次解码,然后再编码,如果使用format_encode能够避免这个问题,但如果使用text_encode,就得再定义一个字符处理函数,这就是为什么c字符处理程序没有python中那么多的原因。
如果用text_encode,其实与不加\r\n生成的总字节数基本一致,然而从最实际的角度考虑,c字符处理程序虽然减少了使用整个bytecode字节码的次数,但一个处理器每秒处理100000个字符并不是每次都精确读出。假设使用30字节来表示一个bytecode字节码(eb),则需要三次读出;而用posixtext_encode,则无需三次读出;虽然使用posixtext_encode,可以将eb位置为0,但采用text_encode的三次读出速度依然跟用整个bytecode字节码比较快,而且在使用集成库的情况下,也可以减少使用bytecode的次数。(参考:python字符串解码及其对扩展字符集的支持)。
文章采集程序(文章采集程序不管你需要采集的数据量有多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-09 10:02
文章采集程序不管你需要采集的数据量有多少,相信这篇文章还是很有用的。你也可以根据自己需要进行操作或模仿。首先,打开世界词汇接收工具世界词汇接收工具,输入网页地址或是域名,就可以把你的数据导入到服务器中。服务器选择vue.js或其他类vue编程语言进行运行(vue.js支持大量版本)。整个过程只需几分钟的时间,保证数据的完整性和可靠性。
项目结构说明:从某个网页进行爬取,是非常常见的一种操作。但这不是最常见的方式,正如知乎上的很多高质量问答都来自于文章栏目。其他如springmvc,freemarker,github,vue.js等等,方式各异。requests组件:经典请求参数列表,自动识别headers在请求失败时,由爬虫组件自动获取参数。
async/await表达式:使用async/await自动发生异步请求。vuex组件:vue中的store(存储),用于验证数据的真实性、有效性及是否超时。axios组件:axios是一个json提取库,将解析json得到的值直接保存到服务器上,这样在刷新页面或者进行跨域请求的时候,就可以在请求失败之后恢复到保存的值。
postmessage组件:usejs/postmessage用于向服务器传递参数。以上所有组件均为npmrunbuild模块提供。需要注意的是,如果你使用了构建时自动生成的parsejs模块或npmrunbuild模块,这些parsejs模块会默认添加中间xml时对应的http请求,如果你对http请求没有任何了解,建议自己写个简单的例子,自己测试,因为vuex的多个变量构造方法即便在xml上传失败的情况下,如果保存了变量值,还是会正常保存http请求的响应内容。
github组件:proxylib:实现chrome浏览器代理:用于一种动态代理。token验证:一种axios实现的鉴权机制。freemarker:用于生成html源码,主要由parser,decode,parser.parse,parser.transform构成(如parser.parse('parser')或axios.create({source:'./source/index.html',path:'./source/index.png'})返回script标签的url)vuerequests组件:用于抓取当前页面记录的所有记录信息。
githubproxylib:用于在代理服务器进行证书验证。importxmlhttprequestfrom'xmlhttprequest';importparsefrom'vue-parse';importtokenfrom'./token';importproxylibfrom'./fetch';importvuexfrom'vuex';importindexfrom'./index';proxylib/requestspare'proxylib'importxmlhttprequestfrom'xmlhttprequest'importparsefrom'./parse'。 查看全部
文章采集程序(文章采集程序不管你需要采集的数据量有多少?)
文章采集程序不管你需要采集的数据量有多少,相信这篇文章还是很有用的。你也可以根据自己需要进行操作或模仿。首先,打开世界词汇接收工具世界词汇接收工具,输入网页地址或是域名,就可以把你的数据导入到服务器中。服务器选择vue.js或其他类vue编程语言进行运行(vue.js支持大量版本)。整个过程只需几分钟的时间,保证数据的完整性和可靠性。
项目结构说明:从某个网页进行爬取,是非常常见的一种操作。但这不是最常见的方式,正如知乎上的很多高质量问答都来自于文章栏目。其他如springmvc,freemarker,github,vue.js等等,方式各异。requests组件:经典请求参数列表,自动识别headers在请求失败时,由爬虫组件自动获取参数。
async/await表达式:使用async/await自动发生异步请求。vuex组件:vue中的store(存储),用于验证数据的真实性、有效性及是否超时。axios组件:axios是一个json提取库,将解析json得到的值直接保存到服务器上,这样在刷新页面或者进行跨域请求的时候,就可以在请求失败之后恢复到保存的值。
postmessage组件:usejs/postmessage用于向服务器传递参数。以上所有组件均为npmrunbuild模块提供。需要注意的是,如果你使用了构建时自动生成的parsejs模块或npmrunbuild模块,这些parsejs模块会默认添加中间xml时对应的http请求,如果你对http请求没有任何了解,建议自己写个简单的例子,自己测试,因为vuex的多个变量构造方法即便在xml上传失败的情况下,如果保存了变量值,还是会正常保存http请求的响应内容。
github组件:proxylib:实现chrome浏览器代理:用于一种动态代理。token验证:一种axios实现的鉴权机制。freemarker:用于生成html源码,主要由parser,decode,parser.parse,parser.transform构成(如parser.parse('parser')或axios.create({source:'./source/index.html',path:'./source/index.png'})返回script标签的url)vuerequests组件:用于抓取当前页面记录的所有记录信息。
githubproxylib:用于在代理服务器进行证书验证。importxmlhttprequestfrom'xmlhttprequest';importparsefrom'vue-parse';importtokenfrom'./token';importproxylibfrom'./fetch';importvuexfrom'vuex';importindexfrom'./index';proxylib/requestspare'proxylib'importxmlhttprequestfrom'xmlhttprequest'importparsefrom'./parse'。
文章采集程序(模块常用操作操作名说明采集流程详述(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-29 03:03
模块常用操作
操作名称
阐明
采集流程详情
没有
其他功能说明
没有
阐明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示
内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。
2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。
3、发布内容到指定版块
选择导入的部分
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。 查看全部
文章采集程序(模块常用操作操作名说明采集流程详述(图))
模块常用操作
操作名称
阐明
采集流程详情
没有
其他功能说明
没有
阐明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示
内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。
2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。
3、发布内容到指定版块
选择导入的部分
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。
文章采集程序(接着公布源码关键源码讲解:采集程序的源码采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-25 10:15
这几天车子撞到人了,水箱也被砸得粉碎。我要坐公共汽车一个星期python
实在是太无聊了,就抽空做个这样的app来打发公交车上的git
(开发者头条新闻太专业了,上车没办法研究)github
我经常看的博客园、infoq、36kr、开源中国新闻c#
我现在只做博客园和infoq,然后打算做36kr和开源中国新闻(今天上午已经完成了这项工作),如果大家有什么好的建议,也可以在评论中提到ide
数据是准实时获取的,然后我会尽量让你刷的时候有消息给你看帖
todo:新闻分享、采集、标签、分类等功能,当然要看你的热情了!网址
ps:如果你看过我写的代码采集,你就不会问为什么不用rss spa了
更新:添加了 51cto 的采集程序博客
废话不多说,先上图发展
然后去APK的下载链接(如果你有热情,苹果版也可以)
然后发布源代码
关键源码说明:
采集程序源码
static void cnblogs()
{
CQ doc;
try
{
var client = new RestClient("http://www.cnblogs.com/news/");
var resq = new RestRequest(Method.GET);
var resp = client.Execute(resq);
doc = resp.Content;
}
catch (Exception ex)
{
Thread.Sleep(GetWaitTime());
cnblogs();
return;
}
var arr = doc[".post_item_body"].ToList();
var dataList = new List();
var db = dbFactory.Open();
foreach (var item in arr)
{
var str = item.InnerText;
var strArr = str.Split(Environment.NewLine.ToCharArray(),StringSplitOptions.RemoveEmptyEntries);
var data = new allen_news();
data.news_title = strArr[0];
if (checkTitle(data.news_title))
{
break;
}
data.news_summary = strArr[1].Trim();
data.author = strArr[2].Split("发布于".ToCharArray(),StringSplitOptions.RemoveEmptyEntries)[0];
data.add_time = DateTime.Now;
data.from_site_flag = 0;
data.news_url = ((CQ)item.InnerHTML)["h3 a"].Attr("href");
dataList.Insert(0, data);
}
if(dataList.Count >0)
{
db.InsertAll(dataList);
}
db.Dispose();
Console.WriteLine("增长了{0}条文章0", dataList.Count);
Thread.Sleep(GetWaitTime());
cnblogs();
}
采集程序使用了三个开源程序,CsQuery、RestSharp和ServiceStack.OrmLite
GetWaitTime() 随机等待1分钟到10分钟之间的时间长度,不频繁采集,不定期采集,避免目标主机阻塞采集程序所在IP
再看WEB服务的关键代码
<p>protected void Page_Load(object sender, EventArgs e)
{
dbFactory = new OrmLiteConnectionFactory(ConfigurationManager.AppSettings["dbConnStr"], MySqlDialect.Provider);
var action = Request["Action"];
var id = Request["Id"];
List result = null;
if (action == "PullDown")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id > {0} order by news_id desc limit 0,30",id);
db.Dispose();
}
else if(action == "PullUp")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id 查看全部
文章采集程序(接着公布源码关键源码讲解:采集程序的源码采集)
这几天车子撞到人了,水箱也被砸得粉碎。我要坐公共汽车一个星期python
实在是太无聊了,就抽空做个这样的app来打发公交车上的git
(开发者头条新闻太专业了,上车没办法研究)github
我经常看的博客园、infoq、36kr、开源中国新闻c#
我现在只做博客园和infoq,然后打算做36kr和开源中国新闻(今天上午已经完成了这项工作),如果大家有什么好的建议,也可以在评论中提到ide
数据是准实时获取的,然后我会尽量让你刷的时候有消息给你看帖
todo:新闻分享、采集、标签、分类等功能,当然要看你的热情了!网址
ps:如果你看过我写的代码采集,你就不会问为什么不用rss spa了
更新:添加了 51cto 的采集程序博客
废话不多说,先上图发展
然后去APK的下载链接(如果你有热情,苹果版也可以)
然后发布源代码
关键源码说明:
采集程序源码
static void cnblogs()
{
CQ doc;
try
{
var client = new RestClient("http://www.cnblogs.com/news/";);
var resq = new RestRequest(Method.GET);
var resp = client.Execute(resq);
doc = resp.Content;
}
catch (Exception ex)
{
Thread.Sleep(GetWaitTime());
cnblogs();
return;
}
var arr = doc[".post_item_body"].ToList();
var dataList = new List();
var db = dbFactory.Open();
foreach (var item in arr)
{
var str = item.InnerText;
var strArr = str.Split(Environment.NewLine.ToCharArray(),StringSplitOptions.RemoveEmptyEntries);
var data = new allen_news();
data.news_title = strArr[0];
if (checkTitle(data.news_title))
{
break;
}
data.news_summary = strArr[1].Trim();
data.author = strArr[2].Split("发布于".ToCharArray(),StringSplitOptions.RemoveEmptyEntries)[0];
data.add_time = DateTime.Now;
data.from_site_flag = 0;
data.news_url = ((CQ)item.InnerHTML)["h3 a"].Attr("href");
dataList.Insert(0, data);
}
if(dataList.Count >0)
{
db.InsertAll(dataList);
}
db.Dispose();
Console.WriteLine("增长了{0}条文章0", dataList.Count);
Thread.Sleep(GetWaitTime());
cnblogs();
}
采集程序使用了三个开源程序,CsQuery、RestSharp和ServiceStack.OrmLite
GetWaitTime() 随机等待1分钟到10分钟之间的时间长度,不频繁采集,不定期采集,避免目标主机阻塞采集程序所在IP
再看WEB服务的关键代码
<p>protected void Page_Load(object sender, EventArgs e)
{
dbFactory = new OrmLiteConnectionFactory(ConfigurationManager.AppSettings["dbConnStr"], MySqlDialect.Provider);
var action = Request["Action"];
var id = Request["Id"];
List result = null;
if (action == "PullDown")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id > {0} order by news_id desc limit 0,30",id);
db.Dispose();
}
else if(action == "PullUp")
{
var db = dbFactory.Open();
result = db.SelectFmt("select * from allen_news where news_id
文章采集程序(如何防止网站被恶意采集?收录又能防止被采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-15 08:01
面对自己的网站恶意采集,很多站长束手无策。尤其是对方采集发布的文章秒秒就被采纳了,我自己的原创反而变成了“转载”。少量被采集击倒是无害的,但是如果持续时间长了,对你自己的网站优化是非常不利的。那么如何防止网站被恶意采集呢?有没有办法不影响收录,防止网站变成采集?当然!
防止恶意采集骗人
经常查看服务器日志,屏蔽异常IP,防止恶意采集进入网站。
1、采集文章网站 的 IP。许多 网站 服务器与 采集 服务器相同。
2、流量大的 IP。这样的IP一般都是采集爬虫,直接屏蔽掉。
3、封IP的具体方法有很多。
通过对方的IP地址找到对方的主机服务商或机房。联系主办公司或机房。键入版权声明的副本,将电子邮件或传真发送到主办公司或计算机房。要求他们停止 采集网站 的服务器。然后联系对方的域名注册商,将版权声明的文本Email给他们。要求域名注册商停止对方的域名解析。
技巧2
文章 的命名尽量不规则。例如,如果你的文章是.htm,请在它之前或之后生成一个日期,如:20160514-1.htm,日期在它的前面,适合一些初学者< @采集.
技巧3
不要把所有的文章放在一个目录下,可以用日期生成不同的目录名。
四招
文章选择不同的模板,准备更多的模板。添加文章时,可以选择不同的模板。一般的采集程序是有针对性的,在采集页面会被分析。如果发现所有页面的布局不规则,采集程序一般会选择放弃。
技巧五张图片输出
重要数据直接作为图片输出。据说起点小说的vip章就是这样实现的。这种方法很彻底,缺点是消耗服务器性能和磁盘空间。
六个动态模板
采集都是通过制定好的饥饿规则,所以如果采集所在的页面没有规则,仍然可以防止采集。可以预先制作N套模板,最终的结果都差不多,只是HTML代码结构不同。比如有的用some use,有的用div,有的用table。每次显示或输出时都会随机调用模板。一旦发生这种情况,除了“人肉”之外,基本上可以阻止大部分采集程序。 查看全部
文章采集程序(如何防止网站被恶意采集?收录又能防止被采集)
面对自己的网站恶意采集,很多站长束手无策。尤其是对方采集发布的文章秒秒就被采纳了,我自己的原创反而变成了“转载”。少量被采集击倒是无害的,但是如果持续时间长了,对你自己的网站优化是非常不利的。那么如何防止网站被恶意采集呢?有没有办法不影响收录,防止网站变成采集?当然!
防止恶意采集骗人
经常查看服务器日志,屏蔽异常IP,防止恶意采集进入网站。
1、采集文章网站 的 IP。许多 网站 服务器与 采集 服务器相同。
2、流量大的 IP。这样的IP一般都是采集爬虫,直接屏蔽掉。
3、封IP的具体方法有很多。
通过对方的IP地址找到对方的主机服务商或机房。联系主办公司或机房。键入版权声明的副本,将电子邮件或传真发送到主办公司或计算机房。要求他们停止 采集网站 的服务器。然后联系对方的域名注册商,将版权声明的文本Email给他们。要求域名注册商停止对方的域名解析。
技巧2
文章 的命名尽量不规则。例如,如果你的文章是.htm,请在它之前或之后生成一个日期,如:20160514-1.htm,日期在它的前面,适合一些初学者< @采集.
技巧3
不要把所有的文章放在一个目录下,可以用日期生成不同的目录名。
四招
文章选择不同的模板,准备更多的模板。添加文章时,可以选择不同的模板。一般的采集程序是有针对性的,在采集页面会被分析。如果发现所有页面的布局不规则,采集程序一般会选择放弃。
技巧五张图片输出
重要数据直接作为图片输出。据说起点小说的vip章就是这样实现的。这种方法很彻底,缺点是消耗服务器性能和磁盘空间。
六个动态模板
采集都是通过制定好的饥饿规则,所以如果采集所在的页面没有规则,仍然可以防止采集。可以预先制作N套模板,最终的结果都差不多,只是HTML代码结构不同。比如有的用some use,有的用div,有的用table。每次显示或输出时都会随机调用模板。一旦发生这种情况,除了“人肉”之外,基本上可以阻止大部分采集程序。
文章采集程序(小说采集规则怎么写,新手站长来说如何选择? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-03-14 04:00
)
小说采集的规则怎么写,对于新手站长来说,采集规则很头疼,小说采集软件不需要填写复杂的采集规则,页面简洁,配置简单,上手新颖采集。采集之后,支持自动发布。不仅支持杰奇cms、奇文cms、一意cms等小说网站cms,还支持市面上常见的DEDE。、WordPress、Empire等都可以使用。
与其他类型的网站相比,小说网站更注重用户体验,体现在文章更新频率、网页打开速度、页面布局等方面。小说采集软件对上述SEO兼容性强,采集后的内容支持标签保留;敏感词过滤;文章 清洗(URL、号码、组织名称清洗);图像优化(图像替换/本地化/水印)等
Novel采集 软件帮助我们采集资料。在优化小说网站时,我们可以考虑和选择以下几点:
1.域名选择
一个好的域名可以让用户更容易记住。为新站申请域名时,域名应尽量简短易记。域名应该和我们的站名有一定的联系。
2.空间选择
Novel网站需要大数据存储,所以我们可以选择vps主机或者云主机。硬盘选型可以大一点,关键是速度和稳定性跟得上。香港的vps主机是我们的首选。优点是不用备案就便宜。空间的选择是我们的首要任务。
3.网站cms
有很多 cms 小说网站,无论是 Jackie、Strange 还是 Easy Read。在选择我们的cms之前,我们还是要仔细分析一下,从用户体验、网站维护、时间和空间成本的角度。充分理性分析后,根据自己的网站特点选择,毕竟适合自己的才是最好的。
4.VPS拨号功能
目前很多网站都有限制同一IP频繁访问网站的功能,Novel采集软件有VPS拨号功能,Nove采集软件可以为 采集 使用代理 IP 绕过限制。支持定时发布采集,真正实现全天候自动化管理。
小说采集软件或工具的本质是代替人力从网页中获取大量数据。软件帮助我们完成重复性和规律性的工作,所以我们不能只用虚构采集软件来采集数据;也可以用来查看我们的网站收录、排名等数据;自动发布和网站推送也可以通过软件完成。帮助我们更好地管理网站。
查看全部
文章采集程序(小说采集规则怎么写,新手站长来说如何选择?
)
小说采集的规则怎么写,对于新手站长来说,采集规则很头疼,小说采集软件不需要填写复杂的采集规则,页面简洁,配置简单,上手新颖采集。采集之后,支持自动发布。不仅支持杰奇cms、奇文cms、一意cms等小说网站cms,还支持市面上常见的DEDE。、WordPress、Empire等都可以使用。
与其他类型的网站相比,小说网站更注重用户体验,体现在文章更新频率、网页打开速度、页面布局等方面。小说采集软件对上述SEO兼容性强,采集后的内容支持标签保留;敏感词过滤;文章 清洗(URL、号码、组织名称清洗);图像优化(图像替换/本地化/水印)等
Novel采集 软件帮助我们采集资料。在优化小说网站时,我们可以考虑和选择以下几点:
1.域名选择
一个好的域名可以让用户更容易记住。为新站申请域名时,域名应尽量简短易记。域名应该和我们的站名有一定的联系。
2.空间选择
Novel网站需要大数据存储,所以我们可以选择vps主机或者云主机。硬盘选型可以大一点,关键是速度和稳定性跟得上。香港的vps主机是我们的首选。优点是不用备案就便宜。空间的选择是我们的首要任务。
3.网站cms
有很多 cms 小说网站,无论是 Jackie、Strange 还是 Easy Read。在选择我们的cms之前,我们还是要仔细分析一下,从用户体验、网站维护、时间和空间成本的角度。充分理性分析后,根据自己的网站特点选择,毕竟适合自己的才是最好的。
4.VPS拨号功能
目前很多网站都有限制同一IP频繁访问网站的功能,Novel采集软件有VPS拨号功能,Nove采集软件可以为 采集 使用代理 IP 绕过限制。支持定时发布采集,真正实现全天候自动化管理。
小说采集软件或工具的本质是代替人力从网页中获取大量数据。软件帮助我们完成重复性和规律性的工作,所以我们不能只用虚构采集软件来采集数据;也可以用来查看我们的网站收录、排名等数据;自动发布和网站推送也可以通过软件完成。帮助我们更好地管理网站。
文章采集程序(为什么要用DedeCMS插件?如何利用插件让网站收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-11 12:21
<p>为什么要使用 Dedecms 插件?如何使用 Dedecms 插件对 网站收录 和 关键词 进行排名。网站的标题(Title)、描述(KeyWords)和关键词(描述)是网站中权重最高的三个部分,也是 查看全部
文章采集程序(优采云文章采集器定期更新:文章采集+AI伪原创检测)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-11 03:25
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术捕获行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。
优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。
优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。 查看全部
文章采集程序(优采云文章采集器定期更新:文章采集+AI伪原创检测)
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术捕获行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。
优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。
优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。
文章采集程序(织梦CMS采集规则之文章采集器完美解决了网站内容问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-06 18:11
织梦cms采集聚合文章采集器,基于织梦DEDEcms网站 采集和站群采集,可以根据关键词、RSS和页面监控等定期量化,可以在伪原创SEO之后更新发布优化,不用写采集规则! 织梦cms采集文章规则采集器不知道大家有没有看懂,可能有些站长还没联系! 采集工具一般用于网站内容填充或一些站群或大型门户网站,也有企业网站使用。当然有些个人网站也用采集可以,因为有些情况你不想自己更新文章,或者需要的文章网站太多更新了,比如新闻网站,都用采集。
我们来说说织梦内容管理系统(Dedecms),它以简洁、实用和开源着称。是国内最知名的PHP开源网站管理系统,也是最人性化的PHP类cms系统,但是相关的采集不多,很多PHP初学者都在网上找织梦cms采集,很多织梦cms采集教程都不是最新的,有的是付费的,还有一些采集教程存储在百度云中,对站长来说很不方便!关于织梦cms网站采集的类型,织梦cms采集文章采集器@的规则>完美解决网站的内容填充问题。
织梦文章采集器有什么优势:
无需编写采集规则,设置后自动采集关键词:不同于传统的采集模式,可以根据用户自定义的方式进行关键词 pan采集、pan采集的优点是通过采集和关键词的不同搜索结果,可以不执行采集 指定一个或多个站点上的站点。 @采集,降低采集网站被搜索引擎判定为镜像网站,被搜索引擎惩罚的风险。
多种伪原创和优化方法来提高收录率和关键词排名:自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤和同义词替换等方法提升采集文章原创性能,提升搜索引擎收录、网站权重和关键词排名。
全自动采集,无需人工干预:当用户访问网站时,触发程序运行,根据搜索引擎(可自定义)通过搜索引擎到设置的关键字(可自定义)采集的URL,然后自动抓取网页的内容,程序通过精确的计算分析网页,丢弃不是文章的内容页的URL @>,提取出优秀的文章内容,最后进行伪原创、导入、生成,所有这些操作过程都是自动完成的,无需人工干预。在做大量内容采集时,也可以挂在VPS服务器采集上,加快采集速度。
效果很明显,网站采集首选:只需简单配置即可自动采集发布,熟悉织梦dedecms站长很容易搞定开始了。
织梦cms采集规则的文章采集器的好处是即使不在线也可以保持网站@ >每天都有新内容发布,因为是配置为自动发布,只要设置了,就可以定时定量更新。各种伪原创和优化方法来提高收录率和排名自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法对采集返回的文章进行处理,提升采集文章原创的性能,帮助搜索引擎优化,提升搜索引擎< @收录、网站 权重和 关键词 排名。
织梦采集 节点是由 织梦 守护进程自动带来的,采集 节点是完全免费的,但是 采集 不是很强大,有很多某事无法实现。
我们要知道网站基本有采集的需求。作为一个SEO优化者,我们没有那么强大的技术支持,所以只能使用一些工具来实现采集。填写内容,实现网站SEO优化,提升网站的收录,关键词的添加和关键词的排名,最终实现积累流量,实现流量转化。 查看全部
文章采集程序(织梦CMS采集规则之文章采集器完美解决了网站内容问题)
织梦cms采集聚合文章采集器,基于织梦DEDEcms网站 采集和站群采集,可以根据关键词、RSS和页面监控等定期量化,可以在伪原创SEO之后更新发布优化,不用写采集规则! 织梦cms采集文章规则采集器不知道大家有没有看懂,可能有些站长还没联系! 采集工具一般用于网站内容填充或一些站群或大型门户网站,也有企业网站使用。当然有些个人网站也用采集可以,因为有些情况你不想自己更新文章,或者需要的文章网站太多更新了,比如新闻网站,都用采集。
我们来说说织梦内容管理系统(Dedecms),它以简洁、实用和开源着称。是国内最知名的PHP开源网站管理系统,也是最人性化的PHP类cms系统,但是相关的采集不多,很多PHP初学者都在网上找织梦cms采集,很多织梦cms采集教程都不是最新的,有的是付费的,还有一些采集教程存储在百度云中,对站长来说很不方便!关于织梦cms网站采集的类型,织梦cms采集文章采集器@的规则>完美解决网站的内容填充问题。
织梦文章采集器有什么优势:
无需编写采集规则,设置后自动采集关键词:不同于传统的采集模式,可以根据用户自定义的方式进行关键词 pan采集、pan采集的优点是通过采集和关键词的不同搜索结果,可以不执行采集 指定一个或多个站点上的站点。 @采集,降低采集网站被搜索引擎判定为镜像网站,被搜索引擎惩罚的风险。
多种伪原创和优化方法来提高收录率和关键词排名:自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤和同义词替换等方法提升采集文章原创性能,提升搜索引擎收录、网站权重和关键词排名。
全自动采集,无需人工干预:当用户访问网站时,触发程序运行,根据搜索引擎(可自定义)通过搜索引擎到设置的关键字(可自定义)采集的URL,然后自动抓取网页的内容,程序通过精确的计算分析网页,丢弃不是文章的内容页的URL @>,提取出优秀的文章内容,最后进行伪原创、导入、生成,所有这些操作过程都是自动完成的,无需人工干预。在做大量内容采集时,也可以挂在VPS服务器采集上,加快采集速度。
效果很明显,网站采集首选:只需简单配置即可自动采集发布,熟悉织梦dedecms站长很容易搞定开始了。
织梦cms采集规则的文章采集器的好处是即使不在线也可以保持网站@ >每天都有新内容发布,因为是配置为自动发布,只要设置了,就可以定时定量更新。各种伪原创和优化方法来提高收录率和排名自动标题、段落重排、高级混淆、自动内部链接、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法对采集返回的文章进行处理,提升采集文章原创的性能,帮助搜索引擎优化,提升搜索引擎< @收录、网站 权重和 关键词 排名。
织梦采集 节点是由 织梦 守护进程自动带来的,采集 节点是完全免费的,但是 采集 不是很强大,有很多某事无法实现。
我们要知道网站基本有采集的需求。作为一个SEO优化者,我们没有那么强大的技术支持,所以只能使用一些工具来实现采集。填写内容,实现网站SEO优化,提升网站的收录,关键词的添加和关键词的排名,最终实现积累流量,实现流量转化。
文章采集程序(计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址来做连接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-03-06 06:05
文章采集程序开发相比于手机应用采集程序开发简单许多,可使用一个客户端软件或者一个网页程序在两个操作系统上连接,随意两个操作系统相互联接,然后采集对方的动态信息。此项目受前端开发能力,以及开发者的稳定性限制,我们的程序出现了大量的bug。公司有多名员工参与,时间并不是问题,只要能够解决。但开发时间却要4个月时间。
这样就造成了服务器不能够容纳软件模块发生任何更新,不过好在我们的服务器服务稳定,且后台服务器完善。lbs四线程一次性采集任意的点、线、面数据,也就是我们说的任意点、任意线、任意面数据。比如浏览器地址页面、http请求的url等,所以我们的程序支持多点采集和多线程采集。做一些有趣的情况需要切换动态调试台,我们会采用技术上调试台三遍运行的方式,而且这三遍运行是无法操作后台任何地方的,但程序可以左右四边双向移动,这样无论做任何有趣的情况都可以被采集。
计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址带宽来做连接。动态调试台连接时在浏览器输入相应的公网地址进行连接,虽然我们的可以自己手动指定页面ip,但是会影响到采集时间和性能。为什么我们计算机上网速度这么慢?我们是一对一的使用,实际连接时可以发送一个protobuf方法将response的header格式信息发送过去,如果是双向的情况下是保证是通过最低ip获取响应,如果是单向连接时会知道对方设备的ip地址,于是建立单向流量,来连接单向的网络和数据源端的响应,所以如果和现有源搭配起来,在设备上要走很多额外流量,不仅速度慢而且地址冲突不能使用。
当然有人会说使用libpng那样只需要一个接口就可以了,但是libpng要求点要是png格式的,而api一般是只支持jpg格式,为了动态加载非png格式的源文件,这就导致采集缓存的流量比较大,流量大的机器会造成带宽冲突,数据更新慢。当然了,如果不需要处理地址冲突,可以实现一个接口加载所有的信息,同时可以流量不冲突的取出源文件。
获取这类响应后,我们需要对采集过程做重构,因为没有办法忽略掉一部分的数据,或者去除一些数据不需要的信息。同时还需要做好服务器和数据源之间的接口协议规范。所以这个架构的设计有不少的问题。比如连接速度最终会取决于服务器负载能力,数据源端的传输速度,而数据源端的传输一般都是通过http请求,一般公网都是http,或者也可以通过squid的http服务进行连接,但是速度并不是太快,同时api本身也有一些限制。所以最好不要使用api或者squid进行连接。 查看全部
文章采集程序(计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址来做连接)
文章采集程序开发相比于手机应用采集程序开发简单许多,可使用一个客户端软件或者一个网页程序在两个操作系统上连接,随意两个操作系统相互联接,然后采集对方的动态信息。此项目受前端开发能力,以及开发者的稳定性限制,我们的程序出现了大量的bug。公司有多名员工参与,时间并不是问题,只要能够解决。但开发时间却要4个月时间。
这样就造成了服务器不能够容纳软件模块发生任何更新,不过好在我们的服务器服务稳定,且后台服务器完善。lbs四线程一次性采集任意的点、线、面数据,也就是我们说的任意点、任意线、任意面数据。比如浏览器地址页面、http请求的url等,所以我们的程序支持多点采集和多线程采集。做一些有趣的情况需要切换动态调试台,我们会采用技术上调试台三遍运行的方式,而且这三遍运行是无法操作后台任何地方的,但程序可以左右四边双向移动,这样无论做任何有趣的情况都可以被采集。
计算机上网络普遍使用300k,但是我们后台可以使用特定技术获取最大地址带宽来做连接。动态调试台连接时在浏览器输入相应的公网地址进行连接,虽然我们的可以自己手动指定页面ip,但是会影响到采集时间和性能。为什么我们计算机上网速度这么慢?我们是一对一的使用,实际连接时可以发送一个protobuf方法将response的header格式信息发送过去,如果是双向的情况下是保证是通过最低ip获取响应,如果是单向连接时会知道对方设备的ip地址,于是建立单向流量,来连接单向的网络和数据源端的响应,所以如果和现有源搭配起来,在设备上要走很多额外流量,不仅速度慢而且地址冲突不能使用。
当然有人会说使用libpng那样只需要一个接口就可以了,但是libpng要求点要是png格式的,而api一般是只支持jpg格式,为了动态加载非png格式的源文件,这就导致采集缓存的流量比较大,流量大的机器会造成带宽冲突,数据更新慢。当然了,如果不需要处理地址冲突,可以实现一个接口加载所有的信息,同时可以流量不冲突的取出源文件。
获取这类响应后,我们需要对采集过程做重构,因为没有办法忽略掉一部分的数据,或者去除一些数据不需要的信息。同时还需要做好服务器和数据源之间的接口协议规范。所以这个架构的设计有不少的问题。比如连接速度最终会取决于服务器负载能力,数据源端的传输速度,而数据源端的传输一般都是通过http请求,一般公网都是http,或者也可以通过squid的http服务进行连接,但是速度并不是太快,同时api本身也有一些限制。所以最好不要使用api或者squid进行连接。
文章采集程序(文章采集程序读取好像有限制,还有什么google+)
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-04 19:03
文章采集程序,
dropbox读取好像有限制,pps主要是就是用于备份。但是pps也能做网盘,还可以投票啥的。还有什么google+,gmail,googleshopping。
这个是pps在收费我这边曾经用过,不过是在dropbox中保存数据,然后又用公司公用的在线的云储存服务器(同样我也不知道是什么,我上班几年从来都不买公司的云储存服务,相当于自己的私有云)对数据进行备份。我只是说,如果你有对相关信息需要保存的时候,网上一搜或者就知道可能有备份。
就是用来解决大文件的读取问题的pps只要做到保存视频、图片等文件,基本上就不用考虑连接的问题,节省了大量的资源,数据量不会比googleslides要小。
是某一个数据集,每日量保持在100万以上,
谢邀。想了解的人多一点。
备份备份,重要的东西备份好。
文件少,
真正的软件保存的方式如下:如果alice以前不在windows8上使用onedrive的话,那么我可以使用dropbox来同步alice的文件。如果alice在pps上从来没有使用过onedrive,我可以使用dropbox来同步alice的文件。但如果有bobandgoldhat,就不是这么容易的了,他们会使用相同的方法同步到windows8.1上面。 查看全部
文章采集程序(文章采集程序读取好像有限制,还有什么google+)
文章采集程序,
dropbox读取好像有限制,pps主要是就是用于备份。但是pps也能做网盘,还可以投票啥的。还有什么google+,gmail,googleshopping。
这个是pps在收费我这边曾经用过,不过是在dropbox中保存数据,然后又用公司公用的在线的云储存服务器(同样我也不知道是什么,我上班几年从来都不买公司的云储存服务,相当于自己的私有云)对数据进行备份。我只是说,如果你有对相关信息需要保存的时候,网上一搜或者就知道可能有备份。
就是用来解决大文件的读取问题的pps只要做到保存视频、图片等文件,基本上就不用考虑连接的问题,节省了大量的资源,数据量不会比googleslides要小。
是某一个数据集,每日量保持在100万以上,
谢邀。想了解的人多一点。
备份备份,重要的东西备份好。
文件少,
真正的软件保存的方式如下:如果alice以前不在windows8上使用onedrive的话,那么我可以使用dropbox来同步alice的文件。如果alice在pps上从来没有使用过onedrive,我可以使用dropbox来同步alice的文件。但如果有bobandgoldhat,就不是这么容易的了,他们会使用相同的方法同步到windows8.1上面。
文章采集程序(SEO优化:优化关键字,网站优化效果受关键字难度的影响 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-01 22:15
)
不同cms专注于不同领域。 Applecms专注于视频,Raincms专注于小说,WordPress专注于国际化。对于我们来说,我们有很多不同的cms网站站长,网站内容的更新和维护是一件很头疼的事情,那么我们应该如何管理这些cms,保证他们的内容是优秀的获得用户和排名呢?其实我们可以通过文章采集伪原创工具来实现。
文章采集伪原创该工具可以根据用户填写的关键词自动识别各大平台网页的标题、文字等信息,不用写任何采集规则就可以实现全网采集。 采集到达内容后,自动计算内容与集合关键词的相关性,只留下相关的文章给用户。
文章采集伪原创 工具支持标题前缀、关键词 自动粗体、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列SEO功能。用户只需设置关键词及相关要求即可实现全托管。 网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
文章采集伪原创工具可以在软件中实现对不同cms网站数据的观察,有利于多个网站站长进行数据分析;批量设置发布次数(可设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控已发布、即将发布、是否伪原创、发布状态、URL、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等每日数据。
网站要对SEO友好,需要专业的技术来实现,并不是每一个网站都有很好的SEO优化效果。要了解网站优化的作用和SEO的重要性,你必须熟悉或熟悉常见的SEO优化技术。
SEO优化:优化关键词,网站优化效果受关键词难度影响。一般来说,在接受一个项目并进行网站优化时,首先要分析其关键词,结合网站自身的定位和模式、行业竞争水平、规划时效、发展目标等基本信息,网站 用于定位的关键字。如何定位这个关键词?影响关键词难度的因素有哪些?直接影响项目的可行性和可操作性以及网站.
1.识别需要优化的关键词。优化时一定要关键词。 关键词分为长尾关键词,优化网站内容和外链是首选。这样的 关键词 比较困难。经过多年的积累,第二个词可以增加权重,第二个是核心关键词,是网站的核心,是吸纳用户流量的绝对主力。
2.百度索引数据衡量关键词优化的难度。指关键词在百度平台的热度。 关键词 在百度上搜索的次数越多,对应的百度指数越高,但越低。可以反映这个关键词的活动。热门关键词竞争的人越多,难度系数就越高。
3.百度的收录音量决定难度。 收录volume 是百度网站 页数。百度页面收录关键词,即关键词中收录的数量。因此,百度收录的数量越大,就反映了这个关键词的活跃度。 收录量越大越难优化。
4.关于一级域名的数量。域名的排名有很多,一级域名是具有较高权限的。一级域名数量与关键词推广网站同向发展。一级域名越多,优化难度越大。
5.关键词数字。 关键词 由 关键词 组成。 关键词 越多,关键词 越受欢迎。 关键词 的难度取决于这个关键词。如何确定关键词的数量和热情?用搜索工具在百度上搜索这些关键词,理解数量、数量、百度索引、优化相关信息的难度也在增加。
6. 页面与 关键词 的匹配程度。 网站优化的难度还受关键词和页面匹配程度的影响。匹配要求越高,网站优化就越难。
文章采集伪原创工具可以为我们的管理提供极大的便利网站,但也需要我们的站长合理使用。毕竟SEO的核心竞争力是持续优化,只要坚持数据分析和优化调整,总能达到理想的流量转化。
查看全部
文章采集程序(SEO优化:优化关键字,网站优化效果受关键字难度的影响
)
不同cms专注于不同领域。 Applecms专注于视频,Raincms专注于小说,WordPress专注于国际化。对于我们来说,我们有很多不同的cms网站站长,网站内容的更新和维护是一件很头疼的事情,那么我们应该如何管理这些cms,保证他们的内容是优秀的获得用户和排名呢?其实我们可以通过文章采集伪原创工具来实现。
文章采集伪原创该工具可以根据用户填写的关键词自动识别各大平台网页的标题、文字等信息,不用写任何采集规则就可以实现全网采集。 采集到达内容后,自动计算内容与集合关键词的相关性,只留下相关的文章给用户。
文章采集伪原创 工具支持标题前缀、关键词 自动粗体、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列SEO功能。用户只需设置关键词及相关要求即可实现全托管。 网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
文章采集伪原创工具可以在软件中实现对不同cms网站数据的观察,有利于多个网站站长进行数据分析;批量设置发布次数(可设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控已发布、即将发布、是否伪原创、发布状态、URL、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等每日数据。
网站要对SEO友好,需要专业的技术来实现,并不是每一个网站都有很好的SEO优化效果。要了解网站优化的作用和SEO的重要性,你必须熟悉或熟悉常见的SEO优化技术。
SEO优化:优化关键词,网站优化效果受关键词难度影响。一般来说,在接受一个项目并进行网站优化时,首先要分析其关键词,结合网站自身的定位和模式、行业竞争水平、规划时效、发展目标等基本信息,网站 用于定位的关键字。如何定位这个关键词?影响关键词难度的因素有哪些?直接影响项目的可行性和可操作性以及网站.
1.识别需要优化的关键词。优化时一定要关键词。 关键词分为长尾关键词,优化网站内容和外链是首选。这样的 关键词 比较困难。经过多年的积累,第二个词可以增加权重,第二个是核心关键词,是网站的核心,是吸纳用户流量的绝对主力。
2.百度索引数据衡量关键词优化的难度。指关键词在百度平台的热度。 关键词 在百度上搜索的次数越多,对应的百度指数越高,但越低。可以反映这个关键词的活动。热门关键词竞争的人越多,难度系数就越高。
3.百度的收录音量决定难度。 收录volume 是百度网站 页数。百度页面收录关键词,即关键词中收录的数量。因此,百度收录的数量越大,就反映了这个关键词的活跃度。 收录量越大越难优化。
4.关于一级域名的数量。域名的排名有很多,一级域名是具有较高权限的。一级域名数量与关键词推广网站同向发展。一级域名越多,优化难度越大。
5.关键词数字。 关键词 由 关键词 组成。 关键词 越多,关键词 越受欢迎。 关键词 的难度取决于这个关键词。如何确定关键词的数量和热情?用搜索工具在百度上搜索这些关键词,理解数量、数量、百度索引、优化相关信息的难度也在增加。
6. 页面与 关键词 的匹配程度。 网站优化的难度还受关键词和页面匹配程度的影响。匹配要求越高,网站优化就越难。
文章采集伪原创工具可以为我们的管理提供极大的便利网站,但也需要我们的站长合理使用。毕竟SEO的核心竞争力是持续优化,只要坚持数据分析和优化调整,总能达到理想的流量转化。
文章采集程序(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-27 22:03
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?
一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress 查看全部
文章采集程序(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?
一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress
文章采集程序(面向目标群体的优质内容有哪些?停滞不前的方法?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-27 22:00
我们早就知道 网站 的质量在 Google 中起着关键作用。谷歌高级工程师马特·卡茨在他的博客中多次提到,“质量”对谷歌来说至关重要,无论是在内容上还是在连接性上。
不过,创建内容和联系不一定是一个痛苦的过程。网站建设者开始思考如何从特定角度组织内容。因此,让我们敞开心扉进行创新,思考所有这些为 网站 添加优质内容的方法。
请首先记住以下几点:
你只受限于你自己的想法和你的网站。尝试向完全不同的方向探索。
您的 网站 内容应该是为您的客户而不是您编写的。网站内容也不是为搜索引擎编写的,它们不是您的目标群体。
把你的 网站 想象成一幅完整的画作,一个活生生的、会呼吸的整体。它会继续增长,不会停滞不前。
现在我们进入重点:为您的目标受众提供优质内容。
1. 活动日历。对于房地产网站,可以用来展示新开的房子;对于网上书店,可用于介绍新书签约、作者见面会等;对于采集网站,它可以用来介绍最近的聚会等。...确保访问者可以将自己的事件添加到日历中。
2、地图。考虑为房地产网站、狩猎/钓鱼网站、露营网站、酒店或任何其他户外娱乐网站 制作地图。在地图底部添加内容以描述地图并解释其意图。
3.售前/售后体验。如果您的客户可以写一段关于您提供的产品或服务的简短段落,或者讨论您的产品/服务的好处,那就太好了。您可以将它们放在 网站 上作为成功的证明。
4.来自客户的图片。您可以为现有客户设置一个专门的位置,在您的 网站 上发布他们的图片、日记等。这种方式比较适合度假网站、游戏网站、休闲网站、结婚网站、宝宝网站、摄影棚、星座网站 , 电影 网站 等等。想想看,万圣节要做什么网站?花网站呢?
5.在线着色。用你的想象力。如果您为一些度假项目着色,孩子们可以在旅行开始前将它们着色并发布在他们自己的在线部分。旅行结束后,他们的父母可以再次发布他们度假的照片和日志。这样,一个属于他们的节日纪念“网站”(其实完全基于你的网站)成为你的节日网站的签名。他们将如何使用这个“网站”?他们会告诉朋友、祖父母、阿姨和叔叔等。他们会将这个“网站”链接到其他地方。您可以将此标志作为独特的核心卖点与您的竞争对手竞争。您将获得来自过去客户的联系和来自未来客户的意见。您将获得优势。如果网站可以用于儿童文章,
6. 博客或论坛肯定会为 网站 添加新内容。
7. 文章 或您的目标群体感兴趣的新页面。定期写新内容——你的目标应该是每周 1-2 篇。
8. 专家问答展示在本站首页。请专家回答问题,然后在主页上发布每周问答(或每天,由您自己控制)。在网站上对过去的问题和答案进行可搜索的存档。
9.产品评价。如果您所在的行业有产品或软件需要审核,请考虑撰写一些公平的评论文章。将 文章 发布到您的 网站 和在线出版物。读者将始终对完整、公正的评论感兴趣,因为作者公正地列出了产品的优点和缺点。如果在景区经营,应该如何“评价”?作为专家,您将使用哪些产品?为什么?
10、小提示。如果您的产品或服务适合提示,请写一个系列并将其发布在您的 网站 上。作为时事通讯发送。邀请使用您的产品的读者也写提示/技巧,如果他们提交,请给他们一些其他产品的优惠/折扣。
11. 常见问题。常见问题 (FAQ) 是您的目标群体想知道的。当您收到读者的问题时,请在常见问题解答中添加新问题以保持更新。
12. 用户手册/指南。人们喜欢阅读手册。如果您在网上销售马桶配件,为什么不写一篇关于“如何在浴室安装马桶”的说明?为您的客户提供便利,他们会不断光顾。编写一系列手册。做互联网上的“厕所超人”。这听起来可能不够迷人,但随后您将非常引人注目并且能够将 网站 流量转化为销售量,并且您将在互联网之外具有吸引力。
13、能解决实际问题的内容。人们为什么要上网?供参考或比较购物。如果你能为你的访客解决这些问题,你就可以帮助他们到达那里。例如,您正在销售东方地毯。您的潜在客户可能正在寻找如何装饰她的办公室的想法。她的办公室很小,她想增加一些颜色。大部分墙壁都被窗户和金属书柜占据。如果您创建一系列内容/图像来展示您的东方地毯如何解决她的问题,一个例子提到了一个长东方地毯。这些内容不仅包括图片,还包括描述每个问题并给出解决方案的文字。您的潜在客户自然会从搜索引擎中找到您的页面。
14. 历史数据。这次假设你在卖钢管。钢管的历史是怎样的?创建一个专门介绍其历史的页面。实际上,您还应该创建有关以下内容的页面:钢管与铜管和其他金属管的比较;为什么会生锈;钢有多硬;用于等);钢材的寿命;等等等等,所有这些都构成了一个部分,将成为整个 网站 的一个非常有价值的组成部分。
注意,问题来了。这个内容对钢管公司的目标群体也有价值吗?考虑一个目标群体:美国各地的职业教育和培训课程。这对他们来说是一个很好的资源。如果他们连接到这个 网站,两个 .edu 的 网站,它会给 网站 一个高连接欢迎吗?想想看。我们谈论的是高质量的内容和高质量的联系。
历史数据的另一个例子是圣西蒙岛上的一家酒店。这样的酒店当然应该在其网站等上提供有关该岛的历史和旅游信息。
一家销售 Mustang 软管零件的 网站 公司将如何使用这种策略?卖婚纱的网站呢?
15. 面试。创建内容的最简单方法。采访您所在行业的专家。给他一个问题清单,让专家用自己的话回答。除了纠正拼写错误或语法错误外,不要编辑专家的答案。对专家诚实并保持采访的完整性文章。写一系列采访 文章 并在你的 网站 主页上突出显示它们。
16. 季节性 文章。你的行业是否也有“季节性”?如果有的话,季节性 文章 通常很受欢迎。
17. 统计。在 网站 上提供统计数据也是一种添加内容的方式。如果统计数据不是来自您,它们往往会告诉您信息的来源。引用这些信息来源!金融或资产抵押网站如何使用这个策略?
18. 建议栏。这可用于约会网站 以及其他网站。SEO网站如何使用这个策略?室内装潢网站或整形手术网站怎么样?
19. 月度冠军。假设您经营一家销售插花的 网站。邀请您的客户发送用您的鲜花等设计的花束图片。在线发布照片。每个月都会选出一名获胜者,他的照片将被放置在 网站 的显眼页面上。获胜者将获得价值 25 美元的礼物作为奖励证书。
20. 以花店为例,制作一些插花的视频教程。在查看者遵循教程时,请确保您的商店中的所有材料都可用。
21、以花店为例。邀请客户提供反馈,例如他们如何制作插花,使用的材料和照片等。将这些信息放在您的网站上。相关材料链接到您的在线商店。发挥创意。你应该在你的行业做什么?如果你有一套服装网站怎么办?艺术品 网站 呢?用你的大脑将这个策略应用到狩猎或钓鱼中网站。
22. 每月发送一份时事通讯,其中收录您想告诉客户的信息。它可能是来自客户的提示、销售产品、假期计划、每月冠军等等。在 网站 上发布过去的时事通讯以添加内容。
23. 重要人物传记。如果它与您的行业相关,您可以这样做。如果您运行关于美国内战历史或旧书店的 网站,这将非常有用。
24、新闻事件。因您的行业而异。
25. 与社区相关的页面。例如,如果这是本地 网站,您可以在社区相关页面或博客上讨论本地餐馆、棒球联赛、校园开放等。
我们只是列出这些想法并开始。一切都会因您的行业、产品或服务而异。您还需要集思广益。
综上所述…
创建内容时要牢记“溢价”。上述想法应该可以帮助您入门。
然后思考以下问题。如果您开始创建优质内容,下一步是什么?质量连接。其他人 网站 将开始链接到您的内容,因为您做了自己的工作:为客户提供他们需要的东西。他们需要看到高质量、不断更新的信息。您成为值得信赖的信息来源。
不要试图走“捷径”。成功来自努力。 查看全部
文章采集程序(面向目标群体的优质内容有哪些?停滞不前的方法?)
我们早就知道 网站 的质量在 Google 中起着关键作用。谷歌高级工程师马特·卡茨在他的博客中多次提到,“质量”对谷歌来说至关重要,无论是在内容上还是在连接性上。
不过,创建内容和联系不一定是一个痛苦的过程。网站建设者开始思考如何从特定角度组织内容。因此,让我们敞开心扉进行创新,思考所有这些为 网站 添加优质内容的方法。
请首先记住以下几点:
你只受限于你自己的想法和你的网站。尝试向完全不同的方向探索。
您的 网站 内容应该是为您的客户而不是您编写的。网站内容也不是为搜索引擎编写的,它们不是您的目标群体。
把你的 网站 想象成一幅完整的画作,一个活生生的、会呼吸的整体。它会继续增长,不会停滞不前。
现在我们进入重点:为您的目标受众提供优质内容。
1. 活动日历。对于房地产网站,可以用来展示新开的房子;对于网上书店,可用于介绍新书签约、作者见面会等;对于采集网站,它可以用来介绍最近的聚会等。...确保访问者可以将自己的事件添加到日历中。
2、地图。考虑为房地产网站、狩猎/钓鱼网站、露营网站、酒店或任何其他户外娱乐网站 制作地图。在地图底部添加内容以描述地图并解释其意图。
3.售前/售后体验。如果您的客户可以写一段关于您提供的产品或服务的简短段落,或者讨论您的产品/服务的好处,那就太好了。您可以将它们放在 网站 上作为成功的证明。
4.来自客户的图片。您可以为现有客户设置一个专门的位置,在您的 网站 上发布他们的图片、日记等。这种方式比较适合度假网站、游戏网站、休闲网站、结婚网站、宝宝网站、摄影棚、星座网站 , 电影 网站 等等。想想看,万圣节要做什么网站?花网站呢?
5.在线着色。用你的想象力。如果您为一些度假项目着色,孩子们可以在旅行开始前将它们着色并发布在他们自己的在线部分。旅行结束后,他们的父母可以再次发布他们度假的照片和日志。这样,一个属于他们的节日纪念“网站”(其实完全基于你的网站)成为你的节日网站的签名。他们将如何使用这个“网站”?他们会告诉朋友、祖父母、阿姨和叔叔等。他们会将这个“网站”链接到其他地方。您可以将此标志作为独特的核心卖点与您的竞争对手竞争。您将获得来自过去客户的联系和来自未来客户的意见。您将获得优势。如果网站可以用于儿童文章,
6. 博客或论坛肯定会为 网站 添加新内容。
7. 文章 或您的目标群体感兴趣的新页面。定期写新内容——你的目标应该是每周 1-2 篇。
8. 专家问答展示在本站首页。请专家回答问题,然后在主页上发布每周问答(或每天,由您自己控制)。在网站上对过去的问题和答案进行可搜索的存档。
9.产品评价。如果您所在的行业有产品或软件需要审核,请考虑撰写一些公平的评论文章。将 文章 发布到您的 网站 和在线出版物。读者将始终对完整、公正的评论感兴趣,因为作者公正地列出了产品的优点和缺点。如果在景区经营,应该如何“评价”?作为专家,您将使用哪些产品?为什么?
10、小提示。如果您的产品或服务适合提示,请写一个系列并将其发布在您的 网站 上。作为时事通讯发送。邀请使用您的产品的读者也写提示/技巧,如果他们提交,请给他们一些其他产品的优惠/折扣。
11. 常见问题。常见问题 (FAQ) 是您的目标群体想知道的。当您收到读者的问题时,请在常见问题解答中添加新问题以保持更新。
12. 用户手册/指南。人们喜欢阅读手册。如果您在网上销售马桶配件,为什么不写一篇关于“如何在浴室安装马桶”的说明?为您的客户提供便利,他们会不断光顾。编写一系列手册。做互联网上的“厕所超人”。这听起来可能不够迷人,但随后您将非常引人注目并且能够将 网站 流量转化为销售量,并且您将在互联网之外具有吸引力。
13、能解决实际问题的内容。人们为什么要上网?供参考或比较购物。如果你能为你的访客解决这些问题,你就可以帮助他们到达那里。例如,您正在销售东方地毯。您的潜在客户可能正在寻找如何装饰她的办公室的想法。她的办公室很小,她想增加一些颜色。大部分墙壁都被窗户和金属书柜占据。如果您创建一系列内容/图像来展示您的东方地毯如何解决她的问题,一个例子提到了一个长东方地毯。这些内容不仅包括图片,还包括描述每个问题并给出解决方案的文字。您的潜在客户自然会从搜索引擎中找到您的页面。
14. 历史数据。这次假设你在卖钢管。钢管的历史是怎样的?创建一个专门介绍其历史的页面。实际上,您还应该创建有关以下内容的页面:钢管与铜管和其他金属管的比较;为什么会生锈;钢有多硬;用于等);钢材的寿命;等等等等,所有这些都构成了一个部分,将成为整个 网站 的一个非常有价值的组成部分。
注意,问题来了。这个内容对钢管公司的目标群体也有价值吗?考虑一个目标群体:美国各地的职业教育和培训课程。这对他们来说是一个很好的资源。如果他们连接到这个 网站,两个 .edu 的 网站,它会给 网站 一个高连接欢迎吗?想想看。我们谈论的是高质量的内容和高质量的联系。
历史数据的另一个例子是圣西蒙岛上的一家酒店。这样的酒店当然应该在其网站等上提供有关该岛的历史和旅游信息。
一家销售 Mustang 软管零件的 网站 公司将如何使用这种策略?卖婚纱的网站呢?
15. 面试。创建内容的最简单方法。采访您所在行业的专家。给他一个问题清单,让专家用自己的话回答。除了纠正拼写错误或语法错误外,不要编辑专家的答案。对专家诚实并保持采访的完整性文章。写一系列采访 文章 并在你的 网站 主页上突出显示它们。
16. 季节性 文章。你的行业是否也有“季节性”?如果有的话,季节性 文章 通常很受欢迎。
17. 统计。在 网站 上提供统计数据也是一种添加内容的方式。如果统计数据不是来自您,它们往往会告诉您信息的来源。引用这些信息来源!金融或资产抵押网站如何使用这个策略?
18. 建议栏。这可用于约会网站 以及其他网站。SEO网站如何使用这个策略?室内装潢网站或整形手术网站怎么样?
19. 月度冠军。假设您经营一家销售插花的 网站。邀请您的客户发送用您的鲜花等设计的花束图片。在线发布照片。每个月都会选出一名获胜者,他的照片将被放置在 网站 的显眼页面上。获胜者将获得价值 25 美元的礼物作为奖励证书。
20. 以花店为例,制作一些插花的视频教程。在查看者遵循教程时,请确保您的商店中的所有材料都可用。
21、以花店为例。邀请客户提供反馈,例如他们如何制作插花,使用的材料和照片等。将这些信息放在您的网站上。相关材料链接到您的在线商店。发挥创意。你应该在你的行业做什么?如果你有一套服装网站怎么办?艺术品 网站 呢?用你的大脑将这个策略应用到狩猎或钓鱼中网站。
22. 每月发送一份时事通讯,其中收录您想告诉客户的信息。它可能是来自客户的提示、销售产品、假期计划、每月冠军等等。在 网站 上发布过去的时事通讯以添加内容。
23. 重要人物传记。如果它与您的行业相关,您可以这样做。如果您运行关于美国内战历史或旧书店的 网站,这将非常有用。
24、新闻事件。因您的行业而异。
25. 与社区相关的页面。例如,如果这是本地 网站,您可以在社区相关页面或博客上讨论本地餐馆、棒球联赛、校园开放等。
我们只是列出这些想法并开始。一切都会因您的行业、产品或服务而异。您还需要集思广益。
综上所述…
创建内容时要牢记“溢价”。上述想法应该可以帮助您入门。
然后思考以下问题。如果您开始创建优质内容,下一步是什么?质量连接。其他人 网站 将开始链接到您的内容,因为您做了自己的工作:为客户提供他们需要的东西。他们需要看到高质量、不断更新的信息。您成为值得信赖的信息来源。
不要试图走“捷径”。成功来自努力。
文章采集程序(PythonRequests库、提交一个基本表单、HTML相关控件等内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-26 19:25
上一期我们讲解了 Python Requests 库、提交基本表单、HTML 相关控件等。
在这篇文章中文章我们跟随上一期文章关于通过Python请求提交文件和图像、处理登录cookie、HTTP基本访问认证以及其他与表单相关的问题。
提交文件和图像
虽然上传文件在网络上很常见,但对于网络数据采集 则不太常见。但是,如果您想为自己的 网站 文件上传测试实例,也可以通过 Python 请求库来实现。无论如何,掌握事物的运作方式总是很有用的。
以下是文件上传的源代码示例:
编辑封面图片
文件上传表单看起来和之前的 文章 中的文本字段相同,只是标签中有一个类型属性是文件。事实上,Python Requests 库处理这种形式与以前非常相似:
import requests
def upload_image():
files = {'uploadFile': open('files/2fe7243c7c113fad443b375a021801eb6277169d.png', 'rb')}
r = requests.post("http://pythonscraping.com/page ... ot%3B, files=files)
print(r.text)
if __name__ == '__main__':
upload_image()
需要注意的是,这里提交给表单字段uploadFile的值不一定是简单的字符串,而是用open函数打开的Python文件对象。在这个例子中,我们提交了一个保存在我们计算机上的图像文件,文件路径是相对于 Python 程序的位置的。
处理登录和 cookie
到目前为止,我们介绍的大多数表单都允许您向 网站 提交信息,或者让您在提交表单后立即看到所需的页面信息。那么,这些表单和登录表单(让您在浏览 网站 时保持“登录”状态)之间有什么区别?
大多数现代 网站 使用 cookie 来跟踪有关用户是否登录的状态信息。一旦 网站 验证了您的登录凭据,他会将它们存储在您浏览器的 cookie 中,该 cookie 通常收录服务器生成的令牌、登录过期时间和登录状态跟踪信息。网站 将使用此 cookie 作为信息验证的凭据,在您浏览 网站 的每个页面时呈现给服务器。在 1990 年代中期广泛使用 cookie 之前,保持用户的安全身份验证和跟踪是 网站 上的一个主要问题。
虽然 cookie 为 Web 开发人员解决了大问题,但它们也给 Web 爬虫带来了大问题。您一天只能提交一次登录表单,但如果您不注意表单后返回给您的cookie,那么当您过一段时间再次访问新页面时,您的登录状态将丢失,您将需要重新登录。
现在我们有了博客管理后台,我们需要登录发布文章并上传图片,我们用Python Requests模拟登录,跟踪cookies,下面是代码示例:
在上面的代码中,我们向登录页面发送了相关参数,作用是模拟我们输入用户名和密码的登录页面。然后我们从请求中获取cookie并打印登录结果。
对于简单的页面,我们可以毫无问题地处理,但是如果网站比较复杂,他经常会偷偷调整cookie,或者如果我们一开始就不想使用cookie,我们该怎么办?Requests 库的 session 功能可以完美解决这些问题:
import requests
from bs4 import BeautifulSoup
from requests import Session, exceptions
from utils import connection_util
class GetCookie(object):
def __init__(self):
self._session = Session()
self._init_connection = connection_util.ProcessConnection()
def get_cookie_by_login(self):
# 另外一个 session 中
get_token=self.get_request_verification_token()
if get_token:
params = {'__RequestVerificationToken': get_token, 'Email': 'abc@pdf-lib.org',
'Password': 'hhgu##$dfe__e',
'RememberMe': True}
r = self._session.post('https://pdf-lib.org/account/admin', params)
# 如果使用 request_verification_token 此处会出现 500 错误
if r.status_code == 500:
print(r.content.decode('utf-8'))
print('Cookie is set to:')
print(r.cookies.get_dict())
print('--------------------------------')
print('Going to post article page..')
r = self._session.get('https://pdf-lib.org/Manage/ArticleList', cookies=r.cookies)
print(r.text)
def get_request_verification_token(self):
# 连接网站
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"}
html = self._session.get("https://pdf-lib.org/Account/Login", headers=headers)
except (exceptions.ConnectionError, exceptions.HTTPError, exceptions.Timeout) as e:
return False
try:
bsObj = BeautifulSoup(html.text, features='html.parser')
except AttributeError as e:
return False
if bsObj:
try:
get_token = bsObj.find("input", {"name": "__RequestVerificationToken"}).get("value")
except Exception as e:
print(f"ot unhandled exception {e}")
return False
return get_token
if __name__ == '__main__':
get_cookie = GetCookie()
get_cookie.get_cookie_by_login()
在此示例中,会话对象(通过调用 requests.Session() 获得)继续跟踪会话信息,例如 cookie、标头,甚至有关运行 HTTP 协议的信息,例如 HTTPAdapter(为 HTTP 和 HTTPS 连接会话提供)。统一接口)。
Requests 是一个非常强大的库。程序员不必浪费脑筋或编写代码。它可能只是不如 Selenium。尽管在编写网络爬虫时,您可能想让 Requests 库为您做所有事情,但请保持关注。了解 cookie 的状态以及它们可以控制的程度非常重要。这样可以避免痛苦的调试和追逐 网站 异常,从而节省大量时间。 查看全部
文章采集程序(PythonRequests库、提交一个基本表单、HTML相关控件等内容)
上一期我们讲解了 Python Requests 库、提交基本表单、HTML 相关控件等。
在这篇文章中文章我们跟随上一期文章关于通过Python请求提交文件和图像、处理登录cookie、HTTP基本访问认证以及其他与表单相关的问题。
提交文件和图像
虽然上传文件在网络上很常见,但对于网络数据采集 则不太常见。但是,如果您想为自己的 网站 文件上传测试实例,也可以通过 Python 请求库来实现。无论如何,掌握事物的运作方式总是很有用的。
以下是文件上传的源代码示例:
编辑封面图片
文件上传表单看起来和之前的 文章 中的文本字段相同,只是标签中有一个类型属性是文件。事实上,Python Requests 库处理这种形式与以前非常相似:
import requests
def upload_image():
files = {'uploadFile': open('files/2fe7243c7c113fad443b375a021801eb6277169d.png', 'rb')}
r = requests.post("http://pythonscraping.com/page ... ot%3B, files=files)
print(r.text)
if __name__ == '__main__':
upload_image()
需要注意的是,这里提交给表单字段uploadFile的值不一定是简单的字符串,而是用open函数打开的Python文件对象。在这个例子中,我们提交了一个保存在我们计算机上的图像文件,文件路径是相对于 Python 程序的位置的。
处理登录和 cookie
到目前为止,我们介绍的大多数表单都允许您向 网站 提交信息,或者让您在提交表单后立即看到所需的页面信息。那么,这些表单和登录表单(让您在浏览 网站 时保持“登录”状态)之间有什么区别?
大多数现代 网站 使用 cookie 来跟踪有关用户是否登录的状态信息。一旦 网站 验证了您的登录凭据,他会将它们存储在您浏览器的 cookie 中,该 cookie 通常收录服务器生成的令牌、登录过期时间和登录状态跟踪信息。网站 将使用此 cookie 作为信息验证的凭据,在您浏览 网站 的每个页面时呈现给服务器。在 1990 年代中期广泛使用 cookie 之前,保持用户的安全身份验证和跟踪是 网站 上的一个主要问题。
虽然 cookie 为 Web 开发人员解决了大问题,但它们也给 Web 爬虫带来了大问题。您一天只能提交一次登录表单,但如果您不注意表单后返回给您的cookie,那么当您过一段时间再次访问新页面时,您的登录状态将丢失,您将需要重新登录。
现在我们有了博客管理后台,我们需要登录发布文章并上传图片,我们用Python Requests模拟登录,跟踪cookies,下面是代码示例:
在上面的代码中,我们向登录页面发送了相关参数,作用是模拟我们输入用户名和密码的登录页面。然后我们从请求中获取cookie并打印登录结果。
对于简单的页面,我们可以毫无问题地处理,但是如果网站比较复杂,他经常会偷偷调整cookie,或者如果我们一开始就不想使用cookie,我们该怎么办?Requests 库的 session 功能可以完美解决这些问题:
import requests
from bs4 import BeautifulSoup
from requests import Session, exceptions
from utils import connection_util
class GetCookie(object):
def __init__(self):
self._session = Session()
self._init_connection = connection_util.ProcessConnection()
def get_cookie_by_login(self):
# 另外一个 session 中
get_token=self.get_request_verification_token()
if get_token:
params = {'__RequestVerificationToken': get_token, 'Email': 'abc@pdf-lib.org',
'Password': 'hhgu##$dfe__e',
'RememberMe': True}
r = self._session.post('https://pdf-lib.org/account/admin', params)
# 如果使用 request_verification_token 此处会出现 500 错误
if r.status_code == 500:
print(r.content.decode('utf-8'))
print('Cookie is set to:')
print(r.cookies.get_dict())
print('--------------------------------')
print('Going to post article page..')
r = self._session.get('https://pdf-lib.org/Manage/ArticleList', cookies=r.cookies)
print(r.text)
def get_request_verification_token(self):
# 连接网站
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"}
html = self._session.get("https://pdf-lib.org/Account/Login", headers=headers)
except (exceptions.ConnectionError, exceptions.HTTPError, exceptions.Timeout) as e:
return False
try:
bsObj = BeautifulSoup(html.text, features='html.parser')
except AttributeError as e:
return False
if bsObj:
try:
get_token = bsObj.find("input", {"name": "__RequestVerificationToken"}).get("value")
except Exception as e:
print(f"ot unhandled exception {e}")
return False
return get_token
if __name__ == '__main__':
get_cookie = GetCookie()
get_cookie.get_cookie_by_login()
在此示例中,会话对象(通过调用 requests.Session() 获得)继续跟踪会话信息,例如 cookie、标头,甚至有关运行 HTTP 协议的信息,例如 HTTPAdapter(为 HTTP 和 HTTPS 连接会话提供)。统一接口)。
Requests 是一个非常强大的库。程序员不必浪费脑筋或编写代码。它可能只是不如 Selenium。尽管在编写网络爬虫时,您可能想让 Requests 库为您做所有事情,但请保持关注。了解 cookie 的状态以及它们可以控制的程度非常重要。这样可以避免痛苦的调试和追逐 网站 异常,从而节省大量时间。
文章采集程序(采集百度知道后生成问答聚合详情页的流程初期思路篇)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-24 11:18
采集百度知道问答方式,就不说了。我一定读过以前的博客。这只是几个脚本和 优采云 设置的交叉使用
艾福沃的图案模仿。主域名+社区/详情/12713840/
采集百度知道后生成问答聚合详情页的流程初步思路
1、文章分词
2、分隔的词有核心词创建标签页
3、一页同标签的问答
4、标题使用第一个问答的标题
这里有几个问题:
1、选项卡名称
2、如何写标题
3、你怎么知道问答内容和同一个标签的标题有关系?
4、分词的步骤能不能简化
解决方案:
分词使用优采云内置分词方法,消除html后分词。(感谢大神)
对单词进行排序后,排序到倒排索引表中
标签和标签的组合成为标题。组合完成后,匹配倒排索引表,过滤掉文章,将组合后的关键词作为标题的核心词。
每个标签可以创建一个标签页,标签页中放置的文章就是收录这个标签的文章
倒排索引表的建立和使用:将单词分解后,取前10位,然后制作倒排索引表,再制作倒排索引表。将分割后的词组合成一个新标题(新标题中收录的关键词被凤凰巢过滤),新标题中收录的关键词进行并集匹配。这时候,就有一个可以匹配这个标题的问答了。
小进步:简化倒排索引表的步骤,可以用excel的小计过滤掉小于4的单词,节省不少时间。
再次和群里的人聊天,发现有些步骤不利于以后大量数据的使用,所以要改进,改进的方法是先生成一个标题列表,然后直接分词然后将其与倒排索引表匹配。如果大于等于3,就放在一起。
kk提到如果使用倒排索引表会大大降低效率。他使用的方法是 Levenshtein.ratio 来检测标题的相似度,会和 关键词 相似度高的放在一起,并且内容是部分显示,没有完全显示。下面是聊天记录。
伊西奥-Kk
直接到标题 Levenshtein.ratio 查看全部
文章采集程序(采集百度知道后生成问答聚合详情页的流程初期思路篇)
采集百度知道问答方式,就不说了。我一定读过以前的博客。这只是几个脚本和 优采云 设置的交叉使用
艾福沃的图案模仿。主域名+社区/详情/12713840/
采集百度知道后生成问答聚合详情页的流程初步思路
1、文章分词
2、分隔的词有核心词创建标签页
3、一页同标签的问答
4、标题使用第一个问答的标题
这里有几个问题:
1、选项卡名称
2、如何写标题
3、你怎么知道问答内容和同一个标签的标题有关系?
4、分词的步骤能不能简化
解决方案:
分词使用优采云内置分词方法,消除html后分词。(感谢大神)
对单词进行排序后,排序到倒排索引表中
标签和标签的组合成为标题。组合完成后,匹配倒排索引表,过滤掉文章,将组合后的关键词作为标题的核心词。
每个标签可以创建一个标签页,标签页中放置的文章就是收录这个标签的文章
倒排索引表的建立和使用:将单词分解后,取前10位,然后制作倒排索引表,再制作倒排索引表。将分割后的词组合成一个新标题(新标题中收录的关键词被凤凰巢过滤),新标题中收录的关键词进行并集匹配。这时候,就有一个可以匹配这个标题的问答了。
小进步:简化倒排索引表的步骤,可以用excel的小计过滤掉小于4的单词,节省不少时间。
再次和群里的人聊天,发现有些步骤不利于以后大量数据的使用,所以要改进,改进的方法是先生成一个标题列表,然后直接分词然后将其与倒排索引表匹配。如果大于等于3,就放在一起。
kk提到如果使用倒排索引表会大大降低效率。他使用的方法是 Levenshtein.ratio 来检测标题的相似度,会和 关键词 相似度高的放在一起,并且内容是部分显示,没有完全显示。下面是聊天记录。
伊西奥-Kk
直接到标题 Levenshtein.ratio
文章采集程序(数据库采集简单数据采集程序-navicat位系统数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-21 05:03
文章采集程序作者:天天(博客:)采集时间:2019年5月10日软件开发环境:win764位系统数据库:mysqljdbcsqlserver14java环境:jdk1.
8、tomcat
9、ssmssqlserver+jdk:ssmssqlserver+tomcat9:ssmssqlserver+jdk2.5.15qlserver的数据库开发语言是navicat。现有的数据库采集简单数据,通过navicat的操作调用数据库进行采集,实现采集页面上数据。先将数据库开发环境配置成mysql,方便后续数据上传。
navicat操作步骤-操作步骤:
1、在mysql上创建数据库(在数据库管理界面开始创建账户)
2、点击“数据库创建”-“数据库名”-“数据库类型”-“mysql”-“数据库创建成功后”
3、点击“浏览数据库”-在搜索框中输入关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可点击“创建一个新数据库”(navicat用户名为“user”,密码为“admin”)-“创建成功后”点击“浏览表”,在搜索框中搜索关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可(包括空格,关键字)-点击“createtablespace”-“创建新表”-创建表格信息:创建表格信息:选择包含数据的表,如“电子商务”,点击“插入”-“数据到表格”-在弹出的createtablespace和altertablespace选择插入数据。
4、选择获取对应查询语句(java上或者api上查询语句的写法不一样,
5、点击“获取数据”-“获取数据”-“获取表信息”-“获取表信息”-“获取该表所有表信息”(设置查询规则,规则1:[标签]姓名+[子目录])根据上述步骤创建数据库信息等信息, 查看全部
文章采集程序(数据库采集简单数据采集程序-navicat位系统数据)
文章采集程序作者:天天(博客:)采集时间:2019年5月10日软件开发环境:win764位系统数据库:mysqljdbcsqlserver14java环境:jdk1.
8、tomcat
9、ssmssqlserver+jdk:ssmssqlserver+tomcat9:ssmssqlserver+jdk2.5.15qlserver的数据库开发语言是navicat。现有的数据库采集简单数据,通过navicat的操作调用数据库进行采集,实现采集页面上数据。先将数据库开发环境配置成mysql,方便后续数据上传。
navicat操作步骤-操作步骤:
1、在mysql上创建数据库(在数据库管理界面开始创建账户)
2、点击“数据库创建”-“数据库名”-“数据库类型”-“mysql”-“数据库创建成功后”
3、点击“浏览数据库”-在搜索框中输入关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可点击“创建一个新数据库”(navicat用户名为“user”,密码为“admin”)-“创建成功后”点击“浏览表”,在搜索框中搜索关键字mysql,关键字是你在navicat的搜索框内搜索到的关键字即可(包括空格,关键字)-点击“createtablespace”-“创建新表”-创建表格信息:创建表格信息:选择包含数据的表,如“电子商务”,点击“插入”-“数据到表格”-在弹出的createtablespace和altertablespace选择插入数据。
4、选择获取对应查询语句(java上或者api上查询语句的写法不一样,
5、点击“获取数据”-“获取数据”-“获取表信息”-“获取表信息”-“获取该表所有表信息”(设置查询规则,规则1:[标签]姓名+[子目录])根据上述步骤创建数据库信息等信息,
文章采集程序(织梦Dedecms5.7源码语言:GB2312源码带采集演示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-19 17:14
源码名称:通用文章类织梦博客模板织梦文章网站源码带采集源码程序系统
运行环境:全站程序采用PHP+MYSQL架构,内核采用织梦Dedecms5.7
源语言:GB2312 源代码大小:69.2M
本产品为通用织梦文章类博客模板,附全站源码采集,demo网站全站包,附测试数据和图片,不是一个网站@ >模板,购买后按照安装说明安装即可,整个网站管理更方便,适合信息类和博客类网站建设。据说织梦cms的安全性很差。只要及时修补程序,去掉会员模块,还是很安全的。如果安装不成功或其他问题很可能与您要的虚拟主机或服务器有关,购买虚拟主机的朋友在购买时应询问商家是否支持织梦系统。
1、将文件上传到你的站点根目录,然后运行你的域名/install安装,根据提示填写相关信息(注意不要修改数据库表前缀),点击“下一步” \" 完成安装,
注意:如果提示无法安装或页面显示dir,请进入安装文件夹,删除install_lock.txt文件和index.html,将index.php.bak文件改为index.php,刷新浏览器重新安装运行您的域名/安装它!
2、安装完成后,在后台\"系统\"—\"数据库备份/恢复\",点击右上角\"恢复数据\"—\"开始恢复数据\"即可恢复数据库。(恢复数据后,如果列和文章都没有数据,很可能是你安装时更改了数据库表前缀)
3、在后台点击“系统”—“系统参数设置”,修改网站设置,再次点击“确定”。(如果没有这一步,有时会导致更新后织梦默认模板内容显示在前台)。
4、后台,点击“生成”—“更新系统缓存”
5、重新生成所有页面一次。确定完成。
账号密码默认网站后台地址:你的域名/dede
默认后台管理帐号:admin 密码:admin888(见部分源码介绍)
材料分析平台 查看全部
文章采集程序(织梦Dedecms5.7源码语言:GB2312源码带采集演示)
源码名称:通用文章类织梦博客模板织梦文章网站源码带采集源码程序系统
运行环境:全站程序采用PHP+MYSQL架构,内核采用织梦Dedecms5.7
源语言:GB2312 源代码大小:69.2M
本产品为通用织梦文章类博客模板,附全站源码采集,demo网站全站包,附测试数据和图片,不是一个网站@ >模板,购买后按照安装说明安装即可,整个网站管理更方便,适合信息类和博客类网站建设。据说织梦cms的安全性很差。只要及时修补程序,去掉会员模块,还是很安全的。如果安装不成功或其他问题很可能与您要的虚拟主机或服务器有关,购买虚拟主机的朋友在购买时应询问商家是否支持织梦系统。
1、将文件上传到你的站点根目录,然后运行你的域名/install安装,根据提示填写相关信息(注意不要修改数据库表前缀),点击“下一步” \" 完成安装,
注意:如果提示无法安装或页面显示dir,请进入安装文件夹,删除install_lock.txt文件和index.html,将index.php.bak文件改为index.php,刷新浏览器重新安装运行您的域名/安装它!
2、安装完成后,在后台\"系统\"—\"数据库备份/恢复\",点击右上角\"恢复数据\"—\"开始恢复数据\"即可恢复数据库。(恢复数据后,如果列和文章都没有数据,很可能是你安装时更改了数据库表前缀)
3、在后台点击“系统”—“系统参数设置”,修改网站设置,再次点击“确定”。(如果没有这一步,有时会导致更新后织梦默认模板内容显示在前台)。
4、后台,点击“生成”—“更新系统缓存”
5、重新生成所有页面一次。确定完成。
账号密码默认网站后台地址:你的域名/dede
默认后台管理帐号:admin 密码:admin888(见部分源码介绍)
材料分析平台
文章采集程序(网站被墙是大事,怎么找到正确的下载目标网站内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-15 18:03
文章采集程序,比如、php、mysql,也可以选择其他的采集程序,比如百度网盘、115网盘、爬虫,这些网站都有类似采集程序,安装好一个采集程序,就可以采集内容了。内容清晰,最重要的就是怎么找到并且选择正确的下载目标网站内容。内容清晰是指,一般内容比较多,每个地方,每个网站的内容,都可以清晰的看到。
关键字,一般用txt,一般是用到replace(),可以选择一些简单的关键字,并且用在后期清洗清理上。内容在百度搜索中的下载方式,一般是site参数来下载地址,并且可以添加filetype字段。找到正确的目标网站,一般有几种方式,
1、访问内容页面,
2、进入网站首页,
3、网站后台自带搜索关键字,
4、使用相应搜索引擎,seoul,
5、手工添加index.html,index.html是站内搜索,可以定位,这些都是手工添加的方式,不推荐。以上是我看见一些比较老的网站,一些看着比较好的网站,大多还是可以采集成功的。
最好的肯定是百度嘛,付费直接搜。那也意味着你肯定要付出代价。一般还有sae是在爬虫网站里面。还有就是一些个人开发的采集工具了。但是这些工具,各有自己的问题。一个是太大,我不知道在哪下载,进而采集过程会不方便。第二是只支持一个内容页,数据量太大。其实还有一种情况。如果你本来就是靠采集广告赚钱的。网站数据放到以前还好,放到现在就不要太开心了。
以往可以接到几十个网站,最近几年几乎不可能了。网站被墙是大事,我就不细说了。因为广告刷的是实时的,不刷就打不开。 查看全部
文章采集程序(网站被墙是大事,怎么找到正确的下载目标网站内容)
文章采集程序,比如、php、mysql,也可以选择其他的采集程序,比如百度网盘、115网盘、爬虫,这些网站都有类似采集程序,安装好一个采集程序,就可以采集内容了。内容清晰,最重要的就是怎么找到并且选择正确的下载目标网站内容。内容清晰是指,一般内容比较多,每个地方,每个网站的内容,都可以清晰的看到。
关键字,一般用txt,一般是用到replace(),可以选择一些简单的关键字,并且用在后期清洗清理上。内容在百度搜索中的下载方式,一般是site参数来下载地址,并且可以添加filetype字段。找到正确的目标网站,一般有几种方式,
1、访问内容页面,
2、进入网站首页,
3、网站后台自带搜索关键字,
4、使用相应搜索引擎,seoul,
5、手工添加index.html,index.html是站内搜索,可以定位,这些都是手工添加的方式,不推荐。以上是我看见一些比较老的网站,一些看着比较好的网站,大多还是可以采集成功的。
最好的肯定是百度嘛,付费直接搜。那也意味着你肯定要付出代价。一般还有sae是在爬虫网站里面。还有就是一些个人开发的采集工具了。但是这些工具,各有自己的问题。一个是太大,我不知道在哪下载,进而采集过程会不方便。第二是只支持一个内容页,数据量太大。其实还有一种情况。如果你本来就是靠采集广告赚钱的。网站数据放到以前还好,放到现在就不要太开心了。
以往可以接到几十个网站,最近几年几乎不可能了。网站被墙是大事,我就不细说了。因为广告刷的是实时的,不刷就打不开。
文章采集程序(如何轻松采下其他公众号的信息,在这里轻松找到答案 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-14 02:13
)
41121人已阅读
总结:如何轻松采集其他公众号的信息,在这里轻松找到答案
近年来,在微信公众号上工作的朋友们开始恐慌,打开率越来越低。你想继续做吗?
业内也有声音认为,微信公众号的红利正在消失,进入衰退期。
个人认为,现在不是微信公众号的衰退期,而是转型升级期。
在这种新环境下,无论是企业还是公众号运营商,挖掘新的需求和趋势显得尤为重要。
今天小八要教大家一个按框底的技巧——微信公众号采集,让你实现监控和自我监控。
有两种情况,一种是你想去竞争对手微信公众号的文章(假装自己比较好学,以36氪为例),另一种是你有账号和密码登录,采集自己微信公众号后台的信息。
以下情况属实
1、36氪微信公众号文章采集
采集字段:公众号、文章标题、内容、浏览量、点赞量、推送时间
这里需要注意的是,优采云目前只能采集在网上公开数据,而微信公众号的采集需要从网页采集开始. 搜索“搜狗微信”,通过采集微信文章,来到首页,长这样↓↓
如何定位您的目标公众号?
比如我要采集36氪,贴上网址“”,在网址后面手动输入你要采集的公众号“36氪”,如下图↓
点击进入,你会看到这样的页面
复制此 URL 以启用 优采云采集 平台并将其粘贴进去!
只需设置规则,单击要提取的元素,即可采集!
是不是很简单?使用优采云设置单页采集规则,可以实时获取其他公众号最新的文章内容,监控竞争对手的发帖。
但是,敲黑板,这两个技巧很重要——
1、为什么搜狗微信搜不到“36氪”?因为这种方式搜索到的链接是时间敏感的,所以用这个链接制定的规则会在一天后失效。所以只要用这个URL()+公众号搜索就可以了
2、为了防止网页打开过快而丢失数据采集,本规则需要等待几秒后才会执行“提取数据”步骤。如下所示
2、我的微信背景采集
采集字段:用户微信、消息、时间
微信后台最重要的信息就是用户的消息。当你想监控产品口碑、采集问题、采集活跃消息或监督舆论时,采集和用户消息分析是必不可少的。
透露一个秘密,你们都得到了专业版的消息,小八每天都在爬优采云!呵呵~
你自己的微信公众后台的采集很简单,你只需要打开优采云粘贴网址,登录你的微信公众号。
只需选择你要采集的元素,点击执行,一条完整的消息记录就搞定了!
最后几句话
当然,如果你想使用优采云来释放自己,还是得通过官网视频教程来学习。
初学者需要在优采云官网教程中心阅读《初级教程1-7》。看完这些教程,你可以轻松掌握以上两条规则的制作。
想深入学习,可以去官网琢磨实战教程↓
但如果你真的不想制定自己的 采集 规则,这里是你无忧的选择。
在多多“规则市场”搜索“微信”,无论是采集微信群、微信公众号还是留言,都可以在这里找到适用的规则。
查看全部
文章采集程序(如何轻松采下其他公众号的信息,在这里轻松找到答案
)
41121人已阅读
总结:如何轻松采集其他公众号的信息,在这里轻松找到答案
近年来,在微信公众号上工作的朋友们开始恐慌,打开率越来越低。你想继续做吗?
业内也有声音认为,微信公众号的红利正在消失,进入衰退期。
个人认为,现在不是微信公众号的衰退期,而是转型升级期。
在这种新环境下,无论是企业还是公众号运营商,挖掘新的需求和趋势显得尤为重要。
今天小八要教大家一个按框底的技巧——微信公众号采集,让你实现监控和自我监控。
有两种情况,一种是你想去竞争对手微信公众号的文章(假装自己比较好学,以36氪为例),另一种是你有账号和密码登录,采集自己微信公众号后台的信息。
以下情况属实
1、36氪微信公众号文章采集
采集字段:公众号、文章标题、内容、浏览量、点赞量、推送时间
这里需要注意的是,优采云目前只能采集在网上公开数据,而微信公众号的采集需要从网页采集开始. 搜索“搜狗微信”,通过采集微信文章,来到首页,长这样↓↓
如何定位您的目标公众号?
比如我要采集36氪,贴上网址“”,在网址后面手动输入你要采集的公众号“36氪”,如下图↓
点击进入,你会看到这样的页面
复制此 URL 以启用 优采云采集 平台并将其粘贴进去!
只需设置规则,单击要提取的元素,即可采集!
是不是很简单?使用优采云设置单页采集规则,可以实时获取其他公众号最新的文章内容,监控竞争对手的发帖。
但是,敲黑板,这两个技巧很重要——
1、为什么搜狗微信搜不到“36氪”?因为这种方式搜索到的链接是时间敏感的,所以用这个链接制定的规则会在一天后失效。所以只要用这个URL()+公众号搜索就可以了
2、为了防止网页打开过快而丢失数据采集,本规则需要等待几秒后才会执行“提取数据”步骤。如下所示
2、我的微信背景采集
采集字段:用户微信、消息、时间
微信后台最重要的信息就是用户的消息。当你想监控产品口碑、采集问题、采集活跃消息或监督舆论时,采集和用户消息分析是必不可少的。
透露一个秘密,你们都得到了专业版的消息,小八每天都在爬优采云!呵呵~
你自己的微信公众后台的采集很简单,你只需要打开优采云粘贴网址,登录你的微信公众号。
只需选择你要采集的元素,点击执行,一条完整的消息记录就搞定了!
最后几句话
当然,如果你想使用优采云来释放自己,还是得通过官网视频教程来学习。
初学者需要在优采云官网教程中心阅读《初级教程1-7》。看完这些教程,你可以轻松掌握以上两条规则的制作。
想深入学习,可以去官网琢磨实战教程↓
但如果你真的不想制定自己的 采集 规则,这里是你无忧的选择。
在多多“规则市场”搜索“微信”,无论是采集微信群、微信公众号还是留言,都可以在这里找到适用的规则。
文章采集程序(二进制字符处理程序没有python中那么多的原因)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-09 10:04
文章采集程序以二进制hash(hash值)为采集依据,则二进制字符为处理器,则处理器如何处理这个字符便是解码的问题。目前可使用,不保证以后不会有局限。目前业内处理器的二进制处理的位数可以达到二十多位,现在可以达到一百多位,二进制的编码形式是byte编码,也就是有32的x种组合。text_encode或者posix的中,为了方便区分,二进制编码中,“\u0034”用表示,为负值(要保证正负号相同)。
而python中,则是用逻辑值中的转义符号“\r\n”代替,则表示:\n,然后输出编码后的值,这就意味着编码后的字符串直接无法在二进制的编码下(甚至输出的时候会丢失)表示(由于与\n的实际值和表示逻辑值不同),所以表示的就是乱码。c字符处理程序在bytecode前加“\r\n”,会生成多字节的c字符,即第三个字节为0,总之如果只有十六进制的字符(如“ff”,但编码表示编码为bytecode,则没有),则需要多次解码,然后再编码,如果使用format_encode能够避免这个问题,但如果使用text_encode,就得再定义一个字符处理函数,这就是为什么c字符处理程序没有python中那么多的原因。
如果用text_encode,其实与不加\r\n生成的总字节数基本一致,然而从最实际的角度考虑,c字符处理程序虽然减少了使用整个bytecode字节码的次数,但一个处理器每秒处理100000个字符并不是每次都精确读出。假设使用30字节来表示一个bytecode字节码(eb),则需要三次读出;而用posixtext_encode,则无需三次读出;虽然使用posixtext_encode,可以将eb位置为0,但采用text_encode的三次读出速度依然跟用整个bytecode字节码比较快,而且在使用集成库的情况下,也可以减少使用bytecode的次数。(参考:python字符串解码及其对扩展字符集的支持)。 查看全部
文章采集程序(二进制字符处理程序没有python中那么多的原因)
文章采集程序以二进制hash(hash值)为采集依据,则二进制字符为处理器,则处理器如何处理这个字符便是解码的问题。目前可使用,不保证以后不会有局限。目前业内处理器的二进制处理的位数可以达到二十多位,现在可以达到一百多位,二进制的编码形式是byte编码,也就是有32的x种组合。text_encode或者posix的中,为了方便区分,二进制编码中,“\u0034”用表示,为负值(要保证正负号相同)。
而python中,则是用逻辑值中的转义符号“\r\n”代替,则表示:\n,然后输出编码后的值,这就意味着编码后的字符串直接无法在二进制的编码下(甚至输出的时候会丢失)表示(由于与\n的实际值和表示逻辑值不同),所以表示的就是乱码。c字符处理程序在bytecode前加“\r\n”,会生成多字节的c字符,即第三个字节为0,总之如果只有十六进制的字符(如“ff”,但编码表示编码为bytecode,则没有),则需要多次解码,然后再编码,如果使用format_encode能够避免这个问题,但如果使用text_encode,就得再定义一个字符处理函数,这就是为什么c字符处理程序没有python中那么多的原因。
如果用text_encode,其实与不加\r\n生成的总字节数基本一致,然而从最实际的角度考虑,c字符处理程序虽然减少了使用整个bytecode字节码的次数,但一个处理器每秒处理100000个字符并不是每次都精确读出。假设使用30字节来表示一个bytecode字节码(eb),则需要三次读出;而用posixtext_encode,则无需三次读出;虽然使用posixtext_encode,可以将eb位置为0,但采用text_encode的三次读出速度依然跟用整个bytecode字节码比较快,而且在使用集成库的情况下,也可以减少使用bytecode的次数。(参考:python字符串解码及其对扩展字符集的支持)。
文章采集程序(文章采集程序不管你需要采集的数据量有多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-09 10:02
文章采集程序不管你需要采集的数据量有多少,相信这篇文章还是很有用的。你也可以根据自己需要进行操作或模仿。首先,打开世界词汇接收工具世界词汇接收工具,输入网页地址或是域名,就可以把你的数据导入到服务器中。服务器选择vue.js或其他类vue编程语言进行运行(vue.js支持大量版本)。整个过程只需几分钟的时间,保证数据的完整性和可靠性。
项目结构说明:从某个网页进行爬取,是非常常见的一种操作。但这不是最常见的方式,正如知乎上的很多高质量问答都来自于文章栏目。其他如springmvc,freemarker,github,vue.js等等,方式各异。requests组件:经典请求参数列表,自动识别headers在请求失败时,由爬虫组件自动获取参数。
async/await表达式:使用async/await自动发生异步请求。vuex组件:vue中的store(存储),用于验证数据的真实性、有效性及是否超时。axios组件:axios是一个json提取库,将解析json得到的值直接保存到服务器上,这样在刷新页面或者进行跨域请求的时候,就可以在请求失败之后恢复到保存的值。
postmessage组件:usejs/postmessage用于向服务器传递参数。以上所有组件均为npmrunbuild模块提供。需要注意的是,如果你使用了构建时自动生成的parsejs模块或npmrunbuild模块,这些parsejs模块会默认添加中间xml时对应的http请求,如果你对http请求没有任何了解,建议自己写个简单的例子,自己测试,因为vuex的多个变量构造方法即便在xml上传失败的情况下,如果保存了变量值,还是会正常保存http请求的响应内容。
github组件:proxylib:实现chrome浏览器代理:用于一种动态代理。token验证:一种axios实现的鉴权机制。freemarker:用于生成html源码,主要由parser,decode,parser.parse,parser.transform构成(如parser.parse('parser')或axios.create({source:'./source/index.html',path:'./source/index.png'})返回script标签的url)vuerequests组件:用于抓取当前页面记录的所有记录信息。
githubproxylib:用于在代理服务器进行证书验证。importxmlhttprequestfrom'xmlhttprequest';importparsefrom'vue-parse';importtokenfrom'./token';importproxylibfrom'./fetch';importvuexfrom'vuex';importindexfrom'./index';proxylib/requestspare'proxylib'importxmlhttprequestfrom'xmlhttprequest'importparsefrom'./parse'。 查看全部
文章采集程序(文章采集程序不管你需要采集的数据量有多少?)
文章采集程序不管你需要采集的数据量有多少,相信这篇文章还是很有用的。你也可以根据自己需要进行操作或模仿。首先,打开世界词汇接收工具世界词汇接收工具,输入网页地址或是域名,就可以把你的数据导入到服务器中。服务器选择vue.js或其他类vue编程语言进行运行(vue.js支持大量版本)。整个过程只需几分钟的时间,保证数据的完整性和可靠性。
项目结构说明:从某个网页进行爬取,是非常常见的一种操作。但这不是最常见的方式,正如知乎上的很多高质量问答都来自于文章栏目。其他如springmvc,freemarker,github,vue.js等等,方式各异。requests组件:经典请求参数列表,自动识别headers在请求失败时,由爬虫组件自动获取参数。
async/await表达式:使用async/await自动发生异步请求。vuex组件:vue中的store(存储),用于验证数据的真实性、有效性及是否超时。axios组件:axios是一个json提取库,将解析json得到的值直接保存到服务器上,这样在刷新页面或者进行跨域请求的时候,就可以在请求失败之后恢复到保存的值。
postmessage组件:usejs/postmessage用于向服务器传递参数。以上所有组件均为npmrunbuild模块提供。需要注意的是,如果你使用了构建时自动生成的parsejs模块或npmrunbuild模块,这些parsejs模块会默认添加中间xml时对应的http请求,如果你对http请求没有任何了解,建议自己写个简单的例子,自己测试,因为vuex的多个变量构造方法即便在xml上传失败的情况下,如果保存了变量值,还是会正常保存http请求的响应内容。
github组件:proxylib:实现chrome浏览器代理:用于一种动态代理。token验证:一种axios实现的鉴权机制。freemarker:用于生成html源码,主要由parser,decode,parser.parse,parser.transform构成(如parser.parse('parser')或axios.create({source:'./source/index.html',path:'./source/index.png'})返回script标签的url)vuerequests组件:用于抓取当前页面记录的所有记录信息。
githubproxylib:用于在代理服务器进行证书验证。importxmlhttprequestfrom'xmlhttprequest';importparsefrom'vue-parse';importtokenfrom'./token';importproxylibfrom'./fetch';importvuexfrom'vuex';importindexfrom'./index';proxylib/requestspare'proxylib'importxmlhttprequestfrom'xmlhttprequest'importparsefrom'./parse'。

