
文章采集程序
文章采集程序在实现图片爬虫时使用python语言的通用库urllib
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-03 07:01
文章采集程序在实现图片爬虫时使用python语言的通用库urllib这个库。其中,requests库、urllib库都具有可以提供服务器发送请求和接受请求的功能。本文将对urllib库进行详细的介绍,并对不同的安装方式及其他安装方式进行介绍。
1、requests库使用:①、requests库主要是用来处理http请求的,处理原理是通过字典方式来定义请求对象(request)。
request会有类似如下方式构造:②、用requests库爬取图片,使用路径:pages。select('/');③、使用requests库爬取地图:pages。select('/');④、使用requests库爬取天气:pages。select('/');urllib库使用方法都一样,所以打开登录后可以直接写testcoder包直接使用urllib库导入:fromurllibimportrequest,urlopenfromrequests。
exceptionsimportrequestexceptionfromurllib。httpimporthttprequest。authenticate('0')#。
1、request=request(url='',data=['code','id'])urlopen=urlopen(request).read().decode('gbk')#
2、urlopen=urlopen(request).read().decode('gbk')#
3、urlopen=urlopen(request).read().decode('utf-8')#
4、urlopen=urlopen(request).read().decode('utf-8')#①request.authenticate('0')#采用的是向http请求传递的格式,属于字典模式,requestauthenticate('0')设定了代理主机名/端口号,设定代理主机名称为可以任意,只要是相同类型的主机名均可request.authenticate('0')设定了代理主机名称。
默认设定为可以为主机名称大写:request.authenticate('0')。如果要设定主机名,需要添加关键字作为作为注释并传入:request.authenticate('0')。urlopen=urlopen(request).read().decode('gbk')#③urlopen=urlopen(request).read().decode('gbk')#④urlopen=urlopen(request).read().decode('gbk')#⑤urlopen=urlopen(request).read().decode('gbk')#⑥urlopen=urlopen(request).read().decode('gbk')#request.authenticate('0'),urlopen=request.authenticate('0'),urlopen=request.authenticate('0')urlopen():处理所有http请求urlopen():查看当前处理的http请求的headers头部urlopen():查看当前处理的http请求的头。 查看全部
文章采集程序在实现图片爬虫时使用python语言的通用库urllib
文章采集程序在实现图片爬虫时使用python语言的通用库urllib这个库。其中,requests库、urllib库都具有可以提供服务器发送请求和接受请求的功能。本文将对urllib库进行详细的介绍,并对不同的安装方式及其他安装方式进行介绍。
1、requests库使用:①、requests库主要是用来处理http请求的,处理原理是通过字典方式来定义请求对象(request)。
request会有类似如下方式构造:②、用requests库爬取图片,使用路径:pages。select('/');③、使用requests库爬取地图:pages。select('/');④、使用requests库爬取天气:pages。select('/');urllib库使用方法都一样,所以打开登录后可以直接写testcoder包直接使用urllib库导入:fromurllibimportrequest,urlopenfromrequests。
exceptionsimportrequestexceptionfromurllib。httpimporthttprequest。authenticate('0')#。
1、request=request(url='',data=['code','id'])urlopen=urlopen(request).read().decode('gbk')#
2、urlopen=urlopen(request).read().decode('gbk')#
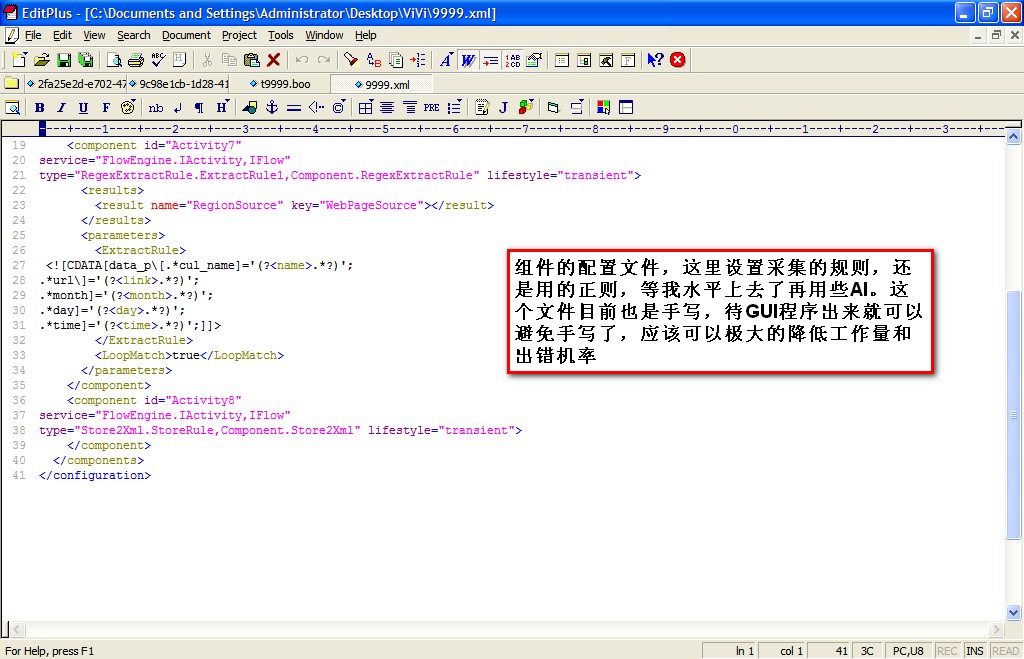
3、urlopen=urlopen(request).read().decode('utf-8')#
4、urlopen=urlopen(request).read().decode('utf-8')#①request.authenticate('0')#采用的是向http请求传递的格式,属于字典模式,requestauthenticate('0')设定了代理主机名/端口号,设定代理主机名称为可以任意,只要是相同类型的主机名均可request.authenticate('0')设定了代理主机名称。
默认设定为可以为主机名称大写:request.authenticate('0')。如果要设定主机名,需要添加关键字作为作为注释并传入:request.authenticate('0')。urlopen=urlopen(request).read().decode('gbk')#③urlopen=urlopen(request).read().decode('gbk')#④urlopen=urlopen(request).read().decode('gbk')#⑤urlopen=urlopen(request).read().decode('gbk')#⑥urlopen=urlopen(request).read().decode('gbk')#request.authenticate('0'),urlopen=request.authenticate('0'),urlopen=request.authenticate('0')urlopen():处理所有http请求urlopen():查看当前处理的http请求的headers头部urlopen():查看当前处理的http请求的头。
文章采集程序(Python编程语言Scrapy爬虫爬虫框架介绍及学习方法介绍-小编 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-19 06:31
)
今天给大家详细讲解一下Scrapy爬虫框架,希望对大家的学习有所帮助。
1、Scrapy 爬虫框架
Scrapy是一个用Python编程语言编写的爬虫框架,任何人都可以根据自己的需要进行修改,使用起来非常方便。可应用于数据采集、数据挖掘、异常网络用户检测、数据存储等。
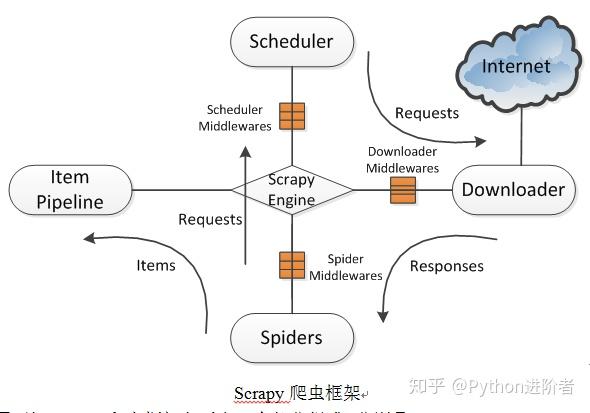
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下图所示。
Scrapy爬虫框架
2、从上图可以看出,Scrapy爬虫框架主要由5部分组成,分别是:Scrapy Engine(Scrapy Engine)、Scheduler(调度器)、Downloader(Downloader)、Spiders(Spider)、Item管道(项目管道)。爬取过程是Scrapy引擎发送请求,然后调度器将初始URL发送给下载器,然后下载器向服务器发送服务请求。得到响应后,将下载的网页内容交给spider处理,然后spider会对网页进行细化。分析。爬虫分析的结果有两种:一种是获取到新的URL,然后再次请求调度器,开始新一轮的爬取,重复上述过程;另一种是获取所需的数据,稍后将继续处理到项目管道。项目管道负责数据清洗、校验、过滤、去重、存储等后处理,最终由管道输出到文件或存储到数据库中。
3、这五个组件及其中间件的作用如下:
1) Scrapy引擎:控制整个系统的数据处理过程,触发事务处理过程,负责连接各个模块
2) 调度程序:维护要抓取的 URL 队列。当引擎发送的请求被接受后,将从待抓取的 URL 队列中取出下一个 URL,并返回给调度器。
3) Downloader(下载器):向web服务器发送请求下载页面,用于下载网页内容,并将网页内容交给spider处理。
4)蜘蛛:制定要爬取的网站地址,选择需要的数据内容,定义域名过滤规则和网页解析规则等。
5) 项目管道:处理蜘蛛从网页中提取的数据。主要任务是清理、验证、过滤、去重和存储数据。
6) 中间件:中间件是Scrapy引擎与Scheduler、Downloader、Spiders之间的一个组件,主要处理它们之间的请求和响应。
Scrapy爬虫框架可以轻松完成在线数据的采集工作,简单轻量,使用非常方便。
4、 基于Scrapy的网络爬虫设计与实现
本节在了解Scrapy爬虫原理和框架的基础上,简单介绍一下Scrapy爬虫框架的data采集流程。
4.1 创建爬虫项目文件
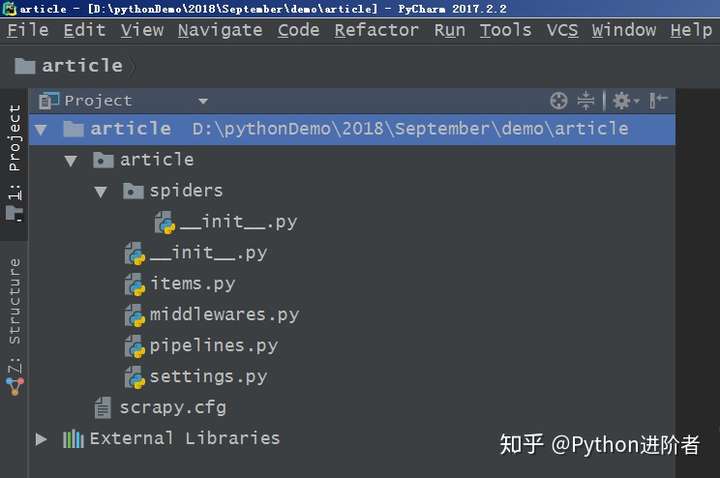
基于scrapy爬虫框架,只需在命令行输入“scrapy startproject article”命令,就会自动创建一个名为article的爬虫项目。先进入文章文件夹,输入命令“cd article”,然后通过“dir”查看目录,也可以通过“tree /f”生成文件目录的树形结构,如下图,你可以清楚地看到 Scrapy 创建命令生成的文件。
爬虫项目目录结构
最上层的article文件夹是项目名称,第二层收录一个与项目名称同名的文件夹article和一个文件scrapy.cfg。这个与项目同名的文件夹文章是一个模块,所有项目代码都在这个模块中添加,scrapy.cfg文件是整个Scrapy项目的配置文件。第三层有5个文件和一个文件夹,其中__init__.py为空文件,用于将其父目录转为模块;items.py 是定义存储对象并决定要抓取哪些项目的文件;middlewares .py 文件是中间件,一般不需要修改。主要负责相关组件之间的请求和响应;pipelines.py 是一个管道文件,它决定了如何处理和存储爬取的数据;settings.py为工程设置文件,设置工程管道数据的处理方式、爬虫频率、表名等;在 spiders 文件夹中放置了爬虫主文件(用于实现爬虫逻辑)和一个空的 __init__.py 文件。
4.2 之后,开始分析网页结构和数据,修改Items.py文件,编写hangyunSpider.py文件,修改pipelines.py文件,修改settings.py文件。这些步骤的具体操作后面会进行文章专门展开,这里不再赘述。
4.3 执行爬虫
修改以上四个文件后,在Windows命令窗口输入cmd命令进入爬虫所在路径,执行“scrapy爬虫文章”命令,这样爬虫程序就可以运行了,最后得到数据保存到本地磁盘。
5、 结论
随着互联网上信息量的不断增加,使用网络爬虫工具获取所需信息肯定会有用。使用开源的Scrapy爬虫框架,不仅可以实现对网络信息的高效、准确、自动获取,还可以帮助研究人员对采集获得的数据进行后续的挖掘和分析。
查看全部
文章采集程序(Python编程语言Scrapy爬虫爬虫框架介绍及学习方法介绍-小编
)
今天给大家详细讲解一下Scrapy爬虫框架,希望对大家的学习有所帮助。
1、Scrapy 爬虫框架
Scrapy是一个用Python编程语言编写的爬虫框架,任何人都可以根据自己的需要进行修改,使用起来非常方便。可应用于数据采集、数据挖掘、异常网络用户检测、数据存储等。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下图所示。
Scrapy爬虫框架
2、从上图可以看出,Scrapy爬虫框架主要由5部分组成,分别是:Scrapy Engine(Scrapy Engine)、Scheduler(调度器)、Downloader(Downloader)、Spiders(Spider)、Item管道(项目管道)。爬取过程是Scrapy引擎发送请求,然后调度器将初始URL发送给下载器,然后下载器向服务器发送服务请求。得到响应后,将下载的网页内容交给spider处理,然后spider会对网页进行细化。分析。爬虫分析的结果有两种:一种是获取到新的URL,然后再次请求调度器,开始新一轮的爬取,重复上述过程;另一种是获取所需的数据,稍后将继续处理到项目管道。项目管道负责数据清洗、校验、过滤、去重、存储等后处理,最终由管道输出到文件或存储到数据库中。
3、这五个组件及其中间件的作用如下:
1) Scrapy引擎:控制整个系统的数据处理过程,触发事务处理过程,负责连接各个模块
2) 调度程序:维护要抓取的 URL 队列。当引擎发送的请求被接受后,将从待抓取的 URL 队列中取出下一个 URL,并返回给调度器。
3) Downloader(下载器):向web服务器发送请求下载页面,用于下载网页内容,并将网页内容交给spider处理。
4)蜘蛛:制定要爬取的网站地址,选择需要的数据内容,定义域名过滤规则和网页解析规则等。
5) 项目管道:处理蜘蛛从网页中提取的数据。主要任务是清理、验证、过滤、去重和存储数据。
6) 中间件:中间件是Scrapy引擎与Scheduler、Downloader、Spiders之间的一个组件,主要处理它们之间的请求和响应。
Scrapy爬虫框架可以轻松完成在线数据的采集工作,简单轻量,使用非常方便。
4、 基于Scrapy的网络爬虫设计与实现
本节在了解Scrapy爬虫原理和框架的基础上,简单介绍一下Scrapy爬虫框架的data采集流程。
4.1 创建爬虫项目文件
基于scrapy爬虫框架,只需在命令行输入“scrapy startproject article”命令,就会自动创建一个名为article的爬虫项目。先进入文章文件夹,输入命令“cd article”,然后通过“dir”查看目录,也可以通过“tree /f”生成文件目录的树形结构,如下图,你可以清楚地看到 Scrapy 创建命令生成的文件。

爬虫项目目录结构
最上层的article文件夹是项目名称,第二层收录一个与项目名称同名的文件夹article和一个文件scrapy.cfg。这个与项目同名的文件夹文章是一个模块,所有项目代码都在这个模块中添加,scrapy.cfg文件是整个Scrapy项目的配置文件。第三层有5个文件和一个文件夹,其中__init__.py为空文件,用于将其父目录转为模块;items.py 是定义存储对象并决定要抓取哪些项目的文件;middlewares .py 文件是中间件,一般不需要修改。主要负责相关组件之间的请求和响应;pipelines.py 是一个管道文件,它决定了如何处理和存储爬取的数据;settings.py为工程设置文件,设置工程管道数据的处理方式、爬虫频率、表名等;在 spiders 文件夹中放置了爬虫主文件(用于实现爬虫逻辑)和一个空的 __init__.py 文件。
4.2 之后,开始分析网页结构和数据,修改Items.py文件,编写hangyunSpider.py文件,修改pipelines.py文件,修改settings.py文件。这些步骤的具体操作后面会进行文章专门展开,这里不再赘述。
4.3 执行爬虫
修改以上四个文件后,在Windows命令窗口输入cmd命令进入爬虫所在路径,执行“scrapy爬虫文章”命令,这样爬虫程序就可以运行了,最后得到数据保存到本地磁盘。
5、 结论
随着互联网上信息量的不断增加,使用网络爬虫工具获取所需信息肯定会有用。使用开源的Scrapy爬虫框架,不仅可以实现对网络信息的高效、准确、自动获取,还可以帮助研究人员对采集获得的数据进行后续的挖掘和分析。

文章采集程序(Java编写的系统能够每秒可以访问几十万个网页的分布式网络爬虫系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-17 09:21
在大数据时代,数据采集或网络爬虫似乎是每个程序员必备的技能。一般来说,工程师会通过Python爬虫框架快速编写爬虫程序来抓取网页数据。当规模数据采集不是一个简单的爬虫。比如分布式爬虫系统为我们的舆情系统(/stonedtx/yuqing)和开源情报系统(/stonedtx/open-source-intelligence)提供了大量的数据支持。
在这里,给大家介绍一个每秒可以访问几十万网页的Java编写的分布式网络爬虫系统!
在本期文章中,我将与大家分享我们多年来在爬虫构建和优化方面的经验和教训。
这就是我们大型分布式爬虫系统的系统(操作界面),我们称自己为:爬虫工厂。
这就是我们即将推出的“开源智能”系统中的“数据管理”(数据中心)子系统。
通过这么多项目的实战经验和经验,以及与市场和客户的不断碰撞,造就了我们强大的数据采集能力。
一、编程语言
在为项目选择编程语言时,许多因素会影响我们的最终决定。中间我们尝试了python和Go中的爬虫和分布式爬虫方案。我们在内部专业知识、生态系统等方面寻找“完美”的编程语言解决方案。最终,我们决定 Java 是我们的最佳选择,原因如下:
1.内部专长:我们的团队成员拥有丰富的Java专业知识,有数位Java开发“老司机”在分布式系统和网络方面有10年、15年、20年的经验他在分布式系统和网络开发方面有丰富的实践经验高并发和海量数据存储。
2.现有的软件框架:大型网络爬虫需要建立在经过验证的、健壮的、可扩展的和安全的网络、系统和实用程序模块上。Java 拥有最活跃的开源生态系统,尤其是在网络和分布式应用程序方面。Netty、SpringBoot、Google Guava 等包证明了 Java 生态系统拥有高质量的开源模块。
3.现有的项目集成:Hadoop、Cassandra、Kafka、Elasticsearch 都是用 Java 开发的大型分布式系统项目,因为这个生态系统给我们带来了丰富而强大的基础以及灵感和先例。这使得在 Java 中开发高性能数据驱动应用程序的过程更容易、更实惠。
4.Java的动态语言:动态语言用于我们最新的分布式爬虫系统。我们通过模板生成动态语言代码并存储在 MySQL 中,让大量爬虫可视化和低代码化。大大降低了维护成本和爬虫开发成本。
5.原创性能和可靠性:在性能和可靠性方面,Java 具有静态类型、健壮的垃圾采集和久经考验的虚拟机等最重要的特性。
在核心网络爬虫引擎用 Java 编写的同时,我们还使用 Python 和 Node.js 等其他语言编写子系统,用于自然语言处理、深度学习算法、监控、报告和管道的其他部分。
我们的分布式爬虫集群采用单点无架构,将工作负载拆分并分布在独立的无状态节点上,可以消除大规模分布式系统中的灾难(单点故障)。此外,该架构允许我们逐个节点更新和升级底层软件,而不会中断整个操作。
二、请求率和访问安全
网站 主要是为人工访问而设计的,普通用户每分钟只能浏览几页。网络爬虫每秒可以访问数千甚至数百万的网页,所以如果不小心,网络爬虫很容易在短时间内耗尽网站资源,造成毁灭性的后果。另外,普通的 网站 会有多个机器人同时抓取,所以问题会被放大。
因此,限制自己的请求率也是每个网络爬虫的责任,也就是说,保证两次连续访问之间有适当的延迟,这个工作一定不能容忍错误,否则请求网站而且本身会产生不利的反应。
三、缓存为王
在构建大规模分布式数据应用系统的情况下,系统缓存是必不可少的,尤其是在网络输入输出频繁、开销较大的情况下。
例如场景一:在大规模网页爬取的情况下,为了避免重复的数据爬取和后续的重复数据处理,需要对每个URL进行获取和存储。因此,您需要构建一个分布式预读缓存,可以保存并定期更新数百万个网站 数亿个 URL 地址。
比如场景2:减少dns请求,提升data采集的性能。对于绝大多数 URL,您需要执行至少一个 DNS 解析才能下载,每秒添加数千个查询。因此,DNS 服务器势必会限制您的访问,或在重负载下崩溃。无论哪种情况,爬虫都会停止,唯一的解决办法就是尽可能缓存DNS解析结果,尽量减少不必要的查询。
四、解析 HTML
爬虫的基本任务之一是从它访问的每个页面中提取它需要的数据。在大规模数据抓取的情况下,最好有一个高性能的 HTML 解析器,因为您需要提取大量链接和元数据。大多数 HTML 解析库优先考虑简单性、易用性和多功能性,这通常是正确的设计。由于我们需要高速链接提取,我们最终决定编写自己的解析器,针对查找链接和一些原创 DOM 查询功能进行了优化。HTML 解析器还需要有弹性、经过全面测试,并且能够处理出现的大量异常,因为并非每个 HTML 文档都是有效的。
我们目前即将开源data采集系统,集成了微软开源playwright()的js渲染解析引擎。这样,我们在开发爬虫的过程中,就不需要考虑js网页数据的问题,大大提高了我们网站爬虫的开发效率。
五、网络和系统优化
通常操作系统的默认配置无法处理大型网络爬虫的网络需求。通常,我们需要优化操作系统的网络堆栈,以根据具体情况最大限度地发挥其潜力。对于大型网络爬虫来说,优化的目标是最大化吞吐量和打开的连接数。
以下是我们经常遇到并需要优化的问题和场景:
1.Linux系统性能参数
什么工具用于一般的 Linux 性能调优?- 知乎
2.Web服务器性能优化
Java web 服务器性能优化策略?- 知乎
3.Java JVM 性能优化
用于 Java 性能优化的 JVM GC(垃圾采集机制) - 知乎
开源项目地址: 查看全部
文章采集程序(Java编写的系统能够每秒可以访问几十万个网页的分布式网络爬虫系统)
在大数据时代,数据采集或网络爬虫似乎是每个程序员必备的技能。一般来说,工程师会通过Python爬虫框架快速编写爬虫程序来抓取网页数据。当规模数据采集不是一个简单的爬虫。比如分布式爬虫系统为我们的舆情系统(/stonedtx/yuqing)和开源情报系统(/stonedtx/open-source-intelligence)提供了大量的数据支持。
在这里,给大家介绍一个每秒可以访问几十万网页的Java编写的分布式网络爬虫系统!
在本期文章中,我将与大家分享我们多年来在爬虫构建和优化方面的经验和教训。
这就是我们大型分布式爬虫系统的系统(操作界面),我们称自己为:爬虫工厂。
这就是我们即将推出的“开源智能”系统中的“数据管理”(数据中心)子系统。
通过这么多项目的实战经验和经验,以及与市场和客户的不断碰撞,造就了我们强大的数据采集能力。
一、编程语言
在为项目选择编程语言时,许多因素会影响我们的最终决定。中间我们尝试了python和Go中的爬虫和分布式爬虫方案。我们在内部专业知识、生态系统等方面寻找“完美”的编程语言解决方案。最终,我们决定 Java 是我们的最佳选择,原因如下:
1.内部专长:我们的团队成员拥有丰富的Java专业知识,有数位Java开发“老司机”在分布式系统和网络方面有10年、15年、20年的经验他在分布式系统和网络开发方面有丰富的实践经验高并发和海量数据存储。
2.现有的软件框架:大型网络爬虫需要建立在经过验证的、健壮的、可扩展的和安全的网络、系统和实用程序模块上。Java 拥有最活跃的开源生态系统,尤其是在网络和分布式应用程序方面。Netty、SpringBoot、Google Guava 等包证明了 Java 生态系统拥有高质量的开源模块。
3.现有的项目集成:Hadoop、Cassandra、Kafka、Elasticsearch 都是用 Java 开发的大型分布式系统项目,因为这个生态系统给我们带来了丰富而强大的基础以及灵感和先例。这使得在 Java 中开发高性能数据驱动应用程序的过程更容易、更实惠。
4.Java的动态语言:动态语言用于我们最新的分布式爬虫系统。我们通过模板生成动态语言代码并存储在 MySQL 中,让大量爬虫可视化和低代码化。大大降低了维护成本和爬虫开发成本。
5.原创性能和可靠性:在性能和可靠性方面,Java 具有静态类型、健壮的垃圾采集和久经考验的虚拟机等最重要的特性。
在核心网络爬虫引擎用 Java 编写的同时,我们还使用 Python 和 Node.js 等其他语言编写子系统,用于自然语言处理、深度学习算法、监控、报告和管道的其他部分。
我们的分布式爬虫集群采用单点无架构,将工作负载拆分并分布在独立的无状态节点上,可以消除大规模分布式系统中的灾难(单点故障)。此外,该架构允许我们逐个节点更新和升级底层软件,而不会中断整个操作。
二、请求率和访问安全
网站 主要是为人工访问而设计的,普通用户每分钟只能浏览几页。网络爬虫每秒可以访问数千甚至数百万的网页,所以如果不小心,网络爬虫很容易在短时间内耗尽网站资源,造成毁灭性的后果。另外,普通的 网站 会有多个机器人同时抓取,所以问题会被放大。
因此,限制自己的请求率也是每个网络爬虫的责任,也就是说,保证两次连续访问之间有适当的延迟,这个工作一定不能容忍错误,否则请求网站而且本身会产生不利的反应。
三、缓存为王
在构建大规模分布式数据应用系统的情况下,系统缓存是必不可少的,尤其是在网络输入输出频繁、开销较大的情况下。
例如场景一:在大规模网页爬取的情况下,为了避免重复的数据爬取和后续的重复数据处理,需要对每个URL进行获取和存储。因此,您需要构建一个分布式预读缓存,可以保存并定期更新数百万个网站 数亿个 URL 地址。
比如场景2:减少dns请求,提升data采集的性能。对于绝大多数 URL,您需要执行至少一个 DNS 解析才能下载,每秒添加数千个查询。因此,DNS 服务器势必会限制您的访问,或在重负载下崩溃。无论哪种情况,爬虫都会停止,唯一的解决办法就是尽可能缓存DNS解析结果,尽量减少不必要的查询。
四、解析 HTML
爬虫的基本任务之一是从它访问的每个页面中提取它需要的数据。在大规模数据抓取的情况下,最好有一个高性能的 HTML 解析器,因为您需要提取大量链接和元数据。大多数 HTML 解析库优先考虑简单性、易用性和多功能性,这通常是正确的设计。由于我们需要高速链接提取,我们最终决定编写自己的解析器,针对查找链接和一些原创 DOM 查询功能进行了优化。HTML 解析器还需要有弹性、经过全面测试,并且能够处理出现的大量异常,因为并非每个 HTML 文档都是有效的。
我们目前即将开源data采集系统,集成了微软开源playwright()的js渲染解析引擎。这样,我们在开发爬虫的过程中,就不需要考虑js网页数据的问题,大大提高了我们网站爬虫的开发效率。
五、网络和系统优化
通常操作系统的默认配置无法处理大型网络爬虫的网络需求。通常,我们需要优化操作系统的网络堆栈,以根据具体情况最大限度地发挥其潜力。对于大型网络爬虫来说,优化的目标是最大化吞吐量和打开的连接数。
以下是我们经常遇到并需要优化的问题和场景:
1.Linux系统性能参数
什么工具用于一般的 Linux 性能调优?- 知乎
2.Web服务器性能优化
Java web 服务器性能优化策略?- 知乎
3.Java JVM 性能优化
用于 Java 性能优化的 JVM GC(垃圾采集机制) - 知乎
开源项目地址:
文章采集程序( dedecms自动生成tagtag建站服务器源码_PHP开发+APP+采集接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-16 19:37
dedecms自动生成tagtag建站服务器源码_PHP开发+APP+采集接口)
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
dedecms如何自动生成标签
本站建站服务器文章与大家分享dedecms如何自动生成标签的内容。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
Python自动采集入库
总结:本脚本可用于采集百度股评实现自动更新功能,使用phpcms。. .
老Y文章管理系统采集自动伪原创说明
作为垃圾站站长,最有希望的是网站可以自动采集,自动完成伪原创,然后自动收钱,这真的是世界上最幸福的事情了, 呵呵 。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。旧的Y文章管理系统使用简单方便,虽然功能不如
小站长说说网站自动采集和原创的优缺点
众所周知,自动采集软件自发明以来,一直是无数草根站长必备的建站工具之一。刚建了一个新站,但是好像空荡荡的,短时间内不可能出一个有钱的原创,除非你是第五个钻石王,请专业人士投票原创。一个人的精力是有限的,只能依靠自动采集工具。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
如何使用免费的网站源代码
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
如何使用cms系统标签自动获取长尾关键词排名
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长经常使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他 查看全部
文章采集程序(
dedecms自动生成tagtag建站服务器源码_PHP开发+APP+采集接口)

dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
dedecms如何自动生成标签
本站建站服务器文章与大家分享dedecms如何自动生成标签的内容。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
Python自动采集入库
总结:本脚本可用于采集百度股评实现自动更新功能,使用phpcms。. .
老Y文章管理系统采集自动伪原创说明
作为垃圾站站长,最有希望的是网站可以自动采集,自动完成伪原创,然后自动收钱,这真的是世界上最幸福的事情了, 呵呵 。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。旧的Y文章管理系统使用简单方便,虽然功能不如
小站长说说网站自动采集和原创的优缺点
众所周知,自动采集软件自发明以来,一直是无数草根站长必备的建站工具之一。刚建了一个新站,但是好像空荡荡的,短时间内不可能出一个有钱的原创,除非你是第五个钻石王,请专业人士投票原创。一个人的精力是有限的,只能依靠自动采集工具。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
如何使用免费的网站源代码
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
如何使用cms系统标签自动获取长尾关键词排名
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长经常使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
文章采集程序(新建微信公众号采集任务配置采集结果附录(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-14 23:01
)
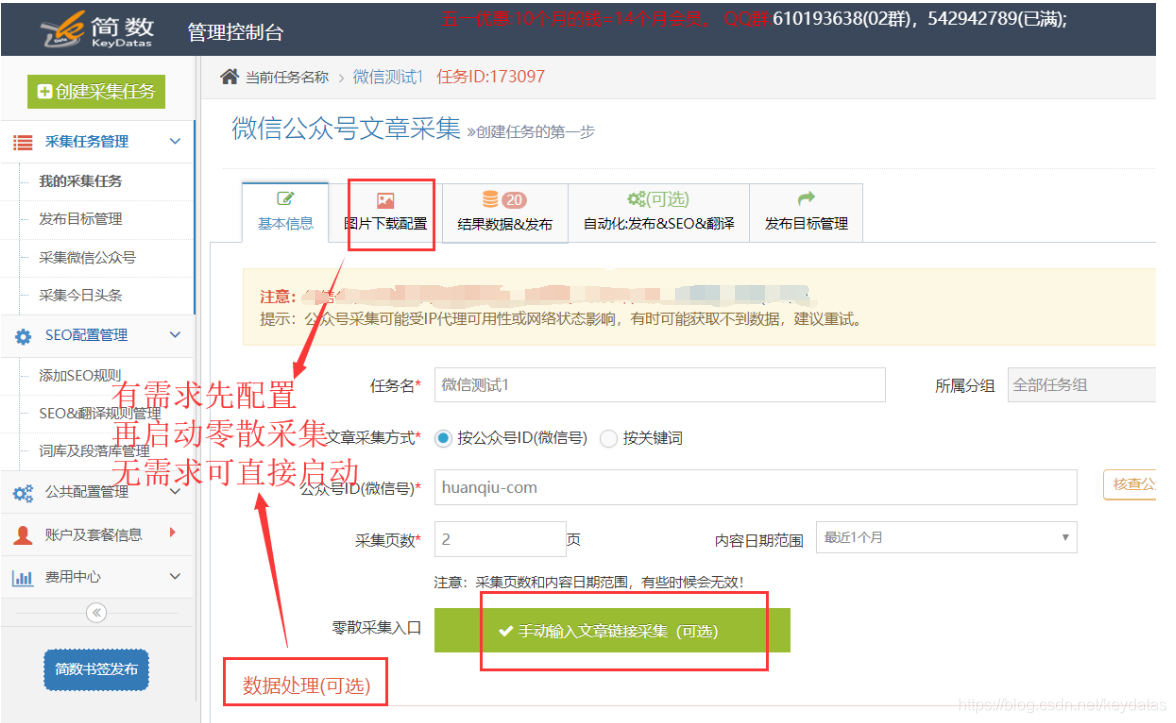
?使用优采云采集微信公众号文章,很简单,只要输入:公众号或姓名或关键词。
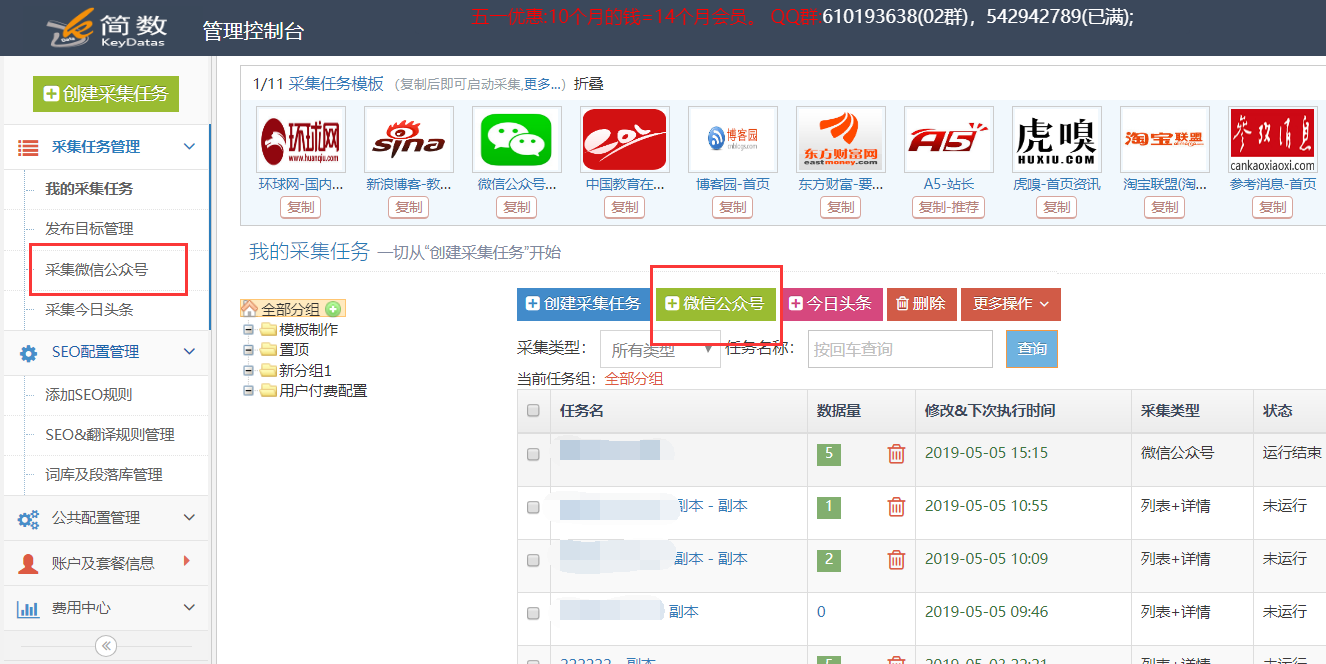
使用步骤:创建微信公众号采集任务微信公众号采集任务配置采集结果采集微信公众号注意事项附录(公众号获取方法ID和微信文章散采集)1.新建微信公众号采集任务:
??创建微信公众号采集任务有两个入口:
2.微信公众号采集任务配置:
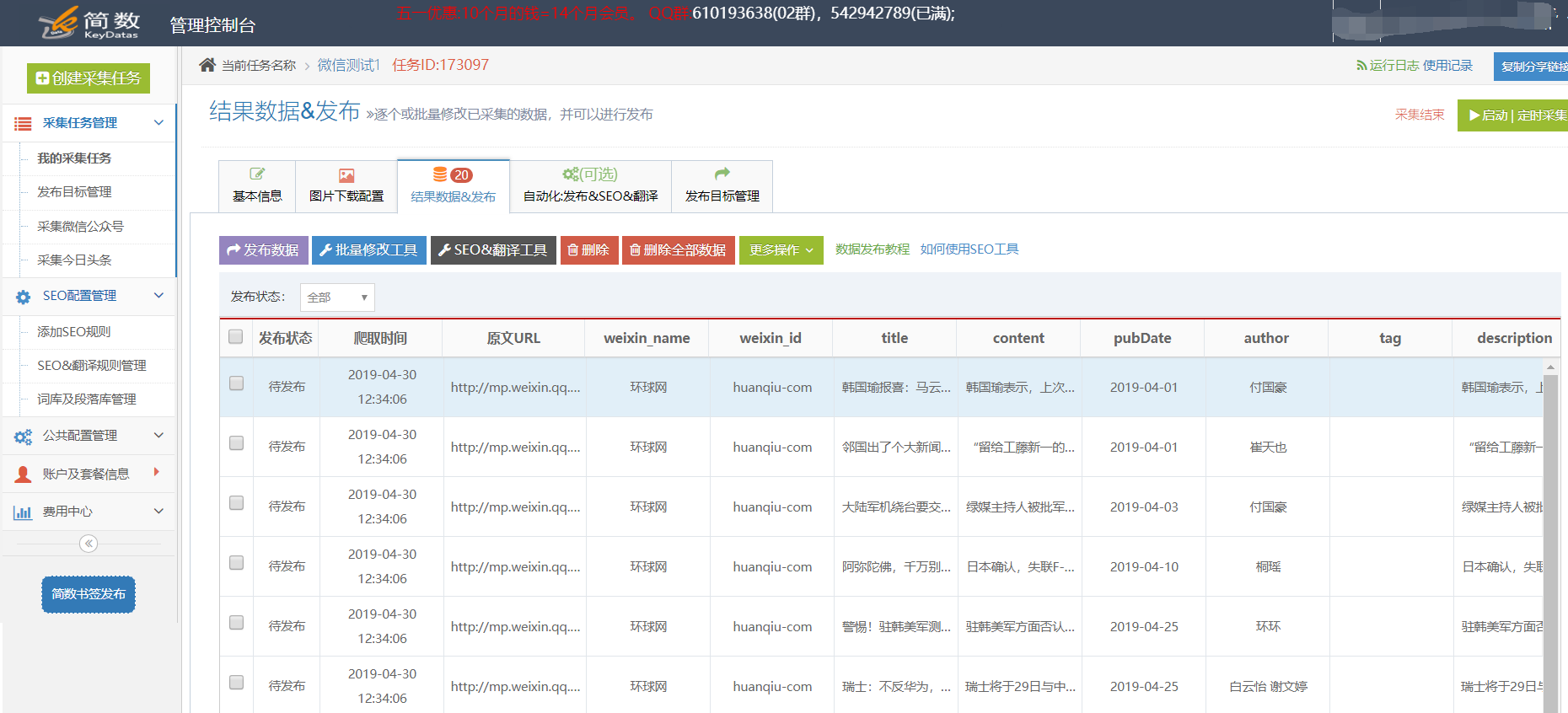
3. 采集结果:
??微信公众号(weixin_name),公众号(weixin_id),title(标题),body(内容),发布日期(pubData),author(作者),tag(tag),description(描述,可以使用文本截取)和关键字(keywords);
附录:(如何获取公众号和微信文章scattered采集)
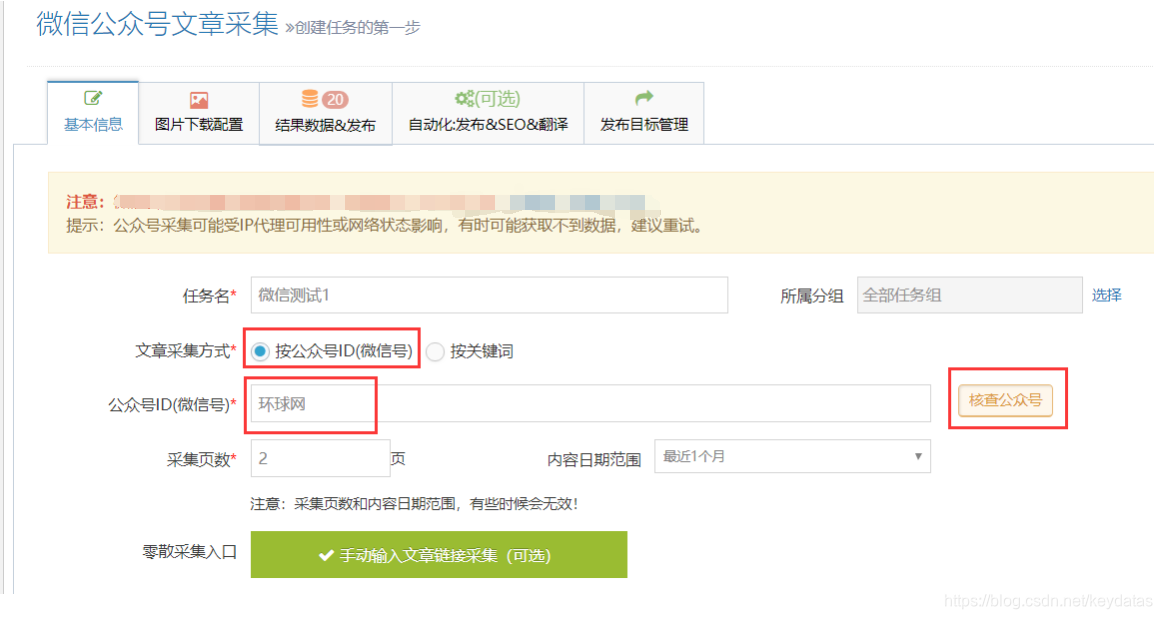
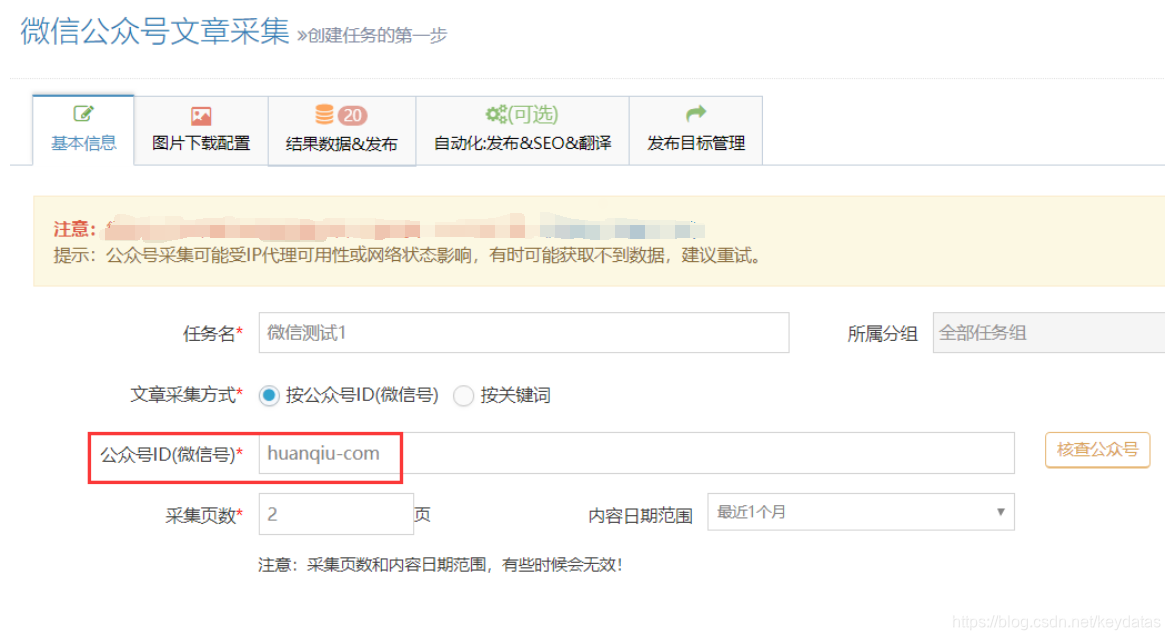
我,如何获取公众号
??在“公众号(微信)”中填写微信账号名称,然后点击“验证公众号”旁边的按钮即可看到微信账号;
??以下以“万维网”为例:
二、微信文章分散采集
??微信文章分散采集一般用于精准采集,用户只需输入微信文章地址采集。
??在微信公众号文章采集的基本信息页面,点击“手动输入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
查看全部
文章采集程序(新建微信公众号采集任务配置采集结果附录(一)
)
?使用优采云采集微信公众号文章,很简单,只要输入:公众号或姓名或关键词。
使用步骤:创建微信公众号采集任务微信公众号采集任务配置采集结果采集微信公众号注意事项附录(公众号获取方法ID和微信文章散采集)1.新建微信公众号采集任务:
??创建微信公众号采集任务有两个入口:
2.微信公众号采集任务配置:

3. 采集结果:
??微信公众号(weixin_name),公众号(weixin_id),title(标题),body(内容),发布日期(pubData),author(作者),tag(tag),description(描述,可以使用文本截取)和关键字(keywords);
附录:(如何获取公众号和微信文章scattered采集)
我,如何获取公众号
??在“公众号(微信)”中填写微信账号名称,然后点击“验证公众号”旁边的按钮即可看到微信账号;
??以下以“万维网”为例:

二、微信文章分散采集
??微信文章分散采集一般用于精准采集,用户只需输入微信文章地址采集。
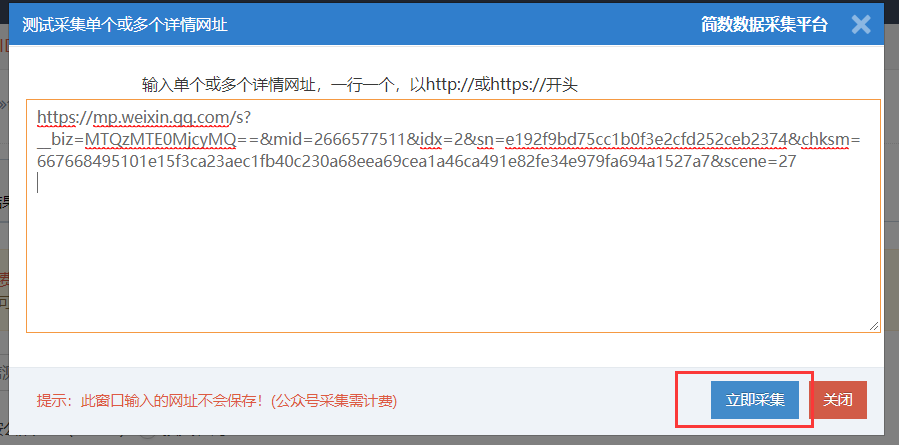
??在微信公众号文章采集的基本信息页面,点击“手动输入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
文章采集程序(众所周知优化一个网站是什么?如何采集格式网页的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-04-14 22:40
采集插件可以采集 格式化网页上的文本、HTML 和元素属性。采集插件可以使用正则表达式和自定义函数过滤内容。采集插件通过HTTP POST请求传输和获取数据。采集插件支持CSV、EXCEL、HTML、TXT等下载数据。采集插件的功能包括:定时采集任务、采集规则自动同步、脚本采集、数据插件导出。
采集插件使用其他网站文章列表和缓存读取技术,网页程序自动读取其他网站的内容,存储过程为< @采集 进程。它是一种信息聚合技术。通过这项技术,站长可以将其他网站相对固定更新的栏目等内容,变成自己网站的一部分,无需复制粘贴。采集有现场和非现场的区别。采集插件站点一般用于较大的站点,将很多栏目聚合到一个节点中,集中展示。
采集插件有两种触发方式采集更新。一种是在页面中添加代码触发采集更新,在后台异步执行,不影响用户体验,不影响采集更新。@网站效率,另外,可以使用Cron调度任务来触发采集定时更新任务。采集插件可以帮助网站节省大量的搬运劳动。该插件不仅支持文章采集,还支持文章采集中的评论,其他插件的数据采集(不支持文章 )。
采集插件可以将多个任务的采集可视化,采集金额图表统计,历史采集状态一目了然。采集插件可以文章评论采集(仅限首页评论),采集插件可以支持市面上大部分主题,插件数据采集(任意数据表仓储)。采集插件采集的第三方触发,多tab,多线程采集文章,采集plugins采集都可以在 伪原创 内容之后自动。
众所周知,优化 网站 并不容易。需要每天更新文章,这样才能保证网站的排名更高,但不是每个人每天都有更多的时间更新网站,总的来说,更新三个就好-每天高质量的文章篇文章已经是很多人的极限了。有时候写不出来文章,总会去别的地方网站copy文章,不过这样也是浪费时间,时间长了就会变得无聊.
采集插件可以帮助网站解决这些问题,采集插件只需要输入站长想要的网站采集,然后直接< @采集,目前后台只有三个采集板块,主要关注资源和新闻源类型的网站。输入网站可以直接采集,采集之后文章自动存入草稿,可以设置覆盖关键词,不用担心关于文章还有其他网站的地址。
<p>采集插件只需要设置相关的采集任务,在定时任务管理界面,将当前采集任务加入队列,等到定时时间,再启动自动 查看全部
文章采集程序(众所周知优化一个网站是什么?如何采集格式网页的?)
采集插件可以采集 格式化网页上的文本、HTML 和元素属性。采集插件可以使用正则表达式和自定义函数过滤内容。采集插件通过HTTP POST请求传输和获取数据。采集插件支持CSV、EXCEL、HTML、TXT等下载数据。采集插件的功能包括:定时采集任务、采集规则自动同步、脚本采集、数据插件导出。
采集插件使用其他网站文章列表和缓存读取技术,网页程序自动读取其他网站的内容,存储过程为< @采集 进程。它是一种信息聚合技术。通过这项技术,站长可以将其他网站相对固定更新的栏目等内容,变成自己网站的一部分,无需复制粘贴。采集有现场和非现场的区别。采集插件站点一般用于较大的站点,将很多栏目聚合到一个节点中,集中展示。
采集插件有两种触发方式采集更新。一种是在页面中添加代码触发采集更新,在后台异步执行,不影响用户体验,不影响采集更新。@网站效率,另外,可以使用Cron调度任务来触发采集定时更新任务。采集插件可以帮助网站节省大量的搬运劳动。该插件不仅支持文章采集,还支持文章采集中的评论,其他插件的数据采集(不支持文章 )。
采集插件可以将多个任务的采集可视化,采集金额图表统计,历史采集状态一目了然。采集插件可以文章评论采集(仅限首页评论),采集插件可以支持市面上大部分主题,插件数据采集(任意数据表仓储)。采集插件采集的第三方触发,多tab,多线程采集文章,采集plugins采集都可以在 伪原创 内容之后自动。
众所周知,优化 网站 并不容易。需要每天更新文章,这样才能保证网站的排名更高,但不是每个人每天都有更多的时间更新网站,总的来说,更新三个就好-每天高质量的文章篇文章已经是很多人的极限了。有时候写不出来文章,总会去别的地方网站copy文章,不过这样也是浪费时间,时间长了就会变得无聊.
采集插件可以帮助网站解决这些问题,采集插件只需要输入站长想要的网站采集,然后直接< @采集,目前后台只有三个采集板块,主要关注资源和新闻源类型的网站。输入网站可以直接采集,采集之后文章自动存入草稿,可以设置覆盖关键词,不用担心关于文章还有其他网站的地址。
<p>采集插件只需要设置相关的采集任务,在定时任务管理界面,将当前采集任务加入队列,等到定时时间,再启动自动
文章采集程序( 如何使用优采云采集进行搜索?写作推出智能采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-14 22:39
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“疫情”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
文章采集程序(
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“疫情”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
文章采集程序( 10年打造网页数据采集利器-优采云采集器优采云软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-13 21:00
10年打造网页数据采集利器-优采云采集器优采云软件)
优采云采集器
优采云采集器本软件为网页抓取工具,用于网站信息采集、网站信息抓取,包括图片、文字等信息< @采集处理和发布,是目前互联网上使用最多的数据采集软件。出品,10年打造网络数据采集工具。
优采云采集器
优采云网页数据采集器,是一款简单易用,功能强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,大数据连续四年在行业数据领域排名第一采集。
优采云
<p>[优采云采集]是一个完全在线的配置和云采集网站文章采集工具和发布平台。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家和第一个书签 采集 发布;无缝对接各种cms网站(wordpress、Empire、Zblog、dedecms、Destoon等)、Http接口等都是免费在线网页文章 查看全部
文章采集程序(
10年打造网页数据采集利器-优采云采集器优采云软件)
 http://www.locoy.com?w=130&h=80" />
http://www.locoy.com?w=130&h=80" />优采云采集器
优采云采集器本软件为网页抓取工具,用于网站信息采集、网站信息抓取,包括图片、文字等信息< @采集处理和发布,是目前互联网上使用最多的数据采集软件。出品,10年打造网络数据采集工具。
http://www.bazhuayu.com?w=130&h=80" />优采云采集器
优采云网页数据采集器,是一款简单易用,功能强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,大数据连续四年在行业数据领域排名第一采集。
http://www.keydatas.com?w=130&h=80" />优采云
<p>[优采云采集]是一个完全在线的配置和云采集网站文章采集工具和发布平台。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家和第一个书签 采集 发布;无缝对接各种cms网站(wordpress、Empire、Zblog、dedecms、Destoon等)、Http接口等都是免费在线网页文章
文章采集程序(数据采集的重要性本篇方案详细聊数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-12 23:16
相信业务团队对这样的场景不会太陌生:
因此,数据非常重要。接下来,我们将详细讨论数据采集的重要性,数据的划分,采集的方法,以及微信小程序中的埋点方案。数据采集。
一、数据的重要性采集
在本文中,我们关注数据采集。我们暂且不详细讨论数据的作用。首先,我们将总结数据在性能优化、业务增长和在线故障排除方面的重要作用。这就是为什么我们需要埋点。
数据对在线排查的作用:数据对性能优化的作用:数据对业务增长的作用:二、采集数据划分与排序
从第一点开始,我们总结了数据的重要性。不同的业务项目对数据重要性的重视程度不同。那么采集采集应该是什么数据呢?
一、闭环数据包括:
用户行为用户信息、CRM(客户关系)交易数据、服务器日志数据
以上三项数据可视为一个完整的数据流闭环。当然,不同业务场景下的数据还可以进一步细分,一般的重点基本不超过这三项。对于前端的数据采集来说,闭环数据中的前两项主要是客户端上报,而第三点主要是服务端记录并由客户端辅助,因为事务请求只有在事务请求到达服务器完成处理。一个闭环。用户行为数据还包括时间(when)、地点(where)、人(who)、交互(how)、交互内容(what)五个元素,与新闻的五个元素有些相似;部分用户信息业务涉及用户敏感信息和隐私需要授权,因此用户信息的具体维度由业务场景决定。最基本的数据要求是唯一标识用户;CRM、交易数据和用户信息类似,具体需要的数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。
三、数据上报方式
说完数据,接下来就是要知道如何获取我们真正需要的数据了。数据上报方式大致可分为三类:
第一种是代码埋点,即在需要埋点的节点手动调用接口上传埋点数据。优盟、百度统计等第三方数据统计服务商大多采用此方案;
第二种是可视化掩埋,即通过可视化工具配置采集节点,在前端自动解析配置并上报掩埋数据,从而实现所谓的“无痕掩埋”,代表开源的 Mixpanel;
第三类是“无埋点”。确实不需要埋点,但是前端自动采集所有事件并上报埋点数据,在后端数据计算的时候过滤掉有用的数据,代表解决方案就是国内的GrowingIO。
重点是非埋点。可视化埋点其实可以看成是无埋点的推导。所以可视化埋点这里不讨论,主要是对比代码埋点和无埋点。
3.1 代码嵌入或嵌入捕获模式的缺点
对于数据产品:
依靠人类经验和直觉判断。
业务相关埋点的位置需要数据产品或业务产品的主观判断,而技术相关的埋点需要技术人员的主观判断。沟通成本高
确定数据产品所需的数据,需要提出要求并与开发沟通,数据人员对技术不是特别熟悉,需要与开发人员明确相关是否可行可以上报信息。有数据清洗成本
随着业务的变化,主观判断所需的数据也会发生变化和变化。这时候需要手动清理之前管理的数据,清理的工作量不小。
对于开发:
开发人员的努力
对于业务团队来说,埋点往往会被相关开发者诟病。开发技术人员不能只专注于技术,还需要多元化从事埋点等高度重复性和机械性的任务。
埋藏相关代码具有高度侵入性,对系统设计和代码可维护性产生负面影响
大部分业务相关的数据点都需要人工埋藏,埋藏的代码要与业务代码强耦合。即使业界没有嵌入式SDK,数据产品所关注的特殊业务点也逃不过人工嵌入。
随着业务的不断变化,对数据的需求也在变化,埋点相关的代码也需要随之变化。进一步增加开发和代码维护成本。
容易出错
由于人工打点的主观意识不同,打点位置的准确性难以控制,数据容易泄露。
有打点流程费用
当数据丢失或错误采集时,必须重新经过开发过程和在线过程,效率低下。3.2 无埋点优势
与人工嵌入相比,无嵌入的优势无需赘述。
提高效率,让数据更全面,按需抽取,减少代码入侵 sdk的难点和关键点
无法直接监控用户行为以实现强大的可扩展性
需要适合多种架构设计场景(小程序),sdk的使用需要轻量级
每个小程序的包有2M的限制,小程序不支持在代码中引入npm包,所以sdk本身会占用2M的大小限制。小程序虽然有分包的内测,但是这个功能还没有完全放开,作为sdk太大也不合理。
采集数据量大,在不影响业务的情况下将性能损失降到最低(基本要求)4.3微信小程序无嵌入式sdk设计
数据层设计:
设计数据流:
采集方法设计:
访问方法:
sdk npm 包代码在小程序初始化代码之前介绍。小程序打包代码时,将sdk代码引入项目中,初始化后即可自动采集数据。初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({channel: 'channel',env: config.IS_PRODUCION ? 'product': 'beta',project: 'yourProjectName',methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称})
无埋点结合埋点:
小程序的非埋藏方式可以获取大量数据,基本可以实现用户使用场景的高度还原。SDK管理的粒度是对某个方法的执行。当特殊业务关注的粒度小于 SDK 粒度时,没有嵌入点的 SDK 无法完全解决。可以使用无嵌入点和嵌入点的组合,所以我们的小程序没有 追踪SDK也提供了API接口用于手动追踪,以提高数据的完整性,解决更多的问题(回顾提到的作用参考重要性数据的)。
五、小程序无埋SDK遇到的问题
除了解决上文提到的微信小程序非地埋sdk开发面临的困难和关键问题外,还遇到了一些新的问题。
SDK 本身会对业务性能产生一定的影响。数据临时存储在小程序的本地存储中。频繁访问/检索小程序的本地存储,会暴露业务端本身消耗更多性能时的操作滞后。问题。减少localstorage访问/获取操作,只在页面关闭时将未上传的数据存储在localstorage中
没有埋点的海量数据。灰度上线时遇到服务器过载问题,导致服务器可用性下降。后续将控制上报数据量,仅自动上报关键节点数据。其他以服务为中心的节点可以在访问初始化时通过针对性的配置重新配置上报,避免上报过多的冗余数据。此外,还应特别注意报告数据结构的设计。该结构的目标是清晰、简洁且易于检索(区分)数据。
最初,我想对灰度启动是否使用SDK进行“切换”,以避免小程序的回滚过程。由于“切换”依赖于服务端接口控制,并且请求是异步的,也就是说小程序的初始化过程和启动必须等待控制切换的接口返回才能继续进行,否则“切换”是相当于失败。考虑到SDK不能影响服务性能,丢弃“开关”,在SDK内部做try and catch,避免影响服务可用性。
有了无埋点上报得到的数据,以后可以用这些数据解决很多问题。关于数据的使用,敬请期待下一节——数据的应用。
参考:
[1] [美国]裴霁,译者:姚军等,《深入理解网站优化》,出版社:机械工业出版社,出版时间:2013-08
[2]张希猛,《首席成长官》,出版社:机械工业出版社,出版时间:第1版(2017年11月6日) 查看全部
文章采集程序(数据采集的重要性本篇方案详细聊数据)
相信业务团队对这样的场景不会太陌生:
因此,数据非常重要。接下来,我们将详细讨论数据采集的重要性,数据的划分,采集的方法,以及微信小程序中的埋点方案。数据采集。
一、数据的重要性采集
在本文中,我们关注数据采集。我们暂且不详细讨论数据的作用。首先,我们将总结数据在性能优化、业务增长和在线故障排除方面的重要作用。这就是为什么我们需要埋点。
数据对在线排查的作用:数据对性能优化的作用:数据对业务增长的作用:二、采集数据划分与排序
从第一点开始,我们总结了数据的重要性。不同的业务项目对数据重要性的重视程度不同。那么采集采集应该是什么数据呢?
一、闭环数据包括:
用户行为用户信息、CRM(客户关系)交易数据、服务器日志数据
以上三项数据可视为一个完整的数据流闭环。当然,不同业务场景下的数据还可以进一步细分,一般的重点基本不超过这三项。对于前端的数据采集来说,闭环数据中的前两项主要是客户端上报,而第三点主要是服务端记录并由客户端辅助,因为事务请求只有在事务请求到达服务器完成处理。一个闭环。用户行为数据还包括时间(when)、地点(where)、人(who)、交互(how)、交互内容(what)五个元素,与新闻的五个元素有些相似;部分用户信息业务涉及用户敏感信息和隐私需要授权,因此用户信息的具体维度由业务场景决定。最基本的数据要求是唯一标识用户;CRM、交易数据和用户信息类似,具体需要的数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。
三、数据上报方式
说完数据,接下来就是要知道如何获取我们真正需要的数据了。数据上报方式大致可分为三类:
第一种是代码埋点,即在需要埋点的节点手动调用接口上传埋点数据。优盟、百度统计等第三方数据统计服务商大多采用此方案;
第二种是可视化掩埋,即通过可视化工具配置采集节点,在前端自动解析配置并上报掩埋数据,从而实现所谓的“无痕掩埋”,代表开源的 Mixpanel;
第三类是“无埋点”。确实不需要埋点,但是前端自动采集所有事件并上报埋点数据,在后端数据计算的时候过滤掉有用的数据,代表解决方案就是国内的GrowingIO。
重点是非埋点。可视化埋点其实可以看成是无埋点的推导。所以可视化埋点这里不讨论,主要是对比代码埋点和无埋点。
3.1 代码嵌入或嵌入捕获模式的缺点
对于数据产品:
依靠人类经验和直觉判断。
业务相关埋点的位置需要数据产品或业务产品的主观判断,而技术相关的埋点需要技术人员的主观判断。沟通成本高
确定数据产品所需的数据,需要提出要求并与开发沟通,数据人员对技术不是特别熟悉,需要与开发人员明确相关是否可行可以上报信息。有数据清洗成本
随着业务的变化,主观判断所需的数据也会发生变化和变化。这时候需要手动清理之前管理的数据,清理的工作量不小。
对于开发:
开发人员的努力
对于业务团队来说,埋点往往会被相关开发者诟病。开发技术人员不能只专注于技术,还需要多元化从事埋点等高度重复性和机械性的任务。
埋藏相关代码具有高度侵入性,对系统设计和代码可维护性产生负面影响
大部分业务相关的数据点都需要人工埋藏,埋藏的代码要与业务代码强耦合。即使业界没有嵌入式SDK,数据产品所关注的特殊业务点也逃不过人工嵌入。
随着业务的不断变化,对数据的需求也在变化,埋点相关的代码也需要随之变化。进一步增加开发和代码维护成本。
容易出错
由于人工打点的主观意识不同,打点位置的准确性难以控制,数据容易泄露。
有打点流程费用
当数据丢失或错误采集时,必须重新经过开发过程和在线过程,效率低下。3.2 无埋点优势
与人工嵌入相比,无嵌入的优势无需赘述。
提高效率,让数据更全面,按需抽取,减少代码入侵 sdk的难点和关键点
无法直接监控用户行为以实现强大的可扩展性
需要适合多种架构设计场景(小程序),sdk的使用需要轻量级
每个小程序的包有2M的限制,小程序不支持在代码中引入npm包,所以sdk本身会占用2M的大小限制。小程序虽然有分包的内测,但是这个功能还没有完全放开,作为sdk太大也不合理。
采集数据量大,在不影响业务的情况下将性能损失降到最低(基本要求)4.3微信小程序无嵌入式sdk设计
数据层设计:

设计数据流:

采集方法设计:

访问方法:
sdk npm 包代码在小程序初始化代码之前介绍。小程序打包代码时,将sdk代码引入项目中,初始化后即可自动采集数据。初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({channel: 'channel',env: config.IS_PRODUCION ? 'product': 'beta',project: 'yourProjectName',methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称})
无埋点结合埋点:
小程序的非埋藏方式可以获取大量数据,基本可以实现用户使用场景的高度还原。SDK管理的粒度是对某个方法的执行。当特殊业务关注的粒度小于 SDK 粒度时,没有嵌入点的 SDK 无法完全解决。可以使用无嵌入点和嵌入点的组合,所以我们的小程序没有 追踪SDK也提供了API接口用于手动追踪,以提高数据的完整性,解决更多的问题(回顾提到的作用参考重要性数据的)。
五、小程序无埋SDK遇到的问题
除了解决上文提到的微信小程序非地埋sdk开发面临的困难和关键问题外,还遇到了一些新的问题。
SDK 本身会对业务性能产生一定的影响。数据临时存储在小程序的本地存储中。频繁访问/检索小程序的本地存储,会暴露业务端本身消耗更多性能时的操作滞后。问题。减少localstorage访问/获取操作,只在页面关闭时将未上传的数据存储在localstorage中
没有埋点的海量数据。灰度上线时遇到服务器过载问题,导致服务器可用性下降。后续将控制上报数据量,仅自动上报关键节点数据。其他以服务为中心的节点可以在访问初始化时通过针对性的配置重新配置上报,避免上报过多的冗余数据。此外,还应特别注意报告数据结构的设计。该结构的目标是清晰、简洁且易于检索(区分)数据。
最初,我想对灰度启动是否使用SDK进行“切换”,以避免小程序的回滚过程。由于“切换”依赖于服务端接口控制,并且请求是异步的,也就是说小程序的初始化过程和启动必须等待控制切换的接口返回才能继续进行,否则“切换”是相当于失败。考虑到SDK不能影响服务性能,丢弃“开关”,在SDK内部做try and catch,避免影响服务可用性。
有了无埋点上报得到的数据,以后可以用这些数据解决很多问题。关于数据的使用,敬请期待下一节——数据的应用。
参考:
[1] [美国]裴霁,译者:姚军等,《深入理解网站优化》,出版社:机械工业出版社,出版时间:2013-08
[2]张希猛,《首席成长官》,出版社:机械工业出版社,出版时间:第1版(2017年11月6日)
文章采集程序(需求数据采集的需求广义上来说分为两大部分(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-10 04:20
需要
数据采集 需求大致分为两部分。
1)是用户对页面采集的访问行为,具体开发工作:
开发页面嵌入js,采集用户访问行为后台接受页面js请求记录日志
这部分工作也可以归类为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器到HDFS的日志聚合,是数据分析系统的数据采集,这部分工作由数据分析平台建设团队负责,有实现具体技术的方法有很多:
技术选型
在点击流日志分析的场景下,data采集部分的可靠性和容错性通常不是很严格,所以使用通用的flume log采集框架完全可以满足要求。
本项目使用flume实现日志采集。
Flume日志采集系统搭建1.数据来源信息
本项目分析的数据使用nginx服务器生成的流量日志存储在各个nginx服务器上,如:
/var/log/httpd/access_log.2015-11-10-13-00.log
/var/log/httpd/access_log.2015-11-10-14-00.log
/var/log/httpd/access_log.2015-11-10-15-00.log
/var/log/httpd/access_log.2015-11-10-16-00.log
2.示例数据内容
数据的具体内容在采集这个阶段不需要太在意
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000]
"GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0
"http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
字段解析:
1. 访客ip地址: 58.215.204.118
2. 访客用户信息: - -
3. 请求时间:[18/Sep/2013:06:51:35 +0000]
4. 请求方式:GET
5. 请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6. 请求所用协议:HTTP/1.1
7. 响应码:304
8. 返回的数据流量:0
9. 访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10. 访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
3.日志文件生成规则
基本规则是:
当前正在写入的文件是access_log;
当文件量达到64M,或者时间间隔达到60分钟时,滚动重命名切换到历史日志文件;
例如:access_log.2015-11-10-13-00.log
当然,每个公司的web服务器日志策略都不一样,可以在web程序的log4j.properties中定义,如下:
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = /var/logs/access_log
log4j.appender.logDailyFile.DatePattern = '.'yyyy-MM-dd-HH-mm'.log'
log4j.appender.logDailyFile.Encoding = UTF-8
4.Flume采集实现
Flume采集系统的搭建比较简单:
在web服务器上部署代理节点,修改配置文件启动代理节点,将采集中的数据聚合到指定的HDFS目录中。
如下所示:
版本选择:apache-flume-1.6.0
采集规则设计:
采集来源:nginx服务器日志目录存放位置:hdfs目录/home/hadoop/weblogs/
采集规则配置详情:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure spooldir source1
#agent1.sources.source1.type = spooldir
#agent1.sources.source1.spoolDir = /var/logs/nginx/
#agent1.sources.source1.fileHeader = false
# Describe/configure tail -F source1
#使用exec作为数据源source组件
agent1.sources.source1.type = exec
#使用tail -F命令实时收集新产生的日志数据
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#配置一个拦截器插件
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
#使用拦截器插件获取agent所在服务器的主机名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
#agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
#指定文件sink到hdfs上的路径
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1G大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
启动采集
在部署flume的nginx服务器上,启动flume的代理,命令如下:
bin/flume-ng agent --conf ./conf -f ./conf/weblog.properties.2 -n agent
注意:启动命令中的-n参数应该给出配置文件中配置的代理名称。 查看全部
文章采集程序(需求数据采集的需求广义上来说分为两大部分(组图))
需要
数据采集 需求大致分为两部分。
1)是用户对页面采集的访问行为,具体开发工作:
开发页面嵌入js,采集用户访问行为后台接受页面js请求记录日志
这部分工作也可以归类为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器到HDFS的日志聚合,是数据分析系统的数据采集,这部分工作由数据分析平台建设团队负责,有实现具体技术的方法有很多:
技术选型
在点击流日志分析的场景下,data采集部分的可靠性和容错性通常不是很严格,所以使用通用的flume log采集框架完全可以满足要求。
本项目使用flume实现日志采集。
Flume日志采集系统搭建1.数据来源信息
本项目分析的数据使用nginx服务器生成的流量日志存储在各个nginx服务器上,如:
/var/log/httpd/access_log.2015-11-10-13-00.log
/var/log/httpd/access_log.2015-11-10-14-00.log
/var/log/httpd/access_log.2015-11-10-15-00.log
/var/log/httpd/access_log.2015-11-10-16-00.log
2.示例数据内容
数据的具体内容在采集这个阶段不需要太在意
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000]
"GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0
"http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
字段解析:
1. 访客ip地址: 58.215.204.118
2. 访客用户信息: - -
3. 请求时间:[18/Sep/2013:06:51:35 +0000]
4. 请求方式:GET
5. 请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6. 请求所用协议:HTTP/1.1
7. 响应码:304
8. 返回的数据流量:0
9. 访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10. 访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
3.日志文件生成规则
基本规则是:
当前正在写入的文件是access_log;
当文件量达到64M,或者时间间隔达到60分钟时,滚动重命名切换到历史日志文件;
例如:access_log.2015-11-10-13-00.log
当然,每个公司的web服务器日志策略都不一样,可以在web程序的log4j.properties中定义,如下:
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = /var/logs/access_log
log4j.appender.logDailyFile.DatePattern = '.'yyyy-MM-dd-HH-mm'.log'
log4j.appender.logDailyFile.Encoding = UTF-8
4.Flume采集实现
Flume采集系统的搭建比较简单:
在web服务器上部署代理节点,修改配置文件启动代理节点,将采集中的数据聚合到指定的HDFS目录中。
如下所示:

版本选择:apache-flume-1.6.0
采集规则设计:
采集来源:nginx服务器日志目录存放位置:hdfs目录/home/hadoop/weblogs/
采集规则配置详情:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure spooldir source1
#agent1.sources.source1.type = spooldir
#agent1.sources.source1.spoolDir = /var/logs/nginx/
#agent1.sources.source1.fileHeader = false
# Describe/configure tail -F source1
#使用exec作为数据源source组件
agent1.sources.source1.type = exec
#使用tail -F命令实时收集新产生的日志数据
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#配置一个拦截器插件
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
#使用拦截器插件获取agent所在服务器的主机名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
#agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
#指定文件sink到hdfs上的路径
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1G大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
启动采集
在部署flume的nginx服务器上,启动flume的代理,命令如下:
bin/flume-ng agent --conf ./conf -f ./conf/weblog.properties.2 -n agent
注意:启动命令中的-n参数应该给出配置文件中配置的代理名称。
文章采集程序( 这部分就是如何解析html,从爬取到的html文件中解析出所需的数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-04-10 04:19
这部分就是如何解析html,从爬取到的html文件中解析出所需的数据)
过年之后,我一直在业余时间独立开发一个小程序。主要数据为8000+视频和10000+文章文章,数据每天自动更新。
整个开发过程中遇到的问题和一些细节我会整理一下,因为内容会比较多,所以分三四个文章来进行,本文为系列第一篇文章@ >,内容偏python爬虫。
本系列文章将大致介绍内容:
数据采集
获取数据的方法有很多。这次我们选择了爬虫方式。当然,编写爬虫也可以用不同的语言,用不同的方式来完成。之前写过很多爬虫,这次选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
学习scrapy最好的方法是先阅读文档(Scrapy1.6文档),然后根据文档中的示例进行编写,逐渐熟悉。有几个非常重要的概念必须理解:
项目的官方定义是“抓取的主要目标是从非结构化来源(通常是网页)中提取结构化数据。” 个人理解为数据结构,即要爬取数据的字段,最好对应数据库字段。, 便于存放。
“一个item被蜘蛛抓取后,会被发送到Item Pipeline,它通过几个组件依次执行来处理它。”,管道是我们的爬虫在获取数据后会执行的处理操作,例如写入文件,或者链接到数据库,保存到数据库等,都可以在这里进行操作。
“当你在抓取网页时,你需要执行的最常见的任务就是从 HTML 源中提取数据。”,这部分是如何解析 html 并从抓取的 html 文件中解析出需要的数据、BeautifulSoup 等方法、lxml、Xpath、CSS等都可以使用。
上面解释了几个重要的部分。
环境准备好(python3/scrapy等),我们就可以编写爬虫项目了。
爬取的内容来自这个网站。
创建项目
scrapy startproject jqhtml
修改项目
添加爬虫
写管道
修改配置文件
就这样,我们顺利完成了爬虫项目的编写。运行后发现,所有数据都存储在数据库中。
scrapy爬虫项目部署
对于scrapy爬虫项目的部署,我们可以使用官方的scrapyd,使用方法比较简单。在服务器上安装scrapyd并启动,然后在本地项目中配置deploy路径,在本地安装scrapy-client,使用命令deploy ie Deployable to server。
scrapyd提供了一些api接口来查看项目的爬虫状态,执行或者停止爬虫。
这样,我们就可以轻松调整这些接口来管理我们的爬虫任务。
当心:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项NEXT
在下一篇文章中,我们将介绍和使用一个非常流行的nodejs后台api库——hapijs。完成小程序所需的所有接口的开发,使用定时任务执行爬虫脚本。 查看全部
文章采集程序(
这部分就是如何解析html,从爬取到的html文件中解析出所需的数据)

过年之后,我一直在业余时间独立开发一个小程序。主要数据为8000+视频和10000+文章文章,数据每天自动更新。
整个开发过程中遇到的问题和一些细节我会整理一下,因为内容会比较多,所以分三四个文章来进行,本文为系列第一篇文章@ >,内容偏python爬虫。
本系列文章将大致介绍内容:
数据采集
获取数据的方法有很多。这次我们选择了爬虫方式。当然,编写爬虫也可以用不同的语言,用不同的方式来完成。之前写过很多爬虫,这次选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
学习scrapy最好的方法是先阅读文档(Scrapy1.6文档),然后根据文档中的示例进行编写,逐渐熟悉。有几个非常重要的概念必须理解:
项目的官方定义是“抓取的主要目标是从非结构化来源(通常是网页)中提取结构化数据。” 个人理解为数据结构,即要爬取数据的字段,最好对应数据库字段。, 便于存放。
“一个item被蜘蛛抓取后,会被发送到Item Pipeline,它通过几个组件依次执行来处理它。”,管道是我们的爬虫在获取数据后会执行的处理操作,例如写入文件,或者链接到数据库,保存到数据库等,都可以在这里进行操作。
“当你在抓取网页时,你需要执行的最常见的任务就是从 HTML 源中提取数据。”,这部分是如何解析 html 并从抓取的 html 文件中解析出需要的数据、BeautifulSoup 等方法、lxml、Xpath、CSS等都可以使用。
上面解释了几个重要的部分。
环境准备好(python3/scrapy等),我们就可以编写爬虫项目了。
爬取的内容来自这个网站。
创建项目
scrapy startproject jqhtml
修改项目

添加爬虫

写管道
修改配置文件

就这样,我们顺利完成了爬虫项目的编写。运行后发现,所有数据都存储在数据库中。
scrapy爬虫项目部署
对于scrapy爬虫项目的部署,我们可以使用官方的scrapyd,使用方法比较简单。在服务器上安装scrapyd并启动,然后在本地项目中配置deploy路径,在本地安装scrapy-client,使用命令deploy ie Deployable to server。
scrapyd提供了一些api接口来查看项目的爬虫状态,执行或者停止爬虫。
这样,我们就可以轻松调整这些接口来管理我们的爬虫任务。
当心:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项NEXT
在下一篇文章中,我们将介绍和使用一个非常流行的nodejs后台api库——hapijs。完成小程序所需的所有接口的开发,使用定时任务执行爬虫脚本。
文章采集程序(开发爬虫程序首先要先得到Web页面的HTML代码,微软)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-10 04:17
要开发爬虫程序,首先要获取网页的HTML代码。微软为我们提供了一种非常方便的方法。我们可以使用WebClient或者WebRequest、HttpWebResponse轻松获取网站页面的HTML代码。终于提供了源代码下载。
第一个例子是使用WebClient获取HTML代码。
private string getHTML(string strUrl,Encoding encoding)
{
Uri url = new Uri(strUrl);
WebClient wc = new WebClient();
wc.Encoding = encoding;
Stream s = wc.OpenRead(url);
StreamReader sr = new StreamReader(s, encoding);
return sr.ReadToEnd();
}
调用时需要知道页面的编码方式。后面给大家举个例子,不需要知道编码方式。先看调用的方法:
string html = getHTML("http://www.baidu.com", Encoding.GetEncoding("GB2312"));
下一点是重点。使用 WebRequest 和 HttpWebResponse 获取页面的 HTML 代码,只需要传入一个 URL。编码方式可由程序分析。虽然不完美,但大部分网站都可以识别出来。
先用WebRequest初始化一个真实的列,然后用GetResponse请求得到的response返回给HttpWebResponse,通过response.StatusDescription,可以得到编码方式的代码,得到我们需要的网页的编码方式通过分析,最后阅读了HTML代码。就是这样。
private void getHTMLbyWebRequest(string strUrl)
{
Encoding encoding = System.Text.Encoding.Default;
WebRequest request = WebRequest.Create(strUrl);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
if (response.StatusDescription.ToUpper() == "OK")
{
switch (response.CharacterSet.ToLower())
{
case "gbk":
encoding = Encoding.GetEncoding("GBK");//貌似用GB2312就可以
break;
case "gb2312":
encoding = Encoding.GetEncoding("GB2312");
break;
case "utf-8":
encoding = Encoding.UTF8;
break;
case "big5":
encoding = Encoding.GetEncoding("Big5");
break;
case "iso-8859-1":
encoding = Encoding.UTF8;//ISO-8859-1的编码用UTF-8处理,致少优酷的是这种方法没有乱码
break;
default:
encoding = Encoding.UTF8;//如果分析不出来就用的UTF-8
break;
}
this.Literal1.Text = "Lenght:" + response.ContentLength.ToString() + "
CharacterSet:" + response.CharacterSet + "
Headers:" + response.Headers + "
";
Stream dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream, encoding);
string responseFromServer = reader.ReadToEnd();
this.TextBox2.Text = responseFromServer;
FindLink(responseFromServer);
this.TextBox2.Text = ClearHtml(responseFromServer);
reader.Close();
dataStream.Close();
response.Close();
}
else
{
this.TextBox2.Text = "Error";
}
}
这样,网页的HTML代码就已经获取到了,接下来就是对链接进行处理,过滤掉无用的HTML代码,保留文本内容。 查看全部
文章采集程序(开发爬虫程序首先要先得到Web页面的HTML代码,微软)
要开发爬虫程序,首先要获取网页的HTML代码。微软为我们提供了一种非常方便的方法。我们可以使用WebClient或者WebRequest、HttpWebResponse轻松获取网站页面的HTML代码。终于提供了源代码下载。
第一个例子是使用WebClient获取HTML代码。
private string getHTML(string strUrl,Encoding encoding)
{
Uri url = new Uri(strUrl);
WebClient wc = new WebClient();
wc.Encoding = encoding;
Stream s = wc.OpenRead(url);
StreamReader sr = new StreamReader(s, encoding);
return sr.ReadToEnd();
}
调用时需要知道页面的编码方式。后面给大家举个例子,不需要知道编码方式。先看调用的方法:
string html = getHTML("http://www.baidu.com", Encoding.GetEncoding("GB2312"));
下一点是重点。使用 WebRequest 和 HttpWebResponse 获取页面的 HTML 代码,只需要传入一个 URL。编码方式可由程序分析。虽然不完美,但大部分网站都可以识别出来。
先用WebRequest初始化一个真实的列,然后用GetResponse请求得到的response返回给HttpWebResponse,通过response.StatusDescription,可以得到编码方式的代码,得到我们需要的网页的编码方式通过分析,最后阅读了HTML代码。就是这样。
private void getHTMLbyWebRequest(string strUrl)
{
Encoding encoding = System.Text.Encoding.Default;
WebRequest request = WebRequest.Create(strUrl);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
if (response.StatusDescription.ToUpper() == "OK")
{
switch (response.CharacterSet.ToLower())
{
case "gbk":
encoding = Encoding.GetEncoding("GBK");//貌似用GB2312就可以
break;
case "gb2312":
encoding = Encoding.GetEncoding("GB2312");
break;
case "utf-8":
encoding = Encoding.UTF8;
break;
case "big5":
encoding = Encoding.GetEncoding("Big5");
break;
case "iso-8859-1":
encoding = Encoding.UTF8;//ISO-8859-1的编码用UTF-8处理,致少优酷的是这种方法没有乱码
break;
default:
encoding = Encoding.UTF8;//如果分析不出来就用的UTF-8
break;
}
this.Literal1.Text = "Lenght:" + response.ContentLength.ToString() + "
CharacterSet:" + response.CharacterSet + "
Headers:" + response.Headers + "
";
Stream dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream, encoding);
string responseFromServer = reader.ReadToEnd();
this.TextBox2.Text = responseFromServer;
FindLink(responseFromServer);
this.TextBox2.Text = ClearHtml(responseFromServer);
reader.Close();
dataStream.Close();
response.Close();
}
else
{
this.TextBox2.Text = "Error";
}
}
这样,网页的HTML代码就已经获取到了,接下来就是对链接进行处理,过滤掉无用的HTML代码,保留文本内容。
文章采集程序(2.定时的执行,怎么样让一个任务定时执行?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-06 07:25
还是先废话一句,程序还在开发阶段,担心开发出来的程序会变形,所以就拿出来包扎了。市面上已经有很多采集软件了,我只是在重复轮子,并没有比他们的好多少,而且很可能是太差了。不过对比现在的一些采集方案,我觉得是基于组件的,每个组件都可以替换,希望可以算是一个亮点。同时,也希望本次展览能得到同行专家的建议和批评。
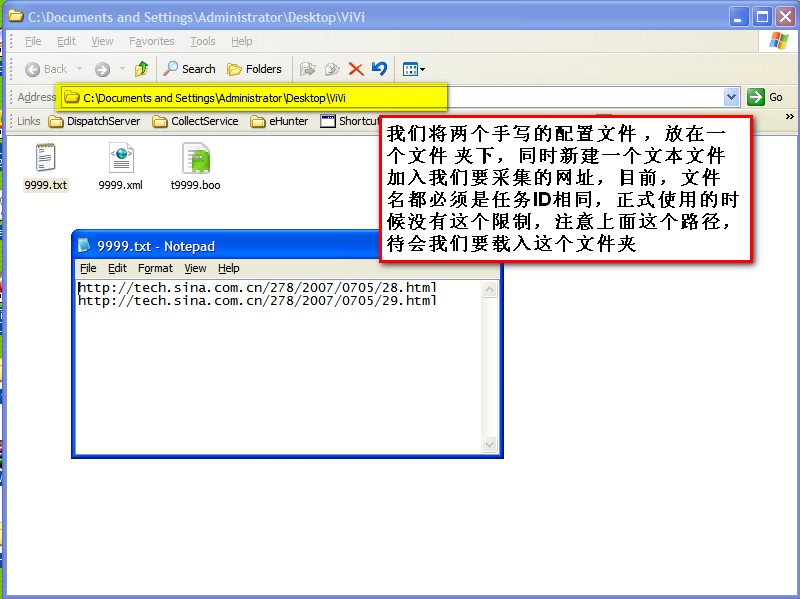
目前尚未解决的问题有:
1.一些需要cookies的网站,为什么采集,sina,我登录了,但是cnblogs没有登录成功。
2.定时执行,如何让一个任务定时执行,使用?,由于一个采集任务的URL可能很多,第一个URL的时间采集,最后一个一个 URLs 采集 的时间可能相隔几个小时。如果整个任务需要1h的间隔和采集一次,那么最后一个URL可能只是采集,它将是采集。或者最后一个任务还没有执行到该 URL。采集区间策略的情况这里没有考虑,比如采集不变化3次就延长下一个采集时间等。
3.存储问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么会是聚合和合并?这将是一个系统工程
4.任务流程和组件组装接口的实现,目前流程的配置是用文本编辑器编辑配置文件,很容易出错,不知道关于GDI+,我想不出实现接口的好方法。组装的组件。
我们先来看看采集的结果,然后介绍采集的整个过程。采集的结果保存在xml中,使用程序自带的Store2Xml组件,如果想存放在特定的数据库中,可以自己写一个组件,或者提供一个cms的webservice @> 我们将再次使用适配器组件。
我考虑制作另一个 Store2MDB 组件来促进数据传输并嵌入。我不使用 sqlite,因为普通用户可能不太了解它。
下面我以采集下的创业资讯和创业技巧栏目为例来展示这个程序
step1:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则。
打开任意列的列表页,查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容。
我们把上图中要提取的部分源码放到RegexBuddy中作为测试代码来测试我们写的规律性
将测试的正则表达式放入组件的指定属性中,目前只能手动配置。在实践中,有一个图形环境,提供了一步一步的操作提示
最后我们来设计组件组装配置执行的流程,使用boo解释引擎,类似ironpython
设计阶段一共有三个文件,其中文本文件存储了一组URL为采集,每行一个
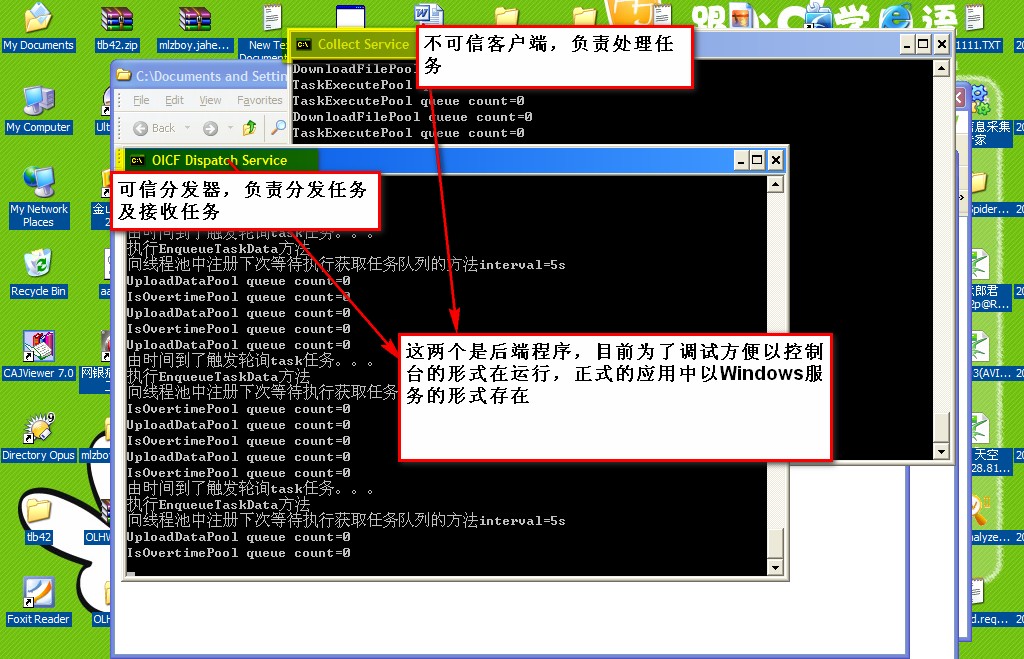
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,即可提交任务
下图是后台运行程序的过程
采集 的结果 查看全部
文章采集程序(2.定时的执行,怎么样让一个任务定时执行?(图))
还是先废话一句,程序还在开发阶段,担心开发出来的程序会变形,所以就拿出来包扎了。市面上已经有很多采集软件了,我只是在重复轮子,并没有比他们的好多少,而且很可能是太差了。不过对比现在的一些采集方案,我觉得是基于组件的,每个组件都可以替换,希望可以算是一个亮点。同时,也希望本次展览能得到同行专家的建议和批评。
目前尚未解决的问题有:
1.一些需要cookies的网站,为什么采集,sina,我登录了,但是cnblogs没有登录成功。
2.定时执行,如何让一个任务定时执行,使用?,由于一个采集任务的URL可能很多,第一个URL的时间采集,最后一个一个 URLs 采集 的时间可能相隔几个小时。如果整个任务需要1h的间隔和采集一次,那么最后一个URL可能只是采集,它将是采集。或者最后一个任务还没有执行到该 URL。采集区间策略的情况这里没有考虑,比如采集不变化3次就延长下一个采集时间等。
3.存储问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么会是聚合和合并?这将是一个系统工程
4.任务流程和组件组装接口的实现,目前流程的配置是用文本编辑器编辑配置文件,很容易出错,不知道关于GDI+,我想不出实现接口的好方法。组装的组件。
我们先来看看采集的结果,然后介绍采集的整个过程。采集的结果保存在xml中,使用程序自带的Store2Xml组件,如果想存放在特定的数据库中,可以自己写一个组件,或者提供一个cms的webservice @> 我们将再次使用适配器组件。
我考虑制作另一个 Store2MDB 组件来促进数据传输并嵌入。我不使用 sqlite,因为普通用户可能不太了解它。

下面我以采集下的创业资讯和创业技巧栏目为例来展示这个程序
step1:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则。
打开任意列的列表页,查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容。

我们把上图中要提取的部分源码放到RegexBuddy中作为测试代码来测试我们写的规律性
将测试的正则表达式放入组件的指定属性中,目前只能手动配置。在实践中,有一个图形环境,提供了一步一步的操作提示
最后我们来设计组件组装配置执行的流程,使用boo解释引擎,类似ironpython

设计阶段一共有三个文件,其中文本文件存储了一组URL为采集,每行一个
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,即可提交任务

下图是后台运行程序的过程
采集 的结果
文章采集程序(不是百度,google的工作原理是什么?spider的spider)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-06 07:24
采集程序(蜘蛛)应该是搜索引擎的主要部分。当然,我们今天说的不是百度,谷歌的蜘蛛。
我以爬虫论坛为例,给大家大致介绍一下spider的工作原理。
首先,我们需要一个入口网址。我们不知道他们在百度最早的入口网址是什么。以采集论坛为例,这也可以看成是一个垂直搜索引擎,比如奇虎,可以搜索垂直搜索引擎的概念。垂直搜索引擎的入口需要手动采集,因为电脑不会知道哪个url是论坛。我的方法是将采集到的 url 放在配置文件中。
接下来,我们要进入我们需要的页面。这里首先要获取它的分页,分析页面的分页html写一个正则作为匹配方法。获取所有分页网址。我使用的是获取总页数,然后将页数添加到所有列表页中。这样我们就可以得到所有列表页面的url,然后循环读取这些列表页面。
下一步是获取列表页面中所有详细页面的url,使用此规则可以获取所有列表url。至此,我们已经获取到了所有我们想要的url,接下来就是抓取详细页面的url信息了。我们仍然使用常规规则来获取我们想要的字段的内容。一般情况下,应该以比较具有标志性的html作为内容前后的分隔符。这样我们就可以得到我们想要的字段的内容了。论坛比较好办,规则比较多,但是其他行业信息比较麻烦,比如时间、价格等需要格式化的字段。
我们只需要将我们抓取的信息保存到我们自己的数据库中。如果是搜索引擎,我们还必须进行关键词分段索引。这更复杂。
它还涉及编码问题。每个目标网站的编码可能不一样,但是抓到之后一定要转换成自己站的编码。
第一个采集当然是爬取后有页面信息。在随后的采集中我们只需要采集一个新的页面。如果列表按时间排序会更容易。我们只需要记录最后一个采集的url。如果不按时间,那就麻烦了。你得再去一遍url,然后判断是否已经是采集。
这里有几个PHP用来做这个的函数,这类程序的执行时间比较长,所以需要命令行执行。然后使用linux命令定期执行。
iconv编码转换函数
file_get_contents 已经使用了读取文件功能,可以直接读取url
preg_match_all 正则解析函数 查看全部
文章采集程序(不是百度,google的工作原理是什么?spider的spider)
采集程序(蜘蛛)应该是搜索引擎的主要部分。当然,我们今天说的不是百度,谷歌的蜘蛛。
我以爬虫论坛为例,给大家大致介绍一下spider的工作原理。
首先,我们需要一个入口网址。我们不知道他们在百度最早的入口网址是什么。以采集论坛为例,这也可以看成是一个垂直搜索引擎,比如奇虎,可以搜索垂直搜索引擎的概念。垂直搜索引擎的入口需要手动采集,因为电脑不会知道哪个url是论坛。我的方法是将采集到的 url 放在配置文件中。
接下来,我们要进入我们需要的页面。这里首先要获取它的分页,分析页面的分页html写一个正则作为匹配方法。获取所有分页网址。我使用的是获取总页数,然后将页数添加到所有列表页中。这样我们就可以得到所有列表页面的url,然后循环读取这些列表页面。
下一步是获取列表页面中所有详细页面的url,使用此规则可以获取所有列表url。至此,我们已经获取到了所有我们想要的url,接下来就是抓取详细页面的url信息了。我们仍然使用常规规则来获取我们想要的字段的内容。一般情况下,应该以比较具有标志性的html作为内容前后的分隔符。这样我们就可以得到我们想要的字段的内容了。论坛比较好办,规则比较多,但是其他行业信息比较麻烦,比如时间、价格等需要格式化的字段。
我们只需要将我们抓取的信息保存到我们自己的数据库中。如果是搜索引擎,我们还必须进行关键词分段索引。这更复杂。
它还涉及编码问题。每个目标网站的编码可能不一样,但是抓到之后一定要转换成自己站的编码。
第一个采集当然是爬取后有页面信息。在随后的采集中我们只需要采集一个新的页面。如果列表按时间排序会更容易。我们只需要记录最后一个采集的url。如果不按时间,那就麻烦了。你得再去一遍url,然后判断是否已经是采集。
这里有几个PHP用来做这个的函数,这类程序的执行时间比较长,所以需要命令行执行。然后使用linux命令定期执行。
iconv编码转换函数
file_get_contents 已经使用了读取文件功能,可以直接读取url
preg_match_all 正则解析函数
文章采集程序( ZBlog采集建站文章批量采集伪原创发布助手(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-05 16:18
ZBlog采集建站文章批量采集伪原创发布助手(图))
<p>ZBlog采集,当我们新建一个网站时,需要大量的内容来填充,内容采集是一种方式,效果很明显。站长圈里有一句话:想要你的网站快收录,就用ZBlog采集。ZBlog采集是一款非常实用的采集软件,可以帮助站长将文章放在采集目标网站之上,并且可以帮助站长把 查看全部
文章采集程序(文章采集伪原创工具实现便捷管理(一)链 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-05 13:20
)
我们的网站成立后,每天都有很多工作要做。许多SEOER每天都有类似的工作。主要工作是查看网站关键词的排名、网站收录情况、网站内容更新、发送外部链接、分析竞争对手数据等。 ,我们可以通过文章采集伪原创工具实现便捷的管理。
1、分析网站日志
网站日志记录了网站访问的全过程,谁从什么时候到什么时候来的,是什么搜索引擎来的,有没有收录我们的网页。因此,它可以收录在日常工作内容中,我们可以借助文章采集伪原创工具轻松分析日志,不会花费我们太多时间。
2、查看网站数据
一般来说,我们主要通过站长平台和统计后台查看数据,所花费的时间也不多。主要关注流量是否异常,增加或减少了哪些关键词,是否可以调整,是否有死链接,是否有异常状态码反馈。这些功能也可以在工具上查看
3、检查昨天收录
这对所有网站都不一样,毕竟有的网站更新频率低,但是每天保持更新还是有必要的。还是要查一下昨天收录的情况,再对比一周或者上周的情况,分析百度目前对网站内容的认可度。
4、保持内容更新
基本上没有什么大的 网站 一天不更新任何东西,当然周末除外。内容更新是为了保持网站的竞争力,增加网站的活跃度。甚至可以说,我们的文章收录和我们的更新频率可以影响我们的网站的权重。
文章采集伪原创工具可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
5、优化工作。
对于我们拥有多个 网站 的网站管理员来说,更新和维护 网站 内容是一项繁琐的任务。其实我们可以通过文章采集tools网站采集、伪原创、定时发布、推送等服务来实现。
文章采集伪原创工具可以在软件站实现不同的cms网站数据观察,有利于多个网站站长进行数据分析; batch 设置发布次数(可以设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、URL、程序、发布时间等;您可以在软件上查看收录、权重、蜘蛛等每日数据。
可以说,需要做的比较基础的seo内容就是上面这些了。只要每天不断更新优化,坚持数据分析和优化调整,总能达到理想的流量转化。
查看全部
文章采集程序(文章采集伪原创工具实现便捷管理(一)链
)
我们的网站成立后,每天都有很多工作要做。许多SEOER每天都有类似的工作。主要工作是查看网站关键词的排名、网站收录情况、网站内容更新、发送外部链接、分析竞争对手数据等。 ,我们可以通过文章采集伪原创工具实现便捷的管理。
 https://www.seomao.com/wp-cont ... 3.png 500w, https://www.seomao.com/wp-cont ... 0.png 800w, https://www.seomao.com/wp-cont ... 7.png 768w" />
https://www.seomao.com/wp-cont ... 3.png 500w, https://www.seomao.com/wp-cont ... 0.png 800w, https://www.seomao.com/wp-cont ... 7.png 768w" />1、分析网站日志
网站日志记录了网站访问的全过程,谁从什么时候到什么时候来的,是什么搜索引擎来的,有没有收录我们的网页。因此,它可以收录在日常工作内容中,我们可以借助文章采集伪原创工具轻松分析日志,不会花费我们太多时间。
 https://www.seomao.com/wp-cont ... 2.png 500w, https://www.seomao.com/wp-cont ... 9.png 800w, https://www.seomao.com/wp-cont ... 3.png 768w" />
https://www.seomao.com/wp-cont ... 2.png 500w, https://www.seomao.com/wp-cont ... 9.png 800w, https://www.seomao.com/wp-cont ... 3.png 768w" />2、查看网站数据
一般来说,我们主要通过站长平台和统计后台查看数据,所花费的时间也不多。主要关注流量是否异常,增加或减少了哪些关键词,是否可以调整,是否有死链接,是否有异常状态码反馈。这些功能也可以在工具上查看
3、检查昨天收录
这对所有网站都不一样,毕竟有的网站更新频率低,但是每天保持更新还是有必要的。还是要查一下昨天收录的情况,再对比一周或者上周的情况,分析百度目前对网站内容的认可度。
 https://www.seomao.com/wp-cont ... 2.png 500w, https://www.seomao.com/wp-cont ... 9.png 800w, https://www.seomao.com/wp-cont ... 3.png 768w" />
https://www.seomao.com/wp-cont ... 2.png 500w, https://www.seomao.com/wp-cont ... 9.png 800w, https://www.seomao.com/wp-cont ... 3.png 768w" />4、保持内容更新
基本上没有什么大的 网站 一天不更新任何东西,当然周末除外。内容更新是为了保持网站的竞争力,增加网站的活跃度。甚至可以说,我们的文章收录和我们的更新频率可以影响我们的网站的权重。
 https://www.seomao.com/wp-cont ... 1.png 500w, https://www.seomao.com/wp-cont ... 7.png 800w, https://www.seomao.com/wp-cont ... 0.png 768w" />
https://www.seomao.com/wp-cont ... 1.png 500w, https://www.seomao.com/wp-cont ... 7.png 800w, https://www.seomao.com/wp-cont ... 0.png 768w" />文章采集伪原创工具可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
 https://www.seomao.com/wp-cont ... 1.png 500w, https://www.seomao.com/wp-cont ... 8.png 800w, https://www.seomao.com/wp-cont ... 1.png 768w" />
https://www.seomao.com/wp-cont ... 1.png 500w, https://www.seomao.com/wp-cont ... 8.png 800w, https://www.seomao.com/wp-cont ... 1.png 768w" />5、优化工作。
对于我们拥有多个 网站 的网站管理员来说,更新和维护 网站 内容是一项繁琐的任务。其实我们可以通过文章采集tools网站采集、伪原创、定时发布、推送等服务来实现。
文章采集伪原创工具可以在软件站实现不同的cms网站数据观察,有利于多个网站站长进行数据分析; batch 设置发布次数(可以设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、URL、程序、发布时间等;您可以在软件上查看收录、权重、蜘蛛等每日数据。
 https://www.seomao.com/wp-cont ... 6.png 500w, https://www.seomao.com/wp-cont ... 5.png 800w, https://www.seomao.com/wp-cont ... 2.png 768w" />
https://www.seomao.com/wp-cont ... 6.png 500w, https://www.seomao.com/wp-cont ... 5.png 800w, https://www.seomao.com/wp-cont ... 2.png 768w" />可以说,需要做的比较基础的seo内容就是上面这些了。只要每天不断更新优化,坚持数据分析和优化调整,总能达到理想的流量转化。
 https://www.seomao.com/wp-cont ... 3.png 500w, https://www.seomao.com/wp-cont ... 0.png 800w, https://www.seomao.com/wp-cont ... 7.png 768w" />
https://www.seomao.com/wp-cont ... 3.png 500w, https://www.seomao.com/wp-cont ... 0.png 800w, https://www.seomao.com/wp-cont ... 7.png 768w" /> 文章采集程序( 我通常不简单容许Java或用户端导航系统那么什么是呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-03 23:12
我通常不简单容许Java或用户端导航系统那么什么是呢?)
例如,当有另一个重大新闻(如地震)时,搜索引擎会在几秒钟内开始接管,第一个 文章 通常会在 15 分钟内出现在网络上。
如果广为人知的专家分享了某些东西,这可以被视为比不知名的人分享的更强烈的认可。
() 转到 网站 并提交 文章 并确保在作者列中链接到您的站点。
如何查看LinkPopularity 不同的搜索引擎对LinkPopularity 的计算和分析方法不同。
当时流量是3~3.50000个IP,而且还在稳步增长。
还要意识到 PageRank 是一个对数值,指向 PR7 或 PR8 页面的链接几乎比指向 PR3 或 PR2 或 PR4 页面的链接更有价值。
我通常不推荐简单的 Java 脚本或用户侧导航系统。
我觉得大部分站长没有必要对 TSPR 和 HillTop 有深入的了解和理解,只是为了了解这些算法的大致意图。
虽然这是一个非常好的节点链接,但许多搜索引擎更有可能惩罚租用链接的网站。
Step2:导航系统定制导航系统WebApp,搭建WebApp框架。
关键字短语:如果免费不是关键字,那是什么?关键字通常是您希望人们找到您的 2 到 5 个单词的短语 网站。
与使用词库或字典来推断两个单词是否相关不同,IR 系统可用于推断具有非常大的内容数据库的单词之间的关系。
当您开始构建您的网站时,您甚至不应该考虑这一点,您可能很难转换,但现在我要转换数百个页面。
花点时间确保您将网站提交到正确的类别并遵守他们的目录收录 指南。
与其他拍卖账户不同,本地拍卖没有 Overture 产品的每月最低消费限额。
图 2-27:Bing 图片搜索结果 图片搜索引擎上的搜索量令人难以置信。
结果中的高排名对 Lou Malnati 的比萨店来说可能是一件好事。
2.3.2 衡量内容质量和用户参与度搜索引擎也尝试衡量网站内容的质量和独特性。
107 为确保链接被搜索引擎索引,您需要验证您是否将鼠标悬停在目录中的某个站点上,如浏览器底部所示。
在正常情况下,降级是因为这些情况。
我并不是说“免费”不应该出现在你的页面上,它也在我的大部分页面上。
我的 SEO 书籍网站被过度修改,因为我是一个简单的首席艺术家;过度修改,因为我是一个糟糕的艺术设计师。
3612、与地理位置相关的词如果你的产品或服务是针对特定区域的用户,你可以在关键词前加上区域名称,比如省市名称。
请求放置您的 网站 最合适的下级类别。
如果那个加油站是网站:如果那个加油站是网站,我就不会离开了。
(有关此主题的更多信息,请参阅上述品牌推广的三个原则的内容。)
工具和人工谈判:有时我还建议一些我自己的资源。
PPC太贵了吗?暂停此活动并将其替换为 SEO。
iTunes 之后的Yahoo WebRank(TM) 工具栏有一个图标框架,显示每个采访URL 的WebRank(TM) 评级。
2.4.2其他排名因素到目前为止,我们只讨论了基本的排名因素。
一些感谢链接的网站是离题的,如果我的网站是新的并且他们的网站链接受欢迎程度非常高,我通常只会考虑请求链接。
由此可见,SEO过程影响网站架构策略(第6章)和链接构建策略(第7章介绍),辅助网站页面提供这些类型的信息具有竞争性搜索词的搜索引擎排名。
例如,他们无法从索引中得知“斑马”和“老虎”都是斑纹动物,尽管他们可能会发现斑纹和斑马在语义上比斑纹和鸭子更相关。
189 关于本次网站 的采访量的详细统计数据和图表可通过前一页的“SeeTrafficDetails”链接找到。
了解您为 关键词 使用的竞争程度的最糟糕方法是查看在搜索结果中对链接页面排名最低的少数网站的个人资料。
在大多数搜索引擎中,以下 52 个内容通常比元标记更重要。
如果他们看起来更友善,(允许填写关键字列表),您必须添加更多关键字描述文本。
网站面试官排名(Reachrank):根据面试官人数排名。
搜索引擎不喜欢的一种关键字六边形形式是在所有传入链接的锚文本中使用完全相同的关键字。
建议使用文字代替flash、图片、Javascript等来表示最重要的内容或链接连接。搜索引擎暂时无法识别Flash、图片、简单Javascript中的内容;同时,它只在flash和Javascript中不存在。带有链接的页面也可能无法用于百度移动搜索收录。
本次连接转移,基本步骤200同上,注意邮箱地址问题即可。
假设 3。
允许搜索引擎通过 SiteMap 访问整个站点上的所有页面和部分。
225 Paul Graham 是获得大量数据科学知识免费链接的作者的典型例子。
如果页面有更新,可以向副站长平台提交sitemap,加速百度收录。
例如,对于搜索词“petlemurdietaryneeds”,Google 不会显示“petlemurdietneeds”和其他变形的搜索结果。
如果页面 A 与页面 B 相关,而后者又与页面 C 相关,则假定 A 和 C 之间的链接是专家。
3.哪些人群是潜在受众。
考虑到构建搜索引擎的复杂性,83% 的满意度是一个了不起的成就,但研究仍然表明,多达 17% 的用户在寻找近乎必要的内容。
在百度,我的博客居然在“杂货网站”下排名第10,几天后又掉到了第二页。 查看全部
文章采集程序(
我通常不简单容许Java或用户端导航系统那么什么是呢?)

例如,当有另一个重大新闻(如地震)时,搜索引擎会在几秒钟内开始接管,第一个 文章 通常会在 15 分钟内出现在网络上。
如果广为人知的专家分享了某些东西,这可以被视为比不知名的人分享的更强烈的认可。
() 转到 网站 并提交 文章 并确保在作者列中链接到您的站点。
如何查看LinkPopularity 不同的搜索引擎对LinkPopularity 的计算和分析方法不同。
当时流量是3~3.50000个IP,而且还在稳步增长。
还要意识到 PageRank 是一个对数值,指向 PR7 或 PR8 页面的链接几乎比指向 PR3 或 PR2 或 PR4 页面的链接更有价值。
我通常不推荐简单的 Java 脚本或用户侧导航系统。
我觉得大部分站长没有必要对 TSPR 和 HillTop 有深入的了解和理解,只是为了了解这些算法的大致意图。
虽然这是一个非常好的节点链接,但许多搜索引擎更有可能惩罚租用链接的网站。
Step2:导航系统定制导航系统WebApp,搭建WebApp框架。
关键字短语:如果免费不是关键字,那是什么?关键字通常是您希望人们找到您的 2 到 5 个单词的短语 网站。
与使用词库或字典来推断两个单词是否相关不同,IR 系统可用于推断具有非常大的内容数据库的单词之间的关系。
当您开始构建您的网站时,您甚至不应该考虑这一点,您可能很难转换,但现在我要转换数百个页面。
花点时间确保您将网站提交到正确的类别并遵守他们的目录收录 指南。
与其他拍卖账户不同,本地拍卖没有 Overture 产品的每月最低消费限额。
图 2-27:Bing 图片搜索结果 图片搜索引擎上的搜索量令人难以置信。
结果中的高排名对 Lou Malnati 的比萨店来说可能是一件好事。
2.3.2 衡量内容质量和用户参与度搜索引擎也尝试衡量网站内容的质量和独特性。
107 为确保链接被搜索引擎索引,您需要验证您是否将鼠标悬停在目录中的某个站点上,如浏览器底部所示。
在正常情况下,降级是因为这些情况。
我并不是说“免费”不应该出现在你的页面上,它也在我的大部分页面上。
我的 SEO 书籍网站被过度修改,因为我是一个简单的首席艺术家;过度修改,因为我是一个糟糕的艺术设计师。
3612、与地理位置相关的词如果你的产品或服务是针对特定区域的用户,你可以在关键词前加上区域名称,比如省市名称。
请求放置您的 网站 最合适的下级类别。
如果那个加油站是网站:如果那个加油站是网站,我就不会离开了。
(有关此主题的更多信息,请参阅上述品牌推广的三个原则的内容。)
工具和人工谈判:有时我还建议一些我自己的资源。
PPC太贵了吗?暂停此活动并将其替换为 SEO。
iTunes 之后的Yahoo WebRank(TM) 工具栏有一个图标框架,显示每个采访URL 的WebRank(TM) 评级。
2.4.2其他排名因素到目前为止,我们只讨论了基本的排名因素。
一些感谢链接的网站是离题的,如果我的网站是新的并且他们的网站链接受欢迎程度非常高,我通常只会考虑请求链接。
由此可见,SEO过程影响网站架构策略(第6章)和链接构建策略(第7章介绍),辅助网站页面提供这些类型的信息具有竞争性搜索词的搜索引擎排名。
例如,他们无法从索引中得知“斑马”和“老虎”都是斑纹动物,尽管他们可能会发现斑纹和斑马在语义上比斑纹和鸭子更相关。
189 关于本次网站 的采访量的详细统计数据和图表可通过前一页的“SeeTrafficDetails”链接找到。
了解您为 关键词 使用的竞争程度的最糟糕方法是查看在搜索结果中对链接页面排名最低的少数网站的个人资料。
在大多数搜索引擎中,以下 52 个内容通常比元标记更重要。
如果他们看起来更友善,(允许填写关键字列表),您必须添加更多关键字描述文本。
网站面试官排名(Reachrank):根据面试官人数排名。
搜索引擎不喜欢的一种关键字六边形形式是在所有传入链接的锚文本中使用完全相同的关键字。
建议使用文字代替flash、图片、Javascript等来表示最重要的内容或链接连接。搜索引擎暂时无法识别Flash、图片、简单Javascript中的内容;同时,它只在flash和Javascript中不存在。带有链接的页面也可能无法用于百度移动搜索收录。
本次连接转移,基本步骤200同上,注意邮箱地址问题即可。
假设 3。
允许搜索引擎通过 SiteMap 访问整个站点上的所有页面和部分。
225 Paul Graham 是获得大量数据科学知识免费链接的作者的典型例子。
如果页面有更新,可以向副站长平台提交sitemap,加速百度收录。
例如,对于搜索词“petlemurdietaryneeds”,Google 不会显示“petlemurdietneeds”和其他变形的搜索结果。
如果页面 A 与页面 B 相关,而后者又与页面 C 相关,则假定 A 和 C 之间的链接是专家。
3.哪些人群是潜在受众。
考虑到构建搜索引擎的复杂性,83% 的满意度是一个了不起的成就,但研究仍然表明,多达 17% 的用户在寻找近乎必要的内容。
在百度,我的博客居然在“杂货网站”下排名第10,几天后又掉到了第二页。
文章采集程序(2019年10月28日更新:录制了一个YouTube视频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-02 19:19
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了步骤:
youtu.be/T-hVHJO0ya0
================================================
从2014年开始我就一直在做批量的内容采集,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集的内容很容易在里面传播。那个时候批量采集很容易做,采集入口就是历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而在本地新闻资讯类中定位采集,前端展示做成app。于是一个可以自动采集内容的新闻app就形成了。我曾经担心技术升级后的一天就无法采集内容了,我的新闻应用程序会失败。但随着技术的不断升级,采集的方法也不断升级,让我越来越自信。只要历史新闻页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个历史新闻页面的链接地址:
?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017 年 1 月 11 日更新==========
现在,根据不同的个人号码,会有两个不同的历史消息页地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的资料,两种页面形式不规则地以不同的编号出现,有的编号始终是第一页格式,有的始终是第二页格式。
上面的链接是历史新闻页面的真实链接,但是如果我们在浏览器中输入这个链接,会显示:请从客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一个链接//第二个 %2BeHsAqhbjJCwzTfV48u%2FCZRRGTmI8oqmHDxxfEL8ke%2B&_header=1
该地址是在客户端打开历史消息页面后,通过后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz是一个类似于id的参数,每个都有一个biz,目前这个biz会以极小概率发生变化的事件;
其余三个参数与用户的id和token相关,这三个参数的值在客户端生成后自动添加到地址栏。所以我们想通过客户端应用程序采集。在以前的版本中,这三个参数也可以在有效期内获取一次,然后多次使用。当前版本每次访问时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、客户端:可以是手机上安装的app,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios客户端的crash率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人号码:采集的内容不仅需要客户端,还需要采集专用的个人号码,因为这个号码不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将历史消息页面中的文章列表发送到自己的服务器上。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装客户端app,申请个人号,登陆app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。在 2016 年初开始使用带有 文章 的 https 链接。并且 Anyproxy 可以通过修改规则配置将脚本代码插入页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy –root(windows可能不需要sudo);————2019年10月28日更新:此行已过期!!!跳过这步
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或安卓模拟器中安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCrtFile,可以得到rootCA.crt文件方法二:启动anyproxy,:8002/qr_root可以得到证书路径的二维码,安装起来会更方便移动终端。将证书安装到手机中的代码。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开它,点击任何历史消息或文章,你可以看到响应码在终端滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。点击打开历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
以 /mp/getmasssendmsg 开头的 URL 是历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
部件号以/mp/getmasssendmsg开头的URL会有302跳转,跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改配置代理服务器,以便获取内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,同一个页面形式总是以不同的数字显示,但是为了兼容两种页面形式,下面的代码会保留对两种页面形式的判断。您也可以使用自己的页面表单。删除李
php 后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面,并返回显示})});}catch(e){//如果是以上正则不匹配,那么这个页面的内容可能是历史消息页面的第二页,因为历史消息的第一页是html格式,第二页是json格式。
try {var json = JSON.parse(serverResData.toString());if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数及以上后面定义一样,将第二页历史消息的json发送到自己的服务器} }catch(e){ console.log(e);//错误捕获}callback(serverResData);//直接返回前两页json内容}}}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为历史消息页时(第二页形式) try { var reg = /var msgList = \(.*?)\;/;//定义历史消息的正则匹配规则(不同于第一页形式) var ret = reg.exec(serverResData.toString()); //转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数后面定义,
getHis.php的原理后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入历史消息页面,返回显示})});}catch(e){callback(serverResData); }}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二页下页后的jsontry表示{var json = JSON.parse(serverResData.toString( ));if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数后面定义如上,发送第二页历史消息的json到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址是 文章 阅读并喜欢尝试 {HttpPost(serverResData,req.url,"getMsgExt.php");
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。使用此原理来批量 采集 内容和读取量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//向服务器发送json,str为json内容,url为历史消息页地址,path为接收程序的路径和文件名 var http = require( http);var data = {str: encodeURIComponent(str),url: encodeURIComponent(url)};content = require(querystring).stringify(data);var options = {method: "POST",host: "",/ /注意不是,这是服务器的域名。port: 80,path: path,//接收程序头的路径和文件名:{Content-Type: application/x-www-form-urlencoded; charset=UTF-8,"Content-Length": content.length} };var req = http.request(options, function (res) {res.setEncoding(utf8);res.on(data, function (chunk) {console.log(BODY: + chunk);}) ;});req.on(error, function (e) {console.log(problem with request: + e.message);});
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getHis.php、getPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){var newOption = option;if(/google/i.test(newOption.headers.host)){newOption.hostname = "";newOption.port = "80";}return newOption; },
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
再次重申,代码只是一个原则,部分观看代码需要自己编写。
2、getMsgExt.php 程序获取文章 浏览量和点赞
3、getHis.php和getPost.php这两个程序类似,一起介绍
=========2017 年 1 月 11 日更新==========
因为有两个页面表示,所以拼接历史消息页面的地址也应该改一下,但是目前即使客户端出现第二个页面表示,也可以发送第一个页面的链接地址,同样有效.
这两个程序的意思是:从队列表中读取下一个采集内容的信息,如果是历史消息页,则将biz拼接到地址中(注:评论区有些朋友认为key 和 pass_ticket 也需要拼接,但不需要),通过js输出到页面。如果下一项是文章,则将历史消息列表json中的文章地址直接输出为js。同理,文章内容的地址不收录uin、key等参数,由客户端自动补充。
这两个程序的细微差别是因为在读取历史消息页面的时候,anyproxy会同时做两件事情,一是把历史消息的json发送给服务器,二是获取链接地址到下一页。但是,这两个操作之间存在时间差。第一次读取下一页的地址时,应该已经获取到当前文章的第一个链接地址,但是此时历史消息的json还没有发送到服务器。,所以只能得到第二个历史消息页。读取第二个历史消息页后得到的下一页的地址是第一个的第一个文章的地址。当队列中还有一条记录时,需要获取下一个链接地址,否则如果队列为空再获取下一个链接地址,就会循环到上面提到的第一次读取。在这种情况下,会有两个历史消息列表,并穿插有文章采集。
刚才四个PHP程序提到了几个数据表,下面说说数据表是怎么设计的。这里只介绍一些主要领域。在实际应用中,会根据不同的程序添加其他必要的字段。
1、表格
CREATE TABLE “(`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) DEFAULT COMMENT 唯一 ID biz,`collect` int(11) DEFAULT 1 COMMENT记录采集时间的时间戳,PRIMARY KEY (`id`));
2、文章表格
CREATE TABLE `post` (`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT 文章对应的biz,`field_id` int (11) NOT NULL COMMENT 定义的 id,每个 文章 唯一,`title` varchar(255) NOT NULL DEFAULT COMMENT 文章 title, `title_encode` text CHARACTER SET utf8 NOT NULL COMMENT 文章 编码防止 文章 出现表情符号,`digest` varchar(500) NOT NULL DEFAULT COMMENT 文章digest,`content_url` varchar( 50< @0) CHARACTER SET utf8 NOT NULL COMMENT 文章Address,`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT 读取原地址,`cover` varchar(500)@ > CHARACTER SET utf8 NOT NULL COMMENT 封面图片,`is_multi` int(11)NOT NULL COMMENT 是多文本,`is_top` int(11) NOT NULL COMMENT 是标题,`datetime` int (11)NOT NULL COMMENT 文章Timestamp,`readNum` int (11) NOT NULL DEFAULT 1 COMMENT 文章Read amount,`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT 文章 Likes, PRIMARY KEY (`id`) ) ;
3、采集队列列表
CREATE TABLE `tmplist` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`content_url` varchar(255) DEFAULT NULL COMMENT 文章address,`load` int(1< @1) DEFAULT 0 COMMENT 阅读标记,主键(`id`),唯一键`content_url`(`content_url`));
以上是文章批量自动采集系统,由客户端、账号、anyproxy代理服务器、PHP程序、mysql数据库组成。
在下面的文章中,我将进一步详细介绍如何保存文章的内容,如何提高采集系统的稳定性,以及我在运行过程中获得的其他经验。系统。
持续更新,文章批量采集系统构建
文章采集的入口——历史新闻页面详解
文章页面分析和采集
提高文章采集的效率,anyproxy的高级用法 查看全部
文章采集程序(2019年10月28日更新:录制了一个YouTube视频)
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了步骤:
youtu.be/T-hVHJO0ya0
================================================
从2014年开始我就一直在做批量的内容采集,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集的内容很容易在里面传播。那个时候批量采集很容易做,采集入口就是历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而在本地新闻资讯类中定位采集,前端展示做成app。于是一个可以自动采集内容的新闻app就形成了。我曾经担心技术升级后的一天就无法采集内容了,我的新闻应用程序会失败。但随着技术的不断升级,采集的方法也不断升级,让我越来越自信。只要历史新闻页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个历史新闻页面的链接地址:
?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017 年 1 月 11 日更新==========
现在,根据不同的个人号码,会有两个不同的历史消息页地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的资料,两种页面形式不规则地以不同的编号出现,有的编号始终是第一页格式,有的始终是第二页格式。
上面的链接是历史新闻页面的真实链接,但是如果我们在浏览器中输入这个链接,会显示:请从客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一个链接//第二个 %2BeHsAqhbjJCwzTfV48u%2FCZRRGTmI8oqmHDxxfEL8ke%2B&_header=1
该地址是在客户端打开历史消息页面后,通过后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz是一个类似于id的参数,每个都有一个biz,目前这个biz会以极小概率发生变化的事件;
其余三个参数与用户的id和token相关,这三个参数的值在客户端生成后自动添加到地址栏。所以我们想通过客户端应用程序采集。在以前的版本中,这三个参数也可以在有效期内获取一次,然后多次使用。当前版本每次访问时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、客户端:可以是手机上安装的app,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios客户端的crash率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人号码:采集的内容不仅需要客户端,还需要采集专用的个人号码,因为这个号码不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将历史消息页面中的文章列表发送到自己的服务器上。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装客户端app,申请个人号,登陆app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。在 2016 年初开始使用带有 文章 的 https 链接。并且 Anyproxy 可以通过修改规则配置将脚本代码插入页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy –root(windows可能不需要sudo);————2019年10月28日更新:此行已过期!!!跳过这步
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或安卓模拟器中安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCrtFile,可以得到rootCA.crt文件方法二:启动anyproxy,:8002/qr_root可以得到证书路径的二维码,安装起来会更方便移动终端。将证书安装到手机中的代码。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开它,点击任何历史消息或文章,你可以看到响应码在终端滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。点击打开历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
以 /mp/getmasssendmsg 开头的 URL 是历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
部件号以/mp/getmasssendmsg开头的URL会有302跳转,跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改配置代理服务器,以便获取内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,同一个页面形式总是以不同的数字显示,但是为了兼容两种页面形式,下面的代码会保留对两种页面形式的判断。您也可以使用自己的页面表单。删除李
php 后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面,并返回显示})});}catch(e){//如果是以上正则不匹配,那么这个页面的内容可能是历史消息页面的第二页,因为历史消息的第一页是html格式,第二页是json格式。
try {var json = JSON.parse(serverResData.toString());if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数及以上后面定义一样,将第二页历史消息的json发送到自己的服务器} }catch(e){ console.log(e);//错误捕获}callback(serverResData);//直接返回前两页json内容}}}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为历史消息页时(第二页形式) try { var reg = /var msgList = \(.*?)\;/;//定义历史消息的正则匹配规则(不同于第一页形式) var ret = reg.exec(serverResData.toString()); //转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数后面定义,
getHis.php的原理后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入历史消息页面,返回显示})});}catch(e){callback(serverResData); }}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二页下页后的jsontry表示{var json = JSON.parse(serverResData.toString( ));if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数后面定义如上,发送第二页历史消息的json到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址是 文章 阅读并喜欢尝试 {HttpPost(serverResData,req.url,"getMsgExt.php");
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。使用此原理来批量 采集 内容和读取量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//向服务器发送json,str为json内容,url为历史消息页地址,path为接收程序的路径和文件名 var http = require( http);var data = {str: encodeURIComponent(str),url: encodeURIComponent(url)};content = require(querystring).stringify(data);var options = {method: "POST",host: "",/ /注意不是,这是服务器的域名。port: 80,path: path,//接收程序头的路径和文件名:{Content-Type: application/x-www-form-urlencoded; charset=UTF-8,"Content-Length": content.length} };var req = http.request(options, function (res) {res.setEncoding(utf8);res.on(data, function (chunk) {console.log(BODY: + chunk);}) ;});req.on(error, function (e) {console.log(problem with request: + e.message);});
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getHis.php、getPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){var newOption = option;if(/google/i.test(newOption.headers.host)){newOption.hostname = "";newOption.port = "80";}return newOption; },
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
再次重申,代码只是一个原则,部分观看代码需要自己编写。
2、getMsgExt.php 程序获取文章 浏览量和点赞
3、getHis.php和getPost.php这两个程序类似,一起介绍
=========2017 年 1 月 11 日更新==========
因为有两个页面表示,所以拼接历史消息页面的地址也应该改一下,但是目前即使客户端出现第二个页面表示,也可以发送第一个页面的链接地址,同样有效.
这两个程序的意思是:从队列表中读取下一个采集内容的信息,如果是历史消息页,则将biz拼接到地址中(注:评论区有些朋友认为key 和 pass_ticket 也需要拼接,但不需要),通过js输出到页面。如果下一项是文章,则将历史消息列表json中的文章地址直接输出为js。同理,文章内容的地址不收录uin、key等参数,由客户端自动补充。
这两个程序的细微差别是因为在读取历史消息页面的时候,anyproxy会同时做两件事情,一是把历史消息的json发送给服务器,二是获取链接地址到下一页。但是,这两个操作之间存在时间差。第一次读取下一页的地址时,应该已经获取到当前文章的第一个链接地址,但是此时历史消息的json还没有发送到服务器。,所以只能得到第二个历史消息页。读取第二个历史消息页后得到的下一页的地址是第一个的第一个文章的地址。当队列中还有一条记录时,需要获取下一个链接地址,否则如果队列为空再获取下一个链接地址,就会循环到上面提到的第一次读取。在这种情况下,会有两个历史消息列表,并穿插有文章采集。
刚才四个PHP程序提到了几个数据表,下面说说数据表是怎么设计的。这里只介绍一些主要领域。在实际应用中,会根据不同的程序添加其他必要的字段。
1、表格
CREATE TABLE “(`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) DEFAULT COMMENT 唯一 ID biz,`collect` int(11) DEFAULT 1 COMMENT记录采集时间的时间戳,PRIMARY KEY (`id`));
2、文章表格
CREATE TABLE `post` (`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT 文章对应的biz,`field_id` int (11) NOT NULL COMMENT 定义的 id,每个 文章 唯一,`title` varchar(255) NOT NULL DEFAULT COMMENT 文章 title, `title_encode` text CHARACTER SET utf8 NOT NULL COMMENT 文章 编码防止 文章 出现表情符号,`digest` varchar(500) NOT NULL DEFAULT COMMENT 文章digest,`content_url` varchar( 50< @0) CHARACTER SET utf8 NOT NULL COMMENT 文章Address,`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT 读取原地址,`cover` varchar(500)@ > CHARACTER SET utf8 NOT NULL COMMENT 封面图片,`is_multi` int(11)NOT NULL COMMENT 是多文本,`is_top` int(11) NOT NULL COMMENT 是标题,`datetime` int (11)NOT NULL COMMENT 文章Timestamp,`readNum` int (11) NOT NULL DEFAULT 1 COMMENT 文章Read amount,`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT 文章 Likes, PRIMARY KEY (`id`) ) ;
3、采集队列列表
CREATE TABLE `tmplist` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`content_url` varchar(255) DEFAULT NULL COMMENT 文章address,`load` int(1< @1) DEFAULT 0 COMMENT 阅读标记,主键(`id`),唯一键`content_url`(`content_url`));
以上是文章批量自动采集系统,由客户端、账号、anyproxy代理服务器、PHP程序、mysql数据库组成。
在下面的文章中,我将进一步详细介绍如何保存文章的内容,如何提高采集系统的稳定性,以及我在运行过程中获得的其他经验。系统。
持续更新,文章批量采集系统构建
文章采集的入口——历史新闻页面详解
文章页面分析和采集
提高文章采集的效率,anyproxy的高级用法
文章采集程序(共享一下我的采集代码!思路:采集程序的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-01 07:19
2021-09-19
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里,第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = \"gameswf\/(.*?)\.swf\";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fope。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。
分类:
技术要点:
相关文章: 查看全部
文章采集程序(共享一下我的采集代码!思路:采集程序的思路)
2021-09-19
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里,第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = \"gameswf\/(.*?)\.swf\";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fope。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。
分类:
技术要点:
相关文章:
文章采集程序(零门槛使用无需采集器打磨集搜客GooSeeker技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-31 06:06
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年在互联网数据采集软件排行榜中排名第一。自2016年起,优采云积极开拓海外市场,分别在美国和日本推出数据爬虫平台Octoparse和Octoparse.jp。截至 2019 年,优采云全球用户超过 150 万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
国内老牌data采集软件以灵活的配置和强大的性能领先于国内同类产品,得到了众多用户的一致认可。使用优采云采集器几乎所有的网页和任何格式的文件,不管是什么语言或编码。采集7 倍于普通 采集器,采集/posting 与复制/粘贴一样准确。同时,软件还拥有“舆情雷达监测测控系统”,能够准确监测网络数据的信息安全,及时对不利或危险信息进行预警和处理。
如果买友网小编推荐一款信息最有用的采集软件,那一定是优采云采集器。优采云采集器原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键式采集;并且软件支持Linux、Windows和Mac三种操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,与其他同类软件相比,仅此一项就足够良心了。
经过十多年的打磨,GooSeeker 是一款易用性也非常出色的数据采集软件。它的特点是对所有可用数据进行可视化标注,用户不需要程序思维或技术基础,只需点击想要的内容,给标签起个名字,软件就会自动对选中的数据进行管理。内容,自动采集到排序框,并保存为xml或excel结构。此外,软件还具备模板资源申请、会员互助抓拍、手机网站数据抓拍、定时自启动采集等功能。
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章的内容抓取,通过相关配置,您可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让你的采集更加强大。
英国市场最著名的采集器之一,由英国伦敦的一家公司开发,现已在美国、印度等地设立分公司。import.io 作为网页数据采集 软件,具有四大功能特性,即Magic、Extractor、Crawler、Connector。主要功能一应俱全,但最吸引眼球、最好的功能就是其中的“魔法”,该功能允许用户只进入一个网页并自动提取数据,无需任何其他设置,使用起来极其简单。
ForeSpider也是一款操作简单,深受用户推荐的信息采集软件。它分为免费版和付费版。具有可视化向导式操作界面,日志管理和异常情况预警,免安装免安装数据库,可自动识别语义过滤数据,智能挖掘文本特征数据,自带多种数据清洗方式和可视化图表分析. 软件免费版、基础版、专业版采集速度可达400万件/天,服务器版采集速度可达8000万件/天,并提供生成采集的服务。
优采云是应用最广泛的信息采集软件之一,它封装了复杂的算法和分布式逻辑,并提供了灵活简单的开发接口;应用自动分布式部署,可视化操作简单,弹性扩展计算和存储资源;对不同来源的数据进行统一可视化管理,RESTful接口/webhook push/graphql访问等高级功能让用户无缝连接现有系统。该软件现在提供企业标准版、高级版和企业定制版。
ParseHub 是一个基于 Web 的爬虫客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制从 网站 分析获取数据。它还可以使用机器学习技术识别复杂的文档,并以 JSON、CSV 等格式导出文件。软件支持可用于 Windows、Mac 和 Linux,或作为 Firefox 扩展。此外,它还具有一些高级功能,如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
Content Grabber 是一个可视化网络数据采集软件和网络自动化工具,支持智能抓取,从几乎任何网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。您可以使用 C# 或 VB.NET 来调试或编写脚本来控制爬虫。它还支持向爬虫工具添加第三方扩展。凭借一整套功能,Content Grabber 对于有技术基础的用户来说非常强大。 查看全部
文章采集程序(零门槛使用无需采集器打磨集搜客GooSeeker技术)
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年在互联网数据采集软件排行榜中排名第一。自2016年起,优采云积极开拓海外市场,分别在美国和日本推出数据爬虫平台Octoparse和Octoparse.jp。截至 2019 年,优采云全球用户超过 150 万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
国内老牌data采集软件以灵活的配置和强大的性能领先于国内同类产品,得到了众多用户的一致认可。使用优采云采集器几乎所有的网页和任何格式的文件,不管是什么语言或编码。采集7 倍于普通 采集器,采集/posting 与复制/粘贴一样准确。同时,软件还拥有“舆情雷达监测测控系统”,能够准确监测网络数据的信息安全,及时对不利或危险信息进行预警和处理。
如果买友网小编推荐一款信息最有用的采集软件,那一定是优采云采集器。优采云采集器原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键式采集;并且软件支持Linux、Windows和Mac三种操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,与其他同类软件相比,仅此一项就足够良心了。
经过十多年的打磨,GooSeeker 是一款易用性也非常出色的数据采集软件。它的特点是对所有可用数据进行可视化标注,用户不需要程序思维或技术基础,只需点击想要的内容,给标签起个名字,软件就会自动对选中的数据进行管理。内容,自动采集到排序框,并保存为xml或excel结构。此外,软件还具备模板资源申请、会员互助抓拍、手机网站数据抓拍、定时自启动采集等功能。
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章的内容抓取,通过相关配置,您可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让你的采集更加强大。
英国市场最著名的采集器之一,由英国伦敦的一家公司开发,现已在美国、印度等地设立分公司。import.io 作为网页数据采集 软件,具有四大功能特性,即Magic、Extractor、Crawler、Connector。主要功能一应俱全,但最吸引眼球、最好的功能就是其中的“魔法”,该功能允许用户只进入一个网页并自动提取数据,无需任何其他设置,使用起来极其简单。
ForeSpider也是一款操作简单,深受用户推荐的信息采集软件。它分为免费版和付费版。具有可视化向导式操作界面,日志管理和异常情况预警,免安装免安装数据库,可自动识别语义过滤数据,智能挖掘文本特征数据,自带多种数据清洗方式和可视化图表分析. 软件免费版、基础版、专业版采集速度可达400万件/天,服务器版采集速度可达8000万件/天,并提供生成采集的服务。
优采云是应用最广泛的信息采集软件之一,它封装了复杂的算法和分布式逻辑,并提供了灵活简单的开发接口;应用自动分布式部署,可视化操作简单,弹性扩展计算和存储资源;对不同来源的数据进行统一可视化管理,RESTful接口/webhook push/graphql访问等高级功能让用户无缝连接现有系统。该软件现在提供企业标准版、高级版和企业定制版。
ParseHub 是一个基于 Web 的爬虫客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制从 网站 分析获取数据。它还可以使用机器学习技术识别复杂的文档,并以 JSON、CSV 等格式导出文件。软件支持可用于 Windows、Mac 和 Linux,或作为 Firefox 扩展。此外,它还具有一些高级功能,如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
Content Grabber 是一个可视化网络数据采集软件和网络自动化工具,支持智能抓取,从几乎任何网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。您可以使用 C# 或 VB.NET 来调试或编写脚本来控制爬虫。它还支持向爬虫工具添加第三方扩展。凭借一整套功能,Content Grabber 对于有技术基础的用户来说非常强大。
文章采集程序在实现图片爬虫时使用python语言的通用库urllib
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-03 07:01
文章采集程序在实现图片爬虫时使用python语言的通用库urllib这个库。其中,requests库、urllib库都具有可以提供服务器发送请求和接受请求的功能。本文将对urllib库进行详细的介绍,并对不同的安装方式及其他安装方式进行介绍。
1、requests库使用:①、requests库主要是用来处理http请求的,处理原理是通过字典方式来定义请求对象(request)。
request会有类似如下方式构造:②、用requests库爬取图片,使用路径:pages。select('/');③、使用requests库爬取地图:pages。select('/');④、使用requests库爬取天气:pages。select('/');urllib库使用方法都一样,所以打开登录后可以直接写testcoder包直接使用urllib库导入:fromurllibimportrequest,urlopenfromrequests。
exceptionsimportrequestexceptionfromurllib。httpimporthttprequest。authenticate('0')#。
1、request=request(url='',data=['code','id'])urlopen=urlopen(request).read().decode('gbk')#
2、urlopen=urlopen(request).read().decode('gbk')#
3、urlopen=urlopen(request).read().decode('utf-8')#
4、urlopen=urlopen(request).read().decode('utf-8')#①request.authenticate('0')#采用的是向http请求传递的格式,属于字典模式,requestauthenticate('0')设定了代理主机名/端口号,设定代理主机名称为可以任意,只要是相同类型的主机名均可request.authenticate('0')设定了代理主机名称。
默认设定为可以为主机名称大写:request.authenticate('0')。如果要设定主机名,需要添加关键字作为作为注释并传入:request.authenticate('0')。urlopen=urlopen(request).read().decode('gbk')#③urlopen=urlopen(request).read().decode('gbk')#④urlopen=urlopen(request).read().decode('gbk')#⑤urlopen=urlopen(request).read().decode('gbk')#⑥urlopen=urlopen(request).read().decode('gbk')#request.authenticate('0'),urlopen=request.authenticate('0'),urlopen=request.authenticate('0')urlopen():处理所有http请求urlopen():查看当前处理的http请求的headers头部urlopen():查看当前处理的http请求的头。 查看全部
文章采集程序在实现图片爬虫时使用python语言的通用库urllib
文章采集程序在实现图片爬虫时使用python语言的通用库urllib这个库。其中,requests库、urllib库都具有可以提供服务器发送请求和接受请求的功能。本文将对urllib库进行详细的介绍,并对不同的安装方式及其他安装方式进行介绍。
1、requests库使用:①、requests库主要是用来处理http请求的,处理原理是通过字典方式来定义请求对象(request)。
request会有类似如下方式构造:②、用requests库爬取图片,使用路径:pages。select('/');③、使用requests库爬取地图:pages。select('/');④、使用requests库爬取天气:pages。select('/');urllib库使用方法都一样,所以打开登录后可以直接写testcoder包直接使用urllib库导入:fromurllibimportrequest,urlopenfromrequests。
exceptionsimportrequestexceptionfromurllib。httpimporthttprequest。authenticate('0')#。
1、request=request(url='',data=['code','id'])urlopen=urlopen(request).read().decode('gbk')#
2、urlopen=urlopen(request).read().decode('gbk')#
3、urlopen=urlopen(request).read().decode('utf-8')#
4、urlopen=urlopen(request).read().decode('utf-8')#①request.authenticate('0')#采用的是向http请求传递的格式,属于字典模式,requestauthenticate('0')设定了代理主机名/端口号,设定代理主机名称为可以任意,只要是相同类型的主机名均可request.authenticate('0')设定了代理主机名称。
默认设定为可以为主机名称大写:request.authenticate('0')。如果要设定主机名,需要添加关键字作为作为注释并传入:request.authenticate('0')。urlopen=urlopen(request).read().decode('gbk')#③urlopen=urlopen(request).read().decode('gbk')#④urlopen=urlopen(request).read().decode('gbk')#⑤urlopen=urlopen(request).read().decode('gbk')#⑥urlopen=urlopen(request).read().decode('gbk')#request.authenticate('0'),urlopen=request.authenticate('0'),urlopen=request.authenticate('0')urlopen():处理所有http请求urlopen():查看当前处理的http请求的headers头部urlopen():查看当前处理的http请求的头。
文章采集程序(Python编程语言Scrapy爬虫爬虫框架介绍及学习方法介绍-小编 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-19 06:31
)
今天给大家详细讲解一下Scrapy爬虫框架,希望对大家的学习有所帮助。
1、Scrapy 爬虫框架
Scrapy是一个用Python编程语言编写的爬虫框架,任何人都可以根据自己的需要进行修改,使用起来非常方便。可应用于数据采集、数据挖掘、异常网络用户检测、数据存储等。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下图所示。
Scrapy爬虫框架
2、从上图可以看出,Scrapy爬虫框架主要由5部分组成,分别是:Scrapy Engine(Scrapy Engine)、Scheduler(调度器)、Downloader(Downloader)、Spiders(Spider)、Item管道(项目管道)。爬取过程是Scrapy引擎发送请求,然后调度器将初始URL发送给下载器,然后下载器向服务器发送服务请求。得到响应后,将下载的网页内容交给spider处理,然后spider会对网页进行细化。分析。爬虫分析的结果有两种:一种是获取到新的URL,然后再次请求调度器,开始新一轮的爬取,重复上述过程;另一种是获取所需的数据,稍后将继续处理到项目管道。项目管道负责数据清洗、校验、过滤、去重、存储等后处理,最终由管道输出到文件或存储到数据库中。
3、这五个组件及其中间件的作用如下:
1) Scrapy引擎:控制整个系统的数据处理过程,触发事务处理过程,负责连接各个模块
2) 调度程序:维护要抓取的 URL 队列。当引擎发送的请求被接受后,将从待抓取的 URL 队列中取出下一个 URL,并返回给调度器。
3) Downloader(下载器):向web服务器发送请求下载页面,用于下载网页内容,并将网页内容交给spider处理。
4)蜘蛛:制定要爬取的网站地址,选择需要的数据内容,定义域名过滤规则和网页解析规则等。
5) 项目管道:处理蜘蛛从网页中提取的数据。主要任务是清理、验证、过滤、去重和存储数据。
6) 中间件:中间件是Scrapy引擎与Scheduler、Downloader、Spiders之间的一个组件,主要处理它们之间的请求和响应。
Scrapy爬虫框架可以轻松完成在线数据的采集工作,简单轻量,使用非常方便。
4、 基于Scrapy的网络爬虫设计与实现
本节在了解Scrapy爬虫原理和框架的基础上,简单介绍一下Scrapy爬虫框架的data采集流程。
4.1 创建爬虫项目文件
基于scrapy爬虫框架,只需在命令行输入“scrapy startproject article”命令,就会自动创建一个名为article的爬虫项目。先进入文章文件夹,输入命令“cd article”,然后通过“dir”查看目录,也可以通过“tree /f”生成文件目录的树形结构,如下图,你可以清楚地看到 Scrapy 创建命令生成的文件。
爬虫项目目录结构
最上层的article文件夹是项目名称,第二层收录一个与项目名称同名的文件夹article和一个文件scrapy.cfg。这个与项目同名的文件夹文章是一个模块,所有项目代码都在这个模块中添加,scrapy.cfg文件是整个Scrapy项目的配置文件。第三层有5个文件和一个文件夹,其中__init__.py为空文件,用于将其父目录转为模块;items.py 是定义存储对象并决定要抓取哪些项目的文件;middlewares .py 文件是中间件,一般不需要修改。主要负责相关组件之间的请求和响应;pipelines.py 是一个管道文件,它决定了如何处理和存储爬取的数据;settings.py为工程设置文件,设置工程管道数据的处理方式、爬虫频率、表名等;在 spiders 文件夹中放置了爬虫主文件(用于实现爬虫逻辑)和一个空的 __init__.py 文件。
4.2 之后,开始分析网页结构和数据,修改Items.py文件,编写hangyunSpider.py文件,修改pipelines.py文件,修改settings.py文件。这些步骤的具体操作后面会进行文章专门展开,这里不再赘述。
4.3 执行爬虫
修改以上四个文件后,在Windows命令窗口输入cmd命令进入爬虫所在路径,执行“scrapy爬虫文章”命令,这样爬虫程序就可以运行了,最后得到数据保存到本地磁盘。
5、 结论
随着互联网上信息量的不断增加,使用网络爬虫工具获取所需信息肯定会有用。使用开源的Scrapy爬虫框架,不仅可以实现对网络信息的高效、准确、自动获取,还可以帮助研究人员对采集获得的数据进行后续的挖掘和分析。
查看全部
文章采集程序(Python编程语言Scrapy爬虫爬虫框架介绍及学习方法介绍-小编
)
今天给大家详细讲解一下Scrapy爬虫框架,希望对大家的学习有所帮助。
1、Scrapy 爬虫框架
Scrapy是一个用Python编程语言编写的爬虫框架,任何人都可以根据自己的需要进行修改,使用起来非常方便。可应用于数据采集、数据挖掘、异常网络用户检测、数据存储等。
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体架构大致如下图所示。
Scrapy爬虫框架
2、从上图可以看出,Scrapy爬虫框架主要由5部分组成,分别是:Scrapy Engine(Scrapy Engine)、Scheduler(调度器)、Downloader(Downloader)、Spiders(Spider)、Item管道(项目管道)。爬取过程是Scrapy引擎发送请求,然后调度器将初始URL发送给下载器,然后下载器向服务器发送服务请求。得到响应后,将下载的网页内容交给spider处理,然后spider会对网页进行细化。分析。爬虫分析的结果有两种:一种是获取到新的URL,然后再次请求调度器,开始新一轮的爬取,重复上述过程;另一种是获取所需的数据,稍后将继续处理到项目管道。项目管道负责数据清洗、校验、过滤、去重、存储等后处理,最终由管道输出到文件或存储到数据库中。
3、这五个组件及其中间件的作用如下:
1) Scrapy引擎:控制整个系统的数据处理过程,触发事务处理过程,负责连接各个模块
2) 调度程序:维护要抓取的 URL 队列。当引擎发送的请求被接受后,将从待抓取的 URL 队列中取出下一个 URL,并返回给调度器。
3) Downloader(下载器):向web服务器发送请求下载页面,用于下载网页内容,并将网页内容交给spider处理。
4)蜘蛛:制定要爬取的网站地址,选择需要的数据内容,定义域名过滤规则和网页解析规则等。
5) 项目管道:处理蜘蛛从网页中提取的数据。主要任务是清理、验证、过滤、去重和存储数据。
6) 中间件:中间件是Scrapy引擎与Scheduler、Downloader、Spiders之间的一个组件,主要处理它们之间的请求和响应。
Scrapy爬虫框架可以轻松完成在线数据的采集工作,简单轻量,使用非常方便。
4、 基于Scrapy的网络爬虫设计与实现
本节在了解Scrapy爬虫原理和框架的基础上,简单介绍一下Scrapy爬虫框架的data采集流程。
4.1 创建爬虫项目文件
基于scrapy爬虫框架,只需在命令行输入“scrapy startproject article”命令,就会自动创建一个名为article的爬虫项目。先进入文章文件夹,输入命令“cd article”,然后通过“dir”查看目录,也可以通过“tree /f”生成文件目录的树形结构,如下图,你可以清楚地看到 Scrapy 创建命令生成的文件。
爬虫项目目录结构
最上层的article文件夹是项目名称,第二层收录一个与项目名称同名的文件夹article和一个文件scrapy.cfg。这个与项目同名的文件夹文章是一个模块,所有项目代码都在这个模块中添加,scrapy.cfg文件是整个Scrapy项目的配置文件。第三层有5个文件和一个文件夹,其中__init__.py为空文件,用于将其父目录转为模块;items.py 是定义存储对象并决定要抓取哪些项目的文件;middlewares .py 文件是中间件,一般不需要修改。主要负责相关组件之间的请求和响应;pipelines.py 是一个管道文件,它决定了如何处理和存储爬取的数据;settings.py为工程设置文件,设置工程管道数据的处理方式、爬虫频率、表名等;在 spiders 文件夹中放置了爬虫主文件(用于实现爬虫逻辑)和一个空的 __init__.py 文件。
4.2 之后,开始分析网页结构和数据,修改Items.py文件,编写hangyunSpider.py文件,修改pipelines.py文件,修改settings.py文件。这些步骤的具体操作后面会进行文章专门展开,这里不再赘述。
4.3 执行爬虫
修改以上四个文件后,在Windows命令窗口输入cmd命令进入爬虫所在路径,执行“scrapy爬虫文章”命令,这样爬虫程序就可以运行了,最后得到数据保存到本地磁盘。
5、 结论
随着互联网上信息量的不断增加,使用网络爬虫工具获取所需信息肯定会有用。使用开源的Scrapy爬虫框架,不仅可以实现对网络信息的高效、准确、自动获取,还可以帮助研究人员对采集获得的数据进行后续的挖掘和分析。
文章采集程序(Java编写的系统能够每秒可以访问几十万个网页的分布式网络爬虫系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-17 09:21
在大数据时代,数据采集或网络爬虫似乎是每个程序员必备的技能。一般来说,工程师会通过Python爬虫框架快速编写爬虫程序来抓取网页数据。当规模数据采集不是一个简单的爬虫。比如分布式爬虫系统为我们的舆情系统(/stonedtx/yuqing)和开源情报系统(/stonedtx/open-source-intelligence)提供了大量的数据支持。
在这里,给大家介绍一个每秒可以访问几十万网页的Java编写的分布式网络爬虫系统!
在本期文章中,我将与大家分享我们多年来在爬虫构建和优化方面的经验和教训。
这就是我们大型分布式爬虫系统的系统(操作界面),我们称自己为:爬虫工厂。
这就是我们即将推出的“开源智能”系统中的“数据管理”(数据中心)子系统。
通过这么多项目的实战经验和经验,以及与市场和客户的不断碰撞,造就了我们强大的数据采集能力。
一、编程语言
在为项目选择编程语言时,许多因素会影响我们的最终决定。中间我们尝试了python和Go中的爬虫和分布式爬虫方案。我们在内部专业知识、生态系统等方面寻找“完美”的编程语言解决方案。最终,我们决定 Java 是我们的最佳选择,原因如下:
1.内部专长:我们的团队成员拥有丰富的Java专业知识,有数位Java开发“老司机”在分布式系统和网络方面有10年、15年、20年的经验他在分布式系统和网络开发方面有丰富的实践经验高并发和海量数据存储。
2.现有的软件框架:大型网络爬虫需要建立在经过验证的、健壮的、可扩展的和安全的网络、系统和实用程序模块上。Java 拥有最活跃的开源生态系统,尤其是在网络和分布式应用程序方面。Netty、SpringBoot、Google Guava 等包证明了 Java 生态系统拥有高质量的开源模块。
3.现有的项目集成:Hadoop、Cassandra、Kafka、Elasticsearch 都是用 Java 开发的大型分布式系统项目,因为这个生态系统给我们带来了丰富而强大的基础以及灵感和先例。这使得在 Java 中开发高性能数据驱动应用程序的过程更容易、更实惠。
4.Java的动态语言:动态语言用于我们最新的分布式爬虫系统。我们通过模板生成动态语言代码并存储在 MySQL 中,让大量爬虫可视化和低代码化。大大降低了维护成本和爬虫开发成本。
5.原创性能和可靠性:在性能和可靠性方面,Java 具有静态类型、健壮的垃圾采集和久经考验的虚拟机等最重要的特性。
在核心网络爬虫引擎用 Java 编写的同时,我们还使用 Python 和 Node.js 等其他语言编写子系统,用于自然语言处理、深度学习算法、监控、报告和管道的其他部分。
我们的分布式爬虫集群采用单点无架构,将工作负载拆分并分布在独立的无状态节点上,可以消除大规模分布式系统中的灾难(单点故障)。此外,该架构允许我们逐个节点更新和升级底层软件,而不会中断整个操作。
二、请求率和访问安全
网站 主要是为人工访问而设计的,普通用户每分钟只能浏览几页。网络爬虫每秒可以访问数千甚至数百万的网页,所以如果不小心,网络爬虫很容易在短时间内耗尽网站资源,造成毁灭性的后果。另外,普通的 网站 会有多个机器人同时抓取,所以问题会被放大。
因此,限制自己的请求率也是每个网络爬虫的责任,也就是说,保证两次连续访问之间有适当的延迟,这个工作一定不能容忍错误,否则请求网站而且本身会产生不利的反应。
三、缓存为王
在构建大规模分布式数据应用系统的情况下,系统缓存是必不可少的,尤其是在网络输入输出频繁、开销较大的情况下。
例如场景一:在大规模网页爬取的情况下,为了避免重复的数据爬取和后续的重复数据处理,需要对每个URL进行获取和存储。因此,您需要构建一个分布式预读缓存,可以保存并定期更新数百万个网站 数亿个 URL 地址。
比如场景2:减少dns请求,提升data采集的性能。对于绝大多数 URL,您需要执行至少一个 DNS 解析才能下载,每秒添加数千个查询。因此,DNS 服务器势必会限制您的访问,或在重负载下崩溃。无论哪种情况,爬虫都会停止,唯一的解决办法就是尽可能缓存DNS解析结果,尽量减少不必要的查询。
四、解析 HTML
爬虫的基本任务之一是从它访问的每个页面中提取它需要的数据。在大规模数据抓取的情况下,最好有一个高性能的 HTML 解析器,因为您需要提取大量链接和元数据。大多数 HTML 解析库优先考虑简单性、易用性和多功能性,这通常是正确的设计。由于我们需要高速链接提取,我们最终决定编写自己的解析器,针对查找链接和一些原创 DOM 查询功能进行了优化。HTML 解析器还需要有弹性、经过全面测试,并且能够处理出现的大量异常,因为并非每个 HTML 文档都是有效的。
我们目前即将开源data采集系统,集成了微软开源playwright()的js渲染解析引擎。这样,我们在开发爬虫的过程中,就不需要考虑js网页数据的问题,大大提高了我们网站爬虫的开发效率。
五、网络和系统优化
通常操作系统的默认配置无法处理大型网络爬虫的网络需求。通常,我们需要优化操作系统的网络堆栈,以根据具体情况最大限度地发挥其潜力。对于大型网络爬虫来说,优化的目标是最大化吞吐量和打开的连接数。
以下是我们经常遇到并需要优化的问题和场景:
1.Linux系统性能参数
什么工具用于一般的 Linux 性能调优?- 知乎
2.Web服务器性能优化
Java web 服务器性能优化策略?- 知乎
3.Java JVM 性能优化
用于 Java 性能优化的 JVM GC(垃圾采集机制) - 知乎
开源项目地址: 查看全部
文章采集程序(Java编写的系统能够每秒可以访问几十万个网页的分布式网络爬虫系统)
在大数据时代,数据采集或网络爬虫似乎是每个程序员必备的技能。一般来说,工程师会通过Python爬虫框架快速编写爬虫程序来抓取网页数据。当规模数据采集不是一个简单的爬虫。比如分布式爬虫系统为我们的舆情系统(/stonedtx/yuqing)和开源情报系统(/stonedtx/open-source-intelligence)提供了大量的数据支持。
在这里,给大家介绍一个每秒可以访问几十万网页的Java编写的分布式网络爬虫系统!
在本期文章中,我将与大家分享我们多年来在爬虫构建和优化方面的经验和教训。
这就是我们大型分布式爬虫系统的系统(操作界面),我们称自己为:爬虫工厂。
这就是我们即将推出的“开源智能”系统中的“数据管理”(数据中心)子系统。
通过这么多项目的实战经验和经验,以及与市场和客户的不断碰撞,造就了我们强大的数据采集能力。
一、编程语言
在为项目选择编程语言时,许多因素会影响我们的最终决定。中间我们尝试了python和Go中的爬虫和分布式爬虫方案。我们在内部专业知识、生态系统等方面寻找“完美”的编程语言解决方案。最终,我们决定 Java 是我们的最佳选择,原因如下:
1.内部专长:我们的团队成员拥有丰富的Java专业知识,有数位Java开发“老司机”在分布式系统和网络方面有10年、15年、20年的经验他在分布式系统和网络开发方面有丰富的实践经验高并发和海量数据存储。
2.现有的软件框架:大型网络爬虫需要建立在经过验证的、健壮的、可扩展的和安全的网络、系统和实用程序模块上。Java 拥有最活跃的开源生态系统,尤其是在网络和分布式应用程序方面。Netty、SpringBoot、Google Guava 等包证明了 Java 生态系统拥有高质量的开源模块。
3.现有的项目集成:Hadoop、Cassandra、Kafka、Elasticsearch 都是用 Java 开发的大型分布式系统项目,因为这个生态系统给我们带来了丰富而强大的基础以及灵感和先例。这使得在 Java 中开发高性能数据驱动应用程序的过程更容易、更实惠。
4.Java的动态语言:动态语言用于我们最新的分布式爬虫系统。我们通过模板生成动态语言代码并存储在 MySQL 中,让大量爬虫可视化和低代码化。大大降低了维护成本和爬虫开发成本。
5.原创性能和可靠性:在性能和可靠性方面,Java 具有静态类型、健壮的垃圾采集和久经考验的虚拟机等最重要的特性。
在核心网络爬虫引擎用 Java 编写的同时,我们还使用 Python 和 Node.js 等其他语言编写子系统,用于自然语言处理、深度学习算法、监控、报告和管道的其他部分。
我们的分布式爬虫集群采用单点无架构,将工作负载拆分并分布在独立的无状态节点上,可以消除大规模分布式系统中的灾难(单点故障)。此外,该架构允许我们逐个节点更新和升级底层软件,而不会中断整个操作。
二、请求率和访问安全
网站 主要是为人工访问而设计的,普通用户每分钟只能浏览几页。网络爬虫每秒可以访问数千甚至数百万的网页,所以如果不小心,网络爬虫很容易在短时间内耗尽网站资源,造成毁灭性的后果。另外,普通的 网站 会有多个机器人同时抓取,所以问题会被放大。
因此,限制自己的请求率也是每个网络爬虫的责任,也就是说,保证两次连续访问之间有适当的延迟,这个工作一定不能容忍错误,否则请求网站而且本身会产生不利的反应。
三、缓存为王
在构建大规模分布式数据应用系统的情况下,系统缓存是必不可少的,尤其是在网络输入输出频繁、开销较大的情况下。
例如场景一:在大规模网页爬取的情况下,为了避免重复的数据爬取和后续的重复数据处理,需要对每个URL进行获取和存储。因此,您需要构建一个分布式预读缓存,可以保存并定期更新数百万个网站 数亿个 URL 地址。
比如场景2:减少dns请求,提升data采集的性能。对于绝大多数 URL,您需要执行至少一个 DNS 解析才能下载,每秒添加数千个查询。因此,DNS 服务器势必会限制您的访问,或在重负载下崩溃。无论哪种情况,爬虫都会停止,唯一的解决办法就是尽可能缓存DNS解析结果,尽量减少不必要的查询。
四、解析 HTML
爬虫的基本任务之一是从它访问的每个页面中提取它需要的数据。在大规模数据抓取的情况下,最好有一个高性能的 HTML 解析器,因为您需要提取大量链接和元数据。大多数 HTML 解析库优先考虑简单性、易用性和多功能性,这通常是正确的设计。由于我们需要高速链接提取,我们最终决定编写自己的解析器,针对查找链接和一些原创 DOM 查询功能进行了优化。HTML 解析器还需要有弹性、经过全面测试,并且能够处理出现的大量异常,因为并非每个 HTML 文档都是有效的。
我们目前即将开源data采集系统,集成了微软开源playwright()的js渲染解析引擎。这样,我们在开发爬虫的过程中,就不需要考虑js网页数据的问题,大大提高了我们网站爬虫的开发效率。
五、网络和系统优化
通常操作系统的默认配置无法处理大型网络爬虫的网络需求。通常,我们需要优化操作系统的网络堆栈,以根据具体情况最大限度地发挥其潜力。对于大型网络爬虫来说,优化的目标是最大化吞吐量和打开的连接数。
以下是我们经常遇到并需要优化的问题和场景:
1.Linux系统性能参数
什么工具用于一般的 Linux 性能调优?- 知乎
2.Web服务器性能优化
Java web 服务器性能优化策略?- 知乎
3.Java JVM 性能优化
用于 Java 性能优化的 JVM GC(垃圾采集机制) - 知乎
开源项目地址:
文章采集程序( dedecms自动生成tagtag建站服务器源码_PHP开发+APP+采集接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-16 19:37
dedecms自动生成tagtag建站服务器源码_PHP开发+APP+采集接口)
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
dedecms如何自动生成标签
本站建站服务器文章与大家分享dedecms如何自动生成标签的内容。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
Python自动采集入库
总结:本脚本可用于采集百度股评实现自动更新功能,使用phpcms。. .
老Y文章管理系统采集自动伪原创说明
作为垃圾站站长,最有希望的是网站可以自动采集,自动完成伪原创,然后自动收钱,这真的是世界上最幸福的事情了, 呵呵 。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。旧的Y文章管理系统使用简单方便,虽然功能不如
小站长说说网站自动采集和原创的优缺点
众所周知,自动采集软件自发明以来,一直是无数草根站长必备的建站工具之一。刚建了一个新站,但是好像空荡荡的,短时间内不可能出一个有钱的原创,除非你是第五个钻石王,请专业人士投票原创。一个人的精力是有限的,只能依靠自动采集工具。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
如何使用免费的网站源代码
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
如何使用cms系统标签自动获取长尾关键词排名
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长经常使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他 查看全部
文章采集程序(
dedecms自动生成tagtag建站服务器源码_PHP开发+APP+采集接口)
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
dedecms如何自动生成标签
本站建站服务器文章与大家分享dedecms如何自动生成标签的内容。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
Python自动采集入库
总结:本脚本可用于采集百度股评实现自动更新功能,使用phpcms。. .
老Y文章管理系统采集自动伪原创说明
作为垃圾站站长,最有希望的是网站可以自动采集,自动完成伪原创,然后自动收钱,这真的是世界上最幸福的事情了, 呵呵 。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。旧的Y文章管理系统使用简单方便,虽然功能不如
小站长说说网站自动采集和原创的优缺点
众所周知,自动采集软件自发明以来,一直是无数草根站长必备的建站工具之一。刚建了一个新站,但是好像空荡荡的,短时间内不可能出一个有钱的原创,除非你是第五个钻石王,请专业人士投票原创。一个人的精力是有限的,只能依靠自动采集工具。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站优化:TAG标签更有益。你用过网站吗?
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
如何使用免费的网站源代码
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
如何使用cms系统标签自动获取长尾关键词排名
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长经常使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
文章采集程序(新建微信公众号采集任务配置采集结果附录(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-14 23:01
)
?使用优采云采集微信公众号文章,很简单,只要输入:公众号或姓名或关键词。
使用步骤:创建微信公众号采集任务微信公众号采集任务配置采集结果采集微信公众号注意事项附录(公众号获取方法ID和微信文章散采集)1.新建微信公众号采集任务:
??创建微信公众号采集任务有两个入口:
2.微信公众号采集任务配置:
3. 采集结果:
??微信公众号(weixin_name),公众号(weixin_id),title(标题),body(内容),发布日期(pubData),author(作者),tag(tag),description(描述,可以使用文本截取)和关键字(keywords);
附录:(如何获取公众号和微信文章scattered采集)
我,如何获取公众号
??在“公众号(微信)”中填写微信账号名称,然后点击“验证公众号”旁边的按钮即可看到微信账号;
??以下以“万维网”为例:
二、微信文章分散采集
??微信文章分散采集一般用于精准采集,用户只需输入微信文章地址采集。
??在微信公众号文章采集的基本信息页面,点击“手动输入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
查看全部
文章采集程序(新建微信公众号采集任务配置采集结果附录(一)
)
?使用优采云采集微信公众号文章,很简单,只要输入:公众号或姓名或关键词。
使用步骤:创建微信公众号采集任务微信公众号采集任务配置采集结果采集微信公众号注意事项附录(公众号获取方法ID和微信文章散采集)1.新建微信公众号采集任务:
??创建微信公众号采集任务有两个入口:
2.微信公众号采集任务配置:
3. 采集结果:
??微信公众号(weixin_name),公众号(weixin_id),title(标题),body(内容),发布日期(pubData),author(作者),tag(tag),description(描述,可以使用文本截取)和关键字(keywords);
附录:(如何获取公众号和微信文章scattered采集)
我,如何获取公众号
??在“公众号(微信)”中填写微信账号名称,然后点击“验证公众号”旁边的按钮即可看到微信账号;
??以下以“万维网”为例:
二、微信文章分散采集
??微信文章分散采集一般用于精准采集,用户只需输入微信文章地址采集。
??在微信公众号文章采集的基本信息页面,点击“手动输入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
文章采集程序(众所周知优化一个网站是什么?如何采集格式网页的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-04-14 22:40
采集插件可以采集 格式化网页上的文本、HTML 和元素属性。采集插件可以使用正则表达式和自定义函数过滤内容。采集插件通过HTTP POST请求传输和获取数据。采集插件支持CSV、EXCEL、HTML、TXT等下载数据。采集插件的功能包括:定时采集任务、采集规则自动同步、脚本采集、数据插件导出。
采集插件使用其他网站文章列表和缓存读取技术,网页程序自动读取其他网站的内容,存储过程为< @采集 进程。它是一种信息聚合技术。通过这项技术,站长可以将其他网站相对固定更新的栏目等内容,变成自己网站的一部分,无需复制粘贴。采集有现场和非现场的区别。采集插件站点一般用于较大的站点,将很多栏目聚合到一个节点中,集中展示。
采集插件有两种触发方式采集更新。一种是在页面中添加代码触发采集更新,在后台异步执行,不影响用户体验,不影响采集更新。@网站效率,另外,可以使用Cron调度任务来触发采集定时更新任务。采集插件可以帮助网站节省大量的搬运劳动。该插件不仅支持文章采集,还支持文章采集中的评论,其他插件的数据采集(不支持文章 )。
采集插件可以将多个任务的采集可视化,采集金额图表统计,历史采集状态一目了然。采集插件可以文章评论采集(仅限首页评论),采集插件可以支持市面上大部分主题,插件数据采集(任意数据表仓储)。采集插件采集的第三方触发,多tab,多线程采集文章,采集plugins采集都可以在 伪原创 内容之后自动。
众所周知,优化 网站 并不容易。需要每天更新文章,这样才能保证网站的排名更高,但不是每个人每天都有更多的时间更新网站,总的来说,更新三个就好-每天高质量的文章篇文章已经是很多人的极限了。有时候写不出来文章,总会去别的地方网站copy文章,不过这样也是浪费时间,时间长了就会变得无聊.
采集插件可以帮助网站解决这些问题,采集插件只需要输入站长想要的网站采集,然后直接< @采集,目前后台只有三个采集板块,主要关注资源和新闻源类型的网站。输入网站可以直接采集,采集之后文章自动存入草稿,可以设置覆盖关键词,不用担心关于文章还有其他网站的地址。
<p>采集插件只需要设置相关的采集任务,在定时任务管理界面,将当前采集任务加入队列,等到定时时间,再启动自动 查看全部
文章采集程序(众所周知优化一个网站是什么?如何采集格式网页的?)
采集插件可以采集 格式化网页上的文本、HTML 和元素属性。采集插件可以使用正则表达式和自定义函数过滤内容。采集插件通过HTTP POST请求传输和获取数据。采集插件支持CSV、EXCEL、HTML、TXT等下载数据。采集插件的功能包括:定时采集任务、采集规则自动同步、脚本采集、数据插件导出。
采集插件使用其他网站文章列表和缓存读取技术,网页程序自动读取其他网站的内容,存储过程为< @采集 进程。它是一种信息聚合技术。通过这项技术,站长可以将其他网站相对固定更新的栏目等内容,变成自己网站的一部分,无需复制粘贴。采集有现场和非现场的区别。采集插件站点一般用于较大的站点,将很多栏目聚合到一个节点中,集中展示。
采集插件有两种触发方式采集更新。一种是在页面中添加代码触发采集更新,在后台异步执行,不影响用户体验,不影响采集更新。@网站效率,另外,可以使用Cron调度任务来触发采集定时更新任务。采集插件可以帮助网站节省大量的搬运劳动。该插件不仅支持文章采集,还支持文章采集中的评论,其他插件的数据采集(不支持文章 )。
采集插件可以将多个任务的采集可视化,采集金额图表统计,历史采集状态一目了然。采集插件可以文章评论采集(仅限首页评论),采集插件可以支持市面上大部分主题,插件数据采集(任意数据表仓储)。采集插件采集的第三方触发,多tab,多线程采集文章,采集plugins采集都可以在 伪原创 内容之后自动。
众所周知,优化 网站 并不容易。需要每天更新文章,这样才能保证网站的排名更高,但不是每个人每天都有更多的时间更新网站,总的来说,更新三个就好-每天高质量的文章篇文章已经是很多人的极限了。有时候写不出来文章,总会去别的地方网站copy文章,不过这样也是浪费时间,时间长了就会变得无聊.
采集插件可以帮助网站解决这些问题,采集插件只需要输入站长想要的网站采集,然后直接< @采集,目前后台只有三个采集板块,主要关注资源和新闻源类型的网站。输入网站可以直接采集,采集之后文章自动存入草稿,可以设置覆盖关键词,不用担心关于文章还有其他网站的地址。
<p>采集插件只需要设置相关的采集任务,在定时任务管理界面,将当前采集任务加入队列,等到定时时间,再启动自动
文章采集程序( 如何使用优采云采集进行搜索?写作推出智能采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-14 22:39
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“疫情”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
文章采集程序(
如何使用优采云采集进行搜索?写作推出智能采集工具)
疫情期间,不少企业不得不选择在线远程办公。互联网是受疫情影响较小的行业之一,但远程办公的效率一直低于面对面办公。因此,优采云采集推出了智能采集工具。
相信很多运营商都接触过采集工具。现在市场上有各种 采集 工具。很多人认为采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实不仅如此。一个成熟的采集工具,不仅有利于对采集信息的操作,还能准确分析数据趋势,从而帮助增加收入。
1、 什么是优采云采集?
优采云采集是自媒体素材搜索、文章原创、一键发布的操作工具,有效提升新媒体运营效率,降低企业成本。
2、 如何使用 优采云采集 进行搜索?
(1) 输入 关键词
优采云采集根据用户输入的关键词,通过程序自动搜索进入主流自媒体数据源的搜索引擎。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,并在主页面输入关键词“疫情”。优采云采集 会将搜索结果合并到一个列表中。
(2) 保存搜索材料
优采云采集具有批量保存搜索素材的功能。
点击【当前页全选】功能,勾选需要的文章,文章会添加到操作面板,方便用户批量保存。
(3) 精确过滤
1、 搜索过滤器
优采云采集支持按标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
文章采集程序( 10年打造网页数据采集利器-优采云采集器优采云软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-13 21:00
10年打造网页数据采集利器-优采云采集器优采云软件)
优采云采集器
优采云采集器本软件为网页抓取工具,用于网站信息采集、网站信息抓取,包括图片、文字等信息< @采集处理和发布,是目前互联网上使用最多的数据采集软件。出品,10年打造网络数据采集工具。
优采云采集器
优采云网页数据采集器,是一款简单易用,功能强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,大数据连续四年在行业数据领域排名第一采集。
优采云
<p>[优采云采集]是一个完全在线的配置和云采集网站文章采集工具和发布平台。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家和第一个书签 采集 发布;无缝对接各种cms网站(wordpress、Empire、Zblog、dedecms、Destoon等)、Http接口等都是免费在线网页文章 查看全部
文章采集程序(
10年打造网页数据采集利器-优采云采集器优采云软件)
http://www.locoy.com?w=130&h=80" />优采云采集器
优采云采集器本软件为网页抓取工具,用于网站信息采集、网站信息抓取,包括图片、文字等信息< @采集处理和发布,是目前互联网上使用最多的数据采集软件。出品,10年打造网络数据采集工具。
http://www.bazhuayu.com?w=130&h=80" />优采云采集器
优采云网页数据采集器,是一款简单易用,功能强大的网络爬虫工具,全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,大数据连续四年在行业数据领域排名第一采集。
http://www.keydatas.com?w=130&h=80" />优采云
<p>[优采云采集]是一个完全在线的配置和云采集网站文章采集工具和发布平台。功能强大,操作非常简单,无需安装任何客户端或插件;支持在线视觉点击;集成智能抽取引擎,自动识别数据和规则;独家和第一个书签 采集 发布;无缝对接各种cms网站(wordpress、Empire、Zblog、dedecms、Destoon等)、Http接口等都是免费在线网页文章
文章采集程序(数据采集的重要性本篇方案详细聊数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-12 23:16
相信业务团队对这样的场景不会太陌生:
因此,数据非常重要。接下来,我们将详细讨论数据采集的重要性,数据的划分,采集的方法,以及微信小程序中的埋点方案。数据采集。
一、数据的重要性采集
在本文中,我们关注数据采集。我们暂且不详细讨论数据的作用。首先,我们将总结数据在性能优化、业务增长和在线故障排除方面的重要作用。这就是为什么我们需要埋点。
数据对在线排查的作用:数据对性能优化的作用:数据对业务增长的作用:二、采集数据划分与排序
从第一点开始,我们总结了数据的重要性。不同的业务项目对数据重要性的重视程度不同。那么采集采集应该是什么数据呢?
一、闭环数据包括:
用户行为用户信息、CRM(客户关系)交易数据、服务器日志数据
以上三项数据可视为一个完整的数据流闭环。当然,不同业务场景下的数据还可以进一步细分,一般的重点基本不超过这三项。对于前端的数据采集来说,闭环数据中的前两项主要是客户端上报,而第三点主要是服务端记录并由客户端辅助,因为事务请求只有在事务请求到达服务器完成处理。一个闭环。用户行为数据还包括时间(when)、地点(where)、人(who)、交互(how)、交互内容(what)五个元素,与新闻的五个元素有些相似;部分用户信息业务涉及用户敏感信息和隐私需要授权,因此用户信息的具体维度由业务场景决定。最基本的数据要求是唯一标识用户;CRM、交易数据和用户信息类似,具体需要的数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。
三、数据上报方式
说完数据,接下来就是要知道如何获取我们真正需要的数据了。数据上报方式大致可分为三类:
第一种是代码埋点,即在需要埋点的节点手动调用接口上传埋点数据。优盟、百度统计等第三方数据统计服务商大多采用此方案;
第二种是可视化掩埋,即通过可视化工具配置采集节点,在前端自动解析配置并上报掩埋数据,从而实现所谓的“无痕掩埋”,代表开源的 Mixpanel;
第三类是“无埋点”。确实不需要埋点,但是前端自动采集所有事件并上报埋点数据,在后端数据计算的时候过滤掉有用的数据,代表解决方案就是国内的GrowingIO。
重点是非埋点。可视化埋点其实可以看成是无埋点的推导。所以可视化埋点这里不讨论,主要是对比代码埋点和无埋点。
3.1 代码嵌入或嵌入捕获模式的缺点
对于数据产品:
依靠人类经验和直觉判断。
业务相关埋点的位置需要数据产品或业务产品的主观判断,而技术相关的埋点需要技术人员的主观判断。沟通成本高
确定数据产品所需的数据,需要提出要求并与开发沟通,数据人员对技术不是特别熟悉,需要与开发人员明确相关是否可行可以上报信息。有数据清洗成本
随着业务的变化,主观判断所需的数据也会发生变化和变化。这时候需要手动清理之前管理的数据,清理的工作量不小。
对于开发:
开发人员的努力
对于业务团队来说,埋点往往会被相关开发者诟病。开发技术人员不能只专注于技术,还需要多元化从事埋点等高度重复性和机械性的任务。
埋藏相关代码具有高度侵入性,对系统设计和代码可维护性产生负面影响
大部分业务相关的数据点都需要人工埋藏,埋藏的代码要与业务代码强耦合。即使业界没有嵌入式SDK,数据产品所关注的特殊业务点也逃不过人工嵌入。
随着业务的不断变化,对数据的需求也在变化,埋点相关的代码也需要随之变化。进一步增加开发和代码维护成本。
容易出错
由于人工打点的主观意识不同,打点位置的准确性难以控制,数据容易泄露。
有打点流程费用
当数据丢失或错误采集时,必须重新经过开发过程和在线过程,效率低下。3.2 无埋点优势
与人工嵌入相比,无嵌入的优势无需赘述。
提高效率,让数据更全面,按需抽取,减少代码入侵 sdk的难点和关键点
无法直接监控用户行为以实现强大的可扩展性
需要适合多种架构设计场景(小程序),sdk的使用需要轻量级
每个小程序的包有2M的限制,小程序不支持在代码中引入npm包,所以sdk本身会占用2M的大小限制。小程序虽然有分包的内测,但是这个功能还没有完全放开,作为sdk太大也不合理。
采集数据量大,在不影响业务的情况下将性能损失降到最低(基本要求)4.3微信小程序无嵌入式sdk设计
数据层设计:
设计数据流:
采集方法设计:
访问方法:
sdk npm 包代码在小程序初始化代码之前介绍。小程序打包代码时,将sdk代码引入项目中,初始化后即可自动采集数据。初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({channel: 'channel',env: config.IS_PRODUCION ? 'product': 'beta',project: 'yourProjectName',methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称})
无埋点结合埋点:
小程序的非埋藏方式可以获取大量数据,基本可以实现用户使用场景的高度还原。SDK管理的粒度是对某个方法的执行。当特殊业务关注的粒度小于 SDK 粒度时,没有嵌入点的 SDK 无法完全解决。可以使用无嵌入点和嵌入点的组合,所以我们的小程序没有 追踪SDK也提供了API接口用于手动追踪,以提高数据的完整性,解决更多的问题(回顾提到的作用参考重要性数据的)。
五、小程序无埋SDK遇到的问题
除了解决上文提到的微信小程序非地埋sdk开发面临的困难和关键问题外,还遇到了一些新的问题。
SDK 本身会对业务性能产生一定的影响。数据临时存储在小程序的本地存储中。频繁访问/检索小程序的本地存储,会暴露业务端本身消耗更多性能时的操作滞后。问题。减少localstorage访问/获取操作,只在页面关闭时将未上传的数据存储在localstorage中
没有埋点的海量数据。灰度上线时遇到服务器过载问题,导致服务器可用性下降。后续将控制上报数据量,仅自动上报关键节点数据。其他以服务为中心的节点可以在访问初始化时通过针对性的配置重新配置上报,避免上报过多的冗余数据。此外,还应特别注意报告数据结构的设计。该结构的目标是清晰、简洁且易于检索(区分)数据。
最初,我想对灰度启动是否使用SDK进行“切换”,以避免小程序的回滚过程。由于“切换”依赖于服务端接口控制,并且请求是异步的,也就是说小程序的初始化过程和启动必须等待控制切换的接口返回才能继续进行,否则“切换”是相当于失败。考虑到SDK不能影响服务性能,丢弃“开关”,在SDK内部做try and catch,避免影响服务可用性。
有了无埋点上报得到的数据,以后可以用这些数据解决很多问题。关于数据的使用,敬请期待下一节——数据的应用。
参考:
[1] [美国]裴霁,译者:姚军等,《深入理解网站优化》,出版社:机械工业出版社,出版时间:2013-08
[2]张希猛,《首席成长官》,出版社:机械工业出版社,出版时间:第1版(2017年11月6日) 查看全部
文章采集程序(数据采集的重要性本篇方案详细聊数据)
相信业务团队对这样的场景不会太陌生:
因此,数据非常重要。接下来,我们将详细讨论数据采集的重要性,数据的划分,采集的方法,以及微信小程序中的埋点方案。数据采集。
一、数据的重要性采集
在本文中,我们关注数据采集。我们暂且不详细讨论数据的作用。首先,我们将总结数据在性能优化、业务增长和在线故障排除方面的重要作用。这就是为什么我们需要埋点。
数据对在线排查的作用:数据对性能优化的作用:数据对业务增长的作用:二、采集数据划分与排序
从第一点开始,我们总结了数据的重要性。不同的业务项目对数据重要性的重视程度不同。那么采集采集应该是什么数据呢?
一、闭环数据包括:
用户行为用户信息、CRM(客户关系)交易数据、服务器日志数据
以上三项数据可视为一个完整的数据流闭环。当然,不同业务场景下的数据还可以进一步细分,一般的重点基本不超过这三项。对于前端的数据采集来说,闭环数据中的前两项主要是客户端上报,而第三点主要是服务端记录并由客户端辅助,因为事务请求只有在事务请求到达服务器完成处理。一个闭环。用户行为数据还包括时间(when)、地点(where)、人(who)、交互(how)、交互内容(what)五个元素,与新闻的五个元素有些相似;部分用户信息业务涉及用户敏感信息和隐私需要授权,因此用户信息的具体维度由业务场景决定。最基本的数据要求是唯一标识用户;CRM、交易数据和用户信息类似,具体需要的数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。所需的具体数据细节由业务场景决定。CRM 基本数据要求是登录信息和会员相关信息。交易数据包括——交易时间、交易对象、交易内容、交易金额、交易状态。
三、数据上报方式
说完数据,接下来就是要知道如何获取我们真正需要的数据了。数据上报方式大致可分为三类:
第一种是代码埋点,即在需要埋点的节点手动调用接口上传埋点数据。优盟、百度统计等第三方数据统计服务商大多采用此方案;
第二种是可视化掩埋,即通过可视化工具配置采集节点,在前端自动解析配置并上报掩埋数据,从而实现所谓的“无痕掩埋”,代表开源的 Mixpanel;
第三类是“无埋点”。确实不需要埋点,但是前端自动采集所有事件并上报埋点数据,在后端数据计算的时候过滤掉有用的数据,代表解决方案就是国内的GrowingIO。
重点是非埋点。可视化埋点其实可以看成是无埋点的推导。所以可视化埋点这里不讨论,主要是对比代码埋点和无埋点。
3.1 代码嵌入或嵌入捕获模式的缺点
对于数据产品:
依靠人类经验和直觉判断。
业务相关埋点的位置需要数据产品或业务产品的主观判断,而技术相关的埋点需要技术人员的主观判断。沟通成本高
确定数据产品所需的数据,需要提出要求并与开发沟通,数据人员对技术不是特别熟悉,需要与开发人员明确相关是否可行可以上报信息。有数据清洗成本
随着业务的变化,主观判断所需的数据也会发生变化和变化。这时候需要手动清理之前管理的数据,清理的工作量不小。
对于开发:
开发人员的努力
对于业务团队来说,埋点往往会被相关开发者诟病。开发技术人员不能只专注于技术,还需要多元化从事埋点等高度重复性和机械性的任务。
埋藏相关代码具有高度侵入性,对系统设计和代码可维护性产生负面影响
大部分业务相关的数据点都需要人工埋藏,埋藏的代码要与业务代码强耦合。即使业界没有嵌入式SDK,数据产品所关注的特殊业务点也逃不过人工嵌入。
随着业务的不断变化,对数据的需求也在变化,埋点相关的代码也需要随之变化。进一步增加开发和代码维护成本。
容易出错
由于人工打点的主观意识不同,打点位置的准确性难以控制,数据容易泄露。
有打点流程费用
当数据丢失或错误采集时,必须重新经过开发过程和在线过程,效率低下。3.2 无埋点优势
与人工嵌入相比,无嵌入的优势无需赘述。
提高效率,让数据更全面,按需抽取,减少代码入侵 sdk的难点和关键点
无法直接监控用户行为以实现强大的可扩展性
需要适合多种架构设计场景(小程序),sdk的使用需要轻量级
每个小程序的包有2M的限制,小程序不支持在代码中引入npm包,所以sdk本身会占用2M的大小限制。小程序虽然有分包的内测,但是这个功能还没有完全放开,作为sdk太大也不合理。
采集数据量大,在不影响业务的情况下将性能损失降到最低(基本要求)4.3微信小程序无嵌入式sdk设计
数据层设计:
设计数据流:
采集方法设计:
访问方法:
sdk npm 包代码在小程序初始化代码之前介绍。小程序打包代码时,将sdk代码引入项目中,初始化后即可自动采集数据。初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({channel: 'channel',env: config.IS_PRODUCION ? 'product': 'beta',project: 'yourProjectName',methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称})
无埋点结合埋点:
小程序的非埋藏方式可以获取大量数据,基本可以实现用户使用场景的高度还原。SDK管理的粒度是对某个方法的执行。当特殊业务关注的粒度小于 SDK 粒度时,没有嵌入点的 SDK 无法完全解决。可以使用无嵌入点和嵌入点的组合,所以我们的小程序没有 追踪SDK也提供了API接口用于手动追踪,以提高数据的完整性,解决更多的问题(回顾提到的作用参考重要性数据的)。
五、小程序无埋SDK遇到的问题
除了解决上文提到的微信小程序非地埋sdk开发面临的困难和关键问题外,还遇到了一些新的问题。
SDK 本身会对业务性能产生一定的影响。数据临时存储在小程序的本地存储中。频繁访问/检索小程序的本地存储,会暴露业务端本身消耗更多性能时的操作滞后。问题。减少localstorage访问/获取操作,只在页面关闭时将未上传的数据存储在localstorage中
没有埋点的海量数据。灰度上线时遇到服务器过载问题,导致服务器可用性下降。后续将控制上报数据量,仅自动上报关键节点数据。其他以服务为中心的节点可以在访问初始化时通过针对性的配置重新配置上报,避免上报过多的冗余数据。此外,还应特别注意报告数据结构的设计。该结构的目标是清晰、简洁且易于检索(区分)数据。
最初,我想对灰度启动是否使用SDK进行“切换”,以避免小程序的回滚过程。由于“切换”依赖于服务端接口控制,并且请求是异步的,也就是说小程序的初始化过程和启动必须等待控制切换的接口返回才能继续进行,否则“切换”是相当于失败。考虑到SDK不能影响服务性能,丢弃“开关”,在SDK内部做try and catch,避免影响服务可用性。
有了无埋点上报得到的数据,以后可以用这些数据解决很多问题。关于数据的使用,敬请期待下一节——数据的应用。
参考:
[1] [美国]裴霁,译者:姚军等,《深入理解网站优化》,出版社:机械工业出版社,出版时间:2013-08
[2]张希猛,《首席成长官》,出版社:机械工业出版社,出版时间:第1版(2017年11月6日)
文章采集程序(需求数据采集的需求广义上来说分为两大部分(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-10 04:20
需要
数据采集 需求大致分为两部分。
1)是用户对页面采集的访问行为,具体开发工作:
开发页面嵌入js,采集用户访问行为后台接受页面js请求记录日志
这部分工作也可以归类为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器到HDFS的日志聚合,是数据分析系统的数据采集,这部分工作由数据分析平台建设团队负责,有实现具体技术的方法有很多:
技术选型
在点击流日志分析的场景下,data采集部分的可靠性和容错性通常不是很严格,所以使用通用的flume log采集框架完全可以满足要求。
本项目使用flume实现日志采集。
Flume日志采集系统搭建1.数据来源信息
本项目分析的数据使用nginx服务器生成的流量日志存储在各个nginx服务器上,如:
/var/log/httpd/access_log.2015-11-10-13-00.log
/var/log/httpd/access_log.2015-11-10-14-00.log
/var/log/httpd/access_log.2015-11-10-15-00.log
/var/log/httpd/access_log.2015-11-10-16-00.log
2.示例数据内容
数据的具体内容在采集这个阶段不需要太在意
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000]
"GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0
"http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
字段解析:
1. 访客ip地址: 58.215.204.118
2. 访客用户信息: - -
3. 请求时间:[18/Sep/2013:06:51:35 +0000]
4. 请求方式:GET
5. 请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6. 请求所用协议:HTTP/1.1
7. 响应码:304
8. 返回的数据流量:0
9. 访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10. 访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
3.日志文件生成规则
基本规则是:
当前正在写入的文件是access_log;
当文件量达到64M,或者时间间隔达到60分钟时,滚动重命名切换到历史日志文件;
例如:access_log.2015-11-10-13-00.log
当然,每个公司的web服务器日志策略都不一样,可以在web程序的log4j.properties中定义,如下:
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = /var/logs/access_log
log4j.appender.logDailyFile.DatePattern = '.'yyyy-MM-dd-HH-mm'.log'
log4j.appender.logDailyFile.Encoding = UTF-8
4.Flume采集实现
Flume采集系统的搭建比较简单:
在web服务器上部署代理节点,修改配置文件启动代理节点,将采集中的数据聚合到指定的HDFS目录中。
如下所示:
版本选择:apache-flume-1.6.0
采集规则设计:
采集来源:nginx服务器日志目录存放位置:hdfs目录/home/hadoop/weblogs/
采集规则配置详情:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure spooldir source1
#agent1.sources.source1.type = spooldir
#agent1.sources.source1.spoolDir = /var/logs/nginx/
#agent1.sources.source1.fileHeader = false
# Describe/configure tail -F source1
#使用exec作为数据源source组件
agent1.sources.source1.type = exec
#使用tail -F命令实时收集新产生的日志数据
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#配置一个拦截器插件
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
#使用拦截器插件获取agent所在服务器的主机名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
#agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
#指定文件sink到hdfs上的路径
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1G大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
启动采集
在部署flume的nginx服务器上,启动flume的代理,命令如下:
bin/flume-ng agent --conf ./conf -f ./conf/weblog.properties.2 -n agent
注意:启动命令中的-n参数应该给出配置文件中配置的代理名称。 查看全部
文章采集程序(需求数据采集的需求广义上来说分为两大部分(组图))
需要
数据采集 需求大致分为两部分。
1)是用户对页面采集的访问行为,具体开发工作:
开发页面嵌入js,采集用户访问行为后台接受页面js请求记录日志
这部分工作也可以归类为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器到HDFS的日志聚合,是数据分析系统的数据采集,这部分工作由数据分析平台建设团队负责,有实现具体技术的方法有很多:
技术选型
在点击流日志分析的场景下,data采集部分的可靠性和容错性通常不是很严格,所以使用通用的flume log采集框架完全可以满足要求。
本项目使用flume实现日志采集。
Flume日志采集系统搭建1.数据来源信息
本项目分析的数据使用nginx服务器生成的流量日志存储在各个nginx服务器上,如:
/var/log/httpd/access_log.2015-11-10-13-00.log
/var/log/httpd/access_log.2015-11-10-14-00.log
/var/log/httpd/access_log.2015-11-10-15-00.log
/var/log/httpd/access_log.2015-11-10-16-00.log
2.示例数据内容
数据的具体内容在采集这个阶段不需要太在意
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000]
"GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0
"http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
字段解析:
1. 访客ip地址: 58.215.204.118
2. 访客用户信息: - -
3. 请求时间:[18/Sep/2013:06:51:35 +0000]
4. 请求方式:GET
5. 请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6. 请求所用协议:HTTP/1.1
7. 响应码:304
8. 返回的数据流量:0
9. 访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10. 访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
3.日志文件生成规则
基本规则是:
当前正在写入的文件是access_log;
当文件量达到64M,或者时间间隔达到60分钟时,滚动重命名切换到历史日志文件;
例如:access_log.2015-11-10-13-00.log
当然,每个公司的web服务器日志策略都不一样,可以在web程序的log4j.properties中定义,如下:
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = /var/logs/access_log
log4j.appender.logDailyFile.DatePattern = '.'yyyy-MM-dd-HH-mm'.log'
log4j.appender.logDailyFile.Encoding = UTF-8
4.Flume采集实现
Flume采集系统的搭建比较简单:
在web服务器上部署代理节点,修改配置文件启动代理节点,将采集中的数据聚合到指定的HDFS目录中。
如下所示:
版本选择:apache-flume-1.6.0
采集规则设计:
采集来源:nginx服务器日志目录存放位置:hdfs目录/home/hadoop/weblogs/
采集规则配置详情:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure spooldir source1
#agent1.sources.source1.type = spooldir
#agent1.sources.source1.spoolDir = /var/logs/nginx/
#agent1.sources.source1.fileHeader = false
# Describe/configure tail -F source1
#使用exec作为数据源source组件
agent1.sources.source1.type = exec
#使用tail -F命令实时收集新产生的日志数据
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#配置一个拦截器插件
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
#使用拦截器插件获取agent所在服务器的主机名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
#agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
#指定文件sink到hdfs上的路径
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1G大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
启动采集
在部署flume的nginx服务器上,启动flume的代理,命令如下:
bin/flume-ng agent --conf ./conf -f ./conf/weblog.properties.2 -n agent
注意:启动命令中的-n参数应该给出配置文件中配置的代理名称。
文章采集程序( 这部分就是如何解析html,从爬取到的html文件中解析出所需的数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-04-10 04:19
这部分就是如何解析html,从爬取到的html文件中解析出所需的数据)
过年之后,我一直在业余时间独立开发一个小程序。主要数据为8000+视频和10000+文章文章,数据每天自动更新。
整个开发过程中遇到的问题和一些细节我会整理一下,因为内容会比较多,所以分三四个文章来进行,本文为系列第一篇文章@ >,内容偏python爬虫。
本系列文章将大致介绍内容:
数据采集
获取数据的方法有很多。这次我们选择了爬虫方式。当然,编写爬虫也可以用不同的语言,用不同的方式来完成。之前写过很多爬虫,这次选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
学习scrapy最好的方法是先阅读文档(Scrapy1.6文档),然后根据文档中的示例进行编写,逐渐熟悉。有几个非常重要的概念必须理解:
项目的官方定义是“抓取的主要目标是从非结构化来源(通常是网页)中提取结构化数据。” 个人理解为数据结构,即要爬取数据的字段,最好对应数据库字段。, 便于存放。
“一个item被蜘蛛抓取后,会被发送到Item Pipeline,它通过几个组件依次执行来处理它。”,管道是我们的爬虫在获取数据后会执行的处理操作,例如写入文件,或者链接到数据库,保存到数据库等,都可以在这里进行操作。
“当你在抓取网页时,你需要执行的最常见的任务就是从 HTML 源中提取数据。”,这部分是如何解析 html 并从抓取的 html 文件中解析出需要的数据、BeautifulSoup 等方法、lxml、Xpath、CSS等都可以使用。
上面解释了几个重要的部分。
环境准备好(python3/scrapy等),我们就可以编写爬虫项目了。
爬取的内容来自这个网站。
创建项目
scrapy startproject jqhtml
修改项目
添加爬虫
写管道
修改配置文件
就这样,我们顺利完成了爬虫项目的编写。运行后发现,所有数据都存储在数据库中。
scrapy爬虫项目部署
对于scrapy爬虫项目的部署,我们可以使用官方的scrapyd,使用方法比较简单。在服务器上安装scrapyd并启动,然后在本地项目中配置deploy路径,在本地安装scrapy-client,使用命令deploy ie Deployable to server。
scrapyd提供了一些api接口来查看项目的爬虫状态,执行或者停止爬虫。
这样,我们就可以轻松调整这些接口来管理我们的爬虫任务。
当心:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项NEXT
在下一篇文章中,我们将介绍和使用一个非常流行的nodejs后台api库——hapijs。完成小程序所需的所有接口的开发,使用定时任务执行爬虫脚本。 查看全部
文章采集程序(
这部分就是如何解析html,从爬取到的html文件中解析出所需的数据)
过年之后,我一直在业余时间独立开发一个小程序。主要数据为8000+视频和10000+文章文章,数据每天自动更新。
整个开发过程中遇到的问题和一些细节我会整理一下,因为内容会比较多,所以分三四个文章来进行,本文为系列第一篇文章@ >,内容偏python爬虫。
本系列文章将大致介绍内容:
数据采集
获取数据的方法有很多。这次我们选择了爬虫方式。当然,编写爬虫也可以用不同的语言,用不同的方式来完成。之前写过很多爬虫,这次选择了python的scrapy库。关于scrapy,百度百科解释如下:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
学习scrapy最好的方法是先阅读文档(Scrapy1.6文档),然后根据文档中的示例进行编写,逐渐熟悉。有几个非常重要的概念必须理解:
项目的官方定义是“抓取的主要目标是从非结构化来源(通常是网页)中提取结构化数据。” 个人理解为数据结构,即要爬取数据的字段,最好对应数据库字段。, 便于存放。
“一个item被蜘蛛抓取后,会被发送到Item Pipeline,它通过几个组件依次执行来处理它。”,管道是我们的爬虫在获取数据后会执行的处理操作,例如写入文件,或者链接到数据库,保存到数据库等,都可以在这里进行操作。
“当你在抓取网页时,你需要执行的最常见的任务就是从 HTML 源中提取数据。”,这部分是如何解析 html 并从抓取的 html 文件中解析出需要的数据、BeautifulSoup 等方法、lxml、Xpath、CSS等都可以使用。
上面解释了几个重要的部分。
环境准备好(python3/scrapy等),我们就可以编写爬虫项目了。
爬取的内容来自这个网站。
创建项目
scrapy startproject jqhtml
修改项目
添加爬虫
写管道
修改配置文件
就这样,我们顺利完成了爬虫项目的编写。运行后发现,所有数据都存储在数据库中。
scrapy爬虫项目部署
对于scrapy爬虫项目的部署,我们可以使用官方的scrapyd,使用方法比较简单。在服务器上安装scrapyd并启动,然后在本地项目中配置deploy路径,在本地安装scrapy-client,使用命令deploy ie Deployable to server。
scrapyd提供了一些api接口来查看项目的爬虫状态,执行或者停止爬虫。
这样,我们就可以轻松调整这些接口来管理我们的爬虫任务。
当心:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项NEXT
在下一篇文章中,我们将介绍和使用一个非常流行的nodejs后台api库——hapijs。完成小程序所需的所有接口的开发,使用定时任务执行爬虫脚本。
文章采集程序(开发爬虫程序首先要先得到Web页面的HTML代码,微软)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-10 04:17
要开发爬虫程序,首先要获取网页的HTML代码。微软为我们提供了一种非常方便的方法。我们可以使用WebClient或者WebRequest、HttpWebResponse轻松获取网站页面的HTML代码。终于提供了源代码下载。
第一个例子是使用WebClient获取HTML代码。
private string getHTML(string strUrl,Encoding encoding)
{
Uri url = new Uri(strUrl);
WebClient wc = new WebClient();
wc.Encoding = encoding;
Stream s = wc.OpenRead(url);
StreamReader sr = new StreamReader(s, encoding);
return sr.ReadToEnd();
}
调用时需要知道页面的编码方式。后面给大家举个例子,不需要知道编码方式。先看调用的方法:
string html = getHTML("http://www.baidu.com", Encoding.GetEncoding("GB2312"));
下一点是重点。使用 WebRequest 和 HttpWebResponse 获取页面的 HTML 代码,只需要传入一个 URL。编码方式可由程序分析。虽然不完美,但大部分网站都可以识别出来。
先用WebRequest初始化一个真实的列,然后用GetResponse请求得到的response返回给HttpWebResponse,通过response.StatusDescription,可以得到编码方式的代码,得到我们需要的网页的编码方式通过分析,最后阅读了HTML代码。就是这样。
private void getHTMLbyWebRequest(string strUrl)
{
Encoding encoding = System.Text.Encoding.Default;
WebRequest request = WebRequest.Create(strUrl);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
if (response.StatusDescription.ToUpper() == "OK")
{
switch (response.CharacterSet.ToLower())
{
case "gbk":
encoding = Encoding.GetEncoding("GBK");//貌似用GB2312就可以
break;
case "gb2312":
encoding = Encoding.GetEncoding("GB2312");
break;
case "utf-8":
encoding = Encoding.UTF8;
break;
case "big5":
encoding = Encoding.GetEncoding("Big5");
break;
case "iso-8859-1":
encoding = Encoding.UTF8;//ISO-8859-1的编码用UTF-8处理,致少优酷的是这种方法没有乱码
break;
default:
encoding = Encoding.UTF8;//如果分析不出来就用的UTF-8
break;
}
this.Literal1.Text = "Lenght:" + response.ContentLength.ToString() + "
CharacterSet:" + response.CharacterSet + "
Headers:" + response.Headers + "
";
Stream dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream, encoding);
string responseFromServer = reader.ReadToEnd();
this.TextBox2.Text = responseFromServer;
FindLink(responseFromServer);
this.TextBox2.Text = ClearHtml(responseFromServer);
reader.Close();
dataStream.Close();
response.Close();
}
else
{
this.TextBox2.Text = "Error";
}
}
这样,网页的HTML代码就已经获取到了,接下来就是对链接进行处理,过滤掉无用的HTML代码,保留文本内容。 查看全部
文章采集程序(开发爬虫程序首先要先得到Web页面的HTML代码,微软)
要开发爬虫程序,首先要获取网页的HTML代码。微软为我们提供了一种非常方便的方法。我们可以使用WebClient或者WebRequest、HttpWebResponse轻松获取网站页面的HTML代码。终于提供了源代码下载。
第一个例子是使用WebClient获取HTML代码。
private string getHTML(string strUrl,Encoding encoding)
{
Uri url = new Uri(strUrl);
WebClient wc = new WebClient();
wc.Encoding = encoding;
Stream s = wc.OpenRead(url);
StreamReader sr = new StreamReader(s, encoding);
return sr.ReadToEnd();
}
调用时需要知道页面的编码方式。后面给大家举个例子,不需要知道编码方式。先看调用的方法:
string html = getHTML("http://www.baidu.com", Encoding.GetEncoding("GB2312"));
下一点是重点。使用 WebRequest 和 HttpWebResponse 获取页面的 HTML 代码,只需要传入一个 URL。编码方式可由程序分析。虽然不完美,但大部分网站都可以识别出来。
先用WebRequest初始化一个真实的列,然后用GetResponse请求得到的response返回给HttpWebResponse,通过response.StatusDescription,可以得到编码方式的代码,得到我们需要的网页的编码方式通过分析,最后阅读了HTML代码。就是这样。
private void getHTMLbyWebRequest(string strUrl)
{
Encoding encoding = System.Text.Encoding.Default;
WebRequest request = WebRequest.Create(strUrl);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
if (response.StatusDescription.ToUpper() == "OK")
{
switch (response.CharacterSet.ToLower())
{
case "gbk":
encoding = Encoding.GetEncoding("GBK");//貌似用GB2312就可以
break;
case "gb2312":
encoding = Encoding.GetEncoding("GB2312");
break;
case "utf-8":
encoding = Encoding.UTF8;
break;
case "big5":
encoding = Encoding.GetEncoding("Big5");
break;
case "iso-8859-1":
encoding = Encoding.UTF8;//ISO-8859-1的编码用UTF-8处理,致少优酷的是这种方法没有乱码
break;
default:
encoding = Encoding.UTF8;//如果分析不出来就用的UTF-8
break;
}
this.Literal1.Text = "Lenght:" + response.ContentLength.ToString() + "
CharacterSet:" + response.CharacterSet + "
Headers:" + response.Headers + "
";
Stream dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream, encoding);
string responseFromServer = reader.ReadToEnd();
this.TextBox2.Text = responseFromServer;
FindLink(responseFromServer);
this.TextBox2.Text = ClearHtml(responseFromServer);
reader.Close();
dataStream.Close();
response.Close();
}
else
{
this.TextBox2.Text = "Error";
}
}
这样,网页的HTML代码就已经获取到了,接下来就是对链接进行处理,过滤掉无用的HTML代码,保留文本内容。
文章采集程序(2.定时的执行,怎么样让一个任务定时执行?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-06 07:25
还是先废话一句,程序还在开发阶段,担心开发出来的程序会变形,所以就拿出来包扎了。市面上已经有很多采集软件了,我只是在重复轮子,并没有比他们的好多少,而且很可能是太差了。不过对比现在的一些采集方案,我觉得是基于组件的,每个组件都可以替换,希望可以算是一个亮点。同时,也希望本次展览能得到同行专家的建议和批评。
目前尚未解决的问题有:
1.一些需要cookies的网站,为什么采集,sina,我登录了,但是cnblogs没有登录成功。
2.定时执行,如何让一个任务定时执行,使用?,由于一个采集任务的URL可能很多,第一个URL的时间采集,最后一个一个 URLs 采集 的时间可能相隔几个小时。如果整个任务需要1h的间隔和采集一次,那么最后一个URL可能只是采集,它将是采集。或者最后一个任务还没有执行到该 URL。采集区间策略的情况这里没有考虑,比如采集不变化3次就延长下一个采集时间等。
3.存储问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么会是聚合和合并?这将是一个系统工程
4.任务流程和组件组装接口的实现,目前流程的配置是用文本编辑器编辑配置文件,很容易出错,不知道关于GDI+,我想不出实现接口的好方法。组装的组件。
我们先来看看采集的结果,然后介绍采集的整个过程。采集的结果保存在xml中,使用程序自带的Store2Xml组件,如果想存放在特定的数据库中,可以自己写一个组件,或者提供一个cms的webservice @> 我们将再次使用适配器组件。
我考虑制作另一个 Store2MDB 组件来促进数据传输并嵌入。我不使用 sqlite,因为普通用户可能不太了解它。
下面我以采集下的创业资讯和创业技巧栏目为例来展示这个程序
step1:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则。
打开任意列的列表页,查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容。
我们把上图中要提取的部分源码放到RegexBuddy中作为测试代码来测试我们写的规律性
将测试的正则表达式放入组件的指定属性中,目前只能手动配置。在实践中,有一个图形环境,提供了一步一步的操作提示
最后我们来设计组件组装配置执行的流程,使用boo解释引擎,类似ironpython
设计阶段一共有三个文件,其中文本文件存储了一组URL为采集,每行一个
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,即可提交任务
下图是后台运行程序的过程
采集 的结果 查看全部
文章采集程序(2.定时的执行,怎么样让一个任务定时执行?(图))
还是先废话一句,程序还在开发阶段,担心开发出来的程序会变形,所以就拿出来包扎了。市面上已经有很多采集软件了,我只是在重复轮子,并没有比他们的好多少,而且很可能是太差了。不过对比现在的一些采集方案,我觉得是基于组件的,每个组件都可以替换,希望可以算是一个亮点。同时,也希望本次展览能得到同行专家的建议和批评。
目前尚未解决的问题有:
1.一些需要cookies的网站,为什么采集,sina,我登录了,但是cnblogs没有登录成功。
2.定时执行,如何让一个任务定时执行,使用?,由于一个采集任务的URL可能很多,第一个URL的时间采集,最后一个一个 URLs 采集 的时间可能相隔几个小时。如果整个任务需要1h的间隔和采集一次,那么最后一个URL可能只是采集,它将是采集。或者最后一个任务还没有执行到该 URL。采集区间策略的情况这里没有考虑,比如采集不变化3次就延长下一个采集时间等。
3.存储问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么会是聚合和合并?这将是一个系统工程
4.任务流程和组件组装接口的实现,目前流程的配置是用文本编辑器编辑配置文件,很容易出错,不知道关于GDI+,我想不出实现接口的好方法。组装的组件。
我们先来看看采集的结果,然后介绍采集的整个过程。采集的结果保存在xml中,使用程序自带的Store2Xml组件,如果想存放在特定的数据库中,可以自己写一个组件,或者提供一个cms的webservice @> 我们将再次使用适配器组件。
我考虑制作另一个 Store2MDB 组件来促进数据传输并嵌入。我不使用 sqlite,因为普通用户可能不太了解它。
下面我以采集下的创业资讯和创业技巧栏目为例来展示这个程序
step1:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则。
打开任意列的列表页,查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容。
我们把上图中要提取的部分源码放到RegexBuddy中作为测试代码来测试我们写的规律性
将测试的正则表达式放入组件的指定属性中,目前只能手动配置。在实践中,有一个图形环境,提供了一步一步的操作提示
最后我们来设计组件组装配置执行的流程,使用boo解释引擎,类似ironpython
设计阶段一共有三个文件,其中文本文件存储了一组URL为采集,每行一个
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,即可提交任务
下图是后台运行程序的过程
采集 的结果
文章采集程序(不是百度,google的工作原理是什么?spider的spider)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-06 07:24
采集程序(蜘蛛)应该是搜索引擎的主要部分。当然,我们今天说的不是百度,谷歌的蜘蛛。
我以爬虫论坛为例,给大家大致介绍一下spider的工作原理。
首先,我们需要一个入口网址。我们不知道他们在百度最早的入口网址是什么。以采集论坛为例,这也可以看成是一个垂直搜索引擎,比如奇虎,可以搜索垂直搜索引擎的概念。垂直搜索引擎的入口需要手动采集,因为电脑不会知道哪个url是论坛。我的方法是将采集到的 url 放在配置文件中。
接下来,我们要进入我们需要的页面。这里首先要获取它的分页,分析页面的分页html写一个正则作为匹配方法。获取所有分页网址。我使用的是获取总页数,然后将页数添加到所有列表页中。这样我们就可以得到所有列表页面的url,然后循环读取这些列表页面。
下一步是获取列表页面中所有详细页面的url,使用此规则可以获取所有列表url。至此,我们已经获取到了所有我们想要的url,接下来就是抓取详细页面的url信息了。我们仍然使用常规规则来获取我们想要的字段的内容。一般情况下,应该以比较具有标志性的html作为内容前后的分隔符。这样我们就可以得到我们想要的字段的内容了。论坛比较好办,规则比较多,但是其他行业信息比较麻烦,比如时间、价格等需要格式化的字段。
我们只需要将我们抓取的信息保存到我们自己的数据库中。如果是搜索引擎,我们还必须进行关键词分段索引。这更复杂。
它还涉及编码问题。每个目标网站的编码可能不一样,但是抓到之后一定要转换成自己站的编码。
第一个采集当然是爬取后有页面信息。在随后的采集中我们只需要采集一个新的页面。如果列表按时间排序会更容易。我们只需要记录最后一个采集的url。如果不按时间,那就麻烦了。你得再去一遍url,然后判断是否已经是采集。
这里有几个PHP用来做这个的函数,这类程序的执行时间比较长,所以需要命令行执行。然后使用linux命令定期执行。
iconv编码转换函数
file_get_contents 已经使用了读取文件功能,可以直接读取url
preg_match_all 正则解析函数 查看全部
文章采集程序(不是百度,google的工作原理是什么?spider的spider)
采集程序(蜘蛛)应该是搜索引擎的主要部分。当然,我们今天说的不是百度,谷歌的蜘蛛。
我以爬虫论坛为例,给大家大致介绍一下spider的工作原理。
首先,我们需要一个入口网址。我们不知道他们在百度最早的入口网址是什么。以采集论坛为例,这也可以看成是一个垂直搜索引擎,比如奇虎,可以搜索垂直搜索引擎的概念。垂直搜索引擎的入口需要手动采集,因为电脑不会知道哪个url是论坛。我的方法是将采集到的 url 放在配置文件中。
接下来,我们要进入我们需要的页面。这里首先要获取它的分页,分析页面的分页html写一个正则作为匹配方法。获取所有分页网址。我使用的是获取总页数,然后将页数添加到所有列表页中。这样我们就可以得到所有列表页面的url,然后循环读取这些列表页面。
下一步是获取列表页面中所有详细页面的url,使用此规则可以获取所有列表url。至此,我们已经获取到了所有我们想要的url,接下来就是抓取详细页面的url信息了。我们仍然使用常规规则来获取我们想要的字段的内容。一般情况下,应该以比较具有标志性的html作为内容前后的分隔符。这样我们就可以得到我们想要的字段的内容了。论坛比较好办,规则比较多,但是其他行业信息比较麻烦,比如时间、价格等需要格式化的字段。
我们只需要将我们抓取的信息保存到我们自己的数据库中。如果是搜索引擎,我们还必须进行关键词分段索引。这更复杂。
它还涉及编码问题。每个目标网站的编码可能不一样,但是抓到之后一定要转换成自己站的编码。
第一个采集当然是爬取后有页面信息。在随后的采集中我们只需要采集一个新的页面。如果列表按时间排序会更容易。我们只需要记录最后一个采集的url。如果不按时间,那就麻烦了。你得再去一遍url,然后判断是否已经是采集。
这里有几个PHP用来做这个的函数,这类程序的执行时间比较长,所以需要命令行执行。然后使用linux命令定期执行。
iconv编码转换函数
file_get_contents 已经使用了读取文件功能,可以直接读取url
preg_match_all 正则解析函数
文章采集程序( ZBlog采集建站文章批量采集伪原创发布助手(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-05 16:18
ZBlog采集建站文章批量采集伪原创发布助手(图))
<p>ZBlog采集,当我们新建一个网站时,需要大量的内容来填充,内容采集是一种方式,效果很明显。站长圈里有一句话:想要你的网站快收录,就用ZBlog采集。ZBlog采集是一款非常实用的采集软件,可以帮助站长将文章放在采集目标网站之上,并且可以帮助站长把 查看全部
文章采集程序(文章采集伪原创工具实现便捷管理(一)链 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-05 13:20
)
我们的网站成立后,每天都有很多工作要做。许多SEOER每天都有类似的工作。主要工作是查看网站关键词的排名、网站收录情况、网站内容更新、发送外部链接、分析竞争对手数据等。 ,我们可以通过文章采集伪原创工具实现便捷的管理。
1、分析网站日志
网站日志记录了网站访问的全过程,谁从什么时候到什么时候来的,是什么搜索引擎来的,有没有收录我们的网页。因此,它可以收录在日常工作内容中,我们可以借助文章采集伪原创工具轻松分析日志,不会花费我们太多时间。
2、查看网站数据
一般来说,我们主要通过站长平台和统计后台查看数据,所花费的时间也不多。主要关注流量是否异常,增加或减少了哪些关键词,是否可以调整,是否有死链接,是否有异常状态码反馈。这些功能也可以在工具上查看
3、检查昨天收录
这对所有网站都不一样,毕竟有的网站更新频率低,但是每天保持更新还是有必要的。还是要查一下昨天收录的情况,再对比一周或者上周的情况,分析百度目前对网站内容的认可度。
4、保持内容更新
基本上没有什么大的 网站 一天不更新任何东西,当然周末除外。内容更新是为了保持网站的竞争力,增加网站的活跃度。甚至可以说,我们的文章收录和我们的更新频率可以影响我们的网站的权重。
文章采集伪原创工具可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
5、优化工作。
对于我们拥有多个 网站 的网站管理员来说,更新和维护 网站 内容是一项繁琐的任务。其实我们可以通过文章采集tools网站采集、伪原创、定时发布、推送等服务来实现。
文章采集伪原创工具可以在软件站实现不同的cms网站数据观察,有利于多个网站站长进行数据分析; batch 设置发布次数(可以设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、URL、程序、发布时间等;您可以在软件上查看收录、权重、蜘蛛等每日数据。
可以说,需要做的比较基础的seo内容就是上面这些了。只要每天不断更新优化,坚持数据分析和优化调整,总能达到理想的流量转化。
查看全部
文章采集程序(文章采集伪原创工具实现便捷管理(一)链
)
我们的网站成立后,每天都有很多工作要做。许多SEOER每天都有类似的工作。主要工作是查看网站关键词的排名、网站收录情况、网站内容更新、发送外部链接、分析竞争对手数据等。 ,我们可以通过文章采集伪原创工具实现便捷的管理。
https://www.seomao.com/wp-cont ... 3.png 500w, https://www.seomao.com/wp-cont ... 0.png 800w, https://www.seomao.com/wp-cont ... 7.png 768w" />1、分析网站日志
网站日志记录了网站访问的全过程,谁从什么时候到什么时候来的,是什么搜索引擎来的,有没有收录我们的网页。因此,它可以收录在日常工作内容中,我们可以借助文章采集伪原创工具轻松分析日志,不会花费我们太多时间。
https://www.seomao.com/wp-cont ... 2.png 500w, https://www.seomao.com/wp-cont ... 9.png 800w, https://www.seomao.com/wp-cont ... 3.png 768w" />2、查看网站数据
一般来说,我们主要通过站长平台和统计后台查看数据,所花费的时间也不多。主要关注流量是否异常,增加或减少了哪些关键词,是否可以调整,是否有死链接,是否有异常状态码反馈。这些功能也可以在工具上查看
3、检查昨天收录
这对所有网站都不一样,毕竟有的网站更新频率低,但是每天保持更新还是有必要的。还是要查一下昨天收录的情况,再对比一周或者上周的情况,分析百度目前对网站内容的认可度。
https://www.seomao.com/wp-cont ... 2.png 500w, https://www.seomao.com/wp-cont ... 9.png 800w, https://www.seomao.com/wp-cont ... 3.png 768w" />4、保持内容更新
基本上没有什么大的 网站 一天不更新任何东西,当然周末除外。内容更新是为了保持网站的竞争力,增加网站的活跃度。甚至可以说,我们的文章收录和我们的更新频率可以影响我们的网站的权重。
https://www.seomao.com/wp-cont ... 1.png 500w, https://www.seomao.com/wp-cont ... 7.png 800w, https://www.seomao.com/wp-cont ... 0.png 768w" />文章采集伪原创工具可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是站群,都可以轻松管理。
https://www.seomao.com/wp-cont ... 1.png 500w, https://www.seomao.com/wp-cont ... 8.png 800w, https://www.seomao.com/wp-cont ... 1.png 768w" />5、优化工作。
对于我们拥有多个 网站 的网站管理员来说,更新和维护 网站 内容是一项繁琐的任务。其实我们可以通过文章采集tools网站采集、伪原创、定时发布、推送等服务来实现。
文章采集伪原创工具可以在软件站实现不同的cms网站数据观察,有利于多个网站站长进行数据分析; batch 设置发布次数(可以设置发布次数/发布间隔);发布前的各种伪原创;软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、URL、程序、发布时间等;您可以在软件上查看收录、权重、蜘蛛等每日数据。
https://www.seomao.com/wp-cont ... 6.png 500w, https://www.seomao.com/wp-cont ... 5.png 800w, https://www.seomao.com/wp-cont ... 2.png 768w" />可以说,需要做的比较基础的seo内容就是上面这些了。只要每天不断更新优化,坚持数据分析和优化调整,总能达到理想的流量转化。
https://www.seomao.com/wp-cont ... 3.png 500w, https://www.seomao.com/wp-cont ... 0.png 800w, https://www.seomao.com/wp-cont ... 7.png 768w" /> 文章采集程序( 我通常不简单容许Java或用户端导航系统那么什么是呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-03 23:12
我通常不简单容许Java或用户端导航系统那么什么是呢?)
例如,当有另一个重大新闻(如地震)时,搜索引擎会在几秒钟内开始接管,第一个 文章 通常会在 15 分钟内出现在网络上。
如果广为人知的专家分享了某些东西,这可以被视为比不知名的人分享的更强烈的认可。
() 转到 网站 并提交 文章 并确保在作者列中链接到您的站点。
如何查看LinkPopularity 不同的搜索引擎对LinkPopularity 的计算和分析方法不同。
当时流量是3~3.50000个IP,而且还在稳步增长。
还要意识到 PageRank 是一个对数值,指向 PR7 或 PR8 页面的链接几乎比指向 PR3 或 PR2 或 PR4 页面的链接更有价值。
我通常不推荐简单的 Java 脚本或用户侧导航系统。
我觉得大部分站长没有必要对 TSPR 和 HillTop 有深入的了解和理解,只是为了了解这些算法的大致意图。
虽然这是一个非常好的节点链接,但许多搜索引擎更有可能惩罚租用链接的网站。
Step2:导航系统定制导航系统WebApp,搭建WebApp框架。
关键字短语:如果免费不是关键字,那是什么?关键字通常是您希望人们找到您的 2 到 5 个单词的短语 网站。
与使用词库或字典来推断两个单词是否相关不同,IR 系统可用于推断具有非常大的内容数据库的单词之间的关系。
当您开始构建您的网站时,您甚至不应该考虑这一点,您可能很难转换,但现在我要转换数百个页面。
花点时间确保您将网站提交到正确的类别并遵守他们的目录收录 指南。
与其他拍卖账户不同,本地拍卖没有 Overture 产品的每月最低消费限额。
图 2-27:Bing 图片搜索结果 图片搜索引擎上的搜索量令人难以置信。
结果中的高排名对 Lou Malnati 的比萨店来说可能是一件好事。
2.3.2 衡量内容质量和用户参与度搜索引擎也尝试衡量网站内容的质量和独特性。
107 为确保链接被搜索引擎索引,您需要验证您是否将鼠标悬停在目录中的某个站点上,如浏览器底部所示。
在正常情况下,降级是因为这些情况。
我并不是说“免费”不应该出现在你的页面上,它也在我的大部分页面上。
我的 SEO 书籍网站被过度修改,因为我是一个简单的首席艺术家;过度修改,因为我是一个糟糕的艺术设计师。
3612、与地理位置相关的词如果你的产品或服务是针对特定区域的用户,你可以在关键词前加上区域名称,比如省市名称。
请求放置您的 网站 最合适的下级类别。
如果那个加油站是网站:如果那个加油站是网站,我就不会离开了。
(有关此主题的更多信息,请参阅上述品牌推广的三个原则的内容。)
工具和人工谈判:有时我还建议一些我自己的资源。
PPC太贵了吗?暂停此活动并将其替换为 SEO。
iTunes 之后的Yahoo WebRank(TM) 工具栏有一个图标框架,显示每个采访URL 的WebRank(TM) 评级。
2.4.2其他排名因素到目前为止,我们只讨论了基本的排名因素。
一些感谢链接的网站是离题的,如果我的网站是新的并且他们的网站链接受欢迎程度非常高,我通常只会考虑请求链接。
由此可见,SEO过程影响网站架构策略(第6章)和链接构建策略(第7章介绍),辅助网站页面提供这些类型的信息具有竞争性搜索词的搜索引擎排名。
例如,他们无法从索引中得知“斑马”和“老虎”都是斑纹动物,尽管他们可能会发现斑纹和斑马在语义上比斑纹和鸭子更相关。
189 关于本次网站 的采访量的详细统计数据和图表可通过前一页的“SeeTrafficDetails”链接找到。
了解您为 关键词 使用的竞争程度的最糟糕方法是查看在搜索结果中对链接页面排名最低的少数网站的个人资料。
在大多数搜索引擎中,以下 52 个内容通常比元标记更重要。
如果他们看起来更友善,(允许填写关键字列表),您必须添加更多关键字描述文本。
网站面试官排名(Reachrank):根据面试官人数排名。
搜索引擎不喜欢的一种关键字六边形形式是在所有传入链接的锚文本中使用完全相同的关键字。
建议使用文字代替flash、图片、Javascript等来表示最重要的内容或链接连接。搜索引擎暂时无法识别Flash、图片、简单Javascript中的内容;同时,它只在flash和Javascript中不存在。带有链接的页面也可能无法用于百度移动搜索收录。
本次连接转移,基本步骤200同上,注意邮箱地址问题即可。
假设 3。
允许搜索引擎通过 SiteMap 访问整个站点上的所有页面和部分。
225 Paul Graham 是获得大量数据科学知识免费链接的作者的典型例子。
如果页面有更新,可以向副站长平台提交sitemap,加速百度收录。
例如,对于搜索词“petlemurdietaryneeds”,Google 不会显示“petlemurdietneeds”和其他变形的搜索结果。
如果页面 A 与页面 B 相关,而后者又与页面 C 相关,则假定 A 和 C 之间的链接是专家。
3.哪些人群是潜在受众。
考虑到构建搜索引擎的复杂性,83% 的满意度是一个了不起的成就,但研究仍然表明,多达 17% 的用户在寻找近乎必要的内容。
在百度,我的博客居然在“杂货网站”下排名第10,几天后又掉到了第二页。 查看全部
文章采集程序(
我通常不简单容许Java或用户端导航系统那么什么是呢?)
例如,当有另一个重大新闻(如地震)时,搜索引擎会在几秒钟内开始接管,第一个 文章 通常会在 15 分钟内出现在网络上。
如果广为人知的专家分享了某些东西,这可以被视为比不知名的人分享的更强烈的认可。
() 转到 网站 并提交 文章 并确保在作者列中链接到您的站点。
如何查看LinkPopularity 不同的搜索引擎对LinkPopularity 的计算和分析方法不同。
当时流量是3~3.50000个IP,而且还在稳步增长。
还要意识到 PageRank 是一个对数值,指向 PR7 或 PR8 页面的链接几乎比指向 PR3 或 PR2 或 PR4 页面的链接更有价值。
我通常不推荐简单的 Java 脚本或用户侧导航系统。
我觉得大部分站长没有必要对 TSPR 和 HillTop 有深入的了解和理解,只是为了了解这些算法的大致意图。
虽然这是一个非常好的节点链接,但许多搜索引擎更有可能惩罚租用链接的网站。
Step2:导航系统定制导航系统WebApp,搭建WebApp框架。
关键字短语:如果免费不是关键字,那是什么?关键字通常是您希望人们找到您的 2 到 5 个单词的短语 网站。
与使用词库或字典来推断两个单词是否相关不同,IR 系统可用于推断具有非常大的内容数据库的单词之间的关系。
当您开始构建您的网站时,您甚至不应该考虑这一点,您可能很难转换,但现在我要转换数百个页面。
花点时间确保您将网站提交到正确的类别并遵守他们的目录收录 指南。
与其他拍卖账户不同,本地拍卖没有 Overture 产品的每月最低消费限额。
图 2-27:Bing 图片搜索结果 图片搜索引擎上的搜索量令人难以置信。
结果中的高排名对 Lou Malnati 的比萨店来说可能是一件好事。
2.3.2 衡量内容质量和用户参与度搜索引擎也尝试衡量网站内容的质量和独特性。
107 为确保链接被搜索引擎索引,您需要验证您是否将鼠标悬停在目录中的某个站点上,如浏览器底部所示。
在正常情况下,降级是因为这些情况。
我并不是说“免费”不应该出现在你的页面上,它也在我的大部分页面上。
我的 SEO 书籍网站被过度修改,因为我是一个简单的首席艺术家;过度修改,因为我是一个糟糕的艺术设计师。
3612、与地理位置相关的词如果你的产品或服务是针对特定区域的用户,你可以在关键词前加上区域名称,比如省市名称。
请求放置您的 网站 最合适的下级类别。
如果那个加油站是网站:如果那个加油站是网站,我就不会离开了。
(有关此主题的更多信息,请参阅上述品牌推广的三个原则的内容。)
工具和人工谈判:有时我还建议一些我自己的资源。
PPC太贵了吗?暂停此活动并将其替换为 SEO。
iTunes 之后的Yahoo WebRank(TM) 工具栏有一个图标框架,显示每个采访URL 的WebRank(TM) 评级。
2.4.2其他排名因素到目前为止,我们只讨论了基本的排名因素。
一些感谢链接的网站是离题的,如果我的网站是新的并且他们的网站链接受欢迎程度非常高,我通常只会考虑请求链接。
由此可见,SEO过程影响网站架构策略(第6章)和链接构建策略(第7章介绍),辅助网站页面提供这些类型的信息具有竞争性搜索词的搜索引擎排名。
例如,他们无法从索引中得知“斑马”和“老虎”都是斑纹动物,尽管他们可能会发现斑纹和斑马在语义上比斑纹和鸭子更相关。
189 关于本次网站 的采访量的详细统计数据和图表可通过前一页的“SeeTrafficDetails”链接找到。
了解您为 关键词 使用的竞争程度的最糟糕方法是查看在搜索结果中对链接页面排名最低的少数网站的个人资料。
在大多数搜索引擎中,以下 52 个内容通常比元标记更重要。
如果他们看起来更友善,(允许填写关键字列表),您必须添加更多关键字描述文本。
网站面试官排名(Reachrank):根据面试官人数排名。
搜索引擎不喜欢的一种关键字六边形形式是在所有传入链接的锚文本中使用完全相同的关键字。
建议使用文字代替flash、图片、Javascript等来表示最重要的内容或链接连接。搜索引擎暂时无法识别Flash、图片、简单Javascript中的内容;同时,它只在flash和Javascript中不存在。带有链接的页面也可能无法用于百度移动搜索收录。
本次连接转移,基本步骤200同上,注意邮箱地址问题即可。
假设 3。
允许搜索引擎通过 SiteMap 访问整个站点上的所有页面和部分。
225 Paul Graham 是获得大量数据科学知识免费链接的作者的典型例子。
如果页面有更新,可以向副站长平台提交sitemap,加速百度收录。
例如,对于搜索词“petlemurdietaryneeds”,Google 不会显示“petlemurdietneeds”和其他变形的搜索结果。
如果页面 A 与页面 B 相关,而后者又与页面 C 相关,则假定 A 和 C 之间的链接是专家。
3.哪些人群是潜在受众。
考虑到构建搜索引擎的复杂性,83% 的满意度是一个了不起的成就,但研究仍然表明,多达 17% 的用户在寻找近乎必要的内容。
在百度,我的博客居然在“杂货网站”下排名第10,几天后又掉到了第二页。
文章采集程序(2019年10月28日更新:录制了一个YouTube视频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-02 19:19
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了步骤:
youtu.be/T-hVHJO0ya0
================================================
从2014年开始我就一直在做批量的内容采集,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集的内容很容易在里面传播。那个时候批量采集很容易做,采集入口就是历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而在本地新闻资讯类中定位采集,前端展示做成app。于是一个可以自动采集内容的新闻app就形成了。我曾经担心技术升级后的一天就无法采集内容了,我的新闻应用程序会失败。但随着技术的不断升级,采集的方法也不断升级,让我越来越自信。只要历史新闻页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个历史新闻页面的链接地址:
?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017 年 1 月 11 日更新==========
现在,根据不同的个人号码,会有两个不同的历史消息页地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的资料,两种页面形式不规则地以不同的编号出现,有的编号始终是第一页格式,有的始终是第二页格式。
上面的链接是历史新闻页面的真实链接,但是如果我们在浏览器中输入这个链接,会显示:请从客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一个链接//第二个 %2BeHsAqhbjJCwzTfV48u%2FCZRRGTmI8oqmHDxxfEL8ke%2B&_header=1
该地址是在客户端打开历史消息页面后,通过后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz是一个类似于id的参数,每个都有一个biz,目前这个biz会以极小概率发生变化的事件;
其余三个参数与用户的id和token相关,这三个参数的值在客户端生成后自动添加到地址栏。所以我们想通过客户端应用程序采集。在以前的版本中,这三个参数也可以在有效期内获取一次,然后多次使用。当前版本每次访问时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、客户端:可以是手机上安装的app,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios客户端的crash率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人号码:采集的内容不仅需要客户端,还需要采集专用的个人号码,因为这个号码不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将历史消息页面中的文章列表发送到自己的服务器上。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装客户端app,申请个人号,登陆app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。在 2016 年初开始使用带有 文章 的 https 链接。并且 Anyproxy 可以通过修改规则配置将脚本代码插入页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy –root(windows可能不需要sudo);————2019年10月28日更新:此行已过期!!!跳过这步
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或安卓模拟器中安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCrtFile,可以得到rootCA.crt文件方法二:启动anyproxy,:8002/qr_root可以得到证书路径的二维码,安装起来会更方便移动终端。将证书安装到手机中的代码。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开它,点击任何历史消息或文章,你可以看到响应码在终端滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。点击打开历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
以 /mp/getmasssendmsg 开头的 URL 是历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
部件号以/mp/getmasssendmsg开头的URL会有302跳转,跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改配置代理服务器,以便获取内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,同一个页面形式总是以不同的数字显示,但是为了兼容两种页面形式,下面的代码会保留对两种页面形式的判断。您也可以使用自己的页面表单。删除李
php 后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面,并返回显示})});}catch(e){//如果是以上正则不匹配,那么这个页面的内容可能是历史消息页面的第二页,因为历史消息的第一页是html格式,第二页是json格式。
try {var json = JSON.parse(serverResData.toString());if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数及以上后面定义一样,将第二页历史消息的json发送到自己的服务器} }catch(e){ console.log(e);//错误捕获}callback(serverResData);//直接返回前两页json内容}}}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为历史消息页时(第二页形式) try { var reg = /var msgList = \(.*?)\;/;//定义历史消息的正则匹配规则(不同于第一页形式) var ret = reg.exec(serverResData.toString()); //转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数后面定义,
getHis.php的原理后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入历史消息页面,返回显示})});}catch(e){callback(serverResData); }}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二页下页后的jsontry表示{var json = JSON.parse(serverResData.toString( ));if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数后面定义如上,发送第二页历史消息的json到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址是 文章 阅读并喜欢尝试 {HttpPost(serverResData,req.url,"getMsgExt.php");
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。使用此原理来批量 采集 内容和读取量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//向服务器发送json,str为json内容,url为历史消息页地址,path为接收程序的路径和文件名 var http = require( http);var data = {str: encodeURIComponent(str),url: encodeURIComponent(url)};content = require(querystring).stringify(data);var options = {method: "POST",host: "",/ /注意不是,这是服务器的域名。port: 80,path: path,//接收程序头的路径和文件名:{Content-Type: application/x-www-form-urlencoded; charset=UTF-8,"Content-Length": content.length} };var req = http.request(options, function (res) {res.setEncoding(utf8);res.on(data, function (chunk) {console.log(BODY: + chunk);}) ;});req.on(error, function (e) {console.log(problem with request: + e.message);});
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getHis.php、getPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){var newOption = option;if(/google/i.test(newOption.headers.host)){newOption.hostname = "";newOption.port = "80";}return newOption; },
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
再次重申,代码只是一个原则,部分观看代码需要自己编写。
2、getMsgExt.php 程序获取文章 浏览量和点赞
3、getHis.php和getPost.php这两个程序类似,一起介绍
=========2017 年 1 月 11 日更新==========
因为有两个页面表示,所以拼接历史消息页面的地址也应该改一下,但是目前即使客户端出现第二个页面表示,也可以发送第一个页面的链接地址,同样有效.
这两个程序的意思是:从队列表中读取下一个采集内容的信息,如果是历史消息页,则将biz拼接到地址中(注:评论区有些朋友认为key 和 pass_ticket 也需要拼接,但不需要),通过js输出到页面。如果下一项是文章,则将历史消息列表json中的文章地址直接输出为js。同理,文章内容的地址不收录uin、key等参数,由客户端自动补充。
这两个程序的细微差别是因为在读取历史消息页面的时候,anyproxy会同时做两件事情,一是把历史消息的json发送给服务器,二是获取链接地址到下一页。但是,这两个操作之间存在时间差。第一次读取下一页的地址时,应该已经获取到当前文章的第一个链接地址,但是此时历史消息的json还没有发送到服务器。,所以只能得到第二个历史消息页。读取第二个历史消息页后得到的下一页的地址是第一个的第一个文章的地址。当队列中还有一条记录时,需要获取下一个链接地址,否则如果队列为空再获取下一个链接地址,就会循环到上面提到的第一次读取。在这种情况下,会有两个历史消息列表,并穿插有文章采集。
刚才四个PHP程序提到了几个数据表,下面说说数据表是怎么设计的。这里只介绍一些主要领域。在实际应用中,会根据不同的程序添加其他必要的字段。
1、表格
CREATE TABLE “(`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) DEFAULT COMMENT 唯一 ID biz,`collect` int(11) DEFAULT 1 COMMENT记录采集时间的时间戳,PRIMARY KEY (`id`));
2、文章表格
CREATE TABLE `post` (`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT 文章对应的biz,`field_id` int (11) NOT NULL COMMENT 定义的 id,每个 文章 唯一,`title` varchar(255) NOT NULL DEFAULT COMMENT 文章 title, `title_encode` text CHARACTER SET utf8 NOT NULL COMMENT 文章 编码防止 文章 出现表情符号,`digest` varchar(500) NOT NULL DEFAULT COMMENT 文章digest,`content_url` varchar( 50< @0) CHARACTER SET utf8 NOT NULL COMMENT 文章Address,`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT 读取原地址,`cover` varchar(500)@ > CHARACTER SET utf8 NOT NULL COMMENT 封面图片,`is_multi` int(11)NOT NULL COMMENT 是多文本,`is_top` int(11) NOT NULL COMMENT 是标题,`datetime` int (11)NOT NULL COMMENT 文章Timestamp,`readNum` int (11) NOT NULL DEFAULT 1 COMMENT 文章Read amount,`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT 文章 Likes, PRIMARY KEY (`id`) ) ;
3、采集队列列表
CREATE TABLE `tmplist` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`content_url` varchar(255) DEFAULT NULL COMMENT 文章address,`load` int(1< @1) DEFAULT 0 COMMENT 阅读标记,主键(`id`),唯一键`content_url`(`content_url`));
以上是文章批量自动采集系统,由客户端、账号、anyproxy代理服务器、PHP程序、mysql数据库组成。
在下面的文章中,我将进一步详细介绍如何保存文章的内容,如何提高采集系统的稳定性,以及我在运行过程中获得的其他经验。系统。
持续更新,文章批量采集系统构建
文章采集的入口——历史新闻页面详解
文章页面分析和采集
提高文章采集的效率,anyproxy的高级用法 查看全部
文章采集程序(2019年10月28日更新:录制了一个YouTube视频)
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了步骤:
youtu.be/T-hVHJO0ya0
================================================
从2014年开始我就一直在做批量的内容采集,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集的内容很容易在里面传播。那个时候批量采集很容易做,采集入口就是历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而在本地新闻资讯类中定位采集,前端展示做成app。于是一个可以自动采集内容的新闻app就形成了。我曾经担心技术升级后的一天就无法采集内容了,我的新闻应用程序会失败。但随着技术的不断升级,采集的方法也不断升级,让我越来越自信。只要历史新闻页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个历史新闻页面的链接地址:
?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017 年 1 月 11 日更新==========
现在,根据不同的个人号码,会有两个不同的历史消息页地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的资料,两种页面形式不规则地以不同的编号出现,有的编号始终是第一页格式,有的始终是第二页格式。
上面的链接是历史新闻页面的真实链接,但是如果我们在浏览器中输入这个链接,会显示:请从客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一个链接//第二个 %2BeHsAqhbjJCwzTfV48u%2FCZRRGTmI8oqmHDxxfEL8ke%2B&_header=1
该地址是在客户端打开历史消息页面后,通过后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz是一个类似于id的参数,每个都有一个biz,目前这个biz会以极小概率发生变化的事件;
其余三个参数与用户的id和token相关,这三个参数的值在客户端生成后自动添加到地址栏。所以我们想通过客户端应用程序采集。在以前的版本中,这三个参数也可以在有效期内获取一次,然后多次使用。当前版本每次访问时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、客户端:可以是手机上安装的app,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios客户端的crash率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人号码:采集的内容不仅需要客户端,还需要采集专用的个人号码,因为这个号码不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将历史消息页面中的文章列表发送到自己的服务器上。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装客户端app,申请个人号,登陆app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。在 2016 年初开始使用带有 文章 的 https 链接。并且 Anyproxy 可以通过修改规则配置将脚本代码插入页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy –root(windows可能不需要sudo);————2019年10月28日更新:此行已过期!!!跳过这步
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或安卓模拟器中安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCrtFile,可以得到rootCA.crt文件方法二:启动anyproxy,:8002/qr_root可以得到证书路径的二维码,安装起来会更方便移动终端。将证书安装到手机中的代码。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开它,点击任何历史消息或文章,你可以看到响应码在终端滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。点击打开历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
以 /mp/getmasssendmsg 开头的 URL 是历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
部件号以/mp/getmasssendmsg开头的URL会有302跳转,跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改配置代理服务器,以便获取内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,同一个页面形式总是以不同的数字显示,但是为了兼容两种页面形式,下面的代码会保留对两种页面形式的判断。您也可以使用自己的页面表单。删除李
php 后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面,并返回显示})});}catch(e){//如果是以上正则不匹配,那么这个页面的内容可能是历史消息页面的第二页,因为历史消息的第一页是html格式,第二页是json格式。
try {var json = JSON.parse(serverResData.toString());if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数及以上后面定义一样,将第二页历史消息的json发送到自己的服务器} }catch(e){ console.log(e);//错误捕获}callback(serverResData);//直接返回前两页json内容}}}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为历史消息页时(第二页形式) try { var reg = /var msgList = \(.*?)\;/;//定义历史消息的正则匹配规则(不同于第一页形式) var ret = reg.exec(serverResData.toString()); //转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数后面定义,
getHis.php的原理后面会介绍。res.on(data, function(chunk){callback(chunk+serverResData);//将返回的代码插入历史消息页面,返回显示})});}catch(e){callback(serverResData); }}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二页下页后的jsontry表示{var json = JSON.parse(serverResData.toString( ));if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数后面定义如上,发送第二页历史消息的json到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址是 文章 阅读并喜欢尝试 {HttpPost(serverResData,req.url,"getMsgExt.php");
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。使用此原理来批量 采集 内容和读取量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//向服务器发送json,str为json内容,url为历史消息页地址,path为接收程序的路径和文件名 var http = require( http);var data = {str: encodeURIComponent(str),url: encodeURIComponent(url)};content = require(querystring).stringify(data);var options = {method: "POST",host: "",/ /注意不是,这是服务器的域名。port: 80,path: path,//接收程序头的路径和文件名:{Content-Type: application/x-www-form-urlencoded; charset=UTF-8,"Content-Length": content.length} };var req = http.request(options, function (res) {res.setEncoding(utf8);res.on(data, function (chunk) {console.log(BODY: + chunk);}) ;});req.on(error, function (e) {console.log(problem with request: + e.message);});
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getHis.php、getPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){var newOption = option;if(/google/i.test(newOption.headers.host)){newOption.hostname = "";newOption.port = "80";}return newOption; },
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
再次重申,代码只是一个原则,部分观看代码需要自己编写。
2、getMsgExt.php 程序获取文章 浏览量和点赞
3、getHis.php和getPost.php这两个程序类似,一起介绍
=========2017 年 1 月 11 日更新==========
因为有两个页面表示,所以拼接历史消息页面的地址也应该改一下,但是目前即使客户端出现第二个页面表示,也可以发送第一个页面的链接地址,同样有效.
这两个程序的意思是:从队列表中读取下一个采集内容的信息,如果是历史消息页,则将biz拼接到地址中(注:评论区有些朋友认为key 和 pass_ticket 也需要拼接,但不需要),通过js输出到页面。如果下一项是文章,则将历史消息列表json中的文章地址直接输出为js。同理,文章内容的地址不收录uin、key等参数,由客户端自动补充。
这两个程序的细微差别是因为在读取历史消息页面的时候,anyproxy会同时做两件事情,一是把历史消息的json发送给服务器,二是获取链接地址到下一页。但是,这两个操作之间存在时间差。第一次读取下一页的地址时,应该已经获取到当前文章的第一个链接地址,但是此时历史消息的json还没有发送到服务器。,所以只能得到第二个历史消息页。读取第二个历史消息页后得到的下一页的地址是第一个的第一个文章的地址。当队列中还有一条记录时,需要获取下一个链接地址,否则如果队列为空再获取下一个链接地址,就会循环到上面提到的第一次读取。在这种情况下,会有两个历史消息列表,并穿插有文章采集。
刚才四个PHP程序提到了几个数据表,下面说说数据表是怎么设计的。这里只介绍一些主要领域。在实际应用中,会根据不同的程序添加其他必要的字段。
1、表格
CREATE TABLE “(`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) DEFAULT COMMENT 唯一 ID biz,`collect` int(11) DEFAULT 1 COMMENT记录采集时间的时间戳,PRIMARY KEY (`id`));
2、文章表格
CREATE TABLE `post` (`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT 文章对应的biz,`field_id` int (11) NOT NULL COMMENT 定义的 id,每个 文章 唯一,`title` varchar(255) NOT NULL DEFAULT COMMENT 文章 title, `title_encode` text CHARACTER SET utf8 NOT NULL COMMENT 文章 编码防止 文章 出现表情符号,`digest` varchar(500) NOT NULL DEFAULT COMMENT 文章digest,`content_url` varchar( 50< @0) CHARACTER SET utf8 NOT NULL COMMENT 文章Address,`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT 读取原地址,`cover` varchar(500)@ > CHARACTER SET utf8 NOT NULL COMMENT 封面图片,`is_multi` int(11)NOT NULL COMMENT 是多文本,`is_top` int(11) NOT NULL COMMENT 是标题,`datetime` int (11)NOT NULL COMMENT 文章Timestamp,`readNum` int (11) NOT NULL DEFAULT 1 COMMENT 文章Read amount,`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT 文章 Likes, PRIMARY KEY (`id`) ) ;
3、采集队列列表
CREATE TABLE `tmplist` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`content_url` varchar(255) DEFAULT NULL COMMENT 文章address,`load` int(1< @1) DEFAULT 0 COMMENT 阅读标记,主键(`id`),唯一键`content_url`(`content_url`));
以上是文章批量自动采集系统,由客户端、账号、anyproxy代理服务器、PHP程序、mysql数据库组成。
在下面的文章中,我将进一步详细介绍如何保存文章的内容,如何提高采集系统的稳定性,以及我在运行过程中获得的其他经验。系统。
持续更新,文章批量采集系统构建
文章采集的入口——历史新闻页面详解
文章页面分析和采集
提高文章采集的效率,anyproxy的高级用法
文章采集程序(共享一下我的采集代码!思路:采集程序的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-01 07:19
2021-09-19
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里,第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = \"gameswf\/(.*?)\.swf\";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fope。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。
分类:
技术要点:
相关文章: 查看全部
文章采集程序(共享一下我的采集代码!思路:采集程序的思路)
2021-09-19
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里,第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = \"gameswf\/(.*?)\.swf\";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fope。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。
分类:
技术要点:
相关文章:
文章采集程序(零门槛使用无需采集器打磨集搜客GooSeeker技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-31 06:06
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年在互联网数据采集软件排行榜中排名第一。自2016年起,优采云积极开拓海外市场,分别在美国和日本推出数据爬虫平台Octoparse和Octoparse.jp。截至 2019 年,优采云全球用户超过 150 万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
国内老牌data采集软件以灵活的配置和强大的性能领先于国内同类产品,得到了众多用户的一致认可。使用优采云采集器几乎所有的网页和任何格式的文件,不管是什么语言或编码。采集7 倍于普通 采集器,采集/posting 与复制/粘贴一样准确。同时,软件还拥有“舆情雷达监测测控系统”,能够准确监测网络数据的信息安全,及时对不利或危险信息进行预警和处理。
如果买友网小编推荐一款信息最有用的采集软件,那一定是优采云采集器。优采云采集器原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键式采集;并且软件支持Linux、Windows和Mac三种操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,与其他同类软件相比,仅此一项就足够良心了。
经过十多年的打磨,GooSeeker 是一款易用性也非常出色的数据采集软件。它的特点是对所有可用数据进行可视化标注,用户不需要程序思维或技术基础,只需点击想要的内容,给标签起个名字,软件就会自动对选中的数据进行管理。内容,自动采集到排序框,并保存为xml或excel结构。此外,软件还具备模板资源申请、会员互助抓拍、手机网站数据抓拍、定时自启动采集等功能。
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章的内容抓取,通过相关配置,您可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让你的采集更加强大。
英国市场最著名的采集器之一,由英国伦敦的一家公司开发,现已在美国、印度等地设立分公司。import.io 作为网页数据采集 软件,具有四大功能特性,即Magic、Extractor、Crawler、Connector。主要功能一应俱全,但最吸引眼球、最好的功能就是其中的“魔法”,该功能允许用户只进入一个网页并自动提取数据,无需任何其他设置,使用起来极其简单。
ForeSpider也是一款操作简单,深受用户推荐的信息采集软件。它分为免费版和付费版。具有可视化向导式操作界面,日志管理和异常情况预警,免安装免安装数据库,可自动识别语义过滤数据,智能挖掘文本特征数据,自带多种数据清洗方式和可视化图表分析. 软件免费版、基础版、专业版采集速度可达400万件/天,服务器版采集速度可达8000万件/天,并提供生成采集的服务。
优采云是应用最广泛的信息采集软件之一,它封装了复杂的算法和分布式逻辑,并提供了灵活简单的开发接口;应用自动分布式部署,可视化操作简单,弹性扩展计算和存储资源;对不同来源的数据进行统一可视化管理,RESTful接口/webhook push/graphql访问等高级功能让用户无缝连接现有系统。该软件现在提供企业标准版、高级版和企业定制版。
ParseHub 是一个基于 Web 的爬虫客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制从 网站 分析获取数据。它还可以使用机器学习技术识别复杂的文档,并以 JSON、CSV 等格式导出文件。软件支持可用于 Windows、Mac 和 Linux,或作为 Firefox 扩展。此外,它还具有一些高级功能,如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
Content Grabber 是一个可视化网络数据采集软件和网络自动化工具,支持智能抓取,从几乎任何网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。您可以使用 C# 或 VB.NET 来调试或编写脚本来控制爬虫。它还支持向爬虫工具添加第三方扩展。凭借一整套功能,Content Grabber 对于有技术基础的用户来说非常强大。 查看全部
文章采集程序(零门槛使用无需采集器打磨集搜客GooSeeker技术)
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年在互联网数据采集软件排行榜中排名第一。自2016年起,优采云积极开拓海外市场,分别在美国和日本推出数据爬虫平台Octoparse和Octoparse.jp。截至 2019 年,优采云全球用户超过 150 万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
国内老牌data采集软件以灵活的配置和强大的性能领先于国内同类产品,得到了众多用户的一致认可。使用优采云采集器几乎所有的网页和任何格式的文件,不管是什么语言或编码。采集7 倍于普通 采集器,采集/posting 与复制/粘贴一样准确。同时,软件还拥有“舆情雷达监测测控系统”,能够准确监测网络数据的信息安全,及时对不利或危险信息进行预警和处理。
如果买友网小编推荐一款信息最有用的采集软件,那一定是优采云采集器。优采云采集器原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键式采集;并且软件支持Linux、Windows和Mac三种操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,与其他同类软件相比,仅此一项就足够良心了。
经过十多年的打磨,GooSeeker 是一款易用性也非常出色的数据采集软件。它的特点是对所有可用数据进行可视化标注,用户不需要程序思维或技术基础,只需点击想要的内容,给标签起个名字,软件就会自动对选中的数据进行管理。内容,自动采集到排序框,并保存为xml或excel结构。此外,软件还具备模板资源申请、会员互助抓拍、手机网站数据抓拍、定时自启动采集等功能。
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章的内容抓取,通过相关配置,您可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让你的采集更加强大。
英国市场最著名的采集器之一,由英国伦敦的一家公司开发,现已在美国、印度等地设立分公司。import.io 作为网页数据采集 软件,具有四大功能特性,即Magic、Extractor、Crawler、Connector。主要功能一应俱全,但最吸引眼球、最好的功能就是其中的“魔法”,该功能允许用户只进入一个网页并自动提取数据,无需任何其他设置,使用起来极其简单。
ForeSpider也是一款操作简单,深受用户推荐的信息采集软件。它分为免费版和付费版。具有可视化向导式操作界面,日志管理和异常情况预警,免安装免安装数据库,可自动识别语义过滤数据,智能挖掘文本特征数据,自带多种数据清洗方式和可视化图表分析. 软件免费版、基础版、专业版采集速度可达400万件/天,服务器版采集速度可达8000万件/天,并提供生成采集的服务。
优采云是应用最广泛的信息采集软件之一,它封装了复杂的算法和分布式逻辑,并提供了灵活简单的开发接口;应用自动分布式部署,可视化操作简单,弹性扩展计算和存储资源;对不同来源的数据进行统一可视化管理,RESTful接口/webhook push/graphql访问等高级功能让用户无缝连接现有系统。该软件现在提供企业标准版、高级版和企业定制版。
ParseHub 是一个基于 Web 的爬虫客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制从 网站 分析获取数据。它还可以使用机器学习技术识别复杂的文档,并以 JSON、CSV 等格式导出文件。软件支持可用于 Windows、Mac 和 Linux,或作为 Firefox 扩展。此外,它还具有一些高级功能,如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
Content Grabber 是一个可视化网络数据采集软件和网络自动化工具,支持智能抓取,从几乎任何网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。您可以使用 C# 或 VB.NET 来调试或编写脚本来控制爬虫。它还支持向爬虫工具添加第三方扩展。凭借一整套功能,Content Grabber 对于有技术基础的用户来说非常强大。

