文章采集程序(Java编写的系统能够每秒可以访问几十万个网页的分布式网络爬虫系统)
优采云 发布时间: 2022-04-17 09:21文章采集程序(Java编写的系统能够每秒可以访问几十万个网页的分布式网络爬虫系统)
在大数据时代,数据采集或网络爬虫似乎是每个程序员必备的技能。一般来说,工程师会通过Python爬虫框架快速编写爬虫程序来抓取网页数据。当规模数据采集不是一个简单的爬虫。比如分布式爬虫系统为我们的舆情系统(/stonedtx/yuqing)和开源情报系统(/stonedtx/open-source-intelligence)提供了大量的数据支持。
在这里,给大家介绍一个每秒可以访问几十万网页的Java编写的分布式网络爬虫系统!
在本期文章中,我将与大家分享我们多年来在爬虫构建和优化方面的经验和教训。
这就是我们大型分布式爬虫系统的系统(操作界面),我们称自己为:爬虫工厂。
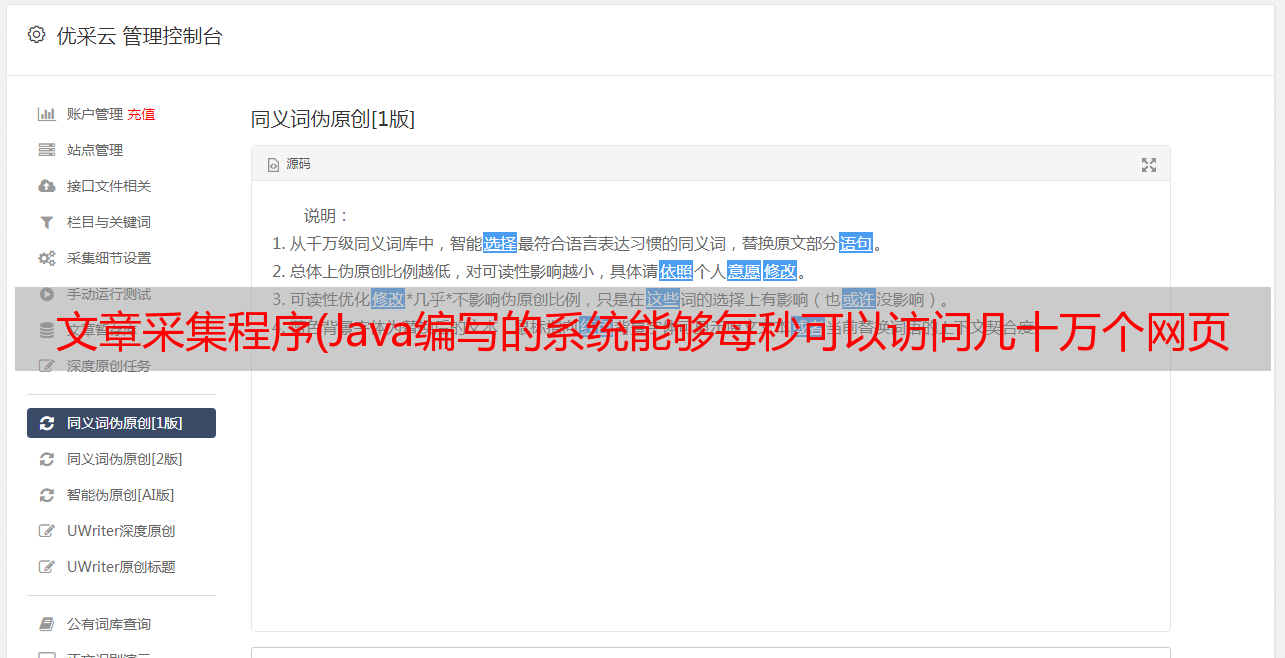
这就是我们即将推出的“开源智能”系统中的“数据管理”(数据中心)子系统。
通过这么多项目的实战经验和经验,以及与市场和客户的不断碰撞,造就了我们强大的数据采集能力。
一、编程语言
在为项目选择编程语言时,许多因素会影响我们的最终决定。中间我们尝试了python和Go中的爬虫和分布式爬虫方案。我们在内部专业知识、生态系统等方面寻找“完美”的编程语言解决方案。最终,我们决定 Java 是我们的最佳选择,原因如下:
1.内部专长:我们的团队成员拥有丰富的Java专业知识,有数位Java开发“老司机”在分布式系统和网络方面有10年、15年、20年的经验他在分布式系统和网络开发方面有丰富的实践经验高并发和海量数据存储。
2.现有的软件框架:大型网络爬虫需要建立在经过验证的、健壮的、可扩展的和安全的网络、系统和实用程序模块上。Java 拥有最活跃的开源生态系统,尤其是在网络和分布式应用程序方面。Netty、SpringBoot、Google Guava 等包证明了 Java 生态系统拥有高质量的开源模块。
3.现有的项目集成:Hadoop、Cassandra、Kafka、Elasticsearch 都是用 Java 开发的大型分布式系统项目,因为这个生态系统给我们带来了丰富而强大的基础以及灵感和先例。这使得在 Java 中开发高性能数据驱动应用程序的过程更容易、更实惠。
4.Java的动态语言:动态语言用于我们最新的分布式爬虫系统。我们通过模板生成动态语言代码并存储在 MySQL 中,让大量爬虫可视化和低代码化。大大降低了维护成本和爬虫开发成本。
5.原创性能和可靠性:在性能和可靠性方面,Java 具有静态类型、健壮的垃圾采集和久经考验的虚拟机等最重要的特性。
在核心网络爬虫引擎用 Java 编写的同时,我们还使用 Python 和 Node.js 等其他语言编写子系统,用于自然语言处理、深度学习算法、监控、报告和管道的其他部分。
我们的分布式爬虫集群采用单点无架构,将工作负载拆分并分布在独立的无状态节点上,可以消除*敏*感*词*分布式系统中的灾难(单点故障)。此外,该架构允许我们逐个节点更新和升级底层软件,而不会中断整个操作。
二、请求率和访问安全
网站 主要是为人工访问而设计的,普通用户每分钟只能浏览几页。网络爬虫每秒可以访问数千甚至数百万的网页,所以如果不小心,网络爬虫很容易在短时间内耗尽网站资源,造成毁灭性的后果。另外,普通的 网站 会有多个机器人同时抓取,所以问题会被放大。
因此,限制自己的请求率也是每个网络爬虫的责任,也就是说,保证两次连续访问之间有适当的延迟,这个工作一定不能容忍错误,否则请求网站而且本身会产生不利的反应。
三、缓存为王
在构建*敏*感*词*分布式数据应用系统的情况下,系统缓存是必不可少的,尤其是在网络输入输出频繁、开销较大的情况下。
例如场景一:在*敏*感*词*网页爬取的情况下,为了避免重复的数据爬取和后续的重复数据处理,需要对每个URL进行获取和存储。因此,您需要构建一个分布式预读缓存,可以保存并定期更新数百万个网站 数亿个 URL 地址。
比如场景2:减少dns请求,提升data采集的性能。对于绝大多数 URL,您需要执行至少一个 DNS 解析才能下载,每秒添加数千个查询。因此,DNS 服务器势必会限制您的访问,或在重负载下崩溃。无论哪种情况,爬虫都会停止,唯一的解决办法就是尽可能缓存DNS解析结果,尽量减少不必要的查询。
四、解析 HTML
爬虫的基本任务之一是从它访问的每个页面中提取它需要的数据。在*敏*感*词*数据抓取的情况下,最好有一个高性能的 HTML 解析器,因为您需要提取大量链接和元数据。大多数 HTML 解析库优先考虑简单性、易用性和*敏*感*词*性,这通常是正确的设计。由于我们需要高速链接提取,我们最终决定编写自己的解析器,针对查找链接和一些原创 DOM 查询功能进行了优化。HTML 解析器还需要有弹性、经过全面测试,并且能够处理出现的大量异常,因为并非每个 HTML 文档都是有效的。
我们目前即将开源data采集系统,集成了微软开源playwright()的js渲染解析引擎。这样,我们在开发爬虫的过程中,就不需要考虑js网页数据的问题,大大提高了我们网站爬虫的开发效率。
五、网络和系统优化
通常操作系统的默认配置无法处理大型网络爬虫的网络需求。通常,我们需要优化操作系统的网络堆栈,以根据具体情况最大限度地发挥其潜力。对于大型网络爬虫来说,优化的目标是最大化吞吐量和打开的连接数。
以下是我们经常遇到并需要优化的问题和场景:
1.Linux系统性能参数
什么工具用于一般的 Linux 性能调优?- 知乎
2.Web服务器性能优化
Java web 服务器性能优化策略?- 知乎
3.Java JVM 性能优化
用于 Java 性能优化的 JVM GC(垃圾采集机制) - 知乎
开源项目地址:

