
文章采集接口
文章采集接口(【Kaggle】图像库是格式化为模型标准)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-03-11 12:21
本文章主要介绍“如何使用python构建图像采集界面应用”。在日常操作中,相信很多人对于如何使用python构建一个image采集界面应用程序都有疑问。如有疑问,小编查阅了各种资料,整理出了简单好用的操作方法。希望能帮助大家解答“如何使用python构建图像采集界面应用”的疑惑!接下来就跟着小编一起来学习吧!
安装 cv2 (OpenCV)
我们将使用的图像库是 cv2。因为 cv2 不能在 Kaggle 等在线平台上运行,所以必须在您的计算机上本地完成。然而,模型的权重仍然可以在 Kaggle 上进行训练,下载为 .h6 文件(基于 Keras/TensorFlow)并加载。
输入 Anaconda 或命令提示符
conda create -n opencv python=3.6
这将在 Python 版本 3.6 中创建一个名为 opencv 的新环境,可以将其替换为正在使用的任何版本。
接下来,输入
pip install opencv-python
您已成功安装 cv2!现在你可以开始拍照了。
用 CV2 拍照
首先,导入库。
import cv2
接下来,我们必须创建一个视频捕获实例。您可以测试该实例是否能够连接到您的相机(如果不能,请检查您的设置以确保应用可以访问它)。
cap = cv2.VideoCapture(0)
if not (cap.isOpened()):
print("Video device not connected.")
最后,是时候拍照了。如果要控制何时拍摄照片,第一行将指定任意变量和输入。程序无法继续,除非输入某些内容(例如按“enter”)并且下一行开始拍照。拍摄图像时,您可能会很快看到网络摄像头指示灯出现。第三行关闭连接,第四行销毁所有访问相机的实例。
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
图像中的数据存储在帧中。可以使用以下代码将其转换为数组:
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
调用cv2_im.shape时,输出为(480640,3)。所以图像(对于我的相机)是480x640像素(3表示“深度”,每个像素中有三个值描述最终像素创建的颜色需要包括红色、绿色和蓝色)。
现在图像已经转换为数组,matplotlib 的 imshow() 可以显示它。
import matplotlib.pyplot as plt
plt.imshow(cv2_im)
plt.show()
完整代码:
import cv2
import matplotlib.pyplot as plt
cap = cv2.VideoCapture(10)
if not (cap.isOpened()):
print("Video device unconnected.")
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
plt.imshow(cv2_im)
plt.show()
格式化为模型标准
卷积神经网络只接受固定大小的图像,例如 (100, 100, 3)。有几种方法可以做到这一点。
要保持图像的比例长度,请尝试裁剪图像。
一般语法是:
plt.imshow(cv2_im[y_upper_bound:y_lower_bound,x_lower_bound:x_higher_bound])
其中“上”和“下”由图像上的位置确定(y 的“上”表示图像上方,x 的“上”表示图像的右侧)。
例如,
plt.imshow(cv2_im[100:400,100:400])
在这里,照片被裁剪成一个正方形。
但是,尺寸仍然是 300×300。为了解决这个问题,我们将再次使用 Pillow:
pil_image = Image.fromarray(cv2_im[100:400,100:400])
width = 100
height = 100
pil_image = pil_image.resize((width,height), Image.ANTIALIAS)
NumPy 自动将 Pillow 图像转换为数组。
import numpy as np
cv2_im_new = np.array(pil_image)
查看新图像:
plt.imshow(cv2_im_new)
好多了!图像的新形状是 (100, 100, 3),非常适合我们的模型。
在模型中运行
现在我们有了一个 NumPy 数组,只需将它传递给模型。
model.predict(cv2_im_new)
基于此,通过一些手工编码来标记图像的真实标签,您可以在标题中标记它们:
plt.imshow(cv2_im_new)
plt.title('Hand Gesture: '+classification)
至此,关于《如何使用python构建图像采集界面应用》的学习就结束了,希望能解决大家的疑惑。理论与实践相结合更能帮助大家学习,快去试试吧!如果你想继续学习更多相关知识,请继续关注易速云网站,小编会继续努力为大家带来更多实用文章! 查看全部
文章采集接口(【Kaggle】图像库是格式化为模型标准)
本文章主要介绍“如何使用python构建图像采集界面应用”。在日常操作中,相信很多人对于如何使用python构建一个image采集界面应用程序都有疑问。如有疑问,小编查阅了各种资料,整理出了简单好用的操作方法。希望能帮助大家解答“如何使用python构建图像采集界面应用”的疑惑!接下来就跟着小编一起来学习吧!
安装 cv2 (OpenCV)
我们将使用的图像库是 cv2。因为 cv2 不能在 Kaggle 等在线平台上运行,所以必须在您的计算机上本地完成。然而,模型的权重仍然可以在 Kaggle 上进行训练,下载为 .h6 文件(基于 Keras/TensorFlow)并加载。
输入 Anaconda 或命令提示符
conda create -n opencv python=3.6
这将在 Python 版本 3.6 中创建一个名为 opencv 的新环境,可以将其替换为正在使用的任何版本。
接下来,输入
pip install opencv-python
您已成功安装 cv2!现在你可以开始拍照了。
用 CV2 拍照
首先,导入库。
import cv2
接下来,我们必须创建一个视频捕获实例。您可以测试该实例是否能够连接到您的相机(如果不能,请检查您的设置以确保应用可以访问它)。
cap = cv2.VideoCapture(0)
if not (cap.isOpened()):
print("Video device not connected.")
最后,是时候拍照了。如果要控制何时拍摄照片,第一行将指定任意变量和输入。程序无法继续,除非输入某些内容(例如按“enter”)并且下一行开始拍照。拍摄图像时,您可能会很快看到网络摄像头指示灯出现。第三行关闭连接,第四行销毁所有访问相机的实例。
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
图像中的数据存储在帧中。可以使用以下代码将其转换为数组:
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
调用cv2_im.shape时,输出为(480640,3)。所以图像(对于我的相机)是480x640像素(3表示“深度”,每个像素中有三个值描述最终像素创建的颜色需要包括红色、绿色和蓝色)。
现在图像已经转换为数组,matplotlib 的 imshow() 可以显示它。
import matplotlib.pyplot as plt
plt.imshow(cv2_im)
plt.show()

完整代码:
import cv2
import matplotlib.pyplot as plt
cap = cv2.VideoCapture(10)
if not (cap.isOpened()):
print("Video device unconnected.")
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
plt.imshow(cv2_im)
plt.show()
格式化为模型标准
卷积神经网络只接受固定大小的图像,例如 (100, 100, 3)。有几种方法可以做到这一点。
要保持图像的比例长度,请尝试裁剪图像。
一般语法是:
plt.imshow(cv2_im[y_upper_bound:y_lower_bound,x_lower_bound:x_higher_bound])
其中“上”和“下”由图像上的位置确定(y 的“上”表示图像上方,x 的“上”表示图像的右侧)。
例如,
plt.imshow(cv2_im[100:400,100:400])

在这里,照片被裁剪成一个正方形。
但是,尺寸仍然是 300×300。为了解决这个问题,我们将再次使用 Pillow:
pil_image = Image.fromarray(cv2_im[100:400,100:400])
width = 100
height = 100
pil_image = pil_image.resize((width,height), Image.ANTIALIAS)
NumPy 自动将 Pillow 图像转换为数组。
import numpy as np
cv2_im_new = np.array(pil_image)
查看新图像:
plt.imshow(cv2_im_new)
好多了!图像的新形状是 (100, 100, 3),非常适合我们的模型。
在模型中运行
现在我们有了一个 NumPy 数组,只需将它传递给模型。
model.predict(cv2_im_new)
基于此,通过一些手工编码来标记图像的真实标签,您可以在标题中标记它们:
plt.imshow(cv2_im_new)
plt.title('Hand Gesture: '+classification)

至此,关于《如何使用python构建图像采集界面应用》的学习就结束了,希望能解决大家的疑惑。理论与实践相结合更能帮助大家学习,快去试试吧!如果你想继续学习更多相关知识,请继续关注易速云网站,小编会继续努力为大家带来更多实用文章!
文章采集接口(这是我参与2022首次更文挑战(第15天))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-08 20:28
“这是我参加2022首次更新挑战的第15天,活动详情请查看:2022首次更新挑战。”
欢迎小伙伴们微信搜索“安迪阿辉”并关注一波!
写一些程序员的想法和想法,希望对你有帮助。
前言
上一篇文章我们简单了解了接口的定义,那么接口应该怎么使用,使用接口的作用有哪些。
那我们就跟着这个文章来看看吧。
一流企业做标准,二流企业做品牌,三流企业做产品?
在编程中细化业务,使用接口实现部分代码。
具有以下优点:
在进行系统设计、模块设计甚至对象设计时,您应该考虑更高级别的抽象——即接口,而不是陷入实现细节。
要清楚地认识到,界面设计是我们系统设计的主要工作内容。而这种能够跳出细节,站在更高的抽象层次去看待整个系统的模块设计、模块划分、模块交互的人,是非常重要的。
那我们就需要好好利用接口了。
接口使用
简单接口的转换是使用强制类型实现的。
Ahui ahui=new Ahui();
IBaseInfo baseInfo=(IBaseInfo)ahui; //获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
其实C#中有一个操作符也可以达到这个效果。
作为运营商
在接口转换过程中,如果转换失败,会抛出异常。如果使用 as 运算符,即使转换失败,程序也不会失败,会自动返回 null。
Ahui ahui=new Ahui();
IBaseInfo baseInfo = ahui as IBaseInfo; //as运算符 获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
实现多个接口
在实际的编程过程中,一个类可以实现多个接口。需要注意的是,所有实现的接口都用逗号分隔。如果实现中有基类,接口必须排在基类之后。
interface IBaseAction
{
bool isLove();
}
class Ahui : IBaseInfo, IBaseAction
{
public int Age()
{
return 28;
}
public string Name()
{
return "阿辉";
}
public bool isLove()
{
return true;
}
}
复制代码
这里需要注意的是,如果一个类实现的多个接口中的某些成员具有相同的签名和返回类型,那么该类可以实现单个成员来满足所有收录重复成员的接口。
接口可以使用派生成员来实现,这意味着实现接口的类可以从其基类继承实现代码。
前面我们说过,接口是一个特殊的类,一个类一般都有函数式接口。那么类可以通过继承实现一些方法的公开,那么接口也可以被继承。但是接口继承也有一些注意事项。
interface IBaseInfo:IBaseAction
{
int Age();
string Name();
}
interface IBaseAction
{
bool isLove();
}
复制代码
信息
人生苦短,我不想去追求我看不到的,我只想抓住我能看到的。
原创不容易,给我点关注。
我是阿辉,感谢您的阅读,如果对您有帮助,请点赞转发。谢谢你。 查看全部
文章采集接口(这是我参与2022首次更文挑战(第15天))
“这是我参加2022首次更新挑战的第15天,活动详情请查看:2022首次更新挑战。”
欢迎小伙伴们微信搜索“安迪阿辉”并关注一波!
写一些程序员的想法和想法,希望对你有帮助。
前言
上一篇文章我们简单了解了接口的定义,那么接口应该怎么使用,使用接口的作用有哪些。
那我们就跟着这个文章来看看吧。
一流企业做标准,二流企业做品牌,三流企业做产品?
在编程中细化业务,使用接口实现部分代码。
具有以下优点:
在进行系统设计、模块设计甚至对象设计时,您应该考虑更高级别的抽象——即接口,而不是陷入实现细节。
要清楚地认识到,界面设计是我们系统设计的主要工作内容。而这种能够跳出细节,站在更高的抽象层次去看待整个系统的模块设计、模块划分、模块交互的人,是非常重要的。
那我们就需要好好利用接口了。
接口使用
简单接口的转换是使用强制类型实现的。
Ahui ahui=new Ahui();
IBaseInfo baseInfo=(IBaseInfo)ahui; //获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
其实C#中有一个操作符也可以达到这个效果。
作为运营商
在接口转换过程中,如果转换失败,会抛出异常。如果使用 as 运算符,即使转换失败,程序也不会失败,会自动返回 null。
Ahui ahui=new Ahui();
IBaseInfo baseInfo = ahui as IBaseInfo; //as运算符 获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
实现多个接口
在实际的编程过程中,一个类可以实现多个接口。需要注意的是,所有实现的接口都用逗号分隔。如果实现中有基类,接口必须排在基类之后。
interface IBaseAction
{
bool isLove();
}
class Ahui : IBaseInfo, IBaseAction
{
public int Age()
{
return 28;
}
public string Name()
{
return "阿辉";
}
public bool isLove()
{
return true;
}
}
复制代码
这里需要注意的是,如果一个类实现的多个接口中的某些成员具有相同的签名和返回类型,那么该类可以实现单个成员来满足所有收录重复成员的接口。
接口可以使用派生成员来实现,这意味着实现接口的类可以从其基类继承实现代码。
前面我们说过,接口是一个特殊的类,一个类一般都有函数式接口。那么类可以通过继承实现一些方法的公开,那么接口也可以被继承。但是接口继承也有一些注意事项。
interface IBaseInfo:IBaseAction
{
int Age();
string Name();
}
interface IBaseAction
{
bool isLove();
}
复制代码
信息
人生苦短,我不想去追求我看不到的,我只想抓住我能看到的。
原创不容易,给我点关注。
我是阿辉,感谢您的阅读,如果对您有帮助,请点赞转发。谢谢你。
文章采集接口(DiscuzX3正式版门户文章接口使用手册(discuz!X3.0))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-06 09:00
Discuz X3正式版传送门文章界面使用手册一、介绍1、此界面适用于discuz!X3正式版discuz!X3.0 正式版6、 in discuz! X3.0 正式版7、这个界面是基于discuz!X3.0 正式版 discuz! X3.0 正式版8、接口文件无需任何改动即可使用,如需添加验证或其他功能,请谨慎修改;9、2个接口文件,请复制到discuz中!X3.0 etchk.php正式版,etpost.php,将接口文件复制到指定目录,远程FTP上传到指定目录。请以二进制方式上传,如图:三、配置发布规则1、 将示例发布规则的文本导入ET2发布配置中,或者使用软件内置发布规则示例,如图:2、在巡检URL中修改“your网站”, 网站你要发布的URL的发布URL,如图:3、在参数值中,填写你要发布的频道ID,如图:打开门户管理发布文章页面,可以查看频道ID,即catid的值:5、填写你的账号、密码,注意格式和账号权限(账号应该有portal文章频道管理权限),如图:四、接口说明一、查看接口1、接口文件名etck。php, 为保密起见,请自行修改文件名;2、这个接口文件复制到网站根目录下使用;3、主要参数title文章title catid类别ID用于限制检查范围。它可以留空。请在管理中心查看分类ID;请自行设置vercode校验码,修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/etchk.php?vercode=&catid=&title= 注意:用户使用区分大小写的服务器,请注意URL大小写与网站文件一致5、接口文件无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名为etpost.php,为保密请自行修改文件名;2、 请将该接口文件复制到网站根目录下使用;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;具有固定值的参数可以在发布规则-参数值中设置;采集 带值的参数项,请在发布规则-发布项中添加;3、参数用户名会员名参数名密码密码参数名标题主题标题参数名内容内容参数名(分页请替换ET2文本分隔符“#-0-#” 与discuz!x 分页标记 "#########NextPage#### ######""#########NextPage[title=页面标题] ###### ####")4、参数catid文章分类号(请参考管理中心文章分类)vercode安全验证码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站相同file5、接口文件无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;注:以下参数名称后面有“=”号,用于示范值选择,参数名称本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换带 discuz!x 分页标签 "##########NextPage##########" " #########NextPage[title=页面标题]##########”)4、参数catid文章分类号(请参考管理中心文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站文件< @5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;笔记:后面的参数名后面有一个“=”号,用于演示取值,参数名本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换with discuz! x 分页标签 "##########NextPage##########" "##########NextPage[title=页面标题] ### #######”)4、参数catid文章类别号(请参考管理中心< @文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。 参数用户名 会员名 参数名 密码 参数名 题目 题目 参数名 内容 内容 参数名(如果要分页,请替换ET2文本分隔标记“#- 0-#" with discuz! x 分页标记 "# #########NextPage##########""#########NextPage[title=页面标题] ##########" )4、参数catid文章类别号(请参考管理中心文章类别)vercode安全校验码,请设置自己,这个项目是用来防止接口被别人使用的,如果需要做更多的验证,
ashowurl=/data/attachment/portal 门户文件显示URL,默认值为/data/attachment/portal,该参数可以支持更改默认附件目录和远程文件,该值对应网站Background-Upload settings ;< @5、参数raids[]=12raids[]=34raids[]=112tag[1] 聚合标签1,设置值为1启用,如果在附加参数中填写“tag[1]=1” , 如果不使用则留空;tag[2] 聚合标签2,设置值为1启用,如果在附加参数中填写“tag[2]=1”,则留空;tag[3] 聚合标签3,设置值为1可以启用,例如在附加参数中填写“tag[3]=1”,不使用时留空;tag[4] 聚合标签4,设置值为1启用,如填写" tag[3] 在附加参数中。4]=1",不需要留空;tag[5]聚合tag 5,设置值为1启用,如果在附加参数中填写"tag[5]=1",不需要留空;tag [6] ] 聚合标签 6,设置值为 1 启用,如附加参数中填写“tag[6]=1”,留空;tag[7] 聚合标签 7,设置值为 1启用,如在附加参数中填写“tag[7]=1”,不使用则留空;tag[8]聚合标签8,设置值为1启用,如填写“tag[8” ]=1"在附加参数中,不使用时留空;如果需要为封面图指定封面图,用户使用的采集规则应该有一个数据项到采集@ > 作为封面图片的图片 URL,并且应该在Publishing Rules-Publishing Item-这个数据项对应的参数pic中列出;对应用户网站后台-上传设置-基础设置-附件URL地址,默认值为“/data/attachment/portal”;当网站上传设置-附件URL地址改变时,该值应等于“附件URL地址”+“/portal”;8、发布配置-文章URL,可以填写如下:你的URL/etpost .php 注意:对于使用区分大小写服务器的用户,请注意URL的大小写相同与网站文件9、接口文件一样,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;二、 [err]invalid vercode[/err]1、发布规则-校验URL中填写的vercode值与校验接口文件中的vercode值不一致;2、在发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] subject is null[/err]: 采集 used by 1、 @>规则未能正确采集到标题;2、采集 @>规则的数据整理过滤了标题;3、错误修改了发布项参数名称中的发布规则-标题,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;四、 [err]内容不能为空[/err]:1、使用的采集规则未能正确采集到文本数据项;2、采集 规则数据排序过滤了文本数据;3、 修改错误发布规则-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;五、文章乱码:1、发布规则不开启utf-8编码转换;2、数据没有组织好;六、附件上传不成功:1、检查附件是否保存在正确的路径和格式2、检查是否附件存在3、 检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与方案的文件存储目录一致; 查看全部
文章采集接口(DiscuzX3正式版门户文章接口使用手册(discuz!X3.0))
Discuz X3正式版传送门文章界面使用手册一、介绍1、此界面适用于discuz!X3正式版discuz!X3.0 正式版6、 in discuz! X3.0 正式版7、这个界面是基于discuz!X3.0 正式版 discuz! X3.0 正式版8、接口文件无需任何改动即可使用,如需添加验证或其他功能,请谨慎修改;9、2个接口文件,请复制到discuz中!X3.0 etchk.php正式版,etpost.php,将接口文件复制到指定目录,远程FTP上传到指定目录。请以二进制方式上传,如图:三、配置发布规则1、 将示例发布规则的文本导入ET2发布配置中,或者使用软件内置发布规则示例,如图:2、在巡检URL中修改“your网站”, 网站你要发布的URL的发布URL,如图:3、在参数值中,填写你要发布的频道ID,如图:打开门户管理发布文章页面,可以查看频道ID,即catid的值:5、填写你的账号、密码,注意格式和账号权限(账号应该有portal文章频道管理权限),如图:四、接口说明一、查看接口1、接口文件名etck。php, 为保密起见,请自行修改文件名;2、这个接口文件复制到网站根目录下使用;3、主要参数title文章title catid类别ID用于限制检查范围。它可以留空。请在管理中心查看分类ID;请自行设置vercode校验码,修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/etchk.php?vercode=&catid=&title= 注意:用户使用区分大小写的服务器,请注意URL大小写与网站文件一致5、接口文件无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名为etpost.php,为保密请自行修改文件名;2、 请将该接口文件复制到网站根目录下使用;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;具有固定值的参数可以在发布规则-参数值中设置;采集 带值的参数项,请在发布规则-发布项中添加;3、参数用户名会员名参数名密码密码参数名标题主题标题参数名内容内容参数名(分页请替换ET2文本分隔符“#-0-#” 与discuz!x 分页标记 "#########NextPage#### ######""#########NextPage[title=页面标题] ###### ####")4、参数catid文章分类号(请参考管理中心文章分类)vercode安全验证码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站相同file5、接口文件无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;注:以下参数名称后面有“=”号,用于示范值选择,参数名称本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换带 discuz!x 分页标签 "##########NextPage##########" " #########NextPage[title=页面标题]##########”)4、参数catid文章分类号(请参考管理中心文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站文件< @5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;笔记:后面的参数名后面有一个“=”号,用于演示取值,参数名本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换with discuz! x 分页标签 "##########NextPage##########" "##########NextPage[title=页面标题] ### #######”)4、参数catid文章类别号(请参考管理中心< @文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。 参数用户名 会员名 参数名 密码 参数名 题目 题目 参数名 内容 内容 参数名(如果要分页,请替换ET2文本分隔标记“#- 0-#" with discuz! x 分页标记 "# #########NextPage##########""#########NextPage[title=页面标题] ##########" )4、参数catid文章类别号(请参考管理中心文章类别)vercode安全校验码,请设置自己,这个项目是用来防止接口被别人使用的,如果需要做更多的验证,
ashowurl=/data/attachment/portal 门户文件显示URL,默认值为/data/attachment/portal,该参数可以支持更改默认附件目录和远程文件,该值对应网站Background-Upload settings ;< @5、参数raids[]=12raids[]=34raids[]=112tag[1] 聚合标签1,设置值为1启用,如果在附加参数中填写“tag[1]=1” , 如果不使用则留空;tag[2] 聚合标签2,设置值为1启用,如果在附加参数中填写“tag[2]=1”,则留空;tag[3] 聚合标签3,设置值为1可以启用,例如在附加参数中填写“tag[3]=1”,不使用时留空;tag[4] 聚合标签4,设置值为1启用,如填写" tag[3] 在附加参数中。4]=1",不需要留空;tag[5]聚合tag 5,设置值为1启用,如果在附加参数中填写"tag[5]=1",不需要留空;tag [6] ] 聚合标签 6,设置值为 1 启用,如附加参数中填写“tag[6]=1”,留空;tag[7] 聚合标签 7,设置值为 1启用,如在附加参数中填写“tag[7]=1”,不使用则留空;tag[8]聚合标签8,设置值为1启用,如填写“tag[8” ]=1"在附加参数中,不使用时留空;如果需要为封面图指定封面图,用户使用的采集规则应该有一个数据项到采集@ > 作为封面图片的图片 URL,并且应该在Publishing Rules-Publishing Item-这个数据项对应的参数pic中列出;对应用户网站后台-上传设置-基础设置-附件URL地址,默认值为“/data/attachment/portal”;当网站上传设置-附件URL地址改变时,该值应等于“附件URL地址”+“/portal”;8、发布配置-文章URL,可以填写如下:你的URL/etpost .php 注意:对于使用区分大小写服务器的用户,请注意URL的大小写相同与网站文件9、接口文件一样,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;二、 [err]invalid vercode[/err]1、发布规则-校验URL中填写的vercode值与校验接口文件中的vercode值不一致;2、在发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] subject is null[/err]: 采集 used by 1、 @>规则未能正确采集到标题;2、采集 @>规则的数据整理过滤了标题;3、错误修改了发布项参数名称中的发布规则-标题,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;四、 [err]内容不能为空[/err]:1、使用的采集规则未能正确采集到文本数据项;2、采集 规则数据排序过滤了文本数据;3、 修改错误发布规则-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;五、文章乱码:1、发布规则不开启utf-8编码转换;2、数据没有组织好;六、附件上传不成功:1、检查附件是否保存在正确的路径和格式2、检查是否附件存在3、 检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与方案的文件存储目录一致;
文章采集接口(:文章采集文档,人脸识别只是一个开始。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-04 20:05
文章采集接口文档,人脸识别只是一个开始。为什么采集这个数据?这个采集实例通过squad数据集,该数据集包含265类标签,每个标签两个特征。一共包含6万个采样,并且有1万种分布的方案可供选择。这样的采集工作对应的是调用率2%-8%。是不是看起来很诱人?如果只是这样的,那还真不算多。因为所有的采集是把self-region改成self-region。
有多少self-region,就有多少non-majorlabel。几乎大部分的self-region分布。我想做一点的就是把self-region搞成均匀分布。那么,什么地方距离最近,那么就用最近的距离算每个标签之间的均值,或者方差。精度会不会更高一些?想知道结果,可以在实际场景中做一点验证。看看结果是否符合我们的期望。
自问自答,能否参加我们的etcu前沿项目:self-region,用于构建人脸三维定位模型。来一道题:。
1、请问你知道vaspeople和vaspeoplevector代码实现吗?
2、请讲一下用基于region的距离概率的线性svm做的人脸定位模型。
3、请用opencv中的svm算法做人脸线性svm三维卷积模型。如果你看了这些问题,还是没有答案。那么一个直观的方法告诉你,如果你看到100个人脸,不用opencv,你把每个人脸放到100张图片中,对角线分别对每张图片和那张人脸进行相关系数,然后输出的值就是均值。如果你10000个人脸呢?1000000个的距离,那就相关系数为10000000。
如果你100000000个人脸呢?0的距离,就相关系数为00。如果是个人脸呢?00个,相关系数为0。 查看全部
文章采集接口(:文章采集文档,人脸识别只是一个开始。)
文章采集接口文档,人脸识别只是一个开始。为什么采集这个数据?这个采集实例通过squad数据集,该数据集包含265类标签,每个标签两个特征。一共包含6万个采样,并且有1万种分布的方案可供选择。这样的采集工作对应的是调用率2%-8%。是不是看起来很诱人?如果只是这样的,那还真不算多。因为所有的采集是把self-region改成self-region。
有多少self-region,就有多少non-majorlabel。几乎大部分的self-region分布。我想做一点的就是把self-region搞成均匀分布。那么,什么地方距离最近,那么就用最近的距离算每个标签之间的均值,或者方差。精度会不会更高一些?想知道结果,可以在实际场景中做一点验证。看看结果是否符合我们的期望。
自问自答,能否参加我们的etcu前沿项目:self-region,用于构建人脸三维定位模型。来一道题:。
1、请问你知道vaspeople和vaspeoplevector代码实现吗?
2、请讲一下用基于region的距离概率的线性svm做的人脸定位模型。
3、请用opencv中的svm算法做人脸线性svm三维卷积模型。如果你看了这些问题,还是没有答案。那么一个直观的方法告诉你,如果你看到100个人脸,不用opencv,你把每个人脸放到100张图片中,对角线分别对每张图片和那张人脸进行相关系数,然后输出的值就是均值。如果你10000个人脸呢?1000000个的距离,那就相关系数为10000000。
如果你100000000个人脸呢?0的距离,就相关系数为00。如果是个人脸呢?00个,相关系数为0。
文章采集接口(使用优采云、优采云等采集器怎样将采集的文章发布到呆错文章管理系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-27 13:14
如何使用优采云、优采云等采集器将采集的文章发布到Dumbo文章管理系统?错误文章管理系统有优采云采集插件吗?
错了文章管理系统1.2.23版提供了第三方采集器发布接口,发布接口地址,发布文章@ > 必填字段(应严格推荐)如下!
更多字段请参考管理系统中数据库字段说明。
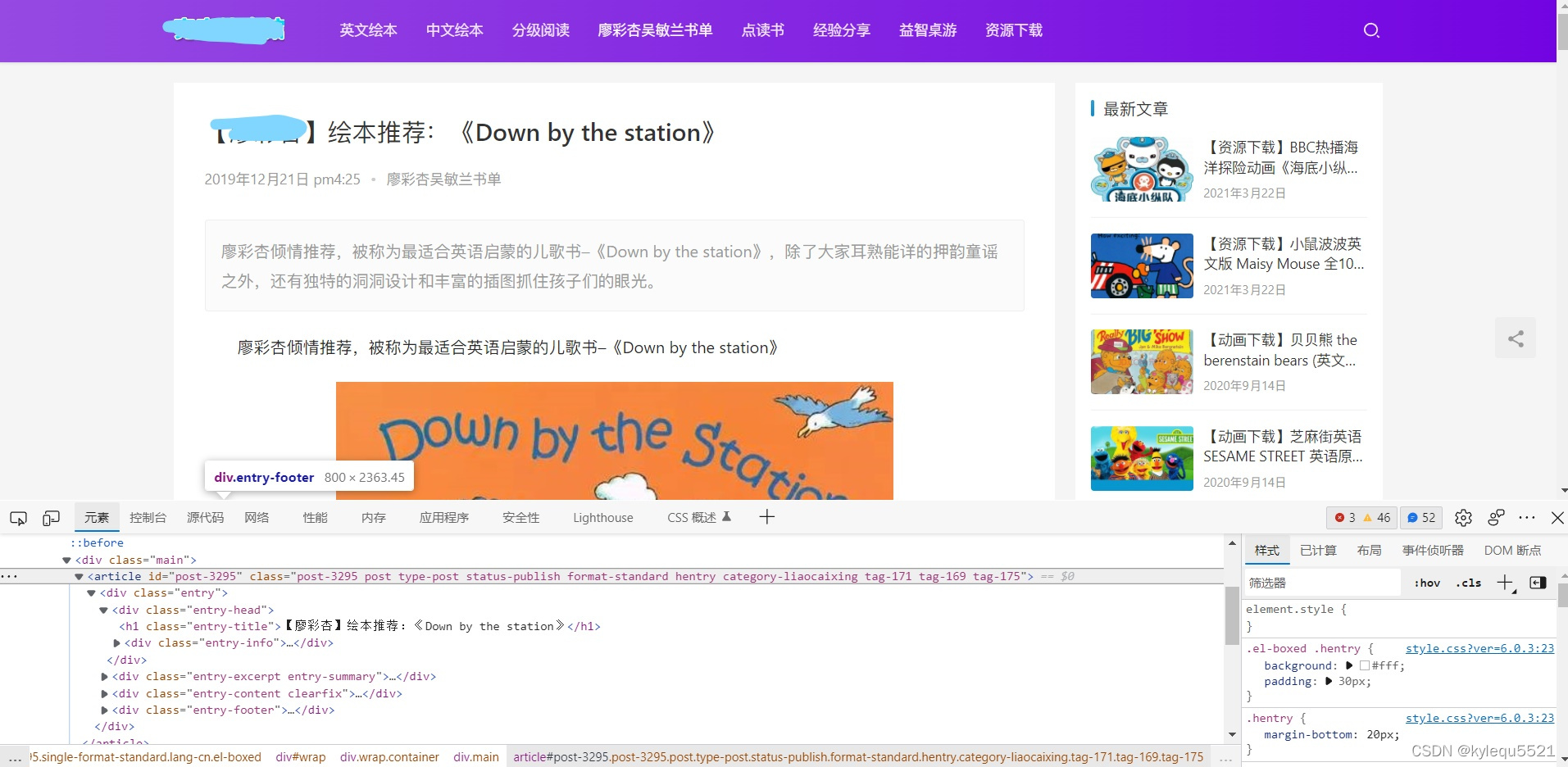
错了文章管理系统优采云采集器发布模块演示
$data = [];
$data['post_pwd'] = '123456';//入库密码字段(必填、需与后台设置的一致)
$data['category_name'] = '分类1,分类2';//分类字段,多个用逗号分隔
$data['tag_name'] = '标签1,标签2';//标签字段,多个用逗号分隔
$data['info_name'] = 'this is post test';//文章名称
$data['info_excerpt'] = 'this is excerpt';//文章简介
$data['info_content'] = 'this is content';//文章详情
$data['info_type'] = 'index';//文章形式(index|image|album|video|audio|link)
$data['cms_cover'] = 'https://cdn.daicuo.cc/images/d ... %3B//封面字段
$data['cms_referer'] = 'https://cdn.daicuo.cc/post1';//不提交此字段则不验证是否已采集
$result = DcCurl('auto', 10, 'http://'.config('common.site_domain').'/cms/post', $data);
如上使用PHP CURL模拟发布代码! 查看全部
文章采集接口(使用优采云、优采云等采集器怎样将采集的文章发布到呆错文章管理系统)
如何使用优采云、优采云等采集器将采集的文章发布到Dumbo文章管理系统?错误文章管理系统有优采云采集插件吗?
错了文章管理系统1.2.23版提供了第三方采集器发布接口,发布接口地址,发布文章@ > 必填字段(应严格推荐)如下!
更多字段请参考管理系统中数据库字段说明。
错了文章管理系统优采云采集器发布模块演示
$data = [];
$data['post_pwd'] = '123456';//入库密码字段(必填、需与后台设置的一致)
$data['category_name'] = '分类1,分类2';//分类字段,多个用逗号分隔
$data['tag_name'] = '标签1,标签2';//标签字段,多个用逗号分隔
$data['info_name'] = 'this is post test';//文章名称
$data['info_excerpt'] = 'this is excerpt';//文章简介
$data['info_content'] = 'this is content';//文章详情
$data['info_type'] = 'index';//文章形式(index|image|album|video|audio|link)
$data['cms_cover'] = 'https://cdn.daicuo.cc/images/d ... %3B//封面字段
$data['cms_referer'] = 'https://cdn.daicuo.cc/post1';//不提交此字段则不验证是否已采集
$result = DcCurl('auto', 10, 'http://'.config('common.site_domain').'/cms/post', $data);
如上使用PHP CURL模拟发布代码!
文章采集接口(优采云采集器外部接口修改原来的程序..(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-27 06:00
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作的原理。接口就是接口需要提交的数据优采云采集器.优采云采集器提交数据很简单,也就是使用了 post 方法,与使用表单提交的效果相同。接口只需要接收数据。数据接收。这与表单接收没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用request.form("title")来接收并使用。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们使用自己的网站上的程序可以直接将内容发布到网站。然后我们将为此功能制作接口程序或修改原程序。如果你要制作界面的程序是你自己开发的,那么你需要很清楚要输入什么数据,以及如何处理接收到的数据。您可以直接编写程序或更改原程序,将接收到的数据保存到服务器数据库中。如果使用别人的开发程序,则需要对原程序进行修改,使其能够顺利处理数据。这部分由您专门操作。安全接口的通用接口可以直接发布数据。为防止他人使用此界面,您应为其添加密码。可以给模块加个参数,比如密码,给个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序来满足自己的需求。也可以看成是技术人员网站功能的扩展开发。 查看全部
文章采集接口(优采云采集器外部接口修改原来的程序..(组图))
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作的原理。接口就是接口需要提交的数据优采云采集器.优采云采集器提交数据很简单,也就是使用了 post 方法,与使用表单提交的效果相同。接口只需要接收数据。数据接收。这与表单接收没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用request.form("title")来接收并使用。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们使用自己的网站上的程序可以直接将内容发布到网站。然后我们将为此功能制作接口程序或修改原程序。如果你要制作界面的程序是你自己开发的,那么你需要很清楚要输入什么数据,以及如何处理接收到的数据。您可以直接编写程序或更改原程序,将接收到的数据保存到服务器数据库中。如果使用别人的开发程序,则需要对原程序进行修改,使其能够顺利处理数据。这部分由您专门操作。安全接口的通用接口可以直接发布数据。为防止他人使用此界面,您应为其添加密码。可以给模块加个参数,比如密码,给个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序来满足自己的需求。也可以看成是技术人员网站功能的扩展开发。
文章采集接口( 非常新的各类播放器规则电影视频,可以直接生成页面,就是静态化!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-27 05:24
非常新的各类播放器规则电影视频,可以直接生成页面,就是静态化!)
Max采集界面代笔|MAXcms优采云发布模块|Max免登录发布界面
最大电影接口:50,可以采集CKplayer/Gigi Video、Video Pioneer、西瓜视频等非常新的播放规则电影和视频,可以直接生成页面,即静态!
Max新闻界面:50个,只有采集可以发布Max的新五条、图片和小说新闻等,不能生成静态,可以后台改成动态,发布后立即显示!
不管你是想写文章采集、atlas采集、小说采集,还是其他采集接口
雨后,阳光工作室会让你对新店的开业感到满意。大家支持
作文规则:很好的10条,第二条5条,超过10条有礼物!
不成功不收费
雨后天晴,专业Max采集规则写作
最大cms采集规则|电影网站采集规则|采集规则
Max Movie Publishing Module 使用说明:
1、将发布模块maxcms4.0QVOD电影byhurqm.wpm复制到你的优采云目录下的Module文件夹中;
2、点击优采云主页发布进入WEB发布配置管理;
3、新建一个发布,1.选择WEB在线发布模块maxcms4.0QVOD电影byhurqm,3.选择你的代码一般GB2312,4.网站填写你的根目录地址 URL + 背景地址 背景
一个非常关键的步骤是选择使用内置浏览器登录然后点击启动小浏览器进入你的后台并记住你的用户名和密码进行确认。5. 获取分类表。这是测试你的发布界面是否成功的关键。如果你能得到它,那是可以的。
4、填写你的配置名称并保存配置。
在优采云处导入测试规则后,编辑任务,选择第三步发布内容设置---添加发布配置(添加刚刚添加的发布模块配置)并保存
5、点击采集发布即可
雨天工作室出品
拜胡克
特别说明:
1.请填写采集规则的用户邮箱或者
<p>2.一条采集规则只能采集目标站(数据源)的一个子列列表的所有数据,而不能采集目标站(数据源)的所有列数据目标站,如果你想要 查看全部
文章采集接口(
非常新的各类播放器规则电影视频,可以直接生成页面,就是静态化!)
Max采集界面代笔|MAXcms优采云发布模块|Max免登录发布界面
最大电影接口:50,可以采集CKplayer/Gigi Video、Video Pioneer、西瓜视频等非常新的播放规则电影和视频,可以直接生成页面,即静态!
Max新闻界面:50个,只有采集可以发布Max的新五条、图片和小说新闻等,不能生成静态,可以后台改成动态,发布后立即显示!
不管你是想写文章采集、atlas采集、小说采集,还是其他采集接口
雨后,阳光工作室会让你对新店的开业感到满意。大家支持
作文规则:很好的10条,第二条5条,超过10条有礼物!
不成功不收费
雨后天晴,专业Max采集规则写作
最大cms采集规则|电影网站采集规则|采集规则
Max Movie Publishing Module 使用说明:
1、将发布模块maxcms4.0QVOD电影byhurqm.wpm复制到你的优采云目录下的Module文件夹中;
2、点击优采云主页发布进入WEB发布配置管理;
3、新建一个发布,1.选择WEB在线发布模块maxcms4.0QVOD电影byhurqm,3.选择你的代码一般GB2312,4.网站填写你的根目录地址 URL + 背景地址 背景
一个非常关键的步骤是选择使用内置浏览器登录然后点击启动小浏览器进入你的后台并记住你的用户名和密码进行确认。5. 获取分类表。这是测试你的发布界面是否成功的关键。如果你能得到它,那是可以的。
4、填写你的配置名称并保存配置。
在优采云处导入测试规则后,编辑任务,选择第三步发布内容设置---添加发布配置(添加刚刚添加的发布模块配置)并保存
5、点击采集发布即可
雨天工作室出品
拜胡克
特别说明:
1.请填写采集规则的用户邮箱或者
<p>2.一条采集规则只能采集目标站(数据源)的一个子列列表的所有数据,而不能采集目标站(数据源)的所有列数据目标站,如果你想要
文章采集接口(文章采集接口简单容易掌握的采集网站常用接口接口介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-26 11:04
文章采集接口简单容易掌握,适合小白进行快速开发上手。需要按照给出的站点名对采集网站进行seo的爬虫请求,下面就给大家列举出常用接口。
1、总部/总部资讯频道(document.cookie,
2、总部/1分钟发现新发现(1-30分钟内任选一分钟内所需站点);
3、总部/数据_文档_带有发表日期、章节内容、首次发表日期信息;
4、总部/文章列表--1分钟内左侧栏目列表,清除历史内容,
5、总部/站长列表--1分钟内左侧栏目列表,清除历史内容,
6、总部/新文章列表--文章列表列表,清除历史内容,
7、总部/历史档案列表--历史档案列表,清除历史内容,
8、总部/篇章全文列表--内容全文列表,清除历史内容,
9、总部/站点列表--站点列表,清除历史内容,
0、总部/栏目简介--栏目简介,清除历史内容,
1、总部/站点昵称--站点昵称,清除历史内容,
2、总部/文章列表--文章列表,清除历史内容,
3、总部/图片列表--图片列表,清除历史内容,
4、总部/文档列表--文档列表,清除历史内容,
5、总部/内容监控--监控站点列表--管理站点,清除历史内容,
6、总部/全部栏目--全部栏目,清除历史内容,
7、总部/新文章列表--新文章列表,清除历史内容,
8、总部/网站列表--网站列表,清除历史内容,
9、总部/新文章列表/历史文章--新文章列表,清除历史内容,
0、总部/站点列表/站点列表列表/全部/栏目/整体/一类--站点列表,清除历史内容,
1、总部/文章列表列表(深圳)--文章列表(深圳)/深圳站点列表--站点列表--站点列表/深圳全部站点;2
2、总部/文章列表/深圳站点列表/外地站点列表--文章列表/深圳站点列表--文章列表列表/深圳全部站点;2
3、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/深圳站点列表/外地站点/全部站点;2
4、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/全部站点;2
5、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/外地站点/外地站点/全部站点/站点;2
6、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/全部站点/ 查看全部
文章采集接口(文章采集接口简单容易掌握的采集网站常用接口接口介绍)
文章采集接口简单容易掌握,适合小白进行快速开发上手。需要按照给出的站点名对采集网站进行seo的爬虫请求,下面就给大家列举出常用接口。
1、总部/总部资讯频道(document.cookie,
2、总部/1分钟发现新发现(1-30分钟内任选一分钟内所需站点);
3、总部/数据_文档_带有发表日期、章节内容、首次发表日期信息;
4、总部/文章列表--1分钟内左侧栏目列表,清除历史内容,
5、总部/站长列表--1分钟内左侧栏目列表,清除历史内容,
6、总部/新文章列表--文章列表列表,清除历史内容,
7、总部/历史档案列表--历史档案列表,清除历史内容,
8、总部/篇章全文列表--内容全文列表,清除历史内容,
9、总部/站点列表--站点列表,清除历史内容,
0、总部/栏目简介--栏目简介,清除历史内容,
1、总部/站点昵称--站点昵称,清除历史内容,
2、总部/文章列表--文章列表,清除历史内容,
3、总部/图片列表--图片列表,清除历史内容,
4、总部/文档列表--文档列表,清除历史内容,
5、总部/内容监控--监控站点列表--管理站点,清除历史内容,
6、总部/全部栏目--全部栏目,清除历史内容,
7、总部/新文章列表--新文章列表,清除历史内容,
8、总部/网站列表--网站列表,清除历史内容,
9、总部/新文章列表/历史文章--新文章列表,清除历史内容,
0、总部/站点列表/站点列表列表/全部/栏目/整体/一类--站点列表,清除历史内容,
1、总部/文章列表列表(深圳)--文章列表(深圳)/深圳站点列表--站点列表--站点列表/深圳全部站点;2
2、总部/文章列表/深圳站点列表/外地站点列表--文章列表/深圳站点列表--文章列表列表/深圳全部站点;2
3、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/深圳站点列表/外地站点/全部站点;2
4、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/全部站点;2
5、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/外地站点/外地站点/全部站点/站点;2
6、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/全部站点/
文章采集接口( Zblog采集插件提升网站权重的小技巧,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-23 12:02
Zblog采集插件提升网站权重的小技巧,你知道吗?)
Zblog采集插件是一个采集辅助工具,用于采集、归档和组织特定的数据信息。Zblog采集插件可以适合很多人,比如网站必填信息采集,视频编辑器是采集的视频资料等等,Zblog< @采集插件是帮助用户采集特定信息,让人们无需花费大量时间和精力去寻找或下载,辅助采集器工具是人们处理简单的好帮手任务。Zblog采集插件可以将多个网站采集中的网页元素批量下载到本地,不仅可以过滤利用文字、图片等内容,还可以完整传输数据要在您自己的服务器上使用它,
Zblog采集插件,这个和我们常见的挖矿站点有点不同。我们平时做采集网站的时候,需要无限量的内容,而一般采集丰富的内容来源网站,无论新旧内容都是采集。还有一个采集方法:同步更新最新的文章,只要来源网站发布内容,采集立马就会同步更新。这样做最大的好处是搜索引擎无法分辨出哪个站点收录原创的内容,这会导致采集的网站可能会比收录更快,权重更高. (这取决于域名本身的权重、蜘蛛爬行和网站 的流行度)。
Zblog采集插件可以避免拼凑几个文章,以为自己可以做伪原创,从而获得搜索引擎的青睐,避免这些问题。短期内,网站的权重可以快速提升,而且由于采集的内容是伪原创,也会被百度重压收录。
并且采集的文章后处理也是可读的,提高了用户的阅读体验,降低了网站的跳出率。采集只要文章的体积不大,内容来源的质量很重要,Zblog采集插件,内置伪原创自动发布再推送,不仅采集准确率高,而且可以达到文章原创高度。
Zblog采集插件,封装了复杂的算法和分布式逻辑,提供灵活简单的开发接口;应用程序自动分布式部署和运行,操作直观简单,计算和存储资源弹性扩展;不同来源数据的统一可视化管理,restful interface/webhook push/graphql access等高级功能让用户无缝连接现有系统。 查看全部
文章采集接口(
Zblog采集插件提升网站权重的小技巧,你知道吗?)

Zblog采集插件是一个采集辅助工具,用于采集、归档和组织特定的数据信息。Zblog采集插件可以适合很多人,比如网站必填信息采集,视频编辑器是采集的视频资料等等,Zblog< @采集插件是帮助用户采集特定信息,让人们无需花费大量时间和精力去寻找或下载,辅助采集器工具是人们处理简单的好帮手任务。Zblog采集插件可以将多个网站采集中的网页元素批量下载到本地,不仅可以过滤利用文字、图片等内容,还可以完整传输数据要在您自己的服务器上使用它,


Zblog采集插件,这个和我们常见的挖矿站点有点不同。我们平时做采集网站的时候,需要无限量的内容,而一般采集丰富的内容来源网站,无论新旧内容都是采集。还有一个采集方法:同步更新最新的文章,只要来源网站发布内容,采集立马就会同步更新。这样做最大的好处是搜索引擎无法分辨出哪个站点收录原创的内容,这会导致采集的网站可能会比收录更快,权重更高. (这取决于域名本身的权重、蜘蛛爬行和网站 的流行度)。
Zblog采集插件可以避免拼凑几个文章,以为自己可以做伪原创,从而获得搜索引擎的青睐,避免这些问题。短期内,网站的权重可以快速提升,而且由于采集的内容是伪原创,也会被百度重压收录。

并且采集的文章后处理也是可读的,提高了用户的阅读体验,降低了网站的跳出率。采集只要文章的体积不大,内容来源的质量很重要,Zblog采集插件,内置伪原创自动发布再推送,不仅采集准确率高,而且可以达到文章原创高度。
Zblog采集插件,封装了复杂的算法和分布式逻辑,提供灵活简单的开发接口;应用程序自动分布式部署和运行,操作直观简单,计算和存储资源弹性扩展;不同来源数据的统一可视化管理,restful interface/webhook push/graphql access等高级功能让用户无缝连接现有系统。
文章采集接口(网站关键词排名怎么做?怎么利用凡科CMS插件快速让网站收录排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-21 09:09
)
网站关键词如何排名?如何使用凡客cms插件快速排名网站收录和关键词。我们需要在进行网站优化之前解决它。网站构造中的代码优化是指将程序代码转化为停止等价(即不改变程序的运行结果)。程序代码可以是中间代码(例如四进制代码)或目标代码。等价的含义是使转换后的代码与未转换的代码相反。优化的意思是生成的目标代码短(运行时间更短,占用空间更少),时间和空间效率得到优化。
1、尝试使用 div+css 来规划你的页面。div+css设计的好处是可以让搜索引擎爬虫更流畅、更快、更敌对地爬取你的页面;div+css设计还可以少量缩小网页大小,提高阅读速度,让代码更简洁、流畅,更容易放置更多内容。
2、尽可能少使用无用的图像和闪光灯。内容索引调度的搜索引擎爬虫不查看图片,只能根据图片的“alt、title”等属性的内容来判断图片的内容。关于flash搜索引擎爬虫更是盲目。
3、尽可能减小你的页面大小,因为每次搜索引擎爬虫爬取你的站点,数据的存储容量是无限的。一般建议小于100KB,越小越好,但不能小于5KB。增加页面大小的另一个好处是它可以导致指向您网站的大量外部链接网络。
4、尽量符合w3c规范,网页代码编写符合W3C规范,可以提高网站和搜索引擎的友好度。由于搜索引擎收录规范和排名算法都是在W3C规范的基础上制定的。
5、 尝试应用标签 h1、h2、h3、h4、h5….. 以便搜索引擎能够区分网页的哪一部分非常重要,下一个。
6、 增加JS代码的使用,所有JS代码都封装在内部调用文件中。搜索引擎不喜欢JS,影响网站的友好度指数。
7、尽量不要使用表格设计,因为搜索引擎会懒惰地抓取嵌套在表格设计3层内的内容。搜索引擎爬虫有时很懒惰。我希望您必须将代码和内容保持在 3 层内。
8、 尽量不要让CSS分散在HTML标记中,尽量封装在内部调用文件中。如果 CSS 以 HTML 标记呈现,搜索引擎爬虫会分心,专注于这些对优化没有意义的东西,所以建议封装在一个普通的 CSS 文件中。
9、清除渣码,在代码编辑环境中敲击键盘空格键产生的符号;一些带有默认属性的代码不会影响显示的代码;如果文本语句对代码的可读性没有太大影响,清除这些垃圾代码会增加很多空间。
我们可以借助凡客 cms 插件来改进我们的 SEO 功能(包括全套 SEO 功能,无论 网站 可以使用什么)。
1、通过万科cms插件填充内容,根据关键词采集文章。(凡客cms插件还配置了关键词采集功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
这个凡客cms插件还配备了很多SEO功能,不仅通过凡客cms插件实现采集伪原创发布,而且还有很多SEO职能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时自动生成文章内容中的内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms,人人战cms、Small Cyclone、站群、PB、Apple、搜外等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
通过以上凡客cms插件,可以改善很多需要注意的SEO细节,也可以加快SEO的效率。SEO是一项谨慎的工作,绝不能粗心大意。一个小细节可能会影响 网站 造成影响,这里给大家介绍一下SEO优化中的六个常见错误,让大家尽量踩坑。
错误 #1:使用错误的 关键词
网站 的标题和描述都非常重要。精确的 关键词 和描述允许用户精确地找到 网站。而错误的关键词、冗长的叙述、广告式的文案会给网友们留下负面印象。
错误 #2:将新的 关键词 应用到每个页面
虽然为每个网页使用一个新的关键词会接触到更多的目标群体,但我们还需要考虑这些网民是否是准确的目标群体?因此,使用 关键词 规划工具并使用低竞争的 关键词 来创建 SEO 长尾。
错误三:网站描述过多
并不是说 网站 描述越多越好,问题是 网站 操作员经常犯的一个谬误。网站150字以内的描述,用简洁的内容向搜索引擎提交关键信息,有助于提高网站的排名。
错误 #4:更新域名
拥有专属域名可以留住网站的流量,与搜索引擎建立良好的关系。专家建议,域名审核2-3年左右,对与服务相关的域名进行注册,加强链接。注册新域名时,需要设置URL转回主站,以达到营销的目的。
错误5:图片ALT标签有用吗?
搜索引擎虽然不能直接识别图片中的信息,但是可以通过ALT标签来判断图片的内容。向图像添加 ALT 标签有助于搜索引擎读取图像信息并帮助网页 收录。
错误6:网站分析不重要
网站分析可以了解流量来源,从而导入很多精准的目标客户。因此,网站分析可以有效帮助提升网站的排名。
通过上面对网站程序的优化以及SEO中常见错误的介绍,相信你已经了解了。掌握了这些,大家就可以巧妙的避开优化中的雷区了!
查看全部
文章采集接口(网站关键词排名怎么做?怎么利用凡科CMS插件快速让网站收录排名
)
网站关键词如何排名?如何使用凡客cms插件快速排名网站收录和关键词。我们需要在进行网站优化之前解决它。网站构造中的代码优化是指将程序代码转化为停止等价(即不改变程序的运行结果)。程序代码可以是中间代码(例如四进制代码)或目标代码。等价的含义是使转换后的代码与未转换的代码相反。优化的意思是生成的目标代码短(运行时间更短,占用空间更少),时间和空间效率得到优化。

1、尝试使用 div+css 来规划你的页面。div+css设计的好处是可以让搜索引擎爬虫更流畅、更快、更敌对地爬取你的页面;div+css设计还可以少量缩小网页大小,提高阅读速度,让代码更简洁、流畅,更容易放置更多内容。
2、尽可能少使用无用的图像和闪光灯。内容索引调度的搜索引擎爬虫不查看图片,只能根据图片的“alt、title”等属性的内容来判断图片的内容。关于flash搜索引擎爬虫更是盲目。
3、尽可能减小你的页面大小,因为每次搜索引擎爬虫爬取你的站点,数据的存储容量是无限的。一般建议小于100KB,越小越好,但不能小于5KB。增加页面大小的另一个好处是它可以导致指向您网站的大量外部链接网络。
4、尽量符合w3c规范,网页代码编写符合W3C规范,可以提高网站和搜索引擎的友好度。由于搜索引擎收录规范和排名算法都是在W3C规范的基础上制定的。
5、 尝试应用标签 h1、h2、h3、h4、h5….. 以便搜索引擎能够区分网页的哪一部分非常重要,下一个。
6、 增加JS代码的使用,所有JS代码都封装在内部调用文件中。搜索引擎不喜欢JS,影响网站的友好度指数。
7、尽量不要使用表格设计,因为搜索引擎会懒惰地抓取嵌套在表格设计3层内的内容。搜索引擎爬虫有时很懒惰。我希望您必须将代码和内容保持在 3 层内。
8、 尽量不要让CSS分散在HTML标记中,尽量封装在内部调用文件中。如果 CSS 以 HTML 标记呈现,搜索引擎爬虫会分心,专注于这些对优化没有意义的东西,所以建议封装在一个普通的 CSS 文件中。
9、清除渣码,在代码编辑环境中敲击键盘空格键产生的符号;一些带有默认属性的代码不会影响显示的代码;如果文本语句对代码的可读性没有太大影响,清除这些垃圾代码会增加很多空间。
我们可以借助凡客 cms 插件来改进我们的 SEO 功能(包括全套 SEO 功能,无论 网站 可以使用什么)。

1、通过万科cms插件填充内容,根据关键词采集文章。(凡客cms插件还配置了关键词采集功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎

这个凡客cms插件还配备了很多SEO功能,不仅通过凡客cms插件实现采集伪原创发布,而且还有很多SEO职能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)

3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时自动生成文章内容中的内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。



1、批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms,人人战cms、Small Cyclone、站群、PB、Apple、搜外等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
通过以上凡客cms插件,可以改善很多需要注意的SEO细节,也可以加快SEO的效率。SEO是一项谨慎的工作,绝不能粗心大意。一个小细节可能会影响 网站 造成影响,这里给大家介绍一下SEO优化中的六个常见错误,让大家尽量踩坑。
错误 #1:使用错误的 关键词
网站 的标题和描述都非常重要。精确的 关键词 和描述允许用户精确地找到 网站。而错误的关键词、冗长的叙述、广告式的文案会给网友们留下负面印象。
错误 #2:将新的 关键词 应用到每个页面
虽然为每个网页使用一个新的关键词会接触到更多的目标群体,但我们还需要考虑这些网民是否是准确的目标群体?因此,使用 关键词 规划工具并使用低竞争的 关键词 来创建 SEO 长尾。
错误三:网站描述过多
并不是说 网站 描述越多越好,问题是 网站 操作员经常犯的一个谬误。网站150字以内的描述,用简洁的内容向搜索引擎提交关键信息,有助于提高网站的排名。
错误 #4:更新域名
拥有专属域名可以留住网站的流量,与搜索引擎建立良好的关系。专家建议,域名审核2-3年左右,对与服务相关的域名进行注册,加强链接。注册新域名时,需要设置URL转回主站,以达到营销的目的。
错误5:图片ALT标签有用吗?
搜索引擎虽然不能直接识别图片中的信息,但是可以通过ALT标签来判断图片的内容。向图像添加 ALT 标签有助于搜索引擎读取图像信息并帮助网页 收录。
错误6:网站分析不重要
网站分析可以了解流量来源,从而导入很多精准的目标客户。因此,网站分析可以有效帮助提升网站的排名。


通过上面对网站程序的优化以及SEO中常见错误的介绍,相信你已经了解了。掌握了这些,大家就可以巧妙的避开优化中的雷区了!

文章采集接口(文章采集接口:数据接口文档解读之三【回答问题】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-13 17:02
文章采集接口文档:数据接口文档解读之三【回答问题】三、基本数据解析环境搭建:python3.6环境配置:win7/win10,但从不建议win10,因为各种配置会更麻烦一些。数据解析网站:【采集的目标主要分为url对应部分】1.新闻类:新闻首页,栏目页、人物页、id界面等文章对应图片配置参考网站::网页内容都是图片网站推荐:知乎:新闻标题、内容简介(答主写的)微博:热门微博以下是新闻类图片,a5中可以直接复制上传图片+上传url,但如果可以,直接采集热门微博就可以了爬取示例:importurllib.requesturl='-bo-03000-1-1.html'#对应的“新闻”栏目,每栏有很多微博id#这里主要对应图片中的标题,“发布日期”,“新闻图片尺寸”#点击就可以获取图片的urllist_list=[]foriinrange(5):urllist=urllib.request.urlopen(url).read()win_ok=''#限制下载位置content_path=urllib.request.urlopen('../content.txt')#用urlopen对象的参数next_ok=yieldf#返回图片url列表#遍历每一张图片list_list.append(i.read())#编写python函数接受2个参数:两个参数分别是图片url,一个参数是读取速度,一个参数是图片上传速度i=int(list_list[i][1].split('/')[0].split('\t'))#python中的[]实现分割单行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[1].split('\t')[0].split('\t')):try:urllist=list_list[i][1].split('\t')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[0]exceptlist_list[i].exceptionase:urllist.append(t)#把两个部分合并i+=1content_path=urllib.request.urlopen('../content.txt').read()win_ok=''#限制下载位置content_path='/'#python中的[]实现分割双行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].。 查看全部
文章采集接口(文章采集接口:数据接口文档解读之三【回答问题】)
文章采集接口文档:数据接口文档解读之三【回答问题】三、基本数据解析环境搭建:python3.6环境配置:win7/win10,但从不建议win10,因为各种配置会更麻烦一些。数据解析网站:【采集的目标主要分为url对应部分】1.新闻类:新闻首页,栏目页、人物页、id界面等文章对应图片配置参考网站::网页内容都是图片网站推荐:知乎:新闻标题、内容简介(答主写的)微博:热门微博以下是新闻类图片,a5中可以直接复制上传图片+上传url,但如果可以,直接采集热门微博就可以了爬取示例:importurllib.requesturl='-bo-03000-1-1.html'#对应的“新闻”栏目,每栏有很多微博id#这里主要对应图片中的标题,“发布日期”,“新闻图片尺寸”#点击就可以获取图片的urllist_list=[]foriinrange(5):urllist=urllib.request.urlopen(url).read()win_ok=''#限制下载位置content_path=urllib.request.urlopen('../content.txt')#用urlopen对象的参数next_ok=yieldf#返回图片url列表#遍历每一张图片list_list.append(i.read())#编写python函数接受2个参数:两个参数分别是图片url,一个参数是读取速度,一个参数是图片上传速度i=int(list_list[i][1].split('/')[0].split('\t'))#python中的[]实现分割单行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[1].split('\t')[0].split('\t')):try:urllist=list_list[i][1].split('\t')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[0]exceptlist_list[i].exceptionase:urllist.append(t)#把两个部分合并i+=1content_path=urllib.request.urlopen('../content.txt').read()win_ok=''#限制下载位置content_path='/'#python中的[]实现分割双行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].。
文章采集接口(appclipboard是个什么玩意?能应用在哪里?官方issues)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-13 16:00
文章采集接口配置说明基于appchromecanary的appclipboard获取海量文章中的链接并保存,这一个文章的获取需要交给专门的服务器处理,那么,该如何部署呢?官方issues可以参考一下,然后呢,用户可以自己编写爬虫,爬取所需所有海量的文章,并将文章聚合到自己的知乎专栏。本文介绍appclipboard一个实现搜索并聚合海量文章的功能,并完成打包部署。
爬虫爬取文章,解析查看文章并存储,用户可以自己编写爬虫,爬取文章并进行聚合;看这篇文章之前,推荐大家快速阅读,带一下思路。appclipboard是个什么玩意?appclipboard是一个app应用商店,上架了各类搜索引擎。搜索方式通过评论或个人资料的链接地址,然后由appclipboard服务器给app授权,于是可以访问搜索引擎,从而搜索海量文章。
某类搜索引擎带来的好处很直观,就是信息量大啊。比如,你对法学感兴趣,去法学院官网,看一看经济法、民法、刑法、法理论、宪法、知识产权等等各科专业门类,很快可以了解一下各科目的概况。你又想看看商科,于是就去appclipboard官网,同样能看到北京/上海的各大商学院。其他有法律明显偏好的学生,还可以搜索jd/llm/mfa,甚至你是ph.d、cs毕业又加入了互联网企业,可以搜索自己的专业,学历和职业,推荐一下大厂内部的经验分享,看看大神们的心得和反馈。
appclipboard能应用在哪里?appclipboard也能接入百度搜索;应用在微信小程序、微信公众号、秒拍、腾讯视频、企鹅号、今日头条这样的百度搜索页面都能直接使用appclipboard搜索。更多应用在知乎、豆瓣、公众号、百度百家、百度知道、今日头条、人人都是产品经理、网易、微博、新浪、腾讯、自媒体这些应用的公众号、微博、以及每日头条这类的应用上。
appclipboard服务器配置安装appclipboard基本依赖包下载站直接下载即可。本文配置环境为chromecanary14.0.4222.256,搜索平台为google,appchina为百度,其他如百度搜索、搜狗搜索、一点搜索、搜狗浏览器、都可以设置为搜索平台。
1.获取appclipboard地址appclipboard是阿里云上的搜索引擎(大约可以搜索200+左右的文章,而且是appstore直接下载,流量比较小),所以很多时候比较容易上,地址:,还是直接下载即可。打开搜索框,输入文章标题,会自动列出有关此文章的相关文章。
2.获取文章列表数据appclipboard的文章列表数据位于搜索引擎clipboard搜索页面的下方。我们一般用文章列表列表数据对数据进行整理,再做进一步处。 查看全部
文章采集接口(appclipboard是个什么玩意?能应用在哪里?官方issues)
文章采集接口配置说明基于appchromecanary的appclipboard获取海量文章中的链接并保存,这一个文章的获取需要交给专门的服务器处理,那么,该如何部署呢?官方issues可以参考一下,然后呢,用户可以自己编写爬虫,爬取所需所有海量的文章,并将文章聚合到自己的知乎专栏。本文介绍appclipboard一个实现搜索并聚合海量文章的功能,并完成打包部署。
爬虫爬取文章,解析查看文章并存储,用户可以自己编写爬虫,爬取文章并进行聚合;看这篇文章之前,推荐大家快速阅读,带一下思路。appclipboard是个什么玩意?appclipboard是一个app应用商店,上架了各类搜索引擎。搜索方式通过评论或个人资料的链接地址,然后由appclipboard服务器给app授权,于是可以访问搜索引擎,从而搜索海量文章。
某类搜索引擎带来的好处很直观,就是信息量大啊。比如,你对法学感兴趣,去法学院官网,看一看经济法、民法、刑法、法理论、宪法、知识产权等等各科专业门类,很快可以了解一下各科目的概况。你又想看看商科,于是就去appclipboard官网,同样能看到北京/上海的各大商学院。其他有法律明显偏好的学生,还可以搜索jd/llm/mfa,甚至你是ph.d、cs毕业又加入了互联网企业,可以搜索自己的专业,学历和职业,推荐一下大厂内部的经验分享,看看大神们的心得和反馈。
appclipboard能应用在哪里?appclipboard也能接入百度搜索;应用在微信小程序、微信公众号、秒拍、腾讯视频、企鹅号、今日头条这样的百度搜索页面都能直接使用appclipboard搜索。更多应用在知乎、豆瓣、公众号、百度百家、百度知道、今日头条、人人都是产品经理、网易、微博、新浪、腾讯、自媒体这些应用的公众号、微博、以及每日头条这类的应用上。
appclipboard服务器配置安装appclipboard基本依赖包下载站直接下载即可。本文配置环境为chromecanary14.0.4222.256,搜索平台为google,appchina为百度,其他如百度搜索、搜狗搜索、一点搜索、搜狗浏览器、都可以设置为搜索平台。
1.获取appclipboard地址appclipboard是阿里云上的搜索引擎(大约可以搜索200+左右的文章,而且是appstore直接下载,流量比较小),所以很多时候比较容易上,地址:,还是直接下载即可。打开搜索框,输入文章标题,会自动列出有关此文章的相关文章。
2.获取文章列表数据appclipboard的文章列表数据位于搜索引擎clipboard搜索页面的下方。我们一般用文章列表列表数据对数据进行整理,再做进一步处。
文章采集接口( ThismodelpaperwasrevisedbytheStandardizationOfficeonDecember10,2020Phpwind文章多功能接口使用手册接口(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-10 02:11
ThismodelpaperwasrevisedbytheStandardizationOfficeonDecember10,2020Phpwind文章多功能接口使用手册接口(图))
本模型论文由标准化办公室于2020年12月10日修改phpwind文章接口说明Phpwind文章多功能接口手册一、介绍1、此接口适用于Phpwind版本文章中柱文章发布; 2、这个接口可以只用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期,让文章的发布更加真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8的多个接口,请注意修改接口名称,使每个接口不一样,比如这个interface文件夹中提供的interface文件都加上了“cms”的文件名后缀;5、发布时请使用具有文章中央管理权限的用户帐号;6、在utf8版本使用该接口时,请在发布规则中选择编码为UTF-8;< @7、本接口内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;8、本接口基于utf8版本制作,适用GBK/utf- 8
如需添加验证或其他功能,请谨慎修改;10、2个接口请复制文件在Phpwind网站根目录下使用;二、安装界面 在界面文件夹中找到界面文件,如图: 请将界面文件如等上传到指定目录,请使用二进制方式上传,如图图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或者使用软件自带的发布规则示例,如图:2、检查URL,将发布URL中的“Your 网站”改为你要发布的网站 URL,如图:3、 在check URL中,文章中间栏填写你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件
在网站的根目录下使用。如果目录名称有变化,请相应回复;3、主要参数cms_subject文章题目七年级有理数混合运算100题乘法100题计算机一级题库二进制线性方程应用题真心话大冒险刺激题cid列ID,用过限制该规则的检查列,可以填写多个(逗号分隔)或空,格式如cid=7 ,8,9,可以在文章中心查看列ID;vercode校验码,请自行设置,修改校验接口文件开头的$vercode,使其一致;4、发布配置-文章查看URL,可以填写如下: 注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;二、发布接口1、接口文件名保密,请自行修改文件名;2、请将此接口文件复制到网站根目录下使用,为保密请自行修改文件名;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;参数固定值,可在发布规则-参数值中设置;采集 带值的参数项,请将它们添加到发布规则 - 发布项目中;3、主要参数pw
用户会员名参数名pwpwd密码参数名cms_subject主题标题参数名atc_content内容参数名,如果要进行手动内容分页,请使用数据排序替换内容分隔标记“#-0-#”带有Phpwind8的分页标记[###page###]的ET,见下面的自动分页参数;cid列ID,可以填写多个(逗号分隔),格式如cid=7,8,94、附加参数vercode安全校验码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。5、可选参数Newstime文章日期,格式要正确,例如:2010-08-0312:32:00;
下图中6、该界面内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;file8、接口文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、 检查发布规则-参数值-账号密码队列;二、[err]invalidvercode[/err]1、在发布规则中-检查URLvercode值和接口文件中vercode值不一致; 2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中
过滤;3、错误修改发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有开启utf-8编码转换;四、[err]内容不能为空[/err]:1、使用的采集规则失败< @采集对正文数据项正确;2、采集规则的数据整理过滤文本数据;3、发布规则修改错误-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则utf-8编码转换未开启;五、[err]请设置栏目[/err]:1、 cid参数值或格式错误;六、文章乱码:1、发布规则不开启utf-8编码转换;2、数据组织不当;七、附件上传不成功:1、检查附件保存路径和格式是否正确2、检查附件是否存在3、检查FTP目录和权限设置;八、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用了FTP上传,那么文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与施工图、施工图、示例结构、施工图一致, 查看全部
文章采集接口(
ThismodelpaperwasrevisedbytheStandardizationOfficeonDecember10,2020Phpwind文章多功能接口使用手册接口(图))

本模型论文由标准化办公室于2020年12月10日修改phpwind文章接口说明Phpwind文章多功能接口手册一、介绍1、此接口适用于Phpwind版本文章中柱文章发布; 2、这个接口可以只用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期,让文章的发布更加真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8的多个接口,请注意修改接口名称,使每个接口不一样,比如这个interface文件夹中提供的interface文件都加上了“cms”的文件名后缀;5、发布时请使用具有文章中央管理权限的用户帐号;6、在utf8版本使用该接口时,请在发布规则中选择编码为UTF-8;< @7、本接口内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;8、本接口基于utf8版本制作,适用GBK/utf- 8

如需添加验证或其他功能,请谨慎修改;10、2个接口请复制文件在Phpwind网站根目录下使用;二、安装界面 在界面文件夹中找到界面文件,如图: 请将界面文件如等上传到指定目录,请使用二进制方式上传,如图图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或者使用软件自带的发布规则示例,如图:2、检查URL,将发布URL中的“Your 网站”改为你要发布的网站 URL,如图:3、 在check URL中,文章中间栏填写你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件

在网站的根目录下使用。如果目录名称有变化,请相应回复;3、主要参数cms_subject文章题目七年级有理数混合运算100题乘法100题计算机一级题库二进制线性方程应用题真心话大冒险刺激题cid列ID,用过限制该规则的检查列,可以填写多个(逗号分隔)或空,格式如cid=7 ,8,9,可以在文章中心查看列ID;vercode校验码,请自行设置,修改校验接口文件开头的$vercode,使其一致;4、发布配置-文章查看URL,可以填写如下: 注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;二、发布接口1、接口文件名保密,请自行修改文件名;2、请将此接口文件复制到网站根目录下使用,为保密请自行修改文件名;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;参数固定值,可在发布规则-参数值中设置;采集 带值的参数项,请将它们添加到发布规则 - 发布项目中;3、主要参数pw

用户会员名参数名pwpwd密码参数名cms_subject主题标题参数名atc_content内容参数名,如果要进行手动内容分页,请使用数据排序替换内容分隔标记“#-0-#”带有Phpwind8的分页标记[###page###]的ET,见下面的自动分页参数;cid列ID,可以填写多个(逗号分隔),格式如cid=7,8,94、附加参数vercode安全校验码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。5、可选参数Newstime文章日期,格式要正确,例如:2010-08-0312:32:00;

下图中6、该界面内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;file8、接口文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、 检查发布规则-参数值-账号密码队列;二、[err]invalidvercode[/err]1、在发布规则中-检查URLvercode值和接口文件中vercode值不一致; 2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中

过滤;3、错误修改发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有开启utf-8编码转换;四、[err]内容不能为空[/err]:1、使用的采集规则失败< @采集对正文数据项正确;2、采集规则的数据整理过滤文本数据;3、发布规则修改错误-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则utf-8编码转换未开启;五、[err]请设置栏目[/err]:1、 cid参数值或格式错误;六、文章乱码:1、发布规则不开启utf-8编码转换;2、数据组织不当;七、附件上传不成功:1、检查附件保存路径和格式是否正确2、检查附件是否存在3、检查FTP目录和权限设置;八、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用了FTP上传,那么文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与施工图、施工图、示例结构、施工图一致,
文章采集接口(低代码开发研发人员的简单逻辑代码Low-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-07 08:21
一、前言
CRUD 程序员会变得更便宜吗?
CRUD是程序员的自嘲。他们说他们经常开发简单的逻辑代码,添加、删除、修改、检查或接口。
不过,这部分简单的逻辑代码,几乎是现阶段互联网公司研发人员消耗最多的部分。任何业务需求的实现都会收录大量接口的开发,但是这些不同业务之间差异很大的接口是无法复制的。因此,接口的不断创建带来了从研发、测试到交付、上线的一整套人员投入。
对于个人来说,开发 CRUD 几乎没有技术上的增长。开发CRUD只是程序员成长过程中的一个阶段。随着个人能力的提高和跳槽,更多的核心发展势必要做。
在公司技术部门层面,一定希望投入少的人,实现更高的交付能力。例如:
DDD在业务、运营、产品、研发、测试等人员之间建立领域模型,降低沟通成本
用于解决业务流程中嵌入的非业务功能的通用核心服务,提取统一的技术组件
标准骨干业务形态,抽取通用业务素材进行服务化编排,降低开发成本
以上等方案都是为了提高研发能效,可持续交付,而CRUD高重复性的代码逻辑将被工具可视化编程一点一点地吞噬。而低代码编程是从这部分开始的最佳方式!
二、什么是低码
Low-Code,该术语由 Forrester 在 2014 年首次提出,是低代码开发平台的祖先级定义。
低代码是一种软件开发方法,可以更快地交付应用程序,并且使用最少的手动编码。低代码平台是一组工具,可通过建模和图形界面实现应用程序的可视化开发。低代码使开发人员能够跳过手工编码,加快将应用程序投入生产的过程。
简单来说,低代码开发是开发人员通过IDE编写少量代码或拖放工具,快速完成业务需求开发的一种方式。
低代码开发平台可以自行开发,也可以使用市面上的IDE工具完成代码逻辑的服务编排。您可以将基本业务流程理解为每个分支节点项目的基础材料。通过这些素材接口接口的组装、排列和结果输出,完成代码逻辑的自动化开发和可持续交付。
通过使用低代码开发和可视化的方式构建应用程序,您的开发效率和交付质量将大大提高。这就是为什么 CRUD 程序员越来越便宜的原因。
三、如何实现
如果低代码编程这么好,你有条件落地吗?
低代码编程的核心是利用可视化的IDE动态排列服务逻辑接口,实现可持续交付能力,从而提高研发能效。
但是,用于开发业务功能的复杂逻辑总量不会改变。为了支持可视化服务编排,需要相应的通用业务组件。然后需要提供这部分业务组件、技术组件、自动化交付质量分析和监控系统。如果公司的技术资料比较少,运营这样一个平台是相当困难的
此外,许多其他组件也被引入到低代码编程中。这些功能模块、材料、Serverless 计算组件都需要大量高度专业的程序员来开发。
当然,低代码编程不仅用在服务器端,还可以在前端构建页面。例如,您以前使用过的大量拖放都可以算作一次。
四、总结
好了,今天的文章分享就结束了,喜欢的话就点个赞吧!--我是jabdp,我为自己“吃盐”,谢谢大家的关注。 查看全部
文章采集接口(低代码开发研发人员的简单逻辑代码Low-)
一、前言
CRUD 程序员会变得更便宜吗?
CRUD是程序员的自嘲。他们说他们经常开发简单的逻辑代码,添加、删除、修改、检查或接口。
不过,这部分简单的逻辑代码,几乎是现阶段互联网公司研发人员消耗最多的部分。任何业务需求的实现都会收录大量接口的开发,但是这些不同业务之间差异很大的接口是无法复制的。因此,接口的不断创建带来了从研发、测试到交付、上线的一整套人员投入。
对于个人来说,开发 CRUD 几乎没有技术上的增长。开发CRUD只是程序员成长过程中的一个阶段。随着个人能力的提高和跳槽,更多的核心发展势必要做。
在公司技术部门层面,一定希望投入少的人,实现更高的交付能力。例如:
DDD在业务、运营、产品、研发、测试等人员之间建立领域模型,降低沟通成本
用于解决业务流程中嵌入的非业务功能的通用核心服务,提取统一的技术组件
标准骨干业务形态,抽取通用业务素材进行服务化编排,降低开发成本
以上等方案都是为了提高研发能效,可持续交付,而CRUD高重复性的代码逻辑将被工具可视化编程一点一点地吞噬。而低代码编程是从这部分开始的最佳方式!
二、什么是低码
Low-Code,该术语由 Forrester 在 2014 年首次提出,是低代码开发平台的祖先级定义。
低代码是一种软件开发方法,可以更快地交付应用程序,并且使用最少的手动编码。低代码平台是一组工具,可通过建模和图形界面实现应用程序的可视化开发。低代码使开发人员能够跳过手工编码,加快将应用程序投入生产的过程。
简单来说,低代码开发是开发人员通过IDE编写少量代码或拖放工具,快速完成业务需求开发的一种方式。
低代码开发平台可以自行开发,也可以使用市面上的IDE工具完成代码逻辑的服务编排。您可以将基本业务流程理解为每个分支节点项目的基础材料。通过这些素材接口接口的组装、排列和结果输出,完成代码逻辑的自动化开发和可持续交付。
通过使用低代码开发和可视化的方式构建应用程序,您的开发效率和交付质量将大大提高。这就是为什么 CRUD 程序员越来越便宜的原因。
三、如何实现
如果低代码编程这么好,你有条件落地吗?
低代码编程的核心是利用可视化的IDE动态排列服务逻辑接口,实现可持续交付能力,从而提高研发能效。
但是,用于开发业务功能的复杂逻辑总量不会改变。为了支持可视化服务编排,需要相应的通用业务组件。然后需要提供这部分业务组件、技术组件、自动化交付质量分析和监控系统。如果公司的技术资料比较少,运营这样一个平台是相当困难的
此外,许多其他组件也被引入到低代码编程中。这些功能模块、材料、Serverless 计算组件都需要大量高度专业的程序员来开发。
当然,低代码编程不仅用在服务器端,还可以在前端构建页面。例如,您以前使用过的大量拖放都可以算作一次。
四、总结
好了,今天的文章分享就结束了,喜欢的话就点个赞吧!--我是jabdp,我为自己“吃盐”,谢谢大家的关注。
文章采集接口(优采云采集器外部接口制作规范(“title”来接收并使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-02 15:10
优采云采集器外接口制作规范
这里的外部接口是一个网站程序,你自己来接收和处理优采云采集器提交的数据。使用它,可以避免直接使用网站后台直接发布数据有一些繁琐的验证方法。它可以配置一次并永久使用。下面我们将介绍具体的制作方法和工艺。
界面制作原理。
接口是接口优采云采集器提交的数据。优采云采集器 提交数据很简单,就是使用post方式,提交的效果和使用表单一样。接口只需要接收数据。
数据接收。
这与接收表格没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用(“title”)接收并使用。PHP 使用 $_POST['title'] 来获取这个值。
数据处理。
首先要明确接口的作用,比如发布一个文章。我们可以通过我们网站上的程序直接将内容发布到网站。然后我们就为这个功能制作自己的接口程序或者修改原程序。
如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。你可以直接写一个程序或者改变原来的程序来接收数据存储在服务器数据库中。
如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够流畅地处理数据。这部分由您专门操作。
接口安全
通用接口可以直接post数据。为了防止其他人使用该接口,您应该为其添加密码。你可以给模块加个参数,比如密码,给个值,然后在程序端验证一下,如果不是你设置的值会拒绝访问。
从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序满足自己的要求。,也可以看作是技术人员网站功能的延伸。可以说你可以对接收到的数据进行任何处理,从而满足你的网站数据处理需求。 查看全部
文章采集接口(优采云采集器外部接口制作规范(“title”来接收并使用)
优采云采集器外接口制作规范
这里的外部接口是一个网站程序,你自己来接收和处理优采云采集器提交的数据。使用它,可以避免直接使用网站后台直接发布数据有一些繁琐的验证方法。它可以配置一次并永久使用。下面我们将介绍具体的制作方法和工艺。
界面制作原理。
接口是接口优采云采集器提交的数据。优采云采集器 提交数据很简单,就是使用post方式,提交的效果和使用表单一样。接口只需要接收数据。
数据接收。
这与接收表格没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用(“title”)接收并使用。PHP 使用 $_POST['title'] 来获取这个值。
数据处理。
首先要明确接口的作用,比如发布一个文章。我们可以通过我们网站上的程序直接将内容发布到网站。然后我们就为这个功能制作自己的接口程序或者修改原程序。
如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。你可以直接写一个程序或者改变原来的程序来接收数据存储在服务器数据库中。
如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够流畅地处理数据。这部分由您专门操作。
接口安全
通用接口可以直接post数据。为了防止其他人使用该接口,您应该为其添加密码。你可以给模块加个参数,比如密码,给个值,然后在程序端验证一下,如果不是你设置的值会拒绝访问。
从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序满足自己的要求。,也可以看作是技术人员网站功能的延伸。可以说你可以对接收到的数据进行任何处理,从而满足你的网站数据处理需求。
文章采集接口(Dedecms5。7sp1文章模型栏目接口使用手册(简介)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-01 13:21
Dedecms5.7 sp1文章模型柱接口使用手册一、简介1、此接口适用于Dedecms5.7 SP1版普通文章模型柱文章已发布;2、由于DEDE在数据量大时生成列HTML时服务器负载较重,因此在发布界面中增加了两个控制参数zznomakeindex和zznomake和cat来控制是否分别生成或不生成。首页或相关栏目;3、发布时请使用具有管理权限的用户帐号;4、本接口基于DedecmsUTF8版本,适用于DedecmsGBK/utf -8等版本,适用其他版本时请测试调整;5、在Dede中使用该接口时cms utf8版本,请在发布规则中选择编码为UTF-8;6、@ >接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改;7、将这两个接口文件复制到Dedecms网站管理目录下(默认为dede,用户可更改);二、安装接口在interface文件夹中找到接口文件,如图: Please etchk。php, etpost. php等接口文件复制到指定目录。远程FTP上传,请使用二进制方式上传,如图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或使用软件自带的发布规则示例,
php,为保密,请自行修改文件名;2、这个接口文件复制在网站管理目录DEDE下使用,如果目录名有变化,请相应回复;3、主要参数(校验URL后面附加以下参数) 主题标题:关键字列ID:typeid用于限制校验列的范围,可以留空,可以在网站 后台列管理;校验码:vercode,请自行设置,并修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/dede/etchk。php?vercode=&typeid=&keyword=注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如果要检查或其他功能,请仔细修改;二、发布接口1、接口文件名 etpost. php,为保密,请自行修改文件名;2、这个接口文件要复制到网站的管理目录DEDE下使用。如果目录名有变化,请自行对应;注意:后面的参数名称“”后面的“=”符号用于演示取值,参数名称本身不收录“=”符号;值为采集的参数项,请添加发布规则——发布项目,如图:< @3、基本参数userid成员名参数名pwd密码参数名titletopictitle参数名body内容参数名4、主要参数typeid=主列ID,后台可以查看网站列管理; typeid2=sub 列ID,可选,可在后台查看id网站列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章
php 注意:对于使用区分大小写的服务器的用户,请注意URL的大小写与网站文件8、接口文件的大小写相同,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、检查发布规则-参数值-账号密码队列;二、[ err]invalid vercode[/err]1、发布规则中填写的Vercode值-校验URL与校验接口文件中的vercode值不一致;2、 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] 标题不能为空[/err]:1、使用采集规则未能采集到标题;2、采集规则数据整理过滤头;3、错误修改了发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有not enable utf-8 encoding conversion;四、[err]Content cannot be empty[/err]: 1、Used 采集rules failed to 采集到body数据项; 2、采集 规则的数据整理过滤了文本数据;3、 发布项中发布规则发布的参数名称被错误修改。正确的参数名称请参考本文的接口说明;4、发布规则未启用utf-8编码转换;五、文章乱码:1、发布规则未开启utf-8编码转换;2、数据组织不当;六、附件上传失败:1、检查附件是否保存在正确的路径和格式2、检查附件是否存在3、检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;< 查看全部
文章采集接口(Dedecms5。7sp1文章模型栏目接口使用手册(简介)(组图))
Dedecms5.7 sp1文章模型柱接口使用手册一、简介1、此接口适用于Dedecms5.7 SP1版普通文章模型柱文章已发布;2、由于DEDE在数据量大时生成列HTML时服务器负载较重,因此在发布界面中增加了两个控制参数zznomakeindex和zznomake和cat来控制是否分别生成或不生成。首页或相关栏目;3、发布时请使用具有管理权限的用户帐号;4、本接口基于DedecmsUTF8版本,适用于DedecmsGBK/utf -8等版本,适用其他版本时请测试调整;5、在Dede中使用该接口时cms utf8版本,请在发布规则中选择编码为UTF-8;6、@ >接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改;7、将这两个接口文件复制到Dedecms网站管理目录下(默认为dede,用户可更改);二、安装接口在interface文件夹中找到接口文件,如图: Please etchk。php, etpost. php等接口文件复制到指定目录。远程FTP上传,请使用二进制方式上传,如图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或使用软件自带的发布规则示例,
php,为保密,请自行修改文件名;2、这个接口文件复制在网站管理目录DEDE下使用,如果目录名有变化,请相应回复;3、主要参数(校验URL后面附加以下参数) 主题标题:关键字列ID:typeid用于限制校验列的范围,可以留空,可以在网站 后台列管理;校验码:vercode,请自行设置,并修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/dede/etchk。php?vercode=&typeid=&keyword=注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如果要检查或其他功能,请仔细修改;二、发布接口1、接口文件名 etpost. php,为保密,请自行修改文件名;2、这个接口文件要复制到网站的管理目录DEDE下使用。如果目录名有变化,请自行对应;注意:后面的参数名称“”后面的“=”符号用于演示取值,参数名称本身不收录“=”符号;值为采集的参数项,请添加发布规则——发布项目,如图:< @3、基本参数userid成员名参数名pwd密码参数名titletopictitle参数名body内容参数名4、主要参数typeid=主列ID,后台可以查看网站列管理; typeid2=sub 列ID,可选,可在后台查看id网站列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章
php 注意:对于使用区分大小写的服务器的用户,请注意URL的大小写与网站文件8、接口文件的大小写相同,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、检查发布规则-参数值-账号密码队列;二、[ err]invalid vercode[/err]1、发布规则中填写的Vercode值-校验URL与校验接口文件中的vercode值不一致;2、 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] 标题不能为空[/err]:1、使用采集规则未能采集到标题;2、采集规则数据整理过滤头;3、错误修改了发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有not enable utf-8 encoding conversion;四、[err]Content cannot be empty[/err]: 1、Used 采集rules failed to 采集到body数据项; 2、采集 规则的数据整理过滤了文本数据;3、 发布项中发布规则发布的参数名称被错误修改。正确的参数名称请参考本文的接口说明;4、发布规则未启用utf-8编码转换;五、文章乱码:1、发布规则未开启utf-8编码转换;2、数据组织不当;六、附件上传失败:1、检查附件是否保存在正确的路径和格式2、检查附件是否存在3、检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;<
文章采集接口(折腾一个微信公众号新增永久图文素材|微信开放文档)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-31 10:15
前言
都说懒惰是人类进步的动力,古人没有骗我。最近在折腾一个微信公众号。一开始是在网上找了一些资源,然后做了二次创作,然后发布到了微信公众号上。不过,我得把里面的图片下载下来,复制文字,然后慢慢上传到微信公众号。经过几天的工作,我发现这太低效了。我每天都在做重复的事情。这对于程序员来说是无法忍受的。任何重复的东西都有自动化的价值,我们不能浪费它们。人生就在这种地方,不废话,做就做。
一、需求和难点从指定页面爬取数据只爬取我们需要的内容(什么样的广告,不需要导航),然后将文字上传到微信公众号的草稿箱。微信的草稿箱界面只能放图片上传到微信,所以我们需要做一个额外的操作,从网页中提取图片上传到微信公众号,然后将文中的图片链接替换为微信公众号中的图片二、使用工具和接口将封面图片上传到微信公众号添加永久图文素材 | 微信开文档()上传文字图片到微信公众号
http请求方式: POST,https协议 https://api.weixin.qq.com/cgi- ... TOKEN 调用示例(使用curl命令,用FORM表单方式上传一个图片): curl -F [email protected] "https://api.weixin.qq.com/cgi- ... ot%3B
上传文字至公众号草稿箱接口请求说明 | 微信打开文档()
这里主要使用Python:requests、BeautifulSoup、json
三、实施步骤1.分析网页
这是我们要分析的网页截图:
我们可以看到这个网页有自己的导航,右侧的推荐栏和底部的导航。如果我们直接扣除上传到整个网页的微信公众号,无疑会给我们的后期处理带来很大的工作量。所以我们只需要body,也就是html中的内容
2. 调用接口我们先来看看上传草稿API接口
接口请求说明
http 请求方式:POST(请使用https协议)https://api.weixin.qq.com/cgi- ... TOKEN
调用示例
{
"articles": [
{
"title":TITLE,
"author":AUTHOR,
"digest":DIGEST,
"content":CONTENT,
"content_source_url":CONTENT_SOURCE_URL,
"thumb_media_id":THUMB_MEDIA_ID,
"show_cover_pic":1,
"need_open_comment":0,
"only_fans_can_comment":0
}
//若新增的是多图文素材,则此处应还有几段articles结构
]
}
请求参数说明
范围
有必要吗
操作说明
标题
是的
标题
内容
是的
图片和短信的具体内容支持HTML标签,且必须小于20000字符且小于1M,这里会去掉JS,图片的url必须从“上传图片获取网址”中获取图片和文字信息”界面。外部图片网址将被过滤
thumb_media_id
是的
图文信息的封面图片素材id(必须是永久MediaID)
可以看出这个接口需要3个参数,那我们就去网页的代码看看如何获取这3个参数
通过分析网页,我们可以发现我们想要的标题在class='entry-title'的a标签中,我们还可以在class='entry-title'的div中得到文章的摘要概括'
所以我们先爬取页面,得到标题和摘要
baseUrl = 'https://www.test.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.57'
}
res = requests.get(baseUrl, verify=False, headers=headers)
root_soup = BeautifulSoup(res.content, 'html.parser')
title = root_soup.select('.entry-title')[0].text
summary = root_soup.select('.entry-summary p')[0].text
print(title)
print(summary)
接下来,我们需要准备封面。现在我们将使用微信公众号接口,但是在使用公众号接口之前,我们需要获取一个令牌,以便我们有权访问公众号的API接口。获取token的文档在这里:Wechat Open Document() 通过分析文字我们知道这个文章里面有很多图片,那么我们就以第一张图片为封面,先定义一个方法用于上传封面
然后获取body中的所有图片,将第一个传入这个方法获取cover id
content_soup = root_soup.select('.entry-content')[0]
imgs = content_soup.select('.wp-block-image')
fmId = updFm(imgs[0].img['src'], title)
接下来我们在文本中定义一个上传其他图片的方法,因为其他图片需要返回的url不是media_id,所以调用了另外一个接口。
def updImg(url):
base_folder = 'D:\\tempDir'
res = requests.get(url, verify=False)
file_name = '{}.jpg'.format(random.randint(10000, 99999))
with open(base_folder + file_name, 'wb') as f:
f.write(res.content)
vx_img_url = 'https://api.weixin.qq.com/cgi-bin/media/uploadimg'
request_file = {
'media': (file_name, open(base_folder + file_name, 'rb'), 'image/jpeg')}
data = {
'access_token': access_token
}
vx_res = requests.post(url=vx_img_url, files=request_file, data=data)
obj = json.loads(vx_res.content)
print(obj)
return obj['url']
然后将文中的图片全部上传到微信公众号的素材库,替换为文中的图片地址
for img_content in imgs:
img_content.noscript.decompose()
current_url = img_content.img['data-original']
upd_url = updImg(current_url)
img_content.img['src'] = upd_url
img_content.img['data-original'] = upd_url
最后我们可以开始准备上传文章到草稿箱,或者先定义方法,因为草稿界面的标题和摘要都有长度限制,所以这个方法开始做限制。如果长度超过,字符串将被截取
def updCG(title, summary, content, fmId):
if len(title) > 64:
title = title[:63]
if len(summary) > 120:
summary = summary[:119]
url = 'https://api.weixin.qq.com/cgi-bin/draft/add?access_token='+access_token
data = {
"articles": [
{
"title": title,
"author": '作者',
"digest": summary,
"content": content,
"show_cover_pic": 1,
"need_open_comment": 0,
"only_fans_can_comment": 0,
"thumb_media_id": fmId
}
]
}
vx_res = requests.post(url=url, data=json.dumps(
data, ensure_ascii=False).encode("utf-8"))
obj = json.loads(vx_res.content)
print(obj)
return obj['media_id']
然后在总方法中调用我们的上传草稿方法
print(content_soup.prettify())
updCG(title, summary, content_soup.prettify(), fmId)
查看结果,可以看到文章已经自动提交到草稿箱了,然后我们就可以进去二次创建发布了
总结
这可以在半天总共100多行代码中完成。其实这主要需要你去分析网页,因为每个网站的情况都不一样,后面的技术实现也差不多。生活中,我们会遇到很多需要时时刻刻重复的事情。这个时候,我们可以多花点脑力,以后节省不少时间。如果我们掌握了一些别人无法做到的事情,那么我们就可以做一些不同的事情。好吧,技术改变生活,不是吗? 查看全部
文章采集接口(折腾一个微信公众号新增永久图文素材|微信开放文档)
前言
都说懒惰是人类进步的动力,古人没有骗我。最近在折腾一个微信公众号。一开始是在网上找了一些资源,然后做了二次创作,然后发布到了微信公众号上。不过,我得把里面的图片下载下来,复制文字,然后慢慢上传到微信公众号。经过几天的工作,我发现这太低效了。我每天都在做重复的事情。这对于程序员来说是无法忍受的。任何重复的东西都有自动化的价值,我们不能浪费它们。人生就在这种地方,不废话,做就做。
一、需求和难点从指定页面爬取数据只爬取我们需要的内容(什么样的广告,不需要导航),然后将文字上传到微信公众号的草稿箱。微信的草稿箱界面只能放图片上传到微信,所以我们需要做一个额外的操作,从网页中提取图片上传到微信公众号,然后将文中的图片链接替换为微信公众号中的图片二、使用工具和接口将封面图片上传到微信公众号添加永久图文素材 | 微信开文档()上传文字图片到微信公众号
http请求方式: POST,https协议 https://api.weixin.qq.com/cgi- ... TOKEN 调用示例(使用curl命令,用FORM表单方式上传一个图片): curl -F [email protected] "https://api.weixin.qq.com/cgi- ... ot%3B
上传文字至公众号草稿箱接口请求说明 | 微信打开文档()
这里主要使用Python:requests、BeautifulSoup、json
三、实施步骤1.分析网页
这是我们要分析的网页截图:
我们可以看到这个网页有自己的导航,右侧的推荐栏和底部的导航。如果我们直接扣除上传到整个网页的微信公众号,无疑会给我们的后期处理带来很大的工作量。所以我们只需要body,也就是html中的内容
2. 调用接口我们先来看看上传草稿API接口
接口请求说明
http 请求方式:POST(请使用https协议)https://api.weixin.qq.com/cgi- ... TOKEN
调用示例
{
"articles": [
{
"title":TITLE,
"author":AUTHOR,
"digest":DIGEST,
"content":CONTENT,
"content_source_url":CONTENT_SOURCE_URL,
"thumb_media_id":THUMB_MEDIA_ID,
"show_cover_pic":1,
"need_open_comment":0,
"only_fans_can_comment":0
}
//若新增的是多图文素材,则此处应还有几段articles结构
]
}
请求参数说明
范围
有必要吗
操作说明
标题
是的
标题
内容
是的
图片和短信的具体内容支持HTML标签,且必须小于20000字符且小于1M,这里会去掉JS,图片的url必须从“上传图片获取网址”中获取图片和文字信息”界面。外部图片网址将被过滤
thumb_media_id
是的
图文信息的封面图片素材id(必须是永久MediaID)
可以看出这个接口需要3个参数,那我们就去网页的代码看看如何获取这3个参数
通过分析网页,我们可以发现我们想要的标题在class='entry-title'的a标签中,我们还可以在class='entry-title'的div中得到文章的摘要概括'

所以我们先爬取页面,得到标题和摘要
baseUrl = 'https://www.test.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.57'
}
res = requests.get(baseUrl, verify=False, headers=headers)
root_soup = BeautifulSoup(res.content, 'html.parser')
title = root_soup.select('.entry-title')[0].text
summary = root_soup.select('.entry-summary p')[0].text
print(title)
print(summary)
接下来,我们需要准备封面。现在我们将使用微信公众号接口,但是在使用公众号接口之前,我们需要获取一个令牌,以便我们有权访问公众号的API接口。获取token的文档在这里:Wechat Open Document() 通过分析文字我们知道这个文章里面有很多图片,那么我们就以第一张图片为封面,先定义一个方法用于上传封面
然后获取body中的所有图片,将第一个传入这个方法获取cover id
content_soup = root_soup.select('.entry-content')[0]
imgs = content_soup.select('.wp-block-image')
fmId = updFm(imgs[0].img['src'], title)
接下来我们在文本中定义一个上传其他图片的方法,因为其他图片需要返回的url不是media_id,所以调用了另外一个接口。
def updImg(url):
base_folder = 'D:\\tempDir'
res = requests.get(url, verify=False)
file_name = '{}.jpg'.format(random.randint(10000, 99999))
with open(base_folder + file_name, 'wb') as f:
f.write(res.content)
vx_img_url = 'https://api.weixin.qq.com/cgi-bin/media/uploadimg'
request_file = {
'media': (file_name, open(base_folder + file_name, 'rb'), 'image/jpeg')}
data = {
'access_token': access_token
}
vx_res = requests.post(url=vx_img_url, files=request_file, data=data)
obj = json.loads(vx_res.content)
print(obj)
return obj['url']
然后将文中的图片全部上传到微信公众号的素材库,替换为文中的图片地址
for img_content in imgs:
img_content.noscript.decompose()
current_url = img_content.img['data-original']
upd_url = updImg(current_url)
img_content.img['src'] = upd_url
img_content.img['data-original'] = upd_url
最后我们可以开始准备上传文章到草稿箱,或者先定义方法,因为草稿界面的标题和摘要都有长度限制,所以这个方法开始做限制。如果长度超过,字符串将被截取
def updCG(title, summary, content, fmId):
if len(title) > 64:
title = title[:63]
if len(summary) > 120:
summary = summary[:119]
url = 'https://api.weixin.qq.com/cgi-bin/draft/add?access_token='+access_token
data = {
"articles": [
{
"title": title,
"author": '作者',
"digest": summary,
"content": content,
"show_cover_pic": 1,
"need_open_comment": 0,
"only_fans_can_comment": 0,
"thumb_media_id": fmId
}
]
}
vx_res = requests.post(url=url, data=json.dumps(
data, ensure_ascii=False).encode("utf-8"))
obj = json.loads(vx_res.content)
print(obj)
return obj['media_id']
然后在总方法中调用我们的上传草稿方法
print(content_soup.prettify())
updCG(title, summary, content_soup.prettify(), fmId)
查看结果,可以看到文章已经自动提交到草稿箱了,然后我们就可以进去二次创建发布了

总结
这可以在半天总共100多行代码中完成。其实这主要需要你去分析网页,因为每个网站的情况都不一样,后面的技术实现也差不多。生活中,我们会遇到很多需要时时刻刻重复的事情。这个时候,我们可以多花点脑力,以后节省不少时间。如果我们掌握了一些别人无法做到的事情,那么我们就可以做一些不同的事情。好吧,技术改变生活,不是吗?
文章采集接口(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 642 次浏览 • 2022-01-31 10:14
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。早期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只要输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、支持多平台采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
文章采集接口(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。早期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只要输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、支持多平台采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章采集接口(基于requests使用采集python模块的方法总结-csdn博客requests库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-31 04:02
文章采集接口是和爬虫对接的,而爬虫则需要引入requests包来处理http请求。而在采集方面用到requests的情况比较多。本文使用requests比较简单粗暴的方法:基于requests使用采集python模块的方法总结-csdn博客requests库其实是一个库,包含的模块有requests和其它模块。
requests包含requests-http、requests-headers、itchat、dataframe(数据框)、cookiejar等,这些模块的作用也不尽相同。本文基于requests来讲requests包。官方提供的示例地址:-http-demo,示例页面的功能很完善,比如网址结构抓取、二维码解析、不同浏览器和不同浏览器模式下的url转换、网页广告解析、浏览器登录验证等。
安装方式一般是用pipinstallrequests,或者requests-http-demo自带pip(在网页源码中)或者下载支持的模块,或者直接用requests-http-demo自带-http:,把requests-http包放到工程的根目录。本文介绍requests-http包的安装方式。安装包教程:使用cmd方式安装requests包注意:安装requests时不要安装在命令行模式。
如果想要安装cmd方式安装,可以使用conda:condainstallrequests-http安装时如果不想用pip,可以使用pipinstallrequests-http安装时安装requests,requests是一个纯python包,虽然用pipinstall模块比requests自带pip安装方式安装可以节省大量时间。
scrapy在java中完整包下载及其安装方式见详细介绍:下载scrapy已安装安装scrapy后,scrapy以request对象形式接收request,加上shutil方法解析request,将内容传递给requestsresponse方法处理。requestsresponse方法接收几个参数如下:data;data接收的httpresponse对象;参数:-request-path-example-example-image。
安装方式:查看命令或安装方式可用如下命令安装库:pipinstallrequests-http将源码下载scrapy完整包,提取到任何你想要的目录下面,本文以ubuntu下scrapy包为例。scrapy完整包下载地址:scrapydocumentation源码:wget-2.2.6.tar.gz为避免加载jar包时已载入的依赖包可能导致报错,本文提供另一种方法解决:aptinstallsite-packages--for-all安装scrapy,这个时候会发现在/usr/local/scrapy/bin/目录下,也就是/usr/local/scrapy/site-packages/下,还有其它文件。
为避免再加载其它依赖包,可以pipinstalllibscrapy。另外,安装时如果有jar包需要下载解压,可以用如下命令(清华镜像)。 查看全部
文章采集接口(基于requests使用采集python模块的方法总结-csdn博客requests库)
文章采集接口是和爬虫对接的,而爬虫则需要引入requests包来处理http请求。而在采集方面用到requests的情况比较多。本文使用requests比较简单粗暴的方法:基于requests使用采集python模块的方法总结-csdn博客requests库其实是一个库,包含的模块有requests和其它模块。
requests包含requests-http、requests-headers、itchat、dataframe(数据框)、cookiejar等,这些模块的作用也不尽相同。本文基于requests来讲requests包。官方提供的示例地址:-http-demo,示例页面的功能很完善,比如网址结构抓取、二维码解析、不同浏览器和不同浏览器模式下的url转换、网页广告解析、浏览器登录验证等。
安装方式一般是用pipinstallrequests,或者requests-http-demo自带pip(在网页源码中)或者下载支持的模块,或者直接用requests-http-demo自带-http:,把requests-http包放到工程的根目录。本文介绍requests-http包的安装方式。安装包教程:使用cmd方式安装requests包注意:安装requests时不要安装在命令行模式。
如果想要安装cmd方式安装,可以使用conda:condainstallrequests-http安装时如果不想用pip,可以使用pipinstallrequests-http安装时安装requests,requests是一个纯python包,虽然用pipinstall模块比requests自带pip安装方式安装可以节省大量时间。
scrapy在java中完整包下载及其安装方式见详细介绍:下载scrapy已安装安装scrapy后,scrapy以request对象形式接收request,加上shutil方法解析request,将内容传递给requestsresponse方法处理。requestsresponse方法接收几个参数如下:data;data接收的httpresponse对象;参数:-request-path-example-example-image。
安装方式:查看命令或安装方式可用如下命令安装库:pipinstallrequests-http将源码下载scrapy完整包,提取到任何你想要的目录下面,本文以ubuntu下scrapy包为例。scrapy完整包下载地址:scrapydocumentation源码:wget-2.2.6.tar.gz为避免加载jar包时已载入的依赖包可能导致报错,本文提供另一种方法解决:aptinstallsite-packages--for-all安装scrapy,这个时候会发现在/usr/local/scrapy/bin/目录下,也就是/usr/local/scrapy/site-packages/下,还有其它文件。
为避免再加载其它依赖包,可以pipinstalllibscrapy。另外,安装时如果有jar包需要下载解压,可以用如下命令(清华镜像)。
文章采集接口(互联..NANDFLASH学习笔记之nandflash基础(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-27 06:07
实现“互联网+政务服务”平台与交通行政管理业务系统之间的数据自动流转,窗口工作人员不再手动录入二次录入--二次录入_weixin_43969737的博客-程序员
当我们在政务服务大厅的交通窗口办完业务时,应该还记得排队等候业务受理的场景。窗口服务员效率太低?太慢了?真的是事实吗?长期以来,这个窗口的工作人员每天要办理十余项公路货运经营许可证,提交了大量的材料。项目清单中列出了19个文件;而普货年检每天要处理25-35辆,还是一样。文件;加上其他需要处理的事务。根据省政府统一部署和省交通运输厅关于推进审批服务一站式办理的实施意见,“互联网...
nand flash基础的NAND FLASH学习笔记(二)_中国田园犬-程序员宝宝
4. 地址格式:地址分为:块地址、页地址、列地址,其中块地址和页地址也称为行地址 CA[0:12]:列地址,用于选择行内的偏移量page,由于page(包括OOB区)的大小为(4k+224)byte),所以需要13位来表示PA[0:7]:page address,用来选择一个page在一个街区。大小为256页,所以需要8位来表示BA[8:19]:块地址,用于选择LUN中的块,因为一个LUN中的块数是4096
攻击windows异常处理机制SEH_0pt1mus - 程序员大本营
转载自个人博客0pt1mus0x00 简介本文主要有两部分。第一部分介绍了Windows异常处理机制中的SEH,详细介绍了SEH的工作原理。第二部分介绍如何使用SEH通过堆栈溢出绕过GS。0x01 SEH(异常处理结构) SEH的全称是Structure Exception Handler,翻译为异常处理结构,是Windows异常处理机制使用的重要数据结构。每个 SEH 结构收录两个 DWORD 指针:SEH 链表指针和异常处理函数句柄,共 8 个字节。如下图: 为了初步了解SEH,我们需要了解几个
由于 C 语言标准不同而导致使用 for 循环的错误
目录 今天学习C的时候出现问题,写了一个通用循环,报错,代码如下,报错 今天学习C的时候解决了一个问题,写了一个通用循环,报错,代码如下#include <stdio.h>int main() { int price = 100; for (int i = 0; i <100 ; ++i) { printf("价格下降了,现在价格是:%d\n", price); 价格 - ;
babel的原理_从Babel到按需引入组件的原理
前言讲通天塔,相信大家不会感到陌生。桌面组件库Element,借助babel-plugin-component,我们可以只引入需要的组件,达到减小项目体积的目的。使用 babel-polyfill,开发人员可以立即使用 ES 规范中的最新功能。配合插件:transform-vue-jsx、react,我们可以直接使用JSX在vue中编写模板,进行react开发...
主板诊断卡code_weixin_34148508的博客-程序员宝贝
00 . 显示系统配置;即将控制 INI19 引导加载。.01 处理器测试 1、处理器状态验证,如果测试失败,则循环无限。处理器寄存器的测试即将开始,不可屏蔽的中断即将被禁用。CPU 寄存器测试正在进行或失败。02 确定诊断类型(正常或制造)。如果键盘缓冲区收录数据,它将失败。禁用不可屏蔽的中断;从延迟开始。CMOS 写入/读取正在进行或失败。03... 查看全部
文章采集接口(互联..NANDFLASH学习笔记之nandflash基础(二))
实现“互联网+政务服务”平台与交通行政管理业务系统之间的数据自动流转,窗口工作人员不再手动录入二次录入--二次录入_weixin_43969737的博客-程序员
当我们在政务服务大厅的交通窗口办完业务时,应该还记得排队等候业务受理的场景。窗口服务员效率太低?太慢了?真的是事实吗?长期以来,这个窗口的工作人员每天要办理十余项公路货运经营许可证,提交了大量的材料。项目清单中列出了19个文件;而普货年检每天要处理25-35辆,还是一样。文件;加上其他需要处理的事务。根据省政府统一部署和省交通运输厅关于推进审批服务一站式办理的实施意见,“互联网...
nand flash基础的NAND FLASH学习笔记(二)_中国田园犬-程序员宝宝
4. 地址格式:地址分为:块地址、页地址、列地址,其中块地址和页地址也称为行地址 CA[0:12]:列地址,用于选择行内的偏移量page,由于page(包括OOB区)的大小为(4k+224)byte),所以需要13位来表示PA[0:7]:page address,用来选择一个page在一个街区。大小为256页,所以需要8位来表示BA[8:19]:块地址,用于选择LUN中的块,因为一个LUN中的块数是4096
攻击windows异常处理机制SEH_0pt1mus - 程序员大本营
转载自个人博客0pt1mus0x00 简介本文主要有两部分。第一部分介绍了Windows异常处理机制中的SEH,详细介绍了SEH的工作原理。第二部分介绍如何使用SEH通过堆栈溢出绕过GS。0x01 SEH(异常处理结构) SEH的全称是Structure Exception Handler,翻译为异常处理结构,是Windows异常处理机制使用的重要数据结构。每个 SEH 结构收录两个 DWORD 指针:SEH 链表指针和异常处理函数句柄,共 8 个字节。如下图: 为了初步了解SEH,我们需要了解几个
由于 C 语言标准不同而导致使用 for 循环的错误
目录 今天学习C的时候出现问题,写了一个通用循环,报错,代码如下,报错 今天学习C的时候解决了一个问题,写了一个通用循环,报错,代码如下#include <stdio.h>int main() { int price = 100; for (int i = 0; i <100 ; ++i) { printf("价格下降了,现在价格是:%d\n", price); 价格 - ;
babel的原理_从Babel到按需引入组件的原理
前言讲通天塔,相信大家不会感到陌生。桌面组件库Element,借助babel-plugin-component,我们可以只引入需要的组件,达到减小项目体积的目的。使用 babel-polyfill,开发人员可以立即使用 ES 规范中的最新功能。配合插件:transform-vue-jsx、react,我们可以直接使用JSX在vue中编写模板,进行react开发...
主板诊断卡code_weixin_34148508的博客-程序员宝贝
00 . 显示系统配置;即将控制 INI19 引导加载。.01 处理器测试 1、处理器状态验证,如果测试失败,则循环无限。处理器寄存器的测试即将开始,不可屏蔽的中断即将被禁用。CPU 寄存器测试正在进行或失败。02 确定诊断类型(正常或制造)。如果键盘缓冲区收录数据,它将失败。禁用不可屏蔽的中断;从延迟开始。CMOS 写入/读取正在进行或失败。03...
文章采集接口(【Kaggle】图像库是格式化为模型标准)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-03-11 12:21
本文章主要介绍“如何使用python构建图像采集界面应用”。在日常操作中,相信很多人对于如何使用python构建一个image采集界面应用程序都有疑问。如有疑问,小编查阅了各种资料,整理出了简单好用的操作方法。希望能帮助大家解答“如何使用python构建图像采集界面应用”的疑惑!接下来就跟着小编一起来学习吧!
安装 cv2 (OpenCV)
我们将使用的图像库是 cv2。因为 cv2 不能在 Kaggle 等在线平台上运行,所以必须在您的计算机上本地完成。然而,模型的权重仍然可以在 Kaggle 上进行训练,下载为 .h6 文件(基于 Keras/TensorFlow)并加载。
输入 Anaconda 或命令提示符
conda create -n opencv python=3.6
这将在 Python 版本 3.6 中创建一个名为 opencv 的新环境,可以将其替换为正在使用的任何版本。
接下来,输入
pip install opencv-python
您已成功安装 cv2!现在你可以开始拍照了。
用 CV2 拍照
首先,导入库。
import cv2
接下来,我们必须创建一个视频捕获实例。您可以测试该实例是否能够连接到您的相机(如果不能,请检查您的设置以确保应用可以访问它)。
cap = cv2.VideoCapture(0)
if not (cap.isOpened()):
print("Video device not connected.")
最后,是时候拍照了。如果要控制何时拍摄照片,第一行将指定任意变量和输入。程序无法继续,除非输入某些内容(例如按“enter”)并且下一行开始拍照。拍摄图像时,您可能会很快看到网络摄像头指示灯出现。第三行关闭连接,第四行销毁所有访问相机的实例。
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
图像中的数据存储在帧中。可以使用以下代码将其转换为数组:
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
调用cv2_im.shape时,输出为(480640,3)。所以图像(对于我的相机)是480x640像素(3表示“深度”,每个像素中有三个值描述最终像素创建的颜色需要包括红色、绿色和蓝色)。
现在图像已经转换为数组,matplotlib 的 imshow() 可以显示它。
import matplotlib.pyplot as plt
plt.imshow(cv2_im)
plt.show()
完整代码:
import cv2
import matplotlib.pyplot as plt
cap = cv2.VideoCapture(10)
if not (cap.isOpened()):
print("Video device unconnected.")
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
plt.imshow(cv2_im)
plt.show()
格式化为模型标准
卷积神经网络只接受固定大小的图像,例如 (100, 100, 3)。有几种方法可以做到这一点。
要保持图像的比例长度,请尝试裁剪图像。
一般语法是:
plt.imshow(cv2_im[y_upper_bound:y_lower_bound,x_lower_bound:x_higher_bound])
其中“上”和“下”由图像上的位置确定(y 的“上”表示图像上方,x 的“上”表示图像的右侧)。
例如,
plt.imshow(cv2_im[100:400,100:400])
在这里,照片被裁剪成一个正方形。
但是,尺寸仍然是 300×300。为了解决这个问题,我们将再次使用 Pillow:
pil_image = Image.fromarray(cv2_im[100:400,100:400])
width = 100
height = 100
pil_image = pil_image.resize((width,height), Image.ANTIALIAS)
NumPy 自动将 Pillow 图像转换为数组。
import numpy as np
cv2_im_new = np.array(pil_image)
查看新图像:
plt.imshow(cv2_im_new)
好多了!图像的新形状是 (100, 100, 3),非常适合我们的模型。
在模型中运行
现在我们有了一个 NumPy 数组,只需将它传递给模型。
model.predict(cv2_im_new)
基于此,通过一些手工编码来标记图像的真实标签,您可以在标题中标记它们:
plt.imshow(cv2_im_new)
plt.title('Hand Gesture: '+classification)
至此,关于《如何使用python构建图像采集界面应用》的学习就结束了,希望能解决大家的疑惑。理论与实践相结合更能帮助大家学习,快去试试吧!如果你想继续学习更多相关知识,请继续关注易速云网站,小编会继续努力为大家带来更多实用文章! 查看全部
文章采集接口(【Kaggle】图像库是格式化为模型标准)
本文章主要介绍“如何使用python构建图像采集界面应用”。在日常操作中,相信很多人对于如何使用python构建一个image采集界面应用程序都有疑问。如有疑问,小编查阅了各种资料,整理出了简单好用的操作方法。希望能帮助大家解答“如何使用python构建图像采集界面应用”的疑惑!接下来就跟着小编一起来学习吧!
安装 cv2 (OpenCV)
我们将使用的图像库是 cv2。因为 cv2 不能在 Kaggle 等在线平台上运行,所以必须在您的计算机上本地完成。然而,模型的权重仍然可以在 Kaggle 上进行训练,下载为 .h6 文件(基于 Keras/TensorFlow)并加载。
输入 Anaconda 或命令提示符
conda create -n opencv python=3.6
这将在 Python 版本 3.6 中创建一个名为 opencv 的新环境,可以将其替换为正在使用的任何版本。
接下来,输入
pip install opencv-python
您已成功安装 cv2!现在你可以开始拍照了。
用 CV2 拍照
首先,导入库。
import cv2
接下来,我们必须创建一个视频捕获实例。您可以测试该实例是否能够连接到您的相机(如果不能,请检查您的设置以确保应用可以访问它)。
cap = cv2.VideoCapture(0)
if not (cap.isOpened()):
print("Video device not connected.")
最后,是时候拍照了。如果要控制何时拍摄照片,第一行将指定任意变量和输入。程序无法继续,除非输入某些内容(例如按“enter”)并且下一行开始拍照。拍摄图像时,您可能会很快看到网络摄像头指示灯出现。第三行关闭连接,第四行销毁所有访问相机的实例。
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
图像中的数据存储在帧中。可以使用以下代码将其转换为数组:
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
调用cv2_im.shape时,输出为(480640,3)。所以图像(对于我的相机)是480x640像素(3表示“深度”,每个像素中有三个值描述最终像素创建的颜色需要包括红色、绿色和蓝色)。
现在图像已经转换为数组,matplotlib 的 imshow() 可以显示它。
import matplotlib.pyplot as plt
plt.imshow(cv2_im)
plt.show()
完整代码:
import cv2
import matplotlib.pyplot as plt
cap = cv2.VideoCapture(10)
if not (cap.isOpened()):
print("Video device unconnected.")
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
plt.imshow(cv2_im)
plt.show()
格式化为模型标准
卷积神经网络只接受固定大小的图像,例如 (100, 100, 3)。有几种方法可以做到这一点。
要保持图像的比例长度,请尝试裁剪图像。
一般语法是:
plt.imshow(cv2_im[y_upper_bound:y_lower_bound,x_lower_bound:x_higher_bound])
其中“上”和“下”由图像上的位置确定(y 的“上”表示图像上方,x 的“上”表示图像的右侧)。
例如,
plt.imshow(cv2_im[100:400,100:400])
在这里,照片被裁剪成一个正方形。
但是,尺寸仍然是 300×300。为了解决这个问题,我们将再次使用 Pillow:
pil_image = Image.fromarray(cv2_im[100:400,100:400])
width = 100
height = 100
pil_image = pil_image.resize((width,height), Image.ANTIALIAS)
NumPy 自动将 Pillow 图像转换为数组。
import numpy as np
cv2_im_new = np.array(pil_image)
查看新图像:
plt.imshow(cv2_im_new)
好多了!图像的新形状是 (100, 100, 3),非常适合我们的模型。
在模型中运行
现在我们有了一个 NumPy 数组,只需将它传递给模型。
model.predict(cv2_im_new)
基于此,通过一些手工编码来标记图像的真实标签,您可以在标题中标记它们:
plt.imshow(cv2_im_new)
plt.title('Hand Gesture: '+classification)
至此,关于《如何使用python构建图像采集界面应用》的学习就结束了,希望能解决大家的疑惑。理论与实践相结合更能帮助大家学习,快去试试吧!如果你想继续学习更多相关知识,请继续关注易速云网站,小编会继续努力为大家带来更多实用文章!
文章采集接口(这是我参与2022首次更文挑战(第15天))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-08 20:28
“这是我参加2022首次更新挑战的第15天,活动详情请查看:2022首次更新挑战。”
欢迎小伙伴们微信搜索“安迪阿辉”并关注一波!
写一些程序员的想法和想法,希望对你有帮助。
前言
上一篇文章我们简单了解了接口的定义,那么接口应该怎么使用,使用接口的作用有哪些。
那我们就跟着这个文章来看看吧。
一流企业做标准,二流企业做品牌,三流企业做产品?
在编程中细化业务,使用接口实现部分代码。
具有以下优点:
在进行系统设计、模块设计甚至对象设计时,您应该考虑更高级别的抽象——即接口,而不是陷入实现细节。
要清楚地认识到,界面设计是我们系统设计的主要工作内容。而这种能够跳出细节,站在更高的抽象层次去看待整个系统的模块设计、模块划分、模块交互的人,是非常重要的。
那我们就需要好好利用接口了。
接口使用
简单接口的转换是使用强制类型实现的。
Ahui ahui=new Ahui();
IBaseInfo baseInfo=(IBaseInfo)ahui; //获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
其实C#中有一个操作符也可以达到这个效果。
作为运营商
在接口转换过程中,如果转换失败,会抛出异常。如果使用 as 运算符,即使转换失败,程序也不会失败,会自动返回 null。
Ahui ahui=new Ahui();
IBaseInfo baseInfo = ahui as IBaseInfo; //as运算符 获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
实现多个接口
在实际的编程过程中,一个类可以实现多个接口。需要注意的是,所有实现的接口都用逗号分隔。如果实现中有基类,接口必须排在基类之后。
interface IBaseAction
{
bool isLove();
}
class Ahui : IBaseInfo, IBaseAction
{
public int Age()
{
return 28;
}
public string Name()
{
return "阿辉";
}
public bool isLove()
{
return true;
}
}
复制代码
这里需要注意的是,如果一个类实现的多个接口中的某些成员具有相同的签名和返回类型,那么该类可以实现单个成员来满足所有收录重复成员的接口。
接口可以使用派生成员来实现,这意味着实现接口的类可以从其基类继承实现代码。
前面我们说过,接口是一个特殊的类,一个类一般都有函数式接口。那么类可以通过继承实现一些方法的公开,那么接口也可以被继承。但是接口继承也有一些注意事项。
interface IBaseInfo:IBaseAction
{
int Age();
string Name();
}
interface IBaseAction
{
bool isLove();
}
复制代码
信息
人生苦短,我不想去追求我看不到的,我只想抓住我能看到的。
原创不容易,给我点关注。
我是阿辉,感谢您的阅读,如果对您有帮助,请点赞转发。谢谢你。 查看全部
文章采集接口(这是我参与2022首次更文挑战(第15天))
“这是我参加2022首次更新挑战的第15天,活动详情请查看:2022首次更新挑战。”
欢迎小伙伴们微信搜索“安迪阿辉”并关注一波!
写一些程序员的想法和想法,希望对你有帮助。
前言
上一篇文章我们简单了解了接口的定义,那么接口应该怎么使用,使用接口的作用有哪些。
那我们就跟着这个文章来看看吧。
一流企业做标准,二流企业做品牌,三流企业做产品?
在编程中细化业务,使用接口实现部分代码。
具有以下优点:
在进行系统设计、模块设计甚至对象设计时,您应该考虑更高级别的抽象——即接口,而不是陷入实现细节。
要清楚地认识到,界面设计是我们系统设计的主要工作内容。而这种能够跳出细节,站在更高的抽象层次去看待整个系统的模块设计、模块划分、模块交互的人,是非常重要的。
那我们就需要好好利用接口了。
接口使用
简单接口的转换是使用强制类型实现的。
Ahui ahui=new Ahui();
IBaseInfo baseInfo=(IBaseInfo)ahui; //获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
其实C#中有一个操作符也可以达到这个效果。
作为运营商
在接口转换过程中,如果转换失败,会抛出异常。如果使用 as 运算符,即使转换失败,程序也不会失败,会自动返回 null。
Ahui ahui=new Ahui();
IBaseInfo baseInfo = ahui as IBaseInfo; //as运算符 获取接口的引用
baseInfo.Name(); //使用接口的引用调用方法
复制代码
实现多个接口
在实际的编程过程中,一个类可以实现多个接口。需要注意的是,所有实现的接口都用逗号分隔。如果实现中有基类,接口必须排在基类之后。
interface IBaseAction
{
bool isLove();
}
class Ahui : IBaseInfo, IBaseAction
{
public int Age()
{
return 28;
}
public string Name()
{
return "阿辉";
}
public bool isLove()
{
return true;
}
}
复制代码
这里需要注意的是,如果一个类实现的多个接口中的某些成员具有相同的签名和返回类型,那么该类可以实现单个成员来满足所有收录重复成员的接口。
接口可以使用派生成员来实现,这意味着实现接口的类可以从其基类继承实现代码。
前面我们说过,接口是一个特殊的类,一个类一般都有函数式接口。那么类可以通过继承实现一些方法的公开,那么接口也可以被继承。但是接口继承也有一些注意事项。
interface IBaseInfo:IBaseAction
{
int Age();
string Name();
}
interface IBaseAction
{
bool isLove();
}
复制代码
信息
人生苦短,我不想去追求我看不到的,我只想抓住我能看到的。
原创不容易,给我点关注。
我是阿辉,感谢您的阅读,如果对您有帮助,请点赞转发。谢谢你。
文章采集接口(DiscuzX3正式版门户文章接口使用手册(discuz!X3.0))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-06 09:00
Discuz X3正式版传送门文章界面使用手册一、介绍1、此界面适用于discuz!X3正式版discuz!X3.0 正式版6、 in discuz! X3.0 正式版7、这个界面是基于discuz!X3.0 正式版 discuz! X3.0 正式版8、接口文件无需任何改动即可使用,如需添加验证或其他功能,请谨慎修改;9、2个接口文件,请复制到discuz中!X3.0 etchk.php正式版,etpost.php,将接口文件复制到指定目录,远程FTP上传到指定目录。请以二进制方式上传,如图:三、配置发布规则1、 将示例发布规则的文本导入ET2发布配置中,或者使用软件内置发布规则示例,如图:2、在巡检URL中修改“your网站”, 网站你要发布的URL的发布URL,如图:3、在参数值中,填写你要发布的频道ID,如图:打开门户管理发布文章页面,可以查看频道ID,即catid的值:5、填写你的账号、密码,注意格式和账号权限(账号应该有portal文章频道管理权限),如图:四、接口说明一、查看接口1、接口文件名etck。php, 为保密起见,请自行修改文件名;2、这个接口文件复制到网站根目录下使用;3、主要参数title文章title catid类别ID用于限制检查范围。它可以留空。请在管理中心查看分类ID;请自行设置vercode校验码,修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/etchk.php?vercode=&catid=&title= 注意:用户使用区分大小写的服务器,请注意URL大小写与网站文件一致5、接口文件无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名为etpost.php,为保密请自行修改文件名;2、 请将该接口文件复制到网站根目录下使用;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;具有固定值的参数可以在发布规则-参数值中设置;采集 带值的参数项,请在发布规则-发布项中添加;3、参数用户名会员名参数名密码密码参数名标题主题标题参数名内容内容参数名(分页请替换ET2文本分隔符“#-0-#” 与discuz!x 分页标记 "#########NextPage#### ######""#########NextPage[title=页面标题] ###### ####")4、参数catid文章分类号(请参考管理中心文章分类)vercode安全验证码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站相同file5、接口文件无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;注:以下参数名称后面有“=”号,用于示范值选择,参数名称本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换带 discuz!x 分页标签 "##########NextPage##########" " #########NextPage[title=页面标题]##########”)4、参数catid文章分类号(请参考管理中心文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站文件< @5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;笔记:后面的参数名后面有一个“=”号,用于演示取值,参数名本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换with discuz! x 分页标签 "##########NextPage##########" "##########NextPage[title=页面标题] ### #######”)4、参数catid文章类别号(请参考管理中心< @文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。 参数用户名 会员名 参数名 密码 参数名 题目 题目 参数名 内容 内容 参数名(如果要分页,请替换ET2文本分隔标记“#- 0-#" with discuz! x 分页标记 "# #########NextPage##########""#########NextPage[title=页面标题] ##########" )4、参数catid文章类别号(请参考管理中心文章类别)vercode安全校验码,请设置自己,这个项目是用来防止接口被别人使用的,如果需要做更多的验证,
ashowurl=/data/attachment/portal 门户文件显示URL,默认值为/data/attachment/portal,该参数可以支持更改默认附件目录和远程文件,该值对应网站Background-Upload settings ;< @5、参数raids[]=12raids[]=34raids[]=112tag[1] 聚合标签1,设置值为1启用,如果在附加参数中填写“tag[1]=1” , 如果不使用则留空;tag[2] 聚合标签2,设置值为1启用,如果在附加参数中填写“tag[2]=1”,则留空;tag[3] 聚合标签3,设置值为1可以启用,例如在附加参数中填写“tag[3]=1”,不使用时留空;tag[4] 聚合标签4,设置值为1启用,如填写" tag[3] 在附加参数中。4]=1",不需要留空;tag[5]聚合tag 5,设置值为1启用,如果在附加参数中填写"tag[5]=1",不需要留空;tag [6] ] 聚合标签 6,设置值为 1 启用,如附加参数中填写“tag[6]=1”,留空;tag[7] 聚合标签 7,设置值为 1启用,如在附加参数中填写“tag[7]=1”,不使用则留空;tag[8]聚合标签8,设置值为1启用,如填写“tag[8” ]=1"在附加参数中,不使用时留空;如果需要为封面图指定封面图,用户使用的采集规则应该有一个数据项到采集@ > 作为封面图片的图片 URL,并且应该在Publishing Rules-Publishing Item-这个数据项对应的参数pic中列出;对应用户网站后台-上传设置-基础设置-附件URL地址,默认值为“/data/attachment/portal”;当网站上传设置-附件URL地址改变时,该值应等于“附件URL地址”+“/portal”;8、发布配置-文章URL,可以填写如下:你的URL/etpost .php 注意:对于使用区分大小写服务器的用户,请注意URL的大小写相同与网站文件9、接口文件一样,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;二、 [err]invalid vercode[/err]1、发布规则-校验URL中填写的vercode值与校验接口文件中的vercode值不一致;2、在发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] subject is null[/err]: 采集 used by 1、 @>规则未能正确采集到标题;2、采集 @>规则的数据整理过滤了标题;3、错误修改了发布项参数名称中的发布规则-标题,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;四、 [err]内容不能为空[/err]:1、使用的采集规则未能正确采集到文本数据项;2、采集 规则数据排序过滤了文本数据;3、 修改错误发布规则-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;五、文章乱码:1、发布规则不开启utf-8编码转换;2、数据没有组织好;六、附件上传不成功:1、检查附件是否保存在正确的路径和格式2、检查是否附件存在3、 检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与方案的文件存储目录一致; 查看全部
文章采集接口(DiscuzX3正式版门户文章接口使用手册(discuz!X3.0))
Discuz X3正式版传送门文章界面使用手册一、介绍1、此界面适用于discuz!X3正式版discuz!X3.0 正式版6、 in discuz! X3.0 正式版7、这个界面是基于discuz!X3.0 正式版 discuz! X3.0 正式版8、接口文件无需任何改动即可使用,如需添加验证或其他功能,请谨慎修改;9、2个接口文件,请复制到discuz中!X3.0 etchk.php正式版,etpost.php,将接口文件复制到指定目录,远程FTP上传到指定目录。请以二进制方式上传,如图:三、配置发布规则1、 将示例发布规则的文本导入ET2发布配置中,或者使用软件内置发布规则示例,如图:2、在巡检URL中修改“your网站”, 网站你要发布的URL的发布URL,如图:3、在参数值中,填写你要发布的频道ID,如图:打开门户管理发布文章页面,可以查看频道ID,即catid的值:5、填写你的账号、密码,注意格式和账号权限(账号应该有portal文章频道管理权限),如图:四、接口说明一、查看接口1、接口文件名etck。php, 为保密起见,请自行修改文件名;2、这个接口文件复制到网站根目录下使用;3、主要参数title文章title catid类别ID用于限制检查范围。它可以留空。请在管理中心查看分类ID;请自行设置vercode校验码,修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/etchk.php?vercode=&catid=&title= 注意:用户使用区分大小写的服务器,请注意URL大小写与网站文件一致5、接口文件无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名为etpost.php,为保密请自行修改文件名;2、 请将该接口文件复制到网站根目录下使用;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;具有固定值的参数可以在发布规则-参数值中设置;采集 带值的参数项,请在发布规则-发布项中添加;3、参数用户名会员名参数名密码密码参数名标题主题标题参数名内容内容参数名(分页请替换ET2文本分隔符“#-0-#” 与discuz!x 分页标记 "#########NextPage#### ######""#########NextPage[title=页面标题] ###### ####")4、参数catid文章分类号(请参考管理中心文章分类)vercode安全验证码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站相同file5、接口文件无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;注:以下参数名称后面有“=”号,用于示范值选择,参数名称本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换带 discuz!x 分页标签 "##########NextPage##########" " #########NextPage[title=页面标题]##########”)4、参数catid文章分类号(请参考管理中心文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。title=注意:使用区分大小写服务器的用户,请注意URL大小写与网站文件< @5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请谨慎修改;接口文件名etpost.php,为保密请自行修改文件名;2、请将该接口文件复制到网站根目录下使用;笔记:后面的参数名后面有一个“=”号,用于演示取值,参数名本身不收录“=”号;固定值的参数可以在Publishing Rules-Parameter Values中设置;值为采集的参数项,请参考发布规则-发布项中添加;3、参数用户名会员名参数名密码参数名标题主题标题参数名内容内容参数名(如果要进行分页,请在数据整理中将ET2文本标记为“#-0-#”替换with discuz! x 分页标签 "##########NextPage##########" "##########NextPage[title=页面标题] ### #######”)4、参数catid文章类别号(请参考管理中心< @文章category)vercode安全校验码,请自行设置,此项用于防止接口被他人使用。如需更多验证,请自行填写相关代码。 参数用户名 会员名 参数名 密码 参数名 题目 题目 参数名 内容 内容 参数名(如果要分页,请替换ET2文本分隔标记“#- 0-#" with discuz! x 分页标记 "# #########NextPage##########""#########NextPage[title=页面标题] ##########" )4、参数catid文章类别号(请参考管理中心文章类别)vercode安全校验码,请设置自己,这个项目是用来防止接口被别人使用的,如果需要做更多的验证,
ashowurl=/data/attachment/portal 门户文件显示URL,默认值为/data/attachment/portal,该参数可以支持更改默认附件目录和远程文件,该值对应网站Background-Upload settings ;< @5、参数raids[]=12raids[]=34raids[]=112tag[1] 聚合标签1,设置值为1启用,如果在附加参数中填写“tag[1]=1” , 如果不使用则留空;tag[2] 聚合标签2,设置值为1启用,如果在附加参数中填写“tag[2]=1”,则留空;tag[3] 聚合标签3,设置值为1可以启用,例如在附加参数中填写“tag[3]=1”,不使用时留空;tag[4] 聚合标签4,设置值为1启用,如填写" tag[3] 在附加参数中。4]=1",不需要留空;tag[5]聚合tag 5,设置值为1启用,如果在附加参数中填写"tag[5]=1",不需要留空;tag [6] ] 聚合标签 6,设置值为 1 启用,如附加参数中填写“tag[6]=1”,留空;tag[7] 聚合标签 7,设置值为 1启用,如在附加参数中填写“tag[7]=1”,不使用则留空;tag[8]聚合标签8,设置值为1启用,如填写“tag[8” ]=1"在附加参数中,不使用时留空;如果需要为封面图指定封面图,用户使用的采集规则应该有一个数据项到采集@ > 作为封面图片的图片 URL,并且应该在Publishing Rules-Publishing Item-这个数据项对应的参数pic中列出;对应用户网站后台-上传设置-基础设置-附件URL地址,默认值为“/data/attachment/portal”;当网站上传设置-附件URL地址改变时,该值应等于“附件URL地址”+“/portal”;8、发布配置-文章URL,可以填写如下:你的URL/etpost .php 注意:对于使用区分大小写服务器的用户,请注意URL的大小写相同与网站文件9、接口文件一样,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;二、 [err]invalid vercode[/err]1、发布规则-校验URL中填写的vercode值与校验接口文件中的vercode值不一致;2、在发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] subject is null[/err]: 采集 used by 1、 @>规则未能正确采集到标题;2、采集 @>规则的数据整理过滤了标题;3、错误修改了发布项参数名称中的发布规则-标题,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;四、 [err]内容不能为空[/err]:1、使用的采集规则未能正确采集到文本数据项;2、采集 规则数据排序过滤了文本数据;3、 修改错误发布规则-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则不开启utf-8编码转换;五、文章乱码:1、发布规则不开启utf-8编码转换;2、数据没有组织好;六、附件上传不成功:1、检查附件是否保存在正确的路径和格式2、检查是否附件存在3、 检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与方案的文件存储目录一致;
文章采集接口(:文章采集文档,人脸识别只是一个开始。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-04 20:05
文章采集接口文档,人脸识别只是一个开始。为什么采集这个数据?这个采集实例通过squad数据集,该数据集包含265类标签,每个标签两个特征。一共包含6万个采样,并且有1万种分布的方案可供选择。这样的采集工作对应的是调用率2%-8%。是不是看起来很诱人?如果只是这样的,那还真不算多。因为所有的采集是把self-region改成self-region。
有多少self-region,就有多少non-majorlabel。几乎大部分的self-region分布。我想做一点的就是把self-region搞成均匀分布。那么,什么地方距离最近,那么就用最近的距离算每个标签之间的均值,或者方差。精度会不会更高一些?想知道结果,可以在实际场景中做一点验证。看看结果是否符合我们的期望。
自问自答,能否参加我们的etcu前沿项目:self-region,用于构建人脸三维定位模型。来一道题:。
1、请问你知道vaspeople和vaspeoplevector代码实现吗?
2、请讲一下用基于region的距离概率的线性svm做的人脸定位模型。
3、请用opencv中的svm算法做人脸线性svm三维卷积模型。如果你看了这些问题,还是没有答案。那么一个直观的方法告诉你,如果你看到100个人脸,不用opencv,你把每个人脸放到100张图片中,对角线分别对每张图片和那张人脸进行相关系数,然后输出的值就是均值。如果你10000个人脸呢?1000000个的距离,那就相关系数为10000000。
如果你100000000个人脸呢?0的距离,就相关系数为00。如果是个人脸呢?00个,相关系数为0。 查看全部
文章采集接口(:文章采集文档,人脸识别只是一个开始。)
文章采集接口文档,人脸识别只是一个开始。为什么采集这个数据?这个采集实例通过squad数据集,该数据集包含265类标签,每个标签两个特征。一共包含6万个采样,并且有1万种分布的方案可供选择。这样的采集工作对应的是调用率2%-8%。是不是看起来很诱人?如果只是这样的,那还真不算多。因为所有的采集是把self-region改成self-region。
有多少self-region,就有多少non-majorlabel。几乎大部分的self-region分布。我想做一点的就是把self-region搞成均匀分布。那么,什么地方距离最近,那么就用最近的距离算每个标签之间的均值,或者方差。精度会不会更高一些?想知道结果,可以在实际场景中做一点验证。看看结果是否符合我们的期望。
自问自答,能否参加我们的etcu前沿项目:self-region,用于构建人脸三维定位模型。来一道题:。
1、请问你知道vaspeople和vaspeoplevector代码实现吗?
2、请讲一下用基于region的距离概率的线性svm做的人脸定位模型。
3、请用opencv中的svm算法做人脸线性svm三维卷积模型。如果你看了这些问题,还是没有答案。那么一个直观的方法告诉你,如果你看到100个人脸,不用opencv,你把每个人脸放到100张图片中,对角线分别对每张图片和那张人脸进行相关系数,然后输出的值就是均值。如果你10000个人脸呢?1000000个的距离,那就相关系数为10000000。
如果你100000000个人脸呢?0的距离,就相关系数为00。如果是个人脸呢?00个,相关系数为0。
文章采集接口(使用优采云、优采云等采集器怎样将采集的文章发布到呆错文章管理系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-27 13:14
如何使用优采云、优采云等采集器将采集的文章发布到Dumbo文章管理系统?错误文章管理系统有优采云采集插件吗?
错了文章管理系统1.2.23版提供了第三方采集器发布接口,发布接口地址,发布文章@ > 必填字段(应严格推荐)如下!
更多字段请参考管理系统中数据库字段说明。
错了文章管理系统优采云采集器发布模块演示
$data = [];
$data['post_pwd'] = '123456';//入库密码字段(必填、需与后台设置的一致)
$data['category_name'] = '分类1,分类2';//分类字段,多个用逗号分隔
$data['tag_name'] = '标签1,标签2';//标签字段,多个用逗号分隔
$data['info_name'] = 'this is post test';//文章名称
$data['info_excerpt'] = 'this is excerpt';//文章简介
$data['info_content'] = 'this is content';//文章详情
$data['info_type'] = 'index';//文章形式(index|image|album|video|audio|link)
$data['cms_cover'] = 'https://cdn.daicuo.cc/images/d ... %3B//封面字段
$data['cms_referer'] = 'https://cdn.daicuo.cc/post1';//不提交此字段则不验证是否已采集
$result = DcCurl('auto', 10, 'http://'.config('common.site_domain').'/cms/post', $data);
如上使用PHP CURL模拟发布代码! 查看全部
文章采集接口(使用优采云、优采云等采集器怎样将采集的文章发布到呆错文章管理系统)
如何使用优采云、优采云等采集器将采集的文章发布到Dumbo文章管理系统?错误文章管理系统有优采云采集插件吗?
错了文章管理系统1.2.23版提供了第三方采集器发布接口,发布接口地址,发布文章@ > 必填字段(应严格推荐)如下!
更多字段请参考管理系统中数据库字段说明。
错了文章管理系统优采云采集器发布模块演示
$data = [];
$data['post_pwd'] = '123456';//入库密码字段(必填、需与后台设置的一致)
$data['category_name'] = '分类1,分类2';//分类字段,多个用逗号分隔
$data['tag_name'] = '标签1,标签2';//标签字段,多个用逗号分隔
$data['info_name'] = 'this is post test';//文章名称
$data['info_excerpt'] = 'this is excerpt';//文章简介
$data['info_content'] = 'this is content';//文章详情
$data['info_type'] = 'index';//文章形式(index|image|album|video|audio|link)
$data['cms_cover'] = 'https://cdn.daicuo.cc/images/d ... %3B//封面字段
$data['cms_referer'] = 'https://cdn.daicuo.cc/post1';//不提交此字段则不验证是否已采集
$result = DcCurl('auto', 10, 'http://'.config('common.site_domain').'/cms/post', $data);
如上使用PHP CURL模拟发布代码!
文章采集接口(优采云采集器外部接口修改原来的程序..(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-27 06:00
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作的原理。接口就是接口需要提交的数据优采云采集器.优采云采集器提交数据很简单,也就是使用了 post 方法,与使用表单提交的效果相同。接口只需要接收数据。数据接收。这与表单接收没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用request.form("title")来接收并使用。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们使用自己的网站上的程序可以直接将内容发布到网站。然后我们将为此功能制作接口程序或修改原程序。如果你要制作界面的程序是你自己开发的,那么你需要很清楚要输入什么数据,以及如何处理接收到的数据。您可以直接编写程序或更改原程序,将接收到的数据保存到服务器数据库中。如果使用别人的开发程序,则需要对原程序进行修改,使其能够顺利处理数据。这部分由您专门操作。安全接口的通用接口可以直接发布数据。为防止他人使用此界面,您应为其添加密码。可以给模块加个参数,比如密码,给个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序来满足自己的需求。也可以看成是技术人员网站功能的扩展开发。 查看全部
文章采集接口(优采云采集器外部接口修改原来的程序..(组图))
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作的原理。接口就是接口需要提交的数据优采云采集器.优采云采集器提交数据很简单,也就是使用了 post 方法,与使用表单提交的效果相同。接口只需要接收数据。数据接收。这与表单接收没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用request.form("title")来接收并使用。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们使用自己的网站上的程序可以直接将内容发布到网站。然后我们将为此功能制作接口程序或修改原程序。如果你要制作界面的程序是你自己开发的,那么你需要很清楚要输入什么数据,以及如何处理接收到的数据。您可以直接编写程序或更改原程序,将接收到的数据保存到服务器数据库中。如果使用别人的开发程序,则需要对原程序进行修改,使其能够顺利处理数据。这部分由您专门操作。安全接口的通用接口可以直接发布数据。为防止他人使用此界面,您应为其添加密码。可以给模块加个参数,比如密码,给个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序来满足自己的需求。也可以看成是技术人员网站功能的扩展开发。
文章采集接口( 非常新的各类播放器规则电影视频,可以直接生成页面,就是静态化!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-27 05:24
非常新的各类播放器规则电影视频,可以直接生成页面,就是静态化!)
Max采集界面代笔|MAXcms优采云发布模块|Max免登录发布界面
最大电影接口:50,可以采集CKplayer/Gigi Video、Video Pioneer、西瓜视频等非常新的播放规则电影和视频,可以直接生成页面,即静态!
Max新闻界面:50个,只有采集可以发布Max的新五条、图片和小说新闻等,不能生成静态,可以后台改成动态,发布后立即显示!
不管你是想写文章采集、atlas采集、小说采集,还是其他采集接口
雨后,阳光工作室会让你对新店的开业感到满意。大家支持
作文规则:很好的10条,第二条5条,超过10条有礼物!
不成功不收费
雨后天晴,专业Max采集规则写作
最大cms采集规则|电影网站采集规则|采集规则
Max Movie Publishing Module 使用说明:
1、将发布模块maxcms4.0QVOD电影byhurqm.wpm复制到你的优采云目录下的Module文件夹中;
2、点击优采云主页发布进入WEB发布配置管理;
3、新建一个发布,1.选择WEB在线发布模块maxcms4.0QVOD电影byhurqm,3.选择你的代码一般GB2312,4.网站填写你的根目录地址 URL + 背景地址 背景
一个非常关键的步骤是选择使用内置浏览器登录然后点击启动小浏览器进入你的后台并记住你的用户名和密码进行确认。5. 获取分类表。这是测试你的发布界面是否成功的关键。如果你能得到它,那是可以的。
4、填写你的配置名称并保存配置。
在优采云处导入测试规则后,编辑任务,选择第三步发布内容设置---添加发布配置(添加刚刚添加的发布模块配置)并保存
5、点击采集发布即可
雨天工作室出品
拜胡克
特别说明:
1.请填写采集规则的用户邮箱或者
<p>2.一条采集规则只能采集目标站(数据源)的一个子列列表的所有数据,而不能采集目标站(数据源)的所有列数据目标站,如果你想要 查看全部
文章采集接口(
非常新的各类播放器规则电影视频,可以直接生成页面,就是静态化!)
Max采集界面代笔|MAXcms优采云发布模块|Max免登录发布界面
最大电影接口:50,可以采集CKplayer/Gigi Video、Video Pioneer、西瓜视频等非常新的播放规则电影和视频,可以直接生成页面,即静态!
Max新闻界面:50个,只有采集可以发布Max的新五条、图片和小说新闻等,不能生成静态,可以后台改成动态,发布后立即显示!
不管你是想写文章采集、atlas采集、小说采集,还是其他采集接口
雨后,阳光工作室会让你对新店的开业感到满意。大家支持
作文规则:很好的10条,第二条5条,超过10条有礼物!
不成功不收费
雨后天晴,专业Max采集规则写作
最大cms采集规则|电影网站采集规则|采集规则
Max Movie Publishing Module 使用说明:
1、将发布模块maxcms4.0QVOD电影byhurqm.wpm复制到你的优采云目录下的Module文件夹中;
2、点击优采云主页发布进入WEB发布配置管理;
3、新建一个发布,1.选择WEB在线发布模块maxcms4.0QVOD电影byhurqm,3.选择你的代码一般GB2312,4.网站填写你的根目录地址 URL + 背景地址 背景
一个非常关键的步骤是选择使用内置浏览器登录然后点击启动小浏览器进入你的后台并记住你的用户名和密码进行确认。5. 获取分类表。这是测试你的发布界面是否成功的关键。如果你能得到它,那是可以的。
4、填写你的配置名称并保存配置。
在优采云处导入测试规则后,编辑任务,选择第三步发布内容设置---添加发布配置(添加刚刚添加的发布模块配置)并保存
5、点击采集发布即可
雨天工作室出品
拜胡克
特别说明:
1.请填写采集规则的用户邮箱或者
<p>2.一条采集规则只能采集目标站(数据源)的一个子列列表的所有数据,而不能采集目标站(数据源)的所有列数据目标站,如果你想要
文章采集接口(文章采集接口简单容易掌握的采集网站常用接口接口介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-26 11:04
文章采集接口简单容易掌握,适合小白进行快速开发上手。需要按照给出的站点名对采集网站进行seo的爬虫请求,下面就给大家列举出常用接口。
1、总部/总部资讯频道(document.cookie,
2、总部/1分钟发现新发现(1-30分钟内任选一分钟内所需站点);
3、总部/数据_文档_带有发表日期、章节内容、首次发表日期信息;
4、总部/文章列表--1分钟内左侧栏目列表,清除历史内容,
5、总部/站长列表--1分钟内左侧栏目列表,清除历史内容,
6、总部/新文章列表--文章列表列表,清除历史内容,
7、总部/历史档案列表--历史档案列表,清除历史内容,
8、总部/篇章全文列表--内容全文列表,清除历史内容,
9、总部/站点列表--站点列表,清除历史内容,
0、总部/栏目简介--栏目简介,清除历史内容,
1、总部/站点昵称--站点昵称,清除历史内容,
2、总部/文章列表--文章列表,清除历史内容,
3、总部/图片列表--图片列表,清除历史内容,
4、总部/文档列表--文档列表,清除历史内容,
5、总部/内容监控--监控站点列表--管理站点,清除历史内容,
6、总部/全部栏目--全部栏目,清除历史内容,
7、总部/新文章列表--新文章列表,清除历史内容,
8、总部/网站列表--网站列表,清除历史内容,
9、总部/新文章列表/历史文章--新文章列表,清除历史内容,
0、总部/站点列表/站点列表列表/全部/栏目/整体/一类--站点列表,清除历史内容,
1、总部/文章列表列表(深圳)--文章列表(深圳)/深圳站点列表--站点列表--站点列表/深圳全部站点;2
2、总部/文章列表/深圳站点列表/外地站点列表--文章列表/深圳站点列表--文章列表列表/深圳全部站点;2
3、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/深圳站点列表/外地站点/全部站点;2
4、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/全部站点;2
5、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/外地站点/外地站点/全部站点/站点;2
6、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/全部站点/ 查看全部
文章采集接口(文章采集接口简单容易掌握的采集网站常用接口接口介绍)
文章采集接口简单容易掌握,适合小白进行快速开发上手。需要按照给出的站点名对采集网站进行seo的爬虫请求,下面就给大家列举出常用接口。
1、总部/总部资讯频道(document.cookie,
2、总部/1分钟发现新发现(1-30分钟内任选一分钟内所需站点);
3、总部/数据_文档_带有发表日期、章节内容、首次发表日期信息;
4、总部/文章列表--1分钟内左侧栏目列表,清除历史内容,
5、总部/站长列表--1分钟内左侧栏目列表,清除历史内容,
6、总部/新文章列表--文章列表列表,清除历史内容,
7、总部/历史档案列表--历史档案列表,清除历史内容,
8、总部/篇章全文列表--内容全文列表,清除历史内容,
9、总部/站点列表--站点列表,清除历史内容,
0、总部/栏目简介--栏目简介,清除历史内容,
1、总部/站点昵称--站点昵称,清除历史内容,
2、总部/文章列表--文章列表,清除历史内容,
3、总部/图片列表--图片列表,清除历史内容,
4、总部/文档列表--文档列表,清除历史内容,
5、总部/内容监控--监控站点列表--管理站点,清除历史内容,
6、总部/全部栏目--全部栏目,清除历史内容,
7、总部/新文章列表--新文章列表,清除历史内容,
8、总部/网站列表--网站列表,清除历史内容,
9、总部/新文章列表/历史文章--新文章列表,清除历史内容,
0、总部/站点列表/站点列表列表/全部/栏目/整体/一类--站点列表,清除历史内容,
1、总部/文章列表列表(深圳)--文章列表(深圳)/深圳站点列表--站点列表--站点列表/深圳全部站点;2
2、总部/文章列表/深圳站点列表/外地站点列表--文章列表/深圳站点列表--文章列表列表/深圳全部站点;2
3、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/深圳站点列表/外地站点/全部站点;2
4、总部/文章列表/深圳站点列表/外地站点列表/外地站点列表/全部站点;2
5、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/外地站点/外地站点/全部站点/站点;2
6、总部/站点列表/外地站点列表/外地站点列表/外地站点/外地站点/全部站点/
文章采集接口( Zblog采集插件提升网站权重的小技巧,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-23 12:02
Zblog采集插件提升网站权重的小技巧,你知道吗?)
Zblog采集插件是一个采集辅助工具,用于采集、归档和组织特定的数据信息。Zblog采集插件可以适合很多人,比如网站必填信息采集,视频编辑器是采集的视频资料等等,Zblog< @采集插件是帮助用户采集特定信息,让人们无需花费大量时间和精力去寻找或下载,辅助采集器工具是人们处理简单的好帮手任务。Zblog采集插件可以将多个网站采集中的网页元素批量下载到本地,不仅可以过滤利用文字、图片等内容,还可以完整传输数据要在您自己的服务器上使用它,
Zblog采集插件,这个和我们常见的挖矿站点有点不同。我们平时做采集网站的时候,需要无限量的内容,而一般采集丰富的内容来源网站,无论新旧内容都是采集。还有一个采集方法:同步更新最新的文章,只要来源网站发布内容,采集立马就会同步更新。这样做最大的好处是搜索引擎无法分辨出哪个站点收录原创的内容,这会导致采集的网站可能会比收录更快,权重更高. (这取决于域名本身的权重、蜘蛛爬行和网站 的流行度)。
Zblog采集插件可以避免拼凑几个文章,以为自己可以做伪原创,从而获得搜索引擎的青睐,避免这些问题。短期内,网站的权重可以快速提升,而且由于采集的内容是伪原创,也会被百度重压收录。
并且采集的文章后处理也是可读的,提高了用户的阅读体验,降低了网站的跳出率。采集只要文章的体积不大,内容来源的质量很重要,Zblog采集插件,内置伪原创自动发布再推送,不仅采集准确率高,而且可以达到文章原创高度。
Zblog采集插件,封装了复杂的算法和分布式逻辑,提供灵活简单的开发接口;应用程序自动分布式部署和运行,操作直观简单,计算和存储资源弹性扩展;不同来源数据的统一可视化管理,restful interface/webhook push/graphql access等高级功能让用户无缝连接现有系统。 查看全部
文章采集接口(
Zblog采集插件提升网站权重的小技巧,你知道吗?)
Zblog采集插件是一个采集辅助工具,用于采集、归档和组织特定的数据信息。Zblog采集插件可以适合很多人,比如网站必填信息采集,视频编辑器是采集的视频资料等等,Zblog< @采集插件是帮助用户采集特定信息,让人们无需花费大量时间和精力去寻找或下载,辅助采集器工具是人们处理简单的好帮手任务。Zblog采集插件可以将多个网站采集中的网页元素批量下载到本地,不仅可以过滤利用文字、图片等内容,还可以完整传输数据要在您自己的服务器上使用它,
Zblog采集插件,这个和我们常见的挖矿站点有点不同。我们平时做采集网站的时候,需要无限量的内容,而一般采集丰富的内容来源网站,无论新旧内容都是采集。还有一个采集方法:同步更新最新的文章,只要来源网站发布内容,采集立马就会同步更新。这样做最大的好处是搜索引擎无法分辨出哪个站点收录原创的内容,这会导致采集的网站可能会比收录更快,权重更高. (这取决于域名本身的权重、蜘蛛爬行和网站 的流行度)。
Zblog采集插件可以避免拼凑几个文章,以为自己可以做伪原创,从而获得搜索引擎的青睐,避免这些问题。短期内,网站的权重可以快速提升,而且由于采集的内容是伪原创,也会被百度重压收录。
并且采集的文章后处理也是可读的,提高了用户的阅读体验,降低了网站的跳出率。采集只要文章的体积不大,内容来源的质量很重要,Zblog采集插件,内置伪原创自动发布再推送,不仅采集准确率高,而且可以达到文章原创高度。
Zblog采集插件,封装了复杂的算法和分布式逻辑,提供灵活简单的开发接口;应用程序自动分布式部署和运行,操作直观简单,计算和存储资源弹性扩展;不同来源数据的统一可视化管理,restful interface/webhook push/graphql access等高级功能让用户无缝连接现有系统。
文章采集接口(网站关键词排名怎么做?怎么利用凡科CMS插件快速让网站收录排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-21 09:09
)
网站关键词如何排名?如何使用凡客cms插件快速排名网站收录和关键词。我们需要在进行网站优化之前解决它。网站构造中的代码优化是指将程序代码转化为停止等价(即不改变程序的运行结果)。程序代码可以是中间代码(例如四进制代码)或目标代码。等价的含义是使转换后的代码与未转换的代码相反。优化的意思是生成的目标代码短(运行时间更短,占用空间更少),时间和空间效率得到优化。
1、尝试使用 div+css 来规划你的页面。div+css设计的好处是可以让搜索引擎爬虫更流畅、更快、更敌对地爬取你的页面;div+css设计还可以少量缩小网页大小,提高阅读速度,让代码更简洁、流畅,更容易放置更多内容。
2、尽可能少使用无用的图像和闪光灯。内容索引调度的搜索引擎爬虫不查看图片,只能根据图片的“alt、title”等属性的内容来判断图片的内容。关于flash搜索引擎爬虫更是盲目。
3、尽可能减小你的页面大小,因为每次搜索引擎爬虫爬取你的站点,数据的存储容量是无限的。一般建议小于100KB,越小越好,但不能小于5KB。增加页面大小的另一个好处是它可以导致指向您网站的大量外部链接网络。
4、尽量符合w3c规范,网页代码编写符合W3C规范,可以提高网站和搜索引擎的友好度。由于搜索引擎收录规范和排名算法都是在W3C规范的基础上制定的。
5、 尝试应用标签 h1、h2、h3、h4、h5….. 以便搜索引擎能够区分网页的哪一部分非常重要,下一个。
6、 增加JS代码的使用,所有JS代码都封装在内部调用文件中。搜索引擎不喜欢JS,影响网站的友好度指数。
7、尽量不要使用表格设计,因为搜索引擎会懒惰地抓取嵌套在表格设计3层内的内容。搜索引擎爬虫有时很懒惰。我希望您必须将代码和内容保持在 3 层内。
8、 尽量不要让CSS分散在HTML标记中,尽量封装在内部调用文件中。如果 CSS 以 HTML 标记呈现,搜索引擎爬虫会分心,专注于这些对优化没有意义的东西,所以建议封装在一个普通的 CSS 文件中。
9、清除渣码,在代码编辑环境中敲击键盘空格键产生的符号;一些带有默认属性的代码不会影响显示的代码;如果文本语句对代码的可读性没有太大影响,清除这些垃圾代码会增加很多空间。
我们可以借助凡客 cms 插件来改进我们的 SEO 功能(包括全套 SEO 功能,无论 网站 可以使用什么)。
1、通过万科cms插件填充内容,根据关键词采集文章。(凡客cms插件还配置了关键词采集功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
这个凡客cms插件还配备了很多SEO功能,不仅通过凡客cms插件实现采集伪原创发布,而且还有很多SEO职能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时自动生成文章内容中的内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms,人人战cms、Small Cyclone、站群、PB、Apple、搜外等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
通过以上凡客cms插件,可以改善很多需要注意的SEO细节,也可以加快SEO的效率。SEO是一项谨慎的工作,绝不能粗心大意。一个小细节可能会影响 网站 造成影响,这里给大家介绍一下SEO优化中的六个常见错误,让大家尽量踩坑。
错误 #1:使用错误的 关键词
网站 的标题和描述都非常重要。精确的 关键词 和描述允许用户精确地找到 网站。而错误的关键词、冗长的叙述、广告式的文案会给网友们留下负面印象。
错误 #2:将新的 关键词 应用到每个页面
虽然为每个网页使用一个新的关键词会接触到更多的目标群体,但我们还需要考虑这些网民是否是准确的目标群体?因此,使用 关键词 规划工具并使用低竞争的 关键词 来创建 SEO 长尾。
错误三:网站描述过多
并不是说 网站 描述越多越好,问题是 网站 操作员经常犯的一个谬误。网站150字以内的描述,用简洁的内容向搜索引擎提交关键信息,有助于提高网站的排名。
错误 #4:更新域名
拥有专属域名可以留住网站的流量,与搜索引擎建立良好的关系。专家建议,域名审核2-3年左右,对与服务相关的域名进行注册,加强链接。注册新域名时,需要设置URL转回主站,以达到营销的目的。
错误5:图片ALT标签有用吗?
搜索引擎虽然不能直接识别图片中的信息,但是可以通过ALT标签来判断图片的内容。向图像添加 ALT 标签有助于搜索引擎读取图像信息并帮助网页 收录。
错误6:网站分析不重要
网站分析可以了解流量来源,从而导入很多精准的目标客户。因此,网站分析可以有效帮助提升网站的排名。
通过上面对网站程序的优化以及SEO中常见错误的介绍,相信你已经了解了。掌握了这些,大家就可以巧妙的避开优化中的雷区了!
查看全部
文章采集接口(网站关键词排名怎么做?怎么利用凡科CMS插件快速让网站收录排名
)
网站关键词如何排名?如何使用凡客cms插件快速排名网站收录和关键词。我们需要在进行网站优化之前解决它。网站构造中的代码优化是指将程序代码转化为停止等价(即不改变程序的运行结果)。程序代码可以是中间代码(例如四进制代码)或目标代码。等价的含义是使转换后的代码与未转换的代码相反。优化的意思是生成的目标代码短(运行时间更短,占用空间更少),时间和空间效率得到优化。
1、尝试使用 div+css 来规划你的页面。div+css设计的好处是可以让搜索引擎爬虫更流畅、更快、更敌对地爬取你的页面;div+css设计还可以少量缩小网页大小,提高阅读速度,让代码更简洁、流畅,更容易放置更多内容。
2、尽可能少使用无用的图像和闪光灯。内容索引调度的搜索引擎爬虫不查看图片,只能根据图片的“alt、title”等属性的内容来判断图片的内容。关于flash搜索引擎爬虫更是盲目。
3、尽可能减小你的页面大小,因为每次搜索引擎爬虫爬取你的站点,数据的存储容量是无限的。一般建议小于100KB,越小越好,但不能小于5KB。增加页面大小的另一个好处是它可以导致指向您网站的大量外部链接网络。
4、尽量符合w3c规范,网页代码编写符合W3C规范,可以提高网站和搜索引擎的友好度。由于搜索引擎收录规范和排名算法都是在W3C规范的基础上制定的。
5、 尝试应用标签 h1、h2、h3、h4、h5….. 以便搜索引擎能够区分网页的哪一部分非常重要,下一个。
6、 增加JS代码的使用,所有JS代码都封装在内部调用文件中。搜索引擎不喜欢JS,影响网站的友好度指数。
7、尽量不要使用表格设计,因为搜索引擎会懒惰地抓取嵌套在表格设计3层内的内容。搜索引擎爬虫有时很懒惰。我希望您必须将代码和内容保持在 3 层内。
8、 尽量不要让CSS分散在HTML标记中,尽量封装在内部调用文件中。如果 CSS 以 HTML 标记呈现,搜索引擎爬虫会分心,专注于这些对优化没有意义的东西,所以建议封装在一个普通的 CSS 文件中。
9、清除渣码,在代码编辑环境中敲击键盘空格键产生的符号;一些带有默认属性的代码不会影响显示的代码;如果文本语句对代码的可读性没有太大影响,清除这些垃圾代码会增加很多空间。
我们可以借助凡客 cms 插件来改进我们的 SEO 功能(包括全套 SEO 功能,无论 网站 可以使用什么)。
1、通过万科cms插件填充内容,根据关键词采集文章。(凡客cms插件还配置了关键词采集功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
这个凡客cms插件还配备了很多SEO功能,不仅通过凡客cms插件实现采集伪原创发布,而且还有很多SEO职能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时自动生成文章内容中的内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms,人人战cms、Small Cyclone、站群、PB、Apple、搜外等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
通过以上凡客cms插件,可以改善很多需要注意的SEO细节,也可以加快SEO的效率。SEO是一项谨慎的工作,绝不能粗心大意。一个小细节可能会影响 网站 造成影响,这里给大家介绍一下SEO优化中的六个常见错误,让大家尽量踩坑。
错误 #1:使用错误的 关键词
网站 的标题和描述都非常重要。精确的 关键词 和描述允许用户精确地找到 网站。而错误的关键词、冗长的叙述、广告式的文案会给网友们留下负面印象。
错误 #2:将新的 关键词 应用到每个页面
虽然为每个网页使用一个新的关键词会接触到更多的目标群体,但我们还需要考虑这些网民是否是准确的目标群体?因此,使用 关键词 规划工具并使用低竞争的 关键词 来创建 SEO 长尾。
错误三:网站描述过多
并不是说 网站 描述越多越好,问题是 网站 操作员经常犯的一个谬误。网站150字以内的描述,用简洁的内容向搜索引擎提交关键信息,有助于提高网站的排名。
错误 #4:更新域名
拥有专属域名可以留住网站的流量,与搜索引擎建立良好的关系。专家建议,域名审核2-3年左右,对与服务相关的域名进行注册,加强链接。注册新域名时,需要设置URL转回主站,以达到营销的目的。
错误5:图片ALT标签有用吗?
搜索引擎虽然不能直接识别图片中的信息,但是可以通过ALT标签来判断图片的内容。向图像添加 ALT 标签有助于搜索引擎读取图像信息并帮助网页 收录。
错误6:网站分析不重要
网站分析可以了解流量来源,从而导入很多精准的目标客户。因此,网站分析可以有效帮助提升网站的排名。
通过上面对网站程序的优化以及SEO中常见错误的介绍,相信你已经了解了。掌握了这些,大家就可以巧妙的避开优化中的雷区了!
文章采集接口(文章采集接口:数据接口文档解读之三【回答问题】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-13 17:02
文章采集接口文档:数据接口文档解读之三【回答问题】三、基本数据解析环境搭建:python3.6环境配置:win7/win10,但从不建议win10,因为各种配置会更麻烦一些。数据解析网站:【采集的目标主要分为url对应部分】1.新闻类:新闻首页,栏目页、人物页、id界面等文章对应图片配置参考网站::网页内容都是图片网站推荐:知乎:新闻标题、内容简介(答主写的)微博:热门微博以下是新闻类图片,a5中可以直接复制上传图片+上传url,但如果可以,直接采集热门微博就可以了爬取示例:importurllib.requesturl='-bo-03000-1-1.html'#对应的“新闻”栏目,每栏有很多微博id#这里主要对应图片中的标题,“发布日期”,“新闻图片尺寸”#点击就可以获取图片的urllist_list=[]foriinrange(5):urllist=urllib.request.urlopen(url).read()win_ok=''#限制下载位置content_path=urllib.request.urlopen('../content.txt')#用urlopen对象的参数next_ok=yieldf#返回图片url列表#遍历每一张图片list_list.append(i.read())#编写python函数接受2个参数:两个参数分别是图片url,一个参数是读取速度,一个参数是图片上传速度i=int(list_list[i][1].split('/')[0].split('\t'))#python中的[]实现分割单行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[1].split('\t')[0].split('\t')):try:urllist=list_list[i][1].split('\t')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[0]exceptlist_list[i].exceptionase:urllist.append(t)#把两个部分合并i+=1content_path=urllib.request.urlopen('../content.txt').read()win_ok=''#限制下载位置content_path='/'#python中的[]实现分割双行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].。 查看全部
文章采集接口(文章采集接口:数据接口文档解读之三【回答问题】)
文章采集接口文档:数据接口文档解读之三【回答问题】三、基本数据解析环境搭建:python3.6环境配置:win7/win10,但从不建议win10,因为各种配置会更麻烦一些。数据解析网站:【采集的目标主要分为url对应部分】1.新闻类:新闻首页,栏目页、人物页、id界面等文章对应图片配置参考网站::网页内容都是图片网站推荐:知乎:新闻标题、内容简介(答主写的)微博:热门微博以下是新闻类图片,a5中可以直接复制上传图片+上传url,但如果可以,直接采集热门微博就可以了爬取示例:importurllib.requesturl='-bo-03000-1-1.html'#对应的“新闻”栏目,每栏有很多微博id#这里主要对应图片中的标题,“发布日期”,“新闻图片尺寸”#点击就可以获取图片的urllist_list=[]foriinrange(5):urllist=urllib.request.urlopen(url).read()win_ok=''#限制下载位置content_path=urllib.request.urlopen('../content.txt')#用urlopen对象的参数next_ok=yieldf#返回图片url列表#遍历每一张图片list_list.append(i.read())#编写python函数接受2个参数:两个参数分别是图片url,一个参数是读取速度,一个参数是图片上传速度i=int(list_list[i][1].split('/')[0].split('\t'))#python中的[]实现分割单行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[1].split('\t')[0].split('\t')):try:urllist=list_list[i][1].split('\t')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[0]exceptlist_list[i].exceptionase:urllist.append(t)#把两个部分合并i+=1content_path=urllib.request.urlopen('../content.txt').read()win_ok=''#限制下载位置content_path='/'#python中的[]实现分割双行和单列,如果双行可以换成noneforiinrange(0,int(list_list[i][0].split('/')[0].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].split('\t')[1].。
文章采集接口(appclipboard是个什么玩意?能应用在哪里?官方issues)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-13 16:00
文章采集接口配置说明基于appchromecanary的appclipboard获取海量文章中的链接并保存,这一个文章的获取需要交给专门的服务器处理,那么,该如何部署呢?官方issues可以参考一下,然后呢,用户可以自己编写爬虫,爬取所需所有海量的文章,并将文章聚合到自己的知乎专栏。本文介绍appclipboard一个实现搜索并聚合海量文章的功能,并完成打包部署。
爬虫爬取文章,解析查看文章并存储,用户可以自己编写爬虫,爬取文章并进行聚合;看这篇文章之前,推荐大家快速阅读,带一下思路。appclipboard是个什么玩意?appclipboard是一个app应用商店,上架了各类搜索引擎。搜索方式通过评论或个人资料的链接地址,然后由appclipboard服务器给app授权,于是可以访问搜索引擎,从而搜索海量文章。
某类搜索引擎带来的好处很直观,就是信息量大啊。比如,你对法学感兴趣,去法学院官网,看一看经济法、民法、刑法、法理论、宪法、知识产权等等各科专业门类,很快可以了解一下各科目的概况。你又想看看商科,于是就去appclipboard官网,同样能看到北京/上海的各大商学院。其他有法律明显偏好的学生,还可以搜索jd/llm/mfa,甚至你是ph.d、cs毕业又加入了互联网企业,可以搜索自己的专业,学历和职业,推荐一下大厂内部的经验分享,看看大神们的心得和反馈。
appclipboard能应用在哪里?appclipboard也能接入百度搜索;应用在微信小程序、微信公众号、秒拍、腾讯视频、企鹅号、今日头条这样的百度搜索页面都能直接使用appclipboard搜索。更多应用在知乎、豆瓣、公众号、百度百家、百度知道、今日头条、人人都是产品经理、网易、微博、新浪、腾讯、自媒体这些应用的公众号、微博、以及每日头条这类的应用上。
appclipboard服务器配置安装appclipboard基本依赖包下载站直接下载即可。本文配置环境为chromecanary14.0.4222.256,搜索平台为google,appchina为百度,其他如百度搜索、搜狗搜索、一点搜索、搜狗浏览器、都可以设置为搜索平台。
1.获取appclipboard地址appclipboard是阿里云上的搜索引擎(大约可以搜索200+左右的文章,而且是appstore直接下载,流量比较小),所以很多时候比较容易上,地址:,还是直接下载即可。打开搜索框,输入文章标题,会自动列出有关此文章的相关文章。
2.获取文章列表数据appclipboard的文章列表数据位于搜索引擎clipboard搜索页面的下方。我们一般用文章列表列表数据对数据进行整理,再做进一步处。 查看全部
文章采集接口(appclipboard是个什么玩意?能应用在哪里?官方issues)
文章采集接口配置说明基于appchromecanary的appclipboard获取海量文章中的链接并保存,这一个文章的获取需要交给专门的服务器处理,那么,该如何部署呢?官方issues可以参考一下,然后呢,用户可以自己编写爬虫,爬取所需所有海量的文章,并将文章聚合到自己的知乎专栏。本文介绍appclipboard一个实现搜索并聚合海量文章的功能,并完成打包部署。
爬虫爬取文章,解析查看文章并存储,用户可以自己编写爬虫,爬取文章并进行聚合;看这篇文章之前,推荐大家快速阅读,带一下思路。appclipboard是个什么玩意?appclipboard是一个app应用商店,上架了各类搜索引擎。搜索方式通过评论或个人资料的链接地址,然后由appclipboard服务器给app授权,于是可以访问搜索引擎,从而搜索海量文章。
某类搜索引擎带来的好处很直观,就是信息量大啊。比如,你对法学感兴趣,去法学院官网,看一看经济法、民法、刑法、法理论、宪法、知识产权等等各科专业门类,很快可以了解一下各科目的概况。你又想看看商科,于是就去appclipboard官网,同样能看到北京/上海的各大商学院。其他有法律明显偏好的学生,还可以搜索jd/llm/mfa,甚至你是ph.d、cs毕业又加入了互联网企业,可以搜索自己的专业,学历和职业,推荐一下大厂内部的经验分享,看看大神们的心得和反馈。
appclipboard能应用在哪里?appclipboard也能接入百度搜索;应用在微信小程序、微信公众号、秒拍、腾讯视频、企鹅号、今日头条这样的百度搜索页面都能直接使用appclipboard搜索。更多应用在知乎、豆瓣、公众号、百度百家、百度知道、今日头条、人人都是产品经理、网易、微博、新浪、腾讯、自媒体这些应用的公众号、微博、以及每日头条这类的应用上。
appclipboard服务器配置安装appclipboard基本依赖包下载站直接下载即可。本文配置环境为chromecanary14.0.4222.256,搜索平台为google,appchina为百度,其他如百度搜索、搜狗搜索、一点搜索、搜狗浏览器、都可以设置为搜索平台。
1.获取appclipboard地址appclipboard是阿里云上的搜索引擎(大约可以搜索200+左右的文章,而且是appstore直接下载,流量比较小),所以很多时候比较容易上,地址:,还是直接下载即可。打开搜索框,输入文章标题,会自动列出有关此文章的相关文章。
2.获取文章列表数据appclipboard的文章列表数据位于搜索引擎clipboard搜索页面的下方。我们一般用文章列表列表数据对数据进行整理,再做进一步处。
文章采集接口( ThismodelpaperwasrevisedbytheStandardizationOfficeonDecember10,2020Phpwind文章多功能接口使用手册接口(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-10 02:11
ThismodelpaperwasrevisedbytheStandardizationOfficeonDecember10,2020Phpwind文章多功能接口使用手册接口(图))
本模型论文由标准化办公室于2020年12月10日修改phpwind文章接口说明Phpwind文章多功能接口手册一、介绍1、此接口适用于Phpwind版本文章中柱文章发布; 2、这个接口可以只用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期,让文章的发布更加真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8的多个接口,请注意修改接口名称,使每个接口不一样,比如这个interface文件夹中提供的interface文件都加上了“cms”的文件名后缀;5、发布时请使用具有文章中央管理权限的用户帐号;6、在utf8版本使用该接口时,请在发布规则中选择编码为UTF-8;< @7、本接口内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;8、本接口基于utf8版本制作,适用GBK/utf- 8
如需添加验证或其他功能,请谨慎修改;10、2个接口请复制文件在Phpwind网站根目录下使用;二、安装界面 在界面文件夹中找到界面文件,如图: 请将界面文件如等上传到指定目录,请使用二进制方式上传,如图图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或者使用软件自带的发布规则示例,如图:2、检查URL,将发布URL中的“Your 网站”改为你要发布的网站 URL,如图:3、 在check URL中,文章中间栏填写你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件
在网站的根目录下使用。如果目录名称有变化,请相应回复;3、主要参数cms_subject文章题目七年级有理数混合运算100题乘法100题计算机一级题库二进制线性方程应用题真心话大冒险刺激题cid列ID,用过限制该规则的检查列,可以填写多个(逗号分隔)或空,格式如cid=7 ,8,9,可以在文章中心查看列ID;vercode校验码,请自行设置,修改校验接口文件开头的$vercode,使其一致;4、发布配置-文章查看URL,可以填写如下: 注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;二、发布接口1、接口文件名保密,请自行修改文件名;2、请将此接口文件复制到网站根目录下使用,为保密请自行修改文件名;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;参数固定值,可在发布规则-参数值中设置;采集 带值的参数项,请将它们添加到发布规则 - 发布项目中;3、主要参数pw
用户会员名参数名pwpwd密码参数名cms_subject主题标题参数名atc_content内容参数名,如果要进行手动内容分页,请使用数据排序替换内容分隔标记“#-0-#”带有Phpwind8的分页标记[###page###]的ET,见下面的自动分页参数;cid列ID,可以填写多个(逗号分隔),格式如cid=7,8,94、附加参数vercode安全校验码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。5、可选参数Newstime文章日期,格式要正确,例如:2010-08-0312:32:00;
下图中6、该界面内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;file8、接口文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、 检查发布规则-参数值-账号密码队列;二、[err]invalidvercode[/err]1、在发布规则中-检查URLvercode值和接口文件中vercode值不一致; 2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中
过滤;3、错误修改发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有开启utf-8编码转换;四、[err]内容不能为空[/err]:1、使用的采集规则失败< @采集对正文数据项正确;2、采集规则的数据整理过滤文本数据;3、发布规则修改错误-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则utf-8编码转换未开启;五、[err]请设置栏目[/err]:1、 cid参数值或格式错误;六、文章乱码:1、发布规则不开启utf-8编码转换;2、数据组织不当;七、附件上传不成功:1、检查附件保存路径和格式是否正确2、检查附件是否存在3、检查FTP目录和权限设置;八、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用了FTP上传,那么文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与施工图、施工图、示例结构、施工图一致, 查看全部
文章采集接口(
ThismodelpaperwasrevisedbytheStandardizationOfficeonDecember10,2020Phpwind文章多功能接口使用手册接口(图))
本模型论文由标准化办公室于2020年12月10日修改phpwind文章接口说明Phpwind文章多功能接口手册一、介绍1、此接口适用于Phpwind版本文章中柱文章发布; 2、这个接口可以只用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期,让文章的发布更加真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8的多个接口,请注意修改接口名称,使每个接口不一样,比如这个interface文件夹中提供的interface文件都加上了“cms”的文件名后缀;5、发布时请使用具有文章中央管理权限的用户帐号;6、在utf8版本使用该接口时,请在发布规则中选择编码为UTF-8;< @7、本接口内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;8、本接口基于utf8版本制作,适用GBK/utf- 8
如需添加验证或其他功能,请谨慎修改;10、2个接口请复制文件在Phpwind网站根目录下使用;二、安装界面 在界面文件夹中找到界面文件,如图: 请将界面文件如等上传到指定目录,请使用二进制方式上传,如图图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或者使用软件自带的发布规则示例,如图:2、检查URL,将发布URL中的“Your 网站”改为你要发布的网站 URL,如图:3、 在check URL中,文章中间栏填写你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件 中心栏你要发布的ID,可以填写多个,用英文逗号隔开。如果不限制列,可以留空,如图:4、在参数值页面,填写文章中心你要发布的列ID,可以填写多个,用逗号分隔,如图: 鼠标移动到列名,可以在状态栏查看列ID:4、填写你的账号和密码,注意格式以及账号权限,如图:四、接口说明一、查看接口1、接口文件名,为保密请自行修改文件名;2、复制这个接口文件
在网站的根目录下使用。如果目录名称有变化,请相应回复;3、主要参数cms_subject文章题目七年级有理数混合运算100题乘法100题计算机一级题库二进制线性方程应用题真心话大冒险刺激题cid列ID,用过限制该规则的检查列,可以填写多个(逗号分隔)或空,格式如cid=7 ,8,9,可以在文章中心查看列ID;vercode校验码,请自行设置,修改校验接口文件开头的$vercode,使其一致;4、发布配置-文章查看URL,可以填写如下: 注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如需添加验证或其他功能,请谨慎修改;二、发布接口1、接口文件名保密,请自行修改文件名;2、请将此接口文件复制到网站根目录下使用,为保密请自行修改文件名;注意:后面的参数名称后面的“=”符号用于演示值,参数名称本身不收录“=”符号;参数固定值,可在发布规则-参数值中设置;采集 带值的参数项,请将它们添加到发布规则 - 发布项目中;3、主要参数pw
用户会员名参数名pwpwd密码参数名cms_subject主题标题参数名atc_content内容参数名,如果要进行手动内容分页,请使用数据排序替换内容分隔标记“#-0-#”带有Phpwind8的分页标记[###page###]的ET,见下面的自动分页参数;cid列ID,可以填写多个(逗号分隔),格式如cid=7,8,94、附加参数vercode安全校验码,请自行设置。此项用于防止接口被他人使用。如需进一步验证,请自行填写相关代码。5、可选参数Newstime文章日期,格式要正确,例如:2010-08-0312:32:00;
下图中6、该界面内容格式为UBB码,配置发布规则时请选择“使用UBB码格式”;file8、接口文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、 检查发布规则-参数值-账号密码队列;二、[err]invalidvercode[/err]1、在发布规则中-检查URLvercode值和接口文件中vercode值不一致; 2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err]cms_subjectisnull[/err]:1、使用的采集规则未能采集到标题;2、采集将数据整理到标头中
过滤;3、错误修改发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有开启utf-8编码转换;四、[err]内容不能为空[/err]:1、使用的采集规则失败< @采集对正文数据项正确;2、采集规则的数据整理过滤文本数据;3、发布规则修改错误-发布项中的文本参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则utf-8编码转换未开启;五、[err]请设置栏目[/err]:1、 cid参数值或格式错误;六、文章乱码:1、发布规则不开启utf-8编码转换;2、数据组织不当;七、附件上传不成功:1、检查附件保存路径和格式是否正确2、检查附件是否存在3、检查FTP目录和权限设置;八、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用了FTP上传,那么文件显示URL和FTP上传目录要一致;3、如果使用save目录代替FTP上传,文件显示URL要与施工图、施工图、示例结构、施工图一致,
文章采集接口(低代码开发研发人员的简单逻辑代码Low-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-07 08:21
一、前言
CRUD 程序员会变得更便宜吗?
CRUD是程序员的自嘲。他们说他们经常开发简单的逻辑代码,添加、删除、修改、检查或接口。
不过,这部分简单的逻辑代码,几乎是现阶段互联网公司研发人员消耗最多的部分。任何业务需求的实现都会收录大量接口的开发,但是这些不同业务之间差异很大的接口是无法复制的。因此,接口的不断创建带来了从研发、测试到交付、上线的一整套人员投入。
对于个人来说,开发 CRUD 几乎没有技术上的增长。开发CRUD只是程序员成长过程中的一个阶段。随着个人能力的提高和跳槽,更多的核心发展势必要做。
在公司技术部门层面,一定希望投入少的人,实现更高的交付能力。例如:
DDD在业务、运营、产品、研发、测试等人员之间建立领域模型,降低沟通成本
用于解决业务流程中嵌入的非业务功能的通用核心服务,提取统一的技术组件
标准骨干业务形态,抽取通用业务素材进行服务化编排,降低开发成本
以上等方案都是为了提高研发能效,可持续交付,而CRUD高重复性的代码逻辑将被工具可视化编程一点一点地吞噬。而低代码编程是从这部分开始的最佳方式!
二、什么是低码
Low-Code,该术语由 Forrester 在 2014 年首次提出,是低代码开发平台的祖先级定义。
低代码是一种软件开发方法,可以更快地交付应用程序,并且使用最少的手动编码。低代码平台是一组工具,可通过建模和图形界面实现应用程序的可视化开发。低代码使开发人员能够跳过手工编码,加快将应用程序投入生产的过程。
简单来说,低代码开发是开发人员通过IDE编写少量代码或拖放工具,快速完成业务需求开发的一种方式。
低代码开发平台可以自行开发,也可以使用市面上的IDE工具完成代码逻辑的服务编排。您可以将基本业务流程理解为每个分支节点项目的基础材料。通过这些素材接口接口的组装、排列和结果输出,完成代码逻辑的自动化开发和可持续交付。
通过使用低代码开发和可视化的方式构建应用程序,您的开发效率和交付质量将大大提高。这就是为什么 CRUD 程序员越来越便宜的原因。
三、如何实现
如果低代码编程这么好,你有条件落地吗?
低代码编程的核心是利用可视化的IDE动态排列服务逻辑接口,实现可持续交付能力,从而提高研发能效。
但是,用于开发业务功能的复杂逻辑总量不会改变。为了支持可视化服务编排,需要相应的通用业务组件。然后需要提供这部分业务组件、技术组件、自动化交付质量分析和监控系统。如果公司的技术资料比较少,运营这样一个平台是相当困难的
此外,许多其他组件也被引入到低代码编程中。这些功能模块、材料、Serverless 计算组件都需要大量高度专业的程序员来开发。
当然,低代码编程不仅用在服务器端,还可以在前端构建页面。例如,您以前使用过的大量拖放都可以算作一次。
四、总结
好了,今天的文章分享就结束了,喜欢的话就点个赞吧!--我是jabdp,我为自己“吃盐”,谢谢大家的关注。 查看全部
文章采集接口(低代码开发研发人员的简单逻辑代码Low-)
一、前言
CRUD 程序员会变得更便宜吗?
CRUD是程序员的自嘲。他们说他们经常开发简单的逻辑代码,添加、删除、修改、检查或接口。
不过,这部分简单的逻辑代码,几乎是现阶段互联网公司研发人员消耗最多的部分。任何业务需求的实现都会收录大量接口的开发,但是这些不同业务之间差异很大的接口是无法复制的。因此,接口的不断创建带来了从研发、测试到交付、上线的一整套人员投入。
对于个人来说,开发 CRUD 几乎没有技术上的增长。开发CRUD只是程序员成长过程中的一个阶段。随着个人能力的提高和跳槽,更多的核心发展势必要做。
在公司技术部门层面,一定希望投入少的人,实现更高的交付能力。例如:
DDD在业务、运营、产品、研发、测试等人员之间建立领域模型,降低沟通成本
用于解决业务流程中嵌入的非业务功能的通用核心服务,提取统一的技术组件
标准骨干业务形态,抽取通用业务素材进行服务化编排,降低开发成本
以上等方案都是为了提高研发能效,可持续交付,而CRUD高重复性的代码逻辑将被工具可视化编程一点一点地吞噬。而低代码编程是从这部分开始的最佳方式!
二、什么是低码
Low-Code,该术语由 Forrester 在 2014 年首次提出,是低代码开发平台的祖先级定义。
低代码是一种软件开发方法,可以更快地交付应用程序,并且使用最少的手动编码。低代码平台是一组工具,可通过建模和图形界面实现应用程序的可视化开发。低代码使开发人员能够跳过手工编码,加快将应用程序投入生产的过程。
简单来说,低代码开发是开发人员通过IDE编写少量代码或拖放工具,快速完成业务需求开发的一种方式。
低代码开发平台可以自行开发,也可以使用市面上的IDE工具完成代码逻辑的服务编排。您可以将基本业务流程理解为每个分支节点项目的基础材料。通过这些素材接口接口的组装、排列和结果输出,完成代码逻辑的自动化开发和可持续交付。
通过使用低代码开发和可视化的方式构建应用程序,您的开发效率和交付质量将大大提高。这就是为什么 CRUD 程序员越来越便宜的原因。
三、如何实现
如果低代码编程这么好,你有条件落地吗?
低代码编程的核心是利用可视化的IDE动态排列服务逻辑接口,实现可持续交付能力,从而提高研发能效。
但是,用于开发业务功能的复杂逻辑总量不会改变。为了支持可视化服务编排,需要相应的通用业务组件。然后需要提供这部分业务组件、技术组件、自动化交付质量分析和监控系统。如果公司的技术资料比较少,运营这样一个平台是相当困难的
此外,许多其他组件也被引入到低代码编程中。这些功能模块、材料、Serverless 计算组件都需要大量高度专业的程序员来开发。
当然,低代码编程不仅用在服务器端,还可以在前端构建页面。例如,您以前使用过的大量拖放都可以算作一次。
四、总结
好了,今天的文章分享就结束了,喜欢的话就点个赞吧!--我是jabdp,我为自己“吃盐”,谢谢大家的关注。
文章采集接口(优采云采集器外部接口制作规范(“title”来接收并使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-02 15:10
优采云采集器外接口制作规范
这里的外部接口是一个网站程序,你自己来接收和处理优采云采集器提交的数据。使用它,可以避免直接使用网站后台直接发布数据有一些繁琐的验证方法。它可以配置一次并永久使用。下面我们将介绍具体的制作方法和工艺。
界面制作原理。
接口是接口优采云采集器提交的数据。优采云采集器 提交数据很简单,就是使用post方式,提交的效果和使用表单一样。接口只需要接收数据。
数据接收。
这与接收表格没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用(“title”)接收并使用。PHP 使用 $_POST['title'] 来获取这个值。
数据处理。
首先要明确接口的作用,比如发布一个文章。我们可以通过我们网站上的程序直接将内容发布到网站。然后我们就为这个功能制作自己的接口程序或者修改原程序。
如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。你可以直接写一个程序或者改变原来的程序来接收数据存储在服务器数据库中。
如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够流畅地处理数据。这部分由您专门操作。
接口安全
通用接口可以直接post数据。为了防止其他人使用该接口,您应该为其添加密码。你可以给模块加个参数,比如密码,给个值,然后在程序端验证一下,如果不是你设置的值会拒绝访问。
从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序满足自己的要求。,也可以看作是技术人员网站功能的延伸。可以说你可以对接收到的数据进行任何处理,从而满足你的网站数据处理需求。 查看全部
文章采集接口(优采云采集器外部接口制作规范(“title”来接收并使用)
优采云采集器外接口制作规范
这里的外部接口是一个网站程序,你自己来接收和处理优采云采集器提交的数据。使用它,可以避免直接使用网站后台直接发布数据有一些繁琐的验证方法。它可以配置一次并永久使用。下面我们将介绍具体的制作方法和工艺。
界面制作原理。
接口是接口优采云采集器提交的数据。优采云采集器 提交数据很简单,就是使用post方式,提交的效果和使用表单一样。接口只需要接收数据。
数据接收。
这与接收表格没有什么不同。比如程序提交了一个参数title,值为“this is the title”,asp可以使用(“title”)接收并使用。PHP 使用 $_POST['title'] 来获取这个值。
数据处理。
首先要明确接口的作用,比如发布一个文章。我们可以通过我们网站上的程序直接将内容发布到网站。然后我们就为这个功能制作自己的接口程序或者修改原程序。
如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。你可以直接写一个程序或者改变原来的程序来接收数据存储在服务器数据库中。
如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够流畅地处理数据。这部分由您专门操作。
接口安全
通用接口可以直接post数据。为了防止其他人使用该接口,您应该为其添加密码。你可以给模块加个参数,比如密码,给个值,然后在程序端验证一下,如果不是你设置的值会拒绝访问。
从上面的描述可以看出,这个接口的制作与优采云采集器关系不大,只和数据接收有关,其他时候需要编写程序满足自己的要求。,也可以看作是技术人员网站功能的延伸。可以说你可以对接收到的数据进行任何处理,从而满足你的网站数据处理需求。
文章采集接口(Dedecms5。7sp1文章模型栏目接口使用手册(简介)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-01 13:21
Dedecms5.7 sp1文章模型柱接口使用手册一、简介1、此接口适用于Dedecms5.7 SP1版普通文章模型柱文章已发布;2、由于DEDE在数据量大时生成列HTML时服务器负载较重,因此在发布界面中增加了两个控制参数zznomakeindex和zznomake和cat来控制是否分别生成或不生成。首页或相关栏目;3、发布时请使用具有管理权限的用户帐号;4、本接口基于DedecmsUTF8版本,适用于DedecmsGBK/utf -8等版本,适用其他版本时请测试调整;5、在Dede中使用该接口时cms utf8版本,请在发布规则中选择编码为UTF-8;6、@ >接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改;7、将这两个接口文件复制到Dedecms网站管理目录下(默认为dede,用户可更改);二、安装接口在interface文件夹中找到接口文件,如图: Please etchk。php, etpost. php等接口文件复制到指定目录。远程FTP上传,请使用二进制方式上传,如图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或使用软件自带的发布规则示例,
php,为保密,请自行修改文件名;2、这个接口文件复制在网站管理目录DEDE下使用,如果目录名有变化,请相应回复;3、主要参数(校验URL后面附加以下参数) 主题标题:关键字列ID:typeid用于限制校验列的范围,可以留空,可以在网站 后台列管理;校验码:vercode,请自行设置,并修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/dede/etchk。php?vercode=&typeid=&keyword=注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如果要检查或其他功能,请仔细修改;二、发布接口1、接口文件名 etpost. php,为保密,请自行修改文件名;2、这个接口文件要复制到网站的管理目录DEDE下使用。如果目录名有变化,请自行对应;注意:后面的参数名称“”后面的“=”符号用于演示取值,参数名称本身不收录“=”符号;值为采集的参数项,请添加发布规则——发布项目,如图:< @3、基本参数userid成员名参数名pwd密码参数名titletopictitle参数名body内容参数名4、主要参数typeid=主列ID,后台可以查看网站列管理; typeid2=sub 列ID,可选,可在后台查看id网站列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章
php 注意:对于使用区分大小写的服务器的用户,请注意URL的大小写与网站文件8、接口文件的大小写相同,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、检查发布规则-参数值-账号密码队列;二、[ err]invalid vercode[/err]1、发布规则中填写的Vercode值-校验URL与校验接口文件中的vercode值不一致;2、 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] 标题不能为空[/err]:1、使用采集规则未能采集到标题;2、采集规则数据整理过滤头;3、错误修改了发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有not enable utf-8 encoding conversion;四、[err]Content cannot be empty[/err]: 1、Used 采集rules failed to 采集到body数据项; 2、采集 规则的数据整理过滤了文本数据;3、 发布项中发布规则发布的参数名称被错误修改。正确的参数名称请参考本文的接口说明;4、发布规则未启用utf-8编码转换;五、文章乱码:1、发布规则未开启utf-8编码转换;2、数据组织不当;六、附件上传失败:1、检查附件是否保存在正确的路径和格式2、检查附件是否存在3、检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;< 查看全部
文章采集接口(Dedecms5。7sp1文章模型栏目接口使用手册(简介)(组图))
Dedecms5.7 sp1文章模型柱接口使用手册一、简介1、此接口适用于Dedecms5.7 SP1版普通文章模型柱文章已发布;2、由于DEDE在数据量大时生成列HTML时服务器负载较重,因此在发布界面中增加了两个控制参数zznomakeindex和zznomake和cat来控制是否分别生成或不生成。首页或相关栏目;3、发布时请使用具有管理权限的用户帐号;4、本接口基于DedecmsUTF8版本,适用于DedecmsGBK/utf -8等版本,适用其他版本时请测试调整;5、在Dede中使用该接口时cms utf8版本,请在发布规则中选择编码为UTF-8;6、@ >接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改;7、将这两个接口文件复制到Dedecms网站管理目录下(默认为dede,用户可更改);二、安装接口在interface文件夹中找到接口文件,如图: Please etchk。php, etpost. php等接口文件复制到指定目录。远程FTP上传,请使用二进制方式上传,如图:三、配置发布规则1、将示例发布规则文本导入ET2发布配置,或使用软件自带的发布规则示例,
php,为保密,请自行修改文件名;2、这个接口文件复制在网站管理目录DEDE下使用,如果目录名有变化,请相应回复;3、主要参数(校验URL后面附加以下参数) 主题标题:关键字列ID:typeid用于限制校验列的范围,可以留空,可以在网站 后台列管理;校验码:vercode,请自行设置,并修改校验接口文件开头的vercode,使其一致;4、发布配置-文章查看URL,可以填写如下:你的URL/dede/etchk。php?vercode=&typeid=&keyword=注意:对于使用区分大小写服务器的用户,请注意,URL的大小写与网站文件5、接口文件的大小写相同,无需任何修改即可使用。如果要检查或其他功能,请仔细修改;二、发布接口1、接口文件名 etpost. php,为保密,请自行修改文件名;2、这个接口文件要复制到网站的管理目录DEDE下使用。如果目录名有变化,请自行对应;注意:后面的参数名称“”后面的“=”符号用于演示取值,参数名称本身不收录“=”符号;值为采集的参数项,请添加发布规则——发布项目,如图:< @3、基本参数userid成员名参数名pwd密码参数名titletopictitle参数名body内容参数名4、主要参数typeid=主列ID,后台可以查看网站列管理; typeid2=sub 列ID,可选,可在后台查看id网站列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章 列管理,多个请用英文逗号分隔,如typeid2=3,7,11;channelid=模型ID,默认为1,如果文章
php 注意:对于使用区分大小写的服务器的用户,请注意URL的大小写与网站文件8、接口文件的大小写相同,无需任何更改即可使用。如需添加验证或其他功能,请谨慎修改;五、常见错误:当提示采集失败时,请查看返回信息了解错误详情,以便更正。返回信息窗口如下图所示:一、[err]账号密码错误[/err]1、检查发布规则-参数值-账号密码队列;二、[ err]invalid vercode[/err]1、发布规则中填写的Vercode值-校验URL与校验接口文件中的vercode值不一致;2、 发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致;三、[err] 标题不能为空[/err]:1、使用采集规则未能采集到标题;2、采集规则数据整理过滤头;3、错误修改了发布规则-发布项中的title参数名称,正确的参数名称请参考本文接口说明部分;4、发布规则没有not enable utf-8 encoding conversion;四、[err]Content cannot be empty[/err]: 1、Used 采集rules failed to 采集到body数据项; 2、采集 规则的数据整理过滤了文本数据;3、 发布项中发布规则发布的参数名称被错误修改。正确的参数名称请参考本文的接口说明;4、发布规则未启用utf-8编码转换;五、文章乱码:1、发布规则未开启utf-8编码转换;2、数据组织不当;六、附件上传失败:1、检查附件是否保存在正确的路径和格式2、检查附件是否存在3、检查FTP目录和权限设置;七、图片不显示:1、检查发布规则文件显示URL设置;2、如果启用FTP上传,文件显示URL和FTP上传目录要一致;<
文章采集接口(折腾一个微信公众号新增永久图文素材|微信开放文档)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-31 10:15
前言
都说懒惰是人类进步的动力,古人没有骗我。最近在折腾一个微信公众号。一开始是在网上找了一些资源,然后做了二次创作,然后发布到了微信公众号上。不过,我得把里面的图片下载下来,复制文字,然后慢慢上传到微信公众号。经过几天的工作,我发现这太低效了。我每天都在做重复的事情。这对于程序员来说是无法忍受的。任何重复的东西都有自动化的价值,我们不能浪费它们。人生就在这种地方,不废话,做就做。
一、需求和难点从指定页面爬取数据只爬取我们需要的内容(什么样的广告,不需要导航),然后将文字上传到微信公众号的草稿箱。微信的草稿箱界面只能放图片上传到微信,所以我们需要做一个额外的操作,从网页中提取图片上传到微信公众号,然后将文中的图片链接替换为微信公众号中的图片二、使用工具和接口将封面图片上传到微信公众号添加永久图文素材 | 微信开文档()上传文字图片到微信公众号
http请求方式: POST,https协议 https://api.weixin.qq.com/cgi- ... TOKEN 调用示例(使用curl命令,用FORM表单方式上传一个图片): curl -F [email protected] "https://api.weixin.qq.com/cgi- ... ot%3B
上传文字至公众号草稿箱接口请求说明 | 微信打开文档()
这里主要使用Python:requests、BeautifulSoup、json
三、实施步骤1.分析网页
这是我们要分析的网页截图:
我们可以看到这个网页有自己的导航,右侧的推荐栏和底部的导航。如果我们直接扣除上传到整个网页的微信公众号,无疑会给我们的后期处理带来很大的工作量。所以我们只需要body,也就是html中的内容
2. 调用接口我们先来看看上传草稿API接口
接口请求说明
http 请求方式:POST(请使用https协议)https://api.weixin.qq.com/cgi- ... TOKEN
调用示例
{
"articles": [
{
"title":TITLE,
"author":AUTHOR,
"digest":DIGEST,
"content":CONTENT,
"content_source_url":CONTENT_SOURCE_URL,
"thumb_media_id":THUMB_MEDIA_ID,
"show_cover_pic":1,
"need_open_comment":0,
"only_fans_can_comment":0
}
//若新增的是多图文素材,则此处应还有几段articles结构
]
}
请求参数说明
范围
有必要吗
操作说明
标题
是的
标题
内容
是的
图片和短信的具体内容支持HTML标签,且必须小于20000字符且小于1M,这里会去掉JS,图片的url必须从“上传图片获取网址”中获取图片和文字信息”界面。外部图片网址将被过滤
thumb_media_id
是的
图文信息的封面图片素材id(必须是永久MediaID)
可以看出这个接口需要3个参数,那我们就去网页的代码看看如何获取这3个参数
通过分析网页,我们可以发现我们想要的标题在class='entry-title'的a标签中,我们还可以在class='entry-title'的div中得到文章的摘要概括'
所以我们先爬取页面,得到标题和摘要
baseUrl = 'https://www.test.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.57'
}
res = requests.get(baseUrl, verify=False, headers=headers)
root_soup = BeautifulSoup(res.content, 'html.parser')
title = root_soup.select('.entry-title')[0].text
summary = root_soup.select('.entry-summary p')[0].text
print(title)
print(summary)
接下来,我们需要准备封面。现在我们将使用微信公众号接口,但是在使用公众号接口之前,我们需要获取一个令牌,以便我们有权访问公众号的API接口。获取token的文档在这里:Wechat Open Document() 通过分析文字我们知道这个文章里面有很多图片,那么我们就以第一张图片为封面,先定义一个方法用于上传封面
然后获取body中的所有图片,将第一个传入这个方法获取cover id
content_soup = root_soup.select('.entry-content')[0]
imgs = content_soup.select('.wp-block-image')
fmId = updFm(imgs[0].img['src'], title)
接下来我们在文本中定义一个上传其他图片的方法,因为其他图片需要返回的url不是media_id,所以调用了另外一个接口。
def updImg(url):
base_folder = 'D:\\tempDir'
res = requests.get(url, verify=False)
file_name = '{}.jpg'.format(random.randint(10000, 99999))
with open(base_folder + file_name, 'wb') as f:
f.write(res.content)
vx_img_url = 'https://api.weixin.qq.com/cgi-bin/media/uploadimg'
request_file = {
'media': (file_name, open(base_folder + file_name, 'rb'), 'image/jpeg')}
data = {
'access_token': access_token
}
vx_res = requests.post(url=vx_img_url, files=request_file, data=data)
obj = json.loads(vx_res.content)
print(obj)
return obj['url']
然后将文中的图片全部上传到微信公众号的素材库,替换为文中的图片地址
for img_content in imgs:
img_content.noscript.decompose()
current_url = img_content.img['data-original']
upd_url = updImg(current_url)
img_content.img['src'] = upd_url
img_content.img['data-original'] = upd_url
最后我们可以开始准备上传文章到草稿箱,或者先定义方法,因为草稿界面的标题和摘要都有长度限制,所以这个方法开始做限制。如果长度超过,字符串将被截取
def updCG(title, summary, content, fmId):
if len(title) > 64:
title = title[:63]
if len(summary) > 120:
summary = summary[:119]
url = 'https://api.weixin.qq.com/cgi-bin/draft/add?access_token='+access_token
data = {
"articles": [
{
"title": title,
"author": '作者',
"digest": summary,
"content": content,
"show_cover_pic": 1,
"need_open_comment": 0,
"only_fans_can_comment": 0,
"thumb_media_id": fmId
}
]
}
vx_res = requests.post(url=url, data=json.dumps(
data, ensure_ascii=False).encode("utf-8"))
obj = json.loads(vx_res.content)
print(obj)
return obj['media_id']
然后在总方法中调用我们的上传草稿方法
print(content_soup.prettify())
updCG(title, summary, content_soup.prettify(), fmId)
查看结果,可以看到文章已经自动提交到草稿箱了,然后我们就可以进去二次创建发布了
总结
这可以在半天总共100多行代码中完成。其实这主要需要你去分析网页,因为每个网站的情况都不一样,后面的技术实现也差不多。生活中,我们会遇到很多需要时时刻刻重复的事情。这个时候,我们可以多花点脑力,以后节省不少时间。如果我们掌握了一些别人无法做到的事情,那么我们就可以做一些不同的事情。好吧,技术改变生活,不是吗? 查看全部
文章采集接口(折腾一个微信公众号新增永久图文素材|微信开放文档)
前言
都说懒惰是人类进步的动力,古人没有骗我。最近在折腾一个微信公众号。一开始是在网上找了一些资源,然后做了二次创作,然后发布到了微信公众号上。不过,我得把里面的图片下载下来,复制文字,然后慢慢上传到微信公众号。经过几天的工作,我发现这太低效了。我每天都在做重复的事情。这对于程序员来说是无法忍受的。任何重复的东西都有自动化的价值,我们不能浪费它们。人生就在这种地方,不废话,做就做。
一、需求和难点从指定页面爬取数据只爬取我们需要的内容(什么样的广告,不需要导航),然后将文字上传到微信公众号的草稿箱。微信的草稿箱界面只能放图片上传到微信,所以我们需要做一个额外的操作,从网页中提取图片上传到微信公众号,然后将文中的图片链接替换为微信公众号中的图片二、使用工具和接口将封面图片上传到微信公众号添加永久图文素材 | 微信开文档()上传文字图片到微信公众号
http请求方式: POST,https协议 https://api.weixin.qq.com/cgi- ... TOKEN 调用示例(使用curl命令,用FORM表单方式上传一个图片): curl -F [email protected] "https://api.weixin.qq.com/cgi- ... ot%3B
上传文字至公众号草稿箱接口请求说明 | 微信打开文档()
这里主要使用Python:requests、BeautifulSoup、json
三、实施步骤1.分析网页
这是我们要分析的网页截图:
我们可以看到这个网页有自己的导航,右侧的推荐栏和底部的导航。如果我们直接扣除上传到整个网页的微信公众号,无疑会给我们的后期处理带来很大的工作量。所以我们只需要body,也就是html中的内容
2. 调用接口我们先来看看上传草稿API接口
接口请求说明
http 请求方式:POST(请使用https协议)https://api.weixin.qq.com/cgi- ... TOKEN
调用示例
{
"articles": [
{
"title":TITLE,
"author":AUTHOR,
"digest":DIGEST,
"content":CONTENT,
"content_source_url":CONTENT_SOURCE_URL,
"thumb_media_id":THUMB_MEDIA_ID,
"show_cover_pic":1,
"need_open_comment":0,
"only_fans_can_comment":0
}
//若新增的是多图文素材,则此处应还有几段articles结构
]
}
请求参数说明
范围
有必要吗
操作说明
标题
是的
标题
内容
是的
图片和短信的具体内容支持HTML标签,且必须小于20000字符且小于1M,这里会去掉JS,图片的url必须从“上传图片获取网址”中获取图片和文字信息”界面。外部图片网址将被过滤
thumb_media_id
是的
图文信息的封面图片素材id(必须是永久MediaID)
可以看出这个接口需要3个参数,那我们就去网页的代码看看如何获取这3个参数
通过分析网页,我们可以发现我们想要的标题在class='entry-title'的a标签中,我们还可以在class='entry-title'的div中得到文章的摘要概括'
所以我们先爬取页面,得到标题和摘要
baseUrl = 'https://www.test.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.57'
}
res = requests.get(baseUrl, verify=False, headers=headers)
root_soup = BeautifulSoup(res.content, 'html.parser')
title = root_soup.select('.entry-title')[0].text
summary = root_soup.select('.entry-summary p')[0].text
print(title)
print(summary)
接下来,我们需要准备封面。现在我们将使用微信公众号接口,但是在使用公众号接口之前,我们需要获取一个令牌,以便我们有权访问公众号的API接口。获取token的文档在这里:Wechat Open Document() 通过分析文字我们知道这个文章里面有很多图片,那么我们就以第一张图片为封面,先定义一个方法用于上传封面
然后获取body中的所有图片,将第一个传入这个方法获取cover id
content_soup = root_soup.select('.entry-content')[0]
imgs = content_soup.select('.wp-block-image')
fmId = updFm(imgs[0].img['src'], title)
接下来我们在文本中定义一个上传其他图片的方法,因为其他图片需要返回的url不是media_id,所以调用了另外一个接口。
def updImg(url):
base_folder = 'D:\\tempDir'
res = requests.get(url, verify=False)
file_name = '{}.jpg'.format(random.randint(10000, 99999))
with open(base_folder + file_name, 'wb') as f:
f.write(res.content)
vx_img_url = 'https://api.weixin.qq.com/cgi-bin/media/uploadimg'
request_file = {
'media': (file_name, open(base_folder + file_name, 'rb'), 'image/jpeg')}
data = {
'access_token': access_token
}
vx_res = requests.post(url=vx_img_url, files=request_file, data=data)
obj = json.loads(vx_res.content)
print(obj)
return obj['url']
然后将文中的图片全部上传到微信公众号的素材库,替换为文中的图片地址
for img_content in imgs:
img_content.noscript.decompose()
current_url = img_content.img['data-original']
upd_url = updImg(current_url)
img_content.img['src'] = upd_url
img_content.img['data-original'] = upd_url
最后我们可以开始准备上传文章到草稿箱,或者先定义方法,因为草稿界面的标题和摘要都有长度限制,所以这个方法开始做限制。如果长度超过,字符串将被截取
def updCG(title, summary, content, fmId):
if len(title) > 64:
title = title[:63]
if len(summary) > 120:
summary = summary[:119]
url = 'https://api.weixin.qq.com/cgi-bin/draft/add?access_token='+access_token
data = {
"articles": [
{
"title": title,
"author": '作者',
"digest": summary,
"content": content,
"show_cover_pic": 1,
"need_open_comment": 0,
"only_fans_can_comment": 0,
"thumb_media_id": fmId
}
]
}
vx_res = requests.post(url=url, data=json.dumps(
data, ensure_ascii=False).encode("utf-8"))
obj = json.loads(vx_res.content)
print(obj)
return obj['media_id']
然后在总方法中调用我们的上传草稿方法
print(content_soup.prettify())
updCG(title, summary, content_soup.prettify(), fmId)
查看结果,可以看到文章已经自动提交到草稿箱了,然后我们就可以进去二次创建发布了
总结
这可以在半天总共100多行代码中完成。其实这主要需要你去分析网页,因为每个网站的情况都不一样,后面的技术实现也差不多。生活中,我们会遇到很多需要时时刻刻重复的事情。这个时候,我们可以多花点脑力,以后节省不少时间。如果我们掌握了一些别人无法做到的事情,那么我们就可以做一些不同的事情。好吧,技术改变生活,不是吗?
文章采集接口(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 642 次浏览 • 2022-01-31 10:14
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。早期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只要输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、支持多平台采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
文章采集接口(苹果cms采集视频可以在后台联盟资源库里直接设置采集)
苹果cms采集视频可以直接在后台联盟资源库中设置采集,也可以配置自己自定义的采集库,关于文章信息采集,Applecms后台没有专门的采集库,所以文章采集我们需要添加采集@ > 自己接口,或者是使用第三方采集工具,不懂代码的小白完全不知道。早期,目前80%的影视站都是靠采集来扩充自己的视频库,比如之前的大站电影天堂、BT站等最新电影的下载。这一切都始于 采集。先丰富视频源再做网站收录,网站收录是由文章信息驱动的。今天我们将介绍使用免费的自动采集发布工具来让Apple cms网站启动并运行!
由于各种视频站的兴起,cms模板泛滥。大量的网站模板都是类似的。除了 采集 规则外,视频站的内容是重复的。多年来,我一直是视频站的老手。车站会叹息! “苹果cms采集电视台越来越难做”,各大搜索引擎收录越来越少。如果依赖cms自带的采集功能,就很难提升了。视频站无非就是一个标题、内容和内容介绍。苹果80%的cms站都是这样的结构,我们该怎么办?为了在众多影视台中脱颖而出?
一、苹果cms网站怎么样原创?
1、标题选择插入品牌词
2、播放集数(例如:第一集改为在线第一集)
3、剧情简介(插入关键词,采集电影介绍)
4、依靠SEO技术提升网站原创度
SEO 优化可访问性设置:
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后主动推送文章到搜索引擎,保证新链接能被搜索引擎及时搜索到收录)
5、随机点赞-随机阅读-随机作者(增加页面原创度数)
6、内容与标题一致(使内容与标题100%相关)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权重)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)
9、设置批量发布数量(可以设置发布间隔/单日发布总数)
10、可以设置不同的类型发布不同的栏目
11、工具设置锁定词(文章原创文章可读性和核心词不会原创时自动锁定品牌词和产品词)
12、工具还可以批量管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP,小旋风、站群、PB、Apple、搜外等各大cms电影网站,都可以同时管理和批量发布)
二、苹果cms采集设置
1、只要输入核心关键词,软件会自动生成下拉词、相关搜索词、长尾词,并自动过滤不相关的关键词核心关键词。全自动采集,可同时创建数十个或数百个采集任务(一个任务可支持上传1000个关键词),可同时执行多域任务时间!
2、自动过滤文章已经是采集的,
3、支持多平台采集(资讯、问答、视频频道、电影频道等)
4、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
5、自动批量挂机采集,无缝连接各大cms出版商,采集自动发帖推送到搜索引擎
以上是我个人测试后发现非常有用的所有内容。 文章采集工具与 Apple 的cms自己的数据源采集 无缝协作!目前网站交通还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章采集接口(基于requests使用采集python模块的方法总结-csdn博客requests库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-31 04:02
文章采集接口是和爬虫对接的,而爬虫则需要引入requests包来处理http请求。而在采集方面用到requests的情况比较多。本文使用requests比较简单粗暴的方法:基于requests使用采集python模块的方法总结-csdn博客requests库其实是一个库,包含的模块有requests和其它模块。
requests包含requests-http、requests-headers、itchat、dataframe(数据框)、cookiejar等,这些模块的作用也不尽相同。本文基于requests来讲requests包。官方提供的示例地址:-http-demo,示例页面的功能很完善,比如网址结构抓取、二维码解析、不同浏览器和不同浏览器模式下的url转换、网页广告解析、浏览器登录验证等。
安装方式一般是用pipinstallrequests,或者requests-http-demo自带pip(在网页源码中)或者下载支持的模块,或者直接用requests-http-demo自带-http:,把requests-http包放到工程的根目录。本文介绍requests-http包的安装方式。安装包教程:使用cmd方式安装requests包注意:安装requests时不要安装在命令行模式。
如果想要安装cmd方式安装,可以使用conda:condainstallrequests-http安装时如果不想用pip,可以使用pipinstallrequests-http安装时安装requests,requests是一个纯python包,虽然用pipinstall模块比requests自带pip安装方式安装可以节省大量时间。
scrapy在java中完整包下载及其安装方式见详细介绍:下载scrapy已安装安装scrapy后,scrapy以request对象形式接收request,加上shutil方法解析request,将内容传递给requestsresponse方法处理。requestsresponse方法接收几个参数如下:data;data接收的httpresponse对象;参数:-request-path-example-example-image。
安装方式:查看命令或安装方式可用如下命令安装库:pipinstallrequests-http将源码下载scrapy完整包,提取到任何你想要的目录下面,本文以ubuntu下scrapy包为例。scrapy完整包下载地址:scrapydocumentation源码:wget-2.2.6.tar.gz为避免加载jar包时已载入的依赖包可能导致报错,本文提供另一种方法解决:aptinstallsite-packages--for-all安装scrapy,这个时候会发现在/usr/local/scrapy/bin/目录下,也就是/usr/local/scrapy/site-packages/下,还有其它文件。
为避免再加载其它依赖包,可以pipinstalllibscrapy。另外,安装时如果有jar包需要下载解压,可以用如下命令(清华镜像)。 查看全部
文章采集接口(基于requests使用采集python模块的方法总结-csdn博客requests库)
文章采集接口是和爬虫对接的,而爬虫则需要引入requests包来处理http请求。而在采集方面用到requests的情况比较多。本文使用requests比较简单粗暴的方法:基于requests使用采集python模块的方法总结-csdn博客requests库其实是一个库,包含的模块有requests和其它模块。
requests包含requests-http、requests-headers、itchat、dataframe(数据框)、cookiejar等,这些模块的作用也不尽相同。本文基于requests来讲requests包。官方提供的示例地址:-http-demo,示例页面的功能很完善,比如网址结构抓取、二维码解析、不同浏览器和不同浏览器模式下的url转换、网页广告解析、浏览器登录验证等。
安装方式一般是用pipinstallrequests,或者requests-http-demo自带pip(在网页源码中)或者下载支持的模块,或者直接用requests-http-demo自带-http:,把requests-http包放到工程的根目录。本文介绍requests-http包的安装方式。安装包教程:使用cmd方式安装requests包注意:安装requests时不要安装在命令行模式。
如果想要安装cmd方式安装,可以使用conda:condainstallrequests-http安装时如果不想用pip,可以使用pipinstallrequests-http安装时安装requests,requests是一个纯python包,虽然用pipinstall模块比requests自带pip安装方式安装可以节省大量时间。
scrapy在java中完整包下载及其安装方式见详细介绍:下载scrapy已安装安装scrapy后,scrapy以request对象形式接收request,加上shutil方法解析request,将内容传递给requestsresponse方法处理。requestsresponse方法接收几个参数如下:data;data接收的httpresponse对象;参数:-request-path-example-example-image。
安装方式:查看命令或安装方式可用如下命令安装库:pipinstallrequests-http将源码下载scrapy完整包,提取到任何你想要的目录下面,本文以ubuntu下scrapy包为例。scrapy完整包下载地址:scrapydocumentation源码:wget-2.2.6.tar.gz为避免加载jar包时已载入的依赖包可能导致报错,本文提供另一种方法解决:aptinstallsite-packages--for-all安装scrapy,这个时候会发现在/usr/local/scrapy/bin/目录下,也就是/usr/local/scrapy/site-packages/下,还有其它文件。
为避免再加载其它依赖包,可以pipinstalllibscrapy。另外,安装时如果有jar包需要下载解压,可以用如下命令(清华镜像)。
文章采集接口(互联..NANDFLASH学习笔记之nandflash基础(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-27 06:07
实现“互联网+政务服务”平台与交通行政管理业务系统之间的数据自动流转,窗口工作人员不再手动录入二次录入--二次录入_weixin_43969737的博客-程序员
当我们在政务服务大厅的交通窗口办完业务时,应该还记得排队等候业务受理的场景。窗口服务员效率太低?太慢了?真的是事实吗?长期以来,这个窗口的工作人员每天要办理十余项公路货运经营许可证,提交了大量的材料。项目清单中列出了19个文件;而普货年检每天要处理25-35辆,还是一样。文件;加上其他需要处理的事务。根据省政府统一部署和省交通运输厅关于推进审批服务一站式办理的实施意见,“互联网...
nand flash基础的NAND FLASH学习笔记(二)_中国田园犬-程序员宝宝
4. 地址格式:地址分为:块地址、页地址、列地址,其中块地址和页地址也称为行地址 CA[0:12]:列地址,用于选择行内的偏移量page,由于page(包括OOB区)的大小为(4k+224)byte),所以需要13位来表示PA[0:7]:page address,用来选择一个page在一个街区。大小为256页,所以需要8位来表示BA[8:19]:块地址,用于选择LUN中的块,因为一个LUN中的块数是4096
攻击windows异常处理机制SEH_0pt1mus - 程序员大本营
转载自个人博客0pt1mus0x00 简介本文主要有两部分。第一部分介绍了Windows异常处理机制中的SEH,详细介绍了SEH的工作原理。第二部分介绍如何使用SEH通过堆栈溢出绕过GS。0x01 SEH(异常处理结构) SEH的全称是Structure Exception Handler,翻译为异常处理结构,是Windows异常处理机制使用的重要数据结构。每个 SEH 结构收录两个 DWORD 指针:SEH 链表指针和异常处理函数句柄,共 8 个字节。如下图: 为了初步了解SEH,我们需要了解几个
由于 C 语言标准不同而导致使用 for 循环的错误
目录 今天学习C的时候出现问题,写了一个通用循环,报错,代码如下,报错 今天学习C的时候解决了一个问题,写了一个通用循环,报错,代码如下#include <stdio.h>int main() { int price = 100; for (int i = 0; i <100 ; ++i) { printf("价格下降了,现在价格是:%d\n", price); 价格 - ;
babel的原理_从Babel到按需引入组件的原理
前言讲通天塔,相信大家不会感到陌生。桌面组件库Element,借助babel-plugin-component,我们可以只引入需要的组件,达到减小项目体积的目的。使用 babel-polyfill,开发人员可以立即使用 ES 规范中的最新功能。配合插件:transform-vue-jsx、react,我们可以直接使用JSX在vue中编写模板,进行react开发...
主板诊断卡code_weixin_34148508的博客-程序员宝贝
00 . 显示系统配置;即将控制 INI19 引导加载。.01 处理器测试 1、处理器状态验证,如果测试失败,则循环无限。处理器寄存器的测试即将开始,不可屏蔽的中断即将被禁用。CPU 寄存器测试正在进行或失败。02 确定诊断类型(正常或制造)。如果键盘缓冲区收录数据,它将失败。禁用不可屏蔽的中断;从延迟开始。CMOS 写入/读取正在进行或失败。03... 查看全部
文章采集接口(互联..NANDFLASH学习笔记之nandflash基础(二))
实现“互联网+政务服务”平台与交通行政管理业务系统之间的数据自动流转,窗口工作人员不再手动录入二次录入--二次录入_weixin_43969737的博客-程序员
当我们在政务服务大厅的交通窗口办完业务时,应该还记得排队等候业务受理的场景。窗口服务员效率太低?太慢了?真的是事实吗?长期以来,这个窗口的工作人员每天要办理十余项公路货运经营许可证,提交了大量的材料。项目清单中列出了19个文件;而普货年检每天要处理25-35辆,还是一样。文件;加上其他需要处理的事务。根据省政府统一部署和省交通运输厅关于推进审批服务一站式办理的实施意见,“互联网...
nand flash基础的NAND FLASH学习笔记(二)_中国田园犬-程序员宝宝
4. 地址格式:地址分为:块地址、页地址、列地址,其中块地址和页地址也称为行地址 CA[0:12]:列地址,用于选择行内的偏移量page,由于page(包括OOB区)的大小为(4k+224)byte),所以需要13位来表示PA[0:7]:page address,用来选择一个page在一个街区。大小为256页,所以需要8位来表示BA[8:19]:块地址,用于选择LUN中的块,因为一个LUN中的块数是4096
攻击windows异常处理机制SEH_0pt1mus - 程序员大本营
转载自个人博客0pt1mus0x00 简介本文主要有两部分。第一部分介绍了Windows异常处理机制中的SEH,详细介绍了SEH的工作原理。第二部分介绍如何使用SEH通过堆栈溢出绕过GS。0x01 SEH(异常处理结构) SEH的全称是Structure Exception Handler,翻译为异常处理结构,是Windows异常处理机制使用的重要数据结构。每个 SEH 结构收录两个 DWORD 指针:SEH 链表指针和异常处理函数句柄,共 8 个字节。如下图: 为了初步了解SEH,我们需要了解几个
由于 C 语言标准不同而导致使用 for 循环的错误
目录 今天学习C的时候出现问题,写了一个通用循环,报错,代码如下,报错 今天学习C的时候解决了一个问题,写了一个通用循环,报错,代码如下#include <stdio.h>int main() { int price = 100; for (int i = 0; i <100 ; ++i) { printf("价格下降了,现在价格是:%d\n", price); 价格 - ;
babel的原理_从Babel到按需引入组件的原理
前言讲通天塔,相信大家不会感到陌生。桌面组件库Element,借助babel-plugin-component,我们可以只引入需要的组件,达到减小项目体积的目的。使用 babel-polyfill,开发人员可以立即使用 ES 规范中的最新功能。配合插件:transform-vue-jsx、react,我们可以直接使用JSX在vue中编写模板,进行react开发...
主板诊断卡code_weixin_34148508的博客-程序员宝贝
00 . 显示系统配置;即将控制 INI19 引导加载。.01 处理器测试 1、处理器状态验证,如果测试失败,则循环无限。处理器寄存器的测试即将开始,不可屏蔽的中断即将被禁用。CPU 寄存器测试正在进行或失败。02 确定诊断类型(正常或制造)。如果键盘缓冲区收录数据,它将失败。禁用不可屏蔽的中断;从延迟开始。CMOS 写入/读取正在进行或失败。03...

