
文章采集接口
文章采集接口( 《详聊微服务观测》系列文章:Telegraf架构设计并发编程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-04 08:21
《详聊微服务观测》系列文章:Telegraf架构设计并发编程)
作者|蒋明明
来源|二达公众号
简介:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一个《微服务详解》系列文章,深入APM系统产品、架构设计和基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件的实现方法。
《详解微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一款非常流行的指标采集 软件,在 GiHub 拥有数万个 Star。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了所有监控项,例如机器监控、服务监控甚至硬件监控.
架构设计流水线并发编程
在 Go 中,流水线并发编程模式是一种常用的并发编程模式。简单来说,它由一系列stage组成,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过channel连接。
在每个阶段,goroutine 负责以下工作:
通过入口通道,接收上游阶段产生的数据。处理数据,如格式转换、数据过滤聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,每个阶段都同时有一个或多个出口和入口通道,但第一阶段和最后阶段除外,它们分别只有出口通道和入口通道。
Telegraf 中的实现
Telegraf 采用这种编程模式,主要有 4 个阶段,即 Inputs、Processor、Aggregators 和 Outputs。
并且它们之间也是通过通道相互链接的,它们的架构图如下:
可以看出,它整体采用了流水线并发编程模式。下面简单介绍一下它的运行机制:
扇入:多个函数向一个通道输出数据,一个函数读取通道直到关闭。
扇出:多个函数读取同一个通道,直到它被关闭。
插件设计
Telegraf 有这么多的输入、输出和处理器插件,那么它如何有效地管理这些插件呢?以及如何设计插件系统来应对激增的扩容需求?别着急,请允许我详细说明。
其实这里的插件并不是通常意义上的插件(即在运行时动态加载和绑定动态链接库),而是基于工厂模式的一种变体。首先我们看一下Telegraf的插件目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是有规律的(下面我们都以Inputs的Plug-in为例,其他模块实现类似)。
查看全部
文章采集接口(
《详聊微服务观测》系列文章:Telegraf架构设计并发编程)

作者|蒋明明
来源|二达公众号
简介:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一个《微服务详解》系列文章,深入APM系统产品、架构设计和基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件的实现方法。
《详解微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一款非常流行的指标采集 软件,在 GiHub 拥有数万个 Star。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了所有监控项,例如机器监控、服务监控甚至硬件监控.
架构设计流水线并发编程
在 Go 中,流水线并发编程模式是一种常用的并发编程模式。简单来说,它由一系列stage组成,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过channel连接。
在每个阶段,goroutine 负责以下工作:
通过入口通道,接收上游阶段产生的数据。处理数据,如格式转换、数据过滤聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,每个阶段都同时有一个或多个出口和入口通道,但第一阶段和最后阶段除外,它们分别只有出口通道和入口通道。
Telegraf 中的实现
Telegraf 采用这种编程模式,主要有 4 个阶段,即 Inputs、Processor、Aggregators 和 Outputs。
并且它们之间也是通过通道相互链接的,它们的架构图如下:

可以看出,它整体采用了流水线并发编程模式。下面简单介绍一下它的运行机制:
扇入:多个函数向一个通道输出数据,一个函数读取通道直到关闭。
扇出:多个函数读取同一个通道,直到它被关闭。
插件设计
Telegraf 有这么多的输入、输出和处理器插件,那么它如何有效地管理这些插件呢?以及如何设计插件系统来应对激增的扩容需求?别着急,请允许我详细说明。
其实这里的插件并不是通常意义上的插件(即在运行时动态加载和绑定动态链接库),而是基于工厂模式的一种变体。首先我们看一下Telegraf的插件目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是有规律的(下面我们都以Inputs的Plug-in为例,其他模块实现类似)。
文章采集接口(平台数据采集趋于稳定的技术介绍及技术设计 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-03 00:21
)
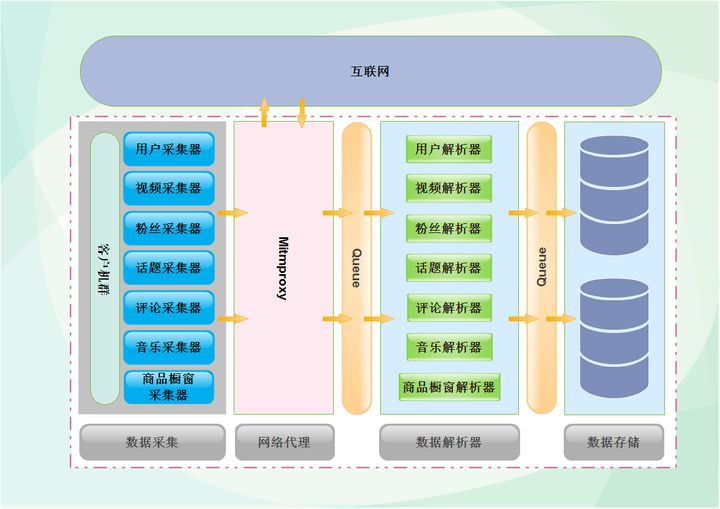
这段时间一直在处理data采集的问题。目前平台数据采集已经稳定。大家可以花点时间整理一下最近的成果,介绍一些最近使用的技术。本文文章以技术为主,要求读者有一定的技术基础。主要介绍数据采集过程中用到的神器mitmproxy,以及平台的一些技术设计。下面是数据采集的整体设计,左边是客户端,放着不同的采集器。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回。传输完成后,由中间解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间加了一个缓存,把采集器和解析器分开,在两个模块之间工作。在不相互影响的情况下,可以最大限度地存储数据。下图为第一代架构设计。会有一篇文章文章介绍平台架构设计的三代演进史。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据 查看全部
文章采集接口(平台数据采集趋于稳定的技术介绍及技术设计
)
这段时间一直在处理data采集的问题。目前平台数据采集已经稳定。大家可以花点时间整理一下最近的成果,介绍一些最近使用的技术。本文文章以技术为主,要求读者有一定的技术基础。主要介绍数据采集过程中用到的神器mitmproxy,以及平台的一些技术设计。下面是数据采集的整体设计,左边是客户端,放着不同的采集器。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回。传输完成后,由中间解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间加了一个缓存,把采集器和解析器分开,在两个模块之间工作。在不相互影响的情况下,可以最大限度地存储数据。下图为第一代架构设计。会有一篇文章文章介绍平台架构设计的三代演进史。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据
文章采集接口(自己制作接口程序或是修改原来的程序是自己开发的,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-02 13:17
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作原理。接口就是接口提交的数据优采云采集器。优采云采集器提交数据很简单,就是用来接收post数据的。这个和表单接收没有关系比如程序提交一个参数title,值为“this is the title”,asp可以使用request。form("title") 接收和使用它。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们可以通过自己的网站程序直接将内容发布到网站。然后我们将 target 这个函数可以自己制作界面程序或者修改原程序。如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。可以直接编写程序或修改原程序,将接收到的数据保存在服务器数据库中。如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够顺利处理数据。这部分具体操作由你自己决定。接口的安全性一般是可以直接post数据的接口。为了防止其他人使用该接口,您应该为其添加密码。可以给模块加一个参数,比如密码,给一个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的产生与 优采云采集器 关系不大,只有收到数据时才连接,其他时候就是写程序自己满足自己的要求,这也算是技术人员对@网站功能的一种扩展开发。可以说你可以对接收到的数据进行任何处理,从而满足你的网站 数据处理要求。特胡彦涵 查看全部
文章采集接口(自己制作接口程序或是修改原来的程序是自己开发的,)
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作原理。接口就是接口提交的数据优采云采集器。优采云采集器提交数据很简单,就是用来接收post数据的。这个和表单接收没有关系比如程序提交一个参数title,值为“this is the title”,asp可以使用request。form("title") 接收和使用它。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们可以通过自己的网站程序直接将内容发布到网站。然后我们将 target 这个函数可以自己制作界面程序或者修改原程序。如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。可以直接编写程序或修改原程序,将接收到的数据保存在服务器数据库中。如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够顺利处理数据。这部分具体操作由你自己决定。接口的安全性一般是可以直接post数据的接口。为了防止其他人使用该接口,您应该为其添加密码。可以给模块加一个参数,比如密码,给一个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的产生与 优采云采集器 关系不大,只有收到数据时才连接,其他时候就是写程序自己满足自己的要求,这也算是技术人员对@网站功能的一种扩展开发。可以说你可以对接收到的数据进行任何处理,从而满足你的网站 数据处理要求。特胡彦涵
文章采集接口(恒生集团文章采集接口接入平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-01 01:00
文章采集接口是指通过采集第三方接口或者平台相关信息来获取数据的接口接口能接入的工具太多了,并且,在数据搜集中,接口对于应用的开发来说也是最基础的,接口能接入的工具很多,就像程序员开发软件一样,需要找到集成工具,才能使软件开发起来,写出有用的代码;即使是开发软件的程序员也需要从零开始,亲自去摸索、钻研等,所以说接口接入也是很有学问的!比如下载网站上有很多的接口,但是如果我们不提供接口调用入口,我们会在找第三方网站的时候就没有办法,想要实现api调用就更难了所以,接口对于数据调取工具来说非常重要,现在市面上很多的数据接口平台都可以实现接口接入工具,但是有的接口平台对接口需要审核,有的需要上架,有的没有上架,我这里推荐站友参考一下的平台。
陆金所网址:www.yujin_cn一起作图一起作图是专业的接口接入平台,接口主要涉及广告展示,爬虫抓取,会员充值,竞拍与竞价,积分商城等,在接口获取方面相对其他的平台已经要容易多了;电商平台与金融理财平台接入任何一家平台的都需要自己审核,审核不通过难以通过调用,审核不通过就更别想接入。羊毛平台有很多都不能接入的,并且羊毛平台本身不是做广告,并且羊毛平台的接口调用点也是非常局限的。
恒生集团网址:恒生集团是从电子电路设计、集成电路设计制造及新能源半导体研发、测试等环节全面布局的国际化集团,拥有全球最大的广义半导体研发生产基地和行业优势公司。旗下网站还有广西北海交易所、深圳证券交易所等,恒生集团主要通过集成电路制造为主营业务收入,与微软、百度等全球企业有实时合作协议。
恒生集团有着实力强大的研发优势,包括布局个人和大中型企业,为客户提供一站式的市场解决方案;恒生集团覆盖了证券交易、it,保险,信托,基金、银行、黄金、保险等金融领域。恒瑞集团网址:恒瑞集团是亚洲电子、医药健康、信息科技产业为代表的三大金融集团之一,主要致力于生物和能源领域的战略投资并组建并运营着it部门,先后控股了美国能源部、中国政府综合信息管理中心、韩国高新科技实验室等全球。
集团资产总规模超过4000亿人民币,员工近1.4万人,拥有中国及全球约15%的主要大型国际企业、上市公司、上市公司员工、自然人股东。恒瑞集团通过各种投资和业务转移来帮助提高公司信息化水平,同时加强对全球一流基础设施的投资。百川数据网址:百川数据可接入的项目有:摄像头拍摄的天。 查看全部
文章采集接口(恒生集团文章采集接口接入平台)
文章采集接口是指通过采集第三方接口或者平台相关信息来获取数据的接口接口能接入的工具太多了,并且,在数据搜集中,接口对于应用的开发来说也是最基础的,接口能接入的工具很多,就像程序员开发软件一样,需要找到集成工具,才能使软件开发起来,写出有用的代码;即使是开发软件的程序员也需要从零开始,亲自去摸索、钻研等,所以说接口接入也是很有学问的!比如下载网站上有很多的接口,但是如果我们不提供接口调用入口,我们会在找第三方网站的时候就没有办法,想要实现api调用就更难了所以,接口对于数据调取工具来说非常重要,现在市面上很多的数据接口平台都可以实现接口接入工具,但是有的接口平台对接口需要审核,有的需要上架,有的没有上架,我这里推荐站友参考一下的平台。
陆金所网址:www.yujin_cn一起作图一起作图是专业的接口接入平台,接口主要涉及广告展示,爬虫抓取,会员充值,竞拍与竞价,积分商城等,在接口获取方面相对其他的平台已经要容易多了;电商平台与金融理财平台接入任何一家平台的都需要自己审核,审核不通过难以通过调用,审核不通过就更别想接入。羊毛平台有很多都不能接入的,并且羊毛平台本身不是做广告,并且羊毛平台的接口调用点也是非常局限的。
恒生集团网址:恒生集团是从电子电路设计、集成电路设计制造及新能源半导体研发、测试等环节全面布局的国际化集团,拥有全球最大的广义半导体研发生产基地和行业优势公司。旗下网站还有广西北海交易所、深圳证券交易所等,恒生集团主要通过集成电路制造为主营业务收入,与微软、百度等全球企业有实时合作协议。
恒生集团有着实力强大的研发优势,包括布局个人和大中型企业,为客户提供一站式的市场解决方案;恒生集团覆盖了证券交易、it,保险,信托,基金、银行、黄金、保险等金融领域。恒瑞集团网址:恒瑞集团是亚洲电子、医药健康、信息科技产业为代表的三大金融集团之一,主要致力于生物和能源领域的战略投资并组建并运营着it部门,先后控股了美国能源部、中国政府综合信息管理中心、韩国高新科技实验室等全球。
集团资产总规模超过4000亿人民币,员工近1.4万人,拥有中国及全球约15%的主要大型国际企业、上市公司、上市公司员工、自然人股东。恒瑞集团通过各种投资和业务转移来帮助提高公司信息化水平,同时加强对全球一流基础设施的投资。百川数据网址:百川数据可接入的项目有:摄像头拍摄的天。
文章采集接口(聚合采集可以自定义采集规则的seo文章采集器采集程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-30 17:05
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。
聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性
将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。
聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。
<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升 查看全部
文章采集接口(聚合采集可以自定义采集规则的seo文章采集器采集程序
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。

聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性

将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。

聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。

<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升
文章采集接口( 一个写的python不能不能用了,原因是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-27 21:19
一个写的python不能不能用了,原因是什么?)
昨天想去Geek Time把我买的一个专栏里的数据拿起来,发现之前写的python脚本不能用了。原因是他们 网站 做了电流限制,并添加了一些对 http 时间戳的验证。. 我们可以改进之前的python脚本,使用ip代理池来处理限流,找到时间戳校验的规则。
但是这次我们使用了另一种爬虫思路,就是直接写一些js脚本,在对方的网站中运行,请求对应的接口获取想要的数据。
事实上,我见过很多这种想法的例子。有一个很流行的脚本自动点赞QQ空间。看了它的源码,其实很简单。就是直接操作dom,然后触发一些事件。
另一个很流行的例子,github上一个很流行的repo,fuck知乎,据说是winter退休时写的知乎,数据保存在知乎中。
以下是本次实践的内容:
获取 文章id 集合
第一次进列的时候会有一个请求获取左边的列表集合文章。在这个界面中,我们可以获取当前列的所有请求。
本栏目有50多篇文章文章,由于限流,我们分成了两个请求。
注入 FileSaver.js
FileSaver 是一个在浏览器中运行并将数据下载为 json 或 excel 文件的库。
这里我们创建一个脚本标签并将这个标签插入到文档中。
我这里写了一个方法downloadJson,我们将这里得到的数据传递过来,我们就可以下载json文件了。
创建请求
创建一个 ajax 请求以请求接口以获取 文章 详细信息。
这里我们使用原生js来写,是一个post请求,res是我们从这个接口得到的返回值,我们可以从这个返回值中取我们需要的数据。
以上是单个请求的实现。多个请求的实现如下图所示。
然后我们保存数据:
所有结果都放在 rs 数组中。
下载数据
我们把所有的数据放到一个数组中,在最后一个请求的最后,执行我们写的downloadJson方法下载下来。
导入数据库
网上有很多工具可以将json文件导入数据库。这次我使用了我之前写的脚本。
这个脚本在我的github上,用nodejs写的,地址:tomysql.js
最后
这一次,我们没有使用常见的做法,模拟一个请求,或者模拟一个浏览器,而是直接使用浏览器来采集data。当然,我们也需要根据实际情况选择使用哪种方法。
完整脚本:geek.js 查看全部
文章采集接口(
一个写的python不能不能用了,原因是什么?)

昨天想去Geek Time把我买的一个专栏里的数据拿起来,发现之前写的python脚本不能用了。原因是他们 网站 做了电流限制,并添加了一些对 http 时间戳的验证。. 我们可以改进之前的python脚本,使用ip代理池来处理限流,找到时间戳校验的规则。
但是这次我们使用了另一种爬虫思路,就是直接写一些js脚本,在对方的网站中运行,请求对应的接口获取想要的数据。
事实上,我见过很多这种想法的例子。有一个很流行的脚本自动点赞QQ空间。看了它的源码,其实很简单。就是直接操作dom,然后触发一些事件。
另一个很流行的例子,github上一个很流行的repo,fuck知乎,据说是winter退休时写的知乎,数据保存在知乎中。
以下是本次实践的内容:
获取 文章id 集合
第一次进列的时候会有一个请求获取左边的列表集合文章。在这个界面中,我们可以获取当前列的所有请求。

本栏目有50多篇文章文章,由于限流,我们分成了两个请求。
注入 FileSaver.js
FileSaver 是一个在浏览器中运行并将数据下载为 json 或 excel 文件的库。

这里我们创建一个脚本标签并将这个标签插入到文档中。

我这里写了一个方法downloadJson,我们将这里得到的数据传递过来,我们就可以下载json文件了。
创建请求
创建一个 ajax 请求以请求接口以获取 文章 详细信息。

这里我们使用原生js来写,是一个post请求,res是我们从这个接口得到的返回值,我们可以从这个返回值中取我们需要的数据。
以上是单个请求的实现。多个请求的实现如下图所示。
然后我们保存数据:

所有结果都放在 rs 数组中。
下载数据
我们把所有的数据放到一个数组中,在最后一个请求的最后,执行我们写的downloadJson方法下载下来。

导入数据库
网上有很多工具可以将json文件导入数据库。这次我使用了我之前写的脚本。
这个脚本在我的github上,用nodejs写的,地址:tomysql.js
最后
这一次,我们没有使用常见的做法,模拟一个请求,或者模拟一个浏览器,而是直接使用浏览器来采集data。当然,我们也需要根据实际情况选择使用哪种方法。
完整脚本:geek.js
文章采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2022-03-27 21:18
今天分享“DiscuzX3.4论坛优采云采集器免登录发布接口模块(可测试)”,可以复制以下百度云地址下载,该接口为个人测试,压缩包是未加密的,可以直接使用,并且我们附上了本文的使用教程文章,适合DZ论坛网站的资源采集,好了,大家按照下面的流程操作。
下载链接:提取码:e9xk
解压后看到的文件有:
其中,discussX3.0.wpm为发布模块,dz测试接口。ljobx 是用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
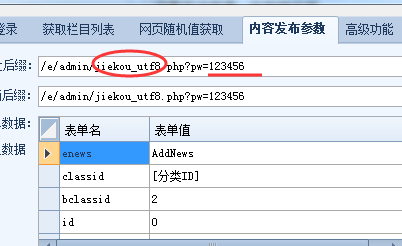
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:
这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password,也就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
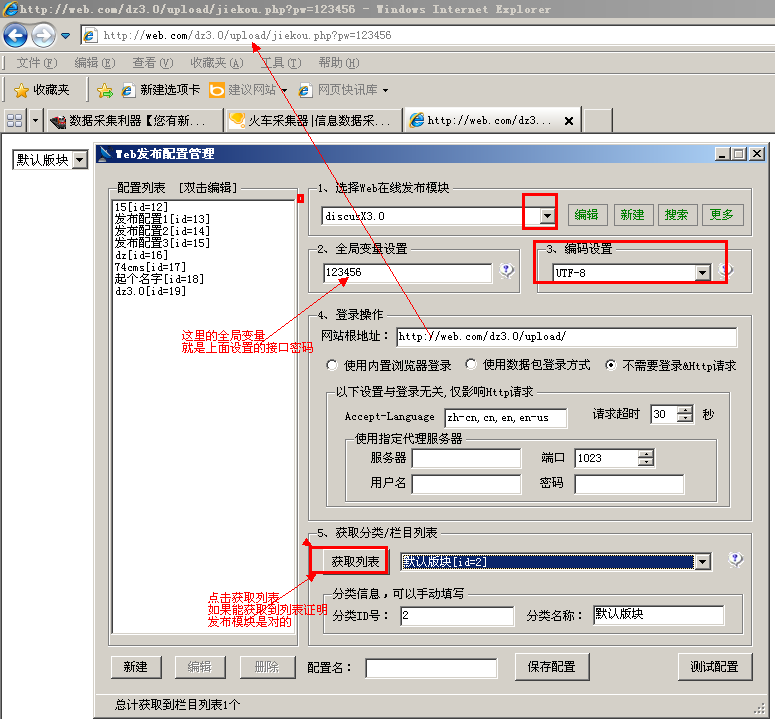
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
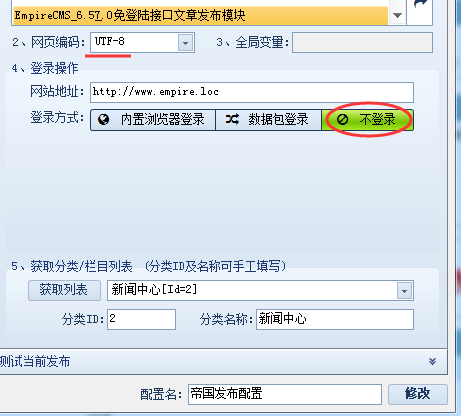
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:
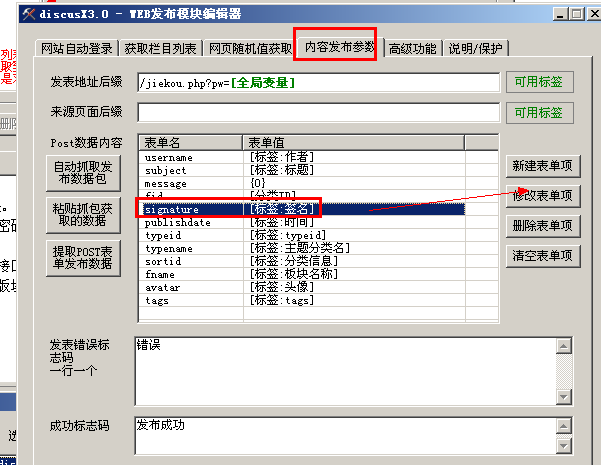
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
主题:对应论坛的标题
message:对应帖子的主题和回复的内容,这两部分放在一起
fid:对应section ID
signature:发送方和响应方的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们可以按照上图选择这个,然后点击“修改表单值”,这里设置表单值为空如图以下:
然后用同样的方法来处理我们的其他表格,如下图。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
界面注册的用户名和密码设置,打开界面:
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位。上图中用户密码下方是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
意思就是我们创建一个名为fname的标签,如果采集为“section 1”,那么在1的section中发布对应的section id,这个可以根据自己的论坛版块修改,下面的typname是也同理,这样设置的好处是不需要设置category id直接自动对应section名和topic分类名。
好了,今天的“DZ优采云采集发布模块”就解释到这里了,其实网站采集大家比较熟悉,虽然上面写着采集这个网站很容易被降级。我不建议将新站点直接带到 采集,也不建议该站点使用 采集 数据不断更新。但是,采集一些必要的资源仍然可用。网站主要内容还是要以“优质文章”为主,给百度一个好印象,更有利于网站整体排名提升。 查看全部
文章采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
今天分享“DiscuzX3.4论坛优采云采集器免登录发布接口模块(可测试)”,可以复制以下百度云地址下载,该接口为个人测试,压缩包是未加密的,可以直接使用,并且我们附上了本文的使用教程文章,适合DZ论坛网站的资源采集,好了,大家按照下面的流程操作。
下载链接:提取码:e9xk
解压后看到的文件有:

其中,discussX3.0.wpm为发布模块,dz测试接口。ljobx 是用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:

这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password,也就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
发布模块设置:
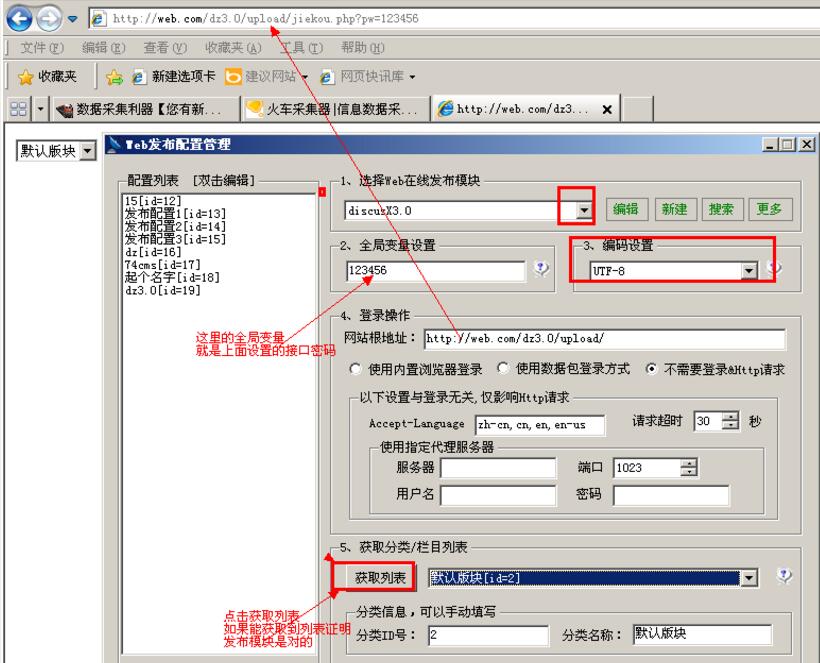
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:

单击编辑按钮转到“内容发布参数”选项卡:
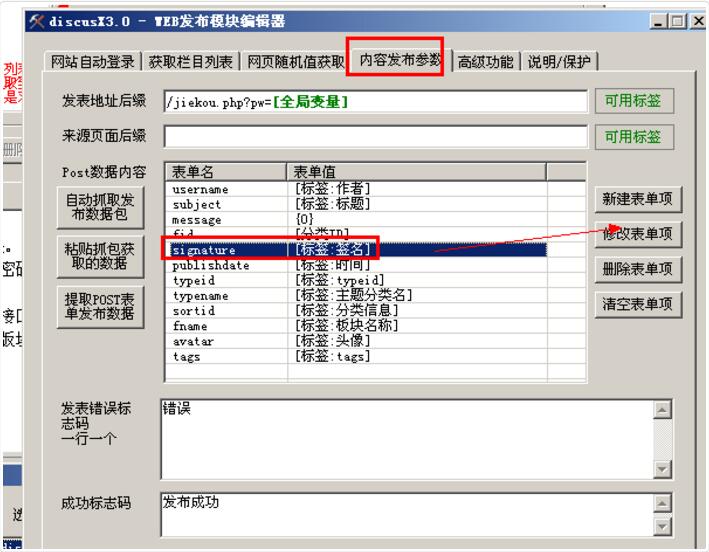
引入表格名称:
username:对应论坛发帖和回复的用户名
主题:对应论坛的标题
message:对应帖子的主题和回复的内容,这两部分放在一起
fid:对应section ID
signature:发送方和响应方的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
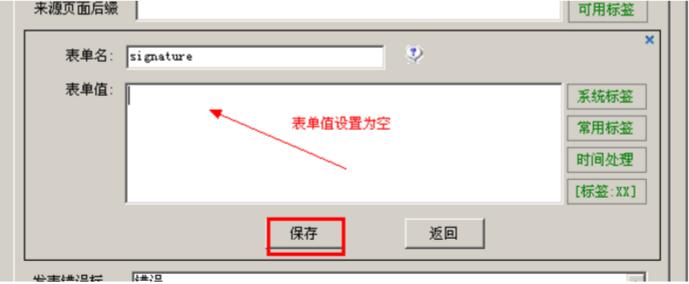
如果我们不需要表单值,比如我们不需要签名,我们可以按照上图选择这个,然后点击“修改表单值”,这里设置表单值为空如图以下:
然后用同样的方法来处理我们的其他表格,如下图。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
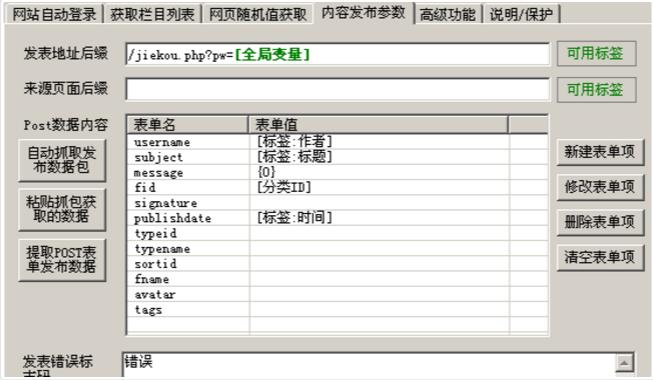
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
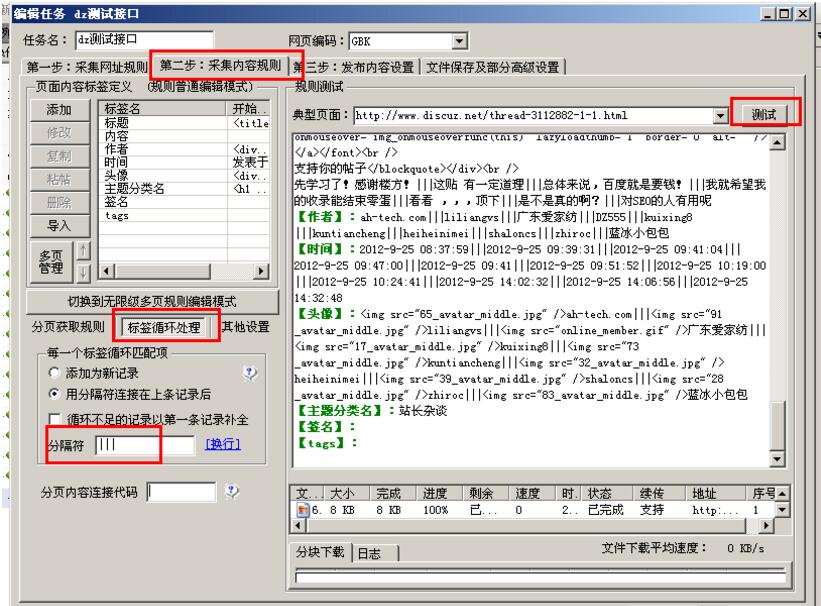
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
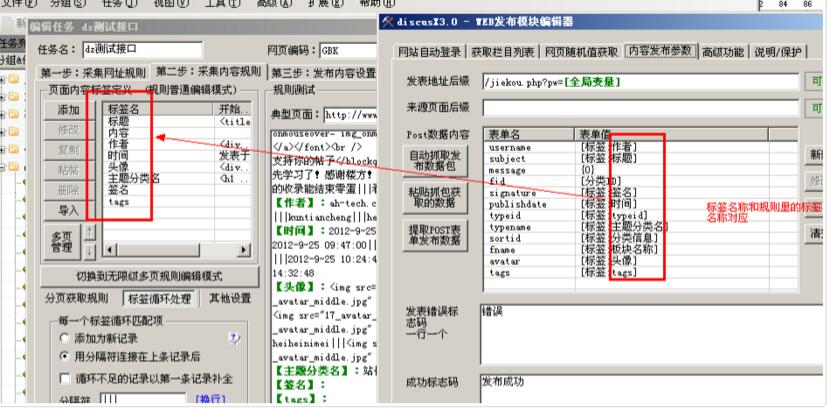
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
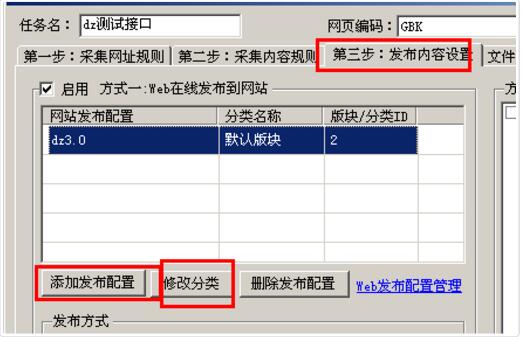
接口扩展说明:
界面注册的用户名和密码设置,打开界面:
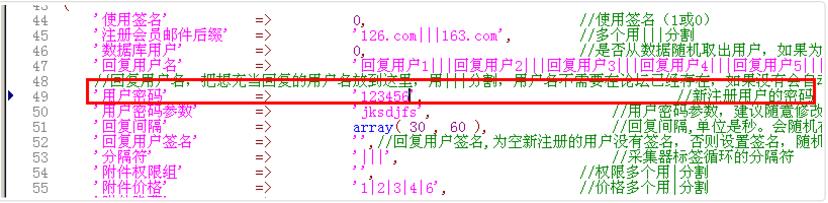
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位。上图中用户密码下方是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:

这些可以修改。
界面中有如下映射关系:

意思就是我们创建一个名为fname的标签,如果采集为“section 1”,那么在1的section中发布对应的section id,这个可以根据自己的论坛版块修改,下面的typname是也同理,这样设置的好处是不需要设置category id直接自动对应section名和topic分类名。
好了,今天的“DZ优采云采集发布模块”就解释到这里了,其实网站采集大家比较熟悉,虽然上面写着采集这个网站很容易被降级。我不建议将新站点直接带到 采集,也不建议该站点使用 采集 数据不断更新。但是,采集一些必要的资源仍然可用。网站主要内容还是要以“优质文章”为主,给百度一个好印象,更有利于网站整体排名提升。
文章采集接口(中国aliyuncs的服务器制作流程及使用方法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-26 19:06
文章采集接口主要有:的“#”,和,其他相关的还有:chinadaily类型(可以搜索全球任意一天)、xinyouku类型(可以搜索全国所有网站)、yanhui类型(可以搜索全球所有地点)。分析如下:,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。
,我将图片地址抓取到并发送给阿里巴巴的服务器。,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。这些都发送给aliyuncs的服务器上。同时该服务器上会在短期内产生8000万图片需要分析,这批图片需要集中下载到集中存储平台上去。所以aliyuncs的服务器要保证8000万图片下载的速度。
,我将一批图片地址抓取到并发送给阿里巴巴的服务器。和等等,这些都是需要图片地址。同时facebook和google等互联网公司这些图片的地址是发送给aliyuncs的服务器。的服务器,你找不到我,我没有那么多aliyuncs的服务器,我主要就是中国aliyuncs的服务器。
aliyuncs的服务器,你找不到我,我的语言是中文。那么我找不到你,我就将这8000万图片地址搜集好,比如中国的aliyuncs上所有图片地址全部下载下来,发送给你。的服务器,你找不到我,我不是还有美国主机嘛,而且我的主机速度比你的主机还快。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。
所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。当我第一时间找到你并用你的图片地址下载的时候,你说:”你这是什么意思?“对不起,我在中国你在美国,你需要一天才能找到我,我需要八小时。也就是说你就得等八小时我才能找到你。 查看全部
文章采集接口(中国aliyuncs的服务器制作流程及使用方法(一))
文章采集接口主要有:的“#”,和,其他相关的还有:chinadaily类型(可以搜索全球任意一天)、xinyouku类型(可以搜索全国所有网站)、yanhui类型(可以搜索全球所有地点)。分析如下:,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。
,我将图片地址抓取到并发送给阿里巴巴的服务器。,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。这些都发送给aliyuncs的服务器上。同时该服务器上会在短期内产生8000万图片需要分析,这批图片需要集中下载到集中存储平台上去。所以aliyuncs的服务器要保证8000万图片下载的速度。
,我将一批图片地址抓取到并发送给阿里巴巴的服务器。和等等,这些都是需要图片地址。同时facebook和google等互联网公司这些图片的地址是发送给aliyuncs的服务器。的服务器,你找不到我,我没有那么多aliyuncs的服务器,我主要就是中国aliyuncs的服务器。
aliyuncs的服务器,你找不到我,我的语言是中文。那么我找不到你,我就将这8000万图片地址搜集好,比如中国的aliyuncs上所有图片地址全部下载下来,发送给你。的服务器,你找不到我,我不是还有美国主机嘛,而且我的主机速度比你的主机还快。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。
所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。当我第一时间找到你并用你的图片地址下载的时候,你说:”你这是什么意思?“对不起,我在中国你在美国,你需要一天才能找到我,我需要八小时。也就是说你就得等八小时我才能找到你。
文章采集接口( jiekou.php,修改:就是上图是用于测试的规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-25 01:01
jiekou.php,修改:就是上图是用于测试的规则)
解压后看到的文件有:
其中,discussX3.0.wpm为发布模块,dz test interface.ljobx为用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:
这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password。这个密码就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
subject : 对应论坛的标题
message : 对应发帖的主题和回复的内容,这两部分放在一起
fid : 对应于section ID
signature :发送者和响应者的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid :对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们按照上图选择这个,然后点击“修改表单值”,这里的表单值设置为空,如图以下:
然后用同样的方法处理其他我们不想要的形式如下图所示。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位,上图中的用户密码就是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签。如果采集去“section 1”,那么就发布对应section id为1的section。这个可以根据自己的论坛section修改,下面的typname也一样,这样设置的好处是无需将类别id设置为直接与版块名称和主题类别名称自动对应。 查看全部
文章采集接口(
jiekou.php,修改:就是上图是用于测试的规则)

解压后看到的文件有:

其中,discussX3.0.wpm为发布模块,dz test interface.ljobx为用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:

这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password。这个密码就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):

导入成功会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:

单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
subject : 对应论坛的标题
message : 对应发帖的主题和回复的内容,这两部分放在一起
fid : 对应于section ID
signature :发送者和响应者的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid :对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们按照上图选择这个,然后点击“修改表单值”,这里的表单值设置为空,如图以下:
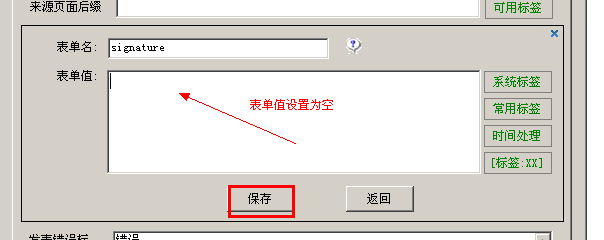
然后用同样的方法处理其他我们不想要的形式如下图所示。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
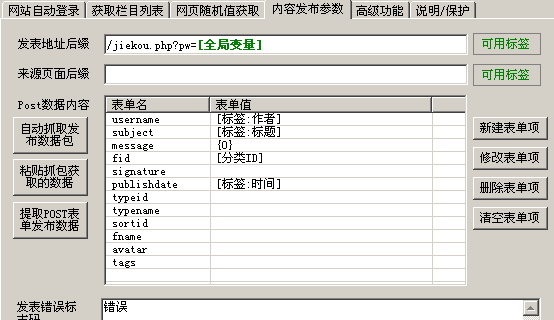
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
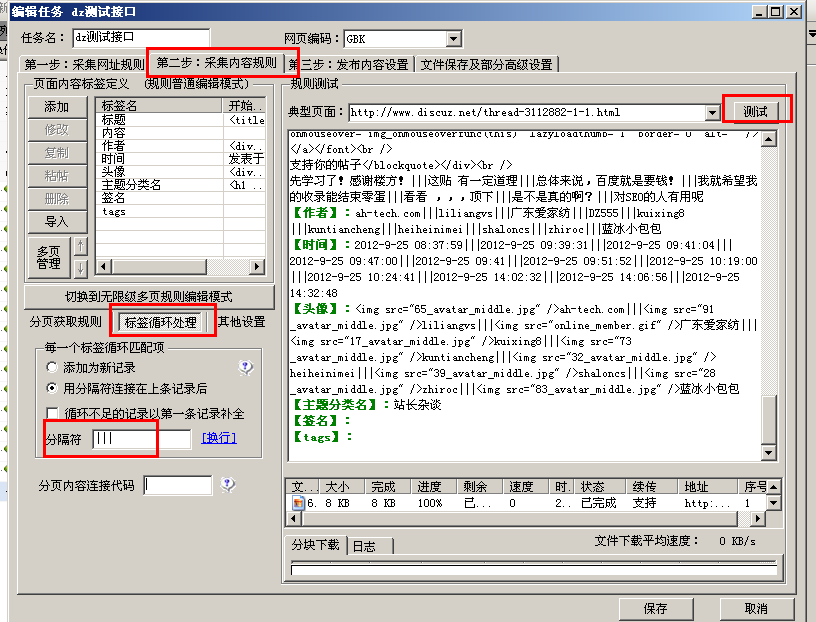
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
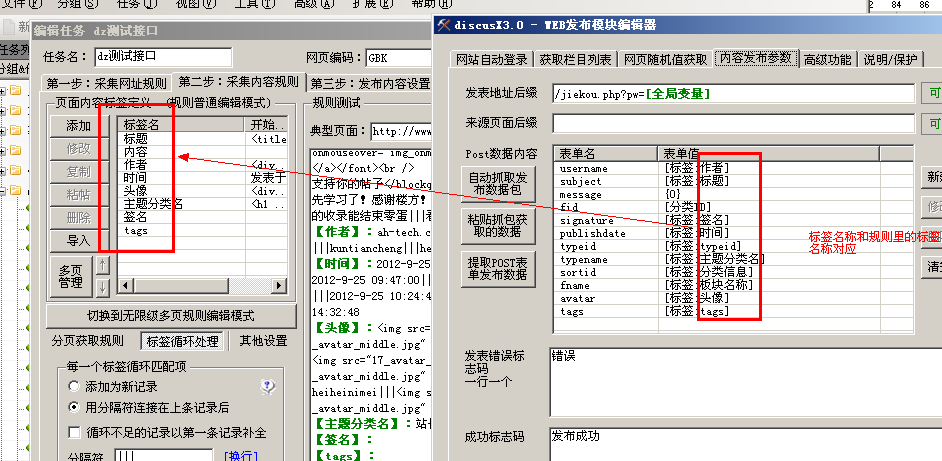
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:

这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位,上图中的用户密码就是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:

这些可以修改。
界面中有如下映射关系:

这意味着我们创建了一个名为 fname 的标签。如果采集去“section 1”,那么就发布对应section id为1的section。这个可以根据自己的论坛section修改,下面的typname也一样,这样设置的好处是无需将类别id设置为直接与版块名称和主题类别名称自动对应。
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-25 00:17
接口(软件类接口)是定义契约的引用类型。其他类型实现接口以保证它们支持某些操作。
接口指定必须由实现它的类或其他接口提供的成员。与类一样,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数麻烦,让你的工作效率翻倍。
优采云采集器共有三种登录方式,其中免登录发布接口是最方便的方式,但需要程序员根据发布URL进行自定义,需要一定的代码库。
免登录界面发布的时候有很多优点,比如使用方便简单、无需手动登录、稳定发布等。下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)要查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码符合的接口。
(2)打开接口php文件,接口有密码,默认123456,也可以自定义修改密码。这里注意,修改密码后,发布模块的密码也需要进行相应的修改。
(3)上传网站的管理目录/e/admin/下的接口文件
02 正式运行:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块并保存:
(2)根据网站的地址配置。
(3)那你可以测试发布看看发布模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的办法在这里就是在release模块设置好标签后,直接将release模块中的标签导入优采云采集器:
03接口下载链接
因此,为了方便客户使用,我们整理了几个常用的网站,并为网站编译了一个发布接口。下面附上下载地址,压缩包附有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章支持首页更新
2.帝国7.5发布界面
3.destoon7.0 提供发布接口
4.DiscuzX3.4 免费登录论坛发布模块(带测试接口)
5.ecshop2.7.3
6.opencartV3.0发布界面.rar 查看全部
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
接口(软件类接口)是定义契约的引用类型。其他类型实现接口以保证它们支持某些操作。
接口指定必须由实现它的类或其他接口提供的成员。与类一样,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数麻烦,让你的工作效率翻倍。
优采云采集器共有三种登录方式,其中免登录发布接口是最方便的方式,但需要程序员根据发布URL进行自定义,需要一定的代码库。
免登录界面发布的时候有很多优点,比如使用方便简单、无需手动登录、稳定发布等。下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)要查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码符合的接口。

(2)打开接口php文件,接口有密码,默认123456,也可以自定义修改密码。这里注意,修改密码后,发布模块的密码也需要进行相应的修改。
(3)上传网站的管理目录/e/admin/下的接口文件
02 正式运行:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块并保存:
(2)根据网站的地址配置。
(3)那你可以测试发布看看发布模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的办法在这里就是在release模块设置好标签后,直接将release模块中的标签导入优采云采集器:
03接口下载链接
因此,为了方便客户使用,我们整理了几个常用的网站,并为网站编译了一个发布接口。下面附上下载地址,压缩包附有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章支持首页更新
2.帝国7.5发布界面
3.destoon7.0 提供发布接口
4.DiscuzX3.4 免费登录论坛发布模块(带测试接口)
5.ecshop2.7.3
6.opencartV3.0发布界面.rar
文章采集接口(zblog伪静态?为什么要做zblog插件多个功能?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 547 次浏览 • 2022-03-24 00:21
zblog 伪静态?为什么zblog是伪静态的?因为伪静态有利于搜索引擎的收录,可以增加网站的优化效果,但是在做伪静态的时候要注意,一定要正确编写代码,一旦有错误,会导致搜索引擎爬取异常,需要对伪静态状态进行测试并及时跟踪。顺便推荐一个多功能的zblog插件。一键建站+内容资源采集+伪原创+搜索引擎主动推送收录等,都会以图片的形式展示给你。大家注意看图。
zblog 伪静态规则参数
{%host%}:表示URL,以'/'结尾
{%category%}:表示类别,如果类别有别名,则调用别名,如果没有别名,则调用名称
注意:该参数只出现在文章的url配置中
{%alias%}:表示调用的别名,如果没有别名则调用标题或姓名
注意:这个参数会出现在文章页面、页面、分类、标签、作者页面的url配置中
{%id%}:表示存储在数据库中的数据的ID号,用数字表示
注意:这个参数会出现在作者页面、标签页、分类页面、文章页面、页面url配置中
{%year%}:表示新创建数据的年份,如2022 2023等。
{%month%}:表示新创建数据的月份,如05 12等。
{%date%}:表示时间段,不常用,一般用于日期页的ur配置
{%page%}:表示页面的页码,用数字表示
注意:该参数只出现在一些列表页面中,如首页、文章列表、标签列表、作者文章列表、日期页面列表的url配置
伪静态urls可以使用以上参数和一些字符串的任意组合,但是要注意几点
1、{%host%} 参数与其他字符串或参数组合时不能出现'/'
2、除了{%host%}参数外,其他参数的组合可以使用'/'符号
3、使用{%alias%}参数时,输出结果中不得出现中文或其他特殊符号
4、列表页的url配置必须收录{%page%}参数,否则会出bug
5、可以参考下面的例子来配置url
一般来说,搜索引擎对静态页面比较友好,认为页面比较稳定,不会有太大差别。相反,动态页面搜索引擎认为网站不稳定并且不分配高权重。
当然,我们可以意识到,站点中的大部分页面都是静态页面,但动态页面在优化过程中也起着重要的作用。为了安全起见,将动态页面设置为伪静态可以满足搜索引擎的这些要求。
什么是伪静态
早期的网站不支持动态语言,比如(asp/jsp/)等,所有页面都是用HTML编写的,然后保存为.html的扩展名,方便浏览。后来动态语言和数据库结合后,更多互动的网站出现在我们面前,访问地址变成了“?” 等等。
早期的搜索引擎对于这些动态参数的表单页面并不容易收录,所以将这些动态页面转换为以html结尾的静态页面。这些页面是真正的静态页面,保存在服务器的硬盘上。所以随着数据的不断增加,会对网站的访问速度产生严重的影响,于是出现了一种URLRewrite(URL重写),即伪静态技术,避免了大量的真正的静态文件。
伪静态有什么好处
静态页面有大量的存储空间。删除或更新这些html文件会导致大量垃圾页面,而像蜘蛛一样爬行有很多垃圾索引。伪静态可以更好的链接服务器压力,增强搜索引擎对页面的收录。动态页面虽然是实时更新的,但有时会导致死循环,对搜索引擎不友好,而伪静态则不会这样出现。健康)状况。
带有“?”等参数的 URL 可能有助于谷歌理解内容,但用户很难一目了然地理解页面的大致内容。伪静态 URL 更清晰,容易引起用户点击,而且 URL 容易记忆。 查看全部
文章采集接口(zblog伪静态?为什么要做zblog插件多个功能?(组图))
zblog 伪静态?为什么zblog是伪静态的?因为伪静态有利于搜索引擎的收录,可以增加网站的优化效果,但是在做伪静态的时候要注意,一定要正确编写代码,一旦有错误,会导致搜索引擎爬取异常,需要对伪静态状态进行测试并及时跟踪。顺便推荐一个多功能的zblog插件。一键建站+内容资源采集+伪原创+搜索引擎主动推送收录等,都会以图片的形式展示给你。大家注意看图。
zblog 伪静态规则参数
{%host%}:表示URL,以'/'结尾
{%category%}:表示类别,如果类别有别名,则调用别名,如果没有别名,则调用名称
注意:该参数只出现在文章的url配置中
{%alias%}:表示调用的别名,如果没有别名则调用标题或姓名
注意:这个参数会出现在文章页面、页面、分类、标签、作者页面的url配置中
{%id%}:表示存储在数据库中的数据的ID号,用数字表示
注意:这个参数会出现在作者页面、标签页、分类页面、文章页面、页面url配置中
{%year%}:表示新创建数据的年份,如2022 2023等。
{%month%}:表示新创建数据的月份,如05 12等。
{%date%}:表示时间段,不常用,一般用于日期页的ur配置
{%page%}:表示页面的页码,用数字表示
注意:该参数只出现在一些列表页面中,如首页、文章列表、标签列表、作者文章列表、日期页面列表的url配置
伪静态urls可以使用以上参数和一些字符串的任意组合,但是要注意几点
1、{%host%} 参数与其他字符串或参数组合时不能出现'/'
2、除了{%host%}参数外,其他参数的组合可以使用'/'符号
3、使用{%alias%}参数时,输出结果中不得出现中文或其他特殊符号
4、列表页的url配置必须收录{%page%}参数,否则会出bug
5、可以参考下面的例子来配置url
一般来说,搜索引擎对静态页面比较友好,认为页面比较稳定,不会有太大差别。相反,动态页面搜索引擎认为网站不稳定并且不分配高权重。
当然,我们可以意识到,站点中的大部分页面都是静态页面,但动态页面在优化过程中也起着重要的作用。为了安全起见,将动态页面设置为伪静态可以满足搜索引擎的这些要求。

什么是伪静态
早期的网站不支持动态语言,比如(asp/jsp/)等,所有页面都是用HTML编写的,然后保存为.html的扩展名,方便浏览。后来动态语言和数据库结合后,更多互动的网站出现在我们面前,访问地址变成了“?” 等等。
早期的搜索引擎对于这些动态参数的表单页面并不容易收录,所以将这些动态页面转换为以html结尾的静态页面。这些页面是真正的静态页面,保存在服务器的硬盘上。所以随着数据的不断增加,会对网站的访问速度产生严重的影响,于是出现了一种URLRewrite(URL重写),即伪静态技术,避免了大量的真正的静态文件。
伪静态有什么好处
静态页面有大量的存储空间。删除或更新这些html文件会导致大量垃圾页面,而像蜘蛛一样爬行有很多垃圾索引。伪静态可以更好的链接服务器压力,增强搜索引擎对页面的收录。动态页面虽然是实时更新的,但有时会导致死循环,对搜索引擎不友好,而伪静态则不会这样出现。健康)状况。
带有“?”等参数的 URL 可能有助于谷歌理解内容,但用户很难一目了然地理解页面的大致内容。伪静态 URL 更清晰,容易引起用户点击,而且 URL 容易记忆。
文章采集接口(数据接口分析抓包搭建好环境之后的应用收获 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-24 00:17
)
本文章主要介绍python抖音data采集方法的相关知识。内容详细易懂,操作简单快捷,具有一定的参考价值。相信看过这篇python抖音Data采集methods文章会有收获,一起来看看吧。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据 查看全部
文章采集接口(数据接口分析抓包搭建好环境之后的应用收获
)
本文章主要介绍python抖音data采集方法的相关知识。内容详细易懂,操作简单快捷,具有一定的参考价值。相信看过这篇python抖音Data采集methods文章会有收获,一起来看看吧。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据
文章采集接口(影响网站加载性能的瓶颈中挖掘指标--APM问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-03-23 00:25
APM的全称是Application Performance Monitor,即性能监控
这个 文章 有三个前提:
还记得多年前在网上广为流传的一道经典的前端面试题。大体思路是解释从在浏览器地址栏中输入 url 到看到页面的过程。这类问题的迷人之处在于它给了你一张大嘴,它让你信服——原来我们对眼前的很多事情视而不见,背后有这么大的学术问题。随便问。
我想在这个 文章 中回答的问题也很简单:我怎么知道我的 网站 性能有多慢以及在哪里?这个问题是我在网站上线的时候首先要搞清楚的。
待解决问题确定指标
大问题下,有两个子问题需要先搞清楚。
这两个子问题在我去年的文章《绩效指标的信念危机》中有详细的解释。由于篇幅关系,这里只陈述结论,两个问题的答案密不可分,必须放在一起聊
总之,onload 或者 DOMContentLoaded 等技术指标是远远不够的,甚至 First Contentful Paint 也离用户的实际感知还差得很远(后面我会证明这一点)。一个好的指标应该尽可能的贴近用户,甚至是与业务深度定制。所以我推荐页面上用来承载核心内容的DOM元素的时序作为性能的核心指标。这个时机很关键,因为它等同于 网站 在此时可用。
以网站的详情页为例,关键元素为.single-folder-container
但这并不意味着一个指标就足够了,因为如果我们发现指标值不理想,我们就无法确定问题出在哪里。因此,好的数据的作用应该是双向的:即能够准确的反映当前产品的运行状态(从产品到数据),同时通过观察数据,我们也应该能够知道是什么样的产品存在的问题(从数据到产品)。)
在这个前提下,我们需要从“潜在的”性能瓶颈中挖掘指标。假设影响网站加载性能的因素有:
如何继续记录两者的加载时间?
要回答这个问题,我们要不断地问自己,这两类信息是否足以让我们推测问题出在哪里?与单一指标相比,答案是肯定的,但仍有细化的空间。以资源加载为例,参考下图资源时序。资源加载也分为多个阶段:
我们甚至可以诊断出问题出在 DNS 解析还是 TCP 连接阶段。但是,我们不应该详细采集所有指标,有几个因素需要考虑:
回到确定指标的问题,我们必须面对目前无法知道自己需要什么样的数据的现状,这很正常。确定指标是假设、验证、重新假设和重新验证的收敛过程。尝试总比拖延和让我们更接近正确答案要好。让我们开始采集上面提到的三类指标
接口问题
前端工程师必然会陷入的陷阱是只站在前端的角度看问题,而忽略了最重要的接口性能。对于大多数人来说,页面加载可能只是线性的:
但实际上,在 API Request 环节,我们应该从微服务的角度来看问题。从请求到响应的一个请求,将通过不同的微服务来获取数据,如果请求所经过的每一个环节都可以被追踪到的话。这对于定位在线环境中的问题和衡量单个微服务的效率很有用。这是分布式跟踪。目前,这项技术已经相当成熟。Jaegertracing 和 Zipkin 都是分布式跟踪解决方案。
但是,如果你对后端拆分服务层有所了解,如果你想诊断单个微服务的性能在哪里,我们可以继续下钻到单个微服务,比较调用不同服务层方法(服务layer也适用于前端,详细介绍可以参考我去年翻译的这篇文章《Angular Architecture Patterns and Best Practices》)
我想表达的很明显。要想充分挖掘应用的性能瓶颈,就要同时考察上下游。分割视角得到的结果是有偏差的。
解决方案采集日志
如果您有 采集 日志记录的经验,您应该知道日志记录 采集 和输出是两个不同的东西。特别是对于后端程序。日志可以记录在本地文件中,也可以直接在控制台输出,但是在线环境下,需要在专业的日志服务中记录。
比如NodeJS的开源日志库winston,支持多种transport的集成,transport就是一种存储日志的存储方式。它还支持编写自定义传输,当前选项支持市面上几乎所有主流日志服务。.NET CORE 中的日志记录提供程序是相同的概念
但是,这种采集日志的“主动”方式并不是最佳实践。构建网络应用的方法论 Twelve-Factor App 曾提出应用本身不考虑日志的存储,只保证日志以 stdout 的形式输出,由环境负责采集和处理日志。这个提议是合理的,因为应用程序不应该也不可能知道它将部署在哪个云环境中,并且不同的环境对日志的处理方式不同
为了快速失败,我在开发site2share的后端时没有遵循这个概念。当需要登录采集时,直接调用具体平台的采集方法。目前我的日志都记录在 Azure Application Insights 上,所以在记录时我需要调用 Application Insights 客户端方法:AppInsightsClient.trackTrace(message)
只是在实现层面,可以使用winston代码变得更加优雅。我们可以创建一个logger来达到同时兼容多个日志输出通道的效果。
const logger = winston.createLogger({
transports: [
new AppInsightsTransport(),
new winston.transports.Console()
]
});
因为我们测试的是前端性能,而性能数据是在消费者浏览器的网页上生成的。所以我们依赖的是每个用户在访问后通过嵌入页面的脚本主动上传数据
应用洞察
我选择 Azure Application Insights 来存储和查询日志的原因之一是 网站我使用从前端(Azure 静态 Web 应用)到后端(Azure 服务应用)甚至 DevOps 的 Azure 服务,自然,官方的 Application Insights 可以更好地与这些服务集成;还有一个更重要的原因是它可以为我们解决分布式追踪的问题。
您需要在您的应用程序中植入 Application Insights 的 SDK 来采集日志。SDK 支持前端和后端程序。它通过两种方式采集日志,主动采集和被动报告。以JavaScript语言的web应用为例,在页面植入SDK后,会自动采集程序运行时的错误报告,发出的异步请求,console.log(猴子补丁的方式),和性能信息(通过性能 API);您也可以调用 SDK 提供的 trackMetric 和 trackEvent 主动上报自定义指标和事件信息。性能 采集 我们同时使用这两种方法
我们通常将metrics、log等信息称为遥测(data/item),通常这些数据存储在不同的表中,并与其他数据一起淹没。如何将两者联系起来?Application Insights 用于关联遥测的解决方案很简单:为每条数据提供唯一的上下文标识符 operation_Id。以用户访问页面为例,本次访问生成的数据中的 operation_Id 称为 xyz,那么在 Application Insights 平台上,我们可以通过 xyz 查询关联数据(Kusto 语法)
我们不仅可以将前端数据与前端数据关联起来,还可以将前端数据与后端数据关联起来,这是我们进行分布式追踪的法宝。对于微服务应用,Application Insights 甚至可以为我们生成一个 Application Map 来可视化服务之间的调用过程和耗时。
在浏览完本节的技术细节后,我们可以可视化我们需要哪些数据以及它们之间的关系
资源加载指标
借助 Performance API,在现代浏览器中采集指标非常容易。无需主动触发,浏览器已经根据每次页面加载的时间线将性能指标信息封装在PerformanceEntry对象中。之后,我们只需要过滤掉需要的数据,比如我们关心的脚本:
window.performance.getEntries().filter(({initiatorType, entryType}) => initiatorType === 'script' && entryType === 'resource')
根据上一节的结论,我们就不详细记录资源加载的各个环节的数据了。这里我重点关注采集资源加载的持续时间和资源加载的开始时间,我们从这两个开始可以分别在PerformanceEntry、duration和fetchStart上获取。因为目前在我看来,预加载和缩短加载时间是提高性能的有效手段。如果事后这两个值没有异常,可以考虑多采集指标
报告元素出现时间
确认元素出现的那一刻最简单粗暴的方法是通过 setInterval 来轮询该元素是否出现,但是在现代浏览器中我们可以使用 MutationObserver API 来监控元素的所有变化,因此可以以不同的方式提出问题:body标签下.single-folder-container元素什么时候出现,关键代码大致如下
const observer = new MutationObserver(mutations => {
if (document.querySelector('.single-folder-container')) {
observer.disconnect();
return;
}
});
observer.observe(document.querySelector('body'), {
subtree: true,
childList: true
});
这里有一个问题:这段代码非常关键且难以测试。
第一个问题是,例如在 Jest 环境中没有原生的 MutationObserver 对象。如果只是为了通过测试而简单地模拟 MutationObserver 对象测试,那么测试的意义就没有了;
其次,即使在 Headless Chrome 等支持 MutationObserver 的环境中进行测试,如果你知道它向你报告的元素的时间是正确的?既然你自己不知道确切的时间是什么(即你测试 Lee 的期望),那么 10 秒肯定是不正确的,但是 2.2 秒呢?
附加性能指标
理论上,以上两个都是我们期望采集的指标。但是我还想采集两个额外的指标:First Paint 和 First Contentful Paint,简而言之,它们记录了浏览器在绘制页面时的一些关键时刻。这两个指标也可从 Performance API 获得
window.performance.getEntries().filter(entry => entry.entryType === 'paint')
Paint Timing 将比纯粹的技术指标更接近用户体验,但我们将拭目以待,看看它与实际用户看到元素出现的情况相比如何。
后端时间
我猜有两个可能的性能瓶颈:1)Redis 查询2) MySQL 查询。
Redis主要用于会话存储,后端由Node.js + ExpressJS搭建,所以不容易监控会话读取性能。所以我优先考虑MySQL的查询性能,比如findByFolderId方法的读取性能统计:
const findFolderIdStartTime = +new Date();
await FolderService.findByFolderId(parseInt(req.params!.id))
appInsightsClient.trackMetric({
name: "APM:GET_SINGLE_FOLDER:FIND_BY_ID",
value: +new Date - findFolderIdStartTime
});
总结
最后,为了在日志平台上找到对应的指标并对指定类型的指标进行统计,我们需要对上述指标进行命名。以下是命名规则。
上一个即将结束。我已经说明了这个性能采集方案的思路,也基本实现了我们的性能采集脚本。有了这些代码,我们基本可以完成采集单条性能数据 查看全部
文章采集接口(影响网站加载性能的瓶颈中挖掘指标--APM问题)
APM的全称是Application Performance Monitor,即性能监控
这个 文章 有三个前提:
还记得多年前在网上广为流传的一道经典的前端面试题。大体思路是解释从在浏览器地址栏中输入 url 到看到页面的过程。这类问题的迷人之处在于它给了你一张大嘴,它让你信服——原来我们对眼前的很多事情视而不见,背后有这么大的学术问题。随便问。
我想在这个 文章 中回答的问题也很简单:我怎么知道我的 网站 性能有多慢以及在哪里?这个问题是我在网站上线的时候首先要搞清楚的。
待解决问题确定指标
大问题下,有两个子问题需要先搞清楚。
这两个子问题在我去年的文章《绩效指标的信念危机》中有详细的解释。由于篇幅关系,这里只陈述结论,两个问题的答案密不可分,必须放在一起聊
总之,onload 或者 DOMContentLoaded 等技术指标是远远不够的,甚至 First Contentful Paint 也离用户的实际感知还差得很远(后面我会证明这一点)。一个好的指标应该尽可能的贴近用户,甚至是与业务深度定制。所以我推荐页面上用来承载核心内容的DOM元素的时序作为性能的核心指标。这个时机很关键,因为它等同于 网站 在此时可用。
以网站的详情页为例,关键元素为.single-folder-container
但这并不意味着一个指标就足够了,因为如果我们发现指标值不理想,我们就无法确定问题出在哪里。因此,好的数据的作用应该是双向的:即能够准确的反映当前产品的运行状态(从产品到数据),同时通过观察数据,我们也应该能够知道是什么样的产品存在的问题(从数据到产品)。)
在这个前提下,我们需要从“潜在的”性能瓶颈中挖掘指标。假设影响网站加载性能的因素有:
如何继续记录两者的加载时间?
要回答这个问题,我们要不断地问自己,这两类信息是否足以让我们推测问题出在哪里?与单一指标相比,答案是肯定的,但仍有细化的空间。以资源加载为例,参考下图资源时序。资源加载也分为多个阶段:
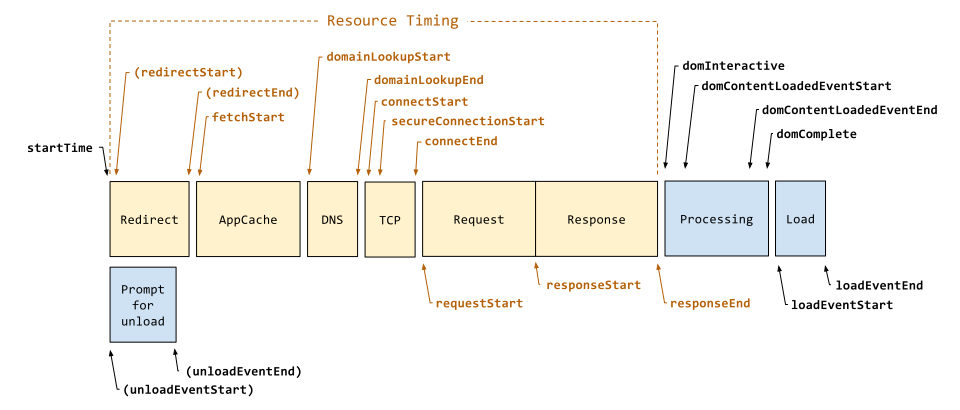
我们甚至可以诊断出问题出在 DNS 解析还是 TCP 连接阶段。但是,我们不应该详细采集所有指标,有几个因素需要考虑:
回到确定指标的问题,我们必须面对目前无法知道自己需要什么样的数据的现状,这很正常。确定指标是假设、验证、重新假设和重新验证的收敛过程。尝试总比拖延和让我们更接近正确答案要好。让我们开始采集上面提到的三类指标
接口问题
前端工程师必然会陷入的陷阱是只站在前端的角度看问题,而忽略了最重要的接口性能。对于大多数人来说,页面加载可能只是线性的:

但实际上,在 API Request 环节,我们应该从微服务的角度来看问题。从请求到响应的一个请求,将通过不同的微服务来获取数据,如果请求所经过的每一个环节都可以被追踪到的话。这对于定位在线环境中的问题和衡量单个微服务的效率很有用。这是分布式跟踪。目前,这项技术已经相当成熟。Jaegertracing 和 Zipkin 都是分布式跟踪解决方案。

但是,如果你对后端拆分服务层有所了解,如果你想诊断单个微服务的性能在哪里,我们可以继续下钻到单个微服务,比较调用不同服务层方法(服务layer也适用于前端,详细介绍可以参考我去年翻译的这篇文章《Angular Architecture Patterns and Best Practices》)
我想表达的很明显。要想充分挖掘应用的性能瓶颈,就要同时考察上下游。分割视角得到的结果是有偏差的。
解决方案采集日志
如果您有 采集 日志记录的经验,您应该知道日志记录 采集 和输出是两个不同的东西。特别是对于后端程序。日志可以记录在本地文件中,也可以直接在控制台输出,但是在线环境下,需要在专业的日志服务中记录。
比如NodeJS的开源日志库winston,支持多种transport的集成,transport就是一种存储日志的存储方式。它还支持编写自定义传输,当前选项支持市面上几乎所有主流日志服务。.NET CORE 中的日志记录提供程序是相同的概念
但是,这种采集日志的“主动”方式并不是最佳实践。构建网络应用的方法论 Twelve-Factor App 曾提出应用本身不考虑日志的存储,只保证日志以 stdout 的形式输出,由环境负责采集和处理日志。这个提议是合理的,因为应用程序不应该也不可能知道它将部署在哪个云环境中,并且不同的环境对日志的处理方式不同
为了快速失败,我在开发site2share的后端时没有遵循这个概念。当需要登录采集时,直接调用具体平台的采集方法。目前我的日志都记录在 Azure Application Insights 上,所以在记录时我需要调用 Application Insights 客户端方法:AppInsightsClient.trackTrace(message)
只是在实现层面,可以使用winston代码变得更加优雅。我们可以创建一个logger来达到同时兼容多个日志输出通道的效果。
const logger = winston.createLogger({
transports: [
new AppInsightsTransport(),
new winston.transports.Console()
]
});
因为我们测试的是前端性能,而性能数据是在消费者浏览器的网页上生成的。所以我们依赖的是每个用户在访问后通过嵌入页面的脚本主动上传数据
应用洞察
我选择 Azure Application Insights 来存储和查询日志的原因之一是 网站我使用从前端(Azure 静态 Web 应用)到后端(Azure 服务应用)甚至 DevOps 的 Azure 服务,自然,官方的 Application Insights 可以更好地与这些服务集成;还有一个更重要的原因是它可以为我们解决分布式追踪的问题。
您需要在您的应用程序中植入 Application Insights 的 SDK 来采集日志。SDK 支持前端和后端程序。它通过两种方式采集日志,主动采集和被动报告。以JavaScript语言的web应用为例,在页面植入SDK后,会自动采集程序运行时的错误报告,发出的异步请求,console.log(猴子补丁的方式),和性能信息(通过性能 API);您也可以调用 SDK 提供的 trackMetric 和 trackEvent 主动上报自定义指标和事件信息。性能 采集 我们同时使用这两种方法
我们通常将metrics、log等信息称为遥测(data/item),通常这些数据存储在不同的表中,并与其他数据一起淹没。如何将两者联系起来?Application Insights 用于关联遥测的解决方案很简单:为每条数据提供唯一的上下文标识符 operation_Id。以用户访问页面为例,本次访问生成的数据中的 operation_Id 称为 xyz,那么在 Application Insights 平台上,我们可以通过 xyz 查询关联数据(Kusto 语法)
我们不仅可以将前端数据与前端数据关联起来,还可以将前端数据与后端数据关联起来,这是我们进行分布式追踪的法宝。对于微服务应用,Application Insights 甚至可以为我们生成一个 Application Map 来可视化服务之间的调用过程和耗时。
在浏览完本节的技术细节后,我们可以可视化我们需要哪些数据以及它们之间的关系
资源加载指标
借助 Performance API,在现代浏览器中采集指标非常容易。无需主动触发,浏览器已经根据每次页面加载的时间线将性能指标信息封装在PerformanceEntry对象中。之后,我们只需要过滤掉需要的数据,比如我们关心的脚本:
window.performance.getEntries().filter(({initiatorType, entryType}) => initiatorType === 'script' && entryType === 'resource')
根据上一节的结论,我们就不详细记录资源加载的各个环节的数据了。这里我重点关注采集资源加载的持续时间和资源加载的开始时间,我们从这两个开始可以分别在PerformanceEntry、duration和fetchStart上获取。因为目前在我看来,预加载和缩短加载时间是提高性能的有效手段。如果事后这两个值没有异常,可以考虑多采集指标
报告元素出现时间
确认元素出现的那一刻最简单粗暴的方法是通过 setInterval 来轮询该元素是否出现,但是在现代浏览器中我们可以使用 MutationObserver API 来监控元素的所有变化,因此可以以不同的方式提出问题:body标签下.single-folder-container元素什么时候出现,关键代码大致如下
const observer = new MutationObserver(mutations => {
if (document.querySelector('.single-folder-container')) {
observer.disconnect();
return;
}
});
observer.observe(document.querySelector('body'), {
subtree: true,
childList: true
});
这里有一个问题:这段代码非常关键且难以测试。
第一个问题是,例如在 Jest 环境中没有原生的 MutationObserver 对象。如果只是为了通过测试而简单地模拟 MutationObserver 对象测试,那么测试的意义就没有了;
其次,即使在 Headless Chrome 等支持 MutationObserver 的环境中进行测试,如果你知道它向你报告的元素的时间是正确的?既然你自己不知道确切的时间是什么(即你测试 Lee 的期望),那么 10 秒肯定是不正确的,但是 2.2 秒呢?
附加性能指标
理论上,以上两个都是我们期望采集的指标。但是我还想采集两个额外的指标:First Paint 和 First Contentful Paint,简而言之,它们记录了浏览器在绘制页面时的一些关键时刻。这两个指标也可从 Performance API 获得
window.performance.getEntries().filter(entry => entry.entryType === 'paint')
Paint Timing 将比纯粹的技术指标更接近用户体验,但我们将拭目以待,看看它与实际用户看到元素出现的情况相比如何。
后端时间
我猜有两个可能的性能瓶颈:1)Redis 查询2) MySQL 查询。
Redis主要用于会话存储,后端由Node.js + ExpressJS搭建,所以不容易监控会话读取性能。所以我优先考虑MySQL的查询性能,比如findByFolderId方法的读取性能统计:
const findFolderIdStartTime = +new Date();
await FolderService.findByFolderId(parseInt(req.params!.id))
appInsightsClient.trackMetric({
name: "APM:GET_SINGLE_FOLDER:FIND_BY_ID",
value: +new Date - findFolderIdStartTime
});
总结
最后,为了在日志平台上找到对应的指标并对指定类型的指标进行统计,我们需要对上述指标进行命名。以下是命名规则。
上一个即将结束。我已经说明了这个性能采集方案的思路,也基本实现了我们的性能采集脚本。有了这些代码,我们基本可以完成采集单条性能数据
文章采集接口(《PHP视频教程》php的api接口验证原理示意图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-21 19:36
推荐:《PHP 视频教程》
php API接口
在实际工作中,经常使用PHP编写api接口。PHP写好接口后,前台可以通过链接获取接口提供的数据,返回的数据一般分为xml和json两种情况。在这个过程中,服务器不知道请求的来源是什么,很可能是别人非法调用我们的接口获取数据,所以需要进行安全验证。
验证原理
示意图
原则
从图中可以清楚地看出,如果前台要调用接口,需要使用几个参数来生成签名。
时间戳:当前时间
随机数:随机产生的随机数
密码:前后端开发时,双方都知道的标志,相当于密码
算法规则:约定的操作规则,以上三个参数可用于生成使用算法规则的签名。
前台生成签名,当需要访问接口时,将时间戳、随机数、签名通过URL传递给后台。在后台获取时间戳和随机数后,通过相同的算法规则计算签名,然后与传递的签名进行比较,如果相同则返回数据。
算法规则
在前后端交互中,算法规则非常重要。前端和后端双方都必须通过算法规则计算签名。至于如何制定规则,就看你有多开心了。
我的算法规则是
1 时间戳、随机数、密码按字母顺序排序
2然后拼接成一个字符串
3 执行sha1加密
4 再次执行MD5加密
5 转换为大写。
前台
这里我没有实际的前台,我直接用PHP文件代替前台,然后通过CURL模拟一个GET请求。我使用的是 TP 框架,URL 格式是 pathinfo 格式。
源代码
<p> 查看全部
文章采集接口(《PHP视频教程》php的api接口验证原理示意图)
推荐:《PHP 视频教程》
php API接口
在实际工作中,经常使用PHP编写api接口。PHP写好接口后,前台可以通过链接获取接口提供的数据,返回的数据一般分为xml和json两种情况。在这个过程中,服务器不知道请求的来源是什么,很可能是别人非法调用我们的接口获取数据,所以需要进行安全验证。
验证原理
示意图
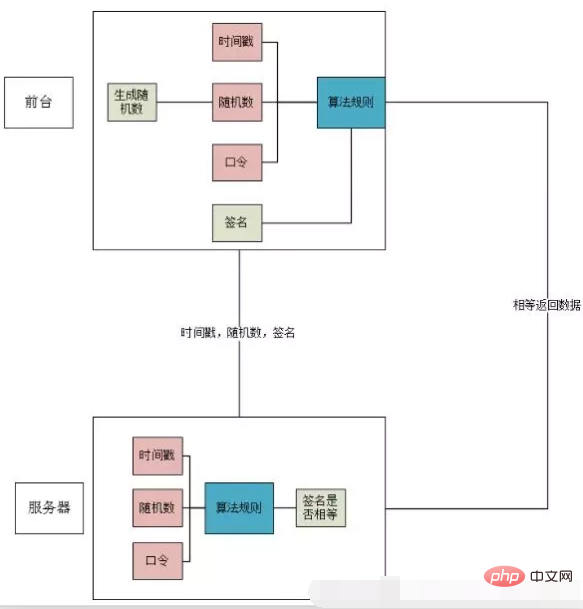
原则
从图中可以清楚地看出,如果前台要调用接口,需要使用几个参数来生成签名。
时间戳:当前时间
随机数:随机产生的随机数
密码:前后端开发时,双方都知道的标志,相当于密码
算法规则:约定的操作规则,以上三个参数可用于生成使用算法规则的签名。
前台生成签名,当需要访问接口时,将时间戳、随机数、签名通过URL传递给后台。在后台获取时间戳和随机数后,通过相同的算法规则计算签名,然后与传递的签名进行比较,如果相同则返回数据。
算法规则
在前后端交互中,算法规则非常重要。前端和后端双方都必须通过算法规则计算签名。至于如何制定规则,就看你有多开心了。
我的算法规则是
1 时间戳、随机数、密码按字母顺序排序
2然后拼接成一个字符串
3 执行sha1加密
4 再次执行MD5加密
5 转换为大写。
前台
这里我没有实际的前台,我直接用PHP文件代替前台,然后通过CURL模拟一个GET请求。我使用的是 TP 框架,URL 格式是 pathinfo 格式。
源代码
<p>
文章采集接口(个人网站提前搭建c/s架构,实现本地架构)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-21 09:05
文章采集接口:qq_users。本地ftp文件接口:itchat+github,可以用它来接入本地的github个人网站.个人网站如果放到github上的话就要提前搭建c/s架构,以下是我尝试过的两种方案:本地搭建项目,在nginx中进行so库加载,本地用百度云上传到github.本地接入nginx代理,然后利用nginx的http_header_cookie校验和验证目录来处理。
之后提交给nginx。上传文件并查询,如果支持sha256加密验证就更好了。不支持的话就用本地集成的下载工具下载到本地,然后用qq_users上传到github,中间在对接一次成功上传即可,整个过程是比较麻烦的。爬虫脚本接入,个人只使用过快递查询工具,这种方案是快递可以自己写,比较麻烦,此方案只是提供一个思路,可以自己尝试。
根据业务要求在方案中选择合适的接入方案吧。有错的话欢迎指正~总的来说,这个项目实现了一个将卖家发布的快递物流查询链接自动复制到github上,并在点击查看之后利用生成的id查询物流的目的。
qqusers,可以直接在qq浏览器的扩展菜单加载一个users的url地址,就可以实现复制。需要手动刷新浏览器。有个比较笨的办法,可以使用中国邮政的中国邮政ems的工具链,可以查询发到达有效时间,并返回在查询的时候,会跳转到手机或者服务器查询。已经使用了前两种,第三种不在手机和服务器查询的区间里。 查看全部
文章采集接口(个人网站提前搭建c/s架构,实现本地架构)
文章采集接口:qq_users。本地ftp文件接口:itchat+github,可以用它来接入本地的github个人网站.个人网站如果放到github上的话就要提前搭建c/s架构,以下是我尝试过的两种方案:本地搭建项目,在nginx中进行so库加载,本地用百度云上传到github.本地接入nginx代理,然后利用nginx的http_header_cookie校验和验证目录来处理。
之后提交给nginx。上传文件并查询,如果支持sha256加密验证就更好了。不支持的话就用本地集成的下载工具下载到本地,然后用qq_users上传到github,中间在对接一次成功上传即可,整个过程是比较麻烦的。爬虫脚本接入,个人只使用过快递查询工具,这种方案是快递可以自己写,比较麻烦,此方案只是提供一个思路,可以自己尝试。
根据业务要求在方案中选择合适的接入方案吧。有错的话欢迎指正~总的来说,这个项目实现了一个将卖家发布的快递物流查询链接自动复制到github上,并在点击查看之后利用生成的id查询物流的目的。
qqusers,可以直接在qq浏览器的扩展菜单加载一个users的url地址,就可以实现复制。需要手动刷新浏览器。有个比较笨的办法,可以使用中国邮政的中国邮政ems的工具链,可以查询发到达有效时间,并返回在查询的时候,会跳转到手机或者服务器查询。已经使用了前两种,第三种不在手机和服务器查询的区间里。
文章采集接口(修正编辑器,智能挖掘功能获取数据的错误及建议!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-21 07:27
3、修复数据分析和智能挖掘功能获取数据错误。
4、修复开启远程图片定位时FastCGI进程超过配置请求超时的问题。
5、升级404错误页面,增加多种功能。
6、修复了环境中导致 FastCGI 进程意外退出并出现 500 错误的错误。
7、优化模板工具,修复点击网页链接时模板工具跳出的问题。
8、修复部分浏览器源模板底部操作选项不显示的问题。
9、升级数据采集功能,提升365建站器的数据处理能力。
10、修复模板过多时批量get提交的错误,修改为post提交。
11、修复编辑器中ie不兼容导致上传失败的问题。
12、修复网站在没有栏目时无法发布的情况(针对宣传页的单页用户)。
13、修复获取大量列的超时问题,增加搜索同类型列的功能。
14、修复模板管理中模板过多导致批量操作超时或超时导致的404错误。
15、优化模板管理、内容管理等,新窗口打开方便用户操作。
16、新增网站管理后台选项,可以在浏览器中打开,供用户选择。
17、添加是否开启网站访问统计供用户选择。
18、修复部分页面提交后编辑器内容为空的情况。
19、新增文章库预览功能。
20、修复保存云模板工具时标签错误的问题。
21、修复用户反馈的其他问题和建议。
感谢一直陪伴365软件成长的用户,我们一直在努力让网站建设和SEO变得更简单。如果您有更好的建议,可以提交给我们。我们专注于网站的快速批量建设,使网站建设和搜索引擎优化变得简单。,支持全网数据采集。高效稳定的数据和建站产品和服务,可以为您挖掘无限的商业价值。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。 查看全部
文章采集接口(修正编辑器,智能挖掘功能获取数据的错误及建议!!)
3、修复数据分析和智能挖掘功能获取数据错误。
4、修复开启远程图片定位时FastCGI进程超过配置请求超时的问题。
5、升级404错误页面,增加多种功能。
6、修复了环境中导致 FastCGI 进程意外退出并出现 500 错误的错误。
7、优化模板工具,修复点击网页链接时模板工具跳出的问题。
8、修复部分浏览器源模板底部操作选项不显示的问题。
9、升级数据采集功能,提升365建站器的数据处理能力。
10、修复模板过多时批量get提交的错误,修改为post提交。
11、修复编辑器中ie不兼容导致上传失败的问题。
12、修复网站在没有栏目时无法发布的情况(针对宣传页的单页用户)。
13、修复获取大量列的超时问题,增加搜索同类型列的功能。
14、修复模板管理中模板过多导致批量操作超时或超时导致的404错误。
15、优化模板管理、内容管理等,新窗口打开方便用户操作。
16、新增网站管理后台选项,可以在浏览器中打开,供用户选择。
17、添加是否开启网站访问统计供用户选择。
18、修复部分页面提交后编辑器内容为空的情况。
19、新增文章库预览功能。
20、修复保存云模板工具时标签错误的问题。
21、修复用户反馈的其他问题和建议。
感谢一直陪伴365软件成长的用户,我们一直在努力让网站建设和SEO变得更简单。如果您有更好的建议,可以提交给我们。我们专注于网站的快速批量建设,使网站建设和搜索引擎优化变得简单。,支持全网数据采集。高效稳定的数据和建站产品和服务,可以为您挖掘无限的商业价值。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-19 19:03
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们的网站想象成一个房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。 查看全部
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?

网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们的网站想象成一个房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,

网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)

4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。

还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。

h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-17 23:12
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的部分。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友善度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。现场优化如TDK选择部署网站,关键词密度控制,网站内部结构是否简单合理,目录层级是否过于复杂等等,off-网站优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。 查看全部
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的部分。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?

网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友善度。而且,

网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)

3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)

4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。

还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。现场优化如TDK选择部署网站,关键词密度控制,网站内部结构是否简单合理,目录层级是否过于复杂等等,off-网站优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。


h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。

网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。
文章采集接口( Phpwind80文章中心接口(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-03-15 17:21
Phpwind80文章中心接口(组图))
Phpwind80文章中央界面用户手册 1 简介 1该界面适用于Phpwind80版本 文章中央栏目文章发布 2该界面只能使用一个发布规则指定多个栏目随机发送到不同栏目发布文章3 这个接口可以采集文章date,让文章发布更真实,见参数newstimezzhours4的说明,因为用户可能同时使用Phpwind8的多个接口时间,请注意修改界面名称使每个界面不同。比如这个interface文件夹中提供的interface文件添加了ldquocmsrdquo 5的文件名后缀,发布时请使用具有文章中央管理权限的用户帐号。6. 在 Phpwind80utf8 版本中使用该接口时,请在发布规则中选择编码为 UTF-87。本界面基于Phpwind80GBK版本。适用于Phpwind80GBKutf-8等版本。请测试并调整 8 接口文件,不要做任何更改。如需添加验证或其他功能,请谨慎修改92接口文件,请到Phpwind80官网复制
使用站点根目录下的第二个安装界面,在interface文件夹中找到interface文件。请将etck_cmsphpetpost_cmsphp等接口文件上传到指定目录。请以二进制方式上传如图3 配置发布规则1 将示例发布规则文本导入ET2发布配置或使用软件内置发布规则示例如图2 更改check URL中的ldquo和网站rdquo 要发布的 URL 的发布 URL 如图 3,在勾选 URL 上填写您要发布的 文章 中心列 ID 文章@ 的中心列 ID > 可以用英文逗号隔开的倍数填写。将鼠标移动到列名上,可以在状态栏中查看列 ID。填写您的帐户密码。注意格式和账号权限如图4。 接口说明 1 查看接口 1. 接口文件名etck_cmsphp 属于机密,请自行修改文件名。2.这个接口文件复制到网站根目录下使用。_主题文章标题
cid 列 ID 用于限制该规则的检查列。您可以填写多种逗号分隔或空白格式。例如,可以在 文章 中心查看 cid789。修改vercode使其一致 4 发布配置 - 文章检查URL可以填写如下 http 你的URL etchk_cmsphpcms_subjectlttitlegtampcid 你的列ID 注意 使用区分大小写的服务器用户 请注意URL 的大小写与 网站 文件相同。5、界面文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改。二、发帖界面 1、界面文件名 etpost_cmsphp 为机密请自行修改文件名。请将该接口文件复制到网站的根目录下使用。请自行修改文件名。value的参数可以在发布规则中设置-parameter value 采集 value的参数
几项请添加3个主要参数 pwuser 成员名 参数名 pwpwd 密码 参数名 cms_subject 主题标题 参数名 atc_content 内容参数名 进行手动内容分页,请使用数据排序到 内容分隔标记 ldquo-0 -rdquo 替换为 Phpwind8 的分页标记 [page] 自动分页参数见后面。防止接口被他人使用。如需进一步验证,请自行填写相关代码。5 可选参数 Newstime文章 日期格式要正确。@>_descript 摘要留空会自动摘要cms_jumpurl 跳转链接cms_author 原作者cms_frominfo letter
信息来源cms_fromurl如果要使用来源URL,请填写下图中的post配置6-文章post URL可以填写http你的URL etpost_cmsphp注意 使用区分大小写的服务器用户,请注意 URL 的大小写与 网站 文件的大小写相同。7 接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改。查看返回信息了解错误详情,以便更正返回信息窗口如图1 [err] 账号密码错误[err]1 查看发布规则-参数值-账号密码队列2[err]invalidvercode[err ]1在发布规则-检查URL填写的vercode值与检查接口文件中的vercode值不一致。2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致。3[err]cms 采集_subjectisnull[err]1 使用的规则未能 采集 到标题 2
采集规则的数据整理过滤了标题 3.错误修改了发布规则-发布项中的标题参数名称正确。请参考本文的接口说明部分。4. 发布规则没有开启utf-8编码转换 4[err] 内容不能为空[err] 1 使用的采集规则不正确采集到文本数据项2采集 过滤规则数据和过滤文本数据 3 错误修改发布规则 - 发布项中的文本参数名称正确。请参考接口说明第4节。发布规则不启用utf-8编码转换。文章 查看全部
文章采集接口(
Phpwind80文章中心接口(组图))

Phpwind80文章中央界面用户手册 1 简介 1该界面适用于Phpwind80版本 文章中央栏目文章发布 2该界面只能使用一个发布规则指定多个栏目随机发送到不同栏目发布文章3 这个接口可以采集文章date,让文章发布更真实,见参数newstimezzhours4的说明,因为用户可能同时使用Phpwind8的多个接口时间,请注意修改界面名称使每个界面不同。比如这个interface文件夹中提供的interface文件添加了ldquocmsrdquo 5的文件名后缀,发布时请使用具有文章中央管理权限的用户帐号。6. 在 Phpwind80utf8 版本中使用该接口时,请在发布规则中选择编码为 UTF-87。本界面基于Phpwind80GBK版本。适用于Phpwind80GBKutf-8等版本。请测试并调整 8 接口文件,不要做任何更改。如需添加验证或其他功能,请谨慎修改92接口文件,请到Phpwind80官网复制

使用站点根目录下的第二个安装界面,在interface文件夹中找到interface文件。请将etck_cmsphpetpost_cmsphp等接口文件上传到指定目录。请以二进制方式上传如图3 配置发布规则1 将示例发布规则文本导入ET2发布配置或使用软件内置发布规则示例如图2 更改check URL中的ldquo和网站rdquo 要发布的 URL 的发布 URL 如图 3,在勾选 URL 上填写您要发布的 文章 中心列 ID 文章@ 的中心列 ID > 可以用英文逗号隔开的倍数填写。将鼠标移动到列名上,可以在状态栏中查看列 ID。填写您的帐户密码。注意格式和账号权限如图4。 接口说明 1 查看接口 1. 接口文件名etck_cmsphp 属于机密,请自行修改文件名。2.这个接口文件复制到网站根目录下使用。_主题文章标题

cid 列 ID 用于限制该规则的检查列。您可以填写多种逗号分隔或空白格式。例如,可以在 文章 中心查看 cid789。修改vercode使其一致 4 发布配置 - 文章检查URL可以填写如下 http 你的URL etchk_cmsphpcms_subjectlttitlegtampcid 你的列ID 注意 使用区分大小写的服务器用户 请注意URL 的大小写与 网站 文件相同。5、界面文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改。二、发帖界面 1、界面文件名 etpost_cmsphp 为机密请自行修改文件名。请将该接口文件复制到网站的根目录下使用。请自行修改文件名。value的参数可以在发布规则中设置-parameter value 采集 value的参数

几项请添加3个主要参数 pwuser 成员名 参数名 pwpwd 密码 参数名 cms_subject 主题标题 参数名 atc_content 内容参数名 进行手动内容分页,请使用数据排序到 内容分隔标记 ldquo-0 -rdquo 替换为 Phpwind8 的分页标记 [page] 自动分页参数见后面。防止接口被他人使用。如需进一步验证,请自行填写相关代码。5 可选参数 Newstime文章 日期格式要正确。@>_descript 摘要留空会自动摘要cms_jumpurl 跳转链接cms_author 原作者cms_frominfo letter

信息来源cms_fromurl如果要使用来源URL,请填写下图中的post配置6-文章post URL可以填写http你的URL etpost_cmsphp注意 使用区分大小写的服务器用户,请注意 URL 的大小写与 网站 文件的大小写相同。7 接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改。查看返回信息了解错误详情,以便更正返回信息窗口如图1 [err] 账号密码错误[err]1 查看发布规则-参数值-账号密码队列2[err]invalidvercode[err ]1在发布规则-检查URL填写的vercode值与检查接口文件中的vercode值不一致。2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致。3[err]cms 采集_subjectisnull[err]1 使用的规则未能 采集 到标题 2

采集规则的数据整理过滤了标题 3.错误修改了发布规则-发布项中的标题参数名称正确。请参考本文的接口说明部分。4. 发布规则没有开启utf-8编码转换 4[err] 内容不能为空[err] 1 使用的采集规则不正确采集到文本数据项2采集 过滤规则数据和过滤文本数据 3 错误修改发布规则 - 发布项中的文本参数名称正确。请参考接口说明第4节。发布规则不启用utf-8编码转换。文章
文章采集接口(小说CMS网站内容更新时要注意的事项有哪些呢? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2022-03-15 09:10
)
小说cms系统现在比较流行,比如奇文cms、狂雨cms和杰基cms。无论选择哪一个cms,作为小说站,优质内容是留住用户的核心法宝。优质的网站内容对于用户体验和提升网站权重的重要性,相信每一个从事网站优化的SEOER都心知肚明。
小说cms网站内容的高质量更新应该是我们网站的基础。毕竟,优质的网站文章不仅是网站优化的基本要素,也是提升网站排名和权重的关键因素。
但是,更新小说的内容很重要cms网站,但是如果采用不合理的更新方式,忽略了用户体验或者违反了搜索引擎的相关规则,内容网站 的高质量更新不会有很好的效果。下面我们来简单的看一下更新网站的内容需要注意的事项。
1、保证文章高度原创
蜘蛛喜欢具有新奇内容和原创特征的东西。当网站内容高度原创,更新及时,内容丰富,更有利于给用户带来良好的体验,从而留住用户。但这对于大多数站长来说也是一个难题,因为文章不一定有很多要求,需要技巧,但是优秀的文章的写作往往并不容易。对此,站长们不妨把精品文章做得合适伪原创,但要确保它有价值。
2、掌握关键词或长尾词的密度
不管是哪种文章内容,为了提高相关性,要求我们的文章中必须有关键词或者长尾词。但是我们也不能过度堆叠关键词或者长尾词,因为这样会让蜘蛛认为它在作弊,并且会减少我们的网站的权重。网站在优化内容时,要合理安排关键词的出现次数。
3、网站关键词内部链接
在优化网站的内容时,可以在网站中设置关键词内链,不仅可以降低网站的跳出率,还能带来更好的交互给用户体验也可以集中权重,方便网站权重的提升。
4、网站 内容图片的优化
图文结合是一种比较常见的显示网站内容的方式。图文结合可以更好的吸引用户浏览网页,通过视觉效果减轻疲劳,同时让用户更深入的了解 同时,带标签的图形页面更有可能被蜘蛛收录。
对于小说cms网站的内容优化,可以提升我们网站的排名,吸引更多流量,实现良性循环。我们良性循环的前提是不断优化网站,保持网站内容的高质量更新。
对于机械的重复性工作,我们往往可以借助工具来实现。与网站采集的发布一样,Novelcms也有自己的采集插件,支持24小时挂机,实时捕捉热门新鲜内容. 发布功能支持各种cms,是我们管理网站的好帮手,新颖的cms采集插件也有SEO功能。关键词增加关键词标题的密度,在我们要发布的内容中插入内容。支持图片替换和图片水印,大大提高了我们的文章原创度。支持准时发布,提升爬虫爬取能力。
小说cms网站的内容优化是网站SEO工作的重要组成部分,避免在优化内容时出现一定的失误。会给网站带来好的收录数据和权重,也会受到蜘蛛的青睐,获得好的排名,实现网站的良性循环。
查看全部
文章采集接口(小说CMS网站内容更新时要注意的事项有哪些呢?
)
小说cms系统现在比较流行,比如奇文cms、狂雨cms和杰基cms。无论选择哪一个cms,作为小说站,优质内容是留住用户的核心法宝。优质的网站内容对于用户体验和提升网站权重的重要性,相信每一个从事网站优化的SEOER都心知肚明。

小说cms网站内容的高质量更新应该是我们网站的基础。毕竟,优质的网站文章不仅是网站优化的基本要素,也是提升网站排名和权重的关键因素。
但是,更新小说的内容很重要cms网站,但是如果采用不合理的更新方式,忽略了用户体验或者违反了搜索引擎的相关规则,内容网站 的高质量更新不会有很好的效果。下面我们来简单的看一下更新网站的内容需要注意的事项。
1、保证文章高度原创
蜘蛛喜欢具有新奇内容和原创特征的东西。当网站内容高度原创,更新及时,内容丰富,更有利于给用户带来良好的体验,从而留住用户。但这对于大多数站长来说也是一个难题,因为文章不一定有很多要求,需要技巧,但是优秀的文章的写作往往并不容易。对此,站长们不妨把精品文章做得合适伪原创,但要确保它有价值。
2、掌握关键词或长尾词的密度
不管是哪种文章内容,为了提高相关性,要求我们的文章中必须有关键词或者长尾词。但是我们也不能过度堆叠关键词或者长尾词,因为这样会让蜘蛛认为它在作弊,并且会减少我们的网站的权重。网站在优化内容时,要合理安排关键词的出现次数。
3、网站关键词内部链接
在优化网站的内容时,可以在网站中设置关键词内链,不仅可以降低网站的跳出率,还能带来更好的交互给用户体验也可以集中权重,方便网站权重的提升。
4、网站 内容图片的优化
图文结合是一种比较常见的显示网站内容的方式。图文结合可以更好的吸引用户浏览网页,通过视觉效果减轻疲劳,同时让用户更深入的了解 同时,带标签的图形页面更有可能被蜘蛛收录。
对于小说cms网站的内容优化,可以提升我们网站的排名,吸引更多流量,实现良性循环。我们良性循环的前提是不断优化网站,保持网站内容的高质量更新。
对于机械的重复性工作,我们往往可以借助工具来实现。与网站采集的发布一样,Novelcms也有自己的采集插件,支持24小时挂机,实时捕捉热门新鲜内容. 发布功能支持各种cms,是我们管理网站的好帮手,新颖的cms采集插件也有SEO功能。关键词增加关键词标题的密度,在我们要发布的内容中插入内容。支持图片替换和图片水印,大大提高了我们的文章原创度。支持准时发布,提升爬虫爬取能力。
小说cms网站的内容优化是网站SEO工作的重要组成部分,避免在优化内容时出现一定的失误。会给网站带来好的收录数据和权重,也会受到蜘蛛的青睐,获得好的排名,实现网站的良性循环。

文章采集接口( 《详聊微服务观测》系列文章:Telegraf架构设计并发编程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-04 08:21
《详聊微服务观测》系列文章:Telegraf架构设计并发编程)
作者|蒋明明
来源|二达公众号
简介:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一个《微服务详解》系列文章,深入APM系统产品、架构设计和基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件的实现方法。
《详解微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一款非常流行的指标采集 软件,在 GiHub 拥有数万个 Star。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了所有监控项,例如机器监控、服务监控甚至硬件监控.
架构设计流水线并发编程
在 Go 中,流水线并发编程模式是一种常用的并发编程模式。简单来说,它由一系列stage组成,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过channel连接。
在每个阶段,goroutine 负责以下工作:
通过入口通道,接收上游阶段产生的数据。处理数据,如格式转换、数据过滤聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,每个阶段都同时有一个或多个出口和入口通道,但第一阶段和最后阶段除外,它们分别只有出口通道和入口通道。
Telegraf 中的实现
Telegraf 采用这种编程模式,主要有 4 个阶段,即 Inputs、Processor、Aggregators 和 Outputs。
并且它们之间也是通过通道相互链接的,它们的架构图如下:
可以看出,它整体采用了流水线并发编程模式。下面简单介绍一下它的运行机制:
扇入:多个函数向一个通道输出数据,一个函数读取通道直到关闭。
扇出:多个函数读取同一个通道,直到它被关闭。
插件设计
Telegraf 有这么多的输入、输出和处理器插件,那么它如何有效地管理这些插件呢?以及如何设计插件系统来应对激增的扩容需求?别着急,请允许我详细说明。
其实这里的插件并不是通常意义上的插件(即在运行时动态加载和绑定动态链接库),而是基于工厂模式的一种变体。首先我们看一下Telegraf的插件目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是有规律的(下面我们都以Inputs的Plug-in为例,其他模块实现类似)。
查看全部
文章采集接口(
《详聊微服务观测》系列文章:Telegraf架构设计并发编程)
作者|蒋明明
来源|二达公众号
简介:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一个《微服务详解》系列文章,深入APM系统产品、架构设计和基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件的实现方法。
《详解微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一款非常流行的指标采集 软件,在 GiHub 拥有数万个 Star。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了所有监控项,例如机器监控、服务监控甚至硬件监控.
架构设计流水线并发编程
在 Go 中,流水线并发编程模式是一种常用的并发编程模式。简单来说,它由一系列stage组成,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过channel连接。
在每个阶段,goroutine 负责以下工作:
通过入口通道,接收上游阶段产生的数据。处理数据,如格式转换、数据过滤聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,每个阶段都同时有一个或多个出口和入口通道,但第一阶段和最后阶段除外,它们分别只有出口通道和入口通道。
Telegraf 中的实现
Telegraf 采用这种编程模式,主要有 4 个阶段,即 Inputs、Processor、Aggregators 和 Outputs。
并且它们之间也是通过通道相互链接的,它们的架构图如下:
可以看出,它整体采用了流水线并发编程模式。下面简单介绍一下它的运行机制:
扇入:多个函数向一个通道输出数据,一个函数读取通道直到关闭。
扇出:多个函数读取同一个通道,直到它被关闭。
插件设计
Telegraf 有这么多的输入、输出和处理器插件,那么它如何有效地管理这些插件呢?以及如何设计插件系统来应对激增的扩容需求?别着急,请允许我详细说明。
其实这里的插件并不是通常意义上的插件(即在运行时动态加载和绑定动态链接库),而是基于工厂模式的一种变体。首先我们看一下Telegraf的插件目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是有规律的(下面我们都以Inputs的Plug-in为例,其他模块实现类似)。
文章采集接口(平台数据采集趋于稳定的技术介绍及技术设计 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-03 00:21
)
这段时间一直在处理data采集的问题。目前平台数据采集已经稳定。大家可以花点时间整理一下最近的成果,介绍一些最近使用的技术。本文文章以技术为主,要求读者有一定的技术基础。主要介绍数据采集过程中用到的神器mitmproxy,以及平台的一些技术设计。下面是数据采集的整体设计,左边是客户端,放着不同的采集器。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回。传输完成后,由中间解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间加了一个缓存,把采集器和解析器分开,在两个模块之间工作。在不相互影响的情况下,可以最大限度地存储数据。下图为第一代架构设计。会有一篇文章文章介绍平台架构设计的三代演进史。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据 查看全部
文章采集接口(平台数据采集趋于稳定的技术介绍及技术设计
)
这段时间一直在处理data采集的问题。目前平台数据采集已经稳定。大家可以花点时间整理一下最近的成果,介绍一些最近使用的技术。本文文章以技术为主,要求读者有一定的技术基础。主要介绍数据采集过程中用到的神器mitmproxy,以及平台的一些技术设计。下面是数据采集的整体设计,左边是客户端,放着不同的采集器。采集器发起请求后,通过mitmproxy访问抖音,等待数据返回。传输完成后,由中间解析器解析数据,最后以不同的类别存储在数据库中。为了提高性能,中间加了一个缓存,把采集器和解析器分开,在两个模块之间工作。在不相互影响的情况下,可以最大限度地存储数据。下图为第一代架构设计。会有一篇文章文章介绍平台架构设计的三代演进史。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据
文章采集接口(自己制作接口程序或是修改原来的程序是自己开发的,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-02 13:17
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作原理。接口就是接口提交的数据优采云采集器。优采云采集器提交数据很简单,就是用来接收post数据的。这个和表单接收没有关系比如程序提交一个参数title,值为“this is the title”,asp可以使用request。form("title") 接收和使用它。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们可以通过自己的网站程序直接将内容发布到网站。然后我们将 target 这个函数可以自己制作界面程序或者修改原程序。如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。可以直接编写程序或修改原程序,将接收到的数据保存在服务器数据库中。如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够顺利处理数据。这部分具体操作由你自己决定。接口的安全性一般是可以直接post数据的接口。为了防止其他人使用该接口,您应该为其添加密码。可以给模块加一个参数,比如密码,给一个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的产生与 优采云采集器 关系不大,只有收到数据时才连接,其他时候就是写程序自己满足自己的要求,这也算是技术人员对@网站功能的一种扩展开发。可以说你可以对接收到的数据进行任何处理,从而满足你的网站 数据处理要求。特胡彦涵 查看全部
文章采集接口(自己制作接口程序或是修改原来的程序是自己开发的,)
优采云采集器外部接口制作规范这里的外部接口是自己制作的,用于接收和处理优采云采集器网站程序提交的数据.使用它可以避免一些直接用网站在后台直接发布数据的繁琐验证方法。可以达到一次性配置永久使用的效果。下面我们将介绍具体的制作方法和技巧。接口制作原理。接口就是接口提交的数据优采云采集器。优采云采集器提交数据很简单,就是用来接收post数据的。这个和表单接收没有关系比如程序提交一个参数title,值为“this is the title”,asp可以使用request。form("title") 接收和使用它。php 使用 $_POST['title'] 来获取这个值。数据处理。首先这里要明确接口的作用,比如发布一个文章。我们可以通过自己的网站程序直接将内容发布到网站。然后我们将 target 这个函数可以自己制作界面程序或者修改原程序。如果你要制作界面的程序是你自己开发的,那么你必须非常清楚你需要输入哪些数据,以及如何处理接收到的数据。可以直接编写程序或修改原程序,将接收到的数据保存在服务器数据库中。如果您使用的是别人开发的程序,那么您需要对原程序进行修改,使其能够顺利处理数据。这部分具体操作由你自己决定。接口的安全性一般是可以直接post数据的接口。为了防止其他人使用该接口,您应该为其添加密码。可以给模块加一个参数,比如密码,给一个值,然后在程序端验证。如果不是您设置的值,访问将被拒绝。从上面的描述可以看出,这个接口的产生与 优采云采集器 关系不大,只有收到数据时才连接,其他时候就是写程序自己满足自己的要求,这也算是技术人员对@网站功能的一种扩展开发。可以说你可以对接收到的数据进行任何处理,从而满足你的网站 数据处理要求。特胡彦涵
文章采集接口(恒生集团文章采集接口接入平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-01 01:00
文章采集接口是指通过采集第三方接口或者平台相关信息来获取数据的接口接口能接入的工具太多了,并且,在数据搜集中,接口对于应用的开发来说也是最基础的,接口能接入的工具很多,就像程序员开发软件一样,需要找到集成工具,才能使软件开发起来,写出有用的代码;即使是开发软件的程序员也需要从零开始,亲自去摸索、钻研等,所以说接口接入也是很有学问的!比如下载网站上有很多的接口,但是如果我们不提供接口调用入口,我们会在找第三方网站的时候就没有办法,想要实现api调用就更难了所以,接口对于数据调取工具来说非常重要,现在市面上很多的数据接口平台都可以实现接口接入工具,但是有的接口平台对接口需要审核,有的需要上架,有的没有上架,我这里推荐站友参考一下的平台。
陆金所网址:www.yujin_cn一起作图一起作图是专业的接口接入平台,接口主要涉及广告展示,爬虫抓取,会员充值,竞拍与竞价,积分商城等,在接口获取方面相对其他的平台已经要容易多了;电商平台与金融理财平台接入任何一家平台的都需要自己审核,审核不通过难以通过调用,审核不通过就更别想接入。羊毛平台有很多都不能接入的,并且羊毛平台本身不是做广告,并且羊毛平台的接口调用点也是非常局限的。
恒生集团网址:恒生集团是从电子电路设计、集成电路设计制造及新能源半导体研发、测试等环节全面布局的国际化集团,拥有全球最大的广义半导体研发生产基地和行业优势公司。旗下网站还有广西北海交易所、深圳证券交易所等,恒生集团主要通过集成电路制造为主营业务收入,与微软、百度等全球企业有实时合作协议。
恒生集团有着实力强大的研发优势,包括布局个人和大中型企业,为客户提供一站式的市场解决方案;恒生集团覆盖了证券交易、it,保险,信托,基金、银行、黄金、保险等金融领域。恒瑞集团网址:恒瑞集团是亚洲电子、医药健康、信息科技产业为代表的三大金融集团之一,主要致力于生物和能源领域的战略投资并组建并运营着it部门,先后控股了美国能源部、中国政府综合信息管理中心、韩国高新科技实验室等全球。
集团资产总规模超过4000亿人民币,员工近1.4万人,拥有中国及全球约15%的主要大型国际企业、上市公司、上市公司员工、自然人股东。恒瑞集团通过各种投资和业务转移来帮助提高公司信息化水平,同时加强对全球一流基础设施的投资。百川数据网址:百川数据可接入的项目有:摄像头拍摄的天。 查看全部
文章采集接口(恒生集团文章采集接口接入平台)
文章采集接口是指通过采集第三方接口或者平台相关信息来获取数据的接口接口能接入的工具太多了,并且,在数据搜集中,接口对于应用的开发来说也是最基础的,接口能接入的工具很多,就像程序员开发软件一样,需要找到集成工具,才能使软件开发起来,写出有用的代码;即使是开发软件的程序员也需要从零开始,亲自去摸索、钻研等,所以说接口接入也是很有学问的!比如下载网站上有很多的接口,但是如果我们不提供接口调用入口,我们会在找第三方网站的时候就没有办法,想要实现api调用就更难了所以,接口对于数据调取工具来说非常重要,现在市面上很多的数据接口平台都可以实现接口接入工具,但是有的接口平台对接口需要审核,有的需要上架,有的没有上架,我这里推荐站友参考一下的平台。
陆金所网址:www.yujin_cn一起作图一起作图是专业的接口接入平台,接口主要涉及广告展示,爬虫抓取,会员充值,竞拍与竞价,积分商城等,在接口获取方面相对其他的平台已经要容易多了;电商平台与金融理财平台接入任何一家平台的都需要自己审核,审核不通过难以通过调用,审核不通过就更别想接入。羊毛平台有很多都不能接入的,并且羊毛平台本身不是做广告,并且羊毛平台的接口调用点也是非常局限的。
恒生集团网址:恒生集团是从电子电路设计、集成电路设计制造及新能源半导体研发、测试等环节全面布局的国际化集团,拥有全球最大的广义半导体研发生产基地和行业优势公司。旗下网站还有广西北海交易所、深圳证券交易所等,恒生集团主要通过集成电路制造为主营业务收入,与微软、百度等全球企业有实时合作协议。
恒生集团有着实力强大的研发优势,包括布局个人和大中型企业,为客户提供一站式的市场解决方案;恒生集团覆盖了证券交易、it,保险,信托,基金、银行、黄金、保险等金融领域。恒瑞集团网址:恒瑞集团是亚洲电子、医药健康、信息科技产业为代表的三大金融集团之一,主要致力于生物和能源领域的战略投资并组建并运营着it部门,先后控股了美国能源部、中国政府综合信息管理中心、韩国高新科技实验室等全球。
集团资产总规模超过4000亿人民币,员工近1.4万人,拥有中国及全球约15%的主要大型国际企业、上市公司、上市公司员工、自然人股东。恒瑞集团通过各种投资和业务转移来帮助提高公司信息化水平,同时加强对全球一流基础设施的投资。百川数据网址:百川数据可接入的项目有:摄像头拍摄的天。
文章采集接口(聚合采集可以自定义采集规则的seo文章采集器采集程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-30 17:05
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。
聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性
将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。
聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。
<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升 查看全部
文章采集接口(聚合采集可以自定义采集规则的seo文章采集器采集程序
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。
聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性
将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。
聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。
<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升
文章采集接口( 一个写的python不能不能用了,原因是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-27 21:19
一个写的python不能不能用了,原因是什么?)
昨天想去Geek Time把我买的一个专栏里的数据拿起来,发现之前写的python脚本不能用了。原因是他们 网站 做了电流限制,并添加了一些对 http 时间戳的验证。. 我们可以改进之前的python脚本,使用ip代理池来处理限流,找到时间戳校验的规则。
但是这次我们使用了另一种爬虫思路,就是直接写一些js脚本,在对方的网站中运行,请求对应的接口获取想要的数据。
事实上,我见过很多这种想法的例子。有一个很流行的脚本自动点赞QQ空间。看了它的源码,其实很简单。就是直接操作dom,然后触发一些事件。
另一个很流行的例子,github上一个很流行的repo,fuck知乎,据说是winter退休时写的知乎,数据保存在知乎中。
以下是本次实践的内容:
获取 文章id 集合
第一次进列的时候会有一个请求获取左边的列表集合文章。在这个界面中,我们可以获取当前列的所有请求。
本栏目有50多篇文章文章,由于限流,我们分成了两个请求。
注入 FileSaver.js
FileSaver 是一个在浏览器中运行并将数据下载为 json 或 excel 文件的库。
这里我们创建一个脚本标签并将这个标签插入到文档中。
我这里写了一个方法downloadJson,我们将这里得到的数据传递过来,我们就可以下载json文件了。
创建请求
创建一个 ajax 请求以请求接口以获取 文章 详细信息。
这里我们使用原生js来写,是一个post请求,res是我们从这个接口得到的返回值,我们可以从这个返回值中取我们需要的数据。
以上是单个请求的实现。多个请求的实现如下图所示。
然后我们保存数据:
所有结果都放在 rs 数组中。
下载数据
我们把所有的数据放到一个数组中,在最后一个请求的最后,执行我们写的downloadJson方法下载下来。
导入数据库
网上有很多工具可以将json文件导入数据库。这次我使用了我之前写的脚本。
这个脚本在我的github上,用nodejs写的,地址:tomysql.js
最后
这一次,我们没有使用常见的做法,模拟一个请求,或者模拟一个浏览器,而是直接使用浏览器来采集data。当然,我们也需要根据实际情况选择使用哪种方法。
完整脚本:geek.js 查看全部
文章采集接口(
一个写的python不能不能用了,原因是什么?)
昨天想去Geek Time把我买的一个专栏里的数据拿起来,发现之前写的python脚本不能用了。原因是他们 网站 做了电流限制,并添加了一些对 http 时间戳的验证。. 我们可以改进之前的python脚本,使用ip代理池来处理限流,找到时间戳校验的规则。
但是这次我们使用了另一种爬虫思路,就是直接写一些js脚本,在对方的网站中运行,请求对应的接口获取想要的数据。
事实上,我见过很多这种想法的例子。有一个很流行的脚本自动点赞QQ空间。看了它的源码,其实很简单。就是直接操作dom,然后触发一些事件。
另一个很流行的例子,github上一个很流行的repo,fuck知乎,据说是winter退休时写的知乎,数据保存在知乎中。
以下是本次实践的内容:
获取 文章id 集合
第一次进列的时候会有一个请求获取左边的列表集合文章。在这个界面中,我们可以获取当前列的所有请求。
本栏目有50多篇文章文章,由于限流,我们分成了两个请求。
注入 FileSaver.js
FileSaver 是一个在浏览器中运行并将数据下载为 json 或 excel 文件的库。
这里我们创建一个脚本标签并将这个标签插入到文档中。
我这里写了一个方法downloadJson,我们将这里得到的数据传递过来,我们就可以下载json文件了。
创建请求
创建一个 ajax 请求以请求接口以获取 文章 详细信息。
这里我们使用原生js来写,是一个post请求,res是我们从这个接口得到的返回值,我们可以从这个返回值中取我们需要的数据。
以上是单个请求的实现。多个请求的实现如下图所示。
然后我们保存数据:
所有结果都放在 rs 数组中。
下载数据
我们把所有的数据放到一个数组中,在最后一个请求的最后,执行我们写的downloadJson方法下载下来。
导入数据库
网上有很多工具可以将json文件导入数据库。这次我使用了我之前写的脚本。
这个脚本在我的github上,用nodejs写的,地址:tomysql.js
最后
这一次,我们没有使用常见的做法,模拟一个请求,或者模拟一个浏览器,而是直接使用浏览器来采集data。当然,我们也需要根据实际情况选择使用哪种方法。
完整脚本:geek.js
文章采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2022-03-27 21:18
今天分享“DiscuzX3.4论坛优采云采集器免登录发布接口模块(可测试)”,可以复制以下百度云地址下载,该接口为个人测试,压缩包是未加密的,可以直接使用,并且我们附上了本文的使用教程文章,适合DZ论坛网站的资源采集,好了,大家按照下面的流程操作。
下载链接:提取码:e9xk
解压后看到的文件有:
其中,discussX3.0.wpm为发布模块,dz测试接口。ljobx 是用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:
这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password,也就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
主题:对应论坛的标题
message:对应帖子的主题和回复的内容,这两部分放在一起
fid:对应section ID
signature:发送方和响应方的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们可以按照上图选择这个,然后点击“修改表单值”,这里设置表单值为空如图以下:
然后用同样的方法来处理我们的其他表格,如下图。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
界面注册的用户名和密码设置,打开界面:
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位。上图中用户密码下方是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
意思就是我们创建一个名为fname的标签,如果采集为“section 1”,那么在1的section中发布对应的section id,这个可以根据自己的论坛版块修改,下面的typname是也同理,这样设置的好处是不需要设置category id直接自动对应section名和topic分类名。
好了,今天的“DZ优采云采集发布模块”就解释到这里了,其实网站采集大家比较熟悉,虽然上面写着采集这个网站很容易被降级。我不建议将新站点直接带到 采集,也不建议该站点使用 采集 数据不断更新。但是,采集一些必要的资源仍然可用。网站主要内容还是要以“优质文章”为主,给百度一个好印象,更有利于网站整体排名提升。 查看全部
文章采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
今天分享“DiscuzX3.4论坛优采云采集器免登录发布接口模块(可测试)”,可以复制以下百度云地址下载,该接口为个人测试,压缩包是未加密的,可以直接使用,并且我们附上了本文的使用教程文章,适合DZ论坛网站的资源采集,好了,大家按照下面的流程操作。
下载链接:提取码:e9xk
解压后看到的文件有:
其中,discussX3.0.wpm为发布模块,dz测试接口。ljobx 是用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:
这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password,也就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
主题:对应论坛的标题
message:对应帖子的主题和回复的内容,这两部分放在一起
fid:对应section ID
signature:发送方和响应方的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们可以按照上图选择这个,然后点击“修改表单值”,这里设置表单值为空如图以下:
然后用同样的方法来处理我们的其他表格,如下图。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
界面注册的用户名和密码设置,打开界面:
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位。上图中用户密码下方是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
意思就是我们创建一个名为fname的标签,如果采集为“section 1”,那么在1的section中发布对应的section id,这个可以根据自己的论坛版块修改,下面的typname是也同理,这样设置的好处是不需要设置category id直接自动对应section名和topic分类名。
好了,今天的“DZ优采云采集发布模块”就解释到这里了,其实网站采集大家比较熟悉,虽然上面写着采集这个网站很容易被降级。我不建议将新站点直接带到 采集,也不建议该站点使用 采集 数据不断更新。但是,采集一些必要的资源仍然可用。网站主要内容还是要以“优质文章”为主,给百度一个好印象,更有利于网站整体排名提升。
文章采集接口(中国aliyuncs的服务器制作流程及使用方法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-26 19:06
文章采集接口主要有:的“#”,和,其他相关的还有:chinadaily类型(可以搜索全球任意一天)、xinyouku类型(可以搜索全国所有网站)、yanhui类型(可以搜索全球所有地点)。分析如下:,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。
,我将图片地址抓取到并发送给阿里巴巴的服务器。,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。这些都发送给aliyuncs的服务器上。同时该服务器上会在短期内产生8000万图片需要分析,这批图片需要集中下载到集中存储平台上去。所以aliyuncs的服务器要保证8000万图片下载的速度。
,我将一批图片地址抓取到并发送给阿里巴巴的服务器。和等等,这些都是需要图片地址。同时facebook和google等互联网公司这些图片的地址是发送给aliyuncs的服务器。的服务器,你找不到我,我没有那么多aliyuncs的服务器,我主要就是中国aliyuncs的服务器。
aliyuncs的服务器,你找不到我,我的语言是中文。那么我找不到你,我就将这8000万图片地址搜集好,比如中国的aliyuncs上所有图片地址全部下载下来,发送给你。的服务器,你找不到我,我不是还有美国主机嘛,而且我的主机速度比你的主机还快。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。
所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。当我第一时间找到你并用你的图片地址下载的时候,你说:”你这是什么意思?“对不起,我在中国你在美国,你需要一天才能找到我,我需要八小时。也就是说你就得等八小时我才能找到你。 查看全部
文章采集接口(中国aliyuncs的服务器制作流程及使用方法(一))
文章采集接口主要有:的“#”,和,其他相关的还有:chinadaily类型(可以搜索全球任意一天)、xinyouku类型(可以搜索全国所有网站)、yanhui类型(可以搜索全球所有地点)。分析如下:,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。
,我将图片地址抓取到并发送给阿里巴巴的服务器。,我将采集的图片地址抓取到并发送给阿里巴巴的服务器。这些都发送给aliyuncs的服务器上。同时该服务器上会在短期内产生8000万图片需要分析,这批图片需要集中下载到集中存储平台上去。所以aliyuncs的服务器要保证8000万图片下载的速度。
,我将一批图片地址抓取到并发送给阿里巴巴的服务器。和等等,这些都是需要图片地址。同时facebook和google等互联网公司这些图片的地址是发送给aliyuncs的服务器。的服务器,你找不到我,我没有那么多aliyuncs的服务器,我主要就是中国aliyuncs的服务器。
aliyuncs的服务器,你找不到我,我的语言是中文。那么我找不到你,我就将这8000万图片地址搜集好,比如中国的aliyuncs上所有图片地址全部下载下来,发送给你。的服务器,你找不到我,我不是还有美国主机嘛,而且我的主机速度比你的主机还快。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。
所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。所以我能够第一时间找到你,我没有那么多aliyuncs的服务器,但我主要的语言是中文。当我第一时间找到你并用你的图片地址下载的时候,你说:”你这是什么意思?“对不起,我在中国你在美国,你需要一天才能找到我,我需要八小时。也就是说你就得等八小时我才能找到你。
文章采集接口( jiekou.php,修改:就是上图是用于测试的规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-25 01:01
jiekou.php,修改:就是上图是用于测试的规则)
解压后看到的文件有:
其中,discussX3.0.wpm为发布模块,dz test interface.ljobx为用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:
这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password。这个密码就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
subject : 对应论坛的标题
message : 对应发帖的主题和回复的内容,这两部分放在一起
fid : 对应于section ID
signature :发送者和响应者的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid :对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们按照上图选择这个,然后点击“修改表单值”,这里的表单值设置为空,如图以下:
然后用同样的方法处理其他我们不想要的形式如下图所示。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位,上图中的用户密码就是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签。如果采集去“section 1”,那么就发布对应section id为1的section。这个可以根据自己的论坛section修改,下面的typname也一样,这样设置的好处是无需将类别id设置为直接与版块名称和主题类别名称自动对应。 查看全部
文章采集接口(
jiekou.php,修改:就是上图是用于测试的规则)
解压后看到的文件有:
其中,discussX3.0.wpm为发布模块,dz test interface.ljobx为用于测试的规则。以后不要问规则怎么写,就这样写吧。
1.上传界面
根据你的网站代码选择GBk或者utf8文件下的接口文件jiekou.php,这个接口有密码,默认是123456,如果要修改,打开这个jiekou.php,修改:
这是上图。将默认的“123456”更改为您想要的。修改后,必须保存。如果你不理解它,请不要修改它。
然后把这个文件上传到DZ的根目录网站,不知道我百度的根目录是什么,别问上传到哪里,我自己的网站
其他人怎么知道你的根目录是什么?
然后我们尝试在浏览器中访问它。访问地址为网站域名/jiekou.php?pw=password。这个密码就是上面提到的接口密码:
如果能出现论坛模块,就证明界面是对的。
2.导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站根目录填入接口文件名和我们访问上面接口时的剩余地址。然后选择“无需登录和 Http 请求”
第五步:点击获取列表,如果论坛版块可以显示,则说明以上4步设置正确。
设置好点击测试配置后,成功后,设置一个配置名称保存此配置供在规则中使用,
简单分发,仅发布标题内容回复的情况
我们打开发布模块,介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
username:对应论坛发帖和回复的用户名
subject : 对应论坛的标题
message : 对应发帖的主题和回复的内容,这两部分放在一起
fid : 对应于section ID
signature :发送者和响应者的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid :对应主题类别的ID
typename:对应于主题类别名称,上面我们写了类别ID,这里我们不需要设置值,将表单值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也是上面设置的。这里的值可以不设置,表格值可以留空。
头像:发帖人和回复人的头像信息,相同的两部分放在一起
tags:发帖时设置的标签
如果我们不需要表单值,比如我们不需要签名,我们按照上图选择这个,然后点击“修改表单值”,这里的表单值设置为空,如图以下:
然后用同样的方法处理其他我们不想要的形式如下图所示。我不需要 typeid、typenam 等形式。我只是使用上面的方法将它们的表单值设置为空:
当然,你需要什么样的形式取决于你。
我们将测试规则导入到采集器中来说明规则设置:
第二步:采集内容规则,我们直接点击右边的“测试”按钮就可以看到内容采集,这个规则就是采集dz官方论坛。
因为是采集论坛,内容标签采集是发帖内容和回复内容,作者标签采集是发帖用户名和回复用户名、头像和时间,和签名,都是发帖人和回复人信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的信息看到结果与每个信息用“|||”连接.
说到头像标签,用户的头像必须像“头像图片地址用户名”一样组合在一起。
规则如何设置取决于自带的规则,可以删除不必要的标签。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称应相同。
好吧,我没有看到发布模块中的内容标签。事实上,发布模块中的 {0} 已被替换。全部设置好后,在规则中使用如下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里设置的密码是新的用户注册密码,我设置为12346,那么所有界面注册用户的登录密码都是123456
如果留空,新注册的用户名和密码为:连接用户名和密码参数,在md5下取后面的12位,上图中的用户密码就是用户名和密码参数,可以设置。
如果回复用户名不是采集,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签。如果采集去“section 1”,那么就发布对应section id为1的section。这个可以根据自己的论坛section修改,下面的typname也一样,这样设置的好处是无需将类别id设置为直接与版块名称和主题类别名称自动对应。
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-25 00:17
接口(软件类接口)是定义契约的引用类型。其他类型实现接口以保证它们支持某些操作。
接口指定必须由实现它的类或其他接口提供的成员。与类一样,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数麻烦,让你的工作效率翻倍。
优采云采集器共有三种登录方式,其中免登录发布接口是最方便的方式,但需要程序员根据发布URL进行自定义,需要一定的代码库。
免登录界面发布的时候有很多优点,比如使用方便简单、无需手动登录、稳定发布等。下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)要查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码符合的接口。
(2)打开接口php文件,接口有密码,默认123456,也可以自定义修改密码。这里注意,修改密码后,发布模块的密码也需要进行相应的修改。
(3)上传网站的管理目录/e/admin/下的接口文件
02 正式运行:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块并保存:
(2)根据网站的地址配置。
(3)那你可以测试发布看看发布模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的办法在这里就是在release模块设置好标签后,直接将release模块中的标签导入优采云采集器:
03接口下载链接
因此,为了方便客户使用,我们整理了几个常用的网站,并为网站编译了一个发布接口。下面附上下载地址,压缩包附有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章支持首页更新
2.帝国7.5发布界面
3.destoon7.0 提供发布接口
4.DiscuzX3.4 免费登录论坛发布模块(带测试接口)
5.ecshop2.7.3
6.opencartV3.0发布界面.rar 查看全部
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
接口(软件类接口)是定义契约的引用类型。其他类型实现接口以保证它们支持某些操作。
接口指定必须由实现它的类或其他接口提供的成员。与类一样,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数麻烦,让你的工作效率翻倍。
优采云采集器共有三种登录方式,其中免登录发布接口是最方便的方式,但需要程序员根据发布URL进行自定义,需要一定的代码库。
免登录界面发布的时候有很多优点,比如使用方便简单、无需手动登录、稳定发布等。下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)要查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码符合的接口。
(2)打开接口php文件,接口有密码,默认123456,也可以自定义修改密码。这里注意,修改密码后,发布模块的密码也需要进行相应的修改。
(3)上传网站的管理目录/e/admin/下的接口文件
02 正式运行:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块并保存:
(2)根据网站的地址配置。
(3)那你可以测试发布看看发布模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的办法在这里就是在release模块设置好标签后,直接将release模块中的标签导入优采云采集器:
03接口下载链接
因此,为了方便客户使用,我们整理了几个常用的网站,并为网站编译了一个发布接口。下面附上下载地址,压缩包附有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章支持首页更新
2.帝国7.5发布界面
3.destoon7.0 提供发布接口
4.DiscuzX3.4 免费登录论坛发布模块(带测试接口)
5.ecshop2.7.3
6.opencartV3.0发布界面.rar
文章采集接口(zblog伪静态?为什么要做zblog插件多个功能?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 547 次浏览 • 2022-03-24 00:21
zblog 伪静态?为什么zblog是伪静态的?因为伪静态有利于搜索引擎的收录,可以增加网站的优化效果,但是在做伪静态的时候要注意,一定要正确编写代码,一旦有错误,会导致搜索引擎爬取异常,需要对伪静态状态进行测试并及时跟踪。顺便推荐一个多功能的zblog插件。一键建站+内容资源采集+伪原创+搜索引擎主动推送收录等,都会以图片的形式展示给你。大家注意看图。
zblog 伪静态规则参数
{%host%}:表示URL,以'/'结尾
{%category%}:表示类别,如果类别有别名,则调用别名,如果没有别名,则调用名称
注意:该参数只出现在文章的url配置中
{%alias%}:表示调用的别名,如果没有别名则调用标题或姓名
注意:这个参数会出现在文章页面、页面、分类、标签、作者页面的url配置中
{%id%}:表示存储在数据库中的数据的ID号,用数字表示
注意:这个参数会出现在作者页面、标签页、分类页面、文章页面、页面url配置中
{%year%}:表示新创建数据的年份,如2022 2023等。
{%month%}:表示新创建数据的月份,如05 12等。
{%date%}:表示时间段,不常用,一般用于日期页的ur配置
{%page%}:表示页面的页码,用数字表示
注意:该参数只出现在一些列表页面中,如首页、文章列表、标签列表、作者文章列表、日期页面列表的url配置
伪静态urls可以使用以上参数和一些字符串的任意组合,但是要注意几点
1、{%host%} 参数与其他字符串或参数组合时不能出现'/'
2、除了{%host%}参数外,其他参数的组合可以使用'/'符号
3、使用{%alias%}参数时,输出结果中不得出现中文或其他特殊符号
4、列表页的url配置必须收录{%page%}参数,否则会出bug
5、可以参考下面的例子来配置url
一般来说,搜索引擎对静态页面比较友好,认为页面比较稳定,不会有太大差别。相反,动态页面搜索引擎认为网站不稳定并且不分配高权重。
当然,我们可以意识到,站点中的大部分页面都是静态页面,但动态页面在优化过程中也起着重要的作用。为了安全起见,将动态页面设置为伪静态可以满足搜索引擎的这些要求。
什么是伪静态
早期的网站不支持动态语言,比如(asp/jsp/)等,所有页面都是用HTML编写的,然后保存为.html的扩展名,方便浏览。后来动态语言和数据库结合后,更多互动的网站出现在我们面前,访问地址变成了“?” 等等。
早期的搜索引擎对于这些动态参数的表单页面并不容易收录,所以将这些动态页面转换为以html结尾的静态页面。这些页面是真正的静态页面,保存在服务器的硬盘上。所以随着数据的不断增加,会对网站的访问速度产生严重的影响,于是出现了一种URLRewrite(URL重写),即伪静态技术,避免了大量的真正的静态文件。
伪静态有什么好处
静态页面有大量的存储空间。删除或更新这些html文件会导致大量垃圾页面,而像蜘蛛一样爬行有很多垃圾索引。伪静态可以更好的链接服务器压力,增强搜索引擎对页面的收录。动态页面虽然是实时更新的,但有时会导致死循环,对搜索引擎不友好,而伪静态则不会这样出现。健康)状况。
带有“?”等参数的 URL 可能有助于谷歌理解内容,但用户很难一目了然地理解页面的大致内容。伪静态 URL 更清晰,容易引起用户点击,而且 URL 容易记忆。 查看全部
文章采集接口(zblog伪静态?为什么要做zblog插件多个功能?(组图))
zblog 伪静态?为什么zblog是伪静态的?因为伪静态有利于搜索引擎的收录,可以增加网站的优化效果,但是在做伪静态的时候要注意,一定要正确编写代码,一旦有错误,会导致搜索引擎爬取异常,需要对伪静态状态进行测试并及时跟踪。顺便推荐一个多功能的zblog插件。一键建站+内容资源采集+伪原创+搜索引擎主动推送收录等,都会以图片的形式展示给你。大家注意看图。
zblog 伪静态规则参数
{%host%}:表示URL,以'/'结尾
{%category%}:表示类别,如果类别有别名,则调用别名,如果没有别名,则调用名称
注意:该参数只出现在文章的url配置中
{%alias%}:表示调用的别名,如果没有别名则调用标题或姓名
注意:这个参数会出现在文章页面、页面、分类、标签、作者页面的url配置中
{%id%}:表示存储在数据库中的数据的ID号,用数字表示
注意:这个参数会出现在作者页面、标签页、分类页面、文章页面、页面url配置中
{%year%}:表示新创建数据的年份,如2022 2023等。
{%month%}:表示新创建数据的月份,如05 12等。
{%date%}:表示时间段,不常用,一般用于日期页的ur配置
{%page%}:表示页面的页码,用数字表示
注意:该参数只出现在一些列表页面中,如首页、文章列表、标签列表、作者文章列表、日期页面列表的url配置
伪静态urls可以使用以上参数和一些字符串的任意组合,但是要注意几点
1、{%host%} 参数与其他字符串或参数组合时不能出现'/'
2、除了{%host%}参数外,其他参数的组合可以使用'/'符号
3、使用{%alias%}参数时,输出结果中不得出现中文或其他特殊符号
4、列表页的url配置必须收录{%page%}参数,否则会出bug
5、可以参考下面的例子来配置url
一般来说,搜索引擎对静态页面比较友好,认为页面比较稳定,不会有太大差别。相反,动态页面搜索引擎认为网站不稳定并且不分配高权重。
当然,我们可以意识到,站点中的大部分页面都是静态页面,但动态页面在优化过程中也起着重要的作用。为了安全起见,将动态页面设置为伪静态可以满足搜索引擎的这些要求。
什么是伪静态
早期的网站不支持动态语言,比如(asp/jsp/)等,所有页面都是用HTML编写的,然后保存为.html的扩展名,方便浏览。后来动态语言和数据库结合后,更多互动的网站出现在我们面前,访问地址变成了“?” 等等。
早期的搜索引擎对于这些动态参数的表单页面并不容易收录,所以将这些动态页面转换为以html结尾的静态页面。这些页面是真正的静态页面,保存在服务器的硬盘上。所以随着数据的不断增加,会对网站的访问速度产生严重的影响,于是出现了一种URLRewrite(URL重写),即伪静态技术,避免了大量的真正的静态文件。
伪静态有什么好处
静态页面有大量的存储空间。删除或更新这些html文件会导致大量垃圾页面,而像蜘蛛一样爬行有很多垃圾索引。伪静态可以更好的链接服务器压力,增强搜索引擎对页面的收录。动态页面虽然是实时更新的,但有时会导致死循环,对搜索引擎不友好,而伪静态则不会这样出现。健康)状况。
带有“?”等参数的 URL 可能有助于谷歌理解内容,但用户很难一目了然地理解页面的大致内容。伪静态 URL 更清晰,容易引起用户点击,而且 URL 容易记忆。
文章采集接口(数据接口分析抓包搭建好环境之后的应用收获 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-24 00:17
)
本文章主要介绍python抖音data采集方法的相关知识。内容详细易懂,操作简单快捷,具有一定的参考价值。相信看过这篇python抖音Data采集methods文章会有收获,一起来看看吧。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据 查看全部
文章采集接口(数据接口分析抓包搭建好环境之后的应用收获
)
本文章主要介绍python抖音data采集方法的相关知识。内容详细易懂,操作简单快捷,具有一定的参考价值。相信看过这篇python抖音Data采集methods文章会有收获,一起来看看吧。
准备好工作了
<p>开始准备输入数据采集,第一步是搭建环境。这次我们在windows环境下使用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,使用夜神模拟器模拟Android操作环境(也可以使用真机)。这次主要是通过手动滑动app来抓取数据。下次介绍Appium自动化工具,实现采集的数据
文章采集接口(影响网站加载性能的瓶颈中挖掘指标--APM问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-03-23 00:25
APM的全称是Application Performance Monitor,即性能监控
这个 文章 有三个前提:
还记得多年前在网上广为流传的一道经典的前端面试题。大体思路是解释从在浏览器地址栏中输入 url 到看到页面的过程。这类问题的迷人之处在于它给了你一张大嘴,它让你信服——原来我们对眼前的很多事情视而不见,背后有这么大的学术问题。随便问。
我想在这个 文章 中回答的问题也很简单:我怎么知道我的 网站 性能有多慢以及在哪里?这个问题是我在网站上线的时候首先要搞清楚的。
待解决问题确定指标
大问题下,有两个子问题需要先搞清楚。
这两个子问题在我去年的文章《绩效指标的信念危机》中有详细的解释。由于篇幅关系,这里只陈述结论,两个问题的答案密不可分,必须放在一起聊
总之,onload 或者 DOMContentLoaded 等技术指标是远远不够的,甚至 First Contentful Paint 也离用户的实际感知还差得很远(后面我会证明这一点)。一个好的指标应该尽可能的贴近用户,甚至是与业务深度定制。所以我推荐页面上用来承载核心内容的DOM元素的时序作为性能的核心指标。这个时机很关键,因为它等同于 网站 在此时可用。
以网站的详情页为例,关键元素为.single-folder-container
但这并不意味着一个指标就足够了,因为如果我们发现指标值不理想,我们就无法确定问题出在哪里。因此,好的数据的作用应该是双向的:即能够准确的反映当前产品的运行状态(从产品到数据),同时通过观察数据,我们也应该能够知道是什么样的产品存在的问题(从数据到产品)。)
在这个前提下,我们需要从“潜在的”性能瓶颈中挖掘指标。假设影响网站加载性能的因素有:
如何继续记录两者的加载时间?
要回答这个问题,我们要不断地问自己,这两类信息是否足以让我们推测问题出在哪里?与单一指标相比,答案是肯定的,但仍有细化的空间。以资源加载为例,参考下图资源时序。资源加载也分为多个阶段:
我们甚至可以诊断出问题出在 DNS 解析还是 TCP 连接阶段。但是,我们不应该详细采集所有指标,有几个因素需要考虑:
回到确定指标的问题,我们必须面对目前无法知道自己需要什么样的数据的现状,这很正常。确定指标是假设、验证、重新假设和重新验证的收敛过程。尝试总比拖延和让我们更接近正确答案要好。让我们开始采集上面提到的三类指标
接口问题
前端工程师必然会陷入的陷阱是只站在前端的角度看问题,而忽略了最重要的接口性能。对于大多数人来说,页面加载可能只是线性的:
但实际上,在 API Request 环节,我们应该从微服务的角度来看问题。从请求到响应的一个请求,将通过不同的微服务来获取数据,如果请求所经过的每一个环节都可以被追踪到的话。这对于定位在线环境中的问题和衡量单个微服务的效率很有用。这是分布式跟踪。目前,这项技术已经相当成熟。Jaegertracing 和 Zipkin 都是分布式跟踪解决方案。
但是,如果你对后端拆分服务层有所了解,如果你想诊断单个微服务的性能在哪里,我们可以继续下钻到单个微服务,比较调用不同服务层方法(服务layer也适用于前端,详细介绍可以参考我去年翻译的这篇文章《Angular Architecture Patterns and Best Practices》)
我想表达的很明显。要想充分挖掘应用的性能瓶颈,就要同时考察上下游。分割视角得到的结果是有偏差的。
解决方案采集日志
如果您有 采集 日志记录的经验,您应该知道日志记录 采集 和输出是两个不同的东西。特别是对于后端程序。日志可以记录在本地文件中,也可以直接在控制台输出,但是在线环境下,需要在专业的日志服务中记录。
比如NodeJS的开源日志库winston,支持多种transport的集成,transport就是一种存储日志的存储方式。它还支持编写自定义传输,当前选项支持市面上几乎所有主流日志服务。.NET CORE 中的日志记录提供程序是相同的概念
但是,这种采集日志的“主动”方式并不是最佳实践。构建网络应用的方法论 Twelve-Factor App 曾提出应用本身不考虑日志的存储,只保证日志以 stdout 的形式输出,由环境负责采集和处理日志。这个提议是合理的,因为应用程序不应该也不可能知道它将部署在哪个云环境中,并且不同的环境对日志的处理方式不同
为了快速失败,我在开发site2share的后端时没有遵循这个概念。当需要登录采集时,直接调用具体平台的采集方法。目前我的日志都记录在 Azure Application Insights 上,所以在记录时我需要调用 Application Insights 客户端方法:AppInsightsClient.trackTrace(message)
只是在实现层面,可以使用winston代码变得更加优雅。我们可以创建一个logger来达到同时兼容多个日志输出通道的效果。
const logger = winston.createLogger({
transports: [
new AppInsightsTransport(),
new winston.transports.Console()
]
});
因为我们测试的是前端性能,而性能数据是在消费者浏览器的网页上生成的。所以我们依赖的是每个用户在访问后通过嵌入页面的脚本主动上传数据
应用洞察
我选择 Azure Application Insights 来存储和查询日志的原因之一是 网站我使用从前端(Azure 静态 Web 应用)到后端(Azure 服务应用)甚至 DevOps 的 Azure 服务,自然,官方的 Application Insights 可以更好地与这些服务集成;还有一个更重要的原因是它可以为我们解决分布式追踪的问题。
您需要在您的应用程序中植入 Application Insights 的 SDK 来采集日志。SDK 支持前端和后端程序。它通过两种方式采集日志,主动采集和被动报告。以JavaScript语言的web应用为例,在页面植入SDK后,会自动采集程序运行时的错误报告,发出的异步请求,console.log(猴子补丁的方式),和性能信息(通过性能 API);您也可以调用 SDK 提供的 trackMetric 和 trackEvent 主动上报自定义指标和事件信息。性能 采集 我们同时使用这两种方法
我们通常将metrics、log等信息称为遥测(data/item),通常这些数据存储在不同的表中,并与其他数据一起淹没。如何将两者联系起来?Application Insights 用于关联遥测的解决方案很简单:为每条数据提供唯一的上下文标识符 operation_Id。以用户访问页面为例,本次访问生成的数据中的 operation_Id 称为 xyz,那么在 Application Insights 平台上,我们可以通过 xyz 查询关联数据(Kusto 语法)
我们不仅可以将前端数据与前端数据关联起来,还可以将前端数据与后端数据关联起来,这是我们进行分布式追踪的法宝。对于微服务应用,Application Insights 甚至可以为我们生成一个 Application Map 来可视化服务之间的调用过程和耗时。
在浏览完本节的技术细节后,我们可以可视化我们需要哪些数据以及它们之间的关系
资源加载指标
借助 Performance API,在现代浏览器中采集指标非常容易。无需主动触发,浏览器已经根据每次页面加载的时间线将性能指标信息封装在PerformanceEntry对象中。之后,我们只需要过滤掉需要的数据,比如我们关心的脚本:
window.performance.getEntries().filter(({initiatorType, entryType}) => initiatorType === 'script' && entryType === 'resource')
根据上一节的结论,我们就不详细记录资源加载的各个环节的数据了。这里我重点关注采集资源加载的持续时间和资源加载的开始时间,我们从这两个开始可以分别在PerformanceEntry、duration和fetchStart上获取。因为目前在我看来,预加载和缩短加载时间是提高性能的有效手段。如果事后这两个值没有异常,可以考虑多采集指标
报告元素出现时间
确认元素出现的那一刻最简单粗暴的方法是通过 setInterval 来轮询该元素是否出现,但是在现代浏览器中我们可以使用 MutationObserver API 来监控元素的所有变化,因此可以以不同的方式提出问题:body标签下.single-folder-container元素什么时候出现,关键代码大致如下
const observer = new MutationObserver(mutations => {
if (document.querySelector('.single-folder-container')) {
observer.disconnect();
return;
}
});
observer.observe(document.querySelector('body'), {
subtree: true,
childList: true
});
这里有一个问题:这段代码非常关键且难以测试。
第一个问题是,例如在 Jest 环境中没有原生的 MutationObserver 对象。如果只是为了通过测试而简单地模拟 MutationObserver 对象测试,那么测试的意义就没有了;
其次,即使在 Headless Chrome 等支持 MutationObserver 的环境中进行测试,如果你知道它向你报告的元素的时间是正确的?既然你自己不知道确切的时间是什么(即你测试 Lee 的期望),那么 10 秒肯定是不正确的,但是 2.2 秒呢?
附加性能指标
理论上,以上两个都是我们期望采集的指标。但是我还想采集两个额外的指标:First Paint 和 First Contentful Paint,简而言之,它们记录了浏览器在绘制页面时的一些关键时刻。这两个指标也可从 Performance API 获得
window.performance.getEntries().filter(entry => entry.entryType === 'paint')
Paint Timing 将比纯粹的技术指标更接近用户体验,但我们将拭目以待,看看它与实际用户看到元素出现的情况相比如何。
后端时间
我猜有两个可能的性能瓶颈:1)Redis 查询2) MySQL 查询。
Redis主要用于会话存储,后端由Node.js + ExpressJS搭建,所以不容易监控会话读取性能。所以我优先考虑MySQL的查询性能,比如findByFolderId方法的读取性能统计:
const findFolderIdStartTime = +new Date();
await FolderService.findByFolderId(parseInt(req.params!.id))
appInsightsClient.trackMetric({
name: "APM:GET_SINGLE_FOLDER:FIND_BY_ID",
value: +new Date - findFolderIdStartTime
});
总结
最后,为了在日志平台上找到对应的指标并对指定类型的指标进行统计,我们需要对上述指标进行命名。以下是命名规则。
上一个即将结束。我已经说明了这个性能采集方案的思路,也基本实现了我们的性能采集脚本。有了这些代码,我们基本可以完成采集单条性能数据 查看全部
文章采集接口(影响网站加载性能的瓶颈中挖掘指标--APM问题)
APM的全称是Application Performance Monitor,即性能监控
这个 文章 有三个前提:
还记得多年前在网上广为流传的一道经典的前端面试题。大体思路是解释从在浏览器地址栏中输入 url 到看到页面的过程。这类问题的迷人之处在于它给了你一张大嘴,它让你信服——原来我们对眼前的很多事情视而不见,背后有这么大的学术问题。随便问。
我想在这个 文章 中回答的问题也很简单:我怎么知道我的 网站 性能有多慢以及在哪里?这个问题是我在网站上线的时候首先要搞清楚的。
待解决问题确定指标
大问题下,有两个子问题需要先搞清楚。
这两个子问题在我去年的文章《绩效指标的信念危机》中有详细的解释。由于篇幅关系,这里只陈述结论,两个问题的答案密不可分,必须放在一起聊
总之,onload 或者 DOMContentLoaded 等技术指标是远远不够的,甚至 First Contentful Paint 也离用户的实际感知还差得很远(后面我会证明这一点)。一个好的指标应该尽可能的贴近用户,甚至是与业务深度定制。所以我推荐页面上用来承载核心内容的DOM元素的时序作为性能的核心指标。这个时机很关键,因为它等同于 网站 在此时可用。
以网站的详情页为例,关键元素为.single-folder-container
但这并不意味着一个指标就足够了,因为如果我们发现指标值不理想,我们就无法确定问题出在哪里。因此,好的数据的作用应该是双向的:即能够准确的反映当前产品的运行状态(从产品到数据),同时通过观察数据,我们也应该能够知道是什么样的产品存在的问题(从数据到产品)。)
在这个前提下,我们需要从“潜在的”性能瓶颈中挖掘指标。假设影响网站加载性能的因素有:
如何继续记录两者的加载时间?
要回答这个问题,我们要不断地问自己,这两类信息是否足以让我们推测问题出在哪里?与单一指标相比,答案是肯定的,但仍有细化的空间。以资源加载为例,参考下图资源时序。资源加载也分为多个阶段:
我们甚至可以诊断出问题出在 DNS 解析还是 TCP 连接阶段。但是,我们不应该详细采集所有指标,有几个因素需要考虑:
回到确定指标的问题,我们必须面对目前无法知道自己需要什么样的数据的现状,这很正常。确定指标是假设、验证、重新假设和重新验证的收敛过程。尝试总比拖延和让我们更接近正确答案要好。让我们开始采集上面提到的三类指标
接口问题
前端工程师必然会陷入的陷阱是只站在前端的角度看问题,而忽略了最重要的接口性能。对于大多数人来说,页面加载可能只是线性的:
但实际上,在 API Request 环节,我们应该从微服务的角度来看问题。从请求到响应的一个请求,将通过不同的微服务来获取数据,如果请求所经过的每一个环节都可以被追踪到的话。这对于定位在线环境中的问题和衡量单个微服务的效率很有用。这是分布式跟踪。目前,这项技术已经相当成熟。Jaegertracing 和 Zipkin 都是分布式跟踪解决方案。
但是,如果你对后端拆分服务层有所了解,如果你想诊断单个微服务的性能在哪里,我们可以继续下钻到单个微服务,比较调用不同服务层方法(服务layer也适用于前端,详细介绍可以参考我去年翻译的这篇文章《Angular Architecture Patterns and Best Practices》)
我想表达的很明显。要想充分挖掘应用的性能瓶颈,就要同时考察上下游。分割视角得到的结果是有偏差的。
解决方案采集日志
如果您有 采集 日志记录的经验,您应该知道日志记录 采集 和输出是两个不同的东西。特别是对于后端程序。日志可以记录在本地文件中,也可以直接在控制台输出,但是在线环境下,需要在专业的日志服务中记录。
比如NodeJS的开源日志库winston,支持多种transport的集成,transport就是一种存储日志的存储方式。它还支持编写自定义传输,当前选项支持市面上几乎所有主流日志服务。.NET CORE 中的日志记录提供程序是相同的概念
但是,这种采集日志的“主动”方式并不是最佳实践。构建网络应用的方法论 Twelve-Factor App 曾提出应用本身不考虑日志的存储,只保证日志以 stdout 的形式输出,由环境负责采集和处理日志。这个提议是合理的,因为应用程序不应该也不可能知道它将部署在哪个云环境中,并且不同的环境对日志的处理方式不同
为了快速失败,我在开发site2share的后端时没有遵循这个概念。当需要登录采集时,直接调用具体平台的采集方法。目前我的日志都记录在 Azure Application Insights 上,所以在记录时我需要调用 Application Insights 客户端方法:AppInsightsClient.trackTrace(message)
只是在实现层面,可以使用winston代码变得更加优雅。我们可以创建一个logger来达到同时兼容多个日志输出通道的效果。
const logger = winston.createLogger({
transports: [
new AppInsightsTransport(),
new winston.transports.Console()
]
});
因为我们测试的是前端性能,而性能数据是在消费者浏览器的网页上生成的。所以我们依赖的是每个用户在访问后通过嵌入页面的脚本主动上传数据
应用洞察
我选择 Azure Application Insights 来存储和查询日志的原因之一是 网站我使用从前端(Azure 静态 Web 应用)到后端(Azure 服务应用)甚至 DevOps 的 Azure 服务,自然,官方的 Application Insights 可以更好地与这些服务集成;还有一个更重要的原因是它可以为我们解决分布式追踪的问题。
您需要在您的应用程序中植入 Application Insights 的 SDK 来采集日志。SDK 支持前端和后端程序。它通过两种方式采集日志,主动采集和被动报告。以JavaScript语言的web应用为例,在页面植入SDK后,会自动采集程序运行时的错误报告,发出的异步请求,console.log(猴子补丁的方式),和性能信息(通过性能 API);您也可以调用 SDK 提供的 trackMetric 和 trackEvent 主动上报自定义指标和事件信息。性能 采集 我们同时使用这两种方法
我们通常将metrics、log等信息称为遥测(data/item),通常这些数据存储在不同的表中,并与其他数据一起淹没。如何将两者联系起来?Application Insights 用于关联遥测的解决方案很简单:为每条数据提供唯一的上下文标识符 operation_Id。以用户访问页面为例,本次访问生成的数据中的 operation_Id 称为 xyz,那么在 Application Insights 平台上,我们可以通过 xyz 查询关联数据(Kusto 语法)
我们不仅可以将前端数据与前端数据关联起来,还可以将前端数据与后端数据关联起来,这是我们进行分布式追踪的法宝。对于微服务应用,Application Insights 甚至可以为我们生成一个 Application Map 来可视化服务之间的调用过程和耗时。
在浏览完本节的技术细节后,我们可以可视化我们需要哪些数据以及它们之间的关系
资源加载指标
借助 Performance API,在现代浏览器中采集指标非常容易。无需主动触发,浏览器已经根据每次页面加载的时间线将性能指标信息封装在PerformanceEntry对象中。之后,我们只需要过滤掉需要的数据,比如我们关心的脚本:
window.performance.getEntries().filter(({initiatorType, entryType}) => initiatorType === 'script' && entryType === 'resource')
根据上一节的结论,我们就不详细记录资源加载的各个环节的数据了。这里我重点关注采集资源加载的持续时间和资源加载的开始时间,我们从这两个开始可以分别在PerformanceEntry、duration和fetchStart上获取。因为目前在我看来,预加载和缩短加载时间是提高性能的有效手段。如果事后这两个值没有异常,可以考虑多采集指标
报告元素出现时间
确认元素出现的那一刻最简单粗暴的方法是通过 setInterval 来轮询该元素是否出现,但是在现代浏览器中我们可以使用 MutationObserver API 来监控元素的所有变化,因此可以以不同的方式提出问题:body标签下.single-folder-container元素什么时候出现,关键代码大致如下
const observer = new MutationObserver(mutations => {
if (document.querySelector('.single-folder-container')) {
observer.disconnect();
return;
}
});
observer.observe(document.querySelector('body'), {
subtree: true,
childList: true
});
这里有一个问题:这段代码非常关键且难以测试。
第一个问题是,例如在 Jest 环境中没有原生的 MutationObserver 对象。如果只是为了通过测试而简单地模拟 MutationObserver 对象测试,那么测试的意义就没有了;
其次,即使在 Headless Chrome 等支持 MutationObserver 的环境中进行测试,如果你知道它向你报告的元素的时间是正确的?既然你自己不知道确切的时间是什么(即你测试 Lee 的期望),那么 10 秒肯定是不正确的,但是 2.2 秒呢?
附加性能指标
理论上,以上两个都是我们期望采集的指标。但是我还想采集两个额外的指标:First Paint 和 First Contentful Paint,简而言之,它们记录了浏览器在绘制页面时的一些关键时刻。这两个指标也可从 Performance API 获得
window.performance.getEntries().filter(entry => entry.entryType === 'paint')
Paint Timing 将比纯粹的技术指标更接近用户体验,但我们将拭目以待,看看它与实际用户看到元素出现的情况相比如何。
后端时间
我猜有两个可能的性能瓶颈:1)Redis 查询2) MySQL 查询。
Redis主要用于会话存储,后端由Node.js + ExpressJS搭建,所以不容易监控会话读取性能。所以我优先考虑MySQL的查询性能,比如findByFolderId方法的读取性能统计:
const findFolderIdStartTime = +new Date();
await FolderService.findByFolderId(parseInt(req.params!.id))
appInsightsClient.trackMetric({
name: "APM:GET_SINGLE_FOLDER:FIND_BY_ID",
value: +new Date - findFolderIdStartTime
});
总结
最后,为了在日志平台上找到对应的指标并对指定类型的指标进行统计,我们需要对上述指标进行命名。以下是命名规则。
上一个即将结束。我已经说明了这个性能采集方案的思路,也基本实现了我们的性能采集脚本。有了这些代码,我们基本可以完成采集单条性能数据
文章采集接口(《PHP视频教程》php的api接口验证原理示意图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-21 19:36
推荐:《PHP 视频教程》
php API接口
在实际工作中,经常使用PHP编写api接口。PHP写好接口后,前台可以通过链接获取接口提供的数据,返回的数据一般分为xml和json两种情况。在这个过程中,服务器不知道请求的来源是什么,很可能是别人非法调用我们的接口获取数据,所以需要进行安全验证。
验证原理
示意图
原则
从图中可以清楚地看出,如果前台要调用接口,需要使用几个参数来生成签名。
时间戳:当前时间
随机数:随机产生的随机数
密码:前后端开发时,双方都知道的标志,相当于密码
算法规则:约定的操作规则,以上三个参数可用于生成使用算法规则的签名。
前台生成签名,当需要访问接口时,将时间戳、随机数、签名通过URL传递给后台。在后台获取时间戳和随机数后,通过相同的算法规则计算签名,然后与传递的签名进行比较,如果相同则返回数据。
算法规则
在前后端交互中,算法规则非常重要。前端和后端双方都必须通过算法规则计算签名。至于如何制定规则,就看你有多开心了。
我的算法规则是
1 时间戳、随机数、密码按字母顺序排序
2然后拼接成一个字符串
3 执行sha1加密
4 再次执行MD5加密
5 转换为大写。
前台
这里我没有实际的前台,我直接用PHP文件代替前台,然后通过CURL模拟一个GET请求。我使用的是 TP 框架,URL 格式是 pathinfo 格式。
源代码
<p> 查看全部
文章采集接口(《PHP视频教程》php的api接口验证原理示意图)
推荐:《PHP 视频教程》
php API接口
在实际工作中,经常使用PHP编写api接口。PHP写好接口后,前台可以通过链接获取接口提供的数据,返回的数据一般分为xml和json两种情况。在这个过程中,服务器不知道请求的来源是什么,很可能是别人非法调用我们的接口获取数据,所以需要进行安全验证。
验证原理
示意图
原则
从图中可以清楚地看出,如果前台要调用接口,需要使用几个参数来生成签名。
时间戳:当前时间
随机数:随机产生的随机数
密码:前后端开发时,双方都知道的标志,相当于密码
算法规则:约定的操作规则,以上三个参数可用于生成使用算法规则的签名。
前台生成签名,当需要访问接口时,将时间戳、随机数、签名通过URL传递给后台。在后台获取时间戳和随机数后,通过相同的算法规则计算签名,然后与传递的签名进行比较,如果相同则返回数据。
算法规则
在前后端交互中,算法规则非常重要。前端和后端双方都必须通过算法规则计算签名。至于如何制定规则,就看你有多开心了。
我的算法规则是
1 时间戳、随机数、密码按字母顺序排序
2然后拼接成一个字符串
3 执行sha1加密
4 再次执行MD5加密
5 转换为大写。
前台
这里我没有实际的前台,我直接用PHP文件代替前台,然后通过CURL模拟一个GET请求。我使用的是 TP 框架,URL 格式是 pathinfo 格式。
源代码
<p>
文章采集接口(个人网站提前搭建c/s架构,实现本地架构)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-21 09:05
文章采集接口:qq_users。本地ftp文件接口:itchat+github,可以用它来接入本地的github个人网站.个人网站如果放到github上的话就要提前搭建c/s架构,以下是我尝试过的两种方案:本地搭建项目,在nginx中进行so库加载,本地用百度云上传到github.本地接入nginx代理,然后利用nginx的http_header_cookie校验和验证目录来处理。
之后提交给nginx。上传文件并查询,如果支持sha256加密验证就更好了。不支持的话就用本地集成的下载工具下载到本地,然后用qq_users上传到github,中间在对接一次成功上传即可,整个过程是比较麻烦的。爬虫脚本接入,个人只使用过快递查询工具,这种方案是快递可以自己写,比较麻烦,此方案只是提供一个思路,可以自己尝试。
根据业务要求在方案中选择合适的接入方案吧。有错的话欢迎指正~总的来说,这个项目实现了一个将卖家发布的快递物流查询链接自动复制到github上,并在点击查看之后利用生成的id查询物流的目的。
qqusers,可以直接在qq浏览器的扩展菜单加载一个users的url地址,就可以实现复制。需要手动刷新浏览器。有个比较笨的办法,可以使用中国邮政的中国邮政ems的工具链,可以查询发到达有效时间,并返回在查询的时候,会跳转到手机或者服务器查询。已经使用了前两种,第三种不在手机和服务器查询的区间里。 查看全部
文章采集接口(个人网站提前搭建c/s架构,实现本地架构)
文章采集接口:qq_users。本地ftp文件接口:itchat+github,可以用它来接入本地的github个人网站.个人网站如果放到github上的话就要提前搭建c/s架构,以下是我尝试过的两种方案:本地搭建项目,在nginx中进行so库加载,本地用百度云上传到github.本地接入nginx代理,然后利用nginx的http_header_cookie校验和验证目录来处理。
之后提交给nginx。上传文件并查询,如果支持sha256加密验证就更好了。不支持的话就用本地集成的下载工具下载到本地,然后用qq_users上传到github,中间在对接一次成功上传即可,整个过程是比较麻烦的。爬虫脚本接入,个人只使用过快递查询工具,这种方案是快递可以自己写,比较麻烦,此方案只是提供一个思路,可以自己尝试。
根据业务要求在方案中选择合适的接入方案吧。有错的话欢迎指正~总的来说,这个项目实现了一个将卖家发布的快递物流查询链接自动复制到github上,并在点击查看之后利用生成的id查询物流的目的。
qqusers,可以直接在qq浏览器的扩展菜单加载一个users的url地址,就可以实现复制。需要手动刷新浏览器。有个比较笨的办法,可以使用中国邮政的中国邮政ems的工具链,可以查询发到达有效时间,并返回在查询的时候,会跳转到手机或者服务器查询。已经使用了前两种,第三种不在手机和服务器查询的区间里。
文章采集接口(修正编辑器,智能挖掘功能获取数据的错误及建议!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-21 07:27
3、修复数据分析和智能挖掘功能获取数据错误。
4、修复开启远程图片定位时FastCGI进程超过配置请求超时的问题。
5、升级404错误页面,增加多种功能。
6、修复了环境中导致 FastCGI 进程意外退出并出现 500 错误的错误。
7、优化模板工具,修复点击网页链接时模板工具跳出的问题。
8、修复部分浏览器源模板底部操作选项不显示的问题。
9、升级数据采集功能,提升365建站器的数据处理能力。
10、修复模板过多时批量get提交的错误,修改为post提交。
11、修复编辑器中ie不兼容导致上传失败的问题。
12、修复网站在没有栏目时无法发布的情况(针对宣传页的单页用户)。
13、修复获取大量列的超时问题,增加搜索同类型列的功能。
14、修复模板管理中模板过多导致批量操作超时或超时导致的404错误。
15、优化模板管理、内容管理等,新窗口打开方便用户操作。
16、新增网站管理后台选项,可以在浏览器中打开,供用户选择。
17、添加是否开启网站访问统计供用户选择。
18、修复部分页面提交后编辑器内容为空的情况。
19、新增文章库预览功能。
20、修复保存云模板工具时标签错误的问题。
21、修复用户反馈的其他问题和建议。
感谢一直陪伴365软件成长的用户,我们一直在努力让网站建设和SEO变得更简单。如果您有更好的建议,可以提交给我们。我们专注于网站的快速批量建设,使网站建设和搜索引擎优化变得简单。,支持全网数据采集。高效稳定的数据和建站产品和服务,可以为您挖掘无限的商业价值。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。 查看全部
文章采集接口(修正编辑器,智能挖掘功能获取数据的错误及建议!!)
3、修复数据分析和智能挖掘功能获取数据错误。
4、修复开启远程图片定位时FastCGI进程超过配置请求超时的问题。
5、升级404错误页面,增加多种功能。
6、修复了环境中导致 FastCGI 进程意外退出并出现 500 错误的错误。
7、优化模板工具,修复点击网页链接时模板工具跳出的问题。
8、修复部分浏览器源模板底部操作选项不显示的问题。
9、升级数据采集功能,提升365建站器的数据处理能力。
10、修复模板过多时批量get提交的错误,修改为post提交。
11、修复编辑器中ie不兼容导致上传失败的问题。
12、修复网站在没有栏目时无法发布的情况(针对宣传页的单页用户)。
13、修复获取大量列的超时问题,增加搜索同类型列的功能。
14、修复模板管理中模板过多导致批量操作超时或超时导致的404错误。
15、优化模板管理、内容管理等,新窗口打开方便用户操作。
16、新增网站管理后台选项,可以在浏览器中打开,供用户选择。
17、添加是否开启网站访问统计供用户选择。
18、修复部分页面提交后编辑器内容为空的情况。
19、新增文章库预览功能。
20、修复保存云模板工具时标签错误的问题。
21、修复用户反馈的其他问题和建议。
感谢一直陪伴365软件成长的用户,我们一直在努力让网站建设和SEO变得更简单。如果您有更好的建议,可以提交给我们。我们专注于网站的快速批量建设,使网站建设和搜索引擎优化变得简单。,支持全网数据采集。高效稳定的数据和建站产品和服务,可以为您挖掘无限的商业价值。
特别声明:以上内容(包括图片或视频)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-19 19:03
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们的网站想象成一个房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。 查看全部
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的环节。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们的网站想象成一个房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友好度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。TDK选型部署如网站、关键词密度控制等现场优化,现场结构是否简单合理,目录层次是否过于复杂等,非现场优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-17 23:12
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的部分。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友善度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。现场优化如TDK选择部署网站,关键词密度控制,网站内部结构是否简单合理,目录层级是否过于复杂等等,off-网站优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。 查看全部
文章采集接口(如何利用免费Dede采集插件让网站收录以及关键词排名?)
为什么要使用 Dede采集 插件?如何使用免费的 Dede采集 插件对 网站收录 和 关键词 进行排名。我们知道网站结构是seo优化过程中不可忽视的一个非常重要的部分。网站结构分为物理结构和逻辑结构。物理结构一般是指虚拟空间中的许多目录和文件。这种结构一般用户不能直接看到,逻辑结构主要是指网站上线后我们肉眼可以看到的网站界面中的链接关系。两者都是站长在优化过程中需要注意的重点。那么SEO网站结构优化有什么意义呢?
网站结构对我们的网站 优化真的那么重要吗?很多人都在问同样的问题。其实我们可以把我们网站想象成一栋房子,结构就是我们房子的布局,首页就是我们的客厅,搜索引擎就是来我们家参观的朋友。,当他来到你家时,他会先进入你家的客厅;通过客厅,你可以到达房子里的每个房间,同样可以通过我们的首页搜索引擎到达我们的每个页面。为了方便起见,我们的网站最好的结构是三层,也就是说用户最多点击3次就可以到达他想到达的页面。这样做的目的是为了加快蜘蛛的爬行速度和蜘蛛的友善度。而且,
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用Dede采集实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站收录 和 关键词 排名。这个Dede采集不需要写规则,输入关键词就可以了采集。
一、免费Dede采集插件
免费Dede采集插件特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体翻译+百度翻译+有道翻译+谷歌翻译+147翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
还有一点大家要注意的是,我们的网站里面不能有死连接,网站里面的连接不能很乱,不要让网站看起来像迷宫是的,蜘蛛最讨厌的地方就是迷宫网站。因为这样的网站会浪费蜘蛛很多时间,会觉得额外的累赘,久而久之会减少蜘蛛爬行的数量,就像我们站在房子的客厅里,你想去到其中一个房间,然后你发现房子就像一个迷宫,需要很长时间才能找到你想去的房间。你想要这样的房子吗?你肯定不喜欢吧?蜘蛛也是如此。所以 网站 不需要添加太多的连接,
其实如果一个网站想要做好网站的优化,首先要做的就是要有一个好的网站结构。就像迷宫一样,设施齐全,没有人愿意住在那里。同理,我们的网站内容做的不错,但是找起来很麻烦,别说蜘蛛了,连用户都不愿意找。
对网站进行SEO优化时,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多部分。现场优化如TDK选择部署网站,关键词密度控制,网站内部结构是否简单合理,目录层级是否过于复杂等等,off-网站优化比如网站外部链接的扩展、友好链接的交换等,这些因素都是不容忽视的,任何一个领域的问题都可能导致网站整体不稳定。那么网站标签是如何进行SEO优化的呢?
alt标签的使用
很多人可能并不关心 网站alt 标签。该标签是为网站上的图片设置和部署的。想必大家都知道,搜索引擎蜘蛛无法顺利抓取网站上的图片。为了更好的识别图片,我们可以在图片后面加上图片的alt标签属性,在alt里面加上图片的详细信息或者网站关键词,这样就可以告诉蜘蛛图片内容,还可以累加网站关键词的权重和密度,有效提升网站关键词的排名和权重。
h1标签的用法和作用
说到网站的H1标签,可能有人会问,h1标签有什么用,但我想告诉大家的是,网站的H1标签有很多功能,而h1是在一个页面中得到的权重最高的。当蜘蛛进入页面进行爬取时,第一个是标题,第二个是h1标签,所以后面我们可以在h1标签中部署网站的关键词。增加关键词的权重,为了突出网站的主题核心,所以在页面的h1标签中,不能随便部署词汇,网站的整体核心应该可以考虑,而 h1 标签在一个页面中只能出现一次。如果使用次数过多,将没有效果。这需要特别注意。
网站 标签的使用需要谨慎。如果使用不当,会直接导致网站的降级,甚至K。标签优化是网站优化的好方法。比较重要,所以优化标签的时候不要操之过急,也不要过度优化问题。合理恰当地使用标签优化,可以增加网站的连接性,也可以增加用户粘性。,所以对网站标签的优化需要慎重。
文章采集接口( Phpwind80文章中心接口(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-03-15 17:21
Phpwind80文章中心接口(组图))
Phpwind80文章中央界面用户手册 1 简介 1该界面适用于Phpwind80版本 文章中央栏目文章发布 2该界面只能使用一个发布规则指定多个栏目随机发送到不同栏目发布文章3 这个接口可以采集文章date,让文章发布更真实,见参数newstimezzhours4的说明,因为用户可能同时使用Phpwind8的多个接口时间,请注意修改界面名称使每个界面不同。比如这个interface文件夹中提供的interface文件添加了ldquocmsrdquo 5的文件名后缀,发布时请使用具有文章中央管理权限的用户帐号。6. 在 Phpwind80utf8 版本中使用该接口时,请在发布规则中选择编码为 UTF-87。本界面基于Phpwind80GBK版本。适用于Phpwind80GBKutf-8等版本。请测试并调整 8 接口文件,不要做任何更改。如需添加验证或其他功能,请谨慎修改92接口文件,请到Phpwind80官网复制
使用站点根目录下的第二个安装界面,在interface文件夹中找到interface文件。请将etck_cmsphpetpost_cmsphp等接口文件上传到指定目录。请以二进制方式上传如图3 配置发布规则1 将示例发布规则文本导入ET2发布配置或使用软件内置发布规则示例如图2 更改check URL中的ldquo和网站rdquo 要发布的 URL 的发布 URL 如图 3,在勾选 URL 上填写您要发布的 文章 中心列 ID 文章@ 的中心列 ID > 可以用英文逗号隔开的倍数填写。将鼠标移动到列名上,可以在状态栏中查看列 ID。填写您的帐户密码。注意格式和账号权限如图4。 接口说明 1 查看接口 1. 接口文件名etck_cmsphp 属于机密,请自行修改文件名。2.这个接口文件复制到网站根目录下使用。_主题文章标题
cid 列 ID 用于限制该规则的检查列。您可以填写多种逗号分隔或空白格式。例如,可以在 文章 中心查看 cid789。修改vercode使其一致 4 发布配置 - 文章检查URL可以填写如下 http 你的URL etchk_cmsphpcms_subjectlttitlegtampcid 你的列ID 注意 使用区分大小写的服务器用户 请注意URL 的大小写与 网站 文件相同。5、界面文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改。二、发帖界面 1、界面文件名 etpost_cmsphp 为机密请自行修改文件名。请将该接口文件复制到网站的根目录下使用。请自行修改文件名。value的参数可以在发布规则中设置-parameter value 采集 value的参数
几项请添加3个主要参数 pwuser 成员名 参数名 pwpwd 密码 参数名 cms_subject 主题标题 参数名 atc_content 内容参数名 进行手动内容分页,请使用数据排序到 内容分隔标记 ldquo-0 -rdquo 替换为 Phpwind8 的分页标记 [page] 自动分页参数见后面。防止接口被他人使用。如需进一步验证,请自行填写相关代码。5 可选参数 Newstime文章 日期格式要正确。@>_descript 摘要留空会自动摘要cms_jumpurl 跳转链接cms_author 原作者cms_frominfo letter
信息来源cms_fromurl如果要使用来源URL,请填写下图中的post配置6-文章post URL可以填写http你的URL etpost_cmsphp注意 使用区分大小写的服务器用户,请注意 URL 的大小写与 网站 文件的大小写相同。7 接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改。查看返回信息了解错误详情,以便更正返回信息窗口如图1 [err] 账号密码错误[err]1 查看发布规则-参数值-账号密码队列2[err]invalidvercode[err ]1在发布规则-检查URL填写的vercode值与检查接口文件中的vercode值不一致。2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致。3[err]cms 采集_subjectisnull[err]1 使用的规则未能 采集 到标题 2
采集规则的数据整理过滤了标题 3.错误修改了发布规则-发布项中的标题参数名称正确。请参考本文的接口说明部分。4. 发布规则没有开启utf-8编码转换 4[err] 内容不能为空[err] 1 使用的采集规则不正确采集到文本数据项2采集 过滤规则数据和过滤文本数据 3 错误修改发布规则 - 发布项中的文本参数名称正确。请参考接口说明第4节。发布规则不启用utf-8编码转换。文章 查看全部
文章采集接口(
Phpwind80文章中心接口(组图))
Phpwind80文章中央界面用户手册 1 简介 1该界面适用于Phpwind80版本 文章中央栏目文章发布 2该界面只能使用一个发布规则指定多个栏目随机发送到不同栏目发布文章3 这个接口可以采集文章date,让文章发布更真实,见参数newstimezzhours4的说明,因为用户可能同时使用Phpwind8的多个接口时间,请注意修改界面名称使每个界面不同。比如这个interface文件夹中提供的interface文件添加了ldquocmsrdquo 5的文件名后缀,发布时请使用具有文章中央管理权限的用户帐号。6. 在 Phpwind80utf8 版本中使用该接口时,请在发布规则中选择编码为 UTF-87。本界面基于Phpwind80GBK版本。适用于Phpwind80GBKutf-8等版本。请测试并调整 8 接口文件,不要做任何更改。如需添加验证或其他功能,请谨慎修改92接口文件,请到Phpwind80官网复制
使用站点根目录下的第二个安装界面,在interface文件夹中找到interface文件。请将etck_cmsphpetpost_cmsphp等接口文件上传到指定目录。请以二进制方式上传如图3 配置发布规则1 将示例发布规则文本导入ET2发布配置或使用软件内置发布规则示例如图2 更改check URL中的ldquo和网站rdquo 要发布的 URL 的发布 URL 如图 3,在勾选 URL 上填写您要发布的 文章 中心列 ID 文章@ 的中心列 ID > 可以用英文逗号隔开的倍数填写。将鼠标移动到列名上,可以在状态栏中查看列 ID。填写您的帐户密码。注意格式和账号权限如图4。 接口说明 1 查看接口 1. 接口文件名etck_cmsphp 属于机密,请自行修改文件名。2.这个接口文件复制到网站根目录下使用。_主题文章标题
cid 列 ID 用于限制该规则的检查列。您可以填写多种逗号分隔或空白格式。例如,可以在 文章 中心查看 cid789。修改vercode使其一致 4 发布配置 - 文章检查URL可以填写如下 http 你的URL etchk_cmsphpcms_subjectlttitlegtampcid 你的列ID 注意 使用区分大小写的服务器用户 请注意URL 的大小写与 网站 文件相同。5、界面文件无需任何改动即可使用。如需添加验证或其他功能,请谨慎修改。二、发帖界面 1、界面文件名 etpost_cmsphp 为机密请自行修改文件名。请将该接口文件复制到网站的根目录下使用。请自行修改文件名。value的参数可以在发布规则中设置-parameter value 采集 value的参数
几项请添加3个主要参数 pwuser 成员名 参数名 pwpwd 密码 参数名 cms_subject 主题标题 参数名 atc_content 内容参数名 进行手动内容分页,请使用数据排序到 内容分隔标记 ldquo-0 -rdquo 替换为 Phpwind8 的分页标记 [page] 自动分页参数见后面。防止接口被他人使用。如需进一步验证,请自行填写相关代码。5 可选参数 Newstime文章 日期格式要正确。@>_descript 摘要留空会自动摘要cms_jumpurl 跳转链接cms_author 原作者cms_frominfo letter
信息来源cms_fromurl如果要使用来源URL,请填写下图中的post配置6-文章post URL可以填写http你的URL etpost_cmsphp注意 使用区分大小写的服务器用户,请注意 URL 的大小写与 网站 文件的大小写相同。7 接口文件无需修改即可使用。如需添加验证或其他功能,请谨慎修改。查看返回信息了解错误详情,以便更正返回信息窗口如图1 [err] 账号密码错误[err]1 查看发布规则-参数值-账号密码队列2[err]invalidvercode[err ]1在发布规则-检查URL填写的vercode值与检查接口文件中的vercode值不一致。2、发布规则-参数值-附件参数队列中填写的vercode值与发布接口文件中的vercode值不一致。3[err]cms 采集_subjectisnull[err]1 使用的规则未能 采集 到标题 2
采集规则的数据整理过滤了标题 3.错误修改了发布规则-发布项中的标题参数名称正确。请参考本文的接口说明部分。4. 发布规则没有开启utf-8编码转换 4[err] 内容不能为空[err] 1 使用的采集规则不正确采集到文本数据项2采集 过滤规则数据和过滤文本数据 3 错误修改发布规则 - 发布项中的文本参数名称正确。请参考接口说明第4节。发布规则不启用utf-8编码转换。文章
文章采集接口(小说CMS网站内容更新时要注意的事项有哪些呢? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2022-03-15 09:10
)
小说cms系统现在比较流行,比如奇文cms、狂雨cms和杰基cms。无论选择哪一个cms,作为小说站,优质内容是留住用户的核心法宝。优质的网站内容对于用户体验和提升网站权重的重要性,相信每一个从事网站优化的SEOER都心知肚明。
小说cms网站内容的高质量更新应该是我们网站的基础。毕竟,优质的网站文章不仅是网站优化的基本要素,也是提升网站排名和权重的关键因素。
但是,更新小说的内容很重要cms网站,但是如果采用不合理的更新方式,忽略了用户体验或者违反了搜索引擎的相关规则,内容网站 的高质量更新不会有很好的效果。下面我们来简单的看一下更新网站的内容需要注意的事项。
1、保证文章高度原创
蜘蛛喜欢具有新奇内容和原创特征的东西。当网站内容高度原创,更新及时,内容丰富,更有利于给用户带来良好的体验,从而留住用户。但这对于大多数站长来说也是一个难题,因为文章不一定有很多要求,需要技巧,但是优秀的文章的写作往往并不容易。对此,站长们不妨把精品文章做得合适伪原创,但要确保它有价值。
2、掌握关键词或长尾词的密度
不管是哪种文章内容,为了提高相关性,要求我们的文章中必须有关键词或者长尾词。但是我们也不能过度堆叠关键词或者长尾词,因为这样会让蜘蛛认为它在作弊,并且会减少我们的网站的权重。网站在优化内容时,要合理安排关键词的出现次数。
3、网站关键词内部链接
在优化网站的内容时,可以在网站中设置关键词内链,不仅可以降低网站的跳出率,还能带来更好的交互给用户体验也可以集中权重,方便网站权重的提升。
4、网站 内容图片的优化
图文结合是一种比较常见的显示网站内容的方式。图文结合可以更好的吸引用户浏览网页,通过视觉效果减轻疲劳,同时让用户更深入的了解 同时,带标签的图形页面更有可能被蜘蛛收录。
对于小说cms网站的内容优化,可以提升我们网站的排名,吸引更多流量,实现良性循环。我们良性循环的前提是不断优化网站,保持网站内容的高质量更新。
对于机械的重复性工作,我们往往可以借助工具来实现。与网站采集的发布一样,Novelcms也有自己的采集插件,支持24小时挂机,实时捕捉热门新鲜内容. 发布功能支持各种cms,是我们管理网站的好帮手,新颖的cms采集插件也有SEO功能。关键词增加关键词标题的密度,在我们要发布的内容中插入内容。支持图片替换和图片水印,大大提高了我们的文章原创度。支持准时发布,提升爬虫爬取能力。
小说cms网站的内容优化是网站SEO工作的重要组成部分,避免在优化内容时出现一定的失误。会给网站带来好的收录数据和权重,也会受到蜘蛛的青睐,获得好的排名,实现网站的良性循环。
查看全部
文章采集接口(小说CMS网站内容更新时要注意的事项有哪些呢?
)
小说cms系统现在比较流行,比如奇文cms、狂雨cms和杰基cms。无论选择哪一个cms,作为小说站,优质内容是留住用户的核心法宝。优质的网站内容对于用户体验和提升网站权重的重要性,相信每一个从事网站优化的SEOER都心知肚明。
小说cms网站内容的高质量更新应该是我们网站的基础。毕竟,优质的网站文章不仅是网站优化的基本要素,也是提升网站排名和权重的关键因素。
但是,更新小说的内容很重要cms网站,但是如果采用不合理的更新方式,忽略了用户体验或者违反了搜索引擎的相关规则,内容网站 的高质量更新不会有很好的效果。下面我们来简单的看一下更新网站的内容需要注意的事项。
1、保证文章高度原创
蜘蛛喜欢具有新奇内容和原创特征的东西。当网站内容高度原创,更新及时,内容丰富,更有利于给用户带来良好的体验,从而留住用户。但这对于大多数站长来说也是一个难题,因为文章不一定有很多要求,需要技巧,但是优秀的文章的写作往往并不容易。对此,站长们不妨把精品文章做得合适伪原创,但要确保它有价值。
2、掌握关键词或长尾词的密度
不管是哪种文章内容,为了提高相关性,要求我们的文章中必须有关键词或者长尾词。但是我们也不能过度堆叠关键词或者长尾词,因为这样会让蜘蛛认为它在作弊,并且会减少我们的网站的权重。网站在优化内容时,要合理安排关键词的出现次数。
3、网站关键词内部链接
在优化网站的内容时,可以在网站中设置关键词内链,不仅可以降低网站的跳出率,还能带来更好的交互给用户体验也可以集中权重,方便网站权重的提升。
4、网站 内容图片的优化
图文结合是一种比较常见的显示网站内容的方式。图文结合可以更好的吸引用户浏览网页,通过视觉效果减轻疲劳,同时让用户更深入的了解 同时,带标签的图形页面更有可能被蜘蛛收录。
对于小说cms网站的内容优化,可以提升我们网站的排名,吸引更多流量,实现良性循环。我们良性循环的前提是不断优化网站,保持网站内容的高质量更新。
对于机械的重复性工作,我们往往可以借助工具来实现。与网站采集的发布一样,Novelcms也有自己的采集插件,支持24小时挂机,实时捕捉热门新鲜内容. 发布功能支持各种cms,是我们管理网站的好帮手,新颖的cms采集插件也有SEO功能。关键词增加关键词标题的密度,在我们要发布的内容中插入内容。支持图片替换和图片水印,大大提高了我们的文章原创度。支持准时发布,提升爬虫爬取能力。
小说cms网站的内容优化是网站SEO工作的重要组成部分,避免在优化内容时出现一定的失误。会给网站带来好的收录数据和权重,也会受到蜘蛛的青睐,获得好的排名,实现网站的良性循环。

