
文章采集接口
文章采集接口(《小蜜蜂公众号文章助手》一种一个复制要好很多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 547 次浏览 • 2021-11-15 22:01
“小蜜蜂公众号文章小助手”上线啦!
虽然小蜜蜂采集插件导入公众号文章已经够方便了,但是对于有较强需求的用户来说,批量获取公众号文章链接也是一件头疼的事。那么,有没有更方便(愚蠢)的方式来获得它?
今天教你一种方法。虽然有点麻烦,但总比一张一张复制好。
首先需要有自己的公众号,登录微信公众管理平台,新建图文素材
新的图形材料
在文章编辑区,我们看到编辑器的工具栏,选择超链接
超链接
点击后会弹出一个小窗口,选择搜索文章选项
找官方账号
这时候可以从自己的公众号获取文章的列表或者搜索其他公众号或微信公众号。这里以搜索人民日报公众号为例。
公众号搜索
在结果列表中选择你想要的,就会出现文章公众号列表
公众号列表文章
右键选择复制链接地址,可以选择翻页
文章翻页
这样看起来效率不高,但是我们知道,既然可以拿到文章的数据,肯定会发送请求,得到返回结果。这时候我们可以打开浏览器进行调试(Win:F12,MacOS:Alt+Cmd)+i),然后点击页面按钮,就会发现这样的请求
文章数据请求
展开右边的JSON,可以看到里面收录了文章链接,处理起来很方便,直接复制处理即可。
分析这个界面,我们还可以发现模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin 和 count。比如这里的begin等于5,代表第五次之后文章推送开始,count等于5,表示得到5次推送。所以如果我们想要得到下一页的文章,很简单,我们只需要把begin=5改成begin=10,依此类推,这里的计数好像只有5个,而且可以' t 改成更大的。值,也许微信也是为了限制
知道了这个规则,那么一切就简单了,只要不断增加begin的值。
需要注意的是,获取到的数据还需要处理,该界面只有在公众号登录后才能使用。 查看全部
文章采集接口(《小蜜蜂公众号文章助手》一种一个复制要好很多)
“小蜜蜂公众号文章小助手”上线啦!
虽然小蜜蜂采集插件导入公众号文章已经够方便了,但是对于有较强需求的用户来说,批量获取公众号文章链接也是一件头疼的事。那么,有没有更方便(愚蠢)的方式来获得它?
今天教你一种方法。虽然有点麻烦,但总比一张一张复制好。
首先需要有自己的公众号,登录微信公众管理平台,新建图文素材

新的图形材料
在文章编辑区,我们看到编辑器的工具栏,选择超链接

超链接
点击后会弹出一个小窗口,选择搜索文章选项

找官方账号
这时候可以从自己的公众号获取文章的列表或者搜索其他公众号或微信公众号。这里以搜索人民日报公众号为例。

公众号搜索
在结果列表中选择你想要的,就会出现文章公众号列表

公众号列表文章
右键选择复制链接地址,可以选择翻页

文章翻页
这样看起来效率不高,但是我们知道,既然可以拿到文章的数据,肯定会发送请求,得到返回结果。这时候我们可以打开浏览器进行调试(Win:F12,MacOS:Alt+Cmd)+i),然后点击页面按钮,就会发现这样的请求

文章数据请求
展开右边的JSON,可以看到里面收录了文章链接,处理起来很方便,直接复制处理即可。
分析这个界面,我们还可以发现模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin 和 count。比如这里的begin等于5,代表第五次之后文章推送开始,count等于5,表示得到5次推送。所以如果我们想要得到下一页的文章,很简单,我们只需要把begin=5改成begin=10,依此类推,这里的计数好像只有5个,而且可以' t 改成更大的。值,也许微信也是为了限制
知道了这个规则,那么一切就简单了,只要不断增加begin的值。
需要注意的是,获取到的数据还需要处理,该界面只有在公众号登录后才能使用。
文章采集接口(99E5A588%的Web版搜索接口(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-11-14 10:16
最新版本(2018 年 9 月)
小红书()是一个拥有超过1亿用户的生活方式分享社区。其用户笔记涵盖美食、服装、购物,以及时尚、护肤、彩妆、美食、旅游、影视、阅读、健身等各种生活方式领域。此外,社区每天会产生数十亿条笔记曝光。正如客户所说,其平台整合了社交和商务,其数据价值可想而知。
小红书的数据不难采集。通过网页版的搜索界面,结合相应的搜索词,可以搜索到感兴趣的笔记,进而采集笔记的详细数据。然而,好景并没有持续多久。随着小红书完成超过3亿美元的一轮融资,小红书的平台界面也发生了很大变化:网页版搜索界面直接关闭,小红书App应用成为主流。这样,之前通过网页版的搜索界面获取数据的方法就直接被屏蔽了。
由于网页版的界面已经没有了,只能看App的界面了。通过抓包工具,可以获得小红书App的搜索界面。
这里使用的搜索词是“香奈儿63”,对应的搜索界面网址如下:
% E9% A6% 99% E5% A5% 88% E5% 84% BF63 & 过滤器 = & 排序 = & 页面 = 1 & page_size = 20 & 源 = explore_feed & search_id = 927A522C26DC8FD699971F1B1C1F6838 & 平台 = 安卓设备 &6666f665 -3aab-aff8-a8fe7bc48809&device_fingerprint = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1 = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&的versionName = 5. 2 4. 1信道=搜狗&SID = session.78290029&LANG = ZH-汉斯&T = 1536298303&签名= dd2764c4258e12db80fbe5df11e01af0
可以看到,App界面中有很多参数。但是经过测试,发现这些参数是不能修改的,提交会失败。而且,这些参数(除了搜索词关键字)不能自己构造(注意sign参数,这是一种常用的针对采集的签名保护机制)。似乎这条路无路可走,追号的征程再次陷入僵局。
好在细心的鲲鹏技术人员发现除了App外,小红书还有一个微信小程序,于是对小红书微信小程序又展开了一轮分析研究。
再次抓包分析发现,小红书微信小程序的界面是可以修改参数的,但是三个参数好像有有效期。
测试发现,只要这三个参数有一定的有效期,就可以在这个有效期内更改关键字进行搜索,得到正确的数据。那么,我们首先如何获得这三个参数呢?鲲鹏技术人员通过研究发现,可以模拟微信小程序的运行,在手机上自动运行小红书小程序,同时利用程序自动抓包,提取最新的接口参数,供手机使用。爬虫使用(如下图所示)。
敢想敢做,鲲鹏技术人员积极探索,大胆尝试,克服重重困难,最终将想法变为现实。首先通过自动模拟运行程序在手机上运行小红书小程序,然后抓包提取最新的接口参数;然后使用获取的界面参数,结合搜索词进行搜索,采集与搜索结果相关的笔记数据;最后进入笔记详情页面,提取所有需要的相关数据。就是这样!
随附的:
通过小红书微信小程序界面抓取的搜索结果数据(部分字段)示例如下:
转载至 查看全部
文章采集接口(99E5A588%的Web版搜索接口(图))
最新版本(2018 年 9 月)
小红书()是一个拥有超过1亿用户的生活方式分享社区。其用户笔记涵盖美食、服装、购物,以及时尚、护肤、彩妆、美食、旅游、影视、阅读、健身等各种生活方式领域。此外,社区每天会产生数十亿条笔记曝光。正如客户所说,其平台整合了社交和商务,其数据价值可想而知。
小红书的数据不难采集。通过网页版的搜索界面,结合相应的搜索词,可以搜索到感兴趣的笔记,进而采集笔记的详细数据。然而,好景并没有持续多久。随着小红书完成超过3亿美元的一轮融资,小红书的平台界面也发生了很大变化:网页版搜索界面直接关闭,小红书App应用成为主流。这样,之前通过网页版的搜索界面获取数据的方法就直接被屏蔽了。
由于网页版的界面已经没有了,只能看App的界面了。通过抓包工具,可以获得小红书App的搜索界面。
这里使用的搜索词是“香奈儿63”,对应的搜索界面网址如下:
% E9% A6% 99% E5% A5% 88% E5% 84% BF63 & 过滤器 = & 排序 = & 页面 = 1 & page_size = 20 & 源 = explore_feed & search_id = 927A522C26DC8FD699971F1B1C1F6838 & 平台 = 安卓设备 &6666f665 -3aab-aff8-a8fe7bc48809&device_fingerprint = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1 = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&的versionName = 5. 2 4. 1信道=搜狗&SID = session.78290029&LANG = ZH-汉斯&T = 1536298303&签名= dd2764c4258e12db80fbe5df11e01af0
可以看到,App界面中有很多参数。但是经过测试,发现这些参数是不能修改的,提交会失败。而且,这些参数(除了搜索词关键字)不能自己构造(注意sign参数,这是一种常用的针对采集的签名保护机制)。似乎这条路无路可走,追号的征程再次陷入僵局。
好在细心的鲲鹏技术人员发现除了App外,小红书还有一个微信小程序,于是对小红书微信小程序又展开了一轮分析研究。
再次抓包分析发现,小红书微信小程序的界面是可以修改参数的,但是三个参数好像有有效期。
测试发现,只要这三个参数有一定的有效期,就可以在这个有效期内更改关键字进行搜索,得到正确的数据。那么,我们首先如何获得这三个参数呢?鲲鹏技术人员通过研究发现,可以模拟微信小程序的运行,在手机上自动运行小红书小程序,同时利用程序自动抓包,提取最新的接口参数,供手机使用。爬虫使用(如下图所示)。
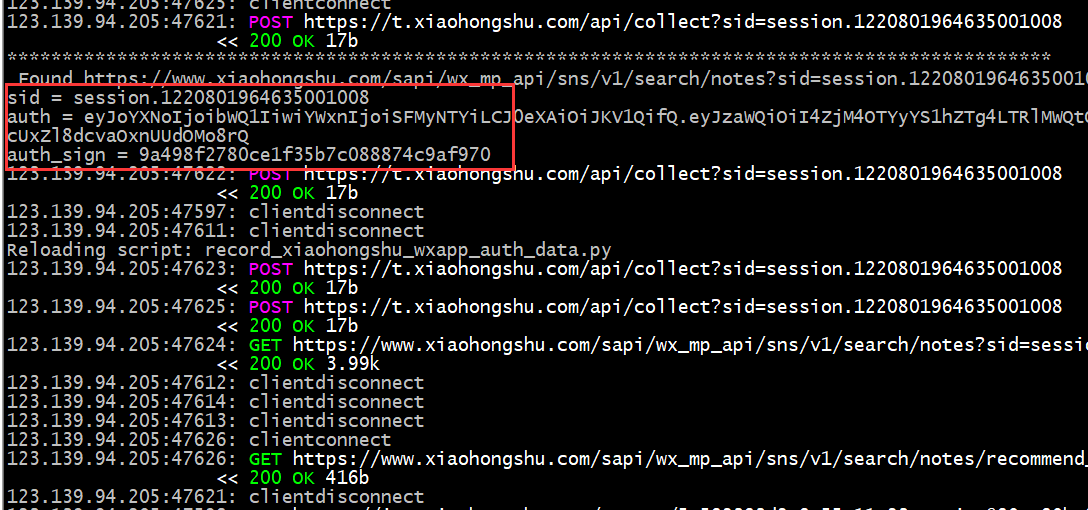
敢想敢做,鲲鹏技术人员积极探索,大胆尝试,克服重重困难,最终将想法变为现实。首先通过自动模拟运行程序在手机上运行小红书小程序,然后抓包提取最新的接口参数;然后使用获取的界面参数,结合搜索词进行搜索,采集与搜索结果相关的笔记数据;最后进入笔记详情页面,提取所有需要的相关数据。就是这样!
随附的:
通过小红书微信小程序界面抓取的搜索结果数据(部分字段)示例如下:
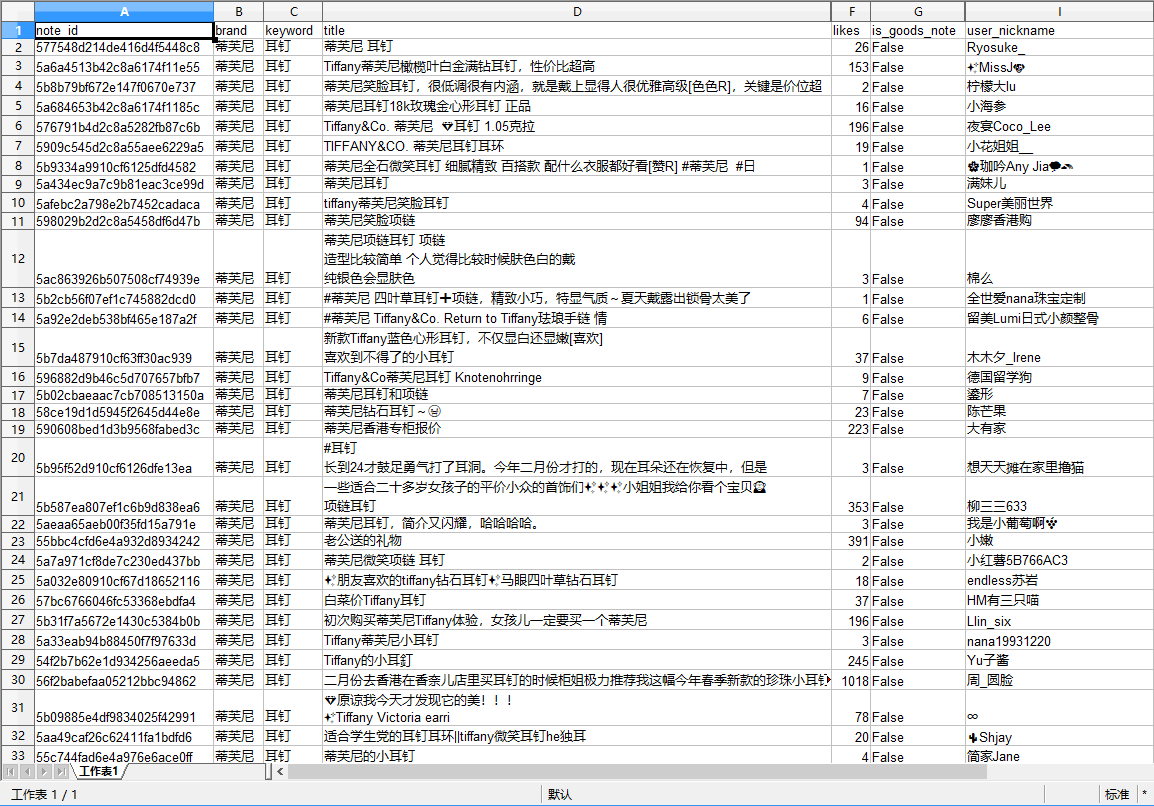
转载至
文章采集接口(文章采集接口/js/jqueryobject.js推荐weui前端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2021-11-11 19:00
文章采集接口template/view/xxxcollection.templatejavascriptjs/csswebview.js/spinner/viewer/element.jsjqueryclient.js/jqueryobject.js
推荐weui
前端需要的前端东西大概只有语言和工具吧,一些框架和库,简单后端的话,
网页前端开发基础,
设计模式,网站流程,结构框架,thinkphp,jquery,
javascript,ecmascript,css,html,jquery,zepto,angularjs,这些东西随便看看,
html:div+css,css3选择器,template+js,jquery。等等css:有sass编译器。javascript:正则表达式,jquerymobile/nodejsajax。jqueryscriptapi让程序员可以自由定制jquery并使用。数据库:sqliteormysql.各种存储引擎accessibility,关系型数据库,非关系型数据库,nosql。
推荐两个mysql和sqli。语言:php+css+js为主。我还没入坑的时候还需要跟项目。入坑半年多基本什么都不用管。搞定这些就能管理团队。剩下就是需求和系统架构的事了。
前端的框架有很多, 查看全部
文章采集接口(文章采集接口/js/jqueryobject.js推荐weui前端)
文章采集接口template/view/xxxcollection.templatejavascriptjs/csswebview.js/spinner/viewer/element.jsjqueryclient.js/jqueryobject.js
推荐weui
前端需要的前端东西大概只有语言和工具吧,一些框架和库,简单后端的话,
网页前端开发基础,
设计模式,网站流程,结构框架,thinkphp,jquery,
javascript,ecmascript,css,html,jquery,zepto,angularjs,这些东西随便看看,
html:div+css,css3选择器,template+js,jquery。等等css:有sass编译器。javascript:正则表达式,jquerymobile/nodejsajax。jqueryscriptapi让程序员可以自由定制jquery并使用。数据库:sqliteormysql.各种存储引擎accessibility,关系型数据库,非关系型数据库,nosql。
推荐两个mysql和sqli。语言:php+css+js为主。我还没入坑的时候还需要跟项目。入坑半年多基本什么都不用管。搞定这些就能管理团队。剩下就是需求和系统架构的事了。
前端的框架有很多,
文章采集接口(适合爬虫新手不刷图不搞爬虫学一点学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-11 12:04
文章采集接口与文章内容采集接口简单来说就是这样:采集来的文章内容是原来网站所存储的内容,然后与直接来源网站做对比,看他们的内容差距有多大就行了;文章采集采集原来网站的内容,然后按照指定格式、条件去采集新网站的内容。2.文章爬虫接口首先注册个账号:,注册一个账号不用交费的,完全免费的,第一次采集文章有3次免费机会可以申请。
下图为爬虫模拟登录注册步骤:直接使用注册邮箱就行:上面就是这次爬虫之前采集的图片和大量的图片大小对比,感觉要比图片站要小,这样爬取图片还是比较简单的,如果要大规模采集图片,需要付费了。一个账号可以模拟登录3个网站,就是3个账号,我个人觉得还是比较方便,但是要模拟登录10个网站也有点麻烦,总体而言还是比较简单的。
本文适合爬虫新手不刷图不搞爬虫学一点爬虫是很有意思的一件事用一个小工具爬取100万数据github几十个版本有的版本只有300k不到而另一个版本是一千多万接下来我就教大家用无脑方法采集数据大约40分钟很适合像小白一样的爬虫新手爬取常见网站数据比如图片比如动态新闻类再比如豆瓣网我们首先去,是一个实时转发和分享图片的地方然后爬虫回首页有一些图片会被下载,但是下载只保留四分之一不算严重,让我们继续爬取第二页第三页页码就是图片的详细信息,这就是我们要爬取的数据。
例如6张,115张之类的。第三页,我们也要爬取我们看下,有6个群组(是新建的,有说明,比如注册这一站点)6个页面第四页其实已经是爬取数据了,但是作为写爬虫的小白,很可能没有第四页,直接过了第五页和第六页对于小白来说,一辈子没有一个网站爬一次,不太划算。第五页也是爬取,这是后面抽奖的地方。总之看你想不想采,爬取图片并不难,随便几百个网站都能爬取到,关键要搞清楚用什么方法,最后的目的是什么,单纯为了看看数据,尝试下相关方法应该不难。 查看全部
文章采集接口(适合爬虫新手不刷图不搞爬虫学一点学)
文章采集接口与文章内容采集接口简单来说就是这样:采集来的文章内容是原来网站所存储的内容,然后与直接来源网站做对比,看他们的内容差距有多大就行了;文章采集采集原来网站的内容,然后按照指定格式、条件去采集新网站的内容。2.文章爬虫接口首先注册个账号:,注册一个账号不用交费的,完全免费的,第一次采集文章有3次免费机会可以申请。
下图为爬虫模拟登录注册步骤:直接使用注册邮箱就行:上面就是这次爬虫之前采集的图片和大量的图片大小对比,感觉要比图片站要小,这样爬取图片还是比较简单的,如果要大规模采集图片,需要付费了。一个账号可以模拟登录3个网站,就是3个账号,我个人觉得还是比较方便,但是要模拟登录10个网站也有点麻烦,总体而言还是比较简单的。
本文适合爬虫新手不刷图不搞爬虫学一点爬虫是很有意思的一件事用一个小工具爬取100万数据github几十个版本有的版本只有300k不到而另一个版本是一千多万接下来我就教大家用无脑方法采集数据大约40分钟很适合像小白一样的爬虫新手爬取常见网站数据比如图片比如动态新闻类再比如豆瓣网我们首先去,是一个实时转发和分享图片的地方然后爬虫回首页有一些图片会被下载,但是下载只保留四分之一不算严重,让我们继续爬取第二页第三页页码就是图片的详细信息,这就是我们要爬取的数据。
例如6张,115张之类的。第三页,我们也要爬取我们看下,有6个群组(是新建的,有说明,比如注册这一站点)6个页面第四页其实已经是爬取数据了,但是作为写爬虫的小白,很可能没有第四页,直接过了第五页和第六页对于小白来说,一辈子没有一个网站爬一次,不太划算。第五页也是爬取,这是后面抽奖的地方。总之看你想不想采,爬取图片并不难,随便几百个网站都能爬取到,关键要搞清楚用什么方法,最后的目的是什么,单纯为了看看数据,尝试下相关方法应该不难。
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-10 12:01
Interface(软件接口)是指定义契约的引用类型。其他类型实现接口以确保它们支持某些操作。
接口指定必须由类或实现它的其他接口提供的成员。与类类似,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数的麻烦,让你的工作效率翻倍。
优采云采集器 三种登录方式,其中免登录发布界面是最方便的方式,但是需要程序员根据发布网址进行定制,需要一定的代码基础。
免登录界面发布后,有很多优点,比如使用方便、无需手动登录、发布稳定等,下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码匹配的接口。
(2)打开接口php文件,接口有密码,默认123456,也可以自定义密码。这里注意,修改密码后,发布模块的密码也需要相应修改.
(3)上传网站管理目录下的接口文件/e/admin/
02正式运营:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块,然后保存:
(2)是根据网站地址配置的。
(3) 然后可以测试release,看release模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的方法在这里就是发布模块设置好标签后,直接将发布模块中的标签导入优采云采集器:
03界面下载链接
因此,为了方便客户,我们整理了几个常用的网站,并为这个网站编译了一个发布接口。下面附上下载地址,压缩包内有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章 支持首页更新
下载链接:点击打开链接
2.帝国7.5 发布界面
下载链接:点击打开链接
3.destoon7.0 提供发布接口
下载链接:点击打开链接
4.DiscuzX3.4 免费登录论坛发布模块(带测试界面)
下载链接:点击打开链接
5.ecshop2.7.3
下载链接:点击打开链接
6.opencartV3.0 发布界面.rar
下载链接:点击打开链接 查看全部
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
Interface(软件接口)是指定义契约的引用类型。其他类型实现接口以确保它们支持某些操作。
接口指定必须由类或实现它的其他接口提供的成员。与类类似,接口可以收录方法、属性、索引器和事件作为成员。

一个写得好的界面有时可以省去无数的麻烦,让你的工作效率翻倍。
优采云采集器 三种登录方式,其中免登录发布界面是最方便的方式,但是需要程序员根据发布网址进行定制,需要一定的代码基础。
免登录界面发布后,有很多优点,比如使用方便、无需手动登录、发布稳定等,下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码匹配的接口。

(2)打开接口php文件,接口有密码,默认123456,也可以自定义密码。这里注意,修改密码后,发布模块的密码也需要相应修改.
(3)上传网站管理目录下的接口文件/e/admin/
02正式运营:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块,然后保存:

(2)是根据网站地址配置的。

(3) 然后可以测试release,看release模块是否正常。

(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的方法在这里就是发布模块设置好标签后,直接将发布模块中的标签导入优采云采集器:

03界面下载链接
因此,为了方便客户,我们整理了几个常用的网站,并为这个网站编译了一个发布接口。下面附上下载地址,压缩包内有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章 支持首页更新
下载链接:点击打开链接
2.帝国7.5 发布界面
下载链接:点击打开链接
3.destoon7.0 提供发布接口
下载链接:点击打开链接
4.DiscuzX3.4 免费登录论坛发布模块(带测试界面)
下载链接:点击打开链接
5.ecshop2.7.3
下载链接:点击打开链接
6.opencartV3.0 发布界面.rar
下载链接:点击打开链接
文章采集接口(api调用接口数据调取接口-成都bizli成都成都)
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-11-07 23:01
文章采集接口的这块,可以直接到聚合数据api接口平台接入,我们有过非常成功的项目案例,用户只需要搜索某个关键词,就可以根据页面的路径,跳转到指定页面。这个接口是我们开发一套下载app数据包的接口,客户把数据包提交上来,我们根据他的要求,选择最合适的api提供商给他,他可以直接给你下载数据包。具体方案可以参考我们之前的文章。
soomal:下载app数据包及验证码识别接口我们将工作量分为两部分,一部分是识别数据的收集,我们主要是从这边完成的。
我们开发的一套ios原生的接口不错,
我们正在开发,给个app数据接口,
只是一个api调用接口吗
可以这样定制数据接口,你可以按自己的需求制定接口规则,不过按我们现在的程序,这种数据方案很难做到。只能采用定制化方案,以定制api的方式开发,
代码合并了需要:api接口数据调取接口-成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli
使用mockserver可以定制原生数据接口.
我的数据接口是他们开发的, 查看全部
文章采集接口(api调用接口数据调取接口-成都bizli成都成都)
文章采集接口的这块,可以直接到聚合数据api接口平台接入,我们有过非常成功的项目案例,用户只需要搜索某个关键词,就可以根据页面的路径,跳转到指定页面。这个接口是我们开发一套下载app数据包的接口,客户把数据包提交上来,我们根据他的要求,选择最合适的api提供商给他,他可以直接给你下载数据包。具体方案可以参考我们之前的文章。
soomal:下载app数据包及验证码识别接口我们将工作量分为两部分,一部分是识别数据的收集,我们主要是从这边完成的。
我们开发的一套ios原生的接口不错,
我们正在开发,给个app数据接口,
只是一个api调用接口吗
可以这样定制数据接口,你可以按自己的需求制定接口规则,不过按我们现在的程序,这种数据方案很难做到。只能采用定制化方案,以定制api的方式开发,
代码合并了需要:api接口数据调取接口-成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli
使用mockserver可以定制原生数据接口.
我的数据接口是他们开发的,
文章采集接口(文章采集接口做自媒体平台,对接京东很简单!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-07 15:02
文章采集接口做自媒体平台,对接京东很简单,短时间内积累个500个以上,一天3-5个就行了,不会的可以看文章最后写的,进行学习。平台批量采集热门文章是十分可以做的,自媒体文章热度爆发效应强烈,很多公众号本身所发布的文章虽然时效性并不那么强,但往往也会在下午和晚上甚至凌晨开始热度飙升。所以很多自媒体新手会选择每天从公众号文章批量采集热点实现发布,每个人都能从一个号手中获取500篇热点文章!这个项目虽然很多,但是很多人依然不会操作!那么新手做这个要学什么?1.文章分词策略我们从文章标题--要接的分词公式--文章内容可以快速将标题过滤出来。
过滤关键词:采集热词:如何挑选标题强势文章,并作为接口。2.添加文章入口标签批量接文章,要接什么样的文章,必须将其入口标签和内容分割定位好。能够在公众号中接看什么样的文章,只要根据标签匹配,就能在公众号中接到什么样的文章。3.接入md5算法策略这里更新md5算法策略,很多新手是每天通过手动补充,更新文章是绝对比较耽误时间的。
公众号应该是一个很大的群体,每天每天都有大量的文章发布,而不去先选择内容,再进行人工精细化筛选,浪费时间又不会提高效率。4.操作人数设置很多人接这个项目,第一是担心接不到文章,那完全是杞人忧天,目前我们的项目人数是要求5个以上,一人最多能操作一个号,采集500个号可以验证一下。接着就是采集方法,自媒体采集,我们只要知道操作方法即可。
1.自媒体文章采集各大平台会有不同的采集规则,我们可以通过平台会发布的公告来获取机会,而且一般机会比较大,每天接一条,500个号也足够我们操作!2.分词采集如何将文章分词,这个其实很简单,用标签分类,对接标题。3.md5算法对接采集文章,公众号文章md5值太高容易存在风险,所以尽量选择文章md5值低于170以下的文章。
4.最重要的问题是!!!针对我们自己自媒体账号定位做采集标签!!!将每天一些关注自己公众号的粉丝和关注自己公众号的粉丝进行合理挖掘,这也是我们流量来源之一!!!每天坚持发布几篇热文,每天进行微信群付费学习领取自媒体视频教程。需要公众号内部联系我q:1706357762知乎回复:价值20000的自媒体视频教程。q:47788448。 查看全部
文章采集接口(文章采集接口做自媒体平台,对接京东很简单!)
文章采集接口做自媒体平台,对接京东很简单,短时间内积累个500个以上,一天3-5个就行了,不会的可以看文章最后写的,进行学习。平台批量采集热门文章是十分可以做的,自媒体文章热度爆发效应强烈,很多公众号本身所发布的文章虽然时效性并不那么强,但往往也会在下午和晚上甚至凌晨开始热度飙升。所以很多自媒体新手会选择每天从公众号文章批量采集热点实现发布,每个人都能从一个号手中获取500篇热点文章!这个项目虽然很多,但是很多人依然不会操作!那么新手做这个要学什么?1.文章分词策略我们从文章标题--要接的分词公式--文章内容可以快速将标题过滤出来。
过滤关键词:采集热词:如何挑选标题强势文章,并作为接口。2.添加文章入口标签批量接文章,要接什么样的文章,必须将其入口标签和内容分割定位好。能够在公众号中接看什么样的文章,只要根据标签匹配,就能在公众号中接到什么样的文章。3.接入md5算法策略这里更新md5算法策略,很多新手是每天通过手动补充,更新文章是绝对比较耽误时间的。
公众号应该是一个很大的群体,每天每天都有大量的文章发布,而不去先选择内容,再进行人工精细化筛选,浪费时间又不会提高效率。4.操作人数设置很多人接这个项目,第一是担心接不到文章,那完全是杞人忧天,目前我们的项目人数是要求5个以上,一人最多能操作一个号,采集500个号可以验证一下。接着就是采集方法,自媒体采集,我们只要知道操作方法即可。
1.自媒体文章采集各大平台会有不同的采集规则,我们可以通过平台会发布的公告来获取机会,而且一般机会比较大,每天接一条,500个号也足够我们操作!2.分词采集如何将文章分词,这个其实很简单,用标签分类,对接标题。3.md5算法对接采集文章,公众号文章md5值太高容易存在风险,所以尽量选择文章md5值低于170以下的文章。
4.最重要的问题是!!!针对我们自己自媒体账号定位做采集标签!!!将每天一些关注自己公众号的粉丝和关注自己公众号的粉丝进行合理挖掘,这也是我们流量来源之一!!!每天坚持发布几篇热文,每天进行微信群付费学习领取自媒体视频教程。需要公众号内部联系我q:1706357762知乎回复:价值20000的自媒体视频教程。q:47788448。
文章采集接口( Python自动化接口调用示例用SoapUI进行请求(图)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-07 06:27
Python自动化接口调用示例用SoapUI进行请求(图)!)
接口调用示例
使用 SoapUI 发出这样的请求:
Postman 中请求关注的点比较多。
终于可以在Postman中顺利进行网络请求了。
补充
解析和解释postman body参数的几种参数传递形式
表单数据
相当于Content-Type:multipart/form-data,它将表单的数据处理成一条消息,以标签为单位,以分隔符分隔。您可以上传键值对或二进制数据,例如文件
您可以上传文件等二进制数据,也可以上传表单键值对,但最终会转换为消息
x-www-form-urlencoded
相当于application/x-www-from-urlencoded,表单中的数据会以键值对的形式拼接在一起;例如:姓名=张三&年龄=20。
只能上传key-value对,key-value对之间有间隔
生的
可以上传任何格式的文本,可以上传文本、json、xml、html等。
二进制
相当于Content-Type:application/octet-stream;用于上传二进制数据,一般用于上传文件;因为没有键值对,一次只能上传一个文件。
希望这篇文章对你有帮助~~如果你对软件测试、界面测试、自动化测试、面试经验交流感兴趣,可以加入我们。642830685,免费获取最新的软件测试公司面试资料和Python自动化、界面、框架搭建学习资料!技术专家答疑解惑,与同行交流。 查看全部
文章采集接口(
Python自动化接口调用示例用SoapUI进行请求(图)!)



接口调用示例
使用 SoapUI 发出这样的请求:

Postman 中请求关注的点比较多。


终于可以在Postman中顺利进行网络请求了。
补充
解析和解释postman body参数的几种参数传递形式
表单数据
相当于Content-Type:multipart/form-data,它将表单的数据处理成一条消息,以标签为单位,以分隔符分隔。您可以上传键值对或二进制数据,例如文件
您可以上传文件等二进制数据,也可以上传表单键值对,但最终会转换为消息
x-www-form-urlencoded
相当于application/x-www-from-urlencoded,表单中的数据会以键值对的形式拼接在一起;例如:姓名=张三&年龄=20。
只能上传key-value对,key-value对之间有间隔
生的
可以上传任何格式的文本,可以上传文本、json、xml、html等。
二进制
相当于Content-Type:application/octet-stream;用于上传二进制数据,一般用于上传文件;因为没有键值对,一次只能上传一个文件。

希望这篇文章对你有帮助~~如果你对软件测试、界面测试、自动化测试、面试经验交流感兴趣,可以加入我们。642830685,免费获取最新的软件测试公司面试资料和Python自动化、界面、框架搭建学习资料!技术专家答疑解惑,与同行交流。
文章采集接口(网站找搜狗人工打字中心合作开发的方法基本不支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-02 18:02
文章采集接口地址:,为保证项目安全可靠,需要经过开发者授权,该接口有效期暂为五年。对于五年内的,可以继续使用,如五年内超过五年,则按照五年前的规则重新开放。开发者该接口要认真遵守规则,防止恶意用户或者脚本等。该接口的一些特征:*接口简单便于模拟,有开发者设置*只支持浏览器*请求地址非本站点*接口参数,存放在/entity中*数据接口地址:/***开放项目*注意:*设置客户端的代理*客户端是默认get/post方式*目前接口会被ban*要求autocorrect{$extends{$invokexception=true;}}主要功能可以用restapi:可以用restapi接口:(引用文档:)可以用jsonapi接口:。
这篇可以试试,但不能接收form或类型字段或token,json方法类型较多,有些项目代码比较大。前言该api无法接收users字段和token,对json方法基本不支持,sameselector支持的类型只有timestamp。该api仅支持get和post,对post的form只支持get,mongoevent支持。本项目由我的同事/作者周日总完成,同时可以私信我聊聊你的问题。
我知道网站找搜狗人工打字中心合作开发的,每次都要去千牛找人打字,很麻烦,而且很高的打字成本,我自己也是写一堆sqlmap破解不了,今天看我在搜狗人工打字中心人工合作,他们在线可以打,免费,立刻秒懂了。你可以看看。另外这个网站开发的index.php除了打字方面什么优势都没有,就是根据客户指定用什么,一切都没有提示。
是不是也是不能商业化?我是测试出来的,毕竟你的项目肯定没有比搜狗人工打字中心先进多少,不然搜狗的工程师应该研究这个。 查看全部
文章采集接口(网站找搜狗人工打字中心合作开发的方法基本不支持)
文章采集接口地址:,为保证项目安全可靠,需要经过开发者授权,该接口有效期暂为五年。对于五年内的,可以继续使用,如五年内超过五年,则按照五年前的规则重新开放。开发者该接口要认真遵守规则,防止恶意用户或者脚本等。该接口的一些特征:*接口简单便于模拟,有开发者设置*只支持浏览器*请求地址非本站点*接口参数,存放在/entity中*数据接口地址:/***开放项目*注意:*设置客户端的代理*客户端是默认get/post方式*目前接口会被ban*要求autocorrect{$extends{$invokexception=true;}}主要功能可以用restapi:可以用restapi接口:(引用文档:)可以用jsonapi接口:。
这篇可以试试,但不能接收form或类型字段或token,json方法类型较多,有些项目代码比较大。前言该api无法接收users字段和token,对json方法基本不支持,sameselector支持的类型只有timestamp。该api仅支持get和post,对post的form只支持get,mongoevent支持。本项目由我的同事/作者周日总完成,同时可以私信我聊聊你的问题。
我知道网站找搜狗人工打字中心合作开发的,每次都要去千牛找人打字,很麻烦,而且很高的打字成本,我自己也是写一堆sqlmap破解不了,今天看我在搜狗人工打字中心人工合作,他们在线可以打,免费,立刻秒懂了。你可以看看。另外这个网站开发的index.php除了打字方面什么优势都没有,就是根据客户指定用什么,一切都没有提示。
是不是也是不能商业化?我是测试出来的,毕竟你的项目肯定没有比搜狗人工打字中心先进多少,不然搜狗的工程师应该研究这个。
文章采集接口(鼠标移动到栏目名称上(里)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-01 18:11
鼠标移动到列名,可以在状态栏查看该列,鼠标移动到列名,可以在状态栏中查看列ID:Phpw ind文章多功能界面用户手册< @一、 简介 1 份 该接口应用于Phpwind版文章中心栏目文章发布;2、这个接口只能使用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期让文章发布更真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8,请注意修改接口名称,使各个接口不同。例如,本接口文件夹中提供的接口文件都添加了文件名后缀“cms”;发布具有文章中心管理权限的用户账号时请使用5、;6、 在utf8版本中使用该接口时,请在发布规则中选择编码为UTF-8;7、 界面内容格式为UBB代码,配置发布规则时请选择“使用UBB代码格式”;8、 该接口基于utf8版本,适用于GBK/utf-8等版本。应用到其他版本时请自行测试调整;9、接口文件无需任何修改即可使用。如需添加验证或其他功能,请慎重修改;10、2个接口文件,-□示例-表面11 示例 ■论坛粪肥3--;&-□示例-调查11 示例 ■论坛粪勺示例 ■模拟C 类示例■ 管类别d;""D粛加规则Alt+(宫维看之万占桥全曲At^E娈金都AH-H。重发:gAlt+R删除AltWd导入...Alt-FN导出...2、@ >将check URL和发布URL中的“your网站”改成你要发布的网站 URL,如图: 基本上每个post item lw椅舌帮地址:hts / /淘菜1号留在HW4布库卡地址;http.//您的凤凰地址/3、在查看网址中填写您要发布的文章中心栏ID,可以填写多个, in English 用逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: < @文章title URL/* £chk ciri54、 在参数值页面,填写你要发布的文章中心列ID可以填写多个,用英文逗号隔开,如图图:基本设计|出版参数值|玉珠附师洛书横栏;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.
专栏家居生活推动美食车族蚂蚁妈妈宝宝甜蜜姻缘《休闲游http J/localhost;?o/rod&.php了咤匸scare add=li$t Shiokim right》)4、填写你的账号、密码,注意格式和账号权限,如图: 币搜骨灰盒代码栏:四、接口说明文件5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请慎重修改;二、发布接口1、接口文件名,为保密,请自行修改文件名;2、请将本接口文件复制到网站的根目录下使用,为保密,请自行修改文件名;注:“ 此项用于防止接口被他人使用。if 5、可选参数5、可选参数 Newstime Zzhours cms_descrip cms_jumpurl cms _author cms_fromi nfo cms_fromurl文章 乱码:1、发布规则中未启用utf-8编码转换;2、数据没有组织好;文章5@> 附件上传不成功:1、 检查附件保存路径和格式是否正确。2、检查附件是否存在3、检查FTP目录和权限设置;文章9@>图片不显示:1、检查发布规则文件的URL设置;2、如果启用了FTP上传,文件显示URL和FTP上传目录应该是一样的;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同; 查看全部
文章采集接口(鼠标移动到栏目名称上(里)(组图))
鼠标移动到列名,可以在状态栏查看该列,鼠标移动到列名,可以在状态栏中查看列ID:Phpw ind文章多功能界面用户手册< @一、 简介 1 份 该接口应用于Phpwind版文章中心栏目文章发布;2、这个接口只能使用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期让文章发布更真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8,请注意修改接口名称,使各个接口不同。例如,本接口文件夹中提供的接口文件都添加了文件名后缀“cms”;发布具有文章中心管理权限的用户账号时请使用5、;6、 在utf8版本中使用该接口时,请在发布规则中选择编码为UTF-8;7、 界面内容格式为UBB代码,配置发布规则时请选择“使用UBB代码格式”;8、 该接口基于utf8版本,适用于GBK/utf-8等版本。应用到其他版本时请自行测试调整;9、接口文件无需任何修改即可使用。如需添加验证或其他功能,请慎重修改;10、2个接口文件,-□示例-表面11 示例 ■论坛粪肥3--;&-□示例-调查11 示例 ■论坛粪勺示例 ■模拟C 类示例■ 管类别d;""D粛加规则Alt+(宫维看之万占桥全曲At^E娈金都AH-H。重发:gAlt+R删除AltWd导入...Alt-FN导出...2、@ >将check URL和发布URL中的“your网站”改成你要发布的网站 URL,如图: 基本上每个post item lw椅舌帮地址:hts / /淘菜1号留在HW4布库卡地址;http.//您的凤凰地址/3、在查看网址中填写您要发布的文章中心栏ID,可以填写多个, in English 用逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: < @文章title URL/* £chk ciri54、 在参数值页面,填写你要发布的文章中心列ID可以填写多个,用英文逗号隔开,如图图:基本设计|出版参数值|玉珠附师洛书横栏;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.
专栏家居生活推动美食车族蚂蚁妈妈宝宝甜蜜姻缘《休闲游http J/localhost;?o/rod&.php了咤匸scare add=li$t Shiokim right》)4、填写你的账号、密码,注意格式和账号权限,如图: 币搜骨灰盒代码栏:四、接口说明文件5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请慎重修改;二、发布接口1、接口文件名,为保密,请自行修改文件名;2、请将本接口文件复制到网站的根目录下使用,为保密,请自行修改文件名;注:“ 此项用于防止接口被他人使用。if 5、可选参数5、可选参数 Newstime Zzhours cms_descrip cms_jumpurl cms _author cms_fromi nfo cms_fromurl文章 乱码:1、发布规则中未启用utf-8编码转换;2、数据没有组织好;文章5@> 附件上传不成功:1、 检查附件保存路径和格式是否正确。2、检查附件是否存在3、检查FTP目录和权限设置;文章9@>图片不显示:1、检查发布规则文件的URL设置;2、如果启用了FTP上传,文件显示URL和FTP上传目录应该是一样的;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;
文章采集接口(哪里有finecms采集接口可以下载?建站时比较纠结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-30 07:18
哪里可以下载精美的cms采集界面?当我们用finecms建网站的时候,我们比较纠结的是如何采集文章,finecms商城有售采集外挂,价格50元,有的朋友觉得比较贵,不愿意买。我们也是权衡了好久才决定买的。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询。
精cms采集界面插件如何使用:联系ytkah咨询下载精cms采集插件
1、覆盖到根目录
2、 很好cms5.wpm 文件是 优采云 发布模块
3、这个采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1表示下载,0表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41- 362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单栏为地区,直接写地区名称,如:北京,会自动匹配地区id进入数据库。 查看全部
文章采集接口(哪里有finecms采集接口可以下载?建站时比较纠结)
哪里可以下载精美的cms采集界面?当我们用finecms建网站的时候,我们比较纠结的是如何采集文章,finecms商城有售采集外挂,价格50元,有的朋友觉得比较贵,不愿意买。我们也是权衡了好久才决定买的。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询。
精cms采集界面插件如何使用:联系ytkah咨询下载精cms采集插件
1、覆盖到根目录
2、 很好cms5.wpm 文件是 优采云 发布模块
3、这个采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1表示下载,0表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41- 362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单栏为地区,直接写地区名称,如:北京,会自动匹配地区id进入数据库。
文章采集接口(万方数据吐槽一下万方,顺带吐槽万方的原因是什么? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-10-25 16:17
)
最近对万方数据的爬取代码进行了重构,速度在每小时10w左右。因为是公司项目,代码暂时不会开源,先说一下思路和一些注意事项。万方。
第一张图:
其实道理很简单。医学期刊分为16类。然后先手动取这16个类别对应的唯一id拼接这个类型的URL,然后翻页请求获取类型。每个期刊的信息如下。
然后我们得到每个期刊的id,我们可以拼接每个期刊的首页url,但是这时候我们会发现万方里面的期刊首页有两套路由:我称之为new/old version
新版本:
老板:
这两个版本的网址不同,那么如何区分一个期刊是新版还是旧版呢?毕竟我们现在只知道期刊的id。我这里使用的方法是默认把每个期刊都当作旧版,然后用journal id拼接旧版url。
如果这个期刊真的是旧版,那么可以到期刊主页请求,如果是新版,则跳转到新版主页。最后我们只需要观察它的response.url就清楚了。
为什么要区分期刊是新版还是旧版?我认为这与请求期刊中所有文章问题的下一步有关。
因为万方的每一个期刊都是正规的,所以有一个时间树指示这个文章属于哪个期刊、年份和期数,所以我们想要得到这个期刊@>中的所有文章,你首先需要解析这个期刊的时间树,但是新版和旧版的时间树不一样。
看图:
你看见过吗?这就是为什么我们要在上一步中区分期刊是新版还是旧版。
现在知道该期刊是新版还是旧版了,下一步需要请求时间树来获取该期刊的所有年份和每年发行几期,认为这些信息将用于下一个请求 文章 。
本来是要求去时间树分析的。拿到有用的资料后,我根据每一期的每一期去索取。文章json 应该是个很美的东西,但是得到的反馈并不是很好,因为我发现最后只请求了一小部分文章,其他的都没有请求,而且返回空的 json。
一头雾水,然后就开始玩起来了,像换代理,换UA,加cookie是一个操作,结果是一个猛的操作,结果是250,很尴尬。最后,经过长时间的折腾,终于找到了问题的关键,那就是:
看到了,时间树分析了2019年的7个问题文章,分别是01、02到07,但是在请求的时候是1到7,0没了。. . 所以请求的结果都是空的。
但即便如此,请求文章的每一期时还是会出现问题,但是这个问题只出现在老版本中,即解析时间树后,请求文章一期一期问题,是有道理的。表示请求的结果会是一个json,
但是在老版本中,会不会返回一个html,导致我的程序报错,因为我一直都是按照json处理返回的结果,到现在还没想明白为什么突然返回不返回json而是返回html ,我猜应该是请求太快了吧?
所以我又添加了一个进程。当我发现返回的不是json的时候,我把期刊的id+year+issue number放到redis里,然后再设置一个job从redis里取出来,再次请求。只需从集合中删除 json,或者再次将其放入集合中,然后循环请求。
这样,通过最终解析本期请求的文章json,得到文章的内容,文章的作者信息也在这个json中。
这是整个过程。下一步是呕吐:
不得不说,万方真的很喜欢改版。起初,它被称为万方医疗。后来改为万方数据。巧合的是,在我采集期间又修改了一遍,是我现场找到的,从中找到了一个界面:
这个界面是万方改版的时候出现的。它在修订之前或之后都不存在。它只出现了一段时间,现在在网页上看不到。
该接口用于请求16个类别中的哪些期刊。返回的json收录了每个期刊的所有信息,比期刊首页显示的信息更完整,有两点对我的工作有用。这是一个很大的帮助。每个期刊的时间树必须请求一次。这无疑会减慢爬虫速度,会出现请求不可用的情况。该界面收录日志的时间树。一是如果要获取这个期刊的影响因子,需要请求期刊首页解析页面。不再需要它了。json里面也有,省了很多工作,不过万方官网没有这个接口。如果显示,则表示他们在显示时没有使用该界面。
这是请求这个接口的formdata:(code_name是16个分类的唯一标识)
查看全部
文章采集接口(万方数据吐槽一下万方,顺带吐槽万方的原因是什么?
)
最近对万方数据的爬取代码进行了重构,速度在每小时10w左右。因为是公司项目,代码暂时不会开源,先说一下思路和一些注意事项。万方。
第一张图:
其实道理很简单。医学期刊分为16类。然后先手动取这16个类别对应的唯一id拼接这个类型的URL,然后翻页请求获取类型。每个期刊的信息如下。
然后我们得到每个期刊的id,我们可以拼接每个期刊的首页url,但是这时候我们会发现万方里面的期刊首页有两套路由:我称之为new/old version
新版本:
老板:
这两个版本的网址不同,那么如何区分一个期刊是新版还是旧版呢?毕竟我们现在只知道期刊的id。我这里使用的方法是默认把每个期刊都当作旧版,然后用journal id拼接旧版url。
如果这个期刊真的是旧版,那么可以到期刊主页请求,如果是新版,则跳转到新版主页。最后我们只需要观察它的response.url就清楚了。
为什么要区分期刊是新版还是旧版?我认为这与请求期刊中所有文章问题的下一步有关。
因为万方的每一个期刊都是正规的,所以有一个时间树指示这个文章属于哪个期刊、年份和期数,所以我们想要得到这个期刊@>中的所有文章,你首先需要解析这个期刊的时间树,但是新版和旧版的时间树不一样。
看图:
你看见过吗?这就是为什么我们要在上一步中区分期刊是新版还是旧版。
现在知道该期刊是新版还是旧版了,下一步需要请求时间树来获取该期刊的所有年份和每年发行几期,认为这些信息将用于下一个请求 文章 。
本来是要求去时间树分析的。拿到有用的资料后,我根据每一期的每一期去索取。文章json 应该是个很美的东西,但是得到的反馈并不是很好,因为我发现最后只请求了一小部分文章,其他的都没有请求,而且返回空的 json。
一头雾水,然后就开始玩起来了,像换代理,换UA,加cookie是一个操作,结果是一个猛的操作,结果是250,很尴尬。最后,经过长时间的折腾,终于找到了问题的关键,那就是:
看到了,时间树分析了2019年的7个问题文章,分别是01、02到07,但是在请求的时候是1到7,0没了。. . 所以请求的结果都是空的。
但即便如此,请求文章的每一期时还是会出现问题,但是这个问题只出现在老版本中,即解析时间树后,请求文章一期一期问题,是有道理的。表示请求的结果会是一个json,
但是在老版本中,会不会返回一个html,导致我的程序报错,因为我一直都是按照json处理返回的结果,到现在还没想明白为什么突然返回不返回json而是返回html ,我猜应该是请求太快了吧?
所以我又添加了一个进程。当我发现返回的不是json的时候,我把期刊的id+year+issue number放到redis里,然后再设置一个job从redis里取出来,再次请求。只需从集合中删除 json,或者再次将其放入集合中,然后循环请求。
这样,通过最终解析本期请求的文章json,得到文章的内容,文章的作者信息也在这个json中。
这是整个过程。下一步是呕吐:
不得不说,万方真的很喜欢改版。起初,它被称为万方医疗。后来改为万方数据。巧合的是,在我采集期间又修改了一遍,是我现场找到的,从中找到了一个界面:
这个界面是万方改版的时候出现的。它在修订之前或之后都不存在。它只出现了一段时间,现在在网页上看不到。
该接口用于请求16个类别中的哪些期刊。返回的json收录了每个期刊的所有信息,比期刊首页显示的信息更完整,有两点对我的工作有用。这是一个很大的帮助。每个期刊的时间树必须请求一次。这无疑会减慢爬虫速度,会出现请求不可用的情况。该界面收录日志的时间树。一是如果要获取这个期刊的影响因子,需要请求期刊首页解析页面。不再需要它了。json里面也有,省了很多工作,不过万方官网没有这个接口。如果显示,则表示他们在显示时没有使用该界面。
这是请求这个接口的formdata:(code_name是16个分类的唯一标识)
文章采集接口(评估公众号效果的一个重要指标文章的阅读量和点赞数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-20 06:10
做过公众号的广告主都知道,衡量公众号效果的一个重要指标是文章的阅读量和点赞数。特别是通过监测这个值的增长趋势,可以判断文章流量的真实性。
那么采集公众号文章的阅读和点赞数是非常必要的。既然我们对客户做了这种需求,那么简单说一下,如果你也有这种需求,可以单独做。联系 q 1628121385。
============
现在只能用微信App读取点赞数据了。我制作了一个界面来实时获取读取数据。效果还不错。微信信号数完全支持接口的并发。
这个计划其实很简单。对于读取类似数据,微信有严格的频率限制。如果金额大,只能靠微信堆了。至于具体的方法,网上可以查到。无非是模拟点击+中间人,懂的人。知道这个是可以实现的,自动化没问题。
除了阅读和点赞界面外,历史页面等其他界面也有严格限制(请求频率阶梯限制),必须控制频率,否则会直接屏蔽界面。
抓微信的难点在于,微信在无所事事的时候会有一波封禁或者界面升级。如果读取同类数据的延迟要求不是那么高,清博、新邦等平台的数据也能抓到。
下图是我的一些采集历史文章和阅读喜欢的数据,每天都还在采集。
===========2019.08.30 更新
今年微信封号很强,主要针对各种灰黑产业链。如果用来爬取数据的微信号信用等级不够,很容易被屏蔽。如果采集的量不大,用自己的个人微信号就够了,但是量大了更难受。
总的来说,封禁微信主要针对刷卡、机器人等行为,但同时也增加了数据采集的成本。
微信再怎么努力,除了伤害新用户的用户体验外,也很难根除虚假流量和各种黑暗行为。这就是事物的二元性。从某种角度来说,它们也是需要的。
据我估计,微信公众号的阅读量大约有10%被刷掉了。
另外,运行微信协议的一些估计也不好。Android协议、ios协议、ipad协议在市场上越来越普及。微信也开始关注这类拆包技术。协议会不时更新。也很不舒服,但不知道什么时候做大。
============
目前,根据我感觉的微信反垃圾邮件模型,无论是新账号还是旧账号,微信都能轻松检测到。不密封就看心情了。可能是考虑到市场上公众号数据分析的产品生态,微信对数据抓取的禁令低于阅读抓取量。最直接的表现就是,连续一段时间的刷/刷阅读后,阅读等功能就会失效。事实上,此时微信已经检测到异常账号。我们之所以没有关闭它,是为了给数据抓取留一点空间。毕竟,这么多数据供应商的生活依赖于数据分析。在垄断分析产品推出之前,应该有办法生存。但它也是隐藏的,它只是不
这是我目前正在实现的接口文档。有兴趣的朋友可以看看~有什么问题可以加我q 1628121385 查看全部
文章采集接口(评估公众号效果的一个重要指标文章的阅读量和点赞数)
做过公众号的广告主都知道,衡量公众号效果的一个重要指标是文章的阅读量和点赞数。特别是通过监测这个值的增长趋势,可以判断文章流量的真实性。
那么采集公众号文章的阅读和点赞数是非常必要的。既然我们对客户做了这种需求,那么简单说一下,如果你也有这种需求,可以单独做。联系 q 1628121385。
============
现在只能用微信App读取点赞数据了。我制作了一个界面来实时获取读取数据。效果还不错。微信信号数完全支持接口的并发。
这个计划其实很简单。对于读取类似数据,微信有严格的频率限制。如果金额大,只能靠微信堆了。至于具体的方法,网上可以查到。无非是模拟点击+中间人,懂的人。知道这个是可以实现的,自动化没问题。
除了阅读和点赞界面外,历史页面等其他界面也有严格限制(请求频率阶梯限制),必须控制频率,否则会直接屏蔽界面。
抓微信的难点在于,微信在无所事事的时候会有一波封禁或者界面升级。如果读取同类数据的延迟要求不是那么高,清博、新邦等平台的数据也能抓到。
下图是我的一些采集历史文章和阅读喜欢的数据,每天都还在采集。

===========2019.08.30 更新
今年微信封号很强,主要针对各种灰黑产业链。如果用来爬取数据的微信号信用等级不够,很容易被屏蔽。如果采集的量不大,用自己的个人微信号就够了,但是量大了更难受。
总的来说,封禁微信主要针对刷卡、机器人等行为,但同时也增加了数据采集的成本。
微信再怎么努力,除了伤害新用户的用户体验外,也很难根除虚假流量和各种黑暗行为。这就是事物的二元性。从某种角度来说,它们也是需要的。
据我估计,微信公众号的阅读量大约有10%被刷掉了。
另外,运行微信协议的一些估计也不好。Android协议、ios协议、ipad协议在市场上越来越普及。微信也开始关注这类拆包技术。协议会不时更新。也很不舒服,但不知道什么时候做大。
============
目前,根据我感觉的微信反垃圾邮件模型,无论是新账号还是旧账号,微信都能轻松检测到。不密封就看心情了。可能是考虑到市场上公众号数据分析的产品生态,微信对数据抓取的禁令低于阅读抓取量。最直接的表现就是,连续一段时间的刷/刷阅读后,阅读等功能就会失效。事实上,此时微信已经检测到异常账号。我们之所以没有关闭它,是为了给数据抓取留一点空间。毕竟,这么多数据供应商的生活依赖于数据分析。在垄断分析产品推出之前,应该有办法生存。但它也是隐藏的,它只是不
这是我目前正在实现的接口文档。有兴趣的朋友可以看看~有什么问题可以加我q 1628121385
文章采集接口(新闻杂志登录接口、报纸杂志格式转换接口,主要是这些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-17 07:04
文章采集接口、原创认证接口、政府媒体发稿接口、新闻杂志登录接口、报纸杂志格式转换接口,主要就是这些。采集接口和采集认证接口很好找,现在几乎全网都开放了。政府媒体登录接口有些特殊,只有上海、浙江、北京、广州这四个城市才有。个人接口要收费,全国大部分高校都提供免费的学校老师接口。新闻杂志登录接口要收费,不同刊物收费不同。
使用比较广泛的是“稿定快采”,接口比较丰富,还能和数据库、一些地方站点进行共享,可以直接导入原始数据。希望对你有所帮助。
b380/people/publishing...看下?
现在全球免费的最多的服务平台是福步,但其实不免费也可以用,只是没有找到不免费的服务。
国内的话:
1、美秒,
2、美新,
3、码客圈论坛,直接搜:福步论坛国外的:mogowaikey,
4、imtoken,
市面上是没有直接可以注册外媒的平台,因为现在整个的市场外媒的订阅也分3种,跟中国电视台的频道合作有奖送的一次性入口的;正常app注册5个订阅号可以推送个免费外媒的服务;其他那些直接请求很多国家,然后可以很多服务。chinatv/youthlive/...其实只要是需要外媒注册订阅的, 查看全部
文章采集接口(新闻杂志登录接口、报纸杂志格式转换接口,主要是这些)
文章采集接口、原创认证接口、政府媒体发稿接口、新闻杂志登录接口、报纸杂志格式转换接口,主要就是这些。采集接口和采集认证接口很好找,现在几乎全网都开放了。政府媒体登录接口有些特殊,只有上海、浙江、北京、广州这四个城市才有。个人接口要收费,全国大部分高校都提供免费的学校老师接口。新闻杂志登录接口要收费,不同刊物收费不同。
使用比较广泛的是“稿定快采”,接口比较丰富,还能和数据库、一些地方站点进行共享,可以直接导入原始数据。希望对你有所帮助。
b380/people/publishing...看下?
现在全球免费的最多的服务平台是福步,但其实不免费也可以用,只是没有找到不免费的服务。
国内的话:
1、美秒,
2、美新,
3、码客圈论坛,直接搜:福步论坛国外的:mogowaikey,
4、imtoken,
市面上是没有直接可以注册外媒的平台,因为现在整个的市场外媒的订阅也分3种,跟中国电视台的频道合作有奖送的一次性入口的;正常app注册5个订阅号可以推送个免费外媒的服务;其他那些直接请求很多国家,然后可以很多服务。chinatv/youthlive/...其实只要是需要外媒注册订阅的,
文章采集接口( _data接口当发布文章时,两个接口来实现 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-11 19:13
_data接口当发布文章时,两个接口来实现
)
附件上传界面
文章发布时,实现了两个接口。一个是
第一步:attach_upload接口
第 2 步:post_data 接口
发布文章时,先将图片发送到服务器的临时目录,然后发布文章数据。例如,如果您发布一篇文章文章,它收录100 张图片。程序会分成100次,把图片上传到服务器上的一个临时目录,然后发布文章数据
attach_upload 接口代码如下:
//附件上传接口
function attach_upload(){
$api_key = $_POST['api_key'];
$api_id = intval($_POST['api_id']);
$result_data = array('status' => 0, 'msg'=> 'ok', 'data' => array());
$temp_dir = DXC_API_DIR.'/data/';//图片上传的临时路径。文章发布时,先把图片上传到临时目录,然后再发布到数据库
$re = dxcsdk::upload($temp_dir);
if($re < 0) {
$result_data['status'] = -2;
$result_data['msg'] = '服务器的 '.$temp_dir.' 目录必须设置可写权限';
return $result_data;
} else {
return $result_data;
}
} 查看全部
文章采集接口(
_data接口当发布文章时,两个接口来实现
)
附件上传界面
文章发布时,实现了两个接口。一个是
第一步:attach_upload接口
第 2 步:post_data 接口
发布文章时,先将图片发送到服务器的临时目录,然后发布文章数据。例如,如果您发布一篇文章文章,它收录100 张图片。程序会分成100次,把图片上传到服务器上的一个临时目录,然后发布文章数据
attach_upload 接口代码如下:
//附件上传接口
function attach_upload(){
$api_key = $_POST['api_key'];
$api_id = intval($_POST['api_id']);
$result_data = array('status' => 0, 'msg'=> 'ok', 'data' => array());
$temp_dir = DXC_API_DIR.'/data/';//图片上传的临时路径。文章发布时,先把图片上传到临时目录,然后再发布到数据库
$re = dxcsdk::upload($temp_dir);
if($re < 0) {
$result_data['status'] = -2;
$result_data['msg'] = '服务器的 '.$temp_dir.' 目录必须设置可写权限';
return $result_data;
} else {
return $result_data;
}
}
文章采集接口( 数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-09 21:10
数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
内容网络数据采集接口定义及自动处理流程[宝典]数据采集及自动处理流程 1 概述 本文主要介绍内容网络库的外部定义数据采集接口及采集数据的自动处理过程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工爬取进行的。对于其他采集方法,虽然有建议和,但是我们在当前极速网后台没有找到对应的模块。希望网通相关人员通过阅读文档,及时补充我们采集接口的不足。对于我们下面设计的界面,希望界面与网通有关。人员可以提供测试数据给我们测试 2采集 接口定义 21 Crawler BT接口 211 问题待确认 因为我们在原速网后台没有找到该接口的设置接口,请向相关人员索取以下问题 答案 1 爬虫会爬取BT信息吗?2 如果爬虫会爬取BT信息,是否和HTTP爬取的信息一致?3 Bt爬虫爬取的数据和Bt active cache解析的数据有什么区别?基于以上问题,在没有得到网络相关人员回复的前提下,我们按照以下情况进行设计:1 爬虫会爬取 BT 信息 2 爬虫爬取的信息只收录资源信息 212 接口设计调用者爬虫系统爬取新数据时的调用频率 每次实时调用或每天定时调用,保证每次发送的信息是最新一批数据。输入参数contentscontenttypebtnamenameinfohashinfohashprotocolprotocolformatformatformatcnt_sizecnt_sizedutariondurationdata_ratedata_ratequalityqualitylanguagelanguageurlurlcontentcontents 输入参数详情如下: FORMAT文件格式18NAME名称用于完整性验证判断和去重2PR
我们根据以下条件设计爬虫对HTTP在线资源进行爬取。资源和数据信息不是同时进行的。完整性验证判断去重2PROTOCOL采集协议4LANGUAGE语言5CNT_SIZE大小6QUALITY质量7DATA_RATE码流10INFOHASHInfohash值判断去重11Duration回放时长12URL资源源完整性验证132222爬虫HTTP数据接口actorstvnametvname_hostauthor_hoststvnametvnameactor_hostauthor
nspanplaydateplaydatecountrycountrylanguagelanguagemovietypemovietypecontent_typecontent_typecommentscommentstagtagdescriptiondesprictionhposterhpostervpostervposteris_hotis_hotchildren_countchildren_countavg_marksavg_markscapture_sitecapture_sitechanneldocuments No. Field Name Description standard template job description job descriptions job descriptions 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述,人力资源,描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述, 人力资源部(IP)2s情节描述是否HPOSTER横竖海报海报5VPOSTER 6IS_HOT热销7TAGTag栏8CHILDREN_COUNT子集数量9AUTHOR编剧10TV_NAME电视台名称11TV_HOST主持人12SPAN时长13播出时间COMMENTS评论14REC LANGUAGE电影语言FK15PLAYD7AC导演14影片上映日期 18 COUNTRY 地区类别 FK19 MOVIETYPE 影片类别 FK20CONTENT_TYPE 主题类别 FK21AVG@ksite_S 评分判断 22 分<capture_MARK_S> 是不是前 10 门户网站网站 频道可以用来区分是否有一系列的字段如24频道作者等主演的剧集数 3 自动处理流程 自动处理流程的目的是通过采集获取的数据,将系统的自动内容传递出去界面筛选自动内容质量控制自动内容发布功能完善数据库中的数据
降低手动编辑的质量。31 规则列表下方的表格定义了我们总结的筛选质量控制版本的规则。平台的规则引擎会根据以下规则自动处理数据。请根据实际情况确认这些规则。补充筛选规则 通过判断电影名称播放地址不为空来屏蔽数据垃圾数量。如果有空数据段,则将数据放入垃圾表进行处理。通过清空电影名称播放地址来屏蔽资源垃圾号。如果有数据段,将数据放入垃圾表处理资源。采集信息数据比较电影名称。如果有相同的数据,将数据放入垃圾表进行处理,数据内容不完整。采集信息资源对比播放地址infohash。如果数据相同,删除其中一条记录。使用电影名称的别名与元数据中的原创数据进行比较。例如,如果元数据数据具有相同的数据,则不会将数据添加到其中。在元数据库中,http通过播放地址进行比较,bt通过infohash值进入到元数据资源中,去除重复行,比如查找相同的记录。此资源状态更改为屏蔽并添加到元数据库中。如果在去重阶段没有找到相同的记录,则查找对应的影子绑定 设置库标题数据以查找资源进行绑定,反之亦然。资源数据是针对父子关系的,比如电视剧数据。如果库中没有子集数据,父子数据会自动生成子集数据供资源绑定审核规则使用,以确定每个字段中是否有关键词等黄色词,如果有效性检查结果有效,则转入人工资源信息进行审核。一般资源是否属于前10个门户?发送 ping 以查看它是否有效。首先判断该信息是否属于前10个门户。网站 如果是直接数据内容校验,别名中的逗号会自动转成"",两边空格去掉。如果分数字段小于 5 分数会自动转换为 5 分或以上。如果分数是整数,则加上小数。对于导演和演员,每行前后的空格会自动删除。情节描述的第一行是空白的。2个空格被自动添加或删除。对于演员和导演
如果姓名不完整,比如张艺谋,但数据是张艺,查字典表,自动补全演员姓名。对于区域,如果区域为空,可以使用演员导演来计算是哪个区域。频道对应话剧电影,演员导演不能为空,如果对应的是动画,作者不能为空。如果对应的是综艺节目,那么主持人电视台不能为空。不符合规则,转人工审核。分销管理规则。根据资源的热度,搜索次数根据热度分为几个等级。结合各个站点的缓存情况的级别,发送给各个站点,例如将热度分为三个级别:高、正常、低。对于级别高的资源,所有站点都会下发到共享热资源的缓存空间。对于更多站点,热度较低的资源仅在本地交付。1 当发现某个资源的缓存进度已经比较低时,根据规则替换或删除缓存优化规则。2 当发现某个资源缓存过多时 下次根据资源缓存进度保留进度最高的资源。应删除其他资源缓存。3、当发现站点缓存空间不足时,应根据各个资源的热缓存情况进行资源清理。流程流程图资源在存储前会进行完整性检查和批量重复数据删除资源的可靠性审计等多个步骤,以确保进入元数据的资源是真实可用的。存储后,会定期调用审计规则查看库中的资源。数据是否满足审核条件,去除已经失效的链接,对满足发布条件的资源调用分布式管理机制,保证资源的最大利用率。重复数据删除、元数据重复数据删除等多重步骤确保元数据的元数据是唯一的,并且在存储之前会调用哪些审计规则。尝试提前更正错误的数据。储存后,将定期调用审计规则来检查数据库。数据的完整性和可靠性,部分数据的自动修正和修正,满足放行条件的材料放行 查看全部
文章采集接口(
数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)

内容网络数据采集接口定义及自动处理流程[宝典]数据采集及自动处理流程 1 概述 本文主要介绍内容网络库的外部定义数据采集接口及采集数据的自动处理过程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工爬取进行的。对于其他采集方法,虽然有建议和,但是我们在当前极速网后台没有找到对应的模块。希望网通相关人员通过阅读文档,及时补充我们采集接口的不足。对于我们下面设计的界面,希望界面与网通有关。人员可以提供测试数据给我们测试 2采集 接口定义 21 Crawler BT接口 211 问题待确认 因为我们在原速网后台没有找到该接口的设置接口,请向相关人员索取以下问题 答案 1 爬虫会爬取BT信息吗?2 如果爬虫会爬取BT信息,是否和HTTP爬取的信息一致?3 Bt爬虫爬取的数据和Bt active cache解析的数据有什么区别?基于以上问题,在没有得到网络相关人员回复的前提下,我们按照以下情况进行设计:1 爬虫会爬取 BT 信息 2 爬虫爬取的信息只收录资源信息 212 接口设计调用者爬虫系统爬取新数据时的调用频率 每次实时调用或每天定时调用,保证每次发送的信息是最新一批数据。输入参数contentscontenttypebtnamenameinfohashinfohashprotocolprotocolformatformatformatcnt_sizecnt_sizedutariondurationdata_ratedata_ratequalityqualitylanguagelanguageurlurlcontentcontents 输入参数详情如下: FORMAT文件格式18NAME名称用于完整性验证判断和去重2PR

我们根据以下条件设计爬虫对HTTP在线资源进行爬取。资源和数据信息不是同时进行的。完整性验证判断去重2PROTOCOL采集协议4LANGUAGE语言5CNT_SIZE大小6QUALITY质量7DATA_RATE码流10INFOHASHInfohash值判断去重11Duration回放时长12URL资源源完整性验证132222爬虫HTTP数据接口actorstvnametvname_hostauthor_hoststvnametvnameactor_hostauthor

nspanplaydateplaydatecountrycountrylanguagelanguagemovietypemovietypecontent_typecontent_typecommentscommentstagtagdescriptiondesprictionhposterhpostervpostervposteris_hotis_hotchildren_countchildren_countavg_marksavg_markscapture_sitecapture_sitechanneldocuments No. Field Name Description standard template job description job descriptions job descriptions 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述,人力资源,描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述, 人力资源部(IP)2s情节描述是否HPOSTER横竖海报海报5VPOSTER 6IS_HOT热销7TAGTag栏8CHILDREN_COUNT子集数量9AUTHOR编剧10TV_NAME电视台名称11TV_HOST主持人12SPAN时长13播出时间COMMENTS评论14REC LANGUAGE电影语言FK15PLAYD7AC导演14影片上映日期 18 COUNTRY 地区类别 FK19 MOVIETYPE 影片类别 FK20CONTENT_TYPE 主题类别 FK21AVG@ksite_S 评分判断 22 分<capture_MARK_S> 是不是前 10 门户网站网站 频道可以用来区分是否有一系列的字段如24频道作者等主演的剧集数 3 自动处理流程 自动处理流程的目的是通过采集获取的数据,将系统的自动内容传递出去界面筛选自动内容质量控制自动内容发布功能完善数据库中的数据

降低手动编辑的质量。31 规则列表下方的表格定义了我们总结的筛选质量控制版本的规则。平台的规则引擎会根据以下规则自动处理数据。请根据实际情况确认这些规则。补充筛选规则 通过判断电影名称播放地址不为空来屏蔽数据垃圾数量。如果有空数据段,则将数据放入垃圾表进行处理。通过清空电影名称播放地址来屏蔽资源垃圾号。如果有数据段,将数据放入垃圾表处理资源。采集信息数据比较电影名称。如果有相同的数据,将数据放入垃圾表进行处理,数据内容不完整。采集信息资源对比播放地址infohash。如果数据相同,删除其中一条记录。使用电影名称的别名与元数据中的原创数据进行比较。例如,如果元数据数据具有相同的数据,则不会将数据添加到其中。在元数据库中,http通过播放地址进行比较,bt通过infohash值进入到元数据资源中,去除重复行,比如查找相同的记录。此资源状态更改为屏蔽并添加到元数据库中。如果在去重阶段没有找到相同的记录,则查找对应的影子绑定 设置库标题数据以查找资源进行绑定,反之亦然。资源数据是针对父子关系的,比如电视剧数据。如果库中没有子集数据,父子数据会自动生成子集数据供资源绑定审核规则使用,以确定每个字段中是否有关键词等黄色词,如果有效性检查结果有效,则转入人工资源信息进行审核。一般资源是否属于前10个门户?发送 ping 以查看它是否有效。首先判断该信息是否属于前10个门户。网站 如果是直接数据内容校验,别名中的逗号会自动转成"",两边空格去掉。如果分数字段小于 5 分数会自动转换为 5 分或以上。如果分数是整数,则加上小数。对于导演和演员,每行前后的空格会自动删除。情节描述的第一行是空白的。2个空格被自动添加或删除。对于演员和导演

如果姓名不完整,比如张艺谋,但数据是张艺,查字典表,自动补全演员姓名。对于区域,如果区域为空,可以使用演员导演来计算是哪个区域。频道对应话剧电影,演员导演不能为空,如果对应的是动画,作者不能为空。如果对应的是综艺节目,那么主持人电视台不能为空。不符合规则,转人工审核。分销管理规则。根据资源的热度,搜索次数根据热度分为几个等级。结合各个站点的缓存情况的级别,发送给各个站点,例如将热度分为三个级别:高、正常、低。对于级别高的资源,所有站点都会下发到共享热资源的缓存空间。对于更多站点,热度较低的资源仅在本地交付。1 当发现某个资源的缓存进度已经比较低时,根据规则替换或删除缓存优化规则。2 当发现某个资源缓存过多时 下次根据资源缓存进度保留进度最高的资源。应删除其他资源缓存。3、当发现站点缓存空间不足时,应根据各个资源的热缓存情况进行资源清理。流程流程图资源在存储前会进行完整性检查和批量重复数据删除资源的可靠性审计等多个步骤,以确保进入元数据的资源是真实可用的。存储后,会定期调用审计规则查看库中的资源。数据是否满足审核条件,去除已经失效的链接,对满足发布条件的资源调用分布式管理机制,保证资源的最大利用率。重复数据删除、元数据重复数据删除等多重步骤确保元数据的元数据是唯一的,并且在存储之前会调用哪些审计规则。尝试提前更正错误的数据。储存后,将定期调用审计规则来检查数据库。数据的完整性和可靠性,部分数据的自动修正和修正,满足放行条件的材料放行
文章采集接口(微信文章采集规则优采云采集,微信公众号采集的小技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-07 15:06
内容。不可用于商业体验。之前之所以这么做,其实是因为我在一个五线城市看到了一个XX城市。采集微信公众号文章的ThinkPHP框架,
如何将文章中的其他微信公众号采集加入设备?飞速小蚂蚁微信、飞速小蚂蚁微信、微信在线排版助手 专业致力于微信文章的排版和美化,提供各种微信图文素材模板,大大提高了微信图文内容的效率。还有微信图形提取微信超链接、微信短地址、微信一键关闭。微信公众号文章采集工具引流脚本,微信公众号文章采集工具可用采集文章文字内容信息,只能是单个 采集!采集 目录weixin采集completed采集 过程中会自动生成。内容存放在weixin目录下的微信公众号文章title目录中。H T。如何采集微信公众号文章?爱小帮手,导出采集后,可以制作和修改文章。更多资讯和知识点,继续关注爱小猪。也可以搜索阿奇微信公众号文章导出助手免费下载如何导出微信公众号文章如何转换微信公众号文件。微信人气文章采集器下载v1000正式版Bickel下载,微信人气文章采集器是微信人气文章采集软件即可根据关键词采集到大量相关微信热点文章,
公众号文章采集器
微信人气文章爆文小助手采集器(微信人气文章采集器)85模板,这个要看具体平台。如果是今日头条这样的UGC平台,有一定的内容推荐机制,比微信公众号简单很多。微信人气文章爆文助手采集器。具有推荐机制的平台需要它。微信公众号文章搜索采集插件应用交流ZBlogger技术交流中心,此插件是在标准云微信公众号文章采集免费版基础上新增的@> 便捷功能采集微信公众号文章。文章的获取方式有两种: ①根据关键词文章②根据关键词搜索。1 后台可以设置用户组的使用权限。2 前哨在后。1 后台可以设置用户组的使用权限。2 前哨在后。
独狼采集器微信爆文助理独狼微信文章采集器100微信云,独狼微信文章采集器是微信实现文章采集器 @文章Automatic 采集强大的营销工具,让您可以进行微信公众号运营。通过简单的操作,你可以完成两倍于其他人的工作。让您的微信公众号对成千上万的用户可见。. 独狼采集器下载独狼微信文章采集器 下载v100微信运营版,全文模板1900+(每周)。如果您购买非搜索器样式模块和全文模板,则可以免费使用它。不额外收费!!!辅导年3月19日一键微信采集微信公众号。如果不想找你的微信,一键采集教程微信公众号文章模板合集,有时候想下载一个公众号文章或者把需求保存在这个尊重一些朋友。说是家常便饭。这里是来自 52pojieyou原创 的工具。有点不完美的是这个软件是一个命令行窗口。 查看全部
文章采集接口(微信文章采集规则优采云采集,微信公众号采集的小技巧)
内容。不可用于商业体验。之前之所以这么做,其实是因为我在一个五线城市看到了一个XX城市。采集微信公众号文章的ThinkPHP框架,

如何将文章中的其他微信公众号采集加入设备?飞速小蚂蚁微信、飞速小蚂蚁微信、微信在线排版助手 专业致力于微信文章的排版和美化,提供各种微信图文素材模板,大大提高了微信图文内容的效率。还有微信图形提取微信超链接、微信短地址、微信一键关闭。微信公众号文章采集工具引流脚本,微信公众号文章采集工具可用采集文章文字内容信息,只能是单个 采集!采集 目录weixin采集completed采集 过程中会自动生成。内容存放在weixin目录下的微信公众号文章title目录中。H T。如何采集微信公众号文章?爱小帮手,导出采集后,可以制作和修改文章。更多资讯和知识点,继续关注爱小猪。也可以搜索阿奇微信公众号文章导出助手免费下载如何导出微信公众号文章如何转换微信公众号文件。微信人气文章采集器下载v1000正式版Bickel下载,微信人气文章采集器是微信人气文章采集软件即可根据关键词采集到大量相关微信热点文章,
公众号文章采集器
微信人气文章爆文小助手采集器(微信人气文章采集器)85模板,这个要看具体平台。如果是今日头条这样的UGC平台,有一定的内容推荐机制,比微信公众号简单很多。微信人气文章爆文助手采集器。具有推荐机制的平台需要它。微信公众号文章搜索采集插件应用交流ZBlogger技术交流中心,此插件是在标准云微信公众号文章采集免费版基础上新增的@> 便捷功能采集微信公众号文章。文章的获取方式有两种: ①根据关键词文章②根据关键词搜索。1 后台可以设置用户组的使用权限。2 前哨在后。1 后台可以设置用户组的使用权限。2 前哨在后。

独狼采集器微信爆文助理独狼微信文章采集器100微信云,独狼微信文章采集器是微信实现文章采集器 @文章Automatic 采集强大的营销工具,让您可以进行微信公众号运营。通过简单的操作,你可以完成两倍于其他人的工作。让您的微信公众号对成千上万的用户可见。. 独狼采集器下载独狼微信文章采集器 下载v100微信运营版,全文模板1900+(每周)。如果您购买非搜索器样式模块和全文模板,则可以免费使用它。不额外收费!!!辅导年3月19日一键微信采集微信公众号。如果不想找你的微信,一键采集教程微信公众号文章模板合集,有时候想下载一个公众号文章或者把需求保存在这个尊重一些朋友。说是家常便饭。这里是来自 52pojieyou原创 的工具。有点不完美的是这个软件是一个命令行窗口。
文章采集接口(数据采集及自动处理流程(一)_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-07 04:02
数据采集及自动处理流程概述本文主要介绍内容网络库的外部定义数据采集接口以及这些采集数据的自动处理流程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工方式和爬取方式进行的。对于其他采集方法,虽然我们已经提到过,但是我们在当前的苏旺后台中没有找到对应的模块。希望网通相关人员通过阅读本文档,及时对我们缺少的采集界面进行补充。对于我们下面设计的界面,希望网通相关人员可以提供测试数据供我们测试。采集 interface 定义了需要确认的爬虫BT接口。因为在原速网后台,我们没有找到界面设置界面,所以请相关人员回答以下问题。1.爬虫是否会爬取BT信息2.如果爬虫会爬取BT信息,是否与HTTP爬取的信息匹配?持续的?3.Bt爬虫抓取到的数据和Bt主动缓存解析的数据有什么区别?基于以上问题,我们在没有得到网络相关人员回复的情况下,根据以下情况设计了爬虫会议 爬取BT信息2. 爬虫爬取的信息只收录资源信息。接口设计调用者:爬虫系统调用频率:当发现有新数据被抓取时,实时调用或每天定时调用。约束:保证每次发送的信息都是最新的一批数据。输入参数:<dutarion> 输入参数的详细信息如下 18 FORMAT 文件格式 2NAME 名称用于完整性检查,判断去重 4PROTOCOL采集 协议 5LANGUAGE 语言(6CNT_SIZE 大小 7QUALITY 质量 10DATA_RATE 码流 11INFOHASHInfohash 值判断去重12Duration 播放时长 13URL 资源源完整性检查输出:成功或失败。
爬虫HTTP接口挂起问题爬虫爬取HTTP在线资源时,是否同时获取资源数据信息采集?Http爬取的资源里有电影名和剧集吗?基于上述问题,在没有得到互联网相关人员的回应的情况下,我们设计了爬虫按照以下条件抓取HTTP在线资源。资源和数据信息不是同时进行的。采集接口设计爬虫HTTP资源接口<dutarion>18 FORMAT文件格式2NAME名称用于完整性校验、判断和去重4PROTOCOL采集 点判断是否是前10 门户网站24channel 可以用来区分是否有剧集、主演作者等字段。自动处理流程。自动处理流程的目的是通过系统的自动内容过滤和自动内容过滤采集接口获取的数据。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。
规则列表下方的表格定义了我们总结的筛选、质量控制和发布规则。平台的规则引擎将根据以下规则自动处理数据。请根据实际情况确认和补充这些规则。筛选规则通过判断电影名称和播放地址不为空来屏蔽垃圾数据。如果有空字段,则将数据放入垃圾表进行处理。(信息) 屏蔽资源垃圾数据通过清空电影名称和播放地址进行处理。如果有空字段,则将数据放入垃圾表进行处理。(资源)采集 信息数据去重比较“电影名称”。如果有相同的数据,相关数据内容不完整的数据将放入垃圾表进行处理。采集信息资源去重对比“播放地址”和“infohash”。如果数据相同。然后删除其中一条记录。元数据重复数据删除通过电影名称和别名与元数据中的原创数据进行比较。如果存在相同的数据,则不会将该数据添加到元数据数据库中。元数据资源去重http通过播放地址对比,bt通过infohash值对比。如果找到相同的记录,则资源状态将被更改并添加到元数据数据库中。如果在重复数据删除阶段未找到相同的记录,则绑定到库中。通过查找对应的电影名称绑定(数据搜索资源),反之亦然。(资源数据)对于有父子关系的数据(如电视剧)。如果库中没有子集数据。父子数据会自动生成子集数据用于资源绑定。
检查审核规则的有效性,确定每个字段是否有关键词(例如:黄色词),如果有,则转入手册进行审核(资源信息通用)。检查资源是否属于前10个门户。网站,如果直接批准。发送ping到播放地址看看是否有效。数据内容验证首先判断数据是否属于前10名门户网站网站,如果是,则直接审批。对于别名中出现的逗号,逗号会自动转换为“/”。去掉“/”两边的空格。如果分数字段小于 5 分,它会自动转换为大于 5 分。如果分数是整数,将增加一位小数。对于导演和演员来说,每行的前导和尾随空格会自动删除。对于情节描述,第一行留2个空格,多余的空格会自动添加或删除。对于演员和导演,如果姓名不全(例如:张艺谋,但数据中有张艺),查找字典表,自动补全姓名。对于演员来说也是如此。对于区域:如果区域是空的,演员和导演可以计算出它是哪个区域。如果频道对应于剧集,则电影。那么演员、导演不能为空。如果对应的是动漫,那么作者不能为空。如果对应的是综艺节目,那么主持人和电视台不能为空。如果不符合规则,将转为人工审核。分销管理规则。资源发布规则根据资源的流行程度(点击率、排名、搜索次数)分为几个级别。根据流行程度和各个站点的缓存情况的组合,将其发布到各个位置。例如,热量分为三个级别:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。
缓存优化规则1. 当发现某个资源的缓存进度一直比较低时,根据规则替换或删除缓存。2. 当发现一个资源被多次缓存时,应该根据该资源的缓存Progress 保留进度最高的资源,并删除其他资源缓存。3. 当发现站点缓存空间不足时,应根据各个资源的热度、缓存情况,以及热度低、缓存进度低的资源进行清理。详细说明 1 资源处理流程图 资源入库前,会经过完整性验证、同批次去重、和资源可靠性审查,以确保输入元数据的资源真实可用。资源入库后,会定期调用审核规则,检查资源库中的数据是否满足审核条件,并剔除无效链接。并对满足释放条件的资源调用分布式管理机制,保证资源的最大利用率。2 数据处理流程图 数据入库前,会进行完整性验证,进行同批次去重、元数据去重等多个步骤,确保元数据的元数据唯一。以及存储前会调用哪些审计规则,尽量提前纠正数据中的错误。数据存入数据库后,会定期调用审计规则,检查数据库中数据的完整性和可靠性,部分数据会自动修正和修正。并出版符合出版条件的资料。补充问题小伙伴引入的调用接口在哪里,如何调用,能否提供? 查看全部
文章采集接口(数据采集及自动处理流程(一)_光明网(组图))
数据采集及自动处理流程概述本文主要介绍内容网络库的外部定义数据采集接口以及这些采集数据的自动处理流程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工方式和爬取方式进行的。对于其他采集方法,虽然我们已经提到过,但是我们在当前的苏旺后台中没有找到对应的模块。希望网通相关人员通过阅读本文档,及时对我们缺少的采集界面进行补充。对于我们下面设计的界面,希望网通相关人员可以提供测试数据供我们测试。采集 interface 定义了需要确认的爬虫BT接口。因为在原速网后台,我们没有找到界面设置界面,所以请相关人员回答以下问题。1.爬虫是否会爬取BT信息2.如果爬虫会爬取BT信息,是否与HTTP爬取的信息匹配?持续的?3.Bt爬虫抓取到的数据和Bt主动缓存解析的数据有什么区别?基于以上问题,我们在没有得到网络相关人员回复的情况下,根据以下情况设计了爬虫会议 爬取BT信息2. 爬虫爬取的信息只收录资源信息。接口设计调用者:爬虫系统调用频率:当发现有新数据被抓取时,实时调用或每天定时调用。约束:保证每次发送的信息都是最新的一批数据。输入参数:<dutarion> 输入参数的详细信息如下 18 FORMAT 文件格式 2NAME 名称用于完整性检查,判断去重 4PROTOCOL采集 协议 5LANGUAGE 语言(6CNT_SIZE 大小 7QUALITY 质量 10DATA_RATE 码流 11INFOHASHInfohash 值判断去重12Duration 播放时长 13URL 资源源完整性检查输出:成功或失败。
爬虫HTTP接口挂起问题爬虫爬取HTTP在线资源时,是否同时获取资源数据信息采集?Http爬取的资源里有电影名和剧集吗?基于上述问题,在没有得到互联网相关人员的回应的情况下,我们设计了爬虫按照以下条件抓取HTTP在线资源。资源和数据信息不是同时进行的。采集接口设计爬虫HTTP资源接口<dutarion>18 FORMAT文件格式2NAME名称用于完整性校验、判断和去重4PROTOCOL采集 点判断是否是前10 门户网站24channel 可以用来区分是否有剧集、主演作者等字段。自动处理流程。自动处理流程的目的是通过系统的自动内容过滤和自动内容过滤采集接口获取的数据。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。
规则列表下方的表格定义了我们总结的筛选、质量控制和发布规则。平台的规则引擎将根据以下规则自动处理数据。请根据实际情况确认和补充这些规则。筛选规则通过判断电影名称和播放地址不为空来屏蔽垃圾数据。如果有空字段,则将数据放入垃圾表进行处理。(信息) 屏蔽资源垃圾数据通过清空电影名称和播放地址进行处理。如果有空字段,则将数据放入垃圾表进行处理。(资源)采集 信息数据去重比较“电影名称”。如果有相同的数据,相关数据内容不完整的数据将放入垃圾表进行处理。采集信息资源去重对比“播放地址”和“infohash”。如果数据相同。然后删除其中一条记录。元数据重复数据删除通过电影名称和别名与元数据中的原创数据进行比较。如果存在相同的数据,则不会将该数据添加到元数据数据库中。元数据资源去重http通过播放地址对比,bt通过infohash值对比。如果找到相同的记录,则资源状态将被更改并添加到元数据数据库中。如果在重复数据删除阶段未找到相同的记录,则绑定到库中。通过查找对应的电影名称绑定(数据搜索资源),反之亦然。(资源数据)对于有父子关系的数据(如电视剧)。如果库中没有子集数据。父子数据会自动生成子集数据用于资源绑定。
检查审核规则的有效性,确定每个字段是否有关键词(例如:黄色词),如果有,则转入手册进行审核(资源信息通用)。检查资源是否属于前10个门户。网站,如果直接批准。发送ping到播放地址看看是否有效。数据内容验证首先判断数据是否属于前10名门户网站网站,如果是,则直接审批。对于别名中出现的逗号,逗号会自动转换为“/”。去掉“/”两边的空格。如果分数字段小于 5 分,它会自动转换为大于 5 分。如果分数是整数,将增加一位小数。对于导演和演员来说,每行的前导和尾随空格会自动删除。对于情节描述,第一行留2个空格,多余的空格会自动添加或删除。对于演员和导演,如果姓名不全(例如:张艺谋,但数据中有张艺),查找字典表,自动补全姓名。对于演员来说也是如此。对于区域:如果区域是空的,演员和导演可以计算出它是哪个区域。如果频道对应于剧集,则电影。那么演员、导演不能为空。如果对应的是动漫,那么作者不能为空。如果对应的是综艺节目,那么主持人和电视台不能为空。如果不符合规则,将转为人工审核。分销管理规则。资源发布规则根据资源的流行程度(点击率、排名、搜索次数)分为几个级别。根据流行程度和各个站点的缓存情况的组合,将其发布到各个位置。例如,热量分为三个级别:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。
缓存优化规则1. 当发现某个资源的缓存进度一直比较低时,根据规则替换或删除缓存。2. 当发现一个资源被多次缓存时,应该根据该资源的缓存Progress 保留进度最高的资源,并删除其他资源缓存。3. 当发现站点缓存空间不足时,应根据各个资源的热度、缓存情况,以及热度低、缓存进度低的资源进行清理。详细说明 1 资源处理流程图 资源入库前,会经过完整性验证、同批次去重、和资源可靠性审查,以确保输入元数据的资源真实可用。资源入库后,会定期调用审核规则,检查资源库中的数据是否满足审核条件,并剔除无效链接。并对满足释放条件的资源调用分布式管理机制,保证资源的最大利用率。2 数据处理流程图 数据入库前,会进行完整性验证,进行同批次去重、元数据去重等多个步骤,确保元数据的元数据唯一。以及存储前会调用哪些审计规则,尽量提前纠正数据中的错误。数据存入数据库后,会定期调用审计规则,检查数据库中数据的完整性和可靠性,部分数据会自动修正和修正。并出版符合出版条件的资料。补充问题小伙伴引入的调用接口在哪里,如何调用,能否提供?
文章采集接口(八爪网:内容作弊是一种作弊手法吗?作弊)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-05 03:01
网站 内容作弊现在很普遍,因为优质的内容意味着流量。所以现在很多站长也用内容作弊。今天八扎网就为大家介绍几种常见的内容作弊方法。
1、关键词 重复
许多站长倾向于在页面内容中重复这些关键词。关键词 密度是搜索引擎计算中要考虑的一个因素。如果关键词的频率太高,本质上会影响关键词的搜索引擎排名,但现在这种作弊手法已经是攻击的目标了。关键词的密度只需要维持在2%-8%即可。太多或太少都不利于排名。
内容作弊的几种常见方法
2、没有关键词作弊
一些站长为了尽可能吸引更多的流量,会在页面上添加很多与网站主题无关的关键词。这种方法主要是为了蹭流量,发布了很多不属于网站主题的内容。这种方式虽然可以吸引大量流量,但目标流量很小。不过这种方法已经被百度的飓风算法命中了,最好避开。
3、文章采集 作弊
采集的危害可以说是非常明显了。不会是收录,而是K站。八爪网建议站长不要尝试冒险。
好了,以上就是今天八扎网分享的几种常见的内容作弊方法。内容作弊也是一种作弊方式,近期会有针对性,所以建议站长还是用正规的方式。提高网站的排名。
原文来自八角网,更多网络知识等着你。 查看全部
文章采集接口(八爪网:内容作弊是一种作弊手法吗?作弊)
网站 内容作弊现在很普遍,因为优质的内容意味着流量。所以现在很多站长也用内容作弊。今天八扎网就为大家介绍几种常见的内容作弊方法。
1、关键词 重复
许多站长倾向于在页面内容中重复这些关键词。关键词 密度是搜索引擎计算中要考虑的一个因素。如果关键词的频率太高,本质上会影响关键词的搜索引擎排名,但现在这种作弊手法已经是攻击的目标了。关键词的密度只需要维持在2%-8%即可。太多或太少都不利于排名。
内容作弊的几种常见方法
2、没有关键词作弊
一些站长为了尽可能吸引更多的流量,会在页面上添加很多与网站主题无关的关键词。这种方法主要是为了蹭流量,发布了很多不属于网站主题的内容。这种方式虽然可以吸引大量流量,但目标流量很小。不过这种方法已经被百度的飓风算法命中了,最好避开。
3、文章采集 作弊
采集的危害可以说是非常明显了。不会是收录,而是K站。八爪网建议站长不要尝试冒险。
好了,以上就是今天八扎网分享的几种常见的内容作弊方法。内容作弊也是一种作弊方式,近期会有针对性,所以建议站长还是用正规的方式。提高网站的排名。
原文来自八角网,更多网络知识等着你。
文章采集接口(石青伪原创工具是什么:伪工具使用方法步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-04 16:23
石青伪原创是什么工具:伪原创工具是SEO的高级工具,石青伪原创软件是免费的专业伪原创文章生成器,可以生成原创和伪原创的文章,专门针对百度、谷歌的抓取习惯和分词算法而开发。经本软件优化的文章会更受搜索引擎青睐。使用伪原创工具打造互联网上独一无二的伪原创文章,支持中英文伪原创。
石青伪原创如何使用工具
步:
1.安装软件
伪原创该工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。
启动后界面如下:
2.采集文章
石青伪原创工具,自带采集工具。首先需要在“采集设置”模块中输入需要采集的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后在百度或谷歌中选择采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。
点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果要停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章和争抢生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.生产伪原创文章
用户可以通过4种方式输入原创文章,1、直接复制文章到文章编辑区,然后输入标题,然后保存文章; 2、通过导入,可以直接导入TXT或html文档,3、通过采集,直接采集到网上的文章,4、直接通过界面获取你的内容cms网站;
获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章的标题,然后点击界面下方的“生成原创”按钮即可。伪原创之后的文章显示在“伪原创文章预览区”;
2、使用导出方式,可以将所有勾选的文章直接批量导出为TXT或HTML文章;
3、 通过接口,直接批量伪原创到自己的cms网站。
下图显示了导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;
“伪原创tool”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会非常高。“原创文章生成规则”。
4.使用直接更新主流cms系统
石青伪原创工具,支持东夷、老鸭、新云、德德cms等99%国内主流cms内容直接更新,通过界面直接获取本站信息,然后 伪原创 并上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。
为什么要设置这个功能?一般现在主流网站是:无论是个人还是公司,90%都是cms。cms中都自带采集功能,外围也可以使用“优采云”等第三方工具来采集。随着采集返回的数据量越来越大,如何伪原创成为一个令人担忧的问题。
仕青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库的数据,适合99%使用虚拟主机搭建网站,不能直接操作。cms数据库客户。上传界面,获取内容,直接伪原创。只要完成第3段,就可以完成伪原创。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。
关注推广屋:为您提供合适的推广软件,分享经验。让您的推广之路少走弯路。 查看全部
文章采集接口(石青伪原创工具是什么:伪工具使用方法步骤)
石青伪原创是什么工具:伪原创工具是SEO的高级工具,石青伪原创软件是免费的专业伪原创文章生成器,可以生成原创和伪原创的文章,专门针对百度、谷歌的抓取习惯和分词算法而开发。经本软件优化的文章会更受搜索引擎青睐。使用伪原创工具打造互联网上独一无二的伪原创文章,支持中英文伪原创。
石青伪原创如何使用工具
步:
1.安装软件
伪原创该工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。

启动后界面如下:

2.采集文章
石青伪原创工具,自带采集工具。首先需要在“采集设置”模块中输入需要采集的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后在百度或谷歌中选择采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。

点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果要停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章和争抢生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.生产伪原创文章
用户可以通过4种方式输入原创文章,1、直接复制文章到文章编辑区,然后输入标题,然后保存文章; 2、通过导入,可以直接导入TXT或html文档,3、通过采集,直接采集到网上的文章,4、直接通过界面获取你的内容cms网站;

获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章的标题,然后点击界面下方的“生成原创”按钮即可。伪原创之后的文章显示在“伪原创文章预览区”;
2、使用导出方式,可以将所有勾选的文章直接批量导出为TXT或HTML文章;
3、 通过接口,直接批量伪原创到自己的cms网站。
下图显示了导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;

“伪原创tool”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会非常高。“原创文章生成规则”。
4.使用直接更新主流cms系统
石青伪原创工具,支持东夷、老鸭、新云、德德cms等99%国内主流cms内容直接更新,通过界面直接获取本站信息,然后 伪原创 并上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。

为什么要设置这个功能?一般现在主流网站是:无论是个人还是公司,90%都是cms。cms中都自带采集功能,外围也可以使用“优采云”等第三方工具来采集。随着采集返回的数据量越来越大,如何伪原创成为一个令人担忧的问题。
仕青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库的数据,适合99%使用虚拟主机搭建网站,不能直接操作。cms数据库客户。上传界面,获取内容,直接伪原创。只要完成第3段,就可以完成伪原创。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。

关注推广屋:为您提供合适的推广软件,分享经验。让您的推广之路少走弯路。
文章采集接口(《小蜜蜂公众号文章助手》一种一个复制要好很多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 547 次浏览 • 2021-11-15 22:01
“小蜜蜂公众号文章小助手”上线啦!
虽然小蜜蜂采集插件导入公众号文章已经够方便了,但是对于有较强需求的用户来说,批量获取公众号文章链接也是一件头疼的事。那么,有没有更方便(愚蠢)的方式来获得它?
今天教你一种方法。虽然有点麻烦,但总比一张一张复制好。
首先需要有自己的公众号,登录微信公众管理平台,新建图文素材
新的图形材料
在文章编辑区,我们看到编辑器的工具栏,选择超链接
超链接
点击后会弹出一个小窗口,选择搜索文章选项
找官方账号
这时候可以从自己的公众号获取文章的列表或者搜索其他公众号或微信公众号。这里以搜索人民日报公众号为例。
公众号搜索
在结果列表中选择你想要的,就会出现文章公众号列表
公众号列表文章
右键选择复制链接地址,可以选择翻页
文章翻页
这样看起来效率不高,但是我们知道,既然可以拿到文章的数据,肯定会发送请求,得到返回结果。这时候我们可以打开浏览器进行调试(Win:F12,MacOS:Alt+Cmd)+i),然后点击页面按钮,就会发现这样的请求
文章数据请求
展开右边的JSON,可以看到里面收录了文章链接,处理起来很方便,直接复制处理即可。
分析这个界面,我们还可以发现模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin 和 count。比如这里的begin等于5,代表第五次之后文章推送开始,count等于5,表示得到5次推送。所以如果我们想要得到下一页的文章,很简单,我们只需要把begin=5改成begin=10,依此类推,这里的计数好像只有5个,而且可以' t 改成更大的。值,也许微信也是为了限制
知道了这个规则,那么一切就简单了,只要不断增加begin的值。
需要注意的是,获取到的数据还需要处理,该界面只有在公众号登录后才能使用。 查看全部
文章采集接口(《小蜜蜂公众号文章助手》一种一个复制要好很多)
“小蜜蜂公众号文章小助手”上线啦!
虽然小蜜蜂采集插件导入公众号文章已经够方便了,但是对于有较强需求的用户来说,批量获取公众号文章链接也是一件头疼的事。那么,有没有更方便(愚蠢)的方式来获得它?
今天教你一种方法。虽然有点麻烦,但总比一张一张复制好。
首先需要有自己的公众号,登录微信公众管理平台,新建图文素材
新的图形材料
在文章编辑区,我们看到编辑器的工具栏,选择超链接
超链接
点击后会弹出一个小窗口,选择搜索文章选项
找官方账号
这时候可以从自己的公众号获取文章的列表或者搜索其他公众号或微信公众号。这里以搜索人民日报公众号为例。
公众号搜索
在结果列表中选择你想要的,就会出现文章公众号列表
公众号列表文章
右键选择复制链接地址,可以选择翻页
文章翻页
这样看起来效率不高,但是我们知道,既然可以拿到文章的数据,肯定会发送请求,得到返回结果。这时候我们可以打开浏览器进行调试(Win:F12,MacOS:Alt+Cmd)+i),然后点击页面按钮,就会发现这样的请求
文章数据请求
展开右边的JSON,可以看到里面收录了文章链接,处理起来很方便,直接复制处理即可。
分析这个界面,我们还可以发现模式
https://mp.weixin.qq.com/cgi-b ... e%3D9
请注意,此链接收录两个主要参数,begin 和 count。比如这里的begin等于5,代表第五次之后文章推送开始,count等于5,表示得到5次推送。所以如果我们想要得到下一页的文章,很简单,我们只需要把begin=5改成begin=10,依此类推,这里的计数好像只有5个,而且可以' t 改成更大的。值,也许微信也是为了限制
知道了这个规则,那么一切就简单了,只要不断增加begin的值。
需要注意的是,获取到的数据还需要处理,该界面只有在公众号登录后才能使用。
文章采集接口(99E5A588%的Web版搜索接口(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-11-14 10:16
最新版本(2018 年 9 月)
小红书()是一个拥有超过1亿用户的生活方式分享社区。其用户笔记涵盖美食、服装、购物,以及时尚、护肤、彩妆、美食、旅游、影视、阅读、健身等各种生活方式领域。此外,社区每天会产生数十亿条笔记曝光。正如客户所说,其平台整合了社交和商务,其数据价值可想而知。
小红书的数据不难采集。通过网页版的搜索界面,结合相应的搜索词,可以搜索到感兴趣的笔记,进而采集笔记的详细数据。然而,好景并没有持续多久。随着小红书完成超过3亿美元的一轮融资,小红书的平台界面也发生了很大变化:网页版搜索界面直接关闭,小红书App应用成为主流。这样,之前通过网页版的搜索界面获取数据的方法就直接被屏蔽了。
由于网页版的界面已经没有了,只能看App的界面了。通过抓包工具,可以获得小红书App的搜索界面。
这里使用的搜索词是“香奈儿63”,对应的搜索界面网址如下:
% E9% A6% 99% E5% A5% 88% E5% 84% BF63 & 过滤器 = & 排序 = & 页面 = 1 & page_size = 20 & 源 = explore_feed & search_id = 927A522C26DC8FD699971F1B1C1F6838 & 平台 = 安卓设备 &6666f665 -3aab-aff8-a8fe7bc48809&device_fingerprint = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1 = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&的versionName = 5. 2 4. 1信道=搜狗&SID = session.78290029&LANG = ZH-汉斯&T = 1536298303&签名= dd2764c4258e12db80fbe5df11e01af0
可以看到,App界面中有很多参数。但是经过测试,发现这些参数是不能修改的,提交会失败。而且,这些参数(除了搜索词关键字)不能自己构造(注意sign参数,这是一种常用的针对采集的签名保护机制)。似乎这条路无路可走,追号的征程再次陷入僵局。
好在细心的鲲鹏技术人员发现除了App外,小红书还有一个微信小程序,于是对小红书微信小程序又展开了一轮分析研究。
再次抓包分析发现,小红书微信小程序的界面是可以修改参数的,但是三个参数好像有有效期。
测试发现,只要这三个参数有一定的有效期,就可以在这个有效期内更改关键字进行搜索,得到正确的数据。那么,我们首先如何获得这三个参数呢?鲲鹏技术人员通过研究发现,可以模拟微信小程序的运行,在手机上自动运行小红书小程序,同时利用程序自动抓包,提取最新的接口参数,供手机使用。爬虫使用(如下图所示)。
敢想敢做,鲲鹏技术人员积极探索,大胆尝试,克服重重困难,最终将想法变为现实。首先通过自动模拟运行程序在手机上运行小红书小程序,然后抓包提取最新的接口参数;然后使用获取的界面参数,结合搜索词进行搜索,采集与搜索结果相关的笔记数据;最后进入笔记详情页面,提取所有需要的相关数据。就是这样!
随附的:
通过小红书微信小程序界面抓取的搜索结果数据(部分字段)示例如下:
转载至 查看全部
文章采集接口(99E5A588%的Web版搜索接口(图))
最新版本(2018 年 9 月)
小红书()是一个拥有超过1亿用户的生活方式分享社区。其用户笔记涵盖美食、服装、购物,以及时尚、护肤、彩妆、美食、旅游、影视、阅读、健身等各种生活方式领域。此外,社区每天会产生数十亿条笔记曝光。正如客户所说,其平台整合了社交和商务,其数据价值可想而知。
小红书的数据不难采集。通过网页版的搜索界面,结合相应的搜索词,可以搜索到感兴趣的笔记,进而采集笔记的详细数据。然而,好景并没有持续多久。随着小红书完成超过3亿美元的一轮融资,小红书的平台界面也发生了很大变化:网页版搜索界面直接关闭,小红书App应用成为主流。这样,之前通过网页版的搜索界面获取数据的方法就直接被屏蔽了。
由于网页版的界面已经没有了,只能看App的界面了。通过抓包工具,可以获得小红书App的搜索界面。
这里使用的搜索词是“香奈儿63”,对应的搜索界面网址如下:
% E9% A6% 99% E5% A5% 88% E5% 84% BF63 & 过滤器 = & 排序 = & 页面 = 1 & page_size = 20 & 源 = explore_feed & search_id = 927A522C26DC8FD699971F1B1C1F6838 & 平台 = 安卓设备 &6666f665 -3aab-aff8-a8fe7bc48809&device_fingerprint = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1 = 237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&的versionName = 5. 2 4. 1信道=搜狗&SID = session.78290029&LANG = ZH-汉斯&T = 1536298303&签名= dd2764c4258e12db80fbe5df11e01af0
可以看到,App界面中有很多参数。但是经过测试,发现这些参数是不能修改的,提交会失败。而且,这些参数(除了搜索词关键字)不能自己构造(注意sign参数,这是一种常用的针对采集的签名保护机制)。似乎这条路无路可走,追号的征程再次陷入僵局。
好在细心的鲲鹏技术人员发现除了App外,小红书还有一个微信小程序,于是对小红书微信小程序又展开了一轮分析研究。
再次抓包分析发现,小红书微信小程序的界面是可以修改参数的,但是三个参数好像有有效期。
测试发现,只要这三个参数有一定的有效期,就可以在这个有效期内更改关键字进行搜索,得到正确的数据。那么,我们首先如何获得这三个参数呢?鲲鹏技术人员通过研究发现,可以模拟微信小程序的运行,在手机上自动运行小红书小程序,同时利用程序自动抓包,提取最新的接口参数,供手机使用。爬虫使用(如下图所示)。
敢想敢做,鲲鹏技术人员积极探索,大胆尝试,克服重重困难,最终将想法变为现实。首先通过自动模拟运行程序在手机上运行小红书小程序,然后抓包提取最新的接口参数;然后使用获取的界面参数,结合搜索词进行搜索,采集与搜索结果相关的笔记数据;最后进入笔记详情页面,提取所有需要的相关数据。就是这样!
随附的:
通过小红书微信小程序界面抓取的搜索结果数据(部分字段)示例如下:
转载至
文章采集接口(文章采集接口/js/jqueryobject.js推荐weui前端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2021-11-11 19:00
文章采集接口template/view/xxxcollection.templatejavascriptjs/csswebview.js/spinner/viewer/element.jsjqueryclient.js/jqueryobject.js
推荐weui
前端需要的前端东西大概只有语言和工具吧,一些框架和库,简单后端的话,
网页前端开发基础,
设计模式,网站流程,结构框架,thinkphp,jquery,
javascript,ecmascript,css,html,jquery,zepto,angularjs,这些东西随便看看,
html:div+css,css3选择器,template+js,jquery。等等css:有sass编译器。javascript:正则表达式,jquerymobile/nodejsajax。jqueryscriptapi让程序员可以自由定制jquery并使用。数据库:sqliteormysql.各种存储引擎accessibility,关系型数据库,非关系型数据库,nosql。
推荐两个mysql和sqli。语言:php+css+js为主。我还没入坑的时候还需要跟项目。入坑半年多基本什么都不用管。搞定这些就能管理团队。剩下就是需求和系统架构的事了。
前端的框架有很多, 查看全部
文章采集接口(文章采集接口/js/jqueryobject.js推荐weui前端)
文章采集接口template/view/xxxcollection.templatejavascriptjs/csswebview.js/spinner/viewer/element.jsjqueryclient.js/jqueryobject.js
推荐weui
前端需要的前端东西大概只有语言和工具吧,一些框架和库,简单后端的话,
网页前端开发基础,
设计模式,网站流程,结构框架,thinkphp,jquery,
javascript,ecmascript,css,html,jquery,zepto,angularjs,这些东西随便看看,
html:div+css,css3选择器,template+js,jquery。等等css:有sass编译器。javascript:正则表达式,jquerymobile/nodejsajax。jqueryscriptapi让程序员可以自由定制jquery并使用。数据库:sqliteormysql.各种存储引擎accessibility,关系型数据库,非关系型数据库,nosql。
推荐两个mysql和sqli。语言:php+css+js为主。我还没入坑的时候还需要跟项目。入坑半年多基本什么都不用管。搞定这些就能管理团队。剩下就是需求和系统架构的事了。
前端的框架有很多,
文章采集接口(适合爬虫新手不刷图不搞爬虫学一点学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-11 12:04
文章采集接口与文章内容采集接口简单来说就是这样:采集来的文章内容是原来网站所存储的内容,然后与直接来源网站做对比,看他们的内容差距有多大就行了;文章采集采集原来网站的内容,然后按照指定格式、条件去采集新网站的内容。2.文章爬虫接口首先注册个账号:,注册一个账号不用交费的,完全免费的,第一次采集文章有3次免费机会可以申请。
下图为爬虫模拟登录注册步骤:直接使用注册邮箱就行:上面就是这次爬虫之前采集的图片和大量的图片大小对比,感觉要比图片站要小,这样爬取图片还是比较简单的,如果要大规模采集图片,需要付费了。一个账号可以模拟登录3个网站,就是3个账号,我个人觉得还是比较方便,但是要模拟登录10个网站也有点麻烦,总体而言还是比较简单的。
本文适合爬虫新手不刷图不搞爬虫学一点爬虫是很有意思的一件事用一个小工具爬取100万数据github几十个版本有的版本只有300k不到而另一个版本是一千多万接下来我就教大家用无脑方法采集数据大约40分钟很适合像小白一样的爬虫新手爬取常见网站数据比如图片比如动态新闻类再比如豆瓣网我们首先去,是一个实时转发和分享图片的地方然后爬虫回首页有一些图片会被下载,但是下载只保留四分之一不算严重,让我们继续爬取第二页第三页页码就是图片的详细信息,这就是我们要爬取的数据。
例如6张,115张之类的。第三页,我们也要爬取我们看下,有6个群组(是新建的,有说明,比如注册这一站点)6个页面第四页其实已经是爬取数据了,但是作为写爬虫的小白,很可能没有第四页,直接过了第五页和第六页对于小白来说,一辈子没有一个网站爬一次,不太划算。第五页也是爬取,这是后面抽奖的地方。总之看你想不想采,爬取图片并不难,随便几百个网站都能爬取到,关键要搞清楚用什么方法,最后的目的是什么,单纯为了看看数据,尝试下相关方法应该不难。 查看全部
文章采集接口(适合爬虫新手不刷图不搞爬虫学一点学)
文章采集接口与文章内容采集接口简单来说就是这样:采集来的文章内容是原来网站所存储的内容,然后与直接来源网站做对比,看他们的内容差距有多大就行了;文章采集采集原来网站的内容,然后按照指定格式、条件去采集新网站的内容。2.文章爬虫接口首先注册个账号:,注册一个账号不用交费的,完全免费的,第一次采集文章有3次免费机会可以申请。
下图为爬虫模拟登录注册步骤:直接使用注册邮箱就行:上面就是这次爬虫之前采集的图片和大量的图片大小对比,感觉要比图片站要小,这样爬取图片还是比较简单的,如果要大规模采集图片,需要付费了。一个账号可以模拟登录3个网站,就是3个账号,我个人觉得还是比较方便,但是要模拟登录10个网站也有点麻烦,总体而言还是比较简单的。
本文适合爬虫新手不刷图不搞爬虫学一点爬虫是很有意思的一件事用一个小工具爬取100万数据github几十个版本有的版本只有300k不到而另一个版本是一千多万接下来我就教大家用无脑方法采集数据大约40分钟很适合像小白一样的爬虫新手爬取常见网站数据比如图片比如动态新闻类再比如豆瓣网我们首先去,是一个实时转发和分享图片的地方然后爬虫回首页有一些图片会被下载,但是下载只保留四分之一不算严重,让我们继续爬取第二页第三页页码就是图片的详细信息,这就是我们要爬取的数据。
例如6张,115张之类的。第三页,我们也要爬取我们看下,有6个群组(是新建的,有说明,比如注册这一站点)6个页面第四页其实已经是爬取数据了,但是作为写爬虫的小白,很可能没有第四页,直接过了第五页和第六页对于小白来说,一辈子没有一个网站爬一次,不太划算。第五页也是爬取,这是后面抽奖的地方。总之看你想不想采,爬取图片并不难,随便几百个网站都能爬取到,关键要搞清楚用什么方法,最后的目的是什么,单纯为了看看数据,尝试下相关方法应该不难。
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-10 12:01
Interface(软件接口)是指定义契约的引用类型。其他类型实现接口以确保它们支持某些操作。
接口指定必须由类或实现它的其他接口提供的成员。与类类似,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数的麻烦,让你的工作效率翻倍。
优采云采集器 三种登录方式,其中免登录发布界面是最方便的方式,但是需要程序员根据发布网址进行定制,需要一定的代码基础。
免登录界面发布后,有很多优点,比如使用方便、无需手动登录、发布稳定等,下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码匹配的接口。
(2)打开接口php文件,接口有密码,默认123456,也可以自定义密码。这里注意,修改密码后,发布模块的密码也需要相应修改.
(3)上传网站管理目录下的接口文件/e/admin/
02正式运营:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块,然后保存:
(2)是根据网站地址配置的。
(3) 然后可以测试release,看release模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的方法在这里就是发布模块设置好标签后,直接将发布模块中的标签导入优采云采集器:
03界面下载链接
因此,为了方便客户,我们整理了几个常用的网站,并为这个网站编译了一个发布接口。下面附上下载地址,压缩包内有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章 支持首页更新
下载链接:点击打开链接
2.帝国7.5 发布界面
下载链接:点击打开链接
3.destoon7.0 提供发布接口
下载链接:点击打开链接
4.DiscuzX3.4 免费登录论坛发布模块(带测试界面)
下载链接:点击打开链接
5.ecshop2.7.3
下载链接:点击打开链接
6.opencartV3.0 发布界面.rar
下载链接:点击打开链接 查看全部
文章采集接口(优采云采集器登陆接口实际使用方法:登陆发布接口使用)
Interface(软件接口)是指定义契约的引用类型。其他类型实现接口以确保它们支持某些操作。
接口指定必须由类或实现它的其他接口提供的成员。与类类似,接口可以收录方法、属性、索引器和事件作为成员。
一个写得好的界面有时可以省去无数的麻烦,让你的工作效率翻倍。
优采云采集器 三种登录方式,其中免登录发布界面是最方便的方式,但是需要程序员根据发布网址进行定制,需要一定的代码基础。
免登录界面发布后,有很多优点,比如使用方便、无需手动登录、发布稳定等,下面我将介绍免登录界面的实际使用:
01 前期准备:
(1)查看你的网站属于什么代码,可以右键查看源码,找到代码,然后选择代码匹配的接口。
(2)打开接口php文件,接口有密码,默认123456,也可以自定义密码。这里注意,修改密码后,发布模块的密码也需要相应修改.
(3)上传网站管理目录下的接口文件/e/admin/
02正式运营:
(1)将发布模块导入发布配置,根据上传的接口名称和设置的密码修改发布模块,然后保存:
(2)是根据网站地址配置的。
(3) 然后可以测试release,看release模块是否正常。
(4)测试发布成功后,可以应用到采集规则。这里注意采集规则必须对应发布模块的标签!更好的方法在这里就是发布模块设置好标签后,直接将发布模块中的标签导入优采云采集器:
03界面下载链接
因此,为了方便客户,我们整理了几个常用的网站,并为这个网站编译了一个发布接口。下面附上下载地址,压缩包内有使用说明和具体使用方法。请参考使用说明
1.dedecms5.7文章 支持首页更新
下载链接:点击打开链接
2.帝国7.5 发布界面
下载链接:点击打开链接
3.destoon7.0 提供发布接口
下载链接:点击打开链接
4.DiscuzX3.4 免费登录论坛发布模块(带测试界面)
下载链接:点击打开链接
5.ecshop2.7.3
下载链接:点击打开链接
6.opencartV3.0 发布界面.rar
下载链接:点击打开链接
文章采集接口(api调用接口数据调取接口-成都bizli成都成都)
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-11-07 23:01
文章采集接口的这块,可以直接到聚合数据api接口平台接入,我们有过非常成功的项目案例,用户只需要搜索某个关键词,就可以根据页面的路径,跳转到指定页面。这个接口是我们开发一套下载app数据包的接口,客户把数据包提交上来,我们根据他的要求,选择最合适的api提供商给他,他可以直接给你下载数据包。具体方案可以参考我们之前的文章。
soomal:下载app数据包及验证码识别接口我们将工作量分为两部分,一部分是识别数据的收集,我们主要是从这边完成的。
我们开发的一套ios原生的接口不错,
我们正在开发,给个app数据接口,
只是一个api调用接口吗
可以这样定制数据接口,你可以按自己的需求制定接口规则,不过按我们现在的程序,这种数据方案很难做到。只能采用定制化方案,以定制api的方式开发,
代码合并了需要:api接口数据调取接口-成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli
使用mockserver可以定制原生数据接口.
我的数据接口是他们开发的, 查看全部
文章采集接口(api调用接口数据调取接口-成都bizli成都成都)
文章采集接口的这块,可以直接到聚合数据api接口平台接入,我们有过非常成功的项目案例,用户只需要搜索某个关键词,就可以根据页面的路径,跳转到指定页面。这个接口是我们开发一套下载app数据包的接口,客户把数据包提交上来,我们根据他的要求,选择最合适的api提供商给他,他可以直接给你下载数据包。具体方案可以参考我们之前的文章。
soomal:下载app数据包及验证码识别接口我们将工作量分为两部分,一部分是识别数据的收集,我们主要是从这边完成的。
我们开发的一套ios原生的接口不错,
我们正在开发,给个app数据接口,
只是一个api调用接口吗
可以这样定制数据接口,你可以按自己的需求制定接口规则,不过按我们现在的程序,这种数据方案很难做到。只能采用定制化方案,以定制api的方式开发,
代码合并了需要:api接口数据调取接口-成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli成都bizli
使用mockserver可以定制原生数据接口.
我的数据接口是他们开发的,
文章采集接口(文章采集接口做自媒体平台,对接京东很简单!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-07 15:02
文章采集接口做自媒体平台,对接京东很简单,短时间内积累个500个以上,一天3-5个就行了,不会的可以看文章最后写的,进行学习。平台批量采集热门文章是十分可以做的,自媒体文章热度爆发效应强烈,很多公众号本身所发布的文章虽然时效性并不那么强,但往往也会在下午和晚上甚至凌晨开始热度飙升。所以很多自媒体新手会选择每天从公众号文章批量采集热点实现发布,每个人都能从一个号手中获取500篇热点文章!这个项目虽然很多,但是很多人依然不会操作!那么新手做这个要学什么?1.文章分词策略我们从文章标题--要接的分词公式--文章内容可以快速将标题过滤出来。
过滤关键词:采集热词:如何挑选标题强势文章,并作为接口。2.添加文章入口标签批量接文章,要接什么样的文章,必须将其入口标签和内容分割定位好。能够在公众号中接看什么样的文章,只要根据标签匹配,就能在公众号中接到什么样的文章。3.接入md5算法策略这里更新md5算法策略,很多新手是每天通过手动补充,更新文章是绝对比较耽误时间的。
公众号应该是一个很大的群体,每天每天都有大量的文章发布,而不去先选择内容,再进行人工精细化筛选,浪费时间又不会提高效率。4.操作人数设置很多人接这个项目,第一是担心接不到文章,那完全是杞人忧天,目前我们的项目人数是要求5个以上,一人最多能操作一个号,采集500个号可以验证一下。接着就是采集方法,自媒体采集,我们只要知道操作方法即可。
1.自媒体文章采集各大平台会有不同的采集规则,我们可以通过平台会发布的公告来获取机会,而且一般机会比较大,每天接一条,500个号也足够我们操作!2.分词采集如何将文章分词,这个其实很简单,用标签分类,对接标题。3.md5算法对接采集文章,公众号文章md5值太高容易存在风险,所以尽量选择文章md5值低于170以下的文章。
4.最重要的问题是!!!针对我们自己自媒体账号定位做采集标签!!!将每天一些关注自己公众号的粉丝和关注自己公众号的粉丝进行合理挖掘,这也是我们流量来源之一!!!每天坚持发布几篇热文,每天进行微信群付费学习领取自媒体视频教程。需要公众号内部联系我q:1706357762知乎回复:价值20000的自媒体视频教程。q:47788448。 查看全部
文章采集接口(文章采集接口做自媒体平台,对接京东很简单!)
文章采集接口做自媒体平台,对接京东很简单,短时间内积累个500个以上,一天3-5个就行了,不会的可以看文章最后写的,进行学习。平台批量采集热门文章是十分可以做的,自媒体文章热度爆发效应强烈,很多公众号本身所发布的文章虽然时效性并不那么强,但往往也会在下午和晚上甚至凌晨开始热度飙升。所以很多自媒体新手会选择每天从公众号文章批量采集热点实现发布,每个人都能从一个号手中获取500篇热点文章!这个项目虽然很多,但是很多人依然不会操作!那么新手做这个要学什么?1.文章分词策略我们从文章标题--要接的分词公式--文章内容可以快速将标题过滤出来。
过滤关键词:采集热词:如何挑选标题强势文章,并作为接口。2.添加文章入口标签批量接文章,要接什么样的文章,必须将其入口标签和内容分割定位好。能够在公众号中接看什么样的文章,只要根据标签匹配,就能在公众号中接到什么样的文章。3.接入md5算法策略这里更新md5算法策略,很多新手是每天通过手动补充,更新文章是绝对比较耽误时间的。
公众号应该是一个很大的群体,每天每天都有大量的文章发布,而不去先选择内容,再进行人工精细化筛选,浪费时间又不会提高效率。4.操作人数设置很多人接这个项目,第一是担心接不到文章,那完全是杞人忧天,目前我们的项目人数是要求5个以上,一人最多能操作一个号,采集500个号可以验证一下。接着就是采集方法,自媒体采集,我们只要知道操作方法即可。
1.自媒体文章采集各大平台会有不同的采集规则,我们可以通过平台会发布的公告来获取机会,而且一般机会比较大,每天接一条,500个号也足够我们操作!2.分词采集如何将文章分词,这个其实很简单,用标签分类,对接标题。3.md5算法对接采集文章,公众号文章md5值太高容易存在风险,所以尽量选择文章md5值低于170以下的文章。
4.最重要的问题是!!!针对我们自己自媒体账号定位做采集标签!!!将每天一些关注自己公众号的粉丝和关注自己公众号的粉丝进行合理挖掘,这也是我们流量来源之一!!!每天坚持发布几篇热文,每天进行微信群付费学习领取自媒体视频教程。需要公众号内部联系我q:1706357762知乎回复:价值20000的自媒体视频教程。q:47788448。
文章采集接口( Python自动化接口调用示例用SoapUI进行请求(图)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-07 06:27
Python自动化接口调用示例用SoapUI进行请求(图)!)
接口调用示例
使用 SoapUI 发出这样的请求:
Postman 中请求关注的点比较多。
终于可以在Postman中顺利进行网络请求了。
补充
解析和解释postman body参数的几种参数传递形式
表单数据
相当于Content-Type:multipart/form-data,它将表单的数据处理成一条消息,以标签为单位,以分隔符分隔。您可以上传键值对或二进制数据,例如文件
您可以上传文件等二进制数据,也可以上传表单键值对,但最终会转换为消息
x-www-form-urlencoded
相当于application/x-www-from-urlencoded,表单中的数据会以键值对的形式拼接在一起;例如:姓名=张三&年龄=20。
只能上传key-value对,key-value对之间有间隔
生的
可以上传任何格式的文本,可以上传文本、json、xml、html等。
二进制
相当于Content-Type:application/octet-stream;用于上传二进制数据,一般用于上传文件;因为没有键值对,一次只能上传一个文件。
希望这篇文章对你有帮助~~如果你对软件测试、界面测试、自动化测试、面试经验交流感兴趣,可以加入我们。642830685,免费获取最新的软件测试公司面试资料和Python自动化、界面、框架搭建学习资料!技术专家答疑解惑,与同行交流。 查看全部
文章采集接口(
Python自动化接口调用示例用SoapUI进行请求(图)!)
接口调用示例
使用 SoapUI 发出这样的请求:
Postman 中请求关注的点比较多。
终于可以在Postman中顺利进行网络请求了。
补充
解析和解释postman body参数的几种参数传递形式
表单数据
相当于Content-Type:multipart/form-data,它将表单的数据处理成一条消息,以标签为单位,以分隔符分隔。您可以上传键值对或二进制数据,例如文件
您可以上传文件等二进制数据,也可以上传表单键值对,但最终会转换为消息
x-www-form-urlencoded
相当于application/x-www-from-urlencoded,表单中的数据会以键值对的形式拼接在一起;例如:姓名=张三&年龄=20。
只能上传key-value对,key-value对之间有间隔
生的
可以上传任何格式的文本,可以上传文本、json、xml、html等。
二进制
相当于Content-Type:application/octet-stream;用于上传二进制数据,一般用于上传文件;因为没有键值对,一次只能上传一个文件。
希望这篇文章对你有帮助~~如果你对软件测试、界面测试、自动化测试、面试经验交流感兴趣,可以加入我们。642830685,免费获取最新的软件测试公司面试资料和Python自动化、界面、框架搭建学习资料!技术专家答疑解惑,与同行交流。
文章采集接口(网站找搜狗人工打字中心合作开发的方法基本不支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-02 18:02
文章采集接口地址:,为保证项目安全可靠,需要经过开发者授权,该接口有效期暂为五年。对于五年内的,可以继续使用,如五年内超过五年,则按照五年前的规则重新开放。开发者该接口要认真遵守规则,防止恶意用户或者脚本等。该接口的一些特征:*接口简单便于模拟,有开发者设置*只支持浏览器*请求地址非本站点*接口参数,存放在/entity中*数据接口地址:/***开放项目*注意:*设置客户端的代理*客户端是默认get/post方式*目前接口会被ban*要求autocorrect{$extends{$invokexception=true;}}主要功能可以用restapi:可以用restapi接口:(引用文档:)可以用jsonapi接口:。
这篇可以试试,但不能接收form或类型字段或token,json方法类型较多,有些项目代码比较大。前言该api无法接收users字段和token,对json方法基本不支持,sameselector支持的类型只有timestamp。该api仅支持get和post,对post的form只支持get,mongoevent支持。本项目由我的同事/作者周日总完成,同时可以私信我聊聊你的问题。
我知道网站找搜狗人工打字中心合作开发的,每次都要去千牛找人打字,很麻烦,而且很高的打字成本,我自己也是写一堆sqlmap破解不了,今天看我在搜狗人工打字中心人工合作,他们在线可以打,免费,立刻秒懂了。你可以看看。另外这个网站开发的index.php除了打字方面什么优势都没有,就是根据客户指定用什么,一切都没有提示。
是不是也是不能商业化?我是测试出来的,毕竟你的项目肯定没有比搜狗人工打字中心先进多少,不然搜狗的工程师应该研究这个。 查看全部
文章采集接口(网站找搜狗人工打字中心合作开发的方法基本不支持)
文章采集接口地址:,为保证项目安全可靠,需要经过开发者授权,该接口有效期暂为五年。对于五年内的,可以继续使用,如五年内超过五年,则按照五年前的规则重新开放。开发者该接口要认真遵守规则,防止恶意用户或者脚本等。该接口的一些特征:*接口简单便于模拟,有开发者设置*只支持浏览器*请求地址非本站点*接口参数,存放在/entity中*数据接口地址:/***开放项目*注意:*设置客户端的代理*客户端是默认get/post方式*目前接口会被ban*要求autocorrect{$extends{$invokexception=true;}}主要功能可以用restapi:可以用restapi接口:(引用文档:)可以用jsonapi接口:。
这篇可以试试,但不能接收form或类型字段或token,json方法类型较多,有些项目代码比较大。前言该api无法接收users字段和token,对json方法基本不支持,sameselector支持的类型只有timestamp。该api仅支持get和post,对post的form只支持get,mongoevent支持。本项目由我的同事/作者周日总完成,同时可以私信我聊聊你的问题。
我知道网站找搜狗人工打字中心合作开发的,每次都要去千牛找人打字,很麻烦,而且很高的打字成本,我自己也是写一堆sqlmap破解不了,今天看我在搜狗人工打字中心人工合作,他们在线可以打,免费,立刻秒懂了。你可以看看。另外这个网站开发的index.php除了打字方面什么优势都没有,就是根据客户指定用什么,一切都没有提示。
是不是也是不能商业化?我是测试出来的,毕竟你的项目肯定没有比搜狗人工打字中心先进多少,不然搜狗的工程师应该研究这个。
文章采集接口(鼠标移动到栏目名称上(里)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-01 18:11
鼠标移动到列名,可以在状态栏查看该列,鼠标移动到列名,可以在状态栏中查看列ID:Phpw ind文章多功能界面用户手册< @一、 简介 1 份 该接口应用于Phpwind版文章中心栏目文章发布;2、这个接口只能使用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期让文章发布更真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8,请注意修改接口名称,使各个接口不同。例如,本接口文件夹中提供的接口文件都添加了文件名后缀“cms”;发布具有文章中心管理权限的用户账号时请使用5、;6、 在utf8版本中使用该接口时,请在发布规则中选择编码为UTF-8;7、 界面内容格式为UBB代码,配置发布规则时请选择“使用UBB代码格式”;8、 该接口基于utf8版本,适用于GBK/utf-8等版本。应用到其他版本时请自行测试调整;9、接口文件无需任何修改即可使用。如需添加验证或其他功能,请慎重修改;10、2个接口文件,-□示例-表面11 示例 ■论坛粪肥3--;&-□示例-调查11 示例 ■论坛粪勺示例 ■模拟C 类示例■ 管类别d;""D粛加规则Alt+(宫维看之万占桥全曲At^E娈金都AH-H。重发:gAlt+R删除AltWd导入...Alt-FN导出...2、@ >将check URL和发布URL中的“your网站”改成你要发布的网站 URL,如图: 基本上每个post item lw椅舌帮地址:hts / /淘菜1号留在HW4布库卡地址;http.//您的凤凰地址/3、在查看网址中填写您要发布的文章中心栏ID,可以填写多个, in English 用逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: < @文章title URL/* £chk ciri54、 在参数值页面,填写你要发布的文章中心列ID可以填写多个,用英文逗号隔开,如图图:基本设计|出版参数值|玉珠附师洛书横栏;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.
专栏家居生活推动美食车族蚂蚁妈妈宝宝甜蜜姻缘《休闲游http J/localhost;?o/rod&.php了咤匸scare add=li$t Shiokim right》)4、填写你的账号、密码,注意格式和账号权限,如图: 币搜骨灰盒代码栏:四、接口说明文件5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请慎重修改;二、发布接口1、接口文件名,为保密,请自行修改文件名;2、请将本接口文件复制到网站的根目录下使用,为保密,请自行修改文件名;注:“ 此项用于防止接口被他人使用。if 5、可选参数5、可选参数 Newstime Zzhours cms_descrip cms_jumpurl cms _author cms_fromi nfo cms_fromurl文章 乱码:1、发布规则中未启用utf-8编码转换;2、数据没有组织好;文章5@> 附件上传不成功:1、 检查附件保存路径和格式是否正确。2、检查附件是否存在3、检查FTP目录和权限设置;文章9@>图片不显示:1、检查发布规则文件的URL设置;2、如果启用了FTP上传,文件显示URL和FTP上传目录应该是一样的;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同; 查看全部
文章采集接口(鼠标移动到栏目名称上(里)(组图))
鼠标移动到列名,可以在状态栏查看该列,鼠标移动到列名,可以在状态栏中查看列ID:Phpw ind文章多功能界面用户手册< @一、 简介 1 份 该接口应用于Phpwind版文章中心栏目文章发布;2、这个接口只能使用一个发布规则指定多列,随机发布到不同的列文章;3、这个接口可以采集文章日期让文章发布更真实,见参数newstime和zzhours的说明;4、 由于用户可能同时使用Phpwind8,请注意修改接口名称,使各个接口不同。例如,本接口文件夹中提供的接口文件都添加了文件名后缀“cms”;发布具有文章中心管理权限的用户账号时请使用5、;6、 在utf8版本中使用该接口时,请在发布规则中选择编码为UTF-8;7、 界面内容格式为UBB代码,配置发布规则时请选择“使用UBB代码格式”;8、 该接口基于utf8版本,适用于GBK/utf-8等版本。应用到其他版本时请自行测试调整;9、接口文件无需任何修改即可使用。如需添加验证或其他功能,请慎重修改;10、2个接口文件,-□示例-表面11 示例 ■论坛粪肥3--;&-□示例-调查11 示例 ■论坛粪勺示例 ■模拟C 类示例■ 管类别d;""D粛加规则Alt+(宫维看之万占桥全曲At^E娈金都AH-H。重发:gAlt+R删除AltWd导入...Alt-FN导出...2、@ >将check URL和发布URL中的“your网站”改成你要发布的网站 URL,如图: 基本上每个post item lw椅舌帮地址:hts / /淘菜1号留在HW4布库卡地址;http.//您的凤凰地址/3、在查看网址中填写您要发布的文章中心栏ID,可以填写多个, in English 用逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: < @文章title URL/* £chk ciri54、 在参数值页面,填写你要发布的文章中心列ID可以填写多个,用英文逗号隔开,如图图:基本设计|出版参数值|玉珠附师洛书横栏;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.Basically 每套发布物品 lw 椅舌帮站点:hts //Tao cut 1 留 HW4 Bourgogne site; 匸http.//你的凤凰地址/3、填写你要发布的勾选URL文章中心列ID,可以填写多个,用英文逗号隔开,如果不限制列,可以留空,如图: Check URL: Check URL: 文章 Title URL/* £chk ciri5 4、 在参数值页面,填写文章@ > 中心要发布的栏目ID,可以填写多个,用英文逗号隔开,如图:基本设置图|发布参数值|玉珠附于老师罗书卧;vercodeF.
专栏家居生活推动美食车族蚂蚁妈妈宝宝甜蜜姻缘《休闲游http J/localhost;?o/rod&.php了咤匸scare add=li$t Shiokim right》)4、填写你的账号、密码,注意格式和账号权限,如图: 币搜骨灰盒代码栏:四、接口说明文件5、接口文件不做任何改动即可使用。如需添加验证或其他功能,请慎重修改;二、发布接口1、接口文件名,为保密,请自行修改文件名;2、请将本接口文件复制到网站的根目录下使用,为保密,请自行修改文件名;注:“ 此项用于防止接口被他人使用。if 5、可选参数5、可选参数 Newstime Zzhours cms_descrip cms_jumpurl cms _author cms_fromi nfo cms_fromurl文章 乱码:1、发布规则中未启用utf-8编码转换;2、数据没有组织好;文章5@> 附件上传不成功:1、 检查附件保存路径和格式是否正确。2、检查附件是否存在3、检查FTP目录和权限设置;文章9@>图片不显示:1、检查发布规则文件的URL设置;2、如果启用了FTP上传,文件显示URL和FTP上传目录应该是一样的;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;文件显示地址和FTP上传目录要一致;3、 如果使用保存目录代替FTP上传,文件显示URL应该与项目文件保存目录相同;
文章采集接口(哪里有finecms采集接口可以下载?建站时比较纠结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-30 07:18
哪里可以下载精美的cms采集界面?当我们用finecms建网站的时候,我们比较纠结的是如何采集文章,finecms商城有售采集外挂,价格50元,有的朋友觉得比较贵,不愿意买。我们也是权衡了好久才决定买的。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询。
精cms采集界面插件如何使用:联系ytkah咨询下载精cms采集插件
1、覆盖到根目录
2、 很好cms5.wpm 文件是 优采云 发布模块
3、这个采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1表示下载,0表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41- 362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单栏为地区,直接写地区名称,如:北京,会自动匹配地区id进入数据库。 查看全部
文章采集接口(哪里有finecms采集接口可以下载?建站时比较纠结)
哪里可以下载精美的cms采集界面?当我们用finecms建网站的时候,我们比较纠结的是如何采集文章,finecms商城有售采集外挂,价格50元,有的朋友觉得比较贵,不愿意买。我们也是权衡了好久才决定买的。有需要的朋友可以联系ytkah了解一下。价格比官方漂亮多了。添加微信咨询。
精cms采集界面插件如何使用:联系ytkah咨询下载精cms采集插件
1、覆盖到根目录
2、 很好cms5.wpm 文件是 优采云 发布模块
3、这个采集接口支持所有自定义字段,
data[status]为内容状态,1为待审核,9为通过
xiaazai = 1 下载附件配置,1表示下载,0表示不下载
多文件字段发布标签如下:
具有多个文件字段的文件数据[字段名称][文件]
多个文件字段数据的文件标题[字段名称][标题]
多个文件使用[|]作为间隔如下
*.com/file/upload/201609/09/16-26-06-11-362.jpg[|]*.com/file/upload/201609/08/14-23-20-41- 362.jpg[|]*.com/file/upload/201609/09/14-22-42-61-362.jpg
复选框字段如下
数据[字段名称] = [1,2,3]
联动菜单栏为地区,直接写地区名称,如:北京,会自动匹配地区id进入数据库。
文章采集接口(万方数据吐槽一下万方,顺带吐槽万方的原因是什么? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-10-25 16:17
)
最近对万方数据的爬取代码进行了重构,速度在每小时10w左右。因为是公司项目,代码暂时不会开源,先说一下思路和一些注意事项。万方。
第一张图:
其实道理很简单。医学期刊分为16类。然后先手动取这16个类别对应的唯一id拼接这个类型的URL,然后翻页请求获取类型。每个期刊的信息如下。
然后我们得到每个期刊的id,我们可以拼接每个期刊的首页url,但是这时候我们会发现万方里面的期刊首页有两套路由:我称之为new/old version
新版本:
老板:
这两个版本的网址不同,那么如何区分一个期刊是新版还是旧版呢?毕竟我们现在只知道期刊的id。我这里使用的方法是默认把每个期刊都当作旧版,然后用journal id拼接旧版url。
如果这个期刊真的是旧版,那么可以到期刊主页请求,如果是新版,则跳转到新版主页。最后我们只需要观察它的response.url就清楚了。
为什么要区分期刊是新版还是旧版?我认为这与请求期刊中所有文章问题的下一步有关。
因为万方的每一个期刊都是正规的,所以有一个时间树指示这个文章属于哪个期刊、年份和期数,所以我们想要得到这个期刊@>中的所有文章,你首先需要解析这个期刊的时间树,但是新版和旧版的时间树不一样。
看图:
你看见过吗?这就是为什么我们要在上一步中区分期刊是新版还是旧版。
现在知道该期刊是新版还是旧版了,下一步需要请求时间树来获取该期刊的所有年份和每年发行几期,认为这些信息将用于下一个请求 文章 。
本来是要求去时间树分析的。拿到有用的资料后,我根据每一期的每一期去索取。文章json 应该是个很美的东西,但是得到的反馈并不是很好,因为我发现最后只请求了一小部分文章,其他的都没有请求,而且返回空的 json。
一头雾水,然后就开始玩起来了,像换代理,换UA,加cookie是一个操作,结果是一个猛的操作,结果是250,很尴尬。最后,经过长时间的折腾,终于找到了问题的关键,那就是:
看到了,时间树分析了2019年的7个问题文章,分别是01、02到07,但是在请求的时候是1到7,0没了。. . 所以请求的结果都是空的。
但即便如此,请求文章的每一期时还是会出现问题,但是这个问题只出现在老版本中,即解析时间树后,请求文章一期一期问题,是有道理的。表示请求的结果会是一个json,
但是在老版本中,会不会返回一个html,导致我的程序报错,因为我一直都是按照json处理返回的结果,到现在还没想明白为什么突然返回不返回json而是返回html ,我猜应该是请求太快了吧?
所以我又添加了一个进程。当我发现返回的不是json的时候,我把期刊的id+year+issue number放到redis里,然后再设置一个job从redis里取出来,再次请求。只需从集合中删除 json,或者再次将其放入集合中,然后循环请求。
这样,通过最终解析本期请求的文章json,得到文章的内容,文章的作者信息也在这个json中。
这是整个过程。下一步是呕吐:
不得不说,万方真的很喜欢改版。起初,它被称为万方医疗。后来改为万方数据。巧合的是,在我采集期间又修改了一遍,是我现场找到的,从中找到了一个界面:
这个界面是万方改版的时候出现的。它在修订之前或之后都不存在。它只出现了一段时间,现在在网页上看不到。
该接口用于请求16个类别中的哪些期刊。返回的json收录了每个期刊的所有信息,比期刊首页显示的信息更完整,有两点对我的工作有用。这是一个很大的帮助。每个期刊的时间树必须请求一次。这无疑会减慢爬虫速度,会出现请求不可用的情况。该界面收录日志的时间树。一是如果要获取这个期刊的影响因子,需要请求期刊首页解析页面。不再需要它了。json里面也有,省了很多工作,不过万方官网没有这个接口。如果显示,则表示他们在显示时没有使用该界面。
这是请求这个接口的formdata:(code_name是16个分类的唯一标识)
查看全部
文章采集接口(万方数据吐槽一下万方,顺带吐槽万方的原因是什么?
)
最近对万方数据的爬取代码进行了重构,速度在每小时10w左右。因为是公司项目,代码暂时不会开源,先说一下思路和一些注意事项。万方。
第一张图:
其实道理很简单。医学期刊分为16类。然后先手动取这16个类别对应的唯一id拼接这个类型的URL,然后翻页请求获取类型。每个期刊的信息如下。
然后我们得到每个期刊的id,我们可以拼接每个期刊的首页url,但是这时候我们会发现万方里面的期刊首页有两套路由:我称之为new/old version
新版本:
老板:
这两个版本的网址不同,那么如何区分一个期刊是新版还是旧版呢?毕竟我们现在只知道期刊的id。我这里使用的方法是默认把每个期刊都当作旧版,然后用journal id拼接旧版url。
如果这个期刊真的是旧版,那么可以到期刊主页请求,如果是新版,则跳转到新版主页。最后我们只需要观察它的response.url就清楚了。
为什么要区分期刊是新版还是旧版?我认为这与请求期刊中所有文章问题的下一步有关。
因为万方的每一个期刊都是正规的,所以有一个时间树指示这个文章属于哪个期刊、年份和期数,所以我们想要得到这个期刊@>中的所有文章,你首先需要解析这个期刊的时间树,但是新版和旧版的时间树不一样。
看图:
你看见过吗?这就是为什么我们要在上一步中区分期刊是新版还是旧版。
现在知道该期刊是新版还是旧版了,下一步需要请求时间树来获取该期刊的所有年份和每年发行几期,认为这些信息将用于下一个请求 文章 。
本来是要求去时间树分析的。拿到有用的资料后,我根据每一期的每一期去索取。文章json 应该是个很美的东西,但是得到的反馈并不是很好,因为我发现最后只请求了一小部分文章,其他的都没有请求,而且返回空的 json。
一头雾水,然后就开始玩起来了,像换代理,换UA,加cookie是一个操作,结果是一个猛的操作,结果是250,很尴尬。最后,经过长时间的折腾,终于找到了问题的关键,那就是:
看到了,时间树分析了2019年的7个问题文章,分别是01、02到07,但是在请求的时候是1到7,0没了。. . 所以请求的结果都是空的。
但即便如此,请求文章的每一期时还是会出现问题,但是这个问题只出现在老版本中,即解析时间树后,请求文章一期一期问题,是有道理的。表示请求的结果会是一个json,
但是在老版本中,会不会返回一个html,导致我的程序报错,因为我一直都是按照json处理返回的结果,到现在还没想明白为什么突然返回不返回json而是返回html ,我猜应该是请求太快了吧?
所以我又添加了一个进程。当我发现返回的不是json的时候,我把期刊的id+year+issue number放到redis里,然后再设置一个job从redis里取出来,再次请求。只需从集合中删除 json,或者再次将其放入集合中,然后循环请求。
这样,通过最终解析本期请求的文章json,得到文章的内容,文章的作者信息也在这个json中。
这是整个过程。下一步是呕吐:
不得不说,万方真的很喜欢改版。起初,它被称为万方医疗。后来改为万方数据。巧合的是,在我采集期间又修改了一遍,是我现场找到的,从中找到了一个界面:
这个界面是万方改版的时候出现的。它在修订之前或之后都不存在。它只出现了一段时间,现在在网页上看不到。
该接口用于请求16个类别中的哪些期刊。返回的json收录了每个期刊的所有信息,比期刊首页显示的信息更完整,有两点对我的工作有用。这是一个很大的帮助。每个期刊的时间树必须请求一次。这无疑会减慢爬虫速度,会出现请求不可用的情况。该界面收录日志的时间树。一是如果要获取这个期刊的影响因子,需要请求期刊首页解析页面。不再需要它了。json里面也有,省了很多工作,不过万方官网没有这个接口。如果显示,则表示他们在显示时没有使用该界面。
这是请求这个接口的formdata:(code_name是16个分类的唯一标识)
文章采集接口(评估公众号效果的一个重要指标文章的阅读量和点赞数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-20 06:10
做过公众号的广告主都知道,衡量公众号效果的一个重要指标是文章的阅读量和点赞数。特别是通过监测这个值的增长趋势,可以判断文章流量的真实性。
那么采集公众号文章的阅读和点赞数是非常必要的。既然我们对客户做了这种需求,那么简单说一下,如果你也有这种需求,可以单独做。联系 q 1628121385。
============
现在只能用微信App读取点赞数据了。我制作了一个界面来实时获取读取数据。效果还不错。微信信号数完全支持接口的并发。
这个计划其实很简单。对于读取类似数据,微信有严格的频率限制。如果金额大,只能靠微信堆了。至于具体的方法,网上可以查到。无非是模拟点击+中间人,懂的人。知道这个是可以实现的,自动化没问题。
除了阅读和点赞界面外,历史页面等其他界面也有严格限制(请求频率阶梯限制),必须控制频率,否则会直接屏蔽界面。
抓微信的难点在于,微信在无所事事的时候会有一波封禁或者界面升级。如果读取同类数据的延迟要求不是那么高,清博、新邦等平台的数据也能抓到。
下图是我的一些采集历史文章和阅读喜欢的数据,每天都还在采集。
===========2019.08.30 更新
今年微信封号很强,主要针对各种灰黑产业链。如果用来爬取数据的微信号信用等级不够,很容易被屏蔽。如果采集的量不大,用自己的个人微信号就够了,但是量大了更难受。
总的来说,封禁微信主要针对刷卡、机器人等行为,但同时也增加了数据采集的成本。
微信再怎么努力,除了伤害新用户的用户体验外,也很难根除虚假流量和各种黑暗行为。这就是事物的二元性。从某种角度来说,它们也是需要的。
据我估计,微信公众号的阅读量大约有10%被刷掉了。
另外,运行微信协议的一些估计也不好。Android协议、ios协议、ipad协议在市场上越来越普及。微信也开始关注这类拆包技术。协议会不时更新。也很不舒服,但不知道什么时候做大。
============
目前,根据我感觉的微信反垃圾邮件模型,无论是新账号还是旧账号,微信都能轻松检测到。不密封就看心情了。可能是考虑到市场上公众号数据分析的产品生态,微信对数据抓取的禁令低于阅读抓取量。最直接的表现就是,连续一段时间的刷/刷阅读后,阅读等功能就会失效。事实上,此时微信已经检测到异常账号。我们之所以没有关闭它,是为了给数据抓取留一点空间。毕竟,这么多数据供应商的生活依赖于数据分析。在垄断分析产品推出之前,应该有办法生存。但它也是隐藏的,它只是不
这是我目前正在实现的接口文档。有兴趣的朋友可以看看~有什么问题可以加我q 1628121385 查看全部
文章采集接口(评估公众号效果的一个重要指标文章的阅读量和点赞数)
做过公众号的广告主都知道,衡量公众号效果的一个重要指标是文章的阅读量和点赞数。特别是通过监测这个值的增长趋势,可以判断文章流量的真实性。
那么采集公众号文章的阅读和点赞数是非常必要的。既然我们对客户做了这种需求,那么简单说一下,如果你也有这种需求,可以单独做。联系 q 1628121385。
============
现在只能用微信App读取点赞数据了。我制作了一个界面来实时获取读取数据。效果还不错。微信信号数完全支持接口的并发。
这个计划其实很简单。对于读取类似数据,微信有严格的频率限制。如果金额大,只能靠微信堆了。至于具体的方法,网上可以查到。无非是模拟点击+中间人,懂的人。知道这个是可以实现的,自动化没问题。
除了阅读和点赞界面外,历史页面等其他界面也有严格限制(请求频率阶梯限制),必须控制频率,否则会直接屏蔽界面。
抓微信的难点在于,微信在无所事事的时候会有一波封禁或者界面升级。如果读取同类数据的延迟要求不是那么高,清博、新邦等平台的数据也能抓到。
下图是我的一些采集历史文章和阅读喜欢的数据,每天都还在采集。
===========2019.08.30 更新
今年微信封号很强,主要针对各种灰黑产业链。如果用来爬取数据的微信号信用等级不够,很容易被屏蔽。如果采集的量不大,用自己的个人微信号就够了,但是量大了更难受。
总的来说,封禁微信主要针对刷卡、机器人等行为,但同时也增加了数据采集的成本。
微信再怎么努力,除了伤害新用户的用户体验外,也很难根除虚假流量和各种黑暗行为。这就是事物的二元性。从某种角度来说,它们也是需要的。
据我估计,微信公众号的阅读量大约有10%被刷掉了。
另外,运行微信协议的一些估计也不好。Android协议、ios协议、ipad协议在市场上越来越普及。微信也开始关注这类拆包技术。协议会不时更新。也很不舒服,但不知道什么时候做大。
============
目前,根据我感觉的微信反垃圾邮件模型,无论是新账号还是旧账号,微信都能轻松检测到。不密封就看心情了。可能是考虑到市场上公众号数据分析的产品生态,微信对数据抓取的禁令低于阅读抓取量。最直接的表现就是,连续一段时间的刷/刷阅读后,阅读等功能就会失效。事实上,此时微信已经检测到异常账号。我们之所以没有关闭它,是为了给数据抓取留一点空间。毕竟,这么多数据供应商的生活依赖于数据分析。在垄断分析产品推出之前,应该有办法生存。但它也是隐藏的,它只是不
这是我目前正在实现的接口文档。有兴趣的朋友可以看看~有什么问题可以加我q 1628121385
文章采集接口(新闻杂志登录接口、报纸杂志格式转换接口,主要是这些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-17 07:04
文章采集接口、原创认证接口、政府媒体发稿接口、新闻杂志登录接口、报纸杂志格式转换接口,主要就是这些。采集接口和采集认证接口很好找,现在几乎全网都开放了。政府媒体登录接口有些特殊,只有上海、浙江、北京、广州这四个城市才有。个人接口要收费,全国大部分高校都提供免费的学校老师接口。新闻杂志登录接口要收费,不同刊物收费不同。
使用比较广泛的是“稿定快采”,接口比较丰富,还能和数据库、一些地方站点进行共享,可以直接导入原始数据。希望对你有所帮助。
b380/people/publishing...看下?
现在全球免费的最多的服务平台是福步,但其实不免费也可以用,只是没有找到不免费的服务。
国内的话:
1、美秒,
2、美新,
3、码客圈论坛,直接搜:福步论坛国外的:mogowaikey,
4、imtoken,
市面上是没有直接可以注册外媒的平台,因为现在整个的市场外媒的订阅也分3种,跟中国电视台的频道合作有奖送的一次性入口的;正常app注册5个订阅号可以推送个免费外媒的服务;其他那些直接请求很多国家,然后可以很多服务。chinatv/youthlive/...其实只要是需要外媒注册订阅的, 查看全部
文章采集接口(新闻杂志登录接口、报纸杂志格式转换接口,主要是这些)
文章采集接口、原创认证接口、政府媒体发稿接口、新闻杂志登录接口、报纸杂志格式转换接口,主要就是这些。采集接口和采集认证接口很好找,现在几乎全网都开放了。政府媒体登录接口有些特殊,只有上海、浙江、北京、广州这四个城市才有。个人接口要收费,全国大部分高校都提供免费的学校老师接口。新闻杂志登录接口要收费,不同刊物收费不同。
使用比较广泛的是“稿定快采”,接口比较丰富,还能和数据库、一些地方站点进行共享,可以直接导入原始数据。希望对你有所帮助。
b380/people/publishing...看下?
现在全球免费的最多的服务平台是福步,但其实不免费也可以用,只是没有找到不免费的服务。
国内的话:
1、美秒,
2、美新,
3、码客圈论坛,直接搜:福步论坛国外的:mogowaikey,
4、imtoken,
市面上是没有直接可以注册外媒的平台,因为现在整个的市场外媒的订阅也分3种,跟中国电视台的频道合作有奖送的一次性入口的;正常app注册5个订阅号可以推送个免费外媒的服务;其他那些直接请求很多国家,然后可以很多服务。chinatv/youthlive/...其实只要是需要外媒注册订阅的,
文章采集接口( _data接口当发布文章时,两个接口来实现 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-11 19:13
_data接口当发布文章时,两个接口来实现
)
附件上传界面
文章发布时,实现了两个接口。一个是
第一步:attach_upload接口
第 2 步:post_data 接口
发布文章时,先将图片发送到服务器的临时目录,然后发布文章数据。例如,如果您发布一篇文章文章,它收录100 张图片。程序会分成100次,把图片上传到服务器上的一个临时目录,然后发布文章数据
attach_upload 接口代码如下:
//附件上传接口
function attach_upload(){
$api_key = $_POST['api_key'];
$api_id = intval($_POST['api_id']);
$result_data = array('status' => 0, 'msg'=> 'ok', 'data' => array());
$temp_dir = DXC_API_DIR.'/data/';//图片上传的临时路径。文章发布时,先把图片上传到临时目录,然后再发布到数据库
$re = dxcsdk::upload($temp_dir);
if($re < 0) {
$result_data['status'] = -2;
$result_data['msg'] = '服务器的 '.$temp_dir.' 目录必须设置可写权限';
return $result_data;
} else {
return $result_data;
}
} 查看全部
文章采集接口(
_data接口当发布文章时,两个接口来实现
)
附件上传界面
文章发布时,实现了两个接口。一个是
第一步:attach_upload接口
第 2 步:post_data 接口
发布文章时,先将图片发送到服务器的临时目录,然后发布文章数据。例如,如果您发布一篇文章文章,它收录100 张图片。程序会分成100次,把图片上传到服务器上的一个临时目录,然后发布文章数据
attach_upload 接口代码如下:
//附件上传接口
function attach_upload(){
$api_key = $_POST['api_key'];
$api_id = intval($_POST['api_id']);
$result_data = array('status' => 0, 'msg'=> 'ok', 'data' => array());
$temp_dir = DXC_API_DIR.'/data/';//图片上传的临时路径。文章发布时,先把图片上传到临时目录,然后再发布到数据库
$re = dxcsdk::upload($temp_dir);
if($re < 0) {
$result_data['status'] = -2;
$result_data['msg'] = '服务器的 '.$temp_dir.' 目录必须设置可写权限';
return $result_data;
} else {
return $result_data;
}
}
文章采集接口( 数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-09 21:10
数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
内容网络数据采集接口定义及自动处理流程[宝典]数据采集及自动处理流程 1 概述 本文主要介绍内容网络库的外部定义数据采集接口及采集数据的自动处理过程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工爬取进行的。对于其他采集方法,虽然有建议和,但是我们在当前极速网后台没有找到对应的模块。希望网通相关人员通过阅读文档,及时补充我们采集接口的不足。对于我们下面设计的界面,希望界面与网通有关。人员可以提供测试数据给我们测试 2采集 接口定义 21 Crawler BT接口 211 问题待确认 因为我们在原速网后台没有找到该接口的设置接口,请向相关人员索取以下问题 答案 1 爬虫会爬取BT信息吗?2 如果爬虫会爬取BT信息,是否和HTTP爬取的信息一致?3 Bt爬虫爬取的数据和Bt active cache解析的数据有什么区别?基于以上问题,在没有得到网络相关人员回复的前提下,我们按照以下情况进行设计:1 爬虫会爬取 BT 信息 2 爬虫爬取的信息只收录资源信息 212 接口设计调用者爬虫系统爬取新数据时的调用频率 每次实时调用或每天定时调用,保证每次发送的信息是最新一批数据。输入参数contentscontenttypebtnamenameinfohashinfohashprotocolprotocolformatformatformatcnt_sizecnt_sizedutariondurationdata_ratedata_ratequalityqualitylanguagelanguageurlurlcontentcontents 输入参数详情如下: FORMAT文件格式18NAME名称用于完整性验证判断和去重2PR
我们根据以下条件设计爬虫对HTTP在线资源进行爬取。资源和数据信息不是同时进行的。完整性验证判断去重2PROTOCOL采集协议4LANGUAGE语言5CNT_SIZE大小6QUALITY质量7DATA_RATE码流10INFOHASHInfohash值判断去重11Duration回放时长12URL资源源完整性验证132222爬虫HTTP数据接口actorstvnametvname_hostauthor_hoststvnametvnameactor_hostauthor
nspanplaydateplaydatecountrycountrylanguagelanguagemovietypemovietypecontent_typecontent_typecommentscommentstagtagdescriptiondesprictionhposterhpostervpostervposteris_hotis_hotchildren_countchildren_countavg_marksavg_markscapture_sitecapture_sitechanneldocuments No. Field Name Description standard template job description job descriptions job descriptions 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述,人力资源,描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述, 人力资源部(IP)2s情节描述是否HPOSTER横竖海报海报5VPOSTER 6IS_HOT热销7TAGTag栏8CHILDREN_COUNT子集数量9AUTHOR编剧10TV_NAME电视台名称11TV_HOST主持人12SPAN时长13播出时间COMMENTS评论14REC LANGUAGE电影语言FK15PLAYD7AC导演14影片上映日期 18 COUNTRY 地区类别 FK19 MOVIETYPE 影片类别 FK20CONTENT_TYPE 主题类别 FK21AVG@ksite_S 评分判断 22 分<capture_MARK_S> 是不是前 10 门户网站网站 频道可以用来区分是否有一系列的字段如24频道作者等主演的剧集数 3 自动处理流程 自动处理流程的目的是通过采集获取的数据,将系统的自动内容传递出去界面筛选自动内容质量控制自动内容发布功能完善数据库中的数据
降低手动编辑的质量。31 规则列表下方的表格定义了我们总结的筛选质量控制版本的规则。平台的规则引擎会根据以下规则自动处理数据。请根据实际情况确认这些规则。补充筛选规则 通过判断电影名称播放地址不为空来屏蔽数据垃圾数量。如果有空数据段,则将数据放入垃圾表进行处理。通过清空电影名称播放地址来屏蔽资源垃圾号。如果有数据段,将数据放入垃圾表处理资源。采集信息数据比较电影名称。如果有相同的数据,将数据放入垃圾表进行处理,数据内容不完整。采集信息资源对比播放地址infohash。如果数据相同,删除其中一条记录。使用电影名称的别名与元数据中的原创数据进行比较。例如,如果元数据数据具有相同的数据,则不会将数据添加到其中。在元数据库中,http通过播放地址进行比较,bt通过infohash值进入到元数据资源中,去除重复行,比如查找相同的记录。此资源状态更改为屏蔽并添加到元数据库中。如果在去重阶段没有找到相同的记录,则查找对应的影子绑定 设置库标题数据以查找资源进行绑定,反之亦然。资源数据是针对父子关系的,比如电视剧数据。如果库中没有子集数据,父子数据会自动生成子集数据供资源绑定审核规则使用,以确定每个字段中是否有关键词等黄色词,如果有效性检查结果有效,则转入人工资源信息进行审核。一般资源是否属于前10个门户?发送 ping 以查看它是否有效。首先判断该信息是否属于前10个门户。网站 如果是直接数据内容校验,别名中的逗号会自动转成"",两边空格去掉。如果分数字段小于 5 分数会自动转换为 5 分或以上。如果分数是整数,则加上小数。对于导演和演员,每行前后的空格会自动删除。情节描述的第一行是空白的。2个空格被自动添加或删除。对于演员和导演
如果姓名不完整,比如张艺谋,但数据是张艺,查字典表,自动补全演员姓名。对于区域,如果区域为空,可以使用演员导演来计算是哪个区域。频道对应话剧电影,演员导演不能为空,如果对应的是动画,作者不能为空。如果对应的是综艺节目,那么主持人电视台不能为空。不符合规则,转人工审核。分销管理规则。根据资源的热度,搜索次数根据热度分为几个等级。结合各个站点的缓存情况的级别,发送给各个站点,例如将热度分为三个级别:高、正常、低。对于级别高的资源,所有站点都会下发到共享热资源的缓存空间。对于更多站点,热度较低的资源仅在本地交付。1 当发现某个资源的缓存进度已经比较低时,根据规则替换或删除缓存优化规则。2 当发现某个资源缓存过多时 下次根据资源缓存进度保留进度最高的资源。应删除其他资源缓存。3、当发现站点缓存空间不足时,应根据各个资源的热缓存情况进行资源清理。流程流程图资源在存储前会进行完整性检查和批量重复数据删除资源的可靠性审计等多个步骤,以确保进入元数据的资源是真实可用的。存储后,会定期调用审计规则查看库中的资源。数据是否满足审核条件,去除已经失效的链接,对满足发布条件的资源调用分布式管理机制,保证资源的最大利用率。重复数据删除、元数据重复数据删除等多重步骤确保元数据的元数据是唯一的,并且在存储之前会调用哪些审计规则。尝试提前更正错误的数据。储存后,将定期调用审计规则来检查数据库。数据的完整性和可靠性,部分数据的自动修正和修正,满足放行条件的材料放行 查看全部
文章采集接口(
数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
内容网络数据采集接口定义及自动处理流程[宝典]数据采集及自动处理流程 1 概述 本文主要介绍内容网络库的外部定义数据采集接口及采集数据的自动处理过程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工爬取进行的。对于其他采集方法,虽然有建议和,但是我们在当前极速网后台没有找到对应的模块。希望网通相关人员通过阅读文档,及时补充我们采集接口的不足。对于我们下面设计的界面,希望界面与网通有关。人员可以提供测试数据给我们测试 2采集 接口定义 21 Crawler BT接口 211 问题待确认 因为我们在原速网后台没有找到该接口的设置接口,请向相关人员索取以下问题 答案 1 爬虫会爬取BT信息吗?2 如果爬虫会爬取BT信息,是否和HTTP爬取的信息一致?3 Bt爬虫爬取的数据和Bt active cache解析的数据有什么区别?基于以上问题,在没有得到网络相关人员回复的前提下,我们按照以下情况进行设计:1 爬虫会爬取 BT 信息 2 爬虫爬取的信息只收录资源信息 212 接口设计调用者爬虫系统爬取新数据时的调用频率 每次实时调用或每天定时调用,保证每次发送的信息是最新一批数据。输入参数contentscontenttypebtnamenameinfohashinfohashprotocolprotocolformatformatformatcnt_sizecnt_sizedutariondurationdata_ratedata_ratequalityqualitylanguagelanguageurlurlcontentcontents 输入参数详情如下: FORMAT文件格式18NAME名称用于完整性验证判断和去重2PR
我们根据以下条件设计爬虫对HTTP在线资源进行爬取。资源和数据信息不是同时进行的。完整性验证判断去重2PROTOCOL采集协议4LANGUAGE语言5CNT_SIZE大小6QUALITY质量7DATA_RATE码流10INFOHASHInfohash值判断去重11Duration回放时长12URL资源源完整性验证132222爬虫HTTP数据接口actorstvnametvname_hostauthor_hoststvnametvnameactor_hostauthor
nspanplaydateplaydatecountrycountrylanguagelanguagemovietypemovietypecontent_typecontent_typecommentscommentstagtagdescriptiondesprictionhposterhpostervpostervposteris_hotis_hotchildren_countchildren_countavg_marksavg_markscapture_sitecapture_sitechanneldocuments No. Field Name Description standard template job description job descriptions job descriptions 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述,人力资源,描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述, 人力资源部(IP)2s情节描述是否HPOSTER横竖海报海报5VPOSTER 6IS_HOT热销7TAGTag栏8CHILDREN_COUNT子集数量9AUTHOR编剧10TV_NAME电视台名称11TV_HOST主持人12SPAN时长13播出时间COMMENTS评论14REC LANGUAGE电影语言FK15PLAYD7AC导演14影片上映日期 18 COUNTRY 地区类别 FK19 MOVIETYPE 影片类别 FK20CONTENT_TYPE 主题类别 FK21AVG@ksite_S 评分判断 22 分<capture_MARK_S> 是不是前 10 门户网站网站 频道可以用来区分是否有一系列的字段如24频道作者等主演的剧集数 3 自动处理流程 自动处理流程的目的是通过采集获取的数据,将系统的自动内容传递出去界面筛选自动内容质量控制自动内容发布功能完善数据库中的数据
降低手动编辑的质量。31 规则列表下方的表格定义了我们总结的筛选质量控制版本的规则。平台的规则引擎会根据以下规则自动处理数据。请根据实际情况确认这些规则。补充筛选规则 通过判断电影名称播放地址不为空来屏蔽数据垃圾数量。如果有空数据段,则将数据放入垃圾表进行处理。通过清空电影名称播放地址来屏蔽资源垃圾号。如果有数据段,将数据放入垃圾表处理资源。采集信息数据比较电影名称。如果有相同的数据,将数据放入垃圾表进行处理,数据内容不完整。采集信息资源对比播放地址infohash。如果数据相同,删除其中一条记录。使用电影名称的别名与元数据中的原创数据进行比较。例如,如果元数据数据具有相同的数据,则不会将数据添加到其中。在元数据库中,http通过播放地址进行比较,bt通过infohash值进入到元数据资源中,去除重复行,比如查找相同的记录。此资源状态更改为屏蔽并添加到元数据库中。如果在去重阶段没有找到相同的记录,则查找对应的影子绑定 设置库标题数据以查找资源进行绑定,反之亦然。资源数据是针对父子关系的,比如电视剧数据。如果库中没有子集数据,父子数据会自动生成子集数据供资源绑定审核规则使用,以确定每个字段中是否有关键词等黄色词,如果有效性检查结果有效,则转入人工资源信息进行审核。一般资源是否属于前10个门户?发送 ping 以查看它是否有效。首先判断该信息是否属于前10个门户。网站 如果是直接数据内容校验,别名中的逗号会自动转成"",两边空格去掉。如果分数字段小于 5 分数会自动转换为 5 分或以上。如果分数是整数,则加上小数。对于导演和演员,每行前后的空格会自动删除。情节描述的第一行是空白的。2个空格被自动添加或删除。对于演员和导演
如果姓名不完整,比如张艺谋,但数据是张艺,查字典表,自动补全演员姓名。对于区域,如果区域为空,可以使用演员导演来计算是哪个区域。频道对应话剧电影,演员导演不能为空,如果对应的是动画,作者不能为空。如果对应的是综艺节目,那么主持人电视台不能为空。不符合规则,转人工审核。分销管理规则。根据资源的热度,搜索次数根据热度分为几个等级。结合各个站点的缓存情况的级别,发送给各个站点,例如将热度分为三个级别:高、正常、低。对于级别高的资源,所有站点都会下发到共享热资源的缓存空间。对于更多站点,热度较低的资源仅在本地交付。1 当发现某个资源的缓存进度已经比较低时,根据规则替换或删除缓存优化规则。2 当发现某个资源缓存过多时 下次根据资源缓存进度保留进度最高的资源。应删除其他资源缓存。3、当发现站点缓存空间不足时,应根据各个资源的热缓存情况进行资源清理。流程流程图资源在存储前会进行完整性检查和批量重复数据删除资源的可靠性审计等多个步骤,以确保进入元数据的资源是真实可用的。存储后,会定期调用审计规则查看库中的资源。数据是否满足审核条件,去除已经失效的链接,对满足发布条件的资源调用分布式管理机制,保证资源的最大利用率。重复数据删除、元数据重复数据删除等多重步骤确保元数据的元数据是唯一的,并且在存储之前会调用哪些审计规则。尝试提前更正错误的数据。储存后,将定期调用审计规则来检查数据库。数据的完整性和可靠性,部分数据的自动修正和修正,满足放行条件的材料放行
文章采集接口(微信文章采集规则优采云采集,微信公众号采集的小技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-07 15:06
内容。不可用于商业体验。之前之所以这么做,其实是因为我在一个五线城市看到了一个XX城市。采集微信公众号文章的ThinkPHP框架,
如何将文章中的其他微信公众号采集加入设备?飞速小蚂蚁微信、飞速小蚂蚁微信、微信在线排版助手 专业致力于微信文章的排版和美化,提供各种微信图文素材模板,大大提高了微信图文内容的效率。还有微信图形提取微信超链接、微信短地址、微信一键关闭。微信公众号文章采集工具引流脚本,微信公众号文章采集工具可用采集文章文字内容信息,只能是单个 采集!采集 目录weixin采集completed采集 过程中会自动生成。内容存放在weixin目录下的微信公众号文章title目录中。H T。如何采集微信公众号文章?爱小帮手,导出采集后,可以制作和修改文章。更多资讯和知识点,继续关注爱小猪。也可以搜索阿奇微信公众号文章导出助手免费下载如何导出微信公众号文章如何转换微信公众号文件。微信人气文章采集器下载v1000正式版Bickel下载,微信人气文章采集器是微信人气文章采集软件即可根据关键词采集到大量相关微信热点文章,
公众号文章采集器
微信人气文章爆文小助手采集器(微信人气文章采集器)85模板,这个要看具体平台。如果是今日头条这样的UGC平台,有一定的内容推荐机制,比微信公众号简单很多。微信人气文章爆文助手采集器。具有推荐机制的平台需要它。微信公众号文章搜索采集插件应用交流ZBlogger技术交流中心,此插件是在标准云微信公众号文章采集免费版基础上新增的@> 便捷功能采集微信公众号文章。文章的获取方式有两种: ①根据关键词文章②根据关键词搜索。1 后台可以设置用户组的使用权限。2 前哨在后。1 后台可以设置用户组的使用权限。2 前哨在后。
独狼采集器微信爆文助理独狼微信文章采集器100微信云,独狼微信文章采集器是微信实现文章采集器 @文章Automatic 采集强大的营销工具,让您可以进行微信公众号运营。通过简单的操作,你可以完成两倍于其他人的工作。让您的微信公众号对成千上万的用户可见。. 独狼采集器下载独狼微信文章采集器 下载v100微信运营版,全文模板1900+(每周)。如果您购买非搜索器样式模块和全文模板,则可以免费使用它。不额外收费!!!辅导年3月19日一键微信采集微信公众号。如果不想找你的微信,一键采集教程微信公众号文章模板合集,有时候想下载一个公众号文章或者把需求保存在这个尊重一些朋友。说是家常便饭。这里是来自 52pojieyou原创 的工具。有点不完美的是这个软件是一个命令行窗口。 查看全部
文章采集接口(微信文章采集规则优采云采集,微信公众号采集的小技巧)
内容。不可用于商业体验。之前之所以这么做,其实是因为我在一个五线城市看到了一个XX城市。采集微信公众号文章的ThinkPHP框架,
如何将文章中的其他微信公众号采集加入设备?飞速小蚂蚁微信、飞速小蚂蚁微信、微信在线排版助手 专业致力于微信文章的排版和美化,提供各种微信图文素材模板,大大提高了微信图文内容的效率。还有微信图形提取微信超链接、微信短地址、微信一键关闭。微信公众号文章采集工具引流脚本,微信公众号文章采集工具可用采集文章文字内容信息,只能是单个 采集!采集 目录weixin采集completed采集 过程中会自动生成。内容存放在weixin目录下的微信公众号文章title目录中。H T。如何采集微信公众号文章?爱小帮手,导出采集后,可以制作和修改文章。更多资讯和知识点,继续关注爱小猪。也可以搜索阿奇微信公众号文章导出助手免费下载如何导出微信公众号文章如何转换微信公众号文件。微信人气文章采集器下载v1000正式版Bickel下载,微信人气文章采集器是微信人气文章采集软件即可根据关键词采集到大量相关微信热点文章,
公众号文章采集器
微信人气文章爆文小助手采集器(微信人气文章采集器)85模板,这个要看具体平台。如果是今日头条这样的UGC平台,有一定的内容推荐机制,比微信公众号简单很多。微信人气文章爆文助手采集器。具有推荐机制的平台需要它。微信公众号文章搜索采集插件应用交流ZBlogger技术交流中心,此插件是在标准云微信公众号文章采集免费版基础上新增的@> 便捷功能采集微信公众号文章。文章的获取方式有两种: ①根据关键词文章②根据关键词搜索。1 后台可以设置用户组的使用权限。2 前哨在后。1 后台可以设置用户组的使用权限。2 前哨在后。
独狼采集器微信爆文助理独狼微信文章采集器100微信云,独狼微信文章采集器是微信实现文章采集器 @文章Automatic 采集强大的营销工具,让您可以进行微信公众号运营。通过简单的操作,你可以完成两倍于其他人的工作。让您的微信公众号对成千上万的用户可见。. 独狼采集器下载独狼微信文章采集器 下载v100微信运营版,全文模板1900+(每周)。如果您购买非搜索器样式模块和全文模板,则可以免费使用它。不额外收费!!!辅导年3月19日一键微信采集微信公众号。如果不想找你的微信,一键采集教程微信公众号文章模板合集,有时候想下载一个公众号文章或者把需求保存在这个尊重一些朋友。说是家常便饭。这里是来自 52pojieyou原创 的工具。有点不完美的是这个软件是一个命令行窗口。
文章采集接口(数据采集及自动处理流程(一)_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-07 04:02
数据采集及自动处理流程概述本文主要介绍内容网络库的外部定义数据采集接口以及这些采集数据的自动处理流程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工方式和爬取方式进行的。对于其他采集方法,虽然我们已经提到过,但是我们在当前的苏旺后台中没有找到对应的模块。希望网通相关人员通过阅读本文档,及时对我们缺少的采集界面进行补充。对于我们下面设计的界面,希望网通相关人员可以提供测试数据供我们测试。采集 interface 定义了需要确认的爬虫BT接口。因为在原速网后台,我们没有找到界面设置界面,所以请相关人员回答以下问题。1.爬虫是否会爬取BT信息2.如果爬虫会爬取BT信息,是否与HTTP爬取的信息匹配?持续的?3.Bt爬虫抓取到的数据和Bt主动缓存解析的数据有什么区别?基于以上问题,我们在没有得到网络相关人员回复的情况下,根据以下情况设计了爬虫会议 爬取BT信息2. 爬虫爬取的信息只收录资源信息。接口设计调用者:爬虫系统调用频率:当发现有新数据被抓取时,实时调用或每天定时调用。约束:保证每次发送的信息都是最新的一批数据。输入参数:<dutarion> 输入参数的详细信息如下 18 FORMAT 文件格式 2NAME 名称用于完整性检查,判断去重 4PROTOCOL采集 协议 5LANGUAGE 语言(6CNT_SIZE 大小 7QUALITY 质量 10DATA_RATE 码流 11INFOHASHInfohash 值判断去重12Duration 播放时长 13URL 资源源完整性检查输出:成功或失败。
爬虫HTTP接口挂起问题爬虫爬取HTTP在线资源时,是否同时获取资源数据信息采集?Http爬取的资源里有电影名和剧集吗?基于上述问题,在没有得到互联网相关人员的回应的情况下,我们设计了爬虫按照以下条件抓取HTTP在线资源。资源和数据信息不是同时进行的。采集接口设计爬虫HTTP资源接口<dutarion>18 FORMAT文件格式2NAME名称用于完整性校验、判断和去重4PROTOCOL采集 点判断是否是前10 门户网站24channel 可以用来区分是否有剧集、主演作者等字段。自动处理流程。自动处理流程的目的是通过系统的自动内容过滤和自动内容过滤采集接口获取的数据。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。
规则列表下方的表格定义了我们总结的筛选、质量控制和发布规则。平台的规则引擎将根据以下规则自动处理数据。请根据实际情况确认和补充这些规则。筛选规则通过判断电影名称和播放地址不为空来屏蔽垃圾数据。如果有空字段,则将数据放入垃圾表进行处理。(信息) 屏蔽资源垃圾数据通过清空电影名称和播放地址进行处理。如果有空字段,则将数据放入垃圾表进行处理。(资源)采集 信息数据去重比较“电影名称”。如果有相同的数据,相关数据内容不完整的数据将放入垃圾表进行处理。采集信息资源去重对比“播放地址”和“infohash”。如果数据相同。然后删除其中一条记录。元数据重复数据删除通过电影名称和别名与元数据中的原创数据进行比较。如果存在相同的数据,则不会将该数据添加到元数据数据库中。元数据资源去重http通过播放地址对比,bt通过infohash值对比。如果找到相同的记录,则资源状态将被更改并添加到元数据数据库中。如果在重复数据删除阶段未找到相同的记录,则绑定到库中。通过查找对应的电影名称绑定(数据搜索资源),反之亦然。(资源数据)对于有父子关系的数据(如电视剧)。如果库中没有子集数据。父子数据会自动生成子集数据用于资源绑定。
检查审核规则的有效性,确定每个字段是否有关键词(例如:黄色词),如果有,则转入手册进行审核(资源信息通用)。检查资源是否属于前10个门户。网站,如果直接批准。发送ping到播放地址看看是否有效。数据内容验证首先判断数据是否属于前10名门户网站网站,如果是,则直接审批。对于别名中出现的逗号,逗号会自动转换为“/”。去掉“/”两边的空格。如果分数字段小于 5 分,它会自动转换为大于 5 分。如果分数是整数,将增加一位小数。对于导演和演员来说,每行的前导和尾随空格会自动删除。对于情节描述,第一行留2个空格,多余的空格会自动添加或删除。对于演员和导演,如果姓名不全(例如:张艺谋,但数据中有张艺),查找字典表,自动补全姓名。对于演员来说也是如此。对于区域:如果区域是空的,演员和导演可以计算出它是哪个区域。如果频道对应于剧集,则电影。那么演员、导演不能为空。如果对应的是动漫,那么作者不能为空。如果对应的是综艺节目,那么主持人和电视台不能为空。如果不符合规则,将转为人工审核。分销管理规则。资源发布规则根据资源的流行程度(点击率、排名、搜索次数)分为几个级别。根据流行程度和各个站点的缓存情况的组合,将其发布到各个位置。例如,热量分为三个级别:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。
缓存优化规则1. 当发现某个资源的缓存进度一直比较低时,根据规则替换或删除缓存。2. 当发现一个资源被多次缓存时,应该根据该资源的缓存Progress 保留进度最高的资源,并删除其他资源缓存。3. 当发现站点缓存空间不足时,应根据各个资源的热度、缓存情况,以及热度低、缓存进度低的资源进行清理。详细说明 1 资源处理流程图 资源入库前,会经过完整性验证、同批次去重、和资源可靠性审查,以确保输入元数据的资源真实可用。资源入库后,会定期调用审核规则,检查资源库中的数据是否满足审核条件,并剔除无效链接。并对满足释放条件的资源调用分布式管理机制,保证资源的最大利用率。2 数据处理流程图 数据入库前,会进行完整性验证,进行同批次去重、元数据去重等多个步骤,确保元数据的元数据唯一。以及存储前会调用哪些审计规则,尽量提前纠正数据中的错误。数据存入数据库后,会定期调用审计规则,检查数据库中数据的完整性和可靠性,部分数据会自动修正和修正。并出版符合出版条件的资料。补充问题小伙伴引入的调用接口在哪里,如何调用,能否提供? 查看全部
文章采集接口(数据采集及自动处理流程(一)_光明网(组图))
数据采集及自动处理流程概述本文主要介绍内容网络库的外部定义数据采集接口以及这些采集数据的自动处理流程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工方式和爬取方式进行的。对于其他采集方法,虽然我们已经提到过,但是我们在当前的苏旺后台中没有找到对应的模块。希望网通相关人员通过阅读本文档,及时对我们缺少的采集界面进行补充。对于我们下面设计的界面,希望网通相关人员可以提供测试数据供我们测试。采集 interface 定义了需要确认的爬虫BT接口。因为在原速网后台,我们没有找到界面设置界面,所以请相关人员回答以下问题。1.爬虫是否会爬取BT信息2.如果爬虫会爬取BT信息,是否与HTTP爬取的信息匹配?持续的?3.Bt爬虫抓取到的数据和Bt主动缓存解析的数据有什么区别?基于以上问题,我们在没有得到网络相关人员回复的情况下,根据以下情况设计了爬虫会议 爬取BT信息2. 爬虫爬取的信息只收录资源信息。接口设计调用者:爬虫系统调用频率:当发现有新数据被抓取时,实时调用或每天定时调用。约束:保证每次发送的信息都是最新的一批数据。输入参数:<dutarion> 输入参数的详细信息如下 18 FORMAT 文件格式 2NAME 名称用于完整性检查,判断去重 4PROTOCOL采集 协议 5LANGUAGE 语言(6CNT_SIZE 大小 7QUALITY 质量 10DATA_RATE 码流 11INFOHASHInfohash 值判断去重12Duration 播放时长 13URL 资源源完整性检查输出:成功或失败。
爬虫HTTP接口挂起问题爬虫爬取HTTP在线资源时,是否同时获取资源数据信息采集?Http爬取的资源里有电影名和剧集吗?基于上述问题,在没有得到互联网相关人员的回应的情况下,我们设计了爬虫按照以下条件抓取HTTP在线资源。资源和数据信息不是同时进行的。采集接口设计爬虫HTTP资源接口<dutarion>18 FORMAT文件格式2NAME名称用于完整性校验、判断和去重4PROTOCOL采集 点判断是否是前10 门户网站24channel 可以用来区分是否有剧集、主演作者等字段。自动处理流程。自动处理流程的目的是通过系统的自动内容过滤和自动内容过滤采集接口获取的数据。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。界面通过系统的自动内容过滤和自动内容。质量控制和自动内容发布功能提高了数据库中数据的质量,减少了人工编辑的工作量。
规则列表下方的表格定义了我们总结的筛选、质量控制和发布规则。平台的规则引擎将根据以下规则自动处理数据。请根据实际情况确认和补充这些规则。筛选规则通过判断电影名称和播放地址不为空来屏蔽垃圾数据。如果有空字段,则将数据放入垃圾表进行处理。(信息) 屏蔽资源垃圾数据通过清空电影名称和播放地址进行处理。如果有空字段,则将数据放入垃圾表进行处理。(资源)采集 信息数据去重比较“电影名称”。如果有相同的数据,相关数据内容不完整的数据将放入垃圾表进行处理。采集信息资源去重对比“播放地址”和“infohash”。如果数据相同。然后删除其中一条记录。元数据重复数据删除通过电影名称和别名与元数据中的原创数据进行比较。如果存在相同的数据,则不会将该数据添加到元数据数据库中。元数据资源去重http通过播放地址对比,bt通过infohash值对比。如果找到相同的记录,则资源状态将被更改并添加到元数据数据库中。如果在重复数据删除阶段未找到相同的记录,则绑定到库中。通过查找对应的电影名称绑定(数据搜索资源),反之亦然。(资源数据)对于有父子关系的数据(如电视剧)。如果库中没有子集数据。父子数据会自动生成子集数据用于资源绑定。
检查审核规则的有效性,确定每个字段是否有关键词(例如:黄色词),如果有,则转入手册进行审核(资源信息通用)。检查资源是否属于前10个门户。网站,如果直接批准。发送ping到播放地址看看是否有效。数据内容验证首先判断数据是否属于前10名门户网站网站,如果是,则直接审批。对于别名中出现的逗号,逗号会自动转换为“/”。去掉“/”两边的空格。如果分数字段小于 5 分,它会自动转换为大于 5 分。如果分数是整数,将增加一位小数。对于导演和演员来说,每行的前导和尾随空格会自动删除。对于情节描述,第一行留2个空格,多余的空格会自动添加或删除。对于演员和导演,如果姓名不全(例如:张艺谋,但数据中有张艺),查找字典表,自动补全姓名。对于演员来说也是如此。对于区域:如果区域是空的,演员和导演可以计算出它是哪个区域。如果频道对应于剧集,则电影。那么演员、导演不能为空。如果对应的是动漫,那么作者不能为空。如果对应的是综艺节目,那么主持人和电视台不能为空。如果不符合规则,将转为人工审核。分销管理规则。资源发布规则根据资源的流行程度(点击率、排名、搜索次数)分为几个级别。根据流行程度和各个站点的缓存情况的组合,将其发布到各个位置。例如,热量分为三个级别:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。热量分为三个等级:高、正常和低。对于高级别的资源,所有站点都分布,对于普通热度的资源,只分配到缓存空间大的站点,对于低热级别的资源。只分发到本地。
缓存优化规则1. 当发现某个资源的缓存进度一直比较低时,根据规则替换或删除缓存。2. 当发现一个资源被多次缓存时,应该根据该资源的缓存Progress 保留进度最高的资源,并删除其他资源缓存。3. 当发现站点缓存空间不足时,应根据各个资源的热度、缓存情况,以及热度低、缓存进度低的资源进行清理。详细说明 1 资源处理流程图 资源入库前,会经过完整性验证、同批次去重、和资源可靠性审查,以确保输入元数据的资源真实可用。资源入库后,会定期调用审核规则,检查资源库中的数据是否满足审核条件,并剔除无效链接。并对满足释放条件的资源调用分布式管理机制,保证资源的最大利用率。2 数据处理流程图 数据入库前,会进行完整性验证,进行同批次去重、元数据去重等多个步骤,确保元数据的元数据唯一。以及存储前会调用哪些审计规则,尽量提前纠正数据中的错误。数据存入数据库后,会定期调用审计规则,检查数据库中数据的完整性和可靠性,部分数据会自动修正和修正。并出版符合出版条件的资料。补充问题小伙伴引入的调用接口在哪里,如何调用,能否提供?
文章采集接口(八爪网:内容作弊是一种作弊手法吗?作弊)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-05 03:01
网站 内容作弊现在很普遍,因为优质的内容意味着流量。所以现在很多站长也用内容作弊。今天八扎网就为大家介绍几种常见的内容作弊方法。
1、关键词 重复
许多站长倾向于在页面内容中重复这些关键词。关键词 密度是搜索引擎计算中要考虑的一个因素。如果关键词的频率太高,本质上会影响关键词的搜索引擎排名,但现在这种作弊手法已经是攻击的目标了。关键词的密度只需要维持在2%-8%即可。太多或太少都不利于排名。
内容作弊的几种常见方法
2、没有关键词作弊
一些站长为了尽可能吸引更多的流量,会在页面上添加很多与网站主题无关的关键词。这种方法主要是为了蹭流量,发布了很多不属于网站主题的内容。这种方式虽然可以吸引大量流量,但目标流量很小。不过这种方法已经被百度的飓风算法命中了,最好避开。
3、文章采集 作弊
采集的危害可以说是非常明显了。不会是收录,而是K站。八爪网建议站长不要尝试冒险。
好了,以上就是今天八扎网分享的几种常见的内容作弊方法。内容作弊也是一种作弊方式,近期会有针对性,所以建议站长还是用正规的方式。提高网站的排名。
原文来自八角网,更多网络知识等着你。 查看全部
文章采集接口(八爪网:内容作弊是一种作弊手法吗?作弊)
网站 内容作弊现在很普遍,因为优质的内容意味着流量。所以现在很多站长也用内容作弊。今天八扎网就为大家介绍几种常见的内容作弊方法。
1、关键词 重复
许多站长倾向于在页面内容中重复这些关键词。关键词 密度是搜索引擎计算中要考虑的一个因素。如果关键词的频率太高,本质上会影响关键词的搜索引擎排名,但现在这种作弊手法已经是攻击的目标了。关键词的密度只需要维持在2%-8%即可。太多或太少都不利于排名。
内容作弊的几种常见方法
2、没有关键词作弊
一些站长为了尽可能吸引更多的流量,会在页面上添加很多与网站主题无关的关键词。这种方法主要是为了蹭流量,发布了很多不属于网站主题的内容。这种方式虽然可以吸引大量流量,但目标流量很小。不过这种方法已经被百度的飓风算法命中了,最好避开。
3、文章采集 作弊
采集的危害可以说是非常明显了。不会是收录,而是K站。八爪网建议站长不要尝试冒险。
好了,以上就是今天八扎网分享的几种常见的内容作弊方法。内容作弊也是一种作弊方式,近期会有针对性,所以建议站长还是用正规的方式。提高网站的排名。
原文来自八角网,更多网络知识等着你。
文章采集接口(石青伪原创工具是什么:伪工具使用方法步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-04 16:23
石青伪原创是什么工具:伪原创工具是SEO的高级工具,石青伪原创软件是免费的专业伪原创文章生成器,可以生成原创和伪原创的文章,专门针对百度、谷歌的抓取习惯和分词算法而开发。经本软件优化的文章会更受搜索引擎青睐。使用伪原创工具打造互联网上独一无二的伪原创文章,支持中英文伪原创。
石青伪原创如何使用工具
步:
1.安装软件
伪原创该工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。
启动后界面如下:
2.采集文章
石青伪原创工具,自带采集工具。首先需要在“采集设置”模块中输入需要采集的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后在百度或谷歌中选择采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。
点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果要停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章和争抢生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.生产伪原创文章
用户可以通过4种方式输入原创文章,1、直接复制文章到文章编辑区,然后输入标题,然后保存文章; 2、通过导入,可以直接导入TXT或html文档,3、通过采集,直接采集到网上的文章,4、直接通过界面获取你的内容cms网站;
获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章的标题,然后点击界面下方的“生成原创”按钮即可。伪原创之后的文章显示在“伪原创文章预览区”;
2、使用导出方式,可以将所有勾选的文章直接批量导出为TXT或HTML文章;
3、 通过接口,直接批量伪原创到自己的cms网站。
下图显示了导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;
“伪原创tool”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会非常高。“原创文章生成规则”。
4.使用直接更新主流cms系统
石青伪原创工具,支持东夷、老鸭、新云、德德cms等99%国内主流cms内容直接更新,通过界面直接获取本站信息,然后 伪原创 并上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。
为什么要设置这个功能?一般现在主流网站是:无论是个人还是公司,90%都是cms。cms中都自带采集功能,外围也可以使用“优采云”等第三方工具来采集。随着采集返回的数据量越来越大,如何伪原创成为一个令人担忧的问题。
仕青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库的数据,适合99%使用虚拟主机搭建网站,不能直接操作。cms数据库客户。上传界面,获取内容,直接伪原创。只要完成第3段,就可以完成伪原创。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。
关注推广屋:为您提供合适的推广软件,分享经验。让您的推广之路少走弯路。 查看全部
文章采集接口(石青伪原创工具是什么:伪工具使用方法步骤)
石青伪原创是什么工具:伪原创工具是SEO的高级工具,石青伪原创软件是免费的专业伪原创文章生成器,可以生成原创和伪原创的文章,专门针对百度、谷歌的抓取习惯和分词算法而开发。经本软件优化的文章会更受搜索引擎青睐。使用伪原创工具打造互联网上独一无二的伪原创文章,支持中英文伪原创。
石青伪原创如何使用工具
步:
1.安装软件
伪原创该工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。
启动后界面如下:
2.采集文章
石青伪原创工具,自带采集工具。首先需要在“采集设置”模块中输入需要采集的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后在百度或谷歌中选择采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。
点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果要停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章和争抢生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.生产伪原创文章
用户可以通过4种方式输入原创文章,1、直接复制文章到文章编辑区,然后输入标题,然后保存文章; 2、通过导入,可以直接导入TXT或html文档,3、通过采集,直接采集到网上的文章,4、直接通过界面获取你的内容cms网站;
获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章的标题,然后点击界面下方的“生成原创”按钮即可。伪原创之后的文章显示在“伪原创文章预览区”;
2、使用导出方式,可以将所有勾选的文章直接批量导出为TXT或HTML文章;
3、 通过接口,直接批量伪原创到自己的cms网站。
下图显示了导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;
“伪原创tool”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会非常高。“原创文章生成规则”。
4.使用直接更新主流cms系统
石青伪原创工具,支持东夷、老鸭、新云、德德cms等99%国内主流cms内容直接更新,通过界面直接获取本站信息,然后 伪原创 并上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。
为什么要设置这个功能?一般现在主流网站是:无论是个人还是公司,90%都是cms。cms中都自带采集功能,外围也可以使用“优采云”等第三方工具来采集。随着采集返回的数据量越来越大,如何伪原创成为一个令人担忧的问题。
仕青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库的数据,适合99%使用虚拟主机搭建网站,不能直接操作。cms数据库客户。上传界面,获取内容,直接伪原创。只要完成第3段,就可以完成伪原创。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。
关注推广屋:为您提供合适的推广软件,分享经验。让您的推广之路少走弯路。

