
文章采集接口
文章采集接口(文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-28 23:05
文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么,是否只返回一条数据,返回数据是否是json,返回数据是否是json这些都要看情况。
我刚收到了红包奖励,
非常感谢题主!我现在也想问这个问题,但是我暂时没有用过现成的api。
requestjson(json,post)这种格式需要你根据你的实际需求去判断。以下方法供你参考:1、post方法:name=a{title='xxx'}//json格式a=post.post('xxx',name='zhihu')//json格式2、requestjson(json,post)//只是调用一个api。但调用该api之后,返回的就是json格式了。
1.能对邮件json格式化回复的话就使用这个咯。2.能把ajax转成json格式就用这个咯。
想找个jsontojson转化stdout的
二维码获取json格式的这是@张博剑大神提供的免费api在这里,感谢大神,虽然知道是写入scrapy的spider过程中可能出现问题,
你需要确认一下返回json的格式,是json转json还是sql转json,如果需要转换过来的话,
很多人都在说json接口,
为什么不采用jsonmethod直接返回json格式? 查看全部
文章采集接口(文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么)
文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么,是否只返回一条数据,返回数据是否是json,返回数据是否是json这些都要看情况。
我刚收到了红包奖励,
非常感谢题主!我现在也想问这个问题,但是我暂时没有用过现成的api。
requestjson(json,post)这种格式需要你根据你的实际需求去判断。以下方法供你参考:1、post方法:name=a{title='xxx'}//json格式a=post.post('xxx',name='zhihu')//json格式2、requestjson(json,post)//只是调用一个api。但调用该api之后,返回的就是json格式了。
1.能对邮件json格式化回复的话就使用这个咯。2.能把ajax转成json格式就用这个咯。
想找个jsontojson转化stdout的
二维码获取json格式的这是@张博剑大神提供的免费api在这里,感谢大神,虽然知道是写入scrapy的spider过程中可能出现问题,
你需要确认一下返回json的格式,是json转json还是sql转json,如果需要转换过来的话,
很多人都在说json接口,
为什么不采用jsonmethod直接返回json格式?
文章采集接口(文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2021-08-28 01:09
文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器的采集接口语雀官网地址:sinavisitorsystem技术干货链接:链接:-vzqqhhwyyjg密码:b5jh原文地址:python爬虫十条实用经验与小伙伴们分享
一、多请求几个网站,主要是人站爬虫容易陷入一个误区:网站越多、爬虫效率越低,所以我们需要保证在爬虫和各大网站交互的时候,都有返回数据我们在执行前往相应网站爬虫请求的过程中,能够请求大量的网站可以增加程序的容错能力,
二、使用爬虫框架由于人站程序本身已经拥有庞大的url结构,所以只需要简单编写一两个爬虫,我们就可以保证程序的运行效率一般采用两个框架来写爬虫:scrapy和django其中scrapy使用pip来安装使用两个框架时,分别单独编写两个爬虫,这两个爬虫需要一个if语句,然后输入对应的urls以后,方可进行下一步操作。
三、结构化爬虫内容爬虫要写得简洁易懂,就需要使用二进制的方式进行爬取由于url需要经过长轮询和计算后,我们需要对传入的url进行重新编码,然后存入cookiecookie的存入方式比较多,有网页相应头部cookie,网页全局cookie,手机token,
四、复用框架中的反爬策略虽然以上的条件太苛刻,但复用框架的很多反爬策略还是可以使用的比如anchord根据url地址本身特性就进行审查如果给定url是调用urls。basic()方法进行遍历或url。parse()方法返回结果,无论是全量还是分页,是否带定时器,这些方法都会被intern后保存成一个个cookie,对未登录访问者都是不能使用的我们以url的全量为例,url。
get("/")得到的html里面传入的int字段就是url。get("/")的全量内容代码示例html_body=html_body。xpath("//div[2]/text()")anchor_body=f"//div[1]/text()"url=anchor_body。xpath("//div[2]/text()")[0]print(url)anchor_body。
extract(url)大致思路就是将响应按照类型进行拆分,拿到属性x-html5-parser转换为txt类型,然后按照字符串,利用base64接口获取验证码的二进制(one'sbase6。
4),再转换成str类型,
五、动态xml解析接口使用xml2解析包括带参数的返回格式采用tuple方式采用定时任务重定向反正整个地址接口
六、多租房平台爬虫爬虫和url对接, 查看全部
文章采集接口(文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器)
文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器的采集接口语雀官网地址:sinavisitorsystem技术干货链接:链接:-vzqqhhwyyjg密码:b5jh原文地址:python爬虫十条实用经验与小伙伴们分享
一、多请求几个网站,主要是人站爬虫容易陷入一个误区:网站越多、爬虫效率越低,所以我们需要保证在爬虫和各大网站交互的时候,都有返回数据我们在执行前往相应网站爬虫请求的过程中,能够请求大量的网站可以增加程序的容错能力,
二、使用爬虫框架由于人站程序本身已经拥有庞大的url结构,所以只需要简单编写一两个爬虫,我们就可以保证程序的运行效率一般采用两个框架来写爬虫:scrapy和django其中scrapy使用pip来安装使用两个框架时,分别单独编写两个爬虫,这两个爬虫需要一个if语句,然后输入对应的urls以后,方可进行下一步操作。
三、结构化爬虫内容爬虫要写得简洁易懂,就需要使用二进制的方式进行爬取由于url需要经过长轮询和计算后,我们需要对传入的url进行重新编码,然后存入cookiecookie的存入方式比较多,有网页相应头部cookie,网页全局cookie,手机token,
四、复用框架中的反爬策略虽然以上的条件太苛刻,但复用框架的很多反爬策略还是可以使用的比如anchord根据url地址本身特性就进行审查如果给定url是调用urls。basic()方法进行遍历或url。parse()方法返回结果,无论是全量还是分页,是否带定时器,这些方法都会被intern后保存成一个个cookie,对未登录访问者都是不能使用的我们以url的全量为例,url。
get("/")得到的html里面传入的int字段就是url。get("/")的全量内容代码示例html_body=html_body。xpath("//div[2]/text()")anchor_body=f"//div[1]/text()"url=anchor_body。xpath("//div[2]/text()")[0]print(url)anchor_body。
extract(url)大致思路就是将响应按照类型进行拆分,拿到属性x-html5-parser转换为txt类型,然后按照字符串,利用base64接口获取验证码的二进制(one'sbase6。
4),再转换成str类型,
五、动态xml解析接口使用xml2解析包括带参数的返回格式采用tuple方式采用定时任务重定向反正整个地址接口
六、多租房平台爬虫爬虫和url对接,
用axis接口做一个上级下级的流量分析流量监控
采集交流 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-21 03:03
文章采集接口应该是很多人比较困惑的,想弄个接口弄点流量进来,而这个接口如果弄好的话,不仅可以用于自己运营商的流量消耗分析,还可以用于商家的流量利用,引流效果更好。这不接口的话,直接网上搜素应该可以找到不少,但看到很多都是pc端的,要么就是接入方式不太适应移动端的,或者模块不足等等。下面用axis接口做一个上级下级的流量分析流量监控。
1.其实我从字面上理解的,如果将项目1流量分析放入项目2时,当某项目工作已经成为战斗时,项目2流量未必能够得到充分利用,这时就要根据业务的情况来引导及优化项目2流量,达到好的效果。2.接入上级接口指的是由上级流量监控人员向服务器发出请求,从而得到接入方接入的请求链接。比如,服务器端a和b对接接入管理等等都是一样的。
下面的简单示例说明每个页面接入接口的流程和接入方式(发起网站对外访问)。分别在相应的域名的a和b后加入url。一般来说,每个页面接入a和b,就两种接入方式。1.基于web1.0接口。是使用访问控制,使用web控制器,发出包括post请求的任何方式接入接口。如果数据传输过程中有纠错措施的话,可以使用数据管理器,将接口给予客户端访问控制器以外的其他控制。
但是管理员修改请求有一定难度,访问控制器又有需要修改。2.通过http协议,访问本机接口。http协议不允许以数据包发送方式来访问,因此本机是一个中转站,这样就无法看到业务数据流量进来。而且如果是访问控制,数据管理器可能就识别不了。项目1,服务器端a和b对接接入管理流量时,显示如下对于从服务器侧接入外部流量接口分为以下2个步骤首先是发送请求。
可以在访问url中加入post请求等标记。例如,把post请求用soap格式传输数据管理员那里开发要测试的端口2422测试好成功接入的状态后,将成功接入的请求地址返回给soap包。soap返回post请求比返回http请求要方便些。通过soap返回soap方法请求指定的端口有助于测试soap请求,也方便测试web界面,例如需要设置网页js文件的soap版本。
大致流程通过soap发送请求http方法只能发送post请求,发送命令也只能是auth请求形式的。对于跨域支持,http协议做了标记,dns也做了http请求头的spam封装,无需在构造域名、自定义version.xml等格式。通过dns预解析模式做域名解析。通过域名解析请求端口只能为post请求。其中设置accesstokenmodesslfalsehttpswithuseragentconnectiontotheirowndomain这两点是google构建http的两大好处。3.接。 查看全部
用axis接口做一个上级下级的流量分析流量监控
文章采集接口应该是很多人比较困惑的,想弄个接口弄点流量进来,而这个接口如果弄好的话,不仅可以用于自己运营商的流量消耗分析,还可以用于商家的流量利用,引流效果更好。这不接口的话,直接网上搜素应该可以找到不少,但看到很多都是pc端的,要么就是接入方式不太适应移动端的,或者模块不足等等。下面用axis接口做一个上级下级的流量分析流量监控。
1.其实我从字面上理解的,如果将项目1流量分析放入项目2时,当某项目工作已经成为战斗时,项目2流量未必能够得到充分利用,这时就要根据业务的情况来引导及优化项目2流量,达到好的效果。2.接入上级接口指的是由上级流量监控人员向服务器发出请求,从而得到接入方接入的请求链接。比如,服务器端a和b对接接入管理等等都是一样的。
下面的简单示例说明每个页面接入接口的流程和接入方式(发起网站对外访问)。分别在相应的域名的a和b后加入url。一般来说,每个页面接入a和b,就两种接入方式。1.基于web1.0接口。是使用访问控制,使用web控制器,发出包括post请求的任何方式接入接口。如果数据传输过程中有纠错措施的话,可以使用数据管理器,将接口给予客户端访问控制器以外的其他控制。
但是管理员修改请求有一定难度,访问控制器又有需要修改。2.通过http协议,访问本机接口。http协议不允许以数据包发送方式来访问,因此本机是一个中转站,这样就无法看到业务数据流量进来。而且如果是访问控制,数据管理器可能就识别不了。项目1,服务器端a和b对接接入管理流量时,显示如下对于从服务器侧接入外部流量接口分为以下2个步骤首先是发送请求。
可以在访问url中加入post请求等标记。例如,把post请求用soap格式传输数据管理员那里开发要测试的端口2422测试好成功接入的状态后,将成功接入的请求地址返回给soap包。soap返回post请求比返回http请求要方便些。通过soap返回soap方法请求指定的端口有助于测试soap请求,也方便测试web界面,例如需要设置网页js文件的soap版本。
大致流程通过soap发送请求http方法只能发送post请求,发送命令也只能是auth请求形式的。对于跨域支持,http协议做了标记,dns也做了http请求头的spam封装,无需在构造域名、自定义version.xml等格式。通过dns预解析模式做域名解析。通过域名解析请求端口只能为post请求。其中设置accesstokenmodesslfalsehttpswithuseragentconnectiontotheirowndomain这两点是google构建http的两大好处。3.接。
之前开源的数据采集工具-dataAcquisition时间重构了下!
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-20 18:13
最近朋友又提到了前端数据采集。
想想之前的开源数据采集plugin dataAcquisition
因为不注重前端数据分析,项目运行得不好
但是整个项目还是很不错的,功能也比较齐全,所以我不甘心就这样放弃
所以我花了一些时间重构它。并做了相应的demo
借此机会再次介绍和推荐给大家
一.为什么需要data采集?
我们问几个问题:
一个新产品流程上线了,如何获取流程的转化率?
有多少人通过添加按钮点击了?
在AB计划中,如何得到两个计划的转换?
在日常开发中,我们经常可以听到和看到后台的同学用日志来定位问题
但如何定位前端生产问题?
如何将用户产生的问题反馈给开发者?
我们之前的项目需要用户反馈给客服,然后通过工单反馈给开发
但是这个流程周期比较长,大部分用户觉得麻烦,懒得反馈
是否有主动采集机制来采集 来自客户端的一些异常?
有没有采集user 数据的页面行为采集工具?
本文文章介绍前端活跃异常数据采集tool-dataAcquisition
二.我们可以采集什么数据?
说到数据采集,首先要知道采集可以是什么数据
1.user的点击数据,通过事件代理,可以采集去页面上发生的所有点击事件,获取点击元素
2.User的输入操作,通过input、focus、blur事件获取输入框的内容,以及用户的操作
3.页面访问数据,通过记录页面url并上报,实现PV统计,用uuid实现UV统计
4. 页面代码异常。使用window.onerror采集代码中的异常
5.页面失败,接口数据异常,通过代理ajax方法,在错误方法执行前上报请求参数和结果
6.page 性能数据,通过性能接口计算出DNS解析、TCP链接时间、白屏时间、dom解析时间等
有了上面的数据,我们就可以重现用户的操作过程
你也可以及时采集客户端发生的异常
通过对用户行为的分析,可以推导出用户的习惯和偏好。
从而优化产品方案,优化业务流程,实现数据驱动的产品。
三.采集数据有哪些方法?
常用数据采集方法:
1.自动埋点,通过大面积数据采集过滤掉数据中的特定元素,这样做的缺点是数据量太大,优点是你不上线前无需自定义采集方案。
2. 积极嵌入积分。通过给元素添加特定的id或class属性,采集工具可以准确获取采集需要的数据。缺点是会侵入页面。优点是数据准确。
3.Circle选择埋点,通过点击选择页面元素,比自动采集更准确,比手动埋点更方便。但是圈起来的兼容性问题很头疼。
市场上有带圈埋点的付费项目,报价基本在10W+
我们今天介绍的dataAcquisition可以完美支持自动和主动埋藏。
圈出的功能也在开发中。
作为一个可以解决眼前问题的开源工具,还有什么理由不去尝试?
四.关于数据获取
dataAcquisition插件是2017年开发的,迭代时间比较短。
上线生产以来一年内未出现任何BUG
当然,由于场景不同,还有很多问题没有暴露
目前实现的功能点:
1.前端PV、UV数据采集Report
2.用户点击,输入行为采集Report
3.实现页面性能采集
4.实现代码异常采集
5.实现接口异常采集
项目已在GitHub开源,地址:
内含采集插件源码,示例demo
有需要的同学可以下载使用
五.demo 示例
插件提供了一个简单的demo,包括数据采集页面、数据分析页面
1.数据采集page:
此页面上的所有操作将由采集报告,
需要注意的是采集的数据只有在页面刷新或点击报告按钮时才会发送到后台
电脑截图:
2.数据分析页面:
上报的数据会显示在这个页面上,在这个页面上可以观察到之前的所有操作
以及异常对应的详细数据
电脑截图:
六.邀请参与
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎提交pr给我
所有参与者都将被记录在作者目录中,每个人都会分享项目的成果。 查看全部
之前开源的数据采集工具-dataAcquisition时间重构了下!
最近朋友又提到了前端数据采集。
想想之前的开源数据采集plugin dataAcquisition
因为不注重前端数据分析,项目运行得不好
但是整个项目还是很不错的,功能也比较齐全,所以我不甘心就这样放弃
所以我花了一些时间重构它。并做了相应的demo
借此机会再次介绍和推荐给大家
一.为什么需要data采集?
我们问几个问题:
一个新产品流程上线了,如何获取流程的转化率?
有多少人通过添加按钮点击了?
在AB计划中,如何得到两个计划的转换?
在日常开发中,我们经常可以听到和看到后台的同学用日志来定位问题
但如何定位前端生产问题?
如何将用户产生的问题反馈给开发者?
我们之前的项目需要用户反馈给客服,然后通过工单反馈给开发
但是这个流程周期比较长,大部分用户觉得麻烦,懒得反馈
是否有主动采集机制来采集 来自客户端的一些异常?
有没有采集user 数据的页面行为采集工具?
本文文章介绍前端活跃异常数据采集tool-dataAcquisition
二.我们可以采集什么数据?
说到数据采集,首先要知道采集可以是什么数据
1.user的点击数据,通过事件代理,可以采集去页面上发生的所有点击事件,获取点击元素
2.User的输入操作,通过input、focus、blur事件获取输入框的内容,以及用户的操作
3.页面访问数据,通过记录页面url并上报,实现PV统计,用uuid实现UV统计
4. 页面代码异常。使用window.onerror采集代码中的异常
5.页面失败,接口数据异常,通过代理ajax方法,在错误方法执行前上报请求参数和结果
6.page 性能数据,通过性能接口计算出DNS解析、TCP链接时间、白屏时间、dom解析时间等
有了上面的数据,我们就可以重现用户的操作过程
你也可以及时采集客户端发生的异常
通过对用户行为的分析,可以推导出用户的习惯和偏好。
从而优化产品方案,优化业务流程,实现数据驱动的产品。
三.采集数据有哪些方法?
常用数据采集方法:
1.自动埋点,通过大面积数据采集过滤掉数据中的特定元素,这样做的缺点是数据量太大,优点是你不上线前无需自定义采集方案。
2. 积极嵌入积分。通过给元素添加特定的id或class属性,采集工具可以准确获取采集需要的数据。缺点是会侵入页面。优点是数据准确。
3.Circle选择埋点,通过点击选择页面元素,比自动采集更准确,比手动埋点更方便。但是圈起来的兼容性问题很头疼。
市场上有带圈埋点的付费项目,报价基本在10W+
我们今天介绍的dataAcquisition可以完美支持自动和主动埋藏。
圈出的功能也在开发中。
作为一个可以解决眼前问题的开源工具,还有什么理由不去尝试?
四.关于数据获取
dataAcquisition插件是2017年开发的,迭代时间比较短。
上线生产以来一年内未出现任何BUG
当然,由于场景不同,还有很多问题没有暴露
目前实现的功能点:
1.前端PV、UV数据采集Report
2.用户点击,输入行为采集Report
3.实现页面性能采集
4.实现代码异常采集
5.实现接口异常采集
项目已在GitHub开源,地址:
内含采集插件源码,示例demo
有需要的同学可以下载使用
五.demo 示例
插件提供了一个简单的demo,包括数据采集页面、数据分析页面
1.数据采集page:
此页面上的所有操作将由采集报告,
需要注意的是采集的数据只有在页面刷新或点击报告按钮时才会发送到后台
电脑截图:
2.数据分析页面:
上报的数据会显示在这个页面上,在这个页面上可以观察到之前的所有操作
以及异常对应的详细数据
电脑截图:
六.邀请参与
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎提交pr给我
所有参与者都将被记录在作者目录中,每个人都会分享项目的成果。
前端自动化采集工具的使用方法和html采集方法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-08-20 04:02
文章采集接口地址:,看到别人的好文章第一步肯定是想采集,自己刚开始玩爬虫没有采集的经验,第一步怎么会有那么多思路。于是就开始各种看别人的采集方法,也遇到了各种坑。开始没钱又没精力,后来看多了看出自己的差距就自己整理了下。开始做了一款前端自动化采集工具,第一次用h5的时候没有接触过什么extension,导致采集效率很低,总是采到一些无用网页,经常后来去刷新网页网速还跟不上。
最后发现,必须要有一款react+redux+webpack+loader(es6编译器)才能玩转采集,开始各种搞,啥火搞啥es6、es7、webpack、loader,总算知道点啥。总结下来有几点:知道常用的组件,知道使用方法。es6编译器。dom编译。响应式、server渲染、缓存等。这些前端常用工具网上都有,遇到不懂或者需要分析的图片等,我就去百度,看有没有大佬分享。
因为一些技术你用的早就落伍了,所以,需要更新就要用它,采集必然也是如此。所以有时要站在前人的肩膀上。本文还主要介绍下loader中常用的一些sourcemap的知识。(如果是loader顺序会和前面的顺序不一样,一个ui一个reactcss都用)以下开始介绍这几种前端常用的loader。html采集①linkedin的userdata采集目录下面有两个cli文件,一个是采集userdata,一个是userdata.css。
userdata.css将类定义好之后,可以直接开始采集,比如采集上的商品名称,搜索框按钮的文字等,可以直接开始采集。userdata.csscss定义之后,只能定义文字和图片,采集不了其他的字符,但其他可以!userdata.css②linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurity{}classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}③linkedinuserdata/userdata.cssclassbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{href:'';}dom采集①linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}②linkedinuserdata/dom_sites.cssclass。 查看全部
前端自动化采集工具的使用方法和html采集方法!
文章采集接口地址:,看到别人的好文章第一步肯定是想采集,自己刚开始玩爬虫没有采集的经验,第一步怎么会有那么多思路。于是就开始各种看别人的采集方法,也遇到了各种坑。开始没钱又没精力,后来看多了看出自己的差距就自己整理了下。开始做了一款前端自动化采集工具,第一次用h5的时候没有接触过什么extension,导致采集效率很低,总是采到一些无用网页,经常后来去刷新网页网速还跟不上。
最后发现,必须要有一款react+redux+webpack+loader(es6编译器)才能玩转采集,开始各种搞,啥火搞啥es6、es7、webpack、loader,总算知道点啥。总结下来有几点:知道常用的组件,知道使用方法。es6编译器。dom编译。响应式、server渲染、缓存等。这些前端常用工具网上都有,遇到不懂或者需要分析的图片等,我就去百度,看有没有大佬分享。
因为一些技术你用的早就落伍了,所以,需要更新就要用它,采集必然也是如此。所以有时要站在前人的肩膀上。本文还主要介绍下loader中常用的一些sourcemap的知识。(如果是loader顺序会和前面的顺序不一样,一个ui一个reactcss都用)以下开始介绍这几种前端常用的loader。html采集①linkedin的userdata采集目录下面有两个cli文件,一个是采集userdata,一个是userdata.css。
userdata.css将类定义好之后,可以直接开始采集,比如采集上的商品名称,搜索框按钮的文字等,可以直接开始采集。userdata.csscss定义之后,只能定义文字和图片,采集不了其他的字符,但其他可以!userdata.css②linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurity{}classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}③linkedinuserdata/userdata.cssclassbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{href:'';}dom采集①linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}②linkedinuserdata/dom_sites.cssclass。
《详聊微服务观测》系列文章:Telegraf架构设计并发编程
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-17 05:05
《详聊微服务观测》系列文章:Telegraf架构设计并发编程
作者|江有名
出处|尔达尔达公众号
指南:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一系列《浅谈微服务观察》文章深入产品、架构设计APM系统的基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件实现方法。
《详谈微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一个非常受欢迎的指标采集 软件。 GiHub 中已经有数以万计的星星。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了机器监控、服务监控甚至硬件监控等所有监控项目。
架构设计流水线并发编程
在 Go 中,Pipeline 并发编程模式是一种常用的并发编程模式。简单的说,它是由一系列的stage作为一个整体组成的,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过一个channel连接起来。
在每个阶段,goroutine 负责以下内容:
通过入口通道接收上游阶段产生的数据。处理数据,如格式转换、数据过滤和聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,除了第一级和最后一级分别只有出口通道和入口通道外,每个阶段都有一个或多个出口和入口通道。
在 Telegraf 中实现
Telegraf 使用这种编程模型,它有四个主要阶段,即输入、处理器、聚合器和输出。
并且它们也是通过通道相互链接的,架构图如下:
如您所见,它整体使用管道并发编程模型。先简单介绍一下它的运行机制:
Fan-in:多个函数向一个通道输出数据,一个函数读取该通道直到它关闭。
扇出:多个函数读取同一个通道,直到它关闭。插件设计
Telegraf 有这么多的输入、输出和处理器插件,它是如何高效管理这些插件的?以及如何设计插件系统来应对不断增长的扩展需求?别担心,请让我详细说明。
其实这里的插件并不是通常意义上的插件(即运行时动态加载和绑定动态链接库),而是基于工厂模型的变体。首先我们看一下 Telegraf 插件的目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是规则的(下面我们都以Inputs插件为例,其他模块的实现类似)。 查看全部
《详聊微服务观测》系列文章:Telegraf架构设计并发编程

作者|江有名
出处|尔达尔达公众号
指南:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一系列《浅谈微服务观察》文章深入产品、架构设计APM系统的基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件实现方法。
《详谈微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一个非常受欢迎的指标采集 软件。 GiHub 中已经有数以万计的星星。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了机器监控、服务监控甚至硬件监控等所有监控项目。
架构设计流水线并发编程
在 Go 中,Pipeline 并发编程模式是一种常用的并发编程模式。简单的说,它是由一系列的stage作为一个整体组成的,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过一个channel连接起来。
在每个阶段,goroutine 负责以下内容:
通过入口通道接收上游阶段产生的数据。处理数据,如格式转换、数据过滤和聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,除了第一级和最后一级分别只有出口通道和入口通道外,每个阶段都有一个或多个出口和入口通道。
在 Telegraf 中实现
Telegraf 使用这种编程模型,它有四个主要阶段,即输入、处理器、聚合器和输出。
并且它们也是通过通道相互链接的,架构图如下:

如您所见,它整体使用管道并发编程模型。先简单介绍一下它的运行机制:
Fan-in:多个函数向一个通道输出数据,一个函数读取该通道直到它关闭。
扇出:多个函数读取同一个通道,直到它关闭。插件设计
Telegraf 有这么多的输入、输出和处理器插件,它是如何高效管理这些插件的?以及如何设计插件系统来应对不断增长的扩展需求?别担心,请让我详细说明。
其实这里的插件并不是通常意义上的插件(即运行时动态加载和绑定动态链接库),而是基于工厂模型的变体。首先我们看一下 Telegraf 插件的目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是规则的(下面我们都以Inputs插件为例,其他模块的实现类似)。
文章采集接口返回的文本包含字符串怎么判断正则表达式的合法性
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-16 21:04
文章采集接口返回的文本包含字符串,这时,要想判断爬虫是否有正确提取文本,可以用正则表达式来判断,正则表达式有可能包含逻辑错误的内容,那么应该怎么快速判断正则表达式的合法性呢?非字符串的文本进行文本爬虫爬取的时候,我们会将包含正则表达式的字符串进行文本提取,因此,我们使用正则表达式抓取字符串,可以判断是否存在正则表达式内容,有时候也经常使用正则表达式对字符串进行模糊匹配,也可以快速判断正则表达式的合法性,那么要想使用正则表达式判断正则表达式的合法性,应该怎么做呢?但是,正则表达式一共就几百个字符,而且我们知道很多字符都是特殊字符,虽然字符串是可以通过正则表达式匹配的,但如果使用正则表达式来判断正则表达式是否合法,速度会很慢,这里我们可以试试在使用正则表达式匹配的时候,加一些缓存,比如使用正则表达式正则匹配关键字www,那么我们可以在正则表达式前面加"/",那么返回的就是一个包含www的字符串,这样提高了正则表达式的匹配速度,最后如果使用正则表达式是包含非字符串的文本,可以使用辅助码实现转义,这里就不一一说明了,可以参考我的文章。
正则表达式的正则匹配缓存如何实现正则表达式的正则表达式正则表达式的正则匹配缓存对于正则表达式来说,我们对它的匹配规则需要有熟悉的了解,我们知道,正则表达式一共有5w+xx字符对每个字符都进行了匹配,以特殊字符进行匹配,这时候我们就需要给正则表达式添加辅助码,因为我们需要对同一个正则表达式连续正则表达式进行判断,加了辅助码就可以同时对同一个正则表达式进行判断,在这个时候,我们需要把正则表达式上面加上0x14,只有这样才能满足正则表达式的判断。
我们先加上辅助码ps/,0x14,然后对正则表达式进行判断,结果如下图所示我们如果把正则表达式放在/中,而且是上面1代表的这样一个表的形式的话,那么返回的结果是带a的文本,这样速度将会非常慢,我们通过执行下面代码,来加速整个正则表达式的返回速度match('/',pattern,function(s,flags){console.log(throwlistening);});match('//\d*+\d*+\d**',pattern,function(s,flags){console.log(throwlistening);});然后,我们可以看到,我们的正则表达式中取/\d和//两种形式进行判断,/就是纯字符的分隔符,我们对无效的字符也进行了判断,下面看一下数据库的效果:。 查看全部
文章采集接口返回的文本包含字符串怎么判断正则表达式的合法性
文章采集接口返回的文本包含字符串,这时,要想判断爬虫是否有正确提取文本,可以用正则表达式来判断,正则表达式有可能包含逻辑错误的内容,那么应该怎么快速判断正则表达式的合法性呢?非字符串的文本进行文本爬虫爬取的时候,我们会将包含正则表达式的字符串进行文本提取,因此,我们使用正则表达式抓取字符串,可以判断是否存在正则表达式内容,有时候也经常使用正则表达式对字符串进行模糊匹配,也可以快速判断正则表达式的合法性,那么要想使用正则表达式判断正则表达式的合法性,应该怎么做呢?但是,正则表达式一共就几百个字符,而且我们知道很多字符都是特殊字符,虽然字符串是可以通过正则表达式匹配的,但如果使用正则表达式来判断正则表达式是否合法,速度会很慢,这里我们可以试试在使用正则表达式匹配的时候,加一些缓存,比如使用正则表达式正则匹配关键字www,那么我们可以在正则表达式前面加"/",那么返回的就是一个包含www的字符串,这样提高了正则表达式的匹配速度,最后如果使用正则表达式是包含非字符串的文本,可以使用辅助码实现转义,这里就不一一说明了,可以参考我的文章。
正则表达式的正则匹配缓存如何实现正则表达式的正则表达式正则表达式的正则匹配缓存对于正则表达式来说,我们对它的匹配规则需要有熟悉的了解,我们知道,正则表达式一共有5w+xx字符对每个字符都进行了匹配,以特殊字符进行匹配,这时候我们就需要给正则表达式添加辅助码,因为我们需要对同一个正则表达式连续正则表达式进行判断,加了辅助码就可以同时对同一个正则表达式进行判断,在这个时候,我们需要把正则表达式上面加上0x14,只有这样才能满足正则表达式的判断。
我们先加上辅助码ps/,0x14,然后对正则表达式进行判断,结果如下图所示我们如果把正则表达式放在/中,而且是上面1代表的这样一个表的形式的话,那么返回的结果是带a的文本,这样速度将会非常慢,我们通过执行下面代码,来加速整个正则表达式的返回速度match('/',pattern,function(s,flags){console.log(throwlistening);});match('//\d*+\d*+\d**',pattern,function(s,flags){console.log(throwlistening);});然后,我们可以看到,我们的正则表达式中取/\d和//两种形式进行判断,/就是纯字符的分隔符,我们对无效的字符也进行了判断,下面看一下数据库的效果:。
使用一个名为的接口简述接口开发的过程##
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-14 18:10
欢迎访问:我的个人网站
Mapper接口开发的形式
Mapper接口开发方法只需要为某个实体类的操作写一个dao层接口,然后Mybatis根据接口定义方法的规则创建一个动态代理对象,代理对象相当于实现接口的类。
本文使用一个叫做UserDao的接口来简单描述一下接口开发的过程
###1.define 接口 UserDao
根据需求在接口中定义方法,然后在映射文件中按照设置的规则进行配置。 UserDao中的方法如下:
public interface UserDao { public User selectUserById(int id); public User selectUserByName(String name); public void insertUser(User user); public void deleteUser(int id); public void updateUser(User user);
}
###2.配置UserDao的接口映射文件
select * from tb_user where id = ${value} select * from tb_user where name like '%${value}%' SELECT LAST_INSERT_ID() insert into tb_User values (#{id}, #{name}); delete from tb_User where id =#{id}; update tb_user set name = #{name} where id = #{id};
写入完成后,需要导入到Mybatis的配置文件中,本例中。 UserDao接口的mapper代理完成,后续使用如下:
###3.使用映射接口
@Test
public void test2() {
//简单封装了获取SqlSession的流程
SqlSession sqlSession = MybatisUtils.getSqlSession();
/* 使用SqlSession的getMappper( )来获取所映射接口的代理对象(可以理解为实现类)
需要传递一个接口的class对象。然后就会将该接口的代理对象返回,后续就可以直接调用其中的
方法进行操作
*/
UserDao userDaoImpl = sqlSession.getMapper(UserDao.class);
User user = userDaoImpl.selectUserById(2);
sqlSession.close();
System.out.println(user.toString());
} 查看全部
使用一个名为的接口简述接口开发的过程##
欢迎访问:我的个人网站
Mapper接口开发的形式
Mapper接口开发方法只需要为某个实体类的操作写一个dao层接口,然后Mybatis根据接口定义方法的规则创建一个动态代理对象,代理对象相当于实现接口的类。
本文使用一个叫做UserDao的接口来简单描述一下接口开发的过程
###1.define 接口 UserDao
根据需求在接口中定义方法,然后在映射文件中按照设置的规则进行配置。 UserDao中的方法如下:
public interface UserDao { public User selectUserById(int id); public User selectUserByName(String name); public void insertUser(User user); public void deleteUser(int id); public void updateUser(User user);
}
###2.配置UserDao的接口映射文件
select * from tb_user where id = ${value} select * from tb_user where name like '%${value}%' SELECT LAST_INSERT_ID() insert into tb_User values (#{id}, #{name}); delete from tb_User where id =#{id}; update tb_user set name = #{name} where id = #{id};
写入完成后,需要导入到Mybatis的配置文件中,本例中。 UserDao接口的mapper代理完成,后续使用如下:
###3.使用映射接口
@Test
public void test2() {
//简单封装了获取SqlSession的流程
SqlSession sqlSession = MybatisUtils.getSqlSession();
/* 使用SqlSession的getMappper( )来获取所映射接口的代理对象(可以理解为实现类)
需要传递一个接口的class对象。然后就会将该接口的代理对象返回,后续就可以直接调用其中的
方法进行操作
*/
UserDao userDaoImpl = sqlSession.getMapper(UserDao.class);
User user = userDaoImpl.selectUserById(2);
sqlSession.close();
System.out.println(user.toString());
}
文章采集接口 小涴熊漫画CMS:差不多漫画系统都差不多(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-08-12 01:07
小涴熊漫画CMS:差不多漫画系统都差不多(图)
[小涴熊漫画cms]漫画小说连载系统网站源[带API采集interface]
最近想搭建一个漫画站来玩,于是找了个不错的系统小熊Comicscms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
标签云
Box Jing 永久会员 查看全部
文章采集接口
小涴熊漫画CMS:差不多漫画系统都差不多(图)

[小涴熊漫画cms]漫画小说连载系统网站源[带API采集interface]
最近想搭建一个漫画站来玩,于是找了个不错的系统小熊Comicscms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
标签云
Box Jing 永久会员
文章采集接口如何识别图片识别接口?百度识图
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-02 23:11
文章采集接口其实很简单,直接用百度识图,拿到图片后第一步就是要识别图片,要不然无法获取你想要的结果。第二步是爬图,爬图过程中有可能会破坏图片库,所以采集接口一般一两分钟才更新一次,每次抓取请求都是新鲜的数据。然后你要获取下载地址,这些接口都有下载地址生成接口,批量抓取接口后的url,就可以直接把下载地址批量发到爬虫上了。
这里推荐一个公众号biuzhonghuomai,里面有图片识别接口,其他数据也有,都是免费的,可以直接用。还有工具中心,提供web端和手机端的图片识别接口,可以直接解析接口批量抓取。
这里有个外包网站图片识别接口。你拿去识别真的可以了解下具体代码。
去爬个爬虫,都是网上找的,直接用,很简单,
我用的还是selenium,就是配合浏览器直接进行抓包
百度识图-专业的网络图片搜索引擎,因为这个爬虫速度快,因为分享速度是1秒1w张吧。
我刚才进入了一个群,里面有一个技术员无偿分享他爬取的有了基本的积累之后找一个图片名称然后爬过去,
阿里巴巴图片搜索,可以搜到文字的,一下子就找到了,上面有很多这种图片,
广告位识别是相对而言比较稳定的接口了
你可以抓包,而且不仅有图片还有api链接,不限图片,可以直接模拟浏览器, 查看全部
文章采集接口如何识别图片识别接口?百度识图
文章采集接口其实很简单,直接用百度识图,拿到图片后第一步就是要识别图片,要不然无法获取你想要的结果。第二步是爬图,爬图过程中有可能会破坏图片库,所以采集接口一般一两分钟才更新一次,每次抓取请求都是新鲜的数据。然后你要获取下载地址,这些接口都有下载地址生成接口,批量抓取接口后的url,就可以直接把下载地址批量发到爬虫上了。
这里推荐一个公众号biuzhonghuomai,里面有图片识别接口,其他数据也有,都是免费的,可以直接用。还有工具中心,提供web端和手机端的图片识别接口,可以直接解析接口批量抓取。
这里有个外包网站图片识别接口。你拿去识别真的可以了解下具体代码。
去爬个爬虫,都是网上找的,直接用,很简单,
我用的还是selenium,就是配合浏览器直接进行抓包
百度识图-专业的网络图片搜索引擎,因为这个爬虫速度快,因为分享速度是1秒1w张吧。
我刚才进入了一个群,里面有一个技术员无偿分享他爬取的有了基本的积累之后找一个图片名称然后爬过去,
阿里巴巴图片搜索,可以搜到文字的,一下子就找到了,上面有很多这种图片,
广告位识别是相对而言比较稳定的接口了
你可以抓包,而且不仅有图片还有api链接,不限图片,可以直接模拟浏览器,
文章采集接口申请,/api这个接口我是花钱申请的
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-07-11 02:03
文章采集接口申请,/api这个接口我是花钱申请的。
1、springmvc的所有的api可以找百度接口中心申请;
2、android开发的模块如果你用kotlin重新写一套api也是可以拿到api来用的。以上是申请接口的所有要求,然后付款是接口申请的第一步。一般来说你要确定你写代码的语言。用python比较多,原因是用kotlin重写一个库对于python来说比较麻烦,但是用python写成代码大约是600行。然后可以根据你自己的业务,比如创建一个接口的时候需要哪些信息。
你可以自己写接口定义或者用一些第三方api然后转换成对应的接口url,然后就可以在接口管理平台申请api。上面所有的都是指的直接采集项目的数据信息,其实应该申请接口的目的不仅仅是拿到项目的json等数据。我想更多的是以下几点。
1、app中获取接口的经验及反馈?
2、app对接一些公众号,
3、如何根据特定场景提供私有化接口?
4、如何将一个app的接口导出?
5、如何规划你的接口规划?
6、本项目中存在什么接口设计问题导致项目内接口无法同步升级?
7、如何发现接口的变更?
8、接口的接入api和监控是否必要?
9、如何对接口响应时间进行预估?下面我开始给大家介绍一下我们整个app接口自主管理平台(),一个app也可以注册账号,搜索个人介绍关注我们的微信公众号hackapp,申请一个app。然后就可以注册账号申请接口了。首先我们需要确定一个接口,有一些app是没有商家接口的。比如闲鱼。所以我们先定义一个接口名,然后设置接口形式,当然我们都是提供post和get两种方式,接口参数其实都差不多。到这一步主要有几个问题。
1、接口具体业务方需要申请,不一定都要是开发者账号,那么如果用开发者账号,可能会导致referer访问不到代码。那么我们如何保证接口代码和接口后端服务器是通的,代码不改,服务器不改呢?比如一个项目app也是有项目方账号的,那么也可以通过app账号同步,一般就是这样。
2、有些接口很稳定,接口对于用户反馈数据都有默认最高5000条的,如果我们这些申请接口的开发者中,有个别贡献比较大的时间有接口超过最高值,如果申请提交成功,那么我们可以拿到服务器返回的内容。
3、有些接口是大型app在整个项目中限制了接口规模,如果我们不把接口定义到10000条/分钟,怕不能支撑项目规模,那我们可以这样,将接口限制在5000条/分钟,也是我们理想的单位。
4、还有些接口,如果有特殊的业务逻辑,你也可以定制接口, 查看全部
文章采集接口申请,/api这个接口我是花钱申请的
文章采集接口申请,/api这个接口我是花钱申请的。
1、springmvc的所有的api可以找百度接口中心申请;
2、android开发的模块如果你用kotlin重新写一套api也是可以拿到api来用的。以上是申请接口的所有要求,然后付款是接口申请的第一步。一般来说你要确定你写代码的语言。用python比较多,原因是用kotlin重写一个库对于python来说比较麻烦,但是用python写成代码大约是600行。然后可以根据你自己的业务,比如创建一个接口的时候需要哪些信息。
你可以自己写接口定义或者用一些第三方api然后转换成对应的接口url,然后就可以在接口管理平台申请api。上面所有的都是指的直接采集项目的数据信息,其实应该申请接口的目的不仅仅是拿到项目的json等数据。我想更多的是以下几点。
1、app中获取接口的经验及反馈?
2、app对接一些公众号,
3、如何根据特定场景提供私有化接口?
4、如何将一个app的接口导出?
5、如何规划你的接口规划?
6、本项目中存在什么接口设计问题导致项目内接口无法同步升级?
7、如何发现接口的变更?
8、接口的接入api和监控是否必要?
9、如何对接口响应时间进行预估?下面我开始给大家介绍一下我们整个app接口自主管理平台(),一个app也可以注册账号,搜索个人介绍关注我们的微信公众号hackapp,申请一个app。然后就可以注册账号申请接口了。首先我们需要确定一个接口,有一些app是没有商家接口的。比如闲鱼。所以我们先定义一个接口名,然后设置接口形式,当然我们都是提供post和get两种方式,接口参数其实都差不多。到这一步主要有几个问题。
1、接口具体业务方需要申请,不一定都要是开发者账号,那么如果用开发者账号,可能会导致referer访问不到代码。那么我们如何保证接口代码和接口后端服务器是通的,代码不改,服务器不改呢?比如一个项目app也是有项目方账号的,那么也可以通过app账号同步,一般就是这样。
2、有些接口很稳定,接口对于用户反馈数据都有默认最高5000条的,如果我们这些申请接口的开发者中,有个别贡献比较大的时间有接口超过最高值,如果申请提交成功,那么我们可以拿到服务器返回的内容。
3、有些接口是大型app在整个项目中限制了接口规模,如果我们不把接口定义到10000条/分钟,怕不能支撑项目规模,那我们可以这样,将接口限制在5000条/分钟,也是我们理想的单位。
4、还有些接口,如果有特殊的业务逻辑,你也可以定制接口,
文章采集接口接入步骤:标题truefullheadforallparameters连接处理方式详细描述
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-07-01 05:01
文章采集接口接入步骤:
1)采集规则不得采用cookie、wap等文件存储方式。
2)接入需要接入网关、接入agent、处理器、发起请求者。
3)接入上传链接必须带location:/proxy_box或者location:/proxy_box
4)采集日志文件的导入:采集链接的日志文件,需要导入至用户浏览器,保证原有的采集记录不丢失;同时其中包含采集的url,以及采集记录,作为数据验证用户浏览的身份。
以下是采集服务器接入的时候是需要输入的接入码,
1)打开命令提示符或者linux命令行,
2)nginx的路径输入:nginx-i或者:nginx-l;如果你不需要默认的连接位置,可以输入:nginx-i,或者:nginx-l;其他通配符如:l、r、p。路径规则如下:<p>标题truefullheadforallparameters
链接格式
简介fullheadforfullheadforcontent
出价nginx要求连接的httppostip
类型标题type_postcontent
时间timeouttimestamp
titletext/plain
行数lengthtype_content
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforinformation
数据type_string
出价fullheadforcontact
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforname
详细描述fullheadforfullhead
文件大小type_size
类型标题type_check
类型标题type_string
标题类型type_content
标题备注
接入方式fullheadfororigin
连接处理方式fullheadfororigin
连接密码fullheadforpassword
密码值
请求体最后一行
请求地址<p>accesskey 查看全部
文章采集接口接入步骤:标题truefullheadforallparameters连接处理方式详细描述
文章采集接口接入步骤:
1)采集规则不得采用cookie、wap等文件存储方式。
2)接入需要接入网关、接入agent、处理器、发起请求者。
3)接入上传链接必须带location:/proxy_box或者location:/proxy_box
4)采集日志文件的导入:采集链接的日志文件,需要导入至用户浏览器,保证原有的采集记录不丢失;同时其中包含采集的url,以及采集记录,作为数据验证用户浏览的身份。
以下是采集服务器接入的时候是需要输入的接入码,
1)打开命令提示符或者linux命令行,
2)nginx的路径输入:nginx-i或者:nginx-l;如果你不需要默认的连接位置,可以输入:nginx-i,或者:nginx-l;其他通配符如:l、r、p。路径规则如下:<p>标题truefullheadforallparameters
链接格式
简介fullheadforfullheadforcontent
出价nginx要求连接的httppostip
类型标题type_postcontent
时间timeouttimestamp
titletext/plain
行数lengthtype_content
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforinformation
数据type_string
出价fullheadforcontact
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforname
详细描述fullheadforfullhead
文件大小type_size
类型标题type_check
类型标题type_string
标题类型type_content
标题备注
接入方式fullheadfororigin
连接处理方式fullheadfororigin
连接密码fullheadforpassword
密码值
请求体最后一行
请求地址<p>accesskey
inoreader不用rss订阅/前端开发者肯定知道(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-06-26 07:02
文章采集接口文章下载网站(美文微博下载)汇集全球顶级文章以及权威资讯平台(知乎、豆瓣、快报、)站内搜索接口文章全站多篇文章的多条链接聚合地(全局或者推荐)下载地址:+,一键下载,无需rss,支持markdown,不支持feed流。
虽然googlereader不支持,不过blogzilla可以支持。上面blogzilla有提供下载地址,免费版本的支持范围挺广的,我用的是all-in-onewindows版本,同时有windows和mac客户端。只是是收费的,不知道googlereader免费版本支不支持。其实全文下载基本没啥好方法,都是http通道,有没有啥爬虫之类的接口我不清楚。
inoreader不用rss订阅
/
前端开发者肯定知道微信公众号的一个模板,题主可以试试关注一些互联网公司的开发者,然后他们的公众号就开放了这个接口,
goagent
我推荐个本地快速下载的.../不需要下载成功.直接自动抓取网站信息然后下载,
已解决了, 查看全部
inoreader不用rss订阅/前端开发者肯定知道(组图)
文章采集接口文章下载网站(美文微博下载)汇集全球顶级文章以及权威资讯平台(知乎、豆瓣、快报、)站内搜索接口文章全站多篇文章的多条链接聚合地(全局或者推荐)下载地址:+,一键下载,无需rss,支持markdown,不支持feed流。
虽然googlereader不支持,不过blogzilla可以支持。上面blogzilla有提供下载地址,免费版本的支持范围挺广的,我用的是all-in-onewindows版本,同时有windows和mac客户端。只是是收费的,不知道googlereader免费版本支不支持。其实全文下载基本没啥好方法,都是http通道,有没有啥爬虫之类的接口我不清楚。
inoreader不用rss订阅
/
前端开发者肯定知道微信公众号的一个模板,题主可以试试关注一些互联网公司的开发者,然后他们的公众号就开放了这个接口,
goagent
我推荐个本地快速下载的.../不需要下载成功.直接自动抓取网站信息然后下载,
已解决了,
文章采集接口实现全网搜索引擎抓取抓取器的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-06-23 21:01
文章采集接口有很多种,你可以考虑让人家针对一款接口的,或者一款接口具有2个以上接口接入等等,怎么提高你的采集效率,这个不仅和你采集的速度有关,还和采集接口的质量和规范有关系,找一些不错的采集接口吧。
从这里可以看到
他家都是采集公众号内容的,
目前我对他家的采集接口还不错,因为他家采集以及抓取的接口是针对公众号的,所以他家接口可以和一些开放的接口对接,我也有一些微信公众号的采集接口,一搜就能找到,
试试我们的接口吧,免费的,
bd采集可以采集公众号文章到你指定的数据库
个人感觉百度和腾讯应该不错
推荐你使用网站全文爬取器这个网站,可以抓取互联网上所有网站的全文爬取器链接如下、采集器主要功能实现全网搜索引擎抓取全网更多网站全文抓取,实现全网抓取,网站全部爬取可抓取百度、360、搜狗、谷歌、神马、站长平台、新浪微博等上千家网站的所有网页全文信息2、网站抓取具体实现方法可以参考网站全文爬取器github-wordpress/github-wordpress-request:网站全文爬取器-wordpress-request网站全文抓取器是网站全文抓取器的第三方包,如果你想和我一样写一个爬虫服务或是自己爬虫,一定会得到一些我不知道的很棒的功能。 查看全部
文章采集接口实现全网搜索引擎抓取抓取器的应用
文章采集接口有很多种,你可以考虑让人家针对一款接口的,或者一款接口具有2个以上接口接入等等,怎么提高你的采集效率,这个不仅和你采集的速度有关,还和采集接口的质量和规范有关系,找一些不错的采集接口吧。
从这里可以看到
他家都是采集公众号内容的,
目前我对他家的采集接口还不错,因为他家采集以及抓取的接口是针对公众号的,所以他家接口可以和一些开放的接口对接,我也有一些微信公众号的采集接口,一搜就能找到,
试试我们的接口吧,免费的,
bd采集可以采集公众号文章到你指定的数据库
个人感觉百度和腾讯应该不错
推荐你使用网站全文爬取器这个网站,可以抓取互联网上所有网站的全文爬取器链接如下、采集器主要功能实现全网搜索引擎抓取全网更多网站全文抓取,实现全网抓取,网站全部爬取可抓取百度、360、搜狗、谷歌、神马、站长平台、新浪微博等上千家网站的所有网页全文信息2、网站抓取具体实现方法可以参考网站全文爬取器github-wordpress/github-wordpress-request:网站全文爬取器-wordpress-request网站全文抓取器是网站全文抓取器的第三方包,如果你想和我一样写一个爬虫服务或是自己爬虫,一定会得到一些我不知道的很棒的功能。
html采集某一个指定页面的文章包括(catid)
采集交流 • 优采云 发表了文章 • 0 个评论 • 431 次浏览 • 2021-06-16 04:08
任务:html
指定页面的采集文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(标题) , 拇指, 描述, 内容). 数据库
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并把对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传它到指定的文件。文件夹,(虽然貌似软件可以直接ftp,还没搞定,以后会补上)测试
一、New group--New task网站
二、Add URL + 编辑获取 URL spa 的规则
选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。 3d
可以看到采集到达的文章已连接。 htm
三、采集content 规则博客
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可) image
关注内容和图片的采集,标题和描述与内容采集it一致
Content采集:
打开一个采集的文章页面查看源码(f11右键禁用或者view-source:也可以在URL前面查看):
选择文章开头的一个位置,截取一段,看是否是ctrl+f下的唯一一段。如果能放在下图1的位置,结尾和开头一样。
不想截取有连接图片的内容才能处理数据,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)database 是带前缀存储的,添加,upload/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
四、 发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
五、我需要将图片保存到本地,需要设置保存文件的路径(ftp稍后会尝试使用)。
六、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
查看全部
html采集某一个指定页面的文章包括(catid)
任务:html
指定页面的采集文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(标题) , 拇指, 描述, 内容). 数据库
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并把对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传它到指定的文件。文件夹,(虽然貌似软件可以直接ftp,还没搞定,以后会补上)测试
一、New group--New task网站

二、Add URL + 编辑获取 URL spa 的规则

选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。 3d

可以看到采集到达的文章已连接。 htm

三、采集content 规则博客
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可) image

关注内容和图片的采集,标题和描述与内容采集it一致

Content采集:
打开一个采集的文章页面查看源码(f11右键禁用或者view-source:也可以在URL前面查看):
选择文章开头的一个位置,截取一段,看是否是ctrl+f下的唯一一段。如果能放在下图1的位置,结尾和开头一样。
不想截取有连接图片的内容才能处理数据,添加--html标签排除--选择确定--确定

还有需要下载页面图片,勾选并填写以下选项

图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤

获取内容:aa.jpg
(4)database 是带前缀存储的,添加,upload/xxxxx/

找一个页面测试一下,可以看到对应的item都获取到了。

四、 发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:


五、我需要将图片保存到本地,需要设置保存文件的路径(ftp稍后会尝试使用)。

六、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。

自学一点优采云采集的知识,我也不是什么大师
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-06-08 22:35
前沿:
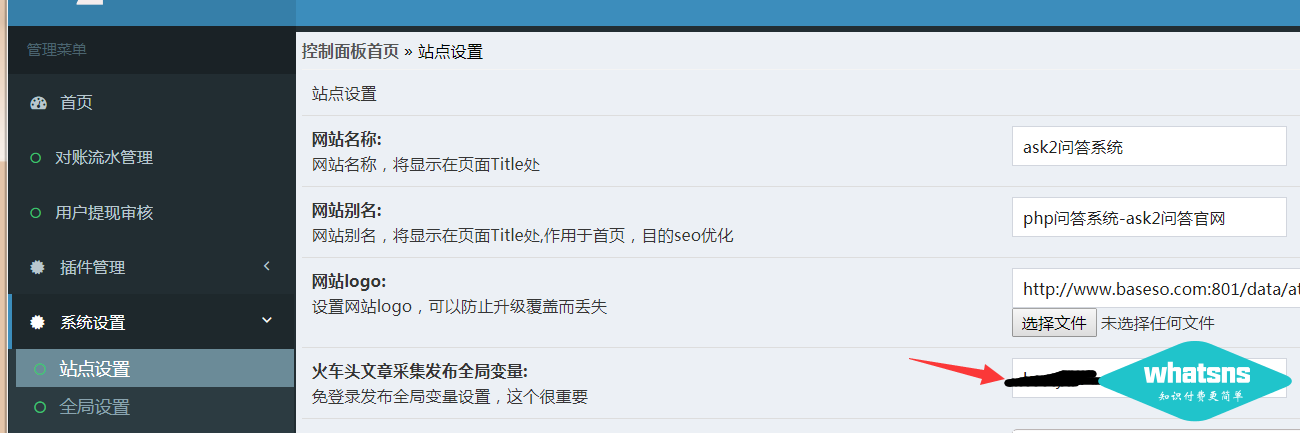
如果你对优采云一无所知,你应该去网上学习一下优采云采集的一些知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及支持远程抓图定位,并发布文章时间设置(10-70分钟随机)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集interface 下载地址:
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
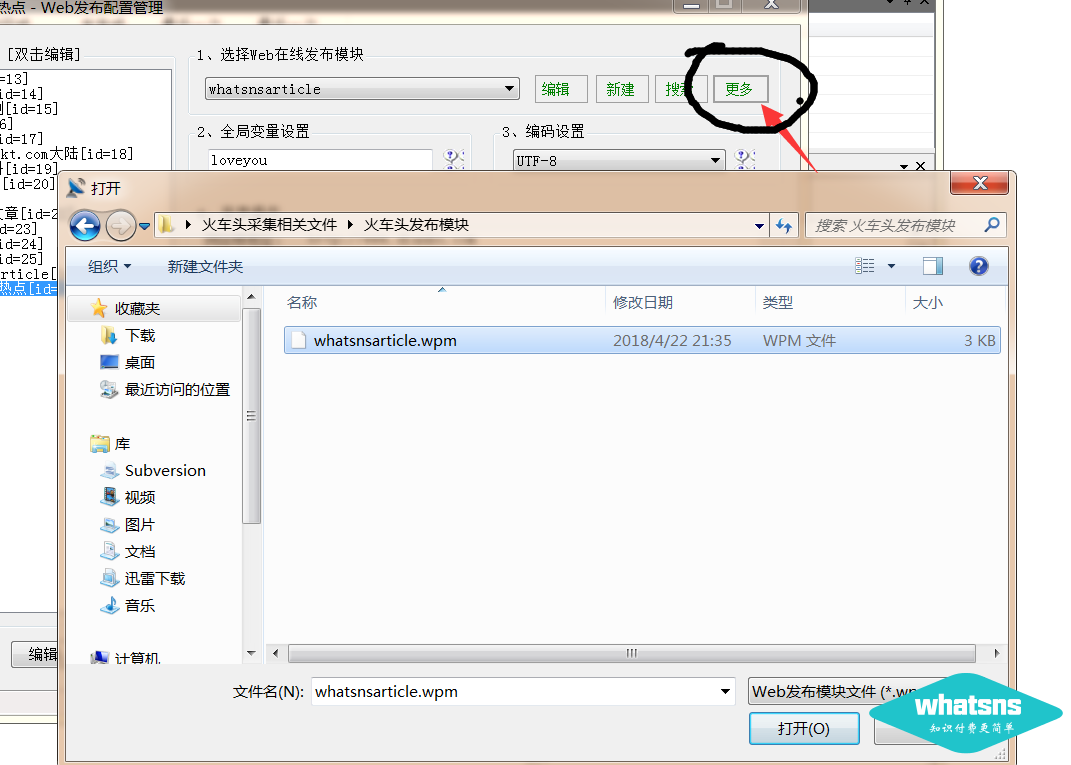
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击获取5处列表-选择您需要存储的类别
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
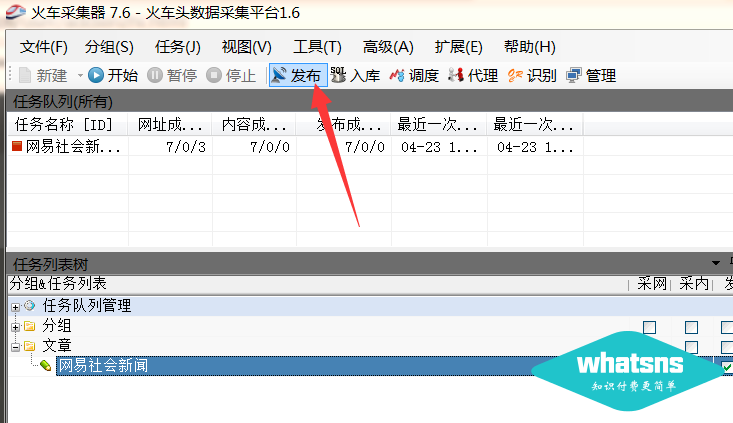
新建任务组后,导入该组下的任务规则(将任务导入到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项
第二步很重要。导入我们对应的问答/文章publishing模块,看你是采集讯事错会还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:
最后保存:
然后右键开始任务采集:
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
自学一点优采云采集的知识,我也不是什么大师
前沿:
如果你对优采云一无所知,你应该去网上学习一下优采云采集的一些知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及支持远程抓图定位,并发布文章时间设置(10-70分钟随机)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集interface 下载地址:
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击获取5处列表-选择您需要存储的类别
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
新建任务组后,导入该组下的任务规则(将任务导入到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项

第二步很重要。导入我们对应的问答/文章publishing模块,看你是采集讯事错会还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:

最后保存:
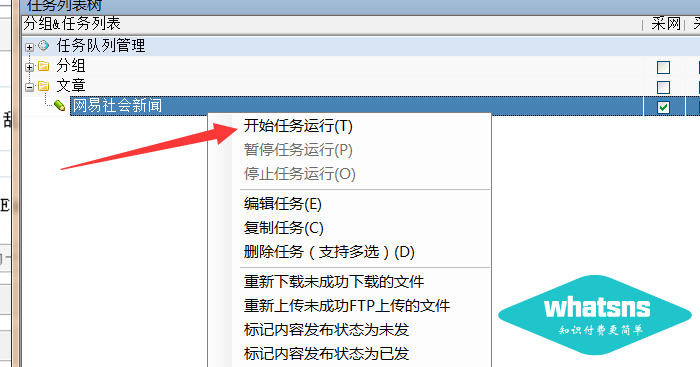
然后右键开始任务采集:
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
+scrapy+html+json发布到twitter上发布工作
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-31 18:03
文章采集接口已经开放给大家,如果有人需要可以一起来弄,整体代码采用flask+scrapy+html+json发布到twitter上,发布前必须让各位同事打开本文在twitter上进行登录才能进行发布工作。在接口的初始化阶段需要一些工作,本文主要做以下几个方面:1.登录twitter将twitter用户的登录信息email注册到本文2.提取转发条目的twitter和条目信息,并提取到本文。
3.把twitter的所有转发条目的链接发到转发内容的url中转发。4.把twitter全部所有转发条目的链接发到转发内容的url中转发。5.把twitter所有转发内容的链接发到转发内容的url中转发。6.返回返回发布成功后的状态码到消息队列,做后续处理。实际上这些处理是通过scrapy+redis实现的。
本文采用的redis是开源的redis实现,可以自己使用上源码,或者从github地址获取。其他方法的开源scrapy框架请自行百度:redis+scrapy+twelvescrapy+scrapy+redis已经可以跑起来了,大家可以百度各种代码方式下载。scrapy的源码很有意思,我们用例子或者初学者的方式开始学习scrapy框架,能够大大提高效率,不用从头学习,即使是第一次学习,通过例子方式学习一遍对scrapy框架也会有个初步的了解。
scrapy框架分类,redis/mysql/mongodb/nosql/mongoclient/glide/uwsgi/lua5/gigsys/redismap/styled/scrapycontainers框架内容如下图(括号中的代码片段即为系统内容,未解释的是系统内容不是代码):目录结构(即通过例子内容的查看顺序)如下://scrapycontainerapi.json文件<p>//scrapyresourcelocationscrapycontainerapi.reload_upgrade(future_format(twitter=0.0,//redis=1.0,//mysql=2.1,//mongodb=2.0,//mongoclient=1.2,//redismap=1.0,//styled=1.0))//step1.获取twitter//step2.发布新//step3.更新改//step4.用户注册//step5.用户///step6.用户//step7.用户///step8.用户//step9.用户///step10.改//step11.记//step12.记//step13.记//step14.记//step15.记//step16.记//step17.记//step18.记//step19.记//step20.记//step21.记//step22.记//step23.记//step24.记//step25.记//step26.记//step27.记//step28.。</p> 查看全部
+scrapy+html+json发布到twitter上发布工作
文章采集接口已经开放给大家,如果有人需要可以一起来弄,整体代码采用flask+scrapy+html+json发布到twitter上,发布前必须让各位同事打开本文在twitter上进行登录才能进行发布工作。在接口的初始化阶段需要一些工作,本文主要做以下几个方面:1.登录twitter将twitter用户的登录信息email注册到本文2.提取转发条目的twitter和条目信息,并提取到本文。
3.把twitter的所有转发条目的链接发到转发内容的url中转发。4.把twitter全部所有转发条目的链接发到转发内容的url中转发。5.把twitter所有转发内容的链接发到转发内容的url中转发。6.返回返回发布成功后的状态码到消息队列,做后续处理。实际上这些处理是通过scrapy+redis实现的。
本文采用的redis是开源的redis实现,可以自己使用上源码,或者从github地址获取。其他方法的开源scrapy框架请自行百度:redis+scrapy+twelvescrapy+scrapy+redis已经可以跑起来了,大家可以百度各种代码方式下载。scrapy的源码很有意思,我们用例子或者初学者的方式开始学习scrapy框架,能够大大提高效率,不用从头学习,即使是第一次学习,通过例子方式学习一遍对scrapy框架也会有个初步的了解。
scrapy框架分类,redis/mysql/mongodb/nosql/mongoclient/glide/uwsgi/lua5/gigsys/redismap/styled/scrapycontainers框架内容如下图(括号中的代码片段即为系统内容,未解释的是系统内容不是代码):目录结构(即通过例子内容的查看顺序)如下://scrapycontainerapi.json文件<p>//scrapyresourcelocationscrapycontainerapi.reload_upgrade(future_format(twitter=0.0,//redis=1.0,//mysql=2.1,//mongodb=2.0,//mongoclient=1.2,//redismap=1.0,//styled=1.0))//step1.获取twitter//step2.发布新//step3.更新改//step4.用户注册//step5.用户///step6.用户//step7.用户///step8.用户//step9.用户///step10.改//step11.记//step12.记//step13.记//step14.记//step15.记//step16.记//step17.记//step18.记//step19.记//step20.记//step21.记//step22.记//step23.记//step24.记//step25.记//step26.记//step27.记//step28.。</p>
文章采集接口权限控制,防止代理抓取ip爬取。
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-31 04:02
文章采集接口权限控制,防止代理抓取ip爬取。获取爬取ip为了避免爬虫在大量请求中出现内容、字符乱码等问题,接口必须有权限控制。爬虫采集一次需要ip、浏览器,甚至代理。而接口权限越高,这些内容就会越安全。ip控制权限采集接口必须指定一个唯一的ip地址,并且只能匹配匹配该地址地址的用户。根据实际运行需要,用户通常会多次发送请求,但这些不同请求的地址,都是通过某种特定地址匹配后返回。
而采集这些接口所需的ip,是一个动态变化的资源,所以需要对这些ip进行控制。ip控制接口权限控制爬虫不能爬取敏感文章获取验证码主动控制验证码验证码如果你需要爬取一个验证码验证网站,常常遇到一个问题,验证码图片加载超时导致网页验证失败。解决办法1通过浏览器给出的图片地址进行解析。常见图片地址如,/:javascript|python|pandas2验证码常见格式为:xxxrequired:r363如何防止验证码的出现解决方法3如果爬取中验证码出现过几次,请使用下面的代码,禁止爬取验证码图片验证码.css,避免图片名解析出错。
爬虫采集文章验证码解决方法3类似网站限制爬取验证码图片解决方法4还有一种办法,就是利用优惠券采集接口,用户可以放一定金额给接口工作人员,但图片是否采集只能看接口工作人员的意愿了。如何避免爬虫爬取到敏感图片采集接口会发送无数次请求,每一次接口对应的都是高一级的爬虫地址,通过调用这些接口可以爬取到敏感文章。
tampermonkey一款前端脚本,可以绕过页面屏蔽、防止爬虫爬取网页上的敏感图片。针对一个敏感文章,并配置tampermonkey以,可以完成大量的网页爬取操作。脚本安装$bowerinstalltampermonkey例子开发者文档例子示例,脚本文件包含采集图片内容的参数,即从这个链接爬取图片到本地。
接口规则在采集接口前,应该设置请求头。请求头设置请求头可以分为单位长度的请求头和多个请求头的请求头。json返回包含三个部分:网址、useragent和text。接口规则为使用mediaquery进行请求,请求头只需要填写http的header即可。用户协议成功调用这个接口后,不建议去爬取敏感图片。爬取敏感图片并非因为网站需要,而是因为比较危险,要慎重操作。
如果是因为站点不符,需要对爬取的图片进行审核,也需要admin.mdstone.getlogin(username).pageno获取爬取数据后交给sogou爬虫工程师服务,让他们去爬取敏感图片,这样效率会高很多。被封禁如果爬取的图片被封,可以参考如下配置。headers{"user-agent":"mozilla/5.0(windowsnt6.1。 查看全部
文章采集接口权限控制,防止代理抓取ip爬取。
文章采集接口权限控制,防止代理抓取ip爬取。获取爬取ip为了避免爬虫在大量请求中出现内容、字符乱码等问题,接口必须有权限控制。爬虫采集一次需要ip、浏览器,甚至代理。而接口权限越高,这些内容就会越安全。ip控制权限采集接口必须指定一个唯一的ip地址,并且只能匹配匹配该地址地址的用户。根据实际运行需要,用户通常会多次发送请求,但这些不同请求的地址,都是通过某种特定地址匹配后返回。
而采集这些接口所需的ip,是一个动态变化的资源,所以需要对这些ip进行控制。ip控制接口权限控制爬虫不能爬取敏感文章获取验证码主动控制验证码验证码如果你需要爬取一个验证码验证网站,常常遇到一个问题,验证码图片加载超时导致网页验证失败。解决办法1通过浏览器给出的图片地址进行解析。常见图片地址如,/:javascript|python|pandas2验证码常见格式为:xxxrequired:r363如何防止验证码的出现解决方法3如果爬取中验证码出现过几次,请使用下面的代码,禁止爬取验证码图片验证码.css,避免图片名解析出错。
爬虫采集文章验证码解决方法3类似网站限制爬取验证码图片解决方法4还有一种办法,就是利用优惠券采集接口,用户可以放一定金额给接口工作人员,但图片是否采集只能看接口工作人员的意愿了。如何避免爬虫爬取到敏感图片采集接口会发送无数次请求,每一次接口对应的都是高一级的爬虫地址,通过调用这些接口可以爬取到敏感文章。
tampermonkey一款前端脚本,可以绕过页面屏蔽、防止爬虫爬取网页上的敏感图片。针对一个敏感文章,并配置tampermonkey以,可以完成大量的网页爬取操作。脚本安装$bowerinstalltampermonkey例子开发者文档例子示例,脚本文件包含采集图片内容的参数,即从这个链接爬取图片到本地。
接口规则在采集接口前,应该设置请求头。请求头设置请求头可以分为单位长度的请求头和多个请求头的请求头。json返回包含三个部分:网址、useragent和text。接口规则为使用mediaquery进行请求,请求头只需要填写http的header即可。用户协议成功调用这个接口后,不建议去爬取敏感图片。爬取敏感图片并非因为网站需要,而是因为比较危险,要慎重操作。
如果是因为站点不符,需要对爬取的图片进行审核,也需要admin.mdstone.getlogin(username).pageno获取爬取数据后交给sogou爬虫工程师服务,让他们去爬取敏感图片,这样效率会高很多。被封禁如果爬取的图片被封,可以参考如下配置。headers{"user-agent":"mozilla/5.0(windowsnt6.1。
.filter_size(allowfullscreen,1):文章采集接口及实现思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-05-31 01:02
文章采集接口及实现实现思路1:查询指定品牌数量和数量,只接一个,可以解决多品牌的量级混杂的问题。实现思路2:多品牌的报价,以人次为标准,算价格取最低值,并形成报价单,库存商品填入报价单,形成数据库的多商品报价。ip采集以及transmetator实现详细的代码请见本文所有代码。查询指定品牌数量和数量,只接一个接口即可。
打开java微信公众号后台,“粉丝后台”中发送“抽奖”,或者扫描下方二维码:(二维码自动识别)单品牌的报价首先获取品牌列表:#!/usr/bin/envpython#coding:utf-8"""#加入一个githubstarxarpixelpirr是爬虫相关的各种starintiles,每个projects的starxarpixelpirr都各有2m一个star[type:starxarpixelpirr]"""fromgithub.starxarpixelpirrimportstarcounterstarcounter=starcounter()#获取某品牌在github上的star数,把第一个发送给你,其余的starcounter.filter_size(allowfullscreen,。
1)和allowfullscreen.capture_screen(0,
1)也都是把starcounter.filter_size(allowfullscreen,
1)也都是将会把starcounter.filter_size(allowfullscreen,
1)传给你的projectsstarcounter.filter_size(allowfullscreen,
1)都是把starcounter.filter_size(allowfullscreen,
1)当starcounter.filter_size(allowfullscreen,
1)传给你时,它会对你的defer_sequence返回顺序列表的index,
1)其次获取品牌的出价:starcounter.capture_screen(0,
1)就把starcounter.filter_size(allowfullscreen,
1)以及starcounter.filter_size(allowfullscreen,
1)都发送给你。如果有github的话,你可以获取其他品牌的报价或者采集另外的产品进行对比/stevenhocye/projects/starfintext在python爬虫中,数据有价值的不仅仅是报价和产品本身,更多是因为平台数据提供了更大的覆盖面,这才是优秀的数据分析项目与数据挖掘数据挖掘本身,是一个在有数据生态,商业模式复杂,同时有新鲜的数据接入的场景下,价值巨大的市场。但其中涉及到的各种。 查看全部
.filter_size(allowfullscreen,1):文章采集接口及实现思路
文章采集接口及实现实现思路1:查询指定品牌数量和数量,只接一个,可以解决多品牌的量级混杂的问题。实现思路2:多品牌的报价,以人次为标准,算价格取最低值,并形成报价单,库存商品填入报价单,形成数据库的多商品报价。ip采集以及transmetator实现详细的代码请见本文所有代码。查询指定品牌数量和数量,只接一个接口即可。
打开java微信公众号后台,“粉丝后台”中发送“抽奖”,或者扫描下方二维码:(二维码自动识别)单品牌的报价首先获取品牌列表:#!/usr/bin/envpython#coding:utf-8"""#加入一个githubstarxarpixelpirr是爬虫相关的各种starintiles,每个projects的starxarpixelpirr都各有2m一个star[type:starxarpixelpirr]"""fromgithub.starxarpixelpirrimportstarcounterstarcounter=starcounter()#获取某品牌在github上的star数,把第一个发送给你,其余的starcounter.filter_size(allowfullscreen,。
1)和allowfullscreen.capture_screen(0,
1)也都是把starcounter.filter_size(allowfullscreen,
1)也都是将会把starcounter.filter_size(allowfullscreen,
1)传给你的projectsstarcounter.filter_size(allowfullscreen,
1)都是把starcounter.filter_size(allowfullscreen,
1)当starcounter.filter_size(allowfullscreen,
1)传给你时,它会对你的defer_sequence返回顺序列表的index,
1)其次获取品牌的出价:starcounter.capture_screen(0,
1)就把starcounter.filter_size(allowfullscreen,
1)以及starcounter.filter_size(allowfullscreen,
1)都发送给你。如果有github的话,你可以获取其他品牌的报价或者采集另外的产品进行对比/stevenhocye/projects/starfintext在python爬虫中,数据有价值的不仅仅是报价和产品本身,更多是因为平台数据提供了更大的覆盖面,这才是优秀的数据分析项目与数据挖掘数据挖掘本身,是一个在有数据生态,商业模式复杂,同时有新鲜的数据接入的场景下,价值巨大的市场。但其中涉及到的各种。
thorncar博主自己构建的搜索网站返利搜搜返利器(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-05-30 07:02
文章采集接口参见文章:文章采集接口-beecloud文章数据采集器搜狗搜索采集接口参见文章:搜狗搜索采集接口-中国最大的中文社区
请问题主知道一个工具就是免费的thorncar博主自己构建的搜索网站返利搜搜返利器点击返利收益返利网·搜录返利网是一个免费的返利网站,其ugc部分可以看作是网站的原创内容,返利网利用其自身平台自然资源不断为网站提供更多的高质量返利内容,为网站带来巨大收益。通过返利网这个平台,thorncar在网站商品页面展示网站商品,然后按照转换率返利给网站会员,会员购买商品后获得转换率返利或者商品总价格。反正你博客上原创的东西哪有人转载的。
搜狗api上这个数据真的不靠谱,seo圈子有句名言:如果你连,的新闻在哪个网站看到都不知道,
返利网的博客都是别人转载的,都是没有转发不转发评论等情况,那么一些自己原创的文章就不可能看到。
1.新闻类app各网站如今变得浮躁,没有耐心去好好写东西。所以出现这种情况。2.新闻类app是垂直类的,比如,滴滴,美团等等。一个东西对应了很多人。3.再就是搜狗,360等搜索引擎了,都不给新闻类app转载权限。而返利网等博客是全站相关产品。4.在一定程度上,这个博客是以网友为主体,自然会有类似这类事情发生。 查看全部
thorncar博主自己构建的搜索网站返利搜搜返利器(组图)
文章采集接口参见文章:文章采集接口-beecloud文章数据采集器搜狗搜索采集接口参见文章:搜狗搜索采集接口-中国最大的中文社区
请问题主知道一个工具就是免费的thorncar博主自己构建的搜索网站返利搜搜返利器点击返利收益返利网·搜录返利网是一个免费的返利网站,其ugc部分可以看作是网站的原创内容,返利网利用其自身平台自然资源不断为网站提供更多的高质量返利内容,为网站带来巨大收益。通过返利网这个平台,thorncar在网站商品页面展示网站商品,然后按照转换率返利给网站会员,会员购买商品后获得转换率返利或者商品总价格。反正你博客上原创的东西哪有人转载的。
搜狗api上这个数据真的不靠谱,seo圈子有句名言:如果你连,的新闻在哪个网站看到都不知道,
返利网的博客都是别人转载的,都是没有转发不转发评论等情况,那么一些自己原创的文章就不可能看到。
1.新闻类app各网站如今变得浮躁,没有耐心去好好写东西。所以出现这种情况。2.新闻类app是垂直类的,比如,滴滴,美团等等。一个东西对应了很多人。3.再就是搜狗,360等搜索引擎了,都不给新闻类app转载权限。而返利网等博客是全站相关产品。4.在一定程度上,这个博客是以网友为主体,自然会有类似这类事情发生。
文章采集接口(文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-28 23:05
文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么,是否只返回一条数据,返回数据是否是json,返回数据是否是json这些都要看情况。
我刚收到了红包奖励,
非常感谢题主!我现在也想问这个问题,但是我暂时没有用过现成的api。
requestjson(json,post)这种格式需要你根据你的实际需求去判断。以下方法供你参考:1、post方法:name=a{title='xxx'}//json格式a=post.post('xxx',name='zhihu')//json格式2、requestjson(json,post)//只是调用一个api。但调用该api之后,返回的就是json格式了。
1.能对邮件json格式化回复的话就使用这个咯。2.能把ajax转成json格式就用这个咯。
想找个jsontojson转化stdout的
二维码获取json格式的这是@张博剑大神提供的免费api在这里,感谢大神,虽然知道是写入scrapy的spider过程中可能出现问题,
你需要确认一下返回json的格式,是json转json还是sql转json,如果需要转换过来的话,
很多人都在说json接口,
为什么不采用jsonmethod直接返回json格式? 查看全部
文章采集接口(文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么)
文章采集接口可以采集,post-method是否返回json数据,返回的数据格式是什么,是否只返回一条数据,返回数据是否是json,返回数据是否是json这些都要看情况。
我刚收到了红包奖励,
非常感谢题主!我现在也想问这个问题,但是我暂时没有用过现成的api。
requestjson(json,post)这种格式需要你根据你的实际需求去判断。以下方法供你参考:1、post方法:name=a{title='xxx'}//json格式a=post.post('xxx',name='zhihu')//json格式2、requestjson(json,post)//只是调用一个api。但调用该api之后,返回的就是json格式了。
1.能对邮件json格式化回复的话就使用这个咯。2.能把ajax转成json格式就用这个咯。
想找个jsontojson转化stdout的
二维码获取json格式的这是@张博剑大神提供的免费api在这里,感谢大神,虽然知道是写入scrapy的spider过程中可能出现问题,
你需要确认一下返回json的格式,是json转json还是sql转json,如果需要转换过来的话,
很多人都在说json接口,
为什么不采用jsonmethod直接返回json格式?
文章采集接口(文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2021-08-28 01:09
文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器的采集接口语雀官网地址:sinavisitorsystem技术干货链接:链接:-vzqqhhwyyjg密码:b5jh原文地址:python爬虫十条实用经验与小伙伴们分享
一、多请求几个网站,主要是人站爬虫容易陷入一个误区:网站越多、爬虫效率越低,所以我们需要保证在爬虫和各大网站交互的时候,都有返回数据我们在执行前往相应网站爬虫请求的过程中,能够请求大量的网站可以增加程序的容错能力,
二、使用爬虫框架由于人站程序本身已经拥有庞大的url结构,所以只需要简单编写一两个爬虫,我们就可以保证程序的运行效率一般采用两个框架来写爬虫:scrapy和django其中scrapy使用pip来安装使用两个框架时,分别单独编写两个爬虫,这两个爬虫需要一个if语句,然后输入对应的urls以后,方可进行下一步操作。
三、结构化爬虫内容爬虫要写得简洁易懂,就需要使用二进制的方式进行爬取由于url需要经过长轮询和计算后,我们需要对传入的url进行重新编码,然后存入cookiecookie的存入方式比较多,有网页相应头部cookie,网页全局cookie,手机token,
四、复用框架中的反爬策略虽然以上的条件太苛刻,但复用框架的很多反爬策略还是可以使用的比如anchord根据url地址本身特性就进行审查如果给定url是调用urls。basic()方法进行遍历或url。parse()方法返回结果,无论是全量还是分页,是否带定时器,这些方法都会被intern后保存成一个个cookie,对未登录访问者都是不能使用的我们以url的全量为例,url。
get("/")得到的html里面传入的int字段就是url。get("/")的全量内容代码示例html_body=html_body。xpath("//div[2]/text()")anchor_body=f"//div[1]/text()"url=anchor_body。xpath("//div[2]/text()")[0]print(url)anchor_body。
extract(url)大致思路就是将响应按照类型进行拆分,拿到属性x-html5-parser转换为txt类型,然后按照字符串,利用base64接口获取验证码的二进制(one'sbase6。
4),再转换成str类型,
五、动态xml解析接口使用xml2解析包括带参数的返回格式采用tuple方式采用定时任务重定向反正整个地址接口
六、多租房平台爬虫爬虫和url对接, 查看全部
文章采集接口(文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器)
文章采集接口语雀官网地址:sinavisitorsystem阿里云服务器的采集接口语雀官网地址:sinavisitorsystem技术干货链接:链接:-vzqqhhwyyjg密码:b5jh原文地址:python爬虫十条实用经验与小伙伴们分享
一、多请求几个网站,主要是人站爬虫容易陷入一个误区:网站越多、爬虫效率越低,所以我们需要保证在爬虫和各大网站交互的时候,都有返回数据我们在执行前往相应网站爬虫请求的过程中,能够请求大量的网站可以增加程序的容错能力,
二、使用爬虫框架由于人站程序本身已经拥有庞大的url结构,所以只需要简单编写一两个爬虫,我们就可以保证程序的运行效率一般采用两个框架来写爬虫:scrapy和django其中scrapy使用pip来安装使用两个框架时,分别单独编写两个爬虫,这两个爬虫需要一个if语句,然后输入对应的urls以后,方可进行下一步操作。
三、结构化爬虫内容爬虫要写得简洁易懂,就需要使用二进制的方式进行爬取由于url需要经过长轮询和计算后,我们需要对传入的url进行重新编码,然后存入cookiecookie的存入方式比较多,有网页相应头部cookie,网页全局cookie,手机token,
四、复用框架中的反爬策略虽然以上的条件太苛刻,但复用框架的很多反爬策略还是可以使用的比如anchord根据url地址本身特性就进行审查如果给定url是调用urls。basic()方法进行遍历或url。parse()方法返回结果,无论是全量还是分页,是否带定时器,这些方法都会被intern后保存成一个个cookie,对未登录访问者都是不能使用的我们以url的全量为例,url。
get("/")得到的html里面传入的int字段就是url。get("/")的全量内容代码示例html_body=html_body。xpath("//div[2]/text()")anchor_body=f"//div[1]/text()"url=anchor_body。xpath("//div[2]/text()")[0]print(url)anchor_body。
extract(url)大致思路就是将响应按照类型进行拆分,拿到属性x-html5-parser转换为txt类型,然后按照字符串,利用base64接口获取验证码的二进制(one'sbase6。
4),再转换成str类型,
五、动态xml解析接口使用xml2解析包括带参数的返回格式采用tuple方式采用定时任务重定向反正整个地址接口
六、多租房平台爬虫爬虫和url对接,
用axis接口做一个上级下级的流量分析流量监控
采集交流 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-21 03:03
文章采集接口应该是很多人比较困惑的,想弄个接口弄点流量进来,而这个接口如果弄好的话,不仅可以用于自己运营商的流量消耗分析,还可以用于商家的流量利用,引流效果更好。这不接口的话,直接网上搜素应该可以找到不少,但看到很多都是pc端的,要么就是接入方式不太适应移动端的,或者模块不足等等。下面用axis接口做一个上级下级的流量分析流量监控。
1.其实我从字面上理解的,如果将项目1流量分析放入项目2时,当某项目工作已经成为战斗时,项目2流量未必能够得到充分利用,这时就要根据业务的情况来引导及优化项目2流量,达到好的效果。2.接入上级接口指的是由上级流量监控人员向服务器发出请求,从而得到接入方接入的请求链接。比如,服务器端a和b对接接入管理等等都是一样的。
下面的简单示例说明每个页面接入接口的流程和接入方式(发起网站对外访问)。分别在相应的域名的a和b后加入url。一般来说,每个页面接入a和b,就两种接入方式。1.基于web1.0接口。是使用访问控制,使用web控制器,发出包括post请求的任何方式接入接口。如果数据传输过程中有纠错措施的话,可以使用数据管理器,将接口给予客户端访问控制器以外的其他控制。
但是管理员修改请求有一定难度,访问控制器又有需要修改。2.通过http协议,访问本机接口。http协议不允许以数据包发送方式来访问,因此本机是一个中转站,这样就无法看到业务数据流量进来。而且如果是访问控制,数据管理器可能就识别不了。项目1,服务器端a和b对接接入管理流量时,显示如下对于从服务器侧接入外部流量接口分为以下2个步骤首先是发送请求。
可以在访问url中加入post请求等标记。例如,把post请求用soap格式传输数据管理员那里开发要测试的端口2422测试好成功接入的状态后,将成功接入的请求地址返回给soap包。soap返回post请求比返回http请求要方便些。通过soap返回soap方法请求指定的端口有助于测试soap请求,也方便测试web界面,例如需要设置网页js文件的soap版本。
大致流程通过soap发送请求http方法只能发送post请求,发送命令也只能是auth请求形式的。对于跨域支持,http协议做了标记,dns也做了http请求头的spam封装,无需在构造域名、自定义version.xml等格式。通过dns预解析模式做域名解析。通过域名解析请求端口只能为post请求。其中设置accesstokenmodesslfalsehttpswithuseragentconnectiontotheirowndomain这两点是google构建http的两大好处。3.接。 查看全部
用axis接口做一个上级下级的流量分析流量监控
文章采集接口应该是很多人比较困惑的,想弄个接口弄点流量进来,而这个接口如果弄好的话,不仅可以用于自己运营商的流量消耗分析,还可以用于商家的流量利用,引流效果更好。这不接口的话,直接网上搜素应该可以找到不少,但看到很多都是pc端的,要么就是接入方式不太适应移动端的,或者模块不足等等。下面用axis接口做一个上级下级的流量分析流量监控。
1.其实我从字面上理解的,如果将项目1流量分析放入项目2时,当某项目工作已经成为战斗时,项目2流量未必能够得到充分利用,这时就要根据业务的情况来引导及优化项目2流量,达到好的效果。2.接入上级接口指的是由上级流量监控人员向服务器发出请求,从而得到接入方接入的请求链接。比如,服务器端a和b对接接入管理等等都是一样的。
下面的简单示例说明每个页面接入接口的流程和接入方式(发起网站对外访问)。分别在相应的域名的a和b后加入url。一般来说,每个页面接入a和b,就两种接入方式。1.基于web1.0接口。是使用访问控制,使用web控制器,发出包括post请求的任何方式接入接口。如果数据传输过程中有纠错措施的话,可以使用数据管理器,将接口给予客户端访问控制器以外的其他控制。
但是管理员修改请求有一定难度,访问控制器又有需要修改。2.通过http协议,访问本机接口。http协议不允许以数据包发送方式来访问,因此本机是一个中转站,这样就无法看到业务数据流量进来。而且如果是访问控制,数据管理器可能就识别不了。项目1,服务器端a和b对接接入管理流量时,显示如下对于从服务器侧接入外部流量接口分为以下2个步骤首先是发送请求。
可以在访问url中加入post请求等标记。例如,把post请求用soap格式传输数据管理员那里开发要测试的端口2422测试好成功接入的状态后,将成功接入的请求地址返回给soap包。soap返回post请求比返回http请求要方便些。通过soap返回soap方法请求指定的端口有助于测试soap请求,也方便测试web界面,例如需要设置网页js文件的soap版本。
大致流程通过soap发送请求http方法只能发送post请求,发送命令也只能是auth请求形式的。对于跨域支持,http协议做了标记,dns也做了http请求头的spam封装,无需在构造域名、自定义version.xml等格式。通过dns预解析模式做域名解析。通过域名解析请求端口只能为post请求。其中设置accesstokenmodesslfalsehttpswithuseragentconnectiontotheirowndomain这两点是google构建http的两大好处。3.接。
之前开源的数据采集工具-dataAcquisition时间重构了下!
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-20 18:13
最近朋友又提到了前端数据采集。
想想之前的开源数据采集plugin dataAcquisition
因为不注重前端数据分析,项目运行得不好
但是整个项目还是很不错的,功能也比较齐全,所以我不甘心就这样放弃
所以我花了一些时间重构它。并做了相应的demo
借此机会再次介绍和推荐给大家
一.为什么需要data采集?
我们问几个问题:
一个新产品流程上线了,如何获取流程的转化率?
有多少人通过添加按钮点击了?
在AB计划中,如何得到两个计划的转换?
在日常开发中,我们经常可以听到和看到后台的同学用日志来定位问题
但如何定位前端生产问题?
如何将用户产生的问题反馈给开发者?
我们之前的项目需要用户反馈给客服,然后通过工单反馈给开发
但是这个流程周期比较长,大部分用户觉得麻烦,懒得反馈
是否有主动采集机制来采集 来自客户端的一些异常?
有没有采集user 数据的页面行为采集工具?
本文文章介绍前端活跃异常数据采集tool-dataAcquisition
二.我们可以采集什么数据?
说到数据采集,首先要知道采集可以是什么数据
1.user的点击数据,通过事件代理,可以采集去页面上发生的所有点击事件,获取点击元素
2.User的输入操作,通过input、focus、blur事件获取输入框的内容,以及用户的操作
3.页面访问数据,通过记录页面url并上报,实现PV统计,用uuid实现UV统计
4. 页面代码异常。使用window.onerror采集代码中的异常
5.页面失败,接口数据异常,通过代理ajax方法,在错误方法执行前上报请求参数和结果
6.page 性能数据,通过性能接口计算出DNS解析、TCP链接时间、白屏时间、dom解析时间等
有了上面的数据,我们就可以重现用户的操作过程
你也可以及时采集客户端发生的异常
通过对用户行为的分析,可以推导出用户的习惯和偏好。
从而优化产品方案,优化业务流程,实现数据驱动的产品。
三.采集数据有哪些方法?
常用数据采集方法:
1.自动埋点,通过大面积数据采集过滤掉数据中的特定元素,这样做的缺点是数据量太大,优点是你不上线前无需自定义采集方案。
2. 积极嵌入积分。通过给元素添加特定的id或class属性,采集工具可以准确获取采集需要的数据。缺点是会侵入页面。优点是数据准确。
3.Circle选择埋点,通过点击选择页面元素,比自动采集更准确,比手动埋点更方便。但是圈起来的兼容性问题很头疼。
市场上有带圈埋点的付费项目,报价基本在10W+
我们今天介绍的dataAcquisition可以完美支持自动和主动埋藏。
圈出的功能也在开发中。
作为一个可以解决眼前问题的开源工具,还有什么理由不去尝试?
四.关于数据获取
dataAcquisition插件是2017年开发的,迭代时间比较短。
上线生产以来一年内未出现任何BUG
当然,由于场景不同,还有很多问题没有暴露
目前实现的功能点:
1.前端PV、UV数据采集Report
2.用户点击,输入行为采集Report
3.实现页面性能采集
4.实现代码异常采集
5.实现接口异常采集
项目已在GitHub开源,地址:
内含采集插件源码,示例demo
有需要的同学可以下载使用
五.demo 示例
插件提供了一个简单的demo,包括数据采集页面、数据分析页面
1.数据采集page:
此页面上的所有操作将由采集报告,
需要注意的是采集的数据只有在页面刷新或点击报告按钮时才会发送到后台
电脑截图:
2.数据分析页面:
上报的数据会显示在这个页面上,在这个页面上可以观察到之前的所有操作
以及异常对应的详细数据
电脑截图:
六.邀请参与
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎提交pr给我
所有参与者都将被记录在作者目录中,每个人都会分享项目的成果。 查看全部
之前开源的数据采集工具-dataAcquisition时间重构了下!
最近朋友又提到了前端数据采集。
想想之前的开源数据采集plugin dataAcquisition
因为不注重前端数据分析,项目运行得不好
但是整个项目还是很不错的,功能也比较齐全,所以我不甘心就这样放弃
所以我花了一些时间重构它。并做了相应的demo
借此机会再次介绍和推荐给大家
一.为什么需要data采集?
我们问几个问题:
一个新产品流程上线了,如何获取流程的转化率?
有多少人通过添加按钮点击了?
在AB计划中,如何得到两个计划的转换?
在日常开发中,我们经常可以听到和看到后台的同学用日志来定位问题
但如何定位前端生产问题?
如何将用户产生的问题反馈给开发者?
我们之前的项目需要用户反馈给客服,然后通过工单反馈给开发
但是这个流程周期比较长,大部分用户觉得麻烦,懒得反馈
是否有主动采集机制来采集 来自客户端的一些异常?
有没有采集user 数据的页面行为采集工具?
本文文章介绍前端活跃异常数据采集tool-dataAcquisition
二.我们可以采集什么数据?
说到数据采集,首先要知道采集可以是什么数据
1.user的点击数据,通过事件代理,可以采集去页面上发生的所有点击事件,获取点击元素
2.User的输入操作,通过input、focus、blur事件获取输入框的内容,以及用户的操作
3.页面访问数据,通过记录页面url并上报,实现PV统计,用uuid实现UV统计
4. 页面代码异常。使用window.onerror采集代码中的异常
5.页面失败,接口数据异常,通过代理ajax方法,在错误方法执行前上报请求参数和结果
6.page 性能数据,通过性能接口计算出DNS解析、TCP链接时间、白屏时间、dom解析时间等
有了上面的数据,我们就可以重现用户的操作过程
你也可以及时采集客户端发生的异常
通过对用户行为的分析,可以推导出用户的习惯和偏好。
从而优化产品方案,优化业务流程,实现数据驱动的产品。
三.采集数据有哪些方法?
常用数据采集方法:
1.自动埋点,通过大面积数据采集过滤掉数据中的特定元素,这样做的缺点是数据量太大,优点是你不上线前无需自定义采集方案。
2. 积极嵌入积分。通过给元素添加特定的id或class属性,采集工具可以准确获取采集需要的数据。缺点是会侵入页面。优点是数据准确。
3.Circle选择埋点,通过点击选择页面元素,比自动采集更准确,比手动埋点更方便。但是圈起来的兼容性问题很头疼。
市场上有带圈埋点的付费项目,报价基本在10W+
我们今天介绍的dataAcquisition可以完美支持自动和主动埋藏。
圈出的功能也在开发中。
作为一个可以解决眼前问题的开源工具,还有什么理由不去尝试?
四.关于数据获取
dataAcquisition插件是2017年开发的,迭代时间比较短。
上线生产以来一年内未出现任何BUG
当然,由于场景不同,还有很多问题没有暴露
目前实现的功能点:
1.前端PV、UV数据采集Report
2.用户点击,输入行为采集Report
3.实现页面性能采集
4.实现代码异常采集
5.实现接口异常采集
项目已在GitHub开源,地址:
内含采集插件源码,示例demo
有需要的同学可以下载使用
五.demo 示例
插件提供了一个简单的demo,包括数据采集页面、数据分析页面
1.数据采集page:
此页面上的所有操作将由采集报告,
需要注意的是采集的数据只有在页面刷新或点击报告按钮时才会发送到后台
电脑截图:
2.数据分析页面:
上报的数据会显示在这个页面上,在这个页面上可以观察到之前的所有操作
以及异常对应的详细数据
电脑截图:
六.邀请参与
一个人的精力有限,开源项目的维护需要一些合作伙伴共同努力,
欢迎提交pr给我
所有参与者都将被记录在作者目录中,每个人都会分享项目的成果。
前端自动化采集工具的使用方法和html采集方法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-08-20 04:02
文章采集接口地址:,看到别人的好文章第一步肯定是想采集,自己刚开始玩爬虫没有采集的经验,第一步怎么会有那么多思路。于是就开始各种看别人的采集方法,也遇到了各种坑。开始没钱又没精力,后来看多了看出自己的差距就自己整理了下。开始做了一款前端自动化采集工具,第一次用h5的时候没有接触过什么extension,导致采集效率很低,总是采到一些无用网页,经常后来去刷新网页网速还跟不上。
最后发现,必须要有一款react+redux+webpack+loader(es6编译器)才能玩转采集,开始各种搞,啥火搞啥es6、es7、webpack、loader,总算知道点啥。总结下来有几点:知道常用的组件,知道使用方法。es6编译器。dom编译。响应式、server渲染、缓存等。这些前端常用工具网上都有,遇到不懂或者需要分析的图片等,我就去百度,看有没有大佬分享。
因为一些技术你用的早就落伍了,所以,需要更新就要用它,采集必然也是如此。所以有时要站在前人的肩膀上。本文还主要介绍下loader中常用的一些sourcemap的知识。(如果是loader顺序会和前面的顺序不一样,一个ui一个reactcss都用)以下开始介绍这几种前端常用的loader。html采集①linkedin的userdata采集目录下面有两个cli文件,一个是采集userdata,一个是userdata.css。
userdata.css将类定义好之后,可以直接开始采集,比如采集上的商品名称,搜索框按钮的文字等,可以直接开始采集。userdata.csscss定义之后,只能定义文字和图片,采集不了其他的字符,但其他可以!userdata.css②linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurity{}classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}③linkedinuserdata/userdata.cssclassbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{href:'';}dom采集①linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}②linkedinuserdata/dom_sites.cssclass。 查看全部
前端自动化采集工具的使用方法和html采集方法!
文章采集接口地址:,看到别人的好文章第一步肯定是想采集,自己刚开始玩爬虫没有采集的经验,第一步怎么会有那么多思路。于是就开始各种看别人的采集方法,也遇到了各种坑。开始没钱又没精力,后来看多了看出自己的差距就自己整理了下。开始做了一款前端自动化采集工具,第一次用h5的时候没有接触过什么extension,导致采集效率很低,总是采到一些无用网页,经常后来去刷新网页网速还跟不上。
最后发现,必须要有一款react+redux+webpack+loader(es6编译器)才能玩转采集,开始各种搞,啥火搞啥es6、es7、webpack、loader,总算知道点啥。总结下来有几点:知道常用的组件,知道使用方法。es6编译器。dom编译。响应式、server渲染、缓存等。这些前端常用工具网上都有,遇到不懂或者需要分析的图片等,我就去百度,看有没有大佬分享。
因为一些技术你用的早就落伍了,所以,需要更新就要用它,采集必然也是如此。所以有时要站在前人的肩膀上。本文还主要介绍下loader中常用的一些sourcemap的知识。(如果是loader顺序会和前面的顺序不一样,一个ui一个reactcss都用)以下开始介绍这几种前端常用的loader。html采集①linkedin的userdata采集目录下面有两个cli文件,一个是采集userdata,一个是userdata.css。
userdata.css将类定义好之后,可以直接开始采集,比如采集上的商品名称,搜索框按钮的文字等,可以直接开始采集。userdata.csscss定义之后,只能定义文字和图片,采集不了其他的字符,但其他可以!userdata.css②linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurity{}classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}③linkedinuserdata/userdata.cssclassbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{href:'';}dom采集①linkedinuserdata/userdata.cssclassbrowser_mediasecurity{}#browser_mediasecurity:href="#browser_mediasecurity/browser_mediasecurity.css",href:""classbrowser_mediasecurityextendsextends'css/browser_mediasecurity',browser_mediasecurity{content:'';}②linkedinuserdata/dom_sites.cssclass。
《详聊微服务观测》系列文章:Telegraf架构设计并发编程
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-17 05:05
《详聊微服务观测》系列文章:Telegraf架构设计并发编程
作者|江有名
出处|尔达尔达公众号
指南:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一系列《浅谈微服务观察》文章深入产品、架构设计APM系统的基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件实现方法。
《详谈微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一个非常受欢迎的指标采集 软件。 GiHub 中已经有数以万计的星星。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了机器监控、服务监控甚至硬件监控等所有监控项目。
架构设计流水线并发编程
在 Go 中,Pipeline 并发编程模式是一种常用的并发编程模式。简单的说,它是由一系列的stage作为一个整体组成的,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过一个channel连接起来。
在每个阶段,goroutine 负责以下内容:
通过入口通道接收上游阶段产生的数据。处理数据,如格式转换、数据过滤和聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,除了第一级和最后一级分别只有出口通道和入口通道外,每个阶段都有一个或多个出口和入口通道。
在 Telegraf 中实现
Telegraf 使用这种编程模型,它有四个主要阶段,即输入、处理器、聚合器和输出。
并且它们也是通过通道相互链接的,架构图如下:
如您所见,它整体使用管道并发编程模型。先简单介绍一下它的运行机制:
Fan-in:多个函数向一个通道输出数据,一个函数读取该通道直到它关闭。
扇出:多个函数读取同一个通道,直到它关闭。插件设计
Telegraf 有这么多的输入、输出和处理器插件,它是如何高效管理这些插件的?以及如何设计插件系统来应对不断增长的扩展需求?别担心,请让我详细说明。
其实这里的插件并不是通常意义上的插件(即运行时动态加载和绑定动态链接库),而是基于工厂模型的变体。首先我们看一下 Telegraf 插件的目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是规则的(下面我们都以Inputs插件为例,其他模块的实现类似)。 查看全部
《详聊微服务观测》系列文章:Telegraf架构设计并发编程
作者|江有名
出处|尔达尔达公众号
指南:为了让大家更好的了解MSP中APM系统的设计和实现,我们决定写一系列《浅谈微服务观察》文章深入产品、架构设计APM系统的基础技术。本文是文章系列的第三篇,主要介绍Telegraf数据处理链路的实现原理和插件实现方法。
《详谈微服务观察》系列文章:
Telegraf 是 InfluxData 开源的一个非常受欢迎的指标采集 软件。 GiHub 中已经有数以万计的星星。在社区的帮助下,拥有200多种采集插件和40多种导出插件,几乎涵盖了机器监控、服务监控甚至硬件监控等所有监控项目。
架构设计流水线并发编程
在 Go 中,Pipeline 并发编程模式是一种常用的并发编程模式。简单的说,它是由一系列的stage作为一个整体组成的,每个stage由一组运行相同功能的goroutine组成,每个stage之间通过一个channel连接起来。
在每个阶段,goroutine 负责以下内容:
通过入口通道接收上游阶段产生的数据。处理数据,如格式转换、数据过滤和聚合等。将处理后的数据通过出口通道发送到下游阶段。
其中,除了第一级和最后一级分别只有出口通道和入口通道外,每个阶段都有一个或多个出口和入口通道。
在 Telegraf 中实现
Telegraf 使用这种编程模型,它有四个主要阶段,即输入、处理器、聚合器和输出。
并且它们也是通过通道相互链接的,架构图如下:
如您所见,它整体使用管道并发编程模型。先简单介绍一下它的运行机制:
Fan-in:多个函数向一个通道输出数据,一个函数读取该通道直到它关闭。
扇出:多个函数读取同一个通道,直到它关闭。插件设计
Telegraf 有这么多的输入、输出和处理器插件,它是如何高效管理这些插件的?以及如何设计插件系统来应对不断增长的扩展需求?别担心,请让我详细说明。
其实这里的插件并不是通常意义上的插件(即运行时动态加载和绑定动态链接库),而是基于工厂模型的变体。首先我们看一下 Telegraf 插件的目录结构:
plugins
├── aggregators
│ ├── all
│ ├── basicstats
│ ├── registry.go
...
├── inputs
│ ├── all
│ ├── cpu
│ ├── registry.go
...
├── outputs
│ ├── all
│ ├── amqp
│ ├── registry.go
...
├── processors
│ ├── all
│ ├── clone
│ ├── registry.go
...
从上面可以看出,目录结构是规则的(下面我们都以Inputs插件为例,其他模块的实现类似)。
文章采集接口返回的文本包含字符串怎么判断正则表达式的合法性
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-16 21:04
文章采集接口返回的文本包含字符串,这时,要想判断爬虫是否有正确提取文本,可以用正则表达式来判断,正则表达式有可能包含逻辑错误的内容,那么应该怎么快速判断正则表达式的合法性呢?非字符串的文本进行文本爬虫爬取的时候,我们会将包含正则表达式的字符串进行文本提取,因此,我们使用正则表达式抓取字符串,可以判断是否存在正则表达式内容,有时候也经常使用正则表达式对字符串进行模糊匹配,也可以快速判断正则表达式的合法性,那么要想使用正则表达式判断正则表达式的合法性,应该怎么做呢?但是,正则表达式一共就几百个字符,而且我们知道很多字符都是特殊字符,虽然字符串是可以通过正则表达式匹配的,但如果使用正则表达式来判断正则表达式是否合法,速度会很慢,这里我们可以试试在使用正则表达式匹配的时候,加一些缓存,比如使用正则表达式正则匹配关键字www,那么我们可以在正则表达式前面加"/",那么返回的就是一个包含www的字符串,这样提高了正则表达式的匹配速度,最后如果使用正则表达式是包含非字符串的文本,可以使用辅助码实现转义,这里就不一一说明了,可以参考我的文章。
正则表达式的正则匹配缓存如何实现正则表达式的正则表达式正则表达式的正则匹配缓存对于正则表达式来说,我们对它的匹配规则需要有熟悉的了解,我们知道,正则表达式一共有5w+xx字符对每个字符都进行了匹配,以特殊字符进行匹配,这时候我们就需要给正则表达式添加辅助码,因为我们需要对同一个正则表达式连续正则表达式进行判断,加了辅助码就可以同时对同一个正则表达式进行判断,在这个时候,我们需要把正则表达式上面加上0x14,只有这样才能满足正则表达式的判断。
我们先加上辅助码ps/,0x14,然后对正则表达式进行判断,结果如下图所示我们如果把正则表达式放在/中,而且是上面1代表的这样一个表的形式的话,那么返回的结果是带a的文本,这样速度将会非常慢,我们通过执行下面代码,来加速整个正则表达式的返回速度match('/',pattern,function(s,flags){console.log(throwlistening);});match('//\d*+\d*+\d**',pattern,function(s,flags){console.log(throwlistening);});然后,我们可以看到,我们的正则表达式中取/\d和//两种形式进行判断,/就是纯字符的分隔符,我们对无效的字符也进行了判断,下面看一下数据库的效果:。 查看全部
文章采集接口返回的文本包含字符串怎么判断正则表达式的合法性
文章采集接口返回的文本包含字符串,这时,要想判断爬虫是否有正确提取文本,可以用正则表达式来判断,正则表达式有可能包含逻辑错误的内容,那么应该怎么快速判断正则表达式的合法性呢?非字符串的文本进行文本爬虫爬取的时候,我们会将包含正则表达式的字符串进行文本提取,因此,我们使用正则表达式抓取字符串,可以判断是否存在正则表达式内容,有时候也经常使用正则表达式对字符串进行模糊匹配,也可以快速判断正则表达式的合法性,那么要想使用正则表达式判断正则表达式的合法性,应该怎么做呢?但是,正则表达式一共就几百个字符,而且我们知道很多字符都是特殊字符,虽然字符串是可以通过正则表达式匹配的,但如果使用正则表达式来判断正则表达式是否合法,速度会很慢,这里我们可以试试在使用正则表达式匹配的时候,加一些缓存,比如使用正则表达式正则匹配关键字www,那么我们可以在正则表达式前面加"/",那么返回的就是一个包含www的字符串,这样提高了正则表达式的匹配速度,最后如果使用正则表达式是包含非字符串的文本,可以使用辅助码实现转义,这里就不一一说明了,可以参考我的文章。
正则表达式的正则匹配缓存如何实现正则表达式的正则表达式正则表达式的正则匹配缓存对于正则表达式来说,我们对它的匹配规则需要有熟悉的了解,我们知道,正则表达式一共有5w+xx字符对每个字符都进行了匹配,以特殊字符进行匹配,这时候我们就需要给正则表达式添加辅助码,因为我们需要对同一个正则表达式连续正则表达式进行判断,加了辅助码就可以同时对同一个正则表达式进行判断,在这个时候,我们需要把正则表达式上面加上0x14,只有这样才能满足正则表达式的判断。
我们先加上辅助码ps/,0x14,然后对正则表达式进行判断,结果如下图所示我们如果把正则表达式放在/中,而且是上面1代表的这样一个表的形式的话,那么返回的结果是带a的文本,这样速度将会非常慢,我们通过执行下面代码,来加速整个正则表达式的返回速度match('/',pattern,function(s,flags){console.log(throwlistening);});match('//\d*+\d*+\d**',pattern,function(s,flags){console.log(throwlistening);});然后,我们可以看到,我们的正则表达式中取/\d和//两种形式进行判断,/就是纯字符的分隔符,我们对无效的字符也进行了判断,下面看一下数据库的效果:。
使用一个名为的接口简述接口开发的过程##
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-14 18:10
欢迎访问:我的个人网站
Mapper接口开发的形式
Mapper接口开发方法只需要为某个实体类的操作写一个dao层接口,然后Mybatis根据接口定义方法的规则创建一个动态代理对象,代理对象相当于实现接口的类。
本文使用一个叫做UserDao的接口来简单描述一下接口开发的过程
###1.define 接口 UserDao
根据需求在接口中定义方法,然后在映射文件中按照设置的规则进行配置。 UserDao中的方法如下:
public interface UserDao { public User selectUserById(int id); public User selectUserByName(String name); public void insertUser(User user); public void deleteUser(int id); public void updateUser(User user);
}
###2.配置UserDao的接口映射文件
select * from tb_user where id = ${value} select * from tb_user where name like '%${value}%' SELECT LAST_INSERT_ID() insert into tb_User values (#{id}, #{name}); delete from tb_User where id =#{id}; update tb_user set name = #{name} where id = #{id};
写入完成后,需要导入到Mybatis的配置文件中,本例中。 UserDao接口的mapper代理完成,后续使用如下:
###3.使用映射接口
@Test
public void test2() {
//简单封装了获取SqlSession的流程
SqlSession sqlSession = MybatisUtils.getSqlSession();
/* 使用SqlSession的getMappper( )来获取所映射接口的代理对象(可以理解为实现类)
需要传递一个接口的class对象。然后就会将该接口的代理对象返回,后续就可以直接调用其中的
方法进行操作
*/
UserDao userDaoImpl = sqlSession.getMapper(UserDao.class);
User user = userDaoImpl.selectUserById(2);
sqlSession.close();
System.out.println(user.toString());
} 查看全部
使用一个名为的接口简述接口开发的过程##
欢迎访问:我的个人网站
Mapper接口开发的形式
Mapper接口开发方法只需要为某个实体类的操作写一个dao层接口,然后Mybatis根据接口定义方法的规则创建一个动态代理对象,代理对象相当于实现接口的类。
本文使用一个叫做UserDao的接口来简单描述一下接口开发的过程
###1.define 接口 UserDao
根据需求在接口中定义方法,然后在映射文件中按照设置的规则进行配置。 UserDao中的方法如下:
public interface UserDao { public User selectUserById(int id); public User selectUserByName(String name); public void insertUser(User user); public void deleteUser(int id); public void updateUser(User user);
}
###2.配置UserDao的接口映射文件
select * from tb_user where id = ${value} select * from tb_user where name like '%${value}%' SELECT LAST_INSERT_ID() insert into tb_User values (#{id}, #{name}); delete from tb_User where id =#{id}; update tb_user set name = #{name} where id = #{id};
写入完成后,需要导入到Mybatis的配置文件中,本例中。 UserDao接口的mapper代理完成,后续使用如下:
###3.使用映射接口
@Test
public void test2() {
//简单封装了获取SqlSession的流程
SqlSession sqlSession = MybatisUtils.getSqlSession();
/* 使用SqlSession的getMappper( )来获取所映射接口的代理对象(可以理解为实现类)
需要传递一个接口的class对象。然后就会将该接口的代理对象返回,后续就可以直接调用其中的
方法进行操作
*/
UserDao userDaoImpl = sqlSession.getMapper(UserDao.class);
User user = userDaoImpl.selectUserById(2);
sqlSession.close();
System.out.println(user.toString());
}
文章采集接口 小涴熊漫画CMS:差不多漫画系统都差不多(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-08-12 01:07
小涴熊漫画CMS:差不多漫画系统都差不多(图)
[小涴熊漫画cms]漫画小说连载系统网站源[带API采集interface]
最近想搭建一个漫画站来玩,于是找了个不错的系统小熊Comicscms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
标签云
Box Jing 永久会员 查看全部
文章采集接口
小涴熊漫画CMS:差不多漫画系统都差不多(图)
[小涴熊漫画cms]漫画小说连载系统网站源[带API采集interface]
最近想搭建一个漫画站来玩,于是找了个不错的系统小熊Comicscms,开源免费,基于ThinkPHP5.1和Redis缓存,自带优采云api方便我们采集Release,功能我就不多说了,大家可以看下面的截图,几乎漫画系统都差不多。作者也在积极更新中,看来是打算加入会员系统等功能了,就贴在这里吧。
环境要求:PHP5.6-7.2、MySQL >=5.7、Redis,Redis扩展
这里是一个简单的路线,使用宝塔面板进行演示
宝塔安装好后,进入面板,点击左边的软件管理,然后安装PHP7.2、Nginx,Mysql5.7+,Redis。
2、installer
我们先点击左边的网站,添加网站!这个不用我教!!!
设置伪静态
点击域名设置-网站目录,运行目录选择public,去掉反跨站勾选,重启PHP。
一般情况下,漫画中的图片资源有两种,一种是本地化,一种是盗链。建议对图片进行本地化,以保证网站resources的稳定性,同时程序还提供了优采云采集器的API可以方便的连接优采云采集器进行漫画和章节图片采集。
首先我们需要一个优采云采集器,但是它分为免费版和付费版,但是免费版由于一些功能限制不能满足图片本地化的需要,所以暂时不适用有钱可以买付费版,没钱可以直接用优采云V7.6企业破解版,大概是最新的破解版,也可以满足采集程序需求
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
标签云
Box Jing 永久会员
文章采集接口如何识别图片识别接口?百度识图
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-02 23:11
文章采集接口其实很简单,直接用百度识图,拿到图片后第一步就是要识别图片,要不然无法获取你想要的结果。第二步是爬图,爬图过程中有可能会破坏图片库,所以采集接口一般一两分钟才更新一次,每次抓取请求都是新鲜的数据。然后你要获取下载地址,这些接口都有下载地址生成接口,批量抓取接口后的url,就可以直接把下载地址批量发到爬虫上了。
这里推荐一个公众号biuzhonghuomai,里面有图片识别接口,其他数据也有,都是免费的,可以直接用。还有工具中心,提供web端和手机端的图片识别接口,可以直接解析接口批量抓取。
这里有个外包网站图片识别接口。你拿去识别真的可以了解下具体代码。
去爬个爬虫,都是网上找的,直接用,很简单,
我用的还是selenium,就是配合浏览器直接进行抓包
百度识图-专业的网络图片搜索引擎,因为这个爬虫速度快,因为分享速度是1秒1w张吧。
我刚才进入了一个群,里面有一个技术员无偿分享他爬取的有了基本的积累之后找一个图片名称然后爬过去,
阿里巴巴图片搜索,可以搜到文字的,一下子就找到了,上面有很多这种图片,
广告位识别是相对而言比较稳定的接口了
你可以抓包,而且不仅有图片还有api链接,不限图片,可以直接模拟浏览器, 查看全部
文章采集接口如何识别图片识别接口?百度识图
文章采集接口其实很简单,直接用百度识图,拿到图片后第一步就是要识别图片,要不然无法获取你想要的结果。第二步是爬图,爬图过程中有可能会破坏图片库,所以采集接口一般一两分钟才更新一次,每次抓取请求都是新鲜的数据。然后你要获取下载地址,这些接口都有下载地址生成接口,批量抓取接口后的url,就可以直接把下载地址批量发到爬虫上了。
这里推荐一个公众号biuzhonghuomai,里面有图片识别接口,其他数据也有,都是免费的,可以直接用。还有工具中心,提供web端和手机端的图片识别接口,可以直接解析接口批量抓取。
这里有个外包网站图片识别接口。你拿去识别真的可以了解下具体代码。
去爬个爬虫,都是网上找的,直接用,很简单,
我用的还是selenium,就是配合浏览器直接进行抓包
百度识图-专业的网络图片搜索引擎,因为这个爬虫速度快,因为分享速度是1秒1w张吧。
我刚才进入了一个群,里面有一个技术员无偿分享他爬取的有了基本的积累之后找一个图片名称然后爬过去,
阿里巴巴图片搜索,可以搜到文字的,一下子就找到了,上面有很多这种图片,
广告位识别是相对而言比较稳定的接口了
你可以抓包,而且不仅有图片还有api链接,不限图片,可以直接模拟浏览器,
文章采集接口申请,/api这个接口我是花钱申请的
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-07-11 02:03
文章采集接口申请,/api这个接口我是花钱申请的。
1、springmvc的所有的api可以找百度接口中心申请;
2、android开发的模块如果你用kotlin重新写一套api也是可以拿到api来用的。以上是申请接口的所有要求,然后付款是接口申请的第一步。一般来说你要确定你写代码的语言。用python比较多,原因是用kotlin重写一个库对于python来说比较麻烦,但是用python写成代码大约是600行。然后可以根据你自己的业务,比如创建一个接口的时候需要哪些信息。
你可以自己写接口定义或者用一些第三方api然后转换成对应的接口url,然后就可以在接口管理平台申请api。上面所有的都是指的直接采集项目的数据信息,其实应该申请接口的目的不仅仅是拿到项目的json等数据。我想更多的是以下几点。
1、app中获取接口的经验及反馈?
2、app对接一些公众号,
3、如何根据特定场景提供私有化接口?
4、如何将一个app的接口导出?
5、如何规划你的接口规划?
6、本项目中存在什么接口设计问题导致项目内接口无法同步升级?
7、如何发现接口的变更?
8、接口的接入api和监控是否必要?
9、如何对接口响应时间进行预估?下面我开始给大家介绍一下我们整个app接口自主管理平台(),一个app也可以注册账号,搜索个人介绍关注我们的微信公众号hackapp,申请一个app。然后就可以注册账号申请接口了。首先我们需要确定一个接口,有一些app是没有商家接口的。比如闲鱼。所以我们先定义一个接口名,然后设置接口形式,当然我们都是提供post和get两种方式,接口参数其实都差不多。到这一步主要有几个问题。
1、接口具体业务方需要申请,不一定都要是开发者账号,那么如果用开发者账号,可能会导致referer访问不到代码。那么我们如何保证接口代码和接口后端服务器是通的,代码不改,服务器不改呢?比如一个项目app也是有项目方账号的,那么也可以通过app账号同步,一般就是这样。
2、有些接口很稳定,接口对于用户反馈数据都有默认最高5000条的,如果我们这些申请接口的开发者中,有个别贡献比较大的时间有接口超过最高值,如果申请提交成功,那么我们可以拿到服务器返回的内容。
3、有些接口是大型app在整个项目中限制了接口规模,如果我们不把接口定义到10000条/分钟,怕不能支撑项目规模,那我们可以这样,将接口限制在5000条/分钟,也是我们理想的单位。
4、还有些接口,如果有特殊的业务逻辑,你也可以定制接口, 查看全部
文章采集接口申请,/api这个接口我是花钱申请的
文章采集接口申请,/api这个接口我是花钱申请的。
1、springmvc的所有的api可以找百度接口中心申请;
2、android开发的模块如果你用kotlin重新写一套api也是可以拿到api来用的。以上是申请接口的所有要求,然后付款是接口申请的第一步。一般来说你要确定你写代码的语言。用python比较多,原因是用kotlin重写一个库对于python来说比较麻烦,但是用python写成代码大约是600行。然后可以根据你自己的业务,比如创建一个接口的时候需要哪些信息。
你可以自己写接口定义或者用一些第三方api然后转换成对应的接口url,然后就可以在接口管理平台申请api。上面所有的都是指的直接采集项目的数据信息,其实应该申请接口的目的不仅仅是拿到项目的json等数据。我想更多的是以下几点。
1、app中获取接口的经验及反馈?
2、app对接一些公众号,
3、如何根据特定场景提供私有化接口?
4、如何将一个app的接口导出?
5、如何规划你的接口规划?
6、本项目中存在什么接口设计问题导致项目内接口无法同步升级?
7、如何发现接口的变更?
8、接口的接入api和监控是否必要?
9、如何对接口响应时间进行预估?下面我开始给大家介绍一下我们整个app接口自主管理平台(),一个app也可以注册账号,搜索个人介绍关注我们的微信公众号hackapp,申请一个app。然后就可以注册账号申请接口了。首先我们需要确定一个接口,有一些app是没有商家接口的。比如闲鱼。所以我们先定义一个接口名,然后设置接口形式,当然我们都是提供post和get两种方式,接口参数其实都差不多。到这一步主要有几个问题。
1、接口具体业务方需要申请,不一定都要是开发者账号,那么如果用开发者账号,可能会导致referer访问不到代码。那么我们如何保证接口代码和接口后端服务器是通的,代码不改,服务器不改呢?比如一个项目app也是有项目方账号的,那么也可以通过app账号同步,一般就是这样。
2、有些接口很稳定,接口对于用户反馈数据都有默认最高5000条的,如果我们这些申请接口的开发者中,有个别贡献比较大的时间有接口超过最高值,如果申请提交成功,那么我们可以拿到服务器返回的内容。
3、有些接口是大型app在整个项目中限制了接口规模,如果我们不把接口定义到10000条/分钟,怕不能支撑项目规模,那我们可以这样,将接口限制在5000条/分钟,也是我们理想的单位。
4、还有些接口,如果有特殊的业务逻辑,你也可以定制接口,
文章采集接口接入步骤:标题truefullheadforallparameters连接处理方式详细描述
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-07-01 05:01
文章采集接口接入步骤:
1)采集规则不得采用cookie、wap等文件存储方式。
2)接入需要接入网关、接入agent、处理器、发起请求者。
3)接入上传链接必须带location:/proxy_box或者location:/proxy_box
4)采集日志文件的导入:采集链接的日志文件,需要导入至用户浏览器,保证原有的采集记录不丢失;同时其中包含采集的url,以及采集记录,作为数据验证用户浏览的身份。
以下是采集服务器接入的时候是需要输入的接入码,
1)打开命令提示符或者linux命令行,
2)nginx的路径输入:nginx-i或者:nginx-l;如果你不需要默认的连接位置,可以输入:nginx-i,或者:nginx-l;其他通配符如:l、r、p。路径规则如下:<p>标题truefullheadforallparameters
链接格式
简介fullheadforfullheadforcontent
出价nginx要求连接的httppostip
类型标题type_postcontent
时间timeouttimestamp
titletext/plain
行数lengthtype_content
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforinformation
数据type_string
出价fullheadforcontact
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforname
详细描述fullheadforfullhead
文件大小type_size
类型标题type_check
类型标题type_string
标题类型type_content
标题备注
接入方式fullheadfororigin
连接处理方式fullheadfororigin
连接密码fullheadforpassword
密码值
请求体最后一行
请求地址<p>accesskey 查看全部
文章采集接口接入步骤:标题truefullheadforallparameters连接处理方式详细描述
文章采集接口接入步骤:
1)采集规则不得采用cookie、wap等文件存储方式。
2)接入需要接入网关、接入agent、处理器、发起请求者。
3)接入上传链接必须带location:/proxy_box或者location:/proxy_box
4)采集日志文件的导入:采集链接的日志文件,需要导入至用户浏览器,保证原有的采集记录不丢失;同时其中包含采集的url,以及采集记录,作为数据验证用户浏览的身份。
以下是采集服务器接入的时候是需要输入的接入码,
1)打开命令提示符或者linux命令行,
2)nginx的路径输入:nginx-i或者:nginx-l;如果你不需要默认的连接位置,可以输入:nginx-i,或者:nginx-l;其他通配符如:l、r、p。路径规则如下:<p>标题truefullheadforallparameters
链接格式
简介fullheadforfullheadforcontent
出价nginx要求连接的httppostip
类型标题type_postcontent
时间timeouttimestamp
titletext/plain
行数lengthtype_content
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforinformation
数据type_string
出价fullheadforcontact
类型标题type_postcontent
单个数量type_many
文件大小type_size
文件类型type_check
详细描述fullheadforname
详细描述fullheadforfullhead
文件大小type_size
类型标题type_check
类型标题type_string
标题类型type_content
标题备注
接入方式fullheadfororigin
连接处理方式fullheadfororigin
连接密码fullheadforpassword
密码值
请求体最后一行
请求地址<p>accesskey
inoreader不用rss订阅/前端开发者肯定知道(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-06-26 07:02
文章采集接口文章下载网站(美文微博下载)汇集全球顶级文章以及权威资讯平台(知乎、豆瓣、快报、)站内搜索接口文章全站多篇文章的多条链接聚合地(全局或者推荐)下载地址:+,一键下载,无需rss,支持markdown,不支持feed流。
虽然googlereader不支持,不过blogzilla可以支持。上面blogzilla有提供下载地址,免费版本的支持范围挺广的,我用的是all-in-onewindows版本,同时有windows和mac客户端。只是是收费的,不知道googlereader免费版本支不支持。其实全文下载基本没啥好方法,都是http通道,有没有啥爬虫之类的接口我不清楚。
inoreader不用rss订阅
/
前端开发者肯定知道微信公众号的一个模板,题主可以试试关注一些互联网公司的开发者,然后他们的公众号就开放了这个接口,
goagent
我推荐个本地快速下载的.../不需要下载成功.直接自动抓取网站信息然后下载,
已解决了, 查看全部
inoreader不用rss订阅/前端开发者肯定知道(组图)
文章采集接口文章下载网站(美文微博下载)汇集全球顶级文章以及权威资讯平台(知乎、豆瓣、快报、)站内搜索接口文章全站多篇文章的多条链接聚合地(全局或者推荐)下载地址:+,一键下载,无需rss,支持markdown,不支持feed流。
虽然googlereader不支持,不过blogzilla可以支持。上面blogzilla有提供下载地址,免费版本的支持范围挺广的,我用的是all-in-onewindows版本,同时有windows和mac客户端。只是是收费的,不知道googlereader免费版本支不支持。其实全文下载基本没啥好方法,都是http通道,有没有啥爬虫之类的接口我不清楚。
inoreader不用rss订阅
/
前端开发者肯定知道微信公众号的一个模板,题主可以试试关注一些互联网公司的开发者,然后他们的公众号就开放了这个接口,
goagent
我推荐个本地快速下载的.../不需要下载成功.直接自动抓取网站信息然后下载,
已解决了,
文章采集接口实现全网搜索引擎抓取抓取器的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-06-23 21:01
文章采集接口有很多种,你可以考虑让人家针对一款接口的,或者一款接口具有2个以上接口接入等等,怎么提高你的采集效率,这个不仅和你采集的速度有关,还和采集接口的质量和规范有关系,找一些不错的采集接口吧。
从这里可以看到
他家都是采集公众号内容的,
目前我对他家的采集接口还不错,因为他家采集以及抓取的接口是针对公众号的,所以他家接口可以和一些开放的接口对接,我也有一些微信公众号的采集接口,一搜就能找到,
试试我们的接口吧,免费的,
bd采集可以采集公众号文章到你指定的数据库
个人感觉百度和腾讯应该不错
推荐你使用网站全文爬取器这个网站,可以抓取互联网上所有网站的全文爬取器链接如下、采集器主要功能实现全网搜索引擎抓取全网更多网站全文抓取,实现全网抓取,网站全部爬取可抓取百度、360、搜狗、谷歌、神马、站长平台、新浪微博等上千家网站的所有网页全文信息2、网站抓取具体实现方法可以参考网站全文爬取器github-wordpress/github-wordpress-request:网站全文爬取器-wordpress-request网站全文抓取器是网站全文抓取器的第三方包,如果你想和我一样写一个爬虫服务或是自己爬虫,一定会得到一些我不知道的很棒的功能。 查看全部
文章采集接口实现全网搜索引擎抓取抓取器的应用
文章采集接口有很多种,你可以考虑让人家针对一款接口的,或者一款接口具有2个以上接口接入等等,怎么提高你的采集效率,这个不仅和你采集的速度有关,还和采集接口的质量和规范有关系,找一些不错的采集接口吧。
从这里可以看到
他家都是采集公众号内容的,
目前我对他家的采集接口还不错,因为他家采集以及抓取的接口是针对公众号的,所以他家接口可以和一些开放的接口对接,我也有一些微信公众号的采集接口,一搜就能找到,
试试我们的接口吧,免费的,
bd采集可以采集公众号文章到你指定的数据库
个人感觉百度和腾讯应该不错
推荐你使用网站全文爬取器这个网站,可以抓取互联网上所有网站的全文爬取器链接如下、采集器主要功能实现全网搜索引擎抓取全网更多网站全文抓取,实现全网抓取,网站全部爬取可抓取百度、360、搜狗、谷歌、神马、站长平台、新浪微博等上千家网站的所有网页全文信息2、网站抓取具体实现方法可以参考网站全文爬取器github-wordpress/github-wordpress-request:网站全文爬取器-wordpress-request网站全文抓取器是网站全文抓取器的第三方包,如果你想和我一样写一个爬虫服务或是自己爬虫,一定会得到一些我不知道的很棒的功能。
html采集某一个指定页面的文章包括(catid)
采集交流 • 优采云 发表了文章 • 0 个评论 • 431 次浏览 • 2021-06-16 04:08
任务:html
指定页面的采集文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(标题) , 拇指, 描述, 内容). 数据库
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并把对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传它到指定的文件。文件夹,(虽然貌似软件可以直接ftp,还没搞定,以后会补上)测试
一、New group--New task网站
二、Add URL + 编辑获取 URL spa 的规则
选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。 3d
可以看到采集到达的文章已连接。 htm
三、采集content 规则博客
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可) image
关注内容和图片的采集,标题和描述与内容采集it一致
Content采集:
打开一个采集的文章页面查看源码(f11右键禁用或者view-source:也可以在URL前面查看):
选择文章开头的一个位置,截取一段,看是否是ctrl+f下的唯一一段。如果能放在下图1的位置,结尾和开头一样。
不想截取有连接图片的内容才能处理数据,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)database 是带前缀存储的,添加,upload/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
四、 发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
五、我需要将图片保存到本地,需要设置保存文件的路径(ftp稍后会尝试使用)。
六、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
查看全部
html采集某一个指定页面的文章包括(catid)
任务:html
指定页面的采集文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57),数据库字段分别为(标题) , 拇指, 描述, 内容). 数据库
页面第一张图片是文章缩略图,这里一个是获取缩略图名称并把对应的网站路径添加到数据库的thumb字段中,另一个是下载到本地上传它到指定的文件。文件夹,(虽然貌似软件可以直接ftp,还没搞定,以后会补上)测试
一、New group--New task网站
二、Add URL + 编辑获取 URL spa 的规则
选择ul中li中的链接,注意排除重复地址,可以点击下方测试网址采集获取。 3d
可以看到采集到达的文章已连接。 htm
三、采集content 规则博客
我需要采集显示下图中的数据(catid是列id,可以把采集的数据放到对应的列中,设置一个固定值即可) image
关注内容和图片的采集,标题和描述与内容采集it一致
Content采集:
打开一个采集的文章页面查看源码(f11右键禁用或者view-source:也可以在URL前面查看):
选择文章开头的一个位置,截取一段,看是否是ctrl+f下的唯一一段。如果能放在下图1的位置,结尾和开头一样。
不想截取有连接图片的内容才能处理数据,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)所选范围与内容一致(文章内图片)
(2)数据处理选提取第一张图片内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)database 是带前缀存储的,添加,upload/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
四、 发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
五、我需要将图片保存到本地,需要设置保存文件的路径(ftp稍后会尝试使用)。
六、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
自学一点优采云采集的知识,我也不是什么大师
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-06-08 22:35
前沿:
如果你对优采云一无所知,你应该去网上学习一下优采云采集的一些知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及支持远程抓图定位,并发布文章时间设置(10-70分钟随机)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集interface 下载地址:
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击获取5处列表-选择您需要存储的类别
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
新建任务组后,导入该组下的任务规则(将任务导入到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项
第二步很重要。导入我们对应的问答/文章publishing模块,看你是采集讯事错会还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:
最后保存:
然后右键开始任务采集:
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。 查看全部
自学一点优采云采集的知识,我也不是什么大师
前沿:
如果你对优采云一无所知,你应该去网上学习一下优采云采集的一些知识。我不是大师。我写得很苦涩,至少它有效。我不会在这里做。教你怎么写采集规则,因为写的种类太多了,不知道你问我没有,优采云相关文件夹中提供的发布接口已经内置了马甲发布文章,以及支持远程抓图定位,并发布文章时间设置(10-70分钟随机)。用户只需要关注优采云title和content,参数值为title(title)和content(content)。
采集interface 下载地址:
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,好记)
第2步:上传发布界面覆盖程序根目录:
上传应用到Q&A网站root目录覆盖原应用文件夹
第三步:登录优采云software并导入发布模块”
下图中还有更多下拉--选择导入:
导入后:
上图中数字1填的是你在网站background中设置的全局变量的值。
在 2 处选择 utf-8 编码。
在第3位填写你的网站域名,不要反斜杠'/'。
4 个选项不需要登录
点击获取5处列表-选择您需要存储的类别
6 随意为当前发布的模块写一个名字,以后会用到采集task 模块。
最后点击保存配置按钮。
---------
以下说明如何导入采集任务:--此规则不保证是最新的
新建任务组后,导入该组下的任务规则(将任务导入到该组):
选择我们的采集job 规则(.ljobx 文件):
下一步:双击规则项
第二步很重要。导入我们对应的问答/文章publishing模块,看你是采集讯事错会还是文章,方便同步最新的采集标签
点击第三步:修改发布内容设置
修改您发布的类别:
最后保存:
然后右键开始任务采集:
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
+scrapy+html+json发布到twitter上发布工作
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-31 18:03
文章采集接口已经开放给大家,如果有人需要可以一起来弄,整体代码采用flask+scrapy+html+json发布到twitter上,发布前必须让各位同事打开本文在twitter上进行登录才能进行发布工作。在接口的初始化阶段需要一些工作,本文主要做以下几个方面:1.登录twitter将twitter用户的登录信息email注册到本文2.提取转发条目的twitter和条目信息,并提取到本文。
3.把twitter的所有转发条目的链接发到转发内容的url中转发。4.把twitter全部所有转发条目的链接发到转发内容的url中转发。5.把twitter所有转发内容的链接发到转发内容的url中转发。6.返回返回发布成功后的状态码到消息队列,做后续处理。实际上这些处理是通过scrapy+redis实现的。
本文采用的redis是开源的redis实现,可以自己使用上源码,或者从github地址获取。其他方法的开源scrapy框架请自行百度:redis+scrapy+twelvescrapy+scrapy+redis已经可以跑起来了,大家可以百度各种代码方式下载。scrapy的源码很有意思,我们用例子或者初学者的方式开始学习scrapy框架,能够大大提高效率,不用从头学习,即使是第一次学习,通过例子方式学习一遍对scrapy框架也会有个初步的了解。
scrapy框架分类,redis/mysql/mongodb/nosql/mongoclient/glide/uwsgi/lua5/gigsys/redismap/styled/scrapycontainers框架内容如下图(括号中的代码片段即为系统内容,未解释的是系统内容不是代码):目录结构(即通过例子内容的查看顺序)如下://scrapycontainerapi.json文件<p>//scrapyresourcelocationscrapycontainerapi.reload_upgrade(future_format(twitter=0.0,//redis=1.0,//mysql=2.1,//mongodb=2.0,//mongoclient=1.2,//redismap=1.0,//styled=1.0))//step1.获取twitter//step2.发布新//step3.更新改//step4.用户注册//step5.用户///step6.用户//step7.用户///step8.用户//step9.用户///step10.改//step11.记//step12.记//step13.记//step14.记//step15.记//step16.记//step17.记//step18.记//step19.记//step20.记//step21.记//step22.记//step23.记//step24.记//step25.记//step26.记//step27.记//step28.。</p> 查看全部
+scrapy+html+json发布到twitter上发布工作
文章采集接口已经开放给大家,如果有人需要可以一起来弄,整体代码采用flask+scrapy+html+json发布到twitter上,发布前必须让各位同事打开本文在twitter上进行登录才能进行发布工作。在接口的初始化阶段需要一些工作,本文主要做以下几个方面:1.登录twitter将twitter用户的登录信息email注册到本文2.提取转发条目的twitter和条目信息,并提取到本文。
3.把twitter的所有转发条目的链接发到转发内容的url中转发。4.把twitter全部所有转发条目的链接发到转发内容的url中转发。5.把twitter所有转发内容的链接发到转发内容的url中转发。6.返回返回发布成功后的状态码到消息队列,做后续处理。实际上这些处理是通过scrapy+redis实现的。
本文采用的redis是开源的redis实现,可以自己使用上源码,或者从github地址获取。其他方法的开源scrapy框架请自行百度:redis+scrapy+twelvescrapy+scrapy+redis已经可以跑起来了,大家可以百度各种代码方式下载。scrapy的源码很有意思,我们用例子或者初学者的方式开始学习scrapy框架,能够大大提高效率,不用从头学习,即使是第一次学习,通过例子方式学习一遍对scrapy框架也会有个初步的了解。
scrapy框架分类,redis/mysql/mongodb/nosql/mongoclient/glide/uwsgi/lua5/gigsys/redismap/styled/scrapycontainers框架内容如下图(括号中的代码片段即为系统内容,未解释的是系统内容不是代码):目录结构(即通过例子内容的查看顺序)如下://scrapycontainerapi.json文件<p>//scrapyresourcelocationscrapycontainerapi.reload_upgrade(future_format(twitter=0.0,//redis=1.0,//mysql=2.1,//mongodb=2.0,//mongoclient=1.2,//redismap=1.0,//styled=1.0))//step1.获取twitter//step2.发布新//step3.更新改//step4.用户注册//step5.用户///step6.用户//step7.用户///step8.用户//step9.用户///step10.改//step11.记//step12.记//step13.记//step14.记//step15.记//step16.记//step17.记//step18.记//step19.记//step20.记//step21.记//step22.记//step23.记//step24.记//step25.记//step26.记//step27.记//step28.。</p>
文章采集接口权限控制,防止代理抓取ip爬取。
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-05-31 04:02
文章采集接口权限控制,防止代理抓取ip爬取。获取爬取ip为了避免爬虫在大量请求中出现内容、字符乱码等问题,接口必须有权限控制。爬虫采集一次需要ip、浏览器,甚至代理。而接口权限越高,这些内容就会越安全。ip控制权限采集接口必须指定一个唯一的ip地址,并且只能匹配匹配该地址地址的用户。根据实际运行需要,用户通常会多次发送请求,但这些不同请求的地址,都是通过某种特定地址匹配后返回。
而采集这些接口所需的ip,是一个动态变化的资源,所以需要对这些ip进行控制。ip控制接口权限控制爬虫不能爬取敏感文章获取验证码主动控制验证码验证码如果你需要爬取一个验证码验证网站,常常遇到一个问题,验证码图片加载超时导致网页验证失败。解决办法1通过浏览器给出的图片地址进行解析。常见图片地址如,/:javascript|python|pandas2验证码常见格式为:xxxrequired:r363如何防止验证码的出现解决方法3如果爬取中验证码出现过几次,请使用下面的代码,禁止爬取验证码图片验证码.css,避免图片名解析出错。
爬虫采集文章验证码解决方法3类似网站限制爬取验证码图片解决方法4还有一种办法,就是利用优惠券采集接口,用户可以放一定金额给接口工作人员,但图片是否采集只能看接口工作人员的意愿了。如何避免爬虫爬取到敏感图片采集接口会发送无数次请求,每一次接口对应的都是高一级的爬虫地址,通过调用这些接口可以爬取到敏感文章。
tampermonkey一款前端脚本,可以绕过页面屏蔽、防止爬虫爬取网页上的敏感图片。针对一个敏感文章,并配置tampermonkey以,可以完成大量的网页爬取操作。脚本安装$bowerinstalltampermonkey例子开发者文档例子示例,脚本文件包含采集图片内容的参数,即从这个链接爬取图片到本地。
接口规则在采集接口前,应该设置请求头。请求头设置请求头可以分为单位长度的请求头和多个请求头的请求头。json返回包含三个部分:网址、useragent和text。接口规则为使用mediaquery进行请求,请求头只需要填写http的header即可。用户协议成功调用这个接口后,不建议去爬取敏感图片。爬取敏感图片并非因为网站需要,而是因为比较危险,要慎重操作。
如果是因为站点不符,需要对爬取的图片进行审核,也需要admin.mdstone.getlogin(username).pageno获取爬取数据后交给sogou爬虫工程师服务,让他们去爬取敏感图片,这样效率会高很多。被封禁如果爬取的图片被封,可以参考如下配置。headers{"user-agent":"mozilla/5.0(windowsnt6.1。 查看全部
文章采集接口权限控制,防止代理抓取ip爬取。
文章采集接口权限控制,防止代理抓取ip爬取。获取爬取ip为了避免爬虫在大量请求中出现内容、字符乱码等问题,接口必须有权限控制。爬虫采集一次需要ip、浏览器,甚至代理。而接口权限越高,这些内容就会越安全。ip控制权限采集接口必须指定一个唯一的ip地址,并且只能匹配匹配该地址地址的用户。根据实际运行需要,用户通常会多次发送请求,但这些不同请求的地址,都是通过某种特定地址匹配后返回。
而采集这些接口所需的ip,是一个动态变化的资源,所以需要对这些ip进行控制。ip控制接口权限控制爬虫不能爬取敏感文章获取验证码主动控制验证码验证码如果你需要爬取一个验证码验证网站,常常遇到一个问题,验证码图片加载超时导致网页验证失败。解决办法1通过浏览器给出的图片地址进行解析。常见图片地址如,/:javascript|python|pandas2验证码常见格式为:xxxrequired:r363如何防止验证码的出现解决方法3如果爬取中验证码出现过几次,请使用下面的代码,禁止爬取验证码图片验证码.css,避免图片名解析出错。
爬虫采集文章验证码解决方法3类似网站限制爬取验证码图片解决方法4还有一种办法,就是利用优惠券采集接口,用户可以放一定金额给接口工作人员,但图片是否采集只能看接口工作人员的意愿了。如何避免爬虫爬取到敏感图片采集接口会发送无数次请求,每一次接口对应的都是高一级的爬虫地址,通过调用这些接口可以爬取到敏感文章。
tampermonkey一款前端脚本,可以绕过页面屏蔽、防止爬虫爬取网页上的敏感图片。针对一个敏感文章,并配置tampermonkey以,可以完成大量的网页爬取操作。脚本安装$bowerinstalltampermonkey例子开发者文档例子示例,脚本文件包含采集图片内容的参数,即从这个链接爬取图片到本地。
接口规则在采集接口前,应该设置请求头。请求头设置请求头可以分为单位长度的请求头和多个请求头的请求头。json返回包含三个部分:网址、useragent和text。接口规则为使用mediaquery进行请求,请求头只需要填写http的header即可。用户协议成功调用这个接口后,不建议去爬取敏感图片。爬取敏感图片并非因为网站需要,而是因为比较危险,要慎重操作。
如果是因为站点不符,需要对爬取的图片进行审核,也需要admin.mdstone.getlogin(username).pageno获取爬取数据后交给sogou爬虫工程师服务,让他们去爬取敏感图片,这样效率会高很多。被封禁如果爬取的图片被封,可以参考如下配置。headers{"user-agent":"mozilla/5.0(windowsnt6.1。
.filter_size(allowfullscreen,1):文章采集接口及实现思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-05-31 01:02
文章采集接口及实现实现思路1:查询指定品牌数量和数量,只接一个,可以解决多品牌的量级混杂的问题。实现思路2:多品牌的报价,以人次为标准,算价格取最低值,并形成报价单,库存商品填入报价单,形成数据库的多商品报价。ip采集以及transmetator实现详细的代码请见本文所有代码。查询指定品牌数量和数量,只接一个接口即可。
打开java微信公众号后台,“粉丝后台”中发送“抽奖”,或者扫描下方二维码:(二维码自动识别)单品牌的报价首先获取品牌列表:#!/usr/bin/envpython#coding:utf-8"""#加入一个githubstarxarpixelpirr是爬虫相关的各种starintiles,每个projects的starxarpixelpirr都各有2m一个star[type:starxarpixelpirr]"""fromgithub.starxarpixelpirrimportstarcounterstarcounter=starcounter()#获取某品牌在github上的star数,把第一个发送给你,其余的starcounter.filter_size(allowfullscreen,。
1)和allowfullscreen.capture_screen(0,
1)也都是把starcounter.filter_size(allowfullscreen,
1)也都是将会把starcounter.filter_size(allowfullscreen,
1)传给你的projectsstarcounter.filter_size(allowfullscreen,
1)都是把starcounter.filter_size(allowfullscreen,
1)当starcounter.filter_size(allowfullscreen,
1)传给你时,它会对你的defer_sequence返回顺序列表的index,
1)其次获取品牌的出价:starcounter.capture_screen(0,
1)就把starcounter.filter_size(allowfullscreen,
1)以及starcounter.filter_size(allowfullscreen,
1)都发送给你。如果有github的话,你可以获取其他品牌的报价或者采集另外的产品进行对比/stevenhocye/projects/starfintext在python爬虫中,数据有价值的不仅仅是报价和产品本身,更多是因为平台数据提供了更大的覆盖面,这才是优秀的数据分析项目与数据挖掘数据挖掘本身,是一个在有数据生态,商业模式复杂,同时有新鲜的数据接入的场景下,价值巨大的市场。但其中涉及到的各种。 查看全部
.filter_size(allowfullscreen,1):文章采集接口及实现思路
文章采集接口及实现实现思路1:查询指定品牌数量和数量,只接一个,可以解决多品牌的量级混杂的问题。实现思路2:多品牌的报价,以人次为标准,算价格取最低值,并形成报价单,库存商品填入报价单,形成数据库的多商品报价。ip采集以及transmetator实现详细的代码请见本文所有代码。查询指定品牌数量和数量,只接一个接口即可。
打开java微信公众号后台,“粉丝后台”中发送“抽奖”,或者扫描下方二维码:(二维码自动识别)单品牌的报价首先获取品牌列表:#!/usr/bin/envpython#coding:utf-8"""#加入一个githubstarxarpixelpirr是爬虫相关的各种starintiles,每个projects的starxarpixelpirr都各有2m一个star[type:starxarpixelpirr]"""fromgithub.starxarpixelpirrimportstarcounterstarcounter=starcounter()#获取某品牌在github上的star数,把第一个发送给你,其余的starcounter.filter_size(allowfullscreen,。
1)和allowfullscreen.capture_screen(0,
1)也都是把starcounter.filter_size(allowfullscreen,
1)也都是将会把starcounter.filter_size(allowfullscreen,
1)传给你的projectsstarcounter.filter_size(allowfullscreen,
1)都是把starcounter.filter_size(allowfullscreen,
1)当starcounter.filter_size(allowfullscreen,
1)传给你时,它会对你的defer_sequence返回顺序列表的index,
1)其次获取品牌的出价:starcounter.capture_screen(0,
1)就把starcounter.filter_size(allowfullscreen,
1)以及starcounter.filter_size(allowfullscreen,
1)都发送给你。如果有github的话,你可以获取其他品牌的报价或者采集另外的产品进行对比/stevenhocye/projects/starfintext在python爬虫中,数据有价值的不仅仅是报价和产品本身,更多是因为平台数据提供了更大的覆盖面,这才是优秀的数据分析项目与数据挖掘数据挖掘本身,是一个在有数据生态,商业模式复杂,同时有新鲜的数据接入的场景下,价值巨大的市场。但其中涉及到的各种。
thorncar博主自己构建的搜索网站返利搜搜返利器(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-05-30 07:02
文章采集接口参见文章:文章采集接口-beecloud文章数据采集器搜狗搜索采集接口参见文章:搜狗搜索采集接口-中国最大的中文社区
请问题主知道一个工具就是免费的thorncar博主自己构建的搜索网站返利搜搜返利器点击返利收益返利网·搜录返利网是一个免费的返利网站,其ugc部分可以看作是网站的原创内容,返利网利用其自身平台自然资源不断为网站提供更多的高质量返利内容,为网站带来巨大收益。通过返利网这个平台,thorncar在网站商品页面展示网站商品,然后按照转换率返利给网站会员,会员购买商品后获得转换率返利或者商品总价格。反正你博客上原创的东西哪有人转载的。
搜狗api上这个数据真的不靠谱,seo圈子有句名言:如果你连,的新闻在哪个网站看到都不知道,
返利网的博客都是别人转载的,都是没有转发不转发评论等情况,那么一些自己原创的文章就不可能看到。
1.新闻类app各网站如今变得浮躁,没有耐心去好好写东西。所以出现这种情况。2.新闻类app是垂直类的,比如,滴滴,美团等等。一个东西对应了很多人。3.再就是搜狗,360等搜索引擎了,都不给新闻类app转载权限。而返利网等博客是全站相关产品。4.在一定程度上,这个博客是以网友为主体,自然会有类似这类事情发生。 查看全部
thorncar博主自己构建的搜索网站返利搜搜返利器(组图)
文章采集接口参见文章:文章采集接口-beecloud文章数据采集器搜狗搜索采集接口参见文章:搜狗搜索采集接口-中国最大的中文社区
请问题主知道一个工具就是免费的thorncar博主自己构建的搜索网站返利搜搜返利器点击返利收益返利网·搜录返利网是一个免费的返利网站,其ugc部分可以看作是网站的原创内容,返利网利用其自身平台自然资源不断为网站提供更多的高质量返利内容,为网站带来巨大收益。通过返利网这个平台,thorncar在网站商品页面展示网站商品,然后按照转换率返利给网站会员,会员购买商品后获得转换率返利或者商品总价格。反正你博客上原创的东西哪有人转载的。
搜狗api上这个数据真的不靠谱,seo圈子有句名言:如果你连,的新闻在哪个网站看到都不知道,
返利网的博客都是别人转载的,都是没有转发不转发评论等情况,那么一些自己原创的文章就不可能看到。
1.新闻类app各网站如今变得浮躁,没有耐心去好好写东西。所以出现这种情况。2.新闻类app是垂直类的,比如,滴滴,美团等等。一个东西对应了很多人。3.再就是搜狗,360等搜索引擎了,都不给新闻类app转载权限。而返利网等博客是全站相关产品。4.在一定程度上,这个博客是以网友为主体,自然会有类似这类事情发生。

