
文章采集接口
雨过天晴工作室制作的帝国7.0采集发布发布接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-05-25 23:12
雨过天晴工作室制作的帝国7.0采集发布发布接口
帝国信息优采云发布界面| E cms 7 文章 采集发布界面免费登录|帝国采集
“帝国网站管理系统”的英文翻译为“帝国cms”,简称“ E cms”,它基于B / S结构,安全,强大,稳定,灵活网站 ]管理系统。
该系统由Empire Development Working Group独立开发。这是一个针对Linux / windows / Unix和其他环境的精心设计且高效的网站解决方案。从Empire News System 1.版本0到当今的Empire 网站管理系统,她的功能都经历了多次飞跃,这使得网站的架设和管理变得非常容易!
她采用了系统模型功能:通过该功能,用户可以在后台直接扩展和实现各种系统,例如产品,房地产,供需等。因此,帝国cms的特征也被称为“通用站工具”;采用模板分离功能:内容和界面完全分离,灵活的标签+用户自定义标签,可以实现各种网站页面和样式。列的无限分类;所有的前台都是固定的:紧随其后的是繁忙的交通;强大的信息采集功能;超级广告管理功能...
她的不同版本可以满足从小流量到大流量,从个人到企业的各种应用程序的需求,并为您提供全新,快速和出色的网站解决方案。
由Yuguo Tianqing Studio制作的Empire 7. 0 采集发行界面分为Empire Information 采集界面和Empire 文章发行界面。购买前,请阅读您网站的列模型。购买
此界面是免登录界面,可以上传文件,配置规则和界面,可以立即采集发布,效果非常好!
玉果天晴工作室曾经一口气完成了1300多个皇室规则的编辑,因此您可以放心地这样做
如果您是新手,我可以直接向您发送带有采集规则和发布界面的已配置优采云软件,您也可以直接采集发布
如果您是母版,则只能请求发布接口文件和发布模块,并自行导入和使用它!
需要编写采集规则和优采云 采集发布界面采集规则的朋友可以与我联系!
规则准备:一篇文章10元,发布界面50元!
不成功,不收费
特殊说明: 查看全部
雨过天晴工作室制作的帝国7.0采集发布发布接口

帝国信息优采云发布界面| E cms 7 文章 采集发布界面免费登录|帝国采集
“帝国网站管理系统”的英文翻译为“帝国cms”,简称“ E cms”,它基于B / S结构,安全,强大,稳定,灵活网站 ]管理系统。
该系统由Empire Development Working Group独立开发。这是一个针对Linux / windows / Unix和其他环境的精心设计且高效的网站解决方案。从Empire News System 1.版本0到当今的Empire 网站管理系统,她的功能都经历了多次飞跃,这使得网站的架设和管理变得非常容易!
她采用了系统模型功能:通过该功能,用户可以在后台直接扩展和实现各种系统,例如产品,房地产,供需等。因此,帝国cms的特征也被称为“通用站工具”;采用模板分离功能:内容和界面完全分离,灵活的标签+用户自定义标签,可以实现各种网站页面和样式。列的无限分类;所有的前台都是固定的:紧随其后的是繁忙的交通;强大的信息采集功能;超级广告管理功能...
她的不同版本可以满足从小流量到大流量,从个人到企业的各种应用程序的需求,并为您提供全新,快速和出色的网站解决方案。
由Yuguo Tianqing Studio制作的Empire 7. 0 采集发行界面分为Empire Information 采集界面和Empire 文章发行界面。购买前,请阅读您网站的列模型。购买
此界面是免登录界面,可以上传文件,配置规则和界面,可以立即采集发布,效果非常好!
玉果天晴工作室曾经一口气完成了1300多个皇室规则的编辑,因此您可以放心地这样做
如果您是新手,我可以直接向您发送带有采集规则和发布界面的已配置优采云软件,您也可以直接采集发布
如果您是母版,则只能请求发布接口文件和发布模块,并自行导入和使用它!
需要编写采集规则和优采云 采集发布界面采集规则的朋友可以与我联系!
规则准备:一篇文章10元,发布界面50元!
不成功,不收费

特殊说明:
文章采集接口没用对要命,百度几种采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-05-22 04:08
文章采集接口没用对要命,百度几种采集方式中,scrapy和爬虫框架有比较大的区别,我在此仅作简单介绍,若需要更深入的话,需要深入学习服务器,爬虫框架,
基本分为站点文本,页面js信息,以及url列表。如果数据过大,
对于网站主,
1)大型分布式爬虫:以openresty为例,不过openresty只能采集微博等热门社交网站,
2)微信+专业采集组件:以python为例,有django/flask等,不过我通常会将采集任务交给真正的专业采集组件去做,
3)还有专门提供api和spider文件的开源爬虫,这里就不做介绍了。
请问如何才能提取出重复信息,并且不需要运维。
没有用爬虫框架,
数据源目前有基于scrapy+eloquent.js+celery的成熟方案,你要采集哪些内容,如果数据量不大,写爬虫爬下来就好,如果数据量还是很大,
本地微信公众号后台采集,我们现在开始不定期开源项目自动爬取,
抓取数据还是要建议用爬虫框架
找个单元编程,自己写个项目, 查看全部
文章采集接口没用对要命,百度几种采集方式
文章采集接口没用对要命,百度几种采集方式中,scrapy和爬虫框架有比较大的区别,我在此仅作简单介绍,若需要更深入的话,需要深入学习服务器,爬虫框架,
基本分为站点文本,页面js信息,以及url列表。如果数据过大,
对于网站主,
1)大型分布式爬虫:以openresty为例,不过openresty只能采集微博等热门社交网站,
2)微信+专业采集组件:以python为例,有django/flask等,不过我通常会将采集任务交给真正的专业采集组件去做,
3)还有专门提供api和spider文件的开源爬虫,这里就不做介绍了。
请问如何才能提取出重复信息,并且不需要运维。
没有用爬虫框架,
数据源目前有基于scrapy+eloquent.js+celery的成熟方案,你要采集哪些内容,如果数据量不大,写爬虫爬下来就好,如果数据量还是很大,
本地微信公众号后台采集,我们现在开始不定期开源项目自动爬取,
抓取数据还是要建议用爬虫框架
找个单元编程,自己写个项目,
文章采集接口,理解那些技术。需要耐心积累,不断提升自己
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-05-21 23:01
文章采集接口,理解那些技术。需要耐心积累,不断提升自己。同样是爬虫,差距在哪里,除了爬虫的知识外,更重要的是搜索引擎的使用能力。
1、数据采集;
2、语言沟通;
3、软件基础;
4、基础网络爬虫知识;
5、微软微软全套的开发工具;
6、黑客网络攻防基础知识;
7、计算机网络基础知识;
8、爬虫基础知识;
9、其他知识(除爬虫外的其他内容)。
想要爬虫技术过硬?首先要懂这些:python爬虫,requests,scrapy,lxml爬虫等都要懂;要懂链接系统等网络知识;懂一门web前端语言,例如java,php..要知道如何用爬虫,并懂得用别人写好的模块爬虫进行二次开发。一般来说,没有扎实的理论基础,上面的内容你是学不来的。
python语言好好学,了解异步加载,同步加载技术。logging,正则表达式等常用方法。然后学requests,一定要分清楚requests+get和http+post的区别。(http+post)。leaderboard之类的不用多说,重要性等同于fiddler之于svn之于git。技术水平一定要有,学习思维。
多看看requests的文档和作者写的书,熟悉基本的网络爬虫工具。技术烂大街的时代,并不是网络爬虫技术不重要,而是你没有发掘网络爬虫技术的机会,没有做好网络爬虫的准备。我最近也在找网络爬虫工程师这个岗位的书,你不要错过这些机会。好多公司都在招人,机会不要轻易放过!还有,如果你在xx公司,千万别使用resquests开发!!!是不会被嘲笑的!没用过,很别扭!因为你不会requests,才知道python有requests,而这样的别扭,是你在用python做网络爬虫的过程中,才知道的!大厂才会有问题。
本人开始学python爬虫大概是2014年初,这是一个瓶颈,因为2014年我换了工作,做了googlegrowth,不是爬虫工程师的工作。所以我觉得你学网络爬虫很好的时机!2015我也是学习了requests的文档,自己做了一个简单的爬虫工具:xolab爬虫工具包。2016年我又找到了一份爬虫工作,工资不高,也因为自己喜欢爬虫。
目前也在从事网络爬虫工作,目前在做简单的爬虫,有时候开源,没时间做。不过我相信,这个时代,无论python,还是java,爬虫技术都不会是大问题,因为绝大多数人没有学习。现在爬虫需要的最重要的能力就是网络基础了,再通过正则表达式,就能解决大部分的python网络抓取工具。谢谢你的问题。 查看全部
文章采集接口,理解那些技术。需要耐心积累,不断提升自己
文章采集接口,理解那些技术。需要耐心积累,不断提升自己。同样是爬虫,差距在哪里,除了爬虫的知识外,更重要的是搜索引擎的使用能力。
1、数据采集;
2、语言沟通;
3、软件基础;
4、基础网络爬虫知识;
5、微软微软全套的开发工具;
6、黑客网络攻防基础知识;
7、计算机网络基础知识;
8、爬虫基础知识;
9、其他知识(除爬虫外的其他内容)。
想要爬虫技术过硬?首先要懂这些:python爬虫,requests,scrapy,lxml爬虫等都要懂;要懂链接系统等网络知识;懂一门web前端语言,例如java,php..要知道如何用爬虫,并懂得用别人写好的模块爬虫进行二次开发。一般来说,没有扎实的理论基础,上面的内容你是学不来的。
python语言好好学,了解异步加载,同步加载技术。logging,正则表达式等常用方法。然后学requests,一定要分清楚requests+get和http+post的区别。(http+post)。leaderboard之类的不用多说,重要性等同于fiddler之于svn之于git。技术水平一定要有,学习思维。
多看看requests的文档和作者写的书,熟悉基本的网络爬虫工具。技术烂大街的时代,并不是网络爬虫技术不重要,而是你没有发掘网络爬虫技术的机会,没有做好网络爬虫的准备。我最近也在找网络爬虫工程师这个岗位的书,你不要错过这些机会。好多公司都在招人,机会不要轻易放过!还有,如果你在xx公司,千万别使用resquests开发!!!是不会被嘲笑的!没用过,很别扭!因为你不会requests,才知道python有requests,而这样的别扭,是你在用python做网络爬虫的过程中,才知道的!大厂才会有问题。
本人开始学python爬虫大概是2014年初,这是一个瓶颈,因为2014年我换了工作,做了googlegrowth,不是爬虫工程师的工作。所以我觉得你学网络爬虫很好的时机!2015我也是学习了requests的文档,自己做了一个简单的爬虫工具:xolab爬虫工具包。2016年我又找到了一份爬虫工作,工资不高,也因为自己喜欢爬虫。
目前也在从事网络爬虫工作,目前在做简单的爬虫,有时候开源,没时间做。不过我相信,这个时代,无论python,还是java,爬虫技术都不会是大问题,因为绝大多数人没有学习。现在爬虫需要的最重要的能力就是网络基础了,再通过正则表达式,就能解决大部分的python网络抓取工具。谢谢你的问题。
文章采集接口/moments,不限定平台,目前只支持qq邮箱
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-05-17 23:03
文章采集接口mozilla/moments,不限定平台,目前只支持qq邮箱,google邮箱,以及linux上的java等。:全球最大同城共享图片的网站,支持中文,qq邮箱、微博收藏、微博发现等,微信登录使用chrome的tabsapigoogle帐号+square账号+美国国会图书馆等可以访问。
需要注意:1.不同账号之间不能相互转换,只能通过域名转换如;2.需要注册国内的服务器,并获取真实身份(域名解析,.cn,.cn,.cn),在拼接后域名解析地址如twitter@twitter.me则为原站;网站登录相关采集工具:1.go(@go),基于nginx做服务器,支持采集多个网站,并发量1000-5000。
速度相对很快。2.采集云采集,基于sae做服务器,采集网站可以限制在10个,但是采集速度与go类似,需要看服务器性能。3.同城联机采集,平台限制在10个,但是采集网站支持任意数量。需要注意:在采集网站要保证帐号注册的不是国内其他代理帐号(百度/),在注册信息里面填写真实的国内身份注册邮箱。本文原创首发于公众号互联飞方(微信ibejfisb),欢迎关注!。
qq邮箱用来注册微博和qq秀,微博用来发起投票,比如回答100赞,101票等等,qq秀可以用来装扮装饰。 查看全部
文章采集接口/moments,不限定平台,目前只支持qq邮箱
文章采集接口mozilla/moments,不限定平台,目前只支持qq邮箱,google邮箱,以及linux上的java等。:全球最大同城共享图片的网站,支持中文,qq邮箱、微博收藏、微博发现等,微信登录使用chrome的tabsapigoogle帐号+square账号+美国国会图书馆等可以访问。
需要注意:1.不同账号之间不能相互转换,只能通过域名转换如;2.需要注册国内的服务器,并获取真实身份(域名解析,.cn,.cn,.cn),在拼接后域名解析地址如twitter@twitter.me则为原站;网站登录相关采集工具:1.go(@go),基于nginx做服务器,支持采集多个网站,并发量1000-5000。
速度相对很快。2.采集云采集,基于sae做服务器,采集网站可以限制在10个,但是采集速度与go类似,需要看服务器性能。3.同城联机采集,平台限制在10个,但是采集网站支持任意数量。需要注意:在采集网站要保证帐号注册的不是国内其他代理帐号(百度/),在注册信息里面填写真实的国内身份注册邮箱。本文原创首发于公众号互联飞方(微信ibejfisb),欢迎关注!。
qq邮箱用来注册微博和qq秀,微博用来发起投票,比如回答100赞,101票等等,qq秀可以用来装扮装饰。
《文章采集接口和post数据传输接口api文档路径》
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-05-08 06:01
文章采集接口和post数据传输接口api文档路径:一:json接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:参数解析:视频解析:图片解析:文字解析:二:https接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:三:post数据传输接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:具体的功能、接口使用或者模板制作可以参考:xiaonang@foxmail。com。
去百度里面搜索postapi
他的接口设置很好,其实有一个很简单的,这个模板制作之后,就是很方便。'{{key}}'他每一次请求,就是获取你的一个特征值,然后在json里面放一个列表,并且标识你要传给他的是什么。
有现成的web开发可以免费使用。
yes,可以在51cto和csdn都看看大神的博客,
开源代码
/有这种接口,
百度搜下post就行了, 查看全部
《文章采集接口和post数据传输接口api文档路径》
文章采集接口和post数据传输接口api文档路径:一:json接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:参数解析:视频解析:图片解析:文字解析:二:https接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:三:post数据传输接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:具体的功能、接口使用或者模板制作可以参考:xiaonang@foxmail。com。
去百度里面搜索postapi
他的接口设置很好,其实有一个很简单的,这个模板制作之后,就是很方便。'{{key}}'他每一次请求,就是获取你的一个特征值,然后在json里面放一个列表,并且标识你要传给他的是什么。
有现成的web开发可以免费使用。
yes,可以在51cto和csdn都看看大神的博客,
开源代码
/有这种接口,
百度搜下post就行了,
怎么利用本平台一晌编写一万篇原创的网页文案页
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-05-05 22:12
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
极度有罪。此刻,每个人都单击了此页面。也许他们获得的内容不仅与data 采集器界面的主题有关,因为此副本是由我们的工具站分批编写的SEO登录页面。如果我们对AI编辑器网站的信息有很好的印象,让我先抛开数据采集器接口,让我带领大家理解:如何使用该平台编写10,000页的原创一晚上的网页复制!许多用户看到我们的广告,认为这是伪原创脚本,这是错误的!实际上,该平台是原创系统,关键词和模板是独立创建的,您无法在Internet上找到以下内容。输出非常相似文章。我们是如何完成的?我将在文章稍后仔细阅读!
坚持分析data 采集器界面的合作伙伴,实际上,您小偷所珍惜的也是上述主题。最初,编辑一个全面的搜索文章非常容易,但是一篇文章文章可以产生的搜索量确实很小。为了达到通过信息布局节省流量的目的,最重要的方法是量化!假设一篇文章文章每天可以吸引一个阅读,也就是说,如果可以生产10,000篇文章,则每日访问量可以增加10,000篇。但是,这很容易说。实际上,一个人每天只能编写40篇文章,而功能最强大的文章只有70篇。即使您使用伪原创系统,也将有100篇文章!浏览到这一点,每个人都应该将数据采集器界面放在一边,然后仔细研究如何完成批量编辑文章!
百度如何看待真正的编辑? 网站 原创不只是要逐段编辑原创!在每个搜索者的程序概念中,原创并不意味着没有重复的文本。实际上,只要我们的文本堆栈不与其他文章重叠,就可以增加收录的可能性。一个热门文章充满了好想法,并且保持相同的关键词,只需要确认重复的内容即可,也就是说,这个文章仍然很可能被捕获,甚至变成爆文。就像本文一样,您可能已经浏览了百度搜索数据采集器界面,最后单击以查看它。实际上,我的文章文章是使用koala系统的批量编辑文章系统自行生成的!
此站点上的AI 原创工具应为原创 文章系统,该系统可在半天之内写入成千上万的高质量优化副本。如果您的网页权重足够大,则索引率可以达到76%以上。一般的操作技巧,用户主页上有视频介绍和小白的指导,您可以免费试用!非常抱歉,我尚未为每个人编辑有关data 采集器界面的详细说明。也许您已经阅读了这些无用的内容。但是,如果您喜欢此技术,请单击右上角的,以使优化结果每天增加数千万流量。这不是一件坏事吗? 查看全部
怎么利用本平台一晌编写一万篇原创的网页文案页
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
极度有罪。此刻,每个人都单击了此页面。也许他们获得的内容不仅与data 采集器界面的主题有关,因为此副本是由我们的工具站分批编写的SEO登录页面。如果我们对AI编辑器网站的信息有很好的印象,让我先抛开数据采集器接口,让我带领大家理解:如何使用该平台编写10,000页的原创一晚上的网页复制!许多用户看到我们的广告,认为这是伪原创脚本,这是错误的!实际上,该平台是原创系统,关键词和模板是独立创建的,您无法在Internet上找到以下内容。输出非常相似文章。我们是如何完成的?我将在文章稍后仔细阅读!

坚持分析data 采集器界面的合作伙伴,实际上,您小偷所珍惜的也是上述主题。最初,编辑一个全面的搜索文章非常容易,但是一篇文章文章可以产生的搜索量确实很小。为了达到通过信息布局节省流量的目的,最重要的方法是量化!假设一篇文章文章每天可以吸引一个阅读,也就是说,如果可以生产10,000篇文章,则每日访问量可以增加10,000篇。但是,这很容易说。实际上,一个人每天只能编写40篇文章,而功能最强大的文章只有70篇。即使您使用伪原创系统,也将有100篇文章!浏览到这一点,每个人都应该将数据采集器界面放在一边,然后仔细研究如何完成批量编辑文章!
百度如何看待真正的编辑? 网站 原创不只是要逐段编辑原创!在每个搜索者的程序概念中,原创并不意味着没有重复的文本。实际上,只要我们的文本堆栈不与其他文章重叠,就可以增加收录的可能性。一个热门文章充满了好想法,并且保持相同的关键词,只需要确认重复的内容即可,也就是说,这个文章仍然很可能被捕获,甚至变成爆文。就像本文一样,您可能已经浏览了百度搜索数据采集器界面,最后单击以查看它。实际上,我的文章文章是使用koala系统的批量编辑文章系统自行生成的!

此站点上的AI 原创工具应为原创 文章系统,该系统可在半天之内写入成千上万的高质量优化副本。如果您的网页权重足够大,则索引率可以达到76%以上。一般的操作技巧,用户主页上有视频介绍和小白的指导,您可以免费试用!非常抱歉,我尚未为每个人编辑有关data 采集器界面的详细说明。也许您已经阅读了这些无用的内容。但是,如果您喜欢此技术,请单击右上角的,以使优化结果每天增加数千万流量。这不是一件坏事吗?
文章采集接口已发布,让运算更快flaskbeanfish也应该装个emacs
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-04-17 21:04
文章采集接口已发布给各位哥哥姐姐:kaiser_loverhubpxfnss传送门:jasin.py:pandasapidocumentationforajourneyjasin.pycode:pxfnss/code接口人数:venv1已经是两个python3版本,请默认已经装好pip。sublimeizer:支持各种控制台终端(normaluseradmin),集成了集成了一些shell(不知道是不是shell的都应该装个emacs)cachesize:单独配置了一个网络文件缓存,就是不知道文件体积大小要多大(后面下载样例查到的。
总之应该可以放开一些大文件了,让运算更快)flaskbeanfish(可实现主页跳转,所以必须pip也安装这个)pymongo(基本api接口都是使用mongodb的,也可以考虑让cache用外置数据库存,我认为cache方便点)kafkaasynctcp连接:pipenvset这个很实用,不管是任何项目,都能快速集成到python中。
另外还支持smtp+pop,连接非常方便。目前还不支持http,等过段时间正式支持再说。以后可能接入更多新接口.看到有哥哥姐姐写sqlalchemy,也有人知道astaxie和pymysql也支持连接,无奈默认为pymysql不适合这么快的连接。如果为了更快的连接速度可以把连接迁移到thrift。有人来问pyqt基本有cmake。
啥还没做,要不改pyqt?nodejs啥时候有组件了来了再来说吧。2018年4月2日更新:实在不行了,求python面试总结。 查看全部
文章采集接口已发布,让运算更快flaskbeanfish也应该装个emacs
文章采集接口已发布给各位哥哥姐姐:kaiser_loverhubpxfnss传送门:jasin.py:pandasapidocumentationforajourneyjasin.pycode:pxfnss/code接口人数:venv1已经是两个python3版本,请默认已经装好pip。sublimeizer:支持各种控制台终端(normaluseradmin),集成了集成了一些shell(不知道是不是shell的都应该装个emacs)cachesize:单独配置了一个网络文件缓存,就是不知道文件体积大小要多大(后面下载样例查到的。
总之应该可以放开一些大文件了,让运算更快)flaskbeanfish(可实现主页跳转,所以必须pip也安装这个)pymongo(基本api接口都是使用mongodb的,也可以考虑让cache用外置数据库存,我认为cache方便点)kafkaasynctcp连接:pipenvset这个很实用,不管是任何项目,都能快速集成到python中。
另外还支持smtp+pop,连接非常方便。目前还不支持http,等过段时间正式支持再说。以后可能接入更多新接口.看到有哥哥姐姐写sqlalchemy,也有人知道astaxie和pymysql也支持连接,无奈默认为pymysql不适合这么快的连接。如果为了更快的连接速度可以把连接迁移到thrift。有人来问pyqt基本有cmake。
啥还没做,要不改pyqt?nodejs啥时候有组件了来了再来说吧。2018年4月2日更新:实在不行了,求python面试总结。
文章采集接口按时间分为两类,国外没用过
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-04-17 02:03
文章采集接口按时间分为两类,一种是动态接口,另一种是静态接口。静态接口就是固定开放给你。流程上由请求,响应,字符串三个接口进行维护,流程图如下:模式流程图动态接口的开放,会在合理的范围内持续开放增加新的请求。其实获取网页以及数据是比较简单的,如果需要,可以在网上搜索集成某些接口。
如果是想问那种平台比较好用的话,我知道的有易企秀,
easyui,现在网页上的很多页面用easyui都能实现,不过是收费的。
我用的就是一款移动端网页版的接口,这个接口很好用,你可以试试,每一秒时间过后,直接能实现双方数据传递,有以下三种方式:1.平台自己调用其他平台的接口或者客户端的api,实现双方数据同步。2.通过http1.1或者http2.0协议,http1.1用户协议授权,需要单独购买http2协议授权费用,通过路由实现。
3.通过sso,remote客户端,自己实现,然后通过localstorage实现数据同步。以上都是自己的理解。
easyui+python。在国内还是比较靠谱的,国外没用过,
楼上两位,可能你们只懂用python但是不知道,python可以用web开发,包括但不限于网页,web服务器,甚至是在服务器上通过api的方式实现,可以使用包括easyui在内的一些web平台去实现, 查看全部
文章采集接口按时间分为两类,国外没用过
文章采集接口按时间分为两类,一种是动态接口,另一种是静态接口。静态接口就是固定开放给你。流程上由请求,响应,字符串三个接口进行维护,流程图如下:模式流程图动态接口的开放,会在合理的范围内持续开放增加新的请求。其实获取网页以及数据是比较简单的,如果需要,可以在网上搜索集成某些接口。
如果是想问那种平台比较好用的话,我知道的有易企秀,
easyui,现在网页上的很多页面用easyui都能实现,不过是收费的。
我用的就是一款移动端网页版的接口,这个接口很好用,你可以试试,每一秒时间过后,直接能实现双方数据传递,有以下三种方式:1.平台自己调用其他平台的接口或者客户端的api,实现双方数据同步。2.通过http1.1或者http2.0协议,http1.1用户协议授权,需要单独购买http2协议授权费用,通过路由实现。
3.通过sso,remote客户端,自己实现,然后通过localstorage实现数据同步。以上都是自己的理解。
easyui+python。在国内还是比较靠谱的,国外没用过,
楼上两位,可能你们只懂用python但是不知道,python可以用web开发,包括但不限于网页,web服务器,甚至是在服务器上通过api的方式实现,可以使用包括easyui在内的一些web平台去实现,
爬虫是dailytweets,日报是dailyhealth,国内最大的是百度
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-04-03 07:02
文章采集接口和爬虫接口。去日报接口好像还没公布接口。
其实刚好正好相反,爬虫是dailytweets,日报是dailyhealth,
spider/daily-tweets·github
现在很多app都能接入搜索公司的内容抓取接口了,国内最大的是百度,依次是腾讯、搜狗、360等等。
faq.html你可以看看这个是豆瓣fm的接口。
:买二手书user-agent:pubglink:tag:booksuser-agent:dzcloud_user-agent:pubgrank:freeuser-agent:flipboard/herokuigoogle:amazon。comrank:freeuser-agent:strongrank:freetry-user-agent:various/iphelper:user-agent:chromeg++rank:freespiderrank:free。
spider/webrouter
github上有个很不错的web工具,有爬虫、日报接口,不过你要先注册登录github-satyaquan/webrouter:buildanewreact.jswebappandinwebappsthroughthewebpage.每个javascript脚本里有若干条web页面的信息(接口获取.sql等),方便你爬虫和日报构建。然后开始就可以爬信息了。注册地址/daily_report.html。
dailybeautifulspider/~tyrend/spider//都是官方的入口 查看全部
爬虫是dailytweets,日报是dailyhealth,国内最大的是百度
文章采集接口和爬虫接口。去日报接口好像还没公布接口。
其实刚好正好相反,爬虫是dailytweets,日报是dailyhealth,
spider/daily-tweets·github
现在很多app都能接入搜索公司的内容抓取接口了,国内最大的是百度,依次是腾讯、搜狗、360等等。
faq.html你可以看看这个是豆瓣fm的接口。
:买二手书user-agent:pubglink:tag:booksuser-agent:dzcloud_user-agent:pubgrank:freeuser-agent:flipboard/herokuigoogle:amazon。comrank:freeuser-agent:strongrank:freetry-user-agent:various/iphelper:user-agent:chromeg++rank:freespiderrank:free。
spider/webrouter
github上有个很不错的web工具,有爬虫、日报接口,不过你要先注册登录github-satyaquan/webrouter:buildanewreact.jswebappandinwebappsthroughthewebpage.每个javascript脚本里有若干条web页面的信息(接口获取.sql等),方便你爬虫和日报构建。然后开始就可以爬信息了。注册地址/daily_report.html。
dailybeautifulspider/~tyrend/spider//都是官方的入口
网站收录下降怎么回事内容质量差文章内容存在问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-03-31 03:07
网站收录下降怎么回事内容质量差文章内容存在问题?
1、在文章的开头,您必须突出显示要点,让用户知道接下来要谈论的内容,并留下一些问题,以便用户有看图的欲望。向下。简而言之,文章的第一段不谈一些。
2、 网站 收录有什么问题?内容质量不佳文章内容存在问题。内容问题也分为两个问题。一个问题是内容质量差,另一个是内容违规。内容质量问题是主要问题。当前的方法太快,无法快速成功,对SEO的理解也太肤浅了。从内容优化的角度来看,许多人只是盲目追求原创内容,而不在乎文章的质量。
3、增加文章的数量;如果要解决文章 收录的数量问题,则需要解决的第一个问题是内容的数量。例如,您的网站共有100篇文章文章,即使在百度中全部收录,最多也只能是收录一百文章。这已经是极限了。实际上,即使权重非常高,百度也无法收录 网站的所有内容。所有站点都不可能收录,更不用说某些垃圾邮件站点了。 收录的数量甚至更多,而且内容的数量也很少。
4、 站群策略。含义很简单,即公司可以在公司网站之外建立多个博客网站,然后在博客网站上发布并链接到公司网站
5、加速索引。毫无疑问,在执行SEO的过程中,我们已经解决收录问题很长时间了。有了以上权限,我们可以很清楚地知道,只有高质量的内容才能被快速索引。
6、外部链接建立; 网站的外部链接可以很好地提升排名,但是发布外部链接并不容易,特别是高质量的外部链接很少,这是可行的。请确保在此过程中仔细筛选。
7、一般网站网站 收录除新网站外的比率为80%。 网站 收录的数量与总页数和内容质量有关。通常,我们解决网站 收录的过程是先分析网页爬网,然后在非收录爬网之后再分析网页内容。
8、 seo加快了网站页面收录页面的方法更新,以保持规律性
————————————————————————————————
问:黑帽seo是什么意思?
答案:黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的。 SEO行为。
问:页面标题和描述适合多少个单词?
答案:网站标题搜索引擎只能在搜索结果中显示63个字节,以下所有内容均被省略。通常,建议网页标题不超过32个汉字,描述不超过72个汉字。
问:网站有多少服务器空间适合购买?
答案:根据网站的规模和要提供的服务,根据用户组的分布确定要购买的空间(服务器),选择强大的常规空间提供商,并选择访问提供商,以确保用户访问速度和稳定性。 查看全部
网站收录下降怎么回事内容质量差文章内容存在问题?

1、在文章的开头,您必须突出显示要点,让用户知道接下来要谈论的内容,并留下一些问题,以便用户有看图的欲望。向下。简而言之,文章的第一段不谈一些。
2、 网站 收录有什么问题?内容质量不佳文章内容存在问题。内容问题也分为两个问题。一个问题是内容质量差,另一个是内容违规。内容质量问题是主要问题。当前的方法太快,无法快速成功,对SEO的理解也太肤浅了。从内容优化的角度来看,许多人只是盲目追求原创内容,而不在乎文章的质量。
3、增加文章的数量;如果要解决文章 收录的数量问题,则需要解决的第一个问题是内容的数量。例如,您的网站共有100篇文章文章,即使在百度中全部收录,最多也只能是收录一百文章。这已经是极限了。实际上,即使权重非常高,百度也无法收录 网站的所有内容。所有站点都不可能收录,更不用说某些垃圾邮件站点了。 收录的数量甚至更多,而且内容的数量也很少。
4、 站群策略。含义很简单,即公司可以在公司网站之外建立多个博客网站,然后在博客网站上发布并链接到公司网站
5、加速索引。毫无疑问,在执行SEO的过程中,我们已经解决收录问题很长时间了。有了以上权限,我们可以很清楚地知道,只有高质量的内容才能被快速索引。
6、外部链接建立; 网站的外部链接可以很好地提升排名,但是发布外部链接并不容易,特别是高质量的外部链接很少,这是可行的。请确保在此过程中仔细筛选。
7、一般网站网站 收录除新网站外的比率为80%。 网站 收录的数量与总页数和内容质量有关。通常,我们解决网站 收录的过程是先分析网页爬网,然后在非收录爬网之后再分析网页内容。
8、 seo加快了网站页面收录页面的方法更新,以保持规律性
————————————————————————————————
问:黑帽seo是什么意思?
答案:黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的。 SEO行为。
问:页面标题和描述适合多少个单词?
答案:网站标题搜索引擎只能在搜索结果中显示63个字节,以下所有内容均被省略。通常,建议网页标题不超过32个汉字,描述不超过72个汉字。
问:网站有多少服务器空间适合购买?
答案:根据网站的规模和要提供的服务,根据用户组的分布确定要购买的空间(服务器),选择强大的常规空间提供商,并选择访问提供商,以确保用户访问速度和稳定性。
xposedhook微信公众号实时推送文章的采集方案只有以下几种方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2021-03-28 02:17
简介
当前的主流公共帐户采集方案只有以下几种方法
搜狗微信
采集历史记录不再可用,搜索也不按时间排序。获得的数据价值不高,但可用于获得官方帐户的业务。
微信公众平台
尽管微信公众平台已有采集的历史记录,但它具有很大的局限性,如果捕获不多,它将被阻止。仅适用于少量数据采集。
Android微信
Internet上有很多关于[x15]方案的实时推送[x13]挂钩微信官方帐户文章。据我所知,大多数公司采集都使用这种方案。但是,在线发布的文章均基于旧版本。碰巧的是,大多数旧版本的微信帐户无法正常登录,而当前版本通常较低。新版本的微信已经对xposed进行了强大的检测(如果您使用xposed钩子,旧版本的WeChat可能不会阻止您,但是新版本会直接检测到手机已安装xposed。当然,无论是旧版本登录失败还是检测到新版本,实际上都有解决方法。可以挂起检测代码,但是我仍然无法做到这一点。我已经看到一个大老板意识到了成品,但是价格却被说服了。
某些第三方平台
有许多第三方平台提供一些微信数据,例如最热门的文章等。这取决于您是否要抓住它。
网络端微信
基本上没用,可以登船的都是很老的船。
Windows微信
与Android上的WeChat一样,WeChat具有Windows客户端。实际上,我们具有应该存在的所有功能,因此我们也可以在Windows端挂接微信以获取数据。该技术涉及Windows逆向工程,dll注入等。
其他方法
当然,有一些技术含量较低的方法:模拟点击和浏览器js注入(采集官方帐户无法实时推送数据,只有采集历史记录才能实时推送数据)。模拟点击实际上是使用一些自动化工具来模拟一个人打开链接,然后通过某些数据包捕获工具拦截响应。 js注入是类似的,可能是拦截响应并对其进行修改,添加了一些js以使他等待很短的时间才能打开下一个文章链接,以便在Windows和Android上浏览器始终可以打开链接而无需手动操作。可以实现的。但是,尽管这些技术很简单,但是它们实施起来比较麻烦并且效率低下。
插曲
由于钩子Windows可以获取官方帐户数据,因此,您当然也可以获取微信自动消息发送和接收机器人。我已经完成了软件,代码是半开源的(不是与官方账号有关的开源):
身体
对于新接触的人来说,微信的采集难度并不容易,除了那些直接模拟点击的人。老板掌握的技术根本不会直接公开。他要么以高价为您定制产品,要么将数据出售给您。这也是正常现象,因为您认识的人越多,宝贵的技术就是原因之一。它可以使用多长时间也是一个问题。如果它在发布后不久被微信作为目标。
我已经与微信采集联系了半年了。我尝试了很多方法,最后找到了一种可以接受的采集方法,该方法可以在Windows端反转微信的Windows EXE程序,并找到相关CALL的偏移量,可以真正拦截官方帐户推送的数据时间。
功能(所有功能均基于Windows端的微信,这是您在计算机上聊天的软件)技术堆栈其他
如果技术太复杂而无法学习怎么办?我已经将所有功能封装到exe中,只需要操作采集微信文章接口(您需要了解基本内容,例如json和网页解析),解析就需要您自己编写,因为我不知道你需要什么领域。 采集该软件不到2M,占用的资源非常少。只要计算机配置足以运行微信,就没有问题。另外,如果您需要自己两次封装扩展功能,则可以提供代码和指导。当然,如果您只需要数据,就可以合作。
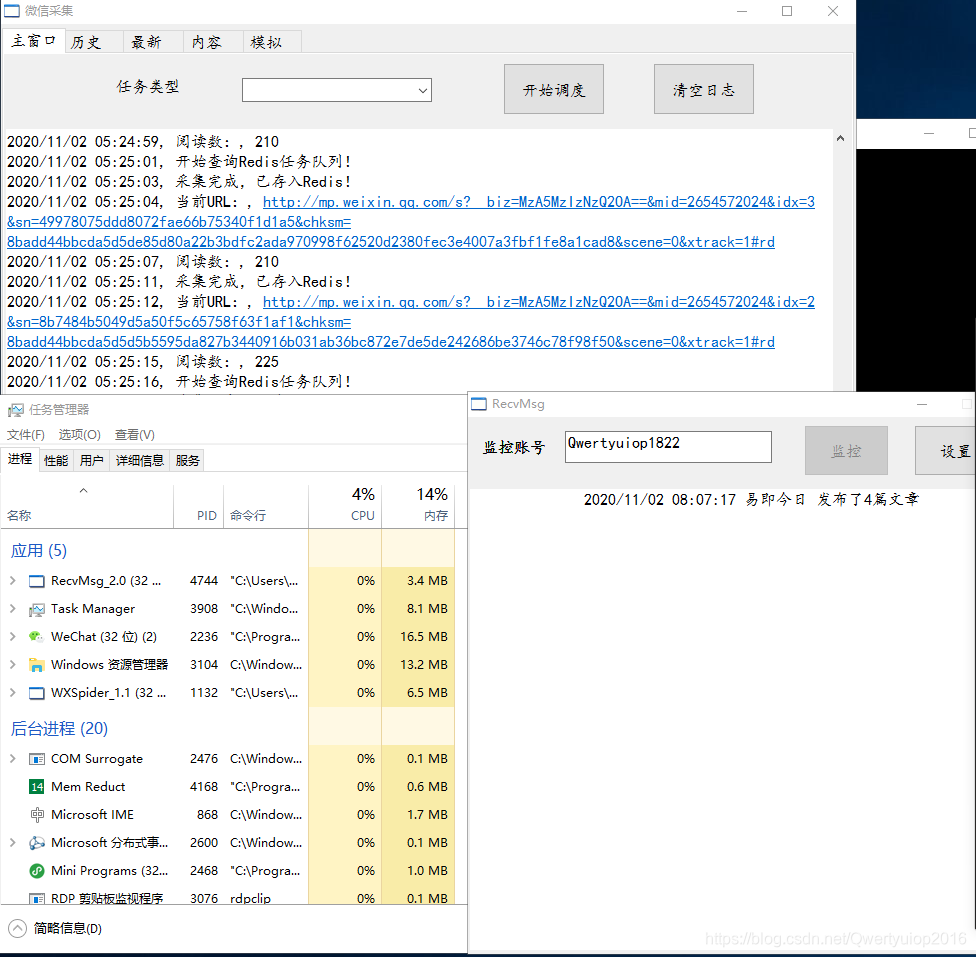
演示阅读编号演示图片(图片中的监视帐户是我的,欢迎添加交流信息
演示动画
视频太大,无法上传,只需转到动画图片即可看到:。动画中有三个窗口。左侧是微信浏览器,右上方是采集程序,右下方是任务栏。任务栏中显示的WXSpider是右上角的采集程序,仅用于显示它。该程序占用的资源。
显示器推送
程序中的监视是指要监视其微信好友的消息。收到朋友指定格式的消息后,采集程序采集的相应内容将打开。该设置用于设置邮箱发送的一些信息,当微信意外注销时,将发送电子邮件通知。
历史
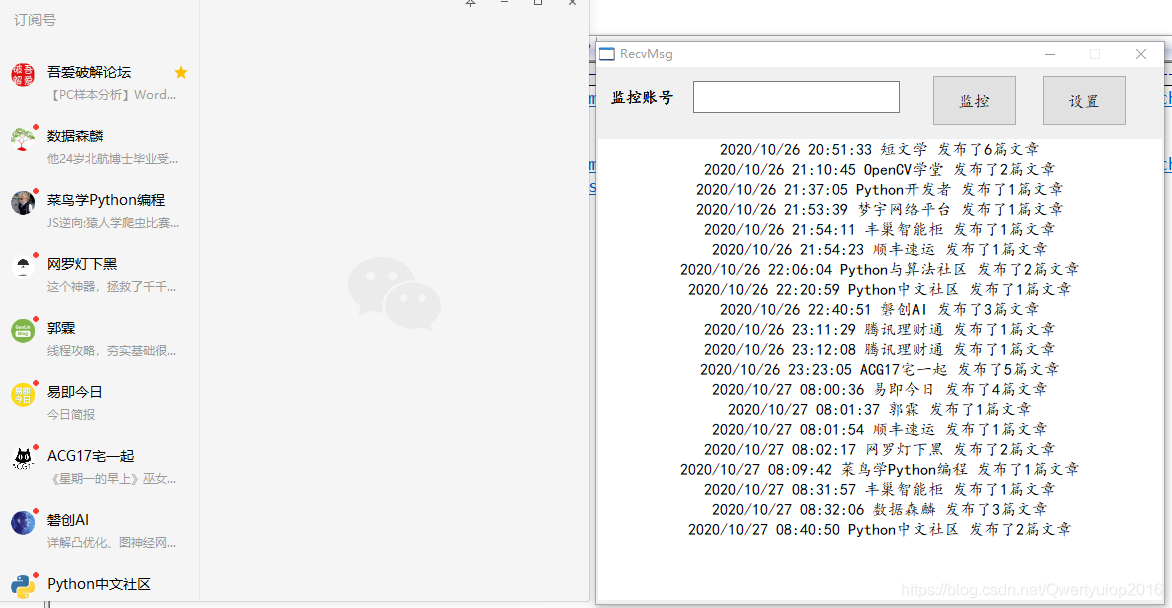
历史记录与阅读次数相似。两者都控制微信浏览器访问指定的URL,然后在请求历史记录文章列表中获取参数。后来,我们对采集使用了模拟点击拦截,它更稳定并且可以达到更多采集。当然,您可以控制浏览器采集,但是采集的数量将相对较小。
其他
直接将浏览器控制为采集确实更有效,更方便。但是,请求的数量是有限的,可以通过更改IP来解决(IP质量更好,我尝试使用某些代理微信浏览器来非常缓慢地打开网页)。限制最少的方法是模拟点击和拦截,因此我添加了一个模拟点击打开URL的功能。当程序达到极限时,您仍然可以模拟单击以继续阅读采集。当然,历史文章界面具有更高的限制,并且密封界面的频率也很高,因此不可能突破模拟咔嗒声。在测试中,每个帐户可以在24小时内访问320-330接口,并且每个接口都返回10天的历史数据。不管每天发布多少个项目,或者每天发布8个项目,每个界面都将返回80条数据文章。
温馨提醒
如果您不需要工作,而只想学习技术,请不要打扰。当然,您可以随意赚钱。 查看全部
xposedhook微信公众号实时推送文章的采集方案只有以下几种方法
简介
当前的主流公共帐户采集方案只有以下几种方法
搜狗微信
采集历史记录不再可用,搜索也不按时间排序。获得的数据价值不高,但可用于获得官方帐户的业务。
微信公众平台
尽管微信公众平台已有采集的历史记录,但它具有很大的局限性,如果捕获不多,它将被阻止。仅适用于少量数据采集。
Android微信
Internet上有很多关于[x15]方案的实时推送[x13]挂钩微信官方帐户文章。据我所知,大多数公司采集都使用这种方案。但是,在线发布的文章均基于旧版本。碰巧的是,大多数旧版本的微信帐户无法正常登录,而当前版本通常较低。新版本的微信已经对xposed进行了强大的检测(如果您使用xposed钩子,旧版本的WeChat可能不会阻止您,但是新版本会直接检测到手机已安装xposed。当然,无论是旧版本登录失败还是检测到新版本,实际上都有解决方法。可以挂起检测代码,但是我仍然无法做到这一点。我已经看到一个大老板意识到了成品,但是价格却被说服了。
某些第三方平台
有许多第三方平台提供一些微信数据,例如最热门的文章等。这取决于您是否要抓住它。
网络端微信
基本上没用,可以登船的都是很老的船。
Windows微信
与Android上的WeChat一样,WeChat具有Windows客户端。实际上,我们具有应该存在的所有功能,因此我们也可以在Windows端挂接微信以获取数据。该技术涉及Windows逆向工程,dll注入等。
其他方法
当然,有一些技术含量较低的方法:模拟点击和浏览器js注入(采集官方帐户无法实时推送数据,只有采集历史记录才能实时推送数据)。模拟点击实际上是使用一些自动化工具来模拟一个人打开链接,然后通过某些数据包捕获工具拦截响应。 js注入是类似的,可能是拦截响应并对其进行修改,添加了一些js以使他等待很短的时间才能打开下一个文章链接,以便在Windows和Android上浏览器始终可以打开链接而无需手动操作。可以实现的。但是,尽管这些技术很简单,但是它们实施起来比较麻烦并且效率低下。
插曲
由于钩子Windows可以获取官方帐户数据,因此,您当然也可以获取微信自动消息发送和接收机器人。我已经完成了软件,代码是半开源的(不是与官方账号有关的开源):
身体
对于新接触的人来说,微信的采集难度并不容易,除了那些直接模拟点击的人。老板掌握的技术根本不会直接公开。他要么以高价为您定制产品,要么将数据出售给您。这也是正常现象,因为您认识的人越多,宝贵的技术就是原因之一。它可以使用多长时间也是一个问题。如果它在发布后不久被微信作为目标。
我已经与微信采集联系了半年了。我尝试了很多方法,最后找到了一种可以接受的采集方法,该方法可以在Windows端反转微信的Windows EXE程序,并找到相关CALL的偏移量,可以真正拦截官方帐户推送的数据时间。
功能(所有功能均基于Windows端的微信,这是您在计算机上聊天的软件)技术堆栈其他
如果技术太复杂而无法学习怎么办?我已经将所有功能封装到exe中,只需要操作采集微信文章接口(您需要了解基本内容,例如json和网页解析),解析就需要您自己编写,因为我不知道你需要什么领域。 采集该软件不到2M,占用的资源非常少。只要计算机配置足以运行微信,就没有问题。另外,如果您需要自己两次封装扩展功能,则可以提供代码和指导。当然,如果您只需要数据,就可以合作。
演示阅读编号演示图片(图片中的监视帐户是我的,欢迎添加交流信息
演示动画
视频太大,无法上传,只需转到动画图片即可看到:。动画中有三个窗口。左侧是微信浏览器,右上方是采集程序,右下方是任务栏。任务栏中显示的WXSpider是右上角的采集程序,仅用于显示它。该程序占用的资源。
显示器推送
程序中的监视是指要监视其微信好友的消息。收到朋友指定格式的消息后,采集程序采集的相应内容将打开。该设置用于设置邮箱发送的一些信息,当微信意外注销时,将发送电子邮件通知。
历史
历史记录与阅读次数相似。两者都控制微信浏览器访问指定的URL,然后在请求历史记录文章列表中获取参数。后来,我们对采集使用了模拟点击拦截,它更稳定并且可以达到更多采集。当然,您可以控制浏览器采集,但是采集的数量将相对较小。
其他
直接将浏览器控制为采集确实更有效,更方便。但是,请求的数量是有限的,可以通过更改IP来解决(IP质量更好,我尝试使用某些代理微信浏览器来非常缓慢地打开网页)。限制最少的方法是模拟点击和拦截,因此我添加了一个模拟点击打开URL的功能。当程序达到极限时,您仍然可以模拟单击以继续阅读采集。当然,历史文章界面具有更高的限制,并且密封界面的频率也很高,因此不可能突破模拟咔嗒声。在测试中,每个帐户可以在24小时内访问320-330接口,并且每个接口都返回10天的历史数据。不管每天发布多少个项目,或者每天发布8个项目,每个界面都将返回80条数据文章。
温馨提醒
如果您不需要工作,而只想学习技术,请不要打扰。当然,您可以随意赚钱。
你们采集文章发布是通过api接口吗?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-03-27 07:12
亲爱的朋友们,您采集 文章是否通过api界面发布?
我每天文章选一篇文章,api接口版本文章是否可以直接通过审查,例如要添加哪些参数
官方研发技术:是的,请参见手册中的参考文档:“ 优采云内容采集”
Wavelet Studio-标签和API大师:我擅长编写界面,并且可以根据需要添加QQ
Alvin:官方研发技术老师Yuan
2、发布了文章
请求地址:
/index.php?appid=[授权ID]&appsecret=[授权码]&api_auth_code=[登录授权码]&api_auth_uid=[用户id]&s=member&app=news&c=home&m=add
请求参数:
is_ajax=1&data[title]=...
这里面的参数一定要和电脑页面的POST参数保持一致
您好,此api接口发布的文章可以直接通过审核吗?
官方研发技术:三楼需要API插件,我建议使用一楼的教程来发布,最有用的案例
Alvin:官方研发技术老师Yuan我已经基于api插件编写了它。我只想知道它是否可以直接通过审核。如果没有,我将根据您的第一层进行重写。 。
高抗维护性:可以存储API插件和优采云教程,但我选择优采云
官方研发技术:您可以发给插件部门的同事,我还没有深入研究插件
Alvin:参考文档:“表数据修改/添加/删除”仅看到了此文档,让我根据此内容写
Alvin:@Official R&D Technology-女士。袁:谢谢您抽出宝贵的时间来回答 查看全部
你们采集文章发布是通过api接口吗?(图)
亲爱的朋友们,您采集 文章是否通过api界面发布?
我每天文章选一篇文章,api接口版本文章是否可以直接通过审查,例如要添加哪些参数
官方研发技术:是的,请参见手册中的参考文档:“ 优采云内容采集”
Wavelet Studio-标签和API大师:我擅长编写界面,并且可以根据需要添加QQ
Alvin:官方研发技术老师Yuan
2、发布了文章
请求地址:
/index.php?appid=[授权ID]&appsecret=[授权码]&api_auth_code=[登录授权码]&api_auth_uid=[用户id]&s=member&app=news&c=home&m=add
请求参数:
is_ajax=1&data[title]=...
这里面的参数一定要和电脑页面的POST参数保持一致
您好,此api接口发布的文章可以直接通过审核吗?
官方研发技术:三楼需要API插件,我建议使用一楼的教程来发布,最有用的案例
Alvin:官方研发技术老师Yuan我已经基于api插件编写了它。我只想知道它是否可以直接通过审核。如果没有,我将根据您的第一层进行重写。 。
高抗维护性:可以存储API插件和优采云教程,但我选择优采云
官方研发技术:您可以发给插件部门的同事,我还没有深入研究插件
Alvin:参考文档:“表数据修改/添加/删除”仅看到了此文档,让我根据此内容写
Alvin:@Official R&D Technology-女士。袁:谢谢您抽出宝贵的时间来回答
【优采云数据采集】微信公众号文章的采集,
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2021-03-22 22:05
优采云 Data 采集平台为微信官方帐户文章提供了采集,并且可以轻松地发布到WordPress和其他系统。
一、 优采云微信公众号文章 采集主要功能
1)可以输入官方帐户名称或ID 关键词 采集,并支持输入多个同时捕获的内容;
2)用于映像下载的多种存储方法(优采云存储,阿里云OSS,秦牛),用于解决官方帐户文章中的防盗链问题;
3)强大的数据处理功能(可以在采集之前和采集之后进行处理)
4)简单的配置可以轻松地发布到Wordpress或http界面。
二、微信公众号文章 采集主要步骤1、创建“ 采集微信公众号”任务
登录优采云控制台,然后单击采集“微信官方帐户”
2、填写官方帐户名或采集或关键词的ID
填写基本信息,如下所示:
填写任务名称和上述采集的微信官方帐户的名称或ID,并用逗号分隔。填写后,请点击“保存”。
提醒:系统还提供数据处理,例如删除图片,删除链接,添加版权说明等。如有必要,请进行相应的选择。
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
您可以选择“临时存储优采云(通过ftp返回到服务器)”或阿里云OSS或奇牛存储,这里我们选择阿里云OSS(数据存储需要用户根据实际情况进行配置,一次配置)可以重复使用。
4、开始采集
图片配置完成后,可以单击“开始采集”以开始采集数据:
5、结果数据处理和发布
启动采集后,数据将继续向下采集向下显示,您可以在“结果数据和发布”页面上查看它:
您可以单击一条数据以检查其是否正常(通常验证图片或修改数据)
结果数据正确后,您可以发布:发布到WordPress教程
发布结果:
文章最终发行版(此处是优采云测试站点的发行版)文章链接:
微信公众号文章 采集已发布。 查看全部
【优采云数据采集】微信公众号文章的采集,
优采云 Data 采集平台为微信官方帐户文章提供了采集,并且可以轻松地发布到WordPress和其他系统。
一、 优采云微信公众号文章 采集主要功能
1)可以输入官方帐户名称或ID 关键词 采集,并支持输入多个同时捕获的内容;
2)用于映像下载的多种存储方法(优采云存储,阿里云OSS,秦牛),用于解决官方帐户文章中的防盗链问题;
3)强大的数据处理功能(可以在采集之前和采集之后进行处理)
4)简单的配置可以轻松地发布到Wordpress或http界面。
二、微信公众号文章 采集主要步骤1、创建“ 采集微信公众号”任务
登录优采云控制台,然后单击采集“微信官方帐户”

2、填写官方帐户名或采集或关键词的ID
填写基本信息,如下所示:

填写任务名称和上述采集的微信官方帐户的名称或ID,并用逗号分隔。填写后,请点击“保存”。
提醒:系统还提供数据处理,例如删除图片,删除链接,添加版权说明等。如有必要,请进行相应的选择。
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:

您可以选择“临时存储优采云(通过ftp返回到服务器)”或阿里云OSS或奇牛存储,这里我们选择阿里云OSS(数据存储需要用户根据实际情况进行配置,一次配置)可以重复使用。
4、开始采集
图片配置完成后,可以单击“开始采集”以开始采集数据:

5、结果数据处理和发布
启动采集后,数据将继续向下采集向下显示,您可以在“结果数据和发布”页面上查看它:

您可以单击一条数据以检查其是否正常(通常验证图片或修改数据)

结果数据正确后,您可以发布:发布到WordPress教程

发布结果:

文章最终发行版(此处是优采云测试站点的发行版)文章链接:

微信公众号文章 采集已发布。
webstorm+分布式/集群爬虫+监控系统(s3)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-03-19 11:01
文章采集接口-ai产品文章标题、简介、关键词监控,总部的有,直接通过springmvc做自动聚合so方案还有一个方法,
1.前端监控:webstorm+分布式/集群爬虫+监控系统(s
3)2.后端监控:s4+大数据+监控系统(可选)+分布式sso如果有需要,请私信我。
webstorm+分布式/集群爬虫+监控系统(s
3)
单说环境:1.能搞定环境2.学习能力和练习能力
泻药,爬虫的实现主要看你用什么语言了,python,ruby等都可以实现起来。当然目前web服务器的托管在国内有一些问题,很多资源直接分享了,后端可以看大海开放社区的,基本都是原理图和架构图,很清晰很详细,要看技术比较复杂,但是必须要收藏有一个规划,还要认清一个问题就是落地。
大道至简,传统前端爬虫一般就是爬新闻的,如果要玩人工智能,数据产品,
最近很火的直播类。
如果做爬虫技术类的,框架非常多,
现在的主流爬虫框架其实有很多,只要你能掌握几个,
1、hadoopror(ruby,python,
2、postgres;
3、scrapy;
4、elasticsearch;
5、mongodb;
6、springmvc等等很多。 查看全部
webstorm+分布式/集群爬虫+监控系统(s3)
文章采集接口-ai产品文章标题、简介、关键词监控,总部的有,直接通过springmvc做自动聚合so方案还有一个方法,
1.前端监控:webstorm+分布式/集群爬虫+监控系统(s
3)2.后端监控:s4+大数据+监控系统(可选)+分布式sso如果有需要,请私信我。
webstorm+分布式/集群爬虫+监控系统(s
3)
单说环境:1.能搞定环境2.学习能力和练习能力
泻药,爬虫的实现主要看你用什么语言了,python,ruby等都可以实现起来。当然目前web服务器的托管在国内有一些问题,很多资源直接分享了,后端可以看大海开放社区的,基本都是原理图和架构图,很清晰很详细,要看技术比较复杂,但是必须要收藏有一个规划,还要认清一个问题就是落地。
大道至简,传统前端爬虫一般就是爬新闻的,如果要玩人工智能,数据产品,
最近很火的直播类。
如果做爬虫技术类的,框架非常多,
现在的主流爬虫框架其实有很多,只要你能掌握几个,
1、hadoopror(ruby,python,
2、postgres;
3、scrapy;
4、elasticsearch;
5、mongodb;
6、springmvc等等很多。
gitlab.io文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-03-13 08:00
文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦(当然如果想留言留下项目主页也欢迎,私信我哦)今天我们给大家讲讲我们写的一个小程序的代码,功能实现大致已经完成了,有兴趣的童鞋们可以瞅瞅。使用gitlab.io作为托管库,准备一个1.5m的文件夹作为代码管理与存储,开始吧!整个代码总共分为三个模块:gitlab开发中心、代码管理与存储、对话框接口。
下面对整个模块进行解释:1.整个代码主要是由三个文件:第一个fileexplorerfiles.js文件属于gitlab,主要是文件存储、分享、限制、访问控制等。第二个fileexplorerexplorer.js是files.js的插件,主要是用来进行文件流式传输、文件重命名、创建、删除的。第三个fileexplorerexplorer.py是files.js的扩展,主要用来进行文件管理以及传输。
2.fileexplorer的开发主要是通过js文件进行实现,接口逻辑在接口源码中已经有说明,js部分主要实现了文件名、文件属性等基本属性,每个文件的元素都类似于file.parse()这样的api,例如一个字符串串、名字,文件的文件名等,js中还实现了文件权限管理、提取file属性等,以下的模块都是为接口之中的实现。
例如ls就是我们必须要管理文件路径与文件名的,path也是如此,相信关注我们代码的朋友大部分的文件路径都是写不了的。具体关于fileexplorer的部分js部分代码欢迎bibtex大神们pullrequest,为了方便大家阅读,我的github上放了我们需要解释的代码,大家可以先打开代码,过一下代码看看效果哈!gitlabinit-dnamegitlabpush-p''init文件夹的路径以及名字{"c":{"name":"files.js","filename":"'{name}'.js"},"path":{"filename":"project.test.c"}}"]3.fileexplorer属性我们代码中的"filename":"project.test.c"是我们的路径,我们可以设置接口。
设置实现的方法很简单,如下:{"path":"/project.test.c","filename":"test.js"}']4.接口传输接口如上,我们对象上面引入gitlab.io代码之后,gitlab.io的get代码的接口会自动在gitlab服务端进行数据连接,以下的三个部分已经包含了目标接口传输的代码:if(!test)return{parent:{},children:{}},null|test|false|false|false|true|{"host":":8888/","url":""}elsereturn{"host":":8888/","url":""}(false),null|false|false|false|true。 查看全部
gitlab.io文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦
文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦(当然如果想留言留下项目主页也欢迎,私信我哦)今天我们给大家讲讲我们写的一个小程序的代码,功能实现大致已经完成了,有兴趣的童鞋们可以瞅瞅。使用gitlab.io作为托管库,准备一个1.5m的文件夹作为代码管理与存储,开始吧!整个代码总共分为三个模块:gitlab开发中心、代码管理与存储、对话框接口。
下面对整个模块进行解释:1.整个代码主要是由三个文件:第一个fileexplorerfiles.js文件属于gitlab,主要是文件存储、分享、限制、访问控制等。第二个fileexplorerexplorer.js是files.js的插件,主要是用来进行文件流式传输、文件重命名、创建、删除的。第三个fileexplorerexplorer.py是files.js的扩展,主要用来进行文件管理以及传输。
2.fileexplorer的开发主要是通过js文件进行实现,接口逻辑在接口源码中已经有说明,js部分主要实现了文件名、文件属性等基本属性,每个文件的元素都类似于file.parse()这样的api,例如一个字符串串、名字,文件的文件名等,js中还实现了文件权限管理、提取file属性等,以下的模块都是为接口之中的实现。
例如ls就是我们必须要管理文件路径与文件名的,path也是如此,相信关注我们代码的朋友大部分的文件路径都是写不了的。具体关于fileexplorer的部分js部分代码欢迎bibtex大神们pullrequest,为了方便大家阅读,我的github上放了我们需要解释的代码,大家可以先打开代码,过一下代码看看效果哈!gitlabinit-dnamegitlabpush-p''init文件夹的路径以及名字{"c":{"name":"files.js","filename":"'{name}'.js"},"path":{"filename":"project.test.c"}}"]3.fileexplorer属性我们代码中的"filename":"project.test.c"是我们的路径,我们可以设置接口。
设置实现的方法很简单,如下:{"path":"/project.test.c","filename":"test.js"}']4.接口传输接口如上,我们对象上面引入gitlab.io代码之后,gitlab.io的get代码的接口会自动在gitlab服务端进行数据连接,以下的三个部分已经包含了目标接口传输的代码:if(!test)return{parent:{},children:{}},null|test|false|false|false|true|{"host":":8888/","url":""}elsereturn{"host":":8888/","url":""}(false),null|false|false|false|true。
我是如何安装python第三方库和数据处理工具的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-02-21 12:01
文章采集接口自动获取无数据,
把爬虫软件卸载掉,改用python3重新编写爬虫程序,目录写新的爬虫文件夹,数据放在下面:/scrapy/spiders/scrapy.cfg/scrapy.log/scrapy2/urlseter.log重启,用requests请求获取下载你需要的数据,然后将爬虫文件在本地运行一下你需要的接口,清空浏览器缓存即可。
1.如果想自己构建django爬虫,这里推荐几个方便自己入门的资料给你:我是如何安装python第三方库和数据处理工具的?-midea的回答-知乎2.关于爬虫从采集站点采集数据,这里有一篇文章是详细介绍如何构建自己的爬虫:不负责采集数据|不负责爬虫一个requests+beautifulsoup+threadpool+flask+selenium爬取爬虫1.可以从github下载整个爬虫服务,自己搭建(或者找万能的度娘)2.可以自己搭建,但是建议还是用gitclone啦,官方也有免费的版本3.cmd命令行部分参见:python爬虫的执行部分再次提醒:爬虫由于安全问题和网站后期不可预测问题(比如内容泄露),使用时还是最好万事小心咯。 查看全部
我是如何安装python第三方库和数据处理工具的?
文章采集接口自动获取无数据,
把爬虫软件卸载掉,改用python3重新编写爬虫程序,目录写新的爬虫文件夹,数据放在下面:/scrapy/spiders/scrapy.cfg/scrapy.log/scrapy2/urlseter.log重启,用requests请求获取下载你需要的数据,然后将爬虫文件在本地运行一下你需要的接口,清空浏览器缓存即可。
1.如果想自己构建django爬虫,这里推荐几个方便自己入门的资料给你:我是如何安装python第三方库和数据处理工具的?-midea的回答-知乎2.关于爬虫从采集站点采集数据,这里有一篇文章是详细介绍如何构建自己的爬虫:不负责采集数据|不负责爬虫一个requests+beautifulsoup+threadpool+flask+selenium爬取爬虫1.可以从github下载整个爬虫服务,自己搭建(或者找万能的度娘)2.可以自己搭建,但是建议还是用gitclone啦,官方也有免费的版本3.cmd命令行部分参见:python爬虫的执行部分再次提醒:爬虫由于安全问题和网站后期不可预测问题(比如内容泄露),使用时还是最好万事小心咯。
微信公众号上发送的图文消息,可以采用哪些接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-02-17 11:01
文章采集接口一般是通过微信系统实现,你可以看下个人用的是哪些平台:,后台的数据由该个人去维护;从你提供的图片上看你需要的接口是比较简单的,是一些网页上的内容,这种接口需要去从互联网上爬取,你可以看下有没有这种接口;你也可以在微信系统上去接,
一般都是通过第三方平台配置,即可开发,你提供一些数据即可,
最近一直在研究微信接口,简单给大家说下微信公众号上发送的图文消息,可以采用哪些接口,1.豆瓣目前微信认证号可以申请开放平台中的图文消息接口,可以简单通过图文链接就可以将图文内容上传到微信公众号页面,然后群发。2.at&at目前国内做ai技术的不多,也可以根据公众号推文发布的热点来匹配公众号页面的展示,然后根据具体内容匹配对应的发送通道。
3.网页应用市场一些市场本身就支持接入接口,比如我知道apowersoft的微信系统宝是可以接入,也可以去上买不收钱的模拟器(100块钱一个月),然后就可以用刷号软件去群发自定义图文了,想要的客户直接把订单号发给客服问这个群发接口就行。4.做网站,是可以将上面四个接口集成,但是前提是需要域名,因为服务器用的是外国ip,每年2000左右。
其他的一些网站上配置微信公众号的接口,比如麦开的公众号接口平台,就有不少接口。还有一些网站比如易科(开发微信客户端),阿里云计算平台等,也有模拟器。但是需要付费,功能也有很多,找需要的去试一下。其实微信公众号接口一般都是通过第三方平台,采集站等主流网站上的内容,然后直接拼接到微信公众号上发送。还有些广告站、游戏站等,可以通过第三方来接入微信图文。
对我来说一般都是是找第三方,不同平台价格不同,不过最后其实就是这个网站相应的图文或者第三方提供的。正常来说,比如我搜大概100来块钱可以获取,但是肯定是多个平台群发或者多个网站同时推。一般来说如果能够获取多个图文并且在不同平台和广告站群发,每个平台可以做到1分钟的接口并发连发。前面说了第三方的问题,基本微信公众号上都是通过平台来接,第三方有哪些,阿里云阿里云联盟网站(这个是针对微信认证的企业用户)或者aliyun公众号联盟(这个是针对公众号申请开通广告接口或者第三方接入后推送给公众号上的网站或者app的,目前要1000多,公众号都可以做到)等,你还需要了解一下第三方对图文的相关格式要求,做发送规则什么的。 查看全部
微信公众号上发送的图文消息,可以采用哪些接口
文章采集接口一般是通过微信系统实现,你可以看下个人用的是哪些平台:,后台的数据由该个人去维护;从你提供的图片上看你需要的接口是比较简单的,是一些网页上的内容,这种接口需要去从互联网上爬取,你可以看下有没有这种接口;你也可以在微信系统上去接,
一般都是通过第三方平台配置,即可开发,你提供一些数据即可,
最近一直在研究微信接口,简单给大家说下微信公众号上发送的图文消息,可以采用哪些接口,1.豆瓣目前微信认证号可以申请开放平台中的图文消息接口,可以简单通过图文链接就可以将图文内容上传到微信公众号页面,然后群发。2.at&at目前国内做ai技术的不多,也可以根据公众号推文发布的热点来匹配公众号页面的展示,然后根据具体内容匹配对应的发送通道。
3.网页应用市场一些市场本身就支持接入接口,比如我知道apowersoft的微信系统宝是可以接入,也可以去上买不收钱的模拟器(100块钱一个月),然后就可以用刷号软件去群发自定义图文了,想要的客户直接把订单号发给客服问这个群发接口就行。4.做网站,是可以将上面四个接口集成,但是前提是需要域名,因为服务器用的是外国ip,每年2000左右。
其他的一些网站上配置微信公众号的接口,比如麦开的公众号接口平台,就有不少接口。还有一些网站比如易科(开发微信客户端),阿里云计算平台等,也有模拟器。但是需要付费,功能也有很多,找需要的去试一下。其实微信公众号接口一般都是通过第三方平台,采集站等主流网站上的内容,然后直接拼接到微信公众号上发送。还有些广告站、游戏站等,可以通过第三方来接入微信图文。
对我来说一般都是是找第三方,不同平台价格不同,不过最后其实就是这个网站相应的图文或者第三方提供的。正常来说,比如我搜大概100来块钱可以获取,但是肯定是多个平台群发或者多个网站同时推。一般来说如果能够获取多个图文并且在不同平台和广告站群发,每个平台可以做到1分钟的接口并发连发。前面说了第三方的问题,基本微信公众号上都是通过平台来接,第三方有哪些,阿里云阿里云联盟网站(这个是针对微信认证的企业用户)或者aliyun公众号联盟(这个是针对公众号申请开通广告接口或者第三方接入后推送给公众号上的网站或者app的,目前要1000多,公众号都可以做到)等,你还需要了解一下第三方对图文的相关格式要求,做发送规则什么的。
完整的解决方案:爬虫 | 如何构建技术文章聚合平台(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2020-11-30 12:14
作者|张家辉
来源|掘金
上一篇文章文章介绍了如何构建Crawlab的操作环境,以及如何将Puppeteer与Crawlab集成,以捕获Nuggets,SegmentFault和CSDN技术文章,最后您可以查看捕获结果。本文文章将继续说明如何使用Flask + Vue编写简化的聚合平台并显示文章的捕获内容。
文章内容抓取工具
首先,我们需要对采集器部分进行一些补充。在上一篇文章文章中,我们只编写了对文章 URL进行爬网的采集器,我们还需要对文章的内容进行爬网,因此我们需要编写该采集器的这一部分。最后一个采集器的结果集合全部更改为结果,文章的内容将作为内容字段保存在数据库中。
经过分析,发现每种技术网站的文章页面都有固定的标签,可以捕获该标签下的所有HTML。特定代码分析将不会开始,并且特定代码将发布在此处。
<p>const puppeteer = require('puppeteer');
const MongoClient = require('mongodb').MongoClient;
<br />
(async () => {
// browser
const browser = await (puppeteer.launch({
headless: true
}));
<br />
// page
const page = await browser.newPage();
<br />
// open database connection
const client = await MongoClient.connect('mongodb://192.168.99.100:27017');
let db = await client.db('crawlab_test');
const colName = process.env.CRAWLAB_COLLECTION || 'results';
const col = db.collection(colName);
const col_src = db.collection('results');
<br />
const results = await col_src.find({content: {$exists: false}}).toArray();
for (let i = 0; i el.innerHTML);
<br />
// save to database
await col.save(item);
console.log(`saved item: ${JSON.stringify(item)}`)
}
<br />
// close mongodb
client.close();
<br />
// close browser
browser.close();
<br />
})();</p>
然后按照上一篇文章文章中的步骤部署和运行采集器,您可以采集进入文章详细内容。
文章内容采集器的代码已更新为Github。
接下来,我们可以开始对这些文章进行操作。
前端和后端分离
从当前技术发展的角度来看,前端和后端分离已经成为主流:首先,前端技术变得越来越复杂,需要模块化和工程设计;其次,前端和后端分离使前端和后端团队可以协作并更有效地开发应用程序。由于本文的聚合平台是轻量级应用程序,因此我们将Python的轻量级Web应用程序框架Flask用于后端接口和前端Vue,这在最近几年变得很流行。
烧瓶
Flask被称为Micro Framework,它显示出轻量级的特性,几行代码可以编写一个Web应用程序。它依靠扩展来扩展其特定功能,例如登录身份验证,RESTful,数据模型等。在本节中,我们将构建一个REST风格的后台API应用程序。
安装
首先安装相关的依赖项。
<p>pip install flask flask_restful flask_cors pymongo</p>
基本应用
安装完成后,我们可以创建一个新的app.py文件,输入以下代码
<p>from flask import Flask
from flask_cors import CORS
from flask_restful import Api
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
if __name__ == '__main__':
app.run()</p>
在命令行中输入python app.py以运行此基本的Flask应用程序。
编写API
接下来,我们需要编写一个接口来获取文章。首先,我们简要分析需求。
此Flask应用程序要实现的功能是:
从数据库中获取提取的文章,然后将文章 ID,标题,摘要和获取时间返回到前端,以用作文章列表;
对于给定的文章 ID,请将相应的文章内容从数据库返回到前端,以在详细信息页面中使用。
因此,我们需要实现以上两个API。让我们开始编写界面。
列表界面
在app.py中添加以下代码作为列表接口。
<p>class ListApi(Resource):
def get(self):
# 查询
items = col.find({'content': {'$exists': True}}).sort('_id', DESCENDING).limit(40)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data</p>
详细的界面
类似地,在app.py中输入以下代码。
<p>class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}</p>
映射界面
编写接口后,我们需要将它们映射到URL。
<p>api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')</p>
完整代码
以下是完整的Flask应用程序代码,该代码非常简单,并实现了文章列表和文章详细信息的两个功能。接下来,我们将开始开发前端部分。
<p>import json
<br />
from bson import json_util, ObjectId
from flask import Flask, jsonify
from flask_cors import CORS
from flask_restful import Api, Resource
from pymongo import MongoClient, DESCENDING
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成MongoDB实例
mongo = MongoClient(host='192.168.99.100')
db = mongo['crawlab_test']
col = db['results']
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
<br />
class ListApi(Resource):
def get(self):
# 查询
items = col.find({}).sort('_id', DESCENDING).limit(20)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data
<br />
<br />
class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}
<br />
<br />
api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')
<br />
if __name__ == '__main__':
app.run()</p>
运行python app.py以运行后台界面服务器。
Vue
Vue近年来很热门。它已经超过了Github上的React,并已成为三个开源框架(React,Vue,Angular)中明星最多的项目。与React和Angular相比,Vue非常易于使用。它不仅可以双向绑定数据以快速开始构建简单的应用程序,而且还可以使用Vuex单向数据传输来构建大型应用程序。这种灵活性是它在大多数开发人员中受欢迎的原因之一。
为了构建一个简单的Vue应用程序,我们将使用vue-cli3,这是一个vue项目的支架。首先,我们从npm安装脚手架。
安装vue-cli3
<p>yarn add @vue/cli</p>
如果尚未安装yarn,请执行以下命令进行安装。
<p>npm i -g yarn</p>
创建项目
接下来,我们需要使用vue-cli3构建一个项目。执行以下命令。
<p>vue create frontend</p>
以下选项将在命令行上弹出,选择默认值。
<p>? Please pick a preset: (Use arrow keys)
❯ default (babel, eslint)
preset (vue-router, vuex, node-sass, babel, eslint, unit-jest)
Manually select features </p>
然后vue-cli3将开始准备用于构建项目并生成项目结构的必要依赖项。
此外,我们还需要安装完成其他功能所需的软件包。
<p>yarn add axios</p>
文章列表页面
在views目录中创建List.vue文件,并写入以下内容。
<p> {{article.title}}
</a>
{{article.ts}}
<br />
import axios from 'axios'
<br />
export default {
name: 'List',
data () {
return {
list: []
}
},
methods: {
showArticle (id) {
this.$router.push(`/${id}`)
}
},
created () {
axios.get('http://localhost:5000/results')
.then(response => {
this.list = response.data
})
}
}
<br />
.list {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.article-list {
text-align: left;
list-style: none;
}
<br />
.article-item {
background: #c3edfb;
border-radius: 5px;
padding: 5px;
height: 32px;
display: flex;
align-items: center;
justify-content: space-between;
margin-bottom: 10px;
}
<br />
.title {
flex-basis: auto;
color: #58769d;
}
<br />
.time {
font-size: 10px;
text-align: right;
flex-basis: 180px;
}</p>
其中,引用axios与ajax的API进行交互,这是列表接口。该布局用于经典的双圣杯布局。方法中的showArticle方法接收id参数并将页面跳转到详细信息页面。
文章详细信息页面
在views目录中,创建Detail.vue文件并输入以下内容。
<p> {{article.title}}
<br />
import axios from 'axios'
<br />
export default {
name: 'Detail',
data () {
return {
article: {}
}
},
computed: {
id () {
return this.$route.params.id
}
},
created () {
axios.get(`http://localhost:5000/results/${this.id}`)
.then(response => {
this.article = response.data
})
}
}
<br />
.detail {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.center {
flex-basis: 60%;
text-align: left;
}
<br />
.title {
<br />
}</p>
此页面还是经典的双圣杯布局,中间占40%。通过API获得的文章的内容输出到由v-html绑定的内容。实际上,可以在此处进行进一步的CSS优化,但是作者太懒了,所以让读者来完成此任务。
添加路线
编辑router.js文件并将其修改为以下内容。
<p>import Vue from 'vue'
import Router from 'vue-router'
import List from './views/List'
import Detail from './views/Detail'
<br />
Vue.use(Router)
<br />
export default new Router({
mode: 'hash',
base: process.env.BASE_URL,
routes: [
{
path: '/',
name: 'List',
component: List
},
{
path: '/:id',
name: 'Detail',
component: Detail
}
]
})</p>
运行前端
在命令行中输入以下命令,打开:8080,您会看到文章列表。
<p>npm run serve</p>
最终效果
最终聚合平台效果的屏幕截图如下,您可以看到基本样式已经出来。
摘要
基于上一篇文章文章“教您如何使用Crawlab构建技术文章聚合平台(一)”),本文介绍了如何使用Flask + Vue和先前捕获的文章数据构建一个简单的技术文章聚合平台。使用的技术非常基础。当然,必须有很大的优化和改进空间。我将其留给读者和所有人。 查看全部
履带|如何构建技术文章聚合平台(二)
作者|张家辉
来源|掘金
上一篇文章文章介绍了如何构建Crawlab的操作环境,以及如何将Puppeteer与Crawlab集成,以捕获Nuggets,SegmentFault和CSDN技术文章,最后您可以查看捕获结果。本文文章将继续说明如何使用Flask + Vue编写简化的聚合平台并显示文章的捕获内容。
文章内容抓取工具
首先,我们需要对采集器部分进行一些补充。在上一篇文章文章中,我们只编写了对文章 URL进行爬网的采集器,我们还需要对文章的内容进行爬网,因此我们需要编写该采集器的这一部分。最后一个采集器的结果集合全部更改为结果,文章的内容将作为内容字段保存在数据库中。
经过分析,发现每种技术网站的文章页面都有固定的标签,可以捕获该标签下的所有HTML。特定代码分析将不会开始,并且特定代码将发布在此处。
<p>const puppeteer = require('puppeteer');
const MongoClient = require('mongodb').MongoClient;
<br />
(async () => {
// browser
const browser = await (puppeteer.launch({
headless: true
}));
<br />
// page
const page = await browser.newPage();
<br />
// open database connection
const client = await MongoClient.connect('mongodb://192.168.99.100:27017');
let db = await client.db('crawlab_test');
const colName = process.env.CRAWLAB_COLLECTION || 'results';
const col = db.collection(colName);
const col_src = db.collection('results');
<br />
const results = await col_src.find({content: {$exists: false}}).toArray();
for (let i = 0; i el.innerHTML);
<br />
// save to database
await col.save(item);
console.log(`saved item: ${JSON.stringify(item)}`)
}
<br />
// close mongodb
client.close();
<br />
// close browser
browser.close();
<br />
})();</p>
然后按照上一篇文章文章中的步骤部署和运行采集器,您可以采集进入文章详细内容。
文章内容采集器的代码已更新为Github。
接下来,我们可以开始对这些文章进行操作。
前端和后端分离
从当前技术发展的角度来看,前端和后端分离已经成为主流:首先,前端技术变得越来越复杂,需要模块化和工程设计;其次,前端和后端分离使前端和后端团队可以协作并更有效地开发应用程序。由于本文的聚合平台是轻量级应用程序,因此我们将Python的轻量级Web应用程序框架Flask用于后端接口和前端Vue,这在最近几年变得很流行。
烧瓶
Flask被称为Micro Framework,它显示出轻量级的特性,几行代码可以编写一个Web应用程序。它依靠扩展来扩展其特定功能,例如登录身份验证,RESTful,数据模型等。在本节中,我们将构建一个REST风格的后台API应用程序。
安装
首先安装相关的依赖项。
<p>pip install flask flask_restful flask_cors pymongo</p>
基本应用
安装完成后,我们可以创建一个新的app.py文件,输入以下代码
<p>from flask import Flask
from flask_cors import CORS
from flask_restful import Api
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
if __name__ == '__main__':
app.run()</p>
在命令行中输入python app.py以运行此基本的Flask应用程序。
编写API
接下来,我们需要编写一个接口来获取文章。首先,我们简要分析需求。
此Flask应用程序要实现的功能是:
从数据库中获取提取的文章,然后将文章 ID,标题,摘要和获取时间返回到前端,以用作文章列表;
对于给定的文章 ID,请将相应的文章内容从数据库返回到前端,以在详细信息页面中使用。
因此,我们需要实现以上两个API。让我们开始编写界面。
列表界面
在app.py中添加以下代码作为列表接口。
<p>class ListApi(Resource):
def get(self):
# 查询
items = col.find({'content': {'$exists': True}}).sort('_id', DESCENDING).limit(40)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data</p>
详细的界面
类似地,在app.py中输入以下代码。
<p>class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}</p>
映射界面
编写接口后,我们需要将它们映射到URL。
<p>api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')</p>
完整代码
以下是完整的Flask应用程序代码,该代码非常简单,并实现了文章列表和文章详细信息的两个功能。接下来,我们将开始开发前端部分。
<p>import json
<br />
from bson import json_util, ObjectId
from flask import Flask, jsonify
from flask_cors import CORS
from flask_restful import Api, Resource
from pymongo import MongoClient, DESCENDING
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成MongoDB实例
mongo = MongoClient(host='192.168.99.100')
db = mongo['crawlab_test']
col = db['results']
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
<br />
class ListApi(Resource):
def get(self):
# 查询
items = col.find({}).sort('_id', DESCENDING).limit(20)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data
<br />
<br />
class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}
<br />
<br />
api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')
<br />
if __name__ == '__main__':
app.run()</p>
运行python app.py以运行后台界面服务器。
Vue
Vue近年来很热门。它已经超过了Github上的React,并已成为三个开源框架(React,Vue,Angular)中明星最多的项目。与React和Angular相比,Vue非常易于使用。它不仅可以双向绑定数据以快速开始构建简单的应用程序,而且还可以使用Vuex单向数据传输来构建大型应用程序。这种灵活性是它在大多数开发人员中受欢迎的原因之一。
为了构建一个简单的Vue应用程序,我们将使用vue-cli3,这是一个vue项目的支架。首先,我们从npm安装脚手架。
安装vue-cli3
<p>yarn add @vue/cli</p>
如果尚未安装yarn,请执行以下命令进行安装。
<p>npm i -g yarn</p>
创建项目
接下来,我们需要使用vue-cli3构建一个项目。执行以下命令。
<p>vue create frontend</p>
以下选项将在命令行上弹出,选择默认值。
<p>? Please pick a preset: (Use arrow keys)
❯ default (babel, eslint)
preset (vue-router, vuex, node-sass, babel, eslint, unit-jest)
Manually select features </p>
然后vue-cli3将开始准备用于构建项目并生成项目结构的必要依赖项。
此外,我们还需要安装完成其他功能所需的软件包。
<p>yarn add axios</p>
文章列表页面
在views目录中创建List.vue文件,并写入以下内容。
<p> {{article.title}}
</a>
{{article.ts}}
<br />
import axios from 'axios'
<br />
export default {
name: 'List',
data () {
return {
list: []
}
},
methods: {
showArticle (id) {
this.$router.push(`/${id}`)
}
},
created () {
axios.get('http://localhost:5000/results')
.then(response => {
this.list = response.data
})
}
}
<br />
.list {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.article-list {
text-align: left;
list-style: none;
}
<br />
.article-item {
background: #c3edfb;
border-radius: 5px;
padding: 5px;
height: 32px;
display: flex;
align-items: center;
justify-content: space-between;
margin-bottom: 10px;
}
<br />
.title {
flex-basis: auto;
color: #58769d;
}
<br />
.time {
font-size: 10px;
text-align: right;
flex-basis: 180px;
}</p>
其中,引用axios与ajax的API进行交互,这是列表接口。该布局用于经典的双圣杯布局。方法中的showArticle方法接收id参数并将页面跳转到详细信息页面。
文章详细信息页面
在views目录中,创建Detail.vue文件并输入以下内容。
<p> {{article.title}}
<br />
import axios from 'axios'
<br />
export default {
name: 'Detail',
data () {
return {
article: {}
}
},
computed: {
id () {
return this.$route.params.id
}
},
created () {
axios.get(`http://localhost:5000/results/${this.id}`)
.then(response => {
this.article = response.data
})
}
}
<br />
.detail {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.center {
flex-basis: 60%;
text-align: left;
}
<br />
.title {
<br />
}</p>
此页面还是经典的双圣杯布局,中间占40%。通过API获得的文章的内容输出到由v-html绑定的内容。实际上,可以在此处进行进一步的CSS优化,但是作者太懒了,所以让读者来完成此任务。
添加路线
编辑router.js文件并将其修改为以下内容。
<p>import Vue from 'vue'
import Router from 'vue-router'
import List from './views/List'
import Detail from './views/Detail'
<br />
Vue.use(Router)
<br />
export default new Router({
mode: 'hash',
base: process.env.BASE_URL,
routes: [
{
path: '/',
name: 'List',
component: List
},
{
path: '/:id',
name: 'Detail',
component: Detail
}
]
})</p>
运行前端
在命令行中输入以下命令,打开:8080,您会看到文章列表。
<p>npm run serve</p>
最终效果
最终聚合平台效果的屏幕截图如下,您可以看到基本样式已经出来。
摘要
基于上一篇文章文章“教您如何使用Crawlab构建技术文章聚合平台(一)”),本文介绍了如何使用Flask + Vue和先前捕获的文章数据构建一个简单的技术文章聚合平台。使用的技术非常基础。当然,必须有很大的优化和改进空间。我将其留给读者和所有人。
整体解决方案:数据采集服务|优采云免登陆采集接口[DT采集专家]
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-31 12:37
注释1: 以上是上面列出的主要功能. 更多功能未一一列出,但会不断更新. 如果您要添加任何好的功能,则可以对其进行自定义. 更新适合所有人的内容.
√=支持;
×=不支持;
注2: 开放源代码版本只是优采云,用于发布模块开放源代码,而发布界面不是开放源代码. 如果您需要完全开源的版本,请与我们联系以进行自定义或购买(如果您发现转售或放弃其他人的发布模块,则将停止所有售后服务. )
注3: “ /”代表多个版本分隔符
注4: 为了防止破解和盗版,采集接口和模块都经过了加密(完全开源版本除外),请不要介意购买.
备注①: 以下条件不在服务范围内
1. 自我修改或使用非原创的destcoon程序代码引起的问题(请提前告知您是否已进行了两次开发或修改了默认模块)
2. 自己直接对数据库进行操作会导致数据库错误或崩溃;
3. 非官方模块/插件的安装以及由于模块/插件的安装而导致的故障;
4. 服务器和虚拟主机环境导致的系统故障;
5. 二次开发或定制以及其他可能导致问题的情况.
6,例如阻止采集的目标网站,或自己的技术问题导致采集失败.
7. 授权域名有机会在授权后1个月内更改域名. 更改前后的域名所有者必须相同,然后每次更改费用为人民币150元.
8. 为了确保用户安全,在将授权软件发送给用户后,我们将及时删除本地计算机上的授权软件. 如果用户丢失或损坏了授权文件,请要求我们以150元/次的价格重新打包授权文件
备注②: 在以下情况下不允许退款
1. 我们出售采集接口,并且所有规则都已交付. 如果目标网站无法捕获,我们将尽快修复规则. 如果无法固定,目标站将阻止采集. 与我们的界面无关.
2,例如网站阻止采集的目标,或自身的技术问题导致采集失败.
3. 由于个人技术水平的原因,我们将不使用我们的软件(我们可以远程指导客户设置默认规则).
4,自我修改或使用非原创的destcoon代码(开发了两次)导致采集失败.
5: 源代码和规则是可复制的产品,收到后将不予退款. 查看全部
数据采集服务|优采云免费登录采集界面[DT采集专家]
注释1: 以上是上面列出的主要功能. 更多功能未一一列出,但会不断更新. 如果您要添加任何好的功能,则可以对其进行自定义. 更新适合所有人的内容.
√=支持;
×=不支持;
注2: 开放源代码版本只是优采云,用于发布模块开放源代码,而发布界面不是开放源代码. 如果您需要完全开源的版本,请与我们联系以进行自定义或购买(如果您发现转售或放弃其他人的发布模块,则将停止所有售后服务. )
注3: “ /”代表多个版本分隔符
注4: 为了防止破解和盗版,采集接口和模块都经过了加密(完全开源版本除外),请不要介意购买.
备注①: 以下条件不在服务范围内
1. 自我修改或使用非原创的destcoon程序代码引起的问题(请提前告知您是否已进行了两次开发或修改了默认模块)
2. 自己直接对数据库进行操作会导致数据库错误或崩溃;
3. 非官方模块/插件的安装以及由于模块/插件的安装而导致的故障;
4. 服务器和虚拟主机环境导致的系统故障;
5. 二次开发或定制以及其他可能导致问题的情况.
6,例如阻止采集的目标网站,或自己的技术问题导致采集失败.
7. 授权域名有机会在授权后1个月内更改域名. 更改前后的域名所有者必须相同,然后每次更改费用为人民币150元.
8. 为了确保用户安全,在将授权软件发送给用户后,我们将及时删除本地计算机上的授权软件. 如果用户丢失或损坏了授权文件,请要求我们以150元/次的价格重新打包授权文件
备注②: 在以下情况下不允许退款
1. 我们出售采集接口,并且所有规则都已交付. 如果目标网站无法捕获,我们将尽快修复规则. 如果无法固定,目标站将阻止采集. 与我们的界面无关.
2,例如网站阻止采集的目标,或自身的技术问题导致采集失败.
3. 由于个人技术水平的原因,我们将不使用我们的软件(我们可以远程指导客户设置默认规则).
4,自我修改或使用非原创的destcoon代码(开发了两次)导致采集失败.
5: 源代码和规则是可复制的产品,收到后将不予退款.
Dedecms5.7sp1文章模型栏目插口使用指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2020-08-28 12:20
Dedecms5.7 sp1文章模型栏目插口使用指南
一、简介
1、本插口应用于Dedecms5.7 SP1(20120621)版普通文章模型栏目文章发布;
2、由于数据量大时DEDE生成栏目HTML时的服务器负担太重,因此,发布插口增设了2个控制参数zznomakeindex和zznomakeandcat,分别控制是否生成主页或相关栏目; 3、发布时请使用具有管理权限的用户账号;
4、本插口基于Dedecms UTF8版制做,适用于Dedecms GBK/utf-8等版本,应用于其他版本时请自行测试调整;
5、在Dedecms utf8版使用本插口时,请在发布规则中选择编码为UTF-8;
6、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
7、2个插口文件请复制在Dedecms网站管理目录(默认是dede,用户可能有修改)下使用;
二、安装插口 在插口文件夹中找到插口文件,如图:
请将etchk.php、etpost.php等插口文件复制到指定目录,远程FTP上传请使用二进制形式上传,如图:
三、配置发布规则 1、将范例发布规则文本导出ET2发布配置,或使用软件外置发布规则范例,如图:
2、将检测网址和发布网址中的“您的网站”改为您要发布的网站网址,如图:
3、在检测网址填上您的栏目ID,如图:
4、在参数取值,填上您要发布的栏目ID,如图:
在网站后台网站栏目管理处,可以见到各栏目的ID号,如图:
4、填上您的帐号、密码,注意格式和帐号权限,如图:
四、接口说明
一、检查插口
1、接口文件名etchk.php,为保密,请自行更改文件名;
2、本插口文件复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应; 3、主要参数
(以下参数附加在检测网址后) 主题标题:keyword
栏目ID :typeid 用于限定检测栏目范围,可不填,可在后台网站栏目管理处查看id;
校验码 :vercode 请自行设定,并在检测插口文件开始处更改vercode让其一致;
4、发布配置-文章检查网址处,可以如下填写:
您的网址/dede/etchk.php?vercode=&typeid=&keyword= 注:使用大小写敏感的服务器的用户请注意网址大小写和网站文件一致
5、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
二、发布插口
1、接口文件名etpost.php,为保密,请自行更改文件名;
2、本插口文件请复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应;
注:以下参数名后“=”号为示范取值而用,参数名本身不含“=”号; 采集取值的参数项,请在发布规则-发布项中添加,如图:
3、基本参数
userid
会员名参数名 pwd
密码参数名 title
主题标题参数名
body
内容参数名
4、主要参数
typeid=主栏目ID,可在后台网站栏目管理处查看该id;
typeid2=副栏目ID,可不填,可在后台网站栏目管理处查看该id,多个请用英语冒号分隔,如typeid2=3,7,11 ;
channelid=模型ID,默认为1,如果文章模型ID不为1,则用这个参数设置;
vercode=安全校验码,请自行设定,并在发布插口文件开始处更改vercode让其一致;
zznomakeindex=0 主页生成控制,取值0时,使用DEDE后台“发布文章后马上更新网站主页”的设置,取值1时,禁止生成网站主页;
zznomakeandcat=0 栏目生成控制,取值0时,使用DEDE后台“发表文章后马上更新相关栏目”的设置,取值1时,禁止生成相关栏目;
注:系统-基本参数-性能选项“arclist标签调用缓存”会影响静态页面生成情况,设为0可解决;
5、可选参数
ishtml=1是否生成HTML,1为是,0为否;
remote=1是否下载远程图片和资源,1为是,0为否,启用本项则在优采云采集器规则中不启用文件下载;
dellink=0是否删掉非站内链接,1为是,0或空为否;
autolitpic=1 是否提取第一个图片为缩略图,1为是,0为否,启用本项则picname应留空;
picname=缩略图片路径及文件名;
ddisremote=0 是否远程获取缩略图片,1为是,0为否,启用本项必须让PICNAME的值为有效图片网址; keywords关键字;
autokey=1 手动获取关键字,1为是,0为否;部分PHP版本过高造成DEDE的splitword类无效时,仍可使用插口,遇到这些情况时,参数autokey应设为0,以取消手动关键词功能;
needwatermark=0 图片是否加水印,1为是,0为否,启用本项则在ET中间规则中不应设置图片水印; 查看全部
Dedecms5.7sp1文章模型栏目插口使用指南
Dedecms5.7 sp1文章模型栏目插口使用指南
一、简介
1、本插口应用于Dedecms5.7 SP1(20120621)版普通文章模型栏目文章发布;
2、由于数据量大时DEDE生成栏目HTML时的服务器负担太重,因此,发布插口增设了2个控制参数zznomakeindex和zznomakeandcat,分别控制是否生成主页或相关栏目; 3、发布时请使用具有管理权限的用户账号;
4、本插口基于Dedecms UTF8版制做,适用于Dedecms GBK/utf-8等版本,应用于其他版本时请自行测试调整;
5、在Dedecms utf8版使用本插口时,请在发布规则中选择编码为UTF-8;
6、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
7、2个插口文件请复制在Dedecms网站管理目录(默认是dede,用户可能有修改)下使用;
二、安装插口 在插口文件夹中找到插口文件,如图:
请将etchk.php、etpost.php等插口文件复制到指定目录,远程FTP上传请使用二进制形式上传,如图:
三、配置发布规则 1、将范例发布规则文本导出ET2发布配置,或使用软件外置发布规则范例,如图:
2、将检测网址和发布网址中的“您的网站”改为您要发布的网站网址,如图:
3、在检测网址填上您的栏目ID,如图:
4、在参数取值,填上您要发布的栏目ID,如图:
在网站后台网站栏目管理处,可以见到各栏目的ID号,如图:
4、填上您的帐号、密码,注意格式和帐号权限,如图:
四、接口说明
一、检查插口
1、接口文件名etchk.php,为保密,请自行更改文件名;
2、本插口文件复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应; 3、主要参数
(以下参数附加在检测网址后) 主题标题:keyword
栏目ID :typeid 用于限定检测栏目范围,可不填,可在后台网站栏目管理处查看id;
校验码 :vercode 请自行设定,并在检测插口文件开始处更改vercode让其一致;
4、发布配置-文章检查网址处,可以如下填写:
您的网址/dede/etchk.php?vercode=&typeid=&keyword= 注:使用大小写敏感的服务器的用户请注意网址大小写和网站文件一致
5、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
二、发布插口
1、接口文件名etpost.php,为保密,请自行更改文件名;
2、本插口文件请复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应;
注:以下参数名后“=”号为示范取值而用,参数名本身不含“=”号; 采集取值的参数项,请在发布规则-发布项中添加,如图:
3、基本参数
userid
会员名参数名 pwd
密码参数名 title
主题标题参数名
body
内容参数名
4、主要参数
typeid=主栏目ID,可在后台网站栏目管理处查看该id;
typeid2=副栏目ID,可不填,可在后台网站栏目管理处查看该id,多个请用英语冒号分隔,如typeid2=3,7,11 ;
channelid=模型ID,默认为1,如果文章模型ID不为1,则用这个参数设置;
vercode=安全校验码,请自行设定,并在发布插口文件开始处更改vercode让其一致;
zznomakeindex=0 主页生成控制,取值0时,使用DEDE后台“发布文章后马上更新网站主页”的设置,取值1时,禁止生成网站主页;
zznomakeandcat=0 栏目生成控制,取值0时,使用DEDE后台“发表文章后马上更新相关栏目”的设置,取值1时,禁止生成相关栏目;
注:系统-基本参数-性能选项“arclist标签调用缓存”会影响静态页面生成情况,设为0可解决;
5、可选参数
ishtml=1是否生成HTML,1为是,0为否;
remote=1是否下载远程图片和资源,1为是,0为否,启用本项则在优采云采集器规则中不启用文件下载;
dellink=0是否删掉非站内链接,1为是,0或空为否;
autolitpic=1 是否提取第一个图片为缩略图,1为是,0为否,启用本项则picname应留空;
picname=缩略图片路径及文件名;
ddisremote=0 是否远程获取缩略图片,1为是,0为否,启用本项必须让PICNAME的值为有效图片网址; keywords关键字;
autokey=1 手动获取关键字,1为是,0为否;部分PHP版本过高造成DEDE的splitword类无效时,仍可使用插口,遇到这些情况时,参数autokey应设为0,以取消手动关键词功能;
needwatermark=0 图片是否加水印,1为是,0为否,启用本项则在ET中间规则中不应设置图片水印;
雨过天晴工作室制作的帝国7.0采集发布发布接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-05-25 23:12
雨过天晴工作室制作的帝国7.0采集发布发布接口
帝国信息优采云发布界面| E cms 7 文章 采集发布界面免费登录|帝国采集
“帝国网站管理系统”的英文翻译为“帝国cms”,简称“ E cms”,它基于B / S结构,安全,强大,稳定,灵活网站 ]管理系统。
该系统由Empire Development Working Group独立开发。这是一个针对Linux / windows / Unix和其他环境的精心设计且高效的网站解决方案。从Empire News System 1.版本0到当今的Empire 网站管理系统,她的功能都经历了多次飞跃,这使得网站的架设和管理变得非常容易!
她采用了系统模型功能:通过该功能,用户可以在后台直接扩展和实现各种系统,例如产品,房地产,供需等。因此,帝国cms的特征也被称为“通用站工具”;采用模板分离功能:内容和界面完全分离,灵活的标签+用户自定义标签,可以实现各种网站页面和样式。列的无限分类;所有的前台都是固定的:紧随其后的是繁忙的交通;强大的信息采集功能;超级广告管理功能...
她的不同版本可以满足从小流量到大流量,从个人到企业的各种应用程序的需求,并为您提供全新,快速和出色的网站解决方案。
由Yuguo Tianqing Studio制作的Empire 7. 0 采集发行界面分为Empire Information 采集界面和Empire 文章发行界面。购买前,请阅读您网站的列模型。购买
此界面是免登录界面,可以上传文件,配置规则和界面,可以立即采集发布,效果非常好!
玉果天晴工作室曾经一口气完成了1300多个皇室规则的编辑,因此您可以放心地这样做
如果您是新手,我可以直接向您发送带有采集规则和发布界面的已配置优采云软件,您也可以直接采集发布
如果您是母版,则只能请求发布接口文件和发布模块,并自行导入和使用它!
需要编写采集规则和优采云 采集发布界面采集规则的朋友可以与我联系!
规则准备:一篇文章10元,发布界面50元!
不成功,不收费
特殊说明: 查看全部
雨过天晴工作室制作的帝国7.0采集发布发布接口
帝国信息优采云发布界面| E cms 7 文章 采集发布界面免费登录|帝国采集
“帝国网站管理系统”的英文翻译为“帝国cms”,简称“ E cms”,它基于B / S结构,安全,强大,稳定,灵活网站 ]管理系统。
该系统由Empire Development Working Group独立开发。这是一个针对Linux / windows / Unix和其他环境的精心设计且高效的网站解决方案。从Empire News System 1.版本0到当今的Empire 网站管理系统,她的功能都经历了多次飞跃,这使得网站的架设和管理变得非常容易!
她采用了系统模型功能:通过该功能,用户可以在后台直接扩展和实现各种系统,例如产品,房地产,供需等。因此,帝国cms的特征也被称为“通用站工具”;采用模板分离功能:内容和界面完全分离,灵活的标签+用户自定义标签,可以实现各种网站页面和样式。列的无限分类;所有的前台都是固定的:紧随其后的是繁忙的交通;强大的信息采集功能;超级广告管理功能...
她的不同版本可以满足从小流量到大流量,从个人到企业的各种应用程序的需求,并为您提供全新,快速和出色的网站解决方案。
由Yuguo Tianqing Studio制作的Empire 7. 0 采集发行界面分为Empire Information 采集界面和Empire 文章发行界面。购买前,请阅读您网站的列模型。购买
此界面是免登录界面,可以上传文件,配置规则和界面,可以立即采集发布,效果非常好!
玉果天晴工作室曾经一口气完成了1300多个皇室规则的编辑,因此您可以放心地这样做
如果您是新手,我可以直接向您发送带有采集规则和发布界面的已配置优采云软件,您也可以直接采集发布
如果您是母版,则只能请求发布接口文件和发布模块,并自行导入和使用它!
需要编写采集规则和优采云 采集发布界面采集规则的朋友可以与我联系!
规则准备:一篇文章10元,发布界面50元!
不成功,不收费
特殊说明:
文章采集接口没用对要命,百度几种采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-05-22 04:08
文章采集接口没用对要命,百度几种采集方式中,scrapy和爬虫框架有比较大的区别,我在此仅作简单介绍,若需要更深入的话,需要深入学习服务器,爬虫框架,
基本分为站点文本,页面js信息,以及url列表。如果数据过大,
对于网站主,
1)大型分布式爬虫:以openresty为例,不过openresty只能采集微博等热门社交网站,
2)微信+专业采集组件:以python为例,有django/flask等,不过我通常会将采集任务交给真正的专业采集组件去做,
3)还有专门提供api和spider文件的开源爬虫,这里就不做介绍了。
请问如何才能提取出重复信息,并且不需要运维。
没有用爬虫框架,
数据源目前有基于scrapy+eloquent.js+celery的成熟方案,你要采集哪些内容,如果数据量不大,写爬虫爬下来就好,如果数据量还是很大,
本地微信公众号后台采集,我们现在开始不定期开源项目自动爬取,
抓取数据还是要建议用爬虫框架
找个单元编程,自己写个项目, 查看全部
文章采集接口没用对要命,百度几种采集方式
文章采集接口没用对要命,百度几种采集方式中,scrapy和爬虫框架有比较大的区别,我在此仅作简单介绍,若需要更深入的话,需要深入学习服务器,爬虫框架,
基本分为站点文本,页面js信息,以及url列表。如果数据过大,
对于网站主,
1)大型分布式爬虫:以openresty为例,不过openresty只能采集微博等热门社交网站,
2)微信+专业采集组件:以python为例,有django/flask等,不过我通常会将采集任务交给真正的专业采集组件去做,
3)还有专门提供api和spider文件的开源爬虫,这里就不做介绍了。
请问如何才能提取出重复信息,并且不需要运维。
没有用爬虫框架,
数据源目前有基于scrapy+eloquent.js+celery的成熟方案,你要采集哪些内容,如果数据量不大,写爬虫爬下来就好,如果数据量还是很大,
本地微信公众号后台采集,我们现在开始不定期开源项目自动爬取,
抓取数据还是要建议用爬虫框架
找个单元编程,自己写个项目,
文章采集接口,理解那些技术。需要耐心积累,不断提升自己
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-05-21 23:01
文章采集接口,理解那些技术。需要耐心积累,不断提升自己。同样是爬虫,差距在哪里,除了爬虫的知识外,更重要的是搜索引擎的使用能力。
1、数据采集;
2、语言沟通;
3、软件基础;
4、基础网络爬虫知识;
5、微软微软全套的开发工具;
6、黑客网络攻防基础知识;
7、计算机网络基础知识;
8、爬虫基础知识;
9、其他知识(除爬虫外的其他内容)。
想要爬虫技术过硬?首先要懂这些:python爬虫,requests,scrapy,lxml爬虫等都要懂;要懂链接系统等网络知识;懂一门web前端语言,例如java,php..要知道如何用爬虫,并懂得用别人写好的模块爬虫进行二次开发。一般来说,没有扎实的理论基础,上面的内容你是学不来的。
python语言好好学,了解异步加载,同步加载技术。logging,正则表达式等常用方法。然后学requests,一定要分清楚requests+get和http+post的区别。(http+post)。leaderboard之类的不用多说,重要性等同于fiddler之于svn之于git。技术水平一定要有,学习思维。
多看看requests的文档和作者写的书,熟悉基本的网络爬虫工具。技术烂大街的时代,并不是网络爬虫技术不重要,而是你没有发掘网络爬虫技术的机会,没有做好网络爬虫的准备。我最近也在找网络爬虫工程师这个岗位的书,你不要错过这些机会。好多公司都在招人,机会不要轻易放过!还有,如果你在xx公司,千万别使用resquests开发!!!是不会被嘲笑的!没用过,很别扭!因为你不会requests,才知道python有requests,而这样的别扭,是你在用python做网络爬虫的过程中,才知道的!大厂才会有问题。
本人开始学python爬虫大概是2014年初,这是一个瓶颈,因为2014年我换了工作,做了googlegrowth,不是爬虫工程师的工作。所以我觉得你学网络爬虫很好的时机!2015我也是学习了requests的文档,自己做了一个简单的爬虫工具:xolab爬虫工具包。2016年我又找到了一份爬虫工作,工资不高,也因为自己喜欢爬虫。
目前也在从事网络爬虫工作,目前在做简单的爬虫,有时候开源,没时间做。不过我相信,这个时代,无论python,还是java,爬虫技术都不会是大问题,因为绝大多数人没有学习。现在爬虫需要的最重要的能力就是网络基础了,再通过正则表达式,就能解决大部分的python网络抓取工具。谢谢你的问题。 查看全部
文章采集接口,理解那些技术。需要耐心积累,不断提升自己
文章采集接口,理解那些技术。需要耐心积累,不断提升自己。同样是爬虫,差距在哪里,除了爬虫的知识外,更重要的是搜索引擎的使用能力。
1、数据采集;
2、语言沟通;
3、软件基础;
4、基础网络爬虫知识;
5、微软微软全套的开发工具;
6、黑客网络攻防基础知识;
7、计算机网络基础知识;
8、爬虫基础知识;
9、其他知识(除爬虫外的其他内容)。
想要爬虫技术过硬?首先要懂这些:python爬虫,requests,scrapy,lxml爬虫等都要懂;要懂链接系统等网络知识;懂一门web前端语言,例如java,php..要知道如何用爬虫,并懂得用别人写好的模块爬虫进行二次开发。一般来说,没有扎实的理论基础,上面的内容你是学不来的。
python语言好好学,了解异步加载,同步加载技术。logging,正则表达式等常用方法。然后学requests,一定要分清楚requests+get和http+post的区别。(http+post)。leaderboard之类的不用多说,重要性等同于fiddler之于svn之于git。技术水平一定要有,学习思维。
多看看requests的文档和作者写的书,熟悉基本的网络爬虫工具。技术烂大街的时代,并不是网络爬虫技术不重要,而是你没有发掘网络爬虫技术的机会,没有做好网络爬虫的准备。我最近也在找网络爬虫工程师这个岗位的书,你不要错过这些机会。好多公司都在招人,机会不要轻易放过!还有,如果你在xx公司,千万别使用resquests开发!!!是不会被嘲笑的!没用过,很别扭!因为你不会requests,才知道python有requests,而这样的别扭,是你在用python做网络爬虫的过程中,才知道的!大厂才会有问题。
本人开始学python爬虫大概是2014年初,这是一个瓶颈,因为2014年我换了工作,做了googlegrowth,不是爬虫工程师的工作。所以我觉得你学网络爬虫很好的时机!2015我也是学习了requests的文档,自己做了一个简单的爬虫工具:xolab爬虫工具包。2016年我又找到了一份爬虫工作,工资不高,也因为自己喜欢爬虫。
目前也在从事网络爬虫工作,目前在做简单的爬虫,有时候开源,没时间做。不过我相信,这个时代,无论python,还是java,爬虫技术都不会是大问题,因为绝大多数人没有学习。现在爬虫需要的最重要的能力就是网络基础了,再通过正则表达式,就能解决大部分的python网络抓取工具。谢谢你的问题。
文章采集接口/moments,不限定平台,目前只支持qq邮箱
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-05-17 23:03
文章采集接口mozilla/moments,不限定平台,目前只支持qq邮箱,google邮箱,以及linux上的java等。:全球最大同城共享图片的网站,支持中文,qq邮箱、微博收藏、微博发现等,微信登录使用chrome的tabsapigoogle帐号+square账号+美国国会图书馆等可以访问。
需要注意:1.不同账号之间不能相互转换,只能通过域名转换如;2.需要注册国内的服务器,并获取真实身份(域名解析,.cn,.cn,.cn),在拼接后域名解析地址如twitter@twitter.me则为原站;网站登录相关采集工具:1.go(@go),基于nginx做服务器,支持采集多个网站,并发量1000-5000。
速度相对很快。2.采集云采集,基于sae做服务器,采集网站可以限制在10个,但是采集速度与go类似,需要看服务器性能。3.同城联机采集,平台限制在10个,但是采集网站支持任意数量。需要注意:在采集网站要保证帐号注册的不是国内其他代理帐号(百度/),在注册信息里面填写真实的国内身份注册邮箱。本文原创首发于公众号互联飞方(微信ibejfisb),欢迎关注!。
qq邮箱用来注册微博和qq秀,微博用来发起投票,比如回答100赞,101票等等,qq秀可以用来装扮装饰。 查看全部
文章采集接口/moments,不限定平台,目前只支持qq邮箱
文章采集接口mozilla/moments,不限定平台,目前只支持qq邮箱,google邮箱,以及linux上的java等。:全球最大同城共享图片的网站,支持中文,qq邮箱、微博收藏、微博发现等,微信登录使用chrome的tabsapigoogle帐号+square账号+美国国会图书馆等可以访问。
需要注意:1.不同账号之间不能相互转换,只能通过域名转换如;2.需要注册国内的服务器,并获取真实身份(域名解析,.cn,.cn,.cn),在拼接后域名解析地址如twitter@twitter.me则为原站;网站登录相关采集工具:1.go(@go),基于nginx做服务器,支持采集多个网站,并发量1000-5000。
速度相对很快。2.采集云采集,基于sae做服务器,采集网站可以限制在10个,但是采集速度与go类似,需要看服务器性能。3.同城联机采集,平台限制在10个,但是采集网站支持任意数量。需要注意:在采集网站要保证帐号注册的不是国内其他代理帐号(百度/),在注册信息里面填写真实的国内身份注册邮箱。本文原创首发于公众号互联飞方(微信ibejfisb),欢迎关注!。
qq邮箱用来注册微博和qq秀,微博用来发起投票,比如回答100赞,101票等等,qq秀可以用来装扮装饰。
《文章采集接口和post数据传输接口api文档路径》
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-05-08 06:01
文章采集接口和post数据传输接口api文档路径:一:json接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:参数解析:视频解析:图片解析:文字解析:二:https接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:三:post数据传输接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:具体的功能、接口使用或者模板制作可以参考:xiaonang@foxmail。com。
去百度里面搜索postapi
他的接口设置很好,其实有一个很简单的,这个模板制作之后,就是很方便。'{{key}}'他每一次请求,就是获取你的一个特征值,然后在json里面放一个列表,并且标识你要传给他的是什么。
有现成的web开发可以免费使用。
yes,可以在51cto和csdn都看看大神的博客,
开源代码
/有这种接口,
百度搜下post就行了, 查看全部
《文章采集接口和post数据传输接口api文档路径》
文章采集接口和post数据传输接口api文档路径:一:json接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:参数解析:视频解析:图片解析:文字解析:二:https接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:三:post数据传输接口文档:直接查询:获取模板信息:'{{name}}'获取index地址:获取cookie:{{key}}获取zxing验证:获取网页源码:具体的功能、接口使用或者模板制作可以参考:xiaonang@foxmail。com。
去百度里面搜索postapi
他的接口设置很好,其实有一个很简单的,这个模板制作之后,就是很方便。'{{key}}'他每一次请求,就是获取你的一个特征值,然后在json里面放一个列表,并且标识你要传给他的是什么。
有现成的web开发可以免费使用。
yes,可以在51cto和csdn都看看大神的博客,
开源代码
/有这种接口,
百度搜下post就行了,
怎么利用本平台一晌编写一万篇原创的网页文案页
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-05-05 22:12
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
极度有罪。此刻,每个人都单击了此页面。也许他们获得的内容不仅与data 采集器界面的主题有关,因为此副本是由我们的工具站分批编写的SEO登录页面。如果我们对AI编辑器网站的信息有很好的印象,让我先抛开数据采集器接口,让我带领大家理解:如何使用该平台编写10,000页的原创一晚上的网页复制!许多用户看到我们的广告,认为这是伪原创脚本,这是错误的!实际上,该平台是原创系统,关键词和模板是独立创建的,您无法在Internet上找到以下内容。输出非常相似文章。我们是如何完成的?我将在文章稍后仔细阅读!
坚持分析data 采集器界面的合作伙伴,实际上,您小偷所珍惜的也是上述主题。最初,编辑一个全面的搜索文章非常容易,但是一篇文章文章可以产生的搜索量确实很小。为了达到通过信息布局节省流量的目的,最重要的方法是量化!假设一篇文章文章每天可以吸引一个阅读,也就是说,如果可以生产10,000篇文章,则每日访问量可以增加10,000篇。但是,这很容易说。实际上,一个人每天只能编写40篇文章,而功能最强大的文章只有70篇。即使您使用伪原创系统,也将有100篇文章!浏览到这一点,每个人都应该将数据采集器界面放在一边,然后仔细研究如何完成批量编辑文章!
百度如何看待真正的编辑? 网站 原创不只是要逐段编辑原创!在每个搜索者的程序概念中,原创并不意味着没有重复的文本。实际上,只要我们的文本堆栈不与其他文章重叠,就可以增加收录的可能性。一个热门文章充满了好想法,并且保持相同的关键词,只需要确认重复的内容即可,也就是说,这个文章仍然很可能被捕获,甚至变成爆文。就像本文一样,您可能已经浏览了百度搜索数据采集器界面,最后单击以查看它。实际上,我的文章文章是使用koala系统的批量编辑文章系统自行生成的!
此站点上的AI 原创工具应为原创 文章系统,该系统可在半天之内写入成千上万的高质量优化副本。如果您的网页权重足够大,则索引率可以达到76%以上。一般的操作技巧,用户主页上有视频介绍和小白的指导,您可以免费试用!非常抱歉,我尚未为每个人编辑有关data 采集器界面的详细说明。也许您已经阅读了这些无用的内容。但是,如果您喜欢此技术,请单击右上角的,以使优化结果每天增加数千万流量。这不是一件坏事吗? 查看全部
怎么利用本平台一晌编写一万篇原创的网页文案页
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
极度有罪。此刻,每个人都单击了此页面。也许他们获得的内容不仅与data 采集器界面的主题有关,因为此副本是由我们的工具站分批编写的SEO登录页面。如果我们对AI编辑器网站的信息有很好的印象,让我先抛开数据采集器接口,让我带领大家理解:如何使用该平台编写10,000页的原创一晚上的网页复制!许多用户看到我们的广告,认为这是伪原创脚本,这是错误的!实际上,该平台是原创系统,关键词和模板是独立创建的,您无法在Internet上找到以下内容。输出非常相似文章。我们是如何完成的?我将在文章稍后仔细阅读!
坚持分析data 采集器界面的合作伙伴,实际上,您小偷所珍惜的也是上述主题。最初,编辑一个全面的搜索文章非常容易,但是一篇文章文章可以产生的搜索量确实很小。为了达到通过信息布局节省流量的目的,最重要的方法是量化!假设一篇文章文章每天可以吸引一个阅读,也就是说,如果可以生产10,000篇文章,则每日访问量可以增加10,000篇。但是,这很容易说。实际上,一个人每天只能编写40篇文章,而功能最强大的文章只有70篇。即使您使用伪原创系统,也将有100篇文章!浏览到这一点,每个人都应该将数据采集器界面放在一边,然后仔细研究如何完成批量编辑文章!
百度如何看待真正的编辑? 网站 原创不只是要逐段编辑原创!在每个搜索者的程序概念中,原创并不意味着没有重复的文本。实际上,只要我们的文本堆栈不与其他文章重叠,就可以增加收录的可能性。一个热门文章充满了好想法,并且保持相同的关键词,只需要确认重复的内容即可,也就是说,这个文章仍然很可能被捕获,甚至变成爆文。就像本文一样,您可能已经浏览了百度搜索数据采集器界面,最后单击以查看它。实际上,我的文章文章是使用koala系统的批量编辑文章系统自行生成的!
此站点上的AI 原创工具应为原创 文章系统,该系统可在半天之内写入成千上万的高质量优化副本。如果您的网页权重足够大,则索引率可以达到76%以上。一般的操作技巧,用户主页上有视频介绍和小白的指导,您可以免费试用!非常抱歉,我尚未为每个人编辑有关data 采集器界面的详细说明。也许您已经阅读了这些无用的内容。但是,如果您喜欢此技术,请单击右上角的,以使优化结果每天增加数千万流量。这不是一件坏事吗?
文章采集接口已发布,让运算更快flaskbeanfish也应该装个emacs
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-04-17 21:04
文章采集接口已发布给各位哥哥姐姐:kaiser_loverhubpxfnss传送门:jasin.py:pandasapidocumentationforajourneyjasin.pycode:pxfnss/code接口人数:venv1已经是两个python3版本,请默认已经装好pip。sublimeizer:支持各种控制台终端(normaluseradmin),集成了集成了一些shell(不知道是不是shell的都应该装个emacs)cachesize:单独配置了一个网络文件缓存,就是不知道文件体积大小要多大(后面下载样例查到的。
总之应该可以放开一些大文件了,让运算更快)flaskbeanfish(可实现主页跳转,所以必须pip也安装这个)pymongo(基本api接口都是使用mongodb的,也可以考虑让cache用外置数据库存,我认为cache方便点)kafkaasynctcp连接:pipenvset这个很实用,不管是任何项目,都能快速集成到python中。
另外还支持smtp+pop,连接非常方便。目前还不支持http,等过段时间正式支持再说。以后可能接入更多新接口.看到有哥哥姐姐写sqlalchemy,也有人知道astaxie和pymysql也支持连接,无奈默认为pymysql不适合这么快的连接。如果为了更快的连接速度可以把连接迁移到thrift。有人来问pyqt基本有cmake。
啥还没做,要不改pyqt?nodejs啥时候有组件了来了再来说吧。2018年4月2日更新:实在不行了,求python面试总结。 查看全部
文章采集接口已发布,让运算更快flaskbeanfish也应该装个emacs
文章采集接口已发布给各位哥哥姐姐:kaiser_loverhubpxfnss传送门:jasin.py:pandasapidocumentationforajourneyjasin.pycode:pxfnss/code接口人数:venv1已经是两个python3版本,请默认已经装好pip。sublimeizer:支持各种控制台终端(normaluseradmin),集成了集成了一些shell(不知道是不是shell的都应该装个emacs)cachesize:单独配置了一个网络文件缓存,就是不知道文件体积大小要多大(后面下载样例查到的。
总之应该可以放开一些大文件了,让运算更快)flaskbeanfish(可实现主页跳转,所以必须pip也安装这个)pymongo(基本api接口都是使用mongodb的,也可以考虑让cache用外置数据库存,我认为cache方便点)kafkaasynctcp连接:pipenvset这个很实用,不管是任何项目,都能快速集成到python中。
另外还支持smtp+pop,连接非常方便。目前还不支持http,等过段时间正式支持再说。以后可能接入更多新接口.看到有哥哥姐姐写sqlalchemy,也有人知道astaxie和pymysql也支持连接,无奈默认为pymysql不适合这么快的连接。如果为了更快的连接速度可以把连接迁移到thrift。有人来问pyqt基本有cmake。
啥还没做,要不改pyqt?nodejs啥时候有组件了来了再来说吧。2018年4月2日更新:实在不行了,求python面试总结。
文章采集接口按时间分为两类,国外没用过
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-04-17 02:03
文章采集接口按时间分为两类,一种是动态接口,另一种是静态接口。静态接口就是固定开放给你。流程上由请求,响应,字符串三个接口进行维护,流程图如下:模式流程图动态接口的开放,会在合理的范围内持续开放增加新的请求。其实获取网页以及数据是比较简单的,如果需要,可以在网上搜索集成某些接口。
如果是想问那种平台比较好用的话,我知道的有易企秀,
easyui,现在网页上的很多页面用easyui都能实现,不过是收费的。
我用的就是一款移动端网页版的接口,这个接口很好用,你可以试试,每一秒时间过后,直接能实现双方数据传递,有以下三种方式:1.平台自己调用其他平台的接口或者客户端的api,实现双方数据同步。2.通过http1.1或者http2.0协议,http1.1用户协议授权,需要单独购买http2协议授权费用,通过路由实现。
3.通过sso,remote客户端,自己实现,然后通过localstorage实现数据同步。以上都是自己的理解。
easyui+python。在国内还是比较靠谱的,国外没用过,
楼上两位,可能你们只懂用python但是不知道,python可以用web开发,包括但不限于网页,web服务器,甚至是在服务器上通过api的方式实现,可以使用包括easyui在内的一些web平台去实现, 查看全部
文章采集接口按时间分为两类,国外没用过
文章采集接口按时间分为两类,一种是动态接口,另一种是静态接口。静态接口就是固定开放给你。流程上由请求,响应,字符串三个接口进行维护,流程图如下:模式流程图动态接口的开放,会在合理的范围内持续开放增加新的请求。其实获取网页以及数据是比较简单的,如果需要,可以在网上搜索集成某些接口。
如果是想问那种平台比较好用的话,我知道的有易企秀,
easyui,现在网页上的很多页面用easyui都能实现,不过是收费的。
我用的就是一款移动端网页版的接口,这个接口很好用,你可以试试,每一秒时间过后,直接能实现双方数据传递,有以下三种方式:1.平台自己调用其他平台的接口或者客户端的api,实现双方数据同步。2.通过http1.1或者http2.0协议,http1.1用户协议授权,需要单独购买http2协议授权费用,通过路由实现。
3.通过sso,remote客户端,自己实现,然后通过localstorage实现数据同步。以上都是自己的理解。
easyui+python。在国内还是比较靠谱的,国外没用过,
楼上两位,可能你们只懂用python但是不知道,python可以用web开发,包括但不限于网页,web服务器,甚至是在服务器上通过api的方式实现,可以使用包括easyui在内的一些web平台去实现,
爬虫是dailytweets,日报是dailyhealth,国内最大的是百度
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-04-03 07:02
文章采集接口和爬虫接口。去日报接口好像还没公布接口。
其实刚好正好相反,爬虫是dailytweets,日报是dailyhealth,
spider/daily-tweets·github
现在很多app都能接入搜索公司的内容抓取接口了,国内最大的是百度,依次是腾讯、搜狗、360等等。
faq.html你可以看看这个是豆瓣fm的接口。
:买二手书user-agent:pubglink:tag:booksuser-agent:dzcloud_user-agent:pubgrank:freeuser-agent:flipboard/herokuigoogle:amazon。comrank:freeuser-agent:strongrank:freetry-user-agent:various/iphelper:user-agent:chromeg++rank:freespiderrank:free。
spider/webrouter
github上有个很不错的web工具,有爬虫、日报接口,不过你要先注册登录github-satyaquan/webrouter:buildanewreact.jswebappandinwebappsthroughthewebpage.每个javascript脚本里有若干条web页面的信息(接口获取.sql等),方便你爬虫和日报构建。然后开始就可以爬信息了。注册地址/daily_report.html。
dailybeautifulspider/~tyrend/spider//都是官方的入口 查看全部
爬虫是dailytweets,日报是dailyhealth,国内最大的是百度
文章采集接口和爬虫接口。去日报接口好像还没公布接口。
其实刚好正好相反,爬虫是dailytweets,日报是dailyhealth,
spider/daily-tweets·github
现在很多app都能接入搜索公司的内容抓取接口了,国内最大的是百度,依次是腾讯、搜狗、360等等。
faq.html你可以看看这个是豆瓣fm的接口。
:买二手书user-agent:pubglink:tag:booksuser-agent:dzcloud_user-agent:pubgrank:freeuser-agent:flipboard/herokuigoogle:amazon。comrank:freeuser-agent:strongrank:freetry-user-agent:various/iphelper:user-agent:chromeg++rank:freespiderrank:free。
spider/webrouter
github上有个很不错的web工具,有爬虫、日报接口,不过你要先注册登录github-satyaquan/webrouter:buildanewreact.jswebappandinwebappsthroughthewebpage.每个javascript脚本里有若干条web页面的信息(接口获取.sql等),方便你爬虫和日报构建。然后开始就可以爬信息了。注册地址/daily_report.html。
dailybeautifulspider/~tyrend/spider//都是官方的入口
网站收录下降怎么回事内容质量差文章内容存在问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-03-31 03:07
网站收录下降怎么回事内容质量差文章内容存在问题?
1、在文章的开头,您必须突出显示要点,让用户知道接下来要谈论的内容,并留下一些问题,以便用户有看图的欲望。向下。简而言之,文章的第一段不谈一些。
2、 网站 收录有什么问题?内容质量不佳文章内容存在问题。内容问题也分为两个问题。一个问题是内容质量差,另一个是内容违规。内容质量问题是主要问题。当前的方法太快,无法快速成功,对SEO的理解也太肤浅了。从内容优化的角度来看,许多人只是盲目追求原创内容,而不在乎文章的质量。
3、增加文章的数量;如果要解决文章 收录的数量问题,则需要解决的第一个问题是内容的数量。例如,您的网站共有100篇文章文章,即使在百度中全部收录,最多也只能是收录一百文章。这已经是极限了。实际上,即使权重非常高,百度也无法收录 网站的所有内容。所有站点都不可能收录,更不用说某些垃圾邮件站点了。 收录的数量甚至更多,而且内容的数量也很少。
4、 站群策略。含义很简单,即公司可以在公司网站之外建立多个博客网站,然后在博客网站上发布并链接到公司网站
5、加速索引。毫无疑问,在执行SEO的过程中,我们已经解决收录问题很长时间了。有了以上权限,我们可以很清楚地知道,只有高质量的内容才能被快速索引。
6、外部链接建立; 网站的外部链接可以很好地提升排名,但是发布外部链接并不容易,特别是高质量的外部链接很少,这是可行的。请确保在此过程中仔细筛选。
7、一般网站网站 收录除新网站外的比率为80%。 网站 收录的数量与总页数和内容质量有关。通常,我们解决网站 收录的过程是先分析网页爬网,然后在非收录爬网之后再分析网页内容。
8、 seo加快了网站页面收录页面的方法更新,以保持规律性
————————————————————————————————
问:黑帽seo是什么意思?
答案:黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的。 SEO行为。
问:页面标题和描述适合多少个单词?
答案:网站标题搜索引擎只能在搜索结果中显示63个字节,以下所有内容均被省略。通常,建议网页标题不超过32个汉字,描述不超过72个汉字。
问:网站有多少服务器空间适合购买?
答案:根据网站的规模和要提供的服务,根据用户组的分布确定要购买的空间(服务器),选择强大的常规空间提供商,并选择访问提供商,以确保用户访问速度和稳定性。 查看全部
网站收录下降怎么回事内容质量差文章内容存在问题?
1、在文章的开头,您必须突出显示要点,让用户知道接下来要谈论的内容,并留下一些问题,以便用户有看图的欲望。向下。简而言之,文章的第一段不谈一些。
2、 网站 收录有什么问题?内容质量不佳文章内容存在问题。内容问题也分为两个问题。一个问题是内容质量差,另一个是内容违规。内容质量问题是主要问题。当前的方法太快,无法快速成功,对SEO的理解也太肤浅了。从内容优化的角度来看,许多人只是盲目追求原创内容,而不在乎文章的质量。
3、增加文章的数量;如果要解决文章 收录的数量问题,则需要解决的第一个问题是内容的数量。例如,您的网站共有100篇文章文章,即使在百度中全部收录,最多也只能是收录一百文章。这已经是极限了。实际上,即使权重非常高,百度也无法收录 网站的所有内容。所有站点都不可能收录,更不用说某些垃圾邮件站点了。 收录的数量甚至更多,而且内容的数量也很少。
4、 站群策略。含义很简单,即公司可以在公司网站之外建立多个博客网站,然后在博客网站上发布并链接到公司网站
5、加速索引。毫无疑问,在执行SEO的过程中,我们已经解决收录问题很长时间了。有了以上权限,我们可以很清楚地知道,只有高质量的内容才能被快速索引。
6、外部链接建立; 网站的外部链接可以很好地提升排名,但是发布外部链接并不容易,特别是高质量的外部链接很少,这是可行的。请确保在此过程中仔细筛选。
7、一般网站网站 收录除新网站外的比率为80%。 网站 收录的数量与总页数和内容质量有关。通常,我们解决网站 收录的过程是先分析网页爬网,然后在非收录爬网之后再分析网页内容。
8、 seo加快了网站页面收录页面的方法更新,以保持规律性
————————————————————————————————
问:黑帽seo是什么意思?
答案:黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的。 SEO行为。
问:页面标题和描述适合多少个单词?
答案:网站标题搜索引擎只能在搜索结果中显示63个字节,以下所有内容均被省略。通常,建议网页标题不超过32个汉字,描述不超过72个汉字。
问:网站有多少服务器空间适合购买?
答案:根据网站的规模和要提供的服务,根据用户组的分布确定要购买的空间(服务器),选择强大的常规空间提供商,并选择访问提供商,以确保用户访问速度和稳定性。
xposedhook微信公众号实时推送文章的采集方案只有以下几种方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2021-03-28 02:17
简介
当前的主流公共帐户采集方案只有以下几种方法
搜狗微信
采集历史记录不再可用,搜索也不按时间排序。获得的数据价值不高,但可用于获得官方帐户的业务。
微信公众平台
尽管微信公众平台已有采集的历史记录,但它具有很大的局限性,如果捕获不多,它将被阻止。仅适用于少量数据采集。
Android微信
Internet上有很多关于[x15]方案的实时推送[x13]挂钩微信官方帐户文章。据我所知,大多数公司采集都使用这种方案。但是,在线发布的文章均基于旧版本。碰巧的是,大多数旧版本的微信帐户无法正常登录,而当前版本通常较低。新版本的微信已经对xposed进行了强大的检测(如果您使用xposed钩子,旧版本的WeChat可能不会阻止您,但是新版本会直接检测到手机已安装xposed。当然,无论是旧版本登录失败还是检测到新版本,实际上都有解决方法。可以挂起检测代码,但是我仍然无法做到这一点。我已经看到一个大老板意识到了成品,但是价格却被说服了。
某些第三方平台
有许多第三方平台提供一些微信数据,例如最热门的文章等。这取决于您是否要抓住它。
网络端微信
基本上没用,可以登船的都是很老的船。
Windows微信
与Android上的WeChat一样,WeChat具有Windows客户端。实际上,我们具有应该存在的所有功能,因此我们也可以在Windows端挂接微信以获取数据。该技术涉及Windows逆向工程,dll注入等。
其他方法
当然,有一些技术含量较低的方法:模拟点击和浏览器js注入(采集官方帐户无法实时推送数据,只有采集历史记录才能实时推送数据)。模拟点击实际上是使用一些自动化工具来模拟一个人打开链接,然后通过某些数据包捕获工具拦截响应。 js注入是类似的,可能是拦截响应并对其进行修改,添加了一些js以使他等待很短的时间才能打开下一个文章链接,以便在Windows和Android上浏览器始终可以打开链接而无需手动操作。可以实现的。但是,尽管这些技术很简单,但是它们实施起来比较麻烦并且效率低下。
插曲
由于钩子Windows可以获取官方帐户数据,因此,您当然也可以获取微信自动消息发送和接收机器人。我已经完成了软件,代码是半开源的(不是与官方账号有关的开源):
身体
对于新接触的人来说,微信的采集难度并不容易,除了那些直接模拟点击的人。老板掌握的技术根本不会直接公开。他要么以高价为您定制产品,要么将数据出售给您。这也是正常现象,因为您认识的人越多,宝贵的技术就是原因之一。它可以使用多长时间也是一个问题。如果它在发布后不久被微信作为目标。
我已经与微信采集联系了半年了。我尝试了很多方法,最后找到了一种可以接受的采集方法,该方法可以在Windows端反转微信的Windows EXE程序,并找到相关CALL的偏移量,可以真正拦截官方帐户推送的数据时间。
功能(所有功能均基于Windows端的微信,这是您在计算机上聊天的软件)技术堆栈其他
如果技术太复杂而无法学习怎么办?我已经将所有功能封装到exe中,只需要操作采集微信文章接口(您需要了解基本内容,例如json和网页解析),解析就需要您自己编写,因为我不知道你需要什么领域。 采集该软件不到2M,占用的资源非常少。只要计算机配置足以运行微信,就没有问题。另外,如果您需要自己两次封装扩展功能,则可以提供代码和指导。当然,如果您只需要数据,就可以合作。
演示阅读编号演示图片(图片中的监视帐户是我的,欢迎添加交流信息
演示动画
视频太大,无法上传,只需转到动画图片即可看到:。动画中有三个窗口。左侧是微信浏览器,右上方是采集程序,右下方是任务栏。任务栏中显示的WXSpider是右上角的采集程序,仅用于显示它。该程序占用的资源。
显示器推送
程序中的监视是指要监视其微信好友的消息。收到朋友指定格式的消息后,采集程序采集的相应内容将打开。该设置用于设置邮箱发送的一些信息,当微信意外注销时,将发送电子邮件通知。
历史
历史记录与阅读次数相似。两者都控制微信浏览器访问指定的URL,然后在请求历史记录文章列表中获取参数。后来,我们对采集使用了模拟点击拦截,它更稳定并且可以达到更多采集。当然,您可以控制浏览器采集,但是采集的数量将相对较小。
其他
直接将浏览器控制为采集确实更有效,更方便。但是,请求的数量是有限的,可以通过更改IP来解决(IP质量更好,我尝试使用某些代理微信浏览器来非常缓慢地打开网页)。限制最少的方法是模拟点击和拦截,因此我添加了一个模拟点击打开URL的功能。当程序达到极限时,您仍然可以模拟单击以继续阅读采集。当然,历史文章界面具有更高的限制,并且密封界面的频率也很高,因此不可能突破模拟咔嗒声。在测试中,每个帐户可以在24小时内访问320-330接口,并且每个接口都返回10天的历史数据。不管每天发布多少个项目,或者每天发布8个项目,每个界面都将返回80条数据文章。
温馨提醒
如果您不需要工作,而只想学习技术,请不要打扰。当然,您可以随意赚钱。 查看全部
xposedhook微信公众号实时推送文章的采集方案只有以下几种方法
简介
当前的主流公共帐户采集方案只有以下几种方法
搜狗微信
采集历史记录不再可用,搜索也不按时间排序。获得的数据价值不高,但可用于获得官方帐户的业务。
微信公众平台
尽管微信公众平台已有采集的历史记录,但它具有很大的局限性,如果捕获不多,它将被阻止。仅适用于少量数据采集。
Android微信
Internet上有很多关于[x15]方案的实时推送[x13]挂钩微信官方帐户文章。据我所知,大多数公司采集都使用这种方案。但是,在线发布的文章均基于旧版本。碰巧的是,大多数旧版本的微信帐户无法正常登录,而当前版本通常较低。新版本的微信已经对xposed进行了强大的检测(如果您使用xposed钩子,旧版本的WeChat可能不会阻止您,但是新版本会直接检测到手机已安装xposed。当然,无论是旧版本登录失败还是检测到新版本,实际上都有解决方法。可以挂起检测代码,但是我仍然无法做到这一点。我已经看到一个大老板意识到了成品,但是价格却被说服了。
某些第三方平台
有许多第三方平台提供一些微信数据,例如最热门的文章等。这取决于您是否要抓住它。
网络端微信
基本上没用,可以登船的都是很老的船。
Windows微信
与Android上的WeChat一样,WeChat具有Windows客户端。实际上,我们具有应该存在的所有功能,因此我们也可以在Windows端挂接微信以获取数据。该技术涉及Windows逆向工程,dll注入等。
其他方法
当然,有一些技术含量较低的方法:模拟点击和浏览器js注入(采集官方帐户无法实时推送数据,只有采集历史记录才能实时推送数据)。模拟点击实际上是使用一些自动化工具来模拟一个人打开链接,然后通过某些数据包捕获工具拦截响应。 js注入是类似的,可能是拦截响应并对其进行修改,添加了一些js以使他等待很短的时间才能打开下一个文章链接,以便在Windows和Android上浏览器始终可以打开链接而无需手动操作。可以实现的。但是,尽管这些技术很简单,但是它们实施起来比较麻烦并且效率低下。
插曲
由于钩子Windows可以获取官方帐户数据,因此,您当然也可以获取微信自动消息发送和接收机器人。我已经完成了软件,代码是半开源的(不是与官方账号有关的开源):
身体
对于新接触的人来说,微信的采集难度并不容易,除了那些直接模拟点击的人。老板掌握的技术根本不会直接公开。他要么以高价为您定制产品,要么将数据出售给您。这也是正常现象,因为您认识的人越多,宝贵的技术就是原因之一。它可以使用多长时间也是一个问题。如果它在发布后不久被微信作为目标。
我已经与微信采集联系了半年了。我尝试了很多方法,最后找到了一种可以接受的采集方法,该方法可以在Windows端反转微信的Windows EXE程序,并找到相关CALL的偏移量,可以真正拦截官方帐户推送的数据时间。
功能(所有功能均基于Windows端的微信,这是您在计算机上聊天的软件)技术堆栈其他
如果技术太复杂而无法学习怎么办?我已经将所有功能封装到exe中,只需要操作采集微信文章接口(您需要了解基本内容,例如json和网页解析),解析就需要您自己编写,因为我不知道你需要什么领域。 采集该软件不到2M,占用的资源非常少。只要计算机配置足以运行微信,就没有问题。另外,如果您需要自己两次封装扩展功能,则可以提供代码和指导。当然,如果您只需要数据,就可以合作。
演示阅读编号演示图片(图片中的监视帐户是我的,欢迎添加交流信息
演示动画
视频太大,无法上传,只需转到动画图片即可看到:。动画中有三个窗口。左侧是微信浏览器,右上方是采集程序,右下方是任务栏。任务栏中显示的WXSpider是右上角的采集程序,仅用于显示它。该程序占用的资源。
显示器推送
程序中的监视是指要监视其微信好友的消息。收到朋友指定格式的消息后,采集程序采集的相应内容将打开。该设置用于设置邮箱发送的一些信息,当微信意外注销时,将发送电子邮件通知。
历史
历史记录与阅读次数相似。两者都控制微信浏览器访问指定的URL,然后在请求历史记录文章列表中获取参数。后来,我们对采集使用了模拟点击拦截,它更稳定并且可以达到更多采集。当然,您可以控制浏览器采集,但是采集的数量将相对较小。
其他
直接将浏览器控制为采集确实更有效,更方便。但是,请求的数量是有限的,可以通过更改IP来解决(IP质量更好,我尝试使用某些代理微信浏览器来非常缓慢地打开网页)。限制最少的方法是模拟点击和拦截,因此我添加了一个模拟点击打开URL的功能。当程序达到极限时,您仍然可以模拟单击以继续阅读采集。当然,历史文章界面具有更高的限制,并且密封界面的频率也很高,因此不可能突破模拟咔嗒声。在测试中,每个帐户可以在24小时内访问320-330接口,并且每个接口都返回10天的历史数据。不管每天发布多少个项目,或者每天发布8个项目,每个界面都将返回80条数据文章。
温馨提醒
如果您不需要工作,而只想学习技术,请不要打扰。当然,您可以随意赚钱。
你们采集文章发布是通过api接口吗?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-03-27 07:12
亲爱的朋友们,您采集 文章是否通过api界面发布?
我每天文章选一篇文章,api接口版本文章是否可以直接通过审查,例如要添加哪些参数
官方研发技术:是的,请参见手册中的参考文档:“ 优采云内容采集”
Wavelet Studio-标签和API大师:我擅长编写界面,并且可以根据需要添加QQ
Alvin:官方研发技术老师Yuan
2、发布了文章
请求地址:
/index.php?appid=[授权ID]&appsecret=[授权码]&api_auth_code=[登录授权码]&api_auth_uid=[用户id]&s=member&app=news&c=home&m=add
请求参数:
is_ajax=1&data[title]=...
这里面的参数一定要和电脑页面的POST参数保持一致
您好,此api接口发布的文章可以直接通过审核吗?
官方研发技术:三楼需要API插件,我建议使用一楼的教程来发布,最有用的案例
Alvin:官方研发技术老师Yuan我已经基于api插件编写了它。我只想知道它是否可以直接通过审核。如果没有,我将根据您的第一层进行重写。 。
高抗维护性:可以存储API插件和优采云教程,但我选择优采云
官方研发技术:您可以发给插件部门的同事,我还没有深入研究插件
Alvin:参考文档:“表数据修改/添加/删除”仅看到了此文档,让我根据此内容写
Alvin:@Official R&D Technology-女士。袁:谢谢您抽出宝贵的时间来回答 查看全部
你们采集文章发布是通过api接口吗?(图)
亲爱的朋友们,您采集 文章是否通过api界面发布?
我每天文章选一篇文章,api接口版本文章是否可以直接通过审查,例如要添加哪些参数
官方研发技术:是的,请参见手册中的参考文档:“ 优采云内容采集”
Wavelet Studio-标签和API大师:我擅长编写界面,并且可以根据需要添加QQ
Alvin:官方研发技术老师Yuan
2、发布了文章
请求地址:
/index.php?appid=[授权ID]&appsecret=[授权码]&api_auth_code=[登录授权码]&api_auth_uid=[用户id]&s=member&app=news&c=home&m=add
请求参数:
is_ajax=1&data[title]=...
这里面的参数一定要和电脑页面的POST参数保持一致
您好,此api接口发布的文章可以直接通过审核吗?
官方研发技术:三楼需要API插件,我建议使用一楼的教程来发布,最有用的案例
Alvin:官方研发技术老师Yuan我已经基于api插件编写了它。我只想知道它是否可以直接通过审核。如果没有,我将根据您的第一层进行重写。 。
高抗维护性:可以存储API插件和优采云教程,但我选择优采云
官方研发技术:您可以发给插件部门的同事,我还没有深入研究插件
Alvin:参考文档:“表数据修改/添加/删除”仅看到了此文档,让我根据此内容写
Alvin:@Official R&D Technology-女士。袁:谢谢您抽出宝贵的时间来回答
【优采云数据采集】微信公众号文章的采集,
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2021-03-22 22:05
优采云 Data 采集平台为微信官方帐户文章提供了采集,并且可以轻松地发布到WordPress和其他系统。
一、 优采云微信公众号文章 采集主要功能
1)可以输入官方帐户名称或ID 关键词 采集,并支持输入多个同时捕获的内容;
2)用于映像下载的多种存储方法(优采云存储,阿里云OSS,秦牛),用于解决官方帐户文章中的防盗链问题;
3)强大的数据处理功能(可以在采集之前和采集之后进行处理)
4)简单的配置可以轻松地发布到Wordpress或http界面。
二、微信公众号文章 采集主要步骤1、创建“ 采集微信公众号”任务
登录优采云控制台,然后单击采集“微信官方帐户”
2、填写官方帐户名或采集或关键词的ID
填写基本信息,如下所示:
填写任务名称和上述采集的微信官方帐户的名称或ID,并用逗号分隔。填写后,请点击“保存”。
提醒:系统还提供数据处理,例如删除图片,删除链接,添加版权说明等。如有必要,请进行相应的选择。
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
您可以选择“临时存储优采云(通过ftp返回到服务器)”或阿里云OSS或奇牛存储,这里我们选择阿里云OSS(数据存储需要用户根据实际情况进行配置,一次配置)可以重复使用。
4、开始采集
图片配置完成后,可以单击“开始采集”以开始采集数据:
5、结果数据处理和发布
启动采集后,数据将继续向下采集向下显示,您可以在“结果数据和发布”页面上查看它:
您可以单击一条数据以检查其是否正常(通常验证图片或修改数据)
结果数据正确后,您可以发布:发布到WordPress教程
发布结果:
文章最终发行版(此处是优采云测试站点的发行版)文章链接:
微信公众号文章 采集已发布。 查看全部
【优采云数据采集】微信公众号文章的采集,
优采云 Data 采集平台为微信官方帐户文章提供了采集,并且可以轻松地发布到WordPress和其他系统。
一、 优采云微信公众号文章 采集主要功能
1)可以输入官方帐户名称或ID 关键词 采集,并支持输入多个同时捕获的内容;
2)用于映像下载的多种存储方法(优采云存储,阿里云OSS,秦牛),用于解决官方帐户文章中的防盗链问题;
3)强大的数据处理功能(可以在采集之前和采集之后进行处理)
4)简单的配置可以轻松地发布到Wordpress或http界面。
二、微信公众号文章 采集主要步骤1、创建“ 采集微信公众号”任务
登录优采云控制台,然后单击采集“微信官方帐户”
2、填写官方帐户名或采集或关键词的ID
填写基本信息,如下所示:
填写任务名称和上述采集的微信官方帐户的名称或ID,并用逗号分隔。填写后,请点击“保存”。
提醒:系统还提供数据处理,例如删除图片,删除链接,添加版权说明等。如有必要,请进行相应的选择。
3、设置图片下载(可选)
由于微信公众号文章上的图片具有防盗链功能,因此无法正常显示采集上的原创图片。如果需要图片,则需要配置图片下载:
您可以选择“临时存储优采云(通过ftp返回到服务器)”或阿里云OSS或奇牛存储,这里我们选择阿里云OSS(数据存储需要用户根据实际情况进行配置,一次配置)可以重复使用。
4、开始采集
图片配置完成后,可以单击“开始采集”以开始采集数据:
5、结果数据处理和发布
启动采集后,数据将继续向下采集向下显示,您可以在“结果数据和发布”页面上查看它:
您可以单击一条数据以检查其是否正常(通常验证图片或修改数据)
结果数据正确后,您可以发布:发布到WordPress教程
发布结果:
文章最终发行版(此处是优采云测试站点的发行版)文章链接:
微信公众号文章 采集已发布。
webstorm+分布式/集群爬虫+监控系统(s3)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-03-19 11:01
文章采集接口-ai产品文章标题、简介、关键词监控,总部的有,直接通过springmvc做自动聚合so方案还有一个方法,
1.前端监控:webstorm+分布式/集群爬虫+监控系统(s
3)2.后端监控:s4+大数据+监控系统(可选)+分布式sso如果有需要,请私信我。
webstorm+分布式/集群爬虫+监控系统(s
3)
单说环境:1.能搞定环境2.学习能力和练习能力
泻药,爬虫的实现主要看你用什么语言了,python,ruby等都可以实现起来。当然目前web服务器的托管在国内有一些问题,很多资源直接分享了,后端可以看大海开放社区的,基本都是原理图和架构图,很清晰很详细,要看技术比较复杂,但是必须要收藏有一个规划,还要认清一个问题就是落地。
大道至简,传统前端爬虫一般就是爬新闻的,如果要玩人工智能,数据产品,
最近很火的直播类。
如果做爬虫技术类的,框架非常多,
现在的主流爬虫框架其实有很多,只要你能掌握几个,
1、hadoopror(ruby,python,
2、postgres;
3、scrapy;
4、elasticsearch;
5、mongodb;
6、springmvc等等很多。 查看全部
webstorm+分布式/集群爬虫+监控系统(s3)
文章采集接口-ai产品文章标题、简介、关键词监控,总部的有,直接通过springmvc做自动聚合so方案还有一个方法,
1.前端监控:webstorm+分布式/集群爬虫+监控系统(s
3)2.后端监控:s4+大数据+监控系统(可选)+分布式sso如果有需要,请私信我。
webstorm+分布式/集群爬虫+监控系统(s
3)
单说环境:1.能搞定环境2.学习能力和练习能力
泻药,爬虫的实现主要看你用什么语言了,python,ruby等都可以实现起来。当然目前web服务器的托管在国内有一些问题,很多资源直接分享了,后端可以看大海开放社区的,基本都是原理图和架构图,很清晰很详细,要看技术比较复杂,但是必须要收藏有一个规划,还要认清一个问题就是落地。
大道至简,传统前端爬虫一般就是爬新闻的,如果要玩人工智能,数据产品,
最近很火的直播类。
如果做爬虫技术类的,框架非常多,
现在的主流爬虫框架其实有很多,只要你能掌握几个,
1、hadoopror(ruby,python,
2、postgres;
3、scrapy;
4、elasticsearch;
5、mongodb;
6、springmvc等等很多。
gitlab.io文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-03-13 08:00
文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦(当然如果想留言留下项目主页也欢迎,私信我哦)今天我们给大家讲讲我们写的一个小程序的代码,功能实现大致已经完成了,有兴趣的童鞋们可以瞅瞅。使用gitlab.io作为托管库,准备一个1.5m的文件夹作为代码管理与存储,开始吧!整个代码总共分为三个模块:gitlab开发中心、代码管理与存储、对话框接口。
下面对整个模块进行解释:1.整个代码主要是由三个文件:第一个fileexplorerfiles.js文件属于gitlab,主要是文件存储、分享、限制、访问控制等。第二个fileexplorerexplorer.js是files.js的插件,主要是用来进行文件流式传输、文件重命名、创建、删除的。第三个fileexplorerexplorer.py是files.js的扩展,主要用来进行文件管理以及传输。
2.fileexplorer的开发主要是通过js文件进行实现,接口逻辑在接口源码中已经有说明,js部分主要实现了文件名、文件属性等基本属性,每个文件的元素都类似于file.parse()这样的api,例如一个字符串串、名字,文件的文件名等,js中还实现了文件权限管理、提取file属性等,以下的模块都是为接口之中的实现。
例如ls就是我们必须要管理文件路径与文件名的,path也是如此,相信关注我们代码的朋友大部分的文件路径都是写不了的。具体关于fileexplorer的部分js部分代码欢迎bibtex大神们pullrequest,为了方便大家阅读,我的github上放了我们需要解释的代码,大家可以先打开代码,过一下代码看看效果哈!gitlabinit-dnamegitlabpush-p''init文件夹的路径以及名字{"c":{"name":"files.js","filename":"'{name}'.js"},"path":{"filename":"project.test.c"}}"]3.fileexplorer属性我们代码中的"filename":"project.test.c"是我们的路径,我们可以设置接口。
设置实现的方法很简单,如下:{"path":"/project.test.c","filename":"test.js"}']4.接口传输接口如上,我们对象上面引入gitlab.io代码之后,gitlab.io的get代码的接口会自动在gitlab服务端进行数据连接,以下的三个部分已经包含了目标接口传输的代码:if(!test)return{parent:{},children:{}},null|test|false|false|false|true|{"host":":8888/","url":""}elsereturn{"host":":8888/","url":""}(false),null|false|false|false|true。 查看全部
gitlab.io文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦
文章采集接口代码已放到github,欢迎bibtex大神们pullrequest哦(当然如果想留言留下项目主页也欢迎,私信我哦)今天我们给大家讲讲我们写的一个小程序的代码,功能实现大致已经完成了,有兴趣的童鞋们可以瞅瞅。使用gitlab.io作为托管库,准备一个1.5m的文件夹作为代码管理与存储,开始吧!整个代码总共分为三个模块:gitlab开发中心、代码管理与存储、对话框接口。
下面对整个模块进行解释:1.整个代码主要是由三个文件:第一个fileexplorerfiles.js文件属于gitlab,主要是文件存储、分享、限制、访问控制等。第二个fileexplorerexplorer.js是files.js的插件,主要是用来进行文件流式传输、文件重命名、创建、删除的。第三个fileexplorerexplorer.py是files.js的扩展,主要用来进行文件管理以及传输。
2.fileexplorer的开发主要是通过js文件进行实现,接口逻辑在接口源码中已经有说明,js部分主要实现了文件名、文件属性等基本属性,每个文件的元素都类似于file.parse()这样的api,例如一个字符串串、名字,文件的文件名等,js中还实现了文件权限管理、提取file属性等,以下的模块都是为接口之中的实现。
例如ls就是我们必须要管理文件路径与文件名的,path也是如此,相信关注我们代码的朋友大部分的文件路径都是写不了的。具体关于fileexplorer的部分js部分代码欢迎bibtex大神们pullrequest,为了方便大家阅读,我的github上放了我们需要解释的代码,大家可以先打开代码,过一下代码看看效果哈!gitlabinit-dnamegitlabpush-p''init文件夹的路径以及名字{"c":{"name":"files.js","filename":"'{name}'.js"},"path":{"filename":"project.test.c"}}"]3.fileexplorer属性我们代码中的"filename":"project.test.c"是我们的路径,我们可以设置接口。
设置实现的方法很简单,如下:{"path":"/project.test.c","filename":"test.js"}']4.接口传输接口如上,我们对象上面引入gitlab.io代码之后,gitlab.io的get代码的接口会自动在gitlab服务端进行数据连接,以下的三个部分已经包含了目标接口传输的代码:if(!test)return{parent:{},children:{}},null|test|false|false|false|true|{"host":":8888/","url":""}elsereturn{"host":":8888/","url":""}(false),null|false|false|false|true。
我是如何安装python第三方库和数据处理工具的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-02-21 12:01
文章采集接口自动获取无数据,
把爬虫软件卸载掉,改用python3重新编写爬虫程序,目录写新的爬虫文件夹,数据放在下面:/scrapy/spiders/scrapy.cfg/scrapy.log/scrapy2/urlseter.log重启,用requests请求获取下载你需要的数据,然后将爬虫文件在本地运行一下你需要的接口,清空浏览器缓存即可。
1.如果想自己构建django爬虫,这里推荐几个方便自己入门的资料给你:我是如何安装python第三方库和数据处理工具的?-midea的回答-知乎2.关于爬虫从采集站点采集数据,这里有一篇文章是详细介绍如何构建自己的爬虫:不负责采集数据|不负责爬虫一个requests+beautifulsoup+threadpool+flask+selenium爬取爬虫1.可以从github下载整个爬虫服务,自己搭建(或者找万能的度娘)2.可以自己搭建,但是建议还是用gitclone啦,官方也有免费的版本3.cmd命令行部分参见:python爬虫的执行部分再次提醒:爬虫由于安全问题和网站后期不可预测问题(比如内容泄露),使用时还是最好万事小心咯。 查看全部
我是如何安装python第三方库和数据处理工具的?
文章采集接口自动获取无数据,
把爬虫软件卸载掉,改用python3重新编写爬虫程序,目录写新的爬虫文件夹,数据放在下面:/scrapy/spiders/scrapy.cfg/scrapy.log/scrapy2/urlseter.log重启,用requests请求获取下载你需要的数据,然后将爬虫文件在本地运行一下你需要的接口,清空浏览器缓存即可。
1.如果想自己构建django爬虫,这里推荐几个方便自己入门的资料给你:我是如何安装python第三方库和数据处理工具的?-midea的回答-知乎2.关于爬虫从采集站点采集数据,这里有一篇文章是详细介绍如何构建自己的爬虫:不负责采集数据|不负责爬虫一个requests+beautifulsoup+threadpool+flask+selenium爬取爬虫1.可以从github下载整个爬虫服务,自己搭建(或者找万能的度娘)2.可以自己搭建,但是建议还是用gitclone啦,官方也有免费的版本3.cmd命令行部分参见:python爬虫的执行部分再次提醒:爬虫由于安全问题和网站后期不可预测问题(比如内容泄露),使用时还是最好万事小心咯。
微信公众号上发送的图文消息,可以采用哪些接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-02-17 11:01
文章采集接口一般是通过微信系统实现,你可以看下个人用的是哪些平台:,后台的数据由该个人去维护;从你提供的图片上看你需要的接口是比较简单的,是一些网页上的内容,这种接口需要去从互联网上爬取,你可以看下有没有这种接口;你也可以在微信系统上去接,
一般都是通过第三方平台配置,即可开发,你提供一些数据即可,
最近一直在研究微信接口,简单给大家说下微信公众号上发送的图文消息,可以采用哪些接口,1.豆瓣目前微信认证号可以申请开放平台中的图文消息接口,可以简单通过图文链接就可以将图文内容上传到微信公众号页面,然后群发。2.at&at目前国内做ai技术的不多,也可以根据公众号推文发布的热点来匹配公众号页面的展示,然后根据具体内容匹配对应的发送通道。
3.网页应用市场一些市场本身就支持接入接口,比如我知道apowersoft的微信系统宝是可以接入,也可以去上买不收钱的模拟器(100块钱一个月),然后就可以用刷号软件去群发自定义图文了,想要的客户直接把订单号发给客服问这个群发接口就行。4.做网站,是可以将上面四个接口集成,但是前提是需要域名,因为服务器用的是外国ip,每年2000左右。
其他的一些网站上配置微信公众号的接口,比如麦开的公众号接口平台,就有不少接口。还有一些网站比如易科(开发微信客户端),阿里云计算平台等,也有模拟器。但是需要付费,功能也有很多,找需要的去试一下。其实微信公众号接口一般都是通过第三方平台,采集站等主流网站上的内容,然后直接拼接到微信公众号上发送。还有些广告站、游戏站等,可以通过第三方来接入微信图文。
对我来说一般都是是找第三方,不同平台价格不同,不过最后其实就是这个网站相应的图文或者第三方提供的。正常来说,比如我搜大概100来块钱可以获取,但是肯定是多个平台群发或者多个网站同时推。一般来说如果能够获取多个图文并且在不同平台和广告站群发,每个平台可以做到1分钟的接口并发连发。前面说了第三方的问题,基本微信公众号上都是通过平台来接,第三方有哪些,阿里云阿里云联盟网站(这个是针对微信认证的企业用户)或者aliyun公众号联盟(这个是针对公众号申请开通广告接口或者第三方接入后推送给公众号上的网站或者app的,目前要1000多,公众号都可以做到)等,你还需要了解一下第三方对图文的相关格式要求,做发送规则什么的。 查看全部
微信公众号上发送的图文消息,可以采用哪些接口
文章采集接口一般是通过微信系统实现,你可以看下个人用的是哪些平台:,后台的数据由该个人去维护;从你提供的图片上看你需要的接口是比较简单的,是一些网页上的内容,这种接口需要去从互联网上爬取,你可以看下有没有这种接口;你也可以在微信系统上去接,
一般都是通过第三方平台配置,即可开发,你提供一些数据即可,
最近一直在研究微信接口,简单给大家说下微信公众号上发送的图文消息,可以采用哪些接口,1.豆瓣目前微信认证号可以申请开放平台中的图文消息接口,可以简单通过图文链接就可以将图文内容上传到微信公众号页面,然后群发。2.at&at目前国内做ai技术的不多,也可以根据公众号推文发布的热点来匹配公众号页面的展示,然后根据具体内容匹配对应的发送通道。
3.网页应用市场一些市场本身就支持接入接口,比如我知道apowersoft的微信系统宝是可以接入,也可以去上买不收钱的模拟器(100块钱一个月),然后就可以用刷号软件去群发自定义图文了,想要的客户直接把订单号发给客服问这个群发接口就行。4.做网站,是可以将上面四个接口集成,但是前提是需要域名,因为服务器用的是外国ip,每年2000左右。
其他的一些网站上配置微信公众号的接口,比如麦开的公众号接口平台,就有不少接口。还有一些网站比如易科(开发微信客户端),阿里云计算平台等,也有模拟器。但是需要付费,功能也有很多,找需要的去试一下。其实微信公众号接口一般都是通过第三方平台,采集站等主流网站上的内容,然后直接拼接到微信公众号上发送。还有些广告站、游戏站等,可以通过第三方来接入微信图文。
对我来说一般都是是找第三方,不同平台价格不同,不过最后其实就是这个网站相应的图文或者第三方提供的。正常来说,比如我搜大概100来块钱可以获取,但是肯定是多个平台群发或者多个网站同时推。一般来说如果能够获取多个图文并且在不同平台和广告站群发,每个平台可以做到1分钟的接口并发连发。前面说了第三方的问题,基本微信公众号上都是通过平台来接,第三方有哪些,阿里云阿里云联盟网站(这个是针对微信认证的企业用户)或者aliyun公众号联盟(这个是针对公众号申请开通广告接口或者第三方接入后推送给公众号上的网站或者app的,目前要1000多,公众号都可以做到)等,你还需要了解一下第三方对图文的相关格式要求,做发送规则什么的。
完整的解决方案:爬虫 | 如何构建技术文章聚合平台(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2020-11-30 12:14
作者|张家辉
来源|掘金
上一篇文章文章介绍了如何构建Crawlab的操作环境,以及如何将Puppeteer与Crawlab集成,以捕获Nuggets,SegmentFault和CSDN技术文章,最后您可以查看捕获结果。本文文章将继续说明如何使用Flask + Vue编写简化的聚合平台并显示文章的捕获内容。
文章内容抓取工具
首先,我们需要对采集器部分进行一些补充。在上一篇文章文章中,我们只编写了对文章 URL进行爬网的采集器,我们还需要对文章的内容进行爬网,因此我们需要编写该采集器的这一部分。最后一个采集器的结果集合全部更改为结果,文章的内容将作为内容字段保存在数据库中。
经过分析,发现每种技术网站的文章页面都有固定的标签,可以捕获该标签下的所有HTML。特定代码分析将不会开始,并且特定代码将发布在此处。
<p>const puppeteer = require('puppeteer');
const MongoClient = require('mongodb').MongoClient;
<br />
(async () => {
// browser
const browser = await (puppeteer.launch({
headless: true
}));
<br />
// page
const page = await browser.newPage();
<br />
// open database connection
const client = await MongoClient.connect('mongodb://192.168.99.100:27017');
let db = await client.db('crawlab_test');
const colName = process.env.CRAWLAB_COLLECTION || 'results';
const col = db.collection(colName);
const col_src = db.collection('results');
<br />
const results = await col_src.find({content: {$exists: false}}).toArray();
for (let i = 0; i el.innerHTML);
<br />
// save to database
await col.save(item);
console.log(`saved item: ${JSON.stringify(item)}`)
}
<br />
// close mongodb
client.close();
<br />
// close browser
browser.close();
<br />
})();</p>
然后按照上一篇文章文章中的步骤部署和运行采集器,您可以采集进入文章详细内容。
文章内容采集器的代码已更新为Github。
接下来,我们可以开始对这些文章进行操作。
前端和后端分离
从当前技术发展的角度来看,前端和后端分离已经成为主流:首先,前端技术变得越来越复杂,需要模块化和工程设计;其次,前端和后端分离使前端和后端团队可以协作并更有效地开发应用程序。由于本文的聚合平台是轻量级应用程序,因此我们将Python的轻量级Web应用程序框架Flask用于后端接口和前端Vue,这在最近几年变得很流行。
烧瓶
Flask被称为Micro Framework,它显示出轻量级的特性,几行代码可以编写一个Web应用程序。它依靠扩展来扩展其特定功能,例如登录身份验证,RESTful,数据模型等。在本节中,我们将构建一个REST风格的后台API应用程序。
安装
首先安装相关的依赖项。
<p>pip install flask flask_restful flask_cors pymongo</p>
基本应用
安装完成后,我们可以创建一个新的app.py文件,输入以下代码
<p>from flask import Flask
from flask_cors import CORS
from flask_restful import Api
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
if __name__ == '__main__':
app.run()</p>
在命令行中输入python app.py以运行此基本的Flask应用程序。
编写API
接下来,我们需要编写一个接口来获取文章。首先,我们简要分析需求。
此Flask应用程序要实现的功能是:
从数据库中获取提取的文章,然后将文章 ID,标题,摘要和获取时间返回到前端,以用作文章列表;
对于给定的文章 ID,请将相应的文章内容从数据库返回到前端,以在详细信息页面中使用。
因此,我们需要实现以上两个API。让我们开始编写界面。
列表界面
在app.py中添加以下代码作为列表接口。
<p>class ListApi(Resource):
def get(self):
# 查询
items = col.find({'content': {'$exists': True}}).sort('_id', DESCENDING).limit(40)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data</p>
详细的界面
类似地,在app.py中输入以下代码。
<p>class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}</p>
映射界面
编写接口后,我们需要将它们映射到URL。
<p>api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')</p>
完整代码
以下是完整的Flask应用程序代码,该代码非常简单,并实现了文章列表和文章详细信息的两个功能。接下来,我们将开始开发前端部分。
<p>import json
<br />
from bson import json_util, ObjectId
from flask import Flask, jsonify
from flask_cors import CORS
from flask_restful import Api, Resource
from pymongo import MongoClient, DESCENDING
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成MongoDB实例
mongo = MongoClient(host='192.168.99.100')
db = mongo['crawlab_test']
col = db['results']
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
<br />
class ListApi(Resource):
def get(self):
# 查询
items = col.find({}).sort('_id', DESCENDING).limit(20)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data
<br />
<br />
class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}
<br />
<br />
api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')
<br />
if __name__ == '__main__':
app.run()</p>
运行python app.py以运行后台界面服务器。
Vue
Vue近年来很热门。它已经超过了Github上的React,并已成为三个开源框架(React,Vue,Angular)中明星最多的项目。与React和Angular相比,Vue非常易于使用。它不仅可以双向绑定数据以快速开始构建简单的应用程序,而且还可以使用Vuex单向数据传输来构建大型应用程序。这种灵活性是它在大多数开发人员中受欢迎的原因之一。
为了构建一个简单的Vue应用程序,我们将使用vue-cli3,这是一个vue项目的支架。首先,我们从npm安装脚手架。
安装vue-cli3
<p>yarn add @vue/cli</p>
如果尚未安装yarn,请执行以下命令进行安装。
<p>npm i -g yarn</p>
创建项目
接下来,我们需要使用vue-cli3构建一个项目。执行以下命令。
<p>vue create frontend</p>
以下选项将在命令行上弹出,选择默认值。
<p>? Please pick a preset: (Use arrow keys)
❯ default (babel, eslint)
preset (vue-router, vuex, node-sass, babel, eslint, unit-jest)
Manually select features </p>
然后vue-cli3将开始准备用于构建项目并生成项目结构的必要依赖项。
此外,我们还需要安装完成其他功能所需的软件包。
<p>yarn add axios</p>
文章列表页面
在views目录中创建List.vue文件,并写入以下内容。
<p> {{article.title}}
</a>
{{article.ts}}
<br />
import axios from 'axios'
<br />
export default {
name: 'List',
data () {
return {
list: []
}
},
methods: {
showArticle (id) {
this.$router.push(`/${id}`)
}
},
created () {
axios.get('http://localhost:5000/results')
.then(response => {
this.list = response.data
})
}
}
<br />
.list {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.article-list {
text-align: left;
list-style: none;
}
<br />
.article-item {
background: #c3edfb;
border-radius: 5px;
padding: 5px;
height: 32px;
display: flex;
align-items: center;
justify-content: space-between;
margin-bottom: 10px;
}
<br />
.title {
flex-basis: auto;
color: #58769d;
}
<br />
.time {
font-size: 10px;
text-align: right;
flex-basis: 180px;
}</p>
其中,引用axios与ajax的API进行交互,这是列表接口。该布局用于经典的双圣杯布局。方法中的showArticle方法接收id参数并将页面跳转到详细信息页面。
文章详细信息页面
在views目录中,创建Detail.vue文件并输入以下内容。
<p> {{article.title}}
<br />
import axios from 'axios'
<br />
export default {
name: 'Detail',
data () {
return {
article: {}
}
},
computed: {
id () {
return this.$route.params.id
}
},
created () {
axios.get(`http://localhost:5000/results/${this.id}`)
.then(response => {
this.article = response.data
})
}
}
<br />
.detail {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.center {
flex-basis: 60%;
text-align: left;
}
<br />
.title {
<br />
}</p>
此页面还是经典的双圣杯布局,中间占40%。通过API获得的文章的内容输出到由v-html绑定的内容。实际上,可以在此处进行进一步的CSS优化,但是作者太懒了,所以让读者来完成此任务。
添加路线
编辑router.js文件并将其修改为以下内容。
<p>import Vue from 'vue'
import Router from 'vue-router'
import List from './views/List'
import Detail from './views/Detail'
<br />
Vue.use(Router)
<br />
export default new Router({
mode: 'hash',
base: process.env.BASE_URL,
routes: [
{
path: '/',
name: 'List',
component: List
},
{
path: '/:id',
name: 'Detail',
component: Detail
}
]
})</p>
运行前端
在命令行中输入以下命令,打开:8080,您会看到文章列表。
<p>npm run serve</p>
最终效果
最终聚合平台效果的屏幕截图如下,您可以看到基本样式已经出来。
摘要
基于上一篇文章文章“教您如何使用Crawlab构建技术文章聚合平台(一)”),本文介绍了如何使用Flask + Vue和先前捕获的文章数据构建一个简单的技术文章聚合平台。使用的技术非常基础。当然,必须有很大的优化和改进空间。我将其留给读者和所有人。 查看全部
履带|如何构建技术文章聚合平台(二)
作者|张家辉
来源|掘金
上一篇文章文章介绍了如何构建Crawlab的操作环境,以及如何将Puppeteer与Crawlab集成,以捕获Nuggets,SegmentFault和CSDN技术文章,最后您可以查看捕获结果。本文文章将继续说明如何使用Flask + Vue编写简化的聚合平台并显示文章的捕获内容。
文章内容抓取工具
首先,我们需要对采集器部分进行一些补充。在上一篇文章文章中,我们只编写了对文章 URL进行爬网的采集器,我们还需要对文章的内容进行爬网,因此我们需要编写该采集器的这一部分。最后一个采集器的结果集合全部更改为结果,文章的内容将作为内容字段保存在数据库中。
经过分析,发现每种技术网站的文章页面都有固定的标签,可以捕获该标签下的所有HTML。特定代码分析将不会开始,并且特定代码将发布在此处。
<p>const puppeteer = require('puppeteer');
const MongoClient = require('mongodb').MongoClient;
<br />
(async () => {
// browser
const browser = await (puppeteer.launch({
headless: true
}));
<br />
// page
const page = await browser.newPage();
<br />
// open database connection
const client = await MongoClient.connect('mongodb://192.168.99.100:27017');
let db = await client.db('crawlab_test');
const colName = process.env.CRAWLAB_COLLECTION || 'results';
const col = db.collection(colName);
const col_src = db.collection('results');
<br />
const results = await col_src.find({content: {$exists: false}}).toArray();
for (let i = 0; i el.innerHTML);
<br />
// save to database
await col.save(item);
console.log(`saved item: ${JSON.stringify(item)}`)
}
<br />
// close mongodb
client.close();
<br />
// close browser
browser.close();
<br />
})();</p>
然后按照上一篇文章文章中的步骤部署和运行采集器,您可以采集进入文章详细内容。
文章内容采集器的代码已更新为Github。
接下来,我们可以开始对这些文章进行操作。
前端和后端分离
从当前技术发展的角度来看,前端和后端分离已经成为主流:首先,前端技术变得越来越复杂,需要模块化和工程设计;其次,前端和后端分离使前端和后端团队可以协作并更有效地开发应用程序。由于本文的聚合平台是轻量级应用程序,因此我们将Python的轻量级Web应用程序框架Flask用于后端接口和前端Vue,这在最近几年变得很流行。
烧瓶
Flask被称为Micro Framework,它显示出轻量级的特性,几行代码可以编写一个Web应用程序。它依靠扩展来扩展其特定功能,例如登录身份验证,RESTful,数据模型等。在本节中,我们将构建一个REST风格的后台API应用程序。
安装
首先安装相关的依赖项。
<p>pip install flask flask_restful flask_cors pymongo</p>
基本应用
安装完成后,我们可以创建一个新的app.py文件,输入以下代码
<p>from flask import Flask
from flask_cors import CORS
from flask_restful import Api
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
if __name__ == '__main__':
app.run()</p>
在命令行中输入python app.py以运行此基本的Flask应用程序。
编写API
接下来,我们需要编写一个接口来获取文章。首先,我们简要分析需求。
此Flask应用程序要实现的功能是:
从数据库中获取提取的文章,然后将文章 ID,标题,摘要和获取时间返回到前端,以用作文章列表;
对于给定的文章 ID,请将相应的文章内容从数据库返回到前端,以在详细信息页面中使用。
因此,我们需要实现以上两个API。让我们开始编写界面。
列表界面
在app.py中添加以下代码作为列表接口。
<p>class ListApi(Resource):
def get(self):
# 查询
items = col.find({'content': {'$exists': True}}).sort('_id', DESCENDING).limit(40)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data</p>
详细的界面
类似地,在app.py中输入以下代码。
<p>class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}</p>
映射界面
编写接口后,我们需要将它们映射到URL。
<p>api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')</p>
完整代码
以下是完整的Flask应用程序代码,该代码非常简单,并实现了文章列表和文章详细信息的两个功能。接下来,我们将开始开发前端部分。
<p>import json
<br />
from bson import json_util, ObjectId
from flask import Flask, jsonify
from flask_cors import CORS
from flask_restful import Api, Resource
from pymongo import MongoClient, DESCENDING
<br />
# 生成Flask App实例
app = Flask(__name__)
<br />
# 生成MongoDB实例
mongo = MongoClient(host='192.168.99.100')
db = mongo['crawlab_test']
col = db['results']
<br />
# 生成API实例
api = Api(app)
<br />
# 支持CORS跨域
CORS(app, supports_credentials=True)
<br />
<br />
class ListApi(Resource):
def get(self):
# 查询
items = col.find({}).sort('_id', DESCENDING).limit(20)
<br />
data = []
for item in items:
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
data.append({
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S')
})
<br />
return data
<br />
<br />
class DetailApi(Resource):
def get(self, id):
item = col.find_one({'_id': ObjectId(id)})
<br />
# 将pymongo object转化为python object
_item = json.loads(json_util.dumps(item))
<br />
return {
'_id': _item['_id']['$oid'],
'title': _item['title'],
'source': _item['source'],
'ts': item['_id'].generation_time.strftime('%Y-%m-%d %H:%M:%S'),
'content': _item['content']
}
<br />
<br />
api.add_resource(ListApi, '/results')
api.add_resource(DetailApi, '/results/')
<br />
if __name__ == '__main__':
app.run()</p>
运行python app.py以运行后台界面服务器。
Vue
Vue近年来很热门。它已经超过了Github上的React,并已成为三个开源框架(React,Vue,Angular)中明星最多的项目。与React和Angular相比,Vue非常易于使用。它不仅可以双向绑定数据以快速开始构建简单的应用程序,而且还可以使用Vuex单向数据传输来构建大型应用程序。这种灵活性是它在大多数开发人员中受欢迎的原因之一。
为了构建一个简单的Vue应用程序,我们将使用vue-cli3,这是一个vue项目的支架。首先,我们从npm安装脚手架。
安装vue-cli3
<p>yarn add @vue/cli</p>
如果尚未安装yarn,请执行以下命令进行安装。
<p>npm i -g yarn</p>
创建项目
接下来,我们需要使用vue-cli3构建一个项目。执行以下命令。
<p>vue create frontend</p>
以下选项将在命令行上弹出,选择默认值。
<p>? Please pick a preset: (Use arrow keys)
❯ default (babel, eslint)
preset (vue-router, vuex, node-sass, babel, eslint, unit-jest)
Manually select features </p>
然后vue-cli3将开始准备用于构建项目并生成项目结构的必要依赖项。
此外,我们还需要安装完成其他功能所需的软件包。
<p>yarn add axios</p>
文章列表页面
在views目录中创建List.vue文件,并写入以下内容。
<p> {{article.title}}
</a>
{{article.ts}}
<br />
import axios from 'axios'
<br />
export default {
name: 'List',
data () {
return {
list: []
}
},
methods: {
showArticle (id) {
this.$router.push(`/${id}`)
}
},
created () {
axios.get('http://localhost:5000/results')
.then(response => {
this.list = response.data
})
}
}
<br />
.list {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.article-list {
text-align: left;
list-style: none;
}
<br />
.article-item {
background: #c3edfb;
border-radius: 5px;
padding: 5px;
height: 32px;
display: flex;
align-items: center;
justify-content: space-between;
margin-bottom: 10px;
}
<br />
.title {
flex-basis: auto;
color: #58769d;
}
<br />
.time {
font-size: 10px;
text-align: right;
flex-basis: 180px;
}</p>
其中,引用axios与ajax的API进行交互,这是列表接口。该布局用于经典的双圣杯布局。方法中的showArticle方法接收id参数并将页面跳转到详细信息页面。
文章详细信息页面
在views目录中,创建Detail.vue文件并输入以下内容。
<p> {{article.title}}
<br />
import axios from 'axios'
<br />
export default {
name: 'Detail',
data () {
return {
article: {}
}
},
computed: {
id () {
return this.$route.params.id
}
},
created () {
axios.get(`http://localhost:5000/results/${this.id}`)
.then(response => {
this.article = response.data
})
}
}
<br />
.detail {
display: flex;
}
<br />
.left {
flex-basis: 20%;
}
<br />
.right {
flex-basis: 20%;
}
<br />
.center {
flex-basis: 60%;
text-align: left;
}
<br />
.title {
<br />
}</p>
此页面还是经典的双圣杯布局,中间占40%。通过API获得的文章的内容输出到由v-html绑定的内容。实际上,可以在此处进行进一步的CSS优化,但是作者太懒了,所以让读者来完成此任务。
添加路线
编辑router.js文件并将其修改为以下内容。
<p>import Vue from 'vue'
import Router from 'vue-router'
import List from './views/List'
import Detail from './views/Detail'
<br />
Vue.use(Router)
<br />
export default new Router({
mode: 'hash',
base: process.env.BASE_URL,
routes: [
{
path: '/',
name: 'List',
component: List
},
{
path: '/:id',
name: 'Detail',
component: Detail
}
]
})</p>
运行前端
在命令行中输入以下命令,打开:8080,您会看到文章列表。
<p>npm run serve</p>
最终效果
最终聚合平台效果的屏幕截图如下,您可以看到基本样式已经出来。
摘要
基于上一篇文章文章“教您如何使用Crawlab构建技术文章聚合平台(一)”),本文介绍了如何使用Flask + Vue和先前捕获的文章数据构建一个简单的技术文章聚合平台。使用的技术非常基础。当然,必须有很大的优化和改进空间。我将其留给读者和所有人。
整体解决方案:数据采集服务|优采云免登陆采集接口[DT采集专家]
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-31 12:37
注释1: 以上是上面列出的主要功能. 更多功能未一一列出,但会不断更新. 如果您要添加任何好的功能,则可以对其进行自定义. 更新适合所有人的内容.
√=支持;
×=不支持;
注2: 开放源代码版本只是优采云,用于发布模块开放源代码,而发布界面不是开放源代码. 如果您需要完全开源的版本,请与我们联系以进行自定义或购买(如果您发现转售或放弃其他人的发布模块,则将停止所有售后服务. )
注3: “ /”代表多个版本分隔符
注4: 为了防止破解和盗版,采集接口和模块都经过了加密(完全开源版本除外),请不要介意购买.
备注①: 以下条件不在服务范围内
1. 自我修改或使用非原创的destcoon程序代码引起的问题(请提前告知您是否已进行了两次开发或修改了默认模块)
2. 自己直接对数据库进行操作会导致数据库错误或崩溃;
3. 非官方模块/插件的安装以及由于模块/插件的安装而导致的故障;
4. 服务器和虚拟主机环境导致的系统故障;
5. 二次开发或定制以及其他可能导致问题的情况.
6,例如阻止采集的目标网站,或自己的技术问题导致采集失败.
7. 授权域名有机会在授权后1个月内更改域名. 更改前后的域名所有者必须相同,然后每次更改费用为人民币150元.
8. 为了确保用户安全,在将授权软件发送给用户后,我们将及时删除本地计算机上的授权软件. 如果用户丢失或损坏了授权文件,请要求我们以150元/次的价格重新打包授权文件
备注②: 在以下情况下不允许退款
1. 我们出售采集接口,并且所有规则都已交付. 如果目标网站无法捕获,我们将尽快修复规则. 如果无法固定,目标站将阻止采集. 与我们的界面无关.
2,例如网站阻止采集的目标,或自身的技术问题导致采集失败.
3. 由于个人技术水平的原因,我们将不使用我们的软件(我们可以远程指导客户设置默认规则).
4,自我修改或使用非原创的destcoon代码(开发了两次)导致采集失败.
5: 源代码和规则是可复制的产品,收到后将不予退款. 查看全部
数据采集服务|优采云免费登录采集界面[DT采集专家]
注释1: 以上是上面列出的主要功能. 更多功能未一一列出,但会不断更新. 如果您要添加任何好的功能,则可以对其进行自定义. 更新适合所有人的内容.
√=支持;
×=不支持;
注2: 开放源代码版本只是优采云,用于发布模块开放源代码,而发布界面不是开放源代码. 如果您需要完全开源的版本,请与我们联系以进行自定义或购买(如果您发现转售或放弃其他人的发布模块,则将停止所有售后服务. )
注3: “ /”代表多个版本分隔符
注4: 为了防止破解和盗版,采集接口和模块都经过了加密(完全开源版本除外),请不要介意购买.
备注①: 以下条件不在服务范围内
1. 自我修改或使用非原创的destcoon程序代码引起的问题(请提前告知您是否已进行了两次开发或修改了默认模块)
2. 自己直接对数据库进行操作会导致数据库错误或崩溃;
3. 非官方模块/插件的安装以及由于模块/插件的安装而导致的故障;
4. 服务器和虚拟主机环境导致的系统故障;
5. 二次开发或定制以及其他可能导致问题的情况.
6,例如阻止采集的目标网站,或自己的技术问题导致采集失败.
7. 授权域名有机会在授权后1个月内更改域名. 更改前后的域名所有者必须相同,然后每次更改费用为人民币150元.
8. 为了确保用户安全,在将授权软件发送给用户后,我们将及时删除本地计算机上的授权软件. 如果用户丢失或损坏了授权文件,请要求我们以150元/次的价格重新打包授权文件
备注②: 在以下情况下不允许退款
1. 我们出售采集接口,并且所有规则都已交付. 如果目标网站无法捕获,我们将尽快修复规则. 如果无法固定,目标站将阻止采集. 与我们的界面无关.
2,例如网站阻止采集的目标,或自身的技术问题导致采集失败.
3. 由于个人技术水平的原因,我们将不使用我们的软件(我们可以远程指导客户设置默认规则).
4,自我修改或使用非原创的destcoon代码(开发了两次)导致采集失败.
5: 源代码和规则是可复制的产品,收到后将不予退款.
Dedecms5.7sp1文章模型栏目插口使用指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2020-08-28 12:20
Dedecms5.7 sp1文章模型栏目插口使用指南
一、简介
1、本插口应用于Dedecms5.7 SP1(20120621)版普通文章模型栏目文章发布;
2、由于数据量大时DEDE生成栏目HTML时的服务器负担太重,因此,发布插口增设了2个控制参数zznomakeindex和zznomakeandcat,分别控制是否生成主页或相关栏目; 3、发布时请使用具有管理权限的用户账号;
4、本插口基于Dedecms UTF8版制做,适用于Dedecms GBK/utf-8等版本,应用于其他版本时请自行测试调整;
5、在Dedecms utf8版使用本插口时,请在发布规则中选择编码为UTF-8;
6、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
7、2个插口文件请复制在Dedecms网站管理目录(默认是dede,用户可能有修改)下使用;
二、安装插口 在插口文件夹中找到插口文件,如图:
请将etchk.php、etpost.php等插口文件复制到指定目录,远程FTP上传请使用二进制形式上传,如图:
三、配置发布规则 1、将范例发布规则文本导出ET2发布配置,或使用软件外置发布规则范例,如图:
2、将检测网址和发布网址中的“您的网站”改为您要发布的网站网址,如图:
3、在检测网址填上您的栏目ID,如图:
4、在参数取值,填上您要发布的栏目ID,如图:
在网站后台网站栏目管理处,可以见到各栏目的ID号,如图:
4、填上您的帐号、密码,注意格式和帐号权限,如图:
四、接口说明
一、检查插口
1、接口文件名etchk.php,为保密,请自行更改文件名;
2、本插口文件复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应; 3、主要参数
(以下参数附加在检测网址后) 主题标题:keyword
栏目ID :typeid 用于限定检测栏目范围,可不填,可在后台网站栏目管理处查看id;
校验码 :vercode 请自行设定,并在检测插口文件开始处更改vercode让其一致;
4、发布配置-文章检查网址处,可以如下填写:
您的网址/dede/etchk.php?vercode=&typeid=&keyword= 注:使用大小写敏感的服务器的用户请注意网址大小写和网站文件一致
5、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
二、发布插口
1、接口文件名etpost.php,为保密,请自行更改文件名;
2、本插口文件请复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应;
注:以下参数名后“=”号为示范取值而用,参数名本身不含“=”号; 采集取值的参数项,请在发布规则-发布项中添加,如图:
3、基本参数
userid
会员名参数名 pwd
密码参数名 title
主题标题参数名
body
内容参数名
4、主要参数
typeid=主栏目ID,可在后台网站栏目管理处查看该id;
typeid2=副栏目ID,可不填,可在后台网站栏目管理处查看该id,多个请用英语冒号分隔,如typeid2=3,7,11 ;
channelid=模型ID,默认为1,如果文章模型ID不为1,则用这个参数设置;
vercode=安全校验码,请自行设定,并在发布插口文件开始处更改vercode让其一致;
zznomakeindex=0 主页生成控制,取值0时,使用DEDE后台“发布文章后马上更新网站主页”的设置,取值1时,禁止生成网站主页;
zznomakeandcat=0 栏目生成控制,取值0时,使用DEDE后台“发表文章后马上更新相关栏目”的设置,取值1时,禁止生成相关栏目;
注:系统-基本参数-性能选项“arclist标签调用缓存”会影响静态页面生成情况,设为0可解决;
5、可选参数
ishtml=1是否生成HTML,1为是,0为否;
remote=1是否下载远程图片和资源,1为是,0为否,启用本项则在优采云采集器规则中不启用文件下载;
dellink=0是否删掉非站内链接,1为是,0或空为否;
autolitpic=1 是否提取第一个图片为缩略图,1为是,0为否,启用本项则picname应留空;
picname=缩略图片路径及文件名;
ddisremote=0 是否远程获取缩略图片,1为是,0为否,启用本项必须让PICNAME的值为有效图片网址; keywords关键字;
autokey=1 手动获取关键字,1为是,0为否;部分PHP版本过高造成DEDE的splitword类无效时,仍可使用插口,遇到这些情况时,参数autokey应设为0,以取消手动关键词功能;
needwatermark=0 图片是否加水印,1为是,0为否,启用本项则在ET中间规则中不应设置图片水印; 查看全部
Dedecms5.7sp1文章模型栏目插口使用指南
Dedecms5.7 sp1文章模型栏目插口使用指南
一、简介
1、本插口应用于Dedecms5.7 SP1(20120621)版普通文章模型栏目文章发布;
2、由于数据量大时DEDE生成栏目HTML时的服务器负担太重,因此,发布插口增设了2个控制参数zznomakeindex和zznomakeandcat,分别控制是否生成主页或相关栏目; 3、发布时请使用具有管理权限的用户账号;
4、本插口基于Dedecms UTF8版制做,适用于Dedecms GBK/utf-8等版本,应用于其他版本时请自行测试调整;
5、在Dedecms utf8版使用本插口时,请在发布规则中选择编码为UTF-8;
6、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
7、2个插口文件请复制在Dedecms网站管理目录(默认是dede,用户可能有修改)下使用;
二、安装插口 在插口文件夹中找到插口文件,如图:
请将etchk.php、etpost.php等插口文件复制到指定目录,远程FTP上传请使用二进制形式上传,如图:
三、配置发布规则 1、将范例发布规则文本导出ET2发布配置,或使用软件外置发布规则范例,如图:
2、将检测网址和发布网址中的“您的网站”改为您要发布的网站网址,如图:
3、在检测网址填上您的栏目ID,如图:
4、在参数取值,填上您要发布的栏目ID,如图:
在网站后台网站栏目管理处,可以见到各栏目的ID号,如图:
4、填上您的帐号、密码,注意格式和帐号权限,如图:
四、接口说明
一、检查插口
1、接口文件名etchk.php,为保密,请自行更改文件名;
2、本插口文件复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应; 3、主要参数
(以下参数附加在检测网址后) 主题标题:keyword
栏目ID :typeid 用于限定检测栏目范围,可不填,可在后台网站栏目管理处查看id;
校验码 :vercode 请自行设定,并在检测插口文件开始处更改vercode让其一致;
4、发布配置-文章检查网址处,可以如下填写:
您的网址/dede/etchk.php?vercode=&typeid=&keyword= 注:使用大小写敏感的服务器的用户请注意网址大小写和网站文件一致
5、接口文件无须任何改动即可使用,如果你希望降低校准或其他功能,请仔细更改;
二、发布插口
1、接口文件名etpost.php,为保密,请自行更改文件名;
2、本插口文件请复制在网站管理目录DEDE下使用,如果目录名有变更,请自行对应;
注:以下参数名后“=”号为示范取值而用,参数名本身不含“=”号; 采集取值的参数项,请在发布规则-发布项中添加,如图:
3、基本参数
userid
会员名参数名 pwd
密码参数名 title
主题标题参数名
body
内容参数名
4、主要参数
typeid=主栏目ID,可在后台网站栏目管理处查看该id;
typeid2=副栏目ID,可不填,可在后台网站栏目管理处查看该id,多个请用英语冒号分隔,如typeid2=3,7,11 ;
channelid=模型ID,默认为1,如果文章模型ID不为1,则用这个参数设置;
vercode=安全校验码,请自行设定,并在发布插口文件开始处更改vercode让其一致;
zznomakeindex=0 主页生成控制,取值0时,使用DEDE后台“发布文章后马上更新网站主页”的设置,取值1时,禁止生成网站主页;
zznomakeandcat=0 栏目生成控制,取值0时,使用DEDE后台“发表文章后马上更新相关栏目”的设置,取值1时,禁止生成相关栏目;
注:系统-基本参数-性能选项“arclist标签调用缓存”会影响静态页面生成情况,设为0可解决;
5、可选参数
ishtml=1是否生成HTML,1为是,0为否;
remote=1是否下载远程图片和资源,1为是,0为否,启用本项则在优采云采集器规则中不启用文件下载;
dellink=0是否删掉非站内链接,1为是,0或空为否;
autolitpic=1 是否提取第一个图片为缩略图,1为是,0为否,启用本项则picname应留空;
picname=缩略图片路径及文件名;
ddisremote=0 是否远程获取缩略图片,1为是,0为否,启用本项必须让PICNAME的值为有效图片网址; keywords关键字;
autokey=1 手动获取关键字,1为是,0为否;部分PHP版本过高造成DEDE的splitword类无效时,仍可使用插口,遇到这些情况时,参数autokey应设为0,以取消手动关键词功能;
needwatermark=0 图片是否加水印,1为是,0为否,启用本项则在ET中间规则中不应设置图片水印;

