
文章采集接口
数据剖析系列篇:数据采集哪家强?
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-27 02:44
前几天有人问我,说她们是一家创业公司,我们也特别想做数据剖析、机器学习这种,但是我们没有数据啊!这可怎么办?我们也不懂那些数据从哪里来,更不懂技术方面的东西,公司也就几个人,还都是从传统公司或则刚结业的。
当时我就给他打了个比喻,这就有点像我们没米如何做饭一样。如果真的没米了,我们可以自己去种稻,也可以去超市上买米,也可以拿其他东西和他人家做交换,也可以喝玉米。
那同样,我们没数据,那就要想办法去采集数据啊。如果你是个spy man,那肯定也要各类采集情报。
我们常见的数据搜集分内部和外部两方面:
1.内部:
a)历史log日志+会员信息;
b)基于基础标签特点预测;
c)集团各业务、子公司数据等。
2.外部:
a)爬虫采集引擎;
b)数据选购;
c)合作公司数据交换;
d)收购兼并公司;
e)营销等手段。
针对内部已有数据那些自毋须多说,谁还会。重点说一说我们常用的网路爬虫形式。
在这块数据采集基于本身需求的规模,如果是大规模的维护系统,可以用专门的采集引擎,比如基于apache服务器的nutch。
如果以填充网站为目的,觉得那个网站的内容好,想借为已用,这种需求随机灵活,而对抓取量又不太高的采集,可以采集python的爬虫工具scrapy。
当然php也有可以实现各类网站抓取的方法,但是其实没有成形的框架,因为抓取本质是基本网路合同,http哪些的,所以你对那些合同了解的清楚,又懂一些脚本语言,基本就会画出一个可以实现你需求的采集的工具。但是效率就千差万别了。框架会提供你建立采集的多元素补充,你几乎涉及到采集应该处理的全部问题,它都给你提供了对应的方案,你有耐心死扣方案,总能弄懂他传授你的意思,然后按理为之,就可以不断把自己的爬虫实现上去。但是采集只是数据处理的一个环节,采集之后怎样对数据提纯精炼,基于自己商业化目的的导向,可能还涉及到知识产权等问题,当然这不是技术采集考虑的层面了。至于数据的剖析,当然,我都是用python多一点,python提供了许多外置的math函数处理库,比如说numpy,scipy,matplotlib,这些网上都有对应的使用教程,入库或把采集到的数据按这种组件可以处理的格式保存,然后把数据导出进来,就这样折腾折腾。
另外对于中级用户,介绍下现成的工具:
优采云
优采云应该是国外采集软件最成功的典型之一,使用人数包括收费用户数目上应当是最多的
优点:功能比较齐全,采集速度比较快,主要针对cms,短时间可以采集很多,过滤,替换都不错,比较详尽;
技术:技术主要是峰会支持,帮助文件多,上手容易。有收费、免费版本
缺点:功能复杂,软件越来越大,比较占用显存和CPU资源,大批量采集速度不行,资源回收控制得不好,受CS构架限制
优采云
可能大部分人还不知道,这是我自主研制的,以前仍然用爬虫写程序,java、python等,后面认为很麻烦,就摆弄着要做的简单一些,然后就无法收手了,最近仍然在进行产品迭代。
优点:功能聚合性强、速度快、saas构架、数据可预览、数据规则市场、api等多种输出方法、免费
缺点:知名度还比较低
三人行
主要针对峰会的采集,功能比较健全
优点:还是针对峰会,适合开峰会的
技术:收费技术,免费有广告
缺点:超级复杂,上手难,对cms支持比较差
ET工具
优点:无人值守,自动更新,适合常年做站,用户群主要集中在常年做站潜水站长。软件清晰,必备功能也太齐全,关键是软件免费,听说早已降低采集中英文翻译功能。
技术:论坛支持,软件本身免费,但是也提供收费服务。帮助文件较少,上手不容易
缺点:对峰会和CMS的支持通常
海纳
优点:海量,可以抓取网站很多一个关键词文章,似乎适合做网站的专题,特别是文章类、博客类
技术:无论坛 收费,免费有功能限制
缺点:分类不便捷,也就说采集文章归类不便捷,要自动(自动容易混淆),特定插口,采集的内容有限
优采云
优点:非常适宜采集discuz峰会
缺点:过于专情,兼容性不好。
End
作者:面包君 查看全部
数据剖析系列篇:数据采集哪家强?
前几天有人问我,说她们是一家创业公司,我们也特别想做数据剖析、机器学习这种,但是我们没有数据啊!这可怎么办?我们也不懂那些数据从哪里来,更不懂技术方面的东西,公司也就几个人,还都是从传统公司或则刚结业的。
当时我就给他打了个比喻,这就有点像我们没米如何做饭一样。如果真的没米了,我们可以自己去种稻,也可以去超市上买米,也可以拿其他东西和他人家做交换,也可以喝玉米。

那同样,我们没数据,那就要想办法去采集数据啊。如果你是个spy man,那肯定也要各类采集情报。
我们常见的数据搜集分内部和外部两方面:
1.内部:
a)历史log日志+会员信息;
b)基于基础标签特点预测;
c)集团各业务、子公司数据等。
2.外部:
a)爬虫采集引擎;
b)数据选购;
c)合作公司数据交换;
d)收购兼并公司;
e)营销等手段。

针对内部已有数据那些自毋须多说,谁还会。重点说一说我们常用的网路爬虫形式。
在这块数据采集基于本身需求的规模,如果是大规模的维护系统,可以用专门的采集引擎,比如基于apache服务器的nutch。
如果以填充网站为目的,觉得那个网站的内容好,想借为已用,这种需求随机灵活,而对抓取量又不太高的采集,可以采集python的爬虫工具scrapy。
当然php也有可以实现各类网站抓取的方法,但是其实没有成形的框架,因为抓取本质是基本网路合同,http哪些的,所以你对那些合同了解的清楚,又懂一些脚本语言,基本就会画出一个可以实现你需求的采集的工具。但是效率就千差万别了。框架会提供你建立采集的多元素补充,你几乎涉及到采集应该处理的全部问题,它都给你提供了对应的方案,你有耐心死扣方案,总能弄懂他传授你的意思,然后按理为之,就可以不断把自己的爬虫实现上去。但是采集只是数据处理的一个环节,采集之后怎样对数据提纯精炼,基于自己商业化目的的导向,可能还涉及到知识产权等问题,当然这不是技术采集考虑的层面了。至于数据的剖析,当然,我都是用python多一点,python提供了许多外置的math函数处理库,比如说numpy,scipy,matplotlib,这些网上都有对应的使用教程,入库或把采集到的数据按这种组件可以处理的格式保存,然后把数据导出进来,就这样折腾折腾。

另外对于中级用户,介绍下现成的工具:
优采云
优采云应该是国外采集软件最成功的典型之一,使用人数包括收费用户数目上应当是最多的
优点:功能比较齐全,采集速度比较快,主要针对cms,短时间可以采集很多,过滤,替换都不错,比较详尽;
技术:技术主要是峰会支持,帮助文件多,上手容易。有收费、免费版本
缺点:功能复杂,软件越来越大,比较占用显存和CPU资源,大批量采集速度不行,资源回收控制得不好,受CS构架限制
优采云
可能大部分人还不知道,这是我自主研制的,以前仍然用爬虫写程序,java、python等,后面认为很麻烦,就摆弄着要做的简单一些,然后就无法收手了,最近仍然在进行产品迭代。
优点:功能聚合性强、速度快、saas构架、数据可预览、数据规则市场、api等多种输出方法、免费
缺点:知名度还比较低
三人行
主要针对峰会的采集,功能比较健全
优点:还是针对峰会,适合开峰会的
技术:收费技术,免费有广告
缺点:超级复杂,上手难,对cms支持比较差
ET工具
优点:无人值守,自动更新,适合常年做站,用户群主要集中在常年做站潜水站长。软件清晰,必备功能也太齐全,关键是软件免费,听说早已降低采集中英文翻译功能。
技术:论坛支持,软件本身免费,但是也提供收费服务。帮助文件较少,上手不容易
缺点:对峰会和CMS的支持通常
海纳
优点:海量,可以抓取网站很多一个关键词文章,似乎适合做网站的专题,特别是文章类、博客类
技术:无论坛 收费,免费有功能限制
缺点:分类不便捷,也就说采集文章归类不便捷,要自动(自动容易混淆),特定插口,采集的内容有限
优采云
优点:非常适宜采集discuz峰会
缺点:过于专情,兼容性不好。
End
作者:面包君
用php写一个采集“百度相关搜索”关键词的api接口程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 896 次浏览 • 2020-08-26 09:02
采集百度相关搜索词,这个应用对于做网路推广的小伙伴应当能用到,就是你在百度搜索一个关键词把相关搜索词采集下来,用来做网路营销用。今天分享一段简单的代码,来实现搜索一个关键词,直接返回显示在网页上采集到的相关搜索词。如果你你自觉得你是程序前辈,请绕路,本程序很简单,勿喷。
一、应用需求分析
1、用get形式递交你要搜索的关键词
2、直接把采集到的“相关搜索”词显示在本页面,一行一个显示
二、简单剖析实现步骤
1、分析百度搜索是如何递交你搜索的关键词的总结出,百度搜索是如何组合链接的,也就是“关键词”,直接在浏览器粘贴这个链接你才会发觉这个页面就是你搜索的关键词的页面。当然还有其他参数,小伙伴可以自己研究。
2、获取这个页面的源代码,程序是只认识源代码,不会跟人一样用耳朵区分。
3、分析相关搜索词那种地方的代码,用语言不好形容,等下自己看代码吧。然后用正则提取下来搜索词就行了。
三、直接看代码吧,只有一个文件,没几行代码,感兴趣的小伙伴自己去试试吧。
四、来瞧瞧最后的显示疗效吧
把这段代码放在你自己服务器上,直接在浏览器搜索相应链接?key=关键词,页面都会显示你搜索词的相关搜索词了。就写这了写太累,感兴趣的小伙伴,关注一下本头条号吧。 查看全部
用php写一个采集“百度相关搜索”关键词的api接口程序
采集百度相关搜索词,这个应用对于做网路推广的小伙伴应当能用到,就是你在百度搜索一个关键词把相关搜索词采集下来,用来做网路营销用。今天分享一段简单的代码,来实现搜索一个关键词,直接返回显示在网页上采集到的相关搜索词。如果你你自觉得你是程序前辈,请绕路,本程序很简单,勿喷。
一、应用需求分析
1、用get形式递交你要搜索的关键词
2、直接把采集到的“相关搜索”词显示在本页面,一行一个显示
二、简单剖析实现步骤
1、分析百度搜索是如何递交你搜索的关键词的总结出,百度搜索是如何组合链接的,也就是“关键词”,直接在浏览器粘贴这个链接你才会发觉这个页面就是你搜索的关键词的页面。当然还有其他参数,小伙伴可以自己研究。
2、获取这个页面的源代码,程序是只认识源代码,不会跟人一样用耳朵区分。
3、分析相关搜索词那种地方的代码,用语言不好形容,等下自己看代码吧。然后用正则提取下来搜索词就行了。
三、直接看代码吧,只有一个文件,没几行代码,感兴趣的小伙伴自己去试试吧。
四、来瞧瞧最后的显示疗效吧
把这段代码放在你自己服务器上,直接在浏览器搜索相应链接?key=关键词,页面都会显示你搜索词的相关搜索词了。就写这了写太累,感兴趣的小伙伴,关注一下本头条号吧。
第 11 篇:基于 drf-haystack 的文章搜索插口
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-26 00:20
作者:HelloGitHub-追梦人物
在 django 博客教程中,我们使用了 django-haystack 和 Elasticsearch 进行文章内容的搜索。django-haystack 默认返回的搜索结果是一个类似于 django QuerySet 的对象,需要配合模板系统使用,因为未被序列化,所以未能直接用于 django-rest-framework 的插口。当然解决方案也很简单,编写相应的序列化器将返回结果序列化就可以了。
但是,通过之前的功能我们看见,使用 django-rest-framework 是一个近乎标准化但又沉闷无聊的过程:首先是编撰序列化器用于序列化资源,然后是编撰视图集,提供对资源各种操作的插口。既然是标准化的东西,肯定早已有人写好了相关的功能以供复用。此时就要发挥开源社区的力量,去 GitHub 使用关键词 rest haystack 搜索,果然搜到一个 drf-haystack 开源项目,专门用于解决 django-rest-framework 和 haystack 结合使用的问题。因此我们就不再重复造轮子,直接使用开源第三方库来实现我们的需求。
既然要使用第三方库,第一步其实是安装它,进入项目根目录,运行:
$ pipenv install drf-haystack
由于须要使用到搜索功能,因此须要启动 Elasticsearch 服务,最简单的方法就是使用项目中编排的 Elasticsearch 镜像启动容器。
项目根目录下运行如下命令启动全部项目所需的容器服务:
$ docker-compose -f local.yml up --build
启动完成后运行 docker ps 命令可以检测到如下 2 个运行的容器,说明启动成功:
hellodjango_rest_framework_tutorial_local
hellodjango_rest_framework_tutorial_elasticsearch_local
接着创建一些文章,以便用于搜索测试,可以自己在 admin 后台添加,当然最简单的方式是运行项目中的 fake.py 脚本,批量生成测试数据:
$ docker-compose -f local.yml run --rm
hellodjango.rest.framework.tutorial.local python -m scripts.fake
测试文章生成后,还要运行下边的命令给文章的内容创建索引,这样搜索引擎能够按照索引搜索到相应的内容:
注意
如果生成索引时见到如下错误:
elasticsearch.exceptions.ConnectionError: ConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve) caused by: NewConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve)
这是因为项目配置中 Elasticsearch 服务的 URL 配置出错造成,解决方式是步入 settings/local.py 配置文件中,将搜索设置改为下边的内容:
HAYSTACK_CONNECTIONS['default']['URL'] = ':9200/'
因为这个 URL 地址需和容器编排文件 local.yml 中指定的容器服务名一致 Docker 才能正确解析。
现在万事具备了,数据库中早已有了文章,搜索服务早已有了文章的索引,只须要等待客户端来进行查询,然后返回结果。所以接下来就步入到 django-rest-framework 标准开发流程:定义序列化器 -> 编写视图 -> 配置路由,这样一个标准的搜索插口就开发下来了。
先来定义序列化器,粗略过一遍 drf-haystack 官方文档[3],依葫芦画瓢创建文章(Post) 的 Serializer
根据官方文档的介绍,为了复用早已定义好用于序列化文章列表的序列化器,我们直接承继了 PostListSerializer,同时我们还混进了 HaystackSerializerMixin,这是 drf-haystack 的混入类,提供搜索结果序列化相关的功能。
另外内部类 Meta 同样承继 PostListSerializer.Meta,这样就无需重复定义序列化数组列表 fields。关键的地方在这个 search_fields,这个列表申明用于搜索的数组(通常都定义为索引数组),我们在上一部教程设置 django-haystack 时,文章的索引数组设置的名子叫 text,如果对这一块有疑问,可以简单回顾一下 Django Haystack 全文检索与关键词高亮[4] 中的内容。
然后编撰视图集,需承继 HaystackViewSet:
这个视图集特别简单,只须要通过类属性 index_models 声明须要搜索的模型,以及搜索结果的序列化器就行了,剩余的功能均由 HaystackViewSet 内部替我们实现了。
最后是在路由器中注册视图集,自动生成 URL 模式:
搞定了!一套标准化的 django-restful-framework 开发流程,不过大量工作已由 drf-haystack 在背后替我们完成,我们只写了极其少量的代码即实现了一套搜索插口。
来瞧瞧搜索疗效。我们启动 Docker 容器,在浏览器输入如下格式的 URL:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python manage.py rebuild_index# 输出如下Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.Are you sure you wish to continue? [y/N] yRemoving all documents from your index because you said so.All documents removed.Indexing 201 文章GET /hellodjango_blog_tutorial/_mapping [status:404 request:0.005s]
将 key-word 替换为须要搜索的关键字,例如将其替换为 markdown,测试集数据中得到的搜索结果如下:
搜索结果符合预期,但略微有一点不太好的地方,就是没有高亮的标题和摘要,我们希望将来显示的结果应当是下边这样的,因此返回的数据必须支持这样的显示:
关键词高亮的实现原理似乎十分简单,通过解析整段文本,将搜索关键词替换为由 HTML 标签包裹的富文本,并给这个包裹标签设置 CSS 样式,让其显示不同的字体颜色就可以了。
了解其原理后其实就是实现其功能,不过 django-haystack 已经为我们造好了轮子,而且在上一部教程的 Django Haystack 全文检索与关键词高亮[5],我们还对默认的高亮辅助类进行了整修,优化了文章标题被从关键字位置截断的问题,因此我们使用改建后的辅助类来对须要高亮的结果进行处理。
需要高亮的虽然是 2 个数组,一个是 title、一个是 body。而 body 我们不需要完整的内容,只须要摘出其中一部分作为搜索结果的摘要即可。这两个功能,辅助类均早已为我们提供了,我们只须要调用所需的方式就行。
注意到这儿我们须要对 title、body 两个数组进行高亮处理,其基本逻辑虽然就是接收 title、body 的值作为输入,高亮处理后再输出。回顾一下序列化器的序列化数组,其实也是接收某个数组的值作为输入,对其进行处理,将其转化为可序列化的结果后输出,和我们须要的逻辑太象。但是,django-rest-framework 并没有提供这种比较个性化需求的序列化数组,因此接下来我们接触 drf 的一点中级用法——自定义序列化数组。
自定义序列化数组虽然十分的简单,基本流程分两步走:
从 drf 官方提供的序列化数组中找一个数据类型最为接近的作为父类。重写 to_representation 方法,加入自己的序列化逻辑。
以我们的需求为例。因为 title、body 均为字符型,因此选择父类序列化数组为 CharField,定义一个 HighlightedCharField 字段如下:
django-rest-framework 通过调用序列化数组的 to_representation 方法对输入的值进行序列化,这个方式接收的第一个参数就是须要序列化的值。在我们自定义的逻辑中,首先调用父类 CharField 的 to_representation 方法,父类序列化的逻辑是将任何输入的值都转为字符串;接着我们从 context 属性中取得 request 对象,这个对象就是视图中的 HTTP 请求对象,但是由于 django 中 request 对象难以象 flask 那样从全局获取,因此 drf 在视图中将其保存在了序列化器和序列化数组的 context 属性中便于在视图外访问;获取 request 对象的目的是希望获取查询的关键字,query_params 属性是一个类字典对象,用于记录来自 URL 的查询参数,例如我们之前测试查询功能时调用的 URL 为 /api/search/?text=markdown,所以 query_params 保存了 URL 中的查询参数,将其封装为一个类数组对象 {"text": "markdown"},这里 text 的值就是查询的关键字,我们将它传给 Highlighter 辅助类,然后调用 highlight 方法将须要序列化的值进行进一步的高亮处理。
序列化数组定义好后,我们就可以在序列化器中用它了:
title 字段原先使用默认的 CharField 进行序列化,这里我们重新指定为自定义的 HighlightedCharField,这样序列化后的值就是高亮的格式。
summary 是我们新增的数组,注意我们序列化的对象是文章 Post,但这个对象是没有 summary 这个属性的,但是 summary 其实是对属性 body 序列化后的结果,因此我们通过指定序列化化数组的 source 参数,指定值的来源。
最后别忘了在 fields 中声明全部序列化的数组,主要是把新增的 summary 加进去。
来瞧瞧改进后的搜索疗效:
注意观察返回的 title 和 summary,我们搜索的关键词是 markdown,可以看见所有 markdown 关键字都被包裹了一个 span 标签,并且设置了 class 属性为 highlighted,只要设置好 css 样式,页面所有的 markdown 关键词都会显示不同的颜色,从而实现搜索关键词高亮的疗效了。
当然,我们如今并没有实际用到这个特点,下一部教程我们将使用 Vue 来开发博客,到时候调用搜索插口领到搜索结果后才会实际用到了。 查看全部
第 11 篇:基于 drf-haystack 的文章搜索插口
作者:HelloGitHub-追梦人物
在 django 博客教程中,我们使用了 django-haystack 和 Elasticsearch 进行文章内容的搜索。django-haystack 默认返回的搜索结果是一个类似于 django QuerySet 的对象,需要配合模板系统使用,因为未被序列化,所以未能直接用于 django-rest-framework 的插口。当然解决方案也很简单,编写相应的序列化器将返回结果序列化就可以了。
但是,通过之前的功能我们看见,使用 django-rest-framework 是一个近乎标准化但又沉闷无聊的过程:首先是编撰序列化器用于序列化资源,然后是编撰视图集,提供对资源各种操作的插口。既然是标准化的东西,肯定早已有人写好了相关的功能以供复用。此时就要发挥开源社区的力量,去 GitHub 使用关键词 rest haystack 搜索,果然搜到一个 drf-haystack 开源项目,专门用于解决 django-rest-framework 和 haystack 结合使用的问题。因此我们就不再重复造轮子,直接使用开源第三方库来实现我们的需求。
既然要使用第三方库,第一步其实是安装它,进入项目根目录,运行:
$ pipenv install drf-haystack
由于须要使用到搜索功能,因此须要启动 Elasticsearch 服务,最简单的方法就是使用项目中编排的 Elasticsearch 镜像启动容器。
项目根目录下运行如下命令启动全部项目所需的容器服务:
$ docker-compose -f local.yml up --build
启动完成后运行 docker ps 命令可以检测到如下 2 个运行的容器,说明启动成功:
hellodjango_rest_framework_tutorial_local
hellodjango_rest_framework_tutorial_elasticsearch_local
接着创建一些文章,以便用于搜索测试,可以自己在 admin 后台添加,当然最简单的方式是运行项目中的 fake.py 脚本,批量生成测试数据:
$ docker-compose -f local.yml run --rm
hellodjango.rest.framework.tutorial.local python -m scripts.fake
测试文章生成后,还要运行下边的命令给文章的内容创建索引,这样搜索引擎能够按照索引搜索到相应的内容:
注意
如果生成索引时见到如下错误:
elasticsearch.exceptions.ConnectionError: ConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve) caused by: NewConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve)
这是因为项目配置中 Elasticsearch 服务的 URL 配置出错造成,解决方式是步入 settings/local.py 配置文件中,将搜索设置改为下边的内容:
HAYSTACK_CONNECTIONS['default']['URL'] = ':9200/'
因为这个 URL 地址需和容器编排文件 local.yml 中指定的容器服务名一致 Docker 才能正确解析。
现在万事具备了,数据库中早已有了文章,搜索服务早已有了文章的索引,只须要等待客户端来进行查询,然后返回结果。所以接下来就步入到 django-rest-framework 标准开发流程:定义序列化器 -> 编写视图 -> 配置路由,这样一个标准的搜索插口就开发下来了。
先来定义序列化器,粗略过一遍 drf-haystack 官方文档[3],依葫芦画瓢创建文章(Post) 的 Serializer
根据官方文档的介绍,为了复用早已定义好用于序列化文章列表的序列化器,我们直接承继了 PostListSerializer,同时我们还混进了 HaystackSerializerMixin,这是 drf-haystack 的混入类,提供搜索结果序列化相关的功能。
另外内部类 Meta 同样承继 PostListSerializer.Meta,这样就无需重复定义序列化数组列表 fields。关键的地方在这个 search_fields,这个列表申明用于搜索的数组(通常都定义为索引数组),我们在上一部教程设置 django-haystack 时,文章的索引数组设置的名子叫 text,如果对这一块有疑问,可以简单回顾一下 Django Haystack 全文检索与关键词高亮[4] 中的内容。
然后编撰视图集,需承继 HaystackViewSet:
这个视图集特别简单,只须要通过类属性 index_models 声明须要搜索的模型,以及搜索结果的序列化器就行了,剩余的功能均由 HaystackViewSet 内部替我们实现了。
最后是在路由器中注册视图集,自动生成 URL 模式:
搞定了!一套标准化的 django-restful-framework 开发流程,不过大量工作已由 drf-haystack 在背后替我们完成,我们只写了极其少量的代码即实现了一套搜索插口。
来瞧瞧搜索疗效。我们启动 Docker 容器,在浏览器输入如下格式的 URL:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python manage.py rebuild_index# 输出如下Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.Are you sure you wish to continue? [y/N] yRemoving all documents from your index because you said so.All documents removed.Indexing 201 文章GET /hellodjango_blog_tutorial/_mapping [status:404 request:0.005s]
将 key-word 替换为须要搜索的关键字,例如将其替换为 markdown,测试集数据中得到的搜索结果如下:
搜索结果符合预期,但略微有一点不太好的地方,就是没有高亮的标题和摘要,我们希望将来显示的结果应当是下边这样的,因此返回的数据必须支持这样的显示:
关键词高亮的实现原理似乎十分简单,通过解析整段文本,将搜索关键词替换为由 HTML 标签包裹的富文本,并给这个包裹标签设置 CSS 样式,让其显示不同的字体颜色就可以了。
了解其原理后其实就是实现其功能,不过 django-haystack 已经为我们造好了轮子,而且在上一部教程的 Django Haystack 全文检索与关键词高亮[5],我们还对默认的高亮辅助类进行了整修,优化了文章标题被从关键字位置截断的问题,因此我们使用改建后的辅助类来对须要高亮的结果进行处理。
需要高亮的虽然是 2 个数组,一个是 title、一个是 body。而 body 我们不需要完整的内容,只须要摘出其中一部分作为搜索结果的摘要即可。这两个功能,辅助类均早已为我们提供了,我们只须要调用所需的方式就行。
注意到这儿我们须要对 title、body 两个数组进行高亮处理,其基本逻辑虽然就是接收 title、body 的值作为输入,高亮处理后再输出。回顾一下序列化器的序列化数组,其实也是接收某个数组的值作为输入,对其进行处理,将其转化为可序列化的结果后输出,和我们须要的逻辑太象。但是,django-rest-framework 并没有提供这种比较个性化需求的序列化数组,因此接下来我们接触 drf 的一点中级用法——自定义序列化数组。
自定义序列化数组虽然十分的简单,基本流程分两步走:
从 drf 官方提供的序列化数组中找一个数据类型最为接近的作为父类。重写 to_representation 方法,加入自己的序列化逻辑。
以我们的需求为例。因为 title、body 均为字符型,因此选择父类序列化数组为 CharField,定义一个 HighlightedCharField 字段如下:
django-rest-framework 通过调用序列化数组的 to_representation 方法对输入的值进行序列化,这个方式接收的第一个参数就是须要序列化的值。在我们自定义的逻辑中,首先调用父类 CharField 的 to_representation 方法,父类序列化的逻辑是将任何输入的值都转为字符串;接着我们从 context 属性中取得 request 对象,这个对象就是视图中的 HTTP 请求对象,但是由于 django 中 request 对象难以象 flask 那样从全局获取,因此 drf 在视图中将其保存在了序列化器和序列化数组的 context 属性中便于在视图外访问;获取 request 对象的目的是希望获取查询的关键字,query_params 属性是一个类字典对象,用于记录来自 URL 的查询参数,例如我们之前测试查询功能时调用的 URL 为 /api/search/?text=markdown,所以 query_params 保存了 URL 中的查询参数,将其封装为一个类数组对象 {"text": "markdown"},这里 text 的值就是查询的关键字,我们将它传给 Highlighter 辅助类,然后调用 highlight 方法将须要序列化的值进行进一步的高亮处理。
序列化数组定义好后,我们就可以在序列化器中用它了:
title 字段原先使用默认的 CharField 进行序列化,这里我们重新指定为自定义的 HighlightedCharField,这样序列化后的值就是高亮的格式。
summary 是我们新增的数组,注意我们序列化的对象是文章 Post,但这个对象是没有 summary 这个属性的,但是 summary 其实是对属性 body 序列化后的结果,因此我们通过指定序列化化数组的 source 参数,指定值的来源。
最后别忘了在 fields 中声明全部序列化的数组,主要是把新增的 summary 加进去。
来瞧瞧改进后的搜索疗效:
注意观察返回的 title 和 summary,我们搜索的关键词是 markdown,可以看见所有 markdown 关键字都被包裹了一个 span 标签,并且设置了 class 属性为 highlighted,只要设置好 css 样式,页面所有的 markdown 关键词都会显示不同的颜色,从而实现搜索关键词高亮的疗效了。
当然,我们如今并没有实际用到这个特点,下一部教程我们将使用 Vue 来开发博客,到时候调用搜索插口领到搜索结果后才会实际用到了。
采集微信公众号文章教程是哪些?怎样批量采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-25 19:17
大家在编辑陌陌公证号上面的文章的时侯,一般都是先进行文章采集的,那么采集微信公众号文章教程是哪些?怎样批量采集呢?下面拓途数据就来详尽的介绍下这种问题,以提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是如何的?
步骤一:点击采集,复制须要采集的陌陌文章链接地址到陌陌文章网址框中。
这里获取陌陌文章链接主要有2种方式:
方法一:直接在手机上找到文章点击右上角复制。
方法二:通过笔记本端的搜狗浏览器陌陌栏目进行搜索,可以通过下边的“点击获取”进入。
步骤二:点击采集,此时文章内容早已全部被采集到陌陌编辑器上了,可以进行对文章的编辑更改。
采集微信公众号文章教程之怎么批量采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索到相关站点 ,注册或则登陆以后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取就可以啦!
NO.3 进入采集爬虫后,点击爬虫设置。
首先由于搜狗微信搜索有图片防盗链 所以须要在功能设置里开启图片云托管,这点很重要,切记,不然你的图片显示不下来,到时候就难堪了……
再进行自定义设置,你可以同时采集多个微信公众号的文章,最多500个!特别注意:是输入微信号而不是陌陌名称哦!
数据采集进行完毕,可以进行数据发布吗?答案是其实可以!
NO.1 发布数据只需两个步骤: 安装发布插件 ——> 使用发布插口。你可以选择发布到数据库或则发布到网站上。
如果你不知道如何安装插件的话,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,根据文档提示,一步一步来就OK了。
插件安装成功,接下来就来新建一个发布项吧!这里这么多个,选一个你喜欢的就行了。
选完发布插口,填写你要发布的网站地址和密码。同时,系统会进行手动检查,检测插件是否已正确安装。
字段映射的话,一般情况下系统会默认选择好的,但是,你要认为有要调整的地方,也是可以更改的。
内容替换这是一个可选项,可填可不填。
完成设置就可以进行数据发布了。
NO.2 在爬取结果页面可以看见采集爬虫按照你设置的信息爬取到的全部内容,发布结果可以进行手动发布或则自动发布。
自动发布:开启手动发布后,爬取到的数据会手动发布到网站上或则数据库,这感觉简直6到要起飞了!
当然,你也可以选择自动发布,发布时可以选择单项或多项发布。在发布之前,你还可以进行预览,看看这篇文章的内容是啥。
如果认为木有问题就可以发布数据了。
发布成功后,可以点击链接进行查看。
采集微信公众号文章教程
微信公众号文章采集思路
一、通过android客户端获取到陌陌用户登入信息(即大号)。
二、提供微信公众号信息(biz)。
三、通过http协议剖析文章接口,写陌陌爬虫程序,需要用到前面两种资源,即大号越多,爬取速率越快。
微信爬虫引擎为分布式,可多实例布署工作。
最后实现的疗效为:
android客户端程序定时获取陌陌用户登入信息,保存到数据库中。数据库中保存大量的公众号信息,爬虫引擎工作时,去数据库获取要爬取公众号的信息与陌陌大号的身分信息。
通过以上的内容,我们早已了解了采集微信公众号文章教程的内容了,可见,采集微信公众号文章的方式还是比较简单的,如果只须要根据前面的方式去做就可以了。 查看全部
采集微信公众号文章教程是哪些?怎样批量采集
大家在编辑陌陌公证号上面的文章的时侯,一般都是先进行文章采集的,那么采集微信公众号文章教程是哪些?怎样批量采集呢?下面拓途数据就来详尽的介绍下这种问题,以提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是如何的?
步骤一:点击采集,复制须要采集的陌陌文章链接地址到陌陌文章网址框中。
这里获取陌陌文章链接主要有2种方式:
方法一:直接在手机上找到文章点击右上角复制。
方法二:通过笔记本端的搜狗浏览器陌陌栏目进行搜索,可以通过下边的“点击获取”进入。
步骤二:点击采集,此时文章内容早已全部被采集到陌陌编辑器上了,可以进行对文章的编辑更改。
采集微信公众号文章教程之怎么批量采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索到相关站点 ,注册或则登陆以后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取就可以啦!
NO.3 进入采集爬虫后,点击爬虫设置。
首先由于搜狗微信搜索有图片防盗链 所以须要在功能设置里开启图片云托管,这点很重要,切记,不然你的图片显示不下来,到时候就难堪了……
再进行自定义设置,你可以同时采集多个微信公众号的文章,最多500个!特别注意:是输入微信号而不是陌陌名称哦!
数据采集进行完毕,可以进行数据发布吗?答案是其实可以!
NO.1 发布数据只需两个步骤: 安装发布插件 ——> 使用发布插口。你可以选择发布到数据库或则发布到网站上。
如果你不知道如何安装插件的话,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,根据文档提示,一步一步来就OK了。
插件安装成功,接下来就来新建一个发布项吧!这里这么多个,选一个你喜欢的就行了。
选完发布插口,填写你要发布的网站地址和密码。同时,系统会进行手动检查,检测插件是否已正确安装。
字段映射的话,一般情况下系统会默认选择好的,但是,你要认为有要调整的地方,也是可以更改的。
内容替换这是一个可选项,可填可不填。
完成设置就可以进行数据发布了。
NO.2 在爬取结果页面可以看见采集爬虫按照你设置的信息爬取到的全部内容,发布结果可以进行手动发布或则自动发布。
自动发布:开启手动发布后,爬取到的数据会手动发布到网站上或则数据库,这感觉简直6到要起飞了!
当然,你也可以选择自动发布,发布时可以选择单项或多项发布。在发布之前,你还可以进行预览,看看这篇文章的内容是啥。
如果认为木有问题就可以发布数据了。
发布成功后,可以点击链接进行查看。
采集微信公众号文章教程
微信公众号文章采集思路
一、通过android客户端获取到陌陌用户登入信息(即大号)。
二、提供微信公众号信息(biz)。
三、通过http协议剖析文章接口,写陌陌爬虫程序,需要用到前面两种资源,即大号越多,爬取速率越快。
微信爬虫引擎为分布式,可多实例布署工作。
最后实现的疗效为:
android客户端程序定时获取陌陌用户登入信息,保存到数据库中。数据库中保存大量的公众号信息,爬虫引擎工作时,去数据库获取要爬取公众号的信息与陌陌大号的身分信息。
通过以上的内容,我们早已了解了采集微信公众号文章教程的内容了,可见,采集微信公众号文章的方式还是比较简单的,如果只须要根据前面的方式去做就可以了。
页面埋点
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2020-08-24 09:07
对一个网站进行流量剖析,首先要做的就是数据采集;而采集的形式大至两种形式
对于网站前端来说,数据上报一般有如下几种方式
直接向后台发送get请求,伪装成js或者图片请求
http://click.dangdang.com/page ... id%3D &res=1920,1080||1903,5211&title=当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款&trace_id=nohead&special=guan=1;page=id:1|name:当首;&cif=&rsv1=&rsv2=&rsv3=&platform=pc&r=0.857700135627224
https://a.stat.xiaomi.com/js/m ... D1920*1080&language=zh-CN&vendor=Google%20Inc.&platform=Win32&gu=&miwd=&edm_task=&masid=&client_id=&pu=&rf=0&mutid=&muwd=&domain_id=100&pageid=81190ccc4d52f577&curl=https%3A%2F%2Fwww.mi.com%2F&xmv=1536571987936_2638_1542615493495&v=1.0.0&vuuid=7ERAQ0IQQIBIFMAV
https://warriors.jd.com/log.gi ... 83904|19&v={"t1":"pc_homepage","t2":"basic","p0":"{\"rept\":\"impr\",\"poi\":\"head|focus|08\",\"text\":\"11.19个护感恩节\",\"url\":\"//sale.jd.com/act/1dCqk7TBj5porf8.html\",\"desc\":\"个护电器\",\"mcinfo\":\"00755652-05703860-1100950352-M#0-2-1--58--#1-tb-#300-9908298#pc-home\",\"biclk\":\"1#6328b7df38f1cf2c1fd7c296f1e920cd7b603c53-101-619081#9908298\"}","pinid":"-","je":0,"sc":"24-bit","sr":"1920x1080","ul":"zh-cn","cs":"UTF-8","dt":"京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!","hn":"www.jd.com","fl":"-","os":"win","br":"chrome","bv":"68.0.3440.106","wb":"1536298255","xb":"1542165688","yb":1542615817,"zb":19,"cb":1,"usc":"direct","ucp":"-","umd":"none","uct":"-","ct":1542615839771,"lt":0,"tad":"-","jdv":"122270672|direct|-|none|-|1542165687598","dataver":"0.1"}&ref=&rm=1542615839772
回到数据采集端
nginx + lua
这种形式须要在nginx端配置日志格式;接收到后端日志搜集恳求后,会对恳求解析,并将日志数据记录在本地c盘;这种形式,有几个显著的缺点:
日志储存在本地c盘,通常我们在做大数据离线剖析,数据都是储存在hdfs上;所以这些方法就不可防止须要将日志上传到hdfs起来;因为是日志文件方式储存,所以没办法做实时的统计剖析
后台搜集
这个就须要开发一个日志搜集服务端,提供一个http get服务;这个服务将上报的数据推送到kafka中;相比第一种形式,后台搜集,你就不需要去各个服务器去搜集日志文件;数据推送到kafka,也就意味着,我们可以使用storm,sparkstreaming进行实时剖析;这个也是目前使用最广的形式
站点的数据采集流程【后台搜集为例】
首先是数据上报后端;用过友盟统计和百度统计的朋友都晓得,想要使用友盟百度站点统计功能,首先要做的就是,在站点嵌入一段js或则html代码,大概象这个样子
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
这段代码的意思,就是动态加载远程的js[:8089/xmst.js],嵌入到须要统计服务的站点;xmst.js代码如下
var params = {};
//Document对象数据
if (document) {
params.domain = document.domain || ''; //获取域名
params.url = document.URL || ''; //当前Url地址
params.title = document.title || '';
params.referrer = document.referrer || ''; //上一跳路径
}
//Window对象数据
if (window && window.screen) {
params.sh = window.screen.height || 0; //获取显示屏信息
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if (navigator) {
params.lang = navigator.language || ''; //获取所用语言种类
}
params['age'] = '111'
//解析_maq配置
if (_maq) {
for (var i in _maq) { //获取埋点阶段,传递过来的用户行为
params[i] = _maq[i]
}
};
function args_build(){
//拼接参数串
var args = '';
for (var i in params) {
// alert(i);
if (args != '') {
args += '&';
}
args += i + '=' + params[i]; //将所有获取到的信息进行拼接
}
return args;
};
//页面自动加载
function page_load(){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
// alert("请求到的后端脚本为" + src);
img.src = src;
};
// 点击事件
function a_click(maps){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
for (var i in maps) {
params[i] = maps[i]
}
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
img.src = src;
}
page_load();
加载了这个脚本的页面会手动调用page_load()方法,这个技巧会将后端的数据伪装成一个长宽都为1象素img get恳求,请求明文如下
页面浏览报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp
页面点击报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp&pageid=index.html&pcpid=pcpid
浏览和点击报文,区别在于pageid=index.html&pcpid=pcpid,pcpid定义为页面位置【例如点击了某个链接;触发了a_click(maps)方法】;
使用这些方法主要是为了解决跨域的问题,因为大多数情况下,统计脚本不单单为一个站点服务,域名也不可能全都一样;
服务端插口
http://localhost:8089/flow/log.gif?args=params
采集端代码如下【省略push kafka过程】
package com.fan.ga.gaserver.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import javax.imageio.ImageIO;
import javax.servlet.http.HttpServletResponse;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.io.OutputStream;
@Controller
@RequestMapping("/flow")
public class LogCollector {
Logger logger = LoggerFactory.getLogger(LogCollector.class);
// http://localhost:8089/flow/log.gif?args=asfafd
@RequestMapping(value = "log.gif")
public void analysis(String args, HttpServletResponse response) throws IOException {
logger.info(args);
response.setHeader("Pragma", "No-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
response.setContentType("image/gif");
OutputStream out = response.getOutputStream();
BufferedImage image = new BufferedImage(1, 1, BufferedImage.TYPE_INT_RGB);
ImageIO.write(image, "gif", out);
out.flush();
}
}
站点index.html页面
page test
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
首页
detail
End 查看全部
页面埋点
对一个网站进行流量剖析,首先要做的就是数据采集;而采集的形式大至两种形式
对于网站前端来说,数据上报一般有如下几种方式
直接向后台发送get请求,伪装成js或者图片请求
http://click.dangdang.com/page ... id%3D &res=1920,1080||1903,5211&title=当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款&trace_id=nohead&special=guan=1;page=id:1|name:当首;&cif=&rsv1=&rsv2=&rsv3=&platform=pc&r=0.857700135627224
https://a.stat.xiaomi.com/js/m ... D1920*1080&language=zh-CN&vendor=Google%20Inc.&platform=Win32&gu=&miwd=&edm_task=&masid=&client_id=&pu=&rf=0&mutid=&muwd=&domain_id=100&pageid=81190ccc4d52f577&curl=https%3A%2F%2Fwww.mi.com%2F&xmv=1536571987936_2638_1542615493495&v=1.0.0&vuuid=7ERAQ0IQQIBIFMAV
https://warriors.jd.com/log.gi ... 83904|19&v={"t1":"pc_homepage","t2":"basic","p0":"{\"rept\":\"impr\",\"poi\":\"head|focus|08\",\"text\":\"11.19个护感恩节\",\"url\":\"//sale.jd.com/act/1dCqk7TBj5porf8.html\",\"desc\":\"个护电器\",\"mcinfo\":\"00755652-05703860-1100950352-M#0-2-1--58--#1-tb-#300-9908298#pc-home\",\"biclk\":\"1#6328b7df38f1cf2c1fd7c296f1e920cd7b603c53-101-619081#9908298\"}","pinid":"-","je":0,"sc":"24-bit","sr":"1920x1080","ul":"zh-cn","cs":"UTF-8","dt":"京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!","hn":"www.jd.com","fl":"-","os":"win","br":"chrome","bv":"68.0.3440.106","wb":"1536298255","xb":"1542165688","yb":1542615817,"zb":19,"cb":1,"usc":"direct","ucp":"-","umd":"none","uct":"-","ct":1542615839771,"lt":0,"tad":"-","jdv":"122270672|direct|-|none|-|1542165687598","dataver":"0.1"}&ref=&rm=1542615839772
回到数据采集端
nginx + lua
这种形式须要在nginx端配置日志格式;接收到后端日志搜集恳求后,会对恳求解析,并将日志数据记录在本地c盘;这种形式,有几个显著的缺点:
日志储存在本地c盘,通常我们在做大数据离线剖析,数据都是储存在hdfs上;所以这些方法就不可防止须要将日志上传到hdfs起来;因为是日志文件方式储存,所以没办法做实时的统计剖析
后台搜集
这个就须要开发一个日志搜集服务端,提供一个http get服务;这个服务将上报的数据推送到kafka中;相比第一种形式,后台搜集,你就不需要去各个服务器去搜集日志文件;数据推送到kafka,也就意味着,我们可以使用storm,sparkstreaming进行实时剖析;这个也是目前使用最广的形式
站点的数据采集流程【后台搜集为例】
首先是数据上报后端;用过友盟统计和百度统计的朋友都晓得,想要使用友盟百度站点统计功能,首先要做的就是,在站点嵌入一段js或则html代码,大概象这个样子
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
这段代码的意思,就是动态加载远程的js[:8089/xmst.js],嵌入到须要统计服务的站点;xmst.js代码如下
var params = {};
//Document对象数据
if (document) {
params.domain = document.domain || ''; //获取域名
params.url = document.URL || ''; //当前Url地址
params.title = document.title || '';
params.referrer = document.referrer || ''; //上一跳路径
}
//Window对象数据
if (window && window.screen) {
params.sh = window.screen.height || 0; //获取显示屏信息
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if (navigator) {
params.lang = navigator.language || ''; //获取所用语言种类
}
params['age'] = '111'
//解析_maq配置
if (_maq) {
for (var i in _maq) { //获取埋点阶段,传递过来的用户行为
params[i] = _maq[i]
}
};
function args_build(){
//拼接参数串
var args = '';
for (var i in params) {
// alert(i);
if (args != '') {
args += '&';
}
args += i + '=' + params[i]; //将所有获取到的信息进行拼接
}
return args;
};
//页面自动加载
function page_load(){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
// alert("请求到的后端脚本为" + src);
img.src = src;
};
// 点击事件
function a_click(maps){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
for (var i in maps) {
params[i] = maps[i]
}
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
img.src = src;
}
page_load();
加载了这个脚本的页面会手动调用page_load()方法,这个技巧会将后端的数据伪装成一个长宽都为1象素img get恳求,请求明文如下
页面浏览报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp
页面点击报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp&pageid=index.html&pcpid=pcpid
浏览和点击报文,区别在于pageid=index.html&pcpid=pcpid,pcpid定义为页面位置【例如点击了某个链接;触发了a_click(maps)方法】;
使用这些方法主要是为了解决跨域的问题,因为大多数情况下,统计脚本不单单为一个站点服务,域名也不可能全都一样;
服务端插口
http://localhost:8089/flow/log.gif?args=params
采集端代码如下【省略push kafka过程】
package com.fan.ga.gaserver.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import javax.imageio.ImageIO;
import javax.servlet.http.HttpServletResponse;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.io.OutputStream;
@Controller
@RequestMapping("/flow")
public class LogCollector {
Logger logger = LoggerFactory.getLogger(LogCollector.class);
// http://localhost:8089/flow/log.gif?args=asfafd
@RequestMapping(value = "log.gif")
public void analysis(String args, HttpServletResponse response) throws IOException {
logger.info(args);
response.setHeader("Pragma", "No-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
response.setContentType("image/gif");
OutputStream out = response.getOutputStream();
BufferedImage image = new BufferedImage(1, 1, BufferedImage.TYPE_INT_RGB);
ImageIO.write(image, "gif", out);
out.flush();
}
}
站点index.html页面
page test
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
首页
detail
End
如何采集小红书最新版(2018年9月)数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-08-23 20:21
本文原创作者:鲲之鹏()
本文原创链接:
小红书(),号称拥有超过一亿用户的生活方式分享社区,其用户笔记内容涵括吃穿玩乐买,涉及潮流、护肤、彩妆、美食、旅行、影视、读书、健身等各个生活方式领域,再加上社区每晚形成数十亿次的笔记爆光,正如顾客所言,其平台是集social和commerce于一体的,其数据价值可想而知。
小红书的数据起初也并不难采集,通过Web版的搜索插口,结合相应的搜索词,就可以搜索到感兴趣的笔记,进而搜集到笔记的详情数据。然而好景不长,随着小红书完成了一轮超过 3 亿美元的财务融资,小红书的平台插口也发生了很大的变化:Web版的搜索插口直接关掉,小红书App的应用成为主流。这样一来,之前通过Web版的搜索插口来抓取数据的方式,就直接被封死了。
既然Web版的插口不能用了,那就只能瞧瞧App的插口了。通过抓包工具,可以获取到小红书App的搜索插口。
这里使用的搜索词是“香奈儿63”,对应的搜索插口URL如下:
%E9%A6%99%E5%A5%88%E5%84%BF63&filters=&sort=&page=1&page_size=20&source=explore_feed&search_id=927A522C26DC8FD699971F1B1C1F6838&platform=Android&deviceId=560c6663-a66f-3aab-aff8-a8fe7bc48809&device_fingerprint=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&versionName=5.24.1&channel=Sogou&sid=session.78290029&lang=zh-Hans&t=1536298303&sign=dd2764c4258e12db80fbe5df11e01af0
可以看见,App插口中的参数好多。然而经过测试,发现那些参数不能更改,改了递交都会失败。而且,这些参数(搜索词keyword除外)也未能自行构造(注意sign参数,这是现今反采集常用的签名保护机制)。看来此路不通啊,抓数之旅再度陷入僵局。
还好,细心的鲲鹏技术人员发觉,除了App,小红书还有个陌陌小程序,于是展开又一轮对小红书陌陌小程序的剖析研究。
再次抓包剖析发觉,小红书陌陌小程序的插口可以更改参数,但是其中三个参数看起来是有有效期的。
测试发觉,只要这三个参数有一定时间的有效期,那就可以在这个有效期内,改变keyword进行搜索,并得到正确的数据。 那么,怎么能第一时间获取到这三个参数呢?鲲鹏技术人员通过研究发觉,可以用模拟操作陌陌小程序的方式,自动操作手机上的小红书小程序,同时用程序手动抓包截取,提取到最新的插口参数以供爬虫使用(如下图所示)。
敢想敢为,鲲鹏技术人员积极探求,大胆尝试,克服重重困难,终把看法弄成了现实。首先通过手动模拟操作程序,操作手机上的小红书小程序,然后抓包提取到最新的插口参数;接下来使用获取到的插口参数,结合搜索词执行搜索,并搜集搜索结果中的笔记相关数据;最后步入笔记详情页,提取所有须要的相关数据。大功告成!
附:
通过小红书陌陌小程序插口抓取到的搜索结果数据(部分数组)示例如下图:
点击这儿可以查看在线示例数据
说明:该文章为鲲之鹏()原创文章 ,您不仅可以发表评论外,还可以转载到别的网站,但是请保留源地址,谢谢!!(尊重别人劳动,我们共同努力) 查看全部
如何采集小红书最新版(2018年9月)数据
本文原创作者:鲲之鹏()
本文原创链接:
小红书(),号称拥有超过一亿用户的生活方式分享社区,其用户笔记内容涵括吃穿玩乐买,涉及潮流、护肤、彩妆、美食、旅行、影视、读书、健身等各个生活方式领域,再加上社区每晚形成数十亿次的笔记爆光,正如顾客所言,其平台是集social和commerce于一体的,其数据价值可想而知。
小红书的数据起初也并不难采集,通过Web版的搜索插口,结合相应的搜索词,就可以搜索到感兴趣的笔记,进而搜集到笔记的详情数据。然而好景不长,随着小红书完成了一轮超过 3 亿美元的财务融资,小红书的平台插口也发生了很大的变化:Web版的搜索插口直接关掉,小红书App的应用成为主流。这样一来,之前通过Web版的搜索插口来抓取数据的方式,就直接被封死了。
既然Web版的插口不能用了,那就只能瞧瞧App的插口了。通过抓包工具,可以获取到小红书App的搜索插口。
这里使用的搜索词是“香奈儿63”,对应的搜索插口URL如下:
%E9%A6%99%E5%A5%88%E5%84%BF63&filters=&sort=&page=1&page_size=20&source=explore_feed&search_id=927A522C26DC8FD699971F1B1C1F6838&platform=Android&deviceId=560c6663-a66f-3aab-aff8-a8fe7bc48809&device_fingerprint=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&versionName=5.24.1&channel=Sogou&sid=session.78290029&lang=zh-Hans&t=1536298303&sign=dd2764c4258e12db80fbe5df11e01af0
可以看见,App插口中的参数好多。然而经过测试,发现那些参数不能更改,改了递交都会失败。而且,这些参数(搜索词keyword除外)也未能自行构造(注意sign参数,这是现今反采集常用的签名保护机制)。看来此路不通啊,抓数之旅再度陷入僵局。
还好,细心的鲲鹏技术人员发觉,除了App,小红书还有个陌陌小程序,于是展开又一轮对小红书陌陌小程序的剖析研究。
再次抓包剖析发觉,小红书陌陌小程序的插口可以更改参数,但是其中三个参数看起来是有有效期的。
测试发觉,只要这三个参数有一定时间的有效期,那就可以在这个有效期内,改变keyword进行搜索,并得到正确的数据。 那么,怎么能第一时间获取到这三个参数呢?鲲鹏技术人员通过研究发觉,可以用模拟操作陌陌小程序的方式,自动操作手机上的小红书小程序,同时用程序手动抓包截取,提取到最新的插口参数以供爬虫使用(如下图所示)。
敢想敢为,鲲鹏技术人员积极探求,大胆尝试,克服重重困难,终把看法弄成了现实。首先通过手动模拟操作程序,操作手机上的小红书小程序,然后抓包提取到最新的插口参数;接下来使用获取到的插口参数,结合搜索词执行搜索,并搜集搜索结果中的笔记相关数据;最后步入笔记详情页,提取所有须要的相关数据。大功告成!
附:
通过小红书陌陌小程序插口抓取到的搜索结果数据(部分数组)示例如下图:
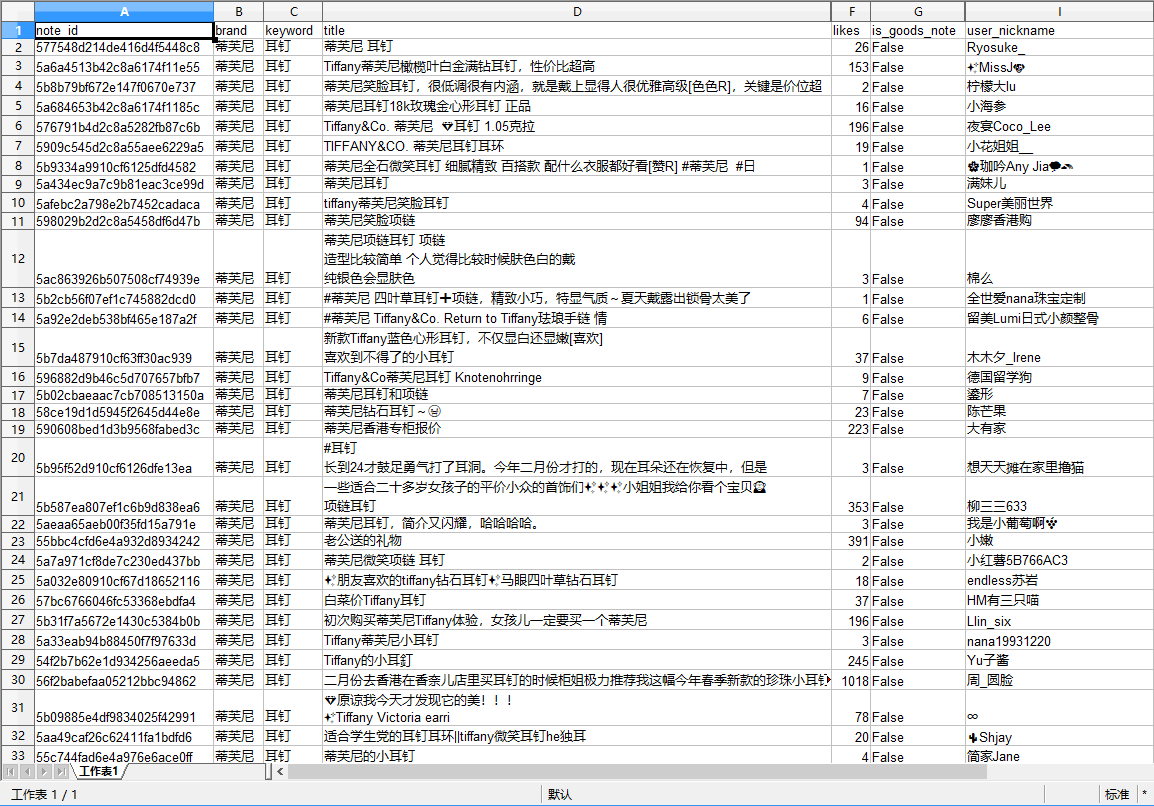
点击这儿可以查看在线示例数据
说明:该文章为鲲之鹏()原创文章 ,您不仅可以发表评论外,还可以转载到别的网站,但是请保留源地址,谢谢!!(尊重别人劳动,我们共同努力)
内容网数据采集接口定义及手动处理流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-08-21 17:21
数据采集及手动处理流程1 概述 本文主要描述内容网库对外定义的数据采集接口以及对于那些采集数据的手动处理流程。通过对现速网的剖析,我们觉得对于数据的采集主要是通过手工形式,爬虫爬取形式进行的,对于其他的采集方式,网信其实有提到,但是我们在如今的速网后台没有发觉相应的模块,希望网信相关人员通过对该文档的阅读,对于我们缺乏的采集接口做及时的补充。对于我们下边所设计的插口,希望网信相关人员可以提供测试数据供我们测试,2 采集接口定义2.1 爬虫 BT 接口2.1.1 待确认问题由于在原有的速网后台中,我们没有发觉该插口的设置界面,所以请相关人员就一下几个问题给予解答1. 爬虫是否会去爬取 BT 的信息2. 如果爬虫会爬取 BT 的信息,那么和 HTTP 爬取的信息是否一致?3. Bt 爬虫爬取的数据与 Bt 主动缓存解析的数据有哪些区别基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计1.爬虫会爬取 BT 信息2.爬虫爬取的信息仅收录资源信息。2.1.2 接口设计调用方:爬虫系统调用频度:当发觉爬取到新的数据时实时调用或则每晚定时调用约束:确保每次发送的信息都是最新批次的数据输入参数: 输入参数明细如下18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准输出:成功或则失败。
2.2 爬虫 HTTP 接口2.2.1 待确认问题1. 爬虫爬取 HTTP 在线资源时,资源资料信息是否同时采集?2. Http 爬取的资源中 是否带有电影名称 ,集数?基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计爬虫爬取 HTTP 在线资源时,资源和资料信息不是同时进行采集2.2.2 接口设计2.2.2.1 爬虫 HTTP 资源插口 18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准2.2.2.2 爬虫 HTTP 资料插口 编号 字段名称 说明 备注2 NAME 名称 电影名称3 LABEL 别名 4 DESCRIPTION 描述 电影的剧情描述5 HPOSTER 横向海报 6 VPOSTER 竖向海报 7 IS_HOT 是否热点 8 TAG Tag 栏 9 CHILDREN_COUNT 子集数目 10 AUTHOR 编剧 11 TV_NAME 电视台名 12 TV_HOST 主持人 13 SPAN 时长 播放时间14 COMMENTS 点评 15 LANGUAGE 影视语言(FK) 16 ACTORS 主要艺人 17 DIRECTORS 导演 18 PLAYDATE 影视开播日期 19 COUNTRY 地区分类(FK) 20 MOVIETYPE 影视分类(FK) 21 CONTENT_TYPE 题材分类(FK) 22 AVG_MARKS 评分 23 capture_site 采集点 判断是不是 10 大门户网站24 channel 频道 可用于分辨是否有集数,主演作者等一系列数组3 3 自动处理流程 手动处理流程的目的是对于采集接口获得的数据通过系统的手动内容筛选,自动内容质控,自动内容发布功能增强入库数据的质量,减轻人工编辑的工作量。
3.1 规则列表下方表格中定义了我们归纳出的筛选,质控,发布的规则,平台的规则引擎会手动按照下方的规则对数据进行处理。请按照实际情况对这种规则进行确认以及补充。筛选规则屏蔽资料垃圾数据通过对电影名称,播放地址进行非空判别。如有空数组,则把该数据放在垃圾表中处理。(资料) 屏蔽资源垃圾数据通过对电影名称,播放地址进行排空处理。如有空数组,则把该数据放在垃圾表中处理。(资源) 采集信息资料去重对“影片名称”进行比对。如有相同数据,则把该相对数据内容不全的资料放在垃圾表中处理。 采集信息资源去重对“播放地址”,“infohash”进行比对。如果数据相同。则删掉其中一条记录。 元数据资料去重 通过影片名,别名与元数据中原先资料进行对比,如果有相同资料,则此资料不添加到元数据库中。 元数据资源去重 http通过播放地址进行对比,bt通过infohash值进行对比。如找到相同记录,此资源状态改为屏蔽 添加到元数据库中。绑定入库 如果在去重阶段未找到相同记录。通过查找对应的电影名(资料查找资源) 进行绑定,反之,亦然。(资源 资料)对于有父子级关系的(例如电视剧)资料。如果库中没有子集资料。父子资料会手动生成子集资料供资源绑定。
审核规则合法性校准 判断各数组中是否有关键词(例如:黄色词句),如果有则转到人工待初审(资源 资料通用)资源有效性校准 资源是否属于 10 大门户网站,如果是直接初审通过。向播放地址发送 ping 看是否有效。资料内容校准 首先判定资料是否属于 10 大门户网站,如果是,直接初审通过。对别称中出现的冒号,顿号手动转换成"/".去除”/“两边的空格。评分数组倘若高于 5 分,自动转为 5 分以上,如果评分为整数,则添加一位小数。对于编剧,演员,自动清除每一行的 前后空格。 对于剧情描述,首行空 2 个空格,自动添加或删掉多余空格。对于艺人,导演,如果名子不全(例如:张艺谋,但资料中是张艺)查找字典表,自动补全名称。演员亦是这么。 对于地区:如果地区为空,可通过艺人,导演来推测是那个地区。 假如频道对应的剧集,影片。那么艺人,导演不能为空。如果对应是动画,那么作者不能为空。如果对应是综艺,那么主持人,电视台不能为空。不符合规则,转为人工代初审分布管理规则 资源发布规则 根据资源的热度(点击率,排行,搜索次数)划分出若干个等级,根据热度等级的结合每位局点的缓存情况,下发到各个局点。
例如将热度分为高,普通,低3 个等级,对于等级为高的资源下发所有局点,对于热度为普通的资源只下发到缓存空间多的局点,对于热度等级为低的资源只下发到本地。缓存优化规则 1.当发觉某个资源的缓存进度仍然处于比较低的时侯,根据规则替换或则删掉该缓存2.当发觉一个资源被缓存多次时,应依据资源的缓存进度保留进度最高的资源,删除其他资源缓存。3.当发觉局点缓存空间过高,应按照每位资源的热度,缓存情况,清理资源,清理热度低,缓存进度低的资源。3.2 详尽描述 1 资源处理流程图资源在入库前,会进行完整性校准,同批次去重,资源可靠性初审等多重步骤,保证步入元数据的资源是真实可用。 资源在入库后会定时调用初审规则查看资源库中的数据是否符合初审条件,对于早已失效的链接等进行剔除操作。并且对符合发布条件的资源调用 分布管理机制,保证资源的最大利用率。2 资料处理流程图资料在入库前,会进行完整性校准,同批次去重,与元数据库去重等多重步骤,保证元数据的资料是惟一的。并且在入库之前也会调用哪些初审规则,尽量提早修正资料的中错误。 资料在入库后会定时调用初审规则查看资料库中数据完整性,可靠性,并对一些数据手动进行校准,修正。
并且对符合发布条件的资料进行发布。4 补充问题 合作伙伴引入调用插口在哪,该怎么调用,能否提供?三严三实举办以来,我认真学习了习近平总书记系列讲话,研读了中央、区、市、县关于党的群众路线教育实践活动有关文件和资料。我对个人“四风”方面存在的问题及缘由进行了认真的反省、查摆和分析,找出了自身存在的众多差别和不足,理出了问题存在的缘由,明确了今后努力的方向和整改举措。现将对照检测情况报告如下,不妥之处,敬请诸位领导和同志们批评见谅。 一、存在的突出问题 一是学习深度广度不够。学习上存在形式主义,学习的全面性和系统性不强,在抽时间和挤时间学习上还不够自觉,致使自己的学习无论从广度和深度上都有些缺乏。学习制度坚持的不好,客观上指出工作忙、压力大和事务多,有时不耐心、不耐烦、不耐久,实则是缺少学习的拼劲和恒心。学用结合的关系处理的不够好,写文章、搞材料有时上网堆砌,求全求美求好看,结合本单位和实际工作的实质内容少,实用性不强。比如,每天对各级各种报纸甚少及时去阅读。因而,使自己的知识水平跟不上新形势的须要,工作标准不高,唱功好,做功差,忽视了理论对实际工作的指导作用。 二是服务不深入不主动。
工作上有时习惯于按部就班,习惯于常规思维,习惯于凭老观念想新问题,在统筹全局、分工协作、围绕中心、协调方方面面上还不够好。存在着为领导服务、为基层服务不够到位的问题,参谋和助手作用发挥得不够充分。比如,到乡镇、部门、企业了解情况,有时浮皮潦草,不够全面系统。与基层群众谈心交流少,没有真正深入到群众当中了解一线情况,掌握的第一手资料不全不深,“书到用时方恨少”,不能为领导决策提供更好的服务。 三是工作执行力不强。日常工作中与办公室同志谈心谈话少,对党员思想状态了解不深,疏于管理。办公室其实制订颁布了公文代办、工作守则等规章制度,但执行的意识不强,有时流于形式。比如,办公场所禁止吸烟,这一点我没有严格执行,有时还在办公室抽烟。 四是工作创新力不高。有时工作上习惯于照猫画虎,工作但求过得去、不求过得硬,存在着求稳怕乱的思想和患得患失心理,导致工作上不能完全放开四肢、甩开手臂去干,缺少一种勇于负责的担当和魄力。比如,做协调工作,有时真成了“传麦克风”和“二传手”,只传达领导交办的事项,缺乏与有关领导和同志共同接洽怎样把事情做得更好,创造性地举办工作。 五是深入基层调查研究不够。工作中,有时疏于具体事务,到基层一线督查不多,针对性不强,有时为了完成任务而督查,多了一些“官气”、少了一些“士气”。
往往是听汇报的多,直接聆听群众意见的少;了解面上情况多,发现深层次问题少。比如,对省委提出的用三分之一时间下基层搞督查活动,在实际工作中却没有做到。即使下基层,有时也是走马观花,蜻蜓点水,让看什么看哪些,让听哪些听哪些。在基层扶贫工作上,有时只重视出谋划策,抓落实、抓具体的少,对群众身边的一些小事情、小问题关心少、关注不够。 六是主观能动性发挥不够。自觉得在办公室工作多年,已经能否胜任工作,有自傲情绪,缺乏俯下身子、虚心讨教、不耻下问的心态。对待新问题、新情况,习惯于按照简单经验提出解决办法,创新不足,主观上存在满足现况,不思进取思想,主观能动性发挥不够。 七是对工作细节注重不够。作为办公室负责人,存在抓大放小,不能做到知上、知下、知左、知右、知里、知外,有时在一些小的问题上、细节上没有做好,导致工作落实不到位,出现误差。 八是工作效率不是很高。面对比较繁杂的工作任务,工作有时拈轻怕重、拖拉应付、不够认真。存在不推不动、不够主动,推一推进一动、有些被动。比如,文稿材料的撰写,有时东拼西凑、生搬硬套、缺乏深入思索。有时也存在着推诿扯皮现象,不能及时完成,质量也无法保证。对于领导交办的事项,有时跟踪、督导的不够,不能及时协调代办,缺乏应有的紧迫感,缺乏开拓创新精神,致使工作效率不高。
二、产生问题的诱因剖析 认真反省和深刻探讨自身存在的问题与不足,主要是自己没有强化世界观、人生观、价值观的改建,不重视提升自身修养,同时受社会不良风气的影响,在具体应对上没有挺好地掌握自己,碍于情面随波逐流。产生问题的缘由主要有以下几方面。 (一)自身放松了政治理论学习。对政治理论学习的重要性认识不足,重视程度不够。尤其是在处理工作与学习关系方面,把工作当做硬任务,把学习当做软指标,对政治理论学习投入的心思和精力不足,缺乏自觉学习的主动性和积极性。 (二)宗旨意识有所淡化。由于乡镇工作比较辛苦,从基层回到机关工作后,产生了松口气的念头,有时不自觉形成了优越感和骄傲自满的情绪。听惯了来自各方面的赞扬之声,深入基层少,对群众的呼声、疾苦、困难了解不够,没有树立较强的大局意识和责任意识,使得自己有时会片面地觉得只要做好本职工作,完成领导交办的任务就行了,而无法完全发挥自身的主观能动性,缺乏做好工作应有的责任心和紧迫感。 (三)忧患意识不强。只是片面见到了自身工作生活环境的变化,吃苦耐劳的精神有些欠缺,开拓进取、奋发有为、敢于冲锋、勇于担当的锐气有所弱化。有做“太平官”的意识,身处领导岗位,求新、求发展意识薄弱,表率作用发挥得不够好,忽视了工作的积极性、主动性和创造性。
(四)勤政廉政意识有所弱化。随着自身经济条件的改善,降低了约束标准,勤俭节约的传统美德有些淡化,对奢靡之风的极端危害性认识不足,没有造成高度注重。 诚然,造成自身存 在问题的诱因远不止这种,还有好多,如自身的固化思维方法,缺乏居安思危的深层次思索等。 三、今后的努力方向和改进举措 查摆问题,剖析症结,关键在于“洗澡治病”、解决问题。本人决心从党性原则出发,端正心态、认真对待,在今后的工作中采取强有力举措,立行立改,取得实效。 (一)求真务实 办公室校长作为承上启下、协调全局、沟通内外的重要角色,要立足发展、改革的新形势、新情况,以务实的作风和良好的品质作出垂范。 一是提高大局意识。要站在全局高度想问题,立足本职岗位做工作。要重视换位思索,真正做到想领导之所想、谋领导之所谋,及早提出比较成熟的意见和建议,供领导决策参考。要擅于从错综复杂的事务性工作中解脱下来,理清思路,明确目标,发挥自己应有的作用。 二是提高超前意识。要认真研究领会组织意图和领导思路,围绕领导关心的重大问题进行广泛深入的调查研究,为领导决策提供真实情况和可靠根据。要广泛采集资料,研究各乡镇、机关单位的新情况、新经验、新做法,借“他山之石”来攻玉,为领导提出决策预案。
因此,在想问题、办事情时,要赶前不赶后,尽可能早半拍、快半拍,提高敏感性,增强主动性。唯其这么,才能变被动为主动,“参谋”才能参在点子上,“助手”才能助到关键处。 三是提高创新意识。要加强服务理念,做深、做透、做好服务工作;要以协调、配合作为服务的主要手段和技巧,做到服务不越位;要围绕解决难点和热点问题举办服务,切实通过服务和协调把你们普遍关心、关注的热点焦点问题解决好,以实际行动取信于民。 (二)勤政为民 办公室既是贯彻落实省委、政府决议的执行部门,也是督促落实省委、政府决议的监督部门。破除官僚主义,勤政为民应该做好“四件事”。 一是擅于走入群众。从群众中来,到群众中去,是党的各项工作才能取得成功的一大法宝。开展群众路线教育活动,破解“官僚主义”,依靠的仍然是人民群众。工作中,要力戒高高在上、脱离群众、脱离实际的“官老爷”做派,多与群众接触,从群众中吸取智慧和力量,养成问计于民的好习惯。 二是敢于解难事。务实从严,是每位干部党员对待工作的正确心态。要把这些心态落实到每一项工作中去,要戒掉贪恋淫逸、讲求舒适、怕吃苦、饱食终日、碌碌无为的不良作风,承担起肩上的责任,做到为官一任,作为一方。
三是简化办事程序。要急群众所急、想群众所想,尽最大可能提升办事效率,加快办事速率,一切从实际出发,勤俭从政,效率为先。 四是接受监督。联系群众更要相信群众,加强民主更要多听民声。工作中时时处处应当考虑到群众利益,自觉主动接受群众监督,让工作举办得更有人气和活力。 (三)艰苦奋斗 要统筹制订领导干部办公用房、住房、配车、秘书配备、公务接待等工作生活待遇标准,落实不附赠、不接受礼品的规定,切实解决违背规定和超标准享受待遇的各类问题。要结合“治治病”的要求,按照中央八项规定,边学边查边整改,对照穿衣镜,深挖思想症结,净化心灵,摒弃享乐主义,坚持艰苦奋斗,以良好的精神状态和奋发有为的面貌赢取人民群众信任。 (四)廉洁自律 作为干部党员,无论什么时候,群众本色不能变,群众情结不能淡。要自觉强化党性修养,牢记全心全意为人民服务的宗旨,净化思想、洗涤灵魂、增强党性、明确航向。在一直保持为人民服务中追求高雅的生活情趣、锻造完善和谐的心理状态、 查看全部
内容网数据采集接口定义及手动处理流程
数据采集及手动处理流程1 概述 本文主要描述内容网库对外定义的数据采集接口以及对于那些采集数据的手动处理流程。通过对现速网的剖析,我们觉得对于数据的采集主要是通过手工形式,爬虫爬取形式进行的,对于其他的采集方式,网信其实有提到,但是我们在如今的速网后台没有发觉相应的模块,希望网信相关人员通过对该文档的阅读,对于我们缺乏的采集接口做及时的补充。对于我们下边所设计的插口,希望网信相关人员可以提供测试数据供我们测试,2 采集接口定义2.1 爬虫 BT 接口2.1.1 待确认问题由于在原有的速网后台中,我们没有发觉该插口的设置界面,所以请相关人员就一下几个问题给予解答1. 爬虫是否会去爬取 BT 的信息2. 如果爬虫会爬取 BT 的信息,那么和 HTTP 爬取的信息是否一致?3. Bt 爬虫爬取的数据与 Bt 主动缓存解析的数据有哪些区别基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计1.爬虫会爬取 BT 信息2.爬虫爬取的信息仅收录资源信息。2.1.2 接口设计调用方:爬虫系统调用频度:当发觉爬取到新的数据时实时调用或则每晚定时调用约束:确保每次发送的信息都是最新批次的数据输入参数: 输入参数明细如下18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准输出:成功或则失败。
2.2 爬虫 HTTP 接口2.2.1 待确认问题1. 爬虫爬取 HTTP 在线资源时,资源资料信息是否同时采集?2. Http 爬取的资源中 是否带有电影名称 ,集数?基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计爬虫爬取 HTTP 在线资源时,资源和资料信息不是同时进行采集2.2.2 接口设计2.2.2.1 爬虫 HTTP 资源插口 18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准2.2.2.2 爬虫 HTTP 资料插口 编号 字段名称 说明 备注2 NAME 名称 电影名称3 LABEL 别名 4 DESCRIPTION 描述 电影的剧情描述5 HPOSTER 横向海报 6 VPOSTER 竖向海报 7 IS_HOT 是否热点 8 TAG Tag 栏 9 CHILDREN_COUNT 子集数目 10 AUTHOR 编剧 11 TV_NAME 电视台名 12 TV_HOST 主持人 13 SPAN 时长 播放时间14 COMMENTS 点评 15 LANGUAGE 影视语言(FK) 16 ACTORS 主要艺人 17 DIRECTORS 导演 18 PLAYDATE 影视开播日期 19 COUNTRY 地区分类(FK) 20 MOVIETYPE 影视分类(FK) 21 CONTENT_TYPE 题材分类(FK) 22 AVG_MARKS 评分 23 capture_site 采集点 判断是不是 10 大门户网站24 channel 频道 可用于分辨是否有集数,主演作者等一系列数组3 3 自动处理流程 手动处理流程的目的是对于采集接口获得的数据通过系统的手动内容筛选,自动内容质控,自动内容发布功能增强入库数据的质量,减轻人工编辑的工作量。
3.1 规则列表下方表格中定义了我们归纳出的筛选,质控,发布的规则,平台的规则引擎会手动按照下方的规则对数据进行处理。请按照实际情况对这种规则进行确认以及补充。筛选规则屏蔽资料垃圾数据通过对电影名称,播放地址进行非空判别。如有空数组,则把该数据放在垃圾表中处理。(资料) 屏蔽资源垃圾数据通过对电影名称,播放地址进行排空处理。如有空数组,则把该数据放在垃圾表中处理。(资源) 采集信息资料去重对“影片名称”进行比对。如有相同数据,则把该相对数据内容不全的资料放在垃圾表中处理。 采集信息资源去重对“播放地址”,“infohash”进行比对。如果数据相同。则删掉其中一条记录。 元数据资料去重 通过影片名,别名与元数据中原先资料进行对比,如果有相同资料,则此资料不添加到元数据库中。 元数据资源去重 http通过播放地址进行对比,bt通过infohash值进行对比。如找到相同记录,此资源状态改为屏蔽 添加到元数据库中。绑定入库 如果在去重阶段未找到相同记录。通过查找对应的电影名(资料查找资源) 进行绑定,反之,亦然。(资源 资料)对于有父子级关系的(例如电视剧)资料。如果库中没有子集资料。父子资料会手动生成子集资料供资源绑定。
审核规则合法性校准 判断各数组中是否有关键词(例如:黄色词句),如果有则转到人工待初审(资源 资料通用)资源有效性校准 资源是否属于 10 大门户网站,如果是直接初审通过。向播放地址发送 ping 看是否有效。资料内容校准 首先判定资料是否属于 10 大门户网站,如果是,直接初审通过。对别称中出现的冒号,顿号手动转换成"/".去除”/“两边的空格。评分数组倘若高于 5 分,自动转为 5 分以上,如果评分为整数,则添加一位小数。对于编剧,演员,自动清除每一行的 前后空格。 对于剧情描述,首行空 2 个空格,自动添加或删掉多余空格。对于艺人,导演,如果名子不全(例如:张艺谋,但资料中是张艺)查找字典表,自动补全名称。演员亦是这么。 对于地区:如果地区为空,可通过艺人,导演来推测是那个地区。 假如频道对应的剧集,影片。那么艺人,导演不能为空。如果对应是动画,那么作者不能为空。如果对应是综艺,那么主持人,电视台不能为空。不符合规则,转为人工代初审分布管理规则 资源发布规则 根据资源的热度(点击率,排行,搜索次数)划分出若干个等级,根据热度等级的结合每位局点的缓存情况,下发到各个局点。
例如将热度分为高,普通,低3 个等级,对于等级为高的资源下发所有局点,对于热度为普通的资源只下发到缓存空间多的局点,对于热度等级为低的资源只下发到本地。缓存优化规则 1.当发觉某个资源的缓存进度仍然处于比较低的时侯,根据规则替换或则删掉该缓存2.当发觉一个资源被缓存多次时,应依据资源的缓存进度保留进度最高的资源,删除其他资源缓存。3.当发觉局点缓存空间过高,应按照每位资源的热度,缓存情况,清理资源,清理热度低,缓存进度低的资源。3.2 详尽描述 1 资源处理流程图资源在入库前,会进行完整性校准,同批次去重,资源可靠性初审等多重步骤,保证步入元数据的资源是真实可用。 资源在入库后会定时调用初审规则查看资源库中的数据是否符合初审条件,对于早已失效的链接等进行剔除操作。并且对符合发布条件的资源调用 分布管理机制,保证资源的最大利用率。2 资料处理流程图资料在入库前,会进行完整性校准,同批次去重,与元数据库去重等多重步骤,保证元数据的资料是惟一的。并且在入库之前也会调用哪些初审规则,尽量提早修正资料的中错误。 资料在入库后会定时调用初审规则查看资料库中数据完整性,可靠性,并对一些数据手动进行校准,修正。
并且对符合发布条件的资料进行发布。4 补充问题 合作伙伴引入调用插口在哪,该怎么调用,能否提供?三严三实举办以来,我认真学习了习近平总书记系列讲话,研读了中央、区、市、县关于党的群众路线教育实践活动有关文件和资料。我对个人“四风”方面存在的问题及缘由进行了认真的反省、查摆和分析,找出了自身存在的众多差别和不足,理出了问题存在的缘由,明确了今后努力的方向和整改举措。现将对照检测情况报告如下,不妥之处,敬请诸位领导和同志们批评见谅。 一、存在的突出问题 一是学习深度广度不够。学习上存在形式主义,学习的全面性和系统性不强,在抽时间和挤时间学习上还不够自觉,致使自己的学习无论从广度和深度上都有些缺乏。学习制度坚持的不好,客观上指出工作忙、压力大和事务多,有时不耐心、不耐烦、不耐久,实则是缺少学习的拼劲和恒心。学用结合的关系处理的不够好,写文章、搞材料有时上网堆砌,求全求美求好看,结合本单位和实际工作的实质内容少,实用性不强。比如,每天对各级各种报纸甚少及时去阅读。因而,使自己的知识水平跟不上新形势的须要,工作标准不高,唱功好,做功差,忽视了理论对实际工作的指导作用。 二是服务不深入不主动。
工作上有时习惯于按部就班,习惯于常规思维,习惯于凭老观念想新问题,在统筹全局、分工协作、围绕中心、协调方方面面上还不够好。存在着为领导服务、为基层服务不够到位的问题,参谋和助手作用发挥得不够充分。比如,到乡镇、部门、企业了解情况,有时浮皮潦草,不够全面系统。与基层群众谈心交流少,没有真正深入到群众当中了解一线情况,掌握的第一手资料不全不深,“书到用时方恨少”,不能为领导决策提供更好的服务。 三是工作执行力不强。日常工作中与办公室同志谈心谈话少,对党员思想状态了解不深,疏于管理。办公室其实制订颁布了公文代办、工作守则等规章制度,但执行的意识不强,有时流于形式。比如,办公场所禁止吸烟,这一点我没有严格执行,有时还在办公室抽烟。 四是工作创新力不高。有时工作上习惯于照猫画虎,工作但求过得去、不求过得硬,存在着求稳怕乱的思想和患得患失心理,导致工作上不能完全放开四肢、甩开手臂去干,缺少一种勇于负责的担当和魄力。比如,做协调工作,有时真成了“传麦克风”和“二传手”,只传达领导交办的事项,缺乏与有关领导和同志共同接洽怎样把事情做得更好,创造性地举办工作。 五是深入基层调查研究不够。工作中,有时疏于具体事务,到基层一线督查不多,针对性不强,有时为了完成任务而督查,多了一些“官气”、少了一些“士气”。
往往是听汇报的多,直接聆听群众意见的少;了解面上情况多,发现深层次问题少。比如,对省委提出的用三分之一时间下基层搞督查活动,在实际工作中却没有做到。即使下基层,有时也是走马观花,蜻蜓点水,让看什么看哪些,让听哪些听哪些。在基层扶贫工作上,有时只重视出谋划策,抓落实、抓具体的少,对群众身边的一些小事情、小问题关心少、关注不够。 六是主观能动性发挥不够。自觉得在办公室工作多年,已经能否胜任工作,有自傲情绪,缺乏俯下身子、虚心讨教、不耻下问的心态。对待新问题、新情况,习惯于按照简单经验提出解决办法,创新不足,主观上存在满足现况,不思进取思想,主观能动性发挥不够。 七是对工作细节注重不够。作为办公室负责人,存在抓大放小,不能做到知上、知下、知左、知右、知里、知外,有时在一些小的问题上、细节上没有做好,导致工作落实不到位,出现误差。 八是工作效率不是很高。面对比较繁杂的工作任务,工作有时拈轻怕重、拖拉应付、不够认真。存在不推不动、不够主动,推一推进一动、有些被动。比如,文稿材料的撰写,有时东拼西凑、生搬硬套、缺乏深入思索。有时也存在着推诿扯皮现象,不能及时完成,质量也无法保证。对于领导交办的事项,有时跟踪、督导的不够,不能及时协调代办,缺乏应有的紧迫感,缺乏开拓创新精神,致使工作效率不高。
二、产生问题的诱因剖析 认真反省和深刻探讨自身存在的问题与不足,主要是自己没有强化世界观、人生观、价值观的改建,不重视提升自身修养,同时受社会不良风气的影响,在具体应对上没有挺好地掌握自己,碍于情面随波逐流。产生问题的缘由主要有以下几方面。 (一)自身放松了政治理论学习。对政治理论学习的重要性认识不足,重视程度不够。尤其是在处理工作与学习关系方面,把工作当做硬任务,把学习当做软指标,对政治理论学习投入的心思和精力不足,缺乏自觉学习的主动性和积极性。 (二)宗旨意识有所淡化。由于乡镇工作比较辛苦,从基层回到机关工作后,产生了松口气的念头,有时不自觉形成了优越感和骄傲自满的情绪。听惯了来自各方面的赞扬之声,深入基层少,对群众的呼声、疾苦、困难了解不够,没有树立较强的大局意识和责任意识,使得自己有时会片面地觉得只要做好本职工作,完成领导交办的任务就行了,而无法完全发挥自身的主观能动性,缺乏做好工作应有的责任心和紧迫感。 (三)忧患意识不强。只是片面见到了自身工作生活环境的变化,吃苦耐劳的精神有些欠缺,开拓进取、奋发有为、敢于冲锋、勇于担当的锐气有所弱化。有做“太平官”的意识,身处领导岗位,求新、求发展意识薄弱,表率作用发挥得不够好,忽视了工作的积极性、主动性和创造性。
(四)勤政廉政意识有所弱化。随着自身经济条件的改善,降低了约束标准,勤俭节约的传统美德有些淡化,对奢靡之风的极端危害性认识不足,没有造成高度注重。 诚然,造成自身存 在问题的诱因远不止这种,还有好多,如自身的固化思维方法,缺乏居安思危的深层次思索等。 三、今后的努力方向和改进举措 查摆问题,剖析症结,关键在于“洗澡治病”、解决问题。本人决心从党性原则出发,端正心态、认真对待,在今后的工作中采取强有力举措,立行立改,取得实效。 (一)求真务实 办公室校长作为承上启下、协调全局、沟通内外的重要角色,要立足发展、改革的新形势、新情况,以务实的作风和良好的品质作出垂范。 一是提高大局意识。要站在全局高度想问题,立足本职岗位做工作。要重视换位思索,真正做到想领导之所想、谋领导之所谋,及早提出比较成熟的意见和建议,供领导决策参考。要擅于从错综复杂的事务性工作中解脱下来,理清思路,明确目标,发挥自己应有的作用。 二是提高超前意识。要认真研究领会组织意图和领导思路,围绕领导关心的重大问题进行广泛深入的调查研究,为领导决策提供真实情况和可靠根据。要广泛采集资料,研究各乡镇、机关单位的新情况、新经验、新做法,借“他山之石”来攻玉,为领导提出决策预案。
因此,在想问题、办事情时,要赶前不赶后,尽可能早半拍、快半拍,提高敏感性,增强主动性。唯其这么,才能变被动为主动,“参谋”才能参在点子上,“助手”才能助到关键处。 三是提高创新意识。要加强服务理念,做深、做透、做好服务工作;要以协调、配合作为服务的主要手段和技巧,做到服务不越位;要围绕解决难点和热点问题举办服务,切实通过服务和协调把你们普遍关心、关注的热点焦点问题解决好,以实际行动取信于民。 (二)勤政为民 办公室既是贯彻落实省委、政府决议的执行部门,也是督促落实省委、政府决议的监督部门。破除官僚主义,勤政为民应该做好“四件事”。 一是擅于走入群众。从群众中来,到群众中去,是党的各项工作才能取得成功的一大法宝。开展群众路线教育活动,破解“官僚主义”,依靠的仍然是人民群众。工作中,要力戒高高在上、脱离群众、脱离实际的“官老爷”做派,多与群众接触,从群众中吸取智慧和力量,养成问计于民的好习惯。 二是敢于解难事。务实从严,是每位干部党员对待工作的正确心态。要把这些心态落实到每一项工作中去,要戒掉贪恋淫逸、讲求舒适、怕吃苦、饱食终日、碌碌无为的不良作风,承担起肩上的责任,做到为官一任,作为一方。
三是简化办事程序。要急群众所急、想群众所想,尽最大可能提升办事效率,加快办事速率,一切从实际出发,勤俭从政,效率为先。 四是接受监督。联系群众更要相信群众,加强民主更要多听民声。工作中时时处处应当考虑到群众利益,自觉主动接受群众监督,让工作举办得更有人气和活力。 (三)艰苦奋斗 要统筹制订领导干部办公用房、住房、配车、秘书配备、公务接待等工作生活待遇标准,落实不附赠、不接受礼品的规定,切实解决违背规定和超标准享受待遇的各类问题。要结合“治治病”的要求,按照中央八项规定,边学边查边整改,对照穿衣镜,深挖思想症结,净化心灵,摒弃享乐主义,坚持艰苦奋斗,以良好的精神状态和奋发有为的面貌赢取人民群众信任。 (四)廉洁自律 作为干部党员,无论什么时候,群众本色不能变,群众情结不能淡。要自觉强化党性修养,牢记全心全意为人民服务的宗旨,净化思想、洗涤灵魂、增强党性、明确航向。在一直保持为人民服务中追求高雅的生活情趣、锻造完善和谐的心理状态、
管理系统和帝国CMS两个建站系统那个更好
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-20 20:42
chinawoss
一个好的旅游网站管理系统(简称旅游CMS)最好具有自主知识产权和良好的升级机制,长期稳定的升级既能能保证系统功能越来越建立又能保证系统使用数据安全。
其次做为旅游CMS系统,网站的系统功能要建立,不应当存在网站前台诠释后台不能控制的功能,好的CMS系统包括前台的模块增减、排序都能从后台直接控制。同时要涵盖旅游行业运营所须要的系统常见功能。
产品系统Products
线路、酒店、门票、租车、机票、签证、团购(套餐)、个性订制;(可扩充导游、特产等功能);
文章系统Articles
目的地手册、游记功略、景点、图片相册、问答、点评、帮助系统;
用户系统Users
在线订单、在线支付、生成订单邮件/邮箱通知、点评、问答、短信短信群发;会员管理、供应商管理;
营销策略Marketing
SEO插口、社会化分享插口、积分、返现策略;出发地、目的地营销构架、支持泛解析二级域名结构、专题营销、广告管理、伪静态规则设置、生成静态页面等;
支付体系Payment
集成:支持支付宝、快钱、银联、汇潮等在线支付插口;
扩展插口Expansion
文章采集接口、Dz峰会、UCenter、Google电子地图;已集成:第三方登录插口、短信平台插口等;
设置中心Set center
目的地4级分类、属性2级自定义、内容分类自定义、出发地设置、站点设置、系统参数管理、数据备份、操作日志;
营销助手Assistant
关键词统计、关键词智能链接、tag词设置、访问来源统计、热搜词统计、智能sitemap、死链自查
增值应用Value-added
系统升级、模板替换、营销指导、问题反馈、扩展应用等;
最后做为旅游CMS系统要有开放的态度程序开源不加密是保证用户二次开发的基础,也是可以称为CMS系统的前提。如果程序加密了,很多核心的订制功能将收到限制,不利于后期特色营运。当然开源须要勇气,直接面对盗版横行,一方面须要旅游CMS系统提供良好的售后升级和营运指导彰显正版的价值,另一方面也须要我们自己使用者具有维护正版的正确认识,只有我们使用正版付费,才可能得到持续建立的售后支持和安全升级保证系统正常营运推广。 查看全部
管理系统和帝国CMS两个建站系统那个更好
chinawoss
一个好的旅游网站管理系统(简称旅游CMS)最好具有自主知识产权和良好的升级机制,长期稳定的升级既能能保证系统功能越来越建立又能保证系统使用数据安全。
其次做为旅游CMS系统,网站的系统功能要建立,不应当存在网站前台诠释后台不能控制的功能,好的CMS系统包括前台的模块增减、排序都能从后台直接控制。同时要涵盖旅游行业运营所须要的系统常见功能。
产品系统Products
线路、酒店、门票、租车、机票、签证、团购(套餐)、个性订制;(可扩充导游、特产等功能);
文章系统Articles
目的地手册、游记功略、景点、图片相册、问答、点评、帮助系统;
用户系统Users
在线订单、在线支付、生成订单邮件/邮箱通知、点评、问答、短信短信群发;会员管理、供应商管理;
营销策略Marketing
SEO插口、社会化分享插口、积分、返现策略;出发地、目的地营销构架、支持泛解析二级域名结构、专题营销、广告管理、伪静态规则设置、生成静态页面等;
支付体系Payment
集成:支持支付宝、快钱、银联、汇潮等在线支付插口;
扩展插口Expansion
文章采集接口、Dz峰会、UCenter、Google电子地图;已集成:第三方登录插口、短信平台插口等;
设置中心Set center
目的地4级分类、属性2级自定义、内容分类自定义、出发地设置、站点设置、系统参数管理、数据备份、操作日志;
营销助手Assistant
关键词统计、关键词智能链接、tag词设置、访问来源统计、热搜词统计、智能sitemap、死链自查
增值应用Value-added
系统升级、模板替换、营销指导、问题反馈、扩展应用等;
最后做为旅游CMS系统要有开放的态度程序开源不加密是保证用户二次开发的基础,也是可以称为CMS系统的前提。如果程序加密了,很多核心的订制功能将收到限制,不利于后期特色营运。当然开源须要勇气,直接面对盗版横行,一方面须要旅游CMS系统提供良好的售后升级和营运指导彰显正版的价值,另一方面也须要我们自己使用者具有维护正版的正确认识,只有我们使用正版付费,才可能得到持续建立的售后支持和安全升级保证系统正常营运推广。
DesToon7.0版优采云免登入采集接口 v20180514
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-19 18:17
DesToon7.0版优采云免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon7.0版优采云免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon7.0版优采云免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon7.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon7.0版优采云免登入采集接口截图 查看全部
DesToon7.0版优采云免登入采集接口 v20180514
DesToon7.0版优采云免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon7.0版优采云免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon7.0版优采云免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon7.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon7.0版优采云免登入采集接口截图
文章采集接口 [开源
采集交流 • 优采云 发表了文章 • 0 个评论 • 526 次浏览 • 2020-08-18 20:00
[开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [四] JSON数据解析
[DotnetSpider 系列目录]场景模拟
接上一篇, 假设因为漏存JD SKU对应的店面信息。这时我们须要重新完全采集所有的SKU数据吗?补爬的话历史数据就用不了了。因此,去易迅页面上找看是否有提供相关的插口。
查找API恳求插口
安装 Fiddler, 并打开
在谷歌浏览器中访问:,1343,9719
在Fiddler查找一条条的访问记录,找到我们想要的插口
编写爬虫
分析返回的数据结果,我们可以先写出数据对象的定义(观察Expression的值早已是JsonPath查询表达式了,同时Type必须设置为Type = SelectorType.JsonPath)。另外须要注意的是,这次的爬虫是更新型爬虫,就是说采集到的数据补充回原表,那么就一定要设置字段是哪些,即在数据类上添加字段的定义
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
定义Pipeline的类型为Update
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source= ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
由于返回的数据中还有一个json()这样的pagging,所以须要先做一个截取操作,框架提供了PageHandler插口,并且我们实现了大量常用的Handler,用于HTML的解析前的一些处理操作,因此完整的代码如下
public class JdShopDetailSpider : EntitySpiderBuilder
{
protected override EntitySpider GetEntitySpider()
{
var context = new EntitySpider(new Site())
{
TaskGroup = "JD SKU Weekly",
Identity = "JD Shop details " + DateTimeUtils.MondayRunId,
CachedSize = 1,
ThreadNum = 8,
Downloader = new HttpClientDownloader
{
DownloadCompleteHandlers = new IDownloadCompleteHandler[]
{
new SubContentHandler
{
Start = "json(",
End = ");",
StartOffset = 5,
EndOffset = 0
}
}
},
PrepareStartUrls = new PrepareStartUrls[]
{
new BaseDbPrepareStartUrls()
{
Source = DataSource.MySql,
ConnectString = "Database='test';Data Source= localhost;User ID=root;Password=1qazZAQ!;Port=3306",
QueryString = $"SELECT * FROM jd.sku_v2_{DateTimeUtils.MondayRunId} WHERE shopname is null or shopid is null order by sku",
Columns = new [] {new DataColumn { Name = "sku"} },
FormateStrings = new List { "http://chat1.jd.com/api/checkC ... st%3D{0}&callback=json" }
}
}
};
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source=localhost ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
context.AddEntityType(typeof(ProductUpdater), new TargetUrlExtractor
{
Region = new Selector { Type = SelectorType.XPath, Expression = "//*[@id=\"J_bottomPage\"]" },
Patterns = new List { @"&page=[0-9]+&" }
});
return context;
}
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
}
posted @ 2017-04-14 10:26网路蚂蚁阅读(1417)评论(0)编辑 查看全部
文章采集接口 [开源
[开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [四] JSON数据解析
[DotnetSpider 系列目录]场景模拟
接上一篇, 假设因为漏存JD SKU对应的店面信息。这时我们须要重新完全采集所有的SKU数据吗?补爬的话历史数据就用不了了。因此,去易迅页面上找看是否有提供相关的插口。
查找API恳求插口
安装 Fiddler, 并打开
在谷歌浏览器中访问:,1343,9719
在Fiddler查找一条条的访问记录,找到我们想要的插口

编写爬虫
分析返回的数据结果,我们可以先写出数据对象的定义(观察Expression的值早已是JsonPath查询表达式了,同时Type必须设置为Type = SelectorType.JsonPath)。另外须要注意的是,这次的爬虫是更新型爬虫,就是说采集到的数据补充回原表,那么就一定要设置字段是哪些,即在数据类上添加字段的定义

[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
定义Pipeline的类型为Update
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source= ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
由于返回的数据中还有一个json()这样的pagging,所以须要先做一个截取操作,框架提供了PageHandler插口,并且我们实现了大量常用的Handler,用于HTML的解析前的一些处理操作,因此完整的代码如下
public class JdShopDetailSpider : EntitySpiderBuilder
{
protected override EntitySpider GetEntitySpider()
{
var context = new EntitySpider(new Site())
{
TaskGroup = "JD SKU Weekly",
Identity = "JD Shop details " + DateTimeUtils.MondayRunId,
CachedSize = 1,
ThreadNum = 8,
Downloader = new HttpClientDownloader
{
DownloadCompleteHandlers = new IDownloadCompleteHandler[]
{
new SubContentHandler
{
Start = "json(",
End = ");",
StartOffset = 5,
EndOffset = 0
}
}
},
PrepareStartUrls = new PrepareStartUrls[]
{
new BaseDbPrepareStartUrls()
{
Source = DataSource.MySql,
ConnectString = "Database='test';Data Source= localhost;User ID=root;Password=1qazZAQ!;Port=3306",
QueryString = $"SELECT * FROM jd.sku_v2_{DateTimeUtils.MondayRunId} WHERE shopname is null or shopid is null order by sku",
Columns = new [] {new DataColumn { Name = "sku"} },
FormateStrings = new List { "http://chat1.jd.com/api/checkC ... st%3D{0}&callback=json" }
}
}
};
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source=localhost ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
context.AddEntityType(typeof(ProductUpdater), new TargetUrlExtractor
{
Region = new Selector { Type = SelectorType.XPath, Expression = "//*[@id=\"J_bottomPage\"]" },
Patterns = new List { @"&page=[0-9]+&" }
});
return context;
}
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
}
posted @ 2017-04-14 10:26网路蚂蚁阅读(1417)评论(0)编辑
最新微信公众号采集方案详尽介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2020-08-18 17:51
目前比较有效的几种微信公众号的采集方式:
1、通过web端素材管理插口的方法
2、通过appium从手机端
3、通过逆向工程暴力获取
4、通过第三方服务插口
5、搜狗微信公众号插口(已凉)
个人及小团体对公众号内容获取数目不多的情况下通常还会采用前两种相对简单方便成本低的方法去获取内容,不差钱的团队肯定就买第三方服务了,靠提供微信公众号采集接口的服务赢利的肯定就是逆向工程了.我介绍第一种比较简单适宜小规模采集的方案
1、首先我们须要注册个属于自己的公众号平台微信公众号注册地址
2、注册成功后步入点击如图所示的素材管理
3、点击素材管理后点击如图所示的新建图文消息
4、点击新建图文消息后点击如图所示的超链接
5、点解超链接后点击如图所示的选择其他公众号
6、这时候就可以输入我们想要获取公众号内容的名子去搜索查询
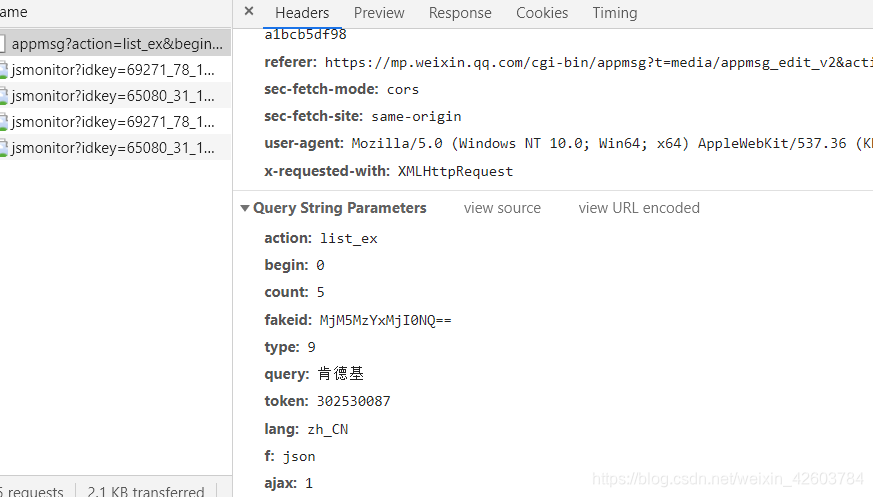
7、我们通过抓包查看剖析下
通过抓包也不难剖析出恳求参数的话就是我截图那样,稍后代码上将会呈现下来,然后通过恳求response返回的内容也可以看见诸如title、link、概要、更新时间等等的内容这儿我们主要取title和url,我要说明一下我们通过这些方法获取的link是临时链接并不是手机端打开那样的永久链接并且也无妨我们只要通过访问临时链接把内容下载出来就可以了这个临时链接的有效时长虽然也是太长时间的,如果我们想转换成永久链接我们可以通过手机端打开得到的就是永久链接地址了
大体概述下代码流程
1、调用登陆函数login_wechat通过webdrive扫码登陆微信公众号,这里不采用手动输入帐号密码的方法登陆是因为虽然输入帐号密码还是须要扫码确认
2、登录成功获取cookie信息保存本地cookie.txt文件
3、调用采集函数get_content获取cookie.txt的cookie值并提取token
4、拼接好我们须要的恳求参数后恳求素材管理中插口中我们待采集公众号信息
5、通过恳求插口获取文章的title、link并实现翻页功能
6、拿到我们待采集文章的link后恳求link地址下载文章内容
7、将title、link、内容对应保存csv文件 查看全部
最新微信公众号采集方案详尽介绍
目前比较有效的几种微信公众号的采集方式:
1、通过web端素材管理插口的方法
2、通过appium从手机端
3、通过逆向工程暴力获取
4、通过第三方服务插口
5、搜狗微信公众号插口(已凉)
个人及小团体对公众号内容获取数目不多的情况下通常还会采用前两种相对简单方便成本低的方法去获取内容,不差钱的团队肯定就买第三方服务了,靠提供微信公众号采集接口的服务赢利的肯定就是逆向工程了.我介绍第一种比较简单适宜小规模采集的方案
1、首先我们须要注册个属于自己的公众号平台微信公众号注册地址
2、注册成功后步入点击如图所示的素材管理
3、点击素材管理后点击如图所示的新建图文消息
4、点击新建图文消息后点击如图所示的超链接
5、点解超链接后点击如图所示的选择其他公众号
6、这时候就可以输入我们想要获取公众号内容的名子去搜索查询

7、我们通过抓包查看剖析下
通过抓包也不难剖析出恳求参数的话就是我截图那样,稍后代码上将会呈现下来,然后通过恳求response返回的内容也可以看见诸如title、link、概要、更新时间等等的内容这儿我们主要取title和url,我要说明一下我们通过这些方法获取的link是临时链接并不是手机端打开那样的永久链接并且也无妨我们只要通过访问临时链接把内容下载出来就可以了这个临时链接的有效时长虽然也是太长时间的,如果我们想转换成永久链接我们可以通过手机端打开得到的就是永久链接地址了
大体概述下代码流程
1、调用登陆函数login_wechat通过webdrive扫码登陆微信公众号,这里不采用手动输入帐号密码的方法登陆是因为虽然输入帐号密码还是须要扫码确认
2、登录成功获取cookie信息保存本地cookie.txt文件
3、调用采集函数get_content获取cookie.txt的cookie值并提取token
4、拼接好我们须要的恳求参数后恳求素材管理中插口中我们待采集公众号信息
5、通过恳求插口获取文章的title、link并实现翻页功能
6、拿到我们待采集文章的link后恳求link地址下载文章内容
7、将title、link、内容对应保存csv文件
优采云采集器下载地址 已被下载次
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2020-08-18 12:16
优采云采集器是任何一个须要从网页获取信息的利器,这个是一款可以使你的信息采集可以显得很简单的工具。优采云转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料编的愈发简单和容易了。
软件特色
满足多种业务场景
适合产品、运营、销售、数据剖析、政府机关、电商从业者、学术研究等多种身分职业
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的繁杂,支持更多网站的采集。
使用方式
先我们新建一个任务-->进入流程设计页面-->添加一个循环步骤到流程中-->选中循环步骤-->勾选上软件右方的URL 列表勾选框-->打开URL列表文本框-->将打算好的URL列表填写到文本框中
接下来往循环中推入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页
到这儿,循环打开网页的流程就配置完成了,运行流程的时侯,系统会挨个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。 查看全部
优采云采集器下载地址 已被下载次
优采云采集器是任何一个须要从网页获取信息的利器,这个是一款可以使你的信息采集可以显得很简单的工具。优采云转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料编的愈发简单和容易了。
软件特色
满足多种业务场景
适合产品、运营、销售、数据剖析、政府机关、电商从业者、学术研究等多种身分职业
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的繁杂,支持更多网站的采集。
使用方式
先我们新建一个任务-->进入流程设计页面-->添加一个循环步骤到流程中-->选中循环步骤-->勾选上软件右方的URL 列表勾选框-->打开URL列表文本框-->将打算好的URL列表填写到文本框中
接下来往循环中推入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页
到这儿,循环打开网页的流程就配置完成了,运行流程的时侯,系统会挨个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。
DesToon6.0 UTF8版免登入采集接口 v20180514
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-13 05:02
DesToon6.0 UTF8版免登入采集接口 v20180514更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DT采集专家 DesToon6.0免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 UTF8版免登入采集接口截图 查看全部
DesToon6.0 UTF8版免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon6.0 UTF8版免登入采集接口 v20180514更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DT采集专家 DesToon6.0免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 UTF8版免登入采集接口截图
最新百度博客发布插口 多帐号随机发布文章,推广神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-12 13:45
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客:
又做了百度的手动登入,百度之前我是不会模拟她的手动登入的,因为百度很早就早已把登陆表单数据通过javascript隐藏的就像18层地狱,多次尝试去读它的js代码,由于本人精力效率早已没有,没有往年那样可以有那个耐心去研究她的js,百度我也只是看了部份js,了解了少部份登陆相关的代码,然后去构造post数据 提交给登陆url,结果成功的登陆了百度,提交的post数据是正确的,获取了cookie。
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客: 查看全部
又做了百度的手动登入,百度之前我是不会模拟她的手动登入的,因为百度很早就早已把登陆表单数据通过javascript隐藏的就像18层地狱,多次尝试去读它的js代码,由于本人精力效率早已没有,没有往年那样可以有那个耐心去研究她的js,百度我也只是看了部份js,了解了少部份登陆相关的代码,然后去构造post数据 提交给登陆url,结果成功的登陆了百度,提交的post数据是正确的,获取了cookie。
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客:
又做了百度的手动登入,百度之前我是不会模拟她的手动登入的,因为百度很早就早已把登陆表单数据通过javascript隐藏的就像18层地狱,多次尝试去读它的js代码,由于本人精力效率早已没有,没有往年那样可以有那个耐心去研究她的js,百度我也只是看了部份js,了解了少部份登陆相关的代码,然后去构造post数据 提交给登陆url,结果成功的登陆了百度,提交的post数据是正确的,获取了cookie。
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客:
DesToon6.0 GBK版免登入采集接口 v20180514
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-12 11:34
DesToon6.0 GBK版免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon6.0 GBK版免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 GBK版免登入采集接口截图 查看全部
DesToon6.0 GBK版免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon6.0 GBK版免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon6.0 GBK版免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 GBK版免登入采集接口截图
做一个聚合类新闻app。负责爬虫相关联工作,很想知道同行的app怎么做的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-12 03:36
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。 查看全部
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。
面试官:比如有10万个网站,有哪些方式才能快速的采集到数据吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-10 17:29
字节跳动笔试锦集(二):项目HR高频笔试总结
数据采集采集架构中各模块详尽剖析
爬虫工程师,如何高效的支持数据剖析人员的工作?
基于大数据平台的互联网数据采集平台基本构架
数据采集中,如何构建一套行之有效的监控体系?
面试准备、HR、Android技术等笔试问题汇总
昨天有一个网友说,他近来笔试了几家公司,有一个问题被问到了好几次,每次都回答的不是很好。
面试官:比如有10万个网站需要采集,你有哪些方式快速的获取到数据?
想回答好这个问题,其实须要你有足够的知识面,有足够的技术储备。
最近,我们也在急聘,每周还会笔试十几个人,感觉合适的也就一两个,大多数和那位网友的情况差不多,都欠缺整体思维,那怕这些有三四年工作经验的老司机。他们解决具体问题的能力太强,却极少能由点及面,站在一个新的高度,全面思索问题。
10万个网站的采集覆盖度,已经比大多数的专业舆情监控公司的数据采集范围都广了。要达到面试官说的采集需求,就须要我们从网站的搜集,直到数据储存的各个方面进行综合考虑,给出一个合适的方案,以达到节约成本,提高工作效率的目的。
下面我们就从网站的搜集,直到数据储存的各方面,做个简单的介绍。
一、10万个网站从那里来?
一般来说,采集的网站,都是依照公司业务的发展,逐渐积累上去的。
我们如今假定,这是一个初创公司的需求。公司刚才创立,这么多网站,基本上可以说是冷启动。那么我们怎么搜集到这10万个网站呢?可以有以下几种形式:
1)历史业务的积累
不管是冷启动,还是哪些,既然有采集需求,一定是有项目或产品有这方面的需求,其相关的人员前期一定督查过一些数据来源,采集了一些比较重要的网站。这些都可以作为我们搜集网站和采集的原创种子。
2)关联网站
在一些网站的顶部,一般都有相关网站的链接。尤其是政府类型的网站,通常会有下级相关部门的官网。
3)网站导航
有些网站可能为了某种目的(比如引流等),采集一些网站,并对其进行归类进行展示,以便捷人们查找。这些网站可以快速的为我们提供第一批种子网站。然后,我们再通过网站关联等其他形式获取更多的网站。
4)搜索引擎
也可以打算一些与公司业务相关的关键词,去百度、搜狗等搜索引擎中搜索,通过对搜索结果进行处理,提取相应的网站,作为我们的种子网站。
5)第三方平台
比如一些第三方的SaaS平台,都会有7~15天的免费试用。所以,我们就可以借助这段时间,把与我们业务相关的数据采集下来,然后提取出其中的网站,作为我们初始采集种子。
虽然,这种方法是最有效,最快的网站采集方法。但是在试用期内,获取10万个网站的可能也极小,所以尚须要结合上述的关联网站等其他形式,以便快速获取所需网站。
通过以上五种方法,相信我们可以很快的搜集到,我们须要的10万个网站。但是,这么多网站,我们该怎么管理?如何晓得其正常与否呢?
二、10万个网站如何管理?
当我们搜集到10万个网站以后,首先面对的就是怎样管理、如何配置采集规则、如何监控网站正常与否等。
1)如何管理
10万个网站,如果没有专门的系统来管理,那将是一场灾难。
同时,可能因为业务的须要,比如智能推荐等,需要我们对网站进行一些预处理(比如打标签)。此时,一个网站管理系统将是必须的。
2)如何配置采集规则
前期我们搜集的10万个网站只是首页,如果只把首页作为采集任务,那么就只能采集到首页极少的信息,漏采率很大。
如果要按照首页URL进行全站采集,则对服务器资源消耗又比较大,成本偏高。所以,我们须要配置我们关心的栏目,并对其进行采集。
但是,10万个网站,如何快速、高效的配置栏目呢?目前,我们以手动解析HTML源码的方法,进行栏目的半自动化配置。
当然,我们也试验过机器学习的方法来处理,不过疗效还不是很理想。
由于须要采集的网站量达到10万级别,所以一定不要使用xpath等精确定位的方法进行采集。否则,等你把这10万网站配置好,黄花菜都凉了。
同时,数据采集一定要使用通用爬虫,使用正则表达式的形式来匹配列表数据。在采集正文时,通过使用算法来解析时间、正文等属性;
3)如何监控
由于有10万网站,这些网站中每晚还会有网站改版,或者栏目改版,或新增/下架栏目等。所以,需要按照采集的数据情况,简单的剖析一下网站的情况。
比如,一个网站几天都没有新数据,一定是出现了问题。要么网站改版,导致信息正则失效常,要么就是网站本身出现问题。
为了提升采集效率,可以使用一个单独的服务,每隔一段时间,检测一次网站和栏目的情况。一是测量网站、栏目是否能正常访问;二要检查配置的栏目信息正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万个网站,配置完栏目之后,采集的入口URL应当会达到百万级别。采集器怎么高效的获取这种入口URL进行采集呢?
如果把这种URL放在数据库中,不管是MySQL,还是Oracle,采集器获取采集任务这一操作,都会浪费好多时间,大大增加采集效率。
如何解决这个问题呢?内存数据库便是首选,如Redis、 Mongo DB 等。一般采集用Redis来做缓存。所以,可以在配置栏目的同时,把栏目信息同步到Redis中,作为采集任务缓存队列。
四、网站如何采集?
就像是你想达到月薪百万,最大机率是要去华为、阿里、腾讯这些一线大厂,而且还须要到一定的级别才行。这条路注定不易。
同样,如果须要采集百万级别的列表URL,常规的方式也一定是难以实现。
必须使用分布式+多进程+多线程的形式。同时,还须要结合显存数据库Redis等做缓存,已实现高效获取任务,以及对采集信息进行排重;
同时,信息的解析,如发布时间、正文等,也必须使用算法来处理。比如现今比较火的GNE,
有些属性,可以在列表采集时获取的,就尽量不要放在和正文一起进行解析。比如:标题。一般情况下,从列表中获取到的,标题的准确度,要远小于算法从信息html源码中解析的。
同时,如果有一些特殊网站、或者一些特殊需求,我们再采用订制开发的方法进行处理即可。
五、统一数据储存插口
为了保持采集的及时性,10万个网站的采集,可能须要十几二十台服务器。同时,每台服务器上又布署N个采集器,再加上一些订制开发的脚本,整体采集器的数目将会达到上百个。
如果每位采集器/定制脚本,都自行开发一套自己的数据保存插口,则开发、调试都会浪费不少时间。而且后续的运维,也将是一件非揪心的事情。尤其是业务有所变化,需要调整时。所以,统一数据储存插口还是太有必要的。
由于数据储存插口统一,当我们须要相对数据做一些特殊处理时,比如:清洗、矫正等,就不用再去更改每位采集存储部份,只须要更改一下插口,重新布署即可。
快速、方便、快捷。
六、数据及采集监控
10万个网站的采集覆盖度,每天的数据量绝对在200万以上。由于数据解析的算法无论多精确,总是不能达到100%(能达到90%就十分不错了)。所以,数据解析一定会存在异常情况。比如:发布时间小于当前时间、正文中收录相关新闻信息等等。
但是,由于我们统一了数据储存插口,此时就可以在插口处,进行统一的数据质量校准。以便按照异常情况,来优化采集器及订制脚本。
同时,还可以统计每位网站或栏目的数据采集情况。以便才能及时地判定,当前采集的网站/栏目信源是否正常,以便保证仍然有10万个有效的采集网站。
七、数据储存
由于每晚采集的数据量较大,普通的数据库(如:mysql、Oracle等)已经难以胜任。即使象Mongo DB这样的NoSql数据库,也早已不再适用。此时,ES、Solr等分布式索引是目前最好的选择。
至于是否上Hadoop、HBase等大数据平台,那就看具体情况了。在预算不多的情况下,可以先搭建分布式索引集群,大数据平台可以后续考虑。
为了保证查询的响应速率,分布式索引中尽量不要保存正文的信息。像标题、发布时间、URL等可以保存,这样在显示列表数据时可以降低二次查询。
在没有上大数据平台期间,可以把正文以固定的数据标准,保存到txt等文件系统中。后续上大数据平台后,再转存到HBASE中即可。
八、自动化运维
由于服务器、采集器,以及订制脚本较多,单纯的靠人工进行布署、启动、更新、运行情况监控等,已经变得十分的繁杂,且容易出现人为失误。
所以,必须有一套自动化运维系统,能够实现对采集器/脚本进行布署、启动、关闭、运行等,以便才能在出现变动时快速的响应。
“比如有10万个网站需要采集,你有哪些方式快速的获取到数据?”,如果你能回答出这种,拿到一个不错的offer应当没哪些悬念。
最后,愿正在找工作的诸位同学,都能收获满意的offer,找到一个不错的平台。
面试#数据采集 查看全部
字节跳动笔试锦集(一):Android Framework高频面试题总结
字节跳动笔试锦集(二):项目HR高频笔试总结
数据采集采集架构中各模块详尽剖析
爬虫工程师,如何高效的支持数据剖析人员的工作?
基于大数据平台的互联网数据采集平台基本构架
数据采集中,如何构建一套行之有效的监控体系?
面试准备、HR、Android技术等笔试问题汇总
昨天有一个网友说,他近来笔试了几家公司,有一个问题被问到了好几次,每次都回答的不是很好。
面试官:比如有10万个网站需要采集,你有哪些方式快速的获取到数据?
想回答好这个问题,其实须要你有足够的知识面,有足够的技术储备。
最近,我们也在急聘,每周还会笔试十几个人,感觉合适的也就一两个,大多数和那位网友的情况差不多,都欠缺整体思维,那怕这些有三四年工作经验的老司机。他们解决具体问题的能力太强,却极少能由点及面,站在一个新的高度,全面思索问题。
10万个网站的采集覆盖度,已经比大多数的专业舆情监控公司的数据采集范围都广了。要达到面试官说的采集需求,就须要我们从网站的搜集,直到数据储存的各个方面进行综合考虑,给出一个合适的方案,以达到节约成本,提高工作效率的目的。
下面我们就从网站的搜集,直到数据储存的各方面,做个简单的介绍。
一、10万个网站从那里来?
一般来说,采集的网站,都是依照公司业务的发展,逐渐积累上去的。
我们如今假定,这是一个初创公司的需求。公司刚才创立,这么多网站,基本上可以说是冷启动。那么我们怎么搜集到这10万个网站呢?可以有以下几种形式:
1)历史业务的积累
不管是冷启动,还是哪些,既然有采集需求,一定是有项目或产品有这方面的需求,其相关的人员前期一定督查过一些数据来源,采集了一些比较重要的网站。这些都可以作为我们搜集网站和采集的原创种子。
2)关联网站
在一些网站的顶部,一般都有相关网站的链接。尤其是政府类型的网站,通常会有下级相关部门的官网。
3)网站导航
有些网站可能为了某种目的(比如引流等),采集一些网站,并对其进行归类进行展示,以便捷人们查找。这些网站可以快速的为我们提供第一批种子网站。然后,我们再通过网站关联等其他形式获取更多的网站。
4)搜索引擎
也可以打算一些与公司业务相关的关键词,去百度、搜狗等搜索引擎中搜索,通过对搜索结果进行处理,提取相应的网站,作为我们的种子网站。
5)第三方平台
比如一些第三方的SaaS平台,都会有7~15天的免费试用。所以,我们就可以借助这段时间,把与我们业务相关的数据采集下来,然后提取出其中的网站,作为我们初始采集种子。
虽然,这种方法是最有效,最快的网站采集方法。但是在试用期内,获取10万个网站的可能也极小,所以尚须要结合上述的关联网站等其他形式,以便快速获取所需网站。
通过以上五种方法,相信我们可以很快的搜集到,我们须要的10万个网站。但是,这么多网站,我们该怎么管理?如何晓得其正常与否呢?
二、10万个网站如何管理?
当我们搜集到10万个网站以后,首先面对的就是怎样管理、如何配置采集规则、如何监控网站正常与否等。
1)如何管理
10万个网站,如果没有专门的系统来管理,那将是一场灾难。
同时,可能因为业务的须要,比如智能推荐等,需要我们对网站进行一些预处理(比如打标签)。此时,一个网站管理系统将是必须的。
2)如何配置采集规则
前期我们搜集的10万个网站只是首页,如果只把首页作为采集任务,那么就只能采集到首页极少的信息,漏采率很大。
如果要按照首页URL进行全站采集,则对服务器资源消耗又比较大,成本偏高。所以,我们须要配置我们关心的栏目,并对其进行采集。
但是,10万个网站,如何快速、高效的配置栏目呢?目前,我们以手动解析HTML源码的方法,进行栏目的半自动化配置。
当然,我们也试验过机器学习的方法来处理,不过疗效还不是很理想。
由于须要采集的网站量达到10万级别,所以一定不要使用xpath等精确定位的方法进行采集。否则,等你把这10万网站配置好,黄花菜都凉了。
同时,数据采集一定要使用通用爬虫,使用正则表达式的形式来匹配列表数据。在采集正文时,通过使用算法来解析时间、正文等属性;
3)如何监控
由于有10万网站,这些网站中每晚还会有网站改版,或者栏目改版,或新增/下架栏目等。所以,需要按照采集的数据情况,简单的剖析一下网站的情况。
比如,一个网站几天都没有新数据,一定是出现了问题。要么网站改版,导致信息正则失效常,要么就是网站本身出现问题。
为了提升采集效率,可以使用一个单独的服务,每隔一段时间,检测一次网站和栏目的情况。一是测量网站、栏目是否能正常访问;二要检查配置的栏目信息正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万个网站,配置完栏目之后,采集的入口URL应当会达到百万级别。采集器怎么高效的获取这种入口URL进行采集呢?
如果把这种URL放在数据库中,不管是MySQL,还是Oracle,采集器获取采集任务这一操作,都会浪费好多时间,大大增加采集效率。
如何解决这个问题呢?内存数据库便是首选,如Redis、 Mongo DB 等。一般采集用Redis来做缓存。所以,可以在配置栏目的同时,把栏目信息同步到Redis中,作为采集任务缓存队列。
四、网站如何采集?
就像是你想达到月薪百万,最大机率是要去华为、阿里、腾讯这些一线大厂,而且还须要到一定的级别才行。这条路注定不易。
同样,如果须要采集百万级别的列表URL,常规的方式也一定是难以实现。
必须使用分布式+多进程+多线程的形式。同时,还须要结合显存数据库Redis等做缓存,已实现高效获取任务,以及对采集信息进行排重;
同时,信息的解析,如发布时间、正文等,也必须使用算法来处理。比如现今比较火的GNE,
有些属性,可以在列表采集时获取的,就尽量不要放在和正文一起进行解析。比如:标题。一般情况下,从列表中获取到的,标题的准确度,要远小于算法从信息html源码中解析的。
同时,如果有一些特殊网站、或者一些特殊需求,我们再采用订制开发的方法进行处理即可。
五、统一数据储存插口
为了保持采集的及时性,10万个网站的采集,可能须要十几二十台服务器。同时,每台服务器上又布署N个采集器,再加上一些订制开发的脚本,整体采集器的数目将会达到上百个。
如果每位采集器/定制脚本,都自行开发一套自己的数据保存插口,则开发、调试都会浪费不少时间。而且后续的运维,也将是一件非揪心的事情。尤其是业务有所变化,需要调整时。所以,统一数据储存插口还是太有必要的。
由于数据储存插口统一,当我们须要相对数据做一些特殊处理时,比如:清洗、矫正等,就不用再去更改每位采集存储部份,只须要更改一下插口,重新布署即可。
快速、方便、快捷。
六、数据及采集监控
10万个网站的采集覆盖度,每天的数据量绝对在200万以上。由于数据解析的算法无论多精确,总是不能达到100%(能达到90%就十分不错了)。所以,数据解析一定会存在异常情况。比如:发布时间小于当前时间、正文中收录相关新闻信息等等。
但是,由于我们统一了数据储存插口,此时就可以在插口处,进行统一的数据质量校准。以便按照异常情况,来优化采集器及订制脚本。
同时,还可以统计每位网站或栏目的数据采集情况。以便才能及时地判定,当前采集的网站/栏目信源是否正常,以便保证仍然有10万个有效的采集网站。
七、数据储存
由于每晚采集的数据量较大,普通的数据库(如:mysql、Oracle等)已经难以胜任。即使象Mongo DB这样的NoSql数据库,也早已不再适用。此时,ES、Solr等分布式索引是目前最好的选择。
至于是否上Hadoop、HBase等大数据平台,那就看具体情况了。在预算不多的情况下,可以先搭建分布式索引集群,大数据平台可以后续考虑。
为了保证查询的响应速率,分布式索引中尽量不要保存正文的信息。像标题、发布时间、URL等可以保存,这样在显示列表数据时可以降低二次查询。
在没有上大数据平台期间,可以把正文以固定的数据标准,保存到txt等文件系统中。后续上大数据平台后,再转存到HBASE中即可。
八、自动化运维
由于服务器、采集器,以及订制脚本较多,单纯的靠人工进行布署、启动、更新、运行情况监控等,已经变得十分的繁杂,且容易出现人为失误。
所以,必须有一套自动化运维系统,能够实现对采集器/脚本进行布署、启动、关闭、运行等,以便才能在出现变动时快速的响应。
“比如有10万个网站需要采集,你有哪些方式快速的获取到数据?”,如果你能回答出这种,拿到一个不错的offer应当没哪些悬念。
最后,愿正在找工作的诸位同学,都能收获满意的offer,找到一个不错的平台。
面试#数据采集
网站数据批量采集服务|优采云免登录采集接口[DESTOON数据内容采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-10 16:21
DESTOON二次开发。DESTOON数据采集。
简单说明 :
用优采云采集器对提升工作效率确实很有用
每天要到第三方家装平台上传自己网站的家装案例,首先要到自己的网站把图片弄出来,如果自动弄得吓死,可以直接ftp登陆网站服务器将所有图片案例下载出来,但是没权限只能从网站上面弄,这就用到了优采云,直接将想要的图片全部下载出来,然后用美图秀秀批量处理大小加水印logo,这样早已大大提升了效率!这里存在一个问题就是优采云保存时不能将整篇案例保存为以文章名称的文件夹,只能以时间哪些的,这样我上传案例就难以这篇文章对应哪个图片,可能自己不会,操作时只能对应这篇看源码找图片的名称,幸亏整篇文章的图片都有特点,处理时速率还可以!
再就是例如我要剖析网站的收录率,在百度site自己的域名,然后用优采云采集title,一般规则的网站都是文章名_栏目名_网站名,这样我们可以用excel估算出该栏目被收录了多少条,然后减去该栏目下的总量,然后估算出收录率,百度site结果页的网站url是转码的,采集下来也不能剖析,可能有别的办法,但是自己没找到
这里还须要注意的是假如默认设置采集下的标题都是不分开的,看起来是一坨!需要勾选添加为新纪录,这样采集下来的数据就是一行一行的,简单明了!
感觉优采云采集器的功能太强悍,需要自己举一反三,教程直接到优采云官网去看视频教程,但是可以在例如优酷等视频网站看到他人借助优采云采集器做一些特别有用的事
服务范围
1、门户网站或企业网站需要大量的数据且为正规行业内容; 查看全部
网站数据批量采集服务|优采云免登录采集接口[DESTOON数据内容采集]
DESTOON二次开发。DESTOON数据采集。
简单说明 :
用优采云采集器对提升工作效率确实很有用
每天要到第三方家装平台上传自己网站的家装案例,首先要到自己的网站把图片弄出来,如果自动弄得吓死,可以直接ftp登陆网站服务器将所有图片案例下载出来,但是没权限只能从网站上面弄,这就用到了优采云,直接将想要的图片全部下载出来,然后用美图秀秀批量处理大小加水印logo,这样早已大大提升了效率!这里存在一个问题就是优采云保存时不能将整篇案例保存为以文章名称的文件夹,只能以时间哪些的,这样我上传案例就难以这篇文章对应哪个图片,可能自己不会,操作时只能对应这篇看源码找图片的名称,幸亏整篇文章的图片都有特点,处理时速率还可以!
再就是例如我要剖析网站的收录率,在百度site自己的域名,然后用优采云采集title,一般规则的网站都是文章名_栏目名_网站名,这样我们可以用excel估算出该栏目被收录了多少条,然后减去该栏目下的总量,然后估算出收录率,百度site结果页的网站url是转码的,采集下来也不能剖析,可能有别的办法,但是自己没找到

这里还须要注意的是假如默认设置采集下的标题都是不分开的,看起来是一坨!需要勾选添加为新纪录,这样采集下来的数据就是一行一行的,简单明了!

感觉优采云采集器的功能太强悍,需要自己举一反三,教程直接到优采云官网去看视频教程,但是可以在例如优酷等视频网站看到他人借助优采云采集器做一些特别有用的事
服务范围
1、门户网站或企业网站需要大量的数据且为正规行业内容;
苹果cms采集接口配置教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 604 次浏览 • 2020-08-09 20:48
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。可以参考教程:苹果cms采集后未能播放缘由排查及解决教程
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。不会添加播放器可参考:苹果cms采集后播放器的导出添加教程 查看全部
1,今天教你们怎样添加采集自定义资源库;进入后台我们随意以某资源站为例,接口可以到你要采集的网站上获取就可以了 一般都在网站的帮助中心:添加方式如下图(添加后进行测试不成功须要填写附加参数 &ct=1)
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。可以参考教程:苹果cms采集后未能播放缘由排查及解决教程
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。不会添加播放器可参考:苹果cms采集后播放器的导出添加教程
全网邮箱email地址采集api接口及实现剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-08-09 18:14
这样的在线工具原理与普通的客户端工具(例如八虾采集工具等)是一样的,所以这儿以这个在线工具作为参考进行实现剖析。
邮箱采集原理:
1、根据要采集的url地址,获取页面html内容,然后采用正则匹配出页面的url列表、邮箱地址列表。
2、分两个进程:
①保存邮箱地址;
②分析采集子页面url的邮箱地址;
基本源码(golang):
<p>
//采集入口方法
func CollectEmail(hosturl string) (EmailObj, []string, error) {
emailObj := new(EmailObj)
var inhost []string
//获取主域名
uparse, err := url.Parse(hosturl)
if err != nil {
return *emailObj, inhost, err
}
emailObj.Surl = hosturl
//
bodystr, err := HttpGetV2(hosturl)
if err != nil {
return *emailObj, inhost, errors.New("get request error")
}
//是否是gbk编码
pos := strings.Index(bodystr, "charset=gb")
pos2 := strings.Index(bodystr, "bg2312")
if pos != -1 || pos2 != -1 {
decodeBytes, err := simplifiedchinese.GB18030.NewDecoder().Bytes([]byte(bodystr))
if err != nil {
return *emailObj, inhost, errors.New("simplifiedchinese coding change error")
}
bodystr = string(decodeBytes)
}
//获取邮箱地地址
emailObj.Emails = append(emailObj.Emails, matchEmail(bodystr)...)
//获取联系手机
emailObj.Phones = append(emailObj.Phones, matchPhone(bodystr)...)
//获取内页链接列表
matchUrls := matchUrls(bodystr)
for _, item := range matchUrls {
itemparse, err := url.Parse(item)
if err != nil {
continue
}
if strings.Index(itemparse.Path, ".js") != -1 || strings.Index(itemparse.Path, ".css") != -1 {
continue
}
if itemparse.Host == uparse.Host {
inhost = append(inhost, item)
}
if itemparse.Scheme != "http" && itemparse.Scheme != "https" {
if strings.Index(itemparse.Path, "/") == 0 {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+itemparse.Path)
} else {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+"/"+itemparse.Path)
}
continue
}
}
//获取内页email
inhost = RemoveRepeatedElement(inhost)
emailObj.Emails = RemoveRepeatedElement(emailObj.Emails)
return *emailObj, inhost, nil
}
func matchEmail(str string) (email []string) {
var emailList []string
//re, _ := regexp.Compile("\\ 查看全部
先上一个在线邮箱采集demo样例:
这样的在线工具原理与普通的客户端工具(例如八虾采集工具等)是一样的,所以这儿以这个在线工具作为参考进行实现剖析。
邮箱采集原理:
1、根据要采集的url地址,获取页面html内容,然后采用正则匹配出页面的url列表、邮箱地址列表。
2、分两个进程:
①保存邮箱地址;
②分析采集子页面url的邮箱地址;
基本源码(golang):
<p>
//采集入口方法
func CollectEmail(hosturl string) (EmailObj, []string, error) {
emailObj := new(EmailObj)
var inhost []string
//获取主域名
uparse, err := url.Parse(hosturl)
if err != nil {
return *emailObj, inhost, err
}
emailObj.Surl = hosturl
//
bodystr, err := HttpGetV2(hosturl)
if err != nil {
return *emailObj, inhost, errors.New("get request error")
}
//是否是gbk编码
pos := strings.Index(bodystr, "charset=gb")
pos2 := strings.Index(bodystr, "bg2312")
if pos != -1 || pos2 != -1 {
decodeBytes, err := simplifiedchinese.GB18030.NewDecoder().Bytes([]byte(bodystr))
if err != nil {
return *emailObj, inhost, errors.New("simplifiedchinese coding change error")
}
bodystr = string(decodeBytes)
}
//获取邮箱地地址
emailObj.Emails = append(emailObj.Emails, matchEmail(bodystr)...)
//获取联系手机
emailObj.Phones = append(emailObj.Phones, matchPhone(bodystr)...)
//获取内页链接列表
matchUrls := matchUrls(bodystr)
for _, item := range matchUrls {
itemparse, err := url.Parse(item)
if err != nil {
continue
}
if strings.Index(itemparse.Path, ".js") != -1 || strings.Index(itemparse.Path, ".css") != -1 {
continue
}
if itemparse.Host == uparse.Host {
inhost = append(inhost, item)
}
if itemparse.Scheme != "http" && itemparse.Scheme != "https" {
if strings.Index(itemparse.Path, "/") == 0 {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+itemparse.Path)
} else {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+"/"+itemparse.Path)
}
continue
}
}
//获取内页email
inhost = RemoveRepeatedElement(inhost)
emailObj.Emails = RemoveRepeatedElement(emailObj.Emails)
return *emailObj, inhost, nil
}
func matchEmail(str string) (email []string) {
var emailList []string
//re, _ := regexp.Compile("\\
数据剖析系列篇:数据采集哪家强?
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-27 02:44
前几天有人问我,说她们是一家创业公司,我们也特别想做数据剖析、机器学习这种,但是我们没有数据啊!这可怎么办?我们也不懂那些数据从哪里来,更不懂技术方面的东西,公司也就几个人,还都是从传统公司或则刚结业的。
当时我就给他打了个比喻,这就有点像我们没米如何做饭一样。如果真的没米了,我们可以自己去种稻,也可以去超市上买米,也可以拿其他东西和他人家做交换,也可以喝玉米。
那同样,我们没数据,那就要想办法去采集数据啊。如果你是个spy man,那肯定也要各类采集情报。
我们常见的数据搜集分内部和外部两方面:
1.内部:
a)历史log日志+会员信息;
b)基于基础标签特点预测;
c)集团各业务、子公司数据等。
2.外部:
a)爬虫采集引擎;
b)数据选购;
c)合作公司数据交换;
d)收购兼并公司;
e)营销等手段。
针对内部已有数据那些自毋须多说,谁还会。重点说一说我们常用的网路爬虫形式。
在这块数据采集基于本身需求的规模,如果是大规模的维护系统,可以用专门的采集引擎,比如基于apache服务器的nutch。
如果以填充网站为目的,觉得那个网站的内容好,想借为已用,这种需求随机灵活,而对抓取量又不太高的采集,可以采集python的爬虫工具scrapy。
当然php也有可以实现各类网站抓取的方法,但是其实没有成形的框架,因为抓取本质是基本网路合同,http哪些的,所以你对那些合同了解的清楚,又懂一些脚本语言,基本就会画出一个可以实现你需求的采集的工具。但是效率就千差万别了。框架会提供你建立采集的多元素补充,你几乎涉及到采集应该处理的全部问题,它都给你提供了对应的方案,你有耐心死扣方案,总能弄懂他传授你的意思,然后按理为之,就可以不断把自己的爬虫实现上去。但是采集只是数据处理的一个环节,采集之后怎样对数据提纯精炼,基于自己商业化目的的导向,可能还涉及到知识产权等问题,当然这不是技术采集考虑的层面了。至于数据的剖析,当然,我都是用python多一点,python提供了许多外置的math函数处理库,比如说numpy,scipy,matplotlib,这些网上都有对应的使用教程,入库或把采集到的数据按这种组件可以处理的格式保存,然后把数据导出进来,就这样折腾折腾。
另外对于中级用户,介绍下现成的工具:
优采云
优采云应该是国外采集软件最成功的典型之一,使用人数包括收费用户数目上应当是最多的
优点:功能比较齐全,采集速度比较快,主要针对cms,短时间可以采集很多,过滤,替换都不错,比较详尽;
技术:技术主要是峰会支持,帮助文件多,上手容易。有收费、免费版本
缺点:功能复杂,软件越来越大,比较占用显存和CPU资源,大批量采集速度不行,资源回收控制得不好,受CS构架限制
优采云
可能大部分人还不知道,这是我自主研制的,以前仍然用爬虫写程序,java、python等,后面认为很麻烦,就摆弄着要做的简单一些,然后就无法收手了,最近仍然在进行产品迭代。
优点:功能聚合性强、速度快、saas构架、数据可预览、数据规则市场、api等多种输出方法、免费
缺点:知名度还比较低
三人行
主要针对峰会的采集,功能比较健全
优点:还是针对峰会,适合开峰会的
技术:收费技术,免费有广告
缺点:超级复杂,上手难,对cms支持比较差
ET工具
优点:无人值守,自动更新,适合常年做站,用户群主要集中在常年做站潜水站长。软件清晰,必备功能也太齐全,关键是软件免费,听说早已降低采集中英文翻译功能。
技术:论坛支持,软件本身免费,但是也提供收费服务。帮助文件较少,上手不容易
缺点:对峰会和CMS的支持通常
海纳
优点:海量,可以抓取网站很多一个关键词文章,似乎适合做网站的专题,特别是文章类、博客类
技术:无论坛 收费,免费有功能限制
缺点:分类不便捷,也就说采集文章归类不便捷,要自动(自动容易混淆),特定插口,采集的内容有限
优采云
优点:非常适宜采集discuz峰会
缺点:过于专情,兼容性不好。
End
作者:面包君 查看全部
数据剖析系列篇:数据采集哪家强?
前几天有人问我,说她们是一家创业公司,我们也特别想做数据剖析、机器学习这种,但是我们没有数据啊!这可怎么办?我们也不懂那些数据从哪里来,更不懂技术方面的东西,公司也就几个人,还都是从传统公司或则刚结业的。
当时我就给他打了个比喻,这就有点像我们没米如何做饭一样。如果真的没米了,我们可以自己去种稻,也可以去超市上买米,也可以拿其他东西和他人家做交换,也可以喝玉米。
那同样,我们没数据,那就要想办法去采集数据啊。如果你是个spy man,那肯定也要各类采集情报。
我们常见的数据搜集分内部和外部两方面:
1.内部:
a)历史log日志+会员信息;
b)基于基础标签特点预测;
c)集团各业务、子公司数据等。
2.外部:
a)爬虫采集引擎;
b)数据选购;
c)合作公司数据交换;
d)收购兼并公司;
e)营销等手段。
针对内部已有数据那些自毋须多说,谁还会。重点说一说我们常用的网路爬虫形式。
在这块数据采集基于本身需求的规模,如果是大规模的维护系统,可以用专门的采集引擎,比如基于apache服务器的nutch。
如果以填充网站为目的,觉得那个网站的内容好,想借为已用,这种需求随机灵活,而对抓取量又不太高的采集,可以采集python的爬虫工具scrapy。
当然php也有可以实现各类网站抓取的方法,但是其实没有成形的框架,因为抓取本质是基本网路合同,http哪些的,所以你对那些合同了解的清楚,又懂一些脚本语言,基本就会画出一个可以实现你需求的采集的工具。但是效率就千差万别了。框架会提供你建立采集的多元素补充,你几乎涉及到采集应该处理的全部问题,它都给你提供了对应的方案,你有耐心死扣方案,总能弄懂他传授你的意思,然后按理为之,就可以不断把自己的爬虫实现上去。但是采集只是数据处理的一个环节,采集之后怎样对数据提纯精炼,基于自己商业化目的的导向,可能还涉及到知识产权等问题,当然这不是技术采集考虑的层面了。至于数据的剖析,当然,我都是用python多一点,python提供了许多外置的math函数处理库,比如说numpy,scipy,matplotlib,这些网上都有对应的使用教程,入库或把采集到的数据按这种组件可以处理的格式保存,然后把数据导出进来,就这样折腾折腾。
另外对于中级用户,介绍下现成的工具:
优采云
优采云应该是国外采集软件最成功的典型之一,使用人数包括收费用户数目上应当是最多的
优点:功能比较齐全,采集速度比较快,主要针对cms,短时间可以采集很多,过滤,替换都不错,比较详尽;
技术:技术主要是峰会支持,帮助文件多,上手容易。有收费、免费版本
缺点:功能复杂,软件越来越大,比较占用显存和CPU资源,大批量采集速度不行,资源回收控制得不好,受CS构架限制
优采云
可能大部分人还不知道,这是我自主研制的,以前仍然用爬虫写程序,java、python等,后面认为很麻烦,就摆弄着要做的简单一些,然后就无法收手了,最近仍然在进行产品迭代。
优点:功能聚合性强、速度快、saas构架、数据可预览、数据规则市场、api等多种输出方法、免费
缺点:知名度还比较低
三人行
主要针对峰会的采集,功能比较健全
优点:还是针对峰会,适合开峰会的
技术:收费技术,免费有广告
缺点:超级复杂,上手难,对cms支持比较差
ET工具
优点:无人值守,自动更新,适合常年做站,用户群主要集中在常年做站潜水站长。软件清晰,必备功能也太齐全,关键是软件免费,听说早已降低采集中英文翻译功能。
技术:论坛支持,软件本身免费,但是也提供收费服务。帮助文件较少,上手不容易
缺点:对峰会和CMS的支持通常
海纳
优点:海量,可以抓取网站很多一个关键词文章,似乎适合做网站的专题,特别是文章类、博客类
技术:无论坛 收费,免费有功能限制
缺点:分类不便捷,也就说采集文章归类不便捷,要自动(自动容易混淆),特定插口,采集的内容有限
优采云
优点:非常适宜采集discuz峰会
缺点:过于专情,兼容性不好。
End
作者:面包君
用php写一个采集“百度相关搜索”关键词的api接口程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 896 次浏览 • 2020-08-26 09:02
采集百度相关搜索词,这个应用对于做网路推广的小伙伴应当能用到,就是你在百度搜索一个关键词把相关搜索词采集下来,用来做网路营销用。今天分享一段简单的代码,来实现搜索一个关键词,直接返回显示在网页上采集到的相关搜索词。如果你你自觉得你是程序前辈,请绕路,本程序很简单,勿喷。
一、应用需求分析
1、用get形式递交你要搜索的关键词
2、直接把采集到的“相关搜索”词显示在本页面,一行一个显示
二、简单剖析实现步骤
1、分析百度搜索是如何递交你搜索的关键词的总结出,百度搜索是如何组合链接的,也就是“关键词”,直接在浏览器粘贴这个链接你才会发觉这个页面就是你搜索的关键词的页面。当然还有其他参数,小伙伴可以自己研究。
2、获取这个页面的源代码,程序是只认识源代码,不会跟人一样用耳朵区分。
3、分析相关搜索词那种地方的代码,用语言不好形容,等下自己看代码吧。然后用正则提取下来搜索词就行了。
三、直接看代码吧,只有一个文件,没几行代码,感兴趣的小伙伴自己去试试吧。
四、来瞧瞧最后的显示疗效吧
把这段代码放在你自己服务器上,直接在浏览器搜索相应链接?key=关键词,页面都会显示你搜索词的相关搜索词了。就写这了写太累,感兴趣的小伙伴,关注一下本头条号吧。 查看全部
用php写一个采集“百度相关搜索”关键词的api接口程序
采集百度相关搜索词,这个应用对于做网路推广的小伙伴应当能用到,就是你在百度搜索一个关键词把相关搜索词采集下来,用来做网路营销用。今天分享一段简单的代码,来实现搜索一个关键词,直接返回显示在网页上采集到的相关搜索词。如果你你自觉得你是程序前辈,请绕路,本程序很简单,勿喷。
一、应用需求分析
1、用get形式递交你要搜索的关键词
2、直接把采集到的“相关搜索”词显示在本页面,一行一个显示
二、简单剖析实现步骤
1、分析百度搜索是如何递交你搜索的关键词的总结出,百度搜索是如何组合链接的,也就是“关键词”,直接在浏览器粘贴这个链接你才会发觉这个页面就是你搜索的关键词的页面。当然还有其他参数,小伙伴可以自己研究。
2、获取这个页面的源代码,程序是只认识源代码,不会跟人一样用耳朵区分。
3、分析相关搜索词那种地方的代码,用语言不好形容,等下自己看代码吧。然后用正则提取下来搜索词就行了。
三、直接看代码吧,只有一个文件,没几行代码,感兴趣的小伙伴自己去试试吧。
四、来瞧瞧最后的显示疗效吧
把这段代码放在你自己服务器上,直接在浏览器搜索相应链接?key=关键词,页面都会显示你搜索词的相关搜索词了。就写这了写太累,感兴趣的小伙伴,关注一下本头条号吧。
第 11 篇:基于 drf-haystack 的文章搜索插口
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-26 00:20
作者:HelloGitHub-追梦人物
在 django 博客教程中,我们使用了 django-haystack 和 Elasticsearch 进行文章内容的搜索。django-haystack 默认返回的搜索结果是一个类似于 django QuerySet 的对象,需要配合模板系统使用,因为未被序列化,所以未能直接用于 django-rest-framework 的插口。当然解决方案也很简单,编写相应的序列化器将返回结果序列化就可以了。
但是,通过之前的功能我们看见,使用 django-rest-framework 是一个近乎标准化但又沉闷无聊的过程:首先是编撰序列化器用于序列化资源,然后是编撰视图集,提供对资源各种操作的插口。既然是标准化的东西,肯定早已有人写好了相关的功能以供复用。此时就要发挥开源社区的力量,去 GitHub 使用关键词 rest haystack 搜索,果然搜到一个 drf-haystack 开源项目,专门用于解决 django-rest-framework 和 haystack 结合使用的问题。因此我们就不再重复造轮子,直接使用开源第三方库来实现我们的需求。
既然要使用第三方库,第一步其实是安装它,进入项目根目录,运行:
$ pipenv install drf-haystack
由于须要使用到搜索功能,因此须要启动 Elasticsearch 服务,最简单的方法就是使用项目中编排的 Elasticsearch 镜像启动容器。
项目根目录下运行如下命令启动全部项目所需的容器服务:
$ docker-compose -f local.yml up --build
启动完成后运行 docker ps 命令可以检测到如下 2 个运行的容器,说明启动成功:
hellodjango_rest_framework_tutorial_local
hellodjango_rest_framework_tutorial_elasticsearch_local
接着创建一些文章,以便用于搜索测试,可以自己在 admin 后台添加,当然最简单的方式是运行项目中的 fake.py 脚本,批量生成测试数据:
$ docker-compose -f local.yml run --rm
hellodjango.rest.framework.tutorial.local python -m scripts.fake
测试文章生成后,还要运行下边的命令给文章的内容创建索引,这样搜索引擎能够按照索引搜索到相应的内容:
注意
如果生成索引时见到如下错误:
elasticsearch.exceptions.ConnectionError: ConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve) caused by: NewConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve)
这是因为项目配置中 Elasticsearch 服务的 URL 配置出错造成,解决方式是步入 settings/local.py 配置文件中,将搜索设置改为下边的内容:
HAYSTACK_CONNECTIONS['default']['URL'] = ':9200/'
因为这个 URL 地址需和容器编排文件 local.yml 中指定的容器服务名一致 Docker 才能正确解析。
现在万事具备了,数据库中早已有了文章,搜索服务早已有了文章的索引,只须要等待客户端来进行查询,然后返回结果。所以接下来就步入到 django-rest-framework 标准开发流程:定义序列化器 -> 编写视图 -> 配置路由,这样一个标准的搜索插口就开发下来了。
先来定义序列化器,粗略过一遍 drf-haystack 官方文档[3],依葫芦画瓢创建文章(Post) 的 Serializer
根据官方文档的介绍,为了复用早已定义好用于序列化文章列表的序列化器,我们直接承继了 PostListSerializer,同时我们还混进了 HaystackSerializerMixin,这是 drf-haystack 的混入类,提供搜索结果序列化相关的功能。
另外内部类 Meta 同样承继 PostListSerializer.Meta,这样就无需重复定义序列化数组列表 fields。关键的地方在这个 search_fields,这个列表申明用于搜索的数组(通常都定义为索引数组),我们在上一部教程设置 django-haystack 时,文章的索引数组设置的名子叫 text,如果对这一块有疑问,可以简单回顾一下 Django Haystack 全文检索与关键词高亮[4] 中的内容。
然后编撰视图集,需承继 HaystackViewSet:
这个视图集特别简单,只须要通过类属性 index_models 声明须要搜索的模型,以及搜索结果的序列化器就行了,剩余的功能均由 HaystackViewSet 内部替我们实现了。
最后是在路由器中注册视图集,自动生成 URL 模式:
搞定了!一套标准化的 django-restful-framework 开发流程,不过大量工作已由 drf-haystack 在背后替我们完成,我们只写了极其少量的代码即实现了一套搜索插口。
来瞧瞧搜索疗效。我们启动 Docker 容器,在浏览器输入如下格式的 URL:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python manage.py rebuild_index# 输出如下Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.Are you sure you wish to continue? [y/N] yRemoving all documents from your index because you said so.All documents removed.Indexing 201 文章GET /hellodjango_blog_tutorial/_mapping [status:404 request:0.005s]
将 key-word 替换为须要搜索的关键字,例如将其替换为 markdown,测试集数据中得到的搜索结果如下:
搜索结果符合预期,但略微有一点不太好的地方,就是没有高亮的标题和摘要,我们希望将来显示的结果应当是下边这样的,因此返回的数据必须支持这样的显示:
关键词高亮的实现原理似乎十分简单,通过解析整段文本,将搜索关键词替换为由 HTML 标签包裹的富文本,并给这个包裹标签设置 CSS 样式,让其显示不同的字体颜色就可以了。
了解其原理后其实就是实现其功能,不过 django-haystack 已经为我们造好了轮子,而且在上一部教程的 Django Haystack 全文检索与关键词高亮[5],我们还对默认的高亮辅助类进行了整修,优化了文章标题被从关键字位置截断的问题,因此我们使用改建后的辅助类来对须要高亮的结果进行处理。
需要高亮的虽然是 2 个数组,一个是 title、一个是 body。而 body 我们不需要完整的内容,只须要摘出其中一部分作为搜索结果的摘要即可。这两个功能,辅助类均早已为我们提供了,我们只须要调用所需的方式就行。
注意到这儿我们须要对 title、body 两个数组进行高亮处理,其基本逻辑虽然就是接收 title、body 的值作为输入,高亮处理后再输出。回顾一下序列化器的序列化数组,其实也是接收某个数组的值作为输入,对其进行处理,将其转化为可序列化的结果后输出,和我们须要的逻辑太象。但是,django-rest-framework 并没有提供这种比较个性化需求的序列化数组,因此接下来我们接触 drf 的一点中级用法——自定义序列化数组。
自定义序列化数组虽然十分的简单,基本流程分两步走:
从 drf 官方提供的序列化数组中找一个数据类型最为接近的作为父类。重写 to_representation 方法,加入自己的序列化逻辑。
以我们的需求为例。因为 title、body 均为字符型,因此选择父类序列化数组为 CharField,定义一个 HighlightedCharField 字段如下:
django-rest-framework 通过调用序列化数组的 to_representation 方法对输入的值进行序列化,这个方式接收的第一个参数就是须要序列化的值。在我们自定义的逻辑中,首先调用父类 CharField 的 to_representation 方法,父类序列化的逻辑是将任何输入的值都转为字符串;接着我们从 context 属性中取得 request 对象,这个对象就是视图中的 HTTP 请求对象,但是由于 django 中 request 对象难以象 flask 那样从全局获取,因此 drf 在视图中将其保存在了序列化器和序列化数组的 context 属性中便于在视图外访问;获取 request 对象的目的是希望获取查询的关键字,query_params 属性是一个类字典对象,用于记录来自 URL 的查询参数,例如我们之前测试查询功能时调用的 URL 为 /api/search/?text=markdown,所以 query_params 保存了 URL 中的查询参数,将其封装为一个类数组对象 {"text": "markdown"},这里 text 的值就是查询的关键字,我们将它传给 Highlighter 辅助类,然后调用 highlight 方法将须要序列化的值进行进一步的高亮处理。
序列化数组定义好后,我们就可以在序列化器中用它了:
title 字段原先使用默认的 CharField 进行序列化,这里我们重新指定为自定义的 HighlightedCharField,这样序列化后的值就是高亮的格式。
summary 是我们新增的数组,注意我们序列化的对象是文章 Post,但这个对象是没有 summary 这个属性的,但是 summary 其实是对属性 body 序列化后的结果,因此我们通过指定序列化化数组的 source 参数,指定值的来源。
最后别忘了在 fields 中声明全部序列化的数组,主要是把新增的 summary 加进去。
来瞧瞧改进后的搜索疗效:
注意观察返回的 title 和 summary,我们搜索的关键词是 markdown,可以看见所有 markdown 关键字都被包裹了一个 span 标签,并且设置了 class 属性为 highlighted,只要设置好 css 样式,页面所有的 markdown 关键词都会显示不同的颜色,从而实现搜索关键词高亮的疗效了。
当然,我们如今并没有实际用到这个特点,下一部教程我们将使用 Vue 来开发博客,到时候调用搜索插口领到搜索结果后才会实际用到了。 查看全部
第 11 篇:基于 drf-haystack 的文章搜索插口
作者:HelloGitHub-追梦人物
在 django 博客教程中,我们使用了 django-haystack 和 Elasticsearch 进行文章内容的搜索。django-haystack 默认返回的搜索结果是一个类似于 django QuerySet 的对象,需要配合模板系统使用,因为未被序列化,所以未能直接用于 django-rest-framework 的插口。当然解决方案也很简单,编写相应的序列化器将返回结果序列化就可以了。
但是,通过之前的功能我们看见,使用 django-rest-framework 是一个近乎标准化但又沉闷无聊的过程:首先是编撰序列化器用于序列化资源,然后是编撰视图集,提供对资源各种操作的插口。既然是标准化的东西,肯定早已有人写好了相关的功能以供复用。此时就要发挥开源社区的力量,去 GitHub 使用关键词 rest haystack 搜索,果然搜到一个 drf-haystack 开源项目,专门用于解决 django-rest-framework 和 haystack 结合使用的问题。因此我们就不再重复造轮子,直接使用开源第三方库来实现我们的需求。
既然要使用第三方库,第一步其实是安装它,进入项目根目录,运行:
$ pipenv install drf-haystack
由于须要使用到搜索功能,因此须要启动 Elasticsearch 服务,最简单的方法就是使用项目中编排的 Elasticsearch 镜像启动容器。
项目根目录下运行如下命令启动全部项目所需的容器服务:
$ docker-compose -f local.yml up --build
启动完成后运行 docker ps 命令可以检测到如下 2 个运行的容器,说明启动成功:
hellodjango_rest_framework_tutorial_local
hellodjango_rest_framework_tutorial_elasticsearch_local
接着创建一些文章,以便用于搜索测试,可以自己在 admin 后台添加,当然最简单的方式是运行项目中的 fake.py 脚本,批量生成测试数据:
$ docker-compose -f local.yml run --rm
hellodjango.rest.framework.tutorial.local python -m scripts.fake
测试文章生成后,还要运行下边的命令给文章的内容创建索引,这样搜索引擎能够按照索引搜索到相应的内容:
注意
如果生成索引时见到如下错误:
elasticsearch.exceptions.ConnectionError: ConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve) caused by: NewConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve)
这是因为项目配置中 Elasticsearch 服务的 URL 配置出错造成,解决方式是步入 settings/local.py 配置文件中,将搜索设置改为下边的内容:
HAYSTACK_CONNECTIONS['default']['URL'] = ':9200/'
因为这个 URL 地址需和容器编排文件 local.yml 中指定的容器服务名一致 Docker 才能正确解析。
现在万事具备了,数据库中早已有了文章,搜索服务早已有了文章的索引,只须要等待客户端来进行查询,然后返回结果。所以接下来就步入到 django-rest-framework 标准开发流程:定义序列化器 -> 编写视图 -> 配置路由,这样一个标准的搜索插口就开发下来了。
先来定义序列化器,粗略过一遍 drf-haystack 官方文档[3],依葫芦画瓢创建文章(Post) 的 Serializer
根据官方文档的介绍,为了复用早已定义好用于序列化文章列表的序列化器,我们直接承继了 PostListSerializer,同时我们还混进了 HaystackSerializerMixin,这是 drf-haystack 的混入类,提供搜索结果序列化相关的功能。
另外内部类 Meta 同样承继 PostListSerializer.Meta,这样就无需重复定义序列化数组列表 fields。关键的地方在这个 search_fields,这个列表申明用于搜索的数组(通常都定义为索引数组),我们在上一部教程设置 django-haystack 时,文章的索引数组设置的名子叫 text,如果对这一块有疑问,可以简单回顾一下 Django Haystack 全文检索与关键词高亮[4] 中的内容。
然后编撰视图集,需承继 HaystackViewSet:
这个视图集特别简单,只须要通过类属性 index_models 声明须要搜索的模型,以及搜索结果的序列化器就行了,剩余的功能均由 HaystackViewSet 内部替我们实现了。
最后是在路由器中注册视图集,自动生成 URL 模式:
搞定了!一套标准化的 django-restful-framework 开发流程,不过大量工作已由 drf-haystack 在背后替我们完成,我们只写了极其少量的代码即实现了一套搜索插口。
来瞧瞧搜索疗效。我们启动 Docker 容器,在浏览器输入如下格式的 URL:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python manage.py rebuild_index# 输出如下Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.Are you sure you wish to continue? [y/N] yRemoving all documents from your index because you said so.All documents removed.Indexing 201 文章GET /hellodjango_blog_tutorial/_mapping [status:404 request:0.005s]
将 key-word 替换为须要搜索的关键字,例如将其替换为 markdown,测试集数据中得到的搜索结果如下:
搜索结果符合预期,但略微有一点不太好的地方,就是没有高亮的标题和摘要,我们希望将来显示的结果应当是下边这样的,因此返回的数据必须支持这样的显示:
关键词高亮的实现原理似乎十分简单,通过解析整段文本,将搜索关键词替换为由 HTML 标签包裹的富文本,并给这个包裹标签设置 CSS 样式,让其显示不同的字体颜色就可以了。
了解其原理后其实就是实现其功能,不过 django-haystack 已经为我们造好了轮子,而且在上一部教程的 Django Haystack 全文检索与关键词高亮[5],我们还对默认的高亮辅助类进行了整修,优化了文章标题被从关键字位置截断的问题,因此我们使用改建后的辅助类来对须要高亮的结果进行处理。
需要高亮的虽然是 2 个数组,一个是 title、一个是 body。而 body 我们不需要完整的内容,只须要摘出其中一部分作为搜索结果的摘要即可。这两个功能,辅助类均早已为我们提供了,我们只须要调用所需的方式就行。
注意到这儿我们须要对 title、body 两个数组进行高亮处理,其基本逻辑虽然就是接收 title、body 的值作为输入,高亮处理后再输出。回顾一下序列化器的序列化数组,其实也是接收某个数组的值作为输入,对其进行处理,将其转化为可序列化的结果后输出,和我们须要的逻辑太象。但是,django-rest-framework 并没有提供这种比较个性化需求的序列化数组,因此接下来我们接触 drf 的一点中级用法——自定义序列化数组。
自定义序列化数组虽然十分的简单,基本流程分两步走:
从 drf 官方提供的序列化数组中找一个数据类型最为接近的作为父类。重写 to_representation 方法,加入自己的序列化逻辑。
以我们的需求为例。因为 title、body 均为字符型,因此选择父类序列化数组为 CharField,定义一个 HighlightedCharField 字段如下:
django-rest-framework 通过调用序列化数组的 to_representation 方法对输入的值进行序列化,这个方式接收的第一个参数就是须要序列化的值。在我们自定义的逻辑中,首先调用父类 CharField 的 to_representation 方法,父类序列化的逻辑是将任何输入的值都转为字符串;接着我们从 context 属性中取得 request 对象,这个对象就是视图中的 HTTP 请求对象,但是由于 django 中 request 对象难以象 flask 那样从全局获取,因此 drf 在视图中将其保存在了序列化器和序列化数组的 context 属性中便于在视图外访问;获取 request 对象的目的是希望获取查询的关键字,query_params 属性是一个类字典对象,用于记录来自 URL 的查询参数,例如我们之前测试查询功能时调用的 URL 为 /api/search/?text=markdown,所以 query_params 保存了 URL 中的查询参数,将其封装为一个类数组对象 {"text": "markdown"},这里 text 的值就是查询的关键字,我们将它传给 Highlighter 辅助类,然后调用 highlight 方法将须要序列化的值进行进一步的高亮处理。
序列化数组定义好后,我们就可以在序列化器中用它了:
title 字段原先使用默认的 CharField 进行序列化,这里我们重新指定为自定义的 HighlightedCharField,这样序列化后的值就是高亮的格式。
summary 是我们新增的数组,注意我们序列化的对象是文章 Post,但这个对象是没有 summary 这个属性的,但是 summary 其实是对属性 body 序列化后的结果,因此我们通过指定序列化化数组的 source 参数,指定值的来源。
最后别忘了在 fields 中声明全部序列化的数组,主要是把新增的 summary 加进去。
来瞧瞧改进后的搜索疗效:
注意观察返回的 title 和 summary,我们搜索的关键词是 markdown,可以看见所有 markdown 关键字都被包裹了一个 span 标签,并且设置了 class 属性为 highlighted,只要设置好 css 样式,页面所有的 markdown 关键词都会显示不同的颜色,从而实现搜索关键词高亮的疗效了。
当然,我们如今并没有实际用到这个特点,下一部教程我们将使用 Vue 来开发博客,到时候调用搜索插口领到搜索结果后才会实际用到了。
采集微信公众号文章教程是哪些?怎样批量采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-25 19:17
大家在编辑陌陌公证号上面的文章的时侯,一般都是先进行文章采集的,那么采集微信公众号文章教程是哪些?怎样批量采集呢?下面拓途数据就来详尽的介绍下这种问题,以提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是如何的?
步骤一:点击采集,复制须要采集的陌陌文章链接地址到陌陌文章网址框中。
这里获取陌陌文章链接主要有2种方式:
方法一:直接在手机上找到文章点击右上角复制。
方法二:通过笔记本端的搜狗浏览器陌陌栏目进行搜索,可以通过下边的“点击获取”进入。
步骤二:点击采集,此时文章内容早已全部被采集到陌陌编辑器上了,可以进行对文章的编辑更改。
采集微信公众号文章教程之怎么批量采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索到相关站点 ,注册或则登陆以后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取就可以啦!
NO.3 进入采集爬虫后,点击爬虫设置。
首先由于搜狗微信搜索有图片防盗链 所以须要在功能设置里开启图片云托管,这点很重要,切记,不然你的图片显示不下来,到时候就难堪了……
再进行自定义设置,你可以同时采集多个微信公众号的文章,最多500个!特别注意:是输入微信号而不是陌陌名称哦!
数据采集进行完毕,可以进行数据发布吗?答案是其实可以!
NO.1 发布数据只需两个步骤: 安装发布插件 ——> 使用发布插口。你可以选择发布到数据库或则发布到网站上。
如果你不知道如何安装插件的话,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,根据文档提示,一步一步来就OK了。
插件安装成功,接下来就来新建一个发布项吧!这里这么多个,选一个你喜欢的就行了。
选完发布插口,填写你要发布的网站地址和密码。同时,系统会进行手动检查,检测插件是否已正确安装。
字段映射的话,一般情况下系统会默认选择好的,但是,你要认为有要调整的地方,也是可以更改的。
内容替换这是一个可选项,可填可不填。
完成设置就可以进行数据发布了。
NO.2 在爬取结果页面可以看见采集爬虫按照你设置的信息爬取到的全部内容,发布结果可以进行手动发布或则自动发布。
自动发布:开启手动发布后,爬取到的数据会手动发布到网站上或则数据库,这感觉简直6到要起飞了!
当然,你也可以选择自动发布,发布时可以选择单项或多项发布。在发布之前,你还可以进行预览,看看这篇文章的内容是啥。
如果认为木有问题就可以发布数据了。
发布成功后,可以点击链接进行查看。
采集微信公众号文章教程
微信公众号文章采集思路
一、通过android客户端获取到陌陌用户登入信息(即大号)。
二、提供微信公众号信息(biz)。
三、通过http协议剖析文章接口,写陌陌爬虫程序,需要用到前面两种资源,即大号越多,爬取速率越快。
微信爬虫引擎为分布式,可多实例布署工作。
最后实现的疗效为:
android客户端程序定时获取陌陌用户登入信息,保存到数据库中。数据库中保存大量的公众号信息,爬虫引擎工作时,去数据库获取要爬取公众号的信息与陌陌大号的身分信息。
通过以上的内容,我们早已了解了采集微信公众号文章教程的内容了,可见,采集微信公众号文章的方式还是比较简单的,如果只须要根据前面的方式去做就可以了。 查看全部
采集微信公众号文章教程是哪些?怎样批量采集
大家在编辑陌陌公证号上面的文章的时侯,一般都是先进行文章采集的,那么采集微信公众号文章教程是哪些?怎样批量采集呢?下面拓途数据就来详尽的介绍下这种问题,以提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是如何的?
步骤一:点击采集,复制须要采集的陌陌文章链接地址到陌陌文章网址框中。
这里获取陌陌文章链接主要有2种方式:
方法一:直接在手机上找到文章点击右上角复制。
方法二:通过笔记本端的搜狗浏览器陌陌栏目进行搜索,可以通过下边的“点击获取”进入。
步骤二:点击采集,此时文章内容早已全部被采集到陌陌编辑器上了,可以进行对文章的编辑更改。
采集微信公众号文章教程之怎么批量采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索到相关站点 ,注册或则登陆以后,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取就可以啦!
NO.3 进入采集爬虫后,点击爬虫设置。
首先由于搜狗微信搜索有图片防盗链 所以须要在功能设置里开启图片云托管,这点很重要,切记,不然你的图片显示不下来,到时候就难堪了……
再进行自定义设置,你可以同时采集多个微信公众号的文章,最多500个!特别注意:是输入微信号而不是陌陌名称哦!
数据采集进行完毕,可以进行数据发布吗?答案是其实可以!
NO.1 发布数据只需两个步骤: 安装发布插件 ——> 使用发布插口。你可以选择发布到数据库或则发布到网站上。
如果你不知道如何安装插件的话,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,根据文档提示,一步一步来就OK了。
插件安装成功,接下来就来新建一个发布项吧!这里这么多个,选一个你喜欢的就行了。
选完发布插口,填写你要发布的网站地址和密码。同时,系统会进行手动检查,检测插件是否已正确安装。
字段映射的话,一般情况下系统会默认选择好的,但是,你要认为有要调整的地方,也是可以更改的。
内容替换这是一个可选项,可填可不填。
完成设置就可以进行数据发布了。
NO.2 在爬取结果页面可以看见采集爬虫按照你设置的信息爬取到的全部内容,发布结果可以进行手动发布或则自动发布。
自动发布:开启手动发布后,爬取到的数据会手动发布到网站上或则数据库,这感觉简直6到要起飞了!
当然,你也可以选择自动发布,发布时可以选择单项或多项发布。在发布之前,你还可以进行预览,看看这篇文章的内容是啥。
如果认为木有问题就可以发布数据了。
发布成功后,可以点击链接进行查看。
采集微信公众号文章教程
微信公众号文章采集思路
一、通过android客户端获取到陌陌用户登入信息(即大号)。
二、提供微信公众号信息(biz)。
三、通过http协议剖析文章接口,写陌陌爬虫程序,需要用到前面两种资源,即大号越多,爬取速率越快。
微信爬虫引擎为分布式,可多实例布署工作。
最后实现的疗效为:
android客户端程序定时获取陌陌用户登入信息,保存到数据库中。数据库中保存大量的公众号信息,爬虫引擎工作时,去数据库获取要爬取公众号的信息与陌陌大号的身分信息。
通过以上的内容,我们早已了解了采集微信公众号文章教程的内容了,可见,采集微信公众号文章的方式还是比较简单的,如果只须要根据前面的方式去做就可以了。
页面埋点
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2020-08-24 09:07
对一个网站进行流量剖析,首先要做的就是数据采集;而采集的形式大至两种形式
对于网站前端来说,数据上报一般有如下几种方式
直接向后台发送get请求,伪装成js或者图片请求
http://click.dangdang.com/page ... id%3D &res=1920,1080||1903,5211&title=当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款&trace_id=nohead&special=guan=1;page=id:1|name:当首;&cif=&rsv1=&rsv2=&rsv3=&platform=pc&r=0.857700135627224
https://a.stat.xiaomi.com/js/m ... D1920*1080&language=zh-CN&vendor=Google%20Inc.&platform=Win32&gu=&miwd=&edm_task=&masid=&client_id=&pu=&rf=0&mutid=&muwd=&domain_id=100&pageid=81190ccc4d52f577&curl=https%3A%2F%2Fwww.mi.com%2F&xmv=1536571987936_2638_1542615493495&v=1.0.0&vuuid=7ERAQ0IQQIBIFMAV
https://warriors.jd.com/log.gi ... 83904|19&v={"t1":"pc_homepage","t2":"basic","p0":"{\"rept\":\"impr\",\"poi\":\"head|focus|08\",\"text\":\"11.19个护感恩节\",\"url\":\"//sale.jd.com/act/1dCqk7TBj5porf8.html\",\"desc\":\"个护电器\",\"mcinfo\":\"00755652-05703860-1100950352-M#0-2-1--58--#1-tb-#300-9908298#pc-home\",\"biclk\":\"1#6328b7df38f1cf2c1fd7c296f1e920cd7b603c53-101-619081#9908298\"}","pinid":"-","je":0,"sc":"24-bit","sr":"1920x1080","ul":"zh-cn","cs":"UTF-8","dt":"京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!","hn":"www.jd.com","fl":"-","os":"win","br":"chrome","bv":"68.0.3440.106","wb":"1536298255","xb":"1542165688","yb":1542615817,"zb":19,"cb":1,"usc":"direct","ucp":"-","umd":"none","uct":"-","ct":1542615839771,"lt":0,"tad":"-","jdv":"122270672|direct|-|none|-|1542165687598","dataver":"0.1"}&ref=&rm=1542615839772
回到数据采集端
nginx + lua
这种形式须要在nginx端配置日志格式;接收到后端日志搜集恳求后,会对恳求解析,并将日志数据记录在本地c盘;这种形式,有几个显著的缺点:
日志储存在本地c盘,通常我们在做大数据离线剖析,数据都是储存在hdfs上;所以这些方法就不可防止须要将日志上传到hdfs起来;因为是日志文件方式储存,所以没办法做实时的统计剖析
后台搜集
这个就须要开发一个日志搜集服务端,提供一个http get服务;这个服务将上报的数据推送到kafka中;相比第一种形式,后台搜集,你就不需要去各个服务器去搜集日志文件;数据推送到kafka,也就意味着,我们可以使用storm,sparkstreaming进行实时剖析;这个也是目前使用最广的形式
站点的数据采集流程【后台搜集为例】
首先是数据上报后端;用过友盟统计和百度统计的朋友都晓得,想要使用友盟百度站点统计功能,首先要做的就是,在站点嵌入一段js或则html代码,大概象这个样子
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
这段代码的意思,就是动态加载远程的js[:8089/xmst.js],嵌入到须要统计服务的站点;xmst.js代码如下
var params = {};
//Document对象数据
if (document) {
params.domain = document.domain || ''; //获取域名
params.url = document.URL || ''; //当前Url地址
params.title = document.title || '';
params.referrer = document.referrer || ''; //上一跳路径
}
//Window对象数据
if (window && window.screen) {
params.sh = window.screen.height || 0; //获取显示屏信息
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if (navigator) {
params.lang = navigator.language || ''; //获取所用语言种类
}
params['age'] = '111'
//解析_maq配置
if (_maq) {
for (var i in _maq) { //获取埋点阶段,传递过来的用户行为
params[i] = _maq[i]
}
};
function args_build(){
//拼接参数串
var args = '';
for (var i in params) {
// alert(i);
if (args != '') {
args += '&';
}
args += i + '=' + params[i]; //将所有获取到的信息进行拼接
}
return args;
};
//页面自动加载
function page_load(){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
// alert("请求到的后端脚本为" + src);
img.src = src;
};
// 点击事件
function a_click(maps){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
for (var i in maps) {
params[i] = maps[i]
}
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
img.src = src;
}
page_load();
加载了这个脚本的页面会手动调用page_load()方法,这个技巧会将后端的数据伪装成一个长宽都为1象素img get恳求,请求明文如下
页面浏览报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp
页面点击报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp&pageid=index.html&pcpid=pcpid
浏览和点击报文,区别在于pageid=index.html&pcpid=pcpid,pcpid定义为页面位置【例如点击了某个链接;触发了a_click(maps)方法】;
使用这些方法主要是为了解决跨域的问题,因为大多数情况下,统计脚本不单单为一个站点服务,域名也不可能全都一样;
服务端插口
http://localhost:8089/flow/log.gif?args=params
采集端代码如下【省略push kafka过程】
package com.fan.ga.gaserver.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import javax.imageio.ImageIO;
import javax.servlet.http.HttpServletResponse;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.io.OutputStream;
@Controller
@RequestMapping("/flow")
public class LogCollector {
Logger logger = LoggerFactory.getLogger(LogCollector.class);
// http://localhost:8089/flow/log.gif?args=asfafd
@RequestMapping(value = "log.gif")
public void analysis(String args, HttpServletResponse response) throws IOException {
logger.info(args);
response.setHeader("Pragma", "No-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
response.setContentType("image/gif");
OutputStream out = response.getOutputStream();
BufferedImage image = new BufferedImage(1, 1, BufferedImage.TYPE_INT_RGB);
ImageIO.write(image, "gif", out);
out.flush();
}
}
站点index.html页面
page test
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
首页
detail
End 查看全部
页面埋点
对一个网站进行流量剖析,首先要做的就是数据采集;而采集的形式大至两种形式
对于网站前端来说,数据上报一般有如下几种方式
直接向后台发送get请求,伪装成js或者图片请求
http://click.dangdang.com/page ... id%3D &res=1920,1080||1903,5211&title=当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款&trace_id=nohead&special=guan=1;page=id:1|name:当首;&cif=&rsv1=&rsv2=&rsv3=&platform=pc&r=0.857700135627224
https://a.stat.xiaomi.com/js/m ... D1920*1080&language=zh-CN&vendor=Google%20Inc.&platform=Win32&gu=&miwd=&edm_task=&masid=&client_id=&pu=&rf=0&mutid=&muwd=&domain_id=100&pageid=81190ccc4d52f577&curl=https%3A%2F%2Fwww.mi.com%2F&xmv=1536571987936_2638_1542615493495&v=1.0.0&vuuid=7ERAQ0IQQIBIFMAV
https://warriors.jd.com/log.gi ... 83904|19&v={"t1":"pc_homepage","t2":"basic","p0":"{\"rept\":\"impr\",\"poi\":\"head|focus|08\",\"text\":\"11.19个护感恩节\",\"url\":\"//sale.jd.com/act/1dCqk7TBj5porf8.html\",\"desc\":\"个护电器\",\"mcinfo\":\"00755652-05703860-1100950352-M#0-2-1--58--#1-tb-#300-9908298#pc-home\",\"biclk\":\"1#6328b7df38f1cf2c1fd7c296f1e920cd7b603c53-101-619081#9908298\"}","pinid":"-","je":0,"sc":"24-bit","sr":"1920x1080","ul":"zh-cn","cs":"UTF-8","dt":"京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!","hn":"www.jd.com","fl":"-","os":"win","br":"chrome","bv":"68.0.3440.106","wb":"1536298255","xb":"1542165688","yb":1542615817,"zb":19,"cb":1,"usc":"direct","ucp":"-","umd":"none","uct":"-","ct":1542615839771,"lt":0,"tad":"-","jdv":"122270672|direct|-|none|-|1542165687598","dataver":"0.1"}&ref=&rm=1542615839772
回到数据采集端
nginx + lua
这种形式须要在nginx端配置日志格式;接收到后端日志搜集恳求后,会对恳求解析,并将日志数据记录在本地c盘;这种形式,有几个显著的缺点:
日志储存在本地c盘,通常我们在做大数据离线剖析,数据都是储存在hdfs上;所以这些方法就不可防止须要将日志上传到hdfs起来;因为是日志文件方式储存,所以没办法做实时的统计剖析
后台搜集
这个就须要开发一个日志搜集服务端,提供一个http get服务;这个服务将上报的数据推送到kafka中;相比第一种形式,后台搜集,你就不需要去各个服务器去搜集日志文件;数据推送到kafka,也就意味着,我们可以使用storm,sparkstreaming进行实时剖析;这个也是目前使用最广的形式
站点的数据采集流程【后台搜集为例】
首先是数据上报后端;用过友盟统计和百度统计的朋友都晓得,想要使用友盟百度站点统计功能,首先要做的就是,在站点嵌入一段js或则html代码,大概象这个样子
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
这段代码的意思,就是动态加载远程的js[:8089/xmst.js],嵌入到须要统计服务的站点;xmst.js代码如下
var params = {};
//Document对象数据
if (document) {
params.domain = document.domain || ''; //获取域名
params.url = document.URL || ''; //当前Url地址
params.title = document.title || '';
params.referrer = document.referrer || ''; //上一跳路径
}
//Window对象数据
if (window && window.screen) {
params.sh = window.screen.height || 0; //获取显示屏信息
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if (navigator) {
params.lang = navigator.language || ''; //获取所用语言种类
}
params['age'] = '111'
//解析_maq配置
if (_maq) {
for (var i in _maq) { //获取埋点阶段,传递过来的用户行为
params[i] = _maq[i]
}
};
function args_build(){
//拼接参数串
var args = '';
for (var i in params) {
// alert(i);
if (args != '') {
args += '&';
}
args += i + '=' + params[i]; //将所有获取到的信息进行拼接
}
return args;
};
//页面自动加载
function page_load(){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
// alert("请求到的后端脚本为" + src);
img.src = src;
};
// 点击事件
function a_click(maps){
//通过伪装成Image对象,请求后端脚本
var img = new Image(1, 1);
for (var i in maps) {
params[i] = maps[i]
}
var src = 'http://localhost:8089/flow/log.gif?args=' + encodeURIComponent(args_build());
img.src = src;
}
page_load();
加载了这个脚本的页面会手动调用page_load()方法,这个技巧会将后端的数据伪装成一个长宽都为1象素img get恳求,请求明文如下
页面浏览报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp
页面点击报文
http://localhost:8089/flow/log ... Dpage test&referrer=&sh=1080&sw=1920&cd=24&lang=zh-CN&age=111&_setAccount=uuid&ppppp=ppppp&pageid=index.html&pcpid=pcpid
浏览和点击报文,区别在于pageid=index.html&pcpid=pcpid,pcpid定义为页面位置【例如点击了某个链接;触发了a_click(maps)方法】;
使用这些方法主要是为了解决跨域的问题,因为大多数情况下,统计脚本不单单为一个站点服务,域名也不可能全都一样;
服务端插口
http://localhost:8089/flow/log.gif?args=params
采集端代码如下【省略push kafka过程】
package com.fan.ga.gaserver.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import javax.imageio.ImageIO;
import javax.servlet.http.HttpServletResponse;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.io.OutputStream;
@Controller
@RequestMapping("/flow")
public class LogCollector {
Logger logger = LoggerFactory.getLogger(LogCollector.class);
// http://localhost:8089/flow/log.gif?args=asfafd
@RequestMapping(value = "log.gif")
public void analysis(String args, HttpServletResponse response) throws IOException {
logger.info(args);
response.setHeader("Pragma", "No-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
response.setContentType("image/gif");
OutputStream out = response.getOutputStream();
BufferedImage image = new BufferedImage(1, 1, BufferedImage.TYPE_INT_RGB);
ImageIO.write(image, "gif", out);
out.flush();
}
}
站点index.html页面
page test
var _maq = new Array();
_maq['_setAccount'] = 'uuid';
_maq['ppppp'] = 'ppppp';
(function () {
var ma = document.createElement('script');
ma.type = 'text/javascript';
ma.async = true;
ma.src = "http://localhost:8089/xmst.js";
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ma, s);
})();
首页
detail
End
如何采集小红书最新版(2018年9月)数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-08-23 20:21
本文原创作者:鲲之鹏()
本文原创链接:
小红书(),号称拥有超过一亿用户的生活方式分享社区,其用户笔记内容涵括吃穿玩乐买,涉及潮流、护肤、彩妆、美食、旅行、影视、读书、健身等各个生活方式领域,再加上社区每晚形成数十亿次的笔记爆光,正如顾客所言,其平台是集social和commerce于一体的,其数据价值可想而知。
小红书的数据起初也并不难采集,通过Web版的搜索插口,结合相应的搜索词,就可以搜索到感兴趣的笔记,进而搜集到笔记的详情数据。然而好景不长,随着小红书完成了一轮超过 3 亿美元的财务融资,小红书的平台插口也发生了很大的变化:Web版的搜索插口直接关掉,小红书App的应用成为主流。这样一来,之前通过Web版的搜索插口来抓取数据的方式,就直接被封死了。
既然Web版的插口不能用了,那就只能瞧瞧App的插口了。通过抓包工具,可以获取到小红书App的搜索插口。
这里使用的搜索词是“香奈儿63”,对应的搜索插口URL如下:
%E9%A6%99%E5%A5%88%E5%84%BF63&filters=&sort=&page=1&page_size=20&source=explore_feed&search_id=927A522C26DC8FD699971F1B1C1F6838&platform=Android&deviceId=560c6663-a66f-3aab-aff8-a8fe7bc48809&device_fingerprint=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&versionName=5.24.1&channel=Sogou&sid=session.78290029&lang=zh-Hans&t=1536298303&sign=dd2764c4258e12db80fbe5df11e01af0
可以看见,App插口中的参数好多。然而经过测试,发现那些参数不能更改,改了递交都会失败。而且,这些参数(搜索词keyword除外)也未能自行构造(注意sign参数,这是现今反采集常用的签名保护机制)。看来此路不通啊,抓数之旅再度陷入僵局。
还好,细心的鲲鹏技术人员发觉,除了App,小红书还有个陌陌小程序,于是展开又一轮对小红书陌陌小程序的剖析研究。
再次抓包剖析发觉,小红书陌陌小程序的插口可以更改参数,但是其中三个参数看起来是有有效期的。
测试发觉,只要这三个参数有一定时间的有效期,那就可以在这个有效期内,改变keyword进行搜索,并得到正确的数据。 那么,怎么能第一时间获取到这三个参数呢?鲲鹏技术人员通过研究发觉,可以用模拟操作陌陌小程序的方式,自动操作手机上的小红书小程序,同时用程序手动抓包截取,提取到最新的插口参数以供爬虫使用(如下图所示)。
敢想敢为,鲲鹏技术人员积极探求,大胆尝试,克服重重困难,终把看法弄成了现实。首先通过手动模拟操作程序,操作手机上的小红书小程序,然后抓包提取到最新的插口参数;接下来使用获取到的插口参数,结合搜索词执行搜索,并搜集搜索结果中的笔记相关数据;最后步入笔记详情页,提取所有须要的相关数据。大功告成!
附:
通过小红书陌陌小程序插口抓取到的搜索结果数据(部分数组)示例如下图:
点击这儿可以查看在线示例数据
说明:该文章为鲲之鹏()原创文章 ,您不仅可以发表评论外,还可以转载到别的网站,但是请保留源地址,谢谢!!(尊重别人劳动,我们共同努力) 查看全部
如何采集小红书最新版(2018年9月)数据
本文原创作者:鲲之鹏()
本文原创链接:
小红书(),号称拥有超过一亿用户的生活方式分享社区,其用户笔记内容涵括吃穿玩乐买,涉及潮流、护肤、彩妆、美食、旅行、影视、读书、健身等各个生活方式领域,再加上社区每晚形成数十亿次的笔记爆光,正如顾客所言,其平台是集social和commerce于一体的,其数据价值可想而知。
小红书的数据起初也并不难采集,通过Web版的搜索插口,结合相应的搜索词,就可以搜索到感兴趣的笔记,进而搜集到笔记的详情数据。然而好景不长,随着小红书完成了一轮超过 3 亿美元的财务融资,小红书的平台插口也发生了很大的变化:Web版的搜索插口直接关掉,小红书App的应用成为主流。这样一来,之前通过Web版的搜索插口来抓取数据的方式,就直接被封死了。
既然Web版的插口不能用了,那就只能瞧瞧App的插口了。通过抓包工具,可以获取到小红书App的搜索插口。
这里使用的搜索词是“香奈儿63”,对应的搜索插口URL如下:
%E9%A6%99%E5%A5%88%E5%84%BF63&filters=&sort=&page=1&page_size=20&source=explore_feed&search_id=927A522C26DC8FD699971F1B1C1F6838&platform=Android&deviceId=560c6663-a66f-3aab-aff8-a8fe7bc48809&device_fingerprint=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&device_fingerprint1=237dab00272f54a61a24dbf8e788810c0ac01ea060ac16b8048&versionName=5.24.1&channel=Sogou&sid=session.78290029&lang=zh-Hans&t=1536298303&sign=dd2764c4258e12db80fbe5df11e01af0
可以看见,App插口中的参数好多。然而经过测试,发现那些参数不能更改,改了递交都会失败。而且,这些参数(搜索词keyword除外)也未能自行构造(注意sign参数,这是现今反采集常用的签名保护机制)。看来此路不通啊,抓数之旅再度陷入僵局。
还好,细心的鲲鹏技术人员发觉,除了App,小红书还有个陌陌小程序,于是展开又一轮对小红书陌陌小程序的剖析研究。
再次抓包剖析发觉,小红书陌陌小程序的插口可以更改参数,但是其中三个参数看起来是有有效期的。
测试发觉,只要这三个参数有一定时间的有效期,那就可以在这个有效期内,改变keyword进行搜索,并得到正确的数据。 那么,怎么能第一时间获取到这三个参数呢?鲲鹏技术人员通过研究发觉,可以用模拟操作陌陌小程序的方式,自动操作手机上的小红书小程序,同时用程序手动抓包截取,提取到最新的插口参数以供爬虫使用(如下图所示)。
敢想敢为,鲲鹏技术人员积极探求,大胆尝试,克服重重困难,终把看法弄成了现实。首先通过手动模拟操作程序,操作手机上的小红书小程序,然后抓包提取到最新的插口参数;接下来使用获取到的插口参数,结合搜索词执行搜索,并搜集搜索结果中的笔记相关数据;最后步入笔记详情页,提取所有须要的相关数据。大功告成!
附:
通过小红书陌陌小程序插口抓取到的搜索结果数据(部分数组)示例如下图:
点击这儿可以查看在线示例数据
说明:该文章为鲲之鹏()原创文章 ,您不仅可以发表评论外,还可以转载到别的网站,但是请保留源地址,谢谢!!(尊重别人劳动,我们共同努力)
内容网数据采集接口定义及手动处理流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-08-21 17:21
数据采集及手动处理流程1 概述 本文主要描述内容网库对外定义的数据采集接口以及对于那些采集数据的手动处理流程。通过对现速网的剖析,我们觉得对于数据的采集主要是通过手工形式,爬虫爬取形式进行的,对于其他的采集方式,网信其实有提到,但是我们在如今的速网后台没有发觉相应的模块,希望网信相关人员通过对该文档的阅读,对于我们缺乏的采集接口做及时的补充。对于我们下边所设计的插口,希望网信相关人员可以提供测试数据供我们测试,2 采集接口定义2.1 爬虫 BT 接口2.1.1 待确认问题由于在原有的速网后台中,我们没有发觉该插口的设置界面,所以请相关人员就一下几个问题给予解答1. 爬虫是否会去爬取 BT 的信息2. 如果爬虫会爬取 BT 的信息,那么和 HTTP 爬取的信息是否一致?3. Bt 爬虫爬取的数据与 Bt 主动缓存解析的数据有哪些区别基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计1.爬虫会爬取 BT 信息2.爬虫爬取的信息仅收录资源信息。2.1.2 接口设计调用方:爬虫系统调用频度:当发觉爬取到新的数据时实时调用或则每晚定时调用约束:确保每次发送的信息都是最新批次的数据输入参数: 输入参数明细如下18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准输出:成功或则失败。
2.2 爬虫 HTTP 接口2.2.1 待确认问题1. 爬虫爬取 HTTP 在线资源时,资源资料信息是否同时采集?2. Http 爬取的资源中 是否带有电影名称 ,集数?基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计爬虫爬取 HTTP 在线资源时,资源和资料信息不是同时进行采集2.2.2 接口设计2.2.2.1 爬虫 HTTP 资源插口 18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准2.2.2.2 爬虫 HTTP 资料插口 编号 字段名称 说明 备注2 NAME 名称 电影名称3 LABEL 别名 4 DESCRIPTION 描述 电影的剧情描述5 HPOSTER 横向海报 6 VPOSTER 竖向海报 7 IS_HOT 是否热点 8 TAG Tag 栏 9 CHILDREN_COUNT 子集数目 10 AUTHOR 编剧 11 TV_NAME 电视台名 12 TV_HOST 主持人 13 SPAN 时长 播放时间14 COMMENTS 点评 15 LANGUAGE 影视语言(FK) 16 ACTORS 主要艺人 17 DIRECTORS 导演 18 PLAYDATE 影视开播日期 19 COUNTRY 地区分类(FK) 20 MOVIETYPE 影视分类(FK) 21 CONTENT_TYPE 题材分类(FK) 22 AVG_MARKS 评分 23 capture_site 采集点 判断是不是 10 大门户网站24 channel 频道 可用于分辨是否有集数,主演作者等一系列数组3 3 自动处理流程 手动处理流程的目的是对于采集接口获得的数据通过系统的手动内容筛选,自动内容质控,自动内容发布功能增强入库数据的质量,减轻人工编辑的工作量。
3.1 规则列表下方表格中定义了我们归纳出的筛选,质控,发布的规则,平台的规则引擎会手动按照下方的规则对数据进行处理。请按照实际情况对这种规则进行确认以及补充。筛选规则屏蔽资料垃圾数据通过对电影名称,播放地址进行非空判别。如有空数组,则把该数据放在垃圾表中处理。(资料) 屏蔽资源垃圾数据通过对电影名称,播放地址进行排空处理。如有空数组,则把该数据放在垃圾表中处理。(资源) 采集信息资料去重对“影片名称”进行比对。如有相同数据,则把该相对数据内容不全的资料放在垃圾表中处理。 采集信息资源去重对“播放地址”,“infohash”进行比对。如果数据相同。则删掉其中一条记录。 元数据资料去重 通过影片名,别名与元数据中原先资料进行对比,如果有相同资料,则此资料不添加到元数据库中。 元数据资源去重 http通过播放地址进行对比,bt通过infohash值进行对比。如找到相同记录,此资源状态改为屏蔽 添加到元数据库中。绑定入库 如果在去重阶段未找到相同记录。通过查找对应的电影名(资料查找资源) 进行绑定,反之,亦然。(资源 资料)对于有父子级关系的(例如电视剧)资料。如果库中没有子集资料。父子资料会手动生成子集资料供资源绑定。
审核规则合法性校准 判断各数组中是否有关键词(例如:黄色词句),如果有则转到人工待初审(资源 资料通用)资源有效性校准 资源是否属于 10 大门户网站,如果是直接初审通过。向播放地址发送 ping 看是否有效。资料内容校准 首先判定资料是否属于 10 大门户网站,如果是,直接初审通过。对别称中出现的冒号,顿号手动转换成"/".去除”/“两边的空格。评分数组倘若高于 5 分,自动转为 5 分以上,如果评分为整数,则添加一位小数。对于编剧,演员,自动清除每一行的 前后空格。 对于剧情描述,首行空 2 个空格,自动添加或删掉多余空格。对于艺人,导演,如果名子不全(例如:张艺谋,但资料中是张艺)查找字典表,自动补全名称。演员亦是这么。 对于地区:如果地区为空,可通过艺人,导演来推测是那个地区。 假如频道对应的剧集,影片。那么艺人,导演不能为空。如果对应是动画,那么作者不能为空。如果对应是综艺,那么主持人,电视台不能为空。不符合规则,转为人工代初审分布管理规则 资源发布规则 根据资源的热度(点击率,排行,搜索次数)划分出若干个等级,根据热度等级的结合每位局点的缓存情况,下发到各个局点。
例如将热度分为高,普通,低3 个等级,对于等级为高的资源下发所有局点,对于热度为普通的资源只下发到缓存空间多的局点,对于热度等级为低的资源只下发到本地。缓存优化规则 1.当发觉某个资源的缓存进度仍然处于比较低的时侯,根据规则替换或则删掉该缓存2.当发觉一个资源被缓存多次时,应依据资源的缓存进度保留进度最高的资源,删除其他资源缓存。3.当发觉局点缓存空间过高,应按照每位资源的热度,缓存情况,清理资源,清理热度低,缓存进度低的资源。3.2 详尽描述 1 资源处理流程图资源在入库前,会进行完整性校准,同批次去重,资源可靠性初审等多重步骤,保证步入元数据的资源是真实可用。 资源在入库后会定时调用初审规则查看资源库中的数据是否符合初审条件,对于早已失效的链接等进行剔除操作。并且对符合发布条件的资源调用 分布管理机制,保证资源的最大利用率。2 资料处理流程图资料在入库前,会进行完整性校准,同批次去重,与元数据库去重等多重步骤,保证元数据的资料是惟一的。并且在入库之前也会调用哪些初审规则,尽量提早修正资料的中错误。 资料在入库后会定时调用初审规则查看资料库中数据完整性,可靠性,并对一些数据手动进行校准,修正。
并且对符合发布条件的资料进行发布。4 补充问题 合作伙伴引入调用插口在哪,该怎么调用,能否提供?三严三实举办以来,我认真学习了习近平总书记系列讲话,研读了中央、区、市、县关于党的群众路线教育实践活动有关文件和资料。我对个人“四风”方面存在的问题及缘由进行了认真的反省、查摆和分析,找出了自身存在的众多差别和不足,理出了问题存在的缘由,明确了今后努力的方向和整改举措。现将对照检测情况报告如下,不妥之处,敬请诸位领导和同志们批评见谅。 一、存在的突出问题 一是学习深度广度不够。学习上存在形式主义,学习的全面性和系统性不强,在抽时间和挤时间学习上还不够自觉,致使自己的学习无论从广度和深度上都有些缺乏。学习制度坚持的不好,客观上指出工作忙、压力大和事务多,有时不耐心、不耐烦、不耐久,实则是缺少学习的拼劲和恒心。学用结合的关系处理的不够好,写文章、搞材料有时上网堆砌,求全求美求好看,结合本单位和实际工作的实质内容少,实用性不强。比如,每天对各级各种报纸甚少及时去阅读。因而,使自己的知识水平跟不上新形势的须要,工作标准不高,唱功好,做功差,忽视了理论对实际工作的指导作用。 二是服务不深入不主动。
工作上有时习惯于按部就班,习惯于常规思维,习惯于凭老观念想新问题,在统筹全局、分工协作、围绕中心、协调方方面面上还不够好。存在着为领导服务、为基层服务不够到位的问题,参谋和助手作用发挥得不够充分。比如,到乡镇、部门、企业了解情况,有时浮皮潦草,不够全面系统。与基层群众谈心交流少,没有真正深入到群众当中了解一线情况,掌握的第一手资料不全不深,“书到用时方恨少”,不能为领导决策提供更好的服务。 三是工作执行力不强。日常工作中与办公室同志谈心谈话少,对党员思想状态了解不深,疏于管理。办公室其实制订颁布了公文代办、工作守则等规章制度,但执行的意识不强,有时流于形式。比如,办公场所禁止吸烟,这一点我没有严格执行,有时还在办公室抽烟。 四是工作创新力不高。有时工作上习惯于照猫画虎,工作但求过得去、不求过得硬,存在着求稳怕乱的思想和患得患失心理,导致工作上不能完全放开四肢、甩开手臂去干,缺少一种勇于负责的担当和魄力。比如,做协调工作,有时真成了“传麦克风”和“二传手”,只传达领导交办的事项,缺乏与有关领导和同志共同接洽怎样把事情做得更好,创造性地举办工作。 五是深入基层调查研究不够。工作中,有时疏于具体事务,到基层一线督查不多,针对性不强,有时为了完成任务而督查,多了一些“官气”、少了一些“士气”。
往往是听汇报的多,直接聆听群众意见的少;了解面上情况多,发现深层次问题少。比如,对省委提出的用三分之一时间下基层搞督查活动,在实际工作中却没有做到。即使下基层,有时也是走马观花,蜻蜓点水,让看什么看哪些,让听哪些听哪些。在基层扶贫工作上,有时只重视出谋划策,抓落实、抓具体的少,对群众身边的一些小事情、小问题关心少、关注不够。 六是主观能动性发挥不够。自觉得在办公室工作多年,已经能否胜任工作,有自傲情绪,缺乏俯下身子、虚心讨教、不耻下问的心态。对待新问题、新情况,习惯于按照简单经验提出解决办法,创新不足,主观上存在满足现况,不思进取思想,主观能动性发挥不够。 七是对工作细节注重不够。作为办公室负责人,存在抓大放小,不能做到知上、知下、知左、知右、知里、知外,有时在一些小的问题上、细节上没有做好,导致工作落实不到位,出现误差。 八是工作效率不是很高。面对比较繁杂的工作任务,工作有时拈轻怕重、拖拉应付、不够认真。存在不推不动、不够主动,推一推进一动、有些被动。比如,文稿材料的撰写,有时东拼西凑、生搬硬套、缺乏深入思索。有时也存在着推诿扯皮现象,不能及时完成,质量也无法保证。对于领导交办的事项,有时跟踪、督导的不够,不能及时协调代办,缺乏应有的紧迫感,缺乏开拓创新精神,致使工作效率不高。
二、产生问题的诱因剖析 认真反省和深刻探讨自身存在的问题与不足,主要是自己没有强化世界观、人生观、价值观的改建,不重视提升自身修养,同时受社会不良风气的影响,在具体应对上没有挺好地掌握自己,碍于情面随波逐流。产生问题的缘由主要有以下几方面。 (一)自身放松了政治理论学习。对政治理论学习的重要性认识不足,重视程度不够。尤其是在处理工作与学习关系方面,把工作当做硬任务,把学习当做软指标,对政治理论学习投入的心思和精力不足,缺乏自觉学习的主动性和积极性。 (二)宗旨意识有所淡化。由于乡镇工作比较辛苦,从基层回到机关工作后,产生了松口气的念头,有时不自觉形成了优越感和骄傲自满的情绪。听惯了来自各方面的赞扬之声,深入基层少,对群众的呼声、疾苦、困难了解不够,没有树立较强的大局意识和责任意识,使得自己有时会片面地觉得只要做好本职工作,完成领导交办的任务就行了,而无法完全发挥自身的主观能动性,缺乏做好工作应有的责任心和紧迫感。 (三)忧患意识不强。只是片面见到了自身工作生活环境的变化,吃苦耐劳的精神有些欠缺,开拓进取、奋发有为、敢于冲锋、勇于担当的锐气有所弱化。有做“太平官”的意识,身处领导岗位,求新、求发展意识薄弱,表率作用发挥得不够好,忽视了工作的积极性、主动性和创造性。
(四)勤政廉政意识有所弱化。随着自身经济条件的改善,降低了约束标准,勤俭节约的传统美德有些淡化,对奢靡之风的极端危害性认识不足,没有造成高度注重。 诚然,造成自身存 在问题的诱因远不止这种,还有好多,如自身的固化思维方法,缺乏居安思危的深层次思索等。 三、今后的努力方向和改进举措 查摆问题,剖析症结,关键在于“洗澡治病”、解决问题。本人决心从党性原则出发,端正心态、认真对待,在今后的工作中采取强有力举措,立行立改,取得实效。 (一)求真务实 办公室校长作为承上启下、协调全局、沟通内外的重要角色,要立足发展、改革的新形势、新情况,以务实的作风和良好的品质作出垂范。 一是提高大局意识。要站在全局高度想问题,立足本职岗位做工作。要重视换位思索,真正做到想领导之所想、谋领导之所谋,及早提出比较成熟的意见和建议,供领导决策参考。要擅于从错综复杂的事务性工作中解脱下来,理清思路,明确目标,发挥自己应有的作用。 二是提高超前意识。要认真研究领会组织意图和领导思路,围绕领导关心的重大问题进行广泛深入的调查研究,为领导决策提供真实情况和可靠根据。要广泛采集资料,研究各乡镇、机关单位的新情况、新经验、新做法,借“他山之石”来攻玉,为领导提出决策预案。
因此,在想问题、办事情时,要赶前不赶后,尽可能早半拍、快半拍,提高敏感性,增强主动性。唯其这么,才能变被动为主动,“参谋”才能参在点子上,“助手”才能助到关键处。 三是提高创新意识。要加强服务理念,做深、做透、做好服务工作;要以协调、配合作为服务的主要手段和技巧,做到服务不越位;要围绕解决难点和热点问题举办服务,切实通过服务和协调把你们普遍关心、关注的热点焦点问题解决好,以实际行动取信于民。 (二)勤政为民 办公室既是贯彻落实省委、政府决议的执行部门,也是督促落实省委、政府决议的监督部门。破除官僚主义,勤政为民应该做好“四件事”。 一是擅于走入群众。从群众中来,到群众中去,是党的各项工作才能取得成功的一大法宝。开展群众路线教育活动,破解“官僚主义”,依靠的仍然是人民群众。工作中,要力戒高高在上、脱离群众、脱离实际的“官老爷”做派,多与群众接触,从群众中吸取智慧和力量,养成问计于民的好习惯。 二是敢于解难事。务实从严,是每位干部党员对待工作的正确心态。要把这些心态落实到每一项工作中去,要戒掉贪恋淫逸、讲求舒适、怕吃苦、饱食终日、碌碌无为的不良作风,承担起肩上的责任,做到为官一任,作为一方。
三是简化办事程序。要急群众所急、想群众所想,尽最大可能提升办事效率,加快办事速率,一切从实际出发,勤俭从政,效率为先。 四是接受监督。联系群众更要相信群众,加强民主更要多听民声。工作中时时处处应当考虑到群众利益,自觉主动接受群众监督,让工作举办得更有人气和活力。 (三)艰苦奋斗 要统筹制订领导干部办公用房、住房、配车、秘书配备、公务接待等工作生活待遇标准,落实不附赠、不接受礼品的规定,切实解决违背规定和超标准享受待遇的各类问题。要结合“治治病”的要求,按照中央八项规定,边学边查边整改,对照穿衣镜,深挖思想症结,净化心灵,摒弃享乐主义,坚持艰苦奋斗,以良好的精神状态和奋发有为的面貌赢取人民群众信任。 (四)廉洁自律 作为干部党员,无论什么时候,群众本色不能变,群众情结不能淡。要自觉强化党性修养,牢记全心全意为人民服务的宗旨,净化思想、洗涤灵魂、增强党性、明确航向。在一直保持为人民服务中追求高雅的生活情趣、锻造完善和谐的心理状态、 查看全部
内容网数据采集接口定义及手动处理流程
数据采集及手动处理流程1 概述 本文主要描述内容网库对外定义的数据采集接口以及对于那些采集数据的手动处理流程。通过对现速网的剖析,我们觉得对于数据的采集主要是通过手工形式,爬虫爬取形式进行的,对于其他的采集方式,网信其实有提到,但是我们在如今的速网后台没有发觉相应的模块,希望网信相关人员通过对该文档的阅读,对于我们缺乏的采集接口做及时的补充。对于我们下边所设计的插口,希望网信相关人员可以提供测试数据供我们测试,2 采集接口定义2.1 爬虫 BT 接口2.1.1 待确认问题由于在原有的速网后台中,我们没有发觉该插口的设置界面,所以请相关人员就一下几个问题给予解答1. 爬虫是否会去爬取 BT 的信息2. 如果爬虫会爬取 BT 的信息,那么和 HTTP 爬取的信息是否一致?3. Bt 爬虫爬取的数据与 Bt 主动缓存解析的数据有哪些区别基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计1.爬虫会爬取 BT 信息2.爬虫爬取的信息仅收录资源信息。2.1.2 接口设计调用方:爬虫系统调用频度:当发觉爬取到新的数据时实时调用或则每晚定时调用约束:确保每次发送的信息都是最新批次的数据输入参数: 输入参数明细如下18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准输出:成功或则失败。
2.2 爬虫 HTTP 接口2.2.1 待确认问题1. 爬虫爬取 HTTP 在线资源时,资源资料信息是否同时采集?2. Http 爬取的资源中 是否带有电影名称 ,集数?基于上述的问题,在没有获得网信相关人员答复的前提下,我们根据如下条件设计爬虫爬取 HTTP 在线资源时,资源和资料信息不是同时进行采集2.2.2 接口设计2.2.2.1 爬虫 HTTP 资源插口 18 FORMAT 文件格式 2 NAME 名称 用于完整性校准,判断去重 4 PROTOCOL 采集协议 5 LANGUAGE 语言( 6 CNT_SIZE 大小 7 QUALITY 质量 10 DATA_RATE 码流 11 INFOHASH Infohash 值判别去重 12 Duration 播放时长 13 URL 资源来源完整性校准2.2.2.2 爬虫 HTTP 资料插口 编号 字段名称 说明 备注2 NAME 名称 电影名称3 LABEL 别名 4 DESCRIPTION 描述 电影的剧情描述5 HPOSTER 横向海报 6 VPOSTER 竖向海报 7 IS_HOT 是否热点 8 TAG Tag 栏 9 CHILDREN_COUNT 子集数目 10 AUTHOR 编剧 11 TV_NAME 电视台名 12 TV_HOST 主持人 13 SPAN 时长 播放时间14 COMMENTS 点评 15 LANGUAGE 影视语言(FK) 16 ACTORS 主要艺人 17 DIRECTORS 导演 18 PLAYDATE 影视开播日期 19 COUNTRY 地区分类(FK) 20 MOVIETYPE 影视分类(FK) 21 CONTENT_TYPE 题材分类(FK) 22 AVG_MARKS 评分 23 capture_site 采集点 判断是不是 10 大门户网站24 channel 频道 可用于分辨是否有集数,主演作者等一系列数组3 3 自动处理流程 手动处理流程的目的是对于采集接口获得的数据通过系统的手动内容筛选,自动内容质控,自动内容发布功能增强入库数据的质量,减轻人工编辑的工作量。
3.1 规则列表下方表格中定义了我们归纳出的筛选,质控,发布的规则,平台的规则引擎会手动按照下方的规则对数据进行处理。请按照实际情况对这种规则进行确认以及补充。筛选规则屏蔽资料垃圾数据通过对电影名称,播放地址进行非空判别。如有空数组,则把该数据放在垃圾表中处理。(资料) 屏蔽资源垃圾数据通过对电影名称,播放地址进行排空处理。如有空数组,则把该数据放在垃圾表中处理。(资源) 采集信息资料去重对“影片名称”进行比对。如有相同数据,则把该相对数据内容不全的资料放在垃圾表中处理。 采集信息资源去重对“播放地址”,“infohash”进行比对。如果数据相同。则删掉其中一条记录。 元数据资料去重 通过影片名,别名与元数据中原先资料进行对比,如果有相同资料,则此资料不添加到元数据库中。 元数据资源去重 http通过播放地址进行对比,bt通过infohash值进行对比。如找到相同记录,此资源状态改为屏蔽 添加到元数据库中。绑定入库 如果在去重阶段未找到相同记录。通过查找对应的电影名(资料查找资源) 进行绑定,反之,亦然。(资源 资料)对于有父子级关系的(例如电视剧)资料。如果库中没有子集资料。父子资料会手动生成子集资料供资源绑定。
审核规则合法性校准 判断各数组中是否有关键词(例如:黄色词句),如果有则转到人工待初审(资源 资料通用)资源有效性校准 资源是否属于 10 大门户网站,如果是直接初审通过。向播放地址发送 ping 看是否有效。资料内容校准 首先判定资料是否属于 10 大门户网站,如果是,直接初审通过。对别称中出现的冒号,顿号手动转换成"/".去除”/“两边的空格。评分数组倘若高于 5 分,自动转为 5 分以上,如果评分为整数,则添加一位小数。对于编剧,演员,自动清除每一行的 前后空格。 对于剧情描述,首行空 2 个空格,自动添加或删掉多余空格。对于艺人,导演,如果名子不全(例如:张艺谋,但资料中是张艺)查找字典表,自动补全名称。演员亦是这么。 对于地区:如果地区为空,可通过艺人,导演来推测是那个地区。 假如频道对应的剧集,影片。那么艺人,导演不能为空。如果对应是动画,那么作者不能为空。如果对应是综艺,那么主持人,电视台不能为空。不符合规则,转为人工代初审分布管理规则 资源发布规则 根据资源的热度(点击率,排行,搜索次数)划分出若干个等级,根据热度等级的结合每位局点的缓存情况,下发到各个局点。
例如将热度分为高,普通,低3 个等级,对于等级为高的资源下发所有局点,对于热度为普通的资源只下发到缓存空间多的局点,对于热度等级为低的资源只下发到本地。缓存优化规则 1.当发觉某个资源的缓存进度仍然处于比较低的时侯,根据规则替换或则删掉该缓存2.当发觉一个资源被缓存多次时,应依据资源的缓存进度保留进度最高的资源,删除其他资源缓存。3.当发觉局点缓存空间过高,应按照每位资源的热度,缓存情况,清理资源,清理热度低,缓存进度低的资源。3.2 详尽描述 1 资源处理流程图资源在入库前,会进行完整性校准,同批次去重,资源可靠性初审等多重步骤,保证步入元数据的资源是真实可用。 资源在入库后会定时调用初审规则查看资源库中的数据是否符合初审条件,对于早已失效的链接等进行剔除操作。并且对符合发布条件的资源调用 分布管理机制,保证资源的最大利用率。2 资料处理流程图资料在入库前,会进行完整性校准,同批次去重,与元数据库去重等多重步骤,保证元数据的资料是惟一的。并且在入库之前也会调用哪些初审规则,尽量提早修正资料的中错误。 资料在入库后会定时调用初审规则查看资料库中数据完整性,可靠性,并对一些数据手动进行校准,修正。
并且对符合发布条件的资料进行发布。4 补充问题 合作伙伴引入调用插口在哪,该怎么调用,能否提供?三严三实举办以来,我认真学习了习近平总书记系列讲话,研读了中央、区、市、县关于党的群众路线教育实践活动有关文件和资料。我对个人“四风”方面存在的问题及缘由进行了认真的反省、查摆和分析,找出了自身存在的众多差别和不足,理出了问题存在的缘由,明确了今后努力的方向和整改举措。现将对照检测情况报告如下,不妥之处,敬请诸位领导和同志们批评见谅。 一、存在的突出问题 一是学习深度广度不够。学习上存在形式主义,学习的全面性和系统性不强,在抽时间和挤时间学习上还不够自觉,致使自己的学习无论从广度和深度上都有些缺乏。学习制度坚持的不好,客观上指出工作忙、压力大和事务多,有时不耐心、不耐烦、不耐久,实则是缺少学习的拼劲和恒心。学用结合的关系处理的不够好,写文章、搞材料有时上网堆砌,求全求美求好看,结合本单位和实际工作的实质内容少,实用性不强。比如,每天对各级各种报纸甚少及时去阅读。因而,使自己的知识水平跟不上新形势的须要,工作标准不高,唱功好,做功差,忽视了理论对实际工作的指导作用。 二是服务不深入不主动。
工作上有时习惯于按部就班,习惯于常规思维,习惯于凭老观念想新问题,在统筹全局、分工协作、围绕中心、协调方方面面上还不够好。存在着为领导服务、为基层服务不够到位的问题,参谋和助手作用发挥得不够充分。比如,到乡镇、部门、企业了解情况,有时浮皮潦草,不够全面系统。与基层群众谈心交流少,没有真正深入到群众当中了解一线情况,掌握的第一手资料不全不深,“书到用时方恨少”,不能为领导决策提供更好的服务。 三是工作执行力不强。日常工作中与办公室同志谈心谈话少,对党员思想状态了解不深,疏于管理。办公室其实制订颁布了公文代办、工作守则等规章制度,但执行的意识不强,有时流于形式。比如,办公场所禁止吸烟,这一点我没有严格执行,有时还在办公室抽烟。 四是工作创新力不高。有时工作上习惯于照猫画虎,工作但求过得去、不求过得硬,存在着求稳怕乱的思想和患得患失心理,导致工作上不能完全放开四肢、甩开手臂去干,缺少一种勇于负责的担当和魄力。比如,做协调工作,有时真成了“传麦克风”和“二传手”,只传达领导交办的事项,缺乏与有关领导和同志共同接洽怎样把事情做得更好,创造性地举办工作。 五是深入基层调查研究不够。工作中,有时疏于具体事务,到基层一线督查不多,针对性不强,有时为了完成任务而督查,多了一些“官气”、少了一些“士气”。
往往是听汇报的多,直接聆听群众意见的少;了解面上情况多,发现深层次问题少。比如,对省委提出的用三分之一时间下基层搞督查活动,在实际工作中却没有做到。即使下基层,有时也是走马观花,蜻蜓点水,让看什么看哪些,让听哪些听哪些。在基层扶贫工作上,有时只重视出谋划策,抓落实、抓具体的少,对群众身边的一些小事情、小问题关心少、关注不够。 六是主观能动性发挥不够。自觉得在办公室工作多年,已经能否胜任工作,有自傲情绪,缺乏俯下身子、虚心讨教、不耻下问的心态。对待新问题、新情况,习惯于按照简单经验提出解决办法,创新不足,主观上存在满足现况,不思进取思想,主观能动性发挥不够。 七是对工作细节注重不够。作为办公室负责人,存在抓大放小,不能做到知上、知下、知左、知右、知里、知外,有时在一些小的问题上、细节上没有做好,导致工作落实不到位,出现误差。 八是工作效率不是很高。面对比较繁杂的工作任务,工作有时拈轻怕重、拖拉应付、不够认真。存在不推不动、不够主动,推一推进一动、有些被动。比如,文稿材料的撰写,有时东拼西凑、生搬硬套、缺乏深入思索。有时也存在着推诿扯皮现象,不能及时完成,质量也无法保证。对于领导交办的事项,有时跟踪、督导的不够,不能及时协调代办,缺乏应有的紧迫感,缺乏开拓创新精神,致使工作效率不高。
二、产生问题的诱因剖析 认真反省和深刻探讨自身存在的问题与不足,主要是自己没有强化世界观、人生观、价值观的改建,不重视提升自身修养,同时受社会不良风气的影响,在具体应对上没有挺好地掌握自己,碍于情面随波逐流。产生问题的缘由主要有以下几方面。 (一)自身放松了政治理论学习。对政治理论学习的重要性认识不足,重视程度不够。尤其是在处理工作与学习关系方面,把工作当做硬任务,把学习当做软指标,对政治理论学习投入的心思和精力不足,缺乏自觉学习的主动性和积极性。 (二)宗旨意识有所淡化。由于乡镇工作比较辛苦,从基层回到机关工作后,产生了松口气的念头,有时不自觉形成了优越感和骄傲自满的情绪。听惯了来自各方面的赞扬之声,深入基层少,对群众的呼声、疾苦、困难了解不够,没有树立较强的大局意识和责任意识,使得自己有时会片面地觉得只要做好本职工作,完成领导交办的任务就行了,而无法完全发挥自身的主观能动性,缺乏做好工作应有的责任心和紧迫感。 (三)忧患意识不强。只是片面见到了自身工作生活环境的变化,吃苦耐劳的精神有些欠缺,开拓进取、奋发有为、敢于冲锋、勇于担当的锐气有所弱化。有做“太平官”的意识,身处领导岗位,求新、求发展意识薄弱,表率作用发挥得不够好,忽视了工作的积极性、主动性和创造性。
(四)勤政廉政意识有所弱化。随着自身经济条件的改善,降低了约束标准,勤俭节约的传统美德有些淡化,对奢靡之风的极端危害性认识不足,没有造成高度注重。 诚然,造成自身存 在问题的诱因远不止这种,还有好多,如自身的固化思维方法,缺乏居安思危的深层次思索等。 三、今后的努力方向和改进举措 查摆问题,剖析症结,关键在于“洗澡治病”、解决问题。本人决心从党性原则出发,端正心态、认真对待,在今后的工作中采取强有力举措,立行立改,取得实效。 (一)求真务实 办公室校长作为承上启下、协调全局、沟通内外的重要角色,要立足发展、改革的新形势、新情况,以务实的作风和良好的品质作出垂范。 一是提高大局意识。要站在全局高度想问题,立足本职岗位做工作。要重视换位思索,真正做到想领导之所想、谋领导之所谋,及早提出比较成熟的意见和建议,供领导决策参考。要擅于从错综复杂的事务性工作中解脱下来,理清思路,明确目标,发挥自己应有的作用。 二是提高超前意识。要认真研究领会组织意图和领导思路,围绕领导关心的重大问题进行广泛深入的调查研究,为领导决策提供真实情况和可靠根据。要广泛采集资料,研究各乡镇、机关单位的新情况、新经验、新做法,借“他山之石”来攻玉,为领导提出决策预案。
因此,在想问题、办事情时,要赶前不赶后,尽可能早半拍、快半拍,提高敏感性,增强主动性。唯其这么,才能变被动为主动,“参谋”才能参在点子上,“助手”才能助到关键处。 三是提高创新意识。要加强服务理念,做深、做透、做好服务工作;要以协调、配合作为服务的主要手段和技巧,做到服务不越位;要围绕解决难点和热点问题举办服务,切实通过服务和协调把你们普遍关心、关注的热点焦点问题解决好,以实际行动取信于民。 (二)勤政为民 办公室既是贯彻落实省委、政府决议的执行部门,也是督促落实省委、政府决议的监督部门。破除官僚主义,勤政为民应该做好“四件事”。 一是擅于走入群众。从群众中来,到群众中去,是党的各项工作才能取得成功的一大法宝。开展群众路线教育活动,破解“官僚主义”,依靠的仍然是人民群众。工作中,要力戒高高在上、脱离群众、脱离实际的“官老爷”做派,多与群众接触,从群众中吸取智慧和力量,养成问计于民的好习惯。 二是敢于解难事。务实从严,是每位干部党员对待工作的正确心态。要把这些心态落实到每一项工作中去,要戒掉贪恋淫逸、讲求舒适、怕吃苦、饱食终日、碌碌无为的不良作风,承担起肩上的责任,做到为官一任,作为一方。
三是简化办事程序。要急群众所急、想群众所想,尽最大可能提升办事效率,加快办事速率,一切从实际出发,勤俭从政,效率为先。 四是接受监督。联系群众更要相信群众,加强民主更要多听民声。工作中时时处处应当考虑到群众利益,自觉主动接受群众监督,让工作举办得更有人气和活力。 (三)艰苦奋斗 要统筹制订领导干部办公用房、住房、配车、秘书配备、公务接待等工作生活待遇标准,落实不附赠、不接受礼品的规定,切实解决违背规定和超标准享受待遇的各类问题。要结合“治治病”的要求,按照中央八项规定,边学边查边整改,对照穿衣镜,深挖思想症结,净化心灵,摒弃享乐主义,坚持艰苦奋斗,以良好的精神状态和奋发有为的面貌赢取人民群众信任。 (四)廉洁自律 作为干部党员,无论什么时候,群众本色不能变,群众情结不能淡。要自觉强化党性修养,牢记全心全意为人民服务的宗旨,净化思想、洗涤灵魂、增强党性、明确航向。在一直保持为人民服务中追求高雅的生活情趣、锻造完善和谐的心理状态、
管理系统和帝国CMS两个建站系统那个更好
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-20 20:42
chinawoss
一个好的旅游网站管理系统(简称旅游CMS)最好具有自主知识产权和良好的升级机制,长期稳定的升级既能能保证系统功能越来越建立又能保证系统使用数据安全。
其次做为旅游CMS系统,网站的系统功能要建立,不应当存在网站前台诠释后台不能控制的功能,好的CMS系统包括前台的模块增减、排序都能从后台直接控制。同时要涵盖旅游行业运营所须要的系统常见功能。
产品系统Products
线路、酒店、门票、租车、机票、签证、团购(套餐)、个性订制;(可扩充导游、特产等功能);
文章系统Articles
目的地手册、游记功略、景点、图片相册、问答、点评、帮助系统;
用户系统Users
在线订单、在线支付、生成订单邮件/邮箱通知、点评、问答、短信短信群发;会员管理、供应商管理;
营销策略Marketing
SEO插口、社会化分享插口、积分、返现策略;出发地、目的地营销构架、支持泛解析二级域名结构、专题营销、广告管理、伪静态规则设置、生成静态页面等;
支付体系Payment
集成:支持支付宝、快钱、银联、汇潮等在线支付插口;
扩展插口Expansion
文章采集接口、Dz峰会、UCenter、Google电子地图;已集成:第三方登录插口、短信平台插口等;
设置中心Set center
目的地4级分类、属性2级自定义、内容分类自定义、出发地设置、站点设置、系统参数管理、数据备份、操作日志;
营销助手Assistant
关键词统计、关键词智能链接、tag词设置、访问来源统计、热搜词统计、智能sitemap、死链自查
增值应用Value-added
系统升级、模板替换、营销指导、问题反馈、扩展应用等;
最后做为旅游CMS系统要有开放的态度程序开源不加密是保证用户二次开发的基础,也是可以称为CMS系统的前提。如果程序加密了,很多核心的订制功能将收到限制,不利于后期特色营运。当然开源须要勇气,直接面对盗版横行,一方面须要旅游CMS系统提供良好的售后升级和营运指导彰显正版的价值,另一方面也须要我们自己使用者具有维护正版的正确认识,只有我们使用正版付费,才可能得到持续建立的售后支持和安全升级保证系统正常营运推广。 查看全部
管理系统和帝国CMS两个建站系统那个更好
chinawoss
一个好的旅游网站管理系统(简称旅游CMS)最好具有自主知识产权和良好的升级机制,长期稳定的升级既能能保证系统功能越来越建立又能保证系统使用数据安全。
其次做为旅游CMS系统,网站的系统功能要建立,不应当存在网站前台诠释后台不能控制的功能,好的CMS系统包括前台的模块增减、排序都能从后台直接控制。同时要涵盖旅游行业运营所须要的系统常见功能。
产品系统Products
线路、酒店、门票、租车、机票、签证、团购(套餐)、个性订制;(可扩充导游、特产等功能);
文章系统Articles
目的地手册、游记功略、景点、图片相册、问答、点评、帮助系统;
用户系统Users
在线订单、在线支付、生成订单邮件/邮箱通知、点评、问答、短信短信群发;会员管理、供应商管理;
营销策略Marketing
SEO插口、社会化分享插口、积分、返现策略;出发地、目的地营销构架、支持泛解析二级域名结构、专题营销、广告管理、伪静态规则设置、生成静态页面等;
支付体系Payment
集成:支持支付宝、快钱、银联、汇潮等在线支付插口;
扩展插口Expansion
文章采集接口、Dz峰会、UCenter、Google电子地图;已集成:第三方登录插口、短信平台插口等;
设置中心Set center
目的地4级分类、属性2级自定义、内容分类自定义、出发地设置、站点设置、系统参数管理、数据备份、操作日志;
营销助手Assistant
关键词统计、关键词智能链接、tag词设置、访问来源统计、热搜词统计、智能sitemap、死链自查
增值应用Value-added
系统升级、模板替换、营销指导、问题反馈、扩展应用等;
最后做为旅游CMS系统要有开放的态度程序开源不加密是保证用户二次开发的基础,也是可以称为CMS系统的前提。如果程序加密了,很多核心的订制功能将收到限制,不利于后期特色营运。当然开源须要勇气,直接面对盗版横行,一方面须要旅游CMS系统提供良好的售后升级和营运指导彰显正版的价值,另一方面也须要我们自己使用者具有维护正版的正确认识,只有我们使用正版付费,才可能得到持续建立的售后支持和安全升级保证系统正常营运推广。
DesToon7.0版优采云免登入采集接口 v20180514
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-19 18:17
DesToon7.0版优采云免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon7.0版优采云免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon7.0版优采云免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon7.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon7.0版优采云免登入采集接口截图 查看全部
DesToon7.0版优采云免登入采集接口 v20180514
DesToon7.0版优采云免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon7.0版优采云免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon7.0版优采云免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon7.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon7.0版优采云免登入采集接口截图
文章采集接口 [开源
采集交流 • 优采云 发表了文章 • 0 个评论 • 526 次浏览 • 2020-08-18 20:00
[开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [四] JSON数据解析
[DotnetSpider 系列目录]场景模拟
接上一篇, 假设因为漏存JD SKU对应的店面信息。这时我们须要重新完全采集所有的SKU数据吗?补爬的话历史数据就用不了了。因此,去易迅页面上找看是否有提供相关的插口。
查找API恳求插口
安装 Fiddler, 并打开
在谷歌浏览器中访问:,1343,9719
在Fiddler查找一条条的访问记录,找到我们想要的插口
编写爬虫
分析返回的数据结果,我们可以先写出数据对象的定义(观察Expression的值早已是JsonPath查询表达式了,同时Type必须设置为Type = SelectorType.JsonPath)。另外须要注意的是,这次的爬虫是更新型爬虫,就是说采集到的数据补充回原表,那么就一定要设置字段是哪些,即在数据类上添加字段的定义
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
定义Pipeline的类型为Update
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source= ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
由于返回的数据中还有一个json()这样的pagging,所以须要先做一个截取操作,框架提供了PageHandler插口,并且我们实现了大量常用的Handler,用于HTML的解析前的一些处理操作,因此完整的代码如下
public class JdShopDetailSpider : EntitySpiderBuilder
{
protected override EntitySpider GetEntitySpider()
{
var context = new EntitySpider(new Site())
{
TaskGroup = "JD SKU Weekly",
Identity = "JD Shop details " + DateTimeUtils.MondayRunId,
CachedSize = 1,
ThreadNum = 8,
Downloader = new HttpClientDownloader
{
DownloadCompleteHandlers = new IDownloadCompleteHandler[]
{
new SubContentHandler
{
Start = "json(",
End = ");",
StartOffset = 5,
EndOffset = 0
}
}
},
PrepareStartUrls = new PrepareStartUrls[]
{
new BaseDbPrepareStartUrls()
{
Source = DataSource.MySql,
ConnectString = "Database='test';Data Source= localhost;User ID=root;Password=1qazZAQ!;Port=3306",
QueryString = $"SELECT * FROM jd.sku_v2_{DateTimeUtils.MondayRunId} WHERE shopname is null or shopid is null order by sku",
Columns = new [] {new DataColumn { Name = "sku"} },
FormateStrings = new List { "http://chat1.jd.com/api/checkC ... st%3D{0}&callback=json" }
}
}
};
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source=localhost ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
context.AddEntityType(typeof(ProductUpdater), new TargetUrlExtractor
{
Region = new Selector { Type = SelectorType.XPath, Expression = "//*[@id=\"J_bottomPage\"]" },
Patterns = new List { @"&page=[0-9]+&" }
});
return context;
}
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
}
posted @ 2017-04-14 10:26网路蚂蚁阅读(1417)评论(0)编辑 查看全部
文章采集接口 [开源
[开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [四] JSON数据解析
[DotnetSpider 系列目录]场景模拟
接上一篇, 假设因为漏存JD SKU对应的店面信息。这时我们须要重新完全采集所有的SKU数据吗?补爬的话历史数据就用不了了。因此,去易迅页面上找看是否有提供相关的插口。
查找API恳求插口
安装 Fiddler, 并打开
在谷歌浏览器中访问:,1343,9719
在Fiddler查找一条条的访问记录,找到我们想要的插口
编写爬虫
分析返回的数据结果,我们可以先写出数据对象的定义(观察Expression的值早已是JsonPath查询表达式了,同时Type必须设置为Type = SelectorType.JsonPath)。另外须要注意的是,这次的爬虫是更新型爬虫,就是说采集到的数据补充回原表,那么就一定要设置字段是哪些,即在数据类上添加字段的定义
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
定义Pipeline的类型为Update
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source= ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
由于返回的数据中还有一个json()这样的pagging,所以须要先做一个截取操作,框架提供了PageHandler插口,并且我们实现了大量常用的Handler,用于HTML的解析前的一些处理操作,因此完整的代码如下
public class JdShopDetailSpider : EntitySpiderBuilder
{
protected override EntitySpider GetEntitySpider()
{
var context = new EntitySpider(new Site())
{
TaskGroup = "JD SKU Weekly",
Identity = "JD Shop details " + DateTimeUtils.MondayRunId,
CachedSize = 1,
ThreadNum = 8,
Downloader = new HttpClientDownloader
{
DownloadCompleteHandlers = new IDownloadCompleteHandler[]
{
new SubContentHandler
{
Start = "json(",
End = ");",
StartOffset = 5,
EndOffset = 0
}
}
},
PrepareStartUrls = new PrepareStartUrls[]
{
new BaseDbPrepareStartUrls()
{
Source = DataSource.MySql,
ConnectString = "Database='test';Data Source= localhost;User ID=root;Password=1qazZAQ!;Port=3306",
QueryString = $"SELECT * FROM jd.sku_v2_{DateTimeUtils.MondayRunId} WHERE shopname is null or shopid is null order by sku",
Columns = new [] {new DataColumn { Name = "sku"} },
FormateStrings = new List { "http://chat1.jd.com/api/checkC ... st%3D{0}&callback=json" }
}
}
};
context.AddEntityPipeline(new MySqlEntityPipeline
{
ConnectString = "Database='taobao';Data Source=localhost ;User ID=root;Password=1qazZAQ!;Port=4306",
Mode = PipelineMode.Update
});
context.AddEntityType(typeof(ProductUpdater), new TargetUrlExtractor
{
Region = new Selector { Type = SelectorType.XPath, Expression = "//*[@id=\"J_bottomPage\"]" },
Patterns = new List { @"&page=[0-9]+&" }
});
return context;
}
[Schema("jd", "sku_v2", TableSuffix.Monday)]
[EntitySelector(Expression = "$.[*]", Type = SelectorType.JsonPath)]
[Indexes(Primary = "sku")]
public class ProductUpdater : ISpiderEntity
{
[StoredAs("sku", DataType.String, 25)]
[PropertySelector(Expression = "$.pid", Type = SelectorType.JsonPath)]
public string Sku { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertySelector(Expression = "$.seller", Type = SelectorType.JsonPath)]
public string ShopName { get; set; }
[StoredAs("shopid", DataType.String, 25)]
[PropertySelector(Expression = "$.shopId", Type = SelectorType.JsonPath)]
public string ShopId { get; set; }
}
}
posted @ 2017-04-14 10:26网路蚂蚁阅读(1417)评论(0)编辑
最新微信公众号采集方案详尽介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2020-08-18 17:51
目前比较有效的几种微信公众号的采集方式:
1、通过web端素材管理插口的方法
2、通过appium从手机端
3、通过逆向工程暴力获取
4、通过第三方服务插口
5、搜狗微信公众号插口(已凉)
个人及小团体对公众号内容获取数目不多的情况下通常还会采用前两种相对简单方便成本低的方法去获取内容,不差钱的团队肯定就买第三方服务了,靠提供微信公众号采集接口的服务赢利的肯定就是逆向工程了.我介绍第一种比较简单适宜小规模采集的方案
1、首先我们须要注册个属于自己的公众号平台微信公众号注册地址
2、注册成功后步入点击如图所示的素材管理
3、点击素材管理后点击如图所示的新建图文消息
4、点击新建图文消息后点击如图所示的超链接
5、点解超链接后点击如图所示的选择其他公众号
6、这时候就可以输入我们想要获取公众号内容的名子去搜索查询
7、我们通过抓包查看剖析下
通过抓包也不难剖析出恳求参数的话就是我截图那样,稍后代码上将会呈现下来,然后通过恳求response返回的内容也可以看见诸如title、link、概要、更新时间等等的内容这儿我们主要取title和url,我要说明一下我们通过这些方法获取的link是临时链接并不是手机端打开那样的永久链接并且也无妨我们只要通过访问临时链接把内容下载出来就可以了这个临时链接的有效时长虽然也是太长时间的,如果我们想转换成永久链接我们可以通过手机端打开得到的就是永久链接地址了
大体概述下代码流程
1、调用登陆函数login_wechat通过webdrive扫码登陆微信公众号,这里不采用手动输入帐号密码的方法登陆是因为虽然输入帐号密码还是须要扫码确认
2、登录成功获取cookie信息保存本地cookie.txt文件
3、调用采集函数get_content获取cookie.txt的cookie值并提取token
4、拼接好我们须要的恳求参数后恳求素材管理中插口中我们待采集公众号信息
5、通过恳求插口获取文章的title、link并实现翻页功能
6、拿到我们待采集文章的link后恳求link地址下载文章内容
7、将title、link、内容对应保存csv文件 查看全部
最新微信公众号采集方案详尽介绍
目前比较有效的几种微信公众号的采集方式:
1、通过web端素材管理插口的方法
2、通过appium从手机端
3、通过逆向工程暴力获取
4、通过第三方服务插口
5、搜狗微信公众号插口(已凉)
个人及小团体对公众号内容获取数目不多的情况下通常还会采用前两种相对简单方便成本低的方法去获取内容,不差钱的团队肯定就买第三方服务了,靠提供微信公众号采集接口的服务赢利的肯定就是逆向工程了.我介绍第一种比较简单适宜小规模采集的方案
1、首先我们须要注册个属于自己的公众号平台微信公众号注册地址
2、注册成功后步入点击如图所示的素材管理
3、点击素材管理后点击如图所示的新建图文消息
4、点击新建图文消息后点击如图所示的超链接
5、点解超链接后点击如图所示的选择其他公众号
6、这时候就可以输入我们想要获取公众号内容的名子去搜索查询
7、我们通过抓包查看剖析下
通过抓包也不难剖析出恳求参数的话就是我截图那样,稍后代码上将会呈现下来,然后通过恳求response返回的内容也可以看见诸如title、link、概要、更新时间等等的内容这儿我们主要取title和url,我要说明一下我们通过这些方法获取的link是临时链接并不是手机端打开那样的永久链接并且也无妨我们只要通过访问临时链接把内容下载出来就可以了这个临时链接的有效时长虽然也是太长时间的,如果我们想转换成永久链接我们可以通过手机端打开得到的就是永久链接地址了
大体概述下代码流程
1、调用登陆函数login_wechat通过webdrive扫码登陆微信公众号,这里不采用手动输入帐号密码的方法登陆是因为虽然输入帐号密码还是须要扫码确认
2、登录成功获取cookie信息保存本地cookie.txt文件
3、调用采集函数get_content获取cookie.txt的cookie值并提取token
4、拼接好我们须要的恳求参数后恳求素材管理中插口中我们待采集公众号信息
5、通过恳求插口获取文章的title、link并实现翻页功能
6、拿到我们待采集文章的link后恳求link地址下载文章内容
7、将title、link、内容对应保存csv文件
优采云采集器下载地址 已被下载次
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2020-08-18 12:16
优采云采集器是任何一个须要从网页获取信息的利器,这个是一款可以使你的信息采集可以显得很简单的工具。优采云转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料编的愈发简单和容易了。
软件特色
满足多种业务场景
适合产品、运营、销售、数据剖析、政府机关、电商从业者、学术研究等多种身分职业
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的繁杂,支持更多网站的采集。
使用方式
先我们新建一个任务-->进入流程设计页面-->添加一个循环步骤到流程中-->选中循环步骤-->勾选上软件右方的URL 列表勾选框-->打开URL列表文本框-->将打算好的URL列表填写到文本框中
接下来往循环中推入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页
到这儿,循环打开网页的流程就配置完成了,运行流程的时侯,系统会挨个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。 查看全部
优采云采集器下载地址 已被下载次
优采云采集器是任何一个须要从网页获取信息的利器,这个是一款可以使你的信息采集可以显得很简单的工具。优采云转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料编的愈发简单和容易了。
软件特色
满足多种业务场景
适合产品、运营、销售、数据剖析、政府机关、电商从业者、学术研究等多种身分职业
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简易采集
简易采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的繁杂,支持更多网站的采集。
使用方式
先我们新建一个任务-->进入流程设计页面-->添加一个循环步骤到流程中-->选中循环步骤-->勾选上软件右方的URL 列表勾选框-->打开URL列表文本框-->将打算好的URL列表填写到文本框中
接下来往循环中推入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页
到这儿,循环打开网页的流程就配置完成了,运行流程的时侯,系统会挨个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。
DesToon6.0 UTF8版免登入采集接口 v20180514
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-13 05:02
DesToon6.0 UTF8版免登入采集接口 v20180514更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DT采集专家 DesToon6.0免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 UTF8版免登入采集接口截图 查看全部
DesToon6.0 UTF8版免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon6.0 UTF8版免登入采集接口 v20180514更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DT采集专家 DesToon6.0免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 UTF8版免登入采集接口截图
最新百度博客发布插口 多帐号随机发布文章,推广神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-12 13:45
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客:
又做了百度的手动登入,百度之前我是不会模拟她的手动登入的,因为百度很早就早已把登陆表单数据通过javascript隐藏的就像18层地狱,多次尝试去读它的js代码,由于本人精力效率早已没有,没有往年那样可以有那个耐心去研究她的js,百度我也只是看了部份js,了解了少部份登陆相关的代码,然后去构造post数据 提交给登陆url,结果成功的登陆了百度,提交的post数据是正确的,获取了cookie。
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客: 查看全部
又做了百度的手动登入,百度之前我是不会模拟她的手动登入的,因为百度很早就早已把登陆表单数据通过javascript隐藏的就像18层地狱,多次尝试去读它的js代码,由于本人精力效率早已没有,没有往年那样可以有那个耐心去研究她的js,百度我也只是看了部份js,了解了少部份登陆相关的代码,然后去构造post数据 提交给登陆url,结果成功的登陆了百度,提交的post数据是正确的,获取了cookie。
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客:
又做了百度的手动登入,百度之前我是不会模拟她的手动登入的,因为百度很早就早已把登陆表单数据通过javascript隐藏的就像18层地狱,多次尝试去读它的js代码,由于本人精力效率早已没有,没有往年那样可以有那个耐心去研究她的js,百度我也只是看了部份js,了解了少部份登陆相关的代码,然后去构造post数据 提交给登陆url,结果成功的登陆了百度,提交的post数据是正确的,获取了cookie。
能够模拟登陆百度通行证,那么百度旗下的大部分产品都可以用优采云去搞推广了,主要有:百度博客发布博文,百度博文批量评价(这个也不错,效果直接 高效)。
本人也主要是做了百度博文 百度博文评价这2个发布,可实现多帐号随机发布信息,理论上越多帐号,效果越好,但不排除现今各门户站点限制都是比较多的,但我想多帐号去推广后,一些限制就降低了很多很多,但是各门户站点都有大量的人力操作诱因,一般是没有手动的功能的 。不要小看了这种人力操作诱因,是太强悍的限制,多帐号可以解决这个问题。
1.百度博文测试:
该日记:,测试发的日记;
2.博文评价测试:
上面测试的博文,对其评价
我的插口都是如此设置的,需要做2个xml 记录表单数据 网页恳求。
可设置固定帐号 多帐号2种形式发布。
网易博文发布+博文评价,也做了, 不免费提供。
营销推广博客:
DesToon6.0 GBK版免登入采集接口 v20180514
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-12 11:34
DesToon6.0 GBK版免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon6.0 GBK版免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 GBK版免登入采集接口截图 查看全部
DesToon6.0 GBK版免登入采集接口是完全免费提供给你们使用,不限制采集的内容数目、不限制采集的次数、不绑定域名、不限制使用笔记本,完全免费提供给您使用。目前免费版支持入库的蓝筹股有:供应、会员注册、公司关联、求购、资讯、行情、招商、品牌、展会、下载、视频、招聘、团购(DT采集专家destoon收费插口支持destoon系统默认自带所有模块,并且支持模块扩充)。只要您会使用我们优采云免登录入库插口,理论上可以采集任何网站数据入库到您的destoon网站系统中。DT采集专家的免登录入库插口默认打包了优采云采集器,并且免费自带20个采集规则给你们学习参考,具有易学,易懂,易用,成熟稳定等特点,您只须要经过简单的3步设置就可以使用我们的免登录入库插口了。
DesToon6.0 GBK版免登入采集接口 v20180514 更新日志
1:更新默认附送规则至20180514最新版。
2:招商模块入库错误。
DesToon6.0 GBK版免登入采集接口功能特性
01、使用我们的免登录采集接口您可以采集任何网站内容入库到destoon系统中。(前提须要自己会写规则)
02、可以手动关联而且全手动注册会员。
03、DT采集专家 DesToon6.0优采云免登入采集接口是完全免费提供给你们使用,并且无任何广告和使用限制。
04、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的destoon网站上。
05、采集回来的内容可以直接入库到destoon原版网站系统上面,并且也可以在本地编辑后或发布到未初审栏目里、伪原创等二次处理。
06、打包自带优采云采集器和默认规则及模块,只须要简单的上传免登录采集接口、填写您的网址、选择入库分类,就完成了配置。
07、标题图片使用destoon系统函数全手动下载保存在本地或远程,让您的图片永远不会遗失。
08、标题图片会手动承继destoon系统函数加上您destoon网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的内容跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的destoon网站采集的文章的看数跟真实的一样。
12、文章模块手动提取第一张为标题图。
13、采集的内容可以发布到destoon网站对应模块的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
15、不绑定域名、不限制使用笔记本,完全免费提供给您使用。
16、企业网站随机模版,防止千篇一律的采集模板,让采集数据更真实。
17、接口可以设置缩略图长度、宽度,而不需要在网站后台更改。
18、支持用户名前缀、后缀设置。
19、采集接口支持伪原创、24小时全手动采集(需优采云支持)。
20、免登录入库插口通过官方API预留插口入库,100%完全兼容不损数据库。
21、公司多条信息手动归纳到同一公司。
22、更多功能请自己下载意义体验。
DesToon6.0 GBK版免登入采集接口截图
做一个聚合类新闻app。负责爬虫相关联工作,很想知道同行的app怎么做的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-12 03:36
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。 查看全部
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。
面试官:比如有10万个网站,有哪些方式才能快速的采集到数据吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-10 17:29
字节跳动笔试锦集(二):项目HR高频笔试总结
数据采集采集架构中各模块详尽剖析
爬虫工程师,如何高效的支持数据剖析人员的工作?
基于大数据平台的互联网数据采集平台基本构架
数据采集中,如何构建一套行之有效的监控体系?
面试准备、HR、Android技术等笔试问题汇总
昨天有一个网友说,他近来笔试了几家公司,有一个问题被问到了好几次,每次都回答的不是很好。
面试官:比如有10万个网站需要采集,你有哪些方式快速的获取到数据?
想回答好这个问题,其实须要你有足够的知识面,有足够的技术储备。
最近,我们也在急聘,每周还会笔试十几个人,感觉合适的也就一两个,大多数和那位网友的情况差不多,都欠缺整体思维,那怕这些有三四年工作经验的老司机。他们解决具体问题的能力太强,却极少能由点及面,站在一个新的高度,全面思索问题。
10万个网站的采集覆盖度,已经比大多数的专业舆情监控公司的数据采集范围都广了。要达到面试官说的采集需求,就须要我们从网站的搜集,直到数据储存的各个方面进行综合考虑,给出一个合适的方案,以达到节约成本,提高工作效率的目的。
下面我们就从网站的搜集,直到数据储存的各方面,做个简单的介绍。
一、10万个网站从那里来?
一般来说,采集的网站,都是依照公司业务的发展,逐渐积累上去的。
我们如今假定,这是一个初创公司的需求。公司刚才创立,这么多网站,基本上可以说是冷启动。那么我们怎么搜集到这10万个网站呢?可以有以下几种形式:
1)历史业务的积累
不管是冷启动,还是哪些,既然有采集需求,一定是有项目或产品有这方面的需求,其相关的人员前期一定督查过一些数据来源,采集了一些比较重要的网站。这些都可以作为我们搜集网站和采集的原创种子。
2)关联网站
在一些网站的顶部,一般都有相关网站的链接。尤其是政府类型的网站,通常会有下级相关部门的官网。
3)网站导航
有些网站可能为了某种目的(比如引流等),采集一些网站,并对其进行归类进行展示,以便捷人们查找。这些网站可以快速的为我们提供第一批种子网站。然后,我们再通过网站关联等其他形式获取更多的网站。
4)搜索引擎
也可以打算一些与公司业务相关的关键词,去百度、搜狗等搜索引擎中搜索,通过对搜索结果进行处理,提取相应的网站,作为我们的种子网站。
5)第三方平台
比如一些第三方的SaaS平台,都会有7~15天的免费试用。所以,我们就可以借助这段时间,把与我们业务相关的数据采集下来,然后提取出其中的网站,作为我们初始采集种子。
虽然,这种方法是最有效,最快的网站采集方法。但是在试用期内,获取10万个网站的可能也极小,所以尚须要结合上述的关联网站等其他形式,以便快速获取所需网站。
通过以上五种方法,相信我们可以很快的搜集到,我们须要的10万个网站。但是,这么多网站,我们该怎么管理?如何晓得其正常与否呢?
二、10万个网站如何管理?
当我们搜集到10万个网站以后,首先面对的就是怎样管理、如何配置采集规则、如何监控网站正常与否等。
1)如何管理
10万个网站,如果没有专门的系统来管理,那将是一场灾难。
同时,可能因为业务的须要,比如智能推荐等,需要我们对网站进行一些预处理(比如打标签)。此时,一个网站管理系统将是必须的。
2)如何配置采集规则
前期我们搜集的10万个网站只是首页,如果只把首页作为采集任务,那么就只能采集到首页极少的信息,漏采率很大。
如果要按照首页URL进行全站采集,则对服务器资源消耗又比较大,成本偏高。所以,我们须要配置我们关心的栏目,并对其进行采集。
但是,10万个网站,如何快速、高效的配置栏目呢?目前,我们以手动解析HTML源码的方法,进行栏目的半自动化配置。
当然,我们也试验过机器学习的方法来处理,不过疗效还不是很理想。
由于须要采集的网站量达到10万级别,所以一定不要使用xpath等精确定位的方法进行采集。否则,等你把这10万网站配置好,黄花菜都凉了。
同时,数据采集一定要使用通用爬虫,使用正则表达式的形式来匹配列表数据。在采集正文时,通过使用算法来解析时间、正文等属性;
3)如何监控
由于有10万网站,这些网站中每晚还会有网站改版,或者栏目改版,或新增/下架栏目等。所以,需要按照采集的数据情况,简单的剖析一下网站的情况。
比如,一个网站几天都没有新数据,一定是出现了问题。要么网站改版,导致信息正则失效常,要么就是网站本身出现问题。
为了提升采集效率,可以使用一个单独的服务,每隔一段时间,检测一次网站和栏目的情况。一是测量网站、栏目是否能正常访问;二要检查配置的栏目信息正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万个网站,配置完栏目之后,采集的入口URL应当会达到百万级别。采集器怎么高效的获取这种入口URL进行采集呢?
如果把这种URL放在数据库中,不管是MySQL,还是Oracle,采集器获取采集任务这一操作,都会浪费好多时间,大大增加采集效率。
如何解决这个问题呢?内存数据库便是首选,如Redis、 Mongo DB 等。一般采集用Redis来做缓存。所以,可以在配置栏目的同时,把栏目信息同步到Redis中,作为采集任务缓存队列。
四、网站如何采集?
就像是你想达到月薪百万,最大机率是要去华为、阿里、腾讯这些一线大厂,而且还须要到一定的级别才行。这条路注定不易。
同样,如果须要采集百万级别的列表URL,常规的方式也一定是难以实现。
必须使用分布式+多进程+多线程的形式。同时,还须要结合显存数据库Redis等做缓存,已实现高效获取任务,以及对采集信息进行排重;
同时,信息的解析,如发布时间、正文等,也必须使用算法来处理。比如现今比较火的GNE,
有些属性,可以在列表采集时获取的,就尽量不要放在和正文一起进行解析。比如:标题。一般情况下,从列表中获取到的,标题的准确度,要远小于算法从信息html源码中解析的。
同时,如果有一些特殊网站、或者一些特殊需求,我们再采用订制开发的方法进行处理即可。
五、统一数据储存插口
为了保持采集的及时性,10万个网站的采集,可能须要十几二十台服务器。同时,每台服务器上又布署N个采集器,再加上一些订制开发的脚本,整体采集器的数目将会达到上百个。
如果每位采集器/定制脚本,都自行开发一套自己的数据保存插口,则开发、调试都会浪费不少时间。而且后续的运维,也将是一件非揪心的事情。尤其是业务有所变化,需要调整时。所以,统一数据储存插口还是太有必要的。
由于数据储存插口统一,当我们须要相对数据做一些特殊处理时,比如:清洗、矫正等,就不用再去更改每位采集存储部份,只须要更改一下插口,重新布署即可。
快速、方便、快捷。
六、数据及采集监控
10万个网站的采集覆盖度,每天的数据量绝对在200万以上。由于数据解析的算法无论多精确,总是不能达到100%(能达到90%就十分不错了)。所以,数据解析一定会存在异常情况。比如:发布时间小于当前时间、正文中收录相关新闻信息等等。
但是,由于我们统一了数据储存插口,此时就可以在插口处,进行统一的数据质量校准。以便按照异常情况,来优化采集器及订制脚本。
同时,还可以统计每位网站或栏目的数据采集情况。以便才能及时地判定,当前采集的网站/栏目信源是否正常,以便保证仍然有10万个有效的采集网站。
七、数据储存
由于每晚采集的数据量较大,普通的数据库(如:mysql、Oracle等)已经难以胜任。即使象Mongo DB这样的NoSql数据库,也早已不再适用。此时,ES、Solr等分布式索引是目前最好的选择。
至于是否上Hadoop、HBase等大数据平台,那就看具体情况了。在预算不多的情况下,可以先搭建分布式索引集群,大数据平台可以后续考虑。
为了保证查询的响应速率,分布式索引中尽量不要保存正文的信息。像标题、发布时间、URL等可以保存,这样在显示列表数据时可以降低二次查询。
在没有上大数据平台期间,可以把正文以固定的数据标准,保存到txt等文件系统中。后续上大数据平台后,再转存到HBASE中即可。
八、自动化运维
由于服务器、采集器,以及订制脚本较多,单纯的靠人工进行布署、启动、更新、运行情况监控等,已经变得十分的繁杂,且容易出现人为失误。
所以,必须有一套自动化运维系统,能够实现对采集器/脚本进行布署、启动、关闭、运行等,以便才能在出现变动时快速的响应。
“比如有10万个网站需要采集,你有哪些方式快速的获取到数据?”,如果你能回答出这种,拿到一个不错的offer应当没哪些悬念。
最后,愿正在找工作的诸位同学,都能收获满意的offer,找到一个不错的平台。
面试#数据采集 查看全部
字节跳动笔试锦集(一):Android Framework高频面试题总结
字节跳动笔试锦集(二):项目HR高频笔试总结
数据采集采集架构中各模块详尽剖析
爬虫工程师,如何高效的支持数据剖析人员的工作?
基于大数据平台的互联网数据采集平台基本构架
数据采集中,如何构建一套行之有效的监控体系?
面试准备、HR、Android技术等笔试问题汇总
昨天有一个网友说,他近来笔试了几家公司,有一个问题被问到了好几次,每次都回答的不是很好。
面试官:比如有10万个网站需要采集,你有哪些方式快速的获取到数据?
想回答好这个问题,其实须要你有足够的知识面,有足够的技术储备。
最近,我们也在急聘,每周还会笔试十几个人,感觉合适的也就一两个,大多数和那位网友的情况差不多,都欠缺整体思维,那怕这些有三四年工作经验的老司机。他们解决具体问题的能力太强,却极少能由点及面,站在一个新的高度,全面思索问题。
10万个网站的采集覆盖度,已经比大多数的专业舆情监控公司的数据采集范围都广了。要达到面试官说的采集需求,就须要我们从网站的搜集,直到数据储存的各个方面进行综合考虑,给出一个合适的方案,以达到节约成本,提高工作效率的目的。
下面我们就从网站的搜集,直到数据储存的各方面,做个简单的介绍。
一、10万个网站从那里来?
一般来说,采集的网站,都是依照公司业务的发展,逐渐积累上去的。
我们如今假定,这是一个初创公司的需求。公司刚才创立,这么多网站,基本上可以说是冷启动。那么我们怎么搜集到这10万个网站呢?可以有以下几种形式:
1)历史业务的积累
不管是冷启动,还是哪些,既然有采集需求,一定是有项目或产品有这方面的需求,其相关的人员前期一定督查过一些数据来源,采集了一些比较重要的网站。这些都可以作为我们搜集网站和采集的原创种子。
2)关联网站
在一些网站的顶部,一般都有相关网站的链接。尤其是政府类型的网站,通常会有下级相关部门的官网。
3)网站导航
有些网站可能为了某种目的(比如引流等),采集一些网站,并对其进行归类进行展示,以便捷人们查找。这些网站可以快速的为我们提供第一批种子网站。然后,我们再通过网站关联等其他形式获取更多的网站。
4)搜索引擎
也可以打算一些与公司业务相关的关键词,去百度、搜狗等搜索引擎中搜索,通过对搜索结果进行处理,提取相应的网站,作为我们的种子网站。
5)第三方平台
比如一些第三方的SaaS平台,都会有7~15天的免费试用。所以,我们就可以借助这段时间,把与我们业务相关的数据采集下来,然后提取出其中的网站,作为我们初始采集种子。
虽然,这种方法是最有效,最快的网站采集方法。但是在试用期内,获取10万个网站的可能也极小,所以尚须要结合上述的关联网站等其他形式,以便快速获取所需网站。
通过以上五种方法,相信我们可以很快的搜集到,我们须要的10万个网站。但是,这么多网站,我们该怎么管理?如何晓得其正常与否呢?
二、10万个网站如何管理?
当我们搜集到10万个网站以后,首先面对的就是怎样管理、如何配置采集规则、如何监控网站正常与否等。
1)如何管理
10万个网站,如果没有专门的系统来管理,那将是一场灾难。
同时,可能因为业务的须要,比如智能推荐等,需要我们对网站进行一些预处理(比如打标签)。此时,一个网站管理系统将是必须的。
2)如何配置采集规则
前期我们搜集的10万个网站只是首页,如果只把首页作为采集任务,那么就只能采集到首页极少的信息,漏采率很大。
如果要按照首页URL进行全站采集,则对服务器资源消耗又比较大,成本偏高。所以,我们须要配置我们关心的栏目,并对其进行采集。
但是,10万个网站,如何快速、高效的配置栏目呢?目前,我们以手动解析HTML源码的方法,进行栏目的半自动化配置。
当然,我们也试验过机器学习的方法来处理,不过疗效还不是很理想。
由于须要采集的网站量达到10万级别,所以一定不要使用xpath等精确定位的方法进行采集。否则,等你把这10万网站配置好,黄花菜都凉了。
同时,数据采集一定要使用通用爬虫,使用正则表达式的形式来匹配列表数据。在采集正文时,通过使用算法来解析时间、正文等属性;
3)如何监控
由于有10万网站,这些网站中每晚还会有网站改版,或者栏目改版,或新增/下架栏目等。所以,需要按照采集的数据情况,简单的剖析一下网站的情况。
比如,一个网站几天都没有新数据,一定是出现了问题。要么网站改版,导致信息正则失效常,要么就是网站本身出现问题。
为了提升采集效率,可以使用一个单独的服务,每隔一段时间,检测一次网站和栏目的情况。一是测量网站、栏目是否能正常访问;二要检查配置的栏目信息正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万个网站,配置完栏目之后,采集的入口URL应当会达到百万级别。采集器怎么高效的获取这种入口URL进行采集呢?
如果把这种URL放在数据库中,不管是MySQL,还是Oracle,采集器获取采集任务这一操作,都会浪费好多时间,大大增加采集效率。
如何解决这个问题呢?内存数据库便是首选,如Redis、 Mongo DB 等。一般采集用Redis来做缓存。所以,可以在配置栏目的同时,把栏目信息同步到Redis中,作为采集任务缓存队列。
四、网站如何采集?
就像是你想达到月薪百万,最大机率是要去华为、阿里、腾讯这些一线大厂,而且还须要到一定的级别才行。这条路注定不易。
同样,如果须要采集百万级别的列表URL,常规的方式也一定是难以实现。
必须使用分布式+多进程+多线程的形式。同时,还须要结合显存数据库Redis等做缓存,已实现高效获取任务,以及对采集信息进行排重;
同时,信息的解析,如发布时间、正文等,也必须使用算法来处理。比如现今比较火的GNE,
有些属性,可以在列表采集时获取的,就尽量不要放在和正文一起进行解析。比如:标题。一般情况下,从列表中获取到的,标题的准确度,要远小于算法从信息html源码中解析的。
同时,如果有一些特殊网站、或者一些特殊需求,我们再采用订制开发的方法进行处理即可。
五、统一数据储存插口
为了保持采集的及时性,10万个网站的采集,可能须要十几二十台服务器。同时,每台服务器上又布署N个采集器,再加上一些订制开发的脚本,整体采集器的数目将会达到上百个。
如果每位采集器/定制脚本,都自行开发一套自己的数据保存插口,则开发、调试都会浪费不少时间。而且后续的运维,也将是一件非揪心的事情。尤其是业务有所变化,需要调整时。所以,统一数据储存插口还是太有必要的。
由于数据储存插口统一,当我们须要相对数据做一些特殊处理时,比如:清洗、矫正等,就不用再去更改每位采集存储部份,只须要更改一下插口,重新布署即可。
快速、方便、快捷。
六、数据及采集监控
10万个网站的采集覆盖度,每天的数据量绝对在200万以上。由于数据解析的算法无论多精确,总是不能达到100%(能达到90%就十分不错了)。所以,数据解析一定会存在异常情况。比如:发布时间小于当前时间、正文中收录相关新闻信息等等。
但是,由于我们统一了数据储存插口,此时就可以在插口处,进行统一的数据质量校准。以便按照异常情况,来优化采集器及订制脚本。
同时,还可以统计每位网站或栏目的数据采集情况。以便才能及时地判定,当前采集的网站/栏目信源是否正常,以便保证仍然有10万个有效的采集网站。
七、数据储存
由于每晚采集的数据量较大,普通的数据库(如:mysql、Oracle等)已经难以胜任。即使象Mongo DB这样的NoSql数据库,也早已不再适用。此时,ES、Solr等分布式索引是目前最好的选择。
至于是否上Hadoop、HBase等大数据平台,那就看具体情况了。在预算不多的情况下,可以先搭建分布式索引集群,大数据平台可以后续考虑。
为了保证查询的响应速率,分布式索引中尽量不要保存正文的信息。像标题、发布时间、URL等可以保存,这样在显示列表数据时可以降低二次查询。
在没有上大数据平台期间,可以把正文以固定的数据标准,保存到txt等文件系统中。后续上大数据平台后,再转存到HBASE中即可。
八、自动化运维
由于服务器、采集器,以及订制脚本较多,单纯的靠人工进行布署、启动、更新、运行情况监控等,已经变得十分的繁杂,且容易出现人为失误。
所以,必须有一套自动化运维系统,能够实现对采集器/脚本进行布署、启动、关闭、运行等,以便才能在出现变动时快速的响应。
“比如有10万个网站需要采集,你有哪些方式快速的获取到数据?”,如果你能回答出这种,拿到一个不错的offer应当没哪些悬念。
最后,愿正在找工作的诸位同学,都能收获满意的offer,找到一个不错的平台。
面试#数据采集
网站数据批量采集服务|优采云免登录采集接口[DESTOON数据内容采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-10 16:21
DESTOON二次开发。DESTOON数据采集。
简单说明 :
用优采云采集器对提升工作效率确实很有用
每天要到第三方家装平台上传自己网站的家装案例,首先要到自己的网站把图片弄出来,如果自动弄得吓死,可以直接ftp登陆网站服务器将所有图片案例下载出来,但是没权限只能从网站上面弄,这就用到了优采云,直接将想要的图片全部下载出来,然后用美图秀秀批量处理大小加水印logo,这样早已大大提升了效率!这里存在一个问题就是优采云保存时不能将整篇案例保存为以文章名称的文件夹,只能以时间哪些的,这样我上传案例就难以这篇文章对应哪个图片,可能自己不会,操作时只能对应这篇看源码找图片的名称,幸亏整篇文章的图片都有特点,处理时速率还可以!
再就是例如我要剖析网站的收录率,在百度site自己的域名,然后用优采云采集title,一般规则的网站都是文章名_栏目名_网站名,这样我们可以用excel估算出该栏目被收录了多少条,然后减去该栏目下的总量,然后估算出收录率,百度site结果页的网站url是转码的,采集下来也不能剖析,可能有别的办法,但是自己没找到
这里还须要注意的是假如默认设置采集下的标题都是不分开的,看起来是一坨!需要勾选添加为新纪录,这样采集下来的数据就是一行一行的,简单明了!
感觉优采云采集器的功能太强悍,需要自己举一反三,教程直接到优采云官网去看视频教程,但是可以在例如优酷等视频网站看到他人借助优采云采集器做一些特别有用的事
服务范围
1、门户网站或企业网站需要大量的数据且为正规行业内容; 查看全部
网站数据批量采集服务|优采云免登录采集接口[DESTOON数据内容采集]
DESTOON二次开发。DESTOON数据采集。
简单说明 :
用优采云采集器对提升工作效率确实很有用
每天要到第三方家装平台上传自己网站的家装案例,首先要到自己的网站把图片弄出来,如果自动弄得吓死,可以直接ftp登陆网站服务器将所有图片案例下载出来,但是没权限只能从网站上面弄,这就用到了优采云,直接将想要的图片全部下载出来,然后用美图秀秀批量处理大小加水印logo,这样早已大大提升了效率!这里存在一个问题就是优采云保存时不能将整篇案例保存为以文章名称的文件夹,只能以时间哪些的,这样我上传案例就难以这篇文章对应哪个图片,可能自己不会,操作时只能对应这篇看源码找图片的名称,幸亏整篇文章的图片都有特点,处理时速率还可以!
再就是例如我要剖析网站的收录率,在百度site自己的域名,然后用优采云采集title,一般规则的网站都是文章名_栏目名_网站名,这样我们可以用excel估算出该栏目被收录了多少条,然后减去该栏目下的总量,然后估算出收录率,百度site结果页的网站url是转码的,采集下来也不能剖析,可能有别的办法,但是自己没找到
这里还须要注意的是假如默认设置采集下的标题都是不分开的,看起来是一坨!需要勾选添加为新纪录,这样采集下来的数据就是一行一行的,简单明了!
感觉优采云采集器的功能太强悍,需要自己举一反三,教程直接到优采云官网去看视频教程,但是可以在例如优酷等视频网站看到他人借助优采云采集器做一些特别有用的事
服务范围
1、门户网站或企业网站需要大量的数据且为正规行业内容;
苹果cms采集接口配置教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 604 次浏览 • 2020-08-09 20:48
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。可以参考教程:苹果cms采集后未能播放缘由排查及解决教程
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。不会添加播放器可参考:苹果cms采集后播放器的导出添加教程 查看全部
1,今天教你们怎样添加采集自定义资源库;进入后台我们随意以某资源站为例,接口可以到你要采集的网站上获取就可以了 一般都在网站的帮助中心:添加方式如下图(添加后进行测试不成功须要填写附加参数 &ct=1)
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。可以参考教程:苹果cms采集后未能播放缘由排查及解决教程
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。不会添加播放器可参考:苹果cms采集后播放器的导出添加教程
全网邮箱email地址采集api接口及实现剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-08-09 18:14
这样的在线工具原理与普通的客户端工具(例如八虾采集工具等)是一样的,所以这儿以这个在线工具作为参考进行实现剖析。
邮箱采集原理:
1、根据要采集的url地址,获取页面html内容,然后采用正则匹配出页面的url列表、邮箱地址列表。
2、分两个进程:
①保存邮箱地址;
②分析采集子页面url的邮箱地址;
基本源码(golang):
<p>
//采集入口方法
func CollectEmail(hosturl string) (EmailObj, []string, error) {
emailObj := new(EmailObj)
var inhost []string
//获取主域名
uparse, err := url.Parse(hosturl)
if err != nil {
return *emailObj, inhost, err
}
emailObj.Surl = hosturl
//
bodystr, err := HttpGetV2(hosturl)
if err != nil {
return *emailObj, inhost, errors.New("get request error")
}
//是否是gbk编码
pos := strings.Index(bodystr, "charset=gb")
pos2 := strings.Index(bodystr, "bg2312")
if pos != -1 || pos2 != -1 {
decodeBytes, err := simplifiedchinese.GB18030.NewDecoder().Bytes([]byte(bodystr))
if err != nil {
return *emailObj, inhost, errors.New("simplifiedchinese coding change error")
}
bodystr = string(decodeBytes)
}
//获取邮箱地地址
emailObj.Emails = append(emailObj.Emails, matchEmail(bodystr)...)
//获取联系手机
emailObj.Phones = append(emailObj.Phones, matchPhone(bodystr)...)
//获取内页链接列表
matchUrls := matchUrls(bodystr)
for _, item := range matchUrls {
itemparse, err := url.Parse(item)
if err != nil {
continue
}
if strings.Index(itemparse.Path, ".js") != -1 || strings.Index(itemparse.Path, ".css") != -1 {
continue
}
if itemparse.Host == uparse.Host {
inhost = append(inhost, item)
}
if itemparse.Scheme != "http" && itemparse.Scheme != "https" {
if strings.Index(itemparse.Path, "/") == 0 {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+itemparse.Path)
} else {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+"/"+itemparse.Path)
}
continue
}
}
//获取内页email
inhost = RemoveRepeatedElement(inhost)
emailObj.Emails = RemoveRepeatedElement(emailObj.Emails)
return *emailObj, inhost, nil
}
func matchEmail(str string) (email []string) {
var emailList []string
//re, _ := regexp.Compile("\\ 查看全部
先上一个在线邮箱采集demo样例:
这样的在线工具原理与普通的客户端工具(例如八虾采集工具等)是一样的,所以这儿以这个在线工具作为参考进行实现剖析。
邮箱采集原理:
1、根据要采集的url地址,获取页面html内容,然后采用正则匹配出页面的url列表、邮箱地址列表。
2、分两个进程:
①保存邮箱地址;
②分析采集子页面url的邮箱地址;
基本源码(golang):
<p>
//采集入口方法
func CollectEmail(hosturl string) (EmailObj, []string, error) {
emailObj := new(EmailObj)
var inhost []string
//获取主域名
uparse, err := url.Parse(hosturl)
if err != nil {
return *emailObj, inhost, err
}
emailObj.Surl = hosturl
//
bodystr, err := HttpGetV2(hosturl)
if err != nil {
return *emailObj, inhost, errors.New("get request error")
}
//是否是gbk编码
pos := strings.Index(bodystr, "charset=gb")
pos2 := strings.Index(bodystr, "bg2312")
if pos != -1 || pos2 != -1 {
decodeBytes, err := simplifiedchinese.GB18030.NewDecoder().Bytes([]byte(bodystr))
if err != nil {
return *emailObj, inhost, errors.New("simplifiedchinese coding change error")
}
bodystr = string(decodeBytes)
}
//获取邮箱地地址
emailObj.Emails = append(emailObj.Emails, matchEmail(bodystr)...)
//获取联系手机
emailObj.Phones = append(emailObj.Phones, matchPhone(bodystr)...)
//获取内页链接列表
matchUrls := matchUrls(bodystr)
for _, item := range matchUrls {
itemparse, err := url.Parse(item)
if err != nil {
continue
}
if strings.Index(itemparse.Path, ".js") != -1 || strings.Index(itemparse.Path, ".css") != -1 {
continue
}
if itemparse.Host == uparse.Host {
inhost = append(inhost, item)
}
if itemparse.Scheme != "http" && itemparse.Scheme != "https" {
if strings.Index(itemparse.Path, "/") == 0 {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+itemparse.Path)
} else {
inhost = append(inhost, uparse.Scheme+"://"+uparse.Host+"/"+itemparse.Path)
}
continue
}
}
//获取内页email
inhost = RemoveRepeatedElement(inhost)
emailObj.Emails = RemoveRepeatedElement(emailObj.Emails)
return *emailObj, inhost, nil
}
func matchEmail(str string) (email []string) {
var emailList []string
//re, _ := regexp.Compile("\\

