
抓取网页生成电子书
抓取网页生成电子书(一个开源网页拖拽自动生成的JavaScript库,你可以以简单拖拽的方式生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-23 16:18
VvvebJs 是一个通过拖放网页自动生成的开源 JavaScript 库。您可以通过简单的拖放来生成您需要的网页样式。内置jquery和Bootstrap,可以拖拽相关组件构建网页,非常方便。并且可以实时修改代码,功能丰富,使用方便,界面友好,特别适合一些注重展示的网页设计,需要的朋友不要错过!
在线演示:
相关功能
1、组件和块/片段拖放;
2、撤消/重做操作;
3、一个或两个面板接口;
4、为文件管理器和组件层次导航添加新页面;
5、实时代码编辑器;
6、 使用示例 php 脚本上传图片;
7、页面下载或导出html或在服务器上保存页面收录示例PHP脚本;
8、组件/块列表搜索;
9、Bootstrap 4 组件和其他组件。
该编辑器默认附带 Bootstrap 4 和 Widgets 组件,可以使用任何类型的组件和输入进行扩展。
如何使用
要初始化编辑器,请调用 Vvveb.Builder.init。第一个参数是要加载进行编辑的 URL,它必须在同一个子域上进行编辑。第二个参数是页面加载时调用的函数,默认调用编辑器 Gui.init();
结构体
Component Group是组件的集合,例如Bootstrap 4 group由Button和Grid等组件组成,该对象仅用于对编辑器左侧面板中的组件进行分组。比如Widgets组件组只有video和map两个组件,定义如下
Vvveb.ComponentsGroup['Widgets'] = ["widgets/googlemaps", "widgets/video"];
Component是一个对象,它提供了可以放置在画布上的html以及选择组件时可以编辑的属性,比如Video Component,一个带有Url和Target属性的html链接组件定义为:
Vvveb.Components.extend("_base", "html/link", {
nodes: ["a"],
name: "Link",
properties: [{
name: "Url",
key: "href",
htmlAttr: "href",
inputtype: LinkInput
}, {
name: "Target",
key: "target",
htmlAttr: "target",
inputtype: TextInput
}]
});
使用Component属性集合中的Input对象来编辑文本输入、选择、颜色、网格行等属性。例如TextInput扩展了Input对象,定义为:
var TextInput = $.extend({}, Input, {
events: {
"keyup": ['onChange', 'input'],
},
setValue: function(value) {
$('input', this.element).val(value);
},
init: function(data) {
return this.render("textinput", data);
},
}
);
输入还需要在编辑器 html 中定义(在 editor.html 中)。以上是使用浏览器翻译工具简单翻译官网文档。可能有一些不准确的地方。有兴趣的小伙伴可以直接查看相关文档!
设计界面预览
总结
VvvebJs是一款非常强大的网页可视化生成构建工具,让不懂网页设计的朋友也可以通过拖拽的方式生成美观大方的网页,让设计网页就像设计图片一样。VvvebJs 特别适合显示网页。您甚至可以在没有代码的情况下完成复杂的网页设计。总的来说,VvvebJs 是一个值得尝试的工具! 查看全部
抓取网页生成电子书(一个开源网页拖拽自动生成的JavaScript库,你可以以简单拖拽的方式生成)
VvvebJs 是一个通过拖放网页自动生成的开源 JavaScript 库。您可以通过简单的拖放来生成您需要的网页样式。内置jquery和Bootstrap,可以拖拽相关组件构建网页,非常方便。并且可以实时修改代码,功能丰富,使用方便,界面友好,特别适合一些注重展示的网页设计,需要的朋友不要错过!
在线演示:
相关功能
1、组件和块/片段拖放;
2、撤消/重做操作;
3、一个或两个面板接口;
4、为文件管理器和组件层次导航添加新页面;
5、实时代码编辑器;
6、 使用示例 php 脚本上传图片;
7、页面下载或导出html或在服务器上保存页面收录示例PHP脚本;
8、组件/块列表搜索;
9、Bootstrap 4 组件和其他组件。
该编辑器默认附带 Bootstrap 4 和 Widgets 组件,可以使用任何类型的组件和输入进行扩展。
如何使用
要初始化编辑器,请调用 Vvveb.Builder.init。第一个参数是要加载进行编辑的 URL,它必须在同一个子域上进行编辑。第二个参数是页面加载时调用的函数,默认调用编辑器 Gui.init();
结构体
Component Group是组件的集合,例如Bootstrap 4 group由Button和Grid等组件组成,该对象仅用于对编辑器左侧面板中的组件进行分组。比如Widgets组件组只有video和map两个组件,定义如下
Vvveb.ComponentsGroup['Widgets'] = ["widgets/googlemaps", "widgets/video"];
Component是一个对象,它提供了可以放置在画布上的html以及选择组件时可以编辑的属性,比如Video Component,一个带有Url和Target属性的html链接组件定义为:
Vvveb.Components.extend("_base", "html/link", {
nodes: ["a"],
name: "Link",
properties: [{
name: "Url",
key: "href",
htmlAttr: "href",
inputtype: LinkInput
}, {
name: "Target",
key: "target",
htmlAttr: "target",
inputtype: TextInput
}]
});
使用Component属性集合中的Input对象来编辑文本输入、选择、颜色、网格行等属性。例如TextInput扩展了Input对象,定义为:
var TextInput = $.extend({}, Input, {
events: {
"keyup": ['onChange', 'input'],
},
setValue: function(value) {
$('input', this.element).val(value);
},
init: function(data) {
return this.render("textinput", data);
},
}
);
输入还需要在编辑器 html 中定义(在 editor.html 中)。以上是使用浏览器翻译工具简单翻译官网文档。可能有一些不准确的地方。有兴趣的小伙伴可以直接查看相关文档!
设计界面预览
总结
VvvebJs是一款非常强大的网页可视化生成构建工具,让不懂网页设计的朋友也可以通过拖拽的方式生成美观大方的网页,让设计网页就像设计图片一样。VvvebJs 特别适合显示网页。您甚至可以在没有代码的情况下完成复杂的网页设计。总的来说,VvvebJs 是一个值得尝试的工具!
抓取网页生成电子书(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
网站优化 • 优采云 发表了文章 • 0 个评论 • 550 次浏览 • 2022-02-23 16:15
制作自己的学习手册并永久保存互联网信息
* 较早价格标签的合约,文字已被删除
关于文章和信息组织,一个常见的需求是保存某个主题的多篇文章文章,或者一个博客或教程的所有网页,做成类似出版物的电子出版物。可以在手机、平板电脑上阅读或永久保存的书籍。实现此要求的一种方法是使用 Chrome 插件一键将目标网页保存为 ePub 文件。
ePub 的插件大约有十种。经过大量的测试,我最终选择了dotEPUB、WebToWpub、EpubPress、Save as eBook这四个各有侧重、效果更好的插件。本文将分析它们的特点,以帮助您确定哪一种最能满足您的需求。
四个插件的用法和特点
dotEPUB : 将当前窗口的网页另存为 ePub1. 速度:更快2. 水印:开头和结尾的水印3. 图片支持:稍差4. 排版:更好排版
dotEPUB是操作最简单、功能最单一的一种。只需点击插件栏中的 dotEPUB 图标,即可自动将当前网页下载为 ePub 文件。但由于只保存当前网页,因此适用范围较窄。
在这里,打开一个知乎栏目“我们在谈论英语学习时在谈论什么”作为素材尝试抓取,用多看App打开,阅读效果如下。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接为章节并生成为ePub1.速度:更快,有进度条2.水印:无水印3.图片支持:有图片4.排版:排版比较通用
这是我经常使用的插件。它可以爬取当前网页中收录的链接的所有内容。适用于爬取知乎列或博客等网站以列表形式展开内容。网页中的每个链接都会生成一个特定的Epub章节,章节标题就是网页标题。
点击插件,确认开始转换后,进入插件主界面。在主界面中,WebToEpub 允许用户编辑 ePub 的标题、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等操作,还可以反向选择网页列表。此外,您可以通过将图像地址粘贴到 URL 框中来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有的文章,在使用插件之前需要滚动到页面底部完全加载列表。
EpubPress:将当前打开的所有标签捕获为ePub1.速度:正常速度,带有进度条2.水印:无水印3.图像支持:在某些情况下捕获图像会失败< @4. 排版:更好的排版
这是另一个常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到电子邮件地址,可根据需要在右上角的设置中选择。
如果爬取大量标签页,等待时间会明显变长。另请注意,在实际测试中可能无法保存超过 20 个选项卡。
另存为电子书:选择打开的网页并保存为 ePub1. 速度:更快2. 水印:无水印3. 图片支持:带图片4. 排版:更好排版
另存为 eBook 与 EpubPress 类似,都将打开的选项卡保存为 ePub 文件中的章节。但要保存为电子书,需要在浏览网页时点击要保存的网页插件栏中的图标,选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件的标题和调整章节的顺序。
四种使用场景
总结一下四个插件的适用场景,这里简单总结一下情况:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 和 Read Later 等工具之外的另一个想法。对于严肃或系统的内容,制作一本ePub电子书,三两下进行主题阅读会更加连贯,思考可以逐步深化主题。这是电子书和印象笔记以及后来阅读的区别。观点。因此,对于系统学习来说,ePub电子书无疑是一个不错的选择。
回到Chrome插件的话题,一键生成ePub文件的插件普遍的缺点是通过插件制作的电子书不是纯图文,还有一些不相关的内容,如网站中的超链接或评论@> 也可能被 网站 阻止。@收录进入电子书,导致转换效果不佳。文章只提到了目前水平不错的四种ePub转换插件,各有各的不足。
您可以根据个人需求组合两个或多个插件完成ePub转换。 查看全部
抓取网页生成电子书(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
制作自己的学习手册并永久保存互联网信息
* 较早价格标签的合约,文字已被删除
关于文章和信息组织,一个常见的需求是保存某个主题的多篇文章文章,或者一个博客或教程的所有网页,做成类似出版物的电子出版物。可以在手机、平板电脑上阅读或永久保存的书籍。实现此要求的一种方法是使用 Chrome 插件一键将目标网页保存为 ePub 文件。
ePub 的插件大约有十种。经过大量的测试,我最终选择了dotEPUB、WebToWpub、EpubPress、Save as eBook这四个各有侧重、效果更好的插件。本文将分析它们的特点,以帮助您确定哪一种最能满足您的需求。

四个插件的用法和特点
dotEPUB : 将当前窗口的网页另存为 ePub1. 速度:更快2. 水印:开头和结尾的水印3. 图片支持:稍差4. 排版:更好排版
dotEPUB是操作最简单、功能最单一的一种。只需点击插件栏中的 dotEPUB 图标,即可自动将当前网页下载为 ePub 文件。但由于只保存当前网页,因此适用范围较窄。
在这里,打开一个知乎栏目“我们在谈论英语学习时在谈论什么”作为素材尝试抓取,用多看App打开,阅读效果如下。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:

WebToEpub:抓取当前网页中的所有链接为章节并生成为ePub1.速度:更快,有进度条2.水印:无水印3.图片支持:有图片4.排版:排版比较通用
这是我经常使用的插件。它可以爬取当前网页中收录的链接的所有内容。适用于爬取知乎列或博客等网站以列表形式展开内容。网页中的每个链接都会生成一个特定的Epub章节,章节标题就是网页标题。
点击插件,确认开始转换后,进入插件主界面。在主界面中,WebToEpub 允许用户编辑 ePub 的标题、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等操作,还可以反向选择网页列表。此外,您可以通过将图像地址粘贴到 URL 框中来为文件添加封面。

需要注意的是,对于一些动态加载的页面,如果要抓取所有的文章,在使用插件之前需要滚动到页面底部完全加载列表。

EpubPress:将当前打开的所有标签捕获为ePub1.速度:正常速度,带有进度条2.水印:无水印3.图像支持:在某些情况下捕获图像会失败< @4. 排版:更好的排版
这是另一个常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到电子邮件地址,可根据需要在右上角的设置中选择。

如果爬取大量标签页,等待时间会明显变长。另请注意,在实际测试中可能无法保存超过 20 个选项卡。

另存为电子书:选择打开的网页并保存为 ePub1. 速度:更快2. 水印:无水印3. 图片支持:带图片4. 排版:更好排版
另存为 eBook 与 EpubPress 类似,都将打开的选项卡保存为 ePub 文件中的章节。但要保存为电子书,需要在浏览网页时点击要保存的网页插件栏中的图标,选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。

在主界面中,您可以编辑文件的标题和调整章节的顺序。

四种使用场景
总结一下四个插件的适用场景,这里简单总结一下情况:

总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 和 Read Later 等工具之外的另一个想法。对于严肃或系统的内容,制作一本ePub电子书,三两下进行主题阅读会更加连贯,思考可以逐步深化主题。这是电子书和印象笔记以及后来阅读的区别。观点。因此,对于系统学习来说,ePub电子书无疑是一个不错的选择。
回到Chrome插件的话题,一键生成ePub文件的插件普遍的缺点是通过插件制作的电子书不是纯图文,还有一些不相关的内容,如网站中的超链接或评论@> 也可能被 网站 阻止。@收录进入电子书,导致转换效果不佳。文章只提到了目前水平不错的四种ePub转换插件,各有各的不足。
您可以根据个人需求组合两个或多个插件完成ePub转换。
抓取网页生成电子书(如何用Python爬取网页制作电子书思路怎么抓取数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-23 16:13
作者简介:孙宇,软件工程师,长期从事企业信息系统研发,主要擅长后端业务功能的设计与开发。
本文来自作者在GitChat上分享的主题“如何用Python爬取网页制作电子书”。使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
有一个目录选项卡,点击这个选项卡可以查看目录,使用浏览器的元素查看工具,我们可以定位到目录和每章的相关信息,我们可以根据这些信息爬取到具体的页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面排序不是很好,手动排序会耗费太多时间和精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
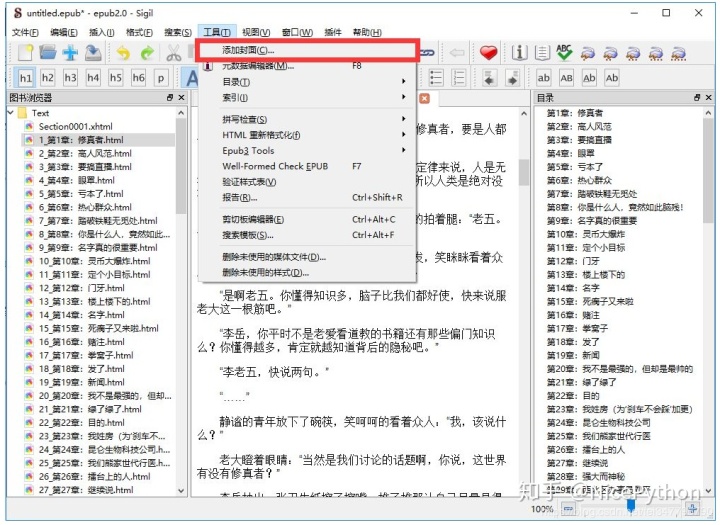
使用 Sigil 创建电子书
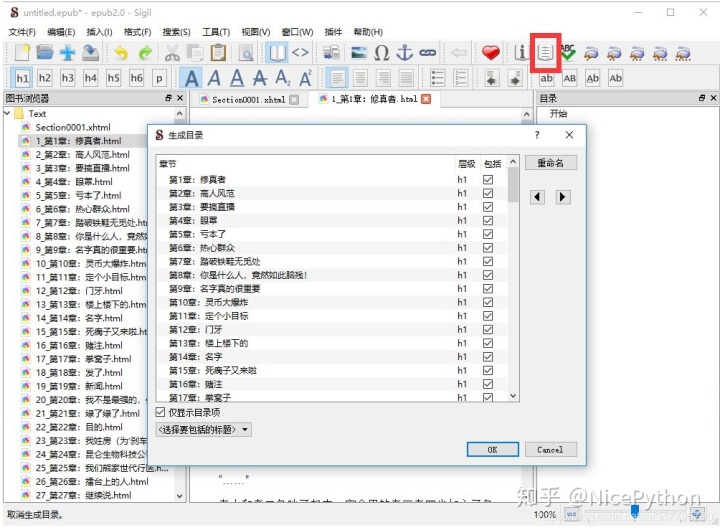
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
. 查看全部
抓取网页生成电子书(如何用Python爬取网页制作电子书思路怎么抓取数据?)
作者简介:孙宇,软件工程师,长期从事企业信息系统研发,主要擅长后端业务功能的设计与开发。
本文来自作者在GitChat上分享的主题“如何用Python爬取网页制作电子书”。使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
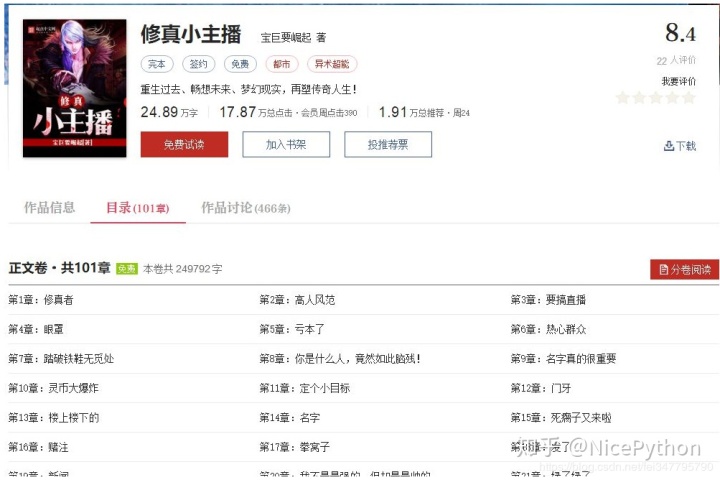
有一个目录选项卡,点击这个选项卡可以查看目录,使用浏览器的元素查看工具,我们可以定位到目录和每章的相关信息,我们可以根据这些信息爬取到具体的页面:
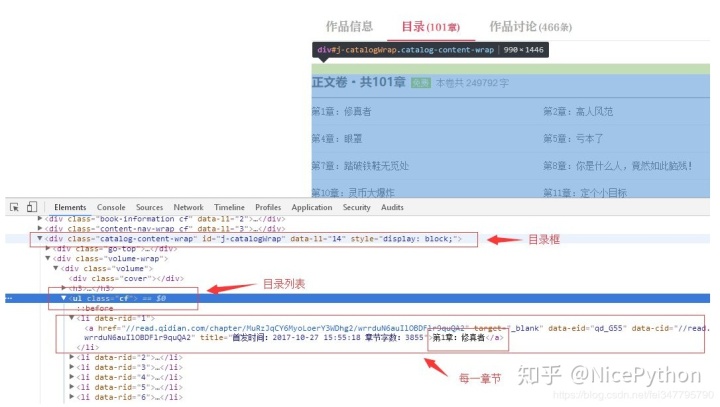
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
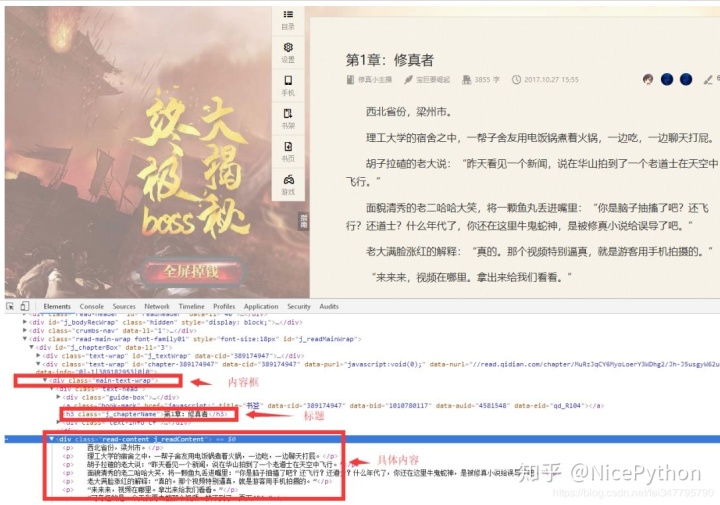
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面排序不是很好,手动排序会耗费太多时间和精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
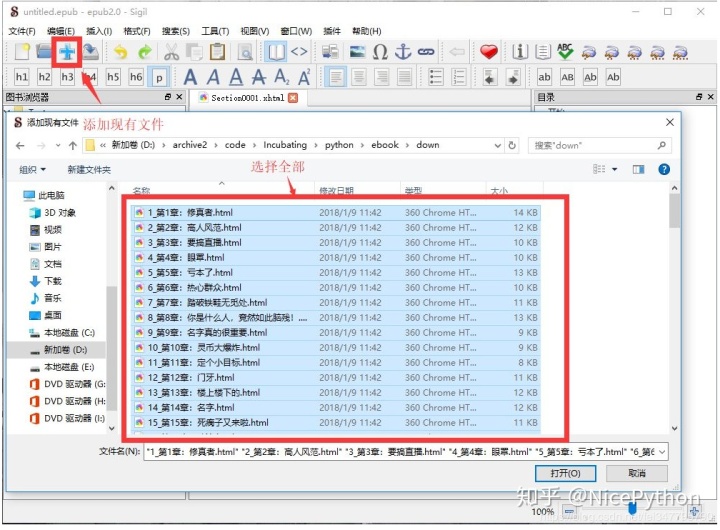
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
.
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-22 21:06
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列 文章地址列表 抓取每个的详细信息 文章导出 PDF 1. 抓取列表
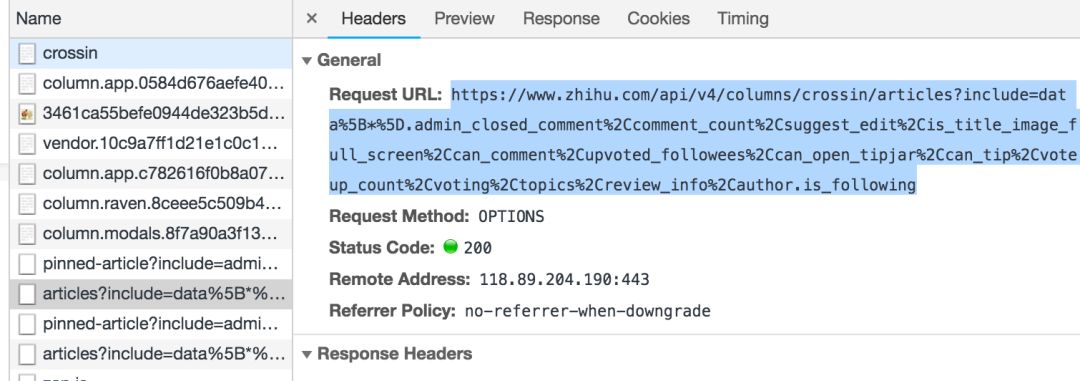
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
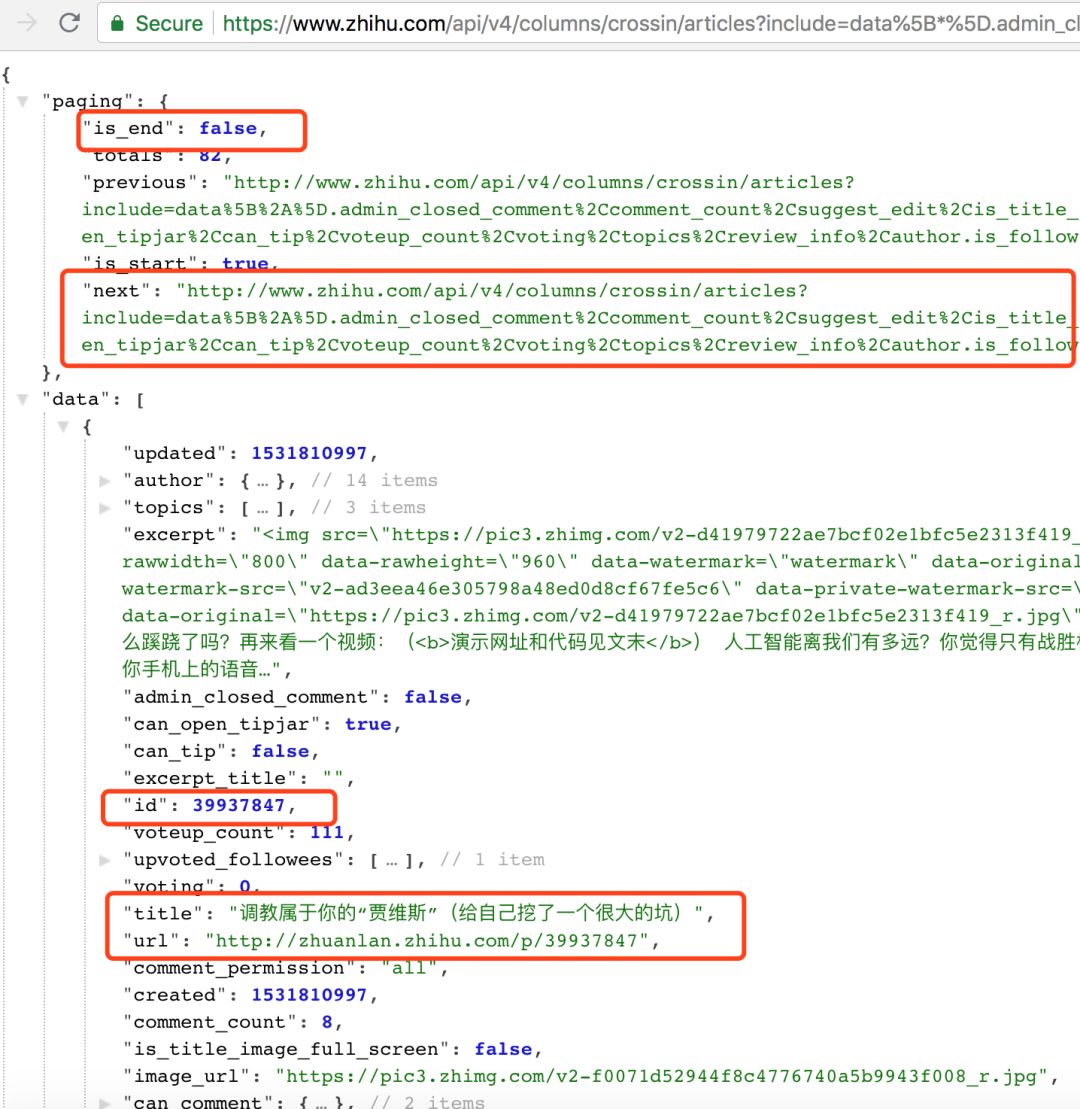
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
whileTrue: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
文章数据:
# 保存id和title(省略) ifj[ 'paging'][ 'is_end']:
breakurl = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果,会添加不带data-actual、src="data:image等标签和属性的效果。我们必须去掉它们才能正常显示。
url = ''+ idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_= 'Post-RichText').prettify()
# 处理内容(略)
withopen(file_name, 'w') asf: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了便于阅读,我们使用 wkhtmltopdf+ pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,都是通过1.抓取列表2.抓取详细内容这两个步骤采集数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:

之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列 文章地址列表 抓取每个的详细信息 文章导出 PDF 1. 抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
whileTrue: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
文章数据:
# 保存id和title(省略) ifj[ 'paging'][ 'is_end']:
breakurl = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果,会添加不带data-actual、src="data:image等标签和属性的效果。我们必须去掉它们才能正常显示。
url = ''+ idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_= 'Post-RichText').prettify()
# 处理内容(略)
withopen(file_name, 'w') asf: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了便于阅读,我们使用 wkhtmltopdf+ pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')

这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,都是通过1.抓取列表2.抓取详细内容这两个步骤采集数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
抓取网页生成电子书(王子网页转换小精灵支持把文件批量转换为网页格式,支持制作漂亮的电子相册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-22 15:12
Prince是一款帮助用户制作chm电子书的软件。王子网页转换精灵支持将文件批量转换为网页格式,支持制作精美的电子相册。主要功能包括网页制作、网页批量转换、电子书制作、文件拆分合并、文件加解密等,欢迎下载使用!
【王子网页转换精灵功能介绍】:
1、 将文本文件批量转换为web文件(txt等转htm)
2、网页文件批量转成文本文件(htm等转成txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件,也可以合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后有更多模板可用。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件,一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、除了转换上面列出的文件类型,还可以自己添加转换类型 查看全部
抓取网页生成电子书(王子网页转换小精灵支持把文件批量转换为网页格式,支持制作漂亮的电子相册)
Prince是一款帮助用户制作chm电子书的软件。王子网页转换精灵支持将文件批量转换为网页格式,支持制作精美的电子相册。主要功能包括网页制作、网页批量转换、电子书制作、文件拆分合并、文件加解密等,欢迎下载使用!
【王子网页转换精灵功能介绍】:
1、 将文本文件批量转换为web文件(txt等转htm)
2、网页文件批量转成文本文件(htm等转成txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件,也可以合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后有更多模板可用。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件,一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、除了转换上面列出的文件类型,还可以自己添加转换类型
抓取网页生成电子书(你好电子书网站制作教程:制作电子书最简单的电子书:介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2022-02-21 04:07
你好电子书网站制作教程:
这 网站 会说清楚
网站电子书网站制作教程:
电子书网站制作教程介绍:
前言电子书网站制作教程:
很多人问我如何制作电子书。我在网上搜索了一下,发现这样的资料并不多,而且都太复杂了,学习如何制作电子书网站教程。于是干脆写了一篇通俗易懂的文章文章,大家一起交流,让更多人学习制作电子书:
电子书(eBook)是一种电子阅读材料,极大地方便了信息的传播和存储,也给我们的学习和工作带来了很多便利。
比如很多摘要可以做成电子书,图文并茂,界面美观,易于阅读,保存完好。
网上有很多小说、教程或其他资料都是用电子书做成的。您想知道这些电子书是如何制作的吗?其实很简单。看完这文章,你就可以制作自己的电子书了。
一。初步知识:
电子书的格式有很多种,包括:EXE文件格式、CHM文件格式、HLP文件格式、PDF文件格式、LIT文件格式、WDL文件格式等,其中有些格式只能用特定的软件打开阅读,如用于 PDF 格式的 Adobe Acrobat Reader 和用于 WDL 格式的华康的 DynaDoc Free Reader。
但总的来说,使用最多的格式是EXE和CHM,所以本文只讨论这两种格式的电子书,其他格式可以通过网上查找相关资料了解。
制作电子书的材料可以是txt文本、html网页、doc文档或图片、flash等。
想要做出更漂亮的电子书,就必须对网页制作和图像处理技术有一定的了解。当然,如果你不知道这些,也没关系。您也可以自己制作电子书。请继续阅读:
二。
制作第一本最简单的电子书:
制作电子书的软件也有很多,不同格式的电子书制作所选择的软件也不同。
快速链接:谁是大师?九大电子书制作工具横评
现在我们使用Netwen Quick Capture制作第一本电子书:
软件名称:CyberArticle
软件版本:V4。
01
软件大小:5367K
授权方式:破解版
下载地址1:
下载地址2:
网文快拍是一款非常优秀的国产分享软件,可以方便的保存和管理网页,也是一款非常实用的电子书制作工具。运行网络文章。
exe后,点击工具栏上的“文件”-“导入”-“从文件夹导入”(或按Ctrl+Alt+F),选择创建电子书资料的文件夹,
从这里可以看出,电子书支持的文档类型很多,txt、html、flash,甚至还有程序源代码文件等等,但是我们只使用最基本的txt文本作为素材。
单击下一步以选择要导入的文件,然后单击下一步以完成导入。
在左侧的资源管理器窗口中,可以看到文件列表的目录树,可以调整它们的文件名和排列顺序,然后可以在右侧窗口中预览文本内容,也可以切换到“编辑”或“来源”选项来编辑文本。
最后点击“文件”-“制作电子书”-“制作电子书(*.
EXE格式)...”或“制作电子书(*.CHM格式)...”,分别制作exe和chm格式的电子书,设置好一些选项后,点击“制作”,很快,一个e -book 会做的很好,简单快捷。
三。创建更精美的电子书:
虽然使用Netwen Quick Capture制作电子书非常方便快捷(可以同时制作exe和chm两种格式的电子书),但是这样的电子书并不是特别漂亮,而且它们的功能是不强。
这时候我们就可以使用eBook Edit Pro、eBook Workshop、eBook Pack Express等专业的电子书制作软件来制作更精美的电子书。推荐使用国内的电子书工坊(e书工坊):
软件名称:e书工坊
软件版本:V1。
4
软件大小:1785K
授权方式:注册版
下载链接:
注册码:名称:ASWord 代码:719FBF71-353B4344-B70CB1A9
使用电子书工坊,可以制作exe格式的电子书,界面非常漂亮,功能强大。
下载安装后,打开电子书工坊,
首先选择要制作的电子书的文件目录,然后在“目录”中添加需要的文件。请务必将文件添加到中间列表框中。您可以直接单击“从文件夹创建”或添加文件将它们一一拖动。然后可以对它们重新排序,首页是电子书的主页(即打开电子书时看到的第一页)。
然后可以在其他选项卡中设置“启动画面”、“界面”、“图标”、“工具栏”等,eBook Workshop提供了非常强大的自定义功能,可以创建非常个性化的界面和功能。
最好点击“保存”,保存工程后点击“编译”,将电子书编译成exe格式。
注意:电子书工坊有个很大的缺点,就是导入的文字不能自动换行,阅读电子书极其不方便。
所以最好不要直接导入文本,而是先转换成网页,再制作。这不仅避免了这个问题,而且还使电子书看起来更好看。
四。将其提升到一个新的水平,以制作更好的电子书
这部分需要你对网页创建有一点了解。
其实一本电子书就是把很多网页打包成一个可执行文件(txt文本也可以看作是网页最简单的形式),所以我们只需要先制作一些网页,然后使用软件如电子书研讨会将它制作成电子书。
我们可以使用 Softscape HTML Maker 来帮助我们快速制作网页:
软件名称:Softscape HTML Maker
软件版本:V3.0
软件大小:1966 KB
授权方式:共享版
下载链接:
它的功能是将文本批量转换成网页。这些网页是带有索引文件、“上一页”和“下一页”链接的 HTML 文件组。
下载安装软件后,运行主程序,
首先点击“添加”导入要转换的文本。然后选择分割文字的方法(即如何分割文字,问题有点复杂,请参考软件自带的帮助文件,上面的描述更清楚),然后选择网页模板,最后点击“开始”输出网页。(如何将文字和图片一起作为网页输入也可以参考软件帮助文件)
在输入的众多网页中,有一个名为m的网页是目录索引页,可以作为制作电子书时的“首页”。
此外,您还可以使用 Frontpage、Dreamwaver 等网页创建工具来处理和修改这些网页。完成后,您可以按照上述步骤创建电子书。
由于界面是中文的,操作比较简单,所以就不再介绍上面提到的软件了。慢慢使用很容易上手。
到目前为止,我们已经学会了如何制作自己的电子书。如果想继续学习电子书制作技术,获取更多电子书资源,可以登录各大电子书网站,比如比较有名的:
书吧
E书时空
我喜欢书
其实这方面的网络很多,搜索一下就清楚了。 查看全部
抓取网页生成电子书(你好电子书网站制作教程:制作电子书最简单的电子书:介绍)
你好电子书网站制作教程:

这 网站 会说清楚

网站电子书网站制作教程:
电子书网站制作教程介绍:
前言电子书网站制作教程:
很多人问我如何制作电子书。我在网上搜索了一下,发现这样的资料并不多,而且都太复杂了,学习如何制作电子书网站教程。于是干脆写了一篇通俗易懂的文章文章,大家一起交流,让更多人学习制作电子书:
电子书(eBook)是一种电子阅读材料,极大地方便了信息的传播和存储,也给我们的学习和工作带来了很多便利。
比如很多摘要可以做成电子书,图文并茂,界面美观,易于阅读,保存完好。
网上有很多小说、教程或其他资料都是用电子书做成的。您想知道这些电子书是如何制作的吗?其实很简单。看完这文章,你就可以制作自己的电子书了。
一。初步知识:
电子书的格式有很多种,包括:EXE文件格式、CHM文件格式、HLP文件格式、PDF文件格式、LIT文件格式、WDL文件格式等,其中有些格式只能用特定的软件打开阅读,如用于 PDF 格式的 Adobe Acrobat Reader 和用于 WDL 格式的华康的 DynaDoc Free Reader。
但总的来说,使用最多的格式是EXE和CHM,所以本文只讨论这两种格式的电子书,其他格式可以通过网上查找相关资料了解。
制作电子书的材料可以是txt文本、html网页、doc文档或图片、flash等。
想要做出更漂亮的电子书,就必须对网页制作和图像处理技术有一定的了解。当然,如果你不知道这些,也没关系。您也可以自己制作电子书。请继续阅读:
二。
制作第一本最简单的电子书:
制作电子书的软件也有很多,不同格式的电子书制作所选择的软件也不同。
快速链接:谁是大师?九大电子书制作工具横评
现在我们使用Netwen Quick Capture制作第一本电子书:
软件名称:CyberArticle
软件版本:V4。
01
软件大小:5367K
授权方式:破解版
下载地址1:
下载地址2:
网文快拍是一款非常优秀的国产分享软件,可以方便的保存和管理网页,也是一款非常实用的电子书制作工具。运行网络文章。
exe后,点击工具栏上的“文件”-“导入”-“从文件夹导入”(或按Ctrl+Alt+F),选择创建电子书资料的文件夹,
从这里可以看出,电子书支持的文档类型很多,txt、html、flash,甚至还有程序源代码文件等等,但是我们只使用最基本的txt文本作为素材。
单击下一步以选择要导入的文件,然后单击下一步以完成导入。
在左侧的资源管理器窗口中,可以看到文件列表的目录树,可以调整它们的文件名和排列顺序,然后可以在右侧窗口中预览文本内容,也可以切换到“编辑”或“来源”选项来编辑文本。
最后点击“文件”-“制作电子书”-“制作电子书(*.
EXE格式)...”或“制作电子书(*.CHM格式)...”,分别制作exe和chm格式的电子书,设置好一些选项后,点击“制作”,很快,一个e -book 会做的很好,简单快捷。
三。创建更精美的电子书:
虽然使用Netwen Quick Capture制作电子书非常方便快捷(可以同时制作exe和chm两种格式的电子书),但是这样的电子书并不是特别漂亮,而且它们的功能是不强。
这时候我们就可以使用eBook Edit Pro、eBook Workshop、eBook Pack Express等专业的电子书制作软件来制作更精美的电子书。推荐使用国内的电子书工坊(e书工坊):
软件名称:e书工坊
软件版本:V1。
4
软件大小:1785K
授权方式:注册版
下载链接:
注册码:名称:ASWord 代码:719FBF71-353B4344-B70CB1A9
使用电子书工坊,可以制作exe格式的电子书,界面非常漂亮,功能强大。
下载安装后,打开电子书工坊,
首先选择要制作的电子书的文件目录,然后在“目录”中添加需要的文件。请务必将文件添加到中间列表框中。您可以直接单击“从文件夹创建”或添加文件将它们一一拖动。然后可以对它们重新排序,首页是电子书的主页(即打开电子书时看到的第一页)。
然后可以在其他选项卡中设置“启动画面”、“界面”、“图标”、“工具栏”等,eBook Workshop提供了非常强大的自定义功能,可以创建非常个性化的界面和功能。
最好点击“保存”,保存工程后点击“编译”,将电子书编译成exe格式。
注意:电子书工坊有个很大的缺点,就是导入的文字不能自动换行,阅读电子书极其不方便。
所以最好不要直接导入文本,而是先转换成网页,再制作。这不仅避免了这个问题,而且还使电子书看起来更好看。
四。将其提升到一个新的水平,以制作更好的电子书
这部分需要你对网页创建有一点了解。
其实一本电子书就是把很多网页打包成一个可执行文件(txt文本也可以看作是网页最简单的形式),所以我们只需要先制作一些网页,然后使用软件如电子书研讨会将它制作成电子书。
我们可以使用 Softscape HTML Maker 来帮助我们快速制作网页:
软件名称:Softscape HTML Maker
软件版本:V3.0
软件大小:1966 KB
授权方式:共享版
下载链接:
它的功能是将文本批量转换成网页。这些网页是带有索引文件、“上一页”和“下一页”链接的 HTML 文件组。
下载安装软件后,运行主程序,
首先点击“添加”导入要转换的文本。然后选择分割文字的方法(即如何分割文字,问题有点复杂,请参考软件自带的帮助文件,上面的描述更清楚),然后选择网页模板,最后点击“开始”输出网页。(如何将文字和图片一起作为网页输入也可以参考软件帮助文件)
在输入的众多网页中,有一个名为m的网页是目录索引页,可以作为制作电子书时的“首页”。
此外,您还可以使用 Frontpage、Dreamwaver 等网页创建工具来处理和修改这些网页。完成后,您可以按照上述步骤创建电子书。
由于界面是中文的,操作比较简单,所以就不再介绍上面提到的软件了。慢慢使用很容易上手。
到目前为止,我们已经学会了如何制作自己的电子书。如果想继续学习电子书制作技术,获取更多电子书资源,可以登录各大电子书网站,比如比较有名的:
书吧
E书时空
我喜欢书
其实这方面的网络很多,搜索一下就清楚了。
抓取网页生成电子书( 软件介绍:网站2PK中文版和appsgeyser的使用细节(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-02-21 01:06
软件介绍:网站2PK中文版和appsgeyser的使用细节(图))
软件介绍:
网站2PK汉化版可以一键直接将网站转换成APK软件。
需要软件java8支持,运行后需要安装java8。
您可以自定义各种设置。鑫哥尝试把日常学习网变成apk,效果非常好!
本次发布说明:
byditzmx
本地化率在99.8%以上。如果没有本地化,可能会有很少的错误提示。
在生成就绪之前翻译按钮图像并替换等待图标。
警告工具提示中添加了一个图标,但除了工具提示文本之外没有其他图标。
修改了应用启动画面的图片大小限制。本来是受限于竖屏最大宽度1280x和最大高度1920,如果有限制的话。
该设置会导致启动画面被拉扯变形,所以根据横屏限制最大宽度为1920x,最大高度为1080。实际上,这取决于网页的显示方式。如果使用竖屏,横屏尺寸可以正常比例显示。
软件截图:
下载链接:
提取码:p5qn
简单的应用开发平台
一种是细致而繁琐。每个代码和标点都有严格的要求,不能出错。APP的开发是在一定的平台上进行的,也就是我们所说的开发平台。主流的开发平台有五个:appInventor、PhoneGap、appsgeyser、Devmyapp和WeX5。五个平台中的每一个都有自己的优势。今天主要讲appInventor和appsgeyser。
1.此前,谷歌实验室已经以教学视频的形式向网友披露了该软件测试版的使用细节。在这个视频中,R&d的人展示了如何使用程序发明者来制作应用程序,也有很多人教网友自己开发新程序。
而且,这个编程软件不必是专业开发的;d 人员甚至根本不需要掌握任何编程知识。由于本软件已预先编写好所有软件代码,用户只需根据需要为其添加服务选项即可。也就是说,我们所要做的就是编写一个简单的代码汇编器。
2、appsgeyser
appsGeyser 允许任何人开发应用程序。当然,这个程序不允许您创建下一个愤怒的小鸟或 Foursquare。但是如果你只是想基于 web 内容构建一个非常简单的应用程序,appsGeyser 将是你最好的选择。appsGeyser 其实很简单。它只有三个选项:第一,它可以生成一个应用程序;第二,输入任意web widget的HTML代码,可以直接转换成Android应用;第三,使用工具抓取网页的部分内容以生成应用程序。
完成工作后,您可以上传到 AndroidMarket(但您必须事先拥有发布者帐户)或自己使用。该应用程序上个月才推出,但其联合创始人 Vasily Salomatov 表示,用户已经使用 appsGeyser 创建了 1,000 个应用程序。
不管什么样的app平台,最重要的是要有清晰的创意。然而,在这些平台中,有些想法无法完全呈现。如果你想玩一个简单的应用程序,这个平台是你的选择,但如果你想要互联网创意建议,你应该选择一个自定义应用程序来制作一个更完美的应用程序。
为企业提供基于IOS和Android系统的移动APP应用定制开发,提供APP产品综合解决方案。 查看全部
抓取网页生成电子书(
软件介绍:网站2PK中文版和appsgeyser的使用细节(图))

软件介绍:
网站2PK汉化版可以一键直接将网站转换成APK软件。
需要软件java8支持,运行后需要安装java8。
您可以自定义各种设置。鑫哥尝试把日常学习网变成apk,效果非常好!
本次发布说明:
byditzmx
本地化率在99.8%以上。如果没有本地化,可能会有很少的错误提示。
在生成就绪之前翻译按钮图像并替换等待图标。
警告工具提示中添加了一个图标,但除了工具提示文本之外没有其他图标。
修改了应用启动画面的图片大小限制。本来是受限于竖屏最大宽度1280x和最大高度1920,如果有限制的话。
该设置会导致启动画面被拉扯变形,所以根据横屏限制最大宽度为1920x,最大高度为1080。实际上,这取决于网页的显示方式。如果使用竖屏,横屏尺寸可以正常比例显示。
软件截图:
下载链接:
提取码:p5qn
简单的应用开发平台
一种是细致而繁琐。每个代码和标点都有严格的要求,不能出错。APP的开发是在一定的平台上进行的,也就是我们所说的开发平台。主流的开发平台有五个:appInventor、PhoneGap、appsgeyser、Devmyapp和WeX5。五个平台中的每一个都有自己的优势。今天主要讲appInventor和appsgeyser。
1.此前,谷歌实验室已经以教学视频的形式向网友披露了该软件测试版的使用细节。在这个视频中,R&d的人展示了如何使用程序发明者来制作应用程序,也有很多人教网友自己开发新程序。
而且,这个编程软件不必是专业开发的;d 人员甚至根本不需要掌握任何编程知识。由于本软件已预先编写好所有软件代码,用户只需根据需要为其添加服务选项即可。也就是说,我们所要做的就是编写一个简单的代码汇编器。
2、appsgeyser
appsGeyser 允许任何人开发应用程序。当然,这个程序不允许您创建下一个愤怒的小鸟或 Foursquare。但是如果你只是想基于 web 内容构建一个非常简单的应用程序,appsGeyser 将是你最好的选择。appsGeyser 其实很简单。它只有三个选项:第一,它可以生成一个应用程序;第二,输入任意web widget的HTML代码,可以直接转换成Android应用;第三,使用工具抓取网页的部分内容以生成应用程序。
完成工作后,您可以上传到 AndroidMarket(但您必须事先拥有发布者帐户)或自己使用。该应用程序上个月才推出,但其联合创始人 Vasily Salomatov 表示,用户已经使用 appsGeyser 创建了 1,000 个应用程序。
不管什么样的app平台,最重要的是要有清晰的创意。然而,在这些平台中,有些想法无法完全呈现。如果你想玩一个简单的应用程序,这个平台是你的选择,但如果你想要互联网创意建议,你应该选择一个自定义应用程序来制作一个更完美的应用程序。
为企业提供基于IOS和Android系统的移动APP应用定制开发,提供APP产品综合解决方案。
抓取网页生成电子书(地铁上也能快速翻完.环境准备:calibreQT)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-17 23:10
简书是个很好的学习者网站,我大多只关注首页的人文章,但最近因为工作繁忙,错过了很多首页的文章,所以我有一个想法,把每日流行的Top生成mobi并推送到kindle。这样一来,在地铁上就能很快搞定。
环境准备:
关于口径安装
sudo -v && wget -nv -O- https://raw.githubusercontent. ... er.py | sudo python -c "import sys; main=lambda:sys.stderr.write('Download failed\n'); exec(sys.stdin.read()); main()"
官网文档提供的安装脚本看似简单,执行后即可安装使用,但调用ebook-convert时gitbook会报错。这里报的错误应该是QT错误(至少我遇到过,具体错误信息忘记截图了)如果遇到这个错误,直接安装QT pyQT即可。calibre安装页面有依赖表
安装 Gitbook
需要安装 nodejs 和 npm 然后执行 npm install -g gitbook-cli
安装建树热
需要强调的是,这部分需要解决很多依赖,
scrapy依赖的python包有很多,这些依赖的python大部分都需要一些系统库。如有需要,需要安装apt-get和yum,如python-devel libffi-devel libxml-devel等...
peewee(数据库ORM)需要mysql-devel,上面的例子都知道,这是我部署后写的,部署过程就不详细记录了,现在只能凭记忆写这一章了。
$ git clone https://github.com/jackeyGao/jianshuHot
$ cd jianshuHot
$ pip install -r requirements.txt
初始化器
$ sh init.sh
邮件配置
这是用于发送电子邮件的 sendEmail 和下载地址。解压后将解压后的sendEmail重命名为/usr/local/bin/sendEmail,理论上可以安装成功。这是免编译的,只需要在机器上安装perl。
然后修改start.sh邮箱配置,写成自己的163邮箱,也可以用其他品牌邮箱,如果用其他品牌别忘了改,改到对应的smtp服务器就好了。
注意:无论您使用哪个电子邮件地址,您都必须将此电子邮件帐户添加到亚马逊的批准发件人电子邮件列表中,以确保您发送的文件可以到达亚马逊云
$ vim start.sh
....
YOURKINDLE_MAIL_ADDRESS="xxxxx@kindle.cn"
YOUR_SEND_MAIL_USERNAME="xxxx@163.com"
YOUR_SEND_MAIL_SECRET = 'xxxxxxxxxxxx'
MOBI_BOOK_PATH='./output/book.mobi'
...
开始爬行
$ sh start.sh
执行后会自动抓取页面生成markdown,下载每个文章的图片,然后gitbook通过markdown生成这个文档列表的book.mobi(output/book.mobi),有文件在 start.sh 的末尾,备份操作会将这个 mobi 备份到 output/books。然后发送到指定kindle地址邮箱。 查看全部
抓取网页生成电子书(地铁上也能快速翻完.环境准备:calibreQT)
简书是个很好的学习者网站,我大多只关注首页的人文章,但最近因为工作繁忙,错过了很多首页的文章,所以我有一个想法,把每日流行的Top生成mobi并推送到kindle。这样一来,在地铁上就能很快搞定。
环境准备:
关于口径安装
sudo -v && wget -nv -O- https://raw.githubusercontent. ... er.py | sudo python -c "import sys; main=lambda:sys.stderr.write('Download failed\n'); exec(sys.stdin.read()); main()"
官网文档提供的安装脚本看似简单,执行后即可安装使用,但调用ebook-convert时gitbook会报错。这里报的错误应该是QT错误(至少我遇到过,具体错误信息忘记截图了)如果遇到这个错误,直接安装QT pyQT即可。calibre安装页面有依赖表
安装 Gitbook
需要安装 nodejs 和 npm 然后执行 npm install -g gitbook-cli
安装建树热
需要强调的是,这部分需要解决很多依赖,
scrapy依赖的python包有很多,这些依赖的python大部分都需要一些系统库。如有需要,需要安装apt-get和yum,如python-devel libffi-devel libxml-devel等...
peewee(数据库ORM)需要mysql-devel,上面的例子都知道,这是我部署后写的,部署过程就不详细记录了,现在只能凭记忆写这一章了。
$ git clone https://github.com/jackeyGao/jianshuHot
$ cd jianshuHot
$ pip install -r requirements.txt
初始化器
$ sh init.sh
邮件配置
这是用于发送电子邮件的 sendEmail 和下载地址。解压后将解压后的sendEmail重命名为/usr/local/bin/sendEmail,理论上可以安装成功。这是免编译的,只需要在机器上安装perl。
然后修改start.sh邮箱配置,写成自己的163邮箱,也可以用其他品牌邮箱,如果用其他品牌别忘了改,改到对应的smtp服务器就好了。
注意:无论您使用哪个电子邮件地址,您都必须将此电子邮件帐户添加到亚马逊的批准发件人电子邮件列表中,以确保您发送的文件可以到达亚马逊云
$ vim start.sh
....
YOURKINDLE_MAIL_ADDRESS="xxxxx@kindle.cn"
YOUR_SEND_MAIL_USERNAME="xxxx@163.com"
YOUR_SEND_MAIL_SECRET = 'xxxxxxxxxxxx'
MOBI_BOOK_PATH='./output/book.mobi'
...
开始爬行
$ sh start.sh
执行后会自动抓取页面生成markdown,下载每个文章的图片,然后gitbook通过markdown生成这个文档列表的book.mobi(output/book.mobi),有文件在 start.sh 的末尾,备份操作会将这个 mobi 备份到 output/books。然后发送到指定kindle地址邮箱。
抓取网页生成电子书(Python标准库unittest办法读取了吗?非也!(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-17 23:10
)
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
本文将介绍一个python库:selenium,最新版本为2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
1 from selenium import webdriver
2
3 browser = webdriver.Firefox()
4 browser.get('http://www.baidu.com/')
【示例一】
1 from selenium import webdriver
2 from selenium.webdriver.common.keys import Keys
3
4 browser = webdriver.Firefox()
5
6 browser.get('http://www.baidu.com')
7 assert '百度' in browser.title
8
9 elem = browser.find_element_by_name('p') # Find the search box
10 elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
11
12 browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
1 import unittest
2
3 class BaiduTestCase(unittest.TestCase):
4
5 def setUp(self):
6 self.browser = webdriver.Firefox()
7 self.addCleanup(self.browser.quit)
8
9 def testPageTitle(self):
10 self.browser.get('http://www.baidu.com')
11 self.assertIn('百度', self.browser.title)
12
13 if __name__ == '__main__':
14 unittest.main(verbosity=2) 查看全部
抓取网页生成电子书(Python标准库unittest办法读取了吗?非也!(图)
)
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
本文将介绍一个python库:selenium,最新版本为2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
1 from selenium import webdriver
2
3 browser = webdriver.Firefox()
4 browser.get('http://www.baidu.com/')
【示例一】
1 from selenium import webdriver
2 from selenium.webdriver.common.keys import Keys
3
4 browser = webdriver.Firefox()
5
6 browser.get('http://www.baidu.com')
7 assert '百度' in browser.title
8
9 elem = browser.find_element_by_name('p') # Find the search box
10 elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
11
12 browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
1 import unittest
2
3 class BaiduTestCase(unittest.TestCase):
4
5 def setUp(self):
6 self.browser = webdriver.Firefox()
7 self.addCleanup(self.browser.quit)
8
9 def testPageTitle(self):
10 self.browser.get('http://www.baidu.com')
11 self.assertIn('百度', self.browser.title)
12
13 if __name__ == '__main__':
14 unittest.main(verbosity=2)
抓取网页生成电子书(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-17 08:18
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e) 查看全部
抓取网页生成电子书(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e)
抓取网页生成电子书(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 912 次浏览 • 2022-02-17 08:16
iefans提供的一款供用户使用成品小说免费下载全书的软件,可以一次性免费阅读全书,现推荐一款免费的全书txt小说电子书下载软件,使用网络图书抓取器,并支持TXT全书免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载TXT全电子书。iefans 提供网络图书采集器的下载地址。需要免费完整小说下载器的朋友,快来下载试试吧。试试看。
网络图书爬虫介绍
Web Book Crawler是一款在线小说下载软件,可以帮助用户下载指定网页的一本书和一章。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载。读后支持断点续下载功能。如果是网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整本小说。
如何使用网络图书刮刀
1.网络小说下载软件下载解压后,双击使用,首次运行会自动生成设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载的小说网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始抓取开始下载。
3.可以提取指定小说目录页面的章节信息并调整,然后按照章节顺序抓取小说内容,在最合适的时候合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
4.在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来了极大的方便。已输入 10 个适用的 网站。选择后可以快速打开网站找到需要的书籍,还可以自动套用相应的代码 查看全部
抓取网页生成电子书(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
iefans提供的一款供用户使用成品小说免费下载全书的软件,可以一次性免费阅读全书,现推荐一款免费的全书txt小说电子书下载软件,使用网络图书抓取器,并支持TXT全书免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载TXT全电子书。iefans 提供网络图书采集器的下载地址。需要免费完整小说下载器的朋友,快来下载试试吧。试试看。
网络图书爬虫介绍
Web Book Crawler是一款在线小说下载软件,可以帮助用户下载指定网页的一本书和一章。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载。读后支持断点续下载功能。如果是网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整本小说。
如何使用网络图书刮刀
1.网络小说下载软件下载解压后,双击使用,首次运行会自动生成设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载的小说网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始抓取开始下载。
3.可以提取指定小说目录页面的章节信息并调整,然后按照章节顺序抓取小说内容,在最合适的时候合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
4.在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来了极大的方便。已输入 10 个适用的 网站。选择后可以快速打开网站找到需要的书籍,还可以自动套用相应的代码
抓取网页生成电子书(网文快捕软件特色介绍的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-15 05:24
Nettext Quick Capture是一款功能实用的网页保存管理软件。本软件可以帮助用户轻松批量保存和管理网页内容,并帮助制作成电子书格式,方便用户获取和提取网页内容。该软件具有超强的稳定性。最大程度保障数据安全,满足用户各种网页内容获取和保存需求。
软件功能
1、超强稳定性:数据管理,最重要的是数据安全,可以提供稳定的程序和安全的数据存储方式。经过严格测试的程序具有高度的稳定性。同时,所有数据都存储在数据库中,这也提供了一种安全可靠的数据存储方式。
2、丰富的导入导出功能:可以导入你的邮件、各种Office文档、PDF、源代码、图片等。同时,您还可以将数据导出为 HTML 文件制作电子书,无需 CyberArticle 即可使用。以后即使不再使用,也可以使用您的数据,不用担心数据丢失。
3、便捷的数据共享:让您轻松共享数据。无论您是在公司还是在家里,您都可以同时使用局域网来管理您的数据。所有操作都自动保存到数据库中,无需任何同步工作。您也可以使用WebShare 组件,您可以将您的数据发布到浏览器上面。这样,即使其他人没有安装该软件,只要有浏览器,就可以查看数据。
4、强大的开放性:公开数据的存储方式,提供丰富的二次开发接口。您可以使用脚本语言来扩展 CyberArticle 的功能,也可以使用高级语言编写各种插件以更好地满足您的需求。
5、完全支持各种浏览器:支持IE、火狐、谷歌Chrome浏览器、苹果safari浏览器、Opera。各类主流浏览器一网打尽,各类网页一网打尽。
6、PDF 支持:您可以导入 PDF 文件。导入的PDF文件可以轻松统一搜索。
7、统一管理功能:将所有导入的文档统一转换为HTML文件,采用统一的管理、检索、编辑方式,让您不再关心格式。
8、提供谷歌桌面搜索和IFilter插件,让你使用桌面搜索软件统一进行全文搜索。
9、提供版本控制功能,可以保存每一个历史修改记录。
软件功能
保存页面
1. 网页中的任何资源都可以在IE(包括IE核心浏览器)、火狐、谷歌浏览器、Safari和Opera等支持的浏览器中完整无缺地保存,特别是还可以保存一些资源,例如 YouTube 上的视频。它已成为网页保存领域流行的优秀软件。
2. 网页可以批量保存。
3. 可以导入Office文档:doc、ppt、xls、rtf。
4. 可以通过全文搜索导入 PDF 文件。
5.可以导入源代码文件,支持颜色标注。
5. 可以导入图片、flash等,也支持导入任意文件的附件。
资源管理
1. 以 HTML 格式保存所有资源,您可以在全文搜索、批处理、输出和电子书制作中以相同的方式管理它们。
2.设置一个文章为IE采集,可以添加多个书签,轻松实现多级文档管理。
3. 您还可以编辑书中的资源。
4.Nettext Quick Capture可以实现你书中的大量操作,比如分类、标注颜色、批处理等。 查看全部
抓取网页生成电子书(网文快捕软件特色介绍的应用)
Nettext Quick Capture是一款功能实用的网页保存管理软件。本软件可以帮助用户轻松批量保存和管理网页内容,并帮助制作成电子书格式,方便用户获取和提取网页内容。该软件具有超强的稳定性。最大程度保障数据安全,满足用户各种网页内容获取和保存需求。
软件功能
1、超强稳定性:数据管理,最重要的是数据安全,可以提供稳定的程序和安全的数据存储方式。经过严格测试的程序具有高度的稳定性。同时,所有数据都存储在数据库中,这也提供了一种安全可靠的数据存储方式。
2、丰富的导入导出功能:可以导入你的邮件、各种Office文档、PDF、源代码、图片等。同时,您还可以将数据导出为 HTML 文件制作电子书,无需 CyberArticle 即可使用。以后即使不再使用,也可以使用您的数据,不用担心数据丢失。
3、便捷的数据共享:让您轻松共享数据。无论您是在公司还是在家里,您都可以同时使用局域网来管理您的数据。所有操作都自动保存到数据库中,无需任何同步工作。您也可以使用WebShare 组件,您可以将您的数据发布到浏览器上面。这样,即使其他人没有安装该软件,只要有浏览器,就可以查看数据。
4、强大的开放性:公开数据的存储方式,提供丰富的二次开发接口。您可以使用脚本语言来扩展 CyberArticle 的功能,也可以使用高级语言编写各种插件以更好地满足您的需求。
5、完全支持各种浏览器:支持IE、火狐、谷歌Chrome浏览器、苹果safari浏览器、Opera。各类主流浏览器一网打尽,各类网页一网打尽。
6、PDF 支持:您可以导入 PDF 文件。导入的PDF文件可以轻松统一搜索。
7、统一管理功能:将所有导入的文档统一转换为HTML文件,采用统一的管理、检索、编辑方式,让您不再关心格式。
8、提供谷歌桌面搜索和IFilter插件,让你使用桌面搜索软件统一进行全文搜索。
9、提供版本控制功能,可以保存每一个历史修改记录。
软件功能
保存页面
1. 网页中的任何资源都可以在IE(包括IE核心浏览器)、火狐、谷歌浏览器、Safari和Opera等支持的浏览器中完整无缺地保存,特别是还可以保存一些资源,例如 YouTube 上的视频。它已成为网页保存领域流行的优秀软件。
2. 网页可以批量保存。
3. 可以导入Office文档:doc、ppt、xls、rtf。
4. 可以通过全文搜索导入 PDF 文件。
5.可以导入源代码文件,支持颜色标注。
5. 可以导入图片、flash等,也支持导入任意文件的附件。
资源管理
1. 以 HTML 格式保存所有资源,您可以在全文搜索、批处理、输出和电子书制作中以相同的方式管理它们。
2.设置一个文章为IE采集,可以添加多个书签,轻松实现多级文档管理。
3. 您还可以编辑书中的资源。
4.Nettext Quick Capture可以实现你书中的大量操作,比如分类、标注颜色、批处理等。
抓取网页生成电子书(你喜欢制作chm电子书吗?想把文件批量转换为网页格式吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-14 18:07
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、简繁体转换、文件格式转换、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为五种格式之一,HTML、TXT、RTF、DOC、XML
14、支持HTML网页文件一键生成电子书。
15、支持简繁体转换(GB2312->BIG5BIG5->GB2312)
16、网页特效采集与管理功能。并且可以方便的批量插入网页
17、反编译 CHM 电子书。
18、在线搜索功能。集成强大的中文搜索引擎---百度搜索
19、已经提供了几个 CSS 和模板。你也可以自己写。让过渡更随意
20、提供从html文件生成电子书的两个选项
21、支持ppt(powerpoint)文件一步生成电子书
22、支持xls(excel)文件一键生成电子书
23、文字和网页文字的批量替换
24、HTML TXT RTF DOC XML等格式可以任意相互转换
25、除了转换上面列出的文件类型,还可以自己添加转换类型 查看全部
抓取网页生成电子书(你喜欢制作chm电子书吗?想把文件批量转换为网页格式吗)
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、简繁体转换、文件格式转换、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为五种格式之一,HTML、TXT、RTF、DOC、XML
14、支持HTML网页文件一键生成电子书。
15、支持简繁体转换(GB2312->BIG5BIG5->GB2312)
16、网页特效采集与管理功能。并且可以方便的批量插入网页
17、反编译 CHM 电子书。
18、在线搜索功能。集成强大的中文搜索引擎---百度搜索
19、已经提供了几个 CSS 和模板。你也可以自己写。让过渡更随意
20、提供从html文件生成电子书的两个选项
21、支持ppt(powerpoint)文件一步生成电子书
22、支持xls(excel)文件一键生成电子书
23、文字和网页文字的批量替换
24、HTML TXT RTF DOC XML等格式可以任意相互转换
25、除了转换上面列出的文件类型,还可以自己添加转换类型
抓取网页生成电子书( 站点地图是一个网站所有链接的容器。你了解吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-14 18:05
站点地图是一个网站所有链接的容器。你了解吗?)
站点地图是网站所有链接的容器。许多 网站 连接很深,爬虫很难爬取。站点地图可以方便爬虫爬取 网站 页面。通过对网站页面的爬取,可以清楚的了解网站,网站地图一般存放在根目录并命名为sitemap来引导爬虫,添加网站的收录 @>重要内容页面。站点地图是根据网站的结构、框架和内容生成的导航网页文件。站点地图非常适合改善用户体验,它们为网站访问者提供方向并帮助迷路的访问者找到他们想查看的页面。
定义
站点地图是一种可视化工具,指示信息资源的位置和连接,并具有导航功能。关键在于四个方面:信息获取、信息检索、信息表示和信息关联。简而言之,就是将首页的信息按照类别以地图的形式列出,并提供相应的链接,可以为用户提供首页的整体信息,是用户准确查找的快捷入口他们需要的信息。
分类
1、sitemap(sitemap.xml,sitemap.txt) 这类站点地图收录网站的所有链接,一般提交给爬虫爬取。让搜索引擎转到 收录网站 内容。
2、网站导航,主要针对访问网站的用户。对网站连接进行分类,排序后展示在用户面前。
特征
可以烧结
这是站点地图应具有的重要功能。因为对图形的理解比文字更快更准确。这里所说的站点地图的内容虽然是用文字来表达的,但它是以地图的形式出现的,并且列出了每一栏的相关类别和子栏目。他们之间的关系表达得很清楚。它具有很强的能见度。它是用户查找所需信息资源的便捷方式。
加速
此功能在站点地图上尤为明显。网页内容清晰地显示在“地图”上,用户对首页信息一目了然。在站点地图上,还为显示的类别提供了超链接,用户可以点击超链接直接进入他们需要的栏目。这使用户能够准确、快速地找到他们需要的信息。
同步更新
站点地图是使用首页信息的辅助工具,它必须是随着首页信息内容的变化而建立的站点地图。随着首页信息的变化,它会及时调整自己的内容,保持与首页信息的高度一致性。
构建技巧
重要页面
如果站点地图收录太多链接,人们会在浏览时迷路。因此,如果 网站 页的总数超过 100,则需要选择最重要的页。推荐选择以下页面放在网站地图上:产品分类页面;主要产品页面;常见问题和帮助页面;页面被转换;访问量最高的 10 个页面;如果有现场搜索引擎,请从搜索引擎中选择点击次数最多的页面。
地图布局
站点地图布局必须简洁,所有链接均为标准HTML文本,并收录尽可能多的关键字,站点地图中不要使用图片制作链接,以免爬虫爬取。确保对链接使用标准 HTML 文本,包括尽可能多的目标关键字。例如,标题“我们的产品”可以替换为“无害除草剂、杀虫剂和杀菌剂”。
顾客习惯
用户通常希望每个页面底部都有指向站点地图的链接,以利用这种习惯。如果 网站 有搜索栏,请在搜索栏附近添加指向 网站 地图的链接,甚至将指向站点地图的链接放置在搜索结果页面上的固定位置。
将站点地图写入 robots.txt
引擎爬虫进来爬取网页时,会先检查robots.txt。如果先将sitemap写入robots.txt,效率会大大提高,从而获得搜索引擎的青睐。
产生
网上生成sitemap的方式有很多种,比如在线生成、软件生成等。Sitemap地图可以提交给各大搜索引擎,让搜索引擎更好的在网站页面上执行收录 ,而且我们还可以通过robots.txt告诉搜索引擎地图的位置。将准备好的网站映射上传到网站根目录。最重要的是将网站地图链接地址添加到robots文件中,使网站地图在页面上方便蜘蛛抓取位置,一般将网站地图放在页眉和页脚。
1、网站普通html格式的地图
其目的是帮助用户了解整个网站。Html格式的网站map是根据网站的结构特点制定的,将网站的功能结构和服务内容依次列出。通常,网站 主页具有指向该格式的 网站 地图的链接。
2、XML 站点地图通常称为站点地图(大写 S)
简单地说,站点地图是 网站 上的链接列表。创建站点地图并将其提交给搜索引擎可以让网站 的内容完全收录,包括那些隐藏得更深的页面。这是网站与搜索引擎交谈的好方法。
3、搜索引擎识别的地图
因为各个搜索引擎主要对地图格式的识别不同,所以推荐使用以下格式:
百度:推荐使用网站的Html格式地图
Google:推荐网站XML 格式的地图
雅虎:网站推荐txt格式的地图
重要性
1、搜索引擎让爬虫每天爬网爬取页面。站点地图的作用是为爬虫构建一个方便快捷的爬取通道,因为网站页面是一层一层的链接,可能会有死链接。如果没有站点地图,由于死链接,爬虫无法在页面上爬取,因此它无法收录 那些损坏的链接。
2、sitemaps的存在不仅仅是为了满足搜索引擎爬虫,也是为了方便网站访问者浏览网站,尤其是门户类型网站,由于信息量大许多访问者通过站点地图找到他们需要的信息页面,这也可以改善用户体验。
3、Sitemap 可以增加链接页面的权重,因为sitemap 是指向其他页面的链接。此时,站点地图会向页面添加导入链接。我们都知道导入链接的增加会影响页面的权重,所以增加页面的权重,页面权重的增加也会增加页面的收录率。
注意事项
真实有效
站点地图的主要目的是方便搜索和抓取。如果地图有死链接或者断链,会影响网站网站在搜索引擎中的权重,所以要仔细检查是否有错误的链接地址,检查网站的链接是否正确提交前通过站长工具有效。
简化
站点地图中不应有重复链接,应使用标准 W3C 格式的地图文件。布局应简洁明了。如果地图是内容地图,每个页面收录的内容链接不要超过100个,并且应该以分页的形式逐个打开。
更新
建议经常更新sitemap,方便搜索爬虫爬取频率的发展。经常会产生新的地图内容,这样的网站内容可以更快地被搜索引擎收录抓取,而网站内容也可以尽快被搜索引擎检索到。
多样性
站点地图不仅仅是为了搜索引擎,也是为了方便查看者,所以网站地图应该兼顾搜索引擎和查看者。我们通常为一个 网站 构建三个站点地图。sitemap.html 页面美观、简洁、大方,让浏览器很容易找到目标页面,同时也很开心。XML仔细研究了自己的网站,把重要的页面标记出来,不需要的页面加上NO FOLLOW,更有利于搜索引擎识别。URLLIST.TXT 或 ROBOTS.TXT 如果方便的话,最好自己做。雅虎等搜索引擎比较认可,谷歌也有这个项目。另外,网站地图位置要写在robots文本中,也就是格式。 查看全部
抓取网页生成电子书(
站点地图是一个网站所有链接的容器。你了解吗?)

站点地图是网站所有链接的容器。许多 网站 连接很深,爬虫很难爬取。站点地图可以方便爬虫爬取 网站 页面。通过对网站页面的爬取,可以清楚的了解网站,网站地图一般存放在根目录并命名为sitemap来引导爬虫,添加网站的收录 @>重要内容页面。站点地图是根据网站的结构、框架和内容生成的导航网页文件。站点地图非常适合改善用户体验,它们为网站访问者提供方向并帮助迷路的访问者找到他们想查看的页面。
定义
站点地图是一种可视化工具,指示信息资源的位置和连接,并具有导航功能。关键在于四个方面:信息获取、信息检索、信息表示和信息关联。简而言之,就是将首页的信息按照类别以地图的形式列出,并提供相应的链接,可以为用户提供首页的整体信息,是用户准确查找的快捷入口他们需要的信息。
分类
1、sitemap(sitemap.xml,sitemap.txt) 这类站点地图收录网站的所有链接,一般提交给爬虫爬取。让搜索引擎转到 收录网站 内容。
2、网站导航,主要针对访问网站的用户。对网站连接进行分类,排序后展示在用户面前。
特征
可以烧结
这是站点地图应具有的重要功能。因为对图形的理解比文字更快更准确。这里所说的站点地图的内容虽然是用文字来表达的,但它是以地图的形式出现的,并且列出了每一栏的相关类别和子栏目。他们之间的关系表达得很清楚。它具有很强的能见度。它是用户查找所需信息资源的便捷方式。
加速
此功能在站点地图上尤为明显。网页内容清晰地显示在“地图”上,用户对首页信息一目了然。在站点地图上,还为显示的类别提供了超链接,用户可以点击超链接直接进入他们需要的栏目。这使用户能够准确、快速地找到他们需要的信息。
同步更新
站点地图是使用首页信息的辅助工具,它必须是随着首页信息内容的变化而建立的站点地图。随着首页信息的变化,它会及时调整自己的内容,保持与首页信息的高度一致性。
构建技巧
重要页面
如果站点地图收录太多链接,人们会在浏览时迷路。因此,如果 网站 页的总数超过 100,则需要选择最重要的页。推荐选择以下页面放在网站地图上:产品分类页面;主要产品页面;常见问题和帮助页面;页面被转换;访问量最高的 10 个页面;如果有现场搜索引擎,请从搜索引擎中选择点击次数最多的页面。
地图布局
站点地图布局必须简洁,所有链接均为标准HTML文本,并收录尽可能多的关键字,站点地图中不要使用图片制作链接,以免爬虫爬取。确保对链接使用标准 HTML 文本,包括尽可能多的目标关键字。例如,标题“我们的产品”可以替换为“无害除草剂、杀虫剂和杀菌剂”。
顾客习惯
用户通常希望每个页面底部都有指向站点地图的链接,以利用这种习惯。如果 网站 有搜索栏,请在搜索栏附近添加指向 网站 地图的链接,甚至将指向站点地图的链接放置在搜索结果页面上的固定位置。
将站点地图写入 robots.txt
引擎爬虫进来爬取网页时,会先检查robots.txt。如果先将sitemap写入robots.txt,效率会大大提高,从而获得搜索引擎的青睐。
产生
网上生成sitemap的方式有很多种,比如在线生成、软件生成等。Sitemap地图可以提交给各大搜索引擎,让搜索引擎更好的在网站页面上执行收录 ,而且我们还可以通过robots.txt告诉搜索引擎地图的位置。将准备好的网站映射上传到网站根目录。最重要的是将网站地图链接地址添加到robots文件中,使网站地图在页面上方便蜘蛛抓取位置,一般将网站地图放在页眉和页脚。
1、网站普通html格式的地图
其目的是帮助用户了解整个网站。Html格式的网站map是根据网站的结构特点制定的,将网站的功能结构和服务内容依次列出。通常,网站 主页具有指向该格式的 网站 地图的链接。
2、XML 站点地图通常称为站点地图(大写 S)
简单地说,站点地图是 网站 上的链接列表。创建站点地图并将其提交给搜索引擎可以让网站 的内容完全收录,包括那些隐藏得更深的页面。这是网站与搜索引擎交谈的好方法。
3、搜索引擎识别的地图
因为各个搜索引擎主要对地图格式的识别不同,所以推荐使用以下格式:
百度:推荐使用网站的Html格式地图
Google:推荐网站XML 格式的地图
雅虎:网站推荐txt格式的地图
重要性
1、搜索引擎让爬虫每天爬网爬取页面。站点地图的作用是为爬虫构建一个方便快捷的爬取通道,因为网站页面是一层一层的链接,可能会有死链接。如果没有站点地图,由于死链接,爬虫无法在页面上爬取,因此它无法收录 那些损坏的链接。
2、sitemaps的存在不仅仅是为了满足搜索引擎爬虫,也是为了方便网站访问者浏览网站,尤其是门户类型网站,由于信息量大许多访问者通过站点地图找到他们需要的信息页面,这也可以改善用户体验。
3、Sitemap 可以增加链接页面的权重,因为sitemap 是指向其他页面的链接。此时,站点地图会向页面添加导入链接。我们都知道导入链接的增加会影响页面的权重,所以增加页面的权重,页面权重的增加也会增加页面的收录率。
注意事项
真实有效
站点地图的主要目的是方便搜索和抓取。如果地图有死链接或者断链,会影响网站网站在搜索引擎中的权重,所以要仔细检查是否有错误的链接地址,检查网站的链接是否正确提交前通过站长工具有效。
简化
站点地图中不应有重复链接,应使用标准 W3C 格式的地图文件。布局应简洁明了。如果地图是内容地图,每个页面收录的内容链接不要超过100个,并且应该以分页的形式逐个打开。
更新
建议经常更新sitemap,方便搜索爬虫爬取频率的发展。经常会产生新的地图内容,这样的网站内容可以更快地被搜索引擎收录抓取,而网站内容也可以尽快被搜索引擎检索到。
多样性
站点地图不仅仅是为了搜索引擎,也是为了方便查看者,所以网站地图应该兼顾搜索引擎和查看者。我们通常为一个 网站 构建三个站点地图。sitemap.html 页面美观、简洁、大方,让浏览器很容易找到目标页面,同时也很开心。XML仔细研究了自己的网站,把重要的页面标记出来,不需要的页面加上NO FOLLOW,更有利于搜索引擎识别。URLLIST.TXT 或 ROBOTS.TXT 如果方便的话,最好自己做。雅虎等搜索引擎比较认可,谷歌也有这个项目。另外,网站地图位置要写在robots文本中,也就是格式。
抓取网页生成电子书(目录各种尝试生成PDF提取文章内容选择文|李晓飞总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2022-02-14 18:04
目录各种尝试生成PDF提取文章内容选择优化总结参考正文 | 李小飞来源:Python技术“ID:pythonall”爬虫程序大家一定不陌生,只要写一个就可以获取网页上的信息,甚至可以通过请求自...
目录选择最佳摘要参考
正文 | 李晓飞
来源:python科技《ID:pythonall》
爬虫程序想必大家都不陌生。您可以通过编写一个获取网页信息,甚至可以通过请求自动生成 Python 脚本 [1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但问题是没有限制爬取范围,也就是说没有清晰的页面结构。
对于一个页面,除了核心的文章内容外,还有页眉、拖尾、左右列表栏等。有的页框使用div布局,有的使用table,即使使用了div,样式和网站 的布局不同。
但问题必须解决。我想,既然各种网页的核心内容都是搜索引擎抓取的,那我们应该也能做到,拿起Python,说到做到!
各种尝试
如何解决?
生成 PDF
我开始想一个比较棘手的方法,就是使用一个工具(wkhtmltopdf[2])从目标网页生成一个PDF文件。
好处是不用关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源代码级别搜索 PDF,但生成 PDF 有很多缺点:
它消耗大量计算资源,效率低,错误率高,体积太大。
数万条数据已经超过200GB。如果数据量增加,只有存储将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构并且可读性降低。更糟糕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。就像搜索引擎学习一样,就是想办法找出页面的核心内容。
我们知道,一般情况下,页面上的核心内容(比如文章部分)是比较集中的,我们可以从这个地方入手分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里我只截取了提取 文章 部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试了几页确实不错。
但是,在大量提取过程中,发现很多页面无法提取数据。仔细观察会发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,p多是首选,在它的基础上看到的div少。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(s编程客栈el)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
即发现的文章体是不稳定的,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,因此需要重新设计算法。
我发现文字集中的地方往往是文章的主体,而之前的方法没有考虑到这一点,只是机械地找了最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近的地方应该越有可能是文章主题,也就是说计算是离p越近的节点权重应该越大,离p越远的节点有一个很多 p 及时,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度的原理,即越靠近中心,密度就越高,远离中心的地方密度呈指数下降,这样就可以把密度中心筛掉。
50%的斜率是怎么来的?
事实上,它是通过实验确定的。一开始我设置为90%,但是body节点最后总是最好的,因为body收录了所有的文本内容。
经过反复试验,确定 50% 是一个不错的值,如果不适合您的应用,请进行调整。
总结
在描述了我如何选择 文章 主题之后,我发现它实际上并不是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要你理解了处理问题的常规方式,处理日常编程就足够了。当遇到不确定的问题,没有办法提取简单的模型时,常规思维显然是不够的。
因此,我们通常应该看一些数学强,解决不确定问题的方法,以提高我们的编程适应性,扩大我们的技能范围。
希望这篇短文能对你有所启发,欢迎在留言区交流讨论,对比你的心!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮擦:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246 查看全部
抓取网页生成电子书(目录各种尝试生成PDF提取文章内容选择文|李晓飞总结)
目录各种尝试生成PDF提取文章内容选择优化总结参考正文 | 李小飞来源:Python技术“ID:pythonall”爬虫程序大家一定不陌生,只要写一个就可以获取网页上的信息,甚至可以通过请求自...
目录选择最佳摘要参考

正文 | 李晓飞
来源:python科技《ID:pythonall》
爬虫程序想必大家都不陌生。您可以通过编写一个获取网页信息,甚至可以通过请求自动生成 Python 脚本 [1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但问题是没有限制爬取范围,也就是说没有清晰的页面结构。
对于一个页面,除了核心的文章内容外,还有页眉、拖尾、左右列表栏等。有的页框使用div布局,有的使用table,即使使用了div,样式和网站 的布局不同。
但问题必须解决。我想,既然各种网页的核心内容都是搜索引擎抓取的,那我们应该也能做到,拿起Python,说到做到!
各种尝试
如何解决?
生成 PDF
我开始想一个比较棘手的方法,就是使用一个工具(wkhtmltopdf[2])从目标网页生成一个PDF文件。
好处是不用关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源代码级别搜索 PDF,但生成 PDF 有很多缺点:
它消耗大量计算资源,效率低,错误率高,体积太大。
数万条数据已经超过200GB。如果数据量增加,只有存储将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构并且可读性降低。更糟糕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。就像搜索引擎学习一样,就是想办法找出页面的核心内容。
我们知道,一般情况下,页面上的核心内容(比如文章部分)是比较集中的,我们可以从这个地方入手分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里我只截取了提取 文章 部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试了几页确实不错。
但是,在大量提取过程中,发现很多页面无法提取数据。仔细观察会发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,p多是首选,在它的基础上看到的div少。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(s编程客栈el)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
即发现的文章体是不稳定的,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,因此需要重新设计算法。
我发现文字集中的地方往往是文章的主体,而之前的方法没有考虑到这一点,只是机械地找了最大的p。
还有一点,网页结构是一棵DOM树[6]

那么离p标签越近的地方应该越有可能是文章主题,也就是说计算是离p越近的节点权重应该越大,离p越远的节点有一个很多 p 及时,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度的原理,即越靠近中心,密度就越高,远离中心的地方密度呈指数下降,这样就可以把密度中心筛掉。
50%的斜率是怎么来的?
事实上,它是通过实验确定的。一开始我设置为90%,但是body节点最后总是最好的,因为body收录了所有的文本内容。
经过反复试验,确定 50% 是一个不错的值,如果不适合您的应用,请进行调整。
总结
在描述了我如何选择 文章 主题之后,我发现它实际上并不是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要你理解了处理问题的常规方式,处理日常编程就足够了。当遇到不确定的问题,没有办法提取简单的模型时,常规思维显然是不够的。
因此,我们通常应该看一些数学强,解决不确定问题的方法,以提高我们的编程适应性,扩大我们的技能范围。
希望这篇短文能对你有所启发,欢迎在留言区交流讨论,对比你的心!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮擦:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-13 23:03
)
无意中发现了一个可以免费下载电子书的网站,一下子勾起了我的采集瘾,恨不得下载这些书,就在不久前,请求的作者kennethreitz发布了一个新的图书馆请求-html ,不仅可以请求网页,还可以解析 HTML 文档。事不宜迟,让我们开始吧。
安装
安装很简单,只需执行:
pip install requests-html
而已。
分析页面结构
通过检查浏览器中的元素,您可以发现这本电子书 网站 是使用 WordPress 构建的。主页列表元素非常简单和规则。
所以我们可以通过查找 .entry-title > a 得到所有图书详情页的链接,然后我们到详情页找到下载链接,如下图
可以发现.download-links > a中的链接就是该书的下载链接。回到列表页面,可以发现站点有700多个页面,所以我们可以循环列表获取所有的下载链接。
Requests-html 快速指南
发送 GET 请求:
Requests-html 的方便之处在于它解析 html 就像使用 jQuery 一样容易,例如:
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
查看全部
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图)
)
无意中发现了一个可以免费下载电子书的网站,一下子勾起了我的采集瘾,恨不得下载这些书,就在不久前,请求的作者kennethreitz发布了一个新的图书馆请求-html ,不仅可以请求网页,还可以解析 HTML 文档。事不宜迟,让我们开始吧。
安装
安装很简单,只需执行:
pip install requests-html
而已。
分析页面结构
通过检查浏览器中的元素,您可以发现这本电子书 网站 是使用 WordPress 构建的。主页列表元素非常简单和规则。
所以我们可以通过查找 .entry-title > a 得到所有图书详情页的链接,然后我们到详情页找到下载链接,如下图
可以发现.download-links > a中的链接就是该书的下载链接。回到列表页面,可以发现站点有700多个页面,所以我们可以循环列表获取所有的下载链接。
Requests-html 快速指南
发送 GET 请求:
Requests-html 的方便之处在于它解析 html 就像使用 jQuery 一样容易,例如:
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-13 22:30
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin的编程课堂)
)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
爬取列文章地址列表
抓取每个文章的详细内容
导出 PDF
1. 爬取列表
如何分析网页上的请求在前面的 文章 中有所描述。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
而 True: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
对于数据中的文章:
# 如果 j['paging']['is_end'] 保存 id 和 title(省略):
中断 url = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = '' + idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_='Post-RichText').prettify()
# 处理内容(略)
使用 open(file_name, 'w') 作为 f: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin的编程课堂)

)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:


之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
爬取列文章地址列表
抓取每个文章的详细内容
导出 PDF
1. 爬取列表
如何分析网页上的请求在前面的 文章 中有所描述。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:

观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。

使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
而 True: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
对于数据中的文章:
# 如果 j['paging']['is_end'] 保存 id 和 title(省略):
中断 url = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)

2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = '' + idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_='Post-RichText').prettify()
# 处理内容(略)
使用 open(file_name, 'w') 作为 f: f.write(content)

至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')

这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
抓取网页生成电子书(上一个迭代任务是将一个html网页转换成pdf的知识点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-13 16:06
最后一个迭代任务是将 html 网页转换为 pdf。 pdf转现有系统的插件是TCPDF,但是这个插件太老了,支持的css样式和html标签太少。在尝试用 TCPDF 写了两天后,我放弃了。
然后改成wkhtmltopdf,不得不说wkhtmltopdf终于完美的把网页转换成pdf了。接下来写一下本次生成pdf用到的知识点。
参考文献文章:
1、封面:
封面可以定制。我写了另一个html页面作为这个pdf的封面,然后用命令添加了。
比如:cover.html就是我写的封面,效果如下:
然后生成pdf封面的命令是这个:wkhtmltopdf cover http://api-dev.inboyu.com/pdf- ... 04312
其中:http://api-dev.inboyu.com/pdf- ... 04312
是这个cover.html访问路径。
accessToken 是返回页面上标题和申请人所需要的参数。
2、页眉、页脚
页眉和页脚也可以添加一个html作为封面。不过我没试过,只是用了wkhtmltopdf提供的命令。
wkhtmltopdf --header-left "XXX有限公司" --header-right "[date] [time] 机密文件请勿外传" --header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
3、目录
本次迭代的亮点是这个目录,也被wkhtmltopdf代替了,因为目录TCPDF不知道怎么实现(或者根本无法实现)。
我们最终生成的目录如下所示:
是不是比带有pdf的侧边栏书签好看多了?哈哈
这个目录是如何实现的?
这里需要注意的是,新的wkhtmltopd版本不支持。我使用 wkhtmltopdf 0.12.3.
然后根据网页中的H1、H2...标签确定目录。所以网页应该已经准备好了。
接下来就是一行命令:
wkhtmltopdf toc
总而言之,我必须从网页生成带有自定义封面、目录、页眉、页脚的 pdf 的所有命令如下:
wkhtmltopdf --header-left "XXX科技有限公司" --header-right "[date] [time] 机密文件请勿外传"
--header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
cover http://api-dev.inboyu.com/pdf- ... 04312
toc --toc-header-text "目录" https://api-test.inboyu.com/pd ... 04312 D:\\1.pdf
备注:
1、--toc-header-text "目录" 将目录变成中文,不然是contents。
2、http://api-test.inboyu.com/pdf ... 04312 是要转换成pdf的网页。
3、D:\\1.pdf 是存放pdf的地址,因为在本地调试,所以我存在了D盘目录下。
就这么简单,转换后的pdf和网页差不多。
另外:
1、页面布局主要是pdf中表格布局可能被截断的问题,解决方法:
tr{page-break-inside: avoid;}
2、使用page-break-before:left;使以下三个都在生成的pdf中打开一个新页面。
3、我的pdf里也加了水印,好像wkhtmltopdf没有提供水印的方法(我还是找不到,如果有人用wkhtmltopdf提供的方法,希望大家告诉我,谢谢!)
我的做法是剪一张带水印的图片,如下:
然后将它添加到这个网页的最外层父元素作为背景,然后重复背景,例如:
//网页内容
//网页内容
//网页内容
终于实现了水印的效果。需要提醒的是,在做水印的时候,我们网页的效果和pdf的效果可能会有差距。生成pdf后,水印的间距会变差。这时候可以调整你的网页窗口大小,让你的网页收紧生成的pdf,然后调整水印,让最终生成的pdf准确无误,包括上面提到的封面。偏差)。
我的pdf水印效果如下:
4、如果有图表,如果看到别人说加动画:false;禁止动画,可以显示,否则生成的pdf中的图表会是空白的。
或者(我使用的方法):
1、先用 结合echarts生成一个图表。
2、然后调用echarts的getDataURL方法生成一个图片地址放到
let echartKLine = echarts.init($('.js-kline'));
echartKLine.setOption(option);
window.onresize = echartKLine.resize;
$("#js-img").attr("src",echartKLine.getDataURL())
最后隐藏 js-kline,显示 js-img。
相当于把图表变成了和这个图表长得一摸一样的图片。
至此,基本上所有的问题都涉及到了。生成的 pdf 与网页几乎完全相同。 查看全部
抓取网页生成电子书(上一个迭代任务是将一个html网页转换成pdf的知识点)
最后一个迭代任务是将 html 网页转换为 pdf。 pdf转现有系统的插件是TCPDF,但是这个插件太老了,支持的css样式和html标签太少。在尝试用 TCPDF 写了两天后,我放弃了。
然后改成wkhtmltopdf,不得不说wkhtmltopdf终于完美的把网页转换成pdf了。接下来写一下本次生成pdf用到的知识点。
参考文献文章:
1、封面:
封面可以定制。我写了另一个html页面作为这个pdf的封面,然后用命令添加了。
比如:cover.html就是我写的封面,效果如下:

然后生成pdf封面的命令是这个:wkhtmltopdf cover http://api-dev.inboyu.com/pdf- ... 04312
其中:http://api-dev.inboyu.com/pdf- ... 04312
是这个cover.html访问路径。
accessToken 是返回页面上标题和申请人所需要的参数。
2、页眉、页脚
页眉和页脚也可以添加一个html作为封面。不过我没试过,只是用了wkhtmltopdf提供的命令。
wkhtmltopdf --header-left "XXX有限公司" --header-right "[date] [time] 机密文件请勿外传" --header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
3、目录
本次迭代的亮点是这个目录,也被wkhtmltopdf代替了,因为目录TCPDF不知道怎么实现(或者根本无法实现)。
我们最终生成的目录如下所示:

是不是比带有pdf的侧边栏书签好看多了?哈哈
这个目录是如何实现的?
这里需要注意的是,新的wkhtmltopd版本不支持。我使用 wkhtmltopdf 0.12.3.
然后根据网页中的H1、H2...标签确定目录。所以网页应该已经准备好了。
接下来就是一行命令:
wkhtmltopdf toc
总而言之,我必须从网页生成带有自定义封面、目录、页眉、页脚的 pdf 的所有命令如下:
wkhtmltopdf --header-left "XXX科技有限公司" --header-right "[date] [time] 机密文件请勿外传"
--header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
cover http://api-dev.inboyu.com/pdf- ... 04312
toc --toc-header-text "目录" https://api-test.inboyu.com/pd ... 04312 D:\\1.pdf
备注:
1、--toc-header-text "目录" 将目录变成中文,不然是contents。
2、http://api-test.inboyu.com/pdf ... 04312 是要转换成pdf的网页。
3、D:\\1.pdf 是存放pdf的地址,因为在本地调试,所以我存在了D盘目录下。
就这么简单,转换后的pdf和网页差不多。
另外:
1、页面布局主要是pdf中表格布局可能被截断的问题,解决方法:
tr{page-break-inside: avoid;}
2、使用page-break-before:left;使以下三个都在生成的pdf中打开一个新页面。
3、我的pdf里也加了水印,好像wkhtmltopdf没有提供水印的方法(我还是找不到,如果有人用wkhtmltopdf提供的方法,希望大家告诉我,谢谢!)
我的做法是剪一张带水印的图片,如下:

然后将它添加到这个网页的最外层父元素作为背景,然后重复背景,例如:
//网页内容
//网页内容
//网页内容
终于实现了水印的效果。需要提醒的是,在做水印的时候,我们网页的效果和pdf的效果可能会有差距。生成pdf后,水印的间距会变差。这时候可以调整你的网页窗口大小,让你的网页收紧生成的pdf,然后调整水印,让最终生成的pdf准确无误,包括上面提到的封面。偏差)。
我的pdf水印效果如下:

4、如果有图表,如果看到别人说加动画:false;禁止动画,可以显示,否则生成的pdf中的图表会是空白的。
或者(我使用的方法):
1、先用 结合echarts生成一个图表。
2、然后调用echarts的getDataURL方法生成一个图片地址放到
let echartKLine = echarts.init($('.js-kline'));
echartKLine.setOption(option);
window.onresize = echartKLine.resize;
$("#js-img").attr("src",echartKLine.getDataURL())
最后隐藏 js-kline,显示 js-img。
相当于把图表变成了和这个图表长得一摸一样的图片。
至此,基本上所有的问题都涉及到了。生成的 pdf 与网页几乎完全相同。
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-13 02:17
看来写爬虫并不比使用 Python 更合适。Python社区提供的爬虫工具琳琅满目,你可以分分钟写一个爬虫,里面有各种可以直接使用的库。今天,我正在考虑写一个爬虫。,爬取廖雪峰的Python教程,制作成PDF电子书,供大家离线阅读。
在开始写爬虫之前,我们先分析一下网站1的页面结构。页面左侧是教程的目录大纲,每个URL对应右侧一个文章,右上角是文章的标题,中间是正文部分文章的,body的内容是我们关注的重点,我们要爬取的数据是所有网页的body部分,底部是用户的评论区,评论区对我们来说很重要它没有用,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。request和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个穿梭机,我们可以快速工作,不需要像scrapy这样的爬虫框架。这有点像用小程序杀鸡。另外,既然html文件转换成pdf,就必须有相应的库支持,wkhtmltopdf是一个很好的工具,可以用于多平台html到pdf的转换,pdfkit是wkhtmltopdf的Python包。首先安装以下依赖项,
然后安装 wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台,直接从wkhtmltopdf官网下载稳定版2并安装。安装完成后,将程序的执行路径添加到系统环境的$PATH变量中。否则,如果pdfkit找不到wkhtmltopdf,就会出现“No wkhtmltopdf executable found”的错误。Ubuntu和CentOS可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编码了,不过最好在写代码之前整理一下思路。该程序的目的是将所有URL对应的html正文部分保存在本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将一个URL对应的html body保存到本地,然后找到所有的URL,进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到文字对应的div标签:
, div 是页面的正文内容。在本地使用请求加载整个页面后,您可以使用 beautifulsoup 操作 HTML dom 元素以提取正文内容。
具体实现代码如下:使用soup.find_all函数找到body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析页面左侧的所有URL。同样的方法,找到左侧的菜单选项卡 查看全部
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
看来写爬虫并不比使用 Python 更合适。Python社区提供的爬虫工具琳琅满目,你可以分分钟写一个爬虫,里面有各种可以直接使用的库。今天,我正在考虑写一个爬虫。,爬取廖雪峰的Python教程,制作成PDF电子书,供大家离线阅读。
在开始写爬虫之前,我们先分析一下网站1的页面结构。页面左侧是教程的目录大纲,每个URL对应右侧一个文章,右上角是文章的标题,中间是正文部分文章的,body的内容是我们关注的重点,我们要爬取的数据是所有网页的body部分,底部是用户的评论区,评论区对我们来说很重要它没有用,所以可以忽略。

工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。request和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个穿梭机,我们可以快速工作,不需要像scrapy这样的爬虫框架。这有点像用小程序杀鸡。另外,既然html文件转换成pdf,就必须有相应的库支持,wkhtmltopdf是一个很好的工具,可以用于多平台html到pdf的转换,pdfkit是wkhtmltopdf的Python包。首先安装以下依赖项,
然后安装 wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台,直接从wkhtmltopdf官网下载稳定版2并安装。安装完成后,将程序的执行路径添加到系统环境的$PATH变量中。否则,如果pdfkit找不到wkhtmltopdf,就会出现“No wkhtmltopdf executable found”的错误。Ubuntu和CentOS可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编码了,不过最好在写代码之前整理一下思路。该程序的目的是将所有URL对应的html正文部分保存在本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将一个URL对应的html body保存到本地,然后找到所有的URL,进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到文字对应的div标签:
, div 是页面的正文内容。在本地使用请求加载整个页面后,您可以使用 beautifulsoup 操作 HTML dom 元素以提取正文内容。

具体实现代码如下:使用soup.find_all函数找到body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析页面左侧的所有URL。同样的方法,找到左侧的菜单选项卡
抓取网页生成电子书(一款专为PDF文件打造的页面提取工具介绍!免费下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-12 12:24
)
PDF Page Extractor 是一款专为 PDF 文件设计的页面提取工具。界面直观清晰,功能一目了然,操作简单易用。可以将PDF文件的一页或多页批量提取到一个新文档中。这也很简单。您只需添加文件、设置提取页面、保存路径等信息,即可快速从单个或多个PDF页面中提取指定页面。并且软件支持提取单页、连续多页、提取最后一页、自定义页等多种提取类型。它可以在没有任何其他软件支持的情况下从 PDF 中提取页面。它可以提取单页,或者连续的多页,或者不连续的多页,并且可以添加密码保护和文档限制。如果源文档受密码保护或限制,请在提取页面之前对其进行解密。您还可以添加水印以有效保护您的文档。欢迎有需要的用户免费下载体验!
功能介绍1、快速方便地提取PDF文件中的一页或多页,并保存为新文档。
2、可以连续提取多页,输入起始页码和结束页码即可。
3、无需任何其他软件支持即可实现PDF提取页面。
4、可以提取单个页面,或多个连续页面,或多个不连续页面。
5、可以添加密码保护和文档限制。
6、您可以添加水印以有效保护您的文档。软件功能1、同时处理单个 PDF 或整个目录
2、在输出文件中添加个性化水印
3、加密生成的PDF文件并设置内容权限
4、删除源文件上解压出来的页面,重新保存
5、提取单页,输入要提取的页码
6、提取多个连续页面,输入起始页码和结束页码
7、最后提取,请输入最后提取多少页
8、自定义页面,例如:1、3、5-8、10-20
9、在提取页面前,输入提取页面前半部分的百分比。使用方法1、安装后打开PDF解压页面软件,将文件或文件拖放到软件或点击添加文件或添加文件夹,右键删除或打开添加的文件;
2、提取页面设置;
3、保存设置;
4、点击【提取页面】按钮;
5、提取完成。
6、需要保密处理的可以点击“设置”按钮添加水印和密码
查看全部
抓取网页生成电子书(一款专为PDF文件打造的页面提取工具介绍!免费下载
)
PDF Page Extractor 是一款专为 PDF 文件设计的页面提取工具。界面直观清晰,功能一目了然,操作简单易用。可以将PDF文件的一页或多页批量提取到一个新文档中。这也很简单。您只需添加文件、设置提取页面、保存路径等信息,即可快速从单个或多个PDF页面中提取指定页面。并且软件支持提取单页、连续多页、提取最后一页、自定义页等多种提取类型。它可以在没有任何其他软件支持的情况下从 PDF 中提取页面。它可以提取单页,或者连续的多页,或者不连续的多页,并且可以添加密码保护和文档限制。如果源文档受密码保护或限制,请在提取页面之前对其进行解密。您还可以添加水印以有效保护您的文档。欢迎有需要的用户免费下载体验!

功能介绍1、快速方便地提取PDF文件中的一页或多页,并保存为新文档。
2、可以连续提取多页,输入起始页码和结束页码即可。
3、无需任何其他软件支持即可实现PDF提取页面。
4、可以提取单个页面,或多个连续页面,或多个不连续页面。
5、可以添加密码保护和文档限制。
6、您可以添加水印以有效保护您的文档。软件功能1、同时处理单个 PDF 或整个目录
2、在输出文件中添加个性化水印
3、加密生成的PDF文件并设置内容权限
4、删除源文件上解压出来的页面,重新保存
5、提取单页,输入要提取的页码
6、提取多个连续页面,输入起始页码和结束页码
7、最后提取,请输入最后提取多少页
8、自定义页面,例如:1、3、5-8、10-20
9、在提取页面前,输入提取页面前半部分的百分比。使用方法1、安装后打开PDF解压页面软件,将文件或文件拖放到软件或点击添加文件或添加文件夹,右键删除或打开添加的文件;

2、提取页面设置;

3、保存设置;

4、点击【提取页面】按钮;

5、提取完成。
6、需要保密处理的可以点击“设置”按钮添加水印和密码

抓取网页生成电子书(一个开源网页拖拽自动生成的JavaScript库,你可以以简单拖拽的方式生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-23 16:18
VvvebJs 是一个通过拖放网页自动生成的开源 JavaScript 库。您可以通过简单的拖放来生成您需要的网页样式。内置jquery和Bootstrap,可以拖拽相关组件构建网页,非常方便。并且可以实时修改代码,功能丰富,使用方便,界面友好,特别适合一些注重展示的网页设计,需要的朋友不要错过!
在线演示:
相关功能
1、组件和块/片段拖放;
2、撤消/重做操作;
3、一个或两个面板接口;
4、为文件管理器和组件层次导航添加新页面;
5、实时代码编辑器;
6、 使用示例 php 脚本上传图片;
7、页面下载或导出html或在服务器上保存页面收录示例PHP脚本;
8、组件/块列表搜索;
9、Bootstrap 4 组件和其他组件。
该编辑器默认附带 Bootstrap 4 和 Widgets 组件,可以使用任何类型的组件和输入进行扩展。
如何使用
要初始化编辑器,请调用 Vvveb.Builder.init。第一个参数是要加载进行编辑的 URL,它必须在同一个子域上进行编辑。第二个参数是页面加载时调用的函数,默认调用编辑器 Gui.init();
结构体
Component Group是组件的集合,例如Bootstrap 4 group由Button和Grid等组件组成,该对象仅用于对编辑器左侧面板中的组件进行分组。比如Widgets组件组只有video和map两个组件,定义如下
Vvveb.ComponentsGroup['Widgets'] = ["widgets/googlemaps", "widgets/video"];
Component是一个对象,它提供了可以放置在画布上的html以及选择组件时可以编辑的属性,比如Video Component,一个带有Url和Target属性的html链接组件定义为:
Vvveb.Components.extend("_base", "html/link", {
nodes: ["a"],
name: "Link",
properties: [{
name: "Url",
key: "href",
htmlAttr: "href",
inputtype: LinkInput
}, {
name: "Target",
key: "target",
htmlAttr: "target",
inputtype: TextInput
}]
});
使用Component属性集合中的Input对象来编辑文本输入、选择、颜色、网格行等属性。例如TextInput扩展了Input对象,定义为:
var TextInput = $.extend({}, Input, {
events: {
"keyup": ['onChange', 'input'],
},
setValue: function(value) {
$('input', this.element).val(value);
},
init: function(data) {
return this.render("textinput", data);
},
}
);
输入还需要在编辑器 html 中定义(在 editor.html 中)。以上是使用浏览器翻译工具简单翻译官网文档。可能有一些不准确的地方。有兴趣的小伙伴可以直接查看相关文档!
设计界面预览
总结
VvvebJs是一款非常强大的网页可视化生成构建工具,让不懂网页设计的朋友也可以通过拖拽的方式生成美观大方的网页,让设计网页就像设计图片一样。VvvebJs 特别适合显示网页。您甚至可以在没有代码的情况下完成复杂的网页设计。总的来说,VvvebJs 是一个值得尝试的工具! 查看全部
抓取网页生成电子书(一个开源网页拖拽自动生成的JavaScript库,你可以以简单拖拽的方式生成)
VvvebJs 是一个通过拖放网页自动生成的开源 JavaScript 库。您可以通过简单的拖放来生成您需要的网页样式。内置jquery和Bootstrap,可以拖拽相关组件构建网页,非常方便。并且可以实时修改代码,功能丰富,使用方便,界面友好,特别适合一些注重展示的网页设计,需要的朋友不要错过!
在线演示:
相关功能
1、组件和块/片段拖放;
2、撤消/重做操作;
3、一个或两个面板接口;
4、为文件管理器和组件层次导航添加新页面;
5、实时代码编辑器;
6、 使用示例 php 脚本上传图片;
7、页面下载或导出html或在服务器上保存页面收录示例PHP脚本;
8、组件/块列表搜索;
9、Bootstrap 4 组件和其他组件。
该编辑器默认附带 Bootstrap 4 和 Widgets 组件,可以使用任何类型的组件和输入进行扩展。
如何使用
要初始化编辑器,请调用 Vvveb.Builder.init。第一个参数是要加载进行编辑的 URL,它必须在同一个子域上进行编辑。第二个参数是页面加载时调用的函数,默认调用编辑器 Gui.init();
结构体
Component Group是组件的集合,例如Bootstrap 4 group由Button和Grid等组件组成,该对象仅用于对编辑器左侧面板中的组件进行分组。比如Widgets组件组只有video和map两个组件,定义如下
Vvveb.ComponentsGroup['Widgets'] = ["widgets/googlemaps", "widgets/video"];
Component是一个对象,它提供了可以放置在画布上的html以及选择组件时可以编辑的属性,比如Video Component,一个带有Url和Target属性的html链接组件定义为:
Vvveb.Components.extend("_base", "html/link", {
nodes: ["a"],
name: "Link",
properties: [{
name: "Url",
key: "href",
htmlAttr: "href",
inputtype: LinkInput
}, {
name: "Target",
key: "target",
htmlAttr: "target",
inputtype: TextInput
}]
});
使用Component属性集合中的Input对象来编辑文本输入、选择、颜色、网格行等属性。例如TextInput扩展了Input对象,定义为:
var TextInput = $.extend({}, Input, {
events: {
"keyup": ['onChange', 'input'],
},
setValue: function(value) {
$('input', this.element).val(value);
},
init: function(data) {
return this.render("textinput", data);
},
}
);
输入还需要在编辑器 html 中定义(在 editor.html 中)。以上是使用浏览器翻译工具简单翻译官网文档。可能有一些不准确的地方。有兴趣的小伙伴可以直接查看相关文档!
设计界面预览
总结
VvvebJs是一款非常强大的网页可视化生成构建工具,让不懂网页设计的朋友也可以通过拖拽的方式生成美观大方的网页,让设计网页就像设计图片一样。VvvebJs 特别适合显示网页。您甚至可以在没有代码的情况下完成复杂的网页设计。总的来说,VvvebJs 是一个值得尝试的工具!
抓取网页生成电子书(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
网站优化 • 优采云 发表了文章 • 0 个评论 • 550 次浏览 • 2022-02-23 16:15
制作自己的学习手册并永久保存互联网信息
* 较早价格标签的合约,文字已被删除
关于文章和信息组织,一个常见的需求是保存某个主题的多篇文章文章,或者一个博客或教程的所有网页,做成类似出版物的电子出版物。可以在手机、平板电脑上阅读或永久保存的书籍。实现此要求的一种方法是使用 Chrome 插件一键将目标网页保存为 ePub 文件。
ePub 的插件大约有十种。经过大量的测试,我最终选择了dotEPUB、WebToWpub、EpubPress、Save as eBook这四个各有侧重、效果更好的插件。本文将分析它们的特点,以帮助您确定哪一种最能满足您的需求。
四个插件的用法和特点
dotEPUB : 将当前窗口的网页另存为 ePub1. 速度:更快2. 水印:开头和结尾的水印3. 图片支持:稍差4. 排版:更好排版
dotEPUB是操作最简单、功能最单一的一种。只需点击插件栏中的 dotEPUB 图标,即可自动将当前网页下载为 ePub 文件。但由于只保存当前网页,因此适用范围较窄。
在这里,打开一个知乎栏目“我们在谈论英语学习时在谈论什么”作为素材尝试抓取,用多看App打开,阅读效果如下。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接为章节并生成为ePub1.速度:更快,有进度条2.水印:无水印3.图片支持:有图片4.排版:排版比较通用
这是我经常使用的插件。它可以爬取当前网页中收录的链接的所有内容。适用于爬取知乎列或博客等网站以列表形式展开内容。网页中的每个链接都会生成一个特定的Epub章节,章节标题就是网页标题。
点击插件,确认开始转换后,进入插件主界面。在主界面中,WebToEpub 允许用户编辑 ePub 的标题、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等操作,还可以反向选择网页列表。此外,您可以通过将图像地址粘贴到 URL 框中来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有的文章,在使用插件之前需要滚动到页面底部完全加载列表。
EpubPress:将当前打开的所有标签捕获为ePub1.速度:正常速度,带有进度条2.水印:无水印3.图像支持:在某些情况下捕获图像会失败< @4. 排版:更好的排版
这是另一个常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到电子邮件地址,可根据需要在右上角的设置中选择。
如果爬取大量标签页,等待时间会明显变长。另请注意,在实际测试中可能无法保存超过 20 个选项卡。
另存为电子书:选择打开的网页并保存为 ePub1. 速度:更快2. 水印:无水印3. 图片支持:带图片4. 排版:更好排版
另存为 eBook 与 EpubPress 类似,都将打开的选项卡保存为 ePub 文件中的章节。但要保存为电子书,需要在浏览网页时点击要保存的网页插件栏中的图标,选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件的标题和调整章节的顺序。
四种使用场景
总结一下四个插件的适用场景,这里简单总结一下情况:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 和 Read Later 等工具之外的另一个想法。对于严肃或系统的内容,制作一本ePub电子书,三两下进行主题阅读会更加连贯,思考可以逐步深化主题。这是电子书和印象笔记以及后来阅读的区别。观点。因此,对于系统学习来说,ePub电子书无疑是一个不错的选择。
回到Chrome插件的话题,一键生成ePub文件的插件普遍的缺点是通过插件制作的电子书不是纯图文,还有一些不相关的内容,如网站中的超链接或评论@> 也可能被 网站 阻止。@收录进入电子书,导致转换效果不佳。文章只提到了目前水平不错的四种ePub转换插件,各有各的不足。
您可以根据个人需求组合两个或多个插件完成ePub转换。 查看全部
抓取网页生成电子书(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
制作自己的学习手册并永久保存互联网信息
* 较早价格标签的合约,文字已被删除
关于文章和信息组织,一个常见的需求是保存某个主题的多篇文章文章,或者一个博客或教程的所有网页,做成类似出版物的电子出版物。可以在手机、平板电脑上阅读或永久保存的书籍。实现此要求的一种方法是使用 Chrome 插件一键将目标网页保存为 ePub 文件。
ePub 的插件大约有十种。经过大量的测试,我最终选择了dotEPUB、WebToWpub、EpubPress、Save as eBook这四个各有侧重、效果更好的插件。本文将分析它们的特点,以帮助您确定哪一种最能满足您的需求。
四个插件的用法和特点
dotEPUB : 将当前窗口的网页另存为 ePub1. 速度:更快2. 水印:开头和结尾的水印3. 图片支持:稍差4. 排版:更好排版
dotEPUB是操作最简单、功能最单一的一种。只需点击插件栏中的 dotEPUB 图标,即可自动将当前网页下载为 ePub 文件。但由于只保存当前网页,因此适用范围较窄。
在这里,打开一个知乎栏目“我们在谈论英语学习时在谈论什么”作为素材尝试抓取,用多看App打开,阅读效果如下。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接为章节并生成为ePub1.速度:更快,有进度条2.水印:无水印3.图片支持:有图片4.排版:排版比较通用
这是我经常使用的插件。它可以爬取当前网页中收录的链接的所有内容。适用于爬取知乎列或博客等网站以列表形式展开内容。网页中的每个链接都会生成一个特定的Epub章节,章节标题就是网页标题。
点击插件,确认开始转换后,进入插件主界面。在主界面中,WebToEpub 允许用户编辑 ePub 的标题、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等操作,还可以反向选择网页列表。此外,您可以通过将图像地址粘贴到 URL 框中来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有的文章,在使用插件之前需要滚动到页面底部完全加载列表。
EpubPress:将当前打开的所有标签捕获为ePub1.速度:正常速度,带有进度条2.水印:无水印3.图像支持:在某些情况下捕获图像会失败< @4. 排版:更好的排版
这是另一个常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到电子邮件地址,可根据需要在右上角的设置中选择。
如果爬取大量标签页,等待时间会明显变长。另请注意,在实际测试中可能无法保存超过 20 个选项卡。
另存为电子书:选择打开的网页并保存为 ePub1. 速度:更快2. 水印:无水印3. 图片支持:带图片4. 排版:更好排版
另存为 eBook 与 EpubPress 类似,都将打开的选项卡保存为 ePub 文件中的章节。但要保存为电子书,需要在浏览网页时点击要保存的网页插件栏中的图标,选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件的标题和调整章节的顺序。
四种使用场景
总结一下四个插件的适用场景,这里简单总结一下情况:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 和 Read Later 等工具之外的另一个想法。对于严肃或系统的内容,制作一本ePub电子书,三两下进行主题阅读会更加连贯,思考可以逐步深化主题。这是电子书和印象笔记以及后来阅读的区别。观点。因此,对于系统学习来说,ePub电子书无疑是一个不错的选择。
回到Chrome插件的话题,一键生成ePub文件的插件普遍的缺点是通过插件制作的电子书不是纯图文,还有一些不相关的内容,如网站中的超链接或评论@> 也可能被 网站 阻止。@收录进入电子书,导致转换效果不佳。文章只提到了目前水平不错的四种ePub转换插件,各有各的不足。
您可以根据个人需求组合两个或多个插件完成ePub转换。
抓取网页生成电子书(如何用Python爬取网页制作电子书思路怎么抓取数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-23 16:13
作者简介:孙宇,软件工程师,长期从事企业信息系统研发,主要擅长后端业务功能的设计与开发。
本文来自作者在GitChat上分享的主题“如何用Python爬取网页制作电子书”。使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
有一个目录选项卡,点击这个选项卡可以查看目录,使用浏览器的元素查看工具,我们可以定位到目录和每章的相关信息,我们可以根据这些信息爬取到具体的页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面排序不是很好,手动排序会耗费太多时间和精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
. 查看全部
抓取网页生成电子书(如何用Python爬取网页制作电子书思路怎么抓取数据?)
作者简介:孙宇,软件工程师,长期从事企业信息系统研发,主要擅长后端业务功能的设计与开发。
本文来自作者在GitChat上分享的主题“如何用Python爬取网页制作电子书”。使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
有一个目录选项卡,点击这个选项卡可以查看目录,使用浏览器的元素查看工具,我们可以定位到目录和每章的相关信息,我们可以根据这些信息爬取到具体的页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面排序不是很好,手动排序会耗费太多时间和精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
.
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-22 21:06
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列 文章地址列表 抓取每个的详细信息 文章导出 PDF 1. 抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
whileTrue: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
文章数据:
# 保存id和title(省略) ifj[ 'paging'][ 'is_end']:
breakurl = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果,会添加不带data-actual、src="data:image等标签和属性的效果。我们必须去掉它们才能正常显示。
url = ''+ idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_= 'Post-RichText').prettify()
# 处理内容(略)
withopen(file_name, 'w') asf: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了便于阅读,我们使用 wkhtmltopdf+ pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,都是通过1.抓取列表2.抓取详细内容这两个步骤采集数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列 文章地址列表 抓取每个的详细信息 文章导出 PDF 1. 抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
whileTrue: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
文章数据:
# 保存id和title(省略) ifj[ 'paging'][ 'is_end']:
breakurl = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果,会添加不带data-actual、src="data:image等标签和属性的效果。我们必须去掉它们才能正常显示。
url = ''+ idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_= 'Post-RichText').prettify()
# 处理内容(略)
withopen(file_name, 'w') asf: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了便于阅读,我们使用 wkhtmltopdf+ pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,都是通过1.抓取列表2.抓取详细内容这两个步骤采集数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
抓取网页生成电子书(王子网页转换小精灵支持把文件批量转换为网页格式,支持制作漂亮的电子相册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-22 15:12
Prince是一款帮助用户制作chm电子书的软件。王子网页转换精灵支持将文件批量转换为网页格式,支持制作精美的电子相册。主要功能包括网页制作、网页批量转换、电子书制作、文件拆分合并、文件加解密等,欢迎下载使用!
【王子网页转换精灵功能介绍】:
1、 将文本文件批量转换为web文件(txt等转htm)
2、网页文件批量转成文本文件(htm等转成txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件,也可以合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后有更多模板可用。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件,一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、除了转换上面列出的文件类型,还可以自己添加转换类型 查看全部
抓取网页生成电子书(王子网页转换小精灵支持把文件批量转换为网页格式,支持制作漂亮的电子相册)
Prince是一款帮助用户制作chm电子书的软件。王子网页转换精灵支持将文件批量转换为网页格式,支持制作精美的电子相册。主要功能包括网页制作、网页批量转换、电子书制作、文件拆分合并、文件加解密等,欢迎下载使用!
【王子网页转换精灵功能介绍】:
1、 将文本文件批量转换为web文件(txt等转htm)
2、网页文件批量转成文本文件(htm等转成txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件,也可以合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后有更多模板可用。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件,一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、除了转换上面列出的文件类型,还可以自己添加转换类型
抓取网页生成电子书(你好电子书网站制作教程:制作电子书最简单的电子书:介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2022-02-21 04:07
你好电子书网站制作教程:
这 网站 会说清楚
网站电子书网站制作教程:
电子书网站制作教程介绍:
前言电子书网站制作教程:
很多人问我如何制作电子书。我在网上搜索了一下,发现这样的资料并不多,而且都太复杂了,学习如何制作电子书网站教程。于是干脆写了一篇通俗易懂的文章文章,大家一起交流,让更多人学习制作电子书:
电子书(eBook)是一种电子阅读材料,极大地方便了信息的传播和存储,也给我们的学习和工作带来了很多便利。
比如很多摘要可以做成电子书,图文并茂,界面美观,易于阅读,保存完好。
网上有很多小说、教程或其他资料都是用电子书做成的。您想知道这些电子书是如何制作的吗?其实很简单。看完这文章,你就可以制作自己的电子书了。
一。初步知识:
电子书的格式有很多种,包括:EXE文件格式、CHM文件格式、HLP文件格式、PDF文件格式、LIT文件格式、WDL文件格式等,其中有些格式只能用特定的软件打开阅读,如用于 PDF 格式的 Adobe Acrobat Reader 和用于 WDL 格式的华康的 DynaDoc Free Reader。
但总的来说,使用最多的格式是EXE和CHM,所以本文只讨论这两种格式的电子书,其他格式可以通过网上查找相关资料了解。
制作电子书的材料可以是txt文本、html网页、doc文档或图片、flash等。
想要做出更漂亮的电子书,就必须对网页制作和图像处理技术有一定的了解。当然,如果你不知道这些,也没关系。您也可以自己制作电子书。请继续阅读:
二。
制作第一本最简单的电子书:
制作电子书的软件也有很多,不同格式的电子书制作所选择的软件也不同。
快速链接:谁是大师?九大电子书制作工具横评
现在我们使用Netwen Quick Capture制作第一本电子书:
软件名称:CyberArticle
软件版本:V4。
01
软件大小:5367K
授权方式:破解版
下载地址1:
下载地址2:
网文快拍是一款非常优秀的国产分享软件,可以方便的保存和管理网页,也是一款非常实用的电子书制作工具。运行网络文章。
exe后,点击工具栏上的“文件”-“导入”-“从文件夹导入”(或按Ctrl+Alt+F),选择创建电子书资料的文件夹,
从这里可以看出,电子书支持的文档类型很多,txt、html、flash,甚至还有程序源代码文件等等,但是我们只使用最基本的txt文本作为素材。
单击下一步以选择要导入的文件,然后单击下一步以完成导入。
在左侧的资源管理器窗口中,可以看到文件列表的目录树,可以调整它们的文件名和排列顺序,然后可以在右侧窗口中预览文本内容,也可以切换到“编辑”或“来源”选项来编辑文本。
最后点击“文件”-“制作电子书”-“制作电子书(*.
EXE格式)...”或“制作电子书(*.CHM格式)...”,分别制作exe和chm格式的电子书,设置好一些选项后,点击“制作”,很快,一个e -book 会做的很好,简单快捷。
三。创建更精美的电子书:
虽然使用Netwen Quick Capture制作电子书非常方便快捷(可以同时制作exe和chm两种格式的电子书),但是这样的电子书并不是特别漂亮,而且它们的功能是不强。
这时候我们就可以使用eBook Edit Pro、eBook Workshop、eBook Pack Express等专业的电子书制作软件来制作更精美的电子书。推荐使用国内的电子书工坊(e书工坊):
软件名称:e书工坊
软件版本:V1。
4
软件大小:1785K
授权方式:注册版
下载链接:
注册码:名称:ASWord 代码:719FBF71-353B4344-B70CB1A9
使用电子书工坊,可以制作exe格式的电子书,界面非常漂亮,功能强大。
下载安装后,打开电子书工坊,
首先选择要制作的电子书的文件目录,然后在“目录”中添加需要的文件。请务必将文件添加到中间列表框中。您可以直接单击“从文件夹创建”或添加文件将它们一一拖动。然后可以对它们重新排序,首页是电子书的主页(即打开电子书时看到的第一页)。
然后可以在其他选项卡中设置“启动画面”、“界面”、“图标”、“工具栏”等,eBook Workshop提供了非常强大的自定义功能,可以创建非常个性化的界面和功能。
最好点击“保存”,保存工程后点击“编译”,将电子书编译成exe格式。
注意:电子书工坊有个很大的缺点,就是导入的文字不能自动换行,阅读电子书极其不方便。
所以最好不要直接导入文本,而是先转换成网页,再制作。这不仅避免了这个问题,而且还使电子书看起来更好看。
四。将其提升到一个新的水平,以制作更好的电子书
这部分需要你对网页创建有一点了解。
其实一本电子书就是把很多网页打包成一个可执行文件(txt文本也可以看作是网页最简单的形式),所以我们只需要先制作一些网页,然后使用软件如电子书研讨会将它制作成电子书。
我们可以使用 Softscape HTML Maker 来帮助我们快速制作网页:
软件名称:Softscape HTML Maker
软件版本:V3.0
软件大小:1966 KB
授权方式:共享版
下载链接:
它的功能是将文本批量转换成网页。这些网页是带有索引文件、“上一页”和“下一页”链接的 HTML 文件组。
下载安装软件后,运行主程序,
首先点击“添加”导入要转换的文本。然后选择分割文字的方法(即如何分割文字,问题有点复杂,请参考软件自带的帮助文件,上面的描述更清楚),然后选择网页模板,最后点击“开始”输出网页。(如何将文字和图片一起作为网页输入也可以参考软件帮助文件)
在输入的众多网页中,有一个名为m的网页是目录索引页,可以作为制作电子书时的“首页”。
此外,您还可以使用 Frontpage、Dreamwaver 等网页创建工具来处理和修改这些网页。完成后,您可以按照上述步骤创建电子书。
由于界面是中文的,操作比较简单,所以就不再介绍上面提到的软件了。慢慢使用很容易上手。
到目前为止,我们已经学会了如何制作自己的电子书。如果想继续学习电子书制作技术,获取更多电子书资源,可以登录各大电子书网站,比如比较有名的:
书吧
E书时空
我喜欢书
其实这方面的网络很多,搜索一下就清楚了。 查看全部
抓取网页生成电子书(你好电子书网站制作教程:制作电子书最简单的电子书:介绍)
你好电子书网站制作教程:
这 网站 会说清楚
网站电子书网站制作教程:
电子书网站制作教程介绍:
前言电子书网站制作教程:
很多人问我如何制作电子书。我在网上搜索了一下,发现这样的资料并不多,而且都太复杂了,学习如何制作电子书网站教程。于是干脆写了一篇通俗易懂的文章文章,大家一起交流,让更多人学习制作电子书:
电子书(eBook)是一种电子阅读材料,极大地方便了信息的传播和存储,也给我们的学习和工作带来了很多便利。
比如很多摘要可以做成电子书,图文并茂,界面美观,易于阅读,保存完好。
网上有很多小说、教程或其他资料都是用电子书做成的。您想知道这些电子书是如何制作的吗?其实很简单。看完这文章,你就可以制作自己的电子书了。
一。初步知识:
电子书的格式有很多种,包括:EXE文件格式、CHM文件格式、HLP文件格式、PDF文件格式、LIT文件格式、WDL文件格式等,其中有些格式只能用特定的软件打开阅读,如用于 PDF 格式的 Adobe Acrobat Reader 和用于 WDL 格式的华康的 DynaDoc Free Reader。
但总的来说,使用最多的格式是EXE和CHM,所以本文只讨论这两种格式的电子书,其他格式可以通过网上查找相关资料了解。
制作电子书的材料可以是txt文本、html网页、doc文档或图片、flash等。
想要做出更漂亮的电子书,就必须对网页制作和图像处理技术有一定的了解。当然,如果你不知道这些,也没关系。您也可以自己制作电子书。请继续阅读:
二。
制作第一本最简单的电子书:
制作电子书的软件也有很多,不同格式的电子书制作所选择的软件也不同。
快速链接:谁是大师?九大电子书制作工具横评
现在我们使用Netwen Quick Capture制作第一本电子书:
软件名称:CyberArticle
软件版本:V4。
01
软件大小:5367K
授权方式:破解版
下载地址1:
下载地址2:
网文快拍是一款非常优秀的国产分享软件,可以方便的保存和管理网页,也是一款非常实用的电子书制作工具。运行网络文章。
exe后,点击工具栏上的“文件”-“导入”-“从文件夹导入”(或按Ctrl+Alt+F),选择创建电子书资料的文件夹,
从这里可以看出,电子书支持的文档类型很多,txt、html、flash,甚至还有程序源代码文件等等,但是我们只使用最基本的txt文本作为素材。
单击下一步以选择要导入的文件,然后单击下一步以完成导入。
在左侧的资源管理器窗口中,可以看到文件列表的目录树,可以调整它们的文件名和排列顺序,然后可以在右侧窗口中预览文本内容,也可以切换到“编辑”或“来源”选项来编辑文本。
最后点击“文件”-“制作电子书”-“制作电子书(*.
EXE格式)...”或“制作电子书(*.CHM格式)...”,分别制作exe和chm格式的电子书,设置好一些选项后,点击“制作”,很快,一个e -book 会做的很好,简单快捷。
三。创建更精美的电子书:
虽然使用Netwen Quick Capture制作电子书非常方便快捷(可以同时制作exe和chm两种格式的电子书),但是这样的电子书并不是特别漂亮,而且它们的功能是不强。
这时候我们就可以使用eBook Edit Pro、eBook Workshop、eBook Pack Express等专业的电子书制作软件来制作更精美的电子书。推荐使用国内的电子书工坊(e书工坊):
软件名称:e书工坊
软件版本:V1。
4
软件大小:1785K
授权方式:注册版
下载链接:
注册码:名称:ASWord 代码:719FBF71-353B4344-B70CB1A9
使用电子书工坊,可以制作exe格式的电子书,界面非常漂亮,功能强大。
下载安装后,打开电子书工坊,
首先选择要制作的电子书的文件目录,然后在“目录”中添加需要的文件。请务必将文件添加到中间列表框中。您可以直接单击“从文件夹创建”或添加文件将它们一一拖动。然后可以对它们重新排序,首页是电子书的主页(即打开电子书时看到的第一页)。
然后可以在其他选项卡中设置“启动画面”、“界面”、“图标”、“工具栏”等,eBook Workshop提供了非常强大的自定义功能,可以创建非常个性化的界面和功能。
最好点击“保存”,保存工程后点击“编译”,将电子书编译成exe格式。
注意:电子书工坊有个很大的缺点,就是导入的文字不能自动换行,阅读电子书极其不方便。
所以最好不要直接导入文本,而是先转换成网页,再制作。这不仅避免了这个问题,而且还使电子书看起来更好看。
四。将其提升到一个新的水平,以制作更好的电子书
这部分需要你对网页创建有一点了解。
其实一本电子书就是把很多网页打包成一个可执行文件(txt文本也可以看作是网页最简单的形式),所以我们只需要先制作一些网页,然后使用软件如电子书研讨会将它制作成电子书。
我们可以使用 Softscape HTML Maker 来帮助我们快速制作网页:
软件名称:Softscape HTML Maker
软件版本:V3.0
软件大小:1966 KB
授权方式:共享版
下载链接:
它的功能是将文本批量转换成网页。这些网页是带有索引文件、“上一页”和“下一页”链接的 HTML 文件组。
下载安装软件后,运行主程序,
首先点击“添加”导入要转换的文本。然后选择分割文字的方法(即如何分割文字,问题有点复杂,请参考软件自带的帮助文件,上面的描述更清楚),然后选择网页模板,最后点击“开始”输出网页。(如何将文字和图片一起作为网页输入也可以参考软件帮助文件)
在输入的众多网页中,有一个名为m的网页是目录索引页,可以作为制作电子书时的“首页”。
此外,您还可以使用 Frontpage、Dreamwaver 等网页创建工具来处理和修改这些网页。完成后,您可以按照上述步骤创建电子书。
由于界面是中文的,操作比较简单,所以就不再介绍上面提到的软件了。慢慢使用很容易上手。
到目前为止,我们已经学会了如何制作自己的电子书。如果想继续学习电子书制作技术,获取更多电子书资源,可以登录各大电子书网站,比如比较有名的:
书吧
E书时空
我喜欢书
其实这方面的网络很多,搜索一下就清楚了。
抓取网页生成电子书( 软件介绍:网站2PK中文版和appsgeyser的使用细节(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-02-21 01:06
软件介绍:网站2PK中文版和appsgeyser的使用细节(图))
软件介绍:
网站2PK汉化版可以一键直接将网站转换成APK软件。
需要软件java8支持,运行后需要安装java8。
您可以自定义各种设置。鑫哥尝试把日常学习网变成apk,效果非常好!
本次发布说明:
byditzmx
本地化率在99.8%以上。如果没有本地化,可能会有很少的错误提示。
在生成就绪之前翻译按钮图像并替换等待图标。
警告工具提示中添加了一个图标,但除了工具提示文本之外没有其他图标。
修改了应用启动画面的图片大小限制。本来是受限于竖屏最大宽度1280x和最大高度1920,如果有限制的话。
该设置会导致启动画面被拉扯变形,所以根据横屏限制最大宽度为1920x,最大高度为1080。实际上,这取决于网页的显示方式。如果使用竖屏,横屏尺寸可以正常比例显示。
软件截图:
下载链接:
提取码:p5qn
简单的应用开发平台
一种是细致而繁琐。每个代码和标点都有严格的要求,不能出错。APP的开发是在一定的平台上进行的,也就是我们所说的开发平台。主流的开发平台有五个:appInventor、PhoneGap、appsgeyser、Devmyapp和WeX5。五个平台中的每一个都有自己的优势。今天主要讲appInventor和appsgeyser。
1.此前,谷歌实验室已经以教学视频的形式向网友披露了该软件测试版的使用细节。在这个视频中,R&d的人展示了如何使用程序发明者来制作应用程序,也有很多人教网友自己开发新程序。
而且,这个编程软件不必是专业开发的;d 人员甚至根本不需要掌握任何编程知识。由于本软件已预先编写好所有软件代码,用户只需根据需要为其添加服务选项即可。也就是说,我们所要做的就是编写一个简单的代码汇编器。
2、appsgeyser
appsGeyser 允许任何人开发应用程序。当然,这个程序不允许您创建下一个愤怒的小鸟或 Foursquare。但是如果你只是想基于 web 内容构建一个非常简单的应用程序,appsGeyser 将是你最好的选择。appsGeyser 其实很简单。它只有三个选项:第一,它可以生成一个应用程序;第二,输入任意web widget的HTML代码,可以直接转换成Android应用;第三,使用工具抓取网页的部分内容以生成应用程序。
完成工作后,您可以上传到 AndroidMarket(但您必须事先拥有发布者帐户)或自己使用。该应用程序上个月才推出,但其联合创始人 Vasily Salomatov 表示,用户已经使用 appsGeyser 创建了 1,000 个应用程序。
不管什么样的app平台,最重要的是要有清晰的创意。然而,在这些平台中,有些想法无法完全呈现。如果你想玩一个简单的应用程序,这个平台是你的选择,但如果你想要互联网创意建议,你应该选择一个自定义应用程序来制作一个更完美的应用程序。
为企业提供基于IOS和Android系统的移动APP应用定制开发,提供APP产品综合解决方案。 查看全部
抓取网页生成电子书(
软件介绍:网站2PK中文版和appsgeyser的使用细节(图))
软件介绍:
网站2PK汉化版可以一键直接将网站转换成APK软件。
需要软件java8支持,运行后需要安装java8。
您可以自定义各种设置。鑫哥尝试把日常学习网变成apk,效果非常好!
本次发布说明:
byditzmx
本地化率在99.8%以上。如果没有本地化,可能会有很少的错误提示。
在生成就绪之前翻译按钮图像并替换等待图标。
警告工具提示中添加了一个图标,但除了工具提示文本之外没有其他图标。
修改了应用启动画面的图片大小限制。本来是受限于竖屏最大宽度1280x和最大高度1920,如果有限制的话。
该设置会导致启动画面被拉扯变形,所以根据横屏限制最大宽度为1920x,最大高度为1080。实际上,这取决于网页的显示方式。如果使用竖屏,横屏尺寸可以正常比例显示。
软件截图:
下载链接:
提取码:p5qn
简单的应用开发平台
一种是细致而繁琐。每个代码和标点都有严格的要求,不能出错。APP的开发是在一定的平台上进行的,也就是我们所说的开发平台。主流的开发平台有五个:appInventor、PhoneGap、appsgeyser、Devmyapp和WeX5。五个平台中的每一个都有自己的优势。今天主要讲appInventor和appsgeyser。
1.此前,谷歌实验室已经以教学视频的形式向网友披露了该软件测试版的使用细节。在这个视频中,R&d的人展示了如何使用程序发明者来制作应用程序,也有很多人教网友自己开发新程序。
而且,这个编程软件不必是专业开发的;d 人员甚至根本不需要掌握任何编程知识。由于本软件已预先编写好所有软件代码,用户只需根据需要为其添加服务选项即可。也就是说,我们所要做的就是编写一个简单的代码汇编器。
2、appsgeyser
appsGeyser 允许任何人开发应用程序。当然,这个程序不允许您创建下一个愤怒的小鸟或 Foursquare。但是如果你只是想基于 web 内容构建一个非常简单的应用程序,appsGeyser 将是你最好的选择。appsGeyser 其实很简单。它只有三个选项:第一,它可以生成一个应用程序;第二,输入任意web widget的HTML代码,可以直接转换成Android应用;第三,使用工具抓取网页的部分内容以生成应用程序。
完成工作后,您可以上传到 AndroidMarket(但您必须事先拥有发布者帐户)或自己使用。该应用程序上个月才推出,但其联合创始人 Vasily Salomatov 表示,用户已经使用 appsGeyser 创建了 1,000 个应用程序。
不管什么样的app平台,最重要的是要有清晰的创意。然而,在这些平台中,有些想法无法完全呈现。如果你想玩一个简单的应用程序,这个平台是你的选择,但如果你想要互联网创意建议,你应该选择一个自定义应用程序来制作一个更完美的应用程序。
为企业提供基于IOS和Android系统的移动APP应用定制开发,提供APP产品综合解决方案。
抓取网页生成电子书(地铁上也能快速翻完.环境准备:calibreQT)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-17 23:10
简书是个很好的学习者网站,我大多只关注首页的人文章,但最近因为工作繁忙,错过了很多首页的文章,所以我有一个想法,把每日流行的Top生成mobi并推送到kindle。这样一来,在地铁上就能很快搞定。
环境准备:
关于口径安装
sudo -v && wget -nv -O- https://raw.githubusercontent. ... er.py | sudo python -c "import sys; main=lambda:sys.stderr.write('Download failed\n'); exec(sys.stdin.read()); main()"
官网文档提供的安装脚本看似简单,执行后即可安装使用,但调用ebook-convert时gitbook会报错。这里报的错误应该是QT错误(至少我遇到过,具体错误信息忘记截图了)如果遇到这个错误,直接安装QT pyQT即可。calibre安装页面有依赖表
安装 Gitbook
需要安装 nodejs 和 npm 然后执行 npm install -g gitbook-cli
安装建树热
需要强调的是,这部分需要解决很多依赖,
scrapy依赖的python包有很多,这些依赖的python大部分都需要一些系统库。如有需要,需要安装apt-get和yum,如python-devel libffi-devel libxml-devel等...
peewee(数据库ORM)需要mysql-devel,上面的例子都知道,这是我部署后写的,部署过程就不详细记录了,现在只能凭记忆写这一章了。
$ git clone https://github.com/jackeyGao/jianshuHot
$ cd jianshuHot
$ pip install -r requirements.txt
初始化器
$ sh init.sh
邮件配置
这是用于发送电子邮件的 sendEmail 和下载地址。解压后将解压后的sendEmail重命名为/usr/local/bin/sendEmail,理论上可以安装成功。这是免编译的,只需要在机器上安装perl。
然后修改start.sh邮箱配置,写成自己的163邮箱,也可以用其他品牌邮箱,如果用其他品牌别忘了改,改到对应的smtp服务器就好了。
注意:无论您使用哪个电子邮件地址,您都必须将此电子邮件帐户添加到亚马逊的批准发件人电子邮件列表中,以确保您发送的文件可以到达亚马逊云
$ vim start.sh
....
YOURKINDLE_MAIL_ADDRESS="xxxxx@kindle.cn"
YOUR_SEND_MAIL_USERNAME="xxxx@163.com"
YOUR_SEND_MAIL_SECRET = 'xxxxxxxxxxxx'
MOBI_BOOK_PATH='./output/book.mobi'
...
开始爬行
$ sh start.sh
执行后会自动抓取页面生成markdown,下载每个文章的图片,然后gitbook通过markdown生成这个文档列表的book.mobi(output/book.mobi),有文件在 start.sh 的末尾,备份操作会将这个 mobi 备份到 output/books。然后发送到指定kindle地址邮箱。 查看全部
抓取网页生成电子书(地铁上也能快速翻完.环境准备:calibreQT)
简书是个很好的学习者网站,我大多只关注首页的人文章,但最近因为工作繁忙,错过了很多首页的文章,所以我有一个想法,把每日流行的Top生成mobi并推送到kindle。这样一来,在地铁上就能很快搞定。
环境准备:
关于口径安装
sudo -v && wget -nv -O- https://raw.githubusercontent. ... er.py | sudo python -c "import sys; main=lambda:sys.stderr.write('Download failed\n'); exec(sys.stdin.read()); main()"
官网文档提供的安装脚本看似简单,执行后即可安装使用,但调用ebook-convert时gitbook会报错。这里报的错误应该是QT错误(至少我遇到过,具体错误信息忘记截图了)如果遇到这个错误,直接安装QT pyQT即可。calibre安装页面有依赖表
安装 Gitbook
需要安装 nodejs 和 npm 然后执行 npm install -g gitbook-cli
安装建树热
需要强调的是,这部分需要解决很多依赖,
scrapy依赖的python包有很多,这些依赖的python大部分都需要一些系统库。如有需要,需要安装apt-get和yum,如python-devel libffi-devel libxml-devel等...
peewee(数据库ORM)需要mysql-devel,上面的例子都知道,这是我部署后写的,部署过程就不详细记录了,现在只能凭记忆写这一章了。
$ git clone https://github.com/jackeyGao/jianshuHot
$ cd jianshuHot
$ pip install -r requirements.txt
初始化器
$ sh init.sh
邮件配置
这是用于发送电子邮件的 sendEmail 和下载地址。解压后将解压后的sendEmail重命名为/usr/local/bin/sendEmail,理论上可以安装成功。这是免编译的,只需要在机器上安装perl。
然后修改start.sh邮箱配置,写成自己的163邮箱,也可以用其他品牌邮箱,如果用其他品牌别忘了改,改到对应的smtp服务器就好了。
注意:无论您使用哪个电子邮件地址,您都必须将此电子邮件帐户添加到亚马逊的批准发件人电子邮件列表中,以确保您发送的文件可以到达亚马逊云
$ vim start.sh
....
YOURKINDLE_MAIL_ADDRESS="xxxxx@kindle.cn"
YOUR_SEND_MAIL_USERNAME="xxxx@163.com"
YOUR_SEND_MAIL_SECRET = 'xxxxxxxxxxxx'
MOBI_BOOK_PATH='./output/book.mobi'
...
开始爬行
$ sh start.sh
执行后会自动抓取页面生成markdown,下载每个文章的图片,然后gitbook通过markdown生成这个文档列表的book.mobi(output/book.mobi),有文件在 start.sh 的末尾,备份操作会将这个 mobi 备份到 output/books。然后发送到指定kindle地址邮箱。
抓取网页生成电子书(Python标准库unittest办法读取了吗?非也!(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-17 23:10
)
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
本文将介绍一个python库:selenium,最新版本为2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
1 from selenium import webdriver
2
3 browser = webdriver.Firefox()
4 browser.get('http://www.baidu.com/')
【示例一】
1 from selenium import webdriver
2 from selenium.webdriver.common.keys import Keys
3
4 browser = webdriver.Firefox()
5
6 browser.get('http://www.baidu.com')
7 assert '百度' in browser.title
8
9 elem = browser.find_element_by_name('p') # Find the search box
10 elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
11
12 browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
1 import unittest
2
3 class BaiduTestCase(unittest.TestCase):
4
5 def setUp(self):
6 self.browser = webdriver.Firefox()
7 self.addCleanup(self.browser.quit)
8
9 def testPageTitle(self):
10 self.browser.get('http://www.baidu.com')
11 self.assertIn('百度', self.browser.title)
12
13 if __name__ == '__main__':
14 unittest.main(verbosity=2) 查看全部
抓取网页生成电子书(Python标准库unittest办法读取了吗?非也!(图)
)
使用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
本文将介绍一个python库:selenium,最新版本为2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
1 from selenium import webdriver
2
3 browser = webdriver.Firefox()
4 browser.get('http://www.baidu.com/')
【示例一】
1 from selenium import webdriver
2 from selenium.webdriver.common.keys import Keys
3
4 browser = webdriver.Firefox()
5
6 browser.get('http://www.baidu.com')
7 assert '百度' in browser.title
8
9 elem = browser.find_element_by_name('p') # Find the search box
10 elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
11
12 browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
1 import unittest
2
3 class BaiduTestCase(unittest.TestCase):
4
5 def setUp(self):
6 self.browser = webdriver.Firefox()
7 self.addCleanup(self.browser.quit)
8
9 def testPageTitle(self):
10 self.browser.get('http://www.baidu.com')
11 self.assertIn('百度', self.browser.title)
12
13 if __name__ == '__main__':
14 unittest.main(verbosity=2)
抓取网页生成电子书(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-17 08:18
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e) 查看全部
抓取网页生成电子书(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e)
抓取网页生成电子书(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 912 次浏览 • 2022-02-17 08:16
iefans提供的一款供用户使用成品小说免费下载全书的软件,可以一次性免费阅读全书,现推荐一款免费的全书txt小说电子书下载软件,使用网络图书抓取器,并支持TXT全书免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载TXT全电子书。iefans 提供网络图书采集器的下载地址。需要免费完整小说下载器的朋友,快来下载试试吧。试试看。
网络图书爬虫介绍
Web Book Crawler是一款在线小说下载软件,可以帮助用户下载指定网页的一本书和一章。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载。读后支持断点续下载功能。如果是网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整本小说。
如何使用网络图书刮刀
1.网络小说下载软件下载解压后,双击使用,首次运行会自动生成设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载的小说网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始抓取开始下载。
3.可以提取指定小说目录页面的章节信息并调整,然后按照章节顺序抓取小说内容,在最合适的时候合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
4.在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来了极大的方便。已输入 10 个适用的 网站。选择后可以快速打开网站找到需要的书籍,还可以自动套用相应的代码 查看全部
抓取网页生成电子书(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
iefans提供的一款供用户使用成品小说免费下载全书的软件,可以一次性免费阅读全书,现推荐一款免费的全书txt小说电子书下载软件,使用网络图书抓取器,并支持TXT全书免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载TXT全电子书。iefans 提供网络图书采集器的下载地址。需要免费完整小说下载器的朋友,快来下载试试吧。试试看。
网络图书爬虫介绍
Web Book Crawler是一款在线小说下载软件,可以帮助用户下载指定网页的一本书和一章。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载。读后支持断点续下载功能。如果是网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整本小说。
如何使用网络图书刮刀
1.网络小说下载软件下载解压后,双击使用,首次运行会自动生成设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载的小说网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始抓取开始下载。
3.可以提取指定小说目录页面的章节信息并调整,然后按照章节顺序抓取小说内容,在最合适的时候合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
4.在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来了极大的方便。已输入 10 个适用的 网站。选择后可以快速打开网站找到需要的书籍,还可以自动套用相应的代码
抓取网页生成电子书(网文快捕软件特色介绍的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-15 05:24
Nettext Quick Capture是一款功能实用的网页保存管理软件。本软件可以帮助用户轻松批量保存和管理网页内容,并帮助制作成电子书格式,方便用户获取和提取网页内容。该软件具有超强的稳定性。最大程度保障数据安全,满足用户各种网页内容获取和保存需求。
软件功能
1、超强稳定性:数据管理,最重要的是数据安全,可以提供稳定的程序和安全的数据存储方式。经过严格测试的程序具有高度的稳定性。同时,所有数据都存储在数据库中,这也提供了一种安全可靠的数据存储方式。
2、丰富的导入导出功能:可以导入你的邮件、各种Office文档、PDF、源代码、图片等。同时,您还可以将数据导出为 HTML 文件制作电子书,无需 CyberArticle 即可使用。以后即使不再使用,也可以使用您的数据,不用担心数据丢失。
3、便捷的数据共享:让您轻松共享数据。无论您是在公司还是在家里,您都可以同时使用局域网来管理您的数据。所有操作都自动保存到数据库中,无需任何同步工作。您也可以使用WebShare 组件,您可以将您的数据发布到浏览器上面。这样,即使其他人没有安装该软件,只要有浏览器,就可以查看数据。
4、强大的开放性:公开数据的存储方式,提供丰富的二次开发接口。您可以使用脚本语言来扩展 CyberArticle 的功能,也可以使用高级语言编写各种插件以更好地满足您的需求。
5、完全支持各种浏览器:支持IE、火狐、谷歌Chrome浏览器、苹果safari浏览器、Opera。各类主流浏览器一网打尽,各类网页一网打尽。
6、PDF 支持:您可以导入 PDF 文件。导入的PDF文件可以轻松统一搜索。
7、统一管理功能:将所有导入的文档统一转换为HTML文件,采用统一的管理、检索、编辑方式,让您不再关心格式。
8、提供谷歌桌面搜索和IFilter插件,让你使用桌面搜索软件统一进行全文搜索。
9、提供版本控制功能,可以保存每一个历史修改记录。
软件功能
保存页面
1. 网页中的任何资源都可以在IE(包括IE核心浏览器)、火狐、谷歌浏览器、Safari和Opera等支持的浏览器中完整无缺地保存,特别是还可以保存一些资源,例如 YouTube 上的视频。它已成为网页保存领域流行的优秀软件。
2. 网页可以批量保存。
3. 可以导入Office文档:doc、ppt、xls、rtf。
4. 可以通过全文搜索导入 PDF 文件。
5.可以导入源代码文件,支持颜色标注。
5. 可以导入图片、flash等,也支持导入任意文件的附件。
资源管理
1. 以 HTML 格式保存所有资源,您可以在全文搜索、批处理、输出和电子书制作中以相同的方式管理它们。
2.设置一个文章为IE采集,可以添加多个书签,轻松实现多级文档管理。
3. 您还可以编辑书中的资源。
4.Nettext Quick Capture可以实现你书中的大量操作,比如分类、标注颜色、批处理等。 查看全部
抓取网页生成电子书(网文快捕软件特色介绍的应用)
Nettext Quick Capture是一款功能实用的网页保存管理软件。本软件可以帮助用户轻松批量保存和管理网页内容,并帮助制作成电子书格式,方便用户获取和提取网页内容。该软件具有超强的稳定性。最大程度保障数据安全,满足用户各种网页内容获取和保存需求。
软件功能
1、超强稳定性:数据管理,最重要的是数据安全,可以提供稳定的程序和安全的数据存储方式。经过严格测试的程序具有高度的稳定性。同时,所有数据都存储在数据库中,这也提供了一种安全可靠的数据存储方式。
2、丰富的导入导出功能:可以导入你的邮件、各种Office文档、PDF、源代码、图片等。同时,您还可以将数据导出为 HTML 文件制作电子书,无需 CyberArticle 即可使用。以后即使不再使用,也可以使用您的数据,不用担心数据丢失。
3、便捷的数据共享:让您轻松共享数据。无论您是在公司还是在家里,您都可以同时使用局域网来管理您的数据。所有操作都自动保存到数据库中,无需任何同步工作。您也可以使用WebShare 组件,您可以将您的数据发布到浏览器上面。这样,即使其他人没有安装该软件,只要有浏览器,就可以查看数据。
4、强大的开放性:公开数据的存储方式,提供丰富的二次开发接口。您可以使用脚本语言来扩展 CyberArticle 的功能,也可以使用高级语言编写各种插件以更好地满足您的需求。
5、完全支持各种浏览器:支持IE、火狐、谷歌Chrome浏览器、苹果safari浏览器、Opera。各类主流浏览器一网打尽,各类网页一网打尽。
6、PDF 支持:您可以导入 PDF 文件。导入的PDF文件可以轻松统一搜索。
7、统一管理功能:将所有导入的文档统一转换为HTML文件,采用统一的管理、检索、编辑方式,让您不再关心格式。
8、提供谷歌桌面搜索和IFilter插件,让你使用桌面搜索软件统一进行全文搜索。
9、提供版本控制功能,可以保存每一个历史修改记录。
软件功能
保存页面
1. 网页中的任何资源都可以在IE(包括IE核心浏览器)、火狐、谷歌浏览器、Safari和Opera等支持的浏览器中完整无缺地保存,特别是还可以保存一些资源,例如 YouTube 上的视频。它已成为网页保存领域流行的优秀软件。
2. 网页可以批量保存。
3. 可以导入Office文档:doc、ppt、xls、rtf。
4. 可以通过全文搜索导入 PDF 文件。
5.可以导入源代码文件,支持颜色标注。
5. 可以导入图片、flash等,也支持导入任意文件的附件。
资源管理
1. 以 HTML 格式保存所有资源,您可以在全文搜索、批处理、输出和电子书制作中以相同的方式管理它们。
2.设置一个文章为IE采集,可以添加多个书签,轻松实现多级文档管理。
3. 您还可以编辑书中的资源。
4.Nettext Quick Capture可以实现你书中的大量操作,比如分类、标注颜色、批处理等。
抓取网页生成电子书(你喜欢制作chm电子书吗?想把文件批量转换为网页格式吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-14 18:07
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、简繁体转换、文件格式转换、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为五种格式之一,HTML、TXT、RTF、DOC、XML
14、支持HTML网页文件一键生成电子书。
15、支持简繁体转换(GB2312->BIG5BIG5->GB2312)
16、网页特效采集与管理功能。并且可以方便的批量插入网页
17、反编译 CHM 电子书。
18、在线搜索功能。集成强大的中文搜索引擎---百度搜索
19、已经提供了几个 CSS 和模板。你也可以自己写。让过渡更随意
20、提供从html文件生成电子书的两个选项
21、支持ppt(powerpoint)文件一步生成电子书
22、支持xls(excel)文件一键生成电子书
23、文字和网页文字的批量替换
24、HTML TXT RTF DOC XML等格式可以任意相互转换
25、除了转换上面列出的文件类型,还可以自己添加转换类型 查看全部
抓取网页生成电子书(你喜欢制作chm电子书吗?想把文件批量转换为网页格式吗)
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、简繁体转换、文件格式转换、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为五种格式之一,HTML、TXT、RTF、DOC、XML
14、支持HTML网页文件一键生成电子书。
15、支持简繁体转换(GB2312->BIG5BIG5->GB2312)
16、网页特效采集与管理功能。并且可以方便的批量插入网页
17、反编译 CHM 电子书。
18、在线搜索功能。集成强大的中文搜索引擎---百度搜索
19、已经提供了几个 CSS 和模板。你也可以自己写。让过渡更随意
20、提供从html文件生成电子书的两个选项
21、支持ppt(powerpoint)文件一步生成电子书
22、支持xls(excel)文件一键生成电子书
23、文字和网页文字的批量替换
24、HTML TXT RTF DOC XML等格式可以任意相互转换
25、除了转换上面列出的文件类型,还可以自己添加转换类型
抓取网页生成电子书( 站点地图是一个网站所有链接的容器。你了解吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-14 18:05
站点地图是一个网站所有链接的容器。你了解吗?)
站点地图是网站所有链接的容器。许多 网站 连接很深,爬虫很难爬取。站点地图可以方便爬虫爬取 网站 页面。通过对网站页面的爬取,可以清楚的了解网站,网站地图一般存放在根目录并命名为sitemap来引导爬虫,添加网站的收录 @>重要内容页面。站点地图是根据网站的结构、框架和内容生成的导航网页文件。站点地图非常适合改善用户体验,它们为网站访问者提供方向并帮助迷路的访问者找到他们想查看的页面。
定义
站点地图是一种可视化工具,指示信息资源的位置和连接,并具有导航功能。关键在于四个方面:信息获取、信息检索、信息表示和信息关联。简而言之,就是将首页的信息按照类别以地图的形式列出,并提供相应的链接,可以为用户提供首页的整体信息,是用户准确查找的快捷入口他们需要的信息。
分类
1、sitemap(sitemap.xml,sitemap.txt) 这类站点地图收录网站的所有链接,一般提交给爬虫爬取。让搜索引擎转到 收录网站 内容。
2、网站导航,主要针对访问网站的用户。对网站连接进行分类,排序后展示在用户面前。
特征
可以烧结
这是站点地图应具有的重要功能。因为对图形的理解比文字更快更准确。这里所说的站点地图的内容虽然是用文字来表达的,但它是以地图的形式出现的,并且列出了每一栏的相关类别和子栏目。他们之间的关系表达得很清楚。它具有很强的能见度。它是用户查找所需信息资源的便捷方式。
加速
此功能在站点地图上尤为明显。网页内容清晰地显示在“地图”上,用户对首页信息一目了然。在站点地图上,还为显示的类别提供了超链接,用户可以点击超链接直接进入他们需要的栏目。这使用户能够准确、快速地找到他们需要的信息。
同步更新
站点地图是使用首页信息的辅助工具,它必须是随着首页信息内容的变化而建立的站点地图。随着首页信息的变化,它会及时调整自己的内容,保持与首页信息的高度一致性。
构建技巧
重要页面
如果站点地图收录太多链接,人们会在浏览时迷路。因此,如果 网站 页的总数超过 100,则需要选择最重要的页。推荐选择以下页面放在网站地图上:产品分类页面;主要产品页面;常见问题和帮助页面;页面被转换;访问量最高的 10 个页面;如果有现场搜索引擎,请从搜索引擎中选择点击次数最多的页面。
地图布局
站点地图布局必须简洁,所有链接均为标准HTML文本,并收录尽可能多的关键字,站点地图中不要使用图片制作链接,以免爬虫爬取。确保对链接使用标准 HTML 文本,包括尽可能多的目标关键字。例如,标题“我们的产品”可以替换为“无害除草剂、杀虫剂和杀菌剂”。
顾客习惯
用户通常希望每个页面底部都有指向站点地图的链接,以利用这种习惯。如果 网站 有搜索栏,请在搜索栏附近添加指向 网站 地图的链接,甚至将指向站点地图的链接放置在搜索结果页面上的固定位置。
将站点地图写入 robots.txt
引擎爬虫进来爬取网页时,会先检查robots.txt。如果先将sitemap写入robots.txt,效率会大大提高,从而获得搜索引擎的青睐。
产生
网上生成sitemap的方式有很多种,比如在线生成、软件生成等。Sitemap地图可以提交给各大搜索引擎,让搜索引擎更好的在网站页面上执行收录 ,而且我们还可以通过robots.txt告诉搜索引擎地图的位置。将准备好的网站映射上传到网站根目录。最重要的是将网站地图链接地址添加到robots文件中,使网站地图在页面上方便蜘蛛抓取位置,一般将网站地图放在页眉和页脚。
1、网站普通html格式的地图
其目的是帮助用户了解整个网站。Html格式的网站map是根据网站的结构特点制定的,将网站的功能结构和服务内容依次列出。通常,网站 主页具有指向该格式的 网站 地图的链接。
2、XML 站点地图通常称为站点地图(大写 S)
简单地说,站点地图是 网站 上的链接列表。创建站点地图并将其提交给搜索引擎可以让网站 的内容完全收录,包括那些隐藏得更深的页面。这是网站与搜索引擎交谈的好方法。
3、搜索引擎识别的地图
因为各个搜索引擎主要对地图格式的识别不同,所以推荐使用以下格式:
百度:推荐使用网站的Html格式地图
Google:推荐网站XML 格式的地图
雅虎:网站推荐txt格式的地图
重要性
1、搜索引擎让爬虫每天爬网爬取页面。站点地图的作用是为爬虫构建一个方便快捷的爬取通道,因为网站页面是一层一层的链接,可能会有死链接。如果没有站点地图,由于死链接,爬虫无法在页面上爬取,因此它无法收录 那些损坏的链接。
2、sitemaps的存在不仅仅是为了满足搜索引擎爬虫,也是为了方便网站访问者浏览网站,尤其是门户类型网站,由于信息量大许多访问者通过站点地图找到他们需要的信息页面,这也可以改善用户体验。
3、Sitemap 可以增加链接页面的权重,因为sitemap 是指向其他页面的链接。此时,站点地图会向页面添加导入链接。我们都知道导入链接的增加会影响页面的权重,所以增加页面的权重,页面权重的增加也会增加页面的收录率。
注意事项
真实有效
站点地图的主要目的是方便搜索和抓取。如果地图有死链接或者断链,会影响网站网站在搜索引擎中的权重,所以要仔细检查是否有错误的链接地址,检查网站的链接是否正确提交前通过站长工具有效。
简化
站点地图中不应有重复链接,应使用标准 W3C 格式的地图文件。布局应简洁明了。如果地图是内容地图,每个页面收录的内容链接不要超过100个,并且应该以分页的形式逐个打开。
更新
建议经常更新sitemap,方便搜索爬虫爬取频率的发展。经常会产生新的地图内容,这样的网站内容可以更快地被搜索引擎收录抓取,而网站内容也可以尽快被搜索引擎检索到。
多样性
站点地图不仅仅是为了搜索引擎,也是为了方便查看者,所以网站地图应该兼顾搜索引擎和查看者。我们通常为一个 网站 构建三个站点地图。sitemap.html 页面美观、简洁、大方,让浏览器很容易找到目标页面,同时也很开心。XML仔细研究了自己的网站,把重要的页面标记出来,不需要的页面加上NO FOLLOW,更有利于搜索引擎识别。URLLIST.TXT 或 ROBOTS.TXT 如果方便的话,最好自己做。雅虎等搜索引擎比较认可,谷歌也有这个项目。另外,网站地图位置要写在robots文本中,也就是格式。 查看全部
抓取网页生成电子书(
站点地图是一个网站所有链接的容器。你了解吗?)
站点地图是网站所有链接的容器。许多 网站 连接很深,爬虫很难爬取。站点地图可以方便爬虫爬取 网站 页面。通过对网站页面的爬取,可以清楚的了解网站,网站地图一般存放在根目录并命名为sitemap来引导爬虫,添加网站的收录 @>重要内容页面。站点地图是根据网站的结构、框架和内容生成的导航网页文件。站点地图非常适合改善用户体验,它们为网站访问者提供方向并帮助迷路的访问者找到他们想查看的页面。
定义
站点地图是一种可视化工具,指示信息资源的位置和连接,并具有导航功能。关键在于四个方面:信息获取、信息检索、信息表示和信息关联。简而言之,就是将首页的信息按照类别以地图的形式列出,并提供相应的链接,可以为用户提供首页的整体信息,是用户准确查找的快捷入口他们需要的信息。
分类
1、sitemap(sitemap.xml,sitemap.txt) 这类站点地图收录网站的所有链接,一般提交给爬虫爬取。让搜索引擎转到 收录网站 内容。
2、网站导航,主要针对访问网站的用户。对网站连接进行分类,排序后展示在用户面前。
特征
可以烧结
这是站点地图应具有的重要功能。因为对图形的理解比文字更快更准确。这里所说的站点地图的内容虽然是用文字来表达的,但它是以地图的形式出现的,并且列出了每一栏的相关类别和子栏目。他们之间的关系表达得很清楚。它具有很强的能见度。它是用户查找所需信息资源的便捷方式。
加速
此功能在站点地图上尤为明显。网页内容清晰地显示在“地图”上,用户对首页信息一目了然。在站点地图上,还为显示的类别提供了超链接,用户可以点击超链接直接进入他们需要的栏目。这使用户能够准确、快速地找到他们需要的信息。
同步更新
站点地图是使用首页信息的辅助工具,它必须是随着首页信息内容的变化而建立的站点地图。随着首页信息的变化,它会及时调整自己的内容,保持与首页信息的高度一致性。
构建技巧
重要页面
如果站点地图收录太多链接,人们会在浏览时迷路。因此,如果 网站 页的总数超过 100,则需要选择最重要的页。推荐选择以下页面放在网站地图上:产品分类页面;主要产品页面;常见问题和帮助页面;页面被转换;访问量最高的 10 个页面;如果有现场搜索引擎,请从搜索引擎中选择点击次数最多的页面。
地图布局
站点地图布局必须简洁,所有链接均为标准HTML文本,并收录尽可能多的关键字,站点地图中不要使用图片制作链接,以免爬虫爬取。确保对链接使用标准 HTML 文本,包括尽可能多的目标关键字。例如,标题“我们的产品”可以替换为“无害除草剂、杀虫剂和杀菌剂”。
顾客习惯
用户通常希望每个页面底部都有指向站点地图的链接,以利用这种习惯。如果 网站 有搜索栏,请在搜索栏附近添加指向 网站 地图的链接,甚至将指向站点地图的链接放置在搜索结果页面上的固定位置。
将站点地图写入 robots.txt
引擎爬虫进来爬取网页时,会先检查robots.txt。如果先将sitemap写入robots.txt,效率会大大提高,从而获得搜索引擎的青睐。
产生
网上生成sitemap的方式有很多种,比如在线生成、软件生成等。Sitemap地图可以提交给各大搜索引擎,让搜索引擎更好的在网站页面上执行收录 ,而且我们还可以通过robots.txt告诉搜索引擎地图的位置。将准备好的网站映射上传到网站根目录。最重要的是将网站地图链接地址添加到robots文件中,使网站地图在页面上方便蜘蛛抓取位置,一般将网站地图放在页眉和页脚。
1、网站普通html格式的地图
其目的是帮助用户了解整个网站。Html格式的网站map是根据网站的结构特点制定的,将网站的功能结构和服务内容依次列出。通常,网站 主页具有指向该格式的 网站 地图的链接。
2、XML 站点地图通常称为站点地图(大写 S)
简单地说,站点地图是 网站 上的链接列表。创建站点地图并将其提交给搜索引擎可以让网站 的内容完全收录,包括那些隐藏得更深的页面。这是网站与搜索引擎交谈的好方法。
3、搜索引擎识别的地图
因为各个搜索引擎主要对地图格式的识别不同,所以推荐使用以下格式:
百度:推荐使用网站的Html格式地图
Google:推荐网站XML 格式的地图
雅虎:网站推荐txt格式的地图
重要性
1、搜索引擎让爬虫每天爬网爬取页面。站点地图的作用是为爬虫构建一个方便快捷的爬取通道,因为网站页面是一层一层的链接,可能会有死链接。如果没有站点地图,由于死链接,爬虫无法在页面上爬取,因此它无法收录 那些损坏的链接。
2、sitemaps的存在不仅仅是为了满足搜索引擎爬虫,也是为了方便网站访问者浏览网站,尤其是门户类型网站,由于信息量大许多访问者通过站点地图找到他们需要的信息页面,这也可以改善用户体验。
3、Sitemap 可以增加链接页面的权重,因为sitemap 是指向其他页面的链接。此时,站点地图会向页面添加导入链接。我们都知道导入链接的增加会影响页面的权重,所以增加页面的权重,页面权重的增加也会增加页面的收录率。
注意事项
真实有效
站点地图的主要目的是方便搜索和抓取。如果地图有死链接或者断链,会影响网站网站在搜索引擎中的权重,所以要仔细检查是否有错误的链接地址,检查网站的链接是否正确提交前通过站长工具有效。
简化
站点地图中不应有重复链接,应使用标准 W3C 格式的地图文件。布局应简洁明了。如果地图是内容地图,每个页面收录的内容链接不要超过100个,并且应该以分页的形式逐个打开。
更新
建议经常更新sitemap,方便搜索爬虫爬取频率的发展。经常会产生新的地图内容,这样的网站内容可以更快地被搜索引擎收录抓取,而网站内容也可以尽快被搜索引擎检索到。
多样性
站点地图不仅仅是为了搜索引擎,也是为了方便查看者,所以网站地图应该兼顾搜索引擎和查看者。我们通常为一个 网站 构建三个站点地图。sitemap.html 页面美观、简洁、大方,让浏览器很容易找到目标页面,同时也很开心。XML仔细研究了自己的网站,把重要的页面标记出来,不需要的页面加上NO FOLLOW,更有利于搜索引擎识别。URLLIST.TXT 或 ROBOTS.TXT 如果方便的话,最好自己做。雅虎等搜索引擎比较认可,谷歌也有这个项目。另外,网站地图位置要写在robots文本中,也就是格式。
抓取网页生成电子书(目录各种尝试生成PDF提取文章内容选择文|李晓飞总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2022-02-14 18:04
目录各种尝试生成PDF提取文章内容选择优化总结参考正文 | 李小飞来源:Python技术“ID:pythonall”爬虫程序大家一定不陌生,只要写一个就可以获取网页上的信息,甚至可以通过请求自...
目录选择最佳摘要参考
正文 | 李晓飞
来源:python科技《ID:pythonall》
爬虫程序想必大家都不陌生。您可以通过编写一个获取网页信息,甚至可以通过请求自动生成 Python 脚本 [1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但问题是没有限制爬取范围,也就是说没有清晰的页面结构。
对于一个页面,除了核心的文章内容外,还有页眉、拖尾、左右列表栏等。有的页框使用div布局,有的使用table,即使使用了div,样式和网站 的布局不同。
但问题必须解决。我想,既然各种网页的核心内容都是搜索引擎抓取的,那我们应该也能做到,拿起Python,说到做到!
各种尝试
如何解决?
生成 PDF
我开始想一个比较棘手的方法,就是使用一个工具(wkhtmltopdf[2])从目标网页生成一个PDF文件。
好处是不用关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源代码级别搜索 PDF,但生成 PDF 有很多缺点:
它消耗大量计算资源,效率低,错误率高,体积太大。
数万条数据已经超过200GB。如果数据量增加,只有存储将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构并且可读性降低。更糟糕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。就像搜索引擎学习一样,就是想办法找出页面的核心内容。
我们知道,一般情况下,页面上的核心内容(比如文章部分)是比较集中的,我们可以从这个地方入手分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里我只截取了提取 文章 部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试了几页确实不错。
但是,在大量提取过程中,发现很多页面无法提取数据。仔细观察会发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,p多是首选,在它的基础上看到的div少。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(s编程客栈el)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
即发现的文章体是不稳定的,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,因此需要重新设计算法。
我发现文字集中的地方往往是文章的主体,而之前的方法没有考虑到这一点,只是机械地找了最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近的地方应该越有可能是文章主题,也就是说计算是离p越近的节点权重应该越大,离p越远的节点有一个很多 p 及时,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度的原理,即越靠近中心,密度就越高,远离中心的地方密度呈指数下降,这样就可以把密度中心筛掉。
50%的斜率是怎么来的?
事实上,它是通过实验确定的。一开始我设置为90%,但是body节点最后总是最好的,因为body收录了所有的文本内容。
经过反复试验,确定 50% 是一个不错的值,如果不适合您的应用,请进行调整。
总结
在描述了我如何选择 文章 主题之后,我发现它实际上并不是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要你理解了处理问题的常规方式,处理日常编程就足够了。当遇到不确定的问题,没有办法提取简单的模型时,常规思维显然是不够的。
因此,我们通常应该看一些数学强,解决不确定问题的方法,以提高我们的编程适应性,扩大我们的技能范围。
希望这篇短文能对你有所启发,欢迎在留言区交流讨论,对比你的心!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮擦:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246 查看全部
抓取网页生成电子书(目录各种尝试生成PDF提取文章内容选择文|李晓飞总结)
目录各种尝试生成PDF提取文章内容选择优化总结参考正文 | 李小飞来源:Python技术“ID:pythonall”爬虫程序大家一定不陌生,只要写一个就可以获取网页上的信息,甚至可以通过请求自...
目录选择最佳摘要参考
正文 | 李晓飞
来源:python科技《ID:pythonall》
爬虫程序想必大家都不陌生。您可以通过编写一个获取网页信息,甚至可以通过请求自动生成 Python 脚本 [1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但问题是没有限制爬取范围,也就是说没有清晰的页面结构。
对于一个页面,除了核心的文章内容外,还有页眉、拖尾、左右列表栏等。有的页框使用div布局,有的使用table,即使使用了div,样式和网站 的布局不同。
但问题必须解决。我想,既然各种网页的核心内容都是搜索引擎抓取的,那我们应该也能做到,拿起Python,说到做到!
各种尝试
如何解决?
生成 PDF
我开始想一个比较棘手的方法,就是使用一个工具(wkhtmltopdf[2])从目标网页生成一个PDF文件。
好处是不用关心页面的具体形式,就像给页面拍照一样,文章结构就完整了。
虽然可以在源代码级别搜索 PDF,但生成 PDF 有很多缺点:
它消耗大量计算资源,效率低,错误率高,体积太大。
数万条数据已经超过200GB。如果数据量增加,只有存储将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构并且可读性降低。更糟糕的是,网页上有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。就像搜索引擎学习一样,就是想办法找出页面的核心内容。
我们知道,一般情况下,页面上的核心内容(比如文章部分)是比较集中的,我们可以从这个地方入手分析。
所以我写了一段代码。我使用 Scrapy[4] 作为爬虫框架。这里我只截取了提取 文章 部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试了几页确实不错。
但是,在大量提取过程中,发现很多页面无法提取数据。仔细观察会发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,p多是首选,在它的基础上看到的div少。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(s编程客栈el)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
即发现的文章体是不稳定的,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,因此需要重新设计算法。
我发现文字集中的地方往往是文章的主体,而之前的方法没有考虑到这一点,只是机械地找了最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离p标签越近的地方应该越有可能是文章主题,也就是说计算是离p越近的节点权重应该越大,离p越远的节点有一个很多 p 及时,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度的原理,即越靠近中心,密度就越高,远离中心的地方密度呈指数下降,这样就可以把密度中心筛掉。
50%的斜率是怎么来的?
事实上,它是通过实验确定的。一开始我设置为90%,但是body节点最后总是最好的,因为body收录了所有的文本内容。
经过反复试验,确定 50% 是一个不错的值,如果不适合您的应用,请进行调整。
总结
在描述了我如何选择 文章 主题之后,我发现它实际上并不是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要你理解了处理问题的常规方式,处理日常编程就足够了。当遇到不确定的问题,没有办法提取简单的模型时,常规思维显然是不够的。
因此,我们通常应该看一些数学强,解决不确定问题的方法,以提高我们的编程适应性,扩大我们的技能范围。
希望这篇短文能对你有所启发,欢迎在留言区交流讨论,对比你的心!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮擦:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-13 23:03
)
无意中发现了一个可以免费下载电子书的网站,一下子勾起了我的采集瘾,恨不得下载这些书,就在不久前,请求的作者kennethreitz发布了一个新的图书馆请求-html ,不仅可以请求网页,还可以解析 HTML 文档。事不宜迟,让我们开始吧。
安装
安装很简单,只需执行:
pip install requests-html
而已。
分析页面结构
通过检查浏览器中的元素,您可以发现这本电子书 网站 是使用 WordPress 构建的。主页列表元素非常简单和规则。
所以我们可以通过查找 .entry-title > a 得到所有图书详情页的链接,然后我们到详情页找到下载链接,如下图
可以发现.download-links > a中的链接就是该书的下载链接。回到列表页面,可以发现站点有700多个页面,所以我们可以循环列表获取所有的下载链接。
Requests-html 快速指南
发送 GET 请求:
Requests-html 的方便之处在于它解析 html 就像使用 jQuery 一样容易,例如:
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
查看全部
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图)
)
无意中发现了一个可以免费下载电子书的网站,一下子勾起了我的采集瘾,恨不得下载这些书,就在不久前,请求的作者kennethreitz发布了一个新的图书馆请求-html ,不仅可以请求网页,还可以解析 HTML 文档。事不宜迟,让我们开始吧。
安装
安装很简单,只需执行:
pip install requests-html
而已。
分析页面结构
通过检查浏览器中的元素,您可以发现这本电子书 网站 是使用 WordPress 构建的。主页列表元素非常简单和规则。
所以我们可以通过查找 .entry-title > a 得到所有图书详情页的链接,然后我们到详情页找到下载链接,如下图
可以发现.download-links > a中的链接就是该书的下载链接。回到列表页面,可以发现站点有700多个页面,所以我们可以循环列表获取所有的下载链接。
Requests-html 快速指南
发送 GET 请求:
Requests-html 的方便之处在于它解析 html 就像使用 jQuery 一样容易,例如:
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-13 22:30
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin的编程课堂)
)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
爬取列文章地址列表
抓取每个文章的详细内容
导出 PDF
1. 爬取列表
如何分析网页上的请求在前面的 文章 中有所描述。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
而 True: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
对于数据中的文章:
# 如果 j['paging']['is_end'] 保存 id 和 title(省略):
中断 url = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = '' + idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_='Post-RichText').prettify()
# 处理内容(略)
使用 open(file_name, 'w') 作为 f: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin的编程课堂)
)。但万一哪天,你喜欢的回答者被喷到网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是小概率事件(但不会发生),但要注意,可以将关注的栏目导出为电子书,这样可以离线阅读,不怕误删帖。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
爬取列文章地址列表
抓取每个文章的详细内容
导出 PDF
1. 爬取列表
如何分析网页上的请求在前面的 文章 中有所描述。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
而 True: resp = requests.get(url, headers=headers) j = resp.json() data = j['data']
对于数据中的文章:
# 如果 j['paging']['is_end'] 保存 id 和 title(省略):
中断 url = j['paging']['next']
# 按id排序(省略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = '' + idhtml = requests.get(url, headers=headers).textsoup = BeautifulSoup(html, 'lxml')content = soup.find(class_='Post-RichText').prettify()
# 处理内容(略)
使用 open(file_name, 'w') 作为 f: f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
点安装pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(排序(htmls), '知乎.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据这两个步骤. 所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
抓取网页生成电子书(上一个迭代任务是将一个html网页转换成pdf的知识点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-13 16:06
最后一个迭代任务是将 html 网页转换为 pdf。 pdf转现有系统的插件是TCPDF,但是这个插件太老了,支持的css样式和html标签太少。在尝试用 TCPDF 写了两天后,我放弃了。
然后改成wkhtmltopdf,不得不说wkhtmltopdf终于完美的把网页转换成pdf了。接下来写一下本次生成pdf用到的知识点。
参考文献文章:
1、封面:
封面可以定制。我写了另一个html页面作为这个pdf的封面,然后用命令添加了。
比如:cover.html就是我写的封面,效果如下:
然后生成pdf封面的命令是这个:wkhtmltopdf cover http://api-dev.inboyu.com/pdf- ... 04312
其中:http://api-dev.inboyu.com/pdf- ... 04312
是这个cover.html访问路径。
accessToken 是返回页面上标题和申请人所需要的参数。
2、页眉、页脚
页眉和页脚也可以添加一个html作为封面。不过我没试过,只是用了wkhtmltopdf提供的命令。
wkhtmltopdf --header-left "XXX有限公司" --header-right "[date] [time] 机密文件请勿外传" --header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
3、目录
本次迭代的亮点是这个目录,也被wkhtmltopdf代替了,因为目录TCPDF不知道怎么实现(或者根本无法实现)。
我们最终生成的目录如下所示:
是不是比带有pdf的侧边栏书签好看多了?哈哈
这个目录是如何实现的?
这里需要注意的是,新的wkhtmltopd版本不支持。我使用 wkhtmltopdf 0.12.3.
然后根据网页中的H1、H2...标签确定目录。所以网页应该已经准备好了。
接下来就是一行命令:
wkhtmltopdf toc
总而言之,我必须从网页生成带有自定义封面、目录、页眉、页脚的 pdf 的所有命令如下:
wkhtmltopdf --header-left "XXX科技有限公司" --header-right "[date] [time] 机密文件请勿外传"
--header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
cover http://api-dev.inboyu.com/pdf- ... 04312
toc --toc-header-text "目录" https://api-test.inboyu.com/pd ... 04312 D:\\1.pdf
备注:
1、--toc-header-text "目录" 将目录变成中文,不然是contents。
2、http://api-test.inboyu.com/pdf ... 04312 是要转换成pdf的网页。
3、D:\\1.pdf 是存放pdf的地址,因为在本地调试,所以我存在了D盘目录下。
就这么简单,转换后的pdf和网页差不多。
另外:
1、页面布局主要是pdf中表格布局可能被截断的问题,解决方法:
tr{page-break-inside: avoid;}
2、使用page-break-before:left;使以下三个都在生成的pdf中打开一个新页面。
3、我的pdf里也加了水印,好像wkhtmltopdf没有提供水印的方法(我还是找不到,如果有人用wkhtmltopdf提供的方法,希望大家告诉我,谢谢!)
我的做法是剪一张带水印的图片,如下:
然后将它添加到这个网页的最外层父元素作为背景,然后重复背景,例如:
//网页内容
//网页内容
//网页内容
终于实现了水印的效果。需要提醒的是,在做水印的时候,我们网页的效果和pdf的效果可能会有差距。生成pdf后,水印的间距会变差。这时候可以调整你的网页窗口大小,让你的网页收紧生成的pdf,然后调整水印,让最终生成的pdf准确无误,包括上面提到的封面。偏差)。
我的pdf水印效果如下:
4、如果有图表,如果看到别人说加动画:false;禁止动画,可以显示,否则生成的pdf中的图表会是空白的。
或者(我使用的方法):
1、先用 结合echarts生成一个图表。
2、然后调用echarts的getDataURL方法生成一个图片地址放到
let echartKLine = echarts.init($('.js-kline'));
echartKLine.setOption(option);
window.onresize = echartKLine.resize;
$("#js-img").attr("src",echartKLine.getDataURL())
最后隐藏 js-kline,显示 js-img。
相当于把图表变成了和这个图表长得一摸一样的图片。
至此,基本上所有的问题都涉及到了。生成的 pdf 与网页几乎完全相同。 查看全部
抓取网页生成电子书(上一个迭代任务是将一个html网页转换成pdf的知识点)
最后一个迭代任务是将 html 网页转换为 pdf。 pdf转现有系统的插件是TCPDF,但是这个插件太老了,支持的css样式和html标签太少。在尝试用 TCPDF 写了两天后,我放弃了。
然后改成wkhtmltopdf,不得不说wkhtmltopdf终于完美的把网页转换成pdf了。接下来写一下本次生成pdf用到的知识点。
参考文献文章:
1、封面:
封面可以定制。我写了另一个html页面作为这个pdf的封面,然后用命令添加了。
比如:cover.html就是我写的封面,效果如下:
然后生成pdf封面的命令是这个:wkhtmltopdf cover http://api-dev.inboyu.com/pdf- ... 04312
其中:http://api-dev.inboyu.com/pdf- ... 04312
是这个cover.html访问路径。
accessToken 是返回页面上标题和申请人所需要的参数。
2、页眉、页脚
页眉和页脚也可以添加一个html作为封面。不过我没试过,只是用了wkhtmltopdf提供的命令。
wkhtmltopdf --header-left "XXX有限公司" --header-right "[date] [time] 机密文件请勿外传" --header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
3、目录
本次迭代的亮点是这个目录,也被wkhtmltopdf代替了,因为目录TCPDF不知道怎么实现(或者根本无法实现)。
我们最终生成的目录如下所示:
是不是比带有pdf的侧边栏书签好看多了?哈哈
这个目录是如何实现的?
这里需要注意的是,新的wkhtmltopd版本不支持。我使用 wkhtmltopdf 0.12.3.
然后根据网页中的H1、H2...标签确定目录。所以网页应该已经准备好了。
接下来就是一行命令:
wkhtmltopdf toc
总而言之,我必须从网页生成带有自定义封面、目录、页眉、页脚的 pdf 的所有命令如下:
wkhtmltopdf --header-left "XXX科技有限公司" --header-right "[date] [time] 机密文件请勿外传"
--header-line --header-spacing 3 --footer-spacing 3 --footer-center "- 第 [page] 页-"
cover http://api-dev.inboyu.com/pdf- ... 04312
toc --toc-header-text "目录" https://api-test.inboyu.com/pd ... 04312 D:\\1.pdf
备注:
1、--toc-header-text "目录" 将目录变成中文,不然是contents。
2、http://api-test.inboyu.com/pdf ... 04312 是要转换成pdf的网页。
3、D:\\1.pdf 是存放pdf的地址,因为在本地调试,所以我存在了D盘目录下。
就这么简单,转换后的pdf和网页差不多。
另外:
1、页面布局主要是pdf中表格布局可能被截断的问题,解决方法:
tr{page-break-inside: avoid;}
2、使用page-break-before:left;使以下三个都在生成的pdf中打开一个新页面。
3、我的pdf里也加了水印,好像wkhtmltopdf没有提供水印的方法(我还是找不到,如果有人用wkhtmltopdf提供的方法,希望大家告诉我,谢谢!)
我的做法是剪一张带水印的图片,如下:
然后将它添加到这个网页的最外层父元素作为背景,然后重复背景,例如:
//网页内容
//网页内容
//网页内容
终于实现了水印的效果。需要提醒的是,在做水印的时候,我们网页的效果和pdf的效果可能会有差距。生成pdf后,水印的间距会变差。这时候可以调整你的网页窗口大小,让你的网页收紧生成的pdf,然后调整水印,让最终生成的pdf准确无误,包括上面提到的封面。偏差)。
我的pdf水印效果如下:
4、如果有图表,如果看到别人说加动画:false;禁止动画,可以显示,否则生成的pdf中的图表会是空白的。
或者(我使用的方法):
1、先用 结合echarts生成一个图表。
2、然后调用echarts的getDataURL方法生成一个图片地址放到
let echartKLine = echarts.init($('.js-kline'));
echartKLine.setOption(option);
window.onresize = echartKLine.resize;
$("#js-img").attr("src",echartKLine.getDataURL())
最后隐藏 js-kline,显示 js-img。
相当于把图表变成了和这个图表长得一摸一样的图片。
至此,基本上所有的问题都涉及到了。生成的 pdf 与网页几乎完全相同。
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-13 02:17
看来写爬虫并不比使用 Python 更合适。Python社区提供的爬虫工具琳琅满目,你可以分分钟写一个爬虫,里面有各种可以直接使用的库。今天,我正在考虑写一个爬虫。,爬取廖雪峰的Python教程,制作成PDF电子书,供大家离线阅读。
在开始写爬虫之前,我们先分析一下网站1的页面结构。页面左侧是教程的目录大纲,每个URL对应右侧一个文章,右上角是文章的标题,中间是正文部分文章的,body的内容是我们关注的重点,我们要爬取的数据是所有网页的body部分,底部是用户的评论区,评论区对我们来说很重要它没有用,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。request和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个穿梭机,我们可以快速工作,不需要像scrapy这样的爬虫框架。这有点像用小程序杀鸡。另外,既然html文件转换成pdf,就必须有相应的库支持,wkhtmltopdf是一个很好的工具,可以用于多平台html到pdf的转换,pdfkit是wkhtmltopdf的Python包。首先安装以下依赖项,
然后安装 wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台,直接从wkhtmltopdf官网下载稳定版2并安装。安装完成后,将程序的执行路径添加到系统环境的$PATH变量中。否则,如果pdfkit找不到wkhtmltopdf,就会出现“No wkhtmltopdf executable found”的错误。Ubuntu和CentOS可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编码了,不过最好在写代码之前整理一下思路。该程序的目的是将所有URL对应的html正文部分保存在本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将一个URL对应的html body保存到本地,然后找到所有的URL,进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到文字对应的div标签:
, div 是页面的正文内容。在本地使用请求加载整个页面后,您可以使用 beautifulsoup 操作 HTML dom 元素以提取正文内容。
具体实现代码如下:使用soup.find_all函数找到body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析页面左侧的所有URL。同样的方法,找到左侧的菜单选项卡 查看全部
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
看来写爬虫并不比使用 Python 更合适。Python社区提供的爬虫工具琳琅满目,你可以分分钟写一个爬虫,里面有各种可以直接使用的库。今天,我正在考虑写一个爬虫。,爬取廖雪峰的Python教程,制作成PDF电子书,供大家离线阅读。
在开始写爬虫之前,我们先分析一下网站1的页面结构。页面左侧是教程的目录大纲,每个URL对应右侧一个文章,右上角是文章的标题,中间是正文部分文章的,body的内容是我们关注的重点,我们要爬取的数据是所有网页的body部分,底部是用户的评论区,评论区对我们来说很重要它没有用,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。request和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个穿梭机,我们可以快速工作,不需要像scrapy这样的爬虫框架。这有点像用小程序杀鸡。另外,既然html文件转换成pdf,就必须有相应的库支持,wkhtmltopdf是一个很好的工具,可以用于多平台html到pdf的转换,pdfkit是wkhtmltopdf的Python包。首先安装以下依赖项,
然后安装 wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台,直接从wkhtmltopdf官网下载稳定版2并安装。安装完成后,将程序的执行路径添加到系统环境的$PATH变量中。否则,如果pdfkit找不到wkhtmltopdf,就会出现“No wkhtmltopdf executable found”的错误。Ubuntu和CentOS可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编码了,不过最好在写代码之前整理一下思路。该程序的目的是将所有URL对应的html正文部分保存在本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将一个URL对应的html body保存到本地,然后找到所有的URL,进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到文字对应的div标签:
, div 是页面的正文内容。在本地使用请求加载整个页面后,您可以使用 beautifulsoup 操作 HTML dom 元素以提取正文内容。
具体实现代码如下:使用soup.find_all函数找到body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析页面左侧的所有URL。同样的方法,找到左侧的菜单选项卡
抓取网页生成电子书(一款专为PDF文件打造的页面提取工具介绍!免费下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-12 12:24
)
PDF Page Extractor 是一款专为 PDF 文件设计的页面提取工具。界面直观清晰,功能一目了然,操作简单易用。可以将PDF文件的一页或多页批量提取到一个新文档中。这也很简单。您只需添加文件、设置提取页面、保存路径等信息,即可快速从单个或多个PDF页面中提取指定页面。并且软件支持提取单页、连续多页、提取最后一页、自定义页等多种提取类型。它可以在没有任何其他软件支持的情况下从 PDF 中提取页面。它可以提取单页,或者连续的多页,或者不连续的多页,并且可以添加密码保护和文档限制。如果源文档受密码保护或限制,请在提取页面之前对其进行解密。您还可以添加水印以有效保护您的文档。欢迎有需要的用户免费下载体验!
功能介绍1、快速方便地提取PDF文件中的一页或多页,并保存为新文档。
2、可以连续提取多页,输入起始页码和结束页码即可。
3、无需任何其他软件支持即可实现PDF提取页面。
4、可以提取单个页面,或多个连续页面,或多个不连续页面。
5、可以添加密码保护和文档限制。
6、您可以添加水印以有效保护您的文档。软件功能1、同时处理单个 PDF 或整个目录
2、在输出文件中添加个性化水印
3、加密生成的PDF文件并设置内容权限
4、删除源文件上解压出来的页面,重新保存
5、提取单页,输入要提取的页码
6、提取多个连续页面,输入起始页码和结束页码
7、最后提取,请输入最后提取多少页
8、自定义页面,例如:1、3、5-8、10-20
9、在提取页面前,输入提取页面前半部分的百分比。使用方法1、安装后打开PDF解压页面软件,将文件或文件拖放到软件或点击添加文件或添加文件夹,右键删除或打开添加的文件;
2、提取页面设置;
3、保存设置;
4、点击【提取页面】按钮;
5、提取完成。
6、需要保密处理的可以点击“设置”按钮添加水印和密码
查看全部
抓取网页生成电子书(一款专为PDF文件打造的页面提取工具介绍!免费下载
)
PDF Page Extractor 是一款专为 PDF 文件设计的页面提取工具。界面直观清晰,功能一目了然,操作简单易用。可以将PDF文件的一页或多页批量提取到一个新文档中。这也很简单。您只需添加文件、设置提取页面、保存路径等信息,即可快速从单个或多个PDF页面中提取指定页面。并且软件支持提取单页、连续多页、提取最后一页、自定义页等多种提取类型。它可以在没有任何其他软件支持的情况下从 PDF 中提取页面。它可以提取单页,或者连续的多页,或者不连续的多页,并且可以添加密码保护和文档限制。如果源文档受密码保护或限制,请在提取页面之前对其进行解密。您还可以添加水印以有效保护您的文档。欢迎有需要的用户免费下载体验!
功能介绍1、快速方便地提取PDF文件中的一页或多页,并保存为新文档。
2、可以连续提取多页,输入起始页码和结束页码即可。
3、无需任何其他软件支持即可实现PDF提取页面。
4、可以提取单个页面,或多个连续页面,或多个不连续页面。
5、可以添加密码保护和文档限制。
6、您可以添加水印以有效保护您的文档。软件功能1、同时处理单个 PDF 或整个目录
2、在输出文件中添加个性化水印
3、加密生成的PDF文件并设置内容权限
4、删除源文件上解压出来的页面,重新保存
5、提取单页,输入要提取的页码
6、提取多个连续页面,输入起始页码和结束页码
7、最后提取,请输入最后提取多少页
8、自定义页面,例如:1、3、5-8、10-20
9、在提取页面前,输入提取页面前半部分的百分比。使用方法1、安装后打开PDF解压页面软件,将文件或文件拖放到软件或点击添加文件或添加文件夹,右键删除或打开添加的文件;
2、提取页面设置;
3、保存设置;
4、点击【提取页面】按钮;
5、提取完成。
6、需要保密处理的可以点击“设置”按钮添加水印和密码

