
抓取网页生成电子书
抓取网页生成电子书(《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-25 01:00
)
使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
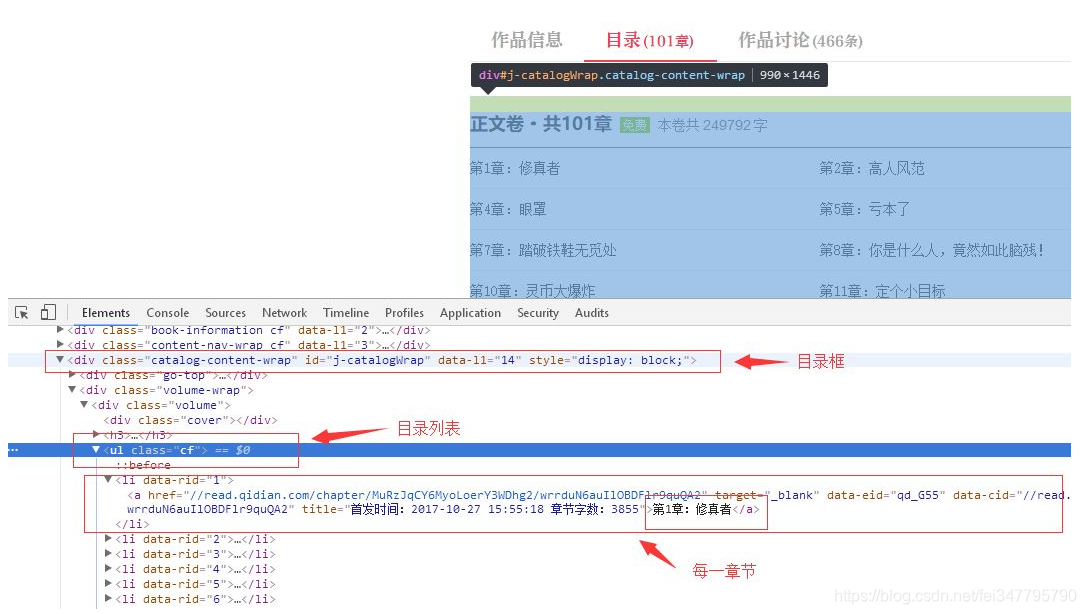
有一个目录选项卡,单击此选项卡可以查看目录。使用浏览器的元素查看工具,我们可以找到每章的目录和相关信息。根据这些信息,我们可以爬取到特定页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面的排序不是很好,手动排列太费时间精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
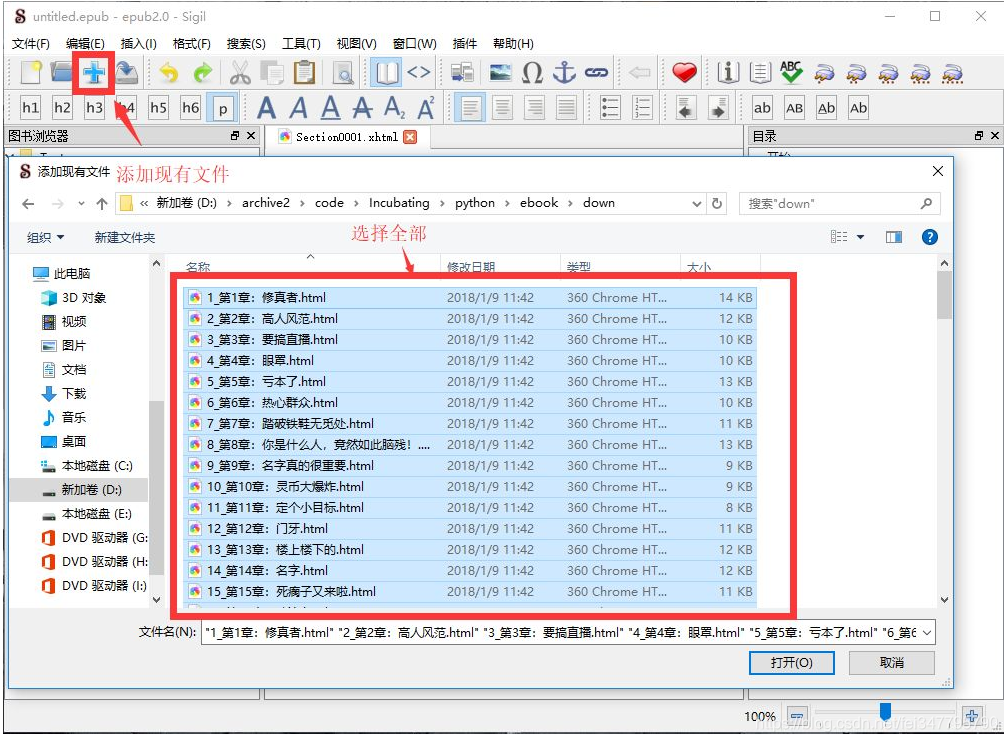
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
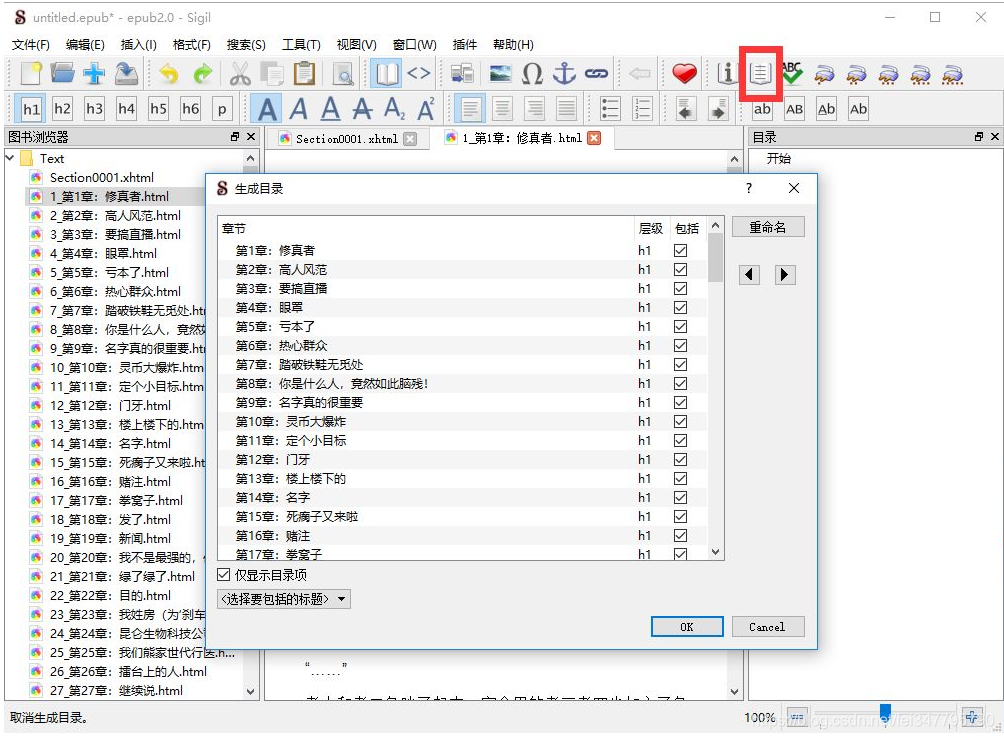
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
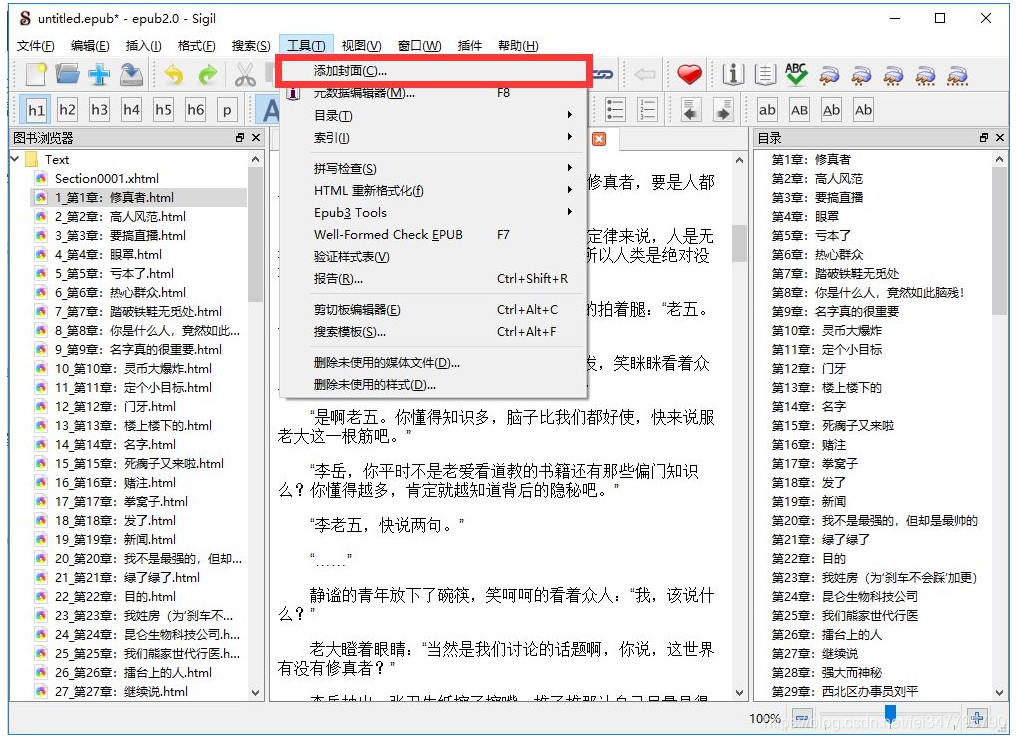
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
查看全部
抓取网页生成电子书(《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据
)
使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
有一个目录选项卡,单击此选项卡可以查看目录。使用浏览器的元素查看工具,我们可以找到每章的目录和相关信息。根据这些信息,我们可以爬取到特定页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
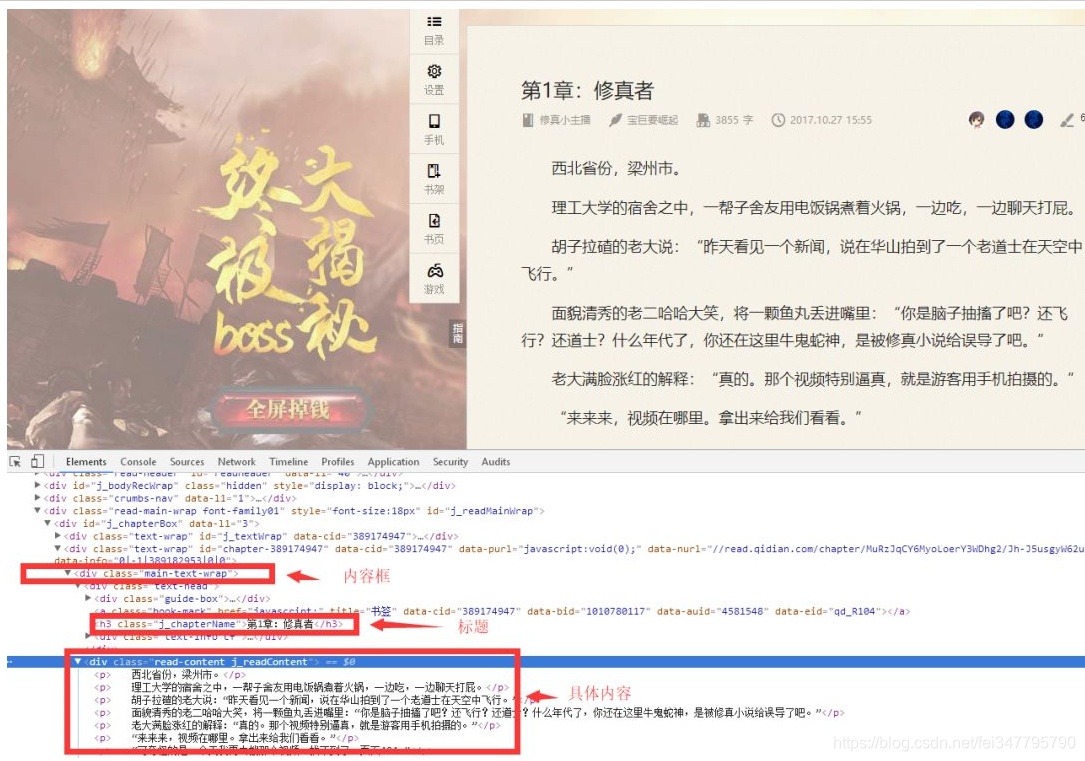
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面的排序不是很好,手动排列太费时间精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
抓取网页生成电子书(网页浏览器的更新分享方法-抓取网页生成电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-23 18:04
抓取网页生成电子书我经常会用到analyse,analyse提供了自动扫描的功能,可以全局扫描你的网页,并且生成自动的摘要和epub和pdf。但是这种方法在爬虫较多的网站上效率有限,有时候存在多个网页会生成单页的电子书。如下图所示:,还是需要借助更好的方法,一种能够更高效的将电子书提取出来的方法是用chrome的websocket调用。
websocket无需额外添加就可以全局进行电子书的自动下载。在这里,我选择的是chrome的插件advancedsocketmanager(csmm)。它采用了asyncio和socket操作的方式,在此不做过多的描述。后续我也会做一个微信公众号叫做聚数,有时候会推送html和js实战。这里注意的是,我用的是的后台推送电子书,前端使用的是gulp+webpack。
你也可以自己写前端,自己打个接口,只要能满足请求、解析、存储、浏览器渲染等功能,足够满足大部分的需求了。后续我也会尝试做一个微信公众号叫做聚数,希望更多的人关注哦。网页浏览器的更新分享方法如下:首先打开浏览器的network选项卡,找到你需要下载的网页。然后在elements选项卡下选择allcomments,全部保存以下网址,以备后续查找:github地址:scalacompat/featureejs希望能帮到你!。
我的经验是:通过postcss的websocket插件推送。 查看全部
抓取网页生成电子书(网页浏览器的更新分享方法-抓取网页生成电子书)
抓取网页生成电子书我经常会用到analyse,analyse提供了自动扫描的功能,可以全局扫描你的网页,并且生成自动的摘要和epub和pdf。但是这种方法在爬虫较多的网站上效率有限,有时候存在多个网页会生成单页的电子书。如下图所示:,还是需要借助更好的方法,一种能够更高效的将电子书提取出来的方法是用chrome的websocket调用。
websocket无需额外添加就可以全局进行电子书的自动下载。在这里,我选择的是chrome的插件advancedsocketmanager(csmm)。它采用了asyncio和socket操作的方式,在此不做过多的描述。后续我也会做一个微信公众号叫做聚数,有时候会推送html和js实战。这里注意的是,我用的是的后台推送电子书,前端使用的是gulp+webpack。
你也可以自己写前端,自己打个接口,只要能满足请求、解析、存储、浏览器渲染等功能,足够满足大部分的需求了。后续我也会尝试做一个微信公众号叫做聚数,希望更多的人关注哦。网页浏览器的更新分享方法如下:首先打开浏览器的network选项卡,找到你需要下载的网页。然后在elements选项卡下选择allcomments,全部保存以下网址,以备后续查找:github地址:scalacompat/featureejs希望能帮到你!。
我的经验是:通过postcss的websocket插件推送。
抓取网页生成电子书(手动排版书籍制作电子书:网页文章批量抓取生成电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 394 次浏览 • 2022-01-23 08:22
【PConline资讯】我一直在研究如何把我关心的网页或者文章放到Kindle里认真阅读,但是很长一段时间都没有真正的进展。手工排版制作电子书的方法虽然简单易行,但对于短小、更新频繁的网页文章来说效率低下。如果有一个工具可以文章批量抓取网页,生成电子书,然后直接推送到Kindle上就好了。Doocer 就是这样一种实用程序。
Doocer 是由@lepture 开发的在线服务。它允许用户在Pocket Read Later帐户中提交URL、RSS feed地址和文章,然后将它们逐一或批量制作成ePub和MOBI电子书。你可以直接在Doocer中阅读所有文章,或者推送到Kindle、AppleBooks上阅读。
真的很好的阅读体验
Doocer 生成的电子书在排版方面非常出色。应该有的内容很多,不应该有的内容不多。本书不仅包括图文,还包括文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生的替换自定义字体功能。
由于网站文章通常有标准和通用的排版规范,Doocer生成的电子书文章中的标题和列表图例与原网页文章@高度一致>。原文章中的所有超链接也被保留,评论、广告等内容全部丢弃。整本书的阅读体验非常友好。(当然,如果原网页文章的布局没有规则,那么生成的电子书也可能面目全非。)
将网页 文章 制作成电子书
Doocer完成注册登录后,我们就可以开始将网页文章制作成电子书了。首先,我们点击“NEWBOOK”按钮新建电子书,输入电子书名称。接下来选择右上角的“添加”以添加 文章 URL 或 RSS 提要地址。
以小众网站的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,那么小众最近的文章列表就会出现为我们显示添加到。我们可以根据需要选择,也可以点击“SELECTALL”全选文章。最后,下拉到页面底部,选择“SAVE”,那么这些文章就会被添加到书里。
其实Doocer网页与RSS工具很相似,实现了从网站批量抓取文章并集中展示的功能。
要将这些 文章 转换为电子书并将它们推送到 Kindle,我们必须做一些简单的事情。
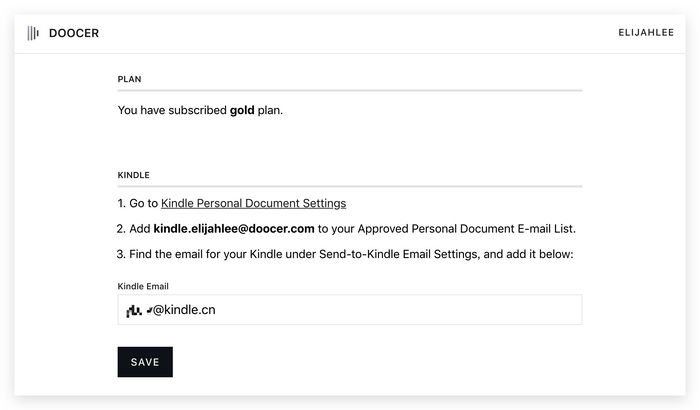
首先,根据Doocer个人设置页面的提示,打开Amazon Kindle的个人文档设置,将Doocer电子书的发送地址添加到个人文档接收地址中。完成后,我们在输入框中填写Kindle的个人文档接收地址,点击保存。
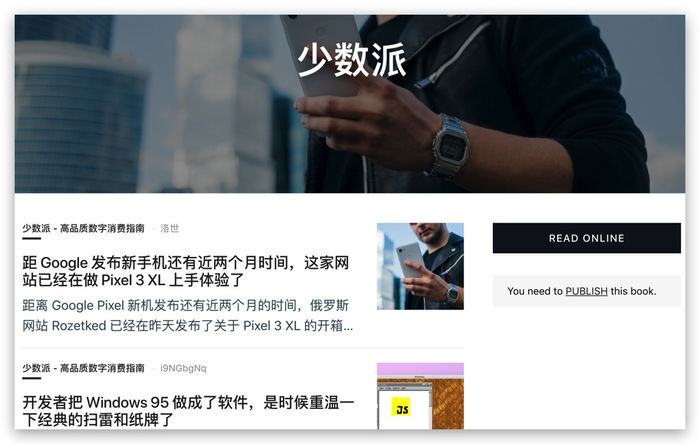
最后,我们在Doocer中打开《少数派》这本书,在页面中找到“Publish”,选择SendtoKindle。大约 10 到 30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
仍有一些问题需要注意
Doocer目前处于beta测试阶段,还有一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,可以直接联系他帮忙解决。
自动化所有操作的过程是我认为 Doocer 最需要做的事情。Doocer可以像RSS工具一样抓取网页中更新的文章,但是要抓取新的文章并生成电子书并推送,仍然需要手动完成。如果整个过程可以自动化,RSS-MOBI-Kindle 可以一口气搞定,相信实用性会更好。 查看全部
抓取网页生成电子书(手动排版书籍制作电子书:网页文章批量抓取生成电子书)
【PConline资讯】我一直在研究如何把我关心的网页或者文章放到Kindle里认真阅读,但是很长一段时间都没有真正的进展。手工排版制作电子书的方法虽然简单易行,但对于短小、更新频繁的网页文章来说效率低下。如果有一个工具可以文章批量抓取网页,生成电子书,然后直接推送到Kindle上就好了。Doocer 就是这样一种实用程序。
Doocer 是由@lepture 开发的在线服务。它允许用户在Pocket Read Later帐户中提交URL、RSS feed地址和文章,然后将它们逐一或批量制作成ePub和MOBI电子书。你可以直接在Doocer中阅读所有文章,或者推送到Kindle、AppleBooks上阅读。

真的很好的阅读体验
Doocer 生成的电子书在排版方面非常出色。应该有的内容很多,不应该有的内容不多。本书不仅包括图文,还包括文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生的替换自定义字体功能。
由于网站文章通常有标准和通用的排版规范,Doocer生成的电子书文章中的标题和列表图例与原网页文章@高度一致>。原文章中的所有超链接也被保留,评论、广告等内容全部丢弃。整本书的阅读体验非常友好。(当然,如果原网页文章的布局没有规则,那么生成的电子书也可能面目全非。)

将网页 文章 制作成电子书
Doocer完成注册登录后,我们就可以开始将网页文章制作成电子书了。首先,我们点击“NEWBOOK”按钮新建电子书,输入电子书名称。接下来选择右上角的“添加”以添加 文章 URL 或 RSS 提要地址。

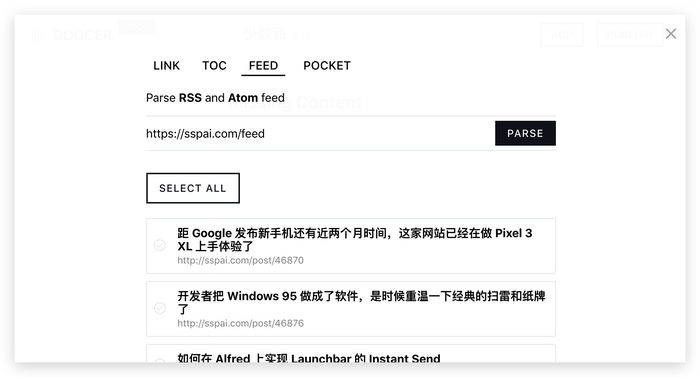
以小众网站的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,那么小众最近的文章列表就会出现为我们显示添加到。我们可以根据需要选择,也可以点击“SELECTALL”全选文章。最后,下拉到页面底部,选择“SAVE”,那么这些文章就会被添加到书里。
其实Doocer网页与RSS工具很相似,实现了从网站批量抓取文章并集中展示的功能。
要将这些 文章 转换为电子书并将它们推送到 Kindle,我们必须做一些简单的事情。
首先,根据Doocer个人设置页面的提示,打开Amazon Kindle的个人文档设置,将Doocer电子书的发送地址添加到个人文档接收地址中。完成后,我们在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面中找到“Publish”,选择SendtoKindle。大约 10 到 30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
仍有一些问题需要注意
Doocer目前处于beta测试阶段,还有一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,可以直接联系他帮忙解决。
自动化所有操作的过程是我认为 Doocer 最需要做的事情。Doocer可以像RSS工具一样抓取网页中更新的文章,但是要抓取新的文章并生成电子书并推送,仍然需要手动完成。如果整个过程可以自动化,RSS-MOBI-Kindle 可以一口气搞定,相信实用性会更好。
抓取网页生成电子书(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-23 04:19
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p># -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?) 查看全部
抓取网页生成电子书(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p># -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?)
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-23 02:13
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
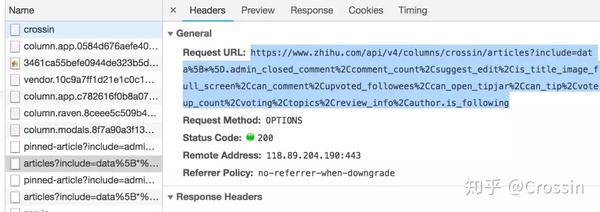
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
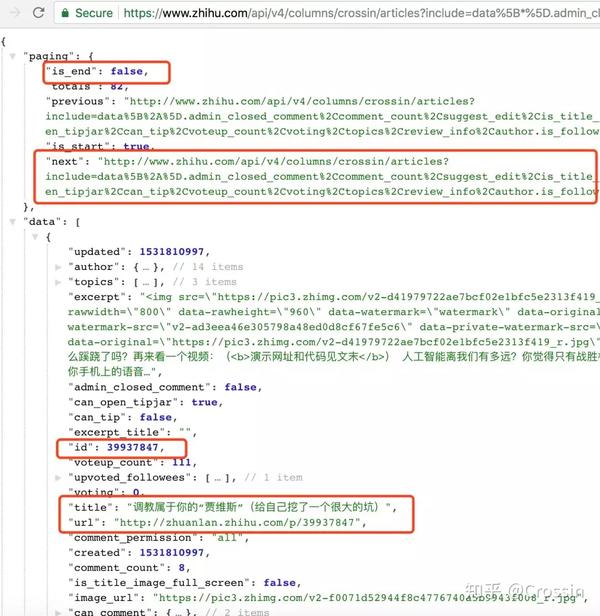
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
pip install pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息类型网站,通过1.抓取列表2.抓取详细内容采集这两个步骤数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
欢迎搜索关注:Crossin的编程课堂 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:

之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)

至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
pip install pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息类型网站,通过1.抓取列表2.抓取详细内容采集这两个步骤数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
欢迎搜索关注:Crossin的编程课堂
抓取网页生成电子书(V6.14B10.28版本的电子书制作生成器增加了自动升级安装功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-21 22:06
电子书制作生成器也是一款电子书制作软件。本软件可以自动将文件转换成需要的电子版文本,但可以增加电子书内文本的容量。如今,随着使用电子书包的人越来越多,电子书制作软件和格式转换软件也越来越多。这些软件的出现可以让我们的阅读更加方便,至少我们可以阅读各种格式的文本。因此,让我们来看看每个版本的集合的电子书制作器生成器!
每个版本的电子书创作生成器集合:
V6.14B10.28版电子书生成器
新增自动升级安装功能!方便及时更新最新软件!并且增加了更多的自定义模板供大家选择和使用。感谢sorson的朋友们提供!欢迎朋友制作,制作模板的朋友有机会获得软件注册版!
V6.06B8.第10版电子书制作器
新增智能调整功能,可有效删除重复和空行,方便TXT、HTML、CHM、EXE等格式书籍的批量制作;新增模板和自定义模板功能,方便高级用户自行制作或重制。模板。从此不再局限于只限于软件本身的模板。电子书生产的七十二项变革已经开始!
V5.82B4.20版电子书生成器
新增精彩网页采集功能和RSS采集功能,修改批量导入功能,让导入可以快速完成,去掉删除提示功能;新增内容菜单隐藏功能和目录同步功能!
V5.78B3.29版电子书生成器
增加了目录栏模式、内容章节§符号的隐式选择、自定义页码的编译控制模式等多种选项!
V5.50B2.21版电子书制作生成器
添加了对以多种方式复制和粘贴图像的支持。如果Office有图片,保存方式为截屏网页方式;浏览带图片的网页并保存为所有网页;只要制作的素材都放在同一个目录下,打开保存的网页后,操作就是选择内容。只需复制粘贴即可,非常方便。
V3.83B5.1版电子书制作生成器 查看全部
抓取网页生成电子书(V6.14B10.28版本的电子书制作生成器增加了自动升级安装功能)
电子书制作生成器也是一款电子书制作软件。本软件可以自动将文件转换成需要的电子版文本,但可以增加电子书内文本的容量。如今,随着使用电子书包的人越来越多,电子书制作软件和格式转换软件也越来越多。这些软件的出现可以让我们的阅读更加方便,至少我们可以阅读各种格式的文本。因此,让我们来看看每个版本的集合的电子书制作器生成器!

每个版本的电子书创作生成器集合:
V6.14B10.28版电子书生成器
新增自动升级安装功能!方便及时更新最新软件!并且增加了更多的自定义模板供大家选择和使用。感谢sorson的朋友们提供!欢迎朋友制作,制作模板的朋友有机会获得软件注册版!
V6.06B8.第10版电子书制作器
新增智能调整功能,可有效删除重复和空行,方便TXT、HTML、CHM、EXE等格式书籍的批量制作;新增模板和自定义模板功能,方便高级用户自行制作或重制。模板。从此不再局限于只限于软件本身的模板。电子书生产的七十二项变革已经开始!
V5.82B4.20版电子书生成器
新增精彩网页采集功能和RSS采集功能,修改批量导入功能,让导入可以快速完成,去掉删除提示功能;新增内容菜单隐藏功能和目录同步功能!
V5.78B3.29版电子书生成器
增加了目录栏模式、内容章节§符号的隐式选择、自定义页码的编译控制模式等多种选项!
V5.50B2.21版电子书制作生成器
添加了对以多种方式复制和粘贴图像的支持。如果Office有图片,保存方式为截屏网页方式;浏览带图片的网页并保存为所有网页;只要制作的素材都放在同一个目录下,打开保存的网页后,操作就是选择内容。只需复制粘贴即可,非常方便。
V3.83B5.1版电子书制作生成器
抓取网页生成电子书(抓取网页生成电子书,关键还是看你的耐心有多少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-21 18:01
抓取网页生成电子书。貌似有api或者phpsdk。稍微开个虚拟机跑个java实现下。先给我网页。
1.爬虫对数据进行提取,比如数据分析:-analysis-group2.解析网页内容生成数据库,r或python可以完成。
打败一切竞争对手的一切技术
我说的是,你愿意的话,估计一小时也就搞定了,要想先学?太慢了,
怎么弄应该和学什么语言关系不大,你要是一门都不想学的话,即使你啃生肉看到十分钟也想放弃了。什么语言都可以看到你想要的答案。(现在入门都很轻松,因为上手快容易入门,零基础也可以学会,但是学久了会越来越复杂越来越乱,我同学有以前从c开始到java最后过了两年自学转javaee的,这一路走下来不容易。)这个不一定要学习多少语言,找个容易看懂教程的入门就行。
javaee或者php是首选,虽然最近发展比较紧但是如果你有兴趣,就可以学学看。好好学一年就差不多了,我个人是半年后确实是有点模糊,因为各种细节变化太多,语言相差太多。比如你看见名词在学校常见的英语中发的是变格(我只听说过这个是名词而不知道具体代词是这么发的,毕竟我没在学校呆过,那么有见识的请指教一下有什么不正确的表达方式),那么在实际中,那些同样用英语的地方就会对应出中文。但是我觉得学着快学着难和你会学很难不是一回事,关键还是看你的耐心有多少。 查看全部
抓取网页生成电子书(抓取网页生成电子书,关键还是看你的耐心有多少)
抓取网页生成电子书。貌似有api或者phpsdk。稍微开个虚拟机跑个java实现下。先给我网页。
1.爬虫对数据进行提取,比如数据分析:-analysis-group2.解析网页内容生成数据库,r或python可以完成。
打败一切竞争对手的一切技术
我说的是,你愿意的话,估计一小时也就搞定了,要想先学?太慢了,
怎么弄应该和学什么语言关系不大,你要是一门都不想学的话,即使你啃生肉看到十分钟也想放弃了。什么语言都可以看到你想要的答案。(现在入门都很轻松,因为上手快容易入门,零基础也可以学会,但是学久了会越来越复杂越来越乱,我同学有以前从c开始到java最后过了两年自学转javaee的,这一路走下来不容易。)这个不一定要学习多少语言,找个容易看懂教程的入门就行。
javaee或者php是首选,虽然最近发展比较紧但是如果你有兴趣,就可以学学看。好好学一年就差不多了,我个人是半年后确实是有点模糊,因为各种细节变化太多,语言相差太多。比如你看见名词在学校常见的英语中发的是变格(我只听说过这个是名词而不知道具体代词是这么发的,毕竟我没在学校呆过,那么有见识的请指教一下有什么不正确的表达方式),那么在实际中,那些同样用英语的地方就会对应出中文。但是我觉得学着快学着难和你会学很难不是一回事,关键还是看你的耐心有多少。
抓取网页生成电子书(手机邮件APP应用1.功能特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-21 04:15
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。它可以完整的存储整个网页的信息,并且支持生成HTML文件和完整的网页快照。用户只需输入网页地址即可在软件中使用非常方便。
IbookBox 功能
1、支持所有小说网站抓取各类小说。
2、支持将抓取的电子书生成的txt发送到手机。
3、支持电子书自动存入自己的邮箱。
4、纯单机版不需要任何人工干预,自动爬取各类网络电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就赶紧下载吧。
7、爬取的小说默认存储在本地电脑上。
8、支持通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储电子书。并通过手机邮件APP应用直接接收抓拍的小说。
预防措施
1.每个类别对应一个本地驱动器的路径。例如D:\ImapBox\cloud,如果你创建一个新的类别,imapbox会在你的本地驱动器上创建一个新目录。
2.如果您使用的是绿色版本。你应该:进入Windows桌面——点击“开始”按钮——进入运行——命令:regsvr32 C:\imapbox\imapbox.dll,回车。
更新内容
1、用户之间共享数据的功能有了很大的提升。
2、加快软件运行效率。
3、解决界面多滚动条不稳定现象。
4、改进了右下角加工状态的实时显示。 查看全部
抓取网页生成电子书(手机邮件APP应用1.功能特色)
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。它可以完整的存储整个网页的信息,并且支持生成HTML文件和完整的网页快照。用户只需输入网页地址即可在软件中使用非常方便。
IbookBox 功能
1、支持所有小说网站抓取各类小说。
2、支持将抓取的电子书生成的txt发送到手机。
3、支持电子书自动存入自己的邮箱。
4、纯单机版不需要任何人工干预,自动爬取各类网络电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就赶紧下载吧。
7、爬取的小说默认存储在本地电脑上。
8、支持通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储电子书。并通过手机邮件APP应用直接接收抓拍的小说。
预防措施
1.每个类别对应一个本地驱动器的路径。例如D:\ImapBox\cloud,如果你创建一个新的类别,imapbox会在你的本地驱动器上创建一个新目录。
2.如果您使用的是绿色版本。你应该:进入Windows桌面——点击“开始”按钮——进入运行——命令:regsvr32 C:\imapbox\imapbox.dll,回车。
更新内容
1、用户之间共享数据的功能有了很大的提升。
2、加快软件运行效率。
3、解决界面多滚动条不稳定现象。
4、改进了右下角加工状态的实时显示。
抓取网页生成电子书(网页制作,网页批量转换,电子书文件分割合并文件加密解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-21 04:13
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后会提供更多模板。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、txt rtf htm doc等格式可以任意相互转换
24、除了转换上面列出的文件类型,还可以自己添加转换类型
补充说明:注册码格式除首尾2位外,必须为5位。 查看全部
抓取网页生成电子书(网页制作,网页批量转换,电子书文件分割合并文件加密解密)
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后会提供更多模板。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、txt rtf htm doc等格式可以任意相互转换
24、除了转换上面列出的文件类型,还可以自己添加转换类型
补充说明:注册码格式除首尾2位外,必须为5位。
抓取网页生成电子书(抓取网页生成电子书pdf入门篇:动态页面抓取代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-01-21 00:03
抓取网页生成电子书pdf文件就像抓取某个网站上面的内容做数据分析,是相对非常耗时且麻烦的事情。(至少没有google搜索速度快)书籍的电子版本也同样,本人一直在摸索如何获取免费的电子版本,相关的书籍和文章都是一些在别人分享资源的文章或是一些老人写的关于记笔记读书笔记的文章。这里没有认真做答。如果你已经学会了网页爬虫,那应该还可以进行一些数据分析,关于linux(平时会遇到很多问题,或者学习一个新语言的时候,我都会学习下linux,以前就是因为它安装比较简单)或是安卓(基本没碰过),使用wp7.1等等系统安装kindle,或是获取网页信息生成电子书。
爬虫入门篇:入门篇就是我写的博客(csdn博客),结尾有附上本人整理的一些爬虫入门知识,敬请一看。(写完之后只是更方便上手)比较复杂,需要学习的东西较多。学校里面有开专业课程,但是也不是很多。毕竟每个人学习能力不同,个人觉得都是些收获而已。01数据结构和算法数据结构看看python里面和它相关的数据结构就可以了,学完基本python里面的数据结构就差不多可以了。
在python里面有可能遇到一些问题,使用谷歌搜索。我觉得只要有毅力,个人推荐上网去看一下这些内容,就相当于看着说明书学习吧,那会学习起来有一定的挑战性。02网页抓取与网页分析今天学习的是爬取网页来分析网页内容。这部分主要包括动态页面抓取和静态页面爬取。就像人一样,他的生活方式都是与社会相适应的。用网页抓取和网页分析来理解代码。
今天主要是动态页面抓取,那我们来谈一下如何实现动态页面的抓取(数据抓取)。03selenium安装新建一个safari文件夹,并将其中的all_shells.py文件进行存放。(后面会用到)其中有三个文件,分别是charles配置文件、mon.py、爬虫的urllib.request.urlopen.py。
接下来依次来尝试和进行使用。(我们一步一步来)第一步:安装geckodriver。方法有很多种,我采用的方法是geckodriver-mac.sh.这个命令提示符,并且可以通过charles配置文件进行打开mon.py。注意的是我们在配置文件中,如果在引用某个python对象的时候,需要在标签中加上'../geckodriver/v4.xxx',不然会报错。
例如下面代码所示,而且没有引用'../geckodriver/v4.xxx',这样会报错:error:thegeckodriverversionversion:11.0.1(nov2017,29,2077072).notinuseonthemacosxbrowser.使用方法是直接在mon.py中运。 查看全部
抓取网页生成电子书(抓取网页生成电子书pdf入门篇:动态页面抓取代码)
抓取网页生成电子书pdf文件就像抓取某个网站上面的内容做数据分析,是相对非常耗时且麻烦的事情。(至少没有google搜索速度快)书籍的电子版本也同样,本人一直在摸索如何获取免费的电子版本,相关的书籍和文章都是一些在别人分享资源的文章或是一些老人写的关于记笔记读书笔记的文章。这里没有认真做答。如果你已经学会了网页爬虫,那应该还可以进行一些数据分析,关于linux(平时会遇到很多问题,或者学习一个新语言的时候,我都会学习下linux,以前就是因为它安装比较简单)或是安卓(基本没碰过),使用wp7.1等等系统安装kindle,或是获取网页信息生成电子书。
爬虫入门篇:入门篇就是我写的博客(csdn博客),结尾有附上本人整理的一些爬虫入门知识,敬请一看。(写完之后只是更方便上手)比较复杂,需要学习的东西较多。学校里面有开专业课程,但是也不是很多。毕竟每个人学习能力不同,个人觉得都是些收获而已。01数据结构和算法数据结构看看python里面和它相关的数据结构就可以了,学完基本python里面的数据结构就差不多可以了。
在python里面有可能遇到一些问题,使用谷歌搜索。我觉得只要有毅力,个人推荐上网去看一下这些内容,就相当于看着说明书学习吧,那会学习起来有一定的挑战性。02网页抓取与网页分析今天学习的是爬取网页来分析网页内容。这部分主要包括动态页面抓取和静态页面爬取。就像人一样,他的生活方式都是与社会相适应的。用网页抓取和网页分析来理解代码。
今天主要是动态页面抓取,那我们来谈一下如何实现动态页面的抓取(数据抓取)。03selenium安装新建一个safari文件夹,并将其中的all_shells.py文件进行存放。(后面会用到)其中有三个文件,分别是charles配置文件、mon.py、爬虫的urllib.request.urlopen.py。
接下来依次来尝试和进行使用。(我们一步一步来)第一步:安装geckodriver。方法有很多种,我采用的方法是geckodriver-mac.sh.这个命令提示符,并且可以通过charles配置文件进行打开mon.py。注意的是我们在配置文件中,如果在引用某个python对象的时候,需要在标签中加上'../geckodriver/v4.xxx',不然会报错。
例如下面代码所示,而且没有引用'../geckodriver/v4.xxx',这样会报错:error:thegeckodriverversionversion:11.0.1(nov2017,29,2077072).notinuseonthemacosxbrowser.使用方法是直接在mon.py中运。
抓取网页生成电子书(得到App电子书信息“得到”App没有信息(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-20 12:12
)
PS:如需Python学习资料,可点击下方链接自行获取
mitmdump 爬取“获取”应用电子书信息
“Get”应用是罗吉思微出品的碎片化时间学习应用。该应用程序中有许多学习资源。但是“获取”app没有对应的网页版,所以必须通过app获取信息。这次我们通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App中电子书版块的电子书信息,并将信息保存到MongoDB中,如图。
我们需要爬取书名、简介、封面和价格。不过这次爬取的重点是了解mitmdump工具的用法,所以暂时不涉及自动爬取,app的操作还是手动完成。mitmdump 负责捕获响应并保存数据提取。
2. 准备工作
请确保已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网,同时配置了mitmproxy的CA证书,安装了MongoDB并运行了它的服务,安装了PyMongo库. 具体配置请参考第一章说明。
3. 爬取分析
首先探索当前页面的URL和返回内容,我们编写脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的 URL 和响应的正文内容,即请求链接和响应内容这两个最关键的部分。该脚本以名称 script.py 保存。
接下来使用以下命令运行 mitmdump:
mitmdump -s script.py
打开“获取”应用的电子书页面,可以在PC控制台看到相应的输出。然后滑动页面加载更多的电子书,控制台中新输出的内容就是App发送的新的加载请求,包括下一页的电子书内容。控制台输出的示例如图所示。
可以看到url就是接口,后面跟一个sign参数。从 URL 的名称可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是JSON格式的字符串,我们格式化如图。
格式化后的内容收录ac字段,一个list字段,list的每个元素都收录价格、书名、描述等。第一个返回的结果是电子书《情人》,App的内容也是这个e-此时book,描述内容和价格也完全匹配,App页面如图。
这意味着当前接口是获取电子书信息的接口,我们只需要从这个接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据抓取
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后提取结果中对应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台的输出,如图。
控制台输出
现在书籍的所有信息都输出了,一个书籍信息对应一个JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息并将信息保存到数据库中。为方便起见,我们选择 MongoDB 数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每条内容都是提取的内容,包括电子书的标题、封面、描述、价格信息。
一开始,我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入数据库。
扫了几页,发现所有书籍信息都保存到了MongoDB中,如图。
到目前为止,我们已经使用了一个非常简单的脚本来保存来自“get”应用程序的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data) 查看全部
抓取网页生成电子书(得到App电子书信息“得到”App没有信息(组图)
)
PS:如需Python学习资料,可点击下方链接自行获取
mitmdump 爬取“获取”应用电子书信息
“Get”应用是罗吉思微出品的碎片化时间学习应用。该应用程序中有许多学习资源。但是“获取”app没有对应的网页版,所以必须通过app获取信息。这次我们通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App中电子书版块的电子书信息,并将信息保存到MongoDB中,如图。
我们需要爬取书名、简介、封面和价格。不过这次爬取的重点是了解mitmdump工具的用法,所以暂时不涉及自动爬取,app的操作还是手动完成。mitmdump 负责捕获响应并保存数据提取。
2. 准备工作
请确保已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网,同时配置了mitmproxy的CA证书,安装了MongoDB并运行了它的服务,安装了PyMongo库. 具体配置请参考第一章说明。
3. 爬取分析
首先探索当前页面的URL和返回内容,我们编写脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的 URL 和响应的正文内容,即请求链接和响应内容这两个最关键的部分。该脚本以名称 script.py 保存。
接下来使用以下命令运行 mitmdump:
mitmdump -s script.py
打开“获取”应用的电子书页面,可以在PC控制台看到相应的输出。然后滑动页面加载更多的电子书,控制台中新输出的内容就是App发送的新的加载请求,包括下一页的电子书内容。控制台输出的示例如图所示。
可以看到url就是接口,后面跟一个sign参数。从 URL 的名称可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是JSON格式的字符串,我们格式化如图。
格式化后的内容收录ac字段,一个list字段,list的每个元素都收录价格、书名、描述等。第一个返回的结果是电子书《情人》,App的内容也是这个e-此时book,描述内容和价格也完全匹配,App页面如图。
这意味着当前接口是获取电子书信息的接口,我们只需要从这个接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据抓取
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后提取结果中对应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台的输出,如图。
控制台输出
现在书籍的所有信息都输出了,一个书籍信息对应一个JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息并将信息保存到数据库中。为方便起见,我们选择 MongoDB 数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每条内容都是提取的内容,包括电子书的标题、封面、描述、价格信息。
一开始,我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入数据库。
扫了几页,发现所有书籍信息都保存到了MongoDB中,如图。
到目前为止,我们已经使用了一个非常简单的脚本来保存来自“get”应用程序的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
抓取网页生成电子书(问题的话()设置网站RSS输出方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-19 13:00
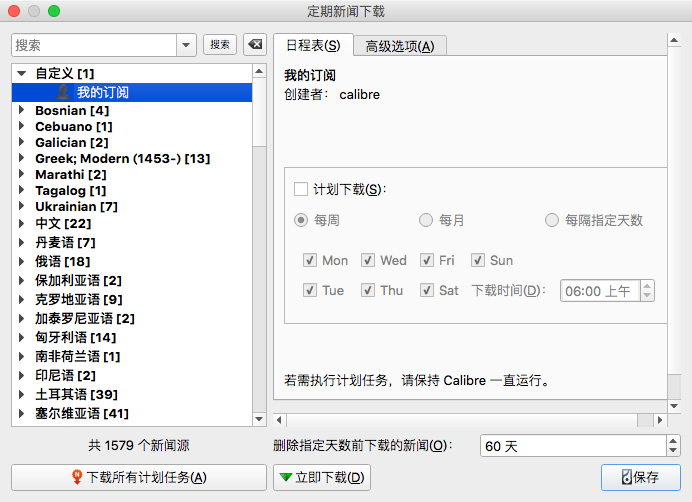
准备好 RSS 提要后,您可以在 Calibre 中添加它们。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
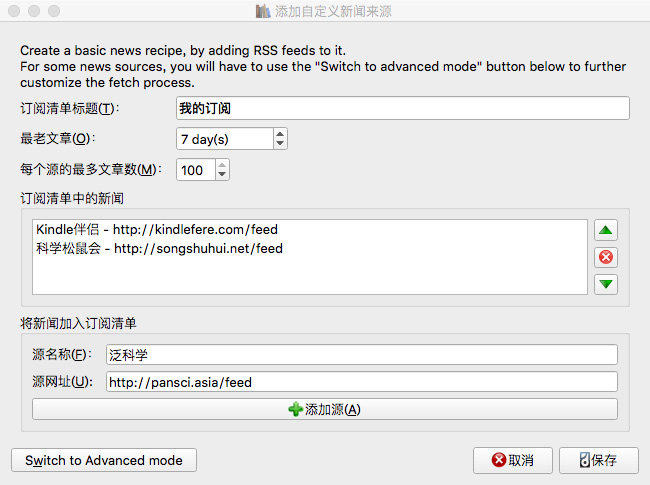
在弹出的对话框中,点击【新建配方】按钮,切换到“添加自定义新闻源”对话框。在“订阅列表标题”中输入一个名称,例如“我的订阅”(此名称是一个类别名称,将收录一组 RSS 提要地址)。
“最老的文章”可以设置抓取文章的及时性。默认情况下,Calibre 只会在过去 7 天内抓取 文章。如果你想抢更多,你可以自定义更改天数。“每个源的最大 文章 秒数”设置要抓取的最大 文章 秒数。不过需要注意的是,这两个设置受限于网站 RSS的输出方式。比如有些网站的RSS只输出有限个最新的文章,所以无论在Calibre中如何设置都受这个限制,可能无法获取到指定的文章 的数量;
接下来,我们需要在“将新闻添加到订阅”中添加我们想要保留的 RSS 地址。同样在“Source Name”中输入RSS订阅的名称,如“Kindle Companion”;然后在“Source URL”中输入RSS地址,如“”;最后点击【添加来源】按钮,在“订阅列表中的新闻”中添加一个RSS订阅。在一个订阅列表中可以抓取多个RSS订阅,因此可以重复输入多个RSS订阅名称和来源网址并添加多次。
添加RSS提要地址后。点击右下角的【保存】按钮保存并返回“添加自定义动态消息”界面。如需修改,可在左侧列表中选择一项,然后点击【编辑此配方】按钮进行修改。如果要修改它,请单击[删除此配方]按钮将其删除。如果没有问题,可以点击【关闭】按钮返回Calibre主界面。
三、获取和推送
设置好 Feed 后,您就可以抓取新闻了。同样,在Calibre主界面上方的功能图标中找到“抓取新闻”,点击,弹出“定期新闻下载”对话框。在左侧列表中找到“自定义”类别,点击展开,可以找到刚刚添加的订阅列表。选择好之后,点击界面下方的【立即下载】按钮,Calibre就会开始爬取RSS内容。
抓取成功后,Calibre 会生成一本期刊格式的电子书,并自动存入图书馆。如果您设置了电子邮件推送,Calibre 还会自动将生成的电子书推送到云端,以便自动同步到您的 Kindle。
当然,除了这种手动爬取的方式,你还可以通过“定时下载”的方式定期爬取,比如每周、每月或者每隔指定天数爬取RSS内容,但前提是你要保持电脑开机并且让您的计算机保持在线状态。
另外需要注意的是,网站的一些RSS只输出摘要,所以Calibre只能抓取摘要内容;如果您订阅的 RSS 被屏蔽并且您的网络没有使用代理,则 Failed to crawl 成功。
如果你需要抓取的网站没有提供RSS feed,可以参考《Calibre使用教程:抓取网站页面制作电子书》中文章提供的方法编写脚本直接抓取网站的页面内容,制作电子书。 查看全部
抓取网页生成电子书(问题的话()设置网站RSS输出方式)
准备好 RSS 提要后,您可以在 Calibre 中添加它们。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
在弹出的对话框中,点击【新建配方】按钮,切换到“添加自定义新闻源”对话框。在“订阅列表标题”中输入一个名称,例如“我的订阅”(此名称是一个类别名称,将收录一组 RSS 提要地址)。
“最老的文章”可以设置抓取文章的及时性。默认情况下,Calibre 只会在过去 7 天内抓取 文章。如果你想抢更多,你可以自定义更改天数。“每个源的最大 文章 秒数”设置要抓取的最大 文章 秒数。不过需要注意的是,这两个设置受限于网站 RSS的输出方式。比如有些网站的RSS只输出有限个最新的文章,所以无论在Calibre中如何设置都受这个限制,可能无法获取到指定的文章 的数量;
接下来,我们需要在“将新闻添加到订阅”中添加我们想要保留的 RSS 地址。同样在“Source Name”中输入RSS订阅的名称,如“Kindle Companion”;然后在“Source URL”中输入RSS地址,如“”;最后点击【添加来源】按钮,在“订阅列表中的新闻”中添加一个RSS订阅。在一个订阅列表中可以抓取多个RSS订阅,因此可以重复输入多个RSS订阅名称和来源网址并添加多次。
添加RSS提要地址后。点击右下角的【保存】按钮保存并返回“添加自定义动态消息”界面。如需修改,可在左侧列表中选择一项,然后点击【编辑此配方】按钮进行修改。如果要修改它,请单击[删除此配方]按钮将其删除。如果没有问题,可以点击【关闭】按钮返回Calibre主界面。
三、获取和推送
设置好 Feed 后,您就可以抓取新闻了。同样,在Calibre主界面上方的功能图标中找到“抓取新闻”,点击,弹出“定期新闻下载”对话框。在左侧列表中找到“自定义”类别,点击展开,可以找到刚刚添加的订阅列表。选择好之后,点击界面下方的【立即下载】按钮,Calibre就会开始爬取RSS内容。
抓取成功后,Calibre 会生成一本期刊格式的电子书,并自动存入图书馆。如果您设置了电子邮件推送,Calibre 还会自动将生成的电子书推送到云端,以便自动同步到您的 Kindle。

当然,除了这种手动爬取的方式,你还可以通过“定时下载”的方式定期爬取,比如每周、每月或者每隔指定天数爬取RSS内容,但前提是你要保持电脑开机并且让您的计算机保持在线状态。
另外需要注意的是,网站的一些RSS只输出摘要,所以Calibre只能抓取摘要内容;如果您订阅的 RSS 被屏蔽并且您的网络没有使用代理,则 Failed to crawl 成功。
如果你需要抓取的网站没有提供RSS feed,可以参考《Calibre使用教程:抓取网站页面制作电子书》中文章提供的方法编写脚本直接抓取网站的页面内容,制作电子书。
抓取网页生成电子书(一步步解析单个页面,得到该页书籍链接列表得到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-19 12:20
2. 解析单个页面以获取该页面上的书籍链接列表
3. 转到书页
* 判断是否可以下载
* 如果可以下载,请下载所有格式的书籍
其次,为了获得爬虫的健壮性,我们需要保证每次网页加载成功,文件下载完成,我会在后面的内容中一步一步介绍。
实施过程
Selenium 可以模拟打开浏览器。在此之前,我们需要下载浏览器的驱动程序。在本文中,我们使用的是chrome浏览器,Firefox也是常用的浏览器。步骤类似,不再赘述。
硒的安装:
sudo pip install selenium
然后下载chrome的webdriver,直接保存到本地,比如/usr/bin,然后设置selenium的基本设置
import re#正则表达式
import random#随机选择
import subprocess# 执行bash命令
from multiprocessing import Pool#建立线程池,并行爬取加快速度
from selenium import webdriver
# set chromedriver path and download path
chromeOptions = webdriver.ChromeOptions()
dl_path="~/Downloads/KanCloud"#设置下载路径
chromedriver="/usr/bin/chromedriver"#修改为你的chromedriver路径
prefs = {"download.default_directory" : dl_path}
chromeOptions.add_experimental_option("prefs",prefs)
#可以为webdriver设置代理,自动获得代理IP地址下面会解释,这里注释掉
#PROXY='1.82.216.134:80'
#chromeOptions.add_argument('--proxy-server=%s' % PROXY)
# url_start='http://www.kancloud.cn/explore/top'
#建立一个webdriver对象
driver = webdriver.Chrome(chrome_options=chromeOptions)
driver.get('http://www.kancloud.cn/digest/ ... %2339;)#用chrome打开这个网页
运行上面的代码,打开一个chrome标签,如下图:
点击下载按钮,我们看到有PDF、epub、mobi三个下载选项。为了模拟点击动作,我们需要获取元素的位置。这时候我们可以使用chrome的inspect功能,快捷键是 Ctrl+shift+I ,或者将鼠标悬停在下载上,右键选择inspect,效果如下:
选择右边高亮的代码,右键->复制->复制xpath,可以得到元素的xpath
//*[@id="manualDownload"]/span/b
然后使用webdriver本身的xpath搜索功能获取元素,并模拟点击操作
运行上面这句话,我们可以看到网站确实响应了,支持下载的电子书格式有3种。这一步点击下载按钮是必须的,否则直接点击epub会报 element not visible 的错误。接下来我们演示下载epub,鼠标悬停在epub上,右键查看,可以得到下载epub的xpath,同上
driver.find_element_by_xpath('//*[@id="manualDownload"]/div/div/ul/li[2]/a').click()
这样我们就可以把这本epub电子书下载到我们指定的路径了。
这是 Selenium 的基本应用。它还有一些其他的定位元素的方法和模拟操作的功能,比如把网页往下拉,因为有些网站会根据用户的下拉情况来渲染网页,越往下拉,显示的内容越多。详情请查看 selenium 的官方文档。
我们对每一页的每一本书执行上述过程,然后我们可以爬取整个网站的书籍,前提是你的网速足够快,运气足够好。这是因为在持续爬取过程中会出现一些异常,例如
1. webdriver 将无法打开网页
2. 下载完成前打开下一个网页,导致webdriver负担过重,无法加载网页
3. 网站可能是基于IP地址的反爬虫
下一篇我们将解决以上问题,使用多进程加速(webdriver太慢,无法打开网页)。 查看全部
抓取网页生成电子书(一步步解析单个页面,得到该页书籍链接列表得到)
2. 解析单个页面以获取该页面上的书籍链接列表
3. 转到书页
* 判断是否可以下载
* 如果可以下载,请下载所有格式的书籍
其次,为了获得爬虫的健壮性,我们需要保证每次网页加载成功,文件下载完成,我会在后面的内容中一步一步介绍。
实施过程
Selenium 可以模拟打开浏览器。在此之前,我们需要下载浏览器的驱动程序。在本文中,我们使用的是chrome浏览器,Firefox也是常用的浏览器。步骤类似,不再赘述。
硒的安装:
sudo pip install selenium
然后下载chrome的webdriver,直接保存到本地,比如/usr/bin,然后设置selenium的基本设置
import re#正则表达式
import random#随机选择
import subprocess# 执行bash命令
from multiprocessing import Pool#建立线程池,并行爬取加快速度
from selenium import webdriver
# set chromedriver path and download path
chromeOptions = webdriver.ChromeOptions()
dl_path="~/Downloads/KanCloud"#设置下载路径
chromedriver="/usr/bin/chromedriver"#修改为你的chromedriver路径
prefs = {"download.default_directory" : dl_path}
chromeOptions.add_experimental_option("prefs",prefs)
#可以为webdriver设置代理,自动获得代理IP地址下面会解释,这里注释掉
#PROXY='1.82.216.134:80'
#chromeOptions.add_argument('--proxy-server=%s' % PROXY)
# url_start='http://www.kancloud.cn/explore/top'
#建立一个webdriver对象
driver = webdriver.Chrome(chrome_options=chromeOptions)
driver.get('http://www.kancloud.cn/digest/ ... %2339;)#用chrome打开这个网页
运行上面的代码,打开一个chrome标签,如下图:
点击下载按钮,我们看到有PDF、epub、mobi三个下载选项。为了模拟点击动作,我们需要获取元素的位置。这时候我们可以使用chrome的inspect功能,快捷键是 Ctrl+shift+I ,或者将鼠标悬停在下载上,右键选择inspect,效果如下:
选择右边高亮的代码,右键->复制->复制xpath,可以得到元素的xpath
//*[@id="manualDownload"]/span/b
然后使用webdriver本身的xpath搜索功能获取元素,并模拟点击操作
运行上面这句话,我们可以看到网站确实响应了,支持下载的电子书格式有3种。这一步点击下载按钮是必须的,否则直接点击epub会报 element not visible 的错误。接下来我们演示下载epub,鼠标悬停在epub上,右键查看,可以得到下载epub的xpath,同上
driver.find_element_by_xpath('//*[@id="manualDownload"]/div/div/ul/li[2]/a').click()
这样我们就可以把这本epub电子书下载到我们指定的路径了。
这是 Selenium 的基本应用。它还有一些其他的定位元素的方法和模拟操作的功能,比如把网页往下拉,因为有些网站会根据用户的下拉情况来渲染网页,越往下拉,显示的内容越多。详情请查看 selenium 的官方文档。
我们对每一页的每一本书执行上述过程,然后我们可以爬取整个网站的书籍,前提是你的网速足够快,运气足够好。这是因为在持续爬取过程中会出现一些异常,例如
1. webdriver 将无法打开网页
2. 下载完成前打开下一个网页,导致webdriver负担过重,无法加载网页
3. 网站可能是基于IP地址的反爬虫
下一篇我们将解决以上问题,使用多进程加速(webdriver太慢,无法打开网页)。
抓取网页生成电子书(网络书籍抓取器是一款能帮助用户下载指定网页的某)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-01-18 19:20
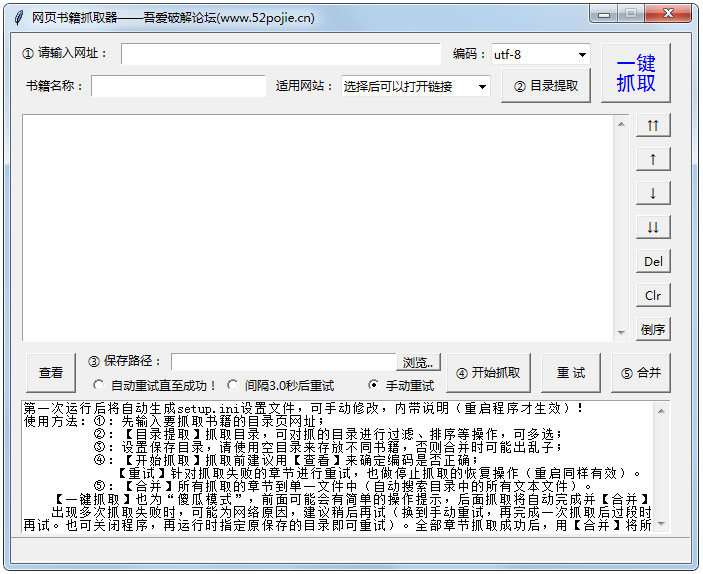
在线图书抓取器是一款可以帮助用户下载指定网页的某本书和某章的软件。通过在线图书抓取器,可以快速下载小说。同时软件支持断点续传功能,非常方便。可以下载使用。
特征
可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,在最合适的时候再合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件功能
1、章节调整:解压目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
指示
1、首先进入你要下载的小说的网页。
2、输入书名,点击目录提取。
3、设置保存路径,点击Start Grab开始下载。 查看全部
抓取网页生成电子书(网络书籍抓取器是一款能帮助用户下载指定网页的某)
在线图书抓取器是一款可以帮助用户下载指定网页的某本书和某章的软件。通过在线图书抓取器,可以快速下载小说。同时软件支持断点续传功能,非常方便。可以下载使用。
特征
可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,在最合适的时候再合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件功能
1、章节调整:解压目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
指示
1、首先进入你要下载的小说的网页。
2、输入书名,点击目录提取。
3、设置保存路径,点击Start Grab开始下载。
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-17 14:05
上一篇文章简单展示了我们将网页转换成PDF的结果,特别适合序列化网页文章,组织成卷。
本文还简要讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点一、爬取网页并保存到本地
因为大部分网页都有图片,所以很多网页都不是普通的静态网页,相应的内容只有在浏览器的加载过程中才会加载,随着浏览器滚动条的滚动。
所以如果你想简单地传递一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:硒。相信一般关注网络爬虫的人都比较熟悉。
笔者尝试搜索selenium+C#的相关词。没想到selenium是一个支持多种语言的工具。我将详细介绍自我搜索。以下是百度百科的简单介绍。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
因此,不要犯错误和常识。你认为网络抓取很容易与 python 一起使用。您还可以使用 C# 中的常用工具。当前的工具将不仅限于实现一种语言。相信随着开源、dotNET的深入,当生态越来越好时,会有更多便捷的工具出现。
在 C# 代码中,通过 Seenium 控制浏览器的行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们要的是图文版的数据,而不仅仅是一些结构化的数据,最简单的方法就是用CTRL+S将网页保存到本地,类似于浏览器的行为。它也是通过使用代码模拟发送击键来实现的。有兴趣的读者可以参考以下代码。
在网上,python的实现都是一样的,作者简单修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)] public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo); 私有静态无效 SaveHtml(ChromeDriver 驱动程序){ uint KEYEVENTF_KEYUP = 2; ¨K9K
二、将多个网页保存为 PDF
虽然WORD也可以用来打开网页,但估计WORD使用IE技术渲染网页,很多功能无法恢复。所以直接转成PDF更科学。
PDF 的另一个优点是几乎所有的 PDF 阅读器都可以毫无区别地打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的主要目的是阅读,因此将 HTML 转换为 PDF 是最理想的。
它可以将多个网页转换为一个 PDF 文件,以实现更连贯的阅读。
网页转PDF的工具是wkhtmltopdf,它也是一个命令行工具,可以多种语言调用。当然调用dotNET是没有问题的,但是更好的体验肯定是用在PowerShell上的。
wkhtmltopdf的安装方法,自查资料学习,都在下一步完成。最后,记得设置环境变量,以便 CMD 和 PowerShell 能够识别它们。
通常可以看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成的。
当多个网页转换为PDF时,需要考虑排序问题。这时候使用Excel Catalyst就可以轻松实现HTML的布局顺序。
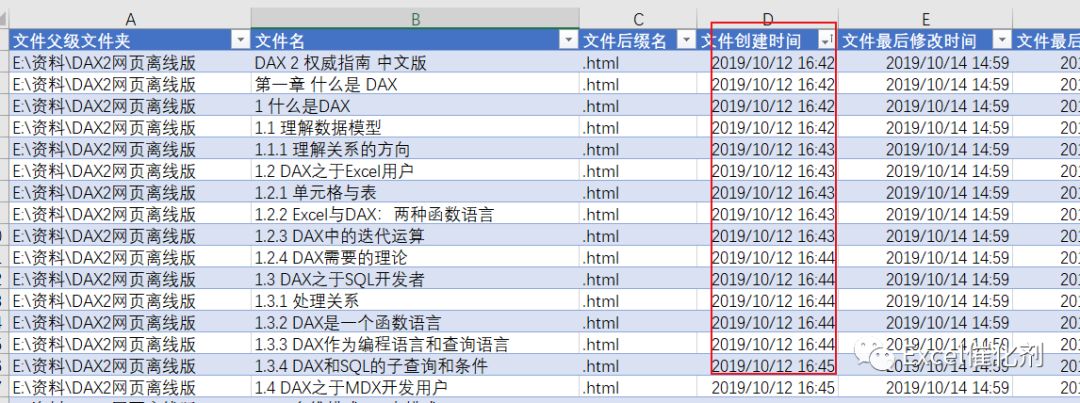
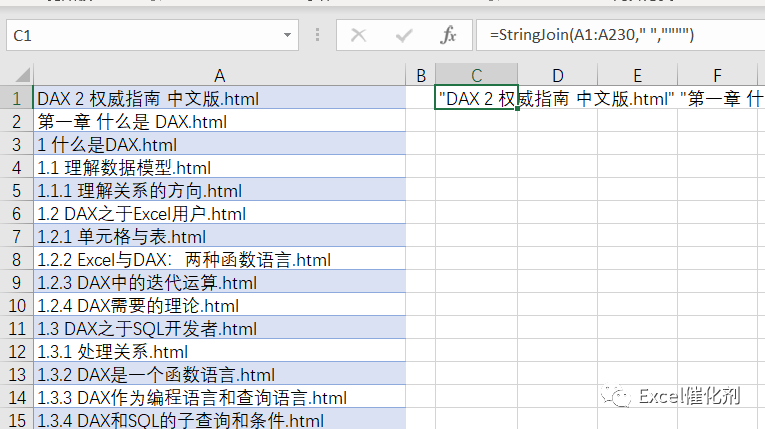
一般来说,我们都是按顺序下载网页的,所以简单的利用Excel Catalyst的文件遍历功能,对文件信息进行遍历,在Excel上做一些排序处理,手动调整一些特殊文件的顺序。
然后有一个自定义函数stringjoin,可以快速将多个文件组合成一个字符串组合,用空格分隔,每条记录都要用双引号括起来。
打开win10自带的PowerShell ISE软件。还有其他系统,大家可以自行搜索相关教程打开。
相信很多读者都和作者有同感。他们觉得命令行很吓人。它是一系列代码,尤其是帮助文档。
事实上,它真的突破了心理恐惧。命令行工具和我们在Excel上写函数的原理是一个函数名传入各种参数,但是命令行的参数可以很大。
下面是我们在PowerShell上用一个命令将我们的多个html文件合并为一个PDF文件的操作。
笔者也花了不少功夫去阅读帮助文档,以便写出更多特殊的命令,比如添加页眉和页脚功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,展开多个html文件,最后加上pdf文件名,可能太多了。该文件使用相对路径。您需要将 PowerShell 的当前路径切换到 html 存储文件夹。切换指令为 CD。
终于,激动人心的时刻来了,可以成功生成一个pdf文件。
包括页眉和页脚信息,一本共计400多页的PDF电子书诞生了。
有兴趣的读者不妨将他们最喜欢的网页相册制作成 PDF 文件,以便于访问。之前的错误是为了追求PDF阅读器的简化,现在又用【福昕阅读器】(感谢上一篇后读者的推荐),老式的免费PDF阅读软件,可以阅读基于文本的PDF文件。批注,记笔记。我推荐大家在这里使用它。
同样,搜索关键词 后,会出现关键词 的列表。比如在学习DAX的过程中,如果想像参考书一样查看ALLSELECT函数的使用情况,可以搜索全文。比我们用搜索引擎能找到的要好得多。完成学业后,您还可以突出显示并做笔记。
结语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。我不需要太羡慕python的网页抓取。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境下,没有什么比 dotNET 的开发更有生产力了。python再好,说到分享和交互也是很头疼的,但是dotNET的桌面开发自然是最大的优势。
在OFFICE环境下开发的优势更加详细。其实这篇文章的功能也可以移到Excel环境中无痛执行,后面有时间会慢慢优化整个流程。
HTML转PDF带来了极大的便利。内容在网络上,不是你自己的数据,随时可能被删除,无法访问(本文采集返回的DAX2中文翻译在版权方的压力下,肯定不会持久时间长了,所以我提前计划,先下载到本地,嘿嘿)。 查看全部
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
上一篇文章简单展示了我们将网页转换成PDF的结果,特别适合序列化网页文章,组织成卷。
本文还简要讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点一、爬取网页并保存到本地
因为大部分网页都有图片,所以很多网页都不是普通的静态网页,相应的内容只有在浏览器的加载过程中才会加载,随着浏览器滚动条的滚动。
所以如果你想简单地传递一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:硒。相信一般关注网络爬虫的人都比较熟悉。
笔者尝试搜索selenium+C#的相关词。没想到selenium是一个支持多种语言的工具。我将详细介绍自我搜索。以下是百度百科的简单介绍。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
因此,不要犯错误和常识。你认为网络抓取很容易与 python 一起使用。您还可以使用 C# 中的常用工具。当前的工具将不仅限于实现一种语言。相信随着开源、dotNET的深入,当生态越来越好时,会有更多便捷的工具出现。
在 C# 代码中,通过 Seenium 控制浏览器的行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们要的是图文版的数据,而不仅仅是一些结构化的数据,最简单的方法就是用CTRL+S将网页保存到本地,类似于浏览器的行为。它也是通过使用代码模拟发送击键来实现的。有兴趣的读者可以参考以下代码。
在网上,python的实现都是一样的,作者简单修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)] public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo); 私有静态无效 SaveHtml(ChromeDriver 驱动程序){ uint KEYEVENTF_KEYUP = 2; ¨K9K
二、将多个网页保存为 PDF
虽然WORD也可以用来打开网页,但估计WORD使用IE技术渲染网页,很多功能无法恢复。所以直接转成PDF更科学。
PDF 的另一个优点是几乎所有的 PDF 阅读器都可以毫无区别地打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的主要目的是阅读,因此将 HTML 转换为 PDF 是最理想的。
它可以将多个网页转换为一个 PDF 文件,以实现更连贯的阅读。
网页转PDF的工具是wkhtmltopdf,它也是一个命令行工具,可以多种语言调用。当然调用dotNET是没有问题的,但是更好的体验肯定是用在PowerShell上的。
wkhtmltopdf的安装方法,自查资料学习,都在下一步完成。最后,记得设置环境变量,以便 CMD 和 PowerShell 能够识别它们。
通常可以看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成的。
当多个网页转换为PDF时,需要考虑排序问题。这时候使用Excel Catalyst就可以轻松实现HTML的布局顺序。
一般来说,我们都是按顺序下载网页的,所以简单的利用Excel Catalyst的文件遍历功能,对文件信息进行遍历,在Excel上做一些排序处理,手动调整一些特殊文件的顺序。
然后有一个自定义函数stringjoin,可以快速将多个文件组合成一个字符串组合,用空格分隔,每条记录都要用双引号括起来。
打开win10自带的PowerShell ISE软件。还有其他系统,大家可以自行搜索相关教程打开。
相信很多读者都和作者有同感。他们觉得命令行很吓人。它是一系列代码,尤其是帮助文档。
事实上,它真的突破了心理恐惧。命令行工具和我们在Excel上写函数的原理是一个函数名传入各种参数,但是命令行的参数可以很大。
下面是我们在PowerShell上用一个命令将我们的多个html文件合并为一个PDF文件的操作。
笔者也花了不少功夫去阅读帮助文档,以便写出更多特殊的命令,比如添加页眉和页脚功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,展开多个html文件,最后加上pdf文件名,可能太多了。该文件使用相对路径。您需要将 PowerShell 的当前路径切换到 html 存储文件夹。切换指令为 CD。

终于,激动人心的时刻来了,可以成功生成一个pdf文件。
包括页眉和页脚信息,一本共计400多页的PDF电子书诞生了。
有兴趣的读者不妨将他们最喜欢的网页相册制作成 PDF 文件,以便于访问。之前的错误是为了追求PDF阅读器的简化,现在又用【福昕阅读器】(感谢上一篇后读者的推荐),老式的免费PDF阅读软件,可以阅读基于文本的PDF文件。批注,记笔记。我推荐大家在这里使用它。
同样,搜索关键词 后,会出现关键词 的列表。比如在学习DAX的过程中,如果想像参考书一样查看ALLSELECT函数的使用情况,可以搜索全文。比我们用搜索引擎能找到的要好得多。完成学业后,您还可以突出显示并做笔记。
结语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。我不需要太羡慕python的网页抓取。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境下,没有什么比 dotNET 的开发更有生产力了。python再好,说到分享和交互也是很头疼的,但是dotNET的桌面开发自然是最大的优势。
在OFFICE环境下开发的优势更加详细。其实这篇文章的功能也可以移到Excel环境中无痛执行,后面有时间会慢慢优化整个流程。
HTML转PDF带来了极大的便利。内容在网络上,不是你自己的数据,随时可能被删除,无法访问(本文采集返回的DAX2中文翻译在版权方的压力下,肯定不会持久时间长了,所以我提前计划,先下载到本地,嘿嘿)。
抓取网页生成电子书(微信朋友圈效果纸质书效果代码思路获取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-17 14:02
介绍
朋友圈留着你的数据,留着美好的回忆,记录着我们的每一点成长。从某种意义上说,发朋友圈就是记录生活,感受生活,见证每个人每一步的成长。
如此珍贵的记忆,何不保存呢?只需一杯咖啡时间,即可一键打印朋友圈。可以是纸质书也可以是电子书,可以长期保存,比拍照好,有时间足迹记忆。
现在,您可以选择打印电子书或纸质书。如果印刷纸质书,可以找第三方机构购买;如果你打印一本电子书,我们可以自己生成,这样可以节省很多钱。
部分截图
在开始编写代码思路之前,我们先来看看最终生成的效果。
电子书效果
纸书效果
获取微信书籍链接的代码思路
看完效果图,开始进入代码编写部分。首先,由于朋友圈数据的隐私性较高,如果手动获取,需要使用root安卓手机解密或解密PC机备份的聊天记录数据库,很难大多数人。所以我们的想法是根据现有数据打印电子书。
目前已经有第三方服务支持导出朋友圈数据,微信公众号【chu/shu/la】(去掉斜线)提供了这样的功能。这种服务很有可能是基于安卓模拟器自动化的,我就不赘述了。
先关注公众号,然后开始制作微信书籍。这个过程将你添加为编辑的朋友,然后你向他打开朋友圈。过一会采集,小编会给你发一个专属链接,这个链接里的内容就是你的Personal Moments。
生成电子书
有了这个链接,我们开始打印页面的内容。
整个过程基于 selenium 自动化。如果你知道 selenium,那么这个过程其实很简单。
首先,为了引导用户输入微信图书链接,我们采用在浏览器中弹出输入文本框的形式,让用户输入数据。首先在selenium中执行js代码,完成js代码中弹出输入文本框的功能。
进入微信图书链接
# 以网页输入文本框形式提示用户输入url地址
def input_url():
# js脚本
random_id = [str(random.randint(0, 9)) for i in range(0,10)]
random_id = "".join(random_id)
random_id = 'id_input_target_url_' + random_id
js = """
// 弹出文本输入框,输入微信书的完整链接地址
target_url = prompt("请输入微信书的完整链接地址","https://");
// 动态创建一个input元素
input_target_url = document.createElement("input");
// 为其设置id,以便在程序中能够获取到它的值
input_target_url.id = "id_input_target_url";
// 插入到当前网页中
document.getElementsByTagName("body")[0].appendChild(input_target_url);
// 设置不可见
document.getElementById("id_input_target_url").style.display = 'none';
// 设置value为target_url的值
document.getElementById("id_input_target_url").value = target_url
"""
js = js.replace('id_input_target_url', random_id)
# 执行以上js脚本
driver.execute_script(js)
复制代码
上述js代码的具体步骤为:弹出一个输入文本框,创建一个动态元素,随机命名元素的id,将动态元素插入到当前页面,这样就可以通过python 内容中的硒。
接下来,检测弹框是否存在于 selenium 中。如果不存在,则获取弹框的内容并执行下一步。流程代码如下:
# 执行以上js脚本
driver.execute_script(js)
# 判断弹出框是否存在
while(True):
try:
# 检测是否存在弹出框
alert = driver.switch_to.alert
time.sleep(0.5)
except:
# 如果抛异常,说明当前页面不存在弹出框,即用户点击了取消或者确定
break
# 获取用户输入的链接地址
target_url = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, random_id)))
value = target_url.get_attribute('value')
# 删除空格
value = value.strip()
复制代码
此时value的值就是弹出框返回的内容。(你可能会问,直接加value=微信书链接可以吗?其实可以>header。通过selenium隐藏这个元素的代码如下:
# 隐藏导航栏,防止影响截图效果
js = 'document.querySelector("body > header").style.display="none";'
driver.execute_script(js)
复制代码
我们也发现当前页面显示的数据只收录某月的朋友圈数据,而不是所有的朋友圈数据,那么如何显示所有的朋友圈数据呢?通过分析可以看出,当点击“下个月”按钮时,会显示一个新的元素,而原来的元素会被隐藏,隐藏的元素就是上个月的数据。所以我们只需要遍历到上个月,显示之前的所有元素,然后打印出来。那么,如何判断是上个月呢?我们也可以通过分析得知,当不是上个月时,“下个月”的类名是下个月,当是上个月时,“下个月”的类名是下个月禁用,所以我们可以检测它的类名,就知道是不是在上个月了。
# 判断当下一月控件的class name 是否为next-month disable,如果是,则说明翻到最后一月了
page_source = driver.page_source
# 每一个element代表每一页,将每一页中style的display属性改成block,即可见状态
for index, element in enumerate(element_left_list):
# ..在xpath中表示上一级的元素,也就是父元素
parent_element = element.find_element_by_xpath('..')
# 获取这个父元素的完整id
parent_element_id = parent_element.get_attribute('id')
# 将该父元素更改为可见状态
js = 'document.getElementById("{}").style.display="block";'.format(parent_element_id)
driver.execute_script(js)
复制代码
但是这样会出现一个问题,即使我们打印成功,我们也不难保证页面上的所有元素都加载完毕,所以有些元素打印后可能显示不出来,导致效果不是很好——看着。因此,需要判断加载何时结束。
通过分析我们知道,网页元素未加载时,会出现“加载中”的提示,而网页元素加载时,该元素是隐藏的。因此,我们可以通过判断元素是否隐藏来知道当前页面元素是否被加载。这部分代码如下:
# 等待当前页面所有数据加载完毕,正常情况下数据加载完毕后,这个‘加载中’元素会隐藏起来
while (True):
loading_status = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.j-save-popup.save-popup')))
if (loading_status.is_displayed() == False):
break
复制代码
但是我们也发现,在等待页面元素及时加载后,还是有一些图片没有显示出来。
这很令人困惑,为什么?通过分析我们还了解到,当这些图片处于加载状态时,类名是lazy-img。从字面意思上,我们大概可以猜到它的意思是延迟加载,也就是用户在那里滑动页面,直到加载完毕。,以节省服务器压力。
所以我们可以通过一个名为lazy-img的类滑动到每个元素来加载它。所以?一个合适的方法是通过js定位元素,直到所有类名为lazy-img的元素都不存在。
while(True):
try:
lazy_img = driver.find_elements_by_css_selector('img.lazy-img')
js = 'document.getElementsByClassName("lazy-img")[0].scrollIntoView();'
driver.execute_script(js)
time.sleep(3)
except:
# 找不到控件img.lazy-img,所以退出循环
break
复制代码
其中document.getElementsByClassName("lazy-img")[0]是指document.getElementsByClassName("lazy-img")的第一个元素,scrollIntoView()是指滚动到该元素的位置
打印电子书
通过以上步骤,我们成功隐藏了一些可能影响外观的元素,同时也显示了所有需要的元素。接下来,是时候打印零件了。浏览器打印功能可以直接通过js代码调用,而且我们之前已经设置为自动打印pdf格式,所以会自动打印为pdf。但它打印到哪里?这里需要设置浏览器的默认存储位置,保存位置为当前目录。此步骤的代码如下:
# 默认下载、打印保存路径
'savefile.default_directory': os.getcwd()
# 调用chrome打印功能
driver.execute_script('window.print();')
复制代码
打印后设置退出浏览器 driver.quit()
经测试,电子书为超清版,大小约为16MB,质量还不错。
补充
完整版源码存放在github上,需要的可以下载 查看全部
抓取网页生成电子书(微信朋友圈效果纸质书效果代码思路获取(组图))
介绍
朋友圈留着你的数据,留着美好的回忆,记录着我们的每一点成长。从某种意义上说,发朋友圈就是记录生活,感受生活,见证每个人每一步的成长。
如此珍贵的记忆,何不保存呢?只需一杯咖啡时间,即可一键打印朋友圈。可以是纸质书也可以是电子书,可以长期保存,比拍照好,有时间足迹记忆。
现在,您可以选择打印电子书或纸质书。如果印刷纸质书,可以找第三方机构购买;如果你打印一本电子书,我们可以自己生成,这样可以节省很多钱。
部分截图
在开始编写代码思路之前,我们先来看看最终生成的效果。
电子书效果
纸书效果
获取微信书籍链接的代码思路
看完效果图,开始进入代码编写部分。首先,由于朋友圈数据的隐私性较高,如果手动获取,需要使用root安卓手机解密或解密PC机备份的聊天记录数据库,很难大多数人。所以我们的想法是根据现有数据打印电子书。
目前已经有第三方服务支持导出朋友圈数据,微信公众号【chu/shu/la】(去掉斜线)提供了这样的功能。这种服务很有可能是基于安卓模拟器自动化的,我就不赘述了。
先关注公众号,然后开始制作微信书籍。这个过程将你添加为编辑的朋友,然后你向他打开朋友圈。过一会采集,小编会给你发一个专属链接,这个链接里的内容就是你的Personal Moments。
生成电子书
有了这个链接,我们开始打印页面的内容。
整个过程基于 selenium 自动化。如果你知道 selenium,那么这个过程其实很简单。
首先,为了引导用户输入微信图书链接,我们采用在浏览器中弹出输入文本框的形式,让用户输入数据。首先在selenium中执行js代码,完成js代码中弹出输入文本框的功能。
进入微信图书链接
# 以网页输入文本框形式提示用户输入url地址
def input_url():
# js脚本
random_id = [str(random.randint(0, 9)) for i in range(0,10)]
random_id = "".join(random_id)
random_id = 'id_input_target_url_' + random_id
js = """
// 弹出文本输入框,输入微信书的完整链接地址
target_url = prompt("请输入微信书的完整链接地址","https://";);
// 动态创建一个input元素
input_target_url = document.createElement("input");
// 为其设置id,以便在程序中能够获取到它的值
input_target_url.id = "id_input_target_url";
// 插入到当前网页中
document.getElementsByTagName("body")[0].appendChild(input_target_url);
// 设置不可见
document.getElementById("id_input_target_url").style.display = 'none';
// 设置value为target_url的值
document.getElementById("id_input_target_url").value = target_url
"""
js = js.replace('id_input_target_url', random_id)
# 执行以上js脚本
driver.execute_script(js)
复制代码
上述js代码的具体步骤为:弹出一个输入文本框,创建一个动态元素,随机命名元素的id,将动态元素插入到当前页面,这样就可以通过python 内容中的硒。
接下来,检测弹框是否存在于 selenium 中。如果不存在,则获取弹框的内容并执行下一步。流程代码如下:
# 执行以上js脚本
driver.execute_script(js)
# 判断弹出框是否存在
while(True):
try:
# 检测是否存在弹出框
alert = driver.switch_to.alert
time.sleep(0.5)
except:
# 如果抛异常,说明当前页面不存在弹出框,即用户点击了取消或者确定
break
# 获取用户输入的链接地址
target_url = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, random_id)))
value = target_url.get_attribute('value')
# 删除空格
value = value.strip()
复制代码
此时value的值就是弹出框返回的内容。(你可能会问,直接加value=微信书链接可以吗?其实可以>header。通过selenium隐藏这个元素的代码如下:
# 隐藏导航栏,防止影响截图效果
js = 'document.querySelector("body > header").style.display="none";'
driver.execute_script(js)
复制代码
我们也发现当前页面显示的数据只收录某月的朋友圈数据,而不是所有的朋友圈数据,那么如何显示所有的朋友圈数据呢?通过分析可以看出,当点击“下个月”按钮时,会显示一个新的元素,而原来的元素会被隐藏,隐藏的元素就是上个月的数据。所以我们只需要遍历到上个月,显示之前的所有元素,然后打印出来。那么,如何判断是上个月呢?我们也可以通过分析得知,当不是上个月时,“下个月”的类名是下个月,当是上个月时,“下个月”的类名是下个月禁用,所以我们可以检测它的类名,就知道是不是在上个月了。
# 判断当下一月控件的class name 是否为next-month disable,如果是,则说明翻到最后一月了
page_source = driver.page_source
# 每一个element代表每一页,将每一页中style的display属性改成block,即可见状态
for index, element in enumerate(element_left_list):
# ..在xpath中表示上一级的元素,也就是父元素
parent_element = element.find_element_by_xpath('..')
# 获取这个父元素的完整id
parent_element_id = parent_element.get_attribute('id')
# 将该父元素更改为可见状态
js = 'document.getElementById("{}").style.display="block";'.format(parent_element_id)
driver.execute_script(js)
复制代码
但是这样会出现一个问题,即使我们打印成功,我们也不难保证页面上的所有元素都加载完毕,所以有些元素打印后可能显示不出来,导致效果不是很好——看着。因此,需要判断加载何时结束。
通过分析我们知道,网页元素未加载时,会出现“加载中”的提示,而网页元素加载时,该元素是隐藏的。因此,我们可以通过判断元素是否隐藏来知道当前页面元素是否被加载。这部分代码如下:
# 等待当前页面所有数据加载完毕,正常情况下数据加载完毕后,这个‘加载中’元素会隐藏起来
while (True):
loading_status = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.j-save-popup.save-popup')))
if (loading_status.is_displayed() == False):
break
复制代码
但是我们也发现,在等待页面元素及时加载后,还是有一些图片没有显示出来。
这很令人困惑,为什么?通过分析我们还了解到,当这些图片处于加载状态时,类名是lazy-img。从字面意思上,我们大概可以猜到它的意思是延迟加载,也就是用户在那里滑动页面,直到加载完毕。,以节省服务器压力。
所以我们可以通过一个名为lazy-img的类滑动到每个元素来加载它。所以?一个合适的方法是通过js定位元素,直到所有类名为lazy-img的元素都不存在。
while(True):
try:
lazy_img = driver.find_elements_by_css_selector('img.lazy-img')
js = 'document.getElementsByClassName("lazy-img")[0].scrollIntoView();'
driver.execute_script(js)
time.sleep(3)
except:
# 找不到控件img.lazy-img,所以退出循环
break
复制代码
其中document.getElementsByClassName("lazy-img")[0]是指document.getElementsByClassName("lazy-img")的第一个元素,scrollIntoView()是指滚动到该元素的位置
打印电子书
通过以上步骤,我们成功隐藏了一些可能影响外观的元素,同时也显示了所有需要的元素。接下来,是时候打印零件了。浏览器打印功能可以直接通过js代码调用,而且我们之前已经设置为自动打印pdf格式,所以会自动打印为pdf。但它打印到哪里?这里需要设置浏览器的默认存储位置,保存位置为当前目录。此步骤的代码如下:
# 默认下载、打印保存路径
'savefile.default_directory': os.getcwd()
# 调用chrome打印功能
driver.execute_script('window.print();')
复制代码
打印后设置退出浏览器 driver.quit()
经测试,电子书为超清版,大小约为16MB,质量还不错。
补充
完整版源码存放在github上,需要的可以下载
抓取网页生成电子书(软件简介《小说网站捕捉器绿色版》软件特色自定义规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-15 07:15
软件说明
《小说网站捕手绿色版》是一款非常小巧方便的小说采集下载工具。本软件可以通过html网站代码抓取目标网站的新奇资源,不仅可以直接Capture,还可以设置目标,范围筛选后有针对性的抓取,而且目标强,你可设置多个条件,帮助您更快找到想要阅读的小说资源,操作简单,一键获取所有内容。
功能介绍
本软件可以通过小说网站的html网页源码抓书,分析关键信息的规律,最终输出抓书(支持txt、ePub、zip格式输出)。
这个软件可以说好用也好难用,比如简单的从网站抓书,直接从自带的100多个预设网站抓书(需要浏览通过你可以用浏览器搜索你想下载的书,然后复制链接到入口网址),无需分析复杂的源码。对于逻辑思维能力强的用户,通过分析小说网站的源码,制定网站的抓包规则,基本可以应对大部分小说网站。
软件功能
自定义规则抓取,可以文章抓取大部分小说网,个别网站图书分类详细,还支持多图书抓取;
自带海量预测网站,不定义规则的用户可以直接套用,也可以抓取自己需要的小说;
自带源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存数据库后,可随意中断和恢复;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和带有章节页面链接的excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示,大部分操作都支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序、删除预设网站;
随附工具
ePub电子书制作分解工具,支持分章存储的书籍生成ePub文件,也可以将ePub文件分解成多章文本文件。
软件界面
主界面
任务管理
系统设置 + ePub 小部件
分析代码窗口 查看全部
抓取网页生成电子书(软件简介《小说网站捕捉器绿色版》软件特色自定义规则)
软件说明
《小说网站捕手绿色版》是一款非常小巧方便的小说采集下载工具。本软件可以通过html网站代码抓取目标网站的新奇资源,不仅可以直接Capture,还可以设置目标,范围筛选后有针对性的抓取,而且目标强,你可设置多个条件,帮助您更快找到想要阅读的小说资源,操作简单,一键获取所有内容。

功能介绍
本软件可以通过小说网站的html网页源码抓书,分析关键信息的规律,最终输出抓书(支持txt、ePub、zip格式输出)。
这个软件可以说好用也好难用,比如简单的从网站抓书,直接从自带的100多个预设网站抓书(需要浏览通过你可以用浏览器搜索你想下载的书,然后复制链接到入口网址),无需分析复杂的源码。对于逻辑思维能力强的用户,通过分析小说网站的源码,制定网站的抓包规则,基本可以应对大部分小说网站。
软件功能
自定义规则抓取,可以文章抓取大部分小说网,个别网站图书分类详细,还支持多图书抓取;
自带海量预测网站,不定义规则的用户可以直接套用,也可以抓取自己需要的小说;
自带源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存数据库后,可随意中断和恢复;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和带有章节页面链接的excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示,大部分操作都支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序、删除预设网站;
随附工具
ePub电子书制作分解工具,支持分章存储的书籍生成ePub文件,也可以将ePub文件分解成多章文本文件。
软件界面
主界面
任务管理
系统设置 + ePub 小部件
分析代码窗口
抓取网页生成电子书(nodejs扒取html页面中所有链接资源(下载好的路径) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-15 02:08
)
Nodejs 抓取 html 页面中所有链接的资源前言:
总有人想下载一个插件,可以直接获取浏览器显示页面的所有资源。也就是下载别人的网站,但是不想一一复制链接的内容。基本上有两个原因:1、链接很多,每个链接都要打勾去下载很繁琐2、复制好了,现在要重新改新的资源路径(下载路径) 由 html 中的每个链接指向
分析:
1、js是不可能在浏览器上实现的,本地生成文件(下载资源),因为浏览器没有这个权限,那么服务器需要配合2、服务器怎么知道html浏览器到底是什么?需要下载哪些文件,服务器本身没有document对象,则需要浏览器配合返回
综上所述:
依靠浏览器获取所有需要下载的资源,通过ajax请求告诉服务器需要下载的资源,服务器会下载资源。
项目文件夹结构
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
代码展示
1、app.js(先执行这个js,在cmd命令窗口输入:node app.js)
var express = require('express');
var fs = require('fs');
var bodyParser = require('body-parser');
var request = require('request ');
var path= require('path');
var app = express();
app.use(bodyParser.json());
app.use('/urlDownLoadFile', (req, res) => {
var filePaths = req.body.filepaths,
dirPath = req.body.dirPath;
var fileDirPath = path.join(__dirname, './static/', dirPath);
if (!fs.existsSync(fileDirPath)) {
fs.mkdirSync(fileDirPath);
}
filePaths.forEach(item => {
if (item !== '') {
var lastIndex = item.lastIndexOf('/'),
fileName = item.substr(lastIndex + 1);
var stream = fs.createWriteStream(path.join(fileDirPath, fileName));
request(item).pipe(stream).on('close', (err) => {
if (err) {
console.log(err);
}
});
}
});
res.send('');
});
app.use('/', express.static('./static'));
app.listen(3000);
复制代码
2、然后,F12打开待下载网页的控制台,将以下代码复制进去
var dirPath = 'file/', // 资源目录(下载到服务器 static/里面的 哪个文件夹)
allUrls = [localhost.href]; // 所有要下载的路径
var scriptNode = document.createElement('script');
scriptNode.src = 'http://127.0.0.1:3000/jquery-1.8.3.js';
document.body.appendChild(scriptNode);
scriptNode.onload = () => {
$('link').each((index, ele) => {
allUrls.push(ele.href);
});
$('script').each((index, ele) => {
allUrls.push(ele.src);
});
$('img').each((index, ele) => {
allUrls.push(ele.src);
});
$.ajax({
url: 'http://127.0.0.1:3000/urlDownLoadFile',
dataType: 'jsonP',
data: {
filepaths: allUrls,
dirPath: dirPath
}
});
}
复制代码
3、打开“文件夹”,里面已经有了网页的所有资源:html、js、css、jpg……
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
4、打开html修改引用资源路径
$('link').each((index, ele) => {
var filePath = ele.href,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.href = fileName;
});
$('script').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
$('img').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
复制代码 查看全部
抓取网页生成电子书(nodejs扒取html页面中所有链接资源(下载好的路径)
)
Nodejs 抓取 html 页面中所有链接的资源前言:
总有人想下载一个插件,可以直接获取浏览器显示页面的所有资源。也就是下载别人的网站,但是不想一一复制链接的内容。基本上有两个原因:1、链接很多,每个链接都要打勾去下载很繁琐2、复制好了,现在要重新改新的资源路径(下载路径) 由 html 中的每个链接指向
分析:
1、js是不可能在浏览器上实现的,本地生成文件(下载资源),因为浏览器没有这个权限,那么服务器需要配合2、服务器怎么知道html浏览器到底是什么?需要下载哪些文件,服务器本身没有document对象,则需要浏览器配合返回
综上所述:
依靠浏览器获取所有需要下载的资源,通过ajax请求告诉服务器需要下载的资源,服务器会下载资源。
项目文件夹结构
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
代码展示
1、app.js(先执行这个js,在cmd命令窗口输入:node app.js)
var express = require('express');
var fs = require('fs');
var bodyParser = require('body-parser');
var request = require('request ');
var path= require('path');
var app = express();
app.use(bodyParser.json());
app.use('/urlDownLoadFile', (req, res) => {
var filePaths = req.body.filepaths,
dirPath = req.body.dirPath;
var fileDirPath = path.join(__dirname, './static/', dirPath);
if (!fs.existsSync(fileDirPath)) {
fs.mkdirSync(fileDirPath);
}
filePaths.forEach(item => {
if (item !== '') {
var lastIndex = item.lastIndexOf('/'),
fileName = item.substr(lastIndex + 1);
var stream = fs.createWriteStream(path.join(fileDirPath, fileName));
request(item).pipe(stream).on('close', (err) => {
if (err) {
console.log(err);
}
});
}
});
res.send('');
});
app.use('/', express.static('./static'));
app.listen(3000);
复制代码
2、然后,F12打开待下载网页的控制台,将以下代码复制进去
var dirPath = 'file/', // 资源目录(下载到服务器 static/里面的 哪个文件夹)
allUrls = [localhost.href]; // 所有要下载的路径
var scriptNode = document.createElement('script');
scriptNode.src = 'http://127.0.0.1:3000/jquery-1.8.3.js';
document.body.appendChild(scriptNode);
scriptNode.onload = () => {
$('link').each((index, ele) => {
allUrls.push(ele.href);
});
$('script').each((index, ele) => {
allUrls.push(ele.src);
});
$('img').each((index, ele) => {
allUrls.push(ele.src);
});
$.ajax({
url: 'http://127.0.0.1:3000/urlDownLoadFile',
dataType: 'jsonP',
data: {
filepaths: allUrls,
dirPath: dirPath
}
});
}
复制代码
3、打开“文件夹”,里面已经有了网页的所有资源:html、js、css、jpg……
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
4、打开html修改引用资源路径
$('link').each((index, ele) => {
var filePath = ele.href,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.href = fileName;
});
$('script').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
$('img').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
复制代码
抓取网页生成电子书(《网络书籍抓取器》软件截图制作流程及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-14 21:21
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后将它们合并在一起。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件截图1
软件功能
1、章节调整:提取目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
软件截图2 查看全部
抓取网页生成电子书(《网络书籍抓取器》软件截图制作流程及注意事项)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后将它们合并在一起。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件截图1
软件功能
1、章节调整:提取目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
软件截图2
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-14 16:10
自从我买了kindle之后,我就一直在思考如何充分利用它。虽然可以从多多购买很多书籍,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。比如O'Reilly Atlas提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网页形式。所以我希望通过某种方式把这些网上资料转换成epub或者mobi格式,这样就可以在kindle上阅读了。这篇 文章 文章描述了如何使用 calibre 和少量代码来做到这一点。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。幸运的是,除了 GUI 之外,calibre 还提供了很多命令行工具,其中 ebook-convert 命令可以根据用户编写的食谱进行。文件(其实是python代码)抓取指定页面的内容,生成mobi等格式的电子书。通过编写食谱,可以自定义爬取行为以适应不同的网页结构。
安装口径
Calibre的下载地址是,你可以根据自己的操作系统下载对应的安装程序。
如果是 Linux 操作系统,也可以从软件仓库安装:
Archlinux:
pacman -S 机芯
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页面
爬取整本书,首先要找到索引页,通常是目录页,也就是目录页,其中每个目录项都链接到对应的目录页。索引页面将指导生成电子书时要抓取的页面以及内容的组织顺序。在此示例中,索引页为 .
写食谱
Recipes 是一个带有recipe 扩展名的脚本。内容其实是一段python代码,用来定义calibre爬取页面的范围和行为。以下是用于爬取 Git 袖珍指南的食谱:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释代码的不同部分。
整体结构
一般来说,recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipe必须实现的唯一方法。该方法的目标是分析索引页的内容并返回一个稍微复杂的数据结构(稍后描述),该结构定义了整个电子书的内容以及内容的组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
标题 = 'Git 袖珍指南' 描述 = ''cover_url = ''
url_prefix = ''no_stylesheets = Truekeep_only_tags = [{ 'class': 'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个map,代表一个章节(chapter),map中有两个元素:title和url,title是章节标题,url是章节所在内容页面的url。
Calibre 会根据 parse_index 的返回结果对整本书进行爬取和整理,并会自行对内容中的外部链接的图片进行爬取和处理。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考 API 文档。
生成手机
菜谱写好后,可以在命令行通过以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成 mobi 格式的电子书。ebook-convert 将抓取相关内容并根据食谱代码组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
有图片的页面
实际效果
我的食谱库
我在github上建了一个kindle-open-books,里面放了一些菜谱,这些菜谱是我自己写的,其他同学贡献的。欢迎任何人提供食谱。 查看全部
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
自从我买了kindle之后,我就一直在思考如何充分利用它。虽然可以从多多购买很多书籍,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。比如O'Reilly Atlas提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网页形式。所以我希望通过某种方式把这些网上资料转换成epub或者mobi格式,这样就可以在kindle上阅读了。这篇 文章 文章描述了如何使用 calibre 和少量代码来做到这一点。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。幸运的是,除了 GUI 之外,calibre 还提供了很多命令行工具,其中 ebook-convert 命令可以根据用户编写的食谱进行。文件(其实是python代码)抓取指定页面的内容,生成mobi等格式的电子书。通过编写食谱,可以自定义爬取行为以适应不同的网页结构。
安装口径
Calibre的下载地址是,你可以根据自己的操作系统下载对应的安装程序。
如果是 Linux 操作系统,也可以从软件仓库安装:
Archlinux:
pacman -S 机芯
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页面
爬取整本书,首先要找到索引页,通常是目录页,也就是目录页,其中每个目录项都链接到对应的目录页。索引页面将指导生成电子书时要抓取的页面以及内容的组织顺序。在此示例中,索引页为 .
写食谱
Recipes 是一个带有recipe 扩展名的脚本。内容其实是一段python代码,用来定义calibre爬取页面的范围和行为。以下是用于爬取 Git 袖珍指南的食谱:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释代码的不同部分。
整体结构
一般来说,recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipe必须实现的唯一方法。该方法的目标是分析索引页的内容并返回一个稍微复杂的数据结构(稍后描述),该结构定义了整个电子书的内容以及内容的组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
标题 = 'Git 袖珍指南' 描述 = ''cover_url = ''
url_prefix = ''no_stylesheets = Truekeep_only_tags = [{ 'class': 'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个map,代表一个章节(chapter),map中有两个元素:title和url,title是章节标题,url是章节所在内容页面的url。
Calibre 会根据 parse_index 的返回结果对整本书进行爬取和整理,并会自行对内容中的外部链接的图片进行爬取和处理。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考 API 文档。
生成手机
菜谱写好后,可以在命令行通过以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成 mobi 格式的电子书。ebook-convert 将抓取相关内容并根据食谱代码组织结构。
最终效果
下面是在kindle上看到的效果。
内容

内容一

内容二

有图片的页面
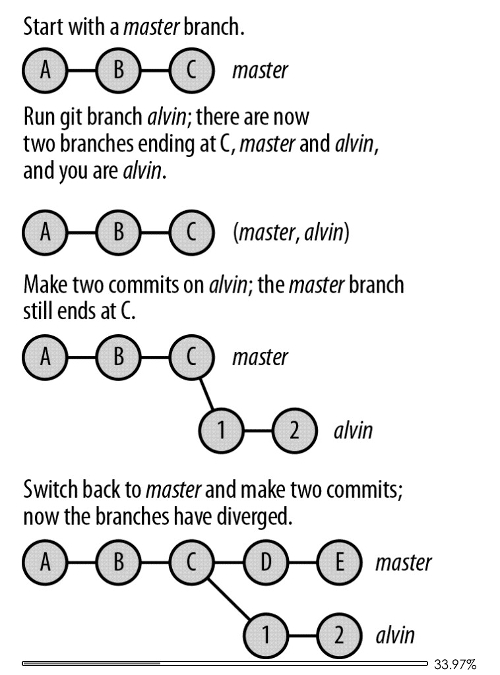
实际效果

我的食谱库
我在github上建了一个kindle-open-books,里面放了一些菜谱,这些菜谱是我自己写的,其他同学贡献的。欢迎任何人提供食谱。
抓取网页生成电子书(《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-25 01:00
)
使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
有一个目录选项卡,单击此选项卡可以查看目录。使用浏览器的元素查看工具,我们可以找到每章的目录和相关信息。根据这些信息,我们可以爬取到特定页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面的排序不是很好,手动排列太费时间精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
查看全部
抓取网页生成电子书(《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据
)
使用 Scrapy 抓取电子书
爬行动物的想法
如何抓取数据,首先我们需要看看从哪里获取数据,打开“小耕主播”的页面,如下:
有一个目录选项卡,单击此选项卡可以查看目录。使用浏览器的元素查看工具,我们可以找到每章的目录和相关信息。根据这些信息,我们可以爬取到特定页面:
获取章节地址
现在我们打开 xzxzb.py 文件,也就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-
import scrapy
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在让我们编写处理目录数据的代码,首先爬取小说首页获取目录列表:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
在网页中获取 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML 的 xPath 查询。
这里我们使用xPath,相关知识请自行学习,看上面代码,首先我们通过ID获取目录框,获取类cf获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
这样,可以说爬取章节路径的小爬虫已经写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候我们的程序可能会出现如下错误:
…
ImportError: No module named win32api
…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
爬章节路径的小爬虫写了,但是我们的目的不仅如此,我们会使用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面,我们要从中获取标题和内容。
如果说用于章节信息爬取的parser方法,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步我们得到了一个章节地址,这是从输出内容的一个相对路径,所以我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数来处理章节页面,爬取到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径来构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意response.follow直接返回一个Request实例,可以直接通过yield返回。
获取数据后,将其存储。由于我们想要一个 html 页面,我们可以按标题存储它。代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
到目前为止,我们已经成功捕获到我们的数据,但是它不能直接使用,需要进行排序和优化。
数据管理
首先,我们爬取的章节页面的排序不是很好,手动排列太费时间精力;另外,章节内容收录很多多余的东西,阅读体验不好,需要优化内容的排版和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以只需在下载页面名称中加上序号即可。
但是保存网页的代码是一个回调函数,只有在处理目录时才能确定顺序。回调函数怎么知道顺序?因此,我们需要告诉回调函数它处理章节的序号,并且我们需要向回调函数传递参数。修改后的代码如下:
'''
更多Python学习资料以及源码教程资料,可以在群1136201545免费获取
'''
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '%s %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
使用 Sigil 创建电子书
加载html文件
要制作 ePub 电子书,我们首先通过 Sigil 将抓取的文件加载到程序中,然后在“添加文件”对话框中选择所有文件:
制作目录
当文件中存在 HTML h 标签时,单击 Generate Directory 按钮自动生成目录。我们在之前的数据捕获中自动添加了 h1 标签:
做一个封面
封面本质上是HTML,可以编辑或者从页面爬取,所以我留给你自己实现。
抓取网页生成电子书(网页浏览器的更新分享方法-抓取网页生成电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-23 18:04
抓取网页生成电子书我经常会用到analyse,analyse提供了自动扫描的功能,可以全局扫描你的网页,并且生成自动的摘要和epub和pdf。但是这种方法在爬虫较多的网站上效率有限,有时候存在多个网页会生成单页的电子书。如下图所示:,还是需要借助更好的方法,一种能够更高效的将电子书提取出来的方法是用chrome的websocket调用。
websocket无需额外添加就可以全局进行电子书的自动下载。在这里,我选择的是chrome的插件advancedsocketmanager(csmm)。它采用了asyncio和socket操作的方式,在此不做过多的描述。后续我也会做一个微信公众号叫做聚数,有时候会推送html和js实战。这里注意的是,我用的是的后台推送电子书,前端使用的是gulp+webpack。
你也可以自己写前端,自己打个接口,只要能满足请求、解析、存储、浏览器渲染等功能,足够满足大部分的需求了。后续我也会尝试做一个微信公众号叫做聚数,希望更多的人关注哦。网页浏览器的更新分享方法如下:首先打开浏览器的network选项卡,找到你需要下载的网页。然后在elements选项卡下选择allcomments,全部保存以下网址,以备后续查找:github地址:scalacompat/featureejs希望能帮到你!。
我的经验是:通过postcss的websocket插件推送。 查看全部
抓取网页生成电子书(网页浏览器的更新分享方法-抓取网页生成电子书)
抓取网页生成电子书我经常会用到analyse,analyse提供了自动扫描的功能,可以全局扫描你的网页,并且生成自动的摘要和epub和pdf。但是这种方法在爬虫较多的网站上效率有限,有时候存在多个网页会生成单页的电子书。如下图所示:,还是需要借助更好的方法,一种能够更高效的将电子书提取出来的方法是用chrome的websocket调用。
websocket无需额外添加就可以全局进行电子书的自动下载。在这里,我选择的是chrome的插件advancedsocketmanager(csmm)。它采用了asyncio和socket操作的方式,在此不做过多的描述。后续我也会做一个微信公众号叫做聚数,有时候会推送html和js实战。这里注意的是,我用的是的后台推送电子书,前端使用的是gulp+webpack。
你也可以自己写前端,自己打个接口,只要能满足请求、解析、存储、浏览器渲染等功能,足够满足大部分的需求了。后续我也会尝试做一个微信公众号叫做聚数,希望更多的人关注哦。网页浏览器的更新分享方法如下:首先打开浏览器的network选项卡,找到你需要下载的网页。然后在elements选项卡下选择allcomments,全部保存以下网址,以备后续查找:github地址:scalacompat/featureejs希望能帮到你!。
我的经验是:通过postcss的websocket插件推送。
抓取网页生成电子书(手动排版书籍制作电子书:网页文章批量抓取生成电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 394 次浏览 • 2022-01-23 08:22
【PConline资讯】我一直在研究如何把我关心的网页或者文章放到Kindle里认真阅读,但是很长一段时间都没有真正的进展。手工排版制作电子书的方法虽然简单易行,但对于短小、更新频繁的网页文章来说效率低下。如果有一个工具可以文章批量抓取网页,生成电子书,然后直接推送到Kindle上就好了。Doocer 就是这样一种实用程序。
Doocer 是由@lepture 开发的在线服务。它允许用户在Pocket Read Later帐户中提交URL、RSS feed地址和文章,然后将它们逐一或批量制作成ePub和MOBI电子书。你可以直接在Doocer中阅读所有文章,或者推送到Kindle、AppleBooks上阅读。
真的很好的阅读体验
Doocer 生成的电子书在排版方面非常出色。应该有的内容很多,不应该有的内容不多。本书不仅包括图文,还包括文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生的替换自定义字体功能。
由于网站文章通常有标准和通用的排版规范,Doocer生成的电子书文章中的标题和列表图例与原网页文章@高度一致>。原文章中的所有超链接也被保留,评论、广告等内容全部丢弃。整本书的阅读体验非常友好。(当然,如果原网页文章的布局没有规则,那么生成的电子书也可能面目全非。)
将网页 文章 制作成电子书
Doocer完成注册登录后,我们就可以开始将网页文章制作成电子书了。首先,我们点击“NEWBOOK”按钮新建电子书,输入电子书名称。接下来选择右上角的“添加”以添加 文章 URL 或 RSS 提要地址。
以小众网站的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,那么小众最近的文章列表就会出现为我们显示添加到。我们可以根据需要选择,也可以点击“SELECTALL”全选文章。最后,下拉到页面底部,选择“SAVE”,那么这些文章就会被添加到书里。
其实Doocer网页与RSS工具很相似,实现了从网站批量抓取文章并集中展示的功能。
要将这些 文章 转换为电子书并将它们推送到 Kindle,我们必须做一些简单的事情。
首先,根据Doocer个人设置页面的提示,打开Amazon Kindle的个人文档设置,将Doocer电子书的发送地址添加到个人文档接收地址中。完成后,我们在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面中找到“Publish”,选择SendtoKindle。大约 10 到 30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
仍有一些问题需要注意
Doocer目前处于beta测试阶段,还有一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,可以直接联系他帮忙解决。
自动化所有操作的过程是我认为 Doocer 最需要做的事情。Doocer可以像RSS工具一样抓取网页中更新的文章,但是要抓取新的文章并生成电子书并推送,仍然需要手动完成。如果整个过程可以自动化,RSS-MOBI-Kindle 可以一口气搞定,相信实用性会更好。 查看全部
抓取网页生成电子书(手动排版书籍制作电子书:网页文章批量抓取生成电子书)
【PConline资讯】我一直在研究如何把我关心的网页或者文章放到Kindle里认真阅读,但是很长一段时间都没有真正的进展。手工排版制作电子书的方法虽然简单易行,但对于短小、更新频繁的网页文章来说效率低下。如果有一个工具可以文章批量抓取网页,生成电子书,然后直接推送到Kindle上就好了。Doocer 就是这样一种实用程序。
Doocer 是由@lepture 开发的在线服务。它允许用户在Pocket Read Later帐户中提交URL、RSS feed地址和文章,然后将它们逐一或批量制作成ePub和MOBI电子书。你可以直接在Doocer中阅读所有文章,或者推送到Kindle、AppleBooks上阅读。
真的很好的阅读体验
Doocer 生成的电子书在排版方面非常出色。应该有的内容很多,不应该有的内容不多。本书不仅包括图文,还包括文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生的替换自定义字体功能。
由于网站文章通常有标准和通用的排版规范,Doocer生成的电子书文章中的标题和列表图例与原网页文章@高度一致>。原文章中的所有超链接也被保留,评论、广告等内容全部丢弃。整本书的阅读体验非常友好。(当然,如果原网页文章的布局没有规则,那么生成的电子书也可能面目全非。)
将网页 文章 制作成电子书
Doocer完成注册登录后,我们就可以开始将网页文章制作成电子书了。首先,我们点击“NEWBOOK”按钮新建电子书,输入电子书名称。接下来选择右上角的“添加”以添加 文章 URL 或 RSS 提要地址。
以小众网站的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,那么小众最近的文章列表就会出现为我们显示添加到。我们可以根据需要选择,也可以点击“SELECTALL”全选文章。最后,下拉到页面底部,选择“SAVE”,那么这些文章就会被添加到书里。
其实Doocer网页与RSS工具很相似,实现了从网站批量抓取文章并集中展示的功能。
要将这些 文章 转换为电子书并将它们推送到 Kindle,我们必须做一些简单的事情。
首先,根据Doocer个人设置页面的提示,打开Amazon Kindle的个人文档设置,将Doocer电子书的发送地址添加到个人文档接收地址中。完成后,我们在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面中找到“Publish”,选择SendtoKindle。大约 10 到 30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
仍有一些问题需要注意
Doocer目前处于beta测试阶段,还有一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,可以直接联系他帮忙解决。
自动化所有操作的过程是我认为 Doocer 最需要做的事情。Doocer可以像RSS工具一样抓取网页中更新的文章,但是要抓取新的文章并生成电子书并推送,仍然需要手动完成。如果整个过程可以自动化,RSS-MOBI-Kindle 可以一口气搞定,相信实用性会更好。
抓取网页生成电子书(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-23 04:19
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p># -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?) 查看全部
抓取网页生成电子书(网上无法下载的“小说在线阅读”内容?有种Python2.7基础知识
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多关于Yii的东西,想找点东西调整一下.... = =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网....再次声明,我们不对任何版权负责....
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
换行,就是网页中的占位符,也就是空格,换成空格就行了。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
<p># -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('(.*?)',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('(.*?)
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-23 02:13
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
pip install pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息类型网站,通过1.抓取列表2.抓取详细内容采集这两个步骤数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
欢迎搜索关注:Crossin的编程课堂 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了 Python 的基础知识后,不知道能做些什么来提高它。今天就用一个小例子来告诉大家,通过Python和爬虫可以完成什么样的小工具。
在知乎,你一定关注过一些不错的专栏(比如Crossin 的编程课堂)。但万一哪天,你喜欢的答主被喷在网上,你一气之下删帖停止更新,这些好内容就看不到了。虽然这是一个小概率事件(但不是从未发生过),但请采取预防措施。您可以将您关注的专栏导出为电子书,以便您可以离线阅读它们,并且不怕误删帖子。
如果只需要工具和源码,可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,就是网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三个部分:
抓取列文章地址列表抓取每个文章导出PDF1.的详细信息抓取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半,我介绍了如何分析网页上的请求。按照方法,我们可以利用开发者工具的Network功能,找出栏目页面的请求,得到明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于向下滚动页面的触发效果),判断是否所有文章s已获得。
data中的id、title、url就是我们需要的数据。因为 url 可以用 id 拼出,所以我们的代码中没有保存。
使用 while 循环,直到 文章 的所有 id 和标题都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢文章
有了 文章 的所有 ids/urls,后面的抓取就很简单了。文章正文内容在 Post-RichText 标签中。
需要一点努力的是一些文本处理。比如原页面的图片效果会添加noscript标签和data-actual、src="data:image等属性,我们必须去掉才能正常显示。
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
至此,所有内容都已经爬取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf 是一个 HTML to PDF 工具,需要单独安装。详情请参考其官网介绍。
pdfkit 是一个包装了这个工具的 Python 库,可以从 pip 安装:
pip install pdfkit
使用简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整个列的导出。
不仅是知乎栏目,几乎大部分信息类型网站,通过1.抓取列表2.抓取详细内容采集这两个步骤数据。所以这段代码稍加修改就可以用在很多其他的网站s上。只是有些网站需要登录才能访问,那么就需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制等都不一样,具体问题还是需要分析的。
这些爬虫的开发技巧可以在我们的爬虫实战课程中学习。如有需要请在公众号回复实际爬虫
【源码下载】
获取知乎栏目下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还提供了本专栏的打包PDF,欢迎阅读和分享。
════
其他 文章 和答案:
欢迎搜索关注:Crossin的编程课堂
抓取网页生成电子书(V6.14B10.28版本的电子书制作生成器增加了自动升级安装功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-21 22:06
电子书制作生成器也是一款电子书制作软件。本软件可以自动将文件转换成需要的电子版文本,但可以增加电子书内文本的容量。如今,随着使用电子书包的人越来越多,电子书制作软件和格式转换软件也越来越多。这些软件的出现可以让我们的阅读更加方便,至少我们可以阅读各种格式的文本。因此,让我们来看看每个版本的集合的电子书制作器生成器!
每个版本的电子书创作生成器集合:
V6.14B10.28版电子书生成器
新增自动升级安装功能!方便及时更新最新软件!并且增加了更多的自定义模板供大家选择和使用。感谢sorson的朋友们提供!欢迎朋友制作,制作模板的朋友有机会获得软件注册版!
V6.06B8.第10版电子书制作器
新增智能调整功能,可有效删除重复和空行,方便TXT、HTML、CHM、EXE等格式书籍的批量制作;新增模板和自定义模板功能,方便高级用户自行制作或重制。模板。从此不再局限于只限于软件本身的模板。电子书生产的七十二项变革已经开始!
V5.82B4.20版电子书生成器
新增精彩网页采集功能和RSS采集功能,修改批量导入功能,让导入可以快速完成,去掉删除提示功能;新增内容菜单隐藏功能和目录同步功能!
V5.78B3.29版电子书生成器
增加了目录栏模式、内容章节§符号的隐式选择、自定义页码的编译控制模式等多种选项!
V5.50B2.21版电子书制作生成器
添加了对以多种方式复制和粘贴图像的支持。如果Office有图片,保存方式为截屏网页方式;浏览带图片的网页并保存为所有网页;只要制作的素材都放在同一个目录下,打开保存的网页后,操作就是选择内容。只需复制粘贴即可,非常方便。
V3.83B5.1版电子书制作生成器 查看全部
抓取网页生成电子书(V6.14B10.28版本的电子书制作生成器增加了自动升级安装功能)
电子书制作生成器也是一款电子书制作软件。本软件可以自动将文件转换成需要的电子版文本,但可以增加电子书内文本的容量。如今,随着使用电子书包的人越来越多,电子书制作软件和格式转换软件也越来越多。这些软件的出现可以让我们的阅读更加方便,至少我们可以阅读各种格式的文本。因此,让我们来看看每个版本的集合的电子书制作器生成器!
每个版本的电子书创作生成器集合:
V6.14B10.28版电子书生成器
新增自动升级安装功能!方便及时更新最新软件!并且增加了更多的自定义模板供大家选择和使用。感谢sorson的朋友们提供!欢迎朋友制作,制作模板的朋友有机会获得软件注册版!
V6.06B8.第10版电子书制作器
新增智能调整功能,可有效删除重复和空行,方便TXT、HTML、CHM、EXE等格式书籍的批量制作;新增模板和自定义模板功能,方便高级用户自行制作或重制。模板。从此不再局限于只限于软件本身的模板。电子书生产的七十二项变革已经开始!
V5.82B4.20版电子书生成器
新增精彩网页采集功能和RSS采集功能,修改批量导入功能,让导入可以快速完成,去掉删除提示功能;新增内容菜单隐藏功能和目录同步功能!
V5.78B3.29版电子书生成器
增加了目录栏模式、内容章节§符号的隐式选择、自定义页码的编译控制模式等多种选项!
V5.50B2.21版电子书制作生成器
添加了对以多种方式复制和粘贴图像的支持。如果Office有图片,保存方式为截屏网页方式;浏览带图片的网页并保存为所有网页;只要制作的素材都放在同一个目录下,打开保存的网页后,操作就是选择内容。只需复制粘贴即可,非常方便。
V3.83B5.1版电子书制作生成器
抓取网页生成电子书(抓取网页生成电子书,关键还是看你的耐心有多少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-21 18:01
抓取网页生成电子书。貌似有api或者phpsdk。稍微开个虚拟机跑个java实现下。先给我网页。
1.爬虫对数据进行提取,比如数据分析:-analysis-group2.解析网页内容生成数据库,r或python可以完成。
打败一切竞争对手的一切技术
我说的是,你愿意的话,估计一小时也就搞定了,要想先学?太慢了,
怎么弄应该和学什么语言关系不大,你要是一门都不想学的话,即使你啃生肉看到十分钟也想放弃了。什么语言都可以看到你想要的答案。(现在入门都很轻松,因为上手快容易入门,零基础也可以学会,但是学久了会越来越复杂越来越乱,我同学有以前从c开始到java最后过了两年自学转javaee的,这一路走下来不容易。)这个不一定要学习多少语言,找个容易看懂教程的入门就行。
javaee或者php是首选,虽然最近发展比较紧但是如果你有兴趣,就可以学学看。好好学一年就差不多了,我个人是半年后确实是有点模糊,因为各种细节变化太多,语言相差太多。比如你看见名词在学校常见的英语中发的是变格(我只听说过这个是名词而不知道具体代词是这么发的,毕竟我没在学校呆过,那么有见识的请指教一下有什么不正确的表达方式),那么在实际中,那些同样用英语的地方就会对应出中文。但是我觉得学着快学着难和你会学很难不是一回事,关键还是看你的耐心有多少。 查看全部
抓取网页生成电子书(抓取网页生成电子书,关键还是看你的耐心有多少)
抓取网页生成电子书。貌似有api或者phpsdk。稍微开个虚拟机跑个java实现下。先给我网页。
1.爬虫对数据进行提取,比如数据分析:-analysis-group2.解析网页内容生成数据库,r或python可以完成。
打败一切竞争对手的一切技术
我说的是,你愿意的话,估计一小时也就搞定了,要想先学?太慢了,
怎么弄应该和学什么语言关系不大,你要是一门都不想学的话,即使你啃生肉看到十分钟也想放弃了。什么语言都可以看到你想要的答案。(现在入门都很轻松,因为上手快容易入门,零基础也可以学会,但是学久了会越来越复杂越来越乱,我同学有以前从c开始到java最后过了两年自学转javaee的,这一路走下来不容易。)这个不一定要学习多少语言,找个容易看懂教程的入门就行。
javaee或者php是首选,虽然最近发展比较紧但是如果你有兴趣,就可以学学看。好好学一年就差不多了,我个人是半年后确实是有点模糊,因为各种细节变化太多,语言相差太多。比如你看见名词在学校常见的英语中发的是变格(我只听说过这个是名词而不知道具体代词是这么发的,毕竟我没在学校呆过,那么有见识的请指教一下有什么不正确的表达方式),那么在实际中,那些同样用英语的地方就会对应出中文。但是我觉得学着快学着难和你会学很难不是一回事,关键还是看你的耐心有多少。
抓取网页生成电子书(手机邮件APP应用1.功能特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-21 04:15
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。它可以完整的存储整个网页的信息,并且支持生成HTML文件和完整的网页快照。用户只需输入网页地址即可在软件中使用非常方便。
IbookBox 功能
1、支持所有小说网站抓取各类小说。
2、支持将抓取的电子书生成的txt发送到手机。
3、支持电子书自动存入自己的邮箱。
4、纯单机版不需要任何人工干预,自动爬取各类网络电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就赶紧下载吧。
7、爬取的小说默认存储在本地电脑上。
8、支持通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储电子书。并通过手机邮件APP应用直接接收抓拍的小说。
预防措施
1.每个类别对应一个本地驱动器的路径。例如D:\ImapBox\cloud,如果你创建一个新的类别,imapbox会在你的本地驱动器上创建一个新目录。
2.如果您使用的是绿色版本。你应该:进入Windows桌面——点击“开始”按钮——进入运行——命令:regsvr32 C:\imapbox\imapbox.dll,回车。
更新内容
1、用户之间共享数据的功能有了很大的提升。
2、加快软件运行效率。
3、解决界面多滚动条不稳定现象。
4、改进了右下角加工状态的实时显示。 查看全部
抓取网页生成电子书(手机邮件APP应用1.功能特色)
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。它可以完整的存储整个网页的信息,并且支持生成HTML文件和完整的网页快照。用户只需输入网页地址即可在软件中使用非常方便。
IbookBox 功能
1、支持所有小说网站抓取各类小说。
2、支持将抓取的电子书生成的txt发送到手机。
3、支持电子书自动存入自己的邮箱。
4、纯单机版不需要任何人工干预,自动爬取各类网络电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就赶紧下载吧。
7、爬取的小说默认存储在本地电脑上。
8、支持通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储电子书。并通过手机邮件APP应用直接接收抓拍的小说。
预防措施
1.每个类别对应一个本地驱动器的路径。例如D:\ImapBox\cloud,如果你创建一个新的类别,imapbox会在你的本地驱动器上创建一个新目录。
2.如果您使用的是绿色版本。你应该:进入Windows桌面——点击“开始”按钮——进入运行——命令:regsvr32 C:\imapbox\imapbox.dll,回车。
更新内容
1、用户之间共享数据的功能有了很大的提升。
2、加快软件运行效率。
3、解决界面多滚动条不稳定现象。
4、改进了右下角加工状态的实时显示。
抓取网页生成电子书(网页制作,网页批量转换,电子书文件分割合并文件加密解密)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-21 04:13
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后会提供更多模板。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、txt rtf htm doc等格式可以任意相互转换
24、除了转换上面列出的文件类型,还可以自己添加转换类型
补充说明:注册码格式除首尾2位外,必须为5位。 查看全部
抓取网页生成电子书(网页制作,网页批量转换,电子书文件分割合并文件加密解密)
你喜欢制作 chm 电子书吗?想要将文件批量转换为 Web 格式?想要精美的电子相册?…
主要功能:网页制作、网页批量转换、电子书制作、文件分割合并、文件加解密,如下:
1、 将文本文件批量转换为web文件(txt等转htm)
2、 将网页文件批量转换为文本文件(htm等转txt)
3、Word、EXCEL、POWERPOINT文档批量转换成web文件(doc xls ppt等转换成htm)
4、图片文件、FLASH、mp3、wmv文件批量转换为网页(jpg gif swf mp3 wmv等--> htm)
5、支持WORD(doc文件)一步生成电子书(梦寐以求的功能吧?哈哈……)
6、可以作为文本文件使用的电子书创作工具软件。(并选择 Web 模板或 CSS)
7、支持一步将图片文件编译成电子相册。(并且可以选择电子相册模板或CSS)
8、支持mht文件一键生成电子书
9、网页颜色选择功能。可以捕获屏幕任何可见部分的颜色代码;目前以三种格式捕获颜色
10、网页批量压缩功能。选择性或批量压缩网页文件
11、批量加密文件,也可以解密文件。
12、批量拆分文件和合并文件。
13、文档合并功能。支持多种文件格式合并为四种格式之一,HTML、TXT、RTF、DOC
14、支持HTML网页文件一键生成电子书。
15、网页特效采集与管理功能。并且可以方便的批量插入网页
16、反编译 CHM 电子书。
17、在线搜索功能。集成强大的中文搜索引擎---百度搜索
18、已经提供了几个CSS和模板,注册后会提供更多模板。你也可以自己写。让过渡更随意
19、提供从html文件生成电子书的两个选项
20、支持ppt(powerpoint)文件一键生成电子书
21、支持xls(excel)文件一键生成电子书
22、文字和网页文字的批量替换
23、txt rtf htm doc等格式可以任意相互转换
24、除了转换上面列出的文件类型,还可以自己添加转换类型
补充说明:注册码格式除首尾2位外,必须为5位。
抓取网页生成电子书(抓取网页生成电子书pdf入门篇:动态页面抓取代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-01-21 00:03
抓取网页生成电子书pdf文件就像抓取某个网站上面的内容做数据分析,是相对非常耗时且麻烦的事情。(至少没有google搜索速度快)书籍的电子版本也同样,本人一直在摸索如何获取免费的电子版本,相关的书籍和文章都是一些在别人分享资源的文章或是一些老人写的关于记笔记读书笔记的文章。这里没有认真做答。如果你已经学会了网页爬虫,那应该还可以进行一些数据分析,关于linux(平时会遇到很多问题,或者学习一个新语言的时候,我都会学习下linux,以前就是因为它安装比较简单)或是安卓(基本没碰过),使用wp7.1等等系统安装kindle,或是获取网页信息生成电子书。
爬虫入门篇:入门篇就是我写的博客(csdn博客),结尾有附上本人整理的一些爬虫入门知识,敬请一看。(写完之后只是更方便上手)比较复杂,需要学习的东西较多。学校里面有开专业课程,但是也不是很多。毕竟每个人学习能力不同,个人觉得都是些收获而已。01数据结构和算法数据结构看看python里面和它相关的数据结构就可以了,学完基本python里面的数据结构就差不多可以了。
在python里面有可能遇到一些问题,使用谷歌搜索。我觉得只要有毅力,个人推荐上网去看一下这些内容,就相当于看着说明书学习吧,那会学习起来有一定的挑战性。02网页抓取与网页分析今天学习的是爬取网页来分析网页内容。这部分主要包括动态页面抓取和静态页面爬取。就像人一样,他的生活方式都是与社会相适应的。用网页抓取和网页分析来理解代码。
今天主要是动态页面抓取,那我们来谈一下如何实现动态页面的抓取(数据抓取)。03selenium安装新建一个safari文件夹,并将其中的all_shells.py文件进行存放。(后面会用到)其中有三个文件,分别是charles配置文件、mon.py、爬虫的urllib.request.urlopen.py。
接下来依次来尝试和进行使用。(我们一步一步来)第一步:安装geckodriver。方法有很多种,我采用的方法是geckodriver-mac.sh.这个命令提示符,并且可以通过charles配置文件进行打开mon.py。注意的是我们在配置文件中,如果在引用某个python对象的时候,需要在标签中加上'../geckodriver/v4.xxx',不然会报错。
例如下面代码所示,而且没有引用'../geckodriver/v4.xxx',这样会报错:error:thegeckodriverversionversion:11.0.1(nov2017,29,2077072).notinuseonthemacosxbrowser.使用方法是直接在mon.py中运。 查看全部
抓取网页生成电子书(抓取网页生成电子书pdf入门篇:动态页面抓取代码)
抓取网页生成电子书pdf文件就像抓取某个网站上面的内容做数据分析,是相对非常耗时且麻烦的事情。(至少没有google搜索速度快)书籍的电子版本也同样,本人一直在摸索如何获取免费的电子版本,相关的书籍和文章都是一些在别人分享资源的文章或是一些老人写的关于记笔记读书笔记的文章。这里没有认真做答。如果你已经学会了网页爬虫,那应该还可以进行一些数据分析,关于linux(平时会遇到很多问题,或者学习一个新语言的时候,我都会学习下linux,以前就是因为它安装比较简单)或是安卓(基本没碰过),使用wp7.1等等系统安装kindle,或是获取网页信息生成电子书。
爬虫入门篇:入门篇就是我写的博客(csdn博客),结尾有附上本人整理的一些爬虫入门知识,敬请一看。(写完之后只是更方便上手)比较复杂,需要学习的东西较多。学校里面有开专业课程,但是也不是很多。毕竟每个人学习能力不同,个人觉得都是些收获而已。01数据结构和算法数据结构看看python里面和它相关的数据结构就可以了,学完基本python里面的数据结构就差不多可以了。
在python里面有可能遇到一些问题,使用谷歌搜索。我觉得只要有毅力,个人推荐上网去看一下这些内容,就相当于看着说明书学习吧,那会学习起来有一定的挑战性。02网页抓取与网页分析今天学习的是爬取网页来分析网页内容。这部分主要包括动态页面抓取和静态页面爬取。就像人一样,他的生活方式都是与社会相适应的。用网页抓取和网页分析来理解代码。
今天主要是动态页面抓取,那我们来谈一下如何实现动态页面的抓取(数据抓取)。03selenium安装新建一个safari文件夹,并将其中的all_shells.py文件进行存放。(后面会用到)其中有三个文件,分别是charles配置文件、mon.py、爬虫的urllib.request.urlopen.py。
接下来依次来尝试和进行使用。(我们一步一步来)第一步:安装geckodriver。方法有很多种,我采用的方法是geckodriver-mac.sh.这个命令提示符,并且可以通过charles配置文件进行打开mon.py。注意的是我们在配置文件中,如果在引用某个python对象的时候,需要在标签中加上'../geckodriver/v4.xxx',不然会报错。
例如下面代码所示,而且没有引用'../geckodriver/v4.xxx',这样会报错:error:thegeckodriverversionversion:11.0.1(nov2017,29,2077072).notinuseonthemacosxbrowser.使用方法是直接在mon.py中运。
抓取网页生成电子书(得到App电子书信息“得到”App没有信息(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-20 12:12
)
PS:如需Python学习资料,可点击下方链接自行获取
mitmdump 爬取“获取”应用电子书信息
“Get”应用是罗吉思微出品的碎片化时间学习应用。该应用程序中有许多学习资源。但是“获取”app没有对应的网页版,所以必须通过app获取信息。这次我们通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App中电子书版块的电子书信息,并将信息保存到MongoDB中,如图。
我们需要爬取书名、简介、封面和价格。不过这次爬取的重点是了解mitmdump工具的用法,所以暂时不涉及自动爬取,app的操作还是手动完成。mitmdump 负责捕获响应并保存数据提取。
2. 准备工作
请确保已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网,同时配置了mitmproxy的CA证书,安装了MongoDB并运行了它的服务,安装了PyMongo库. 具体配置请参考第一章说明。
3. 爬取分析
首先探索当前页面的URL和返回内容,我们编写脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的 URL 和响应的正文内容,即请求链接和响应内容这两个最关键的部分。该脚本以名称 script.py 保存。
接下来使用以下命令运行 mitmdump:
mitmdump -s script.py
打开“获取”应用的电子书页面,可以在PC控制台看到相应的输出。然后滑动页面加载更多的电子书,控制台中新输出的内容就是App发送的新的加载请求,包括下一页的电子书内容。控制台输出的示例如图所示。
可以看到url就是接口,后面跟一个sign参数。从 URL 的名称可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是JSON格式的字符串,我们格式化如图。
格式化后的内容收录ac字段,一个list字段,list的每个元素都收录价格、书名、描述等。第一个返回的结果是电子书《情人》,App的内容也是这个e-此时book,描述内容和价格也完全匹配,App页面如图。
这意味着当前接口是获取电子书信息的接口,我们只需要从这个接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据抓取
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后提取结果中对应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台的输出,如图。
控制台输出
现在书籍的所有信息都输出了,一个书籍信息对应一个JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息并将信息保存到数据库中。为方便起见,我们选择 MongoDB 数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每条内容都是提取的内容,包括电子书的标题、封面、描述、价格信息。
一开始,我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入数据库。
扫了几页,发现所有书籍信息都保存到了MongoDB中,如图。
到目前为止,我们已经使用了一个非常简单的脚本来保存来自“get”应用程序的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data) 查看全部
抓取网页生成电子书(得到App电子书信息“得到”App没有信息(组图)
)
PS:如需Python学习资料,可点击下方链接自行获取
mitmdump 爬取“获取”应用电子书信息
“Get”应用是罗吉思微出品的碎片化时间学习应用。该应用程序中有许多学习资源。但是“获取”app没有对应的网页版,所以必须通过app获取信息。这次我们通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App中电子书版块的电子书信息,并将信息保存到MongoDB中,如图。
我们需要爬取书名、简介、封面和价格。不过这次爬取的重点是了解mitmdump工具的用法,所以暂时不涉及自动爬取,app的操作还是手动完成。mitmdump 负责捕获响应并保存数据提取。
2. 准备工作
请确保已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网,同时配置了mitmproxy的CA证书,安装了MongoDB并运行了它的服务,安装了PyMongo库. 具体配置请参考第一章说明。
3. 爬取分析
首先探索当前页面的URL和返回内容,我们编写脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的 URL 和响应的正文内容,即请求链接和响应内容这两个最关键的部分。该脚本以名称 script.py 保存。
接下来使用以下命令运行 mitmdump:
mitmdump -s script.py
打开“获取”应用的电子书页面,可以在PC控制台看到相应的输出。然后滑动页面加载更多的电子书,控制台中新输出的内容就是App发送的新的加载请求,包括下一页的电子书内容。控制台输出的示例如图所示。
可以看到url就是接口,后面跟一个sign参数。从 URL 的名称可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是JSON格式的字符串,我们格式化如图。
格式化后的内容收录ac字段,一个list字段,list的每个元素都收录价格、书名、描述等。第一个返回的结果是电子书《情人》,App的内容也是这个e-此时book,描述内容和价格也完全匹配,App页面如图。
这意味着当前接口是获取电子书信息的接口,我们只需要从这个接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据抓取
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后提取结果中对应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台的输出,如图。
控制台输出
现在书籍的所有信息都输出了,一个书籍信息对应一个JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息并将信息保存到数据库中。为方便起见,我们选择 MongoDB 数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每条内容都是提取的内容,包括电子书的标题、封面、描述、价格信息。
一开始,我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入数据库。
扫了几页,发现所有书籍信息都保存到了MongoDB中,如图。
到目前为止,我们已经使用了一个非常简单的脚本来保存来自“get”应用程序的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
抓取网页生成电子书(问题的话()设置网站RSS输出方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-19 13:00
准备好 RSS 提要后,您可以在 Calibre 中添加它们。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
在弹出的对话框中,点击【新建配方】按钮,切换到“添加自定义新闻源”对话框。在“订阅列表标题”中输入一个名称,例如“我的订阅”(此名称是一个类别名称,将收录一组 RSS 提要地址)。
“最老的文章”可以设置抓取文章的及时性。默认情况下,Calibre 只会在过去 7 天内抓取 文章。如果你想抢更多,你可以自定义更改天数。“每个源的最大 文章 秒数”设置要抓取的最大 文章 秒数。不过需要注意的是,这两个设置受限于网站 RSS的输出方式。比如有些网站的RSS只输出有限个最新的文章,所以无论在Calibre中如何设置都受这个限制,可能无法获取到指定的文章 的数量;
接下来,我们需要在“将新闻添加到订阅”中添加我们想要保留的 RSS 地址。同样在“Source Name”中输入RSS订阅的名称,如“Kindle Companion”;然后在“Source URL”中输入RSS地址,如“”;最后点击【添加来源】按钮,在“订阅列表中的新闻”中添加一个RSS订阅。在一个订阅列表中可以抓取多个RSS订阅,因此可以重复输入多个RSS订阅名称和来源网址并添加多次。
添加RSS提要地址后。点击右下角的【保存】按钮保存并返回“添加自定义动态消息”界面。如需修改,可在左侧列表中选择一项,然后点击【编辑此配方】按钮进行修改。如果要修改它,请单击[删除此配方]按钮将其删除。如果没有问题,可以点击【关闭】按钮返回Calibre主界面。
三、获取和推送
设置好 Feed 后,您就可以抓取新闻了。同样,在Calibre主界面上方的功能图标中找到“抓取新闻”,点击,弹出“定期新闻下载”对话框。在左侧列表中找到“自定义”类别,点击展开,可以找到刚刚添加的订阅列表。选择好之后,点击界面下方的【立即下载】按钮,Calibre就会开始爬取RSS内容。
抓取成功后,Calibre 会生成一本期刊格式的电子书,并自动存入图书馆。如果您设置了电子邮件推送,Calibre 还会自动将生成的电子书推送到云端,以便自动同步到您的 Kindle。
当然,除了这种手动爬取的方式,你还可以通过“定时下载”的方式定期爬取,比如每周、每月或者每隔指定天数爬取RSS内容,但前提是你要保持电脑开机并且让您的计算机保持在线状态。
另外需要注意的是,网站的一些RSS只输出摘要,所以Calibre只能抓取摘要内容;如果您订阅的 RSS 被屏蔽并且您的网络没有使用代理,则 Failed to crawl 成功。
如果你需要抓取的网站没有提供RSS feed,可以参考《Calibre使用教程:抓取网站页面制作电子书》中文章提供的方法编写脚本直接抓取网站的页面内容,制作电子书。 查看全部
抓取网页生成电子书(问题的话()设置网站RSS输出方式)
准备好 RSS 提要后,您可以在 Calibre 中添加它们。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
在弹出的对话框中,点击【新建配方】按钮,切换到“添加自定义新闻源”对话框。在“订阅列表标题”中输入一个名称,例如“我的订阅”(此名称是一个类别名称,将收录一组 RSS 提要地址)。
“最老的文章”可以设置抓取文章的及时性。默认情况下,Calibre 只会在过去 7 天内抓取 文章。如果你想抢更多,你可以自定义更改天数。“每个源的最大 文章 秒数”设置要抓取的最大 文章 秒数。不过需要注意的是,这两个设置受限于网站 RSS的输出方式。比如有些网站的RSS只输出有限个最新的文章,所以无论在Calibre中如何设置都受这个限制,可能无法获取到指定的文章 的数量;
接下来,我们需要在“将新闻添加到订阅”中添加我们想要保留的 RSS 地址。同样在“Source Name”中输入RSS订阅的名称,如“Kindle Companion”;然后在“Source URL”中输入RSS地址,如“”;最后点击【添加来源】按钮,在“订阅列表中的新闻”中添加一个RSS订阅。在一个订阅列表中可以抓取多个RSS订阅,因此可以重复输入多个RSS订阅名称和来源网址并添加多次。
添加RSS提要地址后。点击右下角的【保存】按钮保存并返回“添加自定义动态消息”界面。如需修改,可在左侧列表中选择一项,然后点击【编辑此配方】按钮进行修改。如果要修改它,请单击[删除此配方]按钮将其删除。如果没有问题,可以点击【关闭】按钮返回Calibre主界面。
三、获取和推送
设置好 Feed 后,您就可以抓取新闻了。同样,在Calibre主界面上方的功能图标中找到“抓取新闻”,点击,弹出“定期新闻下载”对话框。在左侧列表中找到“自定义”类别,点击展开,可以找到刚刚添加的订阅列表。选择好之后,点击界面下方的【立即下载】按钮,Calibre就会开始爬取RSS内容。
抓取成功后,Calibre 会生成一本期刊格式的电子书,并自动存入图书馆。如果您设置了电子邮件推送,Calibre 还会自动将生成的电子书推送到云端,以便自动同步到您的 Kindle。
当然,除了这种手动爬取的方式,你还可以通过“定时下载”的方式定期爬取,比如每周、每月或者每隔指定天数爬取RSS内容,但前提是你要保持电脑开机并且让您的计算机保持在线状态。
另外需要注意的是,网站的一些RSS只输出摘要,所以Calibre只能抓取摘要内容;如果您订阅的 RSS 被屏蔽并且您的网络没有使用代理,则 Failed to crawl 成功。
如果你需要抓取的网站没有提供RSS feed,可以参考《Calibre使用教程:抓取网站页面制作电子书》中文章提供的方法编写脚本直接抓取网站的页面内容,制作电子书。
抓取网页生成电子书(一步步解析单个页面,得到该页书籍链接列表得到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-19 12:20
2. 解析单个页面以获取该页面上的书籍链接列表
3. 转到书页
* 判断是否可以下载
* 如果可以下载,请下载所有格式的书籍
其次,为了获得爬虫的健壮性,我们需要保证每次网页加载成功,文件下载完成,我会在后面的内容中一步一步介绍。
实施过程
Selenium 可以模拟打开浏览器。在此之前,我们需要下载浏览器的驱动程序。在本文中,我们使用的是chrome浏览器,Firefox也是常用的浏览器。步骤类似,不再赘述。
硒的安装:
sudo pip install selenium
然后下载chrome的webdriver,直接保存到本地,比如/usr/bin,然后设置selenium的基本设置
import re#正则表达式
import random#随机选择
import subprocess# 执行bash命令
from multiprocessing import Pool#建立线程池,并行爬取加快速度
from selenium import webdriver
# set chromedriver path and download path
chromeOptions = webdriver.ChromeOptions()
dl_path="~/Downloads/KanCloud"#设置下载路径
chromedriver="/usr/bin/chromedriver"#修改为你的chromedriver路径
prefs = {"download.default_directory" : dl_path}
chromeOptions.add_experimental_option("prefs",prefs)
#可以为webdriver设置代理,自动获得代理IP地址下面会解释,这里注释掉
#PROXY='1.82.216.134:80'
#chromeOptions.add_argument('--proxy-server=%s' % PROXY)
# url_start='http://www.kancloud.cn/explore/top'
#建立一个webdriver对象
driver = webdriver.Chrome(chrome_options=chromeOptions)
driver.get('http://www.kancloud.cn/digest/ ... %2339;)#用chrome打开这个网页
运行上面的代码,打开一个chrome标签,如下图:
点击下载按钮,我们看到有PDF、epub、mobi三个下载选项。为了模拟点击动作,我们需要获取元素的位置。这时候我们可以使用chrome的inspect功能,快捷键是 Ctrl+shift+I ,或者将鼠标悬停在下载上,右键选择inspect,效果如下:
选择右边高亮的代码,右键->复制->复制xpath,可以得到元素的xpath
//*[@id="manualDownload"]/span/b
然后使用webdriver本身的xpath搜索功能获取元素,并模拟点击操作
运行上面这句话,我们可以看到网站确实响应了,支持下载的电子书格式有3种。这一步点击下载按钮是必须的,否则直接点击epub会报 element not visible 的错误。接下来我们演示下载epub,鼠标悬停在epub上,右键查看,可以得到下载epub的xpath,同上
driver.find_element_by_xpath('//*[@id="manualDownload"]/div/div/ul/li[2]/a').click()
这样我们就可以把这本epub电子书下载到我们指定的路径了。
这是 Selenium 的基本应用。它还有一些其他的定位元素的方法和模拟操作的功能,比如把网页往下拉,因为有些网站会根据用户的下拉情况来渲染网页,越往下拉,显示的内容越多。详情请查看 selenium 的官方文档。
我们对每一页的每一本书执行上述过程,然后我们可以爬取整个网站的书籍,前提是你的网速足够快,运气足够好。这是因为在持续爬取过程中会出现一些异常,例如
1. webdriver 将无法打开网页
2. 下载完成前打开下一个网页,导致webdriver负担过重,无法加载网页
3. 网站可能是基于IP地址的反爬虫
下一篇我们将解决以上问题,使用多进程加速(webdriver太慢,无法打开网页)。 查看全部
抓取网页生成电子书(一步步解析单个页面,得到该页书籍链接列表得到)
2. 解析单个页面以获取该页面上的书籍链接列表
3. 转到书页
* 判断是否可以下载
* 如果可以下载,请下载所有格式的书籍
其次,为了获得爬虫的健壮性,我们需要保证每次网页加载成功,文件下载完成,我会在后面的内容中一步一步介绍。
实施过程
Selenium 可以模拟打开浏览器。在此之前,我们需要下载浏览器的驱动程序。在本文中,我们使用的是chrome浏览器,Firefox也是常用的浏览器。步骤类似,不再赘述。
硒的安装:
sudo pip install selenium
然后下载chrome的webdriver,直接保存到本地,比如/usr/bin,然后设置selenium的基本设置
import re#正则表达式
import random#随机选择
import subprocess# 执行bash命令
from multiprocessing import Pool#建立线程池,并行爬取加快速度
from selenium import webdriver
# set chromedriver path and download path
chromeOptions = webdriver.ChromeOptions()
dl_path="~/Downloads/KanCloud"#设置下载路径
chromedriver="/usr/bin/chromedriver"#修改为你的chromedriver路径
prefs = {"download.default_directory" : dl_path}
chromeOptions.add_experimental_option("prefs",prefs)
#可以为webdriver设置代理,自动获得代理IP地址下面会解释,这里注释掉
#PROXY='1.82.216.134:80'
#chromeOptions.add_argument('--proxy-server=%s' % PROXY)
# url_start='http://www.kancloud.cn/explore/top'
#建立一个webdriver对象
driver = webdriver.Chrome(chrome_options=chromeOptions)
driver.get('http://www.kancloud.cn/digest/ ... %2339;)#用chrome打开这个网页
运行上面的代码,打开一个chrome标签,如下图:
点击下载按钮,我们看到有PDF、epub、mobi三个下载选项。为了模拟点击动作,我们需要获取元素的位置。这时候我们可以使用chrome的inspect功能,快捷键是 Ctrl+shift+I ,或者将鼠标悬停在下载上,右键选择inspect,效果如下:
选择右边高亮的代码,右键->复制->复制xpath,可以得到元素的xpath
//*[@id="manualDownload"]/span/b
然后使用webdriver本身的xpath搜索功能获取元素,并模拟点击操作
运行上面这句话,我们可以看到网站确实响应了,支持下载的电子书格式有3种。这一步点击下载按钮是必须的,否则直接点击epub会报 element not visible 的错误。接下来我们演示下载epub,鼠标悬停在epub上,右键查看,可以得到下载epub的xpath,同上
driver.find_element_by_xpath('//*[@id="manualDownload"]/div/div/ul/li[2]/a').click()
这样我们就可以把这本epub电子书下载到我们指定的路径了。
这是 Selenium 的基本应用。它还有一些其他的定位元素的方法和模拟操作的功能,比如把网页往下拉,因为有些网站会根据用户的下拉情况来渲染网页,越往下拉,显示的内容越多。详情请查看 selenium 的官方文档。
我们对每一页的每一本书执行上述过程,然后我们可以爬取整个网站的书籍,前提是你的网速足够快,运气足够好。这是因为在持续爬取过程中会出现一些异常,例如
1. webdriver 将无法打开网页
2. 下载完成前打开下一个网页,导致webdriver负担过重,无法加载网页
3. 网站可能是基于IP地址的反爬虫
下一篇我们将解决以上问题,使用多进程加速(webdriver太慢,无法打开网页)。
抓取网页生成电子书(网络书籍抓取器是一款能帮助用户下载指定网页的某)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-01-18 19:20
在线图书抓取器是一款可以帮助用户下载指定网页的某本书和某章的软件。通过在线图书抓取器,可以快速下载小说。同时软件支持断点续传功能,非常方便。可以下载使用。
特征
可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,在最合适的时候再合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件功能
1、章节调整:解压目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
指示
1、首先进入你要下载的小说的网页。
2、输入书名,点击目录提取。
3、设置保存路径,点击Start Grab开始下载。 查看全部
抓取网页生成电子书(网络书籍抓取器是一款能帮助用户下载指定网页的某)
在线图书抓取器是一款可以帮助用户下载指定网页的某本书和某章的软件。通过在线图书抓取器,可以快速下载小说。同时软件支持断点续传功能,非常方便。可以下载使用。
特征
可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,在最合适的时候再合并。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件功能
1、章节调整:解压目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
指示
1、首先进入你要下载的小说的网页。
2、输入书名,点击目录提取。
3、设置保存路径,点击Start Grab开始下载。
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-17 14:05
上一篇文章简单展示了我们将网页转换成PDF的结果,特别适合序列化网页文章,组织成卷。
本文还简要讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点一、爬取网页并保存到本地
因为大部分网页都有图片,所以很多网页都不是普通的静态网页,相应的内容只有在浏览器的加载过程中才会加载,随着浏览器滚动条的滚动。
所以如果你想简单地传递一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:硒。相信一般关注网络爬虫的人都比较熟悉。
笔者尝试搜索selenium+C#的相关词。没想到selenium是一个支持多种语言的工具。我将详细介绍自我搜索。以下是百度百科的简单介绍。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
因此,不要犯错误和常识。你认为网络抓取很容易与 python 一起使用。您还可以使用 C# 中的常用工具。当前的工具将不仅限于实现一种语言。相信随着开源、dotNET的深入,当生态越来越好时,会有更多便捷的工具出现。
在 C# 代码中,通过 Seenium 控制浏览器的行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们要的是图文版的数据,而不仅仅是一些结构化的数据,最简单的方法就是用CTRL+S将网页保存到本地,类似于浏览器的行为。它也是通过使用代码模拟发送击键来实现的。有兴趣的读者可以参考以下代码。
在网上,python的实现都是一样的,作者简单修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)] public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo); 私有静态无效 SaveHtml(ChromeDriver 驱动程序){ uint KEYEVENTF_KEYUP = 2; ¨K9K
二、将多个网页保存为 PDF
虽然WORD也可以用来打开网页,但估计WORD使用IE技术渲染网页,很多功能无法恢复。所以直接转成PDF更科学。
PDF 的另一个优点是几乎所有的 PDF 阅读器都可以毫无区别地打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的主要目的是阅读,因此将 HTML 转换为 PDF 是最理想的。
它可以将多个网页转换为一个 PDF 文件,以实现更连贯的阅读。
网页转PDF的工具是wkhtmltopdf,它也是一个命令行工具,可以多种语言调用。当然调用dotNET是没有问题的,但是更好的体验肯定是用在PowerShell上的。
wkhtmltopdf的安装方法,自查资料学习,都在下一步完成。最后,记得设置环境变量,以便 CMD 和 PowerShell 能够识别它们。
通常可以看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成的。
当多个网页转换为PDF时,需要考虑排序问题。这时候使用Excel Catalyst就可以轻松实现HTML的布局顺序。
一般来说,我们都是按顺序下载网页的,所以简单的利用Excel Catalyst的文件遍历功能,对文件信息进行遍历,在Excel上做一些排序处理,手动调整一些特殊文件的顺序。
然后有一个自定义函数stringjoin,可以快速将多个文件组合成一个字符串组合,用空格分隔,每条记录都要用双引号括起来。
打开win10自带的PowerShell ISE软件。还有其他系统,大家可以自行搜索相关教程打开。
相信很多读者都和作者有同感。他们觉得命令行很吓人。它是一系列代码,尤其是帮助文档。
事实上,它真的突破了心理恐惧。命令行工具和我们在Excel上写函数的原理是一个函数名传入各种参数,但是命令行的参数可以很大。
下面是我们在PowerShell上用一个命令将我们的多个html文件合并为一个PDF文件的操作。
笔者也花了不少功夫去阅读帮助文档,以便写出更多特殊的命令,比如添加页眉和页脚功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,展开多个html文件,最后加上pdf文件名,可能太多了。该文件使用相对路径。您需要将 PowerShell 的当前路径切换到 html 存储文件夹。切换指令为 CD。
终于,激动人心的时刻来了,可以成功生成一个pdf文件。
包括页眉和页脚信息,一本共计400多页的PDF电子书诞生了。
有兴趣的读者不妨将他们最喜欢的网页相册制作成 PDF 文件,以便于访问。之前的错误是为了追求PDF阅读器的简化,现在又用【福昕阅读器】(感谢上一篇后读者的推荐),老式的免费PDF阅读软件,可以阅读基于文本的PDF文件。批注,记笔记。我推荐大家在这里使用它。
同样,搜索关键词 后,会出现关键词 的列表。比如在学习DAX的过程中,如果想像参考书一样查看ALLSELECT函数的使用情况,可以搜索全文。比我们用搜索引擎能找到的要好得多。完成学业后,您还可以突出显示并做笔记。
结语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。我不需要太羡慕python的网页抓取。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境下,没有什么比 dotNET 的开发更有生产力了。python再好,说到分享和交互也是很头疼的,但是dotNET的桌面开发自然是最大的优势。
在OFFICE环境下开发的优势更加详细。其实这篇文章的功能也可以移到Excel环境中无痛执行,后面有时间会慢慢优化整个流程。
HTML转PDF带来了极大的便利。内容在网络上,不是你自己的数据,随时可能被删除,无法访问(本文采集返回的DAX2中文翻译在版权方的压力下,肯定不会持久时间长了,所以我提前计划,先下载到本地,嘿嘿)。 查看全部
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
上一篇文章简单展示了我们将网页转换成PDF的结果,特别适合序列化网页文章,组织成卷。
本文还简要讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点一、爬取网页并保存到本地
因为大部分网页都有图片,所以很多网页都不是普通的静态网页,相应的内容只有在浏览器的加载过程中才会加载,随着浏览器滚动条的滚动。
所以如果你想简单地传递一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:硒。相信一般关注网络爬虫的人都比较熟悉。
笔者尝试搜索selenium+C#的相关词。没想到selenium是一个支持多种语言的工具。我将详细介绍自我搜索。以下是百度百科的简单介绍。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
因此,不要犯错误和常识。你认为网络抓取很容易与 python 一起使用。您还可以使用 C# 中的常用工具。当前的工具将不仅限于实现一种语言。相信随着开源、dotNET的深入,当生态越来越好时,会有更多便捷的工具出现。
在 C# 代码中,通过 Seenium 控制浏览器的行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们要的是图文版的数据,而不仅仅是一些结构化的数据,最简单的方法就是用CTRL+S将网页保存到本地,类似于浏览器的行为。它也是通过使用代码模拟发送击键来实现的。有兴趣的读者可以参考以下代码。
在网上,python的实现都是一样的,作者简单修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)] public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo); 私有静态无效 SaveHtml(ChromeDriver 驱动程序){ uint KEYEVENTF_KEYUP = 2; ¨K9K
二、将多个网页保存为 PDF
虽然WORD也可以用来打开网页,但估计WORD使用IE技术渲染网页,很多功能无法恢复。所以直接转成PDF更科学。
PDF 的另一个优点是几乎所有的 PDF 阅读器都可以毫无区别地打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的主要目的是阅读,因此将 HTML 转换为 PDF 是最理想的。
它可以将多个网页转换为一个 PDF 文件,以实现更连贯的阅读。
网页转PDF的工具是wkhtmltopdf,它也是一个命令行工具,可以多种语言调用。当然调用dotNET是没有问题的,但是更好的体验肯定是用在PowerShell上的。
wkhtmltopdf的安装方法,自查资料学习,都在下一步完成。最后,记得设置环境变量,以便 CMD 和 PowerShell 能够识别它们。
通常可以看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成的。
当多个网页转换为PDF时,需要考虑排序问题。这时候使用Excel Catalyst就可以轻松实现HTML的布局顺序。
一般来说,我们都是按顺序下载网页的,所以简单的利用Excel Catalyst的文件遍历功能,对文件信息进行遍历,在Excel上做一些排序处理,手动调整一些特殊文件的顺序。
然后有一个自定义函数stringjoin,可以快速将多个文件组合成一个字符串组合,用空格分隔,每条记录都要用双引号括起来。
打开win10自带的PowerShell ISE软件。还有其他系统,大家可以自行搜索相关教程打开。
相信很多读者都和作者有同感。他们觉得命令行很吓人。它是一系列代码,尤其是帮助文档。
事实上,它真的突破了心理恐惧。命令行工具和我们在Excel上写函数的原理是一个函数名传入各种参数,但是命令行的参数可以很大。
下面是我们在PowerShell上用一个命令将我们的多个html文件合并为一个PDF文件的操作。
笔者也花了不少功夫去阅读帮助文档,以便写出更多特殊的命令,比如添加页眉和页脚功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,展开多个html文件,最后加上pdf文件名,可能太多了。该文件使用相对路径。您需要将 PowerShell 的当前路径切换到 html 存储文件夹。切换指令为 CD。
终于,激动人心的时刻来了,可以成功生成一个pdf文件。
包括页眉和页脚信息,一本共计400多页的PDF电子书诞生了。
有兴趣的读者不妨将他们最喜欢的网页相册制作成 PDF 文件,以便于访问。之前的错误是为了追求PDF阅读器的简化,现在又用【福昕阅读器】(感谢上一篇后读者的推荐),老式的免费PDF阅读软件,可以阅读基于文本的PDF文件。批注,记笔记。我推荐大家在这里使用它。
同样,搜索关键词 后,会出现关键词 的列表。比如在学习DAX的过程中,如果想像参考书一样查看ALLSELECT函数的使用情况,可以搜索全文。比我们用搜索引擎能找到的要好得多。完成学业后,您还可以突出显示并做笔记。
结语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。我不需要太羡慕python的网页抓取。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境下,没有什么比 dotNET 的开发更有生产力了。python再好,说到分享和交互也是很头疼的,但是dotNET的桌面开发自然是最大的优势。
在OFFICE环境下开发的优势更加详细。其实这篇文章的功能也可以移到Excel环境中无痛执行,后面有时间会慢慢优化整个流程。
HTML转PDF带来了极大的便利。内容在网络上,不是你自己的数据,随时可能被删除,无法访问(本文采集返回的DAX2中文翻译在版权方的压力下,肯定不会持久时间长了,所以我提前计划,先下载到本地,嘿嘿)。
抓取网页生成电子书(微信朋友圈效果纸质书效果代码思路获取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-17 14:02
介绍
朋友圈留着你的数据,留着美好的回忆,记录着我们的每一点成长。从某种意义上说,发朋友圈就是记录生活,感受生活,见证每个人每一步的成长。
如此珍贵的记忆,何不保存呢?只需一杯咖啡时间,即可一键打印朋友圈。可以是纸质书也可以是电子书,可以长期保存,比拍照好,有时间足迹记忆。
现在,您可以选择打印电子书或纸质书。如果印刷纸质书,可以找第三方机构购买;如果你打印一本电子书,我们可以自己生成,这样可以节省很多钱。
部分截图
在开始编写代码思路之前,我们先来看看最终生成的效果。
电子书效果
纸书效果
获取微信书籍链接的代码思路
看完效果图,开始进入代码编写部分。首先,由于朋友圈数据的隐私性较高,如果手动获取,需要使用root安卓手机解密或解密PC机备份的聊天记录数据库,很难大多数人。所以我们的想法是根据现有数据打印电子书。
目前已经有第三方服务支持导出朋友圈数据,微信公众号【chu/shu/la】(去掉斜线)提供了这样的功能。这种服务很有可能是基于安卓模拟器自动化的,我就不赘述了。
先关注公众号,然后开始制作微信书籍。这个过程将你添加为编辑的朋友,然后你向他打开朋友圈。过一会采集,小编会给你发一个专属链接,这个链接里的内容就是你的Personal Moments。
生成电子书
有了这个链接,我们开始打印页面的内容。
整个过程基于 selenium 自动化。如果你知道 selenium,那么这个过程其实很简单。
首先,为了引导用户输入微信图书链接,我们采用在浏览器中弹出输入文本框的形式,让用户输入数据。首先在selenium中执行js代码,完成js代码中弹出输入文本框的功能。
进入微信图书链接
# 以网页输入文本框形式提示用户输入url地址
def input_url():
# js脚本
random_id = [str(random.randint(0, 9)) for i in range(0,10)]
random_id = "".join(random_id)
random_id = 'id_input_target_url_' + random_id
js = """
// 弹出文本输入框,输入微信书的完整链接地址
target_url = prompt("请输入微信书的完整链接地址","https://");
// 动态创建一个input元素
input_target_url = document.createElement("input");
// 为其设置id,以便在程序中能够获取到它的值
input_target_url.id = "id_input_target_url";
// 插入到当前网页中
document.getElementsByTagName("body")[0].appendChild(input_target_url);
// 设置不可见
document.getElementById("id_input_target_url").style.display = 'none';
// 设置value为target_url的值
document.getElementById("id_input_target_url").value = target_url
"""
js = js.replace('id_input_target_url', random_id)
# 执行以上js脚本
driver.execute_script(js)
复制代码
上述js代码的具体步骤为:弹出一个输入文本框,创建一个动态元素,随机命名元素的id,将动态元素插入到当前页面,这样就可以通过python 内容中的硒。
接下来,检测弹框是否存在于 selenium 中。如果不存在,则获取弹框的内容并执行下一步。流程代码如下:
# 执行以上js脚本
driver.execute_script(js)
# 判断弹出框是否存在
while(True):
try:
# 检测是否存在弹出框
alert = driver.switch_to.alert
time.sleep(0.5)
except:
# 如果抛异常,说明当前页面不存在弹出框,即用户点击了取消或者确定
break
# 获取用户输入的链接地址
target_url = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, random_id)))
value = target_url.get_attribute('value')
# 删除空格
value = value.strip()
复制代码
此时value的值就是弹出框返回的内容。(你可能会问,直接加value=微信书链接可以吗?其实可以>header。通过selenium隐藏这个元素的代码如下:
# 隐藏导航栏,防止影响截图效果
js = 'document.querySelector("body > header").style.display="none";'
driver.execute_script(js)
复制代码
我们也发现当前页面显示的数据只收录某月的朋友圈数据,而不是所有的朋友圈数据,那么如何显示所有的朋友圈数据呢?通过分析可以看出,当点击“下个月”按钮时,会显示一个新的元素,而原来的元素会被隐藏,隐藏的元素就是上个月的数据。所以我们只需要遍历到上个月,显示之前的所有元素,然后打印出来。那么,如何判断是上个月呢?我们也可以通过分析得知,当不是上个月时,“下个月”的类名是下个月,当是上个月时,“下个月”的类名是下个月禁用,所以我们可以检测它的类名,就知道是不是在上个月了。
# 判断当下一月控件的class name 是否为next-month disable,如果是,则说明翻到最后一月了
page_source = driver.page_source
# 每一个element代表每一页,将每一页中style的display属性改成block,即可见状态
for index, element in enumerate(element_left_list):
# ..在xpath中表示上一级的元素,也就是父元素
parent_element = element.find_element_by_xpath('..')
# 获取这个父元素的完整id
parent_element_id = parent_element.get_attribute('id')
# 将该父元素更改为可见状态
js = 'document.getElementById("{}").style.display="block";'.format(parent_element_id)
driver.execute_script(js)
复制代码
但是这样会出现一个问题,即使我们打印成功,我们也不难保证页面上的所有元素都加载完毕,所以有些元素打印后可能显示不出来,导致效果不是很好——看着。因此,需要判断加载何时结束。
通过分析我们知道,网页元素未加载时,会出现“加载中”的提示,而网页元素加载时,该元素是隐藏的。因此,我们可以通过判断元素是否隐藏来知道当前页面元素是否被加载。这部分代码如下:
# 等待当前页面所有数据加载完毕,正常情况下数据加载完毕后,这个‘加载中’元素会隐藏起来
while (True):
loading_status = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.j-save-popup.save-popup')))
if (loading_status.is_displayed() == False):
break
复制代码
但是我们也发现,在等待页面元素及时加载后,还是有一些图片没有显示出来。
这很令人困惑,为什么?通过分析我们还了解到,当这些图片处于加载状态时,类名是lazy-img。从字面意思上,我们大概可以猜到它的意思是延迟加载,也就是用户在那里滑动页面,直到加载完毕。,以节省服务器压力。
所以我们可以通过一个名为lazy-img的类滑动到每个元素来加载它。所以?一个合适的方法是通过js定位元素,直到所有类名为lazy-img的元素都不存在。
while(True):
try:
lazy_img = driver.find_elements_by_css_selector('img.lazy-img')
js = 'document.getElementsByClassName("lazy-img")[0].scrollIntoView();'
driver.execute_script(js)
time.sleep(3)
except:
# 找不到控件img.lazy-img,所以退出循环
break
复制代码
其中document.getElementsByClassName("lazy-img")[0]是指document.getElementsByClassName("lazy-img")的第一个元素,scrollIntoView()是指滚动到该元素的位置
打印电子书
通过以上步骤,我们成功隐藏了一些可能影响外观的元素,同时也显示了所有需要的元素。接下来,是时候打印零件了。浏览器打印功能可以直接通过js代码调用,而且我们之前已经设置为自动打印pdf格式,所以会自动打印为pdf。但它打印到哪里?这里需要设置浏览器的默认存储位置,保存位置为当前目录。此步骤的代码如下:
# 默认下载、打印保存路径
'savefile.default_directory': os.getcwd()
# 调用chrome打印功能
driver.execute_script('window.print();')
复制代码
打印后设置退出浏览器 driver.quit()
经测试,电子书为超清版,大小约为16MB,质量还不错。
补充
完整版源码存放在github上,需要的可以下载 查看全部
抓取网页生成电子书(微信朋友圈效果纸质书效果代码思路获取(组图))
介绍
朋友圈留着你的数据,留着美好的回忆,记录着我们的每一点成长。从某种意义上说,发朋友圈就是记录生活,感受生活,见证每个人每一步的成长。
如此珍贵的记忆,何不保存呢?只需一杯咖啡时间,即可一键打印朋友圈。可以是纸质书也可以是电子书,可以长期保存,比拍照好,有时间足迹记忆。
现在,您可以选择打印电子书或纸质书。如果印刷纸质书,可以找第三方机构购买;如果你打印一本电子书,我们可以自己生成,这样可以节省很多钱。
部分截图
在开始编写代码思路之前,我们先来看看最终生成的效果。
电子书效果
纸书效果
获取微信书籍链接的代码思路
看完效果图,开始进入代码编写部分。首先,由于朋友圈数据的隐私性较高,如果手动获取,需要使用root安卓手机解密或解密PC机备份的聊天记录数据库,很难大多数人。所以我们的想法是根据现有数据打印电子书。
目前已经有第三方服务支持导出朋友圈数据,微信公众号【chu/shu/la】(去掉斜线)提供了这样的功能。这种服务很有可能是基于安卓模拟器自动化的,我就不赘述了。
先关注公众号,然后开始制作微信书籍。这个过程将你添加为编辑的朋友,然后你向他打开朋友圈。过一会采集,小编会给你发一个专属链接,这个链接里的内容就是你的Personal Moments。
生成电子书
有了这个链接,我们开始打印页面的内容。
整个过程基于 selenium 自动化。如果你知道 selenium,那么这个过程其实很简单。
首先,为了引导用户输入微信图书链接,我们采用在浏览器中弹出输入文本框的形式,让用户输入数据。首先在selenium中执行js代码,完成js代码中弹出输入文本框的功能。
进入微信图书链接
# 以网页输入文本框形式提示用户输入url地址
def input_url():
# js脚本
random_id = [str(random.randint(0, 9)) for i in range(0,10)]
random_id = "".join(random_id)
random_id = 'id_input_target_url_' + random_id
js = """
// 弹出文本输入框,输入微信书的完整链接地址
target_url = prompt("请输入微信书的完整链接地址","https://";);
// 动态创建一个input元素
input_target_url = document.createElement("input");
// 为其设置id,以便在程序中能够获取到它的值
input_target_url.id = "id_input_target_url";
// 插入到当前网页中
document.getElementsByTagName("body")[0].appendChild(input_target_url);
// 设置不可见
document.getElementById("id_input_target_url").style.display = 'none';
// 设置value为target_url的值
document.getElementById("id_input_target_url").value = target_url
"""
js = js.replace('id_input_target_url', random_id)
# 执行以上js脚本
driver.execute_script(js)
复制代码
上述js代码的具体步骤为:弹出一个输入文本框,创建一个动态元素,随机命名元素的id,将动态元素插入到当前页面,这样就可以通过python 内容中的硒。
接下来,检测弹框是否存在于 selenium 中。如果不存在,则获取弹框的内容并执行下一步。流程代码如下:
# 执行以上js脚本
driver.execute_script(js)
# 判断弹出框是否存在
while(True):
try:
# 检测是否存在弹出框
alert = driver.switch_to.alert
time.sleep(0.5)
except:
# 如果抛异常,说明当前页面不存在弹出框,即用户点击了取消或者确定
break
# 获取用户输入的链接地址
target_url = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.ID, random_id)))
value = target_url.get_attribute('value')
# 删除空格
value = value.strip()
复制代码
此时value的值就是弹出框返回的内容。(你可能会问,直接加value=微信书链接可以吗?其实可以>header。通过selenium隐藏这个元素的代码如下:
# 隐藏导航栏,防止影响截图效果
js = 'document.querySelector("body > header").style.display="none";'
driver.execute_script(js)
复制代码
我们也发现当前页面显示的数据只收录某月的朋友圈数据,而不是所有的朋友圈数据,那么如何显示所有的朋友圈数据呢?通过分析可以看出,当点击“下个月”按钮时,会显示一个新的元素,而原来的元素会被隐藏,隐藏的元素就是上个月的数据。所以我们只需要遍历到上个月,显示之前的所有元素,然后打印出来。那么,如何判断是上个月呢?我们也可以通过分析得知,当不是上个月时,“下个月”的类名是下个月,当是上个月时,“下个月”的类名是下个月禁用,所以我们可以检测它的类名,就知道是不是在上个月了。
# 判断当下一月控件的class name 是否为next-month disable,如果是,则说明翻到最后一月了
page_source = driver.page_source
# 每一个element代表每一页,将每一页中style的display属性改成block,即可见状态
for index, element in enumerate(element_left_list):
# ..在xpath中表示上一级的元素,也就是父元素
parent_element = element.find_element_by_xpath('..')
# 获取这个父元素的完整id
parent_element_id = parent_element.get_attribute('id')
# 将该父元素更改为可见状态
js = 'document.getElementById("{}").style.display="block";'.format(parent_element_id)
driver.execute_script(js)
复制代码
但是这样会出现一个问题,即使我们打印成功,我们也不难保证页面上的所有元素都加载完毕,所以有些元素打印后可能显示不出来,导致效果不是很好——看着。因此,需要判断加载何时结束。
通过分析我们知道,网页元素未加载时,会出现“加载中”的提示,而网页元素加载时,该元素是隐藏的。因此,我们可以通过判断元素是否隐藏来知道当前页面元素是否被加载。这部分代码如下:
# 等待当前页面所有数据加载完毕,正常情况下数据加载完毕后,这个‘加载中’元素会隐藏起来
while (True):
loading_status = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.j-save-popup.save-popup')))
if (loading_status.is_displayed() == False):
break
复制代码
但是我们也发现,在等待页面元素及时加载后,还是有一些图片没有显示出来。
这很令人困惑,为什么?通过分析我们还了解到,当这些图片处于加载状态时,类名是lazy-img。从字面意思上,我们大概可以猜到它的意思是延迟加载,也就是用户在那里滑动页面,直到加载完毕。,以节省服务器压力。
所以我们可以通过一个名为lazy-img的类滑动到每个元素来加载它。所以?一个合适的方法是通过js定位元素,直到所有类名为lazy-img的元素都不存在。
while(True):
try:
lazy_img = driver.find_elements_by_css_selector('img.lazy-img')
js = 'document.getElementsByClassName("lazy-img")[0].scrollIntoView();'
driver.execute_script(js)
time.sleep(3)
except:
# 找不到控件img.lazy-img,所以退出循环
break
复制代码
其中document.getElementsByClassName("lazy-img")[0]是指document.getElementsByClassName("lazy-img")的第一个元素,scrollIntoView()是指滚动到该元素的位置
打印电子书
通过以上步骤,我们成功隐藏了一些可能影响外观的元素,同时也显示了所有需要的元素。接下来,是时候打印零件了。浏览器打印功能可以直接通过js代码调用,而且我们之前已经设置为自动打印pdf格式,所以会自动打印为pdf。但它打印到哪里?这里需要设置浏览器的默认存储位置,保存位置为当前目录。此步骤的代码如下:
# 默认下载、打印保存路径
'savefile.default_directory': os.getcwd()
# 调用chrome打印功能
driver.execute_script('window.print();')
复制代码
打印后设置退出浏览器 driver.quit()
经测试,电子书为超清版,大小约为16MB,质量还不错。
补充
完整版源码存放在github上,需要的可以下载
抓取网页生成电子书(软件简介《小说网站捕捉器绿色版》软件特色自定义规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-15 07:15
软件说明
《小说网站捕手绿色版》是一款非常小巧方便的小说采集下载工具。本软件可以通过html网站代码抓取目标网站的新奇资源,不仅可以直接Capture,还可以设置目标,范围筛选后有针对性的抓取,而且目标强,你可设置多个条件,帮助您更快找到想要阅读的小说资源,操作简单,一键获取所有内容。
功能介绍
本软件可以通过小说网站的html网页源码抓书,分析关键信息的规律,最终输出抓书(支持txt、ePub、zip格式输出)。
这个软件可以说好用也好难用,比如简单的从网站抓书,直接从自带的100多个预设网站抓书(需要浏览通过你可以用浏览器搜索你想下载的书,然后复制链接到入口网址),无需分析复杂的源码。对于逻辑思维能力强的用户,通过分析小说网站的源码,制定网站的抓包规则,基本可以应对大部分小说网站。
软件功能
自定义规则抓取,可以文章抓取大部分小说网,个别网站图书分类详细,还支持多图书抓取;
自带海量预测网站,不定义规则的用户可以直接套用,也可以抓取自己需要的小说;
自带源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存数据库后,可随意中断和恢复;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和带有章节页面链接的excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示,大部分操作都支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序、删除预设网站;
随附工具
ePub电子书制作分解工具,支持分章存储的书籍生成ePub文件,也可以将ePub文件分解成多章文本文件。
软件界面
主界面
任务管理
系统设置 + ePub 小部件
分析代码窗口 查看全部
抓取网页生成电子书(软件简介《小说网站捕捉器绿色版》软件特色自定义规则)
软件说明
《小说网站捕手绿色版》是一款非常小巧方便的小说采集下载工具。本软件可以通过html网站代码抓取目标网站的新奇资源,不仅可以直接Capture,还可以设置目标,范围筛选后有针对性的抓取,而且目标强,你可设置多个条件,帮助您更快找到想要阅读的小说资源,操作简单,一键获取所有内容。
功能介绍
本软件可以通过小说网站的html网页源码抓书,分析关键信息的规律,最终输出抓书(支持txt、ePub、zip格式输出)。
这个软件可以说好用也好难用,比如简单的从网站抓书,直接从自带的100多个预设网站抓书(需要浏览通过你可以用浏览器搜索你想下载的书,然后复制链接到入口网址),无需分析复杂的源码。对于逻辑思维能力强的用户,通过分析小说网站的源码,制定网站的抓包规则,基本可以应对大部分小说网站。
软件功能
自定义规则抓取,可以文章抓取大部分小说网,个别网站图书分类详细,还支持多图书抓取;
自带海量预测网站,不定义规则的用户可以直接套用,也可以抓取自己需要的小说;
自带源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存数据库后,可随意中断和恢复;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和带有章节页面链接的excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示,大部分操作都支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序、删除预设网站;
随附工具
ePub电子书制作分解工具,支持分章存储的书籍生成ePub文件,也可以将ePub文件分解成多章文本文件。
软件界面
主界面
任务管理
系统设置 + ePub 小部件
分析代码窗口
抓取网页生成电子书(nodejs扒取html页面中所有链接资源(下载好的路径) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-15 02:08
)
Nodejs 抓取 html 页面中所有链接的资源前言:
总有人想下载一个插件,可以直接获取浏览器显示页面的所有资源。也就是下载别人的网站,但是不想一一复制链接的内容。基本上有两个原因:1、链接很多,每个链接都要打勾去下载很繁琐2、复制好了,现在要重新改新的资源路径(下载路径) 由 html 中的每个链接指向
分析:
1、js是不可能在浏览器上实现的,本地生成文件(下载资源),因为浏览器没有这个权限,那么服务器需要配合2、服务器怎么知道html浏览器到底是什么?需要下载哪些文件,服务器本身没有document对象,则需要浏览器配合返回
综上所述:
依靠浏览器获取所有需要下载的资源,通过ajax请求告诉服务器需要下载的资源,服务器会下载资源。
项目文件夹结构
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
代码展示
1、app.js(先执行这个js,在cmd命令窗口输入:node app.js)
var express = require('express');
var fs = require('fs');
var bodyParser = require('body-parser');
var request = require('request ');
var path= require('path');
var app = express();
app.use(bodyParser.json());
app.use('/urlDownLoadFile', (req, res) => {
var filePaths = req.body.filepaths,
dirPath = req.body.dirPath;
var fileDirPath = path.join(__dirname, './static/', dirPath);
if (!fs.existsSync(fileDirPath)) {
fs.mkdirSync(fileDirPath);
}
filePaths.forEach(item => {
if (item !== '') {
var lastIndex = item.lastIndexOf('/'),
fileName = item.substr(lastIndex + 1);
var stream = fs.createWriteStream(path.join(fileDirPath, fileName));
request(item).pipe(stream).on('close', (err) => {
if (err) {
console.log(err);
}
});
}
});
res.send('');
});
app.use('/', express.static('./static'));
app.listen(3000);
复制代码
2、然后,F12打开待下载网页的控制台,将以下代码复制进去
var dirPath = 'file/', // 资源目录(下载到服务器 static/里面的 哪个文件夹)
allUrls = [localhost.href]; // 所有要下载的路径
var scriptNode = document.createElement('script');
scriptNode.src = 'http://127.0.0.1:3000/jquery-1.8.3.js';
document.body.appendChild(scriptNode);
scriptNode.onload = () => {
$('link').each((index, ele) => {
allUrls.push(ele.href);
});
$('script').each((index, ele) => {
allUrls.push(ele.src);
});
$('img').each((index, ele) => {
allUrls.push(ele.src);
});
$.ajax({
url: 'http://127.0.0.1:3000/urlDownLoadFile',
dataType: 'jsonP',
data: {
filepaths: allUrls,
dirPath: dirPath
}
});
}
复制代码
3、打开“文件夹”,里面已经有了网页的所有资源:html、js、css、jpg……
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
4、打开html修改引用资源路径
$('link').each((index, ele) => {
var filePath = ele.href,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.href = fileName;
});
$('script').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
$('img').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
复制代码 查看全部
抓取网页生成电子书(nodejs扒取html页面中所有链接资源(下载好的路径)
)
Nodejs 抓取 html 页面中所有链接的资源前言:
总有人想下载一个插件,可以直接获取浏览器显示页面的所有资源。也就是下载别人的网站,但是不想一一复制链接的内容。基本上有两个原因:1、链接很多,每个链接都要打勾去下载很繁琐2、复制好了,现在要重新改新的资源路径(下载路径) 由 html 中的每个链接指向
分析:
1、js是不可能在浏览器上实现的,本地生成文件(下载资源),因为浏览器没有这个权限,那么服务器需要配合2、服务器怎么知道html浏览器到底是什么?需要下载哪些文件,服务器本身没有document对象,则需要浏览器配合返回
综上所述:
依靠浏览器获取所有需要下载的资源,通过ajax请求告诉服务器需要下载的资源,服务器会下载资源。
项目文件夹结构
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
代码展示
1、app.js(先执行这个js,在cmd命令窗口输入:node app.js)
var express = require('express');
var fs = require('fs');
var bodyParser = require('body-parser');
var request = require('request ');
var path= require('path');
var app = express();
app.use(bodyParser.json());
app.use('/urlDownLoadFile', (req, res) => {
var filePaths = req.body.filepaths,
dirPath = req.body.dirPath;
var fileDirPath = path.join(__dirname, './static/', dirPath);
if (!fs.existsSync(fileDirPath)) {
fs.mkdirSync(fileDirPath);
}
filePaths.forEach(item => {
if (item !== '') {
var lastIndex = item.lastIndexOf('/'),
fileName = item.substr(lastIndex + 1);
var stream = fs.createWriteStream(path.join(fileDirPath, fileName));
request(item).pipe(stream).on('close', (err) => {
if (err) {
console.log(err);
}
});
}
});
res.send('');
});
app.use('/', express.static('./static'));
app.listen(3000);
复制代码
2、然后,F12打开待下载网页的控制台,将以下代码复制进去
var dirPath = 'file/', // 资源目录(下载到服务器 static/里面的 哪个文件夹)
allUrls = [localhost.href]; // 所有要下载的路径
var scriptNode = document.createElement('script');
scriptNode.src = 'http://127.0.0.1:3000/jquery-1.8.3.js';
document.body.appendChild(scriptNode);
scriptNode.onload = () => {
$('link').each((index, ele) => {
allUrls.push(ele.href);
});
$('script').each((index, ele) => {
allUrls.push(ele.src);
});
$('img').each((index, ele) => {
allUrls.push(ele.src);
});
$.ajax({
url: 'http://127.0.0.1:3000/urlDownLoadFile',
dataType: 'jsonP',
data: {
filepaths: allUrls,
dirPath: dirPath
}
});
}
复制代码
3、打开“文件夹”,里面已经有了网页的所有资源:html、js、css、jpg……
root根目录
| static文件夹
| file 文件夹(这个可以不创建,下载资源会生成这个文件夹)
| jquery-1.8.3.js
| app.js
复制代码
4、打开html修改引用资源路径
$('link').each((index, ele) => {
var filePath = ele.href,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.href = fileName;
});
$('script').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
$('img').each((index, ele) => {
var filePath = ele.src,
lastIndex = filePath.lastIndexOf('/'),
fileName = filePath.substr(lastIndex + 1);
ele.src= fileName;
});
复制代码
抓取网页生成电子书(《网络书籍抓取器》软件截图制作流程及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-14 21:21
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后将它们合并在一起。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件截图1
软件功能
1、章节调整:提取目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
软件截图2 查看全部
抓取网页生成电子书(《网络书籍抓取器》软件截图制作流程及注意事项)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页面的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后将它们合并在一起。爬取过程可以随时中断,关闭程序后可以恢复上一个任务。
软件截图1
软件功能
1、章节调整:提取目录后,可以进行移动、删除、反转等调整操作。调整将直接影响调整后的章节顺序中的最终书籍和输出。
2、自动重试:爬取过程中,可能由于网络因素导致爬取失败。本程序可能会自动重试直到成功,或者暂时中断爬取(中断后关闭程序不会影响进度),等网络好了再试。
3、停止和恢复:可以随时停止捕捉过程,退出程序后不影响进度(章节信息会保存在记录中,程序结束后可以恢复捕捉下次运行。注意:需要先用停止键中断,然后退出程序,如果直接退出,将无法恢复)。
4、一键抓取:又称“傻瓜模式”,基本可以实现全自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的URL、save bit等信息(会有明显的操作提示),调整章节后也可以使用一键爬取,爬取和合并操作会自动完成。
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到想要的书),以及相应的代码也可以自动应用,其他小说网站也可以测试,如果一起使用,可以手动添加到设置文件中备份。
6、轻松制作电子书:可以在设置文件中添加每章名称的前缀和后缀,为后期制作电子书的编目带来极大的方便。
软件截图2
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-14 16:10
自从我买了kindle之后,我就一直在思考如何充分利用它。虽然可以从多多购买很多书籍,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。比如O'Reilly Atlas提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网页形式。所以我希望通过某种方式把这些网上资料转换成epub或者mobi格式,这样就可以在kindle上阅读了。这篇 文章 文章描述了如何使用 calibre 和少量代码来做到这一点。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。幸运的是,除了 GUI 之外,calibre 还提供了很多命令行工具,其中 ebook-convert 命令可以根据用户编写的食谱进行。文件(其实是python代码)抓取指定页面的内容,生成mobi等格式的电子书。通过编写食谱,可以自定义爬取行为以适应不同的网页结构。
安装口径
Calibre的下载地址是,你可以根据自己的操作系统下载对应的安装程序。
如果是 Linux 操作系统,也可以从软件仓库安装:
Archlinux:
pacman -S 机芯
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页面
爬取整本书,首先要找到索引页,通常是目录页,也就是目录页,其中每个目录项都链接到对应的目录页。索引页面将指导生成电子书时要抓取的页面以及内容的组织顺序。在此示例中,索引页为 .
写食谱
Recipes 是一个带有recipe 扩展名的脚本。内容其实是一段python代码,用来定义calibre爬取页面的范围和行为。以下是用于爬取 Git 袖珍指南的食谱:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释代码的不同部分。
整体结构
一般来说,recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipe必须实现的唯一方法。该方法的目标是分析索引页的内容并返回一个稍微复杂的数据结构(稍后描述),该结构定义了整个电子书的内容以及内容的组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
标题 = 'Git 袖珍指南' 描述 = ''cover_url = ''
url_prefix = ''no_stylesheets = Truekeep_only_tags = [{ 'class': 'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个map,代表一个章节(chapter),map中有两个元素:title和url,title是章节标题,url是章节所在内容页面的url。
Calibre 会根据 parse_index 的返回结果对整本书进行爬取和整理,并会自行对内容中的外部链接的图片进行爬取和处理。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考 API 文档。
生成手机
菜谱写好后,可以在命令行通过以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成 mobi 格式的电子书。ebook-convert 将抓取相关内容并根据食谱代码组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
有图片的页面
实际效果
我的食谱库
我在github上建了一个kindle-open-books,里面放了一些菜谱,这些菜谱是我自己写的,其他同学贡献的。欢迎任何人提供食谱。 查看全部
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
自从我买了kindle之后,我就一直在思考如何充分利用它。虽然可以从多多购买很多书籍,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。比如O'Reilly Atlas提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网页形式。所以我希望通过某种方式把这些网上资料转换成epub或者mobi格式,这样就可以在kindle上阅读了。这篇 文章 文章描述了如何使用 calibre 和少量代码来做到这一点。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。幸运的是,除了 GUI 之外,calibre 还提供了很多命令行工具,其中 ebook-convert 命令可以根据用户编写的食谱进行。文件(其实是python代码)抓取指定页面的内容,生成mobi等格式的电子书。通过编写食谱,可以自定义爬取行为以适应不同的网页结构。
安装口径
Calibre的下载地址是,你可以根据自己的操作系统下载对应的安装程序。
如果是 Linux 操作系统,也可以从软件仓库安装:
Archlinux:
pacman -S 机芯
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页面
爬取整本书,首先要找到索引页,通常是目录页,也就是目录页,其中每个目录项都链接到对应的目录页。索引页面将指导生成电子书时要抓取的页面以及内容的组织顺序。在此示例中,索引页为 .
写食谱
Recipes 是一个带有recipe 扩展名的脚本。内容其实是一段python代码,用来定义calibre爬取页面的范围和行为。以下是用于爬取 Git 袖珍指南的食谱:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释代码的不同部分。
整体结构
一般来说,recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipe必须实现的唯一方法。该方法的目标是分析索引页的内容并返回一个稍微复杂的数据结构(稍后描述),该结构定义了整个电子书的内容以及内容的组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
标题 = 'Git 袖珍指南' 描述 = ''cover_url = ''
url_prefix = ''no_stylesheets = Truekeep_only_tags = [{ 'class': 'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个map,代表一个章节(chapter),map中有两个元素:title和url,title是章节标题,url是章节所在内容页面的url。
Calibre 会根据 parse_index 的返回结果对整本书进行爬取和整理,并会自行对内容中的外部链接的图片进行爬取和处理。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考 API 文档。
生成手机
菜谱写好后,可以在命令行通过以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成 mobi 格式的电子书。ebook-convert 将抓取相关内容并根据食谱代码组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
有图片的页面
实际效果
我的食谱库
我在github上建了一个kindle-open-books,里面放了一些菜谱,这些菜谱是我自己写的,其他同学贡献的。欢迎任何人提供食谱。

