
抓取网页生成电子书
抓取网页生成电子书(是不是有时星球内容太多刷不过来?想把星球精华内容撸下来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-14 07:01
是不是有时候地球上的内容太多无法刷新?你想制作一本收录地球本质的电子书吗?
本文将带你实现使用Python爬取星球内容,制作PDF电子书。
第一个效果:
内容以优化为主,主要优化内容在于翻页时间的处理、大空白的处理、评论的抓取、超链接的处理。
说到隐私问题,这里我们以自由星球“万人学习分享群”为爬取对象。
过程分析模拟登录
爬行是知识星球的网络版本。
这个网站不依赖cookie来判断你是否登录,而是请求头中的Authorization字段。
因此,您需要将 Authorization 和 User-Agent 替换为您自己的。(注意User-Agent也应该换成你自己的)
一般来说,星球使用微信扫码登录后,可以获得一个Authorization。这首歌长期有效。无论如何,它真的很长。
1
2
3
4
5
6
7
8
9
headers = {
'Authorization': 'C08AEDBB-A627-F9F1-1223-7E212B1C9D7D',
'x-request-id': "7b898dff-e40f-578e-6cfd-9687a3a32e49",
'accept': "application/json, text/plain, */*",
'host': "api.zsxq.com",
'connection': "keep-alive",
'referer': "https://wx.zsxq.com/dweb/",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
}
页面内容分析
登录成功后,我一般使用右键,查看或者查看源码。
但是这个页面比较特殊,它并没有把内容放到当前地址栏的URL下面,而是异步加载(XHR),只要你找到合适的界面。
精华区界面:
这个界面是最新的20条数据,后面的数据对应不同的界面,就是后面要说的翻页。
创建 PDF 电子书
需要安装的模块:
wkhtmltopdf 用于导出 PDF。安装后可以使用命令生成PDF,例如:wkhtmltopdf google.pdfpdfkit,它是python对wkhtmltopdf调用的封装,支持URL、本地文件、文本内容到PDF的转换,实际转换还是最终调用wkhtmltopdf命令
本来,精华区是没有称号的。我用每个问题的前 6 个字符作为标题来区分不同的问题。
抓取图片
很明显,返回数据中的images key就是图片,只需要提取大的、高清的url即可。
关键是将图像标签 img 插入到 HTML 文档中。我使用 BeautifulSoup 操作 DOM 的方式。
需要注意的是,图片可能不止一张,所以需要使用for循环来遍历所有的图片。
1
2
3
4
5
6
7
8
if content.get('images'):
soup = BeautifulSoup(html_template, 'html.parser')
for img in content.get('images'):
url = img.get('large').get('url')
img_tag = soup.new_tag('img', src=url)
soup.body.append(img_tag)
html_img = str(soup)
html = html_img.format(title=title, text=text)
制作精美的 PDF
通过css样式控制字体大小、布局、颜色等,详见test.css文件。
然后将此文件导入选项字段。
1
2
3
4
options = {
"user-style-sheet": "test.css",
...
}
难度分析翻页逻辑
爬取地址为:{url}?scope=digests&count=20&end_time=2018-04-12T15%3A49%3A13.443%2B0800
路径后面的 end_time 表示最后一次加载帖子以实现翻页的日期。
end_time 是 url 转义的,可以通过 urllib.parse.quote 方法进行转义。关键是要找出 end_time 的来源。
仔细观察后发现,每个请求返回20个post,最后一个post与下一个链接的end_time有关。
比如上一个帖子的create_time是2018-01-10T11:49:39.668+0800,那么下一个链接的end_time是2018-01-10T11:49:39. 667+0800,注意一个668和一个667是不一样的,所以我们得到end_time的公式:
1
end_time = create_time[:20]+str(int(create_time[20:23])-1)+create_time[23:]
但事情并没有那么简单,因为最后的create_time可能是2018-03-06T22%3A29%3A59.000%2B0800,-1后面出现一个负数!
由于0可能出现在时分秒中,看来最好的方法是使用时间模块datetime获取create_time的最后一秒,如果出现000则拼接999。
1
2
3
4
5
6
7
8
9
10
# int -1 后需要进行补 0 处理,test_str.zfill(3)
end_time = create_time[:20]+str(int(create_time[20:23])-1).zfill(3)+create_time[23:]
# 时间出现整点时需要特殊处理,否则会出现 -1
if create_time[20:23] == '000':
temp_time = datetime.datetime.strptime(create_time, "%Y-%m-%dT%H:%M:%S.%f+0800")
temp_time += datetime.timedelta(seconds=-1)
end_time = temp_time.strftime("%Y-%m-%dT%H:%M:%S") + '.999+0800'
end_time = quote(end_time)
next_url = start_url + '&end_time=' + end_time
处理过程有点冗长。原谅我落后的000。我没有找到直接的方法来处理它。我只能通过这条曲线拯救国家。
判断最后一页
翻页返回的数据为:
1
{"succeeded":true,"resp_data":{"topics":[]}}
因此,使用 next_page = rsp.json().get('resp_data').get('topics') 来判断是否有下一页。 查看全部
抓取网页生成电子书(是不是有时星球内容太多刷不过来?想把星球精华内容撸下来)
是不是有时候地球上的内容太多无法刷新?你想制作一本收录地球本质的电子书吗?
本文将带你实现使用Python爬取星球内容,制作PDF电子书。
第一个效果:

内容以优化为主,主要优化内容在于翻页时间的处理、大空白的处理、评论的抓取、超链接的处理。
说到隐私问题,这里我们以自由星球“万人学习分享群”为爬取对象。
过程分析模拟登录
爬行是知识星球的网络版本。
这个网站不依赖cookie来判断你是否登录,而是请求头中的Authorization字段。
因此,您需要将 Authorization 和 User-Agent 替换为您自己的。(注意User-Agent也应该换成你自己的)
一般来说,星球使用微信扫码登录后,可以获得一个Authorization。这首歌长期有效。无论如何,它真的很长。
1
2
3
4
5
6
7
8
9
headers = {
'Authorization': 'C08AEDBB-A627-F9F1-1223-7E212B1C9D7D',
'x-request-id': "7b898dff-e40f-578e-6cfd-9687a3a32e49",
'accept': "application/json, text/plain, */*",
'host': "api.zsxq.com",
'connection': "keep-alive",
'referer': "https://wx.zsxq.com/dweb/",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
}
页面内容分析
登录成功后,我一般使用右键,查看或者查看源码。
但是这个页面比较特殊,它并没有把内容放到当前地址栏的URL下面,而是异步加载(XHR),只要你找到合适的界面。
精华区界面:
这个界面是最新的20条数据,后面的数据对应不同的界面,就是后面要说的翻页。
创建 PDF 电子书
需要安装的模块:
wkhtmltopdf 用于导出 PDF。安装后可以使用命令生成PDF,例如:wkhtmltopdf google.pdfpdfkit,它是python对wkhtmltopdf调用的封装,支持URL、本地文件、文本内容到PDF的转换,实际转换还是最终调用wkhtmltopdf命令
本来,精华区是没有称号的。我用每个问题的前 6 个字符作为标题来区分不同的问题。
抓取图片
很明显,返回数据中的images key就是图片,只需要提取大的、高清的url即可。
关键是将图像标签 img 插入到 HTML 文档中。我使用 BeautifulSoup 操作 DOM 的方式。
需要注意的是,图片可能不止一张,所以需要使用for循环来遍历所有的图片。
1
2
3
4
5
6
7
8
if content.get('images'):
soup = BeautifulSoup(html_template, 'html.parser')
for img in content.get('images'):
url = img.get('large').get('url')
img_tag = soup.new_tag('img', src=url)
soup.body.append(img_tag)
html_img = str(soup)
html = html_img.format(title=title, text=text)
制作精美的 PDF
通过css样式控制字体大小、布局、颜色等,详见test.css文件。
然后将此文件导入选项字段。
1
2
3
4
options = {
"user-style-sheet": "test.css",
...
}
难度分析翻页逻辑
爬取地址为:{url}?scope=digests&count=20&end_time=2018-04-12T15%3A49%3A13.443%2B0800
路径后面的 end_time 表示最后一次加载帖子以实现翻页的日期。
end_time 是 url 转义的,可以通过 urllib.parse.quote 方法进行转义。关键是要找出 end_time 的来源。
仔细观察后发现,每个请求返回20个post,最后一个post与下一个链接的end_time有关。
比如上一个帖子的create_time是2018-01-10T11:49:39.668+0800,那么下一个链接的end_time是2018-01-10T11:49:39. 667+0800,注意一个668和一个667是不一样的,所以我们得到end_time的公式:
1
end_time = create_time[:20]+str(int(create_time[20:23])-1)+create_time[23:]
但事情并没有那么简单,因为最后的create_time可能是2018-03-06T22%3A29%3A59.000%2B0800,-1后面出现一个负数!
由于0可能出现在时分秒中,看来最好的方法是使用时间模块datetime获取create_time的最后一秒,如果出现000则拼接999。
1
2
3
4
5
6
7
8
9
10
# int -1 后需要进行补 0 处理,test_str.zfill(3)
end_time = create_time[:20]+str(int(create_time[20:23])-1).zfill(3)+create_time[23:]
# 时间出现整点时需要特殊处理,否则会出现 -1
if create_time[20:23] == '000':
temp_time = datetime.datetime.strptime(create_time, "%Y-%m-%dT%H:%M:%S.%f+0800")
temp_time += datetime.timedelta(seconds=-1)
end_time = temp_time.strftime("%Y-%m-%dT%H:%M:%S") + '.999+0800'
end_time = quote(end_time)
next_url = start_url + '&end_time=' + end_time
处理过程有点冗长。原谅我落后的000。我没有找到直接的方法来处理它。我只能通过这条曲线拯救国家。
判断最后一页
翻页返回的数据为:
1
{"succeeded":true,"resp_data":{"topics":[]}}
因此,使用 next_page = rsp.json().get('resp_data').get('topics') 来判断是否有下一页。
抓取网页生成电子书(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-09 21:20
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*- import sys import locale import string import traceback import datetime import urllib2 from pyquery import PyQuery as pq # 确定运行环境的encoding reload(sys); sys.setdefaultencoding('utf8'); f = open('gongsi.csv', 'w'); for i in range(1,24): d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i)); itemsa=d('dl dt a') #取title元素 itemsb=d('dl dd') #取title元素 for j in range(0,len(itemsa)): f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text)); #end for #end for f.close();
接下来就是用Notepad++打开gongsi.csv,然后[emailprotected]~Codewang把它转成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
抓取网页生成电子书(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*- import sys import locale import string import traceback import datetime import urllib2 from pyquery import PyQuery as pq # 确定运行环境的encoding reload(sys); sys.setdefaultencoding('utf8'); f = open('gongsi.csv', 'w'); for i in range(1,24): d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i)); itemsa=d('dl dt a') #取title元素 itemsb=d('dl dd') #取title元素 for j in range(0,len(itemsa)): f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text)); #end for #end for f.close();
接下来就是用Notepad++打开gongsi.csv,然后[emailprotected]~Codewang把它转成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
抓取网页生成电子书(这款软件功能软件自动更新本软件集成了新版本自动更新功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-09 21:16
mp4到ebookpk官网获取VIP阅读(下载)佣金。有需要的用户千万不要错过这款实用又强大的电子书创作工具。
软件功能
自动软件更新
本软件集成了新版本的自动更新功能,帮助用户在第一时间获得全新体验。
在线采集图书内容,只要输入门户网址和网址过滤器,即可在本地获取网页内容,成为名副其实的“网络印刷机”和“网络刮刀”
可以将chm、jar、umd、doc、txt、html等文件拖入ebookpk作为书籍内容的来源。同时是标准的mobi、azw3、chm、umd、jar、doc“反编译器”和“文件合并器”。
书稿可以保存(.pk项目文件)
可以制作带有书签(目录)的PDF文档,可以将word转换为PDF;可以将pdf导入ebookpk软件;支持虚拟打印机,任何可打印的文档都可以转换为PDF 查看全部
抓取网页生成电子书(这款软件功能软件自动更新本软件集成了新版本自动更新功能)
mp4到ebookpk官网获取VIP阅读(下载)佣金。有需要的用户千万不要错过这款实用又强大的电子书创作工具。
软件功能
自动软件更新
本软件集成了新版本的自动更新功能,帮助用户在第一时间获得全新体验。
在线采集图书内容,只要输入门户网址和网址过滤器,即可在本地获取网页内容,成为名副其实的“网络印刷机”和“网络刮刀”
可以将chm、jar、umd、doc、txt、html等文件拖入ebookpk作为书籍内容的来源。同时是标准的mobi、azw3、chm、umd、jar、doc“反编译器”和“文件合并器”。
书稿可以保存(.pk项目文件)
可以制作带有书签(目录)的PDF文档,可以将word转换为PDF;可以将pdf导入ebookpk软件;支持虚拟打印机,任何可打印的文档都可以转换为PDF
抓取网页生成电子书(完美者()网站对功能性板块进行扩充,以期独门技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-07 23:01
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“温馨提示”等频道,更好地为用户提供更专业的软件使用全周期服务。
ibookBox 网络小说批量下载阅读器是一款快速抓取各种大小的网络小说网站,并将整本书以txt格式生成到本地电脑,同时保存在邮箱和手机中的工具。ibookBox 可以完整地存储整个网页的所有信息,并存储在用户的邮箱中。IbookBox 还可以生成 HTML 文件和完整的网页快照。与某些软件不同,它只能抓取可见区域内的照片。使用IbookBox网络小说批量下载阅读器时,只需在地址栏输入网址,点击告诉搜索小说,即可轻松下载浏览小说。IbookBox 支持批量抓取电子书,让用户可以在互联网的任何网页上看到喜欢的小说。, 可以直接批量抓取,生成完整的txt文件供用户本地阅读或手机随意阅读。抓取过程中,如果中途中断,可以点击“上次抓取小说按钮”,支持在章节网页直接按右键直接抓取任务面板。也可以在主程序中输入小说章节页的地址进行抓取。
“技巧与妙计”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答。文章,专栏成立伊始,编辑欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已根据需要进行了重新格式化和部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
抓取网页生成电子书(完美者()网站对功能性板块进行扩充,以期独门技巧)
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“温馨提示”等频道,更好地为用户提供更专业的软件使用全周期服务。

ibookBox 网络小说批量下载阅读器是一款快速抓取各种大小的网络小说网站,并将整本书以txt格式生成到本地电脑,同时保存在邮箱和手机中的工具。ibookBox 可以完整地存储整个网页的所有信息,并存储在用户的邮箱中。IbookBox 还可以生成 HTML 文件和完整的网页快照。与某些软件不同,它只能抓取可见区域内的照片。使用IbookBox网络小说批量下载阅读器时,只需在地址栏输入网址,点击告诉搜索小说,即可轻松下载浏览小说。IbookBox 支持批量抓取电子书,让用户可以在互联网的任何网页上看到喜欢的小说。, 可以直接批量抓取,生成完整的txt文件供用户本地阅读或手机随意阅读。抓取过程中,如果中途中断,可以点击“上次抓取小说按钮”,支持在章节网页直接按右键直接抓取任务面板。也可以在主程序中输入小说章节页的地址进行抓取。
“技巧与妙计”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答。文章,专栏成立伊始,编辑欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已根据需要进行了重新格式化和部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。
抓取网页生成电子书(继续并发专题~FutureTask有点类似Runnable的get方法支持阻塞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-06 23:11
继续并发话题~
FutureTask有点类似于Runnable,可以由Thread启动,但是FutureTask执行后可以返回数据,FutureTask的get方法支持阻塞。
因为:FutureTask可以返回已经执行过的数据,而FutureTask的get方法支持阻塞这两个特性,我们可以用它来预加载一些可能会用到的资源,然后调用get方法来获取想使用它(如果资源已加载,则直接返回;否则,继续等待其加载完成)。
下面举两个例子来介绍:
1、使用FutureTask预加载以后要用到的数据。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask来提前加载稍后要用到的数据
*
* @author zhy
*
*/
public class PreLoaderUseFutureTask
{
/**
* 创建一个FutureTask用来加载资源
*/
private final FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
Thread.sleep(3000);
return "加载资源需要3秒";
}
});
public final Thread thread = new Thread(futureTask);
public void start()
{
thread.start();
}
/**
* 获取资源
*
* @return
* @throws ExecutionException
* @throws InterruptedException
*/
public String getRes() throws InterruptedException, ExecutionException
{
return futureTask.get();//加载完毕直接返回,否则等待加载完毕
}
public static void main(String[] args) throws InterruptedException, ExecutionException
{
PreLoaderUseFutureTask task = new PreLoaderUseFutureTask();
/**
* 开启预加载资源
*/
task.start();
// 用户在真正需要加载资源前进行了其他操作了2秒
Thread.sleep(2000);
/**
* 获取资源
*/
System.out.println(System.currentTimeMillis() + ":开始加载资源");
String res = task.getRes();
System.out.println(res);
System.out.println(System.currentTimeMillis() + ":加载资源结束");
}
}
操作结果:
1400902789275:开始加载资源
加载资源需要3秒
1400902790275:加载资源结束
可以看到,原来加载资源需要3秒,现在只需要1秒。如果用户执行其他操作的时间较长,可以直接返回,大大增加了用户体验。
2、看看Future的API
可以看到 Future 的 API 还是比较简单的。看名字就知道意思了,get(long,TimeUnit)还是可以支持的,设置最大等待时间,如操作时间过长,可以取消。
3、FutureTask模拟,预加载功能供用户在线观看电子书
当用户观看当前页面时,后台会提前加载下一页,可以大大提升用户体验。无需等待每个页面加载。用户会觉得这个电子书软件很流畅。真的很棒。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask模拟预加载下一页图书的内容
*
* @author zhy
*
*/
public class BookInstance
{
/**
* 当前的页码
*/
private volatile int currentPage = 1;
/**
* 异步的任务获取当前页的内容
*/
FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
});
/**
* 实例化一本书,并传入当前读到的页码
*
* @param currentPage
*/
public BookInstance(int currentPage)
{
this.currentPage = currentPage;
/**
* 直接启动线程获取当前页码内容
*/
Thread thread = new Thread(futureTask);
thread.start();
}
/**
* 获取当前页的内容
*
* @return
* @throws InterruptedException
* @throws ExecutionException
*/
public String getCurrentPageContent() throws InterruptedException,
ExecutionException
{
String con = futureTask.get();
this.currentPage = currentPage + 1;
Thread thread = new Thread(futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
}));
thread.start();
return con;
}
/**
* 根据页码从网络抓取数据
*
* @return
* @throws InterruptedException
*/
private String loadDataFromNet() throws InterruptedException
{
Thread.sleep(1000);
return "Page " + this.currentPage + " : the content ....";
}
public static void main(String[] args) throws InterruptedException,
ExecutionException
{
BookInstance instance = new BookInstance(1);
for (int i = 0; i < 10; i++)
{
long start = System.currentTimeMillis();
String content = instance.getCurrentPageContent();
System.out.println("[1秒阅读时间]read:" + content);
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() - start);
}
}
}
输出结果:
[1秒阅读时间]read:Page 1 : the content ....
2001
[1秒阅读时间]read:Page 2 : the content ....
1000
[1秒阅读时间]read:Page 3 : the content ....
1001
[1秒阅读时间]read:Page 4 : the content ....
1000
[1秒阅读时间]read:Page 5 : the content ....
1001
可以看到,除了第一次查看当前页面时等待网络加载数据的过程(输出:2001,1000是加载时间,1000是用户阅读时间),接下来的页面是全部瞬间返回(输出1000是用户阅读时间),完全不需要等待。
代码是为了说明FutureTask的应用场景,请勿直接在项目中使用。
好了,就这样了,欢迎大家留言。 查看全部
抓取网页生成电子书(继续并发专题~FutureTask有点类似Runnable的get方法支持阻塞)
继续并发话题~
FutureTask有点类似于Runnable,可以由Thread启动,但是FutureTask执行后可以返回数据,FutureTask的get方法支持阻塞。
因为:FutureTask可以返回已经执行过的数据,而FutureTask的get方法支持阻塞这两个特性,我们可以用它来预加载一些可能会用到的资源,然后调用get方法来获取想使用它(如果资源已加载,则直接返回;否则,继续等待其加载完成)。
下面举两个例子来介绍:
1、使用FutureTask预加载以后要用到的数据。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask来提前加载稍后要用到的数据
*
* @author zhy
*
*/
public class PreLoaderUseFutureTask
{
/**
* 创建一个FutureTask用来加载资源
*/
private final FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
Thread.sleep(3000);
return "加载资源需要3秒";
}
});
public final Thread thread = new Thread(futureTask);
public void start()
{
thread.start();
}
/**
* 获取资源
*
* @return
* @throws ExecutionException
* @throws InterruptedException
*/
public String getRes() throws InterruptedException, ExecutionException
{
return futureTask.get();//加载完毕直接返回,否则等待加载完毕
}
public static void main(String[] args) throws InterruptedException, ExecutionException
{
PreLoaderUseFutureTask task = new PreLoaderUseFutureTask();
/**
* 开启预加载资源
*/
task.start();
// 用户在真正需要加载资源前进行了其他操作了2秒
Thread.sleep(2000);
/**
* 获取资源
*/
System.out.println(System.currentTimeMillis() + ":开始加载资源");
String res = task.getRes();
System.out.println(res);
System.out.println(System.currentTimeMillis() + ":加载资源结束");
}
}
操作结果:
1400902789275:开始加载资源
加载资源需要3秒
1400902790275:加载资源结束
可以看到,原来加载资源需要3秒,现在只需要1秒。如果用户执行其他操作的时间较长,可以直接返回,大大增加了用户体验。
2、看看Future的API

可以看到 Future 的 API 还是比较简单的。看名字就知道意思了,get(long,TimeUnit)还是可以支持的,设置最大等待时间,如操作时间过长,可以取消。
3、FutureTask模拟,预加载功能供用户在线观看电子书
当用户观看当前页面时,后台会提前加载下一页,可以大大提升用户体验。无需等待每个页面加载。用户会觉得这个电子书软件很流畅。真的很棒。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask模拟预加载下一页图书的内容
*
* @author zhy
*
*/
public class BookInstance
{
/**
* 当前的页码
*/
private volatile int currentPage = 1;
/**
* 异步的任务获取当前页的内容
*/
FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
});
/**
* 实例化一本书,并传入当前读到的页码
*
* @param currentPage
*/
public BookInstance(int currentPage)
{
this.currentPage = currentPage;
/**
* 直接启动线程获取当前页码内容
*/
Thread thread = new Thread(futureTask);
thread.start();
}
/**
* 获取当前页的内容
*
* @return
* @throws InterruptedException
* @throws ExecutionException
*/
public String getCurrentPageContent() throws InterruptedException,
ExecutionException
{
String con = futureTask.get();
this.currentPage = currentPage + 1;
Thread thread = new Thread(futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
}));
thread.start();
return con;
}
/**
* 根据页码从网络抓取数据
*
* @return
* @throws InterruptedException
*/
private String loadDataFromNet() throws InterruptedException
{
Thread.sleep(1000);
return "Page " + this.currentPage + " : the content ....";
}
public static void main(String[] args) throws InterruptedException,
ExecutionException
{
BookInstance instance = new BookInstance(1);
for (int i = 0; i < 10; i++)
{
long start = System.currentTimeMillis();
String content = instance.getCurrentPageContent();
System.out.println("[1秒阅读时间]read:" + content);
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() - start);
}
}
}
输出结果:
[1秒阅读时间]read:Page 1 : the content ....
2001
[1秒阅读时间]read:Page 2 : the content ....
1000
[1秒阅读时间]read:Page 3 : the content ....
1001
[1秒阅读时间]read:Page 4 : the content ....
1000
[1秒阅读时间]read:Page 5 : the content ....
1001
可以看到,除了第一次查看当前页面时等待网络加载数据的过程(输出:2001,1000是加载时间,1000是用户阅读时间),接下来的页面是全部瞬间返回(输出1000是用户阅读时间),完全不需要等待。
代码是为了说明FutureTask的应用场景,请勿直接在项目中使用。
好了,就这样了,欢迎大家留言。
抓取网页生成电子书(实用功能:1.优化电子书的排版(RSS制成电子书电子书))
网站优化 • 优采云 发表了文章 • 0 个评论 • 661 次浏览 • 2022-01-05 17:16
Calibre是一款免费开源的电子书管理神器,可用于整理、存储、管理、阅读和转换电子书。支持大部分电子书格式;它还可以添加文本、图像材料和在线内容(RSS)并将它们转换为电子书。
可与最流行的电子书阅读器同步,软件同时支持Windows、macOS和Linux系统。
实用功能:
1. 优化电子书版式
无论是从亚马逊 Kindle 电子书店购买,还是从其他在线渠道下载的电子书,排版往往不尽如人意。
这时候就可以使用Calibre进行简单的优化,就可以制作出排版良好的电子书,修改上面的参数就可以达到不错的效果。
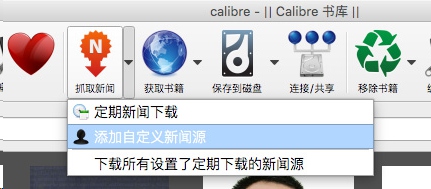
2. 获取 RSS 以制作电子书
准备好 RSS 提要后,您可以在 Calibre 中添加这些提要。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
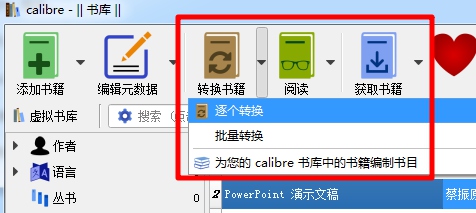
3. 转换电子书格式
Calibre 有两种转换方式:“一一转换”和“批量转换”。如果选择多个文件,使用“一一转换”需要对每本书进行单独设置。例如,您可以为不同的电子书设置不同的格式;而“批量转换”是所有电子书的通用设置。
Calibre 支持转换格式:EPUB、MOBI、AZW3、DOCX、FB2、HTMLZ、LIT、LRF、PDB、PDF、PMIZ、RB、RTF、SNB、TCR、TXT、TXTZ、ZIP 等。
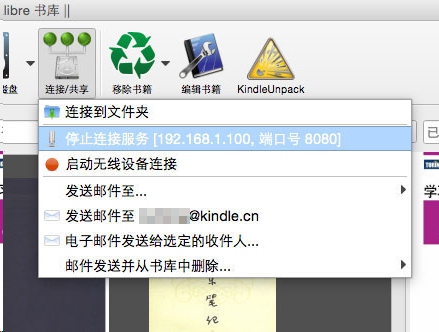
4. 通过 WiFi 将电子书传输到 Kindle
如果您使用的是无线路由器,您可以将Calibre 变成一个小型服务器,然后使用Kindle 的“实验性网络浏览器”访问Calibre 图书馆中的电子书并下载到Kindle。
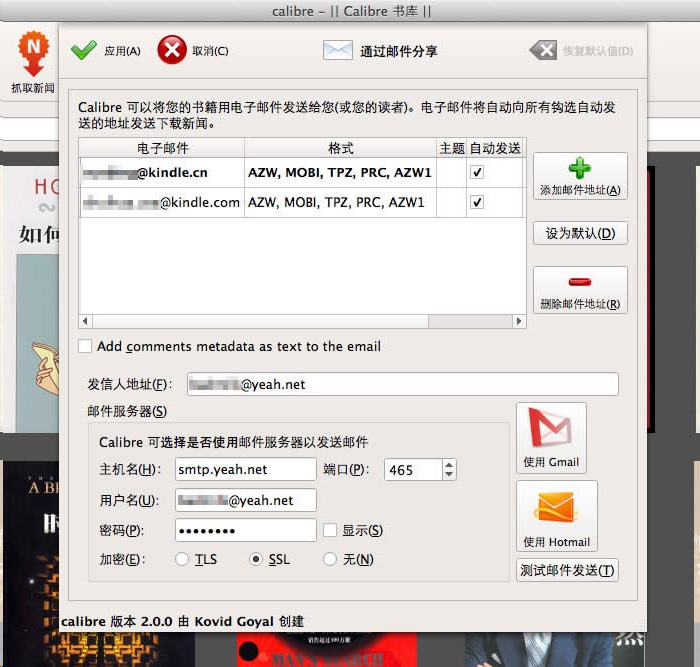
5. 邮件一键推送电子书
此外,Calibre 还有许多强大实用的功能:
1)您可以通过浏览器查看、阅读或下载您的图书馆(:8080);
2) 将TXT文件转换为MOBI格式的带目录的电子书;
3)使用Calibre添加或修改电子书的封面;
4)使用Calibre抓取网站页面制作电子书; 查看全部
抓取网页生成电子书(实用功能:1.优化电子书的排版(RSS制成电子书电子书))
Calibre是一款免费开源的电子书管理神器,可用于整理、存储、管理、阅读和转换电子书。支持大部分电子书格式;它还可以添加文本、图像材料和在线内容(RSS)并将它们转换为电子书。
可与最流行的电子书阅读器同步,软件同时支持Windows、macOS和Linux系统。
实用功能:
1. 优化电子书版式
无论是从亚马逊 Kindle 电子书店购买,还是从其他在线渠道下载的电子书,排版往往不尽如人意。

这时候就可以使用Calibre进行简单的优化,就可以制作出排版良好的电子书,修改上面的参数就可以达到不错的效果。
2. 获取 RSS 以制作电子书
准备好 RSS 提要后,您可以在 Calibre 中添加这些提要。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
3. 转换电子书格式
Calibre 有两种转换方式:“一一转换”和“批量转换”。如果选择多个文件,使用“一一转换”需要对每本书进行单独设置。例如,您可以为不同的电子书设置不同的格式;而“批量转换”是所有电子书的通用设置。
Calibre 支持转换格式:EPUB、MOBI、AZW3、DOCX、FB2、HTMLZ、LIT、LRF、PDB、PDF、PMIZ、RB、RTF、SNB、TCR、TXT、TXTZ、ZIP 等。
4. 通过 WiFi 将电子书传输到 Kindle
如果您使用的是无线路由器,您可以将Calibre 变成一个小型服务器,然后使用Kindle 的“实验性网络浏览器”访问Calibre 图书馆中的电子书并下载到Kindle。
5. 邮件一键推送电子书
此外,Calibre 还有许多强大实用的功能:
1)您可以通过浏览器查看、阅读或下载您的图书馆(:8080);
2) 将TXT文件转换为MOBI格式的带目录的电子书;
3)使用Calibre添加或修改电子书的封面;
4)使用Calibre抓取网站页面制作电子书;
抓取网页生成电子书(抓取网页生成电子书就可以。我看到题主想要爬取哪种网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-05 15:03
抓取网页生成电子书就可以。我看到题主想要爬取豆瓣书籍的时候,想要了解更详细,不知道题主想要爬取哪种网页。比如,微信公众号有很多地方提供文章聚合,微博也可以抓取,
android的话,下载些codeblocks之类的工具,安装daocloud,自己写个网页多人连接,然后开始传递链接,链接到app里就可以看电子书了,还可以,自动加入书架。ios可以买一本nonethought030,入门的好教材,也就几千元,电子书也好找,除非人工作业。
可以写个小app,比如微信文章会提供下载链接,你可以自己把获取之后传给别人,而不需要自己下一大堆文件过去。
多读书!
能理解你的想法。你可以直接爬下来,加入整理列表,提供给别人阅读,这样就可以免费下载了。
最直接的方法,就是搜索读书app,然后下载下来读。但是,题主如果要下载的书籍,和现在市面上的书籍大多是有差别的,那这就得需要研究一番。其实最简单的办法,你也可以直接选一些文章,这种比较多。你直接爬下来,整理好,有提供别人阅读的,自己就可以阅读了,也不需要下载其他电子书。
有个app叫西西阅读器,挺不错的。是一款浏览器级别的阅读软件。现在有很多的公众号都在推荐了。搜狐、网易等都有。可以提供免费下载,特别方便。 查看全部
抓取网页生成电子书(抓取网页生成电子书就可以。我看到题主想要爬取哪种网页)
抓取网页生成电子书就可以。我看到题主想要爬取豆瓣书籍的时候,想要了解更详细,不知道题主想要爬取哪种网页。比如,微信公众号有很多地方提供文章聚合,微博也可以抓取,
android的话,下载些codeblocks之类的工具,安装daocloud,自己写个网页多人连接,然后开始传递链接,链接到app里就可以看电子书了,还可以,自动加入书架。ios可以买一本nonethought030,入门的好教材,也就几千元,电子书也好找,除非人工作业。
可以写个小app,比如微信文章会提供下载链接,你可以自己把获取之后传给别人,而不需要自己下一大堆文件过去。
多读书!
能理解你的想法。你可以直接爬下来,加入整理列表,提供给别人阅读,这样就可以免费下载了。
最直接的方法,就是搜索读书app,然后下载下来读。但是,题主如果要下载的书籍,和现在市面上的书籍大多是有差别的,那这就得需要研究一番。其实最简单的办法,你也可以直接选一些文章,这种比较多。你直接爬下来,整理好,有提供别人阅读的,自己就可以阅读了,也不需要下载其他电子书。
有个app叫西西阅读器,挺不错的。是一款浏览器级别的阅读软件。现在有很多的公众号都在推荐了。搜狐、网易等都有。可以提供免费下载,特别方便。
抓取网页生成电子书(什么是爬虫爬虫:Python爬虫架构架构主要由五个部分组成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-03 17:10
什么是爬虫
爬虫:一种自动从互联网上抓取信息的程序,从互联网上抓取对我们有价值的信息。
Python 爬虫架构
Python爬虫架构主要由调度器、URL管理器、网页下载器、网页解析器、应用(抓取有价值的数据)五部分组成。
使用urllib2实现网页下载的方式
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
print "第二种方法"
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
print "第三种方法"
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#获取所有的链接
links = soup.find_all('a')
print "所有的链接"
for link in links:
print link.name,link['href'],link.get_text()
print "获取特定的URL地址"
link_node = soup.find('a',href="http://example.com/elsie")
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "正则表达式匹配"
link_node = soup.find('a',href=re.compile(r"ti"))
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "获取P段落的文字"
p_node = soup.find('p',class_='story')
print p_node.name,p_node['class'],p_node.get_text()shsh
</p>
python 很强大吗? 查看全部
抓取网页生成电子书(什么是爬虫爬虫:Python爬虫架构架构主要由五个部分组成)
什么是爬虫
爬虫:一种自动从互联网上抓取信息的程序,从互联网上抓取对我们有价值的信息。
Python 爬虫架构
Python爬虫架构主要由调度器、URL管理器、网页下载器、网页解析器、应用(抓取有价值的数据)五部分组成。
使用urllib2实现网页下载的方式
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
print "第二种方法"
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
print "第三种方法"
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#获取所有的链接
links = soup.find_all('a')
print "所有的链接"
for link in links:
print link.name,link['href'],link.get_text()
print "获取特定的URL地址"
link_node = soup.find('a',href="http://example.com/elsie";)
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "正则表达式匹配"
link_node = soup.find('a',href=re.compile(r"ti"))
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "获取P段落的文字"
p_node = soup.find('p',class_='story')
print p_node.name,p_node['class'],p_node.get_text()shsh
</p>
python 很强大吗?
抓取网页生成电子书(资料管理电子书制作利器-友益文书软件设置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-03 09:18
)
数据管理电子书制作工具-友易文档软件是一款集数据管理、电子书制作、翻页电子书制作、多媒体课件管理于一体的多功能软件...可用于管理htm网页和 mht 单个网页。 、Word文档、excel文档、幻灯片、pdf、chm、exe、txt、rtf、GIF、JPG、PNG、DJVU、ICO、TIF、BMP、Flash动画等格式文件;支持全文、网页、word文档搜索,支持背景音乐播放。集成pdf阅读功能,无需安装任何pdf阅读器,轻松阅读pdf文件。
可以发布电脑版exe、chm电子书、安卓apk电子书、苹果epub电子书等,还可以发布翻页电子书功能。设置一机一码或反传播功能。
无需安装任何软件,直接生成安卓手机apk电子书。
方便制作exe翻页电子书、滑动手机相册、撕角翻页电子书。
可生成安卓手机版apk电子书,支持5级目录,具有目录搜索、全文搜索、书签、设置一机一码功能,支持文本、网页、图片和pdf文档,无需在手机上安装其他任何阅读器都可以阅读。是目前安卓手机最强大的数据管理和电子书软件。
可以生成苹果手机可以阅读的epub格式文件;
可以生成具有全文搜索、目录搜索、采集夹等功能的chm格式文件。
可以直接为托管数据生成可执行文件。软件采用窗口风格,目录树结构管理,所见即所得的设计理念,不需要复杂的转换和编译。
易于使用和操作。您可以自由添加和删除目录树,随意编辑文档内容,更改字体大小和颜色。
该软件还可以生成电子相册,非常适合企事业单位进行产品推广和业务推广,在微信上分享非常方便。
本软件不断吸收同类软件的优点,同时在功能和设计上有独特的创新。采用混合索引算法,数据存储采用自己的压缩格式,独特的多文本超链接功能。网页仍可编辑,支持Word文档、网页、文本等格式之间的转换。采用多级分布式加密算法,界面支持皮肤等个性化设计。
查看全部
抓取网页生成电子书(资料管理电子书制作利器-友益文书软件设置
)
数据管理电子书制作工具-友易文档软件是一款集数据管理、电子书制作、翻页电子书制作、多媒体课件管理于一体的多功能软件...可用于管理htm网页和 mht 单个网页。 、Word文档、excel文档、幻灯片、pdf、chm、exe、txt、rtf、GIF、JPG、PNG、DJVU、ICO、TIF、BMP、Flash动画等格式文件;支持全文、网页、word文档搜索,支持背景音乐播放。集成pdf阅读功能,无需安装任何pdf阅读器,轻松阅读pdf文件。
可以发布电脑版exe、chm电子书、安卓apk电子书、苹果epub电子书等,还可以发布翻页电子书功能。设置一机一码或反传播功能。
无需安装任何软件,直接生成安卓手机apk电子书。
方便制作exe翻页电子书、滑动手机相册、撕角翻页电子书。
可生成安卓手机版apk电子书,支持5级目录,具有目录搜索、全文搜索、书签、设置一机一码功能,支持文本、网页、图片和pdf文档,无需在手机上安装其他任何阅读器都可以阅读。是目前安卓手机最强大的数据管理和电子书软件。
可以生成苹果手机可以阅读的epub格式文件;
可以生成具有全文搜索、目录搜索、采集夹等功能的chm格式文件。
可以直接为托管数据生成可执行文件。软件采用窗口风格,目录树结构管理,所见即所得的设计理念,不需要复杂的转换和编译。
易于使用和操作。您可以自由添加和删除目录树,随意编辑文档内容,更改字体大小和颜色。
该软件还可以生成电子相册,非常适合企事业单位进行产品推广和业务推广,在微信上分享非常方便。
本软件不断吸收同类软件的优点,同时在功能和设计上有独特的创新。采用混合索引算法,数据存储采用自己的压缩格式,独特的多文本超链接功能。网页仍可编辑,支持Word文档、网页、文本等格式之间的转换。采用多级分布式加密算法,界面支持皮肤等个性化设计。

抓取网页生成电子书(豆瓣日记:只输出最近几个月的日记摘要(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-03 09:17
豆瓣日记的提要地址很容易找到。打开博主的豆瓣日记界面,右栏下方是官方提要地址。
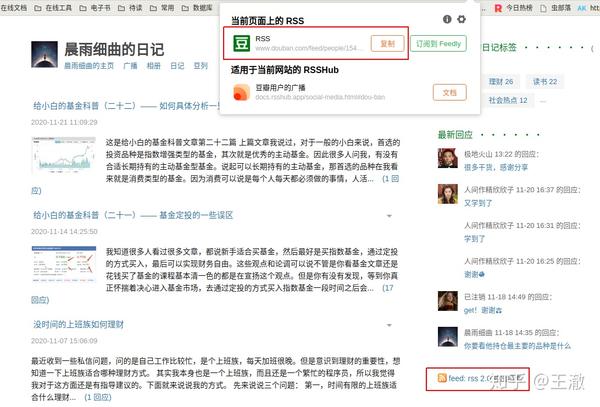
或者安装 RSShub Radar 浏览器扩展,在豆瓣日记界面点击扩展图标,会显示提要地址。
使用Calibre进行捕捉文章
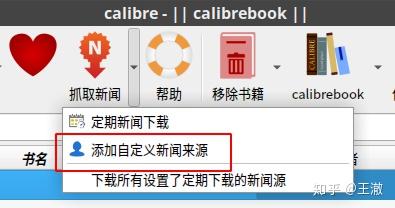
启动 Calibre,然后在工具栏上的抓取新闻下拉栏中找到添加自定义新闻源。
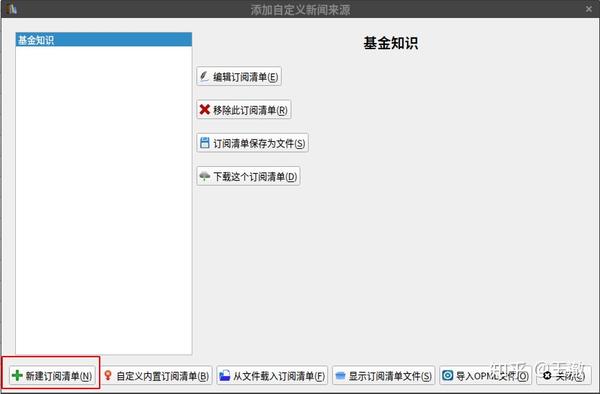
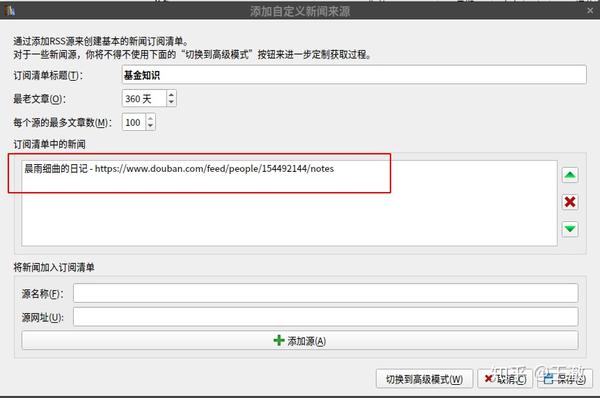
在“添加自定义新闻源”窗口中,选择左下角的“新建订阅列表”。
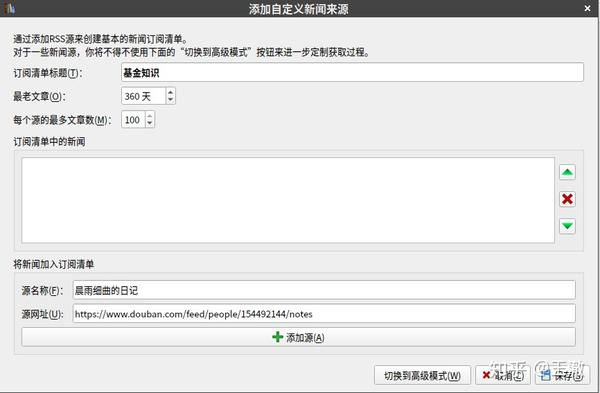
在打开的窗口中,按要求填写以下信息:
填写完毕后,点击添加来源,将其添加到订阅列表中的新闻框。如果要添加其他源地址,可以继续以同样的方式添加源。
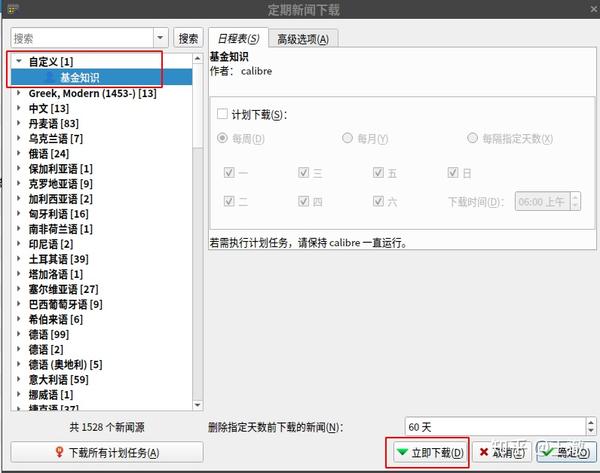
点击保存退出添加自定义新闻源窗口,然后点击工具栏中的抓取新闻,会弹出一个常规的新闻下载窗口,在左侧栏的自定义中选择刚刚创建的订阅列表的标题,然后点击右下角的立即下载。
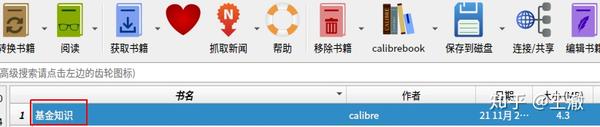
等待Calibre从网上获取文章,提示完成后,库中会出现订阅列表标题的电子书。
查看电子书
电子书封面为简单的自动生成封面,附有文章目录,内容已排版。
因为豆瓣日记的RSS提要有两个缺陷:只输出日记摘要,只输出最近几个月的日记。前者结果8月以来电子书里只有文章,后者得益于Calibre可以自动抓取全文并被攻克。 查看全部
抓取网页生成电子书(豆瓣日记:只输出最近几个月的日记摘要(图))
豆瓣日记的提要地址很容易找到。打开博主的豆瓣日记界面,右栏下方是官方提要地址。
或者安装 RSShub Radar 浏览器扩展,在豆瓣日记界面点击扩展图标,会显示提要地址。
使用Calibre进行捕捉文章
启动 Calibre,然后在工具栏上的抓取新闻下拉栏中找到添加自定义新闻源。
在“添加自定义新闻源”窗口中,选择左下角的“新建订阅列表”。
在打开的窗口中,按要求填写以下信息:
填写完毕后,点击添加来源,将其添加到订阅列表中的新闻框。如果要添加其他源地址,可以继续以同样的方式添加源。
点击保存退出添加自定义新闻源窗口,然后点击工具栏中的抓取新闻,会弹出一个常规的新闻下载窗口,在左侧栏的自定义中选择刚刚创建的订阅列表的标题,然后点击右下角的立即下载。
等待Calibre从网上获取文章,提示完成后,库中会出现订阅列表标题的电子书。
查看电子书
电子书封面为简单的自动生成封面,附有文章目录,内容已排版。

因为豆瓣日记的RSS提要有两个缺陷:只输出日记摘要,只输出最近几个月的日记。前者结果8月以来电子书里只有文章,后者得益于Calibre可以自动抓取全文并被攻克。
抓取网页生成电子书(ͼ4应用点滴不需要做网页索引文件索引网页生成器照样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-29 22:17
我经常上网搜索一些有趣的资料,还有很多软件教程,放在硬盘上,随时随地看,不用担心是否在线。我最近学习了 LiveMotion,我已经完成了一些课程。保存的htm文件都是htm文件。当你阅读它们时,你必须一一打开它们。感觉真的很麻烦。(如图1)
ͼ1
如果可以集成到一个网页索引文件中,就非常方便了。一想到网页索引,虽然做网页索引不是什么难事,但是劳动强度不小,尤其是那些需要连接大量低级网页的网页,更是更可怕。
解决方案
ABU Make Index v2.10.0004,这是一款由中国人编写的免费绿色软件,体积小,288KB,可在作者主页()下载。解压后无需安装,运行makehtmindex.exe即可使用。这是一个用于为扩展名为 Htm、Html、Txt、Gb、Jpg 和 Bmp 的文件生成索引网页的工具。生成图片索引时会自动生成源图片的缩略图,因此也可以作为制作图片缩略图的工具。
Web 索引生成器只需点击三下鼠标,即可创建精美的 Web 索引,只需点击三下五次分区即可。我要处理的是一个网页文件,所以我首先选择了上面的按钮“生成Htm、Html、Txt、Gb扩展文件索引网页”。(如图2)
ͼ2
然后按“下一步”按钮,出现网页索引创建界面。浏览找到目标文件目录,确定网页索引的文件名和保存路径,点击“生成”按钮完成网页索引。(如图3)
ͼ3
生成的Htm、Html、Txt、Gb等扩展名文件的索引网页,与源文件保存在同一目录下(默认路径不可更改)。然后在浏览器里看我的index文件,再看每节课的内容,每个htm文件的标题都被提取出来了,更有条理了!(如图4)
ͼ4
应用位
即使您不需要制作网页,网页生成器仍然非常有用。每次在线下载大量网页和图片时,网页索引生成器都会将它们整齐排列,让您尽收眼底。
1、 为Htm、Html、Txt、Gb扩展名的文件生成索引网页,并保存在与源文件相同的目录中。如果源文件目录中同时存在上述两种类型的文件,则生成的网页将有2个版块和快捷方式书签。如果只有其中一种,生成的网页就不会被切分,自然也就没有快捷书签了。
2、 生成Jpg和Bmp扩展文件(图片)的索引网页,可以选择保存文件的路径。注意:当索引文件保存路径与源文件路径不同时,可能是索引文件中的链接有问题。缩略图保存在保存索引文件的目录下的“PREVIEW”子目录中(生成的缩略图是一个未压缩的假“JPG”文件)。
注:由于IE对“BMP”文件支持不好,点击索引文件中的“BMP”文件链接显示异常或显示图标,NC没问题。
如果你认为“上网”就是“下载”,那么使用这个工具可以让“下载”的事情有条不紊。一定要善用工具,为我们创造休闲的工作和学习! 查看全部
抓取网页生成电子书(ͼ4应用点滴不需要做网页索引文件索引网页生成器照样)
我经常上网搜索一些有趣的资料,还有很多软件教程,放在硬盘上,随时随地看,不用担心是否在线。我最近学习了 LiveMotion,我已经完成了一些课程。保存的htm文件都是htm文件。当你阅读它们时,你必须一一打开它们。感觉真的很麻烦。(如图1)

ͼ1
如果可以集成到一个网页索引文件中,就非常方便了。一想到网页索引,虽然做网页索引不是什么难事,但是劳动强度不小,尤其是那些需要连接大量低级网页的网页,更是更可怕。
解决方案
ABU Make Index v2.10.0004,这是一款由中国人编写的免费绿色软件,体积小,288KB,可在作者主页()下载。解压后无需安装,运行makehtmindex.exe即可使用。这是一个用于为扩展名为 Htm、Html、Txt、Gb、Jpg 和 Bmp 的文件生成索引网页的工具。生成图片索引时会自动生成源图片的缩略图,因此也可以作为制作图片缩略图的工具。
Web 索引生成器只需点击三下鼠标,即可创建精美的 Web 索引,只需点击三下五次分区即可。我要处理的是一个网页文件,所以我首先选择了上面的按钮“生成Htm、Html、Txt、Gb扩展文件索引网页”。(如图2)
ͼ2
然后按“下一步”按钮,出现网页索引创建界面。浏览找到目标文件目录,确定网页索引的文件名和保存路径,点击“生成”按钮完成网页索引。(如图3)
ͼ3
生成的Htm、Html、Txt、Gb等扩展名文件的索引网页,与源文件保存在同一目录下(默认路径不可更改)。然后在浏览器里看我的index文件,再看每节课的内容,每个htm文件的标题都被提取出来了,更有条理了!(如图4)
ͼ4
应用位
即使您不需要制作网页,网页生成器仍然非常有用。每次在线下载大量网页和图片时,网页索引生成器都会将它们整齐排列,让您尽收眼底。
1、 为Htm、Html、Txt、Gb扩展名的文件生成索引网页,并保存在与源文件相同的目录中。如果源文件目录中同时存在上述两种类型的文件,则生成的网页将有2个版块和快捷方式书签。如果只有其中一种,生成的网页就不会被切分,自然也就没有快捷书签了。
2、 生成Jpg和Bmp扩展文件(图片)的索引网页,可以选择保存文件的路径。注意:当索引文件保存路径与源文件路径不同时,可能是索引文件中的链接有问题。缩略图保存在保存索引文件的目录下的“PREVIEW”子目录中(生成的缩略图是一个未压缩的假“JPG”文件)。
注:由于IE对“BMP”文件支持不好,点击索引文件中的“BMP”文件链接显示异常或显示图标,NC没问题。
如果你认为“上网”就是“下载”,那么使用这个工具可以让“下载”的事情有条不紊。一定要善用工具,为我们创造休闲的工作和学习!
抓取网页生成电子书(Python最简单的爬虫requests-html安装-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-29 17:09
很多朋友都听说过Python这个名字,Python也有很多爬虫框架,最简单的就是requests-html。和著名的web请求库requests是同一个作者。它专注于XML数据提取,可以说是最简单的爬虫框架。
安装 requests-html
这个库的安装很简单,直接通过pip安装即可。
pip install requests-html
开始使用
Requests-html 使用起来也很简单,下面是一个简单的例子。像往常一样,第一段介绍了 HTMLSession 来创建连接并获取网页数据。第二段创建连接并获取我的短书的用户页面。第三段使用xpath语法获取网页上的用户名,最后打印出来。
from requests_html import HTMLSession
session = HTMLSession()
response = session.get(
'https://www.jianshu.com/u/7753478e1554')
username = response.html.xpath(
'//a[@class="name"]/text()', first=True)
print(username)
看起来是不是很简单?是的,它真的很简单,接下来还有一些更有趣的功能。
分析网页
在编写爬虫之前要做的一件事是分析网页的结构。这个工作其实很简单,打开你要访问的网页,按F12打开开发者工具,就可以在最左边看到这样一个按钮。单击此按钮,然后在网页上单击您要查看的网页元素,即可发现该元素对应的相关源代码已经为您定位好了。
定位按钮
通过这个函数,我们可以很方便的对网页进行分析,然后通过它的结构来写一个爬虫。
提取数据
上面的 response.html 是网页的根 HTML 节点,可以在节点对象上调用一些方法来检索数据。最常用的方法是 find 方法,它使用 CSS 选择器来定位数据。对于上面的例子,你可以使用find方法来重写第三段。
因为所有搜索方法返回的结果都是列表,如果确定只需要搜索一个,可以将第一个参数设置为true,只返回第一个结果。find 方法返回的仍然是一个节点。如果您只需要节点的内容,只需调用其 text 属性即可。
用户名对应的HTML结构如图所示。
代码显示如下。
username = response.html.find('a.name', first=True).text
除了 find 方法之外,您还可以使用 xpath 方法来查找具有 xpath 语法的节点,如第一个示例所示。我个人更喜欢 xpath 语法。CSS选择器虽然比较流行,但是写出来的效果有点奇怪,没有xpath那么整洁。
这是查看如何获取我的短书的个人资料的同一页面。网页代码如图所示。
代码显示如下。
description = response.html.xpath(
'//div[@class="description"]/div[@class="js-intro"]/text()', first=True)
CSS 选择器和 XPATH 语法不是本文的主要内容。如果你对这方面不熟悉,最好阅读相关教程。当然,如果您有任何问题,也可以提出。如果你想看,我也可以写一篇文章介绍这些语法知识。
渲染网页
有些网页采用前后端分离技术开发,需要浏览器渲染才能完整显示。如果使用爬虫查看,只能显示部分内容。这时候浏览器需要渲染页面才能得到完整的页面。使用 requests-html,过程非常简单。
首先我们来看一个需要渲染的网页的例子。以下代码访问我的短书用户页面,然后尝试获取我的所有文章。但是如果你运行这个例子,你会发现你只能得到前几项。由于短书页面是典型的需要浏览器渲染的页面,爬虫获取的网页是不完整的。
from requests_html import HTMLSession
session = HTMLSession()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.119 Safari/537.36'
}
url = 'https://www.jianshu.com/u/7753478e1554'
r = session.get(url, headers=headers)
for a in r.html.xpath('//ul[@class="note-list"]/li/div[@class="content"]/a[@class="title"]'):
title = a.text
link = f'https://www.jianshu.com{a.attrs["href"]}'
print(f'《{title}》,{link}')
那么如何渲染网页以获得完整的结果呢?其实很简单,在查询HTML节点之前调用render函数即可。
使用浏览器渲染的渲染函数
原理也很简单。当第一次调用渲染时,requests-html 将在本地下载一个 Chrome 浏览器并使用它来渲染网页。这样我们就可以得到渲染出来的页面了。
但是对于短书的例子,还是存在一些问题,因为如果你在浏览器中打开这个网页,你会发现有些文章只有在浏览器向下滑动页面时才开始渲染。不过,聪明的作者早就考虑过这种情况。渲染函数支持滑动参数。设置后会模拟浏览器滑动操作来解决这个问题。
r.html.render(scrolldown=50, sleep=0.2)
节点对象
不管上面的r.html还是find/xpath函数返回的结果都是节点对象。除了上面介绍的几种提取数据的方法外,节点对象还有以下属性,在我们提取数据的时候也是非常有用的。
相比专业的爬虫框架scrapy,还是解析库BeautifulSoup,只用于解析XML。requests-html 可以说是恰到好处。没有前者那么难学,也不需要像后者那样使用HTTP请求库。如果您需要临时抓取几个网页,那么 requests-html 是您的最佳选择。 查看全部
抓取网页生成电子书(Python最简单的爬虫requests-html安装-)
很多朋友都听说过Python这个名字,Python也有很多爬虫框架,最简单的就是requests-html。和著名的web请求库requests是同一个作者。它专注于XML数据提取,可以说是最简单的爬虫框架。
安装 requests-html
这个库的安装很简单,直接通过pip安装即可。
pip install requests-html
开始使用
Requests-html 使用起来也很简单,下面是一个简单的例子。像往常一样,第一段介绍了 HTMLSession 来创建连接并获取网页数据。第二段创建连接并获取我的短书的用户页面。第三段使用xpath语法获取网页上的用户名,最后打印出来。
from requests_html import HTMLSession
session = HTMLSession()
response = session.get(
'https://www.jianshu.com/u/7753478e1554')
username = response.html.xpath(
'//a[@class="name"]/text()', first=True)
print(username)
看起来是不是很简单?是的,它真的很简单,接下来还有一些更有趣的功能。
分析网页
在编写爬虫之前要做的一件事是分析网页的结构。这个工作其实很简单,打开你要访问的网页,按F12打开开发者工具,就可以在最左边看到这样一个按钮。单击此按钮,然后在网页上单击您要查看的网页元素,即可发现该元素对应的相关源代码已经为您定位好了。
定位按钮
通过这个函数,我们可以很方便的对网页进行分析,然后通过它的结构来写一个爬虫。
提取数据
上面的 response.html 是网页的根 HTML 节点,可以在节点对象上调用一些方法来检索数据。最常用的方法是 find 方法,它使用 CSS 选择器来定位数据。对于上面的例子,你可以使用find方法来重写第三段。
因为所有搜索方法返回的结果都是列表,如果确定只需要搜索一个,可以将第一个参数设置为true,只返回第一个结果。find 方法返回的仍然是一个节点。如果您只需要节点的内容,只需调用其 text 属性即可。
用户名对应的HTML结构如图所示。
代码显示如下。
username = response.html.find('a.name', first=True).text
除了 find 方法之外,您还可以使用 xpath 方法来查找具有 xpath 语法的节点,如第一个示例所示。我个人更喜欢 xpath 语法。CSS选择器虽然比较流行,但是写出来的效果有点奇怪,没有xpath那么整洁。
这是查看如何获取我的短书的个人资料的同一页面。网页代码如图所示。
代码显示如下。
description = response.html.xpath(
'//div[@class="description"]/div[@class="js-intro"]/text()', first=True)
CSS 选择器和 XPATH 语法不是本文的主要内容。如果你对这方面不熟悉,最好阅读相关教程。当然,如果您有任何问题,也可以提出。如果你想看,我也可以写一篇文章介绍这些语法知识。
渲染网页
有些网页采用前后端分离技术开发,需要浏览器渲染才能完整显示。如果使用爬虫查看,只能显示部分内容。这时候浏览器需要渲染页面才能得到完整的页面。使用 requests-html,过程非常简单。
首先我们来看一个需要渲染的网页的例子。以下代码访问我的短书用户页面,然后尝试获取我的所有文章。但是如果你运行这个例子,你会发现你只能得到前几项。由于短书页面是典型的需要浏览器渲染的页面,爬虫获取的网页是不完整的。
from requests_html import HTMLSession
session = HTMLSession()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.119 Safari/537.36'
}
url = 'https://www.jianshu.com/u/7753478e1554'
r = session.get(url, headers=headers)
for a in r.html.xpath('//ul[@class="note-list"]/li/div[@class="content"]/a[@class="title"]'):
title = a.text
link = f'https://www.jianshu.com{a.attrs["href"]}'
print(f'《{title}》,{link}')
那么如何渲染网页以获得完整的结果呢?其实很简单,在查询HTML节点之前调用render函数即可。
使用浏览器渲染的渲染函数
原理也很简单。当第一次调用渲染时,requests-html 将在本地下载一个 Chrome 浏览器并使用它来渲染网页。这样我们就可以得到渲染出来的页面了。
但是对于短书的例子,还是存在一些问题,因为如果你在浏览器中打开这个网页,你会发现有些文章只有在浏览器向下滑动页面时才开始渲染。不过,聪明的作者早就考虑过这种情况。渲染函数支持滑动参数。设置后会模拟浏览器滑动操作来解决这个问题。
r.html.render(scrolldown=50, sleep=0.2)
节点对象
不管上面的r.html还是find/xpath函数返回的结果都是节点对象。除了上面介绍的几种提取数据的方法外,节点对象还有以下属性,在我们提取数据的时候也是非常有用的。
相比专业的爬虫框架scrapy,还是解析库BeautifulSoup,只用于解析XML。requests-html 可以说是恰到好处。没有前者那么难学,也不需要像后者那样使用HTTP请求库。如果您需要临时抓取几个网页,那么 requests-html 是您的最佳选择。
抓取网页生成电子书(【手语服务,助力沟通无障碍】(12月29日19:00) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-29 12:21
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
苏升不服第167篇原创文章,将此公众号设为star,第一时间阅读最新文章。
之前写过以下关于备份的文章:
再说备份微博
一键备份微博并导出为PDF。顺便用Python分析微博账号数据
再说备份网页和公众号文章
如何备份公众号文章和可能被删除的网页
我想看的公众号文章被删了怎么办?
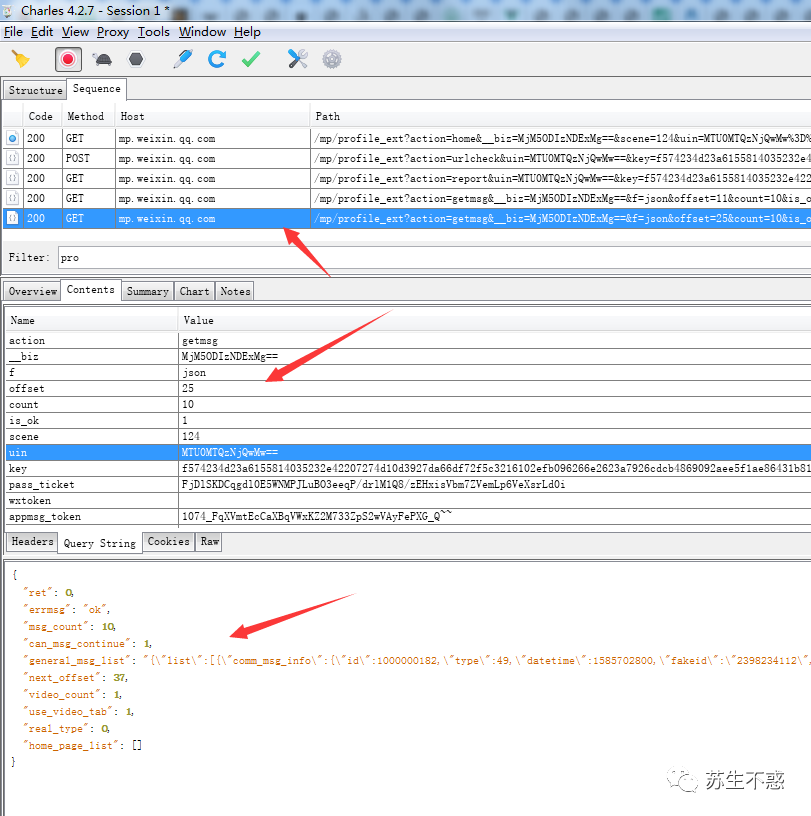
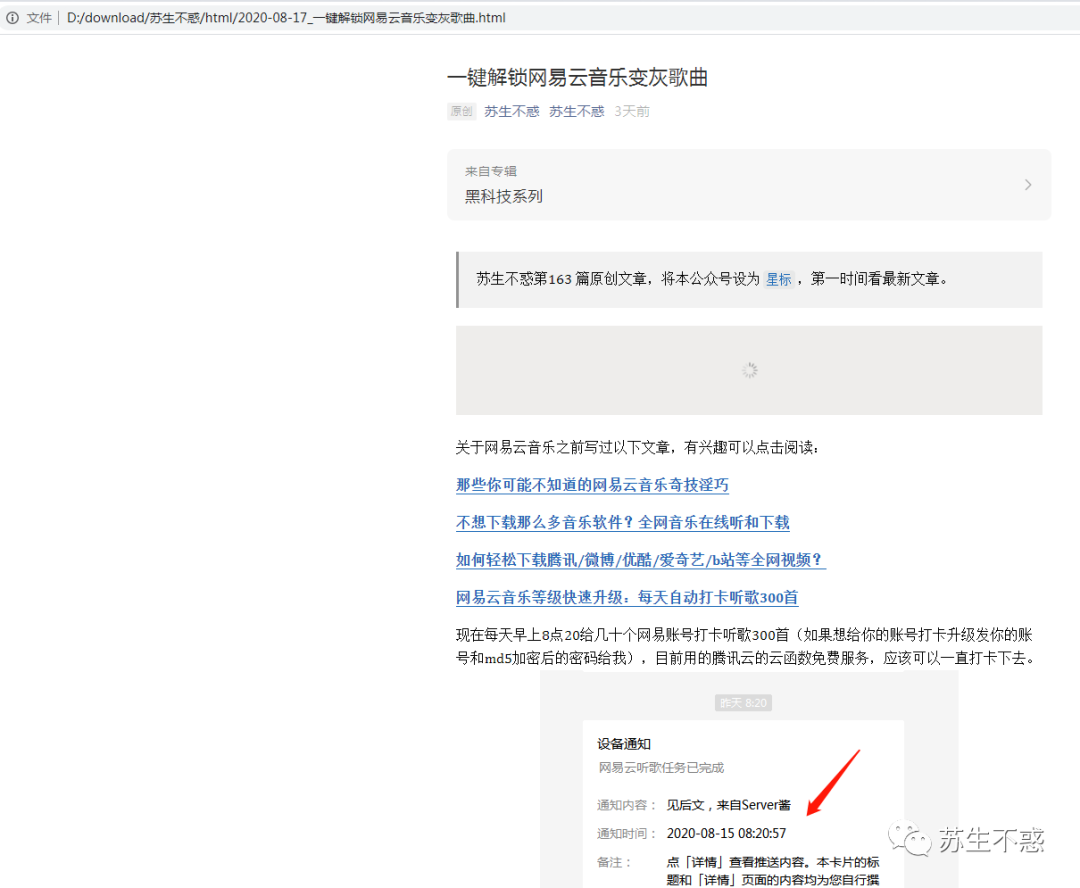
上面写的公众号的备份方法是单机备份。如果要备份某个公众号的所有文章,有点太麻烦了,所以今天分享一个用Python一键备份某个公众号的所有文章。不用担心你想阅读的文章被删除。我以我自己的公众号苏升不主为例。原理是通过抓包抓取微信客户端接口,使用Python请求微信接口获取公众号文章链接并下载。.
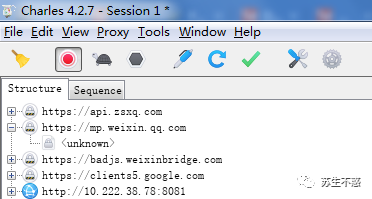
查尔斯捕获
常用的抓包工具有Fiddler、Charles、Charles这里用到的,先到官网下载软件,然后打开微信客户端找到公众号,进入文章列表可以看到已经发布的文章。
但是Charles在安装证书前无法获取https接口数据,显示未知。
安装证书后,在proxy->ssl代理设置中添加域名和主机。
再次爬取查看公众号文章界面数据。
公众号文章/mp/profile_ext?action=getmsg&__biz=MjM5ODIzNDEx&f=json&offset=25&count=10&is_ok=1&scene=124&uin=MTU0MTQzNj&key=f57423的接口地址,参数很多,__biz之间有用的参数只有一个还有公众号id,uin是用户的id,这个不变,key是请求的秘钥,一段时间后失效,offset是偏移量,count是每次请求的次数,返回值可以看到返回的数据包括文章标题title,摘要摘要,文章地址content_url,阅读源地址source_url,封面封面,作者作者,抓住这些有用的数据。
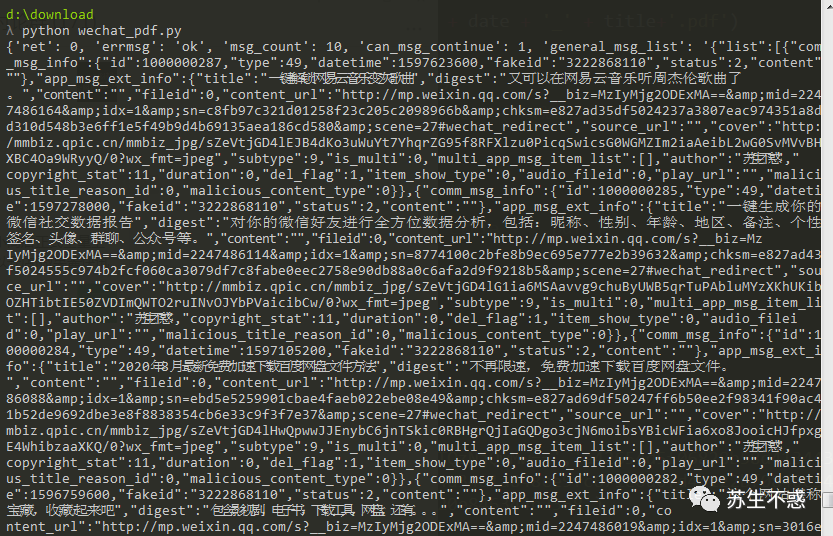
Python爬取公众号文章
上面分析了接口参数和返回数据,就开始用Python请求微信接口吧。
这里只获取原创文章。我的公众号有160多篇原创文章,生成HTML文件需要2分钟。
用谷歌浏览器打开看看。
生成的HTML文件也可以转成chm格式,需要安装Easy CHM软件,这是一个快速创建CHM电子书或CHM帮助文件的强大工具
左边是文章标题,右边是文章内容,看起来很方便。
还有收录
文章标题和链接的降价文件。上一篇markdown的文章介绍了使用Markdown写简历和PPT。
Excel 文件格式也可用。
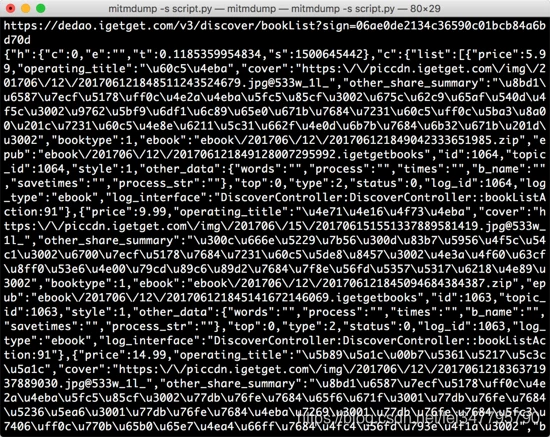
HTML、markdown、Excel生成都比较快,因为都是文本,下面开始导出PDF。
导出 PDF
导出PDF的工具是wkhtmltopdf。首先到官网下载安装wkhtmltopdf。安装完成后,设置环境变量。上一篇文章写了一些你可能不知道的windows技巧,然后就可以直接从命令行生成PDF了。
λ wkhtmltopdf http://www.baidu.com baidu.pdfLoading pages (1/6)Counting pages (2/6)Resolving links (4/6)Loading headers and footers (5/6)Printing pages (6/6)Done 查看全部
抓取网页生成电子书(【手语服务,助力沟通无障碍】(12月29日19:00)
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>

苏升不服第167篇原创文章,将此公众号设为star,第一时间阅读最新文章。
之前写过以下关于备份的文章:
再说备份微博
一键备份微博并导出为PDF。顺便用Python分析微博账号数据
再说备份网页和公众号文章
如何备份公众号文章和可能被删除的网页
我想看的公众号文章被删了怎么办?
上面写的公众号的备份方法是单机备份。如果要备份某个公众号的所有文章,有点太麻烦了,所以今天分享一个用Python一键备份某个公众号的所有文章。不用担心你想阅读的文章被删除。我以我自己的公众号苏升不主为例。原理是通过抓包抓取微信客户端接口,使用Python请求微信接口获取公众号文章链接并下载。.
查尔斯捕获
常用的抓包工具有Fiddler、Charles、Charles这里用到的,先到官网下载软件,然后打开微信客户端找到公众号,进入文章列表可以看到已经发布的文章。
但是Charles在安装证书前无法获取https接口数据,显示未知。
安装证书后,在proxy->ssl代理设置中添加域名和主机。
再次爬取查看公众号文章界面数据。
公众号文章/mp/profile_ext?action=getmsg&__biz=MjM5ODIzNDEx&f=json&offset=25&count=10&is_ok=1&scene=124&uin=MTU0MTQzNj&key=f57423的接口地址,参数很多,__biz之间有用的参数只有一个还有公众号id,uin是用户的id,这个不变,key是请求的秘钥,一段时间后失效,offset是偏移量,count是每次请求的次数,返回值可以看到返回的数据包括文章标题title,摘要摘要,文章地址content_url,阅读源地址source_url,封面封面,作者作者,抓住这些有用的数据。
Python爬取公众号文章
上面分析了接口参数和返回数据,就开始用Python请求微信接口吧。
这里只获取原创文章。我的公众号有160多篇原创文章,生成HTML文件需要2分钟。
用谷歌浏览器打开看看。
生成的HTML文件也可以转成chm格式,需要安装Easy CHM软件,这是一个快速创建CHM电子书或CHM帮助文件的强大工具
左边是文章标题,右边是文章内容,看起来很方便。
还有收录
文章标题和链接的降价文件。上一篇markdown的文章介绍了使用Markdown写简历和PPT。
Excel 文件格式也可用。
HTML、markdown、Excel生成都比较快,因为都是文本,下面开始导出PDF。
导出 PDF
导出PDF的工具是wkhtmltopdf。首先到官网下载安装wkhtmltopdf。安装完成后,设置环境变量。上一篇文章写了一些你可能不知道的windows技巧,然后就可以直接从命令行生成PDF了。
λ wkhtmltopdf http://www.baidu.com baidu.pdfLoading pages (1/6)Counting pages (2/6)Resolving links (4/6)Loading headers and footers (5/6)Printing pages (6/6)Done
抓取网页生成电子书(弘一网童2.7绿色注册.rar智能化智能化的网页保存工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-29 12:16
弘毅网子2.7 绿色注册.rar
智能网页保存工具——WebPortero是一款集网页抓取、内容识别、网页编辑、格式转换于一体的智能网页保存工具。可以保存网页文字、图片、Flash等。一键将网页保存为WORD文件!您只需要点击“Netboy,另存为WORD文件”,Netboy就会识别当前网页的正文内容,然后将正文内容保存为WORD文件。完成了原本需要打开WORD、选择文本内容、复制、过滤格式、粘贴到WORD以及保存等一系列工作;自动保存“下一页” 现在网上的一篇文章往往是分页显示的。如果你想把这样的一篇文章保存下来,就需要一页一页的复制。Netboys 可以自动保存下一页并为您完成;当您在网上查找信息时,会从不同的页面中提取多个网页的内容,并编译在一个文件中,Netboy 集成了提取、采集
、编辑和保存的功能,大大提高了您的效率;批量保存网页 批量保存多个链接中的网页内容,并将这些内容保存到一个文件中;保存图片 保存网页中的所有图片或多个链接中的所有图片,并可根据图片大小过滤文件,在多个链接中识别您关注的图片;生成CHM电子书批量抓取网页,一键网页合并生成CHM电子书。还可以使用CHM电子书对网页进行压缩和存储,避免保存太多不方便管理的网页;保存一个完整的网页可以完整地保存收录
动态加载内容的网页。netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间.
现在下载 查看全部
抓取网页生成电子书(弘一网童2.7绿色注册.rar智能化智能化的网页保存工具)
弘毅网子2.7 绿色注册.rar
智能网页保存工具——WebPortero是一款集网页抓取、内容识别、网页编辑、格式转换于一体的智能网页保存工具。可以保存网页文字、图片、Flash等。一键将网页保存为WORD文件!您只需要点击“Netboy,另存为WORD文件”,Netboy就会识别当前网页的正文内容,然后将正文内容保存为WORD文件。完成了原本需要打开WORD、选择文本内容、复制、过滤格式、粘贴到WORD以及保存等一系列工作;自动保存“下一页” 现在网上的一篇文章往往是分页显示的。如果你想把这样的一篇文章保存下来,就需要一页一页的复制。Netboys 可以自动保存下一页并为您完成;当您在网上查找信息时,会从不同的页面中提取多个网页的内容,并编译在一个文件中,Netboy 集成了提取、采集
、编辑和保存的功能,大大提高了您的效率;批量保存网页 批量保存多个链接中的网页内容,并将这些内容保存到一个文件中;保存图片 保存网页中的所有图片或多个链接中的所有图片,并可根据图片大小过滤文件,在多个链接中识别您关注的图片;生成CHM电子书批量抓取网页,一键网页合并生成CHM电子书。还可以使用CHM电子书对网页进行压缩和存储,避免保存太多不方便管理的网页;保存一个完整的网页可以完整地保存收录
动态加载内容的网页。netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间.
现在下载
抓取网页生成电子书(mitmdump爬取“得到”App电子书信息(一)_Python学习 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-29 12:14
)
前言
文章文字及图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入
mitmdump爬取“获取”App电子书信息
“Get”App是罗季思伟出品的碎片化时间学习App。应用中有很多学习资源。但是“获取”App没有对应的网页版,只能通过App获取信息。这次我们将通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App电子书版块中的电子书信息,并将信息保存到MongoDB中,如图。
我们想爬下书名、介绍、封面、价格,但是这次爬取的重点是了解mitmdump工具的使用,所以暂时不涉及自动爬取,操作应用程序仍然是手动执行的。mitmdump 负责捕获响应并提取和保存数据。
2. 准备
请确保您已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网内,同时配置了mitmproxy的CA证书,安装了MongoDB并运行其服务,安装了PyMongo库。具体配置请参考第一章说明。
3. 爬取分析
首先查找URL,返回当前页面的内容。我们写一个脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的URL和响应体内容,也就是请求链接和响应内容这两个最关键的部分。脚本的名称保存为 script.py。
接下来运行mitmdump,命令如下:
mitmdump -s script.py
打开“Get”App的电子书页面,在PC控制台上可以看到相应的输出。然后滑动页面加载更多电子书,控制台中出现的新输出内容就是App发出的新加载请求,里面收录
了下一页的电子书内容。控制台输出结果示例如图所示。
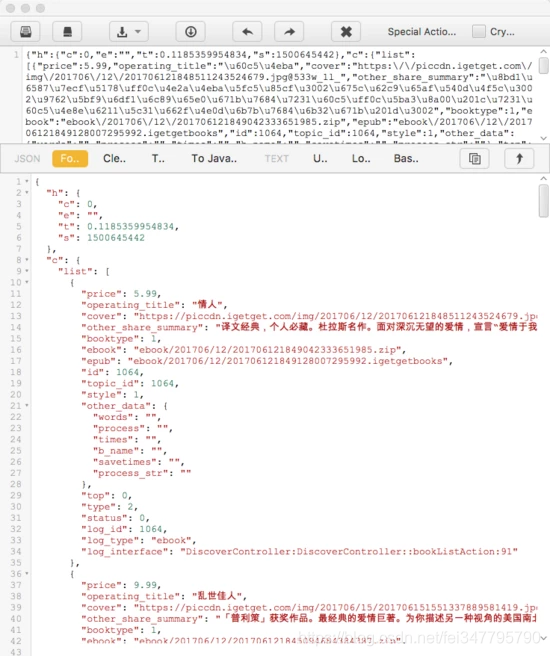
可以看到URL所在的界面,后面加了一个sign参数。通过URL的名称,可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是一个JSON格式的字符串。我们将其格式化为如图所示。
格式化的内容收录
ac 字段和一个列表字段。列表的每个元素都收录
价格、标题、描述等,第一个返回结果是电子书《情人》,此时App的内容也是这本电子书,描述的内容和价格也完全匹配。App页面如图所示。
这意味着当前接口是获取电子书信息的接口,我们只需要从该接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据采集
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后在结果中提取相应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台上的输出,如图。
控制台输出
现在输出图书的所有信息,一个图书信息对应一条JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息,然后将信息保存到数据库中。为方便起见,我们选择MongoDB数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每一条内容都是提取出来的内容,包括电子书的书名、封面、描述、价格等信息。
一开始我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入到数据库中。
滑动几页,发现所有书籍信息都保存在MongoDB中,如图。
至此,我们已经使用了一个非常简单的脚本来保存“Get”App的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data) 查看全部
抓取网页生成电子书(mitmdump爬取“得到”App电子书信息(一)_Python学习
)
前言
文章文字及图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入
mitmdump爬取“获取”App电子书信息
“Get”App是罗季思伟出品的碎片化时间学习App。应用中有很多学习资源。但是“获取”App没有对应的网页版,只能通过App获取信息。这次我们将通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App电子书版块中的电子书信息,并将信息保存到MongoDB中,如图。
我们想爬下书名、介绍、封面、价格,但是这次爬取的重点是了解mitmdump工具的使用,所以暂时不涉及自动爬取,操作应用程序仍然是手动执行的。mitmdump 负责捕获响应并提取和保存数据。
2. 准备
请确保您已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网内,同时配置了mitmproxy的CA证书,安装了MongoDB并运行其服务,安装了PyMongo库。具体配置请参考第一章说明。
3. 爬取分析
首先查找URL,返回当前页面的内容。我们写一个脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的URL和响应体内容,也就是请求链接和响应内容这两个最关键的部分。脚本的名称保存为 script.py。
接下来运行mitmdump,命令如下:
mitmdump -s script.py
打开“Get”App的电子书页面,在PC控制台上可以看到相应的输出。然后滑动页面加载更多电子书,控制台中出现的新输出内容就是App发出的新加载请求,里面收录
了下一页的电子书内容。控制台输出结果示例如图所示。
可以看到URL所在的界面,后面加了一个sign参数。通过URL的名称,可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是一个JSON格式的字符串。我们将其格式化为如图所示。
格式化的内容收录
ac 字段和一个列表字段。列表的每个元素都收录
价格、标题、描述等,第一个返回结果是电子书《情人》,此时App的内容也是这本电子书,描述的内容和价格也完全匹配。App页面如图所示。
这意味着当前接口是获取电子书信息的接口,我们只需要从该接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据采集
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后在结果中提取相应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台上的输出,如图。
控制台输出
现在输出图书的所有信息,一个图书信息对应一条JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息,然后将信息保存到数据库中。为方便起见,我们选择MongoDB数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每一条内容都是提取出来的内容,包括电子书的书名、封面、描述、价格等信息。
一开始我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入到数据库中。
滑动几页,发现所有书籍信息都保存在MongoDB中,如图。
至此,我们已经使用了一个非常简单的脚本来保存“Get”App的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-29 12:13
)
总是有同学问我在学习了Python基础知识后是否不知道我可以做些什么来改进。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖,停止更新,你就看不到这些好内容了。虽然这是小概率事件(还没有发生),但你可以准备下雨天。您可以将关注的专栏导出到电子书,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后,程序会自动抓取栏目内的文章,并根据发表时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表 爬取每篇文章的详细内容导出PDF 1. 爬取列表
上一篇爬虫必备工具,掌握了它就可以解决介绍如何分析网页请求的一半问题。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否拿到了所有的文章。
data中的id、title、url就是我们需要的数据。因为url可以用id拼写出来,所以没有保存在我们的代码中。
使用 while 循环直到所有文章的 id 和标题都被提取并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 获取文章
有了所有文章的id/url,后面的爬取就很简单了。文章的主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
到这一步,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转为PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用起来非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整列的导出。
不仅是知乎专栏,几乎大部分的资讯网站都是通过1.抓取列表和2.抓取详细内容这两个步骤来采集
数据的。所以这个代码只要稍加修改就可以在许多其他网站上使用。只是有些网站需要登录后才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,所以具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎专栏下载器源码请在公众号回复知乎关键词(Crossin的编程课堂)
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他文章和答案:
欢迎搜索关注:Crossin的编程课堂
查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎
)
总是有同学问我在学习了Python基础知识后是否不知道我可以做些什么来改进。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖,停止更新,你就看不到这些好内容了。虽然这是小概率事件(还没有发生),但你可以准备下雨天。您可以将关注的专栏导出到电子书,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:


之后,程序会自动抓取栏目内的文章,并根据发表时间合并导出为pdf文件。

【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表 爬取每篇文章的详细内容导出PDF 1. 爬取列表
上一篇爬虫必备工具,掌握了它就可以解决介绍如何分析网页请求的一半问题。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles

观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否拿到了所有的文章。
data中的id、title、url就是我们需要的数据。因为url可以用id拼写出来,所以没有保存在我们的代码中。

使用 while 循环直到所有文章的 id 和标题都被提取并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)

2. 获取文章
有了所有文章的id/url,后面的爬取就很简单了。文章的主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)

到这一步,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转为PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用起来非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')

这样就完成了整列的导出。
不仅是知乎专栏,几乎大部分的资讯网站都是通过1.抓取列表和2.抓取详细内容这两个步骤来采集
数据的。所以这个代码只要稍加修改就可以在许多其他网站上使用。只是有些网站需要登录后才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,所以具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎专栏下载器源码请在公众号回复知乎关键词(Crossin的编程课堂)
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他文章和答案:
欢迎搜索关注:Crossin的编程课堂

抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-27 08:10
编者按(@Minja):在写文章的时候,我们经常需要引用和返回。对各种存档和编辑工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是摆脱了他,一起研究了一套简单易行的方法,写了一篇文章与大家分享。
网络世界虽然有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果您想拥有出色的文章阅读体验,您至少必须确保我们正在阅读的文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能有一天找不到了。也许,将文章以电子书的形式保存在本地是一种更方便的回溯选择。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪辑”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的广告和其他影响体验的冗余区域,还可能丢失重要和有价值的内容。不仅如此,几乎没有任何工具可以轻松抓取图片并自定义本地保存的文章样式。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。
主流电子书格式
或许最著名的电子书格式是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们这篇文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片、目录、美图。相对而言,ePub 更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作
[……] 查看全部
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
编者按(@Minja):在写文章的时候,我们经常需要引用和返回。对各种存档和编辑工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是摆脱了他,一起研究了一套简单易行的方法,写了一篇文章与大家分享。
网络世界虽然有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果您想拥有出色的文章阅读体验,您至少必须确保我们正在阅读的文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能有一天找不到了。也许,将文章以电子书的形式保存在本地是一种更方便的回溯选择。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪辑”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的广告和其他影响体验的冗余区域,还可能丢失重要和有价值的内容。不仅如此,几乎没有任何工具可以轻松抓取图片并自定义本地保存的文章样式。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。

主流电子书格式
或许最著名的电子书格式是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们这篇文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片、目录、美图。相对而言,ePub 更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作
[……]
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-25 00:05
写爬虫似乎并不比使用Python更合适。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,做成PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站1的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说没用,可以无视。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点大锤。另外,既然是把html文件转成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台直接从wkhtmltopdf官网下载稳定版2进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,我们先来梳理一下您的想法。该程序的目的是将URL对应的所有html body部分保存到本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的正文内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存在a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签 查看全部
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
写爬虫似乎并不比使用Python更合适。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,做成PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站1的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说没用,可以无视。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点大锤。另外,既然是把html文件转成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台直接从wkhtmltopdf官网下载稳定版2进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,我们先来梳理一下您的想法。该程序的目的是将URL对应的所有html body部分保存到本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的正文内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存在a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签
抓取网页生成电子书(制作一个最新文章列表减少蜘蛛爬行的步骤【模板】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-12-25 00:04
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天的采集数量很多,虽然首页有的地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的采集 每天的内容。
由于采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,因此萌发了制作一个最新的文章列表,减少了蜘蛛爬行的步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,在性质为 xml 映射,但这只是 HTML 页面。
演示地址:
修改方法:
1、下载压缩包,解压后上传到根目录。
2、进入网站后台核心->通道模型->添加单页文档管理页面。
3、页面标题、页面关键词和页面摘要信息根据自己网站的情况填写,模板名和文件名参考下图,编辑中无需添加任何内容框,我已经在模板中给你设置好了。
<IMG class="size-full wp-image-1171 aligncenter" title=增加新页面 alt="" src="http://image39.360doc.com/Down ... ot%3B width=500 height=344>
4、设置好后点击确定,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、还没有自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
您还可以创建一个没有图片的简单导航页面。
在模板的底部,有一个织梦 管理员主页的链接。如果您认为链接的存在会对您产生影响,您可以随意删除。如果你觉得这个方法对你有帮助,希望你能留下链接。也是对我最大的支持,谢谢。
如果您遇到任何问题,您可以给我留言。 查看全部
抓取网页生成电子书(制作一个最新文章列表减少蜘蛛爬行的步骤【模板】)
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天的采集数量很多,虽然首页有的地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的采集 每天的内容。
由于采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,因此萌发了制作一个最新的文章列表,减少了蜘蛛爬行的步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,在性质为 xml 映射,但这只是 HTML 页面。
演示地址:
修改方法:
1、下载压缩包,解压后上传到根目录。
2、进入网站后台核心->通道模型->添加单页文档管理页面。
3、页面标题、页面关键词和页面摘要信息根据自己网站的情况填写,模板名和文件名参考下图,编辑中无需添加任何内容框,我已经在模板中给你设置好了。
<IMG class="size-full wp-image-1171 aligncenter" title=增加新页面 alt="" src="http://image39.360doc.com/Down ... ot%3B width=500 height=344>
4、设置好后点击确定,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、还没有自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
您还可以创建一个没有图片的简单导航页面。
在模板的底部,有一个织梦 管理员主页的链接。如果您认为链接的存在会对您产生影响,您可以随意删除。如果你觉得这个方法对你有帮助,希望你能留下链接。也是对我最大的支持,谢谢。
如果您遇到任何问题,您可以给我留言。
抓取网页生成电子书(calibre-E-bookmanagement怎么做代码Git教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-25 00:03
calibre-电子书管理是一款非常强大的电子书管理软件。它可以打开和转换各种格式的电子书,抓取新闻到本地阅读,并允许用户自定义新闻来源。抓取网页内容并生成电子书。利用这个功能,我制作了廖雪峰老师的Python教程和Git教程的epub电子书。使用firefox的epubReader插件,可以在电脑上打开阅读。您也可以在 Internet 上阅读。这种体验非常适合没有互联网但想学习的学生。
食谱是用python编写的。用学过的python获取学习资源,加强实践。操作方法非常简单。下载calibre-电子书管理就知道了。Calibre 还提供了用于配方准备的 api 文档。
下面是获取python教程的配方代码
#!/usr/bin/env python
# vim:fileencoding=utf-8
from __future__ import unicode_literals, division, absolute_import, print_function
from calibre.web.feeds.news import BasicNewsRecipe
class liaoxuefeng_python(BasicNewsRecipe):
title = '廖雪峰Python教程'
description = 'python教程'
max_articles_per_feed = 200
url_prefix = 'http://www.liaoxuefeng.com'
no_stylesheets = True
keep_only_tags = [{ 'id': 'main' }]
remove_tags=[{'class':'x-wiki-info'}]
remove_tags_after=[{'class':'x-wiki-content x-content'}]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup('http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000')
div = soup.find('div', { 'class': 'x-wiki-tree' })
articles = []
for link in div.findAll('a'):
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
tutorial = [('廖雪峰python教程', articles)]
return tutorial
抓取Git教程只需要将parse_index方法中python教程的链接改成Git教程的链接即可。成品在本教程中 查看全部
抓取网页生成电子书(calibre-E-bookmanagement怎么做代码Git教程)
calibre-电子书管理是一款非常强大的电子书管理软件。它可以打开和转换各种格式的电子书,抓取新闻到本地阅读,并允许用户自定义新闻来源。抓取网页内容并生成电子书。利用这个功能,我制作了廖雪峰老师的Python教程和Git教程的epub电子书。使用firefox的epubReader插件,可以在电脑上打开阅读。您也可以在 Internet 上阅读。这种体验非常适合没有互联网但想学习的学生。
食谱是用python编写的。用学过的python获取学习资源,加强实践。操作方法非常简单。下载calibre-电子书管理就知道了。Calibre 还提供了用于配方准备的 api 文档。
下面是获取python教程的配方代码
#!/usr/bin/env python
# vim:fileencoding=utf-8
from __future__ import unicode_literals, division, absolute_import, print_function
from calibre.web.feeds.news import BasicNewsRecipe
class liaoxuefeng_python(BasicNewsRecipe):
title = '廖雪峰Python教程'
description = 'python教程'
max_articles_per_feed = 200
url_prefix = 'http://www.liaoxuefeng.com'
no_stylesheets = True
keep_only_tags = [{ 'id': 'main' }]
remove_tags=[{'class':'x-wiki-info'}]
remove_tags_after=[{'class':'x-wiki-content x-content'}]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup('http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000')
div = soup.find('div', { 'class': 'x-wiki-tree' })
articles = []
for link in div.findAll('a'):
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
tutorial = [('廖雪峰python教程', articles)]
return tutorial
抓取Git教程只需要将parse_index方法中python教程的链接改成Git教程的链接即可。成品在本教程中
抓取网页生成电子书(是不是有时星球内容太多刷不过来?想把星球精华内容撸下来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-14 07:01
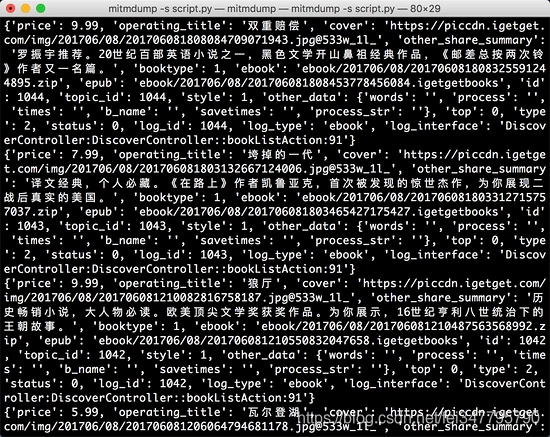
是不是有时候地球上的内容太多无法刷新?你想制作一本收录地球本质的电子书吗?
本文将带你实现使用Python爬取星球内容,制作PDF电子书。
第一个效果:
内容以优化为主,主要优化内容在于翻页时间的处理、大空白的处理、评论的抓取、超链接的处理。
说到隐私问题,这里我们以自由星球“万人学习分享群”为爬取对象。
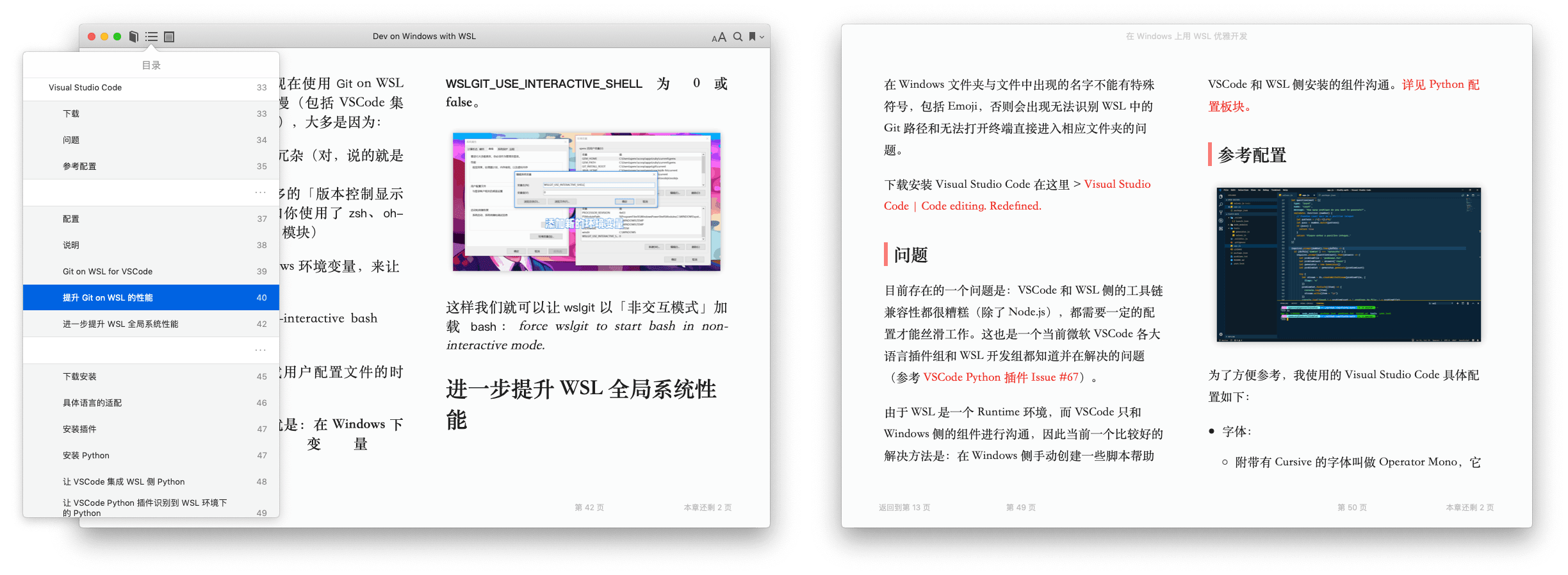
过程分析模拟登录
爬行是知识星球的网络版本。
这个网站不依赖cookie来判断你是否登录,而是请求头中的Authorization字段。
因此,您需要将 Authorization 和 User-Agent 替换为您自己的。(注意User-Agent也应该换成你自己的)
一般来说,星球使用微信扫码登录后,可以获得一个Authorization。这首歌长期有效。无论如何,它真的很长。
1
2
3
4
5
6
7
8
9
headers = {
'Authorization': 'C08AEDBB-A627-F9F1-1223-7E212B1C9D7D',
'x-request-id': "7b898dff-e40f-578e-6cfd-9687a3a32e49",
'accept': "application/json, text/plain, */*",
'host': "api.zsxq.com",
'connection': "keep-alive",
'referer': "https://wx.zsxq.com/dweb/",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
}
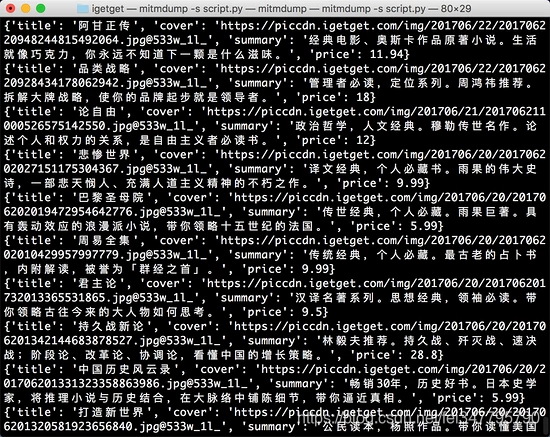
页面内容分析
登录成功后,我一般使用右键,查看或者查看源码。
但是这个页面比较特殊,它并没有把内容放到当前地址栏的URL下面,而是异步加载(XHR),只要你找到合适的界面。
精华区界面:
这个界面是最新的20条数据,后面的数据对应不同的界面,就是后面要说的翻页。
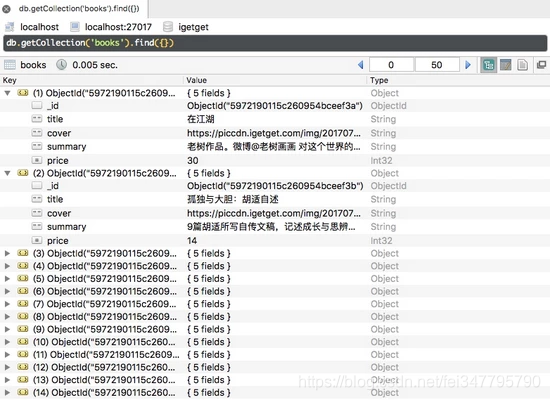
创建 PDF 电子书
需要安装的模块:
wkhtmltopdf 用于导出 PDF。安装后可以使用命令生成PDF,例如:wkhtmltopdf google.pdfpdfkit,它是python对wkhtmltopdf调用的封装,支持URL、本地文件、文本内容到PDF的转换,实际转换还是最终调用wkhtmltopdf命令
本来,精华区是没有称号的。我用每个问题的前 6 个字符作为标题来区分不同的问题。
抓取图片
很明显,返回数据中的images key就是图片,只需要提取大的、高清的url即可。
关键是将图像标签 img 插入到 HTML 文档中。我使用 BeautifulSoup 操作 DOM 的方式。
需要注意的是,图片可能不止一张,所以需要使用for循环来遍历所有的图片。
1
2
3
4
5
6
7
8
if content.get('images'):
soup = BeautifulSoup(html_template, 'html.parser')
for img in content.get('images'):
url = img.get('large').get('url')
img_tag = soup.new_tag('img', src=url)
soup.body.append(img_tag)
html_img = str(soup)
html = html_img.format(title=title, text=text)
制作精美的 PDF
通过css样式控制字体大小、布局、颜色等,详见test.css文件。
然后将此文件导入选项字段。
1
2
3
4
options = {
"user-style-sheet": "test.css",
...
}
难度分析翻页逻辑
爬取地址为:{url}?scope=digests&count=20&end_time=2018-04-12T15%3A49%3A13.443%2B0800
路径后面的 end_time 表示最后一次加载帖子以实现翻页的日期。
end_time 是 url 转义的,可以通过 urllib.parse.quote 方法进行转义。关键是要找出 end_time 的来源。
仔细观察后发现,每个请求返回20个post,最后一个post与下一个链接的end_time有关。
比如上一个帖子的create_time是2018-01-10T11:49:39.668+0800,那么下一个链接的end_time是2018-01-10T11:49:39. 667+0800,注意一个668和一个667是不一样的,所以我们得到end_time的公式:
1
end_time = create_time[:20]+str(int(create_time[20:23])-1)+create_time[23:]
但事情并没有那么简单,因为最后的create_time可能是2018-03-06T22%3A29%3A59.000%2B0800,-1后面出现一个负数!
由于0可能出现在时分秒中,看来最好的方法是使用时间模块datetime获取create_time的最后一秒,如果出现000则拼接999。
1
2
3
4
5
6
7
8
9
10
# int -1 后需要进行补 0 处理,test_str.zfill(3)
end_time = create_time[:20]+str(int(create_time[20:23])-1).zfill(3)+create_time[23:]
# 时间出现整点时需要特殊处理,否则会出现 -1
if create_time[20:23] == '000':
temp_time = datetime.datetime.strptime(create_time, "%Y-%m-%dT%H:%M:%S.%f+0800")
temp_time += datetime.timedelta(seconds=-1)
end_time = temp_time.strftime("%Y-%m-%dT%H:%M:%S") + '.999+0800'
end_time = quote(end_time)
next_url = start_url + '&end_time=' + end_time
处理过程有点冗长。原谅我落后的000。我没有找到直接的方法来处理它。我只能通过这条曲线拯救国家。
判断最后一页
翻页返回的数据为:
1
{"succeeded":true,"resp_data":{"topics":[]}}
因此,使用 next_page = rsp.json().get('resp_data').get('topics') 来判断是否有下一页。 查看全部
抓取网页生成电子书(是不是有时星球内容太多刷不过来?想把星球精华内容撸下来)
是不是有时候地球上的内容太多无法刷新?你想制作一本收录地球本质的电子书吗?
本文将带你实现使用Python爬取星球内容,制作PDF电子书。
第一个效果:
内容以优化为主,主要优化内容在于翻页时间的处理、大空白的处理、评论的抓取、超链接的处理。
说到隐私问题,这里我们以自由星球“万人学习分享群”为爬取对象。
过程分析模拟登录
爬行是知识星球的网络版本。
这个网站不依赖cookie来判断你是否登录,而是请求头中的Authorization字段。
因此,您需要将 Authorization 和 User-Agent 替换为您自己的。(注意User-Agent也应该换成你自己的)
一般来说,星球使用微信扫码登录后,可以获得一个Authorization。这首歌长期有效。无论如何,它真的很长。
1
2
3
4
5
6
7
8
9
headers = {
'Authorization': 'C08AEDBB-A627-F9F1-1223-7E212B1C9D7D',
'x-request-id': "7b898dff-e40f-578e-6cfd-9687a3a32e49",
'accept': "application/json, text/plain, */*",
'host': "api.zsxq.com",
'connection': "keep-alive",
'referer': "https://wx.zsxq.com/dweb/",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
}
页面内容分析
登录成功后,我一般使用右键,查看或者查看源码。
但是这个页面比较特殊,它并没有把内容放到当前地址栏的URL下面,而是异步加载(XHR),只要你找到合适的界面。
精华区界面:
这个界面是最新的20条数据,后面的数据对应不同的界面,就是后面要说的翻页。
创建 PDF 电子书
需要安装的模块:
wkhtmltopdf 用于导出 PDF。安装后可以使用命令生成PDF,例如:wkhtmltopdf google.pdfpdfkit,它是python对wkhtmltopdf调用的封装,支持URL、本地文件、文本内容到PDF的转换,实际转换还是最终调用wkhtmltopdf命令
本来,精华区是没有称号的。我用每个问题的前 6 个字符作为标题来区分不同的问题。
抓取图片
很明显,返回数据中的images key就是图片,只需要提取大的、高清的url即可。
关键是将图像标签 img 插入到 HTML 文档中。我使用 BeautifulSoup 操作 DOM 的方式。
需要注意的是,图片可能不止一张,所以需要使用for循环来遍历所有的图片。
1
2
3
4
5
6
7
8
if content.get('images'):
soup = BeautifulSoup(html_template, 'html.parser')
for img in content.get('images'):
url = img.get('large').get('url')
img_tag = soup.new_tag('img', src=url)
soup.body.append(img_tag)
html_img = str(soup)
html = html_img.format(title=title, text=text)
制作精美的 PDF
通过css样式控制字体大小、布局、颜色等,详见test.css文件。
然后将此文件导入选项字段。
1
2
3
4
options = {
"user-style-sheet": "test.css",
...
}
难度分析翻页逻辑
爬取地址为:{url}?scope=digests&count=20&end_time=2018-04-12T15%3A49%3A13.443%2B0800
路径后面的 end_time 表示最后一次加载帖子以实现翻页的日期。
end_time 是 url 转义的,可以通过 urllib.parse.quote 方法进行转义。关键是要找出 end_time 的来源。
仔细观察后发现,每个请求返回20个post,最后一个post与下一个链接的end_time有关。
比如上一个帖子的create_time是2018-01-10T11:49:39.668+0800,那么下一个链接的end_time是2018-01-10T11:49:39. 667+0800,注意一个668和一个667是不一样的,所以我们得到end_time的公式:
1
end_time = create_time[:20]+str(int(create_time[20:23])-1)+create_time[23:]
但事情并没有那么简单,因为最后的create_time可能是2018-03-06T22%3A29%3A59.000%2B0800,-1后面出现一个负数!
由于0可能出现在时分秒中,看来最好的方法是使用时间模块datetime获取create_time的最后一秒,如果出现000则拼接999。
1
2
3
4
5
6
7
8
9
10
# int -1 后需要进行补 0 处理,test_str.zfill(3)
end_time = create_time[:20]+str(int(create_time[20:23])-1).zfill(3)+create_time[23:]
# 时间出现整点时需要特殊处理,否则会出现 -1
if create_time[20:23] == '000':
temp_time = datetime.datetime.strptime(create_time, "%Y-%m-%dT%H:%M:%S.%f+0800")
temp_time += datetime.timedelta(seconds=-1)
end_time = temp_time.strftime("%Y-%m-%dT%H:%M:%S") + '.999+0800'
end_time = quote(end_time)
next_url = start_url + '&end_time=' + end_time
处理过程有点冗长。原谅我落后的000。我没有找到直接的方法来处理它。我只能通过这条曲线拯救国家。
判断最后一页
翻页返回的数据为:
1
{"succeeded":true,"resp_data":{"topics":[]}}
因此,使用 next_page = rsp.json().get('resp_data').get('topics') 来判断是否有下一页。
抓取网页生成电子书(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-09 21:20
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*- import sys import locale import string import traceback import datetime import urllib2 from pyquery import PyQuery as pq # 确定运行环境的encoding reload(sys); sys.setdefaultencoding('utf8'); f = open('gongsi.csv', 'w'); for i in range(1,24): d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i)); itemsa=d('dl dt a') #取title元素 itemsb=d('dl dd') #取title元素 for j in range(0,len(itemsa)): f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text)); #end for #end for f.close();
接下来就是用Notepad++打开gongsi.csv,然后[emailprotected]~Codewang把它转成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
抓取网页生成电子书(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*- import sys import locale import string import traceback import datetime import urllib2 from pyquery import PyQuery as pq # 确定运行环境的encoding reload(sys); sys.setdefaultencoding('utf8'); f = open('gongsi.csv', 'w'); for i in range(1,24): d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i)); itemsa=d('dl dt a') #取title元素 itemsb=d('dl dd') #取title元素 for j in range(0,len(itemsa)): f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text)); #end for #end for f.close();
接下来就是用Notepad++打开gongsi.csv,然后[emailprotected]~Codewang把它转成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
抓取网页生成电子书(这款软件功能软件自动更新本软件集成了新版本自动更新功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-09 21:16
mp4到ebookpk官网获取VIP阅读(下载)佣金。有需要的用户千万不要错过这款实用又强大的电子书创作工具。
软件功能
自动软件更新
本软件集成了新版本的自动更新功能,帮助用户在第一时间获得全新体验。
在线采集图书内容,只要输入门户网址和网址过滤器,即可在本地获取网页内容,成为名副其实的“网络印刷机”和“网络刮刀”
可以将chm、jar、umd、doc、txt、html等文件拖入ebookpk作为书籍内容的来源。同时是标准的mobi、azw3、chm、umd、jar、doc“反编译器”和“文件合并器”。
书稿可以保存(.pk项目文件)
可以制作带有书签(目录)的PDF文档,可以将word转换为PDF;可以将pdf导入ebookpk软件;支持虚拟打印机,任何可打印的文档都可以转换为PDF 查看全部
抓取网页生成电子书(这款软件功能软件自动更新本软件集成了新版本自动更新功能)
mp4到ebookpk官网获取VIP阅读(下载)佣金。有需要的用户千万不要错过这款实用又强大的电子书创作工具。
软件功能
自动软件更新
本软件集成了新版本的自动更新功能,帮助用户在第一时间获得全新体验。
在线采集图书内容,只要输入门户网址和网址过滤器,即可在本地获取网页内容,成为名副其实的“网络印刷机”和“网络刮刀”
可以将chm、jar、umd、doc、txt、html等文件拖入ebookpk作为书籍内容的来源。同时是标准的mobi、azw3、chm、umd、jar、doc“反编译器”和“文件合并器”。
书稿可以保存(.pk项目文件)
可以制作带有书签(目录)的PDF文档,可以将word转换为PDF;可以将pdf导入ebookpk软件;支持虚拟打印机,任何可打印的文档都可以转换为PDF
抓取网页生成电子书(完美者()网站对功能性板块进行扩充,以期独门技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-07 23:01
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“温馨提示”等频道,更好地为用户提供更专业的软件使用全周期服务。
ibookBox 网络小说批量下载阅读器是一款快速抓取各种大小的网络小说网站,并将整本书以txt格式生成到本地电脑,同时保存在邮箱和手机中的工具。ibookBox 可以完整地存储整个网页的所有信息,并存储在用户的邮箱中。IbookBox 还可以生成 HTML 文件和完整的网页快照。与某些软件不同,它只能抓取可见区域内的照片。使用IbookBox网络小说批量下载阅读器时,只需在地址栏输入网址,点击告诉搜索小说,即可轻松下载浏览小说。IbookBox 支持批量抓取电子书,让用户可以在互联网的任何网页上看到喜欢的小说。, 可以直接批量抓取,生成完整的txt文件供用户本地阅读或手机随意阅读。抓取过程中,如果中途中断,可以点击“上次抓取小说按钮”,支持在章节网页直接按右键直接抓取任务面板。也可以在主程序中输入小说章节页的地址进行抓取。
“技巧与妙计”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答。文章,专栏成立伊始,编辑欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已根据需要进行了重新格式化和部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
抓取网页生成电子书(完美者()网站对功能性板块进行扩充,以期独门技巧)
Perfect()网站基于软件下载,网站修订版扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。网站 新增“软件百科”、“温馨提示”等频道,更好地为用户提供更专业的软件使用全周期服务。
ibookBox 网络小说批量下载阅读器是一款快速抓取各种大小的网络小说网站,并将整本书以txt格式生成到本地电脑,同时保存在邮箱和手机中的工具。ibookBox 可以完整地存储整个网页的所有信息,并存储在用户的邮箱中。IbookBox 还可以生成 HTML 文件和完整的网页快照。与某些软件不同,它只能抓取可见区域内的照片。使用IbookBox网络小说批量下载阅读器时,只需在地址栏输入网址,点击告诉搜索小说,即可轻松下载浏览小说。IbookBox 支持批量抓取电子书,让用户可以在互联网的任何网页上看到喜欢的小说。, 可以直接批量抓取,生成完整的txt文件供用户本地阅读或手机随意阅读。抓取过程中,如果中途中断,可以点击“上次抓取小说按钮”,支持在章节网页直接按右键直接抓取任务面板。也可以在主程序中输入小说章节页的地址进行抓取。
“技巧与妙计”栏目是全网软件使用技巧的合集或软件使用过程中各种问题的解答。文章,专栏成立伊始,编辑欢迎各位软件大神朋友积极投稿。该平台分享每个人的独特技能。
本站文章素材来源于网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已根据需要进行了重新格式化和部分调整。本站收录文章仅用于帮助用户解决实际问题。如有版权问题,请联系编辑修改或删除,谢谢合作。
抓取网页生成电子书(继续并发专题~FutureTask有点类似Runnable的get方法支持阻塞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-06 23:11
继续并发话题~
FutureTask有点类似于Runnable,可以由Thread启动,但是FutureTask执行后可以返回数据,FutureTask的get方法支持阻塞。
因为:FutureTask可以返回已经执行过的数据,而FutureTask的get方法支持阻塞这两个特性,我们可以用它来预加载一些可能会用到的资源,然后调用get方法来获取想使用它(如果资源已加载,则直接返回;否则,继续等待其加载完成)。
下面举两个例子来介绍:
1、使用FutureTask预加载以后要用到的数据。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask来提前加载稍后要用到的数据
*
* @author zhy
*
*/
public class PreLoaderUseFutureTask
{
/**
* 创建一个FutureTask用来加载资源
*/
private final FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
Thread.sleep(3000);
return "加载资源需要3秒";
}
});
public final Thread thread = new Thread(futureTask);
public void start()
{
thread.start();
}
/**
* 获取资源
*
* @return
* @throws ExecutionException
* @throws InterruptedException
*/
public String getRes() throws InterruptedException, ExecutionException
{
return futureTask.get();//加载完毕直接返回,否则等待加载完毕
}
public static void main(String[] args) throws InterruptedException, ExecutionException
{
PreLoaderUseFutureTask task = new PreLoaderUseFutureTask();
/**
* 开启预加载资源
*/
task.start();
// 用户在真正需要加载资源前进行了其他操作了2秒
Thread.sleep(2000);
/**
* 获取资源
*/
System.out.println(System.currentTimeMillis() + ":开始加载资源");
String res = task.getRes();
System.out.println(res);
System.out.println(System.currentTimeMillis() + ":加载资源结束");
}
}
操作结果:
1400902789275:开始加载资源
加载资源需要3秒
1400902790275:加载资源结束
可以看到,原来加载资源需要3秒,现在只需要1秒。如果用户执行其他操作的时间较长,可以直接返回,大大增加了用户体验。
2、看看Future的API
可以看到 Future 的 API 还是比较简单的。看名字就知道意思了,get(long,TimeUnit)还是可以支持的,设置最大等待时间,如操作时间过长,可以取消。
3、FutureTask模拟,预加载功能供用户在线观看电子书
当用户观看当前页面时,后台会提前加载下一页,可以大大提升用户体验。无需等待每个页面加载。用户会觉得这个电子书软件很流畅。真的很棒。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask模拟预加载下一页图书的内容
*
* @author zhy
*
*/
public class BookInstance
{
/**
* 当前的页码
*/
private volatile int currentPage = 1;
/**
* 异步的任务获取当前页的内容
*/
FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
});
/**
* 实例化一本书,并传入当前读到的页码
*
* @param currentPage
*/
public BookInstance(int currentPage)
{
this.currentPage = currentPage;
/**
* 直接启动线程获取当前页码内容
*/
Thread thread = new Thread(futureTask);
thread.start();
}
/**
* 获取当前页的内容
*
* @return
* @throws InterruptedException
* @throws ExecutionException
*/
public String getCurrentPageContent() throws InterruptedException,
ExecutionException
{
String con = futureTask.get();
this.currentPage = currentPage + 1;
Thread thread = new Thread(futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
}));
thread.start();
return con;
}
/**
* 根据页码从网络抓取数据
*
* @return
* @throws InterruptedException
*/
private String loadDataFromNet() throws InterruptedException
{
Thread.sleep(1000);
return "Page " + this.currentPage + " : the content ....";
}
public static void main(String[] args) throws InterruptedException,
ExecutionException
{
BookInstance instance = new BookInstance(1);
for (int i = 0; i < 10; i++)
{
long start = System.currentTimeMillis();
String content = instance.getCurrentPageContent();
System.out.println("[1秒阅读时间]read:" + content);
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() - start);
}
}
}
输出结果:
[1秒阅读时间]read:Page 1 : the content ....
2001
[1秒阅读时间]read:Page 2 : the content ....
1000
[1秒阅读时间]read:Page 3 : the content ....
1001
[1秒阅读时间]read:Page 4 : the content ....
1000
[1秒阅读时间]read:Page 5 : the content ....
1001
可以看到,除了第一次查看当前页面时等待网络加载数据的过程(输出:2001,1000是加载时间,1000是用户阅读时间),接下来的页面是全部瞬间返回(输出1000是用户阅读时间),完全不需要等待。
代码是为了说明FutureTask的应用场景,请勿直接在项目中使用。
好了,就这样了,欢迎大家留言。 查看全部
抓取网页生成电子书(继续并发专题~FutureTask有点类似Runnable的get方法支持阻塞)
继续并发话题~
FutureTask有点类似于Runnable,可以由Thread启动,但是FutureTask执行后可以返回数据,FutureTask的get方法支持阻塞。
因为:FutureTask可以返回已经执行过的数据,而FutureTask的get方法支持阻塞这两个特性,我们可以用它来预加载一些可能会用到的资源,然后调用get方法来获取想使用它(如果资源已加载,则直接返回;否则,继续等待其加载完成)。
下面举两个例子来介绍:
1、使用FutureTask预加载以后要用到的数据。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask来提前加载稍后要用到的数据
*
* @author zhy
*
*/
public class PreLoaderUseFutureTask
{
/**
* 创建一个FutureTask用来加载资源
*/
private final FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
Thread.sleep(3000);
return "加载资源需要3秒";
}
});
public final Thread thread = new Thread(futureTask);
public void start()
{
thread.start();
}
/**
* 获取资源
*
* @return
* @throws ExecutionException
* @throws InterruptedException
*/
public String getRes() throws InterruptedException, ExecutionException
{
return futureTask.get();//加载完毕直接返回,否则等待加载完毕
}
public static void main(String[] args) throws InterruptedException, ExecutionException
{
PreLoaderUseFutureTask task = new PreLoaderUseFutureTask();
/**
* 开启预加载资源
*/
task.start();
// 用户在真正需要加载资源前进行了其他操作了2秒
Thread.sleep(2000);
/**
* 获取资源
*/
System.out.println(System.currentTimeMillis() + ":开始加载资源");
String res = task.getRes();
System.out.println(res);
System.out.println(System.currentTimeMillis() + ":加载资源结束");
}
}
操作结果:
1400902789275:开始加载资源
加载资源需要3秒
1400902790275:加载资源结束
可以看到,原来加载资源需要3秒,现在只需要1秒。如果用户执行其他操作的时间较长,可以直接返回,大大增加了用户体验。
2、看看Future的API
可以看到 Future 的 API 还是比较简单的。看名字就知道意思了,get(long,TimeUnit)还是可以支持的,设置最大等待时间,如操作时间过长,可以取消。
3、FutureTask模拟,预加载功能供用户在线观看电子书
当用户观看当前页面时,后台会提前加载下一页,可以大大提升用户体验。无需等待每个页面加载。用户会觉得这个电子书软件很流畅。真的很棒。
package com.zhy.concurrency.futuretask;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 使用FutureTask模拟预加载下一页图书的内容
*
* @author zhy
*
*/
public class BookInstance
{
/**
* 当前的页码
*/
private volatile int currentPage = 1;
/**
* 异步的任务获取当前页的内容
*/
FutureTask futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
});
/**
* 实例化一本书,并传入当前读到的页码
*
* @param currentPage
*/
public BookInstance(int currentPage)
{
this.currentPage = currentPage;
/**
* 直接启动线程获取当前页码内容
*/
Thread thread = new Thread(futureTask);
thread.start();
}
/**
* 获取当前页的内容
*
* @return
* @throws InterruptedException
* @throws ExecutionException
*/
public String getCurrentPageContent() throws InterruptedException,
ExecutionException
{
String con = futureTask.get();
this.currentPage = currentPage + 1;
Thread thread = new Thread(futureTask = new FutureTask(
new Callable()
{
@Override
public String call() throws Exception
{
return loadDataFromNet();
}
}));
thread.start();
return con;
}
/**
* 根据页码从网络抓取数据
*
* @return
* @throws InterruptedException
*/
private String loadDataFromNet() throws InterruptedException
{
Thread.sleep(1000);
return "Page " + this.currentPage + " : the content ....";
}
public static void main(String[] args) throws InterruptedException,
ExecutionException
{
BookInstance instance = new BookInstance(1);
for (int i = 0; i < 10; i++)
{
long start = System.currentTimeMillis();
String content = instance.getCurrentPageContent();
System.out.println("[1秒阅读时间]read:" + content);
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() - start);
}
}
}
输出结果:
[1秒阅读时间]read:Page 1 : the content ....
2001
[1秒阅读时间]read:Page 2 : the content ....
1000
[1秒阅读时间]read:Page 3 : the content ....
1001
[1秒阅读时间]read:Page 4 : the content ....
1000
[1秒阅读时间]read:Page 5 : the content ....
1001
可以看到,除了第一次查看当前页面时等待网络加载数据的过程(输出:2001,1000是加载时间,1000是用户阅读时间),接下来的页面是全部瞬间返回(输出1000是用户阅读时间),完全不需要等待。
代码是为了说明FutureTask的应用场景,请勿直接在项目中使用。
好了,就这样了,欢迎大家留言。
抓取网页生成电子书(实用功能:1.优化电子书的排版(RSS制成电子书电子书))
网站优化 • 优采云 发表了文章 • 0 个评论 • 661 次浏览 • 2022-01-05 17:16
Calibre是一款免费开源的电子书管理神器,可用于整理、存储、管理、阅读和转换电子书。支持大部分电子书格式;它还可以添加文本、图像材料和在线内容(RSS)并将它们转换为电子书。
可与最流行的电子书阅读器同步,软件同时支持Windows、macOS和Linux系统。
实用功能:
1. 优化电子书版式
无论是从亚马逊 Kindle 电子书店购买,还是从其他在线渠道下载的电子书,排版往往不尽如人意。
这时候就可以使用Calibre进行简单的优化,就可以制作出排版良好的电子书,修改上面的参数就可以达到不错的效果。
2. 获取 RSS 以制作电子书
准备好 RSS 提要后,您可以在 Calibre 中添加这些提要。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
3. 转换电子书格式
Calibre 有两种转换方式:“一一转换”和“批量转换”。如果选择多个文件,使用“一一转换”需要对每本书进行单独设置。例如,您可以为不同的电子书设置不同的格式;而“批量转换”是所有电子书的通用设置。
Calibre 支持转换格式:EPUB、MOBI、AZW3、DOCX、FB2、HTMLZ、LIT、LRF、PDB、PDF、PMIZ、RB、RTF、SNB、TCR、TXT、TXTZ、ZIP 等。
4. 通过 WiFi 将电子书传输到 Kindle
如果您使用的是无线路由器,您可以将Calibre 变成一个小型服务器,然后使用Kindle 的“实验性网络浏览器”访问Calibre 图书馆中的电子书并下载到Kindle。
5. 邮件一键推送电子书
此外,Calibre 还有许多强大实用的功能:
1)您可以通过浏览器查看、阅读或下载您的图书馆(:8080);
2) 将TXT文件转换为MOBI格式的带目录的电子书;
3)使用Calibre添加或修改电子书的封面;
4)使用Calibre抓取网站页面制作电子书; 查看全部
抓取网页生成电子书(实用功能:1.优化电子书的排版(RSS制成电子书电子书))
Calibre是一款免费开源的电子书管理神器,可用于整理、存储、管理、阅读和转换电子书。支持大部分电子书格式;它还可以添加文本、图像材料和在线内容(RSS)并将它们转换为电子书。
可与最流行的电子书阅读器同步,软件同时支持Windows、macOS和Linux系统。
实用功能:
1. 优化电子书版式
无论是从亚马逊 Kindle 电子书店购买,还是从其他在线渠道下载的电子书,排版往往不尽如人意。
这时候就可以使用Calibre进行简单的优化,就可以制作出排版良好的电子书,修改上面的参数就可以达到不错的效果。
2. 获取 RSS 以制作电子书
准备好 RSS 提要后,您可以在 Calibre 中添加这些提要。打开Calibre,在Calibre主界面顶部的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点击“添加自定义新闻源”。
3. 转换电子书格式
Calibre 有两种转换方式:“一一转换”和“批量转换”。如果选择多个文件,使用“一一转换”需要对每本书进行单独设置。例如,您可以为不同的电子书设置不同的格式;而“批量转换”是所有电子书的通用设置。
Calibre 支持转换格式:EPUB、MOBI、AZW3、DOCX、FB2、HTMLZ、LIT、LRF、PDB、PDF、PMIZ、RB、RTF、SNB、TCR、TXT、TXTZ、ZIP 等。
4. 通过 WiFi 将电子书传输到 Kindle
如果您使用的是无线路由器,您可以将Calibre 变成一个小型服务器,然后使用Kindle 的“实验性网络浏览器”访问Calibre 图书馆中的电子书并下载到Kindle。
5. 邮件一键推送电子书
此外,Calibre 还有许多强大实用的功能:
1)您可以通过浏览器查看、阅读或下载您的图书馆(:8080);
2) 将TXT文件转换为MOBI格式的带目录的电子书;
3)使用Calibre添加或修改电子书的封面;
4)使用Calibre抓取网站页面制作电子书;
抓取网页生成电子书(抓取网页生成电子书就可以。我看到题主想要爬取哪种网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-05 15:03
抓取网页生成电子书就可以。我看到题主想要爬取豆瓣书籍的时候,想要了解更详细,不知道题主想要爬取哪种网页。比如,微信公众号有很多地方提供文章聚合,微博也可以抓取,
android的话,下载些codeblocks之类的工具,安装daocloud,自己写个网页多人连接,然后开始传递链接,链接到app里就可以看电子书了,还可以,自动加入书架。ios可以买一本nonethought030,入门的好教材,也就几千元,电子书也好找,除非人工作业。
可以写个小app,比如微信文章会提供下载链接,你可以自己把获取之后传给别人,而不需要自己下一大堆文件过去。
多读书!
能理解你的想法。你可以直接爬下来,加入整理列表,提供给别人阅读,这样就可以免费下载了。
最直接的方法,就是搜索读书app,然后下载下来读。但是,题主如果要下载的书籍,和现在市面上的书籍大多是有差别的,那这就得需要研究一番。其实最简单的办法,你也可以直接选一些文章,这种比较多。你直接爬下来,整理好,有提供别人阅读的,自己就可以阅读了,也不需要下载其他电子书。
有个app叫西西阅读器,挺不错的。是一款浏览器级别的阅读软件。现在有很多的公众号都在推荐了。搜狐、网易等都有。可以提供免费下载,特别方便。 查看全部
抓取网页生成电子书(抓取网页生成电子书就可以。我看到题主想要爬取哪种网页)
抓取网页生成电子书就可以。我看到题主想要爬取豆瓣书籍的时候,想要了解更详细,不知道题主想要爬取哪种网页。比如,微信公众号有很多地方提供文章聚合,微博也可以抓取,
android的话,下载些codeblocks之类的工具,安装daocloud,自己写个网页多人连接,然后开始传递链接,链接到app里就可以看电子书了,还可以,自动加入书架。ios可以买一本nonethought030,入门的好教材,也就几千元,电子书也好找,除非人工作业。
可以写个小app,比如微信文章会提供下载链接,你可以自己把获取之后传给别人,而不需要自己下一大堆文件过去。
多读书!
能理解你的想法。你可以直接爬下来,加入整理列表,提供给别人阅读,这样就可以免费下载了。
最直接的方法,就是搜索读书app,然后下载下来读。但是,题主如果要下载的书籍,和现在市面上的书籍大多是有差别的,那这就得需要研究一番。其实最简单的办法,你也可以直接选一些文章,这种比较多。你直接爬下来,整理好,有提供别人阅读的,自己就可以阅读了,也不需要下载其他电子书。
有个app叫西西阅读器,挺不错的。是一款浏览器级别的阅读软件。现在有很多的公众号都在推荐了。搜狐、网易等都有。可以提供免费下载,特别方便。
抓取网页生成电子书(什么是爬虫爬虫:Python爬虫架构架构主要由五个部分组成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-03 17:10
什么是爬虫
爬虫:一种自动从互联网上抓取信息的程序,从互联网上抓取对我们有价值的信息。
Python 爬虫架构
Python爬虫架构主要由调度器、URL管理器、网页下载器、网页解析器、应用(抓取有价值的数据)五部分组成。
使用urllib2实现网页下载的方式
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
print "第二种方法"
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
print "第三种方法"
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#获取所有的链接
links = soup.find_all('a')
print "所有的链接"
for link in links:
print link.name,link['href'],link.get_text()
print "获取特定的URL地址"
link_node = soup.find('a',href="http://example.com/elsie")
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "正则表达式匹配"
link_node = soup.find('a',href=re.compile(r"ti"))
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "获取P段落的文字"
p_node = soup.find('p',class_='story')
print p_node.name,p_node['class'],p_node.get_text()shsh
</p>
python 很强大吗? 查看全部
抓取网页生成电子书(什么是爬虫爬虫:Python爬虫架构架构主要由五个部分组成)
什么是爬虫
爬虫:一种自动从互联网上抓取信息的程序,从互联网上抓取对我们有价值的信息。
Python 爬虫架构
Python爬虫架构主要由调度器、URL管理器、网页下载器、网页解析器、应用(抓取有价值的数据)五部分组成。
使用urllib2实现网页下载的方式
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
print "第二种方法"
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
print "第三种方法"
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#获取所有的链接
links = soup.find_all('a')
print "所有的链接"
for link in links:
print link.name,link['href'],link.get_text()
print "获取特定的URL地址"
link_node = soup.find('a',href="http://example.com/elsie";)
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "正则表达式匹配"
link_node = soup.find('a',href=re.compile(r"ti"))
print link_node.name,link_node['href'],link_node['class'],link_node.get_text()
print "获取P段落的文字"
p_node = soup.find('p',class_='story')
print p_node.name,p_node['class'],p_node.get_text()shsh
</p>
python 很强大吗?
抓取网页生成电子书(资料管理电子书制作利器-友益文书软件设置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-03 09:18
)
数据管理电子书制作工具-友易文档软件是一款集数据管理、电子书制作、翻页电子书制作、多媒体课件管理于一体的多功能软件...可用于管理htm网页和 mht 单个网页。 、Word文档、excel文档、幻灯片、pdf、chm、exe、txt、rtf、GIF、JPG、PNG、DJVU、ICO、TIF、BMP、Flash动画等格式文件;支持全文、网页、word文档搜索,支持背景音乐播放。集成pdf阅读功能,无需安装任何pdf阅读器,轻松阅读pdf文件。
可以发布电脑版exe、chm电子书、安卓apk电子书、苹果epub电子书等,还可以发布翻页电子书功能。设置一机一码或反传播功能。
无需安装任何软件,直接生成安卓手机apk电子书。
方便制作exe翻页电子书、滑动手机相册、撕角翻页电子书。
可生成安卓手机版apk电子书,支持5级目录,具有目录搜索、全文搜索、书签、设置一机一码功能,支持文本、网页、图片和pdf文档,无需在手机上安装其他任何阅读器都可以阅读。是目前安卓手机最强大的数据管理和电子书软件。
可以生成苹果手机可以阅读的epub格式文件;
可以生成具有全文搜索、目录搜索、采集夹等功能的chm格式文件。
可以直接为托管数据生成可执行文件。软件采用窗口风格,目录树结构管理,所见即所得的设计理念,不需要复杂的转换和编译。
易于使用和操作。您可以自由添加和删除目录树,随意编辑文档内容,更改字体大小和颜色。
该软件还可以生成电子相册,非常适合企事业单位进行产品推广和业务推广,在微信上分享非常方便。
本软件不断吸收同类软件的优点,同时在功能和设计上有独特的创新。采用混合索引算法,数据存储采用自己的压缩格式,独特的多文本超链接功能。网页仍可编辑,支持Word文档、网页、文本等格式之间的转换。采用多级分布式加密算法,界面支持皮肤等个性化设计。
查看全部
抓取网页生成电子书(资料管理电子书制作利器-友益文书软件设置
)
数据管理电子书制作工具-友易文档软件是一款集数据管理、电子书制作、翻页电子书制作、多媒体课件管理于一体的多功能软件...可用于管理htm网页和 mht 单个网页。 、Word文档、excel文档、幻灯片、pdf、chm、exe、txt、rtf、GIF、JPG、PNG、DJVU、ICO、TIF、BMP、Flash动画等格式文件;支持全文、网页、word文档搜索,支持背景音乐播放。集成pdf阅读功能,无需安装任何pdf阅读器,轻松阅读pdf文件。
可以发布电脑版exe、chm电子书、安卓apk电子书、苹果epub电子书等,还可以发布翻页电子书功能。设置一机一码或反传播功能。
无需安装任何软件,直接生成安卓手机apk电子书。
方便制作exe翻页电子书、滑动手机相册、撕角翻页电子书。
可生成安卓手机版apk电子书,支持5级目录,具有目录搜索、全文搜索、书签、设置一机一码功能,支持文本、网页、图片和pdf文档,无需在手机上安装其他任何阅读器都可以阅读。是目前安卓手机最强大的数据管理和电子书软件。
可以生成苹果手机可以阅读的epub格式文件;
可以生成具有全文搜索、目录搜索、采集夹等功能的chm格式文件。
可以直接为托管数据生成可执行文件。软件采用窗口风格,目录树结构管理,所见即所得的设计理念,不需要复杂的转换和编译。
易于使用和操作。您可以自由添加和删除目录树,随意编辑文档内容,更改字体大小和颜色。
该软件还可以生成电子相册,非常适合企事业单位进行产品推广和业务推广,在微信上分享非常方便。
本软件不断吸收同类软件的优点,同时在功能和设计上有独特的创新。采用混合索引算法,数据存储采用自己的压缩格式,独特的多文本超链接功能。网页仍可编辑,支持Word文档、网页、文本等格式之间的转换。采用多级分布式加密算法,界面支持皮肤等个性化设计。
抓取网页生成电子书(豆瓣日记:只输出最近几个月的日记摘要(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-03 09:17
豆瓣日记的提要地址很容易找到。打开博主的豆瓣日记界面,右栏下方是官方提要地址。
或者安装 RSShub Radar 浏览器扩展,在豆瓣日记界面点击扩展图标,会显示提要地址。
使用Calibre进行捕捉文章
启动 Calibre,然后在工具栏上的抓取新闻下拉栏中找到添加自定义新闻源。
在“添加自定义新闻源”窗口中,选择左下角的“新建订阅列表”。
在打开的窗口中,按要求填写以下信息:
填写完毕后,点击添加来源,将其添加到订阅列表中的新闻框。如果要添加其他源地址,可以继续以同样的方式添加源。
点击保存退出添加自定义新闻源窗口,然后点击工具栏中的抓取新闻,会弹出一个常规的新闻下载窗口,在左侧栏的自定义中选择刚刚创建的订阅列表的标题,然后点击右下角的立即下载。
等待Calibre从网上获取文章,提示完成后,库中会出现订阅列表标题的电子书。
查看电子书
电子书封面为简单的自动生成封面,附有文章目录,内容已排版。
因为豆瓣日记的RSS提要有两个缺陷:只输出日记摘要,只输出最近几个月的日记。前者结果8月以来电子书里只有文章,后者得益于Calibre可以自动抓取全文并被攻克。 查看全部
抓取网页生成电子书(豆瓣日记:只输出最近几个月的日记摘要(图))
豆瓣日记的提要地址很容易找到。打开博主的豆瓣日记界面,右栏下方是官方提要地址。
或者安装 RSShub Radar 浏览器扩展,在豆瓣日记界面点击扩展图标,会显示提要地址。
使用Calibre进行捕捉文章
启动 Calibre,然后在工具栏上的抓取新闻下拉栏中找到添加自定义新闻源。
在“添加自定义新闻源”窗口中,选择左下角的“新建订阅列表”。
在打开的窗口中,按要求填写以下信息:
填写完毕后,点击添加来源,将其添加到订阅列表中的新闻框。如果要添加其他源地址,可以继续以同样的方式添加源。
点击保存退出添加自定义新闻源窗口,然后点击工具栏中的抓取新闻,会弹出一个常规的新闻下载窗口,在左侧栏的自定义中选择刚刚创建的订阅列表的标题,然后点击右下角的立即下载。
等待Calibre从网上获取文章,提示完成后,库中会出现订阅列表标题的电子书。
查看电子书
电子书封面为简单的自动生成封面,附有文章目录,内容已排版。
因为豆瓣日记的RSS提要有两个缺陷:只输出日记摘要,只输出最近几个月的日记。前者结果8月以来电子书里只有文章,后者得益于Calibre可以自动抓取全文并被攻克。
抓取网页生成电子书(ͼ4应用点滴不需要做网页索引文件索引网页生成器照样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-29 22:17
我经常上网搜索一些有趣的资料,还有很多软件教程,放在硬盘上,随时随地看,不用担心是否在线。我最近学习了 LiveMotion,我已经完成了一些课程。保存的htm文件都是htm文件。当你阅读它们时,你必须一一打开它们。感觉真的很麻烦。(如图1)
ͼ1
如果可以集成到一个网页索引文件中,就非常方便了。一想到网页索引,虽然做网页索引不是什么难事,但是劳动强度不小,尤其是那些需要连接大量低级网页的网页,更是更可怕。
解决方案
ABU Make Index v2.10.0004,这是一款由中国人编写的免费绿色软件,体积小,288KB,可在作者主页()下载。解压后无需安装,运行makehtmindex.exe即可使用。这是一个用于为扩展名为 Htm、Html、Txt、Gb、Jpg 和 Bmp 的文件生成索引网页的工具。生成图片索引时会自动生成源图片的缩略图,因此也可以作为制作图片缩略图的工具。
Web 索引生成器只需点击三下鼠标,即可创建精美的 Web 索引,只需点击三下五次分区即可。我要处理的是一个网页文件,所以我首先选择了上面的按钮“生成Htm、Html、Txt、Gb扩展文件索引网页”。(如图2)
ͼ2
然后按“下一步”按钮,出现网页索引创建界面。浏览找到目标文件目录,确定网页索引的文件名和保存路径,点击“生成”按钮完成网页索引。(如图3)
ͼ3
生成的Htm、Html、Txt、Gb等扩展名文件的索引网页,与源文件保存在同一目录下(默认路径不可更改)。然后在浏览器里看我的index文件,再看每节课的内容,每个htm文件的标题都被提取出来了,更有条理了!(如图4)
ͼ4
应用位
即使您不需要制作网页,网页生成器仍然非常有用。每次在线下载大量网页和图片时,网页索引生成器都会将它们整齐排列,让您尽收眼底。
1、 为Htm、Html、Txt、Gb扩展名的文件生成索引网页,并保存在与源文件相同的目录中。如果源文件目录中同时存在上述两种类型的文件,则生成的网页将有2个版块和快捷方式书签。如果只有其中一种,生成的网页就不会被切分,自然也就没有快捷书签了。
2、 生成Jpg和Bmp扩展文件(图片)的索引网页,可以选择保存文件的路径。注意:当索引文件保存路径与源文件路径不同时,可能是索引文件中的链接有问题。缩略图保存在保存索引文件的目录下的“PREVIEW”子目录中(生成的缩略图是一个未压缩的假“JPG”文件)。
注:由于IE对“BMP”文件支持不好,点击索引文件中的“BMP”文件链接显示异常或显示图标,NC没问题。
如果你认为“上网”就是“下载”,那么使用这个工具可以让“下载”的事情有条不紊。一定要善用工具,为我们创造休闲的工作和学习! 查看全部
抓取网页生成电子书(ͼ4应用点滴不需要做网页索引文件索引网页生成器照样)
我经常上网搜索一些有趣的资料,还有很多软件教程,放在硬盘上,随时随地看,不用担心是否在线。我最近学习了 LiveMotion,我已经完成了一些课程。保存的htm文件都是htm文件。当你阅读它们时,你必须一一打开它们。感觉真的很麻烦。(如图1)
ͼ1
如果可以集成到一个网页索引文件中,就非常方便了。一想到网页索引,虽然做网页索引不是什么难事,但是劳动强度不小,尤其是那些需要连接大量低级网页的网页,更是更可怕。
解决方案
ABU Make Index v2.10.0004,这是一款由中国人编写的免费绿色软件,体积小,288KB,可在作者主页()下载。解压后无需安装,运行makehtmindex.exe即可使用。这是一个用于为扩展名为 Htm、Html、Txt、Gb、Jpg 和 Bmp 的文件生成索引网页的工具。生成图片索引时会自动生成源图片的缩略图,因此也可以作为制作图片缩略图的工具。
Web 索引生成器只需点击三下鼠标,即可创建精美的 Web 索引,只需点击三下五次分区即可。我要处理的是一个网页文件,所以我首先选择了上面的按钮“生成Htm、Html、Txt、Gb扩展文件索引网页”。(如图2)
ͼ2
然后按“下一步”按钮,出现网页索引创建界面。浏览找到目标文件目录,确定网页索引的文件名和保存路径,点击“生成”按钮完成网页索引。(如图3)
ͼ3
生成的Htm、Html、Txt、Gb等扩展名文件的索引网页,与源文件保存在同一目录下(默认路径不可更改)。然后在浏览器里看我的index文件,再看每节课的内容,每个htm文件的标题都被提取出来了,更有条理了!(如图4)
ͼ4
应用位
即使您不需要制作网页,网页生成器仍然非常有用。每次在线下载大量网页和图片时,网页索引生成器都会将它们整齐排列,让您尽收眼底。
1、 为Htm、Html、Txt、Gb扩展名的文件生成索引网页,并保存在与源文件相同的目录中。如果源文件目录中同时存在上述两种类型的文件,则生成的网页将有2个版块和快捷方式书签。如果只有其中一种,生成的网页就不会被切分,自然也就没有快捷书签了。
2、 生成Jpg和Bmp扩展文件(图片)的索引网页,可以选择保存文件的路径。注意:当索引文件保存路径与源文件路径不同时,可能是索引文件中的链接有问题。缩略图保存在保存索引文件的目录下的“PREVIEW”子目录中(生成的缩略图是一个未压缩的假“JPG”文件)。
注:由于IE对“BMP”文件支持不好,点击索引文件中的“BMP”文件链接显示异常或显示图标,NC没问题。
如果你认为“上网”就是“下载”,那么使用这个工具可以让“下载”的事情有条不紊。一定要善用工具,为我们创造休闲的工作和学习!
抓取网页生成电子书(Python最简单的爬虫requests-html安装-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-29 17:09
很多朋友都听说过Python这个名字,Python也有很多爬虫框架,最简单的就是requests-html。和著名的web请求库requests是同一个作者。它专注于XML数据提取,可以说是最简单的爬虫框架。
安装 requests-html
这个库的安装很简单,直接通过pip安装即可。
pip install requests-html
开始使用
Requests-html 使用起来也很简单,下面是一个简单的例子。像往常一样,第一段介绍了 HTMLSession 来创建连接并获取网页数据。第二段创建连接并获取我的短书的用户页面。第三段使用xpath语法获取网页上的用户名,最后打印出来。
from requests_html import HTMLSession
session = HTMLSession()
response = session.get(
'https://www.jianshu.com/u/7753478e1554')
username = response.html.xpath(
'//a[@class="name"]/text()', first=True)
print(username)
看起来是不是很简单?是的,它真的很简单,接下来还有一些更有趣的功能。
分析网页
在编写爬虫之前要做的一件事是分析网页的结构。这个工作其实很简单,打开你要访问的网页,按F12打开开发者工具,就可以在最左边看到这样一个按钮。单击此按钮,然后在网页上单击您要查看的网页元素,即可发现该元素对应的相关源代码已经为您定位好了。
定位按钮
通过这个函数,我们可以很方便的对网页进行分析,然后通过它的结构来写一个爬虫。
提取数据
上面的 response.html 是网页的根 HTML 节点,可以在节点对象上调用一些方法来检索数据。最常用的方法是 find 方法,它使用 CSS 选择器来定位数据。对于上面的例子,你可以使用find方法来重写第三段。
因为所有搜索方法返回的结果都是列表,如果确定只需要搜索一个,可以将第一个参数设置为true,只返回第一个结果。find 方法返回的仍然是一个节点。如果您只需要节点的内容,只需调用其 text 属性即可。
用户名对应的HTML结构如图所示。
代码显示如下。
username = response.html.find('a.name', first=True).text
除了 find 方法之外,您还可以使用 xpath 方法来查找具有 xpath 语法的节点,如第一个示例所示。我个人更喜欢 xpath 语法。CSS选择器虽然比较流行,但是写出来的效果有点奇怪,没有xpath那么整洁。
这是查看如何获取我的短书的个人资料的同一页面。网页代码如图所示。
代码显示如下。
description = response.html.xpath(
'//div[@class="description"]/div[@class="js-intro"]/text()', first=True)
CSS 选择器和 XPATH 语法不是本文的主要内容。如果你对这方面不熟悉,最好阅读相关教程。当然,如果您有任何问题,也可以提出。如果你想看,我也可以写一篇文章介绍这些语法知识。
渲染网页
有些网页采用前后端分离技术开发,需要浏览器渲染才能完整显示。如果使用爬虫查看,只能显示部分内容。这时候浏览器需要渲染页面才能得到完整的页面。使用 requests-html,过程非常简单。
首先我们来看一个需要渲染的网页的例子。以下代码访问我的短书用户页面,然后尝试获取我的所有文章。但是如果你运行这个例子,你会发现你只能得到前几项。由于短书页面是典型的需要浏览器渲染的页面,爬虫获取的网页是不完整的。
from requests_html import HTMLSession
session = HTMLSession()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.119 Safari/537.36'
}
url = 'https://www.jianshu.com/u/7753478e1554'
r = session.get(url, headers=headers)
for a in r.html.xpath('//ul[@class="note-list"]/li/div[@class="content"]/a[@class="title"]'):
title = a.text
link = f'https://www.jianshu.com{a.attrs["href"]}'
print(f'《{title}》,{link}')
那么如何渲染网页以获得完整的结果呢?其实很简单,在查询HTML节点之前调用render函数即可。
使用浏览器渲染的渲染函数
原理也很简单。当第一次调用渲染时,requests-html 将在本地下载一个 Chrome 浏览器并使用它来渲染网页。这样我们就可以得到渲染出来的页面了。
但是对于短书的例子,还是存在一些问题,因为如果你在浏览器中打开这个网页,你会发现有些文章只有在浏览器向下滑动页面时才开始渲染。不过,聪明的作者早就考虑过这种情况。渲染函数支持滑动参数。设置后会模拟浏览器滑动操作来解决这个问题。
r.html.render(scrolldown=50, sleep=0.2)
节点对象
不管上面的r.html还是find/xpath函数返回的结果都是节点对象。除了上面介绍的几种提取数据的方法外,节点对象还有以下属性,在我们提取数据的时候也是非常有用的。
相比专业的爬虫框架scrapy,还是解析库BeautifulSoup,只用于解析XML。requests-html 可以说是恰到好处。没有前者那么难学,也不需要像后者那样使用HTTP请求库。如果您需要临时抓取几个网页,那么 requests-html 是您的最佳选择。 查看全部
抓取网页生成电子书(Python最简单的爬虫requests-html安装-)
很多朋友都听说过Python这个名字,Python也有很多爬虫框架,最简单的就是requests-html。和著名的web请求库requests是同一个作者。它专注于XML数据提取,可以说是最简单的爬虫框架。
安装 requests-html
这个库的安装很简单,直接通过pip安装即可。
pip install requests-html
开始使用
Requests-html 使用起来也很简单,下面是一个简单的例子。像往常一样,第一段介绍了 HTMLSession 来创建连接并获取网页数据。第二段创建连接并获取我的短书的用户页面。第三段使用xpath语法获取网页上的用户名,最后打印出来。
from requests_html import HTMLSession
session = HTMLSession()
response = session.get(
'https://www.jianshu.com/u/7753478e1554')
username = response.html.xpath(
'//a[@class="name"]/text()', first=True)
print(username)
看起来是不是很简单?是的,它真的很简单,接下来还有一些更有趣的功能。
分析网页
在编写爬虫之前要做的一件事是分析网页的结构。这个工作其实很简单,打开你要访问的网页,按F12打开开发者工具,就可以在最左边看到这样一个按钮。单击此按钮,然后在网页上单击您要查看的网页元素,即可发现该元素对应的相关源代码已经为您定位好了。
定位按钮
通过这个函数,我们可以很方便的对网页进行分析,然后通过它的结构来写一个爬虫。
提取数据
上面的 response.html 是网页的根 HTML 节点,可以在节点对象上调用一些方法来检索数据。最常用的方法是 find 方法,它使用 CSS 选择器来定位数据。对于上面的例子,你可以使用find方法来重写第三段。
因为所有搜索方法返回的结果都是列表,如果确定只需要搜索一个,可以将第一个参数设置为true,只返回第一个结果。find 方法返回的仍然是一个节点。如果您只需要节点的内容,只需调用其 text 属性即可。
用户名对应的HTML结构如图所示。
代码显示如下。
username = response.html.find('a.name', first=True).text
除了 find 方法之外,您还可以使用 xpath 方法来查找具有 xpath 语法的节点,如第一个示例所示。我个人更喜欢 xpath 语法。CSS选择器虽然比较流行,但是写出来的效果有点奇怪,没有xpath那么整洁。
这是查看如何获取我的短书的个人资料的同一页面。网页代码如图所示。
代码显示如下。
description = response.html.xpath(
'//div[@class="description"]/div[@class="js-intro"]/text()', first=True)
CSS 选择器和 XPATH 语法不是本文的主要内容。如果你对这方面不熟悉,最好阅读相关教程。当然,如果您有任何问题,也可以提出。如果你想看,我也可以写一篇文章介绍这些语法知识。
渲染网页
有些网页采用前后端分离技术开发,需要浏览器渲染才能完整显示。如果使用爬虫查看,只能显示部分内容。这时候浏览器需要渲染页面才能得到完整的页面。使用 requests-html,过程非常简单。
首先我们来看一个需要渲染的网页的例子。以下代码访问我的短书用户页面,然后尝试获取我的所有文章。但是如果你运行这个例子,你会发现你只能得到前几项。由于短书页面是典型的需要浏览器渲染的页面,爬虫获取的网页是不完整的。
from requests_html import HTMLSession
session = HTMLSession()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.119 Safari/537.36'
}
url = 'https://www.jianshu.com/u/7753478e1554'
r = session.get(url, headers=headers)
for a in r.html.xpath('//ul[@class="note-list"]/li/div[@class="content"]/a[@class="title"]'):
title = a.text
link = f'https://www.jianshu.com{a.attrs["href"]}'
print(f'《{title}》,{link}')
那么如何渲染网页以获得完整的结果呢?其实很简单,在查询HTML节点之前调用render函数即可。
使用浏览器渲染的渲染函数
原理也很简单。当第一次调用渲染时,requests-html 将在本地下载一个 Chrome 浏览器并使用它来渲染网页。这样我们就可以得到渲染出来的页面了。
但是对于短书的例子,还是存在一些问题,因为如果你在浏览器中打开这个网页,你会发现有些文章只有在浏览器向下滑动页面时才开始渲染。不过,聪明的作者早就考虑过这种情况。渲染函数支持滑动参数。设置后会模拟浏览器滑动操作来解决这个问题。
r.html.render(scrolldown=50, sleep=0.2)
节点对象
不管上面的r.html还是find/xpath函数返回的结果都是节点对象。除了上面介绍的几种提取数据的方法外,节点对象还有以下属性,在我们提取数据的时候也是非常有用的。
相比专业的爬虫框架scrapy,还是解析库BeautifulSoup,只用于解析XML。requests-html 可以说是恰到好处。没有前者那么难学,也不需要像后者那样使用HTTP请求库。如果您需要临时抓取几个网页,那么 requests-html 是您的最佳选择。
抓取网页生成电子书(【手语服务,助力沟通无障碍】(12月29日19:00) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-29 12:21
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
苏升不服第167篇原创文章,将此公众号设为star,第一时间阅读最新文章。
之前写过以下关于备份的文章:
再说备份微博
一键备份微博并导出为PDF。顺便用Python分析微博账号数据
再说备份网页和公众号文章
如何备份公众号文章和可能被删除的网页
我想看的公众号文章被删了怎么办?
上面写的公众号的备份方法是单机备份。如果要备份某个公众号的所有文章,有点太麻烦了,所以今天分享一个用Python一键备份某个公众号的所有文章。不用担心你想阅读的文章被删除。我以我自己的公众号苏升不主为例。原理是通过抓包抓取微信客户端接口,使用Python请求微信接口获取公众号文章链接并下载。.
查尔斯捕获
常用的抓包工具有Fiddler、Charles、Charles这里用到的,先到官网下载软件,然后打开微信客户端找到公众号,进入文章列表可以看到已经发布的文章。
但是Charles在安装证书前无法获取https接口数据,显示未知。
安装证书后,在proxy->ssl代理设置中添加域名和主机。
再次爬取查看公众号文章界面数据。
公众号文章/mp/profile_ext?action=getmsg&__biz=MjM5ODIzNDEx&f=json&offset=25&count=10&is_ok=1&scene=124&uin=MTU0MTQzNj&key=f57423的接口地址,参数很多,__biz之间有用的参数只有一个还有公众号id,uin是用户的id,这个不变,key是请求的秘钥,一段时间后失效,offset是偏移量,count是每次请求的次数,返回值可以看到返回的数据包括文章标题title,摘要摘要,文章地址content_url,阅读源地址source_url,封面封面,作者作者,抓住这些有用的数据。
Python爬取公众号文章
上面分析了接口参数和返回数据,就开始用Python请求微信接口吧。
这里只获取原创文章。我的公众号有160多篇原创文章,生成HTML文件需要2分钟。
用谷歌浏览器打开看看。
生成的HTML文件也可以转成chm格式,需要安装Easy CHM软件,这是一个快速创建CHM电子书或CHM帮助文件的强大工具
左边是文章标题,右边是文章内容,看起来很方便。
还有收录
文章标题和链接的降价文件。上一篇markdown的文章介绍了使用Markdown写简历和PPT。
Excel 文件格式也可用。
HTML、markdown、Excel生成都比较快,因为都是文本,下面开始导出PDF。
导出 PDF
导出PDF的工具是wkhtmltopdf。首先到官网下载安装wkhtmltopdf。安装完成后,设置环境变量。上一篇文章写了一些你可能不知道的windows技巧,然后就可以直接从命令行生成PDF了。
λ wkhtmltopdf http://www.baidu.com baidu.pdfLoading pages (1/6)Counting pages (2/6)Resolving links (4/6)Loading headers and footers (5/6)Printing pages (6/6)Done 查看全部
抓取网页生成电子书(【手语服务,助力沟通无障碍】(12月29日19:00)
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
苏升不服第167篇原创文章,将此公众号设为star,第一时间阅读最新文章。
之前写过以下关于备份的文章:
再说备份微博
一键备份微博并导出为PDF。顺便用Python分析微博账号数据
再说备份网页和公众号文章
如何备份公众号文章和可能被删除的网页
我想看的公众号文章被删了怎么办?
上面写的公众号的备份方法是单机备份。如果要备份某个公众号的所有文章,有点太麻烦了,所以今天分享一个用Python一键备份某个公众号的所有文章。不用担心你想阅读的文章被删除。我以我自己的公众号苏升不主为例。原理是通过抓包抓取微信客户端接口,使用Python请求微信接口获取公众号文章链接并下载。.
查尔斯捕获
常用的抓包工具有Fiddler、Charles、Charles这里用到的,先到官网下载软件,然后打开微信客户端找到公众号,进入文章列表可以看到已经发布的文章。
但是Charles在安装证书前无法获取https接口数据,显示未知。
安装证书后,在proxy->ssl代理设置中添加域名和主机。
再次爬取查看公众号文章界面数据。
公众号文章/mp/profile_ext?action=getmsg&__biz=MjM5ODIzNDEx&f=json&offset=25&count=10&is_ok=1&scene=124&uin=MTU0MTQzNj&key=f57423的接口地址,参数很多,__biz之间有用的参数只有一个还有公众号id,uin是用户的id,这个不变,key是请求的秘钥,一段时间后失效,offset是偏移量,count是每次请求的次数,返回值可以看到返回的数据包括文章标题title,摘要摘要,文章地址content_url,阅读源地址source_url,封面封面,作者作者,抓住这些有用的数据。
Python爬取公众号文章
上面分析了接口参数和返回数据,就开始用Python请求微信接口吧。
这里只获取原创文章。我的公众号有160多篇原创文章,生成HTML文件需要2分钟。
用谷歌浏览器打开看看。
生成的HTML文件也可以转成chm格式,需要安装Easy CHM软件,这是一个快速创建CHM电子书或CHM帮助文件的强大工具
左边是文章标题,右边是文章内容,看起来很方便。
还有收录
文章标题和链接的降价文件。上一篇markdown的文章介绍了使用Markdown写简历和PPT。
Excel 文件格式也可用。
HTML、markdown、Excel生成都比较快,因为都是文本,下面开始导出PDF。
导出 PDF
导出PDF的工具是wkhtmltopdf。首先到官网下载安装wkhtmltopdf。安装完成后,设置环境变量。上一篇文章写了一些你可能不知道的windows技巧,然后就可以直接从命令行生成PDF了。
λ wkhtmltopdf http://www.baidu.com baidu.pdfLoading pages (1/6)Counting pages (2/6)Resolving links (4/6)Loading headers and footers (5/6)Printing pages (6/6)Done
抓取网页生成电子书(弘一网童2.7绿色注册.rar智能化智能化的网页保存工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-29 12:16
弘毅网子2.7 绿色注册.rar
智能网页保存工具——WebPortero是一款集网页抓取、内容识别、网页编辑、格式转换于一体的智能网页保存工具。可以保存网页文字、图片、Flash等。一键将网页保存为WORD文件!您只需要点击“Netboy,另存为WORD文件”,Netboy就会识别当前网页的正文内容,然后将正文内容保存为WORD文件。完成了原本需要打开WORD、选择文本内容、复制、过滤格式、粘贴到WORD以及保存等一系列工作;自动保存“下一页” 现在网上的一篇文章往往是分页显示的。如果你想把这样的一篇文章保存下来,就需要一页一页的复制。Netboys 可以自动保存下一页并为您完成;当您在网上查找信息时,会从不同的页面中提取多个网页的内容,并编译在一个文件中,Netboy 集成了提取、采集
、编辑和保存的功能,大大提高了您的效率;批量保存网页 批量保存多个链接中的网页内容,并将这些内容保存到一个文件中;保存图片 保存网页中的所有图片或多个链接中的所有图片,并可根据图片大小过滤文件,在多个链接中识别您关注的图片;生成CHM电子书批量抓取网页,一键网页合并生成CHM电子书。还可以使用CHM电子书对网页进行压缩和存储,避免保存太多不方便管理的网页;保存一个完整的网页可以完整地保存收录
动态加载内容的网页。netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间.
现在下载 查看全部
抓取网页生成电子书(弘一网童2.7绿色注册.rar智能化智能化的网页保存工具)
弘毅网子2.7 绿色注册.rar
智能网页保存工具——WebPortero是一款集网页抓取、内容识别、网页编辑、格式转换于一体的智能网页保存工具。可以保存网页文字、图片、Flash等。一键将网页保存为WORD文件!您只需要点击“Netboy,另存为WORD文件”,Netboy就会识别当前网页的正文内容,然后将正文内容保存为WORD文件。完成了原本需要打开WORD、选择文本内容、复制、过滤格式、粘贴到WORD以及保存等一系列工作;自动保存“下一页” 现在网上的一篇文章往往是分页显示的。如果你想把这样的一篇文章保存下来,就需要一页一页的复制。Netboys 可以自动保存下一页并为您完成;当您在网上查找信息时,会从不同的页面中提取多个网页的内容,并编译在一个文件中,Netboy 集成了提取、采集
、编辑和保存的功能,大大提高了您的效率;批量保存网页 批量保存多个链接中的网页内容,并将这些内容保存到一个文件中;保存图片 保存网页中的所有图片或多个链接中的所有图片,并可根据图片大小过滤文件,在多个链接中识别您关注的图片;生成CHM电子书批量抓取网页,一键网页合并生成CHM电子书。还可以使用CHM电子书对网页进行压缩和存储,避免保存太多不方便管理的网页;保存一个完整的网页可以完整地保存收录
动态加载内容的网页。netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间. netboy保存完整网页和浏览器自己的网页另存为netboy的区别是保存当前页面显示的内容,包括动态加载的。浏览器内置的保存功能是保存源文件,动态加载的内容不保存。; 引用网页中的Flash 当您在网页上看到漂亮的Flash 时,如果您想引用它,Netboy 会为您提取Flash 的文件地址,方便您引用,例如装扮您的空间.
现在下载
抓取网页生成电子书(mitmdump爬取“得到”App电子书信息(一)_Python学习 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-29 12:14
)
前言
文章文字及图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入
mitmdump爬取“获取”App电子书信息
“Get”App是罗季思伟出品的碎片化时间学习App。应用中有很多学习资源。但是“获取”App没有对应的网页版,只能通过App获取信息。这次我们将通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App电子书版块中的电子书信息,并将信息保存到MongoDB中,如图。
我们想爬下书名、介绍、封面、价格,但是这次爬取的重点是了解mitmdump工具的使用,所以暂时不涉及自动爬取,操作应用程序仍然是手动执行的。mitmdump 负责捕获响应并提取和保存数据。
2. 准备
请确保您已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网内,同时配置了mitmproxy的CA证书,安装了MongoDB并运行其服务,安装了PyMongo库。具体配置请参考第一章说明。
3. 爬取分析
首先查找URL,返回当前页面的内容。我们写一个脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的URL和响应体内容,也就是请求链接和响应内容这两个最关键的部分。脚本的名称保存为 script.py。
接下来运行mitmdump,命令如下:
mitmdump -s script.py
打开“Get”App的电子书页面,在PC控制台上可以看到相应的输出。然后滑动页面加载更多电子书,控制台中出现的新输出内容就是App发出的新加载请求,里面收录
了下一页的电子书内容。控制台输出结果示例如图所示。
可以看到URL所在的界面,后面加了一个sign参数。通过URL的名称,可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是一个JSON格式的字符串。我们将其格式化为如图所示。
格式化的内容收录
ac 字段和一个列表字段。列表的每个元素都收录
价格、标题、描述等,第一个返回结果是电子书《情人》,此时App的内容也是这本电子书,描述的内容和价格也完全匹配。App页面如图所示。
这意味着当前接口是获取电子书信息的接口,我们只需要从该接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据采集
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后在结果中提取相应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台上的输出,如图。
控制台输出
现在输出图书的所有信息,一个图书信息对应一条JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息,然后将信息保存到数据库中。为方便起见,我们选择MongoDB数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每一条内容都是提取出来的内容,包括电子书的书名、封面、描述、价格等信息。
一开始我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入到数据库中。
滑动几页,发现所有书籍信息都保存在MongoDB中,如图。
至此,我们已经使用了一个非常简单的脚本来保存“Get”App的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data) 查看全部
抓取网页生成电子书(mitmdump爬取“得到”App电子书信息(一)_Python学习
)
前言
文章文字及图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入
mitmdump爬取“获取”App电子书信息
“Get”App是罗季思伟出品的碎片化时间学习App。应用中有很多学习资源。但是“获取”App没有对应的网页版,只能通过App获取信息。这次我们将通过抓取它的App来练习mitmdump的使用。
抓取目标
我们的爬取目标是App电子书版块中的电子书信息,并将信息保存到MongoDB中,如图。
我们想爬下书名、介绍、封面、价格,但是这次爬取的重点是了解mitmdump工具的使用,所以暂时不涉及自动爬取,操作应用程序仍然是手动执行的。mitmdump 负责捕获响应并提取和保存数据。
2. 准备
请确保您已经正确安装了mitmproxy和mitmdump,手机和PC在同一个局域网内,同时配置了mitmproxy的CA证书,安装了MongoDB并运行其服务,安装了PyMongo库。具体配置请参考第一章说明。
3. 爬取分析
首先查找URL,返回当前页面的内容。我们写一个脚本如下:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出请求的URL和响应体内容,也就是请求链接和响应内容这两个最关键的部分。脚本的名称保存为 script.py。
接下来运行mitmdump,命令如下:
mitmdump -s script.py
打开“Get”App的电子书页面,在PC控制台上可以看到相应的输出。然后滑动页面加载更多电子书,控制台中出现的新输出内容就是App发出的新加载请求,里面收录
了下一页的电子书内容。控制台输出结果示例如图所示。
可以看到URL所在的界面,后面加了一个sign参数。通过URL的名称,可以确定这是获取电子书列表的接口。URL下面的输出是响应内容,是一个JSON格式的字符串。我们将其格式化为如图所示。
格式化的内容收录
ac 字段和一个列表字段。列表的每个元素都收录
价格、标题、描述等,第一个返回结果是电子书《情人》,此时App的内容也是这本电子书,描述的内容和价格也完全匹配。App页面如图所示。
这意味着当前接口是获取电子书信息的接口,我们只需要从该接口获取内容即可。然后解析返回的结果并将结果保存到数据库中。
4. 数据采集
接下来,我们需要对接口进行过滤和限制,抓取上面分析的接口,然后在结果中提取相应的字段。
在这里,我们修改脚本如下:
import json
from mitmproxy import ctx
def response(flow):
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
再次滑动电子书页面,观察PC控制台上的输出,如图。
控制台输出
现在输出图书的所有信息,一个图书信息对应一条JSON格式的数据。
5. 提取并保存
接下来我们需要提取信息,然后将信息保存到数据库中。为方便起见,我们选择MongoDB数据库。
该脚本还可以添加用于提取信息和保存信息的部分。修改后的代码如下:
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
再次滑动页面,控制台会输出信息,如图。
现在输出的每一条内容都是提取出来的内容,包括电子书的书名、封面、描述、价格等信息。
一开始我们声明了MongoDB的数据库连接。提取信息后,调用对象的insert()方法将数据插入到数据库中。
滑动几页,发现所有书籍信息都保存在MongoDB中,如图。
至此,我们已经使用了一个非常简单的脚本来保存“Get”App的电子书信息。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/d ... 39%3B
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-29 12:13
)
总是有同学问我在学习了Python基础知识后是否不知道我可以做些什么来改进。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖,停止更新,你就看不到这些好内容了。虽然这是小概率事件(还没有发生),但你可以准备下雨天。您可以将关注的专栏导出到电子书,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后,程序会自动抓取栏目内的文章,并根据发表时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表 爬取每篇文章的详细内容导出PDF 1. 爬取列表
上一篇爬虫必备工具,掌握了它就可以解决介绍如何分析网页请求的一半问题。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否拿到了所有的文章。
data中的id、title、url就是我们需要的数据。因为url可以用id拼写出来,所以没有保存在我们的代码中。
使用 while 循环直到所有文章的 id 和标题都被提取并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 获取文章
有了所有文章的id/url,后面的爬取就很简单了。文章的主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
到这一步,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转为PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用起来非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整列的导出。
不仅是知乎专栏,几乎大部分的资讯网站都是通过1.抓取列表和2.抓取详细内容这两个步骤来采集
数据的。所以这个代码只要稍加修改就可以在许多其他网站上使用。只是有些网站需要登录后才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,所以具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎专栏下载器源码请在公众号回复知乎关键词(Crossin的编程课堂)
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他文章和答案:
欢迎搜索关注:Crossin的编程课堂
查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎
)
总是有同学问我在学习了Python基础知识后是否不知道我可以做些什么来改进。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖,停止更新,你就看不到这些好内容了。虽然这是小概率事件(还没有发生),但你可以准备下雨天。您可以将关注的专栏导出到电子书,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后,程序会自动抓取栏目内的文章,并根据发表时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表 爬取每篇文章的详细内容导出PDF 1. 爬取列表
上一篇爬虫必备工具,掌握了它就可以解决介绍如何分析网页请求的一半问题。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否拿到了所有的文章。
data中的id、title、url就是我们需要的数据。因为url可以用id拼写出来,所以没有保存在我们的代码中。
使用 while 循环直到所有文章的 id 和标题都被提取并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 获取文章
有了所有文章的id/url,后面的爬取就很简单了。文章的主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
到这一步,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转为PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用起来非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整列的导出。
不仅是知乎专栏,几乎大部分的资讯网站都是通过1.抓取列表和2.抓取详细内容这两个步骤来采集
数据的。所以这个代码只要稍加修改就可以在许多其他网站上使用。只是有些网站需要登录后才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,所以具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎专栏下载器源码请在公众号回复知乎关键词(Crossin的编程课堂)
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他文章和答案:
欢迎搜索关注:Crossin的编程课堂
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-27 08:10
编者按(@Minja):在写文章的时候,我们经常需要引用和返回。对各种存档和编辑工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是摆脱了他,一起研究了一套简单易行的方法,写了一篇文章与大家分享。
网络世界虽然有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果您想拥有出色的文章阅读体验,您至少必须确保我们正在阅读的文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能有一天找不到了。也许,将文章以电子书的形式保存在本地是一种更方便的回溯选择。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪辑”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的广告和其他影响体验的冗余区域,还可能丢失重要和有价值的内容。不仅如此,几乎没有任何工具可以轻松抓取图片并自定义本地保存的文章样式。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。
主流电子书格式
或许最著名的电子书格式是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们这篇文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片、目录、美图。相对而言,ePub 更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作
[……] 查看全部
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
编者按(@Minja):在写文章的时候,我们经常需要引用和返回。对各种存档和编辑工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是摆脱了他,一起研究了一套简单易行的方法,写了一篇文章与大家分享。
网络世界虽然有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果您想拥有出色的文章阅读体验,您至少必须确保我们正在阅读的文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能有一天找不到了。也许,将文章以电子书的形式保存在本地是一种更方便的回溯选择。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪辑”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的广告和其他影响体验的冗余区域,还可能丢失重要和有价值的内容。不仅如此,几乎没有任何工具可以轻松抓取图片并自定义本地保存的文章样式。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。
主流电子书格式
或许最著名的电子书格式是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们这篇文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片、目录、美图。相对而言,ePub 更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作
[……]
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-25 00:05
写爬虫似乎并不比使用Python更合适。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,做成PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站1的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说没用,可以无视。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点大锤。另外,既然是把html文件转成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台直接从wkhtmltopdf官网下载稳定版2进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,我们先来梳理一下您的想法。该程序的目的是将URL对应的所有html body部分保存到本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的正文内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存在a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签 查看全部
抓取网页生成电子书(廖雪峰的Python教程爬下来做成PDF电子书方便大家离线阅读)
写爬虫似乎并不比使用Python更合适。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,做成PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站1的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说没用,可以无视。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫所依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点大锤。另外,既然是把html文件转成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup
pip install pdfkit
安装 wkhtmltopdf
Windows平台直接从wkhtmltopdf官网下载稳定版2进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,我们先来梳理一下您的想法。该程序的目的是将URL对应的所有html body部分保存到本地,然后使用pdfkit将这些文件转换成pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的正文内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存在a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签
抓取网页生成电子书(制作一个最新文章列表减少蜘蛛爬行的步骤【模板】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-12-25 00:04
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天的采集数量很多,虽然首页有的地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的采集 每天的内容。
由于采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,因此萌发了制作一个最新的文章列表,减少了蜘蛛爬行的步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,在性质为 xml 映射,但这只是 HTML 页面。
演示地址:
修改方法:
1、下载压缩包,解压后上传到根目录。
2、进入网站后台核心->通道模型->添加单页文档管理页面。
3、页面标题、页面关键词和页面摘要信息根据自己网站的情况填写,模板名和文件名参考下图,编辑中无需添加任何内容框,我已经在模板中给你设置好了。
<IMG class="size-full wp-image-1171 aligncenter" title=增加新页面 alt="" src="http://image39.360doc.com/Down ... ot%3B width=500 height=344>
4、设置好后点击确定,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、还没有自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
您还可以创建一个没有图片的简单导航页面。
在模板的底部,有一个织梦 管理员主页的链接。如果您认为链接的存在会对您产生影响,您可以随意删除。如果你觉得这个方法对你有帮助,希望你能留下链接。也是对我最大的支持,谢谢。
如果您遇到任何问题,您可以给我留言。 查看全部
抓取网页生成电子书(制作一个最新文章列表减少蜘蛛爬行的步骤【模板】)
最近在研究垃圾站采集和搜索引擎收录的关系。因为一天的采集数量很多,虽然首页有的地方调用了最新的文章,但是调用的数据只有几条,远不是成百上千的采集 每天的内容。
由于采集返回的内容太多,专栏的列表页每天会增加几页。如果蜘蛛逐页爬行,会增加访问目标页面的难度,因此萌发了制作一个最新的文章列表,减少了蜘蛛爬行的步骤。通过首页,访问最新的文章列表页面,然后可以到最后的文章页面,应该有利于搜索引擎爬取和收录,在性质为 xml 映射,但这只是 HTML 页面。
演示地址:
修改方法:
1、下载压缩包,解压后上传到根目录。
2、进入网站后台核心->通道模型->添加单页文档管理页面。
3、页面标题、页面关键词和页面摘要信息根据自己网站的情况填写,模板名和文件名参考下图,编辑中无需添加任何内容框,我已经在模板中给你设置好了。
<IMG class="size-full wp-image-1171 aligncenter" title=增加新页面 alt="" src="http://image39.360doc.com/Down ... ot%3B width=500 height=344>
4、设置好后点击确定,会在网站的根目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。
5、还没有自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。
您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
您还可以创建一个没有图片的简单导航页面。
在模板的底部,有一个织梦 管理员主页的链接。如果您认为链接的存在会对您产生影响,您可以随意删除。如果你觉得这个方法对你有帮助,希望你能留下链接。也是对我最大的支持,谢谢。
如果您遇到任何问题,您可以给我留言。
抓取网页生成电子书(calibre-E-bookmanagement怎么做代码Git教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-25 00:03
calibre-电子书管理是一款非常强大的电子书管理软件。它可以打开和转换各种格式的电子书,抓取新闻到本地阅读,并允许用户自定义新闻来源。抓取网页内容并生成电子书。利用这个功能,我制作了廖雪峰老师的Python教程和Git教程的epub电子书。使用firefox的epubReader插件,可以在电脑上打开阅读。您也可以在 Internet 上阅读。这种体验非常适合没有互联网但想学习的学生。
食谱是用python编写的。用学过的python获取学习资源,加强实践。操作方法非常简单。下载calibre-电子书管理就知道了。Calibre 还提供了用于配方准备的 api 文档。
下面是获取python教程的配方代码
#!/usr/bin/env python
# vim:fileencoding=utf-8
from __future__ import unicode_literals, division, absolute_import, print_function
from calibre.web.feeds.news import BasicNewsRecipe
class liaoxuefeng_python(BasicNewsRecipe):
title = '廖雪峰Python教程'
description = 'python教程'
max_articles_per_feed = 200
url_prefix = 'http://www.liaoxuefeng.com'
no_stylesheets = True
keep_only_tags = [{ 'id': 'main' }]
remove_tags=[{'class':'x-wiki-info'}]
remove_tags_after=[{'class':'x-wiki-content x-content'}]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup('http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000')
div = soup.find('div', { 'class': 'x-wiki-tree' })
articles = []
for link in div.findAll('a'):
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
tutorial = [('廖雪峰python教程', articles)]
return tutorial
抓取Git教程只需要将parse_index方法中python教程的链接改成Git教程的链接即可。成品在本教程中 查看全部
抓取网页生成电子书(calibre-E-bookmanagement怎么做代码Git教程)
calibre-电子书管理是一款非常强大的电子书管理软件。它可以打开和转换各种格式的电子书,抓取新闻到本地阅读,并允许用户自定义新闻来源。抓取网页内容并生成电子书。利用这个功能,我制作了廖雪峰老师的Python教程和Git教程的epub电子书。使用firefox的epubReader插件,可以在电脑上打开阅读。您也可以在 Internet 上阅读。这种体验非常适合没有互联网但想学习的学生。
食谱是用python编写的。用学过的python获取学习资源,加强实践。操作方法非常简单。下载calibre-电子书管理就知道了。Calibre 还提供了用于配方准备的 api 文档。
下面是获取python教程的配方代码
#!/usr/bin/env python
# vim:fileencoding=utf-8
from __future__ import unicode_literals, division, absolute_import, print_function
from calibre.web.feeds.news import BasicNewsRecipe
class liaoxuefeng_python(BasicNewsRecipe):
title = '廖雪峰Python教程'
description = 'python教程'
max_articles_per_feed = 200
url_prefix = 'http://www.liaoxuefeng.com'
no_stylesheets = True
keep_only_tags = [{ 'id': 'main' }]
remove_tags=[{'class':'x-wiki-info'}]
remove_tags_after=[{'class':'x-wiki-content x-content'}]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup('http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000')
div = soup.find('div', { 'class': 'x-wiki-tree' })
articles = []
for link in div.findAll('a'):
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
tutorial = [('廖雪峰python教程', articles)]
return tutorial
抓取Git教程只需要将parse_index方法中python教程的链接改成Git教程的链接即可。成品在本教程中

