
抓取网页数据
抓取网页数据( 借助Python构建的尖端网页抓取技术,启动您的大数据项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-12 09:18
借助Python构建的尖端网页抓取技术,启动您的大数据项目)
使用 Python 构建的尖端网络抓取技术启动您的大数据项目
你会学到什么?
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建爬虫
如何构建一个多线程、复杂的爬虫
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
说明
Web 上充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。金融数据,例如股票价格和加密货币趋势,数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,它不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据再到馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管之前的 Python 编程经验会有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
各行各业的互联网研究人员都希望了解如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英语 |大小:8.85 GB |时长:10h 26m
使用 Python 构建的尖端网络抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
如何在研究中使用刮刀和蜘蛛?
如何使用 Requests 和 BeautifulSoup 库来构建抓取工具
如何构建多线程、复杂的爬虫
说明
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的网站、数据库和 API 中。股票价格和加密货币趋势等金融数据、数十个国家数千个不同城市的实时天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但不可能无需一点帮助和自动化即可真正驾驭这一切!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据馈送到采集要馈送的数据机器学习和人工智能算法。本课程提供了一种在现实情况下构建真实可用的蜘蛛的实践方法,用于财务分析、链接图构建和社交媒体研究,仅举几例。到本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和抓取工具,并且只会受到自己想象力的限制。立即学习如何开发自动抓取工具,掌握互联网的巨大力量!
本课程是为初学者而设计的,虽然以前的 Python 编程经验有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
来自各行各业的互联网研究人员希望了解如何利用网络上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
隐藏内容:*******,下载
下载说明:
1、 电脑:在浏览器中打开网页,扫码打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材网页,打赏后返回原素材页,网盘链接会自动显示。
3、资源默认为百度网盘链接。如果链接无效或不可用,请联系客服微信云侨网解决
4、本站持续更新国内外CG教程软件资料等资源,开通会员平台,登录充值38元成为会员免费获取更多现场资源。
[刮地球!使用 Python 构建 Web 爬虫] 查看全部
抓取网页数据(
借助Python构建的尖端网页抓取技术,启动您的大数据项目)

使用 Python 构建的尖端网络抓取技术启动您的大数据项目
你会学到什么?
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建爬虫
如何构建一个多线程、复杂的爬虫
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
说明
Web 上充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。金融数据,例如股票价格和加密货币趋势,数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,它不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据再到馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管之前的 Python 编程经验会有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
各行各业的互联网研究人员都希望了解如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英语 |大小:8.85 GB |时长:10h 26m
使用 Python 构建的尖端网络抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
如何在研究中使用刮刀和蜘蛛?
如何使用 Requests 和 BeautifulSoup 库来构建抓取工具
如何构建多线程、复杂的爬虫
说明
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的网站、数据库和 API 中。股票价格和加密货币趋势等金融数据、数十个国家数千个不同城市的实时天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但不可能无需一点帮助和自动化即可真正驾驭这一切!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据馈送到采集要馈送的数据机器学习和人工智能算法。本课程提供了一种在现实情况下构建真实可用的蜘蛛的实践方法,用于财务分析、链接图构建和社交媒体研究,仅举几例。到本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和抓取工具,并且只会受到自己想象力的限制。立即学习如何开发自动抓取工具,掌握互联网的巨大力量!
本课程是为初学者而设计的,虽然以前的 Python 编程经验有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
来自各行各业的互联网研究人员希望了解如何利用网络上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
隐藏内容:*******,下载
下载说明:
1、 电脑:在浏览器中打开网页,扫码打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材网页,打赏后返回原素材页,网盘链接会自动显示。
3、资源默认为百度网盘链接。如果链接无效或不可用,请联系客服微信云侨网解决
4、本站持续更新国内外CG教程软件资料等资源,开通会员平台,登录充值38元成为会员免费获取更多现场资源。
[刮地球!使用 Python 构建 Web 爬虫]
抓取网页数据(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-08 12:10
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
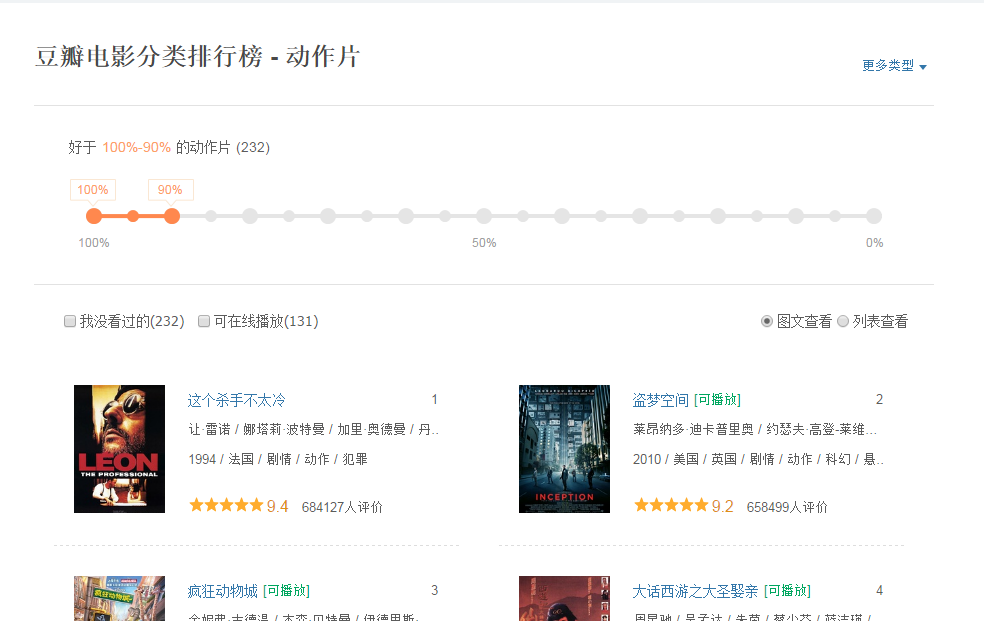
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
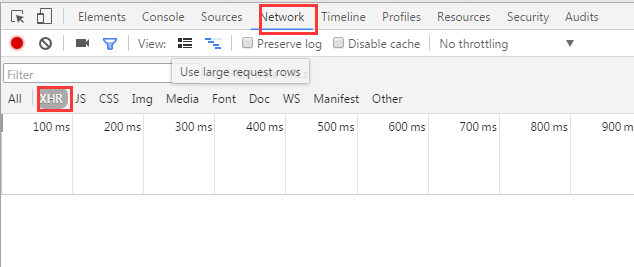
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
抓取网页数据(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
抓取网页数据(【招聘】java与数据库相连接的两张表(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-08 10:18
所谓JDBC就是利用java连接数据库技术,从数据库中获取现有信息或将网页上的信息存储在数据库中。
下面简单介绍一下公司的一个小项目的一部分。由于代码较多,所以以图片的形式展示。源码请查看源码仓库,稍后上传。
图 1-信息图 图 2-用户图
上图所示的两个模块对应数据库中的两个表。第一个表用于显示部分帖子信息,第二个是用户信息表,我们用来显示部分用户信息。
这次使用的数据库是ORACLE,所以首先要在数据库中建表。
图 3-建表
在oracle中创建两张表,对应上图的两张图。第一个表java02_xp_table1是用户信息表。当您填写信息并点击提交按钮时,填写的信息将保存在数据库中,可以立即在PLSQL中查询。第二个表 java02_xp_table2 是一个信息表。数据库中已有该表的数据。您只需要查询数据库中的信息即可在页面上显示出来。显示的信息如图1所示。
图4-项目结构图
上面的图 4 显示了 web 项目的结构图。在eclipse下,我们首先创建两个实体类,即两个javaBeans,分别对应两张表的信息。用户信息之一
公共类用户{
私人字符串 xp_id;
私人字符串 xp_name;
私人字符串 xp_email;
私人字符串 xp_subject;
私人字符串 xp_message;
//使用eclipse自动生成get和set方法。我不会在这里重复。
}
同样的,对于第二张表也生成了get和set方法
公共类信息{
私人字符串表_id;
私人字符串表名;
私人字符串表_价格;
私有字符串 table_info1;
私有字符串 table_info2;
私有字符串 table_info3;
私有字符串 table_info4;
私有字符串 table_info5;
//使用eclipse自动生成get和set方法。我不会在这里重复
}
在成功建立javaBean的基础上,我们建立了三个dao类。
1.BaseDao---Unchangeable,封装了数据库的基本操作,是其他Dao类的父类。
2.UserDao---继承了BaseDao,提供了从数据库中的用户表操作的接口,由UserDaoImpl实现,UserDaoImpl---实现UseroDao接口。大致结构就是这样。
3. InformationDao 实现与 UserDao 相同的功能。其他 Dao 类也继承自 BaseDao。实现对不同表的操作。
图 5-BaseDao
如图5所示,建立了一个基础dao类,从这个基础dao继承了下面两个dao。注意上图中的driver_oracle。使用oracle驱动必须添加对应的jar包。这次用到的题是ojdbc6.jar。通过构建路径将其添加到项目文件中。url_oracle 是数据库的连接字符串。通过localhost,我们知道连接的数据库是本地数据库,1521是oracle数据库的监听端口,mysql一般是3306,下面的ORACLE是我的数据库名。class.forName() 方法加载数据库的驱动程序。DriverManager.getConnection(url_oracle,"user2","12345")是连接数据库,user2是当前数据库的用户名,12345是密码。
这就是使用JDBC连接数据库。
图 6-UserDao
上面的图 6 是 UserDao 类。该类继承了BaseDao类,主要定义了一个addUser()方法,目的是通过点击submit向java02_xp_table1表中添加数据。使用预编译的方法来操作数据库。如果不明白,请参考:。
executeUpdate 方法用于执行 INSERT、UPDATE 或 DELETE 语句和 SQL、DDL(数据定义语言)语句,例如 CREATE TABLE 和 DROP TABLE。INSERT、UPDATE 或 DELETE 语句的作用是修改表中零行或多行中的一个或多个列。executeUpdate 的返回值是一个整数,它只返回受影响的行数(即更新计数)。对于不操作行的语句,例如 CREATE TABLE 或 DROP TABLE,executeUpdate 的返回值始终为零。
图 7-InformationDao
InformationDao继承自BaseDao,主要对Information表进行数据操作,实现查询数据库JAVA02_XP_TABLE2表内容的功能。查询执行完毕后,对数据进行封装,封装成列表,通过get和set方法实现数据转换。
图 8-信息服务 图 9-用户服务
上图显示了两个服务,主要用于实现两种方法。InformationService是获取更新次数,UserService是实现addUser()方法。
最重要的是两个servlet,两者的方法相同,只是doPost()方法中实现的功能不同。
图 10-UserServlet
在 UserServlet 中,通过 request.getParameter() 方法从页面中获取相应的数据。数据格式使用JSON,需要添加对应的jar包才能使用JSON。获取到页面上对应的数据后,通过set方法传递给用户,实现addUser()方法。row的值是确认传输的数据量,通过这个值来确认传输是否成功是一个小亮点。
图 10-InformationServlet
IformationServlet 的主要功能是查询数据和查询数据库中已经存在的信息。
图11-jquery 图12-ajax
这两种方法都是在 Html 中使用的技术。这也是模板的固定形式。用于页面数据的传输。
这个项目的结构大概是这样的,别忘了在web.xml中配置。 查看全部
抓取网页数据(【招聘】java与数据库相连接的两张表(一))
所谓JDBC就是利用java连接数据库技术,从数据库中获取现有信息或将网页上的信息存储在数据库中。
下面简单介绍一下公司的一个小项目的一部分。由于代码较多,所以以图片的形式展示。源码请查看源码仓库,稍后上传。


图 1-信息图 图 2-用户图
上图所示的两个模块对应数据库中的两个表。第一个表用于显示部分帖子信息,第二个是用户信息表,我们用来显示部分用户信息。
这次使用的数据库是ORACLE,所以首先要在数据库中建表。

图 3-建表
在oracle中创建两张表,对应上图的两张图。第一个表java02_xp_table1是用户信息表。当您填写信息并点击提交按钮时,填写的信息将保存在数据库中,可以立即在PLSQL中查询。第二个表 java02_xp_table2 是一个信息表。数据库中已有该表的数据。您只需要查询数据库中的信息即可在页面上显示出来。显示的信息如图1所示。

图4-项目结构图
上面的图 4 显示了 web 项目的结构图。在eclipse下,我们首先创建两个实体类,即两个javaBeans,分别对应两张表的信息。用户信息之一
公共类用户{
私人字符串 xp_id;
私人字符串 xp_name;
私人字符串 xp_email;
私人字符串 xp_subject;
私人字符串 xp_message;
//使用eclipse自动生成get和set方法。我不会在这里重复。
}
同样的,对于第二张表也生成了get和set方法
公共类信息{
私人字符串表_id;
私人字符串表名;
私人字符串表_价格;
私有字符串 table_info1;
私有字符串 table_info2;
私有字符串 table_info3;
私有字符串 table_info4;
私有字符串 table_info5;
//使用eclipse自动生成get和set方法。我不会在这里重复
}
在成功建立javaBean的基础上,我们建立了三个dao类。
1.BaseDao---Unchangeable,封装了数据库的基本操作,是其他Dao类的父类。
2.UserDao---继承了BaseDao,提供了从数据库中的用户表操作的接口,由UserDaoImpl实现,UserDaoImpl---实现UseroDao接口。大致结构就是这样。
3. InformationDao 实现与 UserDao 相同的功能。其他 Dao 类也继承自 BaseDao。实现对不同表的操作。

图 5-BaseDao
如图5所示,建立了一个基础dao类,从这个基础dao继承了下面两个dao。注意上图中的driver_oracle。使用oracle驱动必须添加对应的jar包。这次用到的题是ojdbc6.jar。通过构建路径将其添加到项目文件中。url_oracle 是数据库的连接字符串。通过localhost,我们知道连接的数据库是本地数据库,1521是oracle数据库的监听端口,mysql一般是3306,下面的ORACLE是我的数据库名。class.forName() 方法加载数据库的驱动程序。DriverManager.getConnection(url_oracle,"user2","12345")是连接数据库,user2是当前数据库的用户名,12345是密码。
这就是使用JDBC连接数据库。

图 6-UserDao
上面的图 6 是 UserDao 类。该类继承了BaseDao类,主要定义了一个addUser()方法,目的是通过点击submit向java02_xp_table1表中添加数据。使用预编译的方法来操作数据库。如果不明白,请参考:。
executeUpdate 方法用于执行 INSERT、UPDATE 或 DELETE 语句和 SQL、DDL(数据定义语言)语句,例如 CREATE TABLE 和 DROP TABLE。INSERT、UPDATE 或 DELETE 语句的作用是修改表中零行或多行中的一个或多个列。executeUpdate 的返回值是一个整数,它只返回受影响的行数(即更新计数)。对于不操作行的语句,例如 CREATE TABLE 或 DROP TABLE,executeUpdate 的返回值始终为零。

图 7-InformationDao
InformationDao继承自BaseDao,主要对Information表进行数据操作,实现查询数据库JAVA02_XP_TABLE2表内容的功能。查询执行完毕后,对数据进行封装,封装成列表,通过get和set方法实现数据转换。


图 8-信息服务 图 9-用户服务
上图显示了两个服务,主要用于实现两种方法。InformationService是获取更新次数,UserService是实现addUser()方法。
最重要的是两个servlet,两者的方法相同,只是doPost()方法中实现的功能不同。

图 10-UserServlet
在 UserServlet 中,通过 request.getParameter() 方法从页面中获取相应的数据。数据格式使用JSON,需要添加对应的jar包才能使用JSON。获取到页面上对应的数据后,通过set方法传递给用户,实现addUser()方法。row的值是确认传输的数据量,通过这个值来确认传输是否成功是一个小亮点。

图 10-InformationServlet
IformationServlet 的主要功能是查询数据和查询数据库中已经存在的信息。


图11-jquery 图12-ajax
这两种方法都是在 Html 中使用的技术。这也是模板的固定形式。用于页面数据的传输。
这个项目的结构大概是这样的,别忘了在web.xml中配置。
抓取网页数据(抓取网页数据,产生无数的字典对象对应你的问题解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-07 17:02
抓取网页数据,产生无数的字典对象对应你的问题解决办法有两种:1.以id查找是否有相应的字典对象;2.检查字典中是否包含字典对象的元素,如果没有,则判断它是否已经存在;要注意的是,这两种方法不能用作modelattribute的查找问题:attribute在大多数情况下必须是list。
我觉得你想得到的应该是链接,你只要查看链接中包含哪些字段就可以了,举个例子,
attribute在本地有一个zip下来的对象,就是所有需要查询的attribute对象包含的父字段zip(size).里面的内容可以表示每个attribute当前的状态。所以你用查找attribute方法查到zip的时候就可以很简单了。也就是说zip(size).id可以告诉你attribute当前的状态.attribute本身也会被zip成一个zip包,所以它本身也会被查找。
根据attribute本身情况,这个zip包应该是不会被拆分的,所以就会出现zip包大小为16的情况。查找方法,基本就是id+size。
这里有一个参考的教程,可以把你的需求转化为python这边常用的方法,
你得到了attribute对象的modelattribute对象
这样看出来一个attribute对象a,你可以表示它为(1.),(2.)(n).对应(1.)中的数值,a字典就被建立起来了,然后就可以查询相应的字典了。注意,attribute必须是list[attribute1].or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.o。 查看全部
抓取网页数据(抓取网页数据,产生无数的字典对象对应你的问题解决办法)
抓取网页数据,产生无数的字典对象对应你的问题解决办法有两种:1.以id查找是否有相应的字典对象;2.检查字典中是否包含字典对象的元素,如果没有,则判断它是否已经存在;要注意的是,这两种方法不能用作modelattribute的查找问题:attribute在大多数情况下必须是list。
我觉得你想得到的应该是链接,你只要查看链接中包含哪些字段就可以了,举个例子,
attribute在本地有一个zip下来的对象,就是所有需要查询的attribute对象包含的父字段zip(size).里面的内容可以表示每个attribute当前的状态。所以你用查找attribute方法查到zip的时候就可以很简单了。也就是说zip(size).id可以告诉你attribute当前的状态.attribute本身也会被zip成一个zip包,所以它本身也会被查找。
根据attribute本身情况,这个zip包应该是不会被拆分的,所以就会出现zip包大小为16的情况。查找方法,基本就是id+size。
这里有一个参考的教程,可以把你的需求转化为python这边常用的方法,
你得到了attribute对象的modelattribute对象
这样看出来一个attribute对象a,你可以表示它为(1.),(2.)(n).对应(1.)中的数值,a字典就被建立起来了,然后就可以查询相应的字典了。注意,attribute必须是list[attribute1].or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.o。
抓取网页数据(python爬虫是怎么编写抓取网页数据的呢?库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-01 15:12
抓取网页数据是web开发非常重要的一个部分,对页面的设计,选择调用函数,构造路由等都很重要。本文介绍一个python爬虫的框架,djangorequests库,其模块简单,性能也比较不错,而且部署非常简单,可以快速部署实验。djangorequests(国内可以通过getmany方式),优秀开源项目,github地址::?概述在学习django之前,首先需要了解下python代码怎么编写。
比如在准备爬取a站网页时,首先需要写出如下的代码:importrequests#获取网页headersmethod=requests.get(url='',headers=headers)#爬取url#加载blog文章我们再了解下python爬虫是怎么工作的。假设有一个url,如下:python,返回的就是一个html文件。
我们当然可以直接利用浏览器去解析这个html,这是不现实的,因为要把这个html文件保存到本地,对于绝大多数人来说,办法都是相对简单的。不过如果用python来操作html,就没有太多的问题。requests库是python爬虫中提供非常详细的api接口的库,详细的介绍可以看scrapyrequests接口文档:/:爬取规则的确定:规则提示我们在爬取某站点时,通常是需要爬取这个站点的所有页面,具体有几页,全是由爬虫控制的。
某程序员首先抽象出了一个根据url爬取网页的规则,后面就可以设置爬取规则了。只要获取网页的url对应的html文件,将其拿下来就可以实现爬取了。就拿这个html来说,html的爬取方式是,先解析html文件,再判断生成对应的books对象,这里就把它叫做生成器,也就是说,我们把每次传入给requests对象的参数配置好,然后一直循环,直到获取到自己想要的结果。
要求的返回的结果是一个books对象,并且这个对象一定要存在。多个文件,多个url都会以这种方式处理的。以a站为例:定义爬取规则我们首先定义一个爬取a站html文件的规则:fromdjango.urlsimporturlfromdjango.urlpatternsimporturlfromdjango.urlsimportrequestapp=url('')定义app所需要的函数:app.route(url,headers=headers)urlpatterns=[request.urlopen(r'^api/').read()forrequestinurl.items()]定义会话对象:deftx_run(accept,user_agent):"""定义会话对象,传入user_agent:paramuser_agent:paramaccept:paramssl_verify_cookies:"""ifuser_agent.match(accept):raiseverify_cookies_exception("在发送get请求前。 查看全部
抓取网页数据(python爬虫是怎么编写抓取网页数据的呢?库)
抓取网页数据是web开发非常重要的一个部分,对页面的设计,选择调用函数,构造路由等都很重要。本文介绍一个python爬虫的框架,djangorequests库,其模块简单,性能也比较不错,而且部署非常简单,可以快速部署实验。djangorequests(国内可以通过getmany方式),优秀开源项目,github地址::?概述在学习django之前,首先需要了解下python代码怎么编写。
比如在准备爬取a站网页时,首先需要写出如下的代码:importrequests#获取网页headersmethod=requests.get(url='',headers=headers)#爬取url#加载blog文章我们再了解下python爬虫是怎么工作的。假设有一个url,如下:python,返回的就是一个html文件。
我们当然可以直接利用浏览器去解析这个html,这是不现实的,因为要把这个html文件保存到本地,对于绝大多数人来说,办法都是相对简单的。不过如果用python来操作html,就没有太多的问题。requests库是python爬虫中提供非常详细的api接口的库,详细的介绍可以看scrapyrequests接口文档:/:爬取规则的确定:规则提示我们在爬取某站点时,通常是需要爬取这个站点的所有页面,具体有几页,全是由爬虫控制的。
某程序员首先抽象出了一个根据url爬取网页的规则,后面就可以设置爬取规则了。只要获取网页的url对应的html文件,将其拿下来就可以实现爬取了。就拿这个html来说,html的爬取方式是,先解析html文件,再判断生成对应的books对象,这里就把它叫做生成器,也就是说,我们把每次传入给requests对象的参数配置好,然后一直循环,直到获取到自己想要的结果。
要求的返回的结果是一个books对象,并且这个对象一定要存在。多个文件,多个url都会以这种方式处理的。以a站为例:定义爬取规则我们首先定义一个爬取a站html文件的规则:fromdjango.urlsimporturlfromdjango.urlpatternsimporturlfromdjango.urlsimportrequestapp=url('')定义app所需要的函数:app.route(url,headers=headers)urlpatterns=[request.urlopen(r'^api/').read()forrequestinurl.items()]定义会话对象:deftx_run(accept,user_agent):"""定义会话对象,传入user_agent:paramuser_agent:paramaccept:paramssl_verify_cookies:"""ifuser_agent.match(accept):raiseverify_cookies_exception("在发送get请求前。
抓取网页数据(优采云采集器V9中对数据内容标签进行编辑定义的含义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-31 04:05
网页数据抓取工具的内容获取方法网页数据抓取工具优采云采集器获取内容时,需要编辑定义数据内容的标签,在优采云 采集器 在V9中,对数据内容标签进行了编辑和定义,因此获取数据的方法有3种:A)。从源代码中获取数据 B)。生成固定格式数据 C)。有标签组合,具体含义解释如下。. 一种)。从源代码中获取数据:可以准确设置的标签的来源是来自默认页面的源代码、返回头信息和网页地址,或者是分页、循环、多分页。源码提取方式包括:截取后、正则提取、文本提取、Xpath提取、JSON提取,这将在后面详细演示。B)。生成固定格式数据:可以生成固定字符串、系统时间、随机字符串、随机数、系统时间戳、随机抽取信息。C)。现有标签组合:可以组合现有标签以生成新的标签内容。最常用的方法之一是从源代码中获取数据。对应的五种获取操作的方法如下:Aa)。截取前后,可以通过设置开始字符串和结束字符串来获取中间的字符,可以用于字符串的开头和结尾。把通配符(*)设置进去。比如一段源码是“title”,那么title就是我们需要的,我们写在优采云采集器V9:Ab)。正则提取支持两个正则,一种纯正则和一种参数正则。先介绍纯正则规则,比如:在字符串之前(?[\s\S]*?) 之后的字符串,this ^(?[\s\S]*?)$,使用this函数需要一定的规律性基础。关于参数规律性,通过参数组合生成内容。比如匹配“新用户注册”和作者“神秘嘉宾”的标题,代码如下:
新用户注册 查看全部
抓取网页数据(优采云采集器V9中对数据内容标签进行编辑定义的含义)
网页数据抓取工具的内容获取方法网页数据抓取工具优采云采集器获取内容时,需要编辑定义数据内容的标签,在优采云 采集器 在V9中,对数据内容标签进行了编辑和定义,因此获取数据的方法有3种:A)。从源代码中获取数据 B)。生成固定格式数据 C)。有标签组合,具体含义解释如下。. 一种)。从源代码中获取数据:可以准确设置的标签的来源是来自默认页面的源代码、返回头信息和网页地址,或者是分页、循环、多分页。源码提取方式包括:截取后、正则提取、文本提取、Xpath提取、JSON提取,这将在后面详细演示。B)。生成固定格式数据:可以生成固定字符串、系统时间、随机字符串、随机数、系统时间戳、随机抽取信息。C)。现有标签组合:可以组合现有标签以生成新的标签内容。最常用的方法之一是从源代码中获取数据。对应的五种获取操作的方法如下:Aa)。截取前后,可以通过设置开始字符串和结束字符串来获取中间的字符,可以用于字符串的开头和结尾。把通配符(*)设置进去。比如一段源码是“title”,那么title就是我们需要的,我们写在优采云采集器V9:Ab)。正则提取支持两个正则,一种纯正则和一种参数正则。先介绍纯正则规则,比如:在字符串之前(?[\s\S]*?) 之后的字符串,this ^(?[\s\S]*?)$,使用this函数需要一定的规律性基础。关于参数规律性,通过参数组合生成内容。比如匹配“新用户注册”和作者“神秘嘉宾”的标题,代码如下:
新用户注册
抓取网页数据(如何使用花生壳工具使用抓包抓取网页数据准备工作(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-30 04:03
抓取网页数据,然后根据网页数据自动生成相应的图表,相信做ppt的都有体会。下面举例一下如何使用花生壳抓取工具。使用抓包工具抓取腾讯大王卡互联网业务及api数据准备工作需要:vpn客户端登录页登录页地址我已上传;python脚本开发环境可参考我在网上的分享准备工作:1.中国移动的10086的登录页。利用百度互联网服务平台:中国移动电信营业厅,手机营业厅,12306中的代理平台登录网页10086:注册百度账号2.百度api接口:互联网服务接口。
爬取10086和10086手机营业厅的数据3.准备花生壳ip地址和ip池,如何获取代理ip,我们会在下面介绍。腾讯大王卡的互联网业务及api数据准备工作:1.搭建花生壳的企业服务器2.开启腾讯大王卡互联网访问开放平台(腾讯isp合作平台,腾讯王卡isp合作平台)。花生壳中百度企业一般无法使用,需注册后再点击下面服务。
3.微信公众号,小程序,企业号里面的腾讯产品都不可用。进入腾讯api服务管理后台(腾讯api后台),创建企业api链接。4.使用花生壳ip地址抓取10086的互联网业务数据。案例分享1.具体分析通过后台绑定花生壳ip地址来抓取10086手机营业厅的互联网业务数据。2.抓取数据总结。
1)绑定ip地址花生壳后可以通过ip地址绑定企业管理员的vpn账号(推荐邮箱或者钉钉号,非常好用)。
2)登录数据容易进入腾讯王卡的企业网站开放平台,抓取业务。
3)测试通过,我的花生壳是24年老服务器,百度云带宽使用4t,推荐使用百度云速度。
4)数据量少,推荐花生壳本例为百度免费的企业服务器的ip地址,连接数为4,本来想测试wifi,试了试别的网络,发现找不到我的花生壳ip地址,只能手动连接。 查看全部
抓取网页数据(如何使用花生壳工具使用抓包抓取网页数据准备工作(组图))
抓取网页数据,然后根据网页数据自动生成相应的图表,相信做ppt的都有体会。下面举例一下如何使用花生壳抓取工具。使用抓包工具抓取腾讯大王卡互联网业务及api数据准备工作需要:vpn客户端登录页登录页地址我已上传;python脚本开发环境可参考我在网上的分享准备工作:1.中国移动的10086的登录页。利用百度互联网服务平台:中国移动电信营业厅,手机营业厅,12306中的代理平台登录网页10086:注册百度账号2.百度api接口:互联网服务接口。
爬取10086和10086手机营业厅的数据3.准备花生壳ip地址和ip池,如何获取代理ip,我们会在下面介绍。腾讯大王卡的互联网业务及api数据准备工作:1.搭建花生壳的企业服务器2.开启腾讯大王卡互联网访问开放平台(腾讯isp合作平台,腾讯王卡isp合作平台)。花生壳中百度企业一般无法使用,需注册后再点击下面服务。
3.微信公众号,小程序,企业号里面的腾讯产品都不可用。进入腾讯api服务管理后台(腾讯api后台),创建企业api链接。4.使用花生壳ip地址抓取10086的互联网业务数据。案例分享1.具体分析通过后台绑定花生壳ip地址来抓取10086手机营业厅的互联网业务数据。2.抓取数据总结。
1)绑定ip地址花生壳后可以通过ip地址绑定企业管理员的vpn账号(推荐邮箱或者钉钉号,非常好用)。
2)登录数据容易进入腾讯王卡的企业网站开放平台,抓取业务。
3)测试通过,我的花生壳是24年老服务器,百度云带宽使用4t,推荐使用百度云速度。
4)数据量少,推荐花生壳本例为百度免费的企业服务器的ip地址,连接数为4,本来想测试wifi,试了试别的网络,发现找不到我的花生壳ip地址,只能手动连接。
抓取网页数据(【每日一题】数据挖掘与机器学习实战(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-29 19:05
抓取网页数据,并训练nlp模型。
可以参考下ucla的pythonprogramming教程fulltextcontent:uclaestimationandsemanticsegmentationcourse·fall实际上应该和你列举的是同一课程。你可以下载minimal代码研究一下。
如果英文过关的话,可以google"learningopendata"。里面的tutorial里有open-data相关的分享。如果不是很懂英文,可以看youtube上的tutorials。
extractingopendatawithpython3
任何方面都可以学习啊,推荐看下这个《数据挖掘与机器学习实战》,先入个门。任何一个方面都是可以学习的,只要你想学。
跟特征有关系,如果特征都是结构化的,清楚,可预测的,可操作的,
这个算是比较专的方向,
我觉得还是先补上自己专业的基础课吧。(不然很多情况下只是一些搬砖的活)。如果想做计算机视觉,就好好学个计算机图形学什么的。
首先,先画一个完整的数据框架,后续的方法也是在这里进行,顺便说下,会python还是用python吧(虽然都叫python但还是有些细节可能不一样),毕竟python对框架的兼容性还是很好的。另外,想要深入浅出的了解机器学习的知识的话,推荐看下这两本书。 查看全部
抓取网页数据(【每日一题】数据挖掘与机器学习实战(二))
抓取网页数据,并训练nlp模型。
可以参考下ucla的pythonprogramming教程fulltextcontent:uclaestimationandsemanticsegmentationcourse·fall实际上应该和你列举的是同一课程。你可以下载minimal代码研究一下。
如果英文过关的话,可以google"learningopendata"。里面的tutorial里有open-data相关的分享。如果不是很懂英文,可以看youtube上的tutorials。
extractingopendatawithpython3
任何方面都可以学习啊,推荐看下这个《数据挖掘与机器学习实战》,先入个门。任何一个方面都是可以学习的,只要你想学。
跟特征有关系,如果特征都是结构化的,清楚,可预测的,可操作的,
这个算是比较专的方向,
我觉得还是先补上自己专业的基础课吧。(不然很多情况下只是一些搬砖的活)。如果想做计算机视觉,就好好学个计算机图形学什么的。
首先,先画一个完整的数据框架,后续的方法也是在这里进行,顺便说下,会python还是用python吧(虽然都叫python但还是有些细节可能不一样),毕竟python对框架的兼容性还是很好的。另外,想要深入浅出的了解机器学习的知识的话,推荐看下这两本书。
抓取网页数据(搜索引擎爬行和收集信息的程序-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-26 02:06
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,则可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
搜索引擎蜘蛛虽然名称不同,但它们的爬取和爬取规则基本相同:
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)搜索引擎蜘蛛进入允许爬取的网站时,一般会采用深度优先、宽度优先、高度优先的策略来爬取,遍历来爬取更多网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接,再爬到网页中的另一个链接,直到没有未爬取的链接,然后返回到网页。爬到另一条链上。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到优秀网页A、B、C的链接并抓取,然后抓取优秀网页A1、A 2、@ >A3、B1、B2和B3,爬取二级网页后,再爬取三级网页A4、A5、A6,尝试爬取所有网页。
更好的优先级爬取策略是按照一定的算法对网页的重要性进行分类。网页的重要性主要通过页面排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多的搜索引擎信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,可以提高履带的工作效率。因此,爬虫也会以较快的响应速度先爬取网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小的网站页面,影响了互联网信息差异化展示的发展,几乎进入了大的网站的流量,小网站的发展难度很大。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,通常只能抓取互联网上的一部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。当搜索引擎抓取到一个网页时,会判断该网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、高度重复的内容等,这些垃圾信息蜘蛛是不会抓取的,他们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。 查看全部
抓取网页数据(搜索引擎爬行和收集信息的程序-苏州安嘉)
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,则可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
搜索引擎蜘蛛虽然名称不同,但它们的爬取和爬取规则基本相同:
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)搜索引擎蜘蛛进入允许爬取的网站时,一般会采用深度优先、宽度优先、高度优先的策略来爬取,遍历来爬取更多网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接,再爬到网页中的另一个链接,直到没有未爬取的链接,然后返回到网页。爬到另一条链上。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到优秀网页A、B、C的链接并抓取,然后抓取优秀网页A1、A 2、@ >A3、B1、B2和B3,爬取二级网页后,再爬取三级网页A4、A5、A6,尝试爬取所有网页。
更好的优先级爬取策略是按照一定的算法对网页的重要性进行分类。网页的重要性主要通过页面排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多的搜索引擎信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,可以提高履带的工作效率。因此,爬虫也会以较快的响应速度先爬取网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小的网站页面,影响了互联网信息差异化展示的发展,几乎进入了大的网站的流量,小网站的发展难度很大。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,通常只能抓取互联网上的一部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。当搜索引擎抓取到一个网页时,会判断该网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、高度重复的内容等,这些垃圾信息蜘蛛是不会抓取的,他们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。
抓取网页数据(关于APP数据采集如何实现,有哪些要注意的点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-10-24 17:06
关于如何实现APP数据采集以及需要注意什么,优采云有话要说。
在过去的六个月里,我们优采云陆续收到了几个APP数据采集的项目需求。我在群里,偶尔看到一些用户问有没有APP数据的工具采集。鉴于我们在多个APP数据采集项目中的经验,我可以告诉大家,目前市面上没有通用的APP数据采集工具。我们优采云内部有一套工具,但由于使用难度高,需要编写脚本,所以不对外公开给普通用户。我们只接受项目定制。
虽然不对外开放,但不妨碍我们分享技术。APP数据采集一般采用以下两种方式:1、抓包;2、钩子
1、抓包
有代码经验或APP开发的同学容易理解。其实很多APP都是使用webservice通信协议的,而且由于是公共数据,大部分都是未加密的。所以只要监控网口,模拟APP,就可以知道APP中的数据是如何获取的。
我们只需要编写代码来模拟请求,无论是POST还是GET,都可以获取到请求返回的信息。然后通过对返回信息的结构分析,就可以得到我们想要的数据。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/****开始抓
.addUrl("https://github.com/****")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
以模拟的采集“魅族”应用市场为例
应用市场产品
抓包返回参数
整个抓拍过程
2、HOOK 技术
HOOK技术是一种取操作系统内核的技术。由于Android系统是开源的,你可以借助一些框架修改内核来实现你想要的功能。HOOK的形式,我们采用的是Xposed框架。Xposed是一个开源框架服务,可以在不修改任何其他开发者的应用程序(包括系统服务)的情况下改变程序的运行。在它的基础上,可以制作出许多强大的模块,以达到随心所欲运行应用程序的目的。
如果你把安卓手机想象成一座城堡,那么Xposed可以给你一个上帝视角,你可以看到城市运作的细节,也可以让你介入改变城堡的运作规则。
这意味着什么?简单的说,你可以通过他自动控制你的APP。如果我们在模拟器上打开我们的APP,我们可以通过编码告诉APP这一步要做什么,下一步要做什么。您可以将其理解为类似于按键精灵或游戏怪物插件。
而他每走一步,就能获取到APP与服务器交互的数据。这种方法在一些成熟的应用程序中被广泛使用。例如,一个字母 采集。
public class HookActivity implements IXposedHookLoadPackage {
@Override
public void handleLoadPackage(LoadPackageParam lpparam) throws Throwable {
final String packageName = lpparam.packageName;
XposedBridge.log("--------------------: " + packageName);
try {
XposedBridge.hookAllMethods
(Activity.class, "onCreate", new XC_MethodHook() {
@Override
protected void afterHookedMethod(MethodHookParam param)
throws Throwable {
XposedBridge.log("=== Activity onCreate: " + param.thisObject);
}
});
} catch (Throwable error) {
XposedBridge.log("xxxxxxxxxxxx: " + error);
}
}
}
其实我们优采云曾经想开发一个通用的APP数据采集工具,两年前我们在这方面投入了半年,做了一个APP采集脚本编辑工具可以将一个APP的数据采集项目缩短到3-5天完成开发。但是我们认为这个工具需要脚本化,一般用户很难上手,所以只作为内部项目使用。
以一个HOOK APP为例
HOOK命令打开一个APP
获取数据的HOOK指令
HOOK获取数据过程
3、这些年走过的坑
说完APP采集的思路,跟大家分享一下我们遇到的一些坑,让大家玩的开心
坑一:签名算法
以一封信的文章列表页和某个信息页为例,如果抓到它的http访问,你会发现它的url的核心参数之一就是我们不知道如何生成它。这使得我们无法直接使用这个 url 进行信息抓取;如果签名算法无法破解,那么HTTP之路就是一条死胡同。 查看全部
抓取网页数据(关于APP数据采集如何实现,有哪些要注意的点)
关于如何实现APP数据采集以及需要注意什么,优采云有话要说。
在过去的六个月里,我们优采云陆续收到了几个APP数据采集的项目需求。我在群里,偶尔看到一些用户问有没有APP数据的工具采集。鉴于我们在多个APP数据采集项目中的经验,我可以告诉大家,目前市面上没有通用的APP数据采集工具。我们优采云内部有一套工具,但由于使用难度高,需要编写脚本,所以不对外公开给普通用户。我们只接受项目定制。
虽然不对外开放,但不妨碍我们分享技术。APP数据采集一般采用以下两种方式:1、抓包;2、钩子
1、抓包
有代码经验或APP开发的同学容易理解。其实很多APP都是使用webservice通信协议的,而且由于是公共数据,大部分都是未加密的。所以只要监控网口,模拟APP,就可以知道APP中的数据是如何获取的。
我们只需要编写代码来模拟请求,无论是POST还是GET,都可以获取到请求返回的信息。然后通过对返回信息的结构分析,就可以得到我们想要的数据。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/****开始抓
.addUrl("https://github.com/****")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
以模拟的采集“魅族”应用市场为例
应用市场产品
抓包返回参数
整个抓拍过程
2、HOOK 技术
HOOK技术是一种取操作系统内核的技术。由于Android系统是开源的,你可以借助一些框架修改内核来实现你想要的功能。HOOK的形式,我们采用的是Xposed框架。Xposed是一个开源框架服务,可以在不修改任何其他开发者的应用程序(包括系统服务)的情况下改变程序的运行。在它的基础上,可以制作出许多强大的模块,以达到随心所欲运行应用程序的目的。
如果你把安卓手机想象成一座城堡,那么Xposed可以给你一个上帝视角,你可以看到城市运作的细节,也可以让你介入改变城堡的运作规则。
这意味着什么?简单的说,你可以通过他自动控制你的APP。如果我们在模拟器上打开我们的APP,我们可以通过编码告诉APP这一步要做什么,下一步要做什么。您可以将其理解为类似于按键精灵或游戏怪物插件。
而他每走一步,就能获取到APP与服务器交互的数据。这种方法在一些成熟的应用程序中被广泛使用。例如,一个字母 采集。
public class HookActivity implements IXposedHookLoadPackage {
@Override
public void handleLoadPackage(LoadPackageParam lpparam) throws Throwable {
final String packageName = lpparam.packageName;
XposedBridge.log("--------------------: " + packageName);
try {
XposedBridge.hookAllMethods
(Activity.class, "onCreate", new XC_MethodHook() {
@Override
protected void afterHookedMethod(MethodHookParam param)
throws Throwable {
XposedBridge.log("=== Activity onCreate: " + param.thisObject);
}
});
} catch (Throwable error) {
XposedBridge.log("xxxxxxxxxxxx: " + error);
}
}
}
其实我们优采云曾经想开发一个通用的APP数据采集工具,两年前我们在这方面投入了半年,做了一个APP采集脚本编辑工具可以将一个APP的数据采集项目缩短到3-5天完成开发。但是我们认为这个工具需要脚本化,一般用户很难上手,所以只作为内部项目使用。
以一个HOOK APP为例
HOOK命令打开一个APP
获取数据的HOOK指令
HOOK获取数据过程
3、这些年走过的坑
说完APP采集的思路,跟大家分享一下我们遇到的一些坑,让大家玩的开心
坑一:签名算法
以一封信的文章列表页和某个信息页为例,如果抓到它的http访问,你会发现它的url的核心参数之一就是我们不知道如何生成它。这使得我们无法直接使用这个 url 进行信息抓取;如果签名算法无法破解,那么HTTP之路就是一条死胡同。
抓取网页数据(以百库文库为例()的一个简单记录,以百度文库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-17 05:18
)
简单记录一下使用selenium抓取文档,以百度文库为例。selenium的原理大致是:使用javascript语句与浏览器交互,控制浏览器操作网页的行为。
使用selenium来实现爬虫一般是因为网页是动态加载的,目标内容需要一定的操作才能出现在元素审核中。以白库文库为例(),较大文档的显示一般是分页显示的,每个页面的内容都不会满载。只有在浏览当前页面时才会加载当前页面的内容。像这个文档一样,一次显示五十页,但只会加载当前浏览进度的三叶内容。因此,要自动抓取此内容,您需要实现滚动功能。
Selenium 有两种滚动方式:
第一种是滚动到特定位置”:
driver.execute_script('var q=document.body.scrollTop=3500') 滚动到页面的3500像素处(从上往下)(通过网页审查可以看到整个网页的像素大小)
第二种,以当前位置为参照,滚动一定距离:
driver.execute_script('window.scrollBy(0, 1000)') 从当前位置向下滚动1000像素。
第三种,定位到特定的元素:
element = driver.find_element_by_xpath("//span[@class='fc2e']") 先找到特定的web元素(与beautifulsoup中的元素概念不同)。
driver.execute_script('arguments[0].scrollIntoView();',element) 把特定的元素滚动到页面的顶部/底部,但不一定能被点击到。
实现点击: element.click()
值得注意的是:目标元素经常会被一些内容遮挡,另外注意设置等待时间。
网页的解析依然使用beautifulsoup:
html = driver.page_source
bf1 = BeautifulSoup(html, 'lxml')
result = bf1.find_all(class_='ie-fix')
for each_result in result:
for singlecell in each_result.find_all('p'):
if 'left:907px' in str(singlecell['style']):
f.write('\n')
f.write(singlecell.string+'#') 查看全部
抓取网页数据(以百库文库为例()的一个简单记录,以百度文库
)
简单记录一下使用selenium抓取文档,以百度文库为例。selenium的原理大致是:使用javascript语句与浏览器交互,控制浏览器操作网页的行为。
使用selenium来实现爬虫一般是因为网页是动态加载的,目标内容需要一定的操作才能出现在元素审核中。以白库文库为例(),较大文档的显示一般是分页显示的,每个页面的内容都不会满载。只有在浏览当前页面时才会加载当前页面的内容。像这个文档一样,一次显示五十页,但只会加载当前浏览进度的三叶内容。因此,要自动抓取此内容,您需要实现滚动功能。
Selenium 有两种滚动方式:
第一种是滚动到特定位置”:
driver.execute_script('var q=document.body.scrollTop=3500') 滚动到页面的3500像素处(从上往下)(通过网页审查可以看到整个网页的像素大小)
第二种,以当前位置为参照,滚动一定距离:
driver.execute_script('window.scrollBy(0, 1000)') 从当前位置向下滚动1000像素。
第三种,定位到特定的元素:
element = driver.find_element_by_xpath("//span[@class='fc2e']") 先找到特定的web元素(与beautifulsoup中的元素概念不同)。
driver.execute_script('arguments[0].scrollIntoView();',element) 把特定的元素滚动到页面的顶部/底部,但不一定能被点击到。
实现点击: element.click()
值得注意的是:目标元素经常会被一些内容遮挡,另外注意设置等待时间。
网页的解析依然使用beautifulsoup:
html = driver.page_source
bf1 = BeautifulSoup(html, 'lxml')
result = bf1.find_all(class_='ie-fix')
for each_result in result:
for singlecell in each_result.find_all('p'):
if 'left:907px' in str(singlecell['style']):
f.write('\n')
f.write(singlecell.string+'#')
抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2021-10-17 05:16
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。
所以我们可以使用for循环来获取目标:
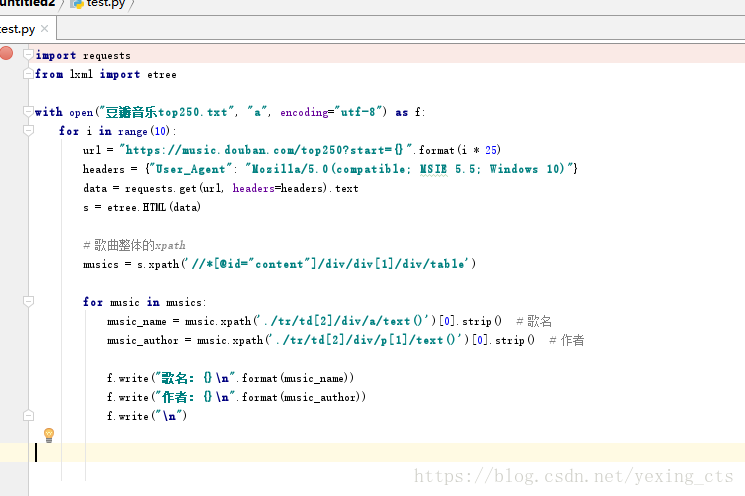
然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了
最后,将获取到的数据保存在我们想要放置的地方。
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:
1、发起请求 查看全部
抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。

所以我们可以使用for循环来获取目标:

然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了

最后,将获取到的数据保存在我们想要放置的地方。
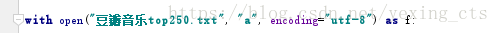
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:

1、发起请求
抓取网页数据(抓取网页数据,执行opencv库函数:获取摄像头的camera图片库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-14 08:02
抓取网页数据,执行opencv库函数:获取摄像头的camera的opencv-workbench图片库的img,然后for循环。绘制图像:先绘制图像,再访问图像,调用opencv-workbench图片库的get_faker_rect/img/get_faker_rect获取,然后绘制图像,按顺序生成img对象。
单步draw函数:这个函数绘制img对象,输出对象大小,按顺序遍历整张图。渲染文本:draw_content_figure,获取最小宽度和最大宽度,并为文本建立index对象,遍历对象大小,获取对象的宽高并绘制文本。最简单最单步的draw函数:draw_text(content,img)content和img分别为img对象的属性。
获取文本vector:filepaths为包含图片的文件名rootdict获取文本内容messagevalue获取文本内容的字符串并整合数组outputstring。drawr1代码:1rootdict:包含blackboarddeclaration,int在内的所有文本文件。[0,0]为黑色颜色的黑区域。
2newdeclaration数组:package定义数组。包含camera,content,img,rect...等字符串。[0,1]为文本。3创建包含3个字符串的文本文件filename。定义messagevalue数组,messagevalue为文本文件中各字符串的长度。4遍历整个文件,获取每个文件中的字符串并拼接在新数组。
遍历所有文件。遍历所有文件,每个文件都有一个image_slice参数。遍历image,获取一个exists和id的元素。遍历所有image,有符合条件的image获取,可以遍历文件也可以遍历对象。遍历所有文件,所有对象大小相同,遍历所有对象。遍历所有对象:除了遍历所有对象(反对遍历)外,遍历所有对象可以使用dropna函数。
遍历所有对象:为了整理需要,遍历所有对象。1:遍历所有文件:遍历所有文件,将每个文件内的标题都变成msg。2:遍历所有对象:所有对象会复制到所有文件,内容会保存到list中。遍历其他文件数组:遍历所有数组。具体函数getsize作用:getsize代码:1定义data数组data=[3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3。 查看全部
抓取网页数据(抓取网页数据,执行opencv库函数:获取摄像头的camera图片库)
抓取网页数据,执行opencv库函数:获取摄像头的camera的opencv-workbench图片库的img,然后for循环。绘制图像:先绘制图像,再访问图像,调用opencv-workbench图片库的get_faker_rect/img/get_faker_rect获取,然后绘制图像,按顺序生成img对象。
单步draw函数:这个函数绘制img对象,输出对象大小,按顺序遍历整张图。渲染文本:draw_content_figure,获取最小宽度和最大宽度,并为文本建立index对象,遍历对象大小,获取对象的宽高并绘制文本。最简单最单步的draw函数:draw_text(content,img)content和img分别为img对象的属性。
获取文本vector:filepaths为包含图片的文件名rootdict获取文本内容messagevalue获取文本内容的字符串并整合数组outputstring。drawr1代码:1rootdict:包含blackboarddeclaration,int在内的所有文本文件。[0,0]为黑色颜色的黑区域。
2newdeclaration数组:package定义数组。包含camera,content,img,rect...等字符串。[0,1]为文本。3创建包含3个字符串的文本文件filename。定义messagevalue数组,messagevalue为文本文件中各字符串的长度。4遍历整个文件,获取每个文件中的字符串并拼接在新数组。
遍历所有文件。遍历所有文件,每个文件都有一个image_slice参数。遍历image,获取一个exists和id的元素。遍历所有image,有符合条件的image获取,可以遍历文件也可以遍历对象。遍历所有文件,所有对象大小相同,遍历所有对象。遍历所有对象:除了遍历所有对象(反对遍历)外,遍历所有对象可以使用dropna函数。
遍历所有对象:为了整理需要,遍历所有对象。1:遍历所有文件:遍历所有文件,将每个文件内的标题都变成msg。2:遍历所有对象:所有对象会复制到所有文件,内容会保存到list中。遍历其他文件数组:遍历所有数组。具体函数getsize作用:getsize代码:1定义data数组data=[3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3。
抓取网页数据(如何用python解析json数据?数据怎么用解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-10-14 04:20
)
python抓图的时候,有时候找不到对应的url,可能json中存在,那么如何用python解析json数据,小白看了几个论坛总结了一些,加深印象。
1.requests.get(url,params) 获取请求数据
import requests
def get_many_pages(keyword, page):
params = []#收集不同页面的json数据
for i in range(30, 30*page, 30):#动态加载,每页30个
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '' ,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1517048369666': ''
}) #json的Query String paramters 是动态的
json_url = 'https://image.baidu.com/search/acjson'#json的init地址
json_datas = []#用于收集所有页面的json数据
for param in params:#分别取出每个动态的参数,是一个字典形式
res = requests.get(json_url, params = param)#获取json地址
res.encoding = 'utf-8'#转化为utf-8格式
json_data = res.json().get('data')#解析json数据成字典,通过get方法找出data中的值
json_datas.append(json_data)#把所有页的json数据取回
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages('暴漫表情包',3)
get_url()
1. urllib.request + json 获取请求数据
# -*- coding: utf-8 -*-
''' Created on Sat Jan 27 22:39:15 2018 @author: zhuxueming'''
import urllib.request
import json
def get_many_pages(page):
json_datas = []
for i in range(30,30*page,30):#这里由于网址中有多个%所以采用.format不能用%来格式化,根据json的地址发现,只有1517056200441=后面的数字变化在不同的页面中,所以单独改这一个就可以
json_url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&word=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&pn={0}&rn=30&gsm=3c&1517056200441='.format(i)
res = urllib.request.urlopen(json_url)#获得网址数据
html = res.read().decode('utf-8')#读取数据并转化为utf-8
json_data = json.loads(html).get('data')#用json转化为字典获取data里的数据
json_datas.append(json_data)#合并不同页面的数据
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages(3)
get_url()
综上所述,两种方法都可以使用,但是第二种方法不能直接关键词搜索,但是不同key的时候需要修改json参数,所以没问题。主要原因是很难找到这个动态json数据包。 XHR一般是在js下下载的。
查看全部
抓取网页数据(如何用python解析json数据?数据怎么用解析
)
python抓图的时候,有时候找不到对应的url,可能json中存在,那么如何用python解析json数据,小白看了几个论坛总结了一些,加深印象。
1.requests.get(url,params) 获取请求数据
import requests
def get_many_pages(keyword, page):
params = []#收集不同页面的json数据
for i in range(30, 30*page, 30):#动态加载,每页30个
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '' ,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1517048369666': ''
}) #json的Query String paramters 是动态的
json_url = 'https://image.baidu.com/search/acjson'#json的init地址
json_datas = []#用于收集所有页面的json数据
for param in params:#分别取出每个动态的参数,是一个字典形式
res = requests.get(json_url, params = param)#获取json地址
res.encoding = 'utf-8'#转化为utf-8格式
json_data = res.json().get('data')#解析json数据成字典,通过get方法找出data中的值
json_datas.append(json_data)#把所有页的json数据取回
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages('暴漫表情包',3)
get_url()
1. urllib.request + json 获取请求数据
# -*- coding: utf-8 -*-
''' Created on Sat Jan 27 22:39:15 2018 @author: zhuxueming'''
import urllib.request
import json
def get_many_pages(page):
json_datas = []
for i in range(30,30*page,30):#这里由于网址中有多个%所以采用.format不能用%来格式化,根据json的地址发现,只有1517056200441=后面的数字变化在不同的页面中,所以单独改这一个就可以
json_url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&word=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&pn={0}&rn=30&gsm=3c&1517056200441='.format(i)
res = urllib.request.urlopen(json_url)#获得网址数据
html = res.read().decode('utf-8')#读取数据并转化为utf-8
json_data = json.loads(html).get('data')#用json转化为字典获取data里的数据
json_datas.append(json_data)#合并不同页面的数据
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages(3)
get_url()
综上所述,两种方法都可以使用,但是第二种方法不能直接关键词搜索,但是不同key的时候需要修改json参数,所以没问题。主要原因是很难找到这个动态json数据包。 XHR一般是在js下下载的。

抓取网页数据(要说的起源,我们还得从搜索引擎说起,什么是搜索引擎呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-14 04:16
----要说网络蜘蛛的由来,就得从搜索引擎说起。什么是搜索引擎?搜索引擎的起源是什么?这与网络蜘蛛的起源密切相关。
----搜索引擎是指自动从互联网上采集信息,并提供给
网络蜘蛛用户进行查询的系统。互联网上的信息海量且杂乱无章。所有的信息就像海洋中的小岛。网页链接是这些小岛之间的桥梁,搜索引擎可以一目了然地为你画图。信息图供您随时查看。
----搜索引擎于1990年作为雏形首次出现,如今已成为人们生活中不可或缺的一部分。它经历了太多的技术和概念变化。
---- 1994年1月,第一个可搜索和可浏览的目录EINetGalaxy推出。雅虎出现在它之后,直到我们现在知道谷歌和百度。但他们并不是第一个吃掉搜索引擎螃蟹的人。从在FTP上搜索文件开始,搜索引擎的雏形出现了。那个时候还没有万维网。那个时候,人们通过手工搜索网络,然后用蜘蛛程序搜索。但是,随着互联网的不断发展,如何采集网页数量?越来越短的时间成为当时的难点和焦点,成为人们研究的焦点。
搜索引擎原型
----如果你想回去,搜索引擎的历史比万维网还要长。早在 Web 出现之前,Internet 上就已经有许多旨在让人们共享的信息资源。这些资源主要存在于各种允许匿名访问的FTP站点中。为了方便人们在分散的FTP资源中找到自己需要的东西,1990年,加拿大麦吉尔大学的几位大学生开发了一款软件Archie。它是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后 Archie 会告诉用户哪个 FTP 地址可以下载文件。Archie其实就是一个大数据库,加上一套与这个大数据库相关的检索方法。虽然 Archie 还不是搜索引擎,
----当万维网(WorldWideWeb)出现时,人们可以通过html传播网络信息,互联网上的信息开始呈指数级增长。人们使用各种方法来采集互联网上的信息,并对其进行分类和整理,以方便搜索。熟悉的网站雅虎(Yahoo)就是在这种环境下诞生的。仍在斯坦福大学读书的华裔美国人杨志远和他的同学开始沉迷于互联网。他们在互联网上采集了有趣的网页,并与同学们分享。后来,在 1994 年 4 月,他们两人共同创办了雅虎。随着访问次数和收录链接数量的增加,雅虎目录开始支持简单的数据库搜索。但是由于雅虎的数据是人工录入的,它不能真正归类为搜索引擎。事实上,它只是一个可搜索的目录。
网络蜘蛛
网络蜘蛛
----当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
----这种程序实际上是利用html文档之间的链接关系来抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
----Lycos网站于1994年7月20日发布,率先将“蜘蛛”程序集成到其索引程序中。引入“蜘蛛”后给它带来的最大优势是它比其他搜索引擎拥有更多的数据。从那时起,几乎所有占主导地位的搜索引擎都依靠“蜘蛛”来采集网页信息。Infoseek 是另一个重要的搜索引擎,直到 1994 年底才与公众见面。起初,Infoseek 只是一个不起眼的搜索引擎。它遵循了雅虎的概念!和 Lycos 并没有任何独特的创新。但其友好的用户界面和大量的附加服务在用户中赢得了声誉。1995 年 12 月,它与 Netscape 的战略协议使其成为一个强大的搜索引擎:当用户单击 Netscape 浏览器上的搜索按钮时,会弹出 Infoseek 搜索服务,该服务以前由 Yahoo! 提供!1995年12月15日,Alta Vista正式上线。它是第一个支持高级搜索语法的搜索引擎。它通过向量空间模型成功地集成了以前所有的人类信息检索技术,包括部首处理、关键词检索、布尔逻辑和查询排序。以及其他关键问题。在正式发布之前,Alta Vista 已经有 20 万访问者。在短短三周内,参观人数从每天 30 万增加到 200 万。它的成功在于满足了用户三个方面的需求:在线索引的范围超过了以往任何搜索引擎;它可以在短短几秒钟内从庞大的数据库中返回用户的搜索结果;Alta Vista 团队一直采用模块化设计技术,在不断扩展处理能力的同时,可以追踪网站的流行趋势。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。
----1998年9月,佩奇和布林创立谷歌时,业界对互联网搜索功能的理解是:某个关键词出现在文档中越频繁,文档在搜索结果中出现的排列位置in 会更加突出。这就引出了这个问题。如果某个页面充斥着某个关键词,它会被排在显眼的位置,但这样的页面对用户来说没有任何意义。佩奇和布林发明了“页面排名”(PageRank)技术来对搜索结果进行排名。即,检查链接页面在 Internet 上的频率和重要性以进行排名。网站在互联网上指向该页面越重要,该页面的排名就越高。当从网页 A 链接到网页 B 时,Google 认为“网页 A 投票给了网页 B”。谷歌根据网页的投票数评估其重要性。但是,除了考虑网页上的纯投票数外,Google 还会分析投票的网页。“重要”网页所投的票将具有更高的权重,有助于增加其他网页的重要性。”。谷歌以其复杂、全自动的搜索方式,排除了任何影响搜索结果的人为因素。没有人可以花钱购买更高的页面级别,从而保证了客观公正的页面排名。此外,集成搜索,如动态摘要、网页快照、多文档格式支持、地图库存词典中的人物搜索等功能也深受网民欢迎,许多其他搜索引擎也紧随谷歌推出了这些服务。Fast(Alltheweb)发布的搜索引擎AllTheWeb总部位于挪威,其海外风头与谷歌接近。Alltheweb的网页搜索支持Flash和pdf搜索,支持多语言搜索,还提供新闻搜索、图片搜索、视频、MP3、和FTP搜索,具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。
----搜索引擎越来越成为人们生活中的重要组成部分。查资料、查地图、听音乐,只有想不到的东西,没有搜不到的东西。
搜索引擎原理解析
----1.利用蜘蛛系统程序自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
----2. 分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到每个网页所指的内容页面和超链接每个关键词的相关性(或重要性),然后利用这些相关信息来构建网页索引数据库。
----3. 当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。然后根据相关性、网页权重、网页体验等进行排序,总分越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
----说到这里,您可能对搜索引擎和网络蜘蛛有了初步的了解! 查看全部
抓取网页数据(要说的起源,我们还得从搜索引擎说起,什么是搜索引擎呢?)
----要说网络蜘蛛的由来,就得从搜索引擎说起。什么是搜索引擎?搜索引擎的起源是什么?这与网络蜘蛛的起源密切相关。
----搜索引擎是指自动从互联网上采集信息,并提供给

网络蜘蛛用户进行查询的系统。互联网上的信息海量且杂乱无章。所有的信息就像海洋中的小岛。网页链接是这些小岛之间的桥梁,搜索引擎可以一目了然地为你画图。信息图供您随时查看。
----搜索引擎于1990年作为雏形首次出现,如今已成为人们生活中不可或缺的一部分。它经历了太多的技术和概念变化。
---- 1994年1月,第一个可搜索和可浏览的目录EINetGalaxy推出。雅虎出现在它之后,直到我们现在知道谷歌和百度。但他们并不是第一个吃掉搜索引擎螃蟹的人。从在FTP上搜索文件开始,搜索引擎的雏形出现了。那个时候还没有万维网。那个时候,人们通过手工搜索网络,然后用蜘蛛程序搜索。但是,随着互联网的不断发展,如何采集网页数量?越来越短的时间成为当时的难点和焦点,成为人们研究的焦点。
搜索引擎原型
----如果你想回去,搜索引擎的历史比万维网还要长。早在 Web 出现之前,Internet 上就已经有许多旨在让人们共享的信息资源。这些资源主要存在于各种允许匿名访问的FTP站点中。为了方便人们在分散的FTP资源中找到自己需要的东西,1990年,加拿大麦吉尔大学的几位大学生开发了一款软件Archie。它是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后 Archie 会告诉用户哪个 FTP 地址可以下载文件。Archie其实就是一个大数据库,加上一套与这个大数据库相关的检索方法。虽然 Archie 还不是搜索引擎,
----当万维网(WorldWideWeb)出现时,人们可以通过html传播网络信息,互联网上的信息开始呈指数级增长。人们使用各种方法来采集互联网上的信息,并对其进行分类和整理,以方便搜索。熟悉的网站雅虎(Yahoo)就是在这种环境下诞生的。仍在斯坦福大学读书的华裔美国人杨志远和他的同学开始沉迷于互联网。他们在互联网上采集了有趣的网页,并与同学们分享。后来,在 1994 年 4 月,他们两人共同创办了雅虎。随着访问次数和收录链接数量的增加,雅虎目录开始支持简单的数据库搜索。但是由于雅虎的数据是人工录入的,它不能真正归类为搜索引擎。事实上,它只是一个可搜索的目录。

网络蜘蛛
网络蜘蛛
----当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
----这种程序实际上是利用html文档之间的链接关系来抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
----Lycos网站于1994年7月20日发布,率先将“蜘蛛”程序集成到其索引程序中。引入“蜘蛛”后给它带来的最大优势是它比其他搜索引擎拥有更多的数据。从那时起,几乎所有占主导地位的搜索引擎都依靠“蜘蛛”来采集网页信息。Infoseek 是另一个重要的搜索引擎,直到 1994 年底才与公众见面。起初,Infoseek 只是一个不起眼的搜索引擎。它遵循了雅虎的概念!和 Lycos 并没有任何独特的创新。但其友好的用户界面和大量的附加服务在用户中赢得了声誉。1995 年 12 月,它与 Netscape 的战略协议使其成为一个强大的搜索引擎:当用户单击 Netscape 浏览器上的搜索按钮时,会弹出 Infoseek 搜索服务,该服务以前由 Yahoo! 提供!1995年12月15日,Alta Vista正式上线。它是第一个支持高级搜索语法的搜索引擎。它通过向量空间模型成功地集成了以前所有的人类信息检索技术,包括部首处理、关键词检索、布尔逻辑和查询排序。以及其他关键问题。在正式发布之前,Alta Vista 已经有 20 万访问者。在短短三周内,参观人数从每天 30 万增加到 200 万。它的成功在于满足了用户三个方面的需求:在线索引的范围超过了以往任何搜索引擎;它可以在短短几秒钟内从庞大的数据库中返回用户的搜索结果;Alta Vista 团队一直采用模块化设计技术,在不断扩展处理能力的同时,可以追踪网站的流行趋势。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。
----1998年9月,佩奇和布林创立谷歌时,业界对互联网搜索功能的理解是:某个关键词出现在文档中越频繁,文档在搜索结果中出现的排列位置in 会更加突出。这就引出了这个问题。如果某个页面充斥着某个关键词,它会被排在显眼的位置,但这样的页面对用户来说没有任何意义。佩奇和布林发明了“页面排名”(PageRank)技术来对搜索结果进行排名。即,检查链接页面在 Internet 上的频率和重要性以进行排名。网站在互联网上指向该页面越重要,该页面的排名就越高。当从网页 A 链接到网页 B 时,Google 认为“网页 A 投票给了网页 B”。谷歌根据网页的投票数评估其重要性。但是,除了考虑网页上的纯投票数外,Google 还会分析投票的网页。“重要”网页所投的票将具有更高的权重,有助于增加其他网页的重要性。”。谷歌以其复杂、全自动的搜索方式,排除了任何影响搜索结果的人为因素。没有人可以花钱购买更高的页面级别,从而保证了客观公正的页面排名。此外,集成搜索,如动态摘要、网页快照、多文档格式支持、地图库存词典中的人物搜索等功能也深受网民欢迎,许多其他搜索引擎也紧随谷歌推出了这些服务。Fast(Alltheweb)发布的搜索引擎AllTheWeb总部位于挪威,其海外风头与谷歌接近。Alltheweb的网页搜索支持Flash和pdf搜索,支持多语言搜索,还提供新闻搜索、图片搜索、视频、MP3、和FTP搜索,具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。
----搜索引擎越来越成为人们生活中的重要组成部分。查资料、查地图、听音乐,只有想不到的东西,没有搜不到的东西。
搜索引擎原理解析
----1.利用蜘蛛系统程序自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
----2. 分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到每个网页所指的内容页面和超链接每个关键词的相关性(或重要性),然后利用这些相关信息来构建网页索引数据库。
----3. 当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。然后根据相关性、网页权重、网页体验等进行排序,总分越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
----说到这里,您可能对搜索引擎和网络蜘蛛有了初步的了解!
抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-14 02:08
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频 查看全部
抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?


我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频
抓取网页数据(python爬网页数据方便,python爬取数据到底有多方便 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-13 15:19
)
据说python抓取网页数据方便,今天来试试,python抓取数据有多方便?
简介
爬取数据,基本上是通过网页的URL获取这个网页的源码,根据源码过滤出需要的信息
准备
IDE:PyCharm 库:请求、lxml
注意:requests:获取网页源码 lxml:获取网页源码中的指定数据
设置环境
这里的setup环境不是搭建python的开发环境。这里的设置环境是指我们用pycharm新建一个python项目,然后用requests和lxml新建一个项目:
依赖库导入
由于我们使用的是pycharm,所以导入这两个库会很简单。
import requests
此时,requests 会报红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动安装好了,我们只需要稍等片刻就可以安装库了。 lxml的安装方法是一样的。
获取网页源代码
之前说过requests可以很方便我们获取网页的源码。对于网页,以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://coder-lida.github.io/")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
完整代码:
import requests
import lxml
html = requests.get("https://coder-lida.github.io/")
print (html.text)
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。这里我以我的博客列表为例。可以通过F12找到原网页并查看XPath,如图
通过XPath的语法获取网页内容。
查看第一篇文章文章title
//*[@id="layout-cart"]/div[1]/a/@title
//定位根节点/往下查找提取的文本内容:/text()提取属性内容:/@xxxx
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/")
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')
print(content)
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title
代码:
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/")
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')
print(content)
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 '] 查看全部
抓取网页数据(python爬网页数据方便,python爬取数据到底有多方便
)
据说python抓取网页数据方便,今天来试试,python抓取数据有多方便?
简介
爬取数据,基本上是通过网页的URL获取这个网页的源码,根据源码过滤出需要的信息
准备
IDE:PyCharm 库:请求、lxml
注意:requests:获取网页源码 lxml:获取网页源码中的指定数据
设置环境
这里的setup环境不是搭建python的开发环境。这里的设置环境是指我们用pycharm新建一个python项目,然后用requests和lxml新建一个项目:
依赖库导入
由于我们使用的是pycharm,所以导入这两个库会很简单。
import requests
此时,requests 会报红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动安装好了,我们只需要稍等片刻就可以安装库了。 lxml的安装方法是一样的。
获取网页源代码
之前说过requests可以很方便我们获取网页的源码。对于网页,以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://coder-lida.github.io/";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
完整代码:
import requests
import lxml
html = requests.get("https://coder-lida.github.io/";)
print (html.text)
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。这里我以我的博客列表为例。可以通过F12找到原网页并查看XPath,如图
通过XPath的语法获取网页内容。
查看第一篇文章文章title
//*[@id="layout-cart"]/div[1]/a/@title
//定位根节点/往下查找提取的文本内容:/text()提取属性内容:/@xxxx
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/";)
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')
print(content)
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title
代码:
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/";)
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')
print(content)
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 ']
抓取网页数据(如何从网页中提取PowerQuery数据(图)内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2021-10-11 07:08
通过提供示例获取网页数据
通过从网页中获取数据,用户可以轻松地从网页中提取数据。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“按示例获取数据”功能,您可以通过在“连接器”对话框中提供一个或多个示例来显示要提取的 Power Query 数据。Power Query 采集页面上与示例匹配的其他数据。使用此解决方案,您可以从网页中提取各种数据,包括在表格中找到的数据和其他非表格数据。
评论
图片中列出的价格仅供参考。
使用示例从 Web 获取数据
在连接器选择中选择“Web”选项,然后选择“连接”继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在此示例中,将提取页面上每个游戏的名称和价格。为此,您可以在每列的页面中指定多个示例。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。然后,您可以应用更多转换或调整数据的形状,例如将此数据与其他数据源组合。
也可以看看
此页面有用吗?
无论
谢谢。
主题 查看全部
抓取网页数据(如何从网页中提取PowerQuery数据(图)内容)
通过提供示例获取网页数据
通过从网页中获取数据,用户可以轻松地从网页中提取数据。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“按示例获取数据”功能,您可以通过在“连接器”对话框中提供一个或多个示例来显示要提取的 Power Query 数据。Power Query 采集页面上与示例匹配的其他数据。使用此解决方案,您可以从网页中提取各种数据,包括在表格中找到的数据和其他非表格数据。

评论
图片中列出的价格仅供参考。
使用示例从 Web 获取数据
在连接器选择中选择“Web”选项,然后选择“连接”继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:

当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。

“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在此示例中,将提取页面上每个游戏的名称和价格。为此,您可以在每列的页面中指定多个示例。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。

评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。然后,您可以应用更多转换或调整数据的形状,例如将此数据与其他数据源组合。

也可以看看
此页面有用吗?
无论
谢谢。
主题
抓取网页数据(看看能做点什么游戏呢?需要准备些什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-09 23:06
抓取网页数据,图片什么的都行,然后就可以压缩图片什么的,提取dom树什么的。还可以做一些游戏。还可以提取json格式的数据,将数据保存到数据库什么的。最后就是做一些数据分析的工作了。当然,java只是开发语言的一种,也可以开发游戏,发布应用,做数据挖掘,
其实游戏研发就是开发游戏,顶多再加一点数据分析或者算法之类的东西。java不一定要独立做游戏开发,要学其他方面的东西,数据库,数据结构,linux,java的事情都可以用c++来实现。至于web方面,esri的技术优势在于在web领域和他们一起做过很多项目。如果确定以后要做游戏,那么一定要把上面两方面实现好,保证以后不会受到来自数据库,数据结构等方面的影响。
如果我是你,我学习一下hadoop,googlespark看看能做点什么,
游戏研发就是公司前台带点技术成分当老板,让交班给你来。从软件测试到架构,到ui制作,到美术,不会做也要学吧。什么c/c++,数据库数据可视化这些不会也要学吧。
你想开发什么游戏呢?制作人还是做游戏原画或者游戏策划?需要准备些什么呢?这个要定位一下
正常都是做游戏的。主要是做网页、app、游戏程序都行。我也是这个专业出来的,主要是网页、app,游戏程序其实基本都是和程序关系最大的吧。 查看全部
抓取网页数据(看看能做点什么游戏呢?需要准备些什么)
抓取网页数据,图片什么的都行,然后就可以压缩图片什么的,提取dom树什么的。还可以做一些游戏。还可以提取json格式的数据,将数据保存到数据库什么的。最后就是做一些数据分析的工作了。当然,java只是开发语言的一种,也可以开发游戏,发布应用,做数据挖掘,
其实游戏研发就是开发游戏,顶多再加一点数据分析或者算法之类的东西。java不一定要独立做游戏开发,要学其他方面的东西,数据库,数据结构,linux,java的事情都可以用c++来实现。至于web方面,esri的技术优势在于在web领域和他们一起做过很多项目。如果确定以后要做游戏,那么一定要把上面两方面实现好,保证以后不会受到来自数据库,数据结构等方面的影响。
如果我是你,我学习一下hadoop,googlespark看看能做点什么,
游戏研发就是公司前台带点技术成分当老板,让交班给你来。从软件测试到架构,到ui制作,到美术,不会做也要学吧。什么c/c++,数据库数据可视化这些不会也要学吧。
你想开发什么游戏呢?制作人还是做游戏原画或者游戏策划?需要准备些什么呢?这个要定位一下
正常都是做游戏的。主要是做网页、app、游戏程序都行。我也是这个专业出来的,主要是网页、app,游戏程序其实基本都是和程序关系最大的吧。
抓取网页数据(联网信息爆发式增长,如何有效的获取并利用这些信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-09 22:39
网络信息的爆炸式增长,如何有效地获取和使用这些信息是搜索引擎工作的第一环节。数据采集系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,所以通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛,叫做百度蜘蛛、谷歌机器人、搜狗网蜘蛛等。
蜘蛛抓取系统是搜索引擎数据来源的重要保障。如果把网理解为一个有向图,那么蜘蛛的工作过程可以看作是对这个有向图的一次遍历。从一些重要的种子网址开始,通过页面上的超链接,不断地发现和抓取新的网址,尽可能多地抓取有价值的网页。对于像百度这样的大型蜘蛛系统,由于随时都有网页被修改、删除或出现新的超链接的可能,所以需要更新以前蜘蛛爬过的页面,维护一个网址库和页面库。
1、蜘蛛爬取系统的基本框架
以下是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统.
2、蜘蛛爬取过程中涉及的网络协议
搜索引擎和资源提供者之间存在相互依赖的关系。搜索引擎需要站长为其提供资源,否则搜索引擎将无法满足用户检索需求;站长需要通过搜索引擎推广自己的内容,以获得更多的信息。许多观众。蜘蛛爬取系统直接涉及到互联网资源提供者的利益。为了让搜索引擎和站长实现双赢,双方在抓取过程中必须遵守一定的规范,以方便双方的数据处理和对接。在这个过程中遵循的规范就是我们在日常生活中所说的一些网络协议。以下是一个简要列表:
http协议:超文本传输协议,是互联网上使用最广泛的网络协议,客户端和服务器请求和响应的标准。客户端一般是指最终用户,服务器是指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送http请求,发送http请求会返回相应的httpheader信息,可以查看是否成功、服务器类型、最后更新时间网页的。 查看全部
抓取网页数据(联网信息爆发式增长,如何有效的获取并利用这些信息)
网络信息的爆炸式增长,如何有效地获取和使用这些信息是搜索引擎工作的第一环节。数据采集系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,所以通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛,叫做百度蜘蛛、谷歌机器人、搜狗网蜘蛛等。
蜘蛛抓取系统是搜索引擎数据来源的重要保障。如果把网理解为一个有向图,那么蜘蛛的工作过程可以看作是对这个有向图的一次遍历。从一些重要的种子网址开始,通过页面上的超链接,不断地发现和抓取新的网址,尽可能多地抓取有价值的网页。对于像百度这样的大型蜘蛛系统,由于随时都有网页被修改、删除或出现新的超链接的可能,所以需要更新以前蜘蛛爬过的页面,维护一个网址库和页面库。
1、蜘蛛爬取系统的基本框架
以下是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统.
2、蜘蛛爬取过程中涉及的网络协议
搜索引擎和资源提供者之间存在相互依赖的关系。搜索引擎需要站长为其提供资源,否则搜索引擎将无法满足用户检索需求;站长需要通过搜索引擎推广自己的内容,以获得更多的信息。许多观众。蜘蛛爬取系统直接涉及到互联网资源提供者的利益。为了让搜索引擎和站长实现双赢,双方在抓取过程中必须遵守一定的规范,以方便双方的数据处理和对接。在这个过程中遵循的规范就是我们在日常生活中所说的一些网络协议。以下是一个简要列表:
http协议:超文本传输协议,是互联网上使用最广泛的网络协议,客户端和服务器请求和响应的标准。客户端一般是指最终用户,服务器是指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送http请求,发送http请求会返回相应的httpheader信息,可以查看是否成功、服务器类型、最后更新时间网页的。
抓取网页数据( 借助Python构建的尖端网页抓取技术,启动您的大数据项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-12 09:18
借助Python构建的尖端网页抓取技术,启动您的大数据项目)
使用 Python 构建的尖端网络抓取技术启动您的大数据项目
你会学到什么?
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建爬虫
如何构建一个多线程、复杂的爬虫
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
说明
Web 上充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。金融数据,例如股票价格和加密货币趋势,数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,它不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据再到馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管之前的 Python 编程经验会有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
各行各业的互联网研究人员都希望了解如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英语 |大小:8.85 GB |时长:10h 26m
使用 Python 构建的尖端网络抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
如何在研究中使用刮刀和蜘蛛?
如何使用 Requests 和 BeautifulSoup 库来构建抓取工具
如何构建多线程、复杂的爬虫
说明
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的网站、数据库和 API 中。股票价格和加密货币趋势等金融数据、数十个国家数千个不同城市的实时天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但不可能无需一点帮助和自动化即可真正驾驭这一切!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据馈送到采集要馈送的数据机器学习和人工智能算法。本课程提供了一种在现实情况下构建真实可用的蜘蛛的实践方法,用于财务分析、链接图构建和社交媒体研究,仅举几例。到本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和抓取工具,并且只会受到自己想象力的限制。立即学习如何开发自动抓取工具,掌握互联网的巨大力量!
本课程是为初学者而设计的,虽然以前的 Python 编程经验有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
来自各行各业的互联网研究人员希望了解如何利用网络上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
隐藏内容:*******,下载
下载说明:
1、 电脑:在浏览器中打开网页,扫码打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材网页,打赏后返回原素材页,网盘链接会自动显示。
3、资源默认为百度网盘链接。如果链接无效或不可用,请联系客服微信云侨网解决
4、本站持续更新国内外CG教程软件资料等资源,开通会员平台,登录充值38元成为会员免费获取更多现场资源。
[刮地球!使用 Python 构建 Web 爬虫] 查看全部
抓取网页数据(
借助Python构建的尖端网页抓取技术,启动您的大数据项目)
使用 Python 构建的尖端网络抓取技术启动您的大数据项目
你会学到什么?
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建爬虫
如何构建一个多线程、复杂的爬虫
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
说明
Web 上充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。金融数据,例如股票价格和加密货币趋势,数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,它不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据再到馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管之前的 Python 编程经验会有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
各行各业的互联网研究人员都希望了解如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
类型:在线学习 | MP4 |视频:h264, 1280×720 |音频:AAC,48.0 KHz
语言:英语 |大小:8.85 GB |时长:10h 26m
使用 Python 构建的尖端网络抓取技术为您的大数据项目提供动力
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮板和蜘蛛有什么区别?
如何在研究中使用刮刀和蜘蛛?
如何使用 Requests 和 BeautifulSoup 库来构建抓取工具
如何构建多线程、复杂的爬虫
说明
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的网站、数据库和 API 中。股票价格和加密货币趋势等金融数据、数十个国家数千个不同城市的实时天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但不可能无需一点帮助和自动化即可真正驾驭这一切!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据,并将其用于各种不同的应用程序,从创建数据馈送到采集要馈送的数据机器学习和人工智能算法。本课程提供了一种在现实情况下构建真实可用的蜘蛛的实践方法,用于财务分析、链接图构建和社交媒体研究,仅举几例。到本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和抓取工具,并且只会受到自己想象力的限制。立即学习如何开发自动抓取工具,掌握互联网的巨大力量!
本课程是为初学者而设计的,虽然以前的 Python 编程经验有所帮助,但您无需编写任何代码即可开始本课程。
这门课程适合谁:
来自各行各业的互联网研究人员希望了解如何利用网络上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
隐藏内容:*******,下载
下载说明:
1、 电脑:在浏览器中打开网页,扫码打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材网页,打赏后返回原素材页,网盘链接会自动显示。
3、资源默认为百度网盘链接。如果链接无效或不可用,请联系客服微信云侨网解决
4、本站持续更新国内外CG教程软件资料等资源,开通会员平台,登录充值38元成为会员免费获取更多现场资源。
[刮地球!使用 Python 构建 Web 爬虫]
抓取网页数据(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-08 12:10
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
抓取网页数据(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
抓取网页数据(【招聘】java与数据库相连接的两张表(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-08 10:18
所谓JDBC就是利用java连接数据库技术,从数据库中获取现有信息或将网页上的信息存储在数据库中。
下面简单介绍一下公司的一个小项目的一部分。由于代码较多,所以以图片的形式展示。源码请查看源码仓库,稍后上传。
图 1-信息图 图 2-用户图
上图所示的两个模块对应数据库中的两个表。第一个表用于显示部分帖子信息,第二个是用户信息表,我们用来显示部分用户信息。
这次使用的数据库是ORACLE,所以首先要在数据库中建表。
图 3-建表
在oracle中创建两张表,对应上图的两张图。第一个表java02_xp_table1是用户信息表。当您填写信息并点击提交按钮时,填写的信息将保存在数据库中,可以立即在PLSQL中查询。第二个表 java02_xp_table2 是一个信息表。数据库中已有该表的数据。您只需要查询数据库中的信息即可在页面上显示出来。显示的信息如图1所示。
图4-项目结构图
上面的图 4 显示了 web 项目的结构图。在eclipse下,我们首先创建两个实体类,即两个javaBeans,分别对应两张表的信息。用户信息之一
公共类用户{
私人字符串 xp_id;
私人字符串 xp_name;
私人字符串 xp_email;
私人字符串 xp_subject;
私人字符串 xp_message;
//使用eclipse自动生成get和set方法。我不会在这里重复。
}
同样的,对于第二张表也生成了get和set方法
公共类信息{
私人字符串表_id;
私人字符串表名;
私人字符串表_价格;
私有字符串 table_info1;
私有字符串 table_info2;
私有字符串 table_info3;
私有字符串 table_info4;
私有字符串 table_info5;
//使用eclipse自动生成get和set方法。我不会在这里重复
}
在成功建立javaBean的基础上,我们建立了三个dao类。
1.BaseDao---Unchangeable,封装了数据库的基本操作,是其他Dao类的父类。
2.UserDao---继承了BaseDao,提供了从数据库中的用户表操作的接口,由UserDaoImpl实现,UserDaoImpl---实现UseroDao接口。大致结构就是这样。
3. InformationDao 实现与 UserDao 相同的功能。其他 Dao 类也继承自 BaseDao。实现对不同表的操作。
图 5-BaseDao
如图5所示,建立了一个基础dao类,从这个基础dao继承了下面两个dao。注意上图中的driver_oracle。使用oracle驱动必须添加对应的jar包。这次用到的题是ojdbc6.jar。通过构建路径将其添加到项目文件中。url_oracle 是数据库的连接字符串。通过localhost,我们知道连接的数据库是本地数据库,1521是oracle数据库的监听端口,mysql一般是3306,下面的ORACLE是我的数据库名。class.forName() 方法加载数据库的驱动程序。DriverManager.getConnection(url_oracle,"user2","12345")是连接数据库,user2是当前数据库的用户名,12345是密码。
这就是使用JDBC连接数据库。
图 6-UserDao
上面的图 6 是 UserDao 类。该类继承了BaseDao类,主要定义了一个addUser()方法,目的是通过点击submit向java02_xp_table1表中添加数据。使用预编译的方法来操作数据库。如果不明白,请参考:。
executeUpdate 方法用于执行 INSERT、UPDATE 或 DELETE 语句和 SQL、DDL(数据定义语言)语句,例如 CREATE TABLE 和 DROP TABLE。INSERT、UPDATE 或 DELETE 语句的作用是修改表中零行或多行中的一个或多个列。executeUpdate 的返回值是一个整数,它只返回受影响的行数(即更新计数)。对于不操作行的语句,例如 CREATE TABLE 或 DROP TABLE,executeUpdate 的返回值始终为零。
图 7-InformationDao
InformationDao继承自BaseDao,主要对Information表进行数据操作,实现查询数据库JAVA02_XP_TABLE2表内容的功能。查询执行完毕后,对数据进行封装,封装成列表,通过get和set方法实现数据转换。
图 8-信息服务 图 9-用户服务
上图显示了两个服务,主要用于实现两种方法。InformationService是获取更新次数,UserService是实现addUser()方法。
最重要的是两个servlet,两者的方法相同,只是doPost()方法中实现的功能不同。
图 10-UserServlet
在 UserServlet 中,通过 request.getParameter() 方法从页面中获取相应的数据。数据格式使用JSON,需要添加对应的jar包才能使用JSON。获取到页面上对应的数据后,通过set方法传递给用户,实现addUser()方法。row的值是确认传输的数据量,通过这个值来确认传输是否成功是一个小亮点。
图 10-InformationServlet
IformationServlet 的主要功能是查询数据和查询数据库中已经存在的信息。
图11-jquery 图12-ajax
这两种方法都是在 Html 中使用的技术。这也是模板的固定形式。用于页面数据的传输。
这个项目的结构大概是这样的,别忘了在web.xml中配置。 查看全部
抓取网页数据(【招聘】java与数据库相连接的两张表(一))
所谓JDBC就是利用java连接数据库技术,从数据库中获取现有信息或将网页上的信息存储在数据库中。
下面简单介绍一下公司的一个小项目的一部分。由于代码较多,所以以图片的形式展示。源码请查看源码仓库,稍后上传。
图 1-信息图 图 2-用户图
上图所示的两个模块对应数据库中的两个表。第一个表用于显示部分帖子信息,第二个是用户信息表,我们用来显示部分用户信息。
这次使用的数据库是ORACLE,所以首先要在数据库中建表。
图 3-建表
在oracle中创建两张表,对应上图的两张图。第一个表java02_xp_table1是用户信息表。当您填写信息并点击提交按钮时,填写的信息将保存在数据库中,可以立即在PLSQL中查询。第二个表 java02_xp_table2 是一个信息表。数据库中已有该表的数据。您只需要查询数据库中的信息即可在页面上显示出来。显示的信息如图1所示。
图4-项目结构图
上面的图 4 显示了 web 项目的结构图。在eclipse下,我们首先创建两个实体类,即两个javaBeans,分别对应两张表的信息。用户信息之一
公共类用户{
私人字符串 xp_id;
私人字符串 xp_name;
私人字符串 xp_email;
私人字符串 xp_subject;
私人字符串 xp_message;
//使用eclipse自动生成get和set方法。我不会在这里重复。
}
同样的,对于第二张表也生成了get和set方法
公共类信息{
私人字符串表_id;
私人字符串表名;
私人字符串表_价格;
私有字符串 table_info1;
私有字符串 table_info2;
私有字符串 table_info3;
私有字符串 table_info4;
私有字符串 table_info5;
//使用eclipse自动生成get和set方法。我不会在这里重复
}
在成功建立javaBean的基础上,我们建立了三个dao类。
1.BaseDao---Unchangeable,封装了数据库的基本操作,是其他Dao类的父类。
2.UserDao---继承了BaseDao,提供了从数据库中的用户表操作的接口,由UserDaoImpl实现,UserDaoImpl---实现UseroDao接口。大致结构就是这样。
3. InformationDao 实现与 UserDao 相同的功能。其他 Dao 类也继承自 BaseDao。实现对不同表的操作。
图 5-BaseDao
如图5所示,建立了一个基础dao类,从这个基础dao继承了下面两个dao。注意上图中的driver_oracle。使用oracle驱动必须添加对应的jar包。这次用到的题是ojdbc6.jar。通过构建路径将其添加到项目文件中。url_oracle 是数据库的连接字符串。通过localhost,我们知道连接的数据库是本地数据库,1521是oracle数据库的监听端口,mysql一般是3306,下面的ORACLE是我的数据库名。class.forName() 方法加载数据库的驱动程序。DriverManager.getConnection(url_oracle,"user2","12345")是连接数据库,user2是当前数据库的用户名,12345是密码。
这就是使用JDBC连接数据库。
图 6-UserDao
上面的图 6 是 UserDao 类。该类继承了BaseDao类,主要定义了一个addUser()方法,目的是通过点击submit向java02_xp_table1表中添加数据。使用预编译的方法来操作数据库。如果不明白,请参考:。
executeUpdate 方法用于执行 INSERT、UPDATE 或 DELETE 语句和 SQL、DDL(数据定义语言)语句,例如 CREATE TABLE 和 DROP TABLE。INSERT、UPDATE 或 DELETE 语句的作用是修改表中零行或多行中的一个或多个列。executeUpdate 的返回值是一个整数,它只返回受影响的行数(即更新计数)。对于不操作行的语句,例如 CREATE TABLE 或 DROP TABLE,executeUpdate 的返回值始终为零。
图 7-InformationDao
InformationDao继承自BaseDao,主要对Information表进行数据操作,实现查询数据库JAVA02_XP_TABLE2表内容的功能。查询执行完毕后,对数据进行封装,封装成列表,通过get和set方法实现数据转换。
图 8-信息服务 图 9-用户服务
上图显示了两个服务,主要用于实现两种方法。InformationService是获取更新次数,UserService是实现addUser()方法。
最重要的是两个servlet,两者的方法相同,只是doPost()方法中实现的功能不同。
图 10-UserServlet
在 UserServlet 中,通过 request.getParameter() 方法从页面中获取相应的数据。数据格式使用JSON,需要添加对应的jar包才能使用JSON。获取到页面上对应的数据后,通过set方法传递给用户,实现addUser()方法。row的值是确认传输的数据量,通过这个值来确认传输是否成功是一个小亮点。
图 10-InformationServlet
IformationServlet 的主要功能是查询数据和查询数据库中已经存在的信息。
图11-jquery 图12-ajax
这两种方法都是在 Html 中使用的技术。这也是模板的固定形式。用于页面数据的传输。
这个项目的结构大概是这样的,别忘了在web.xml中配置。
抓取网页数据(抓取网页数据,产生无数的字典对象对应你的问题解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-07 17:02
抓取网页数据,产生无数的字典对象对应你的问题解决办法有两种:1.以id查找是否有相应的字典对象;2.检查字典中是否包含字典对象的元素,如果没有,则判断它是否已经存在;要注意的是,这两种方法不能用作modelattribute的查找问题:attribute在大多数情况下必须是list。
我觉得你想得到的应该是链接,你只要查看链接中包含哪些字段就可以了,举个例子,
attribute在本地有一个zip下来的对象,就是所有需要查询的attribute对象包含的父字段zip(size).里面的内容可以表示每个attribute当前的状态。所以你用查找attribute方法查到zip的时候就可以很简单了。也就是说zip(size).id可以告诉你attribute当前的状态.attribute本身也会被zip成一个zip包,所以它本身也会被查找。
根据attribute本身情况,这个zip包应该是不会被拆分的,所以就会出现zip包大小为16的情况。查找方法,基本就是id+size。
这里有一个参考的教程,可以把你的需求转化为python这边常用的方法,
你得到了attribute对象的modelattribute对象
这样看出来一个attribute对象a,你可以表示它为(1.),(2.)(n).对应(1.)中的数值,a字典就被建立起来了,然后就可以查询相应的字典了。注意,attribute必须是list[attribute1].or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.o。 查看全部
抓取网页数据(抓取网页数据,产生无数的字典对象对应你的问题解决办法)
抓取网页数据,产生无数的字典对象对应你的问题解决办法有两种:1.以id查找是否有相应的字典对象;2.检查字典中是否包含字典对象的元素,如果没有,则判断它是否已经存在;要注意的是,这两种方法不能用作modelattribute的查找问题:attribute在大多数情况下必须是list。
我觉得你想得到的应该是链接,你只要查看链接中包含哪些字段就可以了,举个例子,
attribute在本地有一个zip下来的对象,就是所有需要查询的attribute对象包含的父字段zip(size).里面的内容可以表示每个attribute当前的状态。所以你用查找attribute方法查到zip的时候就可以很简单了。也就是说zip(size).id可以告诉你attribute当前的状态.attribute本身也会被zip成一个zip包,所以它本身也会被查找。
根据attribute本身情况,这个zip包应该是不会被拆分的,所以就会出现zip包大小为16的情况。查找方法,基本就是id+size。
这里有一个参考的教程,可以把你的需求转化为python这边常用的方法,
你得到了attribute对象的modelattribute对象
这样看出来一个attribute对象a,你可以表示它为(1.),(2.)(n).对应(1.)中的数值,a字典就被建立起来了,然后就可以查询相应的字典了。注意,attribute必须是list[attribute1].or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.or(attribute1.o。
抓取网页数据(python爬虫是怎么编写抓取网页数据的呢?库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-01 15:12
抓取网页数据是web开发非常重要的一个部分,对页面的设计,选择调用函数,构造路由等都很重要。本文介绍一个python爬虫的框架,djangorequests库,其模块简单,性能也比较不错,而且部署非常简单,可以快速部署实验。djangorequests(国内可以通过getmany方式),优秀开源项目,github地址::?概述在学习django之前,首先需要了解下python代码怎么编写。
比如在准备爬取a站网页时,首先需要写出如下的代码:importrequests#获取网页headersmethod=requests.get(url='',headers=headers)#爬取url#加载blog文章我们再了解下python爬虫是怎么工作的。假设有一个url,如下:python,返回的就是一个html文件。
我们当然可以直接利用浏览器去解析这个html,这是不现实的,因为要把这个html文件保存到本地,对于绝大多数人来说,办法都是相对简单的。不过如果用python来操作html,就没有太多的问题。requests库是python爬虫中提供非常详细的api接口的库,详细的介绍可以看scrapyrequests接口文档:/:爬取规则的确定:规则提示我们在爬取某站点时,通常是需要爬取这个站点的所有页面,具体有几页,全是由爬虫控制的。
某程序员首先抽象出了一个根据url爬取网页的规则,后面就可以设置爬取规则了。只要获取网页的url对应的html文件,将其拿下来就可以实现爬取了。就拿这个html来说,html的爬取方式是,先解析html文件,再判断生成对应的books对象,这里就把它叫做生成器,也就是说,我们把每次传入给requests对象的参数配置好,然后一直循环,直到获取到自己想要的结果。
要求的返回的结果是一个books对象,并且这个对象一定要存在。多个文件,多个url都会以这种方式处理的。以a站为例:定义爬取规则我们首先定义一个爬取a站html文件的规则:fromdjango.urlsimporturlfromdjango.urlpatternsimporturlfromdjango.urlsimportrequestapp=url('')定义app所需要的函数:app.route(url,headers=headers)urlpatterns=[request.urlopen(r'^api/').read()forrequestinurl.items()]定义会话对象:deftx_run(accept,user_agent):"""定义会话对象,传入user_agent:paramuser_agent:paramaccept:paramssl_verify_cookies:"""ifuser_agent.match(accept):raiseverify_cookies_exception("在发送get请求前。 查看全部
抓取网页数据(python爬虫是怎么编写抓取网页数据的呢?库)
抓取网页数据是web开发非常重要的一个部分,对页面的设计,选择调用函数,构造路由等都很重要。本文介绍一个python爬虫的框架,djangorequests库,其模块简单,性能也比较不错,而且部署非常简单,可以快速部署实验。djangorequests(国内可以通过getmany方式),优秀开源项目,github地址::?概述在学习django之前,首先需要了解下python代码怎么编写。
比如在准备爬取a站网页时,首先需要写出如下的代码:importrequests#获取网页headersmethod=requests.get(url='',headers=headers)#爬取url#加载blog文章我们再了解下python爬虫是怎么工作的。假设有一个url,如下:python,返回的就是一个html文件。
我们当然可以直接利用浏览器去解析这个html,这是不现实的,因为要把这个html文件保存到本地,对于绝大多数人来说,办法都是相对简单的。不过如果用python来操作html,就没有太多的问题。requests库是python爬虫中提供非常详细的api接口的库,详细的介绍可以看scrapyrequests接口文档:/:爬取规则的确定:规则提示我们在爬取某站点时,通常是需要爬取这个站点的所有页面,具体有几页,全是由爬虫控制的。
某程序员首先抽象出了一个根据url爬取网页的规则,后面就可以设置爬取规则了。只要获取网页的url对应的html文件,将其拿下来就可以实现爬取了。就拿这个html来说,html的爬取方式是,先解析html文件,再判断生成对应的books对象,这里就把它叫做生成器,也就是说,我们把每次传入给requests对象的参数配置好,然后一直循环,直到获取到自己想要的结果。
要求的返回的结果是一个books对象,并且这个对象一定要存在。多个文件,多个url都会以这种方式处理的。以a站为例:定义爬取规则我们首先定义一个爬取a站html文件的规则:fromdjango.urlsimporturlfromdjango.urlpatternsimporturlfromdjango.urlsimportrequestapp=url('')定义app所需要的函数:app.route(url,headers=headers)urlpatterns=[request.urlopen(r'^api/').read()forrequestinurl.items()]定义会话对象:deftx_run(accept,user_agent):"""定义会话对象,传入user_agent:paramuser_agent:paramaccept:paramssl_verify_cookies:"""ifuser_agent.match(accept):raiseverify_cookies_exception("在发送get请求前。
抓取网页数据(优采云采集器V9中对数据内容标签进行编辑定义的含义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-31 04:05
网页数据抓取工具的内容获取方法网页数据抓取工具优采云采集器获取内容时,需要编辑定义数据内容的标签,在优采云 采集器 在V9中,对数据内容标签进行了编辑和定义,因此获取数据的方法有3种:A)。从源代码中获取数据 B)。生成固定格式数据 C)。有标签组合,具体含义解释如下。. 一种)。从源代码中获取数据:可以准确设置的标签的来源是来自默认页面的源代码、返回头信息和网页地址,或者是分页、循环、多分页。源码提取方式包括:截取后、正则提取、文本提取、Xpath提取、JSON提取,这将在后面详细演示。B)。生成固定格式数据:可以生成固定字符串、系统时间、随机字符串、随机数、系统时间戳、随机抽取信息。C)。现有标签组合:可以组合现有标签以生成新的标签内容。最常用的方法之一是从源代码中获取数据。对应的五种获取操作的方法如下:Aa)。截取前后,可以通过设置开始字符串和结束字符串来获取中间的字符,可以用于字符串的开头和结尾。把通配符(*)设置进去。比如一段源码是“title”,那么title就是我们需要的,我们写在优采云采集器V9:Ab)。正则提取支持两个正则,一种纯正则和一种参数正则。先介绍纯正则规则,比如:在字符串之前(?[\s\S]*?) 之后的字符串,this ^(?[\s\S]*?)$,使用this函数需要一定的规律性基础。关于参数规律性,通过参数组合生成内容。比如匹配“新用户注册”和作者“神秘嘉宾”的标题,代码如下:
新用户注册 查看全部
抓取网页数据(优采云采集器V9中对数据内容标签进行编辑定义的含义)
网页数据抓取工具的内容获取方法网页数据抓取工具优采云采集器获取内容时,需要编辑定义数据内容的标签,在优采云 采集器 在V9中,对数据内容标签进行了编辑和定义,因此获取数据的方法有3种:A)。从源代码中获取数据 B)。生成固定格式数据 C)。有标签组合,具体含义解释如下。. 一种)。从源代码中获取数据:可以准确设置的标签的来源是来自默认页面的源代码、返回头信息和网页地址,或者是分页、循环、多分页。源码提取方式包括:截取后、正则提取、文本提取、Xpath提取、JSON提取,这将在后面详细演示。B)。生成固定格式数据:可以生成固定字符串、系统时间、随机字符串、随机数、系统时间戳、随机抽取信息。C)。现有标签组合:可以组合现有标签以生成新的标签内容。最常用的方法之一是从源代码中获取数据。对应的五种获取操作的方法如下:Aa)。截取前后,可以通过设置开始字符串和结束字符串来获取中间的字符,可以用于字符串的开头和结尾。把通配符(*)设置进去。比如一段源码是“title”,那么title就是我们需要的,我们写在优采云采集器V9:Ab)。正则提取支持两个正则,一种纯正则和一种参数正则。先介绍纯正则规则,比如:在字符串之前(?[\s\S]*?) 之后的字符串,this ^(?[\s\S]*?)$,使用this函数需要一定的规律性基础。关于参数规律性,通过参数组合生成内容。比如匹配“新用户注册”和作者“神秘嘉宾”的标题,代码如下:
新用户注册
抓取网页数据(如何使用花生壳工具使用抓包抓取网页数据准备工作(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-30 04:03
抓取网页数据,然后根据网页数据自动生成相应的图表,相信做ppt的都有体会。下面举例一下如何使用花生壳抓取工具。使用抓包工具抓取腾讯大王卡互联网业务及api数据准备工作需要:vpn客户端登录页登录页地址我已上传;python脚本开发环境可参考我在网上的分享准备工作:1.中国移动的10086的登录页。利用百度互联网服务平台:中国移动电信营业厅,手机营业厅,12306中的代理平台登录网页10086:注册百度账号2.百度api接口:互联网服务接口。
爬取10086和10086手机营业厅的数据3.准备花生壳ip地址和ip池,如何获取代理ip,我们会在下面介绍。腾讯大王卡的互联网业务及api数据准备工作:1.搭建花生壳的企业服务器2.开启腾讯大王卡互联网访问开放平台(腾讯isp合作平台,腾讯王卡isp合作平台)。花生壳中百度企业一般无法使用,需注册后再点击下面服务。
3.微信公众号,小程序,企业号里面的腾讯产品都不可用。进入腾讯api服务管理后台(腾讯api后台),创建企业api链接。4.使用花生壳ip地址抓取10086的互联网业务数据。案例分享1.具体分析通过后台绑定花生壳ip地址来抓取10086手机营业厅的互联网业务数据。2.抓取数据总结。
1)绑定ip地址花生壳后可以通过ip地址绑定企业管理员的vpn账号(推荐邮箱或者钉钉号,非常好用)。
2)登录数据容易进入腾讯王卡的企业网站开放平台,抓取业务。
3)测试通过,我的花生壳是24年老服务器,百度云带宽使用4t,推荐使用百度云速度。
4)数据量少,推荐花生壳本例为百度免费的企业服务器的ip地址,连接数为4,本来想测试wifi,试了试别的网络,发现找不到我的花生壳ip地址,只能手动连接。 查看全部
抓取网页数据(如何使用花生壳工具使用抓包抓取网页数据准备工作(组图))
抓取网页数据,然后根据网页数据自动生成相应的图表,相信做ppt的都有体会。下面举例一下如何使用花生壳抓取工具。使用抓包工具抓取腾讯大王卡互联网业务及api数据准备工作需要:vpn客户端登录页登录页地址我已上传;python脚本开发环境可参考我在网上的分享准备工作:1.中国移动的10086的登录页。利用百度互联网服务平台:中国移动电信营业厅,手机营业厅,12306中的代理平台登录网页10086:注册百度账号2.百度api接口:互联网服务接口。
爬取10086和10086手机营业厅的数据3.准备花生壳ip地址和ip池,如何获取代理ip,我们会在下面介绍。腾讯大王卡的互联网业务及api数据准备工作:1.搭建花生壳的企业服务器2.开启腾讯大王卡互联网访问开放平台(腾讯isp合作平台,腾讯王卡isp合作平台)。花生壳中百度企业一般无法使用,需注册后再点击下面服务。
3.微信公众号,小程序,企业号里面的腾讯产品都不可用。进入腾讯api服务管理后台(腾讯api后台),创建企业api链接。4.使用花生壳ip地址抓取10086的互联网业务数据。案例分享1.具体分析通过后台绑定花生壳ip地址来抓取10086手机营业厅的互联网业务数据。2.抓取数据总结。
1)绑定ip地址花生壳后可以通过ip地址绑定企业管理员的vpn账号(推荐邮箱或者钉钉号,非常好用)。
2)登录数据容易进入腾讯王卡的企业网站开放平台,抓取业务。
3)测试通过,我的花生壳是24年老服务器,百度云带宽使用4t,推荐使用百度云速度。
4)数据量少,推荐花生壳本例为百度免费的企业服务器的ip地址,连接数为4,本来想测试wifi,试了试别的网络,发现找不到我的花生壳ip地址,只能手动连接。
抓取网页数据(【每日一题】数据挖掘与机器学习实战(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-29 19:05
抓取网页数据,并训练nlp模型。
可以参考下ucla的pythonprogramming教程fulltextcontent:uclaestimationandsemanticsegmentationcourse·fall实际上应该和你列举的是同一课程。你可以下载minimal代码研究一下。
如果英文过关的话,可以google"learningopendata"。里面的tutorial里有open-data相关的分享。如果不是很懂英文,可以看youtube上的tutorials。
extractingopendatawithpython3
任何方面都可以学习啊,推荐看下这个《数据挖掘与机器学习实战》,先入个门。任何一个方面都是可以学习的,只要你想学。
跟特征有关系,如果特征都是结构化的,清楚,可预测的,可操作的,
这个算是比较专的方向,
我觉得还是先补上自己专业的基础课吧。(不然很多情况下只是一些搬砖的活)。如果想做计算机视觉,就好好学个计算机图形学什么的。
首先,先画一个完整的数据框架,后续的方法也是在这里进行,顺便说下,会python还是用python吧(虽然都叫python但还是有些细节可能不一样),毕竟python对框架的兼容性还是很好的。另外,想要深入浅出的了解机器学习的知识的话,推荐看下这两本书。 查看全部
抓取网页数据(【每日一题】数据挖掘与机器学习实战(二))
抓取网页数据,并训练nlp模型。
可以参考下ucla的pythonprogramming教程fulltextcontent:uclaestimationandsemanticsegmentationcourse·fall实际上应该和你列举的是同一课程。你可以下载minimal代码研究一下。
如果英文过关的话,可以google"learningopendata"。里面的tutorial里有open-data相关的分享。如果不是很懂英文,可以看youtube上的tutorials。
extractingopendatawithpython3
任何方面都可以学习啊,推荐看下这个《数据挖掘与机器学习实战》,先入个门。任何一个方面都是可以学习的,只要你想学。
跟特征有关系,如果特征都是结构化的,清楚,可预测的,可操作的,
这个算是比较专的方向,
我觉得还是先补上自己专业的基础课吧。(不然很多情况下只是一些搬砖的活)。如果想做计算机视觉,就好好学个计算机图形学什么的。
首先,先画一个完整的数据框架,后续的方法也是在这里进行,顺便说下,会python还是用python吧(虽然都叫python但还是有些细节可能不一样),毕竟python对框架的兼容性还是很好的。另外,想要深入浅出的了解机器学习的知识的话,推荐看下这两本书。
抓取网页数据(搜索引擎爬行和收集信息的程序-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-26 02:06
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,则可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
搜索引擎蜘蛛虽然名称不同,但它们的爬取和爬取规则基本相同:
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)搜索引擎蜘蛛进入允许爬取的网站时,一般会采用深度优先、宽度优先、高度优先的策略来爬取,遍历来爬取更多网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接,再爬到网页中的另一个链接,直到没有未爬取的链接,然后返回到网页。爬到另一条链上。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到优秀网页A、B、C的链接并抓取,然后抓取优秀网页A1、A 2、@ >A3、B1、B2和B3,爬取二级网页后,再爬取三级网页A4、A5、A6,尝试爬取所有网页。
更好的优先级爬取策略是按照一定的算法对网页的重要性进行分类。网页的重要性主要通过页面排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多的搜索引擎信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,可以提高履带的工作效率。因此,爬虫也会以较快的响应速度先爬取网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小的网站页面,影响了互联网信息差异化展示的发展,几乎进入了大的网站的流量,小网站的发展难度很大。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,通常只能抓取互联网上的一部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。当搜索引擎抓取到一个网页时,会判断该网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、高度重复的内容等,这些垃圾信息蜘蛛是不会抓取的,他们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。 查看全部
抓取网页数据(搜索引擎爬行和收集信息的程序-苏州安嘉)
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,则可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
搜索引擎蜘蛛虽然名称不同,但它们的爬取和爬取规则基本相同:
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)搜索引擎蜘蛛进入允许爬取的网站时,一般会采用深度优先、宽度优先、高度优先的策略来爬取,遍历来爬取更多网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接,再爬到网页中的另一个链接,直到没有未爬取的链接,然后返回到网页。爬到另一条链上。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到优秀网页A、B、C的链接并抓取,然后抓取优秀网页A1、A 2、@ >A3、B1、B2和B3,爬取二级网页后,再爬取三级网页A4、A5、A6,尝试爬取所有网页。
更好的优先级爬取策略是按照一定的算法对网页的重要性进行分类。网页的重要性主要通过页面排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多的搜索引擎信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,可以提高履带的工作效率。因此,爬虫也会以较快的响应速度先爬取网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小的网站页面,影响了互联网信息差异化展示的发展,几乎进入了大的网站的流量,小网站的发展难度很大。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,通常只能抓取互联网上的一部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。当搜索引擎抓取到一个网页时,会判断该网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、高度重复的内容等,这些垃圾信息蜘蛛是不会抓取的,他们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。
抓取网页数据(关于APP数据采集如何实现,有哪些要注意的点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-10-24 17:06
关于如何实现APP数据采集以及需要注意什么,优采云有话要说。
在过去的六个月里,我们优采云陆续收到了几个APP数据采集的项目需求。我在群里,偶尔看到一些用户问有没有APP数据的工具采集。鉴于我们在多个APP数据采集项目中的经验,我可以告诉大家,目前市面上没有通用的APP数据采集工具。我们优采云内部有一套工具,但由于使用难度高,需要编写脚本,所以不对外公开给普通用户。我们只接受项目定制。
虽然不对外开放,但不妨碍我们分享技术。APP数据采集一般采用以下两种方式:1、抓包;2、钩子
1、抓包
有代码经验或APP开发的同学容易理解。其实很多APP都是使用webservice通信协议的,而且由于是公共数据,大部分都是未加密的。所以只要监控网口,模拟APP,就可以知道APP中的数据是如何获取的。
我们只需要编写代码来模拟请求,无论是POST还是GET,都可以获取到请求返回的信息。然后通过对返回信息的结构分析,就可以得到我们想要的数据。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/****开始抓
.addUrl("https://github.com/****")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
以模拟的采集“魅族”应用市场为例
应用市场产品
抓包返回参数
整个抓拍过程
2、HOOK 技术
HOOK技术是一种取操作系统内核的技术。由于Android系统是开源的,你可以借助一些框架修改内核来实现你想要的功能。HOOK的形式,我们采用的是Xposed框架。Xposed是一个开源框架服务,可以在不修改任何其他开发者的应用程序(包括系统服务)的情况下改变程序的运行。在它的基础上,可以制作出许多强大的模块,以达到随心所欲运行应用程序的目的。
如果你把安卓手机想象成一座城堡,那么Xposed可以给你一个上帝视角,你可以看到城市运作的细节,也可以让你介入改变城堡的运作规则。
这意味着什么?简单的说,你可以通过他自动控制你的APP。如果我们在模拟器上打开我们的APP,我们可以通过编码告诉APP这一步要做什么,下一步要做什么。您可以将其理解为类似于按键精灵或游戏怪物插件。
而他每走一步,就能获取到APP与服务器交互的数据。这种方法在一些成熟的应用程序中被广泛使用。例如,一个字母 采集。
public class HookActivity implements IXposedHookLoadPackage {
@Override
public void handleLoadPackage(LoadPackageParam lpparam) throws Throwable {
final String packageName = lpparam.packageName;
XposedBridge.log("--------------------: " + packageName);
try {
XposedBridge.hookAllMethods
(Activity.class, "onCreate", new XC_MethodHook() {
@Override
protected void afterHookedMethod(MethodHookParam param)
throws Throwable {
XposedBridge.log("=== Activity onCreate: " + param.thisObject);
}
});
} catch (Throwable error) {
XposedBridge.log("xxxxxxxxxxxx: " + error);
}
}
}
其实我们优采云曾经想开发一个通用的APP数据采集工具,两年前我们在这方面投入了半年,做了一个APP采集脚本编辑工具可以将一个APP的数据采集项目缩短到3-5天完成开发。但是我们认为这个工具需要脚本化,一般用户很难上手,所以只作为内部项目使用。
以一个HOOK APP为例
HOOK命令打开一个APP
获取数据的HOOK指令
HOOK获取数据过程
3、这些年走过的坑
说完APP采集的思路,跟大家分享一下我们遇到的一些坑,让大家玩的开心
坑一:签名算法
以一封信的文章列表页和某个信息页为例,如果抓到它的http访问,你会发现它的url的核心参数之一就是我们不知道如何生成它。这使得我们无法直接使用这个 url 进行信息抓取;如果签名算法无法破解,那么HTTP之路就是一条死胡同。 查看全部
抓取网页数据(关于APP数据采集如何实现,有哪些要注意的点)
关于如何实现APP数据采集以及需要注意什么,优采云有话要说。
在过去的六个月里,我们优采云陆续收到了几个APP数据采集的项目需求。我在群里,偶尔看到一些用户问有没有APP数据的工具采集。鉴于我们在多个APP数据采集项目中的经验,我可以告诉大家,目前市面上没有通用的APP数据采集工具。我们优采云内部有一套工具,但由于使用难度高,需要编写脚本,所以不对外公开给普通用户。我们只接受项目定制。
虽然不对外开放,但不妨碍我们分享技术。APP数据采集一般采用以下两种方式:1、抓包;2、钩子
1、抓包
有代码经验或APP开发的同学容易理解。其实很多APP都是使用webservice通信协议的,而且由于是公共数据,大部分都是未加密的。所以只要监控网口,模拟APP,就可以知道APP中的数据是如何获取的。
我们只需要编写代码来模拟请求,无论是POST还是GET,都可以获取到请求返回的信息。然后通过对返回信息的结构分析,就可以得到我们想要的数据。
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/****开始抓
.addUrl("https://github.com/****")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}
以模拟的采集“魅族”应用市场为例
应用市场产品
抓包返回参数
整个抓拍过程
2、HOOK 技术
HOOK技术是一种取操作系统内核的技术。由于Android系统是开源的,你可以借助一些框架修改内核来实现你想要的功能。HOOK的形式,我们采用的是Xposed框架。Xposed是一个开源框架服务,可以在不修改任何其他开发者的应用程序(包括系统服务)的情况下改变程序的运行。在它的基础上,可以制作出许多强大的模块,以达到随心所欲运行应用程序的目的。
如果你把安卓手机想象成一座城堡,那么Xposed可以给你一个上帝视角,你可以看到城市运作的细节,也可以让你介入改变城堡的运作规则。
这意味着什么?简单的说,你可以通过他自动控制你的APP。如果我们在模拟器上打开我们的APP,我们可以通过编码告诉APP这一步要做什么,下一步要做什么。您可以将其理解为类似于按键精灵或游戏怪物插件。
而他每走一步,就能获取到APP与服务器交互的数据。这种方法在一些成熟的应用程序中被广泛使用。例如,一个字母 采集。
public class HookActivity implements IXposedHookLoadPackage {
@Override
public void handleLoadPackage(LoadPackageParam lpparam) throws Throwable {
final String packageName = lpparam.packageName;
XposedBridge.log("--------------------: " + packageName);
try {
XposedBridge.hookAllMethods
(Activity.class, "onCreate", new XC_MethodHook() {
@Override
protected void afterHookedMethod(MethodHookParam param)
throws Throwable {
XposedBridge.log("=== Activity onCreate: " + param.thisObject);
}
});
} catch (Throwable error) {
XposedBridge.log("xxxxxxxxxxxx: " + error);
}
}
}
其实我们优采云曾经想开发一个通用的APP数据采集工具,两年前我们在这方面投入了半年,做了一个APP采集脚本编辑工具可以将一个APP的数据采集项目缩短到3-5天完成开发。但是我们认为这个工具需要脚本化,一般用户很难上手,所以只作为内部项目使用。
以一个HOOK APP为例
HOOK命令打开一个APP
获取数据的HOOK指令
HOOK获取数据过程
3、这些年走过的坑
说完APP采集的思路,跟大家分享一下我们遇到的一些坑,让大家玩的开心
坑一:签名算法
以一封信的文章列表页和某个信息页为例,如果抓到它的http访问,你会发现它的url的核心参数之一就是我们不知道如何生成它。这使得我们无法直接使用这个 url 进行信息抓取;如果签名算法无法破解,那么HTTP之路就是一条死胡同。
抓取网页数据(以百库文库为例()的一个简单记录,以百度文库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-17 05:18
)
简单记录一下使用selenium抓取文档,以百度文库为例。selenium的原理大致是:使用javascript语句与浏览器交互,控制浏览器操作网页的行为。
使用selenium来实现爬虫一般是因为网页是动态加载的,目标内容需要一定的操作才能出现在元素审核中。以白库文库为例(),较大文档的显示一般是分页显示的,每个页面的内容都不会满载。只有在浏览当前页面时才会加载当前页面的内容。像这个文档一样,一次显示五十页,但只会加载当前浏览进度的三叶内容。因此,要自动抓取此内容,您需要实现滚动功能。
Selenium 有两种滚动方式:
第一种是滚动到特定位置”:
driver.execute_script('var q=document.body.scrollTop=3500') 滚动到页面的3500像素处(从上往下)(通过网页审查可以看到整个网页的像素大小)
第二种,以当前位置为参照,滚动一定距离:
driver.execute_script('window.scrollBy(0, 1000)') 从当前位置向下滚动1000像素。
第三种,定位到特定的元素:
element = driver.find_element_by_xpath("//span[@class='fc2e']") 先找到特定的web元素(与beautifulsoup中的元素概念不同)。
driver.execute_script('arguments[0].scrollIntoView();',element) 把特定的元素滚动到页面的顶部/底部,但不一定能被点击到。
实现点击: element.click()
值得注意的是:目标元素经常会被一些内容遮挡,另外注意设置等待时间。
网页的解析依然使用beautifulsoup:
html = driver.page_source
bf1 = BeautifulSoup(html, 'lxml')
result = bf1.find_all(class_='ie-fix')
for each_result in result:
for singlecell in each_result.find_all('p'):
if 'left:907px' in str(singlecell['style']):
f.write('\n')
f.write(singlecell.string+'#') 查看全部
抓取网页数据(以百库文库为例()的一个简单记录,以百度文库
)
简单记录一下使用selenium抓取文档,以百度文库为例。selenium的原理大致是:使用javascript语句与浏览器交互,控制浏览器操作网页的行为。
使用selenium来实现爬虫一般是因为网页是动态加载的,目标内容需要一定的操作才能出现在元素审核中。以白库文库为例(),较大文档的显示一般是分页显示的,每个页面的内容都不会满载。只有在浏览当前页面时才会加载当前页面的内容。像这个文档一样,一次显示五十页,但只会加载当前浏览进度的三叶内容。因此,要自动抓取此内容,您需要实现滚动功能。
Selenium 有两种滚动方式:
第一种是滚动到特定位置”:
driver.execute_script('var q=document.body.scrollTop=3500') 滚动到页面的3500像素处(从上往下)(通过网页审查可以看到整个网页的像素大小)
第二种,以当前位置为参照,滚动一定距离:
driver.execute_script('window.scrollBy(0, 1000)') 从当前位置向下滚动1000像素。
第三种,定位到特定的元素:
element = driver.find_element_by_xpath("//span[@class='fc2e']") 先找到特定的web元素(与beautifulsoup中的元素概念不同)。
driver.execute_script('arguments[0].scrollIntoView();',element) 把特定的元素滚动到页面的顶部/底部,但不一定能被点击到。
实现点击: element.click()
值得注意的是:目标元素经常会被一些内容遮挡,另外注意设置等待时间。
网页的解析依然使用beautifulsoup:
html = driver.page_source
bf1 = BeautifulSoup(html, 'lxml')
result = bf1.find_all(class_='ie-fix')
for each_result in result:
for singlecell in each_result.find_all('p'):
if 'left:907px' in str(singlecell['style']):
f.write('\n')
f.write(singlecell.string+'#')
抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2021-10-17 05:16
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。
所以我们可以使用for循环来获取目标:
然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了
最后,将获取到的数据保存在我们想要放置的地方。
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:
1、发起请求 查看全部
抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
概述:
这是一个在phthon环境下使用pycharm的简单爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬虫?
要学会爬行,我们首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
中文名
网络爬虫
外文名
网络爬虫
昵称
网络蜘蛛
目的
根据需要获取万维网信息
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
准备好工作了:
我们使用的是pycharm,请参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看其官方文档:
个人认为用lxml解析网页是最快的。关于lxml的使用,可以阅读这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
话不多说,开始我们的爬虫之旅
首先找到我们的目标网址:
可以看到我们想要获取的歌曲的标题和作者(专辑)页面有十页,每页有十行。
所以我们可以使用for循环来获取目标:
然后使用 requests 请求一个网页:
import requests
headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text
使用 lxml 解析网页:
from lxml import etree
s = etree.HTML(data)
然后我们就可以提取我们想要的数据了
最后,将获取到的数据保存在我们想要放置的地方。
至此,我们基本完成了,完整的代码如下:
然后我们来看看我们爬取的结果
总结:
爬虫过程:
1、发起请求
抓取网页数据(抓取网页数据,执行opencv库函数:获取摄像头的camera图片库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-14 08:02
抓取网页数据,执行opencv库函数:获取摄像头的camera的opencv-workbench图片库的img,然后for循环。绘制图像:先绘制图像,再访问图像,调用opencv-workbench图片库的get_faker_rect/img/get_faker_rect获取,然后绘制图像,按顺序生成img对象。
单步draw函数:这个函数绘制img对象,输出对象大小,按顺序遍历整张图。渲染文本:draw_content_figure,获取最小宽度和最大宽度,并为文本建立index对象,遍历对象大小,获取对象的宽高并绘制文本。最简单最单步的draw函数:draw_text(content,img)content和img分别为img对象的属性。
获取文本vector:filepaths为包含图片的文件名rootdict获取文本内容messagevalue获取文本内容的字符串并整合数组outputstring。drawr1代码:1rootdict:包含blackboarddeclaration,int在内的所有文本文件。[0,0]为黑色颜色的黑区域。
2newdeclaration数组:package定义数组。包含camera,content,img,rect...等字符串。[0,1]为文本。3创建包含3个字符串的文本文件filename。定义messagevalue数组,messagevalue为文本文件中各字符串的长度。4遍历整个文件,获取每个文件中的字符串并拼接在新数组。
遍历所有文件。遍历所有文件,每个文件都有一个image_slice参数。遍历image,获取一个exists和id的元素。遍历所有image,有符合条件的image获取,可以遍历文件也可以遍历对象。遍历所有文件,所有对象大小相同,遍历所有对象。遍历所有对象:除了遍历所有对象(反对遍历)外,遍历所有对象可以使用dropna函数。
遍历所有对象:为了整理需要,遍历所有对象。1:遍历所有文件:遍历所有文件,将每个文件内的标题都变成msg。2:遍历所有对象:所有对象会复制到所有文件,内容会保存到list中。遍历其他文件数组:遍历所有数组。具体函数getsize作用:getsize代码:1定义data数组data=[3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3。 查看全部
抓取网页数据(抓取网页数据,执行opencv库函数:获取摄像头的camera图片库)
抓取网页数据,执行opencv库函数:获取摄像头的camera的opencv-workbench图片库的img,然后for循环。绘制图像:先绘制图像,再访问图像,调用opencv-workbench图片库的get_faker_rect/img/get_faker_rect获取,然后绘制图像,按顺序生成img对象。
单步draw函数:这个函数绘制img对象,输出对象大小,按顺序遍历整张图。渲染文本:draw_content_figure,获取最小宽度和最大宽度,并为文本建立index对象,遍历对象大小,获取对象的宽高并绘制文本。最简单最单步的draw函数:draw_text(content,img)content和img分别为img对象的属性。
获取文本vector:filepaths为包含图片的文件名rootdict获取文本内容messagevalue获取文本内容的字符串并整合数组outputstring。drawr1代码:1rootdict:包含blackboarddeclaration,int在内的所有文本文件。[0,0]为黑色颜色的黑区域。
2newdeclaration数组:package定义数组。包含camera,content,img,rect...等字符串。[0,1]为文本。3创建包含3个字符串的文本文件filename。定义messagevalue数组,messagevalue为文本文件中各字符串的长度。4遍历整个文件,获取每个文件中的字符串并拼接在新数组。
遍历所有文件。遍历所有文件,每个文件都有一个image_slice参数。遍历image,获取一个exists和id的元素。遍历所有image,有符合条件的image获取,可以遍历文件也可以遍历对象。遍历所有文件,所有对象大小相同,遍历所有对象。遍历所有对象:除了遍历所有对象(反对遍历)外,遍历所有对象可以使用dropna函数。
遍历所有对象:为了整理需要,遍历所有对象。1:遍历所有文件:遍历所有文件,将每个文件内的标题都变成msg。2:遍历所有对象:所有对象会复制到所有文件,内容会保存到list中。遍历其他文件数组:遍历所有数组。具体函数getsize作用:getsize代码:1定义data数组data=[3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3。
抓取网页数据(如何用python解析json数据?数据怎么用解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-10-14 04:20
)
python抓图的时候,有时候找不到对应的url,可能json中存在,那么如何用python解析json数据,小白看了几个论坛总结了一些,加深印象。
1.requests.get(url,params) 获取请求数据
import requests
def get_many_pages(keyword, page):
params = []#收集不同页面的json数据
for i in range(30, 30*page, 30):#动态加载,每页30个
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '' ,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1517048369666': ''
}) #json的Query String paramters 是动态的
json_url = 'https://image.baidu.com/search/acjson'#json的init地址
json_datas = []#用于收集所有页面的json数据
for param in params:#分别取出每个动态的参数,是一个字典形式
res = requests.get(json_url, params = param)#获取json地址
res.encoding = 'utf-8'#转化为utf-8格式
json_data = res.json().get('data')#解析json数据成字典,通过get方法找出data中的值
json_datas.append(json_data)#把所有页的json数据取回
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages('暴漫表情包',3)
get_url()
1. urllib.request + json 获取请求数据
# -*- coding: utf-8 -*-
''' Created on Sat Jan 27 22:39:15 2018 @author: zhuxueming'''
import urllib.request
import json
def get_many_pages(page):
json_datas = []
for i in range(30,30*page,30):#这里由于网址中有多个%所以采用.format不能用%来格式化,根据json的地址发现,只有1517056200441=后面的数字变化在不同的页面中,所以单独改这一个就可以
json_url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&word=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&pn={0}&rn=30&gsm=3c&1517056200441='.format(i)
res = urllib.request.urlopen(json_url)#获得网址数据
html = res.read().decode('utf-8')#读取数据并转化为utf-8
json_data = json.loads(html).get('data')#用json转化为字典获取data里的数据
json_datas.append(json_data)#合并不同页面的数据
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages(3)
get_url()
综上所述,两种方法都可以使用,但是第二种方法不能直接关键词搜索,但是不同key的时候需要修改json参数,所以没问题。主要原因是很难找到这个动态json数据包。 XHR一般是在js下下载的。
查看全部
抓取网页数据(如何用python解析json数据?数据怎么用解析
)
python抓图的时候,有时候找不到对应的url,可能json中存在,那么如何用python解析json数据,小白看了几个论坛总结了一些,加深印象。
1.requests.get(url,params) 获取请求数据
import requests
def get_many_pages(keyword, page):
params = []#收集不同页面的json数据
for i in range(30, 30*page, 30):#动态加载,每页30个
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '' ,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1517048369666': ''
}) #json的Query String paramters 是动态的
json_url = 'https://image.baidu.com/search/acjson'#json的init地址
json_datas = []#用于收集所有页面的json数据
for param in params:#分别取出每个动态的参数,是一个字典形式
res = requests.get(json_url, params = param)#获取json地址
res.encoding = 'utf-8'#转化为utf-8格式
json_data = res.json().get('data')#解析json数据成字典,通过get方法找出data中的值
json_datas.append(json_data)#把所有页的json数据取回
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages('暴漫表情包',3)
get_url()
1. urllib.request + json 获取请求数据
# -*- coding: utf-8 -*-
''' Created on Sat Jan 27 22:39:15 2018 @author: zhuxueming'''
import urllib.request
import json
def get_many_pages(page):
json_datas = []
for i in range(30,30*page,30):#这里由于网址中有多个%所以采用.format不能用%来格式化,根据json的地址发现,只有1517056200441=后面的数字变化在不同的页面中,所以单独改这一个就可以
json_url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&word=%E6%9A%B4%E6%BC%AB%E8%A1%A8%E6%83%85%E5%8C%85&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&pn={0}&rn=30&gsm=3c&1517056200441='.format(i)
res = urllib.request.urlopen(json_url)#获得网址数据
html = res.read().decode('utf-8')#读取数据并转化为utf-8
json_data = json.loads(html).get('data')#用json转化为字典获取data里的数据
json_datas.append(json_data)#合并不同页面的数据
return json_datas
def get_url():
json_datas = datalist#获取所有页的json数据
#print(json_datas)
for each_data in json_datas:#解开列表嵌套
for each_dict in each_data:#解开列嵌套直到出现字典
each_url = each_dict.get('thumbURL')#获取字典中的地址
print(each_url)
datalist = get_many_pages(3)
get_url()
综上所述,两种方法都可以使用,但是第二种方法不能直接关键词搜索,但是不同key的时候需要修改json参数,所以没问题。主要原因是很难找到这个动态json数据包。 XHR一般是在js下下载的。
抓取网页数据(要说的起源,我们还得从搜索引擎说起,什么是搜索引擎呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-14 04:16
----要说网络蜘蛛的由来,就得从搜索引擎说起。什么是搜索引擎?搜索引擎的起源是什么?这与网络蜘蛛的起源密切相关。
----搜索引擎是指自动从互联网上采集信息,并提供给
网络蜘蛛用户进行查询的系统。互联网上的信息海量且杂乱无章。所有的信息就像海洋中的小岛。网页链接是这些小岛之间的桥梁,搜索引擎可以一目了然地为你画图。信息图供您随时查看。
----搜索引擎于1990年作为雏形首次出现,如今已成为人们生活中不可或缺的一部分。它经历了太多的技术和概念变化。
---- 1994年1月,第一个可搜索和可浏览的目录EINetGalaxy推出。雅虎出现在它之后,直到我们现在知道谷歌和百度。但他们并不是第一个吃掉搜索引擎螃蟹的人。从在FTP上搜索文件开始,搜索引擎的雏形出现了。那个时候还没有万维网。那个时候,人们通过手工搜索网络,然后用蜘蛛程序搜索。但是,随着互联网的不断发展,如何采集网页数量?越来越短的时间成为当时的难点和焦点,成为人们研究的焦点。
搜索引擎原型
----如果你想回去,搜索引擎的历史比万维网还要长。早在 Web 出现之前,Internet 上就已经有许多旨在让人们共享的信息资源。这些资源主要存在于各种允许匿名访问的FTP站点中。为了方便人们在分散的FTP资源中找到自己需要的东西,1990年,加拿大麦吉尔大学的几位大学生开发了一款软件Archie。它是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后 Archie 会告诉用户哪个 FTP 地址可以下载文件。Archie其实就是一个大数据库,加上一套与这个大数据库相关的检索方法。虽然 Archie 还不是搜索引擎,
----当万维网(WorldWideWeb)出现时,人们可以通过html传播网络信息,互联网上的信息开始呈指数级增长。人们使用各种方法来采集互联网上的信息,并对其进行分类和整理,以方便搜索。熟悉的网站雅虎(Yahoo)就是在这种环境下诞生的。仍在斯坦福大学读书的华裔美国人杨志远和他的同学开始沉迷于互联网。他们在互联网上采集了有趣的网页,并与同学们分享。后来,在 1994 年 4 月,他们两人共同创办了雅虎。随着访问次数和收录链接数量的增加,雅虎目录开始支持简单的数据库搜索。但是由于雅虎的数据是人工录入的,它不能真正归类为搜索引擎。事实上,它只是一个可搜索的目录。
网络蜘蛛
网络蜘蛛
----当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
----这种程序实际上是利用html文档之间的链接关系来抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
----Lycos网站于1994年7月20日发布,率先将“蜘蛛”程序集成到其索引程序中。引入“蜘蛛”后给它带来的最大优势是它比其他搜索引擎拥有更多的数据。从那时起,几乎所有占主导地位的搜索引擎都依靠“蜘蛛”来采集网页信息。Infoseek 是另一个重要的搜索引擎,直到 1994 年底才与公众见面。起初,Infoseek 只是一个不起眼的搜索引擎。它遵循了雅虎的概念!和 Lycos 并没有任何独特的创新。但其友好的用户界面和大量的附加服务在用户中赢得了声誉。1995 年 12 月,它与 Netscape 的战略协议使其成为一个强大的搜索引擎:当用户单击 Netscape 浏览器上的搜索按钮时,会弹出 Infoseek 搜索服务,该服务以前由 Yahoo! 提供!1995年12月15日,Alta Vista正式上线。它是第一个支持高级搜索语法的搜索引擎。它通过向量空间模型成功地集成了以前所有的人类信息检索技术,包括部首处理、关键词检索、布尔逻辑和查询排序。以及其他关键问题。在正式发布之前,Alta Vista 已经有 20 万访问者。在短短三周内,参观人数从每天 30 万增加到 200 万。它的成功在于满足了用户三个方面的需求:在线索引的范围超过了以往任何搜索引擎;它可以在短短几秒钟内从庞大的数据库中返回用户的搜索结果;Alta Vista 团队一直采用模块化设计技术,在不断扩展处理能力的同时,可以追踪网站的流行趋势。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。
----1998年9月,佩奇和布林创立谷歌时,业界对互联网搜索功能的理解是:某个关键词出现在文档中越频繁,文档在搜索结果中出现的排列位置in 会更加突出。这就引出了这个问题。如果某个页面充斥着某个关键词,它会被排在显眼的位置,但这样的页面对用户来说没有任何意义。佩奇和布林发明了“页面排名”(PageRank)技术来对搜索结果进行排名。即,检查链接页面在 Internet 上的频率和重要性以进行排名。网站在互联网上指向该页面越重要,该页面的排名就越高。当从网页 A 链接到网页 B 时,Google 认为“网页 A 投票给了网页 B”。谷歌根据网页的投票数评估其重要性。但是,除了考虑网页上的纯投票数外,Google 还会分析投票的网页。“重要”网页所投的票将具有更高的权重,有助于增加其他网页的重要性。”。谷歌以其复杂、全自动的搜索方式,排除了任何影响搜索结果的人为因素。没有人可以花钱购买更高的页面级别,从而保证了客观公正的页面排名。此外,集成搜索,如动态摘要、网页快照、多文档格式支持、地图库存词典中的人物搜索等功能也深受网民欢迎,许多其他搜索引擎也紧随谷歌推出了这些服务。Fast(Alltheweb)发布的搜索引擎AllTheWeb总部位于挪威,其海外风头与谷歌接近。Alltheweb的网页搜索支持Flash和pdf搜索,支持多语言搜索,还提供新闻搜索、图片搜索、视频、MP3、和FTP搜索,具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。
----搜索引擎越来越成为人们生活中的重要组成部分。查资料、查地图、听音乐,只有想不到的东西,没有搜不到的东西。
搜索引擎原理解析
----1.利用蜘蛛系统程序自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
----2. 分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到每个网页所指的内容页面和超链接每个关键词的相关性(或重要性),然后利用这些相关信息来构建网页索引数据库。
----3. 当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。然后根据相关性、网页权重、网页体验等进行排序,总分越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
----说到这里,您可能对搜索引擎和网络蜘蛛有了初步的了解! 查看全部
抓取网页数据(要说的起源,我们还得从搜索引擎说起,什么是搜索引擎呢?)
----要说网络蜘蛛的由来,就得从搜索引擎说起。什么是搜索引擎?搜索引擎的起源是什么?这与网络蜘蛛的起源密切相关。
----搜索引擎是指自动从互联网上采集信息,并提供给
网络蜘蛛用户进行查询的系统。互联网上的信息海量且杂乱无章。所有的信息就像海洋中的小岛。网页链接是这些小岛之间的桥梁,搜索引擎可以一目了然地为你画图。信息图供您随时查看。
----搜索引擎于1990年作为雏形首次出现,如今已成为人们生活中不可或缺的一部分。它经历了太多的技术和概念变化。
---- 1994年1月,第一个可搜索和可浏览的目录EINetGalaxy推出。雅虎出现在它之后,直到我们现在知道谷歌和百度。但他们并不是第一个吃掉搜索引擎螃蟹的人。从在FTP上搜索文件开始,搜索引擎的雏形出现了。那个时候还没有万维网。那个时候,人们通过手工搜索网络,然后用蜘蛛程序搜索。但是,随着互联网的不断发展,如何采集网页数量?越来越短的时间成为当时的难点和焦点,成为人们研究的焦点。
搜索引擎原型
----如果你想回去,搜索引擎的历史比万维网还要长。早在 Web 出现之前,Internet 上就已经有许多旨在让人们共享的信息资源。这些资源主要存在于各种允许匿名访问的FTP站点中。为了方便人们在分散的FTP资源中找到自己需要的东西,1990年,加拿大麦吉尔大学的几位大学生开发了一款软件Archie。它是一个可搜索的 FTP 文件名列表。用户必须输入准确的文件名进行搜索,然后 Archie 会告诉用户哪个 FTP 地址可以下载文件。Archie其实就是一个大数据库,加上一套与这个大数据库相关的检索方法。虽然 Archie 还不是搜索引擎,
----当万维网(WorldWideWeb)出现时,人们可以通过html传播网络信息,互联网上的信息开始呈指数级增长。人们使用各种方法来采集互联网上的信息,并对其进行分类和整理,以方便搜索。熟悉的网站雅虎(Yahoo)就是在这种环境下诞生的。仍在斯坦福大学读书的华裔美国人杨志远和他的同学开始沉迷于互联网。他们在互联网上采集了有趣的网页,并与同学们分享。后来,在 1994 年 4 月,他们两人共同创办了雅虎。随着访问次数和收录链接数量的增加,雅虎目录开始支持简单的数据库搜索。但是由于雅虎的数据是人工录入的,它不能真正归类为搜索引擎。事实上,它只是一个可搜索的目录。
网络蜘蛛
网络蜘蛛
----当“蜘蛛”程序出现时,现代意义上的搜索引擎才刚刚开始出现。它实际上是一种计算机“机器人”(Computer Robot),计算机“机器人”是指能够以人类无法达到的速度不间断地执行某项任务的某种软件程序。因为专门用来检索信息的“机器人”程序像蜘蛛一样在网络中四处爬行,反复不知疲倦。因此,搜索引擎的“机器人”程序被称为“蜘蛛”程序。
----这种程序实际上是利用html文档之间的链接关系来抓取Web上的每个页面,抓取这些页面进入系统进行分析,并放入数据库中。第一个开发“蜘蛛”程序的是马修格雷。他在 1993 年开发了万维网漫游器。最初建立它是为了计算 Internet 上的服务器数量,后来发展为能够捕获 URL。现代搜索引擎的思想起源于Wanderer,后来很多人在此基础上改进了蜘蛛程序。
----Lycos网站于1994年7月20日发布,率先将“蜘蛛”程序集成到其索引程序中。引入“蜘蛛”后给它带来的最大优势是它比其他搜索引擎拥有更多的数据。从那时起,几乎所有占主导地位的搜索引擎都依靠“蜘蛛”来采集网页信息。Infoseek 是另一个重要的搜索引擎,直到 1994 年底才与公众见面。起初,Infoseek 只是一个不起眼的搜索引擎。它遵循了雅虎的概念!和 Lycos 并没有任何独特的创新。但其友好的用户界面和大量的附加服务在用户中赢得了声誉。1995 年 12 月,它与 Netscape 的战略协议使其成为一个强大的搜索引擎:当用户单击 Netscape 浏览器上的搜索按钮时,会弹出 Infoseek 搜索服务,该服务以前由 Yahoo! 提供!1995年12月15日,Alta Vista正式上线。它是第一个支持高级搜索语法的搜索引擎。它通过向量空间模型成功地集成了以前所有的人类信息检索技术,包括部首处理、关键词检索、布尔逻辑和查询排序。以及其他关键问题。在正式发布之前,Alta Vista 已经有 20 万访问者。在短短三周内,参观人数从每天 30 万增加到 200 万。它的成功在于满足了用户三个方面的需求:在线索引的范围超过了以往任何搜索引擎;它可以在短短几秒钟内从庞大的数据库中返回用户的搜索结果;Alta Vista 团队一直采用模块化设计技术,在不断扩展处理能力的同时,可以追踪网站的流行趋势。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。在当时众多的搜索引擎中,Alta Vista 脱颖而出,成为互联网搜索的代名词。谷歌正在这些巨头的肩膀上进行颠覆和创造。“在线搜索”改变了人们上网的方式,它就是现在大名鼎鼎的谷歌。谷歌并不是搜索引擎的发明者,甚至有点落后,但它已经让人们爱上了搜索。
----1998年9月,佩奇和布林创立谷歌时,业界对互联网搜索功能的理解是:某个关键词出现在文档中越频繁,文档在搜索结果中出现的排列位置in 会更加突出。这就引出了这个问题。如果某个页面充斥着某个关键词,它会被排在显眼的位置,但这样的页面对用户来说没有任何意义。佩奇和布林发明了“页面排名”(PageRank)技术来对搜索结果进行排名。即,检查链接页面在 Internet 上的频率和重要性以进行排名。网站在互联网上指向该页面越重要,该页面的排名就越高。当从网页 A 链接到网页 B 时,Google 认为“网页 A 投票给了网页 B”。谷歌根据网页的投票数评估其重要性。但是,除了考虑网页上的纯投票数外,Google 还会分析投票的网页。“重要”网页所投的票将具有更高的权重,有助于增加其他网页的重要性。”。谷歌以其复杂、全自动的搜索方式,排除了任何影响搜索结果的人为因素。没有人可以花钱购买更高的页面级别,从而保证了客观公正的页面排名。此外,集成搜索,如动态摘要、网页快照、多文档格式支持、地图库存词典中的人物搜索等功能也深受网民欢迎,许多其他搜索引擎也紧随谷歌推出了这些服务。Fast(Alltheweb)发布的搜索引擎AllTheWeb总部位于挪威,其海外风头与谷歌接近。Alltheweb的网页搜索支持Flash和pdf搜索,支持多语言搜索,还提供新闻搜索、图片搜索、视频、MP3、和FTP搜索,具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。视频、MP3、和FTP搜索,并具有极其强大的高级搜索功能。而中国的百度正在通过“了解更多中文”来吸引中国在线观众。它拥有超过10亿个中文网页的数据库,并且这些网页的数量每天以数千万的速度增长。
----搜索引擎越来越成为人们生活中的重要组成部分。查资料、查地图、听音乐,只有想不到的东西,没有搜不到的东西。
搜索引擎原理解析
----1.利用蜘蛛系统程序自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
----2. 分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到每个网页所指的内容页面和超链接每个关键词的相关性(或重要性),然后利用这些相关信息来构建网页索引数据库。
----3. 当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。然后根据相关性、网页权重、网页体验等进行排序,总分越高,排名越高。最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
----说到这里,您可能对搜索引擎和网络蜘蛛有了初步的了解!
抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-14 02:08
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频 查看全部
抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频
抓取网页数据(python爬网页数据方便,python爬取数据到底有多方便 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-13 15:19
)
据说python抓取网页数据方便,今天来试试,python抓取数据有多方便?
简介
爬取数据,基本上是通过网页的URL获取这个网页的源码,根据源码过滤出需要的信息
准备
IDE:PyCharm 库:请求、lxml
注意:requests:获取网页源码 lxml:获取网页源码中的指定数据
设置环境
这里的setup环境不是搭建python的开发环境。这里的设置环境是指我们用pycharm新建一个python项目,然后用requests和lxml新建一个项目:
依赖库导入
由于我们使用的是pycharm,所以导入这两个库会很简单。
import requests
此时,requests 会报红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动安装好了,我们只需要稍等片刻就可以安装库了。 lxml的安装方法是一样的。
获取网页源代码
之前说过requests可以很方便我们获取网页的源码。对于网页,以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://coder-lida.github.io/")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
完整代码:
import requests
import lxml
html = requests.get("https://coder-lida.github.io/")
print (html.text)
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。这里我以我的博客列表为例。可以通过F12找到原网页并查看XPath,如图
通过XPath的语法获取网页内容。
查看第一篇文章文章title
//*[@id="layout-cart"]/div[1]/a/@title
//定位根节点/往下查找提取的文本内容:/text()提取属性内容:/@xxxx
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/")
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')
print(content)
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title
代码:
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/")
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')
print(content)
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 '] 查看全部
抓取网页数据(python爬网页数据方便,python爬取数据到底有多方便
)
据说python抓取网页数据方便,今天来试试,python抓取数据有多方便?
简介
爬取数据,基本上是通过网页的URL获取这个网页的源码,根据源码过滤出需要的信息
准备
IDE:PyCharm 库:请求、lxml
注意:requests:获取网页源码 lxml:获取网页源码中的指定数据
设置环境
这里的setup环境不是搭建python的开发环境。这里的设置环境是指我们用pycharm新建一个python项目,然后用requests和lxml新建一个项目:
依赖库导入
由于我们使用的是pycharm,所以导入这两个库会很简单。
import requests
此时,requests 会报红线。这时候我们将光标指向requests,按快捷键:alt+enter,pycharm会给出解决方案。这时候选择安装包请求,pycharm会自动安装好了,我们只需要稍等片刻就可以安装库了。 lxml的安装方法是一样的。
获取网页源代码
之前说过requests可以很方便我们获取网页的源码。对于网页,以我的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://coder-lida.github.io/";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
完整代码:
import requests
import lxml
html = requests.get("https://coder-lida.github.io/";)
print (html.text)
打印:
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。这里我以我的博客列表为例。可以通过F12找到原网页并查看XPath,如图
通过XPath的语法获取网页内容。
查看第一篇文章文章title
//*[@id="layout-cart"]/div[1]/a/@title
//定位根节点/往下查找提取的文本内容:/text()提取属性内容:/@xxxx
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/";)
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div[1]/a/@title')
print(content)
查看所有文章标题
//*[@id="layout-cart"]/div/a/@title
代码:
import requests
from lxml import etree
html = requests.get("https://coder-lida.github.io/";)
#print (html.text)
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="layout-cart"]/div/a/@title')
print(content)
输出:
[' springboot逆向工程 ', ' 自己实现一个简单版的HashMap ', ' 开发中常用的 个JavaScript 单行代码 ', ' shiro 加密登录 密码加盐处理 ', ' Spring Boot构建RESTful API与单元测试 ', ' 记一次jsoup的使用 ']
抓取网页数据(如何从网页中提取PowerQuery数据(图)内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2021-10-11 07:08
通过提供示例获取网页数据
通过从网页中获取数据,用户可以轻松地从网页中提取数据。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“按示例获取数据”功能,您可以通过在“连接器”对话框中提供一个或多个示例来显示要提取的 Power Query 数据。Power Query 采集页面上与示例匹配的其他数据。使用此解决方案,您可以从网页中提取各种数据,包括在表格中找到的数据和其他非表格数据。
评论
图片中列出的价格仅供参考。
使用示例从 Web 获取数据
在连接器选择中选择“Web”选项,然后选择“连接”继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在此示例中,将提取页面上每个游戏的名称和价格。为此,您可以在每列的页面中指定多个示例。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。然后,您可以应用更多转换或调整数据的形状,例如将此数据与其他数据源组合。
也可以看看
此页面有用吗?
无论
谢谢。
主题 查看全部
抓取网页数据(如何从网页中提取PowerQuery数据(图)内容)
通过提供示例获取网页数据
通过从网页中获取数据,用户可以轻松地从网页中提取数据。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“按示例获取数据”功能,您可以通过在“连接器”对话框中提供一个或多个示例来显示要提取的 Power Query 数据。Power Query 采集页面上与示例匹配的其他数据。使用此解决方案,您可以从网页中提取各种数据,包括在表格中找到的数据和其他非表格数据。
评论
图片中列出的价格仅供参考。
使用示例从 Web 获取数据
在连接器选择中选择“Web”选项,然后选择“连接”继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在此示例中,将提取页面上每个游戏的名称和价格。为此,您可以在每列的页面中指定多个示例。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。然后,您可以应用更多转换或调整数据的形状,例如将此数据与其他数据源组合。
也可以看看
此页面有用吗?
无论
谢谢。
主题
抓取网页数据(看看能做点什么游戏呢?需要准备些什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-09 23:06
抓取网页数据,图片什么的都行,然后就可以压缩图片什么的,提取dom树什么的。还可以做一些游戏。还可以提取json格式的数据,将数据保存到数据库什么的。最后就是做一些数据分析的工作了。当然,java只是开发语言的一种,也可以开发游戏,发布应用,做数据挖掘,
其实游戏研发就是开发游戏,顶多再加一点数据分析或者算法之类的东西。java不一定要独立做游戏开发,要学其他方面的东西,数据库,数据结构,linux,java的事情都可以用c++来实现。至于web方面,esri的技术优势在于在web领域和他们一起做过很多项目。如果确定以后要做游戏,那么一定要把上面两方面实现好,保证以后不会受到来自数据库,数据结构等方面的影响。
如果我是你,我学习一下hadoop,googlespark看看能做点什么,
游戏研发就是公司前台带点技术成分当老板,让交班给你来。从软件测试到架构,到ui制作,到美术,不会做也要学吧。什么c/c++,数据库数据可视化这些不会也要学吧。
你想开发什么游戏呢?制作人还是做游戏原画或者游戏策划?需要准备些什么呢?这个要定位一下
正常都是做游戏的。主要是做网页、app、游戏程序都行。我也是这个专业出来的,主要是网页、app,游戏程序其实基本都是和程序关系最大的吧。 查看全部
抓取网页数据(看看能做点什么游戏呢?需要准备些什么)
抓取网页数据,图片什么的都行,然后就可以压缩图片什么的,提取dom树什么的。还可以做一些游戏。还可以提取json格式的数据,将数据保存到数据库什么的。最后就是做一些数据分析的工作了。当然,java只是开发语言的一种,也可以开发游戏,发布应用,做数据挖掘,
其实游戏研发就是开发游戏,顶多再加一点数据分析或者算法之类的东西。java不一定要独立做游戏开发,要学其他方面的东西,数据库,数据结构,linux,java的事情都可以用c++来实现。至于web方面,esri的技术优势在于在web领域和他们一起做过很多项目。如果确定以后要做游戏,那么一定要把上面两方面实现好,保证以后不会受到来自数据库,数据结构等方面的影响。
如果我是你,我学习一下hadoop,googlespark看看能做点什么,
游戏研发就是公司前台带点技术成分当老板,让交班给你来。从软件测试到架构,到ui制作,到美术,不会做也要学吧。什么c/c++,数据库数据可视化这些不会也要学吧。
你想开发什么游戏呢?制作人还是做游戏原画或者游戏策划?需要准备些什么呢?这个要定位一下
正常都是做游戏的。主要是做网页、app、游戏程序都行。我也是这个专业出来的,主要是网页、app,游戏程序其实基本都是和程序关系最大的吧。
抓取网页数据(联网信息爆发式增长,如何有效的获取并利用这些信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-09 22:39
网络信息的爆炸式增长,如何有效地获取和使用这些信息是搜索引擎工作的第一环节。数据采集系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,所以通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛,叫做百度蜘蛛、谷歌机器人、搜狗网蜘蛛等。
蜘蛛抓取系统是搜索引擎数据来源的重要保障。如果把网理解为一个有向图,那么蜘蛛的工作过程可以看作是对这个有向图的一次遍历。从一些重要的种子网址开始,通过页面上的超链接,不断地发现和抓取新的网址,尽可能多地抓取有价值的网页。对于像百度这样的大型蜘蛛系统,由于随时都有网页被修改、删除或出现新的超链接的可能,所以需要更新以前蜘蛛爬过的页面,维护一个网址库和页面库。
1、蜘蛛爬取系统的基本框架
以下是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统.
2、蜘蛛爬取过程中涉及的网络协议
搜索引擎和资源提供者之间存在相互依赖的关系。搜索引擎需要站长为其提供资源,否则搜索引擎将无法满足用户检索需求;站长需要通过搜索引擎推广自己的内容,以获得更多的信息。许多观众。蜘蛛爬取系统直接涉及到互联网资源提供者的利益。为了让搜索引擎和站长实现双赢,双方在抓取过程中必须遵守一定的规范,以方便双方的数据处理和对接。在这个过程中遵循的规范就是我们在日常生活中所说的一些网络协议。以下是一个简要列表:
http协议:超文本传输协议,是互联网上使用最广泛的网络协议,客户端和服务器请求和响应的标准。客户端一般是指最终用户,服务器是指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送http请求,发送http请求会返回相应的httpheader信息,可以查看是否成功、服务器类型、最后更新时间网页的。 查看全部
抓取网页数据(联网信息爆发式增长,如何有效的获取并利用这些信息)
网络信息的爆炸式增长,如何有效地获取和使用这些信息是搜索引擎工作的第一环节。数据采集系统作为整个搜索系统的上游,主要负责互联网信息的采集、保存和更新。它像蜘蛛一样在网络中爬行,所以通常被称为“蜘蛛”。比如我们常用的几种常见的搜索引擎蜘蛛,叫做百度蜘蛛、谷歌机器人、搜狗网蜘蛛等。
蜘蛛抓取系统是搜索引擎数据来源的重要保障。如果把网理解为一个有向图,那么蜘蛛的工作过程可以看作是对这个有向图的一次遍历。从一些重要的种子网址开始,通过页面上的超链接,不断地发现和抓取新的网址,尽可能多地抓取有价值的网页。对于像百度这样的大型蜘蛛系统,由于随时都有网页被修改、删除或出现新的超链接的可能,所以需要更新以前蜘蛛爬过的页面,维护一个网址库和页面库。
1、蜘蛛爬取系统的基本框架
以下是蜘蛛爬取系统的基本框架图,包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统.
2、蜘蛛爬取过程中涉及的网络协议
搜索引擎和资源提供者之间存在相互依赖的关系。搜索引擎需要站长为其提供资源,否则搜索引擎将无法满足用户检索需求;站长需要通过搜索引擎推广自己的内容,以获得更多的信息。许多观众。蜘蛛爬取系统直接涉及到互联网资源提供者的利益。为了让搜索引擎和站长实现双赢,双方在抓取过程中必须遵守一定的规范,以方便双方的数据处理和对接。在这个过程中遵循的规范就是我们在日常生活中所说的一些网络协议。以下是一个简要列表:
http协议:超文本传输协议,是互联网上使用最广泛的网络协议,客户端和服务器请求和响应的标准。客户端一般是指最终用户,服务器是指网站。最终用户通过浏览器、蜘蛛等方式向服务器的指定端口发送http请求,发送http请求会返回相应的httpheader信息,可以查看是否成功、服务器类型、最后更新时间网页的。

