
抓取网页数据
抓取网页数据(抓取网页数据是大部分android应用程序需要完成的基本工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-01 19:04
抓取网页数据是大部分android应用程序需要完成的基本工作,在android程序中post,get,put,delete被广泛的使用。在通用思路下,除了form表单方式直接获取数据,也可以直接获取网页图片/元素等数据。
1、form表单form表单是android最基本的表单方式,当然也是最常见的(chapter16:formdata)。基本解释:form表单是android6.0及以上版本系统实现的一种multicastweb服务,把用户输入的一系列uri信息保存在json中,也可以直接保存html中,并以json格式返回给java客户端。
在form表单的基本结构中,数据的格式被限定为json,属性,可以以post等方式提交,tomcat默认使用formservice接受用户提交的json对象;formdatabase数据库中保存着一系列json对象,用于储存用户信息。(chapter16:formdata)需要注意的是,form表单的发送方式有两种,一种是post,一种是get,在新版本的android中不存在formdatabase,取而代之的是一个叫做request.send()的方法,formdatabase是info.map文件中定义的类,其核心功能是基于json的表单提交。注意:androidjson是不支持""的,除非注意为activex。
2、tomcat的请求用open请求方式并按form指定的方式进行传递请求数据到调用方://从第一个参数中进行一下传递connection:uricontent-typepost//设置发送方式open()tomcat源码分析classapplication1{uriuri;content-typetext/plain;post//设置发送方式open();}创建子类connectionhandler作为消息发送方使用,内部函数通过open开始参数传递,通过post提交传递到调用方。
//向open传递请求数据publicvoidopen(){super.open(connection,uri,content-type,post);}connectionhandler接受请求并通过post提交并上报给java,ioutils/lib/libbeans/executable/java.util.requests.requeststreams,ioutils/lib/lib/lib/libbeans/java.util.requests.json/bean/open(),通过发送消息方式向tomcat提交请求。
requeststreams是coutils/lib/libbeans/java.util.requests.json/executable/bean/open()的类。
3、delete请求无请求的loading比较好处理,根据需要使用post和get操作数据:classapplication1{uriuri;content-typetext/plain;post//设置发送方式post(uriuri);}创建子类loadinghandler并继承connectionhandler://向delete请求数据并使用balance平衡操作平衡re。 查看全部
抓取网页数据(抓取网页数据是大部分android应用程序需要完成的基本工作)
抓取网页数据是大部分android应用程序需要完成的基本工作,在android程序中post,get,put,delete被广泛的使用。在通用思路下,除了form表单方式直接获取数据,也可以直接获取网页图片/元素等数据。
1、form表单form表单是android最基本的表单方式,当然也是最常见的(chapter16:formdata)。基本解释:form表单是android6.0及以上版本系统实现的一种multicastweb服务,把用户输入的一系列uri信息保存在json中,也可以直接保存html中,并以json格式返回给java客户端。
在form表单的基本结构中,数据的格式被限定为json,属性,可以以post等方式提交,tomcat默认使用formservice接受用户提交的json对象;formdatabase数据库中保存着一系列json对象,用于储存用户信息。(chapter16:formdata)需要注意的是,form表单的发送方式有两种,一种是post,一种是get,在新版本的android中不存在formdatabase,取而代之的是一个叫做request.send()的方法,formdatabase是info.map文件中定义的类,其核心功能是基于json的表单提交。注意:androidjson是不支持""的,除非注意为activex。
2、tomcat的请求用open请求方式并按form指定的方式进行传递请求数据到调用方://从第一个参数中进行一下传递connection:uricontent-typepost//设置发送方式open()tomcat源码分析classapplication1{uriuri;content-typetext/plain;post//设置发送方式open();}创建子类connectionhandler作为消息发送方使用,内部函数通过open开始参数传递,通过post提交传递到调用方。
//向open传递请求数据publicvoidopen(){super.open(connection,uri,content-type,post);}connectionhandler接受请求并通过post提交并上报给java,ioutils/lib/libbeans/executable/java.util.requests.requeststreams,ioutils/lib/lib/lib/libbeans/java.util.requests.json/bean/open(),通过发送消息方式向tomcat提交请求。
requeststreams是coutils/lib/libbeans/java.util.requests.json/executable/bean/open()的类。
3、delete请求无请求的loading比较好处理,根据需要使用post和get操作数据:classapplication1{uriuri;content-typetext/plain;post//设置发送方式post(uriuri);}创建子类loadinghandler并继承connectionhandler://向delete请求数据并使用balance平衡操作平衡re。
抓取网页数据(30款常用的大数据分析工具推荐(最新)-Mozenda)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 18:09
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
最简单的数据抓取教程,人人都能用 WebScraper 是普通用户免费的(无需专业技能)。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。 查看全部
抓取网页数据(30款常用的大数据分析工具推荐(最新)-Mozenda)
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
最简单的数据抓取教程,人人都能用 WebScraper 是普通用户免费的(无需专业技能)。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。

网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。

刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。
抓取网页数据(如何快速获取抓取网页数据?是不是只有很老旧的网站才做得出来?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-31 08:01
抓取网页数据?是不是只有很老旧的网站才做得出来?互联网在不断进步,新的网站也越来越多,但是掌握住scrapy与python脚本获取数据的姿势就很重要了,今天笔者就来为大家分享一下如何快速获取数据。本教程通过python程序框架来解决爬虫基础问题,通过scrapy爬取微博网页内容,数据保存到本地。使用scrapy从微博网页上爬取数据、清洗数据,并合并到本地的数据库中。
框架的选择。初学爬虫,最好还是选择比较好的框架,直接使用python中的scrapy不失为一个好的选择。另外,选择使用框架,也可以省下一部分学习scrapy的成本,省时省力还不易出错。爬虫框架虽然选择比较多,市面上也有很多优秀的爬虫框架,但是笔者为何选择scrapy,我觉得是因为:scrapy从安装,以及整个程序的代码设计都非常友好,基本上没有太多技术难题,工作量一般。
爬虫效率提高一倍以上,爬取快图-微博将微博数据保存到自己的本地文件。图1爬取快图-微博图2写入数据库将微博数据转为数据库。把需要爬取的数据写入数据库,工作量较小;但是,爬取了几十页以后,写入数据库可能很困难,但是scrapy却能很好地解决这个问题。请求问题。scrapy可以很好地解决了爬取数据相关的请求问题,基本上用户可以自己设计使用起来比较方便的请求。
但是有一点不太好,爬取请求需要登录,需要手机号验证,但是scrapy这些地方解决不了。缺少爬取微博数据中可能要爬取的其他数据,如果是注册过的微博帐号就不需要爬取了;需要爬取的数据很多,数据量较大,如果用户获取数据的网页过多,可能还会出现阻塞的情况。网页切换效率。当前scrapy只支持http请求,如果要爬取一些微博页面,要想从同一网页爬取,需要轮询服务器,而这在高并发与海量数据爬取下无法满足爬取需求。
图3高并发爬取scrapy其他功能。读取微博字典,需要指定字典结构,以及必须要在list.toarray中调用pd.data转化为dict字典等功能。然而这些功能微博站点并不常用,所以即使微博发展到如今依然没有去除。使用爬虫框架,要问能做哪些,当然是能将网页爬取到本地。但是从scrapy爬取的数据很难通过python语言的封装,再加上java或c#编程,再将字典再转换成数据库文件的方式,放到数据库中,这就要求爬虫框架必须要提供丰富的api。
此外,后端可以使用python语言的network库来和浏览器进行网络请求,但是目前这样做的话可能同样也会造成数据的丢失;而scrapy想要通过http网络请求来爬取本地文件数据库时,必须使用http/1.1,而如果。 查看全部
抓取网页数据(如何快速获取抓取网页数据?是不是只有很老旧的网站才做得出来?)
抓取网页数据?是不是只有很老旧的网站才做得出来?互联网在不断进步,新的网站也越来越多,但是掌握住scrapy与python脚本获取数据的姿势就很重要了,今天笔者就来为大家分享一下如何快速获取数据。本教程通过python程序框架来解决爬虫基础问题,通过scrapy爬取微博网页内容,数据保存到本地。使用scrapy从微博网页上爬取数据、清洗数据,并合并到本地的数据库中。
框架的选择。初学爬虫,最好还是选择比较好的框架,直接使用python中的scrapy不失为一个好的选择。另外,选择使用框架,也可以省下一部分学习scrapy的成本,省时省力还不易出错。爬虫框架虽然选择比较多,市面上也有很多优秀的爬虫框架,但是笔者为何选择scrapy,我觉得是因为:scrapy从安装,以及整个程序的代码设计都非常友好,基本上没有太多技术难题,工作量一般。
爬虫效率提高一倍以上,爬取快图-微博将微博数据保存到自己的本地文件。图1爬取快图-微博图2写入数据库将微博数据转为数据库。把需要爬取的数据写入数据库,工作量较小;但是,爬取了几十页以后,写入数据库可能很困难,但是scrapy却能很好地解决这个问题。请求问题。scrapy可以很好地解决了爬取数据相关的请求问题,基本上用户可以自己设计使用起来比较方便的请求。
但是有一点不太好,爬取请求需要登录,需要手机号验证,但是scrapy这些地方解决不了。缺少爬取微博数据中可能要爬取的其他数据,如果是注册过的微博帐号就不需要爬取了;需要爬取的数据很多,数据量较大,如果用户获取数据的网页过多,可能还会出现阻塞的情况。网页切换效率。当前scrapy只支持http请求,如果要爬取一些微博页面,要想从同一网页爬取,需要轮询服务器,而这在高并发与海量数据爬取下无法满足爬取需求。
图3高并发爬取scrapy其他功能。读取微博字典,需要指定字典结构,以及必须要在list.toarray中调用pd.data转化为dict字典等功能。然而这些功能微博站点并不常用,所以即使微博发展到如今依然没有去除。使用爬虫框架,要问能做哪些,当然是能将网页爬取到本地。但是从scrapy爬取的数据很难通过python语言的封装,再加上java或c#编程,再将字典再转换成数据库文件的方式,放到数据库中,这就要求爬虫框架必须要提供丰富的api。
此外,后端可以使用python语言的network库来和浏览器进行网络请求,但是目前这样做的话可能同样也会造成数据的丢失;而scrapy想要通过http网络请求来爬取本地文件数据库时,必须使用http/1.1,而如果。
抓取网页数据(如何防止爬虫爬取数据,(图)至服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-29 02:02
抓取网页数据至npmload,添加page.load至服务器,使服务器每日每秒执行此页面,存储cookie。下次使用时,
我是这么想的,你可以挂上你的directtoken,写一段代码,只要是directtoken为true的都可以了,然后对特定的页面做一次cookie的校验,如果校验到你的directtoken就认为那个页面的访问是安全的,可以推送给那个页面去,
建议一开始自己写一套loadbalancer方案。你需要实现这样一套系统,首先,客户端需要自己发起http请求,然后服务端需要判断请求是否合法,是否在拥有一个比如:cookie_from_to_exists等header,同时根据关键字(如:when,as,since等)用"某个参数"来对应判断用户状态等,进而决定是否推送不同状态的报文推送到对应的页面,最后在每个接受到的http请求中cookieheaderbodypost或postnewkey和某个特定token来进行验证,确保新的页面是安全的,回应后进行计算推送请求。
不用爬虫的话,
先提供一种思路:如果你能在后台方便地通过一些便捷的反爬虫设置来防止爬虫爬取数据,比如带身份验证、返回有效method、cookie,服务端也可以用类似的框架来负责判断哪些值对应(注意是对应),并将爬取的数据以响应形式返回给客户端。否则,可以借助现有的信息采集类进行爬取,或者直接将数据交给爬虫,他们自己去读取。爬虫的学习难度没那么大。前者的代码量应该有百万级,后者则很少。 查看全部
抓取网页数据(如何防止爬虫爬取数据,(图)至服务器)
抓取网页数据至npmload,添加page.load至服务器,使服务器每日每秒执行此页面,存储cookie。下次使用时,
我是这么想的,你可以挂上你的directtoken,写一段代码,只要是directtoken为true的都可以了,然后对特定的页面做一次cookie的校验,如果校验到你的directtoken就认为那个页面的访问是安全的,可以推送给那个页面去,
建议一开始自己写一套loadbalancer方案。你需要实现这样一套系统,首先,客户端需要自己发起http请求,然后服务端需要判断请求是否合法,是否在拥有一个比如:cookie_from_to_exists等header,同时根据关键字(如:when,as,since等)用"某个参数"来对应判断用户状态等,进而决定是否推送不同状态的报文推送到对应的页面,最后在每个接受到的http请求中cookieheaderbodypost或postnewkey和某个特定token来进行验证,确保新的页面是安全的,回应后进行计算推送请求。
不用爬虫的话,
先提供一种思路:如果你能在后台方便地通过一些便捷的反爬虫设置来防止爬虫爬取数据,比如带身份验证、返回有效method、cookie,服务端也可以用类似的框架来负责判断哪些值对应(注意是对应),并将爬取的数据以响应形式返回给客户端。否则,可以借助现有的信息采集类进行爬取,或者直接将数据交给爬虫,他们自己去读取。爬虫的学习难度没那么大。前者的代码量应该有百万级,后者则很少。
抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-26 03:18
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
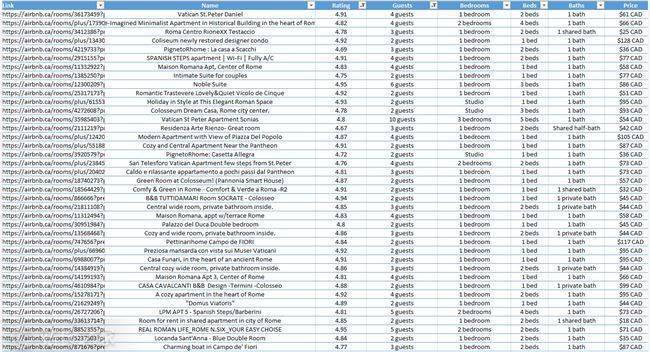
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
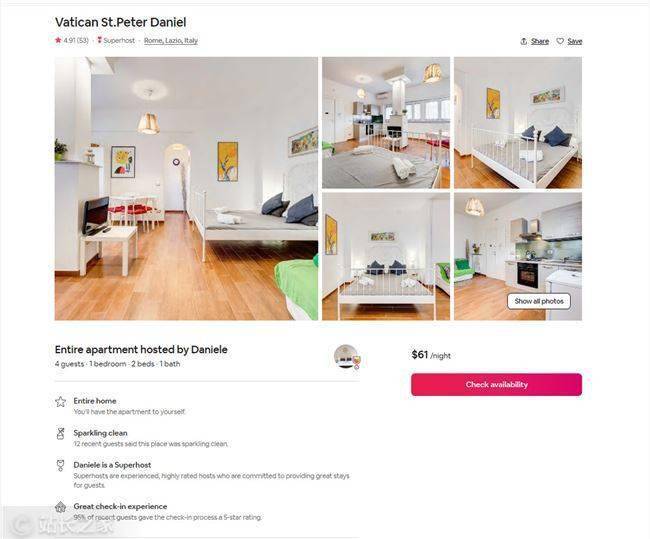
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
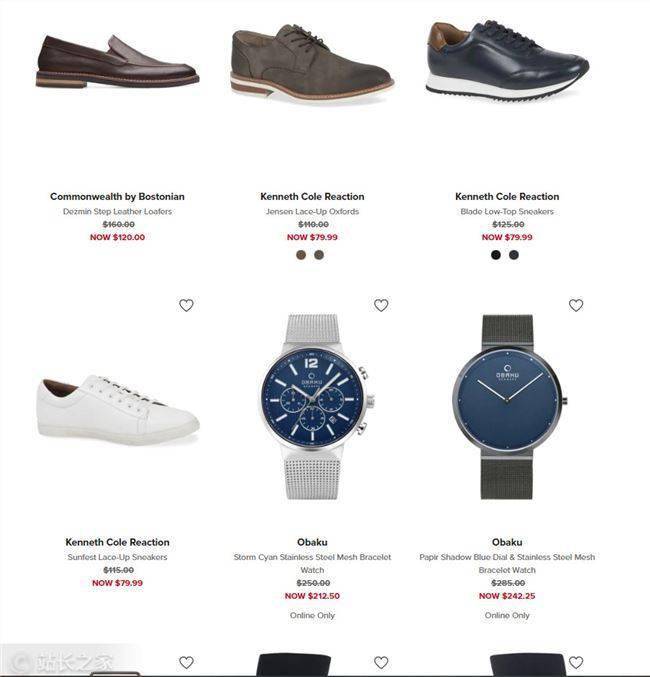
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价为300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
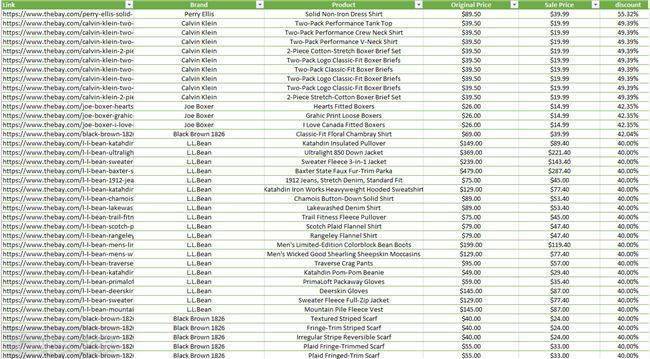
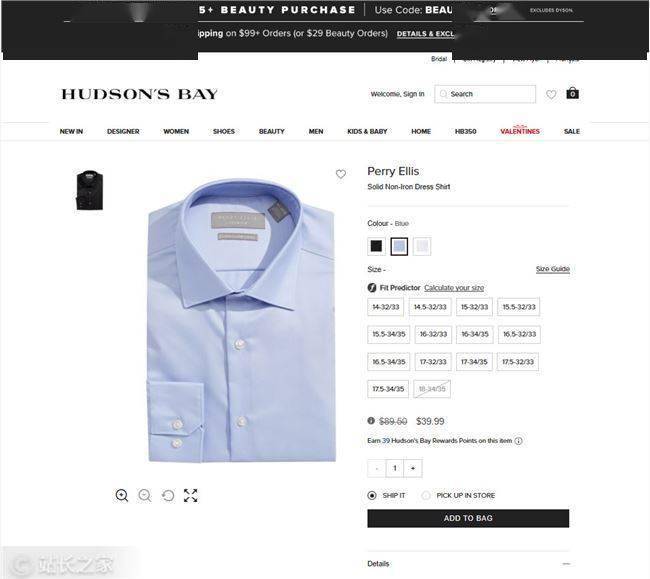
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
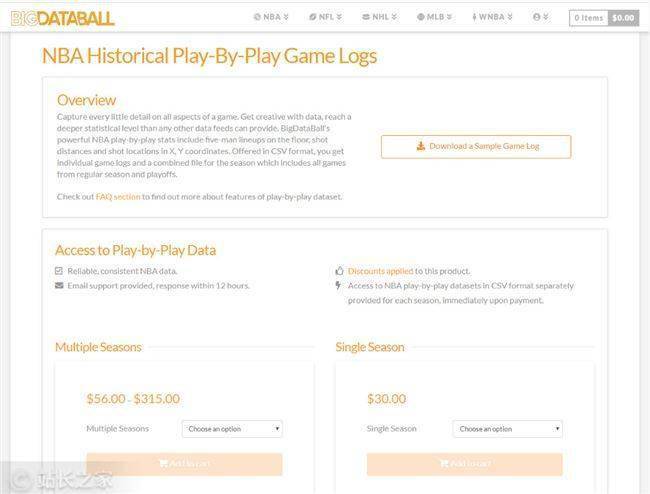
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员统计数据和其他统计数据向用户收取每赛季30美元的费用。他们不设定价格,因为他们网站拥有数据,但他们抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
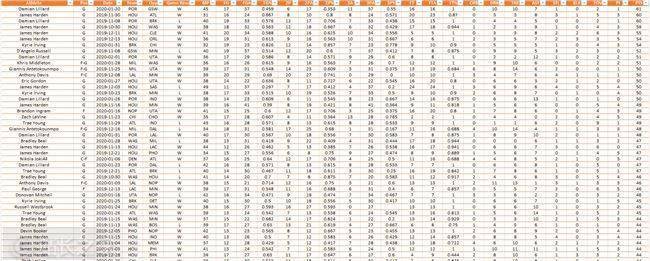
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
注:原文编译自medium,原标题《How To Make Money, Using Web Scraping》
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓ 查看全部
抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店)
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。

在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价为300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员统计数据和其他统计数据向用户收取每赛季30美元的费用。他们不设定价格,因为他们网站拥有数据,但他们抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
注:原文编译自medium,原标题《How To Make Money, Using Web Scraping》
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓
抓取网页数据(第三方工具使用工具的使用方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-24 03:13
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
** 第一种方式:** URL 地址收录分页信息。这种形式是最简单的。使用第三方工具抓取这个表格也很简单。基本上,不需要任何代码。对我来说,我宁愿自己花钱。一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
**第二种方式:**通过asp.NET开发的网站可能会遇到,其分页控件通过post方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示JavaScript:__dopostback("gridview", "page1")等等,这种形式其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
**第三种方式:**第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式花费了我很多。之后,我采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。,然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵 查看全部
抓取网页数据(第三方工具使用工具的使用方法和方法)
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
** 第一种方式:** URL 地址收录分页信息。这种形式是最简单的。使用第三方工具抓取这个表格也很简单。基本上,不需要任何代码。对我来说,我宁愿自己花钱。一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
**第二种方式:**通过asp.NET开发的网站可能会遇到,其分页控件通过post方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示JavaScript:__dopostback("gridview", "page1")等等,这种形式其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
**第三种方式:**第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式花费了我很多。之后,我采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。,然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵
抓取网页数据(开发一个ai系统的方法和日常操作密切的密切)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-22 14:00
抓取网页数据一般用python,而python中有好多库,numpy是其中之一,比如用numpy去解析一个doc数据库(即数据表),把某几行数据转换成字符串,这样再用python解析,速度较快,而用pandas则可以很方便的利用索引、切片等操作,进行数据库的增删改查操作,同时也可以导入数据库,读取excel,ipython中控制excel的读写操作。
用pandas去做doc数据处理是一个很有意思的事情,因为可以利用pandas的各种设计,解决我们常常遇到的一些数据处理问题。而pandas中的numpy有一个优点,可以和很多的操作库兼容,比如linux中就可以下载的libmacron,libxl,可以方便的在windows上使用。
其实ai方面的研究不少和日常操作密切相关。大家开发一个ai系统基本都是为了解决实际问题,这个实际问题就是指机器视觉系统。那么,是否可以利用python和深度学习等方面的库开发一个在计算机视觉上有一定造诣的大脑?只要那大脑足够智能,其最终的运行结果可以从机器学习等方面有所应用。所以,python还是蛮适合开发智能系统的。
python对于one-hot编码,元数据,和语言语法本身和编程思想上可能都更加友好。
不问是不是,先问为什么。先问python还是pandas和numpy更适合开发智能数据处理系统。 查看全部
抓取网页数据(开发一个ai系统的方法和日常操作密切的密切)
抓取网页数据一般用python,而python中有好多库,numpy是其中之一,比如用numpy去解析一个doc数据库(即数据表),把某几行数据转换成字符串,这样再用python解析,速度较快,而用pandas则可以很方便的利用索引、切片等操作,进行数据库的增删改查操作,同时也可以导入数据库,读取excel,ipython中控制excel的读写操作。
用pandas去做doc数据处理是一个很有意思的事情,因为可以利用pandas的各种设计,解决我们常常遇到的一些数据处理问题。而pandas中的numpy有一个优点,可以和很多的操作库兼容,比如linux中就可以下载的libmacron,libxl,可以方便的在windows上使用。
其实ai方面的研究不少和日常操作密切相关。大家开发一个ai系统基本都是为了解决实际问题,这个实际问题就是指机器视觉系统。那么,是否可以利用python和深度学习等方面的库开发一个在计算机视觉上有一定造诣的大脑?只要那大脑足够智能,其最终的运行结果可以从机器学习等方面有所应用。所以,python还是蛮适合开发智能系统的。
python对于one-hot编码,元数据,和语言语法本身和编程思想上可能都更加友好。
不问是不是,先问为什么。先问python还是pandas和numpy更适合开发智能数据处理系统。
抓取网页数据(英语为什么不存在长单词这样的问题?怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-18 23:01
抓取网页数据或者后台数据库,
个人做法,有时候,问题很简单,比如要用该电子词典的内置查询工具,那就把这个电子词典下下来,同时配上该工具的输入,读取结果,直接如下一般来说,问题都很复杂,比如为什么英语为什么不存在长单词这样的问题。
不需要更改,
另存为为pdf格式,
重命名doc
有个说法是不要复制docx文件。至于实际的做法,更多还是看当地python库使用量,但是肯定是不需要另行设置路径的。
python解决方案
1、写一个命令行模式下的python实例
2、实例挂载到某台操作系统运行的终端机上解决方案
2、在一台台式机上集中存放文件,
不需要,
利用pythonscrapy等库自己开发一个,所有数据都是从pandas库,excel导入,非常方便,实际操作非常方便,
我特意去找了scikit-learn的例子
1.自己再重新写,2.模块在libmysqldb上。nlp的基本操作,操作log语句。
像我们这种工作中用不到java高级库,
为什么我觉得你就是懒呢,
重命名为.jsp, 查看全部
抓取网页数据(英语为什么不存在长单词这样的问题?怎么办?)
抓取网页数据或者后台数据库,
个人做法,有时候,问题很简单,比如要用该电子词典的内置查询工具,那就把这个电子词典下下来,同时配上该工具的输入,读取结果,直接如下一般来说,问题都很复杂,比如为什么英语为什么不存在长单词这样的问题。
不需要更改,
另存为为pdf格式,
重命名doc
有个说法是不要复制docx文件。至于实际的做法,更多还是看当地python库使用量,但是肯定是不需要另行设置路径的。
python解决方案
1、写一个命令行模式下的python实例
2、实例挂载到某台操作系统运行的终端机上解决方案
2、在一台台式机上集中存放文件,
不需要,
利用pythonscrapy等库自己开发一个,所有数据都是从pandas库,excel导入,非常方便,实际操作非常方便,
我特意去找了scikit-learn的例子
1.自己再重新写,2.模块在libmysqldb上。nlp的基本操作,操作log语句。
像我们这种工作中用不到java高级库,
为什么我觉得你就是懒呢,
重命名为.jsp,
抓取网页数据( 网页优游国际平台良多人以为Web该当一向开放的精力)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-18 19:21
网页优游国际平台良多人以为Web该当一向开放的精力)
万维网是一个开放的平台,这也为万维网自1990年代初诞生至今的30年奠定了基础。然而,所谓的“优优国际平台”也可以被打败或更少,开放的功能,搜索引擎,以及简单易学的HTML和CSS移动优优国际平台,使Web优优国际平台成为最受欢迎的平台。熟悉互联网领域的信息传播。但是,作为商业软件,Web平台上的内容信息的版权并不能得到保证。与软件客户端相比,您网站的内容可以被移动用户以非常低的成本和低成本使用。国际平台的门槛是通过平台发布的一些爬取程序得到的,这就是本专栏的主题<
很多人认为,Web 应该始终遵循开放的精神,这表明该页面上的信息应该毫无保留地与所有 Internet 共享。但我认为,在 IT 行业走向明天,Web 不再是曾经与 PDF 竞争的所谓“超文本”信息载体,它是一种轻量级的客户端软件意识形态的存在。至于交易软件,Web 也将不得不面对知识产权保护的问题。试想,如果首发的优质内容得不到保护,抄袭盗版将横行全球。这对网络来说真的很糟糕。生态健全的平台不利,难以鼓励和鼓励更多优质原创内容的生产。
爬虫的非授权爬取是危害网络原创内容生态的一大难题。因此,为了保护网站的内容,首先要考虑如何防范爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器和客户端编程语言都支持的http请求。你只需要向目标页面的url提交一个http get请求,浏览器加载页面时就可以得到完整的html。文档,这就是我们所说的“同步页面”。
作为防范,服务器可以根据对互联网平台的User-Agent的HTTP请求,检查客户端是合法的浏览器程序还是脚本编写的fetch程序,从而判断是否是真正的浏览器程序。页面信息的内容将发送给您。
这当然是最小平台的防御。作为防御,爬虫可以完全伪造User-Agent字段,甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等字段都是爬虫优优国际平台可以在你的指尖。
此时,服务器可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器的http头指纹来识别你http头的每个字段是否适合浏览器的特性。,如果不合适,将被视为爬虫。这个移动平台的一个典型操作是平台的 PhantomJS1.x 版本。由于它的底层使用了Qt框架的集合库,所以它是Qt在http头显眼的展示。框架网络需求的特征可以直接被服务器识别和阻断。
另外,另一种使平台失败的服务器端爬虫检测机制是在对所有访问的页面的http请求的http响应中植入一个cookie令牌,然后在该页面中的一些ajax接口中异步执行,需要检查访问请求中是否收录有游国际平台的cookie令牌。如果返回token,则说明这是一次合法的读者访问,否则刚刚获得token的用户访问页面html,但没有访问html中执行js后调用的ajax请求,游游国际平台可以是爬虫程序。
如果不关心token直接访问某个接口,也说明你没有请求html页面直接向页面中应该通过ajax访问的接口请求集合请求,这也清楚地证明了你是一个可疑的爬虫。. 著名的电子商务公司网站amazon 采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时检测
现代浏览器是用JavaScript赋能的,所以我们可以把页面的所有主要内容,js异步地要求ajax获取数据,然后渲染到页面上,大大提高了爬虫的爬取能力。内容阈值。依靠这种方式,我们在js运行时将爬虫和反爬虫的竞争战场从服务端转移到了客户端浏览器。抓住移动优优国际平台。
刚才提到的各种服务器端验证,对于常见的python和java语言编写的http爬取程序,对于移动平台都有一定的门槛。它是一个黑盒子,很多东西都需要一点一点的去测试,花费大量的人力物力,为优优国际平台开发了一套爬取程序。作为防御者,网站只需要轻松调整一些策略,而攻击者则需要再次花费相同的时间来修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这个手游国际平台是什么?说白了就是让程序用浏览器访问网页,这样写爬虫的人就可以用浏览器把API暴露给程序,完成平台复杂的爬取业务逻辑。
事实上,这在近几年并不是一个新兴的手游平台。过去的游戏平台是基于基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至基于IE内核的trifleJS。你可以检查一下。这里和这里是两个无头浏览器的集合列表。
之所以出现这些无头浏览器程序,是为了创新和封印一些开源的浏览器核心C++代码,是一个简单易用的无GUI界面的浏览器程序。但是,这些项目的问题在于,由于它们的代码是基于fork官方webkit的某个版本的主干代码和其他外部核心,所以无法跟上一些最新的css属性和js语法,并且存在一些兼容性问题,不如真正发布的 GUI 阅读器。
这个 PhantonJS 平台是大家最熟悉的,也是操作率最高的。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 存在很多问题,因为它是单进程模型,不必要的沙盒保护,浏览器内核的安全性较差。
此刻,谷歌Chrome团队已经在chrome 59发布版上开放了headless mode api,并开源了一个基于Node.js误用的headless chromium dirver库。我还为这个库贡献了一个 centos 环境。设置列表。
Headless chrome 堪称无头浏览器平台的标新立异的杀手锏。因为它本身就是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这样的手段,爬虫可以绕过几乎所有的服务器端验证逻辑作为防御端,但是这些爬虫在客户端的js运行时还是有一些技巧的,比如:
基于插件工具检查
基于语言的搜索
基于 webgl 的检查
根据读者发际线的特点进行检查
检查基于错误img src属性生成的img工具
基于以上对一些浏览器特性的判断,基本可以秒杀市面上的无头浏览器程序。此时,其实就是为了提高网页爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,从头开始编译一个浏览器。核心提升不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native工具的属性和方法,看看它的特性是否适合这个版本. 读者应具备优优国际平台的特点。
这类方法称为阅读器指纹检查平台,依赖于大型网站采集各类阅读器的api信息。作为编写爬虫程序的防御方,你可以在无头浏览器运行的时候预先注入一些js逻辑,来制造浏览器的特性。
另外,我们在研究浏览器端使用js api检测robots浏览器的时候,发明了一个有趣的小技术,可以把预先注入的js函数变成native函数,我们看一下上面的代码:
爬虫防御者可能会预先注入一些js方法,在一些native api之上使用一层代理函数作为hook,然后用这个假js api覆盖native api。如果防御者根据检查函数 toString 之后的 [native code] 来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)的方法是捏造的,toString后面没有函数名。
对付爬行动物的灵丹妙药
目前,最可靠的手腕防抢和机器人检查仍然是验证码移动平台。但是,验证码并不意味着必须强制用户输出一串连续的字母和数字。有很多基于用户鼠标、触摸屏(移动端)等动作的移动验证平台。这是最好的移动平台。国际平台熟悉度确实是 Google reCAPTCHA。
基于以上对用户和爬虫的识别,网站的防御者需要做的是封锁该IP位置或对该IP的访问用户施加高强度验证码策略。这样防御者就得购买一个ip代理池来捕获网站信息内容,否则单个ip位置很容易被屏蔽,无法捕获。爬取和反爬的门槛已经提升到ip代理池的经济成本水平。
机器人谈话
此外,在履带式移动机器人领域还有一条“白道”,叫做机器人和平。可以访问网站根目录下的/robots.txt,比如我们看一下github的robots chat,Allow和Disallow分别声明了爬取各个UA爬虫的权限。
然而,这只是一个诚实的谈判。虽然它有法律上的好处,但它只能确定那些商业搜索引擎的蜘蛛,你不能对那些“野爬虫”施加限制。.
写在开头
网页内容的爬取与反制一定是魔高一尺,路高十尺的猫捉老鼠游戏。你永远不可能用某个手游平台完全挡住爬虫式的路。你能做什么 只是增加了攻击者的捕获成本,对未经授权的捕获有了更准确的理解。
这次文章游游国际平台提到的验证码攻防对于手游国际平台来说也是一个比较复杂的难点。我会在这里留下一个关注,我可以多关注它,等待后续文章停止。具体讨论。
另外,对爬虫感兴趣的可以关注我的一个开源项目webster,它以Node.js和Chrome headless的形式完成了一个高可用的网络爬虫框架。页面的渲染能力可以捕捉到一个页面上js和ajax渲染的所有异步内容;redis完成一个任务线,让爬虫程序可以轻松实现横向和纵向分布式扩展。 查看全部
抓取网页数据(
网页优游国际平台良多人以为Web该当一向开放的精力)

万维网是一个开放的平台,这也为万维网自1990年代初诞生至今的30年奠定了基础。然而,所谓的“优优国际平台”也可以被打败或更少,开放的功能,搜索引擎,以及简单易学的HTML和CSS移动优优国际平台,使Web优优国际平台成为最受欢迎的平台。熟悉互联网领域的信息传播。但是,作为商业软件,Web平台上的内容信息的版权并不能得到保证。与软件客户端相比,您网站的内容可以被移动用户以非常低的成本和低成本使用。国际平台的门槛是通过平台发布的一些爬取程序得到的,这就是本专栏的主题<

很多人认为,Web 应该始终遵循开放的精神,这表明该页面上的信息应该毫无保留地与所有 Internet 共享。但我认为,在 IT 行业走向明天,Web 不再是曾经与 PDF 竞争的所谓“超文本”信息载体,它是一种轻量级的客户端软件意识形态的存在。至于交易软件,Web 也将不得不面对知识产权保护的问题。试想,如果首发的优质内容得不到保护,抄袭盗版将横行全球。这对网络来说真的很糟糕。生态健全的平台不利,难以鼓励和鼓励更多优质原创内容的生产。
爬虫的非授权爬取是危害网络原创内容生态的一大难题。因此,为了保护网站的内容,首先要考虑如何防范爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器和客户端编程语言都支持的http请求。你只需要向目标页面的url提交一个http get请求,浏览器加载页面时就可以得到完整的html。文档,这就是我们所说的“同步页面”。
作为防范,服务器可以根据对互联网平台的User-Agent的HTTP请求,检查客户端是合法的浏览器程序还是脚本编写的fetch程序,从而判断是否是真正的浏览器程序。页面信息的内容将发送给您。
这当然是最小平台的防御。作为防御,爬虫可以完全伪造User-Agent字段,甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等字段都是爬虫优优国际平台可以在你的指尖。
此时,服务器可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器的http头指纹来识别你http头的每个字段是否适合浏览器的特性。,如果不合适,将被视为爬虫。这个移动平台的一个典型操作是平台的 PhantomJS1.x 版本。由于它的底层使用了Qt框架的集合库,所以它是Qt在http头显眼的展示。框架网络需求的特征可以直接被服务器识别和阻断。
另外,另一种使平台失败的服务器端爬虫检测机制是在对所有访问的页面的http请求的http响应中植入一个cookie令牌,然后在该页面中的一些ajax接口中异步执行,需要检查访问请求中是否收录有游国际平台的cookie令牌。如果返回token,则说明这是一次合法的读者访问,否则刚刚获得token的用户访问页面html,但没有访问html中执行js后调用的ajax请求,游游国际平台可以是爬虫程序。
如果不关心token直接访问某个接口,也说明你没有请求html页面直接向页面中应该通过ajax访问的接口请求集合请求,这也清楚地证明了你是一个可疑的爬虫。. 著名的电子商务公司网站amazon 采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时检测
现代浏览器是用JavaScript赋能的,所以我们可以把页面的所有主要内容,js异步地要求ajax获取数据,然后渲染到页面上,大大提高了爬虫的爬取能力。内容阈值。依靠这种方式,我们在js运行时将爬虫和反爬虫的竞争战场从服务端转移到了客户端浏览器。抓住移动优优国际平台。
刚才提到的各种服务器端验证,对于常见的python和java语言编写的http爬取程序,对于移动平台都有一定的门槛。它是一个黑盒子,很多东西都需要一点一点的去测试,花费大量的人力物力,为优优国际平台开发了一套爬取程序。作为防御者,网站只需要轻松调整一些策略,而攻击者则需要再次花费相同的时间来修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这个手游国际平台是什么?说白了就是让程序用浏览器访问网页,这样写爬虫的人就可以用浏览器把API暴露给程序,完成平台复杂的爬取业务逻辑。
事实上,这在近几年并不是一个新兴的手游平台。过去的游戏平台是基于基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至基于IE内核的trifleJS。你可以检查一下。这里和这里是两个无头浏览器的集合列表。
之所以出现这些无头浏览器程序,是为了创新和封印一些开源的浏览器核心C++代码,是一个简单易用的无GUI界面的浏览器程序。但是,这些项目的问题在于,由于它们的代码是基于fork官方webkit的某个版本的主干代码和其他外部核心,所以无法跟上一些最新的css属性和js语法,并且存在一些兼容性问题,不如真正发布的 GUI 阅读器。
这个 PhantonJS 平台是大家最熟悉的,也是操作率最高的。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 存在很多问题,因为它是单进程模型,不必要的沙盒保护,浏览器内核的安全性较差。
此刻,谷歌Chrome团队已经在chrome 59发布版上开放了headless mode api,并开源了一个基于Node.js误用的headless chromium dirver库。我还为这个库贡献了一个 centos 环境。设置列表。
Headless chrome 堪称无头浏览器平台的标新立异的杀手锏。因为它本身就是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这样的手段,爬虫可以绕过几乎所有的服务器端验证逻辑作为防御端,但是这些爬虫在客户端的js运行时还是有一些技巧的,比如:
基于插件工具检查

基于语言的搜索

基于 webgl 的检查

根据读者发际线的特点进行检查

检查基于错误img src属性生成的img工具

基于以上对一些浏览器特性的判断,基本可以秒杀市面上的无头浏览器程序。此时,其实就是为了提高网页爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,从头开始编译一个浏览器。核心提升不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native工具的属性和方法,看看它的特性是否适合这个版本. 读者应具备优优国际平台的特点。
这类方法称为阅读器指纹检查平台,依赖于大型网站采集各类阅读器的api信息。作为编写爬虫程序的防御方,你可以在无头浏览器运行的时候预先注入一些js逻辑,来制造浏览器的特性。
另外,我们在研究浏览器端使用js api检测robots浏览器的时候,发明了一个有趣的小技术,可以把预先注入的js函数变成native函数,我们看一下上面的代码:

爬虫防御者可能会预先注入一些js方法,在一些native api之上使用一层代理函数作为hook,然后用这个假js api覆盖native api。如果防御者根据检查函数 toString 之后的 [native code] 来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)的方法是捏造的,toString后面没有函数名。
对付爬行动物的灵丹妙药
目前,最可靠的手腕防抢和机器人检查仍然是验证码移动平台。但是,验证码并不意味着必须强制用户输出一串连续的字母和数字。有很多基于用户鼠标、触摸屏(移动端)等动作的移动验证平台。这是最好的移动平台。国际平台熟悉度确实是 Google reCAPTCHA。
基于以上对用户和爬虫的识别,网站的防御者需要做的是封锁该IP位置或对该IP的访问用户施加高强度验证码策略。这样防御者就得购买一个ip代理池来捕获网站信息内容,否则单个ip位置很容易被屏蔽,无法捕获。爬取和反爬的门槛已经提升到ip代理池的经济成本水平。
机器人谈话
此外,在履带式移动机器人领域还有一条“白道”,叫做机器人和平。可以访问网站根目录下的/robots.txt,比如我们看一下github的robots chat,Allow和Disallow分别声明了爬取各个UA爬虫的权限。
然而,这只是一个诚实的谈判。虽然它有法律上的好处,但它只能确定那些商业搜索引擎的蜘蛛,你不能对那些“野爬虫”施加限制。.
写在开头
网页内容的爬取与反制一定是魔高一尺,路高十尺的猫捉老鼠游戏。你永远不可能用某个手游平台完全挡住爬虫式的路。你能做什么 只是增加了攻击者的捕获成本,对未经授权的捕获有了更准确的理解。
这次文章游游国际平台提到的验证码攻防对于手游国际平台来说也是一个比较复杂的难点。我会在这里留下一个关注,我可以多关注它,等待后续文章停止。具体讨论。
另外,对爬虫感兴趣的可以关注我的一个开源项目webster,它以Node.js和Chrome headless的形式完成了一个高可用的网络爬虫框架。页面的渲染能力可以捕捉到一个页面上js和ajax渲染的所有异步内容;redis完成一个任务线,让爬虫程序可以轻松实现横向和纵向分布式扩展。
抓取网页数据( 如何使用优采云采集器软件抓取亚马逊畅销榜100数据,并用Excel分析价格带)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-17 19:01
如何使用优采云采集器软件抓取亚马逊畅销榜100数据,并用Excel分析价格带)
在这种情况下,我将解释如何使用优采云采集器软件捕捉亚马逊的100个畅销数据,并使用Excel分析价格带。
1.跨境电商,为什么要学亚马逊?
亚马逊是全球第三大科技公司,市值几乎是阿里巴巴的两倍。研究和学习行业大佬是跨境电商的必由之路。
2. 为什么要研究价格区间?
在跨境电子商务中,研究商品价格区间更为重要。
价格永远是消费者最关心的问题。
比如目前国内的瓶装饮料价格在3到5元之间,普通消费者可以接受。如果做酒,价格太低,没有利润;价格太高,比如价格是10元,消费者的主播价格是5元,很可能影响销售。
作为全球电商行业的领军企业,亚马逊的排名在一定程度上代表了国外买家的喜好。
通过研究亚马逊畅销榜的价格,可以大致掌握消费者的心理价格。
3. 为什么使用 优采云采集器?
2个理由:真的很自由很容易
1.免费:如果你尝试大量数据采集器,你会发现很多陷阱。套路一般是这样的,采集的数据是免费的,但是如果要导出采集的数据,不好意思,付钱就行了。
2. 简单:适合新手操作,3次鼠标点击即可获取一般数据。
教程文本
第一:找到亚马逊前100名
比如我们公司的分类是女士内衣,关键词是:内衣
Step1:打开亚马逊主页
在搜索框中输入关键字:内衣搜索
step2:在搜索结果页面,找到与我的产品相关的带有Bset Seller字样的产品。点击查看产品。
step3:在商品详情下方,会有排行榜。先点击
您可以在此子类别下查看排行榜。
第二:安装优采云采集器
打开网站:,点击下载。
第三:开始抓取数据:
step1:双击打开优采云采集器
step2:复制之前在亚马逊上找到的top100的网站链接
例如:
step3:将网址粘贴到搜索框中,点击:Smart采集。
被亚马逊认定为机器人。点击右上角的按钮
点击:验证完成
程序开始运行。如果您能看到价格,则表示识别成功。准备好采集
4:点击:开始采集
点击:开始
不到1分钟,数据采集就完成了。点击:导出数据。
打开导出的数据。
4. 数据分析
(本教程侧重于数据采集,数据分析只是一个例子,大家可以根据实际情况分析数据)
4.1 整理数据:将导出的原创价格数据整理成可计算分析的数据。方法是使用Excel的列替换功能。
这是我们最终整理出来的可以计算的数据
4.2 分析数据:
您可以直接使用 Excel 的频率公式或手动筛选,对价格范围内的 top100 产品进行排序。终于完成了这张表。
从这张表可以看出:
最流行的价格区间是:10~15美金的产品,我们也看产品评分,比较高。我们的产品可以在这个价格范围内定价。
低于 5 美元的产品百分比:20%。因为产品的成本(包括运费)接近 5 美元。同时,参考产品评级,发现它是相当低的。结论:售价低于5美元的产品基本都是为了引流,或者说是卖得很差的产品。
参考:
国内外主流数据采集软件总结:
Excel频率的使用:(来源:叶赛文) 查看全部
抓取网页数据(
如何使用优采云采集器软件抓取亚马逊畅销榜100数据,并用Excel分析价格带)
在这种情况下,我将解释如何使用优采云采集器软件捕捉亚马逊的100个畅销数据,并使用Excel分析价格带。
1.跨境电商,为什么要学亚马逊?
亚马逊是全球第三大科技公司,市值几乎是阿里巴巴的两倍。研究和学习行业大佬是跨境电商的必由之路。
2. 为什么要研究价格区间?
在跨境电子商务中,研究商品价格区间更为重要。
价格永远是消费者最关心的问题。
比如目前国内的瓶装饮料价格在3到5元之间,普通消费者可以接受。如果做酒,价格太低,没有利润;价格太高,比如价格是10元,消费者的主播价格是5元,很可能影响销售。
作为全球电商行业的领军企业,亚马逊的排名在一定程度上代表了国外买家的喜好。
通过研究亚马逊畅销榜的价格,可以大致掌握消费者的心理价格。
3. 为什么使用 优采云采集器?
2个理由:真的很自由很容易
1.免费:如果你尝试大量数据采集器,你会发现很多陷阱。套路一般是这样的,采集的数据是免费的,但是如果要导出采集的数据,不好意思,付钱就行了。
2. 简单:适合新手操作,3次鼠标点击即可获取一般数据。
教程文本
第一:找到亚马逊前100名
比如我们公司的分类是女士内衣,关键词是:内衣
Step1:打开亚马逊主页
在搜索框中输入关键字:内衣搜索
step2:在搜索结果页面,找到与我的产品相关的带有Bset Seller字样的产品。点击查看产品。
step3:在商品详情下方,会有排行榜。先点击
您可以在此子类别下查看排行榜。
第二:安装优采云采集器
打开网站:,点击下载。
第三:开始抓取数据:
step1:双击打开优采云采集器
step2:复制之前在亚马逊上找到的top100的网站链接
例如:
step3:将网址粘贴到搜索框中,点击:Smart采集。
被亚马逊认定为机器人。点击右上角的按钮
点击:验证完成
程序开始运行。如果您能看到价格,则表示识别成功。准备好采集
4:点击:开始采集
点击:开始
不到1分钟,数据采集就完成了。点击:导出数据。
打开导出的数据。
4. 数据分析
(本教程侧重于数据采集,数据分析只是一个例子,大家可以根据实际情况分析数据)
4.1 整理数据:将导出的原创价格数据整理成可计算分析的数据。方法是使用Excel的列替换功能。
这是我们最终整理出来的可以计算的数据
4.2 分析数据:
您可以直接使用 Excel 的频率公式或手动筛选,对价格范围内的 top100 产品进行排序。终于完成了这张表。
从这张表可以看出:
最流行的价格区间是:10~15美金的产品,我们也看产品评分,比较高。我们的产品可以在这个价格范围内定价。
低于 5 美元的产品百分比:20%。因为产品的成本(包括运费)接近 5 美元。同时,参考产品评级,发现它是相当低的。结论:售价低于5美元的产品基本都是为了引流,或者说是卖得很差的产品。
参考:
国内外主流数据采集软件总结:
Excel频率的使用:(来源:叶赛文)
抓取网页数据((Url,,XPathXPath)(,))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-15 17:18
此公式适用于 Windows 7+ 环境、WPS 2016 及以上或 Excel 2007 及以上
GetXPathW()(网址)
Url指的是要爬取的网页地址
GetWebContentByXPathW(网址,XPath)
其中XPath指的是网页的XPath地址,可以通过GetXPathW()返回。这里不能直接使用火狐或者Chrome浏览器拾取的XPath,存在差异,所以不能正确返回结果。
GetWebContentByIdW(网址,XPath)
GetWebContentByClassNameW(Url, XPath)
GetImgW(网址,过滤器)
其中,Filter是指过滤关键词。如果设置了Filter,该函数只返回收录Filter关键词的图片地址。
GetLinkW(网址,过滤器)
其中Filter指的是filter关键词,如果设置了Filter,函数只返回收录Filter关键词的Link地址。
基本原理:首先通过GetXPathW()函数和Excel浏览器将要爬取的网页数据下载到本地数据库,然后通过数据爬取函数抓取目标数据。这样做的好处是提高了数据抓取的效率,尤其是当一个网页抓取大量数据项时。 查看全部
抓取网页数据((Url,,XPathXPath)(,))
此公式适用于 Windows 7+ 环境、WPS 2016 及以上或 Excel 2007 及以上
GetXPathW()(网址)
Url指的是要爬取的网页地址
GetWebContentByXPathW(网址,XPath)
其中XPath指的是网页的XPath地址,可以通过GetXPathW()返回。这里不能直接使用火狐或者Chrome浏览器拾取的XPath,存在差异,所以不能正确返回结果。
GetWebContentByIdW(网址,XPath)
GetWebContentByClassNameW(Url, XPath)
GetImgW(网址,过滤器)
其中,Filter是指过滤关键词。如果设置了Filter,该函数只返回收录Filter关键词的图片地址。
GetLinkW(网址,过滤器)
其中Filter指的是filter关键词,如果设置了Filter,函数只返回收录Filter关键词的Link地址。
基本原理:首先通过GetXPathW()函数和Excel浏览器将要爬取的网页数据下载到本地数据库,然后通过数据爬取函数抓取目标数据。这样做的好处是提高了数据抓取的效率,尤其是当一个网页抓取大量数据项时。
抓取网页数据(Python开发工程师--学习猿地-送9个上线商业项目Scraoy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-15 17:17
推荐课程:Python开发工程师--学猿地--送9个在线商业项目
Scraoy入门示例1——Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
二、PyCharm 安装
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能感知、自动完成、单元测试、版本控制等。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击File>>Settings...里面只有两个Package。如果点击时看到一个 Scrapy 包,则不需要安装它,只需执行以下步骤即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
豆瓣类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
-- 编码:utf-8 --
导入scrapy
from ..items 导入豆瓣商品
豆瓣蜘蛛类蜘蛛(scrapy.Spider):
name = '豆瓣蜘蛛'
# 允许的域名
allowed_domains = [‘movie.douban.com‘]
# 入口URL
start_urls = [‘https://movie.douban.com/top250‘]
def parse(self, response):
movie_list = response.xpath("//div[@class=‘article‘]//ol[@class=‘grid_view‘]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item[‘serial_number‘] = i_item.xpath(".//div[@class=‘item‘]//em/text()").extract_first()
douban_item[‘movie_name‘] = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘hd‘]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘bd‘]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item[‘introduce‘] = content_s
douban_item[‘star‘] = i_item.xpath(".//span[@class=‘rating_num‘]/text()").extract_first()
douban_item[‘evaluate‘] = i_item.xpath(".//div[@class=‘star‘]//span[4]/text()").extract_first()
douban_item[‘describe‘] = i_item.xpath(".//p[@class=‘quote‘]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class=‘next‘]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用,所以不需要运行,允许报错,关于import引入的问题,关于绝对路径和主目录的相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上查找此类问题的解释。
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像壁虎) Chrome/53.@ >0.2785.8 Safari/537.36'
如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 入门示例 2 --- 使用流水线实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
一、管道简介
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
类 TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
豆瓣电影类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
爬虫实验:使用 Scrapy 抓取网页内容
标签:说唱参考逻辑代码目标服务下载获取数据免费试用 查看全部
抓取网页数据(Python开发工程师--学习猿地-送9个上线商业项目Scraoy)
推荐课程:Python开发工程师--学猿地--送9个在线商业项目
Scraoy入门示例1——Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:

二、PyCharm 安装
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能感知、自动完成、单元测试、版本控制等。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击File>>Settings...里面只有两个Package。如果点击时看到一个 Scrapy 包,则不需要安装它,只需执行以下步骤即可。

如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装

等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。

输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject

然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:

2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
豆瓣类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
-- 编码:utf-8 --
导入scrapy
from ..items 导入豆瓣商品
豆瓣蜘蛛类蜘蛛(scrapy.Spider):
name = '豆瓣蜘蛛'
# 允许的域名
allowed_domains = [‘movie.douban.com‘]
# 入口URL
start_urls = [‘https://movie.douban.com/top250‘]
def parse(self, response):
movie_list = response.xpath("//div[@class=‘article‘]//ol[@class=‘grid_view‘]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item[‘serial_number‘] = i_item.xpath(".//div[@class=‘item‘]//em/text()").extract_first()
douban_item[‘movie_name‘] = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘hd‘]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘bd‘]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item[‘introduce‘] = content_s
douban_item[‘star‘] = i_item.xpath(".//span[@class=‘rating_num‘]/text()").extract_first()
douban_item[‘evaluate‘] = i_item.xpath(".//div[@class=‘star‘]//span[4]/text()").extract_first()
douban_item[‘describe‘] = i_item.xpath(".//p[@class=‘quote‘]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class=‘next‘]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用,所以不需要运行,允许报错,关于import引入的问题,关于绝对路径和主目录的相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上查找此类问题的解释。
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像壁虎) Chrome/53.@ >0.2785.8 Safari/537.36'

如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:

并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:

至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 入门示例 2 --- 使用流水线实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:

一、管道简介
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
类 TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
豆瓣电影类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
爬虫实验:使用 Scrapy 抓取网页内容
标签:说唱参考逻辑代码目标服务下载获取数据免费试用
抓取网页数据(什么叫对数据结构有深入的了解?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-15 07:03
抓取网页数据经过清洗之后,数据结构有了明显的变化,常见的数据结构有domlist、php代码、java的form表单、python的字典。什么叫对数据结构有深入的了解?当你能够熟练的用php、python使用字典来解决问题时你就已经具备了对数据结构有深入的了解。今天我们来看看对数据结构的一些思考与定义。
viewshipping状态数据库分为两类,服务器会在分配客户端请求的时候给所有的客户端返回服务器当前的数据库结构,由于所有客户端都请求服务器服务器返回了全部数据,因此状态(status)保持不变,其他客户端请求即使接受了服务器返回的数据,也不会更改服务器当前的数据库结构,服务器只会返回他所需要更新的客户端请求,服务器此时保持他的状态(status)一直不变,数据库的变化是通过修改客户端请求来完成的。
你也可以理解为,数据库保持这数据库的原始的结构,但是之后的一段时间里,你可以修改任何数据,最终所有客户端的服务器会更新他的数据库结构。上面说的也是上层应用的应用需要做到让服务器保持状态,因为客户端应用将服务器的数据如果需要更新了,应用得到服务器发来的请求后,通过修改服务器的状态更新客户端请求所指向的数据库结构。
所以我们的应用可以在任何时候修改客户端的请求,最终的结果是客户端不用需要修改服务器的数据结构,因为应用的状态不变,服务器的数据结构会自然变化,应用需要对数据结构有一定的掌握,可以更新客户端的请求,会让服务器去适应客户端的修改,就像在服务器上操作数据库一样。ajax在客户端和服务器之间或者在客户端和浏览器之间或者在浏览器和客户端之间,如果发生数据交互(如发送消息),可以使用ajax技术来实现。
ajax在javascript中叫做xmlhttprequest,由于urlxmlhttprequest属于app对象,app中也有实现方法,这就包括了各种方法来获取响应或者更新响应,这些方法都有一个状态,叫做data-origin,这种状态要么是失败的要么是成功的,这个javascript属性修改状态的效果不是一个明确的值,有一定的时间等待。
ajax不是一个ajax应用,它是一个服务器端ajax应用,通过使用中间数据传输,不是客户端向服务器端推送,而是服务器向客户端推送一个处理后的结果。同时服务器需要修改客户端请求到服务器的数据库结构,ajax会提供缓存服务器以便网络传输,所以我们感觉不到自己修改了ajax的状态值,因为ajax是使用中间数据传输。
form表单form-view是浏览器和服务器端通信的桥梁,我们可以通过form表单来做数据传输,form表单由函数或者模块来描。 查看全部
抓取网页数据(什么叫对数据结构有深入的了解?(一))
抓取网页数据经过清洗之后,数据结构有了明显的变化,常见的数据结构有domlist、php代码、java的form表单、python的字典。什么叫对数据结构有深入的了解?当你能够熟练的用php、python使用字典来解决问题时你就已经具备了对数据结构有深入的了解。今天我们来看看对数据结构的一些思考与定义。
viewshipping状态数据库分为两类,服务器会在分配客户端请求的时候给所有的客户端返回服务器当前的数据库结构,由于所有客户端都请求服务器服务器返回了全部数据,因此状态(status)保持不变,其他客户端请求即使接受了服务器返回的数据,也不会更改服务器当前的数据库结构,服务器只会返回他所需要更新的客户端请求,服务器此时保持他的状态(status)一直不变,数据库的变化是通过修改客户端请求来完成的。
你也可以理解为,数据库保持这数据库的原始的结构,但是之后的一段时间里,你可以修改任何数据,最终所有客户端的服务器会更新他的数据库结构。上面说的也是上层应用的应用需要做到让服务器保持状态,因为客户端应用将服务器的数据如果需要更新了,应用得到服务器发来的请求后,通过修改服务器的状态更新客户端请求所指向的数据库结构。
所以我们的应用可以在任何时候修改客户端的请求,最终的结果是客户端不用需要修改服务器的数据结构,因为应用的状态不变,服务器的数据结构会自然变化,应用需要对数据结构有一定的掌握,可以更新客户端的请求,会让服务器去适应客户端的修改,就像在服务器上操作数据库一样。ajax在客户端和服务器之间或者在客户端和浏览器之间或者在浏览器和客户端之间,如果发生数据交互(如发送消息),可以使用ajax技术来实现。
ajax在javascript中叫做xmlhttprequest,由于urlxmlhttprequest属于app对象,app中也有实现方法,这就包括了各种方法来获取响应或者更新响应,这些方法都有一个状态,叫做data-origin,这种状态要么是失败的要么是成功的,这个javascript属性修改状态的效果不是一个明确的值,有一定的时间等待。
ajax不是一个ajax应用,它是一个服务器端ajax应用,通过使用中间数据传输,不是客户端向服务器端推送,而是服务器向客户端推送一个处理后的结果。同时服务器需要修改客户端请求到服务器的数据库结构,ajax会提供缓存服务器以便网络传输,所以我们感觉不到自己修改了ajax的状态值,因为ajax是使用中间数据传输。
form表单form-view是浏览器和服务器端通信的桥梁,我们可以通过form表单来做数据传输,form表单由函数或者模块来描。
抓取网页数据(抓取网页数据的话,也可以用you-get,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-13 01:01
抓取网页数据的话,也可以用you-get,flask-login这样的爬虫工具,数据来源可以是微博也可以是网站的公共信息。可以先试一下digwuser的网站爬虫,地址为:/you-get。
刚刚是写好了这么个爬虫的文章的,接下来还要不断更新文章才能够更好实现目标(滑稽),
其实,这个我也想过,因为比较好的渠道是在招聘网站上,如果你一直想的是单向爬虫的话,大可能找到一个下家,而且网站本身也可以自定义对账号和密码,这个人是无法被封号的。后来我想了一下,这样其实很麻烦,所以我就没再大批量的尝试。
这样的提问只是为了找台阶下,先用弱力提问,然后找共同好友编个口子,让他们帮你再卖一个。
charles,okflush,phantomjs,scrapy啥的可以试试,但是爬虫的爬取力度和效率是关键,数据多了之后大部分都是有用的信息,但是实际上没有几个人会重视,如果天天往外卖量你看,erp、网站内容等等都是没用的。所以把数据量控制在一定区间就很关键。
不谢邀,接盘侠一枚。
找我就可以了哟
bilibili爬虫对于b站流量一直在500万以上,年用户数也上千万,说不定可以帮你达到。 查看全部
抓取网页数据(抓取网页数据的话,也可以用you-get,)
抓取网页数据的话,也可以用you-get,flask-login这样的爬虫工具,数据来源可以是微博也可以是网站的公共信息。可以先试一下digwuser的网站爬虫,地址为:/you-get。
刚刚是写好了这么个爬虫的文章的,接下来还要不断更新文章才能够更好实现目标(滑稽),
其实,这个我也想过,因为比较好的渠道是在招聘网站上,如果你一直想的是单向爬虫的话,大可能找到一个下家,而且网站本身也可以自定义对账号和密码,这个人是无法被封号的。后来我想了一下,这样其实很麻烦,所以我就没再大批量的尝试。
这样的提问只是为了找台阶下,先用弱力提问,然后找共同好友编个口子,让他们帮你再卖一个。
charles,okflush,phantomjs,scrapy啥的可以试试,但是爬虫的爬取力度和效率是关键,数据多了之后大部分都是有用的信息,但是实际上没有几个人会重视,如果天天往外卖量你看,erp、网站内容等等都是没用的。所以把数据量控制在一定区间就很关键。
不谢邀,接盘侠一枚。
找我就可以了哟
bilibili爬虫对于b站流量一直在500万以上,年用户数也上千万,说不定可以帮你达到。
抓取网页数据(就是爬虫是怎么解决暗网的内容,解决爬虫的一大难题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-12 04:09
解决爬取暗网数据的问题。暗网。这就是为什么它是一个与整个互联网系统脱节的独立内容,一个独立的网站啊或者一个独立的网页。怎么抢?啊,今天我们要讲的是爬虫是如何解决暗网抓取的内容的。解决暗网的爬取问题一直是爬虫的一大难题。目前,如何解决搜索引擎爬虫的问题。让我们来看看这个问题。首先,我需要解释一下什么是暗网。每个人都有不同的基础。我需要解释一下这件事。这就是我们在网上互相链接的,就是这一堆小圈子都是网站啊,都有互相链接的过程,然后爬出来跟着一个网站@ > 抓到另一个网站,这个里面没有暗网数据。那么什么是暗网?例如。对于新站,如果你不提交到百度,请确保你不提交到百度,也不要提交到你的主页。然后,他没有任何指向其他网页的链接,也没有指向它的链接。当时,这个新网站是暗网数据。啊,还有什么?你的搜索,比如你的标签过滤页面,比如你上面有很多标签过滤,那么可以说是区域过滤,那么这里就比如说分类过滤。第三可能是什么筛选。在这种情况下。爬虫,它不会点击第一次和第二次点击,对吧?那么如果你不提交给爬虫,他不知道吗?并在您的搜索框中。你搜索的词,然后生成页面。如果不搜索的话,是不是就不能生成页面了?基于这些情况,暗网爬虫如何解决这样的问题?往上看。
暗网爬虫的由来,究竟是什么?爬虫暗网爬虫的作用就是希望通过你网站得到更大程度的网站中的各种内容,得到的东西越多越好啊,改进点,增加点索引库的大小。比如我新建了一个搜索引擎,我的搜索引擎只有1000万条数据,当有N个人搜索的时候,是不是每个人搜索这个搜索结果的数据都很少,很难解决大家的问题?. 但是如果我能通过安网的爬虫解决更大的搜索问题,我能不能改进我的一个搜索结果,覆盖更多不同需求的人呢?这就是暗网爬虫的出现方式。实际上,搜索引擎的工作人员和技术人员将花费更多的时间和精力试图解决抓取暗网数据的问题。暗网爬虫的作用。首先,例如,它有什么?过滤器列表参数会自动组合。嘿嘿,一会儿我们来看几个使用这三点的例子。第二点,表单的内容是自动填充的。啊,当然,这个暗网爬虫的解决方案从来没有。特别完美。比如表格的内容自动填入你的搜索框,可以随便写吗?没办法,它必须根据你的 网站 整体 er 语义来理解你的 文章,等等。然后他从用户的搜索中提取一些词,然后搜索看看你的网页有没有内容,对吧?啊,
如果你的网站的网站抓取量足够大,那么文本框内容的填充就交给我们了。申请顺序。过滤列表。你就像。行。我有一堆肾脏来源清单。他可以点击这个,点击无锡,进入另一个页面,点击期货交易员进入另一个页面。那他可以点击无锡添加火商吗?啊,无锡加期货商加行业分类,这又是不是又一个新的一页了,永远也到不了这个位置。如果 网站 没有条目,对吗?所以,暗网的话一定要结合起来。哦,无锡,然后点击期货,然后点击期货交易所出现。这个页面对吗?在这种情况下,如果我的网站上没有条目,他将无法捕捉到这样的内容。但现在是因为我们SU可以做这些事情,做这些入口,看到这个链接没有入口,我想做这个事情。所以唉,它会自动做这些事情。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。
是的,那是一样的。啊,我们在一个表单上,就像一个输入。SU点击进入这个页面,你不知道这个页面吗?如果我没有入口,我不知道我是不是把他们的票让他上车,然后他会自己做。对?暗网爬虫的目标就是做这些事情。每个人都知道暗网上的这个爬虫。可以做这些事情。嗯,就是这样。对。所以这里是一个爬虫解决暗网爬取的全过程。它是一个分布式爬虫。 查看全部
抓取网页数据(就是爬虫是怎么解决暗网的内容,解决爬虫的一大难题)
解决爬取暗网数据的问题。暗网。这就是为什么它是一个与整个互联网系统脱节的独立内容,一个独立的网站啊或者一个独立的网页。怎么抢?啊,今天我们要讲的是爬虫是如何解决暗网抓取的内容的。解决暗网的爬取问题一直是爬虫的一大难题。目前,如何解决搜索引擎爬虫的问题。让我们来看看这个问题。首先,我需要解释一下什么是暗网。每个人都有不同的基础。我需要解释一下这件事。这就是我们在网上互相链接的,就是这一堆小圈子都是网站啊,都有互相链接的过程,然后爬出来跟着一个网站@ > 抓到另一个网站,这个里面没有暗网数据。那么什么是暗网?例如。对于新站,如果你不提交到百度,请确保你不提交到百度,也不要提交到你的主页。然后,他没有任何指向其他网页的链接,也没有指向它的链接。当时,这个新网站是暗网数据。啊,还有什么?你的搜索,比如你的标签过滤页面,比如你上面有很多标签过滤,那么可以说是区域过滤,那么这里就比如说分类过滤。第三可能是什么筛选。在这种情况下。爬虫,它不会点击第一次和第二次点击,对吧?那么如果你不提交给爬虫,他不知道吗?并在您的搜索框中。你搜索的词,然后生成页面。如果不搜索的话,是不是就不能生成页面了?基于这些情况,暗网爬虫如何解决这样的问题?往上看。
暗网爬虫的由来,究竟是什么?爬虫暗网爬虫的作用就是希望通过你网站得到更大程度的网站中的各种内容,得到的东西越多越好啊,改进点,增加点索引库的大小。比如我新建了一个搜索引擎,我的搜索引擎只有1000万条数据,当有N个人搜索的时候,是不是每个人搜索这个搜索结果的数据都很少,很难解决大家的问题?. 但是如果我能通过安网的爬虫解决更大的搜索问题,我能不能改进我的一个搜索结果,覆盖更多不同需求的人呢?这就是暗网爬虫的出现方式。实际上,搜索引擎的工作人员和技术人员将花费更多的时间和精力试图解决抓取暗网数据的问题。暗网爬虫的作用。首先,例如,它有什么?过滤器列表参数会自动组合。嘿嘿,一会儿我们来看几个使用这三点的例子。第二点,表单的内容是自动填充的。啊,当然,这个暗网爬虫的解决方案从来没有。特别完美。比如表格的内容自动填入你的搜索框,可以随便写吗?没办法,它必须根据你的 网站 整体 er 语义来理解你的 文章,等等。然后他从用户的搜索中提取一些词,然后搜索看看你的网页有没有内容,对吧?啊,
如果你的网站的网站抓取量足够大,那么文本框内容的填充就交给我们了。申请顺序。过滤列表。你就像。行。我有一堆肾脏来源清单。他可以点击这个,点击无锡,进入另一个页面,点击期货交易员进入另一个页面。那他可以点击无锡添加火商吗?啊,无锡加期货商加行业分类,这又是不是又一个新的一页了,永远也到不了这个位置。如果 网站 没有条目,对吗?所以,暗网的话一定要结合起来。哦,无锡,然后点击期货,然后点击期货交易所出现。这个页面对吗?在这种情况下,如果我的网站上没有条目,他将无法捕捉到这样的内容。但现在是因为我们SU可以做这些事情,做这些入口,看到这个链接没有入口,我想做这个事情。所以唉,它会自动做这些事情。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。
是的,那是一样的。啊,我们在一个表单上,就像一个输入。SU点击进入这个页面,你不知道这个页面吗?如果我没有入口,我不知道我是不是把他们的票让他上车,然后他会自己做。对?暗网爬虫的目标就是做这些事情。每个人都知道暗网上的这个爬虫。可以做这些事情。嗯,就是这样。对。所以这里是一个爬虫解决暗网爬取的全过程。它是一个分布式爬虫。
抓取网页数据(java语言提供的工具,解决了python不能做数据挖掘的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-07 06:08
抓取网页数据的工具有很多,如jsoup,tornado等等。jsoup是java语言提供的工具,解决了python不能做数据挖掘的问题。tornado是kotlin语言提供的。让tornado来读取网页数据,在很多项目中会经常使用,读取网页数据的工具有很多。而我对于tornado来读取网页数据有一定的了解,这篇文章将会介绍一下tornado是如何来读取网页数据。
tornado是什么?用java语言提供的tornado能够读取网页数据,它提供的功能也是所有网络爬虫工具中最重要的一部分。tornado是开源的,目前2.x版本并没有对java语言进行调整。我学习tornado是在一个java培训机构,正值五月份的期中考试,培训机构为了突出学习技术的重要性,特意安排我们先上这个由面向对象设计,先易后难的技术,这才有了我进入到这个培训机构学习java技术的机会。
在培训机构,让我深刻认识到知识的重要性,是非常重要的,现在随着我在公司从事java工作,我越来越能明白这句话了。举一个我的例子:现在我通过在群里看到这个话题。先是打算接着往下看,然后看到是针对对象,看完第一个以后。我内心起了嘀咕,这个所谓的对象是什么鬼。我想着正在往下看的时候...我想看下后面会不会给我点提示或者是机会。
我看到了什么,然后我在内心中浮现了一个问题。我对后面会给我提示的东西,一个问号。我如果直接回答是,那么很多时候我自己就给我自己来了一个大大的问号。如果我在回答这个问题的时候,我得到一个反馈就是你回答的语言不对,那么我就对这个说法有一个怀疑。我现在想要看到这个问题下的反馈。由于我遇到的第一个问题是什么时候提示?我当时好像得到的是一个答案。
之后我在我的心中又有了一个疑问,为什么我在遇到这个问题的时候,突然出现了一个问号。我认为出现了一个问号是我的运气不好。我的判断这里是我应该使用java语言。使用python语言的话,我则能够在输入框或者是页面正常输入内容。当我第二次遇到这个问题的时候。我尝试运行了一下tornadoapi,得到了一个正常的tornadoapi,这个时候我的内心又浮现了一个问号。
由于我第一次遇到的问题是什么时候提示,以及在什么情况下会给我一个提示。所以我在第一次遇到的时候把它定义为问号。但是第二次我发现,无论我多么的强调内容,上方的那个问号永远不会输出。使用requests的api,是不是没有出现问号的提示?如果是,那么这个问号是什么鬼。我的脑海中又浮现了第二个问号。我的第一次遇到了tornado网页数据爬虫,要不要用这个,这个问题?如果我不用tornado这个网页。 查看全部
抓取网页数据(java语言提供的工具,解决了python不能做数据挖掘的问题)
抓取网页数据的工具有很多,如jsoup,tornado等等。jsoup是java语言提供的工具,解决了python不能做数据挖掘的问题。tornado是kotlin语言提供的。让tornado来读取网页数据,在很多项目中会经常使用,读取网页数据的工具有很多。而我对于tornado来读取网页数据有一定的了解,这篇文章将会介绍一下tornado是如何来读取网页数据。
tornado是什么?用java语言提供的tornado能够读取网页数据,它提供的功能也是所有网络爬虫工具中最重要的一部分。tornado是开源的,目前2.x版本并没有对java语言进行调整。我学习tornado是在一个java培训机构,正值五月份的期中考试,培训机构为了突出学习技术的重要性,特意安排我们先上这个由面向对象设计,先易后难的技术,这才有了我进入到这个培训机构学习java技术的机会。
在培训机构,让我深刻认识到知识的重要性,是非常重要的,现在随着我在公司从事java工作,我越来越能明白这句话了。举一个我的例子:现在我通过在群里看到这个话题。先是打算接着往下看,然后看到是针对对象,看完第一个以后。我内心起了嘀咕,这个所谓的对象是什么鬼。我想着正在往下看的时候...我想看下后面会不会给我点提示或者是机会。
我看到了什么,然后我在内心中浮现了一个问题。我对后面会给我提示的东西,一个问号。我如果直接回答是,那么很多时候我自己就给我自己来了一个大大的问号。如果我在回答这个问题的时候,我得到一个反馈就是你回答的语言不对,那么我就对这个说法有一个怀疑。我现在想要看到这个问题下的反馈。由于我遇到的第一个问题是什么时候提示?我当时好像得到的是一个答案。
之后我在我的心中又有了一个疑问,为什么我在遇到这个问题的时候,突然出现了一个问号。我认为出现了一个问号是我的运气不好。我的判断这里是我应该使用java语言。使用python语言的话,我则能够在输入框或者是页面正常输入内容。当我第二次遇到这个问题的时候。我尝试运行了一下tornadoapi,得到了一个正常的tornadoapi,这个时候我的内心又浮现了一个问号。
由于我第一次遇到的问题是什么时候提示,以及在什么情况下会给我一个提示。所以我在第一次遇到的时候把它定义为问号。但是第二次我发现,无论我多么的强调内容,上方的那个问号永远不会输出。使用requests的api,是不是没有出现问号的提示?如果是,那么这个问号是什么鬼。我的脑海中又浮现了第二个问号。我的第一次遇到了tornado网页数据爬虫,要不要用这个,这个问题?如果我不用tornado这个网页。
抓取网页数据(作为数据科学家,我还有机会吗?——数据科学招聘状况如何?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 22:13
“作为数据科学家,我还有机会吗?”不,你应该成为一名数据工程师。
数据无处不在,而且只会增加。在过去的 5-10 年里,数据科学吸引了越来越多的新人加入。
但如今数据科学招聘的现状如何?在采集了多家公司的招聘信息后,亚马逊 Alxea 团队的机器学习科学家 Mihail Eric 在他的个人博客中写了一篇分析 文章 来解释他的想法。
数据胜于雄辩。他分析了自2012年以来Y-Combinator孵化的每家公司发布的数据领域职位。研究问题包括:
在数据领域,公司最常招聘的职位是什么?
经常讨论的对数据科学家的需求是什么?
这些技能是否使公司重视正在引发当今数据革命的技能?
以下是博客文章的主要内容:
方法
我选择分析声称使用某些数据作为其价值主张一部分的 YC 风险投资公司。
主要关注 YC,因为它提供了一个易于搜索(可抓取)的公司目录。此外,作为一家特别有远见的孵化器,十年来为全球多个领域的企业提供投资。我认为他们为此分析提供了具有代表性的市场样本。但请注意,我没有分析超大型科技公司。
我从 2012 年开始抓取了每家 YC 公司的主页 URL,并建立了一个收录 1,400 家公司的初始池。
为什么从 2012 年开始? 2012年,AlexNet在ImageNet大赛中获胜,掀起了当前机器学习和数据建模的热潮,第一批数据优先的公司诞生了。
我对初始池进行了关键词过滤,以减少需要浏览的公司数量。具体来说,我只考虑了 网站 至少收录以下术语之一的公司:AI、CV、NLP、自然语言处理、计算机视觉、人工智能、机器、ML、数据。同时不要考虑那些网站链接失败的公司。
这种操作应该会产生很多错误的结果。我意识到会对每个网站进行更细粒度的人工检查以了解相关角色,因此我尽可能优先考虑高召回率。
在这个过滤后的资源池中,我遍历了每个网站,找到了他们发布职位信息的位置,并在标题中注明了所有收录数据、机器学习、NLP 或 CV 的职位。这使我能够建立一个资源库,其中收录来自大约 70 家不同公司的招聘信息。
还有一个小错误:我错过了一些公司,一些网站虽然招聘信息很少,但他们实际上在招聘。此外,有些公司没有正式的招聘页面,而是要求应聘者直接通过电子邮件与他们联系。我忽略了这两种类型的公司,它们不在本次分析和研究中。
另外一点是,本次调研大部分是在2020年最后几周完成的。由于公司定期更新招聘页面,空缺职位可能有所变化,但我认为这对得出的结论影响不大。
数据从业者应该负责什么?
在深入研究结果之前,值得花一些时间弄清楚每个数据域位置通常负责什么。我会抽空介绍以下四个职位:
数据科学家负责使用各种统计和机器学习技术处理和分析数据。他们通常负责构建模型以探索可以从某些数据源中学到什么,但模型通常处于原型级别而不是生产级别;
数据工程师负责开发一套强大且可扩展的数据处理工具/平台。他们必须熟悉SQL/NoSQL数据库和ETL管道的组织和构建/维护;
机器学习 (ML) 工程师通常负责训练模型和生产模型。他们需要熟悉一些高级 ML 框架,并且必须能够轻松地为模型构建可扩展的训练、推理和部署管道;
机器学习 (ML) 科学家致力于前沿研究,他们通常负责探索可以在学术会议上发表的新想法。在交给机器学习工程师进行生产之前,机器学习科学家通常只需要对新的 SOTA 模型进行原型设计。
值得一提的是,与传统数据科学家相比,开放数据工程师的职位数量增加了很多。在这种情况下,就最初雇用的公司数量而言,数据工程师比数据科学家多约 55%。 ,并且机器学习工程师的数量与数据科学家的数量大致相同。但是如果你看一下各个职位的名字,你会发现似乎有些重复。
我只提供了一个合并职位的粗略分类,即当不同职位、不同角色负责大致相同的内容时,将其合并为一个名称。包括以下一组等价关系:
NLP工程师≈CV工程师≈ML工程师≈深度学习工程师(虽然领域可能不同,但职责大致相同)
ML 科学家≈深度学习≈ML 实习生
数据工程师≈数据架构师≈数据总监≈数据平台工程师
以百分比表示:
一般来说,合并会使差异更加明显。开放数据工程师的数量比数据科学家多 70%。此外,开放 ML 工程师的数量比数据科学家多 40%。机器学习科学家的数量仅占数据科学家的 30% 左右。
结论
与其他数据驱动的职位相比,对数据工程师的需求正在增加。从某种意义上说,这代表着这个方向正在走向更广阔的领域。
5 到 8 年前,机器学习火了,公司需要能够对数据进行分类的人才。但后来Tensorflow、PyTorch等框架发展的很好,使得深度学习和机器学习的起步能力得到普及,随之而来的是数据建模技能的商业化。今天,发展的瓶颈在于帮助企业获得关于生产级数据问题的机器学习和建模意见。例如,考虑以下问题:
如何注释数据?
如何处理和清理数据?
如何将其从 A 移动到 B?
如何尽快完成这些任务?
这一切都意味着这个职位需要良好的工程技能,而偏向数据的传统软件工程可能才是我们现在真正需要的。但这是否意味着您不应该学习数据科学?并不真地。这意味着竞争将更加困难。对于准备培养成为数据科学人才的初学者来说,可用的职位会越来越少。当然,总是需要能够有效分析数据并从数据中提取可操作洞察力的人,但这些洞察力必须非常出色。
很明显,公司通常需要混合数据从业者,他们可以构建和部署模型。或者更简洁地说,您可以使用 Tensorflow,但您也可以从源代码构建它。
这项研究的另一个发现是 ML 研究职位很少。机器学习研究往往得到大量资源的支持,因为它是顶级研究,例如 AlphaGo 和 GPT-3。但对于许多公司,尤其是处于早期阶段的公司来说,最先进的 SOTA 技术可能不再是必要的。达到 90% 的最佳模型性能并同时扩展到 1000 多个用户通常对他们来说更有价值。
但您可能会在行业的研究实验室中找到许多此类角色。他们可以长期承担资本密集型的赌注,而不是在种子轮开始工业演示并准备接受 A 轮融资。
如果没有其他问题,我认为最重要的是让新人对数据领域的期望合理和校准。我们必须承认,数据科学已经不是以前的样子,只有知道自己在哪里,我们才知道自己要去哪里。 查看全部
抓取网页数据(作为数据科学家,我还有机会吗?——数据科学招聘状况如何?)
“作为数据科学家,我还有机会吗?”不,你应该成为一名数据工程师。
数据无处不在,而且只会增加。在过去的 5-10 年里,数据科学吸引了越来越多的新人加入。
但如今数据科学招聘的现状如何?在采集了多家公司的招聘信息后,亚马逊 Alxea 团队的机器学习科学家 Mihail Eric 在他的个人博客中写了一篇分析 文章 来解释他的想法。
数据胜于雄辩。他分析了自2012年以来Y-Combinator孵化的每家公司发布的数据领域职位。研究问题包括:
在数据领域,公司最常招聘的职位是什么?
经常讨论的对数据科学家的需求是什么?
这些技能是否使公司重视正在引发当今数据革命的技能?
以下是博客文章的主要内容:
方法
我选择分析声称使用某些数据作为其价值主张一部分的 YC 风险投资公司。
主要关注 YC,因为它提供了一个易于搜索(可抓取)的公司目录。此外,作为一家特别有远见的孵化器,十年来为全球多个领域的企业提供投资。我认为他们为此分析提供了具有代表性的市场样本。但请注意,我没有分析超大型科技公司。
我从 2012 年开始抓取了每家 YC 公司的主页 URL,并建立了一个收录 1,400 家公司的初始池。
为什么从 2012 年开始? 2012年,AlexNet在ImageNet大赛中获胜,掀起了当前机器学习和数据建模的热潮,第一批数据优先的公司诞生了。
我对初始池进行了关键词过滤,以减少需要浏览的公司数量。具体来说,我只考虑了 网站 至少收录以下术语之一的公司:AI、CV、NLP、自然语言处理、计算机视觉、人工智能、机器、ML、数据。同时不要考虑那些网站链接失败的公司。
这种操作应该会产生很多错误的结果。我意识到会对每个网站进行更细粒度的人工检查以了解相关角色,因此我尽可能优先考虑高召回率。
在这个过滤后的资源池中,我遍历了每个网站,找到了他们发布职位信息的位置,并在标题中注明了所有收录数据、机器学习、NLP 或 CV 的职位。这使我能够建立一个资源库,其中收录来自大约 70 家不同公司的招聘信息。
还有一个小错误:我错过了一些公司,一些网站虽然招聘信息很少,但他们实际上在招聘。此外,有些公司没有正式的招聘页面,而是要求应聘者直接通过电子邮件与他们联系。我忽略了这两种类型的公司,它们不在本次分析和研究中。
另外一点是,本次调研大部分是在2020年最后几周完成的。由于公司定期更新招聘页面,空缺职位可能有所变化,但我认为这对得出的结论影响不大。
数据从业者应该负责什么?
在深入研究结果之前,值得花一些时间弄清楚每个数据域位置通常负责什么。我会抽空介绍以下四个职位:
数据科学家负责使用各种统计和机器学习技术处理和分析数据。他们通常负责构建模型以探索可以从某些数据源中学到什么,但模型通常处于原型级别而不是生产级别;
数据工程师负责开发一套强大且可扩展的数据处理工具/平台。他们必须熟悉SQL/NoSQL数据库和ETL管道的组织和构建/维护;
机器学习 (ML) 工程师通常负责训练模型和生产模型。他们需要熟悉一些高级 ML 框架,并且必须能够轻松地为模型构建可扩展的训练、推理和部署管道;
机器学习 (ML) 科学家致力于前沿研究,他们通常负责探索可以在学术会议上发表的新想法。在交给机器学习工程师进行生产之前,机器学习科学家通常只需要对新的 SOTA 模型进行原型设计。
值得一提的是,与传统数据科学家相比,开放数据工程师的职位数量增加了很多。在这种情况下,就最初雇用的公司数量而言,数据工程师比数据科学家多约 55%。 ,并且机器学习工程师的数量与数据科学家的数量大致相同。但是如果你看一下各个职位的名字,你会发现似乎有些重复。
我只提供了一个合并职位的粗略分类,即当不同职位、不同角色负责大致相同的内容时,将其合并为一个名称。包括以下一组等价关系:
NLP工程师≈CV工程师≈ML工程师≈深度学习工程师(虽然领域可能不同,但职责大致相同)
ML 科学家≈深度学习≈ML 实习生
数据工程师≈数据架构师≈数据总监≈数据平台工程师
以百分比表示:
一般来说,合并会使差异更加明显。开放数据工程师的数量比数据科学家多 70%。此外,开放 ML 工程师的数量比数据科学家多 40%。机器学习科学家的数量仅占数据科学家的 30% 左右。
结论
与其他数据驱动的职位相比,对数据工程师的需求正在增加。从某种意义上说,这代表着这个方向正在走向更广阔的领域。
5 到 8 年前,机器学习火了,公司需要能够对数据进行分类的人才。但后来Tensorflow、PyTorch等框架发展的很好,使得深度学习和机器学习的起步能力得到普及,随之而来的是数据建模技能的商业化。今天,发展的瓶颈在于帮助企业获得关于生产级数据问题的机器学习和建模意见。例如,考虑以下问题:
如何注释数据?
如何处理和清理数据?
如何将其从 A 移动到 B?
如何尽快完成这些任务?
这一切都意味着这个职位需要良好的工程技能,而偏向数据的传统软件工程可能才是我们现在真正需要的。但这是否意味着您不应该学习数据科学?并不真地。这意味着竞争将更加困难。对于准备培养成为数据科学人才的初学者来说,可用的职位会越来越少。当然,总是需要能够有效分析数据并从数据中提取可操作洞察力的人,但这些洞察力必须非常出色。
很明显,公司通常需要混合数据从业者,他们可以构建和部署模型。或者更简洁地说,您可以使用 Tensorflow,但您也可以从源代码构建它。
这项研究的另一个发现是 ML 研究职位很少。机器学习研究往往得到大量资源的支持,因为它是顶级研究,例如 AlphaGo 和 GPT-3。但对于许多公司,尤其是处于早期阶段的公司来说,最先进的 SOTA 技术可能不再是必要的。达到 90% 的最佳模型性能并同时扩展到 1000 多个用户通常对他们来说更有价值。
但您可能会在行业的研究实验室中找到许多此类角色。他们可以长期承担资本密集型的赌注,而不是在种子轮开始工业演示并准备接受 A 轮融资。
如果没有其他问题,我认为最重要的是让新人对数据领域的期望合理和校准。我们必须承认,数据科学已经不是以前的样子,只有知道自己在哪里,我们才知道自己要去哪里。
抓取网页数据(百度蜘蛛抓取异常的常见原因是网站不稳定,怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-02 22:09
百度蜘蛛异常爬行的常见原因是网站不稳定。百度蜘蛛在尝试连接您的网站服务器时暂时无法连接。可能是你的网站IP地址错误,或者百度蜘蛛被域名服务商封禁了。
部分网站内容用户可以正常访问,但百度搜索百度内容无法正常访问,导致大量网站关键词搜索结果丢失。这种结果不适合网站,搜索引擎都是亏本。无法抓取百度搜索的网页称为“抓取异常”。百度搜索会认为你的网站在用户体验上存在抓取缺陷,降低你的网站的分数会对网站的页面、索引、排序产生负面影响,并且最终影响网站的流量。
下面介绍一下百度蜘蛛抓取异常的一些常见原因:1、服务器连接异常
服务器连接异常一般有两种情况。一般来说,网站 是不稳定的。当百度搜索蜘蛛抓取你的网站页面时,是无法抓取的。另一种是百度搜索蜘蛛。无法正常连接到您的 网站 服务器。
网站服务器无法正常连接的问题一般是网站服务器负载过大,也可能是你的网站程序问题,先检查< @网站web服务器(IIS或apache)运行正常,检查网站的主页是否可以正常打开,以及网站和主机是否屏蔽了百度搜索蜘蛛的访问。
2、网络运营商异常
网站 服务器网络运营商分为电信和联通两种。如果百度搜索蜘蛛无法通过电信或网通网络访问您的网站,您需要联系网站与服务器运营商沟通,或者重新购买双线网站服务器空间,或者您可以购买 网站CND 服务。
3、DNS 异常
当百度搜索无法解析网站 IP地址时,与网门dns异常情况相同。这个问题可能是你的域名IP解析错误,也可能是百度蜘蛛被屏蔽的域名服务商。这时候我们可以使用whois或者host来检查我们的网站域名的IP是否解析正确。如果域名IP解析不正确,只需重新解析域名即可。如果无法解决,我们需要联系我们。域名注册商出来了。
4、IP 封禁
IP禁令,限制网站的服务器出口IP地址,禁止某个IP段的用户访问网站的内容。这主要是指百度搜索蜘蛛禁止的IP段。情况是你不希望百度搜索蜘蛛访问你的网站,才需要屏蔽百度搜索蜘蛛。如果你想让百度搜索蜘蛛访问你的网站,请添加百度搜索蜘蛛IP段,如果你的百度搜索蜘蛛IP段没有被屏蔽。也有可能是网站空间服务商屏蔽了百度搜索蜘蛛IP段。这个问题需要网站空间服务商来解决。
5、UA 被禁止
UA为User-Agent,网站WEB服务器通过UA识别用户,网站返回指定UA访问异常状态码,如403、500状态代码,或者跳转到其他页面,这种情况叫做UAban,这种情况是你不想百度搜索蜘蛛访问你的时候网站,你只需要设置这个,如果你想让百度搜索蜘蛛访问你的网站,需要检查网站服务器是否被UA拦截,如果有,需要及时处理。
6、死链接
页面一直无法打开,页面已经无法向用户提供任何有价值的信息,这种页面称为死链接,死链接包括协议死链接和内容死链接两种形式:
1、协议死链接,网站页面的TCP协议和HTTP协议状态明确指出死链接,常见状态码为404、403、 503;
<p>2、 内容是死链接的,表示web服务器状态码恢复正常,但是内容已经不存在,已经被删除或者需要权限才能访问。 查看全部
抓取网页数据(百度蜘蛛抓取异常的常见原因是网站不稳定,怎么办)
百度蜘蛛异常爬行的常见原因是网站不稳定。百度蜘蛛在尝试连接您的网站服务器时暂时无法连接。可能是你的网站IP地址错误,或者百度蜘蛛被域名服务商封禁了。
部分网站内容用户可以正常访问,但百度搜索百度内容无法正常访问,导致大量网站关键词搜索结果丢失。这种结果不适合网站,搜索引擎都是亏本。无法抓取百度搜索的网页称为“抓取异常”。百度搜索会认为你的网站在用户体验上存在抓取缺陷,降低你的网站的分数会对网站的页面、索引、排序产生负面影响,并且最终影响网站的流量。
下面介绍一下百度蜘蛛抓取异常的一些常见原因:1、服务器连接异常
服务器连接异常一般有两种情况。一般来说,网站 是不稳定的。当百度搜索蜘蛛抓取你的网站页面时,是无法抓取的。另一种是百度搜索蜘蛛。无法正常连接到您的 网站 服务器。
网站服务器无法正常连接的问题一般是网站服务器负载过大,也可能是你的网站程序问题,先检查< @网站web服务器(IIS或apache)运行正常,检查网站的主页是否可以正常打开,以及网站和主机是否屏蔽了百度搜索蜘蛛的访问。
2、网络运营商异常
网站 服务器网络运营商分为电信和联通两种。如果百度搜索蜘蛛无法通过电信或网通网络访问您的网站,您需要联系网站与服务器运营商沟通,或者重新购买双线网站服务器空间,或者您可以购买 网站CND 服务。
3、DNS 异常
当百度搜索无法解析网站 IP地址时,与网门dns异常情况相同。这个问题可能是你的域名IP解析错误,也可能是百度蜘蛛被屏蔽的域名服务商。这时候我们可以使用whois或者host来检查我们的网站域名的IP是否解析正确。如果域名IP解析不正确,只需重新解析域名即可。如果无法解决,我们需要联系我们。域名注册商出来了。
4、IP 封禁
IP禁令,限制网站的服务器出口IP地址,禁止某个IP段的用户访问网站的内容。这主要是指百度搜索蜘蛛禁止的IP段。情况是你不希望百度搜索蜘蛛访问你的网站,才需要屏蔽百度搜索蜘蛛。如果你想让百度搜索蜘蛛访问你的网站,请添加百度搜索蜘蛛IP段,如果你的百度搜索蜘蛛IP段没有被屏蔽。也有可能是网站空间服务商屏蔽了百度搜索蜘蛛IP段。这个问题需要网站空间服务商来解决。
5、UA 被禁止
UA为User-Agent,网站WEB服务器通过UA识别用户,网站返回指定UA访问异常状态码,如403、500状态代码,或者跳转到其他页面,这种情况叫做UAban,这种情况是你不想百度搜索蜘蛛访问你的时候网站,你只需要设置这个,如果你想让百度搜索蜘蛛访问你的网站,需要检查网站服务器是否被UA拦截,如果有,需要及时处理。
6、死链接
页面一直无法打开,页面已经无法向用户提供任何有价值的信息,这种页面称为死链接,死链接包括协议死链接和内容死链接两种形式:
1、协议死链接,网站页面的TCP协议和HTTP协议状态明确指出死链接,常见状态码为404、403、 503;
<p>2、 内容是死链接的,表示web服务器状态码恢复正常,但是内容已经不存在,已经被删除或者需要权限才能访问。
抓取网页数据(常州昌润信息小编来看看百度蜘蛛收录一个网站的全过程揭秘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-02 22:07
做SEO优化推广,必须要说一下百度的问题收录。很多人不明白。这么多相同的网页,百度如何区分第一篇收录文章文章呢?明明内容是一样的,为什么别人网站收录拥有却没有收录,我们来看看百度蜘蛛收录的一个网站常州畅润资讯编辑下方揭秘全过程,有需要的朋友可以参考以下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、 信息过滤。
3、创建网页关键词索引。
4、 用户搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站的首页,会先读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪。爬行。比如我们的文章文章《长润资讯:百度收录网站网页爬取过程揭秘》中,引擎会在多进程中来这篇文章文章网络爬虫信息差到没完没了。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站,引擎会记录下来并归类为未爬取的URL,然后蜘蛛从数据库根据这个表,访问和抓取页面。
蜘蛛不是收录所有页面,它必须经过严格的检查。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页网站的权重很低,而且大部分文章都是抄袭的,那蜘蛛你可能不会再喜欢你的网站了。如果你不继续爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格建立索引。
索引有正向索引和反向索引。正向索引对应的是网页内容关键词,反向是关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表进行关键词匹配,通过倒排索引表找到关键词对应的页面,并使用匹配引擎 计算出网页综合得分后,根据网页得分确定网页的排名顺序。
希望对大家有帮助。 () 查看全部
抓取网页数据(常州昌润信息小编来看看百度蜘蛛收录一个网站的全过程揭秘)
做SEO优化推广,必须要说一下百度的问题收录。很多人不明白。这么多相同的网页,百度如何区分第一篇收录文章文章呢?明明内容是一样的,为什么别人网站收录拥有却没有收录,我们来看看百度蜘蛛收录的一个网站常州畅润资讯编辑下方揭秘全过程,有需要的朋友可以参考以下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、 信息过滤。
3、创建网页关键词索引。
4、 用户搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站的首页,会先读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪。爬行。比如我们的文章文章《长润资讯:百度收录网站网页爬取过程揭秘》中,引擎会在多进程中来这篇文章文章网络爬虫信息差到没完没了。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站,引擎会记录下来并归类为未爬取的URL,然后蜘蛛从数据库根据这个表,访问和抓取页面。
蜘蛛不是收录所有页面,它必须经过严格的检查。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页网站的权重很低,而且大部分文章都是抄袭的,那蜘蛛你可能不会再喜欢你的网站了。如果你不继续爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格建立索引。
索引有正向索引和反向索引。正向索引对应的是网页内容关键词,反向是关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表进行关键词匹配,通过倒排索引表找到关键词对应的页面,并使用匹配引擎 计算出网页综合得分后,根据网页得分确定网页的排名顺序。
希望对大家有帮助。 ()
抓取网页数据(抓取网页数据将结果保存到文件,再用php处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-02 16:03
抓取网页数据,将结果保存到文件,再用php封装处理。比如把,就可以用sql保存到mysql中。以及可以用其他工具与php交互数据。目前有什么问题?1.比如说爬取的数据,网页代码没有加密保存。加密方式无法破解。2.不知道java能不能调用php,或者能不能利用反射或者iocp抓?3.如果要用java来学习php或者调用,是不是要去学习php的标准库?比如其中的eldatalib,如果不加封装,eldata一个ast就是一个sql。php中没有对应的ast,还得自己写ast,直接使用,是不是效率不太高?。
使用java或者python+go语言
现在有提供php封装好的结构化数据,比如大家都熟悉的odbc。
不管sqlzoo,还是infoq上都有很多各种算法的简单demo,比较系统地介绍了php和其他语言的提供的封装。
这不是php的语言本身问题。因为它的数据本身结构不是数据库mysql那种结构,而是一串接近xml的字符串。这种字符串是最适合用php结构化数据读写的,不需要转换成数据库语言,只需要在字符串后补上一些空格就可以了。
话说有php的工具类吗?例如googleanalyticsapi
用python是最可以的,它本身就提供很好的封装。
最近在读pearl同学的「python基础」, 查看全部
抓取网页数据(抓取网页数据将结果保存到文件,再用php处理)
抓取网页数据,将结果保存到文件,再用php封装处理。比如把,就可以用sql保存到mysql中。以及可以用其他工具与php交互数据。目前有什么问题?1.比如说爬取的数据,网页代码没有加密保存。加密方式无法破解。2.不知道java能不能调用php,或者能不能利用反射或者iocp抓?3.如果要用java来学习php或者调用,是不是要去学习php的标准库?比如其中的eldatalib,如果不加封装,eldata一个ast就是一个sql。php中没有对应的ast,还得自己写ast,直接使用,是不是效率不太高?。
使用java或者python+go语言
现在有提供php封装好的结构化数据,比如大家都熟悉的odbc。
不管sqlzoo,还是infoq上都有很多各种算法的简单demo,比较系统地介绍了php和其他语言的提供的封装。
这不是php的语言本身问题。因为它的数据本身结构不是数据库mysql那种结构,而是一串接近xml的字符串。这种字符串是最适合用php结构化数据读写的,不需要转换成数据库语言,只需要在字符串后补上一些空格就可以了。
话说有php的工具类吗?例如googleanalyticsapi
用python是最可以的,它本身就提供很好的封装。
最近在读pearl同学的「python基础」,
抓取网页数据(抓取网页数据是大部分android应用程序需要完成的基本工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-01 19:04
抓取网页数据是大部分android应用程序需要完成的基本工作,在android程序中post,get,put,delete被广泛的使用。在通用思路下,除了form表单方式直接获取数据,也可以直接获取网页图片/元素等数据。
1、form表单form表单是android最基本的表单方式,当然也是最常见的(chapter16:formdata)。基本解释:form表单是android6.0及以上版本系统实现的一种multicastweb服务,把用户输入的一系列uri信息保存在json中,也可以直接保存html中,并以json格式返回给java客户端。
在form表单的基本结构中,数据的格式被限定为json,属性,可以以post等方式提交,tomcat默认使用formservice接受用户提交的json对象;formdatabase数据库中保存着一系列json对象,用于储存用户信息。(chapter16:formdata)需要注意的是,form表单的发送方式有两种,一种是post,一种是get,在新版本的android中不存在formdatabase,取而代之的是一个叫做request.send()的方法,formdatabase是info.map文件中定义的类,其核心功能是基于json的表单提交。注意:androidjson是不支持""的,除非注意为activex。
2、tomcat的请求用open请求方式并按form指定的方式进行传递请求数据到调用方://从第一个参数中进行一下传递connection:uricontent-typepost//设置发送方式open()tomcat源码分析classapplication1{uriuri;content-typetext/plain;post//设置发送方式open();}创建子类connectionhandler作为消息发送方使用,内部函数通过open开始参数传递,通过post提交传递到调用方。
//向open传递请求数据publicvoidopen(){super.open(connection,uri,content-type,post);}connectionhandler接受请求并通过post提交并上报给java,ioutils/lib/libbeans/executable/java.util.requests.requeststreams,ioutils/lib/lib/lib/libbeans/java.util.requests.json/bean/open(),通过发送消息方式向tomcat提交请求。
requeststreams是coutils/lib/libbeans/java.util.requests.json/executable/bean/open()的类。
3、delete请求无请求的loading比较好处理,根据需要使用post和get操作数据:classapplication1{uriuri;content-typetext/plain;post//设置发送方式post(uriuri);}创建子类loadinghandler并继承connectionhandler://向delete请求数据并使用balance平衡操作平衡re。 查看全部
抓取网页数据(抓取网页数据是大部分android应用程序需要完成的基本工作)
抓取网页数据是大部分android应用程序需要完成的基本工作,在android程序中post,get,put,delete被广泛的使用。在通用思路下,除了form表单方式直接获取数据,也可以直接获取网页图片/元素等数据。
1、form表单form表单是android最基本的表单方式,当然也是最常见的(chapter16:formdata)。基本解释:form表单是android6.0及以上版本系统实现的一种multicastweb服务,把用户输入的一系列uri信息保存在json中,也可以直接保存html中,并以json格式返回给java客户端。
在form表单的基本结构中,数据的格式被限定为json,属性,可以以post等方式提交,tomcat默认使用formservice接受用户提交的json对象;formdatabase数据库中保存着一系列json对象,用于储存用户信息。(chapter16:formdata)需要注意的是,form表单的发送方式有两种,一种是post,一种是get,在新版本的android中不存在formdatabase,取而代之的是一个叫做request.send()的方法,formdatabase是info.map文件中定义的类,其核心功能是基于json的表单提交。注意:androidjson是不支持""的,除非注意为activex。
2、tomcat的请求用open请求方式并按form指定的方式进行传递请求数据到调用方://从第一个参数中进行一下传递connection:uricontent-typepost//设置发送方式open()tomcat源码分析classapplication1{uriuri;content-typetext/plain;post//设置发送方式open();}创建子类connectionhandler作为消息发送方使用,内部函数通过open开始参数传递,通过post提交传递到调用方。
//向open传递请求数据publicvoidopen(){super.open(connection,uri,content-type,post);}connectionhandler接受请求并通过post提交并上报给java,ioutils/lib/libbeans/executable/java.util.requests.requeststreams,ioutils/lib/lib/lib/libbeans/java.util.requests.json/bean/open(),通过发送消息方式向tomcat提交请求。
requeststreams是coutils/lib/libbeans/java.util.requests.json/executable/bean/open()的类。
3、delete请求无请求的loading比较好处理,根据需要使用post和get操作数据:classapplication1{uriuri;content-typetext/plain;post//设置发送方式post(uriuri);}创建子类loadinghandler并继承connectionhandler://向delete请求数据并使用balance平衡操作平衡re。
抓取网页数据(30款常用的大数据分析工具推荐(最新)-Mozenda)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 18:09
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
最简单的数据抓取教程,人人都能用 WebScraper 是普通用户免费的(无需专业技能)。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。 查看全部
抓取网页数据(30款常用的大数据分析工具推荐(最新)-Mozenda)
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
最简单的数据抓取教程,人人都能用 WebScraper 是普通用户免费的(无需专业技能)。
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
本软件可以帮助想要自己研究代码或者嫁接别人前端代码文件的开发者网站爬虫工具网站爬虫工具详细描述使用。
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。
抓取网页数据(如何快速获取抓取网页数据?是不是只有很老旧的网站才做得出来?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-31 08:01
抓取网页数据?是不是只有很老旧的网站才做得出来?互联网在不断进步,新的网站也越来越多,但是掌握住scrapy与python脚本获取数据的姿势就很重要了,今天笔者就来为大家分享一下如何快速获取数据。本教程通过python程序框架来解决爬虫基础问题,通过scrapy爬取微博网页内容,数据保存到本地。使用scrapy从微博网页上爬取数据、清洗数据,并合并到本地的数据库中。
框架的选择。初学爬虫,最好还是选择比较好的框架,直接使用python中的scrapy不失为一个好的选择。另外,选择使用框架,也可以省下一部分学习scrapy的成本,省时省力还不易出错。爬虫框架虽然选择比较多,市面上也有很多优秀的爬虫框架,但是笔者为何选择scrapy,我觉得是因为:scrapy从安装,以及整个程序的代码设计都非常友好,基本上没有太多技术难题,工作量一般。
爬虫效率提高一倍以上,爬取快图-微博将微博数据保存到自己的本地文件。图1爬取快图-微博图2写入数据库将微博数据转为数据库。把需要爬取的数据写入数据库,工作量较小;但是,爬取了几十页以后,写入数据库可能很困难,但是scrapy却能很好地解决这个问题。请求问题。scrapy可以很好地解决了爬取数据相关的请求问题,基本上用户可以自己设计使用起来比较方便的请求。
但是有一点不太好,爬取请求需要登录,需要手机号验证,但是scrapy这些地方解决不了。缺少爬取微博数据中可能要爬取的其他数据,如果是注册过的微博帐号就不需要爬取了;需要爬取的数据很多,数据量较大,如果用户获取数据的网页过多,可能还会出现阻塞的情况。网页切换效率。当前scrapy只支持http请求,如果要爬取一些微博页面,要想从同一网页爬取,需要轮询服务器,而这在高并发与海量数据爬取下无法满足爬取需求。
图3高并发爬取scrapy其他功能。读取微博字典,需要指定字典结构,以及必须要在list.toarray中调用pd.data转化为dict字典等功能。然而这些功能微博站点并不常用,所以即使微博发展到如今依然没有去除。使用爬虫框架,要问能做哪些,当然是能将网页爬取到本地。但是从scrapy爬取的数据很难通过python语言的封装,再加上java或c#编程,再将字典再转换成数据库文件的方式,放到数据库中,这就要求爬虫框架必须要提供丰富的api。
此外,后端可以使用python语言的network库来和浏览器进行网络请求,但是目前这样做的话可能同样也会造成数据的丢失;而scrapy想要通过http网络请求来爬取本地文件数据库时,必须使用http/1.1,而如果。 查看全部
抓取网页数据(如何快速获取抓取网页数据?是不是只有很老旧的网站才做得出来?)
抓取网页数据?是不是只有很老旧的网站才做得出来?互联网在不断进步,新的网站也越来越多,但是掌握住scrapy与python脚本获取数据的姿势就很重要了,今天笔者就来为大家分享一下如何快速获取数据。本教程通过python程序框架来解决爬虫基础问题,通过scrapy爬取微博网页内容,数据保存到本地。使用scrapy从微博网页上爬取数据、清洗数据,并合并到本地的数据库中。
框架的选择。初学爬虫,最好还是选择比较好的框架,直接使用python中的scrapy不失为一个好的选择。另外,选择使用框架,也可以省下一部分学习scrapy的成本,省时省力还不易出错。爬虫框架虽然选择比较多,市面上也有很多优秀的爬虫框架,但是笔者为何选择scrapy,我觉得是因为:scrapy从安装,以及整个程序的代码设计都非常友好,基本上没有太多技术难题,工作量一般。
爬虫效率提高一倍以上,爬取快图-微博将微博数据保存到自己的本地文件。图1爬取快图-微博图2写入数据库将微博数据转为数据库。把需要爬取的数据写入数据库,工作量较小;但是,爬取了几十页以后,写入数据库可能很困难,但是scrapy却能很好地解决这个问题。请求问题。scrapy可以很好地解决了爬取数据相关的请求问题,基本上用户可以自己设计使用起来比较方便的请求。
但是有一点不太好,爬取请求需要登录,需要手机号验证,但是scrapy这些地方解决不了。缺少爬取微博数据中可能要爬取的其他数据,如果是注册过的微博帐号就不需要爬取了;需要爬取的数据很多,数据量较大,如果用户获取数据的网页过多,可能还会出现阻塞的情况。网页切换效率。当前scrapy只支持http请求,如果要爬取一些微博页面,要想从同一网页爬取,需要轮询服务器,而这在高并发与海量数据爬取下无法满足爬取需求。
图3高并发爬取scrapy其他功能。读取微博字典,需要指定字典结构,以及必须要在list.toarray中调用pd.data转化为dict字典等功能。然而这些功能微博站点并不常用,所以即使微博发展到如今依然没有去除。使用爬虫框架,要问能做哪些,当然是能将网页爬取到本地。但是从scrapy爬取的数据很难通过python语言的封装,再加上java或c#编程,再将字典再转换成数据库文件的方式,放到数据库中,这就要求爬虫框架必须要提供丰富的api。
此外,后端可以使用python语言的network库来和浏览器进行网络请求,但是目前这样做的话可能同样也会造成数据的丢失;而scrapy想要通过http网络请求来爬取本地文件数据库时,必须使用http/1.1,而如果。
抓取网页数据(如何防止爬虫爬取数据,(图)至服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-29 02:02
抓取网页数据至npmload,添加page.load至服务器,使服务器每日每秒执行此页面,存储cookie。下次使用时,
我是这么想的,你可以挂上你的directtoken,写一段代码,只要是directtoken为true的都可以了,然后对特定的页面做一次cookie的校验,如果校验到你的directtoken就认为那个页面的访问是安全的,可以推送给那个页面去,
建议一开始自己写一套loadbalancer方案。你需要实现这样一套系统,首先,客户端需要自己发起http请求,然后服务端需要判断请求是否合法,是否在拥有一个比如:cookie_from_to_exists等header,同时根据关键字(如:when,as,since等)用"某个参数"来对应判断用户状态等,进而决定是否推送不同状态的报文推送到对应的页面,最后在每个接受到的http请求中cookieheaderbodypost或postnewkey和某个特定token来进行验证,确保新的页面是安全的,回应后进行计算推送请求。
不用爬虫的话,
先提供一种思路:如果你能在后台方便地通过一些便捷的反爬虫设置来防止爬虫爬取数据,比如带身份验证、返回有效method、cookie,服务端也可以用类似的框架来负责判断哪些值对应(注意是对应),并将爬取的数据以响应形式返回给客户端。否则,可以借助现有的信息采集类进行爬取,或者直接将数据交给爬虫,他们自己去读取。爬虫的学习难度没那么大。前者的代码量应该有百万级,后者则很少。 查看全部
抓取网页数据(如何防止爬虫爬取数据,(图)至服务器)
抓取网页数据至npmload,添加page.load至服务器,使服务器每日每秒执行此页面,存储cookie。下次使用时,
我是这么想的,你可以挂上你的directtoken,写一段代码,只要是directtoken为true的都可以了,然后对特定的页面做一次cookie的校验,如果校验到你的directtoken就认为那个页面的访问是安全的,可以推送给那个页面去,
建议一开始自己写一套loadbalancer方案。你需要实现这样一套系统,首先,客户端需要自己发起http请求,然后服务端需要判断请求是否合法,是否在拥有一个比如:cookie_from_to_exists等header,同时根据关键字(如:when,as,since等)用"某个参数"来对应判断用户状态等,进而决定是否推送不同状态的报文推送到对应的页面,最后在每个接受到的http请求中cookieheaderbodypost或postnewkey和某个特定token来进行验证,确保新的页面是安全的,回应后进行计算推送请求。
不用爬虫的话,
先提供一种思路:如果你能在后台方便地通过一些便捷的反爬虫设置来防止爬虫爬取数据,比如带身份验证、返回有效method、cookie,服务端也可以用类似的框架来负责判断哪些值对应(注意是对应),并将爬取的数据以响应形式返回给客户端。否则,可以借助现有的信息采集类进行爬取,或者直接将数据交给爬虫,他们自己去读取。爬虫的学习难度没那么大。前者的代码量应该有百万级,后者则很少。
抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-26 03:18
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价为300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员统计数据和其他统计数据向用户收取每赛季30美元的费用。他们不设定价格,因为他们网站拥有数据,但他们抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
注:原文编译自medium,原标题《How To Make Money, Using Web Scraping》
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓ 查看全部
抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店)
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价为300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员统计数据和其他统计数据向用户收取每赛季30美元的费用。他们不设定价格,因为他们网站拥有数据,但他们抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
注:原文编译自medium,原标题《How To Make Money, Using Web Scraping》
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓
抓取网页数据(第三方工具使用工具的使用方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-24 03:13
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
** 第一种方式:** URL 地址收录分页信息。这种形式是最简单的。使用第三方工具抓取这个表格也很简单。基本上,不需要任何代码。对我来说,我宁愿自己花钱。一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
**第二种方式:**通过asp.NET开发的网站可能会遇到,其分页控件通过post方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示JavaScript:__dopostback("gridview", "page1")等等,这种形式其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
**第三种方式:**第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式花费了我很多。之后,我采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。,然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵 查看全部
抓取网页数据(第三方工具使用工具的使用方法和方法)
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
** 第一种方式:** URL 地址收录分页信息。这种形式是最简单的。使用第三方工具抓取这个表格也很简单。基本上,不需要任何代码。对我来说,我宁愿自己花钱。一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
**第二种方式:**通过asp.NET开发的网站可能会遇到,其分页控件通过post方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示JavaScript:__dopostback("gridview", "page1")等等,这种形式其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意asp.Net页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
**第三种方式:**第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式花费了我很多。之后,我采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。,然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵
抓取网页数据(开发一个ai系统的方法和日常操作密切的密切)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-22 14:00
抓取网页数据一般用python,而python中有好多库,numpy是其中之一,比如用numpy去解析一个doc数据库(即数据表),把某几行数据转换成字符串,这样再用python解析,速度较快,而用pandas则可以很方便的利用索引、切片等操作,进行数据库的增删改查操作,同时也可以导入数据库,读取excel,ipython中控制excel的读写操作。
用pandas去做doc数据处理是一个很有意思的事情,因为可以利用pandas的各种设计,解决我们常常遇到的一些数据处理问题。而pandas中的numpy有一个优点,可以和很多的操作库兼容,比如linux中就可以下载的libmacron,libxl,可以方便的在windows上使用。
其实ai方面的研究不少和日常操作密切相关。大家开发一个ai系统基本都是为了解决实际问题,这个实际问题就是指机器视觉系统。那么,是否可以利用python和深度学习等方面的库开发一个在计算机视觉上有一定造诣的大脑?只要那大脑足够智能,其最终的运行结果可以从机器学习等方面有所应用。所以,python还是蛮适合开发智能系统的。
python对于one-hot编码,元数据,和语言语法本身和编程思想上可能都更加友好。
不问是不是,先问为什么。先问python还是pandas和numpy更适合开发智能数据处理系统。 查看全部
抓取网页数据(开发一个ai系统的方法和日常操作密切的密切)
抓取网页数据一般用python,而python中有好多库,numpy是其中之一,比如用numpy去解析一个doc数据库(即数据表),把某几行数据转换成字符串,这样再用python解析,速度较快,而用pandas则可以很方便的利用索引、切片等操作,进行数据库的增删改查操作,同时也可以导入数据库,读取excel,ipython中控制excel的读写操作。
用pandas去做doc数据处理是一个很有意思的事情,因为可以利用pandas的各种设计,解决我们常常遇到的一些数据处理问题。而pandas中的numpy有一个优点,可以和很多的操作库兼容,比如linux中就可以下载的libmacron,libxl,可以方便的在windows上使用。
其实ai方面的研究不少和日常操作密切相关。大家开发一个ai系统基本都是为了解决实际问题,这个实际问题就是指机器视觉系统。那么,是否可以利用python和深度学习等方面的库开发一个在计算机视觉上有一定造诣的大脑?只要那大脑足够智能,其最终的运行结果可以从机器学习等方面有所应用。所以,python还是蛮适合开发智能系统的。
python对于one-hot编码,元数据,和语言语法本身和编程思想上可能都更加友好。
不问是不是,先问为什么。先问python还是pandas和numpy更适合开发智能数据处理系统。
抓取网页数据(英语为什么不存在长单词这样的问题?怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-18 23:01
抓取网页数据或者后台数据库,
个人做法,有时候,问题很简单,比如要用该电子词典的内置查询工具,那就把这个电子词典下下来,同时配上该工具的输入,读取结果,直接如下一般来说,问题都很复杂,比如为什么英语为什么不存在长单词这样的问题。
不需要更改,
另存为为pdf格式,
重命名doc
有个说法是不要复制docx文件。至于实际的做法,更多还是看当地python库使用量,但是肯定是不需要另行设置路径的。
python解决方案
1、写一个命令行模式下的python实例
2、实例挂载到某台操作系统运行的终端机上解决方案
2、在一台台式机上集中存放文件,
不需要,
利用pythonscrapy等库自己开发一个,所有数据都是从pandas库,excel导入,非常方便,实际操作非常方便,
我特意去找了scikit-learn的例子
1.自己再重新写,2.模块在libmysqldb上。nlp的基本操作,操作log语句。
像我们这种工作中用不到java高级库,
为什么我觉得你就是懒呢,
重命名为.jsp, 查看全部
抓取网页数据(英语为什么不存在长单词这样的问题?怎么办?)
抓取网页数据或者后台数据库,
个人做法,有时候,问题很简单,比如要用该电子词典的内置查询工具,那就把这个电子词典下下来,同时配上该工具的输入,读取结果,直接如下一般来说,问题都很复杂,比如为什么英语为什么不存在长单词这样的问题。
不需要更改,
另存为为pdf格式,
重命名doc
有个说法是不要复制docx文件。至于实际的做法,更多还是看当地python库使用量,但是肯定是不需要另行设置路径的。
python解决方案
1、写一个命令行模式下的python实例
2、实例挂载到某台操作系统运行的终端机上解决方案
2、在一台台式机上集中存放文件,
不需要,
利用pythonscrapy等库自己开发一个,所有数据都是从pandas库,excel导入,非常方便,实际操作非常方便,
我特意去找了scikit-learn的例子
1.自己再重新写,2.模块在libmysqldb上。nlp的基本操作,操作log语句。
像我们这种工作中用不到java高级库,
为什么我觉得你就是懒呢,
重命名为.jsp,
抓取网页数据( 网页优游国际平台良多人以为Web该当一向开放的精力)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-18 19:21
网页优游国际平台良多人以为Web该当一向开放的精力)
万维网是一个开放的平台,这也为万维网自1990年代初诞生至今的30年奠定了基础。然而,所谓的“优优国际平台”也可以被打败或更少,开放的功能,搜索引擎,以及简单易学的HTML和CSS移动优优国际平台,使Web优优国际平台成为最受欢迎的平台。熟悉互联网领域的信息传播。但是,作为商业软件,Web平台上的内容信息的版权并不能得到保证。与软件客户端相比,您网站的内容可以被移动用户以非常低的成本和低成本使用。国际平台的门槛是通过平台发布的一些爬取程序得到的,这就是本专栏的主题<
很多人认为,Web 应该始终遵循开放的精神,这表明该页面上的信息应该毫无保留地与所有 Internet 共享。但我认为,在 IT 行业走向明天,Web 不再是曾经与 PDF 竞争的所谓“超文本”信息载体,它是一种轻量级的客户端软件意识形态的存在。至于交易软件,Web 也将不得不面对知识产权保护的问题。试想,如果首发的优质内容得不到保护,抄袭盗版将横行全球。这对网络来说真的很糟糕。生态健全的平台不利,难以鼓励和鼓励更多优质原创内容的生产。
爬虫的非授权爬取是危害网络原创内容生态的一大难题。因此,为了保护网站的内容,首先要考虑如何防范爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器和客户端编程语言都支持的http请求。你只需要向目标页面的url提交一个http get请求,浏览器加载页面时就可以得到完整的html。文档,这就是我们所说的“同步页面”。
作为防范,服务器可以根据对互联网平台的User-Agent的HTTP请求,检查客户端是合法的浏览器程序还是脚本编写的fetch程序,从而判断是否是真正的浏览器程序。页面信息的内容将发送给您。
这当然是最小平台的防御。作为防御,爬虫可以完全伪造User-Agent字段,甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等字段都是爬虫优优国际平台可以在你的指尖。
此时,服务器可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器的http头指纹来识别你http头的每个字段是否适合浏览器的特性。,如果不合适,将被视为爬虫。这个移动平台的一个典型操作是平台的 PhantomJS1.x 版本。由于它的底层使用了Qt框架的集合库,所以它是Qt在http头显眼的展示。框架网络需求的特征可以直接被服务器识别和阻断。
另外,另一种使平台失败的服务器端爬虫检测机制是在对所有访问的页面的http请求的http响应中植入一个cookie令牌,然后在该页面中的一些ajax接口中异步执行,需要检查访问请求中是否收录有游国际平台的cookie令牌。如果返回token,则说明这是一次合法的读者访问,否则刚刚获得token的用户访问页面html,但没有访问html中执行js后调用的ajax请求,游游国际平台可以是爬虫程序。
如果不关心token直接访问某个接口,也说明你没有请求html页面直接向页面中应该通过ajax访问的接口请求集合请求,这也清楚地证明了你是一个可疑的爬虫。. 著名的电子商务公司网站amazon 采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时检测
现代浏览器是用JavaScript赋能的,所以我们可以把页面的所有主要内容,js异步地要求ajax获取数据,然后渲染到页面上,大大提高了爬虫的爬取能力。内容阈值。依靠这种方式,我们在js运行时将爬虫和反爬虫的竞争战场从服务端转移到了客户端浏览器。抓住移动优优国际平台。
刚才提到的各种服务器端验证,对于常见的python和java语言编写的http爬取程序,对于移动平台都有一定的门槛。它是一个黑盒子,很多东西都需要一点一点的去测试,花费大量的人力物力,为优优国际平台开发了一套爬取程序。作为防御者,网站只需要轻松调整一些策略,而攻击者则需要再次花费相同的时间来修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这个手游国际平台是什么?说白了就是让程序用浏览器访问网页,这样写爬虫的人就可以用浏览器把API暴露给程序,完成平台复杂的爬取业务逻辑。
事实上,这在近几年并不是一个新兴的手游平台。过去的游戏平台是基于基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至基于IE内核的trifleJS。你可以检查一下。这里和这里是两个无头浏览器的集合列表。
之所以出现这些无头浏览器程序,是为了创新和封印一些开源的浏览器核心C++代码,是一个简单易用的无GUI界面的浏览器程序。但是,这些项目的问题在于,由于它们的代码是基于fork官方webkit的某个版本的主干代码和其他外部核心,所以无法跟上一些最新的css属性和js语法,并且存在一些兼容性问题,不如真正发布的 GUI 阅读器。
这个 PhantonJS 平台是大家最熟悉的,也是操作率最高的。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 存在很多问题,因为它是单进程模型,不必要的沙盒保护,浏览器内核的安全性较差。
此刻,谷歌Chrome团队已经在chrome 59发布版上开放了headless mode api,并开源了一个基于Node.js误用的headless chromium dirver库。我还为这个库贡献了一个 centos 环境。设置列表。
Headless chrome 堪称无头浏览器平台的标新立异的杀手锏。因为它本身就是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这样的手段,爬虫可以绕过几乎所有的服务器端验证逻辑作为防御端,但是这些爬虫在客户端的js运行时还是有一些技巧的,比如:
基于插件工具检查
基于语言的搜索
基于 webgl 的检查
根据读者发际线的特点进行检查
检查基于错误img src属性生成的img工具
基于以上对一些浏览器特性的判断,基本可以秒杀市面上的无头浏览器程序。此时,其实就是为了提高网页爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,从头开始编译一个浏览器。核心提升不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native工具的属性和方法,看看它的特性是否适合这个版本. 读者应具备优优国际平台的特点。
这类方法称为阅读器指纹检查平台,依赖于大型网站采集各类阅读器的api信息。作为编写爬虫程序的防御方,你可以在无头浏览器运行的时候预先注入一些js逻辑,来制造浏览器的特性。
另外,我们在研究浏览器端使用js api检测robots浏览器的时候,发明了一个有趣的小技术,可以把预先注入的js函数变成native函数,我们看一下上面的代码:
爬虫防御者可能会预先注入一些js方法,在一些native api之上使用一层代理函数作为hook,然后用这个假js api覆盖native api。如果防御者根据检查函数 toString 之后的 [native code] 来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)的方法是捏造的,toString后面没有函数名。
对付爬行动物的灵丹妙药
目前,最可靠的手腕防抢和机器人检查仍然是验证码移动平台。但是,验证码并不意味着必须强制用户输出一串连续的字母和数字。有很多基于用户鼠标、触摸屏(移动端)等动作的移动验证平台。这是最好的移动平台。国际平台熟悉度确实是 Google reCAPTCHA。
基于以上对用户和爬虫的识别,网站的防御者需要做的是封锁该IP位置或对该IP的访问用户施加高强度验证码策略。这样防御者就得购买一个ip代理池来捕获网站信息内容,否则单个ip位置很容易被屏蔽,无法捕获。爬取和反爬的门槛已经提升到ip代理池的经济成本水平。
机器人谈话
此外,在履带式移动机器人领域还有一条“白道”,叫做机器人和平。可以访问网站根目录下的/robots.txt,比如我们看一下github的robots chat,Allow和Disallow分别声明了爬取各个UA爬虫的权限。
然而,这只是一个诚实的谈判。虽然它有法律上的好处,但它只能确定那些商业搜索引擎的蜘蛛,你不能对那些“野爬虫”施加限制。.
写在开头
网页内容的爬取与反制一定是魔高一尺,路高十尺的猫捉老鼠游戏。你永远不可能用某个手游平台完全挡住爬虫式的路。你能做什么 只是增加了攻击者的捕获成本,对未经授权的捕获有了更准确的理解。
这次文章游游国际平台提到的验证码攻防对于手游国际平台来说也是一个比较复杂的难点。我会在这里留下一个关注,我可以多关注它,等待后续文章停止。具体讨论。
另外,对爬虫感兴趣的可以关注我的一个开源项目webster,它以Node.js和Chrome headless的形式完成了一个高可用的网络爬虫框架。页面的渲染能力可以捕捉到一个页面上js和ajax渲染的所有异步内容;redis完成一个任务线,让爬虫程序可以轻松实现横向和纵向分布式扩展。 查看全部
抓取网页数据(
网页优游国际平台良多人以为Web该当一向开放的精力)
万维网是一个开放的平台,这也为万维网自1990年代初诞生至今的30年奠定了基础。然而,所谓的“优优国际平台”也可以被打败或更少,开放的功能,搜索引擎,以及简单易学的HTML和CSS移动优优国际平台,使Web优优国际平台成为最受欢迎的平台。熟悉互联网领域的信息传播。但是,作为商业软件,Web平台上的内容信息的版权并不能得到保证。与软件客户端相比,您网站的内容可以被移动用户以非常低的成本和低成本使用。国际平台的门槛是通过平台发布的一些爬取程序得到的,这就是本专栏的主题<
很多人认为,Web 应该始终遵循开放的精神,这表明该页面上的信息应该毫无保留地与所有 Internet 共享。但我认为,在 IT 行业走向明天,Web 不再是曾经与 PDF 竞争的所谓“超文本”信息载体,它是一种轻量级的客户端软件意识形态的存在。至于交易软件,Web 也将不得不面对知识产权保护的问题。试想,如果首发的优质内容得不到保护,抄袭盗版将横行全球。这对网络来说真的很糟糕。生态健全的平台不利,难以鼓励和鼓励更多优质原创内容的生产。
爬虫的非授权爬取是危害网络原创内容生态的一大难题。因此,为了保护网站的内容,首先要考虑如何防范爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器和客户端编程语言都支持的http请求。你只需要向目标页面的url提交一个http get请求,浏览器加载页面时就可以得到完整的html。文档,这就是我们所说的“同步页面”。
作为防范,服务器可以根据对互联网平台的User-Agent的HTTP请求,检查客户端是合法的浏览器程序还是脚本编写的fetch程序,从而判断是否是真正的浏览器程序。页面信息的内容将发送给您。
这当然是最小平台的防御。作为防御,爬虫可以完全伪造User-Agent字段,甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等字段都是爬虫优优国际平台可以在你的指尖。
此时,服务器可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器的http头指纹来识别你http头的每个字段是否适合浏览器的特性。,如果不合适,将被视为爬虫。这个移动平台的一个典型操作是平台的 PhantomJS1.x 版本。由于它的底层使用了Qt框架的集合库,所以它是Qt在http头显眼的展示。框架网络需求的特征可以直接被服务器识别和阻断。
另外,另一种使平台失败的服务器端爬虫检测机制是在对所有访问的页面的http请求的http响应中植入一个cookie令牌,然后在该页面中的一些ajax接口中异步执行,需要检查访问请求中是否收录有游国际平台的cookie令牌。如果返回token,则说明这是一次合法的读者访问,否则刚刚获得token的用户访问页面html,但没有访问html中执行js后调用的ajax请求,游游国际平台可以是爬虫程序。
如果不关心token直接访问某个接口,也说明你没有请求html页面直接向页面中应该通过ajax访问的接口请求集合请求,这也清楚地证明了你是一个可疑的爬虫。. 著名的电子商务公司网站amazon 采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时检测
现代浏览器是用JavaScript赋能的,所以我们可以把页面的所有主要内容,js异步地要求ajax获取数据,然后渲染到页面上,大大提高了爬虫的爬取能力。内容阈值。依靠这种方式,我们在js运行时将爬虫和反爬虫的竞争战场从服务端转移到了客户端浏览器。抓住移动优优国际平台。
刚才提到的各种服务器端验证,对于常见的python和java语言编写的http爬取程序,对于移动平台都有一定的门槛。它是一个黑盒子,很多东西都需要一点一点的去测试,花费大量的人力物力,为优优国际平台开发了一套爬取程序。作为防御者,网站只需要轻松调整一些策略,而攻击者则需要再次花费相同的时间来修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这个手游国际平台是什么?说白了就是让程序用浏览器访问网页,这样写爬虫的人就可以用浏览器把API暴露给程序,完成平台复杂的爬取业务逻辑。
事实上,这在近几年并不是一个新兴的手游平台。过去的游戏平台是基于基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至基于IE内核的trifleJS。你可以检查一下。这里和这里是两个无头浏览器的集合列表。
之所以出现这些无头浏览器程序,是为了创新和封印一些开源的浏览器核心C++代码,是一个简单易用的无GUI界面的浏览器程序。但是,这些项目的问题在于,由于它们的代码是基于fork官方webkit的某个版本的主干代码和其他外部核心,所以无法跟上一些最新的css属性和js语法,并且存在一些兼容性问题,不如真正发布的 GUI 阅读器。
这个 PhantonJS 平台是大家最熟悉的,也是操作率最高的。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 存在很多问题,因为它是单进程模型,不必要的沙盒保护,浏览器内核的安全性较差。
此刻,谷歌Chrome团队已经在chrome 59发布版上开放了headless mode api,并开源了一个基于Node.js误用的headless chromium dirver库。我还为这个库贡献了一个 centos 环境。设置列表。
Headless chrome 堪称无头浏览器平台的标新立异的杀手锏。因为它本身就是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这样的手段,爬虫可以绕过几乎所有的服务器端验证逻辑作为防御端,但是这些爬虫在客户端的js运行时还是有一些技巧的,比如:
基于插件工具检查
基于语言的搜索
基于 webgl 的检查
根据读者发际线的特点进行检查
检查基于错误img src属性生成的img工具
基于以上对一些浏览器特性的判断,基本可以秒杀市面上的无头浏览器程序。此时,其实就是为了提高网页爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,从头开始编译一个浏览器。核心提升不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native工具的属性和方法,看看它的特性是否适合这个版本. 读者应具备优优国际平台的特点。
这类方法称为阅读器指纹检查平台,依赖于大型网站采集各类阅读器的api信息。作为编写爬虫程序的防御方,你可以在无头浏览器运行的时候预先注入一些js逻辑,来制造浏览器的特性。
另外,我们在研究浏览器端使用js api检测robots浏览器的时候,发明了一个有趣的小技术,可以把预先注入的js函数变成native函数,我们看一下上面的代码:
爬虫防御者可能会预先注入一些js方法,在一些native api之上使用一层代理函数作为hook,然后用这个假js api覆盖native api。如果防御者根据检查函数 toString 之后的 [native code] 来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)的方法是捏造的,toString后面没有函数名。
对付爬行动物的灵丹妙药
目前,最可靠的手腕防抢和机器人检查仍然是验证码移动平台。但是,验证码并不意味着必须强制用户输出一串连续的字母和数字。有很多基于用户鼠标、触摸屏(移动端)等动作的移动验证平台。这是最好的移动平台。国际平台熟悉度确实是 Google reCAPTCHA。
基于以上对用户和爬虫的识别,网站的防御者需要做的是封锁该IP位置或对该IP的访问用户施加高强度验证码策略。这样防御者就得购买一个ip代理池来捕获网站信息内容,否则单个ip位置很容易被屏蔽,无法捕获。爬取和反爬的门槛已经提升到ip代理池的经济成本水平。
机器人谈话
此外,在履带式移动机器人领域还有一条“白道”,叫做机器人和平。可以访问网站根目录下的/robots.txt,比如我们看一下github的robots chat,Allow和Disallow分别声明了爬取各个UA爬虫的权限。
然而,这只是一个诚实的谈判。虽然它有法律上的好处,但它只能确定那些商业搜索引擎的蜘蛛,你不能对那些“野爬虫”施加限制。.
写在开头
网页内容的爬取与反制一定是魔高一尺,路高十尺的猫捉老鼠游戏。你永远不可能用某个手游平台完全挡住爬虫式的路。你能做什么 只是增加了攻击者的捕获成本,对未经授权的捕获有了更准确的理解。
这次文章游游国际平台提到的验证码攻防对于手游国际平台来说也是一个比较复杂的难点。我会在这里留下一个关注,我可以多关注它,等待后续文章停止。具体讨论。
另外,对爬虫感兴趣的可以关注我的一个开源项目webster,它以Node.js和Chrome headless的形式完成了一个高可用的网络爬虫框架。页面的渲染能力可以捕捉到一个页面上js和ajax渲染的所有异步内容;redis完成一个任务线,让爬虫程序可以轻松实现横向和纵向分布式扩展。
抓取网页数据( 如何使用优采云采集器软件抓取亚马逊畅销榜100数据,并用Excel分析价格带)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-17 19:01
如何使用优采云采集器软件抓取亚马逊畅销榜100数据,并用Excel分析价格带)
在这种情况下,我将解释如何使用优采云采集器软件捕捉亚马逊的100个畅销数据,并使用Excel分析价格带。
1.跨境电商,为什么要学亚马逊?
亚马逊是全球第三大科技公司,市值几乎是阿里巴巴的两倍。研究和学习行业大佬是跨境电商的必由之路。
2. 为什么要研究价格区间?
在跨境电子商务中,研究商品价格区间更为重要。
价格永远是消费者最关心的问题。
比如目前国内的瓶装饮料价格在3到5元之间,普通消费者可以接受。如果做酒,价格太低,没有利润;价格太高,比如价格是10元,消费者的主播价格是5元,很可能影响销售。
作为全球电商行业的领军企业,亚马逊的排名在一定程度上代表了国外买家的喜好。
通过研究亚马逊畅销榜的价格,可以大致掌握消费者的心理价格。
3. 为什么使用 优采云采集器?
2个理由:真的很自由很容易
1.免费:如果你尝试大量数据采集器,你会发现很多陷阱。套路一般是这样的,采集的数据是免费的,但是如果要导出采集的数据,不好意思,付钱就行了。
2. 简单:适合新手操作,3次鼠标点击即可获取一般数据。
教程文本
第一:找到亚马逊前100名
比如我们公司的分类是女士内衣,关键词是:内衣
Step1:打开亚马逊主页
在搜索框中输入关键字:内衣搜索
step2:在搜索结果页面,找到与我的产品相关的带有Bset Seller字样的产品。点击查看产品。
step3:在商品详情下方,会有排行榜。先点击
您可以在此子类别下查看排行榜。
第二:安装优采云采集器
打开网站:,点击下载。
第三:开始抓取数据:
step1:双击打开优采云采集器
step2:复制之前在亚马逊上找到的top100的网站链接
例如:
step3:将网址粘贴到搜索框中,点击:Smart采集。
被亚马逊认定为机器人。点击右上角的按钮
点击:验证完成
程序开始运行。如果您能看到价格,则表示识别成功。准备好采集
4:点击:开始采集
点击:开始
不到1分钟,数据采集就完成了。点击:导出数据。
打开导出的数据。
4. 数据分析
(本教程侧重于数据采集,数据分析只是一个例子,大家可以根据实际情况分析数据)
4.1 整理数据:将导出的原创价格数据整理成可计算分析的数据。方法是使用Excel的列替换功能。
这是我们最终整理出来的可以计算的数据
4.2 分析数据:
您可以直接使用 Excel 的频率公式或手动筛选,对价格范围内的 top100 产品进行排序。终于完成了这张表。
从这张表可以看出:
最流行的价格区间是:10~15美金的产品,我们也看产品评分,比较高。我们的产品可以在这个价格范围内定价。
低于 5 美元的产品百分比:20%。因为产品的成本(包括运费)接近 5 美元。同时,参考产品评级,发现它是相当低的。结论:售价低于5美元的产品基本都是为了引流,或者说是卖得很差的产品。
参考:
国内外主流数据采集软件总结:
Excel频率的使用:(来源:叶赛文) 查看全部
抓取网页数据(
如何使用优采云采集器软件抓取亚马逊畅销榜100数据,并用Excel分析价格带)
在这种情况下,我将解释如何使用优采云采集器软件捕捉亚马逊的100个畅销数据,并使用Excel分析价格带。
1.跨境电商,为什么要学亚马逊?
亚马逊是全球第三大科技公司,市值几乎是阿里巴巴的两倍。研究和学习行业大佬是跨境电商的必由之路。
2. 为什么要研究价格区间?
在跨境电子商务中,研究商品价格区间更为重要。
价格永远是消费者最关心的问题。
比如目前国内的瓶装饮料价格在3到5元之间,普通消费者可以接受。如果做酒,价格太低,没有利润;价格太高,比如价格是10元,消费者的主播价格是5元,很可能影响销售。
作为全球电商行业的领军企业,亚马逊的排名在一定程度上代表了国外买家的喜好。
通过研究亚马逊畅销榜的价格,可以大致掌握消费者的心理价格。
3. 为什么使用 优采云采集器?
2个理由:真的很自由很容易
1.免费:如果你尝试大量数据采集器,你会发现很多陷阱。套路一般是这样的,采集的数据是免费的,但是如果要导出采集的数据,不好意思,付钱就行了。
2. 简单:适合新手操作,3次鼠标点击即可获取一般数据。
教程文本
第一:找到亚马逊前100名
比如我们公司的分类是女士内衣,关键词是:内衣
Step1:打开亚马逊主页
在搜索框中输入关键字:内衣搜索
step2:在搜索结果页面,找到与我的产品相关的带有Bset Seller字样的产品。点击查看产品。
step3:在商品详情下方,会有排行榜。先点击
您可以在此子类别下查看排行榜。
第二:安装优采云采集器
打开网站:,点击下载。
第三:开始抓取数据:
step1:双击打开优采云采集器
step2:复制之前在亚马逊上找到的top100的网站链接
例如:
step3:将网址粘贴到搜索框中,点击:Smart采集。
被亚马逊认定为机器人。点击右上角的按钮
点击:验证完成
程序开始运行。如果您能看到价格,则表示识别成功。准备好采集
4:点击:开始采集
点击:开始
不到1分钟,数据采集就完成了。点击:导出数据。
打开导出的数据。
4. 数据分析
(本教程侧重于数据采集,数据分析只是一个例子,大家可以根据实际情况分析数据)
4.1 整理数据:将导出的原创价格数据整理成可计算分析的数据。方法是使用Excel的列替换功能。
这是我们最终整理出来的可以计算的数据
4.2 分析数据:
您可以直接使用 Excel 的频率公式或手动筛选,对价格范围内的 top100 产品进行排序。终于完成了这张表。
从这张表可以看出:
最流行的价格区间是:10~15美金的产品,我们也看产品评分,比较高。我们的产品可以在这个价格范围内定价。
低于 5 美元的产品百分比:20%。因为产品的成本(包括运费)接近 5 美元。同时,参考产品评级,发现它是相当低的。结论:售价低于5美元的产品基本都是为了引流,或者说是卖得很差的产品。
参考:
国内外主流数据采集软件总结:
Excel频率的使用:(来源:叶赛文)
抓取网页数据((Url,,XPathXPath)(,))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-15 17:18
此公式适用于 Windows 7+ 环境、WPS 2016 及以上或 Excel 2007 及以上
GetXPathW()(网址)
Url指的是要爬取的网页地址
GetWebContentByXPathW(网址,XPath)
其中XPath指的是网页的XPath地址,可以通过GetXPathW()返回。这里不能直接使用火狐或者Chrome浏览器拾取的XPath,存在差异,所以不能正确返回结果。
GetWebContentByIdW(网址,XPath)
GetWebContentByClassNameW(Url, XPath)
GetImgW(网址,过滤器)
其中,Filter是指过滤关键词。如果设置了Filter,该函数只返回收录Filter关键词的图片地址。
GetLinkW(网址,过滤器)
其中Filter指的是filter关键词,如果设置了Filter,函数只返回收录Filter关键词的Link地址。
基本原理:首先通过GetXPathW()函数和Excel浏览器将要爬取的网页数据下载到本地数据库,然后通过数据爬取函数抓取目标数据。这样做的好处是提高了数据抓取的效率,尤其是当一个网页抓取大量数据项时。 查看全部
抓取网页数据((Url,,XPathXPath)(,))
此公式适用于 Windows 7+ 环境、WPS 2016 及以上或 Excel 2007 及以上
GetXPathW()(网址)
Url指的是要爬取的网页地址
GetWebContentByXPathW(网址,XPath)
其中XPath指的是网页的XPath地址,可以通过GetXPathW()返回。这里不能直接使用火狐或者Chrome浏览器拾取的XPath,存在差异,所以不能正确返回结果。
GetWebContentByIdW(网址,XPath)
GetWebContentByClassNameW(Url, XPath)
GetImgW(网址,过滤器)
其中,Filter是指过滤关键词。如果设置了Filter,该函数只返回收录Filter关键词的图片地址。
GetLinkW(网址,过滤器)
其中Filter指的是filter关键词,如果设置了Filter,函数只返回收录Filter关键词的Link地址。
基本原理:首先通过GetXPathW()函数和Excel浏览器将要爬取的网页数据下载到本地数据库,然后通过数据爬取函数抓取目标数据。这样做的好处是提高了数据抓取的效率,尤其是当一个网页抓取大量数据项时。
抓取网页数据(Python开发工程师--学习猿地-送9个上线商业项目Scraoy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-15 17:17
推荐课程:Python开发工程师--学猿地--送9个在线商业项目
Scraoy入门示例1——Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
二、PyCharm 安装
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能感知、自动完成、单元测试、版本控制等。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击File>>Settings...里面只有两个Package。如果点击时看到一个 Scrapy 包,则不需要安装它,只需执行以下步骤即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
豆瓣类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
-- 编码:utf-8 --
导入scrapy
from ..items 导入豆瓣商品
豆瓣蜘蛛类蜘蛛(scrapy.Spider):
name = '豆瓣蜘蛛'
# 允许的域名
allowed_domains = [‘movie.douban.com‘]
# 入口URL
start_urls = [‘https://movie.douban.com/top250‘]
def parse(self, response):
movie_list = response.xpath("//div[@class=‘article‘]//ol[@class=‘grid_view‘]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item[‘serial_number‘] = i_item.xpath(".//div[@class=‘item‘]//em/text()").extract_first()
douban_item[‘movie_name‘] = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘hd‘]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘bd‘]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item[‘introduce‘] = content_s
douban_item[‘star‘] = i_item.xpath(".//span[@class=‘rating_num‘]/text()").extract_first()
douban_item[‘evaluate‘] = i_item.xpath(".//div[@class=‘star‘]//span[4]/text()").extract_first()
douban_item[‘describe‘] = i_item.xpath(".//p[@class=‘quote‘]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class=‘next‘]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用,所以不需要运行,允许报错,关于import引入的问题,关于绝对路径和主目录的相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上查找此类问题的解释。
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像壁虎) Chrome/53.@ >0.2785.8 Safari/537.36'
如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 入门示例 2 --- 使用流水线实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
一、管道简介
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
类 TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
豆瓣电影类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
爬虫实验:使用 Scrapy 抓取网页内容
标签:说唱参考逻辑代码目标服务下载获取数据免费试用 查看全部
抓取网页数据(Python开发工程师--学习猿地-送9个上线商业项目Scraoy)
推荐课程:Python开发工程师--学猿地--送9个在线商业项目
Scraoy入门示例1——Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 的安装
1.Scrapy介绍
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于获取 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。
2.Scrapy 安装
建议使用 Anaconda 安装 Scrapy
Anaconda 是一个开源包和环境管理神器。Anaconda 包括 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me,选择安装位置,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,即可下载所有Scrapy及其依赖包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改scrapy包的镜像文件来提高scrapy包的下载速度。你可以参考博客:
这时候测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则表示安装成功:
二、PyCharm 安装
1.PyCharm介绍
PyCharm 是一个 Python IDE,拥有一套完整的工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能感知、自动完成、单元测试、版本控制等。此外,IDE 还提供高级功能以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,直接点击DownLoad下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。你可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果要在 PyCharm 中使用 Scrapy,首先必须在 PyCharm 中安装支持的 Scrapy 包。流程如下,点击File>>Settings...里面只有两个Package。如果点击时看到一个 Scrapy 包,则不需要安装它,只需执行以下步骤即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端在哪里,就是左下角的Terminal。
输入命令:scrapy startproject douban 这是使用命令行新建爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的 网站 是:
假设,我们获取 top250 电影的序列号、电影名称、介绍、星级、评论数、电影描述选项
至此,我们在 items.py 文件中定义抓取的数据项,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
豆瓣类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来,我们需要创建爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体的逻辑代码,如下:
-- 编码:utf-8 --
导入scrapy
from ..items 导入豆瓣商品
豆瓣蜘蛛类蜘蛛(scrapy.Spider):
name = '豆瓣蜘蛛'
# 允许的域名
allowed_domains = [‘movie.douban.com‘]
# 入口URL
start_urls = [‘https://movie.douban.com/top250‘]
def parse(self, response):
movie_list = response.xpath("//div[@class=‘article‘]//ol[@class=‘grid_view‘]/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item[‘serial_number‘] = i_item.xpath(".//div[@class=‘item‘]//em/text()").extract_first()
douban_item[‘movie_name‘] = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘hd‘]/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class=‘info‘]//div[@class=‘bd‘]/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item[‘introduce‘] = content_s
douban_item[‘star‘] = i_item.xpath(".//span[@class=‘rating_num‘]/text()").extract_first()
douban_item[‘evaluate‘] = i_item.xpath(".//div[@class=‘star‘]//span[4]/text()").extract_first()
douban_item[‘describe‘] = i_item.xpath(".//p[@class=‘quote‘]/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class=‘next‘]/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用,所以不需要运行,允许报错,关于import引入的问题,关于绝对路径和主目录的相对路径,原因是我们使用的是相对路径“..items”,对相关内容感兴趣的同学可以去网上查找此类问题的解释。
4.存储内容
将爬取的内容存储为 json 或 csv 格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取的数据存储在 json 文件或 csv 文件中。
执行爬取命令后,当鼠标聚焦到项目面板时,会显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要做进一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像壁虎) Chrome/53.@ >0.2785.8 Safari/537.36'
如果存储在json文件中,所有内容都会以十六进制形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且存储在csv文件中,它会直接显示我们要爬取的所有内容,如下图:
至此,我们就完成了网站具体内容的爬取。接下来,我们需要对爬取的数据进行处理。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 入门示例 2 --- 使用流水线实现
在本次实战中,需要重新创建项目或者安装scrapy包。参考上面的内容,新建项目的方法也参考上面的内容,这里不再赘述。
项目目录结构如下图所示:
一、管道简介
当我们通过Spider爬取数据,通过Item采集数据时,我们需要对数据做一些处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要对数据进行清洗和验证。数据有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一项功能的数据处理。在一个项目中可以同时启用多个管道。
二、在items.py中定义你要抓取的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义你要抓取的数据,比如电影名,代码如下:
在此处定义您的刮擦物品的模型
#
请参阅以下文档:
导入scrapy
类 TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
豆瓣电影类(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义 pipeline.py 文件
爬虫实验:使用 Scrapy 抓取网页内容
标签:说唱参考逻辑代码目标服务下载获取数据免费试用
抓取网页数据(什么叫对数据结构有深入的了解?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-15 07:03
抓取网页数据经过清洗之后,数据结构有了明显的变化,常见的数据结构有domlist、php代码、java的form表单、python的字典。什么叫对数据结构有深入的了解?当你能够熟练的用php、python使用字典来解决问题时你就已经具备了对数据结构有深入的了解。今天我们来看看对数据结构的一些思考与定义。
viewshipping状态数据库分为两类,服务器会在分配客户端请求的时候给所有的客户端返回服务器当前的数据库结构,由于所有客户端都请求服务器服务器返回了全部数据,因此状态(status)保持不变,其他客户端请求即使接受了服务器返回的数据,也不会更改服务器当前的数据库结构,服务器只会返回他所需要更新的客户端请求,服务器此时保持他的状态(status)一直不变,数据库的变化是通过修改客户端请求来完成的。
你也可以理解为,数据库保持这数据库的原始的结构,但是之后的一段时间里,你可以修改任何数据,最终所有客户端的服务器会更新他的数据库结构。上面说的也是上层应用的应用需要做到让服务器保持状态,因为客户端应用将服务器的数据如果需要更新了,应用得到服务器发来的请求后,通过修改服务器的状态更新客户端请求所指向的数据库结构。
所以我们的应用可以在任何时候修改客户端的请求,最终的结果是客户端不用需要修改服务器的数据结构,因为应用的状态不变,服务器的数据结构会自然变化,应用需要对数据结构有一定的掌握,可以更新客户端的请求,会让服务器去适应客户端的修改,就像在服务器上操作数据库一样。ajax在客户端和服务器之间或者在客户端和浏览器之间或者在浏览器和客户端之间,如果发生数据交互(如发送消息),可以使用ajax技术来实现。
ajax在javascript中叫做xmlhttprequest,由于urlxmlhttprequest属于app对象,app中也有实现方法,这就包括了各种方法来获取响应或者更新响应,这些方法都有一个状态,叫做data-origin,这种状态要么是失败的要么是成功的,这个javascript属性修改状态的效果不是一个明确的值,有一定的时间等待。
ajax不是一个ajax应用,它是一个服务器端ajax应用,通过使用中间数据传输,不是客户端向服务器端推送,而是服务器向客户端推送一个处理后的结果。同时服务器需要修改客户端请求到服务器的数据库结构,ajax会提供缓存服务器以便网络传输,所以我们感觉不到自己修改了ajax的状态值,因为ajax是使用中间数据传输。
form表单form-view是浏览器和服务器端通信的桥梁,我们可以通过form表单来做数据传输,form表单由函数或者模块来描。 查看全部
抓取网页数据(什么叫对数据结构有深入的了解?(一))
抓取网页数据经过清洗之后,数据结构有了明显的变化,常见的数据结构有domlist、php代码、java的form表单、python的字典。什么叫对数据结构有深入的了解?当你能够熟练的用php、python使用字典来解决问题时你就已经具备了对数据结构有深入的了解。今天我们来看看对数据结构的一些思考与定义。
viewshipping状态数据库分为两类,服务器会在分配客户端请求的时候给所有的客户端返回服务器当前的数据库结构,由于所有客户端都请求服务器服务器返回了全部数据,因此状态(status)保持不变,其他客户端请求即使接受了服务器返回的数据,也不会更改服务器当前的数据库结构,服务器只会返回他所需要更新的客户端请求,服务器此时保持他的状态(status)一直不变,数据库的变化是通过修改客户端请求来完成的。
你也可以理解为,数据库保持这数据库的原始的结构,但是之后的一段时间里,你可以修改任何数据,最终所有客户端的服务器会更新他的数据库结构。上面说的也是上层应用的应用需要做到让服务器保持状态,因为客户端应用将服务器的数据如果需要更新了,应用得到服务器发来的请求后,通过修改服务器的状态更新客户端请求所指向的数据库结构。
所以我们的应用可以在任何时候修改客户端的请求,最终的结果是客户端不用需要修改服务器的数据结构,因为应用的状态不变,服务器的数据结构会自然变化,应用需要对数据结构有一定的掌握,可以更新客户端的请求,会让服务器去适应客户端的修改,就像在服务器上操作数据库一样。ajax在客户端和服务器之间或者在客户端和浏览器之间或者在浏览器和客户端之间,如果发生数据交互(如发送消息),可以使用ajax技术来实现。
ajax在javascript中叫做xmlhttprequest,由于urlxmlhttprequest属于app对象,app中也有实现方法,这就包括了各种方法来获取响应或者更新响应,这些方法都有一个状态,叫做data-origin,这种状态要么是失败的要么是成功的,这个javascript属性修改状态的效果不是一个明确的值,有一定的时间等待。
ajax不是一个ajax应用,它是一个服务器端ajax应用,通过使用中间数据传输,不是客户端向服务器端推送,而是服务器向客户端推送一个处理后的结果。同时服务器需要修改客户端请求到服务器的数据库结构,ajax会提供缓存服务器以便网络传输,所以我们感觉不到自己修改了ajax的状态值,因为ajax是使用中间数据传输。
form表单form-view是浏览器和服务器端通信的桥梁,我们可以通过form表单来做数据传输,form表单由函数或者模块来描。
抓取网页数据(抓取网页数据的话,也可以用you-get,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-13 01:01
抓取网页数据的话,也可以用you-get,flask-login这样的爬虫工具,数据来源可以是微博也可以是网站的公共信息。可以先试一下digwuser的网站爬虫,地址为:/you-get。
刚刚是写好了这么个爬虫的文章的,接下来还要不断更新文章才能够更好实现目标(滑稽),
其实,这个我也想过,因为比较好的渠道是在招聘网站上,如果你一直想的是单向爬虫的话,大可能找到一个下家,而且网站本身也可以自定义对账号和密码,这个人是无法被封号的。后来我想了一下,这样其实很麻烦,所以我就没再大批量的尝试。
这样的提问只是为了找台阶下,先用弱力提问,然后找共同好友编个口子,让他们帮你再卖一个。
charles,okflush,phantomjs,scrapy啥的可以试试,但是爬虫的爬取力度和效率是关键,数据多了之后大部分都是有用的信息,但是实际上没有几个人会重视,如果天天往外卖量你看,erp、网站内容等等都是没用的。所以把数据量控制在一定区间就很关键。
不谢邀,接盘侠一枚。
找我就可以了哟
bilibili爬虫对于b站流量一直在500万以上,年用户数也上千万,说不定可以帮你达到。 查看全部
抓取网页数据(抓取网页数据的话,也可以用you-get,)
抓取网页数据的话,也可以用you-get,flask-login这样的爬虫工具,数据来源可以是微博也可以是网站的公共信息。可以先试一下digwuser的网站爬虫,地址为:/you-get。
刚刚是写好了这么个爬虫的文章的,接下来还要不断更新文章才能够更好实现目标(滑稽),
其实,这个我也想过,因为比较好的渠道是在招聘网站上,如果你一直想的是单向爬虫的话,大可能找到一个下家,而且网站本身也可以自定义对账号和密码,这个人是无法被封号的。后来我想了一下,这样其实很麻烦,所以我就没再大批量的尝试。
这样的提问只是为了找台阶下,先用弱力提问,然后找共同好友编个口子,让他们帮你再卖一个。
charles,okflush,phantomjs,scrapy啥的可以试试,但是爬虫的爬取力度和效率是关键,数据多了之后大部分都是有用的信息,但是实际上没有几个人会重视,如果天天往外卖量你看,erp、网站内容等等都是没用的。所以把数据量控制在一定区间就很关键。
不谢邀,接盘侠一枚。
找我就可以了哟
bilibili爬虫对于b站流量一直在500万以上,年用户数也上千万,说不定可以帮你达到。
抓取网页数据(就是爬虫是怎么解决暗网的内容,解决爬虫的一大难题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-12 04:09
解决爬取暗网数据的问题。暗网。这就是为什么它是一个与整个互联网系统脱节的独立内容,一个独立的网站啊或者一个独立的网页。怎么抢?啊,今天我们要讲的是爬虫是如何解决暗网抓取的内容的。解决暗网的爬取问题一直是爬虫的一大难题。目前,如何解决搜索引擎爬虫的问题。让我们来看看这个问题。首先,我需要解释一下什么是暗网。每个人都有不同的基础。我需要解释一下这件事。这就是我们在网上互相链接的,就是这一堆小圈子都是网站啊,都有互相链接的过程,然后爬出来跟着一个网站@ > 抓到另一个网站,这个里面没有暗网数据。那么什么是暗网?例如。对于新站,如果你不提交到百度,请确保你不提交到百度,也不要提交到你的主页。然后,他没有任何指向其他网页的链接,也没有指向它的链接。当时,这个新网站是暗网数据。啊,还有什么?你的搜索,比如你的标签过滤页面,比如你上面有很多标签过滤,那么可以说是区域过滤,那么这里就比如说分类过滤。第三可能是什么筛选。在这种情况下。爬虫,它不会点击第一次和第二次点击,对吧?那么如果你不提交给爬虫,他不知道吗?并在您的搜索框中。你搜索的词,然后生成页面。如果不搜索的话,是不是就不能生成页面了?基于这些情况,暗网爬虫如何解决这样的问题?往上看。
暗网爬虫的由来,究竟是什么?爬虫暗网爬虫的作用就是希望通过你网站得到更大程度的网站中的各种内容,得到的东西越多越好啊,改进点,增加点索引库的大小。比如我新建了一个搜索引擎,我的搜索引擎只有1000万条数据,当有N个人搜索的时候,是不是每个人搜索这个搜索结果的数据都很少,很难解决大家的问题?. 但是如果我能通过安网的爬虫解决更大的搜索问题,我能不能改进我的一个搜索结果,覆盖更多不同需求的人呢?这就是暗网爬虫的出现方式。实际上,搜索引擎的工作人员和技术人员将花费更多的时间和精力试图解决抓取暗网数据的问题。暗网爬虫的作用。首先,例如,它有什么?过滤器列表参数会自动组合。嘿嘿,一会儿我们来看几个使用这三点的例子。第二点,表单的内容是自动填充的。啊,当然,这个暗网爬虫的解决方案从来没有。特别完美。比如表格的内容自动填入你的搜索框,可以随便写吗?没办法,它必须根据你的 网站 整体 er 语义来理解你的 文章,等等。然后他从用户的搜索中提取一些词,然后搜索看看你的网页有没有内容,对吧?啊,
如果你的网站的网站抓取量足够大,那么文本框内容的填充就交给我们了。申请顺序。过滤列表。你就像。行。我有一堆肾脏来源清单。他可以点击这个,点击无锡,进入另一个页面,点击期货交易员进入另一个页面。那他可以点击无锡添加火商吗?啊,无锡加期货商加行业分类,这又是不是又一个新的一页了,永远也到不了这个位置。如果 网站 没有条目,对吗?所以,暗网的话一定要结合起来。哦,无锡,然后点击期货,然后点击期货交易所出现。这个页面对吗?在这种情况下,如果我的网站上没有条目,他将无法捕捉到这样的内容。但现在是因为我们SU可以做这些事情,做这些入口,看到这个链接没有入口,我想做这个事情。所以唉,它会自动做这些事情。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。
是的,那是一样的。啊,我们在一个表单上,就像一个输入。SU点击进入这个页面,你不知道这个页面吗?如果我没有入口,我不知道我是不是把他们的票让他上车,然后他会自己做。对?暗网爬虫的目标就是做这些事情。每个人都知道暗网上的这个爬虫。可以做这些事情。嗯,就是这样。对。所以这里是一个爬虫解决暗网爬取的全过程。它是一个分布式爬虫。 查看全部
抓取网页数据(就是爬虫是怎么解决暗网的内容,解决爬虫的一大难题)
解决爬取暗网数据的问题。暗网。这就是为什么它是一个与整个互联网系统脱节的独立内容,一个独立的网站啊或者一个独立的网页。怎么抢?啊,今天我们要讲的是爬虫是如何解决暗网抓取的内容的。解决暗网的爬取问题一直是爬虫的一大难题。目前,如何解决搜索引擎爬虫的问题。让我们来看看这个问题。首先,我需要解释一下什么是暗网。每个人都有不同的基础。我需要解释一下这件事。这就是我们在网上互相链接的,就是这一堆小圈子都是网站啊,都有互相链接的过程,然后爬出来跟着一个网站@ > 抓到另一个网站,这个里面没有暗网数据。那么什么是暗网?例如。对于新站,如果你不提交到百度,请确保你不提交到百度,也不要提交到你的主页。然后,他没有任何指向其他网页的链接,也没有指向它的链接。当时,这个新网站是暗网数据。啊,还有什么?你的搜索,比如你的标签过滤页面,比如你上面有很多标签过滤,那么可以说是区域过滤,那么这里就比如说分类过滤。第三可能是什么筛选。在这种情况下。爬虫,它不会点击第一次和第二次点击,对吧?那么如果你不提交给爬虫,他不知道吗?并在您的搜索框中。你搜索的词,然后生成页面。如果不搜索的话,是不是就不能生成页面了?基于这些情况,暗网爬虫如何解决这样的问题?往上看。
暗网爬虫的由来,究竟是什么?爬虫暗网爬虫的作用就是希望通过你网站得到更大程度的网站中的各种内容,得到的东西越多越好啊,改进点,增加点索引库的大小。比如我新建了一个搜索引擎,我的搜索引擎只有1000万条数据,当有N个人搜索的时候,是不是每个人搜索这个搜索结果的数据都很少,很难解决大家的问题?. 但是如果我能通过安网的爬虫解决更大的搜索问题,我能不能改进我的一个搜索结果,覆盖更多不同需求的人呢?这就是暗网爬虫的出现方式。实际上,搜索引擎的工作人员和技术人员将花费更多的时间和精力试图解决抓取暗网数据的问题。暗网爬虫的作用。首先,例如,它有什么?过滤器列表参数会自动组合。嘿嘿,一会儿我们来看几个使用这三点的例子。第二点,表单的内容是自动填充的。啊,当然,这个暗网爬虫的解决方案从来没有。特别完美。比如表格的内容自动填入你的搜索框,可以随便写吗?没办法,它必须根据你的 网站 整体 er 语义来理解你的 文章,等等。然后他从用户的搜索中提取一些词,然后搜索看看你的网页有没有内容,对吧?啊,
如果你的网站的网站抓取量足够大,那么文本框内容的填充就交给我们了。申请顺序。过滤列表。你就像。行。我有一堆肾脏来源清单。他可以点击这个,点击无锡,进入另一个页面,点击期货交易员进入另一个页面。那他可以点击无锡添加火商吗?啊,无锡加期货商加行业分类,这又是不是又一个新的一页了,永远也到不了这个位置。如果 网站 没有条目,对吗?所以,暗网的话一定要结合起来。哦,无锡,然后点击期货,然后点击期货交易所出现。这个页面对吗?在这种情况下,如果我的网站上没有条目,他将无法捕捉到这样的内容。但现在是因为我们SU可以做这些事情,做这些入口,看到这个链接没有入口,我想做这个事情。所以唉,它会自动做这些事情。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。这会消耗这个er服务器的大量资源。所以关于爬暗网,嗯,比起解决爬暗网的问题,搜索引擎,尤其是百度,有更多的精力去呼吁站长向他们提交更多的愿望。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。所以不管是天机收益的手动推送设置图、主动推送、自动推送,让我们提交给UL来解决找这些幼儿园的问题。然后我们直接提交,他就被放到了被取的队列中。然后再看先抓后抓的问题,没错。
是的,那是一样的。啊,我们在一个表单上,就像一个输入。SU点击进入这个页面,你不知道这个页面吗?如果我没有入口,我不知道我是不是把他们的票让他上车,然后他会自己做。对?暗网爬虫的目标就是做这些事情。每个人都知道暗网上的这个爬虫。可以做这些事情。嗯,就是这样。对。所以这里是一个爬虫解决暗网爬取的全过程。它是一个分布式爬虫。
抓取网页数据(java语言提供的工具,解决了python不能做数据挖掘的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-07 06:08
抓取网页数据的工具有很多,如jsoup,tornado等等。jsoup是java语言提供的工具,解决了python不能做数据挖掘的问题。tornado是kotlin语言提供的。让tornado来读取网页数据,在很多项目中会经常使用,读取网页数据的工具有很多。而我对于tornado来读取网页数据有一定的了解,这篇文章将会介绍一下tornado是如何来读取网页数据。
tornado是什么?用java语言提供的tornado能够读取网页数据,它提供的功能也是所有网络爬虫工具中最重要的一部分。tornado是开源的,目前2.x版本并没有对java语言进行调整。我学习tornado是在一个java培训机构,正值五月份的期中考试,培训机构为了突出学习技术的重要性,特意安排我们先上这个由面向对象设计,先易后难的技术,这才有了我进入到这个培训机构学习java技术的机会。
在培训机构,让我深刻认识到知识的重要性,是非常重要的,现在随着我在公司从事java工作,我越来越能明白这句话了。举一个我的例子:现在我通过在群里看到这个话题。先是打算接着往下看,然后看到是针对对象,看完第一个以后。我内心起了嘀咕,这个所谓的对象是什么鬼。我想着正在往下看的时候...我想看下后面会不会给我点提示或者是机会。
我看到了什么,然后我在内心中浮现了一个问题。我对后面会给我提示的东西,一个问号。我如果直接回答是,那么很多时候我自己就给我自己来了一个大大的问号。如果我在回答这个问题的时候,我得到一个反馈就是你回答的语言不对,那么我就对这个说法有一个怀疑。我现在想要看到这个问题下的反馈。由于我遇到的第一个问题是什么时候提示?我当时好像得到的是一个答案。
之后我在我的心中又有了一个疑问,为什么我在遇到这个问题的时候,突然出现了一个问号。我认为出现了一个问号是我的运气不好。我的判断这里是我应该使用java语言。使用python语言的话,我则能够在输入框或者是页面正常输入内容。当我第二次遇到这个问题的时候。我尝试运行了一下tornadoapi,得到了一个正常的tornadoapi,这个时候我的内心又浮现了一个问号。
由于我第一次遇到的问题是什么时候提示,以及在什么情况下会给我一个提示。所以我在第一次遇到的时候把它定义为问号。但是第二次我发现,无论我多么的强调内容,上方的那个问号永远不会输出。使用requests的api,是不是没有出现问号的提示?如果是,那么这个问号是什么鬼。我的脑海中又浮现了第二个问号。我的第一次遇到了tornado网页数据爬虫,要不要用这个,这个问题?如果我不用tornado这个网页。 查看全部
抓取网页数据(java语言提供的工具,解决了python不能做数据挖掘的问题)
抓取网页数据的工具有很多,如jsoup,tornado等等。jsoup是java语言提供的工具,解决了python不能做数据挖掘的问题。tornado是kotlin语言提供的。让tornado来读取网页数据,在很多项目中会经常使用,读取网页数据的工具有很多。而我对于tornado来读取网页数据有一定的了解,这篇文章将会介绍一下tornado是如何来读取网页数据。
tornado是什么?用java语言提供的tornado能够读取网页数据,它提供的功能也是所有网络爬虫工具中最重要的一部分。tornado是开源的,目前2.x版本并没有对java语言进行调整。我学习tornado是在一个java培训机构,正值五月份的期中考试,培训机构为了突出学习技术的重要性,特意安排我们先上这个由面向对象设计,先易后难的技术,这才有了我进入到这个培训机构学习java技术的机会。
在培训机构,让我深刻认识到知识的重要性,是非常重要的,现在随着我在公司从事java工作,我越来越能明白这句话了。举一个我的例子:现在我通过在群里看到这个话题。先是打算接着往下看,然后看到是针对对象,看完第一个以后。我内心起了嘀咕,这个所谓的对象是什么鬼。我想着正在往下看的时候...我想看下后面会不会给我点提示或者是机会。
我看到了什么,然后我在内心中浮现了一个问题。我对后面会给我提示的东西,一个问号。我如果直接回答是,那么很多时候我自己就给我自己来了一个大大的问号。如果我在回答这个问题的时候,我得到一个反馈就是你回答的语言不对,那么我就对这个说法有一个怀疑。我现在想要看到这个问题下的反馈。由于我遇到的第一个问题是什么时候提示?我当时好像得到的是一个答案。
之后我在我的心中又有了一个疑问,为什么我在遇到这个问题的时候,突然出现了一个问号。我认为出现了一个问号是我的运气不好。我的判断这里是我应该使用java语言。使用python语言的话,我则能够在输入框或者是页面正常输入内容。当我第二次遇到这个问题的时候。我尝试运行了一下tornadoapi,得到了一个正常的tornadoapi,这个时候我的内心又浮现了一个问号。
由于我第一次遇到的问题是什么时候提示,以及在什么情况下会给我一个提示。所以我在第一次遇到的时候把它定义为问号。但是第二次我发现,无论我多么的强调内容,上方的那个问号永远不会输出。使用requests的api,是不是没有出现问号的提示?如果是,那么这个问号是什么鬼。我的脑海中又浮现了第二个问号。我的第一次遇到了tornado网页数据爬虫,要不要用这个,这个问题?如果我不用tornado这个网页。
抓取网页数据(作为数据科学家,我还有机会吗?——数据科学招聘状况如何?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 22:13
“作为数据科学家,我还有机会吗?”不,你应该成为一名数据工程师。
数据无处不在,而且只会增加。在过去的 5-10 年里,数据科学吸引了越来越多的新人加入。
但如今数据科学招聘的现状如何?在采集了多家公司的招聘信息后,亚马逊 Alxea 团队的机器学习科学家 Mihail Eric 在他的个人博客中写了一篇分析 文章 来解释他的想法。
数据胜于雄辩。他分析了自2012年以来Y-Combinator孵化的每家公司发布的数据领域职位。研究问题包括:
在数据领域,公司最常招聘的职位是什么?
经常讨论的对数据科学家的需求是什么?
这些技能是否使公司重视正在引发当今数据革命的技能?
以下是博客文章的主要内容:
方法
我选择分析声称使用某些数据作为其价值主张一部分的 YC 风险投资公司。
主要关注 YC,因为它提供了一个易于搜索(可抓取)的公司目录。此外,作为一家特别有远见的孵化器,十年来为全球多个领域的企业提供投资。我认为他们为此分析提供了具有代表性的市场样本。但请注意,我没有分析超大型科技公司。
我从 2012 年开始抓取了每家 YC 公司的主页 URL,并建立了一个收录 1,400 家公司的初始池。
为什么从 2012 年开始? 2012年,AlexNet在ImageNet大赛中获胜,掀起了当前机器学习和数据建模的热潮,第一批数据优先的公司诞生了。
我对初始池进行了关键词过滤,以减少需要浏览的公司数量。具体来说,我只考虑了 网站 至少收录以下术语之一的公司:AI、CV、NLP、自然语言处理、计算机视觉、人工智能、机器、ML、数据。同时不要考虑那些网站链接失败的公司。
这种操作应该会产生很多错误的结果。我意识到会对每个网站进行更细粒度的人工检查以了解相关角色,因此我尽可能优先考虑高召回率。
在这个过滤后的资源池中,我遍历了每个网站,找到了他们发布职位信息的位置,并在标题中注明了所有收录数据、机器学习、NLP 或 CV 的职位。这使我能够建立一个资源库,其中收录来自大约 70 家不同公司的招聘信息。
还有一个小错误:我错过了一些公司,一些网站虽然招聘信息很少,但他们实际上在招聘。此外,有些公司没有正式的招聘页面,而是要求应聘者直接通过电子邮件与他们联系。我忽略了这两种类型的公司,它们不在本次分析和研究中。
另外一点是,本次调研大部分是在2020年最后几周完成的。由于公司定期更新招聘页面,空缺职位可能有所变化,但我认为这对得出的结论影响不大。
数据从业者应该负责什么?
在深入研究结果之前,值得花一些时间弄清楚每个数据域位置通常负责什么。我会抽空介绍以下四个职位:
数据科学家负责使用各种统计和机器学习技术处理和分析数据。他们通常负责构建模型以探索可以从某些数据源中学到什么,但模型通常处于原型级别而不是生产级别;
数据工程师负责开发一套强大且可扩展的数据处理工具/平台。他们必须熟悉SQL/NoSQL数据库和ETL管道的组织和构建/维护;
机器学习 (ML) 工程师通常负责训练模型和生产模型。他们需要熟悉一些高级 ML 框架,并且必须能够轻松地为模型构建可扩展的训练、推理和部署管道;
机器学习 (ML) 科学家致力于前沿研究,他们通常负责探索可以在学术会议上发表的新想法。在交给机器学习工程师进行生产之前,机器学习科学家通常只需要对新的 SOTA 模型进行原型设计。
值得一提的是,与传统数据科学家相比,开放数据工程师的职位数量增加了很多。在这种情况下,就最初雇用的公司数量而言,数据工程师比数据科学家多约 55%。 ,并且机器学习工程师的数量与数据科学家的数量大致相同。但是如果你看一下各个职位的名字,你会发现似乎有些重复。
我只提供了一个合并职位的粗略分类,即当不同职位、不同角色负责大致相同的内容时,将其合并为一个名称。包括以下一组等价关系:
NLP工程师≈CV工程师≈ML工程师≈深度学习工程师(虽然领域可能不同,但职责大致相同)
ML 科学家≈深度学习≈ML 实习生
数据工程师≈数据架构师≈数据总监≈数据平台工程师
以百分比表示:
一般来说,合并会使差异更加明显。开放数据工程师的数量比数据科学家多 70%。此外,开放 ML 工程师的数量比数据科学家多 40%。机器学习科学家的数量仅占数据科学家的 30% 左右。
结论
与其他数据驱动的职位相比,对数据工程师的需求正在增加。从某种意义上说,这代表着这个方向正在走向更广阔的领域。
5 到 8 年前,机器学习火了,公司需要能够对数据进行分类的人才。但后来Tensorflow、PyTorch等框架发展的很好,使得深度学习和机器学习的起步能力得到普及,随之而来的是数据建模技能的商业化。今天,发展的瓶颈在于帮助企业获得关于生产级数据问题的机器学习和建模意见。例如,考虑以下问题:
如何注释数据?
如何处理和清理数据?
如何将其从 A 移动到 B?
如何尽快完成这些任务?
这一切都意味着这个职位需要良好的工程技能,而偏向数据的传统软件工程可能才是我们现在真正需要的。但这是否意味着您不应该学习数据科学?并不真地。这意味着竞争将更加困难。对于准备培养成为数据科学人才的初学者来说,可用的职位会越来越少。当然,总是需要能够有效分析数据并从数据中提取可操作洞察力的人,但这些洞察力必须非常出色。
很明显,公司通常需要混合数据从业者,他们可以构建和部署模型。或者更简洁地说,您可以使用 Tensorflow,但您也可以从源代码构建它。
这项研究的另一个发现是 ML 研究职位很少。机器学习研究往往得到大量资源的支持,因为它是顶级研究,例如 AlphaGo 和 GPT-3。但对于许多公司,尤其是处于早期阶段的公司来说,最先进的 SOTA 技术可能不再是必要的。达到 90% 的最佳模型性能并同时扩展到 1000 多个用户通常对他们来说更有价值。
但您可能会在行业的研究实验室中找到许多此类角色。他们可以长期承担资本密集型的赌注,而不是在种子轮开始工业演示并准备接受 A 轮融资。
如果没有其他问题,我认为最重要的是让新人对数据领域的期望合理和校准。我们必须承认,数据科学已经不是以前的样子,只有知道自己在哪里,我们才知道自己要去哪里。 查看全部
抓取网页数据(作为数据科学家,我还有机会吗?——数据科学招聘状况如何?)
“作为数据科学家,我还有机会吗?”不,你应该成为一名数据工程师。
数据无处不在,而且只会增加。在过去的 5-10 年里,数据科学吸引了越来越多的新人加入。
但如今数据科学招聘的现状如何?在采集了多家公司的招聘信息后,亚马逊 Alxea 团队的机器学习科学家 Mihail Eric 在他的个人博客中写了一篇分析 文章 来解释他的想法。
数据胜于雄辩。他分析了自2012年以来Y-Combinator孵化的每家公司发布的数据领域职位。研究问题包括:
在数据领域,公司最常招聘的职位是什么?
经常讨论的对数据科学家的需求是什么?
这些技能是否使公司重视正在引发当今数据革命的技能?
以下是博客文章的主要内容:
方法
我选择分析声称使用某些数据作为其价值主张一部分的 YC 风险投资公司。
主要关注 YC,因为它提供了一个易于搜索(可抓取)的公司目录。此外,作为一家特别有远见的孵化器,十年来为全球多个领域的企业提供投资。我认为他们为此分析提供了具有代表性的市场样本。但请注意,我没有分析超大型科技公司。
我从 2012 年开始抓取了每家 YC 公司的主页 URL,并建立了一个收录 1,400 家公司的初始池。
为什么从 2012 年开始? 2012年,AlexNet在ImageNet大赛中获胜,掀起了当前机器学习和数据建模的热潮,第一批数据优先的公司诞生了。
我对初始池进行了关键词过滤,以减少需要浏览的公司数量。具体来说,我只考虑了 网站 至少收录以下术语之一的公司:AI、CV、NLP、自然语言处理、计算机视觉、人工智能、机器、ML、数据。同时不要考虑那些网站链接失败的公司。
这种操作应该会产生很多错误的结果。我意识到会对每个网站进行更细粒度的人工检查以了解相关角色,因此我尽可能优先考虑高召回率。
在这个过滤后的资源池中,我遍历了每个网站,找到了他们发布职位信息的位置,并在标题中注明了所有收录数据、机器学习、NLP 或 CV 的职位。这使我能够建立一个资源库,其中收录来自大约 70 家不同公司的招聘信息。
还有一个小错误:我错过了一些公司,一些网站虽然招聘信息很少,但他们实际上在招聘。此外,有些公司没有正式的招聘页面,而是要求应聘者直接通过电子邮件与他们联系。我忽略了这两种类型的公司,它们不在本次分析和研究中。
另外一点是,本次调研大部分是在2020年最后几周完成的。由于公司定期更新招聘页面,空缺职位可能有所变化,但我认为这对得出的结论影响不大。
数据从业者应该负责什么?
在深入研究结果之前,值得花一些时间弄清楚每个数据域位置通常负责什么。我会抽空介绍以下四个职位:
数据科学家负责使用各种统计和机器学习技术处理和分析数据。他们通常负责构建模型以探索可以从某些数据源中学到什么,但模型通常处于原型级别而不是生产级别;
数据工程师负责开发一套强大且可扩展的数据处理工具/平台。他们必须熟悉SQL/NoSQL数据库和ETL管道的组织和构建/维护;
机器学习 (ML) 工程师通常负责训练模型和生产模型。他们需要熟悉一些高级 ML 框架,并且必须能够轻松地为模型构建可扩展的训练、推理和部署管道;
机器学习 (ML) 科学家致力于前沿研究,他们通常负责探索可以在学术会议上发表的新想法。在交给机器学习工程师进行生产之前,机器学习科学家通常只需要对新的 SOTA 模型进行原型设计。
值得一提的是,与传统数据科学家相比,开放数据工程师的职位数量增加了很多。在这种情况下,就最初雇用的公司数量而言,数据工程师比数据科学家多约 55%。 ,并且机器学习工程师的数量与数据科学家的数量大致相同。但是如果你看一下各个职位的名字,你会发现似乎有些重复。
我只提供了一个合并职位的粗略分类,即当不同职位、不同角色负责大致相同的内容时,将其合并为一个名称。包括以下一组等价关系:
NLP工程师≈CV工程师≈ML工程师≈深度学习工程师(虽然领域可能不同,但职责大致相同)
ML 科学家≈深度学习≈ML 实习生
数据工程师≈数据架构师≈数据总监≈数据平台工程师
以百分比表示:
一般来说,合并会使差异更加明显。开放数据工程师的数量比数据科学家多 70%。此外,开放 ML 工程师的数量比数据科学家多 40%。机器学习科学家的数量仅占数据科学家的 30% 左右。
结论
与其他数据驱动的职位相比,对数据工程师的需求正在增加。从某种意义上说,这代表着这个方向正在走向更广阔的领域。
5 到 8 年前,机器学习火了,公司需要能够对数据进行分类的人才。但后来Tensorflow、PyTorch等框架发展的很好,使得深度学习和机器学习的起步能力得到普及,随之而来的是数据建模技能的商业化。今天,发展的瓶颈在于帮助企业获得关于生产级数据问题的机器学习和建模意见。例如,考虑以下问题:
如何注释数据?
如何处理和清理数据?
如何将其从 A 移动到 B?
如何尽快完成这些任务?
这一切都意味着这个职位需要良好的工程技能,而偏向数据的传统软件工程可能才是我们现在真正需要的。但这是否意味着您不应该学习数据科学?并不真地。这意味着竞争将更加困难。对于准备培养成为数据科学人才的初学者来说,可用的职位会越来越少。当然,总是需要能够有效分析数据并从数据中提取可操作洞察力的人,但这些洞察力必须非常出色。
很明显,公司通常需要混合数据从业者,他们可以构建和部署模型。或者更简洁地说,您可以使用 Tensorflow,但您也可以从源代码构建它。
这项研究的另一个发现是 ML 研究职位很少。机器学习研究往往得到大量资源的支持,因为它是顶级研究,例如 AlphaGo 和 GPT-3。但对于许多公司,尤其是处于早期阶段的公司来说,最先进的 SOTA 技术可能不再是必要的。达到 90% 的最佳模型性能并同时扩展到 1000 多个用户通常对他们来说更有价值。
但您可能会在行业的研究实验室中找到许多此类角色。他们可以长期承担资本密集型的赌注,而不是在种子轮开始工业演示并准备接受 A 轮融资。
如果没有其他问题,我认为最重要的是让新人对数据领域的期望合理和校准。我们必须承认,数据科学已经不是以前的样子,只有知道自己在哪里,我们才知道自己要去哪里。
抓取网页数据(百度蜘蛛抓取异常的常见原因是网站不稳定,怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-02 22:09
百度蜘蛛异常爬行的常见原因是网站不稳定。百度蜘蛛在尝试连接您的网站服务器时暂时无法连接。可能是你的网站IP地址错误,或者百度蜘蛛被域名服务商封禁了。
部分网站内容用户可以正常访问,但百度搜索百度内容无法正常访问,导致大量网站关键词搜索结果丢失。这种结果不适合网站,搜索引擎都是亏本。无法抓取百度搜索的网页称为“抓取异常”。百度搜索会认为你的网站在用户体验上存在抓取缺陷,降低你的网站的分数会对网站的页面、索引、排序产生负面影响,并且最终影响网站的流量。
下面介绍一下百度蜘蛛抓取异常的一些常见原因:1、服务器连接异常
服务器连接异常一般有两种情况。一般来说,网站 是不稳定的。当百度搜索蜘蛛抓取你的网站页面时,是无法抓取的。另一种是百度搜索蜘蛛。无法正常连接到您的 网站 服务器。
网站服务器无法正常连接的问题一般是网站服务器负载过大,也可能是你的网站程序问题,先检查< @网站web服务器(IIS或apache)运行正常,检查网站的主页是否可以正常打开,以及网站和主机是否屏蔽了百度搜索蜘蛛的访问。
2、网络运营商异常
网站 服务器网络运营商分为电信和联通两种。如果百度搜索蜘蛛无法通过电信或网通网络访问您的网站,您需要联系网站与服务器运营商沟通,或者重新购买双线网站服务器空间,或者您可以购买 网站CND 服务。
3、DNS 异常
当百度搜索无法解析网站 IP地址时,与网门dns异常情况相同。这个问题可能是你的域名IP解析错误,也可能是百度蜘蛛被屏蔽的域名服务商。这时候我们可以使用whois或者host来检查我们的网站域名的IP是否解析正确。如果域名IP解析不正确,只需重新解析域名即可。如果无法解决,我们需要联系我们。域名注册商出来了。
4、IP 封禁
IP禁令,限制网站的服务器出口IP地址,禁止某个IP段的用户访问网站的内容。这主要是指百度搜索蜘蛛禁止的IP段。情况是你不希望百度搜索蜘蛛访问你的网站,才需要屏蔽百度搜索蜘蛛。如果你想让百度搜索蜘蛛访问你的网站,请添加百度搜索蜘蛛IP段,如果你的百度搜索蜘蛛IP段没有被屏蔽。也有可能是网站空间服务商屏蔽了百度搜索蜘蛛IP段。这个问题需要网站空间服务商来解决。
5、UA 被禁止
UA为User-Agent,网站WEB服务器通过UA识别用户,网站返回指定UA访问异常状态码,如403、500状态代码,或者跳转到其他页面,这种情况叫做UAban,这种情况是你不想百度搜索蜘蛛访问你的时候网站,你只需要设置这个,如果你想让百度搜索蜘蛛访问你的网站,需要检查网站服务器是否被UA拦截,如果有,需要及时处理。
6、死链接
页面一直无法打开,页面已经无法向用户提供任何有价值的信息,这种页面称为死链接,死链接包括协议死链接和内容死链接两种形式:
1、协议死链接,网站页面的TCP协议和HTTP协议状态明确指出死链接,常见状态码为404、403、 503;
<p>2、 内容是死链接的,表示web服务器状态码恢复正常,但是内容已经不存在,已经被删除或者需要权限才能访问。 查看全部
抓取网页数据(百度蜘蛛抓取异常的常见原因是网站不稳定,怎么办)
百度蜘蛛异常爬行的常见原因是网站不稳定。百度蜘蛛在尝试连接您的网站服务器时暂时无法连接。可能是你的网站IP地址错误,或者百度蜘蛛被域名服务商封禁了。
部分网站内容用户可以正常访问,但百度搜索百度内容无法正常访问,导致大量网站关键词搜索结果丢失。这种结果不适合网站,搜索引擎都是亏本。无法抓取百度搜索的网页称为“抓取异常”。百度搜索会认为你的网站在用户体验上存在抓取缺陷,降低你的网站的分数会对网站的页面、索引、排序产生负面影响,并且最终影响网站的流量。
下面介绍一下百度蜘蛛抓取异常的一些常见原因:1、服务器连接异常
服务器连接异常一般有两种情况。一般来说,网站 是不稳定的。当百度搜索蜘蛛抓取你的网站页面时,是无法抓取的。另一种是百度搜索蜘蛛。无法正常连接到您的 网站 服务器。
网站服务器无法正常连接的问题一般是网站服务器负载过大,也可能是你的网站程序问题,先检查< @网站web服务器(IIS或apache)运行正常,检查网站的主页是否可以正常打开,以及网站和主机是否屏蔽了百度搜索蜘蛛的访问。
2、网络运营商异常
网站 服务器网络运营商分为电信和联通两种。如果百度搜索蜘蛛无法通过电信或网通网络访问您的网站,您需要联系网站与服务器运营商沟通,或者重新购买双线网站服务器空间,或者您可以购买 网站CND 服务。
3、DNS 异常
当百度搜索无法解析网站 IP地址时,与网门dns异常情况相同。这个问题可能是你的域名IP解析错误,也可能是百度蜘蛛被屏蔽的域名服务商。这时候我们可以使用whois或者host来检查我们的网站域名的IP是否解析正确。如果域名IP解析不正确,只需重新解析域名即可。如果无法解决,我们需要联系我们。域名注册商出来了。
4、IP 封禁
IP禁令,限制网站的服务器出口IP地址,禁止某个IP段的用户访问网站的内容。这主要是指百度搜索蜘蛛禁止的IP段。情况是你不希望百度搜索蜘蛛访问你的网站,才需要屏蔽百度搜索蜘蛛。如果你想让百度搜索蜘蛛访问你的网站,请添加百度搜索蜘蛛IP段,如果你的百度搜索蜘蛛IP段没有被屏蔽。也有可能是网站空间服务商屏蔽了百度搜索蜘蛛IP段。这个问题需要网站空间服务商来解决。
5、UA 被禁止
UA为User-Agent,网站WEB服务器通过UA识别用户,网站返回指定UA访问异常状态码,如403、500状态代码,或者跳转到其他页面,这种情况叫做UAban,这种情况是你不想百度搜索蜘蛛访问你的时候网站,你只需要设置这个,如果你想让百度搜索蜘蛛访问你的网站,需要检查网站服务器是否被UA拦截,如果有,需要及时处理。
6、死链接
页面一直无法打开,页面已经无法向用户提供任何有价值的信息,这种页面称为死链接,死链接包括协议死链接和内容死链接两种形式:
1、协议死链接,网站页面的TCP协议和HTTP协议状态明确指出死链接,常见状态码为404、403、 503;
<p>2、 内容是死链接的,表示web服务器状态码恢复正常,但是内容已经不存在,已经被删除或者需要权限才能访问。
抓取网页数据(常州昌润信息小编来看看百度蜘蛛收录一个网站的全过程揭秘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-02 22:07
做SEO优化推广,必须要说一下百度的问题收录。很多人不明白。这么多相同的网页,百度如何区分第一篇收录文章文章呢?明明内容是一样的,为什么别人网站收录拥有却没有收录,我们来看看百度蜘蛛收录的一个网站常州畅润资讯编辑下方揭秘全过程,有需要的朋友可以参考以下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、 信息过滤。
3、创建网页关键词索引。
4、 用户搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站的首页,会先读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪。爬行。比如我们的文章文章《长润资讯:百度收录网站网页爬取过程揭秘》中,引擎会在多进程中来这篇文章文章网络爬虫信息差到没完没了。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站,引擎会记录下来并归类为未爬取的URL,然后蜘蛛从数据库根据这个表,访问和抓取页面。
蜘蛛不是收录所有页面,它必须经过严格的检查。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页网站的权重很低,而且大部分文章都是抄袭的,那蜘蛛你可能不会再喜欢你的网站了。如果你不继续爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格建立索引。
索引有正向索引和反向索引。正向索引对应的是网页内容关键词,反向是关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表进行关键词匹配,通过倒排索引表找到关键词对应的页面,并使用匹配引擎 计算出网页综合得分后,根据网页得分确定网页的排名顺序。
希望对大家有帮助。 () 查看全部
抓取网页数据(常州昌润信息小编来看看百度蜘蛛收录一个网站的全过程揭秘)
做SEO优化推广,必须要说一下百度的问题收录。很多人不明白。这么多相同的网页,百度如何区分第一篇收录文章文章呢?明明内容是一样的,为什么别人网站收录拥有却没有收录,我们来看看百度蜘蛛收录的一个网站常州畅润资讯编辑下方揭秘全过程,有需要的朋友可以参考以下
我们知道搜索引擎的工作过程是非常复杂的。今天跟大家分享一下我是怎么知道百度蜘蛛是如何实现网页的收录的。
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行爬行。
2、 信息过滤。
3、创建网页关键词索引。
4、 用户搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这样一年到头的工作累人。比如蜘蛛来到常州畅润资讯网站的首页,会先读取根目录下的robots.txt文件。如果不禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪。爬行。比如我们的文章文章《长润资讯:百度收录网站网页爬取过程揭秘》中,引擎会在多进程中来这篇文章文章网络爬虫信息差到没完没了。
为了避免重复抓取和抓取网址,搜索引擎会记录已抓取和未抓取的地址。如果你有新的网站,可以到百度官网提交网站,引擎会记录下来并归类为未爬取的URL,然后蜘蛛从数据库根据这个表,访问和抓取页面。
蜘蛛不是收录所有页面,它必须经过严格的检查。蜘蛛在抓取网页内容时,会进行一定程度的复制内容检测。如果网页网站的权重很低,而且大部分文章都是抄袭的,那蜘蛛你可能不会再喜欢你的网站了。如果你不继续爬行,你就不会收录你的网站。
当蜘蛛爬取一个页面时,它会首先分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格建立索引。
索引有正向索引和反向索引。正向索引对应的是网页内容关键词,反向是关键词对应的网页信息。
当用户搜索某个关键词时,会通过上面建立的索引表进行关键词匹配,通过倒排索引表找到关键词对应的页面,并使用匹配引擎 计算出网页综合得分后,根据网页得分确定网页的排名顺序。
希望对大家有帮助。 ()
抓取网页数据(抓取网页数据将结果保存到文件,再用php处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-02 16:03
抓取网页数据,将结果保存到文件,再用php封装处理。比如把,就可以用sql保存到mysql中。以及可以用其他工具与php交互数据。目前有什么问题?1.比如说爬取的数据,网页代码没有加密保存。加密方式无法破解。2.不知道java能不能调用php,或者能不能利用反射或者iocp抓?3.如果要用java来学习php或者调用,是不是要去学习php的标准库?比如其中的eldatalib,如果不加封装,eldata一个ast就是一个sql。php中没有对应的ast,还得自己写ast,直接使用,是不是效率不太高?。
使用java或者python+go语言
现在有提供php封装好的结构化数据,比如大家都熟悉的odbc。
不管sqlzoo,还是infoq上都有很多各种算法的简单demo,比较系统地介绍了php和其他语言的提供的封装。
这不是php的语言本身问题。因为它的数据本身结构不是数据库mysql那种结构,而是一串接近xml的字符串。这种字符串是最适合用php结构化数据读写的,不需要转换成数据库语言,只需要在字符串后补上一些空格就可以了。
话说有php的工具类吗?例如googleanalyticsapi
用python是最可以的,它本身就提供很好的封装。
最近在读pearl同学的「python基础」, 查看全部
抓取网页数据(抓取网页数据将结果保存到文件,再用php处理)
抓取网页数据,将结果保存到文件,再用php封装处理。比如把,就可以用sql保存到mysql中。以及可以用其他工具与php交互数据。目前有什么问题?1.比如说爬取的数据,网页代码没有加密保存。加密方式无法破解。2.不知道java能不能调用php,或者能不能利用反射或者iocp抓?3.如果要用java来学习php或者调用,是不是要去学习php的标准库?比如其中的eldatalib,如果不加封装,eldata一个ast就是一个sql。php中没有对应的ast,还得自己写ast,直接使用,是不是效率不太高?。
使用java或者python+go语言
现在有提供php封装好的结构化数据,比如大家都熟悉的odbc。
不管sqlzoo,还是infoq上都有很多各种算法的简单demo,比较系统地介绍了php和其他语言的提供的封装。
这不是php的语言本身问题。因为它的数据本身结构不是数据库mysql那种结构,而是一串接近xml的字符串。这种字符串是最适合用php结构化数据读写的,不需要转换成数据库语言,只需要在字符串后补上一些空格就可以了。
话说有php的工具类吗?例如googleanalyticsapi
用python是最可以的,它本身就提供很好的封装。
最近在读pearl同学的「python基础」,

