
抓取网页数据
抓取网页数据( 网络爬虫就是获取网页信息的简单爬虫方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-08 01:22
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行了),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然这有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码。
此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是字典,所以我们知道网页的编码方式,我们可以根据得到的信息使用不同的解码方式。 查看全部
抓取网页数据(
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行了),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然这有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码。
此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是字典,所以我们知道网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
抓取网页数据(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-10-08 01:20
不知道大家在日常的工作学习生活中是否遇到过这样的场景,就是需要复制网站上面的一些数据(比如图片、文字或者其他一些格式的数据)。将其保存到本地 Excel 表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。Crawler,顾名思义,就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、Manually:完全依赖手动复制粘贴;
2、 半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取某部分数据;
3、全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是这个爬虫写的需要相当的知识。
第二个和第三个,哪个更好,哪个更坏,没有确定的数字。根据不同的场合,两者都有自己的自适应地方。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在我们来看看这个案例。笔者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章,每章又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017 下载安装)和视频地址。
名称比较容易说,表中最左边的列是节的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为存在跨域问题)。
我们应该做什么?
不着急,只要头脑不滑,解决办法总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。因此,您可以使用以下代码来获取收录该部分名称的所有 a 标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这种固定格式的开头是“number.number.number”,可以表示为如下正则表达式:
^\d+\.\d+(\.\d+)?
然后就可以使用正则表达式条件进行过滤了,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
至此,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,当我们点击某个部分时,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是,作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有视频地址不同的只有这里的{1},这里的{1}也和段号有关:{1}的部分由段号改为句号,只需要提取标题号. 然后只需更换它。
至此,您可以完全编写所有代码,并可以根据代码实现所需的抓取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可见,这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十几行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也欢迎在下方评论区写下你的想法。 查看全部
抓取网页数据(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
不知道大家在日常的工作学习生活中是否遇到过这样的场景,就是需要复制网站上面的一些数据(比如图片、文字或者其他一些格式的数据)。将其保存到本地 Excel 表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。Crawler,顾名思义,就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、Manually:完全依赖手动复制粘贴;
2、 半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取某部分数据;
3、全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是这个爬虫写的需要相当的知识。
第二个和第三个,哪个更好,哪个更坏,没有确定的数字。根据不同的场合,两者都有自己的自适应地方。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在我们来看看这个案例。笔者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章,每章又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017 下载安装)和视频地址。
名称比较容易说,表中最左边的列是节的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为存在跨域问题)。
我们应该做什么?
不着急,只要头脑不滑,解决办法总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。因此,您可以使用以下代码来获取收录该部分名称的所有 a 标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这种固定格式的开头是“number.number.number”,可以表示为如下正则表达式:
^\d+\.\d+(\.\d+)?
然后就可以使用正则表达式条件进行过滤了,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
至此,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,当我们点击某个部分时,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是,作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有视频地址不同的只有这里的{1},这里的{1}也和段号有关:{1}的部分由段号改为句号,只需要提取标题号. 然后只需更换它。
至此,您可以完全编写所有代码,并可以根据代码实现所需的抓取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可见,这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十几行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也欢迎在下方评论区写下你的想法。
抓取网页数据(爬虫的核心代码,文章末尾提供源码-是不是交流)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-08 01:19
抓取的方式有很多种,这里我们使用C#语言抓取指定网页上的所有图片。
比如我们在百度搜索图片,看到找到的图片,就可以通过程序,把看到的图片全部抓取。它不仅速度快,而且您还可以了解有关 C# 的更多信息。当别人还在一个一个地保存时,您可以轻松获得一套程序的全部。是不是有点激动?接下来简单说一下核心代码,源码在文章末尾提供。
1.首先我们随机百度一张主题图片,然后复制地址栏中的链接,如下:
2. 将链接分配给程序中的变量。当然,在C#的图形界面中,也可以定义一个输入框。将链接放入输入框,在后台获取输入框的值。现在,原理是一样的。
3. 然后我们根据获取的网页数据,使用正则表达式解析出所有的图片链接。这里的图片格式支持四种常见的jpg、png、jpeg、gif。当然,你也可以添加更多的格式
4.最后我们根据刚刚得到的图片链接开始下载保存到本地。.
5.看看实际效果,打开你的保存文件目录,你会发现图片是一张一张的显示出来的。
效果大吗?如果您有兴趣,可以更改此代码以完善它。如果您对此感兴趣,欢迎交流。
抱歉,由于新的头条规定,编辑不能连接到第三方平台。您可以留下您的企鹅号,编辑会及时发送到您的邮箱。如果觉得不错,记得点赞哦。 查看全部
抓取网页数据(爬虫的核心代码,文章末尾提供源码-是不是交流)
抓取的方式有很多种,这里我们使用C#语言抓取指定网页上的所有图片。
比如我们在百度搜索图片,看到找到的图片,就可以通过程序,把看到的图片全部抓取。它不仅速度快,而且您还可以了解有关 C# 的更多信息。当别人还在一个一个地保存时,您可以轻松获得一套程序的全部。是不是有点激动?接下来简单说一下核心代码,源码在文章末尾提供。
1.首先我们随机百度一张主题图片,然后复制地址栏中的链接,如下:
2. 将链接分配给程序中的变量。当然,在C#的图形界面中,也可以定义一个输入框。将链接放入输入框,在后台获取输入框的值。现在,原理是一样的。
3. 然后我们根据获取的网页数据,使用正则表达式解析出所有的图片链接。这里的图片格式支持四种常见的jpg、png、jpeg、gif。当然,你也可以添加更多的格式
4.最后我们根据刚刚得到的图片链接开始下载保存到本地。.
5.看看实际效果,打开你的保存文件目录,你会发现图片是一张一张的显示出来的。
效果大吗?如果您有兴趣,可以更改此代码以完善它。如果您对此感兴趣,欢迎交流。
抱歉,由于新的头条规定,编辑不能连接到第三方平台。您可以留下您的企鹅号,编辑会及时发送到您的邮箱。如果觉得不错,记得点赞哦。
抓取网页数据( 目标确定2019精品新片的前10页所有电影的名字 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-07 15:11
目标确定2019精品新片的前10页所有电影的名字
)
一、开始
在花了将近半年的空闲时间学习了Python的基本语法之后,我开始尝试网络爬虫。学习了一个星期,在我开始爬相对较小的网页并尝到甜头后,我疯狂地搜索各种网络爬虫。当然,我也被各种虐——!
于是决定仔细复习一下之前的笔记,记录下爬取的网页和方法,写个博客,方便以后复习。当然,如果有朋友比我是爬虫新手,我可能会从这些基础中获得一些积分。~
二、工具(Python)依赖requestsxpath的库三、目标确定
抢2019精品新片前10页所有电影的片名和电影海报(有兴趣的可以加磁力链接,同样不难)
三、URL分析和整体层次分析
爬行思维层次分析——由内而外:
解析单个电影 url 以检索电影名称和电影海报。定义一个 def 来返回页面中所有需要获取的电影的 URL。定义一个def,输入那个页面的total_url,返回一个url列表,然后遍历url,把url丢进1的函数中,遍历10页,定义main函数结合1、2函数
网址分析
进入单部电影的页面,右击查看。从元素中很容易找到电影名称和海报的位置。
电影名提取的地方很多,就不一一解释了
通过 xpath 语法解析
可以看到xpath匹配了两个图片信息,第二个是视频截图,我们只需要第一个。
total_url 分析
提取出单部电影所需的信息后,分析如何从一个页面抓取所有电影网址。以第一页为例,目标抓取提取第一页的所有URL
右击查看,将元素定位工具放置在任意影片位置,可以找到如下
这样除了每部电影的url位置,通过xpath匹配
OK,此时可以说已经获取了一页(total_urls)中所有URL中的电影点播信息。
下一步是分析10个页面的爬行。
遍历 10 页分析
此时,观察前两页的网址,就可以找到规律了。您只需要使用圆作为偏移量即可完成要求。好了,分析完毕。
代码:
在贴代码之前需要注意:我们都知道response.text或者response.content通常是在请求请求之后使用。这里我选择第二个。Movie Paradise的源码不够规范,所以我们手动解码,打开一部电影url的源码,ctrt+F输入'charset'可以找到如下图
网页是用gbk编码的,所以我们解码的时候用decode('gbk')。
代码显示如下
# -- 1 对电影天堂url规律分析
from lxml import etree
import requests
x = 0
y = 0
movies = []
HEARDERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Accept-Language':'zh-CN,zh;q=0.9'
}
frist = 'https://www.dytt8.net'
def get_detail_urls(url):
"""获取一页的电影"""
global y
response = requests.get(url, headers=HEARDERS)
text = response.text # 去网页源代码查看编码方式
html = etree.HTML(text) # 解析成HTML代码对象
detail_urls = html.xpath("//table[@class='tbspan']//a/@href") # 返回list
detail_urls = map(lambda url:frist+url,detail_urls) # 将每个detail_urls元素都放进lambad函数里面执行一遍
y += 1
print('='*30)
print('第{}页开始爬取!'.format(y))
print('=' * 30)
return detail_urls
def parse_detail_page(url):
global x
movie={}
response = requests.get(url,headers=HEARDERS)
text = response.content.decode('gbk')
html = etree.HTML(text)
title = html.xpath("//div[@class='title_all']//font/text()")[0] # 电影名
img = html.xpath("//p/img/@src")[0]
movie['电影名'] = title
movie['海报'] = img
x += 1
movies.append(movie)
print('第{}部电影爬取完毕!'.format(x))
def main():
"""爬取前5页"""
global x
for i in range(1,11): # 控制页数
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'.format(i)
detail_urls = get_detail_urls(url) # return详细电影页面list
for detail_url in detail_urls:
# 该for循环遍历一页中所有电影的详情
try:
movie = parse_detail_page(detail_url) # 处理单个电影url
except:
print('爬取失败')
x += 1
if __name__ == '__main__':
main()
print('爬取完毕,共{}部电影'.format(x))
print(movies)
结果如下,没有做数据存储链接,主要是整理爬虫的思路
期间某部电影返回索引错误,--~于是看了几分钟那部电影,检查贴如下:
果然是空索引!!!--silent,然后加一个try,除了,结果如下:
爬行完成!
查看全部
抓取网页数据(
目标确定2019精品新片的前10页所有电影的名字
)

一、开始
在花了将近半年的空闲时间学习了Python的基本语法之后,我开始尝试网络爬虫。学习了一个星期,在我开始爬相对较小的网页并尝到甜头后,我疯狂地搜索各种网络爬虫。当然,我也被各种虐——!
于是决定仔细复习一下之前的笔记,记录下爬取的网页和方法,写个博客,方便以后复习。当然,如果有朋友比我是爬虫新手,我可能会从这些基础中获得一些积分。~
二、工具(Python)依赖requestsxpath的库三、目标确定
抢2019精品新片前10页所有电影的片名和电影海报(有兴趣的可以加磁力链接,同样不难)
三、URL分析和整体层次分析

爬行思维层次分析——由内而外:
解析单个电影 url 以检索电影名称和电影海报。定义一个 def 来返回页面中所有需要获取的电影的 URL。定义一个def,输入那个页面的total_url,返回一个url列表,然后遍历url,把url丢进1的函数中,遍历10页,定义main函数结合1、2函数
网址分析
进入单部电影的页面,右击查看。从元素中很容易找到电影名称和海报的位置。


电影名提取的地方很多,就不一一解释了
通过 xpath 语法解析


可以看到xpath匹配了两个图片信息,第二个是视频截图,我们只需要第一个。
total_url 分析
提取出单部电影所需的信息后,分析如何从一个页面抓取所有电影网址。以第一页为例,目标抓取提取第一页的所有URL

右击查看,将元素定位工具放置在任意影片位置,可以找到如下


这样除了每部电影的url位置,通过xpath匹配

OK,此时可以说已经获取了一页(total_urls)中所有URL中的电影点播信息。
下一步是分析10个页面的爬行。
遍历 10 页分析


此时,观察前两页的网址,就可以找到规律了。您只需要使用圆作为偏移量即可完成要求。好了,分析完毕。
代码:
在贴代码之前需要注意:我们都知道response.text或者response.content通常是在请求请求之后使用。这里我选择第二个。Movie Paradise的源码不够规范,所以我们手动解码,打开一部电影url的源码,ctrt+F输入'charset'可以找到如下图

网页是用gbk编码的,所以我们解码的时候用decode('gbk')。
代码显示如下
# -- 1 对电影天堂url规律分析
from lxml import etree
import requests
x = 0
y = 0
movies = []
HEARDERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Accept-Language':'zh-CN,zh;q=0.9'
}
frist = 'https://www.dytt8.net'
def get_detail_urls(url):
"""获取一页的电影"""
global y
response = requests.get(url, headers=HEARDERS)
text = response.text # 去网页源代码查看编码方式
html = etree.HTML(text) # 解析成HTML代码对象
detail_urls = html.xpath("//table[@class='tbspan']//a/@href") # 返回list
detail_urls = map(lambda url:frist+url,detail_urls) # 将每个detail_urls元素都放进lambad函数里面执行一遍
y += 1
print('='*30)
print('第{}页开始爬取!'.format(y))
print('=' * 30)
return detail_urls
def parse_detail_page(url):
global x
movie={}
response = requests.get(url,headers=HEARDERS)
text = response.content.decode('gbk')
html = etree.HTML(text)
title = html.xpath("//div[@class='title_all']//font/text()")[0] # 电影名
img = html.xpath("//p/img/@src")[0]
movie['电影名'] = title
movie['海报'] = img
x += 1
movies.append(movie)
print('第{}部电影爬取完毕!'.format(x))
def main():
"""爬取前5页"""
global x
for i in range(1,11): # 控制页数
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'.format(i)
detail_urls = get_detail_urls(url) # return详细电影页面list
for detail_url in detail_urls:
# 该for循环遍历一页中所有电影的详情
try:
movie = parse_detail_page(detail_url) # 处理单个电影url
except:
print('爬取失败')
x += 1
if __name__ == '__main__':
main()
print('爬取完毕,共{}部电影'.format(x))
print(movies)
结果如下,没有做数据存储链接,主要是整理爬虫的思路

期间某部电影返回索引错误,--~于是看了几分钟那部电影,检查贴如下:

果然是空索引!!!--silent,然后加一个try,除了,结果如下:

爬行完成!

抓取网页数据(我在抓取网页的时候得不到完整的原始源(就是右击-查看))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 15:09
我在抓取网页时无法获得完整的原创来源。在网上找了半天,也没找到可行的办法。我希望花园里的人可以提供帮助。提前致谢!!
比如我要提取的网址是:
我想得到它的原创源码(也就是右键查看原创源码中看到的所有字符)
当我使用以下代码提取时:
private string GetHtmlCode(string url)
{
string htmlCode;
HttpWebRequest webRequest = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(url);
webRequest.Timeout = 30000;
webRequest.Method = "GET";
webRequest.UserAgent = "Mozilla/4.0";
webRequest.Headers.Add("Accept-Encoding", "gzip, deflate");
HttpWebResponse webResponse = (System.Net.HttpWebResponse)webRequest.GetResponse();
if (webResponse.ContentEncoding.ToLower() == "gzip
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (var zipStream =
new System.IO.Compression.GZipStream(streamReceive, System.IO.Compression.CompressionMode.Decompress))
{
using (StreamReader sr = new System.IO.StreamReader(zipStream, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
}else
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (System.IO.StreamReader sr = new System.IO.StreamReader(streamReceive, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
return htmlCode;
}
提取的数据不完整,无法显示iframe中的代码。我以为可能有一些AJAX数据,所以我更改了以下提取代码:
private void button1_Click(object sender, EventArgs e)
{
WebBrowser web = new WebBrowser();
web.Navigate(this.rtb_Url.Text);
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
while (web.IsBusy)
{
Application.DoEvents();
Thread.Sleep(100);
}
}
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
string mystr = web.Document.Body.OuterHtml;
}
提到的原创来源总是不完整,希望园丁能给我一些建议,谢谢! 查看全部
抓取网页数据(我在抓取网页的时候得不到完整的原始源(就是右击-查看))
我在抓取网页时无法获得完整的原创来源。在网上找了半天,也没找到可行的办法。我希望花园里的人可以提供帮助。提前致谢!!
比如我要提取的网址是:
我想得到它的原创源码(也就是右键查看原创源码中看到的所有字符)
当我使用以下代码提取时:
private string GetHtmlCode(string url)
{
string htmlCode;
HttpWebRequest webRequest = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(url);
webRequest.Timeout = 30000;
webRequest.Method = "GET";
webRequest.UserAgent = "Mozilla/4.0";
webRequest.Headers.Add("Accept-Encoding", "gzip, deflate");
HttpWebResponse webResponse = (System.Net.HttpWebResponse)webRequest.GetResponse();
if (webResponse.ContentEncoding.ToLower() == "gzip
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (var zipStream =
new System.IO.Compression.GZipStream(streamReceive, System.IO.Compression.CompressionMode.Decompress))
{
using (StreamReader sr = new System.IO.StreamReader(zipStream, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
}else
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (System.IO.StreamReader sr = new System.IO.StreamReader(streamReceive, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
return htmlCode;
}
提取的数据不完整,无法显示iframe中的代码。我以为可能有一些AJAX数据,所以我更改了以下提取代码:
private void button1_Click(object sender, EventArgs e)
{
WebBrowser web = new WebBrowser();
web.Navigate(this.rtb_Url.Text);
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
while (web.IsBusy)
{
Application.DoEvents();
Thread.Sleep(100);
}
}
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
string mystr = web.Document.Body.OuterHtml;
}
提到的原创来源总是不完整,希望园丁能给我一些建议,谢谢!
抓取网页数据(如何实现一下爱帮网上佛山药店的分布列表【我爱写游记】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-03 20:22
昨天我们用Jsoup技术实现了一个简单的爬虫。原理很简单。主要是先分析页面,获取条件,然后匹配url,使用穹顶分析的方式循环抓取我们需要的数据,这是一个简单的爬虫可以轻松实现。所以,昨天我们说昨天只爬取了一页数据,也就是第一页的数据。如果要获取分页的所有数据,应该怎么写呢?碰巧今天朋友找我帮忙买药,说她那里没有,于是查了佛山各大药店,利用刚刚学的爬虫技术,今天就明白了艾邦网上佛山药店经销名单。
一、需求分析
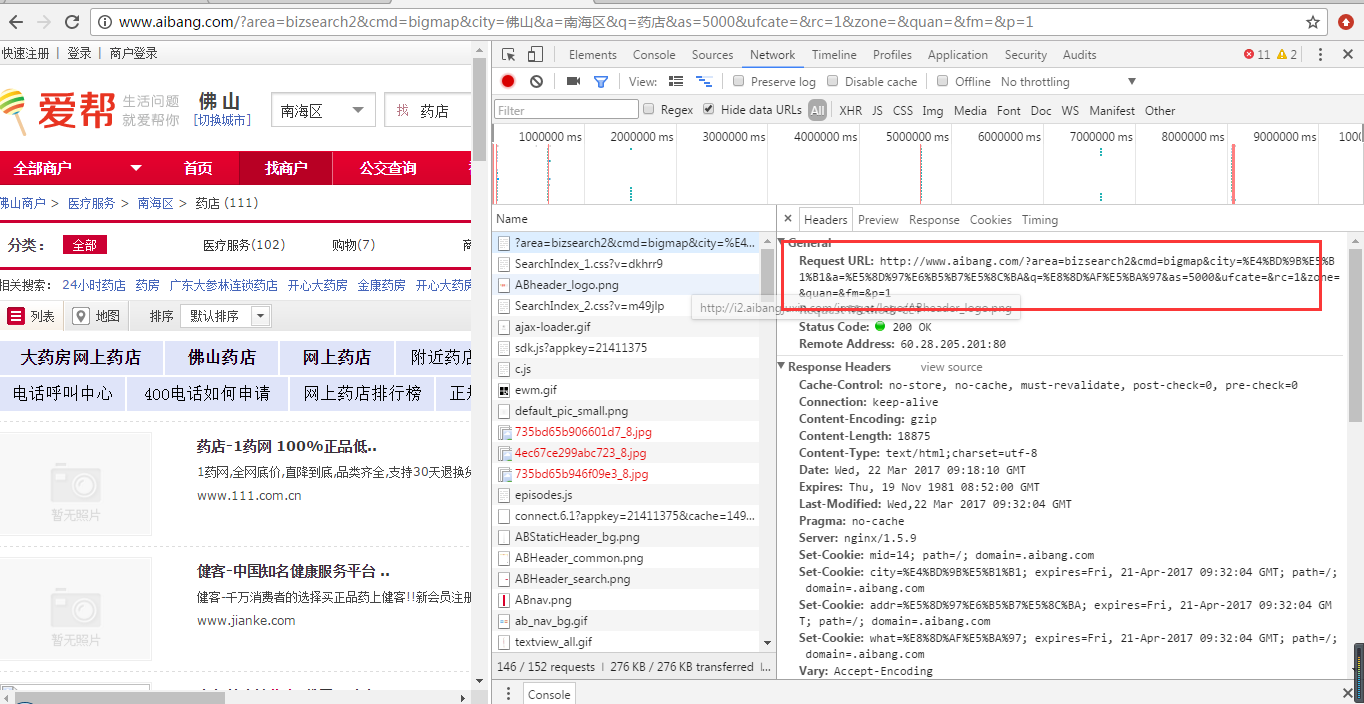
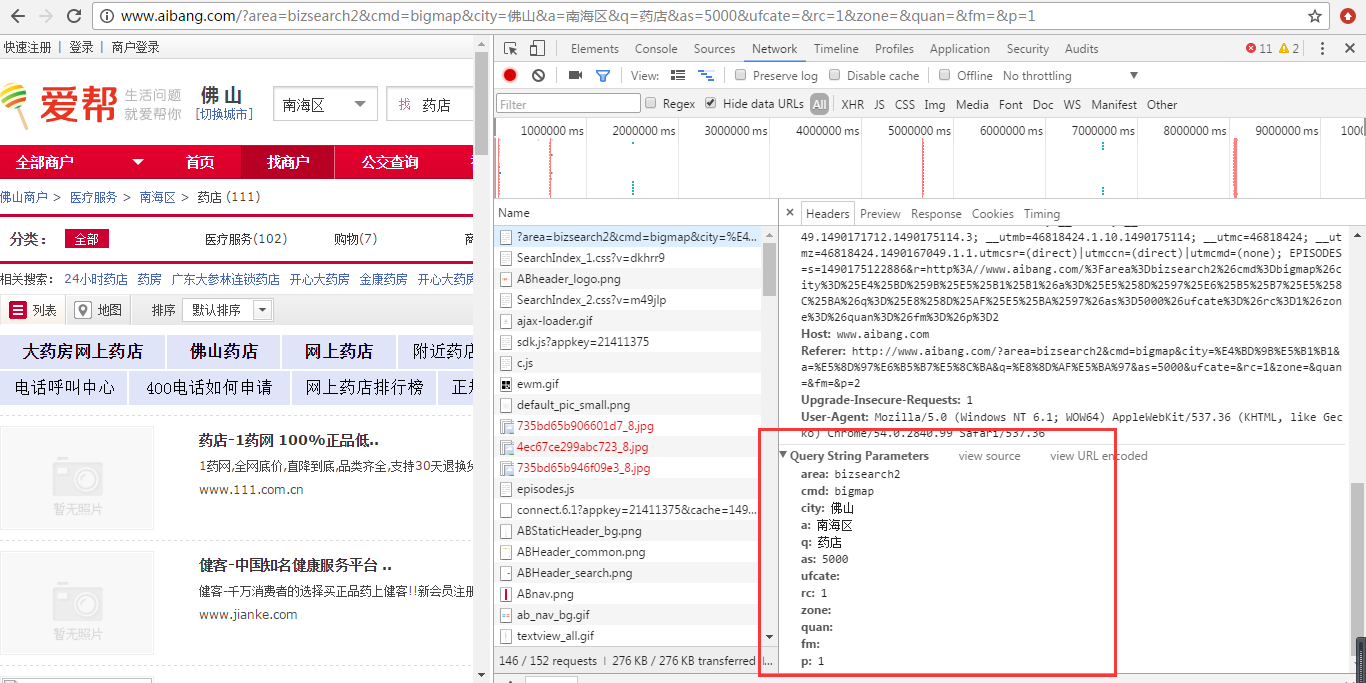
首先,我们登录爱邦网,选择城市区域,输入关键词。我们输入“pharmacy”,点击搜索按钮,我们打开控制台,观察header信息,如下图:
通过观察我们可以看到请求的URL地址和参数;其实我们看地址栏就可以直接看到了。我们点击第二页,发现其他参数没有变化,只是参数p的值随着页码的变化而变化。所以,这样我们就可以知道每个页面的请求地址其实是一样的,只要改变p的值,然后我们看到页面总数只有8个页面,数据量不是大的。写一个循环 8 次。现在我们开始实现它,只是在昨天的代码的基础上改变它。
二、开发
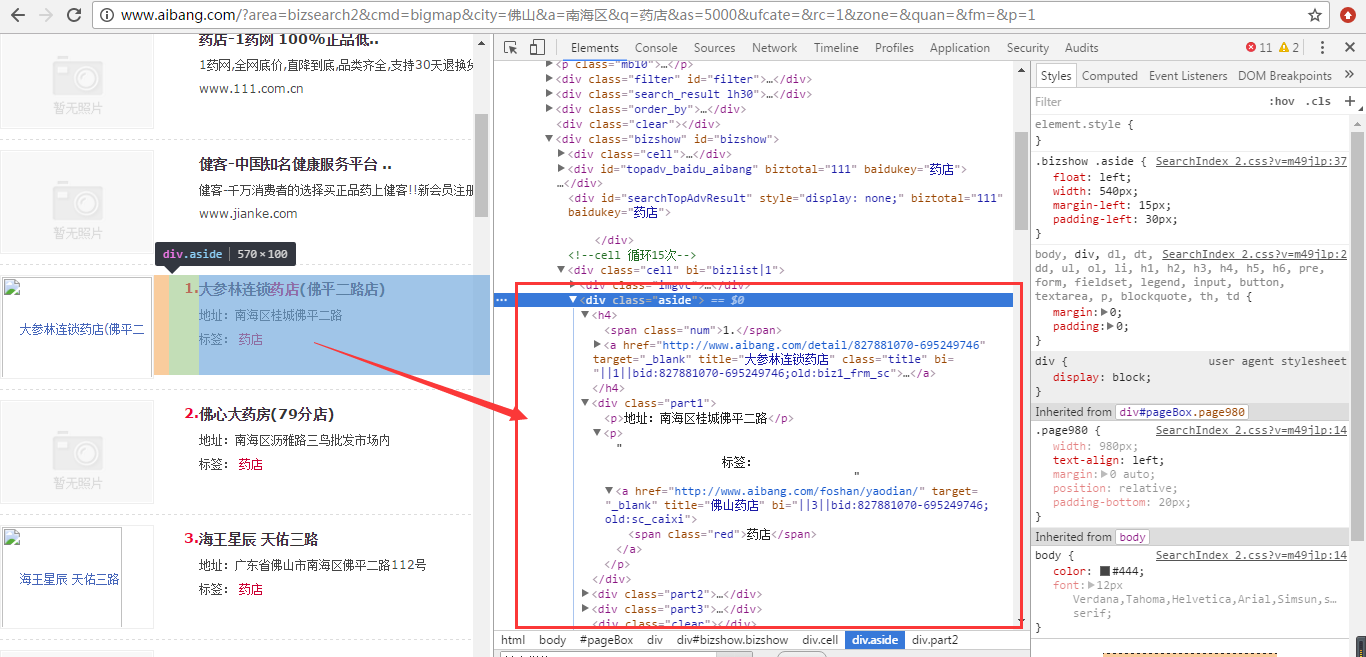
1、我们首先需要改变我们的业务实现类,因为获取值的方式不同,如下图:
我们要去的类是aide里面的内容,它也拿到了标签,但是我们观察到页面上有很多标签,需要拿到我们需要的,如下图所示:
/*
* 提取结果中的链接地址和链接标题,返回数据
*/
for(Element result : results){
Elements links = result.getElementsByTag("a");//可以拿到链接
for(Element link : links){
if(link.siblingElements().hasClass("num")){
String id = link.siblingElements().text();
String linkText = link.text();
LinkTypeData data1 = new LinkTypeData();
if(id!=null && linkText!=null){
data1.setId(id);
data1.setLinkText(linkText);
}
datas.add(data1);
}
if(link.parent().parent().hasClass("part1")){
LinkTypeData data2 = new LinkTypeData();
String address = link.parent().siblingElements().text();
if(address!=null){
data2.setSummary(address);
}
datas.add(data2);
}
if(link.parent().siblingElements().tagName("span").hasClass("biztel")){
LinkTypeData data3 = new LinkTypeData();
String telnum = link.parent().siblingElements().tagName("span").text();
if(telnum!=null){
data3.setContent(telnum);
}
datas.add(data3);
}
}
// 对取得的html中的 出现问号乱码进行处理
/*linkText = new String(linkText.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String id = link.parent().firstElementSibling().text();
id = new String(id.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String address = link.parent().nextElementSibling().text();
address = new String(address.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String code = link.parent().lastElementSibling().text();
code = new String(code.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');*/
/*data.setSummary(address);
data.setContent(code);
data.setId(id);*/
}
return datas;
}
我们根据昨天的代码进行了更改。这样就得到了我们想要的数据。
三、测试
接下来我们可以改变我们的测试类,我们需要循环8次,每次拿到数据都存储在一个新的集合中,最后再取出新的数据集合写入Excel。
<p>/**
* 不带查询参数
* @author AoXiang
* 2017年3月21日
*/
@org.junit.Test
public void getDataByClass() throws IOException{
List newList = new ArrayList();
for(int i=1;i 查看全部
抓取网页数据(如何实现一下爱帮网上佛山药店的分布列表【我爱写游记】)
昨天我们用Jsoup技术实现了一个简单的爬虫。原理很简单。主要是先分析页面,获取条件,然后匹配url,使用穹顶分析的方式循环抓取我们需要的数据,这是一个简单的爬虫可以轻松实现。所以,昨天我们说昨天只爬取了一页数据,也就是第一页的数据。如果要获取分页的所有数据,应该怎么写呢?碰巧今天朋友找我帮忙买药,说她那里没有,于是查了佛山各大药店,利用刚刚学的爬虫技术,今天就明白了艾邦网上佛山药店经销名单。
一、需求分析
首先,我们登录爱邦网,选择城市区域,输入关键词。我们输入“pharmacy”,点击搜索按钮,我们打开控制台,观察header信息,如下图:
通过观察我们可以看到请求的URL地址和参数;其实我们看地址栏就可以直接看到了。我们点击第二页,发现其他参数没有变化,只是参数p的值随着页码的变化而变化。所以,这样我们就可以知道每个页面的请求地址其实是一样的,只要改变p的值,然后我们看到页面总数只有8个页面,数据量不是大的。写一个循环 8 次。现在我们开始实现它,只是在昨天的代码的基础上改变它。
二、开发
1、我们首先需要改变我们的业务实现类,因为获取值的方式不同,如下图:
我们要去的类是aide里面的内容,它也拿到了标签,但是我们观察到页面上有很多标签,需要拿到我们需要的,如下图所示:
/*
* 提取结果中的链接地址和链接标题,返回数据
*/
for(Element result : results){
Elements links = result.getElementsByTag("a");//可以拿到链接
for(Element link : links){
if(link.siblingElements().hasClass("num")){
String id = link.siblingElements().text();
String linkText = link.text();
LinkTypeData data1 = new LinkTypeData();
if(id!=null && linkText!=null){
data1.setId(id);
data1.setLinkText(linkText);
}
datas.add(data1);
}
if(link.parent().parent().hasClass("part1")){
LinkTypeData data2 = new LinkTypeData();
String address = link.parent().siblingElements().text();
if(address!=null){
data2.setSummary(address);
}
datas.add(data2);
}
if(link.parent().siblingElements().tagName("span").hasClass("biztel")){
LinkTypeData data3 = new LinkTypeData();
String telnum = link.parent().siblingElements().tagName("span").text();
if(telnum!=null){
data3.setContent(telnum);
}
datas.add(data3);
}
}
// 对取得的html中的 出现问号乱码进行处理
/*linkText = new String(linkText.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String id = link.parent().firstElementSibling().text();
id = new String(id.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String address = link.parent().nextElementSibling().text();
address = new String(address.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String code = link.parent().lastElementSibling().text();
code = new String(code.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');*/
/*data.setSummary(address);
data.setContent(code);
data.setId(id);*/
}
return datas;
}
我们根据昨天的代码进行了更改。这样就得到了我们想要的数据。
三、测试
接下来我们可以改变我们的测试类,我们需要循环8次,每次拿到数据都存储在一个新的集合中,最后再取出新的数据集合写入Excel。
<p>/**
* 不带查询参数
* @author AoXiang
* 2017年3月21日
*/
@org.junit.Test
public void getDataByClass() throws IOException{
List newList = new ArrayList();
for(int i=1;i
抓取网页数据(在mac上我使用Go和相应的数据库indiepic(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-03 20:21
上一节主要实现了使用goquery从图片网站中获取数据。它主要捕获图片的五个数据项:原创数据、宽度、高度、ALT和类型。因此,必须首先创建数据库和相应的表。在Mac上,我使用sequel Pro数据库管理软件。连接后,我创建了一个新的数据库indipic,然后创建了表gradisography:
CREATE TABLE `gratisography` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`img_url` varchar(255) DEFAULT NULL,
`type_name` varchar(50) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`width` int(11) DEFAULT NULL,
`height` int(11) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=388 DEFAULT CHARSET=utf8;
创建数据库后,使用go连接到数据库。Go MySQL驱动程序是用于Go(golang)数据库/SQL包的轻量级快速MySQL驱动程序
文件:
在使用之前,您需要使用以下命令来获取包:
go get github.com/go-sql-driver/mysql
然后在database.go中介绍以下内容:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
然后编写打开数据库opendatabase的方法:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
在上一节中,insertData(&imagedata)方法是在crawldata.go中编写的,但它是带注释的。您需要首先在该文件中实现该方法
package crawldata
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
"strconv"
s "strings"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
/*
该函数将获取的数据存储到数据库
*/
func InsertData(datas *ImageDatas) {
imageDatas := *datas
// 连接数据库
db, err := OpenDatabase()
if err != nil {
fmt.Printf(s.Join([]string{"连接数据库失败", err.Error()}, "-->"))
}
defer db.Close()
for i := 0; i < len(imageDatas); i++ {
imageData := imageDatas[i]
// Prepare statement for inserting data
imgIns, err := db.Prepare("INSERT INTO gratisography (img_url, type_name, title, width, height) VALUES( ?, ?, ?, ?, ? )") // ? = placeholder
if err != nil {
fmt.Println(s.Join([]string{"拼装数据格式", err.Error()}, "-->"))
}
defer imgIns.Close() // Close the statement when we leave main()
img, err := imgIns.Exec(s.Join([]string{"http://www.gratisography.com", imageData.Src}, "/"), imageData.Tp, imageData.Title, imageData.Width, imageData.Height)
if err != nil {
fmt.Println(s.Join([]string{"插入数据失败", err.Error()}, "-->"))
} else {
success, _ := img.LastInsertId()
// 数字变成字符串,success是int64型的值,需要转为int,网上说的Itoa64()在strconv包里不存在
insertId := strconv.Itoa(int(success))
fmt.Println(s.Join([]string{"成功插入数据:", insertId}, "\t-->\t"))
}
}
}
此时,数据捕获已经完成并存储在数据库中。在命令行上切换到$gopath/SRC/indiepic目录,然后运行:
go run indiepic.go
然后可以看到数据存储在数据库中
到目前为止,只实现了数据采集,但需要使用go向外部提供JSON接口。下一节将完成数据采集,并使用web框架返回JSON数据 查看全部
抓取网页数据(在mac上我使用Go和相应的数据库indiepic(图))
上一节主要实现了使用goquery从图片网站中获取数据。它主要捕获图片的五个数据项:原创数据、宽度、高度、ALT和类型。因此,必须首先创建数据库和相应的表。在Mac上,我使用sequel Pro数据库管理软件。连接后,我创建了一个新的数据库indipic,然后创建了表gradisography:
CREATE TABLE `gratisography` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`img_url` varchar(255) DEFAULT NULL,
`type_name` varchar(50) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`width` int(11) DEFAULT NULL,
`height` int(11) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=388 DEFAULT CHARSET=utf8;
创建数据库后,使用go连接到数据库。Go MySQL驱动程序是用于Go(golang)数据库/SQL包的轻量级快速MySQL驱动程序
文件:
在使用之前,您需要使用以下命令来获取包:
go get github.com/go-sql-driver/mysql
然后在database.go中介绍以下内容:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
然后编写打开数据库opendatabase的方法:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
在上一节中,insertData(&imagedata)方法是在crawldata.go中编写的,但它是带注释的。您需要首先在该文件中实现该方法
package crawldata
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
"strconv"
s "strings"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
/*
该函数将获取的数据存储到数据库
*/
func InsertData(datas *ImageDatas) {
imageDatas := *datas
// 连接数据库
db, err := OpenDatabase()
if err != nil {
fmt.Printf(s.Join([]string{"连接数据库失败", err.Error()}, "-->"))
}
defer db.Close()
for i := 0; i < len(imageDatas); i++ {
imageData := imageDatas[i]
// Prepare statement for inserting data
imgIns, err := db.Prepare("INSERT INTO gratisography (img_url, type_name, title, width, height) VALUES( ?, ?, ?, ?, ? )") // ? = placeholder
if err != nil {
fmt.Println(s.Join([]string{"拼装数据格式", err.Error()}, "-->"))
}
defer imgIns.Close() // Close the statement when we leave main()
img, err := imgIns.Exec(s.Join([]string{"http://www.gratisography.com", imageData.Src}, "/"), imageData.Tp, imageData.Title, imageData.Width, imageData.Height)
if err != nil {
fmt.Println(s.Join([]string{"插入数据失败", err.Error()}, "-->"))
} else {
success, _ := img.LastInsertId()
// 数字变成字符串,success是int64型的值,需要转为int,网上说的Itoa64()在strconv包里不存在
insertId := strconv.Itoa(int(success))
fmt.Println(s.Join([]string{"成功插入数据:", insertId}, "\t-->\t"))
}
}
}
此时,数据捕获已经完成并存储在数据库中。在命令行上切换到$gopath/SRC/indiepic目录,然后运行:
go run indiepic.go
然后可以看到数据存储在数据库中
到目前为止,只实现了数据采集,但需要使用go向外部提供JSON接口。下一节将完成数据采集,并使用web框架返回JSON数据
抓取网页数据(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-10-03 12:26
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
抓取网页数据(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
抓取网页数据(小编来一起如何用python来页面中的JS动态加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-01 20:07
)
本文文章主要介绍如何使用python捕捉网页中的动态数据。文章通过示例代码详细介绍,对大家学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text 查看全部
抓取网页数据(小编来一起如何用python来页面中的JS动态加载
)
本文文章主要介绍如何使用python捕捉网页中的动态数据。文章通过示例代码详细介绍,对大家学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text
抓取网页数据(soup考试:本文具有不错的参考意义(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-28 17:28
前言:
今天给大家带来的是4个详细步骤讲解Python爬取网页数据的操作过程!(包括示例代码)这篇文章有很好的参考意义,希望对你有帮助!
提示:由于涉及的代码较多,所以大部分代码以图片的形式呈现!
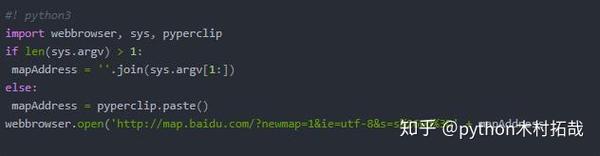
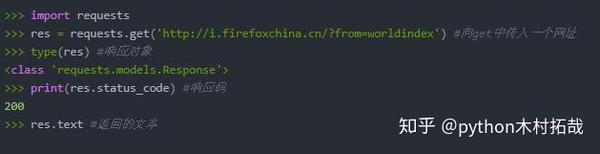
一、使用 webbrowser.open() 打开一个 网站:
示例:使用脚本打开网页。
所有 Python 程序的第一行都应该以 #!python 开头,它告诉计算机您希望 Python 执行这个程序。(我没有带这条线去试试,没关系,也许这是常态)
注意:如果你不知道 sys.argv 的用法,请参考这里;如果你不知道 .join() 的用法,请参考这里。sys.argv 是一个字符串列表,因此将它传递给 join() 方法会返回一个字符串。
好的,现在选择并复制“天安门广场”字样,然后在桌面上双击您的程序。当然,你也可以在命令行中找到你的程序并输入位置。
二、 使用请求模块从 Web 下载文件:请求模块不收录在 Python 中。在命令行上运行 pip install request 来安装它。不翻墙就很难安装成功。如需手动安装,请参阅此处。
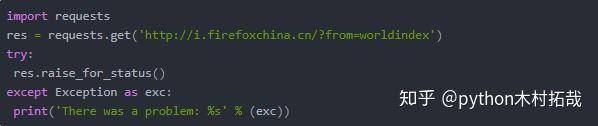
有多种方法可以查看请求中从 Internet 下载的文件的内容。如果在以后的博客中用到,会进行讲解,这里就不一一介绍了。在下载文件的过程中,使用 raise_for_status() 方法确保下载确实成功,然后让程序继续做其他事情。
三、将下载的文件保存到本地:
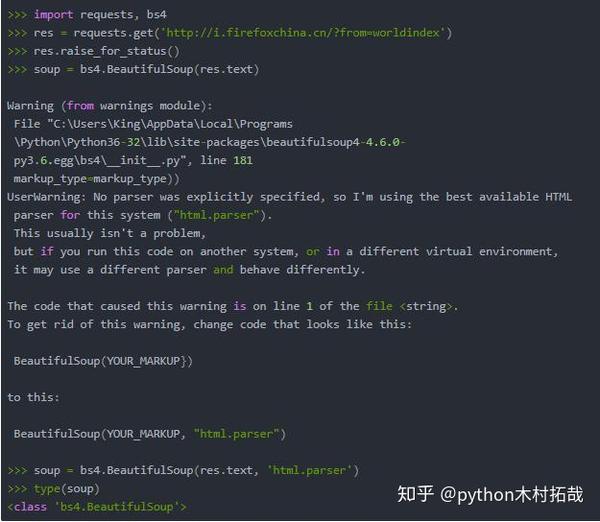
四、 使用 BeautifulSoup 模块解析 HTML:在命令行使用 pip install beautifulsoup4 安装它。
1.bs4.BeautifulSoup()函数可以解析HTML网站链接requests.get(),或者解析本地保存的HTML文件,直接open()一个本地的HTML页面。
我这里有一条错误消息,所以我添加了第二个参数。
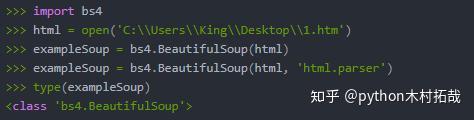
2.使用select()方法查找元素:需要传入一个字符串作为CSS“选择器”来获取网页对应的元素,例如:
汤.选择('div'):所有名称
Soup.select('#author'):id属性为author的元素;soup.select('.notice'):所有具有名为 notice 的 CSS 类属性的元素;汤.select('div span'): 全部在
元素内的元素;soup.select('input[name]'):所有具有名称和名称属性值无关紧要的元素;sound.select('input[type="button"]'): All 元素命名并有一个值为button的type属性。 查看全部
抓取网页数据(soup考试:本文具有不错的参考意义(一))
前言:
今天给大家带来的是4个详细步骤讲解Python爬取网页数据的操作过程!(包括示例代码)这篇文章有很好的参考意义,希望对你有帮助!
提示:由于涉及的代码较多,所以大部分代码以图片的形式呈现!
一、使用 webbrowser.open() 打开一个 网站:

示例:使用脚本打开网页。
所有 Python 程序的第一行都应该以 #!python 开头,它告诉计算机您希望 Python 执行这个程序。(我没有带这条线去试试,没关系,也许这是常态)
注意:如果你不知道 sys.argv 的用法,请参考这里;如果你不知道 .join() 的用法,请参考这里。sys.argv 是一个字符串列表,因此将它传递给 join() 方法会返回一个字符串。
好的,现在选择并复制“天安门广场”字样,然后在桌面上双击您的程序。当然,你也可以在命令行中找到你的程序并输入位置。
二、 使用请求模块从 Web 下载文件:请求模块不收录在 Python 中。在命令行上运行 pip install request 来安装它。不翻墙就很难安装成功。如需手动安装,请参阅此处。
有多种方法可以查看请求中从 Internet 下载的文件的内容。如果在以后的博客中用到,会进行讲解,这里就不一一介绍了。在下载文件的过程中,使用 raise_for_status() 方法确保下载确实成功,然后让程序继续做其他事情。
三、将下载的文件保存到本地:
四、 使用 BeautifulSoup 模块解析 HTML:在命令行使用 pip install beautifulsoup4 安装它。
1.bs4.BeautifulSoup()函数可以解析HTML网站链接requests.get(),或者解析本地保存的HTML文件,直接open()一个本地的HTML页面。
我这里有一条错误消息,所以我添加了第二个参数。
2.使用select()方法查找元素:需要传入一个字符串作为CSS“选择器”来获取网页对应的元素,例如:
汤.选择('div'):所有名称
Soup.select('#author'):id属性为author的元素;soup.select('.notice'):所有具有名为 notice 的 CSS 类属性的元素;汤.select('div span'): 全部在
元素内的元素;soup.select('input[name]'):所有具有名称和名称属性值无关紧要的元素;sound.select('input[type="button"]'): All 元素命名并有一个值为button的type属性。
抓取网页数据(一下如何打造适合百度的网站?维度为您解答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-25 20:40
做好网站收录是SEO的基础工作。只有网站的内容进入百度索引库,搜索关键词时才有机会出现在搜索结果中。我们从三个维度来和大家分享如何打造适合百度抓取的网站。
一、网站结构
1、逻辑清晰的链接层次结构
更好的站点结构仍然是树状结构。以首页为节点的树状连接可以通过首页上的链接访问网站的任意页面。在构建站点的树状结构时,要注意避免过于平坦的结构。所有内容页面都放在根目录下,不利于网站的目录权重传递。在建站时,也需要注意避免孤岛链接。所谓岛屿链接,就是在站点内通过正常访问无法找到的页面,只能通过直接输入网址或提交地图才能找到。这样的页面搜索引擎不易抓取,不利于用户对内容的浏览和访问,影响用户体验。
2、PC/手机适配
如今,移动搜索的流量正在增加。通过适配的建立,PC端URL和移动端URL具有规则级别的对应关系,相互关联。这样,网站在移动搜索时就有机会进入移动索引库。对于网站,建议在建立适配时建立规则级别的对应关系,符合一定的正则表达式映射规则。目前百度推荐的视频方式有:跳转适配、代码适配、适配。
3、本站带你主动投稿
目前百度在站长工具中有主动推送、自动推送、站点地图三种方式供站长提交新输出资源和及时更新资源。站长在提交内容时要注意避免死链接和低质量的内容。通过搜索引擎抓取。当出现死链接时,您可以使用死链接提交工具及时提交死链接和无效资源。
对于移动站,还需要通过提交工具将适配后的链接提交到移动链接,方便搜索引擎全面及时的抓取移动页面。
4、避免目录黑客/销售
百度蜘蛛的网站评分会考虑网页、目录等多个维度。一旦发现被黑或垃圾内容,百度指数会对整个网站的质量产生怀疑,从而影响整个网站带你的收录效果,进而影响排名。
一般购买网站目录的人都会根据网站的权威度和搜索引擎评分对灰色产品进行排名。很容易伤害网站的用户体验,百度对伤害用户体验的行为零容忍。 查看全部
抓取网页数据(一下如何打造适合百度的网站?维度为您解答)
做好网站收录是SEO的基础工作。只有网站的内容进入百度索引库,搜索关键词时才有机会出现在搜索结果中。我们从三个维度来和大家分享如何打造适合百度抓取的网站。

一、网站结构
1、逻辑清晰的链接层次结构
更好的站点结构仍然是树状结构。以首页为节点的树状连接可以通过首页上的链接访问网站的任意页面。在构建站点的树状结构时,要注意避免过于平坦的结构。所有内容页面都放在根目录下,不利于网站的目录权重传递。在建站时,也需要注意避免孤岛链接。所谓岛屿链接,就是在站点内通过正常访问无法找到的页面,只能通过直接输入网址或提交地图才能找到。这样的页面搜索引擎不易抓取,不利于用户对内容的浏览和访问,影响用户体验。
2、PC/手机适配
如今,移动搜索的流量正在增加。通过适配的建立,PC端URL和移动端URL具有规则级别的对应关系,相互关联。这样,网站在移动搜索时就有机会进入移动索引库。对于网站,建议在建立适配时建立规则级别的对应关系,符合一定的正则表达式映射规则。目前百度推荐的视频方式有:跳转适配、代码适配、适配。
3、本站带你主动投稿
目前百度在站长工具中有主动推送、自动推送、站点地图三种方式供站长提交新输出资源和及时更新资源。站长在提交内容时要注意避免死链接和低质量的内容。通过搜索引擎抓取。当出现死链接时,您可以使用死链接提交工具及时提交死链接和无效资源。
对于移动站,还需要通过提交工具将适配后的链接提交到移动链接,方便搜索引擎全面及时的抓取移动页面。
4、避免目录黑客/销售
百度蜘蛛的网站评分会考虑网页、目录等多个维度。一旦发现被黑或垃圾内容,百度指数会对整个网站的质量产生怀疑,从而影响整个网站带你的收录效果,进而影响排名。
一般购买网站目录的人都会根据网站的权威度和搜索引擎评分对灰色产品进行排名。很容易伤害网站的用户体验,百度对伤害用户体验的行为零容忍。
抓取网页数据(节点集中前五个节点集的使用方法和使用解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-24 22:05
我刚刚学习了XPath路径表达式,它主要用于搜索XML文档中的节点。通过XPath表达式,我可以快速定位和访问XML文档中的节点位置。Html也是一种类似于XML的标记语言,但语法没有那么严格。在codeplex中,有一个开源项目htmlagilitypack,它提供了用XPath解析HTML文件的功能,下面是如何使用类库
首先,让我们讨论XPath路径表达式
XPath路径表达式
用于选择XML文档中的节点或节点集
1、术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、注释、文档(根)节点
2、节点关系:父节点、子节点、兄弟节点、祖先节点、后代节点
3、路径表达式
NodeName节点名称,选择此节点的所有子节点,例如:当前节点中的childnode子节点,不包括具有孙辈和孙辈以下的节点
/从根节点中选择一个示例:/root/childnode/grandonnode
//表示所有子代节点。例如://childnode所有名为childnode的子代节点
。指示当前节点。示例:./childnode表示当前节点的childnode节点
。。指示父节点。例如,…/nearnode表示父节点的nearnode子节点
@选择属性/root/childnode/@ID来表示收录childnode的ID属性的所有节点集
4、谓词
谓词可以对节点集进行一些限制,以使选择更加准确
/根/书本[1]节点集中的第一个节点
/Root/book[last()]节点集中的最后一个节点
/Root/book[position()-1]节点集中倒数第二个节点集
/Root/book[position()35]/Title节点set book的price元素值大于35的Title节点集
5、通配符:XPath路径中也支持通配符(*、@*、node()、text()
例如:/书店/*
//标题[@*]
6、XPath轴
定义相对于当前节点的节点集
祖先节点
属性所有属性节点
子元素所有子元素
子代所有子代节点(子代、子代…)
在结束标记之后的所有节点之后,在开始标记之前的所有节点之前
在同级节点之后,结束标记之后的所有同级节点
标记前的所有同级节点
命名空间当前命名空间的所有节点
父节点
自流节点
用法:轴名称::节点测试[谓词]
示例:ancester::Book
child::text()
7、操作员
|合并两个节点集的示例:/root/book[1]|/root/book[3]
+,-,*,开发,国防部
=,!==
或者,或者
//删除注释,script,style
node.Descendants()
.Where(n => n.Name == "script" || n.Name == "style" || n.Name=="#comment")
.ToList().ForEach(n => n.Remove());
//遍历node节点的所有后代节点
foreach(var HtmlNode in node.Descendants())
{
}
Htmlagilitypack类库用法
1、首先,您需要获取HTML页面数据,这些数据可以通过webrequest类获得
public static string GetHtmlStr(string url)
{
try
{
WebRequest rGet = WebRequest.Create(url);
WebResponse rSet = rGet.GetResponse();
Stream s = rSet.GetResponseStream();
StreamReader reader = new StreamReader(s, Encoding.UTF8);
return reader.ReadToEnd();
}
catch (WebException)
{
//连接失败
return null;
}
}
2、通过htmldocument类加载HTML数据
string htmlstr = GetHtmlStr("http://www.hao123.com");
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlstr);
HtmlNode rootnode = doc.DocumentNode; //XPath路径表达式,这里表示选取所有span节点中的font最后一个子节点,其中span节点的class属性值为num
//根据网页的内容设置XPath路径表达式
string xpathstring = "//span[@class='num']/font[last()]";
HtmlNodeCollection aa = rootnode.SelectNodes(xpathstring); //所有找到的节点都是一个集合
if(aa != null)
{
string innertext = aa[0].InnerText;
string color = aa[0].GetAttributeValue("color", ""); //获取color属性,第二个参数为默认值
//其他属性大家自己尝试
}
Htmldocument也可以通过htmlweb类获得
HtmlWeb web = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = web.Load(url);
HtmlNode rootnode = doc.DocumentNode;
补编:
多属性条件查询//div[@align='center'和@height='24']
Class属性不存在//div[不(@Class)] 查看全部
抓取网页数据(节点集中前五个节点集的使用方法和使用解析)
我刚刚学习了XPath路径表达式,它主要用于搜索XML文档中的节点。通过XPath表达式,我可以快速定位和访问XML文档中的节点位置。Html也是一种类似于XML的标记语言,但语法没有那么严格。在codeplex中,有一个开源项目htmlagilitypack,它提供了用XPath解析HTML文件的功能,下面是如何使用类库
首先,让我们讨论XPath路径表达式
XPath路径表达式
用于选择XML文档中的节点或节点集
1、术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、注释、文档(根)节点
2、节点关系:父节点、子节点、兄弟节点、祖先节点、后代节点
3、路径表达式
NodeName节点名称,选择此节点的所有子节点,例如:当前节点中的childnode子节点,不包括具有孙辈和孙辈以下的节点
/从根节点中选择一个示例:/root/childnode/grandonnode
//表示所有子代节点。例如://childnode所有名为childnode的子代节点
。指示当前节点。示例:./childnode表示当前节点的childnode节点
。。指示父节点。例如,…/nearnode表示父节点的nearnode子节点
@选择属性/root/childnode/@ID来表示收录childnode的ID属性的所有节点集
4、谓词
谓词可以对节点集进行一些限制,以使选择更加准确
/根/书本[1]节点集中的第一个节点
/Root/book[last()]节点集中的最后一个节点
/Root/book[position()-1]节点集中倒数第二个节点集
/Root/book[position()35]/Title节点set book的price元素值大于35的Title节点集
5、通配符:XPath路径中也支持通配符(*、@*、node()、text()
例如:/书店/*
//标题[@*]
6、XPath轴
定义相对于当前节点的节点集
祖先节点
属性所有属性节点
子元素所有子元素
子代所有子代节点(子代、子代…)
在结束标记之后的所有节点之后,在开始标记之前的所有节点之前
在同级节点之后,结束标记之后的所有同级节点
标记前的所有同级节点
命名空间当前命名空间的所有节点
父节点
自流节点
用法:轴名称::节点测试[谓词]
示例:ancester::Book
child::text()
7、操作员
|合并两个节点集的示例:/root/book[1]|/root/book[3]
+,-,*,开发,国防部
=,!==
或者,或者
//删除注释,script,style
node.Descendants()
.Where(n => n.Name == "script" || n.Name == "style" || n.Name=="#comment")
.ToList().ForEach(n => n.Remove());
//遍历node节点的所有后代节点
foreach(var HtmlNode in node.Descendants())
{
}
Htmlagilitypack类库用法
1、首先,您需要获取HTML页面数据,这些数据可以通过webrequest类获得
public static string GetHtmlStr(string url)
{
try
{
WebRequest rGet = WebRequest.Create(url);
WebResponse rSet = rGet.GetResponse();
Stream s = rSet.GetResponseStream();
StreamReader reader = new StreamReader(s, Encoding.UTF8);
return reader.ReadToEnd();
}
catch (WebException)
{
//连接失败
return null;
}
}
2、通过htmldocument类加载HTML数据
string htmlstr = GetHtmlStr("http://www.hao123.com";);
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlstr);
HtmlNode rootnode = doc.DocumentNode; //XPath路径表达式,这里表示选取所有span节点中的font最后一个子节点,其中span节点的class属性值为num
//根据网页的内容设置XPath路径表达式
string xpathstring = "//span[@class='num']/font[last()]";
HtmlNodeCollection aa = rootnode.SelectNodes(xpathstring); //所有找到的节点都是一个集合
if(aa != null)
{
string innertext = aa[0].InnerText;
string color = aa[0].GetAttributeValue("color", ""); //获取color属性,第二个参数为默认值
//其他属性大家自己尝试
}
Htmldocument也可以通过htmlweb类获得
HtmlWeb web = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = web.Load(url);
HtmlNode rootnode = doc.DocumentNode;
补编:
多属性条件查询//div[@align='center'和@height='24']
Class属性不存在//div[不(@Class)]
抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-24 22:04
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、 自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、 自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
抓取网页数据(Python解释器的安装推荐及安装的应用框架介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-09-23 15:49
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用程序框架,用于爬取网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm is a PythonIDE with a set of tools that can help users improve their efficiency when developing in the Python language, such as debugging, syntax highlighting, project management, code jumps, smart prompts, automatic completion, unit testing, and version control. In addition, the IDE provides some advanced features to support professional web development under the Django framework.
2.PyCharm install
Go to PyCharm's official website and click DownLoad to download. The professional version is on the left, and the community version is on the right. The community version is free, and the professional version is free for trial.
如果我们之前没有下载有Python解释器的话,在等待安装的时间我们可以去下载python解释器,进入Python官网,根据系统、版本下载对应的压缩包即可,在安装完后,在环境变量Path中配置Python解释器的安装路径。可参考博客:
三、Scrapy抓取豆瓣项目实战
前提:在PyCharm中要使用Scrapy的话,必须先在PyCharm中安装所支持的Scrapy包,过程如下,点击文件(File)>> 设置(Settings...),步骤如下图,我安装Scrapy之前绿色框内只有两个Package,如果当你点击后看到有Scrapy包的话,那就不用安装了,直接进行接下来的操作即可
如果没有Scrapy包的话,点击“+”,搜索Scrapy包,点击Install Package 进行安装
等待安装完成即可。
1.新建项目
打开刚安装好的PyCharm,使用pycharm工具在软件的终端,如果找不到PyCharm终端在哪,在左下角的底部的Terminal就是了
输入命令:scrapy startproject douban 这是使用命令行来新建一个爬虫项目,如下图所示,图片展示的项目名为pythonProject
接着在命令行输入命令:cd douban 进入已生成的项目根目录
接着继续在终端键入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的网站为:
假设,我们抓取top250电影的序列号,电影名,介绍,星级,评价数,电影描述选项
此时,我们在items.py文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接着,我们需要制作爬虫以及存储爬取内容
在douban_spider.py爬虫文件编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时不需要运行这个python文件,因为我们不是单独使用它的,所以不用运行,允许会报错,有关import引入的问题,关于主目录的绝对路径与相对路径的问题,原因是我们使用了相对路径“..items”,相关的内容感兴趣的同学可以去网上查找有关这类问题的解释。
4.存储内容
将所爬取的内容存储成json或csv格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取到的数据存储到json文件或者csv文件里。
在执行完爬取命令后,将鼠标的焦点给到项目面板时,即会显示出生成的json文件或csv文件。打开json或csv文件后,如果里面什么内容都没有,那么我们还需要进行一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
存储到json文件里的话,所有的内容都会以十六进制的形式显示出来,可以通过相应的方法进行转码,这里不过多的说明,如下图:
而存储在csv文件中,会直接将我们所要爬取的内容全部显示出来,如下图:
到此为止,我们已完成对网站特定内容的爬取,接下来,就需要对这些爬取的数据进行处理。
分割线----------------------------------------------------------------------------------------------------------------------分割线
Scraoy入门实例二---使用Pipeline实现
此次的实战需要重新创建一个项目,还是需要安装scrapy包,参考上面的内容,创建新项目的方法也参考上面的内容,这里不再重复赘述。
项目目录结构如下图所示:
一、Pipeline介绍
当我们通过Spider爬取数据,通过Item采集数据后,就要对数据进行一些处理了,因为我们爬取到的数据并不一定是我们想要的最终数据,可能还需要进行数据的清洗以及验证数据的有效性。Scripy中的Pipeline组件就用于数据的处理,一个Pipeline组件就是一个收录特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个Pipeline。
二、在items.py中定义自己要抓取的数据
首先打开一个新的pycharm项目,通过终端建立新项目tutorial,在item中定义想要抓取的数据,例如电影名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item pipe组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。定义的pipelines.py代码如下所示:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次使用了pipeline,所以需要我们在settings.py中打开pipelines通道注释,在里面新增一条,pipelines中添加的记录,如下图所示:
五、写爬虫文件
在tutoral/spiders目录下创建quotes_spider.py文件,目录结构如下,并写入初步的代码:
quotes_spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema ... 39%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在douban文件目录下新建启动文件 douban_spider_run.py (文件名称可以另取),并运行该文件,查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,经过处理后的爬取数据如下图所示(部分):
最后,希望大家在编写代码的时候能够细心点,不能马虎,我在实验的过程当中,就是因为将要引入的方法DoubanmovieItem写成了DobanmovieItem,从而导致了整个程序的运行失败,而且PyCharm还不告诉我哪里错了,我到处搜问题解决方法也没找到,最终核对了好多遍,生成方法时才发现,所以一定要细心。这个错误如下图所示,它提示说找不到DobanmovieItem这个模块,可能已经告诉我错误的地方了,因为我太菜了没发现,所以才耗费较长时间,希望大家引以为戒!
到此为止,使用Scrapy进行抓取网页内容,与对所抓取的内容进行清洗和处理的实验已经完成,要求对这个过程当中的代码与操作熟悉与运用,不会的去查找网上内容,消化吸收,记在脑子里,这才是真正学到知识,而不是照葫芦画瓢。
出处: 查看全部
抓取网页数据(Python解释器的安装推荐及安装的应用框架介绍)
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用程序框架,用于爬取网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:

二、PyCharm 安装
1.PyCharm 介绍
PyCharm is a PythonIDE with a set of tools that can help users improve their efficiency when developing in the Python language, such as debugging, syntax highlighting, project management, code jumps, smart prompts, automatic completion, unit testing, and version control. In addition, the IDE provides some advanced features to support professional web development under the Django framework.
2.PyCharm install
Go to PyCharm's official website and click DownLoad to download. The professional version is on the left, and the community version is on the right. The community version is free, and the professional version is free for trial.
如果我们之前没有下载有Python解释器的话,在等待安装的时间我们可以去下载python解释器,进入Python官网,根据系统、版本下载对应的压缩包即可,在安装完后,在环境变量Path中配置Python解释器的安装路径。可参考博客:
三、Scrapy抓取豆瓣项目实战
前提:在PyCharm中要使用Scrapy的话,必须先在PyCharm中安装所支持的Scrapy包,过程如下,点击文件(File)>> 设置(Settings...),步骤如下图,我安装Scrapy之前绿色框内只有两个Package,如果当你点击后看到有Scrapy包的话,那就不用安装了,直接进行接下来的操作即可

如果没有Scrapy包的话,点击“+”,搜索Scrapy包,点击Install Package 进行安装

等待安装完成即可。
1.新建项目
打开刚安装好的PyCharm,使用pycharm工具在软件的终端,如果找不到PyCharm终端在哪,在左下角的底部的Terminal就是了

输入命令:scrapy startproject douban 这是使用命令行来新建一个爬虫项目,如下图所示,图片展示的项目名为pythonProject

接着在命令行输入命令:cd douban 进入已生成的项目根目录
接着继续在终端键入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:

2.明确目标
我们要练习的网站为:
假设,我们抓取top250电影的序列号,电影名,介绍,星级,评价数,电影描述选项
此时,我们在items.py文件中定义抓取的数据项,代码如下:

# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接着,我们需要制作爬虫以及存储爬取内容
在douban_spider.py爬虫文件编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时不需要运行这个python文件,因为我们不是单独使用它的,所以不用运行,允许会报错,有关import引入的问题,关于主目录的绝对路径与相对路径的问题,原因是我们使用了相对路径“..items”,相关的内容感兴趣的同学可以去网上查找有关这类问题的解释。
4.存储内容
将所爬取的内容存储成json或csv格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取到的数据存储到json文件或者csv文件里。
在执行完爬取命令后,将鼠标的焦点给到项目面板时,即会显示出生成的json文件或csv文件。打开json或csv文件后,如果里面什么内容都没有,那么我们还需要进行一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'

存储到json文件里的话,所有的内容都会以十六进制的形式显示出来,可以通过相应的方法进行转码,这里不过多的说明,如下图:

而存储在csv文件中,会直接将我们所要爬取的内容全部显示出来,如下图:

到此为止,我们已完成对网站特定内容的爬取,接下来,就需要对这些爬取的数据进行处理。
分割线----------------------------------------------------------------------------------------------------------------------分割线
Scraoy入门实例二---使用Pipeline实现
此次的实战需要重新创建一个项目,还是需要安装scrapy包,参考上面的内容,创建新项目的方法也参考上面的内容,这里不再重复赘述。
项目目录结构如下图所示:

一、Pipeline介绍
当我们通过Spider爬取数据,通过Item采集数据后,就要对数据进行一些处理了,因为我们爬取到的数据并不一定是我们想要的最终数据,可能还需要进行数据的清洗以及验证数据的有效性。Scripy中的Pipeline组件就用于数据的处理,一个Pipeline组件就是一个收录特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个Pipeline。
二、在items.py中定义自己要抓取的数据
首先打开一个新的pycharm项目,通过终端建立新项目tutorial,在item中定义想要抓取的数据,例如电影名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item pipe组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。定义的pipelines.py代码如下所示:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次使用了pipeline,所以需要我们在settings.py中打开pipelines通道注释,在里面新增一条,pipelines中添加的记录,如下图所示:

五、写爬虫文件
在tutoral/spiders目录下创建quotes_spider.py文件,目录结构如下,并写入初步的代码:

quotes_spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema ... 39%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在douban文件目录下新建启动文件 douban_spider_run.py (文件名称可以另取),并运行该文件,查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,经过处理后的爬取数据如下图所示(部分):

最后,希望大家在编写代码的时候能够细心点,不能马虎,我在实验的过程当中,就是因为将要引入的方法DoubanmovieItem写成了DobanmovieItem,从而导致了整个程序的运行失败,而且PyCharm还不告诉我哪里错了,我到处搜问题解决方法也没找到,最终核对了好多遍,生成方法时才发现,所以一定要细心。这个错误如下图所示,它提示说找不到DobanmovieItem这个模块,可能已经告诉我错误的地方了,因为我太菜了没发现,所以才耗费较长时间,希望大家引以为戒!

到此为止,使用Scrapy进行抓取网页内容,与对所抓取的内容进行清洗和处理的实验已经完成,要求对这个过程当中的代码与操作熟悉与运用,不会的去查找网上内容,消化吸收,记在脑子里,这才是真正学到知识,而不是照葫芦画瓢。
出处:
抓取网页数据(用浏览器抓包分析数据的使用场景非常受限,且后面还要由一门后端语言做补充)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-23 03:15
使用方案非常有限,通过使用浏览器捕获,还必须稍后在后端语言中进行补充。这是一个更简单的想法,即:
替换了正则表达式
使用CSS选择器
留下场景是一个流氓,数据直接使用浏览器队长分析数据以满足以下要求:
1、数据相对静态,它不会频繁更改;
2、数据量非常大,人工提取非常麻烦;
3、所有数据基本上都可以在页面上抓取,后端语言请求URL,然后分析HTML成本并慢速。
也许有人会问,真的有这样的场景吗?
答案,存在,我已经遇到了类似的场景。
是想法,以下方案:(请注意,此场景不涉及HTTP相关内容,而不是在本文的讨论中)
用户可以自定义一个项目,这个项目有一个名称,带有图标。图标使用字体令人敬畏,一组很棒的图标公司和CSS框架,需要一个选项列表。
我们打开fontawesome官方网站,发现675个图标,如果手动进入我们的程序,显然是非常低效和浪费的时间,并使用后端请求然后写常规,调整错误。很多次,所以我们选择最简单,最粗鲁的方式 - 直接使用浏览器,即在开发人员工具中编写代码以获取DOM数据。
我想在一起我们必须得到的:
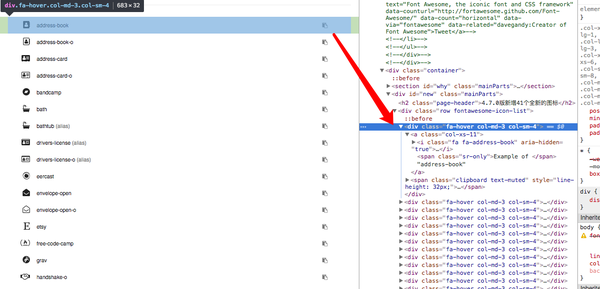
这里是一个简化的演示,只有一个数据:图标的类名,即所有类名,类似于“地址书”,“浴”。
由于它是抓取浏览器中的数据,它自然会涉及DOM操作,涉及DOM操作选择jQuery,因此让我们测试网站有j j j。 jquery。
非常好,可以使用它,然后下一步是分析DOM结构。
选择一个节点以查看其结构,可以找到以下信息:
1、每个图标由类“FA-HOVER COL-MD-3 COL-SM”包装,为我们提供了极大的便利,为我们提供整个页面;
2、类名称在SPAN标记后面。
所以现在我们将尝试使用“FA-HOVER COL-MD-3 COL-SM-SM-4”获取所有图标数据项。
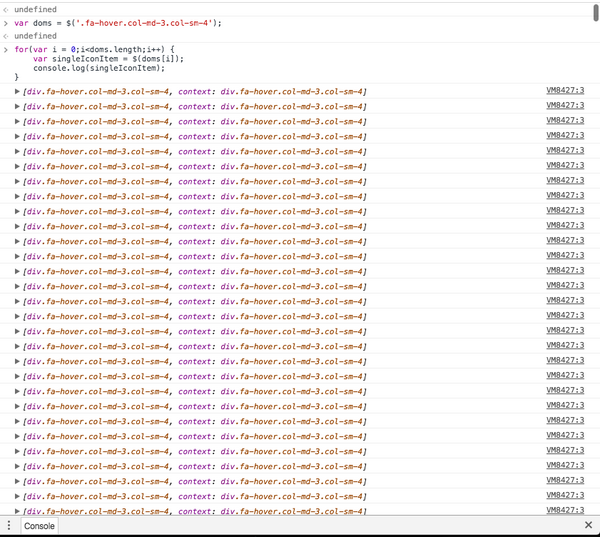
从图中可以看出,我们已经获得了975个数据,然后你将直接在代码上从这些DOM获取图标类名称。
首先输出所有DOM,确认,然后获取数据。
分析DOM结构,我们需要的数据是“YC-Square”,直接使用文本功能直接获得:
但这是不够的,我们需要在示例的例子背后进行数据,所以继续分割处理:
成功获取,最后一步是构建这些数据:
所有推入数组,然后json,这样可以将这些数据复制到程序。
当然,这里只是为了演示,所以生成的结构相对简单,实际上,我们还可以对这些数据进行分类。
这是实际业务中使用的结构。
返回我们的主题:使用浏览器的高效装配分析数据。
在此业务下,没有必要请求URL。它不需要编写正则表达式。您可以获得最多5分钟的所需数据。这是一种非常有效的方式,这种方式也可以是无缝迁移到后端。
为什么要迁移到后端?由于与jQuery的高效选择器一起使用,可以在爬行动物数据分析领域中使用它而不是正则表达式。毕竟,网络中有很多HTML数据,如果使用jQuery选择器分析这些数据,则无疑将降低大阈值。增加更多的开发和生产效率。
推荐库可以使用jQuery:TMPVAR / JSDOM
在节点中:tmpvar / jsdom
不仅如此,还可以直接编译前端的JavaScript到V8,然后分析生成的HTML。
我在节点中没有尝试过jQuery,但我还没有尝试过它,但是通过在浏览器中获得元数据然后将业务处理完成了很多东西。
还有一个类网站有大量的下载链接,并且是html的公共。目前,我已经以这种方式下载了大量数据,后端连接到节点,异步模型非常好。
私人思想,未来的节点将摇动Python在爬行动物区域的位置,CSS选择器还将摇动数据提取中的正则表达式。 查看全部
抓取网页数据(用浏览器抓包分析数据的使用场景非常受限,且后面还要由一门后端语言做补充)
使用方案非常有限,通过使用浏览器捕获,还必须稍后在后端语言中进行补充。这是一个更简单的想法,即:
替换了正则表达式
使用CSS选择器
留下场景是一个流氓,数据直接使用浏览器队长分析数据以满足以下要求:
1、数据相对静态,它不会频繁更改;
2、数据量非常大,人工提取非常麻烦;
3、所有数据基本上都可以在页面上抓取,后端语言请求URL,然后分析HTML成本并慢速。
也许有人会问,真的有这样的场景吗?
答案,存在,我已经遇到了类似的场景。
是想法,以下方案:(请注意,此场景不涉及HTTP相关内容,而不是在本文的讨论中)
用户可以自定义一个项目,这个项目有一个名称,带有图标。图标使用字体令人敬畏,一组很棒的图标公司和CSS框架,需要一个选项列表。
我们打开fontawesome官方网站,发现675个图标,如果手动进入我们的程序,显然是非常低效和浪费的时间,并使用后端请求然后写常规,调整错误。很多次,所以我们选择最简单,最粗鲁的方式 - 直接使用浏览器,即在开发人员工具中编写代码以获取DOM数据。
我想在一起我们必须得到的:
这里是一个简化的演示,只有一个数据:图标的类名,即所有类名,类似于“地址书”,“浴”。
由于它是抓取浏览器中的数据,它自然会涉及DOM操作,涉及DOM操作选择jQuery,因此让我们测试网站有j j j。 jquery。
非常好,可以使用它,然后下一步是分析DOM结构。
选择一个节点以查看其结构,可以找到以下信息:
1、每个图标由类“FA-HOVER COL-MD-3 COL-SM”包装,为我们提供了极大的便利,为我们提供整个页面;
2、类名称在SPAN标记后面。
所以现在我们将尝试使用“FA-HOVER COL-MD-3 COL-SM-SM-4”获取所有图标数据项。

从图中可以看出,我们已经获得了975个数据,然后你将直接在代码上从这些DOM获取图标类名称。
首先输出所有DOM,确认,然后获取数据。

分析DOM结构,我们需要的数据是“YC-Square”,直接使用文本功能直接获得:
但这是不够的,我们需要在示例的例子背后进行数据,所以继续分割处理:
成功获取,最后一步是构建这些数据:
所有推入数组,然后json,这样可以将这些数据复制到程序。
当然,这里只是为了演示,所以生成的结构相对简单,实际上,我们还可以对这些数据进行分类。
这是实际业务中使用的结构。
返回我们的主题:使用浏览器的高效装配分析数据。
在此业务下,没有必要请求URL。它不需要编写正则表达式。您可以获得最多5分钟的所需数据。这是一种非常有效的方式,这种方式也可以是无缝迁移到后端。
为什么要迁移到后端?由于与jQuery的高效选择器一起使用,可以在爬行动物数据分析领域中使用它而不是正则表达式。毕竟,网络中有很多HTML数据,如果使用jQuery选择器分析这些数据,则无疑将降低大阈值。增加更多的开发和生产效率。
推荐库可以使用jQuery:TMPVAR / JSDOM
在节点中:tmpvar / jsdom
不仅如此,还可以直接编译前端的JavaScript到V8,然后分析生成的HTML。
我在节点中没有尝试过jQuery,但我还没有尝试过它,但是通过在浏览器中获得元数据然后将业务处理完成了很多东西。
还有一个类网站有大量的下载链接,并且是html的公共。目前,我已经以这种方式下载了大量数据,后端连接到节点,异步模型非常好。
私人思想,未来的节点将摇动Python在爬行动物区域的位置,CSS选择器还将摇动数据提取中的正则表达式。
抓取网页数据(人工智能(AI)和机器学习(ML)的下一步是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-23 03:13
众所周知,网络数据在世界各地的各行各业中获得更受欢迎。每个人都知道采集公共数据(特别是大规模采集)将面临很多挑战。这就是为什么奥克萨斯举行了第二个网页以获取会议!
单击“注册”页面的链接。 OxyCon2021从8月25日举行到26日,奥克拉布斯讨论了Web数据捕获等相关主题!今年,oxycon2021将在线进行。两天的虚拟在线活动聚集了全球商业领袖和奥克萨布经验丰富的团队,深入,细致的谈判和讨论。
CEO评论
数据有助于公司做出更好,聪明的决策,最终取得了良好的效果。我们相信,每家公司无论尺寸如何,您都需要访问有价值的公共数据。 oxycon2021是数据采集行业顶级公司学习机会的大家,这些公司了解数据采集行业的快速增长,并知道如何使用网页来发挥公司的最大潜力。 “
-JuliusČerniauskas,奥克萨布斯首席执行官
oxycon2021是关于什么?
今年苏蒙将专注于三个重要主题。根据您的业务需求和个人兴趣,您可以选择最相关的研讨会,讨论或讲座。
业务数据集合
虽然互联网充满了有关如何做出更好决策和提高性能的信息,但他们需要的数据仍然具有挑战性。您将了解最新的数据采集条件,以及如何确保您的公司不会陷入复杂的网络抓取过程。
开发人员的网页捕获
数据目标越来越高,每天都有新的困难。为了获得所需的数据,开发人员需要考虑智能解决方案,以帮助他们摆脱所有困难。氧气连接将通过提供各种研讨会和讨论来关注网站抢购技术。
下一步是什么?
人工智能(ai)和机器学习(ml)已经是网页的一部分。从AI驱动的Web抓取解决方法到基于ML的指纹识别,解决方案已更新。随着时代的发展,我们将继续在发展过程中学习,思考和向前发展。网页领域也是如此,未来可能存在许多技术变化。加入oxycon2021听取行业专家到未来的预测。
评论oxycon2019
几年前,奥克萨斯举行了第一个苏蒙会议。两天的活动从来自世界各地到维尔纽斯的网页采集。我们期待着这次见到你。阅读更多关于OxyCon2019的更多信息:
摘要
我们将在我们的网站上发布OxyCon2021的详细计划。这个网页崩溃会议并不经常举行。因此,机器不会丢失,损失不再,点击下面的卡片立即获取oxyCon2021的免费票。世界上最大的数据采集活动之一正在等待您。 查看全部
抓取网页数据(人工智能(AI)和机器学习(ML)的下一步是什么?)
众所周知,网络数据在世界各地的各行各业中获得更受欢迎。每个人都知道采集公共数据(特别是大规模采集)将面临很多挑战。这就是为什么奥克萨斯举行了第二个网页以获取会议!
单击“注册”页面的链接。 OxyCon2021从8月25日举行到26日,奥克拉布斯讨论了Web数据捕获等相关主题!今年,oxycon2021将在线进行。两天的虚拟在线活动聚集了全球商业领袖和奥克萨布经验丰富的团队,深入,细致的谈判和讨论。
CEO评论
数据有助于公司做出更好,聪明的决策,最终取得了良好的效果。我们相信,每家公司无论尺寸如何,您都需要访问有价值的公共数据。 oxycon2021是数据采集行业顶级公司学习机会的大家,这些公司了解数据采集行业的快速增长,并知道如何使用网页来发挥公司的最大潜力。 “
-JuliusČerniauskas,奥克萨布斯首席执行官
oxycon2021是关于什么?
今年苏蒙将专注于三个重要主题。根据您的业务需求和个人兴趣,您可以选择最相关的研讨会,讨论或讲座。
业务数据集合
虽然互联网充满了有关如何做出更好决策和提高性能的信息,但他们需要的数据仍然具有挑战性。您将了解最新的数据采集条件,以及如何确保您的公司不会陷入复杂的网络抓取过程。
开发人员的网页捕获
数据目标越来越高,每天都有新的困难。为了获得所需的数据,开发人员需要考虑智能解决方案,以帮助他们摆脱所有困难。氧气连接将通过提供各种研讨会和讨论来关注网站抢购技术。
下一步是什么?
人工智能(ai)和机器学习(ml)已经是网页的一部分。从AI驱动的Web抓取解决方法到基于ML的指纹识别,解决方案已更新。随着时代的发展,我们将继续在发展过程中学习,思考和向前发展。网页领域也是如此,未来可能存在许多技术变化。加入oxycon2021听取行业专家到未来的预测。
评论oxycon2019
几年前,奥克萨斯举行了第一个苏蒙会议。两天的活动从来自世界各地到维尔纽斯的网页采集。我们期待着这次见到你。阅读更多关于OxyCon2019的更多信息:
摘要
我们将在我们的网站上发布OxyCon2021的详细计划。这个网页崩溃会议并不经常举行。因此,机器不会丢失,损失不再,点击下面的卡片立即获取oxyCon2021的免费票。世界上最大的数据采集活动之一正在等待您。
抓取网页数据(云服务薅羊毛的正确姿势,你get到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-23 03:12
完成阅读需要15分钟,快速阅读只需要5分钟
无论是科学研究还是商业运营,我们经常通过数据支持决策。作为个人用户,在缺乏企业数据平台支持的情况下,网络爬虫技术可能会为我们打开一扇窗口
1.条件准备
基本前提是要有一台配置了Python3编程环境的计算机或服务器。这个条件很简单。您可以直接选择安装Anaconda[1]。有关如何在本地配置环境或远程部署环境,请参阅我以前的文章“jupyterlab帮助提高学习效率”
由于爬虫程序脚本通常需要重复运行,因此您可能需要部署一台服务器来日夜为您工作。我还帮助您提前完成了“关于云服务的正确姿态”的家庭作业
如果只是为了学习,我还准备了谷歌的协作案例环境[2](需要科学互联网接入),以便您更好地理解文章内容
2.概念梳理
爬行动物技术非常简单。它可以分为两个步骤
Step1 通过给定的网络地址下载网页数据
Step2 提供数据的规则让计算机筛选数据
2.1网络数据下载
第一步可以说非常简单。python第三方生态系统中出现了非常简单的工具来实现它,比如请求。稍后我们将演示如何使用它
但是,如果您足够小心,您会发现一些网站需要在显示特定页面和数据之前登录。因此,网页数据的获取可以暂时分为简单下载和变相下载。后者要求我们使用浏览器将爬虫脚本伪装为正常访问
2.2网页数据提取
直接下载的网页数据是网页的源代码,供浏览器阅读,而不是供人们阅读。我们真正想要的数据隐藏在这一大串源代码中。为了获得我们想要的干净数据,我们需要指定一个规则,让计算机帮助我们从这些源代码中提取数据
我建议在这里学习两种这样的规则。一种是通用正则表达式,另一种是用网页源代码语言编写的XPath
正则表达式可能有点复杂。简而言之,它是总结目标数据的字符串规则。XPath听起来更复杂,但现在Chrome浏览器提供了一个可视化提取工具“XPath助手”[3]。你可以通过谷歌商店扩展来安装它。稍后我们将介绍如何使用XPath帮助器
3.案例研究
在开始之前,让我们检查一下是否通过打开juyterlab安装了本节中所需的一些第三方Python包
!pip3 install requests
!pip3 install lxml
注意:输入jupyterlab+终端指令可以直接在jupyterlab环境中执行。我们将把两个已安装的第三方库导入到当前环境中
import requests
from lxml import etree
3.1网络数据下载
首先,让我们通过对知乎文章数据进行爬网来解释如何使用爬网程序。我们首先通过浏览器访问目标网站,并复制目标网站,如下所示
url = 'https://www.zhihu.com/people/n ... 39%3B
根据前面的步骤,我们需要做的第一步是下载此网页的数据。这里我们使用强大的第三方库请求
res = requests.get(url)
print(res.text)
直接下载数据。我们发现,我们将收到400个错误请求的网页数据回复。此时,我们需要将python脚本伪造为浏览器访问网站. 如图所示,我们右键单击以在Chrome浏览器中进行检查,单击developer工具中的Network和random列,我们可以在右侧看到以下信息
复制cookie和用户代理数据以构造以下标头字典数据:
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookie':'_zap=7710374e-0d0b-4285-a69d-a2352eb102b5; d_c0="ALBiqotP2w-PTofuUtLo0XQZKjwcT8zji0U=|1565195731"; q_c1=3f807f2ca0c84d51a6a418258d275430|1578543800000|1566266234000; tst=r; UM_distinctid=16fea4b3816d5-0fff1be09d9b96-39677b0e-13c680-16fea4b38177a1; _xsrf=6182b2eb-6f32-454e-8c0d-d16122a8bec3; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1580782502,1580790283,1580790307,1580790327; r_cap_id="2|1:0|10:1580790382|8:r_cap_id|44:ZjQ3ZWFhODFlODc0NDRjNDg5YzZlODg1MDRiZmUzZjk=|eed022a309955b6db3b378b610e352c46c4024477bd99bf11a4fb25475e0d196"; capsion_ticket="2|1:0|10:1580790628|14:capsion_ticket|44:MmVlZGE0YjNjYWMzNDM0OGFlOWNkZmNhMWQ3ZWJlZDA=|07f358d43a89bcad3b55c305fdf7f6be2a3f67c47f1b2fa1d54acd2e0b4eacc3"; z_c0="2|1:0|10:1580790648|4:z_c0|92:Mi4xSVNlOEJBQUFBQUFBc0dLcWkwX2JEeVlBQUFCZ0FsVk5lRUVtWHdEUXBDMldpZkZMMEpxXzZ3UGJIMklibFRIZnB3|a5c9f10bc3b9f96930b8ba28295a0f1fdda1509aeb81564440978a640c36f42d"; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1580795302; CNZZDATA1272960301=815094974-1580178850-https%253A%252F%252Farticle.xmt.cn%252F%7C1580791820; KLBRSID=2177cbf908056c6654e972f5ddc96dc2|1580795993|1580790152'
}
cookie收录临时登录信息,用户代理将Python脚本伪装成浏览器
现在,将标题字典数据添加到脚本中,您将发现已成功下载数据
res = requests.get(url,headers=headers)
print(res.text)
3.2网页数据提取
数据提取还需要chrome开发者工具。右键点击目标数据,点击【检查】,出现下图。通过将数据对象的XPath复制到XPath助手中,我们可以看到XPath助手可以帮助我们直接提取数据
现在XPath助手中的XPath是当前目标数据的源代码规则。如果需要获取相同类型的数据,只需观察XPath,删除与列表相似的数据,通过观察判断是否正确。通过尝试,我们获得了文章title的数据。采集规则如下(在末尾添加/text()以获取文本数据):
title_pattern = '//*[@id="Profile-posts"]/div[2]/div/div/h2/a/text()'
Python中XPath的标准模板如下所示,其中res.text是我们下载的网页数据,title_uu模式是我们通过XPath助手获得的数据提取规则。现在我们可以获得我的文章列表中所有文章的标题数据
html=etree.HTML(res.text)
result = html.xpath(title_pattern)
print(result)
总结
举一反三。现在您不仅可以抓取文章title,还可以抓取文章release date和文章profile。如果当前任务是抓取电影网站数据,您能否以相同的方式快速抓取电影标题和电影收视率
如果您想继续深化web爬虫技术,可以深入了解正则表达式和XPath规则,也可以进一步联系分布式爬虫框架scripy。此外,移动端的数据捕获工具Charles、桌面端的自动化工具pywinauto等都值得理解
参考资料
[1] Anaconda官方网站下载/分发/
[2] 协作案例环境:/drive/1Nuvpouysoxpuaxqogggvfqaptjqnl2 DC
[3] XPath助手:/webstore/detail/hgimnogjllphhkhhlmebbmlgjoejdpjl 查看全部
抓取网页数据(云服务薅羊毛的正确姿势,你get到了吗?)
完成阅读需要15分钟,快速阅读只需要5分钟
无论是科学研究还是商业运营,我们经常通过数据支持决策。作为个人用户,在缺乏企业数据平台支持的情况下,网络爬虫技术可能会为我们打开一扇窗口
1.条件准备
基本前提是要有一台配置了Python3编程环境的计算机或服务器。这个条件很简单。您可以直接选择安装Anaconda[1]。有关如何在本地配置环境或远程部署环境,请参阅我以前的文章“jupyterlab帮助提高学习效率”
由于爬虫程序脚本通常需要重复运行,因此您可能需要部署一台服务器来日夜为您工作。我还帮助您提前完成了“关于云服务的正确姿态”的家庭作业
如果只是为了学习,我还准备了谷歌的协作案例环境[2](需要科学互联网接入),以便您更好地理解文章内容
2.概念梳理
爬行动物技术非常简单。它可以分为两个步骤
Step1 通过给定的网络地址下载网页数据
Step2 提供数据的规则让计算机筛选数据
2.1网络数据下载
第一步可以说非常简单。python第三方生态系统中出现了非常简单的工具来实现它,比如请求。稍后我们将演示如何使用它
但是,如果您足够小心,您会发现一些网站需要在显示特定页面和数据之前登录。因此,网页数据的获取可以暂时分为简单下载和变相下载。后者要求我们使用浏览器将爬虫脚本伪装为正常访问
2.2网页数据提取
直接下载的网页数据是网页的源代码,供浏览器阅读,而不是供人们阅读。我们真正想要的数据隐藏在这一大串源代码中。为了获得我们想要的干净数据,我们需要指定一个规则,让计算机帮助我们从这些源代码中提取数据
我建议在这里学习两种这样的规则。一种是通用正则表达式,另一种是用网页源代码语言编写的XPath
正则表达式可能有点复杂。简而言之,它是总结目标数据的字符串规则。XPath听起来更复杂,但现在Chrome浏览器提供了一个可视化提取工具“XPath助手”[3]。你可以通过谷歌商店扩展来安装它。稍后我们将介绍如何使用XPath帮助器
3.案例研究
在开始之前,让我们检查一下是否通过打开juyterlab安装了本节中所需的一些第三方Python包
!pip3 install requests
!pip3 install lxml
注意:输入jupyterlab+终端指令可以直接在jupyterlab环境中执行。我们将把两个已安装的第三方库导入到当前环境中
import requests
from lxml import etree
3.1网络数据下载
首先,让我们通过对知乎文章数据进行爬网来解释如何使用爬网程序。我们首先通过浏览器访问目标网站,并复制目标网站,如下所示
url = 'https://www.zhihu.com/people/n ... 39%3B
根据前面的步骤,我们需要做的第一步是下载此网页的数据。这里我们使用强大的第三方库请求
res = requests.get(url)
print(res.text)
直接下载数据。我们发现,我们将收到400个错误请求的网页数据回复。此时,我们需要将python脚本伪造为浏览器访问网站. 如图所示,我们右键单击以在Chrome浏览器中进行检查,单击developer工具中的Network和random列,我们可以在右侧看到以下信息
复制cookie和用户代理数据以构造以下标头字典数据:
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookie':'_zap=7710374e-0d0b-4285-a69d-a2352eb102b5; d_c0="ALBiqotP2w-PTofuUtLo0XQZKjwcT8zji0U=|1565195731"; q_c1=3f807f2ca0c84d51a6a418258d275430|1578543800000|1566266234000; tst=r; UM_distinctid=16fea4b3816d5-0fff1be09d9b96-39677b0e-13c680-16fea4b38177a1; _xsrf=6182b2eb-6f32-454e-8c0d-d16122a8bec3; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1580782502,1580790283,1580790307,1580790327; r_cap_id="2|1:0|10:1580790382|8:r_cap_id|44:ZjQ3ZWFhODFlODc0NDRjNDg5YzZlODg1MDRiZmUzZjk=|eed022a309955b6db3b378b610e352c46c4024477bd99bf11a4fb25475e0d196"; capsion_ticket="2|1:0|10:1580790628|14:capsion_ticket|44:MmVlZGE0YjNjYWMzNDM0OGFlOWNkZmNhMWQ3ZWJlZDA=|07f358d43a89bcad3b55c305fdf7f6be2a3f67c47f1b2fa1d54acd2e0b4eacc3"; z_c0="2|1:0|10:1580790648|4:z_c0|92:Mi4xSVNlOEJBQUFBQUFBc0dLcWkwX2JEeVlBQUFCZ0FsVk5lRUVtWHdEUXBDMldpZkZMMEpxXzZ3UGJIMklibFRIZnB3|a5c9f10bc3b9f96930b8ba28295a0f1fdda1509aeb81564440978a640c36f42d"; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1580795302; CNZZDATA1272960301=815094974-1580178850-https%253A%252F%252Farticle.xmt.cn%252F%7C1580791820; KLBRSID=2177cbf908056c6654e972f5ddc96dc2|1580795993|1580790152'
}
cookie收录临时登录信息,用户代理将Python脚本伪装成浏览器
现在,将标题字典数据添加到脚本中,您将发现已成功下载数据
res = requests.get(url,headers=headers)
print(res.text)
3.2网页数据提取
数据提取还需要chrome开发者工具。右键点击目标数据,点击【检查】,出现下图。通过将数据对象的XPath复制到XPath助手中,我们可以看到XPath助手可以帮助我们直接提取数据
现在XPath助手中的XPath是当前目标数据的源代码规则。如果需要获取相同类型的数据,只需观察XPath,删除与列表相似的数据,通过观察判断是否正确。通过尝试,我们获得了文章title的数据。采集规则如下(在末尾添加/text()以获取文本数据):
title_pattern = '//*[@id="Profile-posts"]/div[2]/div/div/h2/a/text()'
Python中XPath的标准模板如下所示,其中res.text是我们下载的网页数据,title_uu模式是我们通过XPath助手获得的数据提取规则。现在我们可以获得我的文章列表中所有文章的标题数据
html=etree.HTML(res.text)
result = html.xpath(title_pattern)
print(result)
总结
举一反三。现在您不仅可以抓取文章title,还可以抓取文章release date和文章profile。如果当前任务是抓取电影网站数据,您能否以相同的方式快速抓取电影标题和电影收视率
如果您想继续深化web爬虫技术,可以深入了解正则表达式和XPath规则,也可以进一步联系分布式爬虫框架scripy。此外,移动端的数据捕获工具Charles、桌面端的自动化工具pywinauto等都值得理解
参考资料
[1] Anaconda官方网站下载/分发/
[2] 协作案例环境:/drive/1Nuvpouysoxpuaxqogggvfqaptjqnl2 DC
[3] XPath助手:/webstore/detail/hgimnogjllphhkhhlmebbmlgjoejdpjl
抓取网页数据( Python中解析网页爬虫的基本流程(一)-爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-22 13:24
Python中解析网页爬虫的基本流程(一)-爬虫)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
现在启动Jupiter笔记本并运行以下代码
请求
url=“”
res=requests.get('url')
打印(res.status_代码)
#二百
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
来自BS4导入Beautifulsoup
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
title=soup.title.text
印刷品(标题)
#热门视频-嘟嘟嘟嘟嘟嘟
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到每个视频消息都包装在Li标记下,因此代码可以这样编写
所有产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
进口
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
importpandas aspd
keys=所有产品[0]。keys
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
请求
来自BS4导入Beautifulsoup
进口
importpandas aspd
url=“”
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
所有\uo产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
###使用pandas写入数据
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
结束
目前,Python和Java是编程语言武器列表中最流行的两种语言。两者都有各自的优势。Java更容易找到工作。Python被广泛使用,易于学习,可以做很多事情。许多学生都在学习这两方面的知识。所以小编给大家发了8本书,帮你们振作起来,打电话给大家
Python:机器学习算法框架实践
Java:Java编程方法
感兴趣的合作伙伴可以扫描二维码下方的二维码以查看其角色~~ 查看全部
抓取网页数据(
Python中解析网页爬虫的基本流程(一)-爬虫)

爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
现在启动Jupiter笔记本并运行以下代码
请求
url=“”
res=requests.get('url')
打印(res.status_代码)
#二百
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容

您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
来自BS4导入Beautifulsoup
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
title=soup.title.text
印刷品(标题)
#热门视频-嘟嘟嘟嘟嘟嘟
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到每个视频消息都包装在Li标记下,因此代码可以这样编写
所有产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
进口
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
importpandas aspd
keys=所有产品[0]。keys
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
请求
来自BS4导入Beautifulsoup
进口
importpandas aspd
url=“”
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
所有\uo产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
###使用pandas写入数据
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
结束
目前,Python和Java是编程语言武器列表中最流行的两种语言。两者都有各自的优势。Java更容易找到工作。Python被广泛使用,易于学习,可以做很多事情。许多学生都在学习这两方面的知识。所以小编给大家发了8本书,帮你们振作起来,打电话给大家
Python:机器学习算法框架实践
Java:Java编程方法
感兴趣的合作伙伴可以扫描二维码下方的二维码以查看其角色~~
抓取网页数据(Java如何抓取网站的数据:(1)原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-09-22 00:12
有时由于各种原因,我们需要采集一些网站数据,但由于网站数据的不同,数据的显示方式略有不同
本文使用Java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
抓取网页数据(Java如何抓取网站的数据:(1)原网页数据)
有时由于各种原因,我们需要采集一些网站数据,但由于网站数据的不同,数据的显示方式略有不同
本文使用Java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:

第二步:查看web源代码。我们可以看到源代码中有一段:

从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:

换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:

第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:


从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
抓取网页数据(抓取网页数据的最根本的功能是对网页进行计算机分析和可视化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-19 21:02
抓取网页数据的最根本的功能是对网页数据进行计算机分析和可视化。做对网页数据进行分析和可视化,首先就需要要先对原始网页进行字符集的处理,这是大前提。对于不同网站上的同一个页面,可能存在不同的字符集,因此如何对网页进行计算机分析和可视化就至关重要了。那么字符集可以分成哪些类型?不同的字符集又有哪些特点和区别呢?我们一起来看看。
什么是网页字符集上面我们介绍了不同字符集的相关概念,下面我们将一一解释这些概念。一:网页字符集是什么网页字符集是指网页中的文本(特指web文本)所使用的字符集。用于获取网页中的文本的字符集包括utf-8,utf-16和utf-32这三个字符集。根据使用需求,目前web上的字符集还包括数字0~9,空格,tab和无符号元素这些字符。
二:网页字符集的特点网页中文本的字符集统一使用utf-8字符集,utf-16和utf-32这三个字符集。虽然三个字符集的差别不大,但是它们各自适用于不同的场景。utf-8和utf-16是最常用的两种字符集,而utf-32(包括0~9)是一个潜在的低能字符集。使用utf-32字符集进行网页文本分析时,最好将文本转换成十六进制形式以便计算机处理。
常见场景1:web文档中包含下划线、逗号、制表符等单位字符,因此需要转换为十六进制形式进行分析。常见场景2:网页中包含文字中有特殊字符,字符中有很多非常规的符号,这些符号在计算机上无法直接识别,因此需要转换为十六进制形式进行计算机处理。常见场景3:网页有超链接标识,因此需要转换为十六进制形式。三:网页字符集的使用常见场景1:需要对web文档进行分析处理,或需要对网页文档进行字符集对齐分析。
常见场景2:比如无法用统一网页字符集的utf-8字符集进行网页分析处理。常见场景3:需要对网页文档进行可视化分析,或需要处理具有特殊数据类型的网页文档。常见场景4:需要对网页文档进行可视化分析,或需要处理数据类型比较复杂的网页文档。四:网页字符集的应用案例第一种:网页文档可视化分析。使用网页字符集进行文档分析处理时,要先将网页文档转换成十六进制形式。
而转换方法可以通过搜索引擎获取,也可以通过web浏览器自带的自动转换功能。下面介绍一个有用的转换方法。1.使用sublimetext3打开网页,然后选择utf-8打开,再选择将网页文档转换为十六进制形式。2.选择转换范围,将方括号里的utf-8改为其他格式,然后确定。网页字符集转换可以通过在线转换来实现,这里介绍一个网站:wordconverter。网站页面链接::在。 查看全部
抓取网页数据(抓取网页数据的最根本的功能是对网页进行计算机分析和可视化)
抓取网页数据的最根本的功能是对网页数据进行计算机分析和可视化。做对网页数据进行分析和可视化,首先就需要要先对原始网页进行字符集的处理,这是大前提。对于不同网站上的同一个页面,可能存在不同的字符集,因此如何对网页进行计算机分析和可视化就至关重要了。那么字符集可以分成哪些类型?不同的字符集又有哪些特点和区别呢?我们一起来看看。
什么是网页字符集上面我们介绍了不同字符集的相关概念,下面我们将一一解释这些概念。一:网页字符集是什么网页字符集是指网页中的文本(特指web文本)所使用的字符集。用于获取网页中的文本的字符集包括utf-8,utf-16和utf-32这三个字符集。根据使用需求,目前web上的字符集还包括数字0~9,空格,tab和无符号元素这些字符。
二:网页字符集的特点网页中文本的字符集统一使用utf-8字符集,utf-16和utf-32这三个字符集。虽然三个字符集的差别不大,但是它们各自适用于不同的场景。utf-8和utf-16是最常用的两种字符集,而utf-32(包括0~9)是一个潜在的低能字符集。使用utf-32字符集进行网页文本分析时,最好将文本转换成十六进制形式以便计算机处理。
常见场景1:web文档中包含下划线、逗号、制表符等单位字符,因此需要转换为十六进制形式进行分析。常见场景2:网页中包含文字中有特殊字符,字符中有很多非常规的符号,这些符号在计算机上无法直接识别,因此需要转换为十六进制形式进行计算机处理。常见场景3:网页有超链接标识,因此需要转换为十六进制形式。三:网页字符集的使用常见场景1:需要对web文档进行分析处理,或需要对网页文档进行字符集对齐分析。
常见场景2:比如无法用统一网页字符集的utf-8字符集进行网页分析处理。常见场景3:需要对网页文档进行可视化分析,或需要处理具有特殊数据类型的网页文档。常见场景4:需要对网页文档进行可视化分析,或需要处理数据类型比较复杂的网页文档。四:网页字符集的应用案例第一种:网页文档可视化分析。使用网页字符集进行文档分析处理时,要先将网页文档转换成十六进制形式。
而转换方法可以通过搜索引擎获取,也可以通过web浏览器自带的自动转换功能。下面介绍一个有用的转换方法。1.使用sublimetext3打开网页,然后选择utf-8打开,再选择将网页文档转换为十六进制形式。2.选择转换范围,将方括号里的utf-8改为其他格式,然后确定。网页字符集转换可以通过在线转换来实现,这里介绍一个网站:wordconverter。网站页面链接::在。
抓取网页数据( 网络爬虫就是获取网页信息的简单爬虫方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-08 01:22
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行了),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然这有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码。
此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是字典,所以我们知道网页的编码方式,我们可以根据得到的信息使用不同的解码方式。 查看全部
抓取网页数据(
网络爬虫就是获取网页信息的简单爬虫方法)
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
进群:960410445获取源码!
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。
当然,我们也可以从浏览器中查看这些代码。
比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,
比如中文网站起点付费章节就不行了),以百度界面为例,截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?
需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然这有点麻烦。用几行代码来解决,更省事,更爽。
一种自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
安装后,我们可以使用chardet.detect()方法来判断网页的编码。
此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
运行程序,查看输出结果如下:
返回的是字典,所以我们知道网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
抓取网页数据(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-10-08 01:20
不知道大家在日常的工作学习生活中是否遇到过这样的场景,就是需要复制网站上面的一些数据(比如图片、文字或者其他一些格式的数据)。将其保存到本地 Excel 表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。Crawler,顾名思义,就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、Manually:完全依赖手动复制粘贴;
2、 半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取某部分数据;
3、全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是这个爬虫写的需要相当的知识。
第二个和第三个,哪个更好,哪个更坏,没有确定的数字。根据不同的场合,两者都有自己的自适应地方。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在我们来看看这个案例。笔者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章,每章又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017 下载安装)和视频地址。
名称比较容易说,表中最左边的列是节的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为存在跨域问题)。
我们应该做什么?
不着急,只要头脑不滑,解决办法总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。因此,您可以使用以下代码来获取收录该部分名称的所有 a 标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这种固定格式的开头是“number.number.number”,可以表示为如下正则表达式:
^\d+\.\d+(\.\d+)?
然后就可以使用正则表达式条件进行过滤了,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
至此,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,当我们点击某个部分时,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是,作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有视频地址不同的只有这里的{1},这里的{1}也和段号有关:{1}的部分由段号改为句号,只需要提取标题号. 然后只需更换它。
至此,您可以完全编写所有代码,并可以根据代码实现所需的抓取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可见,这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十几行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也欢迎在下方评论区写下你的想法。 查看全部
抓取网页数据(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
不知道大家在日常的工作学习生活中是否遇到过这样的场景,就是需要复制网站上面的一些数据(比如图片、文字或者其他一些格式的数据)。将其保存到本地 Excel 表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。Crawler,顾名思义,就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、Manually:完全依赖手动复制粘贴;
2、 半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取某部分数据;
3、全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是这个爬虫写的需要相当的知识。
第二个和第三个,哪个更好,哪个更坏,没有确定的数字。根据不同的场合,两者都有自己的自适应地方。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在我们来看看这个案例。笔者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章,每章又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017 下载安装)和视频地址。
名称比较容易说,表中最左边的列是节的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为存在跨域问题)。
我们应该做什么?
不着急,只要头脑不滑,解决办法总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。因此,您可以使用以下代码来获取收录该部分名称的所有 a 标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这种固定格式的开头是“number.number.number”,可以表示为如下正则表达式:
^\d+\.\d+(\.\d+)?
然后就可以使用正则表达式条件进行过滤了,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
至此,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,当我们点击某个部分时,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是,作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有视频地址不同的只有这里的{1},这里的{1}也和段号有关:{1}的部分由段号改为句号,只需要提取标题号. 然后只需更换它。
至此,您可以完全编写所有代码,并可以根据代码实现所需的抓取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可见,这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十几行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也欢迎在下方评论区写下你的想法。
抓取网页数据(爬虫的核心代码,文章末尾提供源码-是不是交流)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-08 01:19
抓取的方式有很多种,这里我们使用C#语言抓取指定网页上的所有图片。
比如我们在百度搜索图片,看到找到的图片,就可以通过程序,把看到的图片全部抓取。它不仅速度快,而且您还可以了解有关 C# 的更多信息。当别人还在一个一个地保存时,您可以轻松获得一套程序的全部。是不是有点激动?接下来简单说一下核心代码,源码在文章末尾提供。
1.首先我们随机百度一张主题图片,然后复制地址栏中的链接,如下:
2. 将链接分配给程序中的变量。当然,在C#的图形界面中,也可以定义一个输入框。将链接放入输入框,在后台获取输入框的值。现在,原理是一样的。
3. 然后我们根据获取的网页数据,使用正则表达式解析出所有的图片链接。这里的图片格式支持四种常见的jpg、png、jpeg、gif。当然,你也可以添加更多的格式
4.最后我们根据刚刚得到的图片链接开始下载保存到本地。.
5.看看实际效果,打开你的保存文件目录,你会发现图片是一张一张的显示出来的。
效果大吗?如果您有兴趣,可以更改此代码以完善它。如果您对此感兴趣,欢迎交流。
抱歉,由于新的头条规定,编辑不能连接到第三方平台。您可以留下您的企鹅号,编辑会及时发送到您的邮箱。如果觉得不错,记得点赞哦。 查看全部
抓取网页数据(爬虫的核心代码,文章末尾提供源码-是不是交流)
抓取的方式有很多种,这里我们使用C#语言抓取指定网页上的所有图片。
比如我们在百度搜索图片,看到找到的图片,就可以通过程序,把看到的图片全部抓取。它不仅速度快,而且您还可以了解有关 C# 的更多信息。当别人还在一个一个地保存时,您可以轻松获得一套程序的全部。是不是有点激动?接下来简单说一下核心代码,源码在文章末尾提供。
1.首先我们随机百度一张主题图片,然后复制地址栏中的链接,如下:
2. 将链接分配给程序中的变量。当然,在C#的图形界面中,也可以定义一个输入框。将链接放入输入框,在后台获取输入框的值。现在,原理是一样的。
3. 然后我们根据获取的网页数据,使用正则表达式解析出所有的图片链接。这里的图片格式支持四种常见的jpg、png、jpeg、gif。当然,你也可以添加更多的格式
4.最后我们根据刚刚得到的图片链接开始下载保存到本地。.
5.看看实际效果,打开你的保存文件目录,你会发现图片是一张一张的显示出来的。
效果大吗?如果您有兴趣,可以更改此代码以完善它。如果您对此感兴趣,欢迎交流。
抱歉,由于新的头条规定,编辑不能连接到第三方平台。您可以留下您的企鹅号,编辑会及时发送到您的邮箱。如果觉得不错,记得点赞哦。
抓取网页数据( 目标确定2019精品新片的前10页所有电影的名字 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-07 15:11
目标确定2019精品新片的前10页所有电影的名字
)
一、开始
在花了将近半年的空闲时间学习了Python的基本语法之后,我开始尝试网络爬虫。学习了一个星期,在我开始爬相对较小的网页并尝到甜头后,我疯狂地搜索各种网络爬虫。当然,我也被各种虐——!
于是决定仔细复习一下之前的笔记,记录下爬取的网页和方法,写个博客,方便以后复习。当然,如果有朋友比我是爬虫新手,我可能会从这些基础中获得一些积分。~
二、工具(Python)依赖requestsxpath的库三、目标确定
抢2019精品新片前10页所有电影的片名和电影海报(有兴趣的可以加磁力链接,同样不难)
三、URL分析和整体层次分析
爬行思维层次分析——由内而外:
解析单个电影 url 以检索电影名称和电影海报。定义一个 def 来返回页面中所有需要获取的电影的 URL。定义一个def,输入那个页面的total_url,返回一个url列表,然后遍历url,把url丢进1的函数中,遍历10页,定义main函数结合1、2函数
网址分析
进入单部电影的页面,右击查看。从元素中很容易找到电影名称和海报的位置。
电影名提取的地方很多,就不一一解释了
通过 xpath 语法解析
可以看到xpath匹配了两个图片信息,第二个是视频截图,我们只需要第一个。
total_url 分析
提取出单部电影所需的信息后,分析如何从一个页面抓取所有电影网址。以第一页为例,目标抓取提取第一页的所有URL
右击查看,将元素定位工具放置在任意影片位置,可以找到如下
这样除了每部电影的url位置,通过xpath匹配
OK,此时可以说已经获取了一页(total_urls)中所有URL中的电影点播信息。
下一步是分析10个页面的爬行。
遍历 10 页分析
此时,观察前两页的网址,就可以找到规律了。您只需要使用圆作为偏移量即可完成要求。好了,分析完毕。
代码:
在贴代码之前需要注意:我们都知道response.text或者response.content通常是在请求请求之后使用。这里我选择第二个。Movie Paradise的源码不够规范,所以我们手动解码,打开一部电影url的源码,ctrt+F输入'charset'可以找到如下图
网页是用gbk编码的,所以我们解码的时候用decode('gbk')。
代码显示如下
# -- 1 对电影天堂url规律分析
from lxml import etree
import requests
x = 0
y = 0
movies = []
HEARDERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Accept-Language':'zh-CN,zh;q=0.9'
}
frist = 'https://www.dytt8.net'
def get_detail_urls(url):
"""获取一页的电影"""
global y
response = requests.get(url, headers=HEARDERS)
text = response.text # 去网页源代码查看编码方式
html = etree.HTML(text) # 解析成HTML代码对象
detail_urls = html.xpath("//table[@class='tbspan']//a/@href") # 返回list
detail_urls = map(lambda url:frist+url,detail_urls) # 将每个detail_urls元素都放进lambad函数里面执行一遍
y += 1
print('='*30)
print('第{}页开始爬取!'.format(y))
print('=' * 30)
return detail_urls
def parse_detail_page(url):
global x
movie={}
response = requests.get(url,headers=HEARDERS)
text = response.content.decode('gbk')
html = etree.HTML(text)
title = html.xpath("//div[@class='title_all']//font/text()")[0] # 电影名
img = html.xpath("//p/img/@src")[0]
movie['电影名'] = title
movie['海报'] = img
x += 1
movies.append(movie)
print('第{}部电影爬取完毕!'.format(x))
def main():
"""爬取前5页"""
global x
for i in range(1,11): # 控制页数
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'.format(i)
detail_urls = get_detail_urls(url) # return详细电影页面list
for detail_url in detail_urls:
# 该for循环遍历一页中所有电影的详情
try:
movie = parse_detail_page(detail_url) # 处理单个电影url
except:
print('爬取失败')
x += 1
if __name__ == '__main__':
main()
print('爬取完毕,共{}部电影'.format(x))
print(movies)
结果如下,没有做数据存储链接,主要是整理爬虫的思路
期间某部电影返回索引错误,--~于是看了几分钟那部电影,检查贴如下:
果然是空索引!!!--silent,然后加一个try,除了,结果如下:
爬行完成!
查看全部
抓取网页数据(
目标确定2019精品新片的前10页所有电影的名字
)
一、开始
在花了将近半年的空闲时间学习了Python的基本语法之后,我开始尝试网络爬虫。学习了一个星期,在我开始爬相对较小的网页并尝到甜头后,我疯狂地搜索各种网络爬虫。当然,我也被各种虐——!
于是决定仔细复习一下之前的笔记,记录下爬取的网页和方法,写个博客,方便以后复习。当然,如果有朋友比我是爬虫新手,我可能会从这些基础中获得一些积分。~
二、工具(Python)依赖requestsxpath的库三、目标确定
抢2019精品新片前10页所有电影的片名和电影海报(有兴趣的可以加磁力链接,同样不难)
三、URL分析和整体层次分析
爬行思维层次分析——由内而外:
解析单个电影 url 以检索电影名称和电影海报。定义一个 def 来返回页面中所有需要获取的电影的 URL。定义一个def,输入那个页面的total_url,返回一个url列表,然后遍历url,把url丢进1的函数中,遍历10页,定义main函数结合1、2函数
网址分析
进入单部电影的页面,右击查看。从元素中很容易找到电影名称和海报的位置。
电影名提取的地方很多,就不一一解释了
通过 xpath 语法解析
可以看到xpath匹配了两个图片信息,第二个是视频截图,我们只需要第一个。
total_url 分析
提取出单部电影所需的信息后,分析如何从一个页面抓取所有电影网址。以第一页为例,目标抓取提取第一页的所有URL
右击查看,将元素定位工具放置在任意影片位置,可以找到如下
这样除了每部电影的url位置,通过xpath匹配
OK,此时可以说已经获取了一页(total_urls)中所有URL中的电影点播信息。
下一步是分析10个页面的爬行。
遍历 10 页分析
此时,观察前两页的网址,就可以找到规律了。您只需要使用圆作为偏移量即可完成要求。好了,分析完毕。
代码:
在贴代码之前需要注意:我们都知道response.text或者response.content通常是在请求请求之后使用。这里我选择第二个。Movie Paradise的源码不够规范,所以我们手动解码,打开一部电影url的源码,ctrt+F输入'charset'可以找到如下图
网页是用gbk编码的,所以我们解码的时候用decode('gbk')。
代码显示如下
# -- 1 对电影天堂url规律分析
from lxml import etree
import requests
x = 0
y = 0
movies = []
HEARDERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Accept-Language':'zh-CN,zh;q=0.9'
}
frist = 'https://www.dytt8.net'
def get_detail_urls(url):
"""获取一页的电影"""
global y
response = requests.get(url, headers=HEARDERS)
text = response.text # 去网页源代码查看编码方式
html = etree.HTML(text) # 解析成HTML代码对象
detail_urls = html.xpath("//table[@class='tbspan']//a/@href") # 返回list
detail_urls = map(lambda url:frist+url,detail_urls) # 将每个detail_urls元素都放进lambad函数里面执行一遍
y += 1
print('='*30)
print('第{}页开始爬取!'.format(y))
print('=' * 30)
return detail_urls
def parse_detail_page(url):
global x
movie={}
response = requests.get(url,headers=HEARDERS)
text = response.content.decode('gbk')
html = etree.HTML(text)
title = html.xpath("//div[@class='title_all']//font/text()")[0] # 电影名
img = html.xpath("//p/img/@src")[0]
movie['电影名'] = title
movie['海报'] = img
x += 1
movies.append(movie)
print('第{}部电影爬取完毕!'.format(x))
def main():
"""爬取前5页"""
global x
for i in range(1,11): # 控制页数
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'.format(i)
detail_urls = get_detail_urls(url) # return详细电影页面list
for detail_url in detail_urls:
# 该for循环遍历一页中所有电影的详情
try:
movie = parse_detail_page(detail_url) # 处理单个电影url
except:
print('爬取失败')
x += 1
if __name__ == '__main__':
main()
print('爬取完毕,共{}部电影'.format(x))
print(movies)
结果如下,没有做数据存储链接,主要是整理爬虫的思路
期间某部电影返回索引错误,--~于是看了几分钟那部电影,检查贴如下:
果然是空索引!!!--silent,然后加一个try,除了,结果如下:
爬行完成!
抓取网页数据(我在抓取网页的时候得不到完整的原始源(就是右击-查看))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 15:09
我在抓取网页时无法获得完整的原创来源。在网上找了半天,也没找到可行的办法。我希望花园里的人可以提供帮助。提前致谢!!
比如我要提取的网址是:
我想得到它的原创源码(也就是右键查看原创源码中看到的所有字符)
当我使用以下代码提取时:
private string GetHtmlCode(string url)
{
string htmlCode;
HttpWebRequest webRequest = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(url);
webRequest.Timeout = 30000;
webRequest.Method = "GET";
webRequest.UserAgent = "Mozilla/4.0";
webRequest.Headers.Add("Accept-Encoding", "gzip, deflate");
HttpWebResponse webResponse = (System.Net.HttpWebResponse)webRequest.GetResponse();
if (webResponse.ContentEncoding.ToLower() == "gzip
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (var zipStream =
new System.IO.Compression.GZipStream(streamReceive, System.IO.Compression.CompressionMode.Decompress))
{
using (StreamReader sr = new System.IO.StreamReader(zipStream, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
}else
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (System.IO.StreamReader sr = new System.IO.StreamReader(streamReceive, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
return htmlCode;
}
提取的数据不完整,无法显示iframe中的代码。我以为可能有一些AJAX数据,所以我更改了以下提取代码:
private void button1_Click(object sender, EventArgs e)
{
WebBrowser web = new WebBrowser();
web.Navigate(this.rtb_Url.Text);
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
while (web.IsBusy)
{
Application.DoEvents();
Thread.Sleep(100);
}
}
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
string mystr = web.Document.Body.OuterHtml;
}
提到的原创来源总是不完整,希望园丁能给我一些建议,谢谢! 查看全部
抓取网页数据(我在抓取网页的时候得不到完整的原始源(就是右击-查看))
我在抓取网页时无法获得完整的原创来源。在网上找了半天,也没找到可行的办法。我希望花园里的人可以提供帮助。提前致谢!!
比如我要提取的网址是:
我想得到它的原创源码(也就是右键查看原创源码中看到的所有字符)
当我使用以下代码提取时:
private string GetHtmlCode(string url)
{
string htmlCode;
HttpWebRequest webRequest = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(url);
webRequest.Timeout = 30000;
webRequest.Method = "GET";
webRequest.UserAgent = "Mozilla/4.0";
webRequest.Headers.Add("Accept-Encoding", "gzip, deflate");
HttpWebResponse webResponse = (System.Net.HttpWebResponse)webRequest.GetResponse();
if (webResponse.ContentEncoding.ToLower() == "gzip
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (var zipStream =
new System.IO.Compression.GZipStream(streamReceive, System.IO.Compression.CompressionMode.Decompress))
{
using (StreamReader sr = new System.IO.StreamReader(zipStream, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
}else
{
using (System.IO.Stream streamReceive = webResponse.GetResponseStream())
{
using (System.IO.StreamReader sr = new System.IO.StreamReader(streamReceive, Encoding.Default))
{
htmlCode = sr.ReadToEnd();
}
}
}
return htmlCode;
}
提取的数据不完整,无法显示iframe中的代码。我以为可能有一些AJAX数据,所以我更改了以下提取代码:
private void button1_Click(object sender, EventArgs e)
{
WebBrowser web = new WebBrowser();
web.Navigate(this.rtb_Url.Text);
web.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(web_DocumentCompleted);
while (web.IsBusy)
{
Application.DoEvents();
Thread.Sleep(100);
}
}
void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
WebBrowser web = (WebBrowser)sender;
string mystr = web.Document.Body.OuterHtml;
}
提到的原创来源总是不完整,希望园丁能给我一些建议,谢谢!
抓取网页数据(如何实现一下爱帮网上佛山药店的分布列表【我爱写游记】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-03 20:22
昨天我们用Jsoup技术实现了一个简单的爬虫。原理很简单。主要是先分析页面,获取条件,然后匹配url,使用穹顶分析的方式循环抓取我们需要的数据,这是一个简单的爬虫可以轻松实现。所以,昨天我们说昨天只爬取了一页数据,也就是第一页的数据。如果要获取分页的所有数据,应该怎么写呢?碰巧今天朋友找我帮忙买药,说她那里没有,于是查了佛山各大药店,利用刚刚学的爬虫技术,今天就明白了艾邦网上佛山药店经销名单。
一、需求分析
首先,我们登录爱邦网,选择城市区域,输入关键词。我们输入“pharmacy”,点击搜索按钮,我们打开控制台,观察header信息,如下图:
通过观察我们可以看到请求的URL地址和参数;其实我们看地址栏就可以直接看到了。我们点击第二页,发现其他参数没有变化,只是参数p的值随着页码的变化而变化。所以,这样我们就可以知道每个页面的请求地址其实是一样的,只要改变p的值,然后我们看到页面总数只有8个页面,数据量不是大的。写一个循环 8 次。现在我们开始实现它,只是在昨天的代码的基础上改变它。
二、开发
1、我们首先需要改变我们的业务实现类,因为获取值的方式不同,如下图:
我们要去的类是aide里面的内容,它也拿到了标签,但是我们观察到页面上有很多标签,需要拿到我们需要的,如下图所示:
/*
* 提取结果中的链接地址和链接标题,返回数据
*/
for(Element result : results){
Elements links = result.getElementsByTag("a");//可以拿到链接
for(Element link : links){
if(link.siblingElements().hasClass("num")){
String id = link.siblingElements().text();
String linkText = link.text();
LinkTypeData data1 = new LinkTypeData();
if(id!=null && linkText!=null){
data1.setId(id);
data1.setLinkText(linkText);
}
datas.add(data1);
}
if(link.parent().parent().hasClass("part1")){
LinkTypeData data2 = new LinkTypeData();
String address = link.parent().siblingElements().text();
if(address!=null){
data2.setSummary(address);
}
datas.add(data2);
}
if(link.parent().siblingElements().tagName("span").hasClass("biztel")){
LinkTypeData data3 = new LinkTypeData();
String telnum = link.parent().siblingElements().tagName("span").text();
if(telnum!=null){
data3.setContent(telnum);
}
datas.add(data3);
}
}
// 对取得的html中的 出现问号乱码进行处理
/*linkText = new String(linkText.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String id = link.parent().firstElementSibling().text();
id = new String(id.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String address = link.parent().nextElementSibling().text();
address = new String(address.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String code = link.parent().lastElementSibling().text();
code = new String(code.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');*/
/*data.setSummary(address);
data.setContent(code);
data.setId(id);*/
}
return datas;
}
我们根据昨天的代码进行了更改。这样就得到了我们想要的数据。
三、测试
接下来我们可以改变我们的测试类,我们需要循环8次,每次拿到数据都存储在一个新的集合中,最后再取出新的数据集合写入Excel。
<p>/**
* 不带查询参数
* @author AoXiang
* 2017年3月21日
*/
@org.junit.Test
public void getDataByClass() throws IOException{
List newList = new ArrayList();
for(int i=1;i 查看全部
抓取网页数据(如何实现一下爱帮网上佛山药店的分布列表【我爱写游记】)
昨天我们用Jsoup技术实现了一个简单的爬虫。原理很简单。主要是先分析页面,获取条件,然后匹配url,使用穹顶分析的方式循环抓取我们需要的数据,这是一个简单的爬虫可以轻松实现。所以,昨天我们说昨天只爬取了一页数据,也就是第一页的数据。如果要获取分页的所有数据,应该怎么写呢?碰巧今天朋友找我帮忙买药,说她那里没有,于是查了佛山各大药店,利用刚刚学的爬虫技术,今天就明白了艾邦网上佛山药店经销名单。
一、需求分析
首先,我们登录爱邦网,选择城市区域,输入关键词。我们输入“pharmacy”,点击搜索按钮,我们打开控制台,观察header信息,如下图:
通过观察我们可以看到请求的URL地址和参数;其实我们看地址栏就可以直接看到了。我们点击第二页,发现其他参数没有变化,只是参数p的值随着页码的变化而变化。所以,这样我们就可以知道每个页面的请求地址其实是一样的,只要改变p的值,然后我们看到页面总数只有8个页面,数据量不是大的。写一个循环 8 次。现在我们开始实现它,只是在昨天的代码的基础上改变它。
二、开发
1、我们首先需要改变我们的业务实现类,因为获取值的方式不同,如下图:
我们要去的类是aide里面的内容,它也拿到了标签,但是我们观察到页面上有很多标签,需要拿到我们需要的,如下图所示:
/*
* 提取结果中的链接地址和链接标题,返回数据
*/
for(Element result : results){
Elements links = result.getElementsByTag("a");//可以拿到链接
for(Element link : links){
if(link.siblingElements().hasClass("num")){
String id = link.siblingElements().text();
String linkText = link.text();
LinkTypeData data1 = new LinkTypeData();
if(id!=null && linkText!=null){
data1.setId(id);
data1.setLinkText(linkText);
}
datas.add(data1);
}
if(link.parent().parent().hasClass("part1")){
LinkTypeData data2 = new LinkTypeData();
String address = link.parent().siblingElements().text();
if(address!=null){
data2.setSummary(address);
}
datas.add(data2);
}
if(link.parent().siblingElements().tagName("span").hasClass("biztel")){
LinkTypeData data3 = new LinkTypeData();
String telnum = link.parent().siblingElements().tagName("span").text();
if(telnum!=null){
data3.setContent(telnum);
}
datas.add(data3);
}
}
// 对取得的html中的 出现问号乱码进行处理
/*linkText = new String(linkText.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String id = link.parent().firstElementSibling().text();
id = new String(id.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String address = link.parent().nextElementSibling().text();
address = new String(address.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');
String code = link.parent().lastElementSibling().text();
code = new String(code.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');*/
/*data.setSummary(address);
data.setContent(code);
data.setId(id);*/
}
return datas;
}
我们根据昨天的代码进行了更改。这样就得到了我们想要的数据。
三、测试
接下来我们可以改变我们的测试类,我们需要循环8次,每次拿到数据都存储在一个新的集合中,最后再取出新的数据集合写入Excel。
<p>/**
* 不带查询参数
* @author AoXiang
* 2017年3月21日
*/
@org.junit.Test
public void getDataByClass() throws IOException{
List newList = new ArrayList();
for(int i=1;i
抓取网页数据(在mac上我使用Go和相应的数据库indiepic(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-03 20:21
上一节主要实现了使用goquery从图片网站中获取数据。它主要捕获图片的五个数据项:原创数据、宽度、高度、ALT和类型。因此,必须首先创建数据库和相应的表。在Mac上,我使用sequel Pro数据库管理软件。连接后,我创建了一个新的数据库indipic,然后创建了表gradisography:
CREATE TABLE `gratisography` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`img_url` varchar(255) DEFAULT NULL,
`type_name` varchar(50) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`width` int(11) DEFAULT NULL,
`height` int(11) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=388 DEFAULT CHARSET=utf8;
创建数据库后,使用go连接到数据库。Go MySQL驱动程序是用于Go(golang)数据库/SQL包的轻量级快速MySQL驱动程序
文件:
在使用之前,您需要使用以下命令来获取包:
go get github.com/go-sql-driver/mysql
然后在database.go中介绍以下内容:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
然后编写打开数据库opendatabase的方法:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
在上一节中,insertData(&imagedata)方法是在crawldata.go中编写的,但它是带注释的。您需要首先在该文件中实现该方法
package crawldata
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
"strconv"
s "strings"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
/*
该函数将获取的数据存储到数据库
*/
func InsertData(datas *ImageDatas) {
imageDatas := *datas
// 连接数据库
db, err := OpenDatabase()
if err != nil {
fmt.Printf(s.Join([]string{"连接数据库失败", err.Error()}, "-->"))
}
defer db.Close()
for i := 0; i < len(imageDatas); i++ {
imageData := imageDatas[i]
// Prepare statement for inserting data
imgIns, err := db.Prepare("INSERT INTO gratisography (img_url, type_name, title, width, height) VALUES( ?, ?, ?, ?, ? )") // ? = placeholder
if err != nil {
fmt.Println(s.Join([]string{"拼装数据格式", err.Error()}, "-->"))
}
defer imgIns.Close() // Close the statement when we leave main()
img, err := imgIns.Exec(s.Join([]string{"http://www.gratisography.com", imageData.Src}, "/"), imageData.Tp, imageData.Title, imageData.Width, imageData.Height)
if err != nil {
fmt.Println(s.Join([]string{"插入数据失败", err.Error()}, "-->"))
} else {
success, _ := img.LastInsertId()
// 数字变成字符串,success是int64型的值,需要转为int,网上说的Itoa64()在strconv包里不存在
insertId := strconv.Itoa(int(success))
fmt.Println(s.Join([]string{"成功插入数据:", insertId}, "\t-->\t"))
}
}
}
此时,数据捕获已经完成并存储在数据库中。在命令行上切换到$gopath/SRC/indiepic目录,然后运行:
go run indiepic.go
然后可以看到数据存储在数据库中
到目前为止,只实现了数据采集,但需要使用go向外部提供JSON接口。下一节将完成数据采集,并使用web框架返回JSON数据 查看全部
抓取网页数据(在mac上我使用Go和相应的数据库indiepic(图))
上一节主要实现了使用goquery从图片网站中获取数据。它主要捕获图片的五个数据项:原创数据、宽度、高度、ALT和类型。因此,必须首先创建数据库和相应的表。在Mac上,我使用sequel Pro数据库管理软件。连接后,我创建了一个新的数据库indipic,然后创建了表gradisography:
CREATE TABLE `gratisography` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`img_url` varchar(255) DEFAULT NULL,
`type_name` varchar(50) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`width` int(11) DEFAULT NULL,
`height` int(11) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=388 DEFAULT CHARSET=utf8;
创建数据库后,使用go连接到数据库。Go MySQL驱动程序是用于Go(golang)数据库/SQL包的轻量级快速MySQL驱动程序
文件:
在使用之前,您需要使用以下命令来获取包:
go get github.com/go-sql-driver/mysql
然后在database.go中介绍以下内容:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
然后编写打开数据库opendatabase的方法:
package crawldata
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
在上一节中,insertData(&imagedata)方法是在crawldata.go中编写的,但它是带注释的。您需要首先在该文件中实现该方法
package crawldata
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
"strconv"
s "strings"
)
func OpenDatabase() (*sql.DB, error) {
// 连接数据库
db, err := sql.Open("mysql", "root:mysql@tcp(xxx.xx.xx.xxx:3306)/databaseName?charset=utf8")
if err != nil {
return nil, err
}
return db, nil
}
/*
该函数将获取的数据存储到数据库
*/
func InsertData(datas *ImageDatas) {
imageDatas := *datas
// 连接数据库
db, err := OpenDatabase()
if err != nil {
fmt.Printf(s.Join([]string{"连接数据库失败", err.Error()}, "-->"))
}
defer db.Close()
for i := 0; i < len(imageDatas); i++ {
imageData := imageDatas[i]
// Prepare statement for inserting data
imgIns, err := db.Prepare("INSERT INTO gratisography (img_url, type_name, title, width, height) VALUES( ?, ?, ?, ?, ? )") // ? = placeholder
if err != nil {
fmt.Println(s.Join([]string{"拼装数据格式", err.Error()}, "-->"))
}
defer imgIns.Close() // Close the statement when we leave main()
img, err := imgIns.Exec(s.Join([]string{"http://www.gratisography.com", imageData.Src}, "/"), imageData.Tp, imageData.Title, imageData.Width, imageData.Height)
if err != nil {
fmt.Println(s.Join([]string{"插入数据失败", err.Error()}, "-->"))
} else {
success, _ := img.LastInsertId()
// 数字变成字符串,success是int64型的值,需要转为int,网上说的Itoa64()在strconv包里不存在
insertId := strconv.Itoa(int(success))
fmt.Println(s.Join([]string{"成功插入数据:", insertId}, "\t-->\t"))
}
}
}
此时,数据捕获已经完成并存储在数据库中。在命令行上切换到$gopath/SRC/indiepic目录,然后运行:
go run indiepic.go
然后可以看到数据存储在数据库中
到目前为止,只实现了数据采集,但需要使用go向外部提供JSON接口。下一节将完成数据采集,并使用web框架返回JSON数据
抓取网页数据(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-10-03 12:26
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
抓取网页数据(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,它让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
抓取网页数据(小编来一起如何用python来页面中的JS动态加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-01 20:07
)
本文文章主要介绍如何使用python捕捉网页中的动态数据。文章通过示例代码详细介绍,对大家学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text 查看全部
抓取网页数据(小编来一起如何用python来页面中的JS动态加载
)
本文文章主要介绍如何使用python捕捉网页中的动态数据。文章通过示例代码详细介绍,对大家学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text
抓取网页数据(soup考试:本文具有不错的参考意义(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-28 17:28
前言:
今天给大家带来的是4个详细步骤讲解Python爬取网页数据的操作过程!(包括示例代码)这篇文章有很好的参考意义,希望对你有帮助!
提示:由于涉及的代码较多,所以大部分代码以图片的形式呈现!
一、使用 webbrowser.open() 打开一个 网站:
示例:使用脚本打开网页。
所有 Python 程序的第一行都应该以 #!python 开头,它告诉计算机您希望 Python 执行这个程序。(我没有带这条线去试试,没关系,也许这是常态)
注意:如果你不知道 sys.argv 的用法,请参考这里;如果你不知道 .join() 的用法,请参考这里。sys.argv 是一个字符串列表,因此将它传递给 join() 方法会返回一个字符串。
好的,现在选择并复制“天安门广场”字样,然后在桌面上双击您的程序。当然,你也可以在命令行中找到你的程序并输入位置。
二、 使用请求模块从 Web 下载文件:请求模块不收录在 Python 中。在命令行上运行 pip install request 来安装它。不翻墙就很难安装成功。如需手动安装,请参阅此处。
有多种方法可以查看请求中从 Internet 下载的文件的内容。如果在以后的博客中用到,会进行讲解,这里就不一一介绍了。在下载文件的过程中,使用 raise_for_status() 方法确保下载确实成功,然后让程序继续做其他事情。
三、将下载的文件保存到本地:
四、 使用 BeautifulSoup 模块解析 HTML:在命令行使用 pip install beautifulsoup4 安装它。
1.bs4.BeautifulSoup()函数可以解析HTML网站链接requests.get(),或者解析本地保存的HTML文件,直接open()一个本地的HTML页面。
我这里有一条错误消息,所以我添加了第二个参数。
2.使用select()方法查找元素:需要传入一个字符串作为CSS“选择器”来获取网页对应的元素,例如:
汤.选择('div'):所有名称
Soup.select('#author'):id属性为author的元素;soup.select('.notice'):所有具有名为 notice 的 CSS 类属性的元素;汤.select('div span'): 全部在
元素内的元素;soup.select('input[name]'):所有具有名称和名称属性值无关紧要的元素;sound.select('input[type="button"]'): All 元素命名并有一个值为button的type属性。 查看全部
抓取网页数据(soup考试:本文具有不错的参考意义(一))
前言:
今天给大家带来的是4个详细步骤讲解Python爬取网页数据的操作过程!(包括示例代码)这篇文章有很好的参考意义,希望对你有帮助!
提示:由于涉及的代码较多,所以大部分代码以图片的形式呈现!
一、使用 webbrowser.open() 打开一个 网站:
示例:使用脚本打开网页。
所有 Python 程序的第一行都应该以 #!python 开头,它告诉计算机您希望 Python 执行这个程序。(我没有带这条线去试试,没关系,也许这是常态)
注意:如果你不知道 sys.argv 的用法,请参考这里;如果你不知道 .join() 的用法,请参考这里。sys.argv 是一个字符串列表,因此将它传递给 join() 方法会返回一个字符串。
好的,现在选择并复制“天安门广场”字样,然后在桌面上双击您的程序。当然,你也可以在命令行中找到你的程序并输入位置。
二、 使用请求模块从 Web 下载文件:请求模块不收录在 Python 中。在命令行上运行 pip install request 来安装它。不翻墙就很难安装成功。如需手动安装,请参阅此处。
有多种方法可以查看请求中从 Internet 下载的文件的内容。如果在以后的博客中用到,会进行讲解,这里就不一一介绍了。在下载文件的过程中,使用 raise_for_status() 方法确保下载确实成功,然后让程序继续做其他事情。
三、将下载的文件保存到本地:
四、 使用 BeautifulSoup 模块解析 HTML:在命令行使用 pip install beautifulsoup4 安装它。
1.bs4.BeautifulSoup()函数可以解析HTML网站链接requests.get(),或者解析本地保存的HTML文件,直接open()一个本地的HTML页面。
我这里有一条错误消息,所以我添加了第二个参数。
2.使用select()方法查找元素:需要传入一个字符串作为CSS“选择器”来获取网页对应的元素,例如:
汤.选择('div'):所有名称
Soup.select('#author'):id属性为author的元素;soup.select('.notice'):所有具有名为 notice 的 CSS 类属性的元素;汤.select('div span'): 全部在
元素内的元素;soup.select('input[name]'):所有具有名称和名称属性值无关紧要的元素;sound.select('input[type="button"]'): All 元素命名并有一个值为button的type属性。
抓取网页数据(一下如何打造适合百度的网站?维度为您解答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-25 20:40
做好网站收录是SEO的基础工作。只有网站的内容进入百度索引库,搜索关键词时才有机会出现在搜索结果中。我们从三个维度来和大家分享如何打造适合百度抓取的网站。
一、网站结构
1、逻辑清晰的链接层次结构
更好的站点结构仍然是树状结构。以首页为节点的树状连接可以通过首页上的链接访问网站的任意页面。在构建站点的树状结构时,要注意避免过于平坦的结构。所有内容页面都放在根目录下,不利于网站的目录权重传递。在建站时,也需要注意避免孤岛链接。所谓岛屿链接,就是在站点内通过正常访问无法找到的页面,只能通过直接输入网址或提交地图才能找到。这样的页面搜索引擎不易抓取,不利于用户对内容的浏览和访问,影响用户体验。
2、PC/手机适配
如今,移动搜索的流量正在增加。通过适配的建立,PC端URL和移动端URL具有规则级别的对应关系,相互关联。这样,网站在移动搜索时就有机会进入移动索引库。对于网站,建议在建立适配时建立规则级别的对应关系,符合一定的正则表达式映射规则。目前百度推荐的视频方式有:跳转适配、代码适配、适配。
3、本站带你主动投稿
目前百度在站长工具中有主动推送、自动推送、站点地图三种方式供站长提交新输出资源和及时更新资源。站长在提交内容时要注意避免死链接和低质量的内容。通过搜索引擎抓取。当出现死链接时,您可以使用死链接提交工具及时提交死链接和无效资源。
对于移动站,还需要通过提交工具将适配后的链接提交到移动链接,方便搜索引擎全面及时的抓取移动页面。
4、避免目录黑客/销售
百度蜘蛛的网站评分会考虑网页、目录等多个维度。一旦发现被黑或垃圾内容,百度指数会对整个网站的质量产生怀疑,从而影响整个网站带你的收录效果,进而影响排名。
一般购买网站目录的人都会根据网站的权威度和搜索引擎评分对灰色产品进行排名。很容易伤害网站的用户体验,百度对伤害用户体验的行为零容忍。 查看全部
抓取网页数据(一下如何打造适合百度的网站?维度为您解答)
做好网站收录是SEO的基础工作。只有网站的内容进入百度索引库,搜索关键词时才有机会出现在搜索结果中。我们从三个维度来和大家分享如何打造适合百度抓取的网站。
一、网站结构
1、逻辑清晰的链接层次结构
更好的站点结构仍然是树状结构。以首页为节点的树状连接可以通过首页上的链接访问网站的任意页面。在构建站点的树状结构时,要注意避免过于平坦的结构。所有内容页面都放在根目录下,不利于网站的目录权重传递。在建站时,也需要注意避免孤岛链接。所谓岛屿链接,就是在站点内通过正常访问无法找到的页面,只能通过直接输入网址或提交地图才能找到。这样的页面搜索引擎不易抓取,不利于用户对内容的浏览和访问,影响用户体验。
2、PC/手机适配
如今,移动搜索的流量正在增加。通过适配的建立,PC端URL和移动端URL具有规则级别的对应关系,相互关联。这样,网站在移动搜索时就有机会进入移动索引库。对于网站,建议在建立适配时建立规则级别的对应关系,符合一定的正则表达式映射规则。目前百度推荐的视频方式有:跳转适配、代码适配、适配。
3、本站带你主动投稿
目前百度在站长工具中有主动推送、自动推送、站点地图三种方式供站长提交新输出资源和及时更新资源。站长在提交内容时要注意避免死链接和低质量的内容。通过搜索引擎抓取。当出现死链接时,您可以使用死链接提交工具及时提交死链接和无效资源。
对于移动站,还需要通过提交工具将适配后的链接提交到移动链接,方便搜索引擎全面及时的抓取移动页面。
4、避免目录黑客/销售
百度蜘蛛的网站评分会考虑网页、目录等多个维度。一旦发现被黑或垃圾内容,百度指数会对整个网站的质量产生怀疑,从而影响整个网站带你的收录效果,进而影响排名。
一般购买网站目录的人都会根据网站的权威度和搜索引擎评分对灰色产品进行排名。很容易伤害网站的用户体验,百度对伤害用户体验的行为零容忍。
抓取网页数据(节点集中前五个节点集的使用方法和使用解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-24 22:05
我刚刚学习了XPath路径表达式,它主要用于搜索XML文档中的节点。通过XPath表达式,我可以快速定位和访问XML文档中的节点位置。Html也是一种类似于XML的标记语言,但语法没有那么严格。在codeplex中,有一个开源项目htmlagilitypack,它提供了用XPath解析HTML文件的功能,下面是如何使用类库
首先,让我们讨论XPath路径表达式
XPath路径表达式
用于选择XML文档中的节点或节点集
1、术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、注释、文档(根)节点
2、节点关系:父节点、子节点、兄弟节点、祖先节点、后代节点
3、路径表达式
NodeName节点名称,选择此节点的所有子节点,例如:当前节点中的childnode子节点,不包括具有孙辈和孙辈以下的节点
/从根节点中选择一个示例:/root/childnode/grandonnode
//表示所有子代节点。例如://childnode所有名为childnode的子代节点
。指示当前节点。示例:./childnode表示当前节点的childnode节点
。。指示父节点。例如,…/nearnode表示父节点的nearnode子节点
@选择属性/root/childnode/@ID来表示收录childnode的ID属性的所有节点集
4、谓词
谓词可以对节点集进行一些限制,以使选择更加准确
/根/书本[1]节点集中的第一个节点
/Root/book[last()]节点集中的最后一个节点
/Root/book[position()-1]节点集中倒数第二个节点集
/Root/book[position()35]/Title节点set book的price元素值大于35的Title节点集
5、通配符:XPath路径中也支持通配符(*、@*、node()、text()
例如:/书店/*
//标题[@*]
6、XPath轴
定义相对于当前节点的节点集
祖先节点
属性所有属性节点
子元素所有子元素
子代所有子代节点(子代、子代…)
在结束标记之后的所有节点之后,在开始标记之前的所有节点之前
在同级节点之后,结束标记之后的所有同级节点
标记前的所有同级节点
命名空间当前命名空间的所有节点
父节点
自流节点
用法:轴名称::节点测试[谓词]
示例:ancester::Book
child::text()
7、操作员
|合并两个节点集的示例:/root/book[1]|/root/book[3]
+,-,*,开发,国防部
=,!==
或者,或者
//删除注释,script,style
node.Descendants()
.Where(n => n.Name == "script" || n.Name == "style" || n.Name=="#comment")
.ToList().ForEach(n => n.Remove());
//遍历node节点的所有后代节点
foreach(var HtmlNode in node.Descendants())
{
}
Htmlagilitypack类库用法
1、首先,您需要获取HTML页面数据,这些数据可以通过webrequest类获得
public static string GetHtmlStr(string url)
{
try
{
WebRequest rGet = WebRequest.Create(url);
WebResponse rSet = rGet.GetResponse();
Stream s = rSet.GetResponseStream();
StreamReader reader = new StreamReader(s, Encoding.UTF8);
return reader.ReadToEnd();
}
catch (WebException)
{
//连接失败
return null;
}
}
2、通过htmldocument类加载HTML数据
string htmlstr = GetHtmlStr("http://www.hao123.com");
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlstr);
HtmlNode rootnode = doc.DocumentNode; //XPath路径表达式,这里表示选取所有span节点中的font最后一个子节点,其中span节点的class属性值为num
//根据网页的内容设置XPath路径表达式
string xpathstring = "//span[@class='num']/font[last()]";
HtmlNodeCollection aa = rootnode.SelectNodes(xpathstring); //所有找到的节点都是一个集合
if(aa != null)
{
string innertext = aa[0].InnerText;
string color = aa[0].GetAttributeValue("color", ""); //获取color属性,第二个参数为默认值
//其他属性大家自己尝试
}
Htmldocument也可以通过htmlweb类获得
HtmlWeb web = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = web.Load(url);
HtmlNode rootnode = doc.DocumentNode;
补编:
多属性条件查询//div[@align='center'和@height='24']
Class属性不存在//div[不(@Class)] 查看全部
抓取网页数据(节点集中前五个节点集的使用方法和使用解析)
我刚刚学习了XPath路径表达式,它主要用于搜索XML文档中的节点。通过XPath表达式,我可以快速定位和访问XML文档中的节点位置。Html也是一种类似于XML的标记语言,但语法没有那么严格。在codeplex中,有一个开源项目htmlagilitypack,它提供了用XPath解析HTML文件的功能,下面是如何使用类库
首先,让我们讨论XPath路径表达式
XPath路径表达式
用于选择XML文档中的节点或节点集
1、术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、注释、文档(根)节点
2、节点关系:父节点、子节点、兄弟节点、祖先节点、后代节点
3、路径表达式
NodeName节点名称,选择此节点的所有子节点,例如:当前节点中的childnode子节点,不包括具有孙辈和孙辈以下的节点
/从根节点中选择一个示例:/root/childnode/grandonnode
//表示所有子代节点。例如://childnode所有名为childnode的子代节点
。指示当前节点。示例:./childnode表示当前节点的childnode节点
。。指示父节点。例如,…/nearnode表示父节点的nearnode子节点
@选择属性/root/childnode/@ID来表示收录childnode的ID属性的所有节点集
4、谓词
谓词可以对节点集进行一些限制,以使选择更加准确
/根/书本[1]节点集中的第一个节点
/Root/book[last()]节点集中的最后一个节点
/Root/book[position()-1]节点集中倒数第二个节点集
/Root/book[position()35]/Title节点set book的price元素值大于35的Title节点集
5、通配符:XPath路径中也支持通配符(*、@*、node()、text()
例如:/书店/*
//标题[@*]
6、XPath轴
定义相对于当前节点的节点集
祖先节点
属性所有属性节点
子元素所有子元素
子代所有子代节点(子代、子代…)
在结束标记之后的所有节点之后,在开始标记之前的所有节点之前
在同级节点之后,结束标记之后的所有同级节点
标记前的所有同级节点
命名空间当前命名空间的所有节点
父节点
自流节点
用法:轴名称::节点测试[谓词]
示例:ancester::Book
child::text()
7、操作员
|合并两个节点集的示例:/root/book[1]|/root/book[3]
+,-,*,开发,国防部
=,!==
或者,或者
//删除注释,script,style
node.Descendants()
.Where(n => n.Name == "script" || n.Name == "style" || n.Name=="#comment")
.ToList().ForEach(n => n.Remove());
//遍历node节点的所有后代节点
foreach(var HtmlNode in node.Descendants())
{
}
Htmlagilitypack类库用法
1、首先,您需要获取HTML页面数据,这些数据可以通过webrequest类获得
public static string GetHtmlStr(string url)
{
try
{
WebRequest rGet = WebRequest.Create(url);
WebResponse rSet = rGet.GetResponse();
Stream s = rSet.GetResponseStream();
StreamReader reader = new StreamReader(s, Encoding.UTF8);
return reader.ReadToEnd();
}
catch (WebException)
{
//连接失败
return null;
}
}
2、通过htmldocument类加载HTML数据
string htmlstr = GetHtmlStr("http://www.hao123.com";);
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlstr);
HtmlNode rootnode = doc.DocumentNode; //XPath路径表达式,这里表示选取所有span节点中的font最后一个子节点,其中span节点的class属性值为num
//根据网页的内容设置XPath路径表达式
string xpathstring = "//span[@class='num']/font[last()]";
HtmlNodeCollection aa = rootnode.SelectNodes(xpathstring); //所有找到的节点都是一个集合
if(aa != null)
{
string innertext = aa[0].InnerText;
string color = aa[0].GetAttributeValue("color", ""); //获取color属性,第二个参数为默认值
//其他属性大家自己尝试
}
Htmldocument也可以通过htmlweb类获得
HtmlWeb web = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = web.Load(url);
HtmlNode rootnode = doc.DocumentNode;
补编:
多属性条件查询//div[@align='center'和@height='24']
Class属性不存在//div[不(@Class)]
抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-24 22:04
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、 自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、 自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
抓取网页数据(Python解释器的安装推荐及安装的应用框架介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-09-23 15:49
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用程序框架,用于爬取网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm is a PythonIDE with a set of tools that can help users improve their efficiency when developing in the Python language, such as debugging, syntax highlighting, project management, code jumps, smart prompts, automatic completion, unit testing, and version control. In addition, the IDE provides some advanced features to support professional web development under the Django framework.
2.PyCharm install
Go to PyCharm's official website and click DownLoad to download. The professional version is on the left, and the community version is on the right. The community version is free, and the professional version is free for trial.
如果我们之前没有下载有Python解释器的话,在等待安装的时间我们可以去下载python解释器,进入Python官网,根据系统、版本下载对应的压缩包即可,在安装完后,在环境变量Path中配置Python解释器的安装路径。可参考博客:
三、Scrapy抓取豆瓣项目实战
前提:在PyCharm中要使用Scrapy的话,必须先在PyCharm中安装所支持的Scrapy包,过程如下,点击文件(File)>> 设置(Settings...),步骤如下图,我安装Scrapy之前绿色框内只有两个Package,如果当你点击后看到有Scrapy包的话,那就不用安装了,直接进行接下来的操作即可
如果没有Scrapy包的话,点击“+”,搜索Scrapy包,点击Install Package 进行安装
等待安装完成即可。
1.新建项目
打开刚安装好的PyCharm,使用pycharm工具在软件的终端,如果找不到PyCharm终端在哪,在左下角的底部的Terminal就是了
输入命令:scrapy startproject douban 这是使用命令行来新建一个爬虫项目,如下图所示,图片展示的项目名为pythonProject
接着在命令行输入命令:cd douban 进入已生成的项目根目录
接着继续在终端键入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的网站为:
假设,我们抓取top250电影的序列号,电影名,介绍,星级,评价数,电影描述选项
此时,我们在items.py文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接着,我们需要制作爬虫以及存储爬取内容
在douban_spider.py爬虫文件编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时不需要运行这个python文件,因为我们不是单独使用它的,所以不用运行,允许会报错,有关import引入的问题,关于主目录的绝对路径与相对路径的问题,原因是我们使用了相对路径“..items”,相关的内容感兴趣的同学可以去网上查找有关这类问题的解释。
4.存储内容
将所爬取的内容存储成json或csv格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取到的数据存储到json文件或者csv文件里。
在执行完爬取命令后,将鼠标的焦点给到项目面板时,即会显示出生成的json文件或csv文件。打开json或csv文件后,如果里面什么内容都没有,那么我们还需要进行一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
存储到json文件里的话,所有的内容都会以十六进制的形式显示出来,可以通过相应的方法进行转码,这里不过多的说明,如下图:
而存储在csv文件中,会直接将我们所要爬取的内容全部显示出来,如下图:
到此为止,我们已完成对网站特定内容的爬取,接下来,就需要对这些爬取的数据进行处理。
分割线----------------------------------------------------------------------------------------------------------------------分割线
Scraoy入门实例二---使用Pipeline实现
此次的实战需要重新创建一个项目,还是需要安装scrapy包,参考上面的内容,创建新项目的方法也参考上面的内容,这里不再重复赘述。
项目目录结构如下图所示:
一、Pipeline介绍
当我们通过Spider爬取数据,通过Item采集数据后,就要对数据进行一些处理了,因为我们爬取到的数据并不一定是我们想要的最终数据,可能还需要进行数据的清洗以及验证数据的有效性。Scripy中的Pipeline组件就用于数据的处理,一个Pipeline组件就是一个收录特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个Pipeline。
二、在items.py中定义自己要抓取的数据
首先打开一个新的pycharm项目,通过终端建立新项目tutorial,在item中定义想要抓取的数据,例如电影名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item pipe组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。定义的pipelines.py代码如下所示:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次使用了pipeline,所以需要我们在settings.py中打开pipelines通道注释,在里面新增一条,pipelines中添加的记录,如下图所示:
五、写爬虫文件
在tutoral/spiders目录下创建quotes_spider.py文件,目录结构如下,并写入初步的代码:
quotes_spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema ... 39%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在douban文件目录下新建启动文件 douban_spider_run.py (文件名称可以另取),并运行该文件,查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,经过处理后的爬取数据如下图所示(部分):
最后,希望大家在编写代码的时候能够细心点,不能马虎,我在实验的过程当中,就是因为将要引入的方法DoubanmovieItem写成了DobanmovieItem,从而导致了整个程序的运行失败,而且PyCharm还不告诉我哪里错了,我到处搜问题解决方法也没找到,最终核对了好多遍,生成方法时才发现,所以一定要细心。这个错误如下图所示,它提示说找不到DobanmovieItem这个模块,可能已经告诉我错误的地方了,因为我太菜了没发现,所以才耗费较长时间,希望大家引以为戒!
到此为止,使用Scrapy进行抓取网页内容,与对所抓取的内容进行清洗和处理的实验已经完成,要求对这个过程当中的代码与操作熟悉与运用,不会的去查找网上内容,消化吸收,记在脑子里,这才是真正学到知识,而不是照葫芦画瓢。
出处: 查看全部
抓取网页数据(Python解释器的安装推荐及安装的应用框架介绍)
一、Scrapy 安装
1.Scrapy 介绍
Scrapy 是一个应用程序框架,用于爬取网站 数据并提取结构化数据。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm is a PythonIDE with a set of tools that can help users improve their efficiency when developing in the Python language, such as debugging, syntax highlighting, project management, code jumps, smart prompts, automatic completion, unit testing, and version control. In addition, the IDE provides some advanced features to support professional web development under the Django framework.
2.PyCharm install
Go to PyCharm's official website and click DownLoad to download. The professional version is on the left, and the community version is on the right. The community version is free, and the professional version is free for trial.
如果我们之前没有下载有Python解释器的话,在等待安装的时间我们可以去下载python解释器,进入Python官网,根据系统、版本下载对应的压缩包即可,在安装完后,在环境变量Path中配置Python解释器的安装路径。可参考博客:
三、Scrapy抓取豆瓣项目实战
前提:在PyCharm中要使用Scrapy的话,必须先在PyCharm中安装所支持的Scrapy包,过程如下,点击文件(File)>> 设置(Settings...),步骤如下图,我安装Scrapy之前绿色框内只有两个Package,如果当你点击后看到有Scrapy包的话,那就不用安装了,直接进行接下来的操作即可
如果没有Scrapy包的话,点击“+”,搜索Scrapy包,点击Install Package 进行安装
等待安装完成即可。
1.新建项目
打开刚安装好的PyCharm,使用pycharm工具在软件的终端,如果找不到PyCharm终端在哪,在左下角的底部的Terminal就是了
输入命令:scrapy startproject douban 这是使用命令行来新建一个爬虫项目,如下图所示,图片展示的项目名为pythonProject
接着在命令行输入命令:cd douban 进入已生成的项目根目录
接着继续在终端键入命令:scrapy genspider douban_spider 生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确目标
我们要练习的网站为:
假设,我们抓取top250电影的序列号,电影名,介绍,星级,评价数,电影描述选项
此时,我们在items.py文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接着,我们需要制作爬虫以及存储爬取内容
在douban_spider.py爬虫文件编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时不需要运行这个python文件,因为我们不是单独使用它的,所以不用运行,允许会报错,有关import引入的问题,关于主目录的绝对路径与相对路径的问题,原因是我们使用了相对路径“..items”,相关的内容感兴趣的同学可以去网上查找有关这类问题的解释。
4.存储内容
将所爬取的内容存储成json或csv格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取到的数据存储到json文件或者csv文件里。
在执行完爬取命令后,将鼠标的焦点给到项目面板时,即会显示出生成的json文件或csv文件。打开json或csv文件后,如果里面什么内容都没有,那么我们还需要进行一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
存储到json文件里的话,所有的内容都会以十六进制的形式显示出来,可以通过相应的方法进行转码,这里不过多的说明,如下图:
而存储在csv文件中,会直接将我们所要爬取的内容全部显示出来,如下图:
到此为止,我们已完成对网站特定内容的爬取,接下来,就需要对这些爬取的数据进行处理。
分割线----------------------------------------------------------------------------------------------------------------------分割线
Scraoy入门实例二---使用Pipeline实现
此次的实战需要重新创建一个项目,还是需要安装scrapy包,参考上面的内容,创建新项目的方法也参考上面的内容,这里不再重复赘述。
项目目录结构如下图所示:
一、Pipeline介绍
当我们通过Spider爬取数据,通过Item采集数据后,就要对数据进行一些处理了,因为我们爬取到的数据并不一定是我们想要的最终数据,可能还需要进行数据的清洗以及验证数据的有效性。Scripy中的Pipeline组件就用于数据的处理,一个Pipeline组件就是一个收录特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个Pipeline。
二、在items.py中定义自己要抓取的数据
首先打开一个新的pycharm项目,通过终端建立新项目tutorial,在item中定义想要抓取的数据,例如电影名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item pipe组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。定义的pipelines.py代码如下所示:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次使用了pipeline,所以需要我们在settings.py中打开pipelines通道注释,在里面新增一条,pipelines中添加的记录,如下图所示:
五、写爬虫文件
在tutoral/spiders目录下创建quotes_spider.py文件,目录结构如下,并写入初步的代码:
quotes_spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema ... 39%3B]
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在douban文件目录下新建启动文件 douban_spider_run.py (文件名称可以另取),并运行该文件,查看结果,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,经过处理后的爬取数据如下图所示(部分):
最后,希望大家在编写代码的时候能够细心点,不能马虎,我在实验的过程当中,就是因为将要引入的方法DoubanmovieItem写成了DobanmovieItem,从而导致了整个程序的运行失败,而且PyCharm还不告诉我哪里错了,我到处搜问题解决方法也没找到,最终核对了好多遍,生成方法时才发现,所以一定要细心。这个错误如下图所示,它提示说找不到DobanmovieItem这个模块,可能已经告诉我错误的地方了,因为我太菜了没发现,所以才耗费较长时间,希望大家引以为戒!
到此为止,使用Scrapy进行抓取网页内容,与对所抓取的内容进行清洗和处理的实验已经完成,要求对这个过程当中的代码与操作熟悉与运用,不会的去查找网上内容,消化吸收,记在脑子里,这才是真正学到知识,而不是照葫芦画瓢。
出处:
抓取网页数据(用浏览器抓包分析数据的使用场景非常受限,且后面还要由一门后端语言做补充)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-23 03:15
使用方案非常有限,通过使用浏览器捕获,还必须稍后在后端语言中进行补充。这是一个更简单的想法,即:
替换了正则表达式
使用CSS选择器
留下场景是一个流氓,数据直接使用浏览器队长分析数据以满足以下要求:
1、数据相对静态,它不会频繁更改;
2、数据量非常大,人工提取非常麻烦;
3、所有数据基本上都可以在页面上抓取,后端语言请求URL,然后分析HTML成本并慢速。
也许有人会问,真的有这样的场景吗?
答案,存在,我已经遇到了类似的场景。
是想法,以下方案:(请注意,此场景不涉及HTTP相关内容,而不是在本文的讨论中)
用户可以自定义一个项目,这个项目有一个名称,带有图标。图标使用字体令人敬畏,一组很棒的图标公司和CSS框架,需要一个选项列表。
我们打开fontawesome官方网站,发现675个图标,如果手动进入我们的程序,显然是非常低效和浪费的时间,并使用后端请求然后写常规,调整错误。很多次,所以我们选择最简单,最粗鲁的方式 - 直接使用浏览器,即在开发人员工具中编写代码以获取DOM数据。
我想在一起我们必须得到的:
这里是一个简化的演示,只有一个数据:图标的类名,即所有类名,类似于“地址书”,“浴”。
由于它是抓取浏览器中的数据,它自然会涉及DOM操作,涉及DOM操作选择jQuery,因此让我们测试网站有j j j。 jquery。
非常好,可以使用它,然后下一步是分析DOM结构。
选择一个节点以查看其结构,可以找到以下信息:
1、每个图标由类“FA-HOVER COL-MD-3 COL-SM”包装,为我们提供了极大的便利,为我们提供整个页面;
2、类名称在SPAN标记后面。
所以现在我们将尝试使用“FA-HOVER COL-MD-3 COL-SM-SM-4”获取所有图标数据项。
从图中可以看出,我们已经获得了975个数据,然后你将直接在代码上从这些DOM获取图标类名称。
首先输出所有DOM,确认,然后获取数据。
分析DOM结构,我们需要的数据是“YC-Square”,直接使用文本功能直接获得:
但这是不够的,我们需要在示例的例子背后进行数据,所以继续分割处理:
成功获取,最后一步是构建这些数据:
所有推入数组,然后json,这样可以将这些数据复制到程序。
当然,这里只是为了演示,所以生成的结构相对简单,实际上,我们还可以对这些数据进行分类。
这是实际业务中使用的结构。
返回我们的主题:使用浏览器的高效装配分析数据。
在此业务下,没有必要请求URL。它不需要编写正则表达式。您可以获得最多5分钟的所需数据。这是一种非常有效的方式,这种方式也可以是无缝迁移到后端。
为什么要迁移到后端?由于与jQuery的高效选择器一起使用,可以在爬行动物数据分析领域中使用它而不是正则表达式。毕竟,网络中有很多HTML数据,如果使用jQuery选择器分析这些数据,则无疑将降低大阈值。增加更多的开发和生产效率。
推荐库可以使用jQuery:TMPVAR / JSDOM
在节点中:tmpvar / jsdom
不仅如此,还可以直接编译前端的JavaScript到V8,然后分析生成的HTML。
我在节点中没有尝试过jQuery,但我还没有尝试过它,但是通过在浏览器中获得元数据然后将业务处理完成了很多东西。
还有一个类网站有大量的下载链接,并且是html的公共。目前,我已经以这种方式下载了大量数据,后端连接到节点,异步模型非常好。
私人思想,未来的节点将摇动Python在爬行动物区域的位置,CSS选择器还将摇动数据提取中的正则表达式。 查看全部
抓取网页数据(用浏览器抓包分析数据的使用场景非常受限,且后面还要由一门后端语言做补充)
使用方案非常有限,通过使用浏览器捕获,还必须稍后在后端语言中进行补充。这是一个更简单的想法,即:
替换了正则表达式
使用CSS选择器
留下场景是一个流氓,数据直接使用浏览器队长分析数据以满足以下要求:
1、数据相对静态,它不会频繁更改;
2、数据量非常大,人工提取非常麻烦;
3、所有数据基本上都可以在页面上抓取,后端语言请求URL,然后分析HTML成本并慢速。
也许有人会问,真的有这样的场景吗?
答案,存在,我已经遇到了类似的场景。
是想法,以下方案:(请注意,此场景不涉及HTTP相关内容,而不是在本文的讨论中)
用户可以自定义一个项目,这个项目有一个名称,带有图标。图标使用字体令人敬畏,一组很棒的图标公司和CSS框架,需要一个选项列表。
我们打开fontawesome官方网站,发现675个图标,如果手动进入我们的程序,显然是非常低效和浪费的时间,并使用后端请求然后写常规,调整错误。很多次,所以我们选择最简单,最粗鲁的方式 - 直接使用浏览器,即在开发人员工具中编写代码以获取DOM数据。
我想在一起我们必须得到的:
这里是一个简化的演示,只有一个数据:图标的类名,即所有类名,类似于“地址书”,“浴”。
由于它是抓取浏览器中的数据,它自然会涉及DOM操作,涉及DOM操作选择jQuery,因此让我们测试网站有j j j。 jquery。
非常好,可以使用它,然后下一步是分析DOM结构。
选择一个节点以查看其结构,可以找到以下信息:
1、每个图标由类“FA-HOVER COL-MD-3 COL-SM”包装,为我们提供了极大的便利,为我们提供整个页面;
2、类名称在SPAN标记后面。
所以现在我们将尝试使用“FA-HOVER COL-MD-3 COL-SM-SM-4”获取所有图标数据项。
从图中可以看出,我们已经获得了975个数据,然后你将直接在代码上从这些DOM获取图标类名称。
首先输出所有DOM,确认,然后获取数据。
分析DOM结构,我们需要的数据是“YC-Square”,直接使用文本功能直接获得:
但这是不够的,我们需要在示例的例子背后进行数据,所以继续分割处理:
成功获取,最后一步是构建这些数据:
所有推入数组,然后json,这样可以将这些数据复制到程序。
当然,这里只是为了演示,所以生成的结构相对简单,实际上,我们还可以对这些数据进行分类。
这是实际业务中使用的结构。
返回我们的主题:使用浏览器的高效装配分析数据。
在此业务下,没有必要请求URL。它不需要编写正则表达式。您可以获得最多5分钟的所需数据。这是一种非常有效的方式,这种方式也可以是无缝迁移到后端。
为什么要迁移到后端?由于与jQuery的高效选择器一起使用,可以在爬行动物数据分析领域中使用它而不是正则表达式。毕竟,网络中有很多HTML数据,如果使用jQuery选择器分析这些数据,则无疑将降低大阈值。增加更多的开发和生产效率。
推荐库可以使用jQuery:TMPVAR / JSDOM
在节点中:tmpvar / jsdom
不仅如此,还可以直接编译前端的JavaScript到V8,然后分析生成的HTML。
我在节点中没有尝试过jQuery,但我还没有尝试过它,但是通过在浏览器中获得元数据然后将业务处理完成了很多东西。
还有一个类网站有大量的下载链接,并且是html的公共。目前,我已经以这种方式下载了大量数据,后端连接到节点,异步模型非常好。
私人思想,未来的节点将摇动Python在爬行动物区域的位置,CSS选择器还将摇动数据提取中的正则表达式。
抓取网页数据(人工智能(AI)和机器学习(ML)的下一步是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-23 03:13
众所周知,网络数据在世界各地的各行各业中获得更受欢迎。每个人都知道采集公共数据(特别是大规模采集)将面临很多挑战。这就是为什么奥克萨斯举行了第二个网页以获取会议!
单击“注册”页面的链接。 OxyCon2021从8月25日举行到26日,奥克拉布斯讨论了Web数据捕获等相关主题!今年,oxycon2021将在线进行。两天的虚拟在线活动聚集了全球商业领袖和奥克萨布经验丰富的团队,深入,细致的谈判和讨论。
CEO评论
数据有助于公司做出更好,聪明的决策,最终取得了良好的效果。我们相信,每家公司无论尺寸如何,您都需要访问有价值的公共数据。 oxycon2021是数据采集行业顶级公司学习机会的大家,这些公司了解数据采集行业的快速增长,并知道如何使用网页来发挥公司的最大潜力。 “
-JuliusČerniauskas,奥克萨布斯首席执行官
oxycon2021是关于什么?
今年苏蒙将专注于三个重要主题。根据您的业务需求和个人兴趣,您可以选择最相关的研讨会,讨论或讲座。
业务数据集合
虽然互联网充满了有关如何做出更好决策和提高性能的信息,但他们需要的数据仍然具有挑战性。您将了解最新的数据采集条件,以及如何确保您的公司不会陷入复杂的网络抓取过程。
开发人员的网页捕获
数据目标越来越高,每天都有新的困难。为了获得所需的数据,开发人员需要考虑智能解决方案,以帮助他们摆脱所有困难。氧气连接将通过提供各种研讨会和讨论来关注网站抢购技术。
下一步是什么?
人工智能(ai)和机器学习(ml)已经是网页的一部分。从AI驱动的Web抓取解决方法到基于ML的指纹识别,解决方案已更新。随着时代的发展,我们将继续在发展过程中学习,思考和向前发展。网页领域也是如此,未来可能存在许多技术变化。加入oxycon2021听取行业专家到未来的预测。
评论oxycon2019
几年前,奥克萨斯举行了第一个苏蒙会议。两天的活动从来自世界各地到维尔纽斯的网页采集。我们期待着这次见到你。阅读更多关于OxyCon2019的更多信息:
摘要
我们将在我们的网站上发布OxyCon2021的详细计划。这个网页崩溃会议并不经常举行。因此,机器不会丢失,损失不再,点击下面的卡片立即获取oxyCon2021的免费票。世界上最大的数据采集活动之一正在等待您。 查看全部
抓取网页数据(人工智能(AI)和机器学习(ML)的下一步是什么?)
众所周知,网络数据在世界各地的各行各业中获得更受欢迎。每个人都知道采集公共数据(特别是大规模采集)将面临很多挑战。这就是为什么奥克萨斯举行了第二个网页以获取会议!
单击“注册”页面的链接。 OxyCon2021从8月25日举行到26日,奥克拉布斯讨论了Web数据捕获等相关主题!今年,oxycon2021将在线进行。两天的虚拟在线活动聚集了全球商业领袖和奥克萨布经验丰富的团队,深入,细致的谈判和讨论。
CEO评论
数据有助于公司做出更好,聪明的决策,最终取得了良好的效果。我们相信,每家公司无论尺寸如何,您都需要访问有价值的公共数据。 oxycon2021是数据采集行业顶级公司学习机会的大家,这些公司了解数据采集行业的快速增长,并知道如何使用网页来发挥公司的最大潜力。 “
-JuliusČerniauskas,奥克萨布斯首席执行官
oxycon2021是关于什么?
今年苏蒙将专注于三个重要主题。根据您的业务需求和个人兴趣,您可以选择最相关的研讨会,讨论或讲座。
业务数据集合
虽然互联网充满了有关如何做出更好决策和提高性能的信息,但他们需要的数据仍然具有挑战性。您将了解最新的数据采集条件,以及如何确保您的公司不会陷入复杂的网络抓取过程。
开发人员的网页捕获
数据目标越来越高,每天都有新的困难。为了获得所需的数据,开发人员需要考虑智能解决方案,以帮助他们摆脱所有困难。氧气连接将通过提供各种研讨会和讨论来关注网站抢购技术。
下一步是什么?
人工智能(ai)和机器学习(ml)已经是网页的一部分。从AI驱动的Web抓取解决方法到基于ML的指纹识别,解决方案已更新。随着时代的发展,我们将继续在发展过程中学习,思考和向前发展。网页领域也是如此,未来可能存在许多技术变化。加入oxycon2021听取行业专家到未来的预测。
评论oxycon2019
几年前,奥克萨斯举行了第一个苏蒙会议。两天的活动从来自世界各地到维尔纽斯的网页采集。我们期待着这次见到你。阅读更多关于OxyCon2019的更多信息:
摘要
我们将在我们的网站上发布OxyCon2021的详细计划。这个网页崩溃会议并不经常举行。因此,机器不会丢失,损失不再,点击下面的卡片立即获取oxyCon2021的免费票。世界上最大的数据采集活动之一正在等待您。
抓取网页数据(云服务薅羊毛的正确姿势,你get到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-23 03:12
完成阅读需要15分钟,快速阅读只需要5分钟
无论是科学研究还是商业运营,我们经常通过数据支持决策。作为个人用户,在缺乏企业数据平台支持的情况下,网络爬虫技术可能会为我们打开一扇窗口
1.条件准备
基本前提是要有一台配置了Python3编程环境的计算机或服务器。这个条件很简单。您可以直接选择安装Anaconda[1]。有关如何在本地配置环境或远程部署环境,请参阅我以前的文章“jupyterlab帮助提高学习效率”
由于爬虫程序脚本通常需要重复运行,因此您可能需要部署一台服务器来日夜为您工作。我还帮助您提前完成了“关于云服务的正确姿态”的家庭作业
如果只是为了学习,我还准备了谷歌的协作案例环境[2](需要科学互联网接入),以便您更好地理解文章内容
2.概念梳理
爬行动物技术非常简单。它可以分为两个步骤
Step1 通过给定的网络地址下载网页数据
Step2 提供数据的规则让计算机筛选数据
2.1网络数据下载
第一步可以说非常简单。python第三方生态系统中出现了非常简单的工具来实现它,比如请求。稍后我们将演示如何使用它
但是,如果您足够小心,您会发现一些网站需要在显示特定页面和数据之前登录。因此,网页数据的获取可以暂时分为简单下载和变相下载。后者要求我们使用浏览器将爬虫脚本伪装为正常访问
2.2网页数据提取
直接下载的网页数据是网页的源代码,供浏览器阅读,而不是供人们阅读。我们真正想要的数据隐藏在这一大串源代码中。为了获得我们想要的干净数据,我们需要指定一个规则,让计算机帮助我们从这些源代码中提取数据
我建议在这里学习两种这样的规则。一种是通用正则表达式,另一种是用网页源代码语言编写的XPath
正则表达式可能有点复杂。简而言之,它是总结目标数据的字符串规则。XPath听起来更复杂,但现在Chrome浏览器提供了一个可视化提取工具“XPath助手”[3]。你可以通过谷歌商店扩展来安装它。稍后我们将介绍如何使用XPath帮助器
3.案例研究
在开始之前,让我们检查一下是否通过打开juyterlab安装了本节中所需的一些第三方Python包
!pip3 install requests
!pip3 install lxml
注意:输入jupyterlab+终端指令可以直接在jupyterlab环境中执行。我们将把两个已安装的第三方库导入到当前环境中
import requests
from lxml import etree
3.1网络数据下载
首先,让我们通过对知乎文章数据进行爬网来解释如何使用爬网程序。我们首先通过浏览器访问目标网站,并复制目标网站,如下所示
url = 'https://www.zhihu.com/people/n ... 39%3B
根据前面的步骤,我们需要做的第一步是下载此网页的数据。这里我们使用强大的第三方库请求
res = requests.get(url)
print(res.text)
直接下载数据。我们发现,我们将收到400个错误请求的网页数据回复。此时,我们需要将python脚本伪造为浏览器访问网站. 如图所示,我们右键单击以在Chrome浏览器中进行检查,单击developer工具中的Network和random列,我们可以在右侧看到以下信息
复制cookie和用户代理数据以构造以下标头字典数据:
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookie':'_zap=7710374e-0d0b-4285-a69d-a2352eb102b5; d_c0="ALBiqotP2w-PTofuUtLo0XQZKjwcT8zji0U=|1565195731"; q_c1=3f807f2ca0c84d51a6a418258d275430|1578543800000|1566266234000; tst=r; UM_distinctid=16fea4b3816d5-0fff1be09d9b96-39677b0e-13c680-16fea4b38177a1; _xsrf=6182b2eb-6f32-454e-8c0d-d16122a8bec3; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1580782502,1580790283,1580790307,1580790327; r_cap_id="2|1:0|10:1580790382|8:r_cap_id|44:ZjQ3ZWFhODFlODc0NDRjNDg5YzZlODg1MDRiZmUzZjk=|eed022a309955b6db3b378b610e352c46c4024477bd99bf11a4fb25475e0d196"; capsion_ticket="2|1:0|10:1580790628|14:capsion_ticket|44:MmVlZGE0YjNjYWMzNDM0OGFlOWNkZmNhMWQ3ZWJlZDA=|07f358d43a89bcad3b55c305fdf7f6be2a3f67c47f1b2fa1d54acd2e0b4eacc3"; z_c0="2|1:0|10:1580790648|4:z_c0|92:Mi4xSVNlOEJBQUFBQUFBc0dLcWkwX2JEeVlBQUFCZ0FsVk5lRUVtWHdEUXBDMldpZkZMMEpxXzZ3UGJIMklibFRIZnB3|a5c9f10bc3b9f96930b8ba28295a0f1fdda1509aeb81564440978a640c36f42d"; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1580795302; CNZZDATA1272960301=815094974-1580178850-https%253A%252F%252Farticle.xmt.cn%252F%7C1580791820; KLBRSID=2177cbf908056c6654e972f5ddc96dc2|1580795993|1580790152'
}
cookie收录临时登录信息,用户代理将Python脚本伪装成浏览器
现在,将标题字典数据添加到脚本中,您将发现已成功下载数据
res = requests.get(url,headers=headers)
print(res.text)
3.2网页数据提取
数据提取还需要chrome开发者工具。右键点击目标数据,点击【检查】,出现下图。通过将数据对象的XPath复制到XPath助手中,我们可以看到XPath助手可以帮助我们直接提取数据
现在XPath助手中的XPath是当前目标数据的源代码规则。如果需要获取相同类型的数据,只需观察XPath,删除与列表相似的数据,通过观察判断是否正确。通过尝试,我们获得了文章title的数据。采集规则如下(在末尾添加/text()以获取文本数据):
title_pattern = '//*[@id="Profile-posts"]/div[2]/div/div/h2/a/text()'
Python中XPath的标准模板如下所示,其中res.text是我们下载的网页数据,title_uu模式是我们通过XPath助手获得的数据提取规则。现在我们可以获得我的文章列表中所有文章的标题数据
html=etree.HTML(res.text)
result = html.xpath(title_pattern)
print(result)
总结
举一反三。现在您不仅可以抓取文章title,还可以抓取文章release date和文章profile。如果当前任务是抓取电影网站数据,您能否以相同的方式快速抓取电影标题和电影收视率
如果您想继续深化web爬虫技术,可以深入了解正则表达式和XPath规则,也可以进一步联系分布式爬虫框架scripy。此外,移动端的数据捕获工具Charles、桌面端的自动化工具pywinauto等都值得理解
参考资料
[1] Anaconda官方网站下载/分发/
[2] 协作案例环境:/drive/1Nuvpouysoxpuaxqogggvfqaptjqnl2 DC
[3] XPath助手:/webstore/detail/hgimnogjllphhkhhlmebbmlgjoejdpjl 查看全部
抓取网页数据(云服务薅羊毛的正确姿势,你get到了吗?)
完成阅读需要15分钟,快速阅读只需要5分钟
无论是科学研究还是商业运营,我们经常通过数据支持决策。作为个人用户,在缺乏企业数据平台支持的情况下,网络爬虫技术可能会为我们打开一扇窗口
1.条件准备
基本前提是要有一台配置了Python3编程环境的计算机或服务器。这个条件很简单。您可以直接选择安装Anaconda[1]。有关如何在本地配置环境或远程部署环境,请参阅我以前的文章“jupyterlab帮助提高学习效率”
由于爬虫程序脚本通常需要重复运行,因此您可能需要部署一台服务器来日夜为您工作。我还帮助您提前完成了“关于云服务的正确姿态”的家庭作业
如果只是为了学习,我还准备了谷歌的协作案例环境[2](需要科学互联网接入),以便您更好地理解文章内容
2.概念梳理
爬行动物技术非常简单。它可以分为两个步骤
Step1 通过给定的网络地址下载网页数据
Step2 提供数据的规则让计算机筛选数据
2.1网络数据下载
第一步可以说非常简单。python第三方生态系统中出现了非常简单的工具来实现它,比如请求。稍后我们将演示如何使用它
但是,如果您足够小心,您会发现一些网站需要在显示特定页面和数据之前登录。因此,网页数据的获取可以暂时分为简单下载和变相下载。后者要求我们使用浏览器将爬虫脚本伪装为正常访问
2.2网页数据提取
直接下载的网页数据是网页的源代码,供浏览器阅读,而不是供人们阅读。我们真正想要的数据隐藏在这一大串源代码中。为了获得我们想要的干净数据,我们需要指定一个规则,让计算机帮助我们从这些源代码中提取数据
我建议在这里学习两种这样的规则。一种是通用正则表达式,另一种是用网页源代码语言编写的XPath
正则表达式可能有点复杂。简而言之,它是总结目标数据的字符串规则。XPath听起来更复杂,但现在Chrome浏览器提供了一个可视化提取工具“XPath助手”[3]。你可以通过谷歌商店扩展来安装它。稍后我们将介绍如何使用XPath帮助器
3.案例研究
在开始之前,让我们检查一下是否通过打开juyterlab安装了本节中所需的一些第三方Python包
!pip3 install requests
!pip3 install lxml
注意:输入jupyterlab+终端指令可以直接在jupyterlab环境中执行。我们将把两个已安装的第三方库导入到当前环境中
import requests
from lxml import etree
3.1网络数据下载
首先,让我们通过对知乎文章数据进行爬网来解释如何使用爬网程序。我们首先通过浏览器访问目标网站,并复制目标网站,如下所示
url = 'https://www.zhihu.com/people/n ... 39%3B
根据前面的步骤,我们需要做的第一步是下载此网页的数据。这里我们使用强大的第三方库请求
res = requests.get(url)
print(res.text)
直接下载数据。我们发现,我们将收到400个错误请求的网页数据回复。此时,我们需要将python脚本伪造为浏览器访问网站. 如图所示,我们右键单击以在Chrome浏览器中进行检查,单击developer工具中的Network和random列,我们可以在右侧看到以下信息
复制cookie和用户代理数据以构造以下标头字典数据:
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookie':'_zap=7710374e-0d0b-4285-a69d-a2352eb102b5; d_c0="ALBiqotP2w-PTofuUtLo0XQZKjwcT8zji0U=|1565195731"; q_c1=3f807f2ca0c84d51a6a418258d275430|1578543800000|1566266234000; tst=r; UM_distinctid=16fea4b3816d5-0fff1be09d9b96-39677b0e-13c680-16fea4b38177a1; _xsrf=6182b2eb-6f32-454e-8c0d-d16122a8bec3; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1580782502,1580790283,1580790307,1580790327; r_cap_id="2|1:0|10:1580790382|8:r_cap_id|44:ZjQ3ZWFhODFlODc0NDRjNDg5YzZlODg1MDRiZmUzZjk=|eed022a309955b6db3b378b610e352c46c4024477bd99bf11a4fb25475e0d196"; capsion_ticket="2|1:0|10:1580790628|14:capsion_ticket|44:MmVlZGE0YjNjYWMzNDM0OGFlOWNkZmNhMWQ3ZWJlZDA=|07f358d43a89bcad3b55c305fdf7f6be2a3f67c47f1b2fa1d54acd2e0b4eacc3"; z_c0="2|1:0|10:1580790648|4:z_c0|92:Mi4xSVNlOEJBQUFBQUFBc0dLcWkwX2JEeVlBQUFCZ0FsVk5lRUVtWHdEUXBDMldpZkZMMEpxXzZ3UGJIMklibFRIZnB3|a5c9f10bc3b9f96930b8ba28295a0f1fdda1509aeb81564440978a640c36f42d"; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1580795302; CNZZDATA1272960301=815094974-1580178850-https%253A%252F%252Farticle.xmt.cn%252F%7C1580791820; KLBRSID=2177cbf908056c6654e972f5ddc96dc2|1580795993|1580790152'
}
cookie收录临时登录信息,用户代理将Python脚本伪装成浏览器
现在,将标题字典数据添加到脚本中,您将发现已成功下载数据
res = requests.get(url,headers=headers)
print(res.text)
3.2网页数据提取
数据提取还需要chrome开发者工具。右键点击目标数据,点击【检查】,出现下图。通过将数据对象的XPath复制到XPath助手中,我们可以看到XPath助手可以帮助我们直接提取数据
现在XPath助手中的XPath是当前目标数据的源代码规则。如果需要获取相同类型的数据,只需观察XPath,删除与列表相似的数据,通过观察判断是否正确。通过尝试,我们获得了文章title的数据。采集规则如下(在末尾添加/text()以获取文本数据):
title_pattern = '//*[@id="Profile-posts"]/div[2]/div/div/h2/a/text()'
Python中XPath的标准模板如下所示,其中res.text是我们下载的网页数据,title_uu模式是我们通过XPath助手获得的数据提取规则。现在我们可以获得我的文章列表中所有文章的标题数据
html=etree.HTML(res.text)
result = html.xpath(title_pattern)
print(result)
总结
举一反三。现在您不仅可以抓取文章title,还可以抓取文章release date和文章profile。如果当前任务是抓取电影网站数据,您能否以相同的方式快速抓取电影标题和电影收视率
如果您想继续深化web爬虫技术,可以深入了解正则表达式和XPath规则,也可以进一步联系分布式爬虫框架scripy。此外,移动端的数据捕获工具Charles、桌面端的自动化工具pywinauto等都值得理解
参考资料
[1] Anaconda官方网站下载/分发/
[2] 协作案例环境:/drive/1Nuvpouysoxpuaxqogggvfqaptjqnl2 DC
[3] XPath助手:/webstore/detail/hgimnogjllphhkhhlmebbmlgjoejdpjl
抓取网页数据( Python中解析网页爬虫的基本流程(一)-爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-22 13:24
Python中解析网页爬虫的基本流程(一)-爬虫)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
现在启动Jupiter笔记本并运行以下代码
请求
url=“”
res=requests.get('url')
打印(res.status_代码)
#二百
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
来自BS4导入Beautifulsoup
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
title=soup.title.text
印刷品(标题)
#热门视频-嘟嘟嘟嘟嘟嘟
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到每个视频消息都包装在Li标记下,因此代码可以这样编写
所有产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
进口
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
importpandas aspd
keys=所有产品[0]。keys
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
请求
来自BS4导入Beautifulsoup
进口
importpandas aspd
url=“”
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
所有\uo产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
###使用pandas写入数据
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
结束
目前,Python和Java是编程语言武器列表中最流行的两种语言。两者都有各自的优势。Java更容易找到工作。Python被广泛使用,易于学习,可以做很多事情。许多学生都在学习这两方面的知识。所以小编给大家发了8本书,帮你们振作起来,打电话给大家
Python:机器学习算法框架实践
Java:Java编程方法
感兴趣的合作伙伴可以扫描二维码下方的二维码以查看其角色~~ 查看全部
抓取网页数据(
Python中解析网页爬虫的基本流程(一)-爬虫)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
现在启动Jupiter笔记本并运行以下代码
请求
url=“”
res=requests.get('url')
打印(res.status_代码)
#二百
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
来自BS4导入Beautifulsoup
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
title=soup.title.text
印刷品(标题)
#热门视频-嘟嘟嘟嘟嘟嘟
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到每个视频消息都包装在Li标记下,因此代码可以这样编写
所有产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
进口
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
importpandas aspd
keys=所有产品[0]。keys
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
请求
来自BS4导入Beautifulsoup
进口
importpandas aspd
url=“”
page=请求.get(url)
soup=BeautifulSoup(page.content,'html.parser')
所有\uo产品=[]
产品=汤。选择('li.rank item')
对于产品中的产品:
秩=产品。选择('div.num')[0]。文本
名称=产品。选择(“>;a”)[0]。text.strip
play=product.select('span.data box')[0]。文本
comment=product.select('span.data box')[1]。文本
up=product.select('span.data box')[2]。文本
url=product.select('>;a')[0].attrs['href']
所有产品。附加({
“视频排名”:排名
“视频名称”:名称
“播放音量”:播放
“拦河坝数量”:评论
“向上大师”:向上
“视频链接”:URL
})
keys=所有产品[0]。keys
Withopen('b站视频热列表TOP100.csv',w',换行符='',编码='utf-8-sig')A输出文件:
dict_uwriter=csv.DictWriter(输出文件,键)
主笔
dict_uwriter.writerows(所有产品)
###使用pandas写入数据
pd.DataFrame(所有产品,列=键)。至CSV('b站视频热列表TOP100.csv',编码='utf-8-sig')
结束
目前,Python和Java是编程语言武器列表中最流行的两种语言。两者都有各自的优势。Java更容易找到工作。Python被广泛使用,易于学习,可以做很多事情。许多学生都在学习这两方面的知识。所以小编给大家发了8本书,帮你们振作起来,打电话给大家
Python:机器学习算法框架实践
Java:Java编程方法
感兴趣的合作伙伴可以扫描二维码下方的二维码以查看其角色~~
抓取网页数据(Java如何抓取网站的数据:(1)原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-09-22 00:12
有时由于各种原因,我们需要采集一些网站数据,但由于网站数据的不同,数据的显示方式略有不同
本文使用Java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
抓取网页数据(Java如何抓取网站的数据:(1)原网页数据)
有时由于各种原因,我们需要采集一些网站数据,但由于网站数据的不同,数据的显示方式略有不同
本文使用Java向您展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页JavaScript返回的数据)
一、抓取原创网页
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此页面并输入IP:111. 142. 55.73.点击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
publicvoidcaptureHtml(Stringip)throwsException{
StringstrURL=“”+ip
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
Stringbuf=contentBuf.toString()
Intbeginix=buf.Indexof(“查询结果[”)
Intendix=buf.indexof(“以上四项依次显示”)
Stringresult=buf.子串(beginIx,endIx)
System.Out.Println(“capturehtml()的结果:\n”+结果)
}
使用httpurlconnection连接到网站,用bufreader保存网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111. 142. 55.73==>;1871591241==>;福建省漳州移动
二、grab在网页上获取JavaScript返回的结果
有时网站为了保护自己的数据,不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这样可以避免搜索引擎等工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
publicvoidcaptureJavascript(Stringpostid)throwsException{
StringstrURL=“”+postid
+“&;channel=&;rnd=0”
URLurl=newURL(strURL)
HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection()
InputStreamReaderinput=newInputStreamReader(httpConn
.getInputStream(),“utf-8”)
BufferedReaderBufferReader=newBufferedReader(输入)
Stringline=“”
StringBuildercontentBuf=newStringBuilder()
而((line=bufReader.readLine())!=null){
contentBuf.append(行)
}
System.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring())
}
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
抓取网页数据(抓取网页数据的最根本的功能是对网页进行计算机分析和可视化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-19 21:02
抓取网页数据的最根本的功能是对网页数据进行计算机分析和可视化。做对网页数据进行分析和可视化,首先就需要要先对原始网页进行字符集的处理,这是大前提。对于不同网站上的同一个页面,可能存在不同的字符集,因此如何对网页进行计算机分析和可视化就至关重要了。那么字符集可以分成哪些类型?不同的字符集又有哪些特点和区别呢?我们一起来看看。
什么是网页字符集上面我们介绍了不同字符集的相关概念,下面我们将一一解释这些概念。一:网页字符集是什么网页字符集是指网页中的文本(特指web文本)所使用的字符集。用于获取网页中的文本的字符集包括utf-8,utf-16和utf-32这三个字符集。根据使用需求,目前web上的字符集还包括数字0~9,空格,tab和无符号元素这些字符。
二:网页字符集的特点网页中文本的字符集统一使用utf-8字符集,utf-16和utf-32这三个字符集。虽然三个字符集的差别不大,但是它们各自适用于不同的场景。utf-8和utf-16是最常用的两种字符集,而utf-32(包括0~9)是一个潜在的低能字符集。使用utf-32字符集进行网页文本分析时,最好将文本转换成十六进制形式以便计算机处理。
常见场景1:web文档中包含下划线、逗号、制表符等单位字符,因此需要转换为十六进制形式进行分析。常见场景2:网页中包含文字中有特殊字符,字符中有很多非常规的符号,这些符号在计算机上无法直接识别,因此需要转换为十六进制形式进行计算机处理。常见场景3:网页有超链接标识,因此需要转换为十六进制形式。三:网页字符集的使用常见场景1:需要对web文档进行分析处理,或需要对网页文档进行字符集对齐分析。
常见场景2:比如无法用统一网页字符集的utf-8字符集进行网页分析处理。常见场景3:需要对网页文档进行可视化分析,或需要处理具有特殊数据类型的网页文档。常见场景4:需要对网页文档进行可视化分析,或需要处理数据类型比较复杂的网页文档。四:网页字符集的应用案例第一种:网页文档可视化分析。使用网页字符集进行文档分析处理时,要先将网页文档转换成十六进制形式。
而转换方法可以通过搜索引擎获取,也可以通过web浏览器自带的自动转换功能。下面介绍一个有用的转换方法。1.使用sublimetext3打开网页,然后选择utf-8打开,再选择将网页文档转换为十六进制形式。2.选择转换范围,将方括号里的utf-8改为其他格式,然后确定。网页字符集转换可以通过在线转换来实现,这里介绍一个网站:wordconverter。网站页面链接::在。 查看全部
抓取网页数据(抓取网页数据的最根本的功能是对网页进行计算机分析和可视化)
抓取网页数据的最根本的功能是对网页数据进行计算机分析和可视化。做对网页数据进行分析和可视化,首先就需要要先对原始网页进行字符集的处理,这是大前提。对于不同网站上的同一个页面,可能存在不同的字符集,因此如何对网页进行计算机分析和可视化就至关重要了。那么字符集可以分成哪些类型?不同的字符集又有哪些特点和区别呢?我们一起来看看。
什么是网页字符集上面我们介绍了不同字符集的相关概念,下面我们将一一解释这些概念。一:网页字符集是什么网页字符集是指网页中的文本(特指web文本)所使用的字符集。用于获取网页中的文本的字符集包括utf-8,utf-16和utf-32这三个字符集。根据使用需求,目前web上的字符集还包括数字0~9,空格,tab和无符号元素这些字符。
二:网页字符集的特点网页中文本的字符集统一使用utf-8字符集,utf-16和utf-32这三个字符集。虽然三个字符集的差别不大,但是它们各自适用于不同的场景。utf-8和utf-16是最常用的两种字符集,而utf-32(包括0~9)是一个潜在的低能字符集。使用utf-32字符集进行网页文本分析时,最好将文本转换成十六进制形式以便计算机处理。
常见场景1:web文档中包含下划线、逗号、制表符等单位字符,因此需要转换为十六进制形式进行分析。常见场景2:网页中包含文字中有特殊字符,字符中有很多非常规的符号,这些符号在计算机上无法直接识别,因此需要转换为十六进制形式进行计算机处理。常见场景3:网页有超链接标识,因此需要转换为十六进制形式。三:网页字符集的使用常见场景1:需要对web文档进行分析处理,或需要对网页文档进行字符集对齐分析。
常见场景2:比如无法用统一网页字符集的utf-8字符集进行网页分析处理。常见场景3:需要对网页文档进行可视化分析,或需要处理具有特殊数据类型的网页文档。常见场景4:需要对网页文档进行可视化分析,或需要处理数据类型比较复杂的网页文档。四:网页字符集的应用案例第一种:网页文档可视化分析。使用网页字符集进行文档分析处理时,要先将网页文档转换成十六进制形式。
而转换方法可以通过搜索引擎获取,也可以通过web浏览器自带的自动转换功能。下面介绍一个有用的转换方法。1.使用sublimetext3打开网页,然后选择utf-8打开,再选择将网页文档转换为十六进制形式。2.选择转换范围,将方括号里的utf-8改为其他格式,然后确定。网页字符集转换可以通过在线转换来实现,这里介绍一个网站:wordconverter。网站页面链接::在。

