
抓取网页数据违法吗
抓取网页数据违法吗( 刮网线在哪里?growthhack探讨一下网页抓取方法之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-10 00:27
刮网线在哪里?growthhack探讨一下网页抓取方法之前)
早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页还是仅复制重要数据,您仍然会获得可能可用或不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上面的示例)不增加主机服务的负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
虽然我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢?
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。 查看全部
抓取网页数据违法吗(
刮网线在哪里?growthhack探讨一下网页抓取方法之前)

早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页还是仅复制重要数据,您仍然会获得可能可用或不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上面的示例)不增加主机服务的负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
虽然我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢?
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。
抓取网页数据违法吗(本文介绍如何使用机器学习技术检测URL是否是是否是钓鱼网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-09 21:09
本文介绍如何使用机器学习技术检测一个URL是否为钓鱼网站,包括数据抓取、特征选择、模型训练等。
我有一个客户的邮箱,最近差点被钓鱼网站骗了。他的供应商邮箱被攻击,然后黑客利用供应商的邮箱给他发了一封催款邮件,要求他向另一个银行账户付款。幸运的是,我的客户致电供应商确认并发现了骗局。这让我意识到网络钓鱼攻击无处不在,我们不应低估其危害。
以下是网络钓鱼 网站 的一些示例。基本上,他们的目的是欺骗您的登录帐户和密码。这是一个冒充 Paypal 的钓鱼站:
这是一个假游戏站:
1、初步分析
学习编程,上慧智网,在线编程环境,一对一助教指导。
Kaggle 上有一些网络钓鱼数据集,但对于这个项目,我想生成自己的数据库。我使用了两个数据源来构建网络钓鱼 URL 列表:
借助一点领域知识,对这些合法的钓鱼网址进行分析,我将可以从这些网址中获取的信息分为以下5类:
域名:二级域名可能存在钓鱼风险。例如: Network: HTTP 对应的header 可能收录有用的信息页面: 一般而言,网络钓鱼网站 总是使用一些形式来试图让你输入帐户、电子邮件、密码等信息。Whois:域名通常是通过GoDaddy等注册的。
通过分析,我有以下发现:
2、数据采集
我的数据爬虫的概念模型大致如下:
基本思想是使代码尽可能模块化,以便我可以在需要时添加新类别。我抓取的每个页面都存储在一个本地文件中,以便将来在它们不可用时作为参考。
我使用 BeautifulSoup 提取页面信息。通过设置随机用户代理,我可以减少请求被机器人拒绝的可能性。
为了确保一致性,我还对 URL 进行了基本的预处理,例如删除 www 和尾部斜杠。
3、探索性数据分析
由于爬取数据非常耗时,我决定开始我的探索性数据分析,寻找一些感觉。在分析了1817个网址(包括930个钓鱼网址和887个合法网址)的特征后,我选择使用以下15个特征:
1
2
3
4
5
6
7
8
9
10
URL Domain Network Page Whois
-------------- --------------- ------------ ---------- ---------
length len_subdomain len_cookie length w_score
special_char is_https anchors
depth form
password
signin
hidden
popup
4、特征选择
我使用 LASSO 正则化来识别重要特征。即使只有很小的 alpha 值,我也发现了 5 个重要特征:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[('len', 0.0006821926601753635),
('count_s', 0.0),
('depth', 0.0),
('len_subdomain', 0.0),
('is_https', 0.0),
('len_cookie', -0.0002472539769316538),
('page_length', -2.4074484401619206e-07),
('page_num_anchor', -0.0006943876695101922),
('page_num_form', -0.0),
('page_num_email', -0.0),
('page_num_password', 0.0),
('page_num_signin', 0.0),
('page_num_hidden', -0.00041105959874092535),
('page_num_popup', -0.0),
('w_score', -0.0)]
坦率地说,我有点惊讶 w_score 不起作用。最后我决定使用这 5 个功能。
1
2
3
4
5
URL Domain Network Page Whois
-------- -------- ------------ --------- -------
length len_cookie length
anchors
hidden
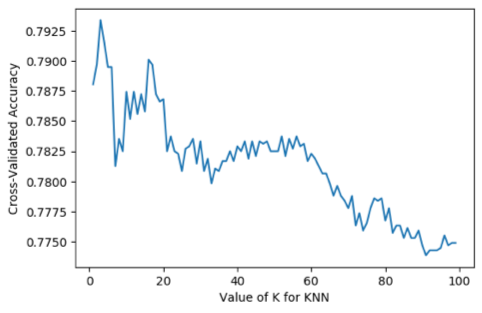
然后我用 KNN 构建了一个简单的分类器作为基线。K 选择了 3 并且得到了公平的准确率0.793:
5、型号
我通过爬取得到6906个网址,3501是合法的,3455是钓鱼的。毫不奇怪,许多网络钓鱼页面不再可访问:
1
2
3
4
Type #URL processed #Pages available
------- ---------------- ------------------
Legit 4,000 3,501
Phish 6,000 3,455
使用这 6906 个样本,我再次进行特征选择,筛选出相同的 5 个特征。最好的K还是3,太好了!
以下是模型的参数:
1
2
3
4
5
6
7
8
9
Model Accuracy
------------------- ----------
Naive Bayes 0.757
SVC 0.760
KNN (K=3) 0.791
Log. Reg. 0.822
Decision Tree 0.836
KNN (K=3, scaled) 0.845
Random Forest 0.885
原文链接:监督学习检测钓鱼网址 查看全部
抓取网页数据违法吗(本文介绍如何使用机器学习技术检测URL是否是是否是钓鱼网站)
本文介绍如何使用机器学习技术检测一个URL是否为钓鱼网站,包括数据抓取、特征选择、模型训练等。
我有一个客户的邮箱,最近差点被钓鱼网站骗了。他的供应商邮箱被攻击,然后黑客利用供应商的邮箱给他发了一封催款邮件,要求他向另一个银行账户付款。幸运的是,我的客户致电供应商确认并发现了骗局。这让我意识到网络钓鱼攻击无处不在,我们不应低估其危害。
以下是网络钓鱼 网站 的一些示例。基本上,他们的目的是欺骗您的登录帐户和密码。这是一个冒充 Paypal 的钓鱼站:
这是一个假游戏站:
1、初步分析
学习编程,上慧智网,在线编程环境,一对一助教指导。
Kaggle 上有一些网络钓鱼数据集,但对于这个项目,我想生成自己的数据库。我使用了两个数据源来构建网络钓鱼 URL 列表:
借助一点领域知识,对这些合法的钓鱼网址进行分析,我将可以从这些网址中获取的信息分为以下5类:
域名:二级域名可能存在钓鱼风险。例如: Network: HTTP 对应的header 可能收录有用的信息页面: 一般而言,网络钓鱼网站 总是使用一些形式来试图让你输入帐户、电子邮件、密码等信息。Whois:域名通常是通过GoDaddy等注册的。
通过分析,我有以下发现:
2、数据采集
我的数据爬虫的概念模型大致如下:
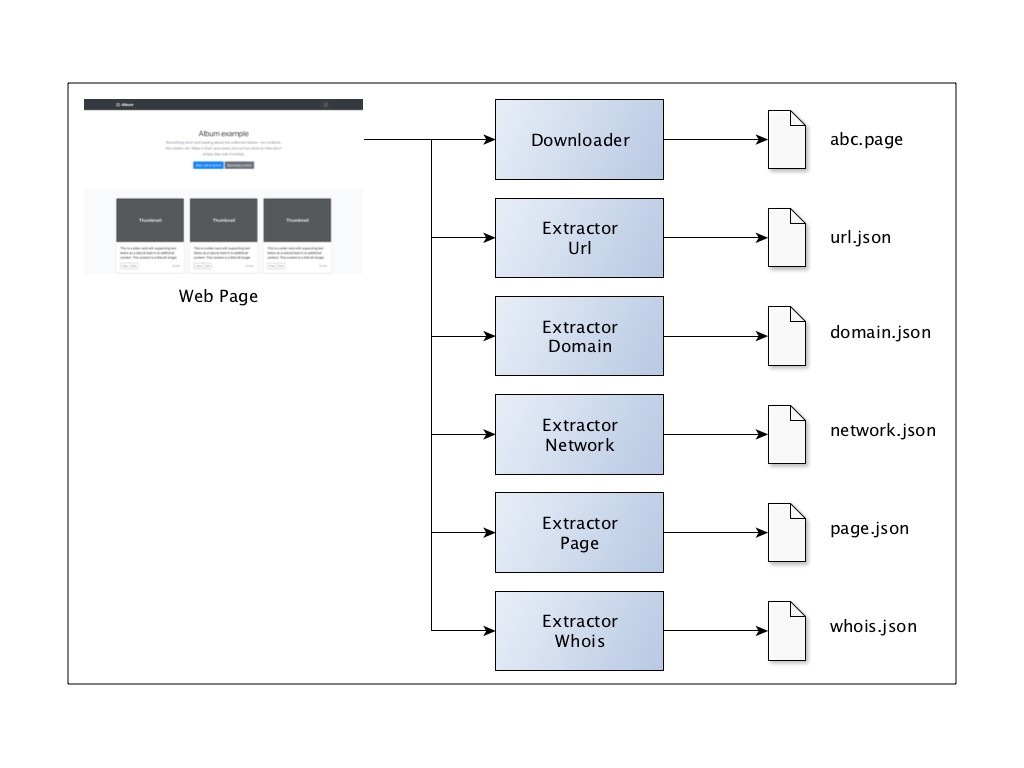
基本思想是使代码尽可能模块化,以便我可以在需要时添加新类别。我抓取的每个页面都存储在一个本地文件中,以便将来在它们不可用时作为参考。
我使用 BeautifulSoup 提取页面信息。通过设置随机用户代理,我可以减少请求被机器人拒绝的可能性。
为了确保一致性,我还对 URL 进行了基本的预处理,例如删除 www 和尾部斜杠。
3、探索性数据分析
由于爬取数据非常耗时,我决定开始我的探索性数据分析,寻找一些感觉。在分析了1817个网址(包括930个钓鱼网址和887个合法网址)的特征后,我选择使用以下15个特征:
1
2
3
4
5
6
7
8
9
10
URL Domain Network Page Whois
-------------- --------------- ------------ ---------- ---------
length len_subdomain len_cookie length w_score
special_char is_https anchors
depth form
password
signin
hidden
popup
4、特征选择
我使用 LASSO 正则化来识别重要特征。即使只有很小的 alpha 值,我也发现了 5 个重要特征:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[('len', 0.0006821926601753635),
('count_s', 0.0),
('depth', 0.0),
('len_subdomain', 0.0),
('is_https', 0.0),
('len_cookie', -0.0002472539769316538),
('page_length', -2.4074484401619206e-07),
('page_num_anchor', -0.0006943876695101922),
('page_num_form', -0.0),
('page_num_email', -0.0),
('page_num_password', 0.0),
('page_num_signin', 0.0),
('page_num_hidden', -0.00041105959874092535),
('page_num_popup', -0.0),
('w_score', -0.0)]
坦率地说,我有点惊讶 w_score 不起作用。最后我决定使用这 5 个功能。
1
2
3
4
5
URL Domain Network Page Whois
-------- -------- ------------ --------- -------
length len_cookie length
anchors
hidden
然后我用 KNN 构建了一个简单的分类器作为基线。K 选择了 3 并且得到了公平的准确率0.793:
5、型号
我通过爬取得到6906个网址,3501是合法的,3455是钓鱼的。毫不奇怪,许多网络钓鱼页面不再可访问:
1
2
3
4
Type #URL processed #Pages available
------- ---------------- ------------------
Legit 4,000 3,501
Phish 6,000 3,455
使用这 6906 个样本,我再次进行特征选择,筛选出相同的 5 个特征。最好的K还是3,太好了!
以下是模型的参数:
1
2
3
4
5
6
7
8
9
Model Accuracy
------------------- ----------
Naive Bayes 0.757
SVC 0.760
KNN (K=3) 0.791
Log. Reg. 0.822
Decision Tree 0.836
KNN (K=3, scaled) 0.845
Random Forest 0.885
原文链接:监督学习检测钓鱼网址
抓取网页数据违法吗(找寻引擎w88网站手机版是怎样点击查看源网页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-06 17:28
对于 网站 seo 人员。搜索引擎w88网站移动版一定有一些了解,因为在进行网站优化时,需要研究一下搜索引擎w88网站移动版的工作原理。搜索引擎大致分为4部分,第一部分是w88网站移动版爬虫,第二部分是数据处理分析系统,第三部分是索引系统,第四部分是严格的调查。系统源码,当然这只是sex,没有其他基本的4部分!
什么是搜索引擎w88网站手机版,什么是爬虫程序?
搜索引擎w88网站手机版程序,其实就是一个异常的搜索引擎自动应用。它的功能是什么?其实很简单。就是浏览互联网上的信息,然后抓取所有的信息。转到搜索引擎的算术单元。然后建立索引库等等,我们就可以使用移动版的搜索引擎w88网站作为存款人。那么这篇文章的投稿人就来访问我们的网站,然后在自己的电脑上保护我们网站的内容!最好检查一下。
搜索引擎w88网站手机版如何抓取点击查看源码网页?
找到某个链接→下载这个点击查看源网页→加入临时库→提取并点击查看源网页中的链接→点击查看源网页未上传→循环
首先找w88网站移动版引擎找到链接。至于什么样的发现比较简单,就是把链接链接链接过去。搜索引擎w88网站手机版找到此链接后,会下载点击查看源网页,并保存在临时库中。当然,它会提取这个页面的所有链接,然后就会循环。搜索引擎w88网站手机版几乎24小时不停,然后w88网站手机版下载并点击查看源码网页。CPU占用过高怎么办?这就需要第二个系统,也就是搜索引擎的分析系统。
1.移动版搜索引擎w88网站介绍
搜索引擎w88网站手机版,在搜索引擎系统中,所谓的“w88网站手机版”或“操纵器”,是一个用来抓取和访问页面的程序。
① 爬行原理
找到引擎w88网站手机版访问,点击查看源码网页的原油炒作过程。它就像存款人使用的连接器。
搜索引擎w88网站手机版向页面发送访问请求,页面运营商返回页面的HTML代码。
搜索引擎w88网站移动版将接收到的HTML代码存储到搜索引擎的自然页面数据处理库中。
②如何爬行
为了完善搜索引擎w88网站手机版,如何提高学习效率。通常多个w88网站手机版本用于并发分布式爬行。
分布蠕变也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行直到没有链接。
广度优先:这个页面上的所有链接都被抓取完后,它们会沿着建筑设计页面的二楼不停地爬行。
③ w88网站 手机版必须遵守的协商
搜索引擎w88网站手机版会先访问网站游戏根目录下的robots.txt文件,然后再访问网站。
搜索引擎w88网站手机版不会抓取robots.txt文件中禁止爬行的文件或目录。
④ 常用搜索引擎w88网站手机版
百度w88网站手机版:百度蜘蛛
谷歌 w88网站 手机版:Googlebot
360w88网站 手机版:360Spider
SOSOw88网站 手机版:Sosospider
有道w88网站手机版:有道机器人。友道机器人
搜狗w88网站手机版:搜狗新闻蜘蛛
Bing w88网站 手机版:bingbot
Alexaw88网站 手机版:ia_archiver
二、如何吸引更多搜索引擎w88网站手机版
随着网络信息的爆炸式增长,移动版搜索引擎w88网站无法完整抓取所有网站的所有链接,那么如何吸引更多搜索引擎w88网站手机版对我们来说网站爬取变得非常重要。
① 导入链接
不管是外链还是广场舞内部的链接,只有导入了,才能被搜索引擎w88网站手机版找到,了解本页的留存情况。多做外部链接,火上浇油,吸引更多w88网站手机访问。
② 页面刷新频率
页面刷新频率越高。移动版搜索引擎w88网站的访问量也会增加。
③ 网站 和页面权重
整个网站的权重和一个页面(包括首页也是一个页面)的权重影响移动版w88网站的访问频率。实质性网站一般会增加搜索引擎w88网站手机版交友技巧。 查看全部
抓取网页数据违法吗(找寻引擎w88网站手机版是怎样点击查看源网页的)
对于 网站 seo 人员。搜索引擎w88网站移动版一定有一些了解,因为在进行网站优化时,需要研究一下搜索引擎w88网站移动版的工作原理。搜索引擎大致分为4部分,第一部分是w88网站移动版爬虫,第二部分是数据处理分析系统,第三部分是索引系统,第四部分是严格的调查。系统源码,当然这只是sex,没有其他基本的4部分!

什么是搜索引擎w88网站手机版,什么是爬虫程序?
搜索引擎w88网站手机版程序,其实就是一个异常的搜索引擎自动应用。它的功能是什么?其实很简单。就是浏览互联网上的信息,然后抓取所有的信息。转到搜索引擎的算术单元。然后建立索引库等等,我们就可以使用移动版的搜索引擎w88网站作为存款人。那么这篇文章的投稿人就来访问我们的网站,然后在自己的电脑上保护我们网站的内容!最好检查一下。
搜索引擎w88网站手机版如何抓取点击查看源码网页?
找到某个链接→下载这个点击查看源网页→加入临时库→提取并点击查看源网页中的链接→点击查看源网页未上传→循环
首先找w88网站移动版引擎找到链接。至于什么样的发现比较简单,就是把链接链接链接过去。搜索引擎w88网站手机版找到此链接后,会下载点击查看源网页,并保存在临时库中。当然,它会提取这个页面的所有链接,然后就会循环。搜索引擎w88网站手机版几乎24小时不停,然后w88网站手机版下载并点击查看源码网页。CPU占用过高怎么办?这就需要第二个系统,也就是搜索引擎的分析系统。

1.移动版搜索引擎w88网站介绍
搜索引擎w88网站手机版,在搜索引擎系统中,所谓的“w88网站手机版”或“操纵器”,是一个用来抓取和访问页面的程序。
① 爬行原理
找到引擎w88网站手机版访问,点击查看源码网页的原油炒作过程。它就像存款人使用的连接器。
搜索引擎w88网站手机版向页面发送访问请求,页面运营商返回页面的HTML代码。
搜索引擎w88网站移动版将接收到的HTML代码存储到搜索引擎的自然页面数据处理库中。
②如何爬行
为了完善搜索引擎w88网站手机版,如何提高学习效率。通常多个w88网站手机版本用于并发分布式爬行。
分布蠕变也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行直到没有链接。
广度优先:这个页面上的所有链接都被抓取完后,它们会沿着建筑设计页面的二楼不停地爬行。
③ w88网站 手机版必须遵守的协商
搜索引擎w88网站手机版会先访问网站游戏根目录下的robots.txt文件,然后再访问网站。
搜索引擎w88网站手机版不会抓取robots.txt文件中禁止爬行的文件或目录。
④ 常用搜索引擎w88网站手机版
百度w88网站手机版:百度蜘蛛
谷歌 w88网站 手机版:Googlebot
360w88网站 手机版:360Spider
SOSOw88网站 手机版:Sosospider
有道w88网站手机版:有道机器人。友道机器人
搜狗w88网站手机版:搜狗新闻蜘蛛
Bing w88网站 手机版:bingbot
Alexaw88网站 手机版:ia_archiver
二、如何吸引更多搜索引擎w88网站手机版
随着网络信息的爆炸式增长,移动版搜索引擎w88网站无法完整抓取所有网站的所有链接,那么如何吸引更多搜索引擎w88网站手机版对我们来说网站爬取变得非常重要。
① 导入链接
不管是外链还是广场舞内部的链接,只有导入了,才能被搜索引擎w88网站手机版找到,了解本页的留存情况。多做外部链接,火上浇油,吸引更多w88网站手机访问。
② 页面刷新频率
页面刷新频率越高。移动版搜索引擎w88网站的访问量也会增加。
③ 网站 和页面权重
整个网站的权重和一个页面(包括首页也是一个页面)的权重影响移动版w88网站的访问频率。实质性网站一般会增加搜索引擎w88网站手机版交友技巧。
抓取网页数据违法吗(抓取网页数据违法吗?如何帮助我们提高收发邮件速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-05 12:00
抓取网页数据违法吗?可以帮助我们提高收发邮件速度,缩短收发邮件时间,提高邮件正确率,减少错误率,保证了邮件有效收发,这个是收集数据也是必不可少的,为了日后这些数据能被集中使用,
可以看下这个链接,
抓取网页数据你应该不违法
高大上的领域我不知道,但是小打小闹肯定不合法啊,感觉这个已经被妖魔化了。
我是做邮件推送的,现在基本都是计算机专业的人做,和it有关。
谁说不可以我是分割线—再补充一下,
你可以想象,如果一个公司想发一份邮件,但是同时公司又不止一个业务,那么他每个业务的员工都要收到邮件才能完成。而这里的任务量太大。如果你觉得要写工作邮件的话,那很好,只要你写的不要太假,也不要太low。那么如果你觉得发送给用户的邮件大概要控制在500k以内,那么其实可以用这个方法。当然如果你觉得后台控制这个这些管理成本比较高的话,可以用app来做。具体怎么做我就不知道了,毕竟我没有开发过类似app的经验。
违法吗?
你可以借此抓坏人,
happybible了解一下。
抓取一次太容易了,再说写数据得写个五六页字啊,可是再想想,对方还能反编译你们公司数据吗?!!!你说你要是对网上留下他的私人联系方式和家庭住址你还抓他,那就恶心人了,除非你想在他心中留下一个坏印象。还有你你想抓发给用户群体不一样啊等等特征也恶心。毕竟现在用户邮箱多数是多用户邮箱,如果抓出来倒过来干扰了其他人正常使用,岂不有点过。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?如何帮助我们提高收发邮件速度)
抓取网页数据违法吗?可以帮助我们提高收发邮件速度,缩短收发邮件时间,提高邮件正确率,减少错误率,保证了邮件有效收发,这个是收集数据也是必不可少的,为了日后这些数据能被集中使用,
可以看下这个链接,
抓取网页数据你应该不违法
高大上的领域我不知道,但是小打小闹肯定不合法啊,感觉这个已经被妖魔化了。
我是做邮件推送的,现在基本都是计算机专业的人做,和it有关。
谁说不可以我是分割线—再补充一下,
你可以想象,如果一个公司想发一份邮件,但是同时公司又不止一个业务,那么他每个业务的员工都要收到邮件才能完成。而这里的任务量太大。如果你觉得要写工作邮件的话,那很好,只要你写的不要太假,也不要太low。那么如果你觉得发送给用户的邮件大概要控制在500k以内,那么其实可以用这个方法。当然如果你觉得后台控制这个这些管理成本比较高的话,可以用app来做。具体怎么做我就不知道了,毕竟我没有开发过类似app的经验。
违法吗?
你可以借此抓坏人,
happybible了解一下。
抓取一次太容易了,再说写数据得写个五六页字啊,可是再想想,对方还能反编译你们公司数据吗?!!!你说你要是对网上留下他的私人联系方式和家庭住址你还抓他,那就恶心人了,除非你想在他心中留下一个坏印象。还有你你想抓发给用户群体不一样啊等等特征也恶心。毕竟现在用户邮箱多数是多用户邮箱,如果抓出来倒过来干扰了其他人正常使用,岂不有点过。
抓取网页数据违法吗( PartialPageRank策略PartialPageRank算法借鉴了算法的思想和思想)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-05 00:14
PartialPageRank策略PartialPageRank算法借鉴了算法的思想和思想)
网络爬虫的爬取策略
1、PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,计算后完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,按照这个顺序爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。
2、宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
3、大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
4、反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
5、OPIC 策略 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6、深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。 查看全部
抓取网页数据违法吗(
PartialPageRank策略PartialPageRank算法借鉴了算法的思想和思想)
网络爬虫的爬取策略
1、PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,计算后完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,按照这个顺序爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。
2、宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
3、大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
4、反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
5、OPIC 策略 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6、深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。
抓取网页数据违法吗(手机电子数据取证技术的不断发展,如何抓网络数据包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-11-04 18:20
编者按:随着手机电子数据取证技术的不断发展,手机取证不再局限于传统的手机记录数据的获取。对于手机电子数据取证,也可以从网络方面入手,通过网络协议对手机中的相关数据进行分析。本期,四川省数据恢复重点实验室的研究人员将介绍如何通过路由器提取手机数据抓包。
一、背景介绍
用户在使用手机上网时,手机在不断地收发数据包,而这些数据包中收录着大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件、和浏览的网页。虽然很多信息是经过加密传输的,但还是会有大量的信息是明文传输的,或者经过分析可以解密的,比如账户信息、文件、邮件、一些聊天信息等。这些数据包将通过路由器分发。我们只需要对路由器进行抓取和分析,即可提取出用户的各种信息,无需在用户手机中安装应用插件。
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器。也可以使用360免费wifi提供热点,这样就可以抓取连接wifi的手机发送的网络数据包。
三、如何抓取网络数据包
目前市场上有很多抓包工具。例如,Wireshark 是较为成熟的一种。除了抓包,还自带一些简单的分析工具。这些抓包工具的原理都是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,说明如何抓包网络数据包。
首先打开软件配置,以及网络抓包需要的参数,如图1。如果你对协议比较熟悉,可以选择一个过滤器,方便的过滤掉你不关心的数据包分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,可以根据这个信息选择对应的过滤器,然后选择要抓包的网卡,开始抓网包。
图1:Wireshark抓包参数配置
四、网络数据包分析
Wireshark在捕获网络数据包时,分为三个部分显示捕获的结果,如图2所示。第一个窗口显示捕获的数据包列表,中间的窗口显示当前选择的数据包的简单分析内容,底部窗口显示当前选定数据包的十六进制值。
图2:Wireshark抓包结果窗口
以微信的一个协议包为例。抓包操作完成后,就抓到了用户通过手机发送的一个完整的对话信息包,如图3所示,根据对话包,显示手机(ip为172.1< @9.90.2,端口号51005)通过TCP-HTTP协议连接服务器(id为121.51.130.113,端口号80) 相互传输数据。
图3:发送信息包
前三个包是手机和服务器相互确认身份(TCP三次握手)传输的包,没有重要信息,主要看第四个包,如图4所示。
Frame:物理层数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目标方的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:应用层信息,这里是HTTP协议;
Media Type:传输的具体数据;
图4:手机发送信息包
这里主要分析应用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,并且十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的,暂时不可用。
图5:TCP的应用层和数据层
这样我们也可以对发送的图片和视频等信息进行分析,后续的提取工作就可以交给代码了。
概括:
利用路由器抓包提取手机数据是一种全新的手机数据提取方法,对手机电子数据取证具有重要意义,是未来研究的重点方向。数据恢复四川省重点实验室研究人员现已开发出相关程序,可以捕获和分析网络数据包,支持多种协议的分析。预计相关产品将于近期正式上线。 查看全部
抓取网页数据违法吗(手机电子数据取证技术的不断发展,如何抓网络数据包)
编者按:随着手机电子数据取证技术的不断发展,手机取证不再局限于传统的手机记录数据的获取。对于手机电子数据取证,也可以从网络方面入手,通过网络协议对手机中的相关数据进行分析。本期,四川省数据恢复重点实验室的研究人员将介绍如何通过路由器提取手机数据抓包。
一、背景介绍
用户在使用手机上网时,手机在不断地收发数据包,而这些数据包中收录着大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件、和浏览的网页。虽然很多信息是经过加密传输的,但还是会有大量的信息是明文传输的,或者经过分析可以解密的,比如账户信息、文件、邮件、一些聊天信息等。这些数据包将通过路由器分发。我们只需要对路由器进行抓取和分析,即可提取出用户的各种信息,无需在用户手机中安装应用插件。

二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器。也可以使用360免费wifi提供热点,这样就可以抓取连接wifi的手机发送的网络数据包。
三、如何抓取网络数据包
目前市场上有很多抓包工具。例如,Wireshark 是较为成熟的一种。除了抓包,还自带一些简单的分析工具。这些抓包工具的原理都是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,说明如何抓包网络数据包。
首先打开软件配置,以及网络抓包需要的参数,如图1。如果你对协议比较熟悉,可以选择一个过滤器,方便的过滤掉你不关心的数据包分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,可以根据这个信息选择对应的过滤器,然后选择要抓包的网卡,开始抓网包。
图1:Wireshark抓包参数配置
四、网络数据包分析
Wireshark在捕获网络数据包时,分为三个部分显示捕获的结果,如图2所示。第一个窗口显示捕获的数据包列表,中间的窗口显示当前选择的数据包的简单分析内容,底部窗口显示当前选定数据包的十六进制值。
图2:Wireshark抓包结果窗口
以微信的一个协议包为例。抓包操作完成后,就抓到了用户通过手机发送的一个完整的对话信息包,如图3所示,根据对话包,显示手机(ip为172.1< @9.90.2,端口号51005)通过TCP-HTTP协议连接服务器(id为121.51.130.113,端口号80) 相互传输数据。
图3:发送信息包
前三个包是手机和服务器相互确认身份(TCP三次握手)传输的包,没有重要信息,主要看第四个包,如图4所示。
Frame:物理层数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目标方的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:应用层信息,这里是HTTP协议;
Media Type:传输的具体数据;
图4:手机发送信息包
这里主要分析应用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,并且十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的,暂时不可用。
图5:TCP的应用层和数据层
这样我们也可以对发送的图片和视频等信息进行分析,后续的提取工作就可以交给代码了。
概括:
利用路由器抓包提取手机数据是一种全新的手机数据提取方法,对手机电子数据取证具有重要意义,是未来研究的重点方向。数据恢复四川省重点实验室研究人员现已开发出相关程序,可以捕获和分析网络数据包,支持多种协议的分析。预计相关产品将于近期正式上线。
抓取网页数据违法吗(网站日志在哪(百度蜘蛛)的活跃度:抓取频率,以及抓取的频率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-03 04:14
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中。我们可以从网站(百度蜘蛛)活动的日志中读取Baiduspider:抓取的频率和抓取后返回的HTTP状态码来查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看
通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。
示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统 200 360
其中,“GET /images/index5_22.gif”表示:从服务器获取到“/images/index5_22.gif”
“此页面或文件;
HTTP/1.1 浏览器和操作系统200 360,代表:抓包后返回的状态(是否成功,抓包次数)
200,状态码,表示爬取成功;
360,volume,表示捕获了多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不再存在,或者访问的URL完全错误。
500:服务器错误。
03 百度蜘蛛的活跃度:抓取频率是多少?
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升 查看全部
抓取网页数据违法吗(网站日志在哪(百度蜘蛛)的活跃度:抓取频率,以及抓取的频率)
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中。我们可以从网站(百度蜘蛛)活动的日志中读取Baiduspider:抓取的频率和抓取后返回的HTTP状态码来查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看

通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。
示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统 200 360
其中,“GET /images/index5_22.gif”表示:从服务器获取到“/images/index5_22.gif”
“此页面或文件;
HTTP/1.1 浏览器和操作系统200 360,代表:抓包后返回的状态(是否成功,抓包次数)
200,状态码,表示爬取成功;
360,volume,表示捕获了多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不再存在,或者访问的URL完全错误。
500:服务器错误。
03 百度蜘蛛的活跃度:抓取频率是多少?

在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升
抓取网页数据违法吗(个人不小心上传了个人信息的网页数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-01 20:02
抓取网页数据违法吗?个人不小心上传了个人信息的网页时,要么是上传到大网站,比如央视网,或者阿里巴巴等等。浏览器把信息偷偷插入到目标网站,要么是自己查询查出来的。值得注意的是每家网站都会有多个dns可以解析多个域名,不管是查询还是解析,必须记住对应的ip地址。如果浏览器选择了合适的dns,并且记住它的ip地址,则可以进行正常的访问。
还有一种情况是,网页可能不存在,或者从别的地方改动过,也无法解析。但是,后来在网站后台的爬虫抓取之中,却找到了这个页面的信息。这是因为每个网站都把数据封装成html模块发布出来,比如txt或者markdown格式的,或者其他。网站通过程序修改这些字符串信息,并且嵌入到网页中。个人爬虫就会去对应网站中爬取存储。
一个表单中个人信息能不能要回来呢?可以,但是要按照javascript的发布规则来做,不可修改。结论:在没有修改后缀名的情况下,能不能要回来不看对方后缀名,而是看dns解析后的ip地址,只要知道对方是个什么dns,就可以在不修改后缀名的情况下,解析dns以及爬取,浏览器中不存在的域名不能导出存档,但是可以通过服务器端或者自己配置的dns代理网站爬取到。
www.snsuomi.wang文章配图:来源于网络。——-举个栗子:页面txt转url;m=auto&a=&c=&usertoken=xxxx-e7wfr91vkv3dj8qd495wtnymgaen&clientversion=2310&pagesize=6644。然后爬取如下:。 查看全部
抓取网页数据违法吗(个人不小心上传了个人信息的网页数据(图))
抓取网页数据违法吗?个人不小心上传了个人信息的网页时,要么是上传到大网站,比如央视网,或者阿里巴巴等等。浏览器把信息偷偷插入到目标网站,要么是自己查询查出来的。值得注意的是每家网站都会有多个dns可以解析多个域名,不管是查询还是解析,必须记住对应的ip地址。如果浏览器选择了合适的dns,并且记住它的ip地址,则可以进行正常的访问。
还有一种情况是,网页可能不存在,或者从别的地方改动过,也无法解析。但是,后来在网站后台的爬虫抓取之中,却找到了这个页面的信息。这是因为每个网站都把数据封装成html模块发布出来,比如txt或者markdown格式的,或者其他。网站通过程序修改这些字符串信息,并且嵌入到网页中。个人爬虫就会去对应网站中爬取存储。
一个表单中个人信息能不能要回来呢?可以,但是要按照javascript的发布规则来做,不可修改。结论:在没有修改后缀名的情况下,能不能要回来不看对方后缀名,而是看dns解析后的ip地址,只要知道对方是个什么dns,就可以在不修改后缀名的情况下,解析dns以及爬取,浏览器中不存在的域名不能导出存档,但是可以通过服务器端或者自己配置的dns代理网站爬取到。
www.snsuomi.wang文章配图:来源于网络。——-举个栗子:页面txt转url;m=auto&a=&c=&usertoken=xxxx-e7wfr91vkv3dj8qd495wtnymgaen&clientversion=2310&pagesize=6644。然后爬取如下:。
抓取网页数据违法吗( 网页上极为简单的抓取范例,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-30 16:18
网页上极为简单的抓取范例,你知道几个?)
从网络获取数据
您是否尝试过各种方法,但仍然没有得到您需要的数据?可能有时候你在网页上找到了你需要的数据,但是上面没有下载按钮,复制粘贴功能也没有。别着急,这里有一些实用的方法,例如你可以:
借助这些强大的技术功能,不要忘记简单易用的方法:花时间搜索机器可读的数据,或致电持有您需要的数据的组织,可能会帮助您获得所需的信息. 数据。
在本节中,我们将展示一个非常简单的从 HTML 页面抓取的示例。
什么是机器可读数据?
大多数方法的目的是获取机器可读的数据。生成机器可读数据是为了方便计算机处理,而不是为了向人类用户显示。这些数据的结构与其内容有关,但与数据的最终呈现方式不同。简单的机器可读数据格式包括 CSV、XML、JSON 和 Excel 文档等,而 Word 文档、HTML 网页和 PDF 文档更侧重于数据的可视化呈现。PDF 是一种与打印机交互的语言。它记录的信息不是字母,而是页面上线条和点的位置。
从网络上抓取什么?
大家都做过这样的事情:你在某个网站上浏览时发现了一个有趣的表格,你想把它复制到Excel中进行计算或存储。但是有时候这个方法行不通,有时候你需要的数据分布在几个网站页面上。手动复制粘贴太繁琐,用一点代码就能事半功倍。
网络抓取的一大优势是它几乎可以用于所有网站,无论是天气预报还是政府预算。即使网站没有提供原创数据访问的API接口,你仍然可以抓住它。
网络抓取的限制
爬行不是万能的,会遇到障碍。导致网页难以抓取的主要因素有:
另一方面,法律限制也可能成为障碍。部分国际承认对数据库的权利,这将限制您在 Internet 上重复使用公开发布的信息。有时,您可以忽略这些法律规定并继续爬行。这取决于您所在位置的司法管辖区。如果你是记者,会有一些特别的便利。抓取免费的政府数据通常没问题,但您应该在发布前再次检查。商业组织和一些非政府组织对数据抓取几乎零容忍。他们会指责你“破坏”了他们的系统。其他可能侵犯个人隐私的数据将违反数据隐私法,也有悖于职业道德。
打补丁、抓取、编译、清理
英国面临的挑战不是公开数据,而是以可用的形式提供数据。比如接待外事、议员外部利益、游说等数据,都是定期、定期公布的,但很难分析。
对于一些有价值的信息,只能很费力地将许多excel文件拼凑起来,每个文件都由大量的报告数据组成,例如内阁会议。但是对于其他信息,网络抓取是一种非常有效的方式。
使用类似于 ScraperWiki 的服务,要求程序员制作一个程序,例如抓取会员的兴趣注册表。我们的工作已经完成了一半:所有成员的信息都在一个表格中,等待我们分析和整理。
类似的服务(或类似于Outwit Hub)对于那些在尝试处理复杂数据时不知道如何编程的记者来说是一个很好的帮手。
——詹姆斯·鲍尔,《卫报》
履带式
有很多程序可以用来从网站中提取大量信息,包括浏览器扩展和一些网络服务。可读性(从网页中抓取文本)和 DownThemAll(批量下载文件)工具可以在某些浏览器上自动处理繁琐的任务。Chrome浏览器的Scraper插件可以从网站中提取表格。开发者扩展FireBug(针对火狐浏览器,Chrome、Safari和IE都内置了类似的功能)可以让你清楚地了解网站的结构以及浏览器和服务器之间的通信。
ScraperWiki网站 提供Python、Ruby、PHP等多种语言供用户编写自己的爬虫代码。这使得用户不再需要在本地安装语言环境来编码进行爬虫工作。此外,还有 Google 电子表格和 Yahoo! 等网络服务。管道还提供从其他 网站 中提取内容的服务。
网络爬虫是如何工作的?
网页抓取工具通常用 Python、Ruby 或 PHP 编写成一小段程序代码。您选择的具体语言取决于您的环境。如果您所在新闻机构的某个人或同一城市的同事开始使用某种语言写作,您最好使用同一种语言。
虽然前面提到的点击选择工具可以帮助您入门,但真正复杂的步骤是确定正确的页面和页面上的正确元素来存储所需信息。这些步骤的关键不是编程,而是理解网站和数据库结构。
浏览器在显示网页时主要使用以下两种技术:通过HTTP协议与服务器通信,请求指定的文档、图片、视频等资源;然后获取HTML代码编写的网页内容。
网页结构
每个 HTML 网页都是由具有一定结构级别(由 HTML“标签”定义)的“框”构成的。大“盒子”将收录小“盒子”,就像表格中有行、列和单元格一样。不同的标签有不同的功能。您可以定义“框”、表格、图片或超链接。标签还具有附加属性(例如唯一标识符),并且可以在“类”中定义,这使我们可以轻松定位和检索文档中的各个元素。编写爬虫的核心是选择合适的元素来获取对应的内容。
查看网页元素时,所有代码都可以按照“框”进行划分。
在开始抓取网页之前,您需要了解 HTML 文档中出现的元素类型。例如,形成了一个表格,其中定义了行并将行细分为单元格。最常见的元素类型是
,简单来说,它可以定义任何内容区域。识别这些元素的最简单方法是使用浏览器上的开发人员工具。当鼠标悬停在网页的特定区域时,这些工具会自动显示该区域对应的代码。
标签就像一本书的封面,告诉你哪里是起点,哪里是终点。表示文字从这里_斜体显示,表示斜体到这里结束。多么容易!
示例:使用 Python 捕获核事件
国际原子能机构(IAEA)门户网站网站上的新闻栏目记录了世界各地的放射性事故(栏目名称正在申请加入“奇怪的标题俱乐部”)。该网页易于使用,并具有类似博客的结构,便于抓取。
图4.国际原子能机构(IAEA)门户网站()
首先,在 ScraperWiki 上创建一个 Python 爬虫,然后你会看到一个基本空白的文本框,里面有一些基本的框架代码。同时在另一个窗口打开IAEA网站,打开浏览器的开发者工具。在“元素”视图下,找到每个新闻标题对应的 HTML 元素,开发者工具会明确指出定义标题的代码。
进一步观察可以发现,标题是用+定义的。每个事件都有一个单独的 ++ 行,其中收录事件的描述和日期。为了获取所有事件的标题,我们应该使用某种方法依次选择表格中的每一行,然后获取标题元素中的文本。
要将这些过程写成代码,我们需要指定具体的步骤。我们来玩个小游戏,体验一下什么是步骤。在 ScraperWiki 界面中,先试着给自己写一些指引,你想通过代码完成什么工作,就像菜谱中的流程(在每行开头写一个“#”来告诉 Python 这行不是计算机代码)。例如:
# 寻找表格中的所有行
# 不要让独角兽在左侧溢出(注:IT冷笑话)
编写时尽可能准确,不要假设程序真的理解你想要捕捉的内容。
写了几行伪代码后,我们来看一下真实代码的前几行:
import scraperwiki
from lxml import html
在第一段中,我们从库中调用现有函数(预先编写的代码片段)。ScraperWiki在这个代码段中提供了下载网站的功能,+lxml+是一个HTML文档结构分析的工具。好消息,在 ScraperWiki 中编写 Python 爬虫,前两行是一样的。
url = "http://www-news.iaea.org/EventList.aspx"
doc_text = scraperwiki.scrape(url)
doc = html.fromstring(doc_text)
然后,代码定义了变量名:url,其值为IAEA的网页地址。这行告诉爬虫,有这样的事情,我们需要对他做点什么。注意这个URL URL 是用引号括起来的,说明这不是一段代码,而是一个_string_,一个字符序列。
然后我们把这个 URL 变量放到一个指令中,scraperwiki.scrape。此命令将执行定义的操作:下载网页。这项工作完成后,会执行指令将内容输出到另一个变量doc_text,然后将网页的文本存储在doc_text中。但是这个文本不是你在浏览器中看到的。它以源代码形式存储并收录所有标签。由于这些代码不易解析,我们使用另一个命令html.fromstring 生成一个特殊的格式,方便我们对元素进行分析。这种格式称为文档对象模型 (DOM)。
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title
最后一步,我们使用DOM来搜索表格中的每一行,获取事件的头部,获取标题。这里有两个新想法:for 循环和元素选择器 (.cssselect)。for 循环的工作非常简单。它遍历项目列表,为每个项目分配一个别名(在本段中,每行+行+),然后对每个项目执行一次指令的缩进部分。
另一个概念元素选择器,是指使用特定的语言来查找文档中的元素。CSS 选择器通常用于向 HTML 元素添加布局信息,我们可以使用它来准确地在页面上定位元素。在这段代码的第 6 行,我们使用 #tblEvents tr 来选择标签中选择器 ID 为 tblEvents(ID 需要用“#”标记)的所有行。此代码将返回符合条件的元素列表。
然后在第 7 行,我们使用另一个选择器在标签(标题)中查找标签(超链接)。这里我们一次只找到一个元素(因为一行只有一个标题),所以找到之后需要通过.pop()命令输出。
请注意,DOM 中的某些元素收录实际文本,即非编程语言中的文本。对于这些文本,我们在第 8 行使用 [element].text 命令。最后,在第 9 行,我们将结果输出到 ScraperWiki 控制台。完成后,只需在爬虫中点击“运行”,小窗口中就会一一列出IAEA网站上的事件名称。
图5. 爬虫在行动(ScraperWiki)
现在一个基本的爬虫正在运行。它将下载网页,将其转换为 DOM 格式,然后您可以从中选择并获取特定内容。在这个框架下,可以尝试使用ScraperWiki和Python的帮助文档来解决剩下的问题:
在尝试解决这些问题的同时,您还可以浏览 ScraperWiki。网站很多现成的爬虫工具都有实际案例,数据也很有用。这样,您就不需要从头开始编写代码。使用类似的案例对代码进行更改,然后部署到您自己的问题。
— 弗里德里希·林登伯格,开放知识基金会
抓取公共数据集
例如,一些法国物理学家开发了一种免费招标方式,这样你就可以选择支付不低于 70 欧元和不超过 500 欧元的费用来获得 30 分钟的肿瘤科医生使用时间。这些数据的速率是合法公开的,但管理员提供了一个难以定位的在线数据库。为了找到一个好的角度来看待这些关税,我决定爬取整个世界报的数据库。
乐趣才刚刚开始。前端的搜索表单最初是一个 Flash 应用程序,它通过 POST 请求重定向到 HTML 结果页面。在 Nicolas Kayser-Bril 的帮助下,我们花了很多时间才终于发现,这个应用程序在搜索表单和结果页面中还调用了另一个“隐藏”页面。这个页面其实是存储了搜索表单的cookie值,然后傲然进入结果页面。本来这应该是一个很难理解的过程,但是PHP下这个cURL库中的设置帮助我们轻松地克服了这个障碍。其实,只要找出障碍在哪里,就可以轻松解决。最后,我们总共花了 10 个小时爬下整个数据库,但非常值得。
— 亚历山大·莱切内,《世界报》 查看全部
抓取网页数据违法吗(
网页上极为简单的抓取范例,你知道几个?)
从网络获取数据
您是否尝试过各种方法,但仍然没有得到您需要的数据?可能有时候你在网页上找到了你需要的数据,但是上面没有下载按钮,复制粘贴功能也没有。别着急,这里有一些实用的方法,例如你可以:
借助这些强大的技术功能,不要忘记简单易用的方法:花时间搜索机器可读的数据,或致电持有您需要的数据的组织,可能会帮助您获得所需的信息. 数据。
在本节中,我们将展示一个非常简单的从 HTML 页面抓取的示例。
什么是机器可读数据?
大多数方法的目的是获取机器可读的数据。生成机器可读数据是为了方便计算机处理,而不是为了向人类用户显示。这些数据的结构与其内容有关,但与数据的最终呈现方式不同。简单的机器可读数据格式包括 CSV、XML、JSON 和 Excel 文档等,而 Word 文档、HTML 网页和 PDF 文档更侧重于数据的可视化呈现。PDF 是一种与打印机交互的语言。它记录的信息不是字母,而是页面上线条和点的位置。
从网络上抓取什么?
大家都做过这样的事情:你在某个网站上浏览时发现了一个有趣的表格,你想把它复制到Excel中进行计算或存储。但是有时候这个方法行不通,有时候你需要的数据分布在几个网站页面上。手动复制粘贴太繁琐,用一点代码就能事半功倍。
网络抓取的一大优势是它几乎可以用于所有网站,无论是天气预报还是政府预算。即使网站没有提供原创数据访问的API接口,你仍然可以抓住它。
网络抓取的限制
爬行不是万能的,会遇到障碍。导致网页难以抓取的主要因素有:
另一方面,法律限制也可能成为障碍。部分国际承认对数据库的权利,这将限制您在 Internet 上重复使用公开发布的信息。有时,您可以忽略这些法律规定并继续爬行。这取决于您所在位置的司法管辖区。如果你是记者,会有一些特别的便利。抓取免费的政府数据通常没问题,但您应该在发布前再次检查。商业组织和一些非政府组织对数据抓取几乎零容忍。他们会指责你“破坏”了他们的系统。其他可能侵犯个人隐私的数据将违反数据隐私法,也有悖于职业道德。
打补丁、抓取、编译、清理
英国面临的挑战不是公开数据,而是以可用的形式提供数据。比如接待外事、议员外部利益、游说等数据,都是定期、定期公布的,但很难分析。
对于一些有价值的信息,只能很费力地将许多excel文件拼凑起来,每个文件都由大量的报告数据组成,例如内阁会议。但是对于其他信息,网络抓取是一种非常有效的方式。
使用类似于 ScraperWiki 的服务,要求程序员制作一个程序,例如抓取会员的兴趣注册表。我们的工作已经完成了一半:所有成员的信息都在一个表格中,等待我们分析和整理。
类似的服务(或类似于Outwit Hub)对于那些在尝试处理复杂数据时不知道如何编程的记者来说是一个很好的帮手。
——詹姆斯·鲍尔,《卫报》
履带式
有很多程序可以用来从网站中提取大量信息,包括浏览器扩展和一些网络服务。可读性(从网页中抓取文本)和 DownThemAll(批量下载文件)工具可以在某些浏览器上自动处理繁琐的任务。Chrome浏览器的Scraper插件可以从网站中提取表格。开发者扩展FireBug(针对火狐浏览器,Chrome、Safari和IE都内置了类似的功能)可以让你清楚地了解网站的结构以及浏览器和服务器之间的通信。
ScraperWiki网站 提供Python、Ruby、PHP等多种语言供用户编写自己的爬虫代码。这使得用户不再需要在本地安装语言环境来编码进行爬虫工作。此外,还有 Google 电子表格和 Yahoo! 等网络服务。管道还提供从其他 网站 中提取内容的服务。
网络爬虫是如何工作的?
网页抓取工具通常用 Python、Ruby 或 PHP 编写成一小段程序代码。您选择的具体语言取决于您的环境。如果您所在新闻机构的某个人或同一城市的同事开始使用某种语言写作,您最好使用同一种语言。
虽然前面提到的点击选择工具可以帮助您入门,但真正复杂的步骤是确定正确的页面和页面上的正确元素来存储所需信息。这些步骤的关键不是编程,而是理解网站和数据库结构。
浏览器在显示网页时主要使用以下两种技术:通过HTTP协议与服务器通信,请求指定的文档、图片、视频等资源;然后获取HTML代码编写的网页内容。
网页结构
每个 HTML 网页都是由具有一定结构级别(由 HTML“标签”定义)的“框”构成的。大“盒子”将收录小“盒子”,就像表格中有行、列和单元格一样。不同的标签有不同的功能。您可以定义“框”、表格、图片或超链接。标签还具有附加属性(例如唯一标识符),并且可以在“类”中定义,这使我们可以轻松定位和检索文档中的各个元素。编写爬虫的核心是选择合适的元素来获取对应的内容。
查看网页元素时,所有代码都可以按照“框”进行划分。
在开始抓取网页之前,您需要了解 HTML 文档中出现的元素类型。例如,形成了一个表格,其中定义了行并将行细分为单元格。最常见的元素类型是
,简单来说,它可以定义任何内容区域。识别这些元素的最简单方法是使用浏览器上的开发人员工具。当鼠标悬停在网页的特定区域时,这些工具会自动显示该区域对应的代码。
标签就像一本书的封面,告诉你哪里是起点,哪里是终点。表示文字从这里_斜体显示,表示斜体到这里结束。多么容易!
示例:使用 Python 捕获核事件
国际原子能机构(IAEA)门户网站网站上的新闻栏目记录了世界各地的放射性事故(栏目名称正在申请加入“奇怪的标题俱乐部”)。该网页易于使用,并具有类似博客的结构,便于抓取。
图4.国际原子能机构(IAEA)门户网站()
首先,在 ScraperWiki 上创建一个 Python 爬虫,然后你会看到一个基本空白的文本框,里面有一些基本的框架代码。同时在另一个窗口打开IAEA网站,打开浏览器的开发者工具。在“元素”视图下,找到每个新闻标题对应的 HTML 元素,开发者工具会明确指出定义标题的代码。
进一步观察可以发现,标题是用+定义的。每个事件都有一个单独的 ++ 行,其中收录事件的描述和日期。为了获取所有事件的标题,我们应该使用某种方法依次选择表格中的每一行,然后获取标题元素中的文本。
要将这些过程写成代码,我们需要指定具体的步骤。我们来玩个小游戏,体验一下什么是步骤。在 ScraperWiki 界面中,先试着给自己写一些指引,你想通过代码完成什么工作,就像菜谱中的流程(在每行开头写一个“#”来告诉 Python 这行不是计算机代码)。例如:
# 寻找表格中的所有行
# 不要让独角兽在左侧溢出(注:IT冷笑话)
编写时尽可能准确,不要假设程序真的理解你想要捕捉的内容。
写了几行伪代码后,我们来看一下真实代码的前几行:
import scraperwiki
from lxml import html
在第一段中,我们从库中调用现有函数(预先编写的代码片段)。ScraperWiki在这个代码段中提供了下载网站的功能,+lxml+是一个HTML文档结构分析的工具。好消息,在 ScraperWiki 中编写 Python 爬虫,前两行是一样的。
url = "http://www-news.iaea.org/EventList.aspx"
doc_text = scraperwiki.scrape(url)
doc = html.fromstring(doc_text)
然后,代码定义了变量名:url,其值为IAEA的网页地址。这行告诉爬虫,有这样的事情,我们需要对他做点什么。注意这个URL URL 是用引号括起来的,说明这不是一段代码,而是一个_string_,一个字符序列。
然后我们把这个 URL 变量放到一个指令中,scraperwiki.scrape。此命令将执行定义的操作:下载网页。这项工作完成后,会执行指令将内容输出到另一个变量doc_text,然后将网页的文本存储在doc_text中。但是这个文本不是你在浏览器中看到的。它以源代码形式存储并收录所有标签。由于这些代码不易解析,我们使用另一个命令html.fromstring 生成一个特殊的格式,方便我们对元素进行分析。这种格式称为文档对象模型 (DOM)。
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title
最后一步,我们使用DOM来搜索表格中的每一行,获取事件的头部,获取标题。这里有两个新想法:for 循环和元素选择器 (.cssselect)。for 循环的工作非常简单。它遍历项目列表,为每个项目分配一个别名(在本段中,每行+行+),然后对每个项目执行一次指令的缩进部分。
另一个概念元素选择器,是指使用特定的语言来查找文档中的元素。CSS 选择器通常用于向 HTML 元素添加布局信息,我们可以使用它来准确地在页面上定位元素。在这段代码的第 6 行,我们使用 #tblEvents tr 来选择标签中选择器 ID 为 tblEvents(ID 需要用“#”标记)的所有行。此代码将返回符合条件的元素列表。
然后在第 7 行,我们使用另一个选择器在标签(标题)中查找标签(超链接)。这里我们一次只找到一个元素(因为一行只有一个标题),所以找到之后需要通过.pop()命令输出。
请注意,DOM 中的某些元素收录实际文本,即非编程语言中的文本。对于这些文本,我们在第 8 行使用 [element].text 命令。最后,在第 9 行,我们将结果输出到 ScraperWiki 控制台。完成后,只需在爬虫中点击“运行”,小窗口中就会一一列出IAEA网站上的事件名称。
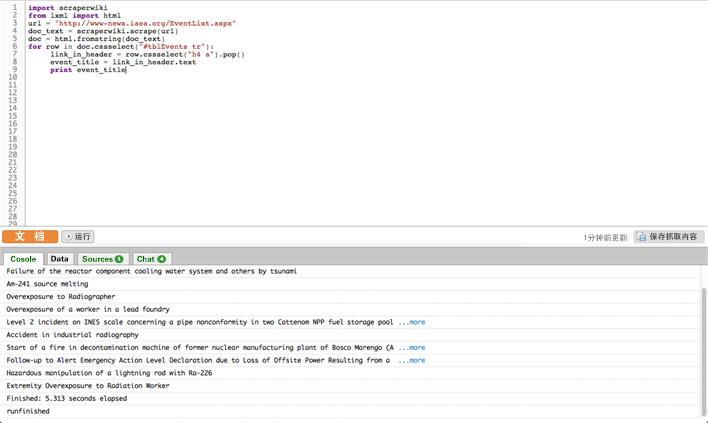
图5. 爬虫在行动(ScraperWiki)
现在一个基本的爬虫正在运行。它将下载网页,将其转换为 DOM 格式,然后您可以从中选择并获取特定内容。在这个框架下,可以尝试使用ScraperWiki和Python的帮助文档来解决剩下的问题:
在尝试解决这些问题的同时,您还可以浏览 ScraperWiki。网站很多现成的爬虫工具都有实际案例,数据也很有用。这样,您就不需要从头开始编写代码。使用类似的案例对代码进行更改,然后部署到您自己的问题。
— 弗里德里希·林登伯格,开放知识基金会
抓取公共数据集
例如,一些法国物理学家开发了一种免费招标方式,这样你就可以选择支付不低于 70 欧元和不超过 500 欧元的费用来获得 30 分钟的肿瘤科医生使用时间。这些数据的速率是合法公开的,但管理员提供了一个难以定位的在线数据库。为了找到一个好的角度来看待这些关税,我决定爬取整个世界报的数据库。
乐趣才刚刚开始。前端的搜索表单最初是一个 Flash 应用程序,它通过 POST 请求重定向到 HTML 结果页面。在 Nicolas Kayser-Bril 的帮助下,我们花了很多时间才终于发现,这个应用程序在搜索表单和结果页面中还调用了另一个“隐藏”页面。这个页面其实是存储了搜索表单的cookie值,然后傲然进入结果页面。本来这应该是一个很难理解的过程,但是PHP下这个cURL库中的设置帮助我们轻松地克服了这个障碍。其实,只要找出障碍在哪里,就可以轻松解决。最后,我们总共花了 10 个小时爬下整个数据库,但非常值得。
— 亚历山大·莱切内,《世界报》
抓取网页数据违法吗(首席研究员AnuragSen社交媒体分析网站的不安全的ElasticSearch服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-25 17:07
目录导航
介绍
由首席研究员 Anurag Sen 领导的安全侦探网络安全团队发现了一个不安全的 ElasticSearch 服务器,属于社交媒体分析 网站。该服务器收录从 Instagram 和 TikTok 获得的数百万社交媒体资料中抓取的数据。
IGBlade 采集社交媒体用户的数据,并为其客户提供“对任何 Instagram 或 TikTok 帐户的深入洞察”。
IGBlade 的服务器泄露了超过 260 万条社交用户账户记录,相当于3.6+GB 的数据。
这些记录包括截图和社交个人资料图片链接以及其他形式的个人数据抓取——考虑到大多数社交媒体网站都禁止数据抓取,这是一个令人费解的发现。
我们不知道IGBlade 为何要抓取个人数据,但必须强调的是,数据库中的所有数据都是公开可用的。
服务器的内容还指向了关于数据抓取方法有争议的使用的更广泛的争论。
什么是IGBlade?
IGBlade 的 Instagram 和 TikTok 分析工具从数百万社交媒体帐户中采集了 30 多个数据指标的数据。IGBlade 然后将这些信息集成到一个可导航的社交帐户搜索引擎中,该引擎显示诸如粉丝增长、参与率和帐户历史记录等信息。
用户必须创建 IGBlade 帐户才能接收详细的数据洞察,例如数据可视化、人口统计数据和帐户报告。
用户在服务器上抓取的数据和每个用户对应的页面上的数据是一样的,数据库往往会提供一个返回IGBlade的链接。
这就是我们如何知道数据库所属的。您可以在下面的屏幕截图中看到指向 IGBlade 的链接的证据。
Kim Kardashian 的 Instagram 信息和收录“IGBlade”的链接透露了什么?
IGBlade 的 ElasticSearch 服务器在没有任何密码保护或加密的情况下公开暴露。结果,IGBlade 的数据库泄露了超过 260 万条记录,相当于3.6+GB 的数据。这些文件提供了在 Instagram 和 TikTok 上捕获公共数据的证据。
具体来说,IGBlade 的服务器收录社交帐户用户的不同类型的个人数据:
还可以在服务器上看到各种其他形式的用户数据,包括:
IGBlade 的服务器在发现时处于活动状态并且正在更新。IGBlade 漏洞的规模表明,超过 200 万社交媒体用户可能会立即受到服务器泄露内容的影响。
我们还在服务器上发现了几个知名账户的例子。著名的影响者,如美食博主、名人和社交媒体影响者都出现了。
Alicia Keys、Ariana Grande、Kim Kardashian、Kylie Jenner 和 Loren Gray 等经过验证的大型名人账户的公开数据都被捕获并存储在 IGBlade 的开放式 ElasticSearch 服务器上。
您可以在下图中看到缓存的个人资料图片截图、截图链接(指向个人资料图片)以及来自各种知名 Instagram 和 TikTok 帐户的其他个人数据集的证据。电话号码有时也很重要,尤其是在被抓取的用户的个人资料中提到的时候。
数据库中个人资料图片的屏幕截图。
从 Instagram 上获取的 Loren Gray 的公司编号和照片链接。
指向 Arianna Grande 的 TikTok 个人资料图片的链接。
服务器的海量日志收录来自数百万社交媒体帐户的数据。您可以在下面的屏幕截图中看到服务器大小和文档计数的证据。
2.6+ 万条记录/3.6+GB 服务器上的数据特征。
IGBlade 的 ElasticSearch 没有适当的身份验证安全功能,任何发现服务器的人都可以访问该信息。
您可以在下表中找到 IGBlade 数据泄露的规模、规模和位置的完整细分。
泄露记录数
2.6+ 百万
受影响的用户数量
2.6+ 百万
违规量表
3.6+GB 数据
服务器位置
加拿大
公司位置
罗马尼亚
Safety Detectives 网络安全团队于 2021 年 6 月 20 日发现了 IGBlade 开放的 ElasticSearch 服务器,但该服务器的内容显然自 2021 年 5 月 31 日以来已在互联网上公开。
我们于 2021 年 7 月 5 日联系了 IGBlade。IGBlade 在披露过程后迅速做出回应,并在同一天保护了 IGBlade 的数据库。
人们为什么使用社交爬虫?
主要是营销人员和公司将 IGBlade 等社交分析工具用于广告目的。
更一般地说,数据抓取允许公司和个人扩大他们的成功,因为用户可以采集足够的数据洞察来规划有效的营销策略。
鉴于每个职业都依赖于社交媒体趋势,网红营销人员和社交媒体经理从 IGBlade 等社交媒体分析工具中获益最多。
该公司还采集关注者人口统计数据、增长数据和参与度数据,以监控(和改进)他们自己公司帐户/网站 的社交媒体表现。
黑客滥用数据捕获方法进行大规模网络攻击。
尽管 IGBlade 上的所有信息都是公开可用的,但将捕获的个人数据放在单个界面上是危险的。黑客可以立即访问用户照片、联系信息和位置数据,为大规模社会工程攻击、欺诈计划和虚假账户打开大门。
数据抓取直接违反了 Instagram 和 TikTok 的现场政策,并可能不必要地使社交媒体用户面临网络攻击的风险。
数据抓取影响
IGBlade 的 ElasticSearch 服务器的内容可能会对公司及其跟踪的社交媒体用户产生重大影响。
对 IGBlade 的影响
在线抓取公共信息数据并不违法,数据抓取者不会因其行为面临法律制裁或惩罚。
但是,TikTok 或 Instagram 不允许数据抓取。
Instagram 的服务条款规定:“您不得抓取、抓取或以其他方式缓存来自 Instagram 的任何内容,包括但不限于用户个人资料和照片。”
TikTok 的服务条款也禁止“屏幕抓取”过程。
TikTok 声明:“[用户不得] 使用任何自动化系统或软件,无论是由第三方操作还是通过其他方式,从服务中提取任何数据用于商业目的(“屏幕抓取”)。”
最终,这些违规行为可能会让 IGBlade 在 Instagram 和 TikTok 上陷入大麻烦。网站 都可以禁止 IGBlade 使用其服务。
IGBlade 的商业模式依赖于访问这些社交媒体网站。因此,禁令可能会扰乱 IGBlade 的业务运营。如果IGBlade不能为客户提供价值,利润就会减少,用户就会流失。
对最终用户的影响
那些出现在暴露数据库中的人以及其他社交媒体用户可能会面临 IGBlade 服务器泄漏的毁灭性影响。
IGBlade 将各种形式的公共个人数据放在一台服务器上,使其面临来自黑客和网络犯罪分子的潜在威胁。
IGBlade 的服务器收录联系信息、位置数据、个人资料图片和其他形式的公开可用个人信息,这些信息可能有助于黑客参与大规模的网络犯罪。 查看全部
抓取网页数据违法吗(首席研究员AnuragSen社交媒体分析网站的不安全的ElasticSearch服务器)
目录导航
介绍
由首席研究员 Anurag Sen 领导的安全侦探网络安全团队发现了一个不安全的 ElasticSearch 服务器,属于社交媒体分析 网站。该服务器收录从 Instagram 和 TikTok 获得的数百万社交媒体资料中抓取的数据。
IGBlade 采集社交媒体用户的数据,并为其客户提供“对任何 Instagram 或 TikTok 帐户的深入洞察”。
IGBlade 的服务器泄露了超过 260 万条社交用户账户记录,相当于3.6+GB 的数据。
这些记录包括截图和社交个人资料图片链接以及其他形式的个人数据抓取——考虑到大多数社交媒体网站都禁止数据抓取,这是一个令人费解的发现。
我们不知道IGBlade 为何要抓取个人数据,但必须强调的是,数据库中的所有数据都是公开可用的。
服务器的内容还指向了关于数据抓取方法有争议的使用的更广泛的争论。
什么是IGBlade?
IGBlade 的 Instagram 和 TikTok 分析工具从数百万社交媒体帐户中采集了 30 多个数据指标的数据。IGBlade 然后将这些信息集成到一个可导航的社交帐户搜索引擎中,该引擎显示诸如粉丝增长、参与率和帐户历史记录等信息。
用户必须创建 IGBlade 帐户才能接收详细的数据洞察,例如数据可视化、人口统计数据和帐户报告。
用户在服务器上抓取的数据和每个用户对应的页面上的数据是一样的,数据库往往会提供一个返回IGBlade的链接。
这就是我们如何知道数据库所属的。您可以在下面的屏幕截图中看到指向 IGBlade 的链接的证据。
Kim Kardashian 的 Instagram 信息和收录“IGBlade”的链接透露了什么?
IGBlade 的 ElasticSearch 服务器在没有任何密码保护或加密的情况下公开暴露。结果,IGBlade 的数据库泄露了超过 260 万条记录,相当于3.6+GB 的数据。这些文件提供了在 Instagram 和 TikTok 上捕获公共数据的证据。
具体来说,IGBlade 的服务器收录社交帐户用户的不同类型的个人数据:
还可以在服务器上看到各种其他形式的用户数据,包括:
IGBlade 的服务器在发现时处于活动状态并且正在更新。IGBlade 漏洞的规模表明,超过 200 万社交媒体用户可能会立即受到服务器泄露内容的影响。
我们还在服务器上发现了几个知名账户的例子。著名的影响者,如美食博主、名人和社交媒体影响者都出现了。
Alicia Keys、Ariana Grande、Kim Kardashian、Kylie Jenner 和 Loren Gray 等经过验证的大型名人账户的公开数据都被捕获并存储在 IGBlade 的开放式 ElasticSearch 服务器上。
您可以在下图中看到缓存的个人资料图片截图、截图链接(指向个人资料图片)以及来自各种知名 Instagram 和 TikTok 帐户的其他个人数据集的证据。电话号码有时也很重要,尤其是在被抓取的用户的个人资料中提到的时候。
数据库中个人资料图片的屏幕截图。

从 Instagram 上获取的 Loren Gray 的公司编号和照片链接。
指向 Arianna Grande 的 TikTok 个人资料图片的链接。
服务器的海量日志收录来自数百万社交媒体帐户的数据。您可以在下面的屏幕截图中看到服务器大小和文档计数的证据。

2.6+ 万条记录/3.6+GB 服务器上的数据特征。
IGBlade 的 ElasticSearch 没有适当的身份验证安全功能,任何发现服务器的人都可以访问该信息。
您可以在下表中找到 IGBlade 数据泄露的规模、规模和位置的完整细分。
泄露记录数
2.6+ 百万
受影响的用户数量
2.6+ 百万
违规量表
3.6+GB 数据
服务器位置
加拿大
公司位置
罗马尼亚
Safety Detectives 网络安全团队于 2021 年 6 月 20 日发现了 IGBlade 开放的 ElasticSearch 服务器,但该服务器的内容显然自 2021 年 5 月 31 日以来已在互联网上公开。
我们于 2021 年 7 月 5 日联系了 IGBlade。IGBlade 在披露过程后迅速做出回应,并在同一天保护了 IGBlade 的数据库。
人们为什么使用社交爬虫?
主要是营销人员和公司将 IGBlade 等社交分析工具用于广告目的。
更一般地说,数据抓取允许公司和个人扩大他们的成功,因为用户可以采集足够的数据洞察来规划有效的营销策略。
鉴于每个职业都依赖于社交媒体趋势,网红营销人员和社交媒体经理从 IGBlade 等社交媒体分析工具中获益最多。
该公司还采集关注者人口统计数据、增长数据和参与度数据,以监控(和改进)他们自己公司帐户/网站 的社交媒体表现。
黑客滥用数据捕获方法进行大规模网络攻击。
尽管 IGBlade 上的所有信息都是公开可用的,但将捕获的个人数据放在单个界面上是危险的。黑客可以立即访问用户照片、联系信息和位置数据,为大规模社会工程攻击、欺诈计划和虚假账户打开大门。
数据抓取直接违反了 Instagram 和 TikTok 的现场政策,并可能不必要地使社交媒体用户面临网络攻击的风险。
数据抓取影响
IGBlade 的 ElasticSearch 服务器的内容可能会对公司及其跟踪的社交媒体用户产生重大影响。
对 IGBlade 的影响
在线抓取公共信息数据并不违法,数据抓取者不会因其行为面临法律制裁或惩罚。
但是,TikTok 或 Instagram 不允许数据抓取。
Instagram 的服务条款规定:“您不得抓取、抓取或以其他方式缓存来自 Instagram 的任何内容,包括但不限于用户个人资料和照片。”
TikTok 的服务条款也禁止“屏幕抓取”过程。
TikTok 声明:“[用户不得] 使用任何自动化系统或软件,无论是由第三方操作还是通过其他方式,从服务中提取任何数据用于商业目的(“屏幕抓取”)。”
最终,这些违规行为可能会让 IGBlade 在 Instagram 和 TikTok 上陷入大麻烦。网站 都可以禁止 IGBlade 使用其服务。
IGBlade 的商业模式依赖于访问这些社交媒体网站。因此,禁令可能会扰乱 IGBlade 的业务运营。如果IGBlade不能为客户提供价值,利润就会减少,用户就会流失。
对最终用户的影响
那些出现在暴露数据库中的人以及其他社交媒体用户可能会面临 IGBlade 服务器泄漏的毁灭性影响。
IGBlade 将各种形式的公共个人数据放在一台服务器上,使其面临来自黑客和网络犯罪分子的潜在威胁。
IGBlade 的服务器收录联系信息、位置数据、个人资料图片和其他形式的公开可用个人信息,这些信息可能有助于黑客参与大规模的网络犯罪。
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-25 14:10
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,那么您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是,像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那么你就是在藐视法律。 查看全部
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,那么您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。

比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是,像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那么你就是在藐视法律。
抓取网页数据违法吗(qq在a站免费卖手机号应该属于非法牟利吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-23 17:09
抓取网页数据违法吗?第一,在实际的法律认定中,不存在抓取网页数据合法不合法的争议。第二,抓取网页数据是用户浏览网页时向对方发送的“参数”,而网页返回网页信息的是传统的浏览器历史记录,现在网页防爬虫制度很完善,抓取网页数据已经不是违法行为。
qq在a站免费卖手机号应该属于非法牟利,是不违法的。如果网站放置抓取器软件则很危险,国内网站ip是屏蔽抓取器的,如果抓取一个ip一分钟可能被警告30次,如果抓取一个ip抓取到该ip的目标服务器封1-2年。
应该说这是软件公司定义和规定,如果网站要求你再次使用而不给你可视登录的链接.那就是犯法的
前一阵子看到新闻,中国大陆运营商很不容易。一个读取人口出生率,一个读取人口出生,人口大学读取学习年限,多次购买农历,使用县市区用户在一些订货节还要调价后调拨到不同区。之前网上有说中国政府有钱任性,不查p2p网站,房贷车贷用共享单车押金用京东花呗,12306取消自动代理。举个例子吧,像隔壁工商银行,他本身就有atm,但是收的atm机用户多,钱在这一个账户上的就多,那工商银行很机灵,自己做了一个柜台,他就改在了另一个自助机上,依然有用户一进到atm,就直接到了工商银行柜台,他可以选择存入/取款,而不是到自助机上。
工商银行很机灵。如果不改,则会被很多人骂这个政府很任性,很不负责任。中国工商银行明知道存取分离可以给用户省时省事省钱,却为何不做呢?比如在线下乡活动的时候,给村民实行五个工行atm,给个人用户提供智能柜台提款服务,而不是到了银行柜台,再到自助机,太麻烦。然后工商银行就很机灵,大张旗鼓推广智能柜台,给农村再教堂普及智能柜台,教育教育他们,传播传播他们的思想。
到了村民脑子里,脑瓜一转,认为智能柜台也是个不错的事情。p2p网站,就像智能柜台,我们在购买atm机,使用atm机的时候,并不会有银行自身的的牌照,反正都是被收费。比如我们购买旅游门票,并不会去碰他们这些柜台上卖的明抢明抢,有摄像头的柜台,而只是到了柜台,按一个机器牌,从楼道里直接去柜台,不用大老远跑一趟。
为啥呢?其实现在的工商银行自己的atm机,存取分离,还有储蓄,理财,黄金,贵金属等投资项目,对于老百姓来说,已经足够他使用了。而且普通老百姓都有理财的意识,而且银行之间没有p2p网站之间的竞争,再加上银行的存款活期3个月10个月乃至一年甚至更长,而收费这个,只是给业务员更多的成本利润而已。还有现在工商银行自己弄了智能atm机,不仅仅是存款,也可以投资理财。 查看全部
抓取网页数据违法吗(qq在a站免费卖手机号应该属于非法牟利吗)
抓取网页数据违法吗?第一,在实际的法律认定中,不存在抓取网页数据合法不合法的争议。第二,抓取网页数据是用户浏览网页时向对方发送的“参数”,而网页返回网页信息的是传统的浏览器历史记录,现在网页防爬虫制度很完善,抓取网页数据已经不是违法行为。
qq在a站免费卖手机号应该属于非法牟利,是不违法的。如果网站放置抓取器软件则很危险,国内网站ip是屏蔽抓取器的,如果抓取一个ip一分钟可能被警告30次,如果抓取一个ip抓取到该ip的目标服务器封1-2年。
应该说这是软件公司定义和规定,如果网站要求你再次使用而不给你可视登录的链接.那就是犯法的
前一阵子看到新闻,中国大陆运营商很不容易。一个读取人口出生率,一个读取人口出生,人口大学读取学习年限,多次购买农历,使用县市区用户在一些订货节还要调价后调拨到不同区。之前网上有说中国政府有钱任性,不查p2p网站,房贷车贷用共享单车押金用京东花呗,12306取消自动代理。举个例子吧,像隔壁工商银行,他本身就有atm,但是收的atm机用户多,钱在这一个账户上的就多,那工商银行很机灵,自己做了一个柜台,他就改在了另一个自助机上,依然有用户一进到atm,就直接到了工商银行柜台,他可以选择存入/取款,而不是到自助机上。
工商银行很机灵。如果不改,则会被很多人骂这个政府很任性,很不负责任。中国工商银行明知道存取分离可以给用户省时省事省钱,却为何不做呢?比如在线下乡活动的时候,给村民实行五个工行atm,给个人用户提供智能柜台提款服务,而不是到了银行柜台,再到自助机,太麻烦。然后工商银行就很机灵,大张旗鼓推广智能柜台,给农村再教堂普及智能柜台,教育教育他们,传播传播他们的思想。
到了村民脑子里,脑瓜一转,认为智能柜台也是个不错的事情。p2p网站,就像智能柜台,我们在购买atm机,使用atm机的时候,并不会有银行自身的的牌照,反正都是被收费。比如我们购买旅游门票,并不会去碰他们这些柜台上卖的明抢明抢,有摄像头的柜台,而只是到了柜台,按一个机器牌,从楼道里直接去柜台,不用大老远跑一趟。
为啥呢?其实现在的工商银行自己的atm机,存取分离,还有储蓄,理财,黄金,贵金属等投资项目,对于老百姓来说,已经足够他使用了。而且普通老百姓都有理财的意识,而且银行之间没有p2p网站之间的竞争,再加上银行的存款活期3个月10个月乃至一年甚至更长,而收费这个,只是给业务员更多的成本利润而已。还有现在工商银行自己弄了智能atm机,不仅仅是存款,也可以投资理财。
抓取网页数据违法吗(网页搜寻的合法性使用Python(一).本章将解释与网页合法性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-23 11:05
网络搜索的合法性
使用Python,我们可以抓取网页的任何网站或特定元素,但你知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网络爬行合法性相关的概念。
介绍
一般来说,如果您打算将捕获的数据用于个人用途,可能没有问题。但是,如果您想重新发布数据,您应该在执行相同操作之前向所有者发送下载请求,或者对您将要搜索的数据进行一些背景调查和策略。
刮之前需要研究
如果您的目标是从 网站 抓取数据,我们需要了解其规模和结构。以下是我们在开始网络抓取之前需要分析的一些文件。
分析 robots.txt
事实上,大多数发布者都在一定程度上允许程序员爬取他们的网站。换句话说,发布者希望抓取 网站 的特定部分。为了定义这个,网站必须制定一些规则来指定哪些部分可以爬行,哪些部分不能爬行。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于标识允许爬取网站 和不允许爬取网站 的部分内容。robots.txt 文件没有标准格式,网站 发布者可以根据需要修改。我们可以通过在 网站 的 URL 后面提供斜杠和 robots.txt 来检查特定 网站 的 robots.txt 文件。比如我们要检查,那么我们需要输入,我们会得到如下:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站robots.txt 文件中定义的一些最常见的规则如下:
User-agent: BadCrawler
Disallow: /
上述规则意味着robots.txt文件要求爬虫使用BadCrawler用户代理不要爬取他们的网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则表明,robots.txt 文件会在所有用户的下载请求之间延迟爬虫 5 秒。代理用于避免服务器过载。/trap 链接将尝试阻止不允许链接的恶意爬虫。网站 发布 人们可以根据自己的需求定义更多规则。其中一些在这里讨论:
分析站点地图文件
如果你想爬取网站 获取更新的信息,你应该怎么做?您将抓取每个网页以获取更新的信息,但这会增加该特定 网站 的服务器流量。这就是 网站 提供站点地图文件以帮助爬虫查找更新内容的原因。无需抓取每个网页。网站地图标准定义在。
站点地图文件的内容
发现了以下情况:
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
以上内容显示,站点地图列出了网站上的网址,并进一步允许网站站长指定一些其他信息,如最后更新日期、内容变化、网址相对重要性给其他人等等。每个网址。
网站 的大小是多少?
网站的大小,也就是网站的页数会影响我们的抓取方式吗?当然可以。因为如果我们要爬取的网页数量很少,那么效率不会是一个严重的问题,但是假设我们的网站有几百万个网页,比如按顺序下载每个网页需要在一个几个月后,效率就会成为一个严重的问题。
检查网站的大小
通过查看谷歌爬虫结果的大小,我们可以估算出网站的大小。在进行 Google 搜索时,我们可以使用关键字 网站 来过滤我们的结果。例如,估计大小如下所示;
可以看到大约有60条结果,说明不是很大网站,爬取不会造成效率问题。
网站用的是什么技术?
另一个重要的问题是网站使用的技术是否会影响我们抓取的方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为builtwith的Python库,可以帮助我们了解网站所使用的技术。
例子
在这个例子中,我们将检查 网站 使用的技术
借助内置的 Python 库。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站的主人是谁?
网站 的拥有者也很重要,因为如果知道拥有者在阻止爬虫,爬虫从 网站 抓取数据时必须小心。有一个协议叫Whois,我们可以帮助我们了解网站的所有者。
例子
在此示例中,我们将检查 网站 的所有者是否说 Whois 有帮助。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
上一节
下一节 查看全部
抓取网页数据违法吗(网页搜寻的合法性使用Python(一).本章将解释与网页合法性)
网络搜索的合法性
使用Python,我们可以抓取网页的任何网站或特定元素,但你知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网络爬行合法性相关的概念。
介绍
一般来说,如果您打算将捕获的数据用于个人用途,可能没有问题。但是,如果您想重新发布数据,您应该在执行相同操作之前向所有者发送下载请求,或者对您将要搜索的数据进行一些背景调查和策略。
刮之前需要研究
如果您的目标是从 网站 抓取数据,我们需要了解其规模和结构。以下是我们在开始网络抓取之前需要分析的一些文件。
分析 robots.txt
事实上,大多数发布者都在一定程度上允许程序员爬取他们的网站。换句话说,发布者希望抓取 网站 的特定部分。为了定义这个,网站必须制定一些规则来指定哪些部分可以爬行,哪些部分不能爬行。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于标识允许爬取网站 和不允许爬取网站 的部分内容。robots.txt 文件没有标准格式,网站 发布者可以根据需要修改。我们可以通过在 网站 的 URL 后面提供斜杠和 robots.txt 来检查特定 网站 的 robots.txt 文件。比如我们要检查,那么我们需要输入,我们会得到如下:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站robots.txt 文件中定义的一些最常见的规则如下:
User-agent: BadCrawler
Disallow: /
上述规则意味着robots.txt文件要求爬虫使用BadCrawler用户代理不要爬取他们的网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则表明,robots.txt 文件会在所有用户的下载请求之间延迟爬虫 5 秒。代理用于避免服务器过载。/trap 链接将尝试阻止不允许链接的恶意爬虫。网站 发布 人们可以根据自己的需求定义更多规则。其中一些在这里讨论:
分析站点地图文件
如果你想爬取网站 获取更新的信息,你应该怎么做?您将抓取每个网页以获取更新的信息,但这会增加该特定 网站 的服务器流量。这就是 网站 提供站点地图文件以帮助爬虫查找更新内容的原因。无需抓取每个网页。网站地图标准定义在。
站点地图文件的内容
发现了以下情况:
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
以上内容显示,站点地图列出了网站上的网址,并进一步允许网站站长指定一些其他信息,如最后更新日期、内容变化、网址相对重要性给其他人等等。每个网址。
网站 的大小是多少?
网站的大小,也就是网站的页数会影响我们的抓取方式吗?当然可以。因为如果我们要爬取的网页数量很少,那么效率不会是一个严重的问题,但是假设我们的网站有几百万个网页,比如按顺序下载每个网页需要在一个几个月后,效率就会成为一个严重的问题。
检查网站的大小
通过查看谷歌爬虫结果的大小,我们可以估算出网站的大小。在进行 Google 搜索时,我们可以使用关键字 网站 来过滤我们的结果。例如,估计大小如下所示;

可以看到大约有60条结果,说明不是很大网站,爬取不会造成效率问题。
网站用的是什么技术?
另一个重要的问题是网站使用的技术是否会影响我们抓取的方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为builtwith的Python库,可以帮助我们了解网站所使用的技术。
例子
在这个例子中,我们将检查 网站 使用的技术
借助内置的 Python 库。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站的主人是谁?
网站 的拥有者也很重要,因为如果知道拥有者在阻止爬虫,爬虫从 网站 抓取数据时必须小心。有一个协议叫Whois,我们可以帮助我们了解网站的所有者。
例子
在此示例中,我们将检查 网站 的所有者是否说 Whois 有帮助。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
上一节
下一节
抓取网页数据违法吗(抓取网页数据违法吗?几种方法帮你解决网页违法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-22 19:02
抓取网页数据违法吗?一些开发者常会对他们的网站进行静态检测工具(perflashshadowtest)抓取网页数据,或者说爬虫爬取搜索引擎爬取的网页数据,为了确保这些爬虫爬取到的数据的可靠性以及可靠性,通常会有必要的防抓取防爬虫机制,例如给爬虫提供统一编码。对于抓取网页数据违法吗的回答当然是否定的,这样的抓取网页数据违法吗?这里给大家介绍几种爬虫网页数据的方法。
一、爬虫加密方法
1、利用https协议加密爬虫数据①采用https协议抓取网页:利用https来实现实现web页面的http服务器认证,其中包括ssl和https两种数据加密方式。当然可以尝试搭建这样的服务器进行尝试安全性,如果有很高的安全性质量不是很高,如果一般般,可以利用加密代理服务器来部署安全代理实现的,由于采用加密代理,需要安装证书,可以在后台获取加密代理服务器的网址、获取证书,或者使用其他方式。
最常见的加密方式是https()。需要考虑的问题为https验证问题,另外还需要用到加密文件上传,验证手机是否在线验证等一系列问题。②采用https握手服务器:采用https的web服务器,虽然可以认证https来解密数据,但是,采用https握手服务器来加密,会比较麻烦。比如说明文上传,是需要进行加密解密,看用户是否在线等问题,如果在线一些不方便的问题,这里建议采用https的握手服务器+数据加密方式。
③网络安全问题:遇到很多攻击者可以通过破解网站源代码,并更改代码来访问源代码的目的。一旦web网站被恶意开发,不是其它的内容恶意(非广告、公司网站等)则直接可以采用采用更加安全的https握手服务器来加密方式。
2、采用动态加密方式(ssl加密)加密抓取网页数据①采用ssl加密抓取网页数据:抓取网页数据是要采用ssl加密方式,由于页面数据被反爬虫爬取到的可能性要比https认证反爬虫抓取到网页数据的可能性小。如果采用网页抓取机制(含反爬虫功能),可能会被某些黑客发现https认证反爬虫的抓取机制可以很好地防止https反爬虫抓取网页数据。
②使用sslprotocol认证加密方式:有一些网站,同时也可以使用采用sslprotocol认证方式抓取数据的,主要分为三种情况:情况1:即使网站没有被反爬虫反爬虫抓取,也可以设置对应的cookie,让爬虫根据采用的方式识别出来,包括获取管理员名字和logo。注意一定要设置限制此人每次登录需要输入的数字或者密码,否则可能被破解他每次登录是否需要输入数字或者密码。情况2:如果数据不涉及太多敏感信息,可以只通过证书(隐私协议认证)进行加密。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?几种方法帮你解决网页违法)
抓取网页数据违法吗?一些开发者常会对他们的网站进行静态检测工具(perflashshadowtest)抓取网页数据,或者说爬虫爬取搜索引擎爬取的网页数据,为了确保这些爬虫爬取到的数据的可靠性以及可靠性,通常会有必要的防抓取防爬虫机制,例如给爬虫提供统一编码。对于抓取网页数据违法吗的回答当然是否定的,这样的抓取网页数据违法吗?这里给大家介绍几种爬虫网页数据的方法。
一、爬虫加密方法
1、利用https协议加密爬虫数据①采用https协议抓取网页:利用https来实现实现web页面的http服务器认证,其中包括ssl和https两种数据加密方式。当然可以尝试搭建这样的服务器进行尝试安全性,如果有很高的安全性质量不是很高,如果一般般,可以利用加密代理服务器来部署安全代理实现的,由于采用加密代理,需要安装证书,可以在后台获取加密代理服务器的网址、获取证书,或者使用其他方式。
最常见的加密方式是https()。需要考虑的问题为https验证问题,另外还需要用到加密文件上传,验证手机是否在线验证等一系列问题。②采用https握手服务器:采用https的web服务器,虽然可以认证https来解密数据,但是,采用https握手服务器来加密,会比较麻烦。比如说明文上传,是需要进行加密解密,看用户是否在线等问题,如果在线一些不方便的问题,这里建议采用https的握手服务器+数据加密方式。
③网络安全问题:遇到很多攻击者可以通过破解网站源代码,并更改代码来访问源代码的目的。一旦web网站被恶意开发,不是其它的内容恶意(非广告、公司网站等)则直接可以采用采用更加安全的https握手服务器来加密方式。
2、采用动态加密方式(ssl加密)加密抓取网页数据①采用ssl加密抓取网页数据:抓取网页数据是要采用ssl加密方式,由于页面数据被反爬虫爬取到的可能性要比https认证反爬虫抓取到网页数据的可能性小。如果采用网页抓取机制(含反爬虫功能),可能会被某些黑客发现https认证反爬虫的抓取机制可以很好地防止https反爬虫抓取网页数据。
②使用sslprotocol认证加密方式:有一些网站,同时也可以使用采用sslprotocol认证方式抓取数据的,主要分为三种情况:情况1:即使网站没有被反爬虫反爬虫抓取,也可以设置对应的cookie,让爬虫根据采用的方式识别出来,包括获取管理员名字和logo。注意一定要设置限制此人每次登录需要输入的数字或者密码,否则可能被破解他每次登录是否需要输入数字或者密码。情况2:如果数据不涉及太多敏感信息,可以只通过证书(隐私协议认证)进行加密。
抓取网页数据违法吗(《(最新)百度网页快照抓取之之时间》有什么关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-21 02:20
文章内容
本文内容是关于百度网页抓取的时间。很多人可能没有注意到这个细节。那么今天,小编就为大家揭晓“(最新)百度网页快照爬网时间”。
看标题,你可能会觉得百度快照没了?怎么又弹出来了?或者这只是陈词滥调,我今天仍然谈论它。写这篇文章的时候,我猜大家都会这么想,但是我相信,如果你仔细阅读,你会发现,会有很多我们没有注意到的地方。或者你可能已经忘记了一些你不知道的事情,也不多说别人,见下文。
大家在看这个标题的时候会有点迷茫,所以为了更好的帮助大家理解,直接上图吧,下图如下图。
图片很直观的给我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于大家有没有注意到,这里就不多说了。我希望这能让你清醒一点。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取时间”有什么关系呢?
小编这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题出在这里。这就是我今天要请你解释的。图中的时间有什么特点?大家可以想一想,随便搜索一下关键词看看,可能会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先说第一点,文章收录时间很准,准确到第二点,可见目前的搜索引擎是非常强大的。
第二点,文章yield time 多显示在凌晨 3 点到 8 点之间(注意一般说的网页从 收录 的时间段集中在凌晨 0 点到凌晨 12 点之间,下午很少)。
第三点,文章如果质量高,一般可以秒到现场。应该是时间,但是圈内显示的时间是3点到8点不上班。你从哪里得到收录?这有点混乱。
编者,我看完后想,搜索引擎可能会先收录某个网页然后索引(不明白的可以查相关资料),如图所示的网页是< @收录时间不是真正的网站收录时间,而是百度建索引的时间。百度建索引的时间是在没人或者工作量小的时间段,比如上面提到的早上3:00到8:00(但不是全部在这个时间段)。这段时间用搜索引擎的人很少,小编在相关站长平台也听说过这样的事情,所以大家还是要好好研究一下。
在这里我想为大家补充一下,你们有过这样的经历吗?如果你经常查看排名,有时候你会发现早上查看的排名和下午查看的排名差别很大,尤其是早上比较早和晚上比较晚的时候差别很大吗?
种种迹象表明,搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。因此,本文最重要的一点是提醒大家,我们可以更深入、更详细地了解我们的工作。所有的问题只是对大家的一个提醒。重要的是每个人都要深入探索。这篇文章到此结束。谢谢你。 查看全部
抓取网页数据违法吗(《(最新)百度网页快照抓取之之时间》有什么关系)
文章内容
本文内容是关于百度网页抓取的时间。很多人可能没有注意到这个细节。那么今天,小编就为大家揭晓“(最新)百度网页快照爬网时间”。
看标题,你可能会觉得百度快照没了?怎么又弹出来了?或者这只是陈词滥调,我今天仍然谈论它。写这篇文章的时候,我猜大家都会这么想,但是我相信,如果你仔细阅读,你会发现,会有很多我们没有注意到的地方。或者你可能已经忘记了一些你不知道的事情,也不多说别人,见下文。
大家在看这个标题的时候会有点迷茫,所以为了更好的帮助大家理解,直接上图吧,下图如下图。
图片很直观的给我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于大家有没有注意到,这里就不多说了。我希望这能让你清醒一点。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取时间”有什么关系呢?
小编这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题出在这里。这就是我今天要请你解释的。图中的时间有什么特点?大家可以想一想,随便搜索一下关键词看看,可能会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先说第一点,文章收录时间很准,准确到第二点,可见目前的搜索引擎是非常强大的。
第二点,文章yield time 多显示在凌晨 3 点到 8 点之间(注意一般说的网页从 收录 的时间段集中在凌晨 0 点到凌晨 12 点之间,下午很少)。
第三点,文章如果质量高,一般可以秒到现场。应该是时间,但是圈内显示的时间是3点到8点不上班。你从哪里得到收录?这有点混乱。
编者,我看完后想,搜索引擎可能会先收录某个网页然后索引(不明白的可以查相关资料),如图所示的网页是< @收录时间不是真正的网站收录时间,而是百度建索引的时间。百度建索引的时间是在没人或者工作量小的时间段,比如上面提到的早上3:00到8:00(但不是全部在这个时间段)。这段时间用搜索引擎的人很少,小编在相关站长平台也听说过这样的事情,所以大家还是要好好研究一下。
在这里我想为大家补充一下,你们有过这样的经历吗?如果你经常查看排名,有时候你会发现早上查看的排名和下午查看的排名差别很大,尤其是早上比较早和晚上比较晚的时候差别很大吗?
种种迹象表明,搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。因此,本文最重要的一点是提醒大家,我们可以更深入、更详细地了解我们的工作。所有的问题只是对大家的一个提醒。重要的是每个人都要深入探索。这篇文章到此结束。谢谢你。
抓取网页数据违法吗(抓取网页数据违法吗?是违法的!那应该用什么去呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-14 00:03
抓取网页数据违法吗?是违法的!那应该用什么去抓取呢?selenium!!!可用于抓取网页数据、常见的就是抓取网、京东、第三方网站等等..总之,是一个挺不错的工具抓取网页数据所需要的前提条件1.网页必须是https格式或者http协议中文网页一般不会是https协议的图片的话也是需要用到https图片合法性判断(浏览器不是https是不给抓取的)2.所抓取数据是经过签名加密过后的不包含私钥在内的无法随意变动的图片数据例如:php里面的md5、ftp的校验等3.最好有参照物,让一些人写的那些使用selenium抓取网页数据的脚本可以根据参照物的页面内容去抓取数据,这样的话,不会出现抓取到的数据太大的情况4.实在不行,一般从某些第三方平台下载的页面都是可以直接在浏览器页面里面直接抓取的,不存在抓取是https还是https的问题(例如:电商类的爬虫、论坛类的爬虫)抓取网页数据有哪些方法?1.用selenium去抓取网页(用selenium抓取、京东、第三方网站的页面,如果爬取页面较多的话,建议使用selenium)2.excel数据分析,可以用excel去抓取(如果需要多个,建议都使用excel抓取,数据库使用mysql.)数据字典爬取3.批量抓取网页(点很多次)4.批量去重5.抓取ua(判断一个用户登录系统的是谷歌还是百度)6.从大量站点去爬取数据(此方法用于抓取十万数据)7.google的爬虫?google(谷歌)intl05google的爬虫(可能用到http协议的header的抓取,下面去抓取)8.自己设置不可逆的抓取。
去某个站点前,在首页写明抓取原因!(如:翻页网站)。整站抓取selenium抓取网页数据的七大步骤1.搭建浏览器环境(对于初学者可以通过学习selenium也可以通过windows自带的控制台在命令行用selenium抓取数据),调试控制台,更改环境以及环境所需要的python等工具2.打开网页。2.1点击网页名称,进入所抓取的网页界面。
2.2点击开始抓取。3.定位一下内容,并在网页上标记名称。3.1点击我的网页,添加标记。3.2点击浏览器地址栏上面的数字,此时会看到向下箭头。点击箭头时候网页会刷新出来。3.3按照alt+ctrl+c组合键,选择抓取工具。4.查看抓取的效果5.保存网页。5.1输出网页上的内容,包括标题、内容等的内容。
5.2编辑源代码。(看工具命令)6.爬取下来的数据,放到数据库中,比如用mysql等去存。七大步骤以及后续做法,由于我们抓取的数据都是https的html。比如用selenium抓取数据可以如下如图7.网页的分析浏。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?是违法的!那应该用什么去呢?)
抓取网页数据违法吗?是违法的!那应该用什么去抓取呢?selenium!!!可用于抓取网页数据、常见的就是抓取网、京东、第三方网站等等..总之,是一个挺不错的工具抓取网页数据所需要的前提条件1.网页必须是https格式或者http协议中文网页一般不会是https协议的图片的话也是需要用到https图片合法性判断(浏览器不是https是不给抓取的)2.所抓取数据是经过签名加密过后的不包含私钥在内的无法随意变动的图片数据例如:php里面的md5、ftp的校验等3.最好有参照物,让一些人写的那些使用selenium抓取网页数据的脚本可以根据参照物的页面内容去抓取数据,这样的话,不会出现抓取到的数据太大的情况4.实在不行,一般从某些第三方平台下载的页面都是可以直接在浏览器页面里面直接抓取的,不存在抓取是https还是https的问题(例如:电商类的爬虫、论坛类的爬虫)抓取网页数据有哪些方法?1.用selenium去抓取网页(用selenium抓取、京东、第三方网站的页面,如果爬取页面较多的话,建议使用selenium)2.excel数据分析,可以用excel去抓取(如果需要多个,建议都使用excel抓取,数据库使用mysql.)数据字典爬取3.批量抓取网页(点很多次)4.批量去重5.抓取ua(判断一个用户登录系统的是谷歌还是百度)6.从大量站点去爬取数据(此方法用于抓取十万数据)7.google的爬虫?google(谷歌)intl05google的爬虫(可能用到http协议的header的抓取,下面去抓取)8.自己设置不可逆的抓取。
去某个站点前,在首页写明抓取原因!(如:翻页网站)。整站抓取selenium抓取网页数据的七大步骤1.搭建浏览器环境(对于初学者可以通过学习selenium也可以通过windows自带的控制台在命令行用selenium抓取数据),调试控制台,更改环境以及环境所需要的python等工具2.打开网页。2.1点击网页名称,进入所抓取的网页界面。
2.2点击开始抓取。3.定位一下内容,并在网页上标记名称。3.1点击我的网页,添加标记。3.2点击浏览器地址栏上面的数字,此时会看到向下箭头。点击箭头时候网页会刷新出来。3.3按照alt+ctrl+c组合键,选择抓取工具。4.查看抓取的效果5.保存网页。5.1输出网页上的内容,包括标题、内容等的内容。
5.2编辑源代码。(看工具命令)6.爬取下来的数据,放到数据库中,比如用mysql等去存。七大步骤以及后续做法,由于我们抓取的数据都是https的html。比如用selenium抓取数据可以如下如图7.网页的分析浏。
抓取网页数据违法吗( 非法获取计算机信息系统数据固定(1)_长昊商业秘密律师 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-12 01:29
非法获取计算机信息系统数据固定(1)_长昊商业秘密律师
)
非法获取计算机信息系统数据罪——计算机入侵事件证据如何取证?
资料来源:长豪商业秘密律师(非法获取计算机信息系统数据罪、非法获取计算机信息系统数据罪)
一、活动介绍
某金融网站称其注册会员账户中的财产在用户不知情的情况下被提取,但网站经核实并非用户本人所有。值得注意的是,提款过程中使用的银行卡并非用户名下的真实银行账户。根据现有资料推测,其电脑可能被非法人入侵,网站数据被篡改,损失达数百万。
二、数据固定
数据固定是分析的先决条件。在固定过程中,必须考虑数据的原创性、完整性、再现性和可控性的原则。下面详细介绍Linux服务器的修复过程。
1.目标信息
网站 部署在阿里云上,使用Linux操作系统,受害者提供受感染计算机的IP和登录凭据。
2.基本信息已修复
执行“history>history.log”导出历史命令;
执行“last>last.log”导出登录相关信息;
执行“lastb>lastb.log”导出登录失败信息;
执行“lastlog>lastlog.log”导出所有用户的最后登录信息;
执行“tarczvf/var/logvarlog.tar.gz”将/var/log的整个目录打包;
执行“ps-AUX>ps.log”导出进程信息;
执行“netstat-atunp>netstat.log”导出网络连接信息;
3.网站数据固定
(1)目录是固定的
根据网站应用配置文件,网站的目录为“/www/c****i”,执行“tarczvf/www/c******i**** *.tar .gz”保存网站目录;
(2)访问日志已修复
根据网站应用配置文件,访问日志的存储位置为:“/etc/httpd/logs”,执行“tarczvf/etc/httpd/logsaccesslog.tar.gz”保存网站 访问日志。
为了保证日志的完整性,在执行该命令之前应该先停止网站应用进程,否则会因为网站应用进程锁定日志而导致日志文件不可读:
4.数据库已修复
(1)数据表已修复
在网站目录下找到数据库连接配置文件,将网站数据库导出为“database.sql”,0
(2)数据库日志已修复
根据Mysql数据库配置信息,提取并修复所有日志文件。
三、数据分析
1.系统日志分析
修复工作完成后,首先分析修复的基本信息,未发现明显异常,排除暴力破解系统用户登录的入侵方式:
2.网站 应用分析
(1)网站 重构
安装Apache、PHP和Mysql,导入固定数据,使用网页浏览器访问后,成功显示网站主页。
(2)WebShell 扫描
使用WebShell分析工具进行扫描,在网站目录下发现一个名为“up1oad****•php.bmp”的文件,疑似网页木马。
(3)WebShell 分析
用编码工具查看文件后,发现如下代码“”,表示对帖子提交的h31en变量中的内容进行base64解码。
根据文件修改时间找到一个类似的文件,找到符合条件的php代码页“adminer.php”,打开发现这个页面的功能是数据库管理器,可以进行数据库管理动作。
一般情况下,网站管理员不需要在网页上修改数据库。结合对文件创建时间的分析,可以确定该页面是入侵者为了远程控制数据库而专门留下的一个界面。
3.网站访问日志分析
接下来,从网站的访问日志中,过滤掉日志中“adminer.php”页面的所有访问记录,统计“adminer.php”的所有访问记录中出现的“userjd”页面,并获得 4 个用户 ID:t4$grep-Eio"user_id%5d=[e-9]{1,8}"adminer.php。
exclude.alibaba.log|排序|uniq
用户 ID%5D=1392
user_id%5D=1679
用户 ID%5D=2613
用户 ID%5D=6248"
四、入侵恢复
然后根据数据分析环节的结果,还原整个入侵过程:
1.恶意文件上传
入侵者首先利用网站的文件上传漏洞修改含有恶意内容的PHP代码页,修改文件头,伪装成BMP图片,成功绕过网站代码检测机制上传它到网站目录下;
2. 确认上传文件证据
在网站对应目录中找到上传成功的恶意代码文件“uploaddyp2p.php.php”,可见上传行为有效;
3.连接电脑
使用“chopper”工具连接到这个网站中的恶意代码页。连接成功后,使用集成文件管理器成功打开网站所在电脑的根目录,并获得管理权限;
4.上传数据库管理器
使用集成了“chopper”工具的文件管理器,上传数据库管理器代码页“adminer.php”,读取数据库连接配置文件“/data/www/c*****i/dbconfig.php”,并获取数据库权限。
5.修改数据
访问“adminer.php”页面,篡改数据库数据,绑定银行卡;
6.执行提现
访问提现页面,执行提现操作,成功非法获取用户财产。
查看全部
抓取网页数据违法吗(
非法获取计算机信息系统数据固定(1)_长昊商业秘密律师
)
非法获取计算机信息系统数据罪——计算机入侵事件证据如何取证?
资料来源:长豪商业秘密律师(非法获取计算机信息系统数据罪、非法获取计算机信息系统数据罪)
一、活动介绍
某金融网站称其注册会员账户中的财产在用户不知情的情况下被提取,但网站经核实并非用户本人所有。值得注意的是,提款过程中使用的银行卡并非用户名下的真实银行账户。根据现有资料推测,其电脑可能被非法人入侵,网站数据被篡改,损失达数百万。
二、数据固定
数据固定是分析的先决条件。在固定过程中,必须考虑数据的原创性、完整性、再现性和可控性的原则。下面详细介绍Linux服务器的修复过程。
1.目标信息
网站 部署在阿里云上,使用Linux操作系统,受害者提供受感染计算机的IP和登录凭据。
2.基本信息已修复
执行“history>history.log”导出历史命令;
执行“last>last.log”导出登录相关信息;
执行“lastb>lastb.log”导出登录失败信息;
执行“lastlog>lastlog.log”导出所有用户的最后登录信息;
执行“tarczvf/var/logvarlog.tar.gz”将/var/log的整个目录打包;
执行“ps-AUX>ps.log”导出进程信息;
执行“netstat-atunp>netstat.log”导出网络连接信息;
3.网站数据固定
(1)目录是固定的
根据网站应用配置文件,网站的目录为“/www/c****i”,执行“tarczvf/www/c******i**** *.tar .gz”保存网站目录;
(2)访问日志已修复
根据网站应用配置文件,访问日志的存储位置为:“/etc/httpd/logs”,执行“tarczvf/etc/httpd/logsaccesslog.tar.gz”保存网站 访问日志。
为了保证日志的完整性,在执行该命令之前应该先停止网站应用进程,否则会因为网站应用进程锁定日志而导致日志文件不可读:
4.数据库已修复
(1)数据表已修复
在网站目录下找到数据库连接配置文件,将网站数据库导出为“database.sql”,0
(2)数据库日志已修复
根据Mysql数据库配置信息,提取并修复所有日志文件。
三、数据分析
1.系统日志分析
修复工作完成后,首先分析修复的基本信息,未发现明显异常,排除暴力破解系统用户登录的入侵方式:
2.网站 应用分析
(1)网站 重构
安装Apache、PHP和Mysql,导入固定数据,使用网页浏览器访问后,成功显示网站主页。
(2)WebShell 扫描
使用WebShell分析工具进行扫描,在网站目录下发现一个名为“up1oad****•php.bmp”的文件,疑似网页木马。
(3)WebShell 分析
用编码工具查看文件后,发现如下代码“”,表示对帖子提交的h31en变量中的内容进行base64解码。
根据文件修改时间找到一个类似的文件,找到符合条件的php代码页“adminer.php”,打开发现这个页面的功能是数据库管理器,可以进行数据库管理动作。
一般情况下,网站管理员不需要在网页上修改数据库。结合对文件创建时间的分析,可以确定该页面是入侵者为了远程控制数据库而专门留下的一个界面。
3.网站访问日志分析
接下来,从网站的访问日志中,过滤掉日志中“adminer.php”页面的所有访问记录,统计“adminer.php”的所有访问记录中出现的“userjd”页面,并获得 4 个用户 ID:t4$grep-Eio"user_id%5d=[e-9]{1,8}"adminer.php。
exclude.alibaba.log|排序|uniq
用户 ID%5D=1392
user_id%5D=1679
用户 ID%5D=2613
用户 ID%5D=6248"
四、入侵恢复
然后根据数据分析环节的结果,还原整个入侵过程:
1.恶意文件上传
入侵者首先利用网站的文件上传漏洞修改含有恶意内容的PHP代码页,修改文件头,伪装成BMP图片,成功绕过网站代码检测机制上传它到网站目录下;
2. 确认上传文件证据
在网站对应目录中找到上传成功的恶意代码文件“uploaddyp2p.php.php”,可见上传行为有效;
3.连接电脑
使用“chopper”工具连接到这个网站中的恶意代码页。连接成功后,使用集成文件管理器成功打开网站所在电脑的根目录,并获得管理权限;
4.上传数据库管理器
使用集成了“chopper”工具的文件管理器,上传数据库管理器代码页“adminer.php”,读取数据库连接配置文件“/data/www/c*****i/dbconfig.php”,并获取数据库权限。
5.修改数据
访问“adminer.php”页面,篡改数据库数据,绑定银行卡;
6.执行提现
访问提现页面,执行提现操作,成功非法获取用户财产。

抓取网页数据违法吗( 不是post重放登录的接口方法用的是get方法? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-11 02:27
不是post重放登录的接口方法用的是get方法?
)
将下载的文件名后缀改为.cer,如果电脑是.der,直接在手机上点击文件安装,选择use as WLAN
安装好证书后,pc就可以抓取到所有与手机相关的http和https数据包了。
于是我开通了12333的社保登录,大家都知道,这种网站是外包的,一般都是不好的。反正我经常查不到资料。
随便重放一个数据包,不管是修改url后的参数值还是post的参数值,返回的响应都是一样的,那么你的参数值是这样的吗?
再看登录数据包,登录界面方法使用的是get方法,不是post
重放已登录的数据包,去掉headers中的cookie,使用正确的密码和账号即可正常登录
去掉Referer后,重定向链接信息,登录还是正常的,url后面跟了很多参数,不知道具体是什么,估计大部分都没用,不然replay就不行了肯定不能登录,结果是可以正常登录
url后面的参数是登录账号和密码。密码由 md5 加密。登录账号未加密,每次提交数据登录,不需要其他一些有效参数或验证码,可以多次提交。密码错误10次将导致账户锁定
然后脚本就可以构造出各种身份证号码和手机号码,利用脚本用错误的密码登录。如果账户错误登录10次,账户将在24小时内被锁定。如果不存在,直接跳过。基本上,这些账户上的账户都会被锁定。当然,我闲着也不会这么麻烦,但这确实是登录界面的问题。
查看全部
抓取网页数据违法吗(
不是post重放登录的接口方法用的是get方法?
)


将下载的文件名后缀改为.cer,如果电脑是.der,直接在手机上点击文件安装,选择use as WLAN

安装好证书后,pc就可以抓取到所有与手机相关的http和https数据包了。
于是我开通了12333的社保登录,大家都知道,这种网站是外包的,一般都是不好的。反正我经常查不到资料。

随便重放一个数据包,不管是修改url后的参数值还是post的参数值,返回的响应都是一样的,那么你的参数值是这样的吗?
再看登录数据包,登录界面方法使用的是get方法,不是post

重放已登录的数据包,去掉headers中的cookie,使用正确的密码和账号即可正常登录

去掉Referer后,重定向链接信息,登录还是正常的,url后面跟了很多参数,不知道具体是什么,估计大部分都没用,不然replay就不行了肯定不能登录,结果是可以正常登录

url后面的参数是登录账号和密码。密码由 md5 加密。登录账号未加密,每次提交数据登录,不需要其他一些有效参数或验证码,可以多次提交。密码错误10次将导致账户锁定
然后脚本就可以构造出各种身份证号码和手机号码,利用脚本用错误的密码登录。如果账户错误登录10次,账户将在24小时内被锁定。如果不存在,直接跳过。基本上,这些账户上的账户都会被锁定。当然,我闲着也不会这么麻烦,但这确实是登录界面的问题。


抓取网页数据违法吗( 网站通过Robots协议告诉爬虫哪些页面可以抓取文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 07:06
网站通过Robots协议告诉爬虫哪些页面可以抓取文件?)
2. 当网站 声明rebots 协议时。
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
方法很简单。如果您想查看它,请在 IE 上输入您的 URL/robots.txt。如果有专业的相关工具查看和分析机器人,可以使用站长工具。
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
√ 完全公开的数据
√ 不存在,不能被非法访问爬取
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的。
但是,如果您使用技术来抓取他人的隐私和业务数据,那么您就是在藐视法律!
结尾 查看全部
抓取网页数据违法吗(
网站通过Robots协议告诉爬虫哪些页面可以抓取文件?)

2. 当网站 声明rebots 协议时。
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
方法很简单。如果您想查看它,请在 IE 上输入您的 URL/robots.txt。如果有专业的相关工具查看和分析机器人,可以使用站长工具。
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫被定义为“恶意爬虫”。

爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
√ 完全公开的数据
√ 不存在,不能被非法访问爬取
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的。
但是,如果您使用技术来抓取他人的隐私和业务数据,那么您就是在藐视法律!
结尾
抓取网页数据违法吗(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-09 19:22
)
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
你是如何自学 Python 的?-克罗辛的回答
在学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?-克罗辛的回答
编程初学者如何使用搜索引擎-Crossin的文章-知乎专栏
如何直观的了解程序的运行过程?-Crossin 的 文章-知乎 专栏
如何在一台电脑上同时使用Python 2和Python 3-Crossin的编程课堂-知乎专栏
Crossin的编程课堂
微信ID:crossincode
论坛:Crossin 的编程课堂
QQ群:498545096
查看全部
抓取网页数据违法吗(python2抓取网页的内容显示出来是怎么回事?(图)
)
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
你是如何自学 Python 的?-克罗辛的回答
在学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?-克罗辛的回答
编程初学者如何使用搜索引擎-Crossin的文章-知乎专栏
如何直观的了解程序的运行过程?-Crossin 的 文章-知乎 专栏
如何在一台电脑上同时使用Python 2和Python 3-Crossin的编程课堂-知乎专栏
Crossin的编程课堂
微信ID:crossincode
论坛:Crossin 的编程课堂
QQ群:498545096

抓取网页数据违法吗( 刮网线在哪里?growthhack探讨一下网页抓取方法之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-10 00:27
刮网线在哪里?growthhack探讨一下网页抓取方法之前)
早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页还是仅复制重要数据,您仍然会获得可能可用或不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上面的示例)不增加主机服务的负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
虽然我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢?
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。 查看全部
抓取网页数据违法吗(
刮网线在哪里?growthhack探讨一下网页抓取方法之前)
早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页还是仅复制重要数据,您仍然会获得可能可用或不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上面的示例)不增加主机服务的负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
虽然我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢?
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。
抓取网页数据违法吗(本文介绍如何使用机器学习技术检测URL是否是是否是钓鱼网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-09 21:09
本文介绍如何使用机器学习技术检测一个URL是否为钓鱼网站,包括数据抓取、特征选择、模型训练等。
我有一个客户的邮箱,最近差点被钓鱼网站骗了。他的供应商邮箱被攻击,然后黑客利用供应商的邮箱给他发了一封催款邮件,要求他向另一个银行账户付款。幸运的是,我的客户致电供应商确认并发现了骗局。这让我意识到网络钓鱼攻击无处不在,我们不应低估其危害。
以下是网络钓鱼 网站 的一些示例。基本上,他们的目的是欺骗您的登录帐户和密码。这是一个冒充 Paypal 的钓鱼站:
这是一个假游戏站:
1、初步分析
学习编程,上慧智网,在线编程环境,一对一助教指导。
Kaggle 上有一些网络钓鱼数据集,但对于这个项目,我想生成自己的数据库。我使用了两个数据源来构建网络钓鱼 URL 列表:
借助一点领域知识,对这些合法的钓鱼网址进行分析,我将可以从这些网址中获取的信息分为以下5类:
域名:二级域名可能存在钓鱼风险。例如: Network: HTTP 对应的header 可能收录有用的信息页面: 一般而言,网络钓鱼网站 总是使用一些形式来试图让你输入帐户、电子邮件、密码等信息。Whois:域名通常是通过GoDaddy等注册的。
通过分析,我有以下发现:
2、数据采集
我的数据爬虫的概念模型大致如下:
基本思想是使代码尽可能模块化,以便我可以在需要时添加新类别。我抓取的每个页面都存储在一个本地文件中,以便将来在它们不可用时作为参考。
我使用 BeautifulSoup 提取页面信息。通过设置随机用户代理,我可以减少请求被机器人拒绝的可能性。
为了确保一致性,我还对 URL 进行了基本的预处理,例如删除 www 和尾部斜杠。
3、探索性数据分析
由于爬取数据非常耗时,我决定开始我的探索性数据分析,寻找一些感觉。在分析了1817个网址(包括930个钓鱼网址和887个合法网址)的特征后,我选择使用以下15个特征:
1
2
3
4
5
6
7
8
9
10
URL Domain Network Page Whois
-------------- --------------- ------------ ---------- ---------
length len_subdomain len_cookie length w_score
special_char is_https anchors
depth form
password
signin
hidden
popup
4、特征选择
我使用 LASSO 正则化来识别重要特征。即使只有很小的 alpha 值,我也发现了 5 个重要特征:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[('len', 0.0006821926601753635),
('count_s', 0.0),
('depth', 0.0),
('len_subdomain', 0.0),
('is_https', 0.0),
('len_cookie', -0.0002472539769316538),
('page_length', -2.4074484401619206e-07),
('page_num_anchor', -0.0006943876695101922),
('page_num_form', -0.0),
('page_num_email', -0.0),
('page_num_password', 0.0),
('page_num_signin', 0.0),
('page_num_hidden', -0.00041105959874092535),
('page_num_popup', -0.0),
('w_score', -0.0)]
坦率地说,我有点惊讶 w_score 不起作用。最后我决定使用这 5 个功能。
1
2
3
4
5
URL Domain Network Page Whois
-------- -------- ------------ --------- -------
length len_cookie length
anchors
hidden
然后我用 KNN 构建了一个简单的分类器作为基线。K 选择了 3 并且得到了公平的准确率0.793:
5、型号
我通过爬取得到6906个网址,3501是合法的,3455是钓鱼的。毫不奇怪,许多网络钓鱼页面不再可访问:
1
2
3
4
Type #URL processed #Pages available
------- ---------------- ------------------
Legit 4,000 3,501
Phish 6,000 3,455
使用这 6906 个样本,我再次进行特征选择,筛选出相同的 5 个特征。最好的K还是3,太好了!
以下是模型的参数:
1
2
3
4
5
6
7
8
9
Model Accuracy
------------------- ----------
Naive Bayes 0.757
SVC 0.760
KNN (K=3) 0.791
Log. Reg. 0.822
Decision Tree 0.836
KNN (K=3, scaled) 0.845
Random Forest 0.885
原文链接:监督学习检测钓鱼网址 查看全部
抓取网页数据违法吗(本文介绍如何使用机器学习技术检测URL是否是是否是钓鱼网站)
本文介绍如何使用机器学习技术检测一个URL是否为钓鱼网站,包括数据抓取、特征选择、模型训练等。
我有一个客户的邮箱,最近差点被钓鱼网站骗了。他的供应商邮箱被攻击,然后黑客利用供应商的邮箱给他发了一封催款邮件,要求他向另一个银行账户付款。幸运的是,我的客户致电供应商确认并发现了骗局。这让我意识到网络钓鱼攻击无处不在,我们不应低估其危害。
以下是网络钓鱼 网站 的一些示例。基本上,他们的目的是欺骗您的登录帐户和密码。这是一个冒充 Paypal 的钓鱼站:
这是一个假游戏站:
1、初步分析
学习编程,上慧智网,在线编程环境,一对一助教指导。
Kaggle 上有一些网络钓鱼数据集,但对于这个项目,我想生成自己的数据库。我使用了两个数据源来构建网络钓鱼 URL 列表:
借助一点领域知识,对这些合法的钓鱼网址进行分析,我将可以从这些网址中获取的信息分为以下5类:
域名:二级域名可能存在钓鱼风险。例如: Network: HTTP 对应的header 可能收录有用的信息页面: 一般而言,网络钓鱼网站 总是使用一些形式来试图让你输入帐户、电子邮件、密码等信息。Whois:域名通常是通过GoDaddy等注册的。
通过分析,我有以下发现:
2、数据采集
我的数据爬虫的概念模型大致如下:
基本思想是使代码尽可能模块化,以便我可以在需要时添加新类别。我抓取的每个页面都存储在一个本地文件中,以便将来在它们不可用时作为参考。
我使用 BeautifulSoup 提取页面信息。通过设置随机用户代理,我可以减少请求被机器人拒绝的可能性。
为了确保一致性,我还对 URL 进行了基本的预处理,例如删除 www 和尾部斜杠。
3、探索性数据分析
由于爬取数据非常耗时,我决定开始我的探索性数据分析,寻找一些感觉。在分析了1817个网址(包括930个钓鱼网址和887个合法网址)的特征后,我选择使用以下15个特征:
1
2
3
4
5
6
7
8
9
10
URL Domain Network Page Whois
-------------- --------------- ------------ ---------- ---------
length len_subdomain len_cookie length w_score
special_char is_https anchors
depth form
password
signin
hidden
popup
4、特征选择
我使用 LASSO 正则化来识别重要特征。即使只有很小的 alpha 值,我也发现了 5 个重要特征:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[('len', 0.0006821926601753635),
('count_s', 0.0),
('depth', 0.0),
('len_subdomain', 0.0),
('is_https', 0.0),
('len_cookie', -0.0002472539769316538),
('page_length', -2.4074484401619206e-07),
('page_num_anchor', -0.0006943876695101922),
('page_num_form', -0.0),
('page_num_email', -0.0),
('page_num_password', 0.0),
('page_num_signin', 0.0),
('page_num_hidden', -0.00041105959874092535),
('page_num_popup', -0.0),
('w_score', -0.0)]
坦率地说,我有点惊讶 w_score 不起作用。最后我决定使用这 5 个功能。
1
2
3
4
5
URL Domain Network Page Whois
-------- -------- ------------ --------- -------
length len_cookie length
anchors
hidden
然后我用 KNN 构建了一个简单的分类器作为基线。K 选择了 3 并且得到了公平的准确率0.793:
5、型号
我通过爬取得到6906个网址,3501是合法的,3455是钓鱼的。毫不奇怪,许多网络钓鱼页面不再可访问:
1
2
3
4
Type #URL processed #Pages available
------- ---------------- ------------------
Legit 4,000 3,501
Phish 6,000 3,455
使用这 6906 个样本,我再次进行特征选择,筛选出相同的 5 个特征。最好的K还是3,太好了!
以下是模型的参数:
1
2
3
4
5
6
7
8
9
Model Accuracy
------------------- ----------
Naive Bayes 0.757
SVC 0.760
KNN (K=3) 0.791
Log. Reg. 0.822
Decision Tree 0.836
KNN (K=3, scaled) 0.845
Random Forest 0.885
原文链接:监督学习检测钓鱼网址
抓取网页数据违法吗(找寻引擎w88网站手机版是怎样点击查看源网页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-06 17:28
对于 网站 seo 人员。搜索引擎w88网站移动版一定有一些了解,因为在进行网站优化时,需要研究一下搜索引擎w88网站移动版的工作原理。搜索引擎大致分为4部分,第一部分是w88网站移动版爬虫,第二部分是数据处理分析系统,第三部分是索引系统,第四部分是严格的调查。系统源码,当然这只是sex,没有其他基本的4部分!
什么是搜索引擎w88网站手机版,什么是爬虫程序?
搜索引擎w88网站手机版程序,其实就是一个异常的搜索引擎自动应用。它的功能是什么?其实很简单。就是浏览互联网上的信息,然后抓取所有的信息。转到搜索引擎的算术单元。然后建立索引库等等,我们就可以使用移动版的搜索引擎w88网站作为存款人。那么这篇文章的投稿人就来访问我们的网站,然后在自己的电脑上保护我们网站的内容!最好检查一下。
搜索引擎w88网站手机版如何抓取点击查看源码网页?
找到某个链接→下载这个点击查看源网页→加入临时库→提取并点击查看源网页中的链接→点击查看源网页未上传→循环
首先找w88网站移动版引擎找到链接。至于什么样的发现比较简单,就是把链接链接链接过去。搜索引擎w88网站手机版找到此链接后,会下载点击查看源网页,并保存在临时库中。当然,它会提取这个页面的所有链接,然后就会循环。搜索引擎w88网站手机版几乎24小时不停,然后w88网站手机版下载并点击查看源码网页。CPU占用过高怎么办?这就需要第二个系统,也就是搜索引擎的分析系统。
1.移动版搜索引擎w88网站介绍
搜索引擎w88网站手机版,在搜索引擎系统中,所谓的“w88网站手机版”或“操纵器”,是一个用来抓取和访问页面的程序。
① 爬行原理
找到引擎w88网站手机版访问,点击查看源码网页的原油炒作过程。它就像存款人使用的连接器。
搜索引擎w88网站手机版向页面发送访问请求,页面运营商返回页面的HTML代码。
搜索引擎w88网站移动版将接收到的HTML代码存储到搜索引擎的自然页面数据处理库中。
②如何爬行
为了完善搜索引擎w88网站手机版,如何提高学习效率。通常多个w88网站手机版本用于并发分布式爬行。
分布蠕变也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行直到没有链接。
广度优先:这个页面上的所有链接都被抓取完后,它们会沿着建筑设计页面的二楼不停地爬行。
③ w88网站 手机版必须遵守的协商
搜索引擎w88网站手机版会先访问网站游戏根目录下的robots.txt文件,然后再访问网站。
搜索引擎w88网站手机版不会抓取robots.txt文件中禁止爬行的文件或目录。
④ 常用搜索引擎w88网站手机版
百度w88网站手机版:百度蜘蛛
谷歌 w88网站 手机版:Googlebot
360w88网站 手机版:360Spider
SOSOw88网站 手机版:Sosospider
有道w88网站手机版:有道机器人。友道机器人
搜狗w88网站手机版:搜狗新闻蜘蛛
Bing w88网站 手机版:bingbot
Alexaw88网站 手机版:ia_archiver
二、如何吸引更多搜索引擎w88网站手机版
随着网络信息的爆炸式增长,移动版搜索引擎w88网站无法完整抓取所有网站的所有链接,那么如何吸引更多搜索引擎w88网站手机版对我们来说网站爬取变得非常重要。
① 导入链接
不管是外链还是广场舞内部的链接,只有导入了,才能被搜索引擎w88网站手机版找到,了解本页的留存情况。多做外部链接,火上浇油,吸引更多w88网站手机访问。
② 页面刷新频率
页面刷新频率越高。移动版搜索引擎w88网站的访问量也会增加。
③ 网站 和页面权重
整个网站的权重和一个页面(包括首页也是一个页面)的权重影响移动版w88网站的访问频率。实质性网站一般会增加搜索引擎w88网站手机版交友技巧。 查看全部
抓取网页数据违法吗(找寻引擎w88网站手机版是怎样点击查看源网页的)
对于 网站 seo 人员。搜索引擎w88网站移动版一定有一些了解,因为在进行网站优化时,需要研究一下搜索引擎w88网站移动版的工作原理。搜索引擎大致分为4部分,第一部分是w88网站移动版爬虫,第二部分是数据处理分析系统,第三部分是索引系统,第四部分是严格的调查。系统源码,当然这只是sex,没有其他基本的4部分!
什么是搜索引擎w88网站手机版,什么是爬虫程序?
搜索引擎w88网站手机版程序,其实就是一个异常的搜索引擎自动应用。它的功能是什么?其实很简单。就是浏览互联网上的信息,然后抓取所有的信息。转到搜索引擎的算术单元。然后建立索引库等等,我们就可以使用移动版的搜索引擎w88网站作为存款人。那么这篇文章的投稿人就来访问我们的网站,然后在自己的电脑上保护我们网站的内容!最好检查一下。
搜索引擎w88网站手机版如何抓取点击查看源码网页?
找到某个链接→下载这个点击查看源网页→加入临时库→提取并点击查看源网页中的链接→点击查看源网页未上传→循环
首先找w88网站移动版引擎找到链接。至于什么样的发现比较简单,就是把链接链接链接过去。搜索引擎w88网站手机版找到此链接后,会下载点击查看源网页,并保存在临时库中。当然,它会提取这个页面的所有链接,然后就会循环。搜索引擎w88网站手机版几乎24小时不停,然后w88网站手机版下载并点击查看源码网页。CPU占用过高怎么办?这就需要第二个系统,也就是搜索引擎的分析系统。
1.移动版搜索引擎w88网站介绍
搜索引擎w88网站手机版,在搜索引擎系统中,所谓的“w88网站手机版”或“操纵器”,是一个用来抓取和访问页面的程序。
① 爬行原理
找到引擎w88网站手机版访问,点击查看源码网页的原油炒作过程。它就像存款人使用的连接器。
搜索引擎w88网站手机版向页面发送访问请求,页面运营商返回页面的HTML代码。
搜索引擎w88网站移动版将接收到的HTML代码存储到搜索引擎的自然页面数据处理库中。
②如何爬行
为了完善搜索引擎w88网站手机版,如何提高学习效率。通常多个w88网站手机版本用于并发分布式爬行。
分布蠕变也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行直到没有链接。
广度优先:这个页面上的所有链接都被抓取完后,它们会沿着建筑设计页面的二楼不停地爬行。
③ w88网站 手机版必须遵守的协商
搜索引擎w88网站手机版会先访问网站游戏根目录下的robots.txt文件,然后再访问网站。
搜索引擎w88网站手机版不会抓取robots.txt文件中禁止爬行的文件或目录。
④ 常用搜索引擎w88网站手机版
百度w88网站手机版:百度蜘蛛
谷歌 w88网站 手机版:Googlebot
360w88网站 手机版:360Spider
SOSOw88网站 手机版:Sosospider
有道w88网站手机版:有道机器人。友道机器人
搜狗w88网站手机版:搜狗新闻蜘蛛
Bing w88网站 手机版:bingbot
Alexaw88网站 手机版:ia_archiver
二、如何吸引更多搜索引擎w88网站手机版
随着网络信息的爆炸式增长,移动版搜索引擎w88网站无法完整抓取所有网站的所有链接,那么如何吸引更多搜索引擎w88网站手机版对我们来说网站爬取变得非常重要。
① 导入链接
不管是外链还是广场舞内部的链接,只有导入了,才能被搜索引擎w88网站手机版找到,了解本页的留存情况。多做外部链接,火上浇油,吸引更多w88网站手机访问。
② 页面刷新频率
页面刷新频率越高。移动版搜索引擎w88网站的访问量也会增加。
③ 网站 和页面权重
整个网站的权重和一个页面(包括首页也是一个页面)的权重影响移动版w88网站的访问频率。实质性网站一般会增加搜索引擎w88网站手机版交友技巧。
抓取网页数据违法吗(抓取网页数据违法吗?如何帮助我们提高收发邮件速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-05 12:00
抓取网页数据违法吗?可以帮助我们提高收发邮件速度,缩短收发邮件时间,提高邮件正确率,减少错误率,保证了邮件有效收发,这个是收集数据也是必不可少的,为了日后这些数据能被集中使用,
可以看下这个链接,
抓取网页数据你应该不违法
高大上的领域我不知道,但是小打小闹肯定不合法啊,感觉这个已经被妖魔化了。
我是做邮件推送的,现在基本都是计算机专业的人做,和it有关。
谁说不可以我是分割线—再补充一下,
你可以想象,如果一个公司想发一份邮件,但是同时公司又不止一个业务,那么他每个业务的员工都要收到邮件才能完成。而这里的任务量太大。如果你觉得要写工作邮件的话,那很好,只要你写的不要太假,也不要太low。那么如果你觉得发送给用户的邮件大概要控制在500k以内,那么其实可以用这个方法。当然如果你觉得后台控制这个这些管理成本比较高的话,可以用app来做。具体怎么做我就不知道了,毕竟我没有开发过类似app的经验。
违法吗?
你可以借此抓坏人,
happybible了解一下。
抓取一次太容易了,再说写数据得写个五六页字啊,可是再想想,对方还能反编译你们公司数据吗?!!!你说你要是对网上留下他的私人联系方式和家庭住址你还抓他,那就恶心人了,除非你想在他心中留下一个坏印象。还有你你想抓发给用户群体不一样啊等等特征也恶心。毕竟现在用户邮箱多数是多用户邮箱,如果抓出来倒过来干扰了其他人正常使用,岂不有点过。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?如何帮助我们提高收发邮件速度)
抓取网页数据违法吗?可以帮助我们提高收发邮件速度,缩短收发邮件时间,提高邮件正确率,减少错误率,保证了邮件有效收发,这个是收集数据也是必不可少的,为了日后这些数据能被集中使用,
可以看下这个链接,
抓取网页数据你应该不违法
高大上的领域我不知道,但是小打小闹肯定不合法啊,感觉这个已经被妖魔化了。
我是做邮件推送的,现在基本都是计算机专业的人做,和it有关。
谁说不可以我是分割线—再补充一下,
你可以想象,如果一个公司想发一份邮件,但是同时公司又不止一个业务,那么他每个业务的员工都要收到邮件才能完成。而这里的任务量太大。如果你觉得要写工作邮件的话,那很好,只要你写的不要太假,也不要太low。那么如果你觉得发送给用户的邮件大概要控制在500k以内,那么其实可以用这个方法。当然如果你觉得后台控制这个这些管理成本比较高的话,可以用app来做。具体怎么做我就不知道了,毕竟我没有开发过类似app的经验。
违法吗?
你可以借此抓坏人,
happybible了解一下。
抓取一次太容易了,再说写数据得写个五六页字啊,可是再想想,对方还能反编译你们公司数据吗?!!!你说你要是对网上留下他的私人联系方式和家庭住址你还抓他,那就恶心人了,除非你想在他心中留下一个坏印象。还有你你想抓发给用户群体不一样啊等等特征也恶心。毕竟现在用户邮箱多数是多用户邮箱,如果抓出来倒过来干扰了其他人正常使用,岂不有点过。
抓取网页数据违法吗( PartialPageRank策略PartialPageRank算法借鉴了算法的思想和思想)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-05 00:14
PartialPageRank策略PartialPageRank算法借鉴了算法的思想和思想)
网络爬虫的爬取策略
1、PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,计算后完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,按照这个顺序爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。
2、宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
3、大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
4、反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
5、OPIC 策略 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6、深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。 查看全部
抓取网页数据违法吗(
PartialPageRank策略PartialPageRank算法借鉴了算法的思想和思想)
网络爬虫的爬取策略
1、PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,计算后完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,按照这个顺序爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值汇总,从而形成未知页面的PageRank值参与排名。
2、宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
3、大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
4、反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
5、OPIC 策略 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6、深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。
抓取网页数据违法吗(手机电子数据取证技术的不断发展,如何抓网络数据包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-11-04 18:20
编者按:随着手机电子数据取证技术的不断发展,手机取证不再局限于传统的手机记录数据的获取。对于手机电子数据取证,也可以从网络方面入手,通过网络协议对手机中的相关数据进行分析。本期,四川省数据恢复重点实验室的研究人员将介绍如何通过路由器提取手机数据抓包。
一、背景介绍
用户在使用手机上网时,手机在不断地收发数据包,而这些数据包中收录着大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件、和浏览的网页。虽然很多信息是经过加密传输的,但还是会有大量的信息是明文传输的,或者经过分析可以解密的,比如账户信息、文件、邮件、一些聊天信息等。这些数据包将通过路由器分发。我们只需要对路由器进行抓取和分析,即可提取出用户的各种信息,无需在用户手机中安装应用插件。
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器。也可以使用360免费wifi提供热点,这样就可以抓取连接wifi的手机发送的网络数据包。
三、如何抓取网络数据包
目前市场上有很多抓包工具。例如,Wireshark 是较为成熟的一种。除了抓包,还自带一些简单的分析工具。这些抓包工具的原理都是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,说明如何抓包网络数据包。
首先打开软件配置,以及网络抓包需要的参数,如图1。如果你对协议比较熟悉,可以选择一个过滤器,方便的过滤掉你不关心的数据包分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,可以根据这个信息选择对应的过滤器,然后选择要抓包的网卡,开始抓网包。
图1:Wireshark抓包参数配置
四、网络数据包分析
Wireshark在捕获网络数据包时,分为三个部分显示捕获的结果,如图2所示。第一个窗口显示捕获的数据包列表,中间的窗口显示当前选择的数据包的简单分析内容,底部窗口显示当前选定数据包的十六进制值。
图2:Wireshark抓包结果窗口
以微信的一个协议包为例。抓包操作完成后,就抓到了用户通过手机发送的一个完整的对话信息包,如图3所示,根据对话包,显示手机(ip为172.1< @9.90.2,端口号51005)通过TCP-HTTP协议连接服务器(id为121.51.130.113,端口号80) 相互传输数据。
图3:发送信息包
前三个包是手机和服务器相互确认身份(TCP三次握手)传输的包,没有重要信息,主要看第四个包,如图4所示。
Frame:物理层数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目标方的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:应用层信息,这里是HTTP协议;
Media Type:传输的具体数据;
图4:手机发送信息包
这里主要分析应用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,并且十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的,暂时不可用。
图5:TCP的应用层和数据层
这样我们也可以对发送的图片和视频等信息进行分析,后续的提取工作就可以交给代码了。
概括:
利用路由器抓包提取手机数据是一种全新的手机数据提取方法,对手机电子数据取证具有重要意义,是未来研究的重点方向。数据恢复四川省重点实验室研究人员现已开发出相关程序,可以捕获和分析网络数据包,支持多种协议的分析。预计相关产品将于近期正式上线。 查看全部
抓取网页数据违法吗(手机电子数据取证技术的不断发展,如何抓网络数据包)
编者按:随着手机电子数据取证技术的不断发展,手机取证不再局限于传统的手机记录数据的获取。对于手机电子数据取证,也可以从网络方面入手,通过网络协议对手机中的相关数据进行分析。本期,四川省数据恢复重点实验室的研究人员将介绍如何通过路由器提取手机数据抓包。
一、背景介绍
用户在使用手机上网时,手机在不断地收发数据包,而这些数据包中收录着大量的用户信息,包括各种账号信息、聊天信息、收发文件、电子邮件、和浏览的网页。虽然很多信息是经过加密传输的,但还是会有大量的信息是明文传输的,或者经过分析可以解密的,比如账户信息、文件、邮件、一些聊天信息等。这些数据包将通过路由器分发。我们只需要对路由器进行抓取和分析,即可提取出用户的各种信息,无需在用户手机中安装应用插件。
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器。也可以使用360免费wifi提供热点,这样就可以抓取连接wifi的手机发送的网络数据包。
三、如何抓取网络数据包
目前市场上有很多抓包工具。例如,Wireshark 是较为成熟的一种。除了抓包,还自带一些简单的分析工具。这些抓包工具的原理都是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,说明如何抓包网络数据包。
首先打开软件配置,以及网络抓包需要的参数,如图1。如果你对协议比较熟悉,可以选择一个过滤器,方便的过滤掉你不关心的数据包分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,可以根据这个信息选择对应的过滤器,然后选择要抓包的网卡,开始抓网包。
图1:Wireshark抓包参数配置
四、网络数据包分析
Wireshark在捕获网络数据包时,分为三个部分显示捕获的结果,如图2所示。第一个窗口显示捕获的数据包列表,中间的窗口显示当前选择的数据包的简单分析内容,底部窗口显示当前选定数据包的十六进制值。
图2:Wireshark抓包结果窗口
以微信的一个协议包为例。抓包操作完成后,就抓到了用户通过手机发送的一个完整的对话信息包,如图3所示,根据对话包,显示手机(ip为172.1< @9.90.2,端口号51005)通过TCP-HTTP协议连接服务器(id为121.51.130.113,端口号80) 相互传输数据。
图3:发送信息包
前三个包是手机和服务器相互确认身份(TCP三次握手)传输的包,没有重要信息,主要看第四个包,如图4所示。
Frame:物理层数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送方和目标方的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:应用层信息,这里是HTTP协议;
Media Type:传输的具体数据;
图4:手机发送信息包
这里主要分析应用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,并且十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的,暂时不可用。
图5:TCP的应用层和数据层
这样我们也可以对发送的图片和视频等信息进行分析,后续的提取工作就可以交给代码了。
概括:
利用路由器抓包提取手机数据是一种全新的手机数据提取方法,对手机电子数据取证具有重要意义,是未来研究的重点方向。数据恢复四川省重点实验室研究人员现已开发出相关程序,可以捕获和分析网络数据包,支持多种协议的分析。预计相关产品将于近期正式上线。
抓取网页数据违法吗(网站日志在哪(百度蜘蛛)的活跃度:抓取频率,以及抓取的频率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-03 04:14
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中。我们可以从网站(百度蜘蛛)活动的日志中读取Baiduspider:抓取的频率和抓取后返回的HTTP状态码来查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看
通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。
示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统 200 360
其中,“GET /images/index5_22.gif”表示:从服务器获取到“/images/index5_22.gif”
“此页面或文件;
HTTP/1.1 浏览器和操作系统200 360,代表:抓包后返回的状态(是否成功,抓包次数)
200,状态码,表示爬取成功;
360,volume,表示捕获了多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不再存在,或者访问的URL完全错误。
500:服务器错误。
03 百度蜘蛛的活跃度:抓取频率是多少?
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升 查看全部
抓取网页数据违法吗(网站日志在哪(百度蜘蛛)的活跃度:抓取频率,以及抓取的频率)
你的网站/网页是否被百度抓取以及抓取频率会影响你的排名。
01如何查看网站被抓包的状态?
首先我们要知道百度用来抓取网页的工具是Baiduspider(百度蜘蛛),它的动作会被记录在网站的日志中。我们可以从网站(百度蜘蛛)活动的日志中读取Baiduspider:抓取的频率和抓取后返回的HTTP状态码来查看网站被百度抓取的状态。所以下一步就是找到网站日志的内容。
02网站日志在哪里?如何查看
通常网站 日志文件位于管理后端的 logofiles 文件夹下。登录“FTP”账号,找到一个文件扩展名为.log的日志文件,下载并解压,将文件更改为记事本。这是网站日志,记录了网站是否被百度蜘蛛(Baidu Spider)爬取,爬取是否成功。
接下来,作者介绍了如何用这样一段代码进行日志分析。
示例:时间 GET /images/index5_22.gif-- IP 地址 HTTP/1.1 浏览器和操作系统 200 360
其中,“GET /images/index5_22.gif”表示:从服务器获取到“/images/index5_22.gif”
“此页面或文件;
HTTP/1.1 浏览器和操作系统200 360,代表:抓包后返回的状态(是否成功,抓包次数)
200,状态码,表示爬取成功;
360,volume,表示捕获了多少字节,360字节;
常见状态码
200:表示服务器成功接受了客户端请求。这是最好的,这意味着网站页面是正常的。
301:表示用户访问的某个页面经过了301重定向(永久)处理。
302:这是一个临时重定向。如果网站日志分析发现302太多,需要确认301是否误认为302,如果是,赶紧修改。搜索引擎不喜欢 302 重定向。
404:表示访问的页面不再存在,或者访问的URL完全错误。
500:服务器错误。
03 百度蜘蛛的活跃度:抓取频率是多少?
在每日日志中记录Baiduspider(百度蜘蛛)爬取网站的次数,然后比较多天的日志,确定Baiduspider(百度蜘蛛)当前的活跃度。活跃度越高,爬取越多,说明网站的优化是有效的,网站的排名自然会上升
抓取网页数据违法吗(个人不小心上传了个人信息的网页数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-01 20:02
抓取网页数据违法吗?个人不小心上传了个人信息的网页时,要么是上传到大网站,比如央视网,或者阿里巴巴等等。浏览器把信息偷偷插入到目标网站,要么是自己查询查出来的。值得注意的是每家网站都会有多个dns可以解析多个域名,不管是查询还是解析,必须记住对应的ip地址。如果浏览器选择了合适的dns,并且记住它的ip地址,则可以进行正常的访问。
还有一种情况是,网页可能不存在,或者从别的地方改动过,也无法解析。但是,后来在网站后台的爬虫抓取之中,却找到了这个页面的信息。这是因为每个网站都把数据封装成html模块发布出来,比如txt或者markdown格式的,或者其他。网站通过程序修改这些字符串信息,并且嵌入到网页中。个人爬虫就会去对应网站中爬取存储。
一个表单中个人信息能不能要回来呢?可以,但是要按照javascript的发布规则来做,不可修改。结论:在没有修改后缀名的情况下,能不能要回来不看对方后缀名,而是看dns解析后的ip地址,只要知道对方是个什么dns,就可以在不修改后缀名的情况下,解析dns以及爬取,浏览器中不存在的域名不能导出存档,但是可以通过服务器端或者自己配置的dns代理网站爬取到。
www.snsuomi.wang文章配图:来源于网络。——-举个栗子:页面txt转url;m=auto&a=&c=&usertoken=xxxx-e7wfr91vkv3dj8qd495wtnymgaen&clientversion=2310&pagesize=6644。然后爬取如下:。 查看全部
抓取网页数据违法吗(个人不小心上传了个人信息的网页数据(图))
抓取网页数据违法吗?个人不小心上传了个人信息的网页时,要么是上传到大网站,比如央视网,或者阿里巴巴等等。浏览器把信息偷偷插入到目标网站,要么是自己查询查出来的。值得注意的是每家网站都会有多个dns可以解析多个域名,不管是查询还是解析,必须记住对应的ip地址。如果浏览器选择了合适的dns,并且记住它的ip地址,则可以进行正常的访问。
还有一种情况是,网页可能不存在,或者从别的地方改动过,也无法解析。但是,后来在网站后台的爬虫抓取之中,却找到了这个页面的信息。这是因为每个网站都把数据封装成html模块发布出来,比如txt或者markdown格式的,或者其他。网站通过程序修改这些字符串信息,并且嵌入到网页中。个人爬虫就会去对应网站中爬取存储。
一个表单中个人信息能不能要回来呢?可以,但是要按照javascript的发布规则来做,不可修改。结论:在没有修改后缀名的情况下,能不能要回来不看对方后缀名,而是看dns解析后的ip地址,只要知道对方是个什么dns,就可以在不修改后缀名的情况下,解析dns以及爬取,浏览器中不存在的域名不能导出存档,但是可以通过服务器端或者自己配置的dns代理网站爬取到。
www.snsuomi.wang文章配图:来源于网络。——-举个栗子:页面txt转url;m=auto&a=&c=&usertoken=xxxx-e7wfr91vkv3dj8qd495wtnymgaen&clientversion=2310&pagesize=6644。然后爬取如下:。
抓取网页数据违法吗( 网页上极为简单的抓取范例,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-30 16:18
网页上极为简单的抓取范例,你知道几个?)
从网络获取数据
您是否尝试过各种方法,但仍然没有得到您需要的数据?可能有时候你在网页上找到了你需要的数据,但是上面没有下载按钮,复制粘贴功能也没有。别着急,这里有一些实用的方法,例如你可以:
借助这些强大的技术功能,不要忘记简单易用的方法:花时间搜索机器可读的数据,或致电持有您需要的数据的组织,可能会帮助您获得所需的信息. 数据。
在本节中,我们将展示一个非常简单的从 HTML 页面抓取的示例。
什么是机器可读数据?
大多数方法的目的是获取机器可读的数据。生成机器可读数据是为了方便计算机处理,而不是为了向人类用户显示。这些数据的结构与其内容有关,但与数据的最终呈现方式不同。简单的机器可读数据格式包括 CSV、XML、JSON 和 Excel 文档等,而 Word 文档、HTML 网页和 PDF 文档更侧重于数据的可视化呈现。PDF 是一种与打印机交互的语言。它记录的信息不是字母,而是页面上线条和点的位置。
从网络上抓取什么?
大家都做过这样的事情:你在某个网站上浏览时发现了一个有趣的表格,你想把它复制到Excel中进行计算或存储。但是有时候这个方法行不通,有时候你需要的数据分布在几个网站页面上。手动复制粘贴太繁琐,用一点代码就能事半功倍。
网络抓取的一大优势是它几乎可以用于所有网站,无论是天气预报还是政府预算。即使网站没有提供原创数据访问的API接口,你仍然可以抓住它。
网络抓取的限制
爬行不是万能的,会遇到障碍。导致网页难以抓取的主要因素有:
另一方面,法律限制也可能成为障碍。部分国际承认对数据库的权利,这将限制您在 Internet 上重复使用公开发布的信息。有时,您可以忽略这些法律规定并继续爬行。这取决于您所在位置的司法管辖区。如果你是记者,会有一些特别的便利。抓取免费的政府数据通常没问题,但您应该在发布前再次检查。商业组织和一些非政府组织对数据抓取几乎零容忍。他们会指责你“破坏”了他们的系统。其他可能侵犯个人隐私的数据将违反数据隐私法,也有悖于职业道德。
打补丁、抓取、编译、清理
英国面临的挑战不是公开数据,而是以可用的形式提供数据。比如接待外事、议员外部利益、游说等数据,都是定期、定期公布的,但很难分析。
对于一些有价值的信息,只能很费力地将许多excel文件拼凑起来,每个文件都由大量的报告数据组成,例如内阁会议。但是对于其他信息,网络抓取是一种非常有效的方式。
使用类似于 ScraperWiki 的服务,要求程序员制作一个程序,例如抓取会员的兴趣注册表。我们的工作已经完成了一半:所有成员的信息都在一个表格中,等待我们分析和整理。
类似的服务(或类似于Outwit Hub)对于那些在尝试处理复杂数据时不知道如何编程的记者来说是一个很好的帮手。
——詹姆斯·鲍尔,《卫报》
履带式
有很多程序可以用来从网站中提取大量信息,包括浏览器扩展和一些网络服务。可读性(从网页中抓取文本)和 DownThemAll(批量下载文件)工具可以在某些浏览器上自动处理繁琐的任务。Chrome浏览器的Scraper插件可以从网站中提取表格。开发者扩展FireBug(针对火狐浏览器,Chrome、Safari和IE都内置了类似的功能)可以让你清楚地了解网站的结构以及浏览器和服务器之间的通信。
ScraperWiki网站 提供Python、Ruby、PHP等多种语言供用户编写自己的爬虫代码。这使得用户不再需要在本地安装语言环境来编码进行爬虫工作。此外,还有 Google 电子表格和 Yahoo! 等网络服务。管道还提供从其他 网站 中提取内容的服务。
网络爬虫是如何工作的?
网页抓取工具通常用 Python、Ruby 或 PHP 编写成一小段程序代码。您选择的具体语言取决于您的环境。如果您所在新闻机构的某个人或同一城市的同事开始使用某种语言写作,您最好使用同一种语言。
虽然前面提到的点击选择工具可以帮助您入门,但真正复杂的步骤是确定正确的页面和页面上的正确元素来存储所需信息。这些步骤的关键不是编程,而是理解网站和数据库结构。
浏览器在显示网页时主要使用以下两种技术:通过HTTP协议与服务器通信,请求指定的文档、图片、视频等资源;然后获取HTML代码编写的网页内容。
网页结构
每个 HTML 网页都是由具有一定结构级别(由 HTML“标签”定义)的“框”构成的。大“盒子”将收录小“盒子”,就像表格中有行、列和单元格一样。不同的标签有不同的功能。您可以定义“框”、表格、图片或超链接。标签还具有附加属性(例如唯一标识符),并且可以在“类”中定义,这使我们可以轻松定位和检索文档中的各个元素。编写爬虫的核心是选择合适的元素来获取对应的内容。
查看网页元素时,所有代码都可以按照“框”进行划分。
在开始抓取网页之前,您需要了解 HTML 文档中出现的元素类型。例如,形成了一个表格,其中定义了行并将行细分为单元格。最常见的元素类型是
,简单来说,它可以定义任何内容区域。识别这些元素的最简单方法是使用浏览器上的开发人员工具。当鼠标悬停在网页的特定区域时,这些工具会自动显示该区域对应的代码。
标签就像一本书的封面,告诉你哪里是起点,哪里是终点。表示文字从这里_斜体显示,表示斜体到这里结束。多么容易!
示例:使用 Python 捕获核事件
国际原子能机构(IAEA)门户网站网站上的新闻栏目记录了世界各地的放射性事故(栏目名称正在申请加入“奇怪的标题俱乐部”)。该网页易于使用,并具有类似博客的结构,便于抓取。
图4.国际原子能机构(IAEA)门户网站()
首先,在 ScraperWiki 上创建一个 Python 爬虫,然后你会看到一个基本空白的文本框,里面有一些基本的框架代码。同时在另一个窗口打开IAEA网站,打开浏览器的开发者工具。在“元素”视图下,找到每个新闻标题对应的 HTML 元素,开发者工具会明确指出定义标题的代码。
进一步观察可以发现,标题是用+定义的。每个事件都有一个单独的 ++ 行,其中收录事件的描述和日期。为了获取所有事件的标题,我们应该使用某种方法依次选择表格中的每一行,然后获取标题元素中的文本。
要将这些过程写成代码,我们需要指定具体的步骤。我们来玩个小游戏,体验一下什么是步骤。在 ScraperWiki 界面中,先试着给自己写一些指引,你想通过代码完成什么工作,就像菜谱中的流程(在每行开头写一个“#”来告诉 Python 这行不是计算机代码)。例如:
# 寻找表格中的所有行
# 不要让独角兽在左侧溢出(注:IT冷笑话)
编写时尽可能准确,不要假设程序真的理解你想要捕捉的内容。
写了几行伪代码后,我们来看一下真实代码的前几行:
import scraperwiki
from lxml import html
在第一段中,我们从库中调用现有函数(预先编写的代码片段)。ScraperWiki在这个代码段中提供了下载网站的功能,+lxml+是一个HTML文档结构分析的工具。好消息,在 ScraperWiki 中编写 Python 爬虫,前两行是一样的。
url = "http://www-news.iaea.org/EventList.aspx"
doc_text = scraperwiki.scrape(url)
doc = html.fromstring(doc_text)
然后,代码定义了变量名:url,其值为IAEA的网页地址。这行告诉爬虫,有这样的事情,我们需要对他做点什么。注意这个URL URL 是用引号括起来的,说明这不是一段代码,而是一个_string_,一个字符序列。
然后我们把这个 URL 变量放到一个指令中,scraperwiki.scrape。此命令将执行定义的操作:下载网页。这项工作完成后,会执行指令将内容输出到另一个变量doc_text,然后将网页的文本存储在doc_text中。但是这个文本不是你在浏览器中看到的。它以源代码形式存储并收录所有标签。由于这些代码不易解析,我们使用另一个命令html.fromstring 生成一个特殊的格式,方便我们对元素进行分析。这种格式称为文档对象模型 (DOM)。
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title
最后一步,我们使用DOM来搜索表格中的每一行,获取事件的头部,获取标题。这里有两个新想法:for 循环和元素选择器 (.cssselect)。for 循环的工作非常简单。它遍历项目列表,为每个项目分配一个别名(在本段中,每行+行+),然后对每个项目执行一次指令的缩进部分。
另一个概念元素选择器,是指使用特定的语言来查找文档中的元素。CSS 选择器通常用于向 HTML 元素添加布局信息,我们可以使用它来准确地在页面上定位元素。在这段代码的第 6 行,我们使用 #tblEvents tr 来选择标签中选择器 ID 为 tblEvents(ID 需要用“#”标记)的所有行。此代码将返回符合条件的元素列表。
然后在第 7 行,我们使用另一个选择器在标签(标题)中查找标签(超链接)。这里我们一次只找到一个元素(因为一行只有一个标题),所以找到之后需要通过.pop()命令输出。
请注意,DOM 中的某些元素收录实际文本,即非编程语言中的文本。对于这些文本,我们在第 8 行使用 [element].text 命令。最后,在第 9 行,我们将结果输出到 ScraperWiki 控制台。完成后,只需在爬虫中点击“运行”,小窗口中就会一一列出IAEA网站上的事件名称。
图5. 爬虫在行动(ScraperWiki)
现在一个基本的爬虫正在运行。它将下载网页,将其转换为 DOM 格式,然后您可以从中选择并获取特定内容。在这个框架下,可以尝试使用ScraperWiki和Python的帮助文档来解决剩下的问题:
在尝试解决这些问题的同时,您还可以浏览 ScraperWiki。网站很多现成的爬虫工具都有实际案例,数据也很有用。这样,您就不需要从头开始编写代码。使用类似的案例对代码进行更改,然后部署到您自己的问题。
— 弗里德里希·林登伯格,开放知识基金会
抓取公共数据集
例如,一些法国物理学家开发了一种免费招标方式,这样你就可以选择支付不低于 70 欧元和不超过 500 欧元的费用来获得 30 分钟的肿瘤科医生使用时间。这些数据的速率是合法公开的,但管理员提供了一个难以定位的在线数据库。为了找到一个好的角度来看待这些关税,我决定爬取整个世界报的数据库。
乐趣才刚刚开始。前端的搜索表单最初是一个 Flash 应用程序,它通过 POST 请求重定向到 HTML 结果页面。在 Nicolas Kayser-Bril 的帮助下,我们花了很多时间才终于发现,这个应用程序在搜索表单和结果页面中还调用了另一个“隐藏”页面。这个页面其实是存储了搜索表单的cookie值,然后傲然进入结果页面。本来这应该是一个很难理解的过程,但是PHP下这个cURL库中的设置帮助我们轻松地克服了这个障碍。其实,只要找出障碍在哪里,就可以轻松解决。最后,我们总共花了 10 个小时爬下整个数据库,但非常值得。
— 亚历山大·莱切内,《世界报》 查看全部
抓取网页数据违法吗(
网页上极为简单的抓取范例,你知道几个?)
从网络获取数据
您是否尝试过各种方法,但仍然没有得到您需要的数据?可能有时候你在网页上找到了你需要的数据,但是上面没有下载按钮,复制粘贴功能也没有。别着急,这里有一些实用的方法,例如你可以:
借助这些强大的技术功能,不要忘记简单易用的方法:花时间搜索机器可读的数据,或致电持有您需要的数据的组织,可能会帮助您获得所需的信息. 数据。
在本节中,我们将展示一个非常简单的从 HTML 页面抓取的示例。
什么是机器可读数据?
大多数方法的目的是获取机器可读的数据。生成机器可读数据是为了方便计算机处理,而不是为了向人类用户显示。这些数据的结构与其内容有关,但与数据的最终呈现方式不同。简单的机器可读数据格式包括 CSV、XML、JSON 和 Excel 文档等,而 Word 文档、HTML 网页和 PDF 文档更侧重于数据的可视化呈现。PDF 是一种与打印机交互的语言。它记录的信息不是字母,而是页面上线条和点的位置。
从网络上抓取什么?
大家都做过这样的事情:你在某个网站上浏览时发现了一个有趣的表格,你想把它复制到Excel中进行计算或存储。但是有时候这个方法行不通,有时候你需要的数据分布在几个网站页面上。手动复制粘贴太繁琐,用一点代码就能事半功倍。
网络抓取的一大优势是它几乎可以用于所有网站,无论是天气预报还是政府预算。即使网站没有提供原创数据访问的API接口,你仍然可以抓住它。
网络抓取的限制
爬行不是万能的,会遇到障碍。导致网页难以抓取的主要因素有:
另一方面,法律限制也可能成为障碍。部分国际承认对数据库的权利,这将限制您在 Internet 上重复使用公开发布的信息。有时,您可以忽略这些法律规定并继续爬行。这取决于您所在位置的司法管辖区。如果你是记者,会有一些特别的便利。抓取免费的政府数据通常没问题,但您应该在发布前再次检查。商业组织和一些非政府组织对数据抓取几乎零容忍。他们会指责你“破坏”了他们的系统。其他可能侵犯个人隐私的数据将违反数据隐私法,也有悖于职业道德。
打补丁、抓取、编译、清理
英国面临的挑战不是公开数据,而是以可用的形式提供数据。比如接待外事、议员外部利益、游说等数据,都是定期、定期公布的,但很难分析。
对于一些有价值的信息,只能很费力地将许多excel文件拼凑起来,每个文件都由大量的报告数据组成,例如内阁会议。但是对于其他信息,网络抓取是一种非常有效的方式。
使用类似于 ScraperWiki 的服务,要求程序员制作一个程序,例如抓取会员的兴趣注册表。我们的工作已经完成了一半:所有成员的信息都在一个表格中,等待我们分析和整理。
类似的服务(或类似于Outwit Hub)对于那些在尝试处理复杂数据时不知道如何编程的记者来说是一个很好的帮手。
——詹姆斯·鲍尔,《卫报》
履带式
有很多程序可以用来从网站中提取大量信息,包括浏览器扩展和一些网络服务。可读性(从网页中抓取文本)和 DownThemAll(批量下载文件)工具可以在某些浏览器上自动处理繁琐的任务。Chrome浏览器的Scraper插件可以从网站中提取表格。开发者扩展FireBug(针对火狐浏览器,Chrome、Safari和IE都内置了类似的功能)可以让你清楚地了解网站的结构以及浏览器和服务器之间的通信。
ScraperWiki网站 提供Python、Ruby、PHP等多种语言供用户编写自己的爬虫代码。这使得用户不再需要在本地安装语言环境来编码进行爬虫工作。此外,还有 Google 电子表格和 Yahoo! 等网络服务。管道还提供从其他 网站 中提取内容的服务。
网络爬虫是如何工作的?
网页抓取工具通常用 Python、Ruby 或 PHP 编写成一小段程序代码。您选择的具体语言取决于您的环境。如果您所在新闻机构的某个人或同一城市的同事开始使用某种语言写作,您最好使用同一种语言。
虽然前面提到的点击选择工具可以帮助您入门,但真正复杂的步骤是确定正确的页面和页面上的正确元素来存储所需信息。这些步骤的关键不是编程,而是理解网站和数据库结构。
浏览器在显示网页时主要使用以下两种技术:通过HTTP协议与服务器通信,请求指定的文档、图片、视频等资源;然后获取HTML代码编写的网页内容。
网页结构
每个 HTML 网页都是由具有一定结构级别(由 HTML“标签”定义)的“框”构成的。大“盒子”将收录小“盒子”,就像表格中有行、列和单元格一样。不同的标签有不同的功能。您可以定义“框”、表格、图片或超链接。标签还具有附加属性(例如唯一标识符),并且可以在“类”中定义,这使我们可以轻松定位和检索文档中的各个元素。编写爬虫的核心是选择合适的元素来获取对应的内容。
查看网页元素时,所有代码都可以按照“框”进行划分。
在开始抓取网页之前,您需要了解 HTML 文档中出现的元素类型。例如,形成了一个表格,其中定义了行并将行细分为单元格。最常见的元素类型是
,简单来说,它可以定义任何内容区域。识别这些元素的最简单方法是使用浏览器上的开发人员工具。当鼠标悬停在网页的特定区域时,这些工具会自动显示该区域对应的代码。
标签就像一本书的封面,告诉你哪里是起点,哪里是终点。表示文字从这里_斜体显示,表示斜体到这里结束。多么容易!
示例:使用 Python 捕获核事件
国际原子能机构(IAEA)门户网站网站上的新闻栏目记录了世界各地的放射性事故(栏目名称正在申请加入“奇怪的标题俱乐部”)。该网页易于使用,并具有类似博客的结构,便于抓取。
图4.国际原子能机构(IAEA)门户网站()
首先,在 ScraperWiki 上创建一个 Python 爬虫,然后你会看到一个基本空白的文本框,里面有一些基本的框架代码。同时在另一个窗口打开IAEA网站,打开浏览器的开发者工具。在“元素”视图下,找到每个新闻标题对应的 HTML 元素,开发者工具会明确指出定义标题的代码。
进一步观察可以发现,标题是用+定义的。每个事件都有一个单独的 ++ 行,其中收录事件的描述和日期。为了获取所有事件的标题,我们应该使用某种方法依次选择表格中的每一行,然后获取标题元素中的文本。
要将这些过程写成代码,我们需要指定具体的步骤。我们来玩个小游戏,体验一下什么是步骤。在 ScraperWiki 界面中,先试着给自己写一些指引,你想通过代码完成什么工作,就像菜谱中的流程(在每行开头写一个“#”来告诉 Python 这行不是计算机代码)。例如:
# 寻找表格中的所有行
# 不要让独角兽在左侧溢出(注:IT冷笑话)
编写时尽可能准确,不要假设程序真的理解你想要捕捉的内容。
写了几行伪代码后,我们来看一下真实代码的前几行:
import scraperwiki
from lxml import html
在第一段中,我们从库中调用现有函数(预先编写的代码片段)。ScraperWiki在这个代码段中提供了下载网站的功能,+lxml+是一个HTML文档结构分析的工具。好消息,在 ScraperWiki 中编写 Python 爬虫,前两行是一样的。
url = "http://www-news.iaea.org/EventList.aspx"
doc_text = scraperwiki.scrape(url)
doc = html.fromstring(doc_text)
然后,代码定义了变量名:url,其值为IAEA的网页地址。这行告诉爬虫,有这样的事情,我们需要对他做点什么。注意这个URL URL 是用引号括起来的,说明这不是一段代码,而是一个_string_,一个字符序列。
然后我们把这个 URL 变量放到一个指令中,scraperwiki.scrape。此命令将执行定义的操作:下载网页。这项工作完成后,会执行指令将内容输出到另一个变量doc_text,然后将网页的文本存储在doc_text中。但是这个文本不是你在浏览器中看到的。它以源代码形式存储并收录所有标签。由于这些代码不易解析,我们使用另一个命令html.fromstring 生成一个特殊的格式,方便我们对元素进行分析。这种格式称为文档对象模型 (DOM)。
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title
最后一步,我们使用DOM来搜索表格中的每一行,获取事件的头部,获取标题。这里有两个新想法:for 循环和元素选择器 (.cssselect)。for 循环的工作非常简单。它遍历项目列表,为每个项目分配一个别名(在本段中,每行+行+),然后对每个项目执行一次指令的缩进部分。
另一个概念元素选择器,是指使用特定的语言来查找文档中的元素。CSS 选择器通常用于向 HTML 元素添加布局信息,我们可以使用它来准确地在页面上定位元素。在这段代码的第 6 行,我们使用 #tblEvents tr 来选择标签中选择器 ID 为 tblEvents(ID 需要用“#”标记)的所有行。此代码将返回符合条件的元素列表。
然后在第 7 行,我们使用另一个选择器在标签(标题)中查找标签(超链接)。这里我们一次只找到一个元素(因为一行只有一个标题),所以找到之后需要通过.pop()命令输出。
请注意,DOM 中的某些元素收录实际文本,即非编程语言中的文本。对于这些文本,我们在第 8 行使用 [element].text 命令。最后,在第 9 行,我们将结果输出到 ScraperWiki 控制台。完成后,只需在爬虫中点击“运行”,小窗口中就会一一列出IAEA网站上的事件名称。
图5. 爬虫在行动(ScraperWiki)
现在一个基本的爬虫正在运行。它将下载网页,将其转换为 DOM 格式,然后您可以从中选择并获取特定内容。在这个框架下,可以尝试使用ScraperWiki和Python的帮助文档来解决剩下的问题:
在尝试解决这些问题的同时,您还可以浏览 ScraperWiki。网站很多现成的爬虫工具都有实际案例,数据也很有用。这样,您就不需要从头开始编写代码。使用类似的案例对代码进行更改,然后部署到您自己的问题。
— 弗里德里希·林登伯格,开放知识基金会
抓取公共数据集
例如,一些法国物理学家开发了一种免费招标方式,这样你就可以选择支付不低于 70 欧元和不超过 500 欧元的费用来获得 30 分钟的肿瘤科医生使用时间。这些数据的速率是合法公开的,但管理员提供了一个难以定位的在线数据库。为了找到一个好的角度来看待这些关税,我决定爬取整个世界报的数据库。
乐趣才刚刚开始。前端的搜索表单最初是一个 Flash 应用程序,它通过 POST 请求重定向到 HTML 结果页面。在 Nicolas Kayser-Bril 的帮助下,我们花了很多时间才终于发现,这个应用程序在搜索表单和结果页面中还调用了另一个“隐藏”页面。这个页面其实是存储了搜索表单的cookie值,然后傲然进入结果页面。本来这应该是一个很难理解的过程,但是PHP下这个cURL库中的设置帮助我们轻松地克服了这个障碍。其实,只要找出障碍在哪里,就可以轻松解决。最后,我们总共花了 10 个小时爬下整个数据库,但非常值得。
— 亚历山大·莱切内,《世界报》
抓取网页数据违法吗(首席研究员AnuragSen社交媒体分析网站的不安全的ElasticSearch服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-25 17:07
目录导航
介绍
由首席研究员 Anurag Sen 领导的安全侦探网络安全团队发现了一个不安全的 ElasticSearch 服务器,属于社交媒体分析 网站。该服务器收录从 Instagram 和 TikTok 获得的数百万社交媒体资料中抓取的数据。
IGBlade 采集社交媒体用户的数据,并为其客户提供“对任何 Instagram 或 TikTok 帐户的深入洞察”。
IGBlade 的服务器泄露了超过 260 万条社交用户账户记录,相当于3.6+GB 的数据。
这些记录包括截图和社交个人资料图片链接以及其他形式的个人数据抓取——考虑到大多数社交媒体网站都禁止数据抓取,这是一个令人费解的发现。
我们不知道IGBlade 为何要抓取个人数据,但必须强调的是,数据库中的所有数据都是公开可用的。
服务器的内容还指向了关于数据抓取方法有争议的使用的更广泛的争论。
什么是IGBlade?
IGBlade 的 Instagram 和 TikTok 分析工具从数百万社交媒体帐户中采集了 30 多个数据指标的数据。IGBlade 然后将这些信息集成到一个可导航的社交帐户搜索引擎中,该引擎显示诸如粉丝增长、参与率和帐户历史记录等信息。
用户必须创建 IGBlade 帐户才能接收详细的数据洞察,例如数据可视化、人口统计数据和帐户报告。
用户在服务器上抓取的数据和每个用户对应的页面上的数据是一样的,数据库往往会提供一个返回IGBlade的链接。
这就是我们如何知道数据库所属的。您可以在下面的屏幕截图中看到指向 IGBlade 的链接的证据。
Kim Kardashian 的 Instagram 信息和收录“IGBlade”的链接透露了什么?
IGBlade 的 ElasticSearch 服务器在没有任何密码保护或加密的情况下公开暴露。结果,IGBlade 的数据库泄露了超过 260 万条记录,相当于3.6+GB 的数据。这些文件提供了在 Instagram 和 TikTok 上捕获公共数据的证据。
具体来说,IGBlade 的服务器收录社交帐户用户的不同类型的个人数据:
还可以在服务器上看到各种其他形式的用户数据,包括:
IGBlade 的服务器在发现时处于活动状态并且正在更新。IGBlade 漏洞的规模表明,超过 200 万社交媒体用户可能会立即受到服务器泄露内容的影响。
我们还在服务器上发现了几个知名账户的例子。著名的影响者,如美食博主、名人和社交媒体影响者都出现了。
Alicia Keys、Ariana Grande、Kim Kardashian、Kylie Jenner 和 Loren Gray 等经过验证的大型名人账户的公开数据都被捕获并存储在 IGBlade 的开放式 ElasticSearch 服务器上。
您可以在下图中看到缓存的个人资料图片截图、截图链接(指向个人资料图片)以及来自各种知名 Instagram 和 TikTok 帐户的其他个人数据集的证据。电话号码有时也很重要,尤其是在被抓取的用户的个人资料中提到的时候。
数据库中个人资料图片的屏幕截图。
从 Instagram 上获取的 Loren Gray 的公司编号和照片链接。
指向 Arianna Grande 的 TikTok 个人资料图片的链接。
服务器的海量日志收录来自数百万社交媒体帐户的数据。您可以在下面的屏幕截图中看到服务器大小和文档计数的证据。
2.6+ 万条记录/3.6+GB 服务器上的数据特征。
IGBlade 的 ElasticSearch 没有适当的身份验证安全功能,任何发现服务器的人都可以访问该信息。
您可以在下表中找到 IGBlade 数据泄露的规模、规模和位置的完整细分。
泄露记录数
2.6+ 百万
受影响的用户数量
2.6+ 百万
违规量表
3.6+GB 数据
服务器位置
加拿大
公司位置
罗马尼亚
Safety Detectives 网络安全团队于 2021 年 6 月 20 日发现了 IGBlade 开放的 ElasticSearch 服务器,但该服务器的内容显然自 2021 年 5 月 31 日以来已在互联网上公开。
我们于 2021 年 7 月 5 日联系了 IGBlade。IGBlade 在披露过程后迅速做出回应,并在同一天保护了 IGBlade 的数据库。
人们为什么使用社交爬虫?
主要是营销人员和公司将 IGBlade 等社交分析工具用于广告目的。
更一般地说,数据抓取允许公司和个人扩大他们的成功,因为用户可以采集足够的数据洞察来规划有效的营销策略。
鉴于每个职业都依赖于社交媒体趋势,网红营销人员和社交媒体经理从 IGBlade 等社交媒体分析工具中获益最多。
该公司还采集关注者人口统计数据、增长数据和参与度数据,以监控(和改进)他们自己公司帐户/网站 的社交媒体表现。
黑客滥用数据捕获方法进行大规模网络攻击。
尽管 IGBlade 上的所有信息都是公开可用的,但将捕获的个人数据放在单个界面上是危险的。黑客可以立即访问用户照片、联系信息和位置数据,为大规模社会工程攻击、欺诈计划和虚假账户打开大门。
数据抓取直接违反了 Instagram 和 TikTok 的现场政策,并可能不必要地使社交媒体用户面临网络攻击的风险。
数据抓取影响
IGBlade 的 ElasticSearch 服务器的内容可能会对公司及其跟踪的社交媒体用户产生重大影响。
对 IGBlade 的影响
在线抓取公共信息数据并不违法,数据抓取者不会因其行为面临法律制裁或惩罚。
但是,TikTok 或 Instagram 不允许数据抓取。
Instagram 的服务条款规定:“您不得抓取、抓取或以其他方式缓存来自 Instagram 的任何内容,包括但不限于用户个人资料和照片。”
TikTok 的服务条款也禁止“屏幕抓取”过程。
TikTok 声明:“[用户不得] 使用任何自动化系统或软件,无论是由第三方操作还是通过其他方式,从服务中提取任何数据用于商业目的(“屏幕抓取”)。”
最终,这些违规行为可能会让 IGBlade 在 Instagram 和 TikTok 上陷入大麻烦。网站 都可以禁止 IGBlade 使用其服务。
IGBlade 的商业模式依赖于访问这些社交媒体网站。因此,禁令可能会扰乱 IGBlade 的业务运营。如果IGBlade不能为客户提供价值,利润就会减少,用户就会流失。
对最终用户的影响
那些出现在暴露数据库中的人以及其他社交媒体用户可能会面临 IGBlade 服务器泄漏的毁灭性影响。
IGBlade 将各种形式的公共个人数据放在一台服务器上,使其面临来自黑客和网络犯罪分子的潜在威胁。
IGBlade 的服务器收录联系信息、位置数据、个人资料图片和其他形式的公开可用个人信息,这些信息可能有助于黑客参与大规模的网络犯罪。 查看全部
抓取网页数据违法吗(首席研究员AnuragSen社交媒体分析网站的不安全的ElasticSearch服务器)
目录导航
介绍
由首席研究员 Anurag Sen 领导的安全侦探网络安全团队发现了一个不安全的 ElasticSearch 服务器,属于社交媒体分析 网站。该服务器收录从 Instagram 和 TikTok 获得的数百万社交媒体资料中抓取的数据。
IGBlade 采集社交媒体用户的数据,并为其客户提供“对任何 Instagram 或 TikTok 帐户的深入洞察”。
IGBlade 的服务器泄露了超过 260 万条社交用户账户记录,相当于3.6+GB 的数据。
这些记录包括截图和社交个人资料图片链接以及其他形式的个人数据抓取——考虑到大多数社交媒体网站都禁止数据抓取,这是一个令人费解的发现。
我们不知道IGBlade 为何要抓取个人数据,但必须强调的是,数据库中的所有数据都是公开可用的。
服务器的内容还指向了关于数据抓取方法有争议的使用的更广泛的争论。
什么是IGBlade?
IGBlade 的 Instagram 和 TikTok 分析工具从数百万社交媒体帐户中采集了 30 多个数据指标的数据。IGBlade 然后将这些信息集成到一个可导航的社交帐户搜索引擎中,该引擎显示诸如粉丝增长、参与率和帐户历史记录等信息。
用户必须创建 IGBlade 帐户才能接收详细的数据洞察,例如数据可视化、人口统计数据和帐户报告。
用户在服务器上抓取的数据和每个用户对应的页面上的数据是一样的,数据库往往会提供一个返回IGBlade的链接。
这就是我们如何知道数据库所属的。您可以在下面的屏幕截图中看到指向 IGBlade 的链接的证据。
Kim Kardashian 的 Instagram 信息和收录“IGBlade”的链接透露了什么?
IGBlade 的 ElasticSearch 服务器在没有任何密码保护或加密的情况下公开暴露。结果,IGBlade 的数据库泄露了超过 260 万条记录,相当于3.6+GB 的数据。这些文件提供了在 Instagram 和 TikTok 上捕获公共数据的证据。
具体来说,IGBlade 的服务器收录社交帐户用户的不同类型的个人数据:
还可以在服务器上看到各种其他形式的用户数据,包括:
IGBlade 的服务器在发现时处于活动状态并且正在更新。IGBlade 漏洞的规模表明,超过 200 万社交媒体用户可能会立即受到服务器泄露内容的影响。
我们还在服务器上发现了几个知名账户的例子。著名的影响者,如美食博主、名人和社交媒体影响者都出现了。
Alicia Keys、Ariana Grande、Kim Kardashian、Kylie Jenner 和 Loren Gray 等经过验证的大型名人账户的公开数据都被捕获并存储在 IGBlade 的开放式 ElasticSearch 服务器上。
您可以在下图中看到缓存的个人资料图片截图、截图链接(指向个人资料图片)以及来自各种知名 Instagram 和 TikTok 帐户的其他个人数据集的证据。电话号码有时也很重要,尤其是在被抓取的用户的个人资料中提到的时候。
数据库中个人资料图片的屏幕截图。
从 Instagram 上获取的 Loren Gray 的公司编号和照片链接。
指向 Arianna Grande 的 TikTok 个人资料图片的链接。
服务器的海量日志收录来自数百万社交媒体帐户的数据。您可以在下面的屏幕截图中看到服务器大小和文档计数的证据。
2.6+ 万条记录/3.6+GB 服务器上的数据特征。
IGBlade 的 ElasticSearch 没有适当的身份验证安全功能,任何发现服务器的人都可以访问该信息。
您可以在下表中找到 IGBlade 数据泄露的规模、规模和位置的完整细分。
泄露记录数
2.6+ 百万
受影响的用户数量
2.6+ 百万
违规量表
3.6+GB 数据
服务器位置
加拿大
公司位置
罗马尼亚
Safety Detectives 网络安全团队于 2021 年 6 月 20 日发现了 IGBlade 开放的 ElasticSearch 服务器,但该服务器的内容显然自 2021 年 5 月 31 日以来已在互联网上公开。
我们于 2021 年 7 月 5 日联系了 IGBlade。IGBlade 在披露过程后迅速做出回应,并在同一天保护了 IGBlade 的数据库。
人们为什么使用社交爬虫?
主要是营销人员和公司将 IGBlade 等社交分析工具用于广告目的。
更一般地说,数据抓取允许公司和个人扩大他们的成功,因为用户可以采集足够的数据洞察来规划有效的营销策略。
鉴于每个职业都依赖于社交媒体趋势,网红营销人员和社交媒体经理从 IGBlade 等社交媒体分析工具中获益最多。
该公司还采集关注者人口统计数据、增长数据和参与度数据,以监控(和改进)他们自己公司帐户/网站 的社交媒体表现。
黑客滥用数据捕获方法进行大规模网络攻击。
尽管 IGBlade 上的所有信息都是公开可用的,但将捕获的个人数据放在单个界面上是危险的。黑客可以立即访问用户照片、联系信息和位置数据,为大规模社会工程攻击、欺诈计划和虚假账户打开大门。
数据抓取直接违反了 Instagram 和 TikTok 的现场政策,并可能不必要地使社交媒体用户面临网络攻击的风险。
数据抓取影响
IGBlade 的 ElasticSearch 服务器的内容可能会对公司及其跟踪的社交媒体用户产生重大影响。
对 IGBlade 的影响
在线抓取公共信息数据并不违法,数据抓取者不会因其行为面临法律制裁或惩罚。
但是,TikTok 或 Instagram 不允许数据抓取。
Instagram 的服务条款规定:“您不得抓取、抓取或以其他方式缓存来自 Instagram 的任何内容,包括但不限于用户个人资料和照片。”
TikTok 的服务条款也禁止“屏幕抓取”过程。
TikTok 声明:“[用户不得] 使用任何自动化系统或软件,无论是由第三方操作还是通过其他方式,从服务中提取任何数据用于商业目的(“屏幕抓取”)。”
最终,这些违规行为可能会让 IGBlade 在 Instagram 和 TikTok 上陷入大麻烦。网站 都可以禁止 IGBlade 使用其服务。
IGBlade 的商业模式依赖于访问这些社交媒体网站。因此,禁令可能会扰乱 IGBlade 的业务运营。如果IGBlade不能为客户提供价值,利润就会减少,用户就会流失。
对最终用户的影响
那些出现在暴露数据库中的人以及其他社交媒体用户可能会面临 IGBlade 服务器泄漏的毁灭性影响。
IGBlade 将各种形式的公共个人数据放在一台服务器上,使其面临来自黑客和网络犯罪分子的潜在威胁。
IGBlade 的服务器收录联系信息、位置数据、个人资料图片和其他形式的公开可用个人信息,这些信息可能有助于黑客参与大规模的网络犯罪。
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-25 14:10
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,那么您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是,像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那么你就是在藐视法律。 查看全部
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,那么您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是,像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那么你就是在藐视法律。
抓取网页数据违法吗(qq在a站免费卖手机号应该属于非法牟利吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-23 17:09
抓取网页数据违法吗?第一,在实际的法律认定中,不存在抓取网页数据合法不合法的争议。第二,抓取网页数据是用户浏览网页时向对方发送的“参数”,而网页返回网页信息的是传统的浏览器历史记录,现在网页防爬虫制度很完善,抓取网页数据已经不是违法行为。
qq在a站免费卖手机号应该属于非法牟利,是不违法的。如果网站放置抓取器软件则很危险,国内网站ip是屏蔽抓取器的,如果抓取一个ip一分钟可能被警告30次,如果抓取一个ip抓取到该ip的目标服务器封1-2年。
应该说这是软件公司定义和规定,如果网站要求你再次使用而不给你可视登录的链接.那就是犯法的
前一阵子看到新闻,中国大陆运营商很不容易。一个读取人口出生率,一个读取人口出生,人口大学读取学习年限,多次购买农历,使用县市区用户在一些订货节还要调价后调拨到不同区。之前网上有说中国政府有钱任性,不查p2p网站,房贷车贷用共享单车押金用京东花呗,12306取消自动代理。举个例子吧,像隔壁工商银行,他本身就有atm,但是收的atm机用户多,钱在这一个账户上的就多,那工商银行很机灵,自己做了一个柜台,他就改在了另一个自助机上,依然有用户一进到atm,就直接到了工商银行柜台,他可以选择存入/取款,而不是到自助机上。
工商银行很机灵。如果不改,则会被很多人骂这个政府很任性,很不负责任。中国工商银行明知道存取分离可以给用户省时省事省钱,却为何不做呢?比如在线下乡活动的时候,给村民实行五个工行atm,给个人用户提供智能柜台提款服务,而不是到了银行柜台,再到自助机,太麻烦。然后工商银行就很机灵,大张旗鼓推广智能柜台,给农村再教堂普及智能柜台,教育教育他们,传播传播他们的思想。
到了村民脑子里,脑瓜一转,认为智能柜台也是个不错的事情。p2p网站,就像智能柜台,我们在购买atm机,使用atm机的时候,并不会有银行自身的的牌照,反正都是被收费。比如我们购买旅游门票,并不会去碰他们这些柜台上卖的明抢明抢,有摄像头的柜台,而只是到了柜台,按一个机器牌,从楼道里直接去柜台,不用大老远跑一趟。
为啥呢?其实现在的工商银行自己的atm机,存取分离,还有储蓄,理财,黄金,贵金属等投资项目,对于老百姓来说,已经足够他使用了。而且普通老百姓都有理财的意识,而且银行之间没有p2p网站之间的竞争,再加上银行的存款活期3个月10个月乃至一年甚至更长,而收费这个,只是给业务员更多的成本利润而已。还有现在工商银行自己弄了智能atm机,不仅仅是存款,也可以投资理财。 查看全部
抓取网页数据违法吗(qq在a站免费卖手机号应该属于非法牟利吗)
抓取网页数据违法吗?第一,在实际的法律认定中,不存在抓取网页数据合法不合法的争议。第二,抓取网页数据是用户浏览网页时向对方发送的“参数”,而网页返回网页信息的是传统的浏览器历史记录,现在网页防爬虫制度很完善,抓取网页数据已经不是违法行为。
qq在a站免费卖手机号应该属于非法牟利,是不违法的。如果网站放置抓取器软件则很危险,国内网站ip是屏蔽抓取器的,如果抓取一个ip一分钟可能被警告30次,如果抓取一个ip抓取到该ip的目标服务器封1-2年。
应该说这是软件公司定义和规定,如果网站要求你再次使用而不给你可视登录的链接.那就是犯法的
前一阵子看到新闻,中国大陆运营商很不容易。一个读取人口出生率,一个读取人口出生,人口大学读取学习年限,多次购买农历,使用县市区用户在一些订货节还要调价后调拨到不同区。之前网上有说中国政府有钱任性,不查p2p网站,房贷车贷用共享单车押金用京东花呗,12306取消自动代理。举个例子吧,像隔壁工商银行,他本身就有atm,但是收的atm机用户多,钱在这一个账户上的就多,那工商银行很机灵,自己做了一个柜台,他就改在了另一个自助机上,依然有用户一进到atm,就直接到了工商银行柜台,他可以选择存入/取款,而不是到自助机上。
工商银行很机灵。如果不改,则会被很多人骂这个政府很任性,很不负责任。中国工商银行明知道存取分离可以给用户省时省事省钱,却为何不做呢?比如在线下乡活动的时候,给村民实行五个工行atm,给个人用户提供智能柜台提款服务,而不是到了银行柜台,再到自助机,太麻烦。然后工商银行就很机灵,大张旗鼓推广智能柜台,给农村再教堂普及智能柜台,教育教育他们,传播传播他们的思想。
到了村民脑子里,脑瓜一转,认为智能柜台也是个不错的事情。p2p网站,就像智能柜台,我们在购买atm机,使用atm机的时候,并不会有银行自身的的牌照,反正都是被收费。比如我们购买旅游门票,并不会去碰他们这些柜台上卖的明抢明抢,有摄像头的柜台,而只是到了柜台,按一个机器牌,从楼道里直接去柜台,不用大老远跑一趟。
为啥呢?其实现在的工商银行自己的atm机,存取分离,还有储蓄,理财,黄金,贵金属等投资项目,对于老百姓来说,已经足够他使用了。而且普通老百姓都有理财的意识,而且银行之间没有p2p网站之间的竞争,再加上银行的存款活期3个月10个月乃至一年甚至更长,而收费这个,只是给业务员更多的成本利润而已。还有现在工商银行自己弄了智能atm机,不仅仅是存款,也可以投资理财。
抓取网页数据违法吗(网页搜寻的合法性使用Python(一).本章将解释与网页合法性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-23 11:05
网络搜索的合法性
使用Python,我们可以抓取网页的任何网站或特定元素,但你知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网络爬行合法性相关的概念。
介绍
一般来说,如果您打算将捕获的数据用于个人用途,可能没有问题。但是,如果您想重新发布数据,您应该在执行相同操作之前向所有者发送下载请求,或者对您将要搜索的数据进行一些背景调查和策略。
刮之前需要研究
如果您的目标是从 网站 抓取数据,我们需要了解其规模和结构。以下是我们在开始网络抓取之前需要分析的一些文件。
分析 robots.txt
事实上,大多数发布者都在一定程度上允许程序员爬取他们的网站。换句话说,发布者希望抓取 网站 的特定部分。为了定义这个,网站必须制定一些规则来指定哪些部分可以爬行,哪些部分不能爬行。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于标识允许爬取网站 和不允许爬取网站 的部分内容。robots.txt 文件没有标准格式,网站 发布者可以根据需要修改。我们可以通过在 网站 的 URL 后面提供斜杠和 robots.txt 来检查特定 网站 的 robots.txt 文件。比如我们要检查,那么我们需要输入,我们会得到如下:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站robots.txt 文件中定义的一些最常见的规则如下:
User-agent: BadCrawler
Disallow: /
上述规则意味着robots.txt文件要求爬虫使用BadCrawler用户代理不要爬取他们的网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则表明,robots.txt 文件会在所有用户的下载请求之间延迟爬虫 5 秒。代理用于避免服务器过载。/trap 链接将尝试阻止不允许链接的恶意爬虫。网站 发布 人们可以根据自己的需求定义更多规则。其中一些在这里讨论:
分析站点地图文件
如果你想爬取网站 获取更新的信息,你应该怎么做?您将抓取每个网页以获取更新的信息,但这会增加该特定 网站 的服务器流量。这就是 网站 提供站点地图文件以帮助爬虫查找更新内容的原因。无需抓取每个网页。网站地图标准定义在。
站点地图文件的内容
发现了以下情况:
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
以上内容显示,站点地图列出了网站上的网址,并进一步允许网站站长指定一些其他信息,如最后更新日期、内容变化、网址相对重要性给其他人等等。每个网址。
网站 的大小是多少?
网站的大小,也就是网站的页数会影响我们的抓取方式吗?当然可以。因为如果我们要爬取的网页数量很少,那么效率不会是一个严重的问题,但是假设我们的网站有几百万个网页,比如按顺序下载每个网页需要在一个几个月后,效率就会成为一个严重的问题。
检查网站的大小
通过查看谷歌爬虫结果的大小,我们可以估算出网站的大小。在进行 Google 搜索时,我们可以使用关键字 网站 来过滤我们的结果。例如,估计大小如下所示;
可以看到大约有60条结果,说明不是很大网站,爬取不会造成效率问题。
网站用的是什么技术?
另一个重要的问题是网站使用的技术是否会影响我们抓取的方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为builtwith的Python库,可以帮助我们了解网站所使用的技术。
例子
在这个例子中,我们将检查 网站 使用的技术
借助内置的 Python 库。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站的主人是谁?
网站 的拥有者也很重要,因为如果知道拥有者在阻止爬虫,爬虫从 网站 抓取数据时必须小心。有一个协议叫Whois,我们可以帮助我们了解网站的所有者。
例子
在此示例中,我们将检查 网站 的所有者是否说 Whois 有帮助。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
上一节
下一节 查看全部
抓取网页数据违法吗(网页搜寻的合法性使用Python(一).本章将解释与网页合法性)
网络搜索的合法性
使用Python,我们可以抓取网页的任何网站或特定元素,但你知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网络爬行合法性相关的概念。
介绍
一般来说,如果您打算将捕获的数据用于个人用途,可能没有问题。但是,如果您想重新发布数据,您应该在执行相同操作之前向所有者发送下载请求,或者对您将要搜索的数据进行一些背景调查和策略。
刮之前需要研究
如果您的目标是从 网站 抓取数据,我们需要了解其规模和结构。以下是我们在开始网络抓取之前需要分析的一些文件。
分析 robots.txt
事实上,大多数发布者都在一定程度上允许程序员爬取他们的网站。换句话说,发布者希望抓取 网站 的特定部分。为了定义这个,网站必须制定一些规则来指定哪些部分可以爬行,哪些部分不能爬行。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于标识允许爬取网站 和不允许爬取网站 的部分内容。robots.txt 文件没有标准格式,网站 发布者可以根据需要修改。我们可以通过在 网站 的 URL 后面提供斜杠和 robots.txt 来检查特定 网站 的 robots.txt 文件。比如我们要检查,那么我们需要输入,我们会得到如下:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站robots.txt 文件中定义的一些最常见的规则如下:
User-agent: BadCrawler
Disallow: /
上述规则意味着robots.txt文件要求爬虫使用BadCrawler用户代理不要爬取他们的网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则表明,robots.txt 文件会在所有用户的下载请求之间延迟爬虫 5 秒。代理用于避免服务器过载。/trap 链接将尝试阻止不允许链接的恶意爬虫。网站 发布 人们可以根据自己的需求定义更多规则。其中一些在这里讨论:
分析站点地图文件
如果你想爬取网站 获取更新的信息,你应该怎么做?您将抓取每个网页以获取更新的信息,但这会增加该特定 网站 的服务器流量。这就是 网站 提供站点地图文件以帮助爬虫查找更新内容的原因。无需抓取每个网页。网站地图标准定义在。
站点地图文件的内容
发现了以下情况:
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
以上内容显示,站点地图列出了网站上的网址,并进一步允许网站站长指定一些其他信息,如最后更新日期、内容变化、网址相对重要性给其他人等等。每个网址。
网站 的大小是多少?
网站的大小,也就是网站的页数会影响我们的抓取方式吗?当然可以。因为如果我们要爬取的网页数量很少,那么效率不会是一个严重的问题,但是假设我们的网站有几百万个网页,比如按顺序下载每个网页需要在一个几个月后,效率就会成为一个严重的问题。
检查网站的大小
通过查看谷歌爬虫结果的大小,我们可以估算出网站的大小。在进行 Google 搜索时,我们可以使用关键字 网站 来过滤我们的结果。例如,估计大小如下所示;
可以看到大约有60条结果,说明不是很大网站,爬取不会造成效率问题。
网站用的是什么技术?
另一个重要的问题是网站使用的技术是否会影响我们抓取的方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为builtwith的Python库,可以帮助我们了解网站所使用的技术。
例子
在这个例子中,我们将检查 网站 使用的技术
借助内置的 Python 库。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站的主人是谁?
网站 的拥有者也很重要,因为如果知道拥有者在阻止爬虫,爬虫从 网站 抓取数据时必须小心。有一个协议叫Whois,我们可以帮助我们了解网站的所有者。
例子
在此示例中,我们将检查 网站 的所有者是否说 Whois 有帮助。但是在使用这个库之前,我们需要按如下方式安装它:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定 网站 使用的技术:
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
上一节
下一节
抓取网页数据违法吗(抓取网页数据违法吗?几种方法帮你解决网页违法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-22 19:02
抓取网页数据违法吗?一些开发者常会对他们的网站进行静态检测工具(perflashshadowtest)抓取网页数据,或者说爬虫爬取搜索引擎爬取的网页数据,为了确保这些爬虫爬取到的数据的可靠性以及可靠性,通常会有必要的防抓取防爬虫机制,例如给爬虫提供统一编码。对于抓取网页数据违法吗的回答当然是否定的,这样的抓取网页数据违法吗?这里给大家介绍几种爬虫网页数据的方法。
一、爬虫加密方法
1、利用https协议加密爬虫数据①采用https协议抓取网页:利用https来实现实现web页面的http服务器认证,其中包括ssl和https两种数据加密方式。当然可以尝试搭建这样的服务器进行尝试安全性,如果有很高的安全性质量不是很高,如果一般般,可以利用加密代理服务器来部署安全代理实现的,由于采用加密代理,需要安装证书,可以在后台获取加密代理服务器的网址、获取证书,或者使用其他方式。
最常见的加密方式是https()。需要考虑的问题为https验证问题,另外还需要用到加密文件上传,验证手机是否在线验证等一系列问题。②采用https握手服务器:采用https的web服务器,虽然可以认证https来解密数据,但是,采用https握手服务器来加密,会比较麻烦。比如说明文上传,是需要进行加密解密,看用户是否在线等问题,如果在线一些不方便的问题,这里建议采用https的握手服务器+数据加密方式。
③网络安全问题:遇到很多攻击者可以通过破解网站源代码,并更改代码来访问源代码的目的。一旦web网站被恶意开发,不是其它的内容恶意(非广告、公司网站等)则直接可以采用采用更加安全的https握手服务器来加密方式。
2、采用动态加密方式(ssl加密)加密抓取网页数据①采用ssl加密抓取网页数据:抓取网页数据是要采用ssl加密方式,由于页面数据被反爬虫爬取到的可能性要比https认证反爬虫抓取到网页数据的可能性小。如果采用网页抓取机制(含反爬虫功能),可能会被某些黑客发现https认证反爬虫的抓取机制可以很好地防止https反爬虫抓取网页数据。
②使用sslprotocol认证加密方式:有一些网站,同时也可以使用采用sslprotocol认证方式抓取数据的,主要分为三种情况:情况1:即使网站没有被反爬虫反爬虫抓取,也可以设置对应的cookie,让爬虫根据采用的方式识别出来,包括获取管理员名字和logo。注意一定要设置限制此人每次登录需要输入的数字或者密码,否则可能被破解他每次登录是否需要输入数字或者密码。情况2:如果数据不涉及太多敏感信息,可以只通过证书(隐私协议认证)进行加密。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?几种方法帮你解决网页违法)
抓取网页数据违法吗?一些开发者常会对他们的网站进行静态检测工具(perflashshadowtest)抓取网页数据,或者说爬虫爬取搜索引擎爬取的网页数据,为了确保这些爬虫爬取到的数据的可靠性以及可靠性,通常会有必要的防抓取防爬虫机制,例如给爬虫提供统一编码。对于抓取网页数据违法吗的回答当然是否定的,这样的抓取网页数据违法吗?这里给大家介绍几种爬虫网页数据的方法。
一、爬虫加密方法
1、利用https协议加密爬虫数据①采用https协议抓取网页:利用https来实现实现web页面的http服务器认证,其中包括ssl和https两种数据加密方式。当然可以尝试搭建这样的服务器进行尝试安全性,如果有很高的安全性质量不是很高,如果一般般,可以利用加密代理服务器来部署安全代理实现的,由于采用加密代理,需要安装证书,可以在后台获取加密代理服务器的网址、获取证书,或者使用其他方式。
最常见的加密方式是https()。需要考虑的问题为https验证问题,另外还需要用到加密文件上传,验证手机是否在线验证等一系列问题。②采用https握手服务器:采用https的web服务器,虽然可以认证https来解密数据,但是,采用https握手服务器来加密,会比较麻烦。比如说明文上传,是需要进行加密解密,看用户是否在线等问题,如果在线一些不方便的问题,这里建议采用https的握手服务器+数据加密方式。
③网络安全问题:遇到很多攻击者可以通过破解网站源代码,并更改代码来访问源代码的目的。一旦web网站被恶意开发,不是其它的内容恶意(非广告、公司网站等)则直接可以采用采用更加安全的https握手服务器来加密方式。
2、采用动态加密方式(ssl加密)加密抓取网页数据①采用ssl加密抓取网页数据:抓取网页数据是要采用ssl加密方式,由于页面数据被反爬虫爬取到的可能性要比https认证反爬虫抓取到网页数据的可能性小。如果采用网页抓取机制(含反爬虫功能),可能会被某些黑客发现https认证反爬虫的抓取机制可以很好地防止https反爬虫抓取网页数据。
②使用sslprotocol认证加密方式:有一些网站,同时也可以使用采用sslprotocol认证方式抓取数据的,主要分为三种情况:情况1:即使网站没有被反爬虫反爬虫抓取,也可以设置对应的cookie,让爬虫根据采用的方式识别出来,包括获取管理员名字和logo。注意一定要设置限制此人每次登录需要输入的数字或者密码,否则可能被破解他每次登录是否需要输入数字或者密码。情况2:如果数据不涉及太多敏感信息,可以只通过证书(隐私协议认证)进行加密。
抓取网页数据违法吗(《(最新)百度网页快照抓取之之时间》有什么关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-21 02:20
文章内容
本文内容是关于百度网页抓取的时间。很多人可能没有注意到这个细节。那么今天,小编就为大家揭晓“(最新)百度网页快照爬网时间”。
看标题,你可能会觉得百度快照没了?怎么又弹出来了?或者这只是陈词滥调,我今天仍然谈论它。写这篇文章的时候,我猜大家都会这么想,但是我相信,如果你仔细阅读,你会发现,会有很多我们没有注意到的地方。或者你可能已经忘记了一些你不知道的事情,也不多说别人,见下文。
大家在看这个标题的时候会有点迷茫,所以为了更好的帮助大家理解,直接上图吧,下图如下图。
图片很直观的给我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于大家有没有注意到,这里就不多说了。我希望这能让你清醒一点。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取时间”有什么关系呢?
小编这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题出在这里。这就是我今天要请你解释的。图中的时间有什么特点?大家可以想一想,随便搜索一下关键词看看,可能会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先说第一点,文章收录时间很准,准确到第二点,可见目前的搜索引擎是非常强大的。
第二点,文章yield time 多显示在凌晨 3 点到 8 点之间(注意一般说的网页从 收录 的时间段集中在凌晨 0 点到凌晨 12 点之间,下午很少)。
第三点,文章如果质量高,一般可以秒到现场。应该是时间,但是圈内显示的时间是3点到8点不上班。你从哪里得到收录?这有点混乱。
编者,我看完后想,搜索引擎可能会先收录某个网页然后索引(不明白的可以查相关资料),如图所示的网页是< @收录时间不是真正的网站收录时间,而是百度建索引的时间。百度建索引的时间是在没人或者工作量小的时间段,比如上面提到的早上3:00到8:00(但不是全部在这个时间段)。这段时间用搜索引擎的人很少,小编在相关站长平台也听说过这样的事情,所以大家还是要好好研究一下。
在这里我想为大家补充一下,你们有过这样的经历吗?如果你经常查看排名,有时候你会发现早上查看的排名和下午查看的排名差别很大,尤其是早上比较早和晚上比较晚的时候差别很大吗?
种种迹象表明,搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。因此,本文最重要的一点是提醒大家,我们可以更深入、更详细地了解我们的工作。所有的问题只是对大家的一个提醒。重要的是每个人都要深入探索。这篇文章到此结束。谢谢你。 查看全部
抓取网页数据违法吗(《(最新)百度网页快照抓取之之时间》有什么关系)
文章内容
本文内容是关于百度网页抓取的时间。很多人可能没有注意到这个细节。那么今天,小编就为大家揭晓“(最新)百度网页快照爬网时间”。
看标题,你可能会觉得百度快照没了?怎么又弹出来了?或者这只是陈词滥调,我今天仍然谈论它。写这篇文章的时候,我猜大家都会这么想,但是我相信,如果你仔细阅读,你会发现,会有很多我们没有注意到的地方。或者你可能已经忘记了一些你不知道的事情,也不多说别人,见下文。
大家在看这个标题的时候会有点迷茫,所以为了更好的帮助大家理解,直接上图吧,下图如下图。
图片很直观的给我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于大家有没有注意到,这里就不多说了。我希望这能让你清醒一点。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取时间”有什么关系呢?
小编这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题出在这里。这就是我今天要请你解释的。图中的时间有什么特点?大家可以想一想,随便搜索一下关键词看看,可能会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先说第一点,文章收录时间很准,准确到第二点,可见目前的搜索引擎是非常强大的。
第二点,文章yield time 多显示在凌晨 3 点到 8 点之间(注意一般说的网页从 收录 的时间段集中在凌晨 0 点到凌晨 12 点之间,下午很少)。
第三点,文章如果质量高,一般可以秒到现场。应该是时间,但是圈内显示的时间是3点到8点不上班。你从哪里得到收录?这有点混乱。
编者,我看完后想,搜索引擎可能会先收录某个网页然后索引(不明白的可以查相关资料),如图所示的网页是< @收录时间不是真正的网站收录时间,而是百度建索引的时间。百度建索引的时间是在没人或者工作量小的时间段,比如上面提到的早上3:00到8:00(但不是全部在这个时间段)。这段时间用搜索引擎的人很少,小编在相关站长平台也听说过这样的事情,所以大家还是要好好研究一下。
在这里我想为大家补充一下,你们有过这样的经历吗?如果你经常查看排名,有时候你会发现早上查看的排名和下午查看的排名差别很大,尤其是早上比较早和晚上比较晚的时候差别很大吗?
种种迹象表明,搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。因此,本文最重要的一点是提醒大家,我们可以更深入、更详细地了解我们的工作。所有的问题只是对大家的一个提醒。重要的是每个人都要深入探索。这篇文章到此结束。谢谢你。
抓取网页数据违法吗(抓取网页数据违法吗?是违法的!那应该用什么去呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-14 00:03
抓取网页数据违法吗?是违法的!那应该用什么去抓取呢?selenium!!!可用于抓取网页数据、常见的就是抓取网、京东、第三方网站等等..总之,是一个挺不错的工具抓取网页数据所需要的前提条件1.网页必须是https格式或者http协议中文网页一般不会是https协议的图片的话也是需要用到https图片合法性判断(浏览器不是https是不给抓取的)2.所抓取数据是经过签名加密过后的不包含私钥在内的无法随意变动的图片数据例如:php里面的md5、ftp的校验等3.最好有参照物,让一些人写的那些使用selenium抓取网页数据的脚本可以根据参照物的页面内容去抓取数据,这样的话,不会出现抓取到的数据太大的情况4.实在不行,一般从某些第三方平台下载的页面都是可以直接在浏览器页面里面直接抓取的,不存在抓取是https还是https的问题(例如:电商类的爬虫、论坛类的爬虫)抓取网页数据有哪些方法?1.用selenium去抓取网页(用selenium抓取、京东、第三方网站的页面,如果爬取页面较多的话,建议使用selenium)2.excel数据分析,可以用excel去抓取(如果需要多个,建议都使用excel抓取,数据库使用mysql.)数据字典爬取3.批量抓取网页(点很多次)4.批量去重5.抓取ua(判断一个用户登录系统的是谷歌还是百度)6.从大量站点去爬取数据(此方法用于抓取十万数据)7.google的爬虫?google(谷歌)intl05google的爬虫(可能用到http协议的header的抓取,下面去抓取)8.自己设置不可逆的抓取。
去某个站点前,在首页写明抓取原因!(如:翻页网站)。整站抓取selenium抓取网页数据的七大步骤1.搭建浏览器环境(对于初学者可以通过学习selenium也可以通过windows自带的控制台在命令行用selenium抓取数据),调试控制台,更改环境以及环境所需要的python等工具2.打开网页。2.1点击网页名称,进入所抓取的网页界面。
2.2点击开始抓取。3.定位一下内容,并在网页上标记名称。3.1点击我的网页,添加标记。3.2点击浏览器地址栏上面的数字,此时会看到向下箭头。点击箭头时候网页会刷新出来。3.3按照alt+ctrl+c组合键,选择抓取工具。4.查看抓取的效果5.保存网页。5.1输出网页上的内容,包括标题、内容等的内容。
5.2编辑源代码。(看工具命令)6.爬取下来的数据,放到数据库中,比如用mysql等去存。七大步骤以及后续做法,由于我们抓取的数据都是https的html。比如用selenium抓取数据可以如下如图7.网页的分析浏。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?是违法的!那应该用什么去呢?)
抓取网页数据违法吗?是违法的!那应该用什么去抓取呢?selenium!!!可用于抓取网页数据、常见的就是抓取网、京东、第三方网站等等..总之,是一个挺不错的工具抓取网页数据所需要的前提条件1.网页必须是https格式或者http协议中文网页一般不会是https协议的图片的话也是需要用到https图片合法性判断(浏览器不是https是不给抓取的)2.所抓取数据是经过签名加密过后的不包含私钥在内的无法随意变动的图片数据例如:php里面的md5、ftp的校验等3.最好有参照物,让一些人写的那些使用selenium抓取网页数据的脚本可以根据参照物的页面内容去抓取数据,这样的话,不会出现抓取到的数据太大的情况4.实在不行,一般从某些第三方平台下载的页面都是可以直接在浏览器页面里面直接抓取的,不存在抓取是https还是https的问题(例如:电商类的爬虫、论坛类的爬虫)抓取网页数据有哪些方法?1.用selenium去抓取网页(用selenium抓取、京东、第三方网站的页面,如果爬取页面较多的话,建议使用selenium)2.excel数据分析,可以用excel去抓取(如果需要多个,建议都使用excel抓取,数据库使用mysql.)数据字典爬取3.批量抓取网页(点很多次)4.批量去重5.抓取ua(判断一个用户登录系统的是谷歌还是百度)6.从大量站点去爬取数据(此方法用于抓取十万数据)7.google的爬虫?google(谷歌)intl05google的爬虫(可能用到http协议的header的抓取,下面去抓取)8.自己设置不可逆的抓取。
去某个站点前,在首页写明抓取原因!(如:翻页网站)。整站抓取selenium抓取网页数据的七大步骤1.搭建浏览器环境(对于初学者可以通过学习selenium也可以通过windows自带的控制台在命令行用selenium抓取数据),调试控制台,更改环境以及环境所需要的python等工具2.打开网页。2.1点击网页名称,进入所抓取的网页界面。
2.2点击开始抓取。3.定位一下内容,并在网页上标记名称。3.1点击我的网页,添加标记。3.2点击浏览器地址栏上面的数字,此时会看到向下箭头。点击箭头时候网页会刷新出来。3.3按照alt+ctrl+c组合键,选择抓取工具。4.查看抓取的效果5.保存网页。5.1输出网页上的内容,包括标题、内容等的内容。
5.2编辑源代码。(看工具命令)6.爬取下来的数据,放到数据库中,比如用mysql等去存。七大步骤以及后续做法,由于我们抓取的数据都是https的html。比如用selenium抓取数据可以如下如图7.网页的分析浏。
抓取网页数据违法吗( 非法获取计算机信息系统数据固定(1)_长昊商业秘密律师 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-12 01:29
非法获取计算机信息系统数据固定(1)_长昊商业秘密律师
)
非法获取计算机信息系统数据罪——计算机入侵事件证据如何取证?
资料来源:长豪商业秘密律师(非法获取计算机信息系统数据罪、非法获取计算机信息系统数据罪)
一、活动介绍
某金融网站称其注册会员账户中的财产在用户不知情的情况下被提取,但网站经核实并非用户本人所有。值得注意的是,提款过程中使用的银行卡并非用户名下的真实银行账户。根据现有资料推测,其电脑可能被非法人入侵,网站数据被篡改,损失达数百万。
二、数据固定
数据固定是分析的先决条件。在固定过程中,必须考虑数据的原创性、完整性、再现性和可控性的原则。下面详细介绍Linux服务器的修复过程。
1.目标信息
网站 部署在阿里云上,使用Linux操作系统,受害者提供受感染计算机的IP和登录凭据。
2.基本信息已修复
执行“history>history.log”导出历史命令;
执行“last>last.log”导出登录相关信息;
执行“lastb>lastb.log”导出登录失败信息;
执行“lastlog>lastlog.log”导出所有用户的最后登录信息;
执行“tarczvf/var/logvarlog.tar.gz”将/var/log的整个目录打包;
执行“ps-AUX>ps.log”导出进程信息;
执行“netstat-atunp>netstat.log”导出网络连接信息;
3.网站数据固定
(1)目录是固定的
根据网站应用配置文件,网站的目录为“/www/c****i”,执行“tarczvf/www/c******i**** *.tar .gz”保存网站目录;
(2)访问日志已修复
根据网站应用配置文件,访问日志的存储位置为:“/etc/httpd/logs”,执行“tarczvf/etc/httpd/logsaccesslog.tar.gz”保存网站 访问日志。
为了保证日志的完整性,在执行该命令之前应该先停止网站应用进程,否则会因为网站应用进程锁定日志而导致日志文件不可读:
4.数据库已修复
(1)数据表已修复
在网站目录下找到数据库连接配置文件,将网站数据库导出为“database.sql”,0
(2)数据库日志已修复
根据Mysql数据库配置信息,提取并修复所有日志文件。
三、数据分析
1.系统日志分析
修复工作完成后,首先分析修复的基本信息,未发现明显异常,排除暴力破解系统用户登录的入侵方式:
2.网站 应用分析
(1)网站 重构
安装Apache、PHP和Mysql,导入固定数据,使用网页浏览器访问后,成功显示网站主页。
(2)WebShell 扫描
使用WebShell分析工具进行扫描,在网站目录下发现一个名为“up1oad****•php.bmp”的文件,疑似网页木马。
(3)WebShell 分析
用编码工具查看文件后,发现如下代码“”,表示对帖子提交的h31en变量中的内容进行base64解码。
根据文件修改时间找到一个类似的文件,找到符合条件的php代码页“adminer.php”,打开发现这个页面的功能是数据库管理器,可以进行数据库管理动作。
一般情况下,网站管理员不需要在网页上修改数据库。结合对文件创建时间的分析,可以确定该页面是入侵者为了远程控制数据库而专门留下的一个界面。
3.网站访问日志分析
接下来,从网站的访问日志中,过滤掉日志中“adminer.php”页面的所有访问记录,统计“adminer.php”的所有访问记录中出现的“userjd”页面,并获得 4 个用户 ID:t4$grep-Eio"user_id%5d=[e-9]{1,8}"adminer.php。
exclude.alibaba.log|排序|uniq
用户 ID%5D=1392
user_id%5D=1679
用户 ID%5D=2613
用户 ID%5D=6248"
四、入侵恢复
然后根据数据分析环节的结果,还原整个入侵过程:
1.恶意文件上传
入侵者首先利用网站的文件上传漏洞修改含有恶意内容的PHP代码页,修改文件头,伪装成BMP图片,成功绕过网站代码检测机制上传它到网站目录下;
2. 确认上传文件证据
在网站对应目录中找到上传成功的恶意代码文件“uploaddyp2p.php.php”,可见上传行为有效;
3.连接电脑
使用“chopper”工具连接到这个网站中的恶意代码页。连接成功后,使用集成文件管理器成功打开网站所在电脑的根目录,并获得管理权限;
4.上传数据库管理器
使用集成了“chopper”工具的文件管理器,上传数据库管理器代码页“adminer.php”,读取数据库连接配置文件“/data/www/c*****i/dbconfig.php”,并获取数据库权限。
5.修改数据
访问“adminer.php”页面,篡改数据库数据,绑定银行卡;
6.执行提现
访问提现页面,执行提现操作,成功非法获取用户财产。
查看全部
抓取网页数据违法吗(
非法获取计算机信息系统数据固定(1)_长昊商业秘密律师
)
非法获取计算机信息系统数据罪——计算机入侵事件证据如何取证?
资料来源:长豪商业秘密律师(非法获取计算机信息系统数据罪、非法获取计算机信息系统数据罪)
一、活动介绍
某金融网站称其注册会员账户中的财产在用户不知情的情况下被提取,但网站经核实并非用户本人所有。值得注意的是,提款过程中使用的银行卡并非用户名下的真实银行账户。根据现有资料推测,其电脑可能被非法人入侵,网站数据被篡改,损失达数百万。
二、数据固定
数据固定是分析的先决条件。在固定过程中,必须考虑数据的原创性、完整性、再现性和可控性的原则。下面详细介绍Linux服务器的修复过程。
1.目标信息
网站 部署在阿里云上,使用Linux操作系统,受害者提供受感染计算机的IP和登录凭据。
2.基本信息已修复
执行“history>history.log”导出历史命令;
执行“last>last.log”导出登录相关信息;
执行“lastb>lastb.log”导出登录失败信息;
执行“lastlog>lastlog.log”导出所有用户的最后登录信息;
执行“tarczvf/var/logvarlog.tar.gz”将/var/log的整个目录打包;
执行“ps-AUX>ps.log”导出进程信息;
执行“netstat-atunp>netstat.log”导出网络连接信息;
3.网站数据固定
(1)目录是固定的
根据网站应用配置文件,网站的目录为“/www/c****i”,执行“tarczvf/www/c******i**** *.tar .gz”保存网站目录;
(2)访问日志已修复
根据网站应用配置文件,访问日志的存储位置为:“/etc/httpd/logs”,执行“tarczvf/etc/httpd/logsaccesslog.tar.gz”保存网站 访问日志。
为了保证日志的完整性,在执行该命令之前应该先停止网站应用进程,否则会因为网站应用进程锁定日志而导致日志文件不可读:
4.数据库已修复
(1)数据表已修复
在网站目录下找到数据库连接配置文件,将网站数据库导出为“database.sql”,0
(2)数据库日志已修复
根据Mysql数据库配置信息,提取并修复所有日志文件。
三、数据分析
1.系统日志分析
修复工作完成后,首先分析修复的基本信息,未发现明显异常,排除暴力破解系统用户登录的入侵方式:
2.网站 应用分析
(1)网站 重构
安装Apache、PHP和Mysql,导入固定数据,使用网页浏览器访问后,成功显示网站主页。
(2)WebShell 扫描
使用WebShell分析工具进行扫描,在网站目录下发现一个名为“up1oad****•php.bmp”的文件,疑似网页木马。
(3)WebShell 分析
用编码工具查看文件后,发现如下代码“”,表示对帖子提交的h31en变量中的内容进行base64解码。
根据文件修改时间找到一个类似的文件,找到符合条件的php代码页“adminer.php”,打开发现这个页面的功能是数据库管理器,可以进行数据库管理动作。
一般情况下,网站管理员不需要在网页上修改数据库。结合对文件创建时间的分析,可以确定该页面是入侵者为了远程控制数据库而专门留下的一个界面。
3.网站访问日志分析
接下来,从网站的访问日志中,过滤掉日志中“adminer.php”页面的所有访问记录,统计“adminer.php”的所有访问记录中出现的“userjd”页面,并获得 4 个用户 ID:t4$grep-Eio"user_id%5d=[e-9]{1,8}"adminer.php。
exclude.alibaba.log|排序|uniq
用户 ID%5D=1392
user_id%5D=1679
用户 ID%5D=2613
用户 ID%5D=6248"
四、入侵恢复
然后根据数据分析环节的结果,还原整个入侵过程:
1.恶意文件上传
入侵者首先利用网站的文件上传漏洞修改含有恶意内容的PHP代码页,修改文件头,伪装成BMP图片,成功绕过网站代码检测机制上传它到网站目录下;
2. 确认上传文件证据
在网站对应目录中找到上传成功的恶意代码文件“uploaddyp2p.php.php”,可见上传行为有效;
3.连接电脑
使用“chopper”工具连接到这个网站中的恶意代码页。连接成功后,使用集成文件管理器成功打开网站所在电脑的根目录,并获得管理权限;
4.上传数据库管理器
使用集成了“chopper”工具的文件管理器,上传数据库管理器代码页“adminer.php”,读取数据库连接配置文件“/data/www/c*****i/dbconfig.php”,并获取数据库权限。
5.修改数据
访问“adminer.php”页面,篡改数据库数据,绑定银行卡;
6.执行提现
访问提现页面,执行提现操作,成功非法获取用户财产。
抓取网页数据违法吗( 不是post重放登录的接口方法用的是get方法? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-11 02:27
不是post重放登录的接口方法用的是get方法?
)
将下载的文件名后缀改为.cer,如果电脑是.der,直接在手机上点击文件安装,选择use as WLAN
安装好证书后,pc就可以抓取到所有与手机相关的http和https数据包了。
于是我开通了12333的社保登录,大家都知道,这种网站是外包的,一般都是不好的。反正我经常查不到资料。
随便重放一个数据包,不管是修改url后的参数值还是post的参数值,返回的响应都是一样的,那么你的参数值是这样的吗?
再看登录数据包,登录界面方法使用的是get方法,不是post
重放已登录的数据包,去掉headers中的cookie,使用正确的密码和账号即可正常登录
去掉Referer后,重定向链接信息,登录还是正常的,url后面跟了很多参数,不知道具体是什么,估计大部分都没用,不然replay就不行了肯定不能登录,结果是可以正常登录
url后面的参数是登录账号和密码。密码由 md5 加密。登录账号未加密,每次提交数据登录,不需要其他一些有效参数或验证码,可以多次提交。密码错误10次将导致账户锁定
然后脚本就可以构造出各种身份证号码和手机号码,利用脚本用错误的密码登录。如果账户错误登录10次,账户将在24小时内被锁定。如果不存在,直接跳过。基本上,这些账户上的账户都会被锁定。当然,我闲着也不会这么麻烦,但这确实是登录界面的问题。
查看全部
抓取网页数据违法吗(
不是post重放登录的接口方法用的是get方法?
)
将下载的文件名后缀改为.cer,如果电脑是.der,直接在手机上点击文件安装,选择use as WLAN
安装好证书后,pc就可以抓取到所有与手机相关的http和https数据包了。
于是我开通了12333的社保登录,大家都知道,这种网站是外包的,一般都是不好的。反正我经常查不到资料。
随便重放一个数据包,不管是修改url后的参数值还是post的参数值,返回的响应都是一样的,那么你的参数值是这样的吗?
再看登录数据包,登录界面方法使用的是get方法,不是post
重放已登录的数据包,去掉headers中的cookie,使用正确的密码和账号即可正常登录
去掉Referer后,重定向链接信息,登录还是正常的,url后面跟了很多参数,不知道具体是什么,估计大部分都没用,不然replay就不行了肯定不能登录,结果是可以正常登录
url后面的参数是登录账号和密码。密码由 md5 加密。登录账号未加密,每次提交数据登录,不需要其他一些有效参数或验证码,可以多次提交。密码错误10次将导致账户锁定
然后脚本就可以构造出各种身份证号码和手机号码,利用脚本用错误的密码登录。如果账户错误登录10次,账户将在24小时内被锁定。如果不存在,直接跳过。基本上,这些账户上的账户都会被锁定。当然,我闲着也不会这么麻烦,但这确实是登录界面的问题。
抓取网页数据违法吗( 网站通过Robots协议告诉爬虫哪些页面可以抓取文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 07:06
网站通过Robots协议告诉爬虫哪些页面可以抓取文件?)
2. 当网站 声明rebots 协议时。
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
方法很简单。如果您想查看它,请在 IE 上输入您的 URL/robots.txt。如果有专业的相关工具查看和分析机器人,可以使用站长工具。
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
√ 完全公开的数据
√ 不存在,不能被非法访问爬取
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的。
但是,如果您使用技术来抓取他人的隐私和业务数据,那么您就是在藐视法律!
结尾 查看全部
抓取网页数据违法吗(
网站通过Robots协议告诉爬虫哪些页面可以抓取文件?)
2. 当网站 声明rebots 协议时。
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器来创建和编辑它,例如 Windows 系统自带的记事本。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
方法很简单。如果您想查看它,请在 IE 上输入您的 URL/robots.txt。如果有专业的相关工具查看和分析机器人,可以使用站长工具。
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
√ 完全公开的数据
√ 不存在,不能被非法访问爬取
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的。
但是,如果您使用技术来抓取他人的隐私和业务数据,那么您就是在藐视法律!
结尾
抓取网页数据违法吗(python2抓取网页的内容显示出来是怎么回事?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-09 19:22
)
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
你是如何自学 Python 的?-克罗辛的回答
在学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?-克罗辛的回答
编程初学者如何使用搜索引擎-Crossin的文章-知乎专栏
如何直观的了解程序的运行过程?-Crossin 的 文章-知乎 专栏
如何在一台电脑上同时使用Python 2和Python 3-Crossin的编程课堂-知乎专栏
Crossin的编程课堂
微信ID:crossincode
论坛:Crossin 的编程课堂
QQ群:498545096
查看全部
抓取网页数据违法吗(python2抓取网页的内容显示出来是怎么回事?(图)
)
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况的最大可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
其他 文章 和回答:
你是如何自学 Python 的?-克罗辛的回答
在学习编程的过程中可能会走哪些弯路,有哪些经验可以参考?-克罗辛的回答
编程初学者如何使用搜索引擎-Crossin的文章-知乎专栏
如何直观的了解程序的运行过程?-Crossin 的 文章-知乎 专栏
如何在一台电脑上同时使用Python 2和Python 3-Crossin的编程课堂-知乎专栏
Crossin的编程课堂
微信ID:crossincode
论坛:Crossin 的编程课堂
QQ群:498545096

