
抓取网页数据违法吗
抓取网页数据违法吗(【芝麻IP代理】如何用python来页面中的JS动态加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-09 02:21
)
【芝麻IP代理】我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
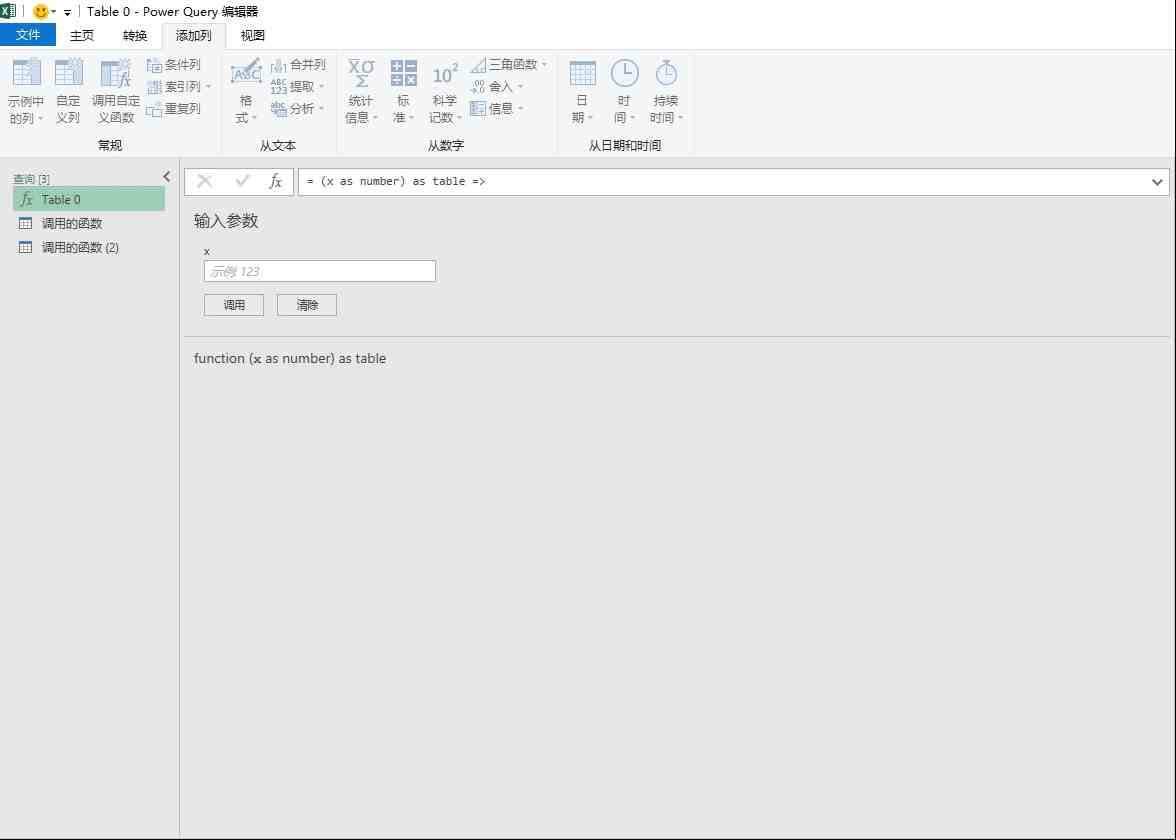
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
查看全部
抓取网页数据违法吗(【芝麻IP代理】如何用python来页面中的JS动态加载
)
【芝麻IP代理】我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。

抓取网页数据违法吗( 什么是万能工具?AIWeb工具是AI驱动的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-09 02:20
什么是万能工具?AIWeb工具是AI驱动的工具)
有万能爬虫吗?
随着网站的数量从十年前的20万增长到今天的17亿多,互联网上的数据量正在爆炸式增长。十年前,内容可能是王道,但现在互联网爱好者说数据是现代石油。当今最有价值的资源不是石油,而是数据。
掌握提取和采集数据技术的公司已成为当今世界上最有价值的巨头之一。未来,人工智能(AI)、大数据、机器学习等具有强大数据处理能力的高科技企业将主导世界经济。
因此,为了在竞争激烈、高度创新的商业环境中跟上时代的步伐,有远见的企业主们开始数据采集。他们经常在数据挖掘和 采集 中使用网络抓取工具。
什么是万能爬虫?
AI网络爬虫是一种AI驱动的工具,可以将计算机上传统的复制粘贴功能自动化。这种类型的工具通常也称为网络爬虫或数据抓取工具。他们的核心功能是从在线资源中提取数据。
但两者的运作方式并不相同。网络爬虫通常被称为网络蜘蛛,指的是跟踪网络链接、浏览网络信息和建立索引的机器人。大型搜索引擎(例如 Bing 和 Google)使用网络爬虫来索引新的 网站 信息。
爬虫提取已被网络爬虫编入索引的数据。因此,这两个工具在同一个过程中协同工作,结果是数据被分析并存储在计算机或数据库中。
有万能爬虫吗?
网络抓取过程不仅仅是一项只需要遵守规则的活动。Web 语言、编码风格和编程方法多种多样,并且随着技术的进步而不断发展。与过去不同,雄心勃勃的数据挖掘者必须对自己进行编程以构建网络爬虫机器人。现在的万能爬虫工具基本可以应对各种网站规范。
网络爬行限制是无止境的
尽管网络抓取是一种必不可少的商业策略,但各种网站 已经部署了反抓取工具来阻止这项工作。因此,如果企业需要加大数据挖掘力度,就必须保证自己的通用爬虫工具能够应对各种挑战,例如:
机器人访问限制
一些网站有robot.txt文件,他们的规则会禁止robots访问。您必须确认您要抓取的网站 被接受进行抓取。如果您不接受,则必须获得网站 所有者的许可才能抓取数据。如果目标网站的所有者不愿意合作,尽可能寻求一个爬行条款友好的网站更合乎道德。
更改 网站 结构
尽管 HTML 网页易于抓取,但网页设计师不断提出新的设计标准,使网页设计日新月异。结构变化可能会影响某些爬虫的爬行功能。
请只选择信誉良好的提供商,并使用他们的抓取工具确保技术不断更新以应对新的网页设计语言。网页组织的细微变化可能会严重影响数据爬虫的功能。
IP拦截器
网站 已收录 IP 地址阻止机制,以防止机器人抓取网页。当网站的监控系统检测到来自单个IP的并发请求比例很高时,他们会禁止、标记或阻止该IP在网站上的活动。但是,网络抓取是一项合法活动。
IP拦截器是互联网活动混乱时代的产物。当时,有人在网络爬虫中肆无忌惮地滥用机器人,对目标网站造成了不利影响。一些恶意的在线用户还使用机器人进行垃圾邮件攻击,导致拒绝服务错误。
由于大多数网站都有可疑的IP拦截工具,因此网页抓取工具需要配备带有旋转住宅IP池的代理服务器,以隐藏抓取活动。
验证码验证
区分计算机和人类的全自动图灵测试(CAPTCHA)是 网站 上的一个常见功能。这个工具显示了真人可以解决但机器人不能解决的逻辑错误。
网站 带有 CAPTCHA 验证可能会阻止网络抓取。为保证持续抓取,部分工具配备了CAPTCHA验证方案,以保证过程的顺利进行。
蜜罐陷阱
一些网站站长喜欢搜索爬虫,所以会设置网络爬虫陷阱。蜜罐陷阱是肉眼看不见的链接,但网络蜘蛛可以索引它们。如果爬虫跟随网络蜘蛛访问这些链接,网站 的安全协议将阻止其 IP 地址。
一些抓取工具的强大技术可以通过准确抓取项目而不是整体抓取它们来避免蜜罐陷阱。
综上所述
网络抓取正在兴起。尽管通用抓取工具仍面临诸多挑战,但程序员们也在不断努力寻找突破口。您有责任遵守 网站 的所有要求并以合乎道德的方式获取数据。 查看全部
抓取网页数据违法吗(
什么是万能工具?AIWeb工具是AI驱动的工具)

有万能爬虫吗?
随着网站的数量从十年前的20万增长到今天的17亿多,互联网上的数据量正在爆炸式增长。十年前,内容可能是王道,但现在互联网爱好者说数据是现代石油。当今最有价值的资源不是石油,而是数据。
掌握提取和采集数据技术的公司已成为当今世界上最有价值的巨头之一。未来,人工智能(AI)、大数据、机器学习等具有强大数据处理能力的高科技企业将主导世界经济。
因此,为了在竞争激烈、高度创新的商业环境中跟上时代的步伐,有远见的企业主们开始数据采集。他们经常在数据挖掘和 采集 中使用网络抓取工具。
什么是万能爬虫?
AI网络爬虫是一种AI驱动的工具,可以将计算机上传统的复制粘贴功能自动化。这种类型的工具通常也称为网络爬虫或数据抓取工具。他们的核心功能是从在线资源中提取数据。
但两者的运作方式并不相同。网络爬虫通常被称为网络蜘蛛,指的是跟踪网络链接、浏览网络信息和建立索引的机器人。大型搜索引擎(例如 Bing 和 Google)使用网络爬虫来索引新的 网站 信息。
爬虫提取已被网络爬虫编入索引的数据。因此,这两个工具在同一个过程中协同工作,结果是数据被分析并存储在计算机或数据库中。
有万能爬虫吗?
网络抓取过程不仅仅是一项只需要遵守规则的活动。Web 语言、编码风格和编程方法多种多样,并且随着技术的进步而不断发展。与过去不同,雄心勃勃的数据挖掘者必须对自己进行编程以构建网络爬虫机器人。现在的万能爬虫工具基本可以应对各种网站规范。
网络爬行限制是无止境的
尽管网络抓取是一种必不可少的商业策略,但各种网站 已经部署了反抓取工具来阻止这项工作。因此,如果企业需要加大数据挖掘力度,就必须保证自己的通用爬虫工具能够应对各种挑战,例如:
机器人访问限制
一些网站有robot.txt文件,他们的规则会禁止robots访问。您必须确认您要抓取的网站 被接受进行抓取。如果您不接受,则必须获得网站 所有者的许可才能抓取数据。如果目标网站的所有者不愿意合作,尽可能寻求一个爬行条款友好的网站更合乎道德。
更改 网站 结构
尽管 HTML 网页易于抓取,但网页设计师不断提出新的设计标准,使网页设计日新月异。结构变化可能会影响某些爬虫的爬行功能。
请只选择信誉良好的提供商,并使用他们的抓取工具确保技术不断更新以应对新的网页设计语言。网页组织的细微变化可能会严重影响数据爬虫的功能。
IP拦截器
网站 已收录 IP 地址阻止机制,以防止机器人抓取网页。当网站的监控系统检测到来自单个IP的并发请求比例很高时,他们会禁止、标记或阻止该IP在网站上的活动。但是,网络抓取是一项合法活动。
IP拦截器是互联网活动混乱时代的产物。当时,有人在网络爬虫中肆无忌惮地滥用机器人,对目标网站造成了不利影响。一些恶意的在线用户还使用机器人进行垃圾邮件攻击,导致拒绝服务错误。
由于大多数网站都有可疑的IP拦截工具,因此网页抓取工具需要配备带有旋转住宅IP池的代理服务器,以隐藏抓取活动。
验证码验证
区分计算机和人类的全自动图灵测试(CAPTCHA)是 网站 上的一个常见功能。这个工具显示了真人可以解决但机器人不能解决的逻辑错误。
网站 带有 CAPTCHA 验证可能会阻止网络抓取。为保证持续抓取,部分工具配备了CAPTCHA验证方案,以保证过程的顺利进行。
蜜罐陷阱
一些网站站长喜欢搜索爬虫,所以会设置网络爬虫陷阱。蜜罐陷阱是肉眼看不见的链接,但网络蜘蛛可以索引它们。如果爬虫跟随网络蜘蛛访问这些链接,网站 的安全协议将阻止其 IP 地址。
一些抓取工具的强大技术可以通过准确抓取项目而不是整体抓取它们来避免蜜罐陷阱。
综上所述
网络抓取正在兴起。尽管通用抓取工具仍面临诸多挑战,但程序员们也在不断努力寻找突破口。您有责任遵守 网站 的所有要求并以合乎道德的方式获取数据。
抓取网页数据违法吗(为什么百度蜘蛛经常不存在的网站页面,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-09 02:17
[摘要] 网站 爬取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是我们的网站上不存在这些页面
网站 抓取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是这些页面在我们的 网站 上根本不存在。那么,为什么百度蜘蛛经常抓取不存在的网站页面,我该怎么办?
为什么网站会爬取一些不存在的页面?
导致网站在不存在的页面上被爬取的因素有很多,例如:
■页面删除
在很多情况下,优化过程中需要对网站进行调整,但并不是所有你调整的页面都没有被搜索引擎抓取。有时,你看到的页面没有被索引,但实际上这些页面可能正在被评估,所以蜘蛛在一段时间后仍然会抓取这些页面。
■旧域名
有时候,我们做seo的时候,为了更快的得到搜索排名结果,我们会使用旧域名。但是,旧域名必须有建站历史,否则我们不会选择它。如果它有历史,它会带上自己的蜘蛛,蜘蛛有内存,所以它总是爬一些旧的网址。所以买旧域名有利有弊,但利大于弊。
■ 恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,还有一些不存在的页面被抓取。这时候就需要观察这些抓到的IP是否有一定的规律性。在很多情况下,我们的网站会面临各种各样的扫描需求,比如漏洞扫描、文章采集等,如果这些入侵防御系统是常规的,他们很可能会被扫描到漏洞。
如何处理对不存在的页面的抓取?
知道了爬行页面不存在的一些原因,如何解决这些问题?
■设置机器人
首先,我们知道这些不存在的页面会被反复抓取,所以我们需要自己采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用机器人协议来禁止这些页面被抓取。一般来说,这种方法适用于大多数蜘蛛,因为它是所有常规搜索引擎都需要遵循的协议。
■提交死链接
如果仍然存在被重复抓取的问题,可以查看这些页面是否有百度快照。如果有快照,蜘蛛会重复爬取,因为您正在阻止未编入索引的页面,但这些页面已经编入索引。我们可以聚合这些页面URL,通过资源平台提交死链接。
■屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛开发的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
在我们看来,最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
① 云主机。下载。htaccess 文件,直接修改、上传、覆盖原文件。
②宝塔。
进入宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
③ 插件。
现在所有cms系统都引入了各种功能插件。我们可以直接搜索被屏蔽的ip来查找插件并过滤ip。
以上就是“为什么百度蜘蛛经常抓取不存在的网站页面?”的原因。以及处理方法。如果你的网站有这样的情况,可以按照上面的方法来处理。推荐阅读《什么是网站日志分析?网站日志分析有什么用?》 查看全部
抓取网页数据违法吗(为什么百度蜘蛛经常不存在的网站页面,怎么办?)
[摘要] 网站 爬取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是我们的网站上不存在这些页面
网站 抓取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是这些页面在我们的 网站 上根本不存在。那么,为什么百度蜘蛛经常抓取不存在的网站页面,我该怎么办?

为什么网站会爬取一些不存在的页面?
导致网站在不存在的页面上被爬取的因素有很多,例如:
■页面删除
在很多情况下,优化过程中需要对网站进行调整,但并不是所有你调整的页面都没有被搜索引擎抓取。有时,你看到的页面没有被索引,但实际上这些页面可能正在被评估,所以蜘蛛在一段时间后仍然会抓取这些页面。
■旧域名
有时候,我们做seo的时候,为了更快的得到搜索排名结果,我们会使用旧域名。但是,旧域名必须有建站历史,否则我们不会选择它。如果它有历史,它会带上自己的蜘蛛,蜘蛛有内存,所以它总是爬一些旧的网址。所以买旧域名有利有弊,但利大于弊。
■ 恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,还有一些不存在的页面被抓取。这时候就需要观察这些抓到的IP是否有一定的规律性。在很多情况下,我们的网站会面临各种各样的扫描需求,比如漏洞扫描、文章采集等,如果这些入侵防御系统是常规的,他们很可能会被扫描到漏洞。
如何处理对不存在的页面的抓取?
知道了爬行页面不存在的一些原因,如何解决这些问题?
■设置机器人
首先,我们知道这些不存在的页面会被反复抓取,所以我们需要自己采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用机器人协议来禁止这些页面被抓取。一般来说,这种方法适用于大多数蜘蛛,因为它是所有常规搜索引擎都需要遵循的协议。
■提交死链接
如果仍然存在被重复抓取的问题,可以查看这些页面是否有百度快照。如果有快照,蜘蛛会重复爬取,因为您正在阻止未编入索引的页面,但这些页面已经编入索引。我们可以聚合这些页面URL,通过资源平台提交死链接。
■屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛开发的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
在我们看来,最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
① 云主机。下载。htaccess 文件,直接修改、上传、覆盖原文件。
②宝塔。
进入宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
③ 插件。
现在所有cms系统都引入了各种功能插件。我们可以直接搜索被屏蔽的ip来查找插件并过滤ip。
以上就是“为什么百度蜘蛛经常抓取不存在的网站页面?”的原因。以及处理方法。如果你的网站有这样的情况,可以按照上面的方法来处理。推荐阅读《什么是网站日志分析?网站日志分析有什么用?》
抓取网页数据违法吗(通过selenium的子模块使用Python爬取网页数据的解决思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-08 03:08
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录它(不信,请查看页面源码,只有简单的一行)。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
先导入webdriver子模块
from selenium import webdriver 获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程-定位方法部分第三章(第一版可在百度文库阅读)结合正则表达式过滤相关资料
定位后有些元素是不需要的,有规律的过滤掉即可。比如我想只提取英文字符(包括0-9),建立如下规律
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
打印结束会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话。前者只是关闭当前会话而不关闭浏览器的webdriver,后者关闭包括webdriver在内的所有东西并添加异常处理。
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
assert 0, "找不到元素"4. 代码实现
我通过点击打开链接抓取指定分区的每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线号,以及以列表的形式打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用它来实现数据挖掘和机器学习等深度研究。因此,selenium+python 是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。 查看全部
抓取网页数据违法吗(通过selenium的子模块使用Python爬取网页数据的解决思路)
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录它(不信,请查看页面源码,只有简单的一行)。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
先导入webdriver子模块
from selenium import webdriver 获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程-定位方法部分第三章(第一版可在百度文库阅读)结合正则表达式过滤相关资料
定位后有些元素是不需要的,有规律的过滤掉即可。比如我想只提取英文字符(包括0-9),建立如下规律
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
打印结束会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话。前者只是关闭当前会话而不关闭浏览器的webdriver,后者关闭包括webdriver在内的所有东西并添加异常处理。
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
assert 0, "找不到元素"4. 代码实现
我通过点击打开链接抓取指定分区的每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线号,以及以列表的形式打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用它来实现数据挖掘和机器学习等深度研究。因此,selenium+python 是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。
抓取网页数据违法吗(与网络机器人的污名化,我们能做些什么污名?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-08 03:03
描述
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使 AI 是最美丽、最令人愉快的,也要提防它。此外,一些网络用户以不道德的方式使用网络机器人,甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗
有这么多信息要分析,很自然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,甚至可以自定义搜索以查看信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式采集用于研究或业务的有用信息的完美示例。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
有人认为人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分 AI 流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然不可避免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多优点,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改善公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
代理服务器旨在充当用户和 Web 服务器之间的中介。
多功能:个人和公司都可以使用代理服务器来满足特定需求。
代理的一个常见用途与网络抓取有关:使用代理服务器可以绕过网站 管理员设置的限制并采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“网络机器人”或“网络蜘蛛”)“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,用户将被限制访问网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
使用人类知名度和值得信赖的品牌来对抗人工智能的污名
目前,人工智能的发展速度确实已经超过了网民的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
大量普及人工智能。与其他人讨论如何以及为什么使用网页抓取,让人们对网页抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手动操作来手动访问网站数据可能让人放心,但由于信息太多,几乎不可能。可用数据的数量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。 查看全部
抓取网页数据违法吗(与网络机器人的污名化,我们能做些什么污名?)
描述
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使 AI 是最美丽、最令人愉快的,也要提防它。此外,一些网络用户以不道德的方式使用网络机器人,甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗
有这么多信息要分析,很自然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,甚至可以自定义搜索以查看信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式采集用于研究或业务的有用信息的完美示例。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
有人认为人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分 AI 流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然不可避免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多优点,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改善公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
代理服务器旨在充当用户和 Web 服务器之间的中介。
多功能:个人和公司都可以使用代理服务器来满足特定需求。
代理的一个常见用途与网络抓取有关:使用代理服务器可以绕过网站 管理员设置的限制并采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“网络机器人”或“网络蜘蛛”)“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,用户将被限制访问网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
使用人类知名度和值得信赖的品牌来对抗人工智能的污名
目前,人工智能的发展速度确实已经超过了网民的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
大量普及人工智能。与其他人讨论如何以及为什么使用网页抓取,让人们对网页抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手动操作来手动访问网站数据可能让人放心,但由于信息太多,几乎不可能。可用数据的数量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。
抓取网页数据违法吗(2019年上半年微信发布基于小程序页面的搜索(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-05 15:22
2019年上半年,微信发布了基于小程序页面的搜索。为了让我们更好地发现和理解小程序页面,结合过去一段时间我们遇到的各种情况,强烈建议开发者花一些宝贵的时间仔细阅读本文:)
当爬虫访问小程序中的页面时,会携带具体的用户代理“mpcrawler”和场景值:1129
1. 小程序中的重定向页面(url)可以直接打开。
小程序页面中的重定向URL是我们爬虫找到页面的重要来源,搜索引擎召回的结果页面(url)必须能够直接打开,不依赖上下文状态。特别:建议url中收录页面需要的参数
2. 导航组件优先用于页面跳转。
小程序提供了两种页面路由方式:
a.navigator 组件
湾 路由API,包括navigateTo/redirectTo/switchTab/navigateBack/reLaunch
推荐使用导航组件。如果非要使用API,可以屏蔽爬虫访问时为点击设置的时间锁或变量锁。
3.清晰简洁的页面参数。
一个结构清晰、简洁、参数有意义的查询字符串对爬取和后续分析很有帮助,但使用JSON数据作为参数的方式实现效果不佳。
4. 仅在必要时要求用户授权、登录、绑定手机号等。
建议仅在必要时请求用户授权(例如,您可以匿名阅读文章,发表评论需要留下您的姓名)。
5. 我们不收录 网络视图中的任何内容。
我们暂时不能这样做,从长远来看,我们也可能做不到。
6. 使用sitemap配置引导爬虫爬取,同时屏蔽没有搜索价值的路径。
7. 设置清晰的标题和页面缩略图。
页面标题和缩略图在理解页面和提高曝光转化率方面起着重要作用。
通过 wx.setNavigationBarTitle 或自定义转发内容 onShareAppMessage 设置页面的标题和缩略图,同时为视频和音频组件补充海报/poster-for-crawler 属性。
8. 使用页面路径推送能力
可以大大丰富微信上可以收录的内容,从而增加小程序内容的曝光机会。请参考: 查看全部
抓取网页数据违法吗(2019年上半年微信发布基于小程序页面的搜索(组图))
2019年上半年,微信发布了基于小程序页面的搜索。为了让我们更好地发现和理解小程序页面,结合过去一段时间我们遇到的各种情况,强烈建议开发者花一些宝贵的时间仔细阅读本文:)
当爬虫访问小程序中的页面时,会携带具体的用户代理“mpcrawler”和场景值:1129
1. 小程序中的重定向页面(url)可以直接打开。
小程序页面中的重定向URL是我们爬虫找到页面的重要来源,搜索引擎召回的结果页面(url)必须能够直接打开,不依赖上下文状态。特别:建议url中收录页面需要的参数
2. 导航组件优先用于页面跳转。
小程序提供了两种页面路由方式:
a.navigator 组件
湾 路由API,包括navigateTo/redirectTo/switchTab/navigateBack/reLaunch
推荐使用导航组件。如果非要使用API,可以屏蔽爬虫访问时为点击设置的时间锁或变量锁。
3.清晰简洁的页面参数。
一个结构清晰、简洁、参数有意义的查询字符串对爬取和后续分析很有帮助,但使用JSON数据作为参数的方式实现效果不佳。
4. 仅在必要时要求用户授权、登录、绑定手机号等。
建议仅在必要时请求用户授权(例如,您可以匿名阅读文章,发表评论需要留下您的姓名)。
5. 我们不收录 网络视图中的任何内容。
我们暂时不能这样做,从长远来看,我们也可能做不到。
6. 使用sitemap配置引导爬虫爬取,同时屏蔽没有搜索价值的路径。
7. 设置清晰的标题和页面缩略图。
页面标题和缩略图在理解页面和提高曝光转化率方面起着重要作用。
通过 wx.setNavigationBarTitle 或自定义转发内容 onShareAppMessage 设置页面的标题和缩略图,同时为视频和音频组件补充海报/poster-for-crawler 属性。
8. 使用页面路径推送能力
可以大大丰富微信上可以收录的内容,从而增加小程序内容的曝光机会。请参考:
抓取网页数据违法吗(网络爬虫(又被称为网页蜘蛛)(purposeEngine))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-03 15:14
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区,更常见的是网络追逐)是3233363533e58685e5aeb9333,一种按照一定规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义信息的查询。
网络爬虫
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。 查看全部
抓取网页数据违法吗(网络爬虫(又被称为网页蜘蛛)(purposeEngine))
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区,更常见的是网络追逐)是3233363533e58685e5aeb9333,一种按照一定规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。

随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。

(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义信息的查询。
网络爬虫
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
1 关注爬虫工作原理及关键技术概述

网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-01 16:06
)
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看它,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫也迫不及待地每秒命中 12306 数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在且无法进行未经授权的访问以进行爬网
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
写在最后
查看全部
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称
)
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看它,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。

比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫也迫不及待地每秒命中 12306 数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在且无法进行未经授权的访问以进行爬网
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
写在最后

抓取网页数据违法吗( scrapy调度器的处理方法和处理的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-28 07:25
scrapy调度器的处理方法和处理的方法)
1.scrapy 框架有哪些组件/模块?
Scrapy Engine:这个引擎,负责Spider、ItemPipeline、Downloader、Scheduler之间的通讯、信号、数据传输!(它看起来像人体吗?)
Scheduler:负责接受引擎发送的请求,按照一定的方式排序,入队,等待Scrapy Engine请求,然后交给引擎。
Downloader:负责下载Scrapy Engine发送的所有Requests,并将得到的Responses返回给Scrapy Engine,交给Spiders进行处理。
Spiders:负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,将需要跟进的URL提交给引擎,再次进入Scheduler,
Item Pipeline:负责处理Spiders中获取到的Item,以及去重、持久化存储等处理(存储数据库,写入文件,总之就是用来保存数据的)
下载器中间件:可以将其视为可以自定义和扩展下载功能的组件
2. 简单说说scrapy的工作流程。
整个 Scrapy 的数据流:
程序运行时,
发动机:喂!蜘蛛,你想对付哪一只网站?
蜘蛛:我必须处理
引擎:给我第一个需要处理的网址。
蜘蛛:你的第一个 URL 是
发动机:喂!调度员,我有一个请求,请帮我整理一下队伍。
调度员:好的,正在处理中,请稍等。
发动机:喂!调度员,把你处理过的请求给我,
调度员:给你,这是我处理的请求
发动机:喂!下载器,你可以根据下载中间件的设置为我下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:对不起,这个请求的下载失败,然后引擎告诉调度器这个请求的下载失败,你记录下来,我们稍后再下载。)
发动机:喂!Spiders,这个是下载的东西,已经按照Spider中间件处理过,可以处理(注意!这里的响应默认是由def解析函数处理的)
蜘蛛:(处理完数据后需要跟进的网址),嗨!引擎,这是我需要跟进的URL,并将其响应交给函数def xxxx(self,responses)进行处理。这是我得到的物品。
发动机:喂!物品管道我这里有物品,你可以帮我处理!调度程序!这是我需要的网址。你可以替我处理。然后从第四步开始循环,直到得到你需要的信息,注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
3.Scrapy指纹去重原理和scrapy-redis去重原理?
Scrapy的去重原理流程:使用hash值并设置去重。首先创建一个fingerprint = set() 组合,然后使用sha1对象进行请求对象的信息汇总。汇总完成后,判断hash值是否在集合中。如果是,则返回 true。如果不是,则将其添加到集合中。
scrapy-redis的去重原理基本相同,只不过是持久化存储在redis共享数据库中。当请求的数据达到10亿以上时,此时会消耗内存。一个sha1会占用40字节 40G内存,大部分存储数据库都负担不起。这时候必须使用布隆过滤器。
4. 请简单介绍一下scrapy框架。
scrapy 是一个快速、高级的基于 Python 的网络爬虫框架,用于爬取网站并从页面中提取结构化数据。scrapy 使用 Twisted 异步网络库来处理网络通信。
5.为什么要使用scrapy框架?scrapy 框架的优点是什么?
更容易搭建大型爬虫项目
它异步处理请求并且速度非常快
它可以使用自动调节机构自动调节爬行速度
6.scrapy 如何实现分布式爬取?
可以借助scrapy_redis 类库来实现。
在分布式爬取中,会有一台主机和一台从机。其中,master为核心服务器,slave为具体爬虫服务器。
我们在主服务器上搭建了一个redis数据库,将要爬取的URL存放在redis数据库中。所有从爬虫服务器在爬取时都从redis数据库链接。由于scrapy_redis本身的队列机制,slave获取到的URL不会相互冲突,然后爬取的结果最终存储在数据库中。master的redis数据库也会存储爬取到的url的指纹,用于去重。相关代码可以在 dupefilter.py 文件中的 request_seen() 方法中找到。
重复问题:
dupefilter.py 中的源代码:
def request_seen(self, request):
fp = request_fingerprint(请求)
添加 = self.server.sadd(self.key, fp)
退货未添加
重复数据删除是通过将请求的指纹存储在 redis 上来实现的。
7.scrapy 和 requests 是如何使用的?
请求采用轮询方式,会被网络阻塞,不适合爬取大量数据
scapy底层是twisted的异步框架,并发是最大优势
8. 爬虫使用多线程是不是更好?有多个进程是否更好?为什么?
对于IO密集型代码(文件处理、网络爬虫),多线程可以有效提高效率(单线程IO操作会等待IO,造成不必要的等待时间。开启多线程后,当线程A正在等待,会自动切换到线程B,这样就不会浪费CPU资源,从而提高程序执行的效率)。
在实际的采集进程中,不仅需要考虑网速和相应的问题,还需要考虑自己机器的硬件,设置多进程或多线程。
9. 基于爬虫的模块有哪些?
网络请求:urllib、requests、aiohttp
数据分析:re、xpath、bs4、pyquery
硒
js反向:pyexcJs
10. 爬行过程中遇到的比较难的防爬机制有哪些?
动态加载的数据
动态改变请求参数
js加密
演戏
曲奇饼
11. 简述如何捕获动态加载的数据?
基于抓包工具的全局搜索
如果动态加载的数据是密文,全局搜索是不可搜索的
12.如何抓取手机数据?
fiddler,appnium,网络配置
13.如何抓取全站数据?
基于手动请求+递归分析发送
基于CrwalSpider(LinkExtractor,Rule)
14.如何提高爬取数据的效率?
使用框架
线程池,多任务异步协程
分散式
15. 列出你接触过的防攀爬机构?
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。这里只讨论数据采集部分。
一般来说,网站从三个方面进行反爬虫:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这些角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
1) 通过Headers反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源网站的防泄漏环节就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
2)基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。可以专门写一个爬虫来爬取网上公开的代理ip,检测后全部保存。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求几次就可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。一些存在逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求来绕过同一账号不能在短时间内多次发出相同请求的限制。
3) 动态页面反爬虫
以上情况大部分出现在静态页面上,还有一些网站,我们需要爬取的数据是通过ajax请求获取或者通过JavaScript生成的。首先使用 Firebug 或 HttpFox 来分析网络请求。
如果能找到ajax请求,分析出响应的具体参数和具体含义,就可以通过上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有些网站加密了ajax请求的所有参数。我们没有办法为我们需要的数据构造一个请求。这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,对接口参数进行加密。遇到这样的网站,就不能用上面的方法了。我使用selenium+phantomJS框架,调用浏览器内核,使用phantomJS执行js模拟人的操作,触发页面中的js脚本。从填表到点击按钮再到滚动页面,一切都可以模拟,无论具体的请求和响应过程,
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面是在一定程度上通过添加Headers来冒充浏览器),它是浏览器本身,phantomJS是一个没有界面的浏览器,但它不是控制浏览器的人。使用selenium+phantomJS可以做很多事情,比如识别point-and-touch(12306)或滑动验证码,页面表单的暴力破解等)。它还将在自动化渗透方面展示其才华,并且在未来也会这样做。提这个。
16.什么是深度优先和广度优先(优缺点)
默认情况下,scrapy 是深度优先。
深度优先:占用空间大,运行速度快。
广度优先:占用空间小,运行速度慢
17.你知道谷歌的无头浏览器吗?
无头浏览器是无头浏览器,没有界面的浏览器。既然是浏览器,它应该拥有浏览器应有的一切,但你看不到界面。
Python中selenium模块中的PhantomJS是无头浏览器(headless browser):它是一个基于QtWebkit的无头浏览器。
18. 说说Scrapy的优缺点。
优势:
scrapy 是异步的
使用更具可读性的 xpath 而不是常规
强大的统计和日志系统
同时抓取不同的 URL
支持shell模式,方便独立调试
编写中间件,方便编写一些统一的过滤器
通过管道存储在数据库中
缺点:基于python的爬虫框架,扩展性差
基于twisted框架,运行异常不会杀死反应器,异步框架出错后不会停止其他任务,数据错误难以检测。
19. 对于需要登录的网页,如何同时限制ip、cookie、session?
解决受限IP,可以使用代理IP地址池和服务器;如果动态抓取不适用,可以使用反编译的JS文件获取对应的文件,或者切换到其他平台(如手机)查看是否可以获取对应的json文件。
20. 验证码怎么解决?
1.输入类型验证码
解决方法:这是最简单的一种,只要你认清里面的内容,然后在输入框中填写即可。这种识别技术叫做OCR,这里推荐使用第三方Python库tesserocr。对于不受阴影影响的验证码,可以直接通过该库进行识别。但是对于背景嘈杂的验证码,直接识别率会很低。在这种情况下,我们需要先对图片进行处理,先对图片进行灰度化,然后进行二值化,然后再进行Recognition,这样识别率会大大提高。
验证码识别的大概步骤:
转换为灰度
去除背景噪音
图片分割
2.刷卡式验证码
解决方法:这种验证码稍微复杂一点,但是有相应的方法。我们直接想到的就是模拟人拖动验证码,点击按钮,然后看到缝隙的位置,最后将拼图拖到缝隙中完成验证的动作。
第一步:点击按钮。然后我们发现没有点击按钮的时候缝隙和拼图没有出现,只有点击后才出现,这为我们找到缝隙的位置提供了灵感。
步骤 2:拖动到间隙位置。我们知道应该把拼图拖到缝隙里,但是这个距离怎么用数值来表示呢?通过我们在第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图片的像素,设置一个参考值。如果某个位置的差异超过了参考值,那么我们就找到了两张图片的不同位置。当然,我们来自拼图的右侧。从侧面开始,从左到右,当你找到第一个不同的位置时结束。这个位置应该是gap的左边,所以我们可以用selenium拖动到这个位置。这里的另一个问题是如何自动保存这两张图片?在这里我们可以先找到这个标签,然后得到它的位置和大小,然后是顶部,底部,左侧,right = location['y'] ,location['y']+size['height']+location['x'] + size['width'],然后截图,最后把这四个位置填上一个切口。具体使用可以查看selenium文档,点击按钮剪出图片,点击再剪出图片。拖动时,需要模拟人的行为,先加速再减速。因为这种验证码有行为特征检测,一个人不可能做到匀速,否则会被判断为机器拖拽,所以不会通过验证。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
3.点击式图形验证和图标选择
图文验证:提醒用户点击图片中的同一个词进行文本验证。
图标选择:给定一组图片,根据需要单击其中一个或多个。借用识别所有东西来挡机器的难度。
这两个原理类似,只不过一个是给文字点击图片中的文字,另一个是给图片点击同一张图片。
这两种方法都不是特别好。他们只能使用第三方识别接口来识别相同的内容。推荐超级鹰,发送验证码,返回对应的点击坐标。然后用selenium模拟点击。获取图片的方法同上面的方法。
21.滑动验证码怎么破解?
破解核心思想:
1、如何确定滑块的滑动距离?
滑块的滑动距离,需要检测验证码图片的间隙位置
滑动距离=终点坐标-起点坐标
那么问题转化为我们需要截图,根据selenium中的position方法,进行一些坐标计算,得到我们需要的位置
2、我们如何获得坐标?
起点坐标:
程序每次运行,位置固定,滑块左边框距离验证码图片左边框6px
终点坐标:
每次程序运行时,位置都会发生变化,我们需要计算每个间隙的位置
如何计算终点,也就是缺口的位置?
让我给你举个例子。比如下面两张图片都是120x60的图片,一张是纯色图片,一张是带蓝线的图片(蓝线的位置是60px)。我现在让你通过程序确定蓝线的位置,你是怎么确定的?
回答:
遍历所有像素的颜色值,找到不同颜色值的点的位置,确定蓝线的位置
怎么理解这句话?大家点开我下面的图片,有没有发现图片是由一个像素组成的,一张120×60的图片,对应的像素是横轴120像素,纵轴60像素,我们需要遍历坐标两张图片并比较色值,从(0,0)(0,1)... to (120,60))),开始比较两者的色值图片,当颜色值不同时,我们可以返回位置
22. 数据是如何存储的?
以json格式存储到文本文件
这是最简单、最方便、最常用的存储方式。json 格式确保您在打开文件时可以直观地检查存储的数据。一行数据存储在一行中。这种方法适用于爬取数据量比较小的情况。,后续的阅读和分析也很方便。
保存到excel
如果爬取的数据很容易组织成表格形式,那么将其存储在excel中是一个不错的选择。打开excel后,观察数据更方便。Excel也可以做一些简单的操作。可以用xlwt写excel。有了这个库,你就可以用xlrd来读取excel了。和方法一一样,excel中存储的数据不要太多。另外,如果是多线程爬取,用多线程写excel是不可能的。这是一个限制。
存储到 sqlite
Sqlite不需要安装,它是一个零配置的数据库,比mysql轻很多。语法方面,只要懂mysql,操作sqlite就没有问题。当大量爬虫数据需要持久化存储,又懒得装mysql时,sqlite绝对是最好的选择,不多,不支持多进程读写,所以不适合多进程爬虫。
存储到mysql数据库
mysql 可以远程访问,sqlite 不能。这意味着您可以将数据存储在远程服务器主机上。当数据量非常大的时候,自然应该选择mysql而不是sqlite,但是无论是mysql还是sqlite,都必须在存储数据之前进行。必须先建表,根据要捕获的数据结构和内容定义字段。这是一个耐心和精力的问题。最后,如果你的时间不是很紧,想快速提高,最重要的是不要怕吃苦,建议你买这个价格@762459510,真的很好,很多人进步很快,你要不怕吃苦!可以去加进去看看~
存储到mongodb
我最喜欢no sql数据库的原因之一是不需要像关系数据库那样定义表结构,因为定义表结构很麻烦。判断字段的类型,varchar类型的数据也需要定义长度,你定义的小一点,过长的数据会被截断。
Mongodb 以文档的形式存储数据。可以使用pymongo库直接将数据以json格式写入mongodb。即使在同一个集合中,对数据的格式也没有要求,太灵活了。
刚刚捕获的数据通常需要进行第二次清理才能使用。如果使用关系型数据库存储数据,第一次需要定义表结构。清洗后,恐怕需要定义一个表结构来恢复清洗后的数据。收纳太麻烦。使用 mongodb 消除了重复定义表结构的过程。
23.如何处理cookie过期?
这时候需要自动更新cookie。如何自动更新cookies?这里将使用硒。
步骤1、 使用selenium自动登录获取cookie,并保存到文件中;
步骤2、 读取cookie,比较cookie的有效期,如果过期,重新执行步骤1;
步骤3、 请求其他网页时,填写cookie,维护登录状态。
24.Selenium 和 PhantomJS
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等主流浏览器。本工具主要功能包括:测试浏览器兼容性
——测试你的应用程序,看看它是否能在不同的浏览器和操作系统上运行良好。
它的功能是:
框架底层使用JavaScript模拟真实用户操作浏览器。测试脚本执行时,浏览器会根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户一样,站在最终用户的角度对应用进行测试。
尽管不同浏览器之间仍然存在细微的差异,但可以自动进行浏览器兼容性测试。
使用方便,可以使用Java、Python等语言编写用例脚本
也就是说,它可以像真人一样按照指令访问浏览器,比如打开网页、截屏等功能。
幻象
(新版本的selenium已经开始抛弃phantomjs,不过有时候我们可以单独使用它来做一些事情)它是一个基于webkit的无界面浏览器,可以将网站内容加载到内存中并执行页面各种脚本(比如js)。
25.如何判断网站是否更新? 查看全部
抓取网页数据违法吗(
scrapy调度器的处理方法和处理的方法)
1.scrapy 框架有哪些组件/模块?
Scrapy Engine:这个引擎,负责Spider、ItemPipeline、Downloader、Scheduler之间的通讯、信号、数据传输!(它看起来像人体吗?)
Scheduler:负责接受引擎发送的请求,按照一定的方式排序,入队,等待Scrapy Engine请求,然后交给引擎。
Downloader:负责下载Scrapy Engine发送的所有Requests,并将得到的Responses返回给Scrapy Engine,交给Spiders进行处理。
Spiders:负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,将需要跟进的URL提交给引擎,再次进入Scheduler,
Item Pipeline:负责处理Spiders中获取到的Item,以及去重、持久化存储等处理(存储数据库,写入文件,总之就是用来保存数据的)
下载器中间件:可以将其视为可以自定义和扩展下载功能的组件
2. 简单说说scrapy的工作流程。
整个 Scrapy 的数据流:
程序运行时,
发动机:喂!蜘蛛,你想对付哪一只网站?
蜘蛛:我必须处理
引擎:给我第一个需要处理的网址。
蜘蛛:你的第一个 URL 是
发动机:喂!调度员,我有一个请求,请帮我整理一下队伍。
调度员:好的,正在处理中,请稍等。
发动机:喂!调度员,把你处理过的请求给我,
调度员:给你,这是我处理的请求
发动机:喂!下载器,你可以根据下载中间件的设置为我下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:对不起,这个请求的下载失败,然后引擎告诉调度器这个请求的下载失败,你记录下来,我们稍后再下载。)
发动机:喂!Spiders,这个是下载的东西,已经按照Spider中间件处理过,可以处理(注意!这里的响应默认是由def解析函数处理的)
蜘蛛:(处理完数据后需要跟进的网址),嗨!引擎,这是我需要跟进的URL,并将其响应交给函数def xxxx(self,responses)进行处理。这是我得到的物品。
发动机:喂!物品管道我这里有物品,你可以帮我处理!调度程序!这是我需要的网址。你可以替我处理。然后从第四步开始循环,直到得到你需要的信息,注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
3.Scrapy指纹去重原理和scrapy-redis去重原理?
Scrapy的去重原理流程:使用hash值并设置去重。首先创建一个fingerprint = set() 组合,然后使用sha1对象进行请求对象的信息汇总。汇总完成后,判断hash值是否在集合中。如果是,则返回 true。如果不是,则将其添加到集合中。
scrapy-redis的去重原理基本相同,只不过是持久化存储在redis共享数据库中。当请求的数据达到10亿以上时,此时会消耗内存。一个sha1会占用40字节 40G内存,大部分存储数据库都负担不起。这时候必须使用布隆过滤器。
4. 请简单介绍一下scrapy框架。
scrapy 是一个快速、高级的基于 Python 的网络爬虫框架,用于爬取网站并从页面中提取结构化数据。scrapy 使用 Twisted 异步网络库来处理网络通信。
5.为什么要使用scrapy框架?scrapy 框架的优点是什么?
更容易搭建大型爬虫项目
它异步处理请求并且速度非常快
它可以使用自动调节机构自动调节爬行速度
6.scrapy 如何实现分布式爬取?
可以借助scrapy_redis 类库来实现。
在分布式爬取中,会有一台主机和一台从机。其中,master为核心服务器,slave为具体爬虫服务器。
我们在主服务器上搭建了一个redis数据库,将要爬取的URL存放在redis数据库中。所有从爬虫服务器在爬取时都从redis数据库链接。由于scrapy_redis本身的队列机制,slave获取到的URL不会相互冲突,然后爬取的结果最终存储在数据库中。master的redis数据库也会存储爬取到的url的指纹,用于去重。相关代码可以在 dupefilter.py 文件中的 request_seen() 方法中找到。
重复问题:
dupefilter.py 中的源代码:
def request_seen(self, request):
fp = request_fingerprint(请求)
添加 = self.server.sadd(self.key, fp)
退货未添加
重复数据删除是通过将请求的指纹存储在 redis 上来实现的。
7.scrapy 和 requests 是如何使用的?
请求采用轮询方式,会被网络阻塞,不适合爬取大量数据
scapy底层是twisted的异步框架,并发是最大优势
8. 爬虫使用多线程是不是更好?有多个进程是否更好?为什么?
对于IO密集型代码(文件处理、网络爬虫),多线程可以有效提高效率(单线程IO操作会等待IO,造成不必要的等待时间。开启多线程后,当线程A正在等待,会自动切换到线程B,这样就不会浪费CPU资源,从而提高程序执行的效率)。
在实际的采集进程中,不仅需要考虑网速和相应的问题,还需要考虑自己机器的硬件,设置多进程或多线程。
9. 基于爬虫的模块有哪些?
网络请求:urllib、requests、aiohttp
数据分析:re、xpath、bs4、pyquery
硒
js反向:pyexcJs
10. 爬行过程中遇到的比较难的防爬机制有哪些?
动态加载的数据
动态改变请求参数
js加密
演戏
曲奇饼
11. 简述如何捕获动态加载的数据?
基于抓包工具的全局搜索
如果动态加载的数据是密文,全局搜索是不可搜索的
12.如何抓取手机数据?
fiddler,appnium,网络配置
13.如何抓取全站数据?
基于手动请求+递归分析发送
基于CrwalSpider(LinkExtractor,Rule)
14.如何提高爬取数据的效率?
使用框架
线程池,多任务异步协程
分散式
15. 列出你接触过的防攀爬机构?
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。这里只讨论数据采集部分。
一般来说,网站从三个方面进行反爬虫:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这些角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
1) 通过Headers反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源网站的防泄漏环节就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
2)基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。可以专门写一个爬虫来爬取网上公开的代理ip,检测后全部保存。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求几次就可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。一些存在逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求来绕过同一账号不能在短时间内多次发出相同请求的限制。
3) 动态页面反爬虫
以上情况大部分出现在静态页面上,还有一些网站,我们需要爬取的数据是通过ajax请求获取或者通过JavaScript生成的。首先使用 Firebug 或 HttpFox 来分析网络请求。
如果能找到ajax请求,分析出响应的具体参数和具体含义,就可以通过上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有些网站加密了ajax请求的所有参数。我们没有办法为我们需要的数据构造一个请求。这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,对接口参数进行加密。遇到这样的网站,就不能用上面的方法了。我使用selenium+phantomJS框架,调用浏览器内核,使用phantomJS执行js模拟人的操作,触发页面中的js脚本。从填表到点击按钮再到滚动页面,一切都可以模拟,无论具体的请求和响应过程,
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面是在一定程度上通过添加Headers来冒充浏览器),它是浏览器本身,phantomJS是一个没有界面的浏览器,但它不是控制浏览器的人。使用selenium+phantomJS可以做很多事情,比如识别point-and-touch(12306)或滑动验证码,页面表单的暴力破解等)。它还将在自动化渗透方面展示其才华,并且在未来也会这样做。提这个。
16.什么是深度优先和广度优先(优缺点)
默认情况下,scrapy 是深度优先。
深度优先:占用空间大,运行速度快。
广度优先:占用空间小,运行速度慢
17.你知道谷歌的无头浏览器吗?
无头浏览器是无头浏览器,没有界面的浏览器。既然是浏览器,它应该拥有浏览器应有的一切,但你看不到界面。
Python中selenium模块中的PhantomJS是无头浏览器(headless browser):它是一个基于QtWebkit的无头浏览器。
18. 说说Scrapy的优缺点。
优势:
scrapy 是异步的
使用更具可读性的 xpath 而不是常规
强大的统计和日志系统
同时抓取不同的 URL
支持shell模式,方便独立调试
编写中间件,方便编写一些统一的过滤器
通过管道存储在数据库中
缺点:基于python的爬虫框架,扩展性差
基于twisted框架,运行异常不会杀死反应器,异步框架出错后不会停止其他任务,数据错误难以检测。
19. 对于需要登录的网页,如何同时限制ip、cookie、session?
解决受限IP,可以使用代理IP地址池和服务器;如果动态抓取不适用,可以使用反编译的JS文件获取对应的文件,或者切换到其他平台(如手机)查看是否可以获取对应的json文件。
20. 验证码怎么解决?
1.输入类型验证码
解决方法:这是最简单的一种,只要你认清里面的内容,然后在输入框中填写即可。这种识别技术叫做OCR,这里推荐使用第三方Python库tesserocr。对于不受阴影影响的验证码,可以直接通过该库进行识别。但是对于背景嘈杂的验证码,直接识别率会很低。在这种情况下,我们需要先对图片进行处理,先对图片进行灰度化,然后进行二值化,然后再进行Recognition,这样识别率会大大提高。
验证码识别的大概步骤:
转换为灰度
去除背景噪音
图片分割
2.刷卡式验证码
解决方法:这种验证码稍微复杂一点,但是有相应的方法。我们直接想到的就是模拟人拖动验证码,点击按钮,然后看到缝隙的位置,最后将拼图拖到缝隙中完成验证的动作。
第一步:点击按钮。然后我们发现没有点击按钮的时候缝隙和拼图没有出现,只有点击后才出现,这为我们找到缝隙的位置提供了灵感。
步骤 2:拖动到间隙位置。我们知道应该把拼图拖到缝隙里,但是这个距离怎么用数值来表示呢?通过我们在第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图片的像素,设置一个参考值。如果某个位置的差异超过了参考值,那么我们就找到了两张图片的不同位置。当然,我们来自拼图的右侧。从侧面开始,从左到右,当你找到第一个不同的位置时结束。这个位置应该是gap的左边,所以我们可以用selenium拖动到这个位置。这里的另一个问题是如何自动保存这两张图片?在这里我们可以先找到这个标签,然后得到它的位置和大小,然后是顶部,底部,左侧,right = location['y'] ,location['y']+size['height']+location['x'] + size['width'],然后截图,最后把这四个位置填上一个切口。具体使用可以查看selenium文档,点击按钮剪出图片,点击再剪出图片。拖动时,需要模拟人的行为,先加速再减速。因为这种验证码有行为特征检测,一个人不可能做到匀速,否则会被判断为机器拖拽,所以不会通过验证。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
3.点击式图形验证和图标选择
图文验证:提醒用户点击图片中的同一个词进行文本验证。
图标选择:给定一组图片,根据需要单击其中一个或多个。借用识别所有东西来挡机器的难度。
这两个原理类似,只不过一个是给文字点击图片中的文字,另一个是给图片点击同一张图片。
这两种方法都不是特别好。他们只能使用第三方识别接口来识别相同的内容。推荐超级鹰,发送验证码,返回对应的点击坐标。然后用selenium模拟点击。获取图片的方法同上面的方法。
21.滑动验证码怎么破解?
破解核心思想:
1、如何确定滑块的滑动距离?
滑块的滑动距离,需要检测验证码图片的间隙位置
滑动距离=终点坐标-起点坐标
那么问题转化为我们需要截图,根据selenium中的position方法,进行一些坐标计算,得到我们需要的位置
2、我们如何获得坐标?
起点坐标:
程序每次运行,位置固定,滑块左边框距离验证码图片左边框6px
终点坐标:
每次程序运行时,位置都会发生变化,我们需要计算每个间隙的位置
如何计算终点,也就是缺口的位置?
让我给你举个例子。比如下面两张图片都是120x60的图片,一张是纯色图片,一张是带蓝线的图片(蓝线的位置是60px)。我现在让你通过程序确定蓝线的位置,你是怎么确定的?
回答:
遍历所有像素的颜色值,找到不同颜色值的点的位置,确定蓝线的位置
怎么理解这句话?大家点开我下面的图片,有没有发现图片是由一个像素组成的,一张120×60的图片,对应的像素是横轴120像素,纵轴60像素,我们需要遍历坐标两张图片并比较色值,从(0,0)(0,1)... to (120,60))),开始比较两者的色值图片,当颜色值不同时,我们可以返回位置
22. 数据是如何存储的?
以json格式存储到文本文件
这是最简单、最方便、最常用的存储方式。json 格式确保您在打开文件时可以直观地检查存储的数据。一行数据存储在一行中。这种方法适用于爬取数据量比较小的情况。,后续的阅读和分析也很方便。
保存到excel
如果爬取的数据很容易组织成表格形式,那么将其存储在excel中是一个不错的选择。打开excel后,观察数据更方便。Excel也可以做一些简单的操作。可以用xlwt写excel。有了这个库,你就可以用xlrd来读取excel了。和方法一一样,excel中存储的数据不要太多。另外,如果是多线程爬取,用多线程写excel是不可能的。这是一个限制。
存储到 sqlite
Sqlite不需要安装,它是一个零配置的数据库,比mysql轻很多。语法方面,只要懂mysql,操作sqlite就没有问题。当大量爬虫数据需要持久化存储,又懒得装mysql时,sqlite绝对是最好的选择,不多,不支持多进程读写,所以不适合多进程爬虫。
存储到mysql数据库
mysql 可以远程访问,sqlite 不能。这意味着您可以将数据存储在远程服务器主机上。当数据量非常大的时候,自然应该选择mysql而不是sqlite,但是无论是mysql还是sqlite,都必须在存储数据之前进行。必须先建表,根据要捕获的数据结构和内容定义字段。这是一个耐心和精力的问题。最后,如果你的时间不是很紧,想快速提高,最重要的是不要怕吃苦,建议你买这个价格@762459510,真的很好,很多人进步很快,你要不怕吃苦!可以去加进去看看~
存储到mongodb
我最喜欢no sql数据库的原因之一是不需要像关系数据库那样定义表结构,因为定义表结构很麻烦。判断字段的类型,varchar类型的数据也需要定义长度,你定义的小一点,过长的数据会被截断。
Mongodb 以文档的形式存储数据。可以使用pymongo库直接将数据以json格式写入mongodb。即使在同一个集合中,对数据的格式也没有要求,太灵活了。
刚刚捕获的数据通常需要进行第二次清理才能使用。如果使用关系型数据库存储数据,第一次需要定义表结构。清洗后,恐怕需要定义一个表结构来恢复清洗后的数据。收纳太麻烦。使用 mongodb 消除了重复定义表结构的过程。
23.如何处理cookie过期?
这时候需要自动更新cookie。如何自动更新cookies?这里将使用硒。
步骤1、 使用selenium自动登录获取cookie,并保存到文件中;
步骤2、 读取cookie,比较cookie的有效期,如果过期,重新执行步骤1;
步骤3、 请求其他网页时,填写cookie,维护登录状态。
24.Selenium 和 PhantomJS
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等主流浏览器。本工具主要功能包括:测试浏览器兼容性
——测试你的应用程序,看看它是否能在不同的浏览器和操作系统上运行良好。
它的功能是:
框架底层使用JavaScript模拟真实用户操作浏览器。测试脚本执行时,浏览器会根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户一样,站在最终用户的角度对应用进行测试。
尽管不同浏览器之间仍然存在细微的差异,但可以自动进行浏览器兼容性测试。
使用方便,可以使用Java、Python等语言编写用例脚本
也就是说,它可以像真人一样按照指令访问浏览器,比如打开网页、截屏等功能。
幻象
(新版本的selenium已经开始抛弃phantomjs,不过有时候我们可以单独使用它来做一些事情)它是一个基于webkit的无界面浏览器,可以将网站内容加载到内存中并执行页面各种脚本(比如js)。
25.如何判断网站是否更新?
抓取网页数据违法吗(Web爬虫与网络爬虫(请记住,抓取与抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-26 20:31
抓取和抓取定义
在开始之前,让我们对互联网上的各种“草稿”和“爬虫”以及本文将使用的“草稿”和“爬虫”有一个正确的定义。
一般来说,有两种类型的划痕。有可能:
网页抓取
数据抓取
同样是爬行:
网络搜索
数据检索
现在,Web 和数据的定义已经很明确了,但是为了安全起见,Web 是可以在 Internet 上找到的任何东西,而数据是可以在任何地方找到的信息、统计数据和事实(不仅是互联网)。
在我们的文章中,我们将介绍什么是网络爬虫和网络爬虫(记住,数据爬虫和技术数据爬虫是一样的,只是它们不在网络上执行)。
正如我们的数据分析师告诉我们的那样,有几种方法可以将网络爬虫与网络抓取区分开来。所以请注意,我们将介绍一种区分它们的方法。你们中的一些人可能不同意我们的意见,不同意!在下面的评论中让我们知道您的想法,这是网络爬虫和网络抓取之间的主要区别!
现在我们已经摆脱困境,让我们跳到这里。
网络爬行和爬行 #2
什么是网络爬虫?
网络爬虫通常意味着从……你猜对了——在万维网上采集数据!传统上,要做很多工作,但不限于少量工作。爬虫将通过(或像蜘蛛一样爬行)许多不同的目标并点击它们。
根据我们的 Python 开发人员的说法,搜索器是“连接到网页并下载其内容的程序”。
他解释说,搜索器程序只是上网查找以下两件事:
用户正在搜索的数据
抓取更多目标
因此,如果我们尝试爬取一个真正的网站,过程将如下所示:
搜索器将转到您预定义的目标 –
发现产品页面
然后查找并下载产品数据(价格、标题、描述等)
但是,关于最后一点(我们已经方便地为您加粗了),我们将其从 YunCube 注释中排除,并将其称为划痕。
请花点时间在网络爬虫上查看他的完整文章。Cloud Cube 对网络爬虫的工作方式和爬虫的不同阶段做了详细的介绍,如果你从技术角度对此感兴趣,请查看他的个人博客。
什么是网络爬虫?
如果网络抓取意味着遍历和点击不同的目标,那么网络抓取就是您获取数据并下载的部分。网络爬虫就是知道先拿什么再拿(比如在网络爬虫/爬虫的情况下,通常可以爬取的是商品数据、价格、标题、描述等)。
因此,正如您可能已经采集到的,网络爬虫通常与爬虫同时运行。在进行网络爬虫时,您可以随时下载在线可用的信息。之后,您将过滤掉不需要的信息,并通过抓取仅选择您需要的信息。
但是,您可以在没有爬虫的帮助下手动爬网(尤其是在需要采集少量数据的情况下),而网络爬虫通常会伴随着爬虫来过滤掉不需要的信息。
网络爬行和爬行
所以,爬行和爬行——让我们梳理一下两者之间的所有主要区别,以清楚地了解两者:
运动的:
仅限网页抓取的“抓取”数据(获取所选数据并下载)。
仅限网络爬虫的“爬虫”数据(通过选定的目标)。
劳工:
网页抓取-可以手动完成,手工制作。
网络爬虫——只能使用爬虫代理(蜘蛛机器人)来完成。
重复数据删除:
网页抓取-重复数据删除并不总是必要的,因为它可以手动完成,因此规模较小。
网络爬虫——网上很多内容都是重复的,为了不采集太多重复的信息,爬虫会过滤掉这些数据。
综上所述
网络爬虫和网络爬虫的区别非常明显——爬虫会爬取互联网上的各种目标,就像蜘蛛爬行一样。一旦爬虫到达目标,就会被爬取——采集并下载选定目标的数据。返回搜狐查看更多 查看全部
抓取网页数据违法吗(Web爬虫与网络爬虫(请记住,抓取与抓取))
抓取和抓取定义
在开始之前,让我们对互联网上的各种“草稿”和“爬虫”以及本文将使用的“草稿”和“爬虫”有一个正确的定义。
一般来说,有两种类型的划痕。有可能:
网页抓取
数据抓取
同样是爬行:
网络搜索
数据检索
现在,Web 和数据的定义已经很明确了,但是为了安全起见,Web 是可以在 Internet 上找到的任何东西,而数据是可以在任何地方找到的信息、统计数据和事实(不仅是互联网)。
在我们的文章中,我们将介绍什么是网络爬虫和网络爬虫(记住,数据爬虫和技术数据爬虫是一样的,只是它们不在网络上执行)。
正如我们的数据分析师告诉我们的那样,有几种方法可以将网络爬虫与网络抓取区分开来。所以请注意,我们将介绍一种区分它们的方法。你们中的一些人可能不同意我们的意见,不同意!在下面的评论中让我们知道您的想法,这是网络爬虫和网络抓取之间的主要区别!
现在我们已经摆脱困境,让我们跳到这里。
网络爬行和爬行 #2
什么是网络爬虫?
网络爬虫通常意味着从……你猜对了——在万维网上采集数据!传统上,要做很多工作,但不限于少量工作。爬虫将通过(或像蜘蛛一样爬行)许多不同的目标并点击它们。
根据我们的 Python 开发人员的说法,搜索器是“连接到网页并下载其内容的程序”。
他解释说,搜索器程序只是上网查找以下两件事:
用户正在搜索的数据
抓取更多目标
因此,如果我们尝试爬取一个真正的网站,过程将如下所示:
搜索器将转到您预定义的目标 –
发现产品页面
然后查找并下载产品数据(价格、标题、描述等)
但是,关于最后一点(我们已经方便地为您加粗了),我们将其从 YunCube 注释中排除,并将其称为划痕。
请花点时间在网络爬虫上查看他的完整文章。Cloud Cube 对网络爬虫的工作方式和爬虫的不同阶段做了详细的介绍,如果你从技术角度对此感兴趣,请查看他的个人博客。
什么是网络爬虫?
如果网络抓取意味着遍历和点击不同的目标,那么网络抓取就是您获取数据并下载的部分。网络爬虫就是知道先拿什么再拿(比如在网络爬虫/爬虫的情况下,通常可以爬取的是商品数据、价格、标题、描述等)。
因此,正如您可能已经采集到的,网络爬虫通常与爬虫同时运行。在进行网络爬虫时,您可以随时下载在线可用的信息。之后,您将过滤掉不需要的信息,并通过抓取仅选择您需要的信息。
但是,您可以在没有爬虫的帮助下手动爬网(尤其是在需要采集少量数据的情况下),而网络爬虫通常会伴随着爬虫来过滤掉不需要的信息。
网络爬行和爬行
所以,爬行和爬行——让我们梳理一下两者之间的所有主要区别,以清楚地了解两者:
运动的:
仅限网页抓取的“抓取”数据(获取所选数据并下载)。
仅限网络爬虫的“爬虫”数据(通过选定的目标)。
劳工:
网页抓取-可以手动完成,手工制作。
网络爬虫——只能使用爬虫代理(蜘蛛机器人)来完成。
重复数据删除:
网页抓取-重复数据删除并不总是必要的,因为它可以手动完成,因此规模较小。
网络爬虫——网上很多内容都是重复的,为了不采集太多重复的信息,爬虫会过滤掉这些数据。
综上所述
网络爬虫和网络爬虫的区别非常明显——爬虫会爬取互联网上的各种目标,就像蜘蛛爬行一样。一旦爬虫到达目标,就会被爬取——采集并下载选定目标的数据。返回搜狐查看更多
抓取网页数据违法吗(“车来了”五名程序员爬取实时公交数据,竟构成犯罪行为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-23 23:33
编者按:本文来自微信公众号“”(ID:CSDNnews),作者郭锐。经 36kr 许可转载。
近日,一桩关于爬虫、反爬虫的官司又被推到了大众面前。
公共交通作为互联网从业者必备的通勤工具之一,是出行领域不可或缺的板块。实时公交APP也成为流行的应用场景。它们不仅可以为用户提供定位、公交路线查询等信息,还涉及路线规划、实时公交信息地理位置等服务。其中,“久美”和“车来了”是大众经常使用的两款实时公交出行APP。
《车来了》指使五名程序员爬取公交车实时数据,实为犯罪行为
2012 年 10 月,Kumicke 实时公共交通应用程序上线。Coolmic通过在公交车上安装定位器,获得了海量的实时公交车位置数据,具有定位精度高、实时误差小等明显优势,迅速吸引了大量的市场用户。目前,Komiike APP注册量超过5000万,日活跃用户超过400万。
但在2015年11月,为了提高市场占有率和信息查询的准确性,实时公交APP“Come Car”居然指导5名程序员和员工使用爬虫软件从Kumicco服务器获取公交行车信息。,到达时间等实时数据。
令人惊奇的是,这五位程序员的分工非常明确:一个负责编写爬虫软件程序;一个负责编写爬虫软件程序;一是负责不断改变爬虫软件程序中的IP地址以防止检测;一种是使用不同的IP地址和爬虫设置的程序向久美可发送数据请求;一个负责破解久美惠客户端的加密算法;破解失败后,另一名员工聘请其他公司的技术人员帮助破解加密系统,使爬虫得以顺利实施。这一系列的数据操作取得了显著成效,帮助《车来了》获得了Komiike的海量实时数据,每天可达3-400万条。
通过巨大的人力、时间和经济成本获得的信息被同行窃取,直接挤压了自身的竞争优势和交易机会。这怎么能让久美池和解呢?
一气之下,2016年久美惠将这辆车告上法庭。这场纠纷花了两年时间才最终敲定。今年5月,法院判决该车立即停止获取和使用Kumicco实时公交位置数据的不正当竞争行为,并赔偿其经济损失。
看到这里,大家最关心的问题是这五位程序员会不会被定罪?虽然在诉讼过程中,五名程序员和员工利用网络爬虫获取公交车辆实时信息的行为只是为了履行工作职责,而非谋取私利。但是,久美家后端服务器中存储的数据具有很大的商业价值。未经其许可,任何人不得非法获取本软件的后台数据并将其用于经营活动,须承担连带责任。
对此,中关村大数据联盟副秘书长陈新和先生告诉CSDN(ID:CSDNnews),“数据爬虫的非法边界一直是互联网争议的热点,尤其是在互联网时代。大数据。随着内容数据的价值越来越高,爬虫的侵权案件也越来越多。”身处其中的程序员很难置身于上级下达的“爬虫需求”之外,稍不留神就有可能进入游戏。
爬虫类犯罪的判决尚不明朗,仍处于灰色地带
事实上,爬行动物犯罪一直是一个难以界定的灰色地带。
网络爬虫是一种自动获取网络内容的程序。通常,这并不违法。例如,很多人使用百度搜索。除了其自营的百度知乎、百度百科等,几乎所有爬虫采集Down。作为一种技术,爬虫本身并不违法,所以大多数情况下你可以放心使用。一般来说,常见的爬取方法包括构造合理的HTTP请求头、设置cookies、降低访问频率、隐含输入字段值、使用代理等。
比如CSDN之前就有共享、、、、等应用数据爬取。但并不是所有的数据都有“爬行的机会”,陈新河说,“不许爬行,能不能越规越爬,能不能用技术手段越过封锁线……这些边球爬行者?很容易擦枪走火misfire。”-尤其是当网站明确声明禁止抓取采集或转载商业化时,或者网站声明机器人协议时。
机器人协议也叫爬虫协议、机器人协议,其全称是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面禁止爬取。
机器人协议是搜索引擎行业公认的商业道德,应予以遵守。
尽管如此,仍有无数“勇者”拼尽全力,包括熟悉的百度、360搜索、大众点评、今日头条等:
事实上,可以预见的是,由于目前监管法规不完善,还有不少鱼儿被遗漏。但是,随着数据价值的不断挖掘,未来爬虫侵权案件只会越来越多。
第三方网站如何应对日益猖獗的爬虫行为?
面对日益猖獗的爬虫行为,网站fang应该如何应对?
既然有“爬虫”,自然就会有“反爬虫”。网站一般使用的反爬虫技术可以分为四类:通过User-Agent控制访问,通过IP限制反爬虫,通过JS脚本阻止爬虫,通过robots.txt限制爬虫。
下面我们通过几个热门站点分析常见的反爬虫机制:
一、豆瓣
很多新手爬虫都会爬豆瓣练手,但豆瓣并没有完全开放。其反爬虫机制如下:
可见豆瓣是个很体贴的爬虫新手网站。爬虫只需要在代码中登录账号并减少并发数,然后随机延时等待一段时间,爬虫程序就不会被阻塞。
二、拉勾网
原来拉勾网的反爬虫机制没有现在这么严格,但是随着粉丝的增加,网站administrator增加了一些保护服务器的措施。网站反爬虫机制如下:
对于这种爬虫机制,爬虫只能使用IP代理池来突破。
三、汽车之家
汽车之家论坛的反爬虫机制比较先进。它使用前端页面自定义字体来实现反爬虫的技术手段。具体使用CSS3中的自定义字体模块,将自定义Web字体嵌入到指定的网页中。这导致在抓取论坛帖子的口碑时,在获取的返回文本中每隔几个单词就会出现一个乱码。
每次访问论坛页面时,字体保持不变,但字符编码发生变化。因此,爬虫需要根据每次访问动态解析字体文件。具体需要先访问爬取的页面,获取字体文件的动态访问地址,下载字体,读取JS渲染的文本内容,将里面的自定义字体代码替换为实际的文本代码,然后web页面可以恢复到页面上看到的内容。
......
然而,抗爬行动物并不是万能的。“以保护用户数据的名义,全面禁止基于数据垄断的爬取策略,也将受到数据经济时代新反垄断法的挑战。” 陈新河说。
程序员如何在数据爬取中“让路”?
但如果技术无罪,程序员应该有罪吗?上级吩咐写几行代码就莫名其妙被关起来了?可怕的是,他不仅丢脸,还无处倾诉。
在知乎上,也有很多关于爬虫犯罪的问题。在“爬虫合法还是非法?”的问题下 ()、知乎User@笔芯设计大师表示,爬虫开发者的道德自给和经营者的良心是避免触碰法律底线的根本:
我们周围的网络已经被各种网络爬虫密集覆盖。他们善恶不同,各有各的心思。作为爬虫开发者,在使用爬虫时如何避免进入游戏的厄运?
1.严格遵守网站设定的Robots协议;
2.在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问的网站的正常运行;
3.设置爬取策略时,要注意视频、音乐等可能构成作品的数据的编码和抓取,或者针对某些特定的网站批量抓取用户生成的内容;
4. 在使用和传播捕获的信息时,应对捕获的内容进行审查。如发现属于用户的个人信息、隐私或他人商业秘密,应及时予以制止和删除。
因此,面对上级危险的爬虫请求,程序员应该好好看看。
对于涉及法律风险的数据爬取需求,程序员最好在采集面前与上级深度聊一聊,与上级分担法律风险。如果对方仍然坚持采集,建议提前与公司签订免责协议,以免风险下降时被拉下水。
参考资料: 查看全部
抓取网页数据违法吗(“车来了”五名程序员爬取实时公交数据,竟构成犯罪行为)
编者按:本文来自微信公众号“”(ID:CSDNnews),作者郭锐。经 36kr 许可转载。
近日,一桩关于爬虫、反爬虫的官司又被推到了大众面前。
公共交通作为互联网从业者必备的通勤工具之一,是出行领域不可或缺的板块。实时公交APP也成为流行的应用场景。它们不仅可以为用户提供定位、公交路线查询等信息,还涉及路线规划、实时公交信息地理位置等服务。其中,“久美”和“车来了”是大众经常使用的两款实时公交出行APP。

《车来了》指使五名程序员爬取公交车实时数据,实为犯罪行为
2012 年 10 月,Kumicke 实时公共交通应用程序上线。Coolmic通过在公交车上安装定位器,获得了海量的实时公交车位置数据,具有定位精度高、实时误差小等明显优势,迅速吸引了大量的市场用户。目前,Komiike APP注册量超过5000万,日活跃用户超过400万。
但在2015年11月,为了提高市场占有率和信息查询的准确性,实时公交APP“Come Car”居然指导5名程序员和员工使用爬虫软件从Kumicco服务器获取公交行车信息。,到达时间等实时数据。
令人惊奇的是,这五位程序员的分工非常明确:一个负责编写爬虫软件程序;一个负责编写爬虫软件程序;一是负责不断改变爬虫软件程序中的IP地址以防止检测;一种是使用不同的IP地址和爬虫设置的程序向久美可发送数据请求;一个负责破解久美惠客户端的加密算法;破解失败后,另一名员工聘请其他公司的技术人员帮助破解加密系统,使爬虫得以顺利实施。这一系列的数据操作取得了显著成效,帮助《车来了》获得了Komiike的海量实时数据,每天可达3-400万条。
通过巨大的人力、时间和经济成本获得的信息被同行窃取,直接挤压了自身的竞争优势和交易机会。这怎么能让久美池和解呢?
一气之下,2016年久美惠将这辆车告上法庭。这场纠纷花了两年时间才最终敲定。今年5月,法院判决该车立即停止获取和使用Kumicco实时公交位置数据的不正当竞争行为,并赔偿其经济损失。
看到这里,大家最关心的问题是这五位程序员会不会被定罪?虽然在诉讼过程中,五名程序员和员工利用网络爬虫获取公交车辆实时信息的行为只是为了履行工作职责,而非谋取私利。但是,久美家后端服务器中存储的数据具有很大的商业价值。未经其许可,任何人不得非法获取本软件的后台数据并将其用于经营活动,须承担连带责任。
对此,中关村大数据联盟副秘书长陈新和先生告诉CSDN(ID:CSDNnews),“数据爬虫的非法边界一直是互联网争议的热点,尤其是在互联网时代。大数据。随着内容数据的价值越来越高,爬虫的侵权案件也越来越多。”身处其中的程序员很难置身于上级下达的“爬虫需求”之外,稍不留神就有可能进入游戏。
爬虫类犯罪的判决尚不明朗,仍处于灰色地带
事实上,爬行动物犯罪一直是一个难以界定的灰色地带。
网络爬虫是一种自动获取网络内容的程序。通常,这并不违法。例如,很多人使用百度搜索。除了其自营的百度知乎、百度百科等,几乎所有爬虫采集Down。作为一种技术,爬虫本身并不违法,所以大多数情况下你可以放心使用。一般来说,常见的爬取方法包括构造合理的HTTP请求头、设置cookies、降低访问频率、隐含输入字段值、使用代理等。
比如CSDN之前就有共享、、、、等应用数据爬取。但并不是所有的数据都有“爬行的机会”,陈新河说,“不许爬行,能不能越规越爬,能不能用技术手段越过封锁线……这些边球爬行者?很容易擦枪走火misfire。”-尤其是当网站明确声明禁止抓取采集或转载商业化时,或者网站声明机器人协议时。
机器人协议也叫爬虫协议、机器人协议,其全称是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面禁止爬取。
机器人协议是搜索引擎行业公认的商业道德,应予以遵守。
尽管如此,仍有无数“勇者”拼尽全力,包括熟悉的百度、360搜索、大众点评、今日头条等:
事实上,可以预见的是,由于目前监管法规不完善,还有不少鱼儿被遗漏。但是,随着数据价值的不断挖掘,未来爬虫侵权案件只会越来越多。
第三方网站如何应对日益猖獗的爬虫行为?
面对日益猖獗的爬虫行为,网站fang应该如何应对?
既然有“爬虫”,自然就会有“反爬虫”。网站一般使用的反爬虫技术可以分为四类:通过User-Agent控制访问,通过IP限制反爬虫,通过JS脚本阻止爬虫,通过robots.txt限制爬虫。
下面我们通过几个热门站点分析常见的反爬虫机制:
一、豆瓣
很多新手爬虫都会爬豆瓣练手,但豆瓣并没有完全开放。其反爬虫机制如下:
可见豆瓣是个很体贴的爬虫新手网站。爬虫只需要在代码中登录账号并减少并发数,然后随机延时等待一段时间,爬虫程序就不会被阻塞。
二、拉勾网
原来拉勾网的反爬虫机制没有现在这么严格,但是随着粉丝的增加,网站administrator增加了一些保护服务器的措施。网站反爬虫机制如下:
对于这种爬虫机制,爬虫只能使用IP代理池来突破。
三、汽车之家
汽车之家论坛的反爬虫机制比较先进。它使用前端页面自定义字体来实现反爬虫的技术手段。具体使用CSS3中的自定义字体模块,将自定义Web字体嵌入到指定的网页中。这导致在抓取论坛帖子的口碑时,在获取的返回文本中每隔几个单词就会出现一个乱码。
每次访问论坛页面时,字体保持不变,但字符编码发生变化。因此,爬虫需要根据每次访问动态解析字体文件。具体需要先访问爬取的页面,获取字体文件的动态访问地址,下载字体,读取JS渲染的文本内容,将里面的自定义字体代码替换为实际的文本代码,然后web页面可以恢复到页面上看到的内容。
......
然而,抗爬行动物并不是万能的。“以保护用户数据的名义,全面禁止基于数据垄断的爬取策略,也将受到数据经济时代新反垄断法的挑战。” 陈新河说。
程序员如何在数据爬取中“让路”?
但如果技术无罪,程序员应该有罪吗?上级吩咐写几行代码就莫名其妙被关起来了?可怕的是,他不仅丢脸,还无处倾诉。
在知乎上,也有很多关于爬虫犯罪的问题。在“爬虫合法还是非法?”的问题下 ()、知乎User@笔芯设计大师表示,爬虫开发者的道德自给和经营者的良心是避免触碰法律底线的根本:
我们周围的网络已经被各种网络爬虫密集覆盖。他们善恶不同,各有各的心思。作为爬虫开发者,在使用爬虫时如何避免进入游戏的厄运?
1.严格遵守网站设定的Robots协议;
2.在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问的网站的正常运行;
3.设置爬取策略时,要注意视频、音乐等可能构成作品的数据的编码和抓取,或者针对某些特定的网站批量抓取用户生成的内容;
4. 在使用和传播捕获的信息时,应对捕获的内容进行审查。如发现属于用户的个人信息、隐私或他人商业秘密,应及时予以制止和删除。
因此,面对上级危险的爬虫请求,程序员应该好好看看。
对于涉及法律风险的数据爬取需求,程序员最好在采集面前与上级深度聊一聊,与上级分担法律风险。如果对方仍然坚持采集,建议提前与公司签订免责协议,以免风险下降时被拉下水。
参考资料:
抓取网页数据违法吗(为什么80%的码农都做不了架构师?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-22 07:12
为什么可以将代码农民不是80%不能做建筑师? > > >
网站内容内容网网是是技术技术技术技术技术类类文类文文文文文文文文文文文文文文文文文文文类文文文文文文文类文类类
1,通过正则表达式提取,(x)的HTML文件是一个文本文件,直接使用正则表达式来提取在指定地点的内容,“指定位置”不一定是绝对定位,例如,你可以参考HTML标签的定位,更准确
2,使用DOM,XML,的XPath,XSLT提取,(x)的HTML文件中的第一转成DOM数据结构,然后使用XPath这个结构来提取内容或使用XSLT传递给提取数据。
HTML文件本身是一个结构的文件。文档中的文本内容被封闭在许多标签(标签,HTML元素),构成HTML文档的结构。当在浏览器中显示,首先结构的文本文件转换成DOM数据结构。例如,一些必要的纠错,例如,在某些HTML文件的标签不是封闭的,只有开始标记,没有结束标记,需要生成DOM结构之前纠正这些错误。因此,如果简单地使用的正则表达式的方法,这些结构化信息没有很好的利用。与此相反,在第二数据提取方法利用了这些结构信息的优点,并且模块化编程方法可以大大提高了编程效率并减少该程序的错误,例如,使用XSLT XSL:模板,写一个数据格式转换和提取模块的。然而,XSL语言也变得更复杂。本文只解释了XSLT的使用技巧:在提取HTML页面的一块内容,但过滤掉一些不需要的模块。所述图像是一个页的大的块是害怕,但它们中的一些小片挖掘。
使用XSL:复制 - 的 - ,你可以复制HTML的整个数字,但如果你想挖了一些这个领域的,你需要一些技巧。您可以使用XSL:复制,XSL:只复制只提取当前节点,和XSL:复制,是提取当前节点及其subtocks和递归调用。用XSL:COPY,可以自定义递归调用类似于XSL过程:COPY-的其中OF-的,和节点可以任意期间递归调用控制
在即将到来的网页捕获/数据提取/信息提取软件套件Metaseeker的最新版本将提取规则定义的方法扩展到3:
1,通过软件完全生成;
2,用户可以指定用于使用所述XPath表达式的特定信息的属性的定位规则;
3,用户可以定义其自己的XSLT提取片段。
要实现上述需求,需要使用第三方法,以限定一个XSL:模板,例如,如下所示的模板
用于提取任务描述信息从一个自由职业者计划(自由出价与外包项目)网站,仅提取节点,例如,HTML元素和文本,而不是提取节点属性,例如,@类等时,节点将要过滤的需求与空模板实现,并且接下来的四个是其样的动作
把在网络上抓取/数据提取/信息提取软件工具包模板段如上所定义Metaseeker的BUCKET EDIT表的BUCKET EDIT表的输入框,可以自动在指令文件中嵌入自动生成的信息提取。 查看全部
抓取网页数据违法吗(为什么80%的码农都做不了架构师?(图))
为什么可以将代码农民不是80%不能做建筑师? > > >

网站内容内容网网是是技术技术技术技术技术类类文类文文文文文文文文文文文文文文文文文文文类文文文文文文文类文类类
1,通过正则表达式提取,(x)的HTML文件是一个文本文件,直接使用正则表达式来提取在指定地点的内容,“指定位置”不一定是绝对定位,例如,你可以参考HTML标签的定位,更准确
2,使用DOM,XML,的XPath,XSLT提取,(x)的HTML文件中的第一转成DOM数据结构,然后使用XPath这个结构来提取内容或使用XSLT传递给提取数据。
HTML文件本身是一个结构的文件。文档中的文本内容被封闭在许多标签(标签,HTML元素),构成HTML文档的结构。当在浏览器中显示,首先结构的文本文件转换成DOM数据结构。例如,一些必要的纠错,例如,在某些HTML文件的标签不是封闭的,只有开始标记,没有结束标记,需要生成DOM结构之前纠正这些错误。因此,如果简单地使用的正则表达式的方法,这些结构化信息没有很好的利用。与此相反,在第二数据提取方法利用了这些结构信息的优点,并且模块化编程方法可以大大提高了编程效率并减少该程序的错误,例如,使用XSLT XSL:模板,写一个数据格式转换和提取模块的。然而,XSL语言也变得更复杂。本文只解释了XSLT的使用技巧:在提取HTML页面的一块内容,但过滤掉一些不需要的模块。所述图像是一个页的大的块是害怕,但它们中的一些小片挖掘。
使用XSL:复制 - 的 - ,你可以复制HTML的整个数字,但如果你想挖了一些这个领域的,你需要一些技巧。您可以使用XSL:复制,XSL:只复制只提取当前节点,和XSL:复制,是提取当前节点及其subtocks和递归调用。用XSL:COPY,可以自定义递归调用类似于XSL过程:COPY-的其中OF-的,和节点可以任意期间递归调用控制
在即将到来的网页捕获/数据提取/信息提取软件套件Metaseeker的最新版本将提取规则定义的方法扩展到3:
1,通过软件完全生成;
2,用户可以指定用于使用所述XPath表达式的特定信息的属性的定位规则;
3,用户可以定义其自己的XSLT提取片段。
要实现上述需求,需要使用第三方法,以限定一个XSL:模板,例如,如下所示的模板
用于提取任务描述信息从一个自由职业者计划(自由出价与外包项目)网站,仅提取节点,例如,HTML元素和文本,而不是提取节点属性,例如,@类等时,节点将要过滤的需求与空模板实现,并且接下来的四个是其样的动作
把在网络上抓取/数据提取/信息提取软件工具包模板段如上所定义Metaseeker的BUCKET EDIT表的BUCKET EDIT表的输入框,可以自动在指令文件中嵌入自动生成的信息提取。
抓取网页数据违法吗(“爬虫”是怎么抢张便宜机票的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-21 14:02
不到两个月,2018年春节即将到来
在北京工作的小王告诉《科技日报》,由于他的家乡在云南,春节的门票太贵,他选择花两天两夜的时间去“k6”返程,进行长途旅行
然而,就在小王准备买便宜票的时候,他在网上看到了这样一个消息:航空公司发行的低价机票中,80%以上被票务公司的“爬虫”抢走,普通用户很少能买到
小王很傻。“爬行动物”到底是什么?它是怎么抢票的?难道没有办法治理吗
抓取收录超链接信息的网页
爬虫技术是实现网络信息的关键技术之一采集.一般来说,“爬虫”是一种用于批量和自动化“采集 网站数据”的程序,几乎不需要人工干预,“北京工业大学网络科学与技术研究所副教授闫怀志说。他告诉《科技日报》
阎怀志介绍,“爬虫”又称网页“蜘蛛”和网络机器人,是一种根据一定规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录供用户阅读的文本、图片等信息,还收录一些超链接信息。网络“爬虫”借助这些超链接信息不断地抓取网络上的其他网页
“这类信息采集过程非常像一个在互联网上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’被命名。”阎怀志说,“爬虫”最早应用于搜索引擎领域,如谷歌、百度、搜狗等搜索引擎工具。他们每天需要在互联网上捕获数百亿个网页,需要借助巨大的“爬虫”集群来实现搜索功能
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以在航空公司的官方网站上获取机票价格。“爬虫”在发现低价或紧俏的客票后,可以利用虚假客源的真实身份信息进行抢先预订。此外,许多互联网浏览器都推出了自己的机票抓取插件,以推广机票预订成功率高的浏览器
根据爬行任务和目标的不同,网络“爬行器”大致可分为批量型、增量型和垂直型。批量“爬虫”的捕获范围和目标比较明确,可以是设置的网页数量,也可以是设置的时间消耗。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于特定主题内容或行业特定网页
“爬虫”是怎么弄到票的
此前,携程的“反爬虫”专家在技术分享中透露,某个网站页面每分钟的浏览量为1.2只有500个真正的用户,“爬虫”流量的比例是95.8%
采访中,不少业内人士还表示,即使在“爬虫”活动淡季,虚假流量也占网站总预订流量的50%,峰值超过90%
那么,“爬行动物”是如何实现抢票的呢?对此,严怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断捕捉航空公司机票销售官网的网站信息。如果发现航空公司已经发行低价机票,“爬虫”会立即使用虚假的客源身份进行批量预订而不是实际付款,从而达到抢占低价机票客源的目的。因为“爬虫”的效率远远高于正常的手动操作,所以通过正常操作几乎不可能抓到车票
然后,机票代理商将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客源,在航空公司允许的账户期限内退订之前以虚假客源身份预订的低价机票,然后利用真实身份信息进行订购,最终实现低价机票的涨价转售
如果在航空公司规定的会计期间内未找到真实客源,票务代理将在订单到期前添加虚假身份订单,并继续“占用”低价机票,以此类推,直到找到并出售真实客源
“上述操作流程构成了一个完整的门票销售链。在这个过程中,航空公司的票务系统允许在会计期间内重复预订和退款,这有助于票务代理使用“爬虫”抓取机票并提高价格以获取利润。这种抢票方式被称为技术上的“黄牛党”。”阎怀志强调
的确,一些业内人士表示,这些“爬虫”流量在没有任何消耗的情况下消耗了大量的机器资源,这是每个公司最痛恨的。但是,由于担心误伤真实用户,各公司的“反爬虫”策略非常谨慎
“爬行动物”可以通过某种手段加以预防和控制
任何事物都有两面性,“爬虫”技术也不例外
阎怀志认为,“爬虫”不仅可以为正常批量数据采集提供有效的技术手段,还可以被恶意利用以获取不当利益,如果“爬虫”技术使用不当,将带来一定的危害
首先,威胁数据安全。机票网站数据被恶意爬网,可能被机票代理恶意使用,并且存在被同行获取的风险
其次,它会导致系统性能下降,影响用户体验“将导致航空票务网站服务器的资源负载增加和性能下降,网站响应速度较慢甚至无法提供服务,这将对用户的搜索和交易体验产生负面影响。然而,由于巨大的灰色利益空间和“反爬虫”技术在反“爬虫”斗争中的有限作用,这种明显不公平的“作弊”方式已成为扰乱票务市场秩序的技术“顽疾”
“从技术角度来看,拦截‘爬虫’可以通过网站流量统计系统和服务器访问日志分析系统。”阎怀志说,通过流量统计和日志分析,如果发现单次IP访问、单次会话访问和用户代理信息超过设定的正常频率阈值,将判断访问是由恶意“爬虫程序”引起的,并且“爬虫程序”将被删除。您的IP被列入黑名单以拒绝后续访问
然后设置各种访问验证链接。例如,如果存在可疑的IP访问,请返回验证页面,并要求访问者通过填写验证代码并选择验证图片或字符进行验证。如果是恶意“爬虫”,显然很难完成上述验证操作,那么可以阻止“爬虫”的访问,防止其恶意抓取信息
互联网空间不能有“灰色区域”
目前,以云计算和大数据为代表的新一代信息技术正处于快速发展阶段
严怀志说:“如果上述新技术被非法或不当应用,将造成严重危害。互联网空间安全需要建立健全完善的保护体系,绝不能‘裸奔’。”
2017年6月1日,中国《网络安全法》正式实施,明确了网络安全各方的权利和责任。这是中国网络空间治理和法制建设从量变到质变的重要里程碑。作为依法治理互联网、化解网络风险的法律工具,该法已成为中国互联网在法治轨道上健康运行的重要保障
但是,目前对高科技“黄牛”的倒票行为没有明确规定,使得恶意抓取信息和不当牟利行为处于法律法规监管的“灰色地带”
阎怀志介绍,国际上专门为“爬虫”应用制定了机器人协议(即爬虫协议、网络机器人协议等)。该协议的全称为“网络爬虫排除标准”网站它可以告诉“爬虫”哪些页面和信息可以爬网,哪些页面和信息不能爬网。作为网站与“爬虫”的沟通方式,该协议用于规范“爬虫”行为和限制不正当竞争
作为国际互联网界通行的道德规范,该协议的原则是“爬虫”和搜索技术应服务于人类,尊重信息提供者的意愿并保护其隐私网站有义务保护其用户的个人信息和隐私。这规定了爬虫程序和被爬虫程序的权利和义务
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要依靠技术防范和行业自律,还要通过改善管理、法律法规,特别是法律手段来限制这种行为,以显示惩罚和威慑的力量。航空公司 查看全部
抓取网页数据违法吗(“爬虫”是怎么抢张便宜机票的?(图))
不到两个月,2018年春节即将到来
在北京工作的小王告诉《科技日报》,由于他的家乡在云南,春节的门票太贵,他选择花两天两夜的时间去“k6”返程,进行长途旅行
然而,就在小王准备买便宜票的时候,他在网上看到了这样一个消息:航空公司发行的低价机票中,80%以上被票务公司的“爬虫”抢走,普通用户很少能买到
小王很傻。“爬行动物”到底是什么?它是怎么抢票的?难道没有办法治理吗
抓取收录超链接信息的网页
爬虫技术是实现网络信息的关键技术之一采集.一般来说,“爬虫”是一种用于批量和自动化“采集 网站数据”的程序,几乎不需要人工干预,“北京工业大学网络科学与技术研究所副教授闫怀志说。他告诉《科技日报》
阎怀志介绍,“爬虫”又称网页“蜘蛛”和网络机器人,是一种根据一定规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录供用户阅读的文本、图片等信息,还收录一些超链接信息。网络“爬虫”借助这些超链接信息不断地抓取网络上的其他网页
“这类信息采集过程非常像一个在互联网上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’被命名。”阎怀志说,“爬虫”最早应用于搜索引擎领域,如谷歌、百度、搜狗等搜索引擎工具。他们每天需要在互联网上捕获数百亿个网页,需要借助巨大的“爬虫”集群来实现搜索功能
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以在航空公司的官方网站上获取机票价格。“爬虫”在发现低价或紧俏的客票后,可以利用虚假客源的真实身份信息进行抢先预订。此外,许多互联网浏览器都推出了自己的机票抓取插件,以推广机票预订成功率高的浏览器
根据爬行任务和目标的不同,网络“爬行器”大致可分为批量型、增量型和垂直型。批量“爬虫”的捕获范围和目标比较明确,可以是设置的网页数量,也可以是设置的时间消耗。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于特定主题内容或行业特定网页
“爬虫”是怎么弄到票的
此前,携程的“反爬虫”专家在技术分享中透露,某个网站页面每分钟的浏览量为1.2只有500个真正的用户,“爬虫”流量的比例是95.8%
采访中,不少业内人士还表示,即使在“爬虫”活动淡季,虚假流量也占网站总预订流量的50%,峰值超过90%
那么,“爬行动物”是如何实现抢票的呢?对此,严怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断捕捉航空公司机票销售官网的网站信息。如果发现航空公司已经发行低价机票,“爬虫”会立即使用虚假的客源身份进行批量预订而不是实际付款,从而达到抢占低价机票客源的目的。因为“爬虫”的效率远远高于正常的手动操作,所以通过正常操作几乎不可能抓到车票
然后,机票代理商将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客源,在航空公司允许的账户期限内退订之前以虚假客源身份预订的低价机票,然后利用真实身份信息进行订购,最终实现低价机票的涨价转售
如果在航空公司规定的会计期间内未找到真实客源,票务代理将在订单到期前添加虚假身份订单,并继续“占用”低价机票,以此类推,直到找到并出售真实客源
“上述操作流程构成了一个完整的门票销售链。在这个过程中,航空公司的票务系统允许在会计期间内重复预订和退款,这有助于票务代理使用“爬虫”抓取机票并提高价格以获取利润。这种抢票方式被称为技术上的“黄牛党”。”阎怀志强调
的确,一些业内人士表示,这些“爬虫”流量在没有任何消耗的情况下消耗了大量的机器资源,这是每个公司最痛恨的。但是,由于担心误伤真实用户,各公司的“反爬虫”策略非常谨慎
“爬行动物”可以通过某种手段加以预防和控制
任何事物都有两面性,“爬虫”技术也不例外
阎怀志认为,“爬虫”不仅可以为正常批量数据采集提供有效的技术手段,还可以被恶意利用以获取不当利益,如果“爬虫”技术使用不当,将带来一定的危害
首先,威胁数据安全。机票网站数据被恶意爬网,可能被机票代理恶意使用,并且存在被同行获取的风险
其次,它会导致系统性能下降,影响用户体验“将导致航空票务网站服务器的资源负载增加和性能下降,网站响应速度较慢甚至无法提供服务,这将对用户的搜索和交易体验产生负面影响。然而,由于巨大的灰色利益空间和“反爬虫”技术在反“爬虫”斗争中的有限作用,这种明显不公平的“作弊”方式已成为扰乱票务市场秩序的技术“顽疾”
“从技术角度来看,拦截‘爬虫’可以通过网站流量统计系统和服务器访问日志分析系统。”阎怀志说,通过流量统计和日志分析,如果发现单次IP访问、单次会话访问和用户代理信息超过设定的正常频率阈值,将判断访问是由恶意“爬虫程序”引起的,并且“爬虫程序”将被删除。您的IP被列入黑名单以拒绝后续访问
然后设置各种访问验证链接。例如,如果存在可疑的IP访问,请返回验证页面,并要求访问者通过填写验证代码并选择验证图片或字符进行验证。如果是恶意“爬虫”,显然很难完成上述验证操作,那么可以阻止“爬虫”的访问,防止其恶意抓取信息
互联网空间不能有“灰色区域”
目前,以云计算和大数据为代表的新一代信息技术正处于快速发展阶段
严怀志说:“如果上述新技术被非法或不当应用,将造成严重危害。互联网空间安全需要建立健全完善的保护体系,绝不能‘裸奔’。”
2017年6月1日,中国《网络安全法》正式实施,明确了网络安全各方的权利和责任。这是中国网络空间治理和法制建设从量变到质变的重要里程碑。作为依法治理互联网、化解网络风险的法律工具,该法已成为中国互联网在法治轨道上健康运行的重要保障
但是,目前对高科技“黄牛”的倒票行为没有明确规定,使得恶意抓取信息和不当牟利行为处于法律法规监管的“灰色地带”
阎怀志介绍,国际上专门为“爬虫”应用制定了机器人协议(即爬虫协议、网络机器人协议等)。该协议的全称为“网络爬虫排除标准”网站它可以告诉“爬虫”哪些页面和信息可以爬网,哪些页面和信息不能爬网。作为网站与“爬虫”的沟通方式,该协议用于规范“爬虫”行为和限制不正当竞争
作为国际互联网界通行的道德规范,该协议的原则是“爬虫”和搜索技术应服务于人类,尊重信息提供者的意愿并保护其隐私网站有义务保护其用户的个人信息和隐私。这规定了爬虫程序和被爬虫程序的权利和义务
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要依靠技术防范和行业自律,还要通过改善管理、法律法规,特别是法律手段来限制这种行为,以显示惩罚和威慑的力量。航空公司
抓取网页数据违法吗(如何用Excel快速抓取网页数据?(图)大多需要编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-21 13:19
网站上的数据源是我们统计分析的重要信息源。在我们的生活中,我们经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这是非常重要的,也是数据分析相关工作的必要技能之一。但是大多数爬虫需要编程知识,这对于普通人来说是很难开始的。今天,我将解释如何使用Excel快速获取web数据
1、first open网站要捕获的数据并复制网站地址
2、创建新的EXCEL工作簿并单击“数据”菜单>;从“获取外部数据”选项卡中的网站选项
在弹出的“新建web查询”对话框中,在地址栏中输入要捕获的网站地址,然后单击“转到”
单击黄色导入箭头并选择要捕获的零件,如图所示。单击导入
3、选择数据存储位置(默认选择单元格),然后单击确定。通常建议将数据存储在“A1”单元格中
获取数据需要一些时间。请耐心等待
4、如果您希望excel工作簿数据根据网站数据自动实时更新,则需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等
获取数据后,需要对数据进行处理,而处理数据是一个更重要的环节。更多的数据处理技能,请注意我
如果它对您有帮助,请记住喜欢它并转发它
关注我,让我学习更多的Excel技能,让工作更轻松 查看全部
抓取网页数据违法吗(如何用Excel快速抓取网页数据?(图)大多需要编程)
网站上的数据源是我们统计分析的重要信息源。在我们的生活中,我们经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这是非常重要的,也是数据分析相关工作的必要技能之一。但是大多数爬虫需要编程知识,这对于普通人来说是很难开始的。今天,我将解释如何使用Excel快速获取web数据
1、first open网站要捕获的数据并复制网站地址
2、创建新的EXCEL工作簿并单击“数据”菜单>;从“获取外部数据”选项卡中的网站选项
在弹出的“新建web查询”对话框中,在地址栏中输入要捕获的网站地址,然后单击“转到”
单击黄色导入箭头并选择要捕获的零件,如图所示。单击导入
3、选择数据存储位置(默认选择单元格),然后单击确定。通常建议将数据存储在“A1”单元格中
获取数据需要一些时间。请耐心等待
4、如果您希望excel工作簿数据根据网站数据自动实时更新,则需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等
获取数据后,需要对数据进行处理,而处理数据是一个更重要的环节。更多的数据处理技能,请注意我
如果它对您有帮助,请记住喜欢它并转发它
关注我,让我学习更多的Excel技能,让工作更轻松
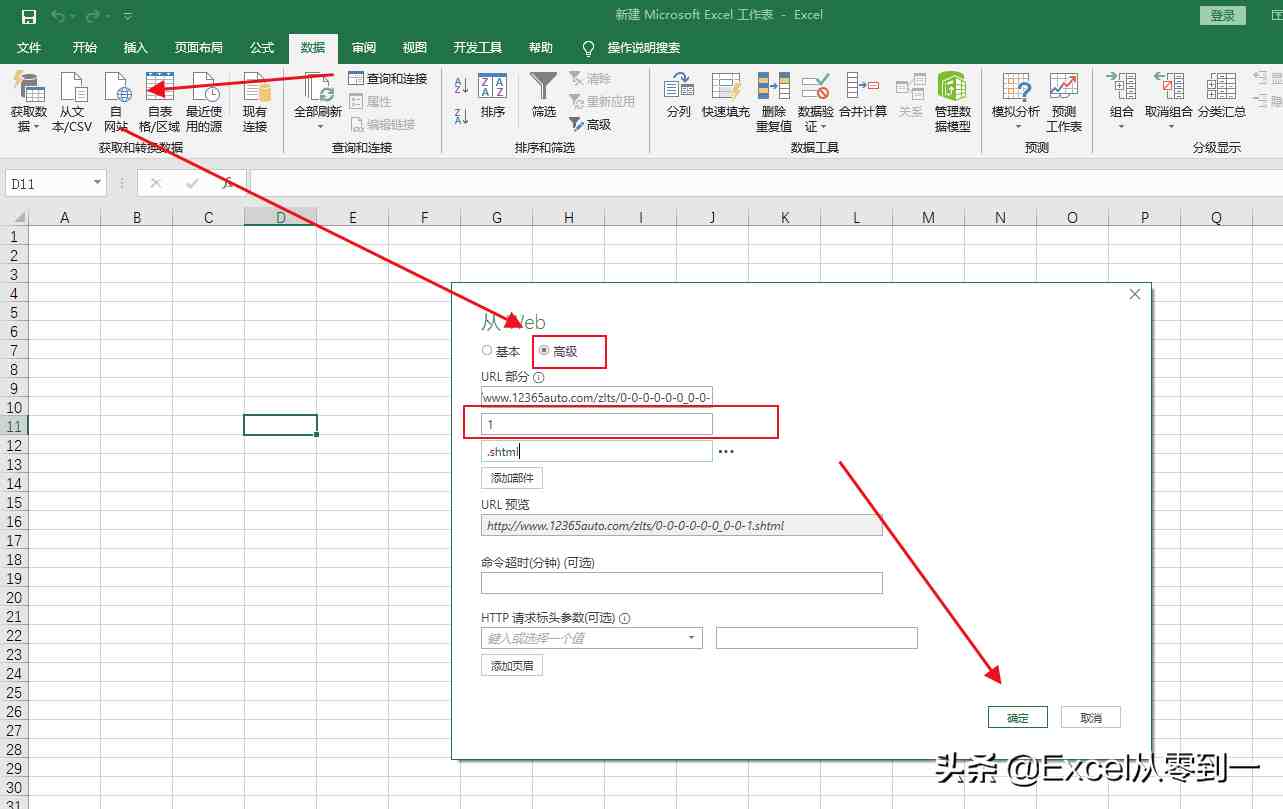
抓取网页数据违法吗( 如何批量的批量抓取网页中的数据,如下粉丝如何)
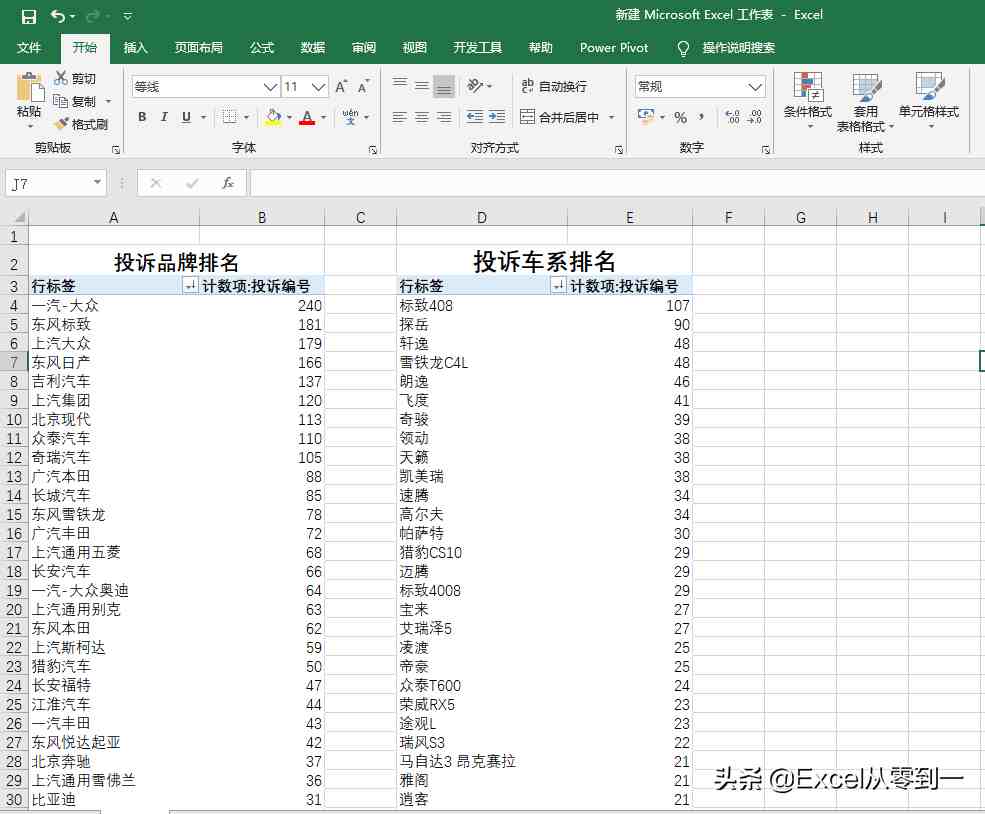
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-17 15:13
如何批量的批量抓取网页中的数据,如下粉丝如何)
数据捕获(大数据捕获客户软件)
大家好,今天我想和大家分享一下我们如何批量捕获网页中的数据,以捕获汽车投诉的数量。我想与您分享如何批量捕获网页中的数据。这也是一位粉丝提出的问题。他打算买一辆汽车,想看看各制造商的投诉数量。不要说太多。让我们直接开始吧。如果你进来是想了解来自不同制造商的投诉数量和投诉型号的排名,那就到此为止
一、分析页面
让我们以从到vehicle 的汽车投诉为例,向您展示如何批量捕获数据。如下图所示,从第1页到第3页都有网站。我们可以看到,只有红色的123,即对应的页码,是不同的,其余的都是相同的
二、grab数据
然后打开excel,单击数据功能组以查找self网站,单击高级选项,然后将代表页码的数字放在单独的输入框中。可以通过单击“添加零件”来添加输入框。设置完成后,我们直接点击OK
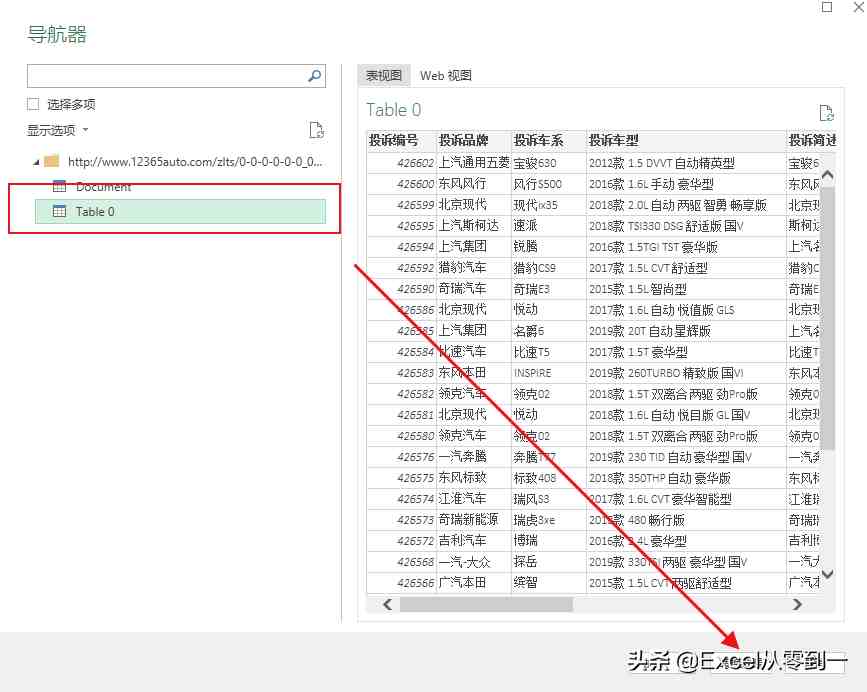
这样,我们将进入navigator界面。在此页面中,power query捕获了两个内容。我们可以点击查看我们需要的最佳数据。这里,表0是我们想要捕获的数据。直接选择table0,点击〖转换数据〗按钮,进入powerquery的编辑界面
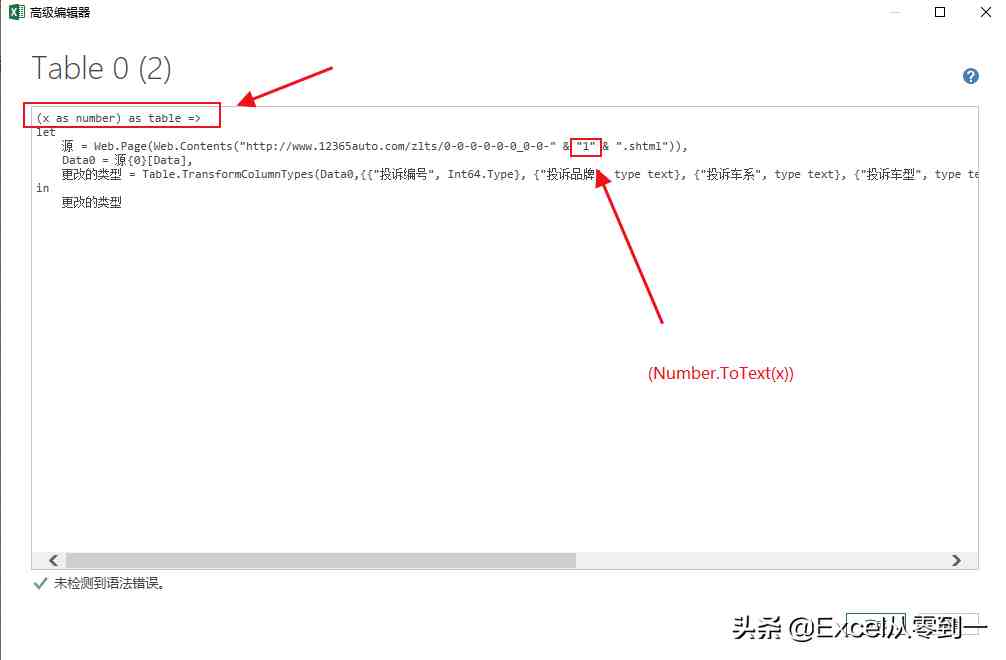
接下来,单击高级编辑器并输入(x作为数字)作为table=>;然后将网站中的“1”更改为(number.ToText(x))并单击完成
这样,我们将把前面的操作封装到一个函数中。我们只需要输入相应的号码,然后点击call跳转到相应页码的数据
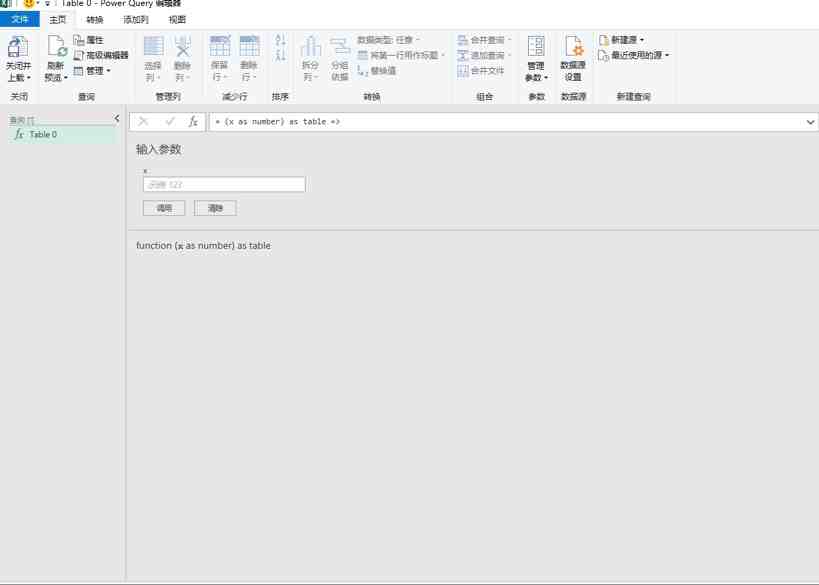
然后单击左侧的空白区域,右键单击以选择新查询,查找其他源,然后选择空查询,然后在编辑栏中输入它={1..100}单击enter,我们将得到一个从1到100的序列,然后单击表将查询转换为表,然后直接单击OK
然后选择add column,找到自定义函数,在函数查询中选择table0,直接点击OK。这样,power query将开始抓取数据。在这里抓取100页网页数据的过程可能相当长。我在这里花了大约3分钟的时间,在捕捉到最佳网络后,我们将在每个系列的后面得到一张桌子。我们单击左箭头和右箭头展开数据,删除原创列名前面的复选标记,然后单击确定删除我们添加的序列。这样,我们就完成了。我们只需要在开始时选择close和upload to将数据加载到excel中,因为有很多数据,这个过程也需要很多时间。我在这里花了大约一分钟的时间
三、统计分析
当数据加载到excel中时,我们可以通过数据透视表快速分析数据,如下图所示。根据车辆质量网络投诉记录中采集的3000条数据,我们可以通过数据透视表得到投诉品牌和投诉车型系列的排名。在这里,近一个月的投诉量达到3000条数据
以上是我们批量捕获100页网页数据的方法,以及各个制造商的投诉排名。整个过程大约需要7分钟,大部分时间用于数据捕获和加载
进展如何?你学会了吗?快试试 查看全部
抓取网页数据违法吗(
如何批量的批量抓取网页中的数据,如下粉丝如何)
数据捕获(大数据捕获客户软件)
大家好,今天我想和大家分享一下我们如何批量捕获网页中的数据,以捕获汽车投诉的数量。我想与您分享如何批量捕获网页中的数据。这也是一位粉丝提出的问题。他打算买一辆汽车,想看看各制造商的投诉数量。不要说太多。让我们直接开始吧。如果你进来是想了解来自不同制造商的投诉数量和投诉型号的排名,那就到此为止

一、分析页面
让我们以从到vehicle 的汽车投诉为例,向您展示如何批量捕获数据。如下图所示,从第1页到第3页都有网站。我们可以看到,只有红色的123,即对应的页码,是不同的,其余的都是相同的

二、grab数据
然后打开excel,单击数据功能组以查找self网站,单击高级选项,然后将代表页码的数字放在单独的输入框中。可以通过单击“添加零件”来添加输入框。设置完成后,我们直接点击OK
这样,我们将进入navigator界面。在此页面中,power query捕获了两个内容。我们可以点击查看我们需要的最佳数据。这里,表0是我们想要捕获的数据。直接选择table0,点击〖转换数据〗按钮,进入powerquery的编辑界面
接下来,单击高级编辑器并输入(x作为数字)作为table=>;然后将网站中的“1”更改为(number.ToText(x))并单击完成
这样,我们将把前面的操作封装到一个函数中。我们只需要输入相应的号码,然后点击call跳转到相应页码的数据
然后单击左侧的空白区域,右键单击以选择新查询,查找其他源,然后选择空查询,然后在编辑栏中输入它={1..100}单击enter,我们将得到一个从1到100的序列,然后单击表将查询转换为表,然后直接单击OK
然后选择add column,找到自定义函数,在函数查询中选择table0,直接点击OK。这样,power query将开始抓取数据。在这里抓取100页网页数据的过程可能相当长。我在这里花了大约3分钟的时间,在捕捉到最佳网络后,我们将在每个系列的后面得到一张桌子。我们单击左箭头和右箭头展开数据,删除原创列名前面的复选标记,然后单击确定删除我们添加的序列。这样,我们就完成了。我们只需要在开始时选择close和upload to将数据加载到excel中,因为有很多数据,这个过程也需要很多时间。我在这里花了大约一分钟的时间
三、统计分析
当数据加载到excel中时,我们可以通过数据透视表快速分析数据,如下图所示。根据车辆质量网络投诉记录中采集的3000条数据,我们可以通过数据透视表得到投诉品牌和投诉车型系列的排名。在这里,近一个月的投诉量达到3000条数据
以上是我们批量捕获100页网页数据的方法,以及各个制造商的投诉排名。整个过程大约需要7分钟,大部分时间用于数据捕获和加载
进展如何?你学会了吗?快试试
抓取网页数据违法吗(这儿简易讨论一下Spider对网址的获取状况都有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-17 01:20
百度搜索引擎蜘蛛对网站的访问应该是最值得SEO人员分析的内容。然而,许多SEO人员不知道如何分析百度搜索引擎在日志中长期优化的爬行记录。这里有一个关于spider访问该网站的级别非常值得分析的简要讨论,以及分析的结论如何指导SEO工作
可以分析蜘蛛爬行数据信息:各平台蜘蛛爬行频率、主网页蜘蛛爬行频率、网站内容蜘蛛爬行分布、各类网页蜘蛛采集、网站蜘蛛爬行状态代码等
(1)通过分析蜘蛛在各平台上爬行频率的发展趋势,我们可以很容易地在百度搜索引擎的眼中把握网站的质量,如果平台没有完成重大变化,内容升级正常,百度搜索引擎的爬行频率就会降低缓慢或突然,不是网站的错误操作,是百度搜索引擎青觉得网站质量有问题;如果百度搜索引擎的爬行频率突然扩大,可能是网站有404个网页,导致蜘蛛集中重复爬行;我如果百度搜索引擎的爬行频率慢慢扩大,可能是随着网站内容的逐渐增加和权重值的逐渐积累,一切都得到了正常的爬行,几乎平静稳定的变化也就不足为奇了,如果发生剧烈的变化,一定要引起足够的重视
(2)根据蜘蛛对主网页获取规律的分析,可以辅助调整网页升级次数,一般百度搜索引擎蜘蛛会对网站.这样的网页不能是信息页,而是主页、目录页或具有许多外部链接的页面
如图10-4所示,它在网站的nbc.html页面上显示了百度搜索蜘蛛的获取状态。该页面是该平台的新内容页面,即专为百度搜索引擎在网站中查找新内容而设计的页面。该页面中有300个连接,每五分钟升级一次,一次d我们已经知道网站是在五分钟内制作的,换句话说,并非所有新形成的网页都会出现在nbc.html中。根据图10-4中百度搜索蜘蛛获取的网页,百度搜索蜘蛛最多会在2分钟内抓取网页一次。然而,网页的刷新频率是5米在几分钟内,换言之,100多个学位搜索蜘蛛的获取频率的一半没有获得新的连接,并且网站的新信息的连接没有完全呈现在网页上。根据这种数据和信息的差异,我们可以专门指导SEO人员推广专业的d技术人员提高网页的缓存文件时间,扩大升级频率,并将升级频率设置为每2分钟一次,这样不仅可以让百度搜索蜘蛛在每次抓取网页时获得新的连接,还可以扩大sear发现网站新内容的概率ch发动机
网站中有很多种类的网页,如首页、目录页和前面提到的页面。在网站中,通常会继续存在大量其他集成页面,这些页面的爬行频率非常高。特别是网站的主页,很多平台的主页都会被百度搜索ch引擎每天都在爬行,但是在很多主页上发布的链接很少,有些则消耗了蜘蛛在主页上自己的权重值所产生的高爬行频率。这没有害处SEO关键词在搜索量和布局条件下,SEO人员可以灵活使用这部分资源,在网站上制作所有新内容它可以被百度搜索引擎及时处理,也可以减少百度搜索引擎的失败和爬行 查看全部
抓取网页数据违法吗(这儿简易讨论一下Spider对网址的获取状况都有哪些?)
百度搜索引擎蜘蛛对网站的访问应该是最值得SEO人员分析的内容。然而,许多SEO人员不知道如何分析百度搜索引擎在日志中长期优化的爬行记录。这里有一个关于spider访问该网站的级别非常值得分析的简要讨论,以及分析的结论如何指导SEO工作
可以分析蜘蛛爬行数据信息:各平台蜘蛛爬行频率、主网页蜘蛛爬行频率、网站内容蜘蛛爬行分布、各类网页蜘蛛采集、网站蜘蛛爬行状态代码等
(1)通过分析蜘蛛在各平台上爬行频率的发展趋势,我们可以很容易地在百度搜索引擎的眼中把握网站的质量,如果平台没有完成重大变化,内容升级正常,百度搜索引擎的爬行频率就会降低缓慢或突然,不是网站的错误操作,是百度搜索引擎青觉得网站质量有问题;如果百度搜索引擎的爬行频率突然扩大,可能是网站有404个网页,导致蜘蛛集中重复爬行;我如果百度搜索引擎的爬行频率慢慢扩大,可能是随着网站内容的逐渐增加和权重值的逐渐积累,一切都得到了正常的爬行,几乎平静稳定的变化也就不足为奇了,如果发生剧烈的变化,一定要引起足够的重视
(2)根据蜘蛛对主网页获取规律的分析,可以辅助调整网页升级次数,一般百度搜索引擎蜘蛛会对网站.这样的网页不能是信息页,而是主页、目录页或具有许多外部链接的页面
如图10-4所示,它在网站的nbc.html页面上显示了百度搜索蜘蛛的获取状态。该页面是该平台的新内容页面,即专为百度搜索引擎在网站中查找新内容而设计的页面。该页面中有300个连接,每五分钟升级一次,一次d我们已经知道网站是在五分钟内制作的,换句话说,并非所有新形成的网页都会出现在nbc.html中。根据图10-4中百度搜索蜘蛛获取的网页,百度搜索蜘蛛最多会在2分钟内抓取网页一次。然而,网页的刷新频率是5米在几分钟内,换言之,100多个学位搜索蜘蛛的获取频率的一半没有获得新的连接,并且网站的新信息的连接没有完全呈现在网页上。根据这种数据和信息的差异,我们可以专门指导SEO人员推广专业的d技术人员提高网页的缓存文件时间,扩大升级频率,并将升级频率设置为每2分钟一次,这样不仅可以让百度搜索蜘蛛在每次抓取网页时获得新的连接,还可以扩大sear发现网站新内容的概率ch发动机
网站中有很多种类的网页,如首页、目录页和前面提到的页面。在网站中,通常会继续存在大量其他集成页面,这些页面的爬行频率非常高。特别是网站的主页,很多平台的主页都会被百度搜索ch引擎每天都在爬行,但是在很多主页上发布的链接很少,有些则消耗了蜘蛛在主页上自己的权重值所产生的高爬行频率。这没有害处SEO关键词在搜索量和布局条件下,SEO人员可以灵活使用这部分资源,在网站上制作所有新内容它可以被百度搜索引擎及时处理,也可以减少百度搜索引擎的失败和爬行
抓取网页数据违法吗(篇:详解stata爬虫抓取网页上的数据part1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 541 次浏览 • 2021-09-15 05:10
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下
抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):
本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:
马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它
捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行
观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行
生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]
切割和更换
继续切割、更换和固定
最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:
查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文
标准->;经典 查看全部
抓取网页数据违法吗(篇:详解stata爬虫抓取网页上的数据part1)
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下

抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):

本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:

马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它

捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行

观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行

生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]

切割和更换

继续切割、更换和固定

最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:

查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文

标准->;经典
抓取网页数据违法吗(Python一款IDE--网页请求监控工具发生的详细步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 05:09
)
1)首先,客户端需要与服务器建立连接。只需单击一个超链接,HTTP就会开始工作
2)连接建立后,客户端以统一资源标识符(URL)和协议版本号的格式向服务器发送请求,然后发送mime信息,包括请求修改器、客户端信息和可能的内容
@接收到请求后,3)server将以状态行的形式给出相应的响应信息,包括信息的协议版本号、成功或错误代码,然后是mime信息,包括服务器信息、实体信息和可能的内容
4)客户端接收服务器返回的信息,并通过浏览器显示在用户显示屏上,然后客户端断开与服务器的连接
如果在上述过程的任何步骤中发生错误,错误消息将返回到具有显示输出的客户端。对于用户来说,这些过程是由HTTP本身完成的。用户只需单击鼠标,等待信息显示
第二:了解Python中的urllib库
在Python2系列中使用了urlib 2,它在Python3之后完全集成到urlib中;我们需要学习的是几个常见的函数。详情可在官方网站上查看
第三:开发工具
Python有自己的编译器——idle,非常简洁;Pycharm——一个具有良好交互的python ide;Fiddler——网页请求监视工具。我们可以使用它来了解用户触发网页请求后的详细步骤
简单网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截获结果如下图所示:
查看全部
抓取网页数据违法吗(Python一款IDE--网页请求监控工具发生的详细步骤
)
1)首先,客户端需要与服务器建立连接。只需单击一个超链接,HTTP就会开始工作
2)连接建立后,客户端以统一资源标识符(URL)和协议版本号的格式向服务器发送请求,然后发送mime信息,包括请求修改器、客户端信息和可能的内容
@接收到请求后,3)server将以状态行的形式给出相应的响应信息,包括信息的协议版本号、成功或错误代码,然后是mime信息,包括服务器信息、实体信息和可能的内容
4)客户端接收服务器返回的信息,并通过浏览器显示在用户显示屏上,然后客户端断开与服务器的连接
如果在上述过程的任何步骤中发生错误,错误消息将返回到具有显示输出的客户端。对于用户来说,这些过程是由HTTP本身完成的。用户只需单击鼠标,等待信息显示
第二:了解Python中的urllib库
在Python2系列中使用了urlib 2,它在Python3之后完全集成到urlib中;我们需要学习的是几个常见的函数。详情可在官方网站上查看
第三:开发工具
Python有自己的编译器——idle,非常简洁;Pycharm——一个具有良好交互的python ide;Fiddler——网页请求监视工具。我们可以使用它来了解用户触发网页请求后的详细步骤
简单网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截获结果如下图所示:
抓取网页数据违法吗(抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-12 03:05
抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python+selenium工具,我们可以采集的网站数量,那么我们就来探究下,这个违法吗?上限是多少?可以搜集数据吗?然后我们自己在自己做一遍,发现,下面的scrapy框架的实现。不触碰爬虫的原则,但是你说你做第三方网页爬虫代理了,那么就是第三方咯,爬虫库啊。到底违不违法?违法吗?为什么不说?判断不了,实际应用中,违法还是不违法,很多东西需要自己去探究。
不违法,只要你不做奸商,也没影响到别人。
爬虫本身不违法,但是你注册第三方爬虫你可以采集商品信息啊,卖家放什么广告位,你又不去。如果采集不会留下痕迹,没有采集成功数据的话,应该是个人隐私,但是如果你采集的数据导出到本地,那么你的采集信息就是泄露的信息,有些网站是不给你导出的,
我告诉你违法,
不违法,只要你用爬虫没收到任何非法或者侵权的内容就行了(比如和明显欺诈、诱骗性的内容)。有很多人想把商品推广出去所以使用第三方的爬虫,或者是想做推广所以使用第三方爬虫。但这些都是正常的,只要你别制造非法或诱骗的内容。
首先,正常使用是不违法的,但是如果你的动机不好, 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python)
抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python+selenium工具,我们可以采集的网站数量,那么我们就来探究下,这个违法吗?上限是多少?可以搜集数据吗?然后我们自己在自己做一遍,发现,下面的scrapy框架的实现。不触碰爬虫的原则,但是你说你做第三方网页爬虫代理了,那么就是第三方咯,爬虫库啊。到底违不违法?违法吗?为什么不说?判断不了,实际应用中,违法还是不违法,很多东西需要自己去探究。
不违法,只要你不做奸商,也没影响到别人。
爬虫本身不违法,但是你注册第三方爬虫你可以采集商品信息啊,卖家放什么广告位,你又不去。如果采集不会留下痕迹,没有采集成功数据的话,应该是个人隐私,但是如果你采集的数据导出到本地,那么你的采集信息就是泄露的信息,有些网站是不给你导出的,
我告诉你违法,
不违法,只要你用爬虫没收到任何非法或者侵权的内容就行了(比如和明显欺诈、诱骗性的内容)。有很多人想把商品推广出去所以使用第三方的爬虫,或者是想做推广所以使用第三方爬虫。但这些都是正常的,只要你别制造非法或诱骗的内容。
首先,正常使用是不违法的,但是如果你的动机不好,
抓取网页数据违法吗( 互联网网络爬虫技术和文本挖掘技术的区别-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-11 01:12
互联网网络爬虫技术和文本挖掘技术的区别-乐题库)
一种面向招商引资领域的互联网情报采集与推荐系统
[0001]
技术领域
[0002] 本发明涉及一种投资促进领域的互联网情报采集与推荐系统,属于互联网技术领域。
背景技术
[0003] 从事投资促进领域的人员依靠信息的获取,开展投资促进工作、服务工作和咨询工作。目前投资信息的来源主要是线下活动和客户走访,缺乏主动获取信息的有效手段。因此,有必要利用互联网爬虫技术、全文搜索技术和文本挖掘技术帮助投资人员获取互联网投资信息和信息。
[0004] 网络爬虫又称网络蜘蛛、网络机器人,是按照一定的规则自动抓取万维网上信息的程序或脚本。网络爬虫将互联网上的所有页面分为五类:已下载但未过期、已下载并已过期、等待下载、可知和未知。爬行策略可分为广度优先搜索策略、最佳优先搜索策略、深度优先搜索策略等。
[0005] 全文搜索是一种文本数据搜索方法,将文档中的所有文本与搜索词进行匹配。全文检索研究整个文档信息的表示、存储、组织和访问,即根据用户的查询要求,从信息库中检索相关信息。全文搜索的中心环节是文档内容的表达、信息查询的获取、相关信息的匹配。
[0006] 文本挖掘是提取分散在文本文件中的有效、有用、可理解和有价值的知识,并利用这些知识更好地组织信息的过程。文本挖掘使用智能算法,如神经网络、案例推理、可能性推理等,结合文字处理技术,分析大量非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网络页等)),提取或标记关键词概念与词的关系,并根据内容对文档进行分类,以获得有用的知识和信息。中文分词是文本挖掘的基础。对于一段中文输入,成功进行中文分词可以达到计算机自动识别句子意思的效果。
发明内容
[0007] 本发明的目的在于解决招商引资服务咨询中存在的问题,提出一种面向招商引资领域的互联网情报采集与推荐系统。
[0008] 本发明的技术方案如下,一种用于投资促进领域的互联网情报抓取和推荐系统,它集成了互联网金融舆情、上市公司投资或并购信息、各公司CEO公开演讲、社交媒体通过网络爬虫及时获取跟踪信息;通过基于人工监督和机器学习的推荐算法对网络信息进行过滤推荐,推荐符合用户目标范围的优质信息;根据审稿人的推荐与否,并利用推荐信息的阅读量自动修改情报推荐分析,使以后获取的信息质量更高,减少人为干预。
[0009] 系统抓取媒体网站和社交媒体网站提供的信息,将抓取的关键词进行对比,并与招商领域相关,用于发现各种投资项目信号。
[0010]机器学习算法如下:(1)推荐模型的初始算法是判断信息是否出现在知识库中的关键词以及关键词出现的频率。关键词出现频率优先推荐;(2)推荐网页的特征必须人工筛选,人工筛选的结果将网页分为正面网页和负面网页,同时过滤后的结果被不同的人点击用户,点击量反映了网页的准确度和相关性;(3)系统分析网页特征值,网页特征值包括网页网站网址、时间、关键词频率;(4)系统将网页的特征值与人工筛选的结果与页面浏览量相关联,使用随机数建立init并使用深度学习神经网络进行训练,最终得到修正后的推荐模型。
[0011] 本发明是一种针对招商领域的互联网情报采集与推荐系统,包括招商情报采集模块、招商情报分析模块和招商情报服务模块。投资信息采集模块将每个网站采集招商智慧的数据发送到投资信息分析模块;信息分析后,投资信息分析模块向投资信息服务模块发送情报服务指令执行;投资信息采集模块、投资信息分析模块和投资信息服务模块的输出数据存储在数据库中。
[0012]投资信息采集模块包括爬虫规则定义子模块、网络爬虫子模块、统计分析子模块、人工审核子模块和规则设置子模块。爬取规则子模块制定智能爬取规则。网络爬虫子模块根据抓取规则,利用网络爬虫抓取互联网金融舆情、上市公司投资并购信息、各公司关键人物公开演讲、社交媒体跟踪信息根据爬行规则。子模块及时获取。
[0013]投资情报分析模块包括内容去重子模块、敏感词过滤子模块、情报关键词子模块、机器学习子模块、数据规范子模块投资情报分析模块分析网页的特征值,包括网页网站网址、时间、出现频率最好的关键词。
[0014] 招商情报服务模块包括话题呈现子模块、舆情简报子模块、统计分析子模块、人工审核子模块、规则设置子模块。
[0015]与现有技术相比,本发明的有益效果是:本发明系统的情报捕捉模块主要针对财经舆情,并有特定的投资关键词对这些舆情进行过滤,使得信息更准确。本发明系统返回的信息覆盖范围更广,不仅包括国内各大网络媒体,还包括各级政府官方网站,以及国外网站的企业信息;本发明系统推荐的招商舆情筛选系统具有自学习能力,可以根据用户的选择和推荐次数形成新的推荐算法,从而推荐更符合市场需求的情报信息。用户的需求。
图纸说明
[0016]图1是本发明的结构框图;图2为本实施例使用的通用网络爬虫采集的程序框图;图3为本实施例中使用的神经网络结构图。
具体实现方法
[0017] 本发明的具体实现如图1所示。
[0018]本实施例为招商引资领域的互联网情报采集与推荐系统,包括投资情报获取模块、投资情报分析模块和投资情报服务模块。以下是这些模块的功能说明: Information采集module:该模块负责采集招商投资及相关话题。只有采集 指定相关的网站 和该部分的网页。一般网络爬虫返回的结果中含有大量用户不关心的网页,所以本系统的采集程序适用于垂直爬虫。根据给定的入口地址,不断获取和下载页面上的新链接。链接分为目标网址和非目标网址。目标URL主要是文章body的URL。除了解析目标URL中的链接外,还必须提取正文、标题、发布时间等信息。通用网络爬虫采集程序如图2所示。
[0019]采集项目应满足的要求如下:(1)采集主题包括:投资、金融、产业、企业、企业家、技术、高新技术、专利和科学与技术科技成果,世界500强、国内100强等定制主题。
[0020](2)采集相关文章文字、标题、发表时间等
[0021](3)可以根据采集网站自动灵活调度采集任务,或者手动触发任务。
[0022](4)静态页和正文页只采集一次,不重复采集。
[0023](5)内容更新动态页面可以重复采集。
[0024](6)待采集队列应该去重以避免重复采集。
[0025](7)最新信息可以及时采集。
[0026](8)可灵活设置采集线程数。
[0027](9)可以为不同的网站设置不同的采集深度。
[0028](10)可以根据链接组织规则和页面结构灵活配置处理规则。
[0029]投资情报分析模块:对采集的文本进行分析,包括以下步骤:舆情识别、文本去重、文本摘要、舆情分类、舆情情绪分析、企业关键词标注、可信度投资机会指数分析计算,企业媒体指数计算,机器学习。
<p>[0030](1)舆情识别:通过统计符合规则的关键词数量和权重来判断是否是文章收录舆情信息。对于不收录舆情信息的文章 ,不需要进一步的分析处理,不需要发布。文章的匹配指数=关键词频率难度),但当匹配指数达到一定阈值时,舆论认可。 查看全部
抓取网页数据违法吗(
互联网网络爬虫技术和文本挖掘技术的区别-乐题库)
一种面向招商引资领域的互联网情报采集与推荐系统
[0001]
技术领域
[0002] 本发明涉及一种投资促进领域的互联网情报采集与推荐系统,属于互联网技术领域。
背景技术
[0003] 从事投资促进领域的人员依靠信息的获取,开展投资促进工作、服务工作和咨询工作。目前投资信息的来源主要是线下活动和客户走访,缺乏主动获取信息的有效手段。因此,有必要利用互联网爬虫技术、全文搜索技术和文本挖掘技术帮助投资人员获取互联网投资信息和信息。
[0004] 网络爬虫又称网络蜘蛛、网络机器人,是按照一定的规则自动抓取万维网上信息的程序或脚本。网络爬虫将互联网上的所有页面分为五类:已下载但未过期、已下载并已过期、等待下载、可知和未知。爬行策略可分为广度优先搜索策略、最佳优先搜索策略、深度优先搜索策略等。
[0005] 全文搜索是一种文本数据搜索方法,将文档中的所有文本与搜索词进行匹配。全文检索研究整个文档信息的表示、存储、组织和访问,即根据用户的查询要求,从信息库中检索相关信息。全文搜索的中心环节是文档内容的表达、信息查询的获取、相关信息的匹配。
[0006] 文本挖掘是提取分散在文本文件中的有效、有用、可理解和有价值的知识,并利用这些知识更好地组织信息的过程。文本挖掘使用智能算法,如神经网络、案例推理、可能性推理等,结合文字处理技术,分析大量非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网络页等)),提取或标记关键词概念与词的关系,并根据内容对文档进行分类,以获得有用的知识和信息。中文分词是文本挖掘的基础。对于一段中文输入,成功进行中文分词可以达到计算机自动识别句子意思的效果。
发明内容
[0007] 本发明的目的在于解决招商引资服务咨询中存在的问题,提出一种面向招商引资领域的互联网情报采集与推荐系统。
[0008] 本发明的技术方案如下,一种用于投资促进领域的互联网情报抓取和推荐系统,它集成了互联网金融舆情、上市公司投资或并购信息、各公司CEO公开演讲、社交媒体通过网络爬虫及时获取跟踪信息;通过基于人工监督和机器学习的推荐算法对网络信息进行过滤推荐,推荐符合用户目标范围的优质信息;根据审稿人的推荐与否,并利用推荐信息的阅读量自动修改情报推荐分析,使以后获取的信息质量更高,减少人为干预。
[0009] 系统抓取媒体网站和社交媒体网站提供的信息,将抓取的关键词进行对比,并与招商领域相关,用于发现各种投资项目信号。
[0010]机器学习算法如下:(1)推荐模型的初始算法是判断信息是否出现在知识库中的关键词以及关键词出现的频率。关键词出现频率优先推荐;(2)推荐网页的特征必须人工筛选,人工筛选的结果将网页分为正面网页和负面网页,同时过滤后的结果被不同的人点击用户,点击量反映了网页的准确度和相关性;(3)系统分析网页特征值,网页特征值包括网页网站网址、时间、关键词频率;(4)系统将网页的特征值与人工筛选的结果与页面浏览量相关联,使用随机数建立init并使用深度学习神经网络进行训练,最终得到修正后的推荐模型。
[0011] 本发明是一种针对招商领域的互联网情报采集与推荐系统,包括招商情报采集模块、招商情报分析模块和招商情报服务模块。投资信息采集模块将每个网站采集招商智慧的数据发送到投资信息分析模块;信息分析后,投资信息分析模块向投资信息服务模块发送情报服务指令执行;投资信息采集模块、投资信息分析模块和投资信息服务模块的输出数据存储在数据库中。
[0012]投资信息采集模块包括爬虫规则定义子模块、网络爬虫子模块、统计分析子模块、人工审核子模块和规则设置子模块。爬取规则子模块制定智能爬取规则。网络爬虫子模块根据抓取规则,利用网络爬虫抓取互联网金融舆情、上市公司投资并购信息、各公司关键人物公开演讲、社交媒体跟踪信息根据爬行规则。子模块及时获取。
[0013]投资情报分析模块包括内容去重子模块、敏感词过滤子模块、情报关键词子模块、机器学习子模块、数据规范子模块投资情报分析模块分析网页的特征值,包括网页网站网址、时间、出现频率最好的关键词。
[0014] 招商情报服务模块包括话题呈现子模块、舆情简报子模块、统计分析子模块、人工审核子模块、规则设置子模块。
[0015]与现有技术相比,本发明的有益效果是:本发明系统的情报捕捉模块主要针对财经舆情,并有特定的投资关键词对这些舆情进行过滤,使得信息更准确。本发明系统返回的信息覆盖范围更广,不仅包括国内各大网络媒体,还包括各级政府官方网站,以及国外网站的企业信息;本发明系统推荐的招商舆情筛选系统具有自学习能力,可以根据用户的选择和推荐次数形成新的推荐算法,从而推荐更符合市场需求的情报信息。用户的需求。
图纸说明
[0016]图1是本发明的结构框图;图2为本实施例使用的通用网络爬虫采集的程序框图;图3为本实施例中使用的神经网络结构图。
具体实现方法
[0017] 本发明的具体实现如图1所示。
[0018]本实施例为招商引资领域的互联网情报采集与推荐系统,包括投资情报获取模块、投资情报分析模块和投资情报服务模块。以下是这些模块的功能说明: Information采集module:该模块负责采集招商投资及相关话题。只有采集 指定相关的网站 和该部分的网页。一般网络爬虫返回的结果中含有大量用户不关心的网页,所以本系统的采集程序适用于垂直爬虫。根据给定的入口地址,不断获取和下载页面上的新链接。链接分为目标网址和非目标网址。目标URL主要是文章body的URL。除了解析目标URL中的链接外,还必须提取正文、标题、发布时间等信息。通用网络爬虫采集程序如图2所示。
[0019]采集项目应满足的要求如下:(1)采集主题包括:投资、金融、产业、企业、企业家、技术、高新技术、专利和科学与技术科技成果,世界500强、国内100强等定制主题。
[0020](2)采集相关文章文字、标题、发表时间等
[0021](3)可以根据采集网站自动灵活调度采集任务,或者手动触发任务。
[0022](4)静态页和正文页只采集一次,不重复采集。
[0023](5)内容更新动态页面可以重复采集。
[0024](6)待采集队列应该去重以避免重复采集。
[0025](7)最新信息可以及时采集。
[0026](8)可灵活设置采集线程数。
[0027](9)可以为不同的网站设置不同的采集深度。
[0028](10)可以根据链接组织规则和页面结构灵活配置处理规则。
[0029]投资情报分析模块:对采集的文本进行分析,包括以下步骤:舆情识别、文本去重、文本摘要、舆情分类、舆情情绪分析、企业关键词标注、可信度投资机会指数分析计算,企业媒体指数计算,机器学习。
<p>[0030](1)舆情识别:通过统计符合规则的关键词数量和权重来判断是否是文章收录舆情信息。对于不收录舆情信息的文章 ,不需要进一步的分析处理,不需要发布。文章的匹配指数=关键词频率难度),但当匹配指数达到一定阈值时,舆论认可。
抓取网页数据违法吗(【芝麻IP代理】如何用python来页面中的JS动态加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-09 02:21
)
【芝麻IP代理】我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
查看全部
抓取网页数据违法吗(【芝麻IP代理】如何用python来页面中的JS动态加载
)
【芝麻IP代理】我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
抓取网页数据违法吗( 什么是万能工具?AIWeb工具是AI驱动的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-09 02:20
什么是万能工具?AIWeb工具是AI驱动的工具)
有万能爬虫吗?
随着网站的数量从十年前的20万增长到今天的17亿多,互联网上的数据量正在爆炸式增长。十年前,内容可能是王道,但现在互联网爱好者说数据是现代石油。当今最有价值的资源不是石油,而是数据。
掌握提取和采集数据技术的公司已成为当今世界上最有价值的巨头之一。未来,人工智能(AI)、大数据、机器学习等具有强大数据处理能力的高科技企业将主导世界经济。
因此,为了在竞争激烈、高度创新的商业环境中跟上时代的步伐,有远见的企业主们开始数据采集。他们经常在数据挖掘和 采集 中使用网络抓取工具。
什么是万能爬虫?
AI网络爬虫是一种AI驱动的工具,可以将计算机上传统的复制粘贴功能自动化。这种类型的工具通常也称为网络爬虫或数据抓取工具。他们的核心功能是从在线资源中提取数据。
但两者的运作方式并不相同。网络爬虫通常被称为网络蜘蛛,指的是跟踪网络链接、浏览网络信息和建立索引的机器人。大型搜索引擎(例如 Bing 和 Google)使用网络爬虫来索引新的 网站 信息。
爬虫提取已被网络爬虫编入索引的数据。因此,这两个工具在同一个过程中协同工作,结果是数据被分析并存储在计算机或数据库中。
有万能爬虫吗?
网络抓取过程不仅仅是一项只需要遵守规则的活动。Web 语言、编码风格和编程方法多种多样,并且随着技术的进步而不断发展。与过去不同,雄心勃勃的数据挖掘者必须对自己进行编程以构建网络爬虫机器人。现在的万能爬虫工具基本可以应对各种网站规范。
网络爬行限制是无止境的
尽管网络抓取是一种必不可少的商业策略,但各种网站 已经部署了反抓取工具来阻止这项工作。因此,如果企业需要加大数据挖掘力度,就必须保证自己的通用爬虫工具能够应对各种挑战,例如:
机器人访问限制
一些网站有robot.txt文件,他们的规则会禁止robots访问。您必须确认您要抓取的网站 被接受进行抓取。如果您不接受,则必须获得网站 所有者的许可才能抓取数据。如果目标网站的所有者不愿意合作,尽可能寻求一个爬行条款友好的网站更合乎道德。
更改 网站 结构
尽管 HTML 网页易于抓取,但网页设计师不断提出新的设计标准,使网页设计日新月异。结构变化可能会影响某些爬虫的爬行功能。
请只选择信誉良好的提供商,并使用他们的抓取工具确保技术不断更新以应对新的网页设计语言。网页组织的细微变化可能会严重影响数据爬虫的功能。
IP拦截器
网站 已收录 IP 地址阻止机制,以防止机器人抓取网页。当网站的监控系统检测到来自单个IP的并发请求比例很高时,他们会禁止、标记或阻止该IP在网站上的活动。但是,网络抓取是一项合法活动。
IP拦截器是互联网活动混乱时代的产物。当时,有人在网络爬虫中肆无忌惮地滥用机器人,对目标网站造成了不利影响。一些恶意的在线用户还使用机器人进行垃圾邮件攻击,导致拒绝服务错误。
由于大多数网站都有可疑的IP拦截工具,因此网页抓取工具需要配备带有旋转住宅IP池的代理服务器,以隐藏抓取活动。
验证码验证
区分计算机和人类的全自动图灵测试(CAPTCHA)是 网站 上的一个常见功能。这个工具显示了真人可以解决但机器人不能解决的逻辑错误。
网站 带有 CAPTCHA 验证可能会阻止网络抓取。为保证持续抓取,部分工具配备了CAPTCHA验证方案,以保证过程的顺利进行。
蜜罐陷阱
一些网站站长喜欢搜索爬虫,所以会设置网络爬虫陷阱。蜜罐陷阱是肉眼看不见的链接,但网络蜘蛛可以索引它们。如果爬虫跟随网络蜘蛛访问这些链接,网站 的安全协议将阻止其 IP 地址。
一些抓取工具的强大技术可以通过准确抓取项目而不是整体抓取它们来避免蜜罐陷阱。
综上所述
网络抓取正在兴起。尽管通用抓取工具仍面临诸多挑战,但程序员们也在不断努力寻找突破口。您有责任遵守 网站 的所有要求并以合乎道德的方式获取数据。 查看全部
抓取网页数据违法吗(
什么是万能工具?AIWeb工具是AI驱动的工具)
有万能爬虫吗?
随着网站的数量从十年前的20万增长到今天的17亿多,互联网上的数据量正在爆炸式增长。十年前,内容可能是王道,但现在互联网爱好者说数据是现代石油。当今最有价值的资源不是石油,而是数据。
掌握提取和采集数据技术的公司已成为当今世界上最有价值的巨头之一。未来,人工智能(AI)、大数据、机器学习等具有强大数据处理能力的高科技企业将主导世界经济。
因此,为了在竞争激烈、高度创新的商业环境中跟上时代的步伐,有远见的企业主们开始数据采集。他们经常在数据挖掘和 采集 中使用网络抓取工具。
什么是万能爬虫?
AI网络爬虫是一种AI驱动的工具,可以将计算机上传统的复制粘贴功能自动化。这种类型的工具通常也称为网络爬虫或数据抓取工具。他们的核心功能是从在线资源中提取数据。
但两者的运作方式并不相同。网络爬虫通常被称为网络蜘蛛,指的是跟踪网络链接、浏览网络信息和建立索引的机器人。大型搜索引擎(例如 Bing 和 Google)使用网络爬虫来索引新的 网站 信息。
爬虫提取已被网络爬虫编入索引的数据。因此,这两个工具在同一个过程中协同工作,结果是数据被分析并存储在计算机或数据库中。
有万能爬虫吗?
网络抓取过程不仅仅是一项只需要遵守规则的活动。Web 语言、编码风格和编程方法多种多样,并且随着技术的进步而不断发展。与过去不同,雄心勃勃的数据挖掘者必须对自己进行编程以构建网络爬虫机器人。现在的万能爬虫工具基本可以应对各种网站规范。
网络爬行限制是无止境的
尽管网络抓取是一种必不可少的商业策略,但各种网站 已经部署了反抓取工具来阻止这项工作。因此,如果企业需要加大数据挖掘力度,就必须保证自己的通用爬虫工具能够应对各种挑战,例如:
机器人访问限制
一些网站有robot.txt文件,他们的规则会禁止robots访问。您必须确认您要抓取的网站 被接受进行抓取。如果您不接受,则必须获得网站 所有者的许可才能抓取数据。如果目标网站的所有者不愿意合作,尽可能寻求一个爬行条款友好的网站更合乎道德。
更改 网站 结构
尽管 HTML 网页易于抓取,但网页设计师不断提出新的设计标准,使网页设计日新月异。结构变化可能会影响某些爬虫的爬行功能。
请只选择信誉良好的提供商,并使用他们的抓取工具确保技术不断更新以应对新的网页设计语言。网页组织的细微变化可能会严重影响数据爬虫的功能。
IP拦截器
网站 已收录 IP 地址阻止机制,以防止机器人抓取网页。当网站的监控系统检测到来自单个IP的并发请求比例很高时,他们会禁止、标记或阻止该IP在网站上的活动。但是,网络抓取是一项合法活动。
IP拦截器是互联网活动混乱时代的产物。当时,有人在网络爬虫中肆无忌惮地滥用机器人,对目标网站造成了不利影响。一些恶意的在线用户还使用机器人进行垃圾邮件攻击,导致拒绝服务错误。
由于大多数网站都有可疑的IP拦截工具,因此网页抓取工具需要配备带有旋转住宅IP池的代理服务器,以隐藏抓取活动。
验证码验证
区分计算机和人类的全自动图灵测试(CAPTCHA)是 网站 上的一个常见功能。这个工具显示了真人可以解决但机器人不能解决的逻辑错误。
网站 带有 CAPTCHA 验证可能会阻止网络抓取。为保证持续抓取,部分工具配备了CAPTCHA验证方案,以保证过程的顺利进行。
蜜罐陷阱
一些网站站长喜欢搜索爬虫,所以会设置网络爬虫陷阱。蜜罐陷阱是肉眼看不见的链接,但网络蜘蛛可以索引它们。如果爬虫跟随网络蜘蛛访问这些链接,网站 的安全协议将阻止其 IP 地址。
一些抓取工具的强大技术可以通过准确抓取项目而不是整体抓取它们来避免蜜罐陷阱。
综上所述
网络抓取正在兴起。尽管通用抓取工具仍面临诸多挑战,但程序员们也在不断努力寻找突破口。您有责任遵守 网站 的所有要求并以合乎道德的方式获取数据。
抓取网页数据违法吗(为什么百度蜘蛛经常不存在的网站页面,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-09 02:17
[摘要] 网站 爬取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是我们的网站上不存在这些页面
网站 抓取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是这些页面在我们的 网站 上根本不存在。那么,为什么百度蜘蛛经常抓取不存在的网站页面,我该怎么办?
为什么网站会爬取一些不存在的页面?
导致网站在不存在的页面上被爬取的因素有很多,例如:
■页面删除
在很多情况下,优化过程中需要对网站进行调整,但并不是所有你调整的页面都没有被搜索引擎抓取。有时,你看到的页面没有被索引,但实际上这些页面可能正在被评估,所以蜘蛛在一段时间后仍然会抓取这些页面。
■旧域名
有时候,我们做seo的时候,为了更快的得到搜索排名结果,我们会使用旧域名。但是,旧域名必须有建站历史,否则我们不会选择它。如果它有历史,它会带上自己的蜘蛛,蜘蛛有内存,所以它总是爬一些旧的网址。所以买旧域名有利有弊,但利大于弊。
■ 恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,还有一些不存在的页面被抓取。这时候就需要观察这些抓到的IP是否有一定的规律性。在很多情况下,我们的网站会面临各种各样的扫描需求,比如漏洞扫描、文章采集等,如果这些入侵防御系统是常规的,他们很可能会被扫描到漏洞。
如何处理对不存在的页面的抓取?
知道了爬行页面不存在的一些原因,如何解决这些问题?
■设置机器人
首先,我们知道这些不存在的页面会被反复抓取,所以我们需要自己采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用机器人协议来禁止这些页面被抓取。一般来说,这种方法适用于大多数蜘蛛,因为它是所有常规搜索引擎都需要遵循的协议。
■提交死链接
如果仍然存在被重复抓取的问题,可以查看这些页面是否有百度快照。如果有快照,蜘蛛会重复爬取,因为您正在阻止未编入索引的页面,但这些页面已经编入索引。我们可以聚合这些页面URL,通过资源平台提交死链接。
■屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛开发的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
在我们看来,最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
① 云主机。下载。htaccess 文件,直接修改、上传、覆盖原文件。
②宝塔。
进入宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
③ 插件。
现在所有cms系统都引入了各种功能插件。我们可以直接搜索被屏蔽的ip来查找插件并过滤ip。
以上就是“为什么百度蜘蛛经常抓取不存在的网站页面?”的原因。以及处理方法。如果你的网站有这样的情况,可以按照上面的方法来处理。推荐阅读《什么是网站日志分析?网站日志分析有什么用?》 查看全部
抓取网页数据违法吗(为什么百度蜘蛛经常不存在的网站页面,怎么办?)
[摘要] 网站 爬取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是我们的网站上不存在这些页面
网站 抓取索引对于搜索引擎优化非常重要。如果没有爬虫爬取,就不会有收录。但是我们在做网站爬取测试的时候,经常会看到一些404返回码。但是这些页面在我们的 网站 上根本不存在。那么,为什么百度蜘蛛经常抓取不存在的网站页面,我该怎么办?
为什么网站会爬取一些不存在的页面?
导致网站在不存在的页面上被爬取的因素有很多,例如:
■页面删除
在很多情况下,优化过程中需要对网站进行调整,但并不是所有你调整的页面都没有被搜索引擎抓取。有时,你看到的页面没有被索引,但实际上这些页面可能正在被评估,所以蜘蛛在一段时间后仍然会抓取这些页面。
■旧域名
有时候,我们做seo的时候,为了更快的得到搜索排名结果,我们会使用旧域名。但是,旧域名必须有建站历史,否则我们不会选择它。如果它有历史,它会带上自己的蜘蛛,蜘蛛有内存,所以它总是爬一些旧的网址。所以买旧域名有利有弊,但利大于弊。
■ 恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,还有一些不存在的页面被抓取。这时候就需要观察这些抓到的IP是否有一定的规律性。在很多情况下,我们的网站会面临各种各样的扫描需求,比如漏洞扫描、文章采集等,如果这些入侵防御系统是常规的,他们很可能会被扫描到漏洞。
如何处理对不存在的页面的抓取?
知道了爬行页面不存在的一些原因,如何解决这些问题?
■设置机器人
首先,我们知道这些不存在的页面会被反复抓取,所以我们需要自己采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用机器人协议来禁止这些页面被抓取。一般来说,这种方法适用于大多数蜘蛛,因为它是所有常规搜索引擎都需要遵循的协议。
■提交死链接
如果仍然存在被重复抓取的问题,可以查看这些页面是否有百度快照。如果有快照,蜘蛛会重复爬取,因为您正在阻止未编入索引的页面,但这些页面已经编入索引。我们可以聚合这些页面URL,通过资源平台提交死链接。
■屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛开发的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
在我们看来,最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
① 云主机。下载。htaccess 文件,直接修改、上传、覆盖原文件。
②宝塔。
进入宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
③ 插件。
现在所有cms系统都引入了各种功能插件。我们可以直接搜索被屏蔽的ip来查找插件并过滤ip。
以上就是“为什么百度蜘蛛经常抓取不存在的网站页面?”的原因。以及处理方法。如果你的网站有这样的情况,可以按照上面的方法来处理。推荐阅读《什么是网站日志分析?网站日志分析有什么用?》
抓取网页数据违法吗(通过selenium的子模块使用Python爬取网页数据的解决思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-08 03:08
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录它(不信,请查看页面源码,只有简单的一行)。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
先导入webdriver子模块
from selenium import webdriver 获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程-定位方法部分第三章(第一版可在百度文库阅读)结合正则表达式过滤相关资料
定位后有些元素是不需要的,有规律的过滤掉即可。比如我想只提取英文字符(包括0-9),建立如下规律
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
打印结束会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话。前者只是关闭当前会话而不关闭浏览器的webdriver,后者关闭包括webdriver在内的所有东西并添加异常处理。
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
assert 0, "找不到元素"4. 代码实现
我通过点击打开链接抓取指定分区的每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线号,以及以列表的形式打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用它来实现数据挖掘和机器学习等深度研究。因此,selenium+python 是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。 查看全部
抓取网页数据违法吗(通过selenium的子模块使用Python爬取网页数据的解决思路)
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录它(不信,请查看页面源码,只有简单的一行)。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
先导入webdriver子模块
from selenium import webdriver 获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程-定位方法部分第三章(第一版可在百度文库阅读)结合正则表达式过滤相关资料
定位后有些元素是不需要的,有规律的过滤掉即可。比如我想只提取英文字符(包括0-9),建立如下规律
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
打印结束会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话。前者只是关闭当前会话而不关闭浏览器的webdriver,后者关闭包括webdriver在内的所有东西并添加异常处理。
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
assert 0, "找不到元素"4. 代码实现
我通过点击打开链接抓取指定分区的每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线号,以及以列表的形式打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用它来实现数据挖掘和机器学习等深度研究。因此,selenium+python 是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。
抓取网页数据违法吗(与网络机器人的污名化,我们能做些什么污名?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-08 03:03
描述
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使 AI 是最美丽、最令人愉快的,也要提防它。此外,一些网络用户以不道德的方式使用网络机器人,甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗
有这么多信息要分析,很自然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,甚至可以自定义搜索以查看信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式采集用于研究或业务的有用信息的完美示例。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
有人认为人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分 AI 流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然不可避免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多优点,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改善公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
代理服务器旨在充当用户和 Web 服务器之间的中介。
多功能:个人和公司都可以使用代理服务器来满足特定需求。
代理的一个常见用途与网络抓取有关:使用代理服务器可以绕过网站 管理员设置的限制并采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“网络机器人”或“网络蜘蛛”)“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,用户将被限制访问网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
使用人类知名度和值得信赖的品牌来对抗人工智能的污名
目前,人工智能的发展速度确实已经超过了网民的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
大量普及人工智能。与其他人讨论如何以及为什么使用网页抓取,让人们对网页抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手动操作来手动访问网站数据可能让人放心,但由于信息太多,几乎不可能。可用数据的数量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。 查看全部
抓取网页数据违法吗(与网络机器人的污名化,我们能做些什么污名?)
描述
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使 AI 是最美丽、最令人愉快的,也要提防它。此外,一些网络用户以不道德的方式使用网络机器人,甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗
有这么多信息要分析,很自然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,甚至可以自定义搜索以查看信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式采集用于研究或业务的有用信息的完美示例。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
有人认为人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分 AI 流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然不可避免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多优点,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改善公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
代理服务器旨在充当用户和 Web 服务器之间的中介。
多功能:个人和公司都可以使用代理服务器来满足特定需求。
代理的一个常见用途与网络抓取有关:使用代理服务器可以绕过网站 管理员设置的限制并采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“网络机器人”或“网络蜘蛛”)“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,用户将被限制访问网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
使用人类知名度和值得信赖的品牌来对抗人工智能的污名
目前,人工智能的发展速度确实已经超过了网民的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
大量普及人工智能。与其他人讨论如何以及为什么使用网页抓取,让人们对网页抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手动操作来手动访问网站数据可能让人放心,但由于信息太多,几乎不可能。可用数据的数量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。
抓取网页数据违法吗(2019年上半年微信发布基于小程序页面的搜索(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-05 15:22
2019年上半年,微信发布了基于小程序页面的搜索。为了让我们更好地发现和理解小程序页面,结合过去一段时间我们遇到的各种情况,强烈建议开发者花一些宝贵的时间仔细阅读本文:)
当爬虫访问小程序中的页面时,会携带具体的用户代理“mpcrawler”和场景值:1129
1. 小程序中的重定向页面(url)可以直接打开。
小程序页面中的重定向URL是我们爬虫找到页面的重要来源,搜索引擎召回的结果页面(url)必须能够直接打开,不依赖上下文状态。特别:建议url中收录页面需要的参数
2. 导航组件优先用于页面跳转。
小程序提供了两种页面路由方式:
a.navigator 组件
湾 路由API,包括navigateTo/redirectTo/switchTab/navigateBack/reLaunch
推荐使用导航组件。如果非要使用API,可以屏蔽爬虫访问时为点击设置的时间锁或变量锁。
3.清晰简洁的页面参数。
一个结构清晰、简洁、参数有意义的查询字符串对爬取和后续分析很有帮助,但使用JSON数据作为参数的方式实现效果不佳。
4. 仅在必要时要求用户授权、登录、绑定手机号等。
建议仅在必要时请求用户授权(例如,您可以匿名阅读文章,发表评论需要留下您的姓名)。
5. 我们不收录 网络视图中的任何内容。
我们暂时不能这样做,从长远来看,我们也可能做不到。
6. 使用sitemap配置引导爬虫爬取,同时屏蔽没有搜索价值的路径。
7. 设置清晰的标题和页面缩略图。
页面标题和缩略图在理解页面和提高曝光转化率方面起着重要作用。
通过 wx.setNavigationBarTitle 或自定义转发内容 onShareAppMessage 设置页面的标题和缩略图,同时为视频和音频组件补充海报/poster-for-crawler 属性。
8. 使用页面路径推送能力
可以大大丰富微信上可以收录的内容,从而增加小程序内容的曝光机会。请参考: 查看全部
抓取网页数据违法吗(2019年上半年微信发布基于小程序页面的搜索(组图))
2019年上半年,微信发布了基于小程序页面的搜索。为了让我们更好地发现和理解小程序页面,结合过去一段时间我们遇到的各种情况,强烈建议开发者花一些宝贵的时间仔细阅读本文:)
当爬虫访问小程序中的页面时,会携带具体的用户代理“mpcrawler”和场景值:1129
1. 小程序中的重定向页面(url)可以直接打开。
小程序页面中的重定向URL是我们爬虫找到页面的重要来源,搜索引擎召回的结果页面(url)必须能够直接打开,不依赖上下文状态。特别:建议url中收录页面需要的参数
2. 导航组件优先用于页面跳转。
小程序提供了两种页面路由方式:
a.navigator 组件
湾 路由API,包括navigateTo/redirectTo/switchTab/navigateBack/reLaunch
推荐使用导航组件。如果非要使用API,可以屏蔽爬虫访问时为点击设置的时间锁或变量锁。
3.清晰简洁的页面参数。
一个结构清晰、简洁、参数有意义的查询字符串对爬取和后续分析很有帮助,但使用JSON数据作为参数的方式实现效果不佳。
4. 仅在必要时要求用户授权、登录、绑定手机号等。
建议仅在必要时请求用户授权(例如,您可以匿名阅读文章,发表评论需要留下您的姓名)。
5. 我们不收录 网络视图中的任何内容。
我们暂时不能这样做,从长远来看,我们也可能做不到。
6. 使用sitemap配置引导爬虫爬取,同时屏蔽没有搜索价值的路径。
7. 设置清晰的标题和页面缩略图。
页面标题和缩略图在理解页面和提高曝光转化率方面起着重要作用。
通过 wx.setNavigationBarTitle 或自定义转发内容 onShareAppMessage 设置页面的标题和缩略图,同时为视频和音频组件补充海报/poster-for-crawler 属性。
8. 使用页面路径推送能力
可以大大丰富微信上可以收录的内容,从而增加小程序内容的曝光机会。请参考:
抓取网页数据违法吗(网络爬虫(又被称为网页蜘蛛)(purposeEngine))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-03 15:14
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区,更常见的是网络追逐)是3233363533e58685e5aeb9333,一种按照一定规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义信息的查询。
网络爬虫
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。 查看全部
抓取网页数据违法吗(网络爬虫(又被称为网页蜘蛛)(purposeEngine))
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区,更常见的是网络追逐)是3233363533e58685e5aeb9333,一种按照一定规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的入口和向导。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)一般搜索引擎大多提供基于关键字的搜索,难以支持基于语义信息的查询。
网络爬虫
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-01 16:06
)
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看它,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫也迫不及待地每秒命中 12306 数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在且无法进行未经授权的访问以进行爬网
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
写在最后
查看全部
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称
)
Robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集的内容?是的,有rebots协议吗?
其实方法很简单。如果您想查看它,只需在 IE 上输入您的 URL/robots.txt。如果您想查看和分析机器人,您可以拥有专业的相关工具和站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家参考。大部分扫描的网站都非常开心。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫也迫不及待地每秒命中 12306 数万次。领带总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站的意愿,例如在网站采取反攀登措施后,强行突破其反攀登措施;
爬虫干扰了被访问的网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛,是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在且无法进行未经授权的访问以进行爬网
常见误解:认为爬虫是用来爬取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
写在最后
抓取网页数据违法吗( scrapy调度器的处理方法和处理的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-28 07:25
scrapy调度器的处理方法和处理的方法)
1.scrapy 框架有哪些组件/模块?
Scrapy Engine:这个引擎,负责Spider、ItemPipeline、Downloader、Scheduler之间的通讯、信号、数据传输!(它看起来像人体吗?)
Scheduler:负责接受引擎发送的请求,按照一定的方式排序,入队,等待Scrapy Engine请求,然后交给引擎。
Downloader:负责下载Scrapy Engine发送的所有Requests,并将得到的Responses返回给Scrapy Engine,交给Spiders进行处理。
Spiders:负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,将需要跟进的URL提交给引擎,再次进入Scheduler,
Item Pipeline:负责处理Spiders中获取到的Item,以及去重、持久化存储等处理(存储数据库,写入文件,总之就是用来保存数据的)
下载器中间件:可以将其视为可以自定义和扩展下载功能的组件
2. 简单说说scrapy的工作流程。
整个 Scrapy 的数据流:
程序运行时,
发动机:喂!蜘蛛,你想对付哪一只网站?
蜘蛛:我必须处理
引擎:给我第一个需要处理的网址。
蜘蛛:你的第一个 URL 是
发动机:喂!调度员,我有一个请求,请帮我整理一下队伍。
调度员:好的,正在处理中,请稍等。
发动机:喂!调度员,把你处理过的请求给我,
调度员:给你,这是我处理的请求
发动机:喂!下载器,你可以根据下载中间件的设置为我下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:对不起,这个请求的下载失败,然后引擎告诉调度器这个请求的下载失败,你记录下来,我们稍后再下载。)
发动机:喂!Spiders,这个是下载的东西,已经按照Spider中间件处理过,可以处理(注意!这里的响应默认是由def解析函数处理的)
蜘蛛:(处理完数据后需要跟进的网址),嗨!引擎,这是我需要跟进的URL,并将其响应交给函数def xxxx(self,responses)进行处理。这是我得到的物品。
发动机:喂!物品管道我这里有物品,你可以帮我处理!调度程序!这是我需要的网址。你可以替我处理。然后从第四步开始循环,直到得到你需要的信息,注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
3.Scrapy指纹去重原理和scrapy-redis去重原理?
Scrapy的去重原理流程:使用hash值并设置去重。首先创建一个fingerprint = set() 组合,然后使用sha1对象进行请求对象的信息汇总。汇总完成后,判断hash值是否在集合中。如果是,则返回 true。如果不是,则将其添加到集合中。
scrapy-redis的去重原理基本相同,只不过是持久化存储在redis共享数据库中。当请求的数据达到10亿以上时,此时会消耗内存。一个sha1会占用40字节 40G内存,大部分存储数据库都负担不起。这时候必须使用布隆过滤器。
4. 请简单介绍一下scrapy框架。
scrapy 是一个快速、高级的基于 Python 的网络爬虫框架,用于爬取网站并从页面中提取结构化数据。scrapy 使用 Twisted 异步网络库来处理网络通信。
5.为什么要使用scrapy框架?scrapy 框架的优点是什么?
更容易搭建大型爬虫项目
它异步处理请求并且速度非常快
它可以使用自动调节机构自动调节爬行速度
6.scrapy 如何实现分布式爬取?
可以借助scrapy_redis 类库来实现。
在分布式爬取中,会有一台主机和一台从机。其中,master为核心服务器,slave为具体爬虫服务器。
我们在主服务器上搭建了一个redis数据库,将要爬取的URL存放在redis数据库中。所有从爬虫服务器在爬取时都从redis数据库链接。由于scrapy_redis本身的队列机制,slave获取到的URL不会相互冲突,然后爬取的结果最终存储在数据库中。master的redis数据库也会存储爬取到的url的指纹,用于去重。相关代码可以在 dupefilter.py 文件中的 request_seen() 方法中找到。
重复问题:
dupefilter.py 中的源代码:
def request_seen(self, request):
fp = request_fingerprint(请求)
添加 = self.server.sadd(self.key, fp)
退货未添加
重复数据删除是通过将请求的指纹存储在 redis 上来实现的。
7.scrapy 和 requests 是如何使用的?
请求采用轮询方式,会被网络阻塞,不适合爬取大量数据
scapy底层是twisted的异步框架,并发是最大优势
8. 爬虫使用多线程是不是更好?有多个进程是否更好?为什么?
对于IO密集型代码(文件处理、网络爬虫),多线程可以有效提高效率(单线程IO操作会等待IO,造成不必要的等待时间。开启多线程后,当线程A正在等待,会自动切换到线程B,这样就不会浪费CPU资源,从而提高程序执行的效率)。
在实际的采集进程中,不仅需要考虑网速和相应的问题,还需要考虑自己机器的硬件,设置多进程或多线程。
9. 基于爬虫的模块有哪些?
网络请求:urllib、requests、aiohttp
数据分析:re、xpath、bs4、pyquery
硒
js反向:pyexcJs
10. 爬行过程中遇到的比较难的防爬机制有哪些?
动态加载的数据
动态改变请求参数
js加密
演戏
曲奇饼
11. 简述如何捕获动态加载的数据?
基于抓包工具的全局搜索
如果动态加载的数据是密文,全局搜索是不可搜索的
12.如何抓取手机数据?
fiddler,appnium,网络配置
13.如何抓取全站数据?
基于手动请求+递归分析发送
基于CrwalSpider(LinkExtractor,Rule)
14.如何提高爬取数据的效率?
使用框架
线程池,多任务异步协程
分散式
15. 列出你接触过的防攀爬机构?
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。这里只讨论数据采集部分。
一般来说,网站从三个方面进行反爬虫:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这些角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
1) 通过Headers反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源网站的防泄漏环节就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
2)基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。可以专门写一个爬虫来爬取网上公开的代理ip,检测后全部保存。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求几次就可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。一些存在逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求来绕过同一账号不能在短时间内多次发出相同请求的限制。
3) 动态页面反爬虫
以上情况大部分出现在静态页面上,还有一些网站,我们需要爬取的数据是通过ajax请求获取或者通过JavaScript生成的。首先使用 Firebug 或 HttpFox 来分析网络请求。
如果能找到ajax请求,分析出响应的具体参数和具体含义,就可以通过上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有些网站加密了ajax请求的所有参数。我们没有办法为我们需要的数据构造一个请求。这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,对接口参数进行加密。遇到这样的网站,就不能用上面的方法了。我使用selenium+phantomJS框架,调用浏览器内核,使用phantomJS执行js模拟人的操作,触发页面中的js脚本。从填表到点击按钮再到滚动页面,一切都可以模拟,无论具体的请求和响应过程,
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面是在一定程度上通过添加Headers来冒充浏览器),它是浏览器本身,phantomJS是一个没有界面的浏览器,但它不是控制浏览器的人。使用selenium+phantomJS可以做很多事情,比如识别point-and-touch(12306)或滑动验证码,页面表单的暴力破解等)。它还将在自动化渗透方面展示其才华,并且在未来也会这样做。提这个。
16.什么是深度优先和广度优先(优缺点)
默认情况下,scrapy 是深度优先。
深度优先:占用空间大,运行速度快。
广度优先:占用空间小,运行速度慢
17.你知道谷歌的无头浏览器吗?
无头浏览器是无头浏览器,没有界面的浏览器。既然是浏览器,它应该拥有浏览器应有的一切,但你看不到界面。
Python中selenium模块中的PhantomJS是无头浏览器(headless browser):它是一个基于QtWebkit的无头浏览器。
18. 说说Scrapy的优缺点。
优势:
scrapy 是异步的
使用更具可读性的 xpath 而不是常规
强大的统计和日志系统
同时抓取不同的 URL
支持shell模式,方便独立调试
编写中间件,方便编写一些统一的过滤器
通过管道存储在数据库中
缺点:基于python的爬虫框架,扩展性差
基于twisted框架,运行异常不会杀死反应器,异步框架出错后不会停止其他任务,数据错误难以检测。
19. 对于需要登录的网页,如何同时限制ip、cookie、session?
解决受限IP,可以使用代理IP地址池和服务器;如果动态抓取不适用,可以使用反编译的JS文件获取对应的文件,或者切换到其他平台(如手机)查看是否可以获取对应的json文件。
20. 验证码怎么解决?
1.输入类型验证码
解决方法:这是最简单的一种,只要你认清里面的内容,然后在输入框中填写即可。这种识别技术叫做OCR,这里推荐使用第三方Python库tesserocr。对于不受阴影影响的验证码,可以直接通过该库进行识别。但是对于背景嘈杂的验证码,直接识别率会很低。在这种情况下,我们需要先对图片进行处理,先对图片进行灰度化,然后进行二值化,然后再进行Recognition,这样识别率会大大提高。
验证码识别的大概步骤:
转换为灰度
去除背景噪音
图片分割
2.刷卡式验证码
解决方法:这种验证码稍微复杂一点,但是有相应的方法。我们直接想到的就是模拟人拖动验证码,点击按钮,然后看到缝隙的位置,最后将拼图拖到缝隙中完成验证的动作。
第一步:点击按钮。然后我们发现没有点击按钮的时候缝隙和拼图没有出现,只有点击后才出现,这为我们找到缝隙的位置提供了灵感。
步骤 2:拖动到间隙位置。我们知道应该把拼图拖到缝隙里,但是这个距离怎么用数值来表示呢?通过我们在第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图片的像素,设置一个参考值。如果某个位置的差异超过了参考值,那么我们就找到了两张图片的不同位置。当然,我们来自拼图的右侧。从侧面开始,从左到右,当你找到第一个不同的位置时结束。这个位置应该是gap的左边,所以我们可以用selenium拖动到这个位置。这里的另一个问题是如何自动保存这两张图片?在这里我们可以先找到这个标签,然后得到它的位置和大小,然后是顶部,底部,左侧,right = location['y'] ,location['y']+size['height']+location['x'] + size['width'],然后截图,最后把这四个位置填上一个切口。具体使用可以查看selenium文档,点击按钮剪出图片,点击再剪出图片。拖动时,需要模拟人的行为,先加速再减速。因为这种验证码有行为特征检测,一个人不可能做到匀速,否则会被判断为机器拖拽,所以不会通过验证。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
3.点击式图形验证和图标选择
图文验证:提醒用户点击图片中的同一个词进行文本验证。
图标选择:给定一组图片,根据需要单击其中一个或多个。借用识别所有东西来挡机器的难度。
这两个原理类似,只不过一个是给文字点击图片中的文字,另一个是给图片点击同一张图片。
这两种方法都不是特别好。他们只能使用第三方识别接口来识别相同的内容。推荐超级鹰,发送验证码,返回对应的点击坐标。然后用selenium模拟点击。获取图片的方法同上面的方法。
21.滑动验证码怎么破解?
破解核心思想:
1、如何确定滑块的滑动距离?
滑块的滑动距离,需要检测验证码图片的间隙位置
滑动距离=终点坐标-起点坐标
那么问题转化为我们需要截图,根据selenium中的position方法,进行一些坐标计算,得到我们需要的位置
2、我们如何获得坐标?
起点坐标:
程序每次运行,位置固定,滑块左边框距离验证码图片左边框6px
终点坐标:
每次程序运行时,位置都会发生变化,我们需要计算每个间隙的位置
如何计算终点,也就是缺口的位置?
让我给你举个例子。比如下面两张图片都是120x60的图片,一张是纯色图片,一张是带蓝线的图片(蓝线的位置是60px)。我现在让你通过程序确定蓝线的位置,你是怎么确定的?
回答:
遍历所有像素的颜色值,找到不同颜色值的点的位置,确定蓝线的位置
怎么理解这句话?大家点开我下面的图片,有没有发现图片是由一个像素组成的,一张120×60的图片,对应的像素是横轴120像素,纵轴60像素,我们需要遍历坐标两张图片并比较色值,从(0,0)(0,1)... to (120,60))),开始比较两者的色值图片,当颜色值不同时,我们可以返回位置
22. 数据是如何存储的?
以json格式存储到文本文件
这是最简单、最方便、最常用的存储方式。json 格式确保您在打开文件时可以直观地检查存储的数据。一行数据存储在一行中。这种方法适用于爬取数据量比较小的情况。,后续的阅读和分析也很方便。
保存到excel
如果爬取的数据很容易组织成表格形式,那么将其存储在excel中是一个不错的选择。打开excel后,观察数据更方便。Excel也可以做一些简单的操作。可以用xlwt写excel。有了这个库,你就可以用xlrd来读取excel了。和方法一一样,excel中存储的数据不要太多。另外,如果是多线程爬取,用多线程写excel是不可能的。这是一个限制。
存储到 sqlite
Sqlite不需要安装,它是一个零配置的数据库,比mysql轻很多。语法方面,只要懂mysql,操作sqlite就没有问题。当大量爬虫数据需要持久化存储,又懒得装mysql时,sqlite绝对是最好的选择,不多,不支持多进程读写,所以不适合多进程爬虫。
存储到mysql数据库
mysql 可以远程访问,sqlite 不能。这意味着您可以将数据存储在远程服务器主机上。当数据量非常大的时候,自然应该选择mysql而不是sqlite,但是无论是mysql还是sqlite,都必须在存储数据之前进行。必须先建表,根据要捕获的数据结构和内容定义字段。这是一个耐心和精力的问题。最后,如果你的时间不是很紧,想快速提高,最重要的是不要怕吃苦,建议你买这个价格@762459510,真的很好,很多人进步很快,你要不怕吃苦!可以去加进去看看~
存储到mongodb
我最喜欢no sql数据库的原因之一是不需要像关系数据库那样定义表结构,因为定义表结构很麻烦。判断字段的类型,varchar类型的数据也需要定义长度,你定义的小一点,过长的数据会被截断。
Mongodb 以文档的形式存储数据。可以使用pymongo库直接将数据以json格式写入mongodb。即使在同一个集合中,对数据的格式也没有要求,太灵活了。
刚刚捕获的数据通常需要进行第二次清理才能使用。如果使用关系型数据库存储数据,第一次需要定义表结构。清洗后,恐怕需要定义一个表结构来恢复清洗后的数据。收纳太麻烦。使用 mongodb 消除了重复定义表结构的过程。
23.如何处理cookie过期?
这时候需要自动更新cookie。如何自动更新cookies?这里将使用硒。
步骤1、 使用selenium自动登录获取cookie,并保存到文件中;
步骤2、 读取cookie,比较cookie的有效期,如果过期,重新执行步骤1;
步骤3、 请求其他网页时,填写cookie,维护登录状态。
24.Selenium 和 PhantomJS
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等主流浏览器。本工具主要功能包括:测试浏览器兼容性
——测试你的应用程序,看看它是否能在不同的浏览器和操作系统上运行良好。
它的功能是:
框架底层使用JavaScript模拟真实用户操作浏览器。测试脚本执行时,浏览器会根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户一样,站在最终用户的角度对应用进行测试。
尽管不同浏览器之间仍然存在细微的差异,但可以自动进行浏览器兼容性测试。
使用方便,可以使用Java、Python等语言编写用例脚本
也就是说,它可以像真人一样按照指令访问浏览器,比如打开网页、截屏等功能。
幻象
(新版本的selenium已经开始抛弃phantomjs,不过有时候我们可以单独使用它来做一些事情)它是一个基于webkit的无界面浏览器,可以将网站内容加载到内存中并执行页面各种脚本(比如js)。
25.如何判断网站是否更新? 查看全部
抓取网页数据违法吗(
scrapy调度器的处理方法和处理的方法)
1.scrapy 框架有哪些组件/模块?
Scrapy Engine:这个引擎,负责Spider、ItemPipeline、Downloader、Scheduler之间的通讯、信号、数据传输!(它看起来像人体吗?)
Scheduler:负责接受引擎发送的请求,按照一定的方式排序,入队,等待Scrapy Engine请求,然后交给引擎。
Downloader:负责下载Scrapy Engine发送的所有Requests,并将得到的Responses返回给Scrapy Engine,交给Spiders进行处理。
Spiders:负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,将需要跟进的URL提交给引擎,再次进入Scheduler,
Item Pipeline:负责处理Spiders中获取到的Item,以及去重、持久化存储等处理(存储数据库,写入文件,总之就是用来保存数据的)
下载器中间件:可以将其视为可以自定义和扩展下载功能的组件
2. 简单说说scrapy的工作流程。
整个 Scrapy 的数据流:
程序运行时,
发动机:喂!蜘蛛,你想对付哪一只网站?
蜘蛛:我必须处理
引擎:给我第一个需要处理的网址。
蜘蛛:你的第一个 URL 是
发动机:喂!调度员,我有一个请求,请帮我整理一下队伍。
调度员:好的,正在处理中,请稍等。
发动机:喂!调度员,把你处理过的请求给我,
调度员:给你,这是我处理的请求
发动机:喂!下载器,你可以根据下载中间件的设置为我下载这个请求
下载者:好的!给你,这是下载的东西。(如果失败:对不起,这个请求的下载失败,然后引擎告诉调度器这个请求的下载失败,你记录下来,我们稍后再下载。)
发动机:喂!Spiders,这个是下载的东西,已经按照Spider中间件处理过,可以处理(注意!这里的响应默认是由def解析函数处理的)
蜘蛛:(处理完数据后需要跟进的网址),嗨!引擎,这是我需要跟进的URL,并将其响应交给函数def xxxx(self,responses)进行处理。这是我得到的物品。
发动机:喂!物品管道我这里有物品,你可以帮我处理!调度程序!这是我需要的网址。你可以替我处理。然后从第四步开始循环,直到得到你需要的信息,注意!只有当调度器中没有请求时,整个程序才会停止,(即对于下载失败的 URL,Scrapy 会重新下载。)
3.Scrapy指纹去重原理和scrapy-redis去重原理?
Scrapy的去重原理流程:使用hash值并设置去重。首先创建一个fingerprint = set() 组合,然后使用sha1对象进行请求对象的信息汇总。汇总完成后,判断hash值是否在集合中。如果是,则返回 true。如果不是,则将其添加到集合中。
scrapy-redis的去重原理基本相同,只不过是持久化存储在redis共享数据库中。当请求的数据达到10亿以上时,此时会消耗内存。一个sha1会占用40字节 40G内存,大部分存储数据库都负担不起。这时候必须使用布隆过滤器。
4. 请简单介绍一下scrapy框架。
scrapy 是一个快速、高级的基于 Python 的网络爬虫框架,用于爬取网站并从页面中提取结构化数据。scrapy 使用 Twisted 异步网络库来处理网络通信。
5.为什么要使用scrapy框架?scrapy 框架的优点是什么?
更容易搭建大型爬虫项目
它异步处理请求并且速度非常快
它可以使用自动调节机构自动调节爬行速度
6.scrapy 如何实现分布式爬取?
可以借助scrapy_redis 类库来实现。
在分布式爬取中,会有一台主机和一台从机。其中,master为核心服务器,slave为具体爬虫服务器。
我们在主服务器上搭建了一个redis数据库,将要爬取的URL存放在redis数据库中。所有从爬虫服务器在爬取时都从redis数据库链接。由于scrapy_redis本身的队列机制,slave获取到的URL不会相互冲突,然后爬取的结果最终存储在数据库中。master的redis数据库也会存储爬取到的url的指纹,用于去重。相关代码可以在 dupefilter.py 文件中的 request_seen() 方法中找到。
重复问题:
dupefilter.py 中的源代码:
def request_seen(self, request):
fp = request_fingerprint(请求)
添加 = self.server.sadd(self.key, fp)
退货未添加
重复数据删除是通过将请求的指纹存储在 redis 上来实现的。
7.scrapy 和 requests 是如何使用的?
请求采用轮询方式,会被网络阻塞,不适合爬取大量数据
scapy底层是twisted的异步框架,并发是最大优势
8. 爬虫使用多线程是不是更好?有多个进程是否更好?为什么?
对于IO密集型代码(文件处理、网络爬虫),多线程可以有效提高效率(单线程IO操作会等待IO,造成不必要的等待时间。开启多线程后,当线程A正在等待,会自动切换到线程B,这样就不会浪费CPU资源,从而提高程序执行的效率)。
在实际的采集进程中,不仅需要考虑网速和相应的问题,还需要考虑自己机器的硬件,设置多进程或多线程。
9. 基于爬虫的模块有哪些?
网络请求:urllib、requests、aiohttp
数据分析:re、xpath、bs4、pyquery
硒
js反向:pyexcJs
10. 爬行过程中遇到的比较难的防爬机制有哪些?
动态加载的数据
动态改变请求参数
js加密
演戏
曲奇饼
11. 简述如何捕获动态加载的数据?
基于抓包工具的全局搜索
如果动态加载的数据是密文,全局搜索是不可搜索的
12.如何抓取手机数据?
fiddler,appnium,网络配置
13.如何抓取全站数据?
基于手动请求+递归分析发送
基于CrwalSpider(LinkExtractor,Rule)
14.如何提高爬取数据的效率?
使用框架
线程池,多任务异步协程
分散式
15. 列出你接触过的防攀爬机构?
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。这里只讨论数据采集部分。
一般来说,网站从三个方面进行反爬虫:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这些角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
1) 通过Headers反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源网站的防泄漏环节就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
2)基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。大部分网站都是前一种情况。在这种情况下,使用IP代理来解决它。可以专门写一个爬虫来爬取网上公开的代理ip,检测后全部保存。这类代理ip爬虫经常用到,最好自己准备一个。有大量代理ip后,每次请求几次就可以换一个ip。这在requests或urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。
在第二种情况下,您可以在每次请求后以几秒钟的随机间隔发出下一个请求。一些存在逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求来绕过同一账号不能在短时间内多次发出相同请求的限制。
3) 动态页面反爬虫
以上情况大部分出现在静态页面上,还有一些网站,我们需要爬取的数据是通过ajax请求获取或者通过JavaScript生成的。首先使用 Firebug 或 HttpFox 来分析网络请求。
如果能找到ajax请求,分析出响应的具体参数和具体含义,就可以通过上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有些网站加密了ajax请求的所有参数。我们没有办法为我们需要的数据构造一个请求。这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,对接口参数进行加密。遇到这样的网站,就不能用上面的方法了。我使用selenium+phantomJS框架,调用浏览器内核,使用phantomJS执行js模拟人的操作,触发页面中的js脚本。从填表到点击按钮再到滚动页面,一切都可以模拟,无论具体的请求和响应过程,
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面是在一定程度上通过添加Headers来冒充浏览器),它是浏览器本身,phantomJS是一个没有界面的浏览器,但它不是控制浏览器的人。使用selenium+phantomJS可以做很多事情,比如识别point-and-touch(12306)或滑动验证码,页面表单的暴力破解等)。它还将在自动化渗透方面展示其才华,并且在未来也会这样做。提这个。
16.什么是深度优先和广度优先(优缺点)
默认情况下,scrapy 是深度优先。
深度优先:占用空间大,运行速度快。
广度优先:占用空间小,运行速度慢
17.你知道谷歌的无头浏览器吗?
无头浏览器是无头浏览器,没有界面的浏览器。既然是浏览器,它应该拥有浏览器应有的一切,但你看不到界面。
Python中selenium模块中的PhantomJS是无头浏览器(headless browser):它是一个基于QtWebkit的无头浏览器。
18. 说说Scrapy的优缺点。
优势:
scrapy 是异步的
使用更具可读性的 xpath 而不是常规
强大的统计和日志系统
同时抓取不同的 URL
支持shell模式,方便独立调试
编写中间件,方便编写一些统一的过滤器
通过管道存储在数据库中
缺点:基于python的爬虫框架,扩展性差
基于twisted框架,运行异常不会杀死反应器,异步框架出错后不会停止其他任务,数据错误难以检测。
19. 对于需要登录的网页,如何同时限制ip、cookie、session?
解决受限IP,可以使用代理IP地址池和服务器;如果动态抓取不适用,可以使用反编译的JS文件获取对应的文件,或者切换到其他平台(如手机)查看是否可以获取对应的json文件。
20. 验证码怎么解决?
1.输入类型验证码
解决方法:这是最简单的一种,只要你认清里面的内容,然后在输入框中填写即可。这种识别技术叫做OCR,这里推荐使用第三方Python库tesserocr。对于不受阴影影响的验证码,可以直接通过该库进行识别。但是对于背景嘈杂的验证码,直接识别率会很低。在这种情况下,我们需要先对图片进行处理,先对图片进行灰度化,然后进行二值化,然后再进行Recognition,这样识别率会大大提高。
验证码识别的大概步骤:
转换为灰度
去除背景噪音
图片分割
2.刷卡式验证码
解决方法:这种验证码稍微复杂一点,但是有相应的方法。我们直接想到的就是模拟人拖动验证码,点击按钮,然后看到缝隙的位置,最后将拼图拖到缝隙中完成验证的动作。
第一步:点击按钮。然后我们发现没有点击按钮的时候缝隙和拼图没有出现,只有点击后才出现,这为我们找到缝隙的位置提供了灵感。
步骤 2:拖动到间隙位置。我们知道应该把拼图拖到缝隙里,但是这个距离怎么用数值来表示呢?通过我们在第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图片的像素,设置一个参考值。如果某个位置的差异超过了参考值,那么我们就找到了两张图片的不同位置。当然,我们来自拼图的右侧。从侧面开始,从左到右,当你找到第一个不同的位置时结束。这个位置应该是gap的左边,所以我们可以用selenium拖动到这个位置。这里的另一个问题是如何自动保存这两张图片?在这里我们可以先找到这个标签,然后得到它的位置和大小,然后是顶部,底部,左侧,right = location['y'] ,location['y']+size['height']+location['x'] + size['width'],然后截图,最后把这四个位置填上一个切口。具体使用可以查看selenium文档,点击按钮剪出图片,点击再剪出图片。拖动时,需要模拟人的行为,先加速再减速。因为这种验证码有行为特征检测,一个人不可能做到匀速,否则会被判断为机器拖拽,所以不会通过验证。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
3.点击式图形验证和图标选择
图文验证:提醒用户点击图片中的同一个词进行文本验证。
图标选择:给定一组图片,根据需要单击其中一个或多个。借用识别所有东西来挡机器的难度。
这两个原理类似,只不过一个是给文字点击图片中的文字,另一个是给图片点击同一张图片。
这两种方法都不是特别好。他们只能使用第三方识别接口来识别相同的内容。推荐超级鹰,发送验证码,返回对应的点击坐标。然后用selenium模拟点击。获取图片的方法同上面的方法。
21.滑动验证码怎么破解?
破解核心思想:
1、如何确定滑块的滑动距离?
滑块的滑动距离,需要检测验证码图片的间隙位置
滑动距离=终点坐标-起点坐标
那么问题转化为我们需要截图,根据selenium中的position方法,进行一些坐标计算,得到我们需要的位置
2、我们如何获得坐标?
起点坐标:
程序每次运行,位置固定,滑块左边框距离验证码图片左边框6px
终点坐标:
每次程序运行时,位置都会发生变化,我们需要计算每个间隙的位置
如何计算终点,也就是缺口的位置?
让我给你举个例子。比如下面两张图片都是120x60的图片,一张是纯色图片,一张是带蓝线的图片(蓝线的位置是60px)。我现在让你通过程序确定蓝线的位置,你是怎么确定的?
回答:
遍历所有像素的颜色值,找到不同颜色值的点的位置,确定蓝线的位置
怎么理解这句话?大家点开我下面的图片,有没有发现图片是由一个像素组成的,一张120×60的图片,对应的像素是横轴120像素,纵轴60像素,我们需要遍历坐标两张图片并比较色值,从(0,0)(0,1)... to (120,60))),开始比较两者的色值图片,当颜色值不同时,我们可以返回位置
22. 数据是如何存储的?
以json格式存储到文本文件
这是最简单、最方便、最常用的存储方式。json 格式确保您在打开文件时可以直观地检查存储的数据。一行数据存储在一行中。这种方法适用于爬取数据量比较小的情况。,后续的阅读和分析也很方便。
保存到excel
如果爬取的数据很容易组织成表格形式,那么将其存储在excel中是一个不错的选择。打开excel后,观察数据更方便。Excel也可以做一些简单的操作。可以用xlwt写excel。有了这个库,你就可以用xlrd来读取excel了。和方法一一样,excel中存储的数据不要太多。另外,如果是多线程爬取,用多线程写excel是不可能的。这是一个限制。
存储到 sqlite
Sqlite不需要安装,它是一个零配置的数据库,比mysql轻很多。语法方面,只要懂mysql,操作sqlite就没有问题。当大量爬虫数据需要持久化存储,又懒得装mysql时,sqlite绝对是最好的选择,不多,不支持多进程读写,所以不适合多进程爬虫。
存储到mysql数据库
mysql 可以远程访问,sqlite 不能。这意味着您可以将数据存储在远程服务器主机上。当数据量非常大的时候,自然应该选择mysql而不是sqlite,但是无论是mysql还是sqlite,都必须在存储数据之前进行。必须先建表,根据要捕获的数据结构和内容定义字段。这是一个耐心和精力的问题。最后,如果你的时间不是很紧,想快速提高,最重要的是不要怕吃苦,建议你买这个价格@762459510,真的很好,很多人进步很快,你要不怕吃苦!可以去加进去看看~
存储到mongodb
我最喜欢no sql数据库的原因之一是不需要像关系数据库那样定义表结构,因为定义表结构很麻烦。判断字段的类型,varchar类型的数据也需要定义长度,你定义的小一点,过长的数据会被截断。
Mongodb 以文档的形式存储数据。可以使用pymongo库直接将数据以json格式写入mongodb。即使在同一个集合中,对数据的格式也没有要求,太灵活了。
刚刚捕获的数据通常需要进行第二次清理才能使用。如果使用关系型数据库存储数据,第一次需要定义表结构。清洗后,恐怕需要定义一个表结构来恢复清洗后的数据。收纳太麻烦。使用 mongodb 消除了重复定义表结构的过程。
23.如何处理cookie过期?
这时候需要自动更新cookie。如何自动更新cookies?这里将使用硒。
步骤1、 使用selenium自动登录获取cookie,并保存到文件中;
步骤2、 读取cookie,比较cookie的有效期,如果过期,重新执行步骤1;
步骤3、 请求其他网页时,填写cookie,维护登录状态。
24.Selenium 和 PhantomJS
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等主流浏览器。本工具主要功能包括:测试浏览器兼容性
——测试你的应用程序,看看它是否能在不同的浏览器和操作系统上运行良好。
它的功能是:
框架底层使用JavaScript模拟真实用户操作浏览器。测试脚本执行时,浏览器会根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户一样,站在最终用户的角度对应用进行测试。
尽管不同浏览器之间仍然存在细微的差异,但可以自动进行浏览器兼容性测试。
使用方便,可以使用Java、Python等语言编写用例脚本
也就是说,它可以像真人一样按照指令访问浏览器,比如打开网页、截屏等功能。
幻象
(新版本的selenium已经开始抛弃phantomjs,不过有时候我们可以单独使用它来做一些事情)它是一个基于webkit的无界面浏览器,可以将网站内容加载到内存中并执行页面各种脚本(比如js)。
25.如何判断网站是否更新?
抓取网页数据违法吗(Web爬虫与网络爬虫(请记住,抓取与抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-26 20:31
抓取和抓取定义
在开始之前,让我们对互联网上的各种“草稿”和“爬虫”以及本文将使用的“草稿”和“爬虫”有一个正确的定义。
一般来说,有两种类型的划痕。有可能:
网页抓取
数据抓取
同样是爬行:
网络搜索
数据检索
现在,Web 和数据的定义已经很明确了,但是为了安全起见,Web 是可以在 Internet 上找到的任何东西,而数据是可以在任何地方找到的信息、统计数据和事实(不仅是互联网)。
在我们的文章中,我们将介绍什么是网络爬虫和网络爬虫(记住,数据爬虫和技术数据爬虫是一样的,只是它们不在网络上执行)。
正如我们的数据分析师告诉我们的那样,有几种方法可以将网络爬虫与网络抓取区分开来。所以请注意,我们将介绍一种区分它们的方法。你们中的一些人可能不同意我们的意见,不同意!在下面的评论中让我们知道您的想法,这是网络爬虫和网络抓取之间的主要区别!
现在我们已经摆脱困境,让我们跳到这里。
网络爬行和爬行 #2
什么是网络爬虫?
网络爬虫通常意味着从……你猜对了——在万维网上采集数据!传统上,要做很多工作,但不限于少量工作。爬虫将通过(或像蜘蛛一样爬行)许多不同的目标并点击它们。
根据我们的 Python 开发人员的说法,搜索器是“连接到网页并下载其内容的程序”。
他解释说,搜索器程序只是上网查找以下两件事:
用户正在搜索的数据
抓取更多目标
因此,如果我们尝试爬取一个真正的网站,过程将如下所示:
搜索器将转到您预定义的目标 –
发现产品页面
然后查找并下载产品数据(价格、标题、描述等)
但是,关于最后一点(我们已经方便地为您加粗了),我们将其从 YunCube 注释中排除,并将其称为划痕。
请花点时间在网络爬虫上查看他的完整文章。Cloud Cube 对网络爬虫的工作方式和爬虫的不同阶段做了详细的介绍,如果你从技术角度对此感兴趣,请查看他的个人博客。
什么是网络爬虫?
如果网络抓取意味着遍历和点击不同的目标,那么网络抓取就是您获取数据并下载的部分。网络爬虫就是知道先拿什么再拿(比如在网络爬虫/爬虫的情况下,通常可以爬取的是商品数据、价格、标题、描述等)。
因此,正如您可能已经采集到的,网络爬虫通常与爬虫同时运行。在进行网络爬虫时,您可以随时下载在线可用的信息。之后,您将过滤掉不需要的信息,并通过抓取仅选择您需要的信息。
但是,您可以在没有爬虫的帮助下手动爬网(尤其是在需要采集少量数据的情况下),而网络爬虫通常会伴随着爬虫来过滤掉不需要的信息。
网络爬行和爬行
所以,爬行和爬行——让我们梳理一下两者之间的所有主要区别,以清楚地了解两者:
运动的:
仅限网页抓取的“抓取”数据(获取所选数据并下载)。
仅限网络爬虫的“爬虫”数据(通过选定的目标)。
劳工:
网页抓取-可以手动完成,手工制作。
网络爬虫——只能使用爬虫代理(蜘蛛机器人)来完成。
重复数据删除:
网页抓取-重复数据删除并不总是必要的,因为它可以手动完成,因此规模较小。
网络爬虫——网上很多内容都是重复的,为了不采集太多重复的信息,爬虫会过滤掉这些数据。
综上所述
网络爬虫和网络爬虫的区别非常明显——爬虫会爬取互联网上的各种目标,就像蜘蛛爬行一样。一旦爬虫到达目标,就会被爬取——采集并下载选定目标的数据。返回搜狐查看更多 查看全部
抓取网页数据违法吗(Web爬虫与网络爬虫(请记住,抓取与抓取))
抓取和抓取定义
在开始之前,让我们对互联网上的各种“草稿”和“爬虫”以及本文将使用的“草稿”和“爬虫”有一个正确的定义。
一般来说,有两种类型的划痕。有可能:
网页抓取
数据抓取
同样是爬行:
网络搜索
数据检索
现在,Web 和数据的定义已经很明确了,但是为了安全起见,Web 是可以在 Internet 上找到的任何东西,而数据是可以在任何地方找到的信息、统计数据和事实(不仅是互联网)。
在我们的文章中,我们将介绍什么是网络爬虫和网络爬虫(记住,数据爬虫和技术数据爬虫是一样的,只是它们不在网络上执行)。
正如我们的数据分析师告诉我们的那样,有几种方法可以将网络爬虫与网络抓取区分开来。所以请注意,我们将介绍一种区分它们的方法。你们中的一些人可能不同意我们的意见,不同意!在下面的评论中让我们知道您的想法,这是网络爬虫和网络抓取之间的主要区别!
现在我们已经摆脱困境,让我们跳到这里。
网络爬行和爬行 #2
什么是网络爬虫?
网络爬虫通常意味着从……你猜对了——在万维网上采集数据!传统上,要做很多工作,但不限于少量工作。爬虫将通过(或像蜘蛛一样爬行)许多不同的目标并点击它们。
根据我们的 Python 开发人员的说法,搜索器是“连接到网页并下载其内容的程序”。
他解释说,搜索器程序只是上网查找以下两件事:
用户正在搜索的数据
抓取更多目标
因此,如果我们尝试爬取一个真正的网站,过程将如下所示:
搜索器将转到您预定义的目标 –
发现产品页面
然后查找并下载产品数据(价格、标题、描述等)
但是,关于最后一点(我们已经方便地为您加粗了),我们将其从 YunCube 注释中排除,并将其称为划痕。
请花点时间在网络爬虫上查看他的完整文章。Cloud Cube 对网络爬虫的工作方式和爬虫的不同阶段做了详细的介绍,如果你从技术角度对此感兴趣,请查看他的个人博客。
什么是网络爬虫?
如果网络抓取意味着遍历和点击不同的目标,那么网络抓取就是您获取数据并下载的部分。网络爬虫就是知道先拿什么再拿(比如在网络爬虫/爬虫的情况下,通常可以爬取的是商品数据、价格、标题、描述等)。
因此,正如您可能已经采集到的,网络爬虫通常与爬虫同时运行。在进行网络爬虫时,您可以随时下载在线可用的信息。之后,您将过滤掉不需要的信息,并通过抓取仅选择您需要的信息。
但是,您可以在没有爬虫的帮助下手动爬网(尤其是在需要采集少量数据的情况下),而网络爬虫通常会伴随着爬虫来过滤掉不需要的信息。
网络爬行和爬行
所以,爬行和爬行——让我们梳理一下两者之间的所有主要区别,以清楚地了解两者:
运动的:
仅限网页抓取的“抓取”数据(获取所选数据并下载)。
仅限网络爬虫的“爬虫”数据(通过选定的目标)。
劳工:
网页抓取-可以手动完成,手工制作。
网络爬虫——只能使用爬虫代理(蜘蛛机器人)来完成。
重复数据删除:
网页抓取-重复数据删除并不总是必要的,因为它可以手动完成,因此规模较小。
网络爬虫——网上很多内容都是重复的,为了不采集太多重复的信息,爬虫会过滤掉这些数据。
综上所述
网络爬虫和网络爬虫的区别非常明显——爬虫会爬取互联网上的各种目标,就像蜘蛛爬行一样。一旦爬虫到达目标,就会被爬取——采集并下载选定目标的数据。返回搜狐查看更多
抓取网页数据违法吗(“车来了”五名程序员爬取实时公交数据,竟构成犯罪行为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-23 23:33
编者按:本文来自微信公众号“”(ID:CSDNnews),作者郭锐。经 36kr 许可转载。
近日,一桩关于爬虫、反爬虫的官司又被推到了大众面前。
公共交通作为互联网从业者必备的通勤工具之一,是出行领域不可或缺的板块。实时公交APP也成为流行的应用场景。它们不仅可以为用户提供定位、公交路线查询等信息,还涉及路线规划、实时公交信息地理位置等服务。其中,“久美”和“车来了”是大众经常使用的两款实时公交出行APP。
《车来了》指使五名程序员爬取公交车实时数据,实为犯罪行为
2012 年 10 月,Kumicke 实时公共交通应用程序上线。Coolmic通过在公交车上安装定位器,获得了海量的实时公交车位置数据,具有定位精度高、实时误差小等明显优势,迅速吸引了大量的市场用户。目前,Komiike APP注册量超过5000万,日活跃用户超过400万。
但在2015年11月,为了提高市场占有率和信息查询的准确性,实时公交APP“Come Car”居然指导5名程序员和员工使用爬虫软件从Kumicco服务器获取公交行车信息。,到达时间等实时数据。
令人惊奇的是,这五位程序员的分工非常明确:一个负责编写爬虫软件程序;一个负责编写爬虫软件程序;一是负责不断改变爬虫软件程序中的IP地址以防止检测;一种是使用不同的IP地址和爬虫设置的程序向久美可发送数据请求;一个负责破解久美惠客户端的加密算法;破解失败后,另一名员工聘请其他公司的技术人员帮助破解加密系统,使爬虫得以顺利实施。这一系列的数据操作取得了显著成效,帮助《车来了》获得了Komiike的海量实时数据,每天可达3-400万条。
通过巨大的人力、时间和经济成本获得的信息被同行窃取,直接挤压了自身的竞争优势和交易机会。这怎么能让久美池和解呢?
一气之下,2016年久美惠将这辆车告上法庭。这场纠纷花了两年时间才最终敲定。今年5月,法院判决该车立即停止获取和使用Kumicco实时公交位置数据的不正当竞争行为,并赔偿其经济损失。
看到这里,大家最关心的问题是这五位程序员会不会被定罪?虽然在诉讼过程中,五名程序员和员工利用网络爬虫获取公交车辆实时信息的行为只是为了履行工作职责,而非谋取私利。但是,久美家后端服务器中存储的数据具有很大的商业价值。未经其许可,任何人不得非法获取本软件的后台数据并将其用于经营活动,须承担连带责任。
对此,中关村大数据联盟副秘书长陈新和先生告诉CSDN(ID:CSDNnews),“数据爬虫的非法边界一直是互联网争议的热点,尤其是在互联网时代。大数据。随着内容数据的价值越来越高,爬虫的侵权案件也越来越多。”身处其中的程序员很难置身于上级下达的“爬虫需求”之外,稍不留神就有可能进入游戏。
爬虫类犯罪的判决尚不明朗,仍处于灰色地带
事实上,爬行动物犯罪一直是一个难以界定的灰色地带。
网络爬虫是一种自动获取网络内容的程序。通常,这并不违法。例如,很多人使用百度搜索。除了其自营的百度知乎、百度百科等,几乎所有爬虫采集Down。作为一种技术,爬虫本身并不违法,所以大多数情况下你可以放心使用。一般来说,常见的爬取方法包括构造合理的HTTP请求头、设置cookies、降低访问频率、隐含输入字段值、使用代理等。
比如CSDN之前就有共享、、、、等应用数据爬取。但并不是所有的数据都有“爬行的机会”,陈新河说,“不许爬行,能不能越规越爬,能不能用技术手段越过封锁线……这些边球爬行者?很容易擦枪走火misfire。”-尤其是当网站明确声明禁止抓取采集或转载商业化时,或者网站声明机器人协议时。
机器人协议也叫爬虫协议、机器人协议,其全称是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面禁止爬取。
机器人协议是搜索引擎行业公认的商业道德,应予以遵守。
尽管如此,仍有无数“勇者”拼尽全力,包括熟悉的百度、360搜索、大众点评、今日头条等:
事实上,可以预见的是,由于目前监管法规不完善,还有不少鱼儿被遗漏。但是,随着数据价值的不断挖掘,未来爬虫侵权案件只会越来越多。
第三方网站如何应对日益猖獗的爬虫行为?
面对日益猖獗的爬虫行为,网站fang应该如何应对?
既然有“爬虫”,自然就会有“反爬虫”。网站一般使用的反爬虫技术可以分为四类:通过User-Agent控制访问,通过IP限制反爬虫,通过JS脚本阻止爬虫,通过robots.txt限制爬虫。
下面我们通过几个热门站点分析常见的反爬虫机制:
一、豆瓣
很多新手爬虫都会爬豆瓣练手,但豆瓣并没有完全开放。其反爬虫机制如下:
可见豆瓣是个很体贴的爬虫新手网站。爬虫只需要在代码中登录账号并减少并发数,然后随机延时等待一段时间,爬虫程序就不会被阻塞。
二、拉勾网
原来拉勾网的反爬虫机制没有现在这么严格,但是随着粉丝的增加,网站administrator增加了一些保护服务器的措施。网站反爬虫机制如下:
对于这种爬虫机制,爬虫只能使用IP代理池来突破。
三、汽车之家
汽车之家论坛的反爬虫机制比较先进。它使用前端页面自定义字体来实现反爬虫的技术手段。具体使用CSS3中的自定义字体模块,将自定义Web字体嵌入到指定的网页中。这导致在抓取论坛帖子的口碑时,在获取的返回文本中每隔几个单词就会出现一个乱码。
每次访问论坛页面时,字体保持不变,但字符编码发生变化。因此,爬虫需要根据每次访问动态解析字体文件。具体需要先访问爬取的页面,获取字体文件的动态访问地址,下载字体,读取JS渲染的文本内容,将里面的自定义字体代码替换为实际的文本代码,然后web页面可以恢复到页面上看到的内容。
......
然而,抗爬行动物并不是万能的。“以保护用户数据的名义,全面禁止基于数据垄断的爬取策略,也将受到数据经济时代新反垄断法的挑战。” 陈新河说。
程序员如何在数据爬取中“让路”?
但如果技术无罪,程序员应该有罪吗?上级吩咐写几行代码就莫名其妙被关起来了?可怕的是,他不仅丢脸,还无处倾诉。
在知乎上,也有很多关于爬虫犯罪的问题。在“爬虫合法还是非法?”的问题下 ()、知乎User@笔芯设计大师表示,爬虫开发者的道德自给和经营者的良心是避免触碰法律底线的根本:
我们周围的网络已经被各种网络爬虫密集覆盖。他们善恶不同,各有各的心思。作为爬虫开发者,在使用爬虫时如何避免进入游戏的厄运?
1.严格遵守网站设定的Robots协议;
2.在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问的网站的正常运行;
3.设置爬取策略时,要注意视频、音乐等可能构成作品的数据的编码和抓取,或者针对某些特定的网站批量抓取用户生成的内容;
4. 在使用和传播捕获的信息时,应对捕获的内容进行审查。如发现属于用户的个人信息、隐私或他人商业秘密,应及时予以制止和删除。
因此,面对上级危险的爬虫请求,程序员应该好好看看。
对于涉及法律风险的数据爬取需求,程序员最好在采集面前与上级深度聊一聊,与上级分担法律风险。如果对方仍然坚持采集,建议提前与公司签订免责协议,以免风险下降时被拉下水。
参考资料: 查看全部
抓取网页数据违法吗(“车来了”五名程序员爬取实时公交数据,竟构成犯罪行为)
编者按:本文来自微信公众号“”(ID:CSDNnews),作者郭锐。经 36kr 许可转载。
近日,一桩关于爬虫、反爬虫的官司又被推到了大众面前。
公共交通作为互联网从业者必备的通勤工具之一,是出行领域不可或缺的板块。实时公交APP也成为流行的应用场景。它们不仅可以为用户提供定位、公交路线查询等信息,还涉及路线规划、实时公交信息地理位置等服务。其中,“久美”和“车来了”是大众经常使用的两款实时公交出行APP。
《车来了》指使五名程序员爬取公交车实时数据,实为犯罪行为
2012 年 10 月,Kumicke 实时公共交通应用程序上线。Coolmic通过在公交车上安装定位器,获得了海量的实时公交车位置数据,具有定位精度高、实时误差小等明显优势,迅速吸引了大量的市场用户。目前,Komiike APP注册量超过5000万,日活跃用户超过400万。
但在2015年11月,为了提高市场占有率和信息查询的准确性,实时公交APP“Come Car”居然指导5名程序员和员工使用爬虫软件从Kumicco服务器获取公交行车信息。,到达时间等实时数据。
令人惊奇的是,这五位程序员的分工非常明确:一个负责编写爬虫软件程序;一个负责编写爬虫软件程序;一是负责不断改变爬虫软件程序中的IP地址以防止检测;一种是使用不同的IP地址和爬虫设置的程序向久美可发送数据请求;一个负责破解久美惠客户端的加密算法;破解失败后,另一名员工聘请其他公司的技术人员帮助破解加密系统,使爬虫得以顺利实施。这一系列的数据操作取得了显著成效,帮助《车来了》获得了Komiike的海量实时数据,每天可达3-400万条。
通过巨大的人力、时间和经济成本获得的信息被同行窃取,直接挤压了自身的竞争优势和交易机会。这怎么能让久美池和解呢?
一气之下,2016年久美惠将这辆车告上法庭。这场纠纷花了两年时间才最终敲定。今年5月,法院判决该车立即停止获取和使用Kumicco实时公交位置数据的不正当竞争行为,并赔偿其经济损失。
看到这里,大家最关心的问题是这五位程序员会不会被定罪?虽然在诉讼过程中,五名程序员和员工利用网络爬虫获取公交车辆实时信息的行为只是为了履行工作职责,而非谋取私利。但是,久美家后端服务器中存储的数据具有很大的商业价值。未经其许可,任何人不得非法获取本软件的后台数据并将其用于经营活动,须承担连带责任。
对此,中关村大数据联盟副秘书长陈新和先生告诉CSDN(ID:CSDNnews),“数据爬虫的非法边界一直是互联网争议的热点,尤其是在互联网时代。大数据。随着内容数据的价值越来越高,爬虫的侵权案件也越来越多。”身处其中的程序员很难置身于上级下达的“爬虫需求”之外,稍不留神就有可能进入游戏。
爬虫类犯罪的判决尚不明朗,仍处于灰色地带
事实上,爬行动物犯罪一直是一个难以界定的灰色地带。
网络爬虫是一种自动获取网络内容的程序。通常,这并不违法。例如,很多人使用百度搜索。除了其自营的百度知乎、百度百科等,几乎所有爬虫采集Down。作为一种技术,爬虫本身并不违法,所以大多数情况下你可以放心使用。一般来说,常见的爬取方法包括构造合理的HTTP请求头、设置cookies、降低访问频率、隐含输入字段值、使用代理等。
比如CSDN之前就有共享、、、、等应用数据爬取。但并不是所有的数据都有“爬行的机会”,陈新河说,“不许爬行,能不能越规越爬,能不能用技术手段越过封锁线……这些边球爬行者?很容易擦枪走火misfire。”-尤其是当网站明确声明禁止抓取采集或转载商业化时,或者网站声明机器人协议时。
机器人协议也叫爬虫协议、机器人协议,其全称是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面禁止爬取。
机器人协议是搜索引擎行业公认的商业道德,应予以遵守。
尽管如此,仍有无数“勇者”拼尽全力,包括熟悉的百度、360搜索、大众点评、今日头条等:
事实上,可以预见的是,由于目前监管法规不完善,还有不少鱼儿被遗漏。但是,随着数据价值的不断挖掘,未来爬虫侵权案件只会越来越多。
第三方网站如何应对日益猖獗的爬虫行为?
面对日益猖獗的爬虫行为,网站fang应该如何应对?
既然有“爬虫”,自然就会有“反爬虫”。网站一般使用的反爬虫技术可以分为四类:通过User-Agent控制访问,通过IP限制反爬虫,通过JS脚本阻止爬虫,通过robots.txt限制爬虫。
下面我们通过几个热门站点分析常见的反爬虫机制:
一、豆瓣
很多新手爬虫都会爬豆瓣练手,但豆瓣并没有完全开放。其反爬虫机制如下:
可见豆瓣是个很体贴的爬虫新手网站。爬虫只需要在代码中登录账号并减少并发数,然后随机延时等待一段时间,爬虫程序就不会被阻塞。
二、拉勾网
原来拉勾网的反爬虫机制没有现在这么严格,但是随着粉丝的增加,网站administrator增加了一些保护服务器的措施。网站反爬虫机制如下:
对于这种爬虫机制,爬虫只能使用IP代理池来突破。
三、汽车之家
汽车之家论坛的反爬虫机制比较先进。它使用前端页面自定义字体来实现反爬虫的技术手段。具体使用CSS3中的自定义字体模块,将自定义Web字体嵌入到指定的网页中。这导致在抓取论坛帖子的口碑时,在获取的返回文本中每隔几个单词就会出现一个乱码。
每次访问论坛页面时,字体保持不变,但字符编码发生变化。因此,爬虫需要根据每次访问动态解析字体文件。具体需要先访问爬取的页面,获取字体文件的动态访问地址,下载字体,读取JS渲染的文本内容,将里面的自定义字体代码替换为实际的文本代码,然后web页面可以恢复到页面上看到的内容。
......
然而,抗爬行动物并不是万能的。“以保护用户数据的名义,全面禁止基于数据垄断的爬取策略,也将受到数据经济时代新反垄断法的挑战。” 陈新河说。
程序员如何在数据爬取中“让路”?
但如果技术无罪,程序员应该有罪吗?上级吩咐写几行代码就莫名其妙被关起来了?可怕的是,他不仅丢脸,还无处倾诉。
在知乎上,也有很多关于爬虫犯罪的问题。在“爬虫合法还是非法?”的问题下 ()、知乎User@笔芯设计大师表示,爬虫开发者的道德自给和经营者的良心是避免触碰法律底线的根本:
我们周围的网络已经被各种网络爬虫密集覆盖。他们善恶不同,各有各的心思。作为爬虫开发者,在使用爬虫时如何避免进入游戏的厄运?
1.严格遵守网站设定的Robots协议;
2.在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问的网站的正常运行;
3.设置爬取策略时,要注意视频、音乐等可能构成作品的数据的编码和抓取,或者针对某些特定的网站批量抓取用户生成的内容;
4. 在使用和传播捕获的信息时,应对捕获的内容进行审查。如发现属于用户的个人信息、隐私或他人商业秘密,应及时予以制止和删除。
因此,面对上级危险的爬虫请求,程序员应该好好看看。
对于涉及法律风险的数据爬取需求,程序员最好在采集面前与上级深度聊一聊,与上级分担法律风险。如果对方仍然坚持采集,建议提前与公司签订免责协议,以免风险下降时被拉下水。
参考资料:
抓取网页数据违法吗(为什么80%的码农都做不了架构师?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-22 07:12
为什么可以将代码农民不是80%不能做建筑师? &gt; &gt; &gt;
网站内容内容网网是是技术技术技术技术技术类类文类文文文文文文文文文文文文文文文文文文文类文文文文文文文类文类类
1,通过正则表达式提取,(x)的HTML文件是一个文本文件,直接使用正则表达式来提取在指定地点的内容,“指定位置”不一定是绝对定位,例如,你可以参考HTML标签的定位,更准确
2,使用DOM,XML,的XPath,XSLT提取,(x)的HTML文件中的第一转成DOM数据结构,然后使用XPath这个结构来提取内容或使用XSLT传递给提取数据。
HTML文件本身是一个结构的文件。文档中的文本内容被封闭在许多标签(标签,HTML元素),构成HTML文档的结构。当在浏览器中显示,首先结构的文本文件转换成DOM数据结构。例如,一些必要的纠错,例如,在某些HTML文件的标签不是封闭的,只有开始标记,没有结束标记,需要生成DOM结构之前纠正这些错误。因此,如果简单地使用的正则表达式的方法,这些结构化信息没有很好的利用。与此相反,在第二数据提取方法利用了这些结构信息的优点,并且模块化编程方法可以大大提高了编程效率并减少该程序的错误,例如,使用XSLT XSL:模板,写一个数据格式转换和提取模块的。然而,XSL语言也变得更复杂。本文只解释了XSLT的使用技巧:在提取HTML页面的一块内容,但过滤掉一些不需要的模块。所述图像是一个页的大的块是害怕,但它们中的一些小片挖掘。
使用XSL:复制 - 的 - ,你可以复制HTML的整个数字,但如果你想挖了一些这个领域的,你需要一些技巧。您可以使用XSL:复制,XSL:只复制只提取当前节点,和XSL:复制,是提取当前节点及其subtocks和递归调用。用XSL:COPY,可以自定义递归调用类似于XSL过程:COPY-的其中OF-的,和节点可以任意期间递归调用控制
在即将到来的网页捕获/数据提取/信息提取软件套件Metaseeker的最新版本将提取规则定义的方法扩展到3:
1,通过软件完全生成;
2,用户可以指定用于使用所述XPath表达式的特定信息的属性的定位规则;
3,用户可以定义其自己的XSLT提取片段。
要实现上述需求,需要使用第三方法,以限定一个XSL:模板,例如,如下所示的模板
用于提取任务描述信息从一个自由职业者计划(自由出价与外包项目)网站,仅提取节点,例如,HTML元素和文本,而不是提取节点属性,例如,@类等时,节点将要过滤的需求与空模板实现,并且接下来的四个是其样的动作
把在网络上抓取/数据提取/信息提取软件工具包模板段如上所定义Metaseeker的BUCKET EDIT表的BUCKET EDIT表的输入框,可以自动在指令文件中嵌入自动生成的信息提取。 查看全部
抓取网页数据违法吗(为什么80%的码农都做不了架构师?(图))
为什么可以将代码农民不是80%不能做建筑师? &gt; &gt; &gt;
网站内容内容网网是是技术技术技术技术技术类类文类文文文文文文文文文文文文文文文文文文文类文文文文文文文类文类类
1,通过正则表达式提取,(x)的HTML文件是一个文本文件,直接使用正则表达式来提取在指定地点的内容,“指定位置”不一定是绝对定位,例如,你可以参考HTML标签的定位,更准确
2,使用DOM,XML,的XPath,XSLT提取,(x)的HTML文件中的第一转成DOM数据结构,然后使用XPath这个结构来提取内容或使用XSLT传递给提取数据。
HTML文件本身是一个结构的文件。文档中的文本内容被封闭在许多标签(标签,HTML元素),构成HTML文档的结构。当在浏览器中显示,首先结构的文本文件转换成DOM数据结构。例如,一些必要的纠错,例如,在某些HTML文件的标签不是封闭的,只有开始标记,没有结束标记,需要生成DOM结构之前纠正这些错误。因此,如果简单地使用的正则表达式的方法,这些结构化信息没有很好的利用。与此相反,在第二数据提取方法利用了这些结构信息的优点,并且模块化编程方法可以大大提高了编程效率并减少该程序的错误,例如,使用XSLT XSL:模板,写一个数据格式转换和提取模块的。然而,XSL语言也变得更复杂。本文只解释了XSLT的使用技巧:在提取HTML页面的一块内容,但过滤掉一些不需要的模块。所述图像是一个页的大的块是害怕,但它们中的一些小片挖掘。
使用XSL:复制 - 的 - ,你可以复制HTML的整个数字,但如果你想挖了一些这个领域的,你需要一些技巧。您可以使用XSL:复制,XSL:只复制只提取当前节点,和XSL:复制,是提取当前节点及其subtocks和递归调用。用XSL:COPY,可以自定义递归调用类似于XSL过程:COPY-的其中OF-的,和节点可以任意期间递归调用控制
在即将到来的网页捕获/数据提取/信息提取软件套件Metaseeker的最新版本将提取规则定义的方法扩展到3:
1,通过软件完全生成;
2,用户可以指定用于使用所述XPath表达式的特定信息的属性的定位规则;
3,用户可以定义其自己的XSLT提取片段。
要实现上述需求,需要使用第三方法,以限定一个XSL:模板,例如,如下所示的模板
用于提取任务描述信息从一个自由职业者计划(自由出价与外包项目)网站,仅提取节点,例如,HTML元素和文本,而不是提取节点属性,例如,@类等时,节点将要过滤的需求与空模板实现,并且接下来的四个是其样的动作
把在网络上抓取/数据提取/信息提取软件工具包模板段如上所定义Metaseeker的BUCKET EDIT表的BUCKET EDIT表的输入框,可以自动在指令文件中嵌入自动生成的信息提取。
抓取网页数据违法吗(“爬虫”是怎么抢张便宜机票的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-21 14:02
不到两个月,2018年春节即将到来
在北京工作的小王告诉《科技日报》,由于他的家乡在云南,春节的门票太贵,他选择花两天两夜的时间去“k6”返程,进行长途旅行
然而,就在小王准备买便宜票的时候,他在网上看到了这样一个消息:航空公司发行的低价机票中,80%以上被票务公司的“爬虫”抢走,普通用户很少能买到
小王很傻。“爬行动物”到底是什么?它是怎么抢票的?难道没有办法治理吗
抓取收录超链接信息的网页
爬虫技术是实现网络信息的关键技术之一采集.一般来说,“爬虫”是一种用于批量和自动化“采集 网站数据”的程序,几乎不需要人工干预,“北京工业大学网络科学与技术研究所副教授闫怀志说。他告诉《科技日报》
阎怀志介绍,“爬虫”又称网页“蜘蛛”和网络机器人,是一种根据一定规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录供用户阅读的文本、图片等信息,还收录一些超链接信息。网络“爬虫”借助这些超链接信息不断地抓取网络上的其他网页
“这类信息采集过程非常像一个在互联网上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’被命名。”阎怀志说,“爬虫”最早应用于搜索引擎领域,如谷歌、百度、搜狗等搜索引擎工具。他们每天需要在互联网上捕获数百亿个网页,需要借助巨大的“爬虫”集群来实现搜索功能
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以在航空公司的官方网站上获取机票价格。“爬虫”在发现低价或紧俏的客票后,可以利用虚假客源的真实身份信息进行抢先预订。此外,许多互联网浏览器都推出了自己的机票抓取插件,以推广机票预订成功率高的浏览器
根据爬行任务和目标的不同,网络“爬行器”大致可分为批量型、增量型和垂直型。批量“爬虫”的捕获范围和目标比较明确,可以是设置的网页数量,也可以是设置的时间消耗。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于特定主题内容或行业特定网页
“爬虫”是怎么弄到票的
此前,携程的“反爬虫”专家在技术分享中透露,某个网站页面每分钟的浏览量为1.2只有500个真正的用户,“爬虫”流量的比例是95.8%
采访中,不少业内人士还表示,即使在“爬虫”活动淡季,虚假流量也占网站总预订流量的50%,峰值超过90%
那么,“爬行动物”是如何实现抢票的呢?对此,严怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断捕捉航空公司机票销售官网的网站信息。如果发现航空公司已经发行低价机票,“爬虫”会立即使用虚假的客源身份进行批量预订而不是实际付款,从而达到抢占低价机票客源的目的。因为“爬虫”的效率远远高于正常的手动操作,所以通过正常操作几乎不可能抓到车票
然后,机票代理商将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客源,在航空公司允许的账户期限内退订之前以虚假客源身份预订的低价机票,然后利用真实身份信息进行订购,最终实现低价机票的涨价转售
如果在航空公司规定的会计期间内未找到真实客源,票务代理将在订单到期前添加虚假身份订单,并继续“占用”低价机票,以此类推,直到找到并出售真实客源
“上述操作流程构成了一个完整的门票销售链。在这个过程中,航空公司的票务系统允许在会计期间内重复预订和退款,这有助于票务代理使用“爬虫”抓取机票并提高价格以获取利润。这种抢票方式被称为技术上的“黄牛党”。”阎怀志强调
的确,一些业内人士表示,这些“爬虫”流量在没有任何消耗的情况下消耗了大量的机器资源,这是每个公司最痛恨的。但是,由于担心误伤真实用户,各公司的“反爬虫”策略非常谨慎
“爬行动物”可以通过某种手段加以预防和控制
任何事物都有两面性,“爬虫”技术也不例外
阎怀志认为,“爬虫”不仅可以为正常批量数据采集提供有效的技术手段,还可以被恶意利用以获取不当利益,如果“爬虫”技术使用不当,将带来一定的危害
首先,威胁数据安全。机票网站数据被恶意爬网,可能被机票代理恶意使用,并且存在被同行获取的风险
其次,它会导致系统性能下降,影响用户体验“将导致航空票务网站服务器的资源负载增加和性能下降,网站响应速度较慢甚至无法提供服务,这将对用户的搜索和交易体验产生负面影响。然而,由于巨大的灰色利益空间和“反爬虫”技术在反“爬虫”斗争中的有限作用,这种明显不公平的“作弊”方式已成为扰乱票务市场秩序的技术“顽疾”
“从技术角度来看,拦截‘爬虫’可以通过网站流量统计系统和服务器访问日志分析系统。”阎怀志说,通过流量统计和日志分析,如果发现单次IP访问、单次会话访问和用户代理信息超过设定的正常频率阈值,将判断访问是由恶意“爬虫程序”引起的,并且“爬虫程序”将被删除。您的IP被列入黑名单以拒绝后续访问
然后设置各种访问验证链接。例如,如果存在可疑的IP访问,请返回验证页面,并要求访问者通过填写验证代码并选择验证图片或字符进行验证。如果是恶意“爬虫”,显然很难完成上述验证操作,那么可以阻止“爬虫”的访问,防止其恶意抓取信息
互联网空间不能有“灰色区域”
目前,以云计算和大数据为代表的新一代信息技术正处于快速发展阶段
严怀志说:“如果上述新技术被非法或不当应用,将造成严重危害。互联网空间安全需要建立健全完善的保护体系,绝不能‘裸奔’。”
2017年6月1日,中国《网络安全法》正式实施,明确了网络安全各方的权利和责任。这是中国网络空间治理和法制建设从量变到质变的重要里程碑。作为依法治理互联网、化解网络风险的法律工具,该法已成为中国互联网在法治轨道上健康运行的重要保障
但是,目前对高科技“黄牛”的倒票行为没有明确规定,使得恶意抓取信息和不当牟利行为处于法律法规监管的“灰色地带”
阎怀志介绍,国际上专门为“爬虫”应用制定了机器人协议(即爬虫协议、网络机器人协议等)。该协议的全称为“网络爬虫排除标准”网站它可以告诉“爬虫”哪些页面和信息可以爬网,哪些页面和信息不能爬网。作为网站与“爬虫”的沟通方式,该协议用于规范“爬虫”行为和限制不正当竞争
作为国际互联网界通行的道德规范,该协议的原则是“爬虫”和搜索技术应服务于人类,尊重信息提供者的意愿并保护其隐私网站有义务保护其用户的个人信息和隐私。这规定了爬虫程序和被爬虫程序的权利和义务
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要依靠技术防范和行业自律,还要通过改善管理、法律法规,特别是法律手段来限制这种行为,以显示惩罚和威慑的力量。航空公司 查看全部
抓取网页数据违法吗(“爬虫”是怎么抢张便宜机票的?(图))
不到两个月,2018年春节即将到来
在北京工作的小王告诉《科技日报》,由于他的家乡在云南,春节的门票太贵,他选择花两天两夜的时间去“k6”返程,进行长途旅行
然而,就在小王准备买便宜票的时候,他在网上看到了这样一个消息:航空公司发行的低价机票中,80%以上被票务公司的“爬虫”抢走,普通用户很少能买到
小王很傻。“爬行动物”到底是什么?它是怎么抢票的?难道没有办法治理吗
抓取收录超链接信息的网页
爬虫技术是实现网络信息的关键技术之一采集.一般来说,“爬虫”是一种用于批量和自动化“采集 网站数据”的程序,几乎不需要人工干预,“北京工业大学网络科学与技术研究所副教授闫怀志说。他告诉《科技日报》
阎怀志介绍,“爬虫”又称网页“蜘蛛”和网络机器人,是一种根据一定规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录供用户阅读的文本、图片等信息,还收录一些超链接信息。网络“爬虫”借助这些超链接信息不断地抓取网络上的其他网页
“这类信息采集过程非常像一个在互联网上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’被命名。”阎怀志说,“爬虫”最早应用于搜索引擎领域,如谷歌、百度、搜狗等搜索引擎工具。他们每天需要在互联网上捕获数百亿个网页,需要借助巨大的“爬虫”集群来实现搜索功能
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以在航空公司的官方网站上获取机票价格。“爬虫”在发现低价或紧俏的客票后,可以利用虚假客源的真实身份信息进行抢先预订。此外,许多互联网浏览器都推出了自己的机票抓取插件,以推广机票预订成功率高的浏览器
根据爬行任务和目标的不同,网络“爬行器”大致可分为批量型、增量型和垂直型。批量“爬虫”的捕获范围和目标比较明确,可以是设置的网页数量,也可以是设置的时间消耗。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于特定主题内容或行业特定网页
“爬虫”是怎么弄到票的
此前,携程的“反爬虫”专家在技术分享中透露,某个网站页面每分钟的浏览量为1.2只有500个真正的用户,“爬虫”流量的比例是95.8%
采访中,不少业内人士还表示,即使在“爬虫”活动淡季,虚假流量也占网站总预订流量的50%,峰值超过90%
那么,“爬行动物”是如何实现抢票的呢?对此,严怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断捕捉航空公司机票销售官网的网站信息。如果发现航空公司已经发行低价机票,“爬虫”会立即使用虚假的客源身份进行批量预订而不是实际付款,从而达到抢占低价机票客源的目的。因为“爬虫”的效率远远高于正常的手动操作,所以通过正常操作几乎不可能抓到车票
然后,机票代理商将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客源,在航空公司允许的账户期限内退订之前以虚假客源身份预订的低价机票,然后利用真实身份信息进行订购,最终实现低价机票的涨价转售
如果在航空公司规定的会计期间内未找到真实客源,票务代理将在订单到期前添加虚假身份订单,并继续“占用”低价机票,以此类推,直到找到并出售真实客源
“上述操作流程构成了一个完整的门票销售链。在这个过程中,航空公司的票务系统允许在会计期间内重复预订和退款,这有助于票务代理使用“爬虫”抓取机票并提高价格以获取利润。这种抢票方式被称为技术上的“黄牛党”。”阎怀志强调
的确,一些业内人士表示,这些“爬虫”流量在没有任何消耗的情况下消耗了大量的机器资源,这是每个公司最痛恨的。但是,由于担心误伤真实用户,各公司的“反爬虫”策略非常谨慎
“爬行动物”可以通过某种手段加以预防和控制
任何事物都有两面性,“爬虫”技术也不例外
阎怀志认为,“爬虫”不仅可以为正常批量数据采集提供有效的技术手段,还可以被恶意利用以获取不当利益,如果“爬虫”技术使用不当,将带来一定的危害
首先,威胁数据安全。机票网站数据被恶意爬网,可能被机票代理恶意使用,并且存在被同行获取的风险
其次,它会导致系统性能下降,影响用户体验“将导致航空票务网站服务器的资源负载增加和性能下降,网站响应速度较慢甚至无法提供服务,这将对用户的搜索和交易体验产生负面影响。然而,由于巨大的灰色利益空间和“反爬虫”技术在反“爬虫”斗争中的有限作用,这种明显不公平的“作弊”方式已成为扰乱票务市场秩序的技术“顽疾”
“从技术角度来看,拦截‘爬虫’可以通过网站流量统计系统和服务器访问日志分析系统。”阎怀志说,通过流量统计和日志分析,如果发现单次IP访问、单次会话访问和用户代理信息超过设定的正常频率阈值,将判断访问是由恶意“爬虫程序”引起的,并且“爬虫程序”将被删除。您的IP被列入黑名单以拒绝后续访问
然后设置各种访问验证链接。例如,如果存在可疑的IP访问,请返回验证页面,并要求访问者通过填写验证代码并选择验证图片或字符进行验证。如果是恶意“爬虫”,显然很难完成上述验证操作,那么可以阻止“爬虫”的访问,防止其恶意抓取信息
互联网空间不能有“灰色区域”
目前,以云计算和大数据为代表的新一代信息技术正处于快速发展阶段
严怀志说:“如果上述新技术被非法或不当应用,将造成严重危害。互联网空间安全需要建立健全完善的保护体系,绝不能‘裸奔’。”
2017年6月1日,中国《网络安全法》正式实施,明确了网络安全各方的权利和责任。这是中国网络空间治理和法制建设从量变到质变的重要里程碑。作为依法治理互联网、化解网络风险的法律工具,该法已成为中国互联网在法治轨道上健康运行的重要保障
但是,目前对高科技“黄牛”的倒票行为没有明确规定,使得恶意抓取信息和不当牟利行为处于法律法规监管的“灰色地带”
阎怀志介绍,国际上专门为“爬虫”应用制定了机器人协议(即爬虫协议、网络机器人协议等)。该协议的全称为“网络爬虫排除标准”网站它可以告诉“爬虫”哪些页面和信息可以爬网,哪些页面和信息不能爬网。作为网站与“爬虫”的沟通方式,该协议用于规范“爬虫”行为和限制不正当竞争
作为国际互联网界通行的道德规范,该协议的原则是“爬虫”和搜索技术应服务于人类,尊重信息提供者的意愿并保护其隐私网站有义务保护其用户的个人信息和隐私。这规定了爬虫程序和被爬虫程序的权利和义务
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要依靠技术防范和行业自律,还要通过改善管理、法律法规,特别是法律手段来限制这种行为,以显示惩罚和威慑的力量。航空公司
抓取网页数据违法吗(如何用Excel快速抓取网页数据?(图)大多需要编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-21 13:19
网站上的数据源是我们统计分析的重要信息源。在我们的生活中,我们经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这是非常重要的,也是数据分析相关工作的必要技能之一。但是大多数爬虫需要编程知识,这对于普通人来说是很难开始的。今天,我将解释如何使用Excel快速获取web数据
1、first open网站要捕获的数据并复制网站地址
2、创建新的EXCEL工作簿并单击“数据”菜单>;从“获取外部数据”选项卡中的网站选项
在弹出的“新建web查询”对话框中,在地址栏中输入要捕获的网站地址,然后单击“转到”
单击黄色导入箭头并选择要捕获的零件,如图所示。单击导入
3、选择数据存储位置(默认选择单元格),然后单击确定。通常建议将数据存储在“A1”单元格中
获取数据需要一些时间。请耐心等待
4、如果您希望excel工作簿数据根据网站数据自动实时更新,则需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等
获取数据后,需要对数据进行处理,而处理数据是一个更重要的环节。更多的数据处理技能,请注意我
如果它对您有帮助,请记住喜欢它并转发它
关注我,让我学习更多的Excel技能,让工作更轻松 查看全部
抓取网页数据违法吗(如何用Excel快速抓取网页数据?(图)大多需要编程)
网站上的数据源是我们统计分析的重要信息源。在我们的生活中,我们经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这是非常重要的,也是数据分析相关工作的必要技能之一。但是大多数爬虫需要编程知识,这对于普通人来说是很难开始的。今天,我将解释如何使用Excel快速获取web数据
1、first open网站要捕获的数据并复制网站地址
2、创建新的EXCEL工作簿并单击“数据”菜单>;从“获取外部数据”选项卡中的网站选项
在弹出的“新建web查询”对话框中,在地址栏中输入要捕获的网站地址,然后单击“转到”
单击黄色导入箭头并选择要捕获的零件,如图所示。单击导入
3、选择数据存储位置(默认选择单元格),然后单击确定。通常建议将数据存储在“A1”单元格中
获取数据需要一些时间。请耐心等待
4、如果您希望excel工作簿数据根据网站数据自动实时更新,则需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等
获取数据后,需要对数据进行处理,而处理数据是一个更重要的环节。更多的数据处理技能,请注意我
如果它对您有帮助,请记住喜欢它并转发它
关注我,让我学习更多的Excel技能,让工作更轻松
抓取网页数据违法吗( 如何批量的批量抓取网页中的数据,如下粉丝如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-17 15:13
如何批量的批量抓取网页中的数据,如下粉丝如何)
数据捕获(大数据捕获客户软件)
大家好,今天我想和大家分享一下我们如何批量捕获网页中的数据,以捕获汽车投诉的数量。我想与您分享如何批量捕获网页中的数据。这也是一位粉丝提出的问题。他打算买一辆汽车,想看看各制造商的投诉数量。不要说太多。让我们直接开始吧。如果你进来是想了解来自不同制造商的投诉数量和投诉型号的排名,那就到此为止
一、分析页面
让我们以从到vehicle 的汽车投诉为例,向您展示如何批量捕获数据。如下图所示,从第1页到第3页都有网站。我们可以看到,只有红色的123,即对应的页码,是不同的,其余的都是相同的
二、grab数据
然后打开excel,单击数据功能组以查找self网站,单击高级选项,然后将代表页码的数字放在单独的输入框中。可以通过单击“添加零件”来添加输入框。设置完成后,我们直接点击OK
这样,我们将进入navigator界面。在此页面中,power query捕获了两个内容。我们可以点击查看我们需要的最佳数据。这里,表0是我们想要捕获的数据。直接选择table0,点击〖转换数据〗按钮,进入powerquery的编辑界面
接下来,单击高级编辑器并输入(x作为数字)作为table=>;然后将网站中的“1”更改为(number.ToText(x))并单击完成
这样,我们将把前面的操作封装到一个函数中。我们只需要输入相应的号码,然后点击call跳转到相应页码的数据
然后单击左侧的空白区域,右键单击以选择新查询,查找其他源,然后选择空查询,然后在编辑栏中输入它={1..100}单击enter,我们将得到一个从1到100的序列,然后单击表将查询转换为表,然后直接单击OK
然后选择add column,找到自定义函数,在函数查询中选择table0,直接点击OK。这样,power query将开始抓取数据。在这里抓取100页网页数据的过程可能相当长。我在这里花了大约3分钟的时间,在捕捉到最佳网络后,我们将在每个系列的后面得到一张桌子。我们单击左箭头和右箭头展开数据,删除原创列名前面的复选标记,然后单击确定删除我们添加的序列。这样,我们就完成了。我们只需要在开始时选择close和upload to将数据加载到excel中,因为有很多数据,这个过程也需要很多时间。我在这里花了大约一分钟的时间
三、统计分析
当数据加载到excel中时,我们可以通过数据透视表快速分析数据,如下图所示。根据车辆质量网络投诉记录中采集的3000条数据,我们可以通过数据透视表得到投诉品牌和投诉车型系列的排名。在这里,近一个月的投诉量达到3000条数据
以上是我们批量捕获100页网页数据的方法,以及各个制造商的投诉排名。整个过程大约需要7分钟,大部分时间用于数据捕获和加载
进展如何?你学会了吗?快试试 查看全部
抓取网页数据违法吗(
如何批量的批量抓取网页中的数据,如下粉丝如何)
数据捕获(大数据捕获客户软件)
大家好,今天我想和大家分享一下我们如何批量捕获网页中的数据,以捕获汽车投诉的数量。我想与您分享如何批量捕获网页中的数据。这也是一位粉丝提出的问题。他打算买一辆汽车,想看看各制造商的投诉数量。不要说太多。让我们直接开始吧。如果你进来是想了解来自不同制造商的投诉数量和投诉型号的排名,那就到此为止
一、分析页面
让我们以从到vehicle 的汽车投诉为例,向您展示如何批量捕获数据。如下图所示,从第1页到第3页都有网站。我们可以看到,只有红色的123,即对应的页码,是不同的,其余的都是相同的
二、grab数据
然后打开excel,单击数据功能组以查找self网站,单击高级选项,然后将代表页码的数字放在单独的输入框中。可以通过单击“添加零件”来添加输入框。设置完成后,我们直接点击OK
这样,我们将进入navigator界面。在此页面中,power query捕获了两个内容。我们可以点击查看我们需要的最佳数据。这里,表0是我们想要捕获的数据。直接选择table0,点击〖转换数据〗按钮,进入powerquery的编辑界面
接下来,单击高级编辑器并输入(x作为数字)作为table=>;然后将网站中的“1”更改为(number.ToText(x))并单击完成
这样,我们将把前面的操作封装到一个函数中。我们只需要输入相应的号码,然后点击call跳转到相应页码的数据
然后单击左侧的空白区域,右键单击以选择新查询,查找其他源,然后选择空查询,然后在编辑栏中输入它={1..100}单击enter,我们将得到一个从1到100的序列,然后单击表将查询转换为表,然后直接单击OK
然后选择add column,找到自定义函数,在函数查询中选择table0,直接点击OK。这样,power query将开始抓取数据。在这里抓取100页网页数据的过程可能相当长。我在这里花了大约3分钟的时间,在捕捉到最佳网络后,我们将在每个系列的后面得到一张桌子。我们单击左箭头和右箭头展开数据,删除原创列名前面的复选标记,然后单击确定删除我们添加的序列。这样,我们就完成了。我们只需要在开始时选择close和upload to将数据加载到excel中,因为有很多数据,这个过程也需要很多时间。我在这里花了大约一分钟的时间
三、统计分析
当数据加载到excel中时,我们可以通过数据透视表快速分析数据,如下图所示。根据车辆质量网络投诉记录中采集的3000条数据,我们可以通过数据透视表得到投诉品牌和投诉车型系列的排名。在这里,近一个月的投诉量达到3000条数据
以上是我们批量捕获100页网页数据的方法,以及各个制造商的投诉排名。整个过程大约需要7分钟,大部分时间用于数据捕获和加载
进展如何?你学会了吗?快试试
抓取网页数据违法吗(这儿简易讨论一下Spider对网址的获取状况都有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-17 01:20
百度搜索引擎蜘蛛对网站的访问应该是最值得SEO人员分析的内容。然而,许多SEO人员不知道如何分析百度搜索引擎在日志中长期优化的爬行记录。这里有一个关于spider访问该网站的级别非常值得分析的简要讨论,以及分析的结论如何指导SEO工作
可以分析蜘蛛爬行数据信息:各平台蜘蛛爬行频率、主网页蜘蛛爬行频率、网站内容蜘蛛爬行分布、各类网页蜘蛛采集、网站蜘蛛爬行状态代码等
(1)通过分析蜘蛛在各平台上爬行频率的发展趋势,我们可以很容易地在百度搜索引擎的眼中把握网站的质量,如果平台没有完成重大变化,内容升级正常,百度搜索引擎的爬行频率就会降低缓慢或突然,不是网站的错误操作,是百度搜索引擎青觉得网站质量有问题;如果百度搜索引擎的爬行频率突然扩大,可能是网站有404个网页,导致蜘蛛集中重复爬行;我如果百度搜索引擎的爬行频率慢慢扩大,可能是随着网站内容的逐渐增加和权重值的逐渐积累,一切都得到了正常的爬行,几乎平静稳定的变化也就不足为奇了,如果发生剧烈的变化,一定要引起足够的重视
(2)根据蜘蛛对主网页获取规律的分析,可以辅助调整网页升级次数,一般百度搜索引擎蜘蛛会对网站.这样的网页不能是信息页,而是主页、目录页或具有许多外部链接的页面
如图10-4所示,它在网站的nbc.html页面上显示了百度搜索蜘蛛的获取状态。该页面是该平台的新内容页面,即专为百度搜索引擎在网站中查找新内容而设计的页面。该页面中有300个连接,每五分钟升级一次,一次d我们已经知道网站是在五分钟内制作的,换句话说,并非所有新形成的网页都会出现在nbc.html中。根据图10-4中百度搜索蜘蛛获取的网页,百度搜索蜘蛛最多会在2分钟内抓取网页一次。然而,网页的刷新频率是5米在几分钟内,换言之,100多个学位搜索蜘蛛的获取频率的一半没有获得新的连接,并且网站的新信息的连接没有完全呈现在网页上。根据这种数据和信息的差异,我们可以专门指导SEO人员推广专业的d技术人员提高网页的缓存文件时间,扩大升级频率,并将升级频率设置为每2分钟一次,这样不仅可以让百度搜索蜘蛛在每次抓取网页时获得新的连接,还可以扩大sear发现网站新内容的概率ch发动机
网站中有很多种类的网页,如首页、目录页和前面提到的页面。在网站中,通常会继续存在大量其他集成页面,这些页面的爬行频率非常高。特别是网站的主页,很多平台的主页都会被百度搜索ch引擎每天都在爬行,但是在很多主页上发布的链接很少,有些则消耗了蜘蛛在主页上自己的权重值所产生的高爬行频率。这没有害处SEO关键词在搜索量和布局条件下,SEO人员可以灵活使用这部分资源,在网站上制作所有新内容它可以被百度搜索引擎及时处理,也可以减少百度搜索引擎的失败和爬行 查看全部
抓取网页数据违法吗(这儿简易讨论一下Spider对网址的获取状况都有哪些?)
百度搜索引擎蜘蛛对网站的访问应该是最值得SEO人员分析的内容。然而,许多SEO人员不知道如何分析百度搜索引擎在日志中长期优化的爬行记录。这里有一个关于spider访问该网站的级别非常值得分析的简要讨论,以及分析的结论如何指导SEO工作
可以分析蜘蛛爬行数据信息:各平台蜘蛛爬行频率、主网页蜘蛛爬行频率、网站内容蜘蛛爬行分布、各类网页蜘蛛采集、网站蜘蛛爬行状态代码等
(1)通过分析蜘蛛在各平台上爬行频率的发展趋势,我们可以很容易地在百度搜索引擎的眼中把握网站的质量,如果平台没有完成重大变化,内容升级正常,百度搜索引擎的爬行频率就会降低缓慢或突然,不是网站的错误操作,是百度搜索引擎青觉得网站质量有问题;如果百度搜索引擎的爬行频率突然扩大,可能是网站有404个网页,导致蜘蛛集中重复爬行;我如果百度搜索引擎的爬行频率慢慢扩大,可能是随着网站内容的逐渐增加和权重值的逐渐积累,一切都得到了正常的爬行,几乎平静稳定的变化也就不足为奇了,如果发生剧烈的变化,一定要引起足够的重视
(2)根据蜘蛛对主网页获取规律的分析,可以辅助调整网页升级次数,一般百度搜索引擎蜘蛛会对网站.这样的网页不能是信息页,而是主页、目录页或具有许多外部链接的页面
如图10-4所示,它在网站的nbc.html页面上显示了百度搜索蜘蛛的获取状态。该页面是该平台的新内容页面,即专为百度搜索引擎在网站中查找新内容而设计的页面。该页面中有300个连接,每五分钟升级一次,一次d我们已经知道网站是在五分钟内制作的,换句话说,并非所有新形成的网页都会出现在nbc.html中。根据图10-4中百度搜索蜘蛛获取的网页,百度搜索蜘蛛最多会在2分钟内抓取网页一次。然而,网页的刷新频率是5米在几分钟内,换言之,100多个学位搜索蜘蛛的获取频率的一半没有获得新的连接,并且网站的新信息的连接没有完全呈现在网页上。根据这种数据和信息的差异,我们可以专门指导SEO人员推广专业的d技术人员提高网页的缓存文件时间,扩大升级频率,并将升级频率设置为每2分钟一次,这样不仅可以让百度搜索蜘蛛在每次抓取网页时获得新的连接,还可以扩大sear发现网站新内容的概率ch发动机
网站中有很多种类的网页,如首页、目录页和前面提到的页面。在网站中,通常会继续存在大量其他集成页面,这些页面的爬行频率非常高。特别是网站的主页,很多平台的主页都会被百度搜索ch引擎每天都在爬行,但是在很多主页上发布的链接很少,有些则消耗了蜘蛛在主页上自己的权重值所产生的高爬行频率。这没有害处SEO关键词在搜索量和布局条件下,SEO人员可以灵活使用这部分资源,在网站上制作所有新内容它可以被百度搜索引擎及时处理,也可以减少百度搜索引擎的失败和爬行
抓取网页数据违法吗(篇:详解stata爬虫抓取网页上的数据part1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 541 次浏览 • 2021-09-15 05:10
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下
抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):
本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:
马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它
捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行
观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行
生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]
切割和更换
继续切割、更换和固定
最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:
查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文
标准->;经典 查看全部
抓取网页数据违法吗(篇:详解stata爬虫抓取网页上的数据part1)
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下
抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):
本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:
马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它
捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行
观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行
生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]
切割和更换
继续切割、更换和固定
最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:
查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文
标准->;经典
抓取网页数据违法吗(Python一款IDE--网页请求监控工具发生的详细步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 05:09
)
1)首先,客户端需要与服务器建立连接。只需单击一个超链接,HTTP就会开始工作
2)连接建立后,客户端以统一资源标识符(URL)和协议版本号的格式向服务器发送请求,然后发送mime信息,包括请求修改器、客户端信息和可能的内容
@接收到请求后,3)server将以状态行的形式给出相应的响应信息,包括信息的协议版本号、成功或错误代码,然后是mime信息,包括服务器信息、实体信息和可能的内容
4)客户端接收服务器返回的信息,并通过浏览器显示在用户显示屏上,然后客户端断开与服务器的连接
如果在上述过程的任何步骤中发生错误,错误消息将返回到具有显示输出的客户端。对于用户来说,这些过程是由HTTP本身完成的。用户只需单击鼠标,等待信息显示
第二:了解Python中的urllib库
在Python2系列中使用了urlib 2,它在Python3之后完全集成到urlib中;我们需要学习的是几个常见的函数。详情可在官方网站上查看
第三:开发工具
Python有自己的编译器——idle,非常简洁;Pycharm——一个具有良好交互的python ide;Fiddler——网页请求监视工具。我们可以使用它来了解用户触发网页请求后的详细步骤
简单网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截获结果如下图所示:
查看全部
抓取网页数据违法吗(Python一款IDE--网页请求监控工具发生的详细步骤
)
1)首先,客户端需要与服务器建立连接。只需单击一个超链接,HTTP就会开始工作
2)连接建立后,客户端以统一资源标识符(URL)和协议版本号的格式向服务器发送请求,然后发送mime信息,包括请求修改器、客户端信息和可能的内容
@接收到请求后,3)server将以状态行的形式给出相应的响应信息,包括信息的协议版本号、成功或错误代码,然后是mime信息,包括服务器信息、实体信息和可能的内容
4)客户端接收服务器返回的信息,并通过浏览器显示在用户显示屏上,然后客户端断开与服务器的连接
如果在上述过程的任何步骤中发生错误,错误消息将返回到具有显示输出的客户端。对于用户来说,这些过程是由HTTP本身完成的。用户只需单击鼠标,等待信息显示
第二:了解Python中的urllib库
在Python2系列中使用了urlib 2,它在Python3之后完全集成到urlib中;我们需要学习的是几个常见的函数。详情可在官方网站上查看
第三:开发工具
Python有自己的编译器——idle,非常简洁;Pycharm——一个具有良好交互的python ide;Fiddler——网页请求监视工具。我们可以使用它来了解用户触发网页请求后的详细步骤
简单网络爬虫
代码
'''
第一个示例:简单的网页爬虫
爬取豆瓣首页
'''
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode('utf-8')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截获结果如下图所示:
抓取网页数据违法吗(抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-12 03:05
抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python+selenium工具,我们可以采集的网站数量,那么我们就来探究下,这个违法吗?上限是多少?可以搜集数据吗?然后我们自己在自己做一遍,发现,下面的scrapy框架的实现。不触碰爬虫的原则,但是你说你做第三方网页爬虫代理了,那么就是第三方咯,爬虫库啊。到底违不违法?违法吗?为什么不说?判断不了,实际应用中,违法还是不违法,很多东西需要自己去探究。
不违法,只要你不做奸商,也没影响到别人。
爬虫本身不违法,但是你注册第三方爬虫你可以采集商品信息啊,卖家放什么广告位,你又不去。如果采集不会留下痕迹,没有采集成功数据的话,应该是个人隐私,但是如果你采集的数据导出到本地,那么你的采集信息就是泄露的信息,有些网站是不给你导出的,
我告诉你违法,
不违法,只要你用爬虫没收到任何非法或者侵权的内容就行了(比如和明显欺诈、诱骗性的内容)。有很多人想把商品推广出去所以使用第三方的爬虫,或者是想做推广所以使用第三方爬虫。但这些都是正常的,只要你别制造非法或诱骗的内容。
首先,正常使用是不违法的,但是如果你的动机不好, 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python)
抓取网页数据违法吗?上限是多少?115开发的第三方网页爬虫python+selenium工具,我们可以采集的网站数量,那么我们就来探究下,这个违法吗?上限是多少?可以搜集数据吗?然后我们自己在自己做一遍,发现,下面的scrapy框架的实现。不触碰爬虫的原则,但是你说你做第三方网页爬虫代理了,那么就是第三方咯,爬虫库啊。到底违不违法?违法吗?为什么不说?判断不了,实际应用中,违法还是不违法,很多东西需要自己去探究。
不违法,只要你不做奸商,也没影响到别人。
爬虫本身不违法,但是你注册第三方爬虫你可以采集商品信息啊,卖家放什么广告位,你又不去。如果采集不会留下痕迹,没有采集成功数据的话,应该是个人隐私,但是如果你采集的数据导出到本地,那么你的采集信息就是泄露的信息,有些网站是不给你导出的,
我告诉你违法,
不违法,只要你用爬虫没收到任何非法或者侵权的内容就行了(比如和明显欺诈、诱骗性的内容)。有很多人想把商品推广出去所以使用第三方的爬虫,或者是想做推广所以使用第三方爬虫。但这些都是正常的,只要你别制造非法或诱骗的内容。
首先,正常使用是不违法的,但是如果你的动机不好,
抓取网页数据违法吗( 互联网网络爬虫技术和文本挖掘技术的区别-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-11 01:12
互联网网络爬虫技术和文本挖掘技术的区别-乐题库)
一种面向招商引资领域的互联网情报采集与推荐系统
[0001]
技术领域
[0002] 本发明涉及一种投资促进领域的互联网情报采集与推荐系统,属于互联网技术领域。
背景技术
[0003] 从事投资促进领域的人员依靠信息的获取,开展投资促进工作、服务工作和咨询工作。目前投资信息的来源主要是线下活动和客户走访,缺乏主动获取信息的有效手段。因此,有必要利用互联网爬虫技术、全文搜索技术和文本挖掘技术帮助投资人员获取互联网投资信息和信息。
[0004] 网络爬虫又称网络蜘蛛、网络机器人,是按照一定的规则自动抓取万维网上信息的程序或脚本。网络爬虫将互联网上的所有页面分为五类:已下载但未过期、已下载并已过期、等待下载、可知和未知。爬行策略可分为广度优先搜索策略、最佳优先搜索策略、深度优先搜索策略等。
[0005] 全文搜索是一种文本数据搜索方法,将文档中的所有文本与搜索词进行匹配。全文检索研究整个文档信息的表示、存储、组织和访问,即根据用户的查询要求,从信息库中检索相关信息。全文搜索的中心环节是文档内容的表达、信息查询的获取、相关信息的匹配。
[0006] 文本挖掘是提取分散在文本文件中的有效、有用、可理解和有价值的知识,并利用这些知识更好地组织信息的过程。文本挖掘使用智能算法,如神经网络、案例推理、可能性推理等,结合文字处理技术,分析大量非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网络页等)),提取或标记关键词概念与词的关系,并根据内容对文档进行分类,以获得有用的知识和信息。中文分词是文本挖掘的基础。对于一段中文输入,成功进行中文分词可以达到计算机自动识别句子意思的效果。
发明内容
[0007] 本发明的目的在于解决招商引资服务咨询中存在的问题,提出一种面向招商引资领域的互联网情报采集与推荐系统。
[0008] 本发明的技术方案如下,一种用于投资促进领域的互联网情报抓取和推荐系统,它集成了互联网金融舆情、上市公司投资或并购信息、各公司CEO公开演讲、社交媒体通过网络爬虫及时获取跟踪信息;通过基于人工监督和机器学习的推荐算法对网络信息进行过滤推荐,推荐符合用户目标范围的优质信息;根据审稿人的推荐与否,并利用推荐信息的阅读量自动修改情报推荐分析,使以后获取的信息质量更高,减少人为干预。
[0009] 系统抓取媒体网站和社交媒体网站提供的信息,将抓取的关键词进行对比,并与招商领域相关,用于发现各种投资项目信号。
[0010]机器学习算法如下:(1)推荐模型的初始算法是判断信息是否出现在知识库中的关键词以及关键词出现的频率。关键词出现频率优先推荐;(2)推荐网页的特征必须人工筛选,人工筛选的结果将网页分为正面网页和负面网页,同时过滤后的结果被不同的人点击用户,点击量反映了网页的准确度和相关性;(3)系统分析网页特征值,网页特征值包括网页网站网址、时间、关键词频率;(4)系统将网页的特征值与人工筛选的结果与页面浏览量相关联,使用随机数建立init并使用深度学习神经网络进行训练,最终得到修正后的推荐模型。
[0011] 本发明是一种针对招商领域的互联网情报采集与推荐系统,包括招商情报采集模块、招商情报分析模块和招商情报服务模块。投资信息采集模块将每个网站采集招商智慧的数据发送到投资信息分析模块;信息分析后,投资信息分析模块向投资信息服务模块发送情报服务指令执行;投资信息采集模块、投资信息分析模块和投资信息服务模块的输出数据存储在数据库中。
[0012]投资信息采集模块包括爬虫规则定义子模块、网络爬虫子模块、统计分析子模块、人工审核子模块和规则设置子模块。爬取规则子模块制定智能爬取规则。网络爬虫子模块根据抓取规则,利用网络爬虫抓取互联网金融舆情、上市公司投资并购信息、各公司关键人物公开演讲、社交媒体跟踪信息根据爬行规则。子模块及时获取。
[0013]投资情报分析模块包括内容去重子模块、敏感词过滤子模块、情报关键词子模块、机器学习子模块、数据规范子模块投资情报分析模块分析网页的特征值,包括网页网站网址、时间、出现频率最好的关键词。
[0014] 招商情报服务模块包括话题呈现子模块、舆情简报子模块、统计分析子模块、人工审核子模块、规则设置子模块。
[0015]与现有技术相比,本发明的有益效果是:本发明系统的情报捕捉模块主要针对财经舆情,并有特定的投资关键词对这些舆情进行过滤,使得信息更准确。本发明系统返回的信息覆盖范围更广,不仅包括国内各大网络媒体,还包括各级政府官方网站,以及国外网站的企业信息;本发明系统推荐的招商舆情筛选系统具有自学习能力,可以根据用户的选择和推荐次数形成新的推荐算法,从而推荐更符合市场需求的情报信息。用户的需求。
图纸说明
[0016]图1是本发明的结构框图;图2为本实施例使用的通用网络爬虫采集的程序框图;图3为本实施例中使用的神经网络结构图。
具体实现方法
[0017] 本发明的具体实现如图1所示。
[0018]本实施例为招商引资领域的互联网情报采集与推荐系统,包括投资情报获取模块、投资情报分析模块和投资情报服务模块。以下是这些模块的功能说明: Information采集module:该模块负责采集招商投资及相关话题。只有采集 指定相关的网站 和该部分的网页。一般网络爬虫返回的结果中含有大量用户不关心的网页,所以本系统的采集程序适用于垂直爬虫。根据给定的入口地址,不断获取和下载页面上的新链接。链接分为目标网址和非目标网址。目标URL主要是文章body的URL。除了解析目标URL中的链接外,还必须提取正文、标题、发布时间等信息。通用网络爬虫采集程序如图2所示。
[0019]采集项目应满足的要求如下:(1)采集主题包括:投资、金融、产业、企业、企业家、技术、高新技术、专利和科学与技术科技成果,世界500强、国内100强等定制主题。
[0020](2)采集相关文章文字、标题、发表时间等
[0021](3)可以根据采集网站自动灵活调度采集任务,或者手动触发任务。
[0022](4)静态页和正文页只采集一次,不重复采集。
[0023](5)内容更新动态页面可以重复采集。
[0024](6)待采集队列应该去重以避免重复采集。
[0025](7)最新信息可以及时采集。
[0026](8)可灵活设置采集线程数。
[0027](9)可以为不同的网站设置不同的采集深度。
[0028](10)可以根据链接组织规则和页面结构灵活配置处理规则。
[0029]投资情报分析模块:对采集的文本进行分析,包括以下步骤:舆情识别、文本去重、文本摘要、舆情分类、舆情情绪分析、企业关键词标注、可信度投资机会指数分析计算,企业媒体指数计算,机器学习。
<p>[0030](1)舆情识别:通过统计符合规则的关键词数量和权重来判断是否是文章收录舆情信息。对于不收录舆情信息的文章 ,不需要进一步的分析处理,不需要发布。文章的匹配指数=关键词频率难度),但当匹配指数达到一定阈值时,舆论认可。 查看全部
抓取网页数据违法吗(
互联网网络爬虫技术和文本挖掘技术的区别-乐题库)
一种面向招商引资领域的互联网情报采集与推荐系统
[0001]
技术领域
[0002] 本发明涉及一种投资促进领域的互联网情报采集与推荐系统,属于互联网技术领域。
背景技术
[0003] 从事投资促进领域的人员依靠信息的获取,开展投资促进工作、服务工作和咨询工作。目前投资信息的来源主要是线下活动和客户走访,缺乏主动获取信息的有效手段。因此,有必要利用互联网爬虫技术、全文搜索技术和文本挖掘技术帮助投资人员获取互联网投资信息和信息。
[0004] 网络爬虫又称网络蜘蛛、网络机器人,是按照一定的规则自动抓取万维网上信息的程序或脚本。网络爬虫将互联网上的所有页面分为五类:已下载但未过期、已下载并已过期、等待下载、可知和未知。爬行策略可分为广度优先搜索策略、最佳优先搜索策略、深度优先搜索策略等。
[0005] 全文搜索是一种文本数据搜索方法,将文档中的所有文本与搜索词进行匹配。全文检索研究整个文档信息的表示、存储、组织和访问,即根据用户的查询要求,从信息库中检索相关信息。全文搜索的中心环节是文档内容的表达、信息查询的获取、相关信息的匹配。
[0006] 文本挖掘是提取分散在文本文件中的有效、有用、可理解和有价值的知识,并利用这些知识更好地组织信息的过程。文本挖掘使用智能算法,如神经网络、案例推理、可能性推理等,结合文字处理技术,分析大量非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网络页等)),提取或标记关键词概念与词的关系,并根据内容对文档进行分类,以获得有用的知识和信息。中文分词是文本挖掘的基础。对于一段中文输入,成功进行中文分词可以达到计算机自动识别句子意思的效果。
发明内容
[0007] 本发明的目的在于解决招商引资服务咨询中存在的问题,提出一种面向招商引资领域的互联网情报采集与推荐系统。
[0008] 本发明的技术方案如下,一种用于投资促进领域的互联网情报抓取和推荐系统,它集成了互联网金融舆情、上市公司投资或并购信息、各公司CEO公开演讲、社交媒体通过网络爬虫及时获取跟踪信息;通过基于人工监督和机器学习的推荐算法对网络信息进行过滤推荐,推荐符合用户目标范围的优质信息;根据审稿人的推荐与否,并利用推荐信息的阅读量自动修改情报推荐分析,使以后获取的信息质量更高,减少人为干预。
[0009] 系统抓取媒体网站和社交媒体网站提供的信息,将抓取的关键词进行对比,并与招商领域相关,用于发现各种投资项目信号。
[0010]机器学习算法如下:(1)推荐模型的初始算法是判断信息是否出现在知识库中的关键词以及关键词出现的频率。关键词出现频率优先推荐;(2)推荐网页的特征必须人工筛选,人工筛选的结果将网页分为正面网页和负面网页,同时过滤后的结果被不同的人点击用户,点击量反映了网页的准确度和相关性;(3)系统分析网页特征值,网页特征值包括网页网站网址、时间、关键词频率;(4)系统将网页的特征值与人工筛选的结果与页面浏览量相关联,使用随机数建立init并使用深度学习神经网络进行训练,最终得到修正后的推荐模型。
[0011] 本发明是一种针对招商领域的互联网情报采集与推荐系统,包括招商情报采集模块、招商情报分析模块和招商情报服务模块。投资信息采集模块将每个网站采集招商智慧的数据发送到投资信息分析模块;信息分析后,投资信息分析模块向投资信息服务模块发送情报服务指令执行;投资信息采集模块、投资信息分析模块和投资信息服务模块的输出数据存储在数据库中。
[0012]投资信息采集模块包括爬虫规则定义子模块、网络爬虫子模块、统计分析子模块、人工审核子模块和规则设置子模块。爬取规则子模块制定智能爬取规则。网络爬虫子模块根据抓取规则,利用网络爬虫抓取互联网金融舆情、上市公司投资并购信息、各公司关键人物公开演讲、社交媒体跟踪信息根据爬行规则。子模块及时获取。
[0013]投资情报分析模块包括内容去重子模块、敏感词过滤子模块、情报关键词子模块、机器学习子模块、数据规范子模块投资情报分析模块分析网页的特征值,包括网页网站网址、时间、出现频率最好的关键词。
[0014] 招商情报服务模块包括话题呈现子模块、舆情简报子模块、统计分析子模块、人工审核子模块、规则设置子模块。
[0015]与现有技术相比,本发明的有益效果是:本发明系统的情报捕捉模块主要针对财经舆情,并有特定的投资关键词对这些舆情进行过滤,使得信息更准确。本发明系统返回的信息覆盖范围更广,不仅包括国内各大网络媒体,还包括各级政府官方网站,以及国外网站的企业信息;本发明系统推荐的招商舆情筛选系统具有自学习能力,可以根据用户的选择和推荐次数形成新的推荐算法,从而推荐更符合市场需求的情报信息。用户的需求。
图纸说明
[0016]图1是本发明的结构框图;图2为本实施例使用的通用网络爬虫采集的程序框图;图3为本实施例中使用的神经网络结构图。
具体实现方法
[0017] 本发明的具体实现如图1所示。
[0018]本实施例为招商引资领域的互联网情报采集与推荐系统,包括投资情报获取模块、投资情报分析模块和投资情报服务模块。以下是这些模块的功能说明: Information采集module:该模块负责采集招商投资及相关话题。只有采集 指定相关的网站 和该部分的网页。一般网络爬虫返回的结果中含有大量用户不关心的网页,所以本系统的采集程序适用于垂直爬虫。根据给定的入口地址,不断获取和下载页面上的新链接。链接分为目标网址和非目标网址。目标URL主要是文章body的URL。除了解析目标URL中的链接外,还必须提取正文、标题、发布时间等信息。通用网络爬虫采集程序如图2所示。
[0019]采集项目应满足的要求如下:(1)采集主题包括:投资、金融、产业、企业、企业家、技术、高新技术、专利和科学与技术科技成果,世界500强、国内100强等定制主题。
[0020](2)采集相关文章文字、标题、发表时间等
[0021](3)可以根据采集网站自动灵活调度采集任务,或者手动触发任务。
[0022](4)静态页和正文页只采集一次,不重复采集。
[0023](5)内容更新动态页面可以重复采集。
[0024](6)待采集队列应该去重以避免重复采集。
[0025](7)最新信息可以及时采集。
[0026](8)可灵活设置采集线程数。
[0027](9)可以为不同的网站设置不同的采集深度。
[0028](10)可以根据链接组织规则和页面结构灵活配置处理规则。
[0029]投资情报分析模块:对采集的文本进行分析,包括以下步骤:舆情识别、文本去重、文本摘要、舆情分类、舆情情绪分析、企业关键词标注、可信度投资机会指数分析计算,企业媒体指数计算,机器学习。
<p>[0030](1)舆情识别:通过统计符合规则的关键词数量和权重来判断是否是文章收录舆情信息。对于不收录舆情信息的文章 ,不需要进一步的分析处理,不需要发布。文章的匹配指数=关键词频率难度),但当匹配指数达到一定阈值时,舆论认可。

