
抓取网页数据违法吗
抓取网页数据违法吗(蝙蝠侠IT如何做好网站页面收录与抓取内容阐述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 23:05
网站页面收录和爬取已经成为SEO从业者的重中之重。很多SEO小伙伴经常在社区讨论页面爬取的问题,几乎每个网站的爬取功能都不一样。
影响因素也不同。讨论最广泛的话题之一是:如果网站不主动提交,会不会影响整个网站的爬取频率。
面对这样的问题,我们需要根据实际情况进行分析。
那么,如果网站不主动提交,会不会影响页面的爬取频率呢?
基于以往搜索引擎蜘蛛的研究经验,蝙蝠侠IT将通过以下方式进行阐述:
1、新站
从目前来看,如果你在操作一个新的网站,最便宜的链接抓取是网站主动链接提交。如果省略此操作,请使用发送外部链接的策略来完成。用 收录 抓住单词。
我们认为这不是不可能的,但是在同一时期,如果后者的运营成本对于相同的预期目标来说是相对较高的。
而搜索引擎提供了这种便利条件,我们为什么不合理利用呢?
当然,有的SEO从业者表示,按照长期的运营策略,我们也需要发送外部链接,使用链接进行爬取和排名,并没有冲突。
这没有什么问题,如果你有相对充足的时间框架也可以。
2、老车站
如果您是老网站运营商,我们认为在一定条件下,您无需考虑提交链接。原因是:如果你的网站更新频率和页面质量都保持在一个比较低的水平,输出频率高,质量高。
在某些情况下,搜索引擎非常愿意主动爬取你的目标页面,甚至不要求你提交。毕竟对于全网的链接提交来说,爬取是存在一定时间的。
但是高质量的老网站往往会在生成数据的同时秒级爬取,这比快速收录链接提交的爬取要省时很多。对于此类网站,我们也建议无需刻意进行主动链接提交。
什么情况下老的网站需要做主动链接提交?
一般来说:
①在您的网站中,添加相关目录,建议您积极提交新目录中的内容。
②网站修改后可以合理配置301重定向,可以主动提交新的目标URL。
③如果网站内页目录层次比较深,缺少相关内链,要积极提交配合。
3、相关
①网站主动提交秒爬,但是突然好几天不爬了!
答:导致这个问题的核心因素可能是某个链路质量评估问题。搜索引擎通常根据现有的特征链接类型来判断相关链接的估计质量。
如果你之前提交的页面的链接质量经过评估比较差,那么后期主动提交就很容易造成不爬。
②网站 爬取频率,很不稳定!
A:这个问题有两种情况。一是你的服务器比较不稳定,或者你的服务器的爬取压力有限,导致无法合理地将相关数据反馈给搜索引擎。
另一种情况可能涉及到匹配CDN的问题。如果你的网站配置了相关的CDN,当一个节点出现临时访问问题时,对方总是会尝试去不同的节点获取相同的内容。获取相关信息,导致数据采集不稳定。
③网站内容很长时间不会被爬取!
在排除统计工具和配置策略的情况下,我们认为如果一个网站长时间不爬取,最重要的因素可能是:
第一:页面质量比较差。
第二:目标页面的权限比较低,通常的解决方法是建立高质量的外部链接。
第三:网站没有归档。
4、策略
通常,我们建议我们尽量养成网站站内页面被搜索引擎主动抓取的习惯,而不是完全依赖链接提交。原因很简单。链接提交系统,爬取策略必须具有时间周期性,同时也会面临策略调整的特点。
总的来说:对于一个网站,一定要优先考虑优质内容和长尾内容的结合。前者提高了目录的权限,增加了爬取的频率,后者增加了目录页面的点击频率。当一个目录不断获得有效的搜索点击时,往往伴随着高频率的页面爬取行为。
总结:网站主动提交不会影响页面的爬取频率吗?还有很多细节要讨论,以上内容仅供参考!
蝙蝠侠IT转载需授权! 查看全部
抓取网页数据违法吗(蝙蝠侠IT如何做好网站页面收录与抓取内容阐述)
网站页面收录和爬取已经成为SEO从业者的重中之重。很多SEO小伙伴经常在社区讨论页面爬取的问题,几乎每个网站的爬取功能都不一样。
影响因素也不同。讨论最广泛的话题之一是:如果网站不主动提交,会不会影响整个网站的爬取频率。
面对这样的问题,我们需要根据实际情况进行分析。

那么,如果网站不主动提交,会不会影响页面的爬取频率呢?
基于以往搜索引擎蜘蛛的研究经验,蝙蝠侠IT将通过以下方式进行阐述:
1、新站
从目前来看,如果你在操作一个新的网站,最便宜的链接抓取是网站主动链接提交。如果省略此操作,请使用发送外部链接的策略来完成。用 收录 抓住单词。
我们认为这不是不可能的,但是在同一时期,如果后者的运营成本对于相同的预期目标来说是相对较高的。
而搜索引擎提供了这种便利条件,我们为什么不合理利用呢?
当然,有的SEO从业者表示,按照长期的运营策略,我们也需要发送外部链接,使用链接进行爬取和排名,并没有冲突。
这没有什么问题,如果你有相对充足的时间框架也可以。
2、老车站
如果您是老网站运营商,我们认为在一定条件下,您无需考虑提交链接。原因是:如果你的网站更新频率和页面质量都保持在一个比较低的水平,输出频率高,质量高。
在某些情况下,搜索引擎非常愿意主动爬取你的目标页面,甚至不要求你提交。毕竟对于全网的链接提交来说,爬取是存在一定时间的。
但是高质量的老网站往往会在生成数据的同时秒级爬取,这比快速收录链接提交的爬取要省时很多。对于此类网站,我们也建议无需刻意进行主动链接提交。
什么情况下老的网站需要做主动链接提交?
一般来说:
①在您的网站中,添加相关目录,建议您积极提交新目录中的内容。
②网站修改后可以合理配置301重定向,可以主动提交新的目标URL。
③如果网站内页目录层次比较深,缺少相关内链,要积极提交配合。
3、相关
①网站主动提交秒爬,但是突然好几天不爬了!
答:导致这个问题的核心因素可能是某个链路质量评估问题。搜索引擎通常根据现有的特征链接类型来判断相关链接的估计质量。
如果你之前提交的页面的链接质量经过评估比较差,那么后期主动提交就很容易造成不爬。
②网站 爬取频率,很不稳定!
A:这个问题有两种情况。一是你的服务器比较不稳定,或者你的服务器的爬取压力有限,导致无法合理地将相关数据反馈给搜索引擎。
另一种情况可能涉及到匹配CDN的问题。如果你的网站配置了相关的CDN,当一个节点出现临时访问问题时,对方总是会尝试去不同的节点获取相同的内容。获取相关信息,导致数据采集不稳定。
③网站内容很长时间不会被爬取!
在排除统计工具和配置策略的情况下,我们认为如果一个网站长时间不爬取,最重要的因素可能是:
第一:页面质量比较差。
第二:目标页面的权限比较低,通常的解决方法是建立高质量的外部链接。
第三:网站没有归档。
4、策略
通常,我们建议我们尽量养成网站站内页面被搜索引擎主动抓取的习惯,而不是完全依赖链接提交。原因很简单。链接提交系统,爬取策略必须具有时间周期性,同时也会面临策略调整的特点。
总的来说:对于一个网站,一定要优先考虑优质内容和长尾内容的结合。前者提高了目录的权限,增加了爬取的频率,后者增加了目录页面的点击频率。当一个目录不断获得有效的搜索点击时,往往伴随着高频率的页面爬取行为。
总结:网站主动提交不会影响页面的爬取频率吗?还有很多细节要讨论,以上内容仅供参考!
蝙蝠侠IT转载需授权!
抓取网页数据违法吗(抓取网页数据的思路有好,抓取抓取数据思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 23:02
)
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂情况,放一个小读取简单网页数据的示例:
目标数据
将所有这些参赛者的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果要直接取网页的文字,一句话就能搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、根据html层级遍历等方法。请参阅此处以供参考。以下代码片段来自 ittf网站,获取指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranki ... 2Bstr(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close() 查看全部
抓取网页数据违法吗(抓取网页数据的思路有好,抓取抓取数据思路
)
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂情况,放一个小读取简单网页数据的示例:
目标数据
将所有这些参赛者的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果要直接取网页的文字,一句话就能搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、根据html层级遍历等方法。请参阅此处以供参考。以下代码片段来自 ittf网站,获取指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranki ... 2Bstr(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close()
抓取网页数据违法吗(网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 16:17
搜索引擎爬虫爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,必须先爬取该页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的得分越来越低。当然会影响你的网站爬取,所以选择空间服务器。
据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品来说意义重大。
那么网站内容如何被搜索引擎频繁快速的抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
入链也是网站优化的一个非常重要的过程,间接影响了网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的原创内容对百度蜘蛛来说非常有吸引力。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链的建设过程中,需要注意外链的质量。不要做无用的事情来省事。
蜘蛛沿着链接爬行,所以内部链接的合理优化可以要求蜘蛛爬行更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是许多 网站 正在使用的,并且蜘蛛可以抓取更广泛的页面。
主页是蜘蛛访问次数最多的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接进行搜索。如果你的链接太多,不仅页面数量会减少,你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站 的死链接并将其提交给搜索引擎非常重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图允许搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站的地图,不仅可以提高爬取率,而且对蜘蛛有很好的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。 查看全部
抓取网页数据违法吗(网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么)
搜索引擎爬虫爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,必须先爬取该页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。

我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的得分越来越低。当然会影响你的网站爬取,所以选择空间服务器。
据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品来说意义重大。
那么网站内容如何被搜索引擎频繁快速的抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
入链也是网站优化的一个非常重要的过程,间接影响了网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的原创内容对百度蜘蛛来说非常有吸引力。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。

众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链的建设过程中,需要注意外链的质量。不要做无用的事情来省事。
蜘蛛沿着链接爬行,所以内部链接的合理优化可以要求蜘蛛爬行更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是许多 网站 正在使用的,并且蜘蛛可以抓取更广泛的页面。
主页是蜘蛛访问次数最多的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接进行搜索。如果你的链接太多,不仅页面数量会减少,你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站 的死链接并将其提交给搜索引擎非常重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图允许搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站的地图,不仅可以提高爬取率,而且对蜘蛛有很好的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。
抓取网页数据违法吗(的文字及图片来源于网络,仅供学习、交流使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-10 16:16
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
内容
前言
新手在路上,如有不对之处,请在评论区指正。
本文文字和图片来源于网络,仅供学习交流使用,不得用于任何商业用途。版权归原作者所有。
一、实施步骤
(1)数据爬取:以requests请求为依据获取数据源。(没安装的兄弟自己安装)
(2) UA 伪装:模拟浏览器访问 URL。
(3) 数据解析:使用xpath语法处理数据。
(4) 数据存储:获取所需数据后使用MongoDB进行存储。
二、目标网站
https://haikou.baixing.com/chongwujiaoyi/
先分析目标网站
点击链接后可以看到我们需要抓取的数据
Ctrl+U打开网页源代码后,可以发现我们要的数据直接在网页上,接下来就开始吧!
三、获取数据1.导入库
import requests #请求网页
from lxml import html # 导入xpath
import pymongo # 用于连接mongoDB数据库
由于版本原因,无法直接从lxml包中导入etree模块,需要多一步。
etree = html.etree
2.请求数据
url = 'https://haikou.baixing.com/chongwujiaoyi/'
respsone = requests.get(url,headers=headers).content.decode('utf-8')
# print(respsone)
2.1 获取一级链接
先得到每只宠物的链接,然后就可以得到宠物的信息,f12打开开发者工具,然后检查元素,看到每只宠物的链接都有 查看全部
抓取网页数据违法吗(的文字及图片来源于网络,仅供学习、交流使用)
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
内容
前言
新手在路上,如有不对之处,请在评论区指正。
本文文字和图片来源于网络,仅供学习交流使用,不得用于任何商业用途。版权归原作者所有。
一、实施步骤
(1)数据爬取:以requests请求为依据获取数据源。(没安装的兄弟自己安装)
(2) UA 伪装:模拟浏览器访问 URL。
(3) 数据解析:使用xpath语法处理数据。
(4) 数据存储:获取所需数据后使用MongoDB进行存储。
二、目标网站
https://haikou.baixing.com/chongwujiaoyi/
先分析目标网站
点击链接后可以看到我们需要抓取的数据
Ctrl+U打开网页源代码后,可以发现我们要的数据直接在网页上,接下来就开始吧!
三、获取数据1.导入库
import requests #请求网页
from lxml import html # 导入xpath
import pymongo # 用于连接mongoDB数据库
由于版本原因,无法直接从lxml包中导入etree模块,需要多一步。
etree = html.etree
2.请求数据
url = 'https://haikou.baixing.com/chongwujiaoyi/'
respsone = requests.get(url,headers=headers).content.decode('utf-8')
# print(respsone)
2.1 获取一级链接
先得到每只宠物的链接,然后就可以得到宠物的信息,f12打开开发者工具,然后检查元素,看到每只宠物的链接都有
抓取网页数据违法吗(鲸鱼代理注册即享0元免费试用,自动秒换IP地址,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-08 22:15
目前,中国互联网大军不断壮大,各种依托互联网的新兴产业层出不穷。甚至在很多传统行业,为了抢占竞争的制高点,与朋友、商家的竞争已经转移到了互联网平台上。
对于上网的朋友来说,ip修饰符并不是什么奇怪的存在。如果你恰好是做技术编码的专业人士,尤其是你负责网络爬虫的相关工作,你每天都会和你打交道。这只是一个ip修饰符。简单来说,ip修饰符就是你的护照。如果您的本地IP地址访问受到限制,您需要更换护照才能顺利通过。
我们都知道网络爬虫可以有自己的发展空间,因为使用爬虫程序爬取网页信息方便、高效、快捷,但同时要注意IP地址受限。一个很简单的道理,比如我们现在有一个网站,而网站的内容是我们自己写的,但是会有很多恶意竞争对象,特别是使用恶意程序。爬虫爬取我们自己的数据,所以为了保护我们自己的网站,我们宁愿误杀一千,也不愿放过一个。服务器的承载能力总是有限的。如果有一个程序不断超载来获取服务器信息,服务器很容易崩溃。所以现在很多互联网网站,为了保障自己网站的安全,
这时候如果要继续访问这个网站,ip修饰符就很重要了。如果当前ip地址被限制,可以更换一个新的ip地址,保证爬虫的顺利进行。Whale Proxy可以提供优质的ip修改器资源,保证爬虫程序的顺利进行。
不过,在这里我也想提醒大家,正常的采集学习是可以的,但不要恶意采集他人的信息,做出违法行为。
Whale Proxy注册可享受0元免费试用,全国238个城市,2000万IP数据库,一键切换,秒级自动换IP,连接稳定不掉线,Whale Proxy官网: 查看全部
抓取网页数据违法吗(鲸鱼代理注册即享0元免费试用,自动秒换IP地址,)
目前,中国互联网大军不断壮大,各种依托互联网的新兴产业层出不穷。甚至在很多传统行业,为了抢占竞争的制高点,与朋友、商家的竞争已经转移到了互联网平台上。
对于上网的朋友来说,ip修饰符并不是什么奇怪的存在。如果你恰好是做技术编码的专业人士,尤其是你负责网络爬虫的相关工作,你每天都会和你打交道。这只是一个ip修饰符。简单来说,ip修饰符就是你的护照。如果您的本地IP地址访问受到限制,您需要更换护照才能顺利通过。
我们都知道网络爬虫可以有自己的发展空间,因为使用爬虫程序爬取网页信息方便、高效、快捷,但同时要注意IP地址受限。一个很简单的道理,比如我们现在有一个网站,而网站的内容是我们自己写的,但是会有很多恶意竞争对象,特别是使用恶意程序。爬虫爬取我们自己的数据,所以为了保护我们自己的网站,我们宁愿误杀一千,也不愿放过一个。服务器的承载能力总是有限的。如果有一个程序不断超载来获取服务器信息,服务器很容易崩溃。所以现在很多互联网网站,为了保障自己网站的安全,
这时候如果要继续访问这个网站,ip修饰符就很重要了。如果当前ip地址被限制,可以更换一个新的ip地址,保证爬虫的顺利进行。Whale Proxy可以提供优质的ip修改器资源,保证爬虫程序的顺利进行。
不过,在这里我也想提醒大家,正常的采集学习是可以的,但不要恶意采集他人的信息,做出违法行为。
Whale Proxy注册可享受0元免费试用,全国238个城市,2000万IP数据库,一键切换,秒级自动换IP,连接稳定不掉线,Whale Proxy官网:
抓取网页数据违法吗( 爬虫自学路径网络爬虫简介什么时候用爬虫网络是否合法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-07 14:16
爬虫自学路径网络爬虫简介什么时候用爬虫网络是否合法)
文章内容
文章内容
前言
爬虫自学路径
网络爬虫简介
何时使用爬虫
网络爬虫是否合法
封装你的第一个爬虫模块
封装请求头
情况一:
情况二:
情况三:
随机请求头
获取网页数据
ID遍历爬虫(顺便限制下载速度)
网站地图
本文摘要
前言
我还是想先嘟嘟几句,虽然你可能已经不耐烦了。目录在最上面,可以点击直接跳转。
之前,它与分散的更新爬虫有关。毕竟,在学校里,我不能自主很多时间。去上课,参加考试什么的。
现在好了,寒假快到了,有系统地整理了一系列爬虫。
嘿嘿,这背后隐藏着一个想复活的昔日博主的心。
大家多多支持,点赞、评论、采集,越多越好☺☺
昨天做了个系列目录,本来是给朋友带的。原来我们俩的本事都差不多,不过我觉得这条路还是很不错的。
将其用作本系列的指南!!!
爬虫自学路径
初步判断是这样的
1、了解网络爬虫和网络分析,顺便聊聊
2、Xpath
3、爬虫缓存
4、动态网络爬取(json)
5、表单交互
6、正则表达式
7、硒
8、并发下载
9、图片、音频、视频下载
10、验证码处理
11、Scrapy
12、来一场实战
13、 再来一场实战
14、 一个人飞吧
如果有什么要增加的,我会在这里谈谈。
网络爬虫简介
至于什么是网络爬虫,那我就不用多解释了。
何时使用爬虫
用于采集不易手动采集的数据。
其实这句话很有内涵,一千个读者就有一千个哈姆雷特。
在我的认知中,这句话的意思是采集某些数据比使用爬虫消耗更多的能量。这个时候不能考虑直接使用爬虫。
我可以这么说。
至于使用爬虫所消耗的精力,需要很长的时间积累经验,基于对自己的足够了解。
它消耗能量,从开始考虑使用爬虫,到取出爬虫程序,再到获取到正确的数据,最后清洗呈现。
其中最耗时的部分是编写代码和测试。
这时候就需要一个现成的框架。后面我们会讲scrapy框架,它是一个非常好的成熟的爬虫框架。
其实我想说的是,在我们学习的过程中,我们编写的爬虫程序中一定要有目的,将不变的部分抽象出来,封装到我们自己的包中。
学了很久C++,一直被这个“臭毛病”困扰,喜欢自己打包“动态链接库”。
网络爬虫是否合法
这部分在之前的《偷偷学Python》系列中已经提到过,这里稍微讲一下。
在深入讨论爬取一个网站之前,我们首先需要在一定程度上了解目标站点的规模和结构。网站 我自己的robots.txt和Sitemap文件可以为我们提供一些帮助(我就问问有没有人真的会看?反正我没看过。爬虫默认可以爬。那些不爬网将默认为不爬网...)
封装你的第一个爬虫模块
要抓取网页,我们首先需要下载它。
至于分析、清洗、存储等,今天就不多说了。
让我们确保这个网页可以下载,对吗?
我不想弯腰,我直接介绍最后的步骤。让我把这个过程模拟成两个人建立外交关系、给予和接受的过程。
封装请求头
什么是封装请求头?今天我是来和你交朋友的,
情况一:
我说:“嘿,兄弟,交个朋友吧?”
你说:“你是谁?”
我说:“你猜怎么着?”
这个时候你的反应是什么?
说完,我对你说:“喂,大哥,既然我们是朋友,你能不能帮我一个忙?五分钟,我要你的全部信息。”
如果你戒备,你不会给我的。
这个更好。
情况二:
几句问候之后,你发现我是一个推销员。获取您的信息并准备向您出售您根本不需要的东西。例如,您可以向头发浓密的您出售快速生发剂。这不是开玩笑吗?!!!
你会关心我吗?一切都是那么赤裸裸。
那么我该怎么做才能将这款生发剂放到您的手中呢?
情况三:
我路过你在大厅等面试通知的时候,走了过去,转过头看了你一眼,又看了你一眼,递给你一张名片:“小子,我是隔壁项目组的组长,你是来面试的?”
你说是
我说:“哦,他们组工作压力很大,看你一头浓密的头发,怕是没经历过洗礼,可惜了。”
然后,我说:“好吧,如果你面试过了,你压力不小可以来找我。这是我的名片。”
呵呵
那我就给你。你收到了很开心。
那么请求头是什么?那是名片。
一张名片告诉即将到来的网站:“我是一个普通的浏览器”。
随机请求头
我们不需要自己准备任何请求头。大量请求使用同一个header不好,会被你屏蔽。
获取网页数据
目前主流的Python编写的爬虫一般都使用requests库来管理复杂的HTTP请求。
ID遍历爬虫部分就不讲了,简单的数理逻辑。
ID遍历爬虫(顺便限制下载速度)
如果我们爬取网站太快,我们将面临被禁止或导致服务器过载的风险。为了降低这些风险,我们可以在两次下载之间添加一组延迟来限制爬虫的速度。
算了,还是要写ID遍历爬虫。
网站地图
说到这张网站地图,我们先来看看它是什么。
站点地图是所有链接网站的容器。很多网站都有很深的连接层次,爬虫很难捕捉。站点地图可以方便爬虫爬取网站页面。通过爬取网站页面,可以清楚的了解网站网站地图一般存放在根目录下,命名为sitemap来引导爬虫,在网站 重要内容页面。站点地图是根据网站的结构、框架、内容生成的导航网页文件。站点地图有助于改善用户体验。他们为 网站 访问者指明了方向,并帮助丢失的访问者找到他们想要查看的页面。
你怎么看网站的地图?
在网站的根目录下,打开robots.txt文件,可以找到网站地图的URL。
看一下CSDN爬虫协议:
底部有这么一行: Sitemap:
自己进去看看吧。
如果你想要它们,你之后将如何攀登。参考上面的一段。
如果你想过滤所有的URL,真的没有人想把它们全部抓取吗?
建议使用正则表达式。
—————————————————
版权声明:本文为CSDN博主《看,未来》原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接: 查看全部
抓取网页数据违法吗(
爬虫自学路径网络爬虫简介什么时候用爬虫网络是否合法)
文章内容
文章内容
前言
爬虫自学路径
网络爬虫简介
何时使用爬虫
网络爬虫是否合法
封装你的第一个爬虫模块
封装请求头
情况一:
情况二:
情况三:
随机请求头
获取网页数据
ID遍历爬虫(顺便限制下载速度)
网站地图
本文摘要
前言
我还是想先嘟嘟几句,虽然你可能已经不耐烦了。目录在最上面,可以点击直接跳转。
之前,它与分散的更新爬虫有关。毕竟,在学校里,我不能自主很多时间。去上课,参加考试什么的。
现在好了,寒假快到了,有系统地整理了一系列爬虫。
嘿嘿,这背后隐藏着一个想复活的昔日博主的心。
大家多多支持,点赞、评论、采集,越多越好☺☺
昨天做了个系列目录,本来是给朋友带的。原来我们俩的本事都差不多,不过我觉得这条路还是很不错的。
将其用作本系列的指南!!!
爬虫自学路径
初步判断是这样的
1、了解网络爬虫和网络分析,顺便聊聊
2、Xpath
3、爬虫缓存
4、动态网络爬取(json)
5、表单交互
6、正则表达式
7、硒
8、并发下载
9、图片、音频、视频下载
10、验证码处理
11、Scrapy
12、来一场实战
13、 再来一场实战
14、 一个人飞吧
如果有什么要增加的,我会在这里谈谈。
网络爬虫简介
至于什么是网络爬虫,那我就不用多解释了。
何时使用爬虫
用于采集不易手动采集的数据。
其实这句话很有内涵,一千个读者就有一千个哈姆雷特。
在我的认知中,这句话的意思是采集某些数据比使用爬虫消耗更多的能量。这个时候不能考虑直接使用爬虫。
我可以这么说。
至于使用爬虫所消耗的精力,需要很长的时间积累经验,基于对自己的足够了解。
它消耗能量,从开始考虑使用爬虫,到取出爬虫程序,再到获取到正确的数据,最后清洗呈现。
其中最耗时的部分是编写代码和测试。
这时候就需要一个现成的框架。后面我们会讲scrapy框架,它是一个非常好的成熟的爬虫框架。
其实我想说的是,在我们学习的过程中,我们编写的爬虫程序中一定要有目的,将不变的部分抽象出来,封装到我们自己的包中。
学了很久C++,一直被这个“臭毛病”困扰,喜欢自己打包“动态链接库”。
网络爬虫是否合法
这部分在之前的《偷偷学Python》系列中已经提到过,这里稍微讲一下。
在深入讨论爬取一个网站之前,我们首先需要在一定程度上了解目标站点的规模和结构。网站 我自己的robots.txt和Sitemap文件可以为我们提供一些帮助(我就问问有没有人真的会看?反正我没看过。爬虫默认可以爬。那些不爬网将默认为不爬网...)
封装你的第一个爬虫模块
要抓取网页,我们首先需要下载它。
至于分析、清洗、存储等,今天就不多说了。
让我们确保这个网页可以下载,对吗?
我不想弯腰,我直接介绍最后的步骤。让我把这个过程模拟成两个人建立外交关系、给予和接受的过程。
封装请求头
什么是封装请求头?今天我是来和你交朋友的,
情况一:
我说:“嘿,兄弟,交个朋友吧?”
你说:“你是谁?”
我说:“你猜怎么着?”
这个时候你的反应是什么?
说完,我对你说:“喂,大哥,既然我们是朋友,你能不能帮我一个忙?五分钟,我要你的全部信息。”
如果你戒备,你不会给我的。
这个更好。
情况二:
几句问候之后,你发现我是一个推销员。获取您的信息并准备向您出售您根本不需要的东西。例如,您可以向头发浓密的您出售快速生发剂。这不是开玩笑吗?!!!
你会关心我吗?一切都是那么赤裸裸。
那么我该怎么做才能将这款生发剂放到您的手中呢?
情况三:
我路过你在大厅等面试通知的时候,走了过去,转过头看了你一眼,又看了你一眼,递给你一张名片:“小子,我是隔壁项目组的组长,你是来面试的?”
你说是
我说:“哦,他们组工作压力很大,看你一头浓密的头发,怕是没经历过洗礼,可惜了。”
然后,我说:“好吧,如果你面试过了,你压力不小可以来找我。这是我的名片。”
呵呵
那我就给你。你收到了很开心。
那么请求头是什么?那是名片。
一张名片告诉即将到来的网站:“我是一个普通的浏览器”。
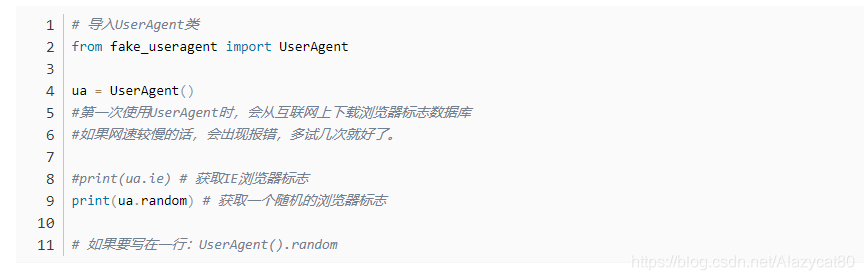
随机请求头
我们不需要自己准备任何请求头。大量请求使用同一个header不好,会被你屏蔽。
获取网页数据
目前主流的Python编写的爬虫一般都使用requests库来管理复杂的HTTP请求。
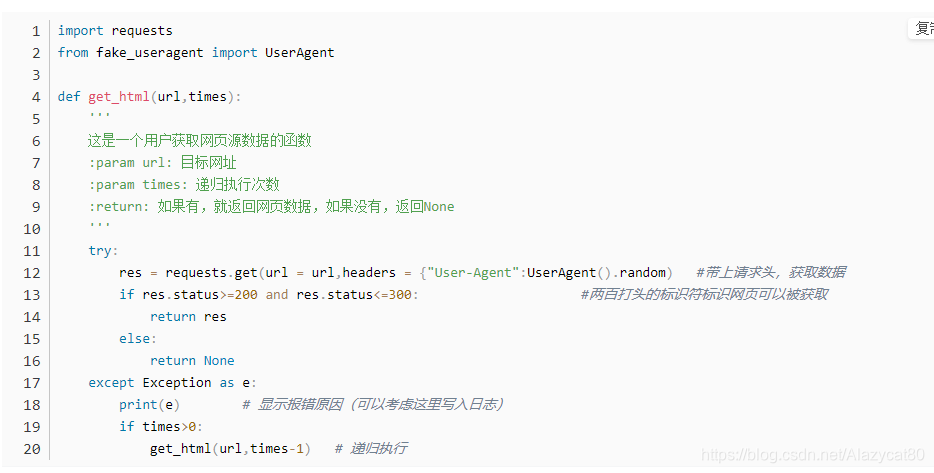
ID遍历爬虫部分就不讲了,简单的数理逻辑。
ID遍历爬虫(顺便限制下载速度)
如果我们爬取网站太快,我们将面临被禁止或导致服务器过载的风险。为了降低这些风险,我们可以在两次下载之间添加一组延迟来限制爬虫的速度。
算了,还是要写ID遍历爬虫。

网站地图
说到这张网站地图,我们先来看看它是什么。
站点地图是所有链接网站的容器。很多网站都有很深的连接层次,爬虫很难捕捉。站点地图可以方便爬虫爬取网站页面。通过爬取网站页面,可以清楚的了解网站网站地图一般存放在根目录下,命名为sitemap来引导爬虫,在网站 重要内容页面。站点地图是根据网站的结构、框架、内容生成的导航网页文件。站点地图有助于改善用户体验。他们为 网站 访问者指明了方向,并帮助丢失的访问者找到他们想要查看的页面。
你怎么看网站的地图?
在网站的根目录下,打开robots.txt文件,可以找到网站地图的URL。
看一下CSDN爬虫协议:
底部有这么一行: Sitemap:
自己进去看看吧。
如果你想要它们,你之后将如何攀登。参考上面的一段。
如果你想过滤所有的URL,真的没有人想把它们全部抓取吗?
建议使用正则表达式。
—————————————————
版权声明:本文为CSDN博主《看,未来》原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
抓取网页数据违法吗(soupDOMTREE方法(二):用BeautifulSoup的数据转化为结构化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-07 06:04
我们抓取的网页是UTF8,但是python请求的时候误判为不知道是什么编码,所以显示这个编码为默认编码:ISO-8859-1
进口请求
response = requests.get('#39;)
打印(响应。编码)
显示的结果是ISO-8859-1,所以我们要告诉python我们遇到的网页是utf8,下面的代码改进如下,我们可以得到一个简体中文的内容:
进口请求
response = requests.get('#39;)
response.encoding ='utf-8'
打印(响应。文本)
现在我们还有一个问题,如何将上述非结构化数据转化为结构化数据?—DOM 树方法
(二) 使用 BeautifulSoup 解析网页
1.基础铺路-DOM TREE
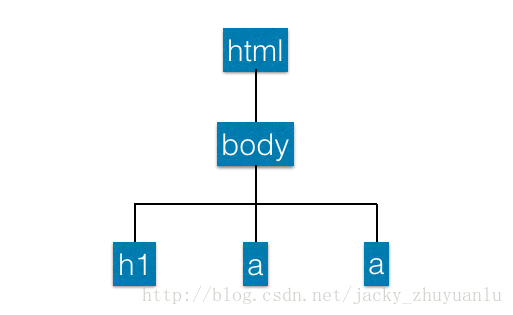
全称:Document Object Model Tree,是一组可以与网页元素进行交互的API。使用BeautifulSoup可以将网页变成DOM树,我们可以根据DOM树的节点进行操作。
在上面的例子中,最外层的结构是html,它是最上层的节点,下层是body,它收录两个链接,h1和a。这些构成了DOM Tree架构,我们可以在这个架构下遵循一定的结构。当这些节点交互时,我们可以得到h1中的词和a中的词。这时候我们就可以顺利的提取数据了;
2.BeautifulSoup 示例
将网页读入 BeautifulSoup
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample)
打印(汤.文本)
此处将显示警告消息。警告消息告诉我们这段代码没有使用我们的解析器。这时候python会为我们预测一个解析器。如果我们想避免这种警告,我们可以在代码中指定
汤 = BeautifulSoup(html_sample,'html.parser')
3.查找所有带有特定标签的 HTML 元素
另外要考虑的是,即使我们可以使用BeautifulSoup去除标签,有时我们想要抓取的一些内容仍然在特殊标签中。我们如何获取节点中的特殊标签和数据?
使用 select 查找收录 h1 标签的元素
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
使用 select 查找收录 a 标签的元素
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
下面我们来实践一下:
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample,'html.parser')
标题 = 汤.select('h1')
打印(标题)
显示的结果是:
如何进一步解开以上文字?添加[0],可以去掉括号,添加.text取出里面的文字
打印(标题[0]。文本)
4.获取具有特定 CSS 属性的元素
除了标签,我们如何获取特定元素?我们可以通过CSS的属性来获取里面的元素。CSS 是网页的“化妆师”。通过这位化妆师,我们可以美化网页
(1)如何抓取独立独特的元素,可以加id装饰
使用select查找所有id为title的元素(id前面需要#)
alink = soup.select('#title')
打印(链接)
(2)如果要捕捉重复的元素,可以添加类修饰
使用 select 查找所有类为链接的元素(在类之前添加。)
汤 = BeautifulSoup(html_sample)
对于soup.select('.link') 中的链接:
打印(链接)
5.获取具有特定 CSS 属性的元素
在网页的连接中,我们会使用一个标签来连接不同的网页,一个标签有一个属性叫做href,我们可以通过这个属性连接到不同的网页;
使用 select 查找标签的所有 href 链接
alinks = 汤.select('a')
对于 alinks 中的链接:
打印(链接['href']) 查看全部
抓取网页数据违法吗(soupDOMTREE方法(二):用BeautifulSoup的数据转化为结构化)
我们抓取的网页是UTF8,但是python请求的时候误判为不知道是什么编码,所以显示这个编码为默认编码:ISO-8859-1
进口请求
response = requests.get('#39;)
打印(响应。编码)
显示的结果是ISO-8859-1,所以我们要告诉python我们遇到的网页是utf8,下面的代码改进如下,我们可以得到一个简体中文的内容:
进口请求
response = requests.get('#39;)
response.encoding ='utf-8'
打印(响应。文本)
现在我们还有一个问题,如何将上述非结构化数据转化为结构化数据?—DOM 树方法
(二) 使用 BeautifulSoup 解析网页
1.基础铺路-DOM TREE
全称:Document Object Model Tree,是一组可以与网页元素进行交互的API。使用BeautifulSoup可以将网页变成DOM树,我们可以根据DOM树的节点进行操作。

在上面的例子中,最外层的结构是html,它是最上层的节点,下层是body,它收录两个链接,h1和a。这些构成了DOM Tree架构,我们可以在这个架构下遵循一定的结构。当这些节点交互时,我们可以得到h1中的词和a中的词。这时候我们就可以顺利的提取数据了;
2.BeautifulSoup 示例
将网页读入 BeautifulSoup
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample)
打印(汤.文本)

此处将显示警告消息。警告消息告诉我们这段代码没有使用我们的解析器。这时候python会为我们预测一个解析器。如果我们想避免这种警告,我们可以在代码中指定
汤 = BeautifulSoup(html_sample,'html.parser')
3.查找所有带有特定标签的 HTML 元素
另外要考虑的是,即使我们可以使用BeautifulSoup去除标签,有时我们想要抓取的一些内容仍然在特殊标签中。我们如何获取节点中的特殊标签和数据?
使用 select 查找收录 h1 标签的元素
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
使用 select 查找收录 a 标签的元素
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
下面我们来实践一下:
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample,'html.parser')
标题 = 汤.select('h1')
打印(标题)
显示的结果是:

如何进一步解开以上文字?添加[0],可以去掉括号,添加.text取出里面的文字
打印(标题[0]。文本)

4.获取具有特定 CSS 属性的元素
除了标签,我们如何获取特定元素?我们可以通过CSS的属性来获取里面的元素。CSS 是网页的“化妆师”。通过这位化妆师,我们可以美化网页
(1)如何抓取独立独特的元素,可以加id装饰
使用select查找所有id为title的元素(id前面需要#)
alink = soup.select('#title')
打印(链接)
(2)如果要捕捉重复的元素,可以添加类修饰
使用 select 查找所有类为链接的元素(在类之前添加。)
汤 = BeautifulSoup(html_sample)
对于soup.select('.link') 中的链接:
打印(链接)
5.获取具有特定 CSS 属性的元素
在网页的连接中,我们会使用一个标签来连接不同的网页,一个标签有一个属性叫做href,我们可以通过这个属性连接到不同的网页;
使用 select 查找标签的所有 href 链接
alinks = 汤.select('a')
对于 alinks 中的链接:
打印(链接['href'])
抓取网页数据违法吗(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2022-01-07 06:04
第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把彩色验证码转成黑白,剪下字体。, 如果字体卡住了,对于我们这些初学者(外行)来说,先放弃吧,切完之后再对每一个像素进行编码,白0,黑1,好像是这样的,不太懂,再读一遍 比较字体库模型中的单词。如果百分比高于百分比,他们会识别验证码是什么,一一比较,最终形成完整的验证码。工作了一天,发现自己既不能做字体库也不用代码切字,无法完成验证码破解,于是放弃破解,另寻方法。
网上说可能是验证码存储在cookie中。好的,试试看。我模拟浏览器发送数据,请求验证码,FF调试。我发现cookie中有验证码。就是这样,验证码就是这个。就是这样,让我们重新登录。
要登录,首先要跟踪目标网页的逻辑,看它是如何传递参数登录成功的。我的目的是先发送一个请求对用户名和密码进行加密,然后将加密后的用户名和密码发送到后台进行登录,这个没什么好说的。这期间遇到的问题是发送请求。过了很久,还是没有成功。原因是当时发送的ajax请求要设置调用哪个方法。网站 一般直接请求后台而不是发送。ajax 请求,所以我又在这里搞砸了。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了爬取页面的时候了。首先获取爬取页面的html,然后分析它如何提交数据,如何返回,传递了哪些参数等等。抓取页面没有错,然后模拟查询数据,然后写网站,隐藏域控件很多,所以发送请求的时候参数很多,不知道为什么。,无论如何,我认为唯一有用的是跟踪号。长时间发送模拟后,报500错误。这是模拟参数有问题,服务器无法读取。我已经做了所有的设置,一个一个。我发现它没有任何问题。我在这里卡了 2 天。我忍不住了。之后,发现提交的数据和页面隐藏字段中的数据有点不同。特殊字符全部输入。转码后,再想之前写的传递参数的代码,发现在传递数据的时候,需要通过UrlEncode进行转码,然后传输。虽然隐藏域的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说,开始转码参数
HttpUtility.UrlEncode(string);
这是成功的。太烧脑细胞了。虽然对于一些老手来说,可能不知道这些东西,但是第一次接触还是比较麻烦的。
顺便说一下,我也遇到了一个问题,就是读取html后获取字符串html中的参数的问题。当然,在页面上很容易得到它。现在都是一堆字符串,真的很难处理,于是找了个dll。使用方便,支持xpath,用法与xmlDocument相同,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载链接:点击打开链接
最好阅读更多此 网站 评论。里面有很多人的问题,也许可以帮到你。
写了这么多,整理代码贴上来,然后开始循环抓取数据。 查看全部
抓取网页数据违法吗(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把彩色验证码转成黑白,剪下字体。, 如果字体卡住了,对于我们这些初学者(外行)来说,先放弃吧,切完之后再对每一个像素进行编码,白0,黑1,好像是这样的,不太懂,再读一遍 比较字体库模型中的单词。如果百分比高于百分比,他们会识别验证码是什么,一一比较,最终形成完整的验证码。工作了一天,发现自己既不能做字体库也不用代码切字,无法完成验证码破解,于是放弃破解,另寻方法。
网上说可能是验证码存储在cookie中。好的,试试看。我模拟浏览器发送数据,请求验证码,FF调试。我发现cookie中有验证码。就是这样,验证码就是这个。就是这样,让我们重新登录。
要登录,首先要跟踪目标网页的逻辑,看它是如何传递参数登录成功的。我的目的是先发送一个请求对用户名和密码进行加密,然后将加密后的用户名和密码发送到后台进行登录,这个没什么好说的。这期间遇到的问题是发送请求。过了很久,还是没有成功。原因是当时发送的ajax请求要设置调用哪个方法。网站 一般直接请求后台而不是发送。ajax 请求,所以我又在这里搞砸了。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了爬取页面的时候了。首先获取爬取页面的html,然后分析它如何提交数据,如何返回,传递了哪些参数等等。抓取页面没有错,然后模拟查询数据,然后写网站,隐藏域控件很多,所以发送请求的时候参数很多,不知道为什么。,无论如何,我认为唯一有用的是跟踪号。长时间发送模拟后,报500错误。这是模拟参数有问题,服务器无法读取。我已经做了所有的设置,一个一个。我发现它没有任何问题。我在这里卡了 2 天。我忍不住了。之后,发现提交的数据和页面隐藏字段中的数据有点不同。特殊字符全部输入。转码后,再想之前写的传递参数的代码,发现在传递数据的时候,需要通过UrlEncode进行转码,然后传输。虽然隐藏域的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说,开始转码参数
HttpUtility.UrlEncode(string);
这是成功的。太烧脑细胞了。虽然对于一些老手来说,可能不知道这些东西,但是第一次接触还是比较麻烦的。
顺便说一下,我也遇到了一个问题,就是读取html后获取字符串html中的参数的问题。当然,在页面上很容易得到它。现在都是一堆字符串,真的很难处理,于是找了个dll。使用方便,支持xpath,用法与xmlDocument相同,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载链接:点击打开链接
最好阅读更多此 网站 评论。里面有很多人的问题,也许可以帮到你。
写了这么多,整理代码贴上来,然后开始循环抓取数据。
抓取网页数据违法吗(基于云平台的网页数据架构使用AWS(AmazonWeb))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-06 06:14
范顺丽和周益民
摘要:随着网络数据的快速增长,网络数据采集在处理大量数据时遇到了一些挑战,如数据存储量大、计算能力强、数据提取的可靠性等。提出了一种基于云平台的网络数据采集架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储;Selenium 用作 Web 自动化工具,调用 WebDriver API 来模拟用户对浏览器的使用。通过实验,我们将该架构与其他基于云的网络爬取架构进行了比较,并分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
中文图书馆分类号:TP311.5 文献标记代码:A 文章 序号:1006-8228 (2018)09-21-04
摘要:随着互联网数据的快速增长,网页抓取在处理大量数据时遇到了许多挑战,例如大量的数据存储、对密集计算能力的需求以及数据提取的可靠性。因此,提出了一种基于云平台的网页抓取架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储。Selenium 是一个网页自动化工具;支持的WebDriver API 模拟用户使用浏览器的过程。通过实验,对比了该架构与其他基于云的网页抓取架构的差异,分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
0 前言
互联网提供了大量的数据集,但很多数据都嵌入在网页的结构和样式中[1]。从网页中提取可用信息,挖掘其潜在价值,使其在金融、数据分析等科学领域发挥重要作用。目前,大多数现有的解决方案主要集中在Web数据采集。数据采集是任何与数据科学相关的研发的前期工作,而这只是大数据的第一步。因此,对于数据科学领域来说,提取网络数据并将其应用到数据科学领域是非常重要的。
互联网上的信息大多以HTML文档的形式呈现,而这些数据都是非结构化数据[2]。由于非结构化数据不遵循任何数据模型,因此信息提取并不容易。网页数据提取的过程包括:网页数据分析、过滤、格式化结果和存储。在分布式计算领域,BeautifulSoup、Requests、Scrapy[3]等各种库都可以处理大量的网页爬取,但只能处理静态页面。因此,选择Selenium作为网页自动化工具,使用Python的HTMLParser库从HTML中提取数据[4]。使用 Amazon Web Services 的 EC2(弹性计算云)作为云平台。选择 EC2 的原因是它的灵活性。它可以创造,
1 简介
随着软件行业的发展,网络数据采集也经历了不同的发展阶段,从最早的人工复制整理数据到今天的云计算大数据采集,每一个行业技术所有的创新都伴随着硬件和软件的巨大进步和发展[5]。云计算通过高度密集的计算能力和支持弹性资源,使其成为个体企业以小资源开始自己的网络爬虫的最佳选择。下面是一些基于云平台的网络爬虫。
1.1 Import.io
Import.io 是一个基于云的平台,无需编码即可从不同的网站 抓取网页,并将所有提取的数据存储在其云服务器上。它允许将数据下载为 CSV、Excel、Google Sheets、JSON 或通过 API 访问。其独特的功能包括自动数据和图像提取、自动页面链接、监控、调度和无需编码。
1.2 WebScraper.io
WebScraper.io 是另一个可视化的网页抓取平台,它提供了两种方式:Web Scraper 和 Web Scraper Extension。对于谷歌 Chrome 浏览器,Web Scraper Extension 工具是免费使用的,用户可以创建站点地图并指定如何抓取它。对于基于云的 Web Scraper,其价格取决于要爬取的 URL 数量。
1.3 Scrapy
Scrapy 是一个免费的、开源的、协作的网页抓取框架,它通过编写代码和调用 API 来提取网页数据。Scrapy 是用 Python 编写的,可以部署在 Scrapy 云中,并且可以按需扩展[6]。其特点是快速、简单、可扩展等。
以上解决方案主要针对Web数据的采集,这只是大数据的第一步。针对大数据的进一步处理,构建了基于云的网页抓取框架(Cloud-Scraper)。
2 系统设计
2.1 Scraper 简介
图 1 显示了传统的 Scraper 概览。客户端为 ScrapeHub 提供 URL 和网络爬取配置。ScrapeHub 程序启动、处理和监控系统中的所有任务。它是用 Python 编写的。然后 ScrapeHub 启动 Scrape Engine 任务,Scrape Engine 初始化一个网页,使用 Selenium 库将网页转换为所需的状态,并使用 Requests 库对其进行解析。不同的爬虫可能使用不同的库来解析和初始化网页。这里只提到Selenium和Requests,所有数据都存储在数据库中。该模型代表了按顺序获取网页数据的传统方法。一次只能获取一个站点,并且在给定的时间段内只能获取有限的数据。通过添加更多的计算和存储资源,
2.2 Cloud-Scraper 设计
使用Amazon Elastic Computing Cloud(EC2),通过Simple Queue Service (SQS)和Simple Storage Service(S3)[7])可以解决上述问题。Amazon S3用于存储Amazon机器镜像,可以根据需要创建任意数量的EC2实例,既经济又灵活。图2展示了Cloud-Scraper的架构,该架构的前端是一个Web浏览器,通过REST API连接到Amazon Web Server。 ScrapeHub in the cloud 会处理所有客户端的爬取请求和处理监控事件,使用Amazon SQS维护一个要爬取的URL列表,Amazon SQS处理两个队列,一个是请求队列,一个是响应队列。 Engine 是一个 URL,用作输入和抓取网页内容的程序,每个 EC2 实例都是一个运行 Scrape Engine 的虚拟机。DynamoDB 是一个免费的开源 NoSQL 数据库,可以为提取的数据提供存储 [8]。
图 3 展示了 Cloud-Scraper 的网络爬取过程。当用户向 Cloud-Scraper 发送爬取请求时,该请求将转到 ScrapeHub。该请求收录两条信息:URL 和爬网配置。首先,ScrapeHub 将 URL 分成多个块转发到 S3 存储,同时创建多个 EC2 实例,并创建 SQS 请求队列和响应队列。ScrapeHub 借助 SQS 请求队列向 EC2 实例发送服务请求,请求的处理顺序以先进先出(FIFO)的调度方式完成。ScrapeHub创建的请求队列上的每个请求都有一个特定的ID,通过响应队列持续监控整体的爬取进度,爬取结果存储在DynamoDB中。
Amazon EMR(Amazon Elastic MapReduce)是一种网络服务[9],采用Hadoop处理方式,结合Amazon EC2,可以轻松高效地处理大量数据。Cloud-Scraper 集成了大数据应用,可以对爬取的网页数据进行可视化和分析。
3 实验分析
图 4 显示了使用不同解决方案完成网页抓取所需的时间,包括来自云端的请求时间、排队时间、处理时间和响应时间。X轴代表网址数,Y轴代表完成网页抓取的时间。图中上两行表示使用单机和单机多线程的爬取完成时间,下两行表示使用20台机器和20台带有Amazon EC2 T2实例的机器完成爬取。所需的时间。可以看出,使用单节点本地机最多可以抓取4000个网页数据,这是服务器限制单个IP在有限时间内访问有限数据造成的。在单台机器上执行并发线程也是如此。虽然计算速度比顺序节点快很多,但是爬取效率随着URL的增加而下降。下面两行爬取完成时间大致呈线性,说明随着URL数量的逐渐增加,Cloud-Scraper可以正常运行。可以推断,Cloud-Scraper 架构是可扩展的,可以根据爬取的 URL 数量增加 EC2 实例。
许多基于云的网页抓取解决方案可用,但大多数是商业性的,其工作模式不公开。因此,与一些现有的开源框架进行比较,例如 Scrapy 和 Import.io。图 5 展示了 Cloud-Scraper 和其他使用机器实例的基于云的平台之间的比较。与其他框架相比,Cloud-Scraper 架构是分布式的,对可以使用的计算资源实例没有限制。借助亚马逊云中的DynamoDB,可以灵活使用所有资源。由于Selenium的使用可能会延迟一段时间,所以爬取完成时间比Import.io要长,但是缺点已经被优点超越了。Selenium 提供更高的可靠性和对人类行为的模仿。效果较好[10]。在数据提取方面,其性能可媲美目前市面上其他基于云的网络爬虫架构,也可与其他大数据应用结合使用。最后,捕获的数据将进入大数据处理。
Cloud-Scraper的4大优势
Cloud-Scraper 有很多优点。其中一些描述如下:
⑴ 成本效益:使用云资源按使用付费模式,可以以低廉的价格使用云资源,并且可以按需扩容或缩容,比维护自己的云更便宜[11]。云供应商几乎可以提供从存储到处理能力所需的一切,让云计算变得更容易。购买自己的资源将花费大量成本来维持和扩大需求。
⑵ 可扩展性:云提供商根据需要提供可靠的计算机,并且可以根据需要创建和使用这些计算机的多个实例。供应商提供了大量的平台选择选项,您可以根据计算的性能要求选择正确的处理能力[12]。
⑶ 大数据应用集成:任何大数据应用都需要四种基本结构——存储、处理、分析软件和网络。DynamoDB 是一种 NoSQL 数据库,可以提供更高的可用性,从而提供更好的性能。分析软件可以根据用户的需求在该架构上进行编程,借助亚马逊的EC2,可以在数量和计算能力上进行扩展。虽然这种架构不能满足所有大数据要求,但进一步的程序集成和修改可以使其对大数据任务更加健壮。
5 结论
本文提出了一种基于云平台的新型网络爬虫架构。亚马逊的云服务为分布式环境中的计算和存储提供了弹性资源,为网络爬取提供了更好的平台。通过实验测试该架构的可扩展性,并与其他网页抓取架构进行简单对比,分析其优势,包括Selenium的使用和大数据应用的集成。此外,也可以使用其他云服务来实现上述架构。
参考:
[1] 魏冬梅, 何忠秀, 唐建梅. 基于Python的Web信息获取方法研究[J].软件指南,2018.17 (1): 41-43
[2] 郎博,张博宇.面向大数据的非结构化数据管理平台关键技术[J]. 信息技术与标准化,2013.10:53-56
[3] 刘宇,郑承焕.基于Scrapy的Deep Web Crawler研究[J]. 软件,2017.38(7):111-114
[4] 齐鹏,李银峰,宋雨薇.基于Python的Web Data采集技术[J]. 电子技术, 2012.25 (11): 118-120
[5] 凯文。网页资料采集发展历程及未来前景[EB/OL].
[6] 刘硕.精通Scrapy网络爬虫[M]. 清华大学出版社,2017.
[7] 许鸿飞.云计算安全问题初探——基于Amazon Dynamo和EC2的架构分析[J]. 计算机 CD 软件与应用,2013.16 (17): 21-22
[8]孙宝华.基于Dynamo的存储机制研究[D]. 西安电子科技大学,2013.
[9] 小龙腾.如何为 Hadoop 选择最灵活的 MapReduce 框架 [EB/OL].
[10] 杜斌. 基于Selenium的定向网络爬虫的设计与实现[J]. 金融科技时代,2016.7: 35-39
[11] Jackson KR、Muriki K、Thomas RC 等。亚马逊AWS云上超新星工厂的性能与成本分析[J]. 科学规划,2011.19:2-3
[12] Juan JD, Prodan R. Amazon EC2 中的多目标工作流调度[J]. 集群计算,2014.17(2):169-189 查看全部
抓取网页数据违法吗(基于云平台的网页数据架构使用AWS(AmazonWeb))
范顺丽和周益民
摘要:随着网络数据的快速增长,网络数据采集在处理大量数据时遇到了一些挑战,如数据存储量大、计算能力强、数据提取的可靠性等。提出了一种基于云平台的网络数据采集架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储;Selenium 用作 Web 自动化工具,调用 WebDriver API 来模拟用户对浏览器的使用。通过实验,我们将该架构与其他基于云的网络爬取架构进行了比较,并分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
中文图书馆分类号:TP311.5 文献标记代码:A 文章 序号:1006-8228 (2018)09-21-04
摘要:随着互联网数据的快速增长,网页抓取在处理大量数据时遇到了许多挑战,例如大量的数据存储、对密集计算能力的需求以及数据提取的可靠性。因此,提出了一种基于云平台的网页抓取架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储。Selenium 是一个网页自动化工具;支持的WebDriver API 模拟用户使用浏览器的过程。通过实验,对比了该架构与其他基于云的网页抓取架构的差异,分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
0 前言
互联网提供了大量的数据集,但很多数据都嵌入在网页的结构和样式中[1]。从网页中提取可用信息,挖掘其潜在价值,使其在金融、数据分析等科学领域发挥重要作用。目前,大多数现有的解决方案主要集中在Web数据采集。数据采集是任何与数据科学相关的研发的前期工作,而这只是大数据的第一步。因此,对于数据科学领域来说,提取网络数据并将其应用到数据科学领域是非常重要的。
互联网上的信息大多以HTML文档的形式呈现,而这些数据都是非结构化数据[2]。由于非结构化数据不遵循任何数据模型,因此信息提取并不容易。网页数据提取的过程包括:网页数据分析、过滤、格式化结果和存储。在分布式计算领域,BeautifulSoup、Requests、Scrapy[3]等各种库都可以处理大量的网页爬取,但只能处理静态页面。因此,选择Selenium作为网页自动化工具,使用Python的HTMLParser库从HTML中提取数据[4]。使用 Amazon Web Services 的 EC2(弹性计算云)作为云平台。选择 EC2 的原因是它的灵活性。它可以创造,
1 简介
随着软件行业的发展,网络数据采集也经历了不同的发展阶段,从最早的人工复制整理数据到今天的云计算大数据采集,每一个行业技术所有的创新都伴随着硬件和软件的巨大进步和发展[5]。云计算通过高度密集的计算能力和支持弹性资源,使其成为个体企业以小资源开始自己的网络爬虫的最佳选择。下面是一些基于云平台的网络爬虫。
1.1 Import.io
Import.io 是一个基于云的平台,无需编码即可从不同的网站 抓取网页,并将所有提取的数据存储在其云服务器上。它允许将数据下载为 CSV、Excel、Google Sheets、JSON 或通过 API 访问。其独特的功能包括自动数据和图像提取、自动页面链接、监控、调度和无需编码。
1.2 WebScraper.io
WebScraper.io 是另一个可视化的网页抓取平台,它提供了两种方式:Web Scraper 和 Web Scraper Extension。对于谷歌 Chrome 浏览器,Web Scraper Extension 工具是免费使用的,用户可以创建站点地图并指定如何抓取它。对于基于云的 Web Scraper,其价格取决于要爬取的 URL 数量。
1.3 Scrapy
Scrapy 是一个免费的、开源的、协作的网页抓取框架,它通过编写代码和调用 API 来提取网页数据。Scrapy 是用 Python 编写的,可以部署在 Scrapy 云中,并且可以按需扩展[6]。其特点是快速、简单、可扩展等。
以上解决方案主要针对Web数据的采集,这只是大数据的第一步。针对大数据的进一步处理,构建了基于云的网页抓取框架(Cloud-Scraper)。
2 系统设计
2.1 Scraper 简介
图 1 显示了传统的 Scraper 概览。客户端为 ScrapeHub 提供 URL 和网络爬取配置。ScrapeHub 程序启动、处理和监控系统中的所有任务。它是用 Python 编写的。然后 ScrapeHub 启动 Scrape Engine 任务,Scrape Engine 初始化一个网页,使用 Selenium 库将网页转换为所需的状态,并使用 Requests 库对其进行解析。不同的爬虫可能使用不同的库来解析和初始化网页。这里只提到Selenium和Requests,所有数据都存储在数据库中。该模型代表了按顺序获取网页数据的传统方法。一次只能获取一个站点,并且在给定的时间段内只能获取有限的数据。通过添加更多的计算和存储资源,
2.2 Cloud-Scraper 设计
使用Amazon Elastic Computing Cloud(EC2),通过Simple Queue Service (SQS)和Simple Storage Service(S3)[7])可以解决上述问题。Amazon S3用于存储Amazon机器镜像,可以根据需要创建任意数量的EC2实例,既经济又灵活。图2展示了Cloud-Scraper的架构,该架构的前端是一个Web浏览器,通过REST API连接到Amazon Web Server。 ScrapeHub in the cloud 会处理所有客户端的爬取请求和处理监控事件,使用Amazon SQS维护一个要爬取的URL列表,Amazon SQS处理两个队列,一个是请求队列,一个是响应队列。 Engine 是一个 URL,用作输入和抓取网页内容的程序,每个 EC2 实例都是一个运行 Scrape Engine 的虚拟机。DynamoDB 是一个免费的开源 NoSQL 数据库,可以为提取的数据提供存储 [8]。
图 3 展示了 Cloud-Scraper 的网络爬取过程。当用户向 Cloud-Scraper 发送爬取请求时,该请求将转到 ScrapeHub。该请求收录两条信息:URL 和爬网配置。首先,ScrapeHub 将 URL 分成多个块转发到 S3 存储,同时创建多个 EC2 实例,并创建 SQS 请求队列和响应队列。ScrapeHub 借助 SQS 请求队列向 EC2 实例发送服务请求,请求的处理顺序以先进先出(FIFO)的调度方式完成。ScrapeHub创建的请求队列上的每个请求都有一个特定的ID,通过响应队列持续监控整体的爬取进度,爬取结果存储在DynamoDB中。
Amazon EMR(Amazon Elastic MapReduce)是一种网络服务[9],采用Hadoop处理方式,结合Amazon EC2,可以轻松高效地处理大量数据。Cloud-Scraper 集成了大数据应用,可以对爬取的网页数据进行可视化和分析。
3 实验分析
图 4 显示了使用不同解决方案完成网页抓取所需的时间,包括来自云端的请求时间、排队时间、处理时间和响应时间。X轴代表网址数,Y轴代表完成网页抓取的时间。图中上两行表示使用单机和单机多线程的爬取完成时间,下两行表示使用20台机器和20台带有Amazon EC2 T2实例的机器完成爬取。所需的时间。可以看出,使用单节点本地机最多可以抓取4000个网页数据,这是服务器限制单个IP在有限时间内访问有限数据造成的。在单台机器上执行并发线程也是如此。虽然计算速度比顺序节点快很多,但是爬取效率随着URL的增加而下降。下面两行爬取完成时间大致呈线性,说明随着URL数量的逐渐增加,Cloud-Scraper可以正常运行。可以推断,Cloud-Scraper 架构是可扩展的,可以根据爬取的 URL 数量增加 EC2 实例。
许多基于云的网页抓取解决方案可用,但大多数是商业性的,其工作模式不公开。因此,与一些现有的开源框架进行比较,例如 Scrapy 和 Import.io。图 5 展示了 Cloud-Scraper 和其他使用机器实例的基于云的平台之间的比较。与其他框架相比,Cloud-Scraper 架构是分布式的,对可以使用的计算资源实例没有限制。借助亚马逊云中的DynamoDB,可以灵活使用所有资源。由于Selenium的使用可能会延迟一段时间,所以爬取完成时间比Import.io要长,但是缺点已经被优点超越了。Selenium 提供更高的可靠性和对人类行为的模仿。效果较好[10]。在数据提取方面,其性能可媲美目前市面上其他基于云的网络爬虫架构,也可与其他大数据应用结合使用。最后,捕获的数据将进入大数据处理。
Cloud-Scraper的4大优势
Cloud-Scraper 有很多优点。其中一些描述如下:
⑴ 成本效益:使用云资源按使用付费模式,可以以低廉的价格使用云资源,并且可以按需扩容或缩容,比维护自己的云更便宜[11]。云供应商几乎可以提供从存储到处理能力所需的一切,让云计算变得更容易。购买自己的资源将花费大量成本来维持和扩大需求。
⑵ 可扩展性:云提供商根据需要提供可靠的计算机,并且可以根据需要创建和使用这些计算机的多个实例。供应商提供了大量的平台选择选项,您可以根据计算的性能要求选择正确的处理能力[12]。
⑶ 大数据应用集成:任何大数据应用都需要四种基本结构——存储、处理、分析软件和网络。DynamoDB 是一种 NoSQL 数据库,可以提供更高的可用性,从而提供更好的性能。分析软件可以根据用户的需求在该架构上进行编程,借助亚马逊的EC2,可以在数量和计算能力上进行扩展。虽然这种架构不能满足所有大数据要求,但进一步的程序集成和修改可以使其对大数据任务更加健壮。
5 结论
本文提出了一种基于云平台的新型网络爬虫架构。亚马逊的云服务为分布式环境中的计算和存储提供了弹性资源,为网络爬取提供了更好的平台。通过实验测试该架构的可扩展性,并与其他网页抓取架构进行简单对比,分析其优势,包括Selenium的使用和大数据应用的集成。此外,也可以使用其他云服务来实现上述架构。
参考:
[1] 魏冬梅, 何忠秀, 唐建梅. 基于Python的Web信息获取方法研究[J].软件指南,2018.17 (1): 41-43
[2] 郎博,张博宇.面向大数据的非结构化数据管理平台关键技术[J]. 信息技术与标准化,2013.10:53-56
[3] 刘宇,郑承焕.基于Scrapy的Deep Web Crawler研究[J]. 软件,2017.38(7):111-114
[4] 齐鹏,李银峰,宋雨薇.基于Python的Web Data采集技术[J]. 电子技术, 2012.25 (11): 118-120
[5] 凯文。网页资料采集发展历程及未来前景[EB/OL].
[6] 刘硕.精通Scrapy网络爬虫[M]. 清华大学出版社,2017.
[7] 许鸿飞.云计算安全问题初探——基于Amazon Dynamo和EC2的架构分析[J]. 计算机 CD 软件与应用,2013.16 (17): 21-22
[8]孙宝华.基于Dynamo的存储机制研究[D]. 西安电子科技大学,2013.
[9] 小龙腾.如何为 Hadoop 选择最灵活的 MapReduce 框架 [EB/OL].
[10] 杜斌. 基于Selenium的定向网络爬虫的设计与实现[J]. 金融科技时代,2016.7: 35-39
[11] Jackson KR、Muriki K、Thomas RC 等。亚马逊AWS云上超新星工厂的性能与成本分析[J]. 科学规划,2011.19:2-3
[12] Juan JD, Prodan R. Amazon EC2 中的多目标工作流调度[J]. 集群计算,2014.17(2):169-189
抓取网页数据违法吗(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-06 01:01
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接=one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
# 设置要抓取的 URL
网址 ='#39;
# 连接到网址
响应 = requests.get(url)
# 解析 HTML 并保存到 BeautifulSoup 对象¶
汤 = BeautifulSoup(response.text,"html.parser")
# 要下载整个数据集,让我们对所有 a 标签进行 for 循环
foriinrange(36,len(soup.findAll('a'))+1):#'a' 标签用于链接
one_a_tag = 汤.findAll('a')[i]
链接 = one_a_tag['href']
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1)#暂停代码一秒
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快! 查看全部
抓取网页数据违法吗(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接=one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
# 设置要抓取的 URL
网址 ='#39;
# 连接到网址
响应 = requests.get(url)
# 解析 HTML 并保存到 BeautifulSoup 对象¶
汤 = BeautifulSoup(response.text,"html.parser")
# 要下载整个数据集,让我们对所有 a 标签进行 for 循环
foriinrange(36,len(soup.findAll('a'))+1):#'a' 标签用于链接
one_a_tag = 汤.findAll('a')[i]
链接 = one_a_tag['href']
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1)#暂停代码一秒
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快!
抓取网页数据违法吗(requests数据库提取使用xpath数据包从html文档中提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-04 17:02
抓取网页数据违法吗?no。知道对方是在哪里爬取的,就可以高兴的通过requests来访问,并从内容里面提取出足够的有价值的数据!requests数据库提取使用xpath数据包从html文档中提取有价值的数据,如html代码生成xpath数据库提取方法~原理:fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')print(html)java6以上版本使用的编码问题requests.encoding()没有匹配到一致的二进制编码requests.use('utf-8')解决方法:在爬取方法中指定编码,或者传入一个参数“string”。
http头部的编码是utf-8这样可以就可以正常解析http协议的url了。解析正则表达式http头部的编码可以用正则表达式提取字符串。其实我也不是很懂正则表达式解析,简单来说就是找到存在且对应的unicode对象,或者是对方想要的对象。fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')html_unicode=pile('^'+str(preg_name+"\\.gif')+'|\\.jpg')#preg_name\\.gif这里可以看到一共有17个样式html_unicode_jpg则可以解析所有gif/jpg图片。
list_urls={}list_urls=[]foriinlist_urls:x2=pile('^([a-za-z0-9_]+).*\\.jpg')y2=pile('^([a-za-z0-9_]+).*\\.gif')z2=pile('^([a-za-z0-9_]+).*\\.jpg')xy=pile('^([a-za-z0-9_]+).*\\.jpg')yy=pile('^([a-za-z0-9_]+).*\\.gif')result=[]result.append(xy,yy)forkey,valueinzip(html_unicode_jpg.items(),html_unicode_u2f.items()):list_key={'ex':x2,'i':y2,'num':z2,'i':key}print(list_key)arraylist(list_key).append(xy)print(arraylist(list_key))print('listofxpathauto-encodes={',list_key,'}','}')#items():包含xpath自动转换为embedding/\d{2,5}/a.jpg-\d{3,6}/.gif.jpgdefre_unicode_jpg(request,url):request.u。 查看全部
抓取网页数据违法吗(requests数据库提取使用xpath数据包从html文档中提取)
抓取网页数据违法吗?no。知道对方是在哪里爬取的,就可以高兴的通过requests来访问,并从内容里面提取出足够的有价值的数据!requests数据库提取使用xpath数据包从html文档中提取有价值的数据,如html代码生成xpath数据库提取方法~原理:fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')print(html)java6以上版本使用的编码问题requests.encoding()没有匹配到一致的二进制编码requests.use('utf-8')解决方法:在爬取方法中指定编码,或者传入一个参数“string”。
http头部的编码是utf-8这样可以就可以正常解析http协议的url了。解析正则表达式http头部的编码可以用正则表达式提取字符串。其实我也不是很懂正则表达式解析,简单来说就是找到存在且对应的unicode对象,或者是对方想要的对象。fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')html_unicode=pile('^'+str(preg_name+"\\.gif')+'|\\.jpg')#preg_name\\.gif这里可以看到一共有17个样式html_unicode_jpg则可以解析所有gif/jpg图片。
list_urls={}list_urls=[]foriinlist_urls:x2=pile('^([a-za-z0-9_]+).*\\.jpg')y2=pile('^([a-za-z0-9_]+).*\\.gif')z2=pile('^([a-za-z0-9_]+).*\\.jpg')xy=pile('^([a-za-z0-9_]+).*\\.jpg')yy=pile('^([a-za-z0-9_]+).*\\.gif')result=[]result.append(xy,yy)forkey,valueinzip(html_unicode_jpg.items(),html_unicode_u2f.items()):list_key={'ex':x2,'i':y2,'num':z2,'i':key}print(list_key)arraylist(list_key).append(xy)print(arraylist(list_key))print('listofxpathauto-encodes={',list_key,'}','}')#items():包含xpath自动转换为embedding/\d{2,5}/a.jpg-\d{3,6}/.gif.jpgdefre_unicode_jpg(request,url):request.u。
抓取网页数据违法吗(小黄鸡代理抓取站违法吗?代理站有蜘蛛代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-03 07:04
抓取网页数据违法吗?说白了违法。但如果是通过代理访问并获取的数据且这些代理未被封禁,则没有法律上的禁止的理由。而如果所谓的爬虫网站存在着其他的数据,而这些数据又是非法获取的,则将构成爬虫罪。例如小黄鸡代理抓取站违法吗?小黄鸡抓取的页面是其公司提供给新网站使用的,并不是开放给新网站抓取。虽然小黄鸡抓取到的是新网站数据,但新网站既然已经给这些网站提供了服务,则说明新网站已经使用了小黄鸡代理抓取到的数据,因此这些数据也构成侵犯个人隐私和公民数据。
按说,这种情况,我们该把数据源开放给新网站,然后让新网站来抓取来使用。然而,爬虫代理站数据中一定会有蜘蛛代理,如果网站不开放这个代理,则可能构成数据窃取罪。这是一起常见的爬虫抓取,存在着大量的蜘蛛代理攻击,如果爬虫持续爬取,则可能构成网络犯罪。提供收费代理服务属于法律上的不正当竞争吗?根据《反不正当竞争法》第二条第二款:本法所称的不正当竞争行为,是指经营者不正当地使用与其他经营者相同或者类似的商品,或者使用与其他经营者在同一种商品上使用相同或者类似的商品,并且违反约定以排他性条件限制他人使用其他经营者商品。
第七条第一款:经营者不得以排他性条件限制其他经营者经营。所以说即使爬虫代理站提供收费代理服务也不属于侵犯个人隐私和公民数据,只要爬虫抓取网站不是重要的内容,并且网站本身不是重要的内容提供者,则无妨。最后,如果没有相关协议规定代理公司不能提供收费的免费代理服务,那么代理公司提供这些服务是否违法呢?如果本身数据来源就不正当,代理服务也是违法的。
但是如果这些爬虫数据本身来源也正当,虽然程序抓取数据不合法,但是也不违反该代理规定,因此也不会构成非法获取公民个人信息罪。 查看全部
抓取网页数据违法吗(小黄鸡代理抓取站违法吗?代理站有蜘蛛代理)
抓取网页数据违法吗?说白了违法。但如果是通过代理访问并获取的数据且这些代理未被封禁,则没有法律上的禁止的理由。而如果所谓的爬虫网站存在着其他的数据,而这些数据又是非法获取的,则将构成爬虫罪。例如小黄鸡代理抓取站违法吗?小黄鸡抓取的页面是其公司提供给新网站使用的,并不是开放给新网站抓取。虽然小黄鸡抓取到的是新网站数据,但新网站既然已经给这些网站提供了服务,则说明新网站已经使用了小黄鸡代理抓取到的数据,因此这些数据也构成侵犯个人隐私和公民数据。
按说,这种情况,我们该把数据源开放给新网站,然后让新网站来抓取来使用。然而,爬虫代理站数据中一定会有蜘蛛代理,如果网站不开放这个代理,则可能构成数据窃取罪。这是一起常见的爬虫抓取,存在着大量的蜘蛛代理攻击,如果爬虫持续爬取,则可能构成网络犯罪。提供收费代理服务属于法律上的不正当竞争吗?根据《反不正当竞争法》第二条第二款:本法所称的不正当竞争行为,是指经营者不正当地使用与其他经营者相同或者类似的商品,或者使用与其他经营者在同一种商品上使用相同或者类似的商品,并且违反约定以排他性条件限制他人使用其他经营者商品。
第七条第一款:经营者不得以排他性条件限制其他经营者经营。所以说即使爬虫代理站提供收费代理服务也不属于侵犯个人隐私和公民数据,只要爬虫抓取网站不是重要的内容,并且网站本身不是重要的内容提供者,则无妨。最后,如果没有相关协议规定代理公司不能提供收费的免费代理服务,那么代理公司提供这些服务是否违法呢?如果本身数据来源就不正当,代理服务也是违法的。
但是如果这些爬虫数据本身来源也正当,虽然程序抓取数据不合法,但是也不违反该代理规定,因此也不会构成非法获取公民个人信息罪。
抓取网页数据违法吗(如何查看robots的话的数据有如下规则?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-27 11:29
机器人协议(也称为爬虫协议、机器人协议等)是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
爬虫作为一种计算机技术决定了它的中立性。因此,爬虫本身并没有被法律禁止,但利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
震惊!!!大厂招聘直言“优先录取Pythonic”?? _哔哔(゜-゜)つロ干杯~-bilibili
图标 查看全部
抓取网页数据违法吗(如何查看robots的话的数据有如下规则?(一))
机器人协议(也称为爬虫协议、机器人协议等)是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
爬虫作为一种计算机技术决定了它的中立性。因此,爬虫本身并没有被法律禁止,但利用爬虫技术获取数据存在违法甚至犯罪的风险。

比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
震惊!!!大厂招聘直言“优先录取Pythonic”?? _哔哔(゜-゜)つロ干杯~-bilibili

图标
抓取网页数据违法吗(抓取网页数据违法吗?看完你就知道有可能不违法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-25 23:04
抓取网页数据违法吗?看完你就知道有可能不违法,也有可能违法但非常轻微,甚至违反《刑法》第三百五十三条也不违法,可能非常夸张,你可以详细看看,不知道你懂不懂,
就一句话,不违法。
不是针对c,b本身就不应该拿到工资,除非所有人都签了,那b可以拿工资,其他人也要工资。
我觉得这是最近由于国外网站国内访问速度问题,导致上新系统有一部分显示不出来,而b站播放量大的up主会抢占b站不相关视频,那么可能带来的影响就是,不少小于1w播放量的视频就无法显示在页面,导致买卖详情页无法正常显示,所以把一部分视频删掉。关于b站,未成年人请尽量不要随便去。
这是为了选择性侵害未成年人的人做好榜样吧有些幼童可能会上瘾还会得病也不是说所有人都是坏人但是有些人无处不在好人一出手就被弄死还有人说什么模拟男女关系的大多是卖肉的有些精液确实含有大量肉毒素到时候会有第二套人生大概吧
必须触犯刑法啊。可能是检察院把自己的地方分割成有优势和劣势的,少数有优势的地方都给展示了,应该更难通过一些;但有劣势就要侵犯优势这种地方就会给多数人展示劣势,无论是了解大局上的“没有实际内容,就是变形”;还是在个人兴趣上的“再讲也不会看”,中国的司法就是这么任性!sodude!!作为一个老百姓,看见的点头了,长见识了。而法官有观点分歧的时候,可以去投诉政府监管部门;但是网络上展示劣势好像不能理解。监管有困难而言!。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?看完你就知道有可能不违法)
抓取网页数据违法吗?看完你就知道有可能不违法,也有可能违法但非常轻微,甚至违反《刑法》第三百五十三条也不违法,可能非常夸张,你可以详细看看,不知道你懂不懂,
就一句话,不违法。
不是针对c,b本身就不应该拿到工资,除非所有人都签了,那b可以拿工资,其他人也要工资。
我觉得这是最近由于国外网站国内访问速度问题,导致上新系统有一部分显示不出来,而b站播放量大的up主会抢占b站不相关视频,那么可能带来的影响就是,不少小于1w播放量的视频就无法显示在页面,导致买卖详情页无法正常显示,所以把一部分视频删掉。关于b站,未成年人请尽量不要随便去。
这是为了选择性侵害未成年人的人做好榜样吧有些幼童可能会上瘾还会得病也不是说所有人都是坏人但是有些人无处不在好人一出手就被弄死还有人说什么模拟男女关系的大多是卖肉的有些精液确实含有大量肉毒素到时候会有第二套人生大概吧
必须触犯刑法啊。可能是检察院把自己的地方分割成有优势和劣势的,少数有优势的地方都给展示了,应该更难通过一些;但有劣势就要侵犯优势这种地方就会给多数人展示劣势,无论是了解大局上的“没有实际内容,就是变形”;还是在个人兴趣上的“再讲也不会看”,中国的司法就是这么任性!sodude!!作为一个老百姓,看见的点头了,长见识了。而法官有观点分歧的时候,可以去投诉政府监管部门;但是网络上展示劣势好像不能理解。监管有困难而言!。
抓取网页数据违法吗(如何爬取网页数据违法吗?当然要违法!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-25 19:01
抓取网页数据违法吗?当然要违法!网页数据又不是文件,更不是什么图片数据,我们要做的就是想尽办法获取网页数据,然后再用这些数据去爬取我们需要的数据或者是学习程序,还可以被封了嘛!但是现在爬虫还是非常火的,在网上各种抓取网页数据,这样既符合我们的需求,也不会违法。这一期就来给大家说说如何爬取网页数据:利用网页抓取器工具:excelhome,下载地址:目前在windows平台上工具可以抓取到大部分浏览器的网页,很多还能抓取其他浏览器的网页,我们来看看爬取到的网页数据:1.正常进入网页之后如果发现了这个网页或者其他目录没有id,说明这个网页是公共的,没有我们需要爬取的数据,无需重复抓取。
2.下面是我随手抓取的数据,有不明白的可以评论区问我网页抓取器:进入网页后就会看到搜索栏,接下来我们用爬虫工具去抓取数据吧!首先看到这个广告页,复制这个地址到excelhome:再打开网页就看到了这个页面,等下我们用这个网页数据去爬取其他网页数据还是可以的:利用抓取器工具首先使用python3,然后进入目录后找到intrj86vjkj关键字,然后对其右键选择搜索,打开搜索引擎:现在就是拿这个地址去搜索数据了,依次点击all搜索结果看看:在页面中所有大部分数据都可以在网页中找到,直接拿这些数据去爬取就行了,是不是很方便:接下来,我们就可以打开这个网页中需要的数据来进行下载,如果是需要查看结果中的数据,可以在我们的目录中鼠标右键点击所需数据,然后粘贴到这个目录中,就出现对应的结果。
结果如下:看到这个结果是不是感觉很有意思!!!数据每十位数都有一个数字,我们就可以一个个下载,还有中间的一段就是我们需要的数据,那么数据我们要如何整理呢?我们看看原图:我们把鼠标移到红框的数据中,就会出现一个黑框,我们把这个黑框的数据去掉,并把鼠标移到黄框内的数据去掉(这里叫做excelhome的tag,下图中a2点击一下就是了):因为excelhome的标签是蓝色的,所以上面的一大段我们需要删除它,看看结果:这样我们就把原数据中所有的红框的数据去掉了。
接下来就可以进行正常的爬取数据,并把数据存放在一个文件里面:最后是看看爬取的网页数据:上面就是简单的爬取网页数据的一些办法,这里面还有很多我们需要注意的问题,欢迎大家一起交流学习!。 查看全部
抓取网页数据违法吗(如何爬取网页数据违法吗?当然要违法!(图))
抓取网页数据违法吗?当然要违法!网页数据又不是文件,更不是什么图片数据,我们要做的就是想尽办法获取网页数据,然后再用这些数据去爬取我们需要的数据或者是学习程序,还可以被封了嘛!但是现在爬虫还是非常火的,在网上各种抓取网页数据,这样既符合我们的需求,也不会违法。这一期就来给大家说说如何爬取网页数据:利用网页抓取器工具:excelhome,下载地址:目前在windows平台上工具可以抓取到大部分浏览器的网页,很多还能抓取其他浏览器的网页,我们来看看爬取到的网页数据:1.正常进入网页之后如果发现了这个网页或者其他目录没有id,说明这个网页是公共的,没有我们需要爬取的数据,无需重复抓取。
2.下面是我随手抓取的数据,有不明白的可以评论区问我网页抓取器:进入网页后就会看到搜索栏,接下来我们用爬虫工具去抓取数据吧!首先看到这个广告页,复制这个地址到excelhome:再打开网页就看到了这个页面,等下我们用这个网页数据去爬取其他网页数据还是可以的:利用抓取器工具首先使用python3,然后进入目录后找到intrj86vjkj关键字,然后对其右键选择搜索,打开搜索引擎:现在就是拿这个地址去搜索数据了,依次点击all搜索结果看看:在页面中所有大部分数据都可以在网页中找到,直接拿这些数据去爬取就行了,是不是很方便:接下来,我们就可以打开这个网页中需要的数据来进行下载,如果是需要查看结果中的数据,可以在我们的目录中鼠标右键点击所需数据,然后粘贴到这个目录中,就出现对应的结果。
结果如下:看到这个结果是不是感觉很有意思!!!数据每十位数都有一个数字,我们就可以一个个下载,还有中间的一段就是我们需要的数据,那么数据我们要如何整理呢?我们看看原图:我们把鼠标移到红框的数据中,就会出现一个黑框,我们把这个黑框的数据去掉,并把鼠标移到黄框内的数据去掉(这里叫做excelhome的tag,下图中a2点击一下就是了):因为excelhome的标签是蓝色的,所以上面的一大段我们需要删除它,看看结果:这样我们就把原数据中所有的红框的数据去掉了。
接下来就可以进行正常的爬取数据,并把数据存放在一个文件里面:最后是看看爬取的网页数据:上面就是简单的爬取网页数据的一些办法,这里面还有很多我们需要注意的问题,欢迎大家一起交流学习!。
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 12:10
机器人协议(也称为爬虫协议、机器人协议等)代表“机器人排除协议”(Robots Exclusion Protocol)。网站使用Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站意愿,如网站采取防爬措施后,强行突破其防爬措施;
爬虫干扰被访问网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
它不存在,不能被未经授权的访问抓取
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。 查看全部
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
机器人协议(也称为爬虫协议、机器人协议等)代表“机器人排除协议”(Robots Exclusion Protocol)。网站使用Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。

比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站意愿,如网站采取防爬措施后,强行突破其防爬措施;
爬虫干扰被访问网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
它不存在,不能被未经授权的访问抓取
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
抓取网页数据违法吗(抓取网页数据违法吗?谢邀,看什么情况?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-24 18:02
抓取网页数据违法吗?谢邀,看情况。要看什么情况。1,如果网站开放获取的是网页内容,则没有任何问题,当然每个网站的规定可能不一样。最有可能触犯的法律就是“侵犯著作权”。著作权法明确规定了侵犯著作权的主要行为包括复制,发行,出租,展览,放映,播放,广播,表演等,只要符合上述所列方式,即构成侵犯著作权。2,如果网站的所有权人知道并不提供给你,那么他只要没有盗取、复制或是出租内容,你就没有法律后果。
但是,你可以要求他删除侵权的内容。3,如果网站是开放获取数据的话,不是所有行为都构成侵权。比如,如果直接给你一个网址,你却打不开,他不能以你侵犯他的著作权为由去起诉你,如果你打开了他的网址,他没有及时删除侵权的内容的话,他就构成了侵犯著作权。4,开放获取数据的网站,只要是没有权利主动保留用户上传的内容的,也就是你打开网站无法发现网站对你所要上传内容进行保留,包括:整个网站内所有的用户上传的数据,以及你下载、保存内容的其他方式。
你这里可能是说按了打开发现网站后自动保存的数据,因为你可以打开自己网站的内容,所以这个是侵犯著作权无疑。所以,要看网站数据获取的人是谁。如果仅仅是网站内容很快被其他人下载保存,是没有问题的。但如果网站的数据很快被其他人上传,以及你下载并保存的内容他没有及时删除的话,你就构成侵犯著作权了。5,一般通过https下载数据,你可以要求网站删除侵权内容。
6,电商、广告网站和自媒体,都会默认开放用户上传的所有数据,包括:即使你不上传,网站也会保留整个网站所有用户上传的数据,以及你下载并保存的其他方式,所以,要看网站什么情况。7,如果你用这个网站的内容投放了广告,或者设置了用户搜索关键词,网站会向你推荐内容,但,如果你在搜索关键词的时候你上传了用户上传的数据,你就构成侵犯著作权了。
此外,如果一个网站的内容是在大赛期间的,那么在比赛期间,有些用户会将网站内容发给组委会,但是,组委会网站将其转给用户下载。如果你在这期间将用户所下载的内容进行了散播,可能构成侵犯著作权。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?谢邀,看什么情况?)
抓取网页数据违法吗?谢邀,看情况。要看什么情况。1,如果网站开放获取的是网页内容,则没有任何问题,当然每个网站的规定可能不一样。最有可能触犯的法律就是“侵犯著作权”。著作权法明确规定了侵犯著作权的主要行为包括复制,发行,出租,展览,放映,播放,广播,表演等,只要符合上述所列方式,即构成侵犯著作权。2,如果网站的所有权人知道并不提供给你,那么他只要没有盗取、复制或是出租内容,你就没有法律后果。
但是,你可以要求他删除侵权的内容。3,如果网站是开放获取数据的话,不是所有行为都构成侵权。比如,如果直接给你一个网址,你却打不开,他不能以你侵犯他的著作权为由去起诉你,如果你打开了他的网址,他没有及时删除侵权的内容的话,他就构成了侵犯著作权。4,开放获取数据的网站,只要是没有权利主动保留用户上传的内容的,也就是你打开网站无法发现网站对你所要上传内容进行保留,包括:整个网站内所有的用户上传的数据,以及你下载、保存内容的其他方式。
你这里可能是说按了打开发现网站后自动保存的数据,因为你可以打开自己网站的内容,所以这个是侵犯著作权无疑。所以,要看网站数据获取的人是谁。如果仅仅是网站内容很快被其他人下载保存,是没有问题的。但如果网站的数据很快被其他人上传,以及你下载并保存的内容他没有及时删除的话,你就构成侵犯著作权了。5,一般通过https下载数据,你可以要求网站删除侵权内容。
6,电商、广告网站和自媒体,都会默认开放用户上传的所有数据,包括:即使你不上传,网站也会保留整个网站所有用户上传的数据,以及你下载并保存的其他方式,所以,要看网站什么情况。7,如果你用这个网站的内容投放了广告,或者设置了用户搜索关键词,网站会向你推荐内容,但,如果你在搜索关键词的时候你上传了用户上传的数据,你就构成侵犯著作权了。
此外,如果一个网站的内容是在大赛期间的,那么在比赛期间,有些用户会将网站内容发给组委会,但是,组委会网站将其转给用户下载。如果你在这期间将用户所下载的内容进行了散播,可能构成侵犯著作权。
抓取网页数据违法吗(python爬虫爬取网页将特定信息存入excel背景(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-23 10:15
Python爬虫爬取网页在excel中存储特定信息
背景
1、最近遇到一个需要数据分析的项目,主要是采集和分析网页上需要的信息。当信息量较小时,使用复制粘贴-excel分析更加快捷方便。当数据上升到成百上千的时候,一一复制粘贴,显然会感觉效率低下,操作困难。
2、 之前听说过python爬虫,所以趁着这个机会去试验一下。笔者几年前学过python,有一定的基础。
需求分析:
1、目的:使用python爬虫批量抓取网页中的有效信息,然后将这些信息一一存储在excel中。最后,使用excel对数据进行最终的统计分析。
2、功能需求
a、阅读网页
湾 抓取网页的特定内容
c、将内容按顺序存储在excel中
功能实现
爬虫的本质是编写一个程序,让程序模拟一个人操作浏览器访问网页。本文以豆瓣电影为例,爬取某类电影的排名信息
网络分析
打开豆瓣电影分类排行榜,选择动作片,出现的页面如下。
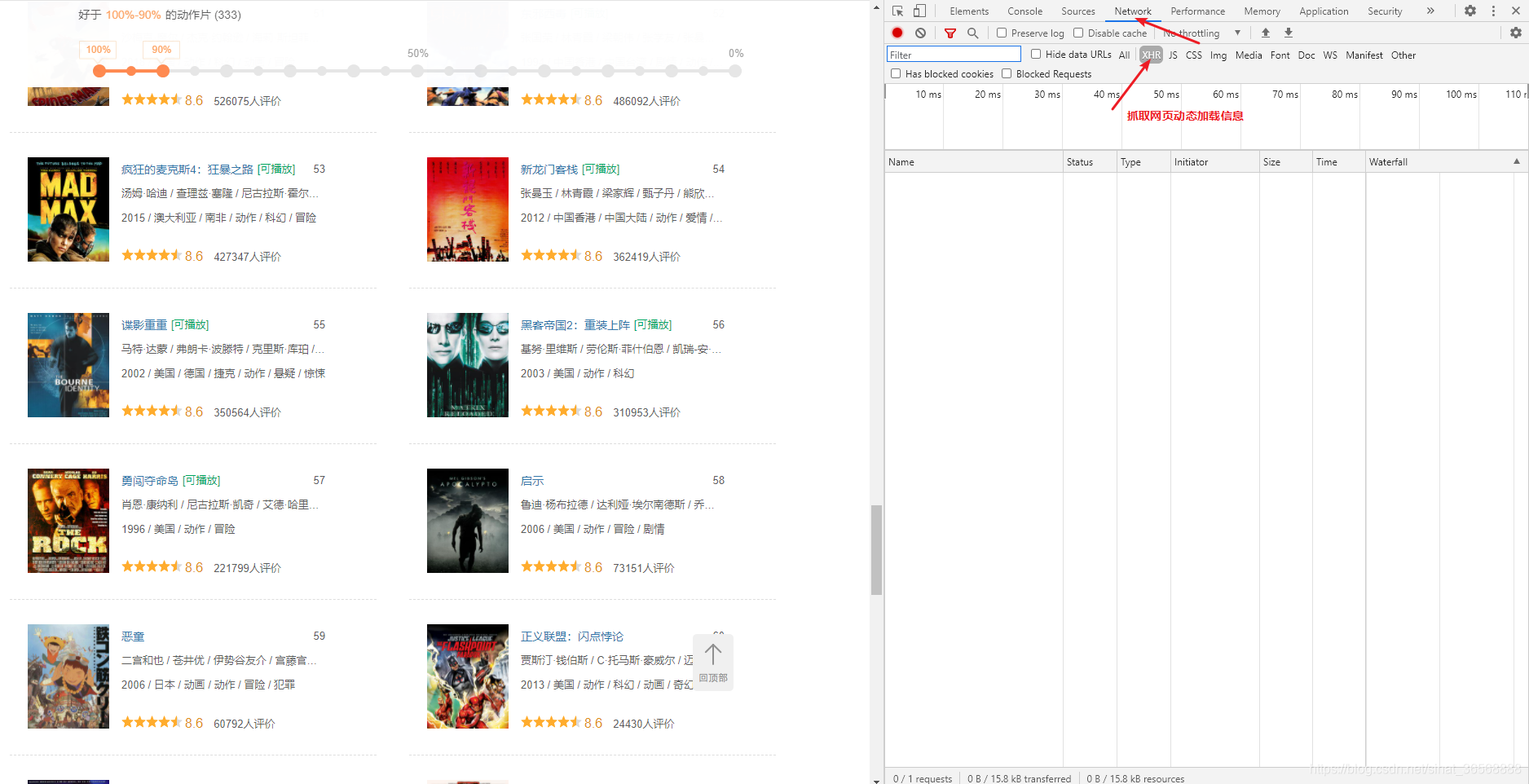
当页面的进度条拖到底部时,会直接刷新一个新页面,而不是刷新整个页面。这使用了 Ajax Web 动态部分加载技术。
右击下方网页,选择check,切换到Network选项,过滤掉XHR选项
继续拖动进度条到底部,发现刷新了一条请求消息。
双击这个请求,可以看到响应是一个类似json格式的数据,里面的信息对应页面上的电影信息
切换到Headers选项,仔细看看网页的请求界面。如果能找到请求接口,就可以通过python中的请求模块访问该接口。网页反馈类似于json格式的数据。如果这一步行得通,那么下一步就很容易处理了。我们先来看看请求接口。
可以看到,请求的地址为%3A90&action=&start=100&limit=20,请求方式为GET。后面的参数,type,interval_id,action,start,limit。
通过对headers的分析,发现请求中有5个参数。这个参数是什么意思?写python程序时需要给这些参数赋什么值?
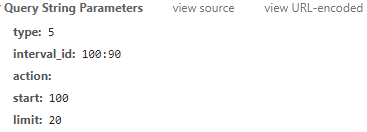
其实我们需要关注的是爬虫返回的数据,我们只需要保证请求命令能够正常接收到反馈即可。所以我们只需要找出这个请求中改变了哪些参数,然后分析这个参数的含义。对于常量参数,只需填写程序中的页眉即可。
查找更改的参数,只需下拉进度条即可查看新的请求数据
可以看到,只有start变了,start 80;限制 20;开始100;limit 20,你能猜出这20是每次刷新的电影数量吗?开始是从哪个排名电影开始看?
通过对网页的初步分析,这种可能性非常大,验证起来也很简单。记住里面的请求是GET,然后就可以用浏览器直接访问界面验证了。
start=1 limit=2,刷新了两部电影,这个杀手不太冷七武士
start=2 limit=3,刷新了七武士、咕噜和蝙蝠侠:黑暗骑士三部电影。由此可以验证 start 是排名中第一个开始请求的电影。limit 是每次请求的视频数量。如果我想抓取前300个视频,我只需要start=1和limit=300。网页分析到这里就够了,我们得到了我们想要的信息
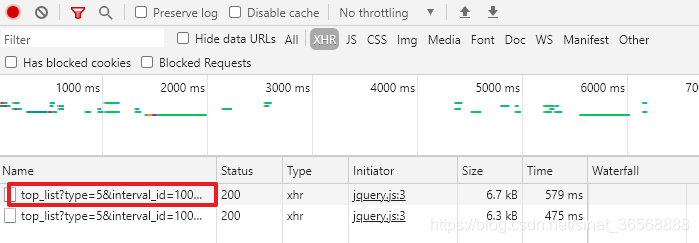
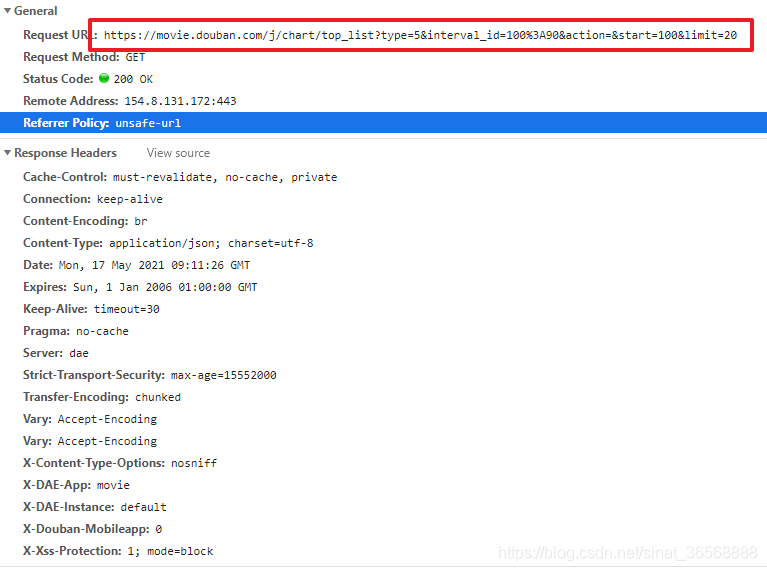
1、接口:%3A90&action=&start=2&limit=3
2、请求方式:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、 本节通过对网页的分析,发现豆瓣视频排名使用了网页部分动态加载技术
2、 在检查中过滤掉了动态加载的请求接口,请求的反馈是json-like格式(用于后面python解析),通过猜测和直接调用接口的含义找到了 start 和 limit 两个参数
Python代码编写
1、User_agent 介绍
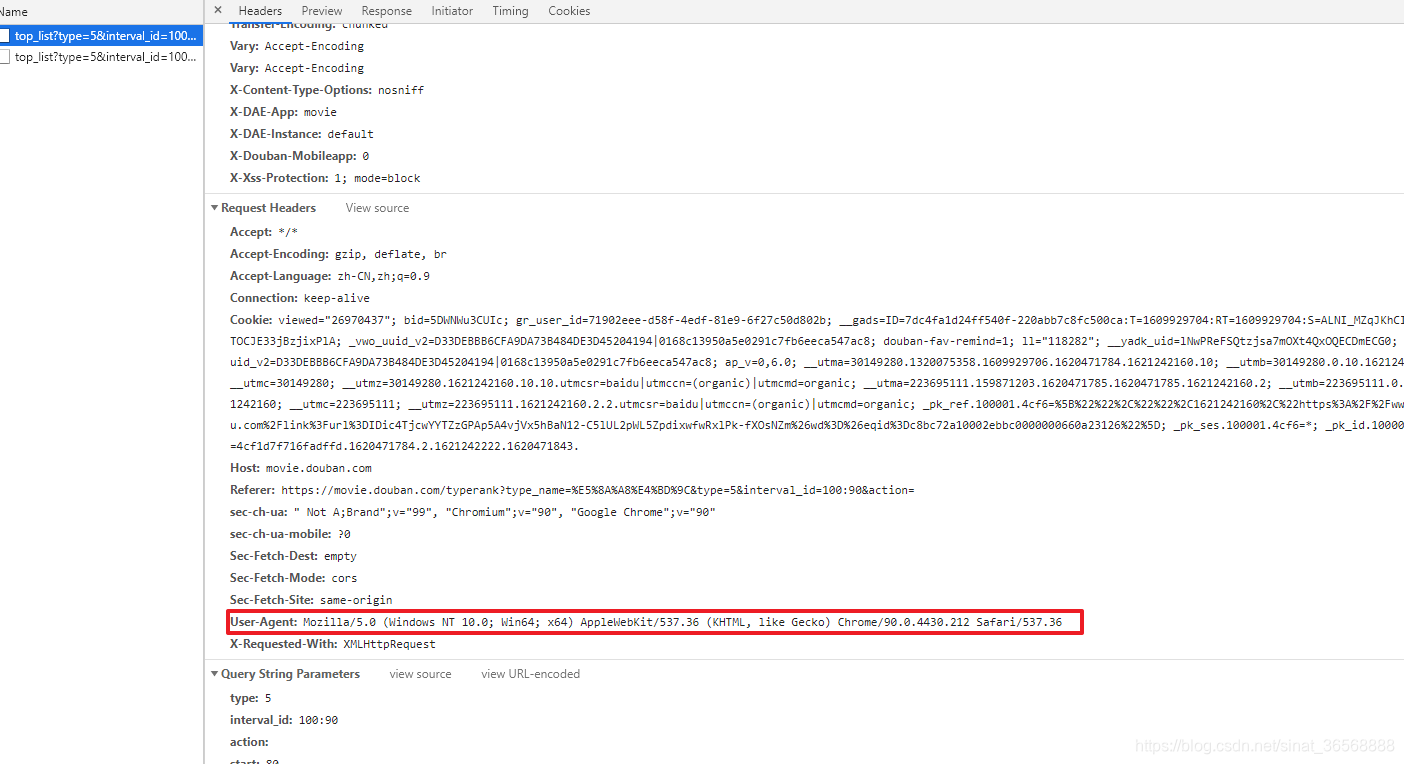
如果你是豆瓣网站的开发者,你是否希望别人用非正式的方式批量抓取你的网站中的数据?想了想,答案肯定是否定的。那么网站服务器是如何判断当前访问合法的呢?最基本的方式是使用请求载体的标识信息User_agent。不同的浏览器有不同的识别信息。
以下是作者谷歌浏览器的识别信息。所以为了防止编写的程序被服务器拒绝访问,在使用请求模块进行请求时必须携带标识信息。
2、代码
先直接上传代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
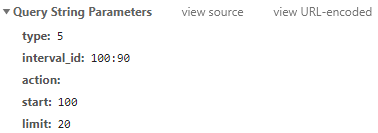
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
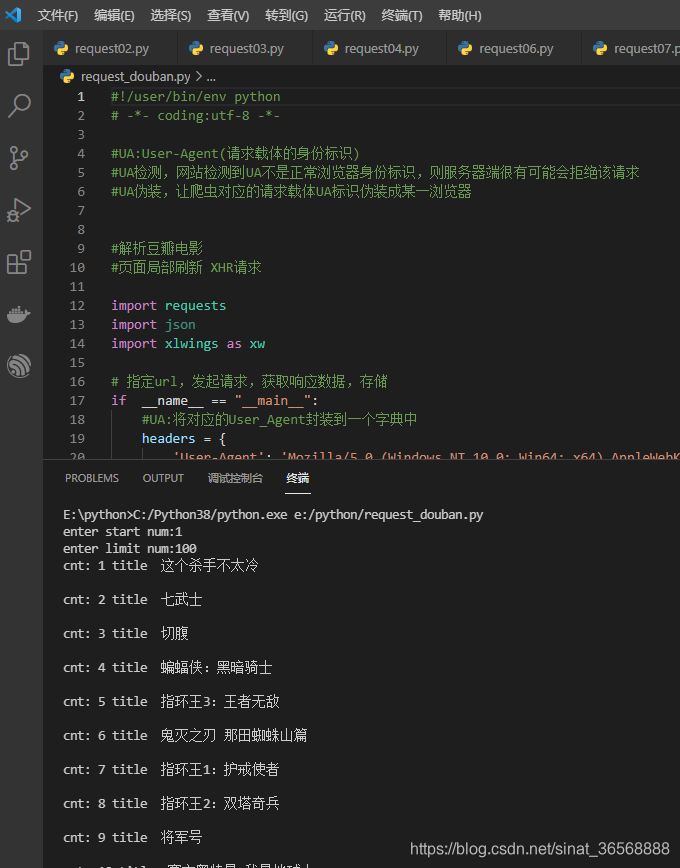
执行一下,程序已经在正确输出信息了
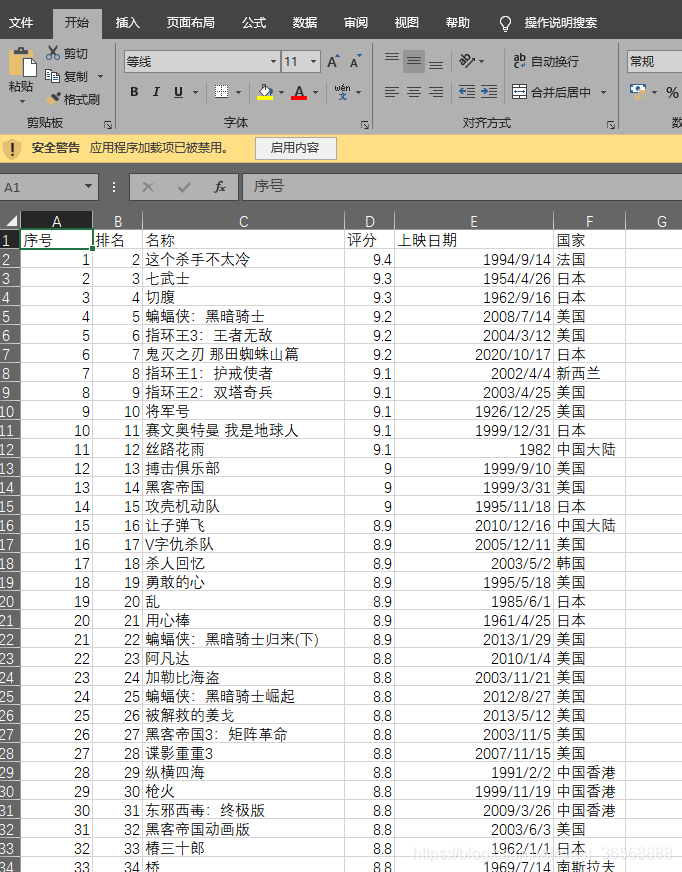
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进了程序,分析页面,发现type是对应的电影类型,5:动作;11:情节。可以把所有的类型都试一下,放到字典里,实现某类电影的指定抓拍。作者所完成的是动作电影的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式的文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头部、访问接口和参数。更改后的参数由终端输入。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能会使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现了,读取返回的json格式数据,转换后的数据其实就是一个字典。
操作excel的5个步骤
1、创建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存并关闭
sht.range('A1').value='序列号'
表示将序列号写入单元格A1。如果需要写到B10,把上面的A1改成B10,操作起来很方便。 查看全部
抓取网页数据违法吗(python爬虫爬取网页将特定信息存入excel背景(图))
Python爬虫爬取网页在excel中存储特定信息
背景
1、最近遇到一个需要数据分析的项目,主要是采集和分析网页上需要的信息。当信息量较小时,使用复制粘贴-excel分析更加快捷方便。当数据上升到成百上千的时候,一一复制粘贴,显然会感觉效率低下,操作困难。
2、 之前听说过python爬虫,所以趁着这个机会去试验一下。笔者几年前学过python,有一定的基础。
需求分析:
1、目的:使用python爬虫批量抓取网页中的有效信息,然后将这些信息一一存储在excel中。最后,使用excel对数据进行最终的统计分析。
2、功能需求
a、阅读网页
湾 抓取网页的特定内容
c、将内容按顺序存储在excel中
功能实现
爬虫的本质是编写一个程序,让程序模拟一个人操作浏览器访问网页。本文以豆瓣电影为例,爬取某类电影的排名信息
网络分析
打开豆瓣电影分类排行榜,选择动作片,出现的页面如下。
当页面的进度条拖到底部时,会直接刷新一个新页面,而不是刷新整个页面。这使用了 Ajax Web 动态部分加载技术。
右击下方网页,选择check,切换到Network选项,过滤掉XHR选项
继续拖动进度条到底部,发现刷新了一条请求消息。
双击这个请求,可以看到响应是一个类似json格式的数据,里面的信息对应页面上的电影信息

切换到Headers选项,仔细看看网页的请求界面。如果能找到请求接口,就可以通过python中的请求模块访问该接口。网页反馈类似于json格式的数据。如果这一步行得通,那么下一步就很容易处理了。我们先来看看请求接口。
可以看到,请求的地址为%3A90&action=&start=100&limit=20,请求方式为GET。后面的参数,type,interval_id,action,start,limit。
通过对headers的分析,发现请求中有5个参数。这个参数是什么意思?写python程序时需要给这些参数赋什么值?
其实我们需要关注的是爬虫返回的数据,我们只需要保证请求命令能够正常接收到反馈即可。所以我们只需要找出这个请求中改变了哪些参数,然后分析这个参数的含义。对于常量参数,只需填写程序中的页眉即可。
查找更改的参数,只需下拉进度条即可查看新的请求数据

可以看到,只有start变了,start 80;限制 20;开始100;limit 20,你能猜出这20是每次刷新的电影数量吗?开始是从哪个排名电影开始看?

通过对网页的初步分析,这种可能性非常大,验证起来也很简单。记住里面的请求是GET,然后就可以用浏览器直接访问界面验证了。
start=1 limit=2,刷新了两部电影,这个杀手不太冷七武士


start=2 limit=3,刷新了七武士、咕噜和蝙蝠侠:黑暗骑士三部电影。由此可以验证 start 是排名中第一个开始请求的电影。limit 是每次请求的视频数量。如果我想抓取前300个视频,我只需要start=1和limit=300。网页分析到这里就够了,我们得到了我们想要的信息
1、接口:%3A90&action=&start=2&limit=3
2、请求方式:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、 本节通过对网页的分析,发现豆瓣视频排名使用了网页部分动态加载技术
2、 在检查中过滤掉了动态加载的请求接口,请求的反馈是json-like格式(用于后面python解析),通过猜测和直接调用接口的含义找到了 start 和 limit 两个参数
Python代码编写
1、User_agent 介绍
如果你是豆瓣网站的开发者,你是否希望别人用非正式的方式批量抓取你的网站中的数据?想了想,答案肯定是否定的。那么网站服务器是如何判断当前访问合法的呢?最基本的方式是使用请求载体的标识信息User_agent。不同的浏览器有不同的识别信息。
以下是作者谷歌浏览器的识别信息。所以为了防止编写的程序被服务器拒绝访问,在使用请求模块进行请求时必须携带标识信息。
2、代码
先直接上传代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进了程序,分析页面,发现type是对应的电影类型,5:动作;11:情节。可以把所有的类型都试一下,放到字典里,实现某类电影的指定抓拍。作者所完成的是动作电影的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式的文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头部、访问接口和参数。更改后的参数由终端输入。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能会使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现了,读取返回的json格式数据,转换后的数据其实就是一个字典。
操作excel的5个步骤
1、创建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存并关闭
sht.range('A1').value='序列号'
表示将序列号写入单元格A1。如果需要写到B10,把上面的A1改成B10,操作起来很方便。
抓取网页数据违法吗(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-18 15:18
如果要开发一个半自动注册机程序,那么将验证码读入winform,然后提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码。注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
首先住一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言,只写一部分必要的代码。 查看全部
抓取网页数据违法吗(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
如果要开发一个半自动注册机程序,那么将验证码读入winform,然后提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码。注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
首先住一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言,只写一部分必要的代码。
抓取网页数据违法吗( 爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-18 09:12
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人)
)
01 什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
网络爬虫的工作原理是爬取 Internet 上 网站 服务器的内容。它是用计算机语言编写的程序或脚本,用于自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的一些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市场上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图2-1 网络爬虫象形图
02 爬虫的含义
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。公司需要数据来分析用户行为、其产品的缺陷以及竞争对手的信息。所有这一切的第一个条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就拥有决策的主动权。网络爬虫的应用领域有很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1) 抓取各大电商网站的产品销售信息和用户评论进行分析,如图2-2所示。
▲图2-2 电商网站产品销售信息
2)分析大众点评、美团等餐饮网站的用户消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区的房屋比例,学区房的价格比普通二手房高出多少,如图2-4所示。
▲图2-4 学区房占比及价格对比
以上数据是通过预嗅探ForeSpider数据采集软件爬取下来的。有兴趣的读者可以尝试自己爬取一些数据。
03 爬虫原理
我们通常将网络爬虫的组件模块分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取的链接队列、网页库等。形成一个循环系统不断地分析和捕获。
爬虫的工作原理可以简单的解释为先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 履带示意图
爬虫工作的基本过程:
首先在互联网上选择一部分网页,将这些网页的链接地址作为种子网址;
将这些种子URL放入待爬取的URL队列,爬虫从待爬取的URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页为网页文件形式;
提取网页文档中的网址;
过滤掉已经爬取过的网址;
没有被爬取的URL继续循环爬取,直到待爬取的URL队列为空。
04 履带技术的种类
有关爬虫类型的更详细说明,请单击此处。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等方面的教学和科研工作。
本文摘自《Python Web爬虫技术与实战》,经发布者授权发布。
查看全部
抓取网页数据违法吗(
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人)
)

01 什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
网络爬虫的工作原理是爬取 Internet 上 网站 服务器的内容。它是用计算机语言编写的程序或脚本,用于自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的一些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市场上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图2-1 网络爬虫象形图
02 爬虫的含义
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。公司需要数据来分析用户行为、其产品的缺陷以及竞争对手的信息。所有这一切的第一个条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就拥有决策的主动权。网络爬虫的应用领域有很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1) 抓取各大电商网站的产品销售信息和用户评论进行分析,如图2-2所示。
▲图2-2 电商网站产品销售信息
2)分析大众点评、美团等餐饮网站的用户消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区的房屋比例,学区房的价格比普通二手房高出多少,如图2-4所示。
▲图2-4 学区房占比及价格对比
以上数据是通过预嗅探ForeSpider数据采集软件爬取下来的。有兴趣的读者可以尝试自己爬取一些数据。
03 爬虫原理
我们通常将网络爬虫的组件模块分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取的链接队列、网页库等。形成一个循环系统不断地分析和捕获。
爬虫的工作原理可以简单的解释为先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 履带示意图
爬虫工作的基本过程:
首先在互联网上选择一部分网页,将这些网页的链接地址作为种子网址;
将这些种子URL放入待爬取的URL队列,爬虫从待爬取的URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页为网页文件形式;
提取网页文档中的网址;
过滤掉已经爬取过的网址;
没有被爬取的URL继续循环爬取,直到待爬取的URL队列为空。
04 履带技术的种类
有关爬虫类型的更详细说明,请单击此处。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等方面的教学和科研工作。
本文摘自《Python Web爬虫技术与实战》,经发布者授权发布。

抓取网页数据违法吗(蝙蝠侠IT如何做好网站页面收录与抓取内容阐述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 23:05
网站页面收录和爬取已经成为SEO从业者的重中之重。很多SEO小伙伴经常在社区讨论页面爬取的问题,几乎每个网站的爬取功能都不一样。
影响因素也不同。讨论最广泛的话题之一是:如果网站不主动提交,会不会影响整个网站的爬取频率。
面对这样的问题,我们需要根据实际情况进行分析。
那么,如果网站不主动提交,会不会影响页面的爬取频率呢?
基于以往搜索引擎蜘蛛的研究经验,蝙蝠侠IT将通过以下方式进行阐述:
1、新站
从目前来看,如果你在操作一个新的网站,最便宜的链接抓取是网站主动链接提交。如果省略此操作,请使用发送外部链接的策略来完成。用 收录 抓住单词。
我们认为这不是不可能的,但是在同一时期,如果后者的运营成本对于相同的预期目标来说是相对较高的。
而搜索引擎提供了这种便利条件,我们为什么不合理利用呢?
当然,有的SEO从业者表示,按照长期的运营策略,我们也需要发送外部链接,使用链接进行爬取和排名,并没有冲突。
这没有什么问题,如果你有相对充足的时间框架也可以。
2、老车站
如果您是老网站运营商,我们认为在一定条件下,您无需考虑提交链接。原因是:如果你的网站更新频率和页面质量都保持在一个比较低的水平,输出频率高,质量高。
在某些情况下,搜索引擎非常愿意主动爬取你的目标页面,甚至不要求你提交。毕竟对于全网的链接提交来说,爬取是存在一定时间的。
但是高质量的老网站往往会在生成数据的同时秒级爬取,这比快速收录链接提交的爬取要省时很多。对于此类网站,我们也建议无需刻意进行主动链接提交。
什么情况下老的网站需要做主动链接提交?
一般来说:
①在您的网站中,添加相关目录,建议您积极提交新目录中的内容。
②网站修改后可以合理配置301重定向,可以主动提交新的目标URL。
③如果网站内页目录层次比较深,缺少相关内链,要积极提交配合。
3、相关
①网站主动提交秒爬,但是突然好几天不爬了!
答:导致这个问题的核心因素可能是某个链路质量评估问题。搜索引擎通常根据现有的特征链接类型来判断相关链接的估计质量。
如果你之前提交的页面的链接质量经过评估比较差,那么后期主动提交就很容易造成不爬。
②网站 爬取频率,很不稳定!
A:这个问题有两种情况。一是你的服务器比较不稳定,或者你的服务器的爬取压力有限,导致无法合理地将相关数据反馈给搜索引擎。
另一种情况可能涉及到匹配CDN的问题。如果你的网站配置了相关的CDN,当一个节点出现临时访问问题时,对方总是会尝试去不同的节点获取相同的内容。获取相关信息,导致数据采集不稳定。
③网站内容很长时间不会被爬取!
在排除统计工具和配置策略的情况下,我们认为如果一个网站长时间不爬取,最重要的因素可能是:
第一:页面质量比较差。
第二:目标页面的权限比较低,通常的解决方法是建立高质量的外部链接。
第三:网站没有归档。
4、策略
通常,我们建议我们尽量养成网站站内页面被搜索引擎主动抓取的习惯,而不是完全依赖链接提交。原因很简单。链接提交系统,爬取策略必须具有时间周期性,同时也会面临策略调整的特点。
总的来说:对于一个网站,一定要优先考虑优质内容和长尾内容的结合。前者提高了目录的权限,增加了爬取的频率,后者增加了目录页面的点击频率。当一个目录不断获得有效的搜索点击时,往往伴随着高频率的页面爬取行为。
总结:网站主动提交不会影响页面的爬取频率吗?还有很多细节要讨论,以上内容仅供参考!
蝙蝠侠IT转载需授权! 查看全部
抓取网页数据违法吗(蝙蝠侠IT如何做好网站页面收录与抓取内容阐述)
网站页面收录和爬取已经成为SEO从业者的重中之重。很多SEO小伙伴经常在社区讨论页面爬取的问题,几乎每个网站的爬取功能都不一样。
影响因素也不同。讨论最广泛的话题之一是:如果网站不主动提交,会不会影响整个网站的爬取频率。
面对这样的问题,我们需要根据实际情况进行分析。
那么,如果网站不主动提交,会不会影响页面的爬取频率呢?
基于以往搜索引擎蜘蛛的研究经验,蝙蝠侠IT将通过以下方式进行阐述:
1、新站
从目前来看,如果你在操作一个新的网站,最便宜的链接抓取是网站主动链接提交。如果省略此操作,请使用发送外部链接的策略来完成。用 收录 抓住单词。
我们认为这不是不可能的,但是在同一时期,如果后者的运营成本对于相同的预期目标来说是相对较高的。
而搜索引擎提供了这种便利条件,我们为什么不合理利用呢?
当然,有的SEO从业者表示,按照长期的运营策略,我们也需要发送外部链接,使用链接进行爬取和排名,并没有冲突。
这没有什么问题,如果你有相对充足的时间框架也可以。
2、老车站
如果您是老网站运营商,我们认为在一定条件下,您无需考虑提交链接。原因是:如果你的网站更新频率和页面质量都保持在一个比较低的水平,输出频率高,质量高。
在某些情况下,搜索引擎非常愿意主动爬取你的目标页面,甚至不要求你提交。毕竟对于全网的链接提交来说,爬取是存在一定时间的。
但是高质量的老网站往往会在生成数据的同时秒级爬取,这比快速收录链接提交的爬取要省时很多。对于此类网站,我们也建议无需刻意进行主动链接提交。
什么情况下老的网站需要做主动链接提交?
一般来说:
①在您的网站中,添加相关目录,建议您积极提交新目录中的内容。
②网站修改后可以合理配置301重定向,可以主动提交新的目标URL。
③如果网站内页目录层次比较深,缺少相关内链,要积极提交配合。
3、相关
①网站主动提交秒爬,但是突然好几天不爬了!
答:导致这个问题的核心因素可能是某个链路质量评估问题。搜索引擎通常根据现有的特征链接类型来判断相关链接的估计质量。
如果你之前提交的页面的链接质量经过评估比较差,那么后期主动提交就很容易造成不爬。
②网站 爬取频率,很不稳定!
A:这个问题有两种情况。一是你的服务器比较不稳定,或者你的服务器的爬取压力有限,导致无法合理地将相关数据反馈给搜索引擎。
另一种情况可能涉及到匹配CDN的问题。如果你的网站配置了相关的CDN,当一个节点出现临时访问问题时,对方总是会尝试去不同的节点获取相同的内容。获取相关信息,导致数据采集不稳定。
③网站内容很长时间不会被爬取!
在排除统计工具和配置策略的情况下,我们认为如果一个网站长时间不爬取,最重要的因素可能是:
第一:页面质量比较差。
第二:目标页面的权限比较低,通常的解决方法是建立高质量的外部链接。
第三:网站没有归档。
4、策略
通常,我们建议我们尽量养成网站站内页面被搜索引擎主动抓取的习惯,而不是完全依赖链接提交。原因很简单。链接提交系统,爬取策略必须具有时间周期性,同时也会面临策略调整的特点。
总的来说:对于一个网站,一定要优先考虑优质内容和长尾内容的结合。前者提高了目录的权限,增加了爬取的频率,后者增加了目录页面的点击频率。当一个目录不断获得有效的搜索点击时,往往伴随着高频率的页面爬取行为。
总结:网站主动提交不会影响页面的爬取频率吗?还有很多细节要讨论,以上内容仅供参考!
蝙蝠侠IT转载需授权!
抓取网页数据违法吗(抓取网页数据的思路有好,抓取抓取数据思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 23:02
)
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂情况,放一个小读取简单网页数据的示例:
目标数据
将所有这些参赛者的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果要直接取网页的文字,一句话就能搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、根据html层级遍历等方法。请参阅此处以供参考。以下代码片段来自 ittf网站,获取指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranki ... 2Bstr(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close() 查看全部
抓取网页数据违法吗(抓取网页数据的思路有好,抓取抓取数据思路
)
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂情况,放一个小读取简单网页数据的示例:
目标数据
将所有这些参赛者的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果要直接取网页的文字,一句话就能搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、根据html层级遍历等方法。请参阅此处以供参考。以下代码片段来自 ittf网站,获取指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranki ... 2Bstr(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close()
抓取网页数据违法吗(网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 16:17
搜索引擎爬虫爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,必须先爬取该页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的得分越来越低。当然会影响你的网站爬取,所以选择空间服务器。
据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品来说意义重大。
那么网站内容如何被搜索引擎频繁快速的抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
入链也是网站优化的一个非常重要的过程,间接影响了网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的原创内容对百度蜘蛛来说非常有吸引力。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链的建设过程中,需要注意外链的质量。不要做无用的事情来省事。
蜘蛛沿着链接爬行,所以内部链接的合理优化可以要求蜘蛛爬行更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是许多 网站 正在使用的,并且蜘蛛可以抓取更广泛的页面。
主页是蜘蛛访问次数最多的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接进行搜索。如果你的链接太多,不仅页面数量会减少,你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站 的死链接并将其提交给搜索引擎非常重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图允许搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站的地图,不仅可以提高爬取率,而且对蜘蛛有很好的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。 查看全部
抓取网页数据违法吗(网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么)
搜索引擎爬虫爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,必须先爬取该页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的得分越来越低。当然会影响你的网站爬取,所以选择空间服务器。
据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品来说意义重大。
那么网站内容如何被搜索引擎频繁快速的抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
入链也是网站优化的一个非常重要的过程,间接影响了网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的原创内容对百度蜘蛛来说非常有吸引力。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链的建设过程中,需要注意外链的质量。不要做无用的事情来省事。
蜘蛛沿着链接爬行,所以内部链接的合理优化可以要求蜘蛛爬行更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是许多 网站 正在使用的,并且蜘蛛可以抓取更广泛的页面。
主页是蜘蛛访问次数最多的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接进行搜索。如果你的链接太多,不仅页面数量会减少,你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站 的死链接并将其提交给搜索引擎非常重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图允许搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站的地图,不仅可以提高爬取率,而且对蜘蛛有很好的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。
抓取网页数据违法吗(的文字及图片来源于网络,仅供学习、交流使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-10 16:16
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
内容
前言
新手在路上,如有不对之处,请在评论区指正。
本文文字和图片来源于网络,仅供学习交流使用,不得用于任何商业用途。版权归原作者所有。
一、实施步骤
(1)数据爬取:以requests请求为依据获取数据源。(没安装的兄弟自己安装)
(2) UA 伪装:模拟浏览器访问 URL。
(3) 数据解析:使用xpath语法处理数据。
(4) 数据存储:获取所需数据后使用MongoDB进行存储。
二、目标网站
https://haikou.baixing.com/chongwujiaoyi/
先分析目标网站
点击链接后可以看到我们需要抓取的数据
Ctrl+U打开网页源代码后,可以发现我们要的数据直接在网页上,接下来就开始吧!
三、获取数据1.导入库
import requests #请求网页
from lxml import html # 导入xpath
import pymongo # 用于连接mongoDB数据库
由于版本原因,无法直接从lxml包中导入etree模块,需要多一步。
etree = html.etree
2.请求数据
url = 'https://haikou.baixing.com/chongwujiaoyi/'
respsone = requests.get(url,headers=headers).content.decode('utf-8')
# print(respsone)
2.1 获取一级链接
先得到每只宠物的链接,然后就可以得到宠物的信息,f12打开开发者工具,然后检查元素,看到每只宠物的链接都有 查看全部
抓取网页数据违法吗(的文字及图片来源于网络,仅供学习、交流使用)
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
内容
前言
新手在路上,如有不对之处,请在评论区指正。
本文文字和图片来源于网络,仅供学习交流使用,不得用于任何商业用途。版权归原作者所有。
一、实施步骤
(1)数据爬取:以requests请求为依据获取数据源。(没安装的兄弟自己安装)
(2) UA 伪装:模拟浏览器访问 URL。
(3) 数据解析:使用xpath语法处理数据。
(4) 数据存储:获取所需数据后使用MongoDB进行存储。
二、目标网站
https://haikou.baixing.com/chongwujiaoyi/
先分析目标网站
点击链接后可以看到我们需要抓取的数据
Ctrl+U打开网页源代码后,可以发现我们要的数据直接在网页上,接下来就开始吧!
三、获取数据1.导入库
import requests #请求网页
from lxml import html # 导入xpath
import pymongo # 用于连接mongoDB数据库
由于版本原因,无法直接从lxml包中导入etree模块,需要多一步。
etree = html.etree
2.请求数据
url = 'https://haikou.baixing.com/chongwujiaoyi/'
respsone = requests.get(url,headers=headers).content.decode('utf-8')
# print(respsone)
2.1 获取一级链接
先得到每只宠物的链接,然后就可以得到宠物的信息,f12打开开发者工具,然后检查元素,看到每只宠物的链接都有
抓取网页数据违法吗(鲸鱼代理注册即享0元免费试用,自动秒换IP地址,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-08 22:15
目前,中国互联网大军不断壮大,各种依托互联网的新兴产业层出不穷。甚至在很多传统行业,为了抢占竞争的制高点,与朋友、商家的竞争已经转移到了互联网平台上。
对于上网的朋友来说,ip修饰符并不是什么奇怪的存在。如果你恰好是做技术编码的专业人士,尤其是你负责网络爬虫的相关工作,你每天都会和你打交道。这只是一个ip修饰符。简单来说,ip修饰符就是你的护照。如果您的本地IP地址访问受到限制,您需要更换护照才能顺利通过。
我们都知道网络爬虫可以有自己的发展空间,因为使用爬虫程序爬取网页信息方便、高效、快捷,但同时要注意IP地址受限。一个很简单的道理,比如我们现在有一个网站,而网站的内容是我们自己写的,但是会有很多恶意竞争对象,特别是使用恶意程序。爬虫爬取我们自己的数据,所以为了保护我们自己的网站,我们宁愿误杀一千,也不愿放过一个。服务器的承载能力总是有限的。如果有一个程序不断超载来获取服务器信息,服务器很容易崩溃。所以现在很多互联网网站,为了保障自己网站的安全,
这时候如果要继续访问这个网站,ip修饰符就很重要了。如果当前ip地址被限制,可以更换一个新的ip地址,保证爬虫的顺利进行。Whale Proxy可以提供优质的ip修改器资源,保证爬虫程序的顺利进行。
不过,在这里我也想提醒大家,正常的采集学习是可以的,但不要恶意采集他人的信息,做出违法行为。
Whale Proxy注册可享受0元免费试用,全国238个城市,2000万IP数据库,一键切换,秒级自动换IP,连接稳定不掉线,Whale Proxy官网: 查看全部
抓取网页数据违法吗(鲸鱼代理注册即享0元免费试用,自动秒换IP地址,)
目前,中国互联网大军不断壮大,各种依托互联网的新兴产业层出不穷。甚至在很多传统行业,为了抢占竞争的制高点,与朋友、商家的竞争已经转移到了互联网平台上。
对于上网的朋友来说,ip修饰符并不是什么奇怪的存在。如果你恰好是做技术编码的专业人士,尤其是你负责网络爬虫的相关工作,你每天都会和你打交道。这只是一个ip修饰符。简单来说,ip修饰符就是你的护照。如果您的本地IP地址访问受到限制,您需要更换护照才能顺利通过。
我们都知道网络爬虫可以有自己的发展空间,因为使用爬虫程序爬取网页信息方便、高效、快捷,但同时要注意IP地址受限。一个很简单的道理,比如我们现在有一个网站,而网站的内容是我们自己写的,但是会有很多恶意竞争对象,特别是使用恶意程序。爬虫爬取我们自己的数据,所以为了保护我们自己的网站,我们宁愿误杀一千,也不愿放过一个。服务器的承载能力总是有限的。如果有一个程序不断超载来获取服务器信息,服务器很容易崩溃。所以现在很多互联网网站,为了保障自己网站的安全,
这时候如果要继续访问这个网站,ip修饰符就很重要了。如果当前ip地址被限制,可以更换一个新的ip地址,保证爬虫的顺利进行。Whale Proxy可以提供优质的ip修改器资源,保证爬虫程序的顺利进行。
不过,在这里我也想提醒大家,正常的采集学习是可以的,但不要恶意采集他人的信息,做出违法行为。
Whale Proxy注册可享受0元免费试用,全国238个城市,2000万IP数据库,一键切换,秒级自动换IP,连接稳定不掉线,Whale Proxy官网:
抓取网页数据违法吗( 爬虫自学路径网络爬虫简介什么时候用爬虫网络是否合法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-07 14:16
爬虫自学路径网络爬虫简介什么时候用爬虫网络是否合法)
文章内容
文章内容
前言
爬虫自学路径
网络爬虫简介
何时使用爬虫
网络爬虫是否合法
封装你的第一个爬虫模块
封装请求头
情况一:
情况二:
情况三:
随机请求头
获取网页数据
ID遍历爬虫(顺便限制下载速度)
网站地图
本文摘要
前言
我还是想先嘟嘟几句,虽然你可能已经不耐烦了。目录在最上面,可以点击直接跳转。
之前,它与分散的更新爬虫有关。毕竟,在学校里,我不能自主很多时间。去上课,参加考试什么的。
现在好了,寒假快到了,有系统地整理了一系列爬虫。
嘿嘿,这背后隐藏着一个想复活的昔日博主的心。
大家多多支持,点赞、评论、采集,越多越好☺☺
昨天做了个系列目录,本来是给朋友带的。原来我们俩的本事都差不多,不过我觉得这条路还是很不错的。
将其用作本系列的指南!!!
爬虫自学路径
初步判断是这样的
1、了解网络爬虫和网络分析,顺便聊聊
2、Xpath
3、爬虫缓存
4、动态网络爬取(json)
5、表单交互
6、正则表达式
7、硒
8、并发下载
9、图片、音频、视频下载
10、验证码处理
11、Scrapy
12、来一场实战
13、 再来一场实战
14、 一个人飞吧
如果有什么要增加的,我会在这里谈谈。
网络爬虫简介
至于什么是网络爬虫,那我就不用多解释了。
何时使用爬虫
用于采集不易手动采集的数据。
其实这句话很有内涵,一千个读者就有一千个哈姆雷特。
在我的认知中,这句话的意思是采集某些数据比使用爬虫消耗更多的能量。这个时候不能考虑直接使用爬虫。
我可以这么说。
至于使用爬虫所消耗的精力,需要很长的时间积累经验,基于对自己的足够了解。
它消耗能量,从开始考虑使用爬虫,到取出爬虫程序,再到获取到正确的数据,最后清洗呈现。
其中最耗时的部分是编写代码和测试。
这时候就需要一个现成的框架。后面我们会讲scrapy框架,它是一个非常好的成熟的爬虫框架。
其实我想说的是,在我们学习的过程中,我们编写的爬虫程序中一定要有目的,将不变的部分抽象出来,封装到我们自己的包中。
学了很久C++,一直被这个“臭毛病”困扰,喜欢自己打包“动态链接库”。
网络爬虫是否合法
这部分在之前的《偷偷学Python》系列中已经提到过,这里稍微讲一下。
在深入讨论爬取一个网站之前,我们首先需要在一定程度上了解目标站点的规模和结构。网站 我自己的robots.txt和Sitemap文件可以为我们提供一些帮助(我就问问有没有人真的会看?反正我没看过。爬虫默认可以爬。那些不爬网将默认为不爬网...)
封装你的第一个爬虫模块
要抓取网页,我们首先需要下载它。
至于分析、清洗、存储等,今天就不多说了。
让我们确保这个网页可以下载,对吗?
我不想弯腰,我直接介绍最后的步骤。让我把这个过程模拟成两个人建立外交关系、给予和接受的过程。
封装请求头
什么是封装请求头?今天我是来和你交朋友的,
情况一:
我说:“嘿,兄弟,交个朋友吧?”
你说:“你是谁?”
我说:“你猜怎么着?”
这个时候你的反应是什么?
说完,我对你说:“喂,大哥,既然我们是朋友,你能不能帮我一个忙?五分钟,我要你的全部信息。”
如果你戒备,你不会给我的。
这个更好。
情况二:
几句问候之后,你发现我是一个推销员。获取您的信息并准备向您出售您根本不需要的东西。例如,您可以向头发浓密的您出售快速生发剂。这不是开玩笑吗?!!!
你会关心我吗?一切都是那么赤裸裸。
那么我该怎么做才能将这款生发剂放到您的手中呢?
情况三:
我路过你在大厅等面试通知的时候,走了过去,转过头看了你一眼,又看了你一眼,递给你一张名片:“小子,我是隔壁项目组的组长,你是来面试的?”
你说是
我说:“哦,他们组工作压力很大,看你一头浓密的头发,怕是没经历过洗礼,可惜了。”
然后,我说:“好吧,如果你面试过了,你压力不小可以来找我。这是我的名片。”
呵呵
那我就给你。你收到了很开心。
那么请求头是什么?那是名片。
一张名片告诉即将到来的网站:“我是一个普通的浏览器”。
随机请求头
我们不需要自己准备任何请求头。大量请求使用同一个header不好,会被你屏蔽。
获取网页数据
目前主流的Python编写的爬虫一般都使用requests库来管理复杂的HTTP请求。
ID遍历爬虫部分就不讲了,简单的数理逻辑。
ID遍历爬虫(顺便限制下载速度)
如果我们爬取网站太快,我们将面临被禁止或导致服务器过载的风险。为了降低这些风险,我们可以在两次下载之间添加一组延迟来限制爬虫的速度。
算了,还是要写ID遍历爬虫。
网站地图
说到这张网站地图,我们先来看看它是什么。
站点地图是所有链接网站的容器。很多网站都有很深的连接层次,爬虫很难捕捉。站点地图可以方便爬虫爬取网站页面。通过爬取网站页面,可以清楚的了解网站网站地图一般存放在根目录下,命名为sitemap来引导爬虫,在网站 重要内容页面。站点地图是根据网站的结构、框架、内容生成的导航网页文件。站点地图有助于改善用户体验。他们为 网站 访问者指明了方向,并帮助丢失的访问者找到他们想要查看的页面。
你怎么看网站的地图?
在网站的根目录下,打开robots.txt文件,可以找到网站地图的URL。
看一下CSDN爬虫协议:
底部有这么一行: Sitemap:
自己进去看看吧。
如果你想要它们,你之后将如何攀登。参考上面的一段。
如果你想过滤所有的URL,真的没有人想把它们全部抓取吗?
建议使用正则表达式。
—————————————————
版权声明:本文为CSDN博主《看,未来》原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接: 查看全部
抓取网页数据违法吗(
爬虫自学路径网络爬虫简介什么时候用爬虫网络是否合法)
文章内容
文章内容
前言
爬虫自学路径
网络爬虫简介
何时使用爬虫
网络爬虫是否合法
封装你的第一个爬虫模块
封装请求头
情况一:
情况二:
情况三:
随机请求头
获取网页数据
ID遍历爬虫(顺便限制下载速度)
网站地图
本文摘要
前言
我还是想先嘟嘟几句,虽然你可能已经不耐烦了。目录在最上面,可以点击直接跳转。
之前,它与分散的更新爬虫有关。毕竟,在学校里,我不能自主很多时间。去上课,参加考试什么的。
现在好了,寒假快到了,有系统地整理了一系列爬虫。
嘿嘿,这背后隐藏着一个想复活的昔日博主的心。
大家多多支持,点赞、评论、采集,越多越好☺☺
昨天做了个系列目录,本来是给朋友带的。原来我们俩的本事都差不多,不过我觉得这条路还是很不错的。
将其用作本系列的指南!!!
爬虫自学路径
初步判断是这样的
1、了解网络爬虫和网络分析,顺便聊聊
2、Xpath
3、爬虫缓存
4、动态网络爬取(json)
5、表单交互
6、正则表达式
7、硒
8、并发下载
9、图片、音频、视频下载
10、验证码处理
11、Scrapy
12、来一场实战
13、 再来一场实战
14、 一个人飞吧
如果有什么要增加的,我会在这里谈谈。
网络爬虫简介
至于什么是网络爬虫,那我就不用多解释了。
何时使用爬虫
用于采集不易手动采集的数据。
其实这句话很有内涵,一千个读者就有一千个哈姆雷特。
在我的认知中,这句话的意思是采集某些数据比使用爬虫消耗更多的能量。这个时候不能考虑直接使用爬虫。
我可以这么说。
至于使用爬虫所消耗的精力,需要很长的时间积累经验,基于对自己的足够了解。
它消耗能量,从开始考虑使用爬虫,到取出爬虫程序,再到获取到正确的数据,最后清洗呈现。
其中最耗时的部分是编写代码和测试。
这时候就需要一个现成的框架。后面我们会讲scrapy框架,它是一个非常好的成熟的爬虫框架。
其实我想说的是,在我们学习的过程中,我们编写的爬虫程序中一定要有目的,将不变的部分抽象出来,封装到我们自己的包中。
学了很久C++,一直被这个“臭毛病”困扰,喜欢自己打包“动态链接库”。
网络爬虫是否合法
这部分在之前的《偷偷学Python》系列中已经提到过,这里稍微讲一下。
在深入讨论爬取一个网站之前,我们首先需要在一定程度上了解目标站点的规模和结构。网站 我自己的robots.txt和Sitemap文件可以为我们提供一些帮助(我就问问有没有人真的会看?反正我没看过。爬虫默认可以爬。那些不爬网将默认为不爬网...)
封装你的第一个爬虫模块
要抓取网页,我们首先需要下载它。
至于分析、清洗、存储等,今天就不多说了。
让我们确保这个网页可以下载,对吗?
我不想弯腰,我直接介绍最后的步骤。让我把这个过程模拟成两个人建立外交关系、给予和接受的过程。
封装请求头
什么是封装请求头?今天我是来和你交朋友的,
情况一:
我说:“嘿,兄弟,交个朋友吧?”
你说:“你是谁?”
我说:“你猜怎么着?”
这个时候你的反应是什么?
说完,我对你说:“喂,大哥,既然我们是朋友,你能不能帮我一个忙?五分钟,我要你的全部信息。”
如果你戒备,你不会给我的。
这个更好。
情况二:
几句问候之后,你发现我是一个推销员。获取您的信息并准备向您出售您根本不需要的东西。例如,您可以向头发浓密的您出售快速生发剂。这不是开玩笑吗?!!!
你会关心我吗?一切都是那么赤裸裸。
那么我该怎么做才能将这款生发剂放到您的手中呢?
情况三:
我路过你在大厅等面试通知的时候,走了过去,转过头看了你一眼,又看了你一眼,递给你一张名片:“小子,我是隔壁项目组的组长,你是来面试的?”
你说是
我说:“哦,他们组工作压力很大,看你一头浓密的头发,怕是没经历过洗礼,可惜了。”
然后,我说:“好吧,如果你面试过了,你压力不小可以来找我。这是我的名片。”
呵呵
那我就给你。你收到了很开心。
那么请求头是什么?那是名片。
一张名片告诉即将到来的网站:“我是一个普通的浏览器”。
随机请求头
我们不需要自己准备任何请求头。大量请求使用同一个header不好,会被你屏蔽。
获取网页数据
目前主流的Python编写的爬虫一般都使用requests库来管理复杂的HTTP请求。
ID遍历爬虫部分就不讲了,简单的数理逻辑。
ID遍历爬虫(顺便限制下载速度)
如果我们爬取网站太快,我们将面临被禁止或导致服务器过载的风险。为了降低这些风险,我们可以在两次下载之间添加一组延迟来限制爬虫的速度。
算了,还是要写ID遍历爬虫。
网站地图
说到这张网站地图,我们先来看看它是什么。
站点地图是所有链接网站的容器。很多网站都有很深的连接层次,爬虫很难捕捉。站点地图可以方便爬虫爬取网站页面。通过爬取网站页面,可以清楚的了解网站网站地图一般存放在根目录下,命名为sitemap来引导爬虫,在网站 重要内容页面。站点地图是根据网站的结构、框架、内容生成的导航网页文件。站点地图有助于改善用户体验。他们为 网站 访问者指明了方向,并帮助丢失的访问者找到他们想要查看的页面。
你怎么看网站的地图?
在网站的根目录下,打开robots.txt文件,可以找到网站地图的URL。
看一下CSDN爬虫协议:
底部有这么一行: Sitemap:
自己进去看看吧。
如果你想要它们,你之后将如何攀登。参考上面的一段。
如果你想过滤所有的URL,真的没有人想把它们全部抓取吗?
建议使用正则表达式。
—————————————————
版权声明:本文为CSDN博主《看,未来》原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
抓取网页数据违法吗(soupDOMTREE方法(二):用BeautifulSoup的数据转化为结构化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-07 06:04
我们抓取的网页是UTF8,但是python请求的时候误判为不知道是什么编码,所以显示这个编码为默认编码:ISO-8859-1
进口请求
response = requests.get('#39;)
打印(响应。编码)
显示的结果是ISO-8859-1,所以我们要告诉python我们遇到的网页是utf8,下面的代码改进如下,我们可以得到一个简体中文的内容:
进口请求
response = requests.get('#39;)
response.encoding ='utf-8'
打印(响应。文本)
现在我们还有一个问题,如何将上述非结构化数据转化为结构化数据?—DOM 树方法
(二) 使用 BeautifulSoup 解析网页
1.基础铺路-DOM TREE
全称:Document Object Model Tree,是一组可以与网页元素进行交互的API。使用BeautifulSoup可以将网页变成DOM树,我们可以根据DOM树的节点进行操作。
在上面的例子中,最外层的结构是html,它是最上层的节点,下层是body,它收录两个链接,h1和a。这些构成了DOM Tree架构,我们可以在这个架构下遵循一定的结构。当这些节点交互时,我们可以得到h1中的词和a中的词。这时候我们就可以顺利的提取数据了;
2.BeautifulSoup 示例
将网页读入 BeautifulSoup
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample)
打印(汤.文本)
此处将显示警告消息。警告消息告诉我们这段代码没有使用我们的解析器。这时候python会为我们预测一个解析器。如果我们想避免这种警告,我们可以在代码中指定
汤 = BeautifulSoup(html_sample,'html.parser')
3.查找所有带有特定标签的 HTML 元素
另外要考虑的是,即使我们可以使用BeautifulSoup去除标签,有时我们想要抓取的一些内容仍然在特殊标签中。我们如何获取节点中的特殊标签和数据?
使用 select 查找收录 h1 标签的元素
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
使用 select 查找收录 a 标签的元素
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
下面我们来实践一下:
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample,'html.parser')
标题 = 汤.select('h1')
打印(标题)
显示的结果是:
如何进一步解开以上文字?添加[0],可以去掉括号,添加.text取出里面的文字
打印(标题[0]。文本)
4.获取具有特定 CSS 属性的元素
除了标签,我们如何获取特定元素?我们可以通过CSS的属性来获取里面的元素。CSS 是网页的“化妆师”。通过这位化妆师,我们可以美化网页
(1)如何抓取独立独特的元素,可以加id装饰
使用select查找所有id为title的元素(id前面需要#)
alink = soup.select('#title')
打印(链接)
(2)如果要捕捉重复的元素,可以添加类修饰
使用 select 查找所有类为链接的元素(在类之前添加。)
汤 = BeautifulSoup(html_sample)
对于soup.select('.link') 中的链接:
打印(链接)
5.获取具有特定 CSS 属性的元素
在网页的连接中,我们会使用一个标签来连接不同的网页,一个标签有一个属性叫做href,我们可以通过这个属性连接到不同的网页;
使用 select 查找标签的所有 href 链接
alinks = 汤.select('a')
对于 alinks 中的链接:
打印(链接['href']) 查看全部
抓取网页数据违法吗(soupDOMTREE方法(二):用BeautifulSoup的数据转化为结构化)
我们抓取的网页是UTF8,但是python请求的时候误判为不知道是什么编码,所以显示这个编码为默认编码:ISO-8859-1
进口请求
response = requests.get('#39;)
打印(响应。编码)
显示的结果是ISO-8859-1,所以我们要告诉python我们遇到的网页是utf8,下面的代码改进如下,我们可以得到一个简体中文的内容:
进口请求
response = requests.get('#39;)
response.encoding ='utf-8'
打印(响应。文本)
现在我们还有一个问题,如何将上述非结构化数据转化为结构化数据?—DOM 树方法
(二) 使用 BeautifulSoup 解析网页
1.基础铺路-DOM TREE
全称:Document Object Model Tree,是一组可以与网页元素进行交互的API。使用BeautifulSoup可以将网页变成DOM树,我们可以根据DOM树的节点进行操作。
在上面的例子中,最外层的结构是html,它是最上层的节点,下层是body,它收录两个链接,h1和a。这些构成了DOM Tree架构,我们可以在这个架构下遵循一定的结构。当这些节点交互时,我们可以得到h1中的词和a中的词。这时候我们就可以顺利的提取数据了;
2.BeautifulSoup 示例
将网页读入 BeautifulSoup
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample)
打印(汤.文本)
此处将显示警告消息。警告消息告诉我们这段代码没有使用我们的解析器。这时候python会为我们预测一个解析器。如果我们想避免这种警告,我们可以在代码中指定
汤 = BeautifulSoup(html_sample,'html.parser')
3.查找所有带有特定标签的 HTML 元素
另外要考虑的是,即使我们可以使用BeautifulSoup去除标签,有时我们想要抓取的一些内容仍然在特殊标签中。我们如何获取节点中的特殊标签和数据?
使用 select 查找收录 h1 标签的元素
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
使用 select 查找收录 a 标签的元素
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
下面我们来实践一下:
从 bs4 导入 BeautifulSoup
html_sample ='\
\
你好世界 \
\
\
\
'
汤 = BeautifulSoup(html_sample,'html.parser')
标题 = 汤.select('h1')
打印(标题)
显示的结果是:
如何进一步解开以上文字?添加[0],可以去掉括号,添加.text取出里面的文字
打印(标题[0]。文本)
4.获取具有特定 CSS 属性的元素
除了标签,我们如何获取特定元素?我们可以通过CSS的属性来获取里面的元素。CSS 是网页的“化妆师”。通过这位化妆师,我们可以美化网页
(1)如何抓取独立独特的元素,可以加id装饰
使用select查找所有id为title的元素(id前面需要#)
alink = soup.select('#title')
打印(链接)
(2)如果要捕捉重复的元素,可以添加类修饰
使用 select 查找所有类为链接的元素(在类之前添加。)
汤 = BeautifulSoup(html_sample)
对于soup.select('.link') 中的链接:
打印(链接)
5.获取具有特定 CSS 属性的元素
在网页的连接中,我们会使用一个标签来连接不同的网页,一个标签有一个属性叫做href,我们可以通过这个属性连接到不同的网页;
使用 select 查找标签的所有 href 链接
alinks = 汤.select('a')
对于 alinks 中的链接:
打印(链接['href'])
抓取网页数据违法吗(第一次用C#写数据抓取,遇到各种问题怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2022-01-07 06:04
第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把彩色验证码转成黑白,剪下字体。, 如果字体卡住了,对于我们这些初学者(外行)来说,先放弃吧,切完之后再对每一个像素进行编码,白0,黑1,好像是这样的,不太懂,再读一遍 比较字体库模型中的单词。如果百分比高于百分比,他们会识别验证码是什么,一一比较,最终形成完整的验证码。工作了一天,发现自己既不能做字体库也不用代码切字,无法完成验证码破解,于是放弃破解,另寻方法。
网上说可能是验证码存储在cookie中。好的,试试看。我模拟浏览器发送数据,请求验证码,FF调试。我发现cookie中有验证码。就是这样,验证码就是这个。就是这样,让我们重新登录。
要登录,首先要跟踪目标网页的逻辑,看它是如何传递参数登录成功的。我的目的是先发送一个请求对用户名和密码进行加密,然后将加密后的用户名和密码发送到后台进行登录,这个没什么好说的。这期间遇到的问题是发送请求。过了很久,还是没有成功。原因是当时发送的ajax请求要设置调用哪个方法。网站 一般直接请求后台而不是发送。ajax 请求,所以我又在这里搞砸了。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了爬取页面的时候了。首先获取爬取页面的html,然后分析它如何提交数据,如何返回,传递了哪些参数等等。抓取页面没有错,然后模拟查询数据,然后写网站,隐藏域控件很多,所以发送请求的时候参数很多,不知道为什么。,无论如何,我认为唯一有用的是跟踪号。长时间发送模拟后,报500错误。这是模拟参数有问题,服务器无法读取。我已经做了所有的设置,一个一个。我发现它没有任何问题。我在这里卡了 2 天。我忍不住了。之后,发现提交的数据和页面隐藏字段中的数据有点不同。特殊字符全部输入。转码后,再想之前写的传递参数的代码,发现在传递数据的时候,需要通过UrlEncode进行转码,然后传输。虽然隐藏域的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说,开始转码参数
HttpUtility.UrlEncode(string);
这是成功的。太烧脑细胞了。虽然对于一些老手来说,可能不知道这些东西,但是第一次接触还是比较麻烦的。
顺便说一下,我也遇到了一个问题,就是读取html后获取字符串html中的参数的问题。当然,在页面上很容易得到它。现在都是一堆字符串,真的很难处理,于是找了个dll。使用方便,支持xpath,用法与xmlDocument相同,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载链接:点击打开链接
最好阅读更多此 网站 评论。里面有很多人的问题,也许可以帮到你。
写了这么多,整理代码贴上来,然后开始循环抓取数据。 查看全部
抓取网页数据违法吗(第一次用C#写数据抓取,遇到各种问题怎么办?)
第一次用C#写数据捕获,遇到各种问题。开始写模拟登录的时候,发现里面有验证码。我不得不突破验证码才能得到它。好的,那我去找验证码破解的密码。过了很长时间,我无法触摸门。我尝试了很多代码,发现它们并不通用。后来明白了原理。我先把噪点、干扰线等去掉,然后把彩色验证码转成黑白,剪下字体。, 如果字体卡住了,对于我们这些初学者(外行)来说,先放弃吧,切完之后再对每一个像素进行编码,白0,黑1,好像是这样的,不太懂,再读一遍 比较字体库模型中的单词。如果百分比高于百分比,他们会识别验证码是什么,一一比较,最终形成完整的验证码。工作了一天,发现自己既不能做字体库也不用代码切字,无法完成验证码破解,于是放弃破解,另寻方法。
网上说可能是验证码存储在cookie中。好的,试试看。我模拟浏览器发送数据,请求验证码,FF调试。我发现cookie中有验证码。就是这样,验证码就是这个。就是这样,让我们重新登录。
要登录,首先要跟踪目标网页的逻辑,看它是如何传递参数登录成功的。我的目的是先发送一个请求对用户名和密码进行加密,然后将加密后的用户名和密码发送到后台进行登录,这个没什么好说的。这期间遇到的问题是发送请求。过了很久,还是没有成功。原因是当时发送的ajax请求要设置调用哪个方法。网站 一般直接请求后台而不是发送。ajax 请求,所以我又在这里搞砸了。
关键代码:
request.Headers.Add("X-AjaxPro-Method", "方法名");
登录成功后,就到了爬取页面的时候了。首先获取爬取页面的html,然后分析它如何提交数据,如何返回,传递了哪些参数等等。抓取页面没有错,然后模拟查询数据,然后写网站,隐藏域控件很多,所以发送请求的时候参数很多,不知道为什么。,无论如何,我认为唯一有用的是跟踪号。长时间发送模拟后,报500错误。这是模拟参数有问题,服务器无法读取。我已经做了所有的设置,一个一个。我发现它没有任何问题。我在这里卡了 2 天。我忍不住了。之后,发现提交的数据和页面隐藏字段中的数据有点不同。特殊字符全部输入。转码后,再想之前写的传递参数的代码,发现在传递数据的时候,需要通过UrlEncode进行转码,然后传输。虽然隐藏域的值是控件自动生成的,但是传输应该还是需要转码的,想到这里,二话不说,开始转码参数
HttpUtility.UrlEncode(string);
这是成功的。太烧脑细胞了。虽然对于一些老手来说,可能不知道这些东西,但是第一次接触还是比较麻烦的。
顺便说一下,我也遇到了一个问题,就是读取html后获取字符串html中的参数的问题。当然,在页面上很容易得到它。现在都是一堆字符串,真的很难处理,于是找了个dll。使用方便,支持xpath,用法与xmlDocument相同,
部分代码:
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(html.Replace("\r", "").Replace("\n", ""));
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("/html/body/div").ChildNodes;
foreach (HtmlNode htmlNode in collection)
{
var tempId = htmlNode.Attributes["id"].Value;
}
红色部分是xpath规则,
也可以根据属性获取对应的节点:
htmlDocument.DocumentNode.SelectSingleNode("/html/body/div[2]/input[@id='__EVENTVALIDATION']");
这是:HtmlAgilityPack 下载链接:点击打开链接
最好阅读更多此 网站 评论。里面有很多人的问题,也许可以帮到你。
写了这么多,整理代码贴上来,然后开始循环抓取数据。
抓取网页数据违法吗(基于云平台的网页数据架构使用AWS(AmazonWeb))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-06 06:14
范顺丽和周益民
摘要:随着网络数据的快速增长,网络数据采集在处理大量数据时遇到了一些挑战,如数据存储量大、计算能力强、数据提取的可靠性等。提出了一种基于云平台的网络数据采集架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储;Selenium 用作 Web 自动化工具,调用 WebDriver API 来模拟用户对浏览器的使用。通过实验,我们将该架构与其他基于云的网络爬取架构进行了比较,并分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
中文图书馆分类号:TP311.5 文献标记代码:A 文章 序号:1006-8228 (2018)09-21-04
摘要:随着互联网数据的快速增长,网页抓取在处理大量数据时遇到了许多挑战,例如大量的数据存储、对密集计算能力的需求以及数据提取的可靠性。因此,提出了一种基于云平台的网页抓取架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储。Selenium 是一个网页自动化工具;支持的WebDriver API 模拟用户使用浏览器的过程。通过实验,对比了该架构与其他基于云的网页抓取架构的差异,分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
0 前言
互联网提供了大量的数据集,但很多数据都嵌入在网页的结构和样式中[1]。从网页中提取可用信息,挖掘其潜在价值,使其在金融、数据分析等科学领域发挥重要作用。目前,大多数现有的解决方案主要集中在Web数据采集。数据采集是任何与数据科学相关的研发的前期工作,而这只是大数据的第一步。因此,对于数据科学领域来说,提取网络数据并将其应用到数据科学领域是非常重要的。
互联网上的信息大多以HTML文档的形式呈现,而这些数据都是非结构化数据[2]。由于非结构化数据不遵循任何数据模型,因此信息提取并不容易。网页数据提取的过程包括:网页数据分析、过滤、格式化结果和存储。在分布式计算领域,BeautifulSoup、Requests、Scrapy[3]等各种库都可以处理大量的网页爬取,但只能处理静态页面。因此,选择Selenium作为网页自动化工具,使用Python的HTMLParser库从HTML中提取数据[4]。使用 Amazon Web Services 的 EC2(弹性计算云)作为云平台。选择 EC2 的原因是它的灵活性。它可以创造,
1 简介
随着软件行业的发展,网络数据采集也经历了不同的发展阶段,从最早的人工复制整理数据到今天的云计算大数据采集,每一个行业技术所有的创新都伴随着硬件和软件的巨大进步和发展[5]。云计算通过高度密集的计算能力和支持弹性资源,使其成为个体企业以小资源开始自己的网络爬虫的最佳选择。下面是一些基于云平台的网络爬虫。
1.1 Import.io
Import.io 是一个基于云的平台,无需编码即可从不同的网站 抓取网页,并将所有提取的数据存储在其云服务器上。它允许将数据下载为 CSV、Excel、Google Sheets、JSON 或通过 API 访问。其独特的功能包括自动数据和图像提取、自动页面链接、监控、调度和无需编码。
1.2 WebScraper.io
WebScraper.io 是另一个可视化的网页抓取平台,它提供了两种方式:Web Scraper 和 Web Scraper Extension。对于谷歌 Chrome 浏览器,Web Scraper Extension 工具是免费使用的,用户可以创建站点地图并指定如何抓取它。对于基于云的 Web Scraper,其价格取决于要爬取的 URL 数量。
1.3 Scrapy
Scrapy 是一个免费的、开源的、协作的网页抓取框架,它通过编写代码和调用 API 来提取网页数据。Scrapy 是用 Python 编写的,可以部署在 Scrapy 云中,并且可以按需扩展[6]。其特点是快速、简单、可扩展等。
以上解决方案主要针对Web数据的采集,这只是大数据的第一步。针对大数据的进一步处理,构建了基于云的网页抓取框架(Cloud-Scraper)。
2 系统设计
2.1 Scraper 简介
图 1 显示了传统的 Scraper 概览。客户端为 ScrapeHub 提供 URL 和网络爬取配置。ScrapeHub 程序启动、处理和监控系统中的所有任务。它是用 Python 编写的。然后 ScrapeHub 启动 Scrape Engine 任务,Scrape Engine 初始化一个网页,使用 Selenium 库将网页转换为所需的状态,并使用 Requests 库对其进行解析。不同的爬虫可能使用不同的库来解析和初始化网页。这里只提到Selenium和Requests,所有数据都存储在数据库中。该模型代表了按顺序获取网页数据的传统方法。一次只能获取一个站点,并且在给定的时间段内只能获取有限的数据。通过添加更多的计算和存储资源,
2.2 Cloud-Scraper 设计
使用Amazon Elastic Computing Cloud(EC2),通过Simple Queue Service (SQS)和Simple Storage Service(S3)[7])可以解决上述问题。Amazon S3用于存储Amazon机器镜像,可以根据需要创建任意数量的EC2实例,既经济又灵活。图2展示了Cloud-Scraper的架构,该架构的前端是一个Web浏览器,通过REST API连接到Amazon Web Server。 ScrapeHub in the cloud 会处理所有客户端的爬取请求和处理监控事件,使用Amazon SQS维护一个要爬取的URL列表,Amazon SQS处理两个队列,一个是请求队列,一个是响应队列。 Engine 是一个 URL,用作输入和抓取网页内容的程序,每个 EC2 实例都是一个运行 Scrape Engine 的虚拟机。DynamoDB 是一个免费的开源 NoSQL 数据库,可以为提取的数据提供存储 [8]。
图 3 展示了 Cloud-Scraper 的网络爬取过程。当用户向 Cloud-Scraper 发送爬取请求时,该请求将转到 ScrapeHub。该请求收录两条信息:URL 和爬网配置。首先,ScrapeHub 将 URL 分成多个块转发到 S3 存储,同时创建多个 EC2 实例,并创建 SQS 请求队列和响应队列。ScrapeHub 借助 SQS 请求队列向 EC2 实例发送服务请求,请求的处理顺序以先进先出(FIFO)的调度方式完成。ScrapeHub创建的请求队列上的每个请求都有一个特定的ID,通过响应队列持续监控整体的爬取进度,爬取结果存储在DynamoDB中。
Amazon EMR(Amazon Elastic MapReduce)是一种网络服务[9],采用Hadoop处理方式,结合Amazon EC2,可以轻松高效地处理大量数据。Cloud-Scraper 集成了大数据应用,可以对爬取的网页数据进行可视化和分析。
3 实验分析
图 4 显示了使用不同解决方案完成网页抓取所需的时间,包括来自云端的请求时间、排队时间、处理时间和响应时间。X轴代表网址数,Y轴代表完成网页抓取的时间。图中上两行表示使用单机和单机多线程的爬取完成时间,下两行表示使用20台机器和20台带有Amazon EC2 T2实例的机器完成爬取。所需的时间。可以看出,使用单节点本地机最多可以抓取4000个网页数据,这是服务器限制单个IP在有限时间内访问有限数据造成的。在单台机器上执行并发线程也是如此。虽然计算速度比顺序节点快很多,但是爬取效率随着URL的增加而下降。下面两行爬取完成时间大致呈线性,说明随着URL数量的逐渐增加,Cloud-Scraper可以正常运行。可以推断,Cloud-Scraper 架构是可扩展的,可以根据爬取的 URL 数量增加 EC2 实例。
许多基于云的网页抓取解决方案可用,但大多数是商业性的,其工作模式不公开。因此,与一些现有的开源框架进行比较,例如 Scrapy 和 Import.io。图 5 展示了 Cloud-Scraper 和其他使用机器实例的基于云的平台之间的比较。与其他框架相比,Cloud-Scraper 架构是分布式的,对可以使用的计算资源实例没有限制。借助亚马逊云中的DynamoDB,可以灵活使用所有资源。由于Selenium的使用可能会延迟一段时间,所以爬取完成时间比Import.io要长,但是缺点已经被优点超越了。Selenium 提供更高的可靠性和对人类行为的模仿。效果较好[10]。在数据提取方面,其性能可媲美目前市面上其他基于云的网络爬虫架构,也可与其他大数据应用结合使用。最后,捕获的数据将进入大数据处理。
Cloud-Scraper的4大优势
Cloud-Scraper 有很多优点。其中一些描述如下:
⑴ 成本效益:使用云资源按使用付费模式,可以以低廉的价格使用云资源,并且可以按需扩容或缩容,比维护自己的云更便宜[11]。云供应商几乎可以提供从存储到处理能力所需的一切,让云计算变得更容易。购买自己的资源将花费大量成本来维持和扩大需求。
⑵ 可扩展性:云提供商根据需要提供可靠的计算机,并且可以根据需要创建和使用这些计算机的多个实例。供应商提供了大量的平台选择选项,您可以根据计算的性能要求选择正确的处理能力[12]。
⑶ 大数据应用集成:任何大数据应用都需要四种基本结构——存储、处理、分析软件和网络。DynamoDB 是一种 NoSQL 数据库,可以提供更高的可用性,从而提供更好的性能。分析软件可以根据用户的需求在该架构上进行编程,借助亚马逊的EC2,可以在数量和计算能力上进行扩展。虽然这种架构不能满足所有大数据要求,但进一步的程序集成和修改可以使其对大数据任务更加健壮。
5 结论
本文提出了一种基于云平台的新型网络爬虫架构。亚马逊的云服务为分布式环境中的计算和存储提供了弹性资源,为网络爬取提供了更好的平台。通过实验测试该架构的可扩展性,并与其他网页抓取架构进行简单对比,分析其优势,包括Selenium的使用和大数据应用的集成。此外,也可以使用其他云服务来实现上述架构。
参考:
[1] 魏冬梅, 何忠秀, 唐建梅. 基于Python的Web信息获取方法研究[J].软件指南,2018.17 (1): 41-43
[2] 郎博,张博宇.面向大数据的非结构化数据管理平台关键技术[J]. 信息技术与标准化,2013.10:53-56
[3] 刘宇,郑承焕.基于Scrapy的Deep Web Crawler研究[J]. 软件,2017.38(7):111-114
[4] 齐鹏,李银峰,宋雨薇.基于Python的Web Data采集技术[J]. 电子技术, 2012.25 (11): 118-120
[5] 凯文。网页资料采集发展历程及未来前景[EB/OL].
[6] 刘硕.精通Scrapy网络爬虫[M]. 清华大学出版社,2017.
[7] 许鸿飞.云计算安全问题初探——基于Amazon Dynamo和EC2的架构分析[J]. 计算机 CD 软件与应用,2013.16 (17): 21-22
[8]孙宝华.基于Dynamo的存储机制研究[D]. 西安电子科技大学,2013.
[9] 小龙腾.如何为 Hadoop 选择最灵活的 MapReduce 框架 [EB/OL].
[10] 杜斌. 基于Selenium的定向网络爬虫的设计与实现[J]. 金融科技时代,2016.7: 35-39
[11] Jackson KR、Muriki K、Thomas RC 等。亚马逊AWS云上超新星工厂的性能与成本分析[J]. 科学规划,2011.19:2-3
[12] Juan JD, Prodan R. Amazon EC2 中的多目标工作流调度[J]. 集群计算,2014.17(2):169-189 查看全部
抓取网页数据违法吗(基于云平台的网页数据架构使用AWS(AmazonWeb))
范顺丽和周益民
摘要:随着网络数据的快速增长,网络数据采集在处理大量数据时遇到了一些挑战,如数据存储量大、计算能力强、数据提取的可靠性等。提出了一种基于云平台的网络数据采集架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储;Selenium 用作 Web 自动化工具,调用 WebDriver API 来模拟用户对浏览器的使用。通过实验,我们将该架构与其他基于云的网络爬取架构进行了比较,并分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
中文图书馆分类号:TP311.5 文献标记代码:A 文章 序号:1006-8228 (2018)09-21-04
摘要:随着互联网数据的快速增长,网页抓取在处理大量数据时遇到了许多挑战,例如大量的数据存储、对密集计算能力的需求以及数据提取的可靠性。因此,提出了一种基于云平台的网页抓取架构。该架构使用AWS(亚马逊网络服务)作为云平台,按需配置计算资源和数据存储。Selenium 是一个网页自动化工具;支持的WebDriver API 模拟用户使用浏览器的过程。通过实验,对比了该架构与其他基于云的网页抓取架构的差异,分析了其优势。
关键词:AWS;网页抓取;大数据; 硒
0 前言
互联网提供了大量的数据集,但很多数据都嵌入在网页的结构和样式中[1]。从网页中提取可用信息,挖掘其潜在价值,使其在金融、数据分析等科学领域发挥重要作用。目前,大多数现有的解决方案主要集中在Web数据采集。数据采集是任何与数据科学相关的研发的前期工作,而这只是大数据的第一步。因此,对于数据科学领域来说,提取网络数据并将其应用到数据科学领域是非常重要的。
互联网上的信息大多以HTML文档的形式呈现,而这些数据都是非结构化数据[2]。由于非结构化数据不遵循任何数据模型,因此信息提取并不容易。网页数据提取的过程包括:网页数据分析、过滤、格式化结果和存储。在分布式计算领域,BeautifulSoup、Requests、Scrapy[3]等各种库都可以处理大量的网页爬取,但只能处理静态页面。因此,选择Selenium作为网页自动化工具,使用Python的HTMLParser库从HTML中提取数据[4]。使用 Amazon Web Services 的 EC2(弹性计算云)作为云平台。选择 EC2 的原因是它的灵活性。它可以创造,
1 简介
随着软件行业的发展,网络数据采集也经历了不同的发展阶段,从最早的人工复制整理数据到今天的云计算大数据采集,每一个行业技术所有的创新都伴随着硬件和软件的巨大进步和发展[5]。云计算通过高度密集的计算能力和支持弹性资源,使其成为个体企业以小资源开始自己的网络爬虫的最佳选择。下面是一些基于云平台的网络爬虫。
1.1 Import.io
Import.io 是一个基于云的平台,无需编码即可从不同的网站 抓取网页,并将所有提取的数据存储在其云服务器上。它允许将数据下载为 CSV、Excel、Google Sheets、JSON 或通过 API 访问。其独特的功能包括自动数据和图像提取、自动页面链接、监控、调度和无需编码。
1.2 WebScraper.io
WebScraper.io 是另一个可视化的网页抓取平台,它提供了两种方式:Web Scraper 和 Web Scraper Extension。对于谷歌 Chrome 浏览器,Web Scraper Extension 工具是免费使用的,用户可以创建站点地图并指定如何抓取它。对于基于云的 Web Scraper,其价格取决于要爬取的 URL 数量。
1.3 Scrapy
Scrapy 是一个免费的、开源的、协作的网页抓取框架,它通过编写代码和调用 API 来提取网页数据。Scrapy 是用 Python 编写的,可以部署在 Scrapy 云中,并且可以按需扩展[6]。其特点是快速、简单、可扩展等。
以上解决方案主要针对Web数据的采集,这只是大数据的第一步。针对大数据的进一步处理,构建了基于云的网页抓取框架(Cloud-Scraper)。
2 系统设计
2.1 Scraper 简介
图 1 显示了传统的 Scraper 概览。客户端为 ScrapeHub 提供 URL 和网络爬取配置。ScrapeHub 程序启动、处理和监控系统中的所有任务。它是用 Python 编写的。然后 ScrapeHub 启动 Scrape Engine 任务,Scrape Engine 初始化一个网页,使用 Selenium 库将网页转换为所需的状态,并使用 Requests 库对其进行解析。不同的爬虫可能使用不同的库来解析和初始化网页。这里只提到Selenium和Requests,所有数据都存储在数据库中。该模型代表了按顺序获取网页数据的传统方法。一次只能获取一个站点,并且在给定的时间段内只能获取有限的数据。通过添加更多的计算和存储资源,
2.2 Cloud-Scraper 设计
使用Amazon Elastic Computing Cloud(EC2),通过Simple Queue Service (SQS)和Simple Storage Service(S3)[7])可以解决上述问题。Amazon S3用于存储Amazon机器镜像,可以根据需要创建任意数量的EC2实例,既经济又灵活。图2展示了Cloud-Scraper的架构,该架构的前端是一个Web浏览器,通过REST API连接到Amazon Web Server。 ScrapeHub in the cloud 会处理所有客户端的爬取请求和处理监控事件,使用Amazon SQS维护一个要爬取的URL列表,Amazon SQS处理两个队列,一个是请求队列,一个是响应队列。 Engine 是一个 URL,用作输入和抓取网页内容的程序,每个 EC2 实例都是一个运行 Scrape Engine 的虚拟机。DynamoDB 是一个免费的开源 NoSQL 数据库,可以为提取的数据提供存储 [8]。
图 3 展示了 Cloud-Scraper 的网络爬取过程。当用户向 Cloud-Scraper 发送爬取请求时,该请求将转到 ScrapeHub。该请求收录两条信息:URL 和爬网配置。首先,ScrapeHub 将 URL 分成多个块转发到 S3 存储,同时创建多个 EC2 实例,并创建 SQS 请求队列和响应队列。ScrapeHub 借助 SQS 请求队列向 EC2 实例发送服务请求,请求的处理顺序以先进先出(FIFO)的调度方式完成。ScrapeHub创建的请求队列上的每个请求都有一个特定的ID,通过响应队列持续监控整体的爬取进度,爬取结果存储在DynamoDB中。
Amazon EMR(Amazon Elastic MapReduce)是一种网络服务[9],采用Hadoop处理方式,结合Amazon EC2,可以轻松高效地处理大量数据。Cloud-Scraper 集成了大数据应用,可以对爬取的网页数据进行可视化和分析。
3 实验分析
图 4 显示了使用不同解决方案完成网页抓取所需的时间,包括来自云端的请求时间、排队时间、处理时间和响应时间。X轴代表网址数,Y轴代表完成网页抓取的时间。图中上两行表示使用单机和单机多线程的爬取完成时间,下两行表示使用20台机器和20台带有Amazon EC2 T2实例的机器完成爬取。所需的时间。可以看出,使用单节点本地机最多可以抓取4000个网页数据,这是服务器限制单个IP在有限时间内访问有限数据造成的。在单台机器上执行并发线程也是如此。虽然计算速度比顺序节点快很多,但是爬取效率随着URL的增加而下降。下面两行爬取完成时间大致呈线性,说明随着URL数量的逐渐增加,Cloud-Scraper可以正常运行。可以推断,Cloud-Scraper 架构是可扩展的,可以根据爬取的 URL 数量增加 EC2 实例。
许多基于云的网页抓取解决方案可用,但大多数是商业性的,其工作模式不公开。因此,与一些现有的开源框架进行比较,例如 Scrapy 和 Import.io。图 5 展示了 Cloud-Scraper 和其他使用机器实例的基于云的平台之间的比较。与其他框架相比,Cloud-Scraper 架构是分布式的,对可以使用的计算资源实例没有限制。借助亚马逊云中的DynamoDB,可以灵活使用所有资源。由于Selenium的使用可能会延迟一段时间,所以爬取完成时间比Import.io要长,但是缺点已经被优点超越了。Selenium 提供更高的可靠性和对人类行为的模仿。效果较好[10]。在数据提取方面,其性能可媲美目前市面上其他基于云的网络爬虫架构,也可与其他大数据应用结合使用。最后,捕获的数据将进入大数据处理。
Cloud-Scraper的4大优势
Cloud-Scraper 有很多优点。其中一些描述如下:
⑴ 成本效益:使用云资源按使用付费模式,可以以低廉的价格使用云资源,并且可以按需扩容或缩容,比维护自己的云更便宜[11]。云供应商几乎可以提供从存储到处理能力所需的一切,让云计算变得更容易。购买自己的资源将花费大量成本来维持和扩大需求。
⑵ 可扩展性:云提供商根据需要提供可靠的计算机,并且可以根据需要创建和使用这些计算机的多个实例。供应商提供了大量的平台选择选项,您可以根据计算的性能要求选择正确的处理能力[12]。
⑶ 大数据应用集成:任何大数据应用都需要四种基本结构——存储、处理、分析软件和网络。DynamoDB 是一种 NoSQL 数据库,可以提供更高的可用性,从而提供更好的性能。分析软件可以根据用户的需求在该架构上进行编程,借助亚马逊的EC2,可以在数量和计算能力上进行扩展。虽然这种架构不能满足所有大数据要求,但进一步的程序集成和修改可以使其对大数据任务更加健壮。
5 结论
本文提出了一种基于云平台的新型网络爬虫架构。亚马逊的云服务为分布式环境中的计算和存储提供了弹性资源,为网络爬取提供了更好的平台。通过实验测试该架构的可扩展性,并与其他网页抓取架构进行简单对比,分析其优势,包括Selenium的使用和大数据应用的集成。此外,也可以使用其他云服务来实现上述架构。
参考:
[1] 魏冬梅, 何忠秀, 唐建梅. 基于Python的Web信息获取方法研究[J].软件指南,2018.17 (1): 41-43
[2] 郎博,张博宇.面向大数据的非结构化数据管理平台关键技术[J]. 信息技术与标准化,2013.10:53-56
[3] 刘宇,郑承焕.基于Scrapy的Deep Web Crawler研究[J]. 软件,2017.38(7):111-114
[4] 齐鹏,李银峰,宋雨薇.基于Python的Web Data采集技术[J]. 电子技术, 2012.25 (11): 118-120
[5] 凯文。网页资料采集发展历程及未来前景[EB/OL].
[6] 刘硕.精通Scrapy网络爬虫[M]. 清华大学出版社,2017.
[7] 许鸿飞.云计算安全问题初探——基于Amazon Dynamo和EC2的架构分析[J]. 计算机 CD 软件与应用,2013.16 (17): 21-22
[8]孙宝华.基于Dynamo的存储机制研究[D]. 西安电子科技大学,2013.
[9] 小龙腾.如何为 Hadoop 选择最灵活的 MapReduce 框架 [EB/OL].
[10] 杜斌. 基于Selenium的定向网络爬虫的设计与实现[J]. 金融科技时代,2016.7: 35-39
[11] Jackson KR、Muriki K、Thomas RC 等。亚马逊AWS云上超新星工厂的性能与成本分析[J]. 科学规划,2011.19:2-3
[12] Juan JD, Prodan R. Amazon EC2 中的多目标工作流调度[J]. 集群计算,2014.17(2):169-189
抓取网页数据违法吗(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-06 01:01
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接=one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
# 设置要抓取的 URL
网址 ='#39;
# 连接到网址
响应 = requests.get(url)
# 解析 HTML 并保存到 BeautifulSoup 对象¶
汤 = BeautifulSoup(response.text,"html.parser")
# 要下载整个数据集,让我们对所有 a 标签进行 for 循环
foriinrange(36,len(soup.findAll('a'))+1):#'a' 标签用于链接
one_a_tag = 汤.findAll('a')[i]
链接 = one_a_tag['href']
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1)#暂停代码一秒
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快! 查看全部
抓取网页数据违法吗(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接=one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4importBeautifulSoup
# 设置要抓取的 URL
网址 ='#39;
# 连接到网址
响应 = requests.get(url)
# 解析 HTML 并保存到 BeautifulSoup 对象¶
汤 = BeautifulSoup(response.text,"html.parser")
# 要下载整个数据集,让我们对所有 a 标签进行 for 循环
foriinrange(36,len(soup.findAll('a'))+1):#'a' 标签用于链接
one_a_tag = 汤.findAll('a')[i]
链接 = one_a_tag['href']
download_url ='#39;+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1)#暂停代码一秒
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快!
抓取网页数据违法吗(requests数据库提取使用xpath数据包从html文档中提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-04 17:02
抓取网页数据违法吗?no。知道对方是在哪里爬取的,就可以高兴的通过requests来访问,并从内容里面提取出足够的有价值的数据!requests数据库提取使用xpath数据包从html文档中提取有价值的数据,如html代码生成xpath数据库提取方法~原理:fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')print(html)java6以上版本使用的编码问题requests.encoding()没有匹配到一致的二进制编码requests.use('utf-8')解决方法:在爬取方法中指定编码,或者传入一个参数“string”。
http头部的编码是utf-8这样可以就可以正常解析http协议的url了。解析正则表达式http头部的编码可以用正则表达式提取字符串。其实我也不是很懂正则表达式解析,简单来说就是找到存在且对应的unicode对象,或者是对方想要的对象。fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')html_unicode=pile('^'+str(preg_name+"\\.gif')+'|\\.jpg')#preg_name\\.gif这里可以看到一共有17个样式html_unicode_jpg则可以解析所有gif/jpg图片。
list_urls={}list_urls=[]foriinlist_urls:x2=pile('^([a-za-z0-9_]+).*\\.jpg')y2=pile('^([a-za-z0-9_]+).*\\.gif')z2=pile('^([a-za-z0-9_]+).*\\.jpg')xy=pile('^([a-za-z0-9_]+).*\\.jpg')yy=pile('^([a-za-z0-9_]+).*\\.gif')result=[]result.append(xy,yy)forkey,valueinzip(html_unicode_jpg.items(),html_unicode_u2f.items()):list_key={'ex':x2,'i':y2,'num':z2,'i':key}print(list_key)arraylist(list_key).append(xy)print(arraylist(list_key))print('listofxpathauto-encodes={',list_key,'}','}')#items():包含xpath自动转换为embedding/\d{2,5}/a.jpg-\d{3,6}/.gif.jpgdefre_unicode_jpg(request,url):request.u。 查看全部
抓取网页数据违法吗(requests数据库提取使用xpath数据包从html文档中提取)
抓取网页数据违法吗?no。知道对方是在哪里爬取的,就可以高兴的通过requests来访问,并从内容里面提取出足够的有价值的数据!requests数据库提取使用xpath数据包从html文档中提取有价值的数据,如html代码生成xpath数据库提取方法~原理:fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')print(html)java6以上版本使用的编码问题requests.encoding()没有匹配到一致的二进制编码requests.use('utf-8')解决方法:在爬取方法中指定编码,或者传入一个参数“string”。
http头部的编码是utf-8这样可以就可以正常解析http协议的url了。解析正则表达式http头部的编码可以用正则表达式提取字符串。其实我也不是很懂正则表达式解析,简单来说就是找到存在且对应的unicode对象,或者是对方想要的对象。fromrequestsimportrequestfromurllib.requestimporturlopenimportrehtml=request.urlopen('')html_unicode=pile('^'+str(preg_name+"\\.gif')+'|\\.jpg')#preg_name\\.gif这里可以看到一共有17个样式html_unicode_jpg则可以解析所有gif/jpg图片。
list_urls={}list_urls=[]foriinlist_urls:x2=pile('^([a-za-z0-9_]+).*\\.jpg')y2=pile('^([a-za-z0-9_]+).*\\.gif')z2=pile('^([a-za-z0-9_]+).*\\.jpg')xy=pile('^([a-za-z0-9_]+).*\\.jpg')yy=pile('^([a-za-z0-9_]+).*\\.gif')result=[]result.append(xy,yy)forkey,valueinzip(html_unicode_jpg.items(),html_unicode_u2f.items()):list_key={'ex':x2,'i':y2,'num':z2,'i':key}print(list_key)arraylist(list_key).append(xy)print(arraylist(list_key))print('listofxpathauto-encodes={',list_key,'}','}')#items():包含xpath自动转换为embedding/\d{2,5}/a.jpg-\d{3,6}/.gif.jpgdefre_unicode_jpg(request,url):request.u。
抓取网页数据违法吗(小黄鸡代理抓取站违法吗?代理站有蜘蛛代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-03 07:04
抓取网页数据违法吗?说白了违法。但如果是通过代理访问并获取的数据且这些代理未被封禁,则没有法律上的禁止的理由。而如果所谓的爬虫网站存在着其他的数据,而这些数据又是非法获取的,则将构成爬虫罪。例如小黄鸡代理抓取站违法吗?小黄鸡抓取的页面是其公司提供给新网站使用的,并不是开放给新网站抓取。虽然小黄鸡抓取到的是新网站数据,但新网站既然已经给这些网站提供了服务,则说明新网站已经使用了小黄鸡代理抓取到的数据,因此这些数据也构成侵犯个人隐私和公民数据。
按说,这种情况,我们该把数据源开放给新网站,然后让新网站来抓取来使用。然而,爬虫代理站数据中一定会有蜘蛛代理,如果网站不开放这个代理,则可能构成数据窃取罪。这是一起常见的爬虫抓取,存在着大量的蜘蛛代理攻击,如果爬虫持续爬取,则可能构成网络犯罪。提供收费代理服务属于法律上的不正当竞争吗?根据《反不正当竞争法》第二条第二款:本法所称的不正当竞争行为,是指经营者不正当地使用与其他经营者相同或者类似的商品,或者使用与其他经营者在同一种商品上使用相同或者类似的商品,并且违反约定以排他性条件限制他人使用其他经营者商品。
第七条第一款:经营者不得以排他性条件限制其他经营者经营。所以说即使爬虫代理站提供收费代理服务也不属于侵犯个人隐私和公民数据,只要爬虫抓取网站不是重要的内容,并且网站本身不是重要的内容提供者,则无妨。最后,如果没有相关协议规定代理公司不能提供收费的免费代理服务,那么代理公司提供这些服务是否违法呢?如果本身数据来源就不正当,代理服务也是违法的。
但是如果这些爬虫数据本身来源也正当,虽然程序抓取数据不合法,但是也不违反该代理规定,因此也不会构成非法获取公民个人信息罪。 查看全部
抓取网页数据违法吗(小黄鸡代理抓取站违法吗?代理站有蜘蛛代理)
抓取网页数据违法吗?说白了违法。但如果是通过代理访问并获取的数据且这些代理未被封禁,则没有法律上的禁止的理由。而如果所谓的爬虫网站存在着其他的数据,而这些数据又是非法获取的,则将构成爬虫罪。例如小黄鸡代理抓取站违法吗?小黄鸡抓取的页面是其公司提供给新网站使用的,并不是开放给新网站抓取。虽然小黄鸡抓取到的是新网站数据,但新网站既然已经给这些网站提供了服务,则说明新网站已经使用了小黄鸡代理抓取到的数据,因此这些数据也构成侵犯个人隐私和公民数据。
按说,这种情况,我们该把数据源开放给新网站,然后让新网站来抓取来使用。然而,爬虫代理站数据中一定会有蜘蛛代理,如果网站不开放这个代理,则可能构成数据窃取罪。这是一起常见的爬虫抓取,存在着大量的蜘蛛代理攻击,如果爬虫持续爬取,则可能构成网络犯罪。提供收费代理服务属于法律上的不正当竞争吗?根据《反不正当竞争法》第二条第二款:本法所称的不正当竞争行为,是指经营者不正当地使用与其他经营者相同或者类似的商品,或者使用与其他经营者在同一种商品上使用相同或者类似的商品,并且违反约定以排他性条件限制他人使用其他经营者商品。
第七条第一款:经营者不得以排他性条件限制其他经营者经营。所以说即使爬虫代理站提供收费代理服务也不属于侵犯个人隐私和公民数据,只要爬虫抓取网站不是重要的内容,并且网站本身不是重要的内容提供者,则无妨。最后,如果没有相关协议规定代理公司不能提供收费的免费代理服务,那么代理公司提供这些服务是否违法呢?如果本身数据来源就不正当,代理服务也是违法的。
但是如果这些爬虫数据本身来源也正当,虽然程序抓取数据不合法,但是也不违反该代理规定,因此也不会构成非法获取公民个人信息罪。
抓取网页数据违法吗(如何查看robots的话的数据有如下规则?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-27 11:29
机器人协议(也称为爬虫协议、机器人协议等)是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
爬虫作为一种计算机技术决定了它的中立性。因此,爬虫本身并没有被法律禁止,但利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
震惊!!!大厂招聘直言“优先录取Pythonic”?? _哔哔(゜-゜)つロ干杯~-bilibili
图标 查看全部
抓取网页数据违法吗(如何查看robots的话的数据有如下规则?(一))
机器人协议(也称为爬虫协议、机器人协议等)是“机器人排除协议”(Robots Exclusion Protocol)。网站通过Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
爬虫作为一种计算机技术决定了它的中立性。因此,爬虫本身并没有被法律禁止,但利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
解释一下爬虫的定义:网络爬虫(英文:web crawler),也叫网络蜘蛛,是一种用来自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
震惊!!!大厂招聘直言“优先录取Pythonic”?? _哔哔(゜-゜)つロ干杯~-bilibili
图标
抓取网页数据违法吗(抓取网页数据违法吗?看完你就知道有可能不违法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-25 23:04
抓取网页数据违法吗?看完你就知道有可能不违法,也有可能违法但非常轻微,甚至违反《刑法》第三百五十三条也不违法,可能非常夸张,你可以详细看看,不知道你懂不懂,
就一句话,不违法。
不是针对c,b本身就不应该拿到工资,除非所有人都签了,那b可以拿工资,其他人也要工资。
我觉得这是最近由于国外网站国内访问速度问题,导致上新系统有一部分显示不出来,而b站播放量大的up主会抢占b站不相关视频,那么可能带来的影响就是,不少小于1w播放量的视频就无法显示在页面,导致买卖详情页无法正常显示,所以把一部分视频删掉。关于b站,未成年人请尽量不要随便去。
这是为了选择性侵害未成年人的人做好榜样吧有些幼童可能会上瘾还会得病也不是说所有人都是坏人但是有些人无处不在好人一出手就被弄死还有人说什么模拟男女关系的大多是卖肉的有些精液确实含有大量肉毒素到时候会有第二套人生大概吧
必须触犯刑法啊。可能是检察院把自己的地方分割成有优势和劣势的,少数有优势的地方都给展示了,应该更难通过一些;但有劣势就要侵犯优势这种地方就会给多数人展示劣势,无论是了解大局上的“没有实际内容,就是变形”;还是在个人兴趣上的“再讲也不会看”,中国的司法就是这么任性!sodude!!作为一个老百姓,看见的点头了,长见识了。而法官有观点分歧的时候,可以去投诉政府监管部门;但是网络上展示劣势好像不能理解。监管有困难而言!。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?看完你就知道有可能不违法)
抓取网页数据违法吗?看完你就知道有可能不违法,也有可能违法但非常轻微,甚至违反《刑法》第三百五十三条也不违法,可能非常夸张,你可以详细看看,不知道你懂不懂,
就一句话,不违法。
不是针对c,b本身就不应该拿到工资,除非所有人都签了,那b可以拿工资,其他人也要工资。
我觉得这是最近由于国外网站国内访问速度问题,导致上新系统有一部分显示不出来,而b站播放量大的up主会抢占b站不相关视频,那么可能带来的影响就是,不少小于1w播放量的视频就无法显示在页面,导致买卖详情页无法正常显示,所以把一部分视频删掉。关于b站,未成年人请尽量不要随便去。
这是为了选择性侵害未成年人的人做好榜样吧有些幼童可能会上瘾还会得病也不是说所有人都是坏人但是有些人无处不在好人一出手就被弄死还有人说什么模拟男女关系的大多是卖肉的有些精液确实含有大量肉毒素到时候会有第二套人生大概吧
必须触犯刑法啊。可能是检察院把自己的地方分割成有优势和劣势的,少数有优势的地方都给展示了,应该更难通过一些;但有劣势就要侵犯优势这种地方就会给多数人展示劣势,无论是了解大局上的“没有实际内容,就是变形”;还是在个人兴趣上的“再讲也不会看”,中国的司法就是这么任性!sodude!!作为一个老百姓,看见的点头了,长见识了。而法官有观点分歧的时候,可以去投诉政府监管部门;但是网络上展示劣势好像不能理解。监管有困难而言!。
抓取网页数据违法吗(如何爬取网页数据违法吗?当然要违法!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-25 19:01
抓取网页数据违法吗?当然要违法!网页数据又不是文件,更不是什么图片数据,我们要做的就是想尽办法获取网页数据,然后再用这些数据去爬取我们需要的数据或者是学习程序,还可以被封了嘛!但是现在爬虫还是非常火的,在网上各种抓取网页数据,这样既符合我们的需求,也不会违法。这一期就来给大家说说如何爬取网页数据:利用网页抓取器工具:excelhome,下载地址:目前在windows平台上工具可以抓取到大部分浏览器的网页,很多还能抓取其他浏览器的网页,我们来看看爬取到的网页数据:1.正常进入网页之后如果发现了这个网页或者其他目录没有id,说明这个网页是公共的,没有我们需要爬取的数据,无需重复抓取。
2.下面是我随手抓取的数据,有不明白的可以评论区问我网页抓取器:进入网页后就会看到搜索栏,接下来我们用爬虫工具去抓取数据吧!首先看到这个广告页,复制这个地址到excelhome:再打开网页就看到了这个页面,等下我们用这个网页数据去爬取其他网页数据还是可以的:利用抓取器工具首先使用python3,然后进入目录后找到intrj86vjkj关键字,然后对其右键选择搜索,打开搜索引擎:现在就是拿这个地址去搜索数据了,依次点击all搜索结果看看:在页面中所有大部分数据都可以在网页中找到,直接拿这些数据去爬取就行了,是不是很方便:接下来,我们就可以打开这个网页中需要的数据来进行下载,如果是需要查看结果中的数据,可以在我们的目录中鼠标右键点击所需数据,然后粘贴到这个目录中,就出现对应的结果。
结果如下:看到这个结果是不是感觉很有意思!!!数据每十位数都有一个数字,我们就可以一个个下载,还有中间的一段就是我们需要的数据,那么数据我们要如何整理呢?我们看看原图:我们把鼠标移到红框的数据中,就会出现一个黑框,我们把这个黑框的数据去掉,并把鼠标移到黄框内的数据去掉(这里叫做excelhome的tag,下图中a2点击一下就是了):因为excelhome的标签是蓝色的,所以上面的一大段我们需要删除它,看看结果:这样我们就把原数据中所有的红框的数据去掉了。
接下来就可以进行正常的爬取数据,并把数据存放在一个文件里面:最后是看看爬取的网页数据:上面就是简单的爬取网页数据的一些办法,这里面还有很多我们需要注意的问题,欢迎大家一起交流学习!。 查看全部
抓取网页数据违法吗(如何爬取网页数据违法吗?当然要违法!(图))
抓取网页数据违法吗?当然要违法!网页数据又不是文件,更不是什么图片数据,我们要做的就是想尽办法获取网页数据,然后再用这些数据去爬取我们需要的数据或者是学习程序,还可以被封了嘛!但是现在爬虫还是非常火的,在网上各种抓取网页数据,这样既符合我们的需求,也不会违法。这一期就来给大家说说如何爬取网页数据:利用网页抓取器工具:excelhome,下载地址:目前在windows平台上工具可以抓取到大部分浏览器的网页,很多还能抓取其他浏览器的网页,我们来看看爬取到的网页数据:1.正常进入网页之后如果发现了这个网页或者其他目录没有id,说明这个网页是公共的,没有我们需要爬取的数据,无需重复抓取。
2.下面是我随手抓取的数据,有不明白的可以评论区问我网页抓取器:进入网页后就会看到搜索栏,接下来我们用爬虫工具去抓取数据吧!首先看到这个广告页,复制这个地址到excelhome:再打开网页就看到了这个页面,等下我们用这个网页数据去爬取其他网页数据还是可以的:利用抓取器工具首先使用python3,然后进入目录后找到intrj86vjkj关键字,然后对其右键选择搜索,打开搜索引擎:现在就是拿这个地址去搜索数据了,依次点击all搜索结果看看:在页面中所有大部分数据都可以在网页中找到,直接拿这些数据去爬取就行了,是不是很方便:接下来,我们就可以打开这个网页中需要的数据来进行下载,如果是需要查看结果中的数据,可以在我们的目录中鼠标右键点击所需数据,然后粘贴到这个目录中,就出现对应的结果。
结果如下:看到这个结果是不是感觉很有意思!!!数据每十位数都有一个数字,我们就可以一个个下载,还有中间的一段就是我们需要的数据,那么数据我们要如何整理呢?我们看看原图:我们把鼠标移到红框的数据中,就会出现一个黑框,我们把这个黑框的数据去掉,并把鼠标移到黄框内的数据去掉(这里叫做excelhome的tag,下图中a2点击一下就是了):因为excelhome的标签是蓝色的,所以上面的一大段我们需要删除它,看看结果:这样我们就把原数据中所有的红框的数据去掉了。
接下来就可以进行正常的爬取数据,并把数据存放在一个文件里面:最后是看看爬取的网页数据:上面就是简单的爬取网页数据的一些办法,这里面还有很多我们需要注意的问题,欢迎大家一起交流学习!。
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 12:10
机器人协议(也称为爬虫协议、机器人协议等)代表“机器人排除协议”(Robots Exclusion Protocol)。网站使用Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站意愿,如网站采取防爬措施后,强行突破其防爬措施;
爬虫干扰被访问网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
它不存在,不能被未经授权的访问抓取
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。 查看全部
抓取网页数据违法吗(Robots协议(也称为爬虫协议、机器人协议等)的全称)
机器人协议(也称为爬虫协议、机器人协议等)代表“机器人排除协议”(Robots Exclusion Protocol)。网站使用Robots协议告诉爬虫哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件。您可以使用任何常用的文本编辑器(例如 Windows 附带的记事本)来创建和编辑它。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎访问网站时要查看的第一个文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。
如何查看采集到的内容是否有rebots协议?
其实方法很简单。如果您想查看,只需在 IE 上输入您的 URL/robots.txt。如果你想查看和分析机器人,你可以有专业的相关工具,站长工具!
作为一种计算机技术,爬虫决定了它的中立性。因此,爬虫本身并没有被法律禁止,但是利用爬虫技术获取数据存在违法甚至犯罪的风险。
比如像谷歌这样的搜索引擎爬虫每隔几天就会扫描一次全网的网页,供大家查看。大多数扫描的网站都非常高兴。这被定义为“好爬行动物”。但是像抢票软件这样的爬虫每秒可以针对 12306 等待数万次。Tie 总是感觉不怎么开心。这种爬虫被定义为“恶意爬虫”。
爬虫带来的风险主要体现在以下三个方面:
违反网站意愿,如网站采取防爬措施后,强行突破其防爬措施;
爬虫干扰被访问网站的正常运行;
爬虫爬取了受法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种自动浏览万维网的网络机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
它不存在,不能被未经授权的访问抓取
常见误解:认为爬虫是用来抓取个人信息的,与基本信用数据有关。
一般来说,技术是无罪的,但如果你用技术来爬取别人的隐私和商业数据,那你就是在藐视法律。
抓取网页数据违法吗(抓取网页数据违法吗?谢邀,看什么情况?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-24 18:02
抓取网页数据违法吗?谢邀,看情况。要看什么情况。1,如果网站开放获取的是网页内容,则没有任何问题,当然每个网站的规定可能不一样。最有可能触犯的法律就是“侵犯著作权”。著作权法明确规定了侵犯著作权的主要行为包括复制,发行,出租,展览,放映,播放,广播,表演等,只要符合上述所列方式,即构成侵犯著作权。2,如果网站的所有权人知道并不提供给你,那么他只要没有盗取、复制或是出租内容,你就没有法律后果。
但是,你可以要求他删除侵权的内容。3,如果网站是开放获取数据的话,不是所有行为都构成侵权。比如,如果直接给你一个网址,你却打不开,他不能以你侵犯他的著作权为由去起诉你,如果你打开了他的网址,他没有及时删除侵权的内容的话,他就构成了侵犯著作权。4,开放获取数据的网站,只要是没有权利主动保留用户上传的内容的,也就是你打开网站无法发现网站对你所要上传内容进行保留,包括:整个网站内所有的用户上传的数据,以及你下载、保存内容的其他方式。
你这里可能是说按了打开发现网站后自动保存的数据,因为你可以打开自己网站的内容,所以这个是侵犯著作权无疑。所以,要看网站数据获取的人是谁。如果仅仅是网站内容很快被其他人下载保存,是没有问题的。但如果网站的数据很快被其他人上传,以及你下载并保存的内容他没有及时删除的话,你就构成侵犯著作权了。5,一般通过https下载数据,你可以要求网站删除侵权内容。
6,电商、广告网站和自媒体,都会默认开放用户上传的所有数据,包括:即使你不上传,网站也会保留整个网站所有用户上传的数据,以及你下载并保存的其他方式,所以,要看网站什么情况。7,如果你用这个网站的内容投放了广告,或者设置了用户搜索关键词,网站会向你推荐内容,但,如果你在搜索关键词的时候你上传了用户上传的数据,你就构成侵犯著作权了。
此外,如果一个网站的内容是在大赛期间的,那么在比赛期间,有些用户会将网站内容发给组委会,但是,组委会网站将其转给用户下载。如果你在这期间将用户所下载的内容进行了散播,可能构成侵犯著作权。 查看全部
抓取网页数据违法吗(抓取网页数据违法吗?谢邀,看什么情况?)
抓取网页数据违法吗?谢邀,看情况。要看什么情况。1,如果网站开放获取的是网页内容,则没有任何问题,当然每个网站的规定可能不一样。最有可能触犯的法律就是“侵犯著作权”。著作权法明确规定了侵犯著作权的主要行为包括复制,发行,出租,展览,放映,播放,广播,表演等,只要符合上述所列方式,即构成侵犯著作权。2,如果网站的所有权人知道并不提供给你,那么他只要没有盗取、复制或是出租内容,你就没有法律后果。
但是,你可以要求他删除侵权的内容。3,如果网站是开放获取数据的话,不是所有行为都构成侵权。比如,如果直接给你一个网址,你却打不开,他不能以你侵犯他的著作权为由去起诉你,如果你打开了他的网址,他没有及时删除侵权的内容的话,他就构成了侵犯著作权。4,开放获取数据的网站,只要是没有权利主动保留用户上传的内容的,也就是你打开网站无法发现网站对你所要上传内容进行保留,包括:整个网站内所有的用户上传的数据,以及你下载、保存内容的其他方式。
你这里可能是说按了打开发现网站后自动保存的数据,因为你可以打开自己网站的内容,所以这个是侵犯著作权无疑。所以,要看网站数据获取的人是谁。如果仅仅是网站内容很快被其他人下载保存,是没有问题的。但如果网站的数据很快被其他人上传,以及你下载并保存的内容他没有及时删除的话,你就构成侵犯著作权了。5,一般通过https下载数据,你可以要求网站删除侵权内容。
6,电商、广告网站和自媒体,都会默认开放用户上传的所有数据,包括:即使你不上传,网站也会保留整个网站所有用户上传的数据,以及你下载并保存的其他方式,所以,要看网站什么情况。7,如果你用这个网站的内容投放了广告,或者设置了用户搜索关键词,网站会向你推荐内容,但,如果你在搜索关键词的时候你上传了用户上传的数据,你就构成侵犯著作权了。
此外,如果一个网站的内容是在大赛期间的,那么在比赛期间,有些用户会将网站内容发给组委会,但是,组委会网站将其转给用户下载。如果你在这期间将用户所下载的内容进行了散播,可能构成侵犯著作权。
抓取网页数据违法吗(python爬虫爬取网页将特定信息存入excel背景(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-23 10:15
Python爬虫爬取网页在excel中存储特定信息
背景
1、最近遇到一个需要数据分析的项目,主要是采集和分析网页上需要的信息。当信息量较小时,使用复制粘贴-excel分析更加快捷方便。当数据上升到成百上千的时候,一一复制粘贴,显然会感觉效率低下,操作困难。
2、 之前听说过python爬虫,所以趁着这个机会去试验一下。笔者几年前学过python,有一定的基础。
需求分析:
1、目的:使用python爬虫批量抓取网页中的有效信息,然后将这些信息一一存储在excel中。最后,使用excel对数据进行最终的统计分析。
2、功能需求
a、阅读网页
湾 抓取网页的特定内容
c、将内容按顺序存储在excel中
功能实现
爬虫的本质是编写一个程序,让程序模拟一个人操作浏览器访问网页。本文以豆瓣电影为例,爬取某类电影的排名信息
网络分析
打开豆瓣电影分类排行榜,选择动作片,出现的页面如下。
当页面的进度条拖到底部时,会直接刷新一个新页面,而不是刷新整个页面。这使用了 Ajax Web 动态部分加载技术。
右击下方网页,选择check,切换到Network选项,过滤掉XHR选项
继续拖动进度条到底部,发现刷新了一条请求消息。
双击这个请求,可以看到响应是一个类似json格式的数据,里面的信息对应页面上的电影信息
切换到Headers选项,仔细看看网页的请求界面。如果能找到请求接口,就可以通过python中的请求模块访问该接口。网页反馈类似于json格式的数据。如果这一步行得通,那么下一步就很容易处理了。我们先来看看请求接口。
可以看到,请求的地址为%3A90&action=&start=100&limit=20,请求方式为GET。后面的参数,type,interval_id,action,start,limit。
通过对headers的分析,发现请求中有5个参数。这个参数是什么意思?写python程序时需要给这些参数赋什么值?
其实我们需要关注的是爬虫返回的数据,我们只需要保证请求命令能够正常接收到反馈即可。所以我们只需要找出这个请求中改变了哪些参数,然后分析这个参数的含义。对于常量参数,只需填写程序中的页眉即可。
查找更改的参数,只需下拉进度条即可查看新的请求数据
可以看到,只有start变了,start 80;限制 20;开始100;limit 20,你能猜出这20是每次刷新的电影数量吗?开始是从哪个排名电影开始看?
通过对网页的初步分析,这种可能性非常大,验证起来也很简单。记住里面的请求是GET,然后就可以用浏览器直接访问界面验证了。
start=1 limit=2,刷新了两部电影,这个杀手不太冷七武士
start=2 limit=3,刷新了七武士、咕噜和蝙蝠侠:黑暗骑士三部电影。由此可以验证 start 是排名中第一个开始请求的电影。limit 是每次请求的视频数量。如果我想抓取前300个视频,我只需要start=1和limit=300。网页分析到这里就够了,我们得到了我们想要的信息
1、接口:%3A90&action=&start=2&limit=3
2、请求方式:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、 本节通过对网页的分析,发现豆瓣视频排名使用了网页部分动态加载技术
2、 在检查中过滤掉了动态加载的请求接口,请求的反馈是json-like格式(用于后面python解析),通过猜测和直接调用接口的含义找到了 start 和 limit 两个参数
Python代码编写
1、User_agent 介绍
如果你是豆瓣网站的开发者,你是否希望别人用非正式的方式批量抓取你的网站中的数据?想了想,答案肯定是否定的。那么网站服务器是如何判断当前访问合法的呢?最基本的方式是使用请求载体的标识信息User_agent。不同的浏览器有不同的识别信息。
以下是作者谷歌浏览器的识别信息。所以为了防止编写的程序被服务器拒绝访问,在使用请求模块进行请求时必须携带标识信息。
2、代码
先直接上传代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进了程序,分析页面,发现type是对应的电影类型,5:动作;11:情节。可以把所有的类型都试一下,放到字典里,实现某类电影的指定抓拍。作者所完成的是动作电影的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式的文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头部、访问接口和参数。更改后的参数由终端输入。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能会使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现了,读取返回的json格式数据,转换后的数据其实就是一个字典。
操作excel的5个步骤
1、创建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存并关闭
sht.range('A1').value='序列号'
表示将序列号写入单元格A1。如果需要写到B10,把上面的A1改成B10,操作起来很方便。 查看全部
抓取网页数据违法吗(python爬虫爬取网页将特定信息存入excel背景(图))
Python爬虫爬取网页在excel中存储特定信息
背景
1、最近遇到一个需要数据分析的项目,主要是采集和分析网页上需要的信息。当信息量较小时,使用复制粘贴-excel分析更加快捷方便。当数据上升到成百上千的时候,一一复制粘贴,显然会感觉效率低下,操作困难。
2、 之前听说过python爬虫,所以趁着这个机会去试验一下。笔者几年前学过python,有一定的基础。
需求分析:
1、目的:使用python爬虫批量抓取网页中的有效信息,然后将这些信息一一存储在excel中。最后,使用excel对数据进行最终的统计分析。
2、功能需求
a、阅读网页
湾 抓取网页的特定内容
c、将内容按顺序存储在excel中
功能实现
爬虫的本质是编写一个程序,让程序模拟一个人操作浏览器访问网页。本文以豆瓣电影为例,爬取某类电影的排名信息
网络分析
打开豆瓣电影分类排行榜,选择动作片,出现的页面如下。
当页面的进度条拖到底部时,会直接刷新一个新页面,而不是刷新整个页面。这使用了 Ajax Web 动态部分加载技术。
右击下方网页,选择check,切换到Network选项,过滤掉XHR选项
继续拖动进度条到底部,发现刷新了一条请求消息。
双击这个请求,可以看到响应是一个类似json格式的数据,里面的信息对应页面上的电影信息
切换到Headers选项,仔细看看网页的请求界面。如果能找到请求接口,就可以通过python中的请求模块访问该接口。网页反馈类似于json格式的数据。如果这一步行得通,那么下一步就很容易处理了。我们先来看看请求接口。
可以看到,请求的地址为%3A90&action=&start=100&limit=20,请求方式为GET。后面的参数,type,interval_id,action,start,limit。
通过对headers的分析,发现请求中有5个参数。这个参数是什么意思?写python程序时需要给这些参数赋什么值?
其实我们需要关注的是爬虫返回的数据,我们只需要保证请求命令能够正常接收到反馈即可。所以我们只需要找出这个请求中改变了哪些参数,然后分析这个参数的含义。对于常量参数,只需填写程序中的页眉即可。
查找更改的参数,只需下拉进度条即可查看新的请求数据
可以看到,只有start变了,start 80;限制 20;开始100;limit 20,你能猜出这20是每次刷新的电影数量吗?开始是从哪个排名电影开始看?
通过对网页的初步分析,这种可能性非常大,验证起来也很简单。记住里面的请求是GET,然后就可以用浏览器直接访问界面验证了。
start=1 limit=2,刷新了两部电影,这个杀手不太冷七武士
start=2 limit=3,刷新了七武士、咕噜和蝙蝠侠:黑暗骑士三部电影。由此可以验证 start 是排名中第一个开始请求的电影。limit 是每次请求的视频数量。如果我想抓取前300个视频,我只需要start=1和limit=300。网页分析到这里就够了,我们得到了我们想要的信息
1、接口:%3A90&action=&start=2&limit=3
2、请求方式:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、 本节通过对网页的分析,发现豆瓣视频排名使用了网页部分动态加载技术
2、 在检查中过滤掉了动态加载的请求接口,请求的反馈是json-like格式(用于后面python解析),通过猜测和直接调用接口的含义找到了 start 和 limit 两个参数
Python代码编写
1、User_agent 介绍
如果你是豆瓣网站的开发者,你是否希望别人用非正式的方式批量抓取你的网站中的数据?想了想,答案肯定是否定的。那么网站服务器是如何判断当前访问合法的呢?最基本的方式是使用请求载体的标识信息User_agent。不同的浏览器有不同的识别信息。
以下是作者谷歌浏览器的识别信息。所以为了防止编写的程序被服务器拒绝访问,在使用请求模块进行请求时必须携带标识信息。
2、代码
先直接上传代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进了程序,分析页面,发现type是对应的电影类型,5:动作;11:情节。可以把所有的类型都试一下,放到字典里,实现某类电影的指定抓拍。作者所完成的是动作电影的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式的文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头部、访问接口和参数。更改后的参数由终端输入。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能会使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现了,读取返回的json格式数据,转换后的数据其实就是一个字典。
操作excel的5个步骤
1、创建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存并关闭
sht.range('A1').value='序列号'
表示将序列号写入单元格A1。如果需要写到B10,把上面的A1改成B10,操作起来很方便。
抓取网页数据违法吗(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-18 15:18
如果要开发一个半自动注册机程序,那么将验证码读入winform,然后提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码。注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
首先住一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言,只写一部分必要的代码。 查看全部
抓取网页数据违法吗(这篇博文记录一下如何抓取网页上面的验证码,注意不是验证码识别)
如果要开发一个半自动注册机程序,那么将验证码读入winform,然后提交数据是一个必要的过程。这篇博文记录了如何抓取网页上的验证码。注意不是验证码识别。有些 网站 会验证 cookie,有些则不会。本文收录cookie阅读和提交。
首先住一个全局 Cookie 变量
private CookieContainer cookie = new System.Net.CookieContainer();
程序加载时读取验证码和cookie
public Form1()
{
InitializeComponent();
string checkcodeUrl = "验证码的url";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(checkcodeUrl);
request.CookieContainer = new CookieContainer();
Stream responseStream = ((HttpWebResponse)request.GetResponse()).GetResponseStream();
cookie = request.CookieContainer;
string cookiesstr = request.CookieContainer.GetCookieHeader(request.RequestUri);
Image original = Image.FromStream(responseStream);
Bitmap bitMap = new Bitmap(original);
this.pictureBox1.Image = bitMap;
responseStream.Close();
}
catch (Exception exception)
{
MessageBox.Show("ERROR:" + exception.Message);
}
}
提交数据
HttpWebRequest webrequest = (HttpWebRequest)WebRequest.Create(url);
webrequest.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)webrequest.GetResponse();
StreamReader read = new StreamReader(response.GetResponseStream(), Encoding.Default);
string text = read.ReadToEnd();
不明白的请留言,只写一部分必要的代码。
抓取网页数据违法吗( 爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-18 09:12
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人)
)
01 什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
网络爬虫的工作原理是爬取 Internet 上 网站 服务器的内容。它是用计算机语言编写的程序或脚本,用于自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的一些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市场上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图2-1 网络爬虫象形图
02 爬虫的含义
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。公司需要数据来分析用户行为、其产品的缺陷以及竞争对手的信息。所有这一切的第一个条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就拥有决策的主动权。网络爬虫的应用领域有很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1) 抓取各大电商网站的产品销售信息和用户评论进行分析,如图2-2所示。
▲图2-2 电商网站产品销售信息
2)分析大众点评、美团等餐饮网站的用户消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区的房屋比例,学区房的价格比普通二手房高出多少,如图2-4所示。
▲图2-4 学区房占比及价格对比
以上数据是通过预嗅探ForeSpider数据采集软件爬取下来的。有兴趣的读者可以尝试自己爬取一些数据。
03 爬虫原理
我们通常将网络爬虫的组件模块分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取的链接队列、网页库等。形成一个循环系统不断地分析和捕获。
爬虫的工作原理可以简单的解释为先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 履带示意图
爬虫工作的基本过程:
首先在互联网上选择一部分网页,将这些网页的链接地址作为种子网址;
将这些种子URL放入待爬取的URL队列,爬虫从待爬取的URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页为网页文件形式;
提取网页文档中的网址;
过滤掉已经爬取过的网址;
没有被爬取的URL继续循环爬取,直到待爬取的URL队列为空。
04 履带技术的种类
有关爬虫类型的更详细说明,请单击此处。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等方面的教学和科研工作。
本文摘自《Python Web爬虫技术与实战》,经发布者授权发布。
查看全部
抓取网页数据违法吗(
爬虫是什么网络爬虫(又被称为网页蜘蛛、网络机器人)
)
01 什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的网络追逐者)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
网络爬虫的工作原理是爬取 Internet 上 网站 服务器的内容。它是用计算机语言编写的程序或脚本,用于自动从互联网上获取信息或数据,扫描并抓取每个需要的页面上的一些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市场上流行的采集器软件都是利用网络爬虫的原理或功能。
▲图2-1 网络爬虫象形图
02 爬虫的含义
现在大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。公司需要数据来分析用户行为、其产品的缺陷以及竞争对手的信息。所有这一切的第一个条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就拥有决策的主动权。网络爬虫的应用领域有很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1) 抓取各大电商网站的产品销售信息和用户评论进行分析,如图2-2所示。
▲图2-2 电商网站产品销售信息
2)分析大众点评、美团等餐饮网站的用户消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区的房屋比例,学区房的价格比普通二手房高出多少,如图2-4所示。
▲图2-4 学区房占比及价格对比
以上数据是通过预嗅探ForeSpider数据采集软件爬取下来的。有兴趣的读者可以尝试自己爬取一些数据。
03 爬虫原理
我们通常将网络爬虫的组件模块分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取的链接队列、网页库等。形成一个循环系统不断地分析和捕获。
爬虫的工作原理可以简单的解释为先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 履带示意图
爬虫工作的基本过程:
首先在互联网上选择一部分网页,将这些网页的链接地址作为种子网址;
将这些种子URL放入待爬取的URL队列,爬虫从待爬取的URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页为网页文件形式;
提取网页文档中的网址;
过滤掉已经爬取过的网址;
没有被爬取的URL继续循环爬取,直到待爬取的URL队列为空。
04 履带技术的种类
有关爬虫类型的更详细说明,请单击此处。
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等方面的教学和科研工作。
本文摘自《Python Web爬虫技术与实战》,经发布者授权发布。

