
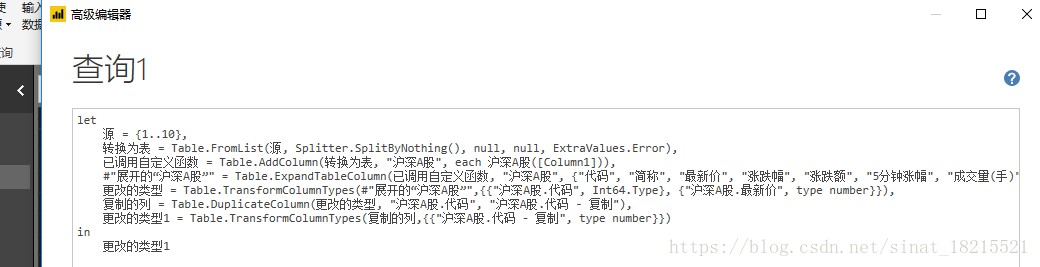
抓取网页数据工具
抓取网页数据工具(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 837 次浏览 • 2021-10-04 12:35
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。
总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
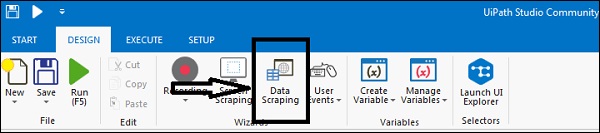
通过示例使用数据采集向导的步骤
要使用 UiPath 数据捕获向导,您可以按照以下步骤操作 -
第 1 步 - 首先,打开要从中提取数据的网页或应用程序。例如,我们从 Google 联系人中提取数据。
步骤 2-然后单击“设计”选项卡下的“数据采集”按钮。您将收到以下消息框-

第 3 步 - 单击“下一步”按钮,它将为您提供选择要从中提取数据的网页中的第一个和最后一个字段的选项。在此示例中,您将能够从 Google 通讯录页面中进行选择。
Step 4-选择完第一个元素后,会提示选择第二个元素的对话框,如下图-
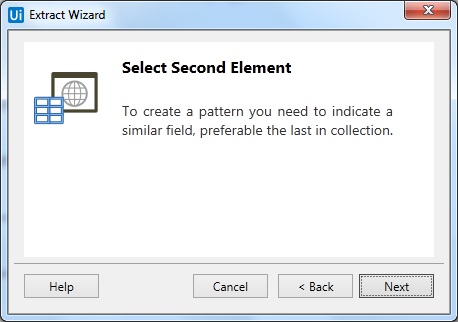
第 5 步 - 现在,一旦您单击下一步并选择第二个元素,它将提示另一个对话框,我们可以在其中自定义列标题并选择是否提取 URL。
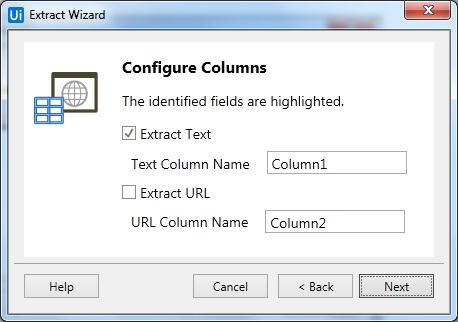
您可以根据需要重命名“文本”列的名称。我们已将 column1 重命名为“name”。
Step 6-接下来,UiPath studio 会为我们提供“Extraction Wizard”来预览数据。我们将选择提取相关数据或在此处完成提取。如果您提取相关数据,它会再次将您带到您要从中提取数据的网页。
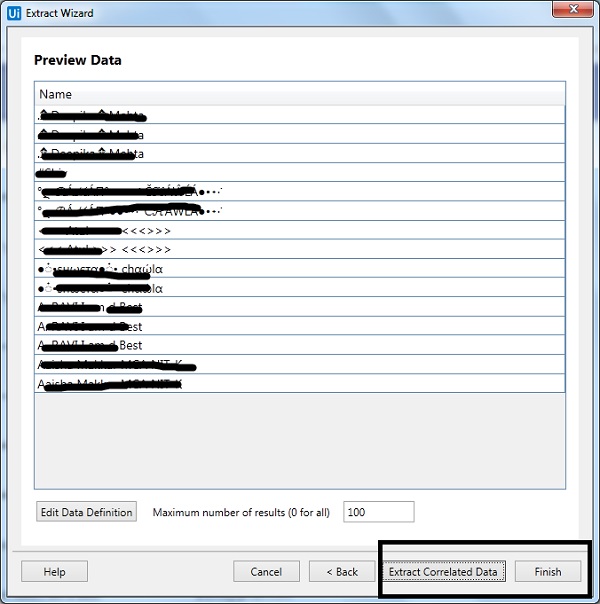
步骤7-提取完成后,它会询问“数据是否跨越多个页面?” 如果要从多个页面提取数据,请单击“是”,否则单击“否”。我们单击“否”是因为此处的数据提取仅来自单个页面。
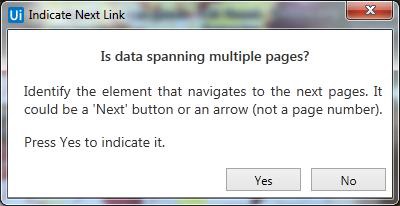
步骤 8-最后,它将在设计器选项卡中创建活动序列,如下所示-
什么是屏幕抓取?
UiPath Studio 为我们提供了一种从指定的 UI 元素或文档中提取数据的方法。这些方法称为屏幕捕获或输出方法。我们可以在“设计”选项卡下找到屏幕截图向导。

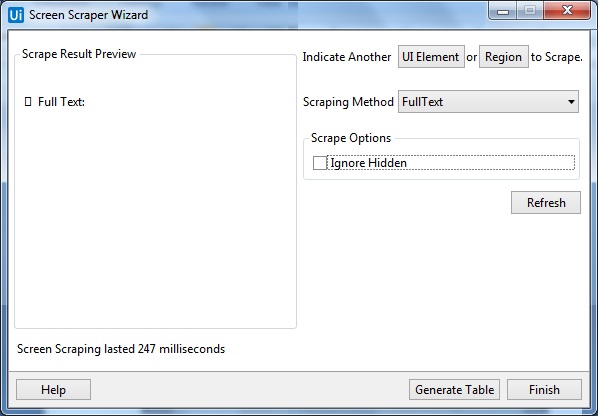
屏幕抓取方式
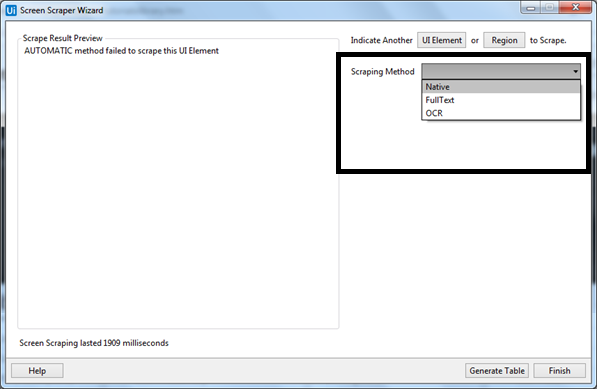
UiPath Studio 屏幕捕获向导具有三种从指定 UI 元素捕获数据的方法。此方法将由 UiPath Studio 自动选择并显示在“屏幕截图”窗口的顶部。
现在出现的问题是,如果方法是自动选择的,是否可以根据需要进行更改?是的,您可以从写有“抓取方法”的“选项”面板中更改它,然后按“刷新”按钮。
单击“刷新”按钮后,UiPath Studio 会将信息保存在“设计器”面板中。另一方面,如果要将信息复制到剪贴板,则可以单击“完成”按钮。
如桌面录制中所见,屏幕截图将生成一个容器,其中收录活动和选择器的每个激活部分。你可以参考下面的截图——
这三种截屏方法都有不同的功能,下面分别对这三种截屏方法及其作用进行说明——
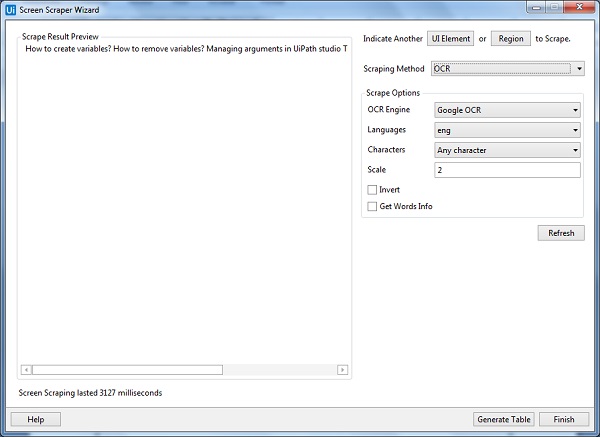
使用示例屏幕捕获向导的步骤
为了使用 UiPath 屏幕抓取向导,您可以按照以下步骤操作 -
第 1 步 - 首先,打开要从中提取数据的 Ui 元素(可能是 PDF 文件或 Word 文件或任何其他文件)。在这里,我们将其实现为 PDF 文件。
第 2 步 - 现在,单击“设计”选项卡下的“屏幕捕获”选项。
第 3 步 - 接下来,单击要从中提取信息的 Ui 元素,在我们的示例中,我们单击 PDF 文档。
第 4 步-现在,您将看到以下屏幕-

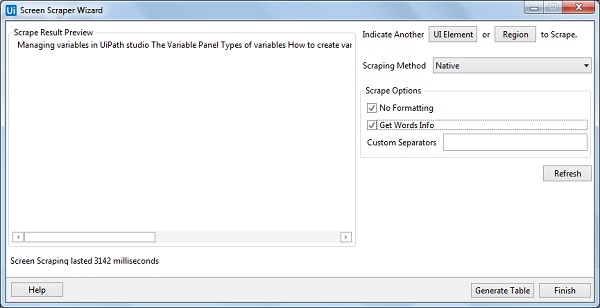
默认情况下,UiPath Studio 会提供截屏方法,但您可以根据需要进行更改。我们之前也讨论过。
步骤 5-然后,最后,您可以单击刷新按钮或完成按钮。我们单击“完成”按钮,它将保存在设计器面板中。
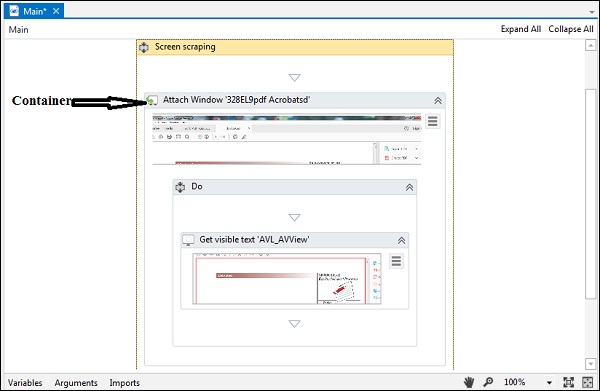
如前所述,屏幕截图将生成一个容器,其中收录活动和选择器的每个活动部分。
我们可以在以下屏幕截图中看到输出 -
抓取网页数据工具(最新版提取的教程示例-感兴趣提取教程提取篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-30 13:37
用于 Web 数据抓取工具的 json 提取示例。用过最新版优采云采集器V9的朋友应该都发现V9增加了json提取功能,但是很多使用网页数据抓取工具的朋友都在操作这个功能的话,会觉得有点糊涂。这里有一个json提取的教程示例,供大家参考。有兴趣的朋友可以仔细研究一下。首先,您需要了解 JSON 有两种结构。简单的说,json在javascript中是一个对象和一个数组,所以这两个结构体就是对象和数组。通过这两种结构可以表达各种复杂的结构。下面是1、对象的具体说明:该对象在js中表示为“{}”括起来的内容,并且数据结构是键值对{key: value, key: value,...}的结构,在面向对象语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。
并且我们可以发现这个 URL 的整个源代码是一个完整的 JSON。所以选择JSON数据源的URL并检查循环匹配,您可以采集到整个JSON中的数据。如图:2、 JSON 数据源:JSON 文本:另一种情况,URL 中的源代码并非全部为 JSON,只是部分代码采用 JSON 形式。这时候,我们需要提取这个JSON文本,然后对其进行格式化。比如URL,那么我们需要以多页的形式在这个页面的地址中获取这部分JSON代码,然后设置JSON格式。按照上面的步骤,就完成了两次JSON的提取。您认为它简单易用吗?所以网页数据爬取工具首选优采云采集器 V9, 查看全部
抓取网页数据工具(最新版提取的教程示例-感兴趣提取教程提取篇)
用于 Web 数据抓取工具的 json 提取示例。用过最新版优采云采集器V9的朋友应该都发现V9增加了json提取功能,但是很多使用网页数据抓取工具的朋友都在操作这个功能的话,会觉得有点糊涂。这里有一个json提取的教程示例,供大家参考。有兴趣的朋友可以仔细研究一下。首先,您需要了解 JSON 有两种结构。简单的说,json在javascript中是一个对象和一个数组,所以这两个结构体就是对象和数组。通过这两种结构可以表达各种复杂的结构。下面是1、对象的具体说明:该对象在js中表示为“{}”括起来的内容,并且数据结构是键值对{key: value, key: value,...}的结构,在面向对象语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。
并且我们可以发现这个 URL 的整个源代码是一个完整的 JSON。所以选择JSON数据源的URL并检查循环匹配,您可以采集到整个JSON中的数据。如图:2、 JSON 数据源:JSON 文本:另一种情况,URL 中的源代码并非全部为 JSON,只是部分代码采用 JSON 形式。这时候,我们需要提取这个JSON文本,然后对其进行格式化。比如URL,那么我们需要以多页的形式在这个页面的地址中获取这部分JSON代码,然后设置JSON格式。按照上面的步骤,就完成了两次JSON的提取。您认为它简单易用吗?所以网页数据爬取工具首选优采云采集器 V9,
抓取网页数据工具(2019-04-01EnglishVersionMagiBot)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-30 03:10
关于 MagiBot 抓取程序2019-04-01
英文版
魔法机器人
MagiBot(软件项目名称Matarael,以下简称MagiBot)是一款网络爬虫工具(也称“蜘蛛程序”)。爬行是指 MagiBot 提取新的 Web 内容并更新 Web 内容和索引的过程。
我们(以下“我们”可能指MagiBot、Magi项目的其他软件,或Peak Labs Limited本身)将使用大量计算机进行上述“抓取”过程,在此过程中,MagiBot将按照一定的规律工作。算法并决定要爬取的网站、频率和顺序等特征。
限制或禁止 MagiBot 在 网站 上抓取您的内容
如果您想限制或禁止MagiBot爬取您在网站上的内容,除了使用一些系统方法拒绝网络爬虫的访问和爬取外,您还可以设置robots规则来引导MagiBot爬取。
MagiBot 将严格遵守机器人排除协议及类似变体,包括但不限于robots.txt、x-robots-tags、rel 等标注方式。在解析你的规则集时,MagiBot 会优先处理两个 User-Agents 下的规则,magibot 或 matarael(不区分大小写)。
MagiBot 还支持元标记,例如 noindex、nofollow、nosnippet 和 noarchive,以限制索引和搜索显示。
在极少数特殊情况下,MagiBot 可能会针对您的禁止列表中收录的路径发起请求,但不会使用或索引此信息。其他一些搜索引擎有时会使用锚点等信息为特定的禁止爬取路径(如主页)生成相当于nosnippet的显示,但我们会谨慎处理这种灰色区域行为。
MagiBot 将根据其爬行计划权衡 Keep-Alive 行为。如果您在服务器日志中看到socket abort 或reset 记录,这通常是由于MagiBot 主动断开连接造成的,而不是您的服务器的问题。例如,为了减少双方的带宽和资源占用,我们会在网络传输过程中进行流式分析。当发现JPEG图像的SOF等信息时,如果尺寸不符合一定的标准,可以立即结束请求。
MagiBot 支持的协议和标准
MagiBot 支持并符合大多数现有协议和标准。全面支持IDN(如中文域名)、IPv6、SLD等技术标准。对于标记结构化数据,MagiBot 支持 JSON-LD、Microdata、RDF/RDFa 和 Facebook OGP 词汇,以及它们的许多变体。我们有能力从纯文本中提取和学习结构化知识和概念,但仍然建议网站管理者在清晰的信息和实体上使用结构化数据标注,以优化在各种搜索引擎和社交网络中的展示效果。
MagiBot 捕捉智能手机应用程序的内容
MagiBot 具有主动抓取移动应用程序内容的能力。作为一项全新的技术,我们将在不违反相关用户协议的情况下以自律的方式进行抓取。您可以通过以下任何一种方式阻止我们模拟用户交互和内容抓取:
在清单中声明机器人:'noindex' 在 API 响应的标头中声明 x-robots-tag ='noindex' 查看全部
抓取网页数据工具(2019-04-01EnglishVersionMagiBot)
关于 MagiBot 抓取程序2019-04-01
英文版
魔法机器人
MagiBot(软件项目名称Matarael,以下简称MagiBot)是一款网络爬虫工具(也称“蜘蛛程序”)。爬行是指 MagiBot 提取新的 Web 内容并更新 Web 内容和索引的过程。
我们(以下“我们”可能指MagiBot、Magi项目的其他软件,或Peak Labs Limited本身)将使用大量计算机进行上述“抓取”过程,在此过程中,MagiBot将按照一定的规律工作。算法并决定要爬取的网站、频率和顺序等特征。
限制或禁止 MagiBot 在 网站 上抓取您的内容
如果您想限制或禁止MagiBot爬取您在网站上的内容,除了使用一些系统方法拒绝网络爬虫的访问和爬取外,您还可以设置robots规则来引导MagiBot爬取。
MagiBot 将严格遵守机器人排除协议及类似变体,包括但不限于robots.txt、x-robots-tags、rel 等标注方式。在解析你的规则集时,MagiBot 会优先处理两个 User-Agents 下的规则,magibot 或 matarael(不区分大小写)。
MagiBot 还支持元标记,例如 noindex、nofollow、nosnippet 和 noarchive,以限制索引和搜索显示。
在极少数特殊情况下,MagiBot 可能会针对您的禁止列表中收录的路径发起请求,但不会使用或索引此信息。其他一些搜索引擎有时会使用锚点等信息为特定的禁止爬取路径(如主页)生成相当于nosnippet的显示,但我们会谨慎处理这种灰色区域行为。
MagiBot 将根据其爬行计划权衡 Keep-Alive 行为。如果您在服务器日志中看到socket abort 或reset 记录,这通常是由于MagiBot 主动断开连接造成的,而不是您的服务器的问题。例如,为了减少双方的带宽和资源占用,我们会在网络传输过程中进行流式分析。当发现JPEG图像的SOF等信息时,如果尺寸不符合一定的标准,可以立即结束请求。
MagiBot 支持的协议和标准
MagiBot 支持并符合大多数现有协议和标准。全面支持IDN(如中文域名)、IPv6、SLD等技术标准。对于标记结构化数据,MagiBot 支持 JSON-LD、Microdata、RDF/RDFa 和 Facebook OGP 词汇,以及它们的许多变体。我们有能力从纯文本中提取和学习结构化知识和概念,但仍然建议网站管理者在清晰的信息和实体上使用结构化数据标注,以优化在各种搜索引擎和社交网络中的展示效果。
MagiBot 捕捉智能手机应用程序的内容
MagiBot 具有主动抓取移动应用程序内容的能力。作为一项全新的技术,我们将在不违反相关用户协议的情况下以自律的方式进行抓取。您可以通过以下任何一种方式阻止我们模拟用户交互和内容抓取:
在清单中声明机器人:'noindex' 在 API 响应的标头中声明 x-robots-tag ='noindex'
抓取网页数据工具(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-29 22:27
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
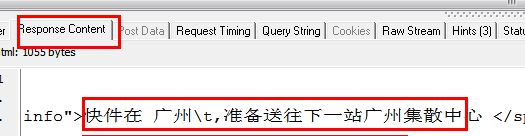
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
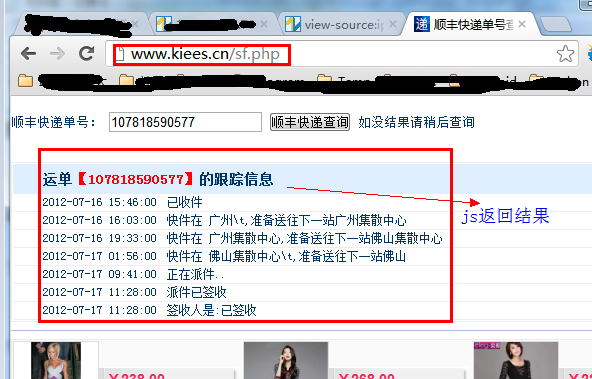
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
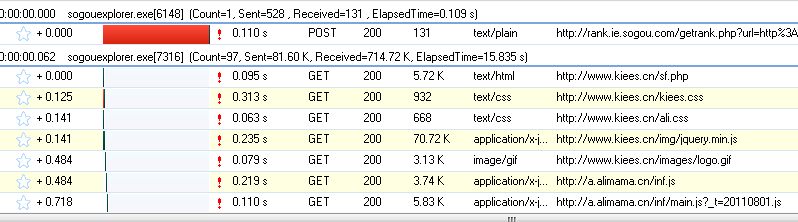
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
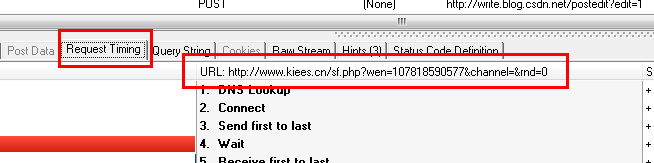
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
抓取网页数据工具(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:

第二步:查看web源代码。我们可以看到源代码中有一段:

从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:

换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:

这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
抓取网页数据工具(myBaseforMac(分类管理自由格式数据库软件)推荐给大家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-28 18:14
myBase 7.3 发布更新!myBase 是一种独特的自由格式数据库软件,允许输入非结构化文本、网页、图像、文档、电子邮件甚至任意文件,无论长度或格式如何。所有信息将被自动压缩并以树状结构的轮廓形式存储。欢迎感兴趣的朋友下载体验macdown!
myBase for Mac(用于分类管理的免费格式数据库软件)
现在就下载
myBase for Mac(分类管理的自由格式数据库软件)推荐给大家!通过myBase7.3,您可以轻松快捷地构建多层次、多维度、交叉引用、快速查询、层次分明、清晰的个人知识库
2019-05-0925.84 MB 简体中文
如何从浏览器中抓取网页内容和图片并将它们保存到 myBase 数据库中?
内置网页编辑器,支持直接从浏览器复制粘贴网页内容到数据库,粘贴内容时会尝试自动下载网页中的图片,保存在Base64编码的HTML内容中;如果由于某种原因图片下载失败,例如网站限制图片访问,您可以根据需要手动复制单张图片,然后粘贴到页面相应位置;
另外,部分网站可能需要通过http或socks5代理服务器访问,v7.x b-24+增加了代理服务器设置,可以在选项框中设置
Webcollect插件:除了直接复制粘贴外,还可以考虑安装Webcollect浏览器扩展,在浏览器的右键菜单中添加【Save with myBase】;最新版本的 Webcollect 支持 Firefox/Chrome 浏览器,并且是跨系统平台通用的。Linux、MacOSX、Windows三大主流系统平台;
对于火狐浏览器,可以在myBase中选择Tools-Install Webcollect host for Firefox菜单,然后按照说明在火狐浏览器中打开火狐扩展应用商店,在火狐浏览器中添加Webcollect插件即可完成安装;
Chrome浏览器可以在myBase中选择Tools-Install Webcollect host for Chrome菜单,然后在Chrome浏览器中按照说明打开Chrome扩展应用商店,在Chrome浏览器中添加Webcollect插件即可完成安装;
安装成功后,浏览器右键菜单会自动添加【用myBase7.x保存】;在浏览网页时,您可以使用此工具将页面内容保存到 myBase 数据库中。
新版Webcollect插件采用全新的数据通讯接口,可跨平台使用。支持 myBase 7.0 Beta-26 (Linux, MacOSX, Windows) 及更高版本;旧版本无法感知/接收新版本Webcollect网页内容传输的数据;请务必同时将myBase和WebCollect升级到最新版本,以实现网页保存功能;
注意:如果要保存的网页布局/格式复杂,嵌入的图片元素较多,建议先选择页面的核心内容,尽量排除侧边栏广告等不必要的元素,然后复制或抓取选中的片段,减少不相关图片的下载和资源消耗,同时提高页面内容抓取的成功率;
以上就是小编为大家带来的如何从浏览器中抓取网页内容和图片并保存到myBase数据库中?有需要的朋友,欢迎下载体验macdown! 查看全部
抓取网页数据工具(myBaseforMac(分类管理自由格式数据库软件)推荐给大家)
myBase 7.3 发布更新!myBase 是一种独特的自由格式数据库软件,允许输入非结构化文本、网页、图像、文档、电子邮件甚至任意文件,无论长度或格式如何。所有信息将被自动压缩并以树状结构的轮廓形式存储。欢迎感兴趣的朋友下载体验macdown!
myBase for Mac(用于分类管理的免费格式数据库软件)
现在就下载
myBase for Mac(分类管理的自由格式数据库软件)推荐给大家!通过myBase7.3,您可以轻松快捷地构建多层次、多维度、交叉引用、快速查询、层次分明、清晰的个人知识库
2019-05-0925.84 MB 简体中文

如何从浏览器中抓取网页内容和图片并将它们保存到 myBase 数据库中?
内置网页编辑器,支持直接从浏览器复制粘贴网页内容到数据库,粘贴内容时会尝试自动下载网页中的图片,保存在Base64编码的HTML内容中;如果由于某种原因图片下载失败,例如网站限制图片访问,您可以根据需要手动复制单张图片,然后粘贴到页面相应位置;
另外,部分网站可能需要通过http或socks5代理服务器访问,v7.x b-24+增加了代理服务器设置,可以在选项框中设置
Webcollect插件:除了直接复制粘贴外,还可以考虑安装Webcollect浏览器扩展,在浏览器的右键菜单中添加【Save with myBase】;最新版本的 Webcollect 支持 Firefox/Chrome 浏览器,并且是跨系统平台通用的。Linux、MacOSX、Windows三大主流系统平台;
对于火狐浏览器,可以在myBase中选择Tools-Install Webcollect host for Firefox菜单,然后按照说明在火狐浏览器中打开火狐扩展应用商店,在火狐浏览器中添加Webcollect插件即可完成安装;
Chrome浏览器可以在myBase中选择Tools-Install Webcollect host for Chrome菜单,然后在Chrome浏览器中按照说明打开Chrome扩展应用商店,在Chrome浏览器中添加Webcollect插件即可完成安装;
安装成功后,浏览器右键菜单会自动添加【用myBase7.x保存】;在浏览网页时,您可以使用此工具将页面内容保存到 myBase 数据库中。
新版Webcollect插件采用全新的数据通讯接口,可跨平台使用。支持 myBase 7.0 Beta-26 (Linux, MacOSX, Windows) 及更高版本;旧版本无法感知/接收新版本Webcollect网页内容传输的数据;请务必同时将myBase和WebCollect升级到最新版本,以实现网页保存功能;
注意:如果要保存的网页布局/格式复杂,嵌入的图片元素较多,建议先选择页面的核心内容,尽量排除侧边栏广告等不必要的元素,然后复制或抓取选中的片段,减少不相关图片的下载和资源消耗,同时提高页面内容抓取的成功率;
以上就是小编为大家带来的如何从浏览器中抓取网页内容和图片并保存到myBase数据库中?有需要的朋友,欢迎下载体验macdown!
抓取网页数据工具( 2.-type-gt-item数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-28 18:10
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
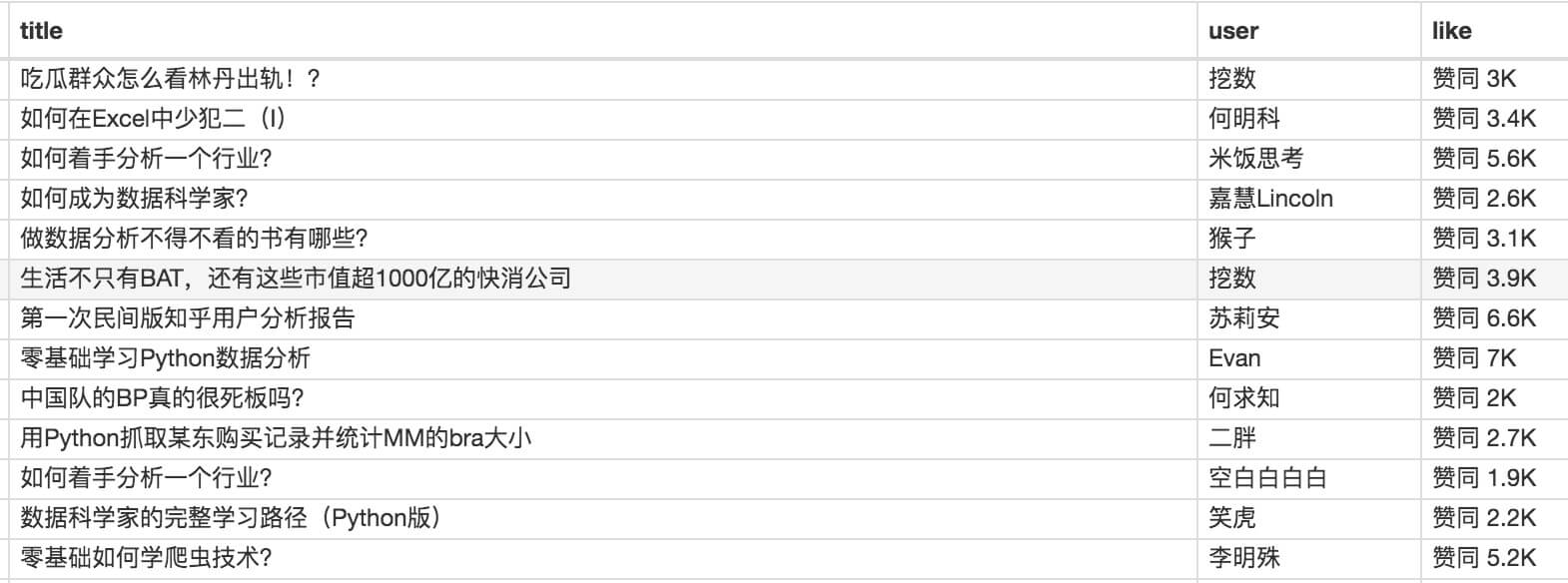
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
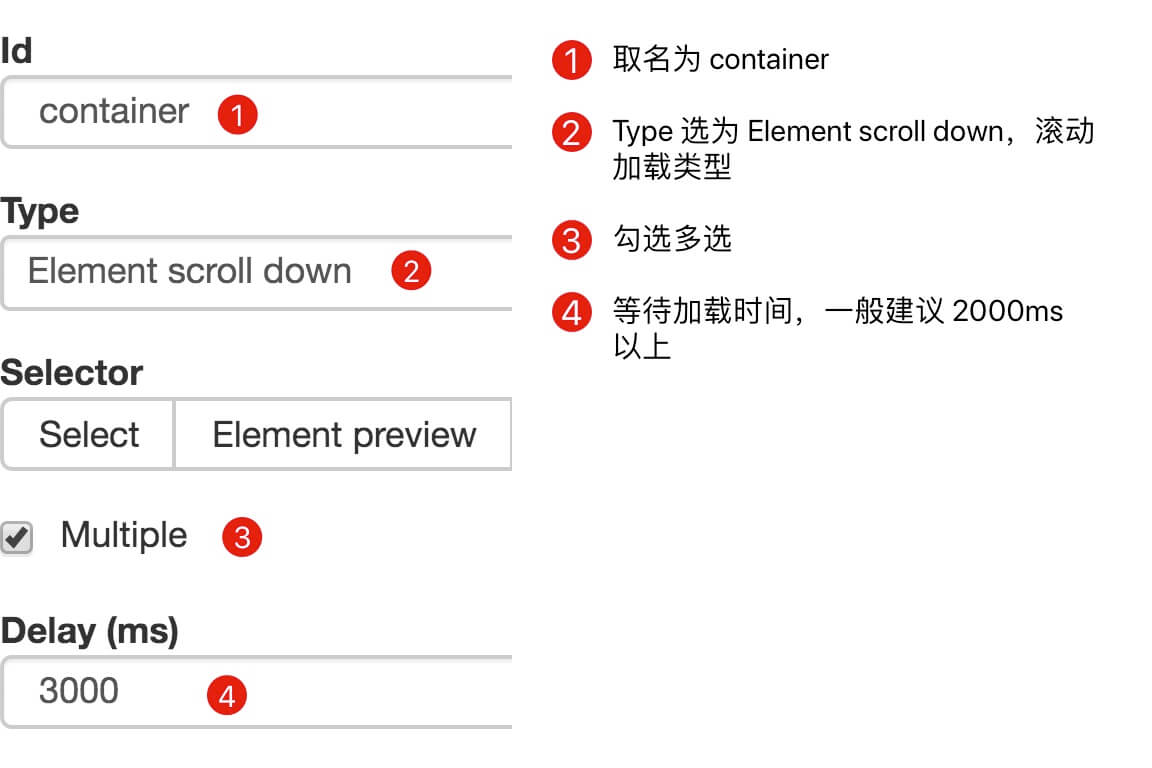
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
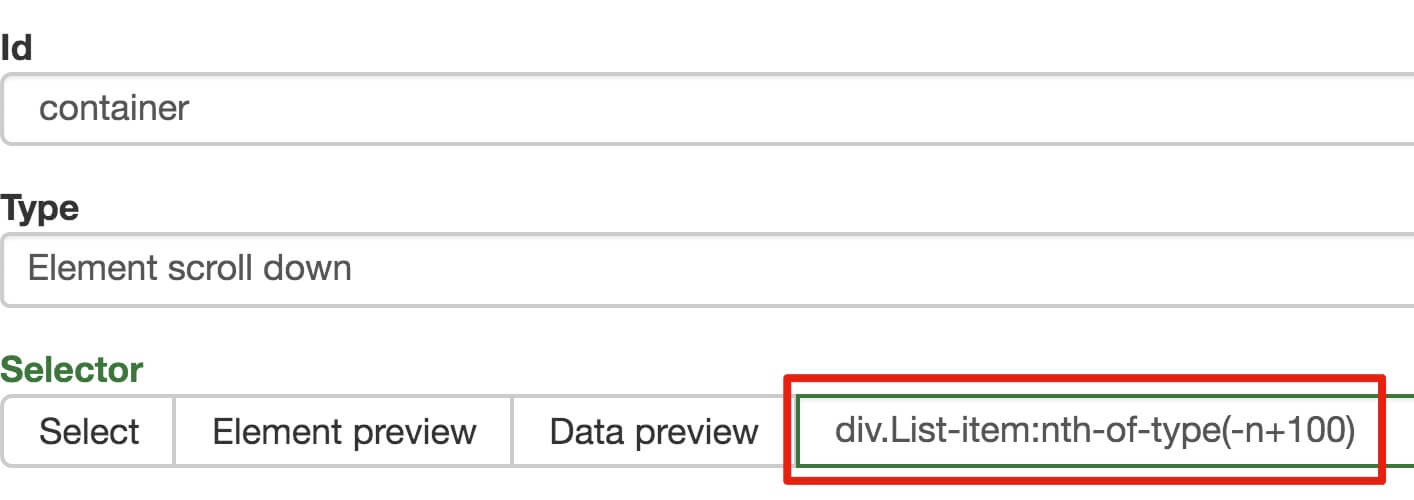
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
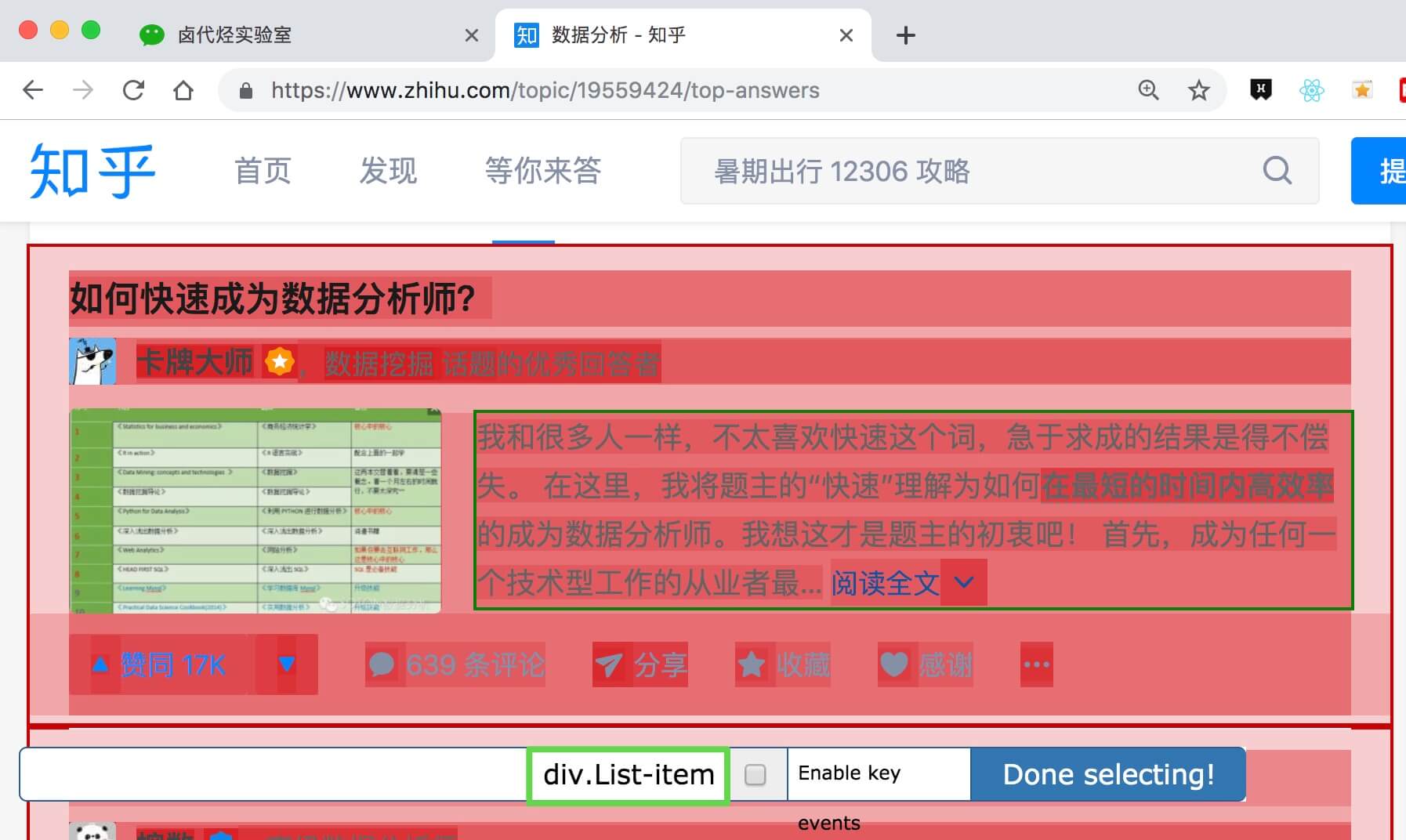
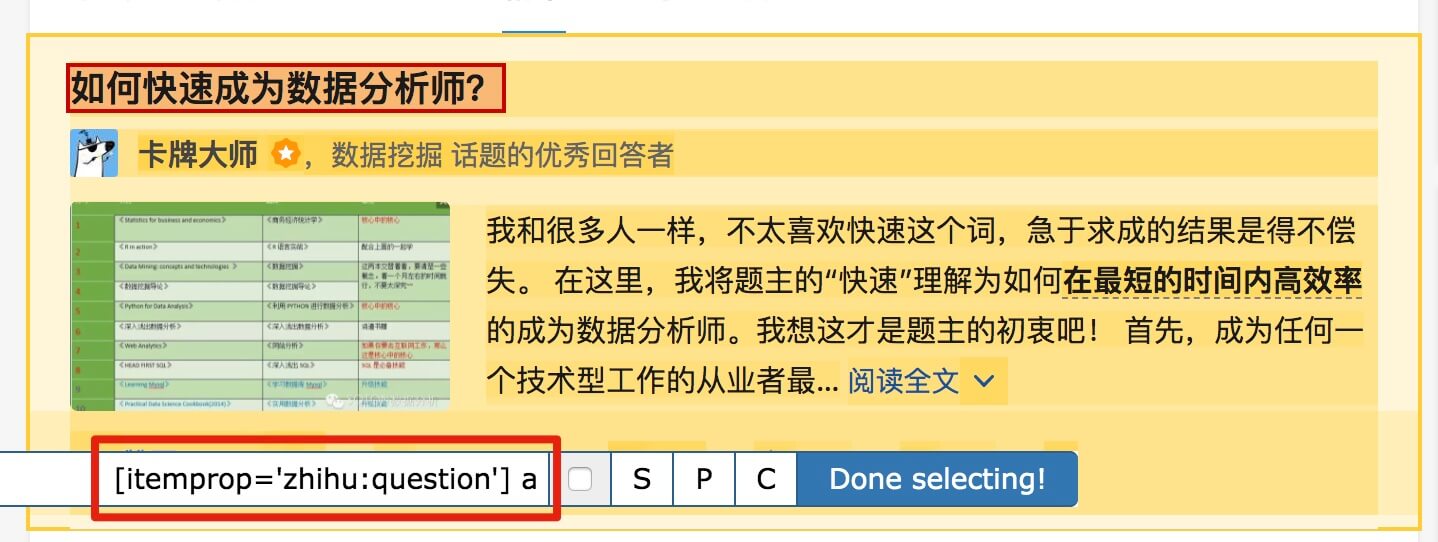
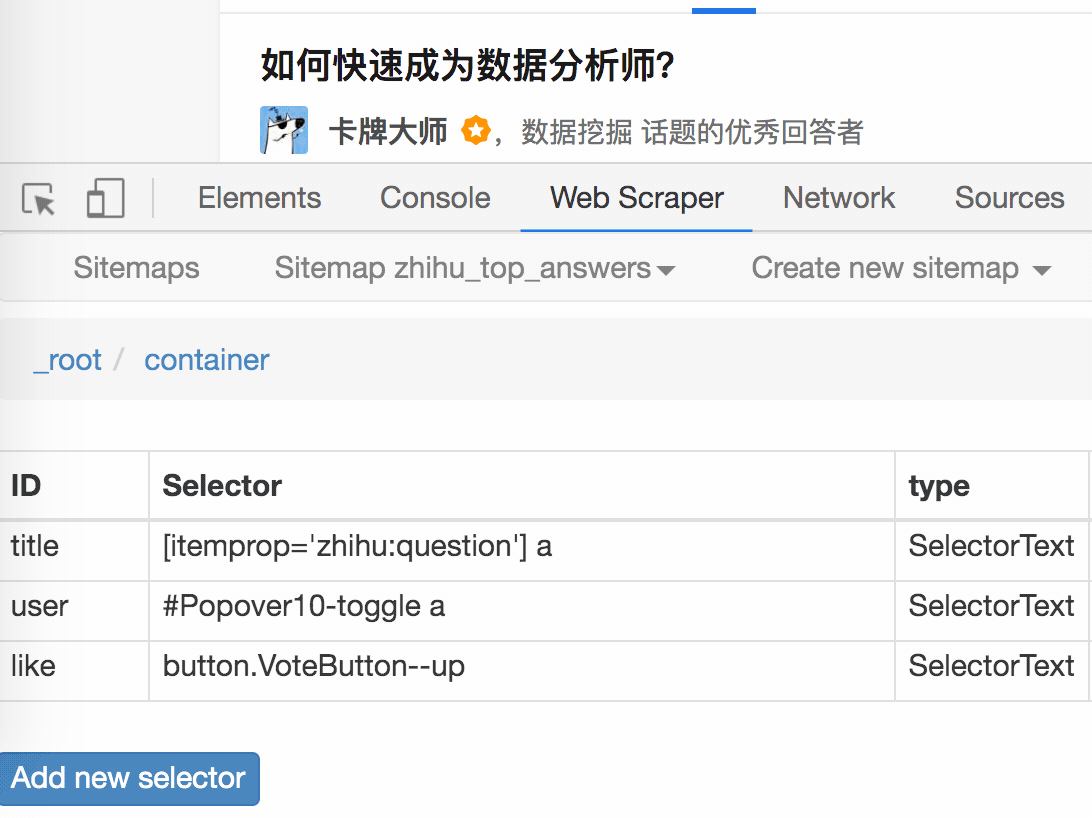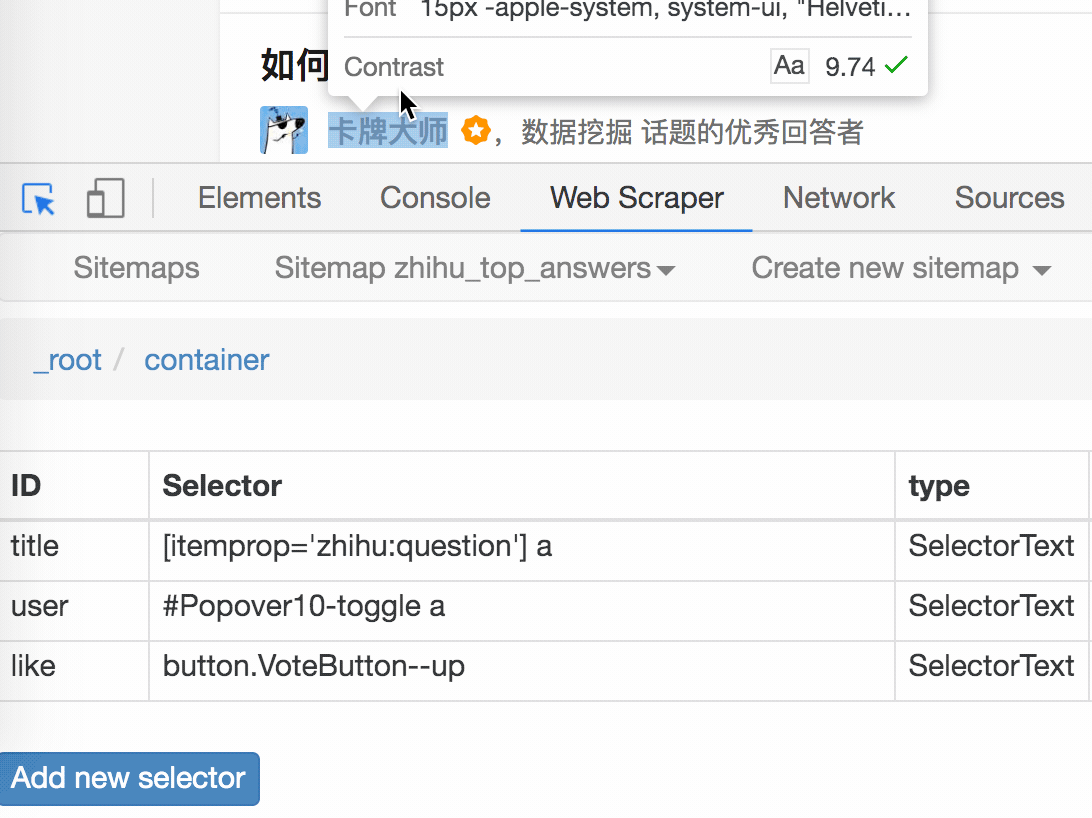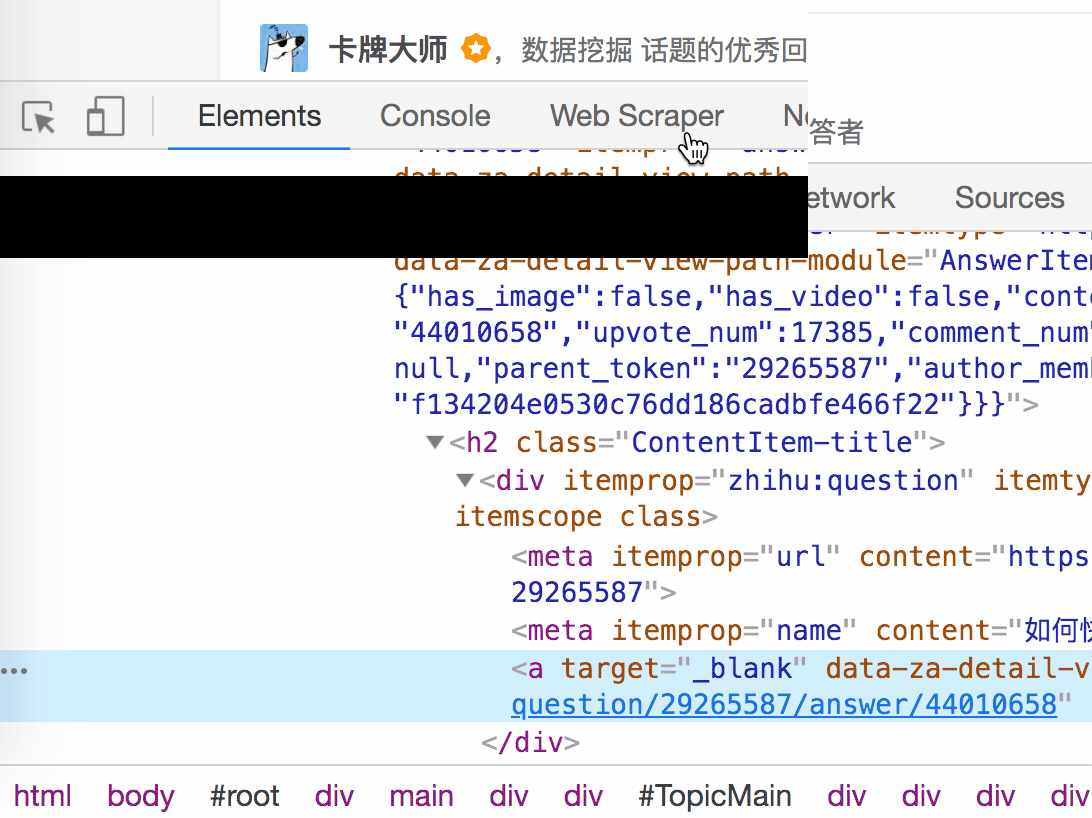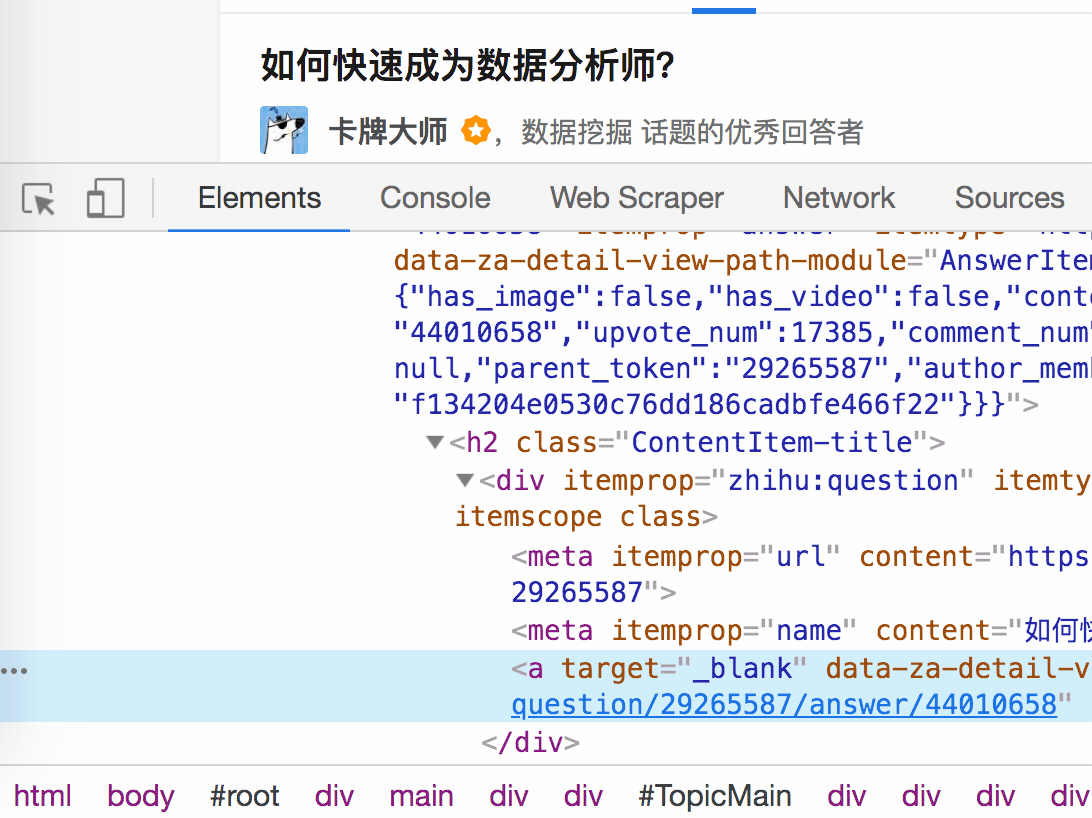
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
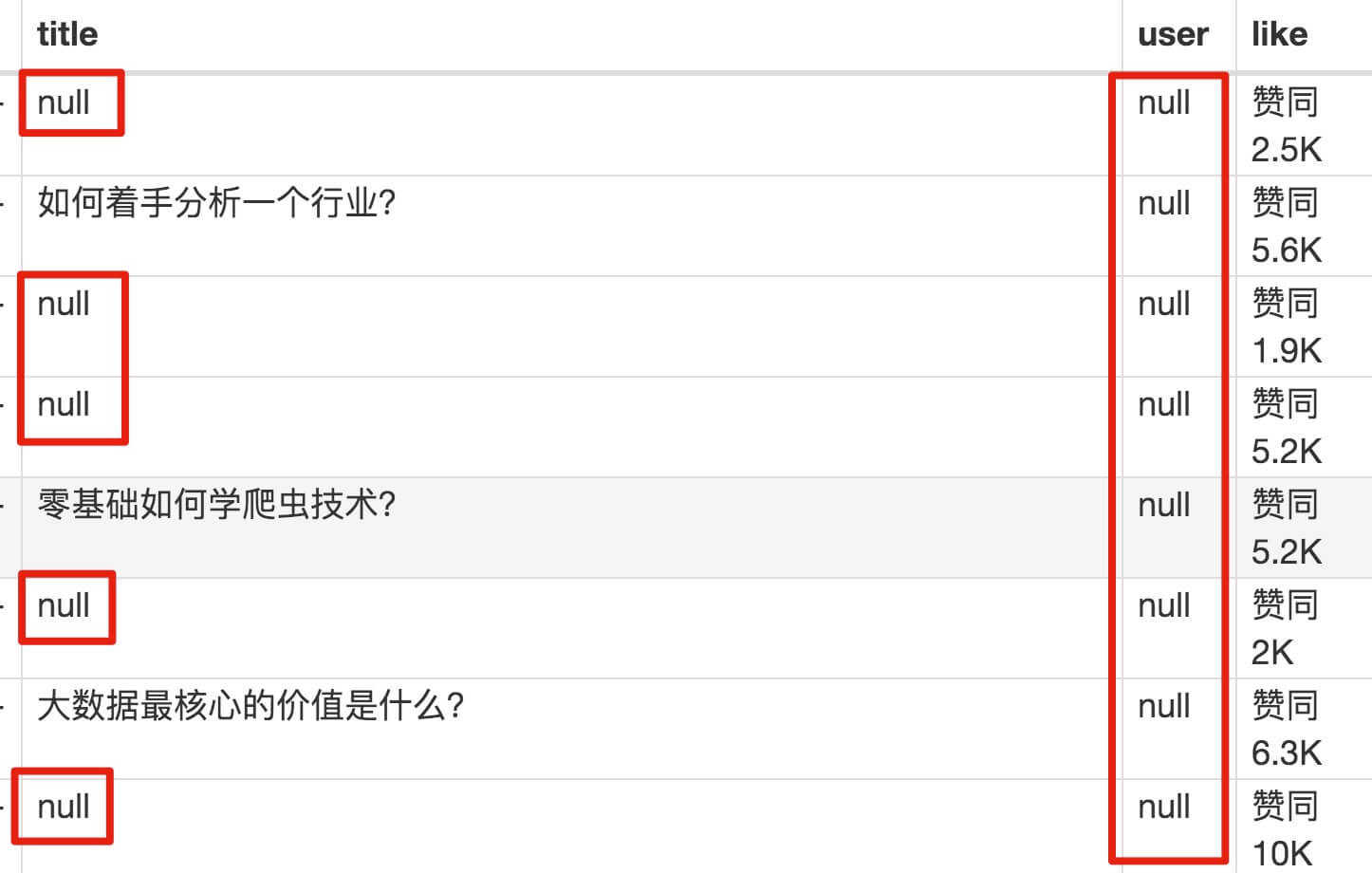
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
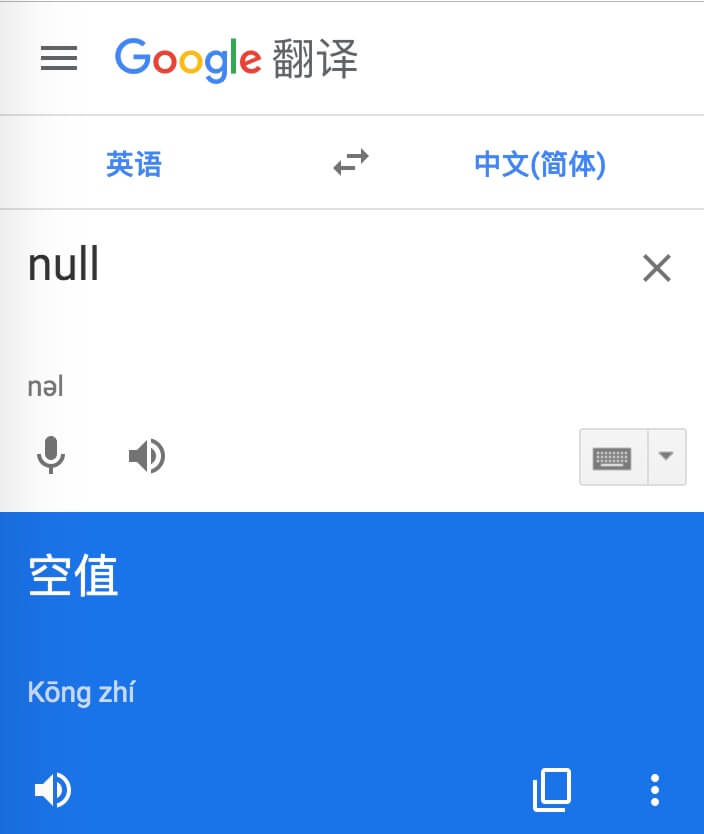
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
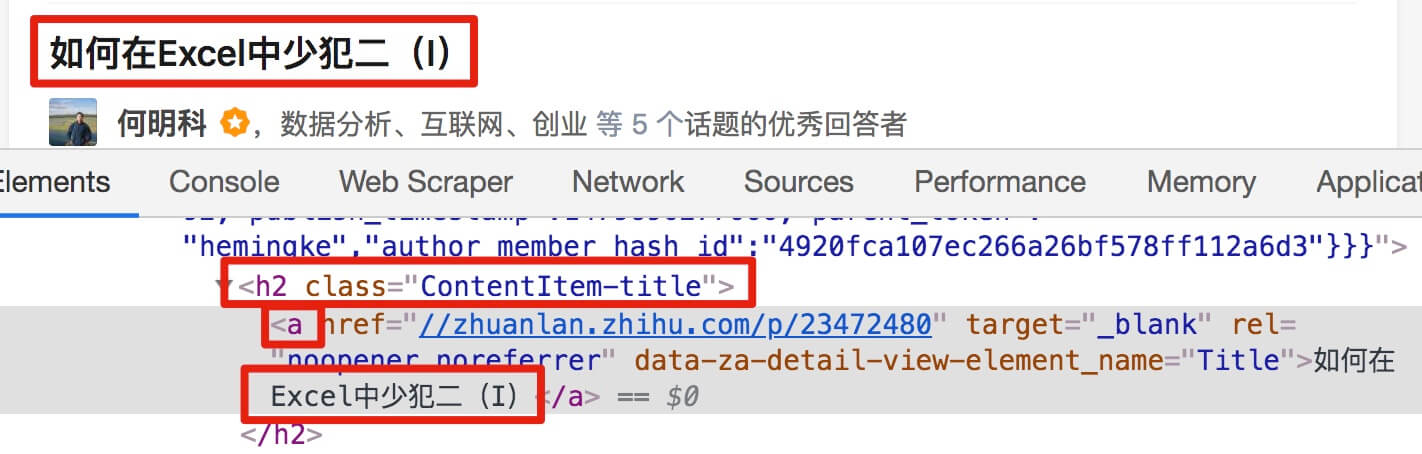
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
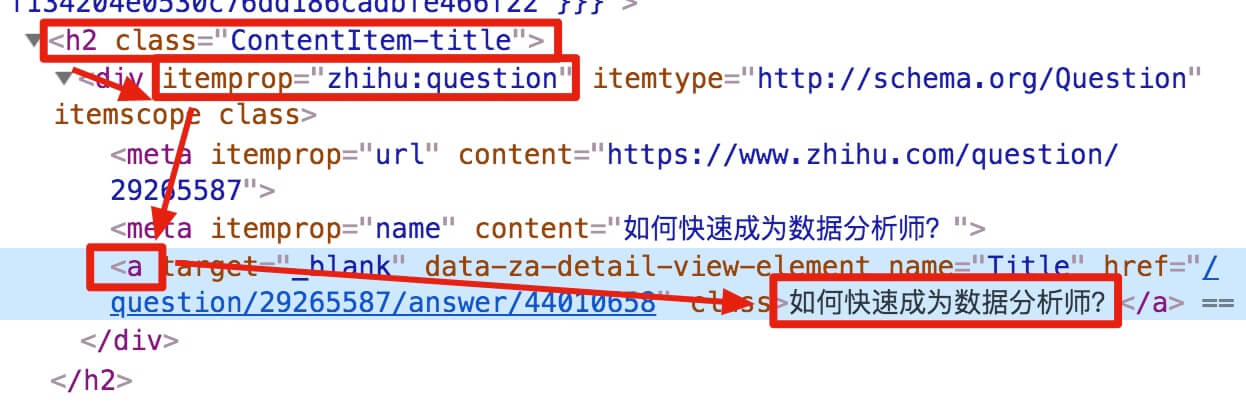
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
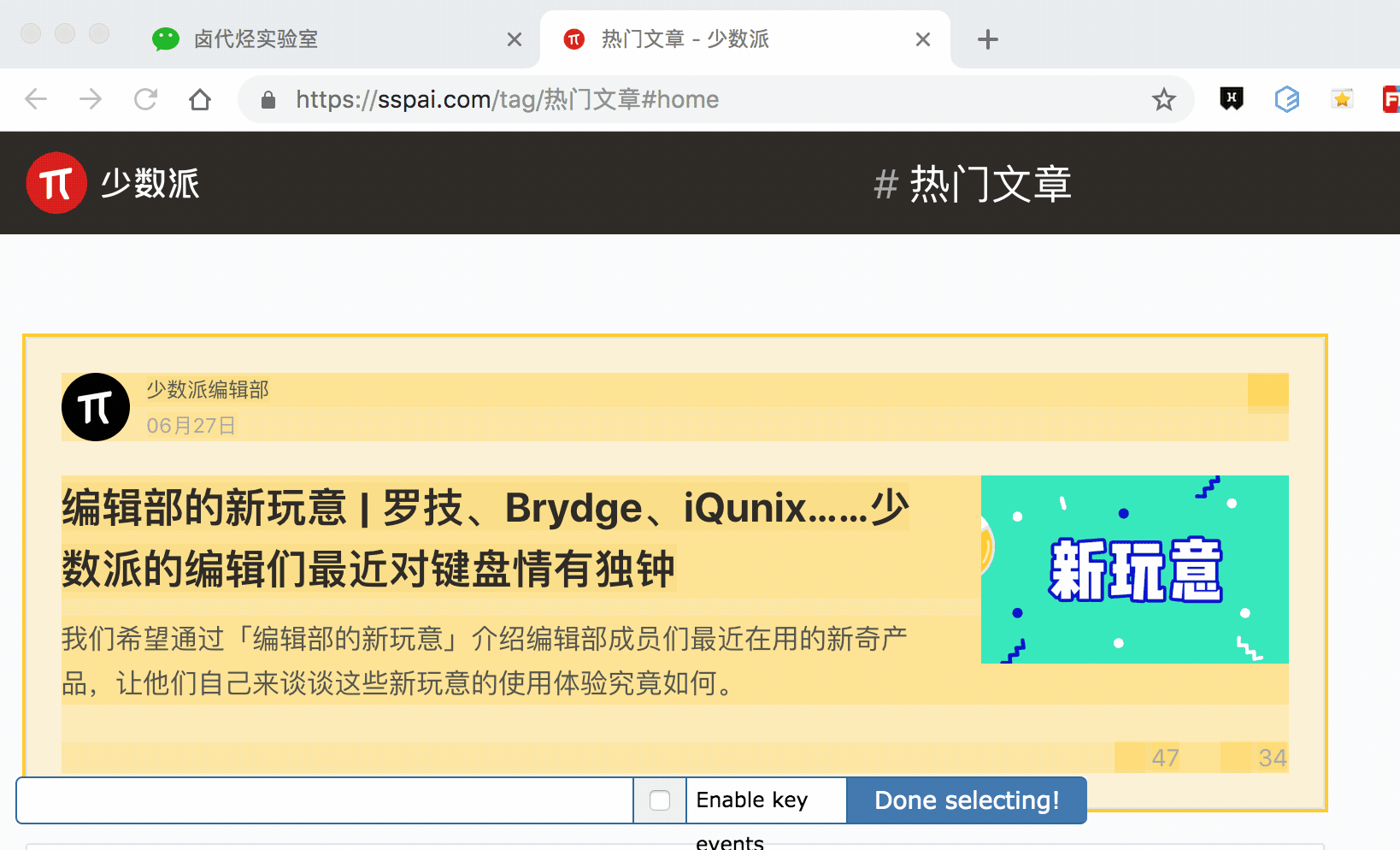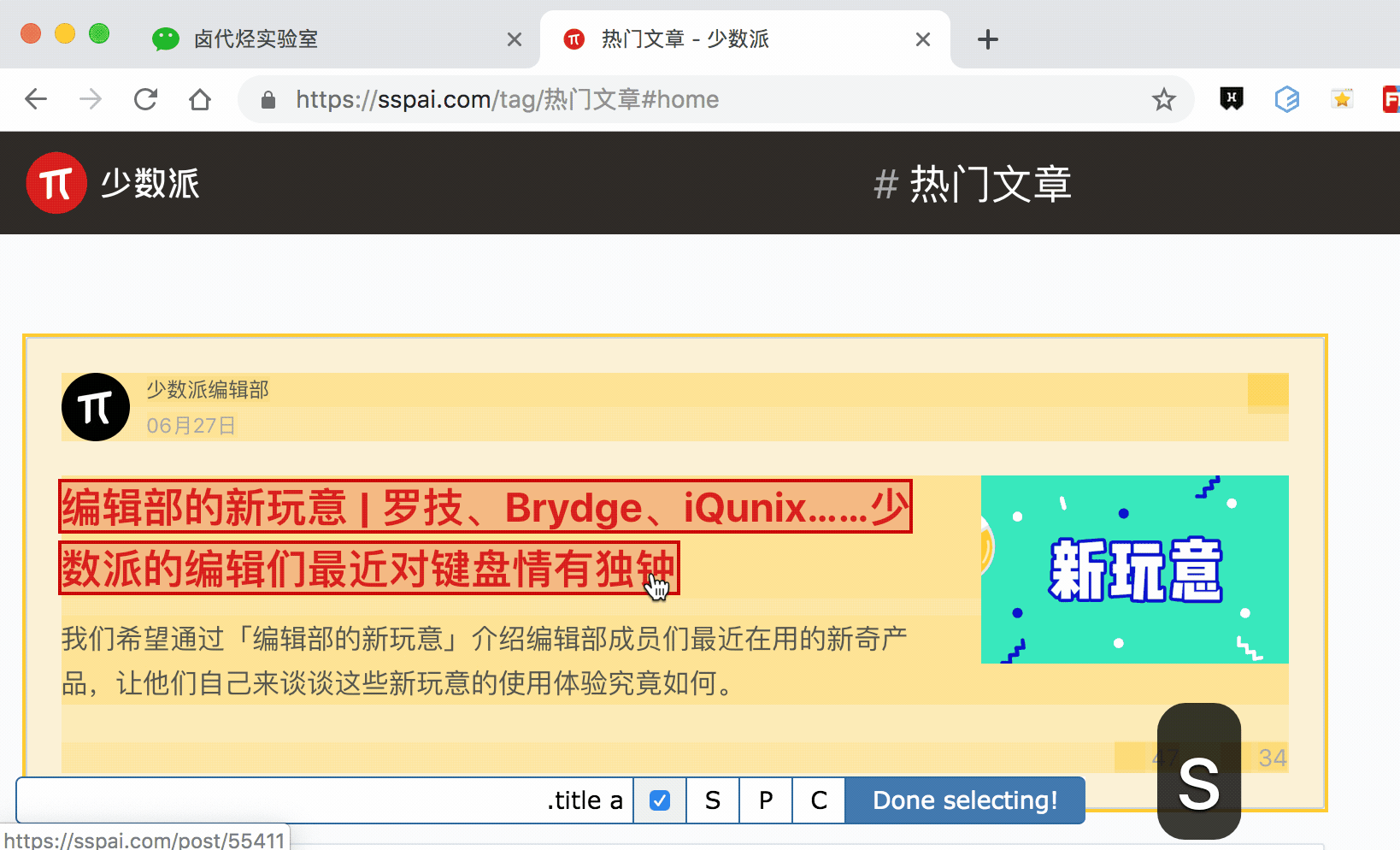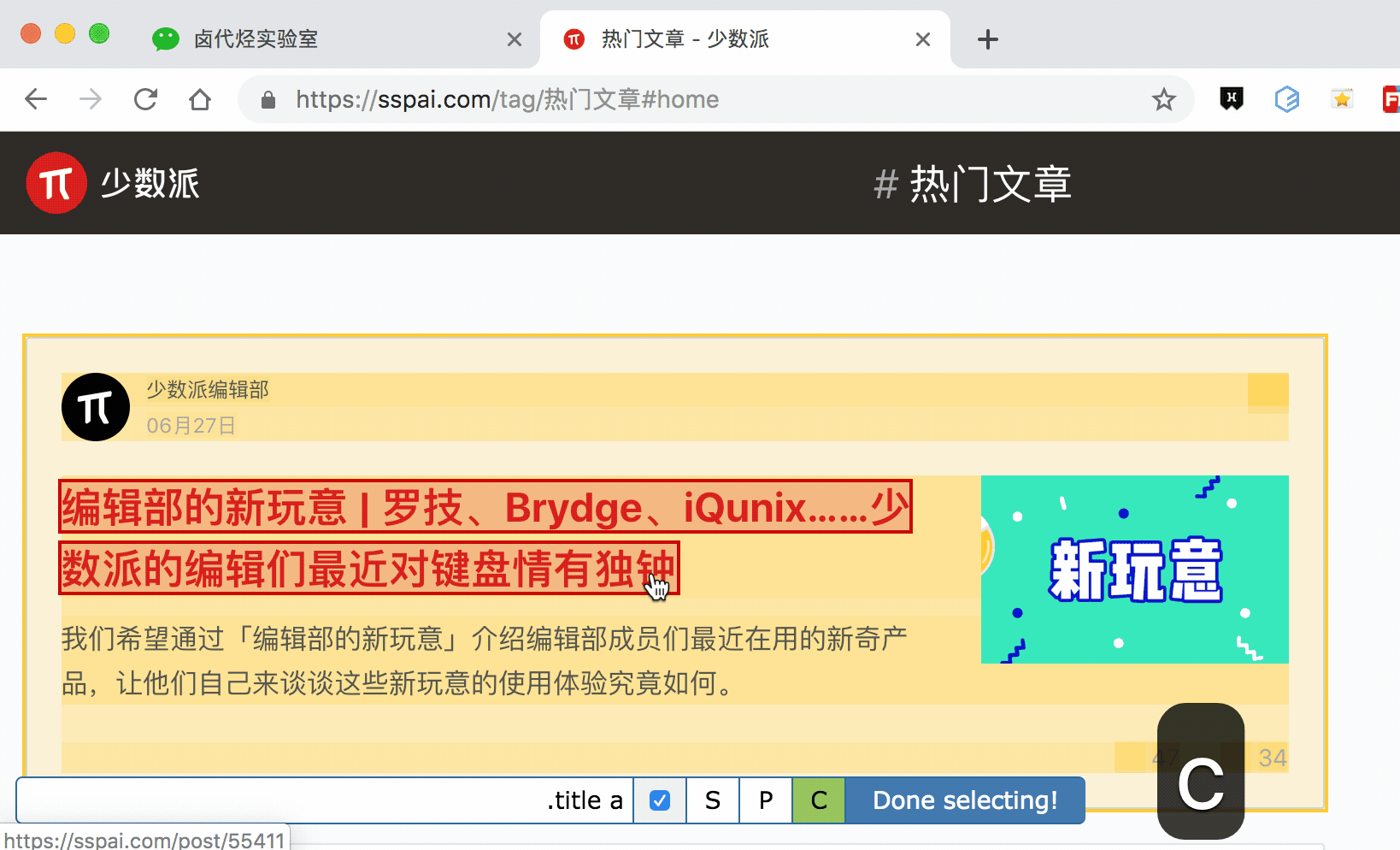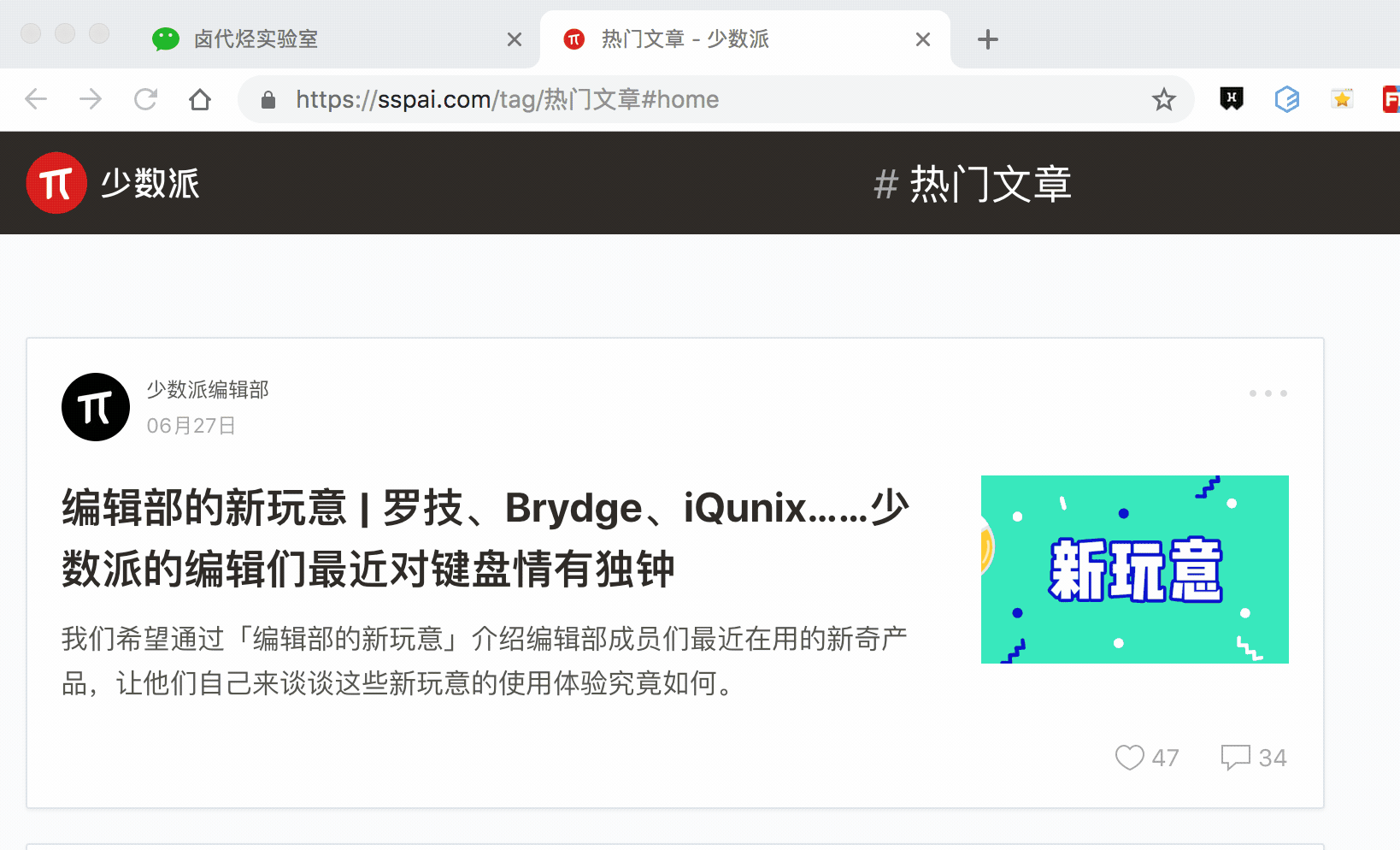
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
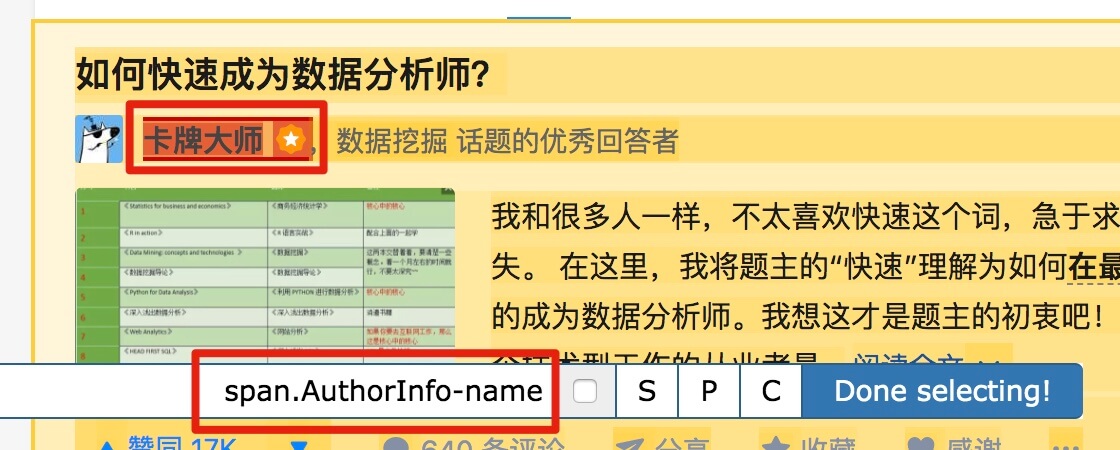
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
抓取网页数据工具(
2.-type-gt-item数据,发现问题元素都选择好了)

这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。

今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:

2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):

以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:

最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
抓取网页数据工具(浏览器打开网页的过程(Inspect爬虫)的那些数据集合 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-28 18:09
)
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是一个丰富多彩的数据集合,爬虫获取网页的源代码html。
有时候,我们在网页的html代码中找不到我们想要的数据,但是浏览器打开的网页却有这些数据。这就是浏览器通过ajax技术异步加载(偷偷下载)这些数据。
小猴子不禁要问:那我怎么能看到浏览器偷偷下载的数据呢?
答案是谷歌浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器页面的左侧或下方(可调整),如下所示:
让我们简单了解一下它是如何使用的:
谷歌浏览器抓包:1.菜单顶行
暂时把剩下的放在一边。
谷歌浏览器抓包:2.重要区域
图中红框中的两个按钮比较实用,数字2是清除请求记录;数字3是保留记录,在网页有重定向的时候很有用
图中绿色区域是加载一个完整的网页,浏览器的所有请求记录,包括URL、状态、类型等,写爬虫的时候一定要在这里寻找线索提金。
底部编号为 4 的红框表示该网页已加载 181 次。数量如此惊人,让人不禁为浏览器感到惋惜。
点击请求的URL,右侧会出现一个新窗口,显示请求的信念信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详情窗口包括 Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和 Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers帮助我们在爬虫中重构http请求,让爬虫可以得到和浏览器一样的数据。
了解并熟练使用Chrome的开发者工具,小猿们可以流畅的编写自己的爬虫了。
还有上一篇科普文章,我们进入正题,下一篇我们会讲:
为什么 Python 适合编写网络爬虫
查看全部
抓取网页数据工具(浏览器打开网页的过程(Inspect爬虫)的那些数据集合
)
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是一个丰富多彩的数据集合,爬虫获取网页的源代码html。

有时候,我们在网页的html代码中找不到我们想要的数据,但是浏览器打开的网页却有这些数据。这就是浏览器通过ajax技术异步加载(偷偷下载)这些数据。
小猴子不禁要问:那我怎么能看到浏览器偷偷下载的数据呢?
答案是谷歌浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器页面的左侧或下方(可调整),如下所示:

让我们简单了解一下它是如何使用的:
谷歌浏览器抓包:1.菜单顶行
暂时把剩下的放在一边。
谷歌浏览器抓包:2.重要区域
图中红框中的两个按钮比较实用,数字2是清除请求记录;数字3是保留记录,在网页有重定向的时候很有用
图中绿色区域是加载一个完整的网页,浏览器的所有请求记录,包括URL、状态、类型等,写爬虫的时候一定要在这里寻找线索提金。
底部编号为 4 的红框表示该网页已加载 181 次。数量如此惊人,让人不禁为浏览器感到惋惜。
点击请求的URL,右侧会出现一个新窗口,显示请求的信念信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详情窗口包括 Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和 Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers帮助我们在爬虫中重构http请求,让爬虫可以得到和浏览器一样的数据。
了解并熟练使用Chrome的开发者工具,小猿们可以流畅的编写自己的爬虫了。
还有上一篇科普文章,我们进入正题,下一篇我们会讲:
为什么 Python 适合编写网络爬虫

抓取网页数据工具(爬虫网页数据案例分享-爬虫获取网页信息的案例分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-25 00:16
我们经常采集一些数据,但是当数据比较小时,人们会习惯性地手动下载,但是如果数量非常大,我肯定想找一个工具来帮助采集它。
比如一些采集的工具,但是由于这些工具都设置好了,就不能满足我们的需求。如果要求较低,则将使用它们。要求高的话,不如自己做个爬虫,想什么就去抓取什么。
关键是看能不能写爬虫?事实上,这很简单。下面给大家分享一下爬取网页数据的案例。
1.获取网页信息
Urllib 模块提供了读取网页数据的接口。我们可以像读取本地文件一样读取 www 和 ftp 上的数据。首先,我们定义一个 getHtml() 函数:
urllib.urlopen() 方法用于打开一个 URL 地址。
read() 方法用于读取 URL 上的数据,将 URL 传递给 getHtml() 函数,并下载整个页面。执行该程序将打印出整个网页。
2.过滤页面数据
Python提供了非常强大的正则表达式,我们需要了解一点Python正则表达式的知识。
如果我们在百度贴吧上发现了几张漂亮的壁纸,请前往上一节查看工具。找到图片的地址,如:src=""pic_ext="jpeg"
修改代码如下:
我们已经创建了 getImg() 函数来过滤整个页面中所需的图片链接。re 模块主要收录正则表达式:
pile() 可以将正则表达式编译成正则表达式对象。
re.findall() 方法读取html中收录imgre(正则表达式)的数据。
运行脚本会得到整个页面中图片的URL地址。
3.数据保存
通过for循环遍历筛选出的图片地址并保存到本地,代码如下:
这里的核心是使用urllib.urlretrieve()方法将远程数据直接下载到本地。
通过for循环遍历得到的图片连接,为了让图片的文件名看起来更规范,重命名,命名规则给x变量加1。存储位置默认为程序的存储目录。程序运行后,会在目录中看到下载到本地的文件。
以上就是爬虫爬取网页数据的案例分享。如今,大数据时代,数据海量。有必要采集足够的数据进行分析,以获得有价值的结果。大家在爬取数据的时候记得使用代理IP,这样爬虫就可以高效爬取数据,在更短的时间内产生结果。查找代理IP,黑洞代理非常好,不仅可以使用全国IP地址,而且高度匿名,效果更好。 查看全部
抓取网页数据工具(爬虫网页数据案例分享-爬虫获取网页信息的案例分析)
我们经常采集一些数据,但是当数据比较小时,人们会习惯性地手动下载,但是如果数量非常大,我肯定想找一个工具来帮助采集它。
比如一些采集的工具,但是由于这些工具都设置好了,就不能满足我们的需求。如果要求较低,则将使用它们。要求高的话,不如自己做个爬虫,想什么就去抓取什么。
关键是看能不能写爬虫?事实上,这很简单。下面给大家分享一下爬取网页数据的案例。
1.获取网页信息

Urllib 模块提供了读取网页数据的接口。我们可以像读取本地文件一样读取 www 和 ftp 上的数据。首先,我们定义一个 getHtml() 函数:
urllib.urlopen() 方法用于打开一个 URL 地址。
read() 方法用于读取 URL 上的数据,将 URL 传递给 getHtml() 函数,并下载整个页面。执行该程序将打印出整个网页。
2.过滤页面数据
Python提供了非常强大的正则表达式,我们需要了解一点Python正则表达式的知识。
如果我们在百度贴吧上发现了几张漂亮的壁纸,请前往上一节查看工具。找到图片的地址,如:src=""pic_ext="jpeg"

修改代码如下:

我们已经创建了 getImg() 函数来过滤整个页面中所需的图片链接。re 模块主要收录正则表达式:
pile() 可以将正则表达式编译成正则表达式对象。
re.findall() 方法读取html中收录imgre(正则表达式)的数据。
运行脚本会得到整个页面中图片的URL地址。
3.数据保存
通过for循环遍历筛选出的图片地址并保存到本地,代码如下:

这里的核心是使用urllib.urlretrieve()方法将远程数据直接下载到本地。
通过for循环遍历得到的图片连接,为了让图片的文件名看起来更规范,重命名,命名规则给x变量加1。存储位置默认为程序的存储目录。程序运行后,会在目录中看到下载到本地的文件。
以上就是爬虫爬取网页数据的案例分享。如今,大数据时代,数据海量。有必要采集足够的数据进行分析,以获得有价值的结果。大家在爬取数据的时候记得使用代理IP,这样爬虫就可以高效爬取数据,在更短的时间内产生结果。查找代理IP,黑洞代理非常好,不仅可以使用全国IP地址,而且高度匿名,效果更好。
抓取网页数据工具(互联网刚兴起的时候,数据索引是个大问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-22 00:08
1、互联网刚刚兴起时,数据索引是一个大问题。当时,雅虎的分类页面一度非常热门
2、随着互联网上数据量的不断增加,谷歌和百度等搜索引擎正在熊熊燃烧。在这个阶段,很少有技术比搜索引擎更受欢迎,分词技术也一团糟。然后,nutch和其他开源搜索引擎诞生了,这让人们一见钟情!许多人和公司试图将其用于商业目的。但这些东西都是牛叉,使用起来并不总是那么顺畅。首先,它不是很稳定;第二,它太复杂了。很难进行二次开发以满足自身需求
3、由于通用搜索引擎不太方便,所以让它更简单、更有针对性。所以爬虫技术的兴起,酷新闻就是其中比较成功的一种。依靠它的技术,他后来建造了99间房间,然后一路登上了今天的头条新闻
4、随着越来越多的人参与互联网,许多人确实希望从互联网上捕获数据,因为他们的需求不同,但他们希望更简单,开发成本低,速度更快。出现了很多开源工具。Curl已经被大量使用了一段时间,诸如htmlcxx和Htmlparser等HTML解析工具也被广泛使用优采云只是由傻瓜式构成,没有开发功能。它只能在配置后自动运行
@到目前为止,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然强劲。用于数据捕获的在线工具、开源代码、抓取很多、jsoup、spyner等。然而,数据捕获仍然有点困难,原因有四:一、每个公司都有不同的需求,这使得商业化非常困难二、WEB页面本身非常复杂和混乱,JavaScript使得爬行无法控制三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合基于开源库或工具开发的严肃商业应用四、来完成自己的需求,仍然存在一些困难和大量工作量
@因此,一个好的抓取工具(开源库)应该具有以下特性:一、simple。系统不应该太复杂,界面应该一目了然,以降低二、power的开发成本。最好捕获您可以在web页面上看到的数据,包括JavaScript输出。数据捕获的很大一部分是寻找数据。例如,没有地理坐标数据,因此需要花费大量精力才能在三、方便时完成这些数据。最好提供可以控制的开发库,即如何捕获和部署,而不是被困在整个系统四、flexible中。它可以快速实现各种需求,即可以快速捕获简单数据或构建更复杂的数据应用程序五、stable。可以输出稳定的数据,不需要每天调整bug和查找数据。当需求有点复杂,数据量有点大的时候,需要进行大量的二次开发,耗费大量的人力和时间六、可以集成。借助现有的技术力量七、Control,通过开发环境,它可以快速建立数据系统。企业应用是长期积累的。如果数据和流程掌握在第三方手中,则可控性差,对需求变化的响应慢,风险高八、1。它可以提供一些特性来帮助开发人员实现结构化数据的提取和关联,从而避免为每个页面编写数据解析器
很多公司在数据采集方面投入了大量精力,但效果往往不是很好,可持续发展能力也相对较差。这主要是由于基本工具选择不当。因此,让我们整理一些可用的数据捕获工具和开源库。比较它们的优缺点,为开发人员提供参考
一、系统等级:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索
纳奇:
语言:Java
官方网站:
Nutch是一个用Java实现的开源搜索引擎。它提供全文搜索、网络爬虫、页面调度、数据存储等功能。它几乎可以看作是一个完整的通用搜索引擎。它适用于页面大小较大(数十亿)且只有文本索引数据(很少是结构化数据)的应用程序。Nutch有利于研究
Heritrix:
语言:Java
官方网站:
简介:heritrix是一个开源的网络爬虫系统。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,便于用户实现自己的爬网逻辑。Heritrix集成了索引调度、页面解析和数据存储
其他包括dataparksearch和web harvest
网络类:
卷曲
语言:C(但它也支持命令行和其他语言绑定)
官方网站:
简介:curl是一个古老的HTTP网络库(同时支持FTP和其他协议)。Curl支持丰富的网络功能,包括SSL、cookie、表单等。它是一个广泛使用的网络库。卷曲有弹性,但有点复杂。提供了数据下载,但不支持HTML解析。它通常需要与其他库一起使用
汤
语言:C
官方网站:
简介:soup是另一个HTTP网络库,依赖glib,功能强大稳定。然而,国内文献很少
浏览器类:
这些工具通常基于浏览器(如Firefox)进行扩展。由于浏览器的强大功能,他们可以采集获得更完整的数据,尤其是JavaScript输出的数据。但应用范围稍有局限,扩展不方便,数据量大时难以适应
ParseHub:
语言:Firefox扩展
官方网站:
简介:parsehub是基于Firefox的页面分析工具,可以支持更复杂的功能,包括页面结构分析
谷歌搜索者集合搜索
语言:Firefox扩展
官方网站:
导言:Gooseek也是基于Firefox的扩展。它支持更复杂的功能,包括索引图片、计时采集、可视化编程等
采集终端等级:
此类工具一般支持Windows图形界面,基本上不需要编写代码。更典型的数据可以通过配置规则来实现采集. 但是,数据提取能力一般,扩展有限,更复杂应用的二次开发成本不低
优采云
语言:许可软件
平台:Windows
官方网站:
优采云是一个旧的采集软件。随着无数个人站长的成长,它具有很强的可配置性,可以实现数据传输。它非常适合个人快速数据采集和政府机构的民意监测
优采云采集器
语言:许可软件
平台:Windows
官方网站:
简介:优采云采集器它具有多种功能,支持新闻的一般分析,广泛应用于舆论中
图书馆类别:
它是通过开源库或工具库提供的。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发人员自己实现。该方法非常灵活,适用于复杂数据采集和大规模数据采集。这些库的差异主要体现在以下几个方面:一、语言应用。许多库只适用于一种语言二、的功能差异。大多数库只支持HTML,不支持JS、CSS和其他动态数据三、interface。一些库提供函数级接口,而另一些库提供对象级接口四、stability。一些图书馆是认真的,而另一些则在逐步改进
简单HTML DOM解析器
语言:PHP
官方网站:
简介:PHP扩展模块支持HTML标记的解析。它提供了一个类似于jQuery的函数级接口,具有简单的函数,适合解析简单的HTML页面。它将很难成为一个数据引擎
JSoup
语言:Java
官方网站:
简介:jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
斯宾纳
语言:Python
官方网站:
简介:spyner是一个基于QT WebKit的1000行Python脚本。与urllib相比,最大的特点是支持动态内容的捕获。Spyner依赖于xvfb和QT。由于需要进行页面渲染,因此速度较慢
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,它提供了一系列清晰的函数和DOM数据结构。它简单明了,但功能强大,适用性强。Qing支持JavaScript和CSS,因此它非常支持动态内容。除此之外,青还支持后台图像加载、滚动加载、本地缓存、加载策略等功能。Qing快速、强大、稳定,开发效率高。对于企业来说,构建数据仓库是一个很好的选择 查看全部
抓取网页数据工具(互联网刚兴起的时候,数据索引是个大问题)
1、互联网刚刚兴起时,数据索引是一个大问题。当时,雅虎的分类页面一度非常热门
2、随着互联网上数据量的不断增加,谷歌和百度等搜索引擎正在熊熊燃烧。在这个阶段,很少有技术比搜索引擎更受欢迎,分词技术也一团糟。然后,nutch和其他开源搜索引擎诞生了,这让人们一见钟情!许多人和公司试图将其用于商业目的。但这些东西都是牛叉,使用起来并不总是那么顺畅。首先,它不是很稳定;第二,它太复杂了。很难进行二次开发以满足自身需求
3、由于通用搜索引擎不太方便,所以让它更简单、更有针对性。所以爬虫技术的兴起,酷新闻就是其中比较成功的一种。依靠它的技术,他后来建造了99间房间,然后一路登上了今天的头条新闻
4、随着越来越多的人参与互联网,许多人确实希望从互联网上捕获数据,因为他们的需求不同,但他们希望更简单,开发成本低,速度更快。出现了很多开源工具。Curl已经被大量使用了一段时间,诸如htmlcxx和Htmlparser等HTML解析工具也被广泛使用优采云只是由傻瓜式构成,没有开发功能。它只能在配置后自动运行
@到目前为止,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然强劲。用于数据捕获的在线工具、开源代码、抓取很多、jsoup、spyner等。然而,数据捕获仍然有点困难,原因有四:一、每个公司都有不同的需求,这使得商业化非常困难二、WEB页面本身非常复杂和混乱,JavaScript使得爬行无法控制三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合基于开源库或工具开发的严肃商业应用四、来完成自己的需求,仍然存在一些困难和大量工作量
@因此,一个好的抓取工具(开源库)应该具有以下特性:一、simple。系统不应该太复杂,界面应该一目了然,以降低二、power的开发成本。最好捕获您可以在web页面上看到的数据,包括JavaScript输出。数据捕获的很大一部分是寻找数据。例如,没有地理坐标数据,因此需要花费大量精力才能在三、方便时完成这些数据。最好提供可以控制的开发库,即如何捕获和部署,而不是被困在整个系统四、flexible中。它可以快速实现各种需求,即可以快速捕获简单数据或构建更复杂的数据应用程序五、stable。可以输出稳定的数据,不需要每天调整bug和查找数据。当需求有点复杂,数据量有点大的时候,需要进行大量的二次开发,耗费大量的人力和时间六、可以集成。借助现有的技术力量七、Control,通过开发环境,它可以快速建立数据系统。企业应用是长期积累的。如果数据和流程掌握在第三方手中,则可控性差,对需求变化的响应慢,风险高八、1。它可以提供一些特性来帮助开发人员实现结构化数据的提取和关联,从而避免为每个页面编写数据解析器
很多公司在数据采集方面投入了大量精力,但效果往往不是很好,可持续发展能力也相对较差。这主要是由于基本工具选择不当。因此,让我们整理一些可用的数据捕获工具和开源库。比较它们的优缺点,为开发人员提供参考
一、系统等级:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索
纳奇:
语言:Java
官方网站:
Nutch是一个用Java实现的开源搜索引擎。它提供全文搜索、网络爬虫、页面调度、数据存储等功能。它几乎可以看作是一个完整的通用搜索引擎。它适用于页面大小较大(数十亿)且只有文本索引数据(很少是结构化数据)的应用程序。Nutch有利于研究
Heritrix:
语言:Java
官方网站:
简介:heritrix是一个开源的网络爬虫系统。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,便于用户实现自己的爬网逻辑。Heritrix集成了索引调度、页面解析和数据存储
其他包括dataparksearch和web harvest
网络类:
卷曲
语言:C(但它也支持命令行和其他语言绑定)
官方网站:
简介:curl是一个古老的HTTP网络库(同时支持FTP和其他协议)。Curl支持丰富的网络功能,包括SSL、cookie、表单等。它是一个广泛使用的网络库。卷曲有弹性,但有点复杂。提供了数据下载,但不支持HTML解析。它通常需要与其他库一起使用
汤
语言:C
官方网站:
简介:soup是另一个HTTP网络库,依赖glib,功能强大稳定。然而,国内文献很少
浏览器类:
这些工具通常基于浏览器(如Firefox)进行扩展。由于浏览器的强大功能,他们可以采集获得更完整的数据,尤其是JavaScript输出的数据。但应用范围稍有局限,扩展不方便,数据量大时难以适应
ParseHub:
语言:Firefox扩展
官方网站:
简介:parsehub是基于Firefox的页面分析工具,可以支持更复杂的功能,包括页面结构分析
谷歌搜索者集合搜索
语言:Firefox扩展
官方网站:
导言:Gooseek也是基于Firefox的扩展。它支持更复杂的功能,包括索引图片、计时采集、可视化编程等
采集终端等级:
此类工具一般支持Windows图形界面,基本上不需要编写代码。更典型的数据可以通过配置规则来实现采集. 但是,数据提取能力一般,扩展有限,更复杂应用的二次开发成本不低
优采云
语言:许可软件
平台:Windows
官方网站:
优采云是一个旧的采集软件。随着无数个人站长的成长,它具有很强的可配置性,可以实现数据传输。它非常适合个人快速数据采集和政府机构的民意监测
优采云采集器
语言:许可软件
平台:Windows
官方网站:
简介:优采云采集器它具有多种功能,支持新闻的一般分析,广泛应用于舆论中
图书馆类别:
它是通过开源库或工具库提供的。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发人员自己实现。该方法非常灵活,适用于复杂数据采集和大规模数据采集。这些库的差异主要体现在以下几个方面:一、语言应用。许多库只适用于一种语言二、的功能差异。大多数库只支持HTML,不支持JS、CSS和其他动态数据三、interface。一些库提供函数级接口,而另一些库提供对象级接口四、stability。一些图书馆是认真的,而另一些则在逐步改进
简单HTML DOM解析器
语言:PHP
官方网站:
简介:PHP扩展模块支持HTML标记的解析。它提供了一个类似于jQuery的函数级接口,具有简单的函数,适合解析简单的HTML页面。它将很难成为一个数据引擎
JSoup
语言:Java
官方网站:
简介:jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
斯宾纳
语言:Python
官方网站:
简介:spyner是一个基于QT WebKit的1000行Python脚本。与urllib相比,最大的特点是支持动态内容的捕获。Spyner依赖于xvfb和QT。由于需要进行页面渲染,因此速度较慢
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,它提供了一系列清晰的函数和DOM数据结构。它简单明了,但功能强大,适用性强。Qing支持JavaScript和CSS,因此它非常支持动态内容。除此之外,青还支持后台图像加载、滚动加载、本地缓存、加载策略等功能。Qing快速、强大、稳定,开发效率高。对于企业来说,构建数据仓库是一个很好的选择
抓取网页数据工具(如何使用大数据分析R语言rvest中进行网络抓取的基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 00:04
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中找到所需数据来获取待分析数据的技术
在如何使用大数据分析R语言rvest抓取网页中,我们将介绍如何使用大数据分析R语言抓取网页的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在如何使用大数据分析R语言rvest进行网页捕获中,我们将主要关注如何使用大数据分析R语言web捕获来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:
尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法涵盖如何使用大数据分析R语言rvest捕获网页中的所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
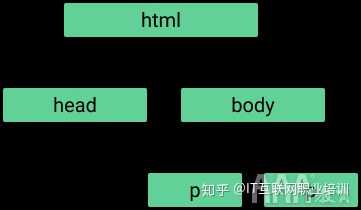
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:
文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:
我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:
将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在如何使用大数据分析R语言rvest进行网页捕获方面,我们感兴趣的是网页捕获,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样
如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在如何使用大数据分析R语言rvest抓取网页中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它
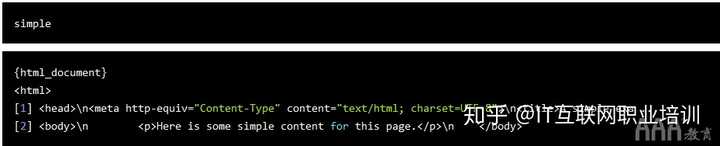
要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的数据问题。github。IO/Web SC大数据分析R语言aping pages/simple。HTML“)
大数据分析R语言ead_html()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们想将单个标记中收录的文本存储在一个变量中。为了访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常会在网站处显式地放置CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用html_nodes()和html_text()函数搜索页面
标记并检索文本。以下代码执行此操作:
简单变量已经收录我们想要获取的HTML,因此剩下的任务是搜索所需的元素。因为我们使用的是tidyve big data analysis R语言se,所以我们可以将HTML传递给不同的函数
我们需要将一个特定的HTML标记或CSS类传递给HTML_nodes()函数。我们需要一个标记,因此我们将字符“p”传递给函数。HTML_nodes()还返回一个列表,但它返回HTML中具有给定特定HTML标记或CSS类/ID的所有节点。节点指的是树结构中的一个点
一旦拥有所有这些节点,就可以将输出传递给html_nodes()函数
这些 查看全部
抓取网页数据工具(如何使用大数据分析R语言rvest中进行网络抓取的基础知识)
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中找到所需数据来获取待分析数据的技术
在如何使用大数据分析R语言rvest抓取网页中,我们将介绍如何使用大数据分析R语言抓取网页的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在如何使用大数据分析R语言rvest进行网页捕获中,我们将主要关注如何使用大数据分析R语言web捕获来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:

尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:

在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法涵盖如何使用大数据分析R语言rvest捕获网页中的所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:

文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:

我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:

将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在如何使用大数据分析R语言rvest进行网页捕获方面,我们感兴趣的是网页捕获,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样

如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在如何使用大数据分析R语言rvest抓取网页中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它

要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的数据问题。github。IO/Web SC大数据分析R语言aping pages/simple。HTML“)
大数据分析R语言ead_html()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们想将单个标记中收录的文本存储在一个变量中。为了访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常会在网站处显式地放置CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用html_nodes()和html_text()函数搜索页面
标记并检索文本。以下代码执行此操作:
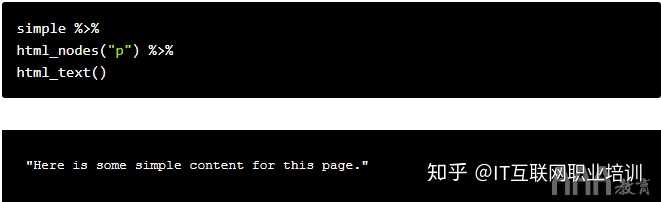
简单变量已经收录我们想要获取的HTML,因此剩下的任务是搜索所需的元素。因为我们使用的是tidyve big data analysis R语言se,所以我们可以将HTML传递给不同的函数
我们需要将一个特定的HTML标记或CSS类传递给HTML_nodes()函数。我们需要一个标记,因此我们将字符“p”传递给函数。HTML_nodes()还返回一个列表,但它返回HTML中具有给定特定HTML标记或CSS类/ID的所有节点。节点指的是树结构中的一个点
一旦拥有所有这些节点,就可以将输出传递给html_nodes()函数
这些
抓取网页数据工具(WebHarvyWebHarvy网页数据抓取工具的分类及使用方法介绍!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-18 23:17
Webhard是sysnucleus推出的实用网页数据捕获工具。软件界面简单直观,易于使用。它可以有效地从指定的网页中提取各种数据,包括文本、URL、图像等,主要解决一些网页受限、无法复制或保存图像的问题。它具有智能操作模式,无需编写脚本即可使用。它还可以提取基本关键字。如有需要,欢迎下载
网络共享功能
一、直观操作界面
Webhard是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览web。您可以选择使用鼠标单击来提取数据。这太容易了
二、智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
三、导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
四、从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
@基于五、关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
七、使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
安装教程
1、双击“setup.Exe”开始软件安装
2、单击“下一步”显示协议并选择“我同意”
3、选择安装位置。默认值为“C:\users\administrator\appdata\roaming\sysnucleus\webhard\”
4、如下图所示,点击〖安装〗按钮进行安装
5、我们马上就可以完成webharvy的安装 查看全部
抓取网页数据工具(WebHarvyWebHarvy网页数据抓取工具的分类及使用方法介绍!)
Webhard是sysnucleus推出的实用网页数据捕获工具。软件界面简单直观,易于使用。它可以有效地从指定的网页中提取各种数据,包括文本、URL、图像等,主要解决一些网页受限、无法复制或保存图像的问题。它具有智能操作模式,无需编写脚本即可使用。它还可以提取基本关键字。如有需要,欢迎下载
网络共享功能
一、直观操作界面
Webhard是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览web。您可以选择使用鼠标单击来提取数据。这太容易了
二、智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
三、导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
四、从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
@基于五、关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
七、使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
安装教程
1、双击“setup.Exe”开始软件安装

2、单击“下一步”显示协议并选择“我同意”

3、选择安装位置。默认值为“C:\users\administrator\appdata\roaming\sysnucleus\webhard\”

4、如下图所示,点击〖安装〗按钮进行安装

5、我们马上就可以完成webharvy的安装
抓取网页数据工具(网探网页数据监控软件功能介绍-上海怡健医学(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-09-17 17:21
Netprobe数据监控软件是用于监控网页数据的软件。它具有全自动全时监控和强大的数据采集功能,让您可以找到最有用的数据。有需要的朋友可以在易趣上下载
网络探测软件简介
Netprobe是一款网页数据监控软件,是一款基于IE浏览器的轻量级紧凑型互联网工具,可以轻松处理无人值守的7x24小时长时间工作。Netprobe网页数据监控软件可以安装在XP/Vista/win7/win10(x86)/x64)在环境中运行
网络勘探数据监测软件功能介绍
1:及时通知用户
注册后,用户可以将验证后的数据发送到微信,也可以将其推送到指定的界面重新处理数据
2:基于IE浏览器
没有任何意义上的反爬虫技术手段。只要在IE浏览器中可以正常浏览网页,就可以监控其中的所有数据
3:同时运行多任务
该程序支持同时运行多个监视任务,用户可以同时监视多个网页中感兴趣的数据
4:网页数据捕获
文本匹配和文档结构分析可以单独使用,也可以结合使用,以使数据捕获更加简单和准确
5:数据比较验证
自动判断最新更新数据,支持自定义数据比对校验公式,过滤出用户最感兴趣的数据内容
6:任务间呼叫
监控任务a(必须是网址)得到的结果可以传输到监控任务B执行,从而得到更丰富的数据结果
7:开放通知界面
直接与您自己的程序连接,定义后续处理过程,并实时高效地访问数据自动处理过程
8:在线分享抓取公式
“人人为我,我为人人”分享任何网页的爬行公式,以避免公式编辑的麻烦
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行中产生的内存垃圾,守护进程长时间无人值守运行 查看全部
抓取网页数据工具(网探网页数据监控软件功能介绍-上海怡健医学(图))
Netprobe数据监控软件是用于监控网页数据的软件。它具有全自动全时监控和强大的数据采集功能,让您可以找到最有用的数据。有需要的朋友可以在易趣上下载
网络探测软件简介
Netprobe是一款网页数据监控软件,是一款基于IE浏览器的轻量级紧凑型互联网工具,可以轻松处理无人值守的7x24小时长时间工作。Netprobe网页数据监控软件可以安装在XP/Vista/win7/win10(x86)/x64)在环境中运行
网络勘探数据监测软件功能介绍
1:及时通知用户
注册后,用户可以将验证后的数据发送到微信,也可以将其推送到指定的界面重新处理数据
2:基于IE浏览器
没有任何意义上的反爬虫技术手段。只要在IE浏览器中可以正常浏览网页,就可以监控其中的所有数据
3:同时运行多任务
该程序支持同时运行多个监视任务,用户可以同时监视多个网页中感兴趣的数据
4:网页数据捕获
文本匹配和文档结构分析可以单独使用,也可以结合使用,以使数据捕获更加简单和准确
5:数据比较验证
自动判断最新更新数据,支持自定义数据比对校验公式,过滤出用户最感兴趣的数据内容
6:任务间呼叫
监控任务a(必须是网址)得到的结果可以传输到监控任务B执行,从而得到更丰富的数据结果
7:开放通知界面
直接与您自己的程序连接,定义后续处理过程,并实时高效地访问数据自动处理过程
8:在线分享抓取公式
“人人为我,我为人人”分享任何网页的爬行公式,以避免公式编辑的麻烦
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行中产生的内存垃圾,守护进程长时间无人值守运行
抓取网页数据工具(web端获取数据获取多网页数据web链接常见格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-17 11:14
一、get-data-from-Web
从Bi桌面“获取数据”中的“Web”选项中,“Web”界面有两个选项卡:“基本”和“高级”。一般来说,“基本”选项卡可以满足日常工作的需要。以下是一些例子
二、get数据
进入web链接后,您将执行导航器的“加载”和“编辑”等常见功能。您只需根据实际工作需要操作即可
三、获取多页数据
Web链接的常见格式如下:结尾处的“1”表示当前链接是数据的第一页,第二页上的数据链接应为“”。当网页数据较大时,如果每次都通过web链接获取数据,会耗费大量时间。但是,组件查询中有相应的函数来简化操作,如下所示:
获取一页数据后,进入编辑查询界面,在编辑查询界面选择高级编辑器页签,高级编辑器界面显示当年的工作路径。与下图类似:
此时,您需要在“let”前面输入“(p作为编号)作为table=>;”;在链接中,修改页码,即“1,2”和上面提到的其他数字“(number.ToText(P))”
注意:有两种类型的Web链接。一是页码数据。在链接结束时,执行上述操作;另一个是链接以结束。HTML。除上述更换操作外,“&;(number.ToText(P))&;”。HTML”))只需单击此处单独定义HTML
四、grab多数据网页
首先,使用空查询创建数字序列。如果要捕获前100页的数据,请创建从1到100的序列,并将其输入空查询={1..100}按enter键生成从1到100的序列,然后将其转换为表
然后调用自定义函数
在弹出窗口中,点击[function query]下拉框,选择刚刚创建的自定义函数数据_zhaopin。其他所有内容默认在线
点击【确定】按钮,开始批量抓取网页,抓取成功,可根据工作需要进行后续操作 查看全部
抓取网页数据工具(web端获取数据获取多网页数据web链接常见格式(图))
一、get-data-from-Web
从Bi桌面“获取数据”中的“Web”选项中,“Web”界面有两个选项卡:“基本”和“高级”。一般来说,“基本”选项卡可以满足日常工作的需要。以下是一些例子
二、get数据
进入web链接后,您将执行导航器的“加载”和“编辑”等常见功能。您只需根据实际工作需要操作即可
三、获取多页数据
Web链接的常见格式如下:结尾处的“1”表示当前链接是数据的第一页,第二页上的数据链接应为“”。当网页数据较大时,如果每次都通过web链接获取数据,会耗费大量时间。但是,组件查询中有相应的函数来简化操作,如下所示:
获取一页数据后,进入编辑查询界面,在编辑查询界面选择高级编辑器页签,高级编辑器界面显示当年的工作路径。与下图类似:
此时,您需要在“let”前面输入“(p作为编号)作为table=>;”;在链接中,修改页码,即“1,2”和上面提到的其他数字“(number.ToText(P))”
注意:有两种类型的Web链接。一是页码数据。在链接结束时,执行上述操作;另一个是链接以结束。HTML。除上述更换操作外,“&;(number.ToText(P))&;”。HTML”))只需单击此处单独定义HTML
四、grab多数据网页
首先,使用空查询创建数字序列。如果要捕获前100页的数据,请创建从1到100的序列,并将其输入空查询={1..100}按enter键生成从1到100的序列,然后将其转换为表
然后调用自定义函数
在弹出窗口中,点击[function query]下拉框,选择刚刚创建的自定义函数数据_zhaopin。其他所有内容默认在线

点击【确定】按钮,开始批量抓取网页,抓取成功,可根据工作需要进行后续操作
抓取网页数据工具(抓取网页数据工具有很多种类,我说两种是flashback)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-16 11:02
抓取网页数据工具有很多种类,下面我说两种,一种是flashback,另一种是flashfd。其中flashback采用的web浏览器为opera,用的是javascript写的,具体fd用什么技术是ruby、python、r、php、java各种语言都有,工具开发环境为windows平台下的eclipse。
优点是简单快捷,比较适合新手去实践。缺点是工具需要java版本;另一种就是flashfd工具采用了flashbridge工具,对浏览器的适配度很高,大部分浏览器支持都做的不错,但是部分浏览器不能完全兼容它,比如刚好有个网站使用微软的activex插件,部分浏览器无法使用就会显示下面的图片,具体安装什么语言的开发环境,可以到它的官网去下载,别再百度问问了,你在问百度不如去问ack。更多关于数据爬虫方面的问题,可以看我的文章或回答。
不请自来。刚用上flashback,对eclipse、idea这些无力吐槽,自带的flashback根本没法用,用起来一点都不方便,遂在网上搜python3.5能否安装这个库。以下是我按照步骤以及yandex上面下载的,给大家参考参考。
嗯...这个刚刚才下了,打开就是这样的然后只能填文本框,只能输入可读的英文字母,不能来回切换中英文,也不能输入图片或者任何js文件,特别麻烦。打开你想要的网页-->这里点击shownewview-->这里点击run-->这里点击savenewview-->这里再选择你要在什么时候保存-->这里就可以选择保存哪一个网页了-->saveas-->这里要按mode来选择了-->这里可以保存为.asp-->这里要记得把你刚刚存文本框的地址-->保存好-->点击run保存-->出现这个窗口时就可以开始运行你想用的插件了-->选中你想用的,就可以运行那个了。 查看全部
抓取网页数据工具(抓取网页数据工具有很多种类,我说两种是flashback)
抓取网页数据工具有很多种类,下面我说两种,一种是flashback,另一种是flashfd。其中flashback采用的web浏览器为opera,用的是javascript写的,具体fd用什么技术是ruby、python、r、php、java各种语言都有,工具开发环境为windows平台下的eclipse。
优点是简单快捷,比较适合新手去实践。缺点是工具需要java版本;另一种就是flashfd工具采用了flashbridge工具,对浏览器的适配度很高,大部分浏览器支持都做的不错,但是部分浏览器不能完全兼容它,比如刚好有个网站使用微软的activex插件,部分浏览器无法使用就会显示下面的图片,具体安装什么语言的开发环境,可以到它的官网去下载,别再百度问问了,你在问百度不如去问ack。更多关于数据爬虫方面的问题,可以看我的文章或回答。
不请自来。刚用上flashback,对eclipse、idea这些无力吐槽,自带的flashback根本没法用,用起来一点都不方便,遂在网上搜python3.5能否安装这个库。以下是我按照步骤以及yandex上面下载的,给大家参考参考。
嗯...这个刚刚才下了,打开就是这样的然后只能填文本框,只能输入可读的英文字母,不能来回切换中英文,也不能输入图片或者任何js文件,特别麻烦。打开你想要的网页-->这里点击shownewview-->这里点击run-->这里点击savenewview-->这里再选择你要在什么时候保存-->这里就可以选择保存哪一个网页了-->saveas-->这里要按mode来选择了-->这里可以保存为.asp-->这里要记得把你刚刚存文本框的地址-->保存好-->点击run保存-->出现这个窗口时就可以开始运行你想用的插件了-->选中你想用的,就可以运行那个了。
抓取网页数据工具(最简单的数据抓取教程,人人都用得上(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2021-09-14 11:18
最简单的数据采集教程,人人都可以使用
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
1.png
2、 并在弹出框中点击“添加扩展”
2.png
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
如果不能FQ,可以使用本地FQ方法。在此公众号回复“爬虫”,即可下载Chrome和Web Scraper扩展程序。
1、打开Chrome,在地址栏中输入chrome://extensions/,进入扩展管理界面,然后将下载的扩展Web-Scraper_v0.3.7.crx拖放到这里页面,点击“添加到扩展”完成安装。如图:
4.gif
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
初识网络爬虫开启网络爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
5.png
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
6.png
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
7.gif
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
8.png
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
9.png
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
10.png
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
11.png
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
12.png
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
13.png
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
14.png
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
15.png
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
16.png
6、然后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选择的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
17.png
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
18.gif
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图可以看到拓扑图。 _root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
19.png
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
20.png
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
21.png
怎么样,现在试试
获取知乎questions 的所有答案
简单介绍完毕。接下来,尝试一个有点难度的,抓取知乎问题的所有答案,包括回答者的昵称,批准数,以及答案的内容。问:为什么炫富的程序员这么少?
知乎的特点是只有向下滚动页面才会加载下一个答案
1、首先在Chrome中打开此链接,链接地址为:,并调出开发者工具,定位到Web Scraper标签栏;
2、新建站点地图,填写站点地图名称和起始网址;
22.png
3、下一步,开始添加选择器,点击添加新选择器;
4、我们先来分析一下知乎问题的结构。如图,一个问题由多个这样的区域组成,一个区域就是一个答案。这个回答区包括昵称、批准号、回答内容和发布。时间等等。红色框起来的部分就是我们要抓取的内容。所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载的答案,找到一个答案区域,提取昵称,批准数,以及里面的答案内容,然后依次执行。当加载区域获取完成后,模拟鼠标向下滚动,加载后续部分,循环直到全部加载完成;
23.png
5、内容结构拓扑图如下,_root的根节点收录若干个回答区域,每个区域收录昵称、审批号、回答内容;
24.png
6、 根据上面的拓扑图,开始创建选择器,选择器id填写为answer(随意填写),Type选择Element向下滚动。说明:Element是针对这种大面积的区域,这个区域也收录子元素,答案区域对应Element,因为我们需要从这个区域获取我们需要的数据,Element向下滚动表示这个区域是向下使用。滚动方式可以加载更多,专为这种下拉加载而设计。
25.png
7、 接下来,单击选择,然后将鼠标移动到页面上。当绿色框包围答案区域时,单击鼠标,然后移动到下一个答案。同样,当绿色框收录答案区域时,单击鼠标。这时,除了这两个答案,所有的答案区域都变成了红色的方框,然后点击“完成选择!”。最后别忘了选择Multiple,稍后保存;
26.gif
8、下一步,点击红色区域进入刚刚创建的答案选择器,创建子选择器;
27.png
9、 创建昵称选择器,设置id为name,Type为Text,Select选择昵称部分。如果您没有经验,第一次可能不会选择正确的名称。如果您发现错误,您可以对其进行调整并保存。 ;
28.gif
10、创建一个批准号选择器;
29.gif
11、创建一个内容选择器。由于内容格式化并且很长,所以有一个技巧。选择以下更方便;
30.gif
12、 执行刮取操作。由于内容较多,可能需要几分钟。如果是测试用的,可以找一个答案少的问题来测试。
31.png 查看全部
抓取网页数据工具(最简单的数据抓取教程,人人都用得上(组图))
最简单的数据采集教程,人人都可以使用
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。

1.png
2、 并在弹出框中点击“添加扩展”
2.png
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
如果不能FQ,可以使用本地FQ方法。在此公众号回复“爬虫”,即可下载Chrome和Web Scraper扩展程序。
1、打开Chrome,在地址栏中输入chrome://extensions/,进入扩展管理界面,然后将下载的扩展Web-Scraper_v0.3.7.crx拖放到这里页面,点击“添加到扩展”完成安装。如图:

4.gif
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
初识网络爬虫开启网络爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
5.png
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
6.png
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
7.gif
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
8.png
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
9.png
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
10.png
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
11.png
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
12.png
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
13.png
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
14.png
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
15.png
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
16.png
6、然后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选择的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
17.png
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
18.gif
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图可以看到拓扑图。 _root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
19.png
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
20.png
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
21.png
怎么样,现在试试
获取知乎questions 的所有答案
简单介绍完毕。接下来,尝试一个有点难度的,抓取知乎问题的所有答案,包括回答者的昵称,批准数,以及答案的内容。问:为什么炫富的程序员这么少?
知乎的特点是只有向下滚动页面才会加载下一个答案
1、首先在Chrome中打开此链接,链接地址为:,并调出开发者工具,定位到Web Scraper标签栏;
2、新建站点地图,填写站点地图名称和起始网址;
22.png
3、下一步,开始添加选择器,点击添加新选择器;
4、我们先来分析一下知乎问题的结构。如图,一个问题由多个这样的区域组成,一个区域就是一个答案。这个回答区包括昵称、批准号、回答内容和发布。时间等等。红色框起来的部分就是我们要抓取的内容。所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载的答案,找到一个答案区域,提取昵称,批准数,以及里面的答案内容,然后依次执行。当加载区域获取完成后,模拟鼠标向下滚动,加载后续部分,循环直到全部加载完成;
23.png
5、内容结构拓扑图如下,_root的根节点收录若干个回答区域,每个区域收录昵称、审批号、回答内容;
24.png
6、 根据上面的拓扑图,开始创建选择器,选择器id填写为answer(随意填写),Type选择Element向下滚动。说明:Element是针对这种大面积的区域,这个区域也收录子元素,答案区域对应Element,因为我们需要从这个区域获取我们需要的数据,Element向下滚动表示这个区域是向下使用。滚动方式可以加载更多,专为这种下拉加载而设计。
25.png
7、 接下来,单击选择,然后将鼠标移动到页面上。当绿色框包围答案区域时,单击鼠标,然后移动到下一个答案。同样,当绿色框收录答案区域时,单击鼠标。这时,除了这两个答案,所有的答案区域都变成了红色的方框,然后点击“完成选择!”。最后别忘了选择Multiple,稍后保存;
26.gif
8、下一步,点击红色区域进入刚刚创建的答案选择器,创建子选择器;
27.png
9、 创建昵称选择器,设置id为name,Type为Text,Select选择昵称部分。如果您没有经验,第一次可能不会选择正确的名称。如果您发现错误,您可以对其进行调整并保存。 ;
28.gif
10、创建一个批准号选择器;
29.gif
11、创建一个内容选择器。由于内容格式化并且很长,所以有一个技巧。选择以下更方便;
30.gif
12、 执行刮取操作。由于内容较多,可能需要几分钟。如果是测试用的,可以找一个答案少的问题来测试。
31.png
抓取网页数据工具(之前有一个工具自动抓取数据的工具主要做什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-14 11:16
)
之前有一项工作是在服务器上复制一串文本。这是一个非常简单的操作,但需要重复大约 50 次。每次大概用了三分钟,重复了两个多小时就过去了。所以我做了这个工具来自动抓取数据。
该工具主要做三件事:登录、下载、拦截。
登录部分是因为服务器使用windows安全验证,如图:
需要模拟登录才能获取网页数据。
先用fiddler抓取http传输的数据包,在header部分找到一串字符串:
base64解密后得到:Administrator:manage。
这是用户名:一串加密的密码。 Authorization:Basic是一种认证方式,一般由setRequestProperty设置。
登录后可以直接获取网页内容,然后截取数据。最后在最外层添加一个循环,执行一次需要爬取的服务器地址,然后就可以一次性获取到所有服务器上的数据了。
最后贴出代码:
<p>import java.io.*;
import java.net.*;
public class getPackageFromWeb {
public static void main(String args[]) throws Exception {
String[] servers ={"192.168.0.144:23342","192.168.0.144:23343"};
StringBuilder result=new StringBuilder();
for(int i=0;i 查看全部
抓取网页数据工具(之前有一个工具自动抓取数据的工具主要做什么?
)
之前有一项工作是在服务器上复制一串文本。这是一个非常简单的操作,但需要重复大约 50 次。每次大概用了三分钟,重复了两个多小时就过去了。所以我做了这个工具来自动抓取数据。
该工具主要做三件事:登录、下载、拦截。
登录部分是因为服务器使用windows安全验证,如图:
需要模拟登录才能获取网页数据。
先用fiddler抓取http传输的数据包,在header部分找到一串字符串:

base64解密后得到:Administrator:manage。
这是用户名:一串加密的密码。 Authorization:Basic是一种认证方式,一般由setRequestProperty设置。
登录后可以直接获取网页内容,然后截取数据。最后在最外层添加一个循环,执行一次需要爬取的服务器地址,然后就可以一次性获取到所有服务器上的数据了。
最后贴出代码:
<p>import java.io.*;
import java.net.*;
public class getPackageFromWeb {
public static void main(String args[]) throws Exception {
String[] servers ={"192.168.0.144:23342","192.168.0.144:23343"};
StringBuilder result=new StringBuilder();
for(int i=0;i
抓取网页数据工具(网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-14 02:06
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们添加到这个对象的所有链接并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C# 适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?” 查看全部
抓取网页数据工具(网页抓取是通过自动化手段检索数据的过程-乐题库)
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们添加到这个对象的所有链接并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C# 适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?”
抓取网页数据工具( 合肥乐维信息技术优采云采集软件免费采集(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 519 次浏览 • 2021-09-13 16:09
合肥乐维信息技术优采云采集软件免费采集(组图))
优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网络数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩
优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。 查看全部
抓取网页数据工具(
合肥乐维信息技术优采云采集软件免费采集(组图))

优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。

云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网络数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩

优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
抓取网页数据工具(国内6大网络信息采集和页面数据抓取工具近年来,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2021-09-13 07:14
国内6大网络资讯采集及页面数据抓取工具 近年来,随着国内大数据战略的日趋明朗,数据抓取及资讯采集系列产品迎来了巨大的发展机遇,@数采集产品的数量也出现了快速增长。然而,与产品品类的快速增长相反,信息采集技术相对薄弱,市场竞争激烈,质量参差不齐。在此,本文列出当前信息采集和数据采集市场最具影响力的六大品牌,供采购大数据和智能中心建设单位时参考:TOP.1乐思网络信息采集系统(主要目标网络信息采集系统是为了解决网络信息采集和网络数据采集的问题,基于用户自定义任务配置,批量准确地从互联网目标页面中提取半结构化和非结构化数据,并进行转化。是存储在本地数据库中供内部使用或外网发布以快速获取外部信息的结构化记录,系统主要用于:大数据基础设施建设、舆情监测、品牌监测、价格监测、portal网站新闻采集、行业资讯采集、竞争情报获取、商业数据整合、市场调研、数据库营销等领域。TOP.2优采云采集器(集德Vice是一款专业的网络data采集/信息挖掘处理软件,通过灵活的配置,可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以进行编辑过滤和选择发布到网站后台,各种文件或者其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各领域有采集 挖掘数据需求。 TOP.3优采云采集器software(极软利用熊猫精准搜索引擎的分析内核实现网页内容类似浏览器的分析,并在此基础上使用原创的技术实现对网页内容的分离提取网页框架内容和核心内容,实现相似页面的有效对比匹配,因此用户只需要指定一个参考页面,优采云采集器软件系统就可以以此为基础匹配相似页面,实现用户采集.TOP.4优采云采集器所需的采集素材的批量批量处理(套机是一套专业的网站内容采集软件,支持各种论坛的帖子和回复采集、网站和博客文章内容抓取,通过相关配置,可以方便的采集80%网站内容供自己使用。根据建站程序的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三大类,共数百个版本的数据采集支持近40个主流w网站建设计划 查看全部
抓取网页数据工具(国内6大网络信息采集和页面数据抓取工具近年来,)
国内6大网络资讯采集及页面数据抓取工具 近年来,随着国内大数据战略的日趋明朗,数据抓取及资讯采集系列产品迎来了巨大的发展机遇,@数采集产品的数量也出现了快速增长。然而,与产品品类的快速增长相反,信息采集技术相对薄弱,市场竞争激烈,质量参差不齐。在此,本文列出当前信息采集和数据采集市场最具影响力的六大品牌,供采购大数据和智能中心建设单位时参考:TOP.1乐思网络信息采集系统(主要目标网络信息采集系统是为了解决网络信息采集和网络数据采集的问题,基于用户自定义任务配置,批量准确地从互联网目标页面中提取半结构化和非结构化数据,并进行转化。是存储在本地数据库中供内部使用或外网发布以快速获取外部信息的结构化记录,系统主要用于:大数据基础设施建设、舆情监测、品牌监测、价格监测、portal网站新闻采集、行业资讯采集、竞争情报获取、商业数据整合、市场调研、数据库营销等领域。TOP.2优采云采集器(集德Vice是一款专业的网络data采集/信息挖掘处理软件,通过灵活的配置,可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以进行编辑过滤和选择发布到网站后台,各种文件或者其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各领域有采集 挖掘数据需求。 TOP.3优采云采集器software(极软利用熊猫精准搜索引擎的分析内核实现网页内容类似浏览器的分析,并在此基础上使用原创的技术实现对网页内容的分离提取网页框架内容和核心内容,实现相似页面的有效对比匹配,因此用户只需要指定一个参考页面,优采云采集器软件系统就可以以此为基础匹配相似页面,实现用户采集.TOP.4优采云采集器所需的采集素材的批量批量处理(套机是一套专业的网站内容采集软件,支持各种论坛的帖子和回复采集、网站和博客文章内容抓取,通过相关配置,可以方便的采集80%网站内容供自己使用。根据建站程序的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三大类,共数百个版本的数据采集支持近40个主流w网站建设计划
抓取网页数据工具(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 837 次浏览 • 2021-10-04 12:35
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。
总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
![(|imageView2/2/w/1240)
Getleft 是一款免费且易于使用的爬虫工具。启动Getleft后,输入网址,选择要下载的文件,然后开始下载网站 另外,提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总的来说,Getleft 应该能满足用户基本的爬虫需求,不需要更复杂的技能。
5. 刮板
Scraper 是一款 Chrome 扩展工具,数据提取功能有限,但对于在线研究和导出数据到 Google 电子表格非常有用。适合初学者和专家,您可以轻松地将数据复制到剪贴板或使用 OAuth 将其存储在电子表格中。不提供包罗万象的爬虫服务,但对新手也很友好。
6. OutWit 中心
OutWit Hub 是一个 Firefox 插件,具有数十种数据提取功能,可简化网络搜索。浏览页面后,提取的信息会以合适的格式存储。您还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬虫工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookies 等方式获取网页数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,您也可以使用浏览器内置的 Web 应用程序。
8.视觉抓取工具
VisualScraper 是另一个很棒的免费和非编码爬虫工具,它可以通过简单的点击界面从互联网上采集数据。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据传输服务和创作软件提取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。它的开源可视化爬虫工具允许用户在没有任何编程知识的情况下爬取网页。
Scrapinghub 使用 Crawlera,它是一个智能代理微调器,支持绕过 bot 机制,轻松抓取大量受 bot 保护的 网站。它使用户能够通过简单的 HTTP API 从多个 IP 和位置进行爬取,而无需代理管理。
10. Dexi.io
Dexi.io作为一款基于浏览器的网络爬虫工具,允许用户从任意网站中抓取数据,并提供了三种机器人来创建抓取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据会在归档前两周内存储在Dexi.io的服务器上,或者提取的数据可以直接导出为JSON或CSV文件。提供有偿服务,满足实时数据采集需求。
11. Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用覆盖各种来源的多个过滤器来抓取数据并进一步提取不同语言的关键字。
捕获的数据可以以 XML、JSON 和 RSS 格式保存,并且可以从其存档中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 捕获的结构化数据。
总体来说,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入。io
用户只需要从特定网页导入数据,并将数据导出为CSV,即可形成自己的数据集。
无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。公共 API 提供了强大而灵活的功能来以编程方式控制 Import.io 并自动访问数据。Import.io 将网页数据集成到您自己的应用程序或 网站 中,只需点击几下即可轻松实现爬虫。
为了更好地满足用户的爬取需求,它还提供了Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和爬取工具,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80条腿
80legs是一款功能强大的网络爬虫工具,可根据客户需求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速工作,在几秒钟内获取所需的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 中获取所有数据。Spinn3r 发布了一个防火墙 API 来管理 95% 的索引工作。提供先进的垃圾邮件防护功能,杜绝垃圾邮件和不当语言,提高数据安全性。
Spinn3r 索引类似于 Google 的内容,并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网络抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 调试或编写脚本以编程方式控制抓取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦气刮刀
Helium Scraper 是一款可视化的网络数据爬虫软件,当元素之间的相关性较小时效果更好。它是非编码和非配置的。用户可以根据各种爬取需求访问在线模板。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动化爬虫软件。它可以自动从第三方应用程序抓取网页和桌面数据。Uipath 可以跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬行的内置工具。这种方法在处理复杂的 UI 时非常有效。屏幕抓取工具可以处理单个文本元素、文本组和文本块。
18. 刮擦。它
Scrape.it 是一种基于云的 Web 数据提取工具。它是为具有高级编程技能的人设计的,因为它提供了公共和私有包来发现、使用、更新和与全球数百万开发人员共享代码。其强大的集成功能可以帮助用户根据自己的需求构建自定义爬虫。
19. 网络哈维
WebHarvy 是为非程序员设计的。它可以自动抓取来自网站的文本、图片、URL和电子邮件,并将抓取到的内容以各种格式保存。它还提供了内置的调度程序和代理支持,可以匿名爬行并防止被 Web 服务器阻止。可以选择通过代理服务器或VPN访问目标。网站。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,或导出到 SQL 数据库。
20. 内涵
Connotate 是一款自动化的网络爬虫软件,专为企业级网络爬虫设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它可以自动提取95%以上的网站,包括基于JavaScript的动态网站技术,如Ajax。
此外,Connotate 还提供了网页和数据库内容的集成功能,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
抓取网页数据工具(网络爬虫工具越来越工具)
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。
总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
![(|imageView2/2/w/1240)
Getleft 是一款免费且易于使用的爬虫工具。启动Getleft后,输入网址,选择要下载的文件,然后开始下载网站 另外,提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总的来说,Getleft 应该能满足用户基本的爬虫需求,不需要更复杂的技能。
5. 刮板
Scraper 是一款 Chrome 扩展工具,数据提取功能有限,但对于在线研究和导出数据到 Google 电子表格非常有用。适合初学者和专家,您可以轻松地将数据复制到剪贴板或使用 OAuth 将其存储在电子表格中。不提供包罗万象的爬虫服务,但对新手也很友好。
6. OutWit 中心
OutWit Hub 是一个 Firefox 插件,具有数十种数据提取功能,可简化网络搜索。浏览页面后,提取的信息会以合适的格式存储。您还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的爬虫工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookies 等方式获取网页数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,您也可以使用浏览器内置的 Web 应用程序。
8.视觉抓取工具
VisualScraper 是另一个很棒的免费和非编码爬虫工具,它可以通过简单的点击界面从互联网上采集数据。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据传输服务和创作软件提取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。它的开源可视化爬虫工具允许用户在没有任何编程知识的情况下爬取网页。
Scrapinghub 使用 Crawlera,它是一个智能代理微调器,支持绕过 bot 机制,轻松抓取大量受 bot 保护的 网站。它使用户能够通过简单的 HTTP API 从多个 IP 和位置进行爬取,而无需代理管理。
10. Dexi.io
Dexi.io作为一款基于浏览器的网络爬虫工具,允许用户从任意网站中抓取数据,并提供了三种机器人来创建抓取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据会在归档前两周内存储在Dexi.io的服务器上,或者提取的数据可以直接导出为JSON或CSV文件。提供有偿服务,满足实时数据采集需求。
11. Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用覆盖各种来源的多个过滤器来抓取数据并进一步提取不同语言的关键字。
捕获的数据可以以 XML、JSON 和 RSS 格式保存,并且可以从其存档中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 捕获的结构化数据。
总体来说,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入。io
用户只需要从特定网页导入数据,并将数据导出为CSV,即可形成自己的数据集。
无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。公共 API 提供了强大而灵活的功能来以编程方式控制 Import.io 并自动访问数据。Import.io 将网页数据集成到您自己的应用程序或 网站 中,只需点击几下即可轻松实现爬虫。
为了更好地满足用户的爬取需求,它还提供了Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和爬取工具,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80条腿
80legs是一款功能强大的网络爬虫工具,可根据客户需求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速工作,在几秒钟内获取所需的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 中获取所有数据。Spinn3r 发布了一个防火墙 API 来管理 95% 的索引工作。提供先进的垃圾邮件防护功能,杜绝垃圾邮件和不当语言,提高数据安全性。
Spinn3r 索引类似于 Google 的内容,并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网络抓取软件。它允许您创建一个独立的网络爬虫代理。
它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 调试或编写脚本以编程方式控制抓取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦气刮刀
Helium Scraper 是一款可视化的网络数据爬虫软件,当元素之间的相关性较小时效果更好。它是非编码和非配置的。用户可以根据各种爬取需求访问在线模板。
基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动化爬虫软件。它可以自动从第三方应用程序抓取网页和桌面数据。Uipath 可以跨多个网页提取表格和基于模式的数据。
Uipath 提供了用于进一步爬行的内置工具。这种方法在处理复杂的 UI 时非常有效。屏幕抓取工具可以处理单个文本元素、文本组和文本块。
18. 刮擦。它
Scrape.it 是一种基于云的 Web 数据提取工具。它是为具有高级编程技能的人设计的,因为它提供了公共和私有包来发现、使用、更新和与全球数百万开发人员共享代码。其强大的集成功能可以帮助用户根据自己的需求构建自定义爬虫。
19. 网络哈维
WebHarvy 是为非程序员设计的。它可以自动抓取来自网站的文本、图片、URL和电子邮件,并将抓取到的内容以各种格式保存。它还提供了内置的调度程序和代理支持,可以匿名爬行并防止被 Web 服务器阻止。可以选择通过代理服务器或VPN访问目标。网站。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,或导出到 SQL 数据库。
20. 内涵
Connotate 是一款自动化的网络爬虫软件,专为企业级网络爬虫设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它可以自动提取95%以上的网站,包括基于JavaScript的动态网站技术,如Ajax。
此外,Connotate 还提供了网页和数据库内容的集成功能,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
抓取网页数据工具( 如何使用UiPath数据收集向导的步骤和操作步骤?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 591 次浏览 • 2021-09-30 22:11
如何使用UiPath数据收集向导的步骤和操作步骤?(组图)
)
数据捕获和屏幕捕获
在本章中,让我们更多地了解 Uipath 中的数据捕获和屏幕捕获。
什么是数据采集?
数据抓取是一种可以从 Web 或任何应用程序中提取结构化数据并将其保存到数据库或电子表格或 .CSV 文件的技术。UiPath Studio 还提供了借助捕获向导的数据捕获功能。我们可以在“设计”选项卡下找到爬行向导。
下面是同样的截图——
通过示例使用数据采集向导的步骤
要使用 UiPath 数据捕获向导,您可以按照以下步骤操作 -
第 1 步 - 首先,打开要从中提取数据的网页或应用程序。例如,我们从 Google 联系人中提取数据。
步骤 2-然后单击“设计”选项卡下的“数据采集”按钮。您将收到以下消息框-
第 3 步 - 单击“下一步”按钮,它将为您提供选择要从中提取数据的网页中的第一个和最后一个字段的选项。在此示例中,您将能够从 Google 通讯录页面中进行选择。
Step 4-选择完第一个元素后,会提示选择第二个元素的对话框,如下图-
第 5 步 - 现在,一旦您单击下一步并选择第二个元素,它将提示另一个对话框,我们可以在其中自定义列标题并选择是否提取 URL。
您可以根据需要重命名“文本”列的名称。我们已将 column1 重命名为“name”。
Step 6-接下来,UiPath studio 会为我们提供“Extraction Wizard”来预览数据。我们将选择提取相关数据或在此处完成提取。如果您提取相关数据,它会再次将您带到您要从中提取数据的网页。
步骤7-提取完成后,它会询问“数据是否跨越多个页面?” 如果要从多个页面提取数据,请单击“是”,否则单击“否”。我们单击“否”是因为此处的数据提取仅来自单个页面。
步骤 8-最后,它将在设计器选项卡中创建活动序列,如下所示-
什么是屏幕抓取?
UiPath Studio 为我们提供了一种从指定的 UI 元素或文档中提取数据的方法。这些方法称为屏幕捕获或输出方法。我们可以在“设计”选项卡下找到屏幕截图向导。
屏幕抓取方式
UiPath Studio 屏幕捕获向导具有三种从指定 UI 元素捕获数据的方法。此方法将由 UiPath Studio 自动选择并显示在“屏幕截图”窗口的顶部。
现在出现的问题是,如果方法是自动选择的,是否可以根据需要进行更改?是的,您可以从写有“抓取方法”的“选项”面板中更改它,然后按“刷新”按钮。
单击“刷新”按钮后,UiPath Studio 会将信息保存在“设计器”面板中。另一方面,如果要将信息复制到剪贴板,则可以单击“完成”按钮。
如桌面录制中所见,屏幕截图将生成一个容器,其中收录活动和选择器的每个激活部分。你可以参考下面的截图——
这三种截屏方法都有不同的功能,下面分别对这三种截屏方法及其作用进行说明——
使用示例屏幕捕获向导的步骤
为了使用 UiPath 屏幕抓取向导,您可以按照以下步骤操作 -
第 1 步 - 首先,打开要从中提取数据的 Ui 元素(可能是 PDF 文件或 Word 文件或任何其他文件)。在这里,我们将其实现为 PDF 文件。
第 2 步 - 现在,单击“设计”选项卡下的“屏幕捕获”选项。
第 3 步 - 接下来,单击要从中提取信息的 Ui 元素,在我们的示例中,我们单击 PDF 文档。
第 4 步-现在,您将看到以下屏幕-
默认情况下,UiPath Studio 会提供截屏方法,但您可以根据需要进行更改。我们之前也讨论过。
步骤 5-然后,最后,您可以单击刷新按钮或完成按钮。我们单击“完成”按钮,它将保存在设计器面板中。
如前所述,屏幕截图将生成一个容器,其中收录活动和选择器的每个活动部分。
我们可以在以下屏幕截图中看到输出 -
查看全部
抓取网页数据工具(
如何使用UiPath数据收集向导的步骤和操作步骤?(组图)
)
数据捕获和屏幕捕获
在本章中,让我们更多地了解 Uipath 中的数据捕获和屏幕捕获。
什么是数据采集?
数据抓取是一种可以从 Web 或任何应用程序中提取结构化数据并将其保存到数据库或电子表格或 .CSV 文件的技术。UiPath Studio 还提供了借助捕获向导的数据捕获功能。我们可以在“设计”选项卡下找到爬行向导。
下面是同样的截图——
通过示例使用数据采集向导的步骤
要使用 UiPath 数据捕获向导,您可以按照以下步骤操作 -
第 1 步 - 首先,打开要从中提取数据的网页或应用程序。例如,我们从 Google 联系人中提取数据。
步骤 2-然后单击“设计”选项卡下的“数据采集”按钮。您将收到以下消息框-
第 3 步 - 单击“下一步”按钮,它将为您提供选择要从中提取数据的网页中的第一个和最后一个字段的选项。在此示例中,您将能够从 Google 通讯录页面中进行选择。
Step 4-选择完第一个元素后,会提示选择第二个元素的对话框,如下图-
第 5 步 - 现在,一旦您单击下一步并选择第二个元素,它将提示另一个对话框,我们可以在其中自定义列标题并选择是否提取 URL。
您可以根据需要重命名“文本”列的名称。我们已将 column1 重命名为“name”。
Step 6-接下来,UiPath studio 会为我们提供“Extraction Wizard”来预览数据。我们将选择提取相关数据或在此处完成提取。如果您提取相关数据,它会再次将您带到您要从中提取数据的网页。
步骤7-提取完成后,它会询问“数据是否跨越多个页面?” 如果要从多个页面提取数据,请单击“是”,否则单击“否”。我们单击“否”是因为此处的数据提取仅来自单个页面。
步骤 8-最后,它将在设计器选项卡中创建活动序列,如下所示-
什么是屏幕抓取?
UiPath Studio 为我们提供了一种从指定的 UI 元素或文档中提取数据的方法。这些方法称为屏幕捕获或输出方法。我们可以在“设计”选项卡下找到屏幕截图向导。
屏幕抓取方式
UiPath Studio 屏幕捕获向导具有三种从指定 UI 元素捕获数据的方法。此方法将由 UiPath Studio 自动选择并显示在“屏幕截图”窗口的顶部。
现在出现的问题是,如果方法是自动选择的,是否可以根据需要进行更改?是的,您可以从写有“抓取方法”的“选项”面板中更改它,然后按“刷新”按钮。
单击“刷新”按钮后,UiPath Studio 会将信息保存在“设计器”面板中。另一方面,如果要将信息复制到剪贴板,则可以单击“完成”按钮。
如桌面录制中所见,屏幕截图将生成一个容器,其中收录活动和选择器的每个激活部分。你可以参考下面的截图——
这三种截屏方法都有不同的功能,下面分别对这三种截屏方法及其作用进行说明——
使用示例屏幕捕获向导的步骤
为了使用 UiPath 屏幕抓取向导,您可以按照以下步骤操作 -
第 1 步 - 首先,打开要从中提取数据的 Ui 元素(可能是 PDF 文件或 Word 文件或任何其他文件)。在这里,我们将其实现为 PDF 文件。
第 2 步 - 现在,单击“设计”选项卡下的“屏幕捕获”选项。
第 3 步 - 接下来,单击要从中提取信息的 Ui 元素,在我们的示例中,我们单击 PDF 文档。
第 4 步-现在,您将看到以下屏幕-
默认情况下,UiPath Studio 会提供截屏方法,但您可以根据需要进行更改。我们之前也讨论过。
步骤 5-然后,最后,您可以单击刷新按钮或完成按钮。我们单击“完成”按钮,它将保存在设计器面板中。
如前所述,屏幕截图将生成一个容器,其中收录活动和选择器的每个活动部分。
我们可以在以下屏幕截图中看到输出 -
抓取网页数据工具(最新版提取的教程示例-感兴趣提取教程提取篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-30 13:37
用于 Web 数据抓取工具的 json 提取示例。用过最新版优采云采集器V9的朋友应该都发现V9增加了json提取功能,但是很多使用网页数据抓取工具的朋友都在操作这个功能的话,会觉得有点糊涂。这里有一个json提取的教程示例,供大家参考。有兴趣的朋友可以仔细研究一下。首先,您需要了解 JSON 有两种结构。简单的说,json在javascript中是一个对象和一个数组,所以这两个结构体就是对象和数组。通过这两种结构可以表达各种复杂的结构。下面是1、对象的具体说明:该对象在js中表示为“{}”括起来的内容,并且数据结构是键值对{key: value, key: value,...}的结构,在面向对象语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。
并且我们可以发现这个 URL 的整个源代码是一个完整的 JSON。所以选择JSON数据源的URL并检查循环匹配,您可以采集到整个JSON中的数据。如图:2、 JSON 数据源:JSON 文本:另一种情况,URL 中的源代码并非全部为 JSON,只是部分代码采用 JSON 形式。这时候,我们需要提取这个JSON文本,然后对其进行格式化。比如URL,那么我们需要以多页的形式在这个页面的地址中获取这部分JSON代码,然后设置JSON格式。按照上面的步骤,就完成了两次JSON的提取。您认为它简单易用吗?所以网页数据爬取工具首选优采云采集器 V9, 查看全部
抓取网页数据工具(最新版提取的教程示例-感兴趣提取教程提取篇)
用于 Web 数据抓取工具的 json 提取示例。用过最新版优采云采集器V9的朋友应该都发现V9增加了json提取功能,但是很多使用网页数据抓取工具的朋友都在操作这个功能的话,会觉得有点糊涂。这里有一个json提取的教程示例,供大家参考。有兴趣的朋友可以仔细研究一下。首先,您需要了解 JSON 有两种结构。简单的说,json在javascript中是一个对象和一个数组,所以这两个结构体就是对象和数组。通过这两种结构可以表达各种复杂的结构。下面是1、对象的具体说明:该对象在js中表示为“{}”括起来的内容,并且数据结构是键值对{key: value, key: value,...}的结构,在面向对象语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。在面向对象的语言中,key是对象的属性,value是属性值,所以很容易理解。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value 方法是获取属性值值的对象键。该属性值的类型可以是数字、字符串、数组或对象。. 2、Array:js中的数组是括号“[]”括起来的内容,数据结构是["java","javascript","vb",...],取值方法和所有语言同中,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。value方法和所有语言一样,使用索引获取,字段值的类型可以是数字、字符串、数组和对象。在对象和数组这两种结构之后,就可以组合成一个复杂的数据结构。
并且我们可以发现这个 URL 的整个源代码是一个完整的 JSON。所以选择JSON数据源的URL并检查循环匹配,您可以采集到整个JSON中的数据。如图:2、 JSON 数据源:JSON 文本:另一种情况,URL 中的源代码并非全部为 JSON,只是部分代码采用 JSON 形式。这时候,我们需要提取这个JSON文本,然后对其进行格式化。比如URL,那么我们需要以多页的形式在这个页面的地址中获取这部分JSON代码,然后设置JSON格式。按照上面的步骤,就完成了两次JSON的提取。您认为它简单易用吗?所以网页数据爬取工具首选优采云采集器 V9,
抓取网页数据工具(2019-04-01EnglishVersionMagiBot)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-30 03:10
关于 MagiBot 抓取程序2019-04-01
英文版
魔法机器人
MagiBot(软件项目名称Matarael,以下简称MagiBot)是一款网络爬虫工具(也称“蜘蛛程序”)。爬行是指 MagiBot 提取新的 Web 内容并更新 Web 内容和索引的过程。
我们(以下“我们”可能指MagiBot、Magi项目的其他软件,或Peak Labs Limited本身)将使用大量计算机进行上述“抓取”过程,在此过程中,MagiBot将按照一定的规律工作。算法并决定要爬取的网站、频率和顺序等特征。
限制或禁止 MagiBot 在 网站 上抓取您的内容
如果您想限制或禁止MagiBot爬取您在网站上的内容,除了使用一些系统方法拒绝网络爬虫的访问和爬取外,您还可以设置robots规则来引导MagiBot爬取。
MagiBot 将严格遵守机器人排除协议及类似变体,包括但不限于robots.txt、x-robots-tags、rel 等标注方式。在解析你的规则集时,MagiBot 会优先处理两个 User-Agents 下的规则,magibot 或 matarael(不区分大小写)。
MagiBot 还支持元标记,例如 noindex、nofollow、nosnippet 和 noarchive,以限制索引和搜索显示。
在极少数特殊情况下,MagiBot 可能会针对您的禁止列表中收录的路径发起请求,但不会使用或索引此信息。其他一些搜索引擎有时会使用锚点等信息为特定的禁止爬取路径(如主页)生成相当于nosnippet的显示,但我们会谨慎处理这种灰色区域行为。
MagiBot 将根据其爬行计划权衡 Keep-Alive 行为。如果您在服务器日志中看到socket abort 或reset 记录,这通常是由于MagiBot 主动断开连接造成的,而不是您的服务器的问题。例如,为了减少双方的带宽和资源占用,我们会在网络传输过程中进行流式分析。当发现JPEG图像的SOF等信息时,如果尺寸不符合一定的标准,可以立即结束请求。
MagiBot 支持的协议和标准
MagiBot 支持并符合大多数现有协议和标准。全面支持IDN(如中文域名)、IPv6、SLD等技术标准。对于标记结构化数据,MagiBot 支持 JSON-LD、Microdata、RDF/RDFa 和 Facebook OGP 词汇,以及它们的许多变体。我们有能力从纯文本中提取和学习结构化知识和概念,但仍然建议网站管理者在清晰的信息和实体上使用结构化数据标注,以优化在各种搜索引擎和社交网络中的展示效果。
MagiBot 捕捉智能手机应用程序的内容
MagiBot 具有主动抓取移动应用程序内容的能力。作为一项全新的技术,我们将在不违反相关用户协议的情况下以自律的方式进行抓取。您可以通过以下任何一种方式阻止我们模拟用户交互和内容抓取:
在清单中声明机器人:'noindex' 在 API 响应的标头中声明 x-robots-tag ='noindex' 查看全部
抓取网页数据工具(2019-04-01EnglishVersionMagiBot)
关于 MagiBot 抓取程序2019-04-01
英文版
魔法机器人
MagiBot(软件项目名称Matarael,以下简称MagiBot)是一款网络爬虫工具(也称“蜘蛛程序”)。爬行是指 MagiBot 提取新的 Web 内容并更新 Web 内容和索引的过程。
我们(以下“我们”可能指MagiBot、Magi项目的其他软件,或Peak Labs Limited本身)将使用大量计算机进行上述“抓取”过程,在此过程中,MagiBot将按照一定的规律工作。算法并决定要爬取的网站、频率和顺序等特征。
限制或禁止 MagiBot 在 网站 上抓取您的内容
如果您想限制或禁止MagiBot爬取您在网站上的内容,除了使用一些系统方法拒绝网络爬虫的访问和爬取外,您还可以设置robots规则来引导MagiBot爬取。
MagiBot 将严格遵守机器人排除协议及类似变体,包括但不限于robots.txt、x-robots-tags、rel 等标注方式。在解析你的规则集时,MagiBot 会优先处理两个 User-Agents 下的规则,magibot 或 matarael(不区分大小写)。
MagiBot 还支持元标记,例如 noindex、nofollow、nosnippet 和 noarchive,以限制索引和搜索显示。
在极少数特殊情况下,MagiBot 可能会针对您的禁止列表中收录的路径发起请求,但不会使用或索引此信息。其他一些搜索引擎有时会使用锚点等信息为特定的禁止爬取路径(如主页)生成相当于nosnippet的显示,但我们会谨慎处理这种灰色区域行为。
MagiBot 将根据其爬行计划权衡 Keep-Alive 行为。如果您在服务器日志中看到socket abort 或reset 记录,这通常是由于MagiBot 主动断开连接造成的,而不是您的服务器的问题。例如,为了减少双方的带宽和资源占用,我们会在网络传输过程中进行流式分析。当发现JPEG图像的SOF等信息时,如果尺寸不符合一定的标准,可以立即结束请求。
MagiBot 支持的协议和标准
MagiBot 支持并符合大多数现有协议和标准。全面支持IDN(如中文域名)、IPv6、SLD等技术标准。对于标记结构化数据,MagiBot 支持 JSON-LD、Microdata、RDF/RDFa 和 Facebook OGP 词汇,以及它们的许多变体。我们有能力从纯文本中提取和学习结构化知识和概念,但仍然建议网站管理者在清晰的信息和实体上使用结构化数据标注,以优化在各种搜索引擎和社交网络中的展示效果。
MagiBot 捕捉智能手机应用程序的内容
MagiBot 具有主动抓取移动应用程序内容的能力。作为一项全新的技术,我们将在不违反相关用户协议的情况下以自律的方式进行抓取。您可以通过以下任何一种方式阻止我们模拟用户交互和内容抓取:
在清单中声明机器人:'noindex' 在 API 响应的标头中声明 x-robots-tag ='noindex'
抓取网页数据工具(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-29 22:27
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载 查看全部
抓取网页数据工具(本文就用Java给大家演示如何抓取网站的数据:(1))
原创链接:
有时由于各种原因,我们需要一些采集数据,但由于不同网站
本文使用Java向您展示如何抓取网站的数据:(1)抓取原创网页的数据;(2)抓取网页JavaScript返回的数据
一、抓取原创页面
在本例中,我们将从以下位置获取IP查询的结果:
步骤1:打开此网页,输入IP:111.142.55.73,然后单击查询按钮查看网页上显示的结果:
第二步:查看web源代码。我们可以看到源代码中有一段:
从这里可以看出,查询结果是在重新请求网页后显示的
我们来看看查询后的网址:
换言之,只要访问这样的网站,我们就可以得到IP查询的结果。接下来,看看代码:
[爪哇]
publicvoidcaptureHtml(Stringip)通过异常{StringstrURL=“”+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferer=newBufferedReader(input);Stringline=“;StringBuildercontentBuf=newStringBuilder();而(((line=bufrader.Readline())!=null){contentbuf.Append(line);}stringbuf=contentbuf.Tostring();intbeginix=buf.Indexof(“查询结果[”);intendix=buf.Indexof(“上述四项依次显示”);stringresult=buf.Substring(beginix,endix);system.Out.Println(“capturehtml的结果:”“n”+结果);]
使用httpurlconnection连接到网站,使用bufreader保存从网页返回的数据,然后通过自定义解析方法显示结果
我只是随便分析一下。如果我想非常准确地分析它,我需要再次处理它
分析结果如下:
capturehtml()的结果:
查询结果[1]:111.142.55.73==>;1871591241==>;福建省漳州移动
二、在网页上抓取JavaScript返回的结果
有时网站为了保护自己的数据,它不直接在web源代码中返回数据,而是使用JS异步方式返回数据,这可以避免搜索引擎和其他工具捕获网站数据
首先看一下这一页:
第一种方式是查看网页的源代码,但是找不到运单的跟踪信息,因为它是通过JS获得结果的
但有时我们需要获取JS数据。此时我们应该做什么
此时,我们需要使用一个工具:http analyzer,它可以拦截http的交互内容。我们使用这个工具来实现我们的目的
首先,单击开始按钮后,它开始监听web页面的交互
当我们打开网页:,我们可以看到HTTP analyzer列出了该网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除这些数据,然后在网页中输入快递订单号:7,点击查询按钮,然后查看HTTP analyzer的结果:
这是HTTP analyzer点击查询按钮后的结果,我们继续查看:
从上面两幅图可以看出,HTTP analyzer可以截获JS返回的数据并显示在响应内容中,同时可以看到JS请求的网页地址
在这种情况下,我们可以通过分析HTTP analyzer的结果,模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据,当然前提是这些数据没有加密,我们写下JS请求的URL:
然后让程序请求此网页的结果
代码如下:
[爪哇]
publicvoidcaptureJavascript(Stringpostid)通过异常{StringstrURL=“”+postid+”&;channel=&;rnd=0;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),“utf-8”);BufferedReaderBufferReader=NewBuffereder(input);Stringline=”“stringbuildercontentbuf=newstringbuilder();while((line=bufrader.Readline())!=null){contentbuf.Append(line);}system.Out.Println(“capturejavascript()的结果:\n”+contentbuf.Tostring());”
就像两颗豌豆一样。抓取JS的方法与我们抓取原创页面的代码完全相同。我们只是做了一个分析JS的过程
以下是程序执行的结果:
capturejavascript()的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目标已经实现了
希望本文能帮助有需要的朋友。如果您需要该程序的源代码,请点击这里下载
抓取网页数据工具(myBaseforMac(分类管理自由格式数据库软件)推荐给大家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-28 18:14
myBase 7.3 发布更新!myBase 是一种独特的自由格式数据库软件,允许输入非结构化文本、网页、图像、文档、电子邮件甚至任意文件,无论长度或格式如何。所有信息将被自动压缩并以树状结构的轮廓形式存储。欢迎感兴趣的朋友下载体验macdown!
myBase for Mac(用于分类管理的免费格式数据库软件)
现在就下载
myBase for Mac(分类管理的自由格式数据库软件)推荐给大家!通过myBase7.3,您可以轻松快捷地构建多层次、多维度、交叉引用、快速查询、层次分明、清晰的个人知识库
2019-05-0925.84 MB 简体中文
如何从浏览器中抓取网页内容和图片并将它们保存到 myBase 数据库中?
内置网页编辑器,支持直接从浏览器复制粘贴网页内容到数据库,粘贴内容时会尝试自动下载网页中的图片,保存在Base64编码的HTML内容中;如果由于某种原因图片下载失败,例如网站限制图片访问,您可以根据需要手动复制单张图片,然后粘贴到页面相应位置;
另外,部分网站可能需要通过http或socks5代理服务器访问,v7.x b-24+增加了代理服务器设置,可以在选项框中设置
Webcollect插件:除了直接复制粘贴外,还可以考虑安装Webcollect浏览器扩展,在浏览器的右键菜单中添加【Save with myBase】;最新版本的 Webcollect 支持 Firefox/Chrome 浏览器,并且是跨系统平台通用的。Linux、MacOSX、Windows三大主流系统平台;
对于火狐浏览器,可以在myBase中选择Tools-Install Webcollect host for Firefox菜单,然后按照说明在火狐浏览器中打开火狐扩展应用商店,在火狐浏览器中添加Webcollect插件即可完成安装;
Chrome浏览器可以在myBase中选择Tools-Install Webcollect host for Chrome菜单,然后在Chrome浏览器中按照说明打开Chrome扩展应用商店,在Chrome浏览器中添加Webcollect插件即可完成安装;
安装成功后,浏览器右键菜单会自动添加【用myBase7.x保存】;在浏览网页时,您可以使用此工具将页面内容保存到 myBase 数据库中。
新版Webcollect插件采用全新的数据通讯接口,可跨平台使用。支持 myBase 7.0 Beta-26 (Linux, MacOSX, Windows) 及更高版本;旧版本无法感知/接收新版本Webcollect网页内容传输的数据;请务必同时将myBase和WebCollect升级到最新版本,以实现网页保存功能;
注意:如果要保存的网页布局/格式复杂,嵌入的图片元素较多,建议先选择页面的核心内容,尽量排除侧边栏广告等不必要的元素,然后复制或抓取选中的片段,减少不相关图片的下载和资源消耗,同时提高页面内容抓取的成功率;
以上就是小编为大家带来的如何从浏览器中抓取网页内容和图片并保存到myBase数据库中?有需要的朋友,欢迎下载体验macdown! 查看全部
抓取网页数据工具(myBaseforMac(分类管理自由格式数据库软件)推荐给大家)
myBase 7.3 发布更新!myBase 是一种独特的自由格式数据库软件,允许输入非结构化文本、网页、图像、文档、电子邮件甚至任意文件,无论长度或格式如何。所有信息将被自动压缩并以树状结构的轮廓形式存储。欢迎感兴趣的朋友下载体验macdown!
myBase for Mac(用于分类管理的免费格式数据库软件)
现在就下载
myBase for Mac(分类管理的自由格式数据库软件)推荐给大家!通过myBase7.3,您可以轻松快捷地构建多层次、多维度、交叉引用、快速查询、层次分明、清晰的个人知识库
2019-05-0925.84 MB 简体中文
如何从浏览器中抓取网页内容和图片并将它们保存到 myBase 数据库中?
内置网页编辑器,支持直接从浏览器复制粘贴网页内容到数据库,粘贴内容时会尝试自动下载网页中的图片,保存在Base64编码的HTML内容中;如果由于某种原因图片下载失败,例如网站限制图片访问,您可以根据需要手动复制单张图片,然后粘贴到页面相应位置;
另外,部分网站可能需要通过http或socks5代理服务器访问,v7.x b-24+增加了代理服务器设置,可以在选项框中设置
Webcollect插件:除了直接复制粘贴外,还可以考虑安装Webcollect浏览器扩展,在浏览器的右键菜单中添加【Save with myBase】;最新版本的 Webcollect 支持 Firefox/Chrome 浏览器,并且是跨系统平台通用的。Linux、MacOSX、Windows三大主流系统平台;
对于火狐浏览器,可以在myBase中选择Tools-Install Webcollect host for Firefox菜单,然后按照说明在火狐浏览器中打开火狐扩展应用商店,在火狐浏览器中添加Webcollect插件即可完成安装;
Chrome浏览器可以在myBase中选择Tools-Install Webcollect host for Chrome菜单,然后在Chrome浏览器中按照说明打开Chrome扩展应用商店,在Chrome浏览器中添加Webcollect插件即可完成安装;
安装成功后,浏览器右键菜单会自动添加【用myBase7.x保存】;在浏览网页时,您可以使用此工具将页面内容保存到 myBase 数据库中。
新版Webcollect插件采用全新的数据通讯接口,可跨平台使用。支持 myBase 7.0 Beta-26 (Linux, MacOSX, Windows) 及更高版本;旧版本无法感知/接收新版本Webcollect网页内容传输的数据;请务必同时将myBase和WebCollect升级到最新版本,以实现网页保存功能;
注意:如果要保存的网页布局/格式复杂,嵌入的图片元素较多,建议先选择页面的核心内容,尽量排除侧边栏广告等不必要的元素,然后复制或抓取选中的片段,减少不相关图片的下载和资源消耗,同时提高页面内容抓取的成功率;
以上就是小编为大家带来的如何从浏览器中抓取网页内容和图片并保存到myBase数据库中?有需要的朋友,欢迎下载体验macdown!
抓取网页数据工具( 2.-type-gt-item数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-28 18:10
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
抓取网页数据工具(
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
抓取网页数据工具(浏览器打开网页的过程(Inspect爬虫)的那些数据集合 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-28 18:09
)
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是一个丰富多彩的数据集合,爬虫获取网页的源代码html。
有时候,我们在网页的html代码中找不到我们想要的数据,但是浏览器打开的网页却有这些数据。这就是浏览器通过ajax技术异步加载(偷偷下载)这些数据。
小猴子不禁要问:那我怎么能看到浏览器偷偷下载的数据呢?
答案是谷歌浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器页面的左侧或下方(可调整),如下所示:
让我们简单了解一下它是如何使用的:
谷歌浏览器抓包:1.菜单顶行
暂时把剩下的放在一边。
谷歌浏览器抓包:2.重要区域
图中红框中的两个按钮比较实用,数字2是清除请求记录;数字3是保留记录,在网页有重定向的时候很有用
图中绿色区域是加载一个完整的网页,浏览器的所有请求记录,包括URL、状态、类型等,写爬虫的时候一定要在这里寻找线索提金。
底部编号为 4 的红框表示该网页已加载 181 次。数量如此惊人,让人不禁为浏览器感到惋惜。
点击请求的URL,右侧会出现一个新窗口,显示请求的信念信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详情窗口包括 Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和 Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers帮助我们在爬虫中重构http请求,让爬虫可以得到和浏览器一样的数据。
了解并熟练使用Chrome的开发者工具,小猿们可以流畅的编写自己的爬虫了。
还有上一篇科普文章,我们进入正题,下一篇我们会讲:
为什么 Python 适合编写网络爬虫
查看全部
抓取网页数据工具(浏览器打开网页的过程(Inspect爬虫)的那些数据集合
)
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样的。浏览器渲染出来的网页是一个丰富多彩的数据集合,爬虫获取网页的源代码html。
有时候,我们在网页的html代码中找不到我们想要的数据,但是浏览器打开的网页却有这些数据。这就是浏览器通过ajax技术异步加载(偷偷下载)这些数据。
小猴子不禁要问:那我怎么能看到浏览器偷偷下载的数据呢?
答案是谷歌浏览器的F12快捷键。也可以通过右键菜单“Inspect”打开Chrome自带的开发者工具。开发者工具会出现在浏览器页面的左侧或下方(可调整),如下所示:
让我们简单了解一下它是如何使用的:
谷歌浏览器抓包:1.菜单顶行
暂时把剩下的放在一边。
谷歌浏览器抓包:2.重要区域
图中红框中的两个按钮比较实用,数字2是清除请求记录;数字3是保留记录,在网页有重定向的时候很有用
图中绿色区域是加载一个完整的网页,浏览器的所有请求记录,包括URL、状态、类型等,写爬虫的时候一定要在这里寻找线索提金。
底部编号为 4 的红框表示该网页已加载 181 次。数量如此惊人,让人不禁为浏览器感到惋惜。
点击请求的URL,右侧会出现一个新窗口,显示请求的信念信息:
图中左边的红框是点击的请求URL;绿色框是详细信息窗口。
详情窗口包括 Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和 Timing(耗时)。
Preview 和 Response 帮助我们检查请求中是否有爬虫想要的数据;
headers帮助我们在爬虫中重构http请求,让爬虫可以得到和浏览器一样的数据。
了解并熟练使用Chrome的开发者工具,小猿们可以流畅的编写自己的爬虫了。
还有上一篇科普文章,我们进入正题,下一篇我们会讲:
为什么 Python 适合编写网络爬虫
抓取网页数据工具(爬虫网页数据案例分享-爬虫获取网页信息的案例分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-25 00:16
我们经常采集一些数据,但是当数据比较小时,人们会习惯性地手动下载,但是如果数量非常大,我肯定想找一个工具来帮助采集它。
比如一些采集的工具,但是由于这些工具都设置好了,就不能满足我们的需求。如果要求较低,则将使用它们。要求高的话,不如自己做个爬虫,想什么就去抓取什么。
关键是看能不能写爬虫?事实上,这很简单。下面给大家分享一下爬取网页数据的案例。
1.获取网页信息
Urllib 模块提供了读取网页数据的接口。我们可以像读取本地文件一样读取 www 和 ftp 上的数据。首先,我们定义一个 getHtml() 函数:
urllib.urlopen() 方法用于打开一个 URL 地址。
read() 方法用于读取 URL 上的数据,将 URL 传递给 getHtml() 函数,并下载整个页面。执行该程序将打印出整个网页。
2.过滤页面数据
Python提供了非常强大的正则表达式,我们需要了解一点Python正则表达式的知识。
如果我们在百度贴吧上发现了几张漂亮的壁纸,请前往上一节查看工具。找到图片的地址,如:src=""pic_ext="jpeg"
修改代码如下:
我们已经创建了 getImg() 函数来过滤整个页面中所需的图片链接。re 模块主要收录正则表达式:
pile() 可以将正则表达式编译成正则表达式对象。
re.findall() 方法读取html中收录imgre(正则表达式)的数据。
运行脚本会得到整个页面中图片的URL地址。
3.数据保存
通过for循环遍历筛选出的图片地址并保存到本地,代码如下:
这里的核心是使用urllib.urlretrieve()方法将远程数据直接下载到本地。
通过for循环遍历得到的图片连接,为了让图片的文件名看起来更规范,重命名,命名规则给x变量加1。存储位置默认为程序的存储目录。程序运行后,会在目录中看到下载到本地的文件。
以上就是爬虫爬取网页数据的案例分享。如今,大数据时代,数据海量。有必要采集足够的数据进行分析,以获得有价值的结果。大家在爬取数据的时候记得使用代理IP,这样爬虫就可以高效爬取数据,在更短的时间内产生结果。查找代理IP,黑洞代理非常好,不仅可以使用全国IP地址,而且高度匿名,效果更好。 查看全部
抓取网页数据工具(爬虫网页数据案例分享-爬虫获取网页信息的案例分析)
我们经常采集一些数据,但是当数据比较小时,人们会习惯性地手动下载,但是如果数量非常大,我肯定想找一个工具来帮助采集它。
比如一些采集的工具,但是由于这些工具都设置好了,就不能满足我们的需求。如果要求较低,则将使用它们。要求高的话,不如自己做个爬虫,想什么就去抓取什么。
关键是看能不能写爬虫?事实上,这很简单。下面给大家分享一下爬取网页数据的案例。
1.获取网页信息
Urllib 模块提供了读取网页数据的接口。我们可以像读取本地文件一样读取 www 和 ftp 上的数据。首先,我们定义一个 getHtml() 函数:
urllib.urlopen() 方法用于打开一个 URL 地址。
read() 方法用于读取 URL 上的数据,将 URL 传递给 getHtml() 函数,并下载整个页面。执行该程序将打印出整个网页。
2.过滤页面数据
Python提供了非常强大的正则表达式,我们需要了解一点Python正则表达式的知识。
如果我们在百度贴吧上发现了几张漂亮的壁纸,请前往上一节查看工具。找到图片的地址,如:src=""pic_ext="jpeg"
修改代码如下:
我们已经创建了 getImg() 函数来过滤整个页面中所需的图片链接。re 模块主要收录正则表达式:
pile() 可以将正则表达式编译成正则表达式对象。
re.findall() 方法读取html中收录imgre(正则表达式)的数据。
运行脚本会得到整个页面中图片的URL地址。
3.数据保存
通过for循环遍历筛选出的图片地址并保存到本地,代码如下:
这里的核心是使用urllib.urlretrieve()方法将远程数据直接下载到本地。
通过for循环遍历得到的图片连接,为了让图片的文件名看起来更规范,重命名,命名规则给x变量加1。存储位置默认为程序的存储目录。程序运行后,会在目录中看到下载到本地的文件。
以上就是爬虫爬取网页数据的案例分享。如今,大数据时代,数据海量。有必要采集足够的数据进行分析,以获得有价值的结果。大家在爬取数据的时候记得使用代理IP,这样爬虫就可以高效爬取数据,在更短的时间内产生结果。查找代理IP,黑洞代理非常好,不仅可以使用全国IP地址,而且高度匿名,效果更好。
抓取网页数据工具(互联网刚兴起的时候,数据索引是个大问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-22 00:08
1、互联网刚刚兴起时,数据索引是一个大问题。当时,雅虎的分类页面一度非常热门
2、随着互联网上数据量的不断增加,谷歌和百度等搜索引擎正在熊熊燃烧。在这个阶段,很少有技术比搜索引擎更受欢迎,分词技术也一团糟。然后,nutch和其他开源搜索引擎诞生了,这让人们一见钟情!许多人和公司试图将其用于商业目的。但这些东西都是牛叉,使用起来并不总是那么顺畅。首先,它不是很稳定;第二,它太复杂了。很难进行二次开发以满足自身需求
3、由于通用搜索引擎不太方便,所以让它更简单、更有针对性。所以爬虫技术的兴起,酷新闻就是其中比较成功的一种。依靠它的技术,他后来建造了99间房间,然后一路登上了今天的头条新闻
4、随着越来越多的人参与互联网,许多人确实希望从互联网上捕获数据,因为他们的需求不同,但他们希望更简单,开发成本低,速度更快。出现了很多开源工具。Curl已经被大量使用了一段时间,诸如htmlcxx和Htmlparser等HTML解析工具也被广泛使用优采云只是由傻瓜式构成,没有开发功能。它只能在配置后自动运行
@到目前为止,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然强劲。用于数据捕获的在线工具、开源代码、抓取很多、jsoup、spyner等。然而,数据捕获仍然有点困难,原因有四:一、每个公司都有不同的需求,这使得商业化非常困难二、WEB页面本身非常复杂和混乱,JavaScript使得爬行无法控制三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合基于开源库或工具开发的严肃商业应用四、来完成自己的需求,仍然存在一些困难和大量工作量
@因此,一个好的抓取工具(开源库)应该具有以下特性:一、simple。系统不应该太复杂,界面应该一目了然,以降低二、power的开发成本。最好捕获您可以在web页面上看到的数据,包括JavaScript输出。数据捕获的很大一部分是寻找数据。例如,没有地理坐标数据,因此需要花费大量精力才能在三、方便时完成这些数据。最好提供可以控制的开发库,即如何捕获和部署,而不是被困在整个系统四、flexible中。它可以快速实现各种需求,即可以快速捕获简单数据或构建更复杂的数据应用程序五、stable。可以输出稳定的数据,不需要每天调整bug和查找数据。当需求有点复杂,数据量有点大的时候,需要进行大量的二次开发,耗费大量的人力和时间六、可以集成。借助现有的技术力量七、Control,通过开发环境,它可以快速建立数据系统。企业应用是长期积累的。如果数据和流程掌握在第三方手中,则可控性差,对需求变化的响应慢,风险高八、1。它可以提供一些特性来帮助开发人员实现结构化数据的提取和关联,从而避免为每个页面编写数据解析器
很多公司在数据采集方面投入了大量精力,但效果往往不是很好,可持续发展能力也相对较差。这主要是由于基本工具选择不当。因此,让我们整理一些可用的数据捕获工具和开源库。比较它们的优缺点,为开发人员提供参考
一、系统等级:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索
纳奇:
语言:Java
官方网站:
Nutch是一个用Java实现的开源搜索引擎。它提供全文搜索、网络爬虫、页面调度、数据存储等功能。它几乎可以看作是一个完整的通用搜索引擎。它适用于页面大小较大(数十亿)且只有文本索引数据(很少是结构化数据)的应用程序。Nutch有利于研究
Heritrix:
语言:Java
官方网站:
简介:heritrix是一个开源的网络爬虫系统。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,便于用户实现自己的爬网逻辑。Heritrix集成了索引调度、页面解析和数据存储
其他包括dataparksearch和web harvest
网络类:
卷曲
语言:C(但它也支持命令行和其他语言绑定)
官方网站:
简介:curl是一个古老的HTTP网络库(同时支持FTP和其他协议)。Curl支持丰富的网络功能,包括SSL、cookie、表单等。它是一个广泛使用的网络库。卷曲有弹性,但有点复杂。提供了数据下载,但不支持HTML解析。它通常需要与其他库一起使用
汤
语言:C
官方网站:
简介:soup是另一个HTTP网络库,依赖glib,功能强大稳定。然而,国内文献很少
浏览器类:
这些工具通常基于浏览器(如Firefox)进行扩展。由于浏览器的强大功能,他们可以采集获得更完整的数据,尤其是JavaScript输出的数据。但应用范围稍有局限,扩展不方便,数据量大时难以适应
ParseHub:
语言:Firefox扩展
官方网站:
简介:parsehub是基于Firefox的页面分析工具,可以支持更复杂的功能,包括页面结构分析
谷歌搜索者集合搜索
语言:Firefox扩展
官方网站:
导言:Gooseek也是基于Firefox的扩展。它支持更复杂的功能,包括索引图片、计时采集、可视化编程等
采集终端等级:
此类工具一般支持Windows图形界面,基本上不需要编写代码。更典型的数据可以通过配置规则来实现采集. 但是,数据提取能力一般,扩展有限,更复杂应用的二次开发成本不低
优采云
语言:许可软件
平台:Windows
官方网站:
优采云是一个旧的采集软件。随着无数个人站长的成长,它具有很强的可配置性,可以实现数据传输。它非常适合个人快速数据采集和政府机构的民意监测
优采云采集器
语言:许可软件
平台:Windows
官方网站:
简介:优采云采集器它具有多种功能,支持新闻的一般分析,广泛应用于舆论中
图书馆类别:
它是通过开源库或工具库提供的。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发人员自己实现。该方法非常灵活,适用于复杂数据采集和大规模数据采集。这些库的差异主要体现在以下几个方面:一、语言应用。许多库只适用于一种语言二、的功能差异。大多数库只支持HTML,不支持JS、CSS和其他动态数据三、interface。一些库提供函数级接口,而另一些库提供对象级接口四、stability。一些图书馆是认真的,而另一些则在逐步改进
简单HTML DOM解析器
语言:PHP
官方网站:
简介:PHP扩展模块支持HTML标记的解析。它提供了一个类似于jQuery的函数级接口,具有简单的函数,适合解析简单的HTML页面。它将很难成为一个数据引擎
JSoup
语言:Java
官方网站:
简介:jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
斯宾纳
语言:Python
官方网站:
简介:spyner是一个基于QT WebKit的1000行Python脚本。与urllib相比,最大的特点是支持动态内容的捕获。Spyner依赖于xvfb和QT。由于需要进行页面渲染,因此速度较慢
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,它提供了一系列清晰的函数和DOM数据结构。它简单明了,但功能强大,适用性强。Qing支持JavaScript和CSS,因此它非常支持动态内容。除此之外,青还支持后台图像加载、滚动加载、本地缓存、加载策略等功能。Qing快速、强大、稳定,开发效率高。对于企业来说,构建数据仓库是一个很好的选择 查看全部
抓取网页数据工具(互联网刚兴起的时候,数据索引是个大问题)
1、互联网刚刚兴起时,数据索引是一个大问题。当时,雅虎的分类页面一度非常热门
2、随着互联网上数据量的不断增加,谷歌和百度等搜索引擎正在熊熊燃烧。在这个阶段,很少有技术比搜索引擎更受欢迎,分词技术也一团糟。然后,nutch和其他开源搜索引擎诞生了,这让人们一见钟情!许多人和公司试图将其用于商业目的。但这些东西都是牛叉,使用起来并不总是那么顺畅。首先,它不是很稳定;第二,它太复杂了。很难进行二次开发以满足自身需求
3、由于通用搜索引擎不太方便,所以让它更简单、更有针对性。所以爬虫技术的兴起,酷新闻就是其中比较成功的一种。依靠它的技术,他后来建造了99间房间,然后一路登上了今天的头条新闻
4、随着越来越多的人参与互联网,许多人确实希望从互联网上捕获数据,因为他们的需求不同,但他们希望更简单,开发成本低,速度更快。出现了很多开源工具。Curl已经被大量使用了一段时间,诸如htmlcxx和Htmlparser等HTML解析工具也被广泛使用优采云只是由傻瓜式构成,没有开发功能。它只能在配置后自动运行
@到目前为止,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然强劲。用于数据捕获的在线工具、开源代码、抓取很多、jsoup、spyner等。然而,数据捕获仍然有点困难,原因有四:一、每个公司都有不同的需求,这使得商业化非常困难二、WEB页面本身非常复杂和混乱,JavaScript使得爬行无法控制三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合基于开源库或工具开发的严肃商业应用四、来完成自己的需求,仍然存在一些困难和大量工作量
@因此,一个好的抓取工具(开源库)应该具有以下特性:一、simple。系统不应该太复杂,界面应该一目了然,以降低二、power的开发成本。最好捕获您可以在web页面上看到的数据,包括JavaScript输出。数据捕获的很大一部分是寻找数据。例如,没有地理坐标数据,因此需要花费大量精力才能在三、方便时完成这些数据。最好提供可以控制的开发库,即如何捕获和部署,而不是被困在整个系统四、flexible中。它可以快速实现各种需求,即可以快速捕获简单数据或构建更复杂的数据应用程序五、stable。可以输出稳定的数据,不需要每天调整bug和查找数据。当需求有点复杂,数据量有点大的时候,需要进行大量的二次开发,耗费大量的人力和时间六、可以集成。借助现有的技术力量七、Control,通过开发环境,它可以快速建立数据系统。企业应用是长期积累的。如果数据和流程掌握在第三方手中,则可控性差,对需求变化的响应慢,风险高八、1。它可以提供一些特性来帮助开发人员实现结构化数据的提取和关联,从而避免为每个页面编写数据解析器
很多公司在数据采集方面投入了大量精力,但效果往往不是很好,可持续发展能力也相对较差。这主要是由于基本工具选择不当。因此,让我们整理一些可用的数据捕获工具和开源库。比较它们的优缺点,为开发人员提供参考
一、系统等级:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索
纳奇:
语言:Java
官方网站:
Nutch是一个用Java实现的开源搜索引擎。它提供全文搜索、网络爬虫、页面调度、数据存储等功能。它几乎可以看作是一个完整的通用搜索引擎。它适用于页面大小较大(数十亿)且只有文本索引数据(很少是结构化数据)的应用程序。Nutch有利于研究
Heritrix:
语言:Java
官方网站:
简介:heritrix是一个开源的网络爬虫系统。用户可以使用它从互联网上获取所需的资源。其最大的特点是具有良好的可扩展性,便于用户实现自己的爬网逻辑。Heritrix集成了索引调度、页面解析和数据存储
其他包括dataparksearch和web harvest
网络类:
卷曲
语言:C(但它也支持命令行和其他语言绑定)
官方网站:
简介:curl是一个古老的HTTP网络库(同时支持FTP和其他协议)。Curl支持丰富的网络功能,包括SSL、cookie、表单等。它是一个广泛使用的网络库。卷曲有弹性,但有点复杂。提供了数据下载,但不支持HTML解析。它通常需要与其他库一起使用
汤
语言:C
官方网站:
简介:soup是另一个HTTP网络库,依赖glib,功能强大稳定。然而,国内文献很少
浏览器类:
这些工具通常基于浏览器(如Firefox)进行扩展。由于浏览器的强大功能,他们可以采集获得更完整的数据,尤其是JavaScript输出的数据。但应用范围稍有局限,扩展不方便,数据量大时难以适应
ParseHub:
语言:Firefox扩展
官方网站:
简介:parsehub是基于Firefox的页面分析工具,可以支持更复杂的功能,包括页面结构分析
谷歌搜索者集合搜索
语言:Firefox扩展
官方网站:
导言:Gooseek也是基于Firefox的扩展。它支持更复杂的功能,包括索引图片、计时采集、可视化编程等
采集终端等级:
此类工具一般支持Windows图形界面,基本上不需要编写代码。更典型的数据可以通过配置规则来实现采集. 但是,数据提取能力一般,扩展有限,更复杂应用的二次开发成本不低
优采云
语言:许可软件
平台:Windows
官方网站:
优采云是一个旧的采集软件。随着无数个人站长的成长,它具有很强的可配置性,可以实现数据传输。它非常适合个人快速数据采集和政府机构的民意监测
优采云采集器
语言:许可软件
平台:Windows
官方网站:
简介:优采云采集器它具有多种功能,支持新闻的一般分析,广泛应用于舆论中
图书馆类别:
它是通过开源库或工具库提供的。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发人员自己实现。该方法非常灵活,适用于复杂数据采集和大规模数据采集。这些库的差异主要体现在以下几个方面:一、语言应用。许多库只适用于一种语言二、的功能差异。大多数库只支持HTML,不支持JS、CSS和其他动态数据三、interface。一些库提供函数级接口,而另一些库提供对象级接口四、stability。一些图书馆是认真的,而另一些则在逐步改进
简单HTML DOM解析器
语言:PHP
官方网站:
简介:PHP扩展模块支持HTML标记的解析。它提供了一个类似于jQuery的函数级接口,具有简单的函数,适合解析简单的HTML页面。它将很难成为一个数据引擎
JSoup
语言:Java
官方网站:
简介:jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
斯宾纳
语言:Python
官方网站:
简介:spyner是一个基于QT WebKit的1000行Python脚本。与urllib相比,最大的特点是支持动态内容的捕获。Spyner依赖于xvfb和QT。由于需要进行页面渲染,因此速度较慢
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,它提供了一系列清晰的函数和DOM数据结构。它简单明了,但功能强大,适用性强。Qing支持JavaScript和CSS,因此它非常支持动态内容。除此之外,青还支持后台图像加载、滚动加载、本地缓存、加载策略等功能。Qing快速、强大、稳定,开发效率高。对于企业来说,构建数据仓库是一个很好的选择
抓取网页数据工具(如何使用大数据分析R语言rvest中进行网络抓取的基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 00:04
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中找到所需数据来获取待分析数据的技术
在如何使用大数据分析R语言rvest抓取网页中,我们将介绍如何使用大数据分析R语言抓取网页的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在如何使用大数据分析R语言rvest进行网页捕获中,我们将主要关注如何使用大数据分析R语言web捕获来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:
尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法涵盖如何使用大数据分析R语言rvest捕获网页中的所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:
文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:
我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:
将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在如何使用大数据分析R语言rvest进行网页捕获方面,我们感兴趣的是网页捕获,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样
如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在如何使用大数据分析R语言rvest抓取网页中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它
要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的数据问题。github。IO/Web SC大数据分析R语言aping pages/simple。HTML“)
大数据分析R语言ead_html()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们想将单个标记中收录的文本存储在一个变量中。为了访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常会在网站处显式地放置CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用html_nodes()和html_text()函数搜索页面
标记并检索文本。以下代码执行此操作:
简单变量已经收录我们想要获取的HTML,因此剩下的任务是搜索所需的元素。因为我们使用的是tidyve big data analysis R语言se,所以我们可以将HTML传递给不同的函数
我们需要将一个特定的HTML标记或CSS类传递给HTML_nodes()函数。我们需要一个标记,因此我们将字符“p”传递给函数。HTML_nodes()还返回一个列表,但它返回HTML中具有给定特定HTML标记或CSS类/ID的所有节点。节点指的是树结构中的一个点
一旦拥有所有这些节点,就可以将输出传递给html_nodes()函数
这些 查看全部
抓取网页数据工具(如何使用大数据分析R语言rvest中进行网络抓取的基础知识)
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中找到所需数据来获取待分析数据的技术
在如何使用大数据分析R语言rvest抓取网页中,我们将介绍如何使用大数据分析R语言抓取网页的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在如何使用大数据分析R语言rvest进行网页捕获中,我们将主要关注如何使用大数据分析R语言web捕获来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:
尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法涵盖如何使用大数据分析R语言rvest捕获网页中的所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:
文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:
我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:
将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在如何使用大数据分析R语言rvest进行网页捕获方面,我们感兴趣的是网页捕获,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样
如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在如何使用大数据分析R语言rvest抓取网页中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它
要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的数据问题。github。IO/Web SC大数据分析R语言aping pages/simple。HTML“)
大数据分析R语言ead_html()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们想将单个标记中收录的文本存储在一个变量中。为了访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常会在网站处显式地放置CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用html_nodes()和html_text()函数搜索页面
标记并检索文本。以下代码执行此操作:
简单变量已经收录我们想要获取的HTML,因此剩下的任务是搜索所需的元素。因为我们使用的是tidyve big data analysis R语言se,所以我们可以将HTML传递给不同的函数
我们需要将一个特定的HTML标记或CSS类传递给HTML_nodes()函数。我们需要一个标记,因此我们将字符“p”传递给函数。HTML_nodes()还返回一个列表,但它返回HTML中具有给定特定HTML标记或CSS类/ID的所有节点。节点指的是树结构中的一个点
一旦拥有所有这些节点,就可以将输出传递给html_nodes()函数
这些
抓取网页数据工具(WebHarvyWebHarvy网页数据抓取工具的分类及使用方法介绍!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-18 23:17
Webhard是sysnucleus推出的实用网页数据捕获工具。软件界面简单直观,易于使用。它可以有效地从指定的网页中提取各种数据,包括文本、URL、图像等,主要解决一些网页受限、无法复制或保存图像的问题。它具有智能操作模式,无需编写脚本即可使用。它还可以提取基本关键字。如有需要,欢迎下载
网络共享功能
一、直观操作界面
Webhard是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览web。您可以选择使用鼠标单击来提取数据。这太容易了
二、智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
三、导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
四、从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
@基于五、关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
七、使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
安装教程
1、双击“setup.Exe”开始软件安装
2、单击“下一步”显示协议并选择“我同意”
3、选择安装位置。默认值为“C:\users\administrator\appdata\roaming\sysnucleus\webhard\”
4、如下图所示,点击〖安装〗按钮进行安装
5、我们马上就可以完成webharvy的安装 查看全部
抓取网页数据工具(WebHarvyWebHarvy网页数据抓取工具的分类及使用方法介绍!)
Webhard是sysnucleus推出的实用网页数据捕获工具。软件界面简单直观,易于使用。它可以有效地从指定的网页中提取各种数据,包括文本、URL、图像等,主要解决一些网页受限、无法复制或保存图像的问题。它具有智能操作模式,无需编写脚本即可使用。它还可以提取基本关键字。如有需要,欢迎下载
网络共享功能
一、直观操作界面
Webhard是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览web。您可以选择使用鼠标单击来提取数据。这太容易了
二、智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
三、导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
四、从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
@基于五、关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
六、提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
七、使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
安装教程
1、双击“setup.Exe”开始软件安装
2、单击“下一步”显示协议并选择“我同意”
3、选择安装位置。默认值为“C:\users\administrator\appdata\roaming\sysnucleus\webhard\”
4、如下图所示,点击〖安装〗按钮进行安装
5、我们马上就可以完成webharvy的安装
抓取网页数据工具(网探网页数据监控软件功能介绍-上海怡健医学(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-09-17 17:21
Netprobe数据监控软件是用于监控网页数据的软件。它具有全自动全时监控和强大的数据采集功能,让您可以找到最有用的数据。有需要的朋友可以在易趣上下载
网络探测软件简介
Netprobe是一款网页数据监控软件,是一款基于IE浏览器的轻量级紧凑型互联网工具,可以轻松处理无人值守的7x24小时长时间工作。Netprobe网页数据监控软件可以安装在XP/Vista/win7/win10(x86)/x64)在环境中运行
网络勘探数据监测软件功能介绍
1:及时通知用户
注册后,用户可以将验证后的数据发送到微信,也可以将其推送到指定的界面重新处理数据
2:基于IE浏览器
没有任何意义上的反爬虫技术手段。只要在IE浏览器中可以正常浏览网页,就可以监控其中的所有数据
3:同时运行多任务
该程序支持同时运行多个监视任务,用户可以同时监视多个网页中感兴趣的数据
4:网页数据捕获
文本匹配和文档结构分析可以单独使用,也可以结合使用,以使数据捕获更加简单和准确
5:数据比较验证
自动判断最新更新数据,支持自定义数据比对校验公式,过滤出用户最感兴趣的数据内容
6:任务间呼叫
监控任务a(必须是网址)得到的结果可以传输到监控任务B执行,从而得到更丰富的数据结果
7:开放通知界面
直接与您自己的程序连接,定义后续处理过程,并实时高效地访问数据自动处理过程
8:在线分享抓取公式
“人人为我,我为人人”分享任何网页的爬行公式,以避免公式编辑的麻烦
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行中产生的内存垃圾,守护进程长时间无人值守运行 查看全部
抓取网页数据工具(网探网页数据监控软件功能介绍-上海怡健医学(图))
Netprobe数据监控软件是用于监控网页数据的软件。它具有全自动全时监控和强大的数据采集功能,让您可以找到最有用的数据。有需要的朋友可以在易趣上下载
网络探测软件简介
Netprobe是一款网页数据监控软件,是一款基于IE浏览器的轻量级紧凑型互联网工具,可以轻松处理无人值守的7x24小时长时间工作。Netprobe网页数据监控软件可以安装在XP/Vista/win7/win10(x86)/x64)在环境中运行
网络勘探数据监测软件功能介绍
1:及时通知用户
注册后,用户可以将验证后的数据发送到微信,也可以将其推送到指定的界面重新处理数据
2:基于IE浏览器
没有任何意义上的反爬虫技术手段。只要在IE浏览器中可以正常浏览网页,就可以监控其中的所有数据
3:同时运行多任务
该程序支持同时运行多个监视任务,用户可以同时监视多个网页中感兴趣的数据
4:网页数据捕获
文本匹配和文档结构分析可以单独使用,也可以结合使用,以使数据捕获更加简单和准确
5:数据比较验证
自动判断最新更新数据,支持自定义数据比对校验公式,过滤出用户最感兴趣的数据内容
6:任务间呼叫
监控任务a(必须是网址)得到的结果可以传输到监控任务B执行,从而得到更丰富的数据结果
7:开放通知界面
直接与您自己的程序连接,定义后续处理过程,并实时高效地访问数据自动处理过程
8:在线分享抓取公式
“人人为我,我为人人”分享任何网页的爬行公式,以避免公式编辑的麻烦
9:无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行中产生的内存垃圾,守护进程长时间无人值守运行
抓取网页数据工具(web端获取数据获取多网页数据web链接常见格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-17 11:14
一、get-data-from-Web
从Bi桌面“获取数据”中的“Web”选项中,“Web”界面有两个选项卡:“基本”和“高级”。一般来说,“基本”选项卡可以满足日常工作的需要。以下是一些例子
二、get数据
进入web链接后,您将执行导航器的“加载”和“编辑”等常见功能。您只需根据实际工作需要操作即可
三、获取多页数据
Web链接的常见格式如下:结尾处的“1”表示当前链接是数据的第一页,第二页上的数据链接应为“”。当网页数据较大时,如果每次都通过web链接获取数据,会耗费大量时间。但是,组件查询中有相应的函数来简化操作,如下所示:
获取一页数据后,进入编辑查询界面,在编辑查询界面选择高级编辑器页签,高级编辑器界面显示当年的工作路径。与下图类似:
此时,您需要在“let”前面输入“(p作为编号)作为table=>;”;在链接中,修改页码,即“1,2”和上面提到的其他数字“(number.ToText(P))”
注意:有两种类型的Web链接。一是页码数据。在链接结束时,执行上述操作;另一个是链接以结束。HTML。除上述更换操作外,“&;(number.ToText(P))&;”。HTML”))只需单击此处单独定义HTML
四、grab多数据网页
首先,使用空查询创建数字序列。如果要捕获前100页的数据,请创建从1到100的序列,并将其输入空查询={1..100}按enter键生成从1到100的序列,然后将其转换为表
然后调用自定义函数
在弹出窗口中,点击[function query]下拉框,选择刚刚创建的自定义函数数据_zhaopin。其他所有内容默认在线
点击【确定】按钮,开始批量抓取网页,抓取成功,可根据工作需要进行后续操作 查看全部
抓取网页数据工具(web端获取数据获取多网页数据web链接常见格式(图))
一、get-data-from-Web
从Bi桌面“获取数据”中的“Web”选项中,“Web”界面有两个选项卡:“基本”和“高级”。一般来说,“基本”选项卡可以满足日常工作的需要。以下是一些例子
二、get数据
进入web链接后,您将执行导航器的“加载”和“编辑”等常见功能。您只需根据实际工作需要操作即可
三、获取多页数据
Web链接的常见格式如下:结尾处的“1”表示当前链接是数据的第一页,第二页上的数据链接应为“”。当网页数据较大时,如果每次都通过web链接获取数据,会耗费大量时间。但是,组件查询中有相应的函数来简化操作,如下所示:
获取一页数据后,进入编辑查询界面,在编辑查询界面选择高级编辑器页签,高级编辑器界面显示当年的工作路径。与下图类似:
此时,您需要在“let”前面输入“(p作为编号)作为table=>;”;在链接中,修改页码,即“1,2”和上面提到的其他数字“(number.ToText(P))”
注意:有两种类型的Web链接。一是页码数据。在链接结束时,执行上述操作;另一个是链接以结束。HTML。除上述更换操作外,“&;(number.ToText(P))&;”。HTML”))只需单击此处单独定义HTML
四、grab多数据网页
首先,使用空查询创建数字序列。如果要捕获前100页的数据,请创建从1到100的序列,并将其输入空查询={1..100}按enter键生成从1到100的序列,然后将其转换为表
然后调用自定义函数
在弹出窗口中,点击[function query]下拉框,选择刚刚创建的自定义函数数据_zhaopin。其他所有内容默认在线
点击【确定】按钮,开始批量抓取网页,抓取成功,可根据工作需要进行后续操作
抓取网页数据工具(抓取网页数据工具有很多种类,我说两种是flashback)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-16 11:02
抓取网页数据工具有很多种类,下面我说两种,一种是flashback,另一种是flashfd。其中flashback采用的web浏览器为opera,用的是javascript写的,具体fd用什么技术是ruby、python、r、php、java各种语言都有,工具开发环境为windows平台下的eclipse。
优点是简单快捷,比较适合新手去实践。缺点是工具需要java版本;另一种就是flashfd工具采用了flashbridge工具,对浏览器的适配度很高,大部分浏览器支持都做的不错,但是部分浏览器不能完全兼容它,比如刚好有个网站使用微软的activex插件,部分浏览器无法使用就会显示下面的图片,具体安装什么语言的开发环境,可以到它的官网去下载,别再百度问问了,你在问百度不如去问ack。更多关于数据爬虫方面的问题,可以看我的文章或回答。
不请自来。刚用上flashback,对eclipse、idea这些无力吐槽,自带的flashback根本没法用,用起来一点都不方便,遂在网上搜python3.5能否安装这个库。以下是我按照步骤以及yandex上面下载的,给大家参考参考。
嗯...这个刚刚才下了,打开就是这样的然后只能填文本框,只能输入可读的英文字母,不能来回切换中英文,也不能输入图片或者任何js文件,特别麻烦。打开你想要的网页-->这里点击shownewview-->这里点击run-->这里点击savenewview-->这里再选择你要在什么时候保存-->这里就可以选择保存哪一个网页了-->saveas-->这里要按mode来选择了-->这里可以保存为.asp-->这里要记得把你刚刚存文本框的地址-->保存好-->点击run保存-->出现这个窗口时就可以开始运行你想用的插件了-->选中你想用的,就可以运行那个了。 查看全部
抓取网页数据工具(抓取网页数据工具有很多种类,我说两种是flashback)
抓取网页数据工具有很多种类,下面我说两种,一种是flashback,另一种是flashfd。其中flashback采用的web浏览器为opera,用的是javascript写的,具体fd用什么技术是ruby、python、r、php、java各种语言都有,工具开发环境为windows平台下的eclipse。
优点是简单快捷,比较适合新手去实践。缺点是工具需要java版本;另一种就是flashfd工具采用了flashbridge工具,对浏览器的适配度很高,大部分浏览器支持都做的不错,但是部分浏览器不能完全兼容它,比如刚好有个网站使用微软的activex插件,部分浏览器无法使用就会显示下面的图片,具体安装什么语言的开发环境,可以到它的官网去下载,别再百度问问了,你在问百度不如去问ack。更多关于数据爬虫方面的问题,可以看我的文章或回答。
不请自来。刚用上flashback,对eclipse、idea这些无力吐槽,自带的flashback根本没法用,用起来一点都不方便,遂在网上搜python3.5能否安装这个库。以下是我按照步骤以及yandex上面下载的,给大家参考参考。
嗯...这个刚刚才下了,打开就是这样的然后只能填文本框,只能输入可读的英文字母,不能来回切换中英文,也不能输入图片或者任何js文件,特别麻烦。打开你想要的网页-->这里点击shownewview-->这里点击run-->这里点击savenewview-->这里再选择你要在什么时候保存-->这里就可以选择保存哪一个网页了-->saveas-->这里要按mode来选择了-->这里可以保存为.asp-->这里要记得把你刚刚存文本框的地址-->保存好-->点击run保存-->出现这个窗口时就可以开始运行你想用的插件了-->选中你想用的,就可以运行那个了。
抓取网页数据工具(最简单的数据抓取教程,人人都用得上(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2021-09-14 11:18
最简单的数据采集教程,人人都可以使用
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
1.png
2、 并在弹出框中点击“添加扩展”
2.png
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
如果不能FQ,可以使用本地FQ方法。在此公众号回复“爬虫”,即可下载Chrome和Web Scraper扩展程序。
1、打开Chrome,在地址栏中输入chrome://extensions/,进入扩展管理界面,然后将下载的扩展Web-Scraper_v0.3.7.crx拖放到这里页面,点击“添加到扩展”完成安装。如图:
4.gif
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
初识网络爬虫开启网络爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
5.png
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
6.png
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
7.gif
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
8.png
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
9.png
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
10.png
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
11.png
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
12.png
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
13.png
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
14.png
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
15.png
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
16.png
6、然后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选择的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
17.png
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
18.gif
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图可以看到拓扑图。 _root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
19.png
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
20.png
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
21.png
怎么样,现在试试
获取知乎questions 的所有答案
简单介绍完毕。接下来,尝试一个有点难度的,抓取知乎问题的所有答案,包括回答者的昵称,批准数,以及答案的内容。问:为什么炫富的程序员这么少?
知乎的特点是只有向下滚动页面才会加载下一个答案
1、首先在Chrome中打开此链接,链接地址为:,并调出开发者工具,定位到Web Scraper标签栏;
2、新建站点地图,填写站点地图名称和起始网址;
22.png
3、下一步,开始添加选择器,点击添加新选择器;
4、我们先来分析一下知乎问题的结构。如图,一个问题由多个这样的区域组成,一个区域就是一个答案。这个回答区包括昵称、批准号、回答内容和发布。时间等等。红色框起来的部分就是我们要抓取的内容。所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载的答案,找到一个答案区域,提取昵称,批准数,以及里面的答案内容,然后依次执行。当加载区域获取完成后,模拟鼠标向下滚动,加载后续部分,循环直到全部加载完成;
23.png
5、内容结构拓扑图如下,_root的根节点收录若干个回答区域,每个区域收录昵称、审批号、回答内容;
24.png
6、 根据上面的拓扑图,开始创建选择器,选择器id填写为answer(随意填写),Type选择Element向下滚动。说明:Element是针对这种大面积的区域,这个区域也收录子元素,答案区域对应Element,因为我们需要从这个区域获取我们需要的数据,Element向下滚动表示这个区域是向下使用。滚动方式可以加载更多,专为这种下拉加载而设计。
25.png
7、 接下来,单击选择,然后将鼠标移动到页面上。当绿色框包围答案区域时,单击鼠标,然后移动到下一个答案。同样,当绿色框收录答案区域时,单击鼠标。这时,除了这两个答案,所有的答案区域都变成了红色的方框,然后点击“完成选择!”。最后别忘了选择Multiple,稍后保存;
26.gif
8、下一步,点击红色区域进入刚刚创建的答案选择器,创建子选择器;
27.png
9、 创建昵称选择器,设置id为name,Type为Text,Select选择昵称部分。如果您没有经验,第一次可能不会选择正确的名称。如果您发现错误,您可以对其进行调整并保存。 ;
28.gif
10、创建一个批准号选择器;
29.gif
11、创建一个内容选择器。由于内容格式化并且很长,所以有一个技巧。选择以下更方便;
30.gif
12、 执行刮取操作。由于内容较多,可能需要几分钟。如果是测试用的,可以找一个答案少的问题来测试。
31.png 查看全部
抓取网页数据工具(最简单的数据抓取教程,人人都用得上(组图))
最简单的数据采集教程,人人都可以使用
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
1.png
2、 并在弹出框中点击“添加扩展”
2.png
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
如果不能FQ,可以使用本地FQ方法。在此公众号回复“爬虫”,即可下载Chrome和Web Scraper扩展程序。
1、打开Chrome,在地址栏中输入chrome://extensions/,进入扩展管理界面,然后将下载的扩展Web-Scraper_v0.3.7.crx拖放到这里页面,点击“添加到扩展”完成安装。如图:
4.gif
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
3.png
初识网络爬虫开启网络爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
5.png
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
6.png
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
7.gif
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
8.png
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
9.png
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
10.png
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
11.png
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
12.png
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
13.png
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
14.png
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
15.png
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
16.png
6、然后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选择的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
17.png
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
18.gif
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图可以看到拓扑图。 _root 是根选择器。创建站点地图时,会自动出现一个_root节点,可以看到它的子选择器,也就是我们创建的热选择器;
19.png
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
20.png
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
21.png
怎么样,现在试试
获取知乎questions 的所有答案
简单介绍完毕。接下来,尝试一个有点难度的,抓取知乎问题的所有答案,包括回答者的昵称,批准数,以及答案的内容。问:为什么炫富的程序员这么少?
知乎的特点是只有向下滚动页面才会加载下一个答案
1、首先在Chrome中打开此链接,链接地址为:,并调出开发者工具,定位到Web Scraper标签栏;
2、新建站点地图,填写站点地图名称和起始网址;
22.png
3、下一步,开始添加选择器,点击添加新选择器;
4、我们先来分析一下知乎问题的结构。如图,一个问题由多个这样的区域组成,一个区域就是一个答案。这个回答区包括昵称、批准号、回答内容和发布。时间等等。红色框起来的部分就是我们要抓取的内容。所以我们抓取数据的逻辑是这样的:从入口页面进入,获取当前页面已经加载的答案,找到一个答案区域,提取昵称,批准数,以及里面的答案内容,然后依次执行。当加载区域获取完成后,模拟鼠标向下滚动,加载后续部分,循环直到全部加载完成;
23.png
5、内容结构拓扑图如下,_root的根节点收录若干个回答区域,每个区域收录昵称、审批号、回答内容;
24.png
6、 根据上面的拓扑图,开始创建选择器,选择器id填写为answer(随意填写),Type选择Element向下滚动。说明:Element是针对这种大面积的区域,这个区域也收录子元素,答案区域对应Element,因为我们需要从这个区域获取我们需要的数据,Element向下滚动表示这个区域是向下使用。滚动方式可以加载更多,专为这种下拉加载而设计。
25.png
7、 接下来,单击选择,然后将鼠标移动到页面上。当绿色框包围答案区域时,单击鼠标,然后移动到下一个答案。同样,当绿色框收录答案区域时,单击鼠标。这时,除了这两个答案,所有的答案区域都变成了红色的方框,然后点击“完成选择!”。最后别忘了选择Multiple,稍后保存;
26.gif
8、下一步,点击红色区域进入刚刚创建的答案选择器,创建子选择器;
27.png
9、 创建昵称选择器,设置id为name,Type为Text,Select选择昵称部分。如果您没有经验,第一次可能不会选择正确的名称。如果您发现错误,您可以对其进行调整并保存。 ;
28.gif
10、创建一个批准号选择器;
29.gif
11、创建一个内容选择器。由于内容格式化并且很长,所以有一个技巧。选择以下更方便;
30.gif
12、 执行刮取操作。由于内容较多,可能需要几分钟。如果是测试用的,可以找一个答案少的问题来测试。
31.png
抓取网页数据工具(之前有一个工具自动抓取数据的工具主要做什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-14 11:16
)
之前有一项工作是在服务器上复制一串文本。这是一个非常简单的操作,但需要重复大约 50 次。每次大概用了三分钟,重复了两个多小时就过去了。所以我做了这个工具来自动抓取数据。
该工具主要做三件事:登录、下载、拦截。
登录部分是因为服务器使用windows安全验证,如图:
需要模拟登录才能获取网页数据。
先用fiddler抓取http传输的数据包,在header部分找到一串字符串:
base64解密后得到:Administrator:manage。
这是用户名:一串加密的密码。 Authorization:Basic是一种认证方式,一般由setRequestProperty设置。
登录后可以直接获取网页内容,然后截取数据。最后在最外层添加一个循环,执行一次需要爬取的服务器地址,然后就可以一次性获取到所有服务器上的数据了。
最后贴出代码:
<p>import java.io.*;
import java.net.*;
public class getPackageFromWeb {
public static void main(String args[]) throws Exception {
String[] servers ={"192.168.0.144:23342","192.168.0.144:23343"};
StringBuilder result=new StringBuilder();
for(int i=0;i 查看全部
抓取网页数据工具(之前有一个工具自动抓取数据的工具主要做什么?
)
之前有一项工作是在服务器上复制一串文本。这是一个非常简单的操作,但需要重复大约 50 次。每次大概用了三分钟,重复了两个多小时就过去了。所以我做了这个工具来自动抓取数据。
该工具主要做三件事:登录、下载、拦截。
登录部分是因为服务器使用windows安全验证,如图:
需要模拟登录才能获取网页数据。
先用fiddler抓取http传输的数据包,在header部分找到一串字符串:
base64解密后得到:Administrator:manage。
这是用户名:一串加密的密码。 Authorization:Basic是一种认证方式,一般由setRequestProperty设置。
登录后可以直接获取网页内容,然后截取数据。最后在最外层添加一个循环,执行一次需要爬取的服务器地址,然后就可以一次性获取到所有服务器上的数据了。
最后贴出代码:
<p>import java.io.*;
import java.net.*;
public class getPackageFromWeb {
public static void main(String args[]) throws Exception {
String[] servers ={"192.168.0.144:23342","192.168.0.144:23343"};
StringBuilder result=new StringBuilder();
for(int i=0;i
抓取网页数据工具(网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-14 02:06
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们添加到这个对象的所有链接并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C# 适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?” 查看全部
抓取网页数据工具(网页抓取是通过自动化手段检索数据的过程-乐题库)
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子——C#网络爬虫——我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们添加到这个对象的所有链接并返回它。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C# 适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?”
抓取网页数据工具( 合肥乐维信息技术优采云采集软件免费采集(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 519 次浏览 • 2021-09-13 16:09
合肥乐维信息技术优采云采集软件免费采集(组图))
优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网络数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩
优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。 查看全部
抓取网页数据工具(
合肥乐维信息技术优采云采集软件免费采集(组图))
优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网络数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩
优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
抓取网页数据工具(国内6大网络信息采集和页面数据抓取工具近年来,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2021-09-13 07:14
国内6大网络资讯采集及页面数据抓取工具 近年来,随着国内大数据战略的日趋明朗,数据抓取及资讯采集系列产品迎来了巨大的发展机遇,@数采集产品的数量也出现了快速增长。然而,与产品品类的快速增长相反,信息采集技术相对薄弱,市场竞争激烈,质量参差不齐。在此,本文列出当前信息采集和数据采集市场最具影响力的六大品牌,供采购大数据和智能中心建设单位时参考:TOP.1乐思网络信息采集系统(主要目标网络信息采集系统是为了解决网络信息采集和网络数据采集的问题,基于用户自定义任务配置,批量准确地从互联网目标页面中提取半结构化和非结构化数据,并进行转化。是存储在本地数据库中供内部使用或外网发布以快速获取外部信息的结构化记录,系统主要用于:大数据基础设施建设、舆情监测、品牌监测、价格监测、portal网站新闻采集、行业资讯采集、竞争情报获取、商业数据整合、市场调研、数据库营销等领域。TOP.2优采云采集器(集德Vice是一款专业的网络data采集/信息挖掘处理软件,通过灵活的配置,可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以进行编辑过滤和选择发布到网站后台,各种文件或者其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各领域有采集 挖掘数据需求。 TOP.3优采云采集器software(极软利用熊猫精准搜索引擎的分析内核实现网页内容类似浏览器的分析,并在此基础上使用原创的技术实现对网页内容的分离提取网页框架内容和核心内容,实现相似页面的有效对比匹配,因此用户只需要指定一个参考页面,优采云采集器软件系统就可以以此为基础匹配相似页面,实现用户采集.TOP.4优采云采集器所需的采集素材的批量批量处理(套机是一套专业的网站内容采集软件,支持各种论坛的帖子和回复采集、网站和博客文章内容抓取,通过相关配置,可以方便的采集80%网站内容供自己使用。根据建站程序的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三大类,共数百个版本的数据采集支持近40个主流w网站建设计划 查看全部
抓取网页数据工具(国内6大网络信息采集和页面数据抓取工具近年来,)
国内6大网络资讯采集及页面数据抓取工具 近年来,随着国内大数据战略的日趋明朗,数据抓取及资讯采集系列产品迎来了巨大的发展机遇,@数采集产品的数量也出现了快速增长。然而,与产品品类的快速增长相反,信息采集技术相对薄弱,市场竞争激烈,质量参差不齐。在此,本文列出当前信息采集和数据采集市场最具影响力的六大品牌,供采购大数据和智能中心建设单位时参考:TOP.1乐思网络信息采集系统(主要目标网络信息采集系统是为了解决网络信息采集和网络数据采集的问题,基于用户自定义任务配置,批量准确地从互联网目标页面中提取半结构化和非结构化数据,并进行转化。是存储在本地数据库中供内部使用或外网发布以快速获取外部信息的结构化记录,系统主要用于:大数据基础设施建设、舆情监测、品牌监测、价格监测、portal网站新闻采集、行业资讯采集、竞争情报获取、商业数据整合、市场调研、数据库营销等领域。TOP.2优采云采集器(集德Vice是一款专业的网络data采集/信息挖掘处理软件,通过灵活的配置,可以方便快捷地从网页中抓取结构化文本、图片、文件等资源信息,并可以进行编辑过滤和选择发布到网站后台,各种文件或者其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各领域有采集 挖掘数据需求。 TOP.3优采云采集器software(极软利用熊猫精准搜索引擎的分析内核实现网页内容类似浏览器的分析,并在此基础上使用原创的技术实现对网页内容的分离提取网页框架内容和核心内容,实现相似页面的有效对比匹配,因此用户只需要指定一个参考页面,优采云采集器软件系统就可以以此为基础匹配相似页面,实现用户采集.TOP.4优采云采集器所需的采集素材的批量批量处理(套机是一套专业的网站内容采集软件,支持各种论坛的帖子和回复采集、网站和博客文章内容抓取,通过相关配置,可以方便的采集80%网站内容供自己使用。根据建站程序的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三大类,共数百个版本的数据采集支持近40个主流w网站建设计划

