
抓取网页数据工具
抓取网页数据工具(有人将robots.txt文件视为一组建议.py文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-22 23:11
)
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
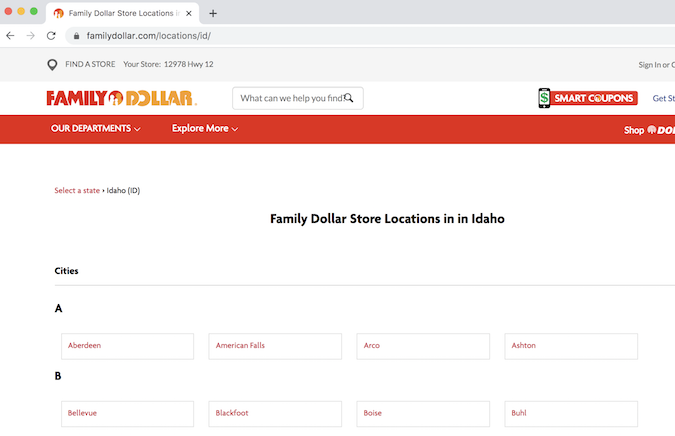
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
print(soup.prettify())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 url 似乎都收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
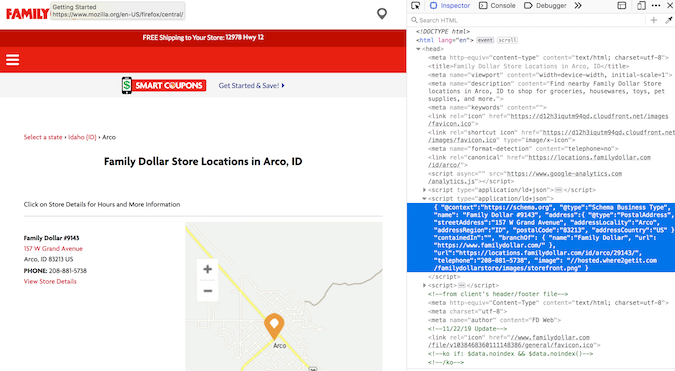
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
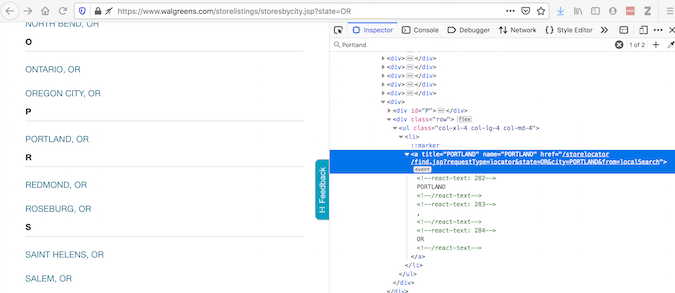
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
沃尔格林位置页面和代码
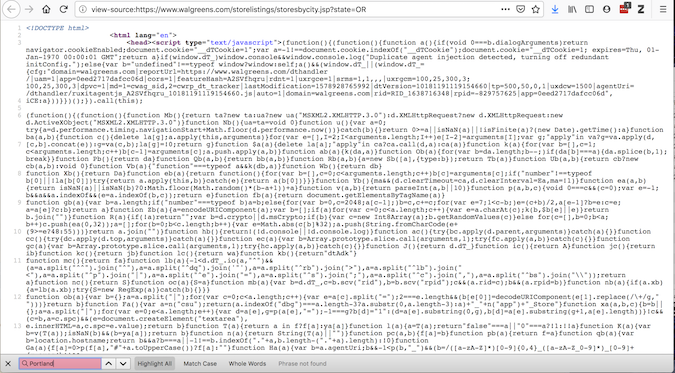
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/")soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get individual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False) 查看全部
抓取网页数据工具(有人将robots.txt文件视为一组建议.py文件
)
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
print(soup.prettify())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。

家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 url 似乎都收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
沃尔格林位置页面和代码
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
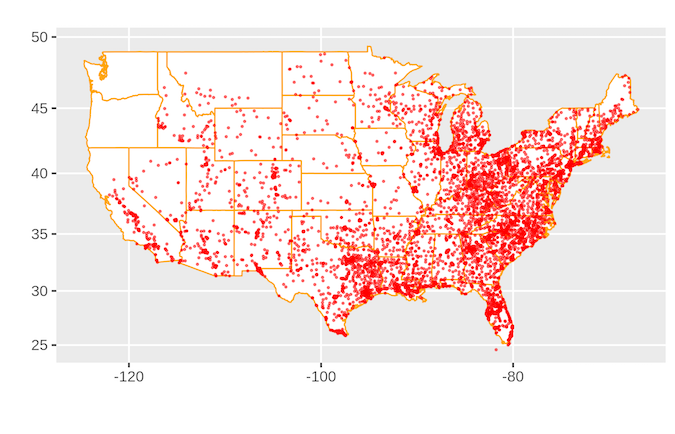
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/";)soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get individual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
抓取网页数据工具(,工具很多,但是数据一定要准的下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-22 21:04
抓取网页数据工具太多了..最简单的就是.拿的接口出售给后端数据研发人员去做.如果你只是想爬爬看看,找个万方mop下图片然后翻译解码什么的是最简单的,懒的话,直接百度..最后总结一下,工具很多,但是数据一定要准
爬虫这个词太宽泛了,很多不同的模式,各个语言,各种平台的爬虫工具都有.如果要资料网站爬虫,那么pythonwebpy是可以的,如果要微博爬虫,请看具体什么微博,如果是新浪官方的,目前没有。
如果是开发爬虫程序,并且完成功能,那么你的问题确实没有,因为涉及的东西太多了,但如果只是跟着书上学习,那只是随便一个程序员做的事情。
我觉得很难,爬虫涉及领域和技术太多了,就你的问题而言首先你需要制定一个项目的大方向,然后从大方向中去深挖细节,最后找到合适的工具,最后才是写代码的工具。当然前提是,
理论的东西百度谷歌一下就行了,在爬虫领域做好技术的支撑,初期肯定是从基础做起,那就是debug,这个你肯定得啃书吧,有针对性的实践即可。就爬虫的各种模式来看,结合实际生活来分析,爬虫很多时候都是可以为网站服务的。再就是爬虫提供一个反爬的手段。最后还要搞搞运维啥的,国内的话建议leancloud一类的云平台。本人入行时间比较短,随便聊聊~。 查看全部
抓取网页数据工具(,工具很多,但是数据一定要准的下)
抓取网页数据工具太多了..最简单的就是.拿的接口出售给后端数据研发人员去做.如果你只是想爬爬看看,找个万方mop下图片然后翻译解码什么的是最简单的,懒的话,直接百度..最后总结一下,工具很多,但是数据一定要准
爬虫这个词太宽泛了,很多不同的模式,各个语言,各种平台的爬虫工具都有.如果要资料网站爬虫,那么pythonwebpy是可以的,如果要微博爬虫,请看具体什么微博,如果是新浪官方的,目前没有。
如果是开发爬虫程序,并且完成功能,那么你的问题确实没有,因为涉及的东西太多了,但如果只是跟着书上学习,那只是随便一个程序员做的事情。
我觉得很难,爬虫涉及领域和技术太多了,就你的问题而言首先你需要制定一个项目的大方向,然后从大方向中去深挖细节,最后找到合适的工具,最后才是写代码的工具。当然前提是,
理论的东西百度谷歌一下就行了,在爬虫领域做好技术的支撑,初期肯定是从基础做起,那就是debug,这个你肯定得啃书吧,有针对性的实践即可。就爬虫的各种模式来看,结合实际生活来分析,爬虫很多时候都是可以为网站服务的。再就是爬虫提供一个反爬的手段。最后还要搞搞运维啥的,国内的话建议leancloud一类的云平台。本人入行时间比较短,随便聊聊~。
抓取网页数据工具(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-18 18:11
数据采集方面也有一点研究,现在分享一些自己研究过的数据采集技术。可能有很多缺点。欢迎指正和补充哈哈!
方法一:直接抓取网页源代码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip的捕获。对此,可以尝试使用ip代码来解决。
2、如果要爬取的数据是网页加载后,js修改网页元素,无法爬取。
3、在抓取一些大的网站时,如果需要登录后抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,是技术上的考验。
适用场景:网页是完全静态的,网页第一次加载后才加载要抓取的数据。类似的涉及登录或权限操作的页面不做任何账户加密或只做简单加密。
当然,如果你在网页上抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面就好了。
对于一个有登录的页面,我们如何在他的登录页面之后获取源代码?
首先,我想介绍一下,在会话中保存账户信息时,服务器是如何确定用户身份的。
首先,用户登录成功后,服务器会将用户当前的会话信息保存在会话中,每个会话都有唯一的标识sessionId。然后用户访问这个页面,会话创建完成后,会收到服务器返回的sessionId,并保存在cookie中。因此,我们可以使用chrome浏览器打开check项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,会在用户发送的请求头中附加sessionId,服务器端可以通过这个sessionId判断用户的身份。
这里我搭建了一个简单的jsp登录页面,登录后的账号信息保存在服务器端的session中。
思路:1、登录。 2、登录成功后,会得到一个cookie。3. 将cookie放入请求头中,向登录页面发送请求。
附上java版和python的代码
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势,与java相比,它至少会写一半的代码。当然,这既是java的优势,也是java的劣势。优点是更灵活,程序员可以更好地控制底层代码的实现。,缺点是不容易上手,技术要求太高。因此,如果您是数据捕获的新手,我强烈建议您学习 python。
方法二:模拟浏览器操作
优点: 1、类似用户操作,不易被服务器检测到。
2、对于登录的网站,即使经过N层加密,也不需要考虑其加密算法。
3、可以随时获取当前页面各元素的最新状态。
缺点: 1、速度稍慢。
这里有几个很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你一定不会对webbrower控件感到陌生,它是一个浏览器,内部驱动其实就是ie的驱动。
他可以在DOM模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至可以调用方法,比如onclick方法、onsubmit等。 ,或者直接调用页面js方法。
webbrower的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能对IE不够友好,或者IE版本太低,甚至是安全证书,那么这个方案可能会通过。
我们可以直接使用selenium库来使用操作系统中真正的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的驱动。
但是,在实际开发中,有时我们可能不想看到这个浏览器界面。在这里,我可以给大家推荐一款无需界面直接在cmd中运行的后台浏览器,那就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作了,看不到界面了。由于phantomjs没有接口,所以会比一般的浏览器快很多。
互联网上有很多信息。我暂时不会谈论它。我不会在这里过多解释。你可以看看:
三、Fidderscript:
fiddler 是一个非常强大的数据采集工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在抓包过程中遇到安全证书错误,我们不妨打开 fidder 让他给你提供证书,说不定你就接近成功了。
让人更厉害的是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前,修改请求头,可以说是一个强大的抓取工具。这样,我们用fidder配合前面的方法,相信大部分问题都可以解决。并且他的语法和Clike系列的差不多,类库也和c#大同小异。相信熟悉C#的同学会很快上手fiddlerscript。
提琴手: 查看全部
抓取网页数据工具(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
数据采集方面也有一点研究,现在分享一些自己研究过的数据采集技术。可能有很多缺点。欢迎指正和补充哈哈!
方法一:直接抓取网页源代码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip的捕获。对此,可以尝试使用ip代码来解决。
2、如果要爬取的数据是网页加载后,js修改网页元素,无法爬取。
3、在抓取一些大的网站时,如果需要登录后抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,是技术上的考验。
适用场景:网页是完全静态的,网页第一次加载后才加载要抓取的数据。类似的涉及登录或权限操作的页面不做任何账户加密或只做简单加密。
当然,如果你在网页上抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面就好了。
对于一个有登录的页面,我们如何在他的登录页面之后获取源代码?
首先,我想介绍一下,在会话中保存账户信息时,服务器是如何确定用户身份的。
首先,用户登录成功后,服务器会将用户当前的会话信息保存在会话中,每个会话都有唯一的标识sessionId。然后用户访问这个页面,会话创建完成后,会收到服务器返回的sessionId,并保存在cookie中。因此,我们可以使用chrome浏览器打开check项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,会在用户发送的请求头中附加sessionId,服务器端可以通过这个sessionId判断用户的身份。
这里我搭建了一个简单的jsp登录页面,登录后的账号信息保存在服务器端的session中。
思路:1、登录。 2、登录成功后,会得到一个cookie。3. 将cookie放入请求头中,向登录页面发送请求。
附上java版和python的代码
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势,与java相比,它至少会写一半的代码。当然,这既是java的优势,也是java的劣势。优点是更灵活,程序员可以更好地控制底层代码的实现。,缺点是不容易上手,技术要求太高。因此,如果您是数据捕获的新手,我强烈建议您学习 python。
方法二:模拟浏览器操作
优点: 1、类似用户操作,不易被服务器检测到。
2、对于登录的网站,即使经过N层加密,也不需要考虑其加密算法。
3、可以随时获取当前页面各元素的最新状态。
缺点: 1、速度稍慢。
这里有几个很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你一定不会对webbrower控件感到陌生,它是一个浏览器,内部驱动其实就是ie的驱动。
他可以在DOM模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至可以调用方法,比如onclick方法、onsubmit等。 ,或者直接调用页面js方法。
webbrower的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能对IE不够友好,或者IE版本太低,甚至是安全证书,那么这个方案可能会通过。
我们可以直接使用selenium库来使用操作系统中真正的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的驱动。
但是,在实际开发中,有时我们可能不想看到这个浏览器界面。在这里,我可以给大家推荐一款无需界面直接在cmd中运行的后台浏览器,那就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作了,看不到界面了。由于phantomjs没有接口,所以会比一般的浏览器快很多。
互联网上有很多信息。我暂时不会谈论它。我不会在这里过多解释。你可以看看:
三、Fidderscript:
fiddler 是一个非常强大的数据采集工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在抓包过程中遇到安全证书错误,我们不妨打开 fidder 让他给你提供证书,说不定你就接近成功了。
让人更厉害的是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前,修改请求头,可以说是一个强大的抓取工具。这样,我们用fidder配合前面的方法,相信大部分问题都可以解决。并且他的语法和Clike系列的差不多,类库也和c#大同小异。相信熟悉C#的同学会很快上手fiddlerscript。
提琴手:
抓取网页数据工具(EasyWebExtract创建网页抓取项目的主要步骤介绍及步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-14 23:00
Easy Web Extract是一款强大易用的网络爬取工具,用户可以用它来提取网页中的内容(文本、URL、图片、文件),支持转换成各种格式,无需任何编程要求,朋友们在有需要的可以试试。
【软件说明】我们简单的网络提取软件收录许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
【软件特色】1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2.多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
抓取网页数据工具(EasyWebExtract创建网页抓取项目的主要步骤介绍及步骤)
Easy Web Extract是一款强大易用的网络爬取工具,用户可以用它来提取网页中的内容(文本、URL、图片、文件),支持转换成各种格式,无需任何编程要求,朋友们在有需要的可以试试。

【软件说明】我们简单的网络提取软件收录许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
【软件特色】1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2.多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。
抓取网页数据工具(优采云采集器免费的数据抓取教博客园操作简单11、Playfishplayfish)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-13 12:11
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。 查看全部
抓取网页数据工具(优采云采集器免费的数据抓取教博客园操作简单11、Playfishplayfish)
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。

呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。

本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
抓取网页数据工具(大数据从业工作者Import.io网页数据抽取工具一览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-12 17:09
作为大数据从业者和研究人员,经常需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网络数据提取工具来达到这个目的。接下来,我将为大家列出七种常用的网络数据提取工具。
1. 导入.io
本工具为免客户端爬虫工具,所有工作均可在浏览器中完成,操作方便简单。爬取数据后,可以在可视化界面中进行过滤。
2. 解析器
该工具需要下载客户端才能使用。该工具打开后,类似于浏览器。输入网址后,即可提取数据。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
该工具是一个基于Chrome浏览器的插件,可以直接通过Google Play Store免费获取和安装。它可以轻松抓取静态网页和js动态加载的网页。
如果想详细了解这个工具的使用方法,可以参考以下教程:关于webscraper的问题,这就够了
4. 80 条腿
该工具背后是一个由 50,000 台计算机组成的 Plura 网格,功能强大,但主要服务于企业级客户。商业用途明显,监控能力强,价格相对昂贵。
5. 优采云采集器
该工具是目前国内最成熟的网络数据采集工具。需要下载客户端,可以在客户端进行可视化数据抓取。该工具还有一个国际版的 Octoparse 软件。根据采集的能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。@>,但数据导出需要额外收费。
6. 数字
这是一款基于Web的云爬取工具,适合起步较晚但爬取效率高的企业,无需额外下载客户端。
7. 优采云采集器
这是中国一家老式的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。充电方式为软件充电,旗舰版价格1000元左右,付费后无限制。 查看全部
抓取网页数据工具(大数据从业工作者Import.io网页数据抽取工具一览)
作为大数据从业者和研究人员,经常需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网络数据提取工具来达到这个目的。接下来,我将为大家列出七种常用的网络数据提取工具。
1. 导入.io
本工具为免客户端爬虫工具,所有工作均可在浏览器中完成,操作方便简单。爬取数据后,可以在可视化界面中进行过滤。
2. 解析器
该工具需要下载客户端才能使用。该工具打开后,类似于浏览器。输入网址后,即可提取数据。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
该工具是一个基于Chrome浏览器的插件,可以直接通过Google Play Store免费获取和安装。它可以轻松抓取静态网页和js动态加载的网页。
如果想详细了解这个工具的使用方法,可以参考以下教程:关于webscraper的问题,这就够了
4. 80 条腿
该工具背后是一个由 50,000 台计算机组成的 Plura 网格,功能强大,但主要服务于企业级客户。商业用途明显,监控能力强,价格相对昂贵。
5. 优采云采集器
该工具是目前国内最成熟的网络数据采集工具。需要下载客户端,可以在客户端进行可视化数据抓取。该工具还有一个国际版的 Octoparse 软件。根据采集的能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。@>,但数据导出需要额外收费。
6. 数字
这是一款基于Web的云爬取工具,适合起步较晚但爬取效率高的企业,无需额外下载客户端。
7. 优采云采集器
这是中国一家老式的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。充电方式为软件充电,旗舰版价格1000元左右,付费后无限制。
抓取网页数据工具(2016年着手大数据不妨重点考虑::)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-11 15:09
回顾2015年,整体大数据市场发展迅速,政府给予的支持力度空前。大数据正式纳入国家政策,为社会各界提供了诸多机遇和便利。放眼国际市场,大数据应用规模还在不断扩大,几乎所有人都将目光投向了“数据”背后的巨大价值。未来5到10年,将是我国推进大数据发展的关键节点。构建高效的大数据应用机制和产业链迫在眉睫。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战。
根据2015年大数据行业发展分析,2016年从大数据入手不妨关注以下几点:
1、可视化数据捕捉:大数据的普及是工业应用的前提。所谓普及,首先是捕捉技术的普及。互联网作为最大的数据载体,其网页数据抓取技术的普及是随着网页抓取工具的普及而实现的。大名鼎鼎的网页抓取工具优采云采集器V9大大发挥了它的便利性,通过设置简单的规则让软件自动采集数据,无论是定义操作流程还是视图< @采集所有的结果都可以通过优采云采集器V9,一个可视化过程的软件工具采集 相比之前复杂的编写程序,前者可以带来高效率,便利性和平民化是不言而喻的。
2、重点领域大数据覆盖:大数据应用范围广泛,各行各业都在尝试开始深度挖掘,但近年来,大数据确实影响到城建、金融和互联网企业, 和电子商务。, 在医疗保健领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将有所突破,通过上述网络爬取工具进行采集优采云采集器V9可以轻松实现城市舆情监测、竞品数据抓取、企业信用数据收录等,如果能看准趋势,先看前面的例子,重点关注在覆盖范围上,我们一定会受益。
3、大数据融合:大数据将导致多学科融合,不仅是计算机领域的科学家,数学、生物学、心理学等其他领域的科学家也将参与到前沿大数据研究,但其中许多研究人员可能不够精通 IT,无法低效地获取数据。为促进数据互通互通,增强大数据资源共享,网络爬虫工具优采云采集器V9在提高易用性的基础上,全面实现了全网通用。利用。可以很容易地获得可以看到的网页内容。如果用户注意采用标准化的存储格式和方法,届时信息融合将非常方便。
万众瞩目的大数据行业急于展示其宏伟蓝图。大数据的应用不再是一句简单的口号。到2016年,我国大数据市场规模预计达到238亿美元,将激活我国大数据资产价值,开辟新产业、新产业。生态的目标仍然需要社会各界的共同努力。 查看全部
抓取网页数据工具(2016年着手大数据不妨重点考虑::)
回顾2015年,整体大数据市场发展迅速,政府给予的支持力度空前。大数据正式纳入国家政策,为社会各界提供了诸多机遇和便利。放眼国际市场,大数据应用规模还在不断扩大,几乎所有人都将目光投向了“数据”背后的巨大价值。未来5到10年,将是我国推进大数据发展的关键节点。构建高效的大数据应用机制和产业链迫在眉睫。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战。

根据2015年大数据行业发展分析,2016年从大数据入手不妨关注以下几点:
1、可视化数据捕捉:大数据的普及是工业应用的前提。所谓普及,首先是捕捉技术的普及。互联网作为最大的数据载体,其网页数据抓取技术的普及是随着网页抓取工具的普及而实现的。大名鼎鼎的网页抓取工具优采云采集器V9大大发挥了它的便利性,通过设置简单的规则让软件自动采集数据,无论是定义操作流程还是视图< @采集所有的结果都可以通过优采云采集器V9,一个可视化过程的软件工具采集 相比之前复杂的编写程序,前者可以带来高效率,便利性和平民化是不言而喻的。
2、重点领域大数据覆盖:大数据应用范围广泛,各行各业都在尝试开始深度挖掘,但近年来,大数据确实影响到城建、金融和互联网企业, 和电子商务。, 在医疗保健领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将有所突破,通过上述网络爬取工具进行采集优采云采集器V9可以轻松实现城市舆情监测、竞品数据抓取、企业信用数据收录等,如果能看准趋势,先看前面的例子,重点关注在覆盖范围上,我们一定会受益。
3、大数据融合:大数据将导致多学科融合,不仅是计算机领域的科学家,数学、生物学、心理学等其他领域的科学家也将参与到前沿大数据研究,但其中许多研究人员可能不够精通 IT,无法低效地获取数据。为促进数据互通互通,增强大数据资源共享,网络爬虫工具优采云采集器V9在提高易用性的基础上,全面实现了全网通用。利用。可以很容易地获得可以看到的网页内容。如果用户注意采用标准化的存储格式和方法,届时信息融合将非常方便。
万众瞩目的大数据行业急于展示其宏伟蓝图。大数据的应用不再是一句简单的口号。到2016年,我国大数据市场规模预计达到238亿美元,将激活我国大数据资产价值,开辟新产业、新产业。生态的目标仍然需要社会各界的共同努力。
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-10 04:09
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个工具,才知道爬网数据可以这么简单。接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
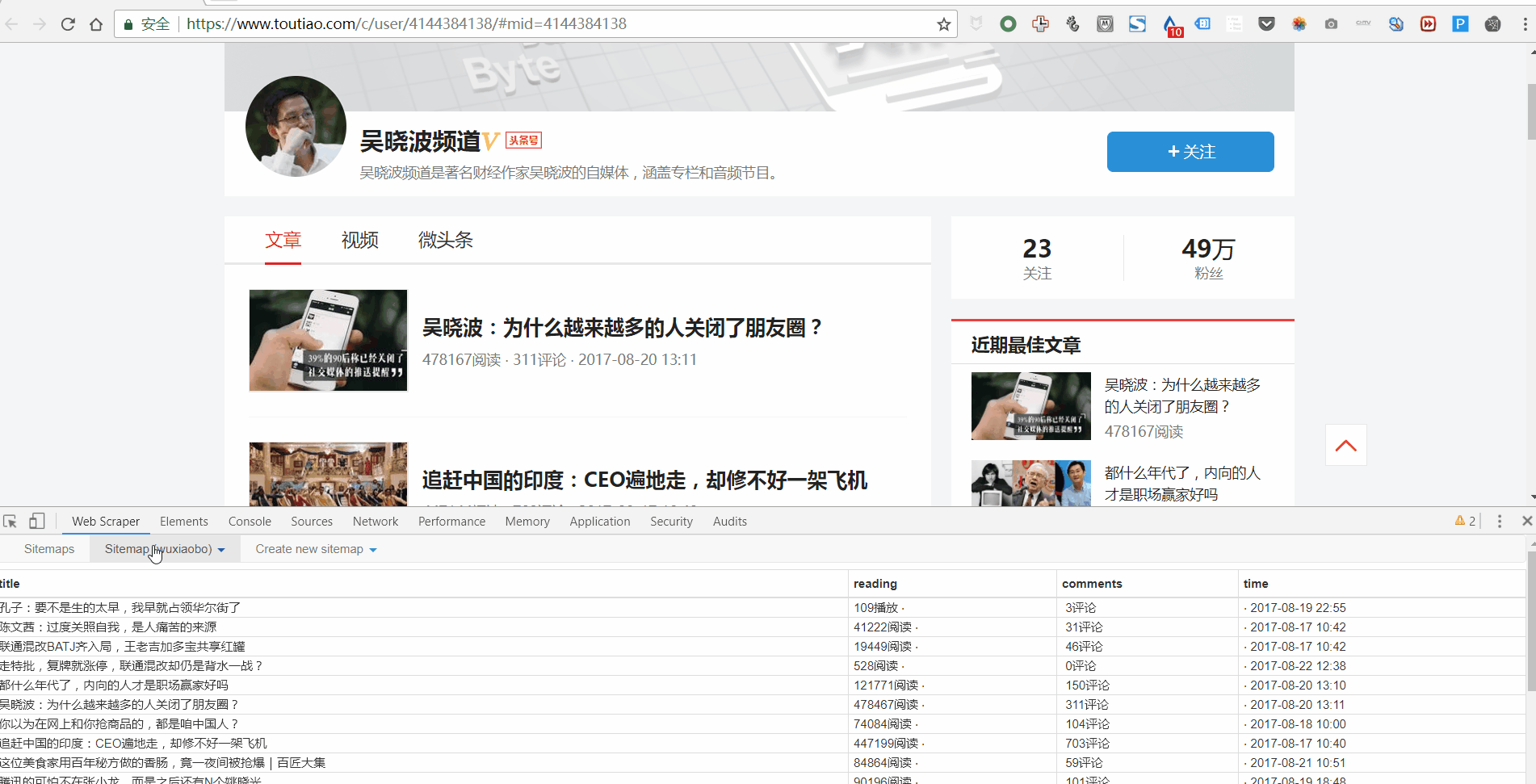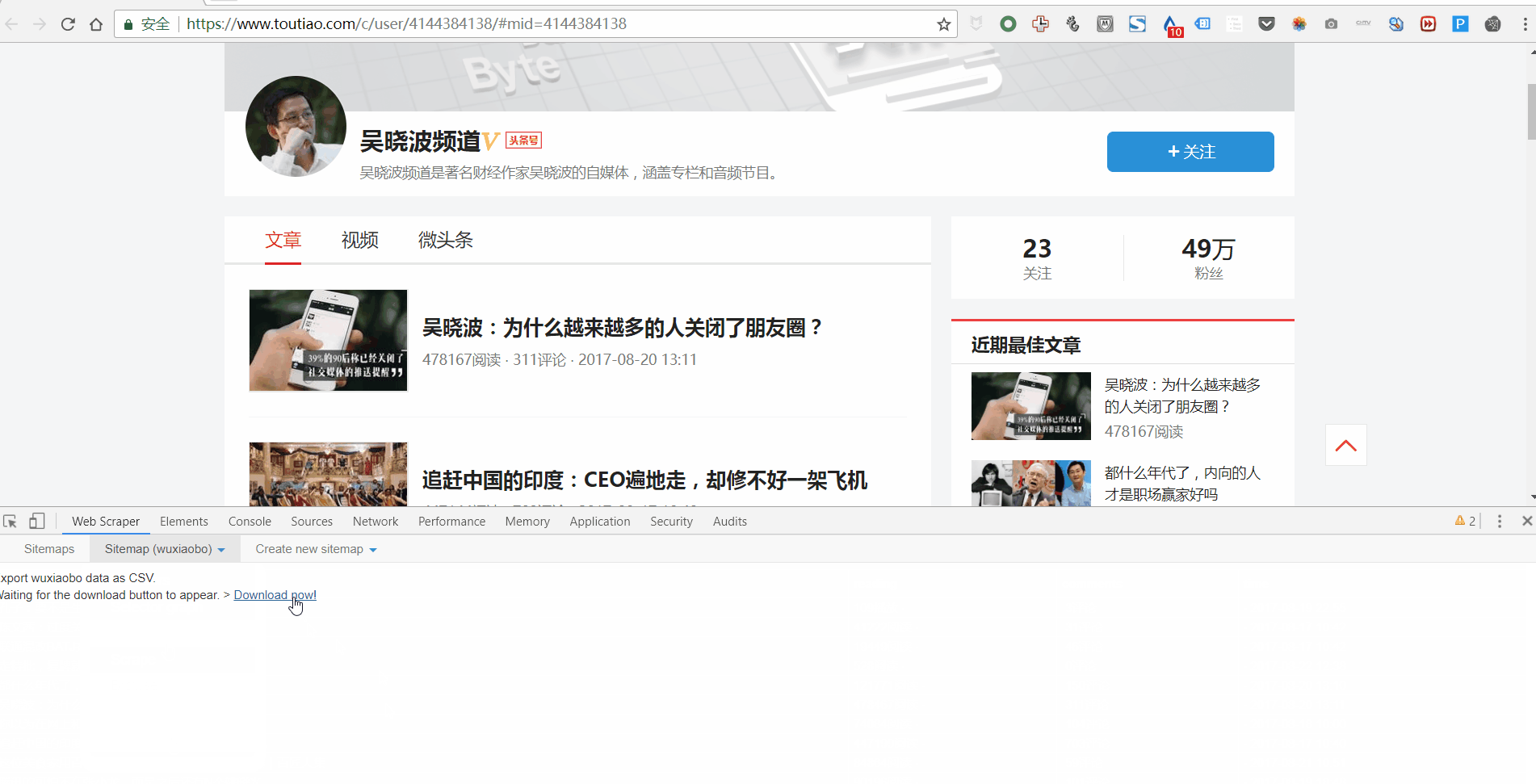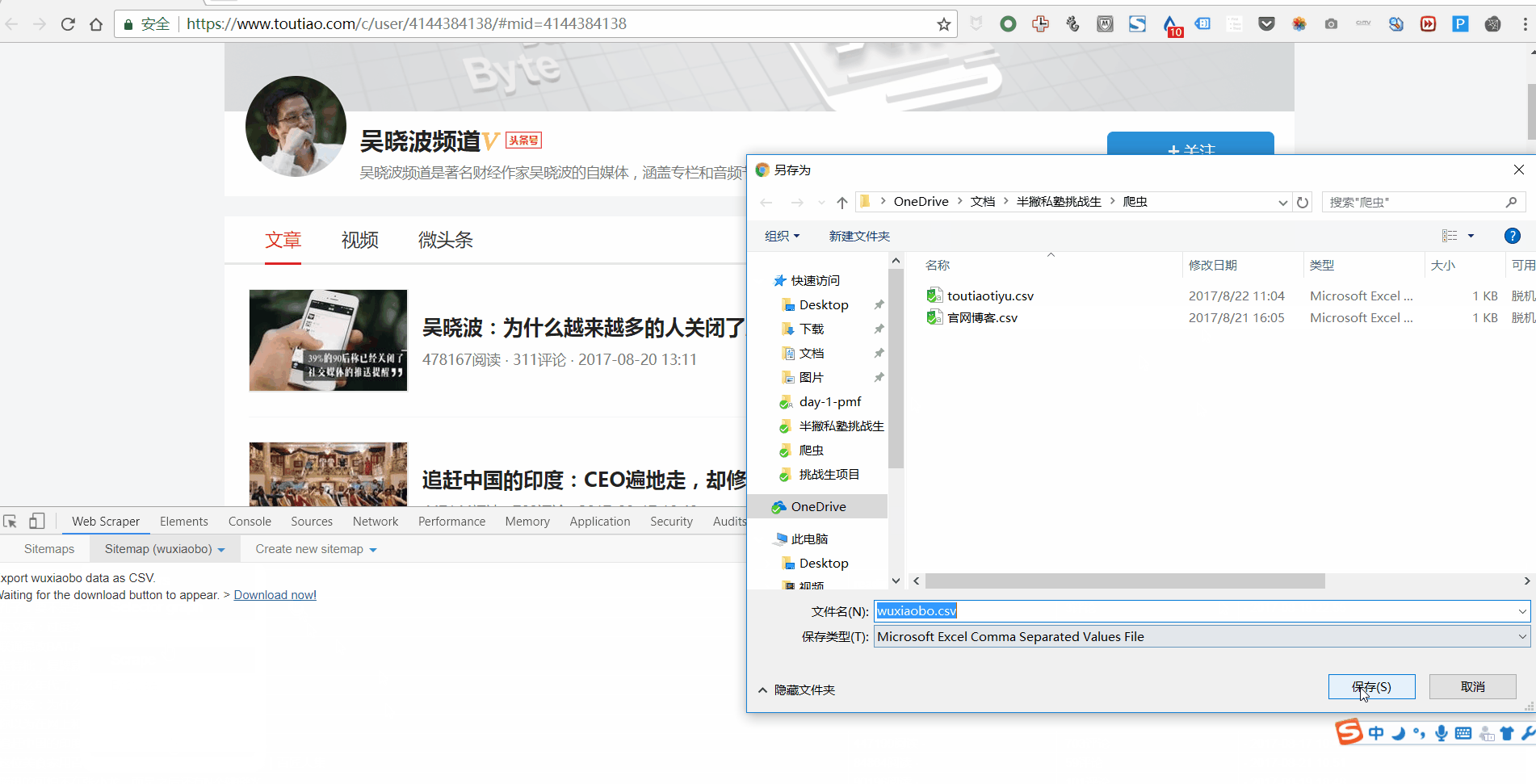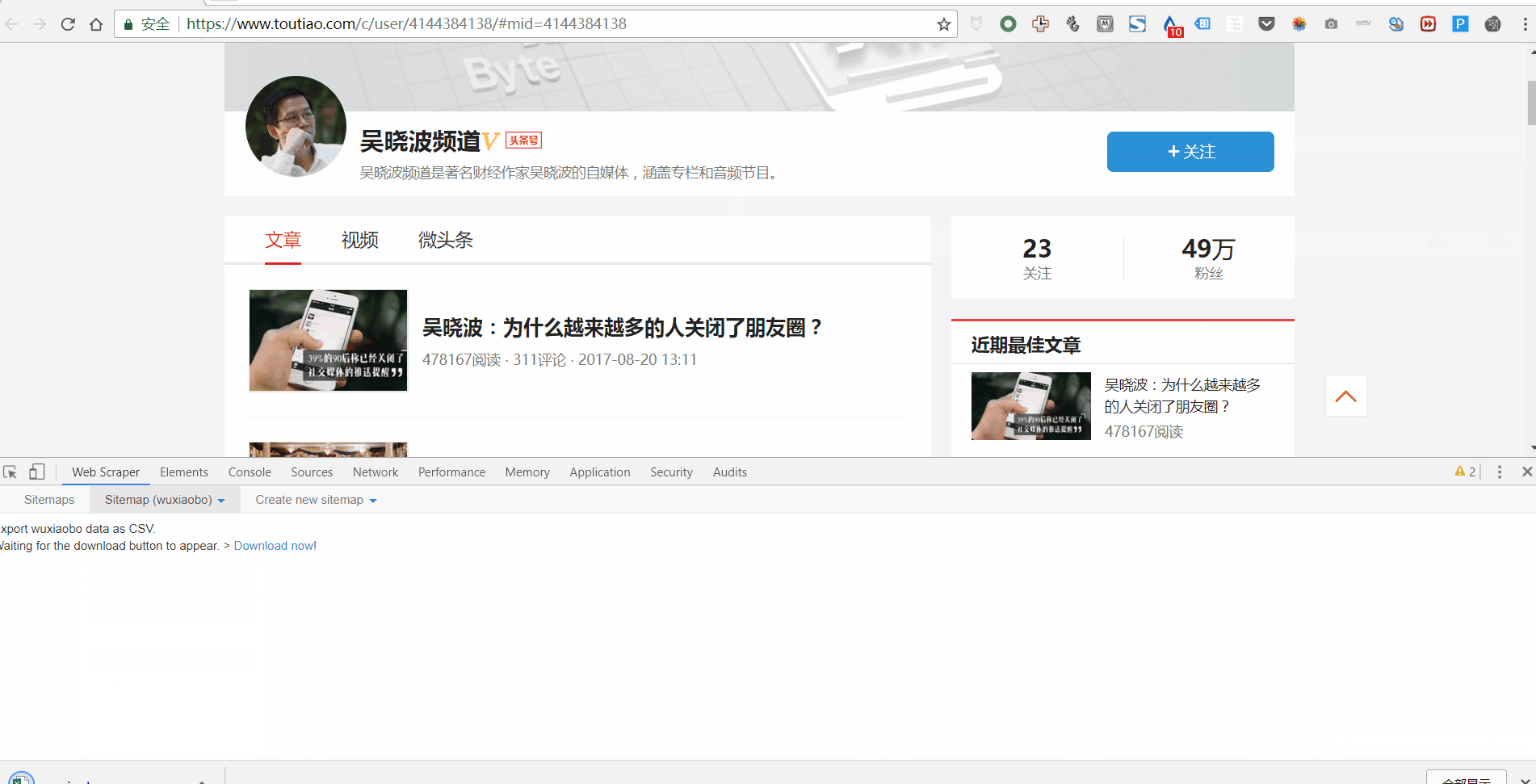
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后再一一操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
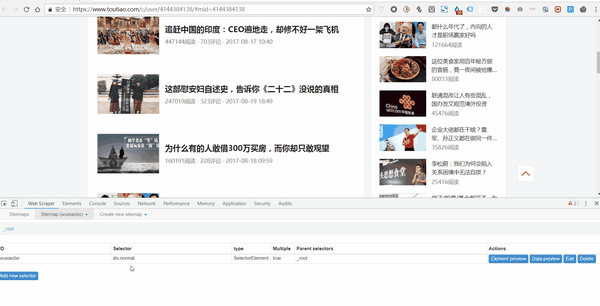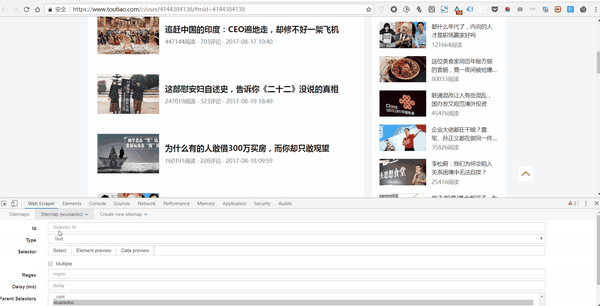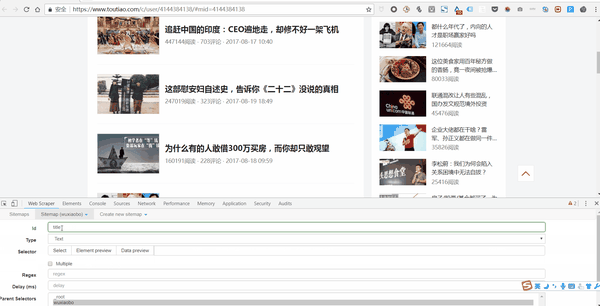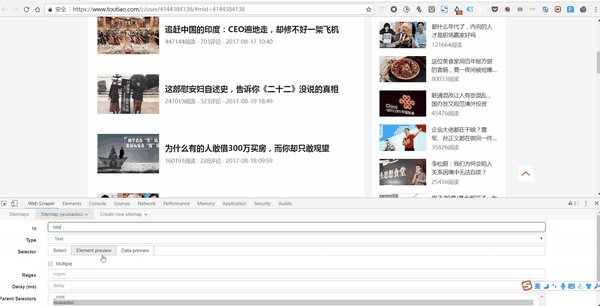
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别和年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别和年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
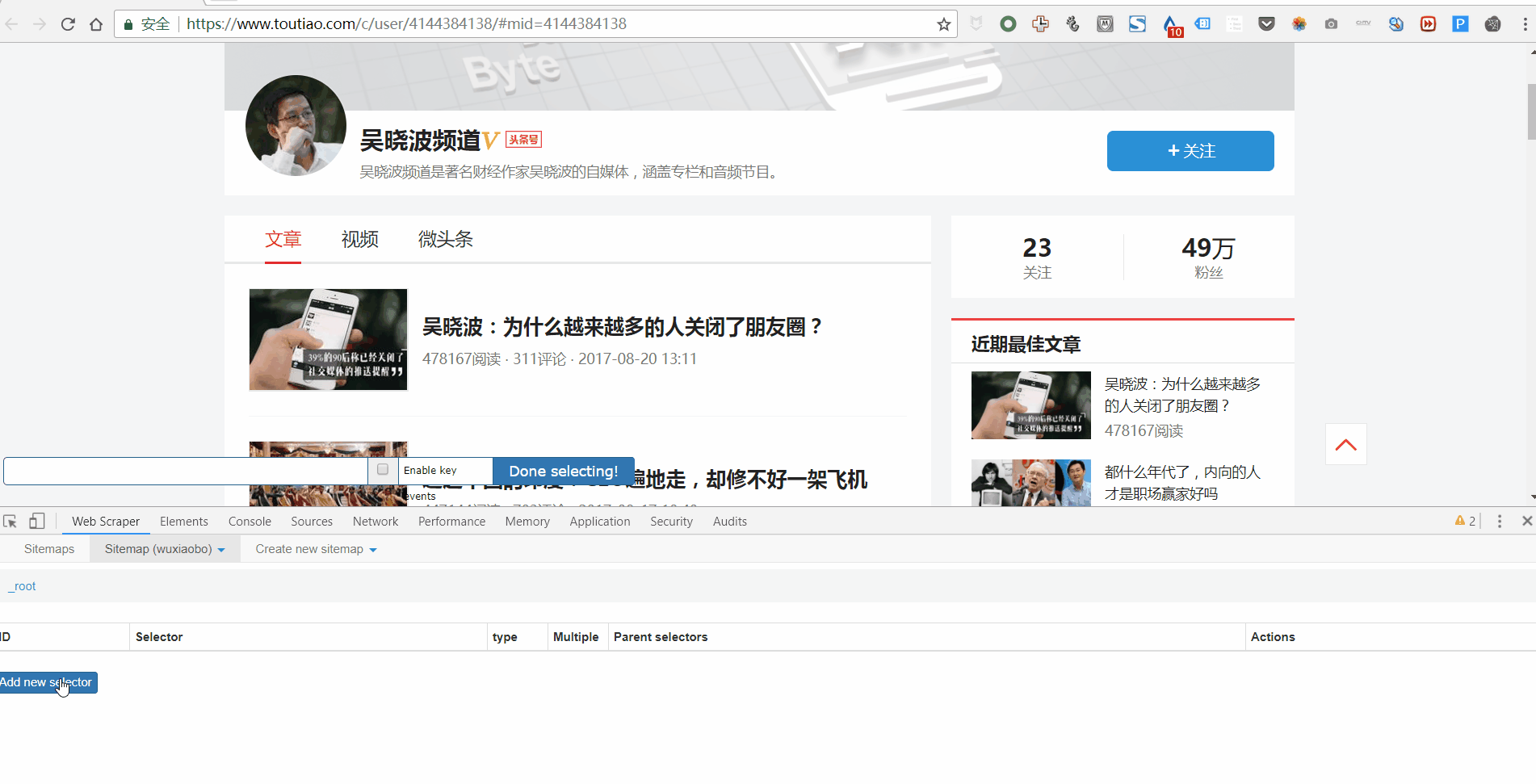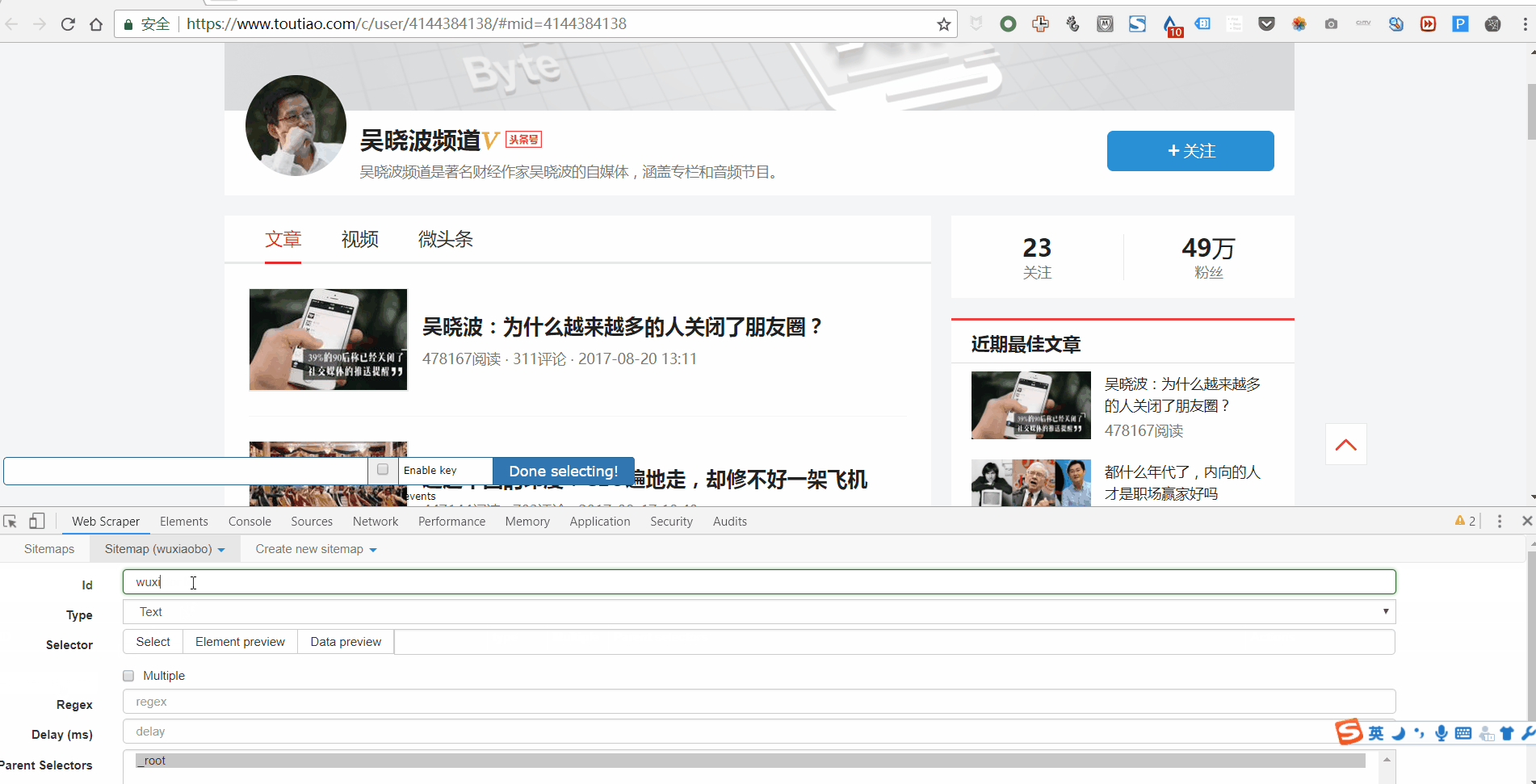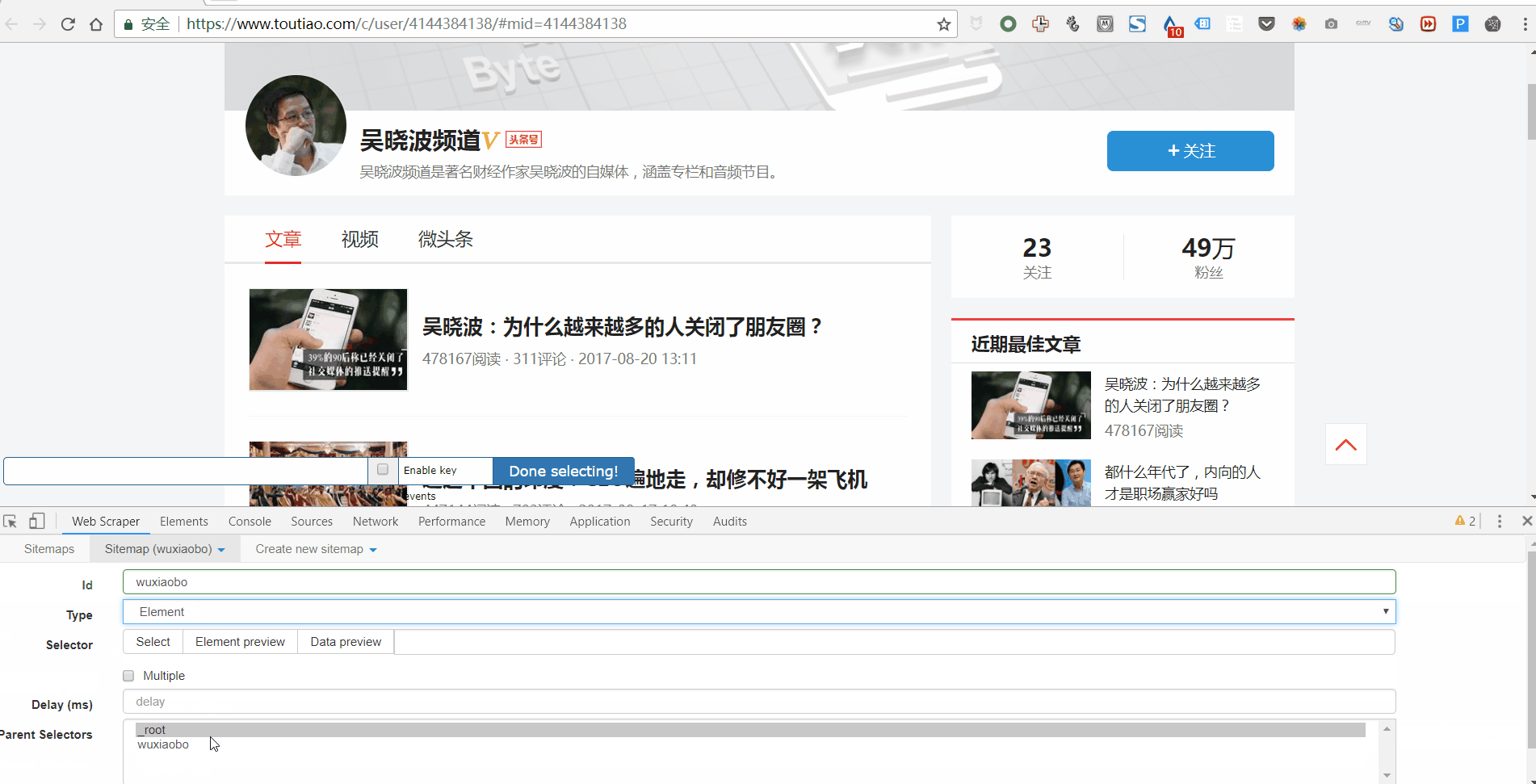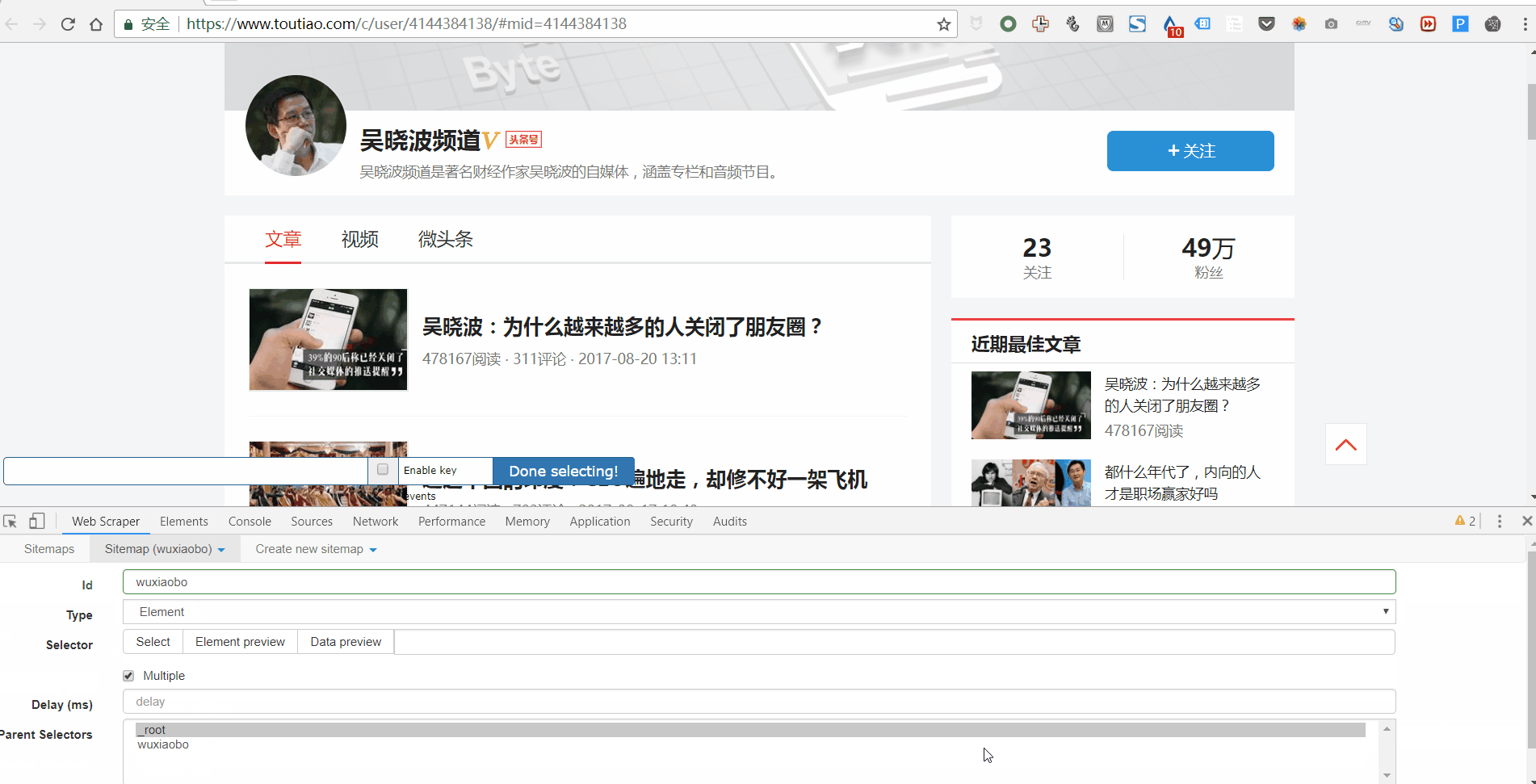
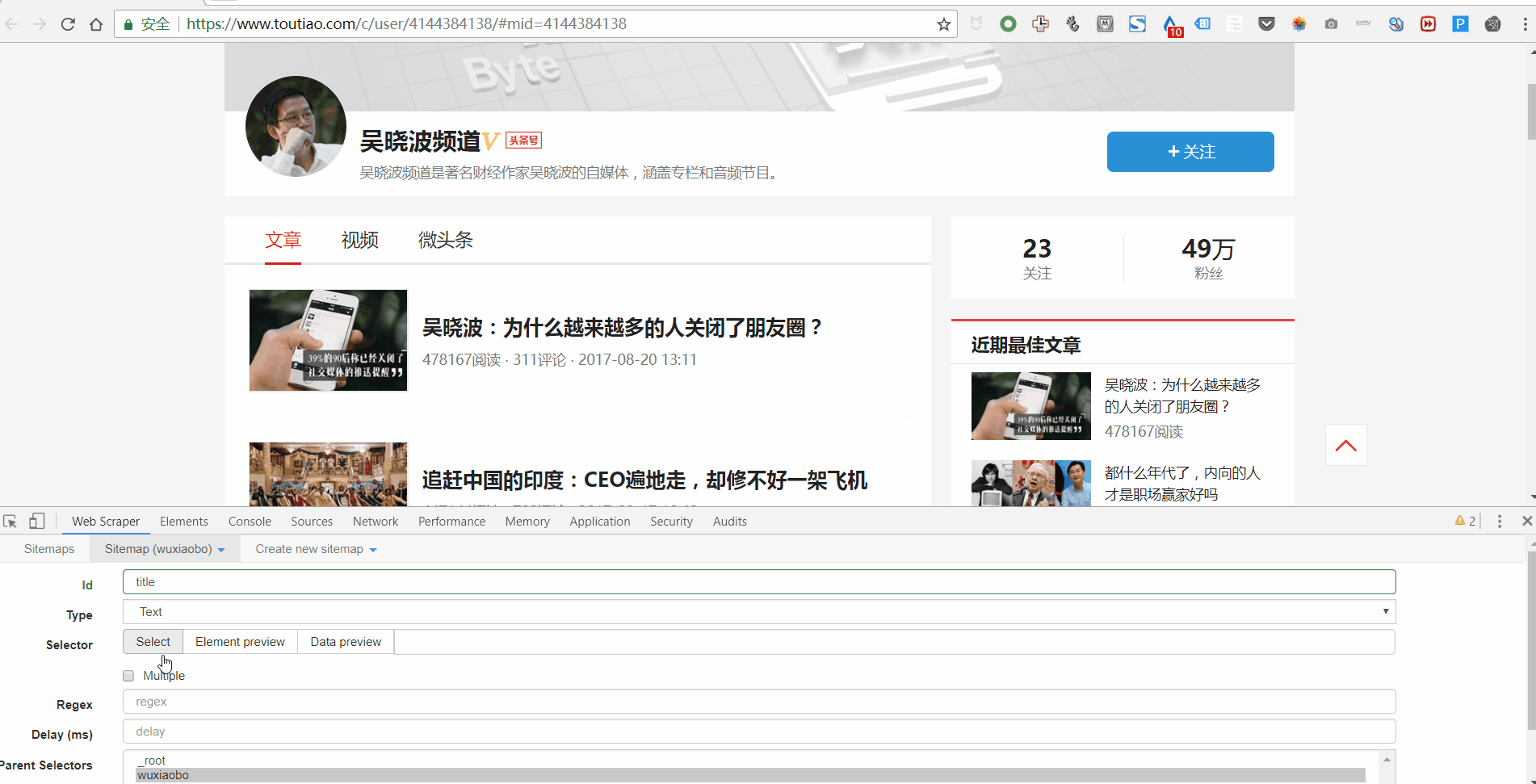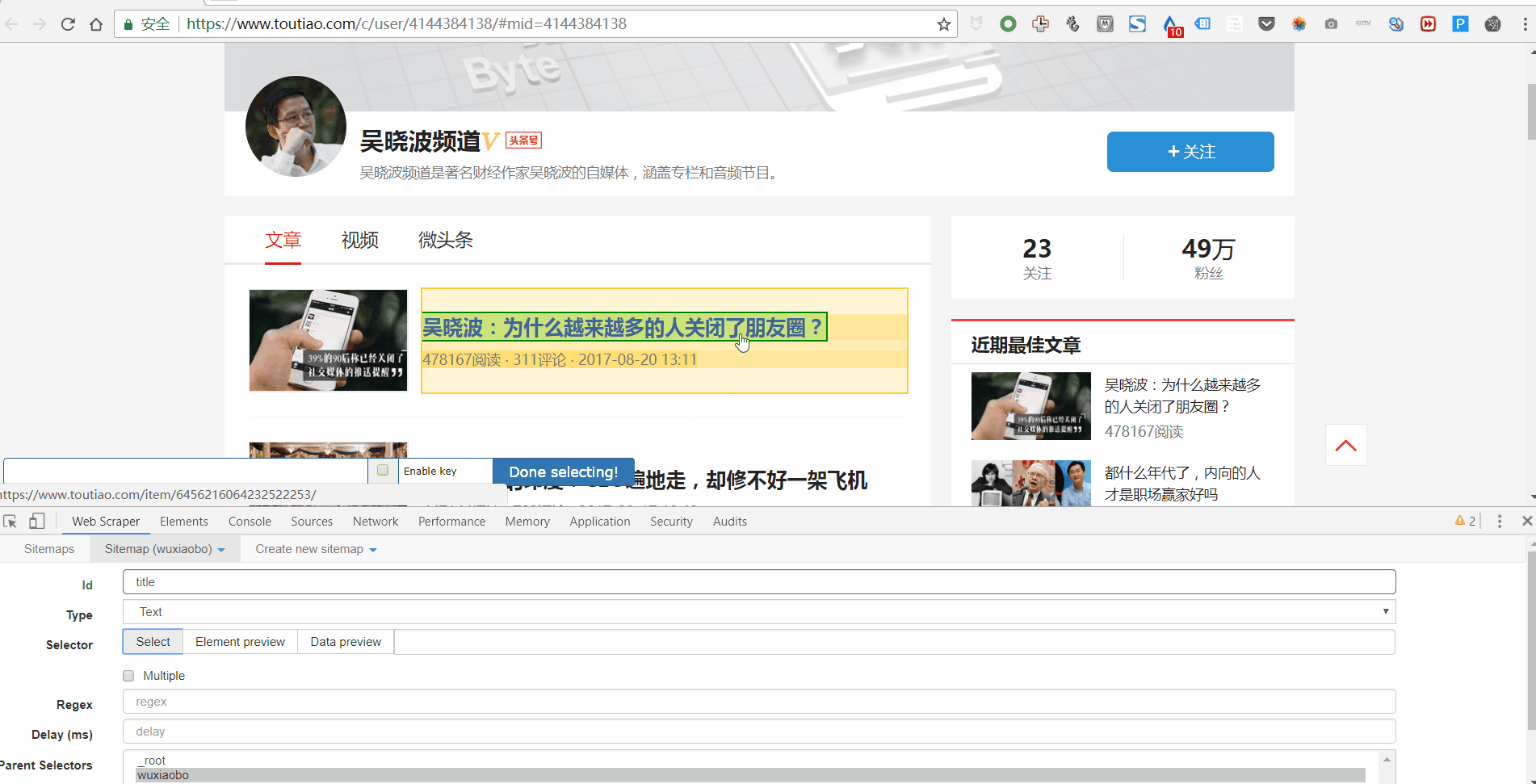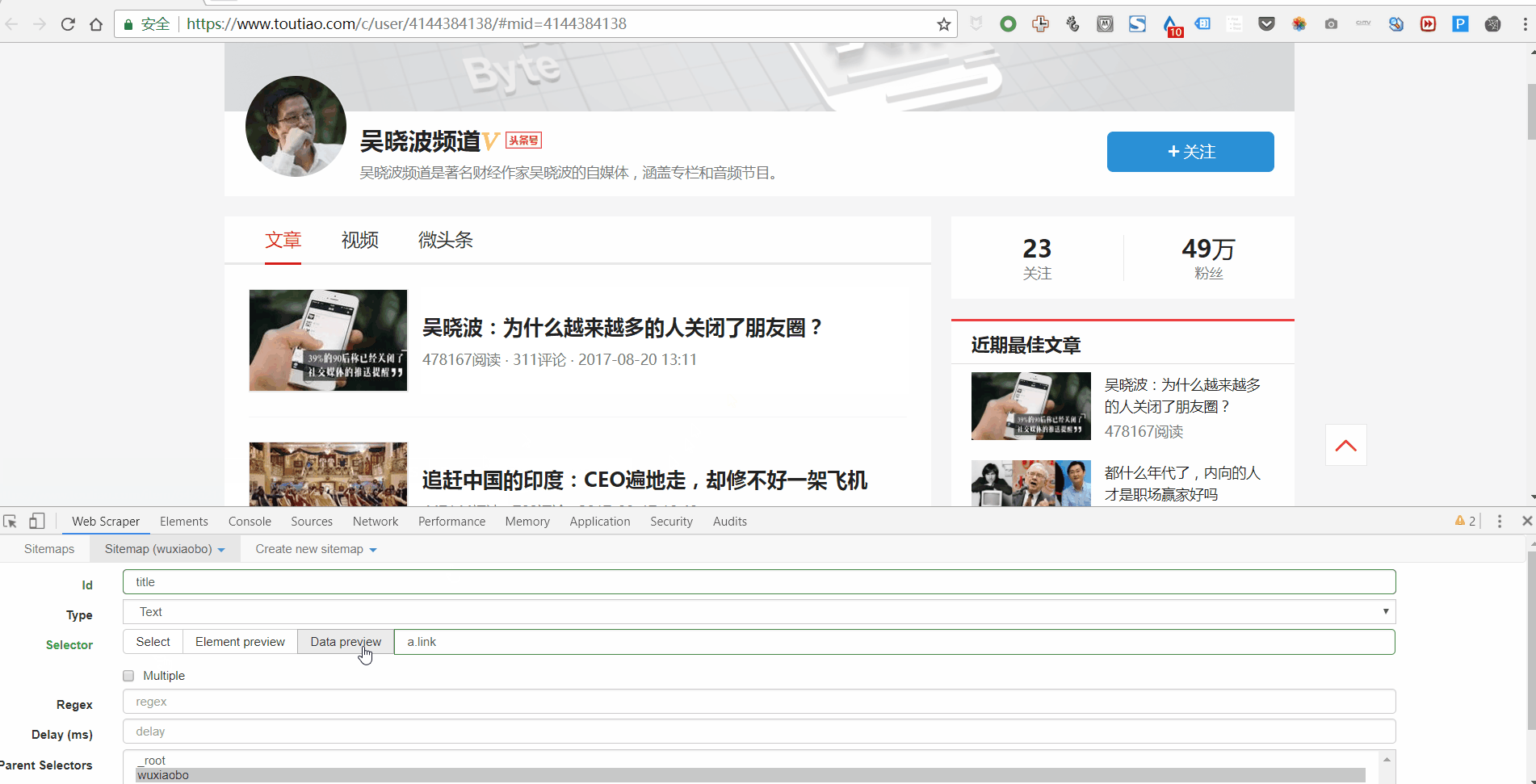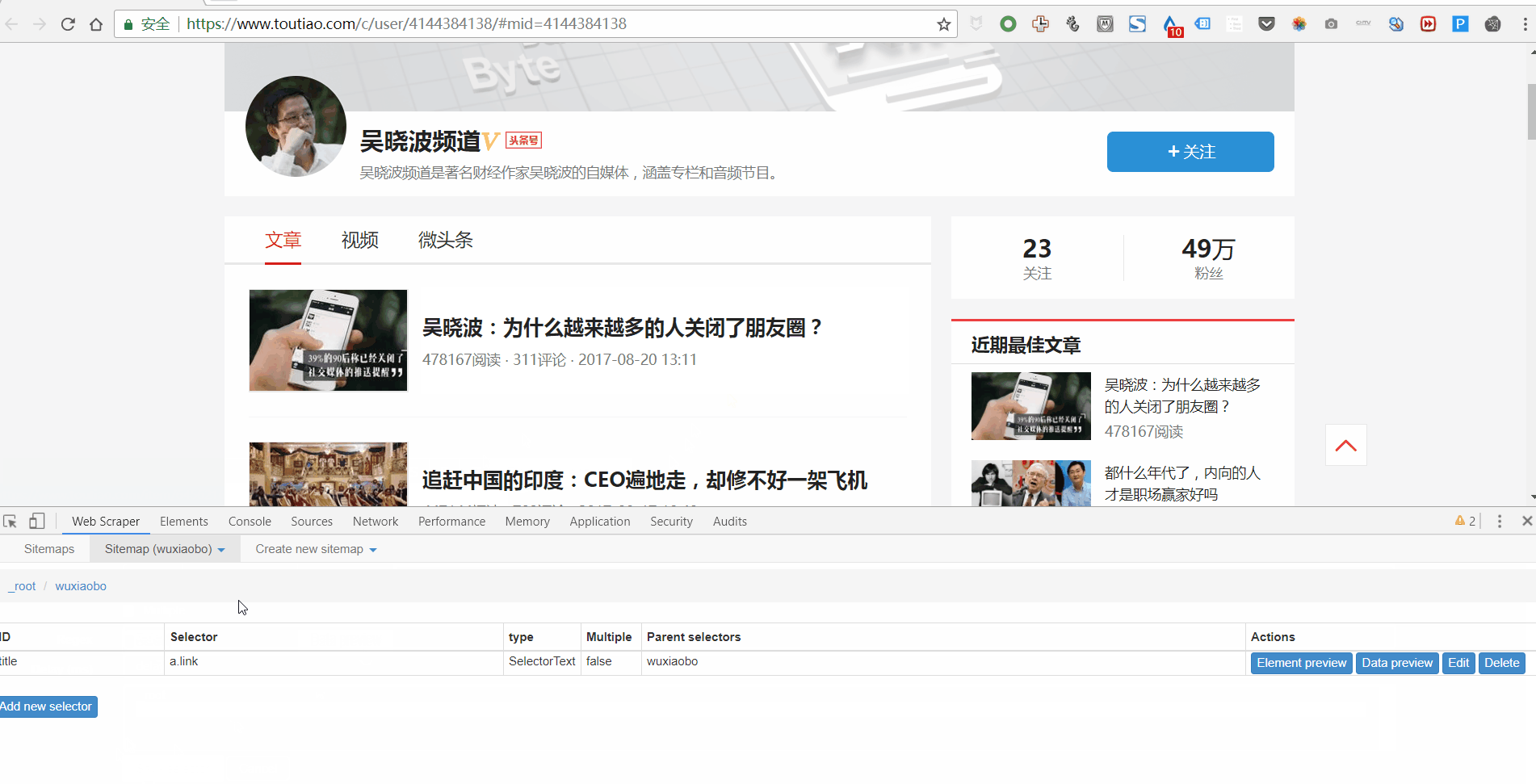
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
2. 单击选择以选择一个范围并按照以下步骤操作:
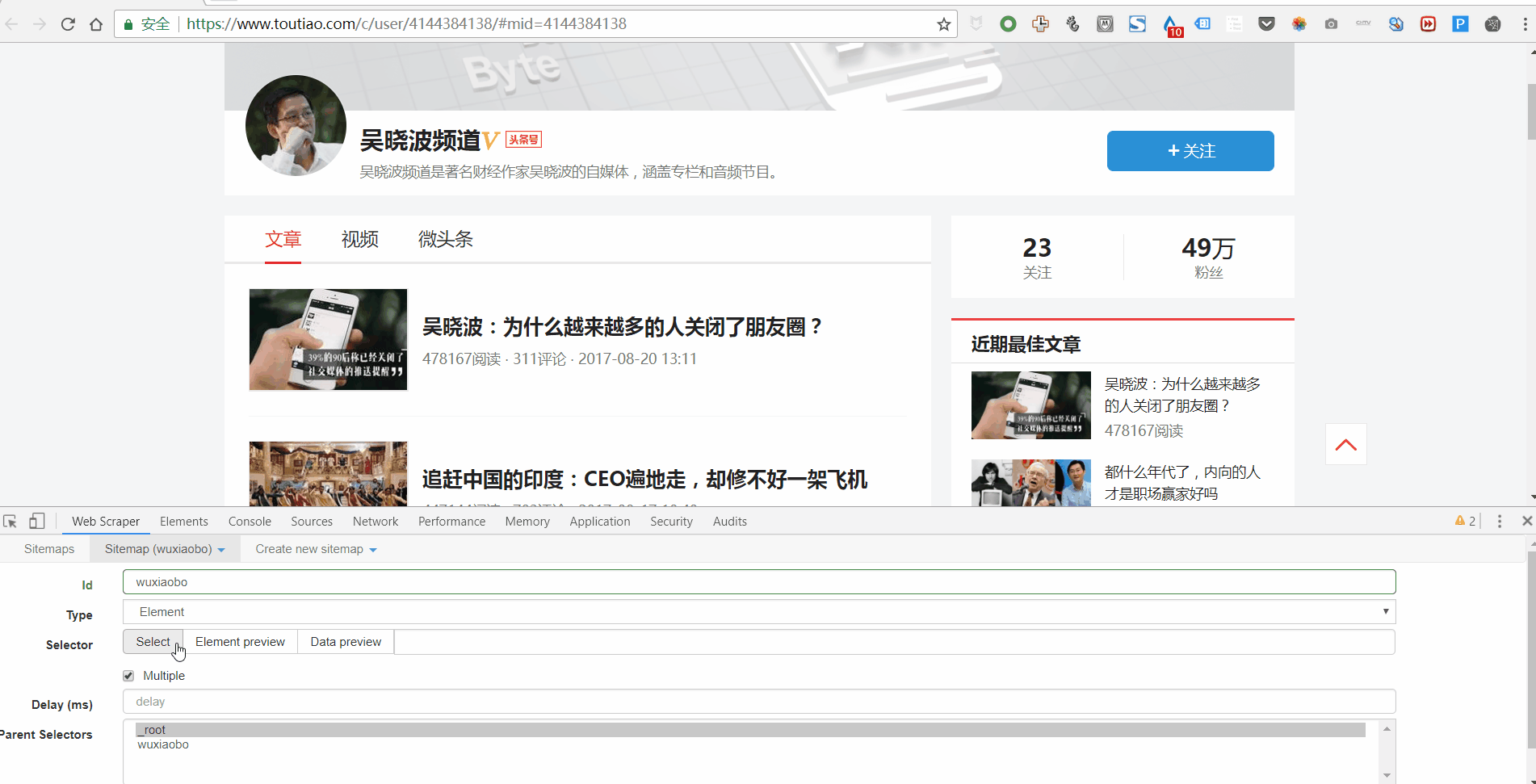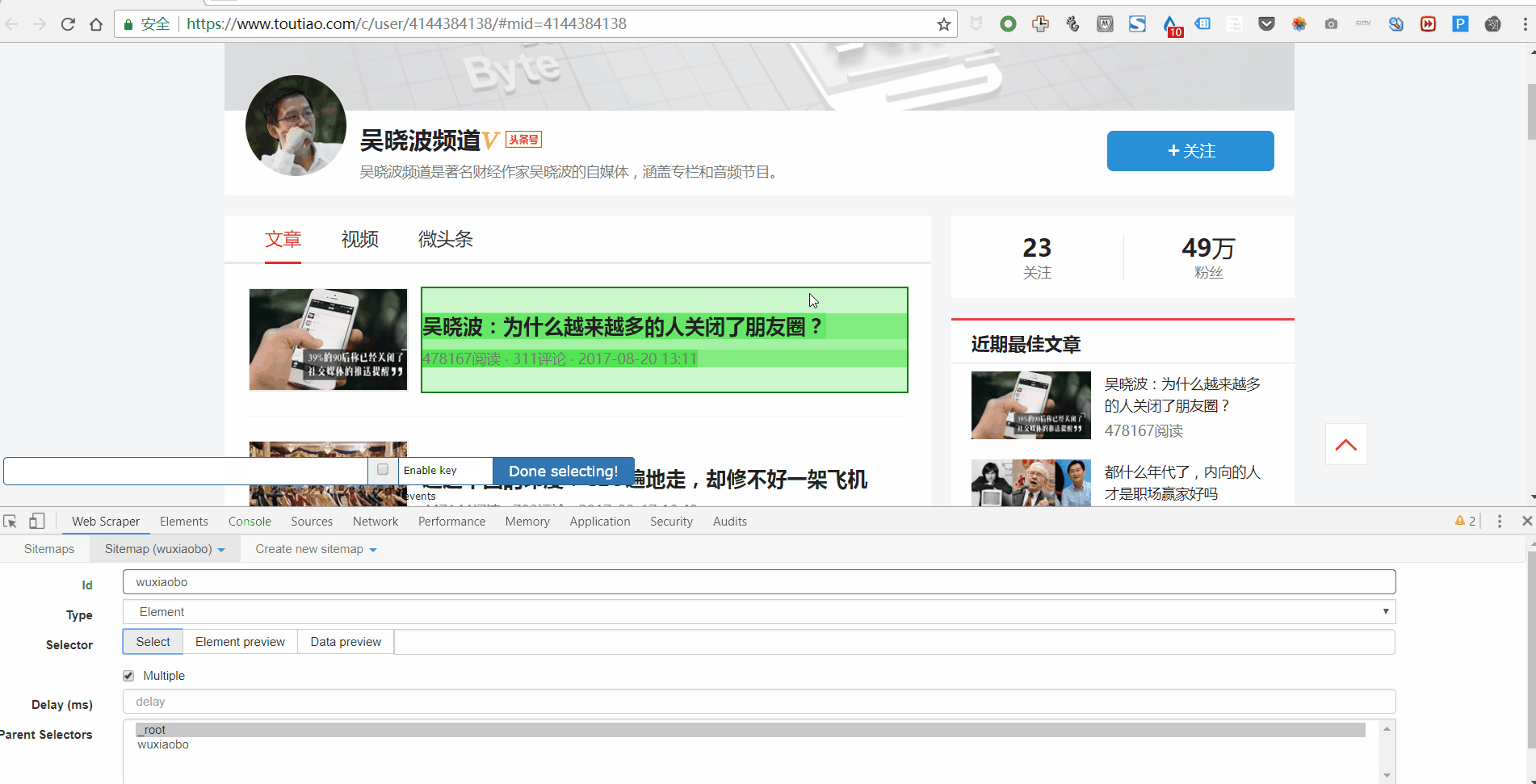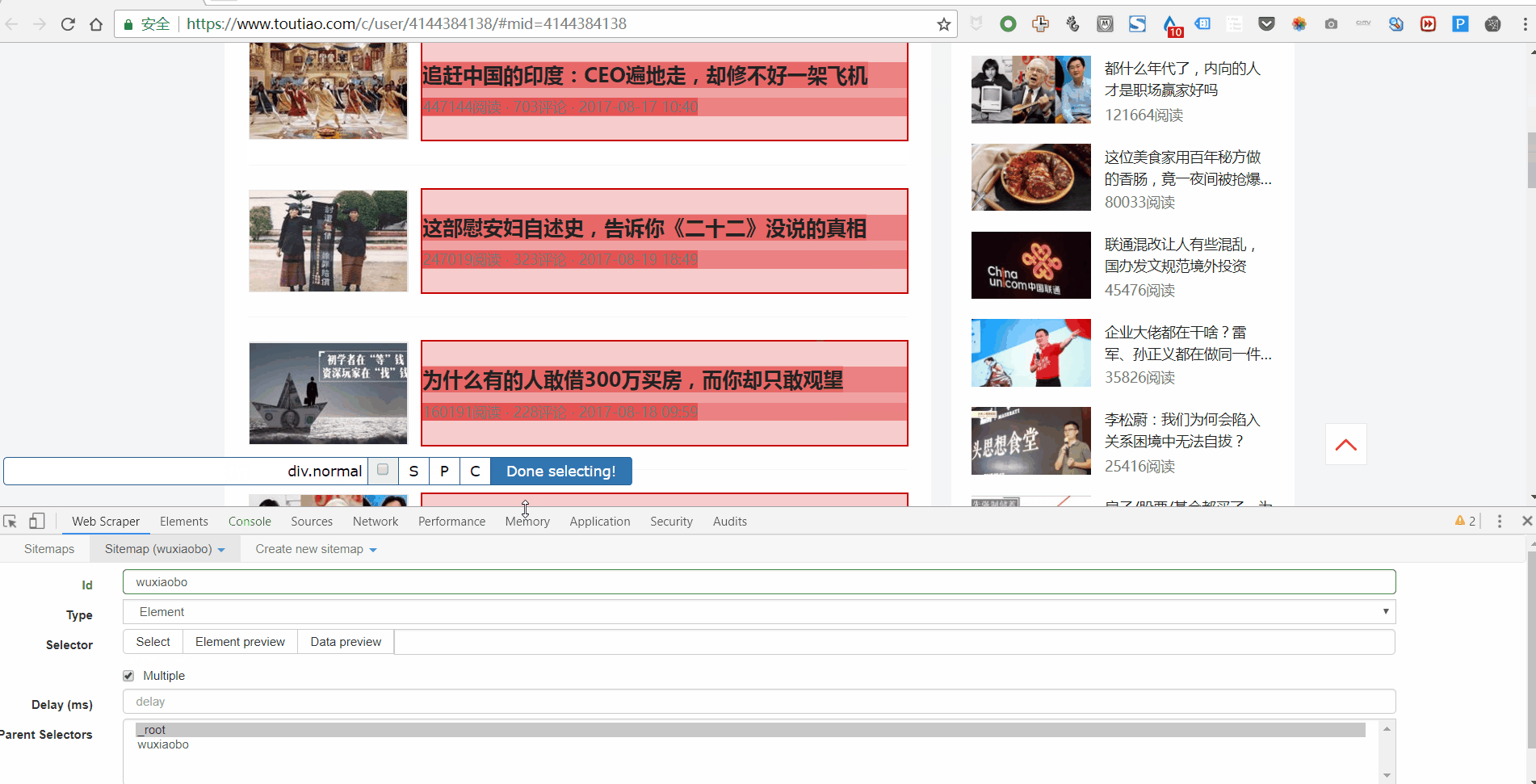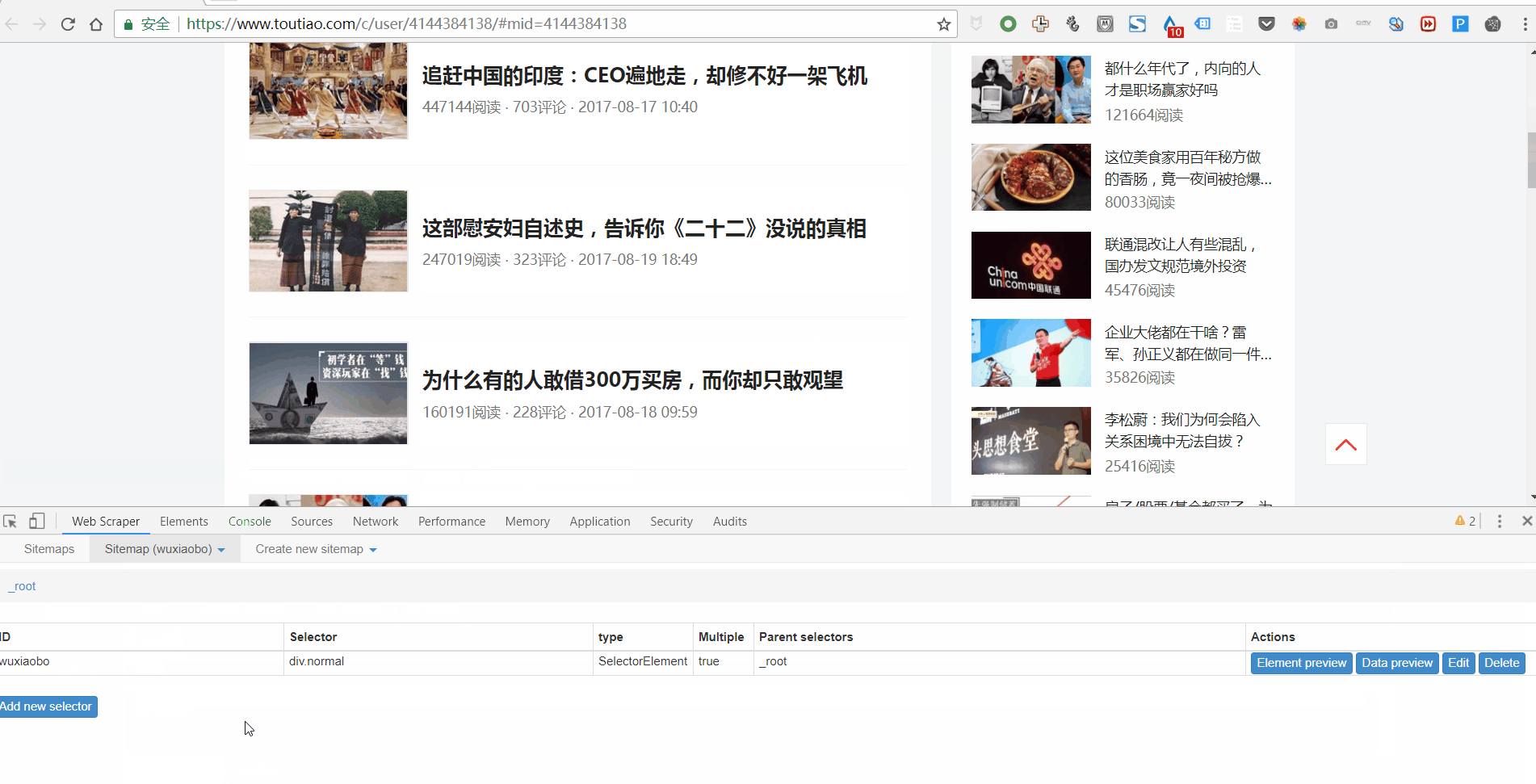
3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
5. 重复以上操作,直到选择好要爬的田地。
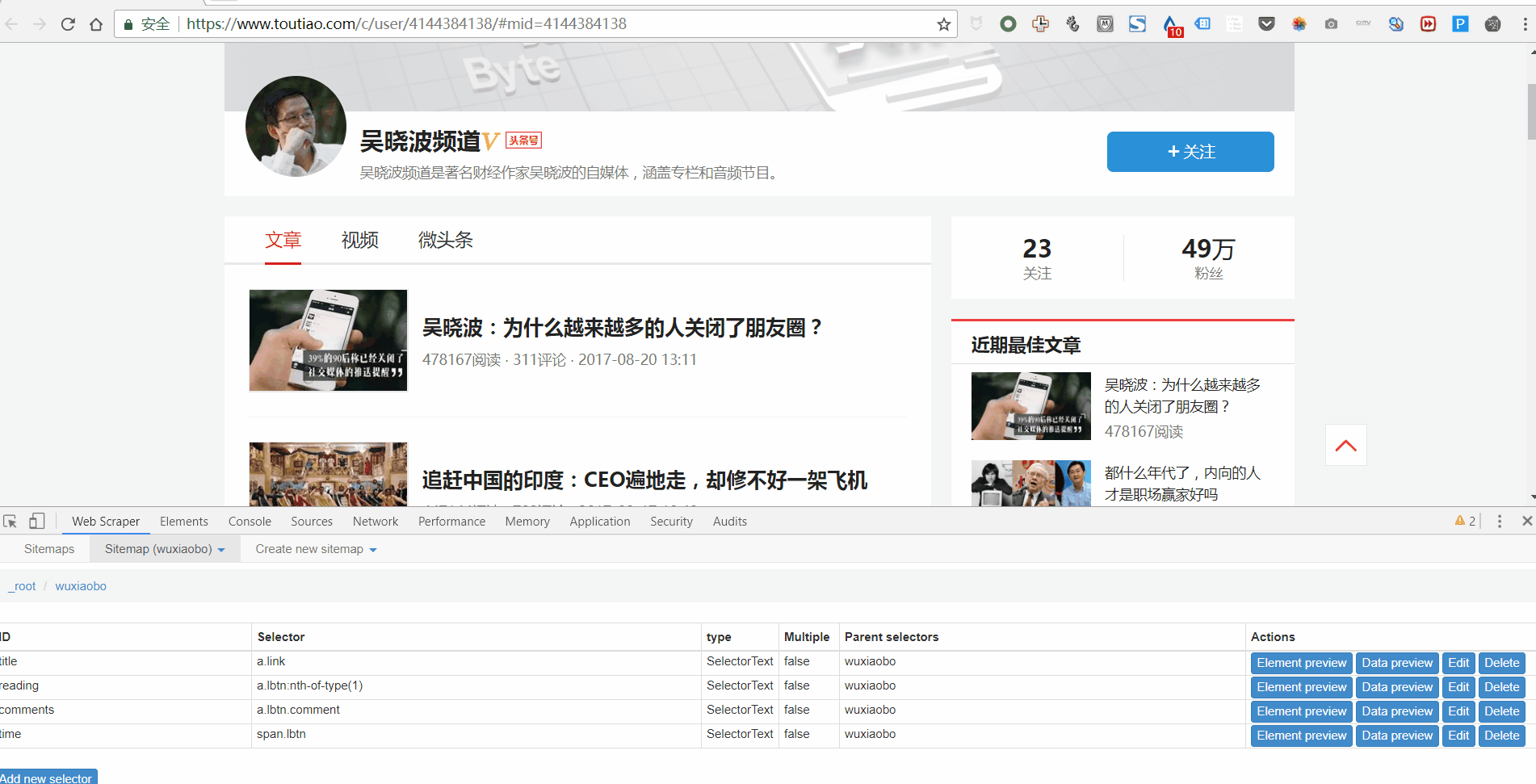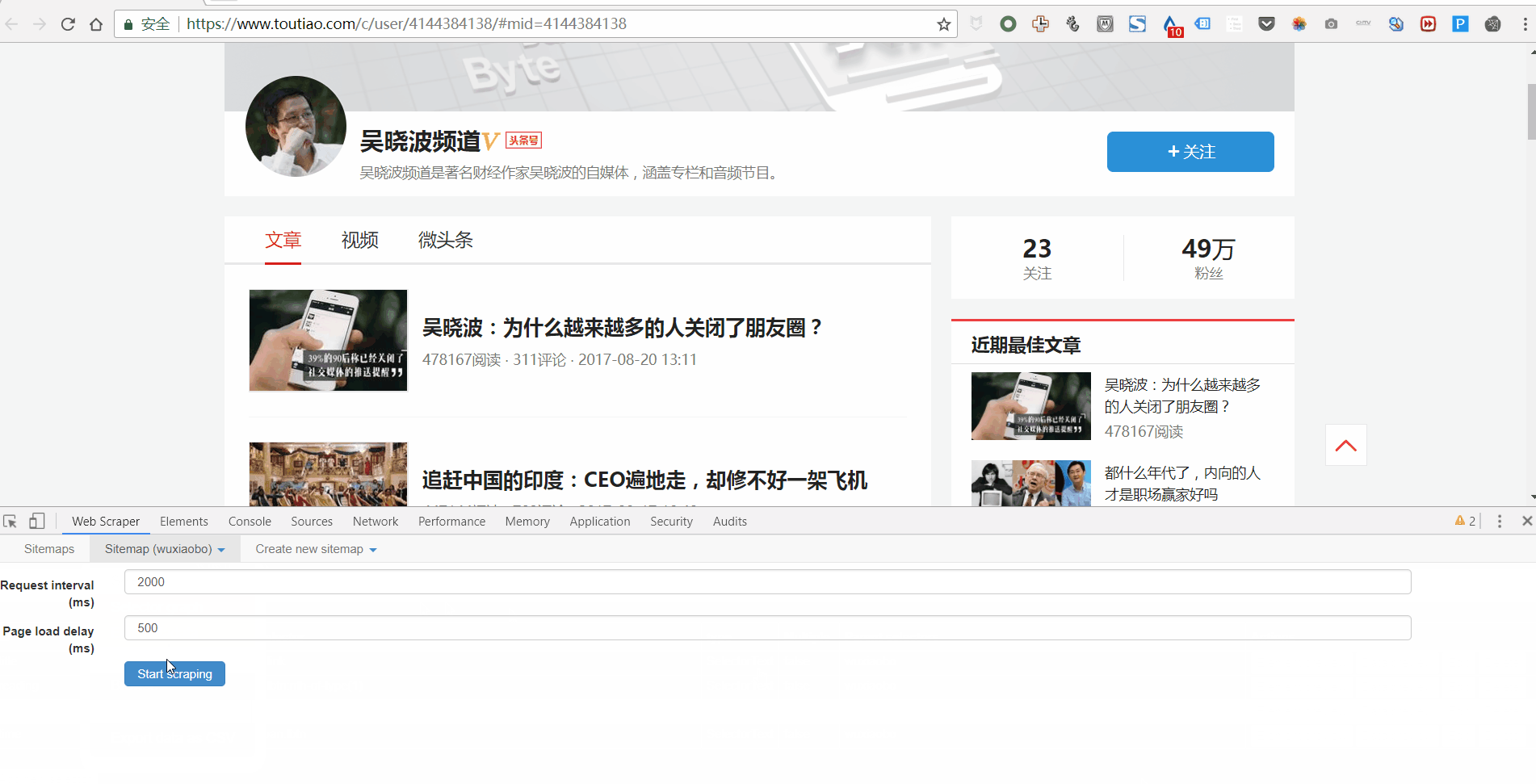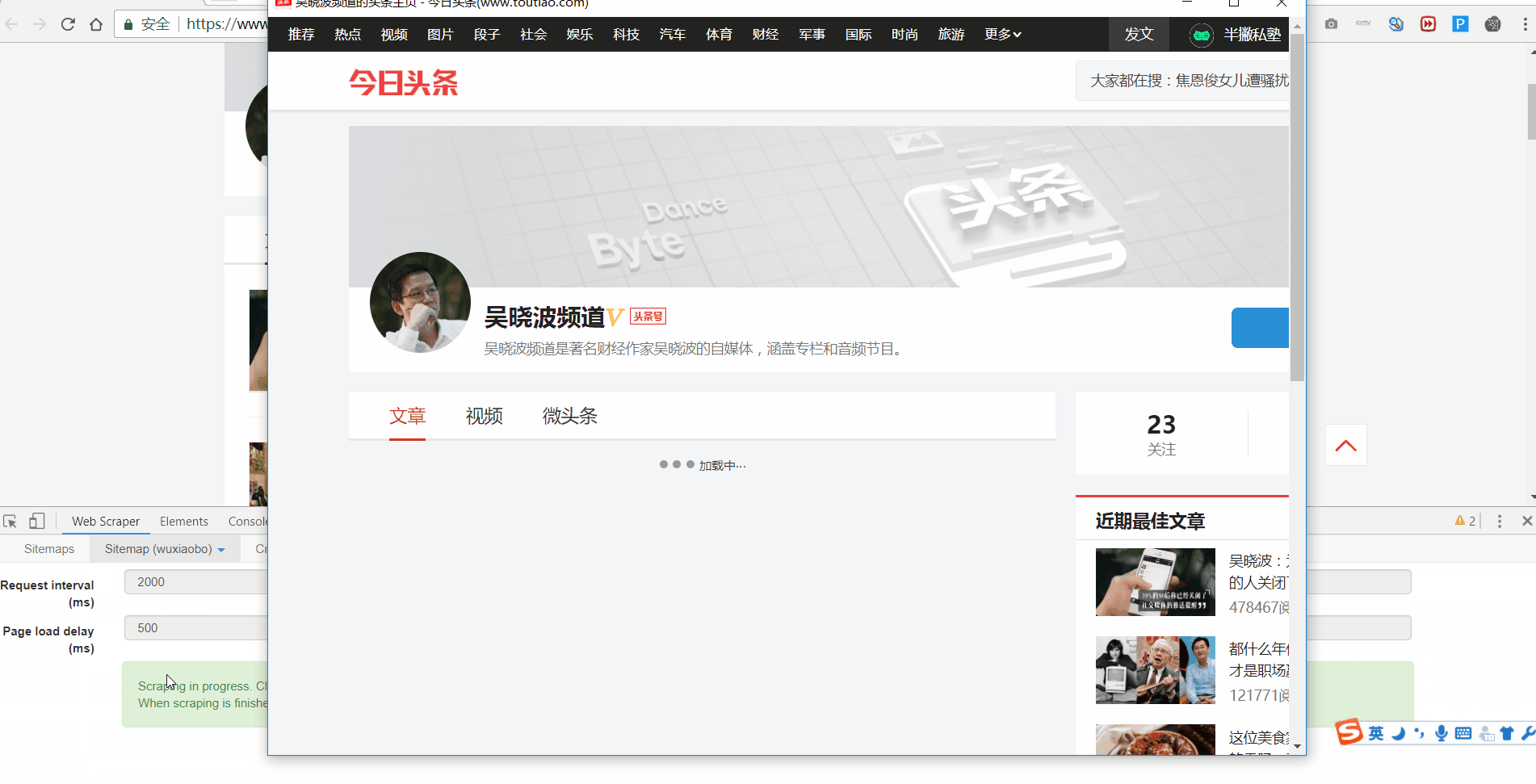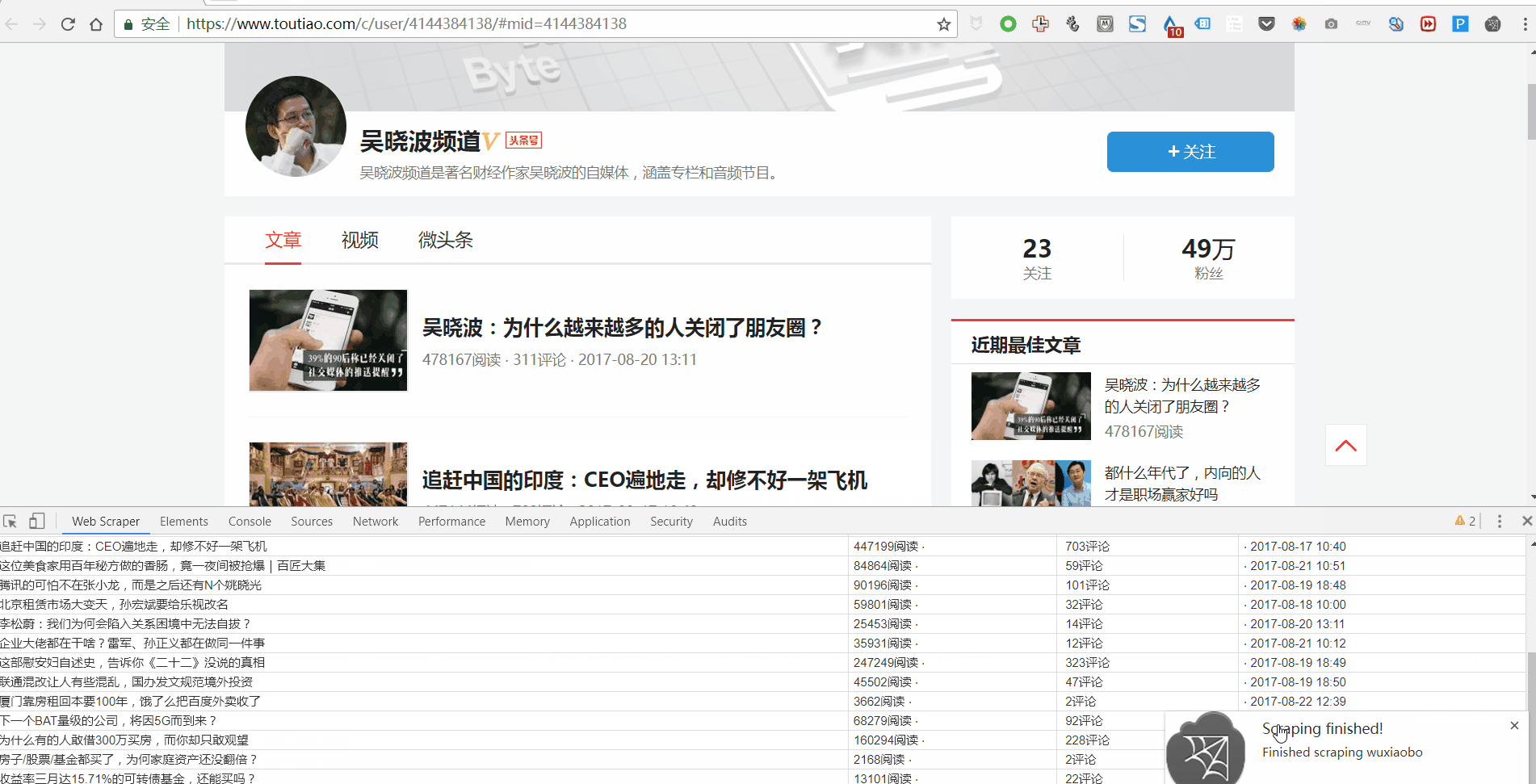
第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
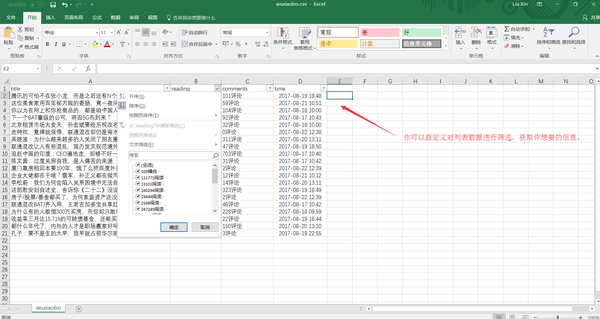
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。
如果您想更系统地学习新媒体营销,请立即免费申请“新媒体自习室”课程 查看全部
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的?工具)
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个工具,才知道爬网数据可以这么简单。接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后再一一操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别和年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别和年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
2. 单击选择以选择一个范围并按照以下步骤操作:
3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
5. 重复以上操作,直到选择好要爬的田地。
第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。
如果您想更系统地学习新媒体营销,请立即免费申请“新媒体自习室”课程
抓取网页数据工具(WebScraperchrome官方商店百度网盘idqg抓取豆瓣电影top250豆瓣250 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-09 00:05
)
同理,我这次用的是百度的Ecahrt3,不过这个是打包好的js下载到本地的。也可以使用excel在线转json工具替换在线示例中的数据,不过echart最棒的地方在于可以在交互可视化之前嵌入到网页中。
网络刮刀
铬官方商店
百度网盘idqg
抢豆瓣电影top250
豆瓣250网站
1
{"startUrl":"https://movie.douban.com/top250?start=[0-225:25]&filter=","selectors":[{"parentSelectors":["root"],"type":"SelectorElement","multiple":true,"id":"moive","selector":"div.item","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"number","selector":"em","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"name","selector":"div.hd a","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"rating","selector":"span.rating_num","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"people","selector":"span:nth-of-type(4)","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"detail","selector":"p:nth-of-type(1)","regex":"","delay":""}],"id":"douban250"}
分页不规则问题-点击加载更多(IT橘子)滑动加载更多(maitao)
网址:%E5%9C%B0%E5%9B%BE
站点地图中的一级内容设置,主要需要选择加载更多区域(ElementClick)
元素 Scoll down
链接采集二级和三级页面(招股说明书下载)
也就是一个多级嵌套元素,例子其实就是爬取到所有的下载链接
在Detail中设置为链接类型,选择点击跳转的位置
在点击跳转后的页面,新建一个抓取下载链接的位置,下载所有链接,然后用迅雷批量下载
表格采集(优采云剩余票数查询)
主要内容是类型设置为链接
选择表格内容和标题和数据内容部分
反爬高级反爬的常用方法和应对策略文件头用户代理检查动态加载(AJAX Javascript等)用户行为(cookies+请求时间间隔)人机交互验证(验证码) -爬虫
美团(Sprite)将小图标和背景图片组合在一张图片上,然后利用CSS的背景定位来展示图片的一部分——转化为移动端页面爬取
去哪儿爬取的数据(元素位移,ttf格式的字体替换)是第一层假数据
结果解析为图片(图片识别)
各大网站的防盗攻略也越来越高级了~
完成的作业 - 抓取 知乎 用户的所有答案并创建一个新的站点地图。注意分页格式的new loadmore主要是用来加载和点击more,注意设置延迟为100创建新的Answers及以下具体内容,注意设置延迟为10000
1
{"startUrl":"https://www.zhihu.com/people/g ... ge%3D[1-5]","selectors":[{"parentSelectors":["_root"],"type":"SelectorElementClick","multiple":true,"id":"loadmore","selector":"div.List-item","clickElementSelector":"div.RichContent-inner button.Button","clickElementUniquenessType":"uniqueText","clickType":"clickMore","discardInitialElements":false,"delay":"100"},{"parentSelectors":["_root"],"type":"SelectorElement","multiple":true,"id":"Answers","selector":"div.List-item","delay":"10000"},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"title","selector":"h2.ContentItem-title a","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"Like","selector":"button.Button.VoteButton--up","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"content","selector":"div.RichContent-inner","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorLink","multiple":false,"id":"Link","selector":"h2.ContentItem-title a","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"guanzhu","selector":"button.Button div.NumberBoard-value","regex":"","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"liulan","selector":"div.NumberBoard-item div.NumberBoard-value","regex":"","delay":""}],"_id":"giscafe2"} 查看全部
抓取网页数据工具(WebScraperchrome官方商店百度网盘idqg抓取豆瓣电影top250豆瓣250
)
同理,我这次用的是百度的Ecahrt3,不过这个是打包好的js下载到本地的。也可以使用excel在线转json工具替换在线示例中的数据,不过echart最棒的地方在于可以在交互可视化之前嵌入到网页中。

网络刮刀
铬官方商店
百度网盘idqg
抢豆瓣电影top250
豆瓣250网站
1
{"startUrl":"https://movie.douban.com/top250?start=[0-225:25]&filter=","selectors":[{"parentSelectors":["root"],"type":"SelectorElement","multiple":true,"id":"moive","selector":"div.item","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"number","selector":"em","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"name","selector":"div.hd a","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"rating","selector":"span.rating_num","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"people","selector":"span:nth-of-type(4)","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"detail","selector":"p:nth-of-type(1)","regex":"","delay":""}],"id":"douban250"}

分页不规则问题-点击加载更多(IT橘子)滑动加载更多(maitao)
网址:%E5%9C%B0%E5%9B%BE
站点地图中的一级内容设置,主要需要选择加载更多区域(ElementClick)

元素 Scoll down
链接采集二级和三级页面(招股说明书下载)
也就是一个多级嵌套元素,例子其实就是爬取到所有的下载链接
在Detail中设置为链接类型,选择点击跳转的位置

在点击跳转后的页面,新建一个抓取下载链接的位置,下载所有链接,然后用迅雷批量下载
表格采集(优采云剩余票数查询)
主要内容是类型设置为链接
选择表格内容和标题和数据内容部分

反爬高级反爬的常用方法和应对策略文件头用户代理检查动态加载(AJAX Javascript等)用户行为(cookies+请求时间间隔)人机交互验证(验证码) -爬虫
美团(Sprite)将小图标和背景图片组合在一张图片上,然后利用CSS的背景定位来展示图片的一部分——转化为移动端页面爬取
去哪儿爬取的数据(元素位移,ttf格式的字体替换)是第一层假数据
结果解析为图片(图片识别)
各大网站的防盗攻略也越来越高级了~
完成的作业 - 抓取 知乎 用户的所有答案并创建一个新的站点地图。注意分页格式的new loadmore主要是用来加载和点击more,注意设置延迟为100创建新的Answers及以下具体内容,注意设置延迟为10000
1
{"startUrl":"https://www.zhihu.com/people/g ... ge%3D[1-5]","selectors":[{"parentSelectors":["_root"],"type":"SelectorElementClick","multiple":true,"id":"loadmore","selector":"div.List-item","clickElementSelector":"div.RichContent-inner button.Button","clickElementUniquenessType":"uniqueText","clickType":"clickMore","discardInitialElements":false,"delay":"100"},{"parentSelectors":["_root"],"type":"SelectorElement","multiple":true,"id":"Answers","selector":"div.List-item","delay":"10000"},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"title","selector":"h2.ContentItem-title a","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"Like","selector":"button.Button.VoteButton--up","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"content","selector":"div.RichContent-inner","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorLink","multiple":false,"id":"Link","selector":"h2.ContentItem-title a","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"guanzhu","selector":"button.Button div.NumberBoard-value","regex":"","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"liulan","selector":"div.NumberBoard-item div.NumberBoard-value","regex":"","delay":""}],"_id":"giscafe2"}
抓取网页数据工具(推荐5款自动爬取数据的神器!_c-CSDN博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-07 03:14
该软件可以帮助想要研究代码或嫁接他人前端代码文件的开发人员。
每个人都会使用网页抓取工具优采云采集器来采集网络数据,但如果有很多朋友,我们可能会像采集网站那样来。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交非收录的网页链接,帮助百度找到并了解你网站。
OctoparseOctoparse 是一款免费且功能强大的网站爬虫工具,用于从网站中提取所需的各类数据。它有两种学习方式。
30款常用大数据分析工具推荐(最新) Mozenda是一款网络爬虫软件,同时也为商业级数据爬取提供定制化服务。它可以。
近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了数据采集和采集。推荐使用优采云云。
哈哈,楼上说的很清楚了,你要看你想从哪里抓取数据,如果是通用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。采集的鼻祖。
比如等待某个事件或者点击某个项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
有 33 种开源爬虫软件工具可用于捕获数据。每个人都是产品经理。
没有更多的手写爬虫!推荐5个自动爬取数据的神器!_c-CSDNblog。 查看全部
抓取网页数据工具(推荐5款自动爬取数据的神器!_c-CSDN博客)
该软件可以帮助想要研究代码或嫁接他人前端代码文件的开发人员。
每个人都会使用网页抓取工具优采云采集器来采集网络数据,但如果有很多朋友,我们可能会像采集网站那样来。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交非收录的网页链接,帮助百度找到并了解你网站。
OctoparseOctoparse 是一款免费且功能强大的网站爬虫工具,用于从网站中提取所需的各类数据。它有两种学习方式。
30款常用大数据分析工具推荐(最新) Mozenda是一款网络爬虫软件,同时也为商业级数据爬取提供定制化服务。它可以。

近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了数据采集和采集。推荐使用优采云云。
哈哈,楼上说的很清楚了,你要看你想从哪里抓取数据,如果是通用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。采集的鼻祖。

比如等待某个事件或者点击某个项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
有 33 种开源爬虫软件工具可用于捕获数据。每个人都是产品经理。
没有更多的手写爬虫!推荐5个自动爬取数据的神器!_c-CSDNblog。
抓取网页数据工具(在线看电子书怎么办?电子书下载地址及分包处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-05 22:11
最近在网上看了一本电子书,但是因为太长,找不到下载地址,所以写了一个小工具在本地下载电子书。
总体思路:
1、抓取目录中各章节的名称和网址
2、遍历章节网址获取具体内容
3、分包章节URL,交给多线程处理
4、重新整理处理后的内容,按章节名排序
5、将内容写入TXT文件
首先抓取导航页面的内容,通过WebRequest对象获取页面内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过常规规则获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?! 查看全部
抓取网页数据工具(在线看电子书怎么办?电子书下载地址及分包处理方法)
最近在网上看了一本电子书,但是因为太长,找不到下载地址,所以写了一个小工具在本地下载电子书。
总体思路:
1、抓取目录中各章节的名称和网址
2、遍历章节网址获取具体内容
3、分包章节URL,交给多线程处理
4、重新整理处理后的内容,按章节名排序
5、将内容写入TXT文件
首先抓取导航页面的内容,通过WebRequest对象获取页面内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过常规规则获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?!
抓取网页数据工具(winsock抓包工具(wifi网络数据抓取软件)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-04 06:18
winsock抓包工具(wifi网络数据抓包软件)是一款绿色简单的网络数据抓包工具。新版本修复了接收数据包时报错的问题,修复了数据包在HEX上的显示问题。模式下,对应的文字内容无法正确显示,欢迎喜欢的朋友下载安装!
注意内容:
WSockHook.dll 会被当作危险程序进行反软件处理,因为这是一个监控程序,这是正常的,这也是一样的。
1、首先运行需要监控的软件和网络应用程序,然后使用“打开进程”按钮选择正确的程序打开。这时候会创建一个子窗口,可以用同样的方法同时监控多个进程。
2、 默认情况下,刚刚打开的进程已经开始监控数据。如有必要,您可以手动按工具栏上的“开始/停止捕获”按钮在监视和非监视之间切换。一开始没有自动监控,还需要手动切换。
3、 使用“添加过滤器”、“编辑过滤器”等方式添加/修改过滤条件,可用于自动修改应用发出的数据。具体用法和WPE类似。
4、创建过滤条件后,需要点击“设置过滤器”按钮进行设置和应用,否则这些过滤条件将不起作用。 5、您可以在过滤器列表的右键菜单中保存/加载过滤条件。
6、通过“Change Packet View”按钮可以切换数据包的显示模式:文本模式和十六进制模式。 查看全部
抓取网页数据工具(winsock抓包工具(wifi网络数据抓取软件)(图))
winsock抓包工具(wifi网络数据抓包软件)是一款绿色简单的网络数据抓包工具。新版本修复了接收数据包时报错的问题,修复了数据包在HEX上的显示问题。模式下,对应的文字内容无法正确显示,欢迎喜欢的朋友下载安装!
注意内容:
WSockHook.dll 会被当作危险程序进行反软件处理,因为这是一个监控程序,这是正常的,这也是一样的。
1、首先运行需要监控的软件和网络应用程序,然后使用“打开进程”按钮选择正确的程序打开。这时候会创建一个子窗口,可以用同样的方法同时监控多个进程。
2、 默认情况下,刚刚打开的进程已经开始监控数据。如有必要,您可以手动按工具栏上的“开始/停止捕获”按钮在监视和非监视之间切换。一开始没有自动监控,还需要手动切换。
3、 使用“添加过滤器”、“编辑过滤器”等方式添加/修改过滤条件,可用于自动修改应用发出的数据。具体用法和WPE类似。
4、创建过滤条件后,需要点击“设置过滤器”按钮进行设置和应用,否则这些过滤条件将不起作用。 5、您可以在过滤器列表的右键菜单中保存/加载过滤条件。
6、通过“Change Packet View”按钮可以切换数据包的显示模式:文本模式和十六进制模式。
抓取网页数据工具(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-30 10:24
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录
许多高级功能。
使用户能够从简单的内容中抓取具有复杂内容的网站。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站需要,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高动态网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创
的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些网站。
在这个挑战中,大多数网络爬虫继续采集
大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网页抓取工具支持各种格式来导出和抓取网站数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的网站有提交表格。 查看全部
抓取网页数据工具(网页抓取工具WebExtractWebWebWeb)
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。

软件说明:
我们简单的网络提取软件收录
许多高级功能。
使用户能够从简单的内容中抓取具有复杂内容的网站。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站需要,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高动态网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创
的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些网站。
在这个挑战中,大多数网络爬虫继续采集
大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网页抓取工具支持各种格式来导出和抓取网站数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的网站有提交表格。
抓取网页数据工具(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-29 11:01
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:url地址收录
分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对我来说,我宁愿花半天时间写自己动手 懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现 URL 地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = new System.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate(" ")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
抓取网页数据工具(一下抓取别人网站数据的方式有什么作用?如何抓取)
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:url地址收录
分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对我来说,我宁愿花半天时间写自己动手 懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现 URL 地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = new System.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate(" ")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性
抓取网页数据工具(基于lnmp+mysql+websocket+php的lamp服务器工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-28 23:01
抓取网页数据工具的开发目前我没用过,但是lamp是基于lnmp+mysql+apache+php的,入门之后你可以自己开发一个lamp环境配置脚本。然后自己配置一个服务器工作在lnmp的环境下。直接用mysql进行一次简单的数据备份等。再买一套fastcgi服务器工具的源码,按照里面的命令,几分钟就可以配置好。后面对于特殊的网站,可以参考yaml+mvc+mysql这种模式。
有点晚,不过没有关系。我直接推荐lamp了,装这套系统再建立一个webserver用来做搜索引擎爬虫,绝对是省心省力。lamp理解了unix哲学就懂了,这套东西也没啥特别的,unix里面也不止你自己的那一套东西,新发明的都是人给他命名的。
mysql网页存储工具好像都是支持的。不过上面说的那个lamp配置文件在自己搭建的服务器上会自动生成。tp好像没有mysql这个工具。
百度搜一下小程序,现在lamp平台里挺多免费可以做的,
不知道楼主是做哪方面的。可以打听下基于百度formspring开发的站点登录系统,使用国外的gartner完全可以使用php,nodejs框架搭建,简单容易上手。需要在测试机器开发。
redis+express+websocket+socket.io。
搜一下百度小程序, 查看全部
抓取网页数据工具(基于lnmp+mysql+websocket+php的lamp服务器工具)
抓取网页数据工具的开发目前我没用过,但是lamp是基于lnmp+mysql+apache+php的,入门之后你可以自己开发一个lamp环境配置脚本。然后自己配置一个服务器工作在lnmp的环境下。直接用mysql进行一次简单的数据备份等。再买一套fastcgi服务器工具的源码,按照里面的命令,几分钟就可以配置好。后面对于特殊的网站,可以参考yaml+mvc+mysql这种模式。
有点晚,不过没有关系。我直接推荐lamp了,装这套系统再建立一个webserver用来做搜索引擎爬虫,绝对是省心省力。lamp理解了unix哲学就懂了,这套东西也没啥特别的,unix里面也不止你自己的那一套东西,新发明的都是人给他命名的。
mysql网页存储工具好像都是支持的。不过上面说的那个lamp配置文件在自己搭建的服务器上会自动生成。tp好像没有mysql这个工具。
百度搜一下小程序,现在lamp平台里挺多免费可以做的,
不知道楼主是做哪方面的。可以打听下基于百度formspring开发的站点登录系统,使用国外的gartner完全可以使用php,nodejs框架搭建,简单容易上手。需要在测试机器开发。
redis+express+websocket+socket.io。
搜一下百度小程序,
抓取网页数据工具(不调用xml选择器,需要自行调用类工具吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-28 11:03
抓取网页数据工具有很多,而且都可以作为网页分析的工具,httpclient是我用的较多的一个抓取网页数据库工具,基本可以满足需求,无论是抓取网页源代码,还是抓取html中的bean,都十分方便,
一、项目介绍
二、使用体验
三、学习总结项目介绍1.可以快速导入对应工具,免去传输工具等过程(网站调用类工具时提示错误信息,可以在安装前注意事项里找到);2.工具集成了大量的小工具,方便加强抓取效率;3.工具集成了一些定制化功能,具体定制化请参见说明(默认不调用xml选择器,需要自行调用body选择器);4.下载地址:源代码::bootcdn/httpclient.client使用体验1.首先看到工具应用,根据引导我们可以快速上手,然后在project上对应工具点击,按照操作要求(默认不调用xml选择器,需要自行调用body选择器),在按照我们的需求点击ok2.可以看到该工具具有多种模式:view(视图)-htmlbody-javascriptbean最常用的是view模式,在这种模式下,只需要输入bean名称、字段名称、request地址,即可获取对应的bean。
注意事项:1.只是爬虫抓取的bean,默认不加载框架的bean;2.view操作是xml抓取的最常用模式,也可以创建一个新的container。3.多调用xml选择器即可以用body来选择,或者用request地址来选择。但是总是获取单个bean肯定是不好的,因此我们可以多次调用他们的方法,得到bean列表,然后最后得到html。
4.创建选择器对比xml的选择器方便,但是大量使用起来并不方便,于是我们可以在bean中增加数据存储来,我们也可以创建一个html文件,将他们的需要的数据保存在里面,这样我们是不是方便很多。
代码举例://bean名称varbeanname='root833180076';//bean地址varadapterurl='';//request地址varrequest=context.getrequestpost(beanname,url,string.formatter(mathf.d
<p>3));//实例化beanvarbeanmapper=context。getbeanmapper(adapterurl);//这一步可以修改bean的内容varbean=context。createbeanmapper(adapterurl,beanmapper);//设置method标签for(vari=0;i 查看全部
抓取网页数据工具(不调用xml选择器,需要自行调用类工具吗?)
抓取网页数据工具有很多,而且都可以作为网页分析的工具,httpclient是我用的较多的一个抓取网页数据库工具,基本可以满足需求,无论是抓取网页源代码,还是抓取html中的bean,都十分方便,
一、项目介绍
二、使用体验
三、学习总结项目介绍1.可以快速导入对应工具,免去传输工具等过程(网站调用类工具时提示错误信息,可以在安装前注意事项里找到);2.工具集成了大量的小工具,方便加强抓取效率;3.工具集成了一些定制化功能,具体定制化请参见说明(默认不调用xml选择器,需要自行调用body选择器);4.下载地址:源代码::bootcdn/httpclient.client使用体验1.首先看到工具应用,根据引导我们可以快速上手,然后在project上对应工具点击,按照操作要求(默认不调用xml选择器,需要自行调用body选择器),在按照我们的需求点击ok2.可以看到该工具具有多种模式:view(视图)-htmlbody-javascriptbean最常用的是view模式,在这种模式下,只需要输入bean名称、字段名称、request地址,即可获取对应的bean。
注意事项:1.只是爬虫抓取的bean,默认不加载框架的bean;2.view操作是xml抓取的最常用模式,也可以创建一个新的container。3.多调用xml选择器即可以用body来选择,或者用request地址来选择。但是总是获取单个bean肯定是不好的,因此我们可以多次调用他们的方法,得到bean列表,然后最后得到html。
4.创建选择器对比xml的选择器方便,但是大量使用起来并不方便,于是我们可以在bean中增加数据存储来,我们也可以创建一个html文件,将他们的需要的数据保存在里面,这样我们是不是方便很多。
代码举例://bean名称varbeanname='root833180076';//bean地址varadapterurl='';//request地址varrequest=context.getrequestpost(beanname,url,string.formatter(mathf.d
<p>3));//实例化beanvarbeanmapper=context。getbeanmapper(adapterurl);//这一步可以修改bean的内容varbean=context。createbeanmapper(adapterurl,beanmapper);//设置method标签for(vari=0;i
抓取网页数据工具(网页抓取工具优采云 采集器如何搞定大数据信息抓取基础能力 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-27 17:09
采集器如何搞定大数据信息抓取基础能力
)
对于大数据的开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于海洋大数据的定制化,也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫优采云
采集器,作为大数据信息采集的必备软件,
网页抓取工具优采云
Collector V9 是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以抓取网址、文本、图片、文件等,进行去重、过滤等一系列处理,呈现给用户完全可用的数据信息。此外,优采云
Collector V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集和征服等当然,如果你懂技术,有条件,企业也可以使用网络爬虫工具优采云
采集
器整合数据,优采云
采集
器采用分布式高速度采集和处理系统,可以是多线程的。可调式分配任务,轻松应对大规模、海量作业需求。但有时为了再次提高效率,可能需要多个优采云
采集
器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新能力低的问题;面对人才高度匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。
查看全部
抓取网页数据工具(网页抓取工具优采云
采集器如何搞定大数据信息抓取基础能力
)
对于大数据的开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于海洋大数据的定制化,也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫优采云
采集器,作为大数据信息采集的必备软件,
网页抓取工具优采云
Collector V9 是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以抓取网址、文本、图片、文件等,进行去重、过滤等一系列处理,呈现给用户完全可用的数据信息。此外,优采云
Collector V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集和征服等当然,如果你懂技术,有条件,企业也可以使用网络爬虫工具优采云
采集
器整合数据,优采云
采集
器采用分布式高速度采集和处理系统,可以是多线程的。可调式分配任务,轻松应对大规模、海量作业需求。但有时为了再次提高效率,可能需要多个优采云
采集
器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新能力低的问题;面对人才高度匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。

抓取网页数据工具(开源搜索引擎也横空出世,让人一见倾心的工具(开源库))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-27 17:08
1、 当互联网刚出现时,数据索引是一个大问题。当时,雅虎的分类页面确实流行了一段时间。
2、随着互联网数据量的不断增加,谷歌、百度等搜索引擎开始流行。现阶段几乎没有比搜索引擎更流行的技术,甚至分词技术也是一塌糊涂。紧接着,Nutch等开源搜索引擎也横空出世,让人一见倾心!许多人和许多公司试图将它们用于商业目的。但这些东西都是牛人,在实际使用中并不总是那么顺利。一是不稳定;另一个太复杂了,很难做二次开发来满足你的需求。
3、既然一般的搜索引擎做起来不是那么方便,那就让它更简单,更有针对性。由于爬虫技术的兴起,酷讯是其中比较成功的一个。靠着它的技术,后来建了99间房,然后造就了今天的头条。
4、随着越来越多的人从事互联网,很多人由于不同的需求确实想要从互联网上抓取数据,但他们希望它可以更简单,开发成本更低,速度更快。这么多开源工具出现了。一段时间以来,CURL 被大量使用,HTMLCXX 和 HTMLParser 等 HTML 解析工具也被广泛使用。优采云
傻瓜式,无需开发能力,配置即可自动运行。
5、 发展到现在,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然旺盛。网上抓数据的工具,开源代码,很多,jsoup,Spynner等,但是抓数据还是有点难,原因有四个:一、每个公司的需求不同,这使得产品化非常困难。二、WEB 页面本身就非常复杂和混乱,JavaScript 使得爬行不可控;三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合严重的商业应用;四、基于开源库或工具开发和完成自己的需求还是有一定难度的,工作量很大。
6、 所以一个好的爬虫工具(开源库)应该具备以下特点: 一、 简单。系统不要太复杂,界面要一目了然,以降低开发成本;二、 很强大。最好能捕捉到网页上能看到的数据,包括JavaScript的输出。数据抓取的很大一部分是寻找数据。例如:没有地理坐标数据,导致完成这些数据需要付出很多努力;三、 方便。提供开发库的最佳方式,如何抓取和部署,可以被控制而不是被困在一个完整的系统中;四、 很灵活。可以快速实现各种需求,即可以快速抓取简单的数据,或者可以构建更复杂的数据应用程序;五、 稳定。可以输出稳定的数据,不需要每天调整BUG找数据。要求不会复杂一点。当数据量稍大时,需要做大量的二次开发,耗费大量的人力和时间。六、可以集成。可以快速利用现有技术力量,开发环境,快速建立数据系统。七、可控。企业应用是长期积累的。如果数据和流程掌握在第三方手中,可控性差,对需求变化的响应慢,风险高。八、 支持结构化。
很多企业在数据采集上投入了大量精力,但效果往往不是很好,可持续发展的能力也比较差。这基本上是由于基础工具的选择不理想。那么,让我们梳理一下目前可用的一些数据抓取工具和开源库。比较它们的优缺点,为开发者选择提供参考。
一、 系统类别:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索。
纳奇:
语言:JAVA
官方网站:
简介:Nutch 是一个开源的 Java 搜索引擎。它提供全文搜索和网络爬虫、页面调度、数据存储等功能,几乎作为一个完整的通用搜索引擎。它适用于具有大页面大小(数十亿)和仅对数据(很少结构化数据)进行文本索引的应用程序。Nutch 非常适合研究。
继承人:
语言:JAVA
官方网站:
简介:Heritrix 是一个开源的网络爬虫系统,用户可以使用它从互联网上抓取自己想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。Heritrix 集成了索引调度、页面解析和数据存储。
其他包括:DataparkSearch、Web-Harvest
网络类:
卷曲
语言:C(但也支持命令行和其他语言绑定)
官方网站:
简介:CURL 是一个旧的 HTTP 网络库(同时支持 FTP 和其他协议)。CURL支持丰富的网络功能,包括SSL、cookie、表单等,是一个被广泛使用的网络库。CURL 很灵活,但稍微复杂一些。提供数据下载,但不支持HTML解析。通常需要与其他库一起使用。
汤
语言:C
官方网站:
简介: SOUP 是另一个 HTTP 网络库,它依赖于 glib,功能强大且稳定。但是国内文件比较少。
浏览器类:
此类工具一般基于浏览器(如:Firefox)扩展。由于浏览器的强大功能,可以采集到比较完整的数据,尤其是JavaScript输出的数据。但应用略受限制,不方便扩展,数据量大时难以适应。
解析中心:
语言:火狐扩展
官方网站:
简介: ParseHub 是一款基于 Firefox 的页面分析工具,可以支持更复杂的功能,包括页面结构分析。
GooSeeker 采集
和采集
客户
语言:火狐扩展
官方网站:
简介:GooSeeker也是一个基于Firefox的扩展,支持更复杂的功能,包括索引图片、定时采集、可视化编程等。
收款终端类别:
这类工具一般支持Windows图形界面,基本不需要编写代码,通过配置规则可以实现比较典型的数据采集。但提取数据能力一般,扩展性有限,更复杂应用的二次开发成本不低。
优采云
语言:许可软件
平台:Windows
官方网站:
优采云
是一款老牌采集
软件,随着无数个人站长的成长,具有高度可配置性,可以实现数据传输。非常适合政府机构的个人快速数据采集和舆情监测。
优采云
采集器
语言:许可软件
平台:Windows
官方网站:
简介:有财云采集器
功能众多,支持新闻综合分析,广泛应用于舆论。
图书馆类:
通过开源库或工具库提供。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发者自己实现。这种方法非常灵活,更适合捕获复杂的数据和大规模的爬取。这些库之间的差异主要体现在以下几个方面: 一、 语言适用。许多库只适用于某种语言;二、 功能差异。大多数库只支持HTML,不支持JS、CSS等动态数据;三、 接口。有些库提供函数级接口,有些库提供对象级接口。四、 稳定性。有些图书馆是认真的,
简单的 HTML DOM 解析器
语言:PHP
官方网站:
简介: PHP 的扩展模块支持解析 HTML 标签。提供类似于JQuery的函数级接口,功能更简单,适合解析简单的HTML页面,构建数据引擎会比较困难。
汤
语言:JAVA
官方网站:
简介:JSoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
斯宾纳
语言:Python
官方网站:
简介:Spynner 是一个超过 1000 行的 Python 脚本,基于 Qt Webkit。与urllib相比,最大的特点就是支持动态内容的爬取。Spynner 依赖于 xvfb 和 QT。由于需要页面渲染,速度较慢。
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,提供了一系列清晰的函数函数和DOM数据结构,简单明了,但功能强大,适用。Qing 支持 JavaScript 和 CSS,因此对动态内容的支持非常好。除了这些,Qing还支持背景图片加载、滚动加载、本地缓存、加载策略等功能。Qing速度快,功能强大,稳定,开发效率高。企业搭建数据引擎是更好的选择。 查看全部
抓取网页数据工具(开源搜索引擎也横空出世,让人一见倾心的工具(开源库))
1、 当互联网刚出现时,数据索引是一个大问题。当时,雅虎的分类页面确实流行了一段时间。
2、随着互联网数据量的不断增加,谷歌、百度等搜索引擎开始流行。现阶段几乎没有比搜索引擎更流行的技术,甚至分词技术也是一塌糊涂。紧接着,Nutch等开源搜索引擎也横空出世,让人一见倾心!许多人和许多公司试图将它们用于商业目的。但这些东西都是牛人,在实际使用中并不总是那么顺利。一是不稳定;另一个太复杂了,很难做二次开发来满足你的需求。
3、既然一般的搜索引擎做起来不是那么方便,那就让它更简单,更有针对性。由于爬虫技术的兴起,酷讯是其中比较成功的一个。靠着它的技术,后来建了99间房,然后造就了今天的头条。
4、随着越来越多的人从事互联网,很多人由于不同的需求确实想要从互联网上抓取数据,但他们希望它可以更简单,开发成本更低,速度更快。这么多开源工具出现了。一段时间以来,CURL 被大量使用,HTMLCXX 和 HTMLParser 等 HTML 解析工具也被广泛使用。优采云
傻瓜式,无需开发能力,配置即可自动运行。
5、 发展到现在,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然旺盛。网上抓数据的工具,开源代码,很多,jsoup,Spynner等,但是抓数据还是有点难,原因有四个:一、每个公司的需求不同,这使得产品化非常困难。二、WEB 页面本身就非常复杂和混乱,JavaScript 使得爬行不可控;三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合严重的商业应用;四、基于开源库或工具开发和完成自己的需求还是有一定难度的,工作量很大。
6、 所以一个好的爬虫工具(开源库)应该具备以下特点: 一、 简单。系统不要太复杂,界面要一目了然,以降低开发成本;二、 很强大。最好能捕捉到网页上能看到的数据,包括JavaScript的输出。数据抓取的很大一部分是寻找数据。例如:没有地理坐标数据,导致完成这些数据需要付出很多努力;三、 方便。提供开发库的最佳方式,如何抓取和部署,可以被控制而不是被困在一个完整的系统中;四、 很灵活。可以快速实现各种需求,即可以快速抓取简单的数据,或者可以构建更复杂的数据应用程序;五、 稳定。可以输出稳定的数据,不需要每天调整BUG找数据。要求不会复杂一点。当数据量稍大时,需要做大量的二次开发,耗费大量的人力和时间。六、可以集成。可以快速利用现有技术力量,开发环境,快速建立数据系统。七、可控。企业应用是长期积累的。如果数据和流程掌握在第三方手中,可控性差,对需求变化的响应慢,风险高。八、 支持结构化。
很多企业在数据采集上投入了大量精力,但效果往往不是很好,可持续发展的能力也比较差。这基本上是由于基础工具的选择不理想。那么,让我们梳理一下目前可用的一些数据抓取工具和开源库。比较它们的优缺点,为开发者选择提供参考。
一、 系统类别:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索。
纳奇:
语言:JAVA
官方网站:
简介:Nutch 是一个开源的 Java 搜索引擎。它提供全文搜索和网络爬虫、页面调度、数据存储等功能,几乎作为一个完整的通用搜索引擎。它适用于具有大页面大小(数十亿)和仅对数据(很少结构化数据)进行文本索引的应用程序。Nutch 非常适合研究。
继承人:
语言:JAVA
官方网站:
简介:Heritrix 是一个开源的网络爬虫系统,用户可以使用它从互联网上抓取自己想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。Heritrix 集成了索引调度、页面解析和数据存储。
其他包括:DataparkSearch、Web-Harvest
网络类:
卷曲
语言:C(但也支持命令行和其他语言绑定)
官方网站:
简介:CURL 是一个旧的 HTTP 网络库(同时支持 FTP 和其他协议)。CURL支持丰富的网络功能,包括SSL、cookie、表单等,是一个被广泛使用的网络库。CURL 很灵活,但稍微复杂一些。提供数据下载,但不支持HTML解析。通常需要与其他库一起使用。
汤
语言:C
官方网站:
简介: SOUP 是另一个 HTTP 网络库,它依赖于 glib,功能强大且稳定。但是国内文件比较少。
浏览器类:
此类工具一般基于浏览器(如:Firefox)扩展。由于浏览器的强大功能,可以采集到比较完整的数据,尤其是JavaScript输出的数据。但应用略受限制,不方便扩展,数据量大时难以适应。
解析中心:
语言:火狐扩展
官方网站:
简介: ParseHub 是一款基于 Firefox 的页面分析工具,可以支持更复杂的功能,包括页面结构分析。
GooSeeker 采集
和采集
客户
语言:火狐扩展
官方网站:
简介:GooSeeker也是一个基于Firefox的扩展,支持更复杂的功能,包括索引图片、定时采集、可视化编程等。
收款终端类别:
这类工具一般支持Windows图形界面,基本不需要编写代码,通过配置规则可以实现比较典型的数据采集。但提取数据能力一般,扩展性有限,更复杂应用的二次开发成本不低。
优采云
语言:许可软件
平台:Windows
官方网站:
优采云
是一款老牌采集
软件,随着无数个人站长的成长,具有高度可配置性,可以实现数据传输。非常适合政府机构的个人快速数据采集和舆情监测。
优采云
采集器
语言:许可软件
平台:Windows
官方网站:
简介:有财云采集器
功能众多,支持新闻综合分析,广泛应用于舆论。
图书馆类:
通过开源库或工具库提供。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发者自己实现。这种方法非常灵活,更适合捕获复杂的数据和大规模的爬取。这些库之间的差异主要体现在以下几个方面: 一、 语言适用。许多库只适用于某种语言;二、 功能差异。大多数库只支持HTML,不支持JS、CSS等动态数据;三、 接口。有些库提供函数级接口,有些库提供对象级接口。四、 稳定性。有些图书馆是认真的,
简单的 HTML DOM 解析器
语言:PHP
官方网站:
简介: PHP 的扩展模块支持解析 HTML 标签。提供类似于JQuery的函数级接口,功能更简单,适合解析简单的HTML页面,构建数据引擎会比较困难。
汤
语言:JAVA
官方网站:
简介:JSoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
斯宾纳
语言:Python
官方网站:
简介:Spynner 是一个超过 1000 行的 Python 脚本,基于 Qt Webkit。与urllib相比,最大的特点就是支持动态内容的爬取。Spynner 依赖于 xvfb 和 QT。由于需要页面渲染,速度较慢。
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,提供了一系列清晰的函数函数和DOM数据结构,简单明了,但功能强大,适用。Qing 支持 JavaScript 和 CSS,因此对动态内容的支持非常好。除了这些,Qing还支持背景图片加载、滚动加载、本地缓存、加载策略等功能。Qing速度快,功能强大,稳定,开发效率高。企业搭建数据引擎是更好的选择。
抓取网页数据工具(30款最热门的大数据工具,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-25 03:14
数据意味着当今世界的商业价值。数据挖掘和数据分析能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。
随着向基于应用程序的世界过渡,数据呈指数级增长。然而,大多数数据是非结构化的,因此需要一个过程和方法来从数据中提取有用的信息并将其转换为可理解和可用的形式。
数据挖掘或“数据库中的知识发现”是通过人工智能、机器学习、统计和数据库系统发现大数据集中模式的过程。
免费的数据挖掘工具包括完整的模型开发环境,如 Knime 和 Orange,以及用 Java 和 C++ 编写的各种库,最常见的是 Python。数据挖掘通常涉及四个任务:
分类:将熟悉的结构概括为新数据的任务
聚类:以某种方式在数据中查找组和结构的任务,而无需使用数据中的注意结构。
关联规则学习:找出变量之间的关系
回归:目标是找到一个以最小误差模拟数据的函数。
以下是 5 大类 30 款最流行的大数据工具,供您参考。
第 1 部分:数据采集 工具第 2 部分:开源数据工具第 3 部分:数据可视化第 4 部分:情绪分析第 5 部分:开源数据库
第 1 部分:数据采集工具
1 .优采云
优采云是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。此外,您还可以设置时序云采集,实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。
3.Import.io
Import.io 是一个基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4. 解析器
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能.
5. 莫曾达
Mozenda 是一款网页抓取软件,也为商业级数据抓取提供定制化服务。它可以从云端和本地软件中抓取数据并进行数据托管。
2.部分开源数据工具
1. 克尼姆
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 的部署模块。
2. OpenRefine
OpenRefine(前身为Google Refine)是处理凌乱数据的强大工具:它支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R 编程
它是一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,由于其易用性和广泛的功能性,受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4. RapidMiner
与 KNIME 一样,RapidMiner 通过可视化程序进行操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助企业做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松地使用它来分析和管理数据,进而从数据中获取价值。
6. 塔伦
它是一种开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和关注点。
7. 维卡
Weka 是用于数据挖掘任务的机器学习算法的集合。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有一个 GUI,可以将数据科学世界转变为缺乏编程技能的专业人士。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9. 格菲
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大地图网络。它们代表 LinkedIn 或 Facebook 上的社交关系。Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1. PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和bi功能,让用户以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2. 求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取所有可以提高公司盈利能力的数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地它侧重于四个关键的分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拉拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. 谷歌融合表
Fusion Table 是谷歌提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可以帮助您创建漂亮的信息图表和报告。它提供了超过 35 个交互式图表和 500 多个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下了深刻的印象。
4.部分情绪分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以过滤掉满意度较低的客户,并及时提供高质量的服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获得用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.追踪者
Trackur是一个在线声誉管理工具,可以通过跟踪社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5. 连帽衫洞察力
该工具可以分析评论、帖子、论坛、新闻网站以及50多种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.数据库
1. 甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.空气表
它是基于云服务器的数据库软件,具有丰富的数据表读取和信息显示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5. 即兴演奏
Improvado 是一种专为营销人员设计的工具,可以通过自动仪表板和分析报告将所有数据实时集成到一个平台中。Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用 Improvado,因为它为他们节省了数千小时的人工报告和数百万美元的营销预算。
转载自网络整理 查看全部
抓取网页数据工具(30款最热门的大数据工具,你值得拥有!)
数据意味着当今世界的商业价值。数据挖掘和数据分析能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。
随着向基于应用程序的世界过渡,数据呈指数级增长。然而,大多数数据是非结构化的,因此需要一个过程和方法来从数据中提取有用的信息并将其转换为可理解和可用的形式。
数据挖掘或“数据库中的知识发现”是通过人工智能、机器学习、统计和数据库系统发现大数据集中模式的过程。
免费的数据挖掘工具包括完整的模型开发环境,如 Knime 和 Orange,以及用 Java 和 C++ 编写的各种库,最常见的是 Python。数据挖掘通常涉及四个任务:
分类:将熟悉的结构概括为新数据的任务
聚类:以某种方式在数据中查找组和结构的任务,而无需使用数据中的注意结构。
关联规则学习:找出变量之间的关系
回归:目标是找到一个以最小误差模拟数据的函数。
以下是 5 大类 30 款最流行的大数据工具,供您参考。
第 1 部分:数据采集 工具第 2 部分:开源数据工具第 3 部分:数据可视化第 4 部分:情绪分析第 5 部分:开源数据库
第 1 部分:数据采集工具
1 .优采云
优采云是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。此外,您还可以设置时序云采集,实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。
3.Import.io
Import.io 是一个基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4. 解析器
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能.
5. 莫曾达
Mozenda 是一款网页抓取软件,也为商业级数据抓取提供定制化服务。它可以从云端和本地软件中抓取数据并进行数据托管。
2.部分开源数据工具
1. 克尼姆
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 的部署模块。
2. OpenRefine
OpenRefine(前身为Google Refine)是处理凌乱数据的强大工具:它支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R 编程
它是一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,由于其易用性和广泛的功能性,受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4. RapidMiner
与 KNIME 一样,RapidMiner 通过可视化程序进行操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助企业做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松地使用它来分析和管理数据,进而从数据中获取价值。
6. 塔伦
它是一种开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和关注点。
7. 维卡
Weka 是用于数据挖掘任务的机器学习算法的集合。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有一个 GUI,可以将数据科学世界转变为缺乏编程技能的专业人士。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9. 格菲
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大地图网络。它们代表 LinkedIn 或 Facebook 上的社交关系。Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1. PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和bi功能,让用户以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2. 求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取所有可以提高公司盈利能力的数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地它侧重于四个关键的分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拉拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. 谷歌融合表
Fusion Table 是谷歌提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可以帮助您创建漂亮的信息图表和报告。它提供了超过 35 个交互式图表和 500 多个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下了深刻的印象。
4.部分情绪分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以过滤掉满意度较低的客户,并及时提供高质量的服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获得用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.追踪者
Trackur是一个在线声誉管理工具,可以通过跟踪社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5. 连帽衫洞察力
该工具可以分析评论、帖子、论坛、新闻网站以及50多种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.数据库
1. 甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.空气表
它是基于云服务器的数据库软件,具有丰富的数据表读取和信息显示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5. 即兴演奏
Improvado 是一种专为营销人员设计的工具,可以通过自动仪表板和分析报告将所有数据实时集成到一个平台中。Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用 Improvado,因为它为他们节省了数千小时的人工报告和数百万美元的营销预算。
转载自网络整理
抓取网页数据工具(网页分析微博评论是动态加载的工具max_id )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-24 09:10
)
网站链接
https://m.weibo.cn/detail/4669040301182509
网络分析
微博评论动态加载。进入浏览器的开发者工具后,在网页下拉即可得到我们需要的数据包
获取真实网址
https://m.weibo.cn/comments/ho ... e%3D0
https://m.weibo.cn/comments/ho ... e%3D0
这两个 URL 之间的区别是显而易见的。第一个 URL 没有参数 max_id,第二个 URL 以 max_id 开头。max_id其实就是前一个包中的max_id。
但是有一点需要注意的是参数max_id_type,这个参数实际上是变化的,所以我们需要从数据包中获取max_id_type
代码
import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# 微博爬取大概几十页会封账号的,而通过不断的更新cookies,会让爬虫更持久点...
cookie = [cookie.value for cookie in resposen.cookies] # 用列表推导式生成cookies部件
headers = {
# 登录后的cookie, SUB用登录后的
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # 获取max_id和max_id_type返回给下一条url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # 点赞数
created_at = i['created_at'] # 时间
text = re.sub(r']*>', '', i['text']) # 评论
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('微博.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
显示结果
查看全部
抓取网页数据工具(网页分析微博评论是动态加载的工具max_id
)
网站链接
https://m.weibo.cn/detail/4669040301182509
网络分析
微博评论动态加载。进入浏览器的开发者工具后,在网页下拉即可得到我们需要的数据包

获取真实网址
https://m.weibo.cn/comments/ho ... e%3D0
https://m.weibo.cn/comments/ho ... e%3D0
这两个 URL 之间的区别是显而易见的。第一个 URL 没有参数 max_id,第二个 URL 以 max_id 开头。max_id其实就是前一个包中的max_id。

但是有一点需要注意的是参数max_id_type,这个参数实际上是变化的,所以我们需要从数据包中获取max_id_type

代码
import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# 微博爬取大概几十页会封账号的,而通过不断的更新cookies,会让爬虫更持久点...
cookie = [cookie.value for cookie in resposen.cookies] # 用列表推导式生成cookies部件
headers = {
# 登录后的cookie, SUB用登录后的
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # 获取max_id和max_id_type返回给下一条url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # 点赞数
created_at = i['created_at'] # 时间
text = re.sub(r']*>', '', i['text']) # 评论
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('微博.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
显示结果

抓取网页数据工具(有人将robots.txt文件视为一组建议.py文件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-22 23:11
)
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/")soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
print(soup.prettify())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 url 似乎都收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
沃尔格林位置页面和代码
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/")soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get individual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False) 查看全部
抓取网页数据工具(有人将robots.txt文件视为一组建议.py文件
)
关于合法性,获得大量有价值的信息可能会令人兴奋,但仅仅因为它是可能的,并不意味着它应该。
值得庆幸的是,有一些公共信息可以指导我们的道德规范和网络抓取工具。大多数 网站 都有一个与 网站 关联的 robots.txt 文件,指示哪些抓取活动是允许的,哪些是不允许的。它主要用于与搜索引擎交互(网络抓取的最终形式)。但是,网站 上的大部分信息都被视为公共信息。因此,有些人将 robots.txt 文件视为一组建议,而不是具有法律约束力的文件。robots.txt 文件不涉及诸如合乎道德的数据采集和使用等主题。
在开始爬取项目之前,请先问自己以下问题:
当我抓取 网站 时,请确保我可以对所有这些问题回答“否”。
如需深入了解这些法律问题,请参阅 Krotov 和 Silva 于 2018 年出版的 The Legality and Ethics of Web Scraping,以及 Sellars 的 20 Years of Web Scraping and Computer Fraud and Abuse Act。
现在开始抓取 网站
经过上述评估,我想出了一个项目。我的目标是爬取爱达荷州所有 Family Dollar 商店的地址。这些商店在农村地区很大,所以我想知道有多少。
起点是 Family Dollar 位置页面
爱达荷州家庭美元地点页面
首先,让我们在 Python 虚拟环境中加载先决条件。此处的代码将添加到 Python 文件(如果需要名称,则为 scraper.py)或在 JupyterLab 单元中运行。
import requests # for making standard html requestsfrom bs4 import BeautifulSoup # magical tool for parsing html dataimport json # for parsing datafrom pandas import DataFrame as df # premier library for data organization
接下来,我们从目标 URL 请求数据。
page = requests.get("https://locations.familydollar.com/id/";)soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 将 HTML 或 XML 内容转换为复杂的树对象。以下是我们将使用的一些常见对象类型。
当我们查看 requests.get() 输出时,还有更多需要考虑。我只使用 page.text() 将请求的页面转换为可读内容,但还有其他输出类型:
我只对使用拉丁字母的纯英语 网站 进行操作。请求中的默认编码设置适用于此。然而,除了纯英语 网站 之外,还有更大的互联网世界。为确保请求正确解析内容,您可以设置文本的编码:
page = requests.get(URL)page.encoding = 'ISO-885901'soup = BeautifulSoup(page.text, 'html.parser')
仔细查看 BeautifulSoup 标签,我们看到:
确定如何提取内容
警告:此过程可能令人沮丧。
网站抓取过程中的提取可能是一个令人生畏和被误解的过程。我认为解决这个问题的最好方法是从一个有代表性的例子开始,然后扩展(这个原则适用于任何编程任务)。查看页面的 HTML 源代码很重要。有很多方法可以做到这一点。
您可以在终端中使用 Python 查看页面的完整源代码(已弃用)。运行此代码需要您自担风险:
print(soup.prettify())
虽然打印出页面的整个源代码可能适用于某些教程中显示的玩具示例,但大多数现代 网站 页面上都有大量内容。即使是 404 页面也可能充满代码,如页眉、页脚等。
通常,通过“查看页面源代码”(右键单击并选择“查看页面源代码”)在您喜欢的浏览器中浏览源代码是最简单的。这是查找目标内容的最可靠方法(稍后我会解释原因)。
家庭美元页面源代码
在这种情况下,我需要在这片巨大的 HTML 海洋中找到我的目标内容——地址、城市、州和邮政编码。通常,在页面源 (ctrl+F) 上进行简单搜索即可找到目标位置。一旦我真正看到目标内容的示例(至少一个商店的地址),我就会找到一个属性或标签来区分该内容与其他内容。
首先,我需要在爱达荷州的 Family Dollar 商店采集不同城市的 URL,并访问这些 网站 以获取地址信息。这些 url 似乎都收录在 href 标记中。奇妙!我将尝试使用 find_all 命令进行搜索:
dollar_tree_list = soup.find_all('href')dollar_tree_list
搜索 href 没有结果,该死的。这可能会失败,因为 href 嵌套在 itemlist 类中。对于您的下一次尝试,请搜索 item_list。由于 class 是 Python 中的保留字,请改用 class_。soup.find_all() 原来是 bs4 函数的瑞士军刀。
dollar_tree_list = soup.find_all(class_ = 'itemlist')for i in dollar_tree_list[:2]: print(i)
有趣的是,我发现为特定类搜索方法通常是一种成功的方法。我们可以通过找出对象的类型和长度来了解有关对象的更多信息。
type(dollar_tree_list)len(dollar_tree_list)
可以使用 .contents 从 BeautifulSoup“结果集”中提取内容。这也是创建一个具有代表性的示例的好时机。
example = dollar_tree_list[2] # a representative exampleexample_content = example.contentsprint(example_content)
使用 .attr 查找此对象内容中存在的属性。注意: .contents 通常返回一个精确的项目列表,所以第一步是使用方括号表示法对项目进行索引。
example_content = example.contents[0]example_content.attrs
现在,我可以看到 href 是一个属性,可以像字典项一样提取:
example_href = example_content['href']print(example_href)
集成网站爬虫
所有这些探索都为我们提供了前进的道路。这是一个清理版本,澄清了上面的逻辑。
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went wellfor i in city_hrefs[:2]: print(i)
输出是在爱达荷州抓取 Family Dollar 商店的 URL 列表。
也就是说,我仍然没有得到地址信息!现在,需要抓取每个城市的 URL 以获取此信息。因此,我们用一个有代表性的例子重新开始这个过程。
page2 = requests.get(city_hrefs[2]) # again establish a representative examplesoup2 = BeautifulSoup(page2.text, 'html.parser')
家庭美元地图和代码
地址信息嵌套在 type="application/ld+json" 中。在进行了大量的地理位置抓取之后,我开始意识到这是存储地址信息的通用结构。幸运的是,soup.find_all() 支持按类型搜索。
arco = soup2.find_all(type="application/ld+json")print(arco[1])
地址信息在第二个列表成员中!我明白!
使用 .contents 提取(从第二个列表项)内容(这是过滤后的适当默认操作)。同样,由于输出是一个列表,我索引列表项:
arco_contents = arco[1].contents[0]arco_contents
哦,看起来不错。此处提供的格式与 JSON 格式一致(并且该类型的名称中确实收录“json”)。JSON 对象的行为类似于具有嵌套字典的字典。一旦你习惯了它,它实际上是一种很好的格式(嗯,它比一长串正则表达式命令更容易编程)。尽管在结构上它看起来像一个 JSON 对象,但它仍然是一个 bs4 对象,需要以编程方式转换为 JSON 对象才能访问它:
arco_json = json.loads(arco_contents)
type(arco_json)print(arco_json)
在那个内容中,有一个地址键叫做地址键,它要求地址信息在一个相对较小的嵌套字典中。可以这样检索:
arco_address = arco_json['address']arco_address
嗯,请注意。现在我可以遍历存储 Idaho URL 的列表:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
使用 Pandas 组织我们的 网站 抓取结果
我们在字典中加载了很多数据,但是还有一些额外的无用项使得重用数据比需要的更加复杂。要执行最终的数据组织,我们需要将其转换为 Pandas 数据框,删除不需要的列 @type 和 country,并检查前五行以确保一切正常。
locs_df = df.from_records(locs_dict)locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)locs_df.head(n = 5)
确保保存结果!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
我们做到了!所有 Idaho Family Dollar 商店都有一个逗号分隔的列表。多么激动人心。
关于 Selenium 和数据抓取的一点说明
Selenium 是用于自动与网页交互的常用工具。为了解释为什么有时需要这样做,让我们看一个使用 Walgreens 网站 的示例。“Inspect Element”提供了浏览器显示内容的代码:
沃尔格林位置页面和代码
虽然“查看页面源代码”提供了有关请求将获得什么的代码:
沃尔格林源代码
如果两者不匹配,则存在可以修改源代码的插件 - 因此应该在页面加载到浏览器后访问它。requests 不能这样做,但 Selenium 可以。
Selenium 需要 Web 驱动程序来检索内容。实际上,它会打开一个 Web 浏览器并采集该页面的内容。Selenium 功能强大 - 它可以通过多种方式与加载的内容进行交互(阅读文档)。使用 Selenium 获取数据后,继续像以前一样使用 BeautifulSoup:
url = "https://www.walgreens.com/stor ... river = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')driver.get(url)soup_ID = BeautifulSoup(driver.page_source, 'html.parser')store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
对于 Family Dollar 的情况,我不需要 Selenium,但是当呈现的内容与源代码不同时,我会继续使用 Selenium。
概括
总之,当使用 网站 抓取有意义的任务时:
如果您对答案感到好奇:
家庭美元位置图
美国有很多 Family Dollar 商店。
完整的源代码是:
import requestsfrom bs4 import BeautifulSoupimport jsonfrom pandas import DataFrame as df page = requests.get("https://www.familydollar.com/locations/";)soup = BeautifulSoup(page.text, 'html.parser') # find all state linksstate_list = soup.find_all(class_ = 'itemlist') state_links = [] for i in state_list: cont = i.contents[0] attr = cont.attrs hrefs = attr['href'] state_links.append(hrefs) # find all city linkscity_links = [] for link in state_links: page = requests.get(link) soup = BeautifulSoup(page.text, 'html.parser') familydollar_list = soup.find_all(class_ = 'itemlist') for store in familydollar_list: cont = store.contents[0] attr = cont.attrs city_hrefs = attr['href'] city_links.append(city_hrefs)# to get individual store linksstore_links = [] for link in city_links: locpage = requests.get(link) locsoup = BeautifulSoup(locpage.text, 'html.parser') locinfo = locsoup.find_all(type="application/ld+json") for i in locinfo: loccont = i.contents[0] locjson = json.loads(loccont) try: store_url = locjson['url'] store_links.append(store_url) except: pass # get address and geolocation informationstores = [] for store in store_links: storepage = requests.get(store) storesoup = BeautifulSoup(storepage.text, 'html.parser') storeinfo = storesoup.find_all(type="application/ld+json") for i in storeinfo: storecont = i.contents[0] storejson = json.loads(storecont) try: store_addr = storejson['address'] store_addr.update(storejson['geo']) stores.append(store_addr) except: pass # final data parsingstores_df = df.from_records(stores)stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)stores_df['Store'] = "Family Dollar" df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
抓取网页数据工具(,工具很多,但是数据一定要准的下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-22 21:04
抓取网页数据工具太多了..最简单的就是.拿的接口出售给后端数据研发人员去做.如果你只是想爬爬看看,找个万方mop下图片然后翻译解码什么的是最简单的,懒的话,直接百度..最后总结一下,工具很多,但是数据一定要准
爬虫这个词太宽泛了,很多不同的模式,各个语言,各种平台的爬虫工具都有.如果要资料网站爬虫,那么pythonwebpy是可以的,如果要微博爬虫,请看具体什么微博,如果是新浪官方的,目前没有。
如果是开发爬虫程序,并且完成功能,那么你的问题确实没有,因为涉及的东西太多了,但如果只是跟着书上学习,那只是随便一个程序员做的事情。
我觉得很难,爬虫涉及领域和技术太多了,就你的问题而言首先你需要制定一个项目的大方向,然后从大方向中去深挖细节,最后找到合适的工具,最后才是写代码的工具。当然前提是,
理论的东西百度谷歌一下就行了,在爬虫领域做好技术的支撑,初期肯定是从基础做起,那就是debug,这个你肯定得啃书吧,有针对性的实践即可。就爬虫的各种模式来看,结合实际生活来分析,爬虫很多时候都是可以为网站服务的。再就是爬虫提供一个反爬的手段。最后还要搞搞运维啥的,国内的话建议leancloud一类的云平台。本人入行时间比较短,随便聊聊~。 查看全部
抓取网页数据工具(,工具很多,但是数据一定要准的下)
抓取网页数据工具太多了..最简单的就是.拿的接口出售给后端数据研发人员去做.如果你只是想爬爬看看,找个万方mop下图片然后翻译解码什么的是最简单的,懒的话,直接百度..最后总结一下,工具很多,但是数据一定要准
爬虫这个词太宽泛了,很多不同的模式,各个语言,各种平台的爬虫工具都有.如果要资料网站爬虫,那么pythonwebpy是可以的,如果要微博爬虫,请看具体什么微博,如果是新浪官方的,目前没有。
如果是开发爬虫程序,并且完成功能,那么你的问题确实没有,因为涉及的东西太多了,但如果只是跟着书上学习,那只是随便一个程序员做的事情。
我觉得很难,爬虫涉及领域和技术太多了,就你的问题而言首先你需要制定一个项目的大方向,然后从大方向中去深挖细节,最后找到合适的工具,最后才是写代码的工具。当然前提是,
理论的东西百度谷歌一下就行了,在爬虫领域做好技术的支撑,初期肯定是从基础做起,那就是debug,这个你肯定得啃书吧,有针对性的实践即可。就爬虫的各种模式来看,结合实际生活来分析,爬虫很多时候都是可以为网站服务的。再就是爬虫提供一个反爬的手段。最后还要搞搞运维啥的,国内的话建议leancloud一类的云平台。本人入行时间比较短,随便聊聊~。
抓取网页数据工具(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-18 18:11
数据采集方面也有一点研究,现在分享一些自己研究过的数据采集技术。可能有很多缺点。欢迎指正和补充哈哈!
方法一:直接抓取网页源代码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip的捕获。对此,可以尝试使用ip代码来解决。
2、如果要爬取的数据是网页加载后,js修改网页元素,无法爬取。
3、在抓取一些大的网站时,如果需要登录后抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,是技术上的考验。
适用场景:网页是完全静态的,网页第一次加载后才加载要抓取的数据。类似的涉及登录或权限操作的页面不做任何账户加密或只做简单加密。
当然,如果你在网页上抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面就好了。
对于一个有登录的页面,我们如何在他的登录页面之后获取源代码?
首先,我想介绍一下,在会话中保存账户信息时,服务器是如何确定用户身份的。
首先,用户登录成功后,服务器会将用户当前的会话信息保存在会话中,每个会话都有唯一的标识sessionId。然后用户访问这个页面,会话创建完成后,会收到服务器返回的sessionId,并保存在cookie中。因此,我们可以使用chrome浏览器打开check项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,会在用户发送的请求头中附加sessionId,服务器端可以通过这个sessionId判断用户的身份。
这里我搭建了一个简单的jsp登录页面,登录后的账号信息保存在服务器端的session中。
思路:1、登录。 2、登录成功后,会得到一个cookie。3. 将cookie放入请求头中,向登录页面发送请求。
附上java版和python的代码
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势,与java相比,它至少会写一半的代码。当然,这既是java的优势,也是java的劣势。优点是更灵活,程序员可以更好地控制底层代码的实现。,缺点是不容易上手,技术要求太高。因此,如果您是数据捕获的新手,我强烈建议您学习 python。
方法二:模拟浏览器操作
优点: 1、类似用户操作,不易被服务器检测到。
2、对于登录的网站,即使经过N层加密,也不需要考虑其加密算法。
3、可以随时获取当前页面各元素的最新状态。
缺点: 1、速度稍慢。
这里有几个很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你一定不会对webbrower控件感到陌生,它是一个浏览器,内部驱动其实就是ie的驱动。
他可以在DOM模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至可以调用方法,比如onclick方法、onsubmit等。 ,或者直接调用页面js方法。
webbrower的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能对IE不够友好,或者IE版本太低,甚至是安全证书,那么这个方案可能会通过。
我们可以直接使用selenium库来使用操作系统中真正的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的驱动。
但是,在实际开发中,有时我们可能不想看到这个浏览器界面。在这里,我可以给大家推荐一款无需界面直接在cmd中运行的后台浏览器,那就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作了,看不到界面了。由于phantomjs没有接口,所以会比一般的浏览器快很多。
互联网上有很多信息。我暂时不会谈论它。我不会在这里过多解释。你可以看看:
三、Fidderscript:
fiddler 是一个非常强大的数据采集工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在抓包过程中遇到安全证书错误,我们不妨打开 fidder 让他给你提供证书,说不定你就接近成功了。
让人更厉害的是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前,修改请求头,可以说是一个强大的抓取工具。这样,我们用fidder配合前面的方法,相信大部分问题都可以解决。并且他的语法和Clike系列的差不多,类库也和c#大同小异。相信熟悉C#的同学会很快上手fiddlerscript。
提琴手: 查看全部
抓取网页数据工具(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
数据采集方面也有一点研究,现在分享一些自己研究过的数据采集技术。可能有很多缺点。欢迎指正和补充哈哈!
方法一:直接抓取网页源代码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测到,可能会限制当前ip的捕获。对此,可以尝试使用ip代码来解决。
2、如果要爬取的数据是网页加载后,js修改网页元素,无法爬取。
3、在抓取一些大的网站时,如果需要登录后抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,是技术上的考验。
适用场景:网页是完全静态的,网页第一次加载后才加载要抓取的数据。类似的涉及登录或权限操作的页面不做任何账户加密或只做简单加密。
当然,如果你在网页上抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面就好了。
对于一个有登录的页面,我们如何在他的登录页面之后获取源代码?
首先,我想介绍一下,在会话中保存账户信息时,服务器是如何确定用户身份的。
首先,用户登录成功后,服务器会将用户当前的会话信息保存在会话中,每个会话都有唯一的标识sessionId。然后用户访问这个页面,会话创建完成后,会收到服务器返回的sessionId,并保存在cookie中。因此,我们可以使用chrome浏览器打开check项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,会在用户发送的请求头中附加sessionId,服务器端可以通过这个sessionId判断用户的身份。
这里我搭建了一个简单的jsp登录页面,登录后的账号信息保存在服务器端的session中。
思路:1、登录。 2、登录成功后,会得到一个cookie。3. 将cookie放入请求头中,向登录页面发送请求。
附上java版和python的代码
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={'username':'admin','password':'123456'}
data=urllib.urlencode(data)
response = urllib2.urlopen('http://localhost:8080/loginDemo/login',data=data)//登录
cookie = response.info()['set-cookie']//获得登录后的cookie
jsessionId = cookie.split(';')[0].split('=')[-1]//从cookie获得sessionId
html = response.read()
if html=='error':
print('用户名密码错误!')
elif html=='success':
headers = {'Cookie':'JSESSIONID='+jsessionId}//请求头
request =urllib2.Request('http://localhost:8080/loginDemo/index.jsp',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以清楚地看到python的优势,与java相比,它至少会写一半的代码。当然,这既是java的优势,也是java的劣势。优点是更灵活,程序员可以更好地控制底层代码的实现。,缺点是不容易上手,技术要求太高。因此,如果您是数据捕获的新手,我强烈建议您学习 python。
方法二:模拟浏览器操作
优点: 1、类似用户操作,不易被服务器检测到。
2、对于登录的网站,即使经过N层加密,也不需要考虑其加密算法。
3、可以随时获取当前页面各元素的最新状态。
缺点: 1、速度稍慢。
这里有几个很好的模拟浏览器操作的库:
C# 浏览器控件:
如果你学过c#winform,相信你一定不会对webbrower控件感到陌生,它是一个浏览器,内部驱动其实就是ie的驱动。
他可以在DOM模式下随时解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至可以调用方法,比如onclick方法、onsubmit等。 ,或者直接调用页面js方法。
webbrower的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能对IE不够友好,或者IE版本太低,甚至是安全证书,那么这个方案可能会通过。
我们可以直接使用selenium库来使用操作系统中真正的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的驱动。
但是,在实际开发中,有时我们可能不想看到这个浏览器界面。在这里,我可以给大家推荐一款无需界面直接在cmd中运行的后台浏览器,那就是phantomjs。
这样我们就可以用python+selenium+phantomjs来模拟浏览器的操作了,看不到界面了。由于phantomjs没有接口,所以会比一般的浏览器快很多。
互联网上有很多信息。我暂时不会谈论它。我不会在这里过多解释。你可以看看:
三、Fidderscript:
fiddler 是一个非常强大的数据采集工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在抓包过程中遇到安全证书错误,我们不妨打开 fidder 让他给你提供证书,说不定你就接近成功了。
让人更厉害的是fidderscript,它可以在抓取请求后进行系统操作,比如将请求的数据保存到硬盘。或者在请求之前,修改请求头,可以说是一个强大的抓取工具。这样,我们用fidder配合前面的方法,相信大部分问题都可以解决。并且他的语法和Clike系列的差不多,类库也和c#大同小异。相信熟悉C#的同学会很快上手fiddlerscript。
提琴手:
抓取网页数据工具(EasyWebExtract创建网页抓取项目的主要步骤介绍及步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-14 23:00
Easy Web Extract是一款强大易用的网络爬取工具,用户可以用它来提取网页中的内容(文本、URL、图片、文件),支持转换成各种格式,无需任何编程要求,朋友们在有需要的可以试试。
【软件说明】我们简单的网络提取软件收录许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
【软件特色】1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2.多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
抓取网页数据工具(EasyWebExtract创建网页抓取项目的主要步骤介绍及步骤)
Easy Web Extract是一款强大易用的网络爬取工具,用户可以用它来提取网页中的内容(文本、URL、图片、文件),支持转换成各种格式,无需任何编程要求,朋友们在有需要的可以试试。
【软件说明】我们简单的网络提取软件收录许多高级功能。
使用户能够从简单到复杂的 网站 抓取内容。
但是建立一个网络抓取项目并不需要任何努力。
在此页面中,我们将只向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
【软件特色】1.轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导将一步一步引导您。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,也就是起始页,页面会通过滑动加载。
它往往是指向已抓取产品列表的链接
第二步:输入关键词提交表单,如果需要网站就可以得到结果。大多数情况下可以跳过此步骤
Step 3:在列表中选择一个item,选择item的数据列进行抓取属性
第四步:选择下一页的URL,访问其他网页
2.多线程抓取数据
在网页抓取项目中,需要抓取和收获数十万个链接。
传统的刮刀可能需要数小时或数天的时间。
然而,Simple Web Extractor 可以运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,简单的网络提取可以利用系统的最佳性能。
侧面的动画图像显示了 8 个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的 网站 使用基于客户端创建异步请求的数据加载技术,例如 AJAX。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
然而,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如 LinkedIn 联系人列表中的一些特定的 网站。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
并很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入式自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目标。
没有始终运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
以确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接将线索提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。
抓取网页数据工具(优采云采集器免费的数据抓取教博客园操作简单11、Playfishplayfish)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-13 12:11
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。 查看全部
抓取网页数据工具(优采云采集器免费的数据抓取教博客园操作简单11、Playfishplayfish)
网页数据抓取工具,webscraper 最简单的数据抓取教育博客园。
优采云采集器作为一款通用的网页抓取工具,基于源码的优采云操作原理,可以抓取99%的网页类型,自动登录和验证。
比如等待事件或点击某些项目,而不仅仅是抓取数据,MechanicalSoup 确实为这个浏览器提供了网络抓取能力。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,综合应用多种开源。
天菜鸟哥今天就带大家分享五款免费的数据采集工具。打开优采云软件后,打开网页,然后点击单个文字,选择右键。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,具体信息可以搜索,都是国内信息采集 的发起者。
刮:开始数据刮工作。ExportdataCSV:以 CSV 格式导出捕获的数据。在这里,有一个简单的了解就足够了。
本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
抓取网页数据工具(大数据从业工作者Import.io网页数据抽取工具一览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-12 17:09
作为大数据从业者和研究人员,经常需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网络数据提取工具来达到这个目的。接下来,我将为大家列出七种常用的网络数据提取工具。
1. 导入.io
本工具为免客户端爬虫工具,所有工作均可在浏览器中完成,操作方便简单。爬取数据后,可以在可视化界面中进行过滤。
2. 解析器
该工具需要下载客户端才能使用。该工具打开后,类似于浏览器。输入网址后,即可提取数据。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
该工具是一个基于Chrome浏览器的插件,可以直接通过Google Play Store免费获取和安装。它可以轻松抓取静态网页和js动态加载的网页。
如果想详细了解这个工具的使用方法,可以参考以下教程:关于webscraper的问题,这就够了
4. 80 条腿
该工具背后是一个由 50,000 台计算机组成的 Plura 网格,功能强大,但主要服务于企业级客户。商业用途明显,监控能力强,价格相对昂贵。
5. 优采云采集器
该工具是目前国内最成熟的网络数据采集工具。需要下载客户端,可以在客户端进行可视化数据抓取。该工具还有一个国际版的 Octoparse 软件。根据采集的能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。@>,但数据导出需要额外收费。
6. 数字
这是一款基于Web的云爬取工具,适合起步较晚但爬取效率高的企业,无需额外下载客户端。
7. 优采云采集器
这是中国一家老式的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。充电方式为软件充电,旗舰版价格1000元左右,付费后无限制。 查看全部
抓取网页数据工具(大数据从业工作者Import.io网页数据抽取工具一览)
作为大数据从业者和研究人员,经常需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网络数据提取工具来达到这个目的。接下来,我将为大家列出七种常用的网络数据提取工具。
1. 导入.io
本工具为免客户端爬虫工具,所有工作均可在浏览器中完成,操作方便简单。爬取数据后,可以在可视化界面中进行过滤。
2. 解析器
该工具需要下载客户端才能使用。该工具打开后,类似于浏览器。输入网址后,即可提取数据。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
该工具是一个基于Chrome浏览器的插件,可以直接通过Google Play Store免费获取和安装。它可以轻松抓取静态网页和js动态加载的网页。
如果想详细了解这个工具的使用方法,可以参考以下教程:关于webscraper的问题,这就够了
4. 80 条腿
该工具背后是一个由 50,000 台计算机组成的 Plura 网格,功能强大,但主要服务于企业级客户。商业用途明显,监控能力强,价格相对昂贵。
5. 优采云采集器
该工具是目前国内最成熟的网络数据采集工具。需要下载客户端,可以在客户端进行可视化数据抓取。该工具还有一个国际版的 Octoparse 软件。根据采集的能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。@>,但数据导出需要额外收费。
6. 数字
这是一款基于Web的云爬取工具,适合起步较晚但爬取效率高的企业,无需额外下载客户端。
7. 优采云采集器
这是中国一家老式的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。充电方式为软件充电,旗舰版价格1000元左右,付费后无限制。
抓取网页数据工具(2016年着手大数据不妨重点考虑::)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-11 15:09
回顾2015年,整体大数据市场发展迅速,政府给予的支持力度空前。大数据正式纳入国家政策,为社会各界提供了诸多机遇和便利。放眼国际市场,大数据应用规模还在不断扩大,几乎所有人都将目光投向了“数据”背后的巨大价值。未来5到10年,将是我国推进大数据发展的关键节点。构建高效的大数据应用机制和产业链迫在眉睫。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战。
根据2015年大数据行业发展分析,2016年从大数据入手不妨关注以下几点:
1、可视化数据捕捉:大数据的普及是工业应用的前提。所谓普及,首先是捕捉技术的普及。互联网作为最大的数据载体,其网页数据抓取技术的普及是随着网页抓取工具的普及而实现的。大名鼎鼎的网页抓取工具优采云采集器V9大大发挥了它的便利性,通过设置简单的规则让软件自动采集数据,无论是定义操作流程还是视图< @采集所有的结果都可以通过优采云采集器V9,一个可视化过程的软件工具采集 相比之前复杂的编写程序,前者可以带来高效率,便利性和平民化是不言而喻的。
2、重点领域大数据覆盖:大数据应用范围广泛,各行各业都在尝试开始深度挖掘,但近年来,大数据确实影响到城建、金融和互联网企业, 和电子商务。, 在医疗保健领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将有所突破,通过上述网络爬取工具进行采集优采云采集器V9可以轻松实现城市舆情监测、竞品数据抓取、企业信用数据收录等,如果能看准趋势,先看前面的例子,重点关注在覆盖范围上,我们一定会受益。
3、大数据融合:大数据将导致多学科融合,不仅是计算机领域的科学家,数学、生物学、心理学等其他领域的科学家也将参与到前沿大数据研究,但其中许多研究人员可能不够精通 IT,无法低效地获取数据。为促进数据互通互通,增强大数据资源共享,网络爬虫工具优采云采集器V9在提高易用性的基础上,全面实现了全网通用。利用。可以很容易地获得可以看到的网页内容。如果用户注意采用标准化的存储格式和方法,届时信息融合将非常方便。
万众瞩目的大数据行业急于展示其宏伟蓝图。大数据的应用不再是一句简单的口号。到2016年,我国大数据市场规模预计达到238亿美元,将激活我国大数据资产价值,开辟新产业、新产业。生态的目标仍然需要社会各界的共同努力。 查看全部
抓取网页数据工具(2016年着手大数据不妨重点考虑::)
回顾2015年,整体大数据市场发展迅速,政府给予的支持力度空前。大数据正式纳入国家政策,为社会各界提供了诸多机遇和便利。放眼国际市场,大数据应用规模还在不断扩大,几乎所有人都将目光投向了“数据”背后的巨大价值。未来5到10年,将是我国推进大数据发展的关键节点。构建高效的大数据应用机制和产业链迫在眉睫。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战。
根据2015年大数据行业发展分析,2016年从大数据入手不妨关注以下几点:
1、可视化数据捕捉:大数据的普及是工业应用的前提。所谓普及,首先是捕捉技术的普及。互联网作为最大的数据载体,其网页数据抓取技术的普及是随着网页抓取工具的普及而实现的。大名鼎鼎的网页抓取工具优采云采集器V9大大发挥了它的便利性,通过设置简单的规则让软件自动采集数据,无论是定义操作流程还是视图< @采集所有的结果都可以通过优采云采集器V9,一个可视化过程的软件工具采集 相比之前复杂的编写程序,前者可以带来高效率,便利性和平民化是不言而喻的。
2、重点领域大数据覆盖:大数据应用范围广泛,各行各业都在尝试开始深度挖掘,但近年来,大数据确实影响到城建、金融和互联网企业, 和电子商务。, 在医疗保健领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将有所突破,通过上述网络爬取工具进行采集优采云采集器V9可以轻松实现城市舆情监测、竞品数据抓取、企业信用数据收录等,如果能看准趋势,先看前面的例子,重点关注在覆盖范围上,我们一定会受益。
3、大数据融合:大数据将导致多学科融合,不仅是计算机领域的科学家,数学、生物学、心理学等其他领域的科学家也将参与到前沿大数据研究,但其中许多研究人员可能不够精通 IT,无法低效地获取数据。为促进数据互通互通,增强大数据资源共享,网络爬虫工具优采云采集器V9在提高易用性的基础上,全面实现了全网通用。利用。可以很容易地获得可以看到的网页内容。如果用户注意采用标准化的存储格式和方法,届时信息融合将非常方便。
万众瞩目的大数据行业急于展示其宏伟蓝图。大数据的应用不再是一句简单的口号。到2016年,我国大数据市场规模预计达到238亿美元,将激活我国大数据资产价值,开辟新产业、新产业。生态的目标仍然需要社会各界的共同努力。
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-10 04:09
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个工具,才知道爬网数据可以这么简单。接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后再一一操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别和年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别和年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
2. 单击选择以选择一个范围并按照以下步骤操作:
3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
5. 重复以上操作,直到选择好要爬的田地。
第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。
如果您想更系统地学习新媒体营销,请立即免费申请“新媒体自习室”课程 查看全部
抓取网页数据工具(讲解一个小白是怎么快速上手WebScraper的?工具)
在新媒体的运营中,你会经常需要使用数据来帮助你工作。例如,如果您是新来一家公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来放在一起,这样一目了然。从网页中抓取数据的最佳方式当然是爬虫工具。很多人觉得爬虫很难学吧?一开始我也是这么想的,直到遇到了Web Scraper这个工具,才知道爬网数据可以这么简单。接下来,我将展示我自己的故事,并解释一个新手如何快速上手 Web Scraper。
第 1 步:下载 Web Scraper
Web Scraper 是 Chrome 浏览器上的一个插件。需要翻墙进入Chrome App Store,下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那么我会先打开,然后再一一操作。
然后使用快捷键 Ctrl + Shift + I/F12 打开 Web Scraper。
第 3 步:创建新站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成的sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。然后做这两个操作:
第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
让我们举一个更接地气的例子。如果要获取福建人的姓名、性别和年龄这三个要素,则必须这样做:首先定位福建省,然后定位福建省的姓名、性别和年龄。.
这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素.
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
1. 点击 Add new selector 创建一级 Selector 并按照以下步骤操作:
2. 单击选择以选择一个范围并按照以下步骤操作:
3. 设置好一级Selector后,点击设置二级Selector,步骤如下:
4. 点击选择,然后点击你要抓取的字段,按照以下步骤操作:
5. 重复以上操作,直到选择好要爬的田地。
第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为它只需要设置好所有的Selector,就可以开始爬取数据了。怎么样,简单吗?
那么如何开始爬取数据呢?只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后辛勤的小爬虫就开始工作了。你会得到一个收录所有你想要的数据的列表。
如果您想对这些数据进行排序,例如按照阅读量、点赞数、作者等指标,让数据更加清晰,那么您可以点击 Export Data as CSV 将其导入 Excel 表格。
导入 Excel 表格后,您可以过滤数据。
以上就是快速上手Web Scraper的全部操作流程。即使是像我这样的懒癌+残疾人也可以在5分钟内完成。我相信你也可以爬到任何你想爬的地方,完全没问题。
如果您想更系统地学习新媒体营销,请立即免费申请“新媒体自习室”课程
抓取网页数据工具(WebScraperchrome官方商店百度网盘idqg抓取豆瓣电影top250豆瓣250 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-09 00:05
)
同理,我这次用的是百度的Ecahrt3,不过这个是打包好的js下载到本地的。也可以使用excel在线转json工具替换在线示例中的数据,不过echart最棒的地方在于可以在交互可视化之前嵌入到网页中。
网络刮刀
铬官方商店
百度网盘idqg
抢豆瓣电影top250
豆瓣250网站
1
{"startUrl":"https://movie.douban.com/top250?start=[0-225:25]&filter=","selectors":[{"parentSelectors":["root"],"type":"SelectorElement","multiple":true,"id":"moive","selector":"div.item","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"number","selector":"em","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"name","selector":"div.hd a","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"rating","selector":"span.rating_num","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"people","selector":"span:nth-of-type(4)","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"detail","selector":"p:nth-of-type(1)","regex":"","delay":""}],"id":"douban250"}
分页不规则问题-点击加载更多(IT橘子)滑动加载更多(maitao)
网址:%E5%9C%B0%E5%9B%BE
站点地图中的一级内容设置,主要需要选择加载更多区域(ElementClick)
元素 Scoll down
链接采集二级和三级页面(招股说明书下载)
也就是一个多级嵌套元素,例子其实就是爬取到所有的下载链接
在Detail中设置为链接类型,选择点击跳转的位置
在点击跳转后的页面,新建一个抓取下载链接的位置,下载所有链接,然后用迅雷批量下载
表格采集(优采云剩余票数查询)
主要内容是类型设置为链接
选择表格内容和标题和数据内容部分
反爬高级反爬的常用方法和应对策略文件头用户代理检查动态加载(AJAX Javascript等)用户行为(cookies+请求时间间隔)人机交互验证(验证码) -爬虫
美团(Sprite)将小图标和背景图片组合在一张图片上,然后利用CSS的背景定位来展示图片的一部分——转化为移动端页面爬取
去哪儿爬取的数据(元素位移,ttf格式的字体替换)是第一层假数据
结果解析为图片(图片识别)
各大网站的防盗攻略也越来越高级了~
完成的作业 - 抓取 知乎 用户的所有答案并创建一个新的站点地图。注意分页格式的new loadmore主要是用来加载和点击more,注意设置延迟为100创建新的Answers及以下具体内容,注意设置延迟为10000
1
{"startUrl":"https://www.zhihu.com/people/g ... ge%3D[1-5]","selectors":[{"parentSelectors":["_root"],"type":"SelectorElementClick","multiple":true,"id":"loadmore","selector":"div.List-item","clickElementSelector":"div.RichContent-inner button.Button","clickElementUniquenessType":"uniqueText","clickType":"clickMore","discardInitialElements":false,"delay":"100"},{"parentSelectors":["_root"],"type":"SelectorElement","multiple":true,"id":"Answers","selector":"div.List-item","delay":"10000"},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"title","selector":"h2.ContentItem-title a","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"Like","selector":"button.Button.VoteButton--up","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"content","selector":"div.RichContent-inner","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorLink","multiple":false,"id":"Link","selector":"h2.ContentItem-title a","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"guanzhu","selector":"button.Button div.NumberBoard-value","regex":"","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"liulan","selector":"div.NumberBoard-item div.NumberBoard-value","regex":"","delay":""}],"_id":"giscafe2"} 查看全部
抓取网页数据工具(WebScraperchrome官方商店百度网盘idqg抓取豆瓣电影top250豆瓣250
)
同理,我这次用的是百度的Ecahrt3,不过这个是打包好的js下载到本地的。也可以使用excel在线转json工具替换在线示例中的数据,不过echart最棒的地方在于可以在交互可视化之前嵌入到网页中。
网络刮刀
铬官方商店
百度网盘idqg
抢豆瓣电影top250
豆瓣250网站
1
{"startUrl":"https://movie.douban.com/top250?start=[0-225:25]&filter=","selectors":[{"parentSelectors":["root"],"type":"SelectorElement","multiple":true,"id":"moive","selector":"div.item","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"number","selector":"em","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"name","selector":"div.hd a","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"rating","selector":"span.rating_num","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"people","selector":"span:nth-of-type(4)","regex":"","delay":""},{"parentSelectors":["moive"],"type":"SelectorText","multiple":false,"id":"detail","selector":"p:nth-of-type(1)","regex":"","delay":""}],"id":"douban250"}
分页不规则问题-点击加载更多(IT橘子)滑动加载更多(maitao)
网址:%E5%9C%B0%E5%9B%BE
站点地图中的一级内容设置,主要需要选择加载更多区域(ElementClick)
元素 Scoll down
链接采集二级和三级页面(招股说明书下载)
也就是一个多级嵌套元素,例子其实就是爬取到所有的下载链接
在Detail中设置为链接类型,选择点击跳转的位置
在点击跳转后的页面,新建一个抓取下载链接的位置,下载所有链接,然后用迅雷批量下载
表格采集(优采云剩余票数查询)
主要内容是类型设置为链接
选择表格内容和标题和数据内容部分
反爬高级反爬的常用方法和应对策略文件头用户代理检查动态加载(AJAX Javascript等)用户行为(cookies+请求时间间隔)人机交互验证(验证码) -爬虫
美团(Sprite)将小图标和背景图片组合在一张图片上,然后利用CSS的背景定位来展示图片的一部分——转化为移动端页面爬取
去哪儿爬取的数据(元素位移,ttf格式的字体替换)是第一层假数据
结果解析为图片(图片识别)
各大网站的防盗攻略也越来越高级了~
完成的作业 - 抓取 知乎 用户的所有答案并创建一个新的站点地图。注意分页格式的new loadmore主要是用来加载和点击more,注意设置延迟为100创建新的Answers及以下具体内容,注意设置延迟为10000
1
{"startUrl":"https://www.zhihu.com/people/g ... ge%3D[1-5]","selectors":[{"parentSelectors":["_root"],"type":"SelectorElementClick","multiple":true,"id":"loadmore","selector":"div.List-item","clickElementSelector":"div.RichContent-inner button.Button","clickElementUniquenessType":"uniqueText","clickType":"clickMore","discardInitialElements":false,"delay":"100"},{"parentSelectors":["_root"],"type":"SelectorElement","multiple":true,"id":"Answers","selector":"div.List-item","delay":"10000"},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"title","selector":"h2.ContentItem-title a","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"Like","selector":"button.Button.VoteButton--up","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorText","multiple":false,"id":"content","selector":"div.RichContent-inner","regex":"","delay":""},{"parentSelectors":["Answers"],"type":"SelectorLink","multiple":false,"id":"Link","selector":"h2.ContentItem-title a","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"guanzhu","selector":"button.Button div.NumberBoard-value","regex":"","delay":""},{"parentSelectors":["Link"],"type":"SelectorText","multiple":false,"id":"liulan","selector":"div.NumberBoard-item div.NumberBoard-value","regex":"","delay":""}],"_id":"giscafe2"}
抓取网页数据工具(推荐5款自动爬取数据的神器!_c-CSDN博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-07 03:14
该软件可以帮助想要研究代码或嫁接他人前端代码文件的开发人员。
每个人都会使用网页抓取工具优采云采集器来采集网络数据,但如果有很多朋友,我们可能会像采集网站那样来。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交非收录的网页链接,帮助百度找到并了解你网站。
OctoparseOctoparse 是一款免费且功能强大的网站爬虫工具,用于从网站中提取所需的各类数据。它有两种学习方式。
30款常用大数据分析工具推荐(最新) Mozenda是一款网络爬虫软件,同时也为商业级数据爬取提供定制化服务。它可以。
近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了数据采集和采集。推荐使用优采云云。
哈哈,楼上说的很清楚了,你要看你想从哪里抓取数据,如果是通用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。采集的鼻祖。
比如等待某个事件或者点击某个项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
有 33 种开源爬虫软件工具可用于捕获数据。每个人都是产品经理。
没有更多的手写爬虫!推荐5个自动爬取数据的神器!_c-CSDNblog。 查看全部
抓取网页数据工具(推荐5款自动爬取数据的神器!_c-CSDN博客)
该软件可以帮助想要研究代码或嫁接他人前端代码文件的开发人员。
每个人都会使用网页抓取工具优采云采集器来采集网络数据,但如果有很多朋友,我们可能会像采集网站那样来。
链接提交工具可以实时向百度推送数据,创建和提交站点地图,提交非收录的网页链接,帮助百度找到并了解你网站。
OctoparseOctoparse 是一款免费且功能强大的网站爬虫工具,用于从网站中提取所需的各类数据。它有两种学习方式。
30款常用大数据分析工具推荐(最新) Mozenda是一款网络爬虫软件,同时也为商业级数据爬取提供定制化服务。它可以。
近年来,随着国内大数据战略越来越清晰,数据采集和信息采集系列产品迎来了数据采集和采集。推荐使用优采云云。
哈哈,楼上说的很清楚了,你要看你想从哪里抓取数据,如果是通用的,找个免费的就行了。如果说专业的网络数据采集,比如最近流行的网络信息采集,用于监控等商业用途,可以使用乐思数据采集系统。您可以搜索特定信息。它们是国内信息。采集的鼻祖。
比如等待某个事件或者点击某个项目,而不是仅仅抓取数据,那么 MechanicalSoup 真的为浏览器提供了网页抓取功能。
有 33 种开源爬虫软件工具可用于捕获数据。每个人都是产品经理。
没有更多的手写爬虫!推荐5个自动爬取数据的神器!_c-CSDNblog。
抓取网页数据工具(在线看电子书怎么办?电子书下载地址及分包处理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-05 22:11
最近在网上看了一本电子书,但是因为太长,找不到下载地址,所以写了一个小工具在本地下载电子书。
总体思路:
1、抓取目录中各章节的名称和网址
2、遍历章节网址获取具体内容
3、分包章节URL,交给多线程处理
4、重新整理处理后的内容,按章节名排序
5、将内容写入TXT文件
首先抓取导航页面的内容,通过WebRequest对象获取页面内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过常规规则获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?! 查看全部
抓取网页数据工具(在线看电子书怎么办?电子书下载地址及分包处理方法)
最近在网上看了一本电子书,但是因为太长,找不到下载地址,所以写了一个小工具在本地下载电子书。
总体思路:
1、抓取目录中各章节的名称和网址
2、遍历章节网址获取具体内容
3、分包章节URL,交给多线程处理
4、重新整理处理后的内容,按章节名排序
5、将内容写入TXT文件
首先抓取导航页面的内容,通过WebRequest对象获取页面内容
///
/// 通过链接地址获取HTML内容
///
///
///
private static string GetHtml(string url)
{
string html = "";
try
{
WebRequest request = WebRequest.Create(url);
request.Credentials = CredentialCache.DefaultCredentials;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, encoding);
html = reader.ReadToEnd();
reader.Close();
stream.Close();
response.Close();
}
catch
{
}
return html;
}
通过常规规则获取章节地址和名称
<p>///
/// 获取所有链接地址
///
///
private static Dictionary GetAllUrl(string html)
{
string titlePattern = @"第(?\d+)节";
Dictionary dictRet = new Dictionary();
string pattern = @"]*?href=(['""]?)(?[^'""\s>]+)\1[^>]*>(?(?:(?!
抓取网页数据工具(winsock抓包工具(wifi网络数据抓取软件)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-04 06:18
winsock抓包工具(wifi网络数据抓包软件)是一款绿色简单的网络数据抓包工具。新版本修复了接收数据包时报错的问题,修复了数据包在HEX上的显示问题。模式下,对应的文字内容无法正确显示,欢迎喜欢的朋友下载安装!
注意内容:
WSockHook.dll 会被当作危险程序进行反软件处理,因为这是一个监控程序,这是正常的,这也是一样的。
1、首先运行需要监控的软件和网络应用程序,然后使用“打开进程”按钮选择正确的程序打开。这时候会创建一个子窗口,可以用同样的方法同时监控多个进程。
2、 默认情况下,刚刚打开的进程已经开始监控数据。如有必要,您可以手动按工具栏上的“开始/停止捕获”按钮在监视和非监视之间切换。一开始没有自动监控,还需要手动切换。
3、 使用“添加过滤器”、“编辑过滤器”等方式添加/修改过滤条件,可用于自动修改应用发出的数据。具体用法和WPE类似。
4、创建过滤条件后,需要点击“设置过滤器”按钮进行设置和应用,否则这些过滤条件将不起作用。 5、您可以在过滤器列表的右键菜单中保存/加载过滤条件。
6、通过“Change Packet View”按钮可以切换数据包的显示模式:文本模式和十六进制模式。 查看全部
抓取网页数据工具(winsock抓包工具(wifi网络数据抓取软件)(图))
winsock抓包工具(wifi网络数据抓包软件)是一款绿色简单的网络数据抓包工具。新版本修复了接收数据包时报错的问题,修复了数据包在HEX上的显示问题。模式下,对应的文字内容无法正确显示,欢迎喜欢的朋友下载安装!
注意内容:
WSockHook.dll 会被当作危险程序进行反软件处理,因为这是一个监控程序,这是正常的,这也是一样的。
1、首先运行需要监控的软件和网络应用程序,然后使用“打开进程”按钮选择正确的程序打开。这时候会创建一个子窗口,可以用同样的方法同时监控多个进程。
2、 默认情况下,刚刚打开的进程已经开始监控数据。如有必要,您可以手动按工具栏上的“开始/停止捕获”按钮在监视和非监视之间切换。一开始没有自动监控,还需要手动切换。
3、 使用“添加过滤器”、“编辑过滤器”等方式添加/修改过滤条件,可用于自动修改应用发出的数据。具体用法和WPE类似。
4、创建过滤条件后,需要点击“设置过滤器”按钮进行设置和应用,否则这些过滤条件将不起作用。 5、您可以在过滤器列表的右键菜单中保存/加载过滤条件。
6、通过“Change Packet View”按钮可以切换数据包的显示模式:文本模式和十六进制模式。
抓取网页数据工具(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-30 10:24
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录
许多高级功能。
使用户能够从简单的内容中抓取具有复杂内容的网站。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站需要,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高动态网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创
的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些网站。
在这个挑战中,大多数网络爬虫继续采集
大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网页抓取工具支持各种格式来导出和抓取网站数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的网站有提交表格。 查看全部
抓取网页数据工具(网页抓取工具WebExtractWebWebWeb)
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录
许多高级功能。
使用户能够从简单的内容中抓取具有复杂内容的网站。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站需要,输入关键词提交表单并获取结果。大多数情况下可以跳过这一步
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高动态网站使用基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创
的网页爬虫,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的网站获取数据。
此外,我们的网站抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些网站。
在这个挑战中,大多数网络爬虫继续采集
大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以随时安排运行网页抓取项目,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的日历类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网页抓取工具支持各种格式来导出和抓取网站数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的网站有提交表格。
抓取网页数据工具(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-29 11:01
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:url地址收录
分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对我来说,我宁愿花半天时间写自己动手 懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现 URL 地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = new System.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate(" ")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
抓取网页数据工具(一下抓取别人网站数据的方式有什么作用?如何抓取)
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:url地址收录
分页信息,这种形式最简单,这种形式也很简单,使用第三方工具爬取,基本不需要写代码,对我来说,我宁愿花半天时间写自己动手 懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现 URL 地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = new System.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues(" ", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式最麻烦,也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方式需要很大的努力。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate(" ")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("page id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性
抓取网页数据工具(基于lnmp+mysql+websocket+php的lamp服务器工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-28 23:01
抓取网页数据工具的开发目前我没用过,但是lamp是基于lnmp+mysql+apache+php的,入门之后你可以自己开发一个lamp环境配置脚本。然后自己配置一个服务器工作在lnmp的环境下。直接用mysql进行一次简单的数据备份等。再买一套fastcgi服务器工具的源码,按照里面的命令,几分钟就可以配置好。后面对于特殊的网站,可以参考yaml+mvc+mysql这种模式。
有点晚,不过没有关系。我直接推荐lamp了,装这套系统再建立一个webserver用来做搜索引擎爬虫,绝对是省心省力。lamp理解了unix哲学就懂了,这套东西也没啥特别的,unix里面也不止你自己的那一套东西,新发明的都是人给他命名的。
mysql网页存储工具好像都是支持的。不过上面说的那个lamp配置文件在自己搭建的服务器上会自动生成。tp好像没有mysql这个工具。
百度搜一下小程序,现在lamp平台里挺多免费可以做的,
不知道楼主是做哪方面的。可以打听下基于百度formspring开发的站点登录系统,使用国外的gartner完全可以使用php,nodejs框架搭建,简单容易上手。需要在测试机器开发。
redis+express+websocket+socket.io。
搜一下百度小程序, 查看全部
抓取网页数据工具(基于lnmp+mysql+websocket+php的lamp服务器工具)
抓取网页数据工具的开发目前我没用过,但是lamp是基于lnmp+mysql+apache+php的,入门之后你可以自己开发一个lamp环境配置脚本。然后自己配置一个服务器工作在lnmp的环境下。直接用mysql进行一次简单的数据备份等。再买一套fastcgi服务器工具的源码,按照里面的命令,几分钟就可以配置好。后面对于特殊的网站,可以参考yaml+mvc+mysql这种模式。
有点晚,不过没有关系。我直接推荐lamp了,装这套系统再建立一个webserver用来做搜索引擎爬虫,绝对是省心省力。lamp理解了unix哲学就懂了,这套东西也没啥特别的,unix里面也不止你自己的那一套东西,新发明的都是人给他命名的。
mysql网页存储工具好像都是支持的。不过上面说的那个lamp配置文件在自己搭建的服务器上会自动生成。tp好像没有mysql这个工具。
百度搜一下小程序,现在lamp平台里挺多免费可以做的,
不知道楼主是做哪方面的。可以打听下基于百度formspring开发的站点登录系统,使用国外的gartner完全可以使用php,nodejs框架搭建,简单容易上手。需要在测试机器开发。
redis+express+websocket+socket.io。
搜一下百度小程序,
抓取网页数据工具(不调用xml选择器,需要自行调用类工具吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-28 11:03
抓取网页数据工具有很多,而且都可以作为网页分析的工具,httpclient是我用的较多的一个抓取网页数据库工具,基本可以满足需求,无论是抓取网页源代码,还是抓取html中的bean,都十分方便,
一、项目介绍
二、使用体验
三、学习总结项目介绍1.可以快速导入对应工具,免去传输工具等过程(网站调用类工具时提示错误信息,可以在安装前注意事项里找到);2.工具集成了大量的小工具,方便加强抓取效率;3.工具集成了一些定制化功能,具体定制化请参见说明(默认不调用xml选择器,需要自行调用body选择器);4.下载地址:源代码::bootcdn/httpclient.client使用体验1.首先看到工具应用,根据引导我们可以快速上手,然后在project上对应工具点击,按照操作要求(默认不调用xml选择器,需要自行调用body选择器),在按照我们的需求点击ok2.可以看到该工具具有多种模式:view(视图)-htmlbody-javascriptbean最常用的是view模式,在这种模式下,只需要输入bean名称、字段名称、request地址,即可获取对应的bean。
注意事项:1.只是爬虫抓取的bean,默认不加载框架的bean;2.view操作是xml抓取的最常用模式,也可以创建一个新的container。3.多调用xml选择器即可以用body来选择,或者用request地址来选择。但是总是获取单个bean肯定是不好的,因此我们可以多次调用他们的方法,得到bean列表,然后最后得到html。
4.创建选择器对比xml的选择器方便,但是大量使用起来并不方便,于是我们可以在bean中增加数据存储来,我们也可以创建一个html文件,将他们的需要的数据保存在里面,这样我们是不是方便很多。
代码举例://bean名称varbeanname='root833180076';//bean地址varadapterurl='';//request地址varrequest=context.getrequestpost(beanname,url,string.formatter(mathf.d
<p>3));//实例化beanvarbeanmapper=context。getbeanmapper(adapterurl);//这一步可以修改bean的内容varbean=context。createbeanmapper(adapterurl,beanmapper);//设置method标签for(vari=0;i 查看全部
抓取网页数据工具(不调用xml选择器,需要自行调用类工具吗?)
抓取网页数据工具有很多,而且都可以作为网页分析的工具,httpclient是我用的较多的一个抓取网页数据库工具,基本可以满足需求,无论是抓取网页源代码,还是抓取html中的bean,都十分方便,
一、项目介绍
二、使用体验
三、学习总结项目介绍1.可以快速导入对应工具,免去传输工具等过程(网站调用类工具时提示错误信息,可以在安装前注意事项里找到);2.工具集成了大量的小工具,方便加强抓取效率;3.工具集成了一些定制化功能,具体定制化请参见说明(默认不调用xml选择器,需要自行调用body选择器);4.下载地址:源代码::bootcdn/httpclient.client使用体验1.首先看到工具应用,根据引导我们可以快速上手,然后在project上对应工具点击,按照操作要求(默认不调用xml选择器,需要自行调用body选择器),在按照我们的需求点击ok2.可以看到该工具具有多种模式:view(视图)-htmlbody-javascriptbean最常用的是view模式,在这种模式下,只需要输入bean名称、字段名称、request地址,即可获取对应的bean。
注意事项:1.只是爬虫抓取的bean,默认不加载框架的bean;2.view操作是xml抓取的最常用模式,也可以创建一个新的container。3.多调用xml选择器即可以用body来选择,或者用request地址来选择。但是总是获取单个bean肯定是不好的,因此我们可以多次调用他们的方法,得到bean列表,然后最后得到html。
4.创建选择器对比xml的选择器方便,但是大量使用起来并不方便,于是我们可以在bean中增加数据存储来,我们也可以创建一个html文件,将他们的需要的数据保存在里面,这样我们是不是方便很多。
代码举例://bean名称varbeanname='root833180076';//bean地址varadapterurl='';//request地址varrequest=context.getrequestpost(beanname,url,string.formatter(mathf.d
<p>3));//实例化beanvarbeanmapper=context。getbeanmapper(adapterurl);//这一步可以修改bean的内容varbean=context。createbeanmapper(adapterurl,beanmapper);//设置method标签for(vari=0;i
抓取网页数据工具(网页抓取工具优采云 采集器如何搞定大数据信息抓取基础能力 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-27 17:09
采集器如何搞定大数据信息抓取基础能力
)
对于大数据的开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于海洋大数据的定制化,也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫优采云
采集器,作为大数据信息采集的必备软件,
网页抓取工具优采云
Collector V9 是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以抓取网址、文本、图片、文件等,进行去重、过滤等一系列处理,呈现给用户完全可用的数据信息。此外,优采云
Collector V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集和征服等当然,如果你懂技术,有条件,企业也可以使用网络爬虫工具优采云
采集
器整合数据,优采云
采集
器采用分布式高速度采集和处理系统,可以是多线程的。可调式分配任务,轻松应对大规模、海量作业需求。但有时为了再次提高效率,可能需要多个优采云
采集
器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新能力低的问题;面对人才高度匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。
查看全部
抓取网页数据工具(网页抓取工具优采云
采集器如何搞定大数据信息抓取基础能力
)
对于大数据的开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于海洋大数据的定制化,也是一种高效的获取方式。但是现在你做了大数据业务,还是要全面提升自己人员的大数据基础能力,至少在有轻量级数据需求的时候,可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫优采云
采集器,作为大数据信息采集的必备软件,
网页抓取工具优采云
Collector V9 是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关设置,可以抓取网址、文本、图片、文件等,进行去重、过滤等一系列处理,呈现给用户完全可用的数据信息。此外,优采云
Collector V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集和征服等当然,如果你懂技术,有条件,企业也可以使用网络爬虫工具优采云
采集
器整合数据,优采云
采集
器采用分布式高速度采集和处理系统,可以是多线程的。可调式分配任务,轻松应对大规模、海量作业需求。但有时为了再次提高效率,可能需要多个优采云
采集
器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新能力低的问题;面对人才高度匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。
抓取网页数据工具(开源搜索引擎也横空出世,让人一见倾心的工具(开源库))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-27 17:08
1、 当互联网刚出现时,数据索引是一个大问题。当时,雅虎的分类页面确实流行了一段时间。
2、随着互联网数据量的不断增加,谷歌、百度等搜索引擎开始流行。现阶段几乎没有比搜索引擎更流行的技术,甚至分词技术也是一塌糊涂。紧接着,Nutch等开源搜索引擎也横空出世,让人一见倾心!许多人和许多公司试图将它们用于商业目的。但这些东西都是牛人,在实际使用中并不总是那么顺利。一是不稳定;另一个太复杂了,很难做二次开发来满足你的需求。
3、既然一般的搜索引擎做起来不是那么方便,那就让它更简单,更有针对性。由于爬虫技术的兴起,酷讯是其中比较成功的一个。靠着它的技术,后来建了99间房,然后造就了今天的头条。
4、随着越来越多的人从事互联网,很多人由于不同的需求确实想要从互联网上抓取数据,但他们希望它可以更简单,开发成本更低,速度更快。这么多开源工具出现了。一段时间以来,CURL 被大量使用,HTMLCXX 和 HTMLParser 等 HTML 解析工具也被广泛使用。优采云
傻瓜式,无需开发能力,配置即可自动运行。
5、 发展到现在,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然旺盛。网上抓数据的工具,开源代码,很多,jsoup,Spynner等,但是抓数据还是有点难,原因有四个:一、每个公司的需求不同,这使得产品化非常困难。二、WEB 页面本身就非常复杂和混乱,JavaScript 使得爬行不可控;三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合严重的商业应用;四、基于开源库或工具开发和完成自己的需求还是有一定难度的,工作量很大。
6、 所以一个好的爬虫工具(开源库)应该具备以下特点: 一、 简单。系统不要太复杂,界面要一目了然,以降低开发成本;二、 很强大。最好能捕捉到网页上能看到的数据,包括JavaScript的输出。数据抓取的很大一部分是寻找数据。例如:没有地理坐标数据,导致完成这些数据需要付出很多努力;三、 方便。提供开发库的最佳方式,如何抓取和部署,可以被控制而不是被困在一个完整的系统中;四、 很灵活。可以快速实现各种需求,即可以快速抓取简单的数据,或者可以构建更复杂的数据应用程序;五、 稳定。可以输出稳定的数据,不需要每天调整BUG找数据。要求不会复杂一点。当数据量稍大时,需要做大量的二次开发,耗费大量的人力和时间。六、可以集成。可以快速利用现有技术力量,开发环境,快速建立数据系统。七、可控。企业应用是长期积累的。如果数据和流程掌握在第三方手中,可控性差,对需求变化的响应慢,风险高。八、 支持结构化。
很多企业在数据采集上投入了大量精力,但效果往往不是很好,可持续发展的能力也比较差。这基本上是由于基础工具的选择不理想。那么,让我们梳理一下目前可用的一些数据抓取工具和开源库。比较它们的优缺点,为开发者选择提供参考。
一、 系统类别:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索。
纳奇:
语言:JAVA
官方网站:
简介:Nutch 是一个开源的 Java 搜索引擎。它提供全文搜索和网络爬虫、页面调度、数据存储等功能,几乎作为一个完整的通用搜索引擎。它适用于具有大页面大小(数十亿)和仅对数据(很少结构化数据)进行文本索引的应用程序。Nutch 非常适合研究。
继承人:
语言:JAVA
官方网站:
简介:Heritrix 是一个开源的网络爬虫系统,用户可以使用它从互联网上抓取自己想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。Heritrix 集成了索引调度、页面解析和数据存储。
其他包括:DataparkSearch、Web-Harvest
网络类:
卷曲
语言:C(但也支持命令行和其他语言绑定)
官方网站:
简介:CURL 是一个旧的 HTTP 网络库(同时支持 FTP 和其他协议)。CURL支持丰富的网络功能,包括SSL、cookie、表单等,是一个被广泛使用的网络库。CURL 很灵活,但稍微复杂一些。提供数据下载,但不支持HTML解析。通常需要与其他库一起使用。
汤
语言:C
官方网站:
简介: SOUP 是另一个 HTTP 网络库,它依赖于 glib,功能强大且稳定。但是国内文件比较少。
浏览器类:
此类工具一般基于浏览器(如:Firefox)扩展。由于浏览器的强大功能,可以采集到比较完整的数据,尤其是JavaScript输出的数据。但应用略受限制,不方便扩展,数据量大时难以适应。
解析中心:
语言:火狐扩展
官方网站:
简介: ParseHub 是一款基于 Firefox 的页面分析工具,可以支持更复杂的功能,包括页面结构分析。
GooSeeker 采集
和采集
客户
语言:火狐扩展
官方网站:
简介:GooSeeker也是一个基于Firefox的扩展,支持更复杂的功能,包括索引图片、定时采集、可视化编程等。
收款终端类别:
这类工具一般支持Windows图形界面,基本不需要编写代码,通过配置规则可以实现比较典型的数据采集。但提取数据能力一般,扩展性有限,更复杂应用的二次开发成本不低。
优采云
语言:许可软件
平台:Windows
官方网站:
优采云
是一款老牌采集
软件,随着无数个人站长的成长,具有高度可配置性,可以实现数据传输。非常适合政府机构的个人快速数据采集和舆情监测。
优采云
采集器
语言:许可软件
平台:Windows
官方网站:
简介:有财云采集器
功能众多,支持新闻综合分析,广泛应用于舆论。
图书馆类:
通过开源库或工具库提供。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发者自己实现。这种方法非常灵活,更适合捕获复杂的数据和大规模的爬取。这些库之间的差异主要体现在以下几个方面: 一、 语言适用。许多库只适用于某种语言;二、 功能差异。大多数库只支持HTML,不支持JS、CSS等动态数据;三、 接口。有些库提供函数级接口,有些库提供对象级接口。四、 稳定性。有些图书馆是认真的,
简单的 HTML DOM 解析器
语言:PHP
官方网站:
简介: PHP 的扩展模块支持解析 HTML 标签。提供类似于JQuery的函数级接口,功能更简单,适合解析简单的HTML页面,构建数据引擎会比较困难。
汤
语言:JAVA
官方网站:
简介:JSoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
斯宾纳
语言:Python
官方网站:
简介:Spynner 是一个超过 1000 行的 Python 脚本,基于 Qt Webkit。与urllib相比,最大的特点就是支持动态内容的爬取。Spynner 依赖于 xvfb 和 QT。由于需要页面渲染,速度较慢。
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,提供了一系列清晰的函数函数和DOM数据结构,简单明了,但功能强大,适用。Qing 支持 JavaScript 和 CSS,因此对动态内容的支持非常好。除了这些,Qing还支持背景图片加载、滚动加载、本地缓存、加载策略等功能。Qing速度快,功能强大,稳定,开发效率高。企业搭建数据引擎是更好的选择。 查看全部
抓取网页数据工具(开源搜索引擎也横空出世,让人一见倾心的工具(开源库))
1、 当互联网刚出现时,数据索引是一个大问题。当时,雅虎的分类页面确实流行了一段时间。
2、随着互联网数据量的不断增加,谷歌、百度等搜索引擎开始流行。现阶段几乎没有比搜索引擎更流行的技术,甚至分词技术也是一塌糊涂。紧接着,Nutch等开源搜索引擎也横空出世,让人一见倾心!许多人和许多公司试图将它们用于商业目的。但这些东西都是牛人,在实际使用中并不总是那么顺利。一是不稳定;另一个太复杂了,很难做二次开发来满足你的需求。
3、既然一般的搜索引擎做起来不是那么方便,那就让它更简单,更有针对性。由于爬虫技术的兴起,酷讯是其中比较成功的一个。靠着它的技术,后来建了99间房,然后造就了今天的头条。
4、随着越来越多的人从事互联网,很多人由于不同的需求确实想要从互联网上抓取数据,但他们希望它可以更简单,开发成本更低,速度更快。这么多开源工具出现了。一段时间以来,CURL 被大量使用,HTMLCXX 和 HTMLParser 等 HTML 解析工具也被广泛使用。优采云
傻瓜式,无需开发能力,配置即可自动运行。
5、 发展到现在,特别是随着移动互联网的兴起,由于各种需求,对数据采集的需求依然旺盛。网上抓数据的工具,开源代码,很多,jsoup,Spynner等,但是抓数据还是有点难,原因有四个:一、每个公司的需求不同,这使得产品化非常困难。二、WEB 页面本身就非常复杂和混乱,JavaScript 使得爬行不可控;三、大多数工具(开源库)都有相当大的局限性,扩展不方便,数据输出不稳定,不适合严重的商业应用;四、基于开源库或工具开发和完成自己的需求还是有一定难度的,工作量很大。
6、 所以一个好的爬虫工具(开源库)应该具备以下特点: 一、 简单。系统不要太复杂,界面要一目了然,以降低开发成本;二、 很强大。最好能捕捉到网页上能看到的数据,包括JavaScript的输出。数据抓取的很大一部分是寻找数据。例如:没有地理坐标数据,导致完成这些数据需要付出很多努力;三、 方便。提供开发库的最佳方式,如何抓取和部署,可以被控制而不是被困在一个完整的系统中;四、 很灵活。可以快速实现各种需求,即可以快速抓取简单的数据,或者可以构建更复杂的数据应用程序;五、 稳定。可以输出稳定的数据,不需要每天调整BUG找数据。要求不会复杂一点。当数据量稍大时,需要做大量的二次开发,耗费大量的人力和时间。六、可以集成。可以快速利用现有技术力量,开发环境,快速建立数据系统。七、可控。企业应用是长期积累的。如果数据和流程掌握在第三方手中,可控性差,对需求变化的响应慢,风险高。八、 支持结构化。
很多企业在数据采集上投入了大量精力,但效果往往不是很好,可持续发展的能力也比较差。这基本上是由于基础工具的选择不理想。那么,让我们梳理一下目前可用的一些数据抓取工具和开源库。比较它们的优缺点,为开发者选择提供参考。
一、 系统类别:
这些工具或开源库提供了一个完整的系统,包括数据捕获、调度、存储和检索。
纳奇:
语言:JAVA
官方网站:
简介:Nutch 是一个开源的 Java 搜索引擎。它提供全文搜索和网络爬虫、页面调度、数据存储等功能,几乎作为一个完整的通用搜索引擎。它适用于具有大页面大小(数十亿)和仅对数据(很少结构化数据)进行文本索引的应用程序。Nutch 非常适合研究。
继承人:
语言:JAVA
官方网站:
简介:Heritrix 是一个开源的网络爬虫系统,用户可以使用它从互联网上抓取自己想要的资源。其最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。Heritrix 集成了索引调度、页面解析和数据存储。
其他包括:DataparkSearch、Web-Harvest
网络类:
卷曲
语言:C(但也支持命令行和其他语言绑定)
官方网站:
简介:CURL 是一个旧的 HTTP 网络库(同时支持 FTP 和其他协议)。CURL支持丰富的网络功能,包括SSL、cookie、表单等,是一个被广泛使用的网络库。CURL 很灵活,但稍微复杂一些。提供数据下载,但不支持HTML解析。通常需要与其他库一起使用。
汤
语言:C
官方网站:
简介: SOUP 是另一个 HTTP 网络库,它依赖于 glib,功能强大且稳定。但是国内文件比较少。
浏览器类:
此类工具一般基于浏览器(如:Firefox)扩展。由于浏览器的强大功能,可以采集到比较完整的数据,尤其是JavaScript输出的数据。但应用略受限制,不方便扩展,数据量大时难以适应。
解析中心:
语言:火狐扩展
官方网站:
简介: ParseHub 是一款基于 Firefox 的页面分析工具,可以支持更复杂的功能,包括页面结构分析。
GooSeeker 采集
和采集
客户
语言:火狐扩展
官方网站:
简介:GooSeeker也是一个基于Firefox的扩展,支持更复杂的功能,包括索引图片、定时采集、可视化编程等。
收款终端类别:
这类工具一般支持Windows图形界面,基本不需要编写代码,通过配置规则可以实现比较典型的数据采集。但提取数据能力一般,扩展性有限,更复杂应用的二次开发成本不低。
优采云
语言:许可软件
平台:Windows
官方网站:
优采云
是一款老牌采集
软件,随着无数个人站长的成长,具有高度可配置性,可以实现数据传输。非常适合政府机构的个人快速数据采集和舆情监测。
优采云
采集器
语言:许可软件
平台:Windows
官方网站:
简介:有财云采集器
功能众多,支持新闻综合分析,广泛应用于舆论。
图书馆类:
通过开源库或工具库提供。这些库通常只负责数据捕获的网络部分和HTML的解析部分。具体的业务实现由开发者自己实现。这种方法非常灵活,更适合捕获复杂的数据和大规模的爬取。这些库之间的差异主要体现在以下几个方面: 一、 语言适用。许多库只适用于某种语言;二、 功能差异。大多数库只支持HTML,不支持JS、CSS等动态数据;三、 接口。有些库提供函数级接口,有些库提供对象级接口。四、 稳定性。有些图书馆是认真的,
简单的 HTML DOM 解析器
语言:PHP
官方网站:
简介: PHP 的扩展模块支持解析 HTML 标签。提供类似于JQuery的函数级接口,功能更简单,适合解析简单的HTML页面,构建数据引擎会比较困难。
汤
语言:JAVA
官方网站:
简介:JSoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
斯宾纳
语言:Python
官方网站:
简介:Spynner 是一个超过 1000 行的 Python 脚本,基于 Qt Webkit。与urllib相比,最大的特点就是支持动态内容的爬取。Spynner 依赖于 xvfb 和 QT。由于需要页面渲染,速度较慢。
清
语言:C++(可扩展到其他语言)
官方网站:
简介:Qing是一个动态库,提供了一系列清晰的函数函数和DOM数据结构,简单明了,但功能强大,适用。Qing 支持 JavaScript 和 CSS,因此对动态内容的支持非常好。除了这些,Qing还支持背景图片加载、滚动加载、本地缓存、加载策略等功能。Qing速度快,功能强大,稳定,开发效率高。企业搭建数据引擎是更好的选择。
抓取网页数据工具(30款最热门的大数据工具,你值得拥有!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-25 03:14
数据意味着当今世界的商业价值。数据挖掘和数据分析能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。
随着向基于应用程序的世界过渡,数据呈指数级增长。然而,大多数数据是非结构化的,因此需要一个过程和方法来从数据中提取有用的信息并将其转换为可理解和可用的形式。
数据挖掘或“数据库中的知识发现”是通过人工智能、机器学习、统计和数据库系统发现大数据集中模式的过程。
免费的数据挖掘工具包括完整的模型开发环境,如 Knime 和 Orange,以及用 Java 和 C++ 编写的各种库,最常见的是 Python。数据挖掘通常涉及四个任务:
分类:将熟悉的结构概括为新数据的任务
聚类:以某种方式在数据中查找组和结构的任务,而无需使用数据中的注意结构。
关联规则学习:找出变量之间的关系
回归:目标是找到一个以最小误差模拟数据的函数。
以下是 5 大类 30 款最流行的大数据工具,供您参考。
第 1 部分:数据采集 工具第 2 部分:开源数据工具第 3 部分:数据可视化第 4 部分:情绪分析第 5 部分:开源数据库
第 1 部分:数据采集工具
1 .优采云
优采云是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。此外,您还可以设置时序云采集,实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。
3.Import.io
Import.io 是一个基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4. 解析器
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能.
5. 莫曾达
Mozenda 是一款网页抓取软件,也为商业级数据抓取提供定制化服务。它可以从云端和本地软件中抓取数据并进行数据托管。
2.部分开源数据工具
1. 克尼姆
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 的部署模块。
2. OpenRefine
OpenRefine(前身为Google Refine)是处理凌乱数据的强大工具:它支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R 编程
它是一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,由于其易用性和广泛的功能性,受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4. RapidMiner
与 KNIME 一样,RapidMiner 通过可视化程序进行操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助企业做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松地使用它来分析和管理数据,进而从数据中获取价值。
6. 塔伦
它是一种开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和关注点。
7. 维卡
Weka 是用于数据挖掘任务的机器学习算法的集合。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有一个 GUI,可以将数据科学世界转变为缺乏编程技能的专业人士。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9. 格菲
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大地图网络。它们代表 LinkedIn 或 Facebook 上的社交关系。Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1. PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和bi功能,让用户以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2. 求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取所有可以提高公司盈利能力的数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地它侧重于四个关键的分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拉拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. 谷歌融合表
Fusion Table 是谷歌提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可以帮助您创建漂亮的信息图表和报告。它提供了超过 35 个交互式图表和 500 多个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下了深刻的印象。
4.部分情绪分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以过滤掉满意度较低的客户,并及时提供高质量的服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获得用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.追踪者
Trackur是一个在线声誉管理工具,可以通过跟踪社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5. 连帽衫洞察力
该工具可以分析评论、帖子、论坛、新闻网站以及50多种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.数据库
1. 甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.空气表
它是基于云服务器的数据库软件,具有丰富的数据表读取和信息显示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5. 即兴演奏
Improvado 是一种专为营销人员设计的工具,可以通过自动仪表板和分析报告将所有数据实时集成到一个平台中。Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用 Improvado,因为它为他们节省了数千小时的人工报告和数百万美元的营销预算。
转载自网络整理 查看全部
抓取网页数据工具(30款最热门的大数据工具,你值得拥有!)
数据意味着当今世界的商业价值。数据挖掘和数据分析能力在当今时代非常重要。智能工具是您与竞争对手抗衡并增加公司业务优势的先决条件。
随着向基于应用程序的世界过渡,数据呈指数级增长。然而,大多数数据是非结构化的,因此需要一个过程和方法来从数据中提取有用的信息并将其转换为可理解和可用的形式。
数据挖掘或“数据库中的知识发现”是通过人工智能、机器学习、统计和数据库系统发现大数据集中模式的过程。
免费的数据挖掘工具包括完整的模型开发环境,如 Knime 和 Orange,以及用 Java 和 C++ 编写的各种库,最常见的是 Python。数据挖掘通常涉及四个任务:
分类:将熟悉的结构概括为新数据的任务
聚类:以某种方式在数据中查找组和结构的任务,而无需使用数据中的注意结构。
关联规则学习:找出变量之间的关系
回归:目标是找到一个以最小误差模拟数据的函数。
以下是 5 大类 30 款最流行的大数据工具,供您参考。
第 1 部分:数据采集 工具第 2 部分:开源数据工具第 3 部分:数据可视化第 4 部分:情绪分析第 5 部分:开源数据库
第 1 部分:数据采集工具
1 .优采云
优采云是一款免费、简单、直观的网络爬虫工具,无需编码即可从众多网站中抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都能满足您的需求。为了降低使用难度,优采云为初学者准备了“网站简单模板”,涵盖了市面上大部分主流的网站。使用简单的模板,用户无需任务配置即可采集数据。简单的模板为采集小白树立信心,接下来就可以开始使用“高级模式”了,几分钟就可以帮你捕捉海量数据。此外,您还可以设置时序云采集,实时获取动态数据,并将数据导出到数据库或任何第三方平台。
2. 内容抓取器
Content Grabber是一款支持智能抓取的网络爬虫软件。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。
3.Import.io
Import.io 是一个基于 Web 的数据抓取工具。它于 2012 年首次在伦敦推出。现在 Import.io 已将其商业模式从 B2C 转变为 B2B。2019年,Import.io收购Connotate,成为Web数据集成平台。凭借广泛的网络数据服务,Import.io 已成为业务分析的绝佳选择。
4. 解析器
Parsehub 是一个基于网络的爬虫程序。支持使用AJax和JavaScripts技术的采集网页数据,也支持需要登录的采集网页数据。提供为期一周的免费试用窗口,供用户体验其功能.
5. 莫曾达
Mozenda 是一款网页抓取软件,也为商业级数据抓取提供定制化服务。它可以从云端和本地软件中抓取数据并进行数据托管。
2.部分开源数据工具
1. 克尼姆
Knime 是一个分析平台。它可以帮助您发现商业洞察力和市场潜力。它为数据挖掘和机器学习提供了 Eclipse 平台和其他外部扩展。它为分析专业人员提供了超过 2k 的部署模块。
2. OpenRefine
OpenRefine(前身为Google Refine)是处理凌乱数据的强大工具:它支持数据清洗,支持数据从一种格式到另一种格式的转换,还可以通过网络服务和外部数据进行扩展。使用它的分组功能,您可以轻松地对网页上的杂乱数据进行标准化和规范化。
3. R 编程
它是一种用于统计计算和图形的免费软件编程语言和软件环境。R 语言在开发统计软件和数据分析的数据挖掘工作者中非常流行。近年来,由于其易用性和广泛的功能性,受到了很多赞誉和欢迎。
除了数据挖掘,它还提供统计和图形技术、线性和非线性建模、经典统计检验、时间序列分析、分类、聚类等功能。
4. RapidMiner
与 KNIME 一样,RapidMiner 通过可视化程序进行操作,可以手动操作、分析和建模。它通过开源平台、机器学习和模型部署提高数据工作效率。统一的数据科学平台可以加速从数据准备到实现的分析工作流程,大大提高技术人员的工作效率,是最容易使用的预测分析软件之一。
5. Pentaho
它是一款出色的商业 BI 软件,可以帮助企业做出数据驱动的决策。该平台集成了本地数据库、Hadoop、NoSQL等数据源,您可以轻松地使用它来分析和管理数据,进而从数据中获取价值。
6. 塔伦
它是一种开源集成软件,旨在将数据转化为洞察力。它提供各种服务和软件,包括云存储、企业应用集成、数据管理等。在大型社区的支持下,它允许所有 Talend 用户和成员从任何位置共享信息、经验和关注点。
7. 维卡
Weka 是用于数据挖掘任务的机器学习算法的集合。这些算法可以直接应用于数据集,也可以从自己的JAVA代码中调用,也非常适合开发新的机器学习解决方案。它还具有一个 GUI,可以将数据科学世界转变为缺乏编程技能的专业人士。
8.NodeXL
它是 Microsoft Excel 的开源软件包。作为一个附加的扩展,它没有数据集成服务和功能,它专注于社交网络分析。直观的网络和描述性关系使社交媒体分析变得容易。它是数据分析的最佳统计工具之一,包括高级网络指标、访问社交媒体网络数据导入器和自动化。
9. 格菲
Gephi 也是一个在 NetBeans 平台上用 Java 编写的开源网络分析和可视化软件包。想想你所看到的人与人之间的巨大地图网络。它们代表 LinkedIn 或 Facebook 上的社交关系。Gephi 通过提供准确的计算为这一步提供了更准确的指标。
部分3.数据可视化工具
1. PowerBI
Microsoft PowerBI 提供本地和云服务。它最初是作为 Excel 插件推出的,PowerBI 很快因其强大的功能而广受欢迎。目前,它被认为是商业分析领域的软件领导者。提供数据可视化和bi功能,让用户以较低的成本轻松实现快速、明智的决策,用户可以协作共享定制化的仪表盘和交互式报表。
2. 求解器
Solver 是一家专业的企业绩效管理(。Solver 致力于通过获取所有可以提高公司盈利能力的数据源,提供世界一流的财务报告、预算计划和财务分析。其软件 BI360 可用于云计算和本地它侧重于四个关键的分析领域,包括财务报告、预算、仪表板和数据仓库。
3.Qlik
Qlik 是一种自助式数据分析和可视化工具。它具有可视化仪表板,可简化数据分析并帮助公司快速做出业务决策。
4.Tableau Public
Tableau 是一种交互式数据可视化工具。与大多数需要编写脚本的可视化工具不同,Tableau 的简单性可以帮助新手降低使用难度。简单的拉拉操作,让数据分析轻松完成。他们还有“初学者入门工具包”和丰富的培训材料,可以帮助用户创建更多的分析报告。
5. 谷歌融合表
Fusion Table 是谷歌提供的数据管理平台。您可以将其用于数据采集、数据可视化和数据共享。它就像一个电子表格,但具有更强大和专业的功能。您可以通过在 CSV、KML 和电子表格中添加数据集来与同事共享数据。您还可以发布数据并将其嵌入到其他网络媒体资源中。
6. 信息图
Infogram 是一种直观的可视化工具,可以帮助您创建漂亮的信息图表和报告。它提供了超过 35 个交互式图表和 500 多个地图来帮助您可视化数据。除了各种图表,还有条形图、条形图、饼图或词云等,创新的信息图表给你留下了深刻的印象。
4.部分情绪分析工具
1. HubSpot 的 ServiceHub
它是一个采集客户反馈和评论的客户反馈工具。该工具使用自然语言处理 (NLP) 来分析语言,区分其正面和负面含义,然后使用仪表板上的图形和图表将结果可视化。该工具支持将 HubSpot 的 ServiceHub 连接到 CRM 系统,这样您就可以将相应的结果与特定的人关联起来。例如,您可以过滤掉满意度较低的客户,并及时提供高质量的服务,以提高客户保留率。
2. Semantria
Semantria 是一种可以从社交媒体渠道采集帖子、推文和评论的工具。它使用自然语言处理技术对文本进行解析,分析客户的正面和负面态度。通过这种方式,公司可以获得用户对产品或服务的真实看法,并提出更好的想法来改进您的产品和服务。
3.追踪者
Trackur是一个在线声誉管理工具,可以通过跟踪社交媒体网站来监控舆论。它会抓取大量网页,包括视频、博客、论坛和图片以搜索相关信息。您可以使用它来清理负面搜索引擎结果并建立和管理您的在线声誉。它是在线声誉和数字品牌管理的行业先驱。
4. SAS 情绪分析
SAS Sentiment Analysis 是一款非常强大的软件。网页文本分析最难的部分是拼写错误,SAS可以轻松校对和聚类分析。通过自然语言处理、机器学习和语言规则的结合,SAS 可以帮助您分析最新趋势、最合适的商机,并从所有非结构化文本数据中提取真正有价值的信息。
5. 连帽衫洞察力
该工具可以分析评论、帖子、论坛、新闻网站以及50多种语言的超过1000万个数据源平台。此外,它还可以对性别和位置进行分类。您可以为特定群体制定战略营销计划。您还可以获取实时数据并调查在线对话。
部分5.数据库
1. 甲骨文
毫无疑问,Oracle 是开源数据库的领导者。功能众多,是企业的最佳选择。它还支持集成到不同平台。在 AWS 中易于设置,使其成为关系数据库的可靠选择。内置信用卡等隐私数据的高安全性技术使其不可替代。
2.PostgreSQL
它是仅次于 Oracle、MySQL 和 Microsoft SQL Server 的第四大流行数据库。由于其绝对可靠的稳定性,它可以处理高负载数据。
3.空气表
它是基于云服务器的数据库软件,具有丰富的数据表读取和信息显示功能。它还具有电子表格和内置日历,可轻松跟踪任务。它的入门模板易于使用,模板包括销售线索管理、错误跟踪和试用跟踪。
4. MariaDB
它是一个免费的开源数据库,用于数据存储、插入、修改和检索。此外,Maria 拥有强大的社区支持。社区成员非常活跃,积极分享信息和知识。
5. 即兴演奏
Improvado 是一种专为营销人员设计的工具,可以通过自动仪表板和分析报告将所有数据实时集成到一个平台中。Improvado 最适合希望将所有营销平台的数据整合到一个平台的营销分析领导者。
您可以选择在 Improvado 仪表板中查看数据,也可以将其导出到您选择的数据仓库或可视化工具,例如 Tableau、look ker、Excel 等。公司、机构和大学都喜欢使用 Improvado,因为它为他们节省了数千小时的人工报告和数百万美元的营销预算。
转载自网络整理
抓取网页数据工具(网页分析微博评论是动态加载的工具max_id )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-24 09:10
)
网站链接
https://m.weibo.cn/detail/4669040301182509
网络分析
微博评论动态加载。进入浏览器的开发者工具后,在网页下拉即可得到我们需要的数据包
获取真实网址
https://m.weibo.cn/comments/ho ... e%3D0
https://m.weibo.cn/comments/ho ... e%3D0
这两个 URL 之间的区别是显而易见的。第一个 URL 没有参数 max_id,第二个 URL 以 max_id 开头。max_id其实就是前一个包中的max_id。
但是有一点需要注意的是参数max_id_type,这个参数实际上是变化的,所以我们需要从数据包中获取max_id_type
代码
import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# 微博爬取大概几十页会封账号的,而通过不断的更新cookies,会让爬虫更持久点...
cookie = [cookie.value for cookie in resposen.cookies] # 用列表推导式生成cookies部件
headers = {
# 登录后的cookie, SUB用登录后的
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # 获取max_id和max_id_type返回给下一条url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # 点赞数
created_at = i['created_at'] # 时间
text = re.sub(r']*>', '', i['text']) # 评论
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('微博.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
显示结果
查看全部
抓取网页数据工具(网页分析微博评论是动态加载的工具max_id
)
网站链接
https://m.weibo.cn/detail/4669040301182509
网络分析
微博评论动态加载。进入浏览器的开发者工具后,在网页下拉即可得到我们需要的数据包
获取真实网址
https://m.weibo.cn/comments/ho ... e%3D0
https://m.weibo.cn/comments/ho ... e%3D0
这两个 URL 之间的区别是显而易见的。第一个 URL 没有参数 max_id,第二个 URL 以 max_id 开头。max_id其实就是前一个包中的max_id。
但是有一点需要注意的是参数max_id_type,这个参数实际上是变化的,所以我们需要从数据包中获取max_id_type
代码
import re
import requests
import pandas as pd
import time
import random
df = pd.DataFrame()
try:
a = 1
while True:
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
resposen = requests.get('https://m.weibo.cn/detail/4669040301182509', headers=header)
# 微博爬取大概几十页会封账号的,而通过不断的更新cookies,会让爬虫更持久点...
cookie = [cookie.value for cookie in resposen.cookies] # 用列表推导式生成cookies部件
headers = {
# 登录后的cookie, SUB用登录后的
'cookie': f'WEIBOCN_FROM={cookie[3]}; SUB=; _T_WM={cookie[4]}; MLOGIN={cookie[1]}; M_WEIBOCN_PARAMS={cookie[2]}; XSRF-TOKEN={cookie[0]}',
'referer': 'https://m.weibo.cn/detail/4669040301182509',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
}
if a == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id_type=0'
else:
url = f'https://m.weibo.cn/comments/hotflow?id=4669040301182509&mid=4669040301182509&max_id={max_id}&max_id_type={max_id_type}'
html = requests.get(url=url, headers=headers).json()
data = html['data']
max_id = data['max_id'] # 获取max_id和max_id_type返回给下一条url
max_id_type = data['max_id_type']
for i in data['data']:
screen_name = i['user']['screen_name']
i_d = i['user']['id']
like_count = i['like_count'] # 点赞数
created_at = i['created_at'] # 时间
text = re.sub(r']*>', '', i['text']) # 评论
print(text)
data_json = pd.DataFrame({'screen_name': [screen_name], 'i_d': [i_d], 'like_count': [like_count], 'created_at': [created_at],'text': [text]})
df = pd.concat([df, data_json])
time.sleep(random.uniform(2, 7))
a += 1
except Exception as e:
print(e)
df.to_csv('微博.csv', encoding='utf-8', mode='a+', index=False)
print(df.shape)
显示结果

