
关键词文章采集源码
【8分钟课堂】判断条件-应用:京东和陌陌采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-22 13:43
本视频介绍判定条件的实际应用,将以易迅和陌陌图文采集进行讲解。
实战案例:
1)判断某一条件(如关键词)是否存在,存在就采集,不存在则不采
例:采集京东商品信息,判断是否自营。是自营,则采集;不是自营,则跳过不采集。
示例网址:
华为&enc=utf-8&wq=华为
2)要采集的数据有多种情况,网页源码存在多种款式,需分开搜集
例:采集搜狗陌陌文章正文和图片URL。
示例网址:
注意事项:
1)默认从左向右执行
先判定左侧的条件,若右侧的分支均不满足条件,最左边的分支将不做判定直接执行
2)允许某个分支中无任何操作步骤
3)具有提取数据步骤的所有分支,分支中的总数组个数、字段名需保持一致
4)对于须要同时判定多个同级条件(即case when),可用多分支实现
5)对于须要同时判定多个不同级条件,则须要嵌套使用多个分支判定
★ 建议将已选好判定条件后的网址装入优采云中采集数据
6)对“存在”或“不存在”即“有”或“无”的判定,其操作性更为简单方便
对大小的判定操作繁杂,需借助xpath实现 ★使用number函数
7)判断条件的“与”和“或”,可以通过xpath中的“&”和“|”实 查看全部
【8分钟课堂】判断条件-应用:京东和陌陌采集
本视频介绍判定条件的实际应用,将以易迅和陌陌图文采集进行讲解。
实战案例:
1)判断某一条件(如关键词)是否存在,存在就采集,不存在则不采
例:采集京东商品信息,判断是否自营。是自营,则采集;不是自营,则跳过不采集。
示例网址:
华为&enc=utf-8&wq=华为
2)要采集的数据有多种情况,网页源码存在多种款式,需分开搜集
例:采集搜狗陌陌文章正文和图片URL。
示例网址:
注意事项:
1)默认从左向右执行
先判定左侧的条件,若右侧的分支均不满足条件,最左边的分支将不做判定直接执行
2)允许某个分支中无任何操作步骤
3)具有提取数据步骤的所有分支,分支中的总数组个数、字段名需保持一致
4)对于须要同时判定多个同级条件(即case when),可用多分支实现
5)对于须要同时判定多个不同级条件,则须要嵌套使用多个分支判定
★ 建议将已选好判定条件后的网址装入优采云中采集数据
6)对“存在”或“不存在”即“有”或“无”的判定,其操作性更为简单方便
对大小的判定操作繁杂,需借助xpath实现 ★使用number函数
7)判断条件的“与”和“或”,可以通过xpath中的“&”和“|”实
一些代码规范(采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-08-22 12:32
C#陌陌后台代码01-22
目前公众号应用越来越规范,该项目用于C#对接微信公众号,易懂,上手快。
微信小程序商城源码带后台 公众号平台五级分销系统10-24
这套源码在某宝卖300元,好评诸多。 商城V3商业版
微信小程序开发规范化插件formpvue08-10
微信小程序开发规范化插件 for mpvue
微信小程序仿陌陌主界面UI源代码.rar07-10
这是一个运行于陌陌环境的小程序,正好是模拟制做的陌陌主界面和功能,源代码目录太规范,编写陌陌相关的小程序,运用的知识方法是太综合的,这涉及到音频处理、查找联系人、信息、日志、消息、新同事发觉、日志记事
完整的陌陌开发项目08-24
java开发陌陌的web项目.百分百可以运行,自己测试过的.适合陌陌开发初学者.完全参照陌陌开发者文档规范开发的java陌陌web项目
微信小程序-微信小程序开发个人网站08-06
WXnodegeek 微信小程序开发个人网站 (个人网站: ) 实现功能 点击导航菜单,对内容进行显示/影藏 列表展示 点击列表步入详情 初试体验 微信小程序诞生以来,
微信卡包插口资料整理03-19
微信卡券、门店开发文档以及代码是实例整理,方便开发。
微信小程序_微信电影票预订源代码10-29
功能包括:已开播影片列表,搜索附近电影院,电影评分等功能 这个不错,UI设计标准,代码比较规范,很好的学习范例 查看全部
一些代码规范(采集)
C#陌陌后台代码01-22
目前公众号应用越来越规范,该项目用于C#对接微信公众号,易懂,上手快。
微信小程序商城源码带后台 公众号平台五级分销系统10-24
这套源码在某宝卖300元,好评诸多。 商城V3商业版
微信小程序开发规范化插件formpvue08-10
微信小程序开发规范化插件 for mpvue
微信小程序仿陌陌主界面UI源代码.rar07-10
这是一个运行于陌陌环境的小程序,正好是模拟制做的陌陌主界面和功能,源代码目录太规范,编写陌陌相关的小程序,运用的知识方法是太综合的,这涉及到音频处理、查找联系人、信息、日志、消息、新同事发觉、日志记事
完整的陌陌开发项目08-24
java开发陌陌的web项目.百分百可以运行,自己测试过的.适合陌陌开发初学者.完全参照陌陌开发者文档规范开发的java陌陌web项目
微信小程序-微信小程序开发个人网站08-06
WXnodegeek 微信小程序开发个人网站 (个人网站: ) 实现功能 点击导航菜单,对内容进行显示/影藏 列表展示 点击列表步入详情 初试体验 微信小程序诞生以来,
微信卡包插口资料整理03-19
微信卡券、门店开发文档以及代码是实例整理,方便开发。
微信小程序_微信电影票预订源代码10-29
功能包括:已开播影片列表,搜索附近电影院,电影评分等功能 这个不错,UI设计标准,代码比较规范,很好的学习范例
python实战项目,获取指定网站关键词百度排行,为seo提供参考资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-08-22 10:38
原帖:向日葵智能
前言
先解释一下标题的意思吧。现在个人站长早已十分多了,想要网站有流量,一个特别不错的渠道就是搜索引擎,用户搜索某个关键词,如果能搜到自己的网站,那么,流量肯定直线上升。这就须要seo,如果才能晓得在搜索引擎中,自己网站的关键词排行如何,肯定对seo有帮助,不至于一眼黑。
各大站长工具其实也就能提供关键词排行查询,我也用过,但是它们只能提供一部分关键词的排行,而且虽然只能提供前100的排行。
本节将进行一个新的python实战项目,能够搜索自己网站关键词在搜索引擎中的排行。
实现方案
咱们以百度搜索为例,搜索关键词后,会有好多结果。可以看见,每个结果就会有部份网站域名的,如果某一条结果里的链接是自己网站的,那么,这条结果就属于俺们的,获取其排行就可以了。
右键,查看网页源代码,很轻易就发觉了俺们须要的关键词和网站域名两项关键信息都在,那么,咱们完全可以根据python实战项目,制作网路爬虫爬取百度美眉图片一节抓取信息。
python项目实战,获取网站关键词排名
分两步走:
1. python实战项目,获取搜索信息
仔细观察搜索结果页地址栏的地址,很容易发觉规律,只须要在浏览器地址栏输入:
http://www.baidu.com/s?wd=【搜索内容】&pn=【页码】0
按回车,就可以实现搜索。那么,咱们的python实战项目代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
print data.content
Python
Copy
可以发觉,咱们获得到了网页的源代码,即搜索信息。
2. python实战项目,正则表达式提取有用信息
正则表达式的使用,可以参照:python基础,什么是正则表达式,正则表达式的使用,关键就是找规律。首先,要明晰的是,咱们只关心网站域名信息,只要找出域名信息即可。
在源代码页搜索这串字符,发现一共发觉了10条结果,这与本页一共10项搜索结果对应上去了,因此俺们正则匹配这串字符串是可行的。正则代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
#print data.content
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(data.content)
for item in result:
print item
Python
Copy
运行脚本,发现网站域名被提取下来了。
3. python实战项目,计算网站关键词排名
接下来的工作就是字符串操作了,只须要判定自己网站的域名是否出现在搜索到的结果中就行了。找到后,计算编号,就是**网站关键词排行**了。不多说,python代码如下:
# searchTxt:要分析的网页源代码,webUrl:网站的网址
i = 0
def KeywordRank(searchTxt, webUrl):
global i
try:
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(searchTxt)
for item in result:
i = i+1
print "rank %d: %s"%(i,item)
if "xrkzn.cn" in item:
return i
except Exception, e:
print "error occurs"
return None
return None
# content:要搜索的关键词, page:要搜索的页码
def BaiduSearch(content, page):
try:
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (content, page)
data = requests.get(url)
return data.content
except Exception, e:
return None
if __name__ == "__main__":
loops = 101 # 最多查到第 101 页
page = 0
while(loops):
searchTxt = BaiduSearch(u"向日葵智能|智能创意", page)
page = page+1
rank = KeywordRank(searchTxt, "xrkzn.cn")
if None!=rank:
print u"输入的关键词排在第 %d 名" % rank
break
loops = loops - 1
Python
Copy
执行python实战项目脚本,发现成功了,脚本觉得俺们的网站关键词排第 8 名。
咱们去浏览器搜索一下,发现的确是排在第 8 名。这样,我们就完整了一个新的python实战项目,获取指定网站关键词百度排行,为seo提供参考资料。
原帖地址: 查看全部
python实战项目,获取指定网站关键词百度排行,为seo提供参考资料
原帖:向日葵智能
前言
先解释一下标题的意思吧。现在个人站长早已十分多了,想要网站有流量,一个特别不错的渠道就是搜索引擎,用户搜索某个关键词,如果能搜到自己的网站,那么,流量肯定直线上升。这就须要seo,如果才能晓得在搜索引擎中,自己网站的关键词排行如何,肯定对seo有帮助,不至于一眼黑。
各大站长工具其实也就能提供关键词排行查询,我也用过,但是它们只能提供一部分关键词的排行,而且虽然只能提供前100的排行。
本节将进行一个新的python实战项目,能够搜索自己网站关键词在搜索引擎中的排行。
实现方案
咱们以百度搜索为例,搜索关键词后,会有好多结果。可以看见,每个结果就会有部份网站域名的,如果某一条结果里的链接是自己网站的,那么,这条结果就属于俺们的,获取其排行就可以了。

右键,查看网页源代码,很轻易就发觉了俺们须要的关键词和网站域名两项关键信息都在,那么,咱们完全可以根据python实战项目,制作网路爬虫爬取百度美眉图片一节抓取信息。

python项目实战,获取网站关键词排名
分两步走:
1. python实战项目,获取搜索信息
仔细观察搜索结果页地址栏的地址,很容易发觉规律,只须要在浏览器地址栏输入:
http://www.baidu.com/s?wd=【搜索内容】&pn=【页码】0
按回车,就可以实现搜索。那么,咱们的python实战项目代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
print data.content
Python
Copy
可以发觉,咱们获得到了网页的源代码,即搜索信息。
2. python实战项目,正则表达式提取有用信息
正则表达式的使用,可以参照:python基础,什么是正则表达式,正则表达式的使用,关键就是找规律。首先,要明晰的是,咱们只关心网站域名信息,只要找出域名信息即可。

在源代码页搜索这串字符,发现一共发觉了10条结果,这与本页一共10项搜索结果对应上去了,因此俺们正则匹配这串字符串是可行的。正则代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
#print data.content
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(data.content)
for item in result:
print item
Python
Copy
运行脚本,发现网站域名被提取下来了。

3. python实战项目,计算网站关键词排名
接下来的工作就是字符串操作了,只须要判定自己网站的域名是否出现在搜索到的结果中就行了。找到后,计算编号,就是**网站关键词排行**了。不多说,python代码如下:
# searchTxt:要分析的网页源代码,webUrl:网站的网址
i = 0
def KeywordRank(searchTxt, webUrl):
global i
try:
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(searchTxt)
for item in result:
i = i+1
print "rank %d: %s"%(i,item)
if "xrkzn.cn" in item:
return i
except Exception, e:
print "error occurs"
return None
return None
# content:要搜索的关键词, page:要搜索的页码
def BaiduSearch(content, page):
try:
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (content, page)
data = requests.get(url)
return data.content
except Exception, e:
return None
if __name__ == "__main__":
loops = 101 # 最多查到第 101 页
page = 0
while(loops):
searchTxt = BaiduSearch(u"向日葵智能|智能创意", page)
page = page+1
rank = KeywordRank(searchTxt, "xrkzn.cn")
if None!=rank:
print u"输入的关键词排在第 %d 名" % rank
break
loops = loops - 1
Python
Copy
执行python实战项目脚本,发现成功了,脚本觉得俺们的网站关键词排第 8 名。

咱们去浏览器搜索一下,发现的确是排在第 8 名。这样,我们就完整了一个新的python实战项目,获取指定网站关键词百度排行,为seo提供参考资料。

原帖地址:
爬取个别网站政策性文件及数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-22 02:11
访问一些政府网站并获取网页
根据需求解析出其中的政策性文件以需求的数据
保存到本地,如果失败则记录在日志中
github:
一、需求介绍(示例北京)
需求介绍见文档%E9%9C%80%E6%B1%82
下面为一个区的需求示例
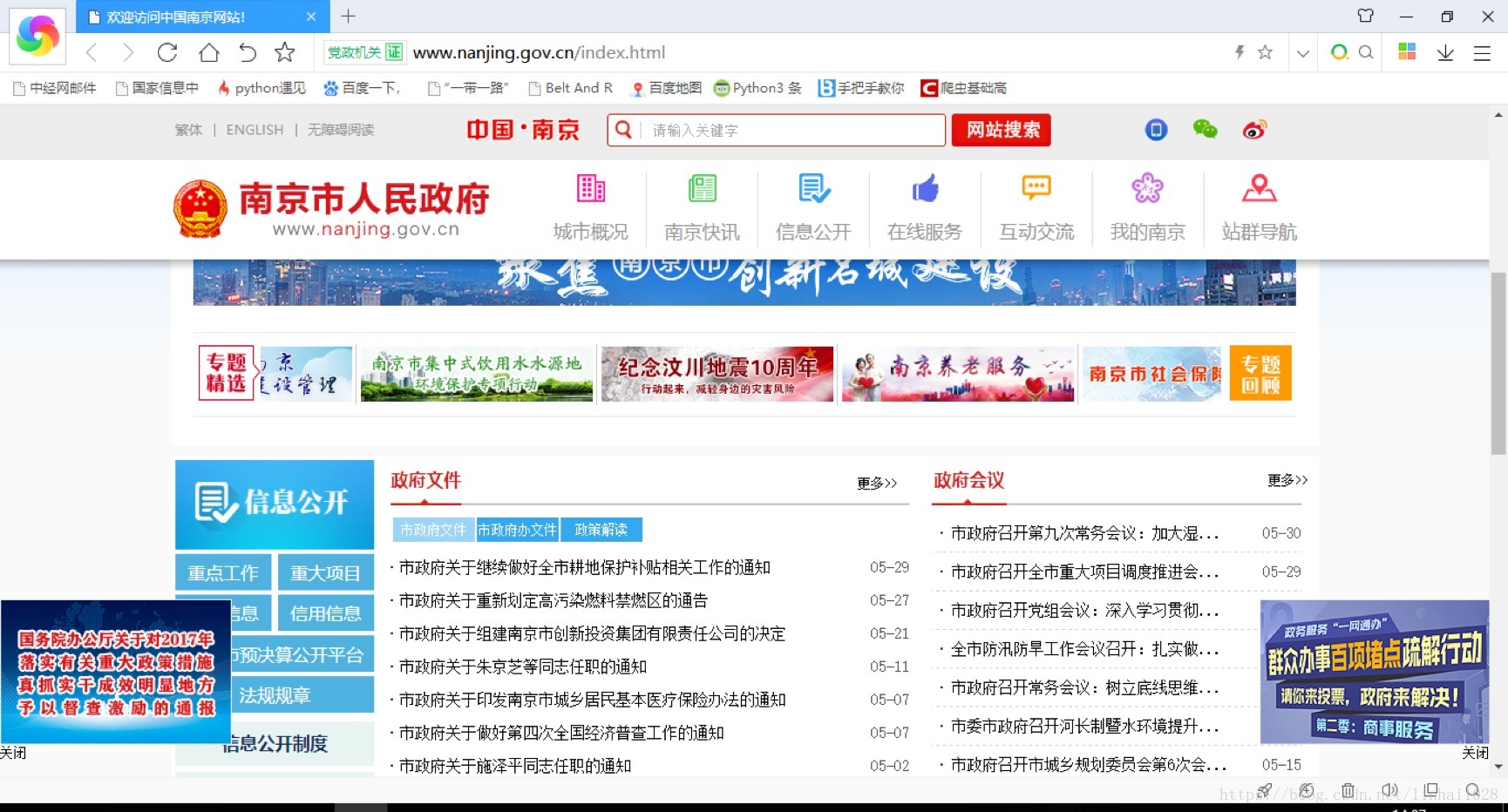
进入政府(部门)官网 找出其中的政府文件栏目,一般在信息公开中
进入政府文件网站红色画圈部份为须要采集的文章。
采集范围为:市政府文件、市政府办公厅文件、部门文件、区文件
进入文章页面
将网页其中的部份内容爬取储存到本地TXT(名称为文件标题)
需采集网页URL、文件信息、文件内容
将网页中的文件下载储存到相应文件夹中,以文章标题命。
具体参考示例
网页中有下载链接或则附件的也需下载到相应的文件夹中
二、代码
源代码:
爬虫泛型,主要用于下载网页(包括启动浏览器下载和程序下载网页),下载图片,获取某html标签的文字内容,下载某大标签的所有文字。 日志类,主要用于写日志,用于保存程序运行过程所需日志,运行后日志保存在logs文件中,以日期命名。craw****.py 主要对应于具体某地网站的网站数据抓取类。三、 运行
cd crawGovData/
python craw****.py # craw****.py 指具体的某市网站数据抓取类
如爬取太原市的数据
cd crawGovData/crawTaiyuann/
python crawTaiyuan.py
python crawTaiyuanFgw.py
python crawTaiyuanWjw.py
...
python crawTaiyuanjxw.py
环境python3requests2.18lxml4.2 查看全部
爬取个别网站政策性文件及数据
访问一些政府网站并获取网页
根据需求解析出其中的政策性文件以需求的数据
保存到本地,如果失败则记录在日志中
github:
一、需求介绍(示例北京)
需求介绍见文档%E9%9C%80%E6%B1%82
下面为一个区的需求示例
进入政府(部门)官网 找出其中的政府文件栏目,一般在信息公开中
进入政府文件网站红色画圈部份为须要采集的文章。
采集范围为:市政府文件、市政府办公厅文件、部门文件、区文件
进入文章页面
将网页其中的部份内容爬取储存到本地TXT(名称为文件标题)
需采集网页URL、文件信息、文件内容
将网页中的文件下载储存到相应文件夹中,以文章标题命。
具体参考示例

网页中有下载链接或则附件的也需下载到相应的文件夹中
二、代码
源代码:
爬虫泛型,主要用于下载网页(包括启动浏览器下载和程序下载网页),下载图片,获取某html标签的文字内容,下载某大标签的所有文字。 日志类,主要用于写日志,用于保存程序运行过程所需日志,运行后日志保存在logs文件中,以日期命名。craw****.py 主要对应于具体某地网站的网站数据抓取类。三、 运行
cd crawGovData/
python craw****.py # craw****.py 指具体的某市网站数据抓取类
如爬取太原市的数据
cd crawGovData/crawTaiyuann/
python crawTaiyuan.py
python crawTaiyuanFgw.py
python crawTaiyuanWjw.py
...
python crawTaiyuanjxw.py
环境python3requests2.18lxml4.2
2020了不容易也有人到搞关键字堆积吧?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-21 02:21
大家的网址沒有排名时,优化器将去百度站长工具意见反馈,许多 网址是网址题目关键字堆积的結果,一旦关键字堆积,将导致 网址关键字排行增加,今日优帮云我给你详尽介绍关键字堆积的害处。
都2020了不容易也有人到搞关键字堆积吧??
1、会导致 网址的网页页面不包括,一旦关键字堆积上去,百度搜索引擎便会认为网址不科学,提升不及时,那麼就不容易收录你的网址。
2、网址会被删除或k,假如百度关键词堆积上去,便会导致 百度关键词沒有排名和总流量太低,乃至沒有,长期性百度搜索引擎也不会爬网。
3、减少客户体验,假如网址是一些同样的关键字,假如客人看有关的內容,全是关键字,将不利百度搜索的爬取。
可是关键词添充在哪些地区形成呢?
网址题目关键字堆字,在我们写网址题目的情况下,是必须添加关键字的,假如网址的关键字反复过多得话,便会出現关键字堆字。
2.百度关键词堆,大家都了解一些网址会出现许多 的关键字,假如所有写出来便会有一堆的状况,一般状况是两到三个就可以了。
3.Alt标示基础打桩。大家都了解,首页的imG文件格式相片必须Alt标示。
4.尝试在文章内容的开头和结尾有一个或2个关键字。假如关键字过多,会导致 关键字沉积。
之上便是优帮云我为大伙儿详尽介绍的关键字累加对网址的害处,及其关键字堆积的好多个层面,期待大伙儿在对网址举办提高时,尽量降低这些关键点。 查看全部
2020了不容易也有人到搞关键字堆积吧?
大家的网址沒有排名时,优化器将去百度站长工具意见反馈,许多 网址是网址题目关键字堆积的結果,一旦关键字堆积,将导致 网址关键字排行增加,今日优帮云我给你详尽介绍关键字堆积的害处。

都2020了不容易也有人到搞关键字堆积吧??
1、会导致 网址的网页页面不包括,一旦关键字堆积上去,百度搜索引擎便会认为网址不科学,提升不及时,那麼就不容易收录你的网址。
2、网址会被删除或k,假如百度关键词堆积上去,便会导致 百度关键词沒有排名和总流量太低,乃至沒有,长期性百度搜索引擎也不会爬网。
3、减少客户体验,假如网址是一些同样的关键字,假如客人看有关的內容,全是关键字,将不利百度搜索的爬取。
可是关键词添充在哪些地区形成呢?
网址题目关键字堆字,在我们写网址题目的情况下,是必须添加关键字的,假如网址的关键字反复过多得话,便会出現关键字堆字。
2.百度关键词堆,大家都了解一些网址会出现许多 的关键字,假如所有写出来便会有一堆的状况,一般状况是两到三个就可以了。
3.Alt标示基础打桩。大家都了解,首页的imG文件格式相片必须Alt标示。
4.尝试在文章内容的开头和结尾有一个或2个关键字。假如关键字过多,会导致 关键字沉积。
之上便是优帮云我为大伙儿详尽介绍的关键字累加对网址的害处,及其关键字堆积的好多个层面,期待大伙儿在对网址举办提高时,尽量降低这些关键点。
页面seo关键词:百度上线版权保护,力图净化百度搜索结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-21 02:15
单单从原创标示而言,事实上百度搜索优化算法早期试着对原创内容的一种标志,早就在前两年,关键运用于PC端,百度搜索的诠释,直至熊掌号宣布发布,才应时而生,被广泛运用。2、原创保护
原创保护,是在熊掌号的基本上,对于原创标示,进一步对原创内容检索利益的保护,关键在
百度搜索快速收录
,排列加壳上,给与大量总流量的下陷。另外,百度搜索近来,加强了原创保护的利益,试着保证95%的原创内容,能够有效的排名在转截与采集以前。3、侵权行为控告
侵权行为揭发,是在原创保护的原生态基本之中,发布的独立线上维权的一个安全通道,原创创作者,可自主提交有关的侵权行为内容,但这里有一个隐含的前提条件:就是说侵权行为文章内容,务必是被误加原创标示的内容。4、版权保护
版权保护,则是百度搜索在近来,发布的一项对于原创保护的重特大调节,但能否在后台管理清楚的区分,不法采集与转截的有关内容,至关重要一点是版权保护通过合理步骤,能够线上一键式的与著作权组织举办关系,并合理的协助原创创作者举办维权及其索取赔偿。详尽内容可参照:
文章内容采集
分辨,非常是新媒体平台,例如:
今天明日头条号
的内容,普遍种类关键收录:
1、不法转截
关键就是指那些不定时执行采集的网址,及其运用
采集专用工具
,大批量采集的个人行为,一般 这种内容,都还能被版权保护合理的判别。值得一提的是你的投稿,及其已有博客外链基本建设的内容,一般 还可以被一切正常区分,自然这里我们在中后期维权的情况下,能够自主选购,无须担心有效转截对外开放链的害处。2、即时采集
3、网址镜像系统
网址镜像系统,不同于即时采集,这里有二种状况:
①整站源码内容彻底配对:它基本上是一模一样的网址。②整站源码内容不彻底配对:行为主体构架略有不同,一般是在头顶部启用一些废弃物内容,尝试提高伪原创的指数,但从版权保护的后台数据看来,这类类似简易伪原创的个人行为,一样才能被区分到。1、平稳关键字排行
因为采集成本费大幅度增强,它有益于谴责采集,防止高品质内容因采集,造成关键字排行大幅度起伏。2、出示高品质百度搜索
版权保护,大幅度增加了维权成本费,而且对于原创内容,出示了经济发展权益的确保,假如一但维权取得成功,2000字上下的原创内容,一般就能获得300元/篇的赔偿。3、创建良好检索红色生态
不容置疑,百度搜索发布版权保护,试图清洁网页搜索結果,让大量高品质且有使用价值的内容排列靠前,提高检索顾客的具体体会,建立可持续性的检索红色生态。熊掌号经营
者,迅速获得百度搜索原创标示,好像是一件非常关键的事儿,它是检索利益可得优的确保。 查看全部
页面seo关键词:百度上线版权保护,力图净化百度搜索结果
单单从原创标示而言,事实上百度搜索优化算法早期试着对原创内容的一种标志,早就在前两年,关键运用于PC端,百度搜索的诠释,直至熊掌号宣布发布,才应时而生,被广泛运用。2、原创保护
原创保护,是在熊掌号的基本上,对于原创标示,进一步对原创内容检索利益的保护,关键在
百度搜索快速收录
,排列加壳上,给与大量总流量的下陷。另外,百度搜索近来,加强了原创保护的利益,试着保证95%的原创内容,能够有效的排名在转截与采集以前。3、侵权行为控告
侵权行为揭发,是在原创保护的原生态基本之中,发布的独立线上维权的一个安全通道,原创创作者,可自主提交有关的侵权行为内容,但这里有一个隐含的前提条件:就是说侵权行为文章内容,务必是被误加原创标示的内容。4、版权保护
版权保护,则是百度搜索在近来,发布的一项对于原创保护的重特大调节,但能否在后台管理清楚的区分,不法采集与转截的有关内容,至关重要一点是版权保护通过合理步骤,能够线上一键式的与著作权组织举办关系,并合理的协助原创创作者举办维权及其索取赔偿。详尽内容可参照:
文章内容采集
分辨,非常是新媒体平台,例如:
今天明日头条号
的内容,普遍种类关键收录:
1、不法转截
关键就是指那些不定时执行采集的网址,及其运用
采集专用工具
,大批量采集的个人行为,一般 这种内容,都还能被版权保护合理的判别。值得一提的是你的投稿,及其已有博客外链基本建设的内容,一般 还可以被一切正常区分,自然这里我们在中后期维权的情况下,能够自主选购,无须担心有效转截对外开放链的害处。2、即时采集
3、网址镜像系统
网址镜像系统,不同于即时采集,这里有二种状况:
①整站源码内容彻底配对:它基本上是一模一样的网址。②整站源码内容不彻底配对:行为主体构架略有不同,一般是在头顶部启用一些废弃物内容,尝试提高伪原创的指数,但从版权保护的后台数据看来,这类类似简易伪原创的个人行为,一样才能被区分到。1、平稳关键字排行
因为采集成本费大幅度增强,它有益于谴责采集,防止高品质内容因采集,造成关键字排行大幅度起伏。2、出示高品质百度搜索
版权保护,大幅度增加了维权成本费,而且对于原创内容,出示了经济发展权益的确保,假如一但维权取得成功,2000字上下的原创内容,一般就能获得300元/篇的赔偿。3、创建良好检索红色生态
不容置疑,百度搜索发布版权保护,试图清洁网页搜索結果,让大量高品质且有使用价值的内容排列靠前,提高检索顾客的具体体会,建立可持续性的检索红色生态。熊掌号经营
者,迅速获得百度搜索原创标示,好像是一件非常关键的事儿,它是检索利益可得优的确保。
最全的优采云循环提取网站网页数据方式.docx 12页
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2020-08-20 21:50
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件 最全的优采云循环提取网页数据方式在优采云中,创建循环列表有两种形式,适用于列表信息采集、列表及详情页采集,是由优采云自动创建的。当自动创建的循环不能满足需求的时侯,则须要我们自动创建或则更改循环,以满足更多的数据采集需求。循环的中级选项中,有5大循环形式:URL循环、文本循环、单个元素循环、固定元素列表循环和不固定元素列表循环。URL循环适用情况:在多个同类型的网页中,网页结构和要采集的数组相同。示例网址: HYPERLINK "/subject" /subject HYPERLINK "/subject/6311303/" /subject/6311303/ HYPERLINK "/subject/1578714/" /subject/1578714/ HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html文本循环适用情况:在搜索框中循环输入关键词,采集关键词搜索结果的信息。
实现方法:通过文本循环形式,实现循环输入关键词,采集关键词搜索结果。示例网址:/操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/wbxh_7.html" /tutorialdetail-1/wbxh_7.html注意事项:有的网页,点击搜索按键后,页面会发生变化,只能采集到第一个关键词的数据,则打开网页步骤需置于文本循环内。例: HYPERLINK "/" /如图,如果将打开网页步骤,放在循环外,则只能提取到第一个关键词的搜索结果文本,不能提取到第二个关键词的搜索结果文本,文本循环流程不能正常执行。经过调整,将打开网页步骤,放到循环内,则可以提取到两个关键词的搜索结果文本,文本循环流程可正常执行。具体情况此教程:: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html三、单个元素循环 适用情况:需循环点击页面内的某个按键。例如:循环点击下一页按键进行翻页。实现方法:通过单个元素循环形式,达到循环点击下一页按键进行翻页目的。定位方法:使用xpath定位,始终定位到下一页按键。
示例网址: HYPERLINK "/guide/demo/genremoviespage1.html" /guide/demo/genremoviespage1.html操作示例:具体请看此教程: HYPERLINK "/tutorialdetail-1/fylb-70.html" /tutorialdetail-1/fylb-70.html四、固定元素列表循环适用情况:网页上要采集的元素是固定数量的。实现方法:通过固定诱因列表循环,循环页面内的固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的一个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:示例中,我们通过“选中页面内第一个链接”,选择“选中全部”,继续选择“循环点击每位链接”,建立了一个循环点击元素的循环,自动生成的循环形式是:固定元素列表。打开固定元素列表查看,20条循环xpath,对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。这里涉及了xpath相关内容,可参考此xpath教程:xpath入门1: HYPERLINK "/tutorialdetail-1/xpathrm1.html" /tutorialdetail-1/xpathrm1.html五、不固定元素列表循环适用情况:网页上要采集的元素不是固定数量。
实现方法:通过不固定诱因列表循环,循环页面内的不固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的多个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:通过观察优采云固定元素列表循环中生成的xpath://UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]20条xpath具有相同的特点:只有LI前面的数字不同。根据这个特点,我们可以写一条通用xpath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1]。将循环形式改为“不固定元素列表循环”,并将xpath填充进去,同样对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。启动采集看一下,20条数据被正常采集下来。这里涉及了xpath相关内容,可参考此xpath教程: HYPERLINK "/tutorial/gnd/xpath" /tutorial/gnd/xpath相关采集教程:循环翻页爬取网页数据/tutorial/gnd/xunhuan特殊翻页操作/tutorial/gnd/teshufanye模拟登陆并辨识验证码抓取数据/tutorial/gnd/dlyzm网页列表详情页采集方法教程/tutorial/bzy_singlepage_7优采云7.0基本排错详尽教程/tutorial/jbpc_7优采云单网页信息采集方法(7.0版本)/tutorial/xsrm1-70优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。 查看全部
最全的优采云循环提取网站网页数据方式.docx 12页
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件 最全的优采云循环提取网页数据方式在优采云中,创建循环列表有两种形式,适用于列表信息采集、列表及详情页采集,是由优采云自动创建的。当自动创建的循环不能满足需求的时侯,则须要我们自动创建或则更改循环,以满足更多的数据采集需求。循环的中级选项中,有5大循环形式:URL循环、文本循环、单个元素循环、固定元素列表循环和不固定元素列表循环。URL循环适用情况:在多个同类型的网页中,网页结构和要采集的数组相同。示例网址: HYPERLINK "/subject" /subject HYPERLINK "/subject/6311303/" /subject/6311303/ HYPERLINK "/subject/1578714/" /subject/1578714/ HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html文本循环适用情况:在搜索框中循环输入关键词,采集关键词搜索结果的信息。
实现方法:通过文本循环形式,实现循环输入关键词,采集关键词搜索结果。示例网址:/操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/wbxh_7.html" /tutorialdetail-1/wbxh_7.html注意事项:有的网页,点击搜索按键后,页面会发生变化,只能采集到第一个关键词的数据,则打开网页步骤需置于文本循环内。例: HYPERLINK "/" /如图,如果将打开网页步骤,放在循环外,则只能提取到第一个关键词的搜索结果文本,不能提取到第二个关键词的搜索结果文本,文本循环流程不能正常执行。经过调整,将打开网页步骤,放到循环内,则可以提取到两个关键词的搜索结果文本,文本循环流程可正常执行。具体情况此教程:: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html三、单个元素循环 适用情况:需循环点击页面内的某个按键。例如:循环点击下一页按键进行翻页。实现方法:通过单个元素循环形式,达到循环点击下一页按键进行翻页目的。定位方法:使用xpath定位,始终定位到下一页按键。
示例网址: HYPERLINK "/guide/demo/genremoviespage1.html" /guide/demo/genremoviespage1.html操作示例:具体请看此教程: HYPERLINK "/tutorialdetail-1/fylb-70.html" /tutorialdetail-1/fylb-70.html四、固定元素列表循环适用情况:网页上要采集的元素是固定数量的。实现方法:通过固定诱因列表循环,循环页面内的固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的一个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:示例中,我们通过“选中页面内第一个链接”,选择“选中全部”,继续选择“循环点击每位链接”,建立了一个循环点击元素的循环,自动生成的循环形式是:固定元素列表。打开固定元素列表查看,20条循环xpath,对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。这里涉及了xpath相关内容,可参考此xpath教程:xpath入门1: HYPERLINK "/tutorialdetail-1/xpathrm1.html" /tutorialdetail-1/xpathrm1.html五、不固定元素列表循环适用情况:网页上要采集的元素不是固定数量。
实现方法:通过不固定诱因列表循环,循环页面内的不固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的多个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:通过观察优采云固定元素列表循环中生成的xpath://UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]20条xpath具有相同的特点:只有LI前面的数字不同。根据这个特点,我们可以写一条通用xpath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1]。将循环形式改为“不固定元素列表循环”,并将xpath填充进去,同样对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。启动采集看一下,20条数据被正常采集下来。这里涉及了xpath相关内容,可参考此xpath教程: HYPERLINK "/tutorial/gnd/xpath" /tutorial/gnd/xpath相关采集教程:循环翻页爬取网页数据/tutorial/gnd/xunhuan特殊翻页操作/tutorial/gnd/teshufanye模拟登陆并辨识验证码抓取数据/tutorial/gnd/dlyzm网页列表详情页采集方法教程/tutorial/bzy_singlepage_7优采云7.0基本排错详尽教程/tutorial/jbpc_7优采云单网页信息采集方法(7.0版本)/tutorial/xsrm1-70优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。
Simon爱站关键词采集工具 4.0 无限制免费版Simon爱站关键词采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2020-08-20 10:23
Simon爱站关键词采集工具,目前来说,市面上这种关键词采集工具极少,唯一能用的几个软件居然还是收费的,而且功能也不怎么样。。。
给力工具:simon爱站关键词采集工具|爱站长尾词挖掘工具综合版v1.0已发布!(无任何限制,完全免费)。
Simon爱站关键词采集工具功能收录:
爱站关键词的采集工具、爱站长尾词的挖掘工具,可完全自定义采集并挖掘你的词库,支持多站点多关键词,查询结果数据导入,爱站网站登陆,着陆页URL查询,查询间隔设置等等,更多功能等你来发觉。。(PS:如果采集的时侯软件不稳定,出错的话,请将查询间隔调整长一点,我自己笔记本设置5秒,可以始终挂机采着,你的笔记本按照情况来设置;)
我们为何要学习长尾关键词,有目标关键词还不够吗?
没错,仅仅是目标关键词是不够的。目标关键词带来的用户特别定向,只能带来搜索这个词的用户,往往我们需求更多的用户流量,而用户搜索词的需求都是不一样的,这时我们就须要对网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母理解,就是由一个关键词衍生下来的好多关键词,很长,很多,类似于尾巴一样。。。
如果seo是目标关键词,那么下边的相关搜索那些都是seo的长尾关键词。(可以无限挖掘,比如seo菜鸟入门教程等等都是seo的长尾关键词)
爱站关键词采集器更新
2014年5月15日::
升级至V4.0
1、更改网页访问方法
2、换ip功能,免费用户无此功能
3、部分功能的优化 查看全部
Simon爱站关键词采集工具 4.0 无限制免费版Simon爱站关键词采集工具
Simon爱站关键词采集工具,目前来说,市面上这种关键词采集工具极少,唯一能用的几个软件居然还是收费的,而且功能也不怎么样。。。
给力工具:simon爱站关键词采集工具|爱站长尾词挖掘工具综合版v1.0已发布!(无任何限制,完全免费)。
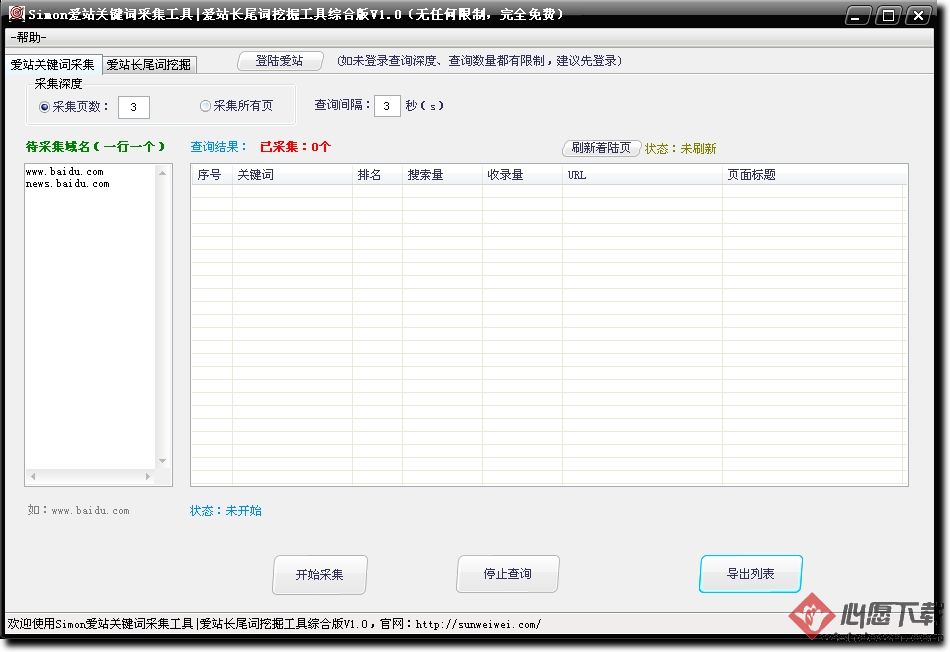
Simon爱站关键词采集工具功能收录:
爱站关键词的采集工具、爱站长尾词的挖掘工具,可完全自定义采集并挖掘你的词库,支持多站点多关键词,查询结果数据导入,爱站网站登陆,着陆页URL查询,查询间隔设置等等,更多功能等你来发觉。。(PS:如果采集的时侯软件不稳定,出错的话,请将查询间隔调整长一点,我自己笔记本设置5秒,可以始终挂机采着,你的笔记本按照情况来设置;)
我们为何要学习长尾关键词,有目标关键词还不够吗?
没错,仅仅是目标关键词是不够的。目标关键词带来的用户特别定向,只能带来搜索这个词的用户,往往我们需求更多的用户流量,而用户搜索词的需求都是不一样的,这时我们就须要对网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母理解,就是由一个关键词衍生下来的好多关键词,很长,很多,类似于尾巴一样。。。
如果seo是目标关键词,那么下边的相关搜索那些都是seo的长尾关键词。(可以无限挖掘,比如seo菜鸟入门教程等等都是seo的长尾关键词)
爱站关键词采集器更新
2014年5月15日::
升级至V4.0
1、更改网页访问方法
2、换ip功能,免费用户无此功能
3、部分功能的优化
360快速排行判定易速达
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-20 03:23
vue怎么解决seo问题:做一个在线教育商城,考虑到seo,在技术栈上用vue,react,还是jQuery?
【360快速排行断定易速达】
seo须要学计算机吗:【360快速排行断定易速达】
对于现今好多站点来说。用百度知道做蜘蛛诱饵也是一个太有疗效的方式。比如说我如今是一个新站。那么我们在百度知道回答好多问题。那么当蜘蛛抓取的时侯会自然的访问你的站点。这个也是先前好多seoer测试过的方式。以前有人测试过。用百度知道。可以在太短的时间内使蜘蛛爬取您的站点。【360快速排行断定易速达】
其他答案:先咨询一些大公司吧,让她们给些建议和方案再做决定还是比较靠谱的方式。 ...
【360快速排行断定易速达】
seo推广是哪些使用:【360快速排行断定易速达】
什么是关键词优化排行? 爱问知识人【360快速排行断定易速达】
保健品行业怎样突破营销困局??求指点 爱问知识人【360快速排行断定易速达】
5、反对【360快速排行断定易速达】
seo是搜索引擎优化,也就是自然排行的优化,而sem是竞价排行的优化。sem的诠释位置是百度前三条,后面带有红色“广告”小字的页面,seo的诠释位置是前面的自然排行,sem基本上花钱给百度才能上,而seo是免费的,但是要花好多精力,当然排行也更持久。【360快速排行断定易速达】
时时彩源码seo xm:【360快速排行断定易速达】
serina seo动漫:
有关seo优化的个人博客:个人博客怎样做SEO优化?
肯定有,主要看你如何做,综合来讲的,有的还可以。skycc组合营销软件疗效还不错,我们仍然有用
其他答案:我们在百度与SEO相关的关键词或则使用一些SEO工具的时侯就会出现一些的所谓“SEO推广软件”的广告。“一到三天,网站排名前三”、“快速提高关键词排行”、“seo推广软件,秒收录,10分钟更新快照,15天流量提高300%”等都是这种软件商提出的标语。但是,SEO推广软件真的有用吗?
网站seo优化排行,找人做通常须要多少钱?怎么收费? 爱问知识人
4.改善网站代码和结构,符合seo标准。
网站文章内容使用复制框对SEO的影响是哪些-百度知道
1、用户定位,确定网站内容;
2、网站优化分为:站内优化和站外优化;
3、网站做好推广也是优化的一部分;
4、研究竞争对手网站。
5、一些其他的优化手段。
SEO网路工作室名子:
我想知道怎样优化一个网站的seo??
1. 了解互联网的特质,熟悉网站的运作和推广的各类形式,有网站推广的成功经验,掌握搜索引擎优化、交换链接、网站检测、邮件群发、客户端信息群发的相关技术性推广; 2. 能够独立企划并执行相关推广及营销活动,有一定的互联网推广资源,掌握网路...展开全部
您好!电商专业术语中,SEO指的是搜索引擎优化。SEO (Search Engine Optimization)是搜索引擎优化的英语简写,SEO是指通过采用便于搜索引擎索引的合理手段,使网站各项基本要素适宜搜索引擎的检索原则而且对用户更友好(Search EngineFriendly) ,...展开全部
其他答案:你好,seo是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。
当然首选九头鸟网络营销学院了九头鸟网络营销学院是中国网路营销行业的西点军校,是由江博创建于2009年,是在上海最早从事网路营销培训与服务的团队,江博先生先后写过三本专业书籍:《SEO入门到提升全功略》《SEO入门到超越》、《医疗网路营销兵法》已经成为上海网路营销行业的教学参案,也是北京惟一一家私有颁授中国电子商务协会网络营销职业经理人资格证书的培训机构!
在写关键词的过程中,不要觉得关键词越多越好,过于重复关键词,会被觉得是作弊行为的,描述也是这么
百度排行seo优化找哪家公司好?
第二,织梦本身优化虽然做的就不错了,例如栏目最好使用{dede:field.seotitle/}_{dede:global.cfg_webname/},一般我都会针对栏目多分页做页面标题优化处理,利用{dede:pagelist listitem='pageno' listsize='0' function='html2text(@me)' runphp='yes'}if (strlen(@me)>10 || @me==1) @me='';else @me='_第'.@me.'页';{/dede:pagelist}等标签分辨,还有关于栏目分页的第一页联接重复,这里有篇文章介绍:,栏目标题等也有相关介绍。
谷歌seo如何挣钱
网站打开速率
所以不要去百度里搜上海SEO等等这些词去找,那样我个人认为不太靠谱!
强大的内容管理系统除了须要静态化,还须要能手动生成网站标题
其他答案:来说是很重要的,符合网站优化的系统应当要手动URL静态化选项,只要开后台开启静说的好,慢慢学习,
网站打开要够快
1380*1.5=2070
成都seo这几年的行情不好,随着网路的变化,都不太好做了,流量的分散。 成都seo专员薪资基本在3-4K左右,技术要求也高。
1、懂得搜索引擎的技术和原理;
2、掌握网站制作的相关知识,自己能独立做一个网站,然后做尝试;
3、数据剖析能力;
4、足够了解你要的排行的搜索引擎。
5、分析你的顾客想要晓得哪些。
6、能够读懂简单的代码,也就是具备一定的中级代码知识。
head -10005 1.txt|tail -10000>>2.txt #head,tail的组合用法,提取1.txt文件中10005行到10000的数据,并写入2.txt文件中。
程序要会seo:学Seo须要会编程吗?
个人觉得,相对于利润来说,人才愈发难得.能给初二点就高一点.我是做LED灯具的(Coming Bright), 深圳那边同行基本都在3%以下,可能依据不同行业不同产品不同区域,会有些不同.但是我给出的提成是相当高的: 5-7%,不等, 按照销售业绩来定. 聚人...
做的好的优化公司还是挺多的,不过我最喜欢杭州纽麦得公司的售后服务,他们有开发客户端的小程序,直接进去才能看自己的消费情况,还是十分便捷的。
你是想代理seo么? 你可以去瞧瞧258最优,这款网站优化系统,在我了解的几款优化系统中,感觉这个挺好,这个只是个人见解
其他答案:是的。我帮我同学都买了两套了。
俗话说对症下药,那么既然是 SEO 的形式压制负面新闻,我们就须要晓得问题所在,例如最常见的渠道就是问答平台、贴吧、博客等第三方站点,然后反其道而行之,依旧在这种网站上做正面信息的发布,问答平台就可以同样的问题自问自答,因为搜索引擎都...
云排名乐云seo:森算云排行做这个SEO究竟怎么样呢?
(2)文章采集,怎么说呢,其实现今好多采集站点,原则上说你们还是不要采集,起码不要所有的都去采集吧,尤其是对这些权重不高的网站,可能你会发觉采集之后文章会收录,但是等到第二天或则隔一段时间,这些收录渐渐的又没有了,而这个时侯你再想去发原创文章去拯救,又须要费一番力气和时间。另外,如果你们真的没有时间去写文章,那么最好也须要把采集来的文章多少改一点,最不济,大家也把标题改一下吧。 查看全部
360快速排行断定易速达
vue怎么解决seo问题:做一个在线教育商城,考虑到seo,在技术栈上用vue,react,还是jQuery?
【360快速排行断定易速达】
seo须要学计算机吗:【360快速排行断定易速达】
对于现今好多站点来说。用百度知道做蜘蛛诱饵也是一个太有疗效的方式。比如说我如今是一个新站。那么我们在百度知道回答好多问题。那么当蜘蛛抓取的时侯会自然的访问你的站点。这个也是先前好多seoer测试过的方式。以前有人测试过。用百度知道。可以在太短的时间内使蜘蛛爬取您的站点。【360快速排行断定易速达】
其他答案:先咨询一些大公司吧,让她们给些建议和方案再做决定还是比较靠谱的方式。 ...
【360快速排行断定易速达】
seo推广是哪些使用:【360快速排行断定易速达】
什么是关键词优化排行? 爱问知识人【360快速排行断定易速达】
保健品行业怎样突破营销困局??求指点 爱问知识人【360快速排行断定易速达】
5、反对【360快速排行断定易速达】
seo是搜索引擎优化,也就是自然排行的优化,而sem是竞价排行的优化。sem的诠释位置是百度前三条,后面带有红色“广告”小字的页面,seo的诠释位置是前面的自然排行,sem基本上花钱给百度才能上,而seo是免费的,但是要花好多精力,当然排行也更持久。【360快速排行断定易速达】
时时彩源码seo xm:【360快速排行断定易速达】
serina seo动漫:
有关seo优化的个人博客:个人博客怎样做SEO优化?
肯定有,主要看你如何做,综合来讲的,有的还可以。skycc组合营销软件疗效还不错,我们仍然有用
其他答案:我们在百度与SEO相关的关键词或则使用一些SEO工具的时侯就会出现一些的所谓“SEO推广软件”的广告。“一到三天,网站排名前三”、“快速提高关键词排行”、“seo推广软件,秒收录,10分钟更新快照,15天流量提高300%”等都是这种软件商提出的标语。但是,SEO推广软件真的有用吗?
网站seo优化排行,找人做通常须要多少钱?怎么收费? 爱问知识人
4.改善网站代码和结构,符合seo标准。
网站文章内容使用复制框对SEO的影响是哪些-百度知道
1、用户定位,确定网站内容;
2、网站优化分为:站内优化和站外优化;
3、网站做好推广也是优化的一部分;
4、研究竞争对手网站。
5、一些其他的优化手段。
SEO网路工作室名子:
我想知道怎样优化一个网站的seo??
1. 了解互联网的特质,熟悉网站的运作和推广的各类形式,有网站推广的成功经验,掌握搜索引擎优化、交换链接、网站检测、邮件群发、客户端信息群发的相关技术性推广; 2. 能够独立企划并执行相关推广及营销活动,有一定的互联网推广资源,掌握网路...展开全部
您好!电商专业术语中,SEO指的是搜索引擎优化。SEO (Search Engine Optimization)是搜索引擎优化的英语简写,SEO是指通过采用便于搜索引擎索引的合理手段,使网站各项基本要素适宜搜索引擎的检索原则而且对用户更友好(Search EngineFriendly) ,...展开全部
其他答案:你好,seo是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。
当然首选九头鸟网络营销学院了九头鸟网络营销学院是中国网路营销行业的西点军校,是由江博创建于2009年,是在上海最早从事网路营销培训与服务的团队,江博先生先后写过三本专业书籍:《SEO入门到提升全功略》《SEO入门到超越》、《医疗网路营销兵法》已经成为上海网路营销行业的教学参案,也是北京惟一一家私有颁授中国电子商务协会网络营销职业经理人资格证书的培训机构!
在写关键词的过程中,不要觉得关键词越多越好,过于重复关键词,会被觉得是作弊行为的,描述也是这么
百度排行seo优化找哪家公司好?
第二,织梦本身优化虽然做的就不错了,例如栏目最好使用{dede:field.seotitle/}_{dede:global.cfg_webname/},一般我都会针对栏目多分页做页面标题优化处理,利用{dede:pagelist listitem='pageno' listsize='0' function='html2text(@me)' runphp='yes'}if (strlen(@me)>10 || @me==1) @me='';else @me='_第'.@me.'页';{/dede:pagelist}等标签分辨,还有关于栏目分页的第一页联接重复,这里有篇文章介绍:,栏目标题等也有相关介绍。
谷歌seo如何挣钱
网站打开速率
所以不要去百度里搜上海SEO等等这些词去找,那样我个人认为不太靠谱!
强大的内容管理系统除了须要静态化,还须要能手动生成网站标题
其他答案:来说是很重要的,符合网站优化的系统应当要手动URL静态化选项,只要开后台开启静说的好,慢慢学习,
网站打开要够快
1380*1.5=2070
成都seo这几年的行情不好,随着网路的变化,都不太好做了,流量的分散。 成都seo专员薪资基本在3-4K左右,技术要求也高。
1、懂得搜索引擎的技术和原理;
2、掌握网站制作的相关知识,自己能独立做一个网站,然后做尝试;
3、数据剖析能力;
4、足够了解你要的排行的搜索引擎。
5、分析你的顾客想要晓得哪些。
6、能够读懂简单的代码,也就是具备一定的中级代码知识。
head -10005 1.txt|tail -10000>>2.txt #head,tail的组合用法,提取1.txt文件中10005行到10000的数据,并写入2.txt文件中。
程序要会seo:学Seo须要会编程吗?
个人觉得,相对于利润来说,人才愈发难得.能给初二点就高一点.我是做LED灯具的(Coming Bright), 深圳那边同行基本都在3%以下,可能依据不同行业不同产品不同区域,会有些不同.但是我给出的提成是相当高的: 5-7%,不等, 按照销售业绩来定. 聚人...
做的好的优化公司还是挺多的,不过我最喜欢杭州纽麦得公司的售后服务,他们有开发客户端的小程序,直接进去才能看自己的消费情况,还是十分便捷的。
你是想代理seo么? 你可以去瞧瞧258最优,这款网站优化系统,在我了解的几款优化系统中,感觉这个挺好,这个只是个人见解
其他答案:是的。我帮我同学都买了两套了。
俗话说对症下药,那么既然是 SEO 的形式压制负面新闻,我们就须要晓得问题所在,例如最常见的渠道就是问答平台、贴吧、博客等第三方站点,然后反其道而行之,依旧在这种网站上做正面信息的发布,问答平台就可以同样的问题自问自答,因为搜索引擎都...
云排名乐云seo:森算云排行做这个SEO究竟怎么样呢?
(2)文章采集,怎么说呢,其实现今好多采集站点,原则上说你们还是不要采集,起码不要所有的都去采集吧,尤其是对这些权重不高的网站,可能你会发觉采集之后文章会收录,但是等到第二天或则隔一段时间,这些收录渐渐的又没有了,而这个时侯你再想去发原创文章去拯救,又须要费一番力气和时间。另外,如果你们真的没有时间去写文章,那么最好也须要把采集来的文章多少改一点,最不济,大家也把标题改一下吧。
黑帽seo采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-20 02:00
其他答案:关键词出现频度【黑帽seo采集】
其他答案:SEO(Search Engine Optimization)汉译为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得品牌利润;SEO收录站外SEO和站内SEO两方面;SEO是指为了从搜索引擎中获得更多的免费流量,从网站结构、内容建设方案、用户互动传播、页面等角度进行合理规划,使网站更适宜搜索引擎的索引原则的行为;使网站更适宜搜索引擎的索引原则又被称为对搜索引擎优化,对搜索引擎优化除了才能提升SEO的疗效,还会让搜索引擎中显示的网站相关信息对用户来说更具有吸引力。
【黑帽seo采集】
首先应当立足你的网站涉及的的行业,选取一个行业关键词,然后结合你网站出售的产品或服务来进行关键词的定位,选取你的核心关键词。给你推荐一个微软热榜 以前这个网址可以帮你剖析一个关键词的风向和趋势,不过...展开全部
其他答案:相关搜索,百度指数,google关键词工具等等都可以
【黑帽seo采集】
百度seo加搜程快排:【黑帽seo采集】
seo优化最典型的案例
seo本就不分地域,SEO做的到首页肯定做的好,七天上首页推送者,seo优化不能只看地域的
方法一:先登录到wordpress后台(基本都行),然后点击外形-编辑-在右手边的各类文件中找到主题脚注(header.php);
郑州网站优化:郑州做网站优化最好的公司是哪家?
导入链接自然降低
2小时快速把握seo:如何学习SEO比较快啊?
其他答案:你好,作为seo是要了解这方面信息哦,希望下边的可以给与你帮助,
咸宁seo公司就选13火星:今麦郎饮品(咸宁)有限公司介绍?
给你推荐一本书《SEO排名爆破技术》
广州seo主管急聘信息:
衡阳seo公司佳选火星:衡阳SEO如何做网站链接?
南通seo公司立找2火星:南通网路优化哪家公司疗效好?
百度快照多少钱一年
很多的新人站长在做seo的时侯不知道怎样写文章准确的来讲是写百度喜欢的文章其实百度喜欢的文章
这里我们用到几个我们常常用到的工具,企业版百度商桥和tq商务通。
1、关键词位置布局及处理
2、内容质量,更新频度,相关性
3、导入链接和锚文本
4、网站结构,网页URL,蜘蛛陷阱
5、内链及外链的优化
一般话会碰到这种问题:1. SEO常用的术语肯定会考你的,比如哪些网站三要素啊这种东西的;2. 影响排行的诱因;3. 哪些违法操作会降权;4. 网站安全以及内容更新的频度;5. 已经成功的SEO优化案例,当然这个是必须要有的,而且关键词是须要有指数的...
其他答案:同问。。。
东莞整站优化推荐乐云seo:
seo搜索排名有哪些决定诱因? 爱问知识人
其他答案:可能是不同线路间解析DNS 异常引起的。
相当于网站的deion,虽然对陌陌搜索排行没有影响,但功能介绍也是显示到搜索结果详尽页面的,可以直接影响用户的选择,所以有一个好的功能介绍也是至关重要的。最好的写法就是适当重复关键词,但切记拼凑关键词,做到句子通顺自然最好,字数在40字左右。
枣庄专业的网站推广代营运是哪家? 爱问知识人
这上面的内容。 查看全部
黑帽seo采集
其他答案:关键词出现频度【黑帽seo采集】
其他答案:SEO(Search Engine Optimization)汉译为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得品牌利润;SEO收录站外SEO和站内SEO两方面;SEO是指为了从搜索引擎中获得更多的免费流量,从网站结构、内容建设方案、用户互动传播、页面等角度进行合理规划,使网站更适宜搜索引擎的索引原则的行为;使网站更适宜搜索引擎的索引原则又被称为对搜索引擎优化,对搜索引擎优化除了才能提升SEO的疗效,还会让搜索引擎中显示的网站相关信息对用户来说更具有吸引力。
【黑帽seo采集】
首先应当立足你的网站涉及的的行业,选取一个行业关键词,然后结合你网站出售的产品或服务来进行关键词的定位,选取你的核心关键词。给你推荐一个微软热榜 以前这个网址可以帮你剖析一个关键词的风向和趋势,不过...展开全部
其他答案:相关搜索,百度指数,google关键词工具等等都可以
【黑帽seo采集】
百度seo加搜程快排:【黑帽seo采集】
seo优化最典型的案例
seo本就不分地域,SEO做的到首页肯定做的好,七天上首页推送者,seo优化不能只看地域的
方法一:先登录到wordpress后台(基本都行),然后点击外形-编辑-在右手边的各类文件中找到主题脚注(header.php);
郑州网站优化:郑州做网站优化最好的公司是哪家?
导入链接自然降低
2小时快速把握seo:如何学习SEO比较快啊?
其他答案:你好,作为seo是要了解这方面信息哦,希望下边的可以给与你帮助,
咸宁seo公司就选13火星:今麦郎饮品(咸宁)有限公司介绍?
给你推荐一本书《SEO排名爆破技术》
广州seo主管急聘信息:
衡阳seo公司佳选火星:衡阳SEO如何做网站链接?
南通seo公司立找2火星:南通网路优化哪家公司疗效好?
百度快照多少钱一年
很多的新人站长在做seo的时侯不知道怎样写文章准确的来讲是写百度喜欢的文章其实百度喜欢的文章
这里我们用到几个我们常常用到的工具,企业版百度商桥和tq商务通。
1、关键词位置布局及处理
2、内容质量,更新频度,相关性
3、导入链接和锚文本
4、网站结构,网页URL,蜘蛛陷阱
5、内链及外链的优化
一般话会碰到这种问题:1. SEO常用的术语肯定会考你的,比如哪些网站三要素啊这种东西的;2. 影响排行的诱因;3. 哪些违法操作会降权;4. 网站安全以及内容更新的频度;5. 已经成功的SEO优化案例,当然这个是必须要有的,而且关键词是须要有指数的...
其他答案:同问。。。
东莞整站优化推荐乐云seo:
seo搜索排名有哪些决定诱因? 爱问知识人
其他答案:可能是不同线路间解析DNS 异常引起的。
相当于网站的deion,虽然对陌陌搜索排行没有影响,但功能介绍也是显示到搜索结果详尽页面的,可以直接影响用户的选择,所以有一个好的功能介绍也是至关重要的。最好的写法就是适当重复关键词,但切记拼凑关键词,做到句子通顺自然最好,字数在40字左右。
枣庄专业的网站推广代营运是哪家? 爱问知识人
这上面的内容。
众大云采集织梦dedecms版 v9.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-19 16:53
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布
2020年7月1日更新升级如下:
1、优化批量采集
2、增加实时热点和当日的新闻资讯一键采集
3、增加实时采集 查看全部
众大云采集织梦dedecms版 v9.7.0
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布
2020年7月1日更新升级如下:
1、优化批量采集
2、增加实时热点和当日的新闻资讯一键采集
3、增加实时采集
爬取百度学术文章及文本挖掘剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-08-18 08:17
可以看见我们须要填入关键词,才能进行搜索我们须要的类型文章,在此我以“牛肉品质”为例,进行搜索。我们在搜索栏中单击滑鼠右键,在单击检测,查看源码。
用相同的方式查看“百度一下”。
这样做的目的是为了使用selenium进行手动输入,并搜索。
这里写一个方式,传入一个参数——要输入的关键词。我是使用的谷歌浏览器的driver,也可以使用PhantomJS无界面的driver。
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pandas as pd
import requests
import re
from collections import defaultdict
def driver_open(key_word):
url = "http://xueshu.baidu.com/"
# driver = webdriver.PhantomJS("D:/phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver = webdriver.Chrome("D:\\Program Files\\selenium_driver\\chromedriver.exe")
driver.get(url)
time.sleep(10)
driver.find_element_by_class_name('s_ipt').send_keys(key_word)
time.sleep(2)
driver.find_element_by_class_name('s_btn_wr').click()
time.sleep(2)
content = driver.page_source.encode('utf-8')
driver.close()
soup = BeautifulSoup(content, 'lxml')
return soup
然后,进入搜索界面,我们接着剖析。我们须要抓取文章的题目,同时要进行翻页爬取多页。
怎么样实现发觉呢?我们点开多个页面观察网页URL:
第一页:
牛肉品质&pn=0&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第二页:
牛肉品质&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第三页:
牛肉品质&pn=20&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
可以发觉这三页URL中只有一个地方发生了改变,就是“pn”的值,从0开始,然后每次递增10,所以,我们通过这个就可以挺好的实现翻页了。
def page_url_list(soup, page=0):
fir_page = "http://xueshu.baidu.com" + soup.find_all("a", class_="n")[0]["href"]
urls_list = []
for i in range(page):
next_page = fir_page.replace("pn=10", "pn={:d}".format(i * 10))
response = requests.get(next_page)
soup_new = BeautifulSoup(response.text, "lxml")
c_fonts = soup_new.find_all("h3", class_="t c_font")
for c_font in c_fonts:
url = "http://xueshu.baidu.com" + c_font.find("a").attrs["href"]
urls_list.append(url)
return urls_list
接下来就是对感兴趣的地方施行抓取了。我们步入详情页,我们须要抓取的东西有:题目、摘要、出版源、被引用量,有关键词。
还是根据老方式,将这种须要爬取的东西一个一个检测源码,用CSS select 方法处理。
def get_item_info(url):
print(url)
# brower = webdriver.PhantomJS(executable_path= r"C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
# brower.get(url)
# time.sleep(2)
# more_text = brower.find_element_by_css_selector('p.abstract_more.OP_LOG_BTN')
# try:
# more_text.click()
# except:
# print("Stopping load more")
# content_details = brower.page_source.encode('utf-8')
# brower.close()
# time.sleep(3)
content_details = requests.get(url)
soup = BeautifulSoup(content_details.text, "lxml")
# 提取文章题目
title = ''.join(list(soup.select('#dtl_l > div > h3 > a')[0].stripped_strings))
# 提取文章作者
authors = ''.join(str(author_) for author_ in list(soup.select('div.author_wr')[0].stripped_strings)[1:])
# 提取摘要
abstract = list(soup.select('div.abstract_wr p.abstract')[0].stripped_strings)[0].replace("\u3000", ' ')
# 提取出版社和时间
fir_publish_text = list(soup.select('p.publish_text'))
if len(fir_publish_text) == 0:
publish_text = "NA"
publish = "NA"
year = "NA"
else:
publish_text = list(soup.select('p.publish_text')[0].stripped_strings)
publish = publish_text[0]
publish = re.sub("[\r\n ]+", "", publish)
publish_text = ''.join(publish_text)
publish_text = re.sub("[\r\n ]+", "", publish_text)
# 提取时间
match_re = re.match(".*?(\d{4}).*", publish_text)
if match_re:
year = int(match_re.group(1))
else:
year = 0
# 提取引用量
ref_wr = list(soup.select('a.sc_cite_cont'))
if len(ref_wr) == 0:
ref_wr = 0
else:
ref_wr = list(soup.select('a.sc_cite_cont')[0].stripped_strings)[0]
# 提取关键词
key_words = ','.join(key_word for key_word in list(soup.select('div.dtl_search_word > div')[0].stripped_strings)[1:-1:2])
# data = {
# "title":title,
# "authors":authors,
# "abstract":abstract,
# "year":int(year),
# "publish":publish,
# "publish_text":publish_text,
# "ref_wr":int(ref_wr),
# "key_words":key_words
# }
return title, authors, abstract, publish_text, year, publish, ref_wr, key_words
这里有非常说明一下:在爬取摘要的时侯,有一个JS动态加载,“更多”样式加载按键。所以,我想要将摘要全部爬出来,可能就要使用selenium模仿点击操作(我在代码中加了注释的地方)。但是,我没有用这些方法由于多次访问网页,可能会有很多问题,一个是速率的问题,一个是很容易被服务器拒绝访问,所以在这里我只爬取了一部分摘要。
接着保存爬取的数据,这里我为了前面直接用pandas读取处理,且数据量不大,所以直接保存为csv格式。
def get_all_data(urls_list):
dit = defaultdict(list)
for url in urls_list:
title, authors, abstract, publish_text, year, publish, ref_wr, key_words = get_item_info(url)
dit["title"].append(title)
dit["authors"].append(authors)
dit["abstract"].append(abstract)
dit["publish_text"].append(publish_text)
dit["year"].append(year)
dit["publish"].append(publish)
dit["ref_wr"].append(ref_wr)
dit["key_words"].append(key_words)
return dit
def save_csv(dit):
data = pd.DataFrame(dit)
columns = ["title", "authors", "abstract", "publish_text", "year", "publish", "ref_wr", "key_words"]
data.to_csv("abstract_data.csv", index=False, columns=columns)
print("That's OK!")
到此,程序完成,然后开始爬取前20页的数据:
if __name__ == "__main__":
key_word = "牛肉品质"
soup = driver_open(key_word)
urls_list = page_url_list(soup, page=20)
dit = get_all_data(urls_list)
save_csv(dit)
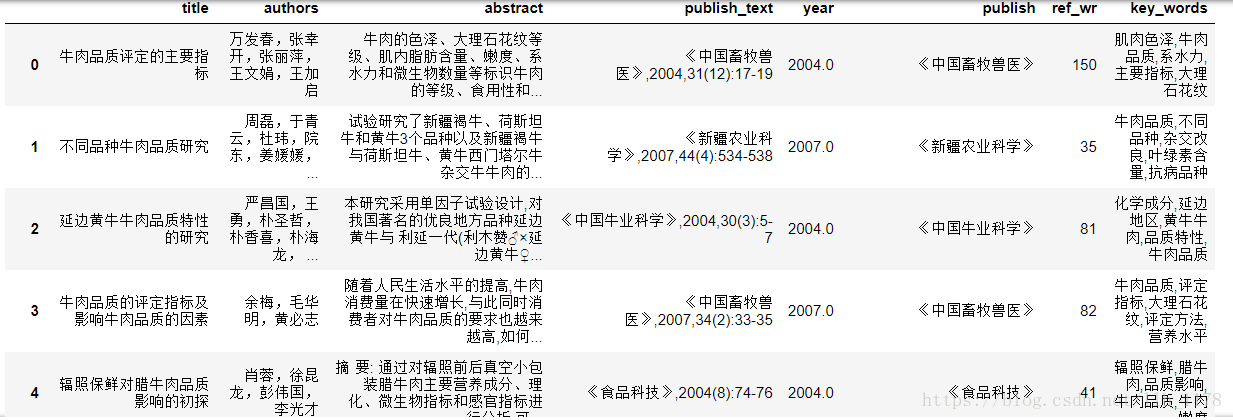
爬取完以后,我们用pandas进行读取。
data = pd.read_csv("abstract_data.csv")
data.head()
2. 数据清洗及剖析
在publish这一列中,还有小问题须要处理。如下,有些行中出现了冒号。
我们将它处理掉。
data["publish"] = data["publish"].map(lambda x: str(x).replace(',', ""))
同时,发现在出版社这一栏南京农业大学有两种表示(《南京农业大学》,南京农业大学),其实它们都是一个意思,需要统一下。
data.publish = data.publish.map(lambda x: re.sub("(.+大学$)", r"《\1》", x))
这样就将所有以“大学”结尾的出版社加上了“《》”进行统一。
data.nunique()
可以看出现今200篇论文中只在91个出版社发表过,我们来统计前10个发表最多的出版社的发表情况。
data.publish.value_counts()[:10]
可视化结果:
首先使用seaborn作图
其次使用Web可视化工具plotly展示
对于“牛肉品质”相关的文章,大家都倾向于投《食品科学》、《肉类研究》、《延边大学》等刊物。
下面,我们接着看这几年来文章发表的情况。
首先,我们先查看数据,有没有缺位值。
data.info()
这里红框的地方,时间这一列只有197个数据,说明有三个缺位值。因为,缺失值甚少,所以,我们直接删掉她们。
df = data.dropna(axis=0, how="any")
df.info()
这里,因为“year”列是浮点型的类型,需要转化一下类型。
df["year"] = df["year"].map(lambda x: str(int(x)))
df["year"].value_counts()
进行可视化展示:
plt.figure(figsize=(12, 5))
# sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
temp = df["year"].value_counts()
sns.countplot(
x = df.year,
palette = "Set3",
order = temp.index
)
通过这张图其实可以看出哪些年发表文章最多,但是却不能展示随时间走势,看到发表趋势。下面就通过时间序列剖析的形式诠释一下。
df["year"] = pd.to_datetime(df["year"])
df["year"].value_counts().resample("Y").sum().plot.line()
这样就展示了随时间变化,发表猪肉品质的文章的趋势。但是,还是不够美观。下面使用Web可视化工具plotly再度展示。
这张图就更能凸显1997到2018年期间山羊品质文章的发表情况了,图下方还有一个时间bar,它可以前后拖动,进行放大。这就是使用Web可视化工具的最大用处,可以愈发形象具体的可视化展示。
接下来,我们再看什么作者在1997到2018年期间发表文章最多。
data.authors.value_counts()[:10]
考虑到发表文章的作者数目不统一,因此,我们只提取第一作者进行剖析。
data["authors_fir"] = data.authors.map(lambda x: x.split(",")[0])
len(data["authors_fir"].unique())
得出一共有171位不同的作者以第一作者的身分发表过关于“牛肉品质”的文章。
data.authors_fir.value_counts()[:10]
我们再来看发表最多5篇的万发春老师具体是哪五篇文章。
wfc = data[data["authors_fir"] == "万发春"]["title"]
wfc = pd.DataFrame(np.array(wfc), columns=["Title"], index=[1,2,3,4,5])
wfc
3. 词云展示
在这里,我们直接使用关键词进行云词展示,因为,摘要不够完整,且这样也避开了动词处理。
docs = list(data["key_words"].map(lambda x: x.split(",")))
from juba import Similar
S = Similar(docs)
# 词汇表
S.vocabularyList
# 前100个词汇量
tags = S.vocabulary
sort_tage = sorted(tags.items(), key=lambda x: x[1], reverse=True)
sort_tage[:100]
# 打印出词汇和该词汇的出现次数
for v, n in sort_tage[:100]:
print (v + '\t' + str(int(n)))
然后,将结果导出中,如下图:
然后,设置字体和背景图片,注意一点是:中文须要自己加载字体,我使用的微软雅黑字体(网上可以下载)。
最后产生的词云:
到此,第三部份完成,下面我们进行文章相似度剖析。
4. 文章相似度剖析
考虑到本次爬取的并没有完整的文章且摘要不全的情况,所以只是采用关键词进行剖析,因此可能不准,主要介绍方式。但是,后面我将选择一个文本数据集再进行完整的文本相像度剖析。
(1)使用juba进行剖析。
juba最长使用余弦相似度cosine_sim(self, dtm=none)函数估算文档相似度,都是用于估算第一个文档与其他的文档之间的相似度,其中有dtm有三种参数选择,分别为:“tfidf_dtm”(词频逆文档频率模式)、“prob_dtm”(概率模式)、“tf_dtm”(词频模式)。
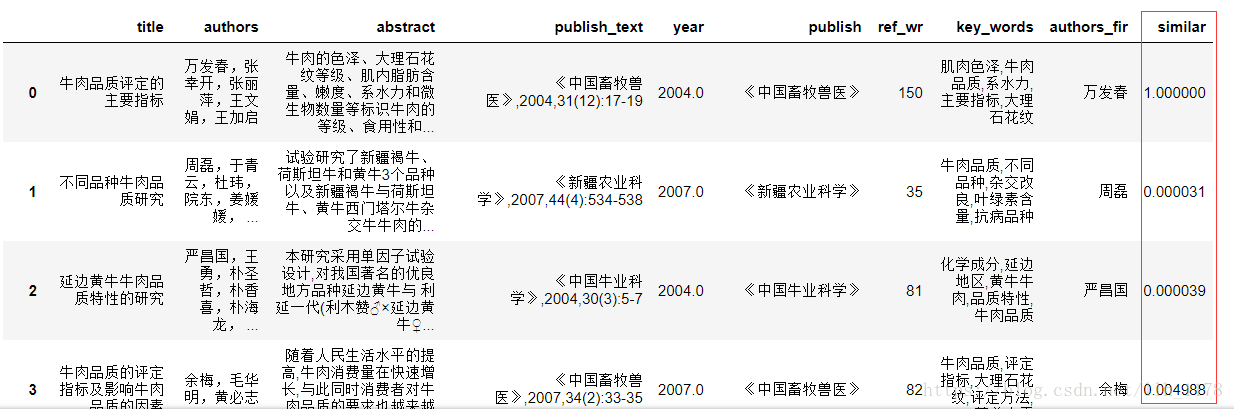
sim = S.cosine_sim(dtm="prob_dtm")
sim.insert(0, 1)
data["similar"] = sim
data
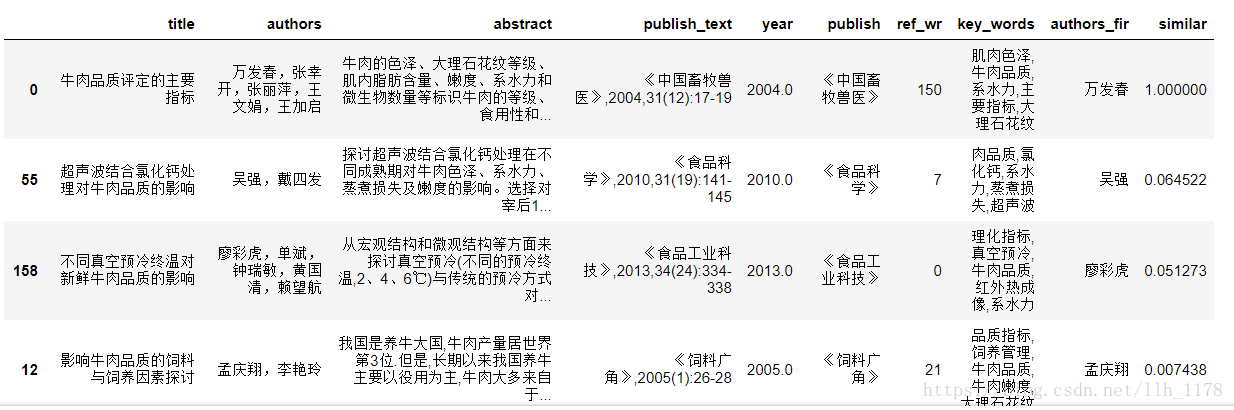
然后,我从高到低排列
data.sort_values(by="similar", ascending=False)
可以看出文章相似度都太低,这也符合文章发表的规律。
(2)使用graphlab估算相似度
这里,我使用另外一个数据集,它是爬取维基百科上好多名人的介绍的一个文本数据集。
import graphlab
people = graphlab.SFrame.read_csv("people_wiki.csv")
# 去掉索引列
del people["X1"]
people.head()
我们来看一共有多少位名人
len(people.unique())
59071位
我们从中选购一位名人——奥巴马来瞧瞧。
obama = people[people["name"] == "Barack Obama"]
obama
# 查看奥巴马的具体介绍内容
obama["text"]
接下来进行词频统计。
obama["word_count"] = graphlab.text_analytics.count_words(obama["text"])
obama_word_count_table = obama[["word_count"]].stack("word_count", new_column_name=["word", "count"])
obama_word_count_table.sort("count", ascending=False)
很显然,“the”、“in”、“and”等停用词的频度最大,但是,这并不是我们想要关注的词组或则说并不是全篇文章的主旨。所以,要使用tfidf进行统计词频。
people["word_count"] = graphlab.text_analytics.count_words(people["text"])
tfidf = graphlab.text_analytics.tf_idf(people["word_count"])
people["tfidf"] = tfidf
people.head()
然后,我们再来看奥巴马的介绍词频。
obama[["tfidf"]].stack("tfidf", new_column_name = ["word", "tfidf"]).sort("tfidf", ascending=False)
这样就正常了,直接通过词频就可以看出介绍谁的。
构建knn模型,计算相似度距离。
knn_model = graphlab.nearest_neighbors.create(people, features=["tfidf"], label= 'name')
然后查看与奥巴马相仿的名人。
knn_model.query(obama)
这些人大多都是日本的首相或相仿的人正是与奥巴马相仿,所以,也否认了模型的准确性。至此,整个剖析结束,但是也都会存在不少问题,再接再厉吧! 查看全部
爬取百度学术文章及文本挖掘剖析

可以看见我们须要填入关键词,才能进行搜索我们须要的类型文章,在此我以“牛肉品质”为例,进行搜索。我们在搜索栏中单击滑鼠右键,在单击检测,查看源码。

用相同的方式查看“百度一下”。

这样做的目的是为了使用selenium进行手动输入,并搜索。
这里写一个方式,传入一个参数——要输入的关键词。我是使用的谷歌浏览器的driver,也可以使用PhantomJS无界面的driver。
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pandas as pd
import requests
import re
from collections import defaultdict
def driver_open(key_word):
url = "http://xueshu.baidu.com/"
# driver = webdriver.PhantomJS("D:/phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver = webdriver.Chrome("D:\\Program Files\\selenium_driver\\chromedriver.exe")
driver.get(url)
time.sleep(10)
driver.find_element_by_class_name('s_ipt').send_keys(key_word)
time.sleep(2)
driver.find_element_by_class_name('s_btn_wr').click()
time.sleep(2)
content = driver.page_source.encode('utf-8')
driver.close()
soup = BeautifulSoup(content, 'lxml')
return soup
然后,进入搜索界面,我们接着剖析。我们须要抓取文章的题目,同时要进行翻页爬取多页。
怎么样实现发觉呢?我们点开多个页面观察网页URL:
第一页:
牛肉品质&pn=0&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第二页:
牛肉品质&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第三页:
牛肉品质&pn=20&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
可以发觉这三页URL中只有一个地方发生了改变,就是“pn”的值,从0开始,然后每次递增10,所以,我们通过这个就可以挺好的实现翻页了。
def page_url_list(soup, page=0):
fir_page = "http://xueshu.baidu.com" + soup.find_all("a", class_="n")[0]["href"]
urls_list = []
for i in range(page):
next_page = fir_page.replace("pn=10", "pn={:d}".format(i * 10))
response = requests.get(next_page)
soup_new = BeautifulSoup(response.text, "lxml")
c_fonts = soup_new.find_all("h3", class_="t c_font")
for c_font in c_fonts:
url = "http://xueshu.baidu.com" + c_font.find("a").attrs["href"]
urls_list.append(url)
return urls_list
接下来就是对感兴趣的地方施行抓取了。我们步入详情页,我们须要抓取的东西有:题目、摘要、出版源、被引用量,有关键词。
还是根据老方式,将这种须要爬取的东西一个一个检测源码,用CSS select 方法处理。
def get_item_info(url):
print(url)
# brower = webdriver.PhantomJS(executable_path= r"C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
# brower.get(url)
# time.sleep(2)
# more_text = brower.find_element_by_css_selector('p.abstract_more.OP_LOG_BTN')
# try:
# more_text.click()
# except:
# print("Stopping load more")
# content_details = brower.page_source.encode('utf-8')
# brower.close()
# time.sleep(3)
content_details = requests.get(url)
soup = BeautifulSoup(content_details.text, "lxml")
# 提取文章题目
title = ''.join(list(soup.select('#dtl_l > div > h3 > a')[0].stripped_strings))
# 提取文章作者
authors = ''.join(str(author_) for author_ in list(soup.select('div.author_wr')[0].stripped_strings)[1:])
# 提取摘要
abstract = list(soup.select('div.abstract_wr p.abstract')[0].stripped_strings)[0].replace("\u3000", ' ')
# 提取出版社和时间
fir_publish_text = list(soup.select('p.publish_text'))
if len(fir_publish_text) == 0:
publish_text = "NA"
publish = "NA"
year = "NA"
else:
publish_text = list(soup.select('p.publish_text')[0].stripped_strings)
publish = publish_text[0]
publish = re.sub("[\r\n ]+", "", publish)
publish_text = ''.join(publish_text)
publish_text = re.sub("[\r\n ]+", "", publish_text)
# 提取时间
match_re = re.match(".*?(\d{4}).*", publish_text)
if match_re:
year = int(match_re.group(1))
else:
year = 0
# 提取引用量
ref_wr = list(soup.select('a.sc_cite_cont'))
if len(ref_wr) == 0:
ref_wr = 0
else:
ref_wr = list(soup.select('a.sc_cite_cont')[0].stripped_strings)[0]
# 提取关键词
key_words = ','.join(key_word for key_word in list(soup.select('div.dtl_search_word > div')[0].stripped_strings)[1:-1:2])
# data = {
# "title":title,
# "authors":authors,
# "abstract":abstract,
# "year":int(year),
# "publish":publish,
# "publish_text":publish_text,
# "ref_wr":int(ref_wr),
# "key_words":key_words
# }
return title, authors, abstract, publish_text, year, publish, ref_wr, key_words
这里有非常说明一下:在爬取摘要的时侯,有一个JS动态加载,“更多”样式加载按键。所以,我想要将摘要全部爬出来,可能就要使用selenium模仿点击操作(我在代码中加了注释的地方)。但是,我没有用这些方法由于多次访问网页,可能会有很多问题,一个是速率的问题,一个是很容易被服务器拒绝访问,所以在这里我只爬取了一部分摘要。
接着保存爬取的数据,这里我为了前面直接用pandas读取处理,且数据量不大,所以直接保存为csv格式。
def get_all_data(urls_list):
dit = defaultdict(list)
for url in urls_list:
title, authors, abstract, publish_text, year, publish, ref_wr, key_words = get_item_info(url)
dit["title"].append(title)
dit["authors"].append(authors)
dit["abstract"].append(abstract)
dit["publish_text"].append(publish_text)
dit["year"].append(year)
dit["publish"].append(publish)
dit["ref_wr"].append(ref_wr)
dit["key_words"].append(key_words)
return dit
def save_csv(dit):
data = pd.DataFrame(dit)
columns = ["title", "authors", "abstract", "publish_text", "year", "publish", "ref_wr", "key_words"]
data.to_csv("abstract_data.csv", index=False, columns=columns)
print("That's OK!")
到此,程序完成,然后开始爬取前20页的数据:
if __name__ == "__main__":
key_word = "牛肉品质"
soup = driver_open(key_word)
urls_list = page_url_list(soup, page=20)
dit = get_all_data(urls_list)
save_csv(dit)
爬取完以后,我们用pandas进行读取。
data = pd.read_csv("abstract_data.csv")
data.head()
2. 数据清洗及剖析
在publish这一列中,还有小问题须要处理。如下,有些行中出现了冒号。

我们将它处理掉。
data["publish"] = data["publish"].map(lambda x: str(x).replace(',', ""))
同时,发现在出版社这一栏南京农业大学有两种表示(《南京农业大学》,南京农业大学),其实它们都是一个意思,需要统一下。
data.publish = data.publish.map(lambda x: re.sub("(.+大学$)", r"《\1》", x))
这样就将所有以“大学”结尾的出版社加上了“《》”进行统一。
data.nunique()
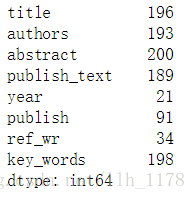
可以看出现今200篇论文中只在91个出版社发表过,我们来统计前10个发表最多的出版社的发表情况。
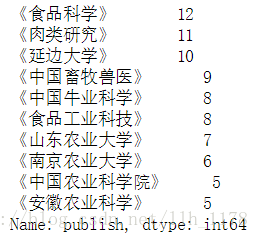
data.publish.value_counts()[:10]
可视化结果:
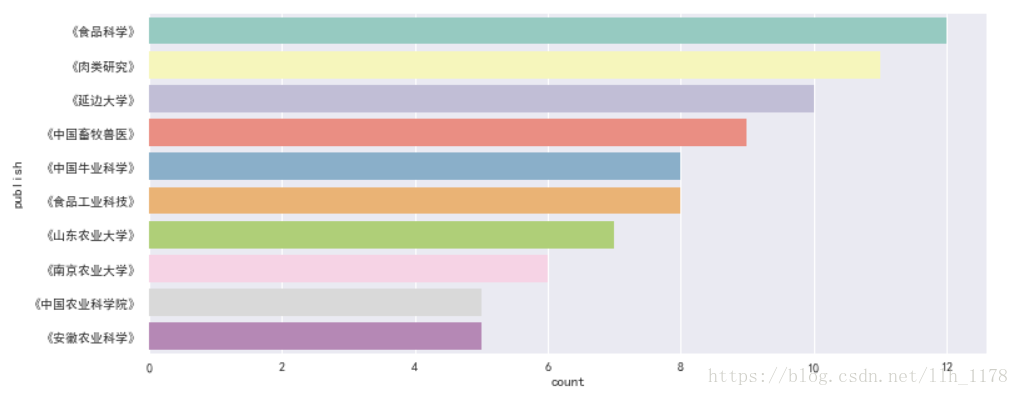
首先使用seaborn作图
其次使用Web可视化工具plotly展示
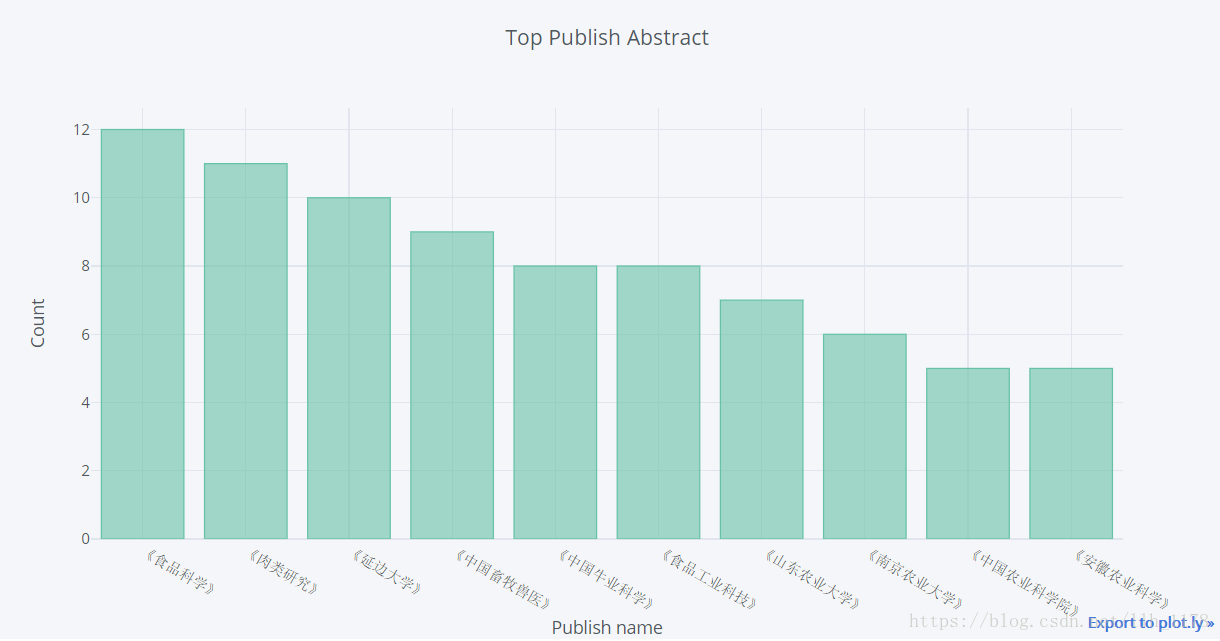
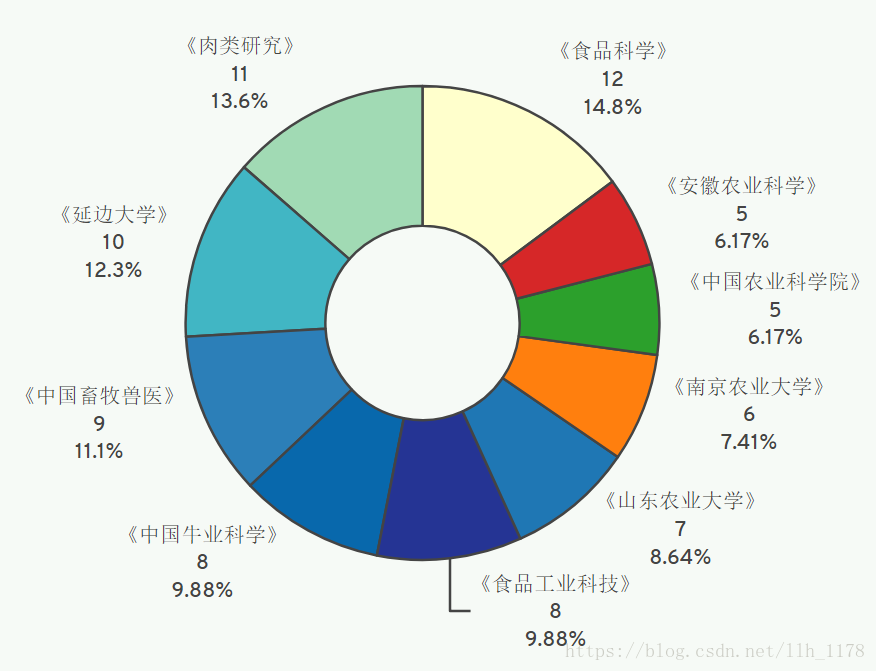
对于“牛肉品质”相关的文章,大家都倾向于投《食品科学》、《肉类研究》、《延边大学》等刊物。
下面,我们接着看这几年来文章发表的情况。
首先,我们先查看数据,有没有缺位值。
data.info()
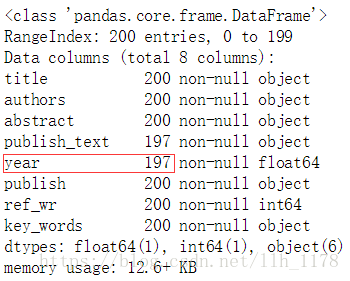
这里红框的地方,时间这一列只有197个数据,说明有三个缺位值。因为,缺失值甚少,所以,我们直接删掉她们。
df = data.dropna(axis=0, how="any")
df.info()

这里,因为“year”列是浮点型的类型,需要转化一下类型。
df["year"] = df["year"].map(lambda x: str(int(x)))
df["year"].value_counts()
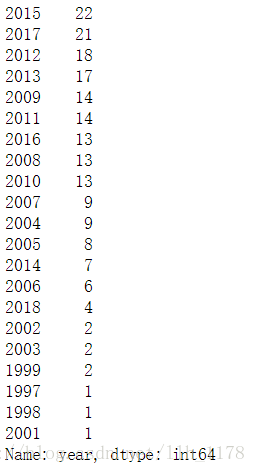
进行可视化展示:
plt.figure(figsize=(12, 5))
# sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
temp = df["year"].value_counts()
sns.countplot(
x = df.year,
palette = "Set3",
order = temp.index
)
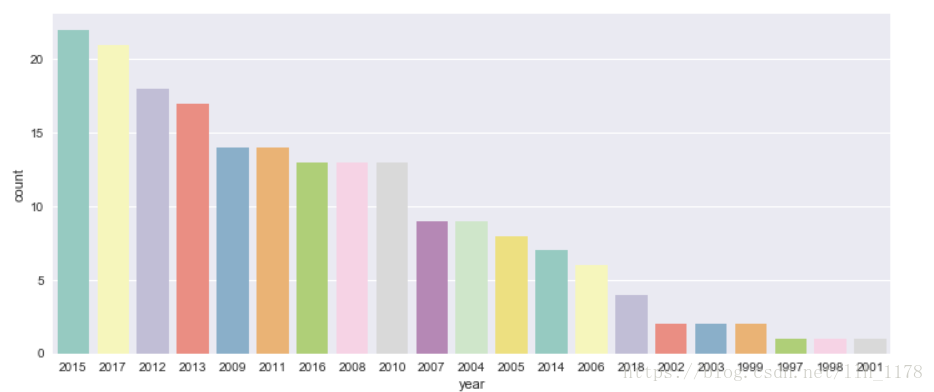
通过这张图其实可以看出哪些年发表文章最多,但是却不能展示随时间走势,看到发表趋势。下面就通过时间序列剖析的形式诠释一下。
df["year"] = pd.to_datetime(df["year"])
df["year"].value_counts().resample("Y").sum().plot.line()
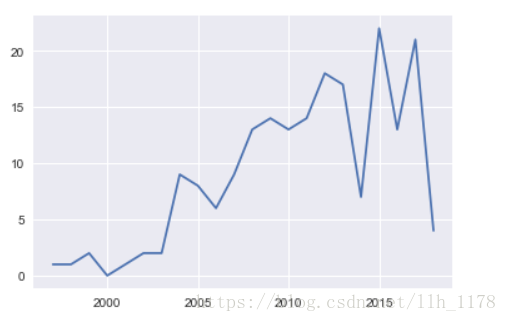
这样就展示了随时间变化,发表猪肉品质的文章的趋势。但是,还是不够美观。下面使用Web可视化工具plotly再度展示。
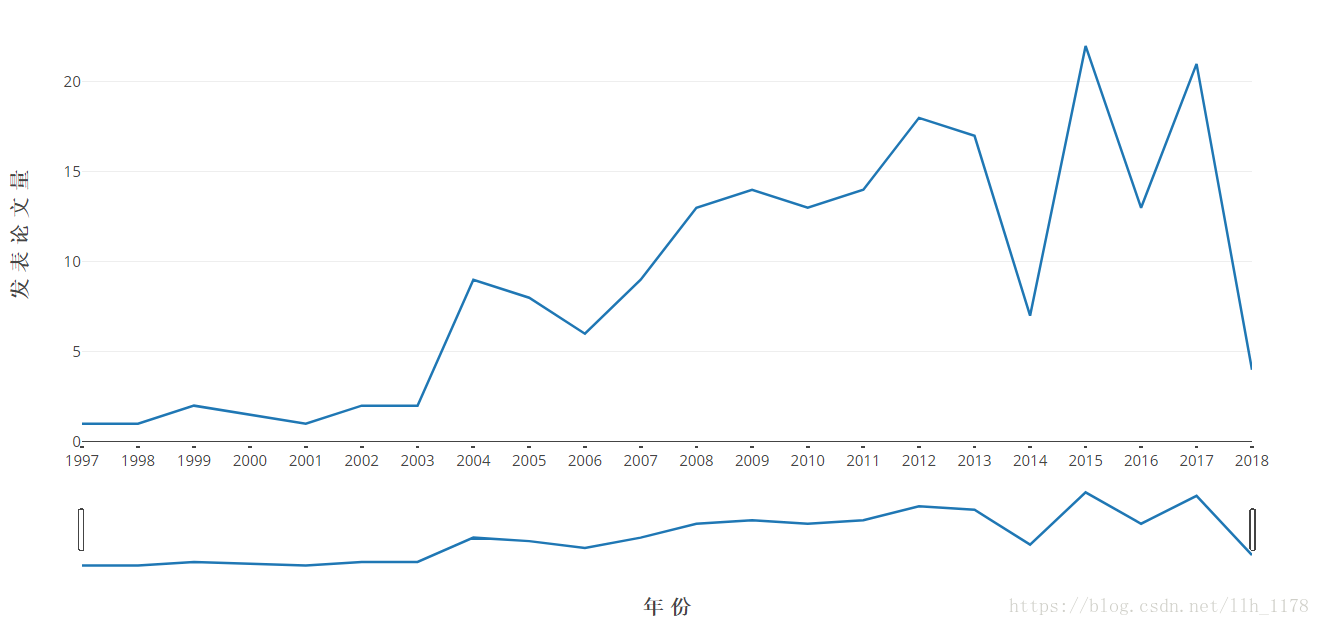
这张图就更能凸显1997到2018年期间山羊品质文章的发表情况了,图下方还有一个时间bar,它可以前后拖动,进行放大。这就是使用Web可视化工具的最大用处,可以愈发形象具体的可视化展示。
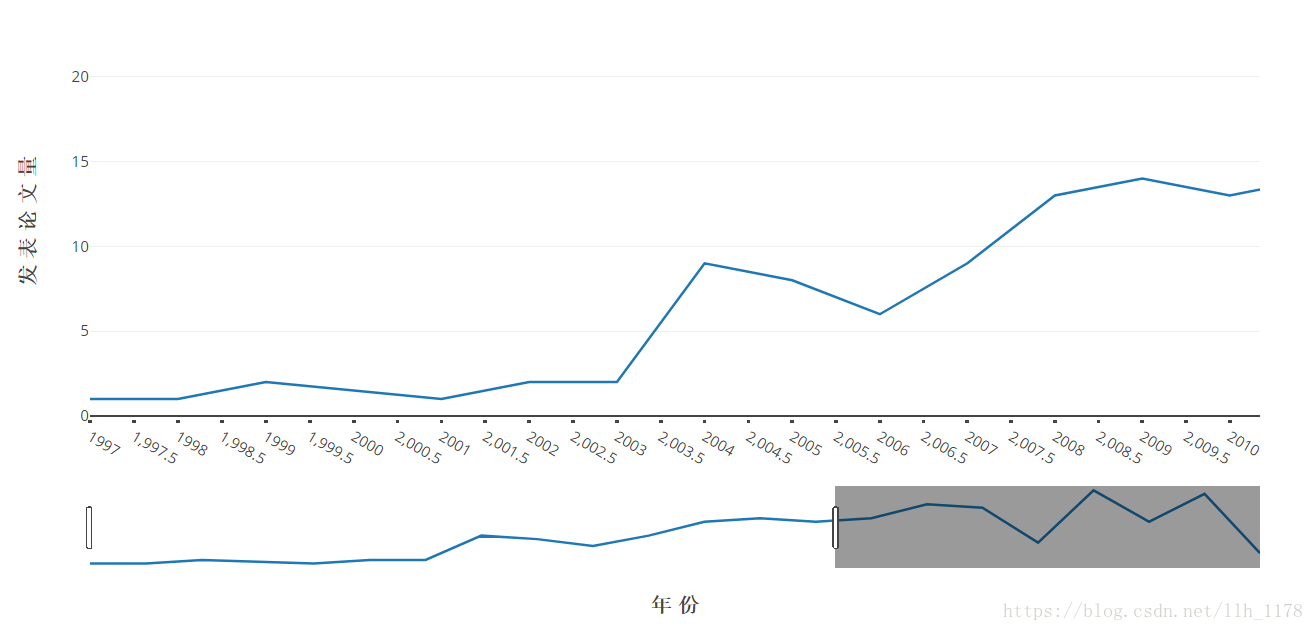
接下来,我们再看什么作者在1997到2018年期间发表文章最多。
data.authors.value_counts()[:10]

考虑到发表文章的作者数目不统一,因此,我们只提取第一作者进行剖析。
data["authors_fir"] = data.authors.map(lambda x: x.split(",")[0])
len(data["authors_fir"].unique())
得出一共有171位不同的作者以第一作者的身分发表过关于“牛肉品质”的文章。
data.authors_fir.value_counts()[:10]

我们再来看发表最多5篇的万发春老师具体是哪五篇文章。
wfc = data[data["authors_fir"] == "万发春"]["title"]
wfc = pd.DataFrame(np.array(wfc), columns=["Title"], index=[1,2,3,4,5])
wfc

3. 词云展示
在这里,我们直接使用关键词进行云词展示,因为,摘要不够完整,且这样也避开了动词处理。
docs = list(data["key_words"].map(lambda x: x.split(",")))
from juba import Similar
S = Similar(docs)
# 词汇表
S.vocabularyList
# 前100个词汇量
tags = S.vocabulary
sort_tage = sorted(tags.items(), key=lambda x: x[1], reverse=True)
sort_tage[:100]
# 打印出词汇和该词汇的出现次数
for v, n in sort_tage[:100]:
print (v + '\t' + str(int(n)))
然后,将结果导出中,如下图:
然后,设置字体和背景图片,注意一点是:中文须要自己加载字体,我使用的微软雅黑字体(网上可以下载)。
最后产生的词云:

到此,第三部份完成,下面我们进行文章相似度剖析。
4. 文章相似度剖析
考虑到本次爬取的并没有完整的文章且摘要不全的情况,所以只是采用关键词进行剖析,因此可能不准,主要介绍方式。但是,后面我将选择一个文本数据集再进行完整的文本相像度剖析。
(1)使用juba进行剖析。
juba最长使用余弦相似度cosine_sim(self, dtm=none)函数估算文档相似度,都是用于估算第一个文档与其他的文档之间的相似度,其中有dtm有三种参数选择,分别为:“tfidf_dtm”(词频逆文档频率模式)、“prob_dtm”(概率模式)、“tf_dtm”(词频模式)。
sim = S.cosine_sim(dtm="prob_dtm")
sim.insert(0, 1)
data["similar"] = sim
data
然后,我从高到低排列
data.sort_values(by="similar", ascending=False)
可以看出文章相似度都太低,这也符合文章发表的规律。
(2)使用graphlab估算相似度
这里,我使用另外一个数据集,它是爬取维基百科上好多名人的介绍的一个文本数据集。
import graphlab
people = graphlab.SFrame.read_csv("people_wiki.csv")
# 去掉索引列
del people["X1"]
people.head()
我们来看一共有多少位名人
len(people.unique())
59071位
我们从中选购一位名人——奥巴马来瞧瞧。
obama = people[people["name"] == "Barack Obama"]
obama

# 查看奥巴马的具体介绍内容
obama["text"]
接下来进行词频统计。
obama["word_count"] = graphlab.text_analytics.count_words(obama["text"])
obama_word_count_table = obama[["word_count"]].stack("word_count", new_column_name=["word", "count"])
obama_word_count_table.sort("count", ascending=False)
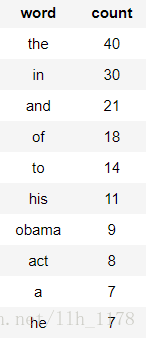
很显然,“the”、“in”、“and”等停用词的频度最大,但是,这并不是我们想要关注的词组或则说并不是全篇文章的主旨。所以,要使用tfidf进行统计词频。
people["word_count"] = graphlab.text_analytics.count_words(people["text"])
tfidf = graphlab.text_analytics.tf_idf(people["word_count"])
people["tfidf"] = tfidf
people.head()
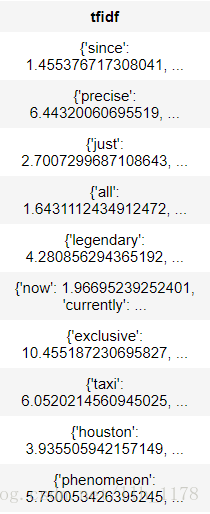
然后,我们再来看奥巴马的介绍词频。
obama[["tfidf"]].stack("tfidf", new_column_name = ["word", "tfidf"]).sort("tfidf", ascending=False)
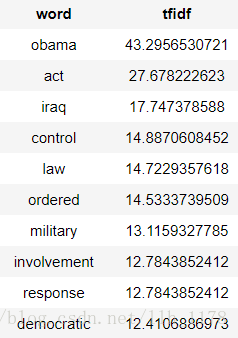
这样就正常了,直接通过词频就可以看出介绍谁的。
构建knn模型,计算相似度距离。
knn_model = graphlab.nearest_neighbors.create(people, features=["tfidf"], label= 'name')
然后查看与奥巴马相仿的名人。
knn_model.query(obama)
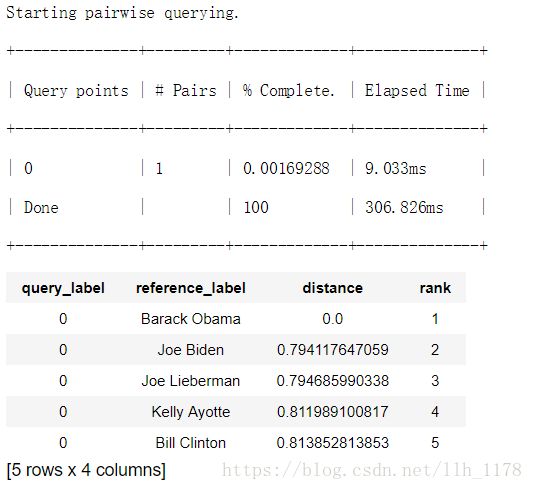
这些人大多都是日本的首相或相仿的人正是与奥巴马相仿,所以,也否认了模型的准确性。至此,整个剖析结束,但是也都会存在不少问题,再接再厉吧!
搜索关键词采集YouTube视频字幕
采集交流 • 优采云 发表了文章 • 0 个评论 • 856 次浏览 • 2020-08-17 14:15
使用python采集YouTube视频字幕
本篇博客纯干货!!!
最近接到leader安排的采集任务,抓取采集世界上最大的视频共享网站YouTube的视频字幕。
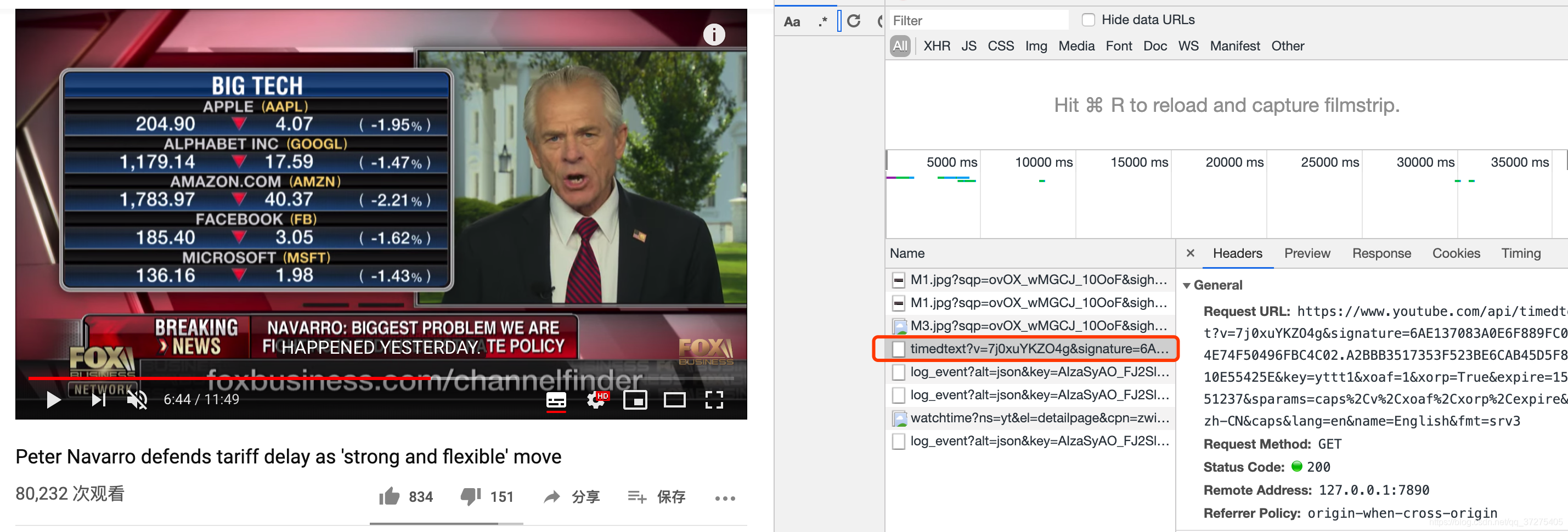
分析目标网站,开始抓包
当我打开视频链接点击显示字幕按键时,通过浏览器抓取到timedtext这样的一个恳求,而返回的内容即将我想要的数据——每个时间点的字幕。
分析该URL有视频ID、signature、key、expire等参数,每次发生变化的是signature,开始通过js突破该参数。过程这儿不做详尽描述。
终于在该视频源代码中找到这样一段js
"playerCaptionsTracklistRenderer\":{\"captionTracks\":[{\"baseUrl\":\"https:\/\/www.youtube.com\/api\/timedtext?xorp=True\\u0026signature=DC15F46CCF5A97B616CFF6EA13626BC34E24B848.454E61B37E4E1AE37BF2C83F311D8EB362B165AA\\u0026hl=zh-CN\\u0026sparams=caps%2Cv%2Cxoaf%2Cxorp%2Cexpire\\u0026expire=1566051203\\u0026caps=\\u0026key=yttt1\\u0026xoaf=1\\u0026v=7j0xuYKZO4g\\u0026lang=en\\u0026name=English\",
原来仍然费尽心思想解析的URL曝露在源码中了,格式化代码后晓得他是一段json串,很多视频信息都在该json中,如发布时间、标题、简介、点击量等;心中的小兴奋?
接下来,通过正则匹配须要的URL
ytplayer_config = json.loads(re.search('ytplayer.config\s*=\s*([^\n]+?});', response.text).group(1))
caption_tracks = json.loads(ytplayer_config['args']['player_response'])['captions']['playerCaptionsTracklistRenderer']['captionTracks']
for c in caption_tracks:
url = c["baseUrl"] # 在url后拼接上&tlang=zh-Hans返回的字幕为中文,&tlang=en-Hans返回的字幕为英文
最后得到字幕URL通过python恳求后解析领到字幕数据。大功告成
有字幕的视频就会有baseUrl这个值,没有字幕的视频这样取会报异常的哦~
YouTube列表翻页
字幕解析下来了,下一步批量采集需要的视频字幕。
需求:
通过搜索采集结果中所有字幕。
分析:
视频翻页是基于ajax请求来的,源码里面的信息始终都是第一页的数据,
ok 那既然这样,我们来分析ajax请求,我喜欢用谷歌浏览器,打开开发者工具,network,来抓包。
鼠标一直往下拉,会自动请求,是个post请求,一看就是返回的视频信息。
看到这儿很高兴,离胜利早已不远了。但,我们先来看下headers 以及发送的post参数,看了以后 就一句 wtf。。。
一万个矮马在奔腾,我把这些加密的参数都标记了,前前端交互,既然是发过去的数据,那肯定早已在后端形成了,至于哪些形成的,那就要一步一步剖析来了,最后。对 我没有剖析下来。。。刚开始挨到挨查看js文件,参数的确是在js上面形成的,但。。。tmd写的很复杂了。。。能力有限,解决不了。难道就这样舍弃了吗。肯定不会,不然 各位也不会见到这篇文章了。于是,我灵机一动,在地址栏上面输入&page=结果,真的返回视频了。。。卧槽 哈哈哈,我当时真是很开心呢。因为后端页面上并没有翻页按键,没想到居然还真的可以这样翻页。。。哈哈
接下来就是匹配每页的视频链接 – 访问 – 获取字幕
完活 交差 回家 吃饭 睡觉咯
感谢观看! 查看全部
搜索关键词采集YouTube视频字幕
使用python采集YouTube视频字幕
本篇博客纯干货!!!
最近接到leader安排的采集任务,抓取采集世界上最大的视频共享网站YouTube的视频字幕。
分析目标网站,开始抓包
当我打开视频链接点击显示字幕按键时,通过浏览器抓取到timedtext这样的一个恳求,而返回的内容即将我想要的数据——每个时间点的字幕。
分析该URL有视频ID、signature、key、expire等参数,每次发生变化的是signature,开始通过js突破该参数。过程这儿不做详尽描述。
终于在该视频源代码中找到这样一段js
"playerCaptionsTracklistRenderer\":{\"captionTracks\":[{\"baseUrl\":\"https:\/\/www.youtube.com\/api\/timedtext?xorp=True\\u0026signature=DC15F46CCF5A97B616CFF6EA13626BC34E24B848.454E61B37E4E1AE37BF2C83F311D8EB362B165AA\\u0026hl=zh-CN\\u0026sparams=caps%2Cv%2Cxoaf%2Cxorp%2Cexpire\\u0026expire=1566051203\\u0026caps=\\u0026key=yttt1\\u0026xoaf=1\\u0026v=7j0xuYKZO4g\\u0026lang=en\\u0026name=English\",
原来仍然费尽心思想解析的URL曝露在源码中了,格式化代码后晓得他是一段json串,很多视频信息都在该json中,如发布时间、标题、简介、点击量等;心中的小兴奋?
接下来,通过正则匹配须要的URL
ytplayer_config = json.loads(re.search('ytplayer.config\s*=\s*([^\n]+?});', response.text).group(1))
caption_tracks = json.loads(ytplayer_config['args']['player_response'])['captions']['playerCaptionsTracklistRenderer']['captionTracks']
for c in caption_tracks:
url = c["baseUrl"] # 在url后拼接上&tlang=zh-Hans返回的字幕为中文,&tlang=en-Hans返回的字幕为英文
最后得到字幕URL通过python恳求后解析领到字幕数据。大功告成
有字幕的视频就会有baseUrl这个值,没有字幕的视频这样取会报异常的哦~
YouTube列表翻页
字幕解析下来了,下一步批量采集需要的视频字幕。
需求:
通过搜索采集结果中所有字幕。
分析:
视频翻页是基于ajax请求来的,源码里面的信息始终都是第一页的数据,
ok 那既然这样,我们来分析ajax请求,我喜欢用谷歌浏览器,打开开发者工具,network,来抓包。
鼠标一直往下拉,会自动请求,是个post请求,一看就是返回的视频信息。
看到这儿很高兴,离胜利早已不远了。但,我们先来看下headers 以及发送的post参数,看了以后 就一句 wtf。。。

一万个矮马在奔腾,我把这些加密的参数都标记了,前前端交互,既然是发过去的数据,那肯定早已在后端形成了,至于哪些形成的,那就要一步一步剖析来了,最后。对 我没有剖析下来。。。刚开始挨到挨查看js文件,参数的确是在js上面形成的,但。。。tmd写的很复杂了。。。能力有限,解决不了。难道就这样舍弃了吗。肯定不会,不然 各位也不会见到这篇文章了。于是,我灵机一动,在地址栏上面输入&page=结果,真的返回视频了。。。卧槽 哈哈哈,我当时真是很开心呢。因为后端页面上并没有翻页按键,没想到居然还真的可以这样翻页。。。哈哈
接下来就是匹配每页的视频链接 – 访问 – 获取字幕
完活 交差 回家 吃饭 睡觉咯
感谢观看!
采集百度搜救结果,图片不显示的解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-08-15 04:56
根据关键字采集百度搜救结果,可以使用curl实现,代码如下:
123456789101112131415161718192021222324252627
输出后发觉有部份图片不能显示
2.采集后的图片不显示缘由剖析
直接在百度中搜救,页面是可以显示图片的。使用firebug查看图片路径,发现采集的图片域名与在百度搜救的图片域名不同。
采集返回的图片域名
正常搜救的图片域名
查看采集与正常搜救的html,发现有个域名转换的js是不一样的
采集
var list = { "graph.baidu.com": "http://graph.baidu.com", "t1.baidu.com":"http://t1.baidu.com", "t2.baidu.com":"http://t2.baidu.com", "t3.baidu.com":"http://t3.baidu.com", "t10.baidu.com":"http://t10.baidu.com", "t11.baidu.com":"http://t11.baidu.com", "t12.baidu.com":"http://t12.baidu.com", "i7.baidu.com":"http://i7.baidu.com", "i8.baidu.com":"http://i8.baidu.com", "i9.baidu.com":"http://i9.baidu.com",};123456789101112
正常搜救
var list = { "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K", "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf", "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf", "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf", "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq", "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq", "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq", "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf", "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf", "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",};123456789101112
因此可以推断是,百度按照来源地址、IP、header等参数,判断假如是采集的,则返回不同的js。
3.采集后图片不显示的解决方式
把采集到的html,根据定义的域名做一次批量转换即可。
<p> 查看全部
1.根据关键字采集百度搜救结果
根据关键字采集百度搜救结果,可以使用curl实现,代码如下:
123456789101112131415161718192021222324252627
输出后发觉有部份图片不能显示

2.采集后的图片不显示缘由剖析
直接在百度中搜救,页面是可以显示图片的。使用firebug查看图片路径,发现采集的图片域名与在百度搜救的图片域名不同。
采集返回的图片域名

正常搜救的图片域名

查看采集与正常搜救的html,发现有个域名转换的js是不一样的
采集
var list = { "graph.baidu.com": "http://graph.baidu.com", "t1.baidu.com":"http://t1.baidu.com", "t2.baidu.com":"http://t2.baidu.com", "t3.baidu.com":"http://t3.baidu.com", "t10.baidu.com":"http://t10.baidu.com", "t11.baidu.com":"http://t11.baidu.com", "t12.baidu.com":"http://t12.baidu.com", "i7.baidu.com":"http://i7.baidu.com", "i8.baidu.com":"http://i8.baidu.com", "i9.baidu.com":"http://i9.baidu.com",};123456789101112
正常搜救
var list = { "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K", "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf", "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf", "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf", "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq", "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq", "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq", "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf", "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf", "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",};123456789101112
因此可以推断是,百度按照来源地址、IP、header等参数,判断假如是采集的,则返回不同的js。
3.采集后图片不显示的解决方式
把采集到的html,根据定义的域名做一次批量转换即可。
<p>
Prometheus源码系列:指标采集(scrapeManager)
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-08-15 02:16
指标采集(scrapeManager)获取服务(targets)的变动,可分为多种情况,以服务降低为例,若有新的job添加,指标采集(scrapeManager)会进行重载,为新的job创建一个scrapePool,并为job中的每位target创建一个scrapeLoop.若job没有变动,只降低了job下对应的targets,则只需创建新的targets对应的scrapeLoop.
为本文剖析的代码都基于版本v2.7.1,会通过dlv输出多个参数的示例,所用的配置文件:Prometheus.yml配置文件示例.
指标采集(scrapeManager)获取实时监控服务(targets)的入口函数:scrapeManager.Run(discoveryManagerScrape.SyncCh()):
<p>
prometheus/cmd/prometheus/main.go
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded. 查看全部
从下篇文章:Prometheus源码系列:服务发觉 (serviceDiscover),我们早已晓得,为了从服务发觉(serviceDiscover)实时获取监控服务(targets),指标采集(scrapeManager)通过解释器把管线(chan)获取来的服务(targets)存进一个map类型:map[string][]*targetgroup.Group.其中,map的key是job_name,map的value是结构体targetgroup.Group,该结构体收录该job_name对应的Targets,Labels和Source.
指标采集(scrapeManager)获取服务(targets)的变动,可分为多种情况,以服务降低为例,若有新的job添加,指标采集(scrapeManager)会进行重载,为新的job创建一个scrapePool,并为job中的每位target创建一个scrapeLoop.若job没有变动,只降低了job下对应的targets,则只需创建新的targets对应的scrapeLoop.
为本文剖析的代码都基于版本v2.7.1,会通过dlv输出多个参数的示例,所用的配置文件:Prometheus.yml配置文件示例.
指标采集(scrapeManager)获取实时监控服务(targets)的入口函数:scrapeManager.Run(discoveryManagerScrape.SyncCh()):
<p>
prometheus/cmd/prometheus/main.go
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded.
UCMS建站系统与万通文章采集软件下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-14 23:20
软件特色
多级栏目,多站点支持支持域名绑定,每个栏目均使用独立的数据表。字段添加便捷快捷,能迅速完成任意栏目的搭建。独创的伪静态系统超级简单的伪静态配置,不必为配置伪静态规则苦恼,也无需繁忙于生成静态文件。伪静态配置开启页面缓存后,配合浏览器304缓存,不需要每次从服务器下载页面,减少服务器流量消耗。栏目网址均能自定义,支持英文网址,每个页面均能设置缓存时间。栏目网址配置详尽介绍自定义内容模型及数组单选框、多选框、列表框、联动分类等超多数组类型,数据来源可以选择任意栏目,快速搭建各类栏目。UCMS权限个栏目每位用户都能设置增删改权限,安全高效.每个栏目每位数组都能订制详尽的html代码过滤规则。MySQL/SQLite,双数据库MySQL数据库推荐文章站,数据量上万的网站使用,安全稳定。SQLite,强烈推荐企业站使用,转移、维护、备份愈加便捷。电脑站&手机站,自动适配开启手机模式后。能手动辨识访客的系统,自动切换到手机版。使用方式UCMS是使用php语言而做的一款开源内容管理系统,可以开发各类站点。在使用前先安装好php运行环境方能使用。运行环境安装好后,直接打开ucms里面的index.php文件开始制做站点。 查看全部
UCMS是一款站长建站工具,拥有多级栏目,支持多站点,;UCMS提供独创的伪静态系统,还可以自定义内容模型及数组,是一款非常好用的免费建站工具。
软件特色
多级栏目,多站点支持支持域名绑定,每个栏目均使用独立的数据表。字段添加便捷快捷,能迅速完成任意栏目的搭建。独创的伪静态系统超级简单的伪静态配置,不必为配置伪静态规则苦恼,也无需繁忙于生成静态文件。伪静态配置开启页面缓存后,配合浏览器304缓存,不需要每次从服务器下载页面,减少服务器流量消耗。栏目网址均能自定义,支持英文网址,每个页面均能设置缓存时间。栏目网址配置详尽介绍自定义内容模型及数组单选框、多选框、列表框、联动分类等超多数组类型,数据来源可以选择任意栏目,快速搭建各类栏目。UCMS权限个栏目每位用户都能设置增删改权限,安全高效.每个栏目每位数组都能订制详尽的html代码过滤规则。MySQL/SQLite,双数据库MySQL数据库推荐文章站,数据量上万的网站使用,安全稳定。SQLite,强烈推荐企业站使用,转移、维护、备份愈加便捷。电脑站&手机站,自动适配开启手机模式后。能手动辨识访客的系统,自动切换到手机版。使用方式UCMS是使用php语言而做的一款开源内容管理系统,可以开发各类站点。在使用前先安装好php运行环境方能使用。运行环境安装好后,直接打开ucms里面的index.php文件开始制做站点。
[DISCUZ插件] 最新 [西风]微信文章采集 专业版 2.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2020-08-14 23:01
功能介绍
后台可按微信号、关键字搜索后批量采集公众号文章,无需任何配置,同时支持批量发布成贴子和门户文章,并且在批量发布时可选择整篇文章要发布到的版块。
前台回帖时可采集单篇陌陌文章,只须要在插件中设置启用的版块和用户组即可。
2.1版后新增定时采集,在插件设置页面定时采集的公众号中填写微信号,一行一个,(如果你的服务器性能和带宽不足,请只填写一个),插件通过计划任务对此处填写的公众号每次抓取最新的且从未采集过的5篇文章(注意:由于陌陌防采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可采集文章中的图片、视频、保留陌陌文章原格式
2、无需任何配置,按微信号、关键字搜索后批量采集
3、可设置发布成贴子时使用的会员
4、批量发布成贴子时,除了发布到默认版块,更可单独设置整篇文章发布到任何一个版块,可单独设置整篇贴子使用的会员
5、可批量发布成门户文章,发布时可单独设置整篇文章发布到的门户频道
6、采集的正文状态有提醒,如果因故采集正文失败,可重复采集
8、前台回帖时编辑器中显示陌陌图标,点击插入陌陌文章网址即可手动插入陌陌文章
9、支持贴子、门户文章审核功能
使用方式
1、安装并启用后,在插件后台设置页面,可修改默认使用的会员uid和发布到的版块
2、点开始采集,按微信号或关键字采集
3、采集最新文章列表成功后,可全选或单独选择要采集正文的文章(比如除去不想要的某篇文章),开始采集正文
4、正文采集完毕后,可对整篇文章单独选择要发布到的版块或则全都发布到默认版块,点击发布即完成
7、在采集记录中可批量发布成门户文章,并可设置整篇文章发布到的门户频道(必须有可用的门户频道)
8、设置前台发贴准许使用陌陌插入文章功能的用户组和版块
采集过程按微信号采集:
1、搜索微信号后点击或直接填写微信号和爱称后点击开始采集
2、展示获取到的最新10-30篇待采集文章的标题,点击标题旁的复选框,确认要采集哪些
3、然后点击下方的 采集正文
4、采集后可在采集结果下方选择 立即发布到蓝筹股 或者 重新采集正文
按关键字采集
1、输入关键字,点击搜索
2、显示获取到的文章标题列表,点击标题旁的复选框,确认要采集哪些
3、点击下方的采集并发布按键,将完成发布
如果发布后前台没有显示文章列表,请点击 后台-工具--更新统计 的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一行一个
2、点击采集,等待完成即可
注意事项
1、由于陌陌防采采集措施,请勿采集过于频繁,否则可能引起你的ip地址被陌陌锁定而未能继续采集
2、如果要采集图片、视频和保留陌陌文章原格式,则必须在相应版块--帖子选项中容许使用html、允许解析图片和容许多媒体
演示截图:
下载权限
白银会员及以上级别可以下载
下载列表
下载地址 查看全部
[DISCUZ插件] 最新 [西风]微信文章采集 专业版 2.0.1 商业版dz插件分享,批量采集公众号文章功能等 佚名 Discuz 2017-01-12
功能介绍
后台可按微信号、关键字搜索后批量采集公众号文章,无需任何配置,同时支持批量发布成贴子和门户文章,并且在批量发布时可选择整篇文章要发布到的版块。
前台回帖时可采集单篇陌陌文章,只须要在插件中设置启用的版块和用户组即可。
2.1版后新增定时采集,在插件设置页面定时采集的公众号中填写微信号,一行一个,(如果你的服务器性能和带宽不足,请只填写一个),插件通过计划任务对此处填写的公众号每次抓取最新的且从未采集过的5篇文章(注意:由于陌陌防采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可采集文章中的图片、视频、保留陌陌文章原格式
2、无需任何配置,按微信号、关键字搜索后批量采集
3、可设置发布成贴子时使用的会员
4、批量发布成贴子时,除了发布到默认版块,更可单独设置整篇文章发布到任何一个版块,可单独设置整篇贴子使用的会员
5、可批量发布成门户文章,发布时可单独设置整篇文章发布到的门户频道
6、采集的正文状态有提醒,如果因故采集正文失败,可重复采集
8、前台回帖时编辑器中显示陌陌图标,点击插入陌陌文章网址即可手动插入陌陌文章
9、支持贴子、门户文章审核功能
使用方式
1、安装并启用后,在插件后台设置页面,可修改默认使用的会员uid和发布到的版块
2、点开始采集,按微信号或关键字采集
3、采集最新文章列表成功后,可全选或单独选择要采集正文的文章(比如除去不想要的某篇文章),开始采集正文
4、正文采集完毕后,可对整篇文章单独选择要发布到的版块或则全都发布到默认版块,点击发布即完成
7、在采集记录中可批量发布成门户文章,并可设置整篇文章发布到的门户频道(必须有可用的门户频道)
8、设置前台发贴准许使用陌陌插入文章功能的用户组和版块
采集过程按微信号采集:
1、搜索微信号后点击或直接填写微信号和爱称后点击开始采集
2、展示获取到的最新10-30篇待采集文章的标题,点击标题旁的复选框,确认要采集哪些
3、然后点击下方的 采集正文
4、采集后可在采集结果下方选择 立即发布到蓝筹股 或者 重新采集正文
按关键字采集
1、输入关键字,点击搜索
2、显示获取到的文章标题列表,点击标题旁的复选框,确认要采集哪些
3、点击下方的采集并发布按键,将完成发布
如果发布后前台没有显示文章列表,请点击 后台-工具--更新统计 的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一行一个
2、点击采集,等待完成即可
注意事项
1、由于陌陌防采采集措施,请勿采集过于频繁,否则可能引起你的ip地址被陌陌锁定而未能继续采集
2、如果要采集图片、视频和保留陌陌文章原格式,则必须在相应版块--帖子选项中容许使用html、允许解析图片和容许多媒体
演示截图:

下载权限
白银会员及以上级别可以下载
下载列表
下载地址
优采云文章采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-14 20:58
在你所须要的类目下,新建一个站点,或在你所须要的类目下,新建一个站点,或者是任务者是任务点击先导添加之后步入网址添加点击先导添加之后步入网址添加通过百度找到最适宜的诊所网址通过百度找到最适宜的诊所网址找到该网址所须要的文章列表页找到该网址所须要的文章列表页添加网址后添加网址后点击尾页点击尾页添加此网址添加此网址将狂出部份添加为键值将狂出部份添加为键值在此处用中文输入格式下添加实际采集页在此处用中文输入格式下添加实际采集页数数填写好后点击添加填写好后点击添加添加好后点击完成添加好后点击完成之后转入该网页的文章列表页中的源代码之后转入该网页的文章列表页中的源代码寻找类似于红框中内的代码寻找类似于红框中内的代码借助查找功能确认此代码为独一无二的代借助查找功能确认此代码为独一无二的代码,无重复,并且在须要采集的文章列表码,无重复,并且在须要采集的文章列表前前将腹部代码添加在这里将腹部代码添加在这里在到源文件中寻找文章列表页尾部的代码在到源文件中寻找文章列表页尾部的代码此为列表页文章底部此为列表页文章底部在此顶部寻找无重复代码在此顶部寻找无重复代码同样通过查找方法确认同样通过查找方法确认之后填写到之后填写到以上信息确认好后,点击以上信息确认好后,点击“点击开始测试网点击开始测试网址采集址采集”采集网址时出现红框内的小记号才算采集采集网址时出现红框内的小记号才算采集成功成功 随意点开红框内任意一个网址,进行文章随意点开红框内任意一个网址,进行文章内容设定内容设定双击网址步入双击网址步入之后点击测试之后点击测试文章内容都会出现文章内容都会出现双击内容进行内容设定双击内容进行内容设定步入文章内容也步入文章内容也查找源代码查找源代码查询文章前部代码,及文章尾部代码查询文章前部代码,及文章尾部代码之后点击确定之后点击确定之后再度点击测试,查看是否成功排除其之后再度点击测试,查看是否成功排除其他代码他代码得到的结果是这样的得到的结果是这样的再度点击内容,进行内容替换,比如说替再度点击内容,进行内容替换,比如说替换诊所名称,地区名称换诊所名称,地区名称之后点击保存文档之后点击保存文档保存到须要保存的云盘里保存到须要保存的云盘里设定好后,点击保存设定好后,点击保存设定好后可以直接转跳到了首页设定好后可以直接转跳到了首页之后点击你之前设定的任务,点击开始,然后点击你之前设定的任务,点击开始,开始任务采集开始任务采集然后等待文章采集然后等待文章采集文章采集完成后会出现类似这样的提示文章采集完成后会出现类似这样的提示之后你们就可以关掉优采云,直接去所保之后你们就可以关掉优采云,直接去所保存的文档下寻找文章里存的文档下寻找文章里
Scrapy结合Selenium采集数据简单实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-14 11:45
前段时间正好有用过selenium自动化模拟打开浏览器采集数据,不能能模拟人为的一些键盘、键盘操作。很强悍,照样能跟scrapy结合的太完美!!!
以下就来打一个简单的在百度输入框输入关键词并点击百度一下进行页面的查询操作,然后再解析页面内容:
快捷创建项目:
scrapy startproject test
scrapy genspider crawltest 'www.baidu.com'
items.py源码:
import scrapy
class TestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
settings.py配置更改(取消注释):
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
#USER_AGENT = 'test (+http://www.yourdomain.com)' # 用户代理
ROBOTSTXT_OBEY = False #设置为False便于打印调试
ITEM_PIPELINES = {
'test.pipelines.JobsPipeline': 1,
} # 用于输出采集的结果,具体操作在pipelines中
爬虫文件crawltest.py源码:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver .chrome.options import Options
from test.items import TestItem
import lxml.html
import time, random
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/']
def open_page(self):
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(self.start_urls[0])
browser.implicitly_wait(10)
return browser
def parse(self, response):
browser = self.open_page()
doc_souce = lxml.html.document_fromstring(browser.page_source)
su = response.xpath('.//input[@id="su"]/@value').extract()
es = doc_souce.xpath('.//input[@id="su"]/@value')
keywd = browser.find_element_by_xpath("//input[@id='kw']")
keywd.send_keys('scrapy')
time.sleep(random.randint(3,5))
browser.find_element_by_xpath("//input[@id='su']").click()
time.sleep(random.randint(3,5)) # 点击完最好要停留下时间,等待页面加载就绪
print(es[0],'ppppppppppppppppp',su[0]) #两个结果一样吗,也就是说selenium打开网页的结果跟内置获取的数据是一致的
doc_souce_01 = lxml.html.document_fromstring(browser.page_source)
result = doc_souce_01.xpath('//span[@class="nums_text"]/text()')
print(result,'000000000000000000')
item = TestItem()
item['title'] = su[0]
yield item
输出pipelines.py源码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
#写入json
# import codecs
# import json
# from scrapy.exceptions import DropItem
# class SpiderctoPipeline(object):
# def __init__(self):
# self.file = open('data.json','w')
# self.file = codecs.open('data.json','w',encoding='utf-8')
# def process_item(self, item, spider):
# line = json.dumps(dict(item),ensure_ascii=False) + '\n'
# self.file.write(line)
# return item
#写入数据库
from twisted.enterprise import adbapi
import pymysql
import pymysql.cursors
class SpiderctoPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,setting):
dbpool=adbapi.ConnectionPool('pymysql',host='127.0.0.1',
db='test',user='root',password='123456',charset='utf8',cursorclass=pymysql.cursors.DictCursor,use_unicode=True)
return cls(dbpool)
def process_item(self, item, spider):
self.dbpool.runInteraction(self.do_insert,item)
def do_insert(self,cursor,item):
insert_info = """
insert into ctolist(title,url,score,hour,student,couse_long,price,updata)
values (%s,%s,%s,%s,%s,%s,%s,%s)
"""
params = (item['title'],item['url'],item['score'],item['hour'],item['student'],item['couse_long'],item['price'],item['updata'])
cursor.execute(insert_info,params)
大功告成,启动爬虫: 查看全部
做爬虫的都不难发觉,有的页面分页,点击下一页,或者指定某页,网址竟然不变,如果是基于scrapy框架采集,那么就没法使用yield迭代url进行页面数据解析采集。
前段时间正好有用过selenium自动化模拟打开浏览器采集数据,不能能模拟人为的一些键盘、键盘操作。很强悍,照样能跟scrapy结合的太完美!!!
以下就来打一个简单的在百度输入框输入关键词并点击百度一下进行页面的查询操作,然后再解析页面内容:
快捷创建项目:
scrapy startproject test
scrapy genspider crawltest 'www.baidu.com'
items.py源码:
import scrapy
class TestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
settings.py配置更改(取消注释):
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
#USER_AGENT = 'test (+http://www.yourdomain.com)' # 用户代理
ROBOTSTXT_OBEY = False #设置为False便于打印调试
ITEM_PIPELINES = {
'test.pipelines.JobsPipeline': 1,
} # 用于输出采集的结果,具体操作在pipelines中
爬虫文件crawltest.py源码:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver .chrome.options import Options
from test.items import TestItem
import lxml.html
import time, random
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/']
def open_page(self):
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(self.start_urls[0])
browser.implicitly_wait(10)
return browser
def parse(self, response):
browser = self.open_page()
doc_souce = lxml.html.document_fromstring(browser.page_source)
su = response.xpath('.//input[@id="su"]/@value').extract()
es = doc_souce.xpath('.//input[@id="su"]/@value')
keywd = browser.find_element_by_xpath("//input[@id='kw']")
keywd.send_keys('scrapy')
time.sleep(random.randint(3,5))
browser.find_element_by_xpath("//input[@id='su']").click()
time.sleep(random.randint(3,5)) # 点击完最好要停留下时间,等待页面加载就绪
print(es[0],'ppppppppppppppppp',su[0]) #两个结果一样吗,也就是说selenium打开网页的结果跟内置获取的数据是一致的
doc_souce_01 = lxml.html.document_fromstring(browser.page_source)
result = doc_souce_01.xpath('//span[@class="nums_text"]/text()')
print(result,'000000000000000000')
item = TestItem()
item['title'] = su[0]
yield item
输出pipelines.py源码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
#写入json
# import codecs
# import json
# from scrapy.exceptions import DropItem
# class SpiderctoPipeline(object):
# def __init__(self):
# self.file = open('data.json','w')
# self.file = codecs.open('data.json','w',encoding='utf-8')
# def process_item(self, item, spider):
# line = json.dumps(dict(item),ensure_ascii=False) + '\n'
# self.file.write(line)
# return item
#写入数据库
from twisted.enterprise import adbapi
import pymysql
import pymysql.cursors
class SpiderctoPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,setting):
dbpool=adbapi.ConnectionPool('pymysql',host='127.0.0.1',
db='test',user='root',password='123456',charset='utf8',cursorclass=pymysql.cursors.DictCursor,use_unicode=True)
return cls(dbpool)
def process_item(self, item, spider):
self.dbpool.runInteraction(self.do_insert,item)
def do_insert(self,cursor,item):
insert_info = """
insert into ctolist(title,url,score,hour,student,couse_long,price,updata)
values (%s,%s,%s,%s,%s,%s,%s,%s)
"""
params = (item['title'],item['url'],item['score'],item['hour'],item['student'],item['couse_long'],item['price'],item['updata'])
cursor.execute(insert_info,params)
大功告成,启动爬虫:
【免费下载】众大云采集Discuz版 v9.3
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-13 19:06
众大云采集Discuz版 v9.3 更新日志
1、“定时采集”中”严格依照计划任务时间”功能的进一步改善。
2、新增实时采集中可以自定义COOKIE采集
3、新增ZAKER新闻的实时采集
4、进一步优化和构建任意网址采集,并外置了5个网站的采集规则实例供你们学习和研究。
众大云采集Discuz版功能
1、最新最热的微信公众号文章采集,每天手动更新。
2、最新最热的各种资讯采集,每天手动更新。
3、输入关键词,采集这个关键词相关的最新内容
4、输入内容页的网址,采集这个网页的内容
5、支持云端通用伪原创和本地伪原创
6、本地伪原创可以在插件设置中自定义词库
7、图片可以一键本地化储存,图片永不遗失
8、可以在后台设置常用采集关键词
9、可以指定用户组和版块使用采集功能
10、支持采集优酷视频、腾讯视频、56视频
11、支持微信公众号内容页上面的视频采集
12、支持笑话、图片、视频、微信公众号等专项垂直采集
13、支持内容手动排版
14、支持批量采集,批量发布
15、支持定时采集,自动发布
免费下载地址:
[reply]下载地址[/reply] 查看全部
安装此众大云采集Discuz版以后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
众大云采集Discuz版 v9.3 更新日志
1、“定时采集”中”严格依照计划任务时间”功能的进一步改善。
2、新增实时采集中可以自定义COOKIE采集
3、新增ZAKER新闻的实时采集
4、进一步优化和构建任意网址采集,并外置了5个网站的采集规则实例供你们学习和研究。
众大云采集Discuz版功能
1、最新最热的微信公众号文章采集,每天手动更新。
2、最新最热的各种资讯采集,每天手动更新。
3、输入关键词,采集这个关键词相关的最新内容
4、输入内容页的网址,采集这个网页的内容
5、支持云端通用伪原创和本地伪原创
6、本地伪原创可以在插件设置中自定义词库
7、图片可以一键本地化储存,图片永不遗失
8、可以在后台设置常用采集关键词
9、可以指定用户组和版块使用采集功能
10、支持采集优酷视频、腾讯视频、56视频
11、支持微信公众号内容页上面的视频采集
12、支持笑话、图片、视频、微信公众号等专项垂直采集
13、支持内容手动排版
14、支持批量采集,批量发布
15、支持定时采集,自动发布
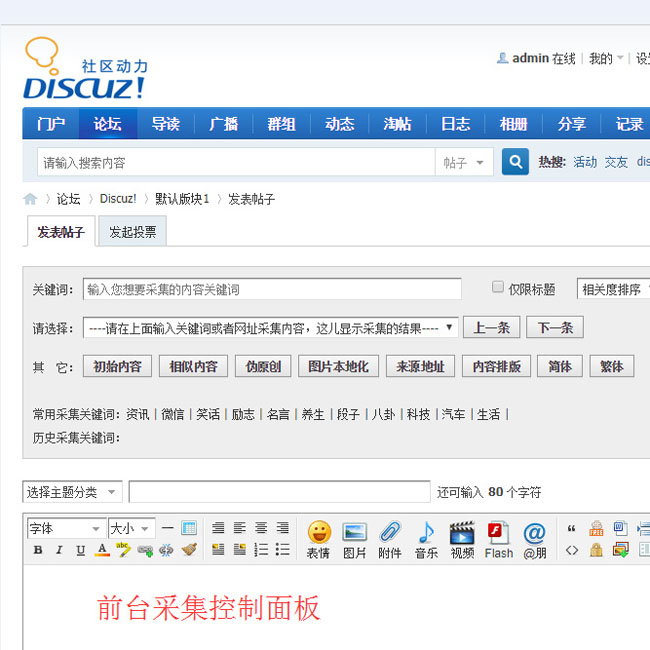
免费下载地址:
[reply]下载地址[/reply]
【8分钟课堂】判断条件-应用:京东和陌陌采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-22 13:43
本视频介绍判定条件的实际应用,将以易迅和陌陌图文采集进行讲解。
实战案例:
1)判断某一条件(如关键词)是否存在,存在就采集,不存在则不采
例:采集京东商品信息,判断是否自营。是自营,则采集;不是自营,则跳过不采集。
示例网址:
华为&enc=utf-8&wq=华为
2)要采集的数据有多种情况,网页源码存在多种款式,需分开搜集
例:采集搜狗陌陌文章正文和图片URL。
示例网址:
注意事项:
1)默认从左向右执行
先判定左侧的条件,若右侧的分支均不满足条件,最左边的分支将不做判定直接执行
2)允许某个分支中无任何操作步骤
3)具有提取数据步骤的所有分支,分支中的总数组个数、字段名需保持一致
4)对于须要同时判定多个同级条件(即case when),可用多分支实现
5)对于须要同时判定多个不同级条件,则须要嵌套使用多个分支判定
★ 建议将已选好判定条件后的网址装入优采云中采集数据
6)对“存在”或“不存在”即“有”或“无”的判定,其操作性更为简单方便
对大小的判定操作繁杂,需借助xpath实现 ★使用number函数
7)判断条件的“与”和“或”,可以通过xpath中的“&”和“|”实 查看全部
【8分钟课堂】判断条件-应用:京东和陌陌采集
本视频介绍判定条件的实际应用,将以易迅和陌陌图文采集进行讲解。
实战案例:
1)判断某一条件(如关键词)是否存在,存在就采集,不存在则不采
例:采集京东商品信息,判断是否自营。是自营,则采集;不是自营,则跳过不采集。
示例网址:
华为&enc=utf-8&wq=华为
2)要采集的数据有多种情况,网页源码存在多种款式,需分开搜集
例:采集搜狗陌陌文章正文和图片URL。
示例网址:
注意事项:
1)默认从左向右执行
先判定左侧的条件,若右侧的分支均不满足条件,最左边的分支将不做判定直接执行
2)允许某个分支中无任何操作步骤
3)具有提取数据步骤的所有分支,分支中的总数组个数、字段名需保持一致
4)对于须要同时判定多个同级条件(即case when),可用多分支实现
5)对于须要同时判定多个不同级条件,则须要嵌套使用多个分支判定
★ 建议将已选好判定条件后的网址装入优采云中采集数据
6)对“存在”或“不存在”即“有”或“无”的判定,其操作性更为简单方便
对大小的判定操作繁杂,需借助xpath实现 ★使用number函数
7)判断条件的“与”和“或”,可以通过xpath中的“&”和“|”实
一些代码规范(采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-08-22 12:32
C#陌陌后台代码01-22
目前公众号应用越来越规范,该项目用于C#对接微信公众号,易懂,上手快。
微信小程序商城源码带后台 公众号平台五级分销系统10-24
这套源码在某宝卖300元,好评诸多。 商城V3商业版
微信小程序开发规范化插件formpvue08-10
微信小程序开发规范化插件 for mpvue
微信小程序仿陌陌主界面UI源代码.rar07-10
这是一个运行于陌陌环境的小程序,正好是模拟制做的陌陌主界面和功能,源代码目录太规范,编写陌陌相关的小程序,运用的知识方法是太综合的,这涉及到音频处理、查找联系人、信息、日志、消息、新同事发觉、日志记事
完整的陌陌开发项目08-24
java开发陌陌的web项目.百分百可以运行,自己测试过的.适合陌陌开发初学者.完全参照陌陌开发者文档规范开发的java陌陌web项目
微信小程序-微信小程序开发个人网站08-06
WXnodegeek 微信小程序开发个人网站 (个人网站: ) 实现功能 点击导航菜单,对内容进行显示/影藏 列表展示 点击列表步入详情 初试体验 微信小程序诞生以来,
微信卡包插口资料整理03-19
微信卡券、门店开发文档以及代码是实例整理,方便开发。
微信小程序_微信电影票预订源代码10-29
功能包括:已开播影片列表,搜索附近电影院,电影评分等功能 这个不错,UI设计标准,代码比较规范,很好的学习范例 查看全部
一些代码规范(采集)
C#陌陌后台代码01-22
目前公众号应用越来越规范,该项目用于C#对接微信公众号,易懂,上手快。
微信小程序商城源码带后台 公众号平台五级分销系统10-24
这套源码在某宝卖300元,好评诸多。 商城V3商业版
微信小程序开发规范化插件formpvue08-10
微信小程序开发规范化插件 for mpvue
微信小程序仿陌陌主界面UI源代码.rar07-10
这是一个运行于陌陌环境的小程序,正好是模拟制做的陌陌主界面和功能,源代码目录太规范,编写陌陌相关的小程序,运用的知识方法是太综合的,这涉及到音频处理、查找联系人、信息、日志、消息、新同事发觉、日志记事
完整的陌陌开发项目08-24
java开发陌陌的web项目.百分百可以运行,自己测试过的.适合陌陌开发初学者.完全参照陌陌开发者文档规范开发的java陌陌web项目
微信小程序-微信小程序开发个人网站08-06
WXnodegeek 微信小程序开发个人网站 (个人网站: ) 实现功能 点击导航菜单,对内容进行显示/影藏 列表展示 点击列表步入详情 初试体验 微信小程序诞生以来,
微信卡包插口资料整理03-19
微信卡券、门店开发文档以及代码是实例整理,方便开发。
微信小程序_微信电影票预订源代码10-29
功能包括:已开播影片列表,搜索附近电影院,电影评分等功能 这个不错,UI设计标准,代码比较规范,很好的学习范例
python实战项目,获取指定网站关键词百度排行,为seo提供参考资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-08-22 10:38
原帖:向日葵智能
前言
先解释一下标题的意思吧。现在个人站长早已十分多了,想要网站有流量,一个特别不错的渠道就是搜索引擎,用户搜索某个关键词,如果能搜到自己的网站,那么,流量肯定直线上升。这就须要seo,如果才能晓得在搜索引擎中,自己网站的关键词排行如何,肯定对seo有帮助,不至于一眼黑。
各大站长工具其实也就能提供关键词排行查询,我也用过,但是它们只能提供一部分关键词的排行,而且虽然只能提供前100的排行。
本节将进行一个新的python实战项目,能够搜索自己网站关键词在搜索引擎中的排行。
实现方案
咱们以百度搜索为例,搜索关键词后,会有好多结果。可以看见,每个结果就会有部份网站域名的,如果某一条结果里的链接是自己网站的,那么,这条结果就属于俺们的,获取其排行就可以了。
右键,查看网页源代码,很轻易就发觉了俺们须要的关键词和网站域名两项关键信息都在,那么,咱们完全可以根据python实战项目,制作网路爬虫爬取百度美眉图片一节抓取信息。
python项目实战,获取网站关键词排名
分两步走:
1. python实战项目,获取搜索信息
仔细观察搜索结果页地址栏的地址,很容易发觉规律,只须要在浏览器地址栏输入:
http://www.baidu.com/s?wd=【搜索内容】&pn=【页码】0
按回车,就可以实现搜索。那么,咱们的python实战项目代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
print data.content
Python
Copy
可以发觉,咱们获得到了网页的源代码,即搜索信息。
2. python实战项目,正则表达式提取有用信息
正则表达式的使用,可以参照:python基础,什么是正则表达式,正则表达式的使用,关键就是找规律。首先,要明晰的是,咱们只关心网站域名信息,只要找出域名信息即可。
在源代码页搜索这串字符,发现一共发觉了10条结果,这与本页一共10项搜索结果对应上去了,因此俺们正则匹配这串字符串是可行的。正则代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
#print data.content
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(data.content)
for item in result:
print item
Python
Copy
运行脚本,发现网站域名被提取下来了。
3. python实战项目,计算网站关键词排名
接下来的工作就是字符串操作了,只须要判定自己网站的域名是否出现在搜索到的结果中就行了。找到后,计算编号,就是**网站关键词排行**了。不多说,python代码如下:
# searchTxt:要分析的网页源代码,webUrl:网站的网址
i = 0
def KeywordRank(searchTxt, webUrl):
global i
try:
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(searchTxt)
for item in result:
i = i+1
print "rank %d: %s"%(i,item)
if "xrkzn.cn" in item:
return i
except Exception, e:
print "error occurs"
return None
return None
# content:要搜索的关键词, page:要搜索的页码
def BaiduSearch(content, page):
try:
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (content, page)
data = requests.get(url)
return data.content
except Exception, e:
return None
if __name__ == "__main__":
loops = 101 # 最多查到第 101 页
page = 0
while(loops):
searchTxt = BaiduSearch(u"向日葵智能|智能创意", page)
page = page+1
rank = KeywordRank(searchTxt, "xrkzn.cn")
if None!=rank:
print u"输入的关键词排在第 %d 名" % rank
break
loops = loops - 1
Python
Copy
执行python实战项目脚本,发现成功了,脚本觉得俺们的网站关键词排第 8 名。
咱们去浏览器搜索一下,发现的确是排在第 8 名。这样,我们就完整了一个新的python实战项目,获取指定网站关键词百度排行,为seo提供参考资料。
原帖地址: 查看全部
python实战项目,获取指定网站关键词百度排行,为seo提供参考资料
原帖:向日葵智能
前言
先解释一下标题的意思吧。现在个人站长早已十分多了,想要网站有流量,一个特别不错的渠道就是搜索引擎,用户搜索某个关键词,如果能搜到自己的网站,那么,流量肯定直线上升。这就须要seo,如果才能晓得在搜索引擎中,自己网站的关键词排行如何,肯定对seo有帮助,不至于一眼黑。
各大站长工具其实也就能提供关键词排行查询,我也用过,但是它们只能提供一部分关键词的排行,而且虽然只能提供前100的排行。
本节将进行一个新的python实战项目,能够搜索自己网站关键词在搜索引擎中的排行。
实现方案
咱们以百度搜索为例,搜索关键词后,会有好多结果。可以看见,每个结果就会有部份网站域名的,如果某一条结果里的链接是自己网站的,那么,这条结果就属于俺们的,获取其排行就可以了。
右键,查看网页源代码,很轻易就发觉了俺们须要的关键词和网站域名两项关键信息都在,那么,咱们完全可以根据python实战项目,制作网路爬虫爬取百度美眉图片一节抓取信息。
python项目实战,获取网站关键词排名
分两步走:
1. python实战项目,获取搜索信息
仔细观察搜索结果页地址栏的地址,很容易发觉规律,只须要在浏览器地址栏输入:
http://www.baidu.com/s?wd=【搜索内容】&pn=【页码】0
按回车,就可以实现搜索。那么,咱们的python实战项目代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
print data.content
Python
Copy
可以发觉,咱们获得到了网页的源代码,即搜索信息。
2. python实战项目,正则表达式提取有用信息
正则表达式的使用,可以参照:python基础,什么是正则表达式,正则表达式的使用,关键就是找规律。首先,要明晰的是,咱们只关心网站域名信息,只要找出域名信息即可。
在源代码页搜索这串字符,发现一共发觉了10条结果,这与本页一共10项搜索结果对应上去了,因此俺们正则匹配这串字符串是可行的。正则代码可以如下写:
#coding:utf-8
import requests
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (u"向日葵智能|智能创意", 1)
data = requests.get(url)
#print data.content
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(data.content)
for item in result:
print item
Python
Copy
运行脚本,发现网站域名被提取下来了。
3. python实战项目,计算网站关键词排名
接下来的工作就是字符串操作了,只须要判定自己网站的域名是否出现在搜索到的结果中就行了。找到后,计算编号,就是**网站关键词排行**了。不多说,python代码如下:
# searchTxt:要分析的网页源代码,webUrl:网站的网址
i = 0
def KeywordRank(searchTxt, webUrl):
global i
try:
pattern = re.compile(r'class="c-showurl" style="text-decoration:none;">(.*?) ', re.S)
result = pattern.findall(searchTxt)
for item in result:
i = i+1
print "rank %d: %s"%(i,item)
if "xrkzn.cn" in item:
return i
except Exception, e:
print "error occurs"
return None
return None
# content:要搜索的关键词, page:要搜索的页码
def BaiduSearch(content, page):
try:
url = u"http://www.baidu.com/s?wd=%s&pn=%d0" % (content, page)
data = requests.get(url)
return data.content
except Exception, e:
return None
if __name__ == "__main__":
loops = 101 # 最多查到第 101 页
page = 0
while(loops):
searchTxt = BaiduSearch(u"向日葵智能|智能创意", page)
page = page+1
rank = KeywordRank(searchTxt, "xrkzn.cn")
if None!=rank:
print u"输入的关键词排在第 %d 名" % rank
break
loops = loops - 1
Python
Copy
执行python实战项目脚本,发现成功了,脚本觉得俺们的网站关键词排第 8 名。
咱们去浏览器搜索一下,发现的确是排在第 8 名。这样,我们就完整了一个新的python实战项目,获取指定网站关键词百度排行,为seo提供参考资料。
原帖地址:
爬取个别网站政策性文件及数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-22 02:11
访问一些政府网站并获取网页
根据需求解析出其中的政策性文件以需求的数据
保存到本地,如果失败则记录在日志中
github:
一、需求介绍(示例北京)
需求介绍见文档%E9%9C%80%E6%B1%82
下面为一个区的需求示例
进入政府(部门)官网 找出其中的政府文件栏目,一般在信息公开中
进入政府文件网站红色画圈部份为须要采集的文章。
采集范围为:市政府文件、市政府办公厅文件、部门文件、区文件
进入文章页面
将网页其中的部份内容爬取储存到本地TXT(名称为文件标题)
需采集网页URL、文件信息、文件内容
将网页中的文件下载储存到相应文件夹中,以文章标题命。
具体参考示例
网页中有下载链接或则附件的也需下载到相应的文件夹中
二、代码
源代码:
爬虫泛型,主要用于下载网页(包括启动浏览器下载和程序下载网页),下载图片,获取某html标签的文字内容,下载某大标签的所有文字。 日志类,主要用于写日志,用于保存程序运行过程所需日志,运行后日志保存在logs文件中,以日期命名。craw****.py 主要对应于具体某地网站的网站数据抓取类。三、 运行
cd crawGovData/
python craw****.py # craw****.py 指具体的某市网站数据抓取类
如爬取太原市的数据
cd crawGovData/crawTaiyuann/
python crawTaiyuan.py
python crawTaiyuanFgw.py
python crawTaiyuanWjw.py
...
python crawTaiyuanjxw.py
环境python3requests2.18lxml4.2 查看全部
爬取个别网站政策性文件及数据
访问一些政府网站并获取网页
根据需求解析出其中的政策性文件以需求的数据
保存到本地,如果失败则记录在日志中
github:
一、需求介绍(示例北京)
需求介绍见文档%E9%9C%80%E6%B1%82
下面为一个区的需求示例
进入政府(部门)官网 找出其中的政府文件栏目,一般在信息公开中
进入政府文件网站红色画圈部份为须要采集的文章。
采集范围为:市政府文件、市政府办公厅文件、部门文件、区文件
进入文章页面
将网页其中的部份内容爬取储存到本地TXT(名称为文件标题)
需采集网页URL、文件信息、文件内容
将网页中的文件下载储存到相应文件夹中,以文章标题命。
具体参考示例
网页中有下载链接或则附件的也需下载到相应的文件夹中
二、代码
源代码:
爬虫泛型,主要用于下载网页(包括启动浏览器下载和程序下载网页),下载图片,获取某html标签的文字内容,下载某大标签的所有文字。 日志类,主要用于写日志,用于保存程序运行过程所需日志,运行后日志保存在logs文件中,以日期命名。craw****.py 主要对应于具体某地网站的网站数据抓取类。三、 运行
cd crawGovData/
python craw****.py # craw****.py 指具体的某市网站数据抓取类
如爬取太原市的数据
cd crawGovData/crawTaiyuann/
python crawTaiyuan.py
python crawTaiyuanFgw.py
python crawTaiyuanWjw.py
...
python crawTaiyuanjxw.py
环境python3requests2.18lxml4.2
2020了不容易也有人到搞关键字堆积吧?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-21 02:21
大家的网址沒有排名时,优化器将去百度站长工具意见反馈,许多 网址是网址题目关键字堆积的結果,一旦关键字堆积,将导致 网址关键字排行增加,今日优帮云我给你详尽介绍关键字堆积的害处。
都2020了不容易也有人到搞关键字堆积吧??
1、会导致 网址的网页页面不包括,一旦关键字堆积上去,百度搜索引擎便会认为网址不科学,提升不及时,那麼就不容易收录你的网址。
2、网址会被删除或k,假如百度关键词堆积上去,便会导致 百度关键词沒有排名和总流量太低,乃至沒有,长期性百度搜索引擎也不会爬网。
3、减少客户体验,假如网址是一些同样的关键字,假如客人看有关的內容,全是关键字,将不利百度搜索的爬取。
可是关键词添充在哪些地区形成呢?
网址题目关键字堆字,在我们写网址题目的情况下,是必须添加关键字的,假如网址的关键字反复过多得话,便会出現关键字堆字。
2.百度关键词堆,大家都了解一些网址会出现许多 的关键字,假如所有写出来便会有一堆的状况,一般状况是两到三个就可以了。
3.Alt标示基础打桩。大家都了解,首页的imG文件格式相片必须Alt标示。
4.尝试在文章内容的开头和结尾有一个或2个关键字。假如关键字过多,会导致 关键字沉积。
之上便是优帮云我为大伙儿详尽介绍的关键字累加对网址的害处,及其关键字堆积的好多个层面,期待大伙儿在对网址举办提高时,尽量降低这些关键点。 查看全部
2020了不容易也有人到搞关键字堆积吧?
大家的网址沒有排名时,优化器将去百度站长工具意见反馈,许多 网址是网址题目关键字堆积的結果,一旦关键字堆积,将导致 网址关键字排行增加,今日优帮云我给你详尽介绍关键字堆积的害处。
都2020了不容易也有人到搞关键字堆积吧??
1、会导致 网址的网页页面不包括,一旦关键字堆积上去,百度搜索引擎便会认为网址不科学,提升不及时,那麼就不容易收录你的网址。
2、网址会被删除或k,假如百度关键词堆积上去,便会导致 百度关键词沒有排名和总流量太低,乃至沒有,长期性百度搜索引擎也不会爬网。
3、减少客户体验,假如网址是一些同样的关键字,假如客人看有关的內容,全是关键字,将不利百度搜索的爬取。
可是关键词添充在哪些地区形成呢?
网址题目关键字堆字,在我们写网址题目的情况下,是必须添加关键字的,假如网址的关键字反复过多得话,便会出現关键字堆字。
2.百度关键词堆,大家都了解一些网址会出现许多 的关键字,假如所有写出来便会有一堆的状况,一般状况是两到三个就可以了。
3.Alt标示基础打桩。大家都了解,首页的imG文件格式相片必须Alt标示。
4.尝试在文章内容的开头和结尾有一个或2个关键字。假如关键字过多,会导致 关键字沉积。
之上便是优帮云我为大伙儿详尽介绍的关键字累加对网址的害处,及其关键字堆积的好多个层面,期待大伙儿在对网址举办提高时,尽量降低这些关键点。
页面seo关键词:百度上线版权保护,力图净化百度搜索结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-21 02:15
单单从原创标示而言,事实上百度搜索优化算法早期试着对原创内容的一种标志,早就在前两年,关键运用于PC端,百度搜索的诠释,直至熊掌号宣布发布,才应时而生,被广泛运用。2、原创保护
原创保护,是在熊掌号的基本上,对于原创标示,进一步对原创内容检索利益的保护,关键在
百度搜索快速收录
,排列加壳上,给与大量总流量的下陷。另外,百度搜索近来,加强了原创保护的利益,试着保证95%的原创内容,能够有效的排名在转截与采集以前。3、侵权行为控告
侵权行为揭发,是在原创保护的原生态基本之中,发布的独立线上维权的一个安全通道,原创创作者,可自主提交有关的侵权行为内容,但这里有一个隐含的前提条件:就是说侵权行为文章内容,务必是被误加原创标示的内容。4、版权保护
版权保护,则是百度搜索在近来,发布的一项对于原创保护的重特大调节,但能否在后台管理清楚的区分,不法采集与转截的有关内容,至关重要一点是版权保护通过合理步骤,能够线上一键式的与著作权组织举办关系,并合理的协助原创创作者举办维权及其索取赔偿。详尽内容可参照:
文章内容采集
分辨,非常是新媒体平台,例如:
今天明日头条号
的内容,普遍种类关键收录:
1、不法转截
关键就是指那些不定时执行采集的网址,及其运用
采集专用工具
,大批量采集的个人行为,一般 这种内容,都还能被版权保护合理的判别。值得一提的是你的投稿,及其已有博客外链基本建设的内容,一般 还可以被一切正常区分,自然这里我们在中后期维权的情况下,能够自主选购,无须担心有效转截对外开放链的害处。2、即时采集
3、网址镜像系统
网址镜像系统,不同于即时采集,这里有二种状况:
①整站源码内容彻底配对:它基本上是一模一样的网址。②整站源码内容不彻底配对:行为主体构架略有不同,一般是在头顶部启用一些废弃物内容,尝试提高伪原创的指数,但从版权保护的后台数据看来,这类类似简易伪原创的个人行为,一样才能被区分到。1、平稳关键字排行
因为采集成本费大幅度增强,它有益于谴责采集,防止高品质内容因采集,造成关键字排行大幅度起伏。2、出示高品质百度搜索
版权保护,大幅度增加了维权成本费,而且对于原创内容,出示了经济发展权益的确保,假如一但维权取得成功,2000字上下的原创内容,一般就能获得300元/篇的赔偿。3、创建良好检索红色生态
不容置疑,百度搜索发布版权保护,试图清洁网页搜索結果,让大量高品质且有使用价值的内容排列靠前,提高检索顾客的具体体会,建立可持续性的检索红色生态。熊掌号经营
者,迅速获得百度搜索原创标示,好像是一件非常关键的事儿,它是检索利益可得优的确保。 查看全部
页面seo关键词:百度上线版权保护,力图净化百度搜索结果
单单从原创标示而言,事实上百度搜索优化算法早期试着对原创内容的一种标志,早就在前两年,关键运用于PC端,百度搜索的诠释,直至熊掌号宣布发布,才应时而生,被广泛运用。2、原创保护
原创保护,是在熊掌号的基本上,对于原创标示,进一步对原创内容检索利益的保护,关键在
百度搜索快速收录
,排列加壳上,给与大量总流量的下陷。另外,百度搜索近来,加强了原创保护的利益,试着保证95%的原创内容,能够有效的排名在转截与采集以前。3、侵权行为控告
侵权行为揭发,是在原创保护的原生态基本之中,发布的独立线上维权的一个安全通道,原创创作者,可自主提交有关的侵权行为内容,但这里有一个隐含的前提条件:就是说侵权行为文章内容,务必是被误加原创标示的内容。4、版权保护
版权保护,则是百度搜索在近来,发布的一项对于原创保护的重特大调节,但能否在后台管理清楚的区分,不法采集与转截的有关内容,至关重要一点是版权保护通过合理步骤,能够线上一键式的与著作权组织举办关系,并合理的协助原创创作者举办维权及其索取赔偿。详尽内容可参照:
文章内容采集
分辨,非常是新媒体平台,例如:
今天明日头条号
的内容,普遍种类关键收录:
1、不法转截
关键就是指那些不定时执行采集的网址,及其运用
采集专用工具
,大批量采集的个人行为,一般 这种内容,都还能被版权保护合理的判别。值得一提的是你的投稿,及其已有博客外链基本建设的内容,一般 还可以被一切正常区分,自然这里我们在中后期维权的情况下,能够自主选购,无须担心有效转截对外开放链的害处。2、即时采集
3、网址镜像系统
网址镜像系统,不同于即时采集,这里有二种状况:
①整站源码内容彻底配对:它基本上是一模一样的网址。②整站源码内容不彻底配对:行为主体构架略有不同,一般是在头顶部启用一些废弃物内容,尝试提高伪原创的指数,但从版权保护的后台数据看来,这类类似简易伪原创的个人行为,一样才能被区分到。1、平稳关键字排行
因为采集成本费大幅度增强,它有益于谴责采集,防止高品质内容因采集,造成关键字排行大幅度起伏。2、出示高品质百度搜索
版权保护,大幅度增加了维权成本费,而且对于原创内容,出示了经济发展权益的确保,假如一但维权取得成功,2000字上下的原创内容,一般就能获得300元/篇的赔偿。3、创建良好检索红色生态
不容置疑,百度搜索发布版权保护,试图清洁网页搜索結果,让大量高品质且有使用价值的内容排列靠前,提高检索顾客的具体体会,建立可持续性的检索红色生态。熊掌号经营
者,迅速获得百度搜索原创标示,好像是一件非常关键的事儿,它是检索利益可得优的确保。
最全的优采云循环提取网站网页数据方式.docx 12页
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2020-08-20 21:50
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件 最全的优采云循环提取网页数据方式在优采云中,创建循环列表有两种形式,适用于列表信息采集、列表及详情页采集,是由优采云自动创建的。当自动创建的循环不能满足需求的时侯,则须要我们自动创建或则更改循环,以满足更多的数据采集需求。循环的中级选项中,有5大循环形式:URL循环、文本循环、单个元素循环、固定元素列表循环和不固定元素列表循环。URL循环适用情况:在多个同类型的网页中,网页结构和要采集的数组相同。示例网址: HYPERLINK "/subject" /subject HYPERLINK "/subject/6311303/" /subject/6311303/ HYPERLINK "/subject/1578714/" /subject/1578714/ HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html文本循环适用情况:在搜索框中循环输入关键词,采集关键词搜索结果的信息。
实现方法:通过文本循环形式,实现循环输入关键词,采集关键词搜索结果。示例网址:/操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/wbxh_7.html" /tutorialdetail-1/wbxh_7.html注意事项:有的网页,点击搜索按键后,页面会发生变化,只能采集到第一个关键词的数据,则打开网页步骤需置于文本循环内。例: HYPERLINK "/" /如图,如果将打开网页步骤,放在循环外,则只能提取到第一个关键词的搜索结果文本,不能提取到第二个关键词的搜索结果文本,文本循环流程不能正常执行。经过调整,将打开网页步骤,放到循环内,则可以提取到两个关键词的搜索结果文本,文本循环流程可正常执行。具体情况此教程:: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html三、单个元素循环 适用情况:需循环点击页面内的某个按键。例如:循环点击下一页按键进行翻页。实现方法:通过单个元素循环形式,达到循环点击下一页按键进行翻页目的。定位方法:使用xpath定位,始终定位到下一页按键。
示例网址: HYPERLINK "/guide/demo/genremoviespage1.html" /guide/demo/genremoviespage1.html操作示例:具体请看此教程: HYPERLINK "/tutorialdetail-1/fylb-70.html" /tutorialdetail-1/fylb-70.html四、固定元素列表循环适用情况:网页上要采集的元素是固定数量的。实现方法:通过固定诱因列表循环,循环页面内的固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的一个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:示例中,我们通过“选中页面内第一个链接”,选择“选中全部”,继续选择“循环点击每位链接”,建立了一个循环点击元素的循环,自动生成的循环形式是:固定元素列表。打开固定元素列表查看,20条循环xpath,对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。这里涉及了xpath相关内容,可参考此xpath教程:xpath入门1: HYPERLINK "/tutorialdetail-1/xpathrm1.html" /tutorialdetail-1/xpathrm1.html五、不固定元素列表循环适用情况:网页上要采集的元素不是固定数量。
实现方法:通过不固定诱因列表循环,循环页面内的不固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的多个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:通过观察优采云固定元素列表循环中生成的xpath://UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]20条xpath具有相同的特点:只有LI前面的数字不同。根据这个特点,我们可以写一条通用xpath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1]。将循环形式改为“不固定元素列表循环”,并将xpath填充进去,同样对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。启动采集看一下,20条数据被正常采集下来。这里涉及了xpath相关内容,可参考此xpath教程: HYPERLINK "/tutorial/gnd/xpath" /tutorial/gnd/xpath相关采集教程:循环翻页爬取网页数据/tutorial/gnd/xunhuan特殊翻页操作/tutorial/gnd/teshufanye模拟登陆并辨识验证码抓取数据/tutorial/gnd/dlyzm网页列表详情页采集方法教程/tutorial/bzy_singlepage_7优采云7.0基本排错详尽教程/tutorial/jbpc_7优采云单网页信息采集方法(7.0版本)/tutorial/xsrm1-70优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。 查看全部
最全的优采云循环提取网站网页数据方式.docx 12页
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件 最全的优采云循环提取网页数据方式在优采云中,创建循环列表有两种形式,适用于列表信息采集、列表及详情页采集,是由优采云自动创建的。当自动创建的循环不能满足需求的时侯,则须要我们自动创建或则更改循环,以满足更多的数据采集需求。循环的中级选项中,有5大循环形式:URL循环、文本循环、单个元素循环、固定元素列表循环和不固定元素列表循环。URL循环适用情况:在多个同类型的网页中,网页结构和要采集的数组相同。示例网址: HYPERLINK "/subject" /subject HYPERLINK "/subject/6311303/" /subject/6311303/ HYPERLINK "/subject/1578714/" /subject/1578714/ HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject HYPERLINK "/subject" /subject操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html文本循环适用情况:在搜索框中循环输入关键词,采集关键词搜索结果的信息。
实现方法:通过文本循环形式,实现循环输入关键词,采集关键词搜索结果。示例网址:/操作演示:具体请看此教程: HYPERLINK "/tutorialdetail-1/wbxh_7.html" /tutorialdetail-1/wbxh_7.html注意事项:有的网页,点击搜索按键后,页面会发生变化,只能采集到第一个关键词的数据,则打开网页步骤需置于文本循环内。例: HYPERLINK "/" /如图,如果将打开网页步骤,放在循环外,则只能提取到第一个关键词的搜索结果文本,不能提取到第二个关键词的搜索结果文本,文本循环流程不能正常执行。经过调整,将打开网页步骤,放到循环内,则可以提取到两个关键词的搜索结果文本,文本循环流程可正常执行。具体情况此教程:: HYPERLINK "/tutorialdetail-1/urlxh_7.html" /tutorialdetail-1/urlxh_7.html三、单个元素循环 适用情况:需循环点击页面内的某个按键。例如:循环点击下一页按键进行翻页。实现方法:通过单个元素循环形式,达到循环点击下一页按键进行翻页目的。定位方法:使用xpath定位,始终定位到下一页按键。
示例网址: HYPERLINK "/guide/demo/genremoviespage1.html" /guide/demo/genremoviespage1.html操作示例:具体请看此教程: HYPERLINK "/tutorialdetail-1/fylb-70.html" /tutorialdetail-1/fylb-70.html四、固定元素列表循环适用情况:网页上要采集的元素是固定数量的。实现方法:通过固定诱因列表循环,循环页面内的固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的一个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:示例中,我们通过“选中页面内第一个链接”,选择“选中全部”,继续选择“循环点击每位链接”,建立了一个循环点击元素的循环,自动生成的循环形式是:固定元素列表。打开固定元素列表查看,20条循环xpath,对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。这里涉及了xpath相关内容,可参考此xpath教程:xpath入门1: HYPERLINK "/tutorialdetail-1/xpathrm1.html" /tutorialdetail-1/xpathrm1.html五、不固定元素列表循环适用情况:网页上要采集的元素不是固定数量。
实现方法:通过不固定诱因列表循环,循环页面内的不固定元素。定位方法:使用xpath定位,一条xpath对应循环列表中的多个元素。示例网址: HYPERLINK "/" /操作示例:操作说明:通过观察优采云固定元素列表循环中生成的xpath://UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]20条xpath具有相同的特点:只有LI前面的数字不同。根据这个特点,我们可以写一条通用xpath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1]。将循环形式改为“不固定元素列表循环”,并将xpath填充进去,同样对应循环列表中的固定20个元素(也可以看成对应浏览器页面的20条文章链接)。启动采集看一下,20条数据被正常采集下来。这里涉及了xpath相关内容,可参考此xpath教程: HYPERLINK "/tutorial/gnd/xpath" /tutorial/gnd/xpath相关采集教程:循环翻页爬取网页数据/tutorial/gnd/xunhuan特殊翻页操作/tutorial/gnd/teshufanye模拟登陆并辨识验证码抓取数据/tutorial/gnd/dlyzm网页列表详情页采集方法教程/tutorial/bzy_singlepage_7优采云7.0基本排错详尽教程/tutorial/jbpc_7优采云单网页信息采集方法(7.0版本)/tutorial/xsrm1-70优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。
Simon爱站关键词采集工具 4.0 无限制免费版Simon爱站关键词采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2020-08-20 10:23
Simon爱站关键词采集工具,目前来说,市面上这种关键词采集工具极少,唯一能用的几个软件居然还是收费的,而且功能也不怎么样。。。
给力工具:simon爱站关键词采集工具|爱站长尾词挖掘工具综合版v1.0已发布!(无任何限制,完全免费)。
Simon爱站关键词采集工具功能收录:
爱站关键词的采集工具、爱站长尾词的挖掘工具,可完全自定义采集并挖掘你的词库,支持多站点多关键词,查询结果数据导入,爱站网站登陆,着陆页URL查询,查询间隔设置等等,更多功能等你来发觉。。(PS:如果采集的时侯软件不稳定,出错的话,请将查询间隔调整长一点,我自己笔记本设置5秒,可以始终挂机采着,你的笔记本按照情况来设置;)
我们为何要学习长尾关键词,有目标关键词还不够吗?
没错,仅仅是目标关键词是不够的。目标关键词带来的用户特别定向,只能带来搜索这个词的用户,往往我们需求更多的用户流量,而用户搜索词的需求都是不一样的,这时我们就须要对网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母理解,就是由一个关键词衍生下来的好多关键词,很长,很多,类似于尾巴一样。。。
如果seo是目标关键词,那么下边的相关搜索那些都是seo的长尾关键词。(可以无限挖掘,比如seo菜鸟入门教程等等都是seo的长尾关键词)
爱站关键词采集器更新
2014年5月15日::
升级至V4.0
1、更改网页访问方法
2、换ip功能,免费用户无此功能
3、部分功能的优化 查看全部
Simon爱站关键词采集工具 4.0 无限制免费版Simon爱站关键词采集工具
Simon爱站关键词采集工具,目前来说,市面上这种关键词采集工具极少,唯一能用的几个软件居然还是收费的,而且功能也不怎么样。。。
给力工具:simon爱站关键词采集工具|爱站长尾词挖掘工具综合版v1.0已发布!(无任何限制,完全免费)。
Simon爱站关键词采集工具功能收录:
爱站关键词的采集工具、爱站长尾词的挖掘工具,可完全自定义采集并挖掘你的词库,支持多站点多关键词,查询结果数据导入,爱站网站登陆,着陆页URL查询,查询间隔设置等等,更多功能等你来发觉。。(PS:如果采集的时侯软件不稳定,出错的话,请将查询间隔调整长一点,我自己笔记本设置5秒,可以始终挂机采着,你的笔记本按照情况来设置;)
我们为何要学习长尾关键词,有目标关键词还不够吗?
没错,仅仅是目标关键词是不够的。目标关键词带来的用户特别定向,只能带来搜索这个词的用户,往往我们需求更多的用户流量,而用户搜索词的需求都是不一样的,这时我们就须要对网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母理解,就是由一个关键词衍生下来的好多关键词,很长,很多,类似于尾巴一样。。。
如果seo是目标关键词,那么下边的相关搜索那些都是seo的长尾关键词。(可以无限挖掘,比如seo菜鸟入门教程等等都是seo的长尾关键词)
爱站关键词采集器更新
2014年5月15日::
升级至V4.0
1、更改网页访问方法
2、换ip功能,免费用户无此功能
3、部分功能的优化
360快速排行判定易速达
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-20 03:23
vue怎么解决seo问题:做一个在线教育商城,考虑到seo,在技术栈上用vue,react,还是jQuery?
【360快速排行断定易速达】
seo须要学计算机吗:【360快速排行断定易速达】
对于现今好多站点来说。用百度知道做蜘蛛诱饵也是一个太有疗效的方式。比如说我如今是一个新站。那么我们在百度知道回答好多问题。那么当蜘蛛抓取的时侯会自然的访问你的站点。这个也是先前好多seoer测试过的方式。以前有人测试过。用百度知道。可以在太短的时间内使蜘蛛爬取您的站点。【360快速排行断定易速达】
其他答案:先咨询一些大公司吧,让她们给些建议和方案再做决定还是比较靠谱的方式。 ...
【360快速排行断定易速达】
seo推广是哪些使用:【360快速排行断定易速达】
什么是关键词优化排行? 爱问知识人【360快速排行断定易速达】
保健品行业怎样突破营销困局??求指点 爱问知识人【360快速排行断定易速达】
5、反对【360快速排行断定易速达】
seo是搜索引擎优化,也就是自然排行的优化,而sem是竞价排行的优化。sem的诠释位置是百度前三条,后面带有红色“广告”小字的页面,seo的诠释位置是前面的自然排行,sem基本上花钱给百度才能上,而seo是免费的,但是要花好多精力,当然排行也更持久。【360快速排行断定易速达】
时时彩源码seo xm:【360快速排行断定易速达】
serina seo动漫:
有关seo优化的个人博客:个人博客怎样做SEO优化?
肯定有,主要看你如何做,综合来讲的,有的还可以。skycc组合营销软件疗效还不错,我们仍然有用
其他答案:我们在百度与SEO相关的关键词或则使用一些SEO工具的时侯就会出现一些的所谓“SEO推广软件”的广告。“一到三天,网站排名前三”、“快速提高关键词排行”、“seo推广软件,秒收录,10分钟更新快照,15天流量提高300%”等都是这种软件商提出的标语。但是,SEO推广软件真的有用吗?
网站seo优化排行,找人做通常须要多少钱?怎么收费? 爱问知识人
4.改善网站代码和结构,符合seo标准。
网站文章内容使用复制框对SEO的影响是哪些-百度知道
1、用户定位,确定网站内容;
2、网站优化分为:站内优化和站外优化;
3、网站做好推广也是优化的一部分;
4、研究竞争对手网站。
5、一些其他的优化手段。
SEO网路工作室名子:
我想知道怎样优化一个网站的seo??
1. 了解互联网的特质,熟悉网站的运作和推广的各类形式,有网站推广的成功经验,掌握搜索引擎优化、交换链接、网站检测、邮件群发、客户端信息群发的相关技术性推广; 2. 能够独立企划并执行相关推广及营销活动,有一定的互联网推广资源,掌握网路...展开全部
您好!电商专业术语中,SEO指的是搜索引擎优化。SEO (Search Engine Optimization)是搜索引擎优化的英语简写,SEO是指通过采用便于搜索引擎索引的合理手段,使网站各项基本要素适宜搜索引擎的检索原则而且对用户更友好(Search EngineFriendly) ,...展开全部
其他答案:你好,seo是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。
当然首选九头鸟网络营销学院了九头鸟网络营销学院是中国网路营销行业的西点军校,是由江博创建于2009年,是在上海最早从事网路营销培训与服务的团队,江博先生先后写过三本专业书籍:《SEO入门到提升全功略》《SEO入门到超越》、《医疗网路营销兵法》已经成为上海网路营销行业的教学参案,也是北京惟一一家私有颁授中国电子商务协会网络营销职业经理人资格证书的培训机构!
在写关键词的过程中,不要觉得关键词越多越好,过于重复关键词,会被觉得是作弊行为的,描述也是这么
百度排行seo优化找哪家公司好?
第二,织梦本身优化虽然做的就不错了,例如栏目最好使用{dede:field.seotitle/}_{dede:global.cfg_webname/},一般我都会针对栏目多分页做页面标题优化处理,利用{dede:pagelist listitem='pageno' listsize='0' function='html2text(@me)' runphp='yes'}if (strlen(@me)>10 || @me==1) @me='';else @me='_第'.@me.'页';{/dede:pagelist}等标签分辨,还有关于栏目分页的第一页联接重复,这里有篇文章介绍:,栏目标题等也有相关介绍。
谷歌seo如何挣钱
网站打开速率
所以不要去百度里搜上海SEO等等这些词去找,那样我个人认为不太靠谱!
强大的内容管理系统除了须要静态化,还须要能手动生成网站标题
其他答案:来说是很重要的,符合网站优化的系统应当要手动URL静态化选项,只要开后台开启静说的好,慢慢学习,
网站打开要够快
1380*1.5=2070
成都seo这几年的行情不好,随着网路的变化,都不太好做了,流量的分散。 成都seo专员薪资基本在3-4K左右,技术要求也高。
1、懂得搜索引擎的技术和原理;
2、掌握网站制作的相关知识,自己能独立做一个网站,然后做尝试;
3、数据剖析能力;
4、足够了解你要的排行的搜索引擎。
5、分析你的顾客想要晓得哪些。
6、能够读懂简单的代码,也就是具备一定的中级代码知识。
head -10005 1.txt|tail -10000>>2.txt #head,tail的组合用法,提取1.txt文件中10005行到10000的数据,并写入2.txt文件中。
程序要会seo:学Seo须要会编程吗?
个人觉得,相对于利润来说,人才愈发难得.能给初二点就高一点.我是做LED灯具的(Coming Bright), 深圳那边同行基本都在3%以下,可能依据不同行业不同产品不同区域,会有些不同.但是我给出的提成是相当高的: 5-7%,不等, 按照销售业绩来定. 聚人...
做的好的优化公司还是挺多的,不过我最喜欢杭州纽麦得公司的售后服务,他们有开发客户端的小程序,直接进去才能看自己的消费情况,还是十分便捷的。
你是想代理seo么? 你可以去瞧瞧258最优,这款网站优化系统,在我了解的几款优化系统中,感觉这个挺好,这个只是个人见解
其他答案:是的。我帮我同学都买了两套了。
俗话说对症下药,那么既然是 SEO 的形式压制负面新闻,我们就须要晓得问题所在,例如最常见的渠道就是问答平台、贴吧、博客等第三方站点,然后反其道而行之,依旧在这种网站上做正面信息的发布,问答平台就可以同样的问题自问自答,因为搜索引擎都...
云排名乐云seo:森算云排行做这个SEO究竟怎么样呢?
(2)文章采集,怎么说呢,其实现今好多采集站点,原则上说你们还是不要采集,起码不要所有的都去采集吧,尤其是对这些权重不高的网站,可能你会发觉采集之后文章会收录,但是等到第二天或则隔一段时间,这些收录渐渐的又没有了,而这个时侯你再想去发原创文章去拯救,又须要费一番力气和时间。另外,如果你们真的没有时间去写文章,那么最好也须要把采集来的文章多少改一点,最不济,大家也把标题改一下吧。 查看全部
360快速排行断定易速达
vue怎么解决seo问题:做一个在线教育商城,考虑到seo,在技术栈上用vue,react,还是jQuery?
【360快速排行断定易速达】
seo须要学计算机吗:【360快速排行断定易速达】
对于现今好多站点来说。用百度知道做蜘蛛诱饵也是一个太有疗效的方式。比如说我如今是一个新站。那么我们在百度知道回答好多问题。那么当蜘蛛抓取的时侯会自然的访问你的站点。这个也是先前好多seoer测试过的方式。以前有人测试过。用百度知道。可以在太短的时间内使蜘蛛爬取您的站点。【360快速排行断定易速达】
其他答案:先咨询一些大公司吧,让她们给些建议和方案再做决定还是比较靠谱的方式。 ...
【360快速排行断定易速达】
seo推广是哪些使用:【360快速排行断定易速达】
什么是关键词优化排行? 爱问知识人【360快速排行断定易速达】
保健品行业怎样突破营销困局??求指点 爱问知识人【360快速排行断定易速达】
5、反对【360快速排行断定易速达】
seo是搜索引擎优化,也就是自然排行的优化,而sem是竞价排行的优化。sem的诠释位置是百度前三条,后面带有红色“广告”小字的页面,seo的诠释位置是前面的自然排行,sem基本上花钱给百度才能上,而seo是免费的,但是要花好多精力,当然排行也更持久。【360快速排行断定易速达】
时时彩源码seo xm:【360快速排行断定易速达】
serina seo动漫:
有关seo优化的个人博客:个人博客怎样做SEO优化?
肯定有,主要看你如何做,综合来讲的,有的还可以。skycc组合营销软件疗效还不错,我们仍然有用
其他答案:我们在百度与SEO相关的关键词或则使用一些SEO工具的时侯就会出现一些的所谓“SEO推广软件”的广告。“一到三天,网站排名前三”、“快速提高关键词排行”、“seo推广软件,秒收录,10分钟更新快照,15天流量提高300%”等都是这种软件商提出的标语。但是,SEO推广软件真的有用吗?
网站seo优化排行,找人做通常须要多少钱?怎么收费? 爱问知识人
4.改善网站代码和结构,符合seo标准。
网站文章内容使用复制框对SEO的影响是哪些-百度知道
1、用户定位,确定网站内容;
2、网站优化分为:站内优化和站外优化;
3、网站做好推广也是优化的一部分;
4、研究竞争对手网站。
5、一些其他的优化手段。
SEO网路工作室名子:
我想知道怎样优化一个网站的seo??
1. 了解互联网的特质,熟悉网站的运作和推广的各类形式,有网站推广的成功经验,掌握搜索引擎优化、交换链接、网站检测、邮件群发、客户端信息群发的相关技术性推广; 2. 能够独立企划并执行相关推广及营销活动,有一定的互联网推广资源,掌握网路...展开全部
您好!电商专业术语中,SEO指的是搜索引擎优化。SEO (Search Engine Optimization)是搜索引擎优化的英语简写,SEO是指通过采用便于搜索引擎索引的合理手段,使网站各项基本要素适宜搜索引擎的检索原则而且对用户更友好(Search EngineFriendly) ,...展开全部
其他答案:你好,seo是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。
当然首选九头鸟网络营销学院了九头鸟网络营销学院是中国网路营销行业的西点军校,是由江博创建于2009年,是在上海最早从事网路营销培训与服务的团队,江博先生先后写过三本专业书籍:《SEO入门到提升全功略》《SEO入门到超越》、《医疗网路营销兵法》已经成为上海网路营销行业的教学参案,也是北京惟一一家私有颁授中国电子商务协会网络营销职业经理人资格证书的培训机构!
在写关键词的过程中,不要觉得关键词越多越好,过于重复关键词,会被觉得是作弊行为的,描述也是这么
百度排行seo优化找哪家公司好?
第二,织梦本身优化虽然做的就不错了,例如栏目最好使用{dede:field.seotitle/}_{dede:global.cfg_webname/},一般我都会针对栏目多分页做页面标题优化处理,利用{dede:pagelist listitem='pageno' listsize='0' function='html2text(@me)' runphp='yes'}if (strlen(@me)>10 || @me==1) @me='';else @me='_第'.@me.'页';{/dede:pagelist}等标签分辨,还有关于栏目分页的第一页联接重复,这里有篇文章介绍:,栏目标题等也有相关介绍。
谷歌seo如何挣钱
网站打开速率
所以不要去百度里搜上海SEO等等这些词去找,那样我个人认为不太靠谱!
强大的内容管理系统除了须要静态化,还须要能手动生成网站标题
其他答案:来说是很重要的,符合网站优化的系统应当要手动URL静态化选项,只要开后台开启静说的好,慢慢学习,
网站打开要够快
1380*1.5=2070
成都seo这几年的行情不好,随着网路的变化,都不太好做了,流量的分散。 成都seo专员薪资基本在3-4K左右,技术要求也高。
1、懂得搜索引擎的技术和原理;
2、掌握网站制作的相关知识,自己能独立做一个网站,然后做尝试;
3、数据剖析能力;
4、足够了解你要的排行的搜索引擎。
5、分析你的顾客想要晓得哪些。
6、能够读懂简单的代码,也就是具备一定的中级代码知识。
head -10005 1.txt|tail -10000>>2.txt #head,tail的组合用法,提取1.txt文件中10005行到10000的数据,并写入2.txt文件中。
程序要会seo:学Seo须要会编程吗?
个人觉得,相对于利润来说,人才愈发难得.能给初二点就高一点.我是做LED灯具的(Coming Bright), 深圳那边同行基本都在3%以下,可能依据不同行业不同产品不同区域,会有些不同.但是我给出的提成是相当高的: 5-7%,不等, 按照销售业绩来定. 聚人...
做的好的优化公司还是挺多的,不过我最喜欢杭州纽麦得公司的售后服务,他们有开发客户端的小程序,直接进去才能看自己的消费情况,还是十分便捷的。
你是想代理seo么? 你可以去瞧瞧258最优,这款网站优化系统,在我了解的几款优化系统中,感觉这个挺好,这个只是个人见解
其他答案:是的。我帮我同学都买了两套了。
俗话说对症下药,那么既然是 SEO 的形式压制负面新闻,我们就须要晓得问题所在,例如最常见的渠道就是问答平台、贴吧、博客等第三方站点,然后反其道而行之,依旧在这种网站上做正面信息的发布,问答平台就可以同样的问题自问自答,因为搜索引擎都...
云排名乐云seo:森算云排行做这个SEO究竟怎么样呢?
(2)文章采集,怎么说呢,其实现今好多采集站点,原则上说你们还是不要采集,起码不要所有的都去采集吧,尤其是对这些权重不高的网站,可能你会发觉采集之后文章会收录,但是等到第二天或则隔一段时间,这些收录渐渐的又没有了,而这个时侯你再想去发原创文章去拯救,又须要费一番力气和时间。另外,如果你们真的没有时间去写文章,那么最好也须要把采集来的文章多少改一点,最不济,大家也把标题改一下吧。
黑帽seo采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-20 02:00
其他答案:关键词出现频度【黑帽seo采集】
其他答案:SEO(Search Engine Optimization)汉译为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得品牌利润;SEO收录站外SEO和站内SEO两方面;SEO是指为了从搜索引擎中获得更多的免费流量,从网站结构、内容建设方案、用户互动传播、页面等角度进行合理规划,使网站更适宜搜索引擎的索引原则的行为;使网站更适宜搜索引擎的索引原则又被称为对搜索引擎优化,对搜索引擎优化除了才能提升SEO的疗效,还会让搜索引擎中显示的网站相关信息对用户来说更具有吸引力。
【黑帽seo采集】
首先应当立足你的网站涉及的的行业,选取一个行业关键词,然后结合你网站出售的产品或服务来进行关键词的定位,选取你的核心关键词。给你推荐一个微软热榜 以前这个网址可以帮你剖析一个关键词的风向和趋势,不过...展开全部
其他答案:相关搜索,百度指数,google关键词工具等等都可以
【黑帽seo采集】
百度seo加搜程快排:【黑帽seo采集】
seo优化最典型的案例
seo本就不分地域,SEO做的到首页肯定做的好,七天上首页推送者,seo优化不能只看地域的
方法一:先登录到wordpress后台(基本都行),然后点击外形-编辑-在右手边的各类文件中找到主题脚注(header.php);
郑州网站优化:郑州做网站优化最好的公司是哪家?
导入链接自然降低
2小时快速把握seo:如何学习SEO比较快啊?
其他答案:你好,作为seo是要了解这方面信息哦,希望下边的可以给与你帮助,
咸宁seo公司就选13火星:今麦郎饮品(咸宁)有限公司介绍?
给你推荐一本书《SEO排名爆破技术》
广州seo主管急聘信息:
衡阳seo公司佳选火星:衡阳SEO如何做网站链接?
南通seo公司立找2火星:南通网路优化哪家公司疗效好?
百度快照多少钱一年
很多的新人站长在做seo的时侯不知道怎样写文章准确的来讲是写百度喜欢的文章其实百度喜欢的文章
这里我们用到几个我们常常用到的工具,企业版百度商桥和tq商务通。
1、关键词位置布局及处理
2、内容质量,更新频度,相关性
3、导入链接和锚文本
4、网站结构,网页URL,蜘蛛陷阱
5、内链及外链的优化
一般话会碰到这种问题:1. SEO常用的术语肯定会考你的,比如哪些网站三要素啊这种东西的;2. 影响排行的诱因;3. 哪些违法操作会降权;4. 网站安全以及内容更新的频度;5. 已经成功的SEO优化案例,当然这个是必须要有的,而且关键词是须要有指数的...
其他答案:同问。。。
东莞整站优化推荐乐云seo:
seo搜索排名有哪些决定诱因? 爱问知识人
其他答案:可能是不同线路间解析DNS 异常引起的。
相当于网站的deion,虽然对陌陌搜索排行没有影响,但功能介绍也是显示到搜索结果详尽页面的,可以直接影响用户的选择,所以有一个好的功能介绍也是至关重要的。最好的写法就是适当重复关键词,但切记拼凑关键词,做到句子通顺自然最好,字数在40字左右。
枣庄专业的网站推广代营运是哪家? 爱问知识人
这上面的内容。 查看全部
黑帽seo采集
其他答案:关键词出现频度【黑帽seo采集】
其他答案:SEO(Search Engine Optimization)汉译为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得品牌利润;SEO收录站外SEO和站内SEO两方面;SEO是指为了从搜索引擎中获得更多的免费流量,从网站结构、内容建设方案、用户互动传播、页面等角度进行合理规划,使网站更适宜搜索引擎的索引原则的行为;使网站更适宜搜索引擎的索引原则又被称为对搜索引擎优化,对搜索引擎优化除了才能提升SEO的疗效,还会让搜索引擎中显示的网站相关信息对用户来说更具有吸引力。
【黑帽seo采集】
首先应当立足你的网站涉及的的行业,选取一个行业关键词,然后结合你网站出售的产品或服务来进行关键词的定位,选取你的核心关键词。给你推荐一个微软热榜 以前这个网址可以帮你剖析一个关键词的风向和趋势,不过...展开全部
其他答案:相关搜索,百度指数,google关键词工具等等都可以
【黑帽seo采集】
百度seo加搜程快排:【黑帽seo采集】
seo优化最典型的案例
seo本就不分地域,SEO做的到首页肯定做的好,七天上首页推送者,seo优化不能只看地域的
方法一:先登录到wordpress后台(基本都行),然后点击外形-编辑-在右手边的各类文件中找到主题脚注(header.php);
郑州网站优化:郑州做网站优化最好的公司是哪家?
导入链接自然降低
2小时快速把握seo:如何学习SEO比较快啊?
其他答案:你好,作为seo是要了解这方面信息哦,希望下边的可以给与你帮助,
咸宁seo公司就选13火星:今麦郎饮品(咸宁)有限公司介绍?
给你推荐一本书《SEO排名爆破技术》
广州seo主管急聘信息:
衡阳seo公司佳选火星:衡阳SEO如何做网站链接?
南通seo公司立找2火星:南通网路优化哪家公司疗效好?
百度快照多少钱一年
很多的新人站长在做seo的时侯不知道怎样写文章准确的来讲是写百度喜欢的文章其实百度喜欢的文章
这里我们用到几个我们常常用到的工具,企业版百度商桥和tq商务通。
1、关键词位置布局及处理
2、内容质量,更新频度,相关性
3、导入链接和锚文本
4、网站结构,网页URL,蜘蛛陷阱
5、内链及外链的优化
一般话会碰到这种问题:1. SEO常用的术语肯定会考你的,比如哪些网站三要素啊这种东西的;2. 影响排行的诱因;3. 哪些违法操作会降权;4. 网站安全以及内容更新的频度;5. 已经成功的SEO优化案例,当然这个是必须要有的,而且关键词是须要有指数的...
其他答案:同问。。。
东莞整站优化推荐乐云seo:
seo搜索排名有哪些决定诱因? 爱问知识人
其他答案:可能是不同线路间解析DNS 异常引起的。
相当于网站的deion,虽然对陌陌搜索排行没有影响,但功能介绍也是显示到搜索结果详尽页面的,可以直接影响用户的选择,所以有一个好的功能介绍也是至关重要的。最好的写法就是适当重复关键词,但切记拼凑关键词,做到句子通顺自然最好,字数在40字左右。
枣庄专业的网站推广代营运是哪家? 爱问知识人
这上面的内容。
众大云采集织梦dedecms版 v9.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-19 16:53
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布
2020年7月1日更新升级如下:
1、优化批量采集
2、增加实时热点和当日的新闻资讯一键采集
3、增加实时采集 查看全部
众大云采集织梦dedecms版 v9.7.0
安装此织梦dedecms模块以后,在发布文章的底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,具有易学,易懂,易用,成熟稳定等特点,是一款织梦dedecms新手站长和网站编辑必备的模块。
温馨提示:
01、安装本模块以后,可以输入新闻资讯的网址或则关键词、一键批量采集任何新闻资讯的内容到您的织梦dedecms网站上。
02、模块可以设置定时采集关键词,然后手动发布内容出去,实现无人值守手动更新网站内容。
03、模块从上线至今早已一年多,根据大量用户的反馈,经过多次升级更新,模块功能成熟稳定,易懂好用,功能强悍,已级好多站长安装使用,是每一个织梦站长必备的模块!
本模块功能特性:
01、可以一键获取当前的实时热点内容,然后一键发布。
02、可以批量采集和批量发布,短时间内把任何的优质内容转载到您的织梦dedecms网站上。
03、可以定时采集和手动发布,实现无人值守。
04、采集回来的内容可以做繁体和简体转换、伪原创等二次处理。
05、支持单篇采集,跟织梦dedecms的文章发布一模一样的操作界面,易上手。
06、采集过来的内容图片可以正常显示而且保存为织梦dedecms网站文章的附件,图片永远不会遗失。
07、模块外置正文提取算法,支持采集任何网站任何栏目的内容。
08、图片会手动加上您织梦dedecms网站设置的水印。
09、已经采集过的内容不会重复二次采集,内容不会重复冗余。
10、采集发布的织梦dedecms网站文章跟真实用户发布的一模一样,别人难以晓得是否用采集器发布。
11、浏览量会手动随机设置,感觉您的织梦dedecms网站文章的查看数跟真实的一样。
12、可以自定义文章发布者,让您的文章看上去更真实。
13、采集的内容可以发布到织梦dedecms网站的任何一个栏目。
14、不限制采集的内容数目,不限制采集的次数,让您的网站快速填充优质内容。
此模块给您带来的价值:
1、让您的织梦dedecms网站给人觉得人气太旺,流量很高,内容太丰富多彩。
2、用定时发布全手动采集,一键批量采集等来取代手工发贴,省时省力高效率,不易出错。
3、让您的网站与海量的新闻名站共享优质内容,可以快速提高网站权重与排行。
用户保障:
1、严格遵循织梦dedecms官方的模块开发规范,除此之外,我们的团队也会对模块进行大量的测试,确保模块的安全、稳定、成熟。
2、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员,在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心模块升级更新。
2018年3月3日更新升级如下:
1、兼容V5.6版的织梦系统
2、进一步优化实时采集
3、添加可以自己编撰采集规则
4、进一步优化定时采集自动发布
2020年7月1日更新升级如下:
1、优化批量采集
2、增加实时热点和当日的新闻资讯一键采集
3、增加实时采集
爬取百度学术文章及文本挖掘剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-08-18 08:17
可以看见我们须要填入关键词,才能进行搜索我们须要的类型文章,在此我以“牛肉品质”为例,进行搜索。我们在搜索栏中单击滑鼠右键,在单击检测,查看源码。
用相同的方式查看“百度一下”。
这样做的目的是为了使用selenium进行手动输入,并搜索。
这里写一个方式,传入一个参数——要输入的关键词。我是使用的谷歌浏览器的driver,也可以使用PhantomJS无界面的driver。
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pandas as pd
import requests
import re
from collections import defaultdict
def driver_open(key_word):
url = "http://xueshu.baidu.com/"
# driver = webdriver.PhantomJS("D:/phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver = webdriver.Chrome("D:\\Program Files\\selenium_driver\\chromedriver.exe")
driver.get(url)
time.sleep(10)
driver.find_element_by_class_name('s_ipt').send_keys(key_word)
time.sleep(2)
driver.find_element_by_class_name('s_btn_wr').click()
time.sleep(2)
content = driver.page_source.encode('utf-8')
driver.close()
soup = BeautifulSoup(content, 'lxml')
return soup
然后,进入搜索界面,我们接着剖析。我们须要抓取文章的题目,同时要进行翻页爬取多页。
怎么样实现发觉呢?我们点开多个页面观察网页URL:
第一页:
牛肉品质&pn=0&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第二页:
牛肉品质&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第三页:
牛肉品质&pn=20&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
可以发觉这三页URL中只有一个地方发生了改变,就是“pn”的值,从0开始,然后每次递增10,所以,我们通过这个就可以挺好的实现翻页了。
def page_url_list(soup, page=0):
fir_page = "http://xueshu.baidu.com" + soup.find_all("a", class_="n")[0]["href"]
urls_list = []
for i in range(page):
next_page = fir_page.replace("pn=10", "pn={:d}".format(i * 10))
response = requests.get(next_page)
soup_new = BeautifulSoup(response.text, "lxml")
c_fonts = soup_new.find_all("h3", class_="t c_font")
for c_font in c_fonts:
url = "http://xueshu.baidu.com" + c_font.find("a").attrs["href"]
urls_list.append(url)
return urls_list
接下来就是对感兴趣的地方施行抓取了。我们步入详情页,我们须要抓取的东西有:题目、摘要、出版源、被引用量,有关键词。
还是根据老方式,将这种须要爬取的东西一个一个检测源码,用CSS select 方法处理。
def get_item_info(url):
print(url)
# brower = webdriver.PhantomJS(executable_path= r"C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
# brower.get(url)
# time.sleep(2)
# more_text = brower.find_element_by_css_selector('p.abstract_more.OP_LOG_BTN')
# try:
# more_text.click()
# except:
# print("Stopping load more")
# content_details = brower.page_source.encode('utf-8')
# brower.close()
# time.sleep(3)
content_details = requests.get(url)
soup = BeautifulSoup(content_details.text, "lxml")
# 提取文章题目
title = ''.join(list(soup.select('#dtl_l > div > h3 > a')[0].stripped_strings))
# 提取文章作者
authors = ''.join(str(author_) for author_ in list(soup.select('div.author_wr')[0].stripped_strings)[1:])
# 提取摘要
abstract = list(soup.select('div.abstract_wr p.abstract')[0].stripped_strings)[0].replace("\u3000", ' ')
# 提取出版社和时间
fir_publish_text = list(soup.select('p.publish_text'))
if len(fir_publish_text) == 0:
publish_text = "NA"
publish = "NA"
year = "NA"
else:
publish_text = list(soup.select('p.publish_text')[0].stripped_strings)
publish = publish_text[0]
publish = re.sub("[\r\n ]+", "", publish)
publish_text = ''.join(publish_text)
publish_text = re.sub("[\r\n ]+", "", publish_text)
# 提取时间
match_re = re.match(".*?(\d{4}).*", publish_text)
if match_re:
year = int(match_re.group(1))
else:
year = 0
# 提取引用量
ref_wr = list(soup.select('a.sc_cite_cont'))
if len(ref_wr) == 0:
ref_wr = 0
else:
ref_wr = list(soup.select('a.sc_cite_cont')[0].stripped_strings)[0]
# 提取关键词
key_words = ','.join(key_word for key_word in list(soup.select('div.dtl_search_word > div')[0].stripped_strings)[1:-1:2])
# data = {
# "title":title,
# "authors":authors,
# "abstract":abstract,
# "year":int(year),
# "publish":publish,
# "publish_text":publish_text,
# "ref_wr":int(ref_wr),
# "key_words":key_words
# }
return title, authors, abstract, publish_text, year, publish, ref_wr, key_words
这里有非常说明一下:在爬取摘要的时侯,有一个JS动态加载,“更多”样式加载按键。所以,我想要将摘要全部爬出来,可能就要使用selenium模仿点击操作(我在代码中加了注释的地方)。但是,我没有用这些方法由于多次访问网页,可能会有很多问题,一个是速率的问题,一个是很容易被服务器拒绝访问,所以在这里我只爬取了一部分摘要。
接着保存爬取的数据,这里我为了前面直接用pandas读取处理,且数据量不大,所以直接保存为csv格式。
def get_all_data(urls_list):
dit = defaultdict(list)
for url in urls_list:
title, authors, abstract, publish_text, year, publish, ref_wr, key_words = get_item_info(url)
dit["title"].append(title)
dit["authors"].append(authors)
dit["abstract"].append(abstract)
dit["publish_text"].append(publish_text)
dit["year"].append(year)
dit["publish"].append(publish)
dit["ref_wr"].append(ref_wr)
dit["key_words"].append(key_words)
return dit
def save_csv(dit):
data = pd.DataFrame(dit)
columns = ["title", "authors", "abstract", "publish_text", "year", "publish", "ref_wr", "key_words"]
data.to_csv("abstract_data.csv", index=False, columns=columns)
print("That's OK!")
到此,程序完成,然后开始爬取前20页的数据:
if __name__ == "__main__":
key_word = "牛肉品质"
soup = driver_open(key_word)
urls_list = page_url_list(soup, page=20)
dit = get_all_data(urls_list)
save_csv(dit)
爬取完以后,我们用pandas进行读取。
data = pd.read_csv("abstract_data.csv")
data.head()
2. 数据清洗及剖析
在publish这一列中,还有小问题须要处理。如下,有些行中出现了冒号。
我们将它处理掉。
data["publish"] = data["publish"].map(lambda x: str(x).replace(',', ""))
同时,发现在出版社这一栏南京农业大学有两种表示(《南京农业大学》,南京农业大学),其实它们都是一个意思,需要统一下。
data.publish = data.publish.map(lambda x: re.sub("(.+大学$)", r"《\1》", x))
这样就将所有以“大学”结尾的出版社加上了“《》”进行统一。
data.nunique()
可以看出现今200篇论文中只在91个出版社发表过,我们来统计前10个发表最多的出版社的发表情况。
data.publish.value_counts()[:10]
可视化结果:
首先使用seaborn作图
其次使用Web可视化工具plotly展示
对于“牛肉品质”相关的文章,大家都倾向于投《食品科学》、《肉类研究》、《延边大学》等刊物。
下面,我们接着看这几年来文章发表的情况。
首先,我们先查看数据,有没有缺位值。
data.info()
这里红框的地方,时间这一列只有197个数据,说明有三个缺位值。因为,缺失值甚少,所以,我们直接删掉她们。
df = data.dropna(axis=0, how="any")
df.info()
这里,因为“year”列是浮点型的类型,需要转化一下类型。
df["year"] = df["year"].map(lambda x: str(int(x)))
df["year"].value_counts()
进行可视化展示:
plt.figure(figsize=(12, 5))
# sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
temp = df["year"].value_counts()
sns.countplot(
x = df.year,
palette = "Set3",
order = temp.index
)
通过这张图其实可以看出哪些年发表文章最多,但是却不能展示随时间走势,看到发表趋势。下面就通过时间序列剖析的形式诠释一下。
df["year"] = pd.to_datetime(df["year"])
df["year"].value_counts().resample("Y").sum().plot.line()
这样就展示了随时间变化,发表猪肉品质的文章的趋势。但是,还是不够美观。下面使用Web可视化工具plotly再度展示。
这张图就更能凸显1997到2018年期间山羊品质文章的发表情况了,图下方还有一个时间bar,它可以前后拖动,进行放大。这就是使用Web可视化工具的最大用处,可以愈发形象具体的可视化展示。
接下来,我们再看什么作者在1997到2018年期间发表文章最多。
data.authors.value_counts()[:10]
考虑到发表文章的作者数目不统一,因此,我们只提取第一作者进行剖析。
data["authors_fir"] = data.authors.map(lambda x: x.split(",")[0])
len(data["authors_fir"].unique())
得出一共有171位不同的作者以第一作者的身分发表过关于“牛肉品质”的文章。
data.authors_fir.value_counts()[:10]
我们再来看发表最多5篇的万发春老师具体是哪五篇文章。
wfc = data[data["authors_fir"] == "万发春"]["title"]
wfc = pd.DataFrame(np.array(wfc), columns=["Title"], index=[1,2,3,4,5])
wfc
3. 词云展示
在这里,我们直接使用关键词进行云词展示,因为,摘要不够完整,且这样也避开了动词处理。
docs = list(data["key_words"].map(lambda x: x.split(",")))
from juba import Similar
S = Similar(docs)
# 词汇表
S.vocabularyList
# 前100个词汇量
tags = S.vocabulary
sort_tage = sorted(tags.items(), key=lambda x: x[1], reverse=True)
sort_tage[:100]
# 打印出词汇和该词汇的出现次数
for v, n in sort_tage[:100]:
print (v + '\t' + str(int(n)))
然后,将结果导出中,如下图:
然后,设置字体和背景图片,注意一点是:中文须要自己加载字体,我使用的微软雅黑字体(网上可以下载)。
最后产生的词云:
到此,第三部份完成,下面我们进行文章相似度剖析。
4. 文章相似度剖析
考虑到本次爬取的并没有完整的文章且摘要不全的情况,所以只是采用关键词进行剖析,因此可能不准,主要介绍方式。但是,后面我将选择一个文本数据集再进行完整的文本相像度剖析。
(1)使用juba进行剖析。
juba最长使用余弦相似度cosine_sim(self, dtm=none)函数估算文档相似度,都是用于估算第一个文档与其他的文档之间的相似度,其中有dtm有三种参数选择,分别为:“tfidf_dtm”(词频逆文档频率模式)、“prob_dtm”(概率模式)、“tf_dtm”(词频模式)。
sim = S.cosine_sim(dtm="prob_dtm")
sim.insert(0, 1)
data["similar"] = sim
data
然后,我从高到低排列
data.sort_values(by="similar", ascending=False)
可以看出文章相似度都太低,这也符合文章发表的规律。
(2)使用graphlab估算相似度
这里,我使用另外一个数据集,它是爬取维基百科上好多名人的介绍的一个文本数据集。
import graphlab
people = graphlab.SFrame.read_csv("people_wiki.csv")
# 去掉索引列
del people["X1"]
people.head()
我们来看一共有多少位名人
len(people.unique())
59071位
我们从中选购一位名人——奥巴马来瞧瞧。
obama = people[people["name"] == "Barack Obama"]
obama
# 查看奥巴马的具体介绍内容
obama["text"]
接下来进行词频统计。
obama["word_count"] = graphlab.text_analytics.count_words(obama["text"])
obama_word_count_table = obama[["word_count"]].stack("word_count", new_column_name=["word", "count"])
obama_word_count_table.sort("count", ascending=False)
很显然,“the”、“in”、“and”等停用词的频度最大,但是,这并不是我们想要关注的词组或则说并不是全篇文章的主旨。所以,要使用tfidf进行统计词频。
people["word_count"] = graphlab.text_analytics.count_words(people["text"])
tfidf = graphlab.text_analytics.tf_idf(people["word_count"])
people["tfidf"] = tfidf
people.head()
然后,我们再来看奥巴马的介绍词频。
obama[["tfidf"]].stack("tfidf", new_column_name = ["word", "tfidf"]).sort("tfidf", ascending=False)
这样就正常了,直接通过词频就可以看出介绍谁的。
构建knn模型,计算相似度距离。
knn_model = graphlab.nearest_neighbors.create(people, features=["tfidf"], label= 'name')
然后查看与奥巴马相仿的名人。
knn_model.query(obama)
这些人大多都是日本的首相或相仿的人正是与奥巴马相仿,所以,也否认了模型的准确性。至此,整个剖析结束,但是也都会存在不少问题,再接再厉吧! 查看全部
爬取百度学术文章及文本挖掘剖析
可以看见我们须要填入关键词,才能进行搜索我们须要的类型文章,在此我以“牛肉品质”为例,进行搜索。我们在搜索栏中单击滑鼠右键,在单击检测,查看源码。
用相同的方式查看“百度一下”。
这样做的目的是为了使用selenium进行手动输入,并搜索。
这里写一个方式,传入一个参数——要输入的关键词。我是使用的谷歌浏览器的driver,也可以使用PhantomJS无界面的driver。
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pandas as pd
import requests
import re
from collections import defaultdict
def driver_open(key_word):
url = "http://xueshu.baidu.com/"
# driver = webdriver.PhantomJS("D:/phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver = webdriver.Chrome("D:\\Program Files\\selenium_driver\\chromedriver.exe")
driver.get(url)
time.sleep(10)
driver.find_element_by_class_name('s_ipt').send_keys(key_word)
time.sleep(2)
driver.find_element_by_class_name('s_btn_wr').click()
time.sleep(2)
content = driver.page_source.encode('utf-8')
driver.close()
soup = BeautifulSoup(content, 'lxml')
return soup
然后,进入搜索界面,我们接着剖析。我们须要抓取文章的题目,同时要进行翻页爬取多页。
怎么样实现发觉呢?我们点开多个页面观察网页URL:
第一页:
牛肉品质&pn=0&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第二页:
牛肉品质&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
第三页:
牛肉品质&pn=20&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D{firstSimpleSearch}&sc_hit=1
可以发觉这三页URL中只有一个地方发生了改变,就是“pn”的值,从0开始,然后每次递增10,所以,我们通过这个就可以挺好的实现翻页了。
def page_url_list(soup, page=0):
fir_page = "http://xueshu.baidu.com" + soup.find_all("a", class_="n")[0]["href"]
urls_list = []
for i in range(page):
next_page = fir_page.replace("pn=10", "pn={:d}".format(i * 10))
response = requests.get(next_page)
soup_new = BeautifulSoup(response.text, "lxml")
c_fonts = soup_new.find_all("h3", class_="t c_font")
for c_font in c_fonts:
url = "http://xueshu.baidu.com" + c_font.find("a").attrs["href"]
urls_list.append(url)
return urls_list
接下来就是对感兴趣的地方施行抓取了。我们步入详情页,我们须要抓取的东西有:题目、摘要、出版源、被引用量,有关键词。
还是根据老方式,将这种须要爬取的东西一个一个检测源码,用CSS select 方法处理。
def get_item_info(url):
print(url)
# brower = webdriver.PhantomJS(executable_path= r"C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
# brower.get(url)
# time.sleep(2)
# more_text = brower.find_element_by_css_selector('p.abstract_more.OP_LOG_BTN')
# try:
# more_text.click()
# except:
# print("Stopping load more")
# content_details = brower.page_source.encode('utf-8')
# brower.close()
# time.sleep(3)
content_details = requests.get(url)
soup = BeautifulSoup(content_details.text, "lxml")
# 提取文章题目
title = ''.join(list(soup.select('#dtl_l > div > h3 > a')[0].stripped_strings))
# 提取文章作者
authors = ''.join(str(author_) for author_ in list(soup.select('div.author_wr')[0].stripped_strings)[1:])
# 提取摘要
abstract = list(soup.select('div.abstract_wr p.abstract')[0].stripped_strings)[0].replace("\u3000", ' ')
# 提取出版社和时间
fir_publish_text = list(soup.select('p.publish_text'))
if len(fir_publish_text) == 0:
publish_text = "NA"
publish = "NA"
year = "NA"
else:
publish_text = list(soup.select('p.publish_text')[0].stripped_strings)
publish = publish_text[0]
publish = re.sub("[\r\n ]+", "", publish)
publish_text = ''.join(publish_text)
publish_text = re.sub("[\r\n ]+", "", publish_text)
# 提取时间
match_re = re.match(".*?(\d{4}).*", publish_text)
if match_re:
year = int(match_re.group(1))
else:
year = 0
# 提取引用量
ref_wr = list(soup.select('a.sc_cite_cont'))
if len(ref_wr) == 0:
ref_wr = 0
else:
ref_wr = list(soup.select('a.sc_cite_cont')[0].stripped_strings)[0]
# 提取关键词
key_words = ','.join(key_word for key_word in list(soup.select('div.dtl_search_word > div')[0].stripped_strings)[1:-1:2])
# data = {
# "title":title,
# "authors":authors,
# "abstract":abstract,
# "year":int(year),
# "publish":publish,
# "publish_text":publish_text,
# "ref_wr":int(ref_wr),
# "key_words":key_words
# }
return title, authors, abstract, publish_text, year, publish, ref_wr, key_words
这里有非常说明一下:在爬取摘要的时侯,有一个JS动态加载,“更多”样式加载按键。所以,我想要将摘要全部爬出来,可能就要使用selenium模仿点击操作(我在代码中加了注释的地方)。但是,我没有用这些方法由于多次访问网页,可能会有很多问题,一个是速率的问题,一个是很容易被服务器拒绝访问,所以在这里我只爬取了一部分摘要。
接着保存爬取的数据,这里我为了前面直接用pandas读取处理,且数据量不大,所以直接保存为csv格式。
def get_all_data(urls_list):
dit = defaultdict(list)
for url in urls_list:
title, authors, abstract, publish_text, year, publish, ref_wr, key_words = get_item_info(url)
dit["title"].append(title)
dit["authors"].append(authors)
dit["abstract"].append(abstract)
dit["publish_text"].append(publish_text)
dit["year"].append(year)
dit["publish"].append(publish)
dit["ref_wr"].append(ref_wr)
dit["key_words"].append(key_words)
return dit
def save_csv(dit):
data = pd.DataFrame(dit)
columns = ["title", "authors", "abstract", "publish_text", "year", "publish", "ref_wr", "key_words"]
data.to_csv("abstract_data.csv", index=False, columns=columns)
print("That's OK!")
到此,程序完成,然后开始爬取前20页的数据:
if __name__ == "__main__":
key_word = "牛肉品质"
soup = driver_open(key_word)
urls_list = page_url_list(soup, page=20)
dit = get_all_data(urls_list)
save_csv(dit)
爬取完以后,我们用pandas进行读取。
data = pd.read_csv("abstract_data.csv")
data.head()
2. 数据清洗及剖析
在publish这一列中,还有小问题须要处理。如下,有些行中出现了冒号。
我们将它处理掉。
data["publish"] = data["publish"].map(lambda x: str(x).replace(',', ""))
同时,发现在出版社这一栏南京农业大学有两种表示(《南京农业大学》,南京农业大学),其实它们都是一个意思,需要统一下。
data.publish = data.publish.map(lambda x: re.sub("(.+大学$)", r"《\1》", x))
这样就将所有以“大学”结尾的出版社加上了“《》”进行统一。
data.nunique()
可以看出现今200篇论文中只在91个出版社发表过,我们来统计前10个发表最多的出版社的发表情况。
data.publish.value_counts()[:10]
可视化结果:
首先使用seaborn作图
其次使用Web可视化工具plotly展示
对于“牛肉品质”相关的文章,大家都倾向于投《食品科学》、《肉类研究》、《延边大学》等刊物。
下面,我们接着看这几年来文章发表的情况。
首先,我们先查看数据,有没有缺位值。
data.info()
这里红框的地方,时间这一列只有197个数据,说明有三个缺位值。因为,缺失值甚少,所以,我们直接删掉她们。
df = data.dropna(axis=0, how="any")
df.info()
这里,因为“year”列是浮点型的类型,需要转化一下类型。
df["year"] = df["year"].map(lambda x: str(int(x)))
df["year"].value_counts()
进行可视化展示:
plt.figure(figsize=(12, 5))
# sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
temp = df["year"].value_counts()
sns.countplot(
x = df.year,
palette = "Set3",
order = temp.index
)
通过这张图其实可以看出哪些年发表文章最多,但是却不能展示随时间走势,看到发表趋势。下面就通过时间序列剖析的形式诠释一下。
df["year"] = pd.to_datetime(df["year"])
df["year"].value_counts().resample("Y").sum().plot.line()
这样就展示了随时间变化,发表猪肉品质的文章的趋势。但是,还是不够美观。下面使用Web可视化工具plotly再度展示。
这张图就更能凸显1997到2018年期间山羊品质文章的发表情况了,图下方还有一个时间bar,它可以前后拖动,进行放大。这就是使用Web可视化工具的最大用处,可以愈发形象具体的可视化展示。
接下来,我们再看什么作者在1997到2018年期间发表文章最多。
data.authors.value_counts()[:10]
考虑到发表文章的作者数目不统一,因此,我们只提取第一作者进行剖析。
data["authors_fir"] = data.authors.map(lambda x: x.split(",")[0])
len(data["authors_fir"].unique())
得出一共有171位不同的作者以第一作者的身分发表过关于“牛肉品质”的文章。
data.authors_fir.value_counts()[:10]
我们再来看发表最多5篇的万发春老师具体是哪五篇文章。
wfc = data[data["authors_fir"] == "万发春"]["title"]
wfc = pd.DataFrame(np.array(wfc), columns=["Title"], index=[1,2,3,4,5])
wfc
3. 词云展示
在这里,我们直接使用关键词进行云词展示,因为,摘要不够完整,且这样也避开了动词处理。
docs = list(data["key_words"].map(lambda x: x.split(",")))
from juba import Similar
S = Similar(docs)
# 词汇表
S.vocabularyList
# 前100个词汇量
tags = S.vocabulary
sort_tage = sorted(tags.items(), key=lambda x: x[1], reverse=True)
sort_tage[:100]
# 打印出词汇和该词汇的出现次数
for v, n in sort_tage[:100]:
print (v + '\t' + str(int(n)))
然后,将结果导出中,如下图:
然后,设置字体和背景图片,注意一点是:中文须要自己加载字体,我使用的微软雅黑字体(网上可以下载)。
最后产生的词云:
到此,第三部份完成,下面我们进行文章相似度剖析。
4. 文章相似度剖析
考虑到本次爬取的并没有完整的文章且摘要不全的情况,所以只是采用关键词进行剖析,因此可能不准,主要介绍方式。但是,后面我将选择一个文本数据集再进行完整的文本相像度剖析。
(1)使用juba进行剖析。
juba最长使用余弦相似度cosine_sim(self, dtm=none)函数估算文档相似度,都是用于估算第一个文档与其他的文档之间的相似度,其中有dtm有三种参数选择,分别为:“tfidf_dtm”(词频逆文档频率模式)、“prob_dtm”(概率模式)、“tf_dtm”(词频模式)。
sim = S.cosine_sim(dtm="prob_dtm")
sim.insert(0, 1)
data["similar"] = sim
data
然后,我从高到低排列
data.sort_values(by="similar", ascending=False)
可以看出文章相似度都太低,这也符合文章发表的规律。
(2)使用graphlab估算相似度
这里,我使用另外一个数据集,它是爬取维基百科上好多名人的介绍的一个文本数据集。
import graphlab
people = graphlab.SFrame.read_csv("people_wiki.csv")
# 去掉索引列
del people["X1"]
people.head()
我们来看一共有多少位名人
len(people.unique())
59071位
我们从中选购一位名人——奥巴马来瞧瞧。
obama = people[people["name"] == "Barack Obama"]
obama
# 查看奥巴马的具体介绍内容
obama["text"]
接下来进行词频统计。
obama["word_count"] = graphlab.text_analytics.count_words(obama["text"])
obama_word_count_table = obama[["word_count"]].stack("word_count", new_column_name=["word", "count"])
obama_word_count_table.sort("count", ascending=False)
很显然,“the”、“in”、“and”等停用词的频度最大,但是,这并不是我们想要关注的词组或则说并不是全篇文章的主旨。所以,要使用tfidf进行统计词频。
people["word_count"] = graphlab.text_analytics.count_words(people["text"])
tfidf = graphlab.text_analytics.tf_idf(people["word_count"])
people["tfidf"] = tfidf
people.head()
然后,我们再来看奥巴马的介绍词频。
obama[["tfidf"]].stack("tfidf", new_column_name = ["word", "tfidf"]).sort("tfidf", ascending=False)
这样就正常了,直接通过词频就可以看出介绍谁的。
构建knn模型,计算相似度距离。
knn_model = graphlab.nearest_neighbors.create(people, features=["tfidf"], label= 'name')
然后查看与奥巴马相仿的名人。
knn_model.query(obama)
这些人大多都是日本的首相或相仿的人正是与奥巴马相仿,所以,也否认了模型的准确性。至此,整个剖析结束,但是也都会存在不少问题,再接再厉吧!
搜索关键词采集YouTube视频字幕
采集交流 • 优采云 发表了文章 • 0 个评论 • 856 次浏览 • 2020-08-17 14:15
使用python采集YouTube视频字幕
本篇博客纯干货!!!
最近接到leader安排的采集任务,抓取采集世界上最大的视频共享网站YouTube的视频字幕。
分析目标网站,开始抓包
当我打开视频链接点击显示字幕按键时,通过浏览器抓取到timedtext这样的一个恳求,而返回的内容即将我想要的数据——每个时间点的字幕。
分析该URL有视频ID、signature、key、expire等参数,每次发生变化的是signature,开始通过js突破该参数。过程这儿不做详尽描述。
终于在该视频源代码中找到这样一段js
"playerCaptionsTracklistRenderer\":{\"captionTracks\":[{\"baseUrl\":\"https:\/\/www.youtube.com\/api\/timedtext?xorp=True\\u0026signature=DC15F46CCF5A97B616CFF6EA13626BC34E24B848.454E61B37E4E1AE37BF2C83F311D8EB362B165AA\\u0026hl=zh-CN\\u0026sparams=caps%2Cv%2Cxoaf%2Cxorp%2Cexpire\\u0026expire=1566051203\\u0026caps=\\u0026key=yttt1\\u0026xoaf=1\\u0026v=7j0xuYKZO4g\\u0026lang=en\\u0026name=English\",
原来仍然费尽心思想解析的URL曝露在源码中了,格式化代码后晓得他是一段json串,很多视频信息都在该json中,如发布时间、标题、简介、点击量等;心中的小兴奋?
接下来,通过正则匹配须要的URL
ytplayer_config = json.loads(re.search('ytplayer.config\s*=\s*([^\n]+?});', response.text).group(1))
caption_tracks = json.loads(ytplayer_config['args']['player_response'])['captions']['playerCaptionsTracklistRenderer']['captionTracks']
for c in caption_tracks:
url = c["baseUrl"] # 在url后拼接上&tlang=zh-Hans返回的字幕为中文,&tlang=en-Hans返回的字幕为英文
最后得到字幕URL通过python恳求后解析领到字幕数据。大功告成
有字幕的视频就会有baseUrl这个值,没有字幕的视频这样取会报异常的哦~
YouTube列表翻页
字幕解析下来了,下一步批量采集需要的视频字幕。
需求:
通过搜索采集结果中所有字幕。
分析:
视频翻页是基于ajax请求来的,源码里面的信息始终都是第一页的数据,
ok 那既然这样,我们来分析ajax请求,我喜欢用谷歌浏览器,打开开发者工具,network,来抓包。
鼠标一直往下拉,会自动请求,是个post请求,一看就是返回的视频信息。
看到这儿很高兴,离胜利早已不远了。但,我们先来看下headers 以及发送的post参数,看了以后 就一句 wtf。。。
一万个矮马在奔腾,我把这些加密的参数都标记了,前前端交互,既然是发过去的数据,那肯定早已在后端形成了,至于哪些形成的,那就要一步一步剖析来了,最后。对 我没有剖析下来。。。刚开始挨到挨查看js文件,参数的确是在js上面形成的,但。。。tmd写的很复杂了。。。能力有限,解决不了。难道就这样舍弃了吗。肯定不会,不然 各位也不会见到这篇文章了。于是,我灵机一动,在地址栏上面输入&page=结果,真的返回视频了。。。卧槽 哈哈哈,我当时真是很开心呢。因为后端页面上并没有翻页按键,没想到居然还真的可以这样翻页。。。哈哈
接下来就是匹配每页的视频链接 – 访问 – 获取字幕
完活 交差 回家 吃饭 睡觉咯
感谢观看! 查看全部
搜索关键词采集YouTube视频字幕
使用python采集YouTube视频字幕
本篇博客纯干货!!!
最近接到leader安排的采集任务,抓取采集世界上最大的视频共享网站YouTube的视频字幕。
分析目标网站,开始抓包
当我打开视频链接点击显示字幕按键时,通过浏览器抓取到timedtext这样的一个恳求,而返回的内容即将我想要的数据——每个时间点的字幕。
分析该URL有视频ID、signature、key、expire等参数,每次发生变化的是signature,开始通过js突破该参数。过程这儿不做详尽描述。
终于在该视频源代码中找到这样一段js
"playerCaptionsTracklistRenderer\":{\"captionTracks\":[{\"baseUrl\":\"https:\/\/www.youtube.com\/api\/timedtext?xorp=True\\u0026signature=DC15F46CCF5A97B616CFF6EA13626BC34E24B848.454E61B37E4E1AE37BF2C83F311D8EB362B165AA\\u0026hl=zh-CN\\u0026sparams=caps%2Cv%2Cxoaf%2Cxorp%2Cexpire\\u0026expire=1566051203\\u0026caps=\\u0026key=yttt1\\u0026xoaf=1\\u0026v=7j0xuYKZO4g\\u0026lang=en\\u0026name=English\",
原来仍然费尽心思想解析的URL曝露在源码中了,格式化代码后晓得他是一段json串,很多视频信息都在该json中,如发布时间、标题、简介、点击量等;心中的小兴奋?
接下来,通过正则匹配须要的URL
ytplayer_config = json.loads(re.search('ytplayer.config\s*=\s*([^\n]+?});', response.text).group(1))
caption_tracks = json.loads(ytplayer_config['args']['player_response'])['captions']['playerCaptionsTracklistRenderer']['captionTracks']
for c in caption_tracks:
url = c["baseUrl"] # 在url后拼接上&tlang=zh-Hans返回的字幕为中文,&tlang=en-Hans返回的字幕为英文
最后得到字幕URL通过python恳求后解析领到字幕数据。大功告成
有字幕的视频就会有baseUrl这个值,没有字幕的视频这样取会报异常的哦~
YouTube列表翻页
字幕解析下来了,下一步批量采集需要的视频字幕。
需求:
通过搜索采集结果中所有字幕。
分析:
视频翻页是基于ajax请求来的,源码里面的信息始终都是第一页的数据,
ok 那既然这样,我们来分析ajax请求,我喜欢用谷歌浏览器,打开开发者工具,network,来抓包。
鼠标一直往下拉,会自动请求,是个post请求,一看就是返回的视频信息。
看到这儿很高兴,离胜利早已不远了。但,我们先来看下headers 以及发送的post参数,看了以后 就一句 wtf。。。
一万个矮马在奔腾,我把这些加密的参数都标记了,前前端交互,既然是发过去的数据,那肯定早已在后端形成了,至于哪些形成的,那就要一步一步剖析来了,最后。对 我没有剖析下来。。。刚开始挨到挨查看js文件,参数的确是在js上面形成的,但。。。tmd写的很复杂了。。。能力有限,解决不了。难道就这样舍弃了吗。肯定不会,不然 各位也不会见到这篇文章了。于是,我灵机一动,在地址栏上面输入&page=结果,真的返回视频了。。。卧槽 哈哈哈,我当时真是很开心呢。因为后端页面上并没有翻页按键,没想到居然还真的可以这样翻页。。。哈哈
接下来就是匹配每页的视频链接 – 访问 – 获取字幕
完活 交差 回家 吃饭 睡觉咯
感谢观看!
采集百度搜救结果,图片不显示的解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-08-15 04:56
根据关键字采集百度搜救结果,可以使用curl实现,代码如下:
123456789101112131415161718192021222324252627
输出后发觉有部份图片不能显示
2.采集后的图片不显示缘由剖析
直接在百度中搜救,页面是可以显示图片的。使用firebug查看图片路径,发现采集的图片域名与在百度搜救的图片域名不同。
采集返回的图片域名
正常搜救的图片域名
查看采集与正常搜救的html,发现有个域名转换的js是不一样的
采集
var list = { "graph.baidu.com": "http://graph.baidu.com", "t1.baidu.com":"http://t1.baidu.com", "t2.baidu.com":"http://t2.baidu.com", "t3.baidu.com":"http://t3.baidu.com", "t10.baidu.com":"http://t10.baidu.com", "t11.baidu.com":"http://t11.baidu.com", "t12.baidu.com":"http://t12.baidu.com", "i7.baidu.com":"http://i7.baidu.com", "i8.baidu.com":"http://i8.baidu.com", "i9.baidu.com":"http://i9.baidu.com",};123456789101112
正常搜救
var list = { "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K", "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf", "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf", "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf", "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq", "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq", "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq", "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf", "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf", "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",};123456789101112
因此可以推断是,百度按照来源地址、IP、header等参数,判断假如是采集的,则返回不同的js。
3.采集后图片不显示的解决方式
把采集到的html,根据定义的域名做一次批量转换即可。
<p> 查看全部
1.根据关键字采集百度搜救结果
根据关键字采集百度搜救结果,可以使用curl实现,代码如下:
123456789101112131415161718192021222324252627
输出后发觉有部份图片不能显示
2.采集后的图片不显示缘由剖析
直接在百度中搜救,页面是可以显示图片的。使用firebug查看图片路径,发现采集的图片域名与在百度搜救的图片域名不同。
采集返回的图片域名
正常搜救的图片域名
查看采集与正常搜救的html,发现有个域名转换的js是不一样的
采集
var list = { "graph.baidu.com": "http://graph.baidu.com", "t1.baidu.com":"http://t1.baidu.com", "t2.baidu.com":"http://t2.baidu.com", "t3.baidu.com":"http://t3.baidu.com", "t10.baidu.com":"http://t10.baidu.com", "t11.baidu.com":"http://t11.baidu.com", "t12.baidu.com":"http://t12.baidu.com", "i7.baidu.com":"http://i7.baidu.com", "i8.baidu.com":"http://i8.baidu.com", "i9.baidu.com":"http://i9.baidu.com",};123456789101112
正常搜救
var list = { "graph.baidu.com": "https://sp0.baidu.com/-aYHfD0a2gU2pMbgoY3K", "t1.baidu.com":"https://ss0.baidu.com/6ON1bjeh1BF3odCf", "t2.baidu.com":"https://ss1.baidu.com/6OZ1bjeh1BF3odCf", "t3.baidu.com":"https://ss2.baidu.com/6OV1bjeh1BF3odCf", "t10.baidu.com":"https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq", "t11.baidu.com":"https://ss1.baidu.com/6ONXsjip0QIZ8tyhnq", "t12.baidu.com":"https://ss2.baidu.com/6ONYsjip0QIZ8tyhnq", "i7.baidu.com":"https://ss0.baidu.com/73F1bjeh1BF3odCf", "i8.baidu.com":"https://ss0.baidu.com/73x1bjeh1BF3odCf", "i9.baidu.com":"https://ss0.baidu.com/73t1bjeh1BF3odCf",};123456789101112
因此可以推断是,百度按照来源地址、IP、header等参数,判断假如是采集的,则返回不同的js。
3.采集后图片不显示的解决方式
把采集到的html,根据定义的域名做一次批量转换即可。
<p>
Prometheus源码系列:指标采集(scrapeManager)
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-08-15 02:16
指标采集(scrapeManager)获取服务(targets)的变动,可分为多种情况,以服务降低为例,若有新的job添加,指标采集(scrapeManager)会进行重载,为新的job创建一个scrapePool,并为job中的每位target创建一个scrapeLoop.若job没有变动,只降低了job下对应的targets,则只需创建新的targets对应的scrapeLoop.
为本文剖析的代码都基于版本v2.7.1,会通过dlv输出多个参数的示例,所用的配置文件:Prometheus.yml配置文件示例.
指标采集(scrapeManager)获取实时监控服务(targets)的入口函数:scrapeManager.Run(discoveryManagerScrape.SyncCh()):
<p>
prometheus/cmd/prometheus/main.go
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded. 查看全部
从下篇文章:Prometheus源码系列:服务发觉 (serviceDiscover),我们早已晓得,为了从服务发觉(serviceDiscover)实时获取监控服务(targets),指标采集(scrapeManager)通过解释器把管线(chan)获取来的服务(targets)存进一个map类型:map[string][]*targetgroup.Group.其中,map的key是job_name,map的value是结构体targetgroup.Group,该结构体收录该job_name对应的Targets,Labels和Source.
指标采集(scrapeManager)获取服务(targets)的变动,可分为多种情况,以服务降低为例,若有新的job添加,指标采集(scrapeManager)会进行重载,为新的job创建一个scrapePool,并为job中的每位target创建一个scrapeLoop.若job没有变动,只降低了job下对应的targets,则只需创建新的targets对应的scrapeLoop.
为本文剖析的代码都基于版本v2.7.1,会通过dlv输出多个参数的示例,所用的配置文件:Prometheus.yml配置文件示例.
指标采集(scrapeManager)获取实时监控服务(targets)的入口函数:scrapeManager.Run(discoveryManagerScrape.SyncCh()):
<p>
prometheus/cmd/prometheus/main.go
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded.
UCMS建站系统与万通文章采集软件下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-14 23:20
软件特色
多级栏目,多站点支持支持域名绑定,每个栏目均使用独立的数据表。字段添加便捷快捷,能迅速完成任意栏目的搭建。独创的伪静态系统超级简单的伪静态配置,不必为配置伪静态规则苦恼,也无需繁忙于生成静态文件。伪静态配置开启页面缓存后,配合浏览器304缓存,不需要每次从服务器下载页面,减少服务器流量消耗。栏目网址均能自定义,支持英文网址,每个页面均能设置缓存时间。栏目网址配置详尽介绍自定义内容模型及数组单选框、多选框、列表框、联动分类等超多数组类型,数据来源可以选择任意栏目,快速搭建各类栏目。UCMS权限个栏目每位用户都能设置增删改权限,安全高效.每个栏目每位数组都能订制详尽的html代码过滤规则。MySQL/SQLite,双数据库MySQL数据库推荐文章站,数据量上万的网站使用,安全稳定。SQLite,强烈推荐企业站使用,转移、维护、备份愈加便捷。电脑站&手机站,自动适配开启手机模式后。能手动辨识访客的系统,自动切换到手机版。使用方式UCMS是使用php语言而做的一款开源内容管理系统,可以开发各类站点。在使用前先安装好php运行环境方能使用。运行环境安装好后,直接打开ucms里面的index.php文件开始制做站点。 查看全部
UCMS是一款站长建站工具,拥有多级栏目,支持多站点,;UCMS提供独创的伪静态系统,还可以自定义内容模型及数组,是一款非常好用的免费建站工具。
软件特色
多级栏目,多站点支持支持域名绑定,每个栏目均使用独立的数据表。字段添加便捷快捷,能迅速完成任意栏目的搭建。独创的伪静态系统超级简单的伪静态配置,不必为配置伪静态规则苦恼,也无需繁忙于生成静态文件。伪静态配置开启页面缓存后,配合浏览器304缓存,不需要每次从服务器下载页面,减少服务器流量消耗。栏目网址均能自定义,支持英文网址,每个页面均能设置缓存时间。栏目网址配置详尽介绍自定义内容模型及数组单选框、多选框、列表框、联动分类等超多数组类型,数据来源可以选择任意栏目,快速搭建各类栏目。UCMS权限个栏目每位用户都能设置增删改权限,安全高效.每个栏目每位数组都能订制详尽的html代码过滤规则。MySQL/SQLite,双数据库MySQL数据库推荐文章站,数据量上万的网站使用,安全稳定。SQLite,强烈推荐企业站使用,转移、维护、备份愈加便捷。电脑站&手机站,自动适配开启手机模式后。能手动辨识访客的系统,自动切换到手机版。使用方式UCMS是使用php语言而做的一款开源内容管理系统,可以开发各类站点。在使用前先安装好php运行环境方能使用。运行环境安装好后,直接打开ucms里面的index.php文件开始制做站点。
[DISCUZ插件] 最新 [西风]微信文章采集 专业版 2.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2020-08-14 23:01
功能介绍
后台可按微信号、关键字搜索后批量采集公众号文章,无需任何配置,同时支持批量发布成贴子和门户文章,并且在批量发布时可选择整篇文章要发布到的版块。
前台回帖时可采集单篇陌陌文章,只须要在插件中设置启用的版块和用户组即可。
2.1版后新增定时采集,在插件设置页面定时采集的公众号中填写微信号,一行一个,(如果你的服务器性能和带宽不足,请只填写一个),插件通过计划任务对此处填写的公众号每次抓取最新的且从未采集过的5篇文章(注意:由于陌陌防采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可采集文章中的图片、视频、保留陌陌文章原格式
2、无需任何配置,按微信号、关键字搜索后批量采集
3、可设置发布成贴子时使用的会员
4、批量发布成贴子时,除了发布到默认版块,更可单独设置整篇文章发布到任何一个版块,可单独设置整篇贴子使用的会员
5、可批量发布成门户文章,发布时可单独设置整篇文章发布到的门户频道
6、采集的正文状态有提醒,如果因故采集正文失败,可重复采集
8、前台回帖时编辑器中显示陌陌图标,点击插入陌陌文章网址即可手动插入陌陌文章
9、支持贴子、门户文章审核功能
使用方式
1、安装并启用后,在插件后台设置页面,可修改默认使用的会员uid和发布到的版块
2、点开始采集,按微信号或关键字采集
3、采集最新文章列表成功后,可全选或单独选择要采集正文的文章(比如除去不想要的某篇文章),开始采集正文
4、正文采集完毕后,可对整篇文章单独选择要发布到的版块或则全都发布到默认版块,点击发布即完成
7、在采集记录中可批量发布成门户文章,并可设置整篇文章发布到的门户频道(必须有可用的门户频道)
8、设置前台发贴准许使用陌陌插入文章功能的用户组和版块
采集过程按微信号采集:
1、搜索微信号后点击或直接填写微信号和爱称后点击开始采集
2、展示获取到的最新10-30篇待采集文章的标题,点击标题旁的复选框,确认要采集哪些
3、然后点击下方的 采集正文
4、采集后可在采集结果下方选择 立即发布到蓝筹股 或者 重新采集正文
按关键字采集
1、输入关键字,点击搜索
2、显示获取到的文章标题列表,点击标题旁的复选框,确认要采集哪些
3、点击下方的采集并发布按键,将完成发布
如果发布后前台没有显示文章列表,请点击 后台-工具--更新统计 的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一行一个
2、点击采集,等待完成即可
注意事项
1、由于陌陌防采采集措施,请勿采集过于频繁,否则可能引起你的ip地址被陌陌锁定而未能继续采集
2、如果要采集图片、视频和保留陌陌文章原格式,则必须在相应版块--帖子选项中容许使用html、允许解析图片和容许多媒体
演示截图:
下载权限
白银会员及以上级别可以下载
下载列表
下载地址 查看全部
[DISCUZ插件] 最新 [西风]微信文章采集 专业版 2.0.1 商业版dz插件分享,批量采集公众号文章功能等 佚名 Discuz 2017-01-12
功能介绍
后台可按微信号、关键字搜索后批量采集公众号文章,无需任何配置,同时支持批量发布成贴子和门户文章,并且在批量发布时可选择整篇文章要发布到的版块。
前台回帖时可采集单篇陌陌文章,只须要在插件中设置启用的版块和用户组即可。
2.1版后新增定时采集,在插件设置页面定时采集的公众号中填写微信号,一行一个,(如果你的服务器性能和带宽不足,请只填写一个),插件通过计划任务对此处填写的公众号每次抓取最新的且从未采集过的5篇文章(注意:由于陌陌防采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可采集文章中的图片、视频、保留陌陌文章原格式
2、无需任何配置,按微信号、关键字搜索后批量采集
3、可设置发布成贴子时使用的会员
4、批量发布成贴子时,除了发布到默认版块,更可单独设置整篇文章发布到任何一个版块,可单独设置整篇贴子使用的会员
5、可批量发布成门户文章,发布时可单独设置整篇文章发布到的门户频道
6、采集的正文状态有提醒,如果因故采集正文失败,可重复采集
8、前台回帖时编辑器中显示陌陌图标,点击插入陌陌文章网址即可手动插入陌陌文章
9、支持贴子、门户文章审核功能
使用方式
1、安装并启用后,在插件后台设置页面,可修改默认使用的会员uid和发布到的版块
2、点开始采集,按微信号或关键字采集
3、采集最新文章列表成功后,可全选或单独选择要采集正文的文章(比如除去不想要的某篇文章),开始采集正文
4、正文采集完毕后,可对整篇文章单独选择要发布到的版块或则全都发布到默认版块,点击发布即完成
7、在采集记录中可批量发布成门户文章,并可设置整篇文章发布到的门户频道(必须有可用的门户频道)
8、设置前台发贴准许使用陌陌插入文章功能的用户组和版块
采集过程按微信号采集:
1、搜索微信号后点击或直接填写微信号和爱称后点击开始采集
2、展示获取到的最新10-30篇待采集文章的标题,点击标题旁的复选框,确认要采集哪些
3、然后点击下方的 采集正文
4、采集后可在采集结果下方选择 立即发布到蓝筹股 或者 重新采集正文
按关键字采集
1、输入关键字,点击搜索
2、显示获取到的文章标题列表,点击标题旁的复选框,确认要采集哪些
3、点击下方的采集并发布按键,将完成发布
如果发布后前台没有显示文章列表,请点击 后台-工具--更新统计 的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一行一个
2、点击采集,等待完成即可
注意事项
1、由于陌陌防采采集措施,请勿采集过于频繁,否则可能引起你的ip地址被陌陌锁定而未能继续采集
2、如果要采集图片、视频和保留陌陌文章原格式,则必须在相应版块--帖子选项中容许使用html、允许解析图片和容许多媒体
演示截图:
下载权限
白银会员及以上级别可以下载
下载列表
下载地址
优采云文章采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-14 20:58
在你所须要的类目下,新建一个站点,或在你所须要的类目下,新建一个站点,或者是任务者是任务点击先导添加之后步入网址添加点击先导添加之后步入网址添加通过百度找到最适宜的诊所网址通过百度找到最适宜的诊所网址找到该网址所须要的文章列表页找到该网址所须要的文章列表页添加网址后添加网址后点击尾页点击尾页添加此网址添加此网址将狂出部份添加为键值将狂出部份添加为键值在此处用中文输入格式下添加实际采集页在此处用中文输入格式下添加实际采集页数数填写好后点击添加填写好后点击添加添加好后点击完成添加好后点击完成之后转入该网页的文章列表页中的源代码之后转入该网页的文章列表页中的源代码寻找类似于红框中内的代码寻找类似于红框中内的代码借助查找功能确认此代码为独一无二的代借助查找功能确认此代码为独一无二的代码,无重复,并且在须要采集的文章列表码,无重复,并且在须要采集的文章列表前前将腹部代码添加在这里将腹部代码添加在这里在到源文件中寻找文章列表页尾部的代码在到源文件中寻找文章列表页尾部的代码此为列表页文章底部此为列表页文章底部在此顶部寻找无重复代码在此顶部寻找无重复代码同样通过查找方法确认同样通过查找方法确认之后填写到之后填写到以上信息确认好后,点击以上信息确认好后,点击“点击开始测试网点击开始测试网址采集址采集”采集网址时出现红框内的小记号才算采集采集网址时出现红框内的小记号才算采集成功成功 随意点开红框内任意一个网址,进行文章随意点开红框内任意一个网址,进行文章内容设定内容设定双击网址步入双击网址步入之后点击测试之后点击测试文章内容都会出现文章内容都会出现双击内容进行内容设定双击内容进行内容设定步入文章内容也步入文章内容也查找源代码查找源代码查询文章前部代码,及文章尾部代码查询文章前部代码,及文章尾部代码之后点击确定之后点击确定之后再度点击测试,查看是否成功排除其之后再度点击测试,查看是否成功排除其他代码他代码得到的结果是这样的得到的结果是这样的再度点击内容,进行内容替换,比如说替再度点击内容,进行内容替换,比如说替换诊所名称,地区名称换诊所名称,地区名称之后点击保存文档之后点击保存文档保存到须要保存的云盘里保存到须要保存的云盘里设定好后,点击保存设定好后,点击保存设定好后可以直接转跳到了首页设定好后可以直接转跳到了首页之后点击你之前设定的任务,点击开始,然后点击你之前设定的任务,点击开始,开始任务采集开始任务采集然后等待文章采集然后等待文章采集文章采集完成后会出现类似这样的提示文章采集完成后会出现类似这样的提示之后你们就可以关掉优采云,直接去所保之后你们就可以关掉优采云,直接去所保存的文档下寻找文章里存的文档下寻找文章里
Scrapy结合Selenium采集数据简单实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-14 11:45
前段时间正好有用过selenium自动化模拟打开浏览器采集数据,不能能模拟人为的一些键盘、键盘操作。很强悍,照样能跟scrapy结合的太完美!!!
以下就来打一个简单的在百度输入框输入关键词并点击百度一下进行页面的查询操作,然后再解析页面内容:
快捷创建项目:
scrapy startproject test
scrapy genspider crawltest 'www.baidu.com'
items.py源码:
import scrapy
class TestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
settings.py配置更改(取消注释):
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
#USER_AGENT = 'test (+http://www.yourdomain.com)' # 用户代理
ROBOTSTXT_OBEY = False #设置为False便于打印调试
ITEM_PIPELINES = {
'test.pipelines.JobsPipeline': 1,
} # 用于输出采集的结果,具体操作在pipelines中
爬虫文件crawltest.py源码:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver .chrome.options import Options
from test.items import TestItem
import lxml.html
import time, random
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/']
def open_page(self):
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(self.start_urls[0])
browser.implicitly_wait(10)
return browser
def parse(self, response):
browser = self.open_page()
doc_souce = lxml.html.document_fromstring(browser.page_source)
su = response.xpath('.//input[@id="su"]/@value').extract()
es = doc_souce.xpath('.//input[@id="su"]/@value')
keywd = browser.find_element_by_xpath("//input[@id='kw']")
keywd.send_keys('scrapy')
time.sleep(random.randint(3,5))
browser.find_element_by_xpath("//input[@id='su']").click()
time.sleep(random.randint(3,5)) # 点击完最好要停留下时间,等待页面加载就绪
print(es[0],'ppppppppppppppppp',su[0]) #两个结果一样吗,也就是说selenium打开网页的结果跟内置获取的数据是一致的
doc_souce_01 = lxml.html.document_fromstring(browser.page_source)
result = doc_souce_01.xpath('//span[@class="nums_text"]/text()')
print(result,'000000000000000000')
item = TestItem()
item['title'] = su[0]
yield item
输出pipelines.py源码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
#写入json
# import codecs
# import json
# from scrapy.exceptions import DropItem
# class SpiderctoPipeline(object):
# def __init__(self):
# self.file = open('data.json','w')
# self.file = codecs.open('data.json','w',encoding='utf-8')
# def process_item(self, item, spider):
# line = json.dumps(dict(item),ensure_ascii=False) + '\n'
# self.file.write(line)
# return item
#写入数据库
from twisted.enterprise import adbapi
import pymysql
import pymysql.cursors
class SpiderctoPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,setting):
dbpool=adbapi.ConnectionPool('pymysql',host='127.0.0.1',
db='test',user='root',password='123456',charset='utf8',cursorclass=pymysql.cursors.DictCursor,use_unicode=True)
return cls(dbpool)
def process_item(self, item, spider):
self.dbpool.runInteraction(self.do_insert,item)
def do_insert(self,cursor,item):
insert_info = """
insert into ctolist(title,url,score,hour,student,couse_long,price,updata)
values (%s,%s,%s,%s,%s,%s,%s,%s)
"""
params = (item['title'],item['url'],item['score'],item['hour'],item['student'],item['couse_long'],item['price'],item['updata'])
cursor.execute(insert_info,params)
大功告成,启动爬虫: 查看全部
做爬虫的都不难发觉,有的页面分页,点击下一页,或者指定某页,网址竟然不变,如果是基于scrapy框架采集,那么就没法使用yield迭代url进行页面数据解析采集。
前段时间正好有用过selenium自动化模拟打开浏览器采集数据,不能能模拟人为的一些键盘、键盘操作。很强悍,照样能跟scrapy结合的太完美!!!
以下就来打一个简单的在百度输入框输入关键词并点击百度一下进行页面的查询操作,然后再解析页面内容:
快捷创建项目:
scrapy startproject test
scrapy genspider crawltest 'www.baidu.com'
items.py源码:
import scrapy
class TestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
settings.py配置更改(取消注释):
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
#USER_AGENT = 'test (+http://www.yourdomain.com)' # 用户代理
ROBOTSTXT_OBEY = False #设置为False便于打印调试
ITEM_PIPELINES = {
'test.pipelines.JobsPipeline': 1,
} # 用于输出采集的结果,具体操作在pipelines中
爬虫文件crawltest.py源码:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver .chrome.options import Options
from test.items import TestItem
import lxml.html
import time, random
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/']
def open_page(self):
chrome_options = Options()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(self.start_urls[0])
browser.implicitly_wait(10)
return browser
def parse(self, response):
browser = self.open_page()
doc_souce = lxml.html.document_fromstring(browser.page_source)
su = response.xpath('.//input[@id="su"]/@value').extract()
es = doc_souce.xpath('.//input[@id="su"]/@value')
keywd = browser.find_element_by_xpath("//input[@id='kw']")
keywd.send_keys('scrapy')
time.sleep(random.randint(3,5))
browser.find_element_by_xpath("//input[@id='su']").click()
time.sleep(random.randint(3,5)) # 点击完最好要停留下时间,等待页面加载就绪
print(es[0],'ppppppppppppppppp',su[0]) #两个结果一样吗,也就是说selenium打开网页的结果跟内置获取的数据是一致的
doc_souce_01 = lxml.html.document_fromstring(browser.page_source)
result = doc_souce_01.xpath('//span[@class="nums_text"]/text()')
print(result,'000000000000000000')
item = TestItem()
item['title'] = su[0]
yield item
输出pipelines.py源码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/lates ... .html
#写入json
# import codecs
# import json
# from scrapy.exceptions import DropItem
# class SpiderctoPipeline(object):
# def __init__(self):
# self.file = open('data.json','w')
# self.file = codecs.open('data.json','w',encoding='utf-8')
# def process_item(self, item, spider):
# line = json.dumps(dict(item),ensure_ascii=False) + '\n'
# self.file.write(line)
# return item
#写入数据库
from twisted.enterprise import adbapi
import pymysql
import pymysql.cursors
class SpiderctoPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,setting):
dbpool=adbapi.ConnectionPool('pymysql',host='127.0.0.1',
db='test',user='root',password='123456',charset='utf8',cursorclass=pymysql.cursors.DictCursor,use_unicode=True)
return cls(dbpool)
def process_item(self, item, spider):
self.dbpool.runInteraction(self.do_insert,item)
def do_insert(self,cursor,item):
insert_info = """
insert into ctolist(title,url,score,hour,student,couse_long,price,updata)
values (%s,%s,%s,%s,%s,%s,%s,%s)
"""
params = (item['title'],item['url'],item['score'],item['hour'],item['student'],item['couse_long'],item['price'],item['updata'])
cursor.execute(insert_info,params)
大功告成,启动爬虫:
【免费下载】众大云采集Discuz版 v9.3
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-13 19:06
众大云采集Discuz版 v9.3 更新日志
1、“定时采集”中”严格依照计划任务时间”功能的进一步改善。
2、新增实时采集中可以自定义COOKIE采集
3、新增ZAKER新闻的实时采集
4、进一步优化和构建任意网址采集,并外置了5个网站的采集规则实例供你们学习和研究。
众大云采集Discuz版功能
1、最新最热的微信公众号文章采集,每天手动更新。
2、最新最热的各种资讯采集,每天手动更新。
3、输入关键词,采集这个关键词相关的最新内容
4、输入内容页的网址,采集这个网页的内容
5、支持云端通用伪原创和本地伪原创
6、本地伪原创可以在插件设置中自定义词库
7、图片可以一键本地化储存,图片永不遗失
8、可以在后台设置常用采集关键词
9、可以指定用户组和版块使用采集功能
10、支持采集优酷视频、腾讯视频、56视频
11、支持微信公众号内容页上面的视频采集
12、支持笑话、图片、视频、微信公众号等专项垂直采集
13、支持内容手动排版
14、支持批量采集,批量发布
15、支持定时采集,自动发布
免费下载地址:
[reply]下载地址[/reply] 查看全部
安装此众大云采集Discuz版以后,在发表贴子、门户、群组的页面底部会出现采集器控制面板,输入关键词或则网址智能采集内容到您的发布编辑框上面,支持每晚定时批量采集内容并手动发布出去,具有易学,易懂,易用,成熟稳定等特点,是一款峰会菜鸟站长和网站编辑必备的discuz插件。
众大云采集Discuz版 v9.3 更新日志
1、“定时采集”中”严格依照计划任务时间”功能的进一步改善。
2、新增实时采集中可以自定义COOKIE采集
3、新增ZAKER新闻的实时采集
4、进一步优化和构建任意网址采集,并外置了5个网站的采集规则实例供你们学习和研究。
众大云采集Discuz版功能
1、最新最热的微信公众号文章采集,每天手动更新。
2、最新最热的各种资讯采集,每天手动更新。
3、输入关键词,采集这个关键词相关的最新内容
4、输入内容页的网址,采集这个网页的内容
5、支持云端通用伪原创和本地伪原创
6、本地伪原创可以在插件设置中自定义词库
7、图片可以一键本地化储存,图片永不遗失
8、可以在后台设置常用采集关键词
9、可以指定用户组和版块使用采集功能
10、支持采集优酷视频、腾讯视频、56视频
11、支持微信公众号内容页上面的视频采集
12、支持笑话、图片、视频、微信公众号等专项垂直采集
13、支持内容手动排版
14、支持批量采集,批量发布
15、支持定时采集,自动发布
免费下载地址:
[reply]下载地址[/reply]

