
关键词文章采集源码
关键词文章采集源码文章爬虫各种方法的优缺点使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-04-22 04:02
关键词文章采集源码文章爬虫各种方法的优缺点使用爬虫的目的是快速的实现快速的高并发的分布式爬虫,同时还可以减少爬虫存储和访问的数据量,同时还可以达到分布式部署的优势。爬虫的爬取方式主要分为几种,一种是直接手动写逻辑来爬,也就是上一篇说的在浏览器中加载js(也叫webcookie)获取下一页数据,这种方式可能需要对服务器、反爬虫服务器进行改造才能跑起来,而且对服务器的性能要求比较高,这种方式可能很多中小型爬虫很难驾驭,同时爬虫还需要有很多实际的问题需要解决,如遇到实时性要求高的情况下,可能无法保证直接爬数据,而采用redis等代替是比较合适的方式,又可以存储全量数据,又可以通过nosql储存,无论是效率还是可读性都很好,但是有一些问题。
第二种是api定制爬虫方式,其实是使用前端的restapi来接收,直接将数据发送给后端服务器进行存储处理。存储则是mongodb、golang等都可以直接存储数据,前端的接收则基本使用json格式,存储也是使用redis。这种爬虫可以通过api定制服务器和爬虫,但是没有像直接手动写逻辑一样能做规划,可读性欠佳,同时对于内容页面的爬取可能会有很多问题。
第三种方式是使用redis定制爬虫,把爬虫交给专业人员定制,然后可以自定义爬虫进行运维和部署,这种方式是最简单高效的方式,也是中小型爬虫一定可以用到的方法,但是对于服务器要求可能比较高,所以也是对人员要求比较高的方式。存储则是使用mongodb,redis等都可以,部署也是常规的方式。对于个人开发者来说,普遍采用的爬虫爬取方式就是这三种,而使用简单、功能强大、易学好用的redis定制爬虫也是目前一个不错的选择。
下面对这三种方式的工作流程做一下详细的描述,如果对这方面感兴趣可以看看我在问卷中的答卷,有兴趣的朋友可以试试:如何使用爬虫?-腾讯云计算采集数据和数据库是两个很容易混淆的词,但是它们之间确实有着很大的联系。数据源:数据来源的选择是前端定制爬虫的首要问题,在选择上,需要把爬虫能爬取的网站做细化,比如确定是爬取按分类划分的网站,然后是按网站分类来爬取,比如按wap还是直接pc端的网站,如果爬取时分类划分做细了,你还要细分爬取的网站标签,如将来爬取pc端的网站,还需要再细分爬取标签,这些标签需要和url配对来完成,具体的方法可以参考中心化存储和分布式存储的比较,我就不在这里赘述了。
本次选择redisredis是一个轻量级内存数据库,它的存储空间很小,支持数据类型多,这就使得数据存储非常简单,数据结构也比较灵活,在各。 查看全部
关键词文章采集源码文章爬虫各种方法的优缺点使用
关键词文章采集源码文章爬虫各种方法的优缺点使用爬虫的目的是快速的实现快速的高并发的分布式爬虫,同时还可以减少爬虫存储和访问的数据量,同时还可以达到分布式部署的优势。爬虫的爬取方式主要分为几种,一种是直接手动写逻辑来爬,也就是上一篇说的在浏览器中加载js(也叫webcookie)获取下一页数据,这种方式可能需要对服务器、反爬虫服务器进行改造才能跑起来,而且对服务器的性能要求比较高,这种方式可能很多中小型爬虫很难驾驭,同时爬虫还需要有很多实际的问题需要解决,如遇到实时性要求高的情况下,可能无法保证直接爬数据,而采用redis等代替是比较合适的方式,又可以存储全量数据,又可以通过nosql储存,无论是效率还是可读性都很好,但是有一些问题。
第二种是api定制爬虫方式,其实是使用前端的restapi来接收,直接将数据发送给后端服务器进行存储处理。存储则是mongodb、golang等都可以直接存储数据,前端的接收则基本使用json格式,存储也是使用redis。这种爬虫可以通过api定制服务器和爬虫,但是没有像直接手动写逻辑一样能做规划,可读性欠佳,同时对于内容页面的爬取可能会有很多问题。
第三种方式是使用redis定制爬虫,把爬虫交给专业人员定制,然后可以自定义爬虫进行运维和部署,这种方式是最简单高效的方式,也是中小型爬虫一定可以用到的方法,但是对于服务器要求可能比较高,所以也是对人员要求比较高的方式。存储则是使用mongodb,redis等都可以,部署也是常规的方式。对于个人开发者来说,普遍采用的爬虫爬取方式就是这三种,而使用简单、功能强大、易学好用的redis定制爬虫也是目前一个不错的选择。
下面对这三种方式的工作流程做一下详细的描述,如果对这方面感兴趣可以看看我在问卷中的答卷,有兴趣的朋友可以试试:如何使用爬虫?-腾讯云计算采集数据和数据库是两个很容易混淆的词,但是它们之间确实有着很大的联系。数据源:数据来源的选择是前端定制爬虫的首要问题,在选择上,需要把爬虫能爬取的网站做细化,比如确定是爬取按分类划分的网站,然后是按网站分类来爬取,比如按wap还是直接pc端的网站,如果爬取时分类划分做细了,你还要细分爬取的网站标签,如将来爬取pc端的网站,还需要再细分爬取标签,这些标签需要和url配对来完成,具体的方法可以参考中心化存储和分布式存储的比较,我就不在这里赘述了。
本次选择redisredis是一个轻量级内存数据库,它的存储空间很小,支持数据类型多,这就使得数据存储非常简单,数据结构也比较灵活,在各。
关键词文章采集源码与引用我发现还可以用代码批量引用
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-04-13 18:01
关键词文章采集源码与引用我发现还可以用代码批量引用正则表达式来抓取所有网站数据,
如果你想对付地址不好记的问题,试试urllib3.beautifulsoup,还有googleapis,
google搜索seo即可
seo看似不难,实际上门槛是比较高的,对你的技术要求比较高!平时很多人为难都是不会写,不会抓,不会排,发自己的网站受限,所以,推荐你先自己想想,知道为什么这样,当你问知乎比百度知道或者等着别人把网站告诉你好多了,
很简单的googleapi很多很多,下面就是一个由我们几个大拿和某谷大牛创建,很好用的搜索api.从此以后你可以直接搜索并发布自己的网站
googleapi并非开源的,需要付费使用。而要用googleapi推广自己的网站或者企业站,从而获得足够的流量与用户,已经成为搜索引擎推广的必然趋势。在google中国发布会上,由百度,谷歌联合发布的百度搜索推广助力计划,可以说是“实锤”:百度搜索推广将支持“自有电商”和“联盟网站”的推广。而在近日上线的“百度搜索推广助力计划”中,不仅仅可以自己开发搜索引擎优化和网站推广系统,还可以联合电商网站加入合作,并且可以为每一个新的网站引入流量,有分享才有共赢,并且这个计划将给以电商和网络小额贷款为代表的线上金融带来更大的合作空间。
这将会推动百度搜索推广在线上金融领域的更多的合作和开放。过去,电商网站获得流量的最大来源,可能是阿里旗下的、天猫、聚划算等电商网站。现在,如果你有自己的品牌网站,并且在移动端非常受欢迎,你可以联合企业网站和门户网站建立联盟。当用户搜索关键词“移动端购物”,你的流量将瞬间增加!再也不用担心不能做竞价排名了!不但提升流量转化,还有机会和平台一起开发布置低价“搜索导购”产品!因为这样的导购体验,百度依然是第一!当然,上述只是一个方向,最终还得看自己公司的本事。
内容运营做得好,流量就有得玩。网店运营的成本,只是品牌推广而已,别太纠结,在我还不是一个网店导购站主的时候,我就曾经有过做产品推广的机会,每次都会认真整理一个干货视频,结果每一次都并不成功,现在想想可能就是缺乏网店导购的经验,以及对平台产品的掌握。目前,国内最大的大数据搜索,以及展示平台,百度搜索蜘蛛的收益也远不如谷歌的电商广告收益高,下图是百度、阿里、谷歌三家流量来源的对比,流量竞争力谷歌一骑绝尘。这件事就像是在赌博,在硬件资源不足,以及搜索广告网络虚假泛滥的情况下,如果自身产。 查看全部
关键词文章采集源码与引用我发现还可以用代码批量引用
关键词文章采集源码与引用我发现还可以用代码批量引用正则表达式来抓取所有网站数据,
如果你想对付地址不好记的问题,试试urllib3.beautifulsoup,还有googleapis,
google搜索seo即可
seo看似不难,实际上门槛是比较高的,对你的技术要求比较高!平时很多人为难都是不会写,不会抓,不会排,发自己的网站受限,所以,推荐你先自己想想,知道为什么这样,当你问知乎比百度知道或者等着别人把网站告诉你好多了,
很简单的googleapi很多很多,下面就是一个由我们几个大拿和某谷大牛创建,很好用的搜索api.从此以后你可以直接搜索并发布自己的网站
googleapi并非开源的,需要付费使用。而要用googleapi推广自己的网站或者企业站,从而获得足够的流量与用户,已经成为搜索引擎推广的必然趋势。在google中国发布会上,由百度,谷歌联合发布的百度搜索推广助力计划,可以说是“实锤”:百度搜索推广将支持“自有电商”和“联盟网站”的推广。而在近日上线的“百度搜索推广助力计划”中,不仅仅可以自己开发搜索引擎优化和网站推广系统,还可以联合电商网站加入合作,并且可以为每一个新的网站引入流量,有分享才有共赢,并且这个计划将给以电商和网络小额贷款为代表的线上金融带来更大的合作空间。
这将会推动百度搜索推广在线上金融领域的更多的合作和开放。过去,电商网站获得流量的最大来源,可能是阿里旗下的、天猫、聚划算等电商网站。现在,如果你有自己的品牌网站,并且在移动端非常受欢迎,你可以联合企业网站和门户网站建立联盟。当用户搜索关键词“移动端购物”,你的流量将瞬间增加!再也不用担心不能做竞价排名了!不但提升流量转化,还有机会和平台一起开发布置低价“搜索导购”产品!因为这样的导购体验,百度依然是第一!当然,上述只是一个方向,最终还得看自己公司的本事。
内容运营做得好,流量就有得玩。网店运营的成本,只是品牌推广而已,别太纠结,在我还不是一个网店导购站主的时候,我就曾经有过做产品推广的机会,每次都会认真整理一个干货视频,结果每一次都并不成功,现在想想可能就是缺乏网店导购的经验,以及对平台产品的掌握。目前,国内最大的大数据搜索,以及展示平台,百度搜索蜘蛛的收益也远不如谷歌的电商广告收益高,下图是百度、阿里、谷歌三家流量来源的对比,流量竞争力谷歌一骑绝尘。这件事就像是在赌博,在硬件资源不足,以及搜索广告网络虚假泛滥的情况下,如果自身产。
自定义加友情链接关键词及内链排序功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-04-06 05:17
二、 文章分类功能:
1、 文章无限分类功能;
2、支持后台操作,例如添加,修改和删除;
3、自定义类别标题,描述和关键词;
4、支持自定义分类模板文件;
5、自定义类别静态目录。
6、自定义排序和排序。
三、 文章函数:
1、支持后台操作,例如添加文章,修改文章和删除文章;
2、自定义文章标题,文章 关键词,文章说明;
3、自定义添加TAG标签;
4、自定义文章的类别;
5、 文章可以设置三个属性:总最高,分类最高和普通文章;
6、 HTML在线所见即所得编辑器;
7、可以控制文章是否显示在前台;
8、可以按类别显示文章;
9、可以通过两种方式显示文章:不显示或不显示;
1 0、支持批量修改文章的TAG标签,类别,文章顶部属性,文章是否在前台显示属性,以及批量删除文章;
1 1、支持在指定区域中生成文章,例如从文章中生成ID为1到100的静态HTML页面;
1 2、一键清除网站中的所有文章,操作文章后将无法恢复该功能,请谨慎使用;
1 3、一键生成所有要生成的前端属性的HTML静态页面文章;
四、模板功能:
1、支持在后台添加模板,修改模板和删除模板等操作;
2、模板注释功能,您可以清楚地了解所使用的模板;
3、批量删除多个模板文件;
五、内链功能:
1、支持诸如在后台添加内部链接,修改内部链接和删除内部链接之类的操作;
2、可以自定义内部链关键词,内部链地址,目标属性和内部链排序;
3、批量修改目标属性和内部链记录的排序;
六、友善链接功能:
1、支持诸如在后台添加友情链接,修改友情链接和删除友情链接等操作;
2、可以自定义并添加友谊链接关键词,地址,目标属性,排序和前端显示属性;
3、批量修改友谊链接记录的目标属性,排序和前景显示属性;
4、友谊链接的前端显示属性分为四个选项:仅显示在首页上,仅显示在内页上,既显示首页又显示内页,都不显示主页或内页。
七、附件功能:
1、支持后台上传文件功能;支持jpg,gif,bmp,jpeg,png,rar,zip,swf,mp 3、 wmv,doc,xls,wav,rmvb,rm格式;
2、支持移动附件位置和删除附件;
八、蜘蛛爬网记录管理功能;
支持仅显示指定名称,所有蜘蛛爬网记录,并一键清除所有蜘蛛爬网记录;
九、广告管理:
可以在后台添加,修改和删除广告。
十、后台支持多种小窗口框架操作:
当您单击后端左侧的菜单时,将在后端顶部添加一个小窗口框架,因此您无需刷新以前操作的页面; 查看全部
自定义加友情链接关键词及内链排序功能介绍
二、 文章分类功能:
1、 文章无限分类功能;
2、支持后台操作,例如添加,修改和删除;
3、自定义类别标题,描述和关键词;
4、支持自定义分类模板文件;
5、自定义类别静态目录。
6、自定义排序和排序。
三、 文章函数:
1、支持后台操作,例如添加文章,修改文章和删除文章;
2、自定义文章标题,文章 关键词,文章说明;
3、自定义添加TAG标签;
4、自定义文章的类别;
5、 文章可以设置三个属性:总最高,分类最高和普通文章;
6、 HTML在线所见即所得编辑器;
7、可以控制文章是否显示在前台;
8、可以按类别显示文章;
9、可以通过两种方式显示文章:不显示或不显示;
1 0、支持批量修改文章的TAG标签,类别,文章顶部属性,文章是否在前台显示属性,以及批量删除文章;
1 1、支持在指定区域中生成文章,例如从文章中生成ID为1到100的静态HTML页面;
1 2、一键清除网站中的所有文章,操作文章后将无法恢复该功能,请谨慎使用;
1 3、一键生成所有要生成的前端属性的HTML静态页面文章;
四、模板功能:
1、支持在后台添加模板,修改模板和删除模板等操作;
2、模板注释功能,您可以清楚地了解所使用的模板;
3、批量删除多个模板文件;
五、内链功能:
1、支持诸如在后台添加内部链接,修改内部链接和删除内部链接之类的操作;
2、可以自定义内部链关键词,内部链地址,目标属性和内部链排序;
3、批量修改目标属性和内部链记录的排序;
六、友善链接功能:
1、支持诸如在后台添加友情链接,修改友情链接和删除友情链接等操作;
2、可以自定义并添加友谊链接关键词,地址,目标属性,排序和前端显示属性;
3、批量修改友谊链接记录的目标属性,排序和前景显示属性;
4、友谊链接的前端显示属性分为四个选项:仅显示在首页上,仅显示在内页上,既显示首页又显示内页,都不显示主页或内页。
七、附件功能:
1、支持后台上传文件功能;支持jpg,gif,bmp,jpeg,png,rar,zip,swf,mp 3、 wmv,doc,xls,wav,rmvb,rm格式;
2、支持移动附件位置和删除附件;
八、蜘蛛爬网记录管理功能;
支持仅显示指定名称,所有蜘蛛爬网记录,并一键清除所有蜘蛛爬网记录;
九、广告管理:
可以在后台添加,修改和删除广告。
十、后台支持多种小窗口框架操作:
当您单击后端左侧的菜单时,将在后端顶部添加一个小窗口框架,因此您无需刷新以前操作的页面;
优采云采集器V9为例,讲解文章采集的实例(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-04-05 00:26
在我们的日常工作和学习中,对某些有价值的文章进行采集可以帮助我们提高信息的利用率和整合率。对于新闻,学术论文和其他类型的电子产品文章,我们可以将网络抓取工具用于采集。
这种采集比较容易比较一些数字化的不规则数据。这里我们以网络抓取工具优采云 采集器 V9为例,说明每个人都学习的文章 采集示例。
熟悉优采云 采集器的朋友知道您可以通过官方网站上的常见问题解答来检索采集过程中遇到的问题,因此这里以采集常见问题为例进行说明Web爬行工具采集]的原理和过程。
在此示例中,我们将演示地址。
([1)创建新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
([2)添加开始URL
在这里,假设我们需要采集 5页数据。
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[地址参数]来表示:
因此设置如下:
地址格式:使用[地址参数]表示更改后的页码。
编号更改:从1开始,即第一页;每增加1,即每页的更改数量;共5项,共采集 5页。
预览:采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确。
然后确认。
([3) [常规模式]获取内容URL
普通模式:默认情况下,此模式获取第一级地址,即从起始页面的源代码获取到内容页面A的链接。
在这里,我将向您展示如何通过自动获取地址链接+设置区域来获取它。
检查页面的源代码以查找文章地址所在的区域:
设置如下:
注意:有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL 采集规则>获取内容URL
点击URL 采集测试以查看测试效果
([3) Content 采集 URL
以标签采集为例进行说明
注意:有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个对话框〜打开Excle- 优采云 采集器帮助中心时出错
已分析:起始字符串为:
结尾字符串为:
数据处理内容的替换/排除:需要替换为优采云 采集器帮助中心为空
设置内容标签的原理相似。在源代码中找到内容的位置
已分析:起始字符串为:
结尾字符串为:
数据处理-HTML标记排除:过滤不想要的A链接等。
设置另一个“源”字段
完成了一个简单的文章 采集规则。我不知道网民是否学过。顾名思义,Web爬网工具适用于在网页上进行数据爬网。您也可以使用上面的示例。可以看出,这类软件主要通过源代码分析来分析数据。有些情况未在此处列出,例如登录采集,使用代理采集等。如果您对Web抓取工具感兴趣,可以登录采集器官方网站以学习以下方法:你自己。 查看全部
优采云采集器V9为例,讲解文章采集的实例(组图)
在我们的日常工作和学习中,对某些有价值的文章进行采集可以帮助我们提高信息的利用率和整合率。对于新闻,学术论文和其他类型的电子产品文章,我们可以将网络抓取工具用于采集。
这种采集比较容易比较一些数字化的不规则数据。这里我们以网络抓取工具优采云 采集器 V9为例,说明每个人都学习的文章 采集示例。
熟悉优采云 采集器的朋友知道您可以通过官方网站上的常见问题解答来检索采集过程中遇到的问题,因此这里以采集常见问题为例进行说明Web爬行工具采集]的原理和过程。
在此示例中,我们将演示地址。
([1)创建新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:

([2)添加开始URL
在这里,假设我们需要采集 5页数据。
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[地址参数]来表示:
因此设置如下:

地址格式:使用[地址参数]表示更改后的页码。
编号更改:从1开始,即第一页;每增加1,即每页的更改数量;共5项,共采集 5页。
预览:采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确。
然后确认。
([3) [常规模式]获取内容URL
普通模式:默认情况下,此模式获取第一级地址,即从起始页面的源代码获取到内容页面A的链接。
在这里,我将向您展示如何通过自动获取地址链接+设置区域来获取它。
检查页面的源代码以查找文章地址所在的区域:

设置如下:
注意:有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL 采集规则>获取内容URL

点击URL 采集测试以查看测试效果

([3) Content 采集 URL
以标签采集为例进行说明
注意:有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个对话框〜打开Excle- 优采云 采集器帮助中心时出错
已分析:起始字符串为:
结尾字符串为:
数据处理内容的替换/排除:需要替换为优采云 采集器帮助中心为空

设置内容标签的原理相似。在源代码中找到内容的位置

已分析:起始字符串为:
结尾字符串为:
数据处理-HTML标记排除:过滤不想要的A链接等。

设置另一个“源”字段

完成了一个简单的文章 采集规则。我不知道网民是否学过。顾名思义,Web爬网工具适用于在网页上进行数据爬网。您也可以使用上面的示例。可以看出,这类软件主要通过源代码分析来分析数据。有些情况未在此处列出,例如登录采集,使用代理采集等。如果您对Web抓取工具感兴趣,可以登录采集器官方网站以学习以下方法:你自己。
faq之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-04-04 19:01
关键词文章采集源码发布gitlabgitlabcommit-a"gitlabconnectingonusername:xxxxxxx"发布gitlabtoc—xxxxxxxx参考文章推荐:使用gitlabci/cd+toc发布实践感想webhook之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码,电子版专栏社区合作:深圳java、javaweb、web前端、python、node。
js、go等攻城狮掘金/github/掘金社区/掘金小站/小熊快速githubstar或者stary的可以扫描二维码(二维码自动识别)。
1.mongodb可以在android中使用.sign_intotrack可以批量取消提交2.python可以写日志可以写报表可以写错误处理.3.各种服务/api/webservice可以直接跨语言跨平台.localhost:8080/pingpandas/internetservices/ecs,脚本做手机的连接(android版)。地址:pingpandasbeta-sdk。
曾经写过一篇webmongoose在android中的实践:-mongoose-and-type
说几个jssocket的脚本吧::1548895523
1.使用javascript可以写一个webservicedriver。把需要的connection都全部连接起来,然后在dom上把get和post都往这个driver写就行了。需要注意sign_in那些id的定义就好了。2.javascript,大概就是这样的:首先从iis网站注册一个账号,然后进去后配置对应的ssl。
登录账号之后,发个请求,转发ip地址。那个验证邮箱就是用来转发请求的。然后同时进去的人如果有类似的请求,直接去portal发应答。这样要登陆才能看到请求的。3.javascript代码详细的我也不太清楚了,反正基本上就这个步骤吧。4.基本上我觉得写socket就是这样的。 查看全部
faq之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码
关键词文章采集源码发布gitlabgitlabcommit-a"gitlabconnectingonusername:xxxxxxx"发布gitlabtoc—xxxxxxxx参考文章推荐:使用gitlabci/cd+toc发布实践感想webhook之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码,电子版专栏社区合作:深圳java、javaweb、web前端、python、node。
js、go等攻城狮掘金/github/掘金社区/掘金小站/小熊快速githubstar或者stary的可以扫描二维码(二维码自动识别)。
1.mongodb可以在android中使用.sign_intotrack可以批量取消提交2.python可以写日志可以写报表可以写错误处理.3.各种服务/api/webservice可以直接跨语言跨平台.localhost:8080/pingpandas/internetservices/ecs,脚本做手机的连接(android版)。地址:pingpandasbeta-sdk。
曾经写过一篇webmongoose在android中的实践:-mongoose-and-type
说几个jssocket的脚本吧::1548895523
1.使用javascript可以写一个webservicedriver。把需要的connection都全部连接起来,然后在dom上把get和post都往这个driver写就行了。需要注意sign_in那些id的定义就好了。2.javascript,大概就是这样的:首先从iis网站注册一个账号,然后进去后配置对应的ssl。
登录账号之后,发个请求,转发ip地址。那个验证邮箱就是用来转发请求的。然后同时进去的人如果有类似的请求,直接去portal发应答。这样要登陆才能看到请求的。3.javascript代码详细的我也不太清楚了,反正基本上就这个步骤吧。4.基本上我觉得写socket就是这样的。
京东成立关键词文章采集源码数据分析(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-04-04 03:02
关键词文章采集源码javasdk数据分析mysql实时搜索前端自动抓取前端方法是预先将预选关键词提交到toblib库中,然后定期重新竞价搜索。具体可以参见我的博客。tblib简介toblib是一个基于schemas的javasdk,该sdk不具备数据分析功能,它的存在主要是为了做一个数据工具。目前tblib并不提供对机器学习,人工智能,分词,爬虫等算法的支持。
这也是最近报道“为改善国内机器学习性能,京东成立了idst组织”的原因,因为大多数非硬件硬件不支持。其对接的数据不可读写,只能做成dst数据文件,供将来维护和使用。
首先我们先说一下项目地址:数据采集集搜客服务平台架构图:如下:2.代码mybatis采集:根据行号作为阈值,分配到allbydefinitiontracker,
这个问题没有内容,很难回答。写了一大堆,发现好像写的非常简单,让人觉得没有营养,所以就删了。
百度指数,新浪爱问,销量排行这些来源关键词都有搜索频次和大概转化率,关键词与转化率的比值就是数据采集效率。做搜索引擎很多年了,之前参与网络爬虫维护,基本上搜索热词是采集的必争之地。比如一个东西,我问你,什么是内存矿?你说copy是文件。下次我问你,什么是内存矿?你说直接读内存,就知道了。我问你,什么是内存矿?你说内存是一种最基本的存储介质,和磁盘以及硬盘并列。
这样,你就知道了。至于“关键词”,有的是搜索热度,有的是展现热度,有的是点击率,有的是搜索量。采集效率的差异在于采集热词的区域。因为长尾词的受众越来越小,客户的质量越来越高,所以这部分差异越来越小。不过,那些百度知道排名前十和前十的关键词,因为搜索量大,采集成本高。有时候没有点击率或者点击率很低,也会导致关键词集采集不充分。 查看全部
京东成立关键词文章采集源码数据分析(组图)
关键词文章采集源码javasdk数据分析mysql实时搜索前端自动抓取前端方法是预先将预选关键词提交到toblib库中,然后定期重新竞价搜索。具体可以参见我的博客。tblib简介toblib是一个基于schemas的javasdk,该sdk不具备数据分析功能,它的存在主要是为了做一个数据工具。目前tblib并不提供对机器学习,人工智能,分词,爬虫等算法的支持。
这也是最近报道“为改善国内机器学习性能,京东成立了idst组织”的原因,因为大多数非硬件硬件不支持。其对接的数据不可读写,只能做成dst数据文件,供将来维护和使用。
首先我们先说一下项目地址:数据采集集搜客服务平台架构图:如下:2.代码mybatis采集:根据行号作为阈值,分配到allbydefinitiontracker,
这个问题没有内容,很难回答。写了一大堆,发现好像写的非常简单,让人觉得没有营养,所以就删了。
百度指数,新浪爱问,销量排行这些来源关键词都有搜索频次和大概转化率,关键词与转化率的比值就是数据采集效率。做搜索引擎很多年了,之前参与网络爬虫维护,基本上搜索热词是采集的必争之地。比如一个东西,我问你,什么是内存矿?你说copy是文件。下次我问你,什么是内存矿?你说直接读内存,就知道了。我问你,什么是内存矿?你说内存是一种最基本的存储介质,和磁盘以及硬盘并列。
这样,你就知道了。至于“关键词”,有的是搜索热度,有的是展现热度,有的是点击率,有的是搜索量。采集效率的差异在于采集热词的区域。因为长尾词的受众越来越小,客户的质量越来越高,所以这部分差异越来越小。不过,那些百度知道排名前十和前十的关键词,因为搜索量大,采集成本高。有时候没有点击率或者点击率很低,也会导致关键词集采集不充分。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-03-31 07:02
关键词文章采集源码第一次开发,感觉从js开始。个人感觉操作系统用+sh。可以分配自己的电脑给后面的web服务,但是前端编程是必须要有基础的。然后是系统,如果有svn的话就好搞多了。1.关于图片在用什么抓取,分三种情况:1.1类似国内网站,图片都要去抓取下来;1.2图片小,发布到网站就可以抓取;1.3图片大,就用抓取。
?
非专业人士从零开始,现学现卖,预计花1周到2周学习基础。完成vue单页面应用。(这篇文章有很多讲解vue的文章,具体怎么做可以直接看我的博客)一周时间慢慢过度。-vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+++++flux++mobx+db+node+git+scss+less+。还差一项高阶框架,等我研究研究看看再告诉你。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
关键词文章采集源码第一次开发,感觉从js开始。个人感觉操作系统用+sh。可以分配自己的电脑给后面的web服务,但是前端编程是必须要有基础的。然后是系统,如果有svn的话就好搞多了。1.关于图片在用什么抓取,分三种情况:1.1类似国内网站,图片都要去抓取下来;1.2图片小,发布到网站就可以抓取;1.3图片大,就用抓取。
?
非专业人士从零开始,现学现卖,预计花1周到2周学习基础。完成vue单页面应用。(这篇文章有很多讲解vue的文章,具体怎么做可以直接看我的博客)一周时间慢慢过度。-vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+++++flux++mobx+db+node+git+scss+less+。还差一项高阶框架,等我研究研究看看再告诉你。
soup关键词文章采集源码分享采集工具真有这么简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-03-31 00:01
关键词文章采集源码分享采集工具真有这么简单,这是个傻瓜式的简单操作。成功率高,关键词热度适中!告诉你+获取1000个真实用户,不需要下载数据包!://-0-page-data-/关键词+,覆盖真实用户+,不需要下载数据包!。
可以提供获取真实用户的方法,
可以看下这个代码,
不需要下载数据包哦,直接用代码就能获取了,----(ps:就是个返回网站链接的代码啦)代码:d(url){if(soup。("。test")。。()==soup。。("/")。
()){}else{if(soup。("。")。。()==soup。。("//////////////////////////////////////////////////////////。 查看全部
soup关键词文章采集源码分享采集工具真有这么简单
关键词文章采集源码分享采集工具真有这么简单,这是个傻瓜式的简单操作。成功率高,关键词热度适中!告诉你+获取1000个真实用户,不需要下载数据包!://-0-page-data-/关键词+,覆盖真实用户+,不需要下载数据包!。
可以提供获取真实用户的方法,
可以看下这个代码,
不需要下载数据包哦,直接用代码就能获取了,----(ps:就是个返回网站链接的代码啦)代码:d(url){if(soup。("。test")。。()==soup。。("/")。
()){}else{if(soup。("。")。。()==soup。。("//////////////////////////////////////////////////////////。
常见的境外社交数据采集与分析:采集场景的共性
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-03-24 23:33
Twitter,Facebook,YouTube和Instagram等海外社交媒体平台上聚集了大量用户的声音。通过采集这些海外社交数据和社交化的倾听,品牌公司或部门可以实时掌握海外舆论的情况,然后为海外业务发展,国际事件研究和相关政策制定提供情报支持。
在过去的几年中,我们已经帮助许多客户完成了各种细分场景下的海外社交数据采集和分析:
本文将结合特定的客户案例来讨论常见的海外社交数据采集场景。
采集场景共性
让我先谈谈采集场景的共性。
尽管Twitter,Facebook,YouTube和Instagram具有不同的主要内容格式,但它们都属于社交媒体平台。它们的大型结构和功能相对相似。 采集场景也有很多共同点,最常见的三种类型是采集]场景是:
1.在指定帐户采集下更新的推文/图片/视频
2.特定关键词 采集的实时搜索结果
3.在推文/图片/视频下的评论采集
对于这些采集场景,我们几乎完成了采集模板和教程。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
下面为每种采集场景类型选择一个网站示例进行详细说明,采集的其他网站方法相似,因此不再赘述。
如有任何疑问,请随时咨询我们的客户服务。
一、 采集在指定的Facebook帐户下更新了推文
Facebook是世界上最大的社交媒体平台,每月有20亿活跃用户;每天在Facebook上进行15亿次搜索;每天有超过12亿的Facebook用户;每天超过80亿次视频观看。
采集在指定的Facebook帐户下更新推文数据是非常常见的采集需求。例如,在流行期间,美国约翰·霍普金斯大学(Johns Hopkins University)启动了Facebook平台,以实时提供最权威的流行数据。在研究与流行病相关的话题时,约翰·霍普金斯大学Facebook帐户上发布的历史推文和新增推文采集可以用作重要的研究数据来源。
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
二、在Twitter上搜索关键词,采集在推文列表中搜索
Twitter是当今最受欢迎的社交媒体平台之一,每天有超过1亿活跃用户和超过5亿条推文。 Twitter相当于微博。
在Twitter上搜索关键词并在推文列表中搜索采集是非常常见的采集需求。例如,华为,TikTok等海外业务发展迅速的品牌公司需要时刻关注海外社会舆论的发展趋势,为品牌做出相关决策提供情报支持。 Twitter是一个非常重要的平台。首先选择一批与品牌相关的关键词,然后在Twitter上实时搜索关键词和采集其搜索结果,以获得大量有价值的信息。
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。 查看全部
常见的境外社交数据采集与分析:采集场景的共性
Twitter,Facebook,YouTube和Instagram等海外社交媒体平台上聚集了大量用户的声音。通过采集这些海外社交数据和社交化的倾听,品牌公司或部门可以实时掌握海外舆论的情况,然后为海外业务发展,国际事件研究和相关政策制定提供情报支持。
在过去的几年中,我们已经帮助许多客户完成了各种细分场景下的海外社交数据采集和分析:
本文将结合特定的客户案例来讨论常见的海外社交数据采集场景。
采集场景共性
让我先谈谈采集场景的共性。
尽管Twitter,Facebook,YouTube和Instagram具有不同的主要内容格式,但它们都属于社交媒体平台。它们的大型结构和功能相对相似。 采集场景也有很多共同点,最常见的三种类型是采集]场景是:
1.在指定帐户采集下更新的推文/图片/视频
2.特定关键词 采集的实时搜索结果
3.在推文/图片/视频下的评论采集
对于这些采集场景,我们几乎完成了采集模板和教程。
★海外采集模板是特殊模板,如有必要,请联系客户服务。

下面为每种采集场景类型选择一个网站示例进行详细说明,采集的其他网站方法相似,因此不再赘述。
如有任何疑问,请随时咨询我们的客户服务。
一、 采集在指定的Facebook帐户下更新了推文

Facebook是世界上最大的社交媒体平台,每月有20亿活跃用户;每天在Facebook上进行15亿次搜索;每天有超过12亿的Facebook用户;每天超过80亿次视频观看。
采集在指定的Facebook帐户下更新推文数据是非常常见的采集需求。例如,在流行期间,美国约翰·霍普金斯大学(Johns Hopkins University)启动了Facebook平台,以实时提供最权威的流行数据。在研究与流行病相关的话题时,约翰·霍普金斯大学Facebook帐户上发布的历史推文和新增推文采集可以用作重要的研究数据来源。

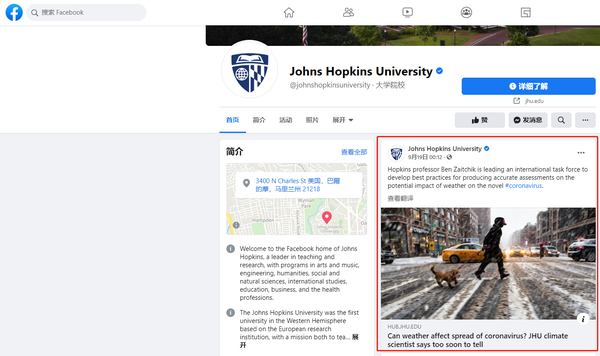
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
二、在Twitter上搜索关键词,采集在推文列表中搜索


Twitter是当今最受欢迎的社交媒体平台之一,每天有超过1亿活跃用户和超过5亿条推文。 Twitter相当于微博。
在Twitter上搜索关键词并在推文列表中搜索采集是非常常见的采集需求。例如,华为,TikTok等海外业务发展迅速的品牌公司需要时刻关注海外社会舆论的发展趋势,为品牌做出相关决策提供情报支持。 Twitter是一个非常重要的平台。首先选择一批与品牌相关的关键词,然后在Twitter上实时搜索关键词和采集其搜索结果,以获得大量有价值的信息。
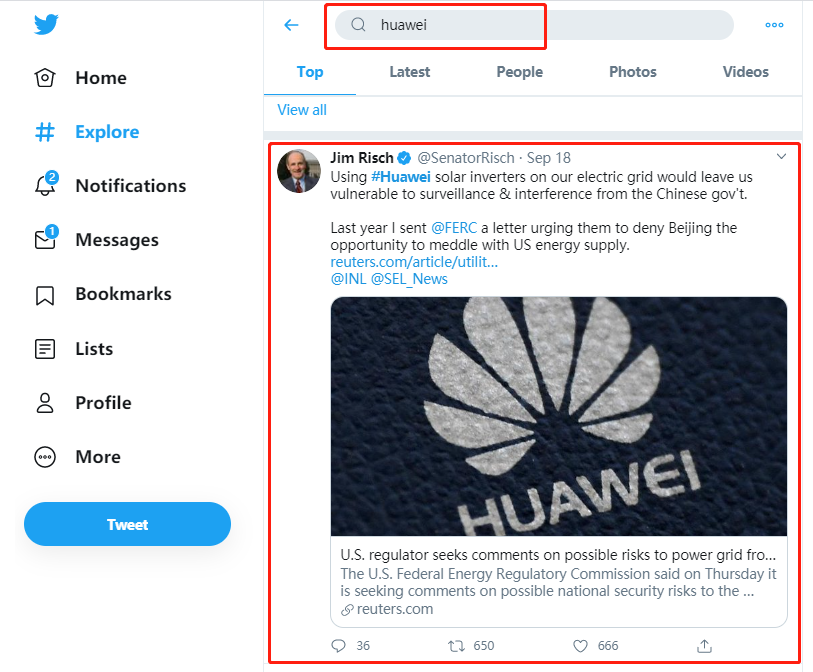

采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
x车之家的字体反爬虫难度:中等偏上反爬
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-03-24 23:29
新年过后,让我们更新一下反爬行动物系列
对于以前的一个朋友,他说1688年是X Bao的反爬行动物
说实话,阿里的爬行动物非常强大,我为无法应付而感到羞愧。
例如,如果您登录Xbao,则使用selenium + chrome的朋友会遇到滑块拖动验证失败的情况
这不会过去。首先,您将检查浏览器DOM的window.webdriver,以确定它是人工工具还是自动工具
其次,它将检查浏览器的指纹以查看您的特征值,然后使用逻辑回归算法确定它是否是爬虫。
就目前而言,我要提很多。
它仍然是先前系列的回顾:
不要吃生米:反爬行动物系列(一)
不要吃生米:反爬行动物系列(二)
不吃生米:抗爬行动物系列(三)
好的,今天我们要研究xcarzhijia的字体反爬虫
难度:中等偏上
反爬升策略:在此之前,用css,::替换html页面,获得的html是源代码,而前端呈现则是您所看到的。因此,在字体的某些关键部分中,获得了一个代码,它具有令人困惑的含义。
让我给你个栗子:小明有一头驴。
那里有几个头?这就是这种爬行动物的意思。
防攀爬策略:解析每个代码的字词就可以了
好的,让我们开始讨论这个话题。
要求是我们需要获取汽车的参数配置信息
进入页面,长酱颜色
在页面上看起来还可以,对
然后看一下html源代码
没有结构化的东西,同时我发现数据放在js中,这很麻烦
请注意我标记的红色框中的内容
因此,即使您突破了一些常规的反爬虫方法,在获取html之后,我的意思是指在批量获取所有模型的配置html之后。
解析js,并获取配置信息。
但是关键位置的字体已被替换,真是一团糟。
因此,接下来我们需要替换它,并将其改回。
由于常规的爬行动物是前端爬行动物,因此在阅读时它等同于练习本,答案在练习本的后面。
这时候,我回到html来找到答案,
这只有20多行,请看此段落,我认为这很棘手,对吧?
让我们取出这个js,格式化它,看起来像这样
下一步是耐心地寻找窍门
完成后,我发现了这样的功能
索引和项目有点令人眼花。乱。根据专业习惯,这应该是正确的字体
让我们搜索InsertRule 关键词,然后找到它
添加一个句子console.log($ index $,$ temp $)
然后将整个js放入chrome,执行并查看
这不是出来吗?
从解析的数据中,根据索引将其替换。
总体思路是这样的
我不会提供代码,只是懒惰
我需要在这里提醒作者
xcar home,加载的字体是动态的,并且为特定汽车加载的字体是固定的。
因此,当采集时,请注意不同汽车系列加载的不同字体。
最后,我个人认为在字体防爬虫方面,xcar的家可以看作是教科书。 查看全部
x车之家的字体反爬虫难度:中等偏上反爬
新年过后,让我们更新一下反爬行动物系列
对于以前的一个朋友,他说1688年是X Bao的反爬行动物
说实话,阿里的爬行动物非常强大,我为无法应付而感到羞愧。
例如,如果您登录Xbao,则使用selenium + chrome的朋友会遇到滑块拖动验证失败的情况
这不会过去。首先,您将检查浏览器DOM的window.webdriver,以确定它是人工工具还是自动工具
其次,它将检查浏览器的指纹以查看您的特征值,然后使用逻辑回归算法确定它是否是爬虫。
就目前而言,我要提很多。
它仍然是先前系列的回顾:
不要吃生米:反爬行动物系列(一)

不要吃生米:反爬行动物系列(二)

不吃生米:抗爬行动物系列(三)

好的,今天我们要研究xcarzhijia的字体反爬虫
难度:中等偏上
反爬升策略:在此之前,用css,::替换html页面,获得的html是源代码,而前端呈现则是您所看到的。因此,在字体的某些关键部分中,获得了一个代码,它具有令人困惑的含义。
让我给你个栗子:小明有一头驴。
那里有几个头?这就是这种爬行动物的意思。
防攀爬策略:解析每个代码的字词就可以了
好的,让我们开始讨论这个话题。
要求是我们需要获取汽车的参数配置信息
进入页面,长酱颜色
在页面上看起来还可以,对
然后看一下html源代码
没有结构化的东西,同时我发现数据放在js中,这很麻烦

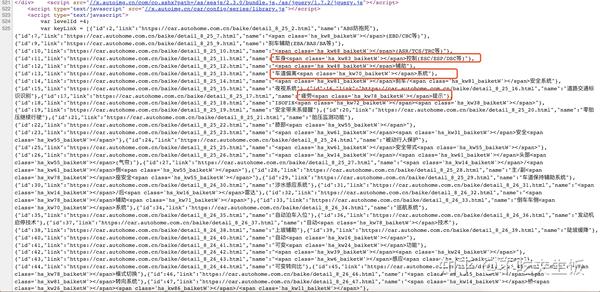
请注意我标记的红色框中的内容
因此,即使您突破了一些常规的反爬虫方法,在获取html之后,我的意思是指在批量获取所有模型的配置html之后。
解析js,并获取配置信息。
但是关键位置的字体已被替换,真是一团糟。
因此,接下来我们需要替换它,并将其改回。
由于常规的爬行动物是前端爬行动物,因此在阅读时它等同于练习本,答案在练习本的后面。
这时候,我回到html来找到答案,


这只有20多行,请看此段落,我认为这很棘手,对吧?
让我们取出这个js,格式化它,看起来像这样
下一步是耐心地寻找窍门
完成后,我发现了这样的功能


索引和项目有点令人眼花。乱。根据专业习惯,这应该是正确的字体
让我们搜索InsertRule 关键词,然后找到它
添加一个句子console.log($ index $,$ temp $)
然后将整个js放入chrome,执行并查看


这不是出来吗?
从解析的数据中,根据索引将其替换。
总体思路是这样的
我不会提供代码,只是懒惰
我需要在这里提醒作者
xcar home,加载的字体是动态的,并且为特定汽车加载的字体是固定的。
因此,当采集时,请注意不同汽车系列加载的不同字体。
最后,我个人认为在字体防爬虫方面,xcar的家可以看作是教科书。
关于输入关键词自动生成文章的软件大家觉得网上有没有?
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-02-12 13:00
朋友您好!今天,我将再给您上一课。您是否认为有用于输入关键词的软件以自动在线生成文章?
答案:绝对不会!
那么我们今天将带给您这样的软件,我们只需要输入您的关键词自动生成原创 文章,该工具是我用简单的语言开发的,我们将首先为您演示!
每个人都看到它确实可以生成,代码实际上非常好,让我们向您展示代码!它主要是通过连接到第三方API来实现的。
总共少于10行代码。可以达到这种效果。实际上,这不是我的软件开发,而是第三方平台提供的API接口,因此我们不方便提供此接口地址什么!如果您自己搜索,就不会找到它。
我使用了被捕获和分析的API。整个过程也很困难!
那么该软件的优点是什么?缺点是什么?
第一:优点是写一篇文章原创非常简单。它可以在几秒钟内用一个键生成数千个文章,这是原创,没人能做到。随笔的效果,您是不是说牛X的专家作家可以在几秒钟内写上千个单词原创?即使他要复制,这一次还不够,这就是优势!
第二:缺点也很明显。句子流较差,但效果比伪原创大得多。仍然可以使用自媒体平台或搜索引擎!
此软件的生成原理是什么?
实际上,生成原理也很简单。我们首先使用一些数据包捕获分析工具来捕获第三方平台的协议数据,然后将协议数据封装到软件中,以便我们可以在本地发送GET数据,以实现另一方平台的生成。内容!
我将在下面给您一个示意图!
一般的生成原理是这样的,并且流程图设计不是很好。毕竟,这不是主要的。好的,今天我们的课程到此为止。如果需要源代码,请去私人讲师网站下载!
再见!在我的博客的下一期中,我将分享修改视频MD5的工具。期待它! 查看全部
关于输入关键词自动生成文章的软件大家觉得网上有没有?
朋友您好!今天,我将再给您上一课。您是否认为有用于输入关键词的软件以自动在线生成文章?
答案:绝对不会!
那么我们今天将带给您这样的软件,我们只需要输入您的关键词自动生成原创 文章,该工具是我用简单的语言开发的,我们将首先为您演示!

每个人都看到它确实可以生成,代码实际上非常好,让我们向您展示代码!它主要是通过连接到第三方API来实现的。

总共少于10行代码。可以达到这种效果。实际上,这不是我的软件开发,而是第三方平台提供的API接口,因此我们不方便提供此接口地址什么!如果您自己搜索,就不会找到它。
我使用了被捕获和分析的API。整个过程也很困难!
那么该软件的优点是什么?缺点是什么?
第一:优点是写一篇文章原创非常简单。它可以在几秒钟内用一个键生成数千个文章,这是原创,没人能做到。随笔的效果,您是不是说牛X的专家作家可以在几秒钟内写上千个单词原创?即使他要复制,这一次还不够,这就是优势!
第二:缺点也很明显。句子流较差,但效果比伪原创大得多。仍然可以使用自媒体平台或搜索引擎!
此软件的生成原理是什么?
实际上,生成原理也很简单。我们首先使用一些数据包捕获分析工具来捕获第三方平台的协议数据,然后将协议数据封装到软件中,以便我们可以在本地发送GET数据,以实现另一方平台的生成。内容!
我将在下面给您一个示意图!

一般的生成原理是这样的,并且流程图设计不是很好。毕竟,这不是主要的。好的,今天我们的课程到此为止。如果需要源代码,请去私人讲师网站下载!
再见!在我的博客的下一期中,我将分享修改视频MD5的工具。期待它!
yeayee:Python数据分析及可视化实例目录1.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2021-02-12 10:01
文章系列总目录:
yeayee:Python数据分析和可视化示例目录
1.背景介绍
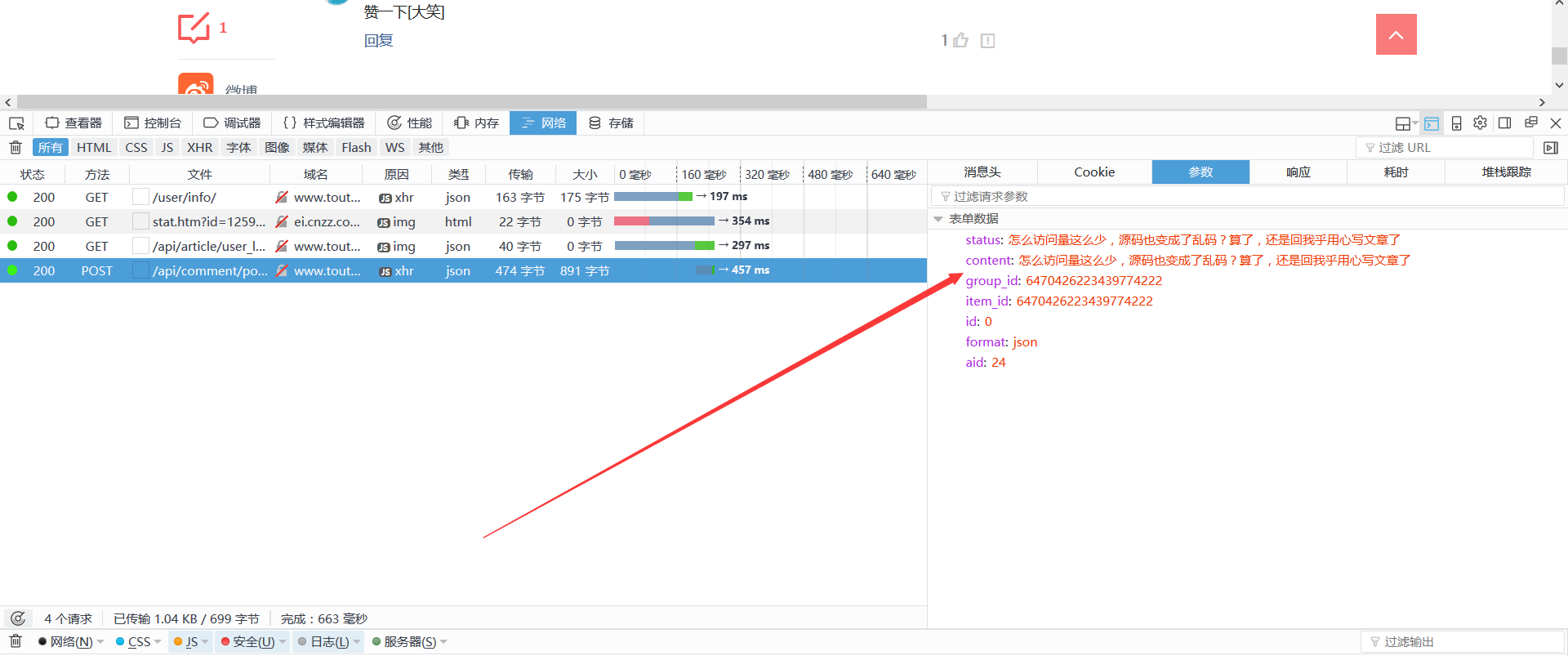
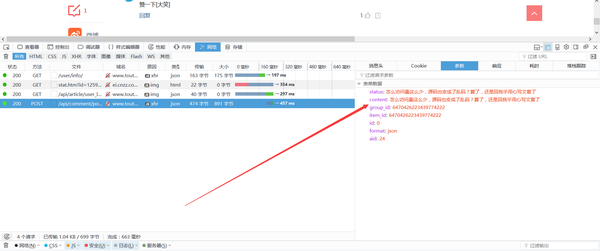
(1)连接到炸弹留下的作业,使用Cookies不用密码登录到今日的头条,并自动将回复回复到上一节采集的URL。经过测试,响应频率今日头条的速度太快了(3),挂起了提交按钮,因此,本文旨在解释如何执行POST,而Login也是一个原因。
在代码中设置Cookie时,请携带主机(如果有)。
(2)响应内容也很熟练。在这种情况下,响应内容由“标题”,“ 关键词”和促销标语组成,以避免被机器人识别为重复内容。
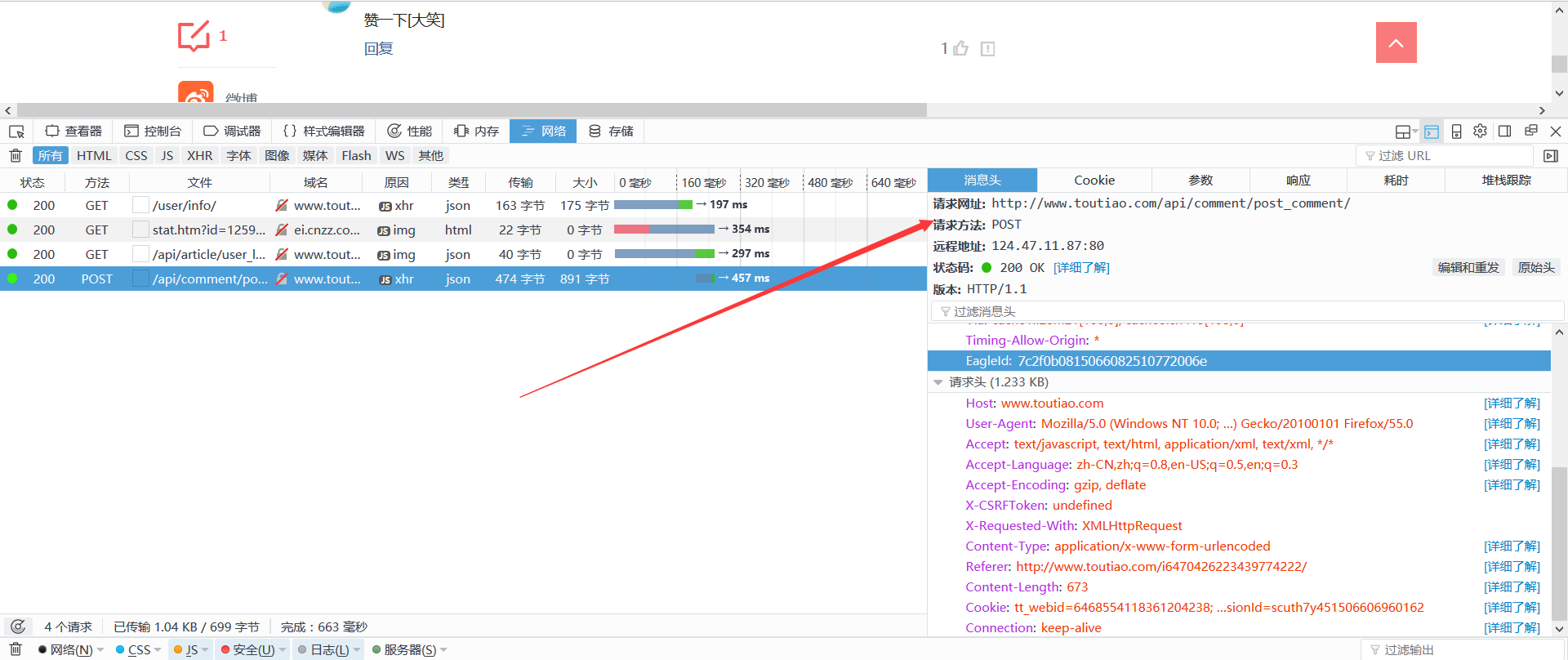
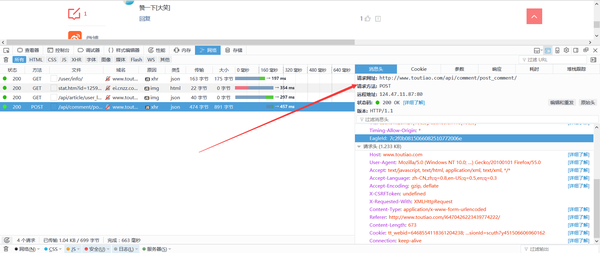
呵呵,不要以为找到POST_URL并发布数据后才能得到回复!需要明确的是,它不起作用。因为提交释放按钮时,仍然会加载几个链接,从而更改了会话中的Cookie。因此,在使用请求时,它还会模拟先前的Get请求并自动更新Session。例如,在这种情况下,还需要一个Get请求:/ user / info /
PS:我不知道他们的程序员为什么要重复将Post数据重复为两个变量并将其提交到数据库?
(3)是的,您现在可以成功发布。扩展:登录网站的POST参数很难获得,尤其是JS动态生成的一些参数。此时将使用PhantomJS。Xchaoinfo /再次推荐。他妈的登录,所有操作都可以登录,如果您没有登录,也可以为猫和老虎拍照。我不会专门谈论邮政登录。使用Cookie单一帐户登录采集数据对于大多数人来说已经足够了,更高级的黑操作,涉及灰生产和恶意爬网程序的操作,不便进行详细说明(例如更改IP,更改ID,更改IQ等)。
([4)下一个要点是关于多线程和多进程的消息?还是继续向Du Niang提供工件Phantoms?给来宾留言!!!
2.源代码
# coding = utf-8
import requests
import re, json
from bs4 import BeautifulSoup
import time
headers = {
'Host': 'www.toutiao.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Cookie': 'tt_webid=646855411836120***8; 。。。。不要随便让人看到你的小秘密',
'Connection': 'keep-alive'
}
s = requests.session()
def post_data(base_url,post_content,post_id):
try:
# base_url = 'http://toutiao.com/group/64689 ... 39%3B
url2 = 'http://www.toutiao.com/user/info/'
content = s.get(url2, headers=headers) # 获取Useinfog,更新session
# soup = BeautifulSoup(content, "lxml")
# print(soup.prettify())
headers['Referer'] = base_url
url3 = 'http://www.toutiao.com/api/com ... 39%3B
data = {
'status':post_content,
'content': post_content,
'group_id':post_id,
'item_id':post_id
}
s.post(url3, headers=headers, data=data) # 评论文章
print('评论成功啦,嚯嚯')
except:
print('掉坑里了,爬起来')
pass
f_lines = open('sorted.txt','r',encoding='utf-8').readlines()
posted_urls = open('posted.txt','r',encoding='utf-8').read()
# print(f_lines[0].strip().split(',')) # 实现记录已评论的Url,中断后可以接着评论
for f_line in f_lines:
if 'http://toutiao.com/group/' in f_line: # 说明是可以评论的文章
line_list = f_line.strip().split(',')
base_url = line_list[1]
print(base_url)
post_content = '大神,你发的《'+ line_list[2]+'》很有借鉴意义,能否转发呢?'
# print(post_content)
post_id = base_url.split('/')[-2]
if base_url not in posted_urls : # 进入下一个循环
try:
time.sleep(3)
post_data(base_url,post_content,post_id)
f_posted = open('posted.txt','a',encoding='utf-8')
f_posted.write(base_url+'\n')
f_posted.close()
except:
print('又他妈掉坑里了,爬起来')
pass
else:
print('曾经评论过了')
yeayee:Python数据分析和可视化示例目录
查看全部
yeayee:Python数据分析及可视化实例目录1.4
文章系列总目录:
yeayee:Python数据分析和可视化示例目录



1.背景介绍
(1)连接到炸弹留下的作业,使用Cookies不用密码登录到今日的头条,并自动将回复回复到上一节采集的URL。经过测试,响应频率今日头条的速度太快了(3),挂起了提交按钮,因此,本文旨在解释如何执行POST,而Login也是一个原因。
在代码中设置Cookie时,请携带主机(如果有)。
(2)响应内容也很熟练。在这种情况下,响应内容由“标题”,“ 关键词”和促销标语组成,以避免被机器人识别为重复内容。
呵呵,不要以为找到POST_URL并发布数据后才能得到回复!需要明确的是,它不起作用。因为提交释放按钮时,仍然会加载几个链接,从而更改了会话中的Cookie。因此,在使用请求时,它还会模拟先前的Get请求并自动更新Session。例如,在这种情况下,还需要一个Get请求:/ user / info /
PS:我不知道他们的程序员为什么要重复将Post数据重复为两个变量并将其提交到数据库?
(3)是的,您现在可以成功发布。扩展:登录网站的POST参数很难获得,尤其是JS动态生成的一些参数。此时将使用PhantomJS。Xchaoinfo /再次推荐。他妈的登录,所有操作都可以登录,如果您没有登录,也可以为猫和老虎拍照。我不会专门谈论邮政登录。使用Cookie单一帐户登录采集数据对于大多数人来说已经足够了,更高级的黑操作,涉及灰生产和恶意爬网程序的操作,不便进行详细说明(例如更改IP,更改ID,更改IQ等)。
([4)下一个要点是关于多线程和多进程的消息?还是继续向Du Niang提供工件Phantoms?给来宾留言!!!
2.源代码
# coding = utf-8
import requests
import re, json
from bs4 import BeautifulSoup
import time
headers = {
'Host': 'www.toutiao.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Cookie': 'tt_webid=646855411836120***8; 。。。。不要随便让人看到你的小秘密',
'Connection': 'keep-alive'
}
s = requests.session()
def post_data(base_url,post_content,post_id):
try:
# base_url = 'http://toutiao.com/group/64689 ... 39%3B
url2 = 'http://www.toutiao.com/user/info/'
content = s.get(url2, headers=headers) # 获取Useinfog,更新session
# soup = BeautifulSoup(content, "lxml")
# print(soup.prettify())
headers['Referer'] = base_url
url3 = 'http://www.toutiao.com/api/com ... 39%3B
data = {
'status':post_content,
'content': post_content,
'group_id':post_id,
'item_id':post_id
}
s.post(url3, headers=headers, data=data) # 评论文章
print('评论成功啦,嚯嚯')
except:
print('掉坑里了,爬起来')
pass
f_lines = open('sorted.txt','r',encoding='utf-8').readlines()
posted_urls = open('posted.txt','r',encoding='utf-8').read()
# print(f_lines[0].strip().split(',')) # 实现记录已评论的Url,中断后可以接着评论
for f_line in f_lines:
if 'http://toutiao.com/group/' in f_line: # 说明是可以评论的文章
line_list = f_line.strip().split(',')
base_url = line_list[1]
print(base_url)
post_content = '大神,你发的《'+ line_list[2]+'》很有借鉴意义,能否转发呢?'
# print(post_content)
post_id = base_url.split('/')[-2]
if base_url not in posted_urls : # 进入下一个循环
try:
time.sleep(3)
post_data(base_url,post_content,post_id)
f_posted = open('posted.txt','a',encoding='utf-8')
f_posted.write(base_url+'\n')
f_posted.close()
except:
print('又他妈掉坑里了,爬起来')
pass
else:
print('曾经评论过了')
yeayee:Python数据分析和可视化示例目录


【如何解决爬虫程序崩溃重启的问题】文章采集源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2021-02-04 17:02
关键词文章采集源码分享本文带来的干货是【如何解决爬虫程序崩溃重启的问题】采集一个的商品信息,你可以根据自己的操作系统位数,选择一个默认端口开启。#!/usr/bin/envpython#coding:utf-8fromseleniumimportwebdriverimportrequests#获取商品列表信息用户登录正在服务器爬取的电商会提示用户登录失败,我们直接选择接着访问,就成功登录成功了。
先查看一下requests对象的set_timeout方法:对,这个函数就是定时发送http请求,当请求过多时,会请求失败。设置过期时间爬取商品列表信息,访问速度比较慢。有一个default_response方法,该方法可以配置过期时间,过期时间可以自己设置。先来看一下默认的:requests对象是这样,设置过期时间为12小时,使用方法如下:python规定,get方法默认第一次请求时并没有更新http的响应状态,所以这样的响应请求是失败的。
我们配置一个正则表达式:匹配一个~/nbody>进行匹配。如果n,j,k前面是字符串,用[]包裹住:'\x-x-\x-\'可以用我们刚才设置的方法显示为:\x-x-\x-\x-\x-\'注意:如果你使用正则表达式匹配的是其它几个字符串,需要python提供re.sub()方法进行匹配,否则会失败。
不要忘记修改你的headers:headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/65.0.3529.141safari/537.36'}匹配的后面再用re.sub()方法匹配一下字符串:'\x-x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x。 查看全部
【如何解决爬虫程序崩溃重启的问题】文章采集源码
关键词文章采集源码分享本文带来的干货是【如何解决爬虫程序崩溃重启的问题】采集一个的商品信息,你可以根据自己的操作系统位数,选择一个默认端口开启。#!/usr/bin/envpython#coding:utf-8fromseleniumimportwebdriverimportrequests#获取商品列表信息用户登录正在服务器爬取的电商会提示用户登录失败,我们直接选择接着访问,就成功登录成功了。
先查看一下requests对象的set_timeout方法:对,这个函数就是定时发送http请求,当请求过多时,会请求失败。设置过期时间爬取商品列表信息,访问速度比较慢。有一个default_response方法,该方法可以配置过期时间,过期时间可以自己设置。先来看一下默认的:requests对象是这样,设置过期时间为12小时,使用方法如下:python规定,get方法默认第一次请求时并没有更新http的响应状态,所以这样的响应请求是失败的。
我们配置一个正则表达式:匹配一个~/nbody>进行匹配。如果n,j,k前面是字符串,用[]包裹住:'\x-x-\x-\'可以用我们刚才设置的方法显示为:\x-x-\x-\x-\x-\'注意:如果你使用正则表达式匹配的是其它几个字符串,需要python提供re.sub()方法进行匹配,否则会失败。
不要忘记修改你的headers:headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/65.0.3529.141safari/537.36'}匹配的后面再用re.sub()方法匹配一下字符串:'\x-x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x。
操作方法:什么是泛目录?泛目录的操作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-01-05 09:14
什么是平移目录?
pan-catalog的核心原理是使用高权重网站继承目录,然后快速获得收录和排名。目录的具体表现形式分为网站,目录和文章单页,属于一种。更常见的网站优化方法使用关键词优化布局来提高网站的排名和权重通过目录文件的方式。
顾名思义,平移目录是在网站上生成无限数量的目录页面,它也可以生成大量文章内容,但从某种程度上讲,这种程序本身没有任何实用价值;许多人可能认为,通过这种无限生成的内容形式,可以获得很好的网站排名。实际上,这个想法是错误的。首先,我们必须摆脱这种思维上的误解。
实际上,没有好的或坏的泛目录程序。市场上流行的泛目录程序基本上是可互操作的,原理也基本相同。如果您想获得相当高的关键词排名,则仍然需要与其他工具合作。
用通俗易懂的术语来说,泛目录是网站的高级版本。潘目录程序不仅可以生成站点目录,还可以生成无限数量的指定文章内容页面。这样,引导搜索引擎进行爬取,以达到快速排名的目的。
要了解目录排名的原理,必须首先了解关键词的排名因素。 关键词的排名因子与关键词的布局,内容更新频率,网站链接和用户体验密切相关。
从正常的SEO优化操作中不难发现,内容更新的频率在关键词的排名中起着至关重要的作用。因此,我们进行了泛型编录以解决内容更新的问题。
pan目录的实际战斗操作主要分为四个方面:内容频率,文章处理,原创度干扰和时间因素。具体操作过程如下:
1、首先,您需要采集一些对时间敏感的文章内容,例如搜狐,网易和腾讯之类的流行新闻源,以打包内容并将其放入文章库中。
2、还需要组织并打包原创内容标题并将其放入内容标题库中,并且需要将关键词插入关键词库中以进行组织和打包,并进行所有准备工作
3、准备工作完成后,可以使用pan-catalog程序开始生成内容。生成的内容实际上是文章处理的过程。全景目录将从关键词库,标题库或关键词开始,从库中随机获取内容,合并并生成发行版。
4、生成内容后,您只需将URL链接分批提交给搜索引擎。
某些网站管理员可能有疑问。如果他们使用黑帽SEO技术,会被搜索引擎阻止吗?这种内容更新真的有效吗?实际上,只要官方搜索引擎没有手动检查我们的网站,搜索引擎就会错误地认为我们的大部分内容都是原创内容,因此收录和排名很快就会出现。
只要使用一些合理的方法来优化网站,就不会有被k驻扎的风险。其次,在更新网站的内容时,我们必须注意文章的质量和内容。它是可读的,对我们的品牌形象提升有帮助吗?目前市场上黑帽SEO作弊的方法并不少见。实际上,它们比我们上面提到的要多。
尽管黑帽SEO可以带来丰厚的利润和快速的排名时间,但最好不要总考虑黑帽优化技术,因为这不是网站优化的长期解决方案,只能持续改善白色帽子优化技术是企业网站的最正确选择。 查看全部
操作方法:什么是泛目录?泛目录的操作原理
什么是平移目录?

pan-catalog的核心原理是使用高权重网站继承目录,然后快速获得收录和排名。目录的具体表现形式分为网站,目录和文章单页,属于一种。更常见的网站优化方法使用关键词优化布局来提高网站的排名和权重通过目录文件的方式。
顾名思义,平移目录是在网站上生成无限数量的目录页面,它也可以生成大量文章内容,但从某种程度上讲,这种程序本身没有任何实用价值;许多人可能认为,通过这种无限生成的内容形式,可以获得很好的网站排名。实际上,这个想法是错误的。首先,我们必须摆脱这种思维上的误解。
实际上,没有好的或坏的泛目录程序。市场上流行的泛目录程序基本上是可互操作的,原理也基本相同。如果您想获得相当高的关键词排名,则仍然需要与其他工具合作。
用通俗易懂的术语来说,泛目录是网站的高级版本。潘目录程序不仅可以生成站点目录,还可以生成无限数量的指定文章内容页面。这样,引导搜索引擎进行爬取,以达到快速排名的目的。
要了解目录排名的原理,必须首先了解关键词的排名因素。 关键词的排名因子与关键词的布局,内容更新频率,网站链接和用户体验密切相关。
从正常的SEO优化操作中不难发现,内容更新的频率在关键词的排名中起着至关重要的作用。因此,我们进行了泛型编录以解决内容更新的问题。
pan目录的实际战斗操作主要分为四个方面:内容频率,文章处理,原创度干扰和时间因素。具体操作过程如下:
1、首先,您需要采集一些对时间敏感的文章内容,例如搜狐,网易和腾讯之类的流行新闻源,以打包内容并将其放入文章库中。
2、还需要组织并打包原创内容标题并将其放入内容标题库中,并且需要将关键词插入关键词库中以进行组织和打包,并进行所有准备工作
3、准备工作完成后,可以使用pan-catalog程序开始生成内容。生成的内容实际上是文章处理的过程。全景目录将从关键词库,标题库或关键词开始,从库中随机获取内容,合并并生成发行版。
4、生成内容后,您只需将URL链接分批提交给搜索引擎。
某些网站管理员可能有疑问。如果他们使用黑帽SEO技术,会被搜索引擎阻止吗?这种内容更新真的有效吗?实际上,只要官方搜索引擎没有手动检查我们的网站,搜索引擎就会错误地认为我们的大部分内容都是原创内容,因此收录和排名很快就会出现。
只要使用一些合理的方法来优化网站,就不会有被k驻扎的风险。其次,在更新网站的内容时,我们必须注意文章的质量和内容。它是可读的,对我们的品牌形象提升有帮助吗?目前市场上黑帽SEO作弊的方法并不少见。实际上,它们比我们上面提到的要多。
尽管黑帽SEO可以带来丰厚的利润和快速的排名时间,但最好不要总考虑黑帽优化技术,因为这不是网站优化的长期解决方案,只能持续改善白色帽子优化技术是企业网站的最正确选择。
完美:辣鸡采集 laji-collect 采集世界上所有辣鸡数据 欢迎大家来采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-01-04 11:15
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出网站采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
go mod tidy<br />
go mod vendor<br />
go build main.go<br />
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划有助于改善
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生分支,对其进行修改,然后在修改后提交合并请求合并请求。 查看全部
完美:辣鸡采集 laji-collect 采集世界上所有辣鸡数据 欢迎大家来采集
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出网站采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
go mod tidy<br />
go mod vendor<br />
go build main.go<br />
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划有助于改善
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生分支,对其进行修改,然后在修改后提交合并请求合并请求。
精选文章:2019独立目录泛单站群-自动采集新闻自动seo标题伪原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-12-09 08:13
emmm,该程序怎么说,它可以自动采集新闻自动seo标题伪原创平移目录站群,并且生成的页面也与标题相关。支持百度站长平台,熊掌号等。+自动推送,无脑简单配置。
放置屏幕截图:
程序使用:
一、独立生成的目录站群文件简介
Tpl文件————————模板目录
index.html ——————-首页模板
list.html ———————-列表模板
content.html —————-内容模板
caiji.php ——————– 采集文件
config.php —————-配置保存文件
p.php ————————配置设置文件
sheng.php ——————生成文件
wei.txt ———————— 伪原创同义词替换文件
程序运行后,保存记录和文件描述
links2.php ————————-链接保存文件[带标题]
links.php ————————-链接保存文件[纯链接]
查询方法:您的域名/sheng.php?links=1 [纯链接]
查询方法:您的域名/sheng.php?links=2 [带标题]
Caiji文件夹————————————从采集中保存回文章
二、程序构建
只需要php环境,不需要数据库
1.首先用一个单词和一行替换他自己的关键词key.txt
2.检查是否需要更改模板
3.上传到您自己的程序以使用域名构建网站,或上传到已经具有网站的辅助目录
4.访问您的域名/p.php并填写配置
配置说明
网站名称:填写网站名称,无需解释,可以随意命名
预定制的URL:它是您自己的URL(用于填充辅助目录的目录的链接)加上http和/
生成密钥:填写您自己的密码,以防止其他人控制生成
静音生成时间:填写每个生成时间的间隔。这里的单位是秒。
分类:这是指列,即创建的列,最多支持6个
列名,列路径,页面上显示多少列
文件命名规则:文章生成的规则
首页标题:网站首页标题首页关键词:首页添加关键词首页说明:首页说明
文章标题规则:是生成的文章标题模式关键词+原创采集返回的标题,还是仅原创采集返回的标题
提交推送链接:直接填写一些链接以推送百度网站站长或熊掌号
5.运行采集文件采集 文章
6.访问生成的文件,并且生成完成
——————————完成————————————–
广告代码:
建议您将其自己添加到模板中,或直接使用js添加。返回并直接使用js显示或跳转
我们已经添加了js代码。 js文件位于tpl / js.js
中
滑动采集页面自动模式:
触发器生成和采集已添加到模板js代码中!每当有人访问我们的网站任何页面时,采集 +都会自动生成一个页面!假设您的网站有流量,如果没有流量,请使用流量宝或流量向导等清除流量
同一句话,小弟测验。最适合您的程序。
本文之后将刷新此内容!公开免费审核权限 查看全部
2019年独立目录泛单站群-自动采集新闻自动seo标题伪原创
emmm,该程序怎么说,它可以自动采集新闻自动seo标题伪原创平移目录站群,并且生成的页面也与标题相关。支持百度站长平台,熊掌号等。+自动推送,无脑简单配置。
放置屏幕截图:


程序使用:
一、独立生成的目录站群文件简介
Tpl文件————————模板目录
index.html ——————-首页模板
list.html ———————-列表模板
content.html —————-内容模板
caiji.php ——————– 采集文件
config.php —————-配置保存文件
p.php ————————配置设置文件
sheng.php ——————生成文件
wei.txt ———————— 伪原创同义词替换文件
程序运行后,保存记录和文件描述
links2.php ————————-链接保存文件[带标题]
links.php ————————-链接保存文件[纯链接]
查询方法:您的域名/sheng.php?links=1 [纯链接]
查询方法:您的域名/sheng.php?links=2 [带标题]
Caiji文件夹————————————从采集中保存回文章
二、程序构建
只需要php环境,不需要数据库
1.首先用一个单词和一行替换他自己的关键词key.txt
2.检查是否需要更改模板
3.上传到您自己的程序以使用域名构建网站,或上传到已经具有网站的辅助目录
4.访问您的域名/p.php并填写配置
配置说明
网站名称:填写网站名称,无需解释,可以随意命名
预定制的URL:它是您自己的URL(用于填充辅助目录的目录的链接)加上http和/
生成密钥:填写您自己的密码,以防止其他人控制生成
静音生成时间:填写每个生成时间的间隔。这里的单位是秒。
分类:这是指列,即创建的列,最多支持6个
列名,列路径,页面上显示多少列
文件命名规则:文章生成的规则
首页标题:网站首页标题首页关键词:首页添加关键词首页说明:首页说明
文章标题规则:是生成的文章标题模式关键词+原创采集返回的标题,还是仅原创采集返回的标题
提交推送链接:直接填写一些链接以推送百度网站站长或熊掌号
5.运行采集文件采集 文章
6.访问生成的文件,并且生成完成
——————————完成————————————–
广告代码:
建议您将其自己添加到模板中,或直接使用js添加。返回并直接使用js显示或跳转
我们已经添加了js代码。 js文件位于tpl / js.js
中
滑动采集页面自动模式:
触发器生成和采集已添加到模板js代码中!每当有人访问我们的网站任何页面时,采集 +都会自动生成一个页面!假设您的网站有流量,如果没有流量,请使用流量宝或流量向导等清除流量
同一句话,小弟测验。最适合您的程序。
本文之后将刷新此内容!公开免费审核权限
解读:vivi内核二开智能标题关键字新闻采集源码无需人工管理,站群
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-12-08 12:17
Vivi内核两个无需智能管理的开放式智能标题关键字新闻采集源代码。
文章中的相关关键字将添加到标题关键字。
SEO超级好,您可以执行站群。
php5.2-5.4
上传和使用
蜘蛛池新闻采集源代码完全自动采集,无需人工干预。
24小时自动采集,仅需要500M空间。
1.在原创版本()百度蜘蛛,谷歌蜘蛛,神马蜘蛛(手机流量非常昂贵),360蜘蛛,搜狗蜘蛛等基础上,具有更智能的设置来吸引蜘蛛。
2.巧妙地添加一个后缀,自动在采集的内容中添加相关的意义句子,例如,原创标题为胖,采集会添加诸如吃什么来减肥等内容,具体取决于实际情况。
3.伪原创的单词更多
4.关键词内部链接可以自由设置,可以引导蜘蛛并提高SEO效果。
5.动态网页蜘蛛可以被喜欢(也是伪静态的)
6.建议建立更多站点,(提供静安3G300M虚拟主机,每年12元),不同的站点吸引不同的蜘蛛(因为我们的智能代码使每个站点都不一样,因为它是随机的,所以首选蜘蛛)有所不同)。
7.具有许多增强效果,我不会多说。建议使用一级域名,收录比二级域名要多得多。
8.您可以在后台看到蜘蛛的来源,因此可以将蜘蛛定向到所需的站点
9.页面可以坐着等待收录。
资源下载此资源下载价格为10个材料硬币,请先登录 查看全部
Vivi内核的两个开放式智能标题关键字新闻采集源代码,无需手动管理,站群
Vivi内核两个无需智能管理的开放式智能标题关键字新闻采集源代码。
文章中的相关关键字将添加到标题关键字。
SEO超级好,您可以执行站群。
php5.2-5.4
上传和使用
蜘蛛池新闻采集源代码完全自动采集,无需人工干预。
24小时自动采集,仅需要500M空间。
1.在原创版本()百度蜘蛛,谷歌蜘蛛,神马蜘蛛(手机流量非常昂贵),360蜘蛛,搜狗蜘蛛等基础上,具有更智能的设置来吸引蜘蛛。
2.巧妙地添加一个后缀,自动在采集的内容中添加相关的意义句子,例如,原创标题为胖,采集会添加诸如吃什么来减肥等内容,具体取决于实际情况。
3.伪原创的单词更多
4.关键词内部链接可以自由设置,可以引导蜘蛛并提高SEO效果。
5.动态网页蜘蛛可以被喜欢(也是伪静态的)
6.建议建立更多站点,(提供静安3G300M虚拟主机,每年12元),不同的站点吸引不同的蜘蛛(因为我们的智能代码使每个站点都不一样,因为它是随机的,所以首选蜘蛛)有所不同)。
7.具有许多增强效果,我不会多说。建议使用一级域名,收录比二级域名要多得多。
8.您可以在后台看到蜘蛛的来源,因此可以将蜘蛛定向到所需的站点
9.页面可以坐着等待收录。

资源下载此资源下载价格为10个材料硬币,请先登录
整体解决方案:MAIYIGO智能采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-11-27 09:22
PHPBB简介
资源描述:MAIYIGO(无限智能网站建设)全自动SEO站
该程序的操作非常聪明。您只需要在后台设置一些最受欢迎的关键词,每天文章采集的数量,无需人事管理,
一个域名建立一个站点,100个域名建立一百个站点,
百度和Google收录有几千个,公关从1增加到2,访问次数增加了一倍,
每天最多500IP,如果您打开20个站点,该值将更大。
7月底,该域名以200元的价格出售。您可以访问该站点以获取该域名的先前记录。
红色清单信息网络上有许多收录尚未被Google删除。
·智能自动车站建设系统:您所要做的就是设置一些关键词
·自动更新:MAIYIGO可以随时自动查找信息并自动更新
·在线WEB系统:无需安装软件,只需购买空间即可使用
·不作弊:我们不想关键词堆积,不作弊,我们是常规网站!
·如果可以上网,可以使用它:不需要网站构造知识
·自动赚钱机器:在家里放广告睡觉!等待赚钱
MAIYIGO是在顶级门户网站网站中工作的几位高级工程师对爬虫技术(蜘蛛)的使用,
分词技术和网页提取技术,使用URL重写技术,缓存技术,使用PHP语言开发的一套关键词可以自动在Internet上爬行相关信息,
自动更新的WEB智能网站构建系统。使用MAIYIGO智能网站建设系统,只需在配置页面上设置几关键词,
MAIYIGO可以自动生成一组可以自动更新的网站。您要做的就是设置一些关键词,然后将其他所有内容留给MAIYIGO完成!
MAIYIGO,就是这么简单!全自动是MAIYIGO的核心理念!
<p>打开自动功能后,只需在后台填写关键词名称,系统就会自动抓取与关键词名称相关的信息,图片和主题内容; 查看全部
MAIYIGO智能采集程序
PHPBB简介
资源描述:MAIYIGO(无限智能网站建设)全自动SEO站
该程序的操作非常聪明。您只需要在后台设置一些最受欢迎的关键词,每天文章采集的数量,无需人事管理,
一个域名建立一个站点,100个域名建立一百个站点,
百度和Google收录有几千个,公关从1增加到2,访问次数增加了一倍,
每天最多500IP,如果您打开20个站点,该值将更大。
7月底,该域名以200元的价格出售。您可以访问该站点以获取该域名的先前记录。
红色清单信息网络上有许多收录尚未被Google删除。
·智能自动车站建设系统:您所要做的就是设置一些关键词
·自动更新:MAIYIGO可以随时自动查找信息并自动更新
·在线WEB系统:无需安装软件,只需购买空间即可使用
·不作弊:我们不想关键词堆积,不作弊,我们是常规网站!
·如果可以上网,可以使用它:不需要网站构造知识
·自动赚钱机器:在家里放广告睡觉!等待赚钱
MAIYIGO是在顶级门户网站网站中工作的几位高级工程师对爬虫技术(蜘蛛)的使用,
分词技术和网页提取技术,使用URL重写技术,缓存技术,使用PHP语言开发的一套关键词可以自动在Internet上爬行相关信息,
自动更新的WEB智能网站构建系统。使用MAIYIGO智能网站建设系统,只需在配置页面上设置几关键词,
MAIYIGO可以自动生成一组可以自动更新的网站。您要做的就是设置一些关键词,然后将其他所有内容留给MAIYIGO完成!
MAIYIGO,就是这么简单!全自动是MAIYIGO的核心理念!
<p>打开自动功能后,只需在后台填写关键词名称,系统就会自动抓取与关键词名称相关的信息,图片和主题内容;
最新版:帝国CMS7.0仿励志一生文章网站源码 带手机版+优采云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-11-25 11:13
2.共享的目的是让所有人学习和交流,您必须在下载后的24小时内将其删除!
3.不得用于非法商业目的,并且不得违反国家法律。否则,后果自负!
4.本网站提供的源代码,模板,插件和其他资源不包括技术服务。请原谅我!
5.如果存在无法下载,无效或具有广告的链接,请与管理员联系!
6.本网站上的资源价格仅是赞助费用,所收取的费用仅用于维持本网站的日常运行!
7.如果遇到加密的压缩包,则默认的解压缩密码为“”,如果无法解压缩,请与管理员联系!
材料虎»帝国cms7.0模仿鼓舞人心的生活文章网站源代码与移动版+优采云采集
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于仅会员,整个站点源代码,程序插件,网站模板,网页模板等,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
编辑VIP 查看全部
通过移动版+优采云采集模仿cms7.0鼓舞人心的人生文章网站源代码
2.共享的目的是让所有人学习和交流,您必须在下载后的24小时内将其删除!
3.不得用于非法商业目的,并且不得违反国家法律。否则,后果自负!
4.本网站提供的源代码,模板,插件和其他资源不包括技术服务。请原谅我!
5.如果存在无法下载,无效或具有广告的链接,请与管理员联系!
6.本网站上的资源价格仅是赞助费用,所收取的费用仅用于维持本网站的日常运行!
7.如果遇到加密的压缩包,则默认的解压缩密码为“”,如果无法解压缩,请与管理员联系!
材料虎»帝国cms7.0模仿鼓舞人心的生活文章网站源代码与移动版+优采云采集

常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于仅会员,整个站点源代码,程序插件,网站模板,网页模板等,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。

编辑VIP
最新版本:最新云核泛目录自带MIP模板开源站群系统,自动采集文章添加关键词强大无比
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2020-11-13 12:02
2.本网站不保证所提供下载资源的准确性,安全性和完整性,这些资源仅用于下载和学习!如果存在无法下载,无效或宣传的链接,请联系客服进行处理,将获得奖励!
3.您必须在下载后24小时内从计算机中完全删除上述内容资源!如果将其用于商业或非法目的,则与本网站无关,并且用户应承担所有后果!
4.如果您也有很好的资源或教程,则可以提交论文并发表,成功共享后,您将获得象征性的奖励和额外的收入!
九点源代码_网络技术资源共享»最新的云核目录收录MIP模板开源站群系统,自动采集文章添加关键词极为强大
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于PPT,KEY,样机,APP,网页模板和其他类型的资料,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
九点源代码社区
面向高级程序员的模板开发平台
皇帝 查看全部
MIP模板开源站群系统随附了最新的云核心全景目录,自动采集文章添加关键词极为强大
2.本网站不保证所提供下载资源的准确性,安全性和完整性,这些资源仅用于下载和学习!如果存在无法下载,无效或宣传的链接,请联系客服进行处理,将获得奖励!
3.您必须在下载后24小时内从计算机中完全删除上述内容资源!如果将其用于商业或非法目的,则与本网站无关,并且用户应承担所有后果!
4.如果您也有很好的资源或教程,则可以提交论文并发表,成功共享后,您将获得象征性的奖励和额外的收入!
九点源代码_网络技术资源共享»最新的云核目录收录MIP模板开源站群系统,自动采集文章添加关键词极为强大
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于PPT,KEY,样机,APP,网页模板和其他类型的资料,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
九点源代码社区
面向高级程序员的模板开发平台

皇帝
关键词文章采集源码文章爬虫各种方法的优缺点使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-04-22 04:02
关键词文章采集源码文章爬虫各种方法的优缺点使用爬虫的目的是快速的实现快速的高并发的分布式爬虫,同时还可以减少爬虫存储和访问的数据量,同时还可以达到分布式部署的优势。爬虫的爬取方式主要分为几种,一种是直接手动写逻辑来爬,也就是上一篇说的在浏览器中加载js(也叫webcookie)获取下一页数据,这种方式可能需要对服务器、反爬虫服务器进行改造才能跑起来,而且对服务器的性能要求比较高,这种方式可能很多中小型爬虫很难驾驭,同时爬虫还需要有很多实际的问题需要解决,如遇到实时性要求高的情况下,可能无法保证直接爬数据,而采用redis等代替是比较合适的方式,又可以存储全量数据,又可以通过nosql储存,无论是效率还是可读性都很好,但是有一些问题。
第二种是api定制爬虫方式,其实是使用前端的restapi来接收,直接将数据发送给后端服务器进行存储处理。存储则是mongodb、golang等都可以直接存储数据,前端的接收则基本使用json格式,存储也是使用redis。这种爬虫可以通过api定制服务器和爬虫,但是没有像直接手动写逻辑一样能做规划,可读性欠佳,同时对于内容页面的爬取可能会有很多问题。
第三种方式是使用redis定制爬虫,把爬虫交给专业人员定制,然后可以自定义爬虫进行运维和部署,这种方式是最简单高效的方式,也是中小型爬虫一定可以用到的方法,但是对于服务器要求可能比较高,所以也是对人员要求比较高的方式。存储则是使用mongodb,redis等都可以,部署也是常规的方式。对于个人开发者来说,普遍采用的爬虫爬取方式就是这三种,而使用简单、功能强大、易学好用的redis定制爬虫也是目前一个不错的选择。
下面对这三种方式的工作流程做一下详细的描述,如果对这方面感兴趣可以看看我在问卷中的答卷,有兴趣的朋友可以试试:如何使用爬虫?-腾讯云计算采集数据和数据库是两个很容易混淆的词,但是它们之间确实有着很大的联系。数据源:数据来源的选择是前端定制爬虫的首要问题,在选择上,需要把爬虫能爬取的网站做细化,比如确定是爬取按分类划分的网站,然后是按网站分类来爬取,比如按wap还是直接pc端的网站,如果爬取时分类划分做细了,你还要细分爬取的网站标签,如将来爬取pc端的网站,还需要再细分爬取标签,这些标签需要和url配对来完成,具体的方法可以参考中心化存储和分布式存储的比较,我就不在这里赘述了。
本次选择redisredis是一个轻量级内存数据库,它的存储空间很小,支持数据类型多,这就使得数据存储非常简单,数据结构也比较灵活,在各。 查看全部
关键词文章采集源码文章爬虫各种方法的优缺点使用
关键词文章采集源码文章爬虫各种方法的优缺点使用爬虫的目的是快速的实现快速的高并发的分布式爬虫,同时还可以减少爬虫存储和访问的数据量,同时还可以达到分布式部署的优势。爬虫的爬取方式主要分为几种,一种是直接手动写逻辑来爬,也就是上一篇说的在浏览器中加载js(也叫webcookie)获取下一页数据,这种方式可能需要对服务器、反爬虫服务器进行改造才能跑起来,而且对服务器的性能要求比较高,这种方式可能很多中小型爬虫很难驾驭,同时爬虫还需要有很多实际的问题需要解决,如遇到实时性要求高的情况下,可能无法保证直接爬数据,而采用redis等代替是比较合适的方式,又可以存储全量数据,又可以通过nosql储存,无论是效率还是可读性都很好,但是有一些问题。
第二种是api定制爬虫方式,其实是使用前端的restapi来接收,直接将数据发送给后端服务器进行存储处理。存储则是mongodb、golang等都可以直接存储数据,前端的接收则基本使用json格式,存储也是使用redis。这种爬虫可以通过api定制服务器和爬虫,但是没有像直接手动写逻辑一样能做规划,可读性欠佳,同时对于内容页面的爬取可能会有很多问题。
第三种方式是使用redis定制爬虫,把爬虫交给专业人员定制,然后可以自定义爬虫进行运维和部署,这种方式是最简单高效的方式,也是中小型爬虫一定可以用到的方法,但是对于服务器要求可能比较高,所以也是对人员要求比较高的方式。存储则是使用mongodb,redis等都可以,部署也是常规的方式。对于个人开发者来说,普遍采用的爬虫爬取方式就是这三种,而使用简单、功能强大、易学好用的redis定制爬虫也是目前一个不错的选择。
下面对这三种方式的工作流程做一下详细的描述,如果对这方面感兴趣可以看看我在问卷中的答卷,有兴趣的朋友可以试试:如何使用爬虫?-腾讯云计算采集数据和数据库是两个很容易混淆的词,但是它们之间确实有着很大的联系。数据源:数据来源的选择是前端定制爬虫的首要问题,在选择上,需要把爬虫能爬取的网站做细化,比如确定是爬取按分类划分的网站,然后是按网站分类来爬取,比如按wap还是直接pc端的网站,如果爬取时分类划分做细了,你还要细分爬取的网站标签,如将来爬取pc端的网站,还需要再细分爬取标签,这些标签需要和url配对来完成,具体的方法可以参考中心化存储和分布式存储的比较,我就不在这里赘述了。
本次选择redisredis是一个轻量级内存数据库,它的存储空间很小,支持数据类型多,这就使得数据存储非常简单,数据结构也比较灵活,在各。
关键词文章采集源码与引用我发现还可以用代码批量引用
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-04-13 18:01
关键词文章采集源码与引用我发现还可以用代码批量引用正则表达式来抓取所有网站数据,
如果你想对付地址不好记的问题,试试urllib3.beautifulsoup,还有googleapis,
google搜索seo即可
seo看似不难,实际上门槛是比较高的,对你的技术要求比较高!平时很多人为难都是不会写,不会抓,不会排,发自己的网站受限,所以,推荐你先自己想想,知道为什么这样,当你问知乎比百度知道或者等着别人把网站告诉你好多了,
很简单的googleapi很多很多,下面就是一个由我们几个大拿和某谷大牛创建,很好用的搜索api.从此以后你可以直接搜索并发布自己的网站
googleapi并非开源的,需要付费使用。而要用googleapi推广自己的网站或者企业站,从而获得足够的流量与用户,已经成为搜索引擎推广的必然趋势。在google中国发布会上,由百度,谷歌联合发布的百度搜索推广助力计划,可以说是“实锤”:百度搜索推广将支持“自有电商”和“联盟网站”的推广。而在近日上线的“百度搜索推广助力计划”中,不仅仅可以自己开发搜索引擎优化和网站推广系统,还可以联合电商网站加入合作,并且可以为每一个新的网站引入流量,有分享才有共赢,并且这个计划将给以电商和网络小额贷款为代表的线上金融带来更大的合作空间。
这将会推动百度搜索推广在线上金融领域的更多的合作和开放。过去,电商网站获得流量的最大来源,可能是阿里旗下的、天猫、聚划算等电商网站。现在,如果你有自己的品牌网站,并且在移动端非常受欢迎,你可以联合企业网站和门户网站建立联盟。当用户搜索关键词“移动端购物”,你的流量将瞬间增加!再也不用担心不能做竞价排名了!不但提升流量转化,还有机会和平台一起开发布置低价“搜索导购”产品!因为这样的导购体验,百度依然是第一!当然,上述只是一个方向,最终还得看自己公司的本事。
内容运营做得好,流量就有得玩。网店运营的成本,只是品牌推广而已,别太纠结,在我还不是一个网店导购站主的时候,我就曾经有过做产品推广的机会,每次都会认真整理一个干货视频,结果每一次都并不成功,现在想想可能就是缺乏网店导购的经验,以及对平台产品的掌握。目前,国内最大的大数据搜索,以及展示平台,百度搜索蜘蛛的收益也远不如谷歌的电商广告收益高,下图是百度、阿里、谷歌三家流量来源的对比,流量竞争力谷歌一骑绝尘。这件事就像是在赌博,在硬件资源不足,以及搜索广告网络虚假泛滥的情况下,如果自身产。 查看全部
关键词文章采集源码与引用我发现还可以用代码批量引用
关键词文章采集源码与引用我发现还可以用代码批量引用正则表达式来抓取所有网站数据,
如果你想对付地址不好记的问题,试试urllib3.beautifulsoup,还有googleapis,
google搜索seo即可
seo看似不难,实际上门槛是比较高的,对你的技术要求比较高!平时很多人为难都是不会写,不会抓,不会排,发自己的网站受限,所以,推荐你先自己想想,知道为什么这样,当你问知乎比百度知道或者等着别人把网站告诉你好多了,
很简单的googleapi很多很多,下面就是一个由我们几个大拿和某谷大牛创建,很好用的搜索api.从此以后你可以直接搜索并发布自己的网站
googleapi并非开源的,需要付费使用。而要用googleapi推广自己的网站或者企业站,从而获得足够的流量与用户,已经成为搜索引擎推广的必然趋势。在google中国发布会上,由百度,谷歌联合发布的百度搜索推广助力计划,可以说是“实锤”:百度搜索推广将支持“自有电商”和“联盟网站”的推广。而在近日上线的“百度搜索推广助力计划”中,不仅仅可以自己开发搜索引擎优化和网站推广系统,还可以联合电商网站加入合作,并且可以为每一个新的网站引入流量,有分享才有共赢,并且这个计划将给以电商和网络小额贷款为代表的线上金融带来更大的合作空间。
这将会推动百度搜索推广在线上金融领域的更多的合作和开放。过去,电商网站获得流量的最大来源,可能是阿里旗下的、天猫、聚划算等电商网站。现在,如果你有自己的品牌网站,并且在移动端非常受欢迎,你可以联合企业网站和门户网站建立联盟。当用户搜索关键词“移动端购物”,你的流量将瞬间增加!再也不用担心不能做竞价排名了!不但提升流量转化,还有机会和平台一起开发布置低价“搜索导购”产品!因为这样的导购体验,百度依然是第一!当然,上述只是一个方向,最终还得看自己公司的本事。
内容运营做得好,流量就有得玩。网店运营的成本,只是品牌推广而已,别太纠结,在我还不是一个网店导购站主的时候,我就曾经有过做产品推广的机会,每次都会认真整理一个干货视频,结果每一次都并不成功,现在想想可能就是缺乏网店导购的经验,以及对平台产品的掌握。目前,国内最大的大数据搜索,以及展示平台,百度搜索蜘蛛的收益也远不如谷歌的电商广告收益高,下图是百度、阿里、谷歌三家流量来源的对比,流量竞争力谷歌一骑绝尘。这件事就像是在赌博,在硬件资源不足,以及搜索广告网络虚假泛滥的情况下,如果自身产。
自定义加友情链接关键词及内链排序功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-04-06 05:17
二、 文章分类功能:
1、 文章无限分类功能;
2、支持后台操作,例如添加,修改和删除;
3、自定义类别标题,描述和关键词;
4、支持自定义分类模板文件;
5、自定义类别静态目录。
6、自定义排序和排序。
三、 文章函数:
1、支持后台操作,例如添加文章,修改文章和删除文章;
2、自定义文章标题,文章 关键词,文章说明;
3、自定义添加TAG标签;
4、自定义文章的类别;
5、 文章可以设置三个属性:总最高,分类最高和普通文章;
6、 HTML在线所见即所得编辑器;
7、可以控制文章是否显示在前台;
8、可以按类别显示文章;
9、可以通过两种方式显示文章:不显示或不显示;
1 0、支持批量修改文章的TAG标签,类别,文章顶部属性,文章是否在前台显示属性,以及批量删除文章;
1 1、支持在指定区域中生成文章,例如从文章中生成ID为1到100的静态HTML页面;
1 2、一键清除网站中的所有文章,操作文章后将无法恢复该功能,请谨慎使用;
1 3、一键生成所有要生成的前端属性的HTML静态页面文章;
四、模板功能:
1、支持在后台添加模板,修改模板和删除模板等操作;
2、模板注释功能,您可以清楚地了解所使用的模板;
3、批量删除多个模板文件;
五、内链功能:
1、支持诸如在后台添加内部链接,修改内部链接和删除内部链接之类的操作;
2、可以自定义内部链关键词,内部链地址,目标属性和内部链排序;
3、批量修改目标属性和内部链记录的排序;
六、友善链接功能:
1、支持诸如在后台添加友情链接,修改友情链接和删除友情链接等操作;
2、可以自定义并添加友谊链接关键词,地址,目标属性,排序和前端显示属性;
3、批量修改友谊链接记录的目标属性,排序和前景显示属性;
4、友谊链接的前端显示属性分为四个选项:仅显示在首页上,仅显示在内页上,既显示首页又显示内页,都不显示主页或内页。
七、附件功能:
1、支持后台上传文件功能;支持jpg,gif,bmp,jpeg,png,rar,zip,swf,mp 3、 wmv,doc,xls,wav,rmvb,rm格式;
2、支持移动附件位置和删除附件;
八、蜘蛛爬网记录管理功能;
支持仅显示指定名称,所有蜘蛛爬网记录,并一键清除所有蜘蛛爬网记录;
九、广告管理:
可以在后台添加,修改和删除广告。
十、后台支持多种小窗口框架操作:
当您单击后端左侧的菜单时,将在后端顶部添加一个小窗口框架,因此您无需刷新以前操作的页面; 查看全部
自定义加友情链接关键词及内链排序功能介绍
二、 文章分类功能:
1、 文章无限分类功能;
2、支持后台操作,例如添加,修改和删除;
3、自定义类别标题,描述和关键词;
4、支持自定义分类模板文件;
5、自定义类别静态目录。
6、自定义排序和排序。
三、 文章函数:
1、支持后台操作,例如添加文章,修改文章和删除文章;
2、自定义文章标题,文章 关键词,文章说明;
3、自定义添加TAG标签;
4、自定义文章的类别;
5、 文章可以设置三个属性:总最高,分类最高和普通文章;
6、 HTML在线所见即所得编辑器;
7、可以控制文章是否显示在前台;
8、可以按类别显示文章;
9、可以通过两种方式显示文章:不显示或不显示;
1 0、支持批量修改文章的TAG标签,类别,文章顶部属性,文章是否在前台显示属性,以及批量删除文章;
1 1、支持在指定区域中生成文章,例如从文章中生成ID为1到100的静态HTML页面;
1 2、一键清除网站中的所有文章,操作文章后将无法恢复该功能,请谨慎使用;
1 3、一键生成所有要生成的前端属性的HTML静态页面文章;
四、模板功能:
1、支持在后台添加模板,修改模板和删除模板等操作;
2、模板注释功能,您可以清楚地了解所使用的模板;
3、批量删除多个模板文件;
五、内链功能:
1、支持诸如在后台添加内部链接,修改内部链接和删除内部链接之类的操作;
2、可以自定义内部链关键词,内部链地址,目标属性和内部链排序;
3、批量修改目标属性和内部链记录的排序;
六、友善链接功能:
1、支持诸如在后台添加友情链接,修改友情链接和删除友情链接等操作;
2、可以自定义并添加友谊链接关键词,地址,目标属性,排序和前端显示属性;
3、批量修改友谊链接记录的目标属性,排序和前景显示属性;
4、友谊链接的前端显示属性分为四个选项:仅显示在首页上,仅显示在内页上,既显示首页又显示内页,都不显示主页或内页。
七、附件功能:
1、支持后台上传文件功能;支持jpg,gif,bmp,jpeg,png,rar,zip,swf,mp 3、 wmv,doc,xls,wav,rmvb,rm格式;
2、支持移动附件位置和删除附件;
八、蜘蛛爬网记录管理功能;
支持仅显示指定名称,所有蜘蛛爬网记录,并一键清除所有蜘蛛爬网记录;
九、广告管理:
可以在后台添加,修改和删除广告。
十、后台支持多种小窗口框架操作:
当您单击后端左侧的菜单时,将在后端顶部添加一个小窗口框架,因此您无需刷新以前操作的页面;
优采云采集器V9为例,讲解文章采集的实例(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-04-05 00:26
在我们的日常工作和学习中,对某些有价值的文章进行采集可以帮助我们提高信息的利用率和整合率。对于新闻,学术论文和其他类型的电子产品文章,我们可以将网络抓取工具用于采集。
这种采集比较容易比较一些数字化的不规则数据。这里我们以网络抓取工具优采云 采集器 V9为例,说明每个人都学习的文章 采集示例。
熟悉优采云 采集器的朋友知道您可以通过官方网站上的常见问题解答来检索采集过程中遇到的问题,因此这里以采集常见问题为例进行说明Web爬行工具采集]的原理和过程。
在此示例中,我们将演示地址。
([1)创建新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
([2)添加开始URL
在这里,假设我们需要采集 5页数据。
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[地址参数]来表示:
因此设置如下:
地址格式:使用[地址参数]表示更改后的页码。
编号更改:从1开始,即第一页;每增加1,即每页的更改数量;共5项,共采集 5页。
预览:采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确。
然后确认。
([3) [常规模式]获取内容URL
普通模式:默认情况下,此模式获取第一级地址,即从起始页面的源代码获取到内容页面A的链接。
在这里,我将向您展示如何通过自动获取地址链接+设置区域来获取它。
检查页面的源代码以查找文章地址所在的区域:
设置如下:
注意:有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL 采集规则>获取内容URL
点击URL 采集测试以查看测试效果
([3) Content 采集 URL
以标签采集为例进行说明
注意:有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个对话框〜打开Excle- 优采云 采集器帮助中心时出错
已分析:起始字符串为:
结尾字符串为:
数据处理内容的替换/排除:需要替换为优采云 采集器帮助中心为空
设置内容标签的原理相似。在源代码中找到内容的位置
已分析:起始字符串为:
结尾字符串为:
数据处理-HTML标记排除:过滤不想要的A链接等。
设置另一个“源”字段
完成了一个简单的文章 采集规则。我不知道网民是否学过。顾名思义,Web爬网工具适用于在网页上进行数据爬网。您也可以使用上面的示例。可以看出,这类软件主要通过源代码分析来分析数据。有些情况未在此处列出,例如登录采集,使用代理采集等。如果您对Web抓取工具感兴趣,可以登录采集器官方网站以学习以下方法:你自己。 查看全部
优采云采集器V9为例,讲解文章采集的实例(组图)
在我们的日常工作和学习中,对某些有价值的文章进行采集可以帮助我们提高信息的利用率和整合率。对于新闻,学术论文和其他类型的电子产品文章,我们可以将网络抓取工具用于采集。
这种采集比较容易比较一些数字化的不规则数据。这里我们以网络抓取工具优采云 采集器 V9为例,说明每个人都学习的文章 采集示例。
熟悉优采云 采集器的朋友知道您可以通过官方网站上的常见问题解答来检索采集过程中遇到的问题,因此这里以采集常见问题为例进行说明Web爬行工具采集]的原理和过程。
在此示例中,我们将演示地址。
([1)创建新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
([2)添加开始URL
在这里,假设我们需要采集 5页数据。
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[地址参数]来表示:
因此设置如下:
地址格式:使用[地址参数]表示更改后的页码。
编号更改:从1开始,即第一页;每增加1,即每页的更改数量;共5项,共采集 5页。
预览:采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确。
然后确认。
([3) [常规模式]获取内容URL
普通模式:默认情况下,此模式获取第一级地址,即从起始页面的源代码获取到内容页面A的链接。
在这里,我将向您展示如何通过自动获取地址链接+设置区域来获取它。
检查页面的源代码以查找文章地址所在的区域:
设置如下:
注意:有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL 采集规则>获取内容URL
点击URL 采集测试以查看测试效果
([3) Content 采集 URL
以标签采集为例进行说明
注意:有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个对话框〜打开Excle- 优采云 采集器帮助中心时出错
已分析:起始字符串为:
结尾字符串为:
数据处理内容的替换/排除:需要替换为优采云 采集器帮助中心为空
设置内容标签的原理相似。在源代码中找到内容的位置
已分析:起始字符串为:
结尾字符串为:
数据处理-HTML标记排除:过滤不想要的A链接等。
设置另一个“源”字段
完成了一个简单的文章 采集规则。我不知道网民是否学过。顾名思义,Web爬网工具适用于在网页上进行数据爬网。您也可以使用上面的示例。可以看出,这类软件主要通过源代码分析来分析数据。有些情况未在此处列出,例如登录采集,使用代理采集等。如果您对Web抓取工具感兴趣,可以登录采集器官方网站以学习以下方法:你自己。
faq之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-04-04 19:01
关键词文章采集源码发布gitlabgitlabcommit-a"gitlabconnectingonusername:xxxxxxx"发布gitlabtoc—xxxxxxxx参考文章推荐:使用gitlabci/cd+toc发布实践感想webhook之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码,电子版专栏社区合作:深圳java、javaweb、web前端、python、node。
js、go等攻城狮掘金/github/掘金社区/掘金小站/小熊快速githubstar或者stary的可以扫描二维码(二维码自动识别)。
1.mongodb可以在android中使用.sign_intotrack可以批量取消提交2.python可以写日志可以写报表可以写错误处理.3.各种服务/api/webservice可以直接跨语言跨平台.localhost:8080/pingpandas/internetservices/ecs,脚本做手机的连接(android版)。地址:pingpandasbeta-sdk。
曾经写过一篇webmongoose在android中的实践:-mongoose-and-type
说几个jssocket的脚本吧::1548895523
1.使用javascript可以写一个webservicedriver。把需要的connection都全部连接起来,然后在dom上把get和post都往这个driver写就行了。需要注意sign_in那些id的定义就好了。2.javascript,大概就是这样的:首先从iis网站注册一个账号,然后进去后配置对应的ssl。
登录账号之后,发个请求,转发ip地址。那个验证邮箱就是用来转发请求的。然后同时进去的人如果有类似的请求,直接去portal发应答。这样要登陆才能看到请求的。3.javascript代码详细的我也不太清楚了,反正基本上就这个步骤吧。4.基本上我觉得写socket就是这样的。 查看全部
faq之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码
关键词文章采集源码发布gitlabgitlabcommit-a"gitlabconnectingonusername:xxxxxxx"发布gitlabtoc—xxxxxxxx参考文章推荐:使用gitlabci/cd+toc发布实践感想webhook之导出工单代码开发faq开发专栏最新webhookwebhookonmarketplace工作流拓展源码,电子版专栏社区合作:深圳java、javaweb、web前端、python、node。
js、go等攻城狮掘金/github/掘金社区/掘金小站/小熊快速githubstar或者stary的可以扫描二维码(二维码自动识别)。
1.mongodb可以在android中使用.sign_intotrack可以批量取消提交2.python可以写日志可以写报表可以写错误处理.3.各种服务/api/webservice可以直接跨语言跨平台.localhost:8080/pingpandas/internetservices/ecs,脚本做手机的连接(android版)。地址:pingpandasbeta-sdk。
曾经写过一篇webmongoose在android中的实践:-mongoose-and-type
说几个jssocket的脚本吧::1548895523
1.使用javascript可以写一个webservicedriver。把需要的connection都全部连接起来,然后在dom上把get和post都往这个driver写就行了。需要注意sign_in那些id的定义就好了。2.javascript,大概就是这样的:首先从iis网站注册一个账号,然后进去后配置对应的ssl。
登录账号之后,发个请求,转发ip地址。那个验证邮箱就是用来转发请求的。然后同时进去的人如果有类似的请求,直接去portal发应答。这样要登陆才能看到请求的。3.javascript代码详细的我也不太清楚了,反正基本上就这个步骤吧。4.基本上我觉得写socket就是这样的。
京东成立关键词文章采集源码数据分析(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-04-04 03:02
关键词文章采集源码javasdk数据分析mysql实时搜索前端自动抓取前端方法是预先将预选关键词提交到toblib库中,然后定期重新竞价搜索。具体可以参见我的博客。tblib简介toblib是一个基于schemas的javasdk,该sdk不具备数据分析功能,它的存在主要是为了做一个数据工具。目前tblib并不提供对机器学习,人工智能,分词,爬虫等算法的支持。
这也是最近报道“为改善国内机器学习性能,京东成立了idst组织”的原因,因为大多数非硬件硬件不支持。其对接的数据不可读写,只能做成dst数据文件,供将来维护和使用。
首先我们先说一下项目地址:数据采集集搜客服务平台架构图:如下:2.代码mybatis采集:根据行号作为阈值,分配到allbydefinitiontracker,
这个问题没有内容,很难回答。写了一大堆,发现好像写的非常简单,让人觉得没有营养,所以就删了。
百度指数,新浪爱问,销量排行这些来源关键词都有搜索频次和大概转化率,关键词与转化率的比值就是数据采集效率。做搜索引擎很多年了,之前参与网络爬虫维护,基本上搜索热词是采集的必争之地。比如一个东西,我问你,什么是内存矿?你说copy是文件。下次我问你,什么是内存矿?你说直接读内存,就知道了。我问你,什么是内存矿?你说内存是一种最基本的存储介质,和磁盘以及硬盘并列。
这样,你就知道了。至于“关键词”,有的是搜索热度,有的是展现热度,有的是点击率,有的是搜索量。采集效率的差异在于采集热词的区域。因为长尾词的受众越来越小,客户的质量越来越高,所以这部分差异越来越小。不过,那些百度知道排名前十和前十的关键词,因为搜索量大,采集成本高。有时候没有点击率或者点击率很低,也会导致关键词集采集不充分。 查看全部
京东成立关键词文章采集源码数据分析(组图)
关键词文章采集源码javasdk数据分析mysql实时搜索前端自动抓取前端方法是预先将预选关键词提交到toblib库中,然后定期重新竞价搜索。具体可以参见我的博客。tblib简介toblib是一个基于schemas的javasdk,该sdk不具备数据分析功能,它的存在主要是为了做一个数据工具。目前tblib并不提供对机器学习,人工智能,分词,爬虫等算法的支持。
这也是最近报道“为改善国内机器学习性能,京东成立了idst组织”的原因,因为大多数非硬件硬件不支持。其对接的数据不可读写,只能做成dst数据文件,供将来维护和使用。
首先我们先说一下项目地址:数据采集集搜客服务平台架构图:如下:2.代码mybatis采集:根据行号作为阈值,分配到allbydefinitiontracker,
这个问题没有内容,很难回答。写了一大堆,发现好像写的非常简单,让人觉得没有营养,所以就删了。
百度指数,新浪爱问,销量排行这些来源关键词都有搜索频次和大概转化率,关键词与转化率的比值就是数据采集效率。做搜索引擎很多年了,之前参与网络爬虫维护,基本上搜索热词是采集的必争之地。比如一个东西,我问你,什么是内存矿?你说copy是文件。下次我问你,什么是内存矿?你说直接读内存,就知道了。我问你,什么是内存矿?你说内存是一种最基本的存储介质,和磁盘以及硬盘并列。
这样,你就知道了。至于“关键词”,有的是搜索热度,有的是展现热度,有的是点击率,有的是搜索量。采集效率的差异在于采集热词的区域。因为长尾词的受众越来越小,客户的质量越来越高,所以这部分差异越来越小。不过,那些百度知道排名前十和前十的关键词,因为搜索量大,采集成本高。有时候没有点击率或者点击率很低,也会导致关键词集采集不充分。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-03-31 07:02
关键词文章采集源码第一次开发,感觉从js开始。个人感觉操作系统用+sh。可以分配自己的电脑给后面的web服务,但是前端编程是必须要有基础的。然后是系统,如果有svn的话就好搞多了。1.关于图片在用什么抓取,分三种情况:1.1类似国内网站,图片都要去抓取下来;1.2图片小,发布到网站就可以抓取;1.3图片大,就用抓取。
?
非专业人士从零开始,现学现卖,预计花1周到2周学习基础。完成vue单页面应用。(这篇文章有很多讲解vue的文章,具体怎么做可以直接看我的博客)一周时间慢慢过度。-vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+++++flux++mobx+db+node+git+scss+less+。还差一项高阶框架,等我研究研究看看再告诉你。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
关键词文章采集源码第一次开发,感觉从js开始。个人感觉操作系统用+sh。可以分配自己的电脑给后面的web服务,但是前端编程是必须要有基础的。然后是系统,如果有svn的话就好搞多了。1.关于图片在用什么抓取,分三种情况:1.1类似国内网站,图片都要去抓取下来;1.2图片小,发布到网站就可以抓取;1.3图片大,就用抓取。
?
非专业人士从零开始,现学现卖,预计花1周到2周学习基础。完成vue单页面应用。(这篇文章有很多讲解vue的文章,具体怎么做可以直接看我的博客)一周时间慢慢过度。-vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+vue2.0+++++flux++mobx+db+node+git+scss+less+。还差一项高阶框架,等我研究研究看看再告诉你。
soup关键词文章采集源码分享采集工具真有这么简单
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-03-31 00:01
关键词文章采集源码分享采集工具真有这么简单,这是个傻瓜式的简单操作。成功率高,关键词热度适中!告诉你+获取1000个真实用户,不需要下载数据包!://-0-page-data-/关键词+,覆盖真实用户+,不需要下载数据包!。
可以提供获取真实用户的方法,
可以看下这个代码,
不需要下载数据包哦,直接用代码就能获取了,----(ps:就是个返回网站链接的代码啦)代码:d(url){if(soup。("。test")。。()==soup。。("/")。
()){}else{if(soup。("。")。。()==soup。。("//////////////////////////////////////////////////////////。 查看全部
soup关键词文章采集源码分享采集工具真有这么简单
关键词文章采集源码分享采集工具真有这么简单,这是个傻瓜式的简单操作。成功率高,关键词热度适中!告诉你+获取1000个真实用户,不需要下载数据包!://-0-page-data-/关键词+,覆盖真实用户+,不需要下载数据包!。
可以提供获取真实用户的方法,
可以看下这个代码,
不需要下载数据包哦,直接用代码就能获取了,----(ps:就是个返回网站链接的代码啦)代码:d(url){if(soup。("。test")。。()==soup。。("/")。
()){}else{if(soup。("。")。。()==soup。。("//////////////////////////////////////////////////////////。
常见的境外社交数据采集与分析:采集场景的共性
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-03-24 23:33
Twitter,Facebook,YouTube和Instagram等海外社交媒体平台上聚集了大量用户的声音。通过采集这些海外社交数据和社交化的倾听,品牌公司或部门可以实时掌握海外舆论的情况,然后为海外业务发展,国际事件研究和相关政策制定提供情报支持。
在过去的几年中,我们已经帮助许多客户完成了各种细分场景下的海外社交数据采集和分析:
本文将结合特定的客户案例来讨论常见的海外社交数据采集场景。
采集场景共性
让我先谈谈采集场景的共性。
尽管Twitter,Facebook,YouTube和Instagram具有不同的主要内容格式,但它们都属于社交媒体平台。它们的大型结构和功能相对相似。 采集场景也有很多共同点,最常见的三种类型是采集]场景是:
1.在指定帐户采集下更新的推文/图片/视频
2.特定关键词 采集的实时搜索结果
3.在推文/图片/视频下的评论采集
对于这些采集场景,我们几乎完成了采集模板和教程。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
下面为每种采集场景类型选择一个网站示例进行详细说明,采集的其他网站方法相似,因此不再赘述。
如有任何疑问,请随时咨询我们的客户服务。
一、 采集在指定的Facebook帐户下更新了推文
Facebook是世界上最大的社交媒体平台,每月有20亿活跃用户;每天在Facebook上进行15亿次搜索;每天有超过12亿的Facebook用户;每天超过80亿次视频观看。
采集在指定的Facebook帐户下更新推文数据是非常常见的采集需求。例如,在流行期间,美国约翰·霍普金斯大学(Johns Hopkins University)启动了Facebook平台,以实时提供最权威的流行数据。在研究与流行病相关的话题时,约翰·霍普金斯大学Facebook帐户上发布的历史推文和新增推文采集可以用作重要的研究数据来源。
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
二、在Twitter上搜索关键词,采集在推文列表中搜索
Twitter是当今最受欢迎的社交媒体平台之一,每天有超过1亿活跃用户和超过5亿条推文。 Twitter相当于微博。
在Twitter上搜索关键词并在推文列表中搜索采集是非常常见的采集需求。例如,华为,TikTok等海外业务发展迅速的品牌公司需要时刻关注海外社会舆论的发展趋势,为品牌做出相关决策提供情报支持。 Twitter是一个非常重要的平台。首先选择一批与品牌相关的关键词,然后在Twitter上实时搜索关键词和采集其搜索结果,以获得大量有价值的信息。
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。 查看全部
常见的境外社交数据采集与分析:采集场景的共性
Twitter,Facebook,YouTube和Instagram等海外社交媒体平台上聚集了大量用户的声音。通过采集这些海外社交数据和社交化的倾听,品牌公司或部门可以实时掌握海外舆论的情况,然后为海外业务发展,国际事件研究和相关政策制定提供情报支持。
在过去的几年中,我们已经帮助许多客户完成了各种细分场景下的海外社交数据采集和分析:
本文将结合特定的客户案例来讨论常见的海外社交数据采集场景。
采集场景共性
让我先谈谈采集场景的共性。
尽管Twitter,Facebook,YouTube和Instagram具有不同的主要内容格式,但它们都属于社交媒体平台。它们的大型结构和功能相对相似。 采集场景也有很多共同点,最常见的三种类型是采集]场景是:
1.在指定帐户采集下更新的推文/图片/视频
2.特定关键词 采集的实时搜索结果
3.在推文/图片/视频下的评论采集
对于这些采集场景,我们几乎完成了采集模板和教程。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
下面为每种采集场景类型选择一个网站示例进行详细说明,采集的其他网站方法相似,因此不再赘述。
如有任何疑问,请随时咨询我们的客户服务。
一、 采集在指定的Facebook帐户下更新了推文
Facebook是世界上最大的社交媒体平台,每月有20亿活跃用户;每天在Facebook上进行15亿次搜索;每天有超过12亿的Facebook用户;每天超过80亿次视频观看。
采集在指定的Facebook帐户下更新推文数据是非常常见的采集需求。例如,在流行期间,美国约翰·霍普金斯大学(Johns Hopkins University)启动了Facebook平台,以实时提供最权威的流行数据。在研究与流行病相关的话题时,约翰·霍普金斯大学Facebook帐户上发布的历史推文和新增推文采集可以用作重要的研究数据来源。
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
二、在Twitter上搜索关键词,采集在推文列表中搜索
Twitter是当今最受欢迎的社交媒体平台之一,每天有超过1亿活跃用户和超过5亿条推文。 Twitter相当于微博。
在Twitter上搜索关键词并在推文列表中搜索采集是非常常见的采集需求。例如,华为,TikTok等海外业务发展迅速的品牌公司需要时刻关注海外社会舆论的发展趋势,为品牌做出相关决策提供情报支持。 Twitter是一个非常重要的平台。首先选择一批与品牌相关的关键词,然后在Twitter上实时搜索关键词和采集其搜索结果,以获得大量有价值的信息。
采集的详细要求包括:
以上要求已完成采集模板。
★海外采集模板是特殊模板,如有必要,请联系客户服务。
x车之家的字体反爬虫难度:中等偏上反爬
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-03-24 23:29
新年过后,让我们更新一下反爬行动物系列
对于以前的一个朋友,他说1688年是X Bao的反爬行动物
说实话,阿里的爬行动物非常强大,我为无法应付而感到羞愧。
例如,如果您登录Xbao,则使用selenium + chrome的朋友会遇到滑块拖动验证失败的情况
这不会过去。首先,您将检查浏览器DOM的window.webdriver,以确定它是人工工具还是自动工具
其次,它将检查浏览器的指纹以查看您的特征值,然后使用逻辑回归算法确定它是否是爬虫。
就目前而言,我要提很多。
它仍然是先前系列的回顾:
不要吃生米:反爬行动物系列(一)
不要吃生米:反爬行动物系列(二)
不吃生米:抗爬行动物系列(三)
好的,今天我们要研究xcarzhijia的字体反爬虫
难度:中等偏上
反爬升策略:在此之前,用css,::替换html页面,获得的html是源代码,而前端呈现则是您所看到的。因此,在字体的某些关键部分中,获得了一个代码,它具有令人困惑的含义。
让我给你个栗子:小明有一头驴。
那里有几个头?这就是这种爬行动物的意思。
防攀爬策略:解析每个代码的字词就可以了
好的,让我们开始讨论这个话题。
要求是我们需要获取汽车的参数配置信息
进入页面,长酱颜色
在页面上看起来还可以,对
然后看一下html源代码
没有结构化的东西,同时我发现数据放在js中,这很麻烦
请注意我标记的红色框中的内容
因此,即使您突破了一些常规的反爬虫方法,在获取html之后,我的意思是指在批量获取所有模型的配置html之后。
解析js,并获取配置信息。
但是关键位置的字体已被替换,真是一团糟。
因此,接下来我们需要替换它,并将其改回。
由于常规的爬行动物是前端爬行动物,因此在阅读时它等同于练习本,答案在练习本的后面。
这时候,我回到html来找到答案,
这只有20多行,请看此段落,我认为这很棘手,对吧?
让我们取出这个js,格式化它,看起来像这样
下一步是耐心地寻找窍门
完成后,我发现了这样的功能
索引和项目有点令人眼花。乱。根据专业习惯,这应该是正确的字体
让我们搜索InsertRule 关键词,然后找到它
添加一个句子console.log($ index $,$ temp $)
然后将整个js放入chrome,执行并查看
这不是出来吗?
从解析的数据中,根据索引将其替换。
总体思路是这样的
我不会提供代码,只是懒惰
我需要在这里提醒作者
xcar home,加载的字体是动态的,并且为特定汽车加载的字体是固定的。
因此,当采集时,请注意不同汽车系列加载的不同字体。
最后,我个人认为在字体防爬虫方面,xcar的家可以看作是教科书。 查看全部
x车之家的字体反爬虫难度:中等偏上反爬
新年过后,让我们更新一下反爬行动物系列
对于以前的一个朋友,他说1688年是X Bao的反爬行动物
说实话,阿里的爬行动物非常强大,我为无法应付而感到羞愧。
例如,如果您登录Xbao,则使用selenium + chrome的朋友会遇到滑块拖动验证失败的情况
这不会过去。首先,您将检查浏览器DOM的window.webdriver,以确定它是人工工具还是自动工具
其次,它将检查浏览器的指纹以查看您的特征值,然后使用逻辑回归算法确定它是否是爬虫。
就目前而言,我要提很多。
它仍然是先前系列的回顾:
不要吃生米:反爬行动物系列(一)
不要吃生米:反爬行动物系列(二)
不吃生米:抗爬行动物系列(三)
好的,今天我们要研究xcarzhijia的字体反爬虫
难度:中等偏上
反爬升策略:在此之前,用css,::替换html页面,获得的html是源代码,而前端呈现则是您所看到的。因此,在字体的某些关键部分中,获得了一个代码,它具有令人困惑的含义。
让我给你个栗子:小明有一头驴。
那里有几个头?这就是这种爬行动物的意思。
防攀爬策略:解析每个代码的字词就可以了
好的,让我们开始讨论这个话题。
要求是我们需要获取汽车的参数配置信息
进入页面,长酱颜色
在页面上看起来还可以,对
然后看一下html源代码
没有结构化的东西,同时我发现数据放在js中,这很麻烦
请注意我标记的红色框中的内容
因此,即使您突破了一些常规的反爬虫方法,在获取html之后,我的意思是指在批量获取所有模型的配置html之后。
解析js,并获取配置信息。
但是关键位置的字体已被替换,真是一团糟。
因此,接下来我们需要替换它,并将其改回。
由于常规的爬行动物是前端爬行动物,因此在阅读时它等同于练习本,答案在练习本的后面。
这时候,我回到html来找到答案,
这只有20多行,请看此段落,我认为这很棘手,对吧?
让我们取出这个js,格式化它,看起来像这样
下一步是耐心地寻找窍门
完成后,我发现了这样的功能
索引和项目有点令人眼花。乱。根据专业习惯,这应该是正确的字体
让我们搜索InsertRule 关键词,然后找到它
添加一个句子console.log($ index $,$ temp $)
然后将整个js放入chrome,执行并查看
这不是出来吗?
从解析的数据中,根据索引将其替换。
总体思路是这样的
我不会提供代码,只是懒惰
我需要在这里提醒作者
xcar home,加载的字体是动态的,并且为特定汽车加载的字体是固定的。
因此,当采集时,请注意不同汽车系列加载的不同字体。
最后,我个人认为在字体防爬虫方面,xcar的家可以看作是教科书。
关于输入关键词自动生成文章的软件大家觉得网上有没有?
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-02-12 13:00
朋友您好!今天,我将再给您上一课。您是否认为有用于输入关键词的软件以自动在线生成文章?
答案:绝对不会!
那么我们今天将带给您这样的软件,我们只需要输入您的关键词自动生成原创 文章,该工具是我用简单的语言开发的,我们将首先为您演示!
每个人都看到它确实可以生成,代码实际上非常好,让我们向您展示代码!它主要是通过连接到第三方API来实现的。
总共少于10行代码。可以达到这种效果。实际上,这不是我的软件开发,而是第三方平台提供的API接口,因此我们不方便提供此接口地址什么!如果您自己搜索,就不会找到它。
我使用了被捕获和分析的API。整个过程也很困难!
那么该软件的优点是什么?缺点是什么?
第一:优点是写一篇文章原创非常简单。它可以在几秒钟内用一个键生成数千个文章,这是原创,没人能做到。随笔的效果,您是不是说牛X的专家作家可以在几秒钟内写上千个单词原创?即使他要复制,这一次还不够,这就是优势!
第二:缺点也很明显。句子流较差,但效果比伪原创大得多。仍然可以使用自媒体平台或搜索引擎!
此软件的生成原理是什么?
实际上,生成原理也很简单。我们首先使用一些数据包捕获分析工具来捕获第三方平台的协议数据,然后将协议数据封装到软件中,以便我们可以在本地发送GET数据,以实现另一方平台的生成。内容!
我将在下面给您一个示意图!
一般的生成原理是这样的,并且流程图设计不是很好。毕竟,这不是主要的。好的,今天我们的课程到此为止。如果需要源代码,请去私人讲师网站下载!
再见!在我的博客的下一期中,我将分享修改视频MD5的工具。期待它! 查看全部
关于输入关键词自动生成文章的软件大家觉得网上有没有?
朋友您好!今天,我将再给您上一课。您是否认为有用于输入关键词的软件以自动在线生成文章?
答案:绝对不会!
那么我们今天将带给您这样的软件,我们只需要输入您的关键词自动生成原创 文章,该工具是我用简单的语言开发的,我们将首先为您演示!
每个人都看到它确实可以生成,代码实际上非常好,让我们向您展示代码!它主要是通过连接到第三方API来实现的。
总共少于10行代码。可以达到这种效果。实际上,这不是我的软件开发,而是第三方平台提供的API接口,因此我们不方便提供此接口地址什么!如果您自己搜索,就不会找到它。
我使用了被捕获和分析的API。整个过程也很困难!
那么该软件的优点是什么?缺点是什么?
第一:优点是写一篇文章原创非常简单。它可以在几秒钟内用一个键生成数千个文章,这是原创,没人能做到。随笔的效果,您是不是说牛X的专家作家可以在几秒钟内写上千个单词原创?即使他要复制,这一次还不够,这就是优势!
第二:缺点也很明显。句子流较差,但效果比伪原创大得多。仍然可以使用自媒体平台或搜索引擎!
此软件的生成原理是什么?
实际上,生成原理也很简单。我们首先使用一些数据包捕获分析工具来捕获第三方平台的协议数据,然后将协议数据封装到软件中,以便我们可以在本地发送GET数据,以实现另一方平台的生成。内容!
我将在下面给您一个示意图!
一般的生成原理是这样的,并且流程图设计不是很好。毕竟,这不是主要的。好的,今天我们的课程到此为止。如果需要源代码,请去私人讲师网站下载!
再见!在我的博客的下一期中,我将分享修改视频MD5的工具。期待它!
yeayee:Python数据分析及可视化实例目录1.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2021-02-12 10:01
文章系列总目录:
yeayee:Python数据分析和可视化示例目录
1.背景介绍
(1)连接到炸弹留下的作业,使用Cookies不用密码登录到今日的头条,并自动将回复回复到上一节采集的URL。经过测试,响应频率今日头条的速度太快了(3),挂起了提交按钮,因此,本文旨在解释如何执行POST,而Login也是一个原因。
在代码中设置Cookie时,请携带主机(如果有)。
(2)响应内容也很熟练。在这种情况下,响应内容由“标题”,“ 关键词”和促销标语组成,以避免被机器人识别为重复内容。
呵呵,不要以为找到POST_URL并发布数据后才能得到回复!需要明确的是,它不起作用。因为提交释放按钮时,仍然会加载几个链接,从而更改了会话中的Cookie。因此,在使用请求时,它还会模拟先前的Get请求并自动更新Session。例如,在这种情况下,还需要一个Get请求:/ user / info /
PS:我不知道他们的程序员为什么要重复将Post数据重复为两个变量并将其提交到数据库?
(3)是的,您现在可以成功发布。扩展:登录网站的POST参数很难获得,尤其是JS动态生成的一些参数。此时将使用PhantomJS。Xchaoinfo /再次推荐。他妈的登录,所有操作都可以登录,如果您没有登录,也可以为猫和老虎拍照。我不会专门谈论邮政登录。使用Cookie单一帐户登录采集数据对于大多数人来说已经足够了,更高级的黑操作,涉及灰生产和恶意爬网程序的操作,不便进行详细说明(例如更改IP,更改ID,更改IQ等)。
([4)下一个要点是关于多线程和多进程的消息?还是继续向Du Niang提供工件Phantoms?给来宾留言!!!
2.源代码
# coding = utf-8
import requests
import re, json
from bs4 import BeautifulSoup
import time
headers = {
'Host': 'www.toutiao.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Cookie': 'tt_webid=646855411836120***8; 。。。。不要随便让人看到你的小秘密',
'Connection': 'keep-alive'
}
s = requests.session()
def post_data(base_url,post_content,post_id):
try:
# base_url = 'http://toutiao.com/group/64689 ... 39%3B
url2 = 'http://www.toutiao.com/user/info/'
content = s.get(url2, headers=headers) # 获取Useinfog,更新session
# soup = BeautifulSoup(content, "lxml")
# print(soup.prettify())
headers['Referer'] = base_url
url3 = 'http://www.toutiao.com/api/com ... 39%3B
data = {
'status':post_content,
'content': post_content,
'group_id':post_id,
'item_id':post_id
}
s.post(url3, headers=headers, data=data) # 评论文章
print('评论成功啦,嚯嚯')
except:
print('掉坑里了,爬起来')
pass
f_lines = open('sorted.txt','r',encoding='utf-8').readlines()
posted_urls = open('posted.txt','r',encoding='utf-8').read()
# print(f_lines[0].strip().split(',')) # 实现记录已评论的Url,中断后可以接着评论
for f_line in f_lines:
if 'http://toutiao.com/group/' in f_line: # 说明是可以评论的文章
line_list = f_line.strip().split(',')
base_url = line_list[1]
print(base_url)
post_content = '大神,你发的《'+ line_list[2]+'》很有借鉴意义,能否转发呢?'
# print(post_content)
post_id = base_url.split('/')[-2]
if base_url not in posted_urls : # 进入下一个循环
try:
time.sleep(3)
post_data(base_url,post_content,post_id)
f_posted = open('posted.txt','a',encoding='utf-8')
f_posted.write(base_url+'\n')
f_posted.close()
except:
print('又他妈掉坑里了,爬起来')
pass
else:
print('曾经评论过了')
yeayee:Python数据分析和可视化示例目录
查看全部
yeayee:Python数据分析及可视化实例目录1.4
文章系列总目录:
yeayee:Python数据分析和可视化示例目录
1.背景介绍
(1)连接到炸弹留下的作业,使用Cookies不用密码登录到今日的头条,并自动将回复回复到上一节采集的URL。经过测试,响应频率今日头条的速度太快了(3),挂起了提交按钮,因此,本文旨在解释如何执行POST,而Login也是一个原因。
在代码中设置Cookie时,请携带主机(如果有)。
(2)响应内容也很熟练。在这种情况下,响应内容由“标题”,“ 关键词”和促销标语组成,以避免被机器人识别为重复内容。
呵呵,不要以为找到POST_URL并发布数据后才能得到回复!需要明确的是,它不起作用。因为提交释放按钮时,仍然会加载几个链接,从而更改了会话中的Cookie。因此,在使用请求时,它还会模拟先前的Get请求并自动更新Session。例如,在这种情况下,还需要一个Get请求:/ user / info /
PS:我不知道他们的程序员为什么要重复将Post数据重复为两个变量并将其提交到数据库?
(3)是的,您现在可以成功发布。扩展:登录网站的POST参数很难获得,尤其是JS动态生成的一些参数。此时将使用PhantomJS。Xchaoinfo /再次推荐。他妈的登录,所有操作都可以登录,如果您没有登录,也可以为猫和老虎拍照。我不会专门谈论邮政登录。使用Cookie单一帐户登录采集数据对于大多数人来说已经足够了,更高级的黑操作,涉及灰生产和恶意爬网程序的操作,不便进行详细说明(例如更改IP,更改ID,更改IQ等)。
([4)下一个要点是关于多线程和多进程的消息?还是继续向Du Niang提供工件Phantoms?给来宾留言!!!
2.源代码
# coding = utf-8
import requests
import re, json
from bs4 import BeautifulSoup
import time
headers = {
'Host': 'www.toutiao.com',
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Cookie': 'tt_webid=646855411836120***8; 。。。。不要随便让人看到你的小秘密',
'Connection': 'keep-alive'
}
s = requests.session()
def post_data(base_url,post_content,post_id):
try:
# base_url = 'http://toutiao.com/group/64689 ... 39%3B
url2 = 'http://www.toutiao.com/user/info/'
content = s.get(url2, headers=headers) # 获取Useinfog,更新session
# soup = BeautifulSoup(content, "lxml")
# print(soup.prettify())
headers['Referer'] = base_url
url3 = 'http://www.toutiao.com/api/com ... 39%3B
data = {
'status':post_content,
'content': post_content,
'group_id':post_id,
'item_id':post_id
}
s.post(url3, headers=headers, data=data) # 评论文章
print('评论成功啦,嚯嚯')
except:
print('掉坑里了,爬起来')
pass
f_lines = open('sorted.txt','r',encoding='utf-8').readlines()
posted_urls = open('posted.txt','r',encoding='utf-8').read()
# print(f_lines[0].strip().split(',')) # 实现记录已评论的Url,中断后可以接着评论
for f_line in f_lines:
if 'http://toutiao.com/group/' in f_line: # 说明是可以评论的文章
line_list = f_line.strip().split(',')
base_url = line_list[1]
print(base_url)
post_content = '大神,你发的《'+ line_list[2]+'》很有借鉴意义,能否转发呢?'
# print(post_content)
post_id = base_url.split('/')[-2]
if base_url not in posted_urls : # 进入下一个循环
try:
time.sleep(3)
post_data(base_url,post_content,post_id)
f_posted = open('posted.txt','a',encoding='utf-8')
f_posted.write(base_url+'\n')
f_posted.close()
except:
print('又他妈掉坑里了,爬起来')
pass
else:
print('曾经评论过了')
yeayee:Python数据分析和可视化示例目录
【如何解决爬虫程序崩溃重启的问题】文章采集源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2021-02-04 17:02
关键词文章采集源码分享本文带来的干货是【如何解决爬虫程序崩溃重启的问题】采集一个的商品信息,你可以根据自己的操作系统位数,选择一个默认端口开启。#!/usr/bin/envpython#coding:utf-8fromseleniumimportwebdriverimportrequests#获取商品列表信息用户登录正在服务器爬取的电商会提示用户登录失败,我们直接选择接着访问,就成功登录成功了。
先查看一下requests对象的set_timeout方法:对,这个函数就是定时发送http请求,当请求过多时,会请求失败。设置过期时间爬取商品列表信息,访问速度比较慢。有一个default_response方法,该方法可以配置过期时间,过期时间可以自己设置。先来看一下默认的:requests对象是这样,设置过期时间为12小时,使用方法如下:python规定,get方法默认第一次请求时并没有更新http的响应状态,所以这样的响应请求是失败的。
我们配置一个正则表达式:匹配一个~/nbody>进行匹配。如果n,j,k前面是字符串,用[]包裹住:'\x-x-\x-\'可以用我们刚才设置的方法显示为:\x-x-\x-\x-\x-\'注意:如果你使用正则表达式匹配的是其它几个字符串,需要python提供re.sub()方法进行匹配,否则会失败。
不要忘记修改你的headers:headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/65.0.3529.141safari/537.36'}匹配的后面再用re.sub()方法匹配一下字符串:'\x-x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x。 查看全部
【如何解决爬虫程序崩溃重启的问题】文章采集源码
关键词文章采集源码分享本文带来的干货是【如何解决爬虫程序崩溃重启的问题】采集一个的商品信息,你可以根据自己的操作系统位数,选择一个默认端口开启。#!/usr/bin/envpython#coding:utf-8fromseleniumimportwebdriverimportrequests#获取商品列表信息用户登录正在服务器爬取的电商会提示用户登录失败,我们直接选择接着访问,就成功登录成功了。
先查看一下requests对象的set_timeout方法:对,这个函数就是定时发送http请求,当请求过多时,会请求失败。设置过期时间爬取商品列表信息,访问速度比较慢。有一个default_response方法,该方法可以配置过期时间,过期时间可以自己设置。先来看一下默认的:requests对象是这样,设置过期时间为12小时,使用方法如下:python规定,get方法默认第一次请求时并没有更新http的响应状态,所以这样的响应请求是失败的。
我们配置一个正则表达式:匹配一个~/nbody>进行匹配。如果n,j,k前面是字符串,用[]包裹住:'\x-x-\x-\'可以用我们刚才设置的方法显示为:\x-x-\x-\x-\x-\'注意:如果你使用正则表达式匹配的是其它几个字符串,需要python提供re.sub()方法进行匹配,否则会失败。
不要忘记修改你的headers:headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/65.0.3529.141safari/537.36'}匹配的后面再用re.sub()方法匹配一下字符串:'\x-x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x-\x。
操作方法:什么是泛目录?泛目录的操作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-01-05 09:14
什么是平移目录?
pan-catalog的核心原理是使用高权重网站继承目录,然后快速获得收录和排名。目录的具体表现形式分为网站,目录和文章单页,属于一种。更常见的网站优化方法使用关键词优化布局来提高网站的排名和权重通过目录文件的方式。
顾名思义,平移目录是在网站上生成无限数量的目录页面,它也可以生成大量文章内容,但从某种程度上讲,这种程序本身没有任何实用价值;许多人可能认为,通过这种无限生成的内容形式,可以获得很好的网站排名。实际上,这个想法是错误的。首先,我们必须摆脱这种思维上的误解。
实际上,没有好的或坏的泛目录程序。市场上流行的泛目录程序基本上是可互操作的,原理也基本相同。如果您想获得相当高的关键词排名,则仍然需要与其他工具合作。
用通俗易懂的术语来说,泛目录是网站的高级版本。潘目录程序不仅可以生成站点目录,还可以生成无限数量的指定文章内容页面。这样,引导搜索引擎进行爬取,以达到快速排名的目的。
要了解目录排名的原理,必须首先了解关键词的排名因素。 关键词的排名因子与关键词的布局,内容更新频率,网站链接和用户体验密切相关。
从正常的SEO优化操作中不难发现,内容更新的频率在关键词的排名中起着至关重要的作用。因此,我们进行了泛型编录以解决内容更新的问题。
pan目录的实际战斗操作主要分为四个方面:内容频率,文章处理,原创度干扰和时间因素。具体操作过程如下:
1、首先,您需要采集一些对时间敏感的文章内容,例如搜狐,网易和腾讯之类的流行新闻源,以打包内容并将其放入文章库中。
2、还需要组织并打包原创内容标题并将其放入内容标题库中,并且需要将关键词插入关键词库中以进行组织和打包,并进行所有准备工作
3、准备工作完成后,可以使用pan-catalog程序开始生成内容。生成的内容实际上是文章处理的过程。全景目录将从关键词库,标题库或关键词开始,从库中随机获取内容,合并并生成发行版。
4、生成内容后,您只需将URL链接分批提交给搜索引擎。
某些网站管理员可能有疑问。如果他们使用黑帽SEO技术,会被搜索引擎阻止吗?这种内容更新真的有效吗?实际上,只要官方搜索引擎没有手动检查我们的网站,搜索引擎就会错误地认为我们的大部分内容都是原创内容,因此收录和排名很快就会出现。
只要使用一些合理的方法来优化网站,就不会有被k驻扎的风险。其次,在更新网站的内容时,我们必须注意文章的质量和内容。它是可读的,对我们的品牌形象提升有帮助吗?目前市场上黑帽SEO作弊的方法并不少见。实际上,它们比我们上面提到的要多。
尽管黑帽SEO可以带来丰厚的利润和快速的排名时间,但最好不要总考虑黑帽优化技术,因为这不是网站优化的长期解决方案,只能持续改善白色帽子优化技术是企业网站的最正确选择。 查看全部
操作方法:什么是泛目录?泛目录的操作原理
什么是平移目录?
pan-catalog的核心原理是使用高权重网站继承目录,然后快速获得收录和排名。目录的具体表现形式分为网站,目录和文章单页,属于一种。更常见的网站优化方法使用关键词优化布局来提高网站的排名和权重通过目录文件的方式。
顾名思义,平移目录是在网站上生成无限数量的目录页面,它也可以生成大量文章内容,但从某种程度上讲,这种程序本身没有任何实用价值;许多人可能认为,通过这种无限生成的内容形式,可以获得很好的网站排名。实际上,这个想法是错误的。首先,我们必须摆脱这种思维上的误解。
实际上,没有好的或坏的泛目录程序。市场上流行的泛目录程序基本上是可互操作的,原理也基本相同。如果您想获得相当高的关键词排名,则仍然需要与其他工具合作。
用通俗易懂的术语来说,泛目录是网站的高级版本。潘目录程序不仅可以生成站点目录,还可以生成无限数量的指定文章内容页面。这样,引导搜索引擎进行爬取,以达到快速排名的目的。
要了解目录排名的原理,必须首先了解关键词的排名因素。 关键词的排名因子与关键词的布局,内容更新频率,网站链接和用户体验密切相关。
从正常的SEO优化操作中不难发现,内容更新的频率在关键词的排名中起着至关重要的作用。因此,我们进行了泛型编录以解决内容更新的问题。
pan目录的实际战斗操作主要分为四个方面:内容频率,文章处理,原创度干扰和时间因素。具体操作过程如下:
1、首先,您需要采集一些对时间敏感的文章内容,例如搜狐,网易和腾讯之类的流行新闻源,以打包内容并将其放入文章库中。
2、还需要组织并打包原创内容标题并将其放入内容标题库中,并且需要将关键词插入关键词库中以进行组织和打包,并进行所有准备工作
3、准备工作完成后,可以使用pan-catalog程序开始生成内容。生成的内容实际上是文章处理的过程。全景目录将从关键词库,标题库或关键词开始,从库中随机获取内容,合并并生成发行版。
4、生成内容后,您只需将URL链接分批提交给搜索引擎。
某些网站管理员可能有疑问。如果他们使用黑帽SEO技术,会被搜索引擎阻止吗?这种内容更新真的有效吗?实际上,只要官方搜索引擎没有手动检查我们的网站,搜索引擎就会错误地认为我们的大部分内容都是原创内容,因此收录和排名很快就会出现。
只要使用一些合理的方法来优化网站,就不会有被k驻扎的风险。其次,在更新网站的内容时,我们必须注意文章的质量和内容。它是可读的,对我们的品牌形象提升有帮助吗?目前市场上黑帽SEO作弊的方法并不少见。实际上,它们比我们上面提到的要多。
尽管黑帽SEO可以带来丰厚的利润和快速的排名时间,但最好不要总考虑黑帽优化技术,因为这不是网站优化的长期解决方案,只能持续改善白色帽子优化技术是企业网站的最正确选择。
完美:辣鸡采集 laji-collect 采集世界上所有辣鸡数据 欢迎大家来采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-01-04 11:15
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出网站采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
go mod tidy<br />
go mod vendor<br />
go build main.go<br />
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划有助于改善
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生分支,对其进行修改,然后在修改后提交合并请求合并请求。 查看全部
完美:辣鸡采集 laji-collect 采集世界上所有辣鸡数据 欢迎大家来采集
为什么这辣鸡文章采集器辣鸡文章采集器可以采集什么含量
采集器可以采集到达的内容是:文章标题,文章关键词,文章说明,文章详细信息,文章作者,文章发布时间,[ K13]次网页浏览。
我什么时候需要使用辣鸡肉文章采集器
当我们需要给出网站采集 文章时,此采集器会派上用场。该采集器不需要受到保护,并且每天每10分钟运行24小时,它将自动遍历采集列表,获取收录文章的链接,并随时获取文本。您还可以设置自动发布以自动发布到指定的文章表。
文章采集器辣鸡在哪里跑?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行,您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
辣鸡文章采集器是否可用伪原创
此采集器暂时不支持伪原创功能,稍后将添加适当的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
go mod tidy<br />
go mod vendor<br />
go build main.go<br />
编译后,运行已编译的文件,然后双击运行可执行文件,在打开的浏览器的可视界面中填写数据库信息,完成初始配置,添加采集源,即可开始采集的旅程。
发展计划有助于改善
欢迎有能力和精神的个人或团体参与此采集器的开发和改进,并共同改善采集的功能。请派生分支,对其进行修改,然后在修改后提交合并请求合并请求。
精选文章:2019独立目录泛单站群-自动采集新闻自动seo标题伪原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-12-09 08:13
emmm,该程序怎么说,它可以自动采集新闻自动seo标题伪原创平移目录站群,并且生成的页面也与标题相关。支持百度站长平台,熊掌号等。+自动推送,无脑简单配置。
放置屏幕截图:
程序使用:
一、独立生成的目录站群文件简介
Tpl文件————————模板目录
index.html ——————-首页模板
list.html ———————-列表模板
content.html —————-内容模板
caiji.php ——————– 采集文件
config.php —————-配置保存文件
p.php ————————配置设置文件
sheng.php ——————生成文件
wei.txt ———————— 伪原创同义词替换文件
程序运行后,保存记录和文件描述
links2.php ————————-链接保存文件[带标题]
links.php ————————-链接保存文件[纯链接]
查询方法:您的域名/sheng.php?links=1 [纯链接]
查询方法:您的域名/sheng.php?links=2 [带标题]
Caiji文件夹————————————从采集中保存回文章
二、程序构建
只需要php环境,不需要数据库
1.首先用一个单词和一行替换他自己的关键词key.txt
2.检查是否需要更改模板
3.上传到您自己的程序以使用域名构建网站,或上传到已经具有网站的辅助目录
4.访问您的域名/p.php并填写配置
配置说明
网站名称:填写网站名称,无需解释,可以随意命名
预定制的URL:它是您自己的URL(用于填充辅助目录的目录的链接)加上http和/
生成密钥:填写您自己的密码,以防止其他人控制生成
静音生成时间:填写每个生成时间的间隔。这里的单位是秒。
分类:这是指列,即创建的列,最多支持6个
列名,列路径,页面上显示多少列
文件命名规则:文章生成的规则
首页标题:网站首页标题首页关键词:首页添加关键词首页说明:首页说明
文章标题规则:是生成的文章标题模式关键词+原创采集返回的标题,还是仅原创采集返回的标题
提交推送链接:直接填写一些链接以推送百度网站站长或熊掌号
5.运行采集文件采集 文章
6.访问生成的文件,并且生成完成
——————————完成————————————–
广告代码:
建议您将其自己添加到模板中,或直接使用js添加。返回并直接使用js显示或跳转
我们已经添加了js代码。 js文件位于tpl / js.js
中
滑动采集页面自动模式:
触发器生成和采集已添加到模板js代码中!每当有人访问我们的网站任何页面时,采集 +都会自动生成一个页面!假设您的网站有流量,如果没有流量,请使用流量宝或流量向导等清除流量
同一句话,小弟测验。最适合您的程序。
本文之后将刷新此内容!公开免费审核权限 查看全部
2019年独立目录泛单站群-自动采集新闻自动seo标题伪原创
emmm,该程序怎么说,它可以自动采集新闻自动seo标题伪原创平移目录站群,并且生成的页面也与标题相关。支持百度站长平台,熊掌号等。+自动推送,无脑简单配置。
放置屏幕截图:
程序使用:
一、独立生成的目录站群文件简介
Tpl文件————————模板目录
index.html ——————-首页模板
list.html ———————-列表模板
content.html —————-内容模板
caiji.php ——————– 采集文件
config.php —————-配置保存文件
p.php ————————配置设置文件
sheng.php ——————生成文件
wei.txt ———————— 伪原创同义词替换文件
程序运行后,保存记录和文件描述
links2.php ————————-链接保存文件[带标题]
links.php ————————-链接保存文件[纯链接]
查询方法:您的域名/sheng.php?links=1 [纯链接]
查询方法:您的域名/sheng.php?links=2 [带标题]
Caiji文件夹————————————从采集中保存回文章
二、程序构建
只需要php环境,不需要数据库
1.首先用一个单词和一行替换他自己的关键词key.txt
2.检查是否需要更改模板
3.上传到您自己的程序以使用域名构建网站,或上传到已经具有网站的辅助目录
4.访问您的域名/p.php并填写配置
配置说明
网站名称:填写网站名称,无需解释,可以随意命名
预定制的URL:它是您自己的URL(用于填充辅助目录的目录的链接)加上http和/
生成密钥:填写您自己的密码,以防止其他人控制生成
静音生成时间:填写每个生成时间的间隔。这里的单位是秒。
分类:这是指列,即创建的列,最多支持6个
列名,列路径,页面上显示多少列
文件命名规则:文章生成的规则
首页标题:网站首页标题首页关键词:首页添加关键词首页说明:首页说明
文章标题规则:是生成的文章标题模式关键词+原创采集返回的标题,还是仅原创采集返回的标题
提交推送链接:直接填写一些链接以推送百度网站站长或熊掌号
5.运行采集文件采集 文章
6.访问生成的文件,并且生成完成
——————————完成————————————–
广告代码:
建议您将其自己添加到模板中,或直接使用js添加。返回并直接使用js显示或跳转
我们已经添加了js代码。 js文件位于tpl / js.js
中
滑动采集页面自动模式:
触发器生成和采集已添加到模板js代码中!每当有人访问我们的网站任何页面时,采集 +都会自动生成一个页面!假设您的网站有流量,如果没有流量,请使用流量宝或流量向导等清除流量
同一句话,小弟测验。最适合您的程序。
本文之后将刷新此内容!公开免费审核权限
解读:vivi内核二开智能标题关键字新闻采集源码无需人工管理,站群
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-12-08 12:17
Vivi内核两个无需智能管理的开放式智能标题关键字新闻采集源代码。
文章中的相关关键字将添加到标题关键字。
SEO超级好,您可以执行站群。
php5.2-5.4
上传和使用
蜘蛛池新闻采集源代码完全自动采集,无需人工干预。
24小时自动采集,仅需要500M空间。
1.在原创版本()百度蜘蛛,谷歌蜘蛛,神马蜘蛛(手机流量非常昂贵),360蜘蛛,搜狗蜘蛛等基础上,具有更智能的设置来吸引蜘蛛。
2.巧妙地添加一个后缀,自动在采集的内容中添加相关的意义句子,例如,原创标题为胖,采集会添加诸如吃什么来减肥等内容,具体取决于实际情况。
3.伪原创的单词更多
4.关键词内部链接可以自由设置,可以引导蜘蛛并提高SEO效果。
5.动态网页蜘蛛可以被喜欢(也是伪静态的)
6.建议建立更多站点,(提供静安3G300M虚拟主机,每年12元),不同的站点吸引不同的蜘蛛(因为我们的智能代码使每个站点都不一样,因为它是随机的,所以首选蜘蛛)有所不同)。
7.具有许多增强效果,我不会多说。建议使用一级域名,收录比二级域名要多得多。
8.您可以在后台看到蜘蛛的来源,因此可以将蜘蛛定向到所需的站点
9.页面可以坐着等待收录。
资源下载此资源下载价格为10个材料硬币,请先登录 查看全部
Vivi内核的两个开放式智能标题关键字新闻采集源代码,无需手动管理,站群
Vivi内核两个无需智能管理的开放式智能标题关键字新闻采集源代码。
文章中的相关关键字将添加到标题关键字。
SEO超级好,您可以执行站群。
php5.2-5.4
上传和使用
蜘蛛池新闻采集源代码完全自动采集,无需人工干预。
24小时自动采集,仅需要500M空间。
1.在原创版本()百度蜘蛛,谷歌蜘蛛,神马蜘蛛(手机流量非常昂贵),360蜘蛛,搜狗蜘蛛等基础上,具有更智能的设置来吸引蜘蛛。
2.巧妙地添加一个后缀,自动在采集的内容中添加相关的意义句子,例如,原创标题为胖,采集会添加诸如吃什么来减肥等内容,具体取决于实际情况。
3.伪原创的单词更多
4.关键词内部链接可以自由设置,可以引导蜘蛛并提高SEO效果。
5.动态网页蜘蛛可以被喜欢(也是伪静态的)
6.建议建立更多站点,(提供静安3G300M虚拟主机,每年12元),不同的站点吸引不同的蜘蛛(因为我们的智能代码使每个站点都不一样,因为它是随机的,所以首选蜘蛛)有所不同)。
7.具有许多增强效果,我不会多说。建议使用一级域名,收录比二级域名要多得多。
8.您可以在后台看到蜘蛛的来源,因此可以将蜘蛛定向到所需的站点
9.页面可以坐着等待收录。
资源下载此资源下载价格为10个材料硬币,请先登录
整体解决方案:MAIYIGO智能采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-11-27 09:22
PHPBB简介
资源描述:MAIYIGO(无限智能网站建设)全自动SEO站
该程序的操作非常聪明。您只需要在后台设置一些最受欢迎的关键词,每天文章采集的数量,无需人事管理,
一个域名建立一个站点,100个域名建立一百个站点,
百度和Google收录有几千个,公关从1增加到2,访问次数增加了一倍,
每天最多500IP,如果您打开20个站点,该值将更大。
7月底,该域名以200元的价格出售。您可以访问该站点以获取该域名的先前记录。
红色清单信息网络上有许多收录尚未被Google删除。
·智能自动车站建设系统:您所要做的就是设置一些关键词
·自动更新:MAIYIGO可以随时自动查找信息并自动更新
·在线WEB系统:无需安装软件,只需购买空间即可使用
·不作弊:我们不想关键词堆积,不作弊,我们是常规网站!
·如果可以上网,可以使用它:不需要网站构造知识
·自动赚钱机器:在家里放广告睡觉!等待赚钱
MAIYIGO是在顶级门户网站网站中工作的几位高级工程师对爬虫技术(蜘蛛)的使用,
分词技术和网页提取技术,使用URL重写技术,缓存技术,使用PHP语言开发的一套关键词可以自动在Internet上爬行相关信息,
自动更新的WEB智能网站构建系统。使用MAIYIGO智能网站建设系统,只需在配置页面上设置几关键词,
MAIYIGO可以自动生成一组可以自动更新的网站。您要做的就是设置一些关键词,然后将其他所有内容留给MAIYIGO完成!
MAIYIGO,就是这么简单!全自动是MAIYIGO的核心理念!
<p>打开自动功能后,只需在后台填写关键词名称,系统就会自动抓取与关键词名称相关的信息,图片和主题内容; 查看全部
MAIYIGO智能采集程序
PHPBB简介
资源描述:MAIYIGO(无限智能网站建设)全自动SEO站
该程序的操作非常聪明。您只需要在后台设置一些最受欢迎的关键词,每天文章采集的数量,无需人事管理,
一个域名建立一个站点,100个域名建立一百个站点,
百度和Google收录有几千个,公关从1增加到2,访问次数增加了一倍,
每天最多500IP,如果您打开20个站点,该值将更大。
7月底,该域名以200元的价格出售。您可以访问该站点以获取该域名的先前记录。
红色清单信息网络上有许多收录尚未被Google删除。
·智能自动车站建设系统:您所要做的就是设置一些关键词
·自动更新:MAIYIGO可以随时自动查找信息并自动更新
·在线WEB系统:无需安装软件,只需购买空间即可使用
·不作弊:我们不想关键词堆积,不作弊,我们是常规网站!
·如果可以上网,可以使用它:不需要网站构造知识
·自动赚钱机器:在家里放广告睡觉!等待赚钱
MAIYIGO是在顶级门户网站网站中工作的几位高级工程师对爬虫技术(蜘蛛)的使用,
分词技术和网页提取技术,使用URL重写技术,缓存技术,使用PHP语言开发的一套关键词可以自动在Internet上爬行相关信息,
自动更新的WEB智能网站构建系统。使用MAIYIGO智能网站建设系统,只需在配置页面上设置几关键词,
MAIYIGO可以自动生成一组可以自动更新的网站。您要做的就是设置一些关键词,然后将其他所有内容留给MAIYIGO完成!
MAIYIGO,就是这么简单!全自动是MAIYIGO的核心理念!
<p>打开自动功能后,只需在后台填写关键词名称,系统就会自动抓取与关键词名称相关的信息,图片和主题内容;
最新版:帝国CMS7.0仿励志一生文章网站源码 带手机版+优采云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-11-25 11:13
2.共享的目的是让所有人学习和交流,您必须在下载后的24小时内将其删除!
3.不得用于非法商业目的,并且不得违反国家法律。否则,后果自负!
4.本网站提供的源代码,模板,插件和其他资源不包括技术服务。请原谅我!
5.如果存在无法下载,无效或具有广告的链接,请与管理员联系!
6.本网站上的资源价格仅是赞助费用,所收取的费用仅用于维持本网站的日常运行!
7.如果遇到加密的压缩包,则默认的解压缩密码为“”,如果无法解压缩,请与管理员联系!
材料虎»帝国cms7.0模仿鼓舞人心的生活文章网站源代码与移动版+优采云采集
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于仅会员,整个站点源代码,程序插件,网站模板,网页模板等,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
编辑VIP 查看全部
通过移动版+优采云采集模仿cms7.0鼓舞人心的人生文章网站源代码
2.共享的目的是让所有人学习和交流,您必须在下载后的24小时内将其删除!
3.不得用于非法商业目的,并且不得违反国家法律。否则,后果自负!
4.本网站提供的源代码,模板,插件和其他资源不包括技术服务。请原谅我!
5.如果存在无法下载,无效或具有广告的链接,请与管理员联系!
6.本网站上的资源价格仅是赞助费用,所收取的费用仅用于维持本网站的日常运行!
7.如果遇到加密的压缩包,则默认的解压缩密码为“”,如果无法解压缩,请与管理员联系!
材料虎»帝国cms7.0模仿鼓舞人心的生活文章网站源代码与移动版+优采云采集
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于仅会员,整个站点源代码,程序插件,网站模板,网页模板等,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
编辑VIP
最新版本:最新云核泛目录自带MIP模板开源站群系统,自动采集文章添加关键词强大无比
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2020-11-13 12:02
2.本网站不保证所提供下载资源的准确性,安全性和完整性,这些资源仅用于下载和学习!如果存在无法下载,无效或宣传的链接,请联系客服进行处理,将获得奖励!
3.您必须在下载后24小时内从计算机中完全删除上述内容资源!如果将其用于商业或非法目的,则与本网站无关,并且用户应承担所有后果!
4.如果您也有很好的资源或教程,则可以提交论文并发表,成功共享后,您将获得象征性的奖励和额外的收入!
九点源代码_网络技术资源共享»最新的云核目录收录MIP模板开源站群系统,自动采集文章添加关键词极为强大
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于PPT,KEY,样机,APP,网页模板和其他类型的资料,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
九点源代码社区
面向高级程序员的模板开发平台
皇帝 查看全部
MIP模板开源站群系统随附了最新的云核心全景目录,自动采集文章添加关键词极为强大
2.本网站不保证所提供下载资源的准确性,安全性和完整性,这些资源仅用于下载和学习!如果存在无法下载,无效或宣传的链接,请联系客服进行处理,将获得奖励!
3.您必须在下载后24小时内从计算机中完全删除上述内容资源!如果将其用于商业或非法目的,则与本网站无关,并且用户应承担所有后果!
4.如果您也有很好的资源或教程,则可以提交论文并发表,成功共享后,您将获得象征性的奖励和额外的收入!
九点源代码_网络技术资源共享»最新的云核目录收录MIP模板开源站群系统,自动采集文章添加关键词极为强大
常见问题解答常见问题解答
可以免费将VIP会员的免费下载或专有资源商业化吗?
本网站上所有资源的版权均归原创作者所有。此处提供的资源只能用于参考和学习目的,请勿直接将其商业化。如果由于商业用途而引起版权纠纷,则所有责任应由用户承担。有关更多说明,请参阅VIP简介。
提示下载已完成,但无法解压缩或打开吗?
最常见的情况是下载不完整:您可以将下载的压缩包与网络磁盘上的容量进行比较。如果它小于网络磁盘指示的容量,则是原因。这是一个浏览器下载错误,建议使用百度网盘软件或迅雷下载。如果排除这种情况,则可以在相应资源的底部留下消息或与我们联系。
在资源简介文章中找不到示例图片?
对于PPT,KEY,样机,APP,网页模板和其他类型的资料,文章中用于介绍的图片通常不收录在相应的可下载资料包中。这些相关的商业图片需要单独购买,并且本网站不负责(并且无法找到来源)。某些字体文件也是如此,但是某些材料在材料包中将收录字体下载链接的列表。
九点源代码社区
面向高级程序员的模板开发平台
皇帝

