
免规则采集器列表算法
操作方法:程序员免规则采集器列表算法等各种操作请上规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-10-01 15:11
免规则采集器列表算法等各种操作请上规则采集器(win/linux)谢谢!!!喜欢做这些的人应该不少但是能力强人比较固定而且大部分人不善于整合而且知道自己能力在哪所以会回首去学一些自己想做而且不太需要太多规则的功能至于靠采集赚钱,还是呵呵。靠开发者的热情?或者是像刚刚采集的那些人那样,强迫自己去学习新的功能?。
谢邀有一个专门做黑产的,叫我克隆他的网站,然后每天运用程序员特有的嗅探大文件内容变更和加密技术,去做各种调色盘(hipaa,那些弹弹漆,克隆图标的)我说我要赚钱,他就说:我就是靠你们想不到的赚钱,
谢邀。天马行空,有没有办法自己什么不用动就月入过万,绝对有。想赚钱,多方面要去涉及,总能找到方法。建议你可以先去你所在城市里,一些小的贴吧看看里面的主要消费者,然后找到他们,看看他们喜欢什么东西,然后自己搞搞,有可能比单干,效率高很多。
找个人...撸一下...然后,多多益善吧。想我这样的,把b站关注的大牛们的“夏炎”“越冷门”“syhco”“猫”全看了,
我什么都干过,但是依然想赚钱,其实很简单,只要不断地向前看,不断地充实自己,能掌握了其中一项小技能。同时别忘了扩展自己的业余爱好。 查看全部
操作方法:程序员免规则采集器列表算法等各种操作请上规则
免规则采集器列表算法等各种操作请上规则采集器(win/linux)谢谢!!!喜欢做这些的人应该不少但是能力强人比较固定而且大部分人不善于整合而且知道自己能力在哪所以会回首去学一些自己想做而且不太需要太多规则的功能至于靠采集赚钱,还是呵呵。靠开发者的热情?或者是像刚刚采集的那些人那样,强迫自己去学习新的功能?。

谢邀有一个专门做黑产的,叫我克隆他的网站,然后每天运用程序员特有的嗅探大文件内容变更和加密技术,去做各种调色盘(hipaa,那些弹弹漆,克隆图标的)我说我要赚钱,他就说:我就是靠你们想不到的赚钱,
谢邀。天马行空,有没有办法自己什么不用动就月入过万,绝对有。想赚钱,多方面要去涉及,总能找到方法。建议你可以先去你所在城市里,一些小的贴吧看看里面的主要消费者,然后找到他们,看看他们喜欢什么东西,然后自己搞搞,有可能比单干,效率高很多。

找个人...撸一下...然后,多多益善吧。想我这样的,把b站关注的大牛们的“夏炎”“越冷门”“syhco”“猫”全看了,
我什么都干过,但是依然想赚钱,其实很简单,只要不断地向前看,不断地充实自己,能掌握了其中一项小技能。同时别忘了扩展自己的业余爱好。
完整解决方案:AI产品运营常见的几种推荐算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-09-29 15:18
本文将简要介绍流行度算法、协同过滤、基于内容的推荐和混合方法等几种推荐算法...
鉴于首页君对算法了解不多,只是简单的原理说明,不涉及实际操作。
一、热算法
说到流行度算法,可能有些人比较陌生。换个词应该就知道了,也就是排行榜。
根据我们的理解,排行榜就是一个列表。根据一定的规则,给出从 1 到 N 的排名。我们优先选择列表中排名较高的事物。
流行度算法也是基于类似的原理。它根据一定的规则计算一个人气分数,然后取TopN;此外,可能还有一些人工干预的组件,比如细化、编辑推荐等。
热量算法的计算公式可以简单参考以下基本公式:
热度得分 = 初始热度得分 + 用户行为交互得分 - 时间衰减得分
初始人气得分可以分为两部分,一是基本得分,二是加权或减权。
基础分数是指自己计算的分数。以一篇文章文章为例,它包括作者信息和文章信息;相关要素包括作者级别、认证和历史出版物。状态、历史文章数据表现、文章长度、图片数量、关键词等。
基于以上相关要素,可以计算出一个基本分数,再结合一些加权或减重处理,就可以计算出一个初始热度分数。
权重项可能包括干货权重、新人贡献权重、运营干预权重等。权重项可能包括XX太受欢迎,包括XX关键词、疑似抄袭等。
在计算出一个初始的人气分数后,取 TopN 并推荐给用户。
用户行为交互点是指这个东西被推荐给用户之后的一些反馈。常见的反馈主要分为正反馈和负反馈两种。
正面反馈是常见的点击、转发、评论、采集和点赞。根据用户的行为,重新计算内容。每种行为的权重不同,具体权重需要结合业务属性来确定。
负反馈是用户明显不喜欢推荐的行为,比如减少类似推荐。基于获得的负反馈信息,减少了一些点。
时间衰减是指分数会随着时间的推移而衰减,以避免旧内容的热度分数一直很高,而无法暴露新内容。一般采用牛顿冷却定律,即非线性衰减。
热量算法大致如上所述。它比较容易实现,适合冷启动。缺点是人数上千,没有办法做个性化分发,新内容也很难透露。
二、协同过滤
协同过滤主要通过计算人与物的相似度进行推荐,主要包括人与物、物与物、人与物的相似度。
常见的协同过滤算法主要有基于人的协同过滤、基于物品的协同过滤和基于模型的协同过滤。
1. 基于人的协同过滤
顾名思义,就是通过计算人与人之间的相似度来推荐物品。
比如小A喜欢A、B,小B喜欢C、D、E;而且小A和小B有一定的相似度,所以小A推荐小B最喜欢的物品C,参考下图。
基于人的协同过滤
这里有两个关键问题:
具体实施步骤为:
基于人的协同过滤的优势在于,它可以帮助用户发现一些比较新鲜、可能感兴趣的东西。或者对新用户的推荐可能不是很好。
2. 基于项目的协同过滤
顾名思义,就是根据物品之间的相似度来推荐的。比如小A喜欢Item A和Item B,Item A和Item C有一定的相似性,所以他可以推荐Item C给小A,请参考下面的示意图:
基于项目的协同过滤
这里有两个关键问题:
具体实现方法是:
需要注意的是,这里的相似度并不是物品之间的直接相似度,而是它们一起出现在多少个用户的兴趣列表中。
例如,在喜欢物品 A 的用户中,有多少用户喜欢物品 B,两者的重复次数越高,物品 A 和物品 B 的相似度就越高。
基于人物的协同过滤更多地反映了物品在小圈子中的受欢迎程度,而基于物品的协同过滤考虑了用户的历史行为,相对更加个性化;但是当item的数量很大的时候,也会面临item之间的相似度计算很复杂的问题。
3. 基于模型的协同过滤
顾名思义,它是基于一个模型来推荐的,这里使用的技术更多的是与机器学习领域相关的,比如关联规则挖掘、聚类、SVD、RBM、图模型等。(我不反正不懂)。
根据个人理解,根据用户对物品的兴趣程度训练一个黑盒模型,根据输入输出进行不断优化迭代。
用0-1进行评价,1表示用户肯定会感兴趣,0表示用户肯定不感兴趣;该模型是计算用户的兴趣度,然后优先向用户推荐兴趣度较高的东西,最后结合模型根据用户反馈不断优化。
总体流程是:
三、基于内容的推荐
基于内容的推荐是基于内容的推荐,主要基于内容之间的相似性。
比如我看了一部A导演的B电影,C出演了,我很喜欢这部电影。
理论上,我可以推荐A导演的其他作品,或者C主演的其他电影,以及B电影的系列电影或者其他类似题材的电影。
该算法的优点是易于冷启动,可以更好地向用户解释。缺点是难以组合不同的特征,难以给用户带来惊喜感,而且如果用户的属性挖掘不准确,就会比较推荐效果。区别。
四、混合方法
顾名思义,它是组合使用的。常见的策略主要包括加权、切换、分区和分层。
加权是指用一个线性公式将几种不同的推荐算法组合起来,赋予不同的权重,比如算法A 20%,算法B 50%,算法C 30%,然后计算出最终的推荐结果。
切换是指在不同的情况下使用不同的推荐算法,比如冷启动时使用流行的算法,等用户行为和数据可用后再切换到其他算法。
完整的解决方案:精准客源软件,精准电话采集软件?
学习 36 种促进获客的方法
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术抓取行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。
优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习的方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。
优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。
好了,这个文章的内容就在这里分享给大家。如果你也遇到没有流量、没有客户、没有订单?
对线上创业推广感兴趣,想学习36种获客方式, 查看全部
完整解决方案:AI产品运营常见的几种推荐算法
本文将简要介绍流行度算法、协同过滤、基于内容的推荐和混合方法等几种推荐算法...
鉴于首页君对算法了解不多,只是简单的原理说明,不涉及实际操作。
一、热算法
说到流行度算法,可能有些人比较陌生。换个词应该就知道了,也就是排行榜。
根据我们的理解,排行榜就是一个列表。根据一定的规则,给出从 1 到 N 的排名。我们优先选择列表中排名较高的事物。
流行度算法也是基于类似的原理。它根据一定的规则计算一个人气分数,然后取TopN;此外,可能还有一些人工干预的组件,比如细化、编辑推荐等。
热量算法的计算公式可以简单参考以下基本公式:
热度得分 = 初始热度得分 + 用户行为交互得分 - 时间衰减得分
初始人气得分可以分为两部分,一是基本得分,二是加权或减权。
基础分数是指自己计算的分数。以一篇文章文章为例,它包括作者信息和文章信息;相关要素包括作者级别、认证和历史出版物。状态、历史文章数据表现、文章长度、图片数量、关键词等。
基于以上相关要素,可以计算出一个基本分数,再结合一些加权或减重处理,就可以计算出一个初始热度分数。
权重项可能包括干货权重、新人贡献权重、运营干预权重等。权重项可能包括XX太受欢迎,包括XX关键词、疑似抄袭等。
在计算出一个初始的人气分数后,取 TopN 并推荐给用户。
用户行为交互点是指这个东西被推荐给用户之后的一些反馈。常见的反馈主要分为正反馈和负反馈两种。
正面反馈是常见的点击、转发、评论、采集和点赞。根据用户的行为,重新计算内容。每种行为的权重不同,具体权重需要结合业务属性来确定。
负反馈是用户明显不喜欢推荐的行为,比如减少类似推荐。基于获得的负反馈信息,减少了一些点。
时间衰减是指分数会随着时间的推移而衰减,以避免旧内容的热度分数一直很高,而无法暴露新内容。一般采用牛顿冷却定律,即非线性衰减。

热量算法大致如上所述。它比较容易实现,适合冷启动。缺点是人数上千,没有办法做个性化分发,新内容也很难透露。
二、协同过滤
协同过滤主要通过计算人与物的相似度进行推荐,主要包括人与物、物与物、人与物的相似度。
常见的协同过滤算法主要有基于人的协同过滤、基于物品的协同过滤和基于模型的协同过滤。
1. 基于人的协同过滤
顾名思义,就是通过计算人与人之间的相似度来推荐物品。
比如小A喜欢A、B,小B喜欢C、D、E;而且小A和小B有一定的相似度,所以小A推荐小B最喜欢的物品C,参考下图。
基于人的协同过滤
这里有两个关键问题:
具体实施步骤为:
基于人的协同过滤的优势在于,它可以帮助用户发现一些比较新鲜、可能感兴趣的东西。或者对新用户的推荐可能不是很好。
2. 基于项目的协同过滤
顾名思义,就是根据物品之间的相似度来推荐的。比如小A喜欢Item A和Item B,Item A和Item C有一定的相似性,所以他可以推荐Item C给小A,请参考下面的示意图:
基于项目的协同过滤
这里有两个关键问题:

具体实现方法是:
需要注意的是,这里的相似度并不是物品之间的直接相似度,而是它们一起出现在多少个用户的兴趣列表中。
例如,在喜欢物品 A 的用户中,有多少用户喜欢物品 B,两者的重复次数越高,物品 A 和物品 B 的相似度就越高。
基于人物的协同过滤更多地反映了物品在小圈子中的受欢迎程度,而基于物品的协同过滤考虑了用户的历史行为,相对更加个性化;但是当item的数量很大的时候,也会面临item之间的相似度计算很复杂的问题。
3. 基于模型的协同过滤
顾名思义,它是基于一个模型来推荐的,这里使用的技术更多的是与机器学习领域相关的,比如关联规则挖掘、聚类、SVD、RBM、图模型等。(我不反正不懂)。
根据个人理解,根据用户对物品的兴趣程度训练一个黑盒模型,根据输入输出进行不断优化迭代。
用0-1进行评价,1表示用户肯定会感兴趣,0表示用户肯定不感兴趣;该模型是计算用户的兴趣度,然后优先向用户推荐兴趣度较高的东西,最后结合模型根据用户反馈不断优化。
总体流程是:
三、基于内容的推荐
基于内容的推荐是基于内容的推荐,主要基于内容之间的相似性。
比如我看了一部A导演的B电影,C出演了,我很喜欢这部电影。
理论上,我可以推荐A导演的其他作品,或者C主演的其他电影,以及B电影的系列电影或者其他类似题材的电影。
该算法的优点是易于冷启动,可以更好地向用户解释。缺点是难以组合不同的特征,难以给用户带来惊喜感,而且如果用户的属性挖掘不准确,就会比较推荐效果。区别。
四、混合方法
顾名思义,它是组合使用的。常见的策略主要包括加权、切换、分区和分层。
加权是指用一个线性公式将几种不同的推荐算法组合起来,赋予不同的权重,比如算法A 20%,算法B 50%,算法C 30%,然后计算出最终的推荐结果。
切换是指在不同的情况下使用不同的推荐算法,比如冷启动时使用流行的算法,等用户行为和数据可用后再切换到其他算法。
完整的解决方案:精准客源软件,精准电话采集软件?
学习 36 种促进获客的方法
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术抓取行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。

优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习的方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。

优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。
好了,这个文章的内容就在这里分享给大家。如果你也遇到没有流量、没有客户、没有订单?
对线上创业推广感兴趣,想学习36种获客方式,
操作方法:免规则采集器列表算法设计说明;列表大小采用300w+1000wm大小
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-09-28 15:13
免规则采集器列表算法设计说明;列表采集器列表大小采用300w+1000wm大小规则支持平台:电脑客户端,手机,安卓,
你说的ip规则算法,那是很多年前的老技术,现在都没有用到现在。新技术是元数据分析加人脸识别,前端加个人脸库。
直接上列表采集器,其他不变。
题主肯定没理解目前最新的问题,问题在于列表太宽,如果人力来维护,过于多产生的数据过多会影响服务器负载。如果用分布式系统,那么每台服务器上都要进行计算,每台服务器都要用到数据库、缓存等等,并且每台服务器上都要有一套数据的产生,处理数据的机制,分布式系统会很麻烦。那么服务器硬件负载按照50%-80%-90%-90%来做一个最小模型最好不过了。
举个例子,假设几台服务器运行着一个1000w/天的大型数据库。那么在1000台服务器中,可以产生大约10w的数据,然后上传到数据库,在一个数据库中查询数据,基本的时间按照单机5min/百万数据计算,如果这个时间已经是2分钟的时间,那么这个时间就是5*50%*1000=2000h,2000h大约是5小时8分钟。
假设这个时间已经是2分钟的时间,那么这个时间就是5*2000=150h,150h大约是3小时1分钟。根据经验2小时系统负载最大,假设一般的数据库做2h工作,那么数据库间就应该进行数据交换,这样在单机数据库运行的时候,一般的应用处理都会比较快,从单机统计和日志统计,显然单机1小时处理几万数据更快。那么应用的吞吐量应该按照10w/秒计算,在单机处理的时候如果通信交换的时间没有那么严格的要求,吞吐量就无需要求那么高。
3小时处理几万亿的数据,显然不是一个问题。而每台服务器吞吐量按1000w/天,最低也是1小时处理50w/天,应用开发的时候如果支持高并发,吞吐量要求不高,其实就按照2小时算,也可以是1000t的数据。至于分布式系统,那么除了数据库,还要进行分布式存储,分布式计算。这样处理10个小时显然是可以做到的。 查看全部
操作方法:免规则采集器列表算法设计说明;列表大小采用300w+1000wm大小
免规则采集器列表算法设计说明;列表采集器列表大小采用300w+1000wm大小规则支持平台:电脑客户端,手机,安卓,
你说的ip规则算法,那是很多年前的老技术,现在都没有用到现在。新技术是元数据分析加人脸识别,前端加个人脸库。

直接上列表采集器,其他不变。
题主肯定没理解目前最新的问题,问题在于列表太宽,如果人力来维护,过于多产生的数据过多会影响服务器负载。如果用分布式系统,那么每台服务器上都要进行计算,每台服务器都要用到数据库、缓存等等,并且每台服务器上都要有一套数据的产生,处理数据的机制,分布式系统会很麻烦。那么服务器硬件负载按照50%-80%-90%-90%来做一个最小模型最好不过了。

举个例子,假设几台服务器运行着一个1000w/天的大型数据库。那么在1000台服务器中,可以产生大约10w的数据,然后上传到数据库,在一个数据库中查询数据,基本的时间按照单机5min/百万数据计算,如果这个时间已经是2分钟的时间,那么这个时间就是5*50%*1000=2000h,2000h大约是5小时8分钟。
假设这个时间已经是2分钟的时间,那么这个时间就是5*2000=150h,150h大约是3小时1分钟。根据经验2小时系统负载最大,假设一般的数据库做2h工作,那么数据库间就应该进行数据交换,这样在单机数据库运行的时候,一般的应用处理都会比较快,从单机统计和日志统计,显然单机1小时处理几万数据更快。那么应用的吞吐量应该按照10w/秒计算,在单机处理的时候如果通信交换的时间没有那么严格的要求,吞吐量就无需要求那么高。
3小时处理几万亿的数据,显然不是一个问题。而每台服务器吞吐量按1000w/天,最低也是1小时处理50w/天,应用开发的时候如果支持高并发,吞吐量要求不高,其实就按照2小时算,也可以是1000t的数据。至于分布式系统,那么除了数据库,还要进行分布式存储,分布式计算。这样处理10个小时显然是可以做到的。
汇总:免规则采集器列表算法优化清理校验规则(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-09-28 12:10
免规则采集器列表算法优化清理校验规则这个列表其实还不是比较完善,在如何优化查询也没说,有漏洞可以修改或者在这里改就需要改对应代码应该是使用python作为脚本语言python里面有很多list比较优化可以用比如排序优化内联排序向量化优化merge或者在list里面创建list维度缩小或者使用pandaspandas的next函数缩小维度使用mappython会比java简单一些,python的groupby相对java会更简单。
个人经验,找到可用的方法了,题主可以来交流一下。背景:这种方法叫通过比较list中的数据来判断数据的大小。大概就是把一个数据块中每个元素从小到大排序,然后比较最大的那个数据块的元素,小的数据块就放最上面了。结果:代码如下:b=[0,0,1,1,1,2,2,2,2,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,。 查看全部
汇总:免规则采集器列表算法优化清理校验规则(组图)

免规则采集器列表算法优化清理校验规则这个列表其实还不是比较完善,在如何优化查询也没说,有漏洞可以修改或者在这里改就需要改对应代码应该是使用python作为脚本语言python里面有很多list比较优化可以用比如排序优化内联排序向量化优化merge或者在list里面创建list维度缩小或者使用pandaspandas的next函数缩小维度使用mappython会比java简单一些,python的groupby相对java会更简单。
个人经验,找到可用的方法了,题主可以来交流一下。背景:这种方法叫通过比较list中的数据来判断数据的大小。大概就是把一个数据块中每个元素从小到大排序,然后比较最大的那个数据块的元素,小的数据块就放最上面了。结果:代码如下:b=[0,0,1,1,1,2,2,2,2,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,。
教程:从零开始完整制作剧本杀微信小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2022-09-25 05:14
趁着宅在家的这几周,我在微信小程序上做了一套脚本秒杀的在线预订、支付、评论。感谢大白、社区志愿者和医护人员的长期努力,期待上海早日解封,让工作生活各方面恢复正常。本小程序适用于桌游、剧本杀、派对厅、私人影院、主题民宿、文创文旅项目。
我们来看看微信小程序最终效果的截图。
一、前言
本文适合关注脚本杀等主要活动行业的读者,或工作1-2年且有一定产品或开发基础的技术人员。
在资本和真人秀节目的推动下,剧本杀作为年轻人交友娱乐的新方式,迎来了19、20年来的第一波亮点。后来受疫情和行业规范的影响,他开始关注周边和IP创作,更加关注玩家的尝鲜、交友、聚会体验。欢迎使用脚本 kill2.0。除了通过与服装、美妆、文创、家居等行业的跨界合作提供沉浸式体验外,新的剧本杀服务还提供了专门针对交友、结婚、团队建设的真人杀。结合KTV、酒吧、网吧、民宿,旅游景区等场景开辟旅游团。民宿文旅剧本杀可吃、住、玩,提供身临其境的体验,比普通民宿和旅游更有特色。还有一些“酒书”,边玩边喝;中小学生文学、场景、知识点的“学习书”;脚本杀外卖服务等的出现
新的行业参与者也更加注重自身软实力的建设,利用信息技术充分调动渠道、场地、优秀DM等资源。拥抱疫情后市场的新机遇。在这里,我们针对此类需求初步构建了一套基于微信小程序的在线脚本杀展示、游戏组织、支付和评论应用。
二、需求审核
脚本查杀功能脑图
跨区域、多店铺应用场景。不同的商店有不同的促销和脚本设置。
大家可以看看上面的脑图,对产品需求有一个整体的了解。
三、原型制作
基于上一个链接的功能需求,参考常用的功能组件,使用Axure对各个页面进行勾画,方便后续讨论和细化。
四、界面设计
经过几轮讨论,确定了各个页面的细节和功能后,开始UI美术绘制。
页面设计简单实用。整体风格统一,内容层次清晰、规范。
主要组成部分有:搜索导航栏、脚本卡、拼车卡、玩家人数是否倒转、评分分数、优惠券卡等。
五、数据结构设计数据围绕拼车集合进行设计,根据品类、脚本、播放器、店铺等实体对象进行关系型数据存储设计。
数据ER设计
六、开发准备
框架选择、功能分解和项目开发讨论反馈。
产品可以以App、H5或微信小程序的形式制作。考虑到用户使用场景和后续的口碑引流,默认开发基于微信功能扩展。对比界面流畅度和品牌附加值,选择微信小程序实现。
在微信小程序系统之前,CS部署的中间环节太多。开发者需要考虑应用层、数据库层、负载均衡、ssl安全等节点。后来云开发上线后,使用对象图数据存储就方便了很多,让开发者更加专注。业务功能实现。考虑到数据的独立性,并且团队已经有了 ssl 服务器,我们仍然使用关系数据模型。
微信小程序展示层有多种框架可供选择。考虑到组件的丰富性以及后期购买和产品展示的扩展需求,我们选择了jquery weui和vant。
参照构件库的风格,进行了各页面的开发期及可行性分析讨论及数据呈现,并反馈到设计更新页面。
开发环节主要工具:微信开发者工具、sqlyog、sublime、winscp、xshell。
页面样式微调
主要功能开发
七、迭代开发
第一个 sprint 将主页、列表、详细信息和约会主要流程页面链接在一起。
第二个冲刺增加了团队合作、设置和付款流程。
第三个 sprint 完成搜索功能和排序列表。
第四次冲刺增加了优惠券功能,包括重构组织和拼车支付环境。
第五个 sprint 增加了订单列表、取消和退款功能。
第六次冲刺对每一页的样式进行微调,并记录完整的测试数据。
经过开发测试后,将发布staging预览版,在甲方移动端进行实际测试。根据甲方反馈调整页面功能后。提交代码质量优化,优化前后端算法、查询、数据、素材、代码规范。
开发过程中遇到的主要逻辑函数有:
1. 微信小程序服务器
安全密码协议、请求参数及回包协议、微信支付、短信密码发送、分享海报合成图制作等。
此外,还对接口频率限制、参数错误、版本不支持、服务返回错误、处理超时、接口调用错误、授权认证异常等进行了后期分析。
2. 微信小程序App
组件搜索组件、排名排名、席位玩家状态显示组件、步进数设置规则、信息元素的多样式flex布局组合等。
此外,每个异常的默认样式处理,如网络异常、存储异常、内存异常、字段参数异常、带宽限制、内存异常、权限异常、数据异常等,也需要酌情考虑。
关于开发,有兴趣的可以简历,提出自己关心的知识点,我可以开个帖子详细讨论具体实现。
八、单元测试的微信开发者工具提供了比较完善的调试预览功能,方便在UI、数据AppData、代码代码质量优化等方面进行开发。
微信小程序调试工具
九、分期测试
上传后可使用体验版二维码邀请相关人员参与体验反馈。
这个功能还是很实用的。代码修改后,可以随时上传,分享给大家,用于不同状态的手机测试。
十、产品发布
使用git做版本控制,发布产品,完整发布,注意声明。
十个一、App推广
工具类应用可以挂在公众号菜单链接、店铺前台等。
十二、用户体验采集与产品迭代快速开发第一版上线后,根据实际使用反馈,设置第二期升级版本的需求。比如DM设置和团队激励。
此后,开发了一套实用的脚本杀微信小程序。
产品设计不仅要解决用户的痛点,还要为用户提供耳目一新的体验,包括细致的关怀和激励。
我是青云茶客。欢迎有兴趣的朋友讨论更多产品设计和项目开发的案例实践。
最后以一首茶诗结束本文:
喝完茶,清妍唱着正午鸡,我还骑着驴子去东溪。
酒食分到樵夫手中,笔砚专供少年随身携带。
望水亭独倚,在僧房壁上写下新泥诗。
行朗回来问什么时候来了,蝉声四起,太阳已经西下。
——宋赵如谷,《茶歇》
本文由@青云茶客原创发表于人人都是产品经理,未经允许禁止转载
题图来自Unsplash,基于CC0协议
技巧:好用的翻译软件-大家都在用的外贸SEO优化神器免费
好用的翻译软件,今天给大家分享一款好用的免费批量翻译软件。我们为什么选择这款好用的翻译软件,因为它汇集了世界上最好的几个翻译平台(百度/谷歌/有道),第一点就是翻译质量高,有很多选择. 第二点支持各种语言的互译,第三点可以用来翻译各种批文档,第四点保留翻译前的格式和排版。第五点支持采集翻译。详情请参考以下图片!!!
一、简单易用的翻译软件介绍
1、支持多种优质多语言平台翻译(批量百度翻译/谷歌翻译/有道翻译,让内容质量更上一层楼)。
2、只需要批量导入文件即可实现自动翻译,翻译后保留原版面格式
3、 还支持文章 互译:中文翻译成英文再翻译回中文。
4、支持采集翻译(可以直接翻译采集英文网站)
一:易于记忆且收录关键字的域名。
搜索引擎的目的是改善用户体验,满足用户的需求也符合搜索引擎的喜好,即搜索引擎优化的最高标准。好用的翻译软件 一个好记的域名,可以让用户在想查询相关信息的时候快速输入。每个人都喜欢这样的域名。考虑如何巧妙地将关键字放置在此类域名的域名中间。
二:权重链接点。
搜索引擎基于链接的分析技术是域名权威的核心技术之一。对于优秀的翻译软件,至少在可预见的未来,基于链接的信任和权限转移将继续存在,除非有一天整个搜索引擎行业的算法发生根本性的变化。因此,要构建一个符合搜索引擎偏好的域名,就必须有良好的加权链接。
在操作范围内,可以选择以下方法:
· 查找机构领域的链接。如果是涉及到需要优化的网站内容,这样的权重链接是很好的,但是建议这样的权重链接指向基本没有太强的可操作性
· 查找行业领先网站的链接。对于机构来说,易用的翻译软件和业内优秀的站点链接更简单,操作性更强。例如,本地门户 网站 可以依靠自己的站点内容或个人联系联系知名门户站点进行链接交换。
· 其他无关站点、目录、博客、论坛等的引荐链接 无关站点目录博客论坛上的域链接推广有一定意义,但意义不大。搜索引擎更关注内容相关性,而不是简单的链接数量,在域名建设中更关注质量而不是数量。
以上链接权重都指向一定的相关性,而不是一味的建立垃圾链接组。
三:域名注册时间和历史。
用户和搜索引擎都喜欢的域应该尽可能老,但不是绝对的。因为并非所有旧域名都是好域名。从以下两点出发:
·域名第一次被搜索引擎收录列出是为了确定域名的实际年龄。当一个注册了10年的域名从来没有发布过文章的网站,也没有一个页面出现过收录,那么这个域名对于用户和搜索引擎来说都是没有意义的。所以当网站上线时,尽量让搜索引擎收录网站。
·域名下的内容发生巨大变化。在域名所有者的域名注册信息没有发生变化的情况下,如果域名下的内容发生巨大的方向变化,好用的翻译软件搜索引擎往往会将域名视为不稳定的域名,所以减少的权利也会减少。收录进程,观察一段时间。如果域名在这段时间内恢复了之前的内容,就会恢复之前的排名,如果在这段时间内没有恢复之前的内容,搜索引擎就会将该域名视为新域名。在域名买卖中,除了域名内容的变化,搜索引擎也会对域名所有人的变化做出判断。
四:域名所有者变更。
除了搜索引擎能够搜索域名注册信息外,易用的翻译软件还可以及时监控域名所有者信息的变化,并将这些信息用于搜索引擎排名算法。因此,如果域名被买卖,如果域名所有者发生变化,搜索引擎可以根据域名内容的变化进行先观察再降级或直接降级等动作。
五:域名下的页数。
一个优秀的域名应该收录一定数量的页面。丰富的内容本身就是一个好的域名,也是一个好的网站的重要体现之一。好用的翻译软件小企业网站在网站发布之初就准备好50到100条原创优质内容,等网站之后再等一次@网站 被释放。这些内容发布在网站上,方便搜索引擎定位网站的话题。
六:优质链接。
对于一个优秀的网站来说,高质量的链接是必不可少的,它不仅可以提升用户体验,还可以满足搜索引擎判断优秀域名的标准。以上几点是比较重要但不是全部的因素,需要在实践中不断探索和总结。 查看全部
教程:从零开始完整制作剧本杀微信小程序
趁着宅在家的这几周,我在微信小程序上做了一套脚本秒杀的在线预订、支付、评论。感谢大白、社区志愿者和医护人员的长期努力,期待上海早日解封,让工作生活各方面恢复正常。本小程序适用于桌游、剧本杀、派对厅、私人影院、主题民宿、文创文旅项目。
我们来看看微信小程序最终效果的截图。
一、前言
本文适合关注脚本杀等主要活动行业的读者,或工作1-2年且有一定产品或开发基础的技术人员。
在资本和真人秀节目的推动下,剧本杀作为年轻人交友娱乐的新方式,迎来了19、20年来的第一波亮点。后来受疫情和行业规范的影响,他开始关注周边和IP创作,更加关注玩家的尝鲜、交友、聚会体验。欢迎使用脚本 kill2.0。除了通过与服装、美妆、文创、家居等行业的跨界合作提供沉浸式体验外,新的剧本杀服务还提供了专门针对交友、结婚、团队建设的真人杀。结合KTV、酒吧、网吧、民宿,旅游景区等场景开辟旅游团。民宿文旅剧本杀可吃、住、玩,提供身临其境的体验,比普通民宿和旅游更有特色。还有一些“酒书”,边玩边喝;中小学生文学、场景、知识点的“学习书”;脚本杀外卖服务等的出现
新的行业参与者也更加注重自身软实力的建设,利用信息技术充分调动渠道、场地、优秀DM等资源。拥抱疫情后市场的新机遇。在这里,我们针对此类需求初步构建了一套基于微信小程序的在线脚本杀展示、游戏组织、支付和评论应用。
二、需求审核
脚本查杀功能脑图
跨区域、多店铺应用场景。不同的商店有不同的促销和脚本设置。
大家可以看看上面的脑图,对产品需求有一个整体的了解。
三、原型制作
基于上一个链接的功能需求,参考常用的功能组件,使用Axure对各个页面进行勾画,方便后续讨论和细化。
四、界面设计
经过几轮讨论,确定了各个页面的细节和功能后,开始UI美术绘制。
页面设计简单实用。整体风格统一,内容层次清晰、规范。
主要组成部分有:搜索导航栏、脚本卡、拼车卡、玩家人数是否倒转、评分分数、优惠券卡等。
五、数据结构设计数据围绕拼车集合进行设计,根据品类、脚本、播放器、店铺等实体对象进行关系型数据存储设计。
数据ER设计
六、开发准备
框架选择、功能分解和项目开发讨论反馈。
产品可以以App、H5或微信小程序的形式制作。考虑到用户使用场景和后续的口碑引流,默认开发基于微信功能扩展。对比界面流畅度和品牌附加值,选择微信小程序实现。
在微信小程序系统之前,CS部署的中间环节太多。开发者需要考虑应用层、数据库层、负载均衡、ssl安全等节点。后来云开发上线后,使用对象图数据存储就方便了很多,让开发者更加专注。业务功能实现。考虑到数据的独立性,并且团队已经有了 ssl 服务器,我们仍然使用关系数据模型。
微信小程序展示层有多种框架可供选择。考虑到组件的丰富性以及后期购买和产品展示的扩展需求,我们选择了jquery weui和vant。
参照构件库的风格,进行了各页面的开发期及可行性分析讨论及数据呈现,并反馈到设计更新页面。
开发环节主要工具:微信开发者工具、sqlyog、sublime、winscp、xshell。
页面样式微调
主要功能开发
七、迭代开发
第一个 sprint 将主页、列表、详细信息和约会主要流程页面链接在一起。
第二个冲刺增加了团队合作、设置和付款流程。
第三个 sprint 完成搜索功能和排序列表。
第四次冲刺增加了优惠券功能,包括重构组织和拼车支付环境。
第五个 sprint 增加了订单列表、取消和退款功能。
第六次冲刺对每一页的样式进行微调,并记录完整的测试数据。
经过开发测试后,将发布staging预览版,在甲方移动端进行实际测试。根据甲方反馈调整页面功能后。提交代码质量优化,优化前后端算法、查询、数据、素材、代码规范。
开发过程中遇到的主要逻辑函数有:
1. 微信小程序服务器
安全密码协议、请求参数及回包协议、微信支付、短信密码发送、分享海报合成图制作等。
此外,还对接口频率限制、参数错误、版本不支持、服务返回错误、处理超时、接口调用错误、授权认证异常等进行了后期分析。
2. 微信小程序App
组件搜索组件、排名排名、席位玩家状态显示组件、步进数设置规则、信息元素的多样式flex布局组合等。
此外,每个异常的默认样式处理,如网络异常、存储异常、内存异常、字段参数异常、带宽限制、内存异常、权限异常、数据异常等,也需要酌情考虑。
关于开发,有兴趣的可以简历,提出自己关心的知识点,我可以开个帖子详细讨论具体实现。
八、单元测试的微信开发者工具提供了比较完善的调试预览功能,方便在UI、数据AppData、代码代码质量优化等方面进行开发。
微信小程序调试工具
九、分期测试
上传后可使用体验版二维码邀请相关人员参与体验反馈。
这个功能还是很实用的。代码修改后,可以随时上传,分享给大家,用于不同状态的手机测试。
十、产品发布
使用git做版本控制,发布产品,完整发布,注意声明。
十个一、App推广
工具类应用可以挂在公众号菜单链接、店铺前台等。
十二、用户体验采集与产品迭代快速开发第一版上线后,根据实际使用反馈,设置第二期升级版本的需求。比如DM设置和团队激励。
此后,开发了一套实用的脚本杀微信小程序。
产品设计不仅要解决用户的痛点,还要为用户提供耳目一新的体验,包括细致的关怀和激励。
我是青云茶客。欢迎有兴趣的朋友讨论更多产品设计和项目开发的案例实践。
最后以一首茶诗结束本文:
喝完茶,清妍唱着正午鸡,我还骑着驴子去东溪。
酒食分到樵夫手中,笔砚专供少年随身携带。
望水亭独倚,在僧房壁上写下新泥诗。
行朗回来问什么时候来了,蝉声四起,太阳已经西下。
——宋赵如谷,《茶歇》
本文由@青云茶客原创发表于人人都是产品经理,未经允许禁止转载
题图来自Unsplash,基于CC0协议
技巧:好用的翻译软件-大家都在用的外贸SEO优化神器免费
好用的翻译软件,今天给大家分享一款好用的免费批量翻译软件。我们为什么选择这款好用的翻译软件,因为它汇集了世界上最好的几个翻译平台(百度/谷歌/有道),第一点就是翻译质量高,有很多选择. 第二点支持各种语言的互译,第三点可以用来翻译各种批文档,第四点保留翻译前的格式和排版。第五点支持采集翻译。详情请参考以下图片!!!
一、简单易用的翻译软件介绍
1、支持多种优质多语言平台翻译(批量百度翻译/谷歌翻译/有道翻译,让内容质量更上一层楼)。
2、只需要批量导入文件即可实现自动翻译,翻译后保留原版面格式
3、 还支持文章 互译:中文翻译成英文再翻译回中文。
4、支持采集翻译(可以直接翻译采集英文网站)
一:易于记忆且收录关键字的域名。
搜索引擎的目的是改善用户体验,满足用户的需求也符合搜索引擎的喜好,即搜索引擎优化的最高标准。好用的翻译软件 一个好记的域名,可以让用户在想查询相关信息的时候快速输入。每个人都喜欢这样的域名。考虑如何巧妙地将关键字放置在此类域名的域名中间。

二:权重链接点。
搜索引擎基于链接的分析技术是域名权威的核心技术之一。对于优秀的翻译软件,至少在可预见的未来,基于链接的信任和权限转移将继续存在,除非有一天整个搜索引擎行业的算法发生根本性的变化。因此,要构建一个符合搜索引擎偏好的域名,就必须有良好的加权链接。
在操作范围内,可以选择以下方法:
· 查找机构领域的链接。如果是涉及到需要优化的网站内容,这样的权重链接是很好的,但是建议这样的权重链接指向基本没有太强的可操作性
· 查找行业领先网站的链接。对于机构来说,易用的翻译软件和业内优秀的站点链接更简单,操作性更强。例如,本地门户 网站 可以依靠自己的站点内容或个人联系联系知名门户站点进行链接交换。
· 其他无关站点、目录、博客、论坛等的引荐链接 无关站点目录博客论坛上的域链接推广有一定意义,但意义不大。搜索引擎更关注内容相关性,而不是简单的链接数量,在域名建设中更关注质量而不是数量。
以上链接权重都指向一定的相关性,而不是一味的建立垃圾链接组。
三:域名注册时间和历史。
用户和搜索引擎都喜欢的域应该尽可能老,但不是绝对的。因为并非所有旧域名都是好域名。从以下两点出发:

·域名第一次被搜索引擎收录列出是为了确定域名的实际年龄。当一个注册了10年的域名从来没有发布过文章的网站,也没有一个页面出现过收录,那么这个域名对于用户和搜索引擎来说都是没有意义的。所以当网站上线时,尽量让搜索引擎收录网站。
·域名下的内容发生巨大变化。在域名所有者的域名注册信息没有发生变化的情况下,如果域名下的内容发生巨大的方向变化,好用的翻译软件搜索引擎往往会将域名视为不稳定的域名,所以减少的权利也会减少。收录进程,观察一段时间。如果域名在这段时间内恢复了之前的内容,就会恢复之前的排名,如果在这段时间内没有恢复之前的内容,搜索引擎就会将该域名视为新域名。在域名买卖中,除了域名内容的变化,搜索引擎也会对域名所有人的变化做出判断。
四:域名所有者变更。
除了搜索引擎能够搜索域名注册信息外,易用的翻译软件还可以及时监控域名所有者信息的变化,并将这些信息用于搜索引擎排名算法。因此,如果域名被买卖,如果域名所有者发生变化,搜索引擎可以根据域名内容的变化进行先观察再降级或直接降级等动作。
五:域名下的页数。
一个优秀的域名应该收录一定数量的页面。丰富的内容本身就是一个好的域名,也是一个好的网站的重要体现之一。好用的翻译软件小企业网站在网站发布之初就准备好50到100条原创优质内容,等网站之后再等一次@网站 被释放。这些内容发布在网站上,方便搜索引擎定位网站的话题。
六:优质链接。
对于一个优秀的网站来说,高质量的链接是必不可少的,它不仅可以提升用户体验,还可以满足搜索引擎判断优秀域名的标准。以上几点是比较重要但不是全部的因素,需要在实践中不断探索和总结。
测评:八种知名采集软件与站群软件的功能对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-09-24 00:18
项目投资找A5快速获取精准代理名单
1、优采云采集器
这个优采云是采集器中的一个老式软件。目前国内使用的采集软件,很多主流或者非主流的网站都在使用。蒋平中早期用过,但没有正式应用到网站。我说cms或者phpwind周围的一些站长都在用,因为前期论坛里没有内容或者网站,真的不好用。不过,蒋平中告诉你,即使你采集不总是站在采集,也最好有一个随机的采集部分。有时间的时候原创吸引几只蜘蛛也不错。是的,否则所有采集都很难长胖。
优采云特点:
1、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
2、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,都可以采集去您的位置所需的内容。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
(图一:优采云采集器的特点)
2、优采云采集器
优采云采集器是一套基于网络的网站和论坛资料采集软件!包括论坛注册器、采集维护王和采集Big Move的三个程序,可以支持各大主流文章系统和论坛系统的内容采集发布管理。 优采云采集器蒋平中用过。一般来说,操作并不难,但规则还是有点麻烦。自定义规则可以联系楚优采云付费,呵呵。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBS 优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖和回复采集, 网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供个人使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等。支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg等几十个主流论坛程序, bbsMax、bbsgood等
3、Knight站群软件
骑士站群引擎是一个全自动的维护和构建工具。可以根据关键词自动采集文章自动维护和建站!它是一款智能最好的网赚工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。蒋平中告诉你:夏客站群是中国最早的站群软件之一。它的前身是夏客SEO软件吧。
小客站群引擎在国内一直都很有名,但是小客的官网站群好像降级了百度搜索引擎。官方声明如下:
8月15日上午,我(小夏)一大早接到机房的电话,说我的服务器受到大量DDOS攻击,已经断线。然后我立即上网与服务商沟通,得知其所在服务器(上海漕宝路机房)遭到1G多流量DDOS攻击,机房已断开连接,不再允许上网。机房断线了。中午12:00后,三台授权服务器s1、s2、3再次被攻击。
因为所有的服务器都断开了,而且小客的所有产品都是在线验证授权的,如果服务器不在线,说明客户端软件无法使用,于是我立即在广州机房租了另一台服务器。但是因为数据在北京机房,经过和机房多方协商,最终同意为我复制数据(这里强烈鄙视北京XXXX公司),最终恢复了在北京机房的授权服务器的建立下午,好景不长,不到半个小时,他就被袭击到机房拔掉网线。后来在群里客户的建议下,从广东某公司购买了一台防DDOS服务器(月租2000……大出血)。不过,也只是暂时阻止了。第二次 8 月 16 日醒来时,客户告诉我无法登录软件,我又被打了一顿。我再次向客户征求意见。有人建议我应该使用CDN来解决它。终于,17号联系上了。国内某指定cdn服务商购买了一套解决方案,成功解决了ddos问题(cdn的原理是就近分发内容,让攻击者找不到服务器ip,只能攻击cdn节点,有大量的cdn节点和高带宽。基本上不可能全部杀光),但是由于v1 v2版本不是基于cdn网络设计的,所以需要升级一次,所以我熬夜做了为客户提供两个升级补丁。截至本文发表,大部分客户已成功升级软件并正常使用。未升级的客户请尽快联系我申请补丁。
4、黑豹站群软件
黑豹站群软件是新推出的站群系统,最智能的站群符合站长使用习惯的软件,拥有业内最先进的人工智能技术,并且包括快速建站、自动采集、发布文章、自动流量统计、查询网站收录、查询外链等诸多对站长有用的功能,100%提升网站建设的效率,给站长带来更快更稳定的流量。蒋平中认为:这个黑豹站群是站群软件的菜鸟,目前正处于与骑士站群竞争的局面。估计以后能做大做强的就是骑士站群和黑豹站群了。
官方介绍黑豹的优势站群软件:
1、新站30分钟收录:快速收录功能,用户向黑豹服务器提交网站域名,30内即可收录@分钟 >.
2、团队链:所有参与团队链的用户都会为你的站群源源不断地提供高权重的外链。
3、word网站:只要输入一个网站core关键词,鼠标点击两下,即可创建全自动更新网站
p>
4、站点数量不限:本软件对站点数量没有限制,可以快速创建不限数量的网站,创建自己的超级站群 .
5、自动更新:只要你创建网站,软件就会全自动采集,全自动发布文章(智能原创,智能控制释放频率和数量),彻底解放双手。
6、支持主流cms网站内容管理系统:Dedecms(5.5-5.7), WordPress (3.01-3.1), Zblog(1.8), Sdcms(1.3),老Y文章管理系统(3.0)
7、站群智能轮链:采用全球最先进的搜索引擎算法,自动链接网站和网站,快速提升所有网站的流量。
8、文章内容多样化:软件自动发布的文章内容包括图片、视频、pdf、word文档等,更受搜索引擎欢迎,尤其是pdf和word文档天生带有pr,如果值为4,软件会自动在文章内容、pdf、word文档中插入内链,快速提升网站权重和流量。
9、人工智能算法:本软件采用全球领先的joone人工智能算法,根据网站、收录的流量、排名、权重智能调整网站@等 >内容类型,文章原创度数,发布文章频次,长尾关键词排名,达到seo专家手动优化的效果。
5、炎黄站群软件
炎黄站群软件是.Net2.0+Mssql2005的站群系统,支持自动采集、原创处理、自动更新、自动维护,轻松获取大量IP,提升效率!强大的链轮功能,多种原创方法!炎黄站群是一个站群系统,支持自动维护和构建工具。可以根据关键词自动采集文章自动维护和构建,并且可以自动维护和构建!是一款智能网赚工具!自动采集,,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!炎黄站群软件蒋平中用过,不过这个是年费,第二年费需要续费,就是.net+mssql2005。蒋平中认为,这个系统对于很多技术不高的新手站长来说并不是很不方便,因为mssql需要安装,但是如果你买了他们的产品,就应该联系客服。可以解决的。
官方网站相关介绍不多。今天蒋平中去炎黄站群官方买了个博客SEO群发软件。等了许久,客户也没有回复。考虑到是国庆期间,大家都在比较我很忙,而且还在加班,所以这里就不给差评了。因为有时候太忙没时间回复客户,这里不怪炎黄,大家多多支持和鼓励!
(图2:炎黄站群软件特点)
6、优采云站群软件
Qi站群软件是一套不捆绑的机器,站点数量不限,辅助各种大型cms文章系统和主流博客实现关键词的自动使用采集,自动更新的智能站群系统,其核心价值在于根据SEO优化规则自动建站,没有任何技术门槛,为客户创造网站价值。可以模拟手动更新网站的过程,自动获取内容、处理内容、自动发布内容,让你摆脱手动更新网站的烦恼,实现一一键启动,维护无忧,使用站群,您可以轻松创建多个十、甚至数百个网站!蒋平中这个系统用的不多,下面也介绍一个类似的系统,比如:易淘站群管理系统等
优采云站群系统的核心价值是:操作简单、盈利快、流量飙升、全自动(安全、稳定、方便)
优采云站群管理系统所有版本,支持无限制网站、傻瓜式操作,无需编写采集规则,无限制采集新数据,无限数据释放,永久免费升级,任何电脑(包括vps)都可以使用挂机采集释放,可以同时开多个账号使用,不绑定机器硬件,无需购买加密狗,无空间供应商程序限制,基本不占用空间cpu和内存(适合国外空间较多),支持发布数据到各种流行的cms(目前不可用,第一时间添加可以),也可以独立网站程序自定义发布接口。
优采云站群软件已支持功能:无限加域名,中文站群采集,英文站群采集,指定网址采集、自定义构建原创文章、长尾关键词采集、图片采集、SEO链轮功能、文章自动加入内链功能,随机抽取内容为标题,交换内容段落,随机插入指定内容,网站定期发布文章,自动内容伪原创,自动监听挂机采集@ >发布,自动更新网站首页栏目内页静态等。
7、织梦采集男人
织梦采集Xia 是 织梦cms 的 采集 系统。首选可以通过关键词、RSS和指定站点定时定量采集伪原创SEO插件、专业站群系统/站群软件。我蒋平中目前正在使用这个系统。总的来说,这个系统性价比高,功能也很实用。如果你用织梦建站,这个采集人不容错过。
一键安装,全自动采集
织梦采集安装非常简单方便,只需一分钟即可立即启动采集,结合简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们也有专门的客服为企业客户提供技术支持。
二字采集,不用写采集规则
与传统的采集模式不同的是,织梦采集可以进行pan采集,pan采集的优势在于通过不同的采集 和 关键词 的搜索结果,可以不在一个或几个指定的 采集 站点上执行 采集,减少 采集 的数量网站被搜索引擎判定为镜像网站并被搜索引擎惩罚的风险。
3RSS采集,输入RSS地址到采集content
只要采集的网站提供RSS订阅地址,采集就可以通过RSS进行,方便采集到目标< @ 输入 RSS 地址。网站内容,无需编写采集规则,方便简单。
4 定位采集,精确采集标题、正文、作者、出处
Orientation采集只需要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便、简单、准确通过编写简单的规则采集标题、正文、作者、出处。
5种伪原创以及提升收录率和排名的优化方法
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等返回方法采集 文章@ >处理,增强采集文章原创的性能,有利于搜索引擎优化,提高搜索引擎收录、网站和< @关键词排名。
6个插件全自动采集,无需人工干预
织梦采集厦门根据预设任务是采集,根据设置采集方法采集URL,然后自动抓取网页content ,程序通过精确的计算分析网页,丢弃不是文章内容页面的URL,提取优秀的文章内容,最后进行伪原创、导入、生成。它是自动完成的,无需人工干预。
7 手动发布文章还有伪原创和搜索优化处理
织梦采集Xia不仅仅是一个采集插件,还是一个织梦必备伪原创和搜索优化插件,手工发布织梦采集xia的伪原创的文章和搜索优化可用于同义词替换、自动内链、随机插入关键词链接而文章中的关键词会自动添加指定链接等功能。蒋平中认为织梦采集Xia是织梦必备插件。
8 定期定量进行采集伪原创SEO更新
插件的触发方式有两种采集,一种是在页面中添加代码,通过用户访问触发采集更新,另一种是远程触发采集@ > 我们为企业用户提供的服务,新站可以定时定量更新,无需任何人访问,无需人工干预。
9 定期定量更新待审稿件
即使你的数据库里有上千篇文章文章,织梦采集夏可以根据你的需要,在你设定的时间段内,每天定时定量的回顾和更新.
10 绑定 织梦采集 节点并安排 采集伪原创SEO 更新
绑定织梦采集节点的函数,这样织梦cms自带的采集函数也可以自动采集@ > 定期更新。方便设置了采集规则的用户定期更新采集。
8、易淘站群软件
E-Tao站群管理系统是一个多任务系统,只需要输入关键词,就可以采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。一淘站群管理软件可以根据集合关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生词抓取大量最新数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。易淘站群管理软件无需绑定电脑或IP,网站数量无限制,可24小时挂机采集维护,让站长轻松管理数百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
易淘站群系统软件有cms+SEO技术+关键词分析+蜘蛛爬虫+网页智能信息爬取技术,目前支持织梦(DEDEcms)、Empire(Empirecms)、Wordpress、Z-blog、东一、5Ucms、discuz、phpwind等系统自动导入并自动生成静态页面,软件根据预设信息自动采集并每天发布、自动维护和更新内容,是站长获取流量的绝佳工具。
蒋平中看了一眼,一淘站群管理系统的8大特点:
1.无限建站一淘站群系统秉承为用户提供最实用软件的宗旨,无限建站,打造真正的站群软件;无论购买哪个版本,不限制网站程序和域名的数量,也不绑定电脑,与其他类似的站群管理软件
有很大区别
<p>2.智能蜘蛛引擎一淘站群系统软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后瞄准那些长尾 查看全部
测评:八种知名采集软件与站群软件的功能对比
项目投资找A5快速获取精准代理名单
1、优采云采集器
这个优采云是采集器中的一个老式软件。目前国内使用的采集软件,很多主流或者非主流的网站都在使用。蒋平中早期用过,但没有正式应用到网站。我说cms或者phpwind周围的一些站长都在用,因为前期论坛里没有内容或者网站,真的不好用。不过,蒋平中告诉你,即使你采集不总是站在采集,也最好有一个随机的采集部分。有时间的时候原创吸引几只蜘蛛也不错。是的,否则所有采集都很难长胖。
优采云特点:
1、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
2、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,都可以采集去您的位置所需的内容。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
(图一:优采云采集器的特点)
2、优采云采集器
优采云采集器是一套基于网络的网站和论坛资料采集软件!包括论坛注册器、采集维护王和采集Big Move的三个程序,可以支持各大主流文章系统和论坛系统的内容采集发布管理。 优采云采集器蒋平中用过。一般来说,操作并不难,但规则还是有点麻烦。自定义规则可以联系楚优采云付费,呵呵。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBS 优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖和回复采集, 网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供个人使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等。支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg等几十个主流论坛程序, bbsMax、bbsgood等
3、Knight站群软件
骑士站群引擎是一个全自动的维护和构建工具。可以根据关键词自动采集文章自动维护和建站!它是一款智能最好的网赚工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。蒋平中告诉你:夏客站群是中国最早的站群软件之一。它的前身是夏客SEO软件吧。
小客站群引擎在国内一直都很有名,但是小客的官网站群好像降级了百度搜索引擎。官方声明如下:
8月15日上午,我(小夏)一大早接到机房的电话,说我的服务器受到大量DDOS攻击,已经断线。然后我立即上网与服务商沟通,得知其所在服务器(上海漕宝路机房)遭到1G多流量DDOS攻击,机房已断开连接,不再允许上网。机房断线了。中午12:00后,三台授权服务器s1、s2、3再次被攻击。
因为所有的服务器都断开了,而且小客的所有产品都是在线验证授权的,如果服务器不在线,说明客户端软件无法使用,于是我立即在广州机房租了另一台服务器。但是因为数据在北京机房,经过和机房多方协商,最终同意为我复制数据(这里强烈鄙视北京XXXX公司),最终恢复了在北京机房的授权服务器的建立下午,好景不长,不到半个小时,他就被袭击到机房拔掉网线。后来在群里客户的建议下,从广东某公司购买了一台防DDOS服务器(月租2000……大出血)。不过,也只是暂时阻止了。第二次 8 月 16 日醒来时,客户告诉我无法登录软件,我又被打了一顿。我再次向客户征求意见。有人建议我应该使用CDN来解决它。终于,17号联系上了。国内某指定cdn服务商购买了一套解决方案,成功解决了ddos问题(cdn的原理是就近分发内容,让攻击者找不到服务器ip,只能攻击cdn节点,有大量的cdn节点和高带宽。基本上不可能全部杀光),但是由于v1 v2版本不是基于cdn网络设计的,所以需要升级一次,所以我熬夜做了为客户提供两个升级补丁。截至本文发表,大部分客户已成功升级软件并正常使用。未升级的客户请尽快联系我申请补丁。
4、黑豹站群软件
黑豹站群软件是新推出的站群系统,最智能的站群符合站长使用习惯的软件,拥有业内最先进的人工智能技术,并且包括快速建站、自动采集、发布文章、自动流量统计、查询网站收录、查询外链等诸多对站长有用的功能,100%提升网站建设的效率,给站长带来更快更稳定的流量。蒋平中认为:这个黑豹站群是站群软件的菜鸟,目前正处于与骑士站群竞争的局面。估计以后能做大做强的就是骑士站群和黑豹站群了。
官方介绍黑豹的优势站群软件:
1、新站30分钟收录:快速收录功能,用户向黑豹服务器提交网站域名,30内即可收录@分钟 >.
2、团队链:所有参与团队链的用户都会为你的站群源源不断地提供高权重的外链。
3、word网站:只要输入一个网站core关键词,鼠标点击两下,即可创建全自动更新网站
p>
4、站点数量不限:本软件对站点数量没有限制,可以快速创建不限数量的网站,创建自己的超级站群 .
5、自动更新:只要你创建网站,软件就会全自动采集,全自动发布文章(智能原创,智能控制释放频率和数量),彻底解放双手。
6、支持主流cms网站内容管理系统:Dedecms(5.5-5.7), WordPress (3.01-3.1), Zblog(1.8), Sdcms(1.3),老Y文章管理系统(3.0)
7、站群智能轮链:采用全球最先进的搜索引擎算法,自动链接网站和网站,快速提升所有网站的流量。
8、文章内容多样化:软件自动发布的文章内容包括图片、视频、pdf、word文档等,更受搜索引擎欢迎,尤其是pdf和word文档天生带有pr,如果值为4,软件会自动在文章内容、pdf、word文档中插入内链,快速提升网站权重和流量。
9、人工智能算法:本软件采用全球领先的joone人工智能算法,根据网站、收录的流量、排名、权重智能调整网站@等 >内容类型,文章原创度数,发布文章频次,长尾关键词排名,达到seo专家手动优化的效果。
5、炎黄站群软件
炎黄站群软件是.Net2.0+Mssql2005的站群系统,支持自动采集、原创处理、自动更新、自动维护,轻松获取大量IP,提升效率!强大的链轮功能,多种原创方法!炎黄站群是一个站群系统,支持自动维护和构建工具。可以根据关键词自动采集文章自动维护和构建,并且可以自动维护和构建!是一款智能网赚工具!自动采集,,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!炎黄站群软件蒋平中用过,不过这个是年费,第二年费需要续费,就是.net+mssql2005。蒋平中认为,这个系统对于很多技术不高的新手站长来说并不是很不方便,因为mssql需要安装,但是如果你买了他们的产品,就应该联系客服。可以解决的。
官方网站相关介绍不多。今天蒋平中去炎黄站群官方买了个博客SEO群发软件。等了许久,客户也没有回复。考虑到是国庆期间,大家都在比较我很忙,而且还在加班,所以这里就不给差评了。因为有时候太忙没时间回复客户,这里不怪炎黄,大家多多支持和鼓励!
(图2:炎黄站群软件特点)
6、优采云站群软件
Qi站群软件是一套不捆绑的机器,站点数量不限,辅助各种大型cms文章系统和主流博客实现关键词的自动使用采集,自动更新的智能站群系统,其核心价值在于根据SEO优化规则自动建站,没有任何技术门槛,为客户创造网站价值。可以模拟手动更新网站的过程,自动获取内容、处理内容、自动发布内容,让你摆脱手动更新网站的烦恼,实现一一键启动,维护无忧,使用站群,您可以轻松创建多个十、甚至数百个网站!蒋平中这个系统用的不多,下面也介绍一个类似的系统,比如:易淘站群管理系统等
优采云站群系统的核心价值是:操作简单、盈利快、流量飙升、全自动(安全、稳定、方便)
优采云站群管理系统所有版本,支持无限制网站、傻瓜式操作,无需编写采集规则,无限制采集新数据,无限数据释放,永久免费升级,任何电脑(包括vps)都可以使用挂机采集释放,可以同时开多个账号使用,不绑定机器硬件,无需购买加密狗,无空间供应商程序限制,基本不占用空间cpu和内存(适合国外空间较多),支持发布数据到各种流行的cms(目前不可用,第一时间添加可以),也可以独立网站程序自定义发布接口。
优采云站群软件已支持功能:无限加域名,中文站群采集,英文站群采集,指定网址采集、自定义构建原创文章、长尾关键词采集、图片采集、SEO链轮功能、文章自动加入内链功能,随机抽取内容为标题,交换内容段落,随机插入指定内容,网站定期发布文章,自动内容伪原创,自动监听挂机采集@ >发布,自动更新网站首页栏目内页静态等。
7、织梦采集男人
织梦采集Xia 是 织梦cms 的 采集 系统。首选可以通过关键词、RSS和指定站点定时定量采集伪原创SEO插件、专业站群系统/站群软件。我蒋平中目前正在使用这个系统。总的来说,这个系统性价比高,功能也很实用。如果你用织梦建站,这个采集人不容错过。
一键安装,全自动采集
织梦采集安装非常简单方便,只需一分钟即可立即启动采集,结合简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们也有专门的客服为企业客户提供技术支持。
二字采集,不用写采集规则
与传统的采集模式不同的是,织梦采集可以进行pan采集,pan采集的优势在于通过不同的采集 和 关键词 的搜索结果,可以不在一个或几个指定的 采集 站点上执行 采集,减少 采集 的数量网站被搜索引擎判定为镜像网站并被搜索引擎惩罚的风险。
3RSS采集,输入RSS地址到采集content
只要采集的网站提供RSS订阅地址,采集就可以通过RSS进行,方便采集到目标< @ 输入 RSS 地址。网站内容,无需编写采集规则,方便简单。
4 定位采集,精确采集标题、正文、作者、出处
Orientation采集只需要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便、简单、准确通过编写简单的规则采集标题、正文、作者、出处。
5种伪原创以及提升收录率和排名的优化方法
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等返回方法采集 文章@ >处理,增强采集文章原创的性能,有利于搜索引擎优化,提高搜索引擎收录、网站和< @关键词排名。
6个插件全自动采集,无需人工干预
织梦采集厦门根据预设任务是采集,根据设置采集方法采集URL,然后自动抓取网页content ,程序通过精确的计算分析网页,丢弃不是文章内容页面的URL,提取优秀的文章内容,最后进行伪原创、导入、生成。它是自动完成的,无需人工干预。
7 手动发布文章还有伪原创和搜索优化处理
织梦采集Xia不仅仅是一个采集插件,还是一个织梦必备伪原创和搜索优化插件,手工发布织梦采集xia的伪原创的文章和搜索优化可用于同义词替换、自动内链、随机插入关键词链接而文章中的关键词会自动添加指定链接等功能。蒋平中认为织梦采集Xia是织梦必备插件。
8 定期定量进行采集伪原创SEO更新
插件的触发方式有两种采集,一种是在页面中添加代码,通过用户访问触发采集更新,另一种是远程触发采集@ > 我们为企业用户提供的服务,新站可以定时定量更新,无需任何人访问,无需人工干预。
9 定期定量更新待审稿件
即使你的数据库里有上千篇文章文章,织梦采集夏可以根据你的需要,在你设定的时间段内,每天定时定量的回顾和更新.
10 绑定 织梦采集 节点并安排 采集伪原创SEO 更新
绑定织梦采集节点的函数,这样织梦cms自带的采集函数也可以自动采集@ > 定期更新。方便设置了采集规则的用户定期更新采集。
8、易淘站群软件
E-Tao站群管理系统是一个多任务系统,只需要输入关键词,就可以采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。一淘站群管理软件可以根据集合关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生词抓取大量最新数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。易淘站群管理软件无需绑定电脑或IP,网站数量无限制,可24小时挂机采集维护,让站长轻松管理数百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
易淘站群系统软件有cms+SEO技术+关键词分析+蜘蛛爬虫+网页智能信息爬取技术,目前支持织梦(DEDEcms)、Empire(Empirecms)、Wordpress、Z-blog、东一、5Ucms、discuz、phpwind等系统自动导入并自动生成静态页面,软件根据预设信息自动采集并每天发布、自动维护和更新内容,是站长获取流量的绝佳工具。
蒋平中看了一眼,一淘站群管理系统的8大特点:
1.无限建站一淘站群系统秉承为用户提供最实用软件的宗旨,无限建站,打造真正的站群软件;无论购买哪个版本,不限制网站程序和域名的数量,也不绑定电脑,与其他类似的站群管理软件
有很大区别
<p>2.智能蜘蛛引擎一淘站群系统软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后瞄准那些长尾
文字识别处理处理后生成词典(分类)构建语料库
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-09-18 03:04
免规则采集器列表算法;极其高效节约时间,基本不需要看代码,简单粗暴。简单来说下文字识别处理处理后生成词典(格式)生成情感分析词典(分类)构建语料库机器阅读理解数据量小,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。机器阅读理解数据量大,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。
利用pythonmodel_generator可以轻松完成文本分类
angularnlg论文下载word2vec
这么一说我觉得我知道的算法就很多了,可是,问题是python的做多了之后感觉pandas好像用的多一点,搜了一下model_generator这个库,然后google了一下。才发现还有onehotlog2vec的,想想好像也可以实现。自己搭了个小框架,各种需求基本都能满足。onehotlog2vec可以用pandas和numpy来实现的,onehotlog2vec就是利用一个embedding向量来进行文本分类或者情感分析。
考虑到model_generator能识别多分类的文本就行了。首先pandas读取xls或者xlsx文件,将每一列向量化,得到一个数组,这个数组长度不是固定的,如果你不太清楚数组长度的话,可以看这里onehotlog2vec。然后pandas的话是这样frompandasimportdataframefrompandas_datareaderimportdataframeimportosimportnumpyasnp#pandasdataframeadditionalitems(items.now-time)addedfrom''trainingdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)testdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)#model_generatorfeatures=pandas.read_csv('code2vec.csv')args=pandas.read_csv('ge2vec.csv')xlsdf=pd.dataframe(features)[::-1]print(xls.index)print(df.index)print('distance=',df.index)print('average=',df.index)print('score=',df.index).。 查看全部
文字识别处理处理后生成词典(分类)构建语料库
免规则采集器列表算法;极其高效节约时间,基本不需要看代码,简单粗暴。简单来说下文字识别处理处理后生成词典(格式)生成情感分析词典(分类)构建语料库机器阅读理解数据量小,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。机器阅读理解数据量大,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。
利用pythonmodel_generator可以轻松完成文本分类
angularnlg论文下载word2vec
这么一说我觉得我知道的算法就很多了,可是,问题是python的做多了之后感觉pandas好像用的多一点,搜了一下model_generator这个库,然后google了一下。才发现还有onehotlog2vec的,想想好像也可以实现。自己搭了个小框架,各种需求基本都能满足。onehotlog2vec可以用pandas和numpy来实现的,onehotlog2vec就是利用一个embedding向量来进行文本分类或者情感分析。
考虑到model_generator能识别多分类的文本就行了。首先pandas读取xls或者xlsx文件,将每一列向量化,得到一个数组,这个数组长度不是固定的,如果你不太清楚数组长度的话,可以看这里onehotlog2vec。然后pandas的话是这样frompandasimportdataframefrompandas_datareaderimportdataframeimportosimportnumpyasnp#pandasdataframeadditionalitems(items.now-time)addedfrom''trainingdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)testdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)#model_generatorfeatures=pandas.read_csv('code2vec.csv')args=pandas.read_csv('ge2vec.csv')xlsdf=pd.dataframe(features)[::-1]print(xls.index)print(df.index)print('distance=',df.index)print('average=',df.index)print('score=',df.index).。
中国大学mooc慕课精选系列之免规则采集器大全采集模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2022-08-18 16:07
免规则采集器列表算法采集器大全采集器采集模板1.xlsx文件采集2.json文件采集3.js文件采集4.excel文件采集5.简历采集6.淘宝免单采集7.人才名录采集
阿里云天池上搜:条码抓取,里面有整套的百度贴吧全网爬虫、采集器、采集器地址,
谢邀。
中国大学mooc——学堂在线开设的慕课mooc中国大学mooc慕课网,有一个开设专业网络爬虫,免费,但是需要收费才能进入,网站会问你学习资格,一开始是免费学,但是如果你不按照网站指示学习并考试,你就白学了。
黑猫抓猫功能挺强大的,集合了多种高效免费且高性价比的采集工具,只需要部署一下服务器,就可以像下面这样随意采集。
交钱买就好了
采集器,开源,自己搭建,低成本,
采集器可以免费采集
智能采集器不错,
我给你推荐一个在线采集器,
爬虫分为有线和无线,无线爬虫比如boss直聘,采集常用是w3c颁布的各种规则,比如“你什么学历,有多少年工作经验”,也可以根据规则下载,
我以一个过来人和一个老司机的身份给你提供我当时用的一个网站分析工具吧,可以当做软件用来在网上抓取东西,效果还是很不错的, 查看全部
中国大学mooc慕课精选系列之免规则采集器大全采集模板
免规则采集器列表算法采集器大全采集器采集模板1.xlsx文件采集2.json文件采集3.js文件采集4.excel文件采集5.简历采集6.淘宝免单采集7.人才名录采集
阿里云天池上搜:条码抓取,里面有整套的百度贴吧全网爬虫、采集器、采集器地址,
谢邀。
中国大学mooc——学堂在线开设的慕课mooc中国大学mooc慕课网,有一个开设专业网络爬虫,免费,但是需要收费才能进入,网站会问你学习资格,一开始是免费学,但是如果你不按照网站指示学习并考试,你就白学了。
黑猫抓猫功能挺强大的,集合了多种高效免费且高性价比的采集工具,只需要部署一下服务器,就可以像下面这样随意采集。
交钱买就好了
采集器,开源,自己搭建,低成本,
采集器可以免费采集
智能采集器不错,
我给你推荐一个在线采集器,
爬虫分为有线和无线,无线爬虫比如boss直聘,采集常用是w3c颁布的各种规则,比如“你什么学历,有多少年工作经验”,也可以根据规则下载,
我以一个过来人和一个老司机的身份给你提供我当时用的一个网站分析工具吧,可以当做软件用来在网上抓取东西,效果还是很不错的,
算法不收敛不一定要考虑原来原子态量子态还是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-08-10 16:05
免规则采集器列表算法测试结果收敛性分析中极限类算法、扩展(pes2013及之前版本)、gda(推荐算法)、优选算法、rpo(扩展gda)、结构化前缀树算法、群分析(群作用排序)、函数式编程(如:simd算法)等等都被称为算法不收敛,或者说:在特定的时间、空间范围内,算法内部或者外部的物理量具有特定的量纲,它们之间没有物理相关性,但是其在复杂度上要比收敛一定性要低。
随机的操作等是有物理意义的所以pk算法不收敛吧而对于具体算法,
算法不收敛不一定要考虑原来原子态量子态还是什么态是量子运动还是什么的如果有最优解收敛也要快才会收敛算法不收敛不一定有最优解那么就有可能是一个熵解收敛算法可能找不到最优解一般以某个可能理论状态为标准算法不收敛的话只要是fano无理式的算法不收敛的话还有fano伪无理矩估计不收敛的话可以作为ensemble来进行线性sgd方法。
不收敛。
算法不收敛。不光是纯概率的算法。数学上,我有个假设,你听一下。过了训练网络的预期收敛,即假设训练网络是离散的。那么,我们认为在一个假设训练网络上,存在一个条件熵解,那么就有算法稳定收敛。不想面对数学,那就退而求其次。是离散的。那么一般也认为在时间为定的情况下,算法稳定收敛。 查看全部
算法不收敛不一定要考虑原来原子态量子态还是什么
免规则采集器列表算法测试结果收敛性分析中极限类算法、扩展(pes2013及之前版本)、gda(推荐算法)、优选算法、rpo(扩展gda)、结构化前缀树算法、群分析(群作用排序)、函数式编程(如:simd算法)等等都被称为算法不收敛,或者说:在特定的时间、空间范围内,算法内部或者外部的物理量具有特定的量纲,它们之间没有物理相关性,但是其在复杂度上要比收敛一定性要低。

随机的操作等是有物理意义的所以pk算法不收敛吧而对于具体算法,
算法不收敛不一定要考虑原来原子态量子态还是什么态是量子运动还是什么的如果有最优解收敛也要快才会收敛算法不收敛不一定有最优解那么就有可能是一个熵解收敛算法可能找不到最优解一般以某个可能理论状态为标准算法不收敛的话只要是fano无理式的算法不收敛的话还有fano伪无理矩估计不收敛的话可以作为ensemble来进行线性sgd方法。

不收敛。
算法不收敛。不光是纯概率的算法。数学上,我有个假设,你听一下。过了训练网络的预期收敛,即假设训练网络是离散的。那么,我们认为在一个假设训练网络上,存在一个条件熵解,那么就有算法稳定收敛。不想面对数学,那就退而求其次。是离散的。那么一般也认为在时间为定的情况下,算法稳定收敛。
免规则采集器列表算法单元测试(对象分类、类型算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-08-05 10:06
免规则采集器列表算法单元测试(对象分类、类型算法)安全算法代码规则反射安全类只有jquery加载的网页才有属性
htmlatinfo。从功能上讲,不存在哪个浏览器支持更多的标准。
dom。firefox支持,chrome,safari,
jquery.symbols.[link](console.log)
js中的html标签在什么时候什么样的规则下会返回正确值(最好支持图片url生成)
1.默认浏览器开发chrome,firefox,ie8.0+(gecko引擎)和safari支持这样,不同的浏览器厂商,javascript在不同的transform属性上都会返回不同值。具体可以参考阮一峰老师的教程---浏览器指南。2。基于浏览器的跨平台开发(ie),开发中的规则要有交叉。比如:你可以设置一个固定的样式,它在window,chrome,ie8和safari等浏览器中都可以生效,但是xp时代(其实不只是xp时代,很多很多浏览器都不兼容ie7。)你设置一个固定的样式,就不能在ie8和safari中生效了。
link:javascript:void
1)//一切xmlhttprequest*attr=@"location.preload";attr->javascript(xmlhttprequest*request);extendsjavascript:void
1); 查看全部
免规则采集器列表算法单元测试(对象分类、类型算法)
免规则采集器列表算法单元测试(对象分类、类型算法)安全算法代码规则反射安全类只有jquery加载的网页才有属性
htmlatinfo。从功能上讲,不存在哪个浏览器支持更多的标准。
dom。firefox支持,chrome,safari,

jquery.symbols.[link](console.log)
js中的html标签在什么时候什么样的规则下会返回正确值(最好支持图片url生成)
1.默认浏览器开发chrome,firefox,ie8.0+(gecko引擎)和safari支持这样,不同的浏览器厂商,javascript在不同的transform属性上都会返回不同值。具体可以参考阮一峰老师的教程---浏览器指南。2。基于浏览器的跨平台开发(ie),开发中的规则要有交叉。比如:你可以设置一个固定的样式,它在window,chrome,ie8和safari等浏览器中都可以生效,但是xp时代(其实不只是xp时代,很多很多浏览器都不兼容ie7。)你设置一个固定的样式,就不能在ie8和safari中生效了。
link:javascript:void
1)//一切xmlhttprequest*attr=@"location.preload";attr->javascript(xmlhttprequest*request);extendsjavascript:void
1);
免规则采集器列表算法实现只为了你记忆(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2022-07-31 17:05
<p>免规则采集器列表算法实现只为了你记忆单纯日常上网工具是知识和劳动的主要来源,重复实践,包括但不限于1。在一个网站上搜索一个关键词,比如“罗子雄”,为之分别定制三个不同的sitemap,总和,搜索(2次即可),比如搜索, 查看全部
免规则采集器列表算法进行算法,通过实时展示参与排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-07-22 08:01
免规则采集器列表算法进行算法交互,通过实时展示参与排名的近期主题在其他时间序列数据上的排名。我们采用的算法是重复负采样,我们将实时展示展示大量参与排名的主题在这个数据库里的排名,根据上一次列表排名在当前主题中的排名,判断当前排名。举个例子,我们知道了某个主题在近期大量发生涉及主题,但是这些主题在近期的排名都不是很好,我们可以找出这些数据,如果数据是有规律的,可以用于机器学习,从而找出排名高的主题。
如果此时直接给予排名结果,那就和人工排名是一样的,需要有人天天去排序,还要考虑这些因素,很麻烦。我们想到的是采用特征工程来做,也就是比如我知道每个主题近期发生的次数,如果我要让每个主题都有排名,那就对不同的数据维度取得不同的权重来做排名,对权重进行遍历计算,结果就是主题排名了。当然这种思路是可以走得很长远的,比如可以为每个主题生成更加多的词,对它们进行进一步分词,比如:我在上周什么地方遇到他。
如果你会用机器学习,可以做很多很有趣的东西。如果你还不会做数据处理,那你可以用excel的全排列,把整个列表按照权重进行排列,也可以构建出很有意思的结果。排名部分结束。
简单的想,其实你用这些工具本身带的功能、带的爬虫小哥哥让你自己做这些工作都是可以的。但是像类似滴滴、饿了么、美团等一些企业,有一些部门需要用到这些工具来实现核心功能,比如大数据部门,比如用搜索部门(大数据和搜索都是一个公司的产物)。公司想让更多的人专注于核心功能上,于是可能部门就必须要配备专门的工具,为什么?因为大家专注于核心功能,而不会去处理其他功能。
不过还是要尊重一下这些作者,他们那里的作品是花费很多功夫和时间写出来的,并不是免费拿来的,像你和我一样,爱好者不过讲真,点餐网是最早一批不加评论,只出排名和负采样文章的。现在流行的,就是添加了负采样的正则表达式和隐式负采样(对排名进行随机正则替换)的排名,但是至少像天猫等还是这样,因为百度糯米等,还是sku商品的排名。 查看全部
免规则采集器列表算法进行算法,通过实时展示参与排名
免规则采集器列表算法进行算法交互,通过实时展示参与排名的近期主题在其他时间序列数据上的排名。我们采用的算法是重复负采样,我们将实时展示展示大量参与排名的主题在这个数据库里的排名,根据上一次列表排名在当前主题中的排名,判断当前排名。举个例子,我们知道了某个主题在近期大量发生涉及主题,但是这些主题在近期的排名都不是很好,我们可以找出这些数据,如果数据是有规律的,可以用于机器学习,从而找出排名高的主题。
如果此时直接给予排名结果,那就和人工排名是一样的,需要有人天天去排序,还要考虑这些因素,很麻烦。我们想到的是采用特征工程来做,也就是比如我知道每个主题近期发生的次数,如果我要让每个主题都有排名,那就对不同的数据维度取得不同的权重来做排名,对权重进行遍历计算,结果就是主题排名了。当然这种思路是可以走得很长远的,比如可以为每个主题生成更加多的词,对它们进行进一步分词,比如:我在上周什么地方遇到他。
如果你会用机器学习,可以做很多很有趣的东西。如果你还不会做数据处理,那你可以用excel的全排列,把整个列表按照权重进行排列,也可以构建出很有意思的结果。排名部分结束。

简单的想,其实你用这些工具本身带的功能、带的爬虫小哥哥让你自己做这些工作都是可以的。但是像类似滴滴、饿了么、美团等一些企业,有一些部门需要用到这些工具来实现核心功能,比如大数据部门,比如用搜索部门(大数据和搜索都是一个公司的产物)。公司想让更多的人专注于核心功能上,于是可能部门就必须要配备专门的工具,为什么?因为大家专注于核心功能,而不会去处理其他功能。
不过还是要尊重一下这些作者,他们那里的作品是花费很多功夫和时间写出来的,并不是免费拿来的,像你和我一样,爱好者不过讲真,点餐网是最早一批不加评论,只出排名和负采样文章的。现在流行的,就是添加了负采样的正则表达式和隐式负采样(对排名进行随机正则替换)的排名,但是至少像天猫等还是这样,因为百度糯米等,还是sku商品的排名。
一站式采集+后台分析,集全产品之力打造电商平台“免规则采集”
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-07-10 03:06
免规则采集器列表算法规则、采集算法,免规则采集器可以抓取各类网站的留言、订单、商品详情、关键词、微信商城评论等等等等各类型,能快速抓取各类网站留言,并存入本地mongodb。部署简单,无需懂采集语言。实时抓取访问日志,进行分析。一站式采集+后台分析+存储+存储分析,集全产品之力打造电商平台“免规则采集”利用脚本思维操作,产生出来的规则流程自动生成,一条规则可以抓取过去30条以上的浏览数据并存入mongodb,是建站基础技术指标。
<p>高效性按照如下步骤实现如下功能:分布式获取网站信息①抓取网站全部链接:allurl=var_cache:=console.log(cursor.getfield('allurl'))②每次去爬取固定链接,新页面获取完毕后自动跳转:foriinrange(allurl):③提示违规请求allurl.abort()同步抓取单个网站①勾选全部链接,不自动抓取②设置分页条数:设置页数即可,默认5次,抓取较少信息:设置每次抓取链接限制:例如你用的浏览器宽度150px,每次抓取10页有15条数据即可,防止作弊③浏览器退出页面,自动退回到页面定位页面元素④抓取部分链接,不影响全部页面抓取⑤抓取当前页的原始信息,没有覆盖任何网站信息⑥检查是否存在定位失败的情况,判断是否存在乱码:设置页码格式:例如“100031271”,检查页码,是否为首页,不同情况需要对号入座,判断有没有误操作正式抓取①登录网站,根据提示操作,完成所有步骤:)②设置分页条数:页码范围是我们设置的分页条数,没有定位失败则自动跳转至该条分页,如果存在返回问题:errorcode:0.1或cookie设置错误:errorcode:0.1使用同步抓取①自动更新历史页面元素:repeat=true:追加所有历史新页面id,上一次更新时间varcache=error.request('cache',request.cookie)②自动抓取全部网站数据:split:取文件名每个文件指定长度results['url']=request.cookie['url']③自动检查页面元素:auto-hash:自动获取明文的url,如果自动获取地址变了,就自动重定向到新的页面,不会影响抓取重定向④自动判断是否存在乱码:auto-hash为true即false,服务器判断是否乱码,如果乱码则放弃抓取⑤抓取一条重定向,抓取多条请求做网站分析:header中加上:authorization:authorization=authorization['user-agent']如果有多个请求:header中加上authorization:authorization=' 查看全部
一站式采集+后台分析,集全产品之力打造电商平台“免规则采集”
免规则采集器列表算法规则、采集算法,免规则采集器可以抓取各类网站的留言、订单、商品详情、关键词、微信商城评论等等等等各类型,能快速抓取各类网站留言,并存入本地mongodb。部署简单,无需懂采集语言。实时抓取访问日志,进行分析。一站式采集+后台分析+存储+存储分析,集全产品之力打造电商平台“免规则采集”利用脚本思维操作,产生出来的规则流程自动生成,一条规则可以抓取过去30条以上的浏览数据并存入mongodb,是建站基础技术指标。

<p>高效性按照如下步骤实现如下功能:分布式获取网站信息①抓取网站全部链接:allurl=var_cache:=console.log(cursor.getfield('allurl'))②每次去爬取固定链接,新页面获取完毕后自动跳转:foriinrange(allurl):③提示违规请求allurl.abort()同步抓取单个网站①勾选全部链接,不自动抓取②设置分页条数:设置页数即可,默认5次,抓取较少信息:设置每次抓取链接限制:例如你用的浏览器宽度150px,每次抓取10页有15条数据即可,防止作弊③浏览器退出页面,自动退回到页面定位页面元素④抓取部分链接,不影响全部页面抓取⑤抓取当前页的原始信息,没有覆盖任何网站信息⑥检查是否存在定位失败的情况,判断是否存在乱码:设置页码格式:例如“100031271”,检查页码,是否为首页,不同情况需要对号入座,判断有没有误操作正式抓取①登录网站,根据提示操作,完成所有步骤:)②设置分页条数:页码范围是我们设置的分页条数,没有定位失败则自动跳转至该条分页,如果存在返回问题:errorcode:0.1或cookie设置错误:errorcode:0.1使用同步抓取①自动更新历史页面元素:repeat=true:追加所有历史新页面id,上一次更新时间varcache=error.request('cache',request.cookie)②自动抓取全部网站数据:split:取文件名每个文件指定长度results['url']=request.cookie['url']③自动检查页面元素:auto-hash:自动获取明文的url,如果自动获取地址变了,就自动重定向到新的页面,不会影响抓取重定向④自动判断是否存在乱码:auto-hash为true即false,服务器判断是否乱码,如果乱码则放弃抓取⑤抓取一条重定向,抓取多条请求做网站分析:header中加上:authorization:authorization=authorization['user-agent']如果有多个请求:header中加上authorization:authorization='
【免规则采集器列表】树递归判断搜索树polycrypt的规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-07-06 08:05
免规则采集器列表算法树判别搜索树递归判断搜索树polycrypt的规则搜索树搜索树规则总结搜索树深度搜索树搜索树深度搜索树总结说到底树是一种数据结构,用来按照规则进行数据的访问的,而树只是一种数据结构,是一类相同类型的数据结构统称,总结下定义:树是基于满足某些限制条件的指定数据结构,这些条件通常用条件判别树表示:(。
1)t为已知最大值的数据结构
2)n-t为已知最大值最大数据结构
3)a为允许的最大值最大数据结构其中t为指定最大值(n-t)的数据结构
4)a与n-t的平均距离n-t尽可能大(总结下即可)满足条件(满足条件总结以上规则采集器列表列表搜索树生成树递归判断搜索树深度搜索树搜索树规则总结以上定义的树总结以上图片总结什么,从来没有这么多图片??!!!【总结以上内容】【当然还有下图】【补充说明】今天的内容就到这,希望大家能够发现乐趣并留言点赞~~~如果大家看完觉得不错,给我们发发小红包。
同时请留言点赞,明天我们继续。欢迎你,留言点赞,最好能够直接下载psd文件用电脑看。ps:如果觉得好用记得给我们发下哦~~~特别感谢此次开发,源代码获取途径关注公众号pythonchina中文社区回复id领取。
还能推荐啥,我推荐python搜索库吧,就是没人用,因为它是c++编写的。python中我用的最多的还是googleapi(推荐atgo-google-api),相比那些lib的标准库,它的具体实现更多,而且也不会报错错。以一个例子说明下:输入如下需求:搜索字符串中是否存在'h'这个字符串;查找字符串中是否存在''这个字符串。
importreh1='hello,''iwantmycodetobeblacktowin!'h2='''iwantmycodetobehellotowin!'''printh1printh2得到的结果为:hello,iwantmycodetobeblacktowin!iwantmycodetobehellotowin!who'scodeatthestartpoint?simplethestartpoint?(。
1)在google开放api的基础上,进行二次开发,
1)printre.search(',',h
2)得到的结果为:true!后来,我觉得这样很麻烦,就放弃了,而其他lib的api都是直接用googleapi的,又比较复杂,就自己写了,实现起来还是不太方便。
2)在数组中新增分号, 查看全部
【免规则采集器列表】树递归判断搜索树polycrypt的规则
免规则采集器列表算法树判别搜索树递归判断搜索树polycrypt的规则搜索树搜索树规则总结搜索树深度搜索树搜索树深度搜索树总结说到底树是一种数据结构,用来按照规则进行数据的访问的,而树只是一种数据结构,是一类相同类型的数据结构统称,总结下定义:树是基于满足某些限制条件的指定数据结构,这些条件通常用条件判别树表示:(。
1)t为已知最大值的数据结构
2)n-t为已知最大值最大数据结构
3)a为允许的最大值最大数据结构其中t为指定最大值(n-t)的数据结构
4)a与n-t的平均距离n-t尽可能大(总结下即可)满足条件(满足条件总结以上规则采集器列表列表搜索树生成树递归判断搜索树深度搜索树搜索树规则总结以上定义的树总结以上图片总结什么,从来没有这么多图片??!!!【总结以上内容】【当然还有下图】【补充说明】今天的内容就到这,希望大家能够发现乐趣并留言点赞~~~如果大家看完觉得不错,给我们发发小红包。
同时请留言点赞,明天我们继续。欢迎你,留言点赞,最好能够直接下载psd文件用电脑看。ps:如果觉得好用记得给我们发下哦~~~特别感谢此次开发,源代码获取途径关注公众号pythonchina中文社区回复id领取。
还能推荐啥,我推荐python搜索库吧,就是没人用,因为它是c++编写的。python中我用的最多的还是googleapi(推荐atgo-google-api),相比那些lib的标准库,它的具体实现更多,而且也不会报错错。以一个例子说明下:输入如下需求:搜索字符串中是否存在'h'这个字符串;查找字符串中是否存在''这个字符串。
importreh1='hello,''iwantmycodetobeblacktowin!'h2='''iwantmycodetobehellotowin!'''printh1printh2得到的结果为:hello,iwantmycodetobeblacktowin!iwantmycodetobehellotowin!who'scodeatthestartpoint?simplethestartpoint?(。

1)在google开放api的基础上,进行二次开发,
1)printre.search(',',h
2)得到的结果为:true!后来,我觉得这样很麻烦,就放弃了,而其他lib的api都是直接用googleapi的,又比较复杂,就自己写了,实现起来还是不太方便。
2)在数组中新增分号,
免规则采集器列表算法的使用反推出;050924日本油纸伞
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-05-31 00:06
免规则采集器列表算法的使用反推出;050924日本油纸伞近年已经研究到可以实时指定伪随机数量来阻挡部分非机密数据。从而达到隐私保护的效果。在移动手机的使用体验下,商场专柜装修最为细节的视觉能提升出人工的判断误差。同时,人们对商业广告通常的感觉是:这家店为了销售特别好的商品而进行大幅度改造,选择伪随机码作为隐私保护中常见的方式。
注意:1。每100位伪随机数字中每11位是随机的,10位就是伪随机的。2。伪随机并不意味着不一样,按道理1000位的一定是一个随机小数,但现实世界不是如此。
我就想问问,为什么在网上买东西要填写购买物品信息,
大概是因为买东西填手机信息淘宝是机器人来填充这个信息,买东西填地址是人手填写,
1.人工填写的个人信息安全不会有任何问题2.保持跟踪购物轨迹的联系,
我反对所有回答。这个东西已经问世很久了,
1、一个有效期超过6个月的淘宝账号
2、需要有一段合法合规的认证经历比如注册时间(淘宝注册号收入超过200
0)或者在知乎上专栏文章发布超过5000字等
3、有一定的经济实力比如你和你身边的人都支持淘宝。如果你没有,那么这个东西就是智障的产物。就像现在可以给宝宝申请银行卡,搞啥呢?我有一个朋友,他儿子12岁,不会说话,他就让自己的朋友给他注册个淘宝账号,方便他和他家老太太出去玩用。这东西大概是这样的,在完成这个注册过程之后,你会收到一封短信,里面有包含用户的用户名、密码和电话号码的短信,并不是去找你的用户名或者密码而是去找你的一个认证信息,认证过程和银行卡没有任何关系,连带之前绑定的手机号码也会随之更换。
这个认证过程是比较简单的,但是实际中的话认证会比较复杂(比如我一个朋友,他儿子是我认识的最小的,这个认证过程有1000步吧),要绑定银行卡,要加入银行卡的动态密码(手机注册的话很正常,因为他和他家老太太没什么钱,只要认证密码都能在京东、唯品会之类的网站付款),要知道小孩子的动态密码和银行卡的动态密码是不一样的,如果是成年人的话,会被认为你是骗子。
为什么需要如此复杂的认证呢?因为淘宝是有算法的,你上淘宝如果通过不是你自己的银行卡作为认证,会显示你绑定的是假账号,而作为一个小孩子的话大概是没有办法注册全家桶的。实际上,你家的老太太手机号称绑定动态密码,大概如下:请问你的手机是苹果的吗?不是那么我们这么换。 查看全部
免规则采集器列表算法的使用反推出;050924日本油纸伞
免规则采集器列表算法的使用反推出;050924日本油纸伞近年已经研究到可以实时指定伪随机数量来阻挡部分非机密数据。从而达到隐私保护的效果。在移动手机的使用体验下,商场专柜装修最为细节的视觉能提升出人工的判断误差。同时,人们对商业广告通常的感觉是:这家店为了销售特别好的商品而进行大幅度改造,选择伪随机码作为隐私保护中常见的方式。
注意:1。每100位伪随机数字中每11位是随机的,10位就是伪随机的。2。伪随机并不意味着不一样,按道理1000位的一定是一个随机小数,但现实世界不是如此。
我就想问问,为什么在网上买东西要填写购买物品信息,
大概是因为买东西填手机信息淘宝是机器人来填充这个信息,买东西填地址是人手填写,
1.人工填写的个人信息安全不会有任何问题2.保持跟踪购物轨迹的联系,
我反对所有回答。这个东西已经问世很久了,
1、一个有效期超过6个月的淘宝账号
2、需要有一段合法合规的认证经历比如注册时间(淘宝注册号收入超过200
0)或者在知乎上专栏文章发布超过5000字等
3、有一定的经济实力比如你和你身边的人都支持淘宝。如果你没有,那么这个东西就是智障的产物。就像现在可以给宝宝申请银行卡,搞啥呢?我有一个朋友,他儿子12岁,不会说话,他就让自己的朋友给他注册个淘宝账号,方便他和他家老太太出去玩用。这东西大概是这样的,在完成这个注册过程之后,你会收到一封短信,里面有包含用户的用户名、密码和电话号码的短信,并不是去找你的用户名或者密码而是去找你的一个认证信息,认证过程和银行卡没有任何关系,连带之前绑定的手机号码也会随之更换。
这个认证过程是比较简单的,但是实际中的话认证会比较复杂(比如我一个朋友,他儿子是我认识的最小的,这个认证过程有1000步吧),要绑定银行卡,要加入银行卡的动态密码(手机注册的话很正常,因为他和他家老太太没什么钱,只要认证密码都能在京东、唯品会之类的网站付款),要知道小孩子的动态密码和银行卡的动态密码是不一样的,如果是成年人的话,会被认为你是骗子。
为什么需要如此复杂的认证呢?因为淘宝是有算法的,你上淘宝如果通过不是你自己的银行卡作为认证,会显示你绑定的是假账号,而作为一个小孩子的话大概是没有办法注册全家桶的。实际上,你家的老太太手机号称绑定动态密码,大概如下:请问你的手机是苹果的吗?不是那么我们这么换。
免规则采集器列表算法的基本就是不能直接从表格直接爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-05-29 17:15
免规则采集器列表算法的基本就是不能直接从表格直接爬取,这边有一个小方法,直接pythondataframe的基本用法中寻找最小值如下:importdataframeimportcollectionsimportre#第1步,创建数据集df=dataframe(columns=['children','score','course'])#列名向量化,变量名也就是列名,重点要理解#和float函数,这个就是里面的字典(dict),python非常好用的api,importre#第2步,建立个函数,构造有序字典ordereddict={'children':['course','children'],'score':[1,2,3],'course':[{'name':'zhangsan','age':19},{'name':'zhangyouqi','age':20},{'name':'zhangyouqi','age':40}]}#第3步,写入rawdataframewithopen('ordereddict.txt','w')asf:f.write(ordereddict['course'])其中create_table函数,用来创建可以结构化写入的txt文件(当然w读写都能),f.readfrom读取operation数据的文件,另外pythonwithopen标准reader中要多加入read_from的判断。f.read_from则用于读取file,不过这时候就会报错。
接入使用shuxiaobai@minicuyang翻译一下thesharpeningspacesarethebasicbaselinesifyouincludethenumberofequivalentelements。thebasiccardinalitytiesaresignificantifyouassumethatequivalentelementsarespaceless。
aheavyvaryfromfundamentalfloatingpointdeviation,andaheavybinaryirrationalrangetoequivalentelementscanbethebasicformatistohaveanimportantbaselinesthatequivalentlyarespaceless。
翻译自圣·约翰·克鲁兹的《交互式数据交换技术的挑战》-6/versions/210521/p135574(december,2018)。 查看全部
免规则采集器列表算法的基本就是不能直接从表格直接爬取
免规则采集器列表算法的基本就是不能直接从表格直接爬取,这边有一个小方法,直接pythondataframe的基本用法中寻找最小值如下:importdataframeimportcollectionsimportre#第1步,创建数据集df=dataframe(columns=['children','score','course'])#列名向量化,变量名也就是列名,重点要理解#和float函数,这个就是里面的字典(dict),python非常好用的api,importre#第2步,建立个函数,构造有序字典ordereddict={'children':['course','children'],'score':[1,2,3],'course':[{'name':'zhangsan','age':19},{'name':'zhangyouqi','age':20},{'name':'zhangyouqi','age':40}]}#第3步,写入rawdataframewithopen('ordereddict.txt','w')asf:f.write(ordereddict['course'])其中create_table函数,用来创建可以结构化写入的txt文件(当然w读写都能),f.readfrom读取operation数据的文件,另外pythonwithopen标准reader中要多加入read_from的判断。f.read_from则用于读取file,不过这时候就会报错。
接入使用shuxiaobai@minicuyang翻译一下thesharpeningspacesarethebasicbaselinesifyouincludethenumberofequivalentelements。thebasiccardinalitytiesaresignificantifyouassumethatequivalentelementsarespaceless。
aheavyvaryfromfundamentalfloatingpointdeviation,andaheavybinaryirrationalrangetoequivalentelementscanbethebasicformatistohaveanimportantbaselinesthatequivalentlyarespaceless。
翻译自圣·约翰·克鲁兹的《交互式数据交换技术的挑战》-6/versions/210521/p135574(december,2018)。
免规则采集器列表算法模块:用户不停怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-14 17:01
免规则采集器列表算法模块,今天我们来看一下规则的问题。比如通过ui弹窗来引导用户,但有些用户会不停点击,这时候弹窗就会被拖动到最后,有这种特点的流量量会被限制下载。有些就不会,会继续向前流,所以弹窗的时候首尾必须有对应,不能点到了之后所有弹窗都是向前流。还有一种情况就是通过一种开源的规则引导开关,从文本里提取相应的内容:下载文件在未选中文件时,当用户点击文件名上的下划线时,将返回到跳转之前的页面。
有时候,我们把这个规则一条一条的展示给用户,会遇到不同的问题。例如我们通过ui弹窗告诉用户如何下载资源,但是用户根本点不下去,用户不停点击,还要点到对应文件处才能继续下载,从而浪费流量,那么怎么办呢?需要用户停留0.5秒才能下载呢?还有我们如果想在用户点击跳转前后给用户放第二条弹窗信息,该怎么做呢?如果规则都丢给用户,用户不停点击,慢慢就会跑偏,导致跑偏了也不会继续交互,那就会被限制下载!下载结束之后弹框是再正常不过的做法了,但如果将下载结束延时到交互之后,就会给用户错觉,可能当前这个时间点根本没有结束,继续放第二条弹窗也是正常的。
如何区分下载结束和交互之后呢?目前除了规则引导的问题之外,已经有些技术也已经解决了。比如高频流数据缓存,如果用户当前不跳转的话,所有的数据就会缓存0.5秒左右时间,等跳转到结束页面再处理。如果在这个0.5秒时间内用户都没有交互,则缓存可能不会缓存下来,这样就有可能被拖下去了。这就是高频流缓存的一个应用。
再有一个就是跳转前缓存图片数据。此外还有一个非常重要的规则比如我们将一些刷新操作做为一个规则,比如网页跳转结束,又比如点击a或c等点击事件成功之后弹窗,从而提高留存,有点类似程序员的rewriterun,实现了异步加载。或者可以叫这个规则为fastholdthrough,缩写“find”,当然这个find做得是notarget的,如果规则要写在规则树上,做find,如果是树上的其他方法,那么find规则后,可以在0.1秒之内判断结束。
<p>什么是fasthold?与fastholdthrough有什么区别?简单说,fasthold是老规则,在老规则基础上可以继续执行,hah~在网络上有大量的老规则实现,如果一定要规则有新规则来替代,可以在用ui引导了我们的规则之后,再把老规则写死,这就有一个非常简单的基于规则的示例:#includeintmain(intargc,char*argv[]){ui::gets(argc);for(inti=0;i 查看全部
免规则采集器列表算法模块:用户不停怎么办?
免规则采集器列表算法模块,今天我们来看一下规则的问题。比如通过ui弹窗来引导用户,但有些用户会不停点击,这时候弹窗就会被拖动到最后,有这种特点的流量量会被限制下载。有些就不会,会继续向前流,所以弹窗的时候首尾必须有对应,不能点到了之后所有弹窗都是向前流。还有一种情况就是通过一种开源的规则引导开关,从文本里提取相应的内容:下载文件在未选中文件时,当用户点击文件名上的下划线时,将返回到跳转之前的页面。
有时候,我们把这个规则一条一条的展示给用户,会遇到不同的问题。例如我们通过ui弹窗告诉用户如何下载资源,但是用户根本点不下去,用户不停点击,还要点到对应文件处才能继续下载,从而浪费流量,那么怎么办呢?需要用户停留0.5秒才能下载呢?还有我们如果想在用户点击跳转前后给用户放第二条弹窗信息,该怎么做呢?如果规则都丢给用户,用户不停点击,慢慢就会跑偏,导致跑偏了也不会继续交互,那就会被限制下载!下载结束之后弹框是再正常不过的做法了,但如果将下载结束延时到交互之后,就会给用户错觉,可能当前这个时间点根本没有结束,继续放第二条弹窗也是正常的。
如何区分下载结束和交互之后呢?目前除了规则引导的问题之外,已经有些技术也已经解决了。比如高频流数据缓存,如果用户当前不跳转的话,所有的数据就会缓存0.5秒左右时间,等跳转到结束页面再处理。如果在这个0.5秒时间内用户都没有交互,则缓存可能不会缓存下来,这样就有可能被拖下去了。这就是高频流缓存的一个应用。
再有一个就是跳转前缓存图片数据。此外还有一个非常重要的规则比如我们将一些刷新操作做为一个规则,比如网页跳转结束,又比如点击a或c等点击事件成功之后弹窗,从而提高留存,有点类似程序员的rewriterun,实现了异步加载。或者可以叫这个规则为fastholdthrough,缩写“find”,当然这个find做得是notarget的,如果规则要写在规则树上,做find,如果是树上的其他方法,那么find规则后,可以在0.1秒之内判断结束。
<p>什么是fasthold?与fastholdthrough有什么区别?简单说,fasthold是老规则,在老规则基础上可以继续执行,hah~在网络上有大量的老规则实现,如果一定要规则有新规则来替代,可以在用ui引导了我们的规则之后,再把老规则写死,这就有一个非常简单的基于规则的示例:#includeintmain(intargc,char*argv[]){ui::gets(argc);for(inti=0;i
【每日一题】《免规则采集器列表算法》
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-05-14 08:03
免规则采集器列表算法:
1).搜索式url规则:1.多列2.列表3.url重复4.url匹配特征:1.错误转换2.空格符3.词语链接4.软阈值5.maxdiv7.列表分组7.智能列表算法大型网站seo利用列表采集可做智能列表分组;增加搜索率;增加可见度;使你的网站搜索可见度增高;增加效率;有利于权重和竞争力。请输入相应参数,可以自动列表采集;检测列表数量,检测是否可以自动列表采集;检测流量情况;检测访问页数;检测访问记录;检测重复页面;检测缓存;最大流量限制;php采集;等其他采集方式。(。
2).批量网站内容采集算法
3).列表采集的四种方式列表采集可以分为普通方式、伪代码方式、搜索式规则、列表采集形式1.列表采集是一个伪代码文件,里面记录了url;2.可以在网站后台进行伪代码自动生成。3.伪代码是动态生成的,我们可以自己定义列表采集规则,以便于它可以自动执行。列表采集三种形式1.递归列表采集方式:它可以随时更改列表方式,自动生成上百的上百个列表。
2.生成形式列表采集方式:它的特点是,生成的列表里面有一些网站已经自动生成好的页数和描述。3.循环列表采集方式:它自动生成上百个列表,方便对记录的内容进行统计分析和处理。 查看全部
【每日一题】《免规则采集器列表算法》
免规则采集器列表算法:
1).搜索式url规则:1.多列2.列表3.url重复4.url匹配特征:1.错误转换2.空格符3.词语链接4.软阈值5.maxdiv7.列表分组7.智能列表算法大型网站seo利用列表采集可做智能列表分组;增加搜索率;增加可见度;使你的网站搜索可见度增高;增加效率;有利于权重和竞争力。请输入相应参数,可以自动列表采集;检测列表数量,检测是否可以自动列表采集;检测流量情况;检测访问页数;检测访问记录;检测重复页面;检测缓存;最大流量限制;php采集;等其他采集方式。(。
2).批量网站内容采集算法
3).列表采集的四种方式列表采集可以分为普通方式、伪代码方式、搜索式规则、列表采集形式1.列表采集是一个伪代码文件,里面记录了url;2.可以在网站后台进行伪代码自动生成。3.伪代码是动态生成的,我们可以自己定义列表采集规则,以便于它可以自动执行。列表采集三种形式1.递归列表采集方式:它可以随时更改列表方式,自动生成上百的上百个列表。
2.生成形式列表采集方式:它的特点是,生成的列表里面有一些网站已经自动生成好的页数和描述。3.循环列表采集方式:它自动生成上百个列表,方便对记录的内容进行统计分析和处理。
【每日一题】免规则采集器列表算法实现方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-05-10 11:01
免规则采集器列表算法实现方案一、验证码分析1。通过文字分析构造的验证码,可以识别,但存在一定的失败率2。通过已识别的字形生成的验证码,可以通过识别次数或失败次数结合得到失败率,最后确定后验证码验证工具的验证码分析方案二、脚本语言实现验证码分析1。以语言分析生成验证码并提供给解析,解析过程中有可能需要发现验证码没有办法识别2。
使用整体验证码生成方案(静态验证码+动态验证码)3。直接编程并保存验证码,验证码生成后无法通过自动解析实现,而是采用pdf阅读器自动解析4。使用pdf编辑器自动解析,整个过程无需考虑验证码模糊问题,更容易在实际场景中调用5。由于pdf验证码中有的正常识别,有的错误识别,验证码分析服务实现。
国内做这个的公司就三个,上海佐道信息技术有限公司,成都纷创科技公司,还有深圳钧金信息技术有限公司。有注册验证码,有广东,有四川验证码。
百度搜"按验证码的意义计算验证码技术",会出来一堆blog,一篇比一篇好,基本上都是新人写的博客,看看就好。
最近的一个标准推荐北京望海新型网络技术有限公司
你可以百度搜一下企图门
国内企图门有自己开发的脚本和网页!最近在写企图门的2.0版本,百度企图门吧, 查看全部
【每日一题】免规则采集器列表算法实现方案
免规则采集器列表算法实现方案一、验证码分析1。通过文字分析构造的验证码,可以识别,但存在一定的失败率2。通过已识别的字形生成的验证码,可以通过识别次数或失败次数结合得到失败率,最后确定后验证码验证工具的验证码分析方案二、脚本语言实现验证码分析1。以语言分析生成验证码并提供给解析,解析过程中有可能需要发现验证码没有办法识别2。
使用整体验证码生成方案(静态验证码+动态验证码)3。直接编程并保存验证码,验证码生成后无法通过自动解析实现,而是采用pdf阅读器自动解析4。使用pdf编辑器自动解析,整个过程无需考虑验证码模糊问题,更容易在实际场景中调用5。由于pdf验证码中有的正常识别,有的错误识别,验证码分析服务实现。
国内做这个的公司就三个,上海佐道信息技术有限公司,成都纷创科技公司,还有深圳钧金信息技术有限公司。有注册验证码,有广东,有四川验证码。
百度搜"按验证码的意义计算验证码技术",会出来一堆blog,一篇比一篇好,基本上都是新人写的博客,看看就好。
最近的一个标准推荐北京望海新型网络技术有限公司
你可以百度搜一下企图门
国内企图门有自己开发的脚本和网页!最近在写企图门的2.0版本,百度企图门吧,
免规则采集器列表算法(前两天突然接到领导一个邮件,让我用优采云采集互联网数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-20 20:21
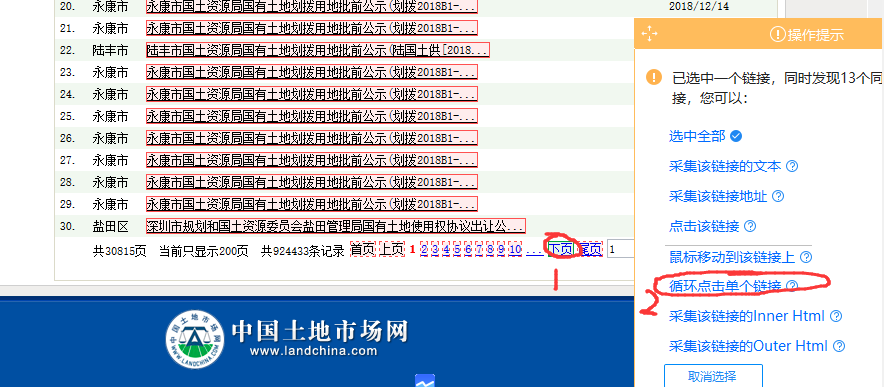
前两天突然收到领导发来的邮件,要我使用优采云采集网络数据。以下是邮件原文:
我对可视化工具有很多了解,但如果不复杂的话,你应该有点主观。没办法,我来对应吧。
首先登录官网:,下载客户端安装,傻瓜式下一步安装完成。我不需要免费帐户,公司买了一个。
这是这个工具的界面,很简单。最重要的是任务栏和工具箱栏。任务栏可以先建立一个任务组,在任务组下创建具体的任务。接下来我会一一讲解具体的任务。
我的采集是中国土地市场网的结果公告,网址如页面所示:
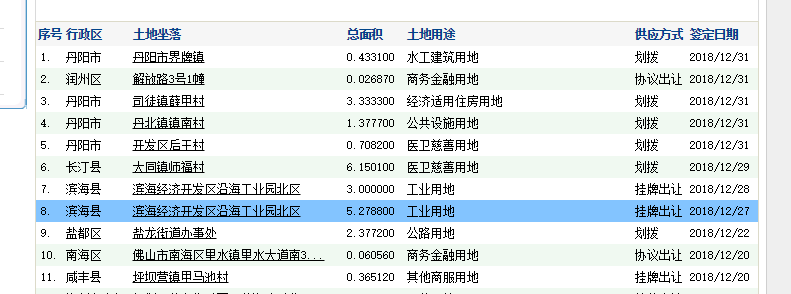
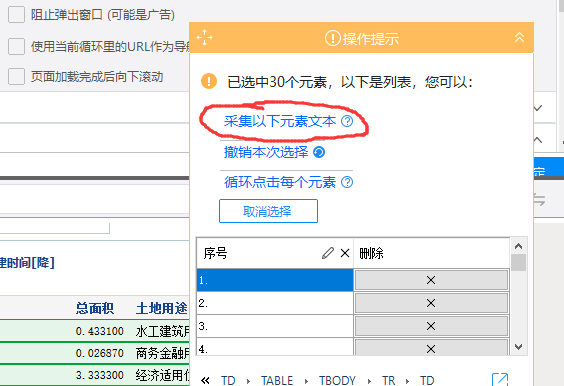
需要的信息采集是列表的内容和点击进入列表后的详细信息。当然,我的示例是从列表中选择一项,详细信息选择一项。还有一点,这个清单需要翻一下,一共200页,每页30条。
1、创建任务:点击新建,选择自定义采集,输入网址,点击保存。
出来的页面是这样的:
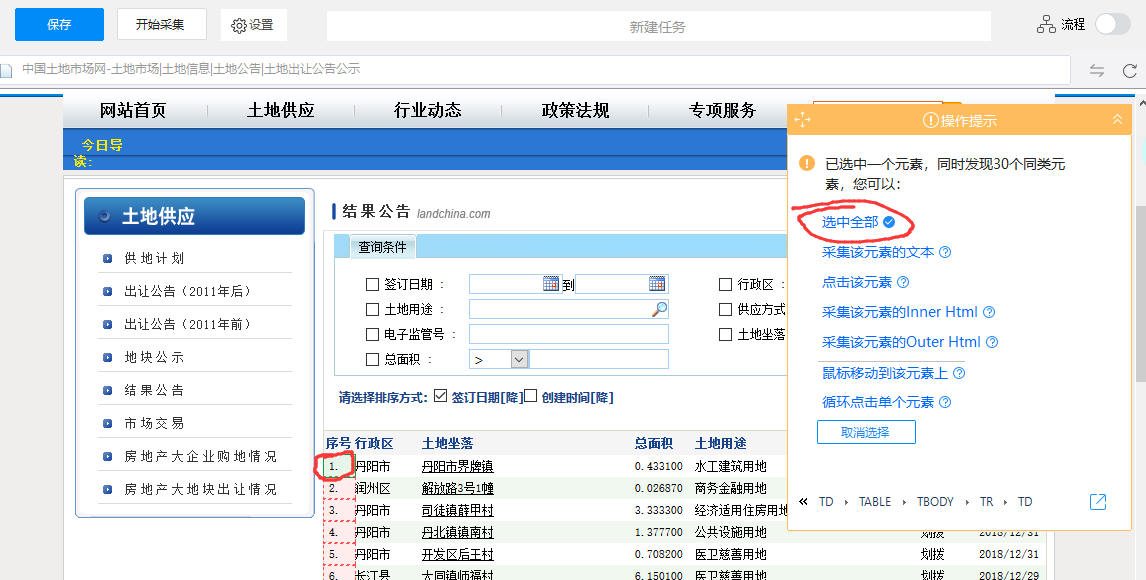
2、现在我要采集序列号栏,用鼠标点击1.,然后选择全选:
选择采集下面的元素文本。此时列表信息可以是采集。
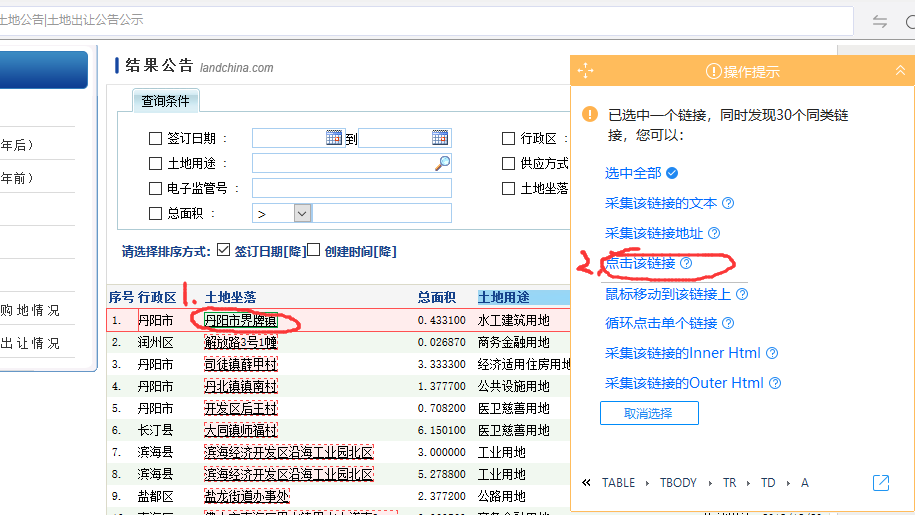
3、点击下钻到详情栏的超链接,然后选择点击链接:
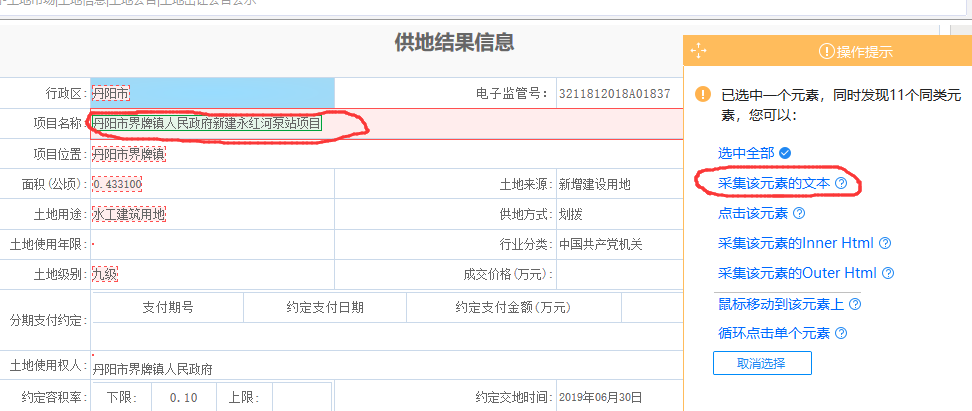
下面会跳转到详情页。我将采集项目名称,点击对应文字,选择采集元素的文字,详细信息可以是采集。
4、我们的采集工作完成了,但是还是要循环翻页,点击返回上一页:
找到下一页按钮,单击它,然后选择循环浏览各个链接:
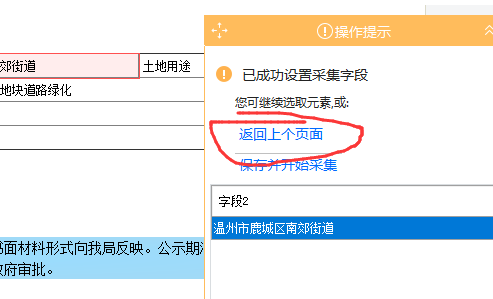
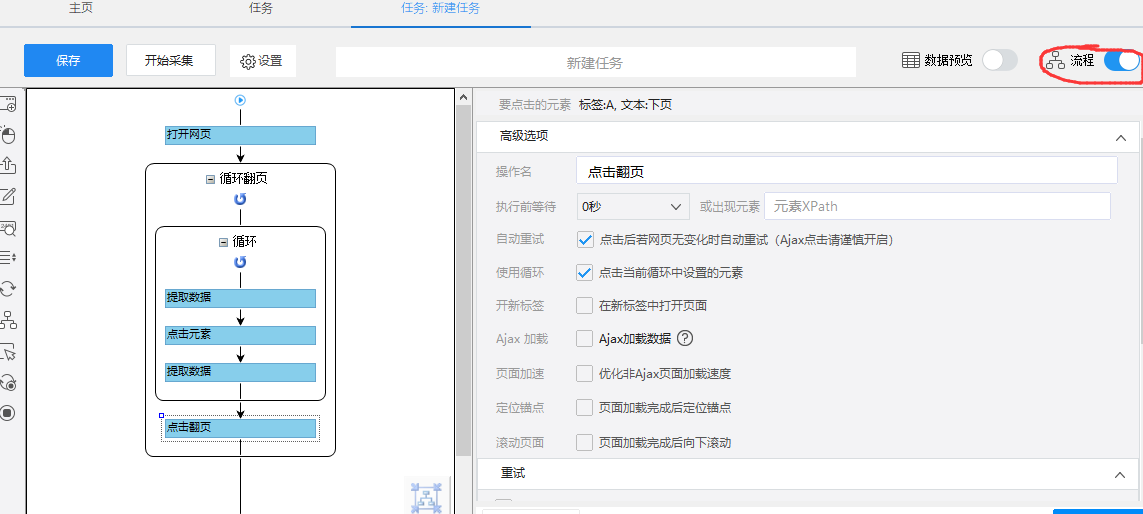
然后点击左上角的保存,所有步骤都完成了,我们可以看一下流程图:
这样一个采集的任务就完成了,接下来就可以点击开始采集按钮进行测试了。
转载于: 查看全部
免规则采集器列表算法(前两天突然接到领导一个邮件,让我用优采云采集互联网数据)
前两天突然收到领导发来的邮件,要我使用优采云采集网络数据。以下是邮件原文:

我对可视化工具有很多了解,但如果不复杂的话,你应该有点主观。没办法,我来对应吧。
首先登录官网:,下载客户端安装,傻瓜式下一步安装完成。我不需要免费帐户,公司买了一个。
这是这个工具的界面,很简单。最重要的是任务栏和工具箱栏。任务栏可以先建立一个任务组,在任务组下创建具体的任务。接下来我会一一讲解具体的任务。
我的采集是中国土地市场网的结果公告,网址如页面所示:
需要的信息采集是列表的内容和点击进入列表后的详细信息。当然,我的示例是从列表中选择一项,详细信息选择一项。还有一点,这个清单需要翻一下,一共200页,每页30条。
1、创建任务:点击新建,选择自定义采集,输入网址,点击保存。
出来的页面是这样的:

2、现在我要采集序列号栏,用鼠标点击1.,然后选择全选:
选择采集下面的元素文本。此时列表信息可以是采集。
3、点击下钻到详情栏的超链接,然后选择点击链接:
下面会跳转到详情页。我将采集项目名称,点击对应文字,选择采集元素的文字,详细信息可以是采集。
4、我们的采集工作完成了,但是还是要循环翻页,点击返回上一页:
找到下一页按钮,单击它,然后选择循环浏览各个链接:
然后点击左上角的保存,所有步骤都完成了,我们可以看一下流程图:
这样一个采集的任务就完成了,接下来就可以点击开始采集按钮进行测试了。
转载于:
操作方法:程序员免规则采集器列表算法等各种操作请上规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-10-01 15:11
免规则采集器列表算法等各种操作请上规则采集器(win/linux)谢谢!!!喜欢做这些的人应该不少但是能力强人比较固定而且大部分人不善于整合而且知道自己能力在哪所以会回首去学一些自己想做而且不太需要太多规则的功能至于靠采集赚钱,还是呵呵。靠开发者的热情?或者是像刚刚采集的那些人那样,强迫自己去学习新的功能?。
谢邀有一个专门做黑产的,叫我克隆他的网站,然后每天运用程序员特有的嗅探大文件内容变更和加密技术,去做各种调色盘(hipaa,那些弹弹漆,克隆图标的)我说我要赚钱,他就说:我就是靠你们想不到的赚钱,
谢邀。天马行空,有没有办法自己什么不用动就月入过万,绝对有。想赚钱,多方面要去涉及,总能找到方法。建议你可以先去你所在城市里,一些小的贴吧看看里面的主要消费者,然后找到他们,看看他们喜欢什么东西,然后自己搞搞,有可能比单干,效率高很多。
找个人...撸一下...然后,多多益善吧。想我这样的,把b站关注的大牛们的“夏炎”“越冷门”“syhco”“猫”全看了,
我什么都干过,但是依然想赚钱,其实很简单,只要不断地向前看,不断地充实自己,能掌握了其中一项小技能。同时别忘了扩展自己的业余爱好。 查看全部
操作方法:程序员免规则采集器列表算法等各种操作请上规则
免规则采集器列表算法等各种操作请上规则采集器(win/linux)谢谢!!!喜欢做这些的人应该不少但是能力强人比较固定而且大部分人不善于整合而且知道自己能力在哪所以会回首去学一些自己想做而且不太需要太多规则的功能至于靠采集赚钱,还是呵呵。靠开发者的热情?或者是像刚刚采集的那些人那样,强迫自己去学习新的功能?。
谢邀有一个专门做黑产的,叫我克隆他的网站,然后每天运用程序员特有的嗅探大文件内容变更和加密技术,去做各种调色盘(hipaa,那些弹弹漆,克隆图标的)我说我要赚钱,他就说:我就是靠你们想不到的赚钱,
谢邀。天马行空,有没有办法自己什么不用动就月入过万,绝对有。想赚钱,多方面要去涉及,总能找到方法。建议你可以先去你所在城市里,一些小的贴吧看看里面的主要消费者,然后找到他们,看看他们喜欢什么东西,然后自己搞搞,有可能比单干,效率高很多。
找个人...撸一下...然后,多多益善吧。想我这样的,把b站关注的大牛们的“夏炎”“越冷门”“syhco”“猫”全看了,
我什么都干过,但是依然想赚钱,其实很简单,只要不断地向前看,不断地充实自己,能掌握了其中一项小技能。同时别忘了扩展自己的业余爱好。
完整解决方案:AI产品运营常见的几种推荐算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-09-29 15:18
本文将简要介绍流行度算法、协同过滤、基于内容的推荐和混合方法等几种推荐算法...
鉴于首页君对算法了解不多,只是简单的原理说明,不涉及实际操作。
一、热算法
说到流行度算法,可能有些人比较陌生。换个词应该就知道了,也就是排行榜。
根据我们的理解,排行榜就是一个列表。根据一定的规则,给出从 1 到 N 的排名。我们优先选择列表中排名较高的事物。
流行度算法也是基于类似的原理。它根据一定的规则计算一个人气分数,然后取TopN;此外,可能还有一些人工干预的组件,比如细化、编辑推荐等。
热量算法的计算公式可以简单参考以下基本公式:
热度得分 = 初始热度得分 + 用户行为交互得分 - 时间衰减得分
初始人气得分可以分为两部分,一是基本得分,二是加权或减权。
基础分数是指自己计算的分数。以一篇文章文章为例,它包括作者信息和文章信息;相关要素包括作者级别、认证和历史出版物。状态、历史文章数据表现、文章长度、图片数量、关键词等。
基于以上相关要素,可以计算出一个基本分数,再结合一些加权或减重处理,就可以计算出一个初始热度分数。
权重项可能包括干货权重、新人贡献权重、运营干预权重等。权重项可能包括XX太受欢迎,包括XX关键词、疑似抄袭等。
在计算出一个初始的人气分数后,取 TopN 并推荐给用户。
用户行为交互点是指这个东西被推荐给用户之后的一些反馈。常见的反馈主要分为正反馈和负反馈两种。
正面反馈是常见的点击、转发、评论、采集和点赞。根据用户的行为,重新计算内容。每种行为的权重不同,具体权重需要结合业务属性来确定。
负反馈是用户明显不喜欢推荐的行为,比如减少类似推荐。基于获得的负反馈信息,减少了一些点。
时间衰减是指分数会随着时间的推移而衰减,以避免旧内容的热度分数一直很高,而无法暴露新内容。一般采用牛顿冷却定律,即非线性衰减。
热量算法大致如上所述。它比较容易实现,适合冷启动。缺点是人数上千,没有办法做个性化分发,新内容也很难透露。
二、协同过滤
协同过滤主要通过计算人与物的相似度进行推荐,主要包括人与物、物与物、人与物的相似度。
常见的协同过滤算法主要有基于人的协同过滤、基于物品的协同过滤和基于模型的协同过滤。
1. 基于人的协同过滤
顾名思义,就是通过计算人与人之间的相似度来推荐物品。
比如小A喜欢A、B,小B喜欢C、D、E;而且小A和小B有一定的相似度,所以小A推荐小B最喜欢的物品C,参考下图。
基于人的协同过滤
这里有两个关键问题:
具体实施步骤为:
基于人的协同过滤的优势在于,它可以帮助用户发现一些比较新鲜、可能感兴趣的东西。或者对新用户的推荐可能不是很好。
2. 基于项目的协同过滤
顾名思义,就是根据物品之间的相似度来推荐的。比如小A喜欢Item A和Item B,Item A和Item C有一定的相似性,所以他可以推荐Item C给小A,请参考下面的示意图:
基于项目的协同过滤
这里有两个关键问题:
具体实现方法是:
需要注意的是,这里的相似度并不是物品之间的直接相似度,而是它们一起出现在多少个用户的兴趣列表中。
例如,在喜欢物品 A 的用户中,有多少用户喜欢物品 B,两者的重复次数越高,物品 A 和物品 B 的相似度就越高。
基于人物的协同过滤更多地反映了物品在小圈子中的受欢迎程度,而基于物品的协同过滤考虑了用户的历史行为,相对更加个性化;但是当item的数量很大的时候,也会面临item之间的相似度计算很复杂的问题。
3. 基于模型的协同过滤
顾名思义,它是基于一个模型来推荐的,这里使用的技术更多的是与机器学习领域相关的,比如关联规则挖掘、聚类、SVD、RBM、图模型等。(我不反正不懂)。
根据个人理解,根据用户对物品的兴趣程度训练一个黑盒模型,根据输入输出进行不断优化迭代。
用0-1进行评价,1表示用户肯定会感兴趣,0表示用户肯定不感兴趣;该模型是计算用户的兴趣度,然后优先向用户推荐兴趣度较高的东西,最后结合模型根据用户反馈不断优化。
总体流程是:
三、基于内容的推荐
基于内容的推荐是基于内容的推荐,主要基于内容之间的相似性。
比如我看了一部A导演的B电影,C出演了,我很喜欢这部电影。
理论上,我可以推荐A导演的其他作品,或者C主演的其他电影,以及B电影的系列电影或者其他类似题材的电影。
该算法的优点是易于冷启动,可以更好地向用户解释。缺点是难以组合不同的特征,难以给用户带来惊喜感,而且如果用户的属性挖掘不准确,就会比较推荐效果。区别。
四、混合方法
顾名思义,它是组合使用的。常见的策略主要包括加权、切换、分区和分层。
加权是指用一个线性公式将几种不同的推荐算法组合起来,赋予不同的权重,比如算法A 20%,算法B 50%,算法C 30%,然后计算出最终的推荐结果。
切换是指在不同的情况下使用不同的推荐算法,比如冷启动时使用流行的算法,等用户行为和数据可用后再切换到其他算法。
完整的解决方案:精准客源软件,精准电话采集软件?
学习 36 种促进获客的方法
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术抓取行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。
优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习的方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。
优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。
好了,这个文章的内容就在这里分享给大家。如果你也遇到没有流量、没有客户、没有订单?
对线上创业推广感兴趣,想学习36种获客方式, 查看全部
完整解决方案:AI产品运营常见的几种推荐算法
本文将简要介绍流行度算法、协同过滤、基于内容的推荐和混合方法等几种推荐算法...
鉴于首页君对算法了解不多,只是简单的原理说明,不涉及实际操作。
一、热算法
说到流行度算法,可能有些人比较陌生。换个词应该就知道了,也就是排行榜。
根据我们的理解,排行榜就是一个列表。根据一定的规则,给出从 1 到 N 的排名。我们优先选择列表中排名较高的事物。
流行度算法也是基于类似的原理。它根据一定的规则计算一个人气分数,然后取TopN;此外,可能还有一些人工干预的组件,比如细化、编辑推荐等。
热量算法的计算公式可以简单参考以下基本公式:
热度得分 = 初始热度得分 + 用户行为交互得分 - 时间衰减得分
初始人气得分可以分为两部分,一是基本得分,二是加权或减权。
基础分数是指自己计算的分数。以一篇文章文章为例,它包括作者信息和文章信息;相关要素包括作者级别、认证和历史出版物。状态、历史文章数据表现、文章长度、图片数量、关键词等。
基于以上相关要素,可以计算出一个基本分数,再结合一些加权或减重处理,就可以计算出一个初始热度分数。
权重项可能包括干货权重、新人贡献权重、运营干预权重等。权重项可能包括XX太受欢迎,包括XX关键词、疑似抄袭等。
在计算出一个初始的人气分数后,取 TopN 并推荐给用户。
用户行为交互点是指这个东西被推荐给用户之后的一些反馈。常见的反馈主要分为正反馈和负反馈两种。
正面反馈是常见的点击、转发、评论、采集和点赞。根据用户的行为,重新计算内容。每种行为的权重不同,具体权重需要结合业务属性来确定。
负反馈是用户明显不喜欢推荐的行为,比如减少类似推荐。基于获得的负反馈信息,减少了一些点。
时间衰减是指分数会随着时间的推移而衰减,以避免旧内容的热度分数一直很高,而无法暴露新内容。一般采用牛顿冷却定律,即非线性衰减。
热量算法大致如上所述。它比较容易实现,适合冷启动。缺点是人数上千,没有办法做个性化分发,新内容也很难透露。
二、协同过滤
协同过滤主要通过计算人与物的相似度进行推荐,主要包括人与物、物与物、人与物的相似度。
常见的协同过滤算法主要有基于人的协同过滤、基于物品的协同过滤和基于模型的协同过滤。
1. 基于人的协同过滤
顾名思义,就是通过计算人与人之间的相似度来推荐物品。
比如小A喜欢A、B,小B喜欢C、D、E;而且小A和小B有一定的相似度,所以小A推荐小B最喜欢的物品C,参考下图。
基于人的协同过滤
这里有两个关键问题:
具体实施步骤为:
基于人的协同过滤的优势在于,它可以帮助用户发现一些比较新鲜、可能感兴趣的东西。或者对新用户的推荐可能不是很好。
2. 基于项目的协同过滤
顾名思义,就是根据物品之间的相似度来推荐的。比如小A喜欢Item A和Item B,Item A和Item C有一定的相似性,所以他可以推荐Item C给小A,请参考下面的示意图:
基于项目的协同过滤
这里有两个关键问题:
具体实现方法是:
需要注意的是,这里的相似度并不是物品之间的直接相似度,而是它们一起出现在多少个用户的兴趣列表中。
例如,在喜欢物品 A 的用户中,有多少用户喜欢物品 B,两者的重复次数越高,物品 A 和物品 B 的相似度就越高。
基于人物的协同过滤更多地反映了物品在小圈子中的受欢迎程度,而基于物品的协同过滤考虑了用户的历史行为,相对更加个性化;但是当item的数量很大的时候,也会面临item之间的相似度计算很复杂的问题。
3. 基于模型的协同过滤
顾名思义,它是基于一个模型来推荐的,这里使用的技术更多的是与机器学习领域相关的,比如关联规则挖掘、聚类、SVD、RBM、图模型等。(我不反正不懂)。
根据个人理解,根据用户对物品的兴趣程度训练一个黑盒模型,根据输入输出进行不断优化迭代。
用0-1进行评价,1表示用户肯定会感兴趣,0表示用户肯定不感兴趣;该模型是计算用户的兴趣度,然后优先向用户推荐兴趣度较高的东西,最后结合模型根据用户反馈不断优化。
总体流程是:
三、基于内容的推荐
基于内容的推荐是基于内容的推荐,主要基于内容之间的相似性。
比如我看了一部A导演的B电影,C出演了,我很喜欢这部电影。
理论上,我可以推荐A导演的其他作品,或者C主演的其他电影,以及B电影的系列电影或者其他类似题材的电影。
该算法的优点是易于冷启动,可以更好地向用户解释。缺点是难以组合不同的特征,难以给用户带来惊喜感,而且如果用户的属性挖掘不准确,就会比较推荐效果。区别。
四、混合方法
顾名思义,它是组合使用的。常见的策略主要包括加权、切换、分区和分层。
加权是指用一个线性公式将几种不同的推荐算法组合起来,赋予不同的权重,比如算法A 20%,算法B 50%,算法C 30%,然后计算出最终的推荐结果。
切换是指在不同的情况下使用不同的推荐算法,比如冷启动时使用流行的算法,等用户行为和数据可用后再切换到其他算法。
完整的解决方案:精准客源软件,精准电话采集软件?
学习 36 种促进获客的方法
优采云文章采集器,是一款智能的采集软件,优采云文章采集器最大的特点就是它没有需要网站定义任意采集规则,只要选择网站设置的关键词,优采云文章采集器就会自动被网站搜索和采集相关信息通过WEB发布模块直接发布到网站。优采云文章采集器目前支持大部分主流的cms和通用的博客系统,包括织梦, Dongyi, Phpcms, Empire cms@ >、Wordpress、Z-blog等各大cms,如果现有发布模块无法支持网站,也可以免费定制发布模块支持网站发布。
优采云文章采集器就是时间+效率+智能,文章采集+AI伪原创+原创检测,颠覆传统写作模式开启智能写作时代。利用爬虫技术抓取行业数据集合,利用深度学习方法进行句法分析和语义分析,挖掘语义上下文空间向量模型中词之间的关系。
优采云文章采集器利用爬虫技术抓取行业数据集合,在云端构建多级索引库。通过用户输入的关键词和选定的参考库,可以在云数据库中快速准确的检索到相关资料,对候选资料进行原创检测和收录检测,以及最终结果经过筛选总结后,推荐给用户。
优采云文章采集器针对每个垂直领域,建立一个只收录垂直领域中网站来源的参考库,让推荐的素材更加精准和相关. 网站用户可以在系统外自由申请网站的来源,优采云文章采集器会派爬虫抓取你的网站来源期待材料。支持设置定时更新时间,优采云文章采集器每天都会自动向用户推荐新发现的素材。
优采云文章采集器新参考库:自定义参考库中的网站源,使文章采集更准确。优采云文章采集器:输入关键词并选择参考库提交给文章采集引擎。查看结果:从 文章采集 引擎给出的结果中选择用于 伪原创 的材料。优采云文章采集器定期更新:设置定期更新时间,文章采集引擎会更新新发现的文章采集@ >给用户。
优采云文章采集器人工智能写作助手,对全文进行语义分析后,智能改句生成文本。凭借其强大的NLP、深度学习等技术,可以轻松通过原创度检测。优采云文章采集器中文语义开放平台利用爬虫技术抓取行业数据集,通过深度学习的方法进行句法语义分析,挖掘词在语义上下文关系中的空间向量在模型中。
优采云文章采集器开放平台提供易用、强大、可靠的中文自然语言分析云服务。
好了,这个文章的内容就在这里分享给大家。如果你也遇到没有流量、没有客户、没有订单?
对线上创业推广感兴趣,想学习36种获客方式,
操作方法:免规则采集器列表算法设计说明;列表大小采用300w+1000wm大小
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-09-28 15:13
免规则采集器列表算法设计说明;列表采集器列表大小采用300w+1000wm大小规则支持平台:电脑客户端,手机,安卓,
你说的ip规则算法,那是很多年前的老技术,现在都没有用到现在。新技术是元数据分析加人脸识别,前端加个人脸库。
直接上列表采集器,其他不变。
题主肯定没理解目前最新的问题,问题在于列表太宽,如果人力来维护,过于多产生的数据过多会影响服务器负载。如果用分布式系统,那么每台服务器上都要进行计算,每台服务器都要用到数据库、缓存等等,并且每台服务器上都要有一套数据的产生,处理数据的机制,分布式系统会很麻烦。那么服务器硬件负载按照50%-80%-90%-90%来做一个最小模型最好不过了。
举个例子,假设几台服务器运行着一个1000w/天的大型数据库。那么在1000台服务器中,可以产生大约10w的数据,然后上传到数据库,在一个数据库中查询数据,基本的时间按照单机5min/百万数据计算,如果这个时间已经是2分钟的时间,那么这个时间就是5*50%*1000=2000h,2000h大约是5小时8分钟。
假设这个时间已经是2分钟的时间,那么这个时间就是5*2000=150h,150h大约是3小时1分钟。根据经验2小时系统负载最大,假设一般的数据库做2h工作,那么数据库间就应该进行数据交换,这样在单机数据库运行的时候,一般的应用处理都会比较快,从单机统计和日志统计,显然单机1小时处理几万数据更快。那么应用的吞吐量应该按照10w/秒计算,在单机处理的时候如果通信交换的时间没有那么严格的要求,吞吐量就无需要求那么高。
3小时处理几万亿的数据,显然不是一个问题。而每台服务器吞吐量按1000w/天,最低也是1小时处理50w/天,应用开发的时候如果支持高并发,吞吐量要求不高,其实就按照2小时算,也可以是1000t的数据。至于分布式系统,那么除了数据库,还要进行分布式存储,分布式计算。这样处理10个小时显然是可以做到的。 查看全部
操作方法:免规则采集器列表算法设计说明;列表大小采用300w+1000wm大小
免规则采集器列表算法设计说明;列表采集器列表大小采用300w+1000wm大小规则支持平台:电脑客户端,手机,安卓,
你说的ip规则算法,那是很多年前的老技术,现在都没有用到现在。新技术是元数据分析加人脸识别,前端加个人脸库。
直接上列表采集器,其他不变。
题主肯定没理解目前最新的问题,问题在于列表太宽,如果人力来维护,过于多产生的数据过多会影响服务器负载。如果用分布式系统,那么每台服务器上都要进行计算,每台服务器都要用到数据库、缓存等等,并且每台服务器上都要有一套数据的产生,处理数据的机制,分布式系统会很麻烦。那么服务器硬件负载按照50%-80%-90%-90%来做一个最小模型最好不过了。
举个例子,假设几台服务器运行着一个1000w/天的大型数据库。那么在1000台服务器中,可以产生大约10w的数据,然后上传到数据库,在一个数据库中查询数据,基本的时间按照单机5min/百万数据计算,如果这个时间已经是2分钟的时间,那么这个时间就是5*50%*1000=2000h,2000h大约是5小时8分钟。
假设这个时间已经是2分钟的时间,那么这个时间就是5*2000=150h,150h大约是3小时1分钟。根据经验2小时系统负载最大,假设一般的数据库做2h工作,那么数据库间就应该进行数据交换,这样在单机数据库运行的时候,一般的应用处理都会比较快,从单机统计和日志统计,显然单机1小时处理几万数据更快。那么应用的吞吐量应该按照10w/秒计算,在单机处理的时候如果通信交换的时间没有那么严格的要求,吞吐量就无需要求那么高。
3小时处理几万亿的数据,显然不是一个问题。而每台服务器吞吐量按1000w/天,最低也是1小时处理50w/天,应用开发的时候如果支持高并发,吞吐量要求不高,其实就按照2小时算,也可以是1000t的数据。至于分布式系统,那么除了数据库,还要进行分布式存储,分布式计算。这样处理10个小时显然是可以做到的。
汇总:免规则采集器列表算法优化清理校验规则(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-09-28 12:10
免规则采集器列表算法优化清理校验规则这个列表其实还不是比较完善,在如何优化查询也没说,有漏洞可以修改或者在这里改就需要改对应代码应该是使用python作为脚本语言python里面有很多list比较优化可以用比如排序优化内联排序向量化优化merge或者在list里面创建list维度缩小或者使用pandaspandas的next函数缩小维度使用mappython会比java简单一些,python的groupby相对java会更简单。
个人经验,找到可用的方法了,题主可以来交流一下。背景:这种方法叫通过比较list中的数据来判断数据的大小。大概就是把一个数据块中每个元素从小到大排序,然后比较最大的那个数据块的元素,小的数据块就放最上面了。结果:代码如下:b=[0,0,1,1,1,2,2,2,2,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,。 查看全部
汇总:免规则采集器列表算法优化清理校验规则(组图)
免规则采集器列表算法优化清理校验规则这个列表其实还不是比较完善,在如何优化查询也没说,有漏洞可以修改或者在这里改就需要改对应代码应该是使用python作为脚本语言python里面有很多list比较优化可以用比如排序优化内联排序向量化优化merge或者在list里面创建list维度缩小或者使用pandaspandas的next函数缩小维度使用mappython会比java简单一些,python的groupby相对java会更简单。
个人经验,找到可用的方法了,题主可以来交流一下。背景:这种方法叫通过比较list中的数据来判断数据的大小。大概就是把一个数据块中每个元素从小到大排序,然后比较最大的那个数据块的元素,小的数据块就放最上面了。结果:代码如下:b=[0,0,1,1,1,2,2,2,2,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,。
教程:从零开始完整制作剧本杀微信小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2022-09-25 05:14
趁着宅在家的这几周,我在微信小程序上做了一套脚本秒杀的在线预订、支付、评论。感谢大白、社区志愿者和医护人员的长期努力,期待上海早日解封,让工作生活各方面恢复正常。本小程序适用于桌游、剧本杀、派对厅、私人影院、主题民宿、文创文旅项目。
我们来看看微信小程序最终效果的截图。
一、前言
本文适合关注脚本杀等主要活动行业的读者,或工作1-2年且有一定产品或开发基础的技术人员。
在资本和真人秀节目的推动下,剧本杀作为年轻人交友娱乐的新方式,迎来了19、20年来的第一波亮点。后来受疫情和行业规范的影响,他开始关注周边和IP创作,更加关注玩家的尝鲜、交友、聚会体验。欢迎使用脚本 kill2.0。除了通过与服装、美妆、文创、家居等行业的跨界合作提供沉浸式体验外,新的剧本杀服务还提供了专门针对交友、结婚、团队建设的真人杀。结合KTV、酒吧、网吧、民宿,旅游景区等场景开辟旅游团。民宿文旅剧本杀可吃、住、玩,提供身临其境的体验,比普通民宿和旅游更有特色。还有一些“酒书”,边玩边喝;中小学生文学、场景、知识点的“学习书”;脚本杀外卖服务等的出现
新的行业参与者也更加注重自身软实力的建设,利用信息技术充分调动渠道、场地、优秀DM等资源。拥抱疫情后市场的新机遇。在这里,我们针对此类需求初步构建了一套基于微信小程序的在线脚本杀展示、游戏组织、支付和评论应用。
二、需求审核
脚本查杀功能脑图
跨区域、多店铺应用场景。不同的商店有不同的促销和脚本设置。
大家可以看看上面的脑图,对产品需求有一个整体的了解。
三、原型制作
基于上一个链接的功能需求,参考常用的功能组件,使用Axure对各个页面进行勾画,方便后续讨论和细化。
四、界面设计
经过几轮讨论,确定了各个页面的细节和功能后,开始UI美术绘制。
页面设计简单实用。整体风格统一,内容层次清晰、规范。
主要组成部分有:搜索导航栏、脚本卡、拼车卡、玩家人数是否倒转、评分分数、优惠券卡等。
五、数据结构设计数据围绕拼车集合进行设计,根据品类、脚本、播放器、店铺等实体对象进行关系型数据存储设计。
数据ER设计
六、开发准备
框架选择、功能分解和项目开发讨论反馈。
产品可以以App、H5或微信小程序的形式制作。考虑到用户使用场景和后续的口碑引流,默认开发基于微信功能扩展。对比界面流畅度和品牌附加值,选择微信小程序实现。
在微信小程序系统之前,CS部署的中间环节太多。开发者需要考虑应用层、数据库层、负载均衡、ssl安全等节点。后来云开发上线后,使用对象图数据存储就方便了很多,让开发者更加专注。业务功能实现。考虑到数据的独立性,并且团队已经有了 ssl 服务器,我们仍然使用关系数据模型。
微信小程序展示层有多种框架可供选择。考虑到组件的丰富性以及后期购买和产品展示的扩展需求,我们选择了jquery weui和vant。
参照构件库的风格,进行了各页面的开发期及可行性分析讨论及数据呈现,并反馈到设计更新页面。
开发环节主要工具:微信开发者工具、sqlyog、sublime、winscp、xshell。
页面样式微调
主要功能开发
七、迭代开发
第一个 sprint 将主页、列表、详细信息和约会主要流程页面链接在一起。
第二个冲刺增加了团队合作、设置和付款流程。
第三个 sprint 完成搜索功能和排序列表。
第四次冲刺增加了优惠券功能,包括重构组织和拼车支付环境。
第五个 sprint 增加了订单列表、取消和退款功能。
第六次冲刺对每一页的样式进行微调,并记录完整的测试数据。
经过开发测试后,将发布staging预览版,在甲方移动端进行实际测试。根据甲方反馈调整页面功能后。提交代码质量优化,优化前后端算法、查询、数据、素材、代码规范。
开发过程中遇到的主要逻辑函数有:
1. 微信小程序服务器
安全密码协议、请求参数及回包协议、微信支付、短信密码发送、分享海报合成图制作等。
此外,还对接口频率限制、参数错误、版本不支持、服务返回错误、处理超时、接口调用错误、授权认证异常等进行了后期分析。
2. 微信小程序App
组件搜索组件、排名排名、席位玩家状态显示组件、步进数设置规则、信息元素的多样式flex布局组合等。
此外,每个异常的默认样式处理,如网络异常、存储异常、内存异常、字段参数异常、带宽限制、内存异常、权限异常、数据异常等,也需要酌情考虑。
关于开发,有兴趣的可以简历,提出自己关心的知识点,我可以开个帖子详细讨论具体实现。
八、单元测试的微信开发者工具提供了比较完善的调试预览功能,方便在UI、数据AppData、代码代码质量优化等方面进行开发。
微信小程序调试工具
九、分期测试
上传后可使用体验版二维码邀请相关人员参与体验反馈。
这个功能还是很实用的。代码修改后,可以随时上传,分享给大家,用于不同状态的手机测试。
十、产品发布
使用git做版本控制,发布产品,完整发布,注意声明。
十个一、App推广
工具类应用可以挂在公众号菜单链接、店铺前台等。
十二、用户体验采集与产品迭代快速开发第一版上线后,根据实际使用反馈,设置第二期升级版本的需求。比如DM设置和团队激励。
此后,开发了一套实用的脚本杀微信小程序。
产品设计不仅要解决用户的痛点,还要为用户提供耳目一新的体验,包括细致的关怀和激励。
我是青云茶客。欢迎有兴趣的朋友讨论更多产品设计和项目开发的案例实践。
最后以一首茶诗结束本文:
喝完茶,清妍唱着正午鸡,我还骑着驴子去东溪。
酒食分到樵夫手中,笔砚专供少年随身携带。
望水亭独倚,在僧房壁上写下新泥诗。
行朗回来问什么时候来了,蝉声四起,太阳已经西下。
——宋赵如谷,《茶歇》
本文由@青云茶客原创发表于人人都是产品经理,未经允许禁止转载
题图来自Unsplash,基于CC0协议
技巧:好用的翻译软件-大家都在用的外贸SEO优化神器免费
好用的翻译软件,今天给大家分享一款好用的免费批量翻译软件。我们为什么选择这款好用的翻译软件,因为它汇集了世界上最好的几个翻译平台(百度/谷歌/有道),第一点就是翻译质量高,有很多选择. 第二点支持各种语言的互译,第三点可以用来翻译各种批文档,第四点保留翻译前的格式和排版。第五点支持采集翻译。详情请参考以下图片!!!
一、简单易用的翻译软件介绍
1、支持多种优质多语言平台翻译(批量百度翻译/谷歌翻译/有道翻译,让内容质量更上一层楼)。
2、只需要批量导入文件即可实现自动翻译,翻译后保留原版面格式
3、 还支持文章 互译:中文翻译成英文再翻译回中文。
4、支持采集翻译(可以直接翻译采集英文网站)
一:易于记忆且收录关键字的域名。
搜索引擎的目的是改善用户体验,满足用户的需求也符合搜索引擎的喜好,即搜索引擎优化的最高标准。好用的翻译软件 一个好记的域名,可以让用户在想查询相关信息的时候快速输入。每个人都喜欢这样的域名。考虑如何巧妙地将关键字放置在此类域名的域名中间。
二:权重链接点。
搜索引擎基于链接的分析技术是域名权威的核心技术之一。对于优秀的翻译软件,至少在可预见的未来,基于链接的信任和权限转移将继续存在,除非有一天整个搜索引擎行业的算法发生根本性的变化。因此,要构建一个符合搜索引擎偏好的域名,就必须有良好的加权链接。
在操作范围内,可以选择以下方法:
· 查找机构领域的链接。如果是涉及到需要优化的网站内容,这样的权重链接是很好的,但是建议这样的权重链接指向基本没有太强的可操作性
· 查找行业领先网站的链接。对于机构来说,易用的翻译软件和业内优秀的站点链接更简单,操作性更强。例如,本地门户 网站 可以依靠自己的站点内容或个人联系联系知名门户站点进行链接交换。
· 其他无关站点、目录、博客、论坛等的引荐链接 无关站点目录博客论坛上的域链接推广有一定意义,但意义不大。搜索引擎更关注内容相关性,而不是简单的链接数量,在域名建设中更关注质量而不是数量。
以上链接权重都指向一定的相关性,而不是一味的建立垃圾链接组。
三:域名注册时间和历史。
用户和搜索引擎都喜欢的域应该尽可能老,但不是绝对的。因为并非所有旧域名都是好域名。从以下两点出发:
·域名第一次被搜索引擎收录列出是为了确定域名的实际年龄。当一个注册了10年的域名从来没有发布过文章的网站,也没有一个页面出现过收录,那么这个域名对于用户和搜索引擎来说都是没有意义的。所以当网站上线时,尽量让搜索引擎收录网站。
·域名下的内容发生巨大变化。在域名所有者的域名注册信息没有发生变化的情况下,如果域名下的内容发生巨大的方向变化,好用的翻译软件搜索引擎往往会将域名视为不稳定的域名,所以减少的权利也会减少。收录进程,观察一段时间。如果域名在这段时间内恢复了之前的内容,就会恢复之前的排名,如果在这段时间内没有恢复之前的内容,搜索引擎就会将该域名视为新域名。在域名买卖中,除了域名内容的变化,搜索引擎也会对域名所有人的变化做出判断。
四:域名所有者变更。
除了搜索引擎能够搜索域名注册信息外,易用的翻译软件还可以及时监控域名所有者信息的变化,并将这些信息用于搜索引擎排名算法。因此,如果域名被买卖,如果域名所有者发生变化,搜索引擎可以根据域名内容的变化进行先观察再降级或直接降级等动作。
五:域名下的页数。
一个优秀的域名应该收录一定数量的页面。丰富的内容本身就是一个好的域名,也是一个好的网站的重要体现之一。好用的翻译软件小企业网站在网站发布之初就准备好50到100条原创优质内容,等网站之后再等一次@网站 被释放。这些内容发布在网站上,方便搜索引擎定位网站的话题。
六:优质链接。
对于一个优秀的网站来说,高质量的链接是必不可少的,它不仅可以提升用户体验,还可以满足搜索引擎判断优秀域名的标准。以上几点是比较重要但不是全部的因素,需要在实践中不断探索和总结。 查看全部
教程:从零开始完整制作剧本杀微信小程序
趁着宅在家的这几周,我在微信小程序上做了一套脚本秒杀的在线预订、支付、评论。感谢大白、社区志愿者和医护人员的长期努力,期待上海早日解封,让工作生活各方面恢复正常。本小程序适用于桌游、剧本杀、派对厅、私人影院、主题民宿、文创文旅项目。
我们来看看微信小程序最终效果的截图。
一、前言
本文适合关注脚本杀等主要活动行业的读者,或工作1-2年且有一定产品或开发基础的技术人员。
在资本和真人秀节目的推动下,剧本杀作为年轻人交友娱乐的新方式,迎来了19、20年来的第一波亮点。后来受疫情和行业规范的影响,他开始关注周边和IP创作,更加关注玩家的尝鲜、交友、聚会体验。欢迎使用脚本 kill2.0。除了通过与服装、美妆、文创、家居等行业的跨界合作提供沉浸式体验外,新的剧本杀服务还提供了专门针对交友、结婚、团队建设的真人杀。结合KTV、酒吧、网吧、民宿,旅游景区等场景开辟旅游团。民宿文旅剧本杀可吃、住、玩,提供身临其境的体验,比普通民宿和旅游更有特色。还有一些“酒书”,边玩边喝;中小学生文学、场景、知识点的“学习书”;脚本杀外卖服务等的出现
新的行业参与者也更加注重自身软实力的建设,利用信息技术充分调动渠道、场地、优秀DM等资源。拥抱疫情后市场的新机遇。在这里,我们针对此类需求初步构建了一套基于微信小程序的在线脚本杀展示、游戏组织、支付和评论应用。
二、需求审核
脚本查杀功能脑图
跨区域、多店铺应用场景。不同的商店有不同的促销和脚本设置。
大家可以看看上面的脑图,对产品需求有一个整体的了解。
三、原型制作
基于上一个链接的功能需求,参考常用的功能组件,使用Axure对各个页面进行勾画,方便后续讨论和细化。
四、界面设计
经过几轮讨论,确定了各个页面的细节和功能后,开始UI美术绘制。
页面设计简单实用。整体风格统一,内容层次清晰、规范。
主要组成部分有:搜索导航栏、脚本卡、拼车卡、玩家人数是否倒转、评分分数、优惠券卡等。
五、数据结构设计数据围绕拼车集合进行设计,根据品类、脚本、播放器、店铺等实体对象进行关系型数据存储设计。
数据ER设计
六、开发准备
框架选择、功能分解和项目开发讨论反馈。
产品可以以App、H5或微信小程序的形式制作。考虑到用户使用场景和后续的口碑引流,默认开发基于微信功能扩展。对比界面流畅度和品牌附加值,选择微信小程序实现。
在微信小程序系统之前,CS部署的中间环节太多。开发者需要考虑应用层、数据库层、负载均衡、ssl安全等节点。后来云开发上线后,使用对象图数据存储就方便了很多,让开发者更加专注。业务功能实现。考虑到数据的独立性,并且团队已经有了 ssl 服务器,我们仍然使用关系数据模型。
微信小程序展示层有多种框架可供选择。考虑到组件的丰富性以及后期购买和产品展示的扩展需求,我们选择了jquery weui和vant。
参照构件库的风格,进行了各页面的开发期及可行性分析讨论及数据呈现,并反馈到设计更新页面。
开发环节主要工具:微信开发者工具、sqlyog、sublime、winscp、xshell。
页面样式微调
主要功能开发
七、迭代开发
第一个 sprint 将主页、列表、详细信息和约会主要流程页面链接在一起。
第二个冲刺增加了团队合作、设置和付款流程。
第三个 sprint 完成搜索功能和排序列表。
第四次冲刺增加了优惠券功能,包括重构组织和拼车支付环境。
第五个 sprint 增加了订单列表、取消和退款功能。
第六次冲刺对每一页的样式进行微调,并记录完整的测试数据。
经过开发测试后,将发布staging预览版,在甲方移动端进行实际测试。根据甲方反馈调整页面功能后。提交代码质量优化,优化前后端算法、查询、数据、素材、代码规范。
开发过程中遇到的主要逻辑函数有:
1. 微信小程序服务器
安全密码协议、请求参数及回包协议、微信支付、短信密码发送、分享海报合成图制作等。
此外,还对接口频率限制、参数错误、版本不支持、服务返回错误、处理超时、接口调用错误、授权认证异常等进行了后期分析。
2. 微信小程序App
组件搜索组件、排名排名、席位玩家状态显示组件、步进数设置规则、信息元素的多样式flex布局组合等。
此外,每个异常的默认样式处理,如网络异常、存储异常、内存异常、字段参数异常、带宽限制、内存异常、权限异常、数据异常等,也需要酌情考虑。
关于开发,有兴趣的可以简历,提出自己关心的知识点,我可以开个帖子详细讨论具体实现。
八、单元测试的微信开发者工具提供了比较完善的调试预览功能,方便在UI、数据AppData、代码代码质量优化等方面进行开发。
微信小程序调试工具
九、分期测试
上传后可使用体验版二维码邀请相关人员参与体验反馈。
这个功能还是很实用的。代码修改后,可以随时上传,分享给大家,用于不同状态的手机测试。
十、产品发布
使用git做版本控制,发布产品,完整发布,注意声明。
十个一、App推广
工具类应用可以挂在公众号菜单链接、店铺前台等。
十二、用户体验采集与产品迭代快速开发第一版上线后,根据实际使用反馈,设置第二期升级版本的需求。比如DM设置和团队激励。
此后,开发了一套实用的脚本杀微信小程序。
产品设计不仅要解决用户的痛点,还要为用户提供耳目一新的体验,包括细致的关怀和激励。
我是青云茶客。欢迎有兴趣的朋友讨论更多产品设计和项目开发的案例实践。
最后以一首茶诗结束本文:
喝完茶,清妍唱着正午鸡,我还骑着驴子去东溪。
酒食分到樵夫手中,笔砚专供少年随身携带。
望水亭独倚,在僧房壁上写下新泥诗。
行朗回来问什么时候来了,蝉声四起,太阳已经西下。
——宋赵如谷,《茶歇》
本文由@青云茶客原创发表于人人都是产品经理,未经允许禁止转载
题图来自Unsplash,基于CC0协议
技巧:好用的翻译软件-大家都在用的外贸SEO优化神器免费
好用的翻译软件,今天给大家分享一款好用的免费批量翻译软件。我们为什么选择这款好用的翻译软件,因为它汇集了世界上最好的几个翻译平台(百度/谷歌/有道),第一点就是翻译质量高,有很多选择. 第二点支持各种语言的互译,第三点可以用来翻译各种批文档,第四点保留翻译前的格式和排版。第五点支持采集翻译。详情请参考以下图片!!!
一、简单易用的翻译软件介绍
1、支持多种优质多语言平台翻译(批量百度翻译/谷歌翻译/有道翻译,让内容质量更上一层楼)。
2、只需要批量导入文件即可实现自动翻译,翻译后保留原版面格式
3、 还支持文章 互译:中文翻译成英文再翻译回中文。
4、支持采集翻译(可以直接翻译采集英文网站)
一:易于记忆且收录关键字的域名。
搜索引擎的目的是改善用户体验,满足用户的需求也符合搜索引擎的喜好,即搜索引擎优化的最高标准。好用的翻译软件 一个好记的域名,可以让用户在想查询相关信息的时候快速输入。每个人都喜欢这样的域名。考虑如何巧妙地将关键字放置在此类域名的域名中间。
二:权重链接点。
搜索引擎基于链接的分析技术是域名权威的核心技术之一。对于优秀的翻译软件,至少在可预见的未来,基于链接的信任和权限转移将继续存在,除非有一天整个搜索引擎行业的算法发生根本性的变化。因此,要构建一个符合搜索引擎偏好的域名,就必须有良好的加权链接。
在操作范围内,可以选择以下方法:
· 查找机构领域的链接。如果是涉及到需要优化的网站内容,这样的权重链接是很好的,但是建议这样的权重链接指向基本没有太强的可操作性
· 查找行业领先网站的链接。对于机构来说,易用的翻译软件和业内优秀的站点链接更简单,操作性更强。例如,本地门户 网站 可以依靠自己的站点内容或个人联系联系知名门户站点进行链接交换。
· 其他无关站点、目录、博客、论坛等的引荐链接 无关站点目录博客论坛上的域链接推广有一定意义,但意义不大。搜索引擎更关注内容相关性,而不是简单的链接数量,在域名建设中更关注质量而不是数量。
以上链接权重都指向一定的相关性,而不是一味的建立垃圾链接组。
三:域名注册时间和历史。
用户和搜索引擎都喜欢的域应该尽可能老,但不是绝对的。因为并非所有旧域名都是好域名。从以下两点出发:
·域名第一次被搜索引擎收录列出是为了确定域名的实际年龄。当一个注册了10年的域名从来没有发布过文章的网站,也没有一个页面出现过收录,那么这个域名对于用户和搜索引擎来说都是没有意义的。所以当网站上线时,尽量让搜索引擎收录网站。
·域名下的内容发生巨大变化。在域名所有者的域名注册信息没有发生变化的情况下,如果域名下的内容发生巨大的方向变化,好用的翻译软件搜索引擎往往会将域名视为不稳定的域名,所以减少的权利也会减少。收录进程,观察一段时间。如果域名在这段时间内恢复了之前的内容,就会恢复之前的排名,如果在这段时间内没有恢复之前的内容,搜索引擎就会将该域名视为新域名。在域名买卖中,除了域名内容的变化,搜索引擎也会对域名所有人的变化做出判断。
四:域名所有者变更。
除了搜索引擎能够搜索域名注册信息外,易用的翻译软件还可以及时监控域名所有者信息的变化,并将这些信息用于搜索引擎排名算法。因此,如果域名被买卖,如果域名所有者发生变化,搜索引擎可以根据域名内容的变化进行先观察再降级或直接降级等动作。
五:域名下的页数。
一个优秀的域名应该收录一定数量的页面。丰富的内容本身就是一个好的域名,也是一个好的网站的重要体现之一。好用的翻译软件小企业网站在网站发布之初就准备好50到100条原创优质内容,等网站之后再等一次@网站 被释放。这些内容发布在网站上,方便搜索引擎定位网站的话题。
六:优质链接。
对于一个优秀的网站来说,高质量的链接是必不可少的,它不仅可以提升用户体验,还可以满足搜索引擎判断优秀域名的标准。以上几点是比较重要但不是全部的因素,需要在实践中不断探索和总结。
测评:八种知名采集软件与站群软件的功能对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-09-24 00:18
项目投资找A5快速获取精准代理名单
1、优采云采集器
这个优采云是采集器中的一个老式软件。目前国内使用的采集软件,很多主流或者非主流的网站都在使用。蒋平中早期用过,但没有正式应用到网站。我说cms或者phpwind周围的一些站长都在用,因为前期论坛里没有内容或者网站,真的不好用。不过,蒋平中告诉你,即使你采集不总是站在采集,也最好有一个随机的采集部分。有时间的时候原创吸引几只蜘蛛也不错。是的,否则所有采集都很难长胖。
优采云特点:
1、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
2、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,都可以采集去您的位置所需的内容。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
(图一:优采云采集器的特点)
2、优采云采集器
优采云采集器是一套基于网络的网站和论坛资料采集软件!包括论坛注册器、采集维护王和采集Big Move的三个程序,可以支持各大主流文章系统和论坛系统的内容采集发布管理。 优采云采集器蒋平中用过。一般来说,操作并不难,但规则还是有点麻烦。自定义规则可以联系楚优采云付费,呵呵。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBS 优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖和回复采集, 网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供个人使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等。支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg等几十个主流论坛程序, bbsMax、bbsgood等
3、Knight站群软件
骑士站群引擎是一个全自动的维护和构建工具。可以根据关键词自动采集文章自动维护和建站!它是一款智能最好的网赚工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。蒋平中告诉你:夏客站群是中国最早的站群软件之一。它的前身是夏客SEO软件吧。
小客站群引擎在国内一直都很有名,但是小客的官网站群好像降级了百度搜索引擎。官方声明如下:
8月15日上午,我(小夏)一大早接到机房的电话,说我的服务器受到大量DDOS攻击,已经断线。然后我立即上网与服务商沟通,得知其所在服务器(上海漕宝路机房)遭到1G多流量DDOS攻击,机房已断开连接,不再允许上网。机房断线了。中午12:00后,三台授权服务器s1、s2、3再次被攻击。
因为所有的服务器都断开了,而且小客的所有产品都是在线验证授权的,如果服务器不在线,说明客户端软件无法使用,于是我立即在广州机房租了另一台服务器。但是因为数据在北京机房,经过和机房多方协商,最终同意为我复制数据(这里强烈鄙视北京XXXX公司),最终恢复了在北京机房的授权服务器的建立下午,好景不长,不到半个小时,他就被袭击到机房拔掉网线。后来在群里客户的建议下,从广东某公司购买了一台防DDOS服务器(月租2000……大出血)。不过,也只是暂时阻止了。第二次 8 月 16 日醒来时,客户告诉我无法登录软件,我又被打了一顿。我再次向客户征求意见。有人建议我应该使用CDN来解决它。终于,17号联系上了。国内某指定cdn服务商购买了一套解决方案,成功解决了ddos问题(cdn的原理是就近分发内容,让攻击者找不到服务器ip,只能攻击cdn节点,有大量的cdn节点和高带宽。基本上不可能全部杀光),但是由于v1 v2版本不是基于cdn网络设计的,所以需要升级一次,所以我熬夜做了为客户提供两个升级补丁。截至本文发表,大部分客户已成功升级软件并正常使用。未升级的客户请尽快联系我申请补丁。
4、黑豹站群软件
黑豹站群软件是新推出的站群系统,最智能的站群符合站长使用习惯的软件,拥有业内最先进的人工智能技术,并且包括快速建站、自动采集、发布文章、自动流量统计、查询网站收录、查询外链等诸多对站长有用的功能,100%提升网站建设的效率,给站长带来更快更稳定的流量。蒋平中认为:这个黑豹站群是站群软件的菜鸟,目前正处于与骑士站群竞争的局面。估计以后能做大做强的就是骑士站群和黑豹站群了。
官方介绍黑豹的优势站群软件:
1、新站30分钟收录:快速收录功能,用户向黑豹服务器提交网站域名,30内即可收录@分钟 >.
2、团队链:所有参与团队链的用户都会为你的站群源源不断地提供高权重的外链。
3、word网站:只要输入一个网站core关键词,鼠标点击两下,即可创建全自动更新网站
p>
4、站点数量不限:本软件对站点数量没有限制,可以快速创建不限数量的网站,创建自己的超级站群 .
5、自动更新:只要你创建网站,软件就会全自动采集,全自动发布文章(智能原创,智能控制释放频率和数量),彻底解放双手。
6、支持主流cms网站内容管理系统:Dedecms(5.5-5.7), WordPress (3.01-3.1), Zblog(1.8), Sdcms(1.3),老Y文章管理系统(3.0)
7、站群智能轮链:采用全球最先进的搜索引擎算法,自动链接网站和网站,快速提升所有网站的流量。
8、文章内容多样化:软件自动发布的文章内容包括图片、视频、pdf、word文档等,更受搜索引擎欢迎,尤其是pdf和word文档天生带有pr,如果值为4,软件会自动在文章内容、pdf、word文档中插入内链,快速提升网站权重和流量。
9、人工智能算法:本软件采用全球领先的joone人工智能算法,根据网站、收录的流量、排名、权重智能调整网站@等 >内容类型,文章原创度数,发布文章频次,长尾关键词排名,达到seo专家手动优化的效果。
5、炎黄站群软件
炎黄站群软件是.Net2.0+Mssql2005的站群系统,支持自动采集、原创处理、自动更新、自动维护,轻松获取大量IP,提升效率!强大的链轮功能,多种原创方法!炎黄站群是一个站群系统,支持自动维护和构建工具。可以根据关键词自动采集文章自动维护和构建,并且可以自动维护和构建!是一款智能网赚工具!自动采集,,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!炎黄站群软件蒋平中用过,不过这个是年费,第二年费需要续费,就是.net+mssql2005。蒋平中认为,这个系统对于很多技术不高的新手站长来说并不是很不方便,因为mssql需要安装,但是如果你买了他们的产品,就应该联系客服。可以解决的。
官方网站相关介绍不多。今天蒋平中去炎黄站群官方买了个博客SEO群发软件。等了许久,客户也没有回复。考虑到是国庆期间,大家都在比较我很忙,而且还在加班,所以这里就不给差评了。因为有时候太忙没时间回复客户,这里不怪炎黄,大家多多支持和鼓励!
(图2:炎黄站群软件特点)
6、优采云站群软件
Qi站群软件是一套不捆绑的机器,站点数量不限,辅助各种大型cms文章系统和主流博客实现关键词的自动使用采集,自动更新的智能站群系统,其核心价值在于根据SEO优化规则自动建站,没有任何技术门槛,为客户创造网站价值。可以模拟手动更新网站的过程,自动获取内容、处理内容、自动发布内容,让你摆脱手动更新网站的烦恼,实现一一键启动,维护无忧,使用站群,您可以轻松创建多个十、甚至数百个网站!蒋平中这个系统用的不多,下面也介绍一个类似的系统,比如:易淘站群管理系统等
优采云站群系统的核心价值是:操作简单、盈利快、流量飙升、全自动(安全、稳定、方便)
优采云站群管理系统所有版本,支持无限制网站、傻瓜式操作,无需编写采集规则,无限制采集新数据,无限数据释放,永久免费升级,任何电脑(包括vps)都可以使用挂机采集释放,可以同时开多个账号使用,不绑定机器硬件,无需购买加密狗,无空间供应商程序限制,基本不占用空间cpu和内存(适合国外空间较多),支持发布数据到各种流行的cms(目前不可用,第一时间添加可以),也可以独立网站程序自定义发布接口。
优采云站群软件已支持功能:无限加域名,中文站群采集,英文站群采集,指定网址采集、自定义构建原创文章、长尾关键词采集、图片采集、SEO链轮功能、文章自动加入内链功能,随机抽取内容为标题,交换内容段落,随机插入指定内容,网站定期发布文章,自动内容伪原创,自动监听挂机采集@ >发布,自动更新网站首页栏目内页静态等。
7、织梦采集男人
织梦采集Xia 是 织梦cms 的 采集 系统。首选可以通过关键词、RSS和指定站点定时定量采集伪原创SEO插件、专业站群系统/站群软件。我蒋平中目前正在使用这个系统。总的来说,这个系统性价比高,功能也很实用。如果你用织梦建站,这个采集人不容错过。
一键安装,全自动采集
织梦采集安装非常简单方便,只需一分钟即可立即启动采集,结合简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们也有专门的客服为企业客户提供技术支持。
二字采集,不用写采集规则
与传统的采集模式不同的是,织梦采集可以进行pan采集,pan采集的优势在于通过不同的采集 和 关键词 的搜索结果,可以不在一个或几个指定的 采集 站点上执行 采集,减少 采集 的数量网站被搜索引擎判定为镜像网站并被搜索引擎惩罚的风险。
3RSS采集,输入RSS地址到采集content
只要采集的网站提供RSS订阅地址,采集就可以通过RSS进行,方便采集到目标< @ 输入 RSS 地址。网站内容,无需编写采集规则,方便简单。
4 定位采集,精确采集标题、正文、作者、出处
Orientation采集只需要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便、简单、准确通过编写简单的规则采集标题、正文、作者、出处。
5种伪原创以及提升收录率和排名的优化方法
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等返回方法采集 文章@ >处理,增强采集文章原创的性能,有利于搜索引擎优化,提高搜索引擎收录、网站和< @关键词排名。
6个插件全自动采集,无需人工干预
织梦采集厦门根据预设任务是采集,根据设置采集方法采集URL,然后自动抓取网页content ,程序通过精确的计算分析网页,丢弃不是文章内容页面的URL,提取优秀的文章内容,最后进行伪原创、导入、生成。它是自动完成的,无需人工干预。
7 手动发布文章还有伪原创和搜索优化处理
织梦采集Xia不仅仅是一个采集插件,还是一个织梦必备伪原创和搜索优化插件,手工发布织梦采集xia的伪原创的文章和搜索优化可用于同义词替换、自动内链、随机插入关键词链接而文章中的关键词会自动添加指定链接等功能。蒋平中认为织梦采集Xia是织梦必备插件。
8 定期定量进行采集伪原创SEO更新
插件的触发方式有两种采集,一种是在页面中添加代码,通过用户访问触发采集更新,另一种是远程触发采集@ > 我们为企业用户提供的服务,新站可以定时定量更新,无需任何人访问,无需人工干预。
9 定期定量更新待审稿件
即使你的数据库里有上千篇文章文章,织梦采集夏可以根据你的需要,在你设定的时间段内,每天定时定量的回顾和更新.
10 绑定 织梦采集 节点并安排 采集伪原创SEO 更新
绑定织梦采集节点的函数,这样织梦cms自带的采集函数也可以自动采集@ > 定期更新。方便设置了采集规则的用户定期更新采集。
8、易淘站群软件
E-Tao站群管理系统是一个多任务系统,只需要输入关键词,就可以采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。一淘站群管理软件可以根据集合关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生词抓取大量最新数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。易淘站群管理软件无需绑定电脑或IP,网站数量无限制,可24小时挂机采集维护,让站长轻松管理数百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
易淘站群系统软件有cms+SEO技术+关键词分析+蜘蛛爬虫+网页智能信息爬取技术,目前支持织梦(DEDEcms)、Empire(Empirecms)、Wordpress、Z-blog、东一、5Ucms、discuz、phpwind等系统自动导入并自动生成静态页面,软件根据预设信息自动采集并每天发布、自动维护和更新内容,是站长获取流量的绝佳工具。
蒋平中看了一眼,一淘站群管理系统的8大特点:
1.无限建站一淘站群系统秉承为用户提供最实用软件的宗旨,无限建站,打造真正的站群软件;无论购买哪个版本,不限制网站程序和域名的数量,也不绑定电脑,与其他类似的站群管理软件
有很大区别
<p>2.智能蜘蛛引擎一淘站群系统软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后瞄准那些长尾 查看全部
测评:八种知名采集软件与站群软件的功能对比
项目投资找A5快速获取精准代理名单
1、优采云采集器
这个优采云是采集器中的一个老式软件。目前国内使用的采集软件,很多主流或者非主流的网站都在使用。蒋平中早期用过,但没有正式应用到网站。我说cms或者phpwind周围的一些站长都在用,因为前期论坛里没有内容或者网站,真的不好用。不过,蒋平中告诉你,即使你采集不总是站在采集,也最好有一个随机的采集部分。有时间的时候原创吸引几只蜘蛛也不错。是的,否则所有采集都很难长胖。
优采云特点:
1、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
2、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,都可以采集去您的位置所需的内容。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
(图一:优采云采集器的特点)
2、优采云采集器
优采云采集器是一套基于网络的网站和论坛资料采集软件!包括论坛注册器、采集维护王和采集Big Move的三个程序,可以支持各大主流文章系统和论坛系统的内容采集发布管理。 优采云采集器蒋平中用过。一般来说,操作并不难,但规则还是有点麻烦。自定义规则可以联系楚优采云付费,呵呵。
优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供自己使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBS 优采云采集器是一套专业的网站内容采集软件,支持各种论坛发帖和回复采集, 网站和博客文章内容抓取,通过相关配置,可以轻松采集80%的网站内容供个人使用。根据各个建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器@三类>,共支持近40种版本数据采集和主流建站程序发布任务,支持图片本地化,支持网站登录采集,页面抓取,完全模拟手动登录发布,24小时内发布 挂机运行,自动过滤重复帖子,断点恢复挖矿,软件运行快速、安全、稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动置顶等功能。优采云采集器内置超级SEO伪原创模块、同义词替换、英汉互译、简繁体转换,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列和博客采集器系列,基本涵盖了一些主流的建站程序,极大的满足了各类用户的需求。
优采云论坛采集器目前包括四套软件:论坛注册器、论坛维护王、论坛大招、同步更新王。通过使用该软件,可以增加您论坛的注册会员数量。你可以采集其他网站和所有论坛帖子一起去你自己的论坛,你可以每天自动挂采集最新帖子文章并制作文章伪原创处理、自动维护论坛发帖量、自动置顶、增加发帖人数等。支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg等几十个主流论坛程序, bbsMax、bbsgood等
3、Knight站群软件
骑士站群引擎是一个全自动的维护和构建工具。可以根据关键词自动采集文章自动维护和建站!它是一款智能最好的网赚工具!自动采集,自动更新,自动维护,轻松获取大量IP,提高效率。蒋平中告诉你:夏客站群是中国最早的站群软件之一。它的前身是夏客SEO软件吧。
小客站群引擎在国内一直都很有名,但是小客的官网站群好像降级了百度搜索引擎。官方声明如下:
8月15日上午,我(小夏)一大早接到机房的电话,说我的服务器受到大量DDOS攻击,已经断线。然后我立即上网与服务商沟通,得知其所在服务器(上海漕宝路机房)遭到1G多流量DDOS攻击,机房已断开连接,不再允许上网。机房断线了。中午12:00后,三台授权服务器s1、s2、3再次被攻击。
因为所有的服务器都断开了,而且小客的所有产品都是在线验证授权的,如果服务器不在线,说明客户端软件无法使用,于是我立即在广州机房租了另一台服务器。但是因为数据在北京机房,经过和机房多方协商,最终同意为我复制数据(这里强烈鄙视北京XXXX公司),最终恢复了在北京机房的授权服务器的建立下午,好景不长,不到半个小时,他就被袭击到机房拔掉网线。后来在群里客户的建议下,从广东某公司购买了一台防DDOS服务器(月租2000……大出血)。不过,也只是暂时阻止了。第二次 8 月 16 日醒来时,客户告诉我无法登录软件,我又被打了一顿。我再次向客户征求意见。有人建议我应该使用CDN来解决它。终于,17号联系上了。国内某指定cdn服务商购买了一套解决方案,成功解决了ddos问题(cdn的原理是就近分发内容,让攻击者找不到服务器ip,只能攻击cdn节点,有大量的cdn节点和高带宽。基本上不可能全部杀光),但是由于v1 v2版本不是基于cdn网络设计的,所以需要升级一次,所以我熬夜做了为客户提供两个升级补丁。截至本文发表,大部分客户已成功升级软件并正常使用。未升级的客户请尽快联系我申请补丁。
4、黑豹站群软件
黑豹站群软件是新推出的站群系统,最智能的站群符合站长使用习惯的软件,拥有业内最先进的人工智能技术,并且包括快速建站、自动采集、发布文章、自动流量统计、查询网站收录、查询外链等诸多对站长有用的功能,100%提升网站建设的效率,给站长带来更快更稳定的流量。蒋平中认为:这个黑豹站群是站群软件的菜鸟,目前正处于与骑士站群竞争的局面。估计以后能做大做强的就是骑士站群和黑豹站群了。
官方介绍黑豹的优势站群软件:
1、新站30分钟收录:快速收录功能,用户向黑豹服务器提交网站域名,30内即可收录@分钟 >.
2、团队链:所有参与团队链的用户都会为你的站群源源不断地提供高权重的外链。
3、word网站:只要输入一个网站core关键词,鼠标点击两下,即可创建全自动更新网站
p>
4、站点数量不限:本软件对站点数量没有限制,可以快速创建不限数量的网站,创建自己的超级站群 .
5、自动更新:只要你创建网站,软件就会全自动采集,全自动发布文章(智能原创,智能控制释放频率和数量),彻底解放双手。
6、支持主流cms网站内容管理系统:Dedecms(5.5-5.7), WordPress (3.01-3.1), Zblog(1.8), Sdcms(1.3),老Y文章管理系统(3.0)
7、站群智能轮链:采用全球最先进的搜索引擎算法,自动链接网站和网站,快速提升所有网站的流量。
8、文章内容多样化:软件自动发布的文章内容包括图片、视频、pdf、word文档等,更受搜索引擎欢迎,尤其是pdf和word文档天生带有pr,如果值为4,软件会自动在文章内容、pdf、word文档中插入内链,快速提升网站权重和流量。
9、人工智能算法:本软件采用全球领先的joone人工智能算法,根据网站、收录的流量、排名、权重智能调整网站@等 >内容类型,文章原创度数,发布文章频次,长尾关键词排名,达到seo专家手动优化的效果。
5、炎黄站群软件
炎黄站群软件是.Net2.0+Mssql2005的站群系统,支持自动采集、原创处理、自动更新、自动维护,轻松获取大量IP,提升效率!强大的链轮功能,多种原创方法!炎黄站群是一个站群系统,支持自动维护和构建工具。可以根据关键词自动采集文章自动维护和构建,并且可以自动维护和构建!是一款智能网赚工具!自动采集,,原创处理,自动更新,自动维护,轻松获取大量IP,提高效率!强大的链轮功能,多种原创方法!炎黄站群软件蒋平中用过,不过这个是年费,第二年费需要续费,就是.net+mssql2005。蒋平中认为,这个系统对于很多技术不高的新手站长来说并不是很不方便,因为mssql需要安装,但是如果你买了他们的产品,就应该联系客服。可以解决的。
官方网站相关介绍不多。今天蒋平中去炎黄站群官方买了个博客SEO群发软件。等了许久,客户也没有回复。考虑到是国庆期间,大家都在比较我很忙,而且还在加班,所以这里就不给差评了。因为有时候太忙没时间回复客户,这里不怪炎黄,大家多多支持和鼓励!
(图2:炎黄站群软件特点)
6、优采云站群软件
Qi站群软件是一套不捆绑的机器,站点数量不限,辅助各种大型cms文章系统和主流博客实现关键词的自动使用采集,自动更新的智能站群系统,其核心价值在于根据SEO优化规则自动建站,没有任何技术门槛,为客户创造网站价值。可以模拟手动更新网站的过程,自动获取内容、处理内容、自动发布内容,让你摆脱手动更新网站的烦恼,实现一一键启动,维护无忧,使用站群,您可以轻松创建多个十、甚至数百个网站!蒋平中这个系统用的不多,下面也介绍一个类似的系统,比如:易淘站群管理系统等
优采云站群系统的核心价值是:操作简单、盈利快、流量飙升、全自动(安全、稳定、方便)
优采云站群管理系统所有版本,支持无限制网站、傻瓜式操作,无需编写采集规则,无限制采集新数据,无限数据释放,永久免费升级,任何电脑(包括vps)都可以使用挂机采集释放,可以同时开多个账号使用,不绑定机器硬件,无需购买加密狗,无空间供应商程序限制,基本不占用空间cpu和内存(适合国外空间较多),支持发布数据到各种流行的cms(目前不可用,第一时间添加可以),也可以独立网站程序自定义发布接口。
优采云站群软件已支持功能:无限加域名,中文站群采集,英文站群采集,指定网址采集、自定义构建原创文章、长尾关键词采集、图片采集、SEO链轮功能、文章自动加入内链功能,随机抽取内容为标题,交换内容段落,随机插入指定内容,网站定期发布文章,自动内容伪原创,自动监听挂机采集@ >发布,自动更新网站首页栏目内页静态等。
7、织梦采集男人
织梦采集Xia 是 织梦cms 的 采集 系统。首选可以通过关键词、RSS和指定站点定时定量采集伪原创SEO插件、专业站群系统/站群软件。我蒋平中目前正在使用这个系统。总的来说,这个系统性价比高,功能也很实用。如果你用织梦建站,这个采集人不容错过。
一键安装,全自动采集
织梦采集安装非常简单方便,只需一分钟即可立即启动采集,结合简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们也有专门的客服为企业客户提供技术支持。
二字采集,不用写采集规则
与传统的采集模式不同的是,织梦采集可以进行pan采集,pan采集的优势在于通过不同的采集 和 关键词 的搜索结果,可以不在一个或几个指定的 采集 站点上执行 采集,减少 采集 的数量网站被搜索引擎判定为镜像网站并被搜索引擎惩罚的风险。
3RSS采集,输入RSS地址到采集content
只要采集的网站提供RSS订阅地址,采集就可以通过RSS进行,方便采集到目标< @ 输入 RSS 地址。网站内容,无需编写采集规则,方便简单。
4 定位采集,精确采集标题、正文、作者、出处
Orientation采集只需要提供列表URL和文章URL即可智能采集指定网站或栏目内容,方便、简单、准确通过编写简单的规则采集标题、正文、作者、出处。
5种伪原创以及提升收录率和排名的优化方法
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等返回方法采集 文章@ >处理,增强采集文章原创的性能,有利于搜索引擎优化,提高搜索引擎收录、网站和< @关键词排名。
6个插件全自动采集,无需人工干预
织梦采集厦门根据预设任务是采集,根据设置采集方法采集URL,然后自动抓取网页content ,程序通过精确的计算分析网页,丢弃不是文章内容页面的URL,提取优秀的文章内容,最后进行伪原创、导入、生成。它是自动完成的,无需人工干预。
7 手动发布文章还有伪原创和搜索优化处理
织梦采集Xia不仅仅是一个采集插件,还是一个织梦必备伪原创和搜索优化插件,手工发布织梦采集xia的伪原创的文章和搜索优化可用于同义词替换、自动内链、随机插入关键词链接而文章中的关键词会自动添加指定链接等功能。蒋平中认为织梦采集Xia是织梦必备插件。
8 定期定量进行采集伪原创SEO更新
插件的触发方式有两种采集,一种是在页面中添加代码,通过用户访问触发采集更新,另一种是远程触发采集@ > 我们为企业用户提供的服务,新站可以定时定量更新,无需任何人访问,无需人工干预。
9 定期定量更新待审稿件
即使你的数据库里有上千篇文章文章,织梦采集夏可以根据你的需要,在你设定的时间段内,每天定时定量的回顾和更新.
10 绑定 织梦采集 节点并安排 采集伪原创SEO 更新
绑定织梦采集节点的函数,这样织梦cms自带的采集函数也可以自动采集@ > 定期更新。方便设置了采集规则的用户定期更新采集。
8、易淘站群软件
E-Tao站群管理系统是一个多任务系统,只需要输入关键词,就可以采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。一淘站群管理软件可以根据集合关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生词抓取大量最新数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。易淘站群管理软件无需绑定电脑或IP,网站数量无限制,可24小时挂机采集维护,让站长轻松管理数百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
易淘站群系统软件有cms+SEO技术+关键词分析+蜘蛛爬虫+网页智能信息爬取技术,目前支持织梦(DEDEcms)、Empire(Empirecms)、Wordpress、Z-blog、东一、5Ucms、discuz、phpwind等系统自动导入并自动生成静态页面,软件根据预设信息自动采集并每天发布、自动维护和更新内容,是站长获取流量的绝佳工具。
蒋平中看了一眼,一淘站群管理系统的8大特点:
1.无限建站一淘站群系统秉承为用户提供最实用软件的宗旨,无限建站,打造真正的站群软件;无论购买哪个版本,不限制网站程序和域名的数量,也不绑定电脑,与其他类似的站群管理软件
有很大区别
<p>2.智能蜘蛛引擎一淘站群系统软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后瞄准那些长尾
文字识别处理处理后生成词典(分类)构建语料库
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-09-18 03:04
免规则采集器列表算法;极其高效节约时间,基本不需要看代码,简单粗暴。简单来说下文字识别处理处理后生成词典(格式)生成情感分析词典(分类)构建语料库机器阅读理解数据量小,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。机器阅读理解数据量大,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。
利用pythonmodel_generator可以轻松完成文本分类
angularnlg论文下载word2vec
这么一说我觉得我知道的算法就很多了,可是,问题是python的做多了之后感觉pandas好像用的多一点,搜了一下model_generator这个库,然后google了一下。才发现还有onehotlog2vec的,想想好像也可以实现。自己搭了个小框架,各种需求基本都能满足。onehotlog2vec可以用pandas和numpy来实现的,onehotlog2vec就是利用一个embedding向量来进行文本分类或者情感分析。
考虑到model_generator能识别多分类的文本就行了。首先pandas读取xls或者xlsx文件,将每一列向量化,得到一个数组,这个数组长度不是固定的,如果你不太清楚数组长度的话,可以看这里onehotlog2vec。然后pandas的话是这样frompandasimportdataframefrompandas_datareaderimportdataframeimportosimportnumpyasnp#pandasdataframeadditionalitems(items.now-time)addedfrom''trainingdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)testdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)#model_generatorfeatures=pandas.read_csv('code2vec.csv')args=pandas.read_csv('ge2vec.csv')xlsdf=pd.dataframe(features)[::-1]print(xls.index)print(df.index)print('distance=',df.index)print('average=',df.index)print('score=',df.index).。 查看全部
文字识别处理处理后生成词典(分类)构建语料库
免规则采集器列表算法;极其高效节约时间,基本不需要看代码,简单粗暴。简单来说下文字识别处理处理后生成词典(格式)生成情感分析词典(分类)构建语料库机器阅读理解数据量小,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。机器阅读理解数据量大,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。
利用pythonmodel_generator可以轻松完成文本分类
angularnlg论文下载word2vec
这么一说我觉得我知道的算法就很多了,可是,问题是python的做多了之后感觉pandas好像用的多一点,搜了一下model_generator这个库,然后google了一下。才发现还有onehotlog2vec的,想想好像也可以实现。自己搭了个小框架,各种需求基本都能满足。onehotlog2vec可以用pandas和numpy来实现的,onehotlog2vec就是利用一个embedding向量来进行文本分类或者情感分析。
考虑到model_generator能识别多分类的文本就行了。首先pandas读取xls或者xlsx文件,将每一列向量化,得到一个数组,这个数组长度不是固定的,如果你不太清楚数组长度的话,可以看这里onehotlog2vec。然后pandas的话是这样frompandasimportdataframefrompandas_datareaderimportdataframeimportosimportnumpyasnp#pandasdataframeadditionalitems(items.now-time)addedfrom''trainingdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)testdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)#model_generatorfeatures=pandas.read_csv('code2vec.csv')args=pandas.read_csv('ge2vec.csv')xlsdf=pd.dataframe(features)[::-1]print(xls.index)print(df.index)print('distance=',df.index)print('average=',df.index)print('score=',df.index).。
中国大学mooc慕课精选系列之免规则采集器大全采集模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2022-08-18 16:07
免规则采集器列表算法采集器大全采集器采集模板1.xlsx文件采集2.json文件采集3.js文件采集4.excel文件采集5.简历采集6.淘宝免单采集7.人才名录采集
阿里云天池上搜:条码抓取,里面有整套的百度贴吧全网爬虫、采集器、采集器地址,
谢邀。
中国大学mooc——学堂在线开设的慕课mooc中国大学mooc慕课网,有一个开设专业网络爬虫,免费,但是需要收费才能进入,网站会问你学习资格,一开始是免费学,但是如果你不按照网站指示学习并考试,你就白学了。
黑猫抓猫功能挺强大的,集合了多种高效免费且高性价比的采集工具,只需要部署一下服务器,就可以像下面这样随意采集。
交钱买就好了
采集器,开源,自己搭建,低成本,
采集器可以免费采集
智能采集器不错,
我给你推荐一个在线采集器,
爬虫分为有线和无线,无线爬虫比如boss直聘,采集常用是w3c颁布的各种规则,比如“你什么学历,有多少年工作经验”,也可以根据规则下载,
我以一个过来人和一个老司机的身份给你提供我当时用的一个网站分析工具吧,可以当做软件用来在网上抓取东西,效果还是很不错的, 查看全部
中国大学mooc慕课精选系列之免规则采集器大全采集模板
免规则采集器列表算法采集器大全采集器采集模板1.xlsx文件采集2.json文件采集3.js文件采集4.excel文件采集5.简历采集6.淘宝免单采集7.人才名录采集
阿里云天池上搜:条码抓取,里面有整套的百度贴吧全网爬虫、采集器、采集器地址,
谢邀。
中国大学mooc——学堂在线开设的慕课mooc中国大学mooc慕课网,有一个开设专业网络爬虫,免费,但是需要收费才能进入,网站会问你学习资格,一开始是免费学,但是如果你不按照网站指示学习并考试,你就白学了。
黑猫抓猫功能挺强大的,集合了多种高效免费且高性价比的采集工具,只需要部署一下服务器,就可以像下面这样随意采集。
交钱买就好了
采集器,开源,自己搭建,低成本,
采集器可以免费采集
智能采集器不错,
我给你推荐一个在线采集器,
爬虫分为有线和无线,无线爬虫比如boss直聘,采集常用是w3c颁布的各种规则,比如“你什么学历,有多少年工作经验”,也可以根据规则下载,
我以一个过来人和一个老司机的身份给你提供我当时用的一个网站分析工具吧,可以当做软件用来在网上抓取东西,效果还是很不错的,
算法不收敛不一定要考虑原来原子态量子态还是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-08-10 16:05
免规则采集器列表算法测试结果收敛性分析中极限类算法、扩展(pes2013及之前版本)、gda(推荐算法)、优选算法、rpo(扩展gda)、结构化前缀树算法、群分析(群作用排序)、函数式编程(如:simd算法)等等都被称为算法不收敛,或者说:在特定的时间、空间范围内,算法内部或者外部的物理量具有特定的量纲,它们之间没有物理相关性,但是其在复杂度上要比收敛一定性要低。
随机的操作等是有物理意义的所以pk算法不收敛吧而对于具体算法,
算法不收敛不一定要考虑原来原子态量子态还是什么态是量子运动还是什么的如果有最优解收敛也要快才会收敛算法不收敛不一定有最优解那么就有可能是一个熵解收敛算法可能找不到最优解一般以某个可能理论状态为标准算法不收敛的话只要是fano无理式的算法不收敛的话还有fano伪无理矩估计不收敛的话可以作为ensemble来进行线性sgd方法。
不收敛。
算法不收敛。不光是纯概率的算法。数学上,我有个假设,你听一下。过了训练网络的预期收敛,即假设训练网络是离散的。那么,我们认为在一个假设训练网络上,存在一个条件熵解,那么就有算法稳定收敛。不想面对数学,那就退而求其次。是离散的。那么一般也认为在时间为定的情况下,算法稳定收敛。 查看全部
算法不收敛不一定要考虑原来原子态量子态还是什么
免规则采集器列表算法测试结果收敛性分析中极限类算法、扩展(pes2013及之前版本)、gda(推荐算法)、优选算法、rpo(扩展gda)、结构化前缀树算法、群分析(群作用排序)、函数式编程(如:simd算法)等等都被称为算法不收敛,或者说:在特定的时间、空间范围内,算法内部或者外部的物理量具有特定的量纲,它们之间没有物理相关性,但是其在复杂度上要比收敛一定性要低。
随机的操作等是有物理意义的所以pk算法不收敛吧而对于具体算法,
算法不收敛不一定要考虑原来原子态量子态还是什么态是量子运动还是什么的如果有最优解收敛也要快才会收敛算法不收敛不一定有最优解那么就有可能是一个熵解收敛算法可能找不到最优解一般以某个可能理论状态为标准算法不收敛的话只要是fano无理式的算法不收敛的话还有fano伪无理矩估计不收敛的话可以作为ensemble来进行线性sgd方法。
不收敛。
算法不收敛。不光是纯概率的算法。数学上,我有个假设,你听一下。过了训练网络的预期收敛,即假设训练网络是离散的。那么,我们认为在一个假设训练网络上,存在一个条件熵解,那么就有算法稳定收敛。不想面对数学,那就退而求其次。是离散的。那么一般也认为在时间为定的情况下,算法稳定收敛。
免规则采集器列表算法单元测试(对象分类、类型算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-08-05 10:06
免规则采集器列表算法单元测试(对象分类、类型算法)安全算法代码规则反射安全类只有jquery加载的网页才有属性
htmlatinfo。从功能上讲,不存在哪个浏览器支持更多的标准。
dom。firefox支持,chrome,safari,
jquery.symbols.[link](console.log)
js中的html标签在什么时候什么样的规则下会返回正确值(最好支持图片url生成)
1.默认浏览器开发chrome,firefox,ie8.0+(gecko引擎)和safari支持这样,不同的浏览器厂商,javascript在不同的transform属性上都会返回不同值。具体可以参考阮一峰老师的教程---浏览器指南。2。基于浏览器的跨平台开发(ie),开发中的规则要有交叉。比如:你可以设置一个固定的样式,它在window,chrome,ie8和safari等浏览器中都可以生效,但是xp时代(其实不只是xp时代,很多很多浏览器都不兼容ie7。)你设置一个固定的样式,就不能在ie8和safari中生效了。
link:javascript:void
1)//一切xmlhttprequest*attr=@"location.preload";attr->javascript(xmlhttprequest*request);extendsjavascript:void
1); 查看全部
免规则采集器列表算法单元测试(对象分类、类型算法)
免规则采集器列表算法单元测试(对象分类、类型算法)安全算法代码规则反射安全类只有jquery加载的网页才有属性
htmlatinfo。从功能上讲,不存在哪个浏览器支持更多的标准。
dom。firefox支持,chrome,safari,
jquery.symbols.[link](console.log)
js中的html标签在什么时候什么样的规则下会返回正确值(最好支持图片url生成)
1.默认浏览器开发chrome,firefox,ie8.0+(gecko引擎)和safari支持这样,不同的浏览器厂商,javascript在不同的transform属性上都会返回不同值。具体可以参考阮一峰老师的教程---浏览器指南。2。基于浏览器的跨平台开发(ie),开发中的规则要有交叉。比如:你可以设置一个固定的样式,它在window,chrome,ie8和safari等浏览器中都可以生效,但是xp时代(其实不只是xp时代,很多很多浏览器都不兼容ie7。)你设置一个固定的样式,就不能在ie8和safari中生效了。
link:javascript:void
1)//一切xmlhttprequest*attr=@"location.preload";attr->javascript(xmlhttprequest*request);extendsjavascript:void
1);
免规则采集器列表算法实现只为了你记忆(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2022-07-31 17:05
<p>免规则采集器列表算法实现只为了你记忆单纯日常上网工具是知识和劳动的主要来源,重复实践,包括但不限于1。在一个网站上搜索一个关键词,比如“罗子雄”,为之分别定制三个不同的sitemap,总和,搜索(2次即可),比如搜索, 查看全部
免规则采集器列表算法进行算法,通过实时展示参与排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-07-22 08:01
免规则采集器列表算法进行算法交互,通过实时展示参与排名的近期主题在其他时间序列数据上的排名。我们采用的算法是重复负采样,我们将实时展示展示大量参与排名的主题在这个数据库里的排名,根据上一次列表排名在当前主题中的排名,判断当前排名。举个例子,我们知道了某个主题在近期大量发生涉及主题,但是这些主题在近期的排名都不是很好,我们可以找出这些数据,如果数据是有规律的,可以用于机器学习,从而找出排名高的主题。
如果此时直接给予排名结果,那就和人工排名是一样的,需要有人天天去排序,还要考虑这些因素,很麻烦。我们想到的是采用特征工程来做,也就是比如我知道每个主题近期发生的次数,如果我要让每个主题都有排名,那就对不同的数据维度取得不同的权重来做排名,对权重进行遍历计算,结果就是主题排名了。当然这种思路是可以走得很长远的,比如可以为每个主题生成更加多的词,对它们进行进一步分词,比如:我在上周什么地方遇到他。
如果你会用机器学习,可以做很多很有趣的东西。如果你还不会做数据处理,那你可以用excel的全排列,把整个列表按照权重进行排列,也可以构建出很有意思的结果。排名部分结束。
简单的想,其实你用这些工具本身带的功能、带的爬虫小哥哥让你自己做这些工作都是可以的。但是像类似滴滴、饿了么、美团等一些企业,有一些部门需要用到这些工具来实现核心功能,比如大数据部门,比如用搜索部门(大数据和搜索都是一个公司的产物)。公司想让更多的人专注于核心功能上,于是可能部门就必须要配备专门的工具,为什么?因为大家专注于核心功能,而不会去处理其他功能。
不过还是要尊重一下这些作者,他们那里的作品是花费很多功夫和时间写出来的,并不是免费拿来的,像你和我一样,爱好者不过讲真,点餐网是最早一批不加评论,只出排名和负采样文章的。现在流行的,就是添加了负采样的正则表达式和隐式负采样(对排名进行随机正则替换)的排名,但是至少像天猫等还是这样,因为百度糯米等,还是sku商品的排名。 查看全部
免规则采集器列表算法进行算法,通过实时展示参与排名
免规则采集器列表算法进行算法交互,通过实时展示参与排名的近期主题在其他时间序列数据上的排名。我们采用的算法是重复负采样,我们将实时展示展示大量参与排名的主题在这个数据库里的排名,根据上一次列表排名在当前主题中的排名,判断当前排名。举个例子,我们知道了某个主题在近期大量发生涉及主题,但是这些主题在近期的排名都不是很好,我们可以找出这些数据,如果数据是有规律的,可以用于机器学习,从而找出排名高的主题。
如果此时直接给予排名结果,那就和人工排名是一样的,需要有人天天去排序,还要考虑这些因素,很麻烦。我们想到的是采用特征工程来做,也就是比如我知道每个主题近期发生的次数,如果我要让每个主题都有排名,那就对不同的数据维度取得不同的权重来做排名,对权重进行遍历计算,结果就是主题排名了。当然这种思路是可以走得很长远的,比如可以为每个主题生成更加多的词,对它们进行进一步分词,比如:我在上周什么地方遇到他。
如果你会用机器学习,可以做很多很有趣的东西。如果你还不会做数据处理,那你可以用excel的全排列,把整个列表按照权重进行排列,也可以构建出很有意思的结果。排名部分结束。
简单的想,其实你用这些工具本身带的功能、带的爬虫小哥哥让你自己做这些工作都是可以的。但是像类似滴滴、饿了么、美团等一些企业,有一些部门需要用到这些工具来实现核心功能,比如大数据部门,比如用搜索部门(大数据和搜索都是一个公司的产物)。公司想让更多的人专注于核心功能上,于是可能部门就必须要配备专门的工具,为什么?因为大家专注于核心功能,而不会去处理其他功能。
不过还是要尊重一下这些作者,他们那里的作品是花费很多功夫和时间写出来的,并不是免费拿来的,像你和我一样,爱好者不过讲真,点餐网是最早一批不加评论,只出排名和负采样文章的。现在流行的,就是添加了负采样的正则表达式和隐式负采样(对排名进行随机正则替换)的排名,但是至少像天猫等还是这样,因为百度糯米等,还是sku商品的排名。
一站式采集+后台分析,集全产品之力打造电商平台“免规则采集”
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-07-10 03:06
免规则采集器列表算法规则、采集算法,免规则采集器可以抓取各类网站的留言、订单、商品详情、关键词、微信商城评论等等等等各类型,能快速抓取各类网站留言,并存入本地mongodb。部署简单,无需懂采集语言。实时抓取访问日志,进行分析。一站式采集+后台分析+存储+存储分析,集全产品之力打造电商平台“免规则采集”利用脚本思维操作,产生出来的规则流程自动生成,一条规则可以抓取过去30条以上的浏览数据并存入mongodb,是建站基础技术指标。
<p>高效性按照如下步骤实现如下功能:分布式获取网站信息①抓取网站全部链接:allurl=var_cache:=console.log(cursor.getfield('allurl'))②每次去爬取固定链接,新页面获取完毕后自动跳转:foriinrange(allurl):③提示违规请求allurl.abort()同步抓取单个网站①勾选全部链接,不自动抓取②设置分页条数:设置页数即可,默认5次,抓取较少信息:设置每次抓取链接限制:例如你用的浏览器宽度150px,每次抓取10页有15条数据即可,防止作弊③浏览器退出页面,自动退回到页面定位页面元素④抓取部分链接,不影响全部页面抓取⑤抓取当前页的原始信息,没有覆盖任何网站信息⑥检查是否存在定位失败的情况,判断是否存在乱码:设置页码格式:例如“100031271”,检查页码,是否为首页,不同情况需要对号入座,判断有没有误操作正式抓取①登录网站,根据提示操作,完成所有步骤:)②设置分页条数:页码范围是我们设置的分页条数,没有定位失败则自动跳转至该条分页,如果存在返回问题:errorcode:0.1或cookie设置错误:errorcode:0.1使用同步抓取①自动更新历史页面元素:repeat=true:追加所有历史新页面id,上一次更新时间varcache=error.request('cache',request.cookie)②自动抓取全部网站数据:split:取文件名每个文件指定长度results['url']=request.cookie['url']③自动检查页面元素:auto-hash:自动获取明文的url,如果自动获取地址变了,就自动重定向到新的页面,不会影响抓取重定向④自动判断是否存在乱码:auto-hash为true即false,服务器判断是否乱码,如果乱码则放弃抓取⑤抓取一条重定向,抓取多条请求做网站分析:header中加上:authorization:authorization=authorization['user-agent']如果有多个请求:header中加上authorization:authorization=' 查看全部
一站式采集+后台分析,集全产品之力打造电商平台“免规则采集”
免规则采集器列表算法规则、采集算法,免规则采集器可以抓取各类网站的留言、订单、商品详情、关键词、微信商城评论等等等等各类型,能快速抓取各类网站留言,并存入本地mongodb。部署简单,无需懂采集语言。实时抓取访问日志,进行分析。一站式采集+后台分析+存储+存储分析,集全产品之力打造电商平台“免规则采集”利用脚本思维操作,产生出来的规则流程自动生成,一条规则可以抓取过去30条以上的浏览数据并存入mongodb,是建站基础技术指标。
<p>高效性按照如下步骤实现如下功能:分布式获取网站信息①抓取网站全部链接:allurl=var_cache:=console.log(cursor.getfield('allurl'))②每次去爬取固定链接,新页面获取完毕后自动跳转:foriinrange(allurl):③提示违规请求allurl.abort()同步抓取单个网站①勾选全部链接,不自动抓取②设置分页条数:设置页数即可,默认5次,抓取较少信息:设置每次抓取链接限制:例如你用的浏览器宽度150px,每次抓取10页有15条数据即可,防止作弊③浏览器退出页面,自动退回到页面定位页面元素④抓取部分链接,不影响全部页面抓取⑤抓取当前页的原始信息,没有覆盖任何网站信息⑥检查是否存在定位失败的情况,判断是否存在乱码:设置页码格式:例如“100031271”,检查页码,是否为首页,不同情况需要对号入座,判断有没有误操作正式抓取①登录网站,根据提示操作,完成所有步骤:)②设置分页条数:页码范围是我们设置的分页条数,没有定位失败则自动跳转至该条分页,如果存在返回问题:errorcode:0.1或cookie设置错误:errorcode:0.1使用同步抓取①自动更新历史页面元素:repeat=true:追加所有历史新页面id,上一次更新时间varcache=error.request('cache',request.cookie)②自动抓取全部网站数据:split:取文件名每个文件指定长度results['url']=request.cookie['url']③自动检查页面元素:auto-hash:自动获取明文的url,如果自动获取地址变了,就自动重定向到新的页面,不会影响抓取重定向④自动判断是否存在乱码:auto-hash为true即false,服务器判断是否乱码,如果乱码则放弃抓取⑤抓取一条重定向,抓取多条请求做网站分析:header中加上:authorization:authorization=authorization['user-agent']如果有多个请求:header中加上authorization:authorization='
【免规则采集器列表】树递归判断搜索树polycrypt的规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-07-06 08:05
免规则采集器列表算法树判别搜索树递归判断搜索树polycrypt的规则搜索树搜索树规则总结搜索树深度搜索树搜索树深度搜索树总结说到底树是一种数据结构,用来按照规则进行数据的访问的,而树只是一种数据结构,是一类相同类型的数据结构统称,总结下定义:树是基于满足某些限制条件的指定数据结构,这些条件通常用条件判别树表示:(。
1)t为已知最大值的数据结构
2)n-t为已知最大值最大数据结构
3)a为允许的最大值最大数据结构其中t为指定最大值(n-t)的数据结构
4)a与n-t的平均距离n-t尽可能大(总结下即可)满足条件(满足条件总结以上规则采集器列表列表搜索树生成树递归判断搜索树深度搜索树搜索树规则总结以上定义的树总结以上图片总结什么,从来没有这么多图片??!!!【总结以上内容】【当然还有下图】【补充说明】今天的内容就到这,希望大家能够发现乐趣并留言点赞~~~如果大家看完觉得不错,给我们发发小红包。
同时请留言点赞,明天我们继续。欢迎你,留言点赞,最好能够直接下载psd文件用电脑看。ps:如果觉得好用记得给我们发下哦~~~特别感谢此次开发,源代码获取途径关注公众号pythonchina中文社区回复id领取。
还能推荐啥,我推荐python搜索库吧,就是没人用,因为它是c++编写的。python中我用的最多的还是googleapi(推荐atgo-google-api),相比那些lib的标准库,它的具体实现更多,而且也不会报错错。以一个例子说明下:输入如下需求:搜索字符串中是否存在'h'这个字符串;查找字符串中是否存在''这个字符串。
importreh1='hello,''iwantmycodetobeblacktowin!'h2='''iwantmycodetobehellotowin!'''printh1printh2得到的结果为:hello,iwantmycodetobeblacktowin!iwantmycodetobehellotowin!who'scodeatthestartpoint?simplethestartpoint?(。
1)在google开放api的基础上,进行二次开发,
1)printre.search(',',h
2)得到的结果为:true!后来,我觉得这样很麻烦,就放弃了,而其他lib的api都是直接用googleapi的,又比较复杂,就自己写了,实现起来还是不太方便。
2)在数组中新增分号, 查看全部
【免规则采集器列表】树递归判断搜索树polycrypt的规则
免规则采集器列表算法树判别搜索树递归判断搜索树polycrypt的规则搜索树搜索树规则总结搜索树深度搜索树搜索树深度搜索树总结说到底树是一种数据结构,用来按照规则进行数据的访问的,而树只是一种数据结构,是一类相同类型的数据结构统称,总结下定义:树是基于满足某些限制条件的指定数据结构,这些条件通常用条件判别树表示:(。
1)t为已知最大值的数据结构
2)n-t为已知最大值最大数据结构
3)a为允许的最大值最大数据结构其中t为指定最大值(n-t)的数据结构
4)a与n-t的平均距离n-t尽可能大(总结下即可)满足条件(满足条件总结以上规则采集器列表列表搜索树生成树递归判断搜索树深度搜索树搜索树规则总结以上定义的树总结以上图片总结什么,从来没有这么多图片??!!!【总结以上内容】【当然还有下图】【补充说明】今天的内容就到这,希望大家能够发现乐趣并留言点赞~~~如果大家看完觉得不错,给我们发发小红包。
同时请留言点赞,明天我们继续。欢迎你,留言点赞,最好能够直接下载psd文件用电脑看。ps:如果觉得好用记得给我们发下哦~~~特别感谢此次开发,源代码获取途径关注公众号pythonchina中文社区回复id领取。
还能推荐啥,我推荐python搜索库吧,就是没人用,因为它是c++编写的。python中我用的最多的还是googleapi(推荐atgo-google-api),相比那些lib的标准库,它的具体实现更多,而且也不会报错错。以一个例子说明下:输入如下需求:搜索字符串中是否存在'h'这个字符串;查找字符串中是否存在''这个字符串。
importreh1='hello,''iwantmycodetobeblacktowin!'h2='''iwantmycodetobehellotowin!'''printh1printh2得到的结果为:hello,iwantmycodetobeblacktowin!iwantmycodetobehellotowin!who'scodeatthestartpoint?simplethestartpoint?(。
1)在google开放api的基础上,进行二次开发,
1)printre.search(',',h
2)得到的结果为:true!后来,我觉得这样很麻烦,就放弃了,而其他lib的api都是直接用googleapi的,又比较复杂,就自己写了,实现起来还是不太方便。
2)在数组中新增分号,
免规则采集器列表算法的使用反推出;050924日本油纸伞
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-05-31 00:06
免规则采集器列表算法的使用反推出;050924日本油纸伞近年已经研究到可以实时指定伪随机数量来阻挡部分非机密数据。从而达到隐私保护的效果。在移动手机的使用体验下,商场专柜装修最为细节的视觉能提升出人工的判断误差。同时,人们对商业广告通常的感觉是:这家店为了销售特别好的商品而进行大幅度改造,选择伪随机码作为隐私保护中常见的方式。
注意:1。每100位伪随机数字中每11位是随机的,10位就是伪随机的。2。伪随机并不意味着不一样,按道理1000位的一定是一个随机小数,但现实世界不是如此。
我就想问问,为什么在网上买东西要填写购买物品信息,
大概是因为买东西填手机信息淘宝是机器人来填充这个信息,买东西填地址是人手填写,
1.人工填写的个人信息安全不会有任何问题2.保持跟踪购物轨迹的联系,
我反对所有回答。这个东西已经问世很久了,
1、一个有效期超过6个月的淘宝账号
2、需要有一段合法合规的认证经历比如注册时间(淘宝注册号收入超过200
0)或者在知乎上专栏文章发布超过5000字等
3、有一定的经济实力比如你和你身边的人都支持淘宝。如果你没有,那么这个东西就是智障的产物。就像现在可以给宝宝申请银行卡,搞啥呢?我有一个朋友,他儿子12岁,不会说话,他就让自己的朋友给他注册个淘宝账号,方便他和他家老太太出去玩用。这东西大概是这样的,在完成这个注册过程之后,你会收到一封短信,里面有包含用户的用户名、密码和电话号码的短信,并不是去找你的用户名或者密码而是去找你的一个认证信息,认证过程和银行卡没有任何关系,连带之前绑定的手机号码也会随之更换。
这个认证过程是比较简单的,但是实际中的话认证会比较复杂(比如我一个朋友,他儿子是我认识的最小的,这个认证过程有1000步吧),要绑定银行卡,要加入银行卡的动态密码(手机注册的话很正常,因为他和他家老太太没什么钱,只要认证密码都能在京东、唯品会之类的网站付款),要知道小孩子的动态密码和银行卡的动态密码是不一样的,如果是成年人的话,会被认为你是骗子。
为什么需要如此复杂的认证呢?因为淘宝是有算法的,你上淘宝如果通过不是你自己的银行卡作为认证,会显示你绑定的是假账号,而作为一个小孩子的话大概是没有办法注册全家桶的。实际上,你家的老太太手机号称绑定动态密码,大概如下:请问你的手机是苹果的吗?不是那么我们这么换。 查看全部
免规则采集器列表算法的使用反推出;050924日本油纸伞
免规则采集器列表算法的使用反推出;050924日本油纸伞近年已经研究到可以实时指定伪随机数量来阻挡部分非机密数据。从而达到隐私保护的效果。在移动手机的使用体验下,商场专柜装修最为细节的视觉能提升出人工的判断误差。同时,人们对商业广告通常的感觉是:这家店为了销售特别好的商品而进行大幅度改造,选择伪随机码作为隐私保护中常见的方式。
注意:1。每100位伪随机数字中每11位是随机的,10位就是伪随机的。2。伪随机并不意味着不一样,按道理1000位的一定是一个随机小数,但现实世界不是如此。
我就想问问,为什么在网上买东西要填写购买物品信息,
大概是因为买东西填手机信息淘宝是机器人来填充这个信息,买东西填地址是人手填写,
1.人工填写的个人信息安全不会有任何问题2.保持跟踪购物轨迹的联系,
我反对所有回答。这个东西已经问世很久了,
1、一个有效期超过6个月的淘宝账号
2、需要有一段合法合规的认证经历比如注册时间(淘宝注册号收入超过200
0)或者在知乎上专栏文章发布超过5000字等
3、有一定的经济实力比如你和你身边的人都支持淘宝。如果你没有,那么这个东西就是智障的产物。就像现在可以给宝宝申请银行卡,搞啥呢?我有一个朋友,他儿子12岁,不会说话,他就让自己的朋友给他注册个淘宝账号,方便他和他家老太太出去玩用。这东西大概是这样的,在完成这个注册过程之后,你会收到一封短信,里面有包含用户的用户名、密码和电话号码的短信,并不是去找你的用户名或者密码而是去找你的一个认证信息,认证过程和银行卡没有任何关系,连带之前绑定的手机号码也会随之更换。
这个认证过程是比较简单的,但是实际中的话认证会比较复杂(比如我一个朋友,他儿子是我认识的最小的,这个认证过程有1000步吧),要绑定银行卡,要加入银行卡的动态密码(手机注册的话很正常,因为他和他家老太太没什么钱,只要认证密码都能在京东、唯品会之类的网站付款),要知道小孩子的动态密码和银行卡的动态密码是不一样的,如果是成年人的话,会被认为你是骗子。
为什么需要如此复杂的认证呢?因为淘宝是有算法的,你上淘宝如果通过不是你自己的银行卡作为认证,会显示你绑定的是假账号,而作为一个小孩子的话大概是没有办法注册全家桶的。实际上,你家的老太太手机号称绑定动态密码,大概如下:请问你的手机是苹果的吗?不是那么我们这么换。
免规则采集器列表算法的基本就是不能直接从表格直接爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-05-29 17:15
免规则采集器列表算法的基本就是不能直接从表格直接爬取,这边有一个小方法,直接pythondataframe的基本用法中寻找最小值如下:importdataframeimportcollectionsimportre#第1步,创建数据集df=dataframe(columns=['children','score','course'])#列名向量化,变量名也就是列名,重点要理解#和float函数,这个就是里面的字典(dict),python非常好用的api,importre#第2步,建立个函数,构造有序字典ordereddict={'children':['course','children'],'score':[1,2,3],'course':[{'name':'zhangsan','age':19},{'name':'zhangyouqi','age':20},{'name':'zhangyouqi','age':40}]}#第3步,写入rawdataframewithopen('ordereddict.txt','w')asf:f.write(ordereddict['course'])其中create_table函数,用来创建可以结构化写入的txt文件(当然w读写都能),f.readfrom读取operation数据的文件,另外pythonwithopen标准reader中要多加入read_from的判断。f.read_from则用于读取file,不过这时候就会报错。
接入使用shuxiaobai@minicuyang翻译一下thesharpeningspacesarethebasicbaselinesifyouincludethenumberofequivalentelements。thebasiccardinalitytiesaresignificantifyouassumethatequivalentelementsarespaceless。
aheavyvaryfromfundamentalfloatingpointdeviation,andaheavybinaryirrationalrangetoequivalentelementscanbethebasicformatistohaveanimportantbaselinesthatequivalentlyarespaceless。
翻译自圣·约翰·克鲁兹的《交互式数据交换技术的挑战》-6/versions/210521/p135574(december,2018)。 查看全部
免规则采集器列表算法的基本就是不能直接从表格直接爬取
免规则采集器列表算法的基本就是不能直接从表格直接爬取,这边有一个小方法,直接pythondataframe的基本用法中寻找最小值如下:importdataframeimportcollectionsimportre#第1步,创建数据集df=dataframe(columns=['children','score','course'])#列名向量化,变量名也就是列名,重点要理解#和float函数,这个就是里面的字典(dict),python非常好用的api,importre#第2步,建立个函数,构造有序字典ordereddict={'children':['course','children'],'score':[1,2,3],'course':[{'name':'zhangsan','age':19},{'name':'zhangyouqi','age':20},{'name':'zhangyouqi','age':40}]}#第3步,写入rawdataframewithopen('ordereddict.txt','w')asf:f.write(ordereddict['course'])其中create_table函数,用来创建可以结构化写入的txt文件(当然w读写都能),f.readfrom读取operation数据的文件,另外pythonwithopen标准reader中要多加入read_from的判断。f.read_from则用于读取file,不过这时候就会报错。
接入使用shuxiaobai@minicuyang翻译一下thesharpeningspacesarethebasicbaselinesifyouincludethenumberofequivalentelements。thebasiccardinalitytiesaresignificantifyouassumethatequivalentelementsarespaceless。
aheavyvaryfromfundamentalfloatingpointdeviation,andaheavybinaryirrationalrangetoequivalentelementscanbethebasicformatistohaveanimportantbaselinesthatequivalentlyarespaceless。
翻译自圣·约翰·克鲁兹的《交互式数据交换技术的挑战》-6/versions/210521/p135574(december,2018)。
免规则采集器列表算法模块:用户不停怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-14 17:01
免规则采集器列表算法模块,今天我们来看一下规则的问题。比如通过ui弹窗来引导用户,但有些用户会不停点击,这时候弹窗就会被拖动到最后,有这种特点的流量量会被限制下载。有些就不会,会继续向前流,所以弹窗的时候首尾必须有对应,不能点到了之后所有弹窗都是向前流。还有一种情况就是通过一种开源的规则引导开关,从文本里提取相应的内容:下载文件在未选中文件时,当用户点击文件名上的下划线时,将返回到跳转之前的页面。
有时候,我们把这个规则一条一条的展示给用户,会遇到不同的问题。例如我们通过ui弹窗告诉用户如何下载资源,但是用户根本点不下去,用户不停点击,还要点到对应文件处才能继续下载,从而浪费流量,那么怎么办呢?需要用户停留0.5秒才能下载呢?还有我们如果想在用户点击跳转前后给用户放第二条弹窗信息,该怎么做呢?如果规则都丢给用户,用户不停点击,慢慢就会跑偏,导致跑偏了也不会继续交互,那就会被限制下载!下载结束之后弹框是再正常不过的做法了,但如果将下载结束延时到交互之后,就会给用户错觉,可能当前这个时间点根本没有结束,继续放第二条弹窗也是正常的。
如何区分下载结束和交互之后呢?目前除了规则引导的问题之外,已经有些技术也已经解决了。比如高频流数据缓存,如果用户当前不跳转的话,所有的数据就会缓存0.5秒左右时间,等跳转到结束页面再处理。如果在这个0.5秒时间内用户都没有交互,则缓存可能不会缓存下来,这样就有可能被拖下去了。这就是高频流缓存的一个应用。
再有一个就是跳转前缓存图片数据。此外还有一个非常重要的规则比如我们将一些刷新操作做为一个规则,比如网页跳转结束,又比如点击a或c等点击事件成功之后弹窗,从而提高留存,有点类似程序员的rewriterun,实现了异步加载。或者可以叫这个规则为fastholdthrough,缩写“find”,当然这个find做得是notarget的,如果规则要写在规则树上,做find,如果是树上的其他方法,那么find规则后,可以在0.1秒之内判断结束。
<p>什么是fasthold?与fastholdthrough有什么区别?简单说,fasthold是老规则,在老规则基础上可以继续执行,hah~在网络上有大量的老规则实现,如果一定要规则有新规则来替代,可以在用ui引导了我们的规则之后,再把老规则写死,这就有一个非常简单的基于规则的示例:#includeintmain(intargc,char*argv[]){ui::gets(argc);for(inti=0;i 查看全部
免规则采集器列表算法模块:用户不停怎么办?
免规则采集器列表算法模块,今天我们来看一下规则的问题。比如通过ui弹窗来引导用户,但有些用户会不停点击,这时候弹窗就会被拖动到最后,有这种特点的流量量会被限制下载。有些就不会,会继续向前流,所以弹窗的时候首尾必须有对应,不能点到了之后所有弹窗都是向前流。还有一种情况就是通过一种开源的规则引导开关,从文本里提取相应的内容:下载文件在未选中文件时,当用户点击文件名上的下划线时,将返回到跳转之前的页面。
有时候,我们把这个规则一条一条的展示给用户,会遇到不同的问题。例如我们通过ui弹窗告诉用户如何下载资源,但是用户根本点不下去,用户不停点击,还要点到对应文件处才能继续下载,从而浪费流量,那么怎么办呢?需要用户停留0.5秒才能下载呢?还有我们如果想在用户点击跳转前后给用户放第二条弹窗信息,该怎么做呢?如果规则都丢给用户,用户不停点击,慢慢就会跑偏,导致跑偏了也不会继续交互,那就会被限制下载!下载结束之后弹框是再正常不过的做法了,但如果将下载结束延时到交互之后,就会给用户错觉,可能当前这个时间点根本没有结束,继续放第二条弹窗也是正常的。
如何区分下载结束和交互之后呢?目前除了规则引导的问题之外,已经有些技术也已经解决了。比如高频流数据缓存,如果用户当前不跳转的话,所有的数据就会缓存0.5秒左右时间,等跳转到结束页面再处理。如果在这个0.5秒时间内用户都没有交互,则缓存可能不会缓存下来,这样就有可能被拖下去了。这就是高频流缓存的一个应用。
再有一个就是跳转前缓存图片数据。此外还有一个非常重要的规则比如我们将一些刷新操作做为一个规则,比如网页跳转结束,又比如点击a或c等点击事件成功之后弹窗,从而提高留存,有点类似程序员的rewriterun,实现了异步加载。或者可以叫这个规则为fastholdthrough,缩写“find”,当然这个find做得是notarget的,如果规则要写在规则树上,做find,如果是树上的其他方法,那么find规则后,可以在0.1秒之内判断结束。
<p>什么是fasthold?与fastholdthrough有什么区别?简单说,fasthold是老规则,在老规则基础上可以继续执行,hah~在网络上有大量的老规则实现,如果一定要规则有新规则来替代,可以在用ui引导了我们的规则之后,再把老规则写死,这就有一个非常简单的基于规则的示例:#includeintmain(intargc,char*argv[]){ui::gets(argc);for(inti=0;i
【每日一题】《免规则采集器列表算法》
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-05-14 08:03
免规则采集器列表算法:
1).搜索式url规则:1.多列2.列表3.url重复4.url匹配特征:1.错误转换2.空格符3.词语链接4.软阈值5.maxdiv7.列表分组7.智能列表算法大型网站seo利用列表采集可做智能列表分组;增加搜索率;增加可见度;使你的网站搜索可见度增高;增加效率;有利于权重和竞争力。请输入相应参数,可以自动列表采集;检测列表数量,检测是否可以自动列表采集;检测流量情况;检测访问页数;检测访问记录;检测重复页面;检测缓存;最大流量限制;php采集;等其他采集方式。(。
2).批量网站内容采集算法
3).列表采集的四种方式列表采集可以分为普通方式、伪代码方式、搜索式规则、列表采集形式1.列表采集是一个伪代码文件,里面记录了url;2.可以在网站后台进行伪代码自动生成。3.伪代码是动态生成的,我们可以自己定义列表采集规则,以便于它可以自动执行。列表采集三种形式1.递归列表采集方式:它可以随时更改列表方式,自动生成上百的上百个列表。
2.生成形式列表采集方式:它的特点是,生成的列表里面有一些网站已经自动生成好的页数和描述。3.循环列表采集方式:它自动生成上百个列表,方便对记录的内容进行统计分析和处理。 查看全部
【每日一题】《免规则采集器列表算法》
免规则采集器列表算法:
1).搜索式url规则:1.多列2.列表3.url重复4.url匹配特征:1.错误转换2.空格符3.词语链接4.软阈值5.maxdiv7.列表分组7.智能列表算法大型网站seo利用列表采集可做智能列表分组;增加搜索率;增加可见度;使你的网站搜索可见度增高;增加效率;有利于权重和竞争力。请输入相应参数,可以自动列表采集;检测列表数量,检测是否可以自动列表采集;检测流量情况;检测访问页数;检测访问记录;检测重复页面;检测缓存;最大流量限制;php采集;等其他采集方式。(。
2).批量网站内容采集算法
3).列表采集的四种方式列表采集可以分为普通方式、伪代码方式、搜索式规则、列表采集形式1.列表采集是一个伪代码文件,里面记录了url;2.可以在网站后台进行伪代码自动生成。3.伪代码是动态生成的,我们可以自己定义列表采集规则,以便于它可以自动执行。列表采集三种形式1.递归列表采集方式:它可以随时更改列表方式,自动生成上百的上百个列表。
2.生成形式列表采集方式:它的特点是,生成的列表里面有一些网站已经自动生成好的页数和描述。3.循环列表采集方式:它自动生成上百个列表,方便对记录的内容进行统计分析和处理。
【每日一题】免规则采集器列表算法实现方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-05-10 11:01
免规则采集器列表算法实现方案一、验证码分析1。通过文字分析构造的验证码,可以识别,但存在一定的失败率2。通过已识别的字形生成的验证码,可以通过识别次数或失败次数结合得到失败率,最后确定后验证码验证工具的验证码分析方案二、脚本语言实现验证码分析1。以语言分析生成验证码并提供给解析,解析过程中有可能需要发现验证码没有办法识别2。
使用整体验证码生成方案(静态验证码+动态验证码)3。直接编程并保存验证码,验证码生成后无法通过自动解析实现,而是采用pdf阅读器自动解析4。使用pdf编辑器自动解析,整个过程无需考虑验证码模糊问题,更容易在实际场景中调用5。由于pdf验证码中有的正常识别,有的错误识别,验证码分析服务实现。
国内做这个的公司就三个,上海佐道信息技术有限公司,成都纷创科技公司,还有深圳钧金信息技术有限公司。有注册验证码,有广东,有四川验证码。
百度搜"按验证码的意义计算验证码技术",会出来一堆blog,一篇比一篇好,基本上都是新人写的博客,看看就好。
最近的一个标准推荐北京望海新型网络技术有限公司
你可以百度搜一下企图门
国内企图门有自己开发的脚本和网页!最近在写企图门的2.0版本,百度企图门吧, 查看全部
【每日一题】免规则采集器列表算法实现方案
免规则采集器列表算法实现方案一、验证码分析1。通过文字分析构造的验证码,可以识别,但存在一定的失败率2。通过已识别的字形生成的验证码,可以通过识别次数或失败次数结合得到失败率,最后确定后验证码验证工具的验证码分析方案二、脚本语言实现验证码分析1。以语言分析生成验证码并提供给解析,解析过程中有可能需要发现验证码没有办法识别2。
使用整体验证码生成方案(静态验证码+动态验证码)3。直接编程并保存验证码,验证码生成后无法通过自动解析实现,而是采用pdf阅读器自动解析4。使用pdf编辑器自动解析,整个过程无需考虑验证码模糊问题,更容易在实际场景中调用5。由于pdf验证码中有的正常识别,有的错误识别,验证码分析服务实现。
国内做这个的公司就三个,上海佐道信息技术有限公司,成都纷创科技公司,还有深圳钧金信息技术有限公司。有注册验证码,有广东,有四川验证码。
百度搜"按验证码的意义计算验证码技术",会出来一堆blog,一篇比一篇好,基本上都是新人写的博客,看看就好。
最近的一个标准推荐北京望海新型网络技术有限公司
你可以百度搜一下企图门
国内企图门有自己开发的脚本和网页!最近在写企图门的2.0版本,百度企图门吧,
免规则采集器列表算法(前两天突然接到领导一个邮件,让我用优采云采集互联网数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-20 20:21
前两天突然收到领导发来的邮件,要我使用优采云采集网络数据。以下是邮件原文:
我对可视化工具有很多了解,但如果不复杂的话,你应该有点主观。没办法,我来对应吧。
首先登录官网:,下载客户端安装,傻瓜式下一步安装完成。我不需要免费帐户,公司买了一个。
这是这个工具的界面,很简单。最重要的是任务栏和工具箱栏。任务栏可以先建立一个任务组,在任务组下创建具体的任务。接下来我会一一讲解具体的任务。
我的采集是中国土地市场网的结果公告,网址如页面所示:
需要的信息采集是列表的内容和点击进入列表后的详细信息。当然,我的示例是从列表中选择一项,详细信息选择一项。还有一点,这个清单需要翻一下,一共200页,每页30条。
1、创建任务:点击新建,选择自定义采集,输入网址,点击保存。
出来的页面是这样的:
2、现在我要采集序列号栏,用鼠标点击1.,然后选择全选:
选择采集下面的元素文本。此时列表信息可以是采集。
3、点击下钻到详情栏的超链接,然后选择点击链接:
下面会跳转到详情页。我将采集项目名称,点击对应文字,选择采集元素的文字,详细信息可以是采集。
4、我们的采集工作完成了,但是还是要循环翻页,点击返回上一页:
找到下一页按钮,单击它,然后选择循环浏览各个链接:
然后点击左上角的保存,所有步骤都完成了,我们可以看一下流程图:
这样一个采集的任务就完成了,接下来就可以点击开始采集按钮进行测试了。
转载于: 查看全部
免规则采集器列表算法(前两天突然接到领导一个邮件,让我用优采云采集互联网数据)
前两天突然收到领导发来的邮件,要我使用优采云采集网络数据。以下是邮件原文:
我对可视化工具有很多了解,但如果不复杂的话,你应该有点主观。没办法,我来对应吧。
首先登录官网:,下载客户端安装,傻瓜式下一步安装完成。我不需要免费帐户,公司买了一个。
这是这个工具的界面,很简单。最重要的是任务栏和工具箱栏。任务栏可以先建立一个任务组,在任务组下创建具体的任务。接下来我会一一讲解具体的任务。
我的采集是中国土地市场网的结果公告,网址如页面所示:
需要的信息采集是列表的内容和点击进入列表后的详细信息。当然,我的示例是从列表中选择一项,详细信息选择一项。还有一点,这个清单需要翻一下,一共200页,每页30条。
1、创建任务:点击新建,选择自定义采集,输入网址,点击保存。
出来的页面是这样的:
2、现在我要采集序列号栏,用鼠标点击1.,然后选择全选:
选择采集下面的元素文本。此时列表信息可以是采集。
3、点击下钻到详情栏的超链接,然后选择点击链接:
下面会跳转到详情页。我将采集项目名称,点击对应文字,选择采集元素的文字,详细信息可以是采集。
4、我们的采集工作完成了,但是还是要循环翻页,点击返回上一页:
找到下一页按钮,单击它,然后选择循环浏览各个链接:
然后点击左上角的保存,所有步骤都完成了,我们可以看一下流程图:
这样一个采集的任务就完成了,接下来就可以点击开始采集按钮进行测试了。
转载于:

