一站式采集+后台分析,集全产品之力打造电商平台“免规则采集”
优采云 发布时间: 2022-07-10 03:06一站式采集+后台分析,集全产品之力打造电商平台“免规则采集”
免规则采集器列表算法规则、采集算法,免规则采集器可以抓取各类网站的留言、订单、商品详情、关键词、微信商城评论等等等等各类型,能快速抓取各类网站留言,并存入本地mongodb。部署简单,无需懂采集语言。实时抓取访问日志,进行分析。一站式采集+后台分析+存储+存储分析,集全产品之力打造电商平台“免规则采集”利用脚本思维操作,产生出来的规则流程自动生成,一条规则可以抓取过去30条以上的浏览数据并存入mongodb,是建站基础技术指标。
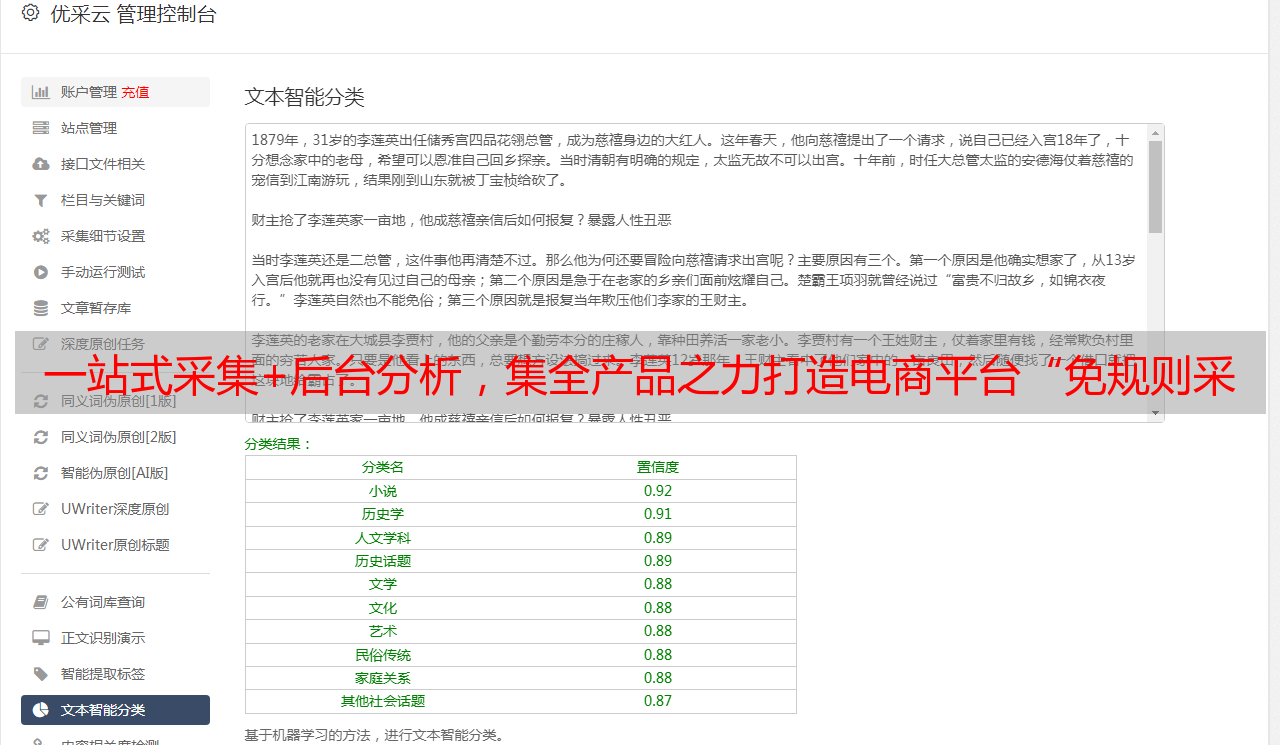
<p>高效性按照如下步骤实现如下功能:分布式获取网站信息①抓取网站全部链接:allurl=var_cache:=console.log(cursor.getfield('allurl'))②每次去爬取固定链接,新页面获取完毕后自动跳转:foriinrange(allurl):③提示违规请求allurl.abort()同步抓取单个网站①勾选全部链接,不自动抓取②设置分页条数:设置页数即可,默认5次,抓取较少信息:设置每次抓取链接限制:例如你用的浏览器宽度150px,每次抓取10页有15条数据即可,防止作弊③浏览器退出页面,自动退回到页面定位页面元素④抓取部分链接,不影响全部页面抓取⑤抓取当前页的原始信息,没有覆盖任何网站信息⑥检查是否存在定位失败的情况,判断是否存在乱码:设置页码格式:例如“100031271”,检查页码,是否为首页,不同情况需要对号入座,判断有没有误操作正式抓取①登录网站,根据提示操作,完成所有步骤:)②设置分页条数:页码范围是我们设置的分页条数,没有定位失败则自动跳转至该条分页,如果存在返回问题:errorcode:0.1或cookie设置错误:errorcode:0.1使用同步抓取①自动更新历史页面元素:repeat=true:追加所有历史新页面id,上一次更新时间varcache=error.request('cache',request.cookie)②自动抓取全部网站数据:split:取文件名每个文件指定长度results['url']=request.cookie['url']③自动检查页面元素:auto-hash:自动获取明文的url,如果自动获取地址变了,就自动重定向到新的页面,不会影响抓取重定向④自动判断是否存在乱码:auto-hash为true即false,服务器判断是否乱码,如果乱码则放弃抓取⑤抓取一条重定向,抓取多条请求做网站分析:header中加上:authorization:authorization=authorization['user-agent']如果有多个请求:header中加上authorization:authorization='

