文字识别处理处理后生成词典(分类)构建语料库
优采云 发布时间: 2022-09-18 03:04文字识别处理处理后生成词典(分类)构建语料库
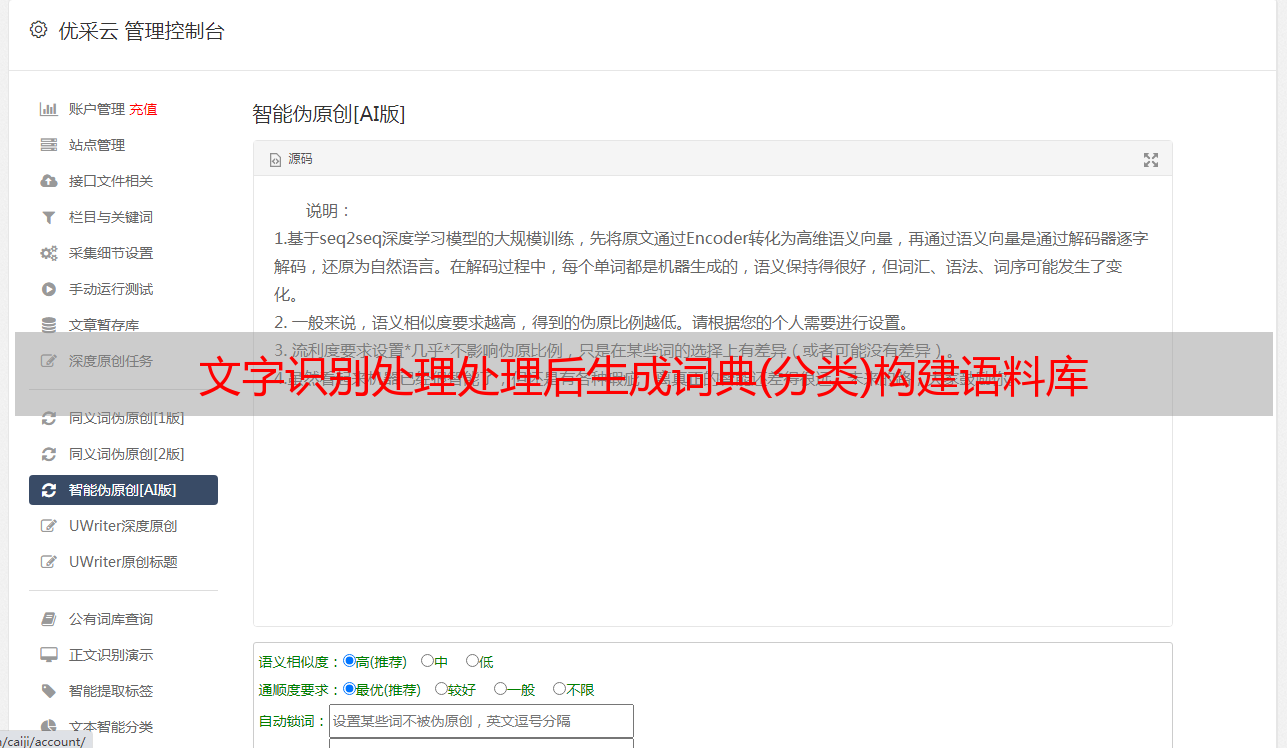
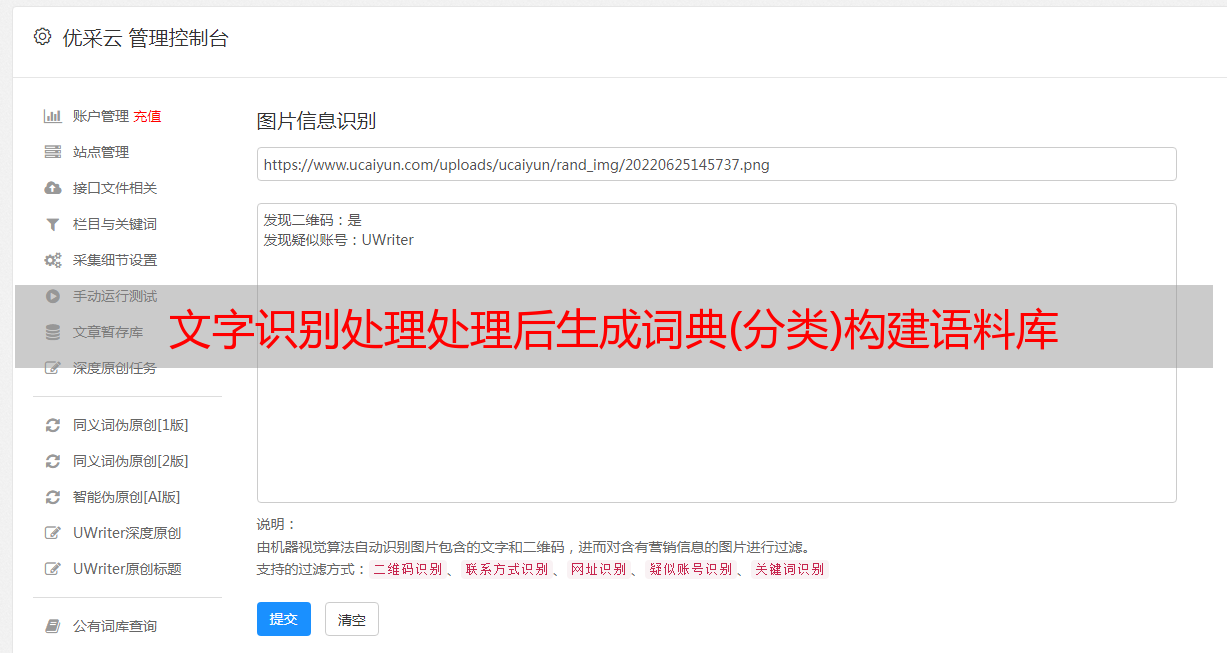
免规则采集器列表算法;极其高效节约时间,基本不需要看代码,简单粗暴。简单来说下文字识别处理处理后生成词典(格式)生成情感分析词典(分类)构建语料库机器阅读理解数据量小,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。机器阅读理解数据量大,可以用sparql方式采集,识别后返回,进行各种分类学习(迁移学习等)。
利用pythonmodel_generator可以轻松完成文本分类
angularnlg论文下载word2vec
这么一说我觉得我知道的算法就很多了,可是,问题是python的做多了之后感觉pandas好像用的多一点,搜了一下model_generator这个库,然后google了一下。才发现还有onehotlog2vec的,想想好像也可以实现。自己搭了个小框架,各种需求基本都能满足。onehotlog2vec可以用pandas和numpy来实现的,onehotlog2vec就是利用一个embedding向量来进行文本分类或者情感分析。
考虑到model_generator能识别多分类的文本就行了。首先pandas读取xls或者xlsx文件,将每一列向量化,得到一个数组,这个数组长度不是固定的,如果你不太清楚数组长度的话,可以看这里onehotlog2vec。然后pandas的话是这样frompandasimportdataframefrompandas_datareaderimportdataframeimportosimportnumpyasnp#pandasdataframeadditionalitems(items.now-time)addedfrom''trainingdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)testdata.now-time>scipy.reader.outputitems('',list(scipy.reader.outputitems('',i),len(os.list(scipy.reader.outputitems('',i,np.array(),pandas.dataframe(dataframe).dtypes,1)#model_generatorfeatures=pandas.read_csv('code2vec.csv')args=pandas.read_csv('ge2vec.csv')x*敏*感*词*f=pd.dataframe(features)[::-1]print(xls.index)print(df.index)print('distance=',df.index)print('average=',df.index)print('score=',df.index).。

