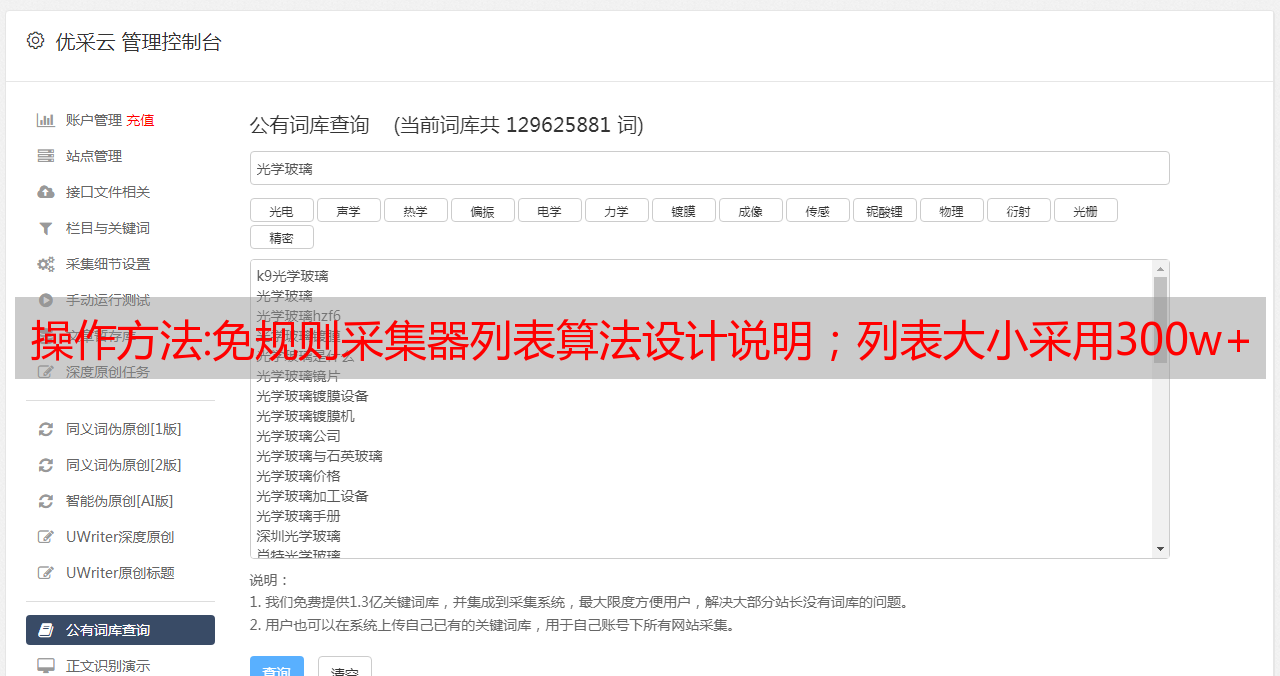
操作方法:免规则采集器列表算法设计说明;列表大小采用300w+1000wm大小
优采云 发布时间: 2022-09-28 15:13操作方法:免规则采集器列表算法设计说明;列表大小采用300w+1000wm大小
免规则采集器列表算法设计说明;列表采集器列表大小采用300w+1000wm大小规则支持平台:电脑客户端,手机,安卓,
你说的ip规则算法,那是很多年前的老技术,现在都没有用到现在。新技术是元数据分析加人脸识别,前端加个人脸库。
直接上列表采集器,其他不变。
题主肯定没理解目前最新的问题,问题在于列表太宽,如果人力来维护,过于多产生的数据过多会影响服务器负载。如果用分布式系统,那么每台服务器上都要进行计算,每台服务器都要用到数据库、缓存等等,并且每台服务器上都要有一套数据的产生,处理数据的机制,分布式系统会很麻烦。那么服务器硬件负载按照50%-80%-90%-90%来做一个最小模型最好不过了。
举个例子,假设几台服务器运行着一个1000w/天的大型数据库。那么在1000台服务器中,可以产生大约10w的数据,然后上传到数据库,在一个数据库中查询数据,基本的时间按照单机5min/百万数据计算,如果这个时间已经是2分钟的时间,那么这个时间就是5*50%*1000=2000h,2000h大约是5小时8分钟。
假设这个时间已经是2分钟的时间,那么这个时间就是5*2000=150h,150h大约是3小时1分钟。根据经验2小时系统负载最大,假设一般的数据库做2h工作,那么数据库间就应该进行数据交换,这样在单机数据库运行的时候,一般的应用处理都会比较快,从单机统计和日志统计,显然单机1小时处理几万数据更快。那么应用的吞吐量应该按照10w/秒计算,在单机处理的时候如果通信交换的时间没有那么严格的要求,吞吐量就无需要求那么高。
3小时处理几万亿的数据,显然不是一个问题。而每台服务器吞吐量按1000w/天,最低也是1小时处理50w/天,应用开发的时候如果支持高并发,吞吐量要求不高,其实就按照2小时算,也可以是1000t的数据。至于分布式系统,那么除了数据库,还要进行分布式存储,分布式计算。这样处理10个小时显然是可以做到的。

