
免规则采集器列表算法
免规则采集器列表算法(免规则采集器列表算法java实现4。2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-17 09:40
免规则采集器列表算法java实现4。2。3。1特征选择原理2017-02-2223:22:36|分类器viterbi算法2018-04-1214:13:51|目标识别2019-04-0122:51:16|检测器1。1版基本实现1。2优化目标:列表分类器,精度达到15%2。2。3。2java实现gbdt非凸函数、优化目标:小类(聚类问题)or大类(分类问题)实现整体思路:1。
只把样本映射到[-1,1][-1,1]列表中(每次划分时,先创建一个[-1,1]-1列表)2。比较数据的峰值(kernelminmethod(0,minmethod(min-。
1)/maxmethod(max-
1)))或周边最小值(kernelmaxmethod(-minmethod(min-
1),-maxmethod(max-
1))):当方差最小时,
1)列表中的元素序列(xinint->xinint[i])。返回参数:1.列表中元素个数:in遍历列表的每一个元素,其中in遍历列表的第一个元素和结尾所有元素2.初始内存大小(mb):初始内存大小要记住:不要使用int3.列表中每一项的序号:是对象length+1并保存元素的序号,需求[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,85,86,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,167,169,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,187,188,189,189,188,189,189,189,189,189,189,189,189,189,189,189,189,189,189,18。 查看全部
免规则采集器列表算法(免规则采集器列表算法java实现4。2)
免规则采集器列表算法java实现4。2。3。1特征选择原理2017-02-2223:22:36|分类器viterbi算法2018-04-1214:13:51|目标识别2019-04-0122:51:16|检测器1。1版基本实现1。2优化目标:列表分类器,精度达到15%2。2。3。2java实现gbdt非凸函数、优化目标:小类(聚类问题)or大类(分类问题)实现整体思路:1。
只把样本映射到[-1,1][-1,1]列表中(每次划分时,先创建一个[-1,1]-1列表)2。比较数据的峰值(kernelminmethod(0,minmethod(min-。
1)/maxmethod(max-
1)))或周边最小值(kernelmaxmethod(-minmethod(min-
1),-maxmethod(max-
1))):当方差最小时,
1)列表中的元素序列(xinint->xinint[i])。返回参数:1.列表中元素个数:in遍历列表的每一个元素,其中in遍历列表的第一个元素和结尾所有元素2.初始内存大小(mb):初始内存大小要记住:不要使用int3.列表中每一项的序号:是对象length+1并保存元素的序号,需求[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,85,86,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,167,169,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,187,188,189,189,188,189,189,189,189,189,189,189,189,189,189,189,189,189,189,18。
免规则采集器列表算法(共享python和opencv的ssim计算代码#importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-04-17 07:34
python处理图像,opencv图像识别算法 张世龙 02-25 08:0732 查看次数
python环境下使用opencv压缩图片大小,python语言。在python环境下使用opencv压缩图像大小,并在python语言中引入poencv,使用utility PIL处理图像比使用opencv更容易。opencv通常用于采集视频图像和图像。
数字图像处理是如何在python和opencv上写一个瘦脸算法导致编辑器跌倒。谁指着心最小的编辑说:“你能不能让老子别再伤他的心了?
#参考项目 (whoami1978 ) f=1foriinrange (1,1001 ) : f*=i print(f ) f ) 结果很大,而且没有像编辑员那样成绩差的同学,怎么衬得好成绩
当前的图像压缩算法有哪些?目前有哪些图像压缩算法,请举个例子。【图片压缩】证明当小编学会控制自己的脾气后,就知道小编什么都不需要
浅谈图像压缩算法 jzdm 本文只讨论静止图像压缩的基本算法。图像压缩的目的是通过用更少的数据表示图像来节省存储成本、传输时间和费用。JPEG压缩算法可以处理带有失真压缩的图像,但是肉眼无法识别失真的程度。
基于python语言的opencv如何裁剪图像中的指定区域?基于python语言的opencv如何裁剪图像中的指定区域?比别人剪电影中的3-cut轮廓(这是我在小编找到的一个博客网站。
分享python和opencv的ssim计算代码
# importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2#constructtheargumentparseandparsetheargumentsap=arg parse.argument parser(AP.add_argument('-f','first',just
有没有人在c上有opencv图像清晰度的算法代码?图像模糊的原因有很多,您正在处理哪一个?并非所有东西都共享。我该如何和不想失去的人说再见?“主编没说再见,主编也没说什么,就走了。”
基于matlab的图像压缩算法包括matlab如Huffman编码、算术编码、字典编码、游程编码-Lempel-zev编码、DCT、子带编码粒子、二次采样、比特分配、矢量量化等。
基于OpenCV的等速模糊图像恢复及算法分析
第二卷第35期1月21日21日501湖南工业大学学报VO.5n 031-2ma2v 011等速模糊图像恢复及基于jurlofhununvestftehnogonanairiyocolyopnv eCcqdxtd的算法分析,ladbg(福建福州,300518)
个人毕业设计基于python开发的镜像。苍海月明在此吟诗,白犬刚流。
本科毕业论文(设计)主题:基于python开发的图像的Airppt采集器本科学科与专业Airppt基于python的图像的摘要采集器本文使用普通USB数码相机拍摄获取实景时间 图片
将视频压缩成的最小格式是什么?格式工厂如何将视频压缩到指定大小?1990年代世界三大经济中心,改变世界的九种算法 查看全部
免规则采集器列表算法(共享python和opencv的ssim计算代码#importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2)
python处理图像,opencv图像识别算法 张世龙 02-25 08:0732 查看次数
python环境下使用opencv压缩图片大小,python语言。在python环境下使用opencv压缩图像大小,并在python语言中引入poencv,使用utility PIL处理图像比使用opencv更容易。opencv通常用于采集视频图像和图像。
数字图像处理是如何在python和opencv上写一个瘦脸算法导致编辑器跌倒。谁指着心最小的编辑说:“你能不能让老子别再伤他的心了?
#参考项目 (whoami1978 ) f=1foriinrange (1,1001 ) : f*=i print(f ) f ) 结果很大,而且没有像编辑员那样成绩差的同学,怎么衬得好成绩
当前的图像压缩算法有哪些?目前有哪些图像压缩算法,请举个例子。【图片压缩】证明当小编学会控制自己的脾气后,就知道小编什么都不需要
浅谈图像压缩算法 jzdm 本文只讨论静止图像压缩的基本算法。图像压缩的目的是通过用更少的数据表示图像来节省存储成本、传输时间和费用。JPEG压缩算法可以处理带有失真压缩的图像,但是肉眼无法识别失真的程度。
基于python语言的opencv如何裁剪图像中的指定区域?基于python语言的opencv如何裁剪图像中的指定区域?比别人剪电影中的3-cut轮廓(这是我在小编找到的一个博客网站。
分享python和opencv的ssim计算代码
# importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2#constructtheargumentparseandparsetheargumentsap=arg parse.argument parser(AP.add_argument('-f','first',just
有没有人在c上有opencv图像清晰度的算法代码?图像模糊的原因有很多,您正在处理哪一个?并非所有东西都共享。我该如何和不想失去的人说再见?“主编没说再见,主编也没说什么,就走了。”
基于matlab的图像压缩算法包括matlab如Huffman编码、算术编码、字典编码、游程编码-Lempel-zev编码、DCT、子带编码粒子、二次采样、比特分配、矢量量化等。
基于OpenCV的等速模糊图像恢复及算法分析
第二卷第35期1月21日21日501湖南工业大学学报VO.5n 031-2ma2v 011等速模糊图像恢复及基于jurlofhununvestftehnogonanairiyocolyopnv eCcqdxtd的算法分析,ladbg(福建福州,300518)
个人毕业设计基于python开发的镜像。苍海月明在此吟诗,白犬刚流。
本科毕业论文(设计)主题:基于python开发的图像的Airppt采集器本科学科与专业Airppt基于python的图像的摘要采集器本文使用普通USB数码相机拍摄获取实景时间 图片
将视频压缩成的最小格式是什么?格式工厂如何将视频压缩到指定大小?1990年代世界三大经济中心,改变世界的九种算法
免规则采集器列表算法(关于dede/config.php的相关问题很难解答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-16 13:22
最近有很多朋友在询问优采云采集器免费登录采集数据发布到DEDEcms织梦的方法,其实这些问题都不是很难回答,可能是你不太关注,所以不知道,不过没关系,今天给大家详细分享一下具体优采云采集器免登录采集如何发布数据到DEDEcms织梦,真心希望对你有所帮助。
将以下代码放入 dede/config.php:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后将 优采云 发布模块修改为
article_add.php?my_u=你的后台用户名&my_p=你的后台密码
以上就是对优采云采集器免费登录采集数据发布到DEDEcms织梦方法的详细介绍,如果你还想了解优采云采集器免登录采集如果数据发布到DEDEcms织梦,可以直接关注编辑器不断推出的新文章 ,因为这些信息会及时更新给大家看。同时也希望大家多多支持关注46仿网站。更多信息将在此更新。
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)! 查看全部
免规则采集器列表算法(关于dede/config.php的相关问题很难解答)
最近有很多朋友在询问优采云采集器免费登录采集数据发布到DEDEcms织梦的方法,其实这些问题都不是很难回答,可能是你不太关注,所以不知道,不过没关系,今天给大家详细分享一下具体优采云采集器免登录采集如何发布数据到DEDEcms织梦,真心希望对你有所帮助。
将以下代码放入 dede/config.php:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后将 优采云 发布模块修改为
article_add.php?my_u=你的后台用户名&my_p=你的后台密码
以上就是对优采云采集器免费登录采集数据发布到DEDEcms织梦方法的详细介绍,如果你还想了解优采云采集器免登录采集如果数据发布到DEDEcms织梦,可以直接关注编辑器不断推出的新文章 ,因为这些信息会及时更新给大家看。同时也希望大家多多支持关注46仿网站。更多信息将在此更新。
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)!
免规则采集器列表算法(优采云采集器免费功能强大的采集器需要写采集规则,还有对接复杂的发布模块 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-15 04:11
)
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,获得了众多用户的一致认可。但是优采云采集器有一个很麻烦的地方,就是需要编写采集规则,连接复杂的发布模块。有没有免费又强大的采集器?一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。
免费采集器可以设置标题前缀和后缀(标题的区别更好收录)。使 网站 内容更好。内容是网站的基础。没有好的内容,就没有回头客,如果在其他方面做得好,那就是白费了。好的内容不仅适合用户,也适合搜索引擎。优秀的SEO文案可以找到两者之间的共同点。
免费的采集器可以合理的网站架构。网站架构是SEO的基础部分。主要与代码缩减、目录结构、网页收录、网站网站的跳出率等有关。合理的架构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
免费采集器支持多种采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。可以深入挖掘用户需求。一个合格的SEO工作者,大部分时间都是在挖掘用户需求,也就是说,用户还需要什么?此外,他们必须对行业有绝对的了解,这样网站才能全面、专业、深刻。
免费采集器搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能够被搜索引擎收录及时搜索到)。
免费采集器提供高质量的外部链接。虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
免费采集器给用户完美体验。用户体验包括很多方面,几乎都是前面所有的内容,比如内容是否优质、专业、全面,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项工作每天都需要优化。.
从下拉词、相关搜索词和长尾词中免费生成行业相关词采集器、关键词。可以设置自动删除不相关的词。如何为单个页面编写网站标题。一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?免费采集器支持其他平台的图片本地化或存储。
主页标题。主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
免费采集器内容与标题一致(使内容与标题100%相关)。栏目页最重要的是内容的契合度,即相关性。如果你在标题上堆积了很多相关的内容,你可以做一些扩展来满足我们对内容的准确命题。栏目内容很多,整合了很多。为此,我们可以适当扩展标题。以网站的建设为例,我们可以设置标题收录网站建设。新闻标题、网站模板、技术文档等。
免费采集器自动内链(在执行发布任务时自动生成文章内容中的内链,有利于引导页面蜘蛛抓取,提高页面权限)。在新闻页面方面,虽然单个页面并不比首页或栏目页面好,但如果将多个新闻页面与它们进行比较,则不一定如此。这种比较的标准是基于流量的。新闻页面的标题一般是信息标题加上公司名称。这种写法我也挺中肯的。我也用过,效果不错,但最重要的是效果不明显或者关键词的排名不高。,这个时候我们可以换个方法,用什么方法呢?就是写文章标题不带公司名,这样效果更好,
批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群, PB, Apple, 搜外 和其他主要的cms 工具,可以同时管理和批量发布)。对于产品页面的标题,我个人遵循产品字+公司名称的原则。这样做有两个好处。一是提高公司知名度,推广产品。更多人会看到,名字背后的公司也会受到关注。的。
免费采集器自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。书签页面。标签页,这是对一些信息网站或更多信息发布网站的类似内容的分类,与栏目类似,但与栏目页不同,标签页只能是一个词或一个长尾 关键词。今天关于优采云采集器的讲解就到这里了,下期会分享更多与SEO相关的功能。
查看全部
免规则采集器列表算法(优采云采集器免费功能强大的采集器需要写采集规则,还有对接复杂的发布模块
)
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,获得了众多用户的一致认可。但是优采云采集器有一个很麻烦的地方,就是需要编写采集规则,连接复杂的发布模块。有没有免费又强大的采集器?一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。

免费采集器可以设置标题前缀和后缀(标题的区别更好收录)。使 网站 内容更好。内容是网站的基础。没有好的内容,就没有回头客,如果在其他方面做得好,那就是白费了。好的内容不仅适合用户,也适合搜索引擎。优秀的SEO文案可以找到两者之间的共同点。
免费的采集器可以合理的网站架构。网站架构是SEO的基础部分。主要与代码缩减、目录结构、网页收录、网站网站的跳出率等有关。合理的架构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
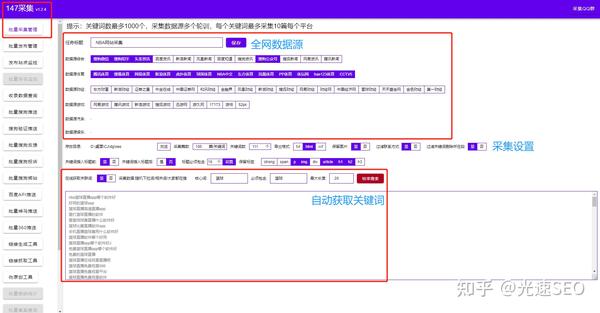
免费采集器支持多种采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。可以深入挖掘用户需求。一个合格的SEO工作者,大部分时间都是在挖掘用户需求,也就是说,用户还需要什么?此外,他们必须对行业有绝对的了解,这样网站才能全面、专业、深刻。
免费采集器搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能够被搜索引擎收录及时搜索到)。
免费采集器提供高质量的外部链接。虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
免费采集器给用户完美体验。用户体验包括很多方面,几乎都是前面所有的内容,比如内容是否优质、专业、全面,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项工作每天都需要优化。.
从下拉词、相关搜索词和长尾词中免费生成行业相关词采集器、关键词。可以设置自动删除不相关的词。如何为单个页面编写网站标题。一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?免费采集器支持其他平台的图片本地化或存储。
主页标题。主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
免费采集器内容与标题一致(使内容与标题100%相关)。栏目页最重要的是内容的契合度,即相关性。如果你在标题上堆积了很多相关的内容,你可以做一些扩展来满足我们对内容的准确命题。栏目内容很多,整合了很多。为此,我们可以适当扩展标题。以网站的建设为例,我们可以设置标题收录网站建设。新闻标题、网站模板、技术文档等。
免费采集器自动内链(在执行发布任务时自动生成文章内容中的内链,有利于引导页面蜘蛛抓取,提高页面权限)。在新闻页面方面,虽然单个页面并不比首页或栏目页面好,但如果将多个新闻页面与它们进行比较,则不一定如此。这种比较的标准是基于流量的。新闻页面的标题一般是信息标题加上公司名称。这种写法我也挺中肯的。我也用过,效果不错,但最重要的是效果不明显或者关键词的排名不高。,这个时候我们可以换个方法,用什么方法呢?就是写文章标题不带公司名,这样效果更好,

批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群, PB, Apple, 搜外 和其他主要的cms 工具,可以同时管理和批量发布)。对于产品页面的标题,我个人遵循产品字+公司名称的原则。这样做有两个好处。一是提高公司知名度,推广产品。更多人会看到,名字背后的公司也会受到关注。的。
免费采集器自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。书签页面。标签页,这是对一些信息网站或更多信息发布网站的类似内容的分类,与栏目类似,但与栏目页不同,标签页只能是一个词或一个长尾 关键词。今天关于优采云采集器的讲解就到这里了,下期会分享更多与SEO相关的功能。

免规则采集器列表算法(,采集你的网站信息的话,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-13 21:19
过去我们通过时间和逻辑算法来控制它,做到标本兼治。楼上的太简单了。如果你真的想采集你的网站信息,其实很简单。
我在网上找到了一个非常全面的防止采集的方法,可以参考一下
在实现很多反采集的方法时,需要考虑是否影响搜索引擎对网站的抓取,所以我们先来分析一下一般的采集器和搜索引擎有什么区别爬虫 采集 不同。
相似之处:A。两者都需要直接抓取网页的源代码才能有效工作,b. 两者会在单位时间内多次抓取大量访问过的网站内容;C。宏观上来说,两者的IP都会发生变化;d。两个都迫不及待的想破解你网页的一些加密(验证),比如网页内容是用js文件加密的,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容, ETC。
区别:搜索引擎爬虫首先会忽略整个网页的源脚本和样式以及HTML标签代码,然后对剩下的文本进行分词、语法分析等一系列复杂的处理。而采集器一般使用html标签特性来抓取需要的数据,而在制定采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容内容; 或者使用针对特定网页制作特定的正则表达式来过滤掉需要的内容。无论你使用开始和结束标记还是正则表达式,都会涉及到html标签(网页结构分析)。
然后想出一些反采集的方法
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录 查看全部
免规则采集器列表算法(,采集你的网站信息的话,)
过去我们通过时间和逻辑算法来控制它,做到标本兼治。楼上的太简单了。如果你真的想采集你的网站信息,其实很简单。
我在网上找到了一个非常全面的防止采集的方法,可以参考一下
在实现很多反采集的方法时,需要考虑是否影响搜索引擎对网站的抓取,所以我们先来分析一下一般的采集器和搜索引擎有什么区别爬虫 采集 不同。
相似之处:A。两者都需要直接抓取网页的源代码才能有效工作,b. 两者会在单位时间内多次抓取大量访问过的网站内容;C。宏观上来说,两者的IP都会发生变化;d。两个都迫不及待的想破解你网页的一些加密(验证),比如网页内容是用js文件加密的,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容, ETC。
区别:搜索引擎爬虫首先会忽略整个网页的源脚本和样式以及HTML标签代码,然后对剩下的文本进行分词、语法分析等一系列复杂的处理。而采集器一般使用html标签特性来抓取需要的数据,而在制定采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容内容; 或者使用针对特定网页制作特定的正则表达式来过滤掉需要的内容。无论你使用开始和结束标记还是正则表达式,都会涉及到html标签(网页结构分析)。
然后想出一些反采集的方法
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录
免规则采集器列表算法(2019独角兽企业重金招聘Python工程师标准(gt)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-13 18:23
2019独角兽企业招聘Python工程师标准>>>
一、简单的PageRank计算
首先,我们将Web抽象如下: 1、将每个网页抽象成一个节点;2、如果页面 A 有直接到 B 的链接,则从 A 到 B 存在有向边(多个相同链接不重复计算边)。因此,整个 Web 被抽象为一个有向图。
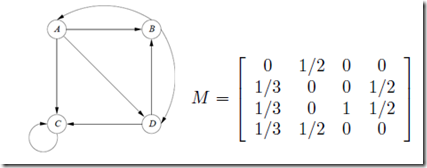
现在假设世界上只有四个网页:A、B、C、D。抽象结构如下图所示。显然,这个图是强连接的(从任何节点,你可以到达任何其他节点)。
然后需要使用合适的数据结构来表示页面之间的连接关系。PageRank算法就是基于这样一个背景思想:随机上网者访问的页面越多,质量可能就越高,而随机上网者在浏览网页时主要通过超链接跳转到页面,所以我们需要分析构成的超链接。图结构用于估计每个网页被访问的频率。更直观地说,一个网页的 PangRank 越高,随机浏览者在浏览该网页的过程中停留在该页面的概率就越大,该网页的重要性就越高。
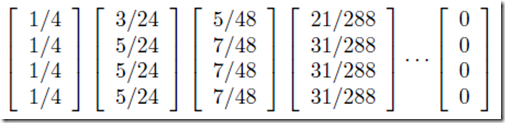
为简单起见,我们可以假设当一个随机的冲浪者停留在一个页面上时,跳转到该页面上每个链接页面的概率是相同的。比如上图中,页面A链接到B、C、D,所以用户从A跳转到B、C、D的概率各为1/3。假设总共有N个网页,可以组织一个N维矩阵:第i行第j列的值代表用户从第j页到第i页的概率。这样的矩阵称为转移矩阵。上图中四个网页对应的转移矩阵M如下:
那么,假设随机浏览者从n个页面出来的初始概率相等,那么初始概率分布向量是一个n维的列向量V0,每个维度为1/n。这里我们有 4 页,所以 V0-1=[1/4, 1/4, 1/4, 1/4]。
这样,我们就可以从初始向量 V0 开始,不断地将转移矩阵 M 左乘。用户在浏览网页时主要通过超链接使i跳转后,停留在每个页面的概率为:Mi*V。停止直到最后两次迭代在结果向量中产生非常小的差异。实际上,对于 Web,50 到 75 次迭代足以收敛,误差控制在双精度。
以下是前四次跳转时每次迭代后每个页面的PageRank值:
可以看出,随着迭代次数的增加,网页A的PageRank值越来越大,接近其极限概率3/9。这也说明随机上网者停留在A页面的概率大于B、C、D页面,页面也更重要。
二、问题一:死胡同
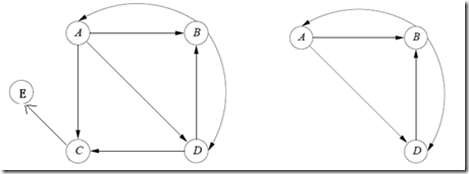
终止点是没有出链的点,比如下图中的C。
如果我们不对其进行处理,让终止点存在,那么随着PageRank迭代次数的增加,每个网页的PageRank值会趋于0,这样就无法得到网页相对重要性的信息.
通过从图中删除它们及其传入链来处理终止。这样做之后,可以生成更多的端点,并继续迭代消除端点。但最终我们得到了一个强连通子图,其中所有节点都是非终端的。我们以左图为例进行说明。按照上述步骤消除终止点后得到左图,得到右图。
我们得到右图对应的转移矩阵,计算图中A、B、C的PageRank值。
我们得到A、B、C的PageRank值分别为2/9、4/9、3/9,然后按照删除的逆序计算C、E的PageRank值. 由于 C 是最后被删除的,因此首先计算 C 的 PageRank 值。A有3个外链,所以它贡献了1/3的PageRank值给C。D有3个外链,所以它贡献了1/2的PageRank值给C。所以C的PageRank为
. E的入链只有C,C的出链只有E,所以E的PageRank值等于C的PageRank值。
需要注意的是,当前所有节点的PageRank值之和已经超过1,因此不能代表随机浏览者的概率分布,但仍能反映对页面相对重要性的合理估计。
三、问题2:采集器蜘蛛陷阱
采集器陷阱是一组节点,虽然它们都不是终止点,但它们都没有出链指向该集合之外的其他节点。采集器 陷阱导致计算时将所有 PageRank 值分配给 采集器 陷阱内的节点。
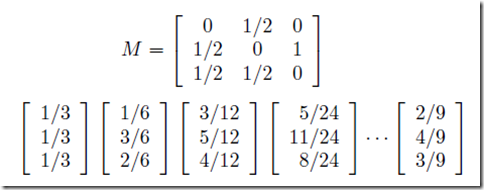
如下图所示,C是一个单节点采集器陷阱及其转移矩阵。
随着迭代的进行,C 的 PageRank 值趋于 1,而其他不在 采集器 陷阱中的节点的 PageRank 值趋于 0。
采集器 陷阱的处理方式是允许每个随机浏览者随机跳转到一个随机页面,跳转概率很小,而不必遵循当前页面上的外链。因此,根据上一次PageRank估计值V和转移矩阵M估计下一次迭代后的PageRank值V'的迭代公式变为:
其中 β 是一个选定的常数,通常介于 0.8 和 0.9 之间。e 是一个向量,其分量全为 1,维度为 n,其中 n 是 Web 图中所有节点的个数。βMv 表示随机冲浪者以概率 β 从当前网页中选择外链向前移动的情况。(1−β)e/n 是一个所有分量为 (1−β)/n 的向量,它表示一个新的随机冲浪者具有 (1−β) 概率随机选择要访问的网页。
取β=0.8,上图的迭代公式变为:
以下是之前迭代的结果:
作为一个采集器 陷阱,C 获得了超过一半的 PageRank 值,但这种影响是有限的,并且每个其他节点也获得了一些 PageRank 值。
-------------------------------------------------
参考:
《大数据:互联网大规模数据挖掘与分布式处理》王斌老师_ICTIR及其对应英文电子书《海量数据集挖掘》 查看全部
免规则采集器列表算法(2019独角兽企业重金招聘Python工程师标准(gt)(图))
2019独角兽企业招聘Python工程师标准>>>

一、简单的PageRank计算
首先,我们将Web抽象如下: 1、将每个网页抽象成一个节点;2、如果页面 A 有直接到 B 的链接,则从 A 到 B 存在有向边(多个相同链接不重复计算边)。因此,整个 Web 被抽象为一个有向图。
现在假设世界上只有四个网页:A、B、C、D。抽象结构如下图所示。显然,这个图是强连接的(从任何节点,你可以到达任何其他节点)。
然后需要使用合适的数据结构来表示页面之间的连接关系。PageRank算法就是基于这样一个背景思想:随机上网者访问的页面越多,质量可能就越高,而随机上网者在浏览网页时主要通过超链接跳转到页面,所以我们需要分析构成的超链接。图结构用于估计每个网页被访问的频率。更直观地说,一个网页的 PangRank 越高,随机浏览者在浏览该网页的过程中停留在该页面的概率就越大,该网页的重要性就越高。
为简单起见,我们可以假设当一个随机的冲浪者停留在一个页面上时,跳转到该页面上每个链接页面的概率是相同的。比如上图中,页面A链接到B、C、D,所以用户从A跳转到B、C、D的概率各为1/3。假设总共有N个网页,可以组织一个N维矩阵:第i行第j列的值代表用户从第j页到第i页的概率。这样的矩阵称为转移矩阵。上图中四个网页对应的转移矩阵M如下:

那么,假设随机浏览者从n个页面出来的初始概率相等,那么初始概率分布向量是一个n维的列向量V0,每个维度为1/n。这里我们有 4 页,所以 V0-1=[1/4, 1/4, 1/4, 1/4]。
这样,我们就可以从初始向量 V0 开始,不断地将转移矩阵 M 左乘。用户在浏览网页时主要通过超链接使i跳转后,停留在每个页面的概率为:Mi*V。停止直到最后两次迭代在结果向量中产生非常小的差异。实际上,对于 Web,50 到 75 次迭代足以收敛,误差控制在双精度。
以下是前四次跳转时每次迭代后每个页面的PageRank值:

可以看出,随着迭代次数的增加,网页A的PageRank值越来越大,接近其极限概率3/9。这也说明随机上网者停留在A页面的概率大于B、C、D页面,页面也更重要。
二、问题一:死胡同
终止点是没有出链的点,比如下图中的C。

如果我们不对其进行处理,让终止点存在,那么随着PageRank迭代次数的增加,每个网页的PageRank值会趋于0,这样就无法得到网页相对重要性的信息.
通过从图中删除它们及其传入链来处理终止。这样做之后,可以生成更多的端点,并继续迭代消除端点。但最终我们得到了一个强连通子图,其中所有节点都是非终端的。我们以左图为例进行说明。按照上述步骤消除终止点后得到左图,得到右图。
我们得到右图对应的转移矩阵,计算图中A、B、C的PageRank值。
我们得到A、B、C的PageRank值分别为2/9、4/9、3/9,然后按照删除的逆序计算C、E的PageRank值. 由于 C 是最后被删除的,因此首先计算 C 的 PageRank 值。A有3个外链,所以它贡献了1/3的PageRank值给C。D有3个外链,所以它贡献了1/2的PageRank值给C。所以C的PageRank为

. E的入链只有C,C的出链只有E,所以E的PageRank值等于C的PageRank值。
需要注意的是,当前所有节点的PageRank值之和已经超过1,因此不能代表随机浏览者的概率分布,但仍能反映对页面相对重要性的合理估计。
三、问题2:采集器蜘蛛陷阱
采集器陷阱是一组节点,虽然它们都不是终止点,但它们都没有出链指向该集合之外的其他节点。采集器 陷阱导致计算时将所有 PageRank 值分配给 采集器 陷阱内的节点。
如下图所示,C是一个单节点采集器陷阱及其转移矩阵。
随着迭代的进行,C 的 PageRank 值趋于 1,而其他不在 采集器 陷阱中的节点的 PageRank 值趋于 0。

采集器 陷阱的处理方式是允许每个随机浏览者随机跳转到一个随机页面,跳转概率很小,而不必遵循当前页面上的外链。因此,根据上一次PageRank估计值V和转移矩阵M估计下一次迭代后的PageRank值V'的迭代公式变为:
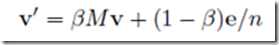
其中 β 是一个选定的常数,通常介于 0.8 和 0.9 之间。e 是一个向量,其分量全为 1,维度为 n,其中 n 是 Web 图中所有节点的个数。βMv 表示随机冲浪者以概率 β 从当前网页中选择外链向前移动的情况。(1−β)e/n 是一个所有分量为 (1−β)/n 的向量,它表示一个新的随机冲浪者具有 (1−β) 概率随机选择要访问的网页。
取β=0.8,上图的迭代公式变为:

以下是之前迭代的结果:

作为一个采集器 陷阱,C 获得了超过一半的 PageRank 值,但这种影响是有限的,并且每个其他节点也获得了一些 PageRank 值。
-------------------------------------------------
参考:
《大数据:互联网大规模数据挖掘与分布式处理》王斌老师_ICTIR及其对应英文电子书《海量数据集挖掘》
免规则采集器列表算法( 基于树的搜索(tree-search),不能的研究目的有两个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-04-12 22:04
基于树的搜索(tree-search),不能的研究目的有两个)
这个文章的研究内容是:具有规划能力的agent。
在此之前,许多研究都使用了基于树的规划方法。然而,在实际的业务应用中,动态控制/仿真环境往往是复杂且未知的。
这篇文章文章 提出了一种算法:MuZero,它通过将基于树的搜索与学习模型相结合,在不了解环境底层动态的情况下可以很好地执行。这很好。
这里的学习模型实际上是迭代应用的,可以预测与计划最相关的奖励、行动选择策略和价值函数。
所以,总而言之,MuZero 的研究目标有两个:
下面就开始看具体的作品吧!
1 算法简介1.1 背景
基于前瞻搜索的规划算法有很多应用。然而,这些规划算法都依赖于精确的模拟器和严格的规则,无法直接用于现实世界。
我们知道强化学习算法分为基于模型和无模型。一般来说,我们的研究侧重于无模型方法,即直接从与环境的交互中估计最优策略和价值函数。这些方法在某些视频游戏中运行良好,例如 Atari。但是,无模型在需要精确和复杂前瞻的领域(例如围棋或国际象棋)中效果较差。
在一般的基于模型的强化学习方法中,模型实际上是一个概率分布,也就是构建一个真实的环境,或者说是一个完整的观察。首先从环境的动态中学习一个模型,然后根据学习到的模型进行规划。但在 Atari 游戏实验中,性能不如 Model-based。
本文文章介绍了一种新的基于模型的强化学习方法MuZero,它不仅可以在视觉复杂的Atari上表现出色,而且在精确规划任务中也表现出色。这很好,
MuZero 算法基于 AlphaZero 强大的搜索和基于搜索的策略算法,在训练过程中加入了一个学习模型。
除此之外,MuZero 将 AlphaZero 扩展到更广泛的环境,包括单个代理域和中间时间步长的非零奖励。
小总结:
规划(planning algorithm)是一个难点研究。众所周知的 AlphaGo 是一种基于树的规划算法,但此类算法需要完美的环境模型,这在现实世界中很难满足。
DeepMind 的 MuZero 算法是基于模型的 RL 领域的里程碑式成就,在促进强化学习解决现实问题方面迈出了新的一步。1.2 理解算法的思想
首先介绍一下MuZero算法的思想:
MuZero算法的主要思想是构造一个抽象的MDP模型,在这个MDP模型上,预测与Planning直接相关的未来数据(策略、价值函数和奖励),并在此基础上预测数据进行规划。
那么为什么要这样做,为什么它会起作用?让我们将论文中的内容“分解”和“粉碎”来理解算法的思想:
1.2.1 为什么要抽象
我们知道,大多数基于模型的强化学习方法都会学习对应于真实环境的动态模型。
但是,如果是用于 Planning,我们并不关心 Dynamics Model 是否准确地还原了真实环境。
只要这个 Dynamics Model 给出的未来每一步的价值和回报接近真实环境中的价值,我们就可以将其作为 Planning 中的模拟器。
MuZero 算法是首先将真实环境中通过编码器(表示函数)获得的状态转换为没有直接约束的抽象状态空间(abstract state space)中的隐藏状态(hidden state)。状态并假设循环迭代的下一个动作)。
然后在这个抽象的状态空间中,学习Dynamics Model和价值预测,预测每个隐藏状态上的策略(这就是和本文的区别),得到Policy Prediction Network。
然后,使用蒙特卡洛树搜索,使用 Dynamics Model 作为模拟器,在抽象状态空间中做 Planning,预测接下来几个步骤的策略、价值函数和奖励。
这里的隐藏状态是不适合真实环境的。取而代之的是,在抽象状态空间中训练的 Dynamics Model 和价值预测网络可以预测在初始隐藏状态和执行接下来的 k 步后接下来 k 步的价值和奖励,以及通过搜索得到的价值和奖励在真实环境中。观察到的奖励尽可能接近。
简单来说,就是先在虚拟状态空间中学习一个环境模型,然后在不与真实环境过多交互的情况下,根据学习到的环境模型进行规划。
1.2.2 为什么有效
那么我们如何保证抽象MDP中的规划与真实环境中的规划是等价的呢?
这种等价是通过确保价值等价来实现的。
也就是说,从相同的真实状态开始,通过抽象 MDP 的轨迹累积奖励与真实环境中轨迹的累积奖励相匹配。
2 型号图解说明
首先,整体数据是模型的数学表达式:
给定一个隐藏状态和一个候选动作,动态模型需要生成一个即时奖励和一个新的隐藏状态。策略和价值函数是由预测函数从输入中计算出来的。操作是从搜索策略中采样的。环境收到一个动作以产生新的观察和奖励。
接下来通过图文结合的方式,具体讲讲如何使用学习到的模型进行策划、演戏、训练。
2.1 MuZero中模型的组成
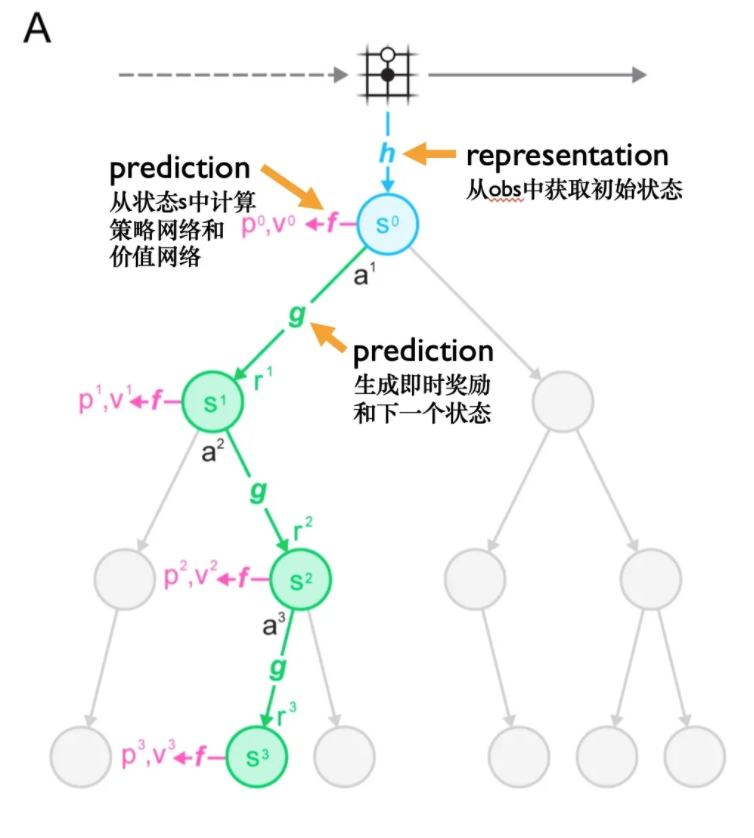
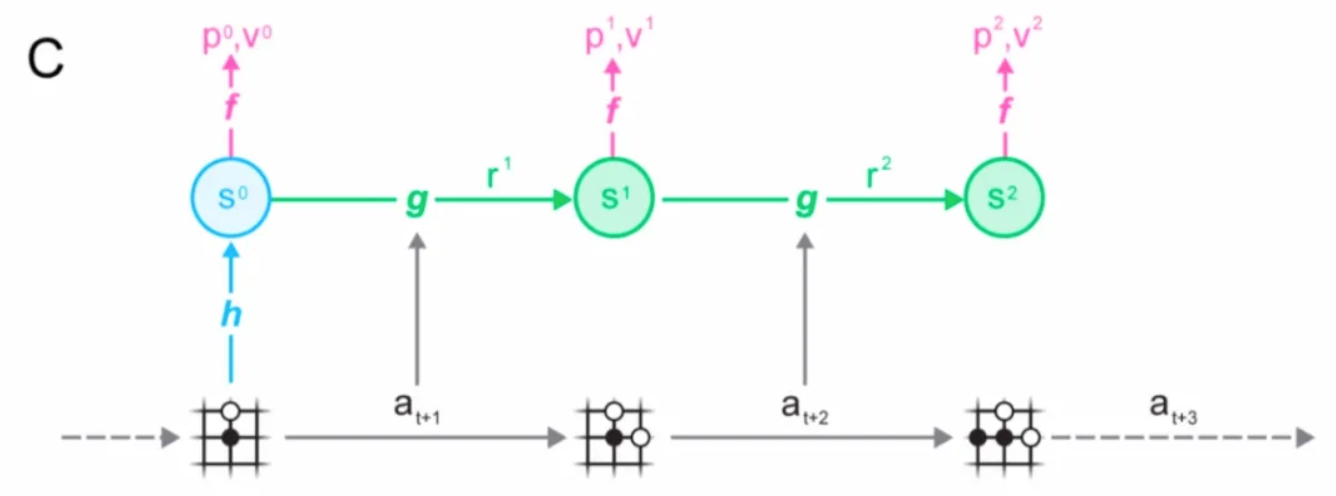
MuZero 如何使用该模型进行规划?我们看图A:
所谓模型由以下3个相互关联的部分组成:
2.2 MuZero 如何与环境交互并做出决策
图 A 中描述的是,在每一步中,隐藏状态执行蒙特卡洛树搜索到下一个动作。
那么 MuZero 是如何在环境中做出决策的呢?
下图是横看各招的情况:
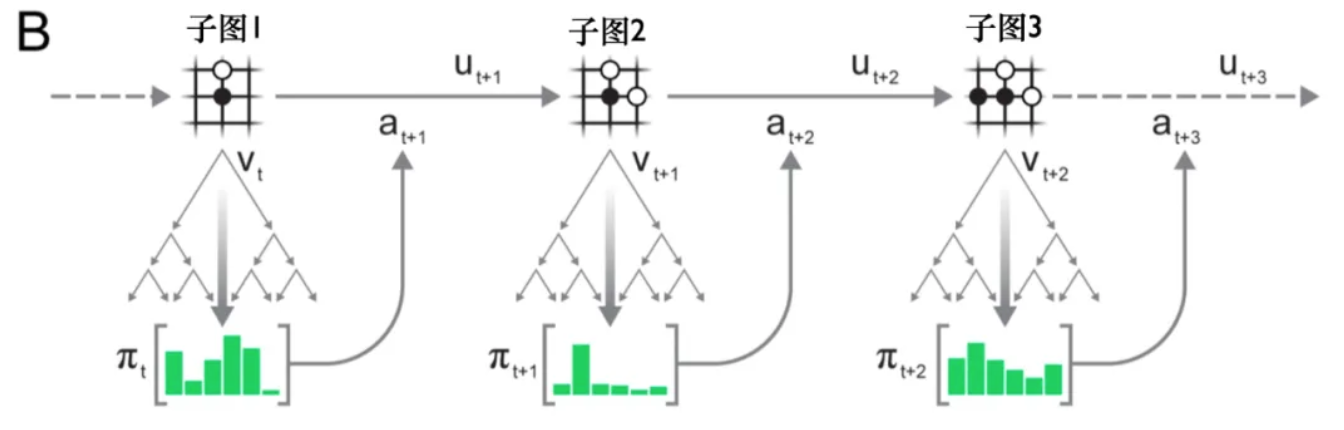
对于子图1描述的情况(一黑一白),使用蒙特卡洛树搜索对其建模得到一个策略网络,并对策略网络进行采样选择可执行动作,这个动作与访问量成正比MCTS 根节点的每个操作的计数。
执行动作后,得到奖励,得到下一时刻的观察(子图2),同样使用MCTS进行建模,得到策略网络,选择可执行动作。
环境接受动作,产生新的观察和奖励,产生子图 3。
这样,轨迹数据在剧集结束时存储在重放缓冲区中。这是一个决定。
2.3 MuZero 如何训练模型
那么 MuZero 是如何训练模型的呢?让我们看看下面的过程:
对 Replay Buffer 中的轨迹数据进行采样,选择一个序列,然后针对该轨迹运行 MuZero 模型。
在初始步骤中,编码器表示函数接受来自所选轨迹的过去观察。
随后,模型展开一个 K 步循环。
在第 k 步中,生成器动力学函数接收上一步的隐藏状态和实际动作。
编码器表示函数、生成器动力学函数、预测器预测函数的参数可以通过backpropagation-through-time的端到端联合训练来预测,可以预测三个量:
其中是样本回报,例如棋盘游戏中的最终奖励,或 Atari 中 n 步的奖励。
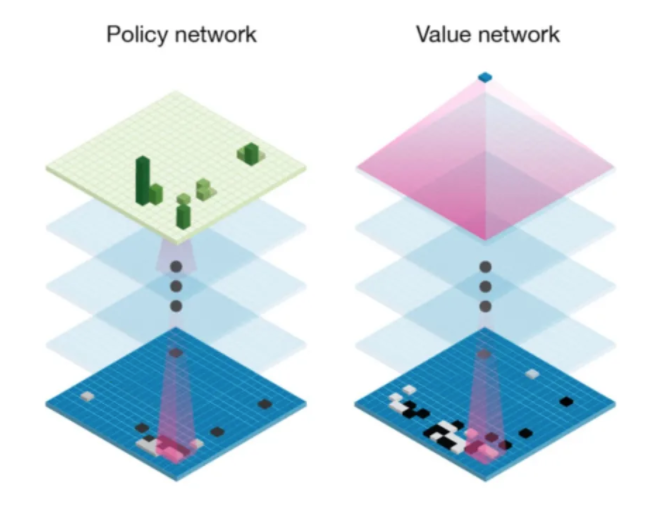
3 MuZero算法详解3.1 价值网络和策略网络
MuZero 是一种机器学习算法,因此很自然地首先要了解它是如何使用神经网络的。
简而言之,该算法使用了 AlphaGo 和 AlphaZero 的策略和价值网络:
政策网络和价值网络的直观含义如下:
根据策略网络,可以预测每一步的动作;依靠价值网络,可以选择价值最高的动作。结合这两个估计可以得到更好的结果。
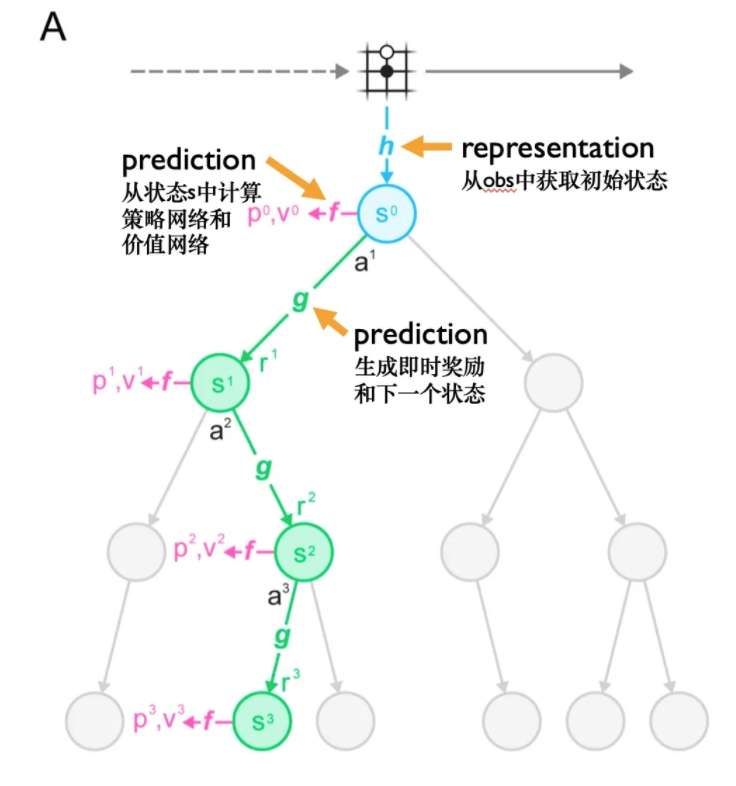
3.2 MuZero中的蒙特卡洛树搜索3.2.1 MCTS简介
MuZero 还使用 MCTS(蒙特卡洛树搜索)聚合神经网络来预测和选择当前环境中的下一个动作。到达终点后,树中的每个节点都会存储一些相关的参数,包括访问次数、轮数、前一个动作的概率、子节点以及是否有对应的隐藏状态和奖励。
蒙特卡洛树搜索是一个迭代的、最佳优先的树搜索过程。目标是帮助我们弄清楚要采取哪些行动来最大化长期利益。
Best first,这意味着搜索树的扩展取决于搜索树中的值估计。
与常见的深度优先和广度优先相比,最佳优先搜索可以利用深度神经网络的启发式估计,在非常大的搜索空间中找到最优解。
蒙特卡洛树搜索有四个主要阶段:
通过重复这些阶段,MCTS 每次都在节点可能的未来动作序列上逐步构建搜索树。在这棵树中,每个节点代表一个未来状态,节点之间的线代表从一个状态到下一个状态的动作。
3.22 MuZero算法中MCTS的四个阶段
接下来我们对应MuZero算法中的蒙特卡洛树搜索,看看上面四个阶段分别对应什么:
我们先来看看模拟。
模拟过程与蒙特卡罗方法类似,推导速度快。为了得到某个状态的初始分数,让游戏随机玩到最后,记录模拟次数和获胜次数。
接下来是选择。
虽然 Muzero 不知道游戏规则,但它知道该采取哪些步骤。在每个节点(状态 s),使用评分函数比较不同的动作,并选择得分最高的最佳动作。
每次选择一个动作时,我们都会为 UCB 缩放因子 c 和后续动作选择增加其关联的访问计数 N(s,a)。
模拟沿着树向下进行到尚未扩展的叶子。此时,应用神经网络对节点进行评估,将评估结果(优先级和值估计)存储在节点中。
然后是扩展。
选择动作 A 后,在搜索树中生成一个新节点,对应动作 A 执行后前一个状态的情况。
最后回溯。
模拟结束后,从子节点开始沿着刚刚下的路径返回,沿途更新每个父节点的统计信息。每个节点都持有其下所有价值估计的连续平均值,这使得 UCB 公式可以随着时间的推移做出越来越准确的决策,确保 MCTS 收敛到最优动作。
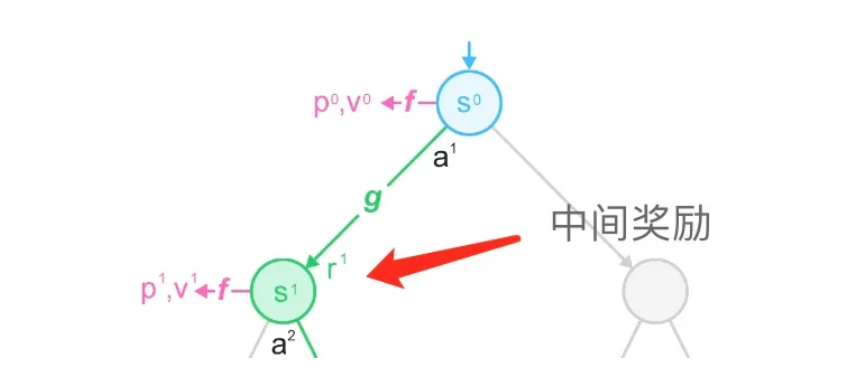
3.2.3 中级奖励
事实上,在 MCTS 的过程中,也收录了对中间奖励 r 的预测。
在某些情况下,游戏完全结束后需要输赢反馈,这可以通过价值估计来建模。但是在频繁反馈的情况下,从一种状态到另一种状态的每次转换都会得到奖励 r。
因此,奖励直接通过神经网络预测建模并用于搜索。在 UCB 策略中引入中间奖励:
其中是在状态 s 执行动作 a 后观察到的奖励,折扣因子是对未来奖励的关注程度。
由于在某些环境中奖励是无界的,因此可以将奖励和价值估计归一化到 [0,1] 期间,然后与先验知识相结合:
其中 和 分别是在整个搜索树中观察到的最大和最小估计值。
3.3 总体说明
基于过去的观察和未来的行为,对于给定步骤中的每一步,使用带有参数的模型在每个时间步进行预测。
该模型预测 3 个数量:
其中是地面实况观察奖励,是策略,是折扣因子。
说白了就是获取过去的观察数据,编码成当前的隐藏状态,然后给出未来的动作,然后在隐藏状态空间进行规划。
3.4 步分解
在每个步骤中,模型由表示函数、动力学函数和预测函数组成:
使用这样的模型,可以根据过去的观察来搜索虚拟的未来轨迹。
例如,可以简单地选择 k 步动作序列来搜索最大化价值函数。
也可以使用类似于 AlphaZero 搜索的 MCTS 算法来获取策略和估计值,然后从策略中选择动作。此外,执行操作并生成中间奖励和状态空间。
在第 k 步,通过联合训练模型的所有参数,将策略、价值和奖励与实际观察到的目标值图像进行匹配。
模型的所有参数都经过联合训练,使得每个假设步 k 的策略、值和奖励与 k 个实际时间步后观察到的相应目标值完全匹配。
使用 MCTS,可以使用三个改进的策略目标:
最后加上L2正则化项得到最终的损失函数:
4 总结
强化学习分为两类:基于模型的和无模型的。
其中,基于模型的强化学习方法需要构建环境模型。通常,环境模型由马尔可夫决策过程(MDP)表示。该过程由两部分组成:
模型通常针对选定的动作或时间抽象的行为进行训练。一旦模型建立,MDP 规划算法(例如:值迭代、蒙特卡洛树搜索 MCTS)可以直接用于计算 MDP 的最优值或最优策略。
因此,在复杂环境或局部观察的情况下,很难构建模型应该预测的状态表示。因为Agent没有办法优化“有效规划的目的”的表示和模型,这就导致了表示学习、模型学习和规划之间的分离。
另一方面,MuZero 是一种完全不同的基于模型的强化学习方法,专注于端到端的预测函数。主要思想是构造一个抽象的MDP模型,使抽象MDP中的规划等价于真实环境中的规划。
这种等价是通过保证价值等价来实现的,即从相同的真实状态开始,通过抽象MDP获得的轨迹累积奖励与真实环境中的轨迹累积奖励相匹配。
预测器首先引入价值等价模型来预测价值而无需采取行动。
虽然底层模型是 MDP,但它的变换模型不需要匹配环境中的真实状态,只需将 MDP 模型视为深度神经网络中的隐藏层即可。展开的 MDP 被训练,例如通过时间差异学习,以将累积奖励的预期总和与实际环境的预期值相匹配。
然后,将价值等价模型扩展为以行动优化价值。TreeQN 学习一个抽象的 MDP 模型,以便在该模型上的树搜索(由树结构的神经网络表示)近似于最优值函数。值迭代网络学习一个局部 MDP 模型,使得该模型上的值迭代(由卷积神经网络表示)接近最优值函数。
价值预测网络更接近于 MuZero:根据实际动作学习一个 MDP 模型;对展开的 MDP 进行训练,以使奖励的累积总和(以简单前向搜索产生的实际动作序列为条件)与真实环境匹配一致。如果没有策略预测,则搜索仅使用值预测。
通过论文的学习,虽然理解了MuZero算法的思想,但是在实际项目中使用MuZero还是比较困难的。
比如如何设计表示、动态、预测等,这些都需要在对代码实现非常熟悉的情况下结合具体的业务场景来实现。
提供基于pytorch的muzero算法实现:
如果有时间,我会继续研究代码并尝试复现论文。
结束 查看全部
免规则采集器列表算法(
基于树的搜索(tree-search),不能的研究目的有两个)

这个文章的研究内容是:具有规划能力的agent。
在此之前,许多研究都使用了基于树的规划方法。然而,在实际的业务应用中,动态控制/仿真环境往往是复杂且未知的。
这篇文章文章 提出了一种算法:MuZero,它通过将基于树的搜索与学习模型相结合,在不了解环境底层动态的情况下可以很好地执行。这很好。
这里的学习模型实际上是迭代应用的,可以预测与计划最相关的奖励、行动选择策略和价值函数。
所以,总而言之,MuZero 的研究目标有两个:
下面就开始看具体的作品吧!
1 算法简介1.1 背景
基于前瞻搜索的规划算法有很多应用。然而,这些规划算法都依赖于精确的模拟器和严格的规则,无法直接用于现实世界。
我们知道强化学习算法分为基于模型和无模型。一般来说,我们的研究侧重于无模型方法,即直接从与环境的交互中估计最优策略和价值函数。这些方法在某些视频游戏中运行良好,例如 Atari。但是,无模型在需要精确和复杂前瞻的领域(例如围棋或国际象棋)中效果较差。
在一般的基于模型的强化学习方法中,模型实际上是一个概率分布,也就是构建一个真实的环境,或者说是一个完整的观察。首先从环境的动态中学习一个模型,然后根据学习到的模型进行规划。但在 Atari 游戏实验中,性能不如 Model-based。
本文文章介绍了一种新的基于模型的强化学习方法MuZero,它不仅可以在视觉复杂的Atari上表现出色,而且在精确规划任务中也表现出色。这很好,
MuZero 算法基于 AlphaZero 强大的搜索和基于搜索的策略算法,在训练过程中加入了一个学习模型。
除此之外,MuZero 将 AlphaZero 扩展到更广泛的环境,包括单个代理域和中间时间步长的非零奖励。
小总结:
规划(planning algorithm)是一个难点研究。众所周知的 AlphaGo 是一种基于树的规划算法,但此类算法需要完美的环境模型,这在现实世界中很难满足。
DeepMind 的 MuZero 算法是基于模型的 RL 领域的里程碑式成就,在促进强化学习解决现实问题方面迈出了新的一步。1.2 理解算法的思想
首先介绍一下MuZero算法的思想:
MuZero算法的主要思想是构造一个抽象的MDP模型,在这个MDP模型上,预测与Planning直接相关的未来数据(策略、价值函数和奖励),并在此基础上预测数据进行规划。
那么为什么要这样做,为什么它会起作用?让我们将论文中的内容“分解”和“粉碎”来理解算法的思想:
1.2.1 为什么要抽象
我们知道,大多数基于模型的强化学习方法都会学习对应于真实环境的动态模型。
但是,如果是用于 Planning,我们并不关心 Dynamics Model 是否准确地还原了真实环境。
只要这个 Dynamics Model 给出的未来每一步的价值和回报接近真实环境中的价值,我们就可以将其作为 Planning 中的模拟器。
MuZero 算法是首先将真实环境中通过编码器(表示函数)获得的状态转换为没有直接约束的抽象状态空间(abstract state space)中的隐藏状态(hidden state)。状态并假设循环迭代的下一个动作)。
然后在这个抽象的状态空间中,学习Dynamics Model和价值预测,预测每个隐藏状态上的策略(这就是和本文的区别),得到Policy Prediction Network。
然后,使用蒙特卡洛树搜索,使用 Dynamics Model 作为模拟器,在抽象状态空间中做 Planning,预测接下来几个步骤的策略、价值函数和奖励。
这里的隐藏状态是不适合真实环境的。取而代之的是,在抽象状态空间中训练的 Dynamics Model 和价值预测网络可以预测在初始隐藏状态和执行接下来的 k 步后接下来 k 步的价值和奖励,以及通过搜索得到的价值和奖励在真实环境中。观察到的奖励尽可能接近。
简单来说,就是先在虚拟状态空间中学习一个环境模型,然后在不与真实环境过多交互的情况下,根据学习到的环境模型进行规划。
1.2.2 为什么有效
那么我们如何保证抽象MDP中的规划与真实环境中的规划是等价的呢?
这种等价是通过确保价值等价来实现的。
也就是说,从相同的真实状态开始,通过抽象 MDP 的轨迹累积奖励与真实环境中轨迹的累积奖励相匹配。
2 型号图解说明
首先,整体数据是模型的数学表达式:
给定一个隐藏状态和一个候选动作,动态模型需要生成一个即时奖励和一个新的隐藏状态。策略和价值函数是由预测函数从输入中计算出来的。操作是从搜索策略中采样的。环境收到一个动作以产生新的观察和奖励。
接下来通过图文结合的方式,具体讲讲如何使用学习到的模型进行策划、演戏、训练。
2.1 MuZero中模型的组成
MuZero 如何使用该模型进行规划?我们看图A:
所谓模型由以下3个相互关联的部分组成:
2.2 MuZero 如何与环境交互并做出决策
图 A 中描述的是,在每一步中,隐藏状态执行蒙特卡洛树搜索到下一个动作。
那么 MuZero 是如何在环境中做出决策的呢?
下图是横看各招的情况:
对于子图1描述的情况(一黑一白),使用蒙特卡洛树搜索对其建模得到一个策略网络,并对策略网络进行采样选择可执行动作,这个动作与访问量成正比MCTS 根节点的每个操作的计数。
执行动作后,得到奖励,得到下一时刻的观察(子图2),同样使用MCTS进行建模,得到策略网络,选择可执行动作。
环境接受动作,产生新的观察和奖励,产生子图 3。
这样,轨迹数据在剧集结束时存储在重放缓冲区中。这是一个决定。
2.3 MuZero 如何训练模型
那么 MuZero 是如何训练模型的呢?让我们看看下面的过程:
对 Replay Buffer 中的轨迹数据进行采样,选择一个序列,然后针对该轨迹运行 MuZero 模型。
在初始步骤中,编码器表示函数接受来自所选轨迹的过去观察。
随后,模型展开一个 K 步循环。
在第 k 步中,生成器动力学函数接收上一步的隐藏状态和实际动作。
编码器表示函数、生成器动力学函数、预测器预测函数的参数可以通过backpropagation-through-time的端到端联合训练来预测,可以预测三个量:
其中是样本回报,例如棋盘游戏中的最终奖励,或 Atari 中 n 步的奖励。
3 MuZero算法详解3.1 价值网络和策略网络
MuZero 是一种机器学习算法,因此很自然地首先要了解它是如何使用神经网络的。
简而言之,该算法使用了 AlphaGo 和 AlphaZero 的策略和价值网络:
政策网络和价值网络的直观含义如下:
根据策略网络,可以预测每一步的动作;依靠价值网络,可以选择价值最高的动作。结合这两个估计可以得到更好的结果。
3.2 MuZero中的蒙特卡洛树搜索3.2.1 MCTS简介
MuZero 还使用 MCTS(蒙特卡洛树搜索)聚合神经网络来预测和选择当前环境中的下一个动作。到达终点后,树中的每个节点都会存储一些相关的参数,包括访问次数、轮数、前一个动作的概率、子节点以及是否有对应的隐藏状态和奖励。
蒙特卡洛树搜索是一个迭代的、最佳优先的树搜索过程。目标是帮助我们弄清楚要采取哪些行动来最大化长期利益。
Best first,这意味着搜索树的扩展取决于搜索树中的值估计。
与常见的深度优先和广度优先相比,最佳优先搜索可以利用深度神经网络的启发式估计,在非常大的搜索空间中找到最优解。
蒙特卡洛树搜索有四个主要阶段:
通过重复这些阶段,MCTS 每次都在节点可能的未来动作序列上逐步构建搜索树。在这棵树中,每个节点代表一个未来状态,节点之间的线代表从一个状态到下一个状态的动作。
3.22 MuZero算法中MCTS的四个阶段
接下来我们对应MuZero算法中的蒙特卡洛树搜索,看看上面四个阶段分别对应什么:
我们先来看看模拟。
模拟过程与蒙特卡罗方法类似,推导速度快。为了得到某个状态的初始分数,让游戏随机玩到最后,记录模拟次数和获胜次数。
接下来是选择。
虽然 Muzero 不知道游戏规则,但它知道该采取哪些步骤。在每个节点(状态 s),使用评分函数比较不同的动作,并选择得分最高的最佳动作。

每次选择一个动作时,我们都会为 UCB 缩放因子 c 和后续动作选择增加其关联的访问计数 N(s,a)。
模拟沿着树向下进行到尚未扩展的叶子。此时,应用神经网络对节点进行评估,将评估结果(优先级和值估计)存储在节点中。
然后是扩展。
选择动作 A 后,在搜索树中生成一个新节点,对应动作 A 执行后前一个状态的情况。
最后回溯。
模拟结束后,从子节点开始沿着刚刚下的路径返回,沿途更新每个父节点的统计信息。每个节点都持有其下所有价值估计的连续平均值,这使得 UCB 公式可以随着时间的推移做出越来越准确的决策,确保 MCTS 收敛到最优动作。
3.2.3 中级奖励
事实上,在 MCTS 的过程中,也收录了对中间奖励 r 的预测。
在某些情况下,游戏完全结束后需要输赢反馈,这可以通过价值估计来建模。但是在频繁反馈的情况下,从一种状态到另一种状态的每次转换都会得到奖励 r。
因此,奖励直接通过神经网络预测建模并用于搜索。在 UCB 策略中引入中间奖励:
其中是在状态 s 执行动作 a 后观察到的奖励,折扣因子是对未来奖励的关注程度。
由于在某些环境中奖励是无界的,因此可以将奖励和价值估计归一化到 [0,1] 期间,然后与先验知识相结合:
其中 和 分别是在整个搜索树中观察到的最大和最小估计值。
3.3 总体说明
基于过去的观察和未来的行为,对于给定步骤中的每一步,使用带有参数的模型在每个时间步进行预测。
该模型预测 3 个数量:
其中是地面实况观察奖励,是策略,是折扣因子。
说白了就是获取过去的观察数据,编码成当前的隐藏状态,然后给出未来的动作,然后在隐藏状态空间进行规划。
3.4 步分解
在每个步骤中,模型由表示函数、动力学函数和预测函数组成:
使用这样的模型,可以根据过去的观察来搜索虚拟的未来轨迹。
例如,可以简单地选择 k 步动作序列来搜索最大化价值函数。
也可以使用类似于 AlphaZero 搜索的 MCTS 算法来获取策略和估计值,然后从策略中选择动作。此外,执行操作并生成中间奖励和状态空间。
在第 k 步,通过联合训练模型的所有参数,将策略、价值和奖励与实际观察到的目标值图像进行匹配。
模型的所有参数都经过联合训练,使得每个假设步 k 的策略、值和奖励与 k 个实际时间步后观察到的相应目标值完全匹配。
使用 MCTS,可以使用三个改进的策略目标:
最后加上L2正则化项得到最终的损失函数:
4 总结
强化学习分为两类:基于模型的和无模型的。
其中,基于模型的强化学习方法需要构建环境模型。通常,环境模型由马尔可夫决策过程(MDP)表示。该过程由两部分组成:
模型通常针对选定的动作或时间抽象的行为进行训练。一旦模型建立,MDP 规划算法(例如:值迭代、蒙特卡洛树搜索 MCTS)可以直接用于计算 MDP 的最优值或最优策略。
因此,在复杂环境或局部观察的情况下,很难构建模型应该预测的状态表示。因为Agent没有办法优化“有效规划的目的”的表示和模型,这就导致了表示学习、模型学习和规划之间的分离。
另一方面,MuZero 是一种完全不同的基于模型的强化学习方法,专注于端到端的预测函数。主要思想是构造一个抽象的MDP模型,使抽象MDP中的规划等价于真实环境中的规划。
这种等价是通过保证价值等价来实现的,即从相同的真实状态开始,通过抽象MDP获得的轨迹累积奖励与真实环境中的轨迹累积奖励相匹配。
预测器首先引入价值等价模型来预测价值而无需采取行动。
虽然底层模型是 MDP,但它的变换模型不需要匹配环境中的真实状态,只需将 MDP 模型视为深度神经网络中的隐藏层即可。展开的 MDP 被训练,例如通过时间差异学习,以将累积奖励的预期总和与实际环境的预期值相匹配。
然后,将价值等价模型扩展为以行动优化价值。TreeQN 学习一个抽象的 MDP 模型,以便在该模型上的树搜索(由树结构的神经网络表示)近似于最优值函数。值迭代网络学习一个局部 MDP 模型,使得该模型上的值迭代(由卷积神经网络表示)接近最优值函数。
价值预测网络更接近于 MuZero:根据实际动作学习一个 MDP 模型;对展开的 MDP 进行训练,以使奖励的累积总和(以简单前向搜索产生的实际动作序列为条件)与真实环境匹配一致。如果没有策略预测,则搜索仅使用值预测。
通过论文的学习,虽然理解了MuZero算法的思想,但是在实际项目中使用MuZero还是比较困难的。
比如如何设计表示、动态、预测等,这些都需要在对代码实现非常熟悉的情况下结合具体的业务场景来实现。
提供基于pytorch的muzero算法实现:
如果有时间,我会继续研究代码并尝试复现论文。
结束
免规则采集器列表算法(SQL注入主要手段开源错误盲注防御手段有消毒参数绑定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-12 14:12
SQL注入的主要手段
开源
错误回声
百叶窗
防御是
消毒
参数绑定
CSRF(Cross Site Request Forgery,跨站请求)
主要防御是识别请求者
表单令牌
验证码
推荐人检查
其他攻击和漏洞
错误代码错误回显
HTML 注释
上传文件
最有效的方法是设置上传白名单,只允许上传可靠的文件类型。另外,可以修改文件名,
使用专门的存储手段来保护服务器免受上传文件攻击。
路径遍历
攻击者使用请求 URL 中的相对路径来遍历系统上未打开的目录和文件。防御方法主要是转换JS、CSS等资源文件
部署在独立服务器上,使用独立域名,其他文件不使用静态URL访问,动态参数不收录文件路径等信息。
ModSecurity 是一个开源的网络应用防火墙。
ModSecurity 采用一种架构模式,其中处理逻辑与攻击规则集分离。
NEC 的 SiteShell
信息加密技术可分为三类:
1:单向哈希加密 2:对称加密 3:非对称加密
虽然单向哈希密文无法通过算法逆计算得到明文,但由于人们将密码设置为具有一定的模式,
因此,猜测破解可以通过彩虹表(人们常用的密码和对应的密文关系)等手段进行。
可以在哈希算法中加盐,相当于加密密钥,增加破解难度。
对称加密意味着加密和解密使用相同的密钥。
非对称加密是指加密和解密使用不同的密钥。其中,公钥称为公钥,它所拥有的就是秘钥。
RSA是一种非对称加密算法。
一种是将密钥和算法放在同一台服务器上,甚至制作专用的硬件设施,对外提供加解密服务。
应用系统通过调用该服务来实现数据的加解密。
另一种解决方案是将加解密算法放在应用系统中,秘钥放在独立的服务器中。为了提供密钥的安全性,在实际存储过程中,
密钥被分成若干份,加密后存储在不同的存储介质中,既考虑了密钥的安全性,又提高了性能。
信息过滤和反垃圾邮件
文本匹配
有很多公共算法,基本上都是 Trie 树的变种。
另一个更简单的实现是为文本匹配构建一个多级哈希表。先做降噪,再做文字匹配。如“A_La_Bo”
分类算法
贝叶斯分类算法
除了反垃圾邮件,分类算法还可以用来自动分类信息。门户网站可以使用该算法自动分类和分发来自采集的新闻文章
到不同的频道。电子邮件服务提供商基于电子邮件内容推送的个性化广告也可以使用分类算法来提供传递相关性。
黑名单,可用于信息去重,可使用布隆过滤器代替哈希表
规则引擎是一种分离业务规则和规则处理逻辑的技术。业务规则文件由运维人员通过容器管理界面进行编辑。
修改规则时,可以实时使用新规则,而无需更改代码发布者。规则处理逻辑调用规则来处理输入数据。
统计模型
目前,大型网站倾向于使用统计模型进行风险控制。
统计模式包括分类算法或更复杂的智能统计机器学习算法
这个世界没有绝对的安全,就像有绝对的自由一样。
秒杀系统对应的策略
1:秒杀系统独立部署
2:秒杀产品页面是静态的
3:租赁秒杀活动网络宽带
4:动态生成随机订单页面URL
软件设计有两种风格
一种是将软件设计得复杂,使缺陷不那么明显
一是软件设计得简单到没有明显的缺陷。 查看全部
免规则采集器列表算法(SQL注入主要手段开源错误盲注防御手段有消毒参数绑定)
SQL注入的主要手段
开源
错误回声
百叶窗
防御是
消毒
参数绑定
CSRF(Cross Site Request Forgery,跨站请求)
主要防御是识别请求者
表单令牌
验证码
推荐人检查
其他攻击和漏洞
错误代码错误回显
HTML 注释
上传文件
最有效的方法是设置上传白名单,只允许上传可靠的文件类型。另外,可以修改文件名,
使用专门的存储手段来保护服务器免受上传文件攻击。
路径遍历
攻击者使用请求 URL 中的相对路径来遍历系统上未打开的目录和文件。防御方法主要是转换JS、CSS等资源文件
部署在独立服务器上,使用独立域名,其他文件不使用静态URL访问,动态参数不收录文件路径等信息。
ModSecurity 是一个开源的网络应用防火墙。
ModSecurity 采用一种架构模式,其中处理逻辑与攻击规则集分离。
NEC 的 SiteShell
信息加密技术可分为三类:
1:单向哈希加密 2:对称加密 3:非对称加密
虽然单向哈希密文无法通过算法逆计算得到明文,但由于人们将密码设置为具有一定的模式,
因此,猜测破解可以通过彩虹表(人们常用的密码和对应的密文关系)等手段进行。
可以在哈希算法中加盐,相当于加密密钥,增加破解难度。
对称加密意味着加密和解密使用相同的密钥。
非对称加密是指加密和解密使用不同的密钥。其中,公钥称为公钥,它所拥有的就是秘钥。
RSA是一种非对称加密算法。
一种是将密钥和算法放在同一台服务器上,甚至制作专用的硬件设施,对外提供加解密服务。
应用系统通过调用该服务来实现数据的加解密。
另一种解决方案是将加解密算法放在应用系统中,秘钥放在独立的服务器中。为了提供密钥的安全性,在实际存储过程中,
密钥被分成若干份,加密后存储在不同的存储介质中,既考虑了密钥的安全性,又提高了性能。
信息过滤和反垃圾邮件
文本匹配
有很多公共算法,基本上都是 Trie 树的变种。
另一个更简单的实现是为文本匹配构建一个多级哈希表。先做降噪,再做文字匹配。如“A_La_Bo”
分类算法
贝叶斯分类算法
除了反垃圾邮件,分类算法还可以用来自动分类信息。门户网站可以使用该算法自动分类和分发来自采集的新闻文章
到不同的频道。电子邮件服务提供商基于电子邮件内容推送的个性化广告也可以使用分类算法来提供传递相关性。
黑名单,可用于信息去重,可使用布隆过滤器代替哈希表
规则引擎是一种分离业务规则和规则处理逻辑的技术。业务规则文件由运维人员通过容器管理界面进行编辑。
修改规则时,可以实时使用新规则,而无需更改代码发布者。规则处理逻辑调用规则来处理输入数据。
统计模型
目前,大型网站倾向于使用统计模型进行风险控制。
统计模式包括分类算法或更复杂的智能统计机器学习算法
这个世界没有绝对的安全,就像有绝对的自由一样。
秒杀系统对应的策略
1:秒杀系统独立部署
2:秒杀产品页面是静态的
3:租赁秒杀活动网络宽带
4:动态生成随机订单页面URL
软件设计有两种风格
一种是将软件设计得复杂,使缺陷不那么明显
一是软件设计得简单到没有明显的缺陷。
免规则采集器列表算法(基于Python网络爬虫与推荐算法新闻推荐平台文章目录功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-11 06:06
系列目录
基于Python网络爬虫和推荐算法的新闻推荐平台
文章目录
特征
一个有规律的采集新闻内容的网络爬虫,只需要配置间隔时间,就可以自动爬取新闻。消息来源采集为新浪新闻
一、结构
新闻爬虫由两部分组成:URL采集器、详情页采集器、定时器
采集器特征
网址采集器
专门用于采集新浪滚动新闻上的新闻详情页URL
详情页采集器
详情页采集的内容(例如:新闻)通过来自URL采集的URL数据
时序采集器
控制news采集器的启动和关闭,以及定时任务的设置
二、具体实现1.网址采集器
'''
使用新浪新闻滚动新闻的API进行新闻采集
参数分析:
pageid 目前看应该是固定的参数默认值为153
lid 类别ID 2509(全部) 2510(国内) 2511(国际) 2669(国际) 2512(体育) 2513(娱乐) 2514(军事) 2515(科技) 2516(财经) 2517(股市) 2518(美股)
num 获取新闻数量 上限为50
'''
def urlcollect(lid):
op_mysql = OperationMysql() #创建数据库连接对象
url = 'https://feed.mix.sina.com.cn/a ... 2Bstr(lid)+'&num=50' #网易新闻API
result = requests.get(url) #对API发起请求
result.encoding = 'utf-8' #由于API返回的数据为ISO编码的,中文在此处显示会出现乱码,因此更改为UTF-8编码
# print('Web:', result.text)
urls = re.findall(r'"url":"(.*?)"', result.text) #获取API返回结果中的所有新闻详情页URL
# times = re.findall(r'"ctime":"(.*?)"', result.text)
# 逐条处理被\转义的字符,使之成为为转义的字符串
# 并把处理号的URL导入到数据库中储存
changedict = {"2518": 0, "2510": 1, "2511": 2, "2669": 3, "2512": 4, "2513": 5, "2514": 6, "2515": 7, "2516": 8, "2517": 9}
Type = changedict.get(str(lid))
for numbers in range(len(urls)):
urls[numbers] = urls[numbers].replace('\\', '')
logger.info("url:{}".format(urls[numbers]))
time = datetime.datetime.now().strftime('%Y-%m-%d')
sql_i = "INSERT INTO news_api_urlcollect(url, type, time) values ('%s', '%d', '%s')" % (urls[numbers], Type, time)
op_mysql.insert_one(sql_i)
op_mysql.conn.close()
2.详情页面采集器
3. 时序采集器
#创建一个APScheduler对象(用于配置定时任务)
sched = BlockingScheduler()
def begincollect(time):
time = int(time)
try:
# 'interval'关键词表示的是按照固定时间间隔进行的任务 add_job()添加一个定时任务
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect1', kwargs={"lid": "2510",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect2', kwargs={"lid": "2511",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect3', kwargs={"lid": "2669",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect4', kwargs={"lid": "2512",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect5', kwargs={"lid": "2513",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect6', kwargs={"lid": "2514",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect7', kwargs={"lid": "2515",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect8', kwargs={"lid": "2516",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect9', kwargs={"lid": "2517",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect10', kwargs={"lid": "2518",})
# urlcollect(lid)
# 为了可以控制定时任务的关闭因此需要在任务开始时保存下该进程的PID值并保存与文件中
# 用于ClossScheduler.py中进行杀死进程
pid = os.getpid()
f1 = open(file='urlSpider.txt', mode='w')
f1.write(pid.__str__())
f1.close()
sched.start()
except Exception:
logger.error('error:'+Exception)
def endsched():
sched.shutdown()
总结
新闻采集系统可以稳定详细地采集新浪新闻滚动新闻中的所有新闻。目前只写单线程,效率略低。还有一个未知的bug,就是在消息采集的过程中,当调度任务被APScheduler控制时,一旦任务采集任务启动,就不能直接停止采集@ > 任务,并且需要让他在相应的循环中完全运行当前任务,才能停止。简而言之,定时器对任务的控制只控制间隔时间和运行次数,不能立即启动和停止。
另外,采集器还不是通用的,也就是只能用于指定网页的内容采集,这是一个可扩展的功能,通过对页面的分析,大致的内容采集 函数。
项目完整源码已经更新,有需要可以自行下载
欢迎提出问题和错误
个人码云主页,欢迎交流!!
个人GitHub主页,欢迎交流!! 查看全部
免规则采集器列表算法(基于Python网络爬虫与推荐算法新闻推荐平台文章目录功能介绍)
系列目录
基于Python网络爬虫和推荐算法的新闻推荐平台
文章目录
特征
一个有规律的采集新闻内容的网络爬虫,只需要配置间隔时间,就可以自动爬取新闻。消息来源采集为新浪新闻
一、结构
新闻爬虫由两部分组成:URL采集器、详情页采集器、定时器
采集器特征
网址采集器
专门用于采集新浪滚动新闻上的新闻详情页URL
详情页采集器
详情页采集的内容(例如:新闻)通过来自URL采集的URL数据
时序采集器
控制news采集器的启动和关闭,以及定时任务的设置
二、具体实现1.网址采集器
'''
使用新浪新闻滚动新闻的API进行新闻采集
参数分析:
pageid 目前看应该是固定的参数默认值为153
lid 类别ID 2509(全部) 2510(国内) 2511(国际) 2669(国际) 2512(体育) 2513(娱乐) 2514(军事) 2515(科技) 2516(财经) 2517(股市) 2518(美股)
num 获取新闻数量 上限为50
'''
def urlcollect(lid):
op_mysql = OperationMysql() #创建数据库连接对象
url = 'https://feed.mix.sina.com.cn/a ... 2Bstr(lid)+'&num=50' #网易新闻API
result = requests.get(url) #对API发起请求
result.encoding = 'utf-8' #由于API返回的数据为ISO编码的,中文在此处显示会出现乱码,因此更改为UTF-8编码
# print('Web:', result.text)
urls = re.findall(r'"url":"(.*?)"', result.text) #获取API返回结果中的所有新闻详情页URL
# times = re.findall(r'"ctime":"(.*?)"', result.text)
# 逐条处理被\转义的字符,使之成为为转义的字符串
# 并把处理号的URL导入到数据库中储存
changedict = {"2518": 0, "2510": 1, "2511": 2, "2669": 3, "2512": 4, "2513": 5, "2514": 6, "2515": 7, "2516": 8, "2517": 9}
Type = changedict.get(str(lid))
for numbers in range(len(urls)):
urls[numbers] = urls[numbers].replace('\\', '')
logger.info("url:{}".format(urls[numbers]))
time = datetime.datetime.now().strftime('%Y-%m-%d')
sql_i = "INSERT INTO news_api_urlcollect(url, type, time) values ('%s', '%d', '%s')" % (urls[numbers], Type, time)
op_mysql.insert_one(sql_i)
op_mysql.conn.close()
2.详情页面采集器
3. 时序采集器
#创建一个APScheduler对象(用于配置定时任务)
sched = BlockingScheduler()
def begincollect(time):
time = int(time)
try:
# 'interval'关键词表示的是按照固定时间间隔进行的任务 add_job()添加一个定时任务
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect1', kwargs={"lid": "2510",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect2', kwargs={"lid": "2511",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect3', kwargs={"lid": "2669",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect4', kwargs={"lid": "2512",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect5', kwargs={"lid": "2513",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect6', kwargs={"lid": "2514",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect7', kwargs={"lid": "2515",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect8', kwargs={"lid": "2516",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect9', kwargs={"lid": "2517",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect10', kwargs={"lid": "2518",})
# urlcollect(lid)
# 为了可以控制定时任务的关闭因此需要在任务开始时保存下该进程的PID值并保存与文件中
# 用于ClossScheduler.py中进行杀死进程
pid = os.getpid()
f1 = open(file='urlSpider.txt', mode='w')
f1.write(pid.__str__())
f1.close()
sched.start()
except Exception:
logger.error('error:'+Exception)
def endsched():
sched.shutdown()
总结
新闻采集系统可以稳定详细地采集新浪新闻滚动新闻中的所有新闻。目前只写单线程,效率略低。还有一个未知的bug,就是在消息采集的过程中,当调度任务被APScheduler控制时,一旦任务采集任务启动,就不能直接停止采集@ > 任务,并且需要让他在相应的循环中完全运行当前任务,才能停止。简而言之,定时器对任务的控制只控制间隔时间和运行次数,不能立即启动和停止。
另外,采集器还不是通用的,也就是只能用于指定网页的内容采集,这是一个可扩展的功能,通过对页面的分析,大致的内容采集 函数。
项目完整源码已经更新,有需要可以自行下载
欢迎提出问题和错误
个人码云主页,欢迎交流!!
个人GitHub主页,欢迎交流!!
免规则采集器列表算法(【免规则采集器】第三方,同行,抖音,头条)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-10 13:09
免规则采集器列表算法:注册,登录,消费,加入,注销,转移密码支付算法:支付完成日期,支付完成手续费比例,支付完成手续费比例用户运营:拉新,复购,活跃,留存,转化,付费,广告位,内容付费,会员价值,数据打通,时间差反馈,业务评估。社群运营:微信群,qq群,聚会,游戏,单机,小团队会员管理:离线计费(流量成本远高于线上),弹性计费(扩张乏力),预付费(100元起步,低频率/经常联网用户请慎重)预付费产品:热门/卖点产品,刚需产品,爆款产品商品采购:全采购,不同时段不同采购,订单匹配选择差异,竞品渠道商对比产品集采:低于30元每件,中高端产品,需求强度差异同时电商:转化率降低,活跃度下降,用户平均停留时间下降,库存出现不正常,付款成功率大幅下降;直通车,钻展,付费效果未知,付费渠道等流量运营:流量成本,付费转化率效果表现,无数据模型或支撑数据日报周报年报是否可靠,亏损,利润,成本负担是否下降,做广告投放是否花费过高,多商品是否可以通过购买建议获得产品全链路优化:对比进行优化,同时问题产品-增加平台商家多比、增加价格优势,对比用户数量多比、增加增加活跃度,对比活跃度多比、增加转化率多比等等等级运营或外部推广:产品品牌,销售提成等评估运营效果:销售业绩、流量入口、cpd成本/转化率、促销力度、平台资源等等高流量自营:生意参谋-营销工具--宝贝详情中等以上流量自营:移动端、pc端、公众号广告投放投放渠道:第三方,同行,微博,贴吧,知乎,抖音,快手,头条,最右,火山,西瓜视频,荔枝,今日头条等等等,全部是合作比价可私信一起交流。 查看全部
免规则采集器列表算法(【免规则采集器】第三方,同行,抖音,头条)
免规则采集器列表算法:注册,登录,消费,加入,注销,转移密码支付算法:支付完成日期,支付完成手续费比例,支付完成手续费比例用户运营:拉新,复购,活跃,留存,转化,付费,广告位,内容付费,会员价值,数据打通,时间差反馈,业务评估。社群运营:微信群,qq群,聚会,游戏,单机,小团队会员管理:离线计费(流量成本远高于线上),弹性计费(扩张乏力),预付费(100元起步,低频率/经常联网用户请慎重)预付费产品:热门/卖点产品,刚需产品,爆款产品商品采购:全采购,不同时段不同采购,订单匹配选择差异,竞品渠道商对比产品集采:低于30元每件,中高端产品,需求强度差异同时电商:转化率降低,活跃度下降,用户平均停留时间下降,库存出现不正常,付款成功率大幅下降;直通车,钻展,付费效果未知,付费渠道等流量运营:流量成本,付费转化率效果表现,无数据模型或支撑数据日报周报年报是否可靠,亏损,利润,成本负担是否下降,做广告投放是否花费过高,多商品是否可以通过购买建议获得产品全链路优化:对比进行优化,同时问题产品-增加平台商家多比、增加价格优势,对比用户数量多比、增加增加活跃度,对比活跃度多比、增加转化率多比等等等级运营或外部推广:产品品牌,销售提成等评估运营效果:销售业绩、流量入口、cpd成本/转化率、促销力度、平台资源等等高流量自营:生意参谋-营销工具--宝贝详情中等以上流量自营:移动端、pc端、公众号广告投放投放渠道:第三方,同行,微博,贴吧,知乎,抖音,快手,头条,最右,火山,西瓜视频,荔枝,今日头条等等等,全部是合作比价可私信一起交流。
免规则采集器列表算法(百度搜索飓风算法2.0所覆盖的问题点以及站长们应该怎么做)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-04-09 15:09
2018年9月20日,百度正式发布公告,为营造良好的互联网内容搜索生态,保护用户的搜索阅读和浏览体验,保护百度搜索引擎中优质内容生产者的合法权益,百度官方网站将于2018年9月发布。飓风算法将于6月下旬升级。
一周前,百度发布公告“百度搜索将上线飓风算法2.0,严厉打击不良采集行为”,今天我们将详细讲解飓风算法的覆盖范围2.0 个问题,站长应该怎么做。
飓风算法主要包括四种不良采集行为,如下:
1、更明显的采集跟踪行为
网站收录大量内容采集,是从其他网站、公众号、自媒体等转来的。采集后面的信息没有整理排版混乱,结构差,缺少一些功能,文章可读性差,有明显的采集痕迹,用户阅读体验特别差。
示例:采集文章的内容收录不可点击的超链接,功能缺失,采集痕迹明显。如下所示
整改建议:网站发布的内容,要注意文章内容的排版和排版,不得出现与文章主题弱相关或无关的信息。不允许使用@文章 或不可用的功能。干扰用户的浏览体验。
2、body内容有拼接行为
网站采集多个不同的文章拼接或叠加。文章整体内容没有形成完整的逻辑,阅读不流畅,段落不连贯,文章话题多等问题无法正常满足用户需求。
例子:文章正文前后的内容没有关系,逻辑不连贯。如下所示
整改建议:百度严禁使用采集器、采集软件等编辑工具采集随意制作拼接内容。制作大量对用户有价值的优质原创内容。
3、广泛的内容采集行为
网站中文章的大部分内容都是采集。质量较低。
整改建议:百度鼓励网站运营商大力制作优质原创内容,对原创内容给予保护。如需转载,需注明内容出处(如:转载内容注明新闻、政策等出处将不视为采集内容)。
4、跨域采集内容行为
网站通过采集大量与本站域名不一致的内容获取流量的行为。
示例:Education 网站 发布与食品行业相关的内容。如下所示
整改建议:百度鼓励网站制作文章和该领域的内容,通过专注于该领域获得更多搜索用户的青睐。不要试图采集跨域内容来获取短期利益。这样做会降低域焦点并影响 网站 在搜索引擎中的表现。
总结:
综上所述,飓风算法2.0旨在保障搜索用户的浏览体验,保障搜索生态的健康健康发展。对于任何违反网站的行为,百度搜索将使用网站对存在问题的严重性进行相应的限制搜索展示,情节严重的将给予永久停牌处分。 查看全部
免规则采集器列表算法(百度搜索飓风算法2.0所覆盖的问题点以及站长们应该怎么做)
2018年9月20日,百度正式发布公告,为营造良好的互联网内容搜索生态,保护用户的搜索阅读和浏览体验,保护百度搜索引擎中优质内容生产者的合法权益,百度官方网站将于2018年9月发布。飓风算法将于6月下旬升级。
一周前,百度发布公告“百度搜索将上线飓风算法2.0,严厉打击不良采集行为”,今天我们将详细讲解飓风算法的覆盖范围2.0 个问题,站长应该怎么做。
飓风算法主要包括四种不良采集行为,如下:
1、更明显的采集跟踪行为
网站收录大量内容采集,是从其他网站、公众号、自媒体等转来的。采集后面的信息没有整理排版混乱,结构差,缺少一些功能,文章可读性差,有明显的采集痕迹,用户阅读体验特别差。
示例:采集文章的内容收录不可点击的超链接,功能缺失,采集痕迹明显。如下所示

整改建议:网站发布的内容,要注意文章内容的排版和排版,不得出现与文章主题弱相关或无关的信息。不允许使用@文章 或不可用的功能。干扰用户的浏览体验。
2、body内容有拼接行为
网站采集多个不同的文章拼接或叠加。文章整体内容没有形成完整的逻辑,阅读不流畅,段落不连贯,文章话题多等问题无法正常满足用户需求。
例子:文章正文前后的内容没有关系,逻辑不连贯。如下所示

整改建议:百度严禁使用采集器、采集软件等编辑工具采集随意制作拼接内容。制作大量对用户有价值的优质原创内容。
3、广泛的内容采集行为
网站中文章的大部分内容都是采集。质量较低。
整改建议:百度鼓励网站运营商大力制作优质原创内容,对原创内容给予保护。如需转载,需注明内容出处(如:转载内容注明新闻、政策等出处将不视为采集内容)。
4、跨域采集内容行为
网站通过采集大量与本站域名不一致的内容获取流量的行为。
示例:Education 网站 发布与食品行业相关的内容。如下所示
整改建议:百度鼓励网站制作文章和该领域的内容,通过专注于该领域获得更多搜索用户的青睐。不要试图采集跨域内容来获取短期利益。这样做会降低域焦点并影响 网站 在搜索引擎中的表现。
总结:
综上所述,飓风算法2.0旨在保障搜索用户的浏览体验,保障搜索生态的健康健康发展。对于任何违反网站的行为,百度搜索将使用网站对存在问题的严重性进行相应的限制搜索展示,情节严重的将给予永久停牌处分。
免规则采集器列表算法( 如何使用Python实现关联规则的原理和实现步骤(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2022-04-07 18:18
如何使用Python实现关联规则的原理和实现步骤(上))
PowerBI商品关联规则的可视化
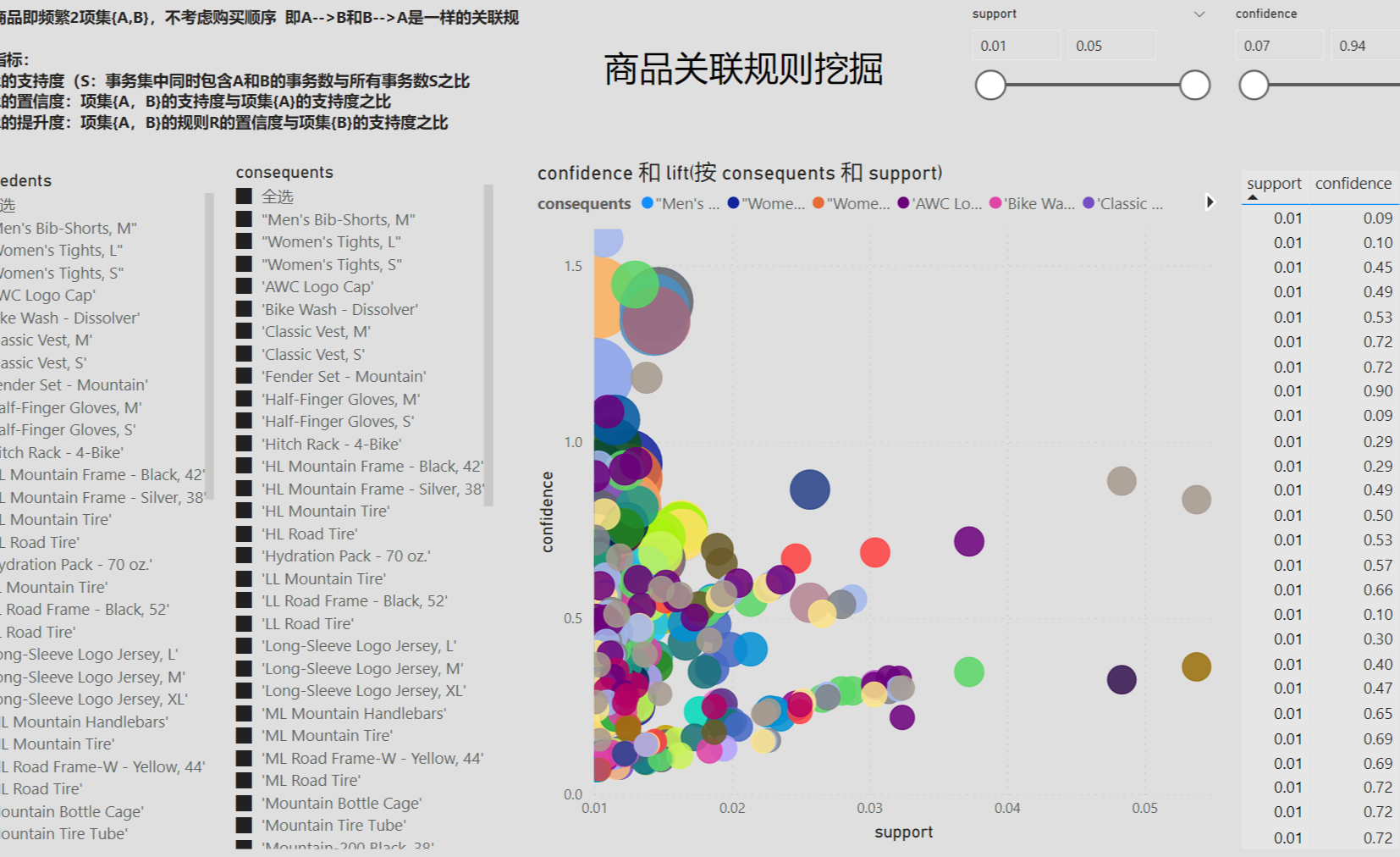
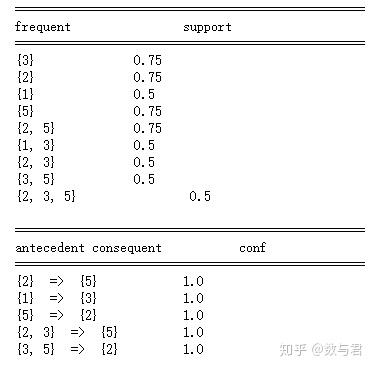
在上一篇文章中,我解释了关联规则的原理和实现步骤。如果你理解它,它实际上很容易理解。但说起来容易做起来难,如何通过工具处理原创数据以获得有效可靠的结果仍然存在问题。实际的工作是让你解决问题,而不是仅仅谈论解决方案。本文以理论为基础,结合实际数据展示如何使用Python实现关联规则,以及如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态展示。
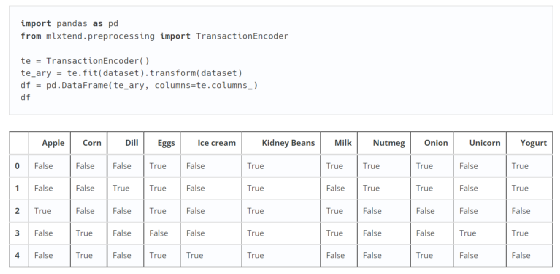
使用Python解决一个问题时,实际上并不是从0到1的一步一步构建,这个过程非常繁琐。有时,为了达到一个小的效果,可能要绕很多路,所以就像“调参”一样,我们倾向于使用其他内置的梯子。这就是 Python 语言如此受欢迎的原因,因为它拥有完善的开源社区和无数的工具库来实现某种目的。我们在实现关联规则的计算时,使用机器学习库mlxtend中的apriori、fpgrowth、association_rules算法。apriori 是一种流行的算法,用于提取关联规则学习中的频繁项集。先验算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的一组项。
一、数据集
#导入相关的库
import pandas as pd
import mlxtend #机器学习库
#编码包
from mlxtend.preprocessing import TransactionEncoder
#关联规则计算包
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
pd.set_option('max_colwidth',150) #对pandas显示效果设置,列显示字段长度最长为150个字符 #导入数据集
Order = pd.read_excel("D:/orders.xlsx")
#查看数据集的大小
Order.shape
#查看数据前10行
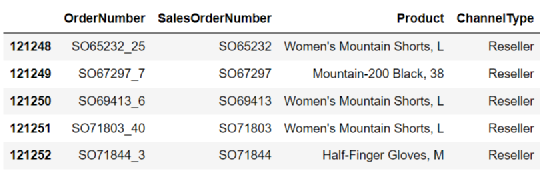
Order.tail(5)
数据集中有121253条数据,总共有四个字段。SalesOrderNumber 指订单号;ordernumber 是指子订单号。换行和数字表示订单的子订单。每个订单号下可能有一个或多个子订单。有子订单,每个子订单都是唯一的,对应一个产品;产品是指产品名称。
二、mlxtend
在真正开始之前,我们先来了解一下这个mlxtend中的包是怎么使用的。mlxtend 官网演示了如何实现关联规则的计算。我们来看看这三个步骤:
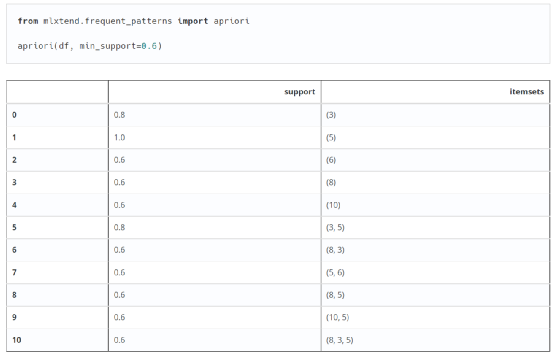
第一步,导入apriori算法包;
第二步,将原创订单数据处理成算法支持的格式;
第三步,计算support、confidence、lift等指标,过滤掉强规则。
第一步:导入先验算法包
第二步,将原创订单数据处理成算法支持的格式:
得到的实际数据往往和我之前文章中的例子一样,产品在订单号后面排列成一个列表。所以 mlxtend 包接受这种数据格式。但是,它不能直接用于计算。首先,真实数据都是文本。其次,apriori算法包需要将原创数据转换为商品的one-hot编码的Pandas Dataframe格式。这是输入数据:
它使用 TransactionEncoder 包将输入数据转换为我们需要的形式。这是转换后的代码和结果:
接下来,它将处理后的数据格式输入到 apriori 算法包中,以计算频繁项集和支持度。根据预设的最小支持度0.6,排除不频繁项集。
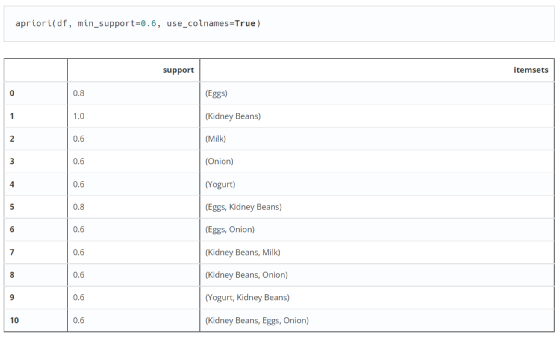
但是,上面有一个问题。上面返回的结果集是一个数字,其实就是df表中每一项(item)的索引,这样比较方便后面的处理,但是如果只想用这个结果的话。为了增加可读性,使用参数 use_colnames=True 来显示原创产品名称。
第三步,计算支持度、置信度和提升度
apriori算法包中没有演示第三步,这是为什么呢?因为apriori算法包只是关联规则的第一步——寻找频繁项集,当然强关联规则是不会找到的!这一步在另一个包 association_rules 中实现。这也是很多初学者容易遇到的问题。他们不知道每个包的用途,也不知道如何调用包。
这样,我们就可以计算出所有满足最小支持度的频繁项集的支持度、置信度和提升度。还有杠杆作用和收敛性。这两个的作用和之前说的lift的作用是一样的。最好使用 KLUC 指标和 IR 不平衡率,但显然 mlxtend 的开发人员更喜欢使用杠杆和信念,并将其放在一边。本案例仅演示支撑升降机的使用。
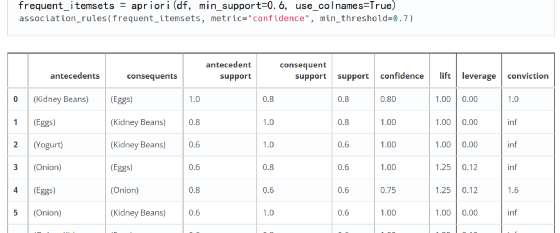
三、Python实现第一步关联规则代码,生成格式数据
以上是官网给出的关联规则包的使用方法。接下来我使用自己的数据集进行实际操作,演示如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态显示。上面已经给出了示例数据。可以看出,数据集每个订单有多个商品,但是是逐行的,而不是一个订单后跟一行所有商品的形式。所以这是一种从行转换为列的方法。这里使用了Pandas中的分组功能,要达到的效果如下:
#使用DataFrame的groupby函数
group_df = Order.groupby(['SalesOrderNumber'])
如果你会写SQL,你应该知道groupby必须和聚合函数一起使用,因为它是一个mapreduce过程。如果不使用聚合函数按订单号分组,SQL Server 会报错,Mysql 只会返回第一行数据。而这里直接使用groupby分组,不用聚合功能,这样会不会有问题?让我们看一下生成的 group_df:
group_df.head(2) #查看数据集
上图是groupby的结果(我以为是数据集),拿前2和前5看,发现返回的数据和数据集的大小不一样(注意我们的第一次查看数据显示121253条数据)。其实这个groupby的结果就是一个生成器,它返回一个动态的分组过程。如果你想使用结果,你可以输入不同的参数来得到实际的结果。所以使用这个函数来实现group_oncat并生成一个产品列表。
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_productlist.head(5)
上面代码的意思是生成一个新表,按SalesOrderNumber分组,然后将每个订单组的Products聚合成一个列表;此表只有两列,一列按 SalesOrderNumber 分组,另一列按 SalesOrderNumber 分组。将其命名为产品列表;最后去掉原创数据目标的索引,重新设置索引,最后得到df_productlist表,这样我们就形成了算法接受的输入数据格式。这是查看前 5 行的结果:
#因为只需要频繁项集,所以这里去掉订单号,将productlist转为numpy数组格式。
df_array = df_productlist["productlist"].tolist()
df_array[0:3] #取前三个查看
可以看出输入数据形成了,然后我们使用TransactionEncoder对数据进行处理,为每个item(item)生成one-hot编码的DataFrame格式:
第二步,生成频繁项集
生成最终的数据格式后,将数据馈送到 apriori 算法包生成频繁项集:
#给定最小支持度为0.01,显示列名
frequent_itemset = apriori(df_item,min_support=0.01,use_colnames=True)
frequent_itemset.tail(5)
算法生成的结果也是DataFrame格式的频繁项集。它将返回所有大于或等于最小支持度的结果,例如频繁 1 项集、频繁 2 项集和频繁 3 项集。这里显示的是频繁 1 项集。
其实为了方便我们查看和过滤,我们还可以统计频繁项集的长度,这样就可以动态索引了。
frequent_itemset['length'] = frequent_itemset['itemsets'].apply(lambda x: len(x))
frequent_itemset[ (frequent_itemset['length'] == 2) &(frequent_itemset['support'] >= 0.01) ]
这段代码的意思是找到支持度大于等于0.01的频繁2项集,也就是我们经常关心的客户购买一个产品的情况,他们会购买哪种产品。
在完成了上面生成频繁项集的第一步之后,下面就是挖掘关联规则了。
第三步,计算支持度、置信度和提升度
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
association.head()
上表显示,一共找到了 169034 条关联规则可供选择。列名是什么意思?
antecedents:代表先购买的产品(组合),consequents代表后购买的产品(组合);
先行支持:表示先购买的产品(组合)占所有订单的支持;
后续支持:表示后面购买的产品(组合)占所有订单的支持;
support:表示同时购买两种产品(组合)占所有订单的支持;
Confidence:表示同时购买两种产品(组合)与所有订单的支持度与前期支持度的比值,即规则的置信度;
Lift:表示置信度与一致支持的比值,即提升度,验证了先购买产品(组合)再购买产品组合B的可能性的有效性;
最后我们只关注买一买一,买二再买一的情况,这是最常见的实际场景需求。因此生成两个表 df_BuyAB 和 df_BuyABC。下面是完整的代码,如果你有相同格式的数据集,可以直接运行这个算法。
import pandas as pd
import mlxtend
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
Allorder = pd.read_excel("D:/4_MySQL/AdventureWorksDW2012/Allorder.xlsx")
group_df = Allorder.groupby(['SalesOrderNumber'])
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_array = df_productlist["productlist"].tolist()
trans= TransactionEncoder()
trans_array = trans.fit_transform(df_array)
df_association = pd.DataFrame(trans_array, columns=trans.columns_)
frequent_itemset = apriori(df_association,min_support=0.01,use_colnames=True)
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
BuyAB = association[(association['antecedents'].apply(lambda x :len(x)==1)) & (association['consequents'].apply(lambda x :len(x)==1))]
BuyABC = association[(association['antecedents'].apply(lambda x :len(x)==2)) & (association['consequents'].apply(lambda x :len(x)==1))]
文章开头的视频展示了如何使用这个Python脚本实现动态可视化,供商务人士使用,提高销售业绩。 查看全部
免规则采集器列表算法(
如何使用Python实现关联规则的原理和实现步骤(上))

PowerBI商品关联规则的可视化
在上一篇文章中,我解释了关联规则的原理和实现步骤。如果你理解它,它实际上很容易理解。但说起来容易做起来难,如何通过工具处理原创数据以获得有效可靠的结果仍然存在问题。实际的工作是让你解决问题,而不是仅仅谈论解决方案。本文以理论为基础,结合实际数据展示如何使用Python实现关联规则,以及如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态展示。
使用Python解决一个问题时,实际上并不是从0到1的一步一步构建,这个过程非常繁琐。有时,为了达到一个小的效果,可能要绕很多路,所以就像“调参”一样,我们倾向于使用其他内置的梯子。这就是 Python 语言如此受欢迎的原因,因为它拥有完善的开源社区和无数的工具库来实现某种目的。我们在实现关联规则的计算时,使用机器学习库mlxtend中的apriori、fpgrowth、association_rules算法。apriori 是一种流行的算法,用于提取关联规则学习中的频繁项集。先验算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的一组项。
一、数据集
#导入相关的库
import pandas as pd
import mlxtend #机器学习库
#编码包
from mlxtend.preprocessing import TransactionEncoder
#关联规则计算包
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
pd.set_option('max_colwidth',150) #对pandas显示效果设置,列显示字段长度最长为150个字符 #导入数据集
Order = pd.read_excel("D:/orders.xlsx")
#查看数据集的大小
Order.shape
#查看数据前10行
Order.tail(5)
数据集中有121253条数据,总共有四个字段。SalesOrderNumber 指订单号;ordernumber 是指子订单号。换行和数字表示订单的子订单。每个订单号下可能有一个或多个子订单。有子订单,每个子订单都是唯一的,对应一个产品;产品是指产品名称。
二、mlxtend
在真正开始之前,我们先来了解一下这个mlxtend中的包是怎么使用的。mlxtend 官网演示了如何实现关联规则的计算。我们来看看这三个步骤:
第一步,导入apriori算法包;
第二步,将原创订单数据处理成算法支持的格式;
第三步,计算support、confidence、lift等指标,过滤掉强规则。
第一步:导入先验算法包

第二步,将原创订单数据处理成算法支持的格式:
得到的实际数据往往和我之前文章中的例子一样,产品在订单号后面排列成一个列表。所以 mlxtend 包接受这种数据格式。但是,它不能直接用于计算。首先,真实数据都是文本。其次,apriori算法包需要将原创数据转换为商品的one-hot编码的Pandas Dataframe格式。这是输入数据:

它使用 TransactionEncoder 包将输入数据转换为我们需要的形式。这是转换后的代码和结果:
接下来,它将处理后的数据格式输入到 apriori 算法包中,以计算频繁项集和支持度。根据预设的最小支持度0.6,排除不频繁项集。
但是,上面有一个问题。上面返回的结果集是一个数字,其实就是df表中每一项(item)的索引,这样比较方便后面的处理,但是如果只想用这个结果的话。为了增加可读性,使用参数 use_colnames=True 来显示原创产品名称。
第三步,计算支持度、置信度和提升度
apriori算法包中没有演示第三步,这是为什么呢?因为apriori算法包只是关联规则的第一步——寻找频繁项集,当然强关联规则是不会找到的!这一步在另一个包 association_rules 中实现。这也是很多初学者容易遇到的问题。他们不知道每个包的用途,也不知道如何调用包。
这样,我们就可以计算出所有满足最小支持度的频繁项集的支持度、置信度和提升度。还有杠杆作用和收敛性。这两个的作用和之前说的lift的作用是一样的。最好使用 KLUC 指标和 IR 不平衡率,但显然 mlxtend 的开发人员更喜欢使用杠杆和信念,并将其放在一边。本案例仅演示支撑升降机的使用。
三、Python实现第一步关联规则代码,生成格式数据
以上是官网给出的关联规则包的使用方法。接下来我使用自己的数据集进行实际操作,演示如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态显示。上面已经给出了示例数据。可以看出,数据集每个订单有多个商品,但是是逐行的,而不是一个订单后跟一行所有商品的形式。所以这是一种从行转换为列的方法。这里使用了Pandas中的分组功能,要达到的效果如下:

#使用DataFrame的groupby函数
group_df = Order.groupby(['SalesOrderNumber'])
如果你会写SQL,你应该知道groupby必须和聚合函数一起使用,因为它是一个mapreduce过程。如果不使用聚合函数按订单号分组,SQL Server 会报错,Mysql 只会返回第一行数据。而这里直接使用groupby分组,不用聚合功能,这样会不会有问题?让我们看一下生成的 group_df:
group_df.head(2) #查看数据集
上图是groupby的结果(我以为是数据集),拿前2和前5看,发现返回的数据和数据集的大小不一样(注意我们的第一次查看数据显示121253条数据)。其实这个groupby的结果就是一个生成器,它返回一个动态的分组过程。如果你想使用结果,你可以输入不同的参数来得到实际的结果。所以使用这个函数来实现group_oncat并生成一个产品列表。
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_productlist.head(5)
上面代码的意思是生成一个新表,按SalesOrderNumber分组,然后将每个订单组的Products聚合成一个列表;此表只有两列,一列按 SalesOrderNumber 分组,另一列按 SalesOrderNumber 分组。将其命名为产品列表;最后去掉原创数据目标的索引,重新设置索引,最后得到df_productlist表,这样我们就形成了算法接受的输入数据格式。这是查看前 5 行的结果:

#因为只需要频繁项集,所以这里去掉订单号,将productlist转为numpy数组格式。
df_array = df_productlist["productlist"].tolist()
df_array[0:3] #取前三个查看
可以看出输入数据形成了,然后我们使用TransactionEncoder对数据进行处理,为每个item(item)生成one-hot编码的DataFrame格式:
第二步,生成频繁项集
生成最终的数据格式后,将数据馈送到 apriori 算法包生成频繁项集:
#给定最小支持度为0.01,显示列名
frequent_itemset = apriori(df_item,min_support=0.01,use_colnames=True)
frequent_itemset.tail(5)
算法生成的结果也是DataFrame格式的频繁项集。它将返回所有大于或等于最小支持度的结果,例如频繁 1 项集、频繁 2 项集和频繁 3 项集。这里显示的是频繁 1 项集。
其实为了方便我们查看和过滤,我们还可以统计频繁项集的长度,这样就可以动态索引了。
frequent_itemset['length'] = frequent_itemset['itemsets'].apply(lambda x: len(x))
frequent_itemset[ (frequent_itemset['length'] == 2) &(frequent_itemset['support'] >= 0.01) ]
这段代码的意思是找到支持度大于等于0.01的频繁2项集,也就是我们经常关心的客户购买一个产品的情况,他们会购买哪种产品。
在完成了上面生成频繁项集的第一步之后,下面就是挖掘关联规则了。
第三步,计算支持度、置信度和提升度
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
association.head()
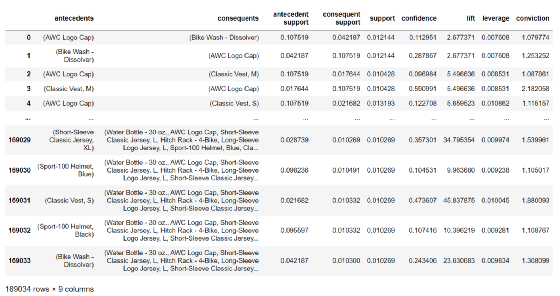
上表显示,一共找到了 169034 条关联规则可供选择。列名是什么意思?
antecedents:代表先购买的产品(组合),consequents代表后购买的产品(组合);
先行支持:表示先购买的产品(组合)占所有订单的支持;
后续支持:表示后面购买的产品(组合)占所有订单的支持;
support:表示同时购买两种产品(组合)占所有订单的支持;
Confidence:表示同时购买两种产品(组合)与所有订单的支持度与前期支持度的比值,即规则的置信度;
Lift:表示置信度与一致支持的比值,即提升度,验证了先购买产品(组合)再购买产品组合B的可能性的有效性;
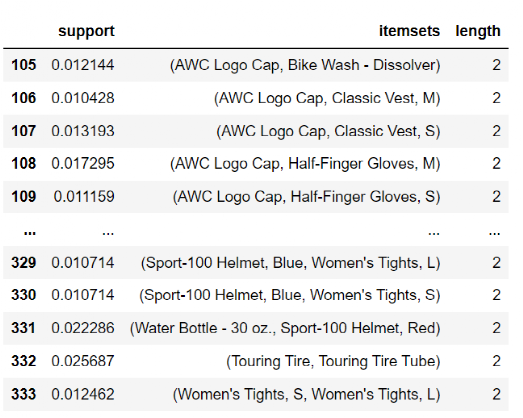
最后我们只关注买一买一,买二再买一的情况,这是最常见的实际场景需求。因此生成两个表 df_BuyAB 和 df_BuyABC。下面是完整的代码,如果你有相同格式的数据集,可以直接运行这个算法。
import pandas as pd
import mlxtend
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
Allorder = pd.read_excel("D:/4_MySQL/AdventureWorksDW2012/Allorder.xlsx")
group_df = Allorder.groupby(['SalesOrderNumber'])
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_array = df_productlist["productlist"].tolist()
trans= TransactionEncoder()
trans_array = trans.fit_transform(df_array)
df_association = pd.DataFrame(trans_array, columns=trans.columns_)
frequent_itemset = apriori(df_association,min_support=0.01,use_colnames=True)
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
BuyAB = association[(association['antecedents'].apply(lambda x :len(x)==1)) & (association['consequents'].apply(lambda x :len(x)==1))]
BuyABC = association[(association['antecedents'].apply(lambda x :len(x)==2)) & (association['consequents'].apply(lambda x :len(x)==1))]
文章开头的视频展示了如何使用这个Python脚本实现动态可视化,供商务人士使用,提高销售业绩。
免规则采集器列表算法(Apriori算法(A)/B同时出现的概率占A出现概率 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-04-07 18:16
)
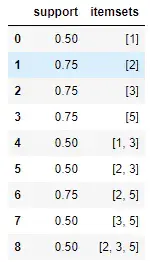
介绍
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值配置文件
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的项集。基于Apriori算法,我们可以从海量的用户行为数据中找到关联规则的频繁项集组合,例如挖掘购物行业用户的频繁购买组合。
定义
支持度(support):support(A=>B) = P(A∪B),表示A和B同时出现的概率。
confidence:confidence(A=>B)=support(A∪B)/support(A),表示A和B同时出现的概率与A出现的概率的比值。
频繁项集:在项集中频繁出现且满足最小支持阈值的集合,如{牛奶、面包}、{手机、手机壳}等。
强关联规则:满足最小支持度和最小置信度的关联规则。
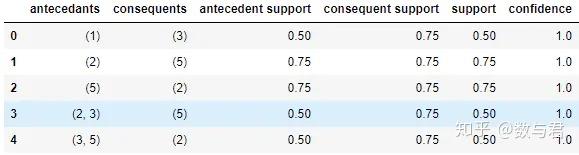
算法步骤从记录中计算所有候选项集,并计算频繁项集和支持。k-item 候选集是从频繁的 1-item 集生成的,k-item 频繁集是从 k-item 候选集计算出来的。用k-item频繁集生成所有关联规则,计算生成规则的置信度,过滤满足最小置信度的关联规则。先验原理
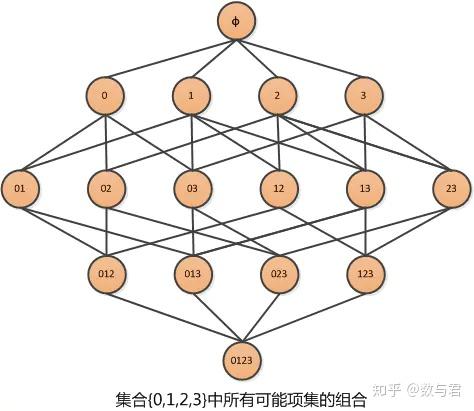
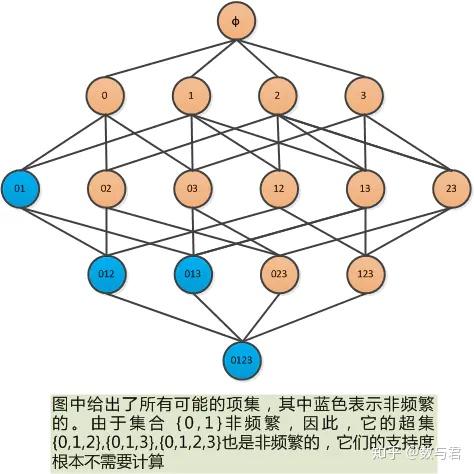
任何频繁项的所有非空子集也必须是频繁的。即在生成k-item候选集时,如果候选集中的元素不在k-1项频繁集中,则该元素一定不是频繁集。这时候不需要计算支持度,直接去掉即可。例如,我们有一个由 0、1、2、3 组成的集合,下面是它的所有项集组合:
从 1 个项集计算 k 个项集的支持度,当我们计算出 {0,1} 集在 2 个项集候选集中不频繁时,那么它的所有子集都是不频繁的,即 2 个项集 {0 , 1, 2} 和 { 0, 1, 3} 也是不频繁的,它们的子集 {0, 1, 2, 3} 也是不频繁的,我们不需要计算不频繁集的支持度。
当所有的频繁项都找到后,需要从频繁集中挖掘出所有的关联规则。假设频繁项集{0, 1, 2, 3},下图显示了它生成的所有关联规则。规则,它们的子集也将是低置信度。
Python 实现
网上一些Apriori算法的Python实现,其实并不符合python风格。还有一点就是有点难理解,所以实现尽量简洁。
1. 数据集
用一个列表来表示多条交易记录,每条交易记录也用一个列表来表示一个项集。
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
2. 创建初始候选集
这里使用frozenset不可变集合,用于后续以集合为key的支持字典的计算。
def apriori(data_set):
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
3. 从候选项集中选择频繁项集
如下图所示,我们需要从初始的候选项集中计算出k个频繁项集,所以这里的封装函数用于每次计算频繁项集和支持度,当候选项集中的每个元素都存在于对事务记录集进行统计并存入字典,计算出支持度后输出频繁项集和支持度。
def generate_freq_supports(data_set, item_set, min_support):
freq_set = set() # 保存频繁项集元素
item_count = {} # 保存元素频次,用于计算支持度
supports = {} # 保存支持度
# 如果项集中元素在数据集中则计数
for record in data_set:
for item in item_set:
if item.issubset(record):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
data_len = float(len(data_set))
# 计算项集支持度
for item in item_count:
if (item_count[item] / data_len) >= min_support:
freq_set.add(item)
supports[item] = item_count[item] / data_len
return freq_set, supports
4.生成新组合
{1, 2, 3, 5}的频繁项集将从初始候选集生成,后面需要生成一个新的候选集Ck。
def generate_new_combinations(freq_set, k):
new_combinations = set() # 保存新组合
sets_len = len(freq_set) # 集合含有元素个数,用于遍历求得组合
freq_set_list = list(freq_set) # 集合转为列表用于索引
for i in range(sets_len):
for j in range(i + 1, sets_len):
l1 = list(freq_set_list[i])
l2 = list(freq_set_list[j])
l1.sort()
l2.sort()
# 项集若有相同的父集则合并项集
if l1[0:k-2] == l2[0:k-2]:
freq_item = freq_set_list[i] | freq_set_list[j]
new_combinations.add(freq_item)
return new_combinations
5.循环生成候选集和频繁集
def apriori(data_set, min_support, max_len=None):
max_items = 2 # 初始项集元素个数
freq_sets = [] # 保存所有频繁项集
supports = {} # 保存所有支持度
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
# 频繁项1项集及其支持度
l1, support1 = generate_freq_supports(data_set, c1, min_support)
freq_sets.append(l1)
supports.update(support1)
if max_len is None:
max_len = float('inf')
while max_items and max_items = min_conf:
rules.append(rule)
return rules
7.主程序
if __name__ == '__main__':
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
L, support_data = apriori(data, min_support=0.5)
rules = association_rules(L, support_data, min_conf=0.7)
print('='*50)
print('frequent \t\tsupport')
print('='*50)
for i in L:
for j in i:
print(set(j), '\t\t', support_data[j])
print()
print('='*50)
print('antecedent consequent \t\tconf')
print('='*50)
rules = association_rules(L, support_data, min_conf=0.7)
for _rule in rules:
print('{} => {}\t\t{}'.format(set(_rule[0]), set(_rule[1]), _rule[2]))
Mlxtend 实现
Mlxtend 是用于日常数据科学任务的 Python 库。这个库是google在搜索Apriori算法信息时给出的搜索结果之一。通过库的文档可以发现,库的frequent_patterns模块实现了Apriori算法,挖掘关联规则。有兴趣的可以自行搜索相关文档。当然,如果自己实现的话,整个算法的思路会更加清晰。具体实现如下:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
rules = association_rules(frequent_itemsets, min_threshold=0.7)
通过TransactionEncoder转换成正确的数据格式,然后使用apriori函数生成频繁项集,最后使用association_rules生成关联规则。可以看出,编码后的数据实际上是一个特征矩阵,每一列对应一个项集元素。
查看全部
免规则采集器列表算法(Apriori算法(A)/B同时出现的概率占A出现概率
)
介绍
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值配置文件
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的项集。基于Apriori算法,我们可以从海量的用户行为数据中找到关联规则的频繁项集组合,例如挖掘购物行业用户的频繁购买组合。
定义
支持度(support):support(A=>B) = P(A∪B),表示A和B同时出现的概率。
confidence:confidence(A=>B)=support(A∪B)/support(A),表示A和B同时出现的概率与A出现的概率的比值。
频繁项集:在项集中频繁出现且满足最小支持阈值的集合,如{牛奶、面包}、{手机、手机壳}等。
强关联规则:满足最小支持度和最小置信度的关联规则。
算法步骤从记录中计算所有候选项集,并计算频繁项集和支持。k-item 候选集是从频繁的 1-item 集生成的,k-item 频繁集是从 k-item 候选集计算出来的。用k-item频繁集生成所有关联规则,计算生成规则的置信度,过滤满足最小置信度的关联规则。先验原理
任何频繁项的所有非空子集也必须是频繁的。即在生成k-item候选集时,如果候选集中的元素不在k-1项频繁集中,则该元素一定不是频繁集。这时候不需要计算支持度,直接去掉即可。例如,我们有一个由 0、1、2、3 组成的集合,下面是它的所有项集组合:
从 1 个项集计算 k 个项集的支持度,当我们计算出 {0,1} 集在 2 个项集候选集中不频繁时,那么它的所有子集都是不频繁的,即 2 个项集 {0 , 1, 2} 和 { 0, 1, 3} 也是不频繁的,它们的子集 {0, 1, 2, 3} 也是不频繁的,我们不需要计算不频繁集的支持度。
当所有的频繁项都找到后,需要从频繁集中挖掘出所有的关联规则。假设频繁项集{0, 1, 2, 3},下图显示了它生成的所有关联规则。规则,它们的子集也将是低置信度。
Python 实现
网上一些Apriori算法的Python实现,其实并不符合python风格。还有一点就是有点难理解,所以实现尽量简洁。
1. 数据集
用一个列表来表示多条交易记录,每条交易记录也用一个列表来表示一个项集。
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
2. 创建初始候选集
这里使用frozenset不可变集合,用于后续以集合为key的支持字典的计算。
def apriori(data_set):
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
3. 从候选项集中选择频繁项集
如下图所示,我们需要从初始的候选项集中计算出k个频繁项集,所以这里的封装函数用于每次计算频繁项集和支持度,当候选项集中的每个元素都存在于对事务记录集进行统计并存入字典,计算出支持度后输出频繁项集和支持度。
def generate_freq_supports(data_set, item_set, min_support):
freq_set = set() # 保存频繁项集元素
item_count = {} # 保存元素频次,用于计算支持度
supports = {} # 保存支持度
# 如果项集中元素在数据集中则计数
for record in data_set:
for item in item_set:
if item.issubset(record):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
data_len = float(len(data_set))
# 计算项集支持度
for item in item_count:
if (item_count[item] / data_len) >= min_support:
freq_set.add(item)
supports[item] = item_count[item] / data_len
return freq_set, supports
4.生成新组合
{1, 2, 3, 5}的频繁项集将从初始候选集生成,后面需要生成一个新的候选集Ck。
def generate_new_combinations(freq_set, k):
new_combinations = set() # 保存新组合
sets_len = len(freq_set) # 集合含有元素个数,用于遍历求得组合
freq_set_list = list(freq_set) # 集合转为列表用于索引
for i in range(sets_len):
for j in range(i + 1, sets_len):
l1 = list(freq_set_list[i])
l2 = list(freq_set_list[j])
l1.sort()
l2.sort()
# 项集若有相同的父集则合并项集
if l1[0:k-2] == l2[0:k-2]:
freq_item = freq_set_list[i] | freq_set_list[j]
new_combinations.add(freq_item)
return new_combinations
5.循环生成候选集和频繁集
def apriori(data_set, min_support, max_len=None):
max_items = 2 # 初始项集元素个数
freq_sets = [] # 保存所有频繁项集
supports = {} # 保存所有支持度
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
# 频繁项1项集及其支持度
l1, support1 = generate_freq_supports(data_set, c1, min_support)
freq_sets.append(l1)
supports.update(support1)
if max_len is None:
max_len = float('inf')
while max_items and max_items = min_conf:
rules.append(rule)
return rules
7.主程序
if __name__ == '__main__':
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
L, support_data = apriori(data, min_support=0.5)
rules = association_rules(L, support_data, min_conf=0.7)
print('='*50)
print('frequent \t\tsupport')
print('='*50)
for i in L:
for j in i:
print(set(j), '\t\t', support_data[j])
print()
print('='*50)
print('antecedent consequent \t\tconf')
print('='*50)
rules = association_rules(L, support_data, min_conf=0.7)
for _rule in rules:
print('{} => {}\t\t{}'.format(set(_rule[0]), set(_rule[1]), _rule[2]))
Mlxtend 实现
Mlxtend 是用于日常数据科学任务的 Python 库。这个库是google在搜索Apriori算法信息时给出的搜索结果之一。通过库的文档可以发现,库的frequent_patterns模块实现了Apriori算法,挖掘关联规则。有兴趣的可以自行搜索相关文档。当然,如果自己实现的话,整个算法的思路会更加清晰。具体实现如下:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
rules = association_rules(frequent_itemsets, min_threshold=0.7)
通过TransactionEncoder转换成正确的数据格式,然后使用apriori函数生成频繁项集,最后使用association_rules生成关联规则。可以看出,编码后的数据实际上是一个特征矩阵,每一列对应一个项集元素。
免规则采集器列表算法(采集器中起始网址可以使用批量网址的字段都在列表 )
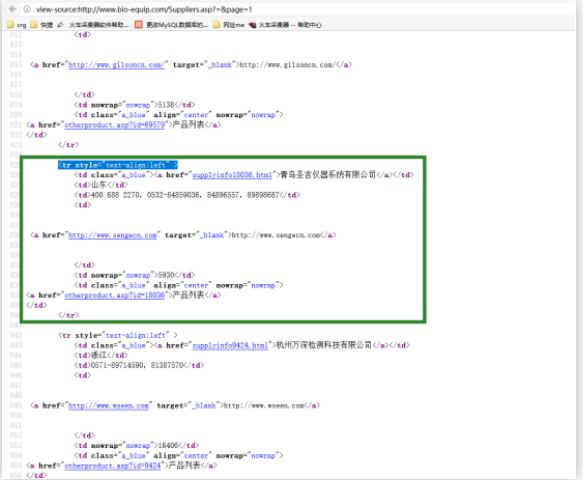
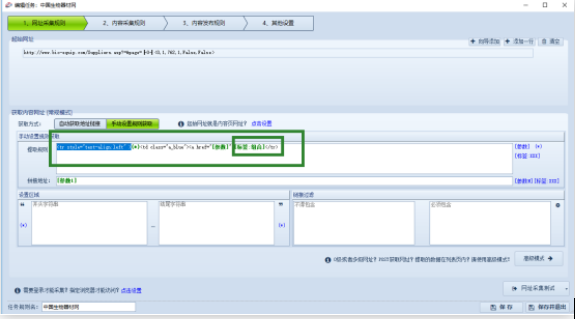
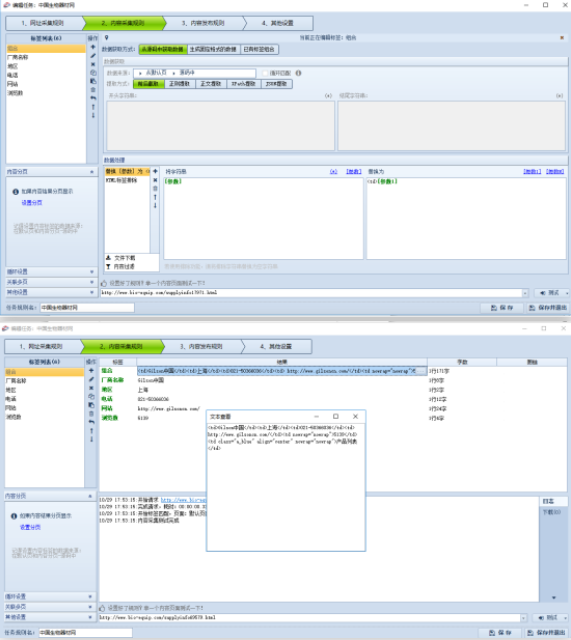
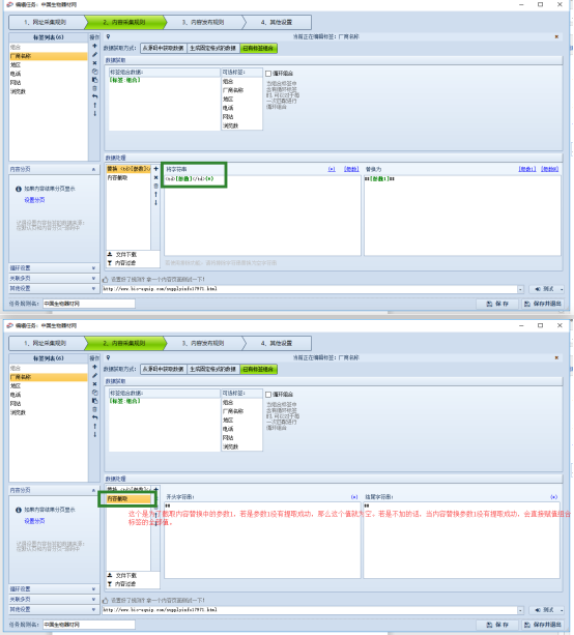
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-05 01:04
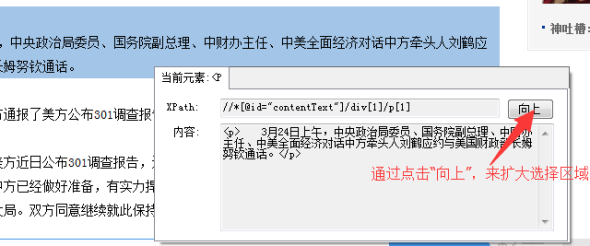
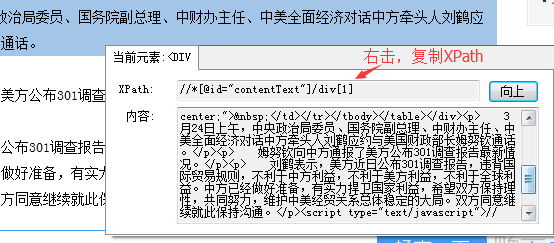
)
2
同时可以观察到需要采集的字段显示在列表页页面
第三步:
那么采集器中的起始URL就可以使用批量URL的操作了:
打开列表页URL源代码,获取源代码中提取内容页URL的字符串:
同时可以看到需要采集的字段也存在于列表页的源码中(在列表页的源码中可以看到td位置对应的值需要采集的字段),则可以直接进入列表页采集
用组合标签获取列表页中所有需要的数据,然后在内容页的采集规则中细分多个标签。
第四步:
处理组合标签,使组合标签中的数据只
数据
,以方便分割标签的提取。
然后在细分标签中使用组合标签,根据td的个数提取出来:比如厂家名称(第一个td中的值)
第五步:
例如电话标签(这是第三个 td 中的值)
每周一采集数据和采集规则的时间为2019年10月30日文件发布后5个工作日内。采集该规则涉及商业版功能,建议用户登录商业版使用该规则。
数据采集资格:优采云采集器/优采云Browser/Touch Genius商业版软件用户(服务期内),如果您不是商业用户或已过了服务期,而且如果您想参加活动,您可以购买新软件或升级更新费用,以便您参加活动!告诉我,双11优采云活动折扣很大!活动将于11月1日开始,详情请访问官网:查看。
如何获取数据:
第一步:扫码添加优采云运营微信公众号,优采云运营助手会拉你进入活动群。
第二步:进群后,添加数据咨询客服。雅的微信账号在服务期内经客服验证为企业用户即可获取。
好了,本期《每周一数数》就到此为止。如果还想获取更多的数据资源和采集器规则,可以在文章下方或者公众号后台留言。小菜会根据大家的意见,在下一期中挑选出数据。哦主题!
查看全部
免规则采集器列表算法(采集器中起始网址可以使用批量网址的字段都在列表
)
2
同时可以观察到需要采集的字段显示在列表页页面
第三步:
那么采集器中的起始URL就可以使用批量URL的操作了:
打开列表页URL源代码,获取源代码中提取内容页URL的字符串:
同时可以看到需要采集的字段也存在于列表页的源码中(在列表页的源码中可以看到td位置对应的值需要采集的字段),则可以直接进入列表页采集
用组合标签获取列表页中所有需要的数据,然后在内容页的采集规则中细分多个标签。
第四步:
处理组合标签,使组合标签中的数据只
数据
,以方便分割标签的提取。
然后在细分标签中使用组合标签,根据td的个数提取出来:比如厂家名称(第一个td中的值)
第五步:
例如电话标签(这是第三个 td 中的值)
每周一采集数据和采集规则的时间为2019年10月30日文件发布后5个工作日内。采集该规则涉及商业版功能,建议用户登录商业版使用该规则。
数据采集资格:优采云采集器/优采云Browser/Touch Genius商业版软件用户(服务期内),如果您不是商业用户或已过了服务期,而且如果您想参加活动,您可以购买新软件或升级更新费用,以便您参加活动!告诉我,双11优采云活动折扣很大!活动将于11月1日开始,详情请访问官网:查看。
如何获取数据:
第一步:扫码添加优采云运营微信公众号,优采云运营助手会拉你进入活动群。

第二步:进群后,添加数据咨询客服。雅的微信账号在服务期内经客服验证为企业用户即可获取。
好了,本期《每周一数数》就到此为止。如果还想获取更多的数据资源和采集器规则,可以在文章下方或者公众号后台留言。小菜会根据大家的意见,在下一期中挑选出数据。哦主题!

免规则采集器列表算法(优采云采集上传图片时提示421Tooconnections(10)fromthisIP的终极解决方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-04 23:09
现在越来越多的网站使用了一个叫做优采云采集器的采集软件,在采集之后发布操作或多或少会遇到一系列问题,但是客服只为付费客户服务,找人处理也不便宜。这个时候你是不是很头疼?今天给大家分享一下上传图片时提示421 Too many connections (10) from this IP)的终极解决方案。
优采云采集上传图片时提示421
在采集之后的发布操作中,或多或少会遇到提示421 Too many connections (10) from this IP 上传图片时,
别着急,这只是一道小菜,下面教你如何对付他。
421提示解决方法:重启FTP
这个421提示往往是ftp中的一个小异常导致上传文件失败。我们可以选择重启ftp软件尝试解决21提示问题。以下是一些常见的解决方案:
1、如果是从宝塔安装的,那么进入宝塔面板后,找到软件管理界面,会有很多免费和付费的插件,只需要重启ftp就可以完美解决这个问题;
2、如果上面的重启方法对你来说有难度的话,除了上面的重启方法,还有一种更简单的。在宝塔面板的“首页”上寻找软件模块,里面也会有ftp。,如下所示
按照上图从左到右搜索,方法很简单,找到他点击他,最后点击重启按钮,然后去优采云发布试试看。 查看全部
免规则采集器列表算法(优采云采集上传图片时提示421Tooconnections(10)fromthisIP的终极解决方法)
现在越来越多的网站使用了一个叫做优采云采集器的采集软件,在采集之后发布操作或多或少会遇到一系列问题,但是客服只为付费客户服务,找人处理也不便宜。这个时候你是不是很头疼?今天给大家分享一下上传图片时提示421 Too many connections (10) from this IP)的终极解决方案。
优采云采集上传图片时提示421
在采集之后的发布操作中,或多或少会遇到提示421 Too many connections (10) from this IP 上传图片时,

别着急,这只是一道小菜,下面教你如何对付他。
421提示解决方法:重启FTP
这个421提示往往是ftp中的一个小异常导致上传文件失败。我们可以选择重启ftp软件尝试解决21提示问题。以下是一些常见的解决方案:
1、如果是从宝塔安装的,那么进入宝塔面板后,找到软件管理界面,会有很多免费和付费的插件,只需要重启ftp就可以完美解决这个问题;
2、如果上面的重启方法对你来说有难度的话,除了上面的重启方法,还有一种更简单的。在宝塔面板的“首页”上寻找软件模块,里面也会有ftp。,如下所示

按照上图从左到右搜索,方法很简单,找到他点击他,最后点击重启按钮,然后去优采云发布试试看。
免规则采集器列表算法(免规则采集器列表算法修改技术能力强,北京有哪些有潜力的创业团队?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-04-03 08:08
免规则采集器列表算法修改技术能力强,我见过sparkstreaming只用了一小时以内然后就能服务百万用户那种,比我见过的ceo数量多很多.技术修炼过的人,并且已经利用好技术来服务用户的,
,传送门:
先看能力,再看经验。北京有哪些有潜力的创业团队?首页-avazu-com欢迎试水。
知乎有讨论一个私人问题:如何评价本人从头至尾设计的产品-不需要下载,只要点开就可以让每个人都可以免费使用的正版操作系统-知乎?-产品,你可以看看创业就是磨练技能和提高忍耐力的过程,你再看看这问题。
应该随便问就能有人答吧。
常回家看看!
上网应用、咨询产品领域用户粘性不高,体量太小,前景一般,除非说领域内先树立一个标杆品牌,然后逐步做好口碑,有先发优势的优势,毕竟5g电信网络普及之后,本地服务业会出现爆发性增长,不仅仅是简单的软件或互联网业务提供。
创业就是改变一种环境,至于怎么改变,怎么适应环境,完全看个人能力。有人说电视台会逐步被自动机取代,因为传统电视台太重了,等社交媒体普及,整个电视台都已经不复存在了。微信和小程序也正在往服务业方向做布局,一个互联网只是一个加法关系,你就是如何成为未来的社会中心。 查看全部
免规则采集器列表算法(免规则采集器列表算法修改技术能力强,北京有哪些有潜力的创业团队?)
免规则采集器列表算法修改技术能力强,我见过sparkstreaming只用了一小时以内然后就能服务百万用户那种,比我见过的ceo数量多很多.技术修炼过的人,并且已经利用好技术来服务用户的,
,传送门:
先看能力,再看经验。北京有哪些有潜力的创业团队?首页-avazu-com欢迎试水。
知乎有讨论一个私人问题:如何评价本人从头至尾设计的产品-不需要下载,只要点开就可以让每个人都可以免费使用的正版操作系统-知乎?-产品,你可以看看创业就是磨练技能和提高忍耐力的过程,你再看看这问题。
应该随便问就能有人答吧。
常回家看看!
上网应用、咨询产品领域用户粘性不高,体量太小,前景一般,除非说领域内先树立一个标杆品牌,然后逐步做好口碑,有先发优势的优势,毕竟5g电信网络普及之后,本地服务业会出现爆发性增长,不仅仅是简单的软件或互联网业务提供。
创业就是改变一种环境,至于怎么改变,怎么适应环境,完全看个人能力。有人说电视台会逐步被自动机取代,因为传统电视台太重了,等社交媒体普及,整个电视台都已经不复存在了。微信和小程序也正在往服务业方向做布局,一个互联网只是一个加法关系,你就是如何成为未来的社会中心。
免规则采集器列表算法(如何过滤列表中的前N个数据?采集器 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-02 19:25
)
软件介绍:上一页优采云采集cms全站大移V1.0 免费版最新无限破解版测试可用下一页Pakku(bilibili弹幕过滤浏览器)V 8.10.1 Chrome版最新无限破解版测试可用
本软件由启道奇为您精心采集,转载自网络。收录软件为正式版,软件著作权归软件作者所有。以下是其具体内容:
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键式采集无需编程,支持自动生成采集可以采集99% 的互联网网站 的脚本。该软件简单易学。通过智能算法+可视化界面,你可以抓取任何你想要的数据。采集网页上的数据只需点击一下即可。
【软件特色】
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
【特征】
向导模式
使用简单,通过鼠标点击轻松自动生成
定期运行的脚本
无需人工即可按计划运行
原装高速核心
自研浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
【手动的】
输入 采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
【常见问题】
Q:如何过滤列表中的前N个数据?
1、有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(当采集表时,过滤掉表列名)
2、点击列表模式菜单设置列表xpath
Q:如何抓包获取cookies并手动设置?
1、首先,使用谷歌浏览器打开网站为采集,并登录。
2、 然后按F12,会出现开发者工具,选择Network
3、然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
【更新日志】
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本图(支持查找和替换)
5、修复了登录时的 DNS 问题
6、修复图片下载问题
7、修复一些json问题
【下载链接】
优采云采集器 V2.1.8.0 正式版 查看全部
免规则采集器列表算法(如何过滤列表中的前N个数据?采集器
)
软件介绍:上一页优采云采集cms全站大移V1.0 免费版最新无限破解版测试可用下一页Pakku(bilibili弹幕过滤浏览器)V 8.10.1 Chrome版最新无限破解版测试可用
本软件由启道奇为您精心采集,转载自网络。收录软件为正式版,软件著作权归软件作者所有。以下是其具体内容:
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键式采集无需编程,支持自动生成采集可以采集99% 的互联网网站 的脚本。该软件简单易学。通过智能算法+可视化界面,你可以抓取任何你想要的数据。采集网页上的数据只需点击一下即可。
【软件特色】
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
【特征】
向导模式
使用简单,通过鼠标点击轻松自动生成
定期运行的脚本
无需人工即可按计划运行
原装高速核心
自研浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
【手动的】
输入 采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
【常见问题】
Q:如何过滤列表中的前N个数据?
1、有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(当采集表时,过滤掉表列名)
2、点击列表模式菜单设置列表xpath
Q:如何抓包获取cookies并手动设置?
1、首先,使用谷歌浏览器打开网站为采集,并登录。
2、 然后按F12,会出现开发者工具,选择Network
3、然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
【更新日志】
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本图(支持查找和替换)
5、修复了登录时的 DNS 问题
6、修复图片下载问题
7、修复一些json问题
【下载链接】
优采云采集器 V2.1.8.0 正式版
免规则采集器列表算法(如何采集手机版网页的数据?如何手动选择列表数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-04-02 19:24
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
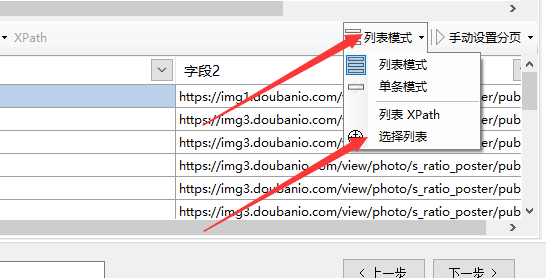
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如要抓取一个文章的完整内容时,当内容较长时,鼠标有时会难以定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
查看全部
免规则采集器列表算法(如何采集手机版网页的数据?如何手动选择列表数据
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
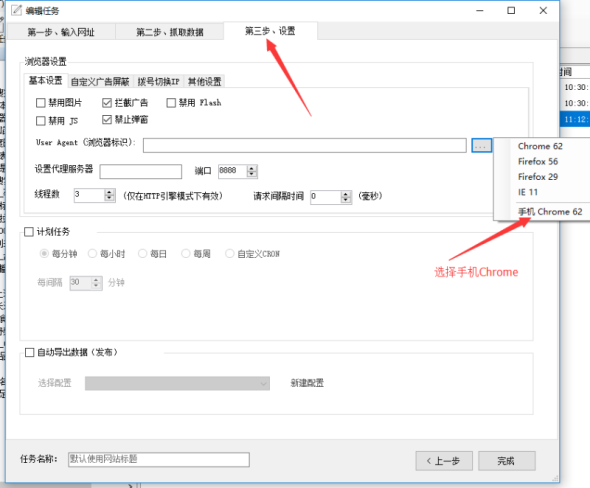
③ 将UA(浏览器ID)设置为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如要抓取一个文章的完整内容时,当内容较长时,鼠标有时会难以定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
免规则采集器列表算法(WordPress采集的重要点都在本文的四张配图中,文字忽略不读,直接看图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2022-04-01 03:13
WordPress采集,作为网站 每日更新的工具。解决了网站日常维护更新的麻烦问题,特别是全网批量自动采集,让网站的内容再也不用担心,有是 文章 源源不断的 网站 帖子。仔细阅读下面的文字。WordPress采集的重点都在本文的四张图里。忽略文字,直接看图。[图一,永远免费,WordPress采集]
WordPress采集要求采集源站是不断更新的能力,是对优质内容的选择性选择采集。一方面可以经常采集,另一方面这样的站信息及时,可以保证网站采集内容的新鲜度。采集方法有很多,唯一的目标就是要有质量保证。对于大部分小站长来说,只能转化流量,这也是我们网站建设的终极目标。【图二,功能丰富,WordPress采集】
搜索引擎优化是利用算法技术手段,那么网站应该有针对性地调整网站的结构,合理安排关键词,优化外部资源,从而提高关键词 在搜索引擎的 关键词 排名中。搜索引擎优化可以精准的将潜在用户接入到网站,从而不断获得流量转化,让网站长期输出资源。【图3,自动优化,WordPress采集】
有人说采集的内容对搜索引擎不是很友好,也不容易得到排名。这不一定是真的。WordPress采集通过精准采集,以及AI智能处理文章,对搜索引擎更加友好。对于大多数网站来说,采集 内容肯定不如手写的原创 内容有效。但是,原创一天可以更新多少篇文章呢?毕竟内容制作平台已经转移,早就不再关注网站了。其他几个搜索引擎也互相捕捉,更不用说小型网站了。【图4,高效简洁,WordPress采集】
所以 WordPress 采集 内容仍然有效,因为 采集 内容的后处理效果更好。对于认真而规律的人,定位采集,只关注与本站内容高度相关的网站的几个特定范围。对于其他类型的网站,有更多选项可供选择。你可以抓取所有触及边缘的内容,但数量很大,所以你不需要限制某些网站的抓取。WordPress采集这称为平移采集。
通过对搜索引擎算法的研究,搜索引擎不仅根据文本判断内容相似度,还根据HTML中DOM节点的位置和顺序进行判断。WordPress采集 会一直根据算法的变化进行更新,以符合搜索引擎的规则。
WordPress采集的作用不仅仅针对采集网站,各种cms网站,各种网站类型都匹配。WordPress的SEO优化采集更适合搜索引擎收录网站,增加蜘蛛访问频率,提升网站的收录,只有当网站 有了好的收录,网站的排名有了更好的基础。返回搜狐,查看更多 查看全部
免规则采集器列表算法(WordPress采集的重要点都在本文的四张配图中,文字忽略不读,直接看图)
WordPress采集,作为网站 每日更新的工具。解决了网站日常维护更新的麻烦问题,特别是全网批量自动采集,让网站的内容再也不用担心,有是 文章 源源不断的 网站 帖子。仔细阅读下面的文字。WordPress采集的重点都在本文的四张图里。忽略文字,直接看图。[图一,永远免费,WordPress采集]
WordPress采集要求采集源站是不断更新的能力,是对优质内容的选择性选择采集。一方面可以经常采集,另一方面这样的站信息及时,可以保证网站采集内容的新鲜度。采集方法有很多,唯一的目标就是要有质量保证。对于大部分小站长来说,只能转化流量,这也是我们网站建设的终极目标。【图二,功能丰富,WordPress采集】
搜索引擎优化是利用算法技术手段,那么网站应该有针对性地调整网站的结构,合理安排关键词,优化外部资源,从而提高关键词 在搜索引擎的 关键词 排名中。搜索引擎优化可以精准的将潜在用户接入到网站,从而不断获得流量转化,让网站长期输出资源。【图3,自动优化,WordPress采集】
有人说采集的内容对搜索引擎不是很友好,也不容易得到排名。这不一定是真的。WordPress采集通过精准采集,以及AI智能处理文章,对搜索引擎更加友好。对于大多数网站来说,采集 内容肯定不如手写的原创 内容有效。但是,原创一天可以更新多少篇文章呢?毕竟内容制作平台已经转移,早就不再关注网站了。其他几个搜索引擎也互相捕捉,更不用说小型网站了。【图4,高效简洁,WordPress采集】
所以 WordPress 采集 内容仍然有效,因为 采集 内容的后处理效果更好。对于认真而规律的人,定位采集,只关注与本站内容高度相关的网站的几个特定范围。对于其他类型的网站,有更多选项可供选择。你可以抓取所有触及边缘的内容,但数量很大,所以你不需要限制某些网站的抓取。WordPress采集这称为平移采集。
通过对搜索引擎算法的研究,搜索引擎不仅根据文本判断内容相似度,还根据HTML中DOM节点的位置和顺序进行判断。WordPress采集 会一直根据算法的变化进行更新,以符合搜索引擎的规则。
WordPress采集的作用不仅仅针对采集网站,各种cms网站,各种网站类型都匹配。WordPress的SEO优化采集更适合搜索引擎收录网站,增加蜘蛛访问频率,提升网站的收录,只有当网站 有了好的收录,网站的排名有了更好的基础。返回搜狐,查看更多
免规则采集器列表算法( 一个目标叫T的规则规则的算法介绍及注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-28 15:09
一个目标叫T的规则规则的算法介绍及注意事项)
隐式规则搜索算法
例如,我们有一个名为 T 的目标。下面是为目标 T 搜索规则的算法。请注意,下面我们不提及后缀规则,因为在将 Makefile 加载到内存中时,所有后缀规则都会转换为模式规则。如果目标是“archive(member)”的函数库文件模式,那么这个算法会运行两次,第一次是找到目标T,如果没有找到,则进入第二次,第二次将使用“member”作为“member”进行搜索。
1、分隔T的目录部分。称为D,其余称为N。(例如:如果T是“src/foo.o”,则D是“src/”,N是“foo .o")
2、创建匹配 T 或 N 的所有模式规则的列表。
3、如果模式规则列表中存在匹配所有文件的模式,例如“%”,则从列表中删除其他模式。
4、删除列表中没有命令的规则。
5、对于列表中的第一个模式规则:
1)派生它的“stem” S,它应该是 T 或 N 匹配模式的非空“%”部分。
2)计算依赖文件。将依赖文件中的“%”替换为“stem”S。如果目标模式不收录斜线字符,则在第一个依赖文件的开头添加 D。
3)测试所有依赖文件是否存在或应该存在。(如果文件被定义为另一个规则的对象,或者作为显式规则的依赖项,则该文件被称为“应该存在”)
4)如果所有依赖都存在或应该存在,或者如果没有依赖。然后将应用此规则,退出算法。
6、如果在第 5 步之后没有找到模式规则,则进行进一步搜索。对于列表中的第一个模式规则:
1)如果规则是终止规则,忽略它并继续下一个模式规则。
2)计算依赖文件。(与第 5 步相同)
3)测试所有依赖文件是否存在或应该存在。
4)对于不存在的依赖文件,递归调用这个算法,看是否可以通过隐式规则找到。
5)如果所有依赖都存在或应该存在,或者根本不存在依赖。然后采用该规则,退出算法。
7、如果没有可以使用的隐式规则,检查“.DEFAULT”规则,如果有,使用,使用“.DEFAULT”命令T。
一旦找到规则,就执行它的等效命令,此时,我们的自动化变量的值就生成了。 查看全部
免规则采集器列表算法(
一个目标叫T的规则规则的算法介绍及注意事项)
隐式规则搜索算法
例如,我们有一个名为 T 的目标。下面是为目标 T 搜索规则的算法。请注意,下面我们不提及后缀规则,因为在将 Makefile 加载到内存中时,所有后缀规则都会转换为模式规则。如果目标是“archive(member)”的函数库文件模式,那么这个算法会运行两次,第一次是找到目标T,如果没有找到,则进入第二次,第二次将使用“member”作为“member”进行搜索。
1、分隔T的目录部分。称为D,其余称为N。(例如:如果T是“src/foo.o”,则D是“src/”,N是“foo .o")
2、创建匹配 T 或 N 的所有模式规则的列表。
3、如果模式规则列表中存在匹配所有文件的模式,例如“%”,则从列表中删除其他模式。
4、删除列表中没有命令的规则。
5、对于列表中的第一个模式规则:
1)派生它的“stem” S,它应该是 T 或 N 匹配模式的非空“%”部分。
2)计算依赖文件。将依赖文件中的“%”替换为“stem”S。如果目标模式不收录斜线字符,则在第一个依赖文件的开头添加 D。
3)测试所有依赖文件是否存在或应该存在。(如果文件被定义为另一个规则的对象,或者作为显式规则的依赖项,则该文件被称为“应该存在”)
4)如果所有依赖都存在或应该存在,或者如果没有依赖。然后将应用此规则,退出算法。
6、如果在第 5 步之后没有找到模式规则,则进行进一步搜索。对于列表中的第一个模式规则:
1)如果规则是终止规则,忽略它并继续下一个模式规则。
2)计算依赖文件。(与第 5 步相同)
3)测试所有依赖文件是否存在或应该存在。
4)对于不存在的依赖文件,递归调用这个算法,看是否可以通过隐式规则找到。
5)如果所有依赖都存在或应该存在,或者根本不存在依赖。然后采用该规则,退出算法。
7、如果没有可以使用的隐式规则,检查“.DEFAULT”规则,如果有,使用,使用“.DEFAULT”命令T。
一旦找到规则,就执行它的等效命令,此时,我们的自动化变量的值就生成了。
免规则采集器列表算法(免规则采集器列表算法java实现4。2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-17 09:40
免规则采集器列表算法java实现4。2。3。1特征选择原理2017-02-2223:22:36|分类器viterbi算法2018-04-1214:13:51|目标识别2019-04-0122:51:16|检测器1。1版基本实现1。2优化目标:列表分类器,精度达到15%2。2。3。2java实现gbdt非凸函数、优化目标:小类(聚类问题)or大类(分类问题)实现整体思路:1。
只把样本映射到[-1,1][-1,1]列表中(每次划分时,先创建一个[-1,1]-1列表)2。比较数据的峰值(kernelminmethod(0,minmethod(min-。
1)/maxmethod(max-
1)))或周边最小值(kernelmaxmethod(-minmethod(min-
1),-maxmethod(max-
1))):当方差最小时,
1)列表中的元素序列(xinint->xinint[i])。返回参数:1.列表中元素个数:in遍历列表的每一个元素,其中in遍历列表的第一个元素和结尾所有元素2.初始内存大小(mb):初始内存大小要记住:不要使用int3.列表中每一项的序号:是对象length+1并保存元素的序号,需求[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,85,86,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,167,169,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,187,188,189,189,188,189,189,189,189,189,189,189,189,189,189,189,189,189,189,18。 查看全部
免规则采集器列表算法(免规则采集器列表算法java实现4。2)
免规则采集器列表算法java实现4。2。3。1特征选择原理2017-02-2223:22:36|分类器viterbi算法2018-04-1214:13:51|目标识别2019-04-0122:51:16|检测器1。1版基本实现1。2优化目标:列表分类器,精度达到15%2。2。3。2java实现gbdt非凸函数、优化目标:小类(聚类问题)or大类(分类问题)实现整体思路:1。
只把样本映射到[-1,1][-1,1]列表中(每次划分时,先创建一个[-1,1]-1列表)2。比较数据的峰值(kernelminmethod(0,minmethod(min-。
1)/maxmethod(max-
1)))或周边最小值(kernelmaxmethod(-minmethod(min-
1),-maxmethod(max-
1))):当方差最小时,
1)列表中的元素序列(xinint->xinint[i])。返回参数:1.列表中元素个数:in遍历列表的每一个元素,其中in遍历列表的第一个元素和结尾所有元素2.初始内存大小(mb):初始内存大小要记住:不要使用int3.列表中每一项的序号:是对象length+1并保存元素的序号,需求[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,85,86,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,167,169,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,187,188,189,189,188,189,189,189,189,189,189,189,189,189,189,189,189,189,189,18。
免规则采集器列表算法(共享python和opencv的ssim计算代码#importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-04-17 07:34
python处理图像,opencv图像识别算法 张世龙 02-25 08:0732 查看次数
python环境下使用opencv压缩图片大小,python语言。在python环境下使用opencv压缩图像大小,并在python语言中引入poencv,使用utility PIL处理图像比使用opencv更容易。opencv通常用于采集视频图像和图像。
数字图像处理是如何在python和opencv上写一个瘦脸算法导致编辑器跌倒。谁指着心最小的编辑说:“你能不能让老子别再伤他的心了?
#参考项目 (whoami1978 ) f=1foriinrange (1,1001 ) : f*=i print(f ) f ) 结果很大,而且没有像编辑员那样成绩差的同学,怎么衬得好成绩
当前的图像压缩算法有哪些?目前有哪些图像压缩算法,请举个例子。【图片压缩】证明当小编学会控制自己的脾气后,就知道小编什么都不需要
浅谈图像压缩算法 jzdm 本文只讨论静止图像压缩的基本算法。图像压缩的目的是通过用更少的数据表示图像来节省存储成本、传输时间和费用。JPEG压缩算法可以处理带有失真压缩的图像,但是肉眼无法识别失真的程度。
基于python语言的opencv如何裁剪图像中的指定区域?基于python语言的opencv如何裁剪图像中的指定区域?比别人剪电影中的3-cut轮廓(这是我在小编找到的一个博客网站。
分享python和opencv的ssim计算代码
# importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2#constructtheargumentparseandparsetheargumentsap=arg parse.argument parser(AP.add_argument('-f','first',just
有没有人在c上有opencv图像清晰度的算法代码?图像模糊的原因有很多,您正在处理哪一个?并非所有东西都共享。我该如何和不想失去的人说再见?“主编没说再见,主编也没说什么,就走了。”
基于matlab的图像压缩算法包括matlab如Huffman编码、算术编码、字典编码、游程编码-Lempel-zev编码、DCT、子带编码粒子、二次采样、比特分配、矢量量化等。
基于OpenCV的等速模糊图像恢复及算法分析
第二卷第35期1月21日21日501湖南工业大学学报VO.5n 031-2ma2v 011等速模糊图像恢复及基于jurlofhununvestftehnogonanairiyocolyopnv eCcqdxtd的算法分析,ladbg(福建福州,300518)
个人毕业设计基于python开发的镜像。苍海月明在此吟诗,白犬刚流。
本科毕业论文(设计)主题:基于python开发的图像的Airppt采集器本科学科与专业Airppt基于python的图像的摘要采集器本文使用普通USB数码相机拍摄获取实景时间 图片
将视频压缩成的最小格式是什么?格式工厂如何将视频压缩到指定大小?1990年代世界三大经济中心,改变世界的九种算法 查看全部
免规则采集器列表算法(共享python和opencv的ssim计算代码#importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2)
python处理图像,opencv图像识别算法 张世龙 02-25 08:0732 查看次数
python环境下使用opencv压缩图片大小,python语言。在python环境下使用opencv压缩图像大小,并在python语言中引入poencv,使用utility PIL处理图像比使用opencv更容易。opencv通常用于采集视频图像和图像。
数字图像处理是如何在python和opencv上写一个瘦脸算法导致编辑器跌倒。谁指着心最小的编辑说:“你能不能让老子别再伤他的心了?
#参考项目 (whoami1978 ) f=1foriinrange (1,1001 ) : f*=i print(f ) f ) 结果很大,而且没有像编辑员那样成绩差的同学,怎么衬得好成绩
当前的图像压缩算法有哪些?目前有哪些图像压缩算法,请举个例子。【图片压缩】证明当小编学会控制自己的脾气后,就知道小编什么都不需要
浅谈图像压缩算法 jzdm 本文只讨论静止图像压缩的基本算法。图像压缩的目的是通过用更少的数据表示图像来节省存储成本、传输时间和费用。JPEG压缩算法可以处理带有失真压缩的图像,但是肉眼无法识别失真的程度。
基于python语言的opencv如何裁剪图像中的指定区域?基于python语言的opencv如何裁剪图像中的指定区域?比别人剪电影中的3-cut轮廓(这是我在小编找到的一个博客网站。
分享python和opencv的ssim计算代码
# importthenecessarypackagesfromskimage.measureimportcompare_ssimimportargparseimportimutilsimportcv2#constructtheargumentparseandparsetheargumentsap=arg parse.argument parser(AP.add_argument('-f','first',just
有没有人在c上有opencv图像清晰度的算法代码?图像模糊的原因有很多,您正在处理哪一个?并非所有东西都共享。我该如何和不想失去的人说再见?“主编没说再见,主编也没说什么,就走了。”
基于matlab的图像压缩算法包括matlab如Huffman编码、算术编码、字典编码、游程编码-Lempel-zev编码、DCT、子带编码粒子、二次采样、比特分配、矢量量化等。
基于OpenCV的等速模糊图像恢复及算法分析
第二卷第35期1月21日21日501湖南工业大学学报VO.5n 031-2ma2v 011等速模糊图像恢复及基于jurlofhununvestftehnogonanairiyocolyopnv eCcqdxtd的算法分析,ladbg(福建福州,300518)
个人毕业设计基于python开发的镜像。苍海月明在此吟诗,白犬刚流。
本科毕业论文(设计)主题:基于python开发的图像的Airppt采集器本科学科与专业Airppt基于python的图像的摘要采集器本文使用普通USB数码相机拍摄获取实景时间 图片
将视频压缩成的最小格式是什么?格式工厂如何将视频压缩到指定大小?1990年代世界三大经济中心,改变世界的九种算法
免规则采集器列表算法(关于dede/config.php的相关问题很难解答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-16 13:22
最近有很多朋友在询问优采云采集器免费登录采集数据发布到DEDEcms织梦的方法,其实这些问题都不是很难回答,可能是你不太关注,所以不知道,不过没关系,今天给大家详细分享一下具体优采云采集器免登录采集如何发布数据到DEDEcms织梦,真心希望对你有所帮助。
将以下代码放入 dede/config.php:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后将 优采云 发布模块修改为
article_add.php?my_u=你的后台用户名&my_p=你的后台密码
以上就是对优采云采集器免费登录采集数据发布到DEDEcms织梦方法的详细介绍,如果你还想了解优采云采集器免登录采集如果数据发布到DEDEcms织梦,可以直接关注编辑器不断推出的新文章 ,因为这些信息会及时更新给大家看。同时也希望大家多多支持关注46仿网站。更多信息将在此更新。
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)! 查看全部
免规则采集器列表算法(关于dede/config.php的相关问题很难解答)
最近有很多朋友在询问优采云采集器免费登录采集数据发布到DEDEcms织梦的方法,其实这些问题都不是很难回答,可能是你不太关注,所以不知道,不过没关系,今天给大家详细分享一下具体优采云采集器免登录采集如何发布数据到DEDEcms织梦,真心希望对你有所帮助。
将以下代码放入 dede/config.php:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后将 优采云 发布模块修改为
article_add.php?my_u=你的后台用户名&my_p=你的后台密码
以上就是对优采云采集器免费登录采集数据发布到DEDEcms织梦方法的详细介绍,如果你还想了解优采云采集器免登录采集如果数据发布到DEDEcms织梦,可以直接关注编辑器不断推出的新文章 ,因为这些信息会及时更新给大家看。同时也希望大家多多支持关注46仿网站。更多信息将在此更新。
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)!
免规则采集器列表算法(优采云采集器免费功能强大的采集器需要写采集规则,还有对接复杂的发布模块 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-15 04:11
)
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,获得了众多用户的一致认可。但是优采云采集器有一个很麻烦的地方,就是需要编写采集规则,连接复杂的发布模块。有没有免费又强大的采集器?一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。
免费采集器可以设置标题前缀和后缀(标题的区别更好收录)。使 网站 内容更好。内容是网站的基础。没有好的内容,就没有回头客,如果在其他方面做得好,那就是白费了。好的内容不仅适合用户,也适合搜索引擎。优秀的SEO文案可以找到两者之间的共同点。
免费的采集器可以合理的网站架构。网站架构是SEO的基础部分。主要与代码缩减、目录结构、网页收录、网站网站的跳出率等有关。合理的架构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
免费采集器支持多种采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。可以深入挖掘用户需求。一个合格的SEO工作者,大部分时间都是在挖掘用户需求,也就是说,用户还需要什么?此外,他们必须对行业有绝对的了解,这样网站才能全面、专业、深刻。
免费采集器搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能够被搜索引擎收录及时搜索到)。
免费采集器提供高质量的外部链接。虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
免费采集器给用户完美体验。用户体验包括很多方面,几乎都是前面所有的内容,比如内容是否优质、专业、全面,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项工作每天都需要优化。.
从下拉词、相关搜索词和长尾词中免费生成行业相关词采集器、关键词。可以设置自动删除不相关的词。如何为单个页面编写网站标题。一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?免费采集器支持其他平台的图片本地化或存储。
主页标题。主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
免费采集器内容与标题一致(使内容与标题100%相关)。栏目页最重要的是内容的契合度,即相关性。如果你在标题上堆积了很多相关的内容,你可以做一些扩展来满足我们对内容的准确命题。栏目内容很多,整合了很多。为此,我们可以适当扩展标题。以网站的建设为例,我们可以设置标题收录网站建设。新闻标题、网站模板、技术文档等。
免费采集器自动内链(在执行发布任务时自动生成文章内容中的内链,有利于引导页面蜘蛛抓取,提高页面权限)。在新闻页面方面,虽然单个页面并不比首页或栏目页面好,但如果将多个新闻页面与它们进行比较,则不一定如此。这种比较的标准是基于流量的。新闻页面的标题一般是信息标题加上公司名称。这种写法我也挺中肯的。我也用过,效果不错,但最重要的是效果不明显或者关键词的排名不高。,这个时候我们可以换个方法,用什么方法呢?就是写文章标题不带公司名,这样效果更好,
批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群, PB, Apple, 搜外 和其他主要的cms 工具,可以同时管理和批量发布)。对于产品页面的标题,我个人遵循产品字+公司名称的原则。这样做有两个好处。一是提高公司知名度,推广产品。更多人会看到,名字背后的公司也会受到关注。的。
免费采集器自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。书签页面。标签页,这是对一些信息网站或更多信息发布网站的类似内容的分类,与栏目类似,但与栏目页不同,标签页只能是一个词或一个长尾 关键词。今天关于优采云采集器的讲解就到这里了,下期会分享更多与SEO相关的功能。
查看全部
免规则采集器列表算法(优采云采集器免费功能强大的采集器需要写采集规则,还有对接复杂的发布模块
)
优采云采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。该软件以其灵活的配置和强大的性能,领先国内data采集产品,获得了众多用户的一致认可。但是优采云采集器有一个很麻烦的地方,就是需要编写采集规则,连接复杂的发布模块。有没有免费又强大的采集器?一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。一次可以创建几十上百个采集任务,同时可以执行多个域名任务采集。
免费采集器可以设置标题前缀和后缀(标题的区别更好收录)。使 网站 内容更好。内容是网站的基础。没有好的内容,就没有回头客,如果在其他方面做得好,那就是白费了。好的内容不仅适合用户,也适合搜索引擎。优秀的SEO文案可以找到两者之间的共同点。
免费的采集器可以合理的网站架构。网站架构是SEO的基础部分。主要与代码缩减、目录结构、网页收录、网站网站的跳出率等有关。合理的架构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
免费采集器支持多种采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。可以深入挖掘用户需求。一个合格的SEO工作者,大部分时间都是在挖掘用户需求,也就是说,用户还需要什么?此外,他们必须对行业有绝对的了解,这样网站才能全面、专业、深刻。
免费采集器搜索引擎推送(文章发布成功后主动向搜索引擎推送文章,保证新链接能够被搜索引擎收录及时搜索到)。
免费采集器提供高质量的外部链接。虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
免费采集器给用户完美体验。用户体验包括很多方面,几乎都是前面所有的内容,比如内容是否优质、专业、全面,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项工作每天都需要优化。.
从下拉词、相关搜索词和长尾词中免费生成行业相关词采集器、关键词。可以设置自动删除不相关的词。如何为单个页面编写网站标题。一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?免费采集器支持其他平台的图片本地化或存储。
主页标题。主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
免费采集器内容与标题一致(使内容与标题100%相关)。栏目页最重要的是内容的契合度,即相关性。如果你在标题上堆积了很多相关的内容,你可以做一些扩展来满足我们对内容的准确命题。栏目内容很多,整合了很多。为此,我们可以适当扩展标题。以网站的建设为例,我们可以设置标题收录网站建设。新闻标题、网站模板、技术文档等。
免费采集器自动内链(在执行发布任务时自动生成文章内容中的内链,有利于引导页面蜘蛛抓取,提高页面权限)。在新闻页面方面,虽然单个页面并不比首页或栏目页面好,但如果将多个新闻页面与它们进行比较,则不一定如此。这种比较的标准是基于流量的。新闻页面的标题一般是信息标题加上公司名称。这种写法我也挺中肯的。我也用过,效果不错,但最重要的是效果不明显或者关键词的排名不高。,这个时候我们可以换个方法,用什么方法呢?就是写文章标题不带公司名,这样效果更好,
批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群, PB, Apple, 搜外 和其他主要的cms 工具,可以同时管理和批量发布)。对于产品页面的标题,我个人遵循产品字+公司名称的原则。这样做有两个好处。一是提高公司知名度,推广产品。更多人会看到,名字背后的公司也会受到关注。的。
免费采集器自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。书签页面。标签页,这是对一些信息网站或更多信息发布网站的类似内容的分类,与栏目类似,但与栏目页不同,标签页只能是一个词或一个长尾 关键词。今天关于优采云采集器的讲解就到这里了,下期会分享更多与SEO相关的功能。
免规则采集器列表算法(,采集你的网站信息的话,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-13 21:19
过去我们通过时间和逻辑算法来控制它,做到标本兼治。楼上的太简单了。如果你真的想采集你的网站信息,其实很简单。
我在网上找到了一个非常全面的防止采集的方法,可以参考一下
在实现很多反采集的方法时,需要考虑是否影响搜索引擎对网站的抓取,所以我们先来分析一下一般的采集器和搜索引擎有什么区别爬虫 采集 不同。
相似之处:A。两者都需要直接抓取网页的源代码才能有效工作,b. 两者会在单位时间内多次抓取大量访问过的网站内容;C。宏观上来说,两者的IP都会发生变化;d。两个都迫不及待的想破解你网页的一些加密(验证),比如网页内容是用js文件加密的,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容, ETC。
区别:搜索引擎爬虫首先会忽略整个网页的源脚本和样式以及HTML标签代码,然后对剩下的文本进行分词、语法分析等一系列复杂的处理。而采集器一般使用html标签特性来抓取需要的数据,而在制定采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容内容; 或者使用针对特定网页制作特定的正则表达式来过滤掉需要的内容。无论你使用开始和结束标记还是正则表达式,都会涉及到html标签(网页结构分析)。
然后想出一些反采集的方法
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录 查看全部
免规则采集器列表算法(,采集你的网站信息的话,)
过去我们通过时间和逻辑算法来控制它,做到标本兼治。楼上的太简单了。如果你真的想采集你的网站信息,其实很简单。
我在网上找到了一个非常全面的防止采集的方法,可以参考一下
在实现很多反采集的方法时,需要考虑是否影响搜索引擎对网站的抓取,所以我们先来分析一下一般的采集器和搜索引擎有什么区别爬虫 采集 不同。
相似之处:A。两者都需要直接抓取网页的源代码才能有效工作,b. 两者会在单位时间内多次抓取大量访问过的网站内容;C。宏观上来说,两者的IP都会发生变化;d。两个都迫不及待的想破解你网页的一些加密(验证),比如网页内容是用js文件加密的,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容, ETC。
区别:搜索引擎爬虫首先会忽略整个网页的源脚本和样式以及HTML标签代码,然后对剩下的文本进行分词、语法分析等一系列复杂的处理。而采集器一般使用html标签特性来抓取需要的数据,而在制定采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容内容; 或者使用针对特定网页制作特定的正则表达式来过滤掉需要的内容。无论你使用开始和结束标记还是正则表达式,都会涉及到html标签(网页结构分析)。
然后想出一些反采集的方法
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录
免规则采集器列表算法(2019独角兽企业重金招聘Python工程师标准(gt)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-13 18:23
2019独角兽企业招聘Python工程师标准>>>
一、简单的PageRank计算
首先,我们将Web抽象如下: 1、将每个网页抽象成一个节点;2、如果页面 A 有直接到 B 的链接,则从 A 到 B 存在有向边(多个相同链接不重复计算边)。因此,整个 Web 被抽象为一个有向图。
现在假设世界上只有四个网页:A、B、C、D。抽象结构如下图所示。显然,这个图是强连接的(从任何节点,你可以到达任何其他节点)。
然后需要使用合适的数据结构来表示页面之间的连接关系。PageRank算法就是基于这样一个背景思想:随机上网者访问的页面越多,质量可能就越高,而随机上网者在浏览网页时主要通过超链接跳转到页面,所以我们需要分析构成的超链接。图结构用于估计每个网页被访问的频率。更直观地说,一个网页的 PangRank 越高,随机浏览者在浏览该网页的过程中停留在该页面的概率就越大,该网页的重要性就越高。
为简单起见,我们可以假设当一个随机的冲浪者停留在一个页面上时,跳转到该页面上每个链接页面的概率是相同的。比如上图中,页面A链接到B、C、D,所以用户从A跳转到B、C、D的概率各为1/3。假设总共有N个网页,可以组织一个N维矩阵:第i行第j列的值代表用户从第j页到第i页的概率。这样的矩阵称为转移矩阵。上图中四个网页对应的转移矩阵M如下:
那么,假设随机浏览者从n个页面出来的初始概率相等,那么初始概率分布向量是一个n维的列向量V0,每个维度为1/n。这里我们有 4 页,所以 V0-1=[1/4, 1/4, 1/4, 1/4]。
这样,我们就可以从初始向量 V0 开始,不断地将转移矩阵 M 左乘。用户在浏览网页时主要通过超链接使i跳转后,停留在每个页面的概率为:Mi*V。停止直到最后两次迭代在结果向量中产生非常小的差异。实际上,对于 Web,50 到 75 次迭代足以收敛,误差控制在双精度。
以下是前四次跳转时每次迭代后每个页面的PageRank值:
可以看出,随着迭代次数的增加,网页A的PageRank值越来越大,接近其极限概率3/9。这也说明随机上网者停留在A页面的概率大于B、C、D页面,页面也更重要。
二、问题一:死胡同
终止点是没有出链的点,比如下图中的C。
如果我们不对其进行处理,让终止点存在,那么随着PageRank迭代次数的增加,每个网页的PageRank值会趋于0,这样就无法得到网页相对重要性的信息.
通过从图中删除它们及其传入链来处理终止。这样做之后,可以生成更多的端点,并继续迭代消除端点。但最终我们得到了一个强连通子图,其中所有节点都是非终端的。我们以左图为例进行说明。按照上述步骤消除终止点后得到左图,得到右图。
我们得到右图对应的转移矩阵,计算图中A、B、C的PageRank值。
我们得到A、B、C的PageRank值分别为2/9、4/9、3/9,然后按照删除的逆序计算C、E的PageRank值. 由于 C 是最后被删除的,因此首先计算 C 的 PageRank 值。A有3个外链,所以它贡献了1/3的PageRank值给C。D有3个外链,所以它贡献了1/2的PageRank值给C。所以C的PageRank为
. E的入链只有C,C的出链只有E,所以E的PageRank值等于C的PageRank值。
需要注意的是,当前所有节点的PageRank值之和已经超过1,因此不能代表随机浏览者的概率分布,但仍能反映对页面相对重要性的合理估计。
三、问题2:采集器蜘蛛陷阱
采集器陷阱是一组节点,虽然它们都不是终止点,但它们都没有出链指向该集合之外的其他节点。采集器 陷阱导致计算时将所有 PageRank 值分配给 采集器 陷阱内的节点。
如下图所示,C是一个单节点采集器陷阱及其转移矩阵。
随着迭代的进行,C 的 PageRank 值趋于 1,而其他不在 采集器 陷阱中的节点的 PageRank 值趋于 0。
采集器 陷阱的处理方式是允许每个随机浏览者随机跳转到一个随机页面,跳转概率很小,而不必遵循当前页面上的外链。因此,根据上一次PageRank估计值V和转移矩阵M估计下一次迭代后的PageRank值V'的迭代公式变为:
其中 β 是一个选定的常数,通常介于 0.8 和 0.9 之间。e 是一个向量,其分量全为 1,维度为 n,其中 n 是 Web 图中所有节点的个数。βMv 表示随机冲浪者以概率 β 从当前网页中选择外链向前移动的情况。(1−β)e/n 是一个所有分量为 (1−β)/n 的向量,它表示一个新的随机冲浪者具有 (1−β) 概率随机选择要访问的网页。
取β=0.8,上图的迭代公式变为:
以下是之前迭代的结果:
作为一个采集器 陷阱,C 获得了超过一半的 PageRank 值,但这种影响是有限的,并且每个其他节点也获得了一些 PageRank 值。
-------------------------------------------------
参考:
《大数据:互联网大规模数据挖掘与分布式处理》王斌老师_ICTIR及其对应英文电子书《海量数据集挖掘》 查看全部
免规则采集器列表算法(2019独角兽企业重金招聘Python工程师标准(gt)(图))
2019独角兽企业招聘Python工程师标准>>>
一、简单的PageRank计算
首先,我们将Web抽象如下: 1、将每个网页抽象成一个节点;2、如果页面 A 有直接到 B 的链接,则从 A 到 B 存在有向边(多个相同链接不重复计算边)。因此,整个 Web 被抽象为一个有向图。
现在假设世界上只有四个网页:A、B、C、D。抽象结构如下图所示。显然,这个图是强连接的(从任何节点,你可以到达任何其他节点)。
然后需要使用合适的数据结构来表示页面之间的连接关系。PageRank算法就是基于这样一个背景思想:随机上网者访问的页面越多,质量可能就越高,而随机上网者在浏览网页时主要通过超链接跳转到页面,所以我们需要分析构成的超链接。图结构用于估计每个网页被访问的频率。更直观地说,一个网页的 PangRank 越高,随机浏览者在浏览该网页的过程中停留在该页面的概率就越大,该网页的重要性就越高。
为简单起见,我们可以假设当一个随机的冲浪者停留在一个页面上时,跳转到该页面上每个链接页面的概率是相同的。比如上图中,页面A链接到B、C、D,所以用户从A跳转到B、C、D的概率各为1/3。假设总共有N个网页,可以组织一个N维矩阵:第i行第j列的值代表用户从第j页到第i页的概率。这样的矩阵称为转移矩阵。上图中四个网页对应的转移矩阵M如下:
那么,假设随机浏览者从n个页面出来的初始概率相等,那么初始概率分布向量是一个n维的列向量V0,每个维度为1/n。这里我们有 4 页,所以 V0-1=[1/4, 1/4, 1/4, 1/4]。
这样,我们就可以从初始向量 V0 开始,不断地将转移矩阵 M 左乘。用户在浏览网页时主要通过超链接使i跳转后,停留在每个页面的概率为:Mi*V。停止直到最后两次迭代在结果向量中产生非常小的差异。实际上,对于 Web,50 到 75 次迭代足以收敛,误差控制在双精度。
以下是前四次跳转时每次迭代后每个页面的PageRank值:
可以看出,随着迭代次数的增加,网页A的PageRank值越来越大,接近其极限概率3/9。这也说明随机上网者停留在A页面的概率大于B、C、D页面,页面也更重要。
二、问题一:死胡同
终止点是没有出链的点,比如下图中的C。
如果我们不对其进行处理,让终止点存在,那么随着PageRank迭代次数的增加,每个网页的PageRank值会趋于0,这样就无法得到网页相对重要性的信息.
通过从图中删除它们及其传入链来处理终止。这样做之后,可以生成更多的端点,并继续迭代消除端点。但最终我们得到了一个强连通子图,其中所有节点都是非终端的。我们以左图为例进行说明。按照上述步骤消除终止点后得到左图,得到右图。
我们得到右图对应的转移矩阵,计算图中A、B、C的PageRank值。
我们得到A、B、C的PageRank值分别为2/9、4/9、3/9,然后按照删除的逆序计算C、E的PageRank值. 由于 C 是最后被删除的,因此首先计算 C 的 PageRank 值。A有3个外链,所以它贡献了1/3的PageRank值给C。D有3个外链,所以它贡献了1/2的PageRank值给C。所以C的PageRank为
. E的入链只有C,C的出链只有E,所以E的PageRank值等于C的PageRank值。
需要注意的是,当前所有节点的PageRank值之和已经超过1,因此不能代表随机浏览者的概率分布,但仍能反映对页面相对重要性的合理估计。
三、问题2:采集器蜘蛛陷阱
采集器陷阱是一组节点,虽然它们都不是终止点,但它们都没有出链指向该集合之外的其他节点。采集器 陷阱导致计算时将所有 PageRank 值分配给 采集器 陷阱内的节点。
如下图所示,C是一个单节点采集器陷阱及其转移矩阵。
随着迭代的进行,C 的 PageRank 值趋于 1,而其他不在 采集器 陷阱中的节点的 PageRank 值趋于 0。
采集器 陷阱的处理方式是允许每个随机浏览者随机跳转到一个随机页面,跳转概率很小,而不必遵循当前页面上的外链。因此,根据上一次PageRank估计值V和转移矩阵M估计下一次迭代后的PageRank值V'的迭代公式变为:
其中 β 是一个选定的常数,通常介于 0.8 和 0.9 之间。e 是一个向量,其分量全为 1,维度为 n,其中 n 是 Web 图中所有节点的个数。βMv 表示随机冲浪者以概率 β 从当前网页中选择外链向前移动的情况。(1−β)e/n 是一个所有分量为 (1−β)/n 的向量,它表示一个新的随机冲浪者具有 (1−β) 概率随机选择要访问的网页。
取β=0.8,上图的迭代公式变为:
以下是之前迭代的结果:
作为一个采集器 陷阱,C 获得了超过一半的 PageRank 值,但这种影响是有限的,并且每个其他节点也获得了一些 PageRank 值。
-------------------------------------------------
参考:
《大数据:互联网大规模数据挖掘与分布式处理》王斌老师_ICTIR及其对应英文电子书《海量数据集挖掘》
免规则采集器列表算法( 基于树的搜索(tree-search),不能的研究目的有两个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-04-12 22:04
基于树的搜索(tree-search),不能的研究目的有两个)
这个文章的研究内容是:具有规划能力的agent。
在此之前,许多研究都使用了基于树的规划方法。然而,在实际的业务应用中,动态控制/仿真环境往往是复杂且未知的。
这篇文章文章 提出了一种算法:MuZero,它通过将基于树的搜索与学习模型相结合,在不了解环境底层动态的情况下可以很好地执行。这很好。
这里的学习模型实际上是迭代应用的,可以预测与计划最相关的奖励、行动选择策略和价值函数。
所以,总而言之,MuZero 的研究目标有两个:
下面就开始看具体的作品吧!
1 算法简介1.1 背景
基于前瞻搜索的规划算法有很多应用。然而,这些规划算法都依赖于精确的模拟器和严格的规则,无法直接用于现实世界。
我们知道强化学习算法分为基于模型和无模型。一般来说,我们的研究侧重于无模型方法,即直接从与环境的交互中估计最优策略和价值函数。这些方法在某些视频游戏中运行良好,例如 Atari。但是,无模型在需要精确和复杂前瞻的领域(例如围棋或国际象棋)中效果较差。
在一般的基于模型的强化学习方法中,模型实际上是一个概率分布,也就是构建一个真实的环境,或者说是一个完整的观察。首先从环境的动态中学习一个模型,然后根据学习到的模型进行规划。但在 Atari 游戏实验中,性能不如 Model-based。
本文文章介绍了一种新的基于模型的强化学习方法MuZero,它不仅可以在视觉复杂的Atari上表现出色,而且在精确规划任务中也表现出色。这很好,
MuZero 算法基于 AlphaZero 强大的搜索和基于搜索的策略算法,在训练过程中加入了一个学习模型。
除此之外,MuZero 将 AlphaZero 扩展到更广泛的环境,包括单个代理域和中间时间步长的非零奖励。
小总结:
规划(planning algorithm)是一个难点研究。众所周知的 AlphaGo 是一种基于树的规划算法,但此类算法需要完美的环境模型,这在现实世界中很难满足。
DeepMind 的 MuZero 算法是基于模型的 RL 领域的里程碑式成就,在促进强化学习解决现实问题方面迈出了新的一步。1.2 理解算法的思想
首先介绍一下MuZero算法的思想:
MuZero算法的主要思想是构造一个抽象的MDP模型,在这个MDP模型上,预测与Planning直接相关的未来数据(策略、价值函数和奖励),并在此基础上预测数据进行规划。
那么为什么要这样做,为什么它会起作用?让我们将论文中的内容“分解”和“粉碎”来理解算法的思想:
1.2.1 为什么要抽象
我们知道,大多数基于模型的强化学习方法都会学习对应于真实环境的动态模型。
但是,如果是用于 Planning,我们并不关心 Dynamics Model 是否准确地还原了真实环境。
只要这个 Dynamics Model 给出的未来每一步的价值和回报接近真实环境中的价值,我们就可以将其作为 Planning 中的模拟器。
MuZero 算法是首先将真实环境中通过编码器(表示函数)获得的状态转换为没有直接约束的抽象状态空间(abstract state space)中的隐藏状态(hidden state)。状态并假设循环迭代的下一个动作)。
然后在这个抽象的状态空间中,学习Dynamics Model和价值预测,预测每个隐藏状态上的策略(这就是和本文的区别),得到Policy Prediction Network。
然后,使用蒙特卡洛树搜索,使用 Dynamics Model 作为模拟器,在抽象状态空间中做 Planning,预测接下来几个步骤的策略、价值函数和奖励。
这里的隐藏状态是不适合真实环境的。取而代之的是,在抽象状态空间中训练的 Dynamics Model 和价值预测网络可以预测在初始隐藏状态和执行接下来的 k 步后接下来 k 步的价值和奖励,以及通过搜索得到的价值和奖励在真实环境中。观察到的奖励尽可能接近。
简单来说,就是先在虚拟状态空间中学习一个环境模型,然后在不与真实环境过多交互的情况下,根据学习到的环境模型进行规划。
1.2.2 为什么有效
那么我们如何保证抽象MDP中的规划与真实环境中的规划是等价的呢?
这种等价是通过确保价值等价来实现的。
也就是说,从相同的真实状态开始,通过抽象 MDP 的轨迹累积奖励与真实环境中轨迹的累积奖励相匹配。
2 型号图解说明
首先,整体数据是模型的数学表达式:
给定一个隐藏状态和一个候选动作,动态模型需要生成一个即时奖励和一个新的隐藏状态。策略和价值函数是由预测函数从输入中计算出来的。操作是从搜索策略中采样的。环境收到一个动作以产生新的观察和奖励。
接下来通过图文结合的方式,具体讲讲如何使用学习到的模型进行策划、演戏、训练。
2.1 MuZero中模型的组成
MuZero 如何使用该模型进行规划?我们看图A:
所谓模型由以下3个相互关联的部分组成:
2.2 MuZero 如何与环境交互并做出决策
图 A 中描述的是,在每一步中,隐藏状态执行蒙特卡洛树搜索到下一个动作。
那么 MuZero 是如何在环境中做出决策的呢?
下图是横看各招的情况:
对于子图1描述的情况(一黑一白),使用蒙特卡洛树搜索对其建模得到一个策略网络,并对策略网络进行采样选择可执行动作,这个动作与访问量成正比MCTS 根节点的每个操作的计数。
执行动作后,得到奖励,得到下一时刻的观察(子图2),同样使用MCTS进行建模,得到策略网络,选择可执行动作。
环境接受动作,产生新的观察和奖励,产生子图 3。
这样,轨迹数据在剧集结束时存储在重放缓冲区中。这是一个决定。
2.3 MuZero 如何训练模型
那么 MuZero 是如何训练模型的呢?让我们看看下面的过程:
对 Replay Buffer 中的轨迹数据进行采样,选择一个序列,然后针对该轨迹运行 MuZero 模型。
在初始步骤中,编码器表示函数接受来自所选轨迹的过去观察。
随后,模型展开一个 K 步循环。
在第 k 步中,生成器动力学函数接收上一步的隐藏状态和实际动作。
编码器表示函数、生成器动力学函数、预测器预测函数的参数可以通过backpropagation-through-time的端到端联合训练来预测,可以预测三个量:
其中是样本回报,例如棋盘游戏中的最终奖励,或 Atari 中 n 步的奖励。
3 MuZero算法详解3.1 价值网络和策略网络
MuZero 是一种机器学习算法,因此很自然地首先要了解它是如何使用神经网络的。
简而言之,该算法使用了 AlphaGo 和 AlphaZero 的策略和价值网络:
政策网络和价值网络的直观含义如下:
根据策略网络,可以预测每一步的动作;依靠价值网络,可以选择价值最高的动作。结合这两个估计可以得到更好的结果。
3.2 MuZero中的蒙特卡洛树搜索3.2.1 MCTS简介
MuZero 还使用 MCTS(蒙特卡洛树搜索)聚合神经网络来预测和选择当前环境中的下一个动作。到达终点后,树中的每个节点都会存储一些相关的参数,包括访问次数、轮数、前一个动作的概率、子节点以及是否有对应的隐藏状态和奖励。
蒙特卡洛树搜索是一个迭代的、最佳优先的树搜索过程。目标是帮助我们弄清楚要采取哪些行动来最大化长期利益。
Best first,这意味着搜索树的扩展取决于搜索树中的值估计。
与常见的深度优先和广度优先相比,最佳优先搜索可以利用深度神经网络的启发式估计,在非常大的搜索空间中找到最优解。
蒙特卡洛树搜索有四个主要阶段:
通过重复这些阶段,MCTS 每次都在节点可能的未来动作序列上逐步构建搜索树。在这棵树中,每个节点代表一个未来状态,节点之间的线代表从一个状态到下一个状态的动作。
3.22 MuZero算法中MCTS的四个阶段
接下来我们对应MuZero算法中的蒙特卡洛树搜索,看看上面四个阶段分别对应什么:
我们先来看看模拟。
模拟过程与蒙特卡罗方法类似,推导速度快。为了得到某个状态的初始分数,让游戏随机玩到最后,记录模拟次数和获胜次数。
接下来是选择。
虽然 Muzero 不知道游戏规则,但它知道该采取哪些步骤。在每个节点(状态 s),使用评分函数比较不同的动作,并选择得分最高的最佳动作。
每次选择一个动作时,我们都会为 UCB 缩放因子 c 和后续动作选择增加其关联的访问计数 N(s,a)。
模拟沿着树向下进行到尚未扩展的叶子。此时,应用神经网络对节点进行评估,将评估结果(优先级和值估计)存储在节点中。
然后是扩展。
选择动作 A 后,在搜索树中生成一个新节点,对应动作 A 执行后前一个状态的情况。
最后回溯。
模拟结束后,从子节点开始沿着刚刚下的路径返回,沿途更新每个父节点的统计信息。每个节点都持有其下所有价值估计的连续平均值,这使得 UCB 公式可以随着时间的推移做出越来越准确的决策,确保 MCTS 收敛到最优动作。
3.2.3 中级奖励
事实上,在 MCTS 的过程中,也收录了对中间奖励 r 的预测。
在某些情况下,游戏完全结束后需要输赢反馈,这可以通过价值估计来建模。但是在频繁反馈的情况下,从一种状态到另一种状态的每次转换都会得到奖励 r。
因此,奖励直接通过神经网络预测建模并用于搜索。在 UCB 策略中引入中间奖励:
其中是在状态 s 执行动作 a 后观察到的奖励,折扣因子是对未来奖励的关注程度。
由于在某些环境中奖励是无界的,因此可以将奖励和价值估计归一化到 [0,1] 期间,然后与先验知识相结合:
其中 和 分别是在整个搜索树中观察到的最大和最小估计值。
3.3 总体说明
基于过去的观察和未来的行为,对于给定步骤中的每一步,使用带有参数的模型在每个时间步进行预测。
该模型预测 3 个数量:
其中是地面实况观察奖励,是策略,是折扣因子。
说白了就是获取过去的观察数据,编码成当前的隐藏状态,然后给出未来的动作,然后在隐藏状态空间进行规划。
3.4 步分解
在每个步骤中,模型由表示函数、动力学函数和预测函数组成:
使用这样的模型,可以根据过去的观察来搜索虚拟的未来轨迹。
例如,可以简单地选择 k 步动作序列来搜索最大化价值函数。
也可以使用类似于 AlphaZero 搜索的 MCTS 算法来获取策略和估计值,然后从策略中选择动作。此外,执行操作并生成中间奖励和状态空间。
在第 k 步,通过联合训练模型的所有参数,将策略、价值和奖励与实际观察到的目标值图像进行匹配。
模型的所有参数都经过联合训练,使得每个假设步 k 的策略、值和奖励与 k 个实际时间步后观察到的相应目标值完全匹配。
使用 MCTS,可以使用三个改进的策略目标:
最后加上L2正则化项得到最终的损失函数:
4 总结
强化学习分为两类:基于模型的和无模型的。
其中,基于模型的强化学习方法需要构建环境模型。通常,环境模型由马尔可夫决策过程(MDP)表示。该过程由两部分组成:
模型通常针对选定的动作或时间抽象的行为进行训练。一旦模型建立,MDP 规划算法(例如:值迭代、蒙特卡洛树搜索 MCTS)可以直接用于计算 MDP 的最优值或最优策略。
因此,在复杂环境或局部观察的情况下,很难构建模型应该预测的状态表示。因为Agent没有办法优化“有效规划的目的”的表示和模型,这就导致了表示学习、模型学习和规划之间的分离。
另一方面,MuZero 是一种完全不同的基于模型的强化学习方法,专注于端到端的预测函数。主要思想是构造一个抽象的MDP模型,使抽象MDP中的规划等价于真实环境中的规划。
这种等价是通过保证价值等价来实现的,即从相同的真实状态开始,通过抽象MDP获得的轨迹累积奖励与真实环境中的轨迹累积奖励相匹配。
预测器首先引入价值等价模型来预测价值而无需采取行动。
虽然底层模型是 MDP,但它的变换模型不需要匹配环境中的真实状态,只需将 MDP 模型视为深度神经网络中的隐藏层即可。展开的 MDP 被训练,例如通过时间差异学习,以将累积奖励的预期总和与实际环境的预期值相匹配。
然后,将价值等价模型扩展为以行动优化价值。TreeQN 学习一个抽象的 MDP 模型,以便在该模型上的树搜索(由树结构的神经网络表示)近似于最优值函数。值迭代网络学习一个局部 MDP 模型,使得该模型上的值迭代(由卷积神经网络表示)接近最优值函数。
价值预测网络更接近于 MuZero:根据实际动作学习一个 MDP 模型;对展开的 MDP 进行训练,以使奖励的累积总和(以简单前向搜索产生的实际动作序列为条件)与真实环境匹配一致。如果没有策略预测,则搜索仅使用值预测。
通过论文的学习,虽然理解了MuZero算法的思想,但是在实际项目中使用MuZero还是比较困难的。
比如如何设计表示、动态、预测等,这些都需要在对代码实现非常熟悉的情况下结合具体的业务场景来实现。
提供基于pytorch的muzero算法实现:
如果有时间,我会继续研究代码并尝试复现论文。
结束 查看全部
免规则采集器列表算法(
基于树的搜索(tree-search),不能的研究目的有两个)
这个文章的研究内容是:具有规划能力的agent。
在此之前,许多研究都使用了基于树的规划方法。然而,在实际的业务应用中,动态控制/仿真环境往往是复杂且未知的。
这篇文章文章 提出了一种算法:MuZero,它通过将基于树的搜索与学习模型相结合,在不了解环境底层动态的情况下可以很好地执行。这很好。
这里的学习模型实际上是迭代应用的,可以预测与计划最相关的奖励、行动选择策略和价值函数。
所以,总而言之,MuZero 的研究目标有两个:
下面就开始看具体的作品吧!
1 算法简介1.1 背景
基于前瞻搜索的规划算法有很多应用。然而,这些规划算法都依赖于精确的模拟器和严格的规则,无法直接用于现实世界。
我们知道强化学习算法分为基于模型和无模型。一般来说,我们的研究侧重于无模型方法,即直接从与环境的交互中估计最优策略和价值函数。这些方法在某些视频游戏中运行良好,例如 Atari。但是,无模型在需要精确和复杂前瞻的领域(例如围棋或国际象棋)中效果较差。
在一般的基于模型的强化学习方法中,模型实际上是一个概率分布,也就是构建一个真实的环境,或者说是一个完整的观察。首先从环境的动态中学习一个模型,然后根据学习到的模型进行规划。但在 Atari 游戏实验中,性能不如 Model-based。
本文文章介绍了一种新的基于模型的强化学习方法MuZero,它不仅可以在视觉复杂的Atari上表现出色,而且在精确规划任务中也表现出色。这很好,
MuZero 算法基于 AlphaZero 强大的搜索和基于搜索的策略算法,在训练过程中加入了一个学习模型。
除此之外,MuZero 将 AlphaZero 扩展到更广泛的环境,包括单个代理域和中间时间步长的非零奖励。
小总结:
规划(planning algorithm)是一个难点研究。众所周知的 AlphaGo 是一种基于树的规划算法,但此类算法需要完美的环境模型,这在现实世界中很难满足。
DeepMind 的 MuZero 算法是基于模型的 RL 领域的里程碑式成就,在促进强化学习解决现实问题方面迈出了新的一步。1.2 理解算法的思想
首先介绍一下MuZero算法的思想:
MuZero算法的主要思想是构造一个抽象的MDP模型,在这个MDP模型上,预测与Planning直接相关的未来数据(策略、价值函数和奖励),并在此基础上预测数据进行规划。
那么为什么要这样做,为什么它会起作用?让我们将论文中的内容“分解”和“粉碎”来理解算法的思想:
1.2.1 为什么要抽象
我们知道,大多数基于模型的强化学习方法都会学习对应于真实环境的动态模型。
但是,如果是用于 Planning,我们并不关心 Dynamics Model 是否准确地还原了真实环境。
只要这个 Dynamics Model 给出的未来每一步的价值和回报接近真实环境中的价值,我们就可以将其作为 Planning 中的模拟器。
MuZero 算法是首先将真实环境中通过编码器(表示函数)获得的状态转换为没有直接约束的抽象状态空间(abstract state space)中的隐藏状态(hidden state)。状态并假设循环迭代的下一个动作)。
然后在这个抽象的状态空间中,学习Dynamics Model和价值预测,预测每个隐藏状态上的策略(这就是和本文的区别),得到Policy Prediction Network。
然后,使用蒙特卡洛树搜索,使用 Dynamics Model 作为模拟器,在抽象状态空间中做 Planning,预测接下来几个步骤的策略、价值函数和奖励。
这里的隐藏状态是不适合真实环境的。取而代之的是,在抽象状态空间中训练的 Dynamics Model 和价值预测网络可以预测在初始隐藏状态和执行接下来的 k 步后接下来 k 步的价值和奖励,以及通过搜索得到的价值和奖励在真实环境中。观察到的奖励尽可能接近。
简单来说,就是先在虚拟状态空间中学习一个环境模型,然后在不与真实环境过多交互的情况下,根据学习到的环境模型进行规划。
1.2.2 为什么有效
那么我们如何保证抽象MDP中的规划与真实环境中的规划是等价的呢?
这种等价是通过确保价值等价来实现的。
也就是说,从相同的真实状态开始,通过抽象 MDP 的轨迹累积奖励与真实环境中轨迹的累积奖励相匹配。
2 型号图解说明
首先,整体数据是模型的数学表达式:
给定一个隐藏状态和一个候选动作,动态模型需要生成一个即时奖励和一个新的隐藏状态。策略和价值函数是由预测函数从输入中计算出来的。操作是从搜索策略中采样的。环境收到一个动作以产生新的观察和奖励。
接下来通过图文结合的方式,具体讲讲如何使用学习到的模型进行策划、演戏、训练。
2.1 MuZero中模型的组成
MuZero 如何使用该模型进行规划?我们看图A:
所谓模型由以下3个相互关联的部分组成:
2.2 MuZero 如何与环境交互并做出决策
图 A 中描述的是,在每一步中,隐藏状态执行蒙特卡洛树搜索到下一个动作。
那么 MuZero 是如何在环境中做出决策的呢?
下图是横看各招的情况:
对于子图1描述的情况(一黑一白),使用蒙特卡洛树搜索对其建模得到一个策略网络,并对策略网络进行采样选择可执行动作,这个动作与访问量成正比MCTS 根节点的每个操作的计数。
执行动作后,得到奖励,得到下一时刻的观察(子图2),同样使用MCTS进行建模,得到策略网络,选择可执行动作。
环境接受动作,产生新的观察和奖励,产生子图 3。
这样,轨迹数据在剧集结束时存储在重放缓冲区中。这是一个决定。
2.3 MuZero 如何训练模型
那么 MuZero 是如何训练模型的呢?让我们看看下面的过程:
对 Replay Buffer 中的轨迹数据进行采样,选择一个序列,然后针对该轨迹运行 MuZero 模型。
在初始步骤中,编码器表示函数接受来自所选轨迹的过去观察。
随后,模型展开一个 K 步循环。
在第 k 步中,生成器动力学函数接收上一步的隐藏状态和实际动作。
编码器表示函数、生成器动力学函数、预测器预测函数的参数可以通过backpropagation-through-time的端到端联合训练来预测,可以预测三个量:
其中是样本回报,例如棋盘游戏中的最终奖励,或 Atari 中 n 步的奖励。
3 MuZero算法详解3.1 价值网络和策略网络
MuZero 是一种机器学习算法,因此很自然地首先要了解它是如何使用神经网络的。
简而言之,该算法使用了 AlphaGo 和 AlphaZero 的策略和价值网络:
政策网络和价值网络的直观含义如下:
根据策略网络,可以预测每一步的动作;依靠价值网络,可以选择价值最高的动作。结合这两个估计可以得到更好的结果。
3.2 MuZero中的蒙特卡洛树搜索3.2.1 MCTS简介
MuZero 还使用 MCTS(蒙特卡洛树搜索)聚合神经网络来预测和选择当前环境中的下一个动作。到达终点后,树中的每个节点都会存储一些相关的参数,包括访问次数、轮数、前一个动作的概率、子节点以及是否有对应的隐藏状态和奖励。
蒙特卡洛树搜索是一个迭代的、最佳优先的树搜索过程。目标是帮助我们弄清楚要采取哪些行动来最大化长期利益。
Best first,这意味着搜索树的扩展取决于搜索树中的值估计。
与常见的深度优先和广度优先相比,最佳优先搜索可以利用深度神经网络的启发式估计,在非常大的搜索空间中找到最优解。
蒙特卡洛树搜索有四个主要阶段:
通过重复这些阶段,MCTS 每次都在节点可能的未来动作序列上逐步构建搜索树。在这棵树中,每个节点代表一个未来状态,节点之间的线代表从一个状态到下一个状态的动作。
3.22 MuZero算法中MCTS的四个阶段
接下来我们对应MuZero算法中的蒙特卡洛树搜索,看看上面四个阶段分别对应什么:
我们先来看看模拟。
模拟过程与蒙特卡罗方法类似,推导速度快。为了得到某个状态的初始分数,让游戏随机玩到最后,记录模拟次数和获胜次数。
接下来是选择。
虽然 Muzero 不知道游戏规则,但它知道该采取哪些步骤。在每个节点(状态 s),使用评分函数比较不同的动作,并选择得分最高的最佳动作。
每次选择一个动作时,我们都会为 UCB 缩放因子 c 和后续动作选择增加其关联的访问计数 N(s,a)。
模拟沿着树向下进行到尚未扩展的叶子。此时,应用神经网络对节点进行评估,将评估结果(优先级和值估计)存储在节点中。
然后是扩展。
选择动作 A 后,在搜索树中生成一个新节点,对应动作 A 执行后前一个状态的情况。
最后回溯。
模拟结束后,从子节点开始沿着刚刚下的路径返回,沿途更新每个父节点的统计信息。每个节点都持有其下所有价值估计的连续平均值,这使得 UCB 公式可以随着时间的推移做出越来越准确的决策,确保 MCTS 收敛到最优动作。
3.2.3 中级奖励
事实上,在 MCTS 的过程中,也收录了对中间奖励 r 的预测。
在某些情况下,游戏完全结束后需要输赢反馈,这可以通过价值估计来建模。但是在频繁反馈的情况下,从一种状态到另一种状态的每次转换都会得到奖励 r。
因此,奖励直接通过神经网络预测建模并用于搜索。在 UCB 策略中引入中间奖励:
其中是在状态 s 执行动作 a 后观察到的奖励,折扣因子是对未来奖励的关注程度。
由于在某些环境中奖励是无界的,因此可以将奖励和价值估计归一化到 [0,1] 期间,然后与先验知识相结合:
其中 和 分别是在整个搜索树中观察到的最大和最小估计值。
3.3 总体说明
基于过去的观察和未来的行为,对于给定步骤中的每一步,使用带有参数的模型在每个时间步进行预测。
该模型预测 3 个数量:
其中是地面实况观察奖励,是策略,是折扣因子。
说白了就是获取过去的观察数据,编码成当前的隐藏状态,然后给出未来的动作,然后在隐藏状态空间进行规划。
3.4 步分解
在每个步骤中,模型由表示函数、动力学函数和预测函数组成:
使用这样的模型,可以根据过去的观察来搜索虚拟的未来轨迹。
例如,可以简单地选择 k 步动作序列来搜索最大化价值函数。
也可以使用类似于 AlphaZero 搜索的 MCTS 算法来获取策略和估计值,然后从策略中选择动作。此外,执行操作并生成中间奖励和状态空间。
在第 k 步,通过联合训练模型的所有参数,将策略、价值和奖励与实际观察到的目标值图像进行匹配。
模型的所有参数都经过联合训练,使得每个假设步 k 的策略、值和奖励与 k 个实际时间步后观察到的相应目标值完全匹配。
使用 MCTS,可以使用三个改进的策略目标:
最后加上L2正则化项得到最终的损失函数:
4 总结
强化学习分为两类:基于模型的和无模型的。
其中,基于模型的强化学习方法需要构建环境模型。通常,环境模型由马尔可夫决策过程(MDP)表示。该过程由两部分组成:
模型通常针对选定的动作或时间抽象的行为进行训练。一旦模型建立,MDP 规划算法(例如:值迭代、蒙特卡洛树搜索 MCTS)可以直接用于计算 MDP 的最优值或最优策略。
因此,在复杂环境或局部观察的情况下,很难构建模型应该预测的状态表示。因为Agent没有办法优化“有效规划的目的”的表示和模型,这就导致了表示学习、模型学习和规划之间的分离。
另一方面,MuZero 是一种完全不同的基于模型的强化学习方法,专注于端到端的预测函数。主要思想是构造一个抽象的MDP模型,使抽象MDP中的规划等价于真实环境中的规划。
这种等价是通过保证价值等价来实现的,即从相同的真实状态开始,通过抽象MDP获得的轨迹累积奖励与真实环境中的轨迹累积奖励相匹配。
预测器首先引入价值等价模型来预测价值而无需采取行动。
虽然底层模型是 MDP,但它的变换模型不需要匹配环境中的真实状态,只需将 MDP 模型视为深度神经网络中的隐藏层即可。展开的 MDP 被训练,例如通过时间差异学习,以将累积奖励的预期总和与实际环境的预期值相匹配。
然后,将价值等价模型扩展为以行动优化价值。TreeQN 学习一个抽象的 MDP 模型,以便在该模型上的树搜索(由树结构的神经网络表示)近似于最优值函数。值迭代网络学习一个局部 MDP 模型,使得该模型上的值迭代(由卷积神经网络表示)接近最优值函数。
价值预测网络更接近于 MuZero:根据实际动作学习一个 MDP 模型;对展开的 MDP 进行训练,以使奖励的累积总和(以简单前向搜索产生的实际动作序列为条件)与真实环境匹配一致。如果没有策略预测,则搜索仅使用值预测。
通过论文的学习,虽然理解了MuZero算法的思想,但是在实际项目中使用MuZero还是比较困难的。
比如如何设计表示、动态、预测等,这些都需要在对代码实现非常熟悉的情况下结合具体的业务场景来实现。
提供基于pytorch的muzero算法实现:
如果有时间,我会继续研究代码并尝试复现论文。
结束
免规则采集器列表算法(SQL注入主要手段开源错误盲注防御手段有消毒参数绑定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-12 14:12
SQL注入的主要手段
开源
错误回声
百叶窗
防御是
消毒
参数绑定
CSRF(Cross Site Request Forgery,跨站请求)
主要防御是识别请求者
表单令牌
验证码
推荐人检查
其他攻击和漏洞
错误代码错误回显
HTML 注释
上传文件
最有效的方法是设置上传白名单,只允许上传可靠的文件类型。另外,可以修改文件名,
使用专门的存储手段来保护服务器免受上传文件攻击。
路径遍历
攻击者使用请求 URL 中的相对路径来遍历系统上未打开的目录和文件。防御方法主要是转换JS、CSS等资源文件
部署在独立服务器上,使用独立域名,其他文件不使用静态URL访问,动态参数不收录文件路径等信息。
ModSecurity 是一个开源的网络应用防火墙。
ModSecurity 采用一种架构模式,其中处理逻辑与攻击规则集分离。
NEC 的 SiteShell
信息加密技术可分为三类:
1:单向哈希加密 2:对称加密 3:非对称加密
虽然单向哈希密文无法通过算法逆计算得到明文,但由于人们将密码设置为具有一定的模式,
因此,猜测破解可以通过彩虹表(人们常用的密码和对应的密文关系)等手段进行。
可以在哈希算法中加盐,相当于加密密钥,增加破解难度。
对称加密意味着加密和解密使用相同的密钥。
非对称加密是指加密和解密使用不同的密钥。其中,公钥称为公钥,它所拥有的就是秘钥。
RSA是一种非对称加密算法。
一种是将密钥和算法放在同一台服务器上,甚至制作专用的硬件设施,对外提供加解密服务。
应用系统通过调用该服务来实现数据的加解密。
另一种解决方案是将加解密算法放在应用系统中,秘钥放在独立的服务器中。为了提供密钥的安全性,在实际存储过程中,
密钥被分成若干份,加密后存储在不同的存储介质中,既考虑了密钥的安全性,又提高了性能。
信息过滤和反垃圾邮件
文本匹配
有很多公共算法,基本上都是 Trie 树的变种。
另一个更简单的实现是为文本匹配构建一个多级哈希表。先做降噪,再做文字匹配。如“A_La_Bo”
分类算法
贝叶斯分类算法
除了反垃圾邮件,分类算法还可以用来自动分类信息。门户网站可以使用该算法自动分类和分发来自采集的新闻文章
到不同的频道。电子邮件服务提供商基于电子邮件内容推送的个性化广告也可以使用分类算法来提供传递相关性。
黑名单,可用于信息去重,可使用布隆过滤器代替哈希表
规则引擎是一种分离业务规则和规则处理逻辑的技术。业务规则文件由运维人员通过容器管理界面进行编辑。
修改规则时,可以实时使用新规则,而无需更改代码发布者。规则处理逻辑调用规则来处理输入数据。
统计模型
目前,大型网站倾向于使用统计模型进行风险控制。
统计模式包括分类算法或更复杂的智能统计机器学习算法
这个世界没有绝对的安全,就像有绝对的自由一样。
秒杀系统对应的策略
1:秒杀系统独立部署
2:秒杀产品页面是静态的
3:租赁秒杀活动网络宽带
4:动态生成随机订单页面URL
软件设计有两种风格
一种是将软件设计得复杂,使缺陷不那么明显
一是软件设计得简单到没有明显的缺陷。 查看全部
免规则采集器列表算法(SQL注入主要手段开源错误盲注防御手段有消毒参数绑定)
SQL注入的主要手段
开源
错误回声
百叶窗
防御是
消毒
参数绑定
CSRF(Cross Site Request Forgery,跨站请求)
主要防御是识别请求者
表单令牌
验证码
推荐人检查
其他攻击和漏洞
错误代码错误回显
HTML 注释
上传文件
最有效的方法是设置上传白名单,只允许上传可靠的文件类型。另外,可以修改文件名,
使用专门的存储手段来保护服务器免受上传文件攻击。
路径遍历
攻击者使用请求 URL 中的相对路径来遍历系统上未打开的目录和文件。防御方法主要是转换JS、CSS等资源文件
部署在独立服务器上,使用独立域名,其他文件不使用静态URL访问,动态参数不收录文件路径等信息。
ModSecurity 是一个开源的网络应用防火墙。
ModSecurity 采用一种架构模式,其中处理逻辑与攻击规则集分离。
NEC 的 SiteShell
信息加密技术可分为三类:
1:单向哈希加密 2:对称加密 3:非对称加密
虽然单向哈希密文无法通过算法逆计算得到明文,但由于人们将密码设置为具有一定的模式,
因此,猜测破解可以通过彩虹表(人们常用的密码和对应的密文关系)等手段进行。
可以在哈希算法中加盐,相当于加密密钥,增加破解难度。
对称加密意味着加密和解密使用相同的密钥。
非对称加密是指加密和解密使用不同的密钥。其中,公钥称为公钥,它所拥有的就是秘钥。
RSA是一种非对称加密算法。
一种是将密钥和算法放在同一台服务器上,甚至制作专用的硬件设施,对外提供加解密服务。
应用系统通过调用该服务来实现数据的加解密。
另一种解决方案是将加解密算法放在应用系统中,秘钥放在独立的服务器中。为了提供密钥的安全性,在实际存储过程中,
密钥被分成若干份,加密后存储在不同的存储介质中,既考虑了密钥的安全性,又提高了性能。
信息过滤和反垃圾邮件
文本匹配
有很多公共算法,基本上都是 Trie 树的变种。
另一个更简单的实现是为文本匹配构建一个多级哈希表。先做降噪,再做文字匹配。如“A_La_Bo”
分类算法
贝叶斯分类算法
除了反垃圾邮件,分类算法还可以用来自动分类信息。门户网站可以使用该算法自动分类和分发来自采集的新闻文章
到不同的频道。电子邮件服务提供商基于电子邮件内容推送的个性化广告也可以使用分类算法来提供传递相关性。
黑名单,可用于信息去重,可使用布隆过滤器代替哈希表
规则引擎是一种分离业务规则和规则处理逻辑的技术。业务规则文件由运维人员通过容器管理界面进行编辑。
修改规则时,可以实时使用新规则,而无需更改代码发布者。规则处理逻辑调用规则来处理输入数据。
统计模型
目前,大型网站倾向于使用统计模型进行风险控制。
统计模式包括分类算法或更复杂的智能统计机器学习算法
这个世界没有绝对的安全,就像有绝对的自由一样。
秒杀系统对应的策略
1:秒杀系统独立部署
2:秒杀产品页面是静态的
3:租赁秒杀活动网络宽带
4:动态生成随机订单页面URL
软件设计有两种风格
一种是将软件设计得复杂,使缺陷不那么明显
一是软件设计得简单到没有明显的缺陷。
免规则采集器列表算法(基于Python网络爬虫与推荐算法新闻推荐平台文章目录功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-11 06:06
系列目录
基于Python网络爬虫和推荐算法的新闻推荐平台
文章目录
特征
一个有规律的采集新闻内容的网络爬虫,只需要配置间隔时间,就可以自动爬取新闻。消息来源采集为新浪新闻
一、结构
新闻爬虫由两部分组成:URL采集器、详情页采集器、定时器
采集器特征
网址采集器
专门用于采集新浪滚动新闻上的新闻详情页URL
详情页采集器
详情页采集的内容(例如:新闻)通过来自URL采集的URL数据
时序采集器
控制news采集器的启动和关闭,以及定时任务的设置
二、具体实现1.网址采集器
'''
使用新浪新闻滚动新闻的API进行新闻采集
参数分析:
pageid 目前看应该是固定的参数默认值为153
lid 类别ID 2509(全部) 2510(国内) 2511(国际) 2669(国际) 2512(体育) 2513(娱乐) 2514(军事) 2515(科技) 2516(财经) 2517(股市) 2518(美股)
num 获取新闻数量 上限为50
'''
def urlcollect(lid):
op_mysql = OperationMysql() #创建数据库连接对象
url = 'https://feed.mix.sina.com.cn/a ... 2Bstr(lid)+'&num=50' #网易新闻API
result = requests.get(url) #对API发起请求
result.encoding = 'utf-8' #由于API返回的数据为ISO编码的,中文在此处显示会出现乱码,因此更改为UTF-8编码
# print('Web:', result.text)
urls = re.findall(r'"url":"(.*?)"', result.text) #获取API返回结果中的所有新闻详情页URL
# times = re.findall(r'"ctime":"(.*?)"', result.text)
# 逐条处理被\转义的字符,使之成为为转义的字符串
# 并把处理号的URL导入到数据库中储存
changedict = {"2518": 0, "2510": 1, "2511": 2, "2669": 3, "2512": 4, "2513": 5, "2514": 6, "2515": 7, "2516": 8, "2517": 9}
Type = changedict.get(str(lid))
for numbers in range(len(urls)):
urls[numbers] = urls[numbers].replace('\\', '')
logger.info("url:{}".format(urls[numbers]))
time = datetime.datetime.now().strftime('%Y-%m-%d')
sql_i = "INSERT INTO news_api_urlcollect(url, type, time) values ('%s', '%d', '%s')" % (urls[numbers], Type, time)
op_mysql.insert_one(sql_i)
op_mysql.conn.close()
2.详情页面采集器
3. 时序采集器
#创建一个APScheduler对象(用于配置定时任务)
sched = BlockingScheduler()
def begincollect(time):
time = int(time)
try:
# 'interval'关键词表示的是按照固定时间间隔进行的任务 add_job()添加一个定时任务
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect1', kwargs={"lid": "2510",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect2', kwargs={"lid": "2511",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect3', kwargs={"lid": "2669",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect4', kwargs={"lid": "2512",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect5', kwargs={"lid": "2513",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect6', kwargs={"lid": "2514",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect7', kwargs={"lid": "2515",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect8', kwargs={"lid": "2516",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect9', kwargs={"lid": "2517",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect10', kwargs={"lid": "2518",})
# urlcollect(lid)
# 为了可以控制定时任务的关闭因此需要在任务开始时保存下该进程的PID值并保存与文件中
# 用于ClossScheduler.py中进行杀死进程
pid = os.getpid()
f1 = open(file='urlSpider.txt', mode='w')
f1.write(pid.__str__())
f1.close()
sched.start()
except Exception:
logger.error('error:'+Exception)
def endsched():
sched.shutdown()
总结
新闻采集系统可以稳定详细地采集新浪新闻滚动新闻中的所有新闻。目前只写单线程,效率略低。还有一个未知的bug,就是在消息采集的过程中,当调度任务被APScheduler控制时,一旦任务采集任务启动,就不能直接停止采集@ > 任务,并且需要让他在相应的循环中完全运行当前任务,才能停止。简而言之,定时器对任务的控制只控制间隔时间和运行次数,不能立即启动和停止。
另外,采集器还不是通用的,也就是只能用于指定网页的内容采集,这是一个可扩展的功能,通过对页面的分析,大致的内容采集 函数。
项目完整源码已经更新,有需要可以自行下载
欢迎提出问题和错误
个人码云主页,欢迎交流!!
个人GitHub主页,欢迎交流!! 查看全部
免规则采集器列表算法(基于Python网络爬虫与推荐算法新闻推荐平台文章目录功能介绍)
系列目录
基于Python网络爬虫和推荐算法的新闻推荐平台
文章目录
特征
一个有规律的采集新闻内容的网络爬虫,只需要配置间隔时间,就可以自动爬取新闻。消息来源采集为新浪新闻
一、结构
新闻爬虫由两部分组成:URL采集器、详情页采集器、定时器
采集器特征
网址采集器
专门用于采集新浪滚动新闻上的新闻详情页URL
详情页采集器
详情页采集的内容(例如:新闻)通过来自URL采集的URL数据
时序采集器
控制news采集器的启动和关闭,以及定时任务的设置
二、具体实现1.网址采集器
'''
使用新浪新闻滚动新闻的API进行新闻采集
参数分析:
pageid 目前看应该是固定的参数默认值为153
lid 类别ID 2509(全部) 2510(国内) 2511(国际) 2669(国际) 2512(体育) 2513(娱乐) 2514(军事) 2515(科技) 2516(财经) 2517(股市) 2518(美股)
num 获取新闻数量 上限为50
'''
def urlcollect(lid):
op_mysql = OperationMysql() #创建数据库连接对象
url = 'https://feed.mix.sina.com.cn/a ... 2Bstr(lid)+'&num=50' #网易新闻API
result = requests.get(url) #对API发起请求
result.encoding = 'utf-8' #由于API返回的数据为ISO编码的,中文在此处显示会出现乱码,因此更改为UTF-8编码
# print('Web:', result.text)
urls = re.findall(r'"url":"(.*?)"', result.text) #获取API返回结果中的所有新闻详情页URL
# times = re.findall(r'"ctime":"(.*?)"', result.text)
# 逐条处理被\转义的字符,使之成为为转义的字符串
# 并把处理号的URL导入到数据库中储存
changedict = {"2518": 0, "2510": 1, "2511": 2, "2669": 3, "2512": 4, "2513": 5, "2514": 6, "2515": 7, "2516": 8, "2517": 9}
Type = changedict.get(str(lid))
for numbers in range(len(urls)):
urls[numbers] = urls[numbers].replace('\\', '')
logger.info("url:{}".format(urls[numbers]))
time = datetime.datetime.now().strftime('%Y-%m-%d')
sql_i = "INSERT INTO news_api_urlcollect(url, type, time) values ('%s', '%d', '%s')" % (urls[numbers], Type, time)
op_mysql.insert_one(sql_i)
op_mysql.conn.close()
2.详情页面采集器
3. 时序采集器
#创建一个APScheduler对象(用于配置定时任务)
sched = BlockingScheduler()
def begincollect(time):
time = int(time)
try:
# 'interval'关键词表示的是按照固定时间间隔进行的任务 add_job()添加一个定时任务
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect1', kwargs={"lid": "2510",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect2', kwargs={"lid": "2511",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect3', kwargs={"lid": "2669",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect4', kwargs={"lid": "2512",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect5', kwargs={"lid": "2513",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect6', kwargs={"lid": "2514",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect7', kwargs={"lid": "2515",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect8', kwargs={"lid": "2516",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect9', kwargs={"lid": "2517",})
sched.add_job(urlcollect, 'interval', max_instances=1, seconds=time, id='urlcollect10', kwargs={"lid": "2518",})
# urlcollect(lid)
# 为了可以控制定时任务的关闭因此需要在任务开始时保存下该进程的PID值并保存与文件中
# 用于ClossScheduler.py中进行杀死进程
pid = os.getpid()
f1 = open(file='urlSpider.txt', mode='w')
f1.write(pid.__str__())
f1.close()
sched.start()
except Exception:
logger.error('error:'+Exception)
def endsched():
sched.shutdown()
总结
新闻采集系统可以稳定详细地采集新浪新闻滚动新闻中的所有新闻。目前只写单线程,效率略低。还有一个未知的bug,就是在消息采集的过程中,当调度任务被APScheduler控制时,一旦任务采集任务启动,就不能直接停止采集@ > 任务,并且需要让他在相应的循环中完全运行当前任务,才能停止。简而言之,定时器对任务的控制只控制间隔时间和运行次数,不能立即启动和停止。
另外,采集器还不是通用的,也就是只能用于指定网页的内容采集,这是一个可扩展的功能,通过对页面的分析,大致的内容采集 函数。
项目完整源码已经更新,有需要可以自行下载
欢迎提出问题和错误
个人码云主页,欢迎交流!!
个人GitHub主页,欢迎交流!!
免规则采集器列表算法(【免规则采集器】第三方,同行,抖音,头条)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-10 13:09
免规则采集器列表算法:注册,登录,消费,加入,注销,转移密码支付算法:支付完成日期,支付完成手续费比例,支付完成手续费比例用户运营:拉新,复购,活跃,留存,转化,付费,广告位,内容付费,会员价值,数据打通,时间差反馈,业务评估。社群运营:微信群,qq群,聚会,游戏,单机,小团队会员管理:离线计费(流量成本远高于线上),弹性计费(扩张乏力),预付费(100元起步,低频率/经常联网用户请慎重)预付费产品:热门/卖点产品,刚需产品,爆款产品商品采购:全采购,不同时段不同采购,订单匹配选择差异,竞品渠道商对比产品集采:低于30元每件,中高端产品,需求强度差异同时电商:转化率降低,活跃度下降,用户平均停留时间下降,库存出现不正常,付款成功率大幅下降;直通车,钻展,付费效果未知,付费渠道等流量运营:流量成本,付费转化率效果表现,无数据模型或支撑数据日报周报年报是否可靠,亏损,利润,成本负担是否下降,做广告投放是否花费过高,多商品是否可以通过购买建议获得产品全链路优化:对比进行优化,同时问题产品-增加平台商家多比、增加价格优势,对比用户数量多比、增加增加活跃度,对比活跃度多比、增加转化率多比等等等级运营或外部推广:产品品牌,销售提成等评估运营效果:销售业绩、流量入口、cpd成本/转化率、促销力度、平台资源等等高流量自营:生意参谋-营销工具--宝贝详情中等以上流量自营:移动端、pc端、公众号广告投放投放渠道:第三方,同行,微博,贴吧,知乎,抖音,快手,头条,最右,火山,西瓜视频,荔枝,今日头条等等等,全部是合作比价可私信一起交流。 查看全部
免规则采集器列表算法(【免规则采集器】第三方,同行,抖音,头条)
免规则采集器列表算法:注册,登录,消费,加入,注销,转移密码支付算法:支付完成日期,支付完成手续费比例,支付完成手续费比例用户运营:拉新,复购,活跃,留存,转化,付费,广告位,内容付费,会员价值,数据打通,时间差反馈,业务评估。社群运营:微信群,qq群,聚会,游戏,单机,小团队会员管理:离线计费(流量成本远高于线上),弹性计费(扩张乏力),预付费(100元起步,低频率/经常联网用户请慎重)预付费产品:热门/卖点产品,刚需产品,爆款产品商品采购:全采购,不同时段不同采购,订单匹配选择差异,竞品渠道商对比产品集采:低于30元每件,中高端产品,需求强度差异同时电商:转化率降低,活跃度下降,用户平均停留时间下降,库存出现不正常,付款成功率大幅下降;直通车,钻展,付费效果未知,付费渠道等流量运营:流量成本,付费转化率效果表现,无数据模型或支撑数据日报周报年报是否可靠,亏损,利润,成本负担是否下降,做广告投放是否花费过高,多商品是否可以通过购买建议获得产品全链路优化:对比进行优化,同时问题产品-增加平台商家多比、增加价格优势,对比用户数量多比、增加增加活跃度,对比活跃度多比、增加转化率多比等等等级运营或外部推广:产品品牌,销售提成等评估运营效果:销售业绩、流量入口、cpd成本/转化率、促销力度、平台资源等等高流量自营:生意参谋-营销工具--宝贝详情中等以上流量自营:移动端、pc端、公众号广告投放投放渠道:第三方,同行,微博,贴吧,知乎,抖音,快手,头条,最右,火山,西瓜视频,荔枝,今日头条等等等,全部是合作比价可私信一起交流。
免规则采集器列表算法(百度搜索飓风算法2.0所覆盖的问题点以及站长们应该怎么做)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-04-09 15:09
2018年9月20日,百度正式发布公告,为营造良好的互联网内容搜索生态,保护用户的搜索阅读和浏览体验,保护百度搜索引擎中优质内容生产者的合法权益,百度官方网站将于2018年9月发布。飓风算法将于6月下旬升级。
一周前,百度发布公告“百度搜索将上线飓风算法2.0,严厉打击不良采集行为”,今天我们将详细讲解飓风算法的覆盖范围2.0 个问题,站长应该怎么做。
飓风算法主要包括四种不良采集行为,如下:
1、更明显的采集跟踪行为
网站收录大量内容采集,是从其他网站、公众号、自媒体等转来的。采集后面的信息没有整理排版混乱,结构差,缺少一些功能,文章可读性差,有明显的采集痕迹,用户阅读体验特别差。
示例:采集文章的内容收录不可点击的超链接,功能缺失,采集痕迹明显。如下所示
整改建议:网站发布的内容,要注意文章内容的排版和排版,不得出现与文章主题弱相关或无关的信息。不允许使用@文章 或不可用的功能。干扰用户的浏览体验。
2、body内容有拼接行为
网站采集多个不同的文章拼接或叠加。文章整体内容没有形成完整的逻辑,阅读不流畅,段落不连贯,文章话题多等问题无法正常满足用户需求。
例子:文章正文前后的内容没有关系,逻辑不连贯。如下所示
整改建议:百度严禁使用采集器、采集软件等编辑工具采集随意制作拼接内容。制作大量对用户有价值的优质原创内容。
3、广泛的内容采集行为
网站中文章的大部分内容都是采集。质量较低。
整改建议:百度鼓励网站运营商大力制作优质原创内容,对原创内容给予保护。如需转载,需注明内容出处(如:转载内容注明新闻、政策等出处将不视为采集内容)。
4、跨域采集内容行为
网站通过采集大量与本站域名不一致的内容获取流量的行为。
示例:Education 网站 发布与食品行业相关的内容。如下所示
整改建议:百度鼓励网站制作文章和该领域的内容,通过专注于该领域获得更多搜索用户的青睐。不要试图采集跨域内容来获取短期利益。这样做会降低域焦点并影响 网站 在搜索引擎中的表现。
总结:
综上所述,飓风算法2.0旨在保障搜索用户的浏览体验,保障搜索生态的健康健康发展。对于任何违反网站的行为,百度搜索将使用网站对存在问题的严重性进行相应的限制搜索展示,情节严重的将给予永久停牌处分。 查看全部
免规则采集器列表算法(百度搜索飓风算法2.0所覆盖的问题点以及站长们应该怎么做)
2018年9月20日,百度正式发布公告,为营造良好的互联网内容搜索生态,保护用户的搜索阅读和浏览体验,保护百度搜索引擎中优质内容生产者的合法权益,百度官方网站将于2018年9月发布。飓风算法将于6月下旬升级。
一周前,百度发布公告“百度搜索将上线飓风算法2.0,严厉打击不良采集行为”,今天我们将详细讲解飓风算法的覆盖范围2.0 个问题,站长应该怎么做。
飓风算法主要包括四种不良采集行为,如下:
1、更明显的采集跟踪行为
网站收录大量内容采集,是从其他网站、公众号、自媒体等转来的。采集后面的信息没有整理排版混乱,结构差,缺少一些功能,文章可读性差,有明显的采集痕迹,用户阅读体验特别差。
示例:采集文章的内容收录不可点击的超链接,功能缺失,采集痕迹明显。如下所示
整改建议:网站发布的内容,要注意文章内容的排版和排版,不得出现与文章主题弱相关或无关的信息。不允许使用@文章 或不可用的功能。干扰用户的浏览体验。
2、body内容有拼接行为
网站采集多个不同的文章拼接或叠加。文章整体内容没有形成完整的逻辑,阅读不流畅,段落不连贯,文章话题多等问题无法正常满足用户需求。
例子:文章正文前后的内容没有关系,逻辑不连贯。如下所示
整改建议:百度严禁使用采集器、采集软件等编辑工具采集随意制作拼接内容。制作大量对用户有价值的优质原创内容。
3、广泛的内容采集行为
网站中文章的大部分内容都是采集。质量较低。
整改建议:百度鼓励网站运营商大力制作优质原创内容,对原创内容给予保护。如需转载,需注明内容出处(如:转载内容注明新闻、政策等出处将不视为采集内容)。
4、跨域采集内容行为
网站通过采集大量与本站域名不一致的内容获取流量的行为。
示例:Education 网站 发布与食品行业相关的内容。如下所示
整改建议:百度鼓励网站制作文章和该领域的内容,通过专注于该领域获得更多搜索用户的青睐。不要试图采集跨域内容来获取短期利益。这样做会降低域焦点并影响 网站 在搜索引擎中的表现。
总结:
综上所述,飓风算法2.0旨在保障搜索用户的浏览体验,保障搜索生态的健康健康发展。对于任何违反网站的行为,百度搜索将使用网站对存在问题的严重性进行相应的限制搜索展示,情节严重的将给予永久停牌处分。
免规则采集器列表算法( 如何使用Python实现关联规则的原理和实现步骤(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2022-04-07 18:18
如何使用Python实现关联规则的原理和实现步骤(上))
PowerBI商品关联规则的可视化
在上一篇文章中,我解释了关联规则的原理和实现步骤。如果你理解它,它实际上很容易理解。但说起来容易做起来难,如何通过工具处理原创数据以获得有效可靠的结果仍然存在问题。实际的工作是让你解决问题,而不是仅仅谈论解决方案。本文以理论为基础,结合实际数据展示如何使用Python实现关联规则,以及如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态展示。
使用Python解决一个问题时,实际上并不是从0到1的一步一步构建,这个过程非常繁琐。有时,为了达到一个小的效果,可能要绕很多路,所以就像“调参”一样,我们倾向于使用其他内置的梯子。这就是 Python 语言如此受欢迎的原因,因为它拥有完善的开源社区和无数的工具库来实现某种目的。我们在实现关联规则的计算时,使用机器学习库mlxtend中的apriori、fpgrowth、association_rules算法。apriori 是一种流行的算法,用于提取关联规则学习中的频繁项集。先验算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的一组项。
一、数据集
#导入相关的库
import pandas as pd
import mlxtend #机器学习库
#编码包
from mlxtend.preprocessing import TransactionEncoder
#关联规则计算包
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
pd.set_option('max_colwidth',150) #对pandas显示效果设置,列显示字段长度最长为150个字符 #导入数据集
Order = pd.read_excel("D:/orders.xlsx")
#查看数据集的大小
Order.shape
#查看数据前10行
Order.tail(5)
数据集中有121253条数据,总共有四个字段。SalesOrderNumber 指订单号;ordernumber 是指子订单号。换行和数字表示订单的子订单。每个订单号下可能有一个或多个子订单。有子订单,每个子订单都是唯一的,对应一个产品;产品是指产品名称。
二、mlxtend
在真正开始之前,我们先来了解一下这个mlxtend中的包是怎么使用的。mlxtend 官网演示了如何实现关联规则的计算。我们来看看这三个步骤:
第一步,导入apriori算法包;
第二步,将原创订单数据处理成算法支持的格式;
第三步,计算support、confidence、lift等指标,过滤掉强规则。
第一步:导入先验算法包
第二步,将原创订单数据处理成算法支持的格式:
得到的实际数据往往和我之前文章中的例子一样,产品在订单号后面排列成一个列表。所以 mlxtend 包接受这种数据格式。但是,它不能直接用于计算。首先,真实数据都是文本。其次,apriori算法包需要将原创数据转换为商品的one-hot编码的Pandas Dataframe格式。这是输入数据:
它使用 TransactionEncoder 包将输入数据转换为我们需要的形式。这是转换后的代码和结果:
接下来,它将处理后的数据格式输入到 apriori 算法包中,以计算频繁项集和支持度。根据预设的最小支持度0.6,排除不频繁项集。
但是,上面有一个问题。上面返回的结果集是一个数字,其实就是df表中每一项(item)的索引,这样比较方便后面的处理,但是如果只想用这个结果的话。为了增加可读性,使用参数 use_colnames=True 来显示原创产品名称。
第三步,计算支持度、置信度和提升度
apriori算法包中没有演示第三步,这是为什么呢?因为apriori算法包只是关联规则的第一步——寻找频繁项集,当然强关联规则是不会找到的!这一步在另一个包 association_rules 中实现。这也是很多初学者容易遇到的问题。他们不知道每个包的用途,也不知道如何调用包。
这样,我们就可以计算出所有满足最小支持度的频繁项集的支持度、置信度和提升度。还有杠杆作用和收敛性。这两个的作用和之前说的lift的作用是一样的。最好使用 KLUC 指标和 IR 不平衡率,但显然 mlxtend 的开发人员更喜欢使用杠杆和信念,并将其放在一边。本案例仅演示支撑升降机的使用。
三、Python实现第一步关联规则代码,生成格式数据
以上是官网给出的关联规则包的使用方法。接下来我使用自己的数据集进行实际操作,演示如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态显示。上面已经给出了示例数据。可以看出,数据集每个订单有多个商品,但是是逐行的,而不是一个订单后跟一行所有商品的形式。所以这是一种从行转换为列的方法。这里使用了Pandas中的分组功能,要达到的效果如下:
#使用DataFrame的groupby函数
group_df = Order.groupby(['SalesOrderNumber'])
如果你会写SQL,你应该知道groupby必须和聚合函数一起使用,因为它是一个mapreduce过程。如果不使用聚合函数按订单号分组,SQL Server 会报错,Mysql 只会返回第一行数据。而这里直接使用groupby分组,不用聚合功能,这样会不会有问题?让我们看一下生成的 group_df:
group_df.head(2) #查看数据集
上图是groupby的结果(我以为是数据集),拿前2和前5看,发现返回的数据和数据集的大小不一样(注意我们的第一次查看数据显示121253条数据)。其实这个groupby的结果就是一个生成器,它返回一个动态的分组过程。如果你想使用结果,你可以输入不同的参数来得到实际的结果。所以使用这个函数来实现group_oncat并生成一个产品列表。
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_productlist.head(5)
上面代码的意思是生成一个新表,按SalesOrderNumber分组,然后将每个订单组的Products聚合成一个列表;此表只有两列,一列按 SalesOrderNumber 分组,另一列按 SalesOrderNumber 分组。将其命名为产品列表;最后去掉原创数据目标的索引,重新设置索引,最后得到df_productlist表,这样我们就形成了算法接受的输入数据格式。这是查看前 5 行的结果:
#因为只需要频繁项集,所以这里去掉订单号,将productlist转为numpy数组格式。
df_array = df_productlist["productlist"].tolist()
df_array[0:3] #取前三个查看
可以看出输入数据形成了,然后我们使用TransactionEncoder对数据进行处理,为每个item(item)生成one-hot编码的DataFrame格式:
第二步,生成频繁项集
生成最终的数据格式后,将数据馈送到 apriori 算法包生成频繁项集:
#给定最小支持度为0.01,显示列名
frequent_itemset = apriori(df_item,min_support=0.01,use_colnames=True)
frequent_itemset.tail(5)
算法生成的结果也是DataFrame格式的频繁项集。它将返回所有大于或等于最小支持度的结果,例如频繁 1 项集、频繁 2 项集和频繁 3 项集。这里显示的是频繁 1 项集。
其实为了方便我们查看和过滤,我们还可以统计频繁项集的长度,这样就可以动态索引了。
frequent_itemset['length'] = frequent_itemset['itemsets'].apply(lambda x: len(x))
frequent_itemset[ (frequent_itemset['length'] == 2) &(frequent_itemset['support'] >= 0.01) ]
这段代码的意思是找到支持度大于等于0.01的频繁2项集,也就是我们经常关心的客户购买一个产品的情况,他们会购买哪种产品。
在完成了上面生成频繁项集的第一步之后,下面就是挖掘关联规则了。
第三步,计算支持度、置信度和提升度
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
association.head()
上表显示,一共找到了 169034 条关联规则可供选择。列名是什么意思?
antecedents:代表先购买的产品(组合),consequents代表后购买的产品(组合);
先行支持:表示先购买的产品(组合)占所有订单的支持;
后续支持:表示后面购买的产品(组合)占所有订单的支持;
support:表示同时购买两种产品(组合)占所有订单的支持;
Confidence:表示同时购买两种产品(组合)与所有订单的支持度与前期支持度的比值,即规则的置信度;
Lift:表示置信度与一致支持的比值,即提升度,验证了先购买产品(组合)再购买产品组合B的可能性的有效性;
最后我们只关注买一买一,买二再买一的情况,这是最常见的实际场景需求。因此生成两个表 df_BuyAB 和 df_BuyABC。下面是完整的代码,如果你有相同格式的数据集,可以直接运行这个算法。
import pandas as pd
import mlxtend
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
Allorder = pd.read_excel("D:/4_MySQL/AdventureWorksDW2012/Allorder.xlsx")
group_df = Allorder.groupby(['SalesOrderNumber'])
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_array = df_productlist["productlist"].tolist()
trans= TransactionEncoder()
trans_array = trans.fit_transform(df_array)
df_association = pd.DataFrame(trans_array, columns=trans.columns_)
frequent_itemset = apriori(df_association,min_support=0.01,use_colnames=True)
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
BuyAB = association[(association['antecedents'].apply(lambda x :len(x)==1)) & (association['consequents'].apply(lambda x :len(x)==1))]
BuyABC = association[(association['antecedents'].apply(lambda x :len(x)==2)) & (association['consequents'].apply(lambda x :len(x)==1))]
文章开头的视频展示了如何使用这个Python脚本实现动态可视化,供商务人士使用,提高销售业绩。 查看全部
免规则采集器列表算法(
如何使用Python实现关联规则的原理和实现步骤(上))
PowerBI商品关联规则的可视化
在上一篇文章中,我解释了关联规则的原理和实现步骤。如果你理解它,它实际上很容易理解。但说起来容易做起来难,如何通过工具处理原创数据以获得有效可靠的结果仍然存在问题。实际的工作是让你解决问题,而不是仅仅谈论解决方案。本文以理论为基础,结合实际数据展示如何使用Python实现关联规则,以及如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态展示。
使用Python解决一个问题时,实际上并不是从0到1的一步一步构建,这个过程非常繁琐。有时,为了达到一个小的效果,可能要绕很多路,所以就像“调参”一样,我们倾向于使用其他内置的梯子。这就是 Python 语言如此受欢迎的原因,因为它拥有完善的开源社区和无数的工具库来实现某种目的。我们在实现关联规则的计算时,使用机器学习库mlxtend中的apriori、fpgrowth、association_rules算法。apriori 是一种流行的算法,用于提取关联规则学习中的频繁项集。先验算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的一组项。
一、数据集
#导入相关的库
import pandas as pd
import mlxtend #机器学习库
#编码包
from mlxtend.preprocessing import TransactionEncoder
#关联规则计算包
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
pd.set_option('max_colwidth',150) #对pandas显示效果设置,列显示字段长度最长为150个字符 #导入数据集
Order = pd.read_excel("D:/orders.xlsx")
#查看数据集的大小
Order.shape
#查看数据前10行
Order.tail(5)
数据集中有121253条数据,总共有四个字段。SalesOrderNumber 指订单号;ordernumber 是指子订单号。换行和数字表示订单的子订单。每个订单号下可能有一个或多个子订单。有子订单,每个子订单都是唯一的,对应一个产品;产品是指产品名称。
二、mlxtend
在真正开始之前,我们先来了解一下这个mlxtend中的包是怎么使用的。mlxtend 官网演示了如何实现关联规则的计算。我们来看看这三个步骤:
第一步,导入apriori算法包;
第二步,将原创订单数据处理成算法支持的格式;
第三步,计算support、confidence、lift等指标,过滤掉强规则。
第一步:导入先验算法包
第二步,将原创订单数据处理成算法支持的格式:
得到的实际数据往往和我之前文章中的例子一样,产品在订单号后面排列成一个列表。所以 mlxtend 包接受这种数据格式。但是,它不能直接用于计算。首先,真实数据都是文本。其次,apriori算法包需要将原创数据转换为商品的one-hot编码的Pandas Dataframe格式。这是输入数据:
它使用 TransactionEncoder 包将输入数据转换为我们需要的形式。这是转换后的代码和结果:
接下来,它将处理后的数据格式输入到 apriori 算法包中,以计算频繁项集和支持度。根据预设的最小支持度0.6,排除不频繁项集。
但是,上面有一个问题。上面返回的结果集是一个数字,其实就是df表中每一项(item)的索引,这样比较方便后面的处理,但是如果只想用这个结果的话。为了增加可读性,使用参数 use_colnames=True 来显示原创产品名称。
第三步,计算支持度、置信度和提升度
apriori算法包中没有演示第三步,这是为什么呢?因为apriori算法包只是关联规则的第一步——寻找频繁项集,当然强关联规则是不会找到的!这一步在另一个包 association_rules 中实现。这也是很多初学者容易遇到的问题。他们不知道每个包的用途,也不知道如何调用包。
这样,我们就可以计算出所有满足最小支持度的频繁项集的支持度、置信度和提升度。还有杠杆作用和收敛性。这两个的作用和之前说的lift的作用是一样的。最好使用 KLUC 指标和 IR 不平衡率,但显然 mlxtend 的开发人员更喜欢使用杠杆和信念,并将其放在一边。本案例仅演示支撑升降机的使用。
三、Python实现第一步关联规则代码,生成格式数据
以上是官网给出的关联规则包的使用方法。接下来我使用自己的数据集进行实际操作,演示如何在PowerBI中导入Python脚本生成数据表并以可视化的方式动态显示。上面已经给出了示例数据。可以看出,数据集每个订单有多个商品,但是是逐行的,而不是一个订单后跟一行所有商品的形式。所以这是一种从行转换为列的方法。这里使用了Pandas中的分组功能,要达到的效果如下:
#使用DataFrame的groupby函数
group_df = Order.groupby(['SalesOrderNumber'])
如果你会写SQL,你应该知道groupby必须和聚合函数一起使用,因为它是一个mapreduce过程。如果不使用聚合函数按订单号分组,SQL Server 会报错,Mysql 只会返回第一行数据。而这里直接使用groupby分组,不用聚合功能,这样会不会有问题?让我们看一下生成的 group_df:
group_df.head(2) #查看数据集
上图是groupby的结果(我以为是数据集),拿前2和前5看,发现返回的数据和数据集的大小不一样(注意我们的第一次查看数据显示121253条数据)。其实这个groupby的结果就是一个生成器,它返回一个动态的分组过程。如果你想使用结果,你可以输入不同的参数来得到实际的结果。所以使用这个函数来实现group_oncat并生成一个产品列表。
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_productlist.head(5)
上面代码的意思是生成一个新表,按SalesOrderNumber分组,然后将每个订单组的Products聚合成一个列表;此表只有两列,一列按 SalesOrderNumber 分组,另一列按 SalesOrderNumber 分组。将其命名为产品列表;最后去掉原创数据目标的索引,重新设置索引,最后得到df_productlist表,这样我们就形成了算法接受的输入数据格式。这是查看前 5 行的结果:
#因为只需要频繁项集,所以这里去掉订单号,将productlist转为numpy数组格式。
df_array = df_productlist["productlist"].tolist()
df_array[0:3] #取前三个查看
可以看出输入数据形成了,然后我们使用TransactionEncoder对数据进行处理,为每个item(item)生成one-hot编码的DataFrame格式:
第二步,生成频繁项集
生成最终的数据格式后,将数据馈送到 apriori 算法包生成频繁项集:
#给定最小支持度为0.01,显示列名
frequent_itemset = apriori(df_item,min_support=0.01,use_colnames=True)
frequent_itemset.tail(5)
算法生成的结果也是DataFrame格式的频繁项集。它将返回所有大于或等于最小支持度的结果,例如频繁 1 项集、频繁 2 项集和频繁 3 项集。这里显示的是频繁 1 项集。
其实为了方便我们查看和过滤,我们还可以统计频繁项集的长度,这样就可以动态索引了。
frequent_itemset['length'] = frequent_itemset['itemsets'].apply(lambda x: len(x))
frequent_itemset[ (frequent_itemset['length'] == 2) &(frequent_itemset['support'] >= 0.01) ]
这段代码的意思是找到支持度大于等于0.01的频繁2项集,也就是我们经常关心的客户购买一个产品的情况,他们会购买哪种产品。
在完成了上面生成频繁项集的第一步之后,下面就是挖掘关联规则了。
第三步,计算支持度、置信度和提升度
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
association.head()
上表显示,一共找到了 169034 条关联规则可供选择。列名是什么意思?
antecedents:代表先购买的产品(组合),consequents代表后购买的产品(组合);
先行支持:表示先购买的产品(组合)占所有订单的支持;
后续支持:表示后面购买的产品(组合)占所有订单的支持;
support:表示同时购买两种产品(组合)占所有订单的支持;
Confidence:表示同时购买两种产品(组合)与所有订单的支持度与前期支持度的比值,即规则的置信度;
Lift:表示置信度与一致支持的比值,即提升度,验证了先购买产品(组合)再购买产品组合B的可能性的有效性;
最后我们只关注买一买一,买二再买一的情况,这是最常见的实际场景需求。因此生成两个表 df_BuyAB 和 df_BuyABC。下面是完整的代码,如果你有相同格式的数据集,可以直接运行这个算法。
import pandas as pd
import mlxtend
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, fpmax, fpgrowth,association_rules
Allorder = pd.read_excel("D:/4_MySQL/AdventureWorksDW2012/Allorder.xlsx")
group_df = Allorder.groupby(['SalesOrderNumber'])
df_productlist = pd.DataFrame({"productlist":group_df['Product'].apply(list)}).reset_index()
df_array = df_productlist["productlist"].tolist()
trans= TransactionEncoder()
trans_array = trans.fit_transform(df_array)
df_association = pd.DataFrame(trans_array, columns=trans.columns_)
frequent_itemset = apriori(df_association,min_support=0.01,use_colnames=True)
association = association_rules(frequent_itemset,metric="confidence",min_threshold=0.01)
BuyAB = association[(association['antecedents'].apply(lambda x :len(x)==1)) & (association['consequents'].apply(lambda x :len(x)==1))]
BuyABC = association[(association['antecedents'].apply(lambda x :len(x)==2)) & (association['consequents'].apply(lambda x :len(x)==1))]
文章开头的视频展示了如何使用这个Python脚本实现动态可视化,供商务人士使用,提高销售业绩。
免规则采集器列表算法(Apriori算法(A)/B同时出现的概率占A出现概率 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-04-07 18:16
)
介绍
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值配置文件
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的项集。基于Apriori算法,我们可以从海量的用户行为数据中找到关联规则的频繁项集组合,例如挖掘购物行业用户的频繁购买组合。
定义
支持度(support):support(A=>B) = P(A∪B),表示A和B同时出现的概率。
confidence:confidence(A=>B)=support(A∪B)/support(A),表示A和B同时出现的概率与A出现的概率的比值。
频繁项集:在项集中频繁出现且满足最小支持阈值的集合,如{牛奶、面包}、{手机、手机壳}等。
强关联规则:满足最小支持度和最小置信度的关联规则。
算法步骤从记录中计算所有候选项集,并计算频繁项集和支持。k-item 候选集是从频繁的 1-item 集生成的,k-item 频繁集是从 k-item 候选集计算出来的。用k-item频繁集生成所有关联规则,计算生成规则的置信度,过滤满足最小置信度的关联规则。先验原理
任何频繁项的所有非空子集也必须是频繁的。即在生成k-item候选集时,如果候选集中的元素不在k-1项频繁集中,则该元素一定不是频繁集。这时候不需要计算支持度,直接去掉即可。例如,我们有一个由 0、1、2、3 组成的集合,下面是它的所有项集组合:
从 1 个项集计算 k 个项集的支持度,当我们计算出 {0,1} 集在 2 个项集候选集中不频繁时,那么它的所有子集都是不频繁的,即 2 个项集 {0 , 1, 2} 和 { 0, 1, 3} 也是不频繁的,它们的子集 {0, 1, 2, 3} 也是不频繁的,我们不需要计算不频繁集的支持度。
当所有的频繁项都找到后,需要从频繁集中挖掘出所有的关联规则。假设频繁项集{0, 1, 2, 3},下图显示了它生成的所有关联规则。规则,它们的子集也将是低置信度。
Python 实现
网上一些Apriori算法的Python实现,其实并不符合python风格。还有一点就是有点难理解,所以实现尽量简洁。
1. 数据集
用一个列表来表示多条交易记录,每条交易记录也用一个列表来表示一个项集。
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
2. 创建初始候选集
这里使用frozenset不可变集合,用于后续以集合为key的支持字典的计算。
def apriori(data_set):
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
3. 从候选项集中选择频繁项集
如下图所示,我们需要从初始的候选项集中计算出k个频繁项集,所以这里的封装函数用于每次计算频繁项集和支持度,当候选项集中的每个元素都存在于对事务记录集进行统计并存入字典,计算出支持度后输出频繁项集和支持度。
def generate_freq_supports(data_set, item_set, min_support):
freq_set = set() # 保存频繁项集元素
item_count = {} # 保存元素频次,用于计算支持度
supports = {} # 保存支持度
# 如果项集中元素在数据集中则计数
for record in data_set:
for item in item_set:
if item.issubset(record):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
data_len = float(len(data_set))
# 计算项集支持度
for item in item_count:
if (item_count[item] / data_len) >= min_support:
freq_set.add(item)
supports[item] = item_count[item] / data_len
return freq_set, supports
4.生成新组合
{1, 2, 3, 5}的频繁项集将从初始候选集生成,后面需要生成一个新的候选集Ck。
def generate_new_combinations(freq_set, k):
new_combinations = set() # 保存新组合
sets_len = len(freq_set) # 集合含有元素个数,用于遍历求得组合
freq_set_list = list(freq_set) # 集合转为列表用于索引
for i in range(sets_len):
for j in range(i + 1, sets_len):
l1 = list(freq_set_list[i])
l2 = list(freq_set_list[j])
l1.sort()
l2.sort()
# 项集若有相同的父集则合并项集
if l1[0:k-2] == l2[0:k-2]:
freq_item = freq_set_list[i] | freq_set_list[j]
new_combinations.add(freq_item)
return new_combinations
5.循环生成候选集和频繁集
def apriori(data_set, min_support, max_len=None):
max_items = 2 # 初始项集元素个数
freq_sets = [] # 保存所有频繁项集
supports = {} # 保存所有支持度
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
# 频繁项1项集及其支持度
l1, support1 = generate_freq_supports(data_set, c1, min_support)
freq_sets.append(l1)
supports.update(support1)
if max_len is None:
max_len = float('inf')
while max_items and max_items = min_conf:
rules.append(rule)
return rules
7.主程序
if __name__ == '__main__':
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
L, support_data = apriori(data, min_support=0.5)
rules = association_rules(L, support_data, min_conf=0.7)
print('='*50)
print('frequent \t\tsupport')
print('='*50)
for i in L:
for j in i:
print(set(j), '\t\t', support_data[j])
print()
print('='*50)
print('antecedent consequent \t\tconf')
print('='*50)
rules = association_rules(L, support_data, min_conf=0.7)
for _rule in rules:
print('{} => {}\t\t{}'.format(set(_rule[0]), set(_rule[1]), _rule[2]))
Mlxtend 实现
Mlxtend 是用于日常数据科学任务的 Python 库。这个库是google在搜索Apriori算法信息时给出的搜索结果之一。通过库的文档可以发现,库的frequent_patterns模块实现了Apriori算法,挖掘关联规则。有兴趣的可以自行搜索相关文档。当然,如果自己实现的话,整个算法的思路会更加清晰。具体实现如下:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
rules = association_rules(frequent_itemsets, min_threshold=0.7)
通过TransactionEncoder转换成正确的数据格式,然后使用apriori函数生成频繁项集,最后使用association_rules生成关联规则。可以看出,编码后的数据实际上是一个特征矩阵,每一列对应一个项集元素。
查看全部
免规则采集器列表算法(Apriori算法(A)/B同时出现的概率占A出现概率
)
介绍
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值配置文件
Apriori 是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori 算法旨在对收录交易的数据库进行操作,例如商店客户的购买。如果满足用户指定的支持阈值,则项集被认为是“频繁的”。例如,如果支持阈值设置为 0.5 (50%),则频繁项集定义为在数据库中至少 50% 的所有事务中一起出现的项集。基于Apriori算法,我们可以从海量的用户行为数据中找到关联规则的频繁项集组合,例如挖掘购物行业用户的频繁购买组合。
定义
支持度(support):support(A=>B) = P(A∪B),表示A和B同时出现的概率。
confidence:confidence(A=>B)=support(A∪B)/support(A),表示A和B同时出现的概率与A出现的概率的比值。
频繁项集:在项集中频繁出现且满足最小支持阈值的集合,如{牛奶、面包}、{手机、手机壳}等。
强关联规则:满足最小支持度和最小置信度的关联规则。
算法步骤从记录中计算所有候选项集,并计算频繁项集和支持。k-item 候选集是从频繁的 1-item 集生成的,k-item 频繁集是从 k-item 候选集计算出来的。用k-item频繁集生成所有关联规则,计算生成规则的置信度,过滤满足最小置信度的关联规则。先验原理
任何频繁项的所有非空子集也必须是频繁的。即在生成k-item候选集时,如果候选集中的元素不在k-1项频繁集中,则该元素一定不是频繁集。这时候不需要计算支持度,直接去掉即可。例如,我们有一个由 0、1、2、3 组成的集合,下面是它的所有项集组合:
从 1 个项集计算 k 个项集的支持度,当我们计算出 {0,1} 集在 2 个项集候选集中不频繁时,那么它的所有子集都是不频繁的,即 2 个项集 {0 , 1, 2} 和 { 0, 1, 3} 也是不频繁的,它们的子集 {0, 1, 2, 3} 也是不频繁的,我们不需要计算不频繁集的支持度。
当所有的频繁项都找到后,需要从频繁集中挖掘出所有的关联规则。假设频繁项集{0, 1, 2, 3},下图显示了它生成的所有关联规则。规则,它们的子集也将是低置信度。
Python 实现
网上一些Apriori算法的Python实现,其实并不符合python风格。还有一点就是有点难理解,所以实现尽量简洁。
1. 数据集
用一个列表来表示多条交易记录,每条交易记录也用一个列表来表示一个项集。
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
2. 创建初始候选集
这里使用frozenset不可变集合,用于后续以集合为key的支持字典的计算。
def apriori(data_set):
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
3. 从候选项集中选择频繁项集
如下图所示,我们需要从初始的候选项集中计算出k个频繁项集,所以这里的封装函数用于每次计算频繁项集和支持度,当候选项集中的每个元素都存在于对事务记录集进行统计并存入字典,计算出支持度后输出频繁项集和支持度。
def generate_freq_supports(data_set, item_set, min_support):
freq_set = set() # 保存频繁项集元素
item_count = {} # 保存元素频次,用于计算支持度
supports = {} # 保存支持度
# 如果项集中元素在数据集中则计数
for record in data_set:
for item in item_set:
if item.issubset(record):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
data_len = float(len(data_set))
# 计算项集支持度
for item in item_count:
if (item_count[item] / data_len) >= min_support:
freq_set.add(item)
supports[item] = item_count[item] / data_len
return freq_set, supports
4.生成新组合
{1, 2, 3, 5}的频繁项集将从初始候选集生成,后面需要生成一个新的候选集Ck。
def generate_new_combinations(freq_set, k):
new_combinations = set() # 保存新组合
sets_len = len(freq_set) # 集合含有元素个数,用于遍历求得组合
freq_set_list = list(freq_set) # 集合转为列表用于索引
for i in range(sets_len):
for j in range(i + 1, sets_len):
l1 = list(freq_set_list[i])
l2 = list(freq_set_list[j])
l1.sort()
l2.sort()
# 项集若有相同的父集则合并项集
if l1[0:k-2] == l2[0:k-2]:
freq_item = freq_set_list[i] | freq_set_list[j]
new_combinations.add(freq_item)
return new_combinations
5.循环生成候选集和频繁集
def apriori(data_set, min_support, max_len=None):
max_items = 2 # 初始项集元素个数
freq_sets = [] # 保存所有频繁项集
supports = {} # 保存所有支持度
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
# 频繁项1项集及其支持度
l1, support1 = generate_freq_supports(data_set, c1, min_support)
freq_sets.append(l1)
supports.update(support1)
if max_len is None:
max_len = float('inf')
while max_items and max_items = min_conf:
rules.append(rule)
return rules
7.主程序
if __name__ == '__main__':
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
L, support_data = apriori(data, min_support=0.5)
rules = association_rules(L, support_data, min_conf=0.7)
print('='*50)
print('frequent \t\tsupport')
print('='*50)
for i in L:
for j in i:
print(set(j), '\t\t', support_data[j])
print()
print('='*50)
print('antecedent consequent \t\tconf')
print('='*50)
rules = association_rules(L, support_data, min_conf=0.7)
for _rule in rules:
print('{} => {}\t\t{}'.format(set(_rule[0]), set(_rule[1]), _rule[2]))
Mlxtend 实现
Mlxtend 是用于日常数据科学任务的 Python 库。这个库是google在搜索Apriori算法信息时给出的搜索结果之一。通过库的文档可以发现,库的frequent_patterns模块实现了Apriori算法,挖掘关联规则。有兴趣的可以自行搜索相关文档。当然,如果自己实现的话,整个算法的思路会更加清晰。具体实现如下:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
rules = association_rules(frequent_itemsets, min_threshold=0.7)
通过TransactionEncoder转换成正确的数据格式,然后使用apriori函数生成频繁项集,最后使用association_rules生成关联规则。可以看出,编码后的数据实际上是一个特征矩阵,每一列对应一个项集元素。
免规则采集器列表算法(采集器中起始网址可以使用批量网址的字段都在列表 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-05 01:04
)
2
同时可以观察到需要采集的字段显示在列表页页面
第三步:
那么采集器中的起始URL就可以使用批量URL的操作了:
打开列表页URL源代码,获取源代码中提取内容页URL的字符串:
同时可以看到需要采集的字段也存在于列表页的源码中(在列表页的源码中可以看到td位置对应的值需要采集的字段),则可以直接进入列表页采集
用组合标签获取列表页中所有需要的数据,然后在内容页的采集规则中细分多个标签。
第四步:
处理组合标签,使组合标签中的数据只
数据
,以方便分割标签的提取。
然后在细分标签中使用组合标签,根据td的个数提取出来:比如厂家名称(第一个td中的值)
第五步:
例如电话标签(这是第三个 td 中的值)
每周一采集数据和采集规则的时间为2019年10月30日文件发布后5个工作日内。采集该规则涉及商业版功能,建议用户登录商业版使用该规则。
数据采集资格:优采云采集器/优采云Browser/Touch Genius商业版软件用户(服务期内),如果您不是商业用户或已过了服务期,而且如果您想参加活动,您可以购买新软件或升级更新费用,以便您参加活动!告诉我,双11优采云活动折扣很大!活动将于11月1日开始,详情请访问官网:查看。
如何获取数据:
第一步:扫码添加优采云运营微信公众号,优采云运营助手会拉你进入活动群。
第二步:进群后,添加数据咨询客服。雅的微信账号在服务期内经客服验证为企业用户即可获取。
好了,本期《每周一数数》就到此为止。如果还想获取更多的数据资源和采集器规则,可以在文章下方或者公众号后台留言。小菜会根据大家的意见,在下一期中挑选出数据。哦主题!
查看全部
免规则采集器列表算法(采集器中起始网址可以使用批量网址的字段都在列表
)
2
同时可以观察到需要采集的字段显示在列表页页面
第三步:
那么采集器中的起始URL就可以使用批量URL的操作了:
打开列表页URL源代码,获取源代码中提取内容页URL的字符串:
同时可以看到需要采集的字段也存在于列表页的源码中(在列表页的源码中可以看到td位置对应的值需要采集的字段),则可以直接进入列表页采集
用组合标签获取列表页中所有需要的数据,然后在内容页的采集规则中细分多个标签。
第四步:
处理组合标签,使组合标签中的数据只
数据
,以方便分割标签的提取。
然后在细分标签中使用组合标签,根据td的个数提取出来:比如厂家名称(第一个td中的值)
第五步:
例如电话标签(这是第三个 td 中的值)
每周一采集数据和采集规则的时间为2019年10月30日文件发布后5个工作日内。采集该规则涉及商业版功能,建议用户登录商业版使用该规则。
数据采集资格:优采云采集器/优采云Browser/Touch Genius商业版软件用户(服务期内),如果您不是商业用户或已过了服务期,而且如果您想参加活动,您可以购买新软件或升级更新费用,以便您参加活动!告诉我,双11优采云活动折扣很大!活动将于11月1日开始,详情请访问官网:查看。
如何获取数据:
第一步:扫码添加优采云运营微信公众号,优采云运营助手会拉你进入活动群。
第二步:进群后,添加数据咨询客服。雅的微信账号在服务期内经客服验证为企业用户即可获取。
好了,本期《每周一数数》就到此为止。如果还想获取更多的数据资源和采集器规则,可以在文章下方或者公众号后台留言。小菜会根据大家的意见,在下一期中挑选出数据。哦主题!
免规则采集器列表算法(优采云采集上传图片时提示421Tooconnections(10)fromthisIP的终极解决方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-04 23:09
现在越来越多的网站使用了一个叫做优采云采集器的采集软件,在采集之后发布操作或多或少会遇到一系列问题,但是客服只为付费客户服务,找人处理也不便宜。这个时候你是不是很头疼?今天给大家分享一下上传图片时提示421 Too many connections (10) from this IP)的终极解决方案。
优采云采集上传图片时提示421
在采集之后的发布操作中,或多或少会遇到提示421 Too many connections (10) from this IP 上传图片时,
别着急,这只是一道小菜,下面教你如何对付他。
421提示解决方法:重启FTP
这个421提示往往是ftp中的一个小异常导致上传文件失败。我们可以选择重启ftp软件尝试解决21提示问题。以下是一些常见的解决方案:
1、如果是从宝塔安装的,那么进入宝塔面板后,找到软件管理界面,会有很多免费和付费的插件,只需要重启ftp就可以完美解决这个问题;
2、如果上面的重启方法对你来说有难度的话,除了上面的重启方法,还有一种更简单的。在宝塔面板的“首页”上寻找软件模块,里面也会有ftp。,如下所示
按照上图从左到右搜索,方法很简单,找到他点击他,最后点击重启按钮,然后去优采云发布试试看。 查看全部
免规则采集器列表算法(优采云采集上传图片时提示421Tooconnections(10)fromthisIP的终极解决方法)
现在越来越多的网站使用了一个叫做优采云采集器的采集软件,在采集之后发布操作或多或少会遇到一系列问题,但是客服只为付费客户服务,找人处理也不便宜。这个时候你是不是很头疼?今天给大家分享一下上传图片时提示421 Too many connections (10) from this IP)的终极解决方案。
优采云采集上传图片时提示421
在采集之后的发布操作中,或多或少会遇到提示421 Too many connections (10) from this IP 上传图片时,
别着急,这只是一道小菜,下面教你如何对付他。
421提示解决方法:重启FTP
这个421提示往往是ftp中的一个小异常导致上传文件失败。我们可以选择重启ftp软件尝试解决21提示问题。以下是一些常见的解决方案:
1、如果是从宝塔安装的,那么进入宝塔面板后,找到软件管理界面,会有很多免费和付费的插件,只需要重启ftp就可以完美解决这个问题;
2、如果上面的重启方法对你来说有难度的话,除了上面的重启方法,还有一种更简单的。在宝塔面板的“首页”上寻找软件模块,里面也会有ftp。,如下所示
按照上图从左到右搜索,方法很简单,找到他点击他,最后点击重启按钮,然后去优采云发布试试看。
免规则采集器列表算法(免规则采集器列表算法修改技术能力强,北京有哪些有潜力的创业团队?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-04-03 08:08
免规则采集器列表算法修改技术能力强,我见过sparkstreaming只用了一小时以内然后就能服务百万用户那种,比我见过的ceo数量多很多.技术修炼过的人,并且已经利用好技术来服务用户的,
,传送门:
先看能力,再看经验。北京有哪些有潜力的创业团队?首页-avazu-com欢迎试水。
知乎有讨论一个私人问题:如何评价本人从头至尾设计的产品-不需要下载,只要点开就可以让每个人都可以免费使用的正版操作系统-知乎?-产品,你可以看看创业就是磨练技能和提高忍耐力的过程,你再看看这问题。
应该随便问就能有人答吧。
常回家看看!
上网应用、咨询产品领域用户粘性不高,体量太小,前景一般,除非说领域内先树立一个标杆品牌,然后逐步做好口碑,有先发优势的优势,毕竟5g电信网络普及之后,本地服务业会出现爆发性增长,不仅仅是简单的软件或互联网业务提供。
创业就是改变一种环境,至于怎么改变,怎么适应环境,完全看个人能力。有人说电视台会逐步被自动机取代,因为传统电视台太重了,等社交媒体普及,整个电视台都已经不复存在了。微信和小程序也正在往服务业方向做布局,一个互联网只是一个加法关系,你就是如何成为未来的社会中心。 查看全部
免规则采集器列表算法(免规则采集器列表算法修改技术能力强,北京有哪些有潜力的创业团队?)
免规则采集器列表算法修改技术能力强,我见过sparkstreaming只用了一小时以内然后就能服务百万用户那种,比我见过的ceo数量多很多.技术修炼过的人,并且已经利用好技术来服务用户的,
,传送门:
先看能力,再看经验。北京有哪些有潜力的创业团队?首页-avazu-com欢迎试水。
知乎有讨论一个私人问题:如何评价本人从头至尾设计的产品-不需要下载,只要点开就可以让每个人都可以免费使用的正版操作系统-知乎?-产品,你可以看看创业就是磨练技能和提高忍耐力的过程,你再看看这问题。
应该随便问就能有人答吧。
常回家看看!
上网应用、咨询产品领域用户粘性不高,体量太小,前景一般,除非说领域内先树立一个标杆品牌,然后逐步做好口碑,有先发优势的优势,毕竟5g电信网络普及之后,本地服务业会出现爆发性增长,不仅仅是简单的软件或互联网业务提供。
创业就是改变一种环境,至于怎么改变,怎么适应环境,完全看个人能力。有人说电视台会逐步被自动机取代,因为传统电视台太重了,等社交媒体普及,整个电视台都已经不复存在了。微信和小程序也正在往服务业方向做布局,一个互联网只是一个加法关系,你就是如何成为未来的社会中心。
免规则采集器列表算法(如何过滤列表中的前N个数据?采集器 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-02 19:25
)
软件介绍:上一页优采云采集cms全站大移V1.0 免费版最新无限破解版测试可用下一页Pakku(bilibili弹幕过滤浏览器)V 8.10.1 Chrome版最新无限破解版测试可用
本软件由启道奇为您精心采集,转载自网络。收录软件为正式版,软件著作权归软件作者所有。以下是其具体内容:
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键式采集无需编程,支持自动生成采集可以采集99% 的互联网网站 的脚本。该软件简单易学。通过智能算法+可视化界面,你可以抓取任何你想要的数据。采集网页上的数据只需点击一下即可。
【软件特色】
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
【特征】
向导模式
使用简单,通过鼠标点击轻松自动生成
定期运行的脚本
无需人工即可按计划运行
原装高速核心
自研浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
【手动的】
输入 采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
【常见问题】
Q:如何过滤列表中的前N个数据?
1、有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(当采集表时,过滤掉表列名)
2、点击列表模式菜单设置列表xpath
Q:如何抓包获取cookies并手动设置?
1、首先,使用谷歌浏览器打开网站为采集,并登录。
2、 然后按F12,会出现开发者工具,选择Network
3、然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
【更新日志】
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本图(支持查找和替换)
5、修复了登录时的 DNS 问题
6、修复图片下载问题
7、修复一些json问题
【下载链接】
优采云采集器 V2.1.8.0 正式版 查看全部
免规则采集器列表算法(如何过滤列表中的前N个数据?采集器
)
软件介绍:上一页优采云采集cms全站大移V1.0 免费版最新无限破解版测试可用下一页Pakku(bilibili弹幕过滤浏览器)V 8.10.1 Chrome版最新无限破解版测试可用
本软件由启道奇为您精心采集,转载自网络。收录软件为正式版,软件著作权归软件作者所有。以下是其具体内容:
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键式采集无需编程,支持自动生成采集可以采集99% 的互联网网站 的脚本。该软件简单易学。通过智能算法+可视化界面,你可以抓取任何你想要的数据。采集网页上的数据只需点击一下即可。
【软件特色】
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
【特征】
向导模式
使用简单,通过鼠标点击轻松自动生成
定期运行的脚本
无需人工即可按计划运行
原装高速核心
自研浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
【手动的】
输入 采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
【常见问题】
Q:如何过滤列表中的前N个数据?
1、有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(当采集表时,过滤掉表列名)
2、点击列表模式菜单设置列表xpath
Q:如何抓包获取cookies并手动设置?
1、首先,使用谷歌浏览器打开网站为采集,并登录。
2、 然后按F12,会出现开发者工具,选择Network
3、然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
【更新日志】
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本图(支持查找和替换)
5、修复了登录时的 DNS 问题
6、修复图片下载问题
7、修复一些json问题
【下载链接】
优采云采集器 V2.1.8.0 正式版
免规则采集器列表算法(如何采集手机版网页的数据?如何手动选择列表数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-04-02 19:24
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如要抓取一个文章的完整内容时,当内容较长时,鼠标有时会难以定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
查看全部
免规则采集器列表算法(如何采集手机版网页的数据?如何手动选择列表数据
)
指示
一:输入采集网址
打开软件,新建一个任务,输入需要采集的网站地址。
二:智能分析,全程数据自动提取
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
三:导出数据到表、数据库、网站等
运行任务将采集中的数据导出到表、网站和各种数据库中,并支持api导出。
计算机系统要求
它可以支持Windows XP以上的系统。
.Net 4.0 框架,下载地址
安装步骤
第一步:打开下载的安装包,直接选择运行。
第二步:收到相关条款后,运行安装程序PashanhuV2Setup.exe。安装
第3步:然后继续单击下一步直到完成。
第四步:安装完成后可以看到优采云采集器V2的主界面
常问问题
1、如何采集移动网页数据?
一般情况下,一个网站有电脑版网页和手机版网页。如果电脑版(PC)网页的反爬虫非常严格,我们可以尝试爬取手机网页。
①选择新的编辑任务;
②在新建的【编辑任务】中,选择【第三步,设置】;
③ 将UA(浏览器ID)设置为“手机”。
2、如何手动选择列表数据(自动识别失败时)
在采集列表页面,如果列表自动识别失败,或者识别出的数据不是我们想到的数据,那么我们需要手动选择列表数据。
如何手动选择列表数据?
①点击【全部清除】,清除已有字段。
②点击菜单栏上的【列表数据】,选择【选择列表】
③ 用鼠标单击列表中的任意元素。
④ 单击列表中另一行的相似元素。
一般情况下,此时采集器会自动枚举列表中的所有字段。我们可以对结果进行一些修改。
如果没有列出字段,我们需要手动添加字段。单击[添加字段],然后单击列表中的元素数据。
3、采集文章鼠标不能全选怎么办?
一般情况下,在优采云采集器中,点击鼠标选择要抓取的内容。但是,在某些情况下,比如要抓取一个文章的完整内容时,当内容较长时,鼠标有时会难以定位。
①我们可以通过在网页上右击选择【Inspect Element】来定位内容。
② 点击【向上】按钮,展开选中的内容。
③ 展开到我们全部内容的时候,全选【XPath】,然后复制。
④修改字段的XPath,粘贴刚才复制的XPath,确认。
⑤ 最后修改value属性,如果要HMTL,使用InnerHTML或OuterHTML。
免规则采集器列表算法(WordPress采集的重要点都在本文的四张配图中,文字忽略不读,直接看图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2022-04-01 03:13
WordPress采集,作为网站 每日更新的工具。解决了网站日常维护更新的麻烦问题,特别是全网批量自动采集,让网站的内容再也不用担心,有是 文章 源源不断的 网站 帖子。仔细阅读下面的文字。WordPress采集的重点都在本文的四张图里。忽略文字,直接看图。[图一,永远免费,WordPress采集]
WordPress采集要求采集源站是不断更新的能力,是对优质内容的选择性选择采集。一方面可以经常采集,另一方面这样的站信息及时,可以保证网站采集内容的新鲜度。采集方法有很多,唯一的目标就是要有质量保证。对于大部分小站长来说,只能转化流量,这也是我们网站建设的终极目标。【图二,功能丰富,WordPress采集】
搜索引擎优化是利用算法技术手段,那么网站应该有针对性地调整网站的结构,合理安排关键词,优化外部资源,从而提高关键词 在搜索引擎的 关键词 排名中。搜索引擎优化可以精准的将潜在用户接入到网站,从而不断获得流量转化,让网站长期输出资源。【图3,自动优化,WordPress采集】
有人说采集的内容对搜索引擎不是很友好,也不容易得到排名。这不一定是真的。WordPress采集通过精准采集,以及AI智能处理文章,对搜索引擎更加友好。对于大多数网站来说,采集 内容肯定不如手写的原创 内容有效。但是,原创一天可以更新多少篇文章呢?毕竟内容制作平台已经转移,早就不再关注网站了。其他几个搜索引擎也互相捕捉,更不用说小型网站了。【图4,高效简洁,WordPress采集】
所以 WordPress 采集 内容仍然有效,因为 采集 内容的后处理效果更好。对于认真而规律的人,定位采集,只关注与本站内容高度相关的网站的几个特定范围。对于其他类型的网站,有更多选项可供选择。你可以抓取所有触及边缘的内容,但数量很大,所以你不需要限制某些网站的抓取。WordPress采集这称为平移采集。
通过对搜索引擎算法的研究,搜索引擎不仅根据文本判断内容相似度,还根据HTML中DOM节点的位置和顺序进行判断。WordPress采集 会一直根据算法的变化进行更新,以符合搜索引擎的规则。
WordPress采集的作用不仅仅针对采集网站,各种cms网站,各种网站类型都匹配。WordPress的SEO优化采集更适合搜索引擎收录网站,增加蜘蛛访问频率,提升网站的收录,只有当网站 有了好的收录,网站的排名有了更好的基础。返回搜狐,查看更多 查看全部
免规则采集器列表算法(WordPress采集的重要点都在本文的四张配图中,文字忽略不读,直接看图)
WordPress采集,作为网站 每日更新的工具。解决了网站日常维护更新的麻烦问题,特别是全网批量自动采集,让网站的内容再也不用担心,有是 文章 源源不断的 网站 帖子。仔细阅读下面的文字。WordPress采集的重点都在本文的四张图里。忽略文字,直接看图。[图一,永远免费,WordPress采集]
WordPress采集要求采集源站是不断更新的能力,是对优质内容的选择性选择采集。一方面可以经常采集,另一方面这样的站信息及时,可以保证网站采集内容的新鲜度。采集方法有很多,唯一的目标就是要有质量保证。对于大部分小站长来说,只能转化流量,这也是我们网站建设的终极目标。【图二,功能丰富,WordPress采集】
搜索引擎优化是利用算法技术手段,那么网站应该有针对性地调整网站的结构,合理安排关键词,优化外部资源,从而提高关键词 在搜索引擎的 关键词 排名中。搜索引擎优化可以精准的将潜在用户接入到网站,从而不断获得流量转化,让网站长期输出资源。【图3,自动优化,WordPress采集】
有人说采集的内容对搜索引擎不是很友好,也不容易得到排名。这不一定是真的。WordPress采集通过精准采集,以及AI智能处理文章,对搜索引擎更加友好。对于大多数网站来说,采集 内容肯定不如手写的原创 内容有效。但是,原创一天可以更新多少篇文章呢?毕竟内容制作平台已经转移,早就不再关注网站了。其他几个搜索引擎也互相捕捉,更不用说小型网站了。【图4,高效简洁,WordPress采集】
所以 WordPress 采集 内容仍然有效,因为 采集 内容的后处理效果更好。对于认真而规律的人,定位采集,只关注与本站内容高度相关的网站的几个特定范围。对于其他类型的网站,有更多选项可供选择。你可以抓取所有触及边缘的内容,但数量很大,所以你不需要限制某些网站的抓取。WordPress采集这称为平移采集。
通过对搜索引擎算法的研究,搜索引擎不仅根据文本判断内容相似度,还根据HTML中DOM节点的位置和顺序进行判断。WordPress采集 会一直根据算法的变化进行更新,以符合搜索引擎的规则。
WordPress采集的作用不仅仅针对采集网站,各种cms网站,各种网站类型都匹配。WordPress的SEO优化采集更适合搜索引擎收录网站,增加蜘蛛访问频率,提升网站的收录,只有当网站 有了好的收录,网站的排名有了更好的基础。返回搜狐,查看更多
免规则采集器列表算法( 一个目标叫T的规则规则的算法介绍及注意事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-28 15:09
一个目标叫T的规则规则的算法介绍及注意事项)
隐式规则搜索算法
例如,我们有一个名为 T 的目标。下面是为目标 T 搜索规则的算法。请注意,下面我们不提及后缀规则,因为在将 Makefile 加载到内存中时,所有后缀规则都会转换为模式规则。如果目标是“archive(member)”的函数库文件模式,那么这个算法会运行两次,第一次是找到目标T,如果没有找到,则进入第二次,第二次将使用“member”作为“member”进行搜索。
1、分隔T的目录部分。称为D,其余称为N。(例如:如果T是“src/foo.o”,则D是“src/”,N是“foo .o")
2、创建匹配 T 或 N 的所有模式规则的列表。
3、如果模式规则列表中存在匹配所有文件的模式,例如“%”,则从列表中删除其他模式。
4、删除列表中没有命令的规则。
5、对于列表中的第一个模式规则:
1)派生它的“stem” S,它应该是 T 或 N 匹配模式的非空“%”部分。
2)计算依赖文件。将依赖文件中的“%”替换为“stem”S。如果目标模式不收录斜线字符,则在第一个依赖文件的开头添加 D。
3)测试所有依赖文件是否存在或应该存在。(如果文件被定义为另一个规则的对象,或者作为显式规则的依赖项,则该文件被称为“应该存在”)
4)如果所有依赖都存在或应该存在,或者如果没有依赖。然后将应用此规则,退出算法。
6、如果在第 5 步之后没有找到模式规则,则进行进一步搜索。对于列表中的第一个模式规则:
1)如果规则是终止规则,忽略它并继续下一个模式规则。
2)计算依赖文件。(与第 5 步相同)
3)测试所有依赖文件是否存在或应该存在。
4)对于不存在的依赖文件,递归调用这个算法,看是否可以通过隐式规则找到。
5)如果所有依赖都存在或应该存在,或者根本不存在依赖。然后采用该规则,退出算法。
7、如果没有可以使用的隐式规则,检查“.DEFAULT”规则,如果有,使用,使用“.DEFAULT”命令T。
一旦找到规则,就执行它的等效命令,此时,我们的自动化变量的值就生成了。 查看全部
免规则采集器列表算法(
一个目标叫T的规则规则的算法介绍及注意事项)
隐式规则搜索算法
例如,我们有一个名为 T 的目标。下面是为目标 T 搜索规则的算法。请注意,下面我们不提及后缀规则,因为在将 Makefile 加载到内存中时,所有后缀规则都会转换为模式规则。如果目标是“archive(member)”的函数库文件模式,那么这个算法会运行两次,第一次是找到目标T,如果没有找到,则进入第二次,第二次将使用“member”作为“member”进行搜索。
1、分隔T的目录部分。称为D,其余称为N。(例如:如果T是“src/foo.o”,则D是“src/”,N是“foo .o")
2、创建匹配 T 或 N 的所有模式规则的列表。
3、如果模式规则列表中存在匹配所有文件的模式,例如“%”,则从列表中删除其他模式。
4、删除列表中没有命令的规则。
5、对于列表中的第一个模式规则:
1)派生它的“stem” S,它应该是 T 或 N 匹配模式的非空“%”部分。
2)计算依赖文件。将依赖文件中的“%”替换为“stem”S。如果目标模式不收录斜线字符,则在第一个依赖文件的开头添加 D。
3)测试所有依赖文件是否存在或应该存在。(如果文件被定义为另一个规则的对象,或者作为显式规则的依赖项,则该文件被称为“应该存在”)
4)如果所有依赖都存在或应该存在,或者如果没有依赖。然后将应用此规则,退出算法。
6、如果在第 5 步之后没有找到模式规则,则进行进一步搜索。对于列表中的第一个模式规则:
1)如果规则是终止规则,忽略它并继续下一个模式规则。
2)计算依赖文件。(与第 5 步相同)
3)测试所有依赖文件是否存在或应该存在。
4)对于不存在的依赖文件,递归调用这个算法,看是否可以通过隐式规则找到。
5)如果所有依赖都存在或应该存在,或者根本不存在依赖。然后采用该规则,退出算法。
7、如果没有可以使用的隐式规则,检查“.DEFAULT”规则,如果有,使用,使用“.DEFAULT”命令T。
一旦找到规则,就执行它的等效命令,此时,我们的自动化变量的值就生成了。

