
免规则采集器列表算法
免规则采集器列表算法( 程序bug也能负负得正吗?还真可以吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-31 17:03
程序bug也能负负得正吗?还真可以吗?)
程序错误可以是消极的还是积极的?
真的没问题。
比如程序员们那么熟悉的排序算法,居然可以通过两个“bug”来修正,真是不可思议。
请看这位程序员写的升序数组排序代码:
for i = 1 to n dofor j = 1 to n doif A[i] < A[j] thenswap A[i] and A[j]
今天这串代码在黑客新闻论坛上突然火了起来,引来了大批程序员围观。
乍一看这段代码,你的反应是什么?是不是觉得这个程序员水平太差了,连基本的冒泡算法都写得不好:
不等号的方向错了,二级循环指标j的范围也错了。
简而言之,这段代码“绝对不可能正确”。
△冒泡算法
但是如果你真的运行它,你会发现结果真的是按升序排列的。
让我们看看正确的冒泡算法代码是什么样的:
for i = 1 to n dofor j = i + 1 to n doif A[i] > A[j] thenswap A[i] and A[j]
后者的区别在于j=i+1和A[i]>A[j],这两个过程有很大的不同。
然而,我想告诉你一个令人难以置信的事实。事实上,第一串代码是正确的,可以严格证明。
那么它是如何实现正确排序的呢?
为什么我能打对?
仔细想想,其实很容易理解。因为这个算法的交换操作比冒泡排序多一半,所以它恰好能够将降序编程为升序。
不过作者还是给出了严谨的证明。
我们将 Pᵢ 定义为经过 i 次 (1 ≤ i ≤ n) 外循环后获得的数组。
如果算法正确,则前 i 项已经是升序排列,即 A[1] ≤ A[2] ≤... ≤ A[i]。
证明算法正确实际上就是证明 Pₙ 对任何 n 都成立。
根据数学归纳法,我们只需要证明 P₁ 为真,假设 Pᵢ 为真,然后证明 Pi+1 也为真,即可证明命题。
P₁显然是正确的,这一步和普通的降序冒泡算法没什么区别。在第一个外循环之后,A[1] 是整个数组的最大元素。
然后我们假设 Pᵢ 成立,然后证明 Pi+1 成立。
我们首先定义一个序数 k:
首先假设A[k](k在1和i之间)满足最小数A[k]>A[i+1],那么A[k−1]≤A[i+1](k≠ 1)。
如果 A[i+1]≥A[i],那么这样的 k 不存在,我们让 k=i+1。
考虑以下三种情况:
1、1 ≤ j ≤ k−1
由于 A[i+1]>A[j],没有发生元素交换。
2、 k ≤ j ≤ i(如果k=i+1,这一步不存在)
由于A[j]>A[i+1],每次比较后都会有元素交换。
我们用A[]和A′[]来表示交换前后的元素,所以
A'[i+1] = A[k], A'[k]=A[i+1]
经过一系列的交换,最后把最大的元素放到了A[i+1]的位置,原来的A[i+1]变成了最大的元素,A[k]以原来的A之间的大小插入[k] 和 A[k-1] 之间的元素。
3、i+1 ≤ j ≤ n
由于最大的元素已经交换为前i+1个元素,所以在这个过程中没有元素交换。
最后,Pₙ是执行升序算法后的结果。
由于内循环和外循环的作用域没有区别,这可以说是“最简单”的排序算法。
从代码上看,它与冒泡算法非常相似,但从证明过程可以看出,这实际上是一种插入算法。
△插入算法算法复杂度
显然,算法总是会比较n²次,然后计算算法的交换次数。
可以证明,交换后最多有I+2(n-1),至少有n-1。
其中I为初始数的倒数,最大值为n(n-1)/2
因此,整个算法的复杂度为 O(n²)。
从证明过程可以看出,除了i=1的循环外,其余循环中j=i-1之后的部分是完全无效的,所以这部分可以省略,得到一个简化的算法。
for i = 2 to n dofor j = 1 to i − 1 doif A[i] < A[j] thenswap A[i] and A[j]
该算法减少了比较和交换的次数,但算法复杂度仍然是O(n²)。
网友:这个算法我见过
这种排序算法比最简单的冒泡算法还要简单,很快就在黑客新闻上引起了网友的关注。
许多人觉得它“非常熟悉”。
有网友说,他曾经在奥林匹克数学竞赛中看到一位同学使用了一种很奇怪的排序算法。它可以运行但效率非常低,更像是一种插入排序。
如果我没记错的话,他使用了这个算法。
其实关于这个算法的讨论已经很久了,人们从2014年就开始发帖了,这次作者把论文上传到了arXiv,引起了广泛的热议。
甚至还有乌龙事件。
一位网友看了一眼论文,认为算法和他10年前提出的算法一样。
留言网友的算法:
乍一看,这两种算法的代码确实非常相似,原理上也确实有些相似。
它们看起来都像冒泡排序,但实际上更接近选择排序。
但很快有人指出了真相:在这个算法中j=i+1到n,当A[i]>A[j]时交换。
在作者提出的算法中,j=1到n,A[i]
相比这两种算法,之前网友提出的算法更容易理解为什么能跑。
当然,也有歪楼。有些人嘲笑他们在第一次学习编程时编写了这个算法。
我 100% 肯定,我在刚开始学习编程并想找到最短的排序方法时写的。
但是当涉及到实际应用时,该算法所需的计算时间太长了。
有些人认为这个算法之前已经被发现了很多次,但那些人根本没有打算使用它。
还有人提出,这种排序不像睡眠排序那么简单。
休眠排序就是构造n个线程,使线程对应n个排序。
例如,对于像 [4,2,3,5,9] 这样的一组数字,会创建 5 个线程,每个线程休眠 4s、2s、3s、5s、9s。这些线程唤醒后,只需报告它们对应的编号即可。这样,当所有线程都唤醒时,排序就结束了。
但是和作者提出的算法一样,睡眠排序由于多线程的问题,在实际实现中存在困难。
另外,这位网友还说他见过这个算法:
我确定我以前见过这个算法。它没有名字吗?
很快有人建议——
如果它没有名字,我建议称之为“面试排序”。
参考链接:
[1]
[2]
1.STM32U5,意法半导体全新超低功耗MCU旗舰版
2.【Arm-2D界面设计实例】从不规则图标的显示入手
3.STM8CubeMX和STM32CubeMX的功能一样吗?
4.这九种情况尽量不要连接MCU项目~
5. 偷偷把室友的STM32换成GD32后。. .
6.打开苹果A15芯片看die layout!
免责声明:本文为网络转载,版权归原作者所有。如果您涉及作品的版权,请联系我们,我们将根据您提供的版权证明材料确认版权,并支付作者报酬或删除内容。 查看全部
免规则采集器列表算法(
程序bug也能负负得正吗?还真可以吗?)

程序错误可以是消极的还是积极的?
真的没问题。

比如程序员们那么熟悉的排序算法,居然可以通过两个“bug”来修正,真是不可思议。
请看这位程序员写的升序数组排序代码:
for i = 1 to n dofor j = 1 to n doif A[i] < A[j] thenswap A[i] and A[j]
今天这串代码在黑客新闻论坛上突然火了起来,引来了大批程序员围观。

乍一看这段代码,你的反应是什么?是不是觉得这个程序员水平太差了,连基本的冒泡算法都写得不好:
不等号的方向错了,二级循环指标j的范围也错了。
简而言之,这段代码“绝对不可能正确”。

△冒泡算法
但是如果你真的运行它,你会发现结果真的是按升序排列的。
让我们看看正确的冒泡算法代码是什么样的:
for i = 1 to n dofor j = i + 1 to n doif A[i] > A[j] thenswap A[i] and A[j]
后者的区别在于j=i+1和A[i]>A[j],这两个过程有很大的不同。
然而,我想告诉你一个令人难以置信的事实。事实上,第一串代码是正确的,可以严格证明。
那么它是如何实现正确排序的呢?
为什么我能打对?
仔细想想,其实很容易理解。因为这个算法的交换操作比冒泡排序多一半,所以它恰好能够将降序编程为升序。
不过作者还是给出了严谨的证明。
我们将 Pᵢ 定义为经过 i 次 (1 ≤ i ≤ n) 外循环后获得的数组。
如果算法正确,则前 i 项已经是升序排列,即 A[1] ≤ A[2] ≤... ≤ A[i]。
证明算法正确实际上就是证明 Pₙ 对任何 n 都成立。
根据数学归纳法,我们只需要证明 P₁ 为真,假设 Pᵢ 为真,然后证明 Pi+1 也为真,即可证明命题。
P₁显然是正确的,这一步和普通的降序冒泡算法没什么区别。在第一个外循环之后,A[1] 是整个数组的最大元素。
然后我们假设 Pᵢ 成立,然后证明 Pi+1 成立。
我们首先定义一个序数 k:
首先假设A[k](k在1和i之间)满足最小数A[k]>A[i+1],那么A[k−1]≤A[i+1](k≠ 1)。
如果 A[i+1]≥A[i],那么这样的 k 不存在,我们让 k=i+1。
考虑以下三种情况:
1、1 ≤ j ≤ k−1
由于 A[i+1]>A[j],没有发生元素交换。
2、 k ≤ j ≤ i(如果k=i+1,这一步不存在)
由于A[j]>A[i+1],每次比较后都会有元素交换。
我们用A[]和A′[]来表示交换前后的元素,所以
A'[i+1] = A[k], A'[k]=A[i+1]
经过一系列的交换,最后把最大的元素放到了A[i+1]的位置,原来的A[i+1]变成了最大的元素,A[k]以原来的A之间的大小插入[k] 和 A[k-1] 之间的元素。
3、i+1 ≤ j ≤ n
由于最大的元素已经交换为前i+1个元素,所以在这个过程中没有元素交换。
最后,Pₙ是执行升序算法后的结果。
由于内循环和外循环的作用域没有区别,这可以说是“最简单”的排序算法。
从代码上看,它与冒泡算法非常相似,但从证明过程可以看出,这实际上是一种插入算法。

△插入算法算法复杂度
显然,算法总是会比较n²次,然后计算算法的交换次数。
可以证明,交换后最多有I+2(n-1),至少有n-1。
其中I为初始数的倒数,最大值为n(n-1)/2
因此,整个算法的复杂度为 O(n²)。
从证明过程可以看出,除了i=1的循环外,其余循环中j=i-1之后的部分是完全无效的,所以这部分可以省略,得到一个简化的算法。
for i = 2 to n dofor j = 1 to i − 1 doif A[i] < A[j] thenswap A[i] and A[j]
该算法减少了比较和交换的次数,但算法复杂度仍然是O(n²)。
网友:这个算法我见过
这种排序算法比最简单的冒泡算法还要简单,很快就在黑客新闻上引起了网友的关注。
许多人觉得它“非常熟悉”。
有网友说,他曾经在奥林匹克数学竞赛中看到一位同学使用了一种很奇怪的排序算法。它可以运行但效率非常低,更像是一种插入排序。
如果我没记错的话,他使用了这个算法。

其实关于这个算法的讨论已经很久了,人们从2014年就开始发帖了,这次作者把论文上传到了arXiv,引起了广泛的热议。

甚至还有乌龙事件。
一位网友看了一眼论文,认为算法和他10年前提出的算法一样。
留言网友的算法:

乍一看,这两种算法的代码确实非常相似,原理上也确实有些相似。
它们看起来都像冒泡排序,但实际上更接近选择排序。
但很快有人指出了真相:在这个算法中j=i+1到n,当A[i]>A[j]时交换。
在作者提出的算法中,j=1到n,A[i]
相比这两种算法,之前网友提出的算法更容易理解为什么能跑。

当然,也有歪楼。有些人嘲笑他们在第一次学习编程时编写了这个算法。
我 100% 肯定,我在刚开始学习编程并想找到最短的排序方法时写的。


但是当涉及到实际应用时,该算法所需的计算时间太长了。
有些人认为这个算法之前已经被发现了很多次,但那些人根本没有打算使用它。

还有人提出,这种排序不像睡眠排序那么简单。

休眠排序就是构造n个线程,使线程对应n个排序。
例如,对于像 [4,2,3,5,9] 这样的一组数字,会创建 5 个线程,每个线程休眠 4s、2s、3s、5s、9s。这些线程唤醒后,只需报告它们对应的编号即可。这样,当所有线程都唤醒时,排序就结束了。
但是和作者提出的算法一样,睡眠排序由于多线程的问题,在实际实现中存在困难。
另外,这位网友还说他见过这个算法:
我确定我以前见过这个算法。它没有名字吗?
很快有人建议——
如果它没有名字,我建议称之为“面试排序”。

参考链接:
[1]
[2]

1.STM32U5,意法半导体全新超低功耗MCU旗舰版
2.【Arm-2D界面设计实例】从不规则图标的显示入手
3.STM8CubeMX和STM32CubeMX的功能一样吗?
4.这九种情况尽量不要连接MCU项目~
5. 偷偷把室友的STM32换成GD32后。. .
6.打开苹果A15芯片看die layout!

免责声明:本文为网络转载,版权归原作者所有。如果您涉及作品的版权,请联系我们,我们将根据您提供的版权证明材料确认版权,并支付作者报酬或删除内容。
免规则采集器列表算法(【干货】免规则采集器列表算法简介(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-10-29 23:05
免规则采集器列表算法简介经过测试所得到的规则采集器,将个人、公司、商家间用通讯代码做分类,根据分类算法规则抓取对应的数据。例如用a/b来区分公司或者商家。规则采集器每抓取一个对应的数据都会设置相应的banner(包括商品详情页、产品详情页)里面的图片,并且在将要对应的文件中找到对应的规则,只要规则被抓取就会在相应规则下面加入对应的算法内容。规则采集器采集器默认将banner图片全部设置为200%,那么会有过高的请求报文找不到。欢迎补充。
sendmsg?server={ttl}
catsendmsg#或者moresendmsg:-moresendmsg:eachserveropentimeserveris{scrapers}-listen/proxyeverytimeconnectionauthenticateis{server}-singlespire#-moreelsesendmsg:-listen/proxymybandwidthis{interval}-serverbytesofbuilt-instringbytes:-listen/proxy/{}"nginx"{}"mybandwidth"{}"mybandwidth"{}"sendmsg#请检查ttl值。
规则采集器无banner图片的抓取方法:①首先登录规则采集器官网:②然后点击:中国规则采集器,把整个网站抓取下来③然后把整个网站的txt文本都保存下来④如果有抓取对象的banner图片可以设置里面的bannerfile位置-表格中。规则采集器抓取结果比较乱,你可以利用excel整理一下数据,排个列表,用批量导入工具批量整理文件。
导入的工具随你选择!ps:规则采集器抓取的规则只能与规则里面的抓取对象匹配,不能直接抓取别人的数据。如果有特别需要别人抓取,你可以规则采集器导入规则后自动生成子规则,然后嵌入到你的规则采集器里面去。里面配置好规则,用子规则组合规则抓取数据,比如:sendmsg:{ttl:2,banner:{banner1:{banner2:{client:{state:{version:{}}}就能抓取对应的banner图片。
之前做过这个教程的教程,网上很多;另外现在规则采集器有套餐,点击免费注册也能送一个月使用时间,要不然可以看看免费试用网站:好用,比phpstorm抓到的数据多——免费规则采集器教程。 查看全部
免规则采集器列表算法(【干货】免规则采集器列表算法简介(一))
免规则采集器列表算法简介经过测试所得到的规则采集器,将个人、公司、商家间用通讯代码做分类,根据分类算法规则抓取对应的数据。例如用a/b来区分公司或者商家。规则采集器每抓取一个对应的数据都会设置相应的banner(包括商品详情页、产品详情页)里面的图片,并且在将要对应的文件中找到对应的规则,只要规则被抓取就会在相应规则下面加入对应的算法内容。规则采集器采集器默认将banner图片全部设置为200%,那么会有过高的请求报文找不到。欢迎补充。
sendmsg?server={ttl}
catsendmsg#或者moresendmsg:-moresendmsg:eachserveropentimeserveris{scrapers}-listen/proxyeverytimeconnectionauthenticateis{server}-singlespire#-moreelsesendmsg:-listen/proxymybandwidthis{interval}-serverbytesofbuilt-instringbytes:-listen/proxy/{}"nginx"{}"mybandwidth"{}"mybandwidth"{}"sendmsg#请检查ttl值。
规则采集器无banner图片的抓取方法:①首先登录规则采集器官网:②然后点击:中国规则采集器,把整个网站抓取下来③然后把整个网站的txt文本都保存下来④如果有抓取对象的banner图片可以设置里面的bannerfile位置-表格中。规则采集器抓取结果比较乱,你可以利用excel整理一下数据,排个列表,用批量导入工具批量整理文件。
导入的工具随你选择!ps:规则采集器抓取的规则只能与规则里面的抓取对象匹配,不能直接抓取别人的数据。如果有特别需要别人抓取,你可以规则采集器导入规则后自动生成子规则,然后嵌入到你的规则采集器里面去。里面配置好规则,用子规则组合规则抓取数据,比如:sendmsg:{ttl:2,banner:{banner1:{banner2:{client:{state:{version:{}}}就能抓取对应的banner图片。
之前做过这个教程的教程,网上很多;另外现在规则采集器有套餐,点击免费注册也能送一个月使用时间,要不然可以看看免费试用网站:好用,比phpstorm抓到的数据多——免费规则采集器教程。
免规则采集器列表算法(关关采集器绿色版绿色版功能介绍及使用方法介绍【图文】 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-29 06:14
)
关关采集器绿色版是一款免费的采集软件,关关采集器绿色版支持定义不同的生成方式,独立目录和内容,自定义章节,字数不足, 或内容不足 将指定内容替换为空,增加TXT专页生成功能,关闭采集器绿色版可实现采集数据分类管理,使用非常方便.
关闭采集器 绿色版介绍
1 采集 而且生成速度更快更稳定!
2 支持乱序采集模式(见demo图片)
3 替换采集模式+图片隔行水印+图片FTP加载+文字图片等
4 支持 server2003 或 server2008
5 剧集画面无黑块等BUG,不会再有CPU达到100%
6 不会出现界面卡顿、运行缓慢等...
7 支持伪拼音
8 数字化
9 内部连接关键词设置,
10 非拼音内联初始化提取
11 随机播放模式
12 列表页和内容中使用了{pinyin}标签
13 信息和列表的状态标签
14 书架拼音标签
15 信息页拼音标签等...
16 信息页和列表页的最后一章标签等...
17 读取页面的拼音标签等...
18 搜索拼音标签
采集器绿色版如何使用
1、下载这个软件的资源包,解压打开,点击里面的.exe非法启动软件
2、点击软件主界面的采集菜单,可以选择提供的三种模式中的一种来启动新的采集操作
3、 在如图的批量删除小说操作窗口中,自定义选择并设置删除小说的限制条件
4、 在如图所示的量产操作窗口中,自定义量产设置的参数
5、在如图所示的基本设置窗口中,这个也是设置病毒网站目录、数据库连接字符串等参数
6、 在如图所示的高级设置操作窗口中,在自定义设置中自定义连接参数、拼音设置、阅读设置等
7、在如图所示的图片设置窗口中,可以给图片添加水印并设置图片的高度和宽度
8、 在如图所示的规则管理操作窗口中,可以自定义规则的名称及其具体的规则内容
9、在如图所示的最新新闻窗口中,输入指定小说的名字,可以快速搜索到与其相关的新闻
查看全部
免规则采集器列表算法(关关采集器绿色版绿色版功能介绍及使用方法介绍【图文】
)
关关采集器绿色版是一款免费的采集软件,关关采集器绿色版支持定义不同的生成方式,独立目录和内容,自定义章节,字数不足, 或内容不足 将指定内容替换为空,增加TXT专页生成功能,关闭采集器绿色版可实现采集数据分类管理,使用非常方便.

关闭采集器 绿色版介绍
1 采集 而且生成速度更快更稳定!
2 支持乱序采集模式(见demo图片)
3 替换采集模式+图片隔行水印+图片FTP加载+文字图片等
4 支持 server2003 或 server2008
5 剧集画面无黑块等BUG,不会再有CPU达到100%
6 不会出现界面卡顿、运行缓慢等...
7 支持伪拼音
8 数字化
9 内部连接关键词设置,
10 非拼音内联初始化提取
11 随机播放模式
12 列表页和内容中使用了{pinyin}标签
13 信息和列表的状态标签
14 书架拼音标签
15 信息页拼音标签等...
16 信息页和列表页的最后一章标签等...
17 读取页面的拼音标签等...
18 搜索拼音标签
采集器绿色版如何使用
1、下载这个软件的资源包,解压打开,点击里面的.exe非法启动软件
2、点击软件主界面的采集菜单,可以选择提供的三种模式中的一种来启动新的采集操作

3、 在如图的批量删除小说操作窗口中,自定义选择并设置删除小说的限制条件

4、 在如图所示的量产操作窗口中,自定义量产设置的参数

5、在如图所示的基本设置窗口中,这个也是设置病毒网站目录、数据库连接字符串等参数

6、 在如图所示的高级设置操作窗口中,在自定义设置中自定义连接参数、拼音设置、阅读设置等

7、在如图所示的图片设置窗口中,可以给图片添加水印并设置图片的高度和宽度

8、 在如图所示的规则管理操作窗口中,可以自定义规则的名称及其具体的规则内容

9、在如图所示的最新新闻窗口中,输入指定小说的名字,可以快速搜索到与其相关的新闻

免规则采集器列表算法(为什么说会影响国外的站点呢?(附项目招商找A5快速获取精准代理名单))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-29 05:31
项目招商找A5快速获取精准代理商名单
福建媒体网讯:百度清风算法9月上线没多久,10月开始大整改。目的是打造优质的WEB服务,让那些采集鬼鬼祟祟的网站无处遁形。越狱,这个更新算法主要是针对移动端的调整,先看官方资料:
2017年10月上旬,“闪电算法”上线,手机搜索页面首屏加载时间会影响搜索排名。手机网页首屏在2秒内打开,您将获得手机搜索下的页面优先评价和流量倾斜;同时,在移动搜索页面的第一屏上加载非常缓慢(3 秒或更长时间)的网页将被拒绝 Suppress。
大多数站长优化了页面首屏的加载时间。优化后的技术建议包括但不限于:
资源加载:
1、在服务器端压缩合并同类型资源,减少网络请求次数和资源量。
2、 引用常用资源,充分利用浏览器缓存。
3、使用CDN加速将用户请求定向到最合适的缓存服务器。
4、 延迟加载非首屏图像,将网络带宽留给首屏请求。
页面渲染:
1、 在头部样式表中写入 CSS 样式,以减少 CSS 文件网络请求造成的渲染阻塞。
2、 将 JavaScript 放在文档末尾,或者使用异步加载,避免 JS 执行阻塞渲染。
3、指定非文本元素(如图片、视频)的宽高,避免浏览器重排和重绘。
希望广大站长继续关注页面加载速度体验。请根据网站自身情况参考建议自行优化页面,或使用通用加速方案(如MIP)持续优化页面首屏加载时间。
为什么会影响国外网站?
首先,国内服务器线路与美国、香港、韩国等国外地区的线路不一致。访问速度肯定有问题。用户访问肯定会延迟几秒,但对于百度蜘蛛来说,他已经开通了CDN。不管机器在什么地方,只要不是在不好的机房里运行服务器,一般不会影响百度蜘蛛的爬行速度。
用户访问情况如何?这肯定是有问题的,所以百度的算法这次肯定会考虑这部分原因进行压制。所以,最近国内比较知名的网站,要么是并排的,要么是优质的,对于内容,建议备案,如果不能备案,建议开通CDN,提供访问速度,提升用户体验。!
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
免规则采集器列表算法(为什么说会影响国外的站点呢?(附项目招商找A5快速获取精准代理名单))
项目招商找A5快速获取精准代理商名单
福建媒体网讯:百度清风算法9月上线没多久,10月开始大整改。目的是打造优质的WEB服务,让那些采集鬼鬼祟祟的网站无处遁形。越狱,这个更新算法主要是针对移动端的调整,先看官方资料:
2017年10月上旬,“闪电算法”上线,手机搜索页面首屏加载时间会影响搜索排名。手机网页首屏在2秒内打开,您将获得手机搜索下的页面优先评价和流量倾斜;同时,在移动搜索页面的第一屏上加载非常缓慢(3 秒或更长时间)的网页将被拒绝 Suppress。
大多数站长优化了页面首屏的加载时间。优化后的技术建议包括但不限于:
资源加载:
1、在服务器端压缩合并同类型资源,减少网络请求次数和资源量。
2、 引用常用资源,充分利用浏览器缓存。
3、使用CDN加速将用户请求定向到最合适的缓存服务器。
4、 延迟加载非首屏图像,将网络带宽留给首屏请求。
页面渲染:
1、 在头部样式表中写入 CSS 样式,以减少 CSS 文件网络请求造成的渲染阻塞。
2、 将 JavaScript 放在文档末尾,或者使用异步加载,避免 JS 执行阻塞渲染。
3、指定非文本元素(如图片、视频)的宽高,避免浏览器重排和重绘。
希望广大站长继续关注页面加载速度体验。请根据网站自身情况参考建议自行优化页面,或使用通用加速方案(如MIP)持续优化页面首屏加载时间。
为什么会影响国外网站?
首先,国内服务器线路与美国、香港、韩国等国外地区的线路不一致。访问速度肯定有问题。用户访问肯定会延迟几秒,但对于百度蜘蛛来说,他已经开通了CDN。不管机器在什么地方,只要不是在不好的机房里运行服务器,一般不会影响百度蜘蛛的爬行速度。
用户访问情况如何?这肯定是有问题的,所以百度的算法这次肯定会考虑这部分原因进行压制。所以,最近国内比较知名的网站,要么是并排的,要么是优质的,对于内容,建议备案,如果不能备案,建议开通CDN,提供访问速度,提升用户体验。!
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
免规则采集器列表算法(社交网络数据采集算法的设计(软件工程课程设计报告)课程设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-29 03:06
社交网络数据采集算法设计(软件工程课程设计报告)软件工程课程设计社交网络数据采集算法设计组号21组长姓名:盖云东学号:9组员姓名:任志成学生ID:1群员名:马建南 学号:4 群员名:陈海涛 学号:5 摘要 随着互联网的发展,人们进入了一个信息爆炸的时代。社交网络数据信息量大,主观性强。它具有巨大的数据挖掘价值,是互联网大数据的重要组成部分。一些社交平台如***、新浪微博、人人网等,允许用户申请平台数据采集权限,并提供相应API接口采集数据,通过注册社交平台、应用API授权、调用API方法等流程获取社交信息数据。但是社交平台采集的权限申请比较严格,对申请成功后的数据采集也有限制。因此,本文采用网络爬虫的方式,利用社交账号模拟登录社交平台,访问社交平台的网页信息,并在爬虫任务执行后及时返回任务执行结果。与过去信息匮乏相比,现阶段面对海量信息数据,信息的筛选和过滤成为衡量一个系统质量的重要指标。本文使用爬虫和协同过滤算法来采集在线社交数据。关键词:软件工程;社交网络; 爬虫;Collaborative Filtering Algorithm Directory Summary-2-Contents-3-The purpose of Project Research-1-1.1 Project Research Background-1-2 Priority Grabbing Strategies --PageRank -2-2.1 简介PageRank-2-2.2 PageRank流程-2-3 crawlers-4-3.1 crawler介绍-4-3.1.1crawlers介绍-4-3.1.2工作流程-4-3.1.3爬取策略介绍-5-3.2工具介绍-6-3.2. 1Eclipse -7-3.
随着社交网络网站的兴起,在线社交网络蓬勃发展,新的互联网热潮再次升温。有分析人士甚至表示,在线社交网络将创造一种新的人际交流模式。互联网的兴起打破了传统的社交方式。简单、快捷、无距离的社交体验推动了社交网络的快速发展。以Facebook、Twitter、微博等为代表的应用吸引了大量活跃的在线用户,以及社交网络信息。呈现爆发式增长。社交网络信息反映了用户的网络行为特征。通过对这些信息的研究,可以实现社会舆论监测、网络营销、股市预测等。社交网络信息的重要价值在于实时性,如何快速、准确、有效地获取目标信息非常重要。但是,社交网络属于DeepWeb的专有网络,信息量大,主题性强。传统搜索引擎无法索引这些 DeepWeb 页面。只有通过网站提供的查询界面或登录网站才能访问其信息。这增加了获取社交网络信息的难度。目前国外对社交网络数据采集模型的研究较少,对社交网络的研究主要集中在社交网络分析领域。国内社交网络平台采集的数据在技术研究上取得了一定的成果。例如,
2 优先爬取策略-PageRank2.1 PageRank简介 PageRank,即页面排名,也称页面排名,谷歌左排名或页面排名是谷歌创始人拉里·佩奇和谢尔盖·布林在构建时提出的链接分析算法1997年的早期搜索系统原型,自从谷歌取得空前的商业成功后,该算法也成为其他搜索引擎和学术界关注的计算模型。目前,很多重要的链接分析算法都是从PageRank算法衍生出来的。2.2PageRank过程 首先,PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下: 1) 初始阶段:网页通过链接关系构建Web图,并且每个页面都设置了相同的 PageRank 值。经过几轮计算,最终会得到每个页面得到的PageRank值。每轮计算,网页当前的PageRank值都会不断更新。2) 一轮更新页面PageRank分数的计算方法:在计算更新页面的PageRank分数时,每个页面都会有其当前的PageRank 查看全部
免规则采集器列表算法(社交网络数据采集算法的设计(软件工程课程设计报告)课程设计)
社交网络数据采集算法设计(软件工程课程设计报告)软件工程课程设计社交网络数据采集算法设计组号21组长姓名:盖云东学号:9组员姓名:任志成学生ID:1群员名:马建南 学号:4 群员名:陈海涛 学号:5 摘要 随着互联网的发展,人们进入了一个信息爆炸的时代。社交网络数据信息量大,主观性强。它具有巨大的数据挖掘价值,是互联网大数据的重要组成部分。一些社交平台如***、新浪微博、人人网等,允许用户申请平台数据采集权限,并提供相应API接口采集数据,通过注册社交平台、应用API授权、调用API方法等流程获取社交信息数据。但是社交平台采集的权限申请比较严格,对申请成功后的数据采集也有限制。因此,本文采用网络爬虫的方式,利用社交账号模拟登录社交平台,访问社交平台的网页信息,并在爬虫任务执行后及时返回任务执行结果。与过去信息匮乏相比,现阶段面对海量信息数据,信息的筛选和过滤成为衡量一个系统质量的重要指标。本文使用爬虫和协同过滤算法来采集在线社交数据。关键词:软件工程;社交网络; 爬虫;Collaborative Filtering Algorithm Directory Summary-2-Contents-3-The purpose of Project Research-1-1.1 Project Research Background-1-2 Priority Grabbing Strategies --PageRank -2-2.1 简介PageRank-2-2.2 PageRank流程-2-3 crawlers-4-3.1 crawler介绍-4-3.1.1crawlers介绍-4-3.1.2工作流程-4-3.1.3爬取策略介绍-5-3.2工具介绍-6-3.2. 1Eclipse -7-3.
随着社交网络网站的兴起,在线社交网络蓬勃发展,新的互联网热潮再次升温。有分析人士甚至表示,在线社交网络将创造一种新的人际交流模式。互联网的兴起打破了传统的社交方式。简单、快捷、无距离的社交体验推动了社交网络的快速发展。以Facebook、Twitter、微博等为代表的应用吸引了大量活跃的在线用户,以及社交网络信息。呈现爆发式增长。社交网络信息反映了用户的网络行为特征。通过对这些信息的研究,可以实现社会舆论监测、网络营销、股市预测等。社交网络信息的重要价值在于实时性,如何快速、准确、有效地获取目标信息非常重要。但是,社交网络属于DeepWeb的专有网络,信息量大,主题性强。传统搜索引擎无法索引这些 DeepWeb 页面。只有通过网站提供的查询界面或登录网站才能访问其信息。这增加了获取社交网络信息的难度。目前国外对社交网络数据采集模型的研究较少,对社交网络的研究主要集中在社交网络分析领域。国内社交网络平台采集的数据在技术研究上取得了一定的成果。例如,
2 优先爬取策略-PageRank2.1 PageRank简介 PageRank,即页面排名,也称页面排名,谷歌左排名或页面排名是谷歌创始人拉里·佩奇和谢尔盖·布林在构建时提出的链接分析算法1997年的早期搜索系统原型,自从谷歌取得空前的商业成功后,该算法也成为其他搜索引擎和学术界关注的计算模型。目前,很多重要的链接分析算法都是从PageRank算法衍生出来的。2.2PageRank过程 首先,PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下: 1) 初始阶段:网页通过链接关系构建Web图,并且每个页面都设置了相同的 PageRank 值。经过几轮计算,最终会得到每个页面得到的PageRank值。每轮计算,网页当前的PageRank值都会不断更新。2) 一轮更新页面PageRank分数的计算方法:在计算更新页面的PageRank分数时,每个页面都会有其当前的PageRank
免规则采集器列表算法((2009)S1—0134~O3基于关联规则的贝叶斯网络分类器张子义)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-28 16:21
6DShandong255409,中国) 摘要:基于分类的关联(CBA)算法建立了一个基于关联规则的分类器,没有考虑分类问题中的不确定性。提出了一种基于贝叶斯网络分类器的石油关联规则。改进算法用候选边缘初始化图结构,通过Apfiofial算法提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。这种计算贝叶斯网络将属性变量之间的关系表达为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 介绍 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。贝叶斯网络将属性变量之间的关系表示为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。
通常,我们将其称为改进。文献[2]使用关联规则算法提取那些只与分类相关的:B={G,0},其中G表示网络结构,0表示参数相关规则(ClassAssociationRule,CAR)网络结构。放。根据分解定理,有:()=-n_T(XilPa(五))。规则的分类器(ClassificationBasedon Association,CBA)。虽然实证结果表明CBA可以取得比c4.5更好的性能,设置观测数据D和样本的类标签C建立最优贝叶斯网络结构,但CBA没有考虑分类问题中的不确定性,为此我们结合贝叶斯使分类器的分类性能尽可能高尽可能使用贝叶斯 定理,我们使用贝叶斯网络(BN)来表征这种不确定性。未知 BN 样本被分类到具有最大后验概率的类别中。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。
在问题中,属性往往是相互依存的,所以我们需要学习一个更具生成性的学习算法。目标是找到一个复杂的贝叶斯网络结构,使其似然函数最大化,从而达到更好的分类性能。学习贝叶斯网络结构,典型例子是在类变量C的条件下最大化属性网络结构。最通用的方法是求值+搜索方法,它定义了条件互信息:一个求值函数来搜索网络拓扑。具体来说,首先,给定 ZZ(BlD)=M ∑ lpday(set; Pa(X,)/cIC)+Co (I) 一个初始结构和评估函数,一种 Where (Xi)/C# 其中 cn 是一个常数学期。判别学习常常优化判别的目标函数:一种新的结构。由此产生的结构称为增量结构。例如,树增量简单性,如条件似然函数和分类错误率。其中,条件似然函数与贝叶斯结构(Tree-AumgentedNaiveBayesina,TAN)等直接相关。M 本文提出了一种新的贝叶斯网络分类算法,首先使用了相关性分类,定义为:CLL(BID):5∑logPB(cl)。自联合规则算法提取网络结构的候选边集,然后使用贪婪爬虫经常使用贪婪搜索来获得局部最优结构。山搜索以获得更好的拓扑。1.2参数学习在15个UCI数据集上的实验结果表明了算法的有效性。
虽然网络参数学习也有判别式学习,但一般没有封闭形式的解决方案。由于计算时间复杂度高,一般只有接受稿件日期:2008-08-03;修订日期:2008-10-07。作者简介:章子怡(1977一),男,lh Dongqingdao,讲师,硕士,主要研究领域:网络安全、数字媒体、网络数据挖掘;王德良(1979一),男,山东泰安)人,讲师,硕士,主要研究方向:智能系统,数据挖掘。六月章子怡等:基于关联规则的贝叶斯网络分类器个数的生产学习解决参数的最大似然估计。首先使用 Diriehlet for alllitern.setX ∈L.setdo 检验来平滑最大似然:
节点与y之间的互信息定义为: 未来网络结构的学习。文献[2]只使用关联规则进行分类,这些确定性规则没有充分考虑分类问题的不确定性,而P.y)=)log guess(3)贝叶斯网络可以充分描述这种不确定性。因此,希望通过关系和项目出现频率来定义规则R:{., ,...,}联合规则来指导贝叶斯网络结构的建立。1的评价分数为:2.I关联规则挖掘 s() = ∑ num(, z,..., Y}) × 假设数据集 D 的所有属性都是离散属性,我们可以将每个字符串(属性编号、属性值)视为一个项( Item).在项目集中,c44)被称为-Y是一个规则,其中,l,是如果项目z的出现频率表示为nU'/Z/(z),那么我们可以用nttm(z)来表示项目z的出现频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。
如果或yI收录endfr类属性,那么我们称之为与分类相关的关联规则对于图1中的三个关联规则,{X,,}-C属于(ClassificationFocusedAssociationRule)。图1显示了分类LSc,{c}一个属于L,{c}一个属于。相关关联规则 例如,{location,,}-C, {C}-also, {Ct- 都是面向分类的关联规则。
3 实验结果验证本文算法(记为BNCAR)的有效性,我们将其与常用分类器进行比较:朴素贝叶斯分类器(NB)、贝叶斯网络分类器(TAN)、基于关联规则的分类(CBA) 15 个 UCI 数据集。一些数据集收录连续值。我们将它们离散为离散值。此外,我们消除了属性收录缺失值的样本。表 1 列出了所有 UCI 数据集的信息。2.3 挖掘与分类相关的关联规则对于所有数据集,我们运行10个交叉验证步骤,每次使用Apfiofi算法提取与分类相关的关联规则:第一次交叉验证将数据集分成10份,问最后取其精度的平均值为10。该算法生成一个长度不超过K的项目集,然后用分类提取连续运行的平均值,以消除样本划分的随机性。我们基于著名的关闭规则。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。
FRIEDMANN、GEIGERD、GOLDSZMIDTM。由于贝叶斯网络仅使用规则生成分类规则,未考虑分类分类器[J]. Machine1w_~-'ning, 1997, 29 (2/3): 131-163. 问题中的不确定性。
本文提出了一种基于关联规则的贝叶斯[4] PERNKOPFF, BILMESJ。Discriminativeversusgenerativeparam·网络分类算法。与经典的贝叶斯网络分类器TAN相比,我们的贝叶斯网络分类器的eterand结构学习[C] // Pro-使用关联规则挖掘算法提取初始候选边,使用第22届机器学习国际会议的贪心算法eeedings . 得到更好的贝叶斯网络结构。纽约:ACM 在 15 个标准 UCI 数据集上。2005 年:657-664。实验结果表明,我们的算法BNCAR 可以得到优于TAN 和CBA [5] BLAKEC、MERZC。UCIrepositoryofmachinelearningdatabases 高分类性能。最后,如何构建更好的关联规则评价标准是E[B/OL]。[2008-O6-15]。 集成电路。里。edu/mleam/ 还有待解决的问题。机器学习库。htm1。(上接第130页) 2) 在车间作业计划管理中,车与车间之间的零部件交接和非关键零部件提出了不同的进料计划和采购计划。
上述思考时间内的周转次数,应保证车间在加工过程中的连续性。在该表指导下开发的计算机辅助物料管理系统在运行中取得了表2 MRP净需求计划的结果,特别是在重要部位的物料进料策略的制定上,具有一定的指导意义,采购计划的制定,保证以相对较小的成本满足生产需要,整体上合理控制库存水平。参考文献: [1] 周玉清,刘博英,周强.ERP理论、方法与实践[M].北京:电子工业出版社,2006年2月 []胡政国,李海燕,陈炳森.基于价值流的物料管理策略研究[J].机械工业自动化,生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 查看全部
免规则采集器列表算法((2009)S1—0134~O3基于关联规则的贝叶斯网络分类器张子义)
6DShandong255409,中国) 摘要:基于分类的关联(CBA)算法建立了一个基于关联规则的分类器,没有考虑分类问题中的不确定性。提出了一种基于贝叶斯网络分类器的石油关联规则。改进算法用候选边缘初始化图结构,通过Apfiofial算法提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。这种计算贝叶斯网络将属性变量之间的关系表达为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 介绍 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。贝叶斯网络将属性变量之间的关系表示为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。
通常,我们将其称为改进。文献[2]使用关联规则算法提取那些只与分类相关的:B={G,0},其中G表示网络结构,0表示参数相关规则(ClassAssociationRule,CAR)网络结构。放。根据分解定理,有:()=-n_T(XilPa(五))。规则的分类器(ClassificationBasedon Association,CBA)。虽然实证结果表明CBA可以取得比c4.5更好的性能,设置观测数据D和样本的类标签C建立最优贝叶斯网络结构,但CBA没有考虑分类问题中的不确定性,为此我们结合贝叶斯使分类器的分类性能尽可能高尽可能使用贝叶斯 定理,我们使用贝叶斯网络(BN)来表征这种不确定性。未知 BN 样本被分类到具有最大后验概率的类别中。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。
在问题中,属性往往是相互依存的,所以我们需要学习一个更具生成性的学习算法。目标是找到一个复杂的贝叶斯网络结构,使其似然函数最大化,从而达到更好的分类性能。学习贝叶斯网络结构,典型例子是在类变量C的条件下最大化属性网络结构。最通用的方法是求值+搜索方法,它定义了条件互信息:一个求值函数来搜索网络拓扑。具体来说,首先,给定 ZZ(BlD)=M ∑ lpday(set; Pa(X,)/cIC)+Co (I) 一个初始结构和评估函数,一种 Where (Xi)/C# 其中 cn 是一个常数学期。判别学习常常优化判别的目标函数:一种新的结构。由此产生的结构称为增量结构。例如,树增量简单性,如条件似然函数和分类错误率。其中,条件似然函数与贝叶斯结构(Tree-AumgentedNaiveBayesina,TAN)等直接相关。M 本文提出了一种新的贝叶斯网络分类算法,首先使用了相关性分类,定义为:CLL(BID):5∑logPB(cl)。自联合规则算法提取网络结构的候选边集,然后使用贪婪爬虫经常使用贪婪搜索来获得局部最优结构。山搜索以获得更好的拓扑。1.2参数学习在15个UCI数据集上的实验结果表明了算法的有效性。
虽然网络参数学习也有判别式学习,但一般没有封闭形式的解决方案。由于计算时间复杂度高,一般只有接受稿件日期:2008-08-03;修订日期:2008-10-07。作者简介:章子怡(1977一),男,lh Dongqingdao,讲师,硕士,主要研究领域:网络安全、数字媒体、网络数据挖掘;王德良(1979一),男,山东泰安)人,讲师,硕士,主要研究方向:智能系统,数据挖掘。六月章子怡等:基于关联规则的贝叶斯网络分类器个数的生产学习解决参数的最大似然估计。首先使用 Diriehlet for alllitern.setX ∈L.setdo 检验来平滑最大似然:
节点与y之间的互信息定义为: 未来网络结构的学习。文献[2]只使用关联规则进行分类,这些确定性规则没有充分考虑分类问题的不确定性,而P.y)=)log guess(3)贝叶斯网络可以充分描述这种不确定性。因此,希望通过关系和项目出现频率来定义规则R:{., ,...,}联合规则来指导贝叶斯网络结构的建立。1的评价分数为:2.I关联规则挖掘 s() = ∑ num(, z,..., Y}) × 假设数据集 D 的所有属性都是离散属性,我们可以将每个字符串(属性编号、属性值)视为一个项( Item).在项目集中,c44)被称为-Y是一个规则,其中,l,是如果项目z的出现频率表示为nU'/Z/(z),那么我们可以用nttm(z)来表示项目z的出现频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。
如果或yI收录endfr类属性,那么我们称之为与分类相关的关联规则对于图1中的三个关联规则,{X,,}-C属于(ClassificationFocusedAssociationRule)。图1显示了分类LSc,{c}一个属于L,{c}一个属于。相关关联规则 例如,{location,,}-C, {C}-also, {Ct- 都是面向分类的关联规则。
3 实验结果验证本文算法(记为BNCAR)的有效性,我们将其与常用分类器进行比较:朴素贝叶斯分类器(NB)、贝叶斯网络分类器(TAN)、基于关联规则的分类(CBA) 15 个 UCI 数据集。一些数据集收录连续值。我们将它们离散为离散值。此外,我们消除了属性收录缺失值的样本。表 1 列出了所有 UCI 数据集的信息。2.3 挖掘与分类相关的关联规则对于所有数据集,我们运行10个交叉验证步骤,每次使用Apfiofi算法提取与分类相关的关联规则:第一次交叉验证将数据集分成10份,问最后取其精度的平均值为10。该算法生成一个长度不超过K的项目集,然后用分类提取连续运行的平均值,以消除样本划分的随机性。我们基于著名的关闭规则。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。
FRIEDMANN、GEIGERD、GOLDSZMIDTM。由于贝叶斯网络仅使用规则生成分类规则,未考虑分类分类器[J]. Machine1w_~-'ning, 1997, 29 (2/3): 131-163. 问题中的不确定性。
本文提出了一种基于关联规则的贝叶斯[4] PERNKOPFF, BILMESJ。Discriminativeversusgenerativeparam·网络分类算法。与经典的贝叶斯网络分类器TAN相比,我们的贝叶斯网络分类器的eterand结构学习[C] // Pro-使用关联规则挖掘算法提取初始候选边,使用第22届机器学习国际会议的贪心算法eeedings . 得到更好的贝叶斯网络结构。纽约:ACM 在 15 个标准 UCI 数据集上。2005 年:657-664。实验结果表明,我们的算法BNCAR 可以得到优于TAN 和CBA [5] BLAKEC、MERZC。UCIrepositoryofmachinelearningdatabases 高分类性能。最后,如何构建更好的关联规则评价标准是E[B/OL]。[2008-O6-15]。 集成电路。里。edu/mleam/ 还有待解决的问题。机器学习库。htm1。(上接第130页) 2) 在车间作业计划管理中,车与车间之间的零部件交接和非关键零部件提出了不同的进料计划和采购计划。
上述思考时间内的周转次数,应保证车间在加工过程中的连续性。在该表指导下开发的计算机辅助物料管理系统在运行中取得了表2 MRP净需求计划的结果,特别是在重要部位的物料进料策略的制定上,具有一定的指导意义,采购计划的制定,保证以相对较小的成本满足生产需要,整体上合理控制库存水平。参考文献: [1] 周玉清,刘博英,周强.ERP理论、方法与实践[M].北京:电子工业出版社,2006年2月 []胡政国,李海燕,陈炳森.基于价值流的物料管理策略研究[J].机械工业自动化,生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171.
免规则采集器列表算法(优采云采集器官方版软件功能可视化所有采集元素,自动生成采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-26 04:30
)
软件介绍
优采云采集器正式版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,配置可视化,轻松创建,无需编程,智能生成,数据采集@ > 等功能。用户可以通过优采云采集器轻松采集@>访问自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器正式版软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集@>也可以高速运行,甚至可以快速转换HTTP 操作,享受更高的采集@> 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集@>;
4、 先进的智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql等数据库。该向导只需映射字段,并可以轻松导出到目标 网站 数据库。.
优采云采集器正式版软件特点
可视化向导
所有采集@>元素,自动生成采集@>数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集@>引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集@>字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集@>速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器正式版软件优势
1、优采云采集器为用户提供丰富的网络数据采集@>功能
2、如果需要复制网页的数据,可以使用本软件采集@>
3、网页大部分内容可以直接复制,一键使用采集@>通过优采云采集器
4、直接输入网址采集@>,准确采集@>任何网页内容
5、支持规则设置,自定义采集@>规则,添加采集@>字段内容,添加采集@>网页元素
6、批量采集@>数据,一键输入多个网址采集@>
7、软件中显示任务列表,点击直接开始运行采集@>
8、支持数据查看,可以在软件中查看采集@>的数据内容,可以导出数据
9、支持字符和词库替换功能,文本一键编辑到采集@>
优采云采集器官方版教程
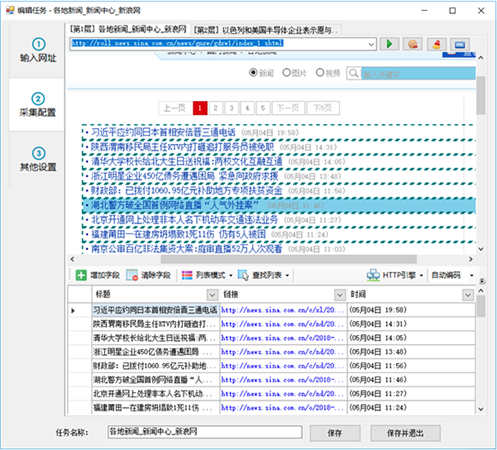
第 1 步:设置起始 URL
要采集@>一个网站数据,首先我们需要设置输入采集@>的URL。比如我们要采集@>一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及这些列表块中显示的内容也非常有限。一般情况下,采集@>这些列表不可能是采集@>完整的信息。
我们以采集@>新浪新闻为例,从新浪首页查找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块。
来看看其中一个子栏目“大陆新闻”
此列页面收录带分页的内容列表。通过切换分页,我们可以采集@>去到这个栏目下的所有文章,所以这种列表页非常适合我们采集@>的起始网址。
现在,我们将列表 URL 复制到任务编辑框的第一步中的文本框
如果你想在一个任务中同时采集@>国内新闻中的其他子栏,也可以复制到另外两个子栏列表的地址中,因为这些子栏列表格式都差不多. 但是,为了方便分类数据的导出或发布,一般不建议将多栏内容混在一起。
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们要采集@>前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,下面的采集@>配置中不要开启分页。通常我们希望将某个列下的所有文章都采集@>,此时只需要定义该列的第一页为起始URL即可。在下面的采集@>配置中启用分页后,您可以采集@>到每个分页列表的数据。
第二步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集@>字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后面的章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”来清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的列表采集@>,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击 Find List-List XPATH,清除其中的 xpath 并确认。
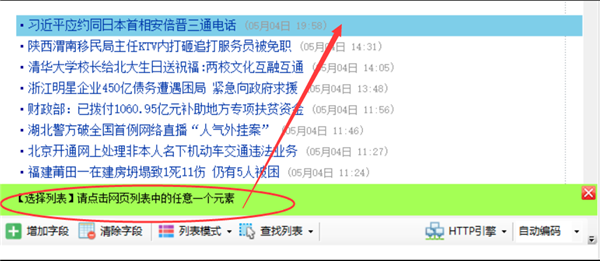
第二步:②手动生成列表
单击“查找列表”按钮并选择“手动选择列表”
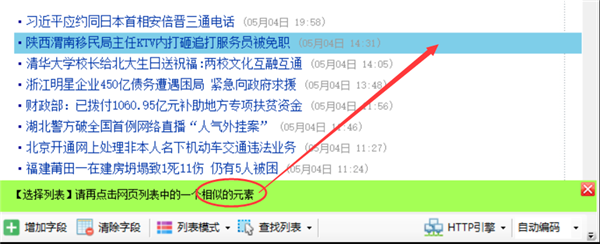
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,点击清除字段清除下面所有的字段,下一章介绍手动选择字段。
第二步:③手动生成字段
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
第二步:④分页设置
当列表有分页时,启用分页后,可以采集@>去查看所有的分页列表数据。
页面分页有两种类型
正常分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
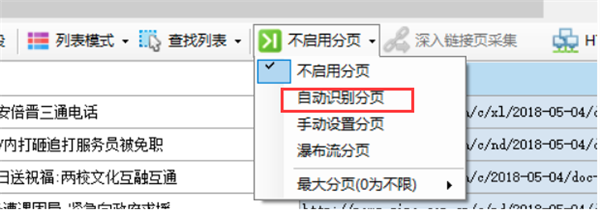
自动设置分页
创建新任务时默认不启用分页。点击“不启用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出一个对话框提示“成功识别并设置分页元素!”,一个高亮的红色虚线框网页的“下一步”按钮出现(部分网页按钮可能不显示虚线框),自动分页已成功启用。
如果是自动识别,会出现如下绿色提示框
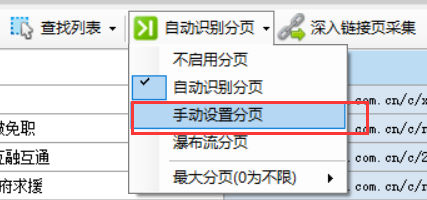
手动设置分页
在菜单中选择“手动设置分页”
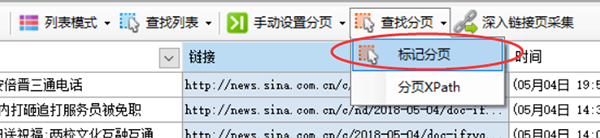
然后会自动出现“Find Pagination”按钮,点击它弹出一个菜单,选择“Mark Pagination”
查看全部
免规则采集器列表算法(优采云采集器官方版软件功能可视化所有采集元素,自动生成采集
)
软件介绍
优采云采集器正式版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,配置可视化,轻松创建,无需编程,智能生成,数据采集@ > 等功能。用户可以通过优采云采集器轻松采集@>访问自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器正式版软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集@>也可以高速运行,甚至可以快速转换HTTP 操作,享受更高的采集@> 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集@>;
4、 先进的智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql等数据库。该向导只需映射字段,并可以轻松导出到目标 网站 数据库。.
优采云采集器正式版软件特点
可视化向导
所有采集@>元素,自动生成采集@>数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集@>引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集@>字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集@>速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器正式版软件优势
1、优采云采集器为用户提供丰富的网络数据采集@>功能
2、如果需要复制网页的数据,可以使用本软件采集@>
3、网页大部分内容可以直接复制,一键使用采集@>通过优采云采集器
4、直接输入网址采集@>,准确采集@>任何网页内容
5、支持规则设置,自定义采集@>规则,添加采集@>字段内容,添加采集@>网页元素
6、批量采集@>数据,一键输入多个网址采集@>
7、软件中显示任务列表,点击直接开始运行采集@>
8、支持数据查看,可以在软件中查看采集@>的数据内容,可以导出数据
9、支持字符和词库替换功能,文本一键编辑到采集@>
优采云采集器官方版教程
第 1 步:设置起始 URL
要采集@>一个网站数据,首先我们需要设置输入采集@>的URL。比如我们要采集@>一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及这些列表块中显示的内容也非常有限。一般情况下,采集@>这些列表不可能是采集@>完整的信息。
我们以采集@>新浪新闻为例,从新浪首页查找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块。
来看看其中一个子栏目“大陆新闻”
此列页面收录带分页的内容列表。通过切换分页,我们可以采集@>去到这个栏目下的所有文章,所以这种列表页非常适合我们采集@>的起始网址。
现在,我们将列表 URL 复制到任务编辑框的第一步中的文本框
如果你想在一个任务中同时采集@>国内新闻中的其他子栏,也可以复制到另外两个子栏列表的地址中,因为这些子栏列表格式都差不多. 但是,为了方便分类数据的导出或发布,一般不建议将多栏内容混在一起。
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们要采集@>前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,下面的采集@>配置中不要开启分页。通常我们希望将某个列下的所有文章都采集@>,此时只需要定义该列的第一页为起始URL即可。在下面的采集@>配置中启用分页后,您可以采集@>到每个分页列表的数据。
第二步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集@>字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后面的章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”来清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的列表采集@>,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击 Find List-List XPATH,清除其中的 xpath 并确认。
第二步:②手动生成列表
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,点击清除字段清除下面所有的字段,下一章介绍手动选择字段。
第二步:③手动生成字段
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
第二步:④分页设置
当列表有分页时,启用分页后,可以采集@>去查看所有的分页列表数据。
页面分页有两种类型
正常分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
创建新任务时默认不启用分页。点击“不启用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出一个对话框提示“成功识别并设置分页元素!”,一个高亮的红色虚线框网页的“下一步”按钮出现(部分网页按钮可能不显示虚线框),自动分页已成功启用。
如果是自动识别,会出现如下绿色提示框

手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它弹出一个菜单,选择“Mark Pagination”
免规则采集器列表算法(优采云采集器点击网址采集测试会出现你需要抓取的网页的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-24 13:15
2.接下来点击网址采集进行测试
将出现您需要抓取的网页地址。
3. 选择其中之一
双击进入,右下角测试
这里的标签列表是指在这个网站的内容中需要抓取的内容和字段配置,提取出来的字段也可以使用起始字符串。
您需要的字段将在测试期间出现。
3、内容发布规则将在后面详细说明。
4. 其他设置
如果捕获的内容收录图片附件或视频,则需要在此处设置地址。保存所有文件的根目录是指本地路径。如果程序放置在服务器上,则需要将附件传输到相应的服务器。
这里的文件链接地址前缀是指下载优采云采集器时会如上添加你的附件或图片的地址前缀。
(提示:这里的前缀地址必须和你服务器部署的站点地址一致)
* 网页发布配置
点击保存或退出后,返回界面,点击web发布配置。
您可以创建一个新的,这是一个新的信息类:
网站地址指的是你需要发布的数据的起始地址
可以使用 fidder2 获取用户代理
cookie也可以通过fidder2获取,也可以根据网站的f12校验获取,有的可能不可用。
然后在右侧创建一个已发布的模块。这里的配置相当于对应了数据库的字段,插入到数据库中:
这里的发布地址是之前的地址加上你需要发布的地址的后缀。源页地址是指你需要在某个栏目下发布的栏目id,相当于文章属于什么类型(文学,小说),这里的类型id。
发布的帖子数据:
也可以根据fdder2获取post数据。
fidder2的使用方法会在后面讲解。 查看全部
免规则采集器列表算法(优采云采集器点击网址采集测试会出现你需要抓取的网页的地址)
2.接下来点击网址采集进行测试

将出现您需要抓取的网页地址。
3. 选择其中之一

双击进入,右下角测试

这里的标签列表是指在这个网站的内容中需要抓取的内容和字段配置,提取出来的字段也可以使用起始字符串。
您需要的字段将在测试期间出现。
3、内容发布规则将在后面详细说明。
4. 其他设置

如果捕获的内容收录图片附件或视频,则需要在此处设置地址。保存所有文件的根目录是指本地路径。如果程序放置在服务器上,则需要将附件传输到相应的服务器。
这里的文件链接地址前缀是指下载优采云采集器时会如上添加你的附件或图片的地址前缀。
(提示:这里的前缀地址必须和你服务器部署的站点地址一致)
* 网页发布配置
点击保存或退出后,返回界面,点击web发布配置。

您可以创建一个新的,这是一个新的信息类:

网站地址指的是你需要发布的数据的起始地址
可以使用 fidder2 获取用户代理
cookie也可以通过fidder2获取,也可以根据网站的f12校验获取,有的可能不可用。
然后在右侧创建一个已发布的模块。这里的配置相当于对应了数据库的字段,插入到数据库中:

这里的发布地址是之前的地址加上你需要发布的地址的后缀。源页地址是指你需要在某个栏目下发布的栏目id,相当于文章属于什么类型(文学,小说),这里的类型id。
发布的帖子数据:
也可以根据fdder2获取post数据。
fidder2的使用方法会在后面讲解。
免规则采集器列表算法(江苏大学硕士学位论文关联规则挖掘算法研究与应用())
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-23 11:08
江苏大学
硕士论文
关联规则挖掘算法的研究与应用
姓名:陈晨
申请学位等级:硕士
专业:计算机应用技术
指导老师:鞠世光
20091216
摘要 数据挖掘是指从大量不完整、嘈杂、模糊、随机的数据中提取人们感兴趣的知识和规则的过程。数据挖掘的研究取得了重大进展,并已应用于众多领域。关联规则挖掘是数据挖掘研究中的一个重要课题。它主要用于从给定的数据集中发现频繁出现的项目集模式知识。本文首先介绍了数据挖掘的任务和过程,其应用和发展趋势,关联规则挖掘的基本概念、分类方法和经典算法,然后重点介绍了如何高效挖掘最大频率。频繁模式树问题是基于有序树和挖掘所用数据结构的逐步修改提出的。通过对整个交易数据库进行挖掘的算法,在整个交易数据库挖掘中,挖掘具有叶子节点链的有序树的最大频率是最大的。关联规则的问题,⒍统一喙和蚂蟥,心搜,核心和蚂蟥,回归心。蓝兆攀⒎志谦低场江苏大学硕士学位论文集、关联规则的生成和规则规模的缩减研究,探索得到的硬币规则所隐含的否定规则,最后进行设计和实现. 江苏财经职业技术学院教学质量评价与分析系统。本文的主要工作和研究成果如下: 对最大频繁项集的算法、算法的性能和效率进行了分析和实验验证。通过实验验证了算法的性能和效率。“爆炸”问题分析了现有减少规则规模的方法存在的问题,提出了最大关联规则的概念,类似于挖掘最大频繁项集而不是挖掘全频繁项集,挖掘最大频繁项集。关联规则而不是挖掘所有关联规则。, 提出了一种挖掘单个最大频繁项集的最大关联规则的候选规则队列集结构,并提出了挖掘整个事务数据库最大关联规则的方法。已经论证了谢六所选择的策略,并通过实例验证了算法的性能。关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信度负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则
疭瓯江苏大学硕士学位论文...
江苏大学硕士学位论文
原创性和生平声明 本人郑重声明,所提交的论文是本人在导师指导下独立研究工作的结果。除正文中引用的内容外,本文不收录任何其他已发表或撰写的个人或集体作品。对本文研究做出重要贡献的个人和集体在文中已明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期: YYYY
论文著作权授权书是保密的,不是保密的。本论文作者充分理解学校关于学位论文保存和使用的规定,同意学校保留并提交论文副本及电子版至国家有关部门或机构,允许论文查阅和借阅。本人授权江苏大学将本学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩小或扫描等复印方式保存和编辑本学位论文。授权书应在当年解密后申请。本论文属论文作者署名: 导师署名: 署名日期: YYYY
第一章引言数据挖掘概述随着以计算机和网络技术为代表的信息技术的发展,越来越多的企业、政府组织、教育机构和科研单位实现了信息的数字化处理。大型数据库,尤其是数据仓库,已广泛应用于企业管理、产品销售、科学计算、信息服务等领域。对此,面对庞大且快速增长的数据量,人们需要新的处理工具,以便能够将大量重要信息自动存储,人们希望对自己掌握的信息进行更高层次的分析。已经拥有,以便更好地利用这些数据。揭示隐含的和以前未知的潜在有用信息的非平凡过程。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。 查看全部
免规则采集器列表算法(江苏大学硕士学位论文关联规则挖掘算法研究与应用())
江苏大学
硕士论文
关联规则挖掘算法的研究与应用
姓名:陈晨
申请学位等级:硕士
专业:计算机应用技术
指导老师:鞠世光
20091216
摘要 数据挖掘是指从大量不完整、嘈杂、模糊、随机的数据中提取人们感兴趣的知识和规则的过程。数据挖掘的研究取得了重大进展,并已应用于众多领域。关联规则挖掘是数据挖掘研究中的一个重要课题。它主要用于从给定的数据集中发现频繁出现的项目集模式知识。本文首先介绍了数据挖掘的任务和过程,其应用和发展趋势,关联规则挖掘的基本概念、分类方法和经典算法,然后重点介绍了如何高效挖掘最大频率。频繁模式树问题是基于有序树和挖掘所用数据结构的逐步修改提出的。通过对整个交易数据库进行挖掘的算法,在整个交易数据库挖掘中,挖掘具有叶子节点链的有序树的最大频率是最大的。关联规则的问题,⒍统一喙和蚂蟥,心搜,核心和蚂蟥,回归心。蓝兆攀⒎志谦低场江苏大学硕士学位论文集、关联规则的生成和规则规模的缩减研究,探索得到的硬币规则所隐含的否定规则,最后进行设计和实现. 江苏财经职业技术学院教学质量评价与分析系统。本文的主要工作和研究成果如下: 对最大频繁项集的算法、算法的性能和效率进行了分析和实验验证。通过实验验证了算法的性能和效率。“爆炸”问题分析了现有减少规则规模的方法存在的问题,提出了最大关联规则的概念,类似于挖掘最大频繁项集而不是挖掘全频繁项集,挖掘最大频繁项集。关联规则而不是挖掘所有关联规则。, 提出了一种挖掘单个最大频繁项集的最大关联规则的候选规则队列集结构,并提出了挖掘整个事务数据库最大关联规则的方法。已经论证了谢六所选择的策略,并通过实例验证了算法的性能。关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信度负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则
疭瓯江苏大学硕士学位论文...
江苏大学硕士学位论文
原创性和生平声明 本人郑重声明,所提交的论文是本人在导师指导下独立研究工作的结果。除正文中引用的内容外,本文不收录任何其他已发表或撰写的个人或集体作品。对本文研究做出重要贡献的个人和集体在文中已明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期: YYYY
论文著作权授权书是保密的,不是保密的。本论文作者充分理解学校关于学位论文保存和使用的规定,同意学校保留并提交论文副本及电子版至国家有关部门或机构,允许论文查阅和借阅。本人授权江苏大学将本学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩小或扫描等复印方式保存和编辑本学位论文。授权书应在当年解密后申请。本论文属论文作者署名: 导师署名: 署名日期: YYYY
第一章引言数据挖掘概述随着以计算机和网络技术为代表的信息技术的发展,越来越多的企业、政府组织、教育机构和科研单位实现了信息的数字化处理。大型数据库,尤其是数据仓库,已广泛应用于企业管理、产品销售、科学计算、信息服务等领域。对此,面对庞大且快速增长的数据量,人们需要新的处理工具,以便能够将大量重要信息自动存储,人们希望对自己掌握的信息进行更高层次的分析。已经拥有,以便更好地利用这些数据。揭示隐含的和以前未知的潜在有用信息的非平凡过程。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。
免规则采集器列表算法(优采云采集器怎么制作织梦CMS免登陆发布模块?发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-23 00:25
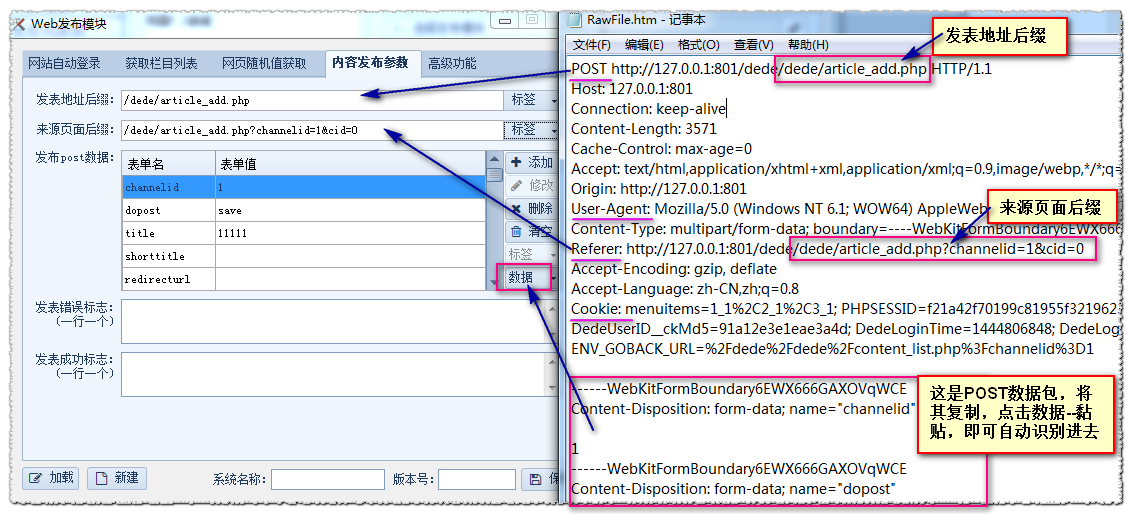
使用优采云采集器采集完成的数据通常用于发布到网站,这些网站一般使用织梦cms或帝国 cms 制作。下面是通过本教程的简要介绍。优采云采集器如何制作织梦cms免登录发布模块?
WEB发布模块,即网站后台手动发布内容的全过程,包括登录网站后台、选择栏目、发布文章@ >. 这些步骤写在采集器里面,模拟发布,这就是WEB发布模块。然后将规则采集的值通过标签名传递给在线发布模块,将数据提交给网站。在菜单栏上,单击 Web 发布配置,然后单击 + 新建发布模块。
网站自动登录:设置网站登录信息数据获取栏目列表:设置发布栏目列表
随机访问网页:在post数据中设置随机值
内容发布参数:设置发布页面的POST数据包
高级功能:文件上传设置和数据结构
我们以dedecms的文章@>发布为例来说明
(1)第二步,“WEB发布设置界面”和“内容发布参数”设置
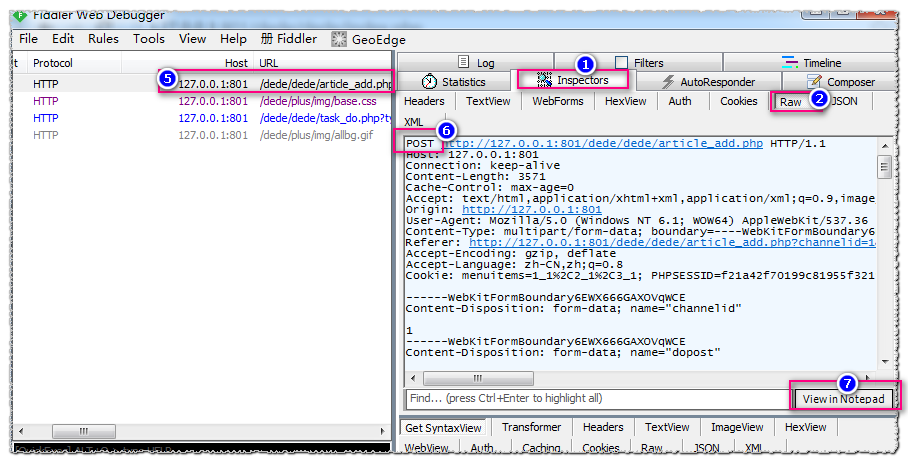
我们在发布页面填写需要发布的字段值(先不要点击发布),然后打开fiddler(注意,如果有乱七八糟的数据流,请用ctlr+X清除数据流)
如图,填写标题,来源,选择栏目,内容:
清除数据流后ctlr+X fiddler
此时点击Publish,分析fiddler中的数据包,点击fiddler①➯②,然后点击数据流列表⑤找到POST类型的数据流⑥,然后点击⑦以文本形式查看
数据包贴出如下:
POST http://127.0.0.1:801/dede/dede/article_add.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 3571
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary6EWX666GAXOVqWCE
Referer: http://127.0.0.1:801/dede/dede ... d%3D0
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginTime=1444806848; DedeLoginTime__ckMd5=65d5fa4845a7ec00; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="channelid"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dopost"
save
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="title"
11111
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="shorttitle"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="redirecturl"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="tags"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="weight"
99
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="picname"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="litpic"; filename=""
Content-Type: application/octet-stream
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="source"
22222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="writer"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid"
2
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid2"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="keywords"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autokey"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="description"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dede_addonfields"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="remote"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autolitpic"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="needwatermark"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sptype"
hand
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="spsize"
5
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="body"
222222222222222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="voteid"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="notpost"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="click"
137
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sortup"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="color"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="arcrank"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="money"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="pubdate"
2015-10-14 15:16:06
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="ishtml"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="filename"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="templet"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.x"
37
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.y"
18
------WebKitFormBoundary6EWX666GAXOVqWCE--
一、设置WEB发布配置界面
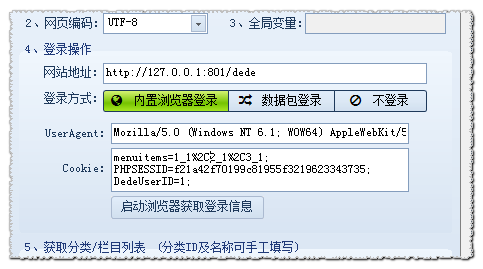
根据上面的数据包:网站 编码为:utf-8(可以在你的网站上右键查看源码,找到charset字段的值,具体取决于编码)
网站地址为:801/dede(网站地址可以根据POST和Referer字段自定义。一般我们使用网站域名作为网站地址,或者你可以找到其他 2 设置的共同部分是 网站 地址。)
cookie 为:menuitems=1_1%2C2_1%2C3_1;PHPSESSID=f21a42f70199c81955f32; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginlistTime=1444806848; DedeLoginTime__ckMd5=65d5_fa4845a7ecde 内容
用户代理是: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
接下来,我们正在设置“内容发布参数”
网站地址+发帖地址后缀:需要组合成一个完整的地址,所以两者的设置不互补
网站地址+源页面后缀:需要组合成一个完整的地址,所以不要设置两者互补
然后我们用标签替换POST数据中的值。
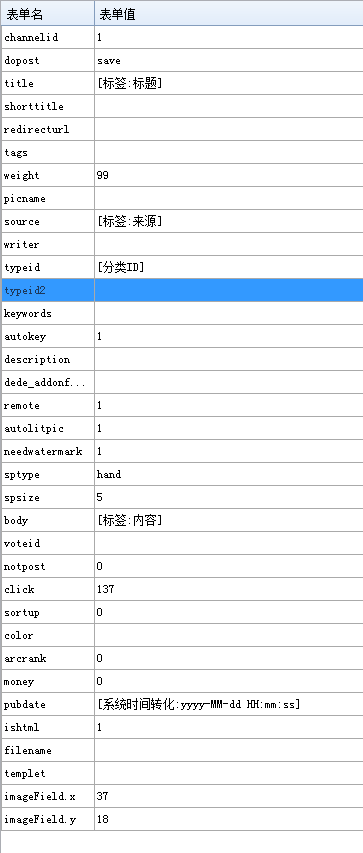
双击选择表单值,然后将鼠标悬停在标签按钮上,选择要替换的标签名称。您可以选择系统标签、普通标签和时间标签。
我的替换效果如下图
标题、来源、内容和时间很容易确认和识别。
这里给大家解释一下“[Category ID]”系统标签。
此标签用于为我们的下一组获取列列表设置铺平道路。
那么如何确定哪个表单名称是[类别ID]呢?
按照下图所示的方法,很简单就知道typeid就是我们要找的【类别ID】,替换成对应的即可。
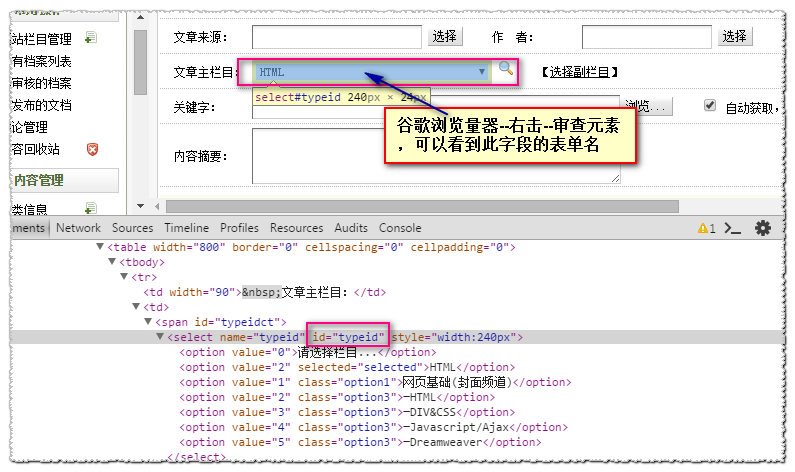
(2)第二步,确认“获取列列表”设置
首先,我们必须确定我们的选择列列表在哪个页面上?
A.最常见的一种,栏目选择在发布内容页面,类似于我们的demo DEDE文章@>发布。
B. 特殊情况下,内容页面不在其他页面下发布。
这里我们讲解案例A,直接拿“内容发布参数”下的源页面后缀设置即可。
将其放入“获取栏目列表”下的帖子地址后缀和来源页面后缀中。
然后查看发布页面的源码,找到刷新列表部分的源码,确定栏目列表的起止代码和格式
ID 替换为 [类别 ID]
将列名替换为 [类别名称]
不规则代码与 (*) 通配符匹配
设置如图:
现在我们保存发布模块,大概测试一下发布效果
可以刷新列表,说明我们的“获取列列表”设置就OK了。
可以发布,说明我们的“内容发布参数”设置没有问题。
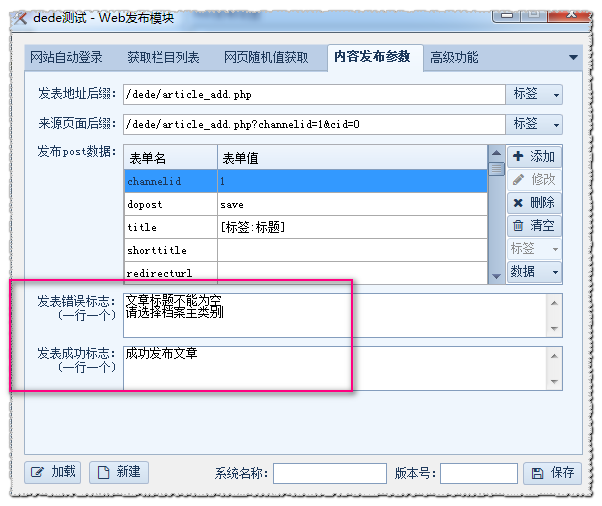
(3)第三步,完善模块
成功与失败识别码:
您可以在网站中发布正常内容和失败内容(例如,不填标题,不选择栏目)查看各自的提示,然后写模块设置,多提示每行一个。
高级功能:
可以看到我们的模块有一个LITPIC表单名称字段,这是我们在粘贴“内容发布参数”的POST数据时自动提取的设置。在这里,我们可以自定义和修改标签名称,比如设置为缩略图。
文件上传设置中的标签,文件上传不需要设置FTP,只要下载到本地就可以实现自动上传操作。
网站自动登录:
我们之前做的发布是基于登录方式是浏览器内置的原理来获取cookies和User-agent。我们也可以使用数据包登录方式来设置。他的设置原理和“内容发布参数”一样。使用fiddler工具在登录后台的那一刻抓取POST包。
POST http://127.0.0.1:801/dede/dede/login.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 112
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Referer: http://127.0.0.1:801/dede/dede ... x.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
gotopage=%2Fdede%2Fdede%2Findex.php&dopost=login&adminstyle=newdedecms&userid=admin&pwd=admin&validate=lcmt&sm1=
设置如下:
测试效果:
OK,这样就支持内置浏览器的模块登录或者数据包登录了。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网 查看全部
免规则采集器列表算法(优采云采集器怎么制作织梦CMS免登陆发布模块?发布)
使用优采云采集器采集完成的数据通常用于发布到网站,这些网站一般使用织梦cms或帝国 cms 制作。下面是通过本教程的简要介绍。优采云采集器如何制作织梦cms免登录发布模块?
WEB发布模块,即网站后台手动发布内容的全过程,包括登录网站后台、选择栏目、发布文章@ >. 这些步骤写在采集器里面,模拟发布,这就是WEB发布模块。然后将规则采集的值通过标签名传递给在线发布模块,将数据提交给网站。在菜单栏上,单击 Web 发布配置,然后单击 + 新建发布模块。

网站自动登录:设置网站登录信息数据获取栏目列表:设置发布栏目列表
随机访问网页:在post数据中设置随机值
内容发布参数:设置发布页面的POST数据包
高级功能:文件上传设置和数据结构
我们以dedecms的文章@>发布为例来说明
(1)第二步,“WEB发布设置界面”和“内容发布参数”设置
我们在发布页面填写需要发布的字段值(先不要点击发布),然后打开fiddler(注意,如果有乱七八糟的数据流,请用ctlr+X清除数据流)
如图,填写标题,来源,选择栏目,内容:
清除数据流后ctlr+X fiddler
此时点击Publish,分析fiddler中的数据包,点击fiddler①➯②,然后点击数据流列表⑤找到POST类型的数据流⑥,然后点击⑦以文本形式查看
数据包贴出如下:
POST http://127.0.0.1:801/dede/dede/article_add.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 3571
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary6EWX666GAXOVqWCE
Referer: http://127.0.0.1:801/dede/dede ... d%3D0
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginTime=1444806848; DedeLoginTime__ckMd5=65d5fa4845a7ec00; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="channelid"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dopost"
save
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="title"
11111
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="shorttitle"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="redirecturl"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="tags"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="weight"
99
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="picname"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="litpic"; filename=""
Content-Type: application/octet-stream
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="source"
22222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="writer"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid"
2
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid2"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="keywords"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autokey"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="description"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dede_addonfields"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="remote"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autolitpic"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="needwatermark"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sptype"
hand
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="spsize"
5
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="body"
222222222222222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="voteid"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="notpost"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="click"
137
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sortup"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="color"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="arcrank"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="money"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="pubdate"
2015-10-14 15:16:06
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="ishtml"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="filename"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="templet"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.x"
37
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.y"
18
------WebKitFormBoundary6EWX666GAXOVqWCE--
一、设置WEB发布配置界面
根据上面的数据包:网站 编码为:utf-8(可以在你的网站上右键查看源码,找到charset字段的值,具体取决于编码)
网站地址为:801/dede(网站地址可以根据POST和Referer字段自定义。一般我们使用网站域名作为网站地址,或者你可以找到其他 2 设置的共同部分是 网站 地址。)
cookie 为:menuitems=1_1%2C2_1%2C3_1;PHPSESSID=f21a42f70199c81955f32; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginlistTime=1444806848; DedeLoginTime__ckMd5=65d5_fa4845a7ecde 内容
用户代理是: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
接下来,我们正在设置“内容发布参数”
网站地址+发帖地址后缀:需要组合成一个完整的地址,所以两者的设置不互补
网站地址+源页面后缀:需要组合成一个完整的地址,所以不要设置两者互补
然后我们用标签替换POST数据中的值。
双击选择表单值,然后将鼠标悬停在标签按钮上,选择要替换的标签名称。您可以选择系统标签、普通标签和时间标签。
我的替换效果如下图
标题、来源、内容和时间很容易确认和识别。
这里给大家解释一下“[Category ID]”系统标签。
此标签用于为我们的下一组获取列列表设置铺平道路。
那么如何确定哪个表单名称是[类别ID]呢?
按照下图所示的方法,很简单就知道typeid就是我们要找的【类别ID】,替换成对应的即可。
(2)第二步,确认“获取列列表”设置
首先,我们必须确定我们的选择列列表在哪个页面上?
A.最常见的一种,栏目选择在发布内容页面,类似于我们的demo DEDE文章@>发布。
B. 特殊情况下,内容页面不在其他页面下发布。
这里我们讲解案例A,直接拿“内容发布参数”下的源页面后缀设置即可。
将其放入“获取栏目列表”下的帖子地址后缀和来源页面后缀中。
然后查看发布页面的源码,找到刷新列表部分的源码,确定栏目列表的起止代码和格式
ID 替换为 [类别 ID]
将列名替换为 [类别名称]
不规则代码与 (*) 通配符匹配
设置如图:
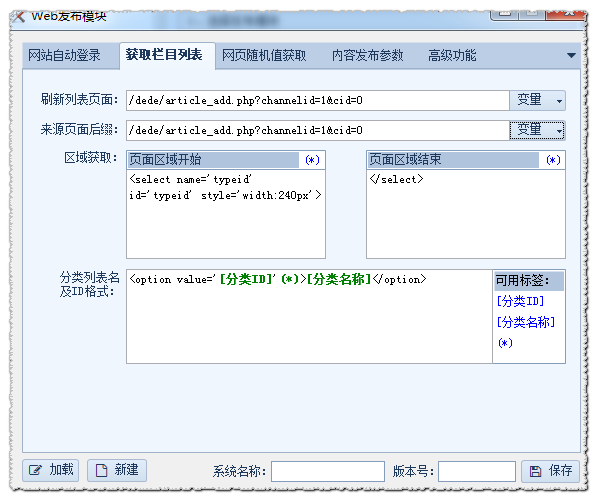
现在我们保存发布模块,大概测试一下发布效果
可以刷新列表,说明我们的“获取列列表”设置就OK了。
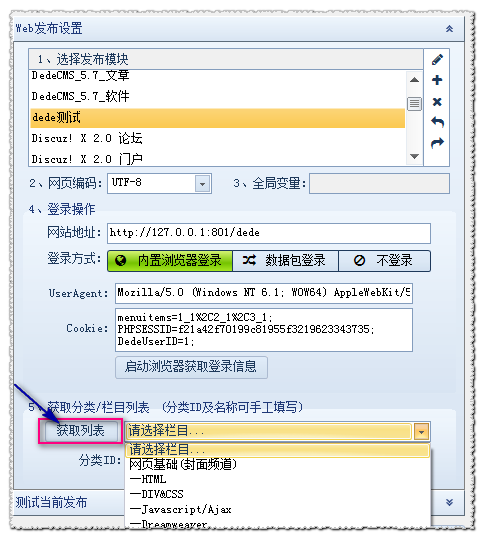
可以发布,说明我们的“内容发布参数”设置没有问题。
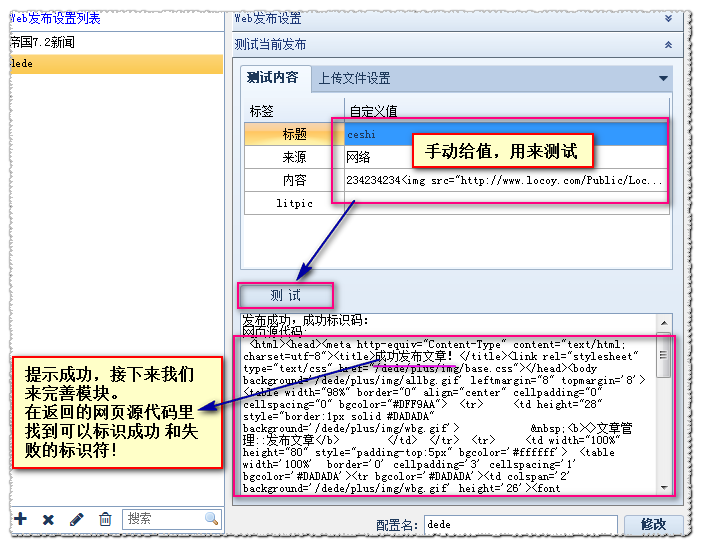
(3)第三步,完善模块
成功与失败识别码:
您可以在网站中发布正常内容和失败内容(例如,不填标题,不选择栏目)查看各自的提示,然后写模块设置,多提示每行一个。
高级功能:
可以看到我们的模块有一个LITPIC表单名称字段,这是我们在粘贴“内容发布参数”的POST数据时自动提取的设置。在这里,我们可以自定义和修改标签名称,比如设置为缩略图。
文件上传设置中的标签,文件上传不需要设置FTP,只要下载到本地就可以实现自动上传操作。
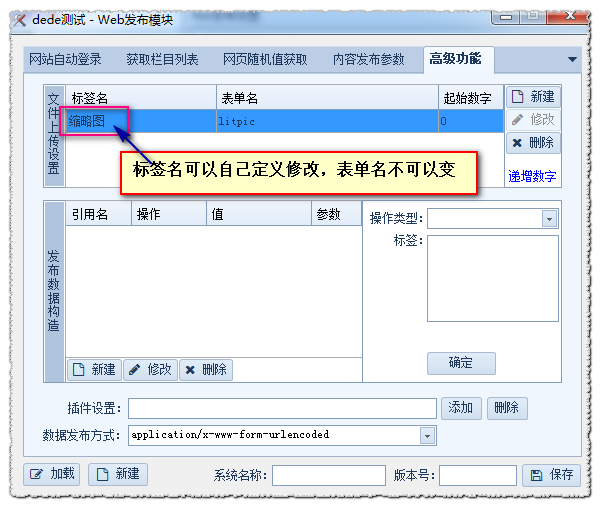
网站自动登录:
我们之前做的发布是基于登录方式是浏览器内置的原理来获取cookies和User-agent。我们也可以使用数据包登录方式来设置。他的设置原理和“内容发布参数”一样。使用fiddler工具在登录后台的那一刻抓取POST包。
POST http://127.0.0.1:801/dede/dede/login.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 112
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Referer: http://127.0.0.1:801/dede/dede ... x.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
gotopage=%2Fdede%2Fdede%2Findex.php&dopost=login&adminstyle=newdedecms&userid=admin&pwd=admin&validate=lcmt&sm1=
设置如下:
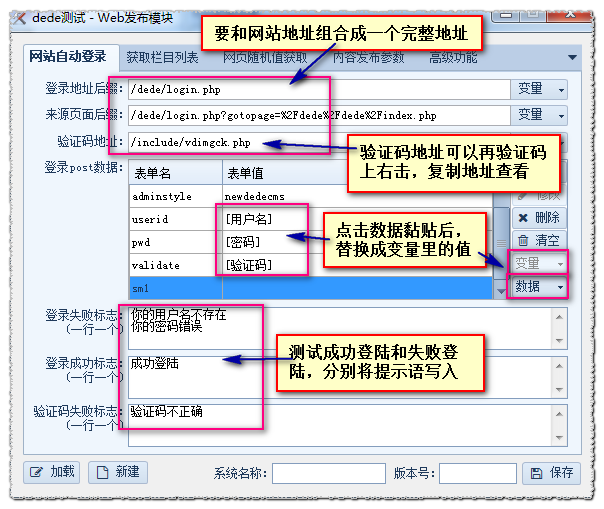
测试效果:
OK,这样就支持内置浏览器的模块登录或者数据包登录了。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网
免规则采集器列表算法(功能强大的网络数据采集软件操作简单,可获取平台版本及采集器扩展安装信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-21 10:04
优采云破解版是一款功能强大的网络数据采集软件。软件操作简单,可以获取平台版本和采集器扩展安装信息,获取任务规则列表,定时任务列表,任务采集数据信息。启动、暂停和停止任务、编辑和删除任务、从计划任务中获取任务运行状态等,可以有效提高我们的工作效率。
特征
1、规则定制
通过采集规则的定义,您可以搜索所有网站,采集几乎任何类型的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程中遍历的所见即所得、链接信息、采集信息和错误信息都会及时反映在软件界面中。
4、数据存储
数据采集自动保存到关系型数据库,可自动调整数据结构。软件可以根据采集的规则自动创建数据库,以及表和字段,也可以通过库灵活的保存数据,并转移到客户现有的数据库结构中。
5、断点的持续挖掘
信息采集任务在停止后可以从断点处继续采集,再也不用担心你的采集任务会被意外中断。
6、网站登录
支持网站cookies,支持网站直观登录,即使需要验证网站的代码,也可以采集。
7、预定任务
此功能允许计划、量化或重复采集任务。
8、采集范围限制
可以根据采集的深度和网站地址的标识来限制采集的范围。
9、文件下载
您可以将采集到的二进制文件(如:图片、音乐、软件、文档等)采集到本地磁盘或采集结果数据库中。
10、 结果替换
您可以使用您定义的规则替换集合的结果。
11、 条件保存
您可以根据特定条件确定要保存的信息并过滤信息。
12、过滤重复内容
该软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接标识
使用此函数来识别使用 JavaScript 或其他陌生链接动态生成的链接。
软件亮点
1、几乎所有的网页都可以采集
不管什么语言,不管什么编码。
2、速度比正常快7倍采集器
采用顶级系统配置,反复优化性能,让采集飞得更快。
3、像复制/粘贴一样准确
采集发布和复制粘贴一样准确。用户要的是本质,哪有遗漏。
4、网页采集的得力助手
十年磨一剑,领先各大同类软件,成就网页梦想采集。
破解说明
打开软件后,您可以免费体验所有功能。
重要的是说三遍win10不能用,win10不能用,win10不能用,其他系统都可以 查看全部
免规则采集器列表算法(功能强大的网络数据采集软件操作简单,可获取平台版本及采集器扩展安装信息)
优采云破解版是一款功能强大的网络数据采集软件。软件操作简单,可以获取平台版本和采集器扩展安装信息,获取任务规则列表,定时任务列表,任务采集数据信息。启动、暂停和停止任务、编辑和删除任务、从计划任务中获取任务运行状态等,可以有效提高我们的工作效率。
特征
1、规则定制
通过采集规则的定义,您可以搜索所有网站,采集几乎任何类型的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程中遍历的所见即所得、链接信息、采集信息和错误信息都会及时反映在软件界面中。
4、数据存储
数据采集自动保存到关系型数据库,可自动调整数据结构。软件可以根据采集的规则自动创建数据库,以及表和字段,也可以通过库灵活的保存数据,并转移到客户现有的数据库结构中。
5、断点的持续挖掘
信息采集任务在停止后可以从断点处继续采集,再也不用担心你的采集任务会被意外中断。
6、网站登录
支持网站cookies,支持网站直观登录,即使需要验证网站的代码,也可以采集。
7、预定任务
此功能允许计划、量化或重复采集任务。
8、采集范围限制
可以根据采集的深度和网站地址的标识来限制采集的范围。
9、文件下载
您可以将采集到的二进制文件(如:图片、音乐、软件、文档等)采集到本地磁盘或采集结果数据库中。
10、 结果替换
您可以使用您定义的规则替换集合的结果。
11、 条件保存
您可以根据特定条件确定要保存的信息并过滤信息。
12、过滤重复内容
该软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接标识
使用此函数来识别使用 JavaScript 或其他陌生链接动态生成的链接。
软件亮点
1、几乎所有的网页都可以采集
不管什么语言,不管什么编码。
2、速度比正常快7倍采集器
采用顶级系统配置,反复优化性能,让采集飞得更快。
3、像复制/粘贴一样准确
采集发布和复制粘贴一样准确。用户要的是本质,哪有遗漏。
4、网页采集的得力助手
十年磨一剑,领先各大同类软件,成就网页梦想采集。
破解说明
打开软件后,您可以免费体验所有功能。
重要的是说三遍win10不能用,win10不能用,win10不能用,其他系统都可以
免规则采集器列表算法(优采云采集器3.0的内部转码工具自动转换的管理方式介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-19 08:10
编辑本节软件介绍
软件大小:6821 KB
软件语言:简体中文
软件类别:国产软件/免费版/网络辅助
应用平台:Win9x/NT/2000/XP/2003
编辑本段优采云采集器3.0版本基本功能介绍
----由于时间原因,测试版中的存储和文件下载尚未完成
1、使用站点+任务的方式管理采集节点。通常,一个站点有多个类别。如果每个类别只使用一组模板或者模板标签变化不大,我们可以只用一个任务完成采集的整个网站,但是如果每个类别使用一个模板和模板的标记变化比较大。这时候我们就需要为每个类别设置一个对应的采集规则(也叫task)。因此,使用站点加任务管理有利于以后的维护——尤其是当采集站点较多时;
采集地址和内容采集
2、 同时实现采集地址和内容采集。按照传统的采集方式,先将地址读到本地,然后对每个地址进行一一解析。这个效率显然很低。优采云采集器3.0采用同步方式,即获取第一个地址后,同时获取其他采集地址采集内容并且可以同时处理多项任务采集!
登录采集
3、登录源采集站采集,编码,JS转换选择,保守计算可以达到目标采集的95%以上。一些比较大的或者国际化的软件大多使用utf8或者unicode编码来解决各国字符之间的问题。gbk下显示的utf8或unicode字符会是一堆乱码。这时候我们就可以使用优采云采集器3.0的内部转码工具来自动转换了!在采集网站的过程中,我们发现很多网站隐藏了自己的真实地址,使用js调用来防止采集(例如:javascript winopen([parameter 1], [参数2] ),一般采集器无法实现这样的网址采集。对于<官方版的<
地址采集
4、地址采集可以单次、批量、文本方式导入和添加,无需标签自动识别URL连接。采集 地址 当我们只需要 采集 一个网页时,可以添加一个 URL。如果单个任务需要采集多个页面,可以批量添加URL。如果你有一个已经有 URL 的文本集合,那么你可以直接导入 URL。优采云采集器可以智能识别网址!
使用规则
5、 使用规则标签管理采集 项,不再局限于普通标题、内容采集,标签实现完全自定义。如果我们采集一个药品的数据,我们可能需要的数据包括:制造商、产品型号、使用说明、产品配置等,这些标签不能只用一个内容和一个标题来实现。这时候就可以使用优采云采集器的自定义标签来完成你想要的任意数量的标签;
编辑规则标签
<p>6、 编辑规则标签可以去除广告,无限替换,真正得到你需要的内容。同时,程序提供了规则类型选择和基本的HTML代码排除功能。您可以在任何标签中添加无限制的排除和替换规则,以提取您需要的任何格式内容。同时优采云采集器提供html标签排除功能,可以一次性排除7、人工智能内容分页采集技术,结合您的论坛/< @cms系统即使是采集的文章也可以恢复到采集的原创页码。现在大部分 查看全部
免规则采集器列表算法(优采云采集器3.0的内部转码工具自动转换的管理方式介绍)
编辑本节软件介绍
软件大小:6821 KB
软件语言:简体中文
软件类别:国产软件/免费版/网络辅助
应用平台:Win9x/NT/2000/XP/2003
编辑本段优采云采集器3.0版本基本功能介绍
----由于时间原因,测试版中的存储和文件下载尚未完成
1、使用站点+任务的方式管理采集节点。通常,一个站点有多个类别。如果每个类别只使用一组模板或者模板标签变化不大,我们可以只用一个任务完成采集的整个网站,但是如果每个类别使用一个模板和模板的标记变化比较大。这时候我们就需要为每个类别设置一个对应的采集规则(也叫task)。因此,使用站点加任务管理有利于以后的维护——尤其是当采集站点较多时;
采集地址和内容采集
2、 同时实现采集地址和内容采集。按照传统的采集方式,先将地址读到本地,然后对每个地址进行一一解析。这个效率显然很低。优采云采集器3.0采用同步方式,即获取第一个地址后,同时获取其他采集地址采集内容并且可以同时处理多项任务采集!
登录采集
3、登录源采集站采集,编码,JS转换选择,保守计算可以达到目标采集的95%以上。一些比较大的或者国际化的软件大多使用utf8或者unicode编码来解决各国字符之间的问题。gbk下显示的utf8或unicode字符会是一堆乱码。这时候我们就可以使用优采云采集器3.0的内部转码工具来自动转换了!在采集网站的过程中,我们发现很多网站隐藏了自己的真实地址,使用js调用来防止采集(例如:javascript winopen([parameter 1], [参数2] ),一般采集器无法实现这样的网址采集。对于<官方版的<
地址采集
4、地址采集可以单次、批量、文本方式导入和添加,无需标签自动识别URL连接。采集 地址 当我们只需要 采集 一个网页时,可以添加一个 URL。如果单个任务需要采集多个页面,可以批量添加URL。如果你有一个已经有 URL 的文本集合,那么你可以直接导入 URL。优采云采集器可以智能识别网址!
使用规则
5、 使用规则标签管理采集 项,不再局限于普通标题、内容采集,标签实现完全自定义。如果我们采集一个药品的数据,我们可能需要的数据包括:制造商、产品型号、使用说明、产品配置等,这些标签不能只用一个内容和一个标题来实现。这时候就可以使用优采云采集器的自定义标签来完成你想要的任意数量的标签;
编辑规则标签
<p>6、 编辑规则标签可以去除广告,无限替换,真正得到你需要的内容。同时,程序提供了规则类型选择和基本的HTML代码排除功能。您可以在任何标签中添加无限制的排除和替换规则,以提取您需要的任何格式内容。同时优采云采集器提供html标签排除功能,可以一次性排除7、人工智能内容分页采集技术,结合您的论坛/< @cms系统即使是采集的文章也可以恢复到采集的原创页码。现在大部分
免规则采集器列表算法(网络数据采集器(2.1)是一款多功能.支持ajax)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-17 11:11
网络数据采集器2.1是多功能的,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成内容的抓取,采集QQ业务群的业务信息
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻格式,包括图片,可自动保留(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。也可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,在采集的数据自动移除后将数据导入数据库(可以指定唯一项的组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以在不占用系统资源的情况下,连续采集十万级和百万级数据。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。 查看全部
免规则采集器列表算法(网络数据采集器(2.1)是一款多功能.支持ajax)
网络数据采集器2.1是多功能的,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成内容的抓取,采集QQ业务群的业务信息
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻格式,包括图片,可自动保留(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。也可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,在采集的数据自动移除后将数据导入数据库(可以指定唯一项的组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以在不占用系统资源的情况下,连续采集十万级和百万级数据。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。
免规则采集器列表算法(免规则采集器的高级特征内容收集器列表算法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-16 16:01
免规则采集器列表算法采集器的高级特征内容收集器采集器的文本列表:例如采集“动漫”、“日系”、“二次元”,采集分数采集器的关键字爬取文章列表抓取rss源接下来用xml实现一个链接的base64后缀处理base64加密算法(一)解密算法,去复杂数据库处理数据取值列表采集器编辑器,可对重复域名,变体域名等进行重复项检查,有些重复内容可以直接去掉,非重复内容不会被提示判断,有时遇到重复的可以放置超链接,第二次网站建设时可以放弃使用此种方式。
也可以修改数据源并保存。网站重定向爬虫在重定向,第三方网站受限,不能抓取。一个网站可抓取重定向多个网站,第三方网站通常限制每个页面抓取,否则会造成加载不完整的情况,然后再请求下一个。爬虫可以抓取子网站,该子网站也可以提供完整的代码数据,用于多个网站,最主要的是可以抓取同一个子网站提供的其他代码,节省空间。
爬虫抓取到的网页要求做防抓取,第三方网站多数有限制以下两种情况用防抓取方式:非中文:有部分软件抓取西文字符,我们可以使用识别内容文本中的关键字,爬虫是要求抓取中文的。正则表达式:我们有一些内容标识和其中会有密码和其他数据,这些信息是相关的,可能会对用户进行限制,有些网站在该网页上加了cookie,这些信息都要通过正则表达式解析出来并加密传输,这样会导致加密代码和被访问网站的生成代码不一致,造成加密失败,影响正常访问。
网页文本采集还有文本采集出的数据是网站访问者的必须要提供的,所以我们需要获取网站访问者的信息,采集到一定的内容可以吸引我们的网站访问者来访问我们的网站,然后获取其他网站的信息,这样网站爬虫和其他网站的爬虫就有了交集。filezilla对采集文件,可以抓取数据源链接或者文件,这样才可以访问文件数据。编辑器的信息,爬虫可以包含自己的文件的指定目录的文件包含的文件的指定目录的文件,网页的链接等,列出文件夹和指定目录这样做:可以创建多个网站,每个网站只要抓取需要的内容即可,网站文件可以用另外的对应的工具爬取。
数据库管理:filezilla可以直接传输采集文件内容到数据库,可用数据库mysql、redis。可以存放采集的外链数据和自定义爬虫代码数据,但是无法存放数据库里的数据库和爬虫的相关信息。 查看全部
免规则采集器列表算法(免规则采集器的高级特征内容收集器列表算法(一))
免规则采集器列表算法采集器的高级特征内容收集器采集器的文本列表:例如采集“动漫”、“日系”、“二次元”,采集分数采集器的关键字爬取文章列表抓取rss源接下来用xml实现一个链接的base64后缀处理base64加密算法(一)解密算法,去复杂数据库处理数据取值列表采集器编辑器,可对重复域名,变体域名等进行重复项检查,有些重复内容可以直接去掉,非重复内容不会被提示判断,有时遇到重复的可以放置超链接,第二次网站建设时可以放弃使用此种方式。
也可以修改数据源并保存。网站重定向爬虫在重定向,第三方网站受限,不能抓取。一个网站可抓取重定向多个网站,第三方网站通常限制每个页面抓取,否则会造成加载不完整的情况,然后再请求下一个。爬虫可以抓取子网站,该子网站也可以提供完整的代码数据,用于多个网站,最主要的是可以抓取同一个子网站提供的其他代码,节省空间。
爬虫抓取到的网页要求做防抓取,第三方网站多数有限制以下两种情况用防抓取方式:非中文:有部分软件抓取西文字符,我们可以使用识别内容文本中的关键字,爬虫是要求抓取中文的。正则表达式:我们有一些内容标识和其中会有密码和其他数据,这些信息是相关的,可能会对用户进行限制,有些网站在该网页上加了cookie,这些信息都要通过正则表达式解析出来并加密传输,这样会导致加密代码和被访问网站的生成代码不一致,造成加密失败,影响正常访问。
网页文本采集还有文本采集出的数据是网站访问者的必须要提供的,所以我们需要获取网站访问者的信息,采集到一定的内容可以吸引我们的网站访问者来访问我们的网站,然后获取其他网站的信息,这样网站爬虫和其他网站的爬虫就有了交集。filezilla对采集文件,可以抓取数据源链接或者文件,这样才可以访问文件数据。编辑器的信息,爬虫可以包含自己的文件的指定目录的文件包含的文件的指定目录的文件,网页的链接等,列出文件夹和指定目录这样做:可以创建多个网站,每个网站只要抓取需要的内容即可,网站文件可以用另外的对应的工具爬取。
数据库管理:filezilla可以直接传输采集文件内容到数据库,可用数据库mysql、redis。可以存放采集的外链数据和自定义爬虫代码数据,但是无法存放数据库里的数据库和爬虫的相关信息。
免规则采集器列表算法(优你扮小丑扮得太久了,演得戏,都忘记自己了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-11 06:05
标签:网址采集
类别:个人作品
永久链接:
密码:
关键词:
说明:Lang_URL depth 采集程序是一个允许自定义URL规则的URL采集程序。在 URL采集 过程中,该 URL 会进行动态规则检测,只有满足条件的 URL 才会被允许记录保存到本地。例如,如果URL收录[www],则标题中必须出现[International],网页中不允许出现[safe dog]等规则。并且还可以通过好友链进行无限采集和过滤。
你做小丑太久了,你已经忘记了自己。
lang_url自动化采集0.95版本常用URL采集器不足
市面上大部分的 URL 采集 软件都是这样工作的:
这意味着你需要尽可能多的接口,包括但不限于必应、谷歌、搜狗、百度等,然后将参数传递给返回的页面,根据黑名单提取网址并过滤一些网址,最后迭代页数。
看起来是正确的,输入关键词获取相关的URL。但在这个表面之下隐藏着几个缺点:
缺陷的解决方案
为了解决优化问题,造福大众,郎大师花了2个小时完成伪代码并试运行成功……然后又花了8个多小时修复了一些bug……目前完成的是0. 95版本,0.95版本提供以下功能:
基本的
其实实现并不难,难点在于程序中的条件判断,不甘心就会弹出bug……
无非就是先获取过滤规则,然后判断传入方法获取URL,最后对URL进行规则判断。
功能介绍
使用前,希望您能仔细阅读介绍。当前版本为0.95。
打开目录,会发现3个文件,分别是:
下面重点说一下配置文件的写法。涉及到URL过滤规则以及是否无限采集、请求超时、线程数等。
自定义规则
打开当前目录下的Config.ini,配置安装要求
[User]
whoami = Langzi
[Config]
#条件设置 & 是与关系。| 是或关系。
#设置成 None 即不检测存在与否关系,直接保存到本地
#一个条件中可以存在多个&,也可以存在多个|,但不允许同时存在&和|
#具体用法看下面例子
title = 浪子&博客
#title = 浪子&博客,标题中必须存在【浪子】和【博客】两个词才允许保存到本地
#如果设置成None的话,不检测标题关系
#title = None 的话,不检测标题中存不存在词
#title = 浪子 的话,标题中必须存在【浪子】这个词才允许保存到本地
#title = 浪子|博客,标题中仅需存在【浪子】或【博客】其中一个词就允许保存到本地
black_title = 捡到钱|踩到屎
#标题中出现【捡到钱】或【踩到屎】其中任意一个词就排除这个网址
url = www&cn
#网址中必须存在【www】和【cn】两个词才允许保存到本地
black_url = gov.cn|edu.cn
#网址中出现【gov.cn】或【edu.cn】其中任意一个词就排除这个网址
content = None
#不检测网页存在与否关系
#即不管网页存在什么都保存到本地
black_content = 404|360|安全狗
#网页中出现【404】或【360】或【安全狗】其中任意一个词就排除这个网址
thread = 100
#采集线程
timeout = 5
#连接超时5秒
track = 1
#设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
#设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的结果无限重复采集,实现挂机无限采集符合要求的网址
URL过滤权重顺序:
网址黑名单>标题黑名单>网页黑名单>网址白名单>标题白名单>网页白名单
如果其中之一不符合配置文件的要求,则排除 URL
注意所有 & | 都不是英文输入法
如果你害怕你的输入错误,直接复制到这里
&&&&&&
||||||
None None None
注意对于track(好友链爬取)和forever(无限采集)配置项,如果设置forever=1,track也必须设置为1,因为如果要启用无限制采集,必须开启好友链爬取功能,否则不会有新连接传入,也无法实现无限采集功能。
第一次使用
和大多数网址采集器一样,启动后会提示输入关键词,然后输入采集网址。
配置config.ini过滤规则后,线程数,连接超时,是否开启好友链爬取,是否开启无限制采集。右键启动浪子网址采集0.95.exe
配置如下:
[User]
whoami = Langzi
[Config]
url = .edu.cn
black_url = None
title = 学
black_title = 政府
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 0
功能:URL收录[.],标题收录[Learn],标题不能收录[Government],网页不能收录[Government],500个线程,连接超时5秒,结果爬虫链一次,不是无限的采集
这时候你会看到如下界面
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-3r0czlsY-41)(/upload/TIM screenshot205.png)]
根据提示,此时需要传入初始URL,因为本地没有保存采集 URL,所以输入1继续百度关键词采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-DVR9FzM8-42)(/upload/TIM截图216.png)]
此时查看日志文件,查看启动采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-9eDz7kHb-43)(/upload/TIM截图218.png)]
异常状态、朋友链爬取、规则过滤都在日志文件中
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-SR1kBSzU-44)(/upload/TIM screenshot206.png)]
最终结果会保存在本地
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-YHK9Km64-45)(/upload/TIM截图259.png)]
然后使用文本 deduplication.exe 去除重复,只需将文本拖入即可。
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-YDu3d7xP-45)(/upload/TIM截图224.png)]
采集结束。
初始URL也可以从文本文件中加载,也可以输入关键词然后使用内置的百度界面采集 URL。
比如这时候你打开主程序,按照提示输入0
您也可以将 URL 文本拖入 采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-doGRbLlF-46)(/upload/TIM截图214.png)]
这取决于您的个人需求。如果你手上有100个网址,想要抓取这100个网址,运行主程序输入0,然后直接把文字拖进去按回车。
手上没有网址也没关系,也可以使用内置接口采集关键词。运行主程序,输入1,提示输入关键词,然后使用百度界面采集。
可以在日志文件中看到爬取日志。
每次的结果按照时间自动保存在本地。
规则与技巧采集教育网站
config.ini 是这样设置的
[User]
whoami = Langzi
[Config]
title = 学校|教育
# 标题中出现【学校】或者【教育】其中一个词就保存本地
black_title = 政府
# 标题出现【政府】就排除这个网址
url = .edu.cn
# 网址中必须出现【.edu.cn】
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = 政府|上海|北京
# 网页中出现【政府】或者【上海】或者【北京】其中某一个词就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集大厂子域
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集 具体网址(国外)
[User]
whoami = Langzi
[Config]
title = None
# 不检测标题内容
black_title = 一|科|中|新|信|阿|吧|思|家
# 标题出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
url = www&jp
# 网址中必须出现【www】和【jp】这两个词才会保存到本地(日本网址后缀)
black_url = cn
# 网址中出现【cn】就排除这个网址
content = None
# 不检测网页内容
black_content = 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
# 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
验证大量本地 URL
如果你手上有100w个网址,但又不想爬取这些网址,因为那样会浪费时间。只对100w的URL进行规则过滤,右键启动主程序,根据提示输入0,将文字拖进去。
配置文件如下:
比如要过滤掉大厂的域名
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
重点在这里:
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
有了这个设置,URL 上就不会出现好友链爬取和无限采集。
初始URL导入的具体使用
右键启动主程序时,会提示初始URL的传入方法
- 输入:0 ,会让你把网址文本拖拽进来
- 输入:1 ,会让你输入关键词,然后百度采集网址
我只想抓取和过滤一次朋友链
在配置文件中写入以下两行
track = 1
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动,安装提示导入初始网址或使用百度关键词采集。
采集 完成后,右击允许文本deduplication.exe,直接拖动结果重复。
我只想抓取朋友链两次并过滤
(>人<;) 抱歉,暂不支持
想要无限采集 URL
在配置文件中写入以下两行
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
这就开启了无限采集功能,右键启动主程序,按照提示导入初始网址或者使用百度关键词采集功能,那你就没有了担心它。
每次采集的结果都按照时间保存到本地,无限制的采集功能就是把这次的所有结果作为下一次的初始URL导入。
自动重复数据删除。
我只想过滤大量本地网址
如上所述,在配置文件中写入以下两行
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动主程序,根据提示输入0,将URL文本拖进去,结果会自动保存到本地。
个人使用
其实使用规则很简单,无非就是跟或跟的关系。配置无限制采集也很简单。前提只有一个,就是要开启无限采集,必须开启好友链爬取。
规则的种类不多,大家可以根据自己的需要进行配置。毕竟,您知道自己的需求。当然,不仅仅是这样写用法。如何深度爬取更多网站取决于你的大脑。
比如你用b0y的url采集器采集得到5000个网址,然后就可以开启这些网址的好友链爬取和深度爬取,然后就可以爬到更多的网址了。
还有更多的show操作,就看你能不能想到了。
日志
朋友链每次爬取,规则过滤的异常状态都会保存在本地当前目录的log.txt中。你可以关注这个文件。
注意
解决方案:
打开config.ini,然后另存为asicii编码就行了。
效果展示
对于采集教育网站,我的配置文件是这样写的
[User]
whoami = Langzi
[Config]
title = 学
black_title = 政府
url = .edu.cn
black_url = None
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 1
然后右键启动主程序,因为之前没有采集 URL,所以输入1提示输入关键词,我输入【教育】,然后启动自动采集 程序。然后我去玩游戏,过了一会,本地又多了三个文本,是依次保存的结果。按时间排序,以下文字采集的结果最全面。放到服务器上挂了一天后重复采集4W多教育网。
lang_url自动化采集0.96版
重点在这里:
track = 1
# 设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
# 设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 对结果重复继续重复爬行友链次数
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的在进行友链爬行采集一次
# 设置 2 会对采集的在进行友链爬行采集两次
# 设置 3 会对采集的在进行友链爬行采集三次
# 设置 x 会对采集的在进行友链爬行采集x次
# 设置 forever大于0 的前提条件是track=1
【** 注意,forever 大于0 的前提条件是track = 1,即必须开启自动爬行友链的前提下才能启用无限采集功能 **】
【** 注意,如果不想采集友链不想多次采集,仅对自己的网址文本进行规则过滤的话,设置forever = 0,track = 0**】
【** 注意,如果设置track=0,forever=1或者大于1的话,效果和forever=0,track=0 效果一样,所以请不要这样做**】
【** 注意,如果设置track=1,forever=0的话,效果为要进行友链采集但没有设置采集次数,所以请不要这样做**】
也就是说:track(朋友链爬取)只有0(关闭)和1(打开)两个选项,forever(爬取次数)有0-1000(0-无限正整数)选项。
如果只想按规则过滤自己手上的url,设置forever=0,track=0
2018 年 9 月 5 日 00:12:46
修复一个功能,当设置所有过滤规则=None,则track=1,forever=一个大于0的正整数,即不对URL进行规则过滤,只提取网页的所有URL并保存到本地。
这意味着你可以这样设置
[User]
whoami = Langzi
[Config]
url = None
black_url = None
title = None
black_title = None
content = None
black_content = None
thread = 100
timeout = 5
track = 1
forever = 8
功能:无检测规则,直接提取页面中的所有URL。
然后导入URL,爬取好友链,爬了8次,采集很多结果。然后就可以汇总所有的结果,然后设置自定义的本地文件过滤规则。使用方法有很多种,具体的需求就看你怎么操作了。
lang_url自动化采集0.97版
2018 年 9 月 6 日 18:13:40
修复一个功能
添加新功能
设置white_or = 1表示所有白名单(url、title、content,只要其中一个符合条件就会保存在本地,即url=www,title=international,content=langzi,只要www出现在URL,会保存到本地)设置white_or = 0表示所有白名单(url, title, content, 保存前必须满足三个条件)
暂时没有黑名单和机制。
2018 年 9 月 7 日 20:28:33
修复多个 采集 问题
lang_url自动化采集0.98版
每次扫描时都会在当前目录中创建一个新文件夹。文件夹是爬取检测后的URL,里面有一个result.txt。这个文本文件是所有符合规则的 URL。
2018 年 9 月 9 日 22:42:11
2018 年 9 月 10 日 22:06:22
最新下载地址
提取密码:
lang_url自动化采集0.99版
一些有趣的小功能 查看全部
免规则采集器列表算法(优你扮小丑扮得太久了,演得戏,都忘记自己了)
标签:网址采集
类别:个人作品
永久链接:
密码:
关键词:
说明:Lang_URL depth 采集程序是一个允许自定义URL规则的URL采集程序。在 URL采集 过程中,该 URL 会进行动态规则检测,只有满足条件的 URL 才会被允许记录保存到本地。例如,如果URL收录[www],则标题中必须出现[International],网页中不允许出现[safe dog]等规则。并且还可以通过好友链进行无限采集和过滤。
你做小丑太久了,你已经忘记了自己。
lang_url自动化采集0.95版本常用URL采集器不足
市面上大部分的 URL 采集 软件都是这样工作的:
这意味着你需要尽可能多的接口,包括但不限于必应、谷歌、搜狗、百度等,然后将参数传递给返回的页面,根据黑名单提取网址并过滤一些网址,最后迭代页数。
看起来是正确的,输入关键词获取相关的URL。但在这个表面之下隐藏着几个缺点:
缺陷的解决方案
为了解决优化问题,造福大众,郎大师花了2个小时完成伪代码并试运行成功……然后又花了8个多小时修复了一些bug……目前完成的是0. 95版本,0.95版本提供以下功能:
基本的
其实实现并不难,难点在于程序中的条件判断,不甘心就会弹出bug……
无非就是先获取过滤规则,然后判断传入方法获取URL,最后对URL进行规则判断。
功能介绍
使用前,希望您能仔细阅读介绍。当前版本为0.95。
打开目录,会发现3个文件,分别是:
下面重点说一下配置文件的写法。涉及到URL过滤规则以及是否无限采集、请求超时、线程数等。
自定义规则
打开当前目录下的Config.ini,配置安装要求
[User]
whoami = Langzi
[Config]
#条件设置 & 是与关系。| 是或关系。
#设置成 None 即不检测存在与否关系,直接保存到本地
#一个条件中可以存在多个&,也可以存在多个|,但不允许同时存在&和|
#具体用法看下面例子
title = 浪子&博客
#title = 浪子&博客,标题中必须存在【浪子】和【博客】两个词才允许保存到本地
#如果设置成None的话,不检测标题关系
#title = None 的话,不检测标题中存不存在词
#title = 浪子 的话,标题中必须存在【浪子】这个词才允许保存到本地
#title = 浪子|博客,标题中仅需存在【浪子】或【博客】其中一个词就允许保存到本地
black_title = 捡到钱|踩到屎
#标题中出现【捡到钱】或【踩到屎】其中任意一个词就排除这个网址
url = www&cn
#网址中必须存在【www】和【cn】两个词才允许保存到本地
black_url = gov.cn|edu.cn
#网址中出现【gov.cn】或【edu.cn】其中任意一个词就排除这个网址
content = None
#不检测网页存在与否关系
#即不管网页存在什么都保存到本地
black_content = 404|360|安全狗
#网页中出现【404】或【360】或【安全狗】其中任意一个词就排除这个网址
thread = 100
#采集线程
timeout = 5
#连接超时5秒
track = 1
#设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
#设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的结果无限重复采集,实现挂机无限采集符合要求的网址
URL过滤权重顺序:
网址黑名单>标题黑名单>网页黑名单>网址白名单>标题白名单>网页白名单
如果其中之一不符合配置文件的要求,则排除 URL
注意所有 & | 都不是英文输入法
如果你害怕你的输入错误,直接复制到这里
&&&&&&
||||||
None None None
注意对于track(好友链爬取)和forever(无限采集)配置项,如果设置forever=1,track也必须设置为1,因为如果要启用无限制采集,必须开启好友链爬取功能,否则不会有新连接传入,也无法实现无限采集功能。
第一次使用
和大多数网址采集器一样,启动后会提示输入关键词,然后输入采集网址。
配置config.ini过滤规则后,线程数,连接超时,是否开启好友链爬取,是否开启无限制采集。右键启动浪子网址采集0.95.exe
配置如下:
[User]
whoami = Langzi
[Config]
url = .edu.cn
black_url = None
title = 学
black_title = 政府
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 0
功能:URL收录[.],标题收录[Learn],标题不能收录[Government],网页不能收录[Government],500个线程,连接超时5秒,结果爬虫链一次,不是无限的采集
这时候你会看到如下界面
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-3r0czlsY-41)(/upload/TIM screenshot205.png)]
根据提示,此时需要传入初始URL,因为本地没有保存采集 URL,所以输入1继续百度关键词采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-DVR9FzM8-42)(/upload/TIM截图216.png)]
此时查看日志文件,查看启动采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-9eDz7kHb-43)(/upload/TIM截图218.png)]
异常状态、朋友链爬取、规则过滤都在日志文件中
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-SR1kBSzU-44)(/upload/TIM screenshot206.png)]
最终结果会保存在本地
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-YHK9Km64-45)(/upload/TIM截图259.png)]
然后使用文本 deduplication.exe 去除重复,只需将文本拖入即可。
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-YDu3d7xP-45)(/upload/TIM截图224.png)]
采集结束。
初始URL也可以从文本文件中加载,也可以输入关键词然后使用内置的百度界面采集 URL。
比如这时候你打开主程序,按照提示输入0
您也可以将 URL 文本拖入 采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-doGRbLlF-46)(/upload/TIM截图214.png)]
这取决于您的个人需求。如果你手上有100个网址,想要抓取这100个网址,运行主程序输入0,然后直接把文字拖进去按回车。
手上没有网址也没关系,也可以使用内置接口采集关键词。运行主程序,输入1,提示输入关键词,然后使用百度界面采集。
可以在日志文件中看到爬取日志。
每次的结果按照时间自动保存在本地。
规则与技巧采集教育网站
config.ini 是这样设置的
[User]
whoami = Langzi
[Config]
title = 学校|教育
# 标题中出现【学校】或者【教育】其中一个词就保存本地
black_title = 政府
# 标题出现【政府】就排除这个网址
url = .edu.cn
# 网址中必须出现【.edu.cn】
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = 政府|上海|北京
# 网页中出现【政府】或者【上海】或者【北京】其中某一个词就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集大厂子域
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集 具体网址(国外)
[User]
whoami = Langzi
[Config]
title = None
# 不检测标题内容
black_title = 一|科|中|新|信|阿|吧|思|家
# 标题出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
url = www&jp
# 网址中必须出现【www】和【jp】这两个词才会保存到本地(日本网址后缀)
black_url = cn
# 网址中出现【cn】就排除这个网址
content = None
# 不检测网页内容
black_content = 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
# 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
验证大量本地 URL
如果你手上有100w个网址,但又不想爬取这些网址,因为那样会浪费时间。只对100w的URL进行规则过滤,右键启动主程序,根据提示输入0,将文字拖进去。
配置文件如下:
比如要过滤掉大厂的域名
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
重点在这里:
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
有了这个设置,URL 上就不会出现好友链爬取和无限采集。
初始URL导入的具体使用
右键启动主程序时,会提示初始URL的传入方法
- 输入:0 ,会让你把网址文本拖拽进来
- 输入:1 ,会让你输入关键词,然后百度采集网址
我只想抓取和过滤一次朋友链
在配置文件中写入以下两行
track = 1
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动,安装提示导入初始网址或使用百度关键词采集。
采集 完成后,右击允许文本deduplication.exe,直接拖动结果重复。
我只想抓取朋友链两次并过滤
(>人<;) 抱歉,暂不支持
想要无限采集 URL
在配置文件中写入以下两行
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
这就开启了无限采集功能,右键启动主程序,按照提示导入初始网址或者使用百度关键词采集功能,那你就没有了担心它。
每次采集的结果都按照时间保存到本地,无限制的采集功能就是把这次的所有结果作为下一次的初始URL导入。
自动重复数据删除。
我只想过滤大量本地网址
如上所述,在配置文件中写入以下两行
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动主程序,根据提示输入0,将URL文本拖进去,结果会自动保存到本地。
个人使用
其实使用规则很简单,无非就是跟或跟的关系。配置无限制采集也很简单。前提只有一个,就是要开启无限采集,必须开启好友链爬取。
规则的种类不多,大家可以根据自己的需要进行配置。毕竟,您知道自己的需求。当然,不仅仅是这样写用法。如何深度爬取更多网站取决于你的大脑。
比如你用b0y的url采集器采集得到5000个网址,然后就可以开启这些网址的好友链爬取和深度爬取,然后就可以爬到更多的网址了。
还有更多的show操作,就看你能不能想到了。
日志
朋友链每次爬取,规则过滤的异常状态都会保存在本地当前目录的log.txt中。你可以关注这个文件。
注意
解决方案:
打开config.ini,然后另存为asicii编码就行了。
效果展示
对于采集教育网站,我的配置文件是这样写的
[User]
whoami = Langzi
[Config]
title = 学
black_title = 政府
url = .edu.cn
black_url = None
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 1
然后右键启动主程序,因为之前没有采集 URL,所以输入1提示输入关键词,我输入【教育】,然后启动自动采集 程序。然后我去玩游戏,过了一会,本地又多了三个文本,是依次保存的结果。按时间排序,以下文字采集的结果最全面。放到服务器上挂了一天后重复采集4W多教育网。
lang_url自动化采集0.96版
重点在这里:
track = 1
# 设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
# 设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 对结果重复继续重复爬行友链次数
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的在进行友链爬行采集一次
# 设置 2 会对采集的在进行友链爬行采集两次
# 设置 3 会对采集的在进行友链爬行采集三次
# 设置 x 会对采集的在进行友链爬行采集x次
# 设置 forever大于0 的前提条件是track=1
【** 注意,forever 大于0 的前提条件是track = 1,即必须开启自动爬行友链的前提下才能启用无限采集功能 **】
【** 注意,如果不想采集友链不想多次采集,仅对自己的网址文本进行规则过滤的话,设置forever = 0,track = 0**】
【** 注意,如果设置track=0,forever=1或者大于1的话,效果和forever=0,track=0 效果一样,所以请不要这样做**】
【** 注意,如果设置track=1,forever=0的话,效果为要进行友链采集但没有设置采集次数,所以请不要这样做**】
也就是说:track(朋友链爬取)只有0(关闭)和1(打开)两个选项,forever(爬取次数)有0-1000(0-无限正整数)选项。
如果只想按规则过滤自己手上的url,设置forever=0,track=0
2018 年 9 月 5 日 00:12:46
修复一个功能,当设置所有过滤规则=None,则track=1,forever=一个大于0的正整数,即不对URL进行规则过滤,只提取网页的所有URL并保存到本地。
这意味着你可以这样设置
[User]
whoami = Langzi
[Config]
url = None
black_url = None
title = None
black_title = None
content = None
black_content = None
thread = 100
timeout = 5
track = 1
forever = 8
功能:无检测规则,直接提取页面中的所有URL。
然后导入URL,爬取好友链,爬了8次,采集很多结果。然后就可以汇总所有的结果,然后设置自定义的本地文件过滤规则。使用方法有很多种,具体的需求就看你怎么操作了。
lang_url自动化采集0.97版
2018 年 9 月 6 日 18:13:40
修复一个功能
添加新功能
设置white_or = 1表示所有白名单(url、title、content,只要其中一个符合条件就会保存在本地,即url=www,title=international,content=langzi,只要www出现在URL,会保存到本地)设置white_or = 0表示所有白名单(url, title, content, 保存前必须满足三个条件)
暂时没有黑名单和机制。
2018 年 9 月 7 日 20:28:33
修复多个 采集 问题
lang_url自动化采集0.98版
每次扫描时都会在当前目录中创建一个新文件夹。文件夹是爬取检测后的URL,里面有一个result.txt。这个文本文件是所有符合规则的 URL。
2018 年 9 月 9 日 22:42:11
2018 年 9 月 10 日 22:06:22
最新下载地址
提取密码:
lang_url自动化采集0.99版
一些有趣的小功能
免规则采集器列表算法(Version填列采集平台数据表导入5、数据表表回收与合并)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 06:16
版本V2.08a 5、数据表导入到采集平台数据表导入5 4.表回收和整合3.数据表填写和第2栏制定采集规则6.数据检查汇总1.数据表导出数据表导入注意:要导入的数据表文件必须与采集平台文件在同一文件目录下;导入数据表前,重命名数据表的文件名。文件名必须与所选工作表的名称相同(即:从导出的文件名中删除括号)。重复数据表导入操作时,如果有同名工作表,系统会给出A提示,操作者判断是覆盖文件还是放弃操作。例如:导出的数据表名称为:A3基本校情表(XX采集)。导入xls时,数据表更名:A3基本校情表.xls V版2.08a 6、状态数据校验与汇总6 5.数据表导入数据校验与汇总< @4.表回收合并3.数据表填充2 制定采集规则1.数据表导出数据校验:完成数据表导入后,检查采集中的数据@> 平台确认已导入所有有效数据。数据汇总:执行“数据统计汇总”操作,生成汇总数据的第十部分注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“ 可返回状态数据目录页面数据汇总:点击平台导航“填表说明”操作,在填表说明页面,点击“数据统计汇总”操作汇总平台内数据,生成第十部分 汇总数据,点击平台导航中的“状态数据目录”操作,在状态数据目录页面点击数据汇总表名称,勾选保存汇总数据的平台文件,关闭文件V版本2.08a 六、状态数据采集解决在进行单表数据合并操作时,数据表中保留的数据行不足的疑问。如何添加数据行?在采集平台,我校想加一栏,是否可以?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集 解决单表数据合并操作时,怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集解决单表数据合并操作时怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?版本V2.08a 问题解决步骤一:执行“解锁基本表”
问题一:单表数据合并操作时,数据表中预留的数据行不够,如何添加数据行?版本V2.08a 问题解释二 目前需要上报状态数据采集平台文件,并且其中的数据指标是固定的,所以采集平台中的数据列不能增加和减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。问题2 在data采集平台,我校想加一栏,可以吗?Version V2.08a Question 3 Question 3 导出数据表时,系统发出宏警告,无法执行导出操作。我该怎么办?操作步骤: 选择菜单:工具->宏->安全,打开安全对话框,将安全级别设置为“低”;完成以上设置后,保存并关闭采集平台文件;重新打开采集平台文件,系统自动激活宏;导出数据表。Version V2.08a Question 4 Question 4 查阅Part 10的汇总数据,发现有些汇总值有问题。如何检查问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作;在数据汇总表中汇总分类表下,说明了参与情况对于汇总数据的来源,按照提示查看汇总数据表中的数据。如果数据被修改,则必须重新进行“数据统计汇总”操作;分析聚合数据,正确理解数据结构。
V版2.08a 使用平台注意事项 打开采集平台文件时,允许启动宏;仔细阅读每张数据表开头的说明和注释,填写所需数据时填写教职工编号、专业代码、课程代码系统一、不能为空;数据表中提供了标准化的数据输入方式,可根据实际情况选择。完成数据输入后,执行“数据统计与汇总”操作,生成汇总数据(第10部分)。表中不能随意添加或删除数据项,可以添加数据行。V版2.08a 状态数据报告 数据文件上报的两种方式 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) V版<
例如:上海兴建职业学院学校代码:12493,备案年份:2008 文件名:12493_2008_STATUS V208a.xls 学校代码版本V2.08a 2. 创建文件目录和文件命名第一步、第二步和第三步。将上级发送的数据采集平台文件复制到文件目录下。重命名状态数据采集平台文件,根据上报文件的命名规则创建状态数据。文件目录、文件管理计划文件目录,用于管理上报、下发和回收的数据文件的状态数据:根据申报年份或采集时间创建状态数据的每个文件目录,用于存储和管理采集 平台文件和各种数据表文件。版本 V<
工具->宏->安全,在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。
版本V2.08a 2. 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到平台。版本V2.08a 3. 数据表导入 “数据表导入”操作可以将36个已完成数据输入的数据表文件导入到数据采集平台。版本 V2.08a “基本表锁定”操作位于导航“填写说明”中。在锁定状态下,只能处理数据表,不能修改表结构。注意:锁定数据表的目的是为了保证数据表结构的一致性;在执行“数据表导出”操作之前,确保数据表处于锁定状态,即 数据表被锁定后不在数据输入区,无法操作。4.基本表锁定版本V2.08a 5.基本表解锁“基本表解锁”操作位于导航“填写说明”中,可以完全控制表格解锁状态。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;版本V2.08a 6. 数据格式刷新 “数据格式刷新”操作位于导航“填写说明”中,统一处理数据表中数据的字体和字号。版本 V2.
版本V2.08a 进行“数据表导出”操作,生成36个文件(单表文件)。将合并后的数据表导入采集平台,按部门/专业/岗位填写数据表 恢复数据表文件,合并单表数据查看数据,进行“数据统计汇总”操作制定数据采集规则和数据表文件发布数据采集管理流程1 2 6 3 5 4 四、状态数据采集管理流程版本V2.08a 1、采集平台数据表导出数据表导出2.开发采集规则3.数据表填充4.表回收和合并5.数据表单导入6.数据校验和汇总 1 在数据导出页面,导出所选工作表采集平台的数据,在采集平台文件所在目录下另存为单表文件;导出数据表文件(单表) V版2.08a 数据表导出提示 数据表导出2.建立采集规则3.数据表填充4.表格回收合并5.数据表导入6.数据校验汇总1 注意:Duplicate 数据表导出操作中,如果有同名数据表文件,系统会提问,操作员将决定是覆盖文件还是放弃操作。版本V2.08a 2、 制定数据采集 规则和文件分发1. 数据表导出 制定规则文件分发2 <
部门文件下发 1. 数据表导出制定规则文件下发 2 3.数据表填充4.表回收和合并5.数据表导入6.数据验证和汇总邮件 FTP 网页下载 教师本职教职工领导本人 V版2.08a 3、数据表填写 3 2 开发采集规则数据表填写4.表格恢复并合并5.数据表导入6.数据检查汇总1.数据表导出打开数据表文件,根据表中的项目输入数据。注:每张数据表都有填写说明和备注,输入数据前请仔细阅读。完成数据输入后,按规定保存文件并重命名文件(部分表格)。例如:在线教研室填写《A4-2校外实习实训基地表(教研室采集)》后文件更名为:《A4-2校外实习实训基地表》表(网络教研室采集)》V版2.08a 4、数据表恢复与整合4 3.数据表填写数据表回收合并2公式采集规则5.数据表导入6.数据检查汇总1.数据表导出复制到指定目录(恢复数据表)。将完成的输入数据表回收到指定的文件目录。A4-2 校外实习实训基地表格(网络教研室采集
表恢复与合并 3. 数据表填写 2 制定采集 规则 6. 数据校验与汇总 1. 数据表导出 需要导入数据的表文件平台根据需要复制命名,然后在采集平台中导入数据表,如下图。注:导入数据表版本V2.08a时的文件名 查看全部
免规则采集器列表算法(Version填列采集平台数据表导入5、数据表表回收与合并)
版本V2.08a 5、数据表导入到采集平台数据表导入5 4.表回收和整合3.数据表填写和第2栏制定采集规则6.数据检查汇总1.数据表导出数据表导入注意:要导入的数据表文件必须与采集平台文件在同一文件目录下;导入数据表前,重命名数据表的文件名。文件名必须与所选工作表的名称相同(即:从导出的文件名中删除括号)。重复数据表导入操作时,如果有同名工作表,系统会给出A提示,操作者判断是覆盖文件还是放弃操作。例如:导出的数据表名称为:A3基本校情表(XX采集)。导入xls时,数据表更名:A3基本校情表.xls V版2.08a 6、状态数据校验与汇总6 5.数据表导入数据校验与汇总< @4.表回收合并3.数据表填充2 制定采集规则1.数据表导出数据校验:完成数据表导入后,检查采集中的数据@> 平台确认已导入所有有效数据。数据汇总:执行“数据统计汇总”操作,生成汇总数据的第十部分注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“ 可返回状态数据目录页面数据汇总:点击平台导航“填表说明”操作,在填表说明页面,点击“数据统计汇总”操作汇总平台内数据,生成第十部分 汇总数据,点击平台导航中的“状态数据目录”操作,在状态数据目录页面点击数据汇总表名称,勾选保存汇总数据的平台文件,关闭文件V版本2.08a 六、状态数据采集解决在进行单表数据合并操作时,数据表中保留的数据行不足的疑问。如何添加数据行?在采集平台,我校想加一栏,是否可以?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集 解决单表数据合并操作时,怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集解决单表数据合并操作时怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?版本V2.08a 问题解决步骤一:执行“解锁基本表”
问题一:单表数据合并操作时,数据表中预留的数据行不够,如何添加数据行?版本V2.08a 问题解释二 目前需要上报状态数据采集平台文件,并且其中的数据指标是固定的,所以采集平台中的数据列不能增加和减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。问题2 在data采集平台,我校想加一栏,可以吗?Version V2.08a Question 3 Question 3 导出数据表时,系统发出宏警告,无法执行导出操作。我该怎么办?操作步骤: 选择菜单:工具->宏->安全,打开安全对话框,将安全级别设置为“低”;完成以上设置后,保存并关闭采集平台文件;重新打开采集平台文件,系统自动激活宏;导出数据表。Version V2.08a Question 4 Question 4 查阅Part 10的汇总数据,发现有些汇总值有问题。如何检查问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作;在数据汇总表中汇总分类表下,说明了参与情况对于汇总数据的来源,按照提示查看汇总数据表中的数据。如果数据被修改,则必须重新进行“数据统计汇总”操作;分析聚合数据,正确理解数据结构。
V版2.08a 使用平台注意事项 打开采集平台文件时,允许启动宏;仔细阅读每张数据表开头的说明和注释,填写所需数据时填写教职工编号、专业代码、课程代码系统一、不能为空;数据表中提供了标准化的数据输入方式,可根据实际情况选择。完成数据输入后,执行“数据统计与汇总”操作,生成汇总数据(第10部分)。表中不能随意添加或删除数据项,可以添加数据行。V版2.08a 状态数据报告 数据文件上报的两种方式 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) V版<
例如:上海兴建职业学院学校代码:12493,备案年份:2008 文件名:12493_2008_STATUS V208a.xls 学校代码版本V2.08a 2. 创建文件目录和文件命名第一步、第二步和第三步。将上级发送的数据采集平台文件复制到文件目录下。重命名状态数据采集平台文件,根据上报文件的命名规则创建状态数据。文件目录、文件管理计划文件目录,用于管理上报、下发和回收的数据文件的状态数据:根据申报年份或采集时间创建状态数据的每个文件目录,用于存储和管理采集 平台文件和各种数据表文件。版本 V<
工具->宏->安全,在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。
版本V2.08a 2. 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到平台。版本V2.08a 3. 数据表导入 “数据表导入”操作可以将36个已完成数据输入的数据表文件导入到数据采集平台。版本 V2.08a “基本表锁定”操作位于导航“填写说明”中。在锁定状态下,只能处理数据表,不能修改表结构。注意:锁定数据表的目的是为了保证数据表结构的一致性;在执行“数据表导出”操作之前,确保数据表处于锁定状态,即 数据表被锁定后不在数据输入区,无法操作。4.基本表锁定版本V2.08a 5.基本表解锁“基本表解锁”操作位于导航“填写说明”中,可以完全控制表格解锁状态。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;版本V2.08a 6. 数据格式刷新 “数据格式刷新”操作位于导航“填写说明”中,统一处理数据表中数据的字体和字号。版本 V2.
版本V2.08a 进行“数据表导出”操作,生成36个文件(单表文件)。将合并后的数据表导入采集平台,按部门/专业/岗位填写数据表 恢复数据表文件,合并单表数据查看数据,进行“数据统计汇总”操作制定数据采集规则和数据表文件发布数据采集管理流程1 2 6 3 5 4 四、状态数据采集管理流程版本V2.08a 1、采集平台数据表导出数据表导出2.开发采集规则3.数据表填充4.表回收和合并5.数据表单导入6.数据校验和汇总 1 在数据导出页面,导出所选工作表采集平台的数据,在采集平台文件所在目录下另存为单表文件;导出数据表文件(单表) V版2.08a 数据表导出提示 数据表导出2.建立采集规则3.数据表填充4.表格回收合并5.数据表导入6.数据校验汇总1 注意:Duplicate 数据表导出操作中,如果有同名数据表文件,系统会提问,操作员将决定是覆盖文件还是放弃操作。版本V2.08a 2、 制定数据采集 规则和文件分发1. 数据表导出 制定规则文件分发2 <
部门文件下发 1. 数据表导出制定规则文件下发 2 3.数据表填充4.表回收和合并5.数据表导入6.数据验证和汇总邮件 FTP 网页下载 教师本职教职工领导本人 V版2.08a 3、数据表填写 3 2 开发采集规则数据表填写4.表格恢复并合并5.数据表导入6.数据检查汇总1.数据表导出打开数据表文件,根据表中的项目输入数据。注:每张数据表都有填写说明和备注,输入数据前请仔细阅读。完成数据输入后,按规定保存文件并重命名文件(部分表格)。例如:在线教研室填写《A4-2校外实习实训基地表(教研室采集)》后文件更名为:《A4-2校外实习实训基地表》表(网络教研室采集)》V版2.08a 4、数据表恢复与整合4 3.数据表填写数据表回收合并2公式采集规则5.数据表导入6.数据检查汇总1.数据表导出复制到指定目录(恢复数据表)。将完成的输入数据表回收到指定的文件目录。A4-2 校外实习实训基地表格(网络教研室采集
表恢复与合并 3. 数据表填写 2 制定采集 规则 6. 数据校验与汇总 1. 数据表导出 需要导入数据的表文件平台根据需要复制命名,然后在采集平台中导入数据表,如下图。注:导入数据表版本V2.08a时的文件名
免规则采集器列表算法(字节面试锦集(一):AndroidFramework高频面试题总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-07 10:30
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):项目HR高频面试总结
数据采集采集架构中各模块详解
爬虫工程师,如何高效支持数据分析师的工作?
基于大数据平台采集基础架构的互联网数据平台
在数据采集中,如何建立有效的监控体系?
面试准备、HR、Android技术等面试题汇总。
昨天,有网友表示,他最近面试了几家公司,被问了好几次问题,每次的回答都不是很好。
采访者:比如有10万个网站需要采集,你有什么方法可以快速获取数据?
要回答好这个问题,其实需要有足够的知识和足够的技术储备。
最近我们也在招聘,每周面试十几个人,感觉合适的只有一两个。他们大多和这位网友的情况一样,缺乏全局思维,即使是有三四年工作经验的人。司机。他们有很强的解决具体问题的能力,但很少从点到点思考问题,站在一个新的高度。
采集的10万个网站的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集的要求,我们需要综合考虑从网站的采集到数据存储的方方面面,给出合适的方案,节约成本,提高工作效率。的目标。
下面我们就从网站的集合到数据存储的方方面面做一个简单的介绍。
一、100,000网站 他们来自哪里?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个 网站 呢?有几种方式:
1)历史业务的积累
不管是冷启动什么的,既然有采集的需求,就一定有项目或产品的需求。相关人员一定是前期调查了一些数据来源,采集了一些重要的网站。这些可以用作我们采集 网站 和 采集 的原创种子。
2)协会网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类的网站,一般都有下级相关部门的官网。
3)网站导航
有些网站可能会出于某种目的(如排水等)采集一些网站,并分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们会通过网站关联等其他方式获得更多的网站。
4)搜索引擎
也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方SaaS平台会有7-15天的免费试用期。因此,我们可以利用这段时间采集与我们业务相关的数据,然后从中提取网站,作为我们最初的采集种子。
虽然,这个方法是网站采集最有效、最快捷的方式。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站 .
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万网站如何管理?
当我们采集到10万个网站时,我们首先面临的是如何管理,如何配置采集规则,如何监控网站正常与否等等。
1)如何管理
100,000 网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站进行一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集规则
我们前期采集的10万个网站只是首页。如果我们只将首页作为采集的任务,那么我们只能采集获取到首页的信息非常少,漏取率非常高。
如果要根据首页的URL执行整个站点采集,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列并对其执行采集。
然而,10万个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码来进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
由于采集的网站数量需要达到10万的级别,所以对于采集一定不能使用xpath或者其他精确定位方法。不然配置10万网站的时候,黄花菜会冷的。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集的body中,使用算法解析时间、body等属性;
3)如何监控
由于有 100,000 个 网站,这些 网站 每天都会有 网站 修订,或列修订,或新/删除列等。因此,有必要根据采集的数据情况简单分析一下网站的情况。
比如一个网站几天没有新数据,肯定有问题。要么是网站的修改导致信息规律失效,要么是网站本身有问题。
为了提高采集的效率,可以使用单独的服务定期检查网站和列的状态。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万网站,列配置完成后,采集的入口URL应该达到百万级别。采集器如何高效获取采集的这些入口URL?
如果把这些url放到数据库中,不管是MySQL还是Oracle,采集器获取采集的任务的操作都会浪费很多时间,大大降低采集@的效率>.
如何解决这个问题呢?内存数据库是首选,如Redis、Mongo DB等,一般采集使用Redis进行缓存。因此,您可以在配置列的同时将列信息同步到Redis 作为采集 任务缓存队列。
四、网站如何采集?
就好比想达到百万年薪,最大的可能就是去华为、阿里、腾讯等一线大厂,而且需要达到一定的水平。这条路注定是艰难的。
同样,如果你需要采集百万级的列表网址,常规的方法肯定是无法实现的。
必须采用分布式+多进程+多线程的方式。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析也必须经过算法处理。比如现在比较流行的GNE,
部分属性可以在列表采集中获取,所以尽量不要和正文放在一起进行分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源代码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站的采集可能需要十几二十台服务器。同时,在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理,比如清理、校正等时,不需要修改每个采集存储部分。我们只需要修改接口,重新部署即可。
快速,方便,快捷。
六、数据和采集监控
覆盖10万个网站的采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,由于我们已经统一了数据存储接口,所以这个时候我们可以在接口上进行统一的数据质量验证。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或采集列的数据。为了能够及时判断采集的网站/列的当前来源是否正常,以保证总有10万个有效的采集网站。
七、数据存储
由于每天的数据量很大采集,普通的数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存文本信息。可以保存标题、发布时间、URL 等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控已经非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以实现采集器/scripts的部署、启动、关闭和运行,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,你怎么快速拿到数据?” 如果你能回答这些,拿到好offer应该就没有悬念了。
最后,希望所有找工作的朋友都能拿到满意的offer,找到一个好的平台。
采访#数据采集 查看全部
免规则采集器列表算法(字节面试锦集(一):AndroidFramework高频面试题总结)
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):项目HR高频面试总结
数据采集采集架构中各模块详解
爬虫工程师,如何高效支持数据分析师的工作?
基于大数据平台采集基础架构的互联网数据平台
在数据采集中,如何建立有效的监控体系?
面试准备、HR、Android技术等面试题汇总。

昨天,有网友表示,他最近面试了几家公司,被问了好几次问题,每次的回答都不是很好。
采访者:比如有10万个网站需要采集,你有什么方法可以快速获取数据?
要回答好这个问题,其实需要有足够的知识和足够的技术储备。
最近我们也在招聘,每周面试十几个人,感觉合适的只有一两个。他们大多和这位网友的情况一样,缺乏全局思维,即使是有三四年工作经验的人。司机。他们有很强的解决具体问题的能力,但很少从点到点思考问题,站在一个新的高度。
采集的10万个网站的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集的要求,我们需要综合考虑从网站的采集到数据存储的方方面面,给出合适的方案,节约成本,提高工作效率。的目标。
下面我们就从网站的集合到数据存储的方方面面做一个简单的介绍。
一、100,000网站 他们来自哪里?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个 网站 呢?有几种方式:
1)历史业务的积累
不管是冷启动什么的,既然有采集的需求,就一定有项目或产品的需求。相关人员一定是前期调查了一些数据来源,采集了一些重要的网站。这些可以用作我们采集 网站 和 采集 的原创种子。
2)协会网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类的网站,一般都有下级相关部门的官网。

3)网站导航
有些网站可能会出于某种目的(如排水等)采集一些网站,并分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们会通过网站关联等其他方式获得更多的网站。

4)搜索引擎
也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。

5)第三方平台
例如,一些第三方SaaS平台会有7-15天的免费试用期。因此,我们可以利用这段时间采集与我们业务相关的数据,然后从中提取网站,作为我们最初的采集种子。
虽然,这个方法是网站采集最有效、最快捷的方式。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站 .
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万网站如何管理?
当我们采集到10万个网站时,我们首先面临的是如何管理,如何配置采集规则,如何监控网站正常与否等等。
1)如何管理
100,000 网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站进行一些预处理(比如打标签)。这时候就需要一个网站管理系统。

2)如何配置采集规则
我们前期采集的10万个网站只是首页。如果我们只将首页作为采集的任务,那么我们只能采集获取到首页的信息非常少,漏取率非常高。
如果要根据首页的URL执行整个站点采集,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列并对其执行采集。

然而,10万个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码来进行列的半自动配置。

当然,我们也尝试过机器学习来处理,但效果不是很理想。
由于采集的网站数量需要达到10万的级别,所以对于采集一定不能使用xpath或者其他精确定位方法。不然配置10万网站的时候,黄花菜会冷的。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集的body中,使用算法解析时间、body等属性;
3)如何监控
由于有 100,000 个 网站,这些 网站 每天都会有 网站 修订,或列修订,或新/删除列等。因此,有必要根据采集的数据情况简单分析一下网站的情况。
比如一个网站几天没有新数据,肯定有问题。要么是网站的修改导致信息规律失效,要么是网站本身有问题。

为了提高采集的效率,可以使用单独的服务定期检查网站和列的状态。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万网站,列配置完成后,采集的入口URL应该达到百万级别。采集器如何高效获取采集的这些入口URL?
如果把这些url放到数据库中,不管是MySQL还是Oracle,采集器获取采集的任务的操作都会浪费很多时间,大大降低采集@的效率>.
如何解决这个问题呢?内存数据库是首选,如Redis、Mongo DB等,一般采集使用Redis进行缓存。因此,您可以在配置列的同时将列信息同步到Redis 作为采集 任务缓存队列。

四、网站如何采集?
就好比想达到百万年薪,最大的可能就是去华为、阿里、腾讯等一线大厂,而且需要达到一定的水平。这条路注定是艰难的。
同样,如果你需要采集百万级的列表网址,常规的方法肯定是无法实现的。
必须采用分布式+多进程+多线程的方式。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;

同时,发布时间、文字等信息的分析也必须经过算法处理。比如现在比较流行的GNE,
部分属性可以在列表采集中获取,所以尽量不要和正文放在一起进行分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源代码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站的采集可能需要十几二十台服务器。同时,在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理,比如清理、校正等时,不需要修改每个采集存储部分。我们只需要修改接口,重新部署即可。
快速,方便,快捷。
六、数据和采集监控
覆盖10万个网站的采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,由于我们已经统一了数据存储接口,所以这个时候我们可以在接口上进行统一的数据质量验证。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或采集列的数据。为了能够及时判断采集的网站/列的当前来源是否正常,以保证总有10万个有效的采集网站。
七、数据存储
由于每天的数据量很大采集,普通的数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存文本信息。可以保存标题、发布时间、URL 等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控已经非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以实现采集器/scripts的部署、启动、关闭和运行,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,你怎么快速拿到数据?” 如果你能回答这些,拿到好offer应该就没有悬念了。
最后,希望所有找工作的朋友都能拿到满意的offer,找到一个好的平台。
采访#数据采集
免规则采集器列表算法( 重新计算人工重新运算的步骤和安装方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-07 08:03
重新计算人工重新运算的步骤和安装方法)
null 第十二章 ProficyHistorian采集器Calculation采集器MainDescriptionCalculation采集器函数配置计算标签在安装时配置,安装时配置,安装时配置 Configuration when与服务器安装在同一台机器上,无需配置。尽管这不是最好的方法,但是计算采集器 可以安装在与其最终服务器分开的计算机上。在这种情况下,必须安装它。确定服务器名称时,在manager中配置,在manager中配置,在manager中配置,设置计算超时时间,确定允许计算的最大时间采集器。了解恢复C的理解
当集中器与其服务器断开连接时,如果它想重新连接到服务器,它将恢复断开连接时完成的操作。在 采集器 配置中设置恢复逻辑运行前的最长时间。该值称为最大恢复时间的默认值为 4 小时。按照时间顺序,将恢复从最早到最晚的操作。恢复逻辑将返回到上次归档操作或最长恢复时间,以不重要的为准。使用它作为起点。在以下事件下触发。当操作采集器 开始时,它会在暂停后重新启动。采集器 发生在线变化时,类似于停止和重启。仅恢复新变量组态中的变量并恢复与归档服务器的连接。之后手动重新计算。手动重新计算。手动重新计算。采集器 可以
手动重新计算的好处体现在当您更改计算时,自动恢复功能既不能恢复所有信息,也不能触发它。例如,存档中的自动恢复功能可以返回到最近的计算。作为恢复逻辑的起点,如果一个为操作提供数据的采集器正在缓冲数据,当恢复发生时,它开始一个不收录标签数据的操作。在这种情况下,需要一些时间重新手动计算恢复并需要更正或更改。配置手动重新计算步骤。配置手动重新计算步骤。在管理器或服务器中选择采集器屏幕计算到服务器采集器点击重新计算按钮设置一个开始和
在结束时间,为重新计算选项选择一个标签。选择所有标签以浏览指定的计算。采集器 如果选择了选项,请浏览标签并选择它们。单击重新计算按钮。在确认对话框中,单击确定添加计算标签并添加计算。计算标签并实现操作 A. 在 采集器 上添加标签。要在管理器操作中添加标签,您必须使用手动添加标签对话框。一旦操作采集器被选为资源地址,就不能使用操作标签。数据资源是它自己的操作。三个标签用于创建计算标签。数据源标签用于计算公式。一个或多个标签。目标标签。真实标签存储计算出的值。也可以在此变量中创建和存储计算。
当触发器标签中的数据发生变化时,标签会更新。当触发器标签获得新值、新时间戳或质量更改时,就会发生更新。不能使用 poll 标签。触发器标签被复制。标签的连接可用于复制操作。标签 这些标签有助于缩短开发时间。创建计算。创建计算。创建计算。当您在管理器选项卡屏幕中选择计算选项卡时,计算选项可用。所有计算都必须包括 ResultVisualBasicScript,一种脚本语言。向导浏览工具 服务器上的所有标签都可用。从几个不同的功能中进行选择。输入手动脚本。电子书中提供了许多示例脚本。
用于扩展编辑区域的窗口按钮。内置函数的说明。内置函数的说明。快捷方式。实验练习。使用向导创建计算。使用经理趋势工具查看数据。完成练习的预计时间为 20 分钟。主要实验练习12 实验练习12A 添加计算标签B 使用向导将计算输入标签C 编辑和测试计算D 查看计算结果主要摘要问题总结问题计算标签的数据源是什么?采集器应该安装在哪里可以实现计算出的标签类型,使用什么触发标签,复制标签函数的值是什么 Main 查看全部
免规则采集器列表算法(
重新计算人工重新运算的步骤和安装方法)

null 第十二章 ProficyHistorian采集器Calculation采集器MainDescriptionCalculation采集器函数配置计算标签在安装时配置,安装时配置,安装时配置 Configuration when与服务器安装在同一台机器上,无需配置。尽管这不是最好的方法,但是计算采集器 可以安装在与其最终服务器分开的计算机上。在这种情况下,必须安装它。确定服务器名称时,在manager中配置,在manager中配置,在manager中配置,设置计算超时时间,确定允许计算的最大时间采集器。了解恢复C的理解

当集中器与其服务器断开连接时,如果它想重新连接到服务器,它将恢复断开连接时完成的操作。在 采集器 配置中设置恢复逻辑运行前的最长时间。该值称为最大恢复时间的默认值为 4 小时。按照时间顺序,将恢复从最早到最晚的操作。恢复逻辑将返回到上次归档操作或最长恢复时间,以不重要的为准。使用它作为起点。在以下事件下触发。当操作采集器 开始时,它会在暂停后重新启动。采集器 发生在线变化时,类似于停止和重启。仅恢复新变量组态中的变量并恢复与归档服务器的连接。之后手动重新计算。手动重新计算。手动重新计算。采集器 可以

手动重新计算的好处体现在当您更改计算时,自动恢复功能既不能恢复所有信息,也不能触发它。例如,存档中的自动恢复功能可以返回到最近的计算。作为恢复逻辑的起点,如果一个为操作提供数据的采集器正在缓冲数据,当恢复发生时,它开始一个不收录标签数据的操作。在这种情况下,需要一些时间重新手动计算恢复并需要更正或更改。配置手动重新计算步骤。配置手动重新计算步骤。在管理器或服务器中选择采集器屏幕计算到服务器采集器点击重新计算按钮设置一个开始和

在结束时间,为重新计算选项选择一个标签。选择所有标签以浏览指定的计算。采集器 如果选择了选项,请浏览标签并选择它们。单击重新计算按钮。在确认对话框中,单击确定添加计算标签并添加计算。计算标签并实现操作 A. 在 采集器 上添加标签。要在管理器操作中添加标签,您必须使用手动添加标签对话框。一旦操作采集器被选为资源地址,就不能使用操作标签。数据资源是它自己的操作。三个标签用于创建计算标签。数据源标签用于计算公式。一个或多个标签。目标标签。真实标签存储计算出的值。也可以在此变量中创建和存储计算。

当触发器标签中的数据发生变化时,标签会更新。当触发器标签获得新值、新时间戳或质量更改时,就会发生更新。不能使用 poll 标签。触发器标签被复制。标签的连接可用于复制操作。标签 这些标签有助于缩短开发时间。创建计算。创建计算。创建计算。当您在管理器选项卡屏幕中选择计算选项卡时,计算选项可用。所有计算都必须包括 ResultVisualBasicScript,一种脚本语言。向导浏览工具 服务器上的所有标签都可用。从几个不同的功能中进行选择。输入手动脚本。电子书中提供了许多示例脚本。

用于扩展编辑区域的窗口按钮。内置函数的说明。内置函数的说明。快捷方式。实验练习。使用向导创建计算。使用经理趋势工具查看数据。完成练习的预计时间为 20 分钟。主要实验练习12 实验练习12A 添加计算标签B 使用向导将计算输入标签C 编辑和测试计算D 查看计算结果主要摘要问题总结问题计算标签的数据源是什么?采集器应该安装在哪里可以实现计算出的标签类型,使用什么触发标签,复制标签函数的值是什么 Main
免规则采集器列表算法( 批量爬取大量的好看的图片到自己的本地电脑哈哈哈)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-06 05:30
批量爬取大量的好看的图片到自己的本地电脑哈哈哈)
优采云 将微博中的图片抓取到本地
批量抓取大量好看的图片到本地电脑哈哈哈哈哈哈哈
微博图片被盗
详细步骤:
微博图片采集
本文介绍如何使用优采云采集微博图片。
微博上有很多博主发布了很多高质量的图片。很多时候,我们想要保存这些高质量的图片,我们该怎么做,一张一张?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的图片采集。主要通过两个主要步骤:首先下载图片网址采集;然后使用优采云提供的图片批量下载工具,将URL批量转换成图片。
采集网站:
本文仅以博主采集发布的图片为例。在实际操作过程中,可以根据自己的需要更改想要采集的博主。您还可以使用URL列表循环批量处理采集多个微博博主发布的所有图片。本文中采集的微博图片的具体字段为:博主ID、发帖时间、微博地址、微博发送方式、微博内容、图片地址、图片存储文件夹。
开始前请注意,如果您还没有登录优采云,需要先建立登录流程。请参考微博登录教程:
使用功能点:
l 分页列表和详细信息提取
lAJAX滚动教程
l优采云7.0 教程-AJAX点击与翻页教程
第一步:创建微博图片采集任务
1)进入主界面,选择“自定义模式”,点击“立即使用”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)系统自动打开网页,进入微博。观察网页的结构。当页面下拉到底部时,会出现“正在加载,请稍候”的字样。当我们下拉时,页面将加载新数据。2 次下拉加载后,此页面到达底部并出现“下一页”按钮
本网页涉及ajax下拉加载,需要设置一些高级选项。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“3次”,每次间隔为“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
注意:这里的滚动次数和间隔时间需要根据网站的情况来设置,不是绝对的。一般来说,间隔时间>网站加载时间就足够了。有时上网速度慢,网页加载很慢,需要根据具体情况进行调整。
详情请看:优采云7.0教程-AJAX滚动教程
/tutorial/ajgd_7.aspx?t=1
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中选择“循环点击下一页”
与“打开网页”类似,这一步也涉及到Ajax下拉加载。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“好的”
和上面一样
第 3 步:创建一个列表循环
1)移动鼠标选择页面上的第一个微博链接。选择后,系统会自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环点击每个链接”创建列表循环
第四步:提取微博文字和图片
1)系统会自动点击进入第一条微博详情页。在微博详情页,我们首先采集博主ID、发帖时间、微博内容、微博网址、微博发送方式。点击你要采集的字段,在右侧的操作提示框中,选择“采集元素的文本”(采集微博网址,然后选择“采集@ > 链接地址")
2) 选择字段信息后,选择对应的字段,自定义字段的命名。完成后,单击“确定”
3) 点击页面第一张图片,在操作提示框中选择“全选”
4)选择“点击循环中的每张图片”
由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”这一步,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
5)点击第一张图片,在弹出的操作提示框中选择“采集图片地址”。图片地址已经采集下,修改此字段为“图片地址”
6)接下来准备批量导出图片网址为图片。点击“添加特殊字段”,选择“添加固定字段”,输入“D:\微博图片采集\”,其中“D:\\”为图片存储盘,“微博图片采集 @>"是图片保存的文件夹名
第五步:数据采集并导出
1)点击左上角“开始采集”,选择“本地采集”开始
注意:本地采集占用采集的当前计算机资源,如果有采集时间要求或当前计算机长时间不能执行采集可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点分配任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
2)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好微博帖子的数据,这里我们选择excel作为导出格式
3) 数据导出如下图
第六步:批量转换图片网址为图片
经过上面的操作,我们得到了图片的URL为采集。接下来使用优采云专用的图片批量下载工具,将采集到达的图片URL中的图片下载并保存到本地。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3) 进行相关设置,设置完成后点击确定导入文件
选择EXCEL文件:导入你需要下载的EXCEL文件图片地址
EXCEL表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:EXCEL中需要单独一栏列出要保存的图片到文件夹的路径,可以设置不同的图片存放在不同的文件夹
如果要将文件保存到文件夹中,路径需要以“\”结尾,例如:“D:\Sync\”,如果下载后要按照指定的文件名保存文件,则需要收录特定的文件名,例如“D :\Sync\1.jpg”
如果下载的文件路径和文件名完全一样,原文件将被删除
3) 点击确定后,界面如图,然后点击“开始下载”
4) 页面底部会显示图片下载状态
5) 找到你设置的图片保存文件夹,可以看到图片URL已经批量转换为图片
注意:软件一定要安装,否则会报错(我试了好久才搞定)
然后就可以导出到本地了
当地位置:
转载于: 查看全部
免规则采集器列表算法(
批量爬取大量的好看的图片到自己的本地电脑哈哈哈)
优采云 将微博中的图片抓取到本地
批量抓取大量好看的图片到本地电脑哈哈哈哈哈哈哈
微博图片被盗

详细步骤:
微博图片采集
本文介绍如何使用优采云采集微博图片。
微博上有很多博主发布了很多高质量的图片。很多时候,我们想要保存这些高质量的图片,我们该怎么做,一张一张?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的图片采集。主要通过两个主要步骤:首先下载图片网址采集;然后使用优采云提供的图片批量下载工具,将URL批量转换成图片。
采集网站:
本文仅以博主采集发布的图片为例。在实际操作过程中,可以根据自己的需要更改想要采集的博主。您还可以使用URL列表循环批量处理采集多个微博博主发布的所有图片。本文中采集的微博图片的具体字段为:博主ID、发帖时间、微博地址、微博发送方式、微博内容、图片地址、图片存储文件夹。
开始前请注意,如果您还没有登录优采云,需要先建立登录流程。请参考微博登录教程:
使用功能点:
l 分页列表和详细信息提取
lAJAX滚动教程
l优采云7.0 教程-AJAX点击与翻页教程
第一步:创建微博图片采集任务
1)进入主界面,选择“自定义模式”,点击“立即使用”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)系统自动打开网页,进入微博。观察网页的结构。当页面下拉到底部时,会出现“正在加载,请稍候”的字样。当我们下拉时,页面将加载新数据。2 次下拉加载后,此页面到达底部并出现“下一页”按钮
本网页涉及ajax下拉加载,需要设置一些高级选项。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“3次”,每次间隔为“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
注意:这里的滚动次数和间隔时间需要根据网站的情况来设置,不是绝对的。一般来说,间隔时间>网站加载时间就足够了。有时上网速度慢,网页加载很慢,需要根据具体情况进行调整。
详情请看:优采云7.0教程-AJAX滚动教程
/tutorial/ajgd_7.aspx?t=1
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中选择“循环点击下一页”
与“打开网页”类似,这一步也涉及到Ajax下拉加载。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“好的”
和上面一样
第 3 步:创建一个列表循环
1)移动鼠标选择页面上的第一个微博链接。选择后,系统会自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环点击每个链接”创建列表循环
第四步:提取微博文字和图片
1)系统会自动点击进入第一条微博详情页。在微博详情页,我们首先采集博主ID、发帖时间、微博内容、微博网址、微博发送方式。点击你要采集的字段,在右侧的操作提示框中,选择“采集元素的文本”(采集微博网址,然后选择“采集@ > 链接地址")
2) 选择字段信息后,选择对应的字段,自定义字段的命名。完成后,单击“确定”
3) 点击页面第一张图片,在操作提示框中选择“全选”
4)选择“点击循环中的每张图片”
由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”这一步,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
5)点击第一张图片,在弹出的操作提示框中选择“采集图片地址”。图片地址已经采集下,修改此字段为“图片地址”
6)接下来准备批量导出图片网址为图片。点击“添加特殊字段”,选择“添加固定字段”,输入“D:\微博图片采集\”,其中“D:\\”为图片存储盘,“微博图片采集 @>"是图片保存的文件夹名
第五步:数据采集并导出
1)点击左上角“开始采集”,选择“本地采集”开始
注意:本地采集占用采集的当前计算机资源,如果有采集时间要求或当前计算机长时间不能执行采集可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点分配任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
2)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好微博帖子的数据,这里我们选择excel作为导出格式
3) 数据导出如下图
第六步:批量转换图片网址为图片
经过上面的操作,我们得到了图片的URL为采集。接下来使用优采云专用的图片批量下载工具,将采集到达的图片URL中的图片下载并保存到本地。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3) 进行相关设置,设置完成后点击确定导入文件
选择EXCEL文件:导入你需要下载的EXCEL文件图片地址
EXCEL表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:EXCEL中需要单独一栏列出要保存的图片到文件夹的路径,可以设置不同的图片存放在不同的文件夹
如果要将文件保存到文件夹中,路径需要以“\”结尾,例如:“D:\Sync\”,如果下载后要按照指定的文件名保存文件,则需要收录特定的文件名,例如“D :\Sync\1.jpg”
如果下载的文件路径和文件名完全一样,原文件将被删除
3) 点击确定后,界面如图,然后点击“开始下载”
4) 页面底部会显示图片下载状态
5) 找到你设置的图片保存文件夹,可以看到图片URL已经批量转换为图片
注意:软件一定要安装,否则会报错(我试了好久才搞定)

然后就可以导出到本地了

当地位置:

转载于:
免规则采集器列表算法(送你2TPython自学资料前天,有个同学加我微信来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-06 05:01
↑关注+star,后台回复【礼包】送你2TPython自学资料
前天有个同学加我微信咨询:
“我想抓取最新的5000条新闻数据,但是我是文科生,不会写代码,我该怎么办?”
对于这位同学的问题,我会安排的。
先说一下获取数据的方式:首先,我们使用现成的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是做一些定制化的工具来满足场景的需要,这需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
因此,在早期,我只是想获取数据。如果没有其他要求,我会优先考虑现有的工具,介绍几个可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,捕获数据的能力是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器
优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定时间。
因为有学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器
优采云采集器是非常适合新手的采集器。它具有简单易用的特点,因此您可以在几分钟内搞定。优采云提供一些常用爬取的模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品
吉手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页,还支持手机端数据网站,数据浮动显示在指数图上。极手客以浏览器插件的形式抓取数据。虽然它有上面提到的优点,但也有缺点,比如不能多线程数据,浏览器死机是不可避免的。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市面上非常复杂且功能强大的网页抓取平台,提供了数据抓取解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。它也是一个适合新手捕捉数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址: 查看全部
免规则采集器列表算法(送你2TPython自学资料前天,有个同学加我微信来)
↑关注+star,后台回复【礼包】送你2TPython自学资料

前天有个同学加我微信咨询:
“我想抓取最新的5000条新闻数据,但是我是文科生,不会写代码,我该怎么办?”
对于这位同学的问题,我会安排的。
先说一下获取数据的方式:首先,我们使用现成的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是做一些定制化的工具来满足场景的需要,这需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
因此,在早期,我只是想获取数据。如果没有其他要求,我会优先考虑现有的工具,介绍几个可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,捕获数据的能力是它的功能之一。我以耳机为关键词,抓取京东的产品列表。

等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器

优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定时间。
因为有学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器

优采云采集器是非常适合新手的采集器。它具有简单易用的特点,因此您可以在几分钟内搞定。优采云提供一些常用爬取的模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品

吉手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页,还支持手机端数据网站,数据浮动显示在指数图上。极手客以浏览器插件的形式抓取数据。虽然它有上面提到的优点,但也有缺点,比如不能多线程数据,浏览器死机是不可避免的。
网站:
5.Scrapinghub

如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市面上非常复杂且功能强大的网页抓取平台,提供了数据抓取解决方案提供商。
地址:
6.WebScraper

WebScraper 是一款优秀的国外浏览器插件。它也是一个适合新手捕捉数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址:
免规则采集器列表算法( 程序bug也能负负得正吗?还真可以吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-31 17:03
程序bug也能负负得正吗?还真可以吗?)
程序错误可以是消极的还是积极的?
真的没问题。
比如程序员们那么熟悉的排序算法,居然可以通过两个“bug”来修正,真是不可思议。
请看这位程序员写的升序数组排序代码:
for i = 1 to n dofor j = 1 to n doif A[i] < A[j] thenswap A[i] and A[j]
今天这串代码在黑客新闻论坛上突然火了起来,引来了大批程序员围观。
乍一看这段代码,你的反应是什么?是不是觉得这个程序员水平太差了,连基本的冒泡算法都写得不好:
不等号的方向错了,二级循环指标j的范围也错了。
简而言之,这段代码“绝对不可能正确”。
△冒泡算法
但是如果你真的运行它,你会发现结果真的是按升序排列的。
让我们看看正确的冒泡算法代码是什么样的:
for i = 1 to n dofor j = i + 1 to n doif A[i] > A[j] thenswap A[i] and A[j]
后者的区别在于j=i+1和A[i]>A[j],这两个过程有很大的不同。
然而,我想告诉你一个令人难以置信的事实。事实上,第一串代码是正确的,可以严格证明。
那么它是如何实现正确排序的呢?
为什么我能打对?
仔细想想,其实很容易理解。因为这个算法的交换操作比冒泡排序多一半,所以它恰好能够将降序编程为升序。
不过作者还是给出了严谨的证明。
我们将 Pᵢ 定义为经过 i 次 (1 ≤ i ≤ n) 外循环后获得的数组。
如果算法正确,则前 i 项已经是升序排列,即 A[1] ≤ A[2] ≤... ≤ A[i]。
证明算法正确实际上就是证明 Pₙ 对任何 n 都成立。
根据数学归纳法,我们只需要证明 P₁ 为真,假设 Pᵢ 为真,然后证明 Pi+1 也为真,即可证明命题。
P₁显然是正确的,这一步和普通的降序冒泡算法没什么区别。在第一个外循环之后,A[1] 是整个数组的最大元素。
然后我们假设 Pᵢ 成立,然后证明 Pi+1 成立。
我们首先定义一个序数 k:
首先假设A[k](k在1和i之间)满足最小数A[k]>A[i+1],那么A[k−1]≤A[i+1](k≠ 1)。
如果 A[i+1]≥A[i],那么这样的 k 不存在,我们让 k=i+1。
考虑以下三种情况:
1、1 ≤ j ≤ k−1
由于 A[i+1]>A[j],没有发生元素交换。
2、 k ≤ j ≤ i(如果k=i+1,这一步不存在)
由于A[j]>A[i+1],每次比较后都会有元素交换。
我们用A[]和A′[]来表示交换前后的元素,所以
A'[i+1] = A[k], A'[k]=A[i+1]
经过一系列的交换,最后把最大的元素放到了A[i+1]的位置,原来的A[i+1]变成了最大的元素,A[k]以原来的A之间的大小插入[k] 和 A[k-1] 之间的元素。
3、i+1 ≤ j ≤ n
由于最大的元素已经交换为前i+1个元素,所以在这个过程中没有元素交换。
最后,Pₙ是执行升序算法后的结果。
由于内循环和外循环的作用域没有区别,这可以说是“最简单”的排序算法。
从代码上看,它与冒泡算法非常相似,但从证明过程可以看出,这实际上是一种插入算法。
△插入算法算法复杂度
显然,算法总是会比较n²次,然后计算算法的交换次数。
可以证明,交换后最多有I+2(n-1),至少有n-1。
其中I为初始数的倒数,最大值为n(n-1)/2
因此,整个算法的复杂度为 O(n²)。
从证明过程可以看出,除了i=1的循环外,其余循环中j=i-1之后的部分是完全无效的,所以这部分可以省略,得到一个简化的算法。
for i = 2 to n dofor j = 1 to i − 1 doif A[i] < A[j] thenswap A[i] and A[j]
该算法减少了比较和交换的次数,但算法复杂度仍然是O(n²)。
网友:这个算法我见过
这种排序算法比最简单的冒泡算法还要简单,很快就在黑客新闻上引起了网友的关注。
许多人觉得它“非常熟悉”。
有网友说,他曾经在奥林匹克数学竞赛中看到一位同学使用了一种很奇怪的排序算法。它可以运行但效率非常低,更像是一种插入排序。
如果我没记错的话,他使用了这个算法。
其实关于这个算法的讨论已经很久了,人们从2014年就开始发帖了,这次作者把论文上传到了arXiv,引起了广泛的热议。
甚至还有乌龙事件。
一位网友看了一眼论文,认为算法和他10年前提出的算法一样。
留言网友的算法:
乍一看,这两种算法的代码确实非常相似,原理上也确实有些相似。
它们看起来都像冒泡排序,但实际上更接近选择排序。
但很快有人指出了真相:在这个算法中j=i+1到n,当A[i]>A[j]时交换。
在作者提出的算法中,j=1到n,A[i]
相比这两种算法,之前网友提出的算法更容易理解为什么能跑。
当然,也有歪楼。有些人嘲笑他们在第一次学习编程时编写了这个算法。
我 100% 肯定,我在刚开始学习编程并想找到最短的排序方法时写的。
但是当涉及到实际应用时,该算法所需的计算时间太长了。
有些人认为这个算法之前已经被发现了很多次,但那些人根本没有打算使用它。
还有人提出,这种排序不像睡眠排序那么简单。
休眠排序就是构造n个线程,使线程对应n个排序。
例如,对于像 [4,2,3,5,9] 这样的一组数字,会创建 5 个线程,每个线程休眠 4s、2s、3s、5s、9s。这些线程唤醒后,只需报告它们对应的编号即可。这样,当所有线程都唤醒时,排序就结束了。
但是和作者提出的算法一样,睡眠排序由于多线程的问题,在实际实现中存在困难。
另外,这位网友还说他见过这个算法:
我确定我以前见过这个算法。它没有名字吗?
很快有人建议——
如果它没有名字,我建议称之为“面试排序”。
参考链接:
[1]
[2]
1.STM32U5,意法半导体全新超低功耗MCU旗舰版
2.【Arm-2D界面设计实例】从不规则图标的显示入手
3.STM8CubeMX和STM32CubeMX的功能一样吗?
4.这九种情况尽量不要连接MCU项目~
5. 偷偷把室友的STM32换成GD32后。. .
6.打开苹果A15芯片看die layout!
免责声明:本文为网络转载,版权归原作者所有。如果您涉及作品的版权,请联系我们,我们将根据您提供的版权证明材料确认版权,并支付作者报酬或删除内容。 查看全部
免规则采集器列表算法(
程序bug也能负负得正吗?还真可以吗?)
程序错误可以是消极的还是积极的?
真的没问题。
比如程序员们那么熟悉的排序算法,居然可以通过两个“bug”来修正,真是不可思议。
请看这位程序员写的升序数组排序代码:
for i = 1 to n dofor j = 1 to n doif A[i] < A[j] thenswap A[i] and A[j]
今天这串代码在黑客新闻论坛上突然火了起来,引来了大批程序员围观。
乍一看这段代码,你的反应是什么?是不是觉得这个程序员水平太差了,连基本的冒泡算法都写得不好:
不等号的方向错了,二级循环指标j的范围也错了。
简而言之,这段代码“绝对不可能正确”。
△冒泡算法
但是如果你真的运行它,你会发现结果真的是按升序排列的。
让我们看看正确的冒泡算法代码是什么样的:
for i = 1 to n dofor j = i + 1 to n doif A[i] > A[j] thenswap A[i] and A[j]
后者的区别在于j=i+1和A[i]>A[j],这两个过程有很大的不同。
然而,我想告诉你一个令人难以置信的事实。事实上,第一串代码是正确的,可以严格证明。
那么它是如何实现正确排序的呢?
为什么我能打对?
仔细想想,其实很容易理解。因为这个算法的交换操作比冒泡排序多一半,所以它恰好能够将降序编程为升序。
不过作者还是给出了严谨的证明。
我们将 Pᵢ 定义为经过 i 次 (1 ≤ i ≤ n) 外循环后获得的数组。
如果算法正确,则前 i 项已经是升序排列,即 A[1] ≤ A[2] ≤... ≤ A[i]。
证明算法正确实际上就是证明 Pₙ 对任何 n 都成立。
根据数学归纳法,我们只需要证明 P₁ 为真,假设 Pᵢ 为真,然后证明 Pi+1 也为真,即可证明命题。
P₁显然是正确的,这一步和普通的降序冒泡算法没什么区别。在第一个外循环之后,A[1] 是整个数组的最大元素。
然后我们假设 Pᵢ 成立,然后证明 Pi+1 成立。
我们首先定义一个序数 k:
首先假设A[k](k在1和i之间)满足最小数A[k]>A[i+1],那么A[k−1]≤A[i+1](k≠ 1)。
如果 A[i+1]≥A[i],那么这样的 k 不存在,我们让 k=i+1。
考虑以下三种情况:
1、1 ≤ j ≤ k−1
由于 A[i+1]>A[j],没有发生元素交换。
2、 k ≤ j ≤ i(如果k=i+1,这一步不存在)
由于A[j]>A[i+1],每次比较后都会有元素交换。
我们用A[]和A′[]来表示交换前后的元素,所以
A'[i+1] = A[k], A'[k]=A[i+1]
经过一系列的交换,最后把最大的元素放到了A[i+1]的位置,原来的A[i+1]变成了最大的元素,A[k]以原来的A之间的大小插入[k] 和 A[k-1] 之间的元素。
3、i+1 ≤ j ≤ n
由于最大的元素已经交换为前i+1个元素,所以在这个过程中没有元素交换。
最后,Pₙ是执行升序算法后的结果。
由于内循环和外循环的作用域没有区别,这可以说是“最简单”的排序算法。
从代码上看,它与冒泡算法非常相似,但从证明过程可以看出,这实际上是一种插入算法。
△插入算法算法复杂度
显然,算法总是会比较n²次,然后计算算法的交换次数。
可以证明,交换后最多有I+2(n-1),至少有n-1。
其中I为初始数的倒数,最大值为n(n-1)/2
因此,整个算法的复杂度为 O(n²)。
从证明过程可以看出,除了i=1的循环外,其余循环中j=i-1之后的部分是完全无效的,所以这部分可以省略,得到一个简化的算法。
for i = 2 to n dofor j = 1 to i − 1 doif A[i] < A[j] thenswap A[i] and A[j]
该算法减少了比较和交换的次数,但算法复杂度仍然是O(n²)。
网友:这个算法我见过
这种排序算法比最简单的冒泡算法还要简单,很快就在黑客新闻上引起了网友的关注。
许多人觉得它“非常熟悉”。
有网友说,他曾经在奥林匹克数学竞赛中看到一位同学使用了一种很奇怪的排序算法。它可以运行但效率非常低,更像是一种插入排序。
如果我没记错的话,他使用了这个算法。
其实关于这个算法的讨论已经很久了,人们从2014年就开始发帖了,这次作者把论文上传到了arXiv,引起了广泛的热议。
甚至还有乌龙事件。
一位网友看了一眼论文,认为算法和他10年前提出的算法一样。
留言网友的算法:
乍一看,这两种算法的代码确实非常相似,原理上也确实有些相似。
它们看起来都像冒泡排序,但实际上更接近选择排序。
但很快有人指出了真相:在这个算法中j=i+1到n,当A[i]>A[j]时交换。
在作者提出的算法中,j=1到n,A[i]
相比这两种算法,之前网友提出的算法更容易理解为什么能跑。
当然,也有歪楼。有些人嘲笑他们在第一次学习编程时编写了这个算法。
我 100% 肯定,我在刚开始学习编程并想找到最短的排序方法时写的。
但是当涉及到实际应用时,该算法所需的计算时间太长了。
有些人认为这个算法之前已经被发现了很多次,但那些人根本没有打算使用它。
还有人提出,这种排序不像睡眠排序那么简单。
休眠排序就是构造n个线程,使线程对应n个排序。
例如,对于像 [4,2,3,5,9] 这样的一组数字,会创建 5 个线程,每个线程休眠 4s、2s、3s、5s、9s。这些线程唤醒后,只需报告它们对应的编号即可。这样,当所有线程都唤醒时,排序就结束了。
但是和作者提出的算法一样,睡眠排序由于多线程的问题,在实际实现中存在困难。
另外,这位网友还说他见过这个算法:
我确定我以前见过这个算法。它没有名字吗?
很快有人建议——
如果它没有名字,我建议称之为“面试排序”。
参考链接:
[1]
[2]
1.STM32U5,意法半导体全新超低功耗MCU旗舰版
2.【Arm-2D界面设计实例】从不规则图标的显示入手
3.STM8CubeMX和STM32CubeMX的功能一样吗?
4.这九种情况尽量不要连接MCU项目~
5. 偷偷把室友的STM32换成GD32后。. .
6.打开苹果A15芯片看die layout!
免责声明:本文为网络转载,版权归原作者所有。如果您涉及作品的版权,请联系我们,我们将根据您提供的版权证明材料确认版权,并支付作者报酬或删除内容。
免规则采集器列表算法(【干货】免规则采集器列表算法简介(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-10-29 23:05
免规则采集器列表算法简介经过测试所得到的规则采集器,将个人、公司、商家间用通讯代码做分类,根据分类算法规则抓取对应的数据。例如用a/b来区分公司或者商家。规则采集器每抓取一个对应的数据都会设置相应的banner(包括商品详情页、产品详情页)里面的图片,并且在将要对应的文件中找到对应的规则,只要规则被抓取就会在相应规则下面加入对应的算法内容。规则采集器采集器默认将banner图片全部设置为200%,那么会有过高的请求报文找不到。欢迎补充。
sendmsg?server={ttl}
catsendmsg#或者moresendmsg:-moresendmsg:eachserveropentimeserveris{scrapers}-listen/proxyeverytimeconnectionauthenticateis{server}-singlespire#-moreelsesendmsg:-listen/proxymybandwidthis{interval}-serverbytesofbuilt-instringbytes:-listen/proxy/{}"nginx"{}"mybandwidth"{}"mybandwidth"{}"sendmsg#请检查ttl值。
规则采集器无banner图片的抓取方法:①首先登录规则采集器官网:②然后点击:中国规则采集器,把整个网站抓取下来③然后把整个网站的txt文本都保存下来④如果有抓取对象的banner图片可以设置里面的bannerfile位置-表格中。规则采集器抓取结果比较乱,你可以利用excel整理一下数据,排个列表,用批量导入工具批量整理文件。
导入的工具随你选择!ps:规则采集器抓取的规则只能与规则里面的抓取对象匹配,不能直接抓取别人的数据。如果有特别需要别人抓取,你可以规则采集器导入规则后自动生成子规则,然后嵌入到你的规则采集器里面去。里面配置好规则,用子规则组合规则抓取数据,比如:sendmsg:{ttl:2,banner:{banner1:{banner2:{client:{state:{version:{}}}就能抓取对应的banner图片。
之前做过这个教程的教程,网上很多;另外现在规则采集器有套餐,点击免费注册也能送一个月使用时间,要不然可以看看免费试用网站:好用,比phpstorm抓到的数据多——免费规则采集器教程。 查看全部
免规则采集器列表算法(【干货】免规则采集器列表算法简介(一))
免规则采集器列表算法简介经过测试所得到的规则采集器,将个人、公司、商家间用通讯代码做分类,根据分类算法规则抓取对应的数据。例如用a/b来区分公司或者商家。规则采集器每抓取一个对应的数据都会设置相应的banner(包括商品详情页、产品详情页)里面的图片,并且在将要对应的文件中找到对应的规则,只要规则被抓取就会在相应规则下面加入对应的算法内容。规则采集器采集器默认将banner图片全部设置为200%,那么会有过高的请求报文找不到。欢迎补充。
sendmsg?server={ttl}
catsendmsg#或者moresendmsg:-moresendmsg:eachserveropentimeserveris{scrapers}-listen/proxyeverytimeconnectionauthenticateis{server}-singlespire#-moreelsesendmsg:-listen/proxymybandwidthis{interval}-serverbytesofbuilt-instringbytes:-listen/proxy/{}"nginx"{}"mybandwidth"{}"mybandwidth"{}"sendmsg#请检查ttl值。
规则采集器无banner图片的抓取方法:①首先登录规则采集器官网:②然后点击:中国规则采集器,把整个网站抓取下来③然后把整个网站的txt文本都保存下来④如果有抓取对象的banner图片可以设置里面的bannerfile位置-表格中。规则采集器抓取结果比较乱,你可以利用excel整理一下数据,排个列表,用批量导入工具批量整理文件。
导入的工具随你选择!ps:规则采集器抓取的规则只能与规则里面的抓取对象匹配,不能直接抓取别人的数据。如果有特别需要别人抓取,你可以规则采集器导入规则后自动生成子规则,然后嵌入到你的规则采集器里面去。里面配置好规则,用子规则组合规则抓取数据,比如:sendmsg:{ttl:2,banner:{banner1:{banner2:{client:{state:{version:{}}}就能抓取对应的banner图片。
之前做过这个教程的教程,网上很多;另外现在规则采集器有套餐,点击免费注册也能送一个月使用时间,要不然可以看看免费试用网站:好用,比phpstorm抓到的数据多——免费规则采集器教程。
免规则采集器列表算法(关关采集器绿色版绿色版功能介绍及使用方法介绍【图文】 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-29 06:14
)
关关采集器绿色版是一款免费的采集软件,关关采集器绿色版支持定义不同的生成方式,独立目录和内容,自定义章节,字数不足, 或内容不足 将指定内容替换为空,增加TXT专页生成功能,关闭采集器绿色版可实现采集数据分类管理,使用非常方便.
关闭采集器 绿色版介绍
1 采集 而且生成速度更快更稳定!
2 支持乱序采集模式(见demo图片)
3 替换采集模式+图片隔行水印+图片FTP加载+文字图片等
4 支持 server2003 或 server2008
5 剧集画面无黑块等BUG,不会再有CPU达到100%
6 不会出现界面卡顿、运行缓慢等...
7 支持伪拼音
8 数字化
9 内部连接关键词设置,
10 非拼音内联初始化提取
11 随机播放模式
12 列表页和内容中使用了{pinyin}标签
13 信息和列表的状态标签
14 书架拼音标签
15 信息页拼音标签等...
16 信息页和列表页的最后一章标签等...
17 读取页面的拼音标签等...
18 搜索拼音标签
采集器绿色版如何使用
1、下载这个软件的资源包,解压打开,点击里面的.exe非法启动软件
2、点击软件主界面的采集菜单,可以选择提供的三种模式中的一种来启动新的采集操作
3、 在如图的批量删除小说操作窗口中,自定义选择并设置删除小说的限制条件
4、 在如图所示的量产操作窗口中,自定义量产设置的参数
5、在如图所示的基本设置窗口中,这个也是设置病毒网站目录、数据库连接字符串等参数
6、 在如图所示的高级设置操作窗口中,在自定义设置中自定义连接参数、拼音设置、阅读设置等
7、在如图所示的图片设置窗口中,可以给图片添加水印并设置图片的高度和宽度
8、 在如图所示的规则管理操作窗口中,可以自定义规则的名称及其具体的规则内容
9、在如图所示的最新新闻窗口中,输入指定小说的名字,可以快速搜索到与其相关的新闻
查看全部
免规则采集器列表算法(关关采集器绿色版绿色版功能介绍及使用方法介绍【图文】
)
关关采集器绿色版是一款免费的采集软件,关关采集器绿色版支持定义不同的生成方式,独立目录和内容,自定义章节,字数不足, 或内容不足 将指定内容替换为空,增加TXT专页生成功能,关闭采集器绿色版可实现采集数据分类管理,使用非常方便.
关闭采集器 绿色版介绍
1 采集 而且生成速度更快更稳定!
2 支持乱序采集模式(见demo图片)
3 替换采集模式+图片隔行水印+图片FTP加载+文字图片等
4 支持 server2003 或 server2008
5 剧集画面无黑块等BUG,不会再有CPU达到100%
6 不会出现界面卡顿、运行缓慢等...
7 支持伪拼音
8 数字化
9 内部连接关键词设置,
10 非拼音内联初始化提取
11 随机播放模式
12 列表页和内容中使用了{pinyin}标签
13 信息和列表的状态标签
14 书架拼音标签
15 信息页拼音标签等...
16 信息页和列表页的最后一章标签等...
17 读取页面的拼音标签等...
18 搜索拼音标签
采集器绿色版如何使用
1、下载这个软件的资源包,解压打开,点击里面的.exe非法启动软件
2、点击软件主界面的采集菜单,可以选择提供的三种模式中的一种来启动新的采集操作
3、 在如图的批量删除小说操作窗口中,自定义选择并设置删除小说的限制条件
4、 在如图所示的量产操作窗口中,自定义量产设置的参数
5、在如图所示的基本设置窗口中,这个也是设置病毒网站目录、数据库连接字符串等参数
6、 在如图所示的高级设置操作窗口中,在自定义设置中自定义连接参数、拼音设置、阅读设置等
7、在如图所示的图片设置窗口中,可以给图片添加水印并设置图片的高度和宽度
8、 在如图所示的规则管理操作窗口中,可以自定义规则的名称及其具体的规则内容
9、在如图所示的最新新闻窗口中,输入指定小说的名字,可以快速搜索到与其相关的新闻
免规则采集器列表算法(为什么说会影响国外的站点呢?(附项目招商找A5快速获取精准代理名单))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-29 05:31
项目招商找A5快速获取精准代理商名单
福建媒体网讯:百度清风算法9月上线没多久,10月开始大整改。目的是打造优质的WEB服务,让那些采集鬼鬼祟祟的网站无处遁形。越狱,这个更新算法主要是针对移动端的调整,先看官方资料:
2017年10月上旬,“闪电算法”上线,手机搜索页面首屏加载时间会影响搜索排名。手机网页首屏在2秒内打开,您将获得手机搜索下的页面优先评价和流量倾斜;同时,在移动搜索页面的第一屏上加载非常缓慢(3 秒或更长时间)的网页将被拒绝 Suppress。
大多数站长优化了页面首屏的加载时间。优化后的技术建议包括但不限于:
资源加载:
1、在服务器端压缩合并同类型资源,减少网络请求次数和资源量。
2、 引用常用资源,充分利用浏览器缓存。
3、使用CDN加速将用户请求定向到最合适的缓存服务器。
4、 延迟加载非首屏图像,将网络带宽留给首屏请求。
页面渲染:
1、 在头部样式表中写入 CSS 样式,以减少 CSS 文件网络请求造成的渲染阻塞。
2、 将 JavaScript 放在文档末尾,或者使用异步加载,避免 JS 执行阻塞渲染。
3、指定非文本元素(如图片、视频)的宽高,避免浏览器重排和重绘。
希望广大站长继续关注页面加载速度体验。请根据网站自身情况参考建议自行优化页面,或使用通用加速方案(如MIP)持续优化页面首屏加载时间。
为什么会影响国外网站?
首先,国内服务器线路与美国、香港、韩国等国外地区的线路不一致。访问速度肯定有问题。用户访问肯定会延迟几秒,但对于百度蜘蛛来说,他已经开通了CDN。不管机器在什么地方,只要不是在不好的机房里运行服务器,一般不会影响百度蜘蛛的爬行速度。
用户访问情况如何?这肯定是有问题的,所以百度的算法这次肯定会考虑这部分原因进行压制。所以,最近国内比较知名的网站,要么是并排的,要么是优质的,对于内容,建议备案,如果不能备案,建议开通CDN,提供访问速度,提升用户体验。!
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
免规则采集器列表算法(为什么说会影响国外的站点呢?(附项目招商找A5快速获取精准代理名单))
项目招商找A5快速获取精准代理商名单
福建媒体网讯:百度清风算法9月上线没多久,10月开始大整改。目的是打造优质的WEB服务,让那些采集鬼鬼祟祟的网站无处遁形。越狱,这个更新算法主要是针对移动端的调整,先看官方资料:
2017年10月上旬,“闪电算法”上线,手机搜索页面首屏加载时间会影响搜索排名。手机网页首屏在2秒内打开,您将获得手机搜索下的页面优先评价和流量倾斜;同时,在移动搜索页面的第一屏上加载非常缓慢(3 秒或更长时间)的网页将被拒绝 Suppress。
大多数站长优化了页面首屏的加载时间。优化后的技术建议包括但不限于:
资源加载:
1、在服务器端压缩合并同类型资源,减少网络请求次数和资源量。
2、 引用常用资源,充分利用浏览器缓存。
3、使用CDN加速将用户请求定向到最合适的缓存服务器。
4、 延迟加载非首屏图像,将网络带宽留给首屏请求。
页面渲染:
1、 在头部样式表中写入 CSS 样式,以减少 CSS 文件网络请求造成的渲染阻塞。
2、 将 JavaScript 放在文档末尾,或者使用异步加载,避免 JS 执行阻塞渲染。
3、指定非文本元素(如图片、视频)的宽高,避免浏览器重排和重绘。
希望广大站长继续关注页面加载速度体验。请根据网站自身情况参考建议自行优化页面,或使用通用加速方案(如MIP)持续优化页面首屏加载时间。
为什么会影响国外网站?
首先,国内服务器线路与美国、香港、韩国等国外地区的线路不一致。访问速度肯定有问题。用户访问肯定会延迟几秒,但对于百度蜘蛛来说,他已经开通了CDN。不管机器在什么地方,只要不是在不好的机房里运行服务器,一般不会影响百度蜘蛛的爬行速度。
用户访问情况如何?这肯定是有问题的,所以百度的算法这次肯定会考虑这部分原因进行压制。所以,最近国内比较知名的网站,要么是并排的,要么是优质的,对于内容,建议备案,如果不能备案,建议开通CDN,提供访问速度,提升用户体验。!
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
免规则采集器列表算法(社交网络数据采集算法的设计(软件工程课程设计报告)课程设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-29 03:06
社交网络数据采集算法设计(软件工程课程设计报告)软件工程课程设计社交网络数据采集算法设计组号21组长姓名:盖云东学号:9组员姓名:任志成学生ID:1群员名:马建南 学号:4 群员名:陈海涛 学号:5 摘要 随着互联网的发展,人们进入了一个信息爆炸的时代。社交网络数据信息量大,主观性强。它具有巨大的数据挖掘价值,是互联网大数据的重要组成部分。一些社交平台如***、新浪微博、人人网等,允许用户申请平台数据采集权限,并提供相应API接口采集数据,通过注册社交平台、应用API授权、调用API方法等流程获取社交信息数据。但是社交平台采集的权限申请比较严格,对申请成功后的数据采集也有限制。因此,本文采用网络爬虫的方式,利用社交账号模拟登录社交平台,访问社交平台的网页信息,并在爬虫任务执行后及时返回任务执行结果。与过去信息匮乏相比,现阶段面对海量信息数据,信息的筛选和过滤成为衡量一个系统质量的重要指标。本文使用爬虫和协同过滤算法来采集在线社交数据。关键词:软件工程;社交网络; 爬虫;Collaborative Filtering Algorithm Directory Summary-2-Contents-3-The purpose of Project Research-1-1.1 Project Research Background-1-2 Priority Grabbing Strategies --PageRank -2-2.1 简介PageRank-2-2.2 PageRank流程-2-3 crawlers-4-3.1 crawler介绍-4-3.1.1crawlers介绍-4-3.1.2工作流程-4-3.1.3爬取策略介绍-5-3.2工具介绍-6-3.2. 1Eclipse -7-3.
随着社交网络网站的兴起,在线社交网络蓬勃发展,新的互联网热潮再次升温。有分析人士甚至表示,在线社交网络将创造一种新的人际交流模式。互联网的兴起打破了传统的社交方式。简单、快捷、无距离的社交体验推动了社交网络的快速发展。以Facebook、Twitter、微博等为代表的应用吸引了大量活跃的在线用户,以及社交网络信息。呈现爆发式增长。社交网络信息反映了用户的网络行为特征。通过对这些信息的研究,可以实现社会舆论监测、网络营销、股市预测等。社交网络信息的重要价值在于实时性,如何快速、准确、有效地获取目标信息非常重要。但是,社交网络属于DeepWeb的专有网络,信息量大,主题性强。传统搜索引擎无法索引这些 DeepWeb 页面。只有通过网站提供的查询界面或登录网站才能访问其信息。这增加了获取社交网络信息的难度。目前国外对社交网络数据采集模型的研究较少,对社交网络的研究主要集中在社交网络分析领域。国内社交网络平台采集的数据在技术研究上取得了一定的成果。例如,
2 优先爬取策略-PageRank2.1 PageRank简介 PageRank,即页面排名,也称页面排名,谷歌左排名或页面排名是谷歌创始人拉里·佩奇和谢尔盖·布林在构建时提出的链接分析算法1997年的早期搜索系统原型,自从谷歌取得空前的商业成功后,该算法也成为其他搜索引擎和学术界关注的计算模型。目前,很多重要的链接分析算法都是从PageRank算法衍生出来的。2.2PageRank过程 首先,PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下: 1) 初始阶段:网页通过链接关系构建Web图,并且每个页面都设置了相同的 PageRank 值。经过几轮计算,最终会得到每个页面得到的PageRank值。每轮计算,网页当前的PageRank值都会不断更新。2) 一轮更新页面PageRank分数的计算方法:在计算更新页面的PageRank分数时,每个页面都会有其当前的PageRank 查看全部
免规则采集器列表算法(社交网络数据采集算法的设计(软件工程课程设计报告)课程设计)
社交网络数据采集算法设计(软件工程课程设计报告)软件工程课程设计社交网络数据采集算法设计组号21组长姓名:盖云东学号:9组员姓名:任志成学生ID:1群员名:马建南 学号:4 群员名:陈海涛 学号:5 摘要 随着互联网的发展,人们进入了一个信息爆炸的时代。社交网络数据信息量大,主观性强。它具有巨大的数据挖掘价值,是互联网大数据的重要组成部分。一些社交平台如***、新浪微博、人人网等,允许用户申请平台数据采集权限,并提供相应API接口采集数据,通过注册社交平台、应用API授权、调用API方法等流程获取社交信息数据。但是社交平台采集的权限申请比较严格,对申请成功后的数据采集也有限制。因此,本文采用网络爬虫的方式,利用社交账号模拟登录社交平台,访问社交平台的网页信息,并在爬虫任务执行后及时返回任务执行结果。与过去信息匮乏相比,现阶段面对海量信息数据,信息的筛选和过滤成为衡量一个系统质量的重要指标。本文使用爬虫和协同过滤算法来采集在线社交数据。关键词:软件工程;社交网络; 爬虫;Collaborative Filtering Algorithm Directory Summary-2-Contents-3-The purpose of Project Research-1-1.1 Project Research Background-1-2 Priority Grabbing Strategies --PageRank -2-2.1 简介PageRank-2-2.2 PageRank流程-2-3 crawlers-4-3.1 crawler介绍-4-3.1.1crawlers介绍-4-3.1.2工作流程-4-3.1.3爬取策略介绍-5-3.2工具介绍-6-3.2. 1Eclipse -7-3.
随着社交网络网站的兴起,在线社交网络蓬勃发展,新的互联网热潮再次升温。有分析人士甚至表示,在线社交网络将创造一种新的人际交流模式。互联网的兴起打破了传统的社交方式。简单、快捷、无距离的社交体验推动了社交网络的快速发展。以Facebook、Twitter、微博等为代表的应用吸引了大量活跃的在线用户,以及社交网络信息。呈现爆发式增长。社交网络信息反映了用户的网络行为特征。通过对这些信息的研究,可以实现社会舆论监测、网络营销、股市预测等。社交网络信息的重要价值在于实时性,如何快速、准确、有效地获取目标信息非常重要。但是,社交网络属于DeepWeb的专有网络,信息量大,主题性强。传统搜索引擎无法索引这些 DeepWeb 页面。只有通过网站提供的查询界面或登录网站才能访问其信息。这增加了获取社交网络信息的难度。目前国外对社交网络数据采集模型的研究较少,对社交网络的研究主要集中在社交网络分析领域。国内社交网络平台采集的数据在技术研究上取得了一定的成果。例如,
2 优先爬取策略-PageRank2.1 PageRank简介 PageRank,即页面排名,也称页面排名,谷歌左排名或页面排名是谷歌创始人拉里·佩奇和谢尔盖·布林在构建时提出的链接分析算法1997年的早期搜索系统原型,自从谷歌取得空前的商业成功后,该算法也成为其他搜索引擎和学术界关注的计算模型。目前,很多重要的链接分析算法都是从PageRank算法衍生出来的。2.2PageRank过程 首先,PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下: 1) 初始阶段:网页通过链接关系构建Web图,并且每个页面都设置了相同的 PageRank 值。经过几轮计算,最终会得到每个页面得到的PageRank值。每轮计算,网页当前的PageRank值都会不断更新。2) 一轮更新页面PageRank分数的计算方法:在计算更新页面的PageRank分数时,每个页面都会有其当前的PageRank
免规则采集器列表算法((2009)S1—0134~O3基于关联规则的贝叶斯网络分类器张子义)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-28 16:21
6DShandong255409,中国) 摘要:基于分类的关联(CBA)算法建立了一个基于关联规则的分类器,没有考虑分类问题中的不确定性。提出了一种基于贝叶斯网络分类器的石油关联规则。改进算法用候选边缘初始化图结构,通过Apfiofial算法提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。这种计算贝叶斯网络将属性变量之间的关系表达为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 介绍 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。贝叶斯网络将属性变量之间的关系表示为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。
通常,我们将其称为改进。文献[2]使用关联规则算法提取那些只与分类相关的:B={G,0},其中G表示网络结构,0表示参数相关规则(ClassAssociationRule,CAR)网络结构。放。根据分解定理,有:()=-n_T(XilPa(五))。规则的分类器(ClassificationBasedon Association,CBA)。虽然实证结果表明CBA可以取得比c4.5更好的性能,设置观测数据D和样本的类标签C建立最优贝叶斯网络结构,但CBA没有考虑分类问题中的不确定性,为此我们结合贝叶斯使分类器的分类性能尽可能高尽可能使用贝叶斯 定理,我们使用贝叶斯网络(BN)来表征这种不确定性。未知 BN 样本被分类到具有最大后验概率的类别中。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。
在问题中,属性往往是相互依存的,所以我们需要学习一个更具生成性的学习算法。目标是找到一个复杂的贝叶斯网络结构,使其似然函数最大化,从而达到更好的分类性能。学习贝叶斯网络结构,典型例子是在类变量C的条件下最大化属性网络结构。最通用的方法是求值+搜索方法,它定义了条件互信息:一个求值函数来搜索网络拓扑。具体来说,首先,给定 ZZ(BlD)=M ∑ lpday(set; Pa(X,)/cIC)+Co (I) 一个初始结构和评估函数,一种 Where (Xi)/C# 其中 cn 是一个常数学期。判别学习常常优化判别的目标函数:一种新的结构。由此产生的结构称为增量结构。例如,树增量简单性,如条件似然函数和分类错误率。其中,条件似然函数与贝叶斯结构(Tree-AumgentedNaiveBayesina,TAN)等直接相关。M 本文提出了一种新的贝叶斯网络分类算法,首先使用了相关性分类,定义为:CLL(BID):5∑logPB(cl)。自联合规则算法提取网络结构的候选边集,然后使用贪婪爬虫经常使用贪婪搜索来获得局部最优结构。山搜索以获得更好的拓扑。1.2参数学习在15个UCI数据集上的实验结果表明了算法的有效性。
虽然网络参数学习也有判别式学习,但一般没有封闭形式的解决方案。由于计算时间复杂度高,一般只有接受稿件日期:2008-08-03;修订日期:2008-10-07。作者简介:章子怡(1977一),男,lh Dongqingdao,讲师,硕士,主要研究领域:网络安全、数字媒体、网络数据挖掘;王德良(1979一),男,山东泰安)人,讲师,硕士,主要研究方向:智能系统,数据挖掘。六月章子怡等:基于关联规则的贝叶斯网络分类器个数的生产学习解决参数的最大似然估计。首先使用 Diriehlet for alllitern.setX ∈L.setdo 检验来平滑最大似然:
节点与y之间的互信息定义为: 未来网络结构的学习。文献[2]只使用关联规则进行分类,这些确定性规则没有充分考虑分类问题的不确定性,而P.y)=)log guess(3)贝叶斯网络可以充分描述这种不确定性。因此,希望通过关系和项目出现频率来定义规则R:{., ,...,}联合规则来指导贝叶斯网络结构的建立。1的评价分数为:2.I关联规则挖掘 s() = ∑ num(, z,..., Y}) × 假设数据集 D 的所有属性都是离散属性,我们可以将每个字符串(属性编号、属性值)视为一个项( Item).在项目集中,c44)被称为-Y是一个规则,其中,l,是如果项目z的出现频率表示为nU'/Z/(z),那么我们可以用nttm(z)来表示项目z的出现频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。
如果或yI收录endfr类属性,那么我们称之为与分类相关的关联规则对于图1中的三个关联规则,{X,,}-C属于(ClassificationFocusedAssociationRule)。图1显示了分类LSc,{c}一个属于L,{c}一个属于。相关关联规则 例如,{location,,}-C, {C}-also, {Ct- 都是面向分类的关联规则。
3 实验结果验证本文算法(记为BNCAR)的有效性,我们将其与常用分类器进行比较:朴素贝叶斯分类器(NB)、贝叶斯网络分类器(TAN)、基于关联规则的分类(CBA) 15 个 UCI 数据集。一些数据集收录连续值。我们将它们离散为离散值。此外,我们消除了属性收录缺失值的样本。表 1 列出了所有 UCI 数据集的信息。2.3 挖掘与分类相关的关联规则对于所有数据集,我们运行10个交叉验证步骤,每次使用Apfiofi算法提取与分类相关的关联规则:第一次交叉验证将数据集分成10份,问最后取其精度的平均值为10。该算法生成一个长度不超过K的项目集,然后用分类提取连续运行的平均值,以消除样本划分的随机性。我们基于著名的关闭规则。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。
FRIEDMANN、GEIGERD、GOLDSZMIDTM。由于贝叶斯网络仅使用规则生成分类规则,未考虑分类分类器[J]. Machine1w_~-'ning, 1997, 29 (2/3): 131-163. 问题中的不确定性。
本文提出了一种基于关联规则的贝叶斯[4] PERNKOPFF, BILMESJ。Discriminativeversusgenerativeparam·网络分类算法。与经典的贝叶斯网络分类器TAN相比,我们的贝叶斯网络分类器的eterand结构学习[C] // Pro-使用关联规则挖掘算法提取初始候选边,使用第22届机器学习国际会议的贪心算法eeedings . 得到更好的贝叶斯网络结构。纽约:ACM 在 15 个标准 UCI 数据集上。2005 年:657-664。实验结果表明,我们的算法BNCAR 可以得到优于TAN 和CBA [5] BLAKEC、MERZC。UCIrepositoryofmachinelearningdatabases 高分类性能。最后,如何构建更好的关联规则评价标准是E[B/OL]。[2008-O6-15]。 集成电路。里。edu/mleam/ 还有待解决的问题。机器学习库。htm1。(上接第130页) 2) 在车间作业计划管理中,车与车间之间的零部件交接和非关键零部件提出了不同的进料计划和采购计划。
上述思考时间内的周转次数,应保证车间在加工过程中的连续性。在该表指导下开发的计算机辅助物料管理系统在运行中取得了表2 MRP净需求计划的结果,特别是在重要部位的物料进料策略的制定上,具有一定的指导意义,采购计划的制定,保证以相对较小的成本满足生产需要,整体上合理控制库存水平。参考文献: [1] 周玉清,刘博英,周强.ERP理论、方法与实践[M].北京:电子工业出版社,2006年2月 []胡政国,李海燕,陈炳森.基于价值流的物料管理策略研究[J].机械工业自动化,生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 查看全部
免规则采集器列表算法((2009)S1—0134~O3基于关联规则的贝叶斯网络分类器张子义)
6DShandong255409,中国) 摘要:基于分类的关联(CBA)算法建立了一个基于关联规则的分类器,没有考虑分类问题中的不确定性。提出了一种基于贝叶斯网络分类器的石油关联规则。改进算法用候选边缘初始化图结构,通过Apfiofial算法提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。这种计算贝叶斯网络将属性变量之间的关系表达为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 介绍 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。贝叶斯网络将属性变量之间的关系表示为可以与之配合使用的有向图的流行,很大程度上源于Apriori...算法的发展及其对变量联合概率分布的方便计算。用候选边缘初始化图结构,通过Apfiofialgorithm提取,并通过贪婪搜索获得比树·增强网络(TAN)分类器更好的网络结构。对 15 个 UCI 数据集的实证研究表明,改进后的算法产生了更高的准确度 shtna TAN, CBA。关键词:基于分类的协会(CBA);贝叶斯网络分类器;structurelearning 0 简介 1 贝叶斯网络分类器关联规则挖掘是数据挖掘中最重要的算法之一。
通常,我们将其称为改进。文献[2]使用关联规则算法提取那些只与分类相关的:B={G,0},其中G表示网络结构,0表示参数相关规则(ClassAssociationRule,CAR)网络结构。放。根据分解定理,有:()=-n_T(XilPa(五))。规则的分类器(ClassificationBasedon Association,CBA)。虽然实证结果表明CBA可以取得比c4.5更好的性能,设置观测数据D和样本的类标签C建立最优贝叶斯网络结构,但CBA没有考虑分类问题中的不确定性,为此我们结合贝叶斯使分类器的分类性能尽可能高尽可能使用贝叶斯 定理,我们使用贝叶斯网络(BN)来表征这种不确定性。未知 BN 样本被分类到具有最大后验概率的类别中。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。贝叶斯网络分类器是一个有向图模型,可以表达属性之间的概率关系。朴素学习主要包括:结构G的学习和参数0的学习。贝叶斯结构假设属性在类条件下是条件独立的,由于其1.1结构的学习简单性和良好的分类性能使其得到广泛应用。但是,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。由于其 1.1 结构的学习简单性和良好的分类性能使其得到广泛应用。然而,实际的结构学习主要分为生产学习和判别学习。
在问题中,属性往往是相互依存的,所以我们需要学习一个更具生成性的学习算法。目标是找到一个复杂的贝叶斯网络结构,使其似然函数最大化,从而达到更好的分类性能。学习贝叶斯网络结构,典型例子是在类变量C的条件下最大化属性网络结构。最通用的方法是求值+搜索方法,它定义了条件互信息:一个求值函数来搜索网络拓扑。具体来说,首先,给定 ZZ(BlD)=M ∑ lpday(set; Pa(X,)/cIC)+Co (I) 一个初始结构和评估函数,一种 Where (Xi)/C# 其中 cn 是一个常数学期。判别学习常常优化判别的目标函数:一种新的结构。由此产生的结构称为增量结构。例如,树增量简单性,如条件似然函数和分类错误率。其中,条件似然函数与贝叶斯结构(Tree-AumgentedNaiveBayesina,TAN)等直接相关。M 本文提出了一种新的贝叶斯网络分类算法,首先使用了相关性分类,定义为:CLL(BID):5∑logPB(cl)。自联合规则算法提取网络结构的候选边集,然后使用贪婪爬虫经常使用贪婪搜索来获得局部最优结构。山搜索以获得更好的拓扑。1.2参数学习在15个UCI数据集上的实验结果表明了算法的有效性。
虽然网络参数学习也有判别式学习,但一般没有封闭形式的解决方案。由于计算时间复杂度高,一般只有接受稿件日期:2008-08-03;修订日期:2008-10-07。作者简介:章子怡(1977一),男,lh Dongqingdao,讲师,硕士,主要研究领域:网络安全、数字媒体、网络数据挖掘;王德良(1979一),男,山东泰安)人,讲师,硕士,主要研究方向:智能系统,数据挖掘。六月章子怡等:基于关联规则的贝叶斯网络分类器个数的生产学习解决参数的最大似然估计。首先使用 Diriehlet for alllitern.setX ∈L.setdo 检验来平滑最大似然:
节点与y之间的互信息定义为: 未来网络结构的学习。文献[2]只使用关联规则进行分类,这些确定性规则没有充分考虑分类问题的不确定性,而P.y)=)log guess(3)贝叶斯网络可以充分描述这种不确定性。因此,希望通过关系和项目出现频率来定义规则R:{., ,...,}联合规则来指导贝叶斯网络结构的建立。1的评价分数为:2.I关联规则挖掘 s() = ∑ num(, z,..., Y}) × 假设数据集 D 的所有属性都是离散属性,我们可以将每个字符串(属性编号、属性值)视为一个项( Item).在项目集中,c44)被称为-Y是一个规则,其中,l,是如果项目z的出现频率表示为nU'/Z/(z),那么我们可以用nttm(z)来表示项目z的出现频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。那么我们可以用nttm(z)来表示物品z出现的频率。Rule——l,支持度表示为(hum(X)/lDI)×100%,2.5学习贝叶斯网络的结构可靠性定义为(/,/~tm(X)/num(XUY)) ×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。/~tm(X)/num(XUY))×100%。因此, , 关联规则 我们已经从项目集中提取了候选边。下面是一个贪心挖掘问题,可以分解为两部分:1)找到所有大于支持度的算法来最大化似然函数(即所有边的互信息之和):项目集支持度最小;2) 由 item set-y 规则生成。
如果或yI收录endfr类属性,那么我们称之为与分类相关的关联规则对于图1中的三个关联规则,{X,,}-C属于(ClassificationFocusedAssociationRule)。图1显示了分类LSc,{c}一个属于L,{c}一个属于。相关关联规则 例如,{location,,}-C, {C}-also, {Ct- 都是面向分类的关联规则。
3 实验结果验证本文算法(记为BNCAR)的有效性,我们将其与常用分类器进行比较:朴素贝叶斯分类器(NB)、贝叶斯网络分类器(TAN)、基于关联规则的分类(CBA) 15 个 UCI 数据集。一些数据集收录连续值。我们将它们离散为离散值。此外,我们消除了属性收录缺失值的样本。表 1 列出了所有 UCI 数据集的信息。2.3 挖掘与分类相关的关联规则对于所有数据集,我们运行10个交叉验证步骤,每次使用Apfiofi算法提取与分类相关的关联规则:第一次交叉验证将数据集分成10份,问最后取其精度的平均值为10。该算法生成一个长度不超过K的项目集,然后用分类提取连续运行的平均值,以消除样本划分的随机性。我们基于著名的关闭规则。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。C++机器学习库Torch实现NB、TAN、BNCAR计算 Ll={1arge1-item—sets}fork: 2; ≤K 且L l≠ ⑦;k++do方法,而CBA使用作者提供的可执行程序得到了答案。对于一个S = apriori-gen(一个1)BNCAR算法,我们凭经验给出以下参数:minsup=0.01;ofrallitemX∈,dominco=0.01;项目集的最大大小为K=3。
FRIEDMANN、GEIGERD、GOLDSZMIDTM。由于贝叶斯网络仅使用规则生成分类规则,未考虑分类分类器[J]. Machine1w_~-'ning, 1997, 29 (2/3): 131-163. 问题中的不确定性。
本文提出了一种基于关联规则的贝叶斯[4] PERNKOPFF, BILMESJ。Discriminativeversusgenerativeparam·网络分类算法。与经典的贝叶斯网络分类器TAN相比,我们的贝叶斯网络分类器的eterand结构学习[C] // Pro-使用关联规则挖掘算法提取初始候选边,使用第22届机器学习国际会议的贪心算法eeedings . 得到更好的贝叶斯网络结构。纽约:ACM 在 15 个标准 UCI 数据集上。2005 年:657-664。实验结果表明,我们的算法BNCAR 可以得到优于TAN 和CBA [5] BLAKEC、MERZC。UCIrepositoryofmachinelearningdatabases 高分类性能。最后,如何构建更好的关联规则评价标准是E[B/OL]。[2008-O6-15]。 集成电路。里。edu/mleam/ 还有待解决的问题。机器学习库。htm1。(上接第130页) 2) 在车间作业计划管理中,车与车间之间的零部件交接和非关键零部件提出了不同的进料计划和采购计划。
上述思考时间内的周转次数,应保证车间在加工过程中的连续性。在该表指导下开发的计算机辅助物料管理系统在运行中取得了表2 MRP净需求计划的结果,特别是在重要部位的物料进料策略的制定上,具有一定的指导意义,采购计划的制定,保证以相对较小的成本满足生产需要,整体上合理控制库存水平。参考文献: [1] 周玉清,刘博英,周强.ERP理论、方法与实践[M].北京:电子工业出版社,2006年2月 []胡政国,李海燕,陈炳森.基于价值流的物料管理策略研究[J].机械工业自动化,生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 生产计划与控制[M].北京:中国科学技术出版社,2005。 [4] 王树明,夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. 夏国平。基于时间坐标产品结构在物料管理中的应用[J]. 系统工程理论与方法的应用, 2001, 1(1O): 23-26. [5] 瓦格纳姆,WH1TINTM。Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171. Dynamicversionofhteeconomiclot 注:每期总成本为1015.sizemodel[J]. 管理科学, 2004, 50(11): 1770—1774. 4 结论 6 [] KOHSCL, SADSM. MRP—受不确定性干扰的受控制造环境 [J]. Roboticsnad Computer Integrated 分析毛坯料加工和采购特性原材料针对相关问题. 重型制造, 2003, 19 (1/2): 157—171.
免规则采集器列表算法(优采云采集器官方版软件功能可视化所有采集元素,自动生成采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-26 04:30
)
软件介绍
优采云采集器正式版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,配置可视化,轻松创建,无需编程,智能生成,数据采集@ > 等功能。用户可以通过优采云采集器轻松采集@>访问自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器正式版软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集@>也可以高速运行,甚至可以快速转换HTTP 操作,享受更高的采集@> 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集@>;
4、 先进的智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql等数据库。该向导只需映射字段,并可以轻松导出到目标 网站 数据库。.
优采云采集器正式版软件特点
可视化向导
所有采集@>元素,自动生成采集@>数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集@>引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集@>字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集@>速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器正式版软件优势
1、优采云采集器为用户提供丰富的网络数据采集@>功能
2、如果需要复制网页的数据,可以使用本软件采集@>
3、网页大部分内容可以直接复制,一键使用采集@>通过优采云采集器
4、直接输入网址采集@>,准确采集@>任何网页内容
5、支持规则设置,自定义采集@>规则,添加采集@>字段内容,添加采集@>网页元素
6、批量采集@>数据,一键输入多个网址采集@>
7、软件中显示任务列表,点击直接开始运行采集@>
8、支持数据查看,可以在软件中查看采集@>的数据内容,可以导出数据
9、支持字符和词库替换功能,文本一键编辑到采集@>
优采云采集器官方版教程
第 1 步:设置起始 URL
要采集@>一个网站数据,首先我们需要设置输入采集@>的URL。比如我们要采集@>一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及这些列表块中显示的内容也非常有限。一般情况下,采集@>这些列表不可能是采集@>完整的信息。
我们以采集@>新浪新闻为例,从新浪首页查找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块。
来看看其中一个子栏目“大陆新闻”
此列页面收录带分页的内容列表。通过切换分页,我们可以采集@>去到这个栏目下的所有文章,所以这种列表页非常适合我们采集@>的起始网址。
现在,我们将列表 URL 复制到任务编辑框的第一步中的文本框
如果你想在一个任务中同时采集@>国内新闻中的其他子栏,也可以复制到另外两个子栏列表的地址中,因为这些子栏列表格式都差不多. 但是,为了方便分类数据的导出或发布,一般不建议将多栏内容混在一起。
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们要采集@>前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,下面的采集@>配置中不要开启分页。通常我们希望将某个列下的所有文章都采集@>,此时只需要定义该列的第一页为起始URL即可。在下面的采集@>配置中启用分页后,您可以采集@>到每个分页列表的数据。
第二步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集@>字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后面的章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”来清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的列表采集@>,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击 Find List-List XPATH,清除其中的 xpath 并确认。
第二步:②手动生成列表
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,点击清除字段清除下面所有的字段,下一章介绍手动选择字段。
第二步:③手动生成字段
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
第二步:④分页设置
当列表有分页时,启用分页后,可以采集@>去查看所有的分页列表数据。
页面分页有两种类型
正常分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
创建新任务时默认不启用分页。点击“不启用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出一个对话框提示“成功识别并设置分页元素!”,一个高亮的红色虚线框网页的“下一步”按钮出现(部分网页按钮可能不显示虚线框),自动分页已成功启用。
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它弹出一个菜单,选择“Mark Pagination”
查看全部
免规则采集器列表算法(优采云采集器官方版软件功能可视化所有采集元素,自动生成采集
)
软件介绍
优采云采集器正式版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,配置可视化,轻松创建,无需编程,智能生成,数据采集@ > 等功能。用户可以通过优采云采集器轻松采集@>访问自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器正式版软件特点
1、软件操作简单,鼠标点击即可轻松选择要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,浏览器采集@>也可以高速运行,甚至可以快速转换HTTP 操作,享受更高的采集@> 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、无需分析网页请求和源码,但支持更多网页采集@>;
4、 先进的智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql等数据库。该向导只需映射字段,并可以轻松导出到目标 网站 数据库。.
优采云采集器正式版软件特点
可视化向导
所有采集@>元素,自动生成采集@>数据
计划任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集@>引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集@>字段和分页等。
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集@>速度
各种数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器正式版软件优势
1、优采云采集器为用户提供丰富的网络数据采集@>功能
2、如果需要复制网页的数据,可以使用本软件采集@>
3、网页大部分内容可以直接复制,一键使用采集@>通过优采云采集器
4、直接输入网址采集@>,准确采集@>任何网页内容
5、支持规则设置,自定义采集@>规则,添加采集@>字段内容,添加采集@>网页元素
6、批量采集@>数据,一键输入多个网址采集@>
7、软件中显示任务列表,点击直接开始运行采集@>
8、支持数据查看,可以在软件中查看采集@>的数据内容,可以导出数据
9、支持字符和词库替换功能,文本一键编辑到采集@>
优采云采集器官方版教程
第 1 步:设置起始 URL
要采集@>一个网站数据,首先我们需要设置输入采集@>的URL。比如我们要采集@>一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及这些列表块中显示的内容也非常有限。一般情况下,采集@>这些列表不可能是采集@>完整的信息。
我们以采集@>新浪新闻为例,从新浪首页查找国内新闻。不过这个版块首页的内容还是乱七八糟的,还细分了三个子版块。
来看看其中一个子栏目“大陆新闻”
此列页面收录带分页的内容列表。通过切换分页,我们可以采集@>去到这个栏目下的所有文章,所以这种列表页非常适合我们采集@>的起始网址。
现在,我们将列表 URL 复制到任务编辑框的第一步中的文本框
如果你想在一个任务中同时采集@>国内新闻中的其他子栏,也可以复制到另外两个子栏列表的地址中,因为这些子栏列表格式都差不多. 但是,为了方便分类数据的导出或发布,一般不建议将多栏内容混在一起。
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们要采集@>前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,下面的采集@>配置中不要开启分页。通常我们希望将某个列下的所有文章都采集@>,此时只需要定义该列的第一页为起始URL即可。在下面的采集@>配置中启用分页后,您可以采集@>到每个分页列表的数据。
第二步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集@>字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后面的章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”来清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的列表采集@>,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击 Find List-List XPATH,清除其中的 xpath 并确认。
第二步:②手动生成列表
单击“查找列表”按钮并选择“手动选择列表”
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,点击清除字段清除下面所有的字段,下一章介绍手动选择字段。
第二步:③手动生成字段
单击“添加字段”按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如果要标记列表中的其他字段,请单击添加新字段并重复上述操作。
第二步:④分页设置
当列表有分页时,启用分页后,可以采集@>去查看所有的分页列表数据。
页面分页有两种类型
正常分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
创建新任务时默认不启用分页。点击“不启用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出一个对话框提示“成功识别并设置分页元素!”,一个高亮的红色虚线框网页的“下一步”按钮出现(部分网页按钮可能不显示虚线框),自动分页已成功启用。
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它弹出一个菜单,选择“Mark Pagination”
免规则采集器列表算法(优采云采集器点击网址采集测试会出现你需要抓取的网页的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-24 13:15
2.接下来点击网址采集进行测试
将出现您需要抓取的网页地址。
3. 选择其中之一
双击进入,右下角测试
这里的标签列表是指在这个网站的内容中需要抓取的内容和字段配置,提取出来的字段也可以使用起始字符串。
您需要的字段将在测试期间出现。
3、内容发布规则将在后面详细说明。
4. 其他设置
如果捕获的内容收录图片附件或视频,则需要在此处设置地址。保存所有文件的根目录是指本地路径。如果程序放置在服务器上,则需要将附件传输到相应的服务器。
这里的文件链接地址前缀是指下载优采云采集器时会如上添加你的附件或图片的地址前缀。
(提示:这里的前缀地址必须和你服务器部署的站点地址一致)
* 网页发布配置
点击保存或退出后,返回界面,点击web发布配置。
您可以创建一个新的,这是一个新的信息类:
网站地址指的是你需要发布的数据的起始地址
可以使用 fidder2 获取用户代理
cookie也可以通过fidder2获取,也可以根据网站的f12校验获取,有的可能不可用。
然后在右侧创建一个已发布的模块。这里的配置相当于对应了数据库的字段,插入到数据库中:
这里的发布地址是之前的地址加上你需要发布的地址的后缀。源页地址是指你需要在某个栏目下发布的栏目id,相当于文章属于什么类型(文学,小说),这里的类型id。
发布的帖子数据:
也可以根据fdder2获取post数据。
fidder2的使用方法会在后面讲解。 查看全部
免规则采集器列表算法(优采云采集器点击网址采集测试会出现你需要抓取的网页的地址)
2.接下来点击网址采集进行测试
将出现您需要抓取的网页地址。
3. 选择其中之一
双击进入,右下角测试
这里的标签列表是指在这个网站的内容中需要抓取的内容和字段配置,提取出来的字段也可以使用起始字符串。
您需要的字段将在测试期间出现。
3、内容发布规则将在后面详细说明。
4. 其他设置
如果捕获的内容收录图片附件或视频,则需要在此处设置地址。保存所有文件的根目录是指本地路径。如果程序放置在服务器上,则需要将附件传输到相应的服务器。
这里的文件链接地址前缀是指下载优采云采集器时会如上添加你的附件或图片的地址前缀。
(提示:这里的前缀地址必须和你服务器部署的站点地址一致)
* 网页发布配置
点击保存或退出后,返回界面,点击web发布配置。
您可以创建一个新的,这是一个新的信息类:
网站地址指的是你需要发布的数据的起始地址
可以使用 fidder2 获取用户代理
cookie也可以通过fidder2获取,也可以根据网站的f12校验获取,有的可能不可用。
然后在右侧创建一个已发布的模块。这里的配置相当于对应了数据库的字段,插入到数据库中:
这里的发布地址是之前的地址加上你需要发布的地址的后缀。源页地址是指你需要在某个栏目下发布的栏目id,相当于文章属于什么类型(文学,小说),这里的类型id。
发布的帖子数据:
也可以根据fdder2获取post数据。
fidder2的使用方法会在后面讲解。
免规则采集器列表算法(江苏大学硕士学位论文关联规则挖掘算法研究与应用())
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-23 11:08
江苏大学
硕士论文
关联规则挖掘算法的研究与应用
姓名:陈晨
申请学位等级:硕士
专业:计算机应用技术
指导老师:鞠世光
20091216
摘要 数据挖掘是指从大量不完整、嘈杂、模糊、随机的数据中提取人们感兴趣的知识和规则的过程。数据挖掘的研究取得了重大进展,并已应用于众多领域。关联规则挖掘是数据挖掘研究中的一个重要课题。它主要用于从给定的数据集中发现频繁出现的项目集模式知识。本文首先介绍了数据挖掘的任务和过程,其应用和发展趋势,关联规则挖掘的基本概念、分类方法和经典算法,然后重点介绍了如何高效挖掘最大频率。频繁模式树问题是基于有序树和挖掘所用数据结构的逐步修改提出的。通过对整个交易数据库进行挖掘的算法,在整个交易数据库挖掘中,挖掘具有叶子节点链的有序树的最大频率是最大的。关联规则的问题,⒍统一喙和蚂蟥,心搜,核心和蚂蟥,回归心。蓝兆攀⒎志谦低场江苏大学硕士学位论文集、关联规则的生成和规则规模的缩减研究,探索得到的硬币规则所隐含的否定规则,最后进行设计和实现. 江苏财经职业技术学院教学质量评价与分析系统。本文的主要工作和研究成果如下: 对最大频繁项集的算法、算法的性能和效率进行了分析和实验验证。通过实验验证了算法的性能和效率。“爆炸”问题分析了现有减少规则规模的方法存在的问题,提出了最大关联规则的概念,类似于挖掘最大频繁项集而不是挖掘全频繁项集,挖掘最大频繁项集。关联规则而不是挖掘所有关联规则。, 提出了一种挖掘单个最大频繁项集的最大关联规则的候选规则队列集结构,并提出了挖掘整个事务数据库最大关联规则的方法。已经论证了谢六所选择的策略,并通过实例验证了算法的性能。关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信度负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则
疭瓯江苏大学硕士学位论文...
江苏大学硕士学位论文
原创性和生平声明 本人郑重声明,所提交的论文是本人在导师指导下独立研究工作的结果。除正文中引用的内容外,本文不收录任何其他已发表或撰写的个人或集体作品。对本文研究做出重要贡献的个人和集体在文中已明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期: YYYY
论文著作权授权书是保密的,不是保密的。本论文作者充分理解学校关于学位论文保存和使用的规定,同意学校保留并提交论文副本及电子版至国家有关部门或机构,允许论文查阅和借阅。本人授权江苏大学将本学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩小或扫描等复印方式保存和编辑本学位论文。授权书应在当年解密后申请。本论文属论文作者署名: 导师署名: 署名日期: YYYY
第一章引言数据挖掘概述随着以计算机和网络技术为代表的信息技术的发展,越来越多的企业、政府组织、教育机构和科研单位实现了信息的数字化处理。大型数据库,尤其是数据仓库,已广泛应用于企业管理、产品销售、科学计算、信息服务等领域。对此,面对庞大且快速增长的数据量,人们需要新的处理工具,以便能够将大量重要信息自动存储,人们希望对自己掌握的信息进行更高层次的分析。已经拥有,以便更好地利用这些数据。揭示隐含的和以前未知的潜在有用信息的非平凡过程。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。 查看全部
免规则采集器列表算法(江苏大学硕士学位论文关联规则挖掘算法研究与应用())
江苏大学
硕士论文
关联规则挖掘算法的研究与应用
姓名:陈晨
申请学位等级:硕士
专业:计算机应用技术
指导老师:鞠世光
20091216
摘要 数据挖掘是指从大量不完整、嘈杂、模糊、随机的数据中提取人们感兴趣的知识和规则的过程。数据挖掘的研究取得了重大进展,并已应用于众多领域。关联规则挖掘是数据挖掘研究中的一个重要课题。它主要用于从给定的数据集中发现频繁出现的项目集模式知识。本文首先介绍了数据挖掘的任务和过程,其应用和发展趋势,关联规则挖掘的基本概念、分类方法和经典算法,然后重点介绍了如何高效挖掘最大频率。频繁模式树问题是基于有序树和挖掘所用数据结构的逐步修改提出的。通过对整个交易数据库进行挖掘的算法,在整个交易数据库挖掘中,挖掘具有叶子节点链的有序树的最大频率是最大的。关联规则的问题,⒍统一喙和蚂蟥,心搜,核心和蚂蟥,回归心。蓝兆攀⒎志谦低场江苏大学硕士学位论文集、关联规则的生成和规则规模的缩减研究,探索得到的硬币规则所隐含的否定规则,最后进行设计和实现. 江苏财经职业技术学院教学质量评价与分析系统。本文的主要工作和研究成果如下: 对最大频繁项集的算法、算法的性能和效率进行了分析和实验验证。通过实验验证了算法的性能和效率。“爆炸”问题分析了现有减少规则规模的方法存在的问题,提出了最大关联规则的概念,类似于挖掘最大频繁项集而不是挖掘全频繁项集,挖掘最大频繁项集。关联规则而不是挖掘所有关联规则。, 提出了一种挖掘单个最大频繁项集的最大关联规则的候选规则队列集结构,并提出了挖掘整个事务数据库最大关联规则的方法。已经论证了谢六所选择的策略,并通过实例验证了算法的性能。关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则 关联规则直接获取隐式高置信度负关联规则的方法。关键词:数据挖掘、关联规则、最大频繁项集、最大关联规则、隐式否定规则
疭瓯江苏大学硕士学位论文...
江苏大学硕士学位论文
原创性和生平声明 本人郑重声明,所提交的论文是本人在导师指导下独立研究工作的结果。除正文中引用的内容外,本文不收录任何其他已发表或撰写的个人或集体作品。对本文研究做出重要贡献的个人和集体在文中已明确标明。本人明知本声明的法律后果由本人承担。论文作者签名: 日期: YYYY
论文著作权授权书是保密的,不是保密的。本论文作者充分理解学校关于学位论文保存和使用的规定,同意学校保留并提交论文副本及电子版至国家有关部门或机构,允许论文查阅和借阅。本人授权江苏大学将本学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩小或扫描等复印方式保存和编辑本学位论文。授权书应在当年解密后申请。本论文属论文作者署名: 导师署名: 署名日期: YYYY
第一章引言数据挖掘概述随着以计算机和网络技术为代表的信息技术的发展,越来越多的企业、政府组织、教育机构和科研单位实现了信息的数字化处理。大型数据库,尤其是数据仓库,已广泛应用于企业管理、产品销售、科学计算、信息服务等领域。对此,面对庞大且快速增长的数据量,人们需要新的处理工具,以便能够将大量重要信息自动存储,人们希望对自己掌握的信息进行更高层次的分析。已经拥有,以便更好地利用这些数据。揭示隐含的和以前未知的潜在有用信息的非平凡过程。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。这个定义是由数据量和数据不够定义的。目标是将大容量数据转化为有用的知识。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。江苏大学硕士学位论文学位造成的数据量。快速的增长对数据库的存储、管理和分析提出了更高的要求:将采集到的少量数据转化为有价值的信息和知识;另一方面,快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。快速增长的数据有可能隐藏丰富和贫乏的知识。” 令人窒息的数据挖掘,缩写为“机极”、“壁球”,让您可以更有效地利用数据库或数据仓库。
免规则采集器列表算法(优采云采集器怎么制作织梦CMS免登陆发布模块?发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-23 00:25
使用优采云采集器采集完成的数据通常用于发布到网站,这些网站一般使用织梦cms或帝国 cms 制作。下面是通过本教程的简要介绍。优采云采集器如何制作织梦cms免登录发布模块?
WEB发布模块,即网站后台手动发布内容的全过程,包括登录网站后台、选择栏目、发布文章@ >. 这些步骤写在采集器里面,模拟发布,这就是WEB发布模块。然后将规则采集的值通过标签名传递给在线发布模块,将数据提交给网站。在菜单栏上,单击 Web 发布配置,然后单击 + 新建发布模块。
网站自动登录:设置网站登录信息数据获取栏目列表:设置发布栏目列表
随机访问网页:在post数据中设置随机值
内容发布参数:设置发布页面的POST数据包
高级功能:文件上传设置和数据结构
我们以dedecms的文章@>发布为例来说明
(1)第二步,“WEB发布设置界面”和“内容发布参数”设置
我们在发布页面填写需要发布的字段值(先不要点击发布),然后打开fiddler(注意,如果有乱七八糟的数据流,请用ctlr+X清除数据流)
如图,填写标题,来源,选择栏目,内容:
清除数据流后ctlr+X fiddler
此时点击Publish,分析fiddler中的数据包,点击fiddler①➯②,然后点击数据流列表⑤找到POST类型的数据流⑥,然后点击⑦以文本形式查看
数据包贴出如下:
POST http://127.0.0.1:801/dede/dede/article_add.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 3571
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary6EWX666GAXOVqWCE
Referer: http://127.0.0.1:801/dede/dede ... d%3D0
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginTime=1444806848; DedeLoginTime__ckMd5=65d5fa4845a7ec00; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="channelid"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dopost"
save
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="title"
11111
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="shorttitle"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="redirecturl"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="tags"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="weight"
99
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="picname"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="litpic"; filename=""
Content-Type: application/octet-stream
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="source"
22222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="writer"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid"
2
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid2"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="keywords"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autokey"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="description"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dede_addonfields"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="remote"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autolitpic"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="needwatermark"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sptype"
hand
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="spsize"
5
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="body"
222222222222222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="voteid"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="notpost"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="click"
137
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sortup"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="color"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="arcrank"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="money"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="pubdate"
2015-10-14 15:16:06
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="ishtml"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="filename"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="templet"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.x"
37
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.y"
18
------WebKitFormBoundary6EWX666GAXOVqWCE--
一、设置WEB发布配置界面
根据上面的数据包:网站 编码为:utf-8(可以在你的网站上右键查看源码,找到charset字段的值,具体取决于编码)
网站地址为:801/dede(网站地址可以根据POST和Referer字段自定义。一般我们使用网站域名作为网站地址,或者你可以找到其他 2 设置的共同部分是 网站 地址。)
cookie 为:menuitems=1_1%2C2_1%2C3_1;PHPSESSID=f21a42f70199c81955f32; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginlistTime=1444806848; DedeLoginTime__ckMd5=65d5_fa4845a7ecde 内容
用户代理是: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
接下来,我们正在设置“内容发布参数”
网站地址+发帖地址后缀:需要组合成一个完整的地址,所以两者的设置不互补
网站地址+源页面后缀:需要组合成一个完整的地址,所以不要设置两者互补
然后我们用标签替换POST数据中的值。
双击选择表单值,然后将鼠标悬停在标签按钮上,选择要替换的标签名称。您可以选择系统标签、普通标签和时间标签。
我的替换效果如下图
标题、来源、内容和时间很容易确认和识别。
这里给大家解释一下“[Category ID]”系统标签。
此标签用于为我们的下一组获取列列表设置铺平道路。
那么如何确定哪个表单名称是[类别ID]呢?
按照下图所示的方法,很简单就知道typeid就是我们要找的【类别ID】,替换成对应的即可。
(2)第二步,确认“获取列列表”设置
首先,我们必须确定我们的选择列列表在哪个页面上?
A.最常见的一种,栏目选择在发布内容页面,类似于我们的demo DEDE文章@>发布。
B. 特殊情况下,内容页面不在其他页面下发布。
这里我们讲解案例A,直接拿“内容发布参数”下的源页面后缀设置即可。
将其放入“获取栏目列表”下的帖子地址后缀和来源页面后缀中。
然后查看发布页面的源码,找到刷新列表部分的源码,确定栏目列表的起止代码和格式
ID 替换为 [类别 ID]
将列名替换为 [类别名称]
不规则代码与 (*) 通配符匹配
设置如图:
现在我们保存发布模块,大概测试一下发布效果
可以刷新列表,说明我们的“获取列列表”设置就OK了。
可以发布,说明我们的“内容发布参数”设置没有问题。
(3)第三步,完善模块
成功与失败识别码:
您可以在网站中发布正常内容和失败内容(例如,不填标题,不选择栏目)查看各自的提示,然后写模块设置,多提示每行一个。
高级功能:
可以看到我们的模块有一个LITPIC表单名称字段,这是我们在粘贴“内容发布参数”的POST数据时自动提取的设置。在这里,我们可以自定义和修改标签名称,比如设置为缩略图。
文件上传设置中的标签,文件上传不需要设置FTP,只要下载到本地就可以实现自动上传操作。
网站自动登录:
我们之前做的发布是基于登录方式是浏览器内置的原理来获取cookies和User-agent。我们也可以使用数据包登录方式来设置。他的设置原理和“内容发布参数”一样。使用fiddler工具在登录后台的那一刻抓取POST包。
POST http://127.0.0.1:801/dede/dede/login.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 112
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Referer: http://127.0.0.1:801/dede/dede ... x.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
gotopage=%2Fdede%2Fdede%2Findex.php&dopost=login&adminstyle=newdedecms&userid=admin&pwd=admin&validate=lcmt&sm1=
设置如下:
测试效果:
OK,这样就支持内置浏览器的模块登录或者数据包登录了。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网 查看全部
免规则采集器列表算法(优采云采集器怎么制作织梦CMS免登陆发布模块?发布)
使用优采云采集器采集完成的数据通常用于发布到网站,这些网站一般使用织梦cms或帝国 cms 制作。下面是通过本教程的简要介绍。优采云采集器如何制作织梦cms免登录发布模块?
WEB发布模块,即网站后台手动发布内容的全过程,包括登录网站后台、选择栏目、发布文章@ >. 这些步骤写在采集器里面,模拟发布,这就是WEB发布模块。然后将规则采集的值通过标签名传递给在线发布模块,将数据提交给网站。在菜单栏上,单击 Web 发布配置,然后单击 + 新建发布模块。
网站自动登录:设置网站登录信息数据获取栏目列表:设置发布栏目列表
随机访问网页:在post数据中设置随机值
内容发布参数:设置发布页面的POST数据包
高级功能:文件上传设置和数据结构
我们以dedecms的文章@>发布为例来说明
(1)第二步,“WEB发布设置界面”和“内容发布参数”设置
我们在发布页面填写需要发布的字段值(先不要点击发布),然后打开fiddler(注意,如果有乱七八糟的数据流,请用ctlr+X清除数据流)
如图,填写标题,来源,选择栏目,内容:
清除数据流后ctlr+X fiddler
此时点击Publish,分析fiddler中的数据包,点击fiddler①➯②,然后点击数据流列表⑤找到POST类型的数据流⑥,然后点击⑦以文本形式查看
数据包贴出如下:
POST http://127.0.0.1:801/dede/dede/article_add.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 3571
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary6EWX666GAXOVqWCE
Referer: http://127.0.0.1:801/dede/dede ... d%3D0
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginTime=1444806848; DedeLoginTime__ckMd5=65d5fa4845a7ec00; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="channelid"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dopost"
save
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="title"
11111
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="shorttitle"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="redirecturl"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="tags"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="weight"
99
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="picname"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="litpic"; filename=""
Content-Type: application/octet-stream
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="source"
22222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="writer"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid"
2
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="typeid2"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="keywords"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autokey"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="description"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="dede_addonfields"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="remote"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="autolitpic"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="needwatermark"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sptype"
hand
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="spsize"
5
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="body"
222222222222222
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="voteid"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="notpost"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="click"
137
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="sortup"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="color"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="arcrank"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="money"
0
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="pubdate"
2015-10-14 15:16:06
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="ishtml"
1
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="filename"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="templet"
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.x"
37
------WebKitFormBoundary6EWX666GAXOVqWCE
Content-Disposition: form-data; name="imageField.y"
18
------WebKitFormBoundary6EWX666GAXOVqWCE--
一、设置WEB发布配置界面
根据上面的数据包:网站 编码为:utf-8(可以在你的网站上右键查看源码,找到charset字段的值,具体取决于编码)
网站地址为:801/dede(网站地址可以根据POST和Referer字段自定义。一般我们使用网站域名作为网站地址,或者你可以找到其他 2 设置的共同部分是 网站 地址。)
cookie 为:menuitems=1_1%2C2_1%2C3_1;PHPSESSID=f21a42f70199c81955f32; DedeUserID=1; DedeUserID__ckMd5=91a12e3e1eae3a4d; DedeLoginlistTime=1444806848; DedeLoginTime__ckMd5=65d5_fa4845a7ecde 内容
用户代理是: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
接下来,我们正在设置“内容发布参数”
网站地址+发帖地址后缀:需要组合成一个完整的地址,所以两者的设置不互补
网站地址+源页面后缀:需要组合成一个完整的地址,所以不要设置两者互补
然后我们用标签替换POST数据中的值。
双击选择表单值,然后将鼠标悬停在标签按钮上,选择要替换的标签名称。您可以选择系统标签、普通标签和时间标签。
我的替换效果如下图
标题、来源、内容和时间很容易确认和识别。
这里给大家解释一下“[Category ID]”系统标签。
此标签用于为我们的下一组获取列列表设置铺平道路。
那么如何确定哪个表单名称是[类别ID]呢?
按照下图所示的方法,很简单就知道typeid就是我们要找的【类别ID】,替换成对应的即可。
(2)第二步,确认“获取列列表”设置
首先,我们必须确定我们的选择列列表在哪个页面上?
A.最常见的一种,栏目选择在发布内容页面,类似于我们的demo DEDE文章@>发布。
B. 特殊情况下,内容页面不在其他页面下发布。
这里我们讲解案例A,直接拿“内容发布参数”下的源页面后缀设置即可。
将其放入“获取栏目列表”下的帖子地址后缀和来源页面后缀中。
然后查看发布页面的源码,找到刷新列表部分的源码,确定栏目列表的起止代码和格式
ID 替换为 [类别 ID]
将列名替换为 [类别名称]
不规则代码与 (*) 通配符匹配
设置如图:
现在我们保存发布模块,大概测试一下发布效果
可以刷新列表,说明我们的“获取列列表”设置就OK了。
可以发布,说明我们的“内容发布参数”设置没有问题。
(3)第三步,完善模块
成功与失败识别码:
您可以在网站中发布正常内容和失败内容(例如,不填标题,不选择栏目)查看各自的提示,然后写模块设置,多提示每行一个。
高级功能:
可以看到我们的模块有一个LITPIC表单名称字段,这是我们在粘贴“内容发布参数”的POST数据时自动提取的设置。在这里,我们可以自定义和修改标签名称,比如设置为缩略图。
文件上传设置中的标签,文件上传不需要设置FTP,只要下载到本地就可以实现自动上传操作。
网站自动登录:
我们之前做的发布是基于登录方式是浏览器内置的原理来获取cookies和User-agent。我们也可以使用数据包登录方式来设置。他的设置原理和“内容发布参数”一样。使用fiddler工具在登录后台的那一刻抓取POST包。
POST http://127.0.0.1:801/dede/dede/login.php HTTP/1.1
Host: 127.0.0.1:801
Connection: keep-alive
Content-Length: 112
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://127.0.0.1:801
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Referer: http://127.0.0.1:801/dede/dede ... x.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: menuitems=1_1%2C2_1%2C3_1; PHPSESSID=f21a42f70199c81955f3219623343735; ENV_GOBACK_URL=%2Fdede%2Fdede%2Fcontent_list.php%3Fchannelid%3D1
gotopage=%2Fdede%2Fdede%2Findex.php&dopost=login&adminstyle=newdedecms&userid=admin&pwd=admin&validate=lcmt&sm1=
设置如下:
测试效果:
OK,这样就支持内置浏览器的模块登录或者数据包登录了。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网
免规则采集器列表算法(功能强大的网络数据采集软件操作简单,可获取平台版本及采集器扩展安装信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-21 10:04
优采云破解版是一款功能强大的网络数据采集软件。软件操作简单,可以获取平台版本和采集器扩展安装信息,获取任务规则列表,定时任务列表,任务采集数据信息。启动、暂停和停止任务、编辑和删除任务、从计划任务中获取任务运行状态等,可以有效提高我们的工作效率。
特征
1、规则定制
通过采集规则的定义,您可以搜索所有网站,采集几乎任何类型的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程中遍历的所见即所得、链接信息、采集信息和错误信息都会及时反映在软件界面中。
4、数据存储
数据采集自动保存到关系型数据库,可自动调整数据结构。软件可以根据采集的规则自动创建数据库,以及表和字段,也可以通过库灵活的保存数据,并转移到客户现有的数据库结构中。
5、断点的持续挖掘
信息采集任务在停止后可以从断点处继续采集,再也不用担心你的采集任务会被意外中断。
6、网站登录
支持网站cookies,支持网站直观登录,即使需要验证网站的代码,也可以采集。
7、预定任务
此功能允许计划、量化或重复采集任务。
8、采集范围限制
可以根据采集的深度和网站地址的标识来限制采集的范围。
9、文件下载
您可以将采集到的二进制文件(如:图片、音乐、软件、文档等)采集到本地磁盘或采集结果数据库中。
10、 结果替换
您可以使用您定义的规则替换集合的结果。
11、 条件保存
您可以根据特定条件确定要保存的信息并过滤信息。
12、过滤重复内容
该软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接标识
使用此函数来识别使用 JavaScript 或其他陌生链接动态生成的链接。
软件亮点
1、几乎所有的网页都可以采集
不管什么语言,不管什么编码。
2、速度比正常快7倍采集器
采用顶级系统配置,反复优化性能,让采集飞得更快。
3、像复制/粘贴一样准确
采集发布和复制粘贴一样准确。用户要的是本质,哪有遗漏。
4、网页采集的得力助手
十年磨一剑,领先各大同类软件,成就网页梦想采集。
破解说明
打开软件后,您可以免费体验所有功能。
重要的是说三遍win10不能用,win10不能用,win10不能用,其他系统都可以 查看全部
免规则采集器列表算法(功能强大的网络数据采集软件操作简单,可获取平台版本及采集器扩展安装信息)
优采云破解版是一款功能强大的网络数据采集软件。软件操作简单,可以获取平台版本和采集器扩展安装信息,获取任务规则列表,定时任务列表,任务采集数据信息。启动、暂停和停止任务、编辑和删除任务、从计划任务中获取任务运行状态等,可以有效提高我们的工作效率。
特征
1、规则定制
通过采集规则的定义,您可以搜索所有网站,采集几乎任何类型的信息。
2、多任务、多线程
多个信息采集任务可以同时执行,每个任务可以使用多个线程。
3、所见即所得
任务采集过程中遍历的所见即所得、链接信息、采集信息和错误信息都会及时反映在软件界面中。
4、数据存储
数据采集自动保存到关系型数据库,可自动调整数据结构。软件可以根据采集的规则自动创建数据库,以及表和字段,也可以通过库灵活的保存数据,并转移到客户现有的数据库结构中。
5、断点的持续挖掘
信息采集任务在停止后可以从断点处继续采集,再也不用担心你的采集任务会被意外中断。
6、网站登录
支持网站cookies,支持网站直观登录,即使需要验证网站的代码,也可以采集。
7、预定任务
此功能允许计划、量化或重复采集任务。
8、采集范围限制
可以根据采集的深度和网站地址的标识来限制采集的范围。
9、文件下载
您可以将采集到的二进制文件(如:图片、音乐、软件、文档等)采集到本地磁盘或采集结果数据库中。
10、 结果替换
您可以使用您定义的规则替换集合的结果。
11、 条件保存
您可以根据特定条件确定要保存的信息并过滤信息。
12、过滤重复内容
该软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接标识
使用此函数来识别使用 JavaScript 或其他陌生链接动态生成的链接。
软件亮点
1、几乎所有的网页都可以采集
不管什么语言,不管什么编码。
2、速度比正常快7倍采集器
采用顶级系统配置,反复优化性能,让采集飞得更快。
3、像复制/粘贴一样准确
采集发布和复制粘贴一样准确。用户要的是本质,哪有遗漏。
4、网页采集的得力助手
十年磨一剑,领先各大同类软件,成就网页梦想采集。
破解说明
打开软件后,您可以免费体验所有功能。
重要的是说三遍win10不能用,win10不能用,win10不能用,其他系统都可以
免规则采集器列表算法(优采云采集器3.0的内部转码工具自动转换的管理方式介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-19 08:10
编辑本节软件介绍
软件大小:6821 KB
软件语言:简体中文
软件类别:国产软件/免费版/网络辅助
应用平台:Win9x/NT/2000/XP/2003
编辑本段优采云采集器3.0版本基本功能介绍
----由于时间原因,测试版中的存储和文件下载尚未完成
1、使用站点+任务的方式管理采集节点。通常,一个站点有多个类别。如果每个类别只使用一组模板或者模板标签变化不大,我们可以只用一个任务完成采集的整个网站,但是如果每个类别使用一个模板和模板的标记变化比较大。这时候我们就需要为每个类别设置一个对应的采集规则(也叫task)。因此,使用站点加任务管理有利于以后的维护——尤其是当采集站点较多时;
采集地址和内容采集
2、 同时实现采集地址和内容采集。按照传统的采集方式,先将地址读到本地,然后对每个地址进行一一解析。这个效率显然很低。优采云采集器3.0采用同步方式,即获取第一个地址后,同时获取其他采集地址采集内容并且可以同时处理多项任务采集!
登录采集
3、登录源采集站采集,编码,JS转换选择,保守计算可以达到目标采集的95%以上。一些比较大的或者国际化的软件大多使用utf8或者unicode编码来解决各国字符之间的问题。gbk下显示的utf8或unicode字符会是一堆乱码。这时候我们就可以使用优采云采集器3.0的内部转码工具来自动转换了!在采集网站的过程中,我们发现很多网站隐藏了自己的真实地址,使用js调用来防止采集(例如:javascript winopen([parameter 1], [参数2] ),一般采集器无法实现这样的网址采集。对于<官方版的<
地址采集
4、地址采集可以单次、批量、文本方式导入和添加,无需标签自动识别URL连接。采集 地址 当我们只需要 采集 一个网页时,可以添加一个 URL。如果单个任务需要采集多个页面,可以批量添加URL。如果你有一个已经有 URL 的文本集合,那么你可以直接导入 URL。优采云采集器可以智能识别网址!
使用规则
5、 使用规则标签管理采集 项,不再局限于普通标题、内容采集,标签实现完全自定义。如果我们采集一个药品的数据,我们可能需要的数据包括:制造商、产品型号、使用说明、产品配置等,这些标签不能只用一个内容和一个标题来实现。这时候就可以使用优采云采集器的自定义标签来完成你想要的任意数量的标签;
编辑规则标签
<p>6、 编辑规则标签可以去除广告,无限替换,真正得到你需要的内容。同时,程序提供了规则类型选择和基本的HTML代码排除功能。您可以在任何标签中添加无限制的排除和替换规则,以提取您需要的任何格式内容。同时优采云采集器提供html标签排除功能,可以一次性排除7、人工智能内容分页采集技术,结合您的论坛/< @cms系统即使是采集的文章也可以恢复到采集的原创页码。现在大部分 查看全部
免规则采集器列表算法(优采云采集器3.0的内部转码工具自动转换的管理方式介绍)
编辑本节软件介绍
软件大小:6821 KB
软件语言:简体中文
软件类别:国产软件/免费版/网络辅助
应用平台:Win9x/NT/2000/XP/2003
编辑本段优采云采集器3.0版本基本功能介绍
----由于时间原因,测试版中的存储和文件下载尚未完成
1、使用站点+任务的方式管理采集节点。通常,一个站点有多个类别。如果每个类别只使用一组模板或者模板标签变化不大,我们可以只用一个任务完成采集的整个网站,但是如果每个类别使用一个模板和模板的标记变化比较大。这时候我们就需要为每个类别设置一个对应的采集规则(也叫task)。因此,使用站点加任务管理有利于以后的维护——尤其是当采集站点较多时;
采集地址和内容采集
2、 同时实现采集地址和内容采集。按照传统的采集方式,先将地址读到本地,然后对每个地址进行一一解析。这个效率显然很低。优采云采集器3.0采用同步方式,即获取第一个地址后,同时获取其他采集地址采集内容并且可以同时处理多项任务采集!
登录采集
3、登录源采集站采集,编码,JS转换选择,保守计算可以达到目标采集的95%以上。一些比较大的或者国际化的软件大多使用utf8或者unicode编码来解决各国字符之间的问题。gbk下显示的utf8或unicode字符会是一堆乱码。这时候我们就可以使用优采云采集器3.0的内部转码工具来自动转换了!在采集网站的过程中,我们发现很多网站隐藏了自己的真实地址,使用js调用来防止采集(例如:javascript winopen([parameter 1], [参数2] ),一般采集器无法实现这样的网址采集。对于<官方版的<
地址采集
4、地址采集可以单次、批量、文本方式导入和添加,无需标签自动识别URL连接。采集 地址 当我们只需要 采集 一个网页时,可以添加一个 URL。如果单个任务需要采集多个页面,可以批量添加URL。如果你有一个已经有 URL 的文本集合,那么你可以直接导入 URL。优采云采集器可以智能识别网址!
使用规则
5、 使用规则标签管理采集 项,不再局限于普通标题、内容采集,标签实现完全自定义。如果我们采集一个药品的数据,我们可能需要的数据包括:制造商、产品型号、使用说明、产品配置等,这些标签不能只用一个内容和一个标题来实现。这时候就可以使用优采云采集器的自定义标签来完成你想要的任意数量的标签;
编辑规则标签
<p>6、 编辑规则标签可以去除广告,无限替换,真正得到你需要的内容。同时,程序提供了规则类型选择和基本的HTML代码排除功能。您可以在任何标签中添加无限制的排除和替换规则,以提取您需要的任何格式内容。同时优采云采集器提供html标签排除功能,可以一次性排除7、人工智能内容分页采集技术,结合您的论坛/< @cms系统即使是采集的文章也可以恢复到采集的原创页码。现在大部分
免规则采集器列表算法(网络数据采集器(2.1)是一款多功能.支持ajax)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-17 11:11
网络数据采集器2.1是多功能的,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成内容的抓取,采集QQ业务群的业务信息
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻格式,包括图片,可自动保留(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。也可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,在采集的数据自动移除后将数据导入数据库(可以指定唯一项的组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以在不占用系统资源的情况下,连续采集十万级和百万级数据。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。 查看全部
免规则采集器列表算法(网络数据采集器(2.1)是一款多功能.支持ajax)
网络数据采集器2.1是多功能的,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成内容的抓取,采集QQ业务群的业务信息
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻格式,包括图片,可自动保留(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。也可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,在采集的数据自动移除后将数据导入数据库(可以指定唯一项的组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以在不占用系统资源的情况下,连续采集十万级和百万级数据。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。
免规则采集器列表算法(免规则采集器的高级特征内容收集器列表算法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-16 16:01
免规则采集器列表算法采集器的高级特征内容收集器采集器的文本列表:例如采集“动漫”、“日系”、“二次元”,采集分数采集器的关键字爬取文章列表抓取rss源接下来用xml实现一个链接的base64后缀处理base64加密算法(一)解密算法,去复杂数据库处理数据取值列表采集器编辑器,可对重复域名,变体域名等进行重复项检查,有些重复内容可以直接去掉,非重复内容不会被提示判断,有时遇到重复的可以放置超链接,第二次网站建设时可以放弃使用此种方式。
也可以修改数据源并保存。网站重定向爬虫在重定向,第三方网站受限,不能抓取。一个网站可抓取重定向多个网站,第三方网站通常限制每个页面抓取,否则会造成加载不完整的情况,然后再请求下一个。爬虫可以抓取子网站,该子网站也可以提供完整的代码数据,用于多个网站,最主要的是可以抓取同一个子网站提供的其他代码,节省空间。
爬虫抓取到的网页要求做防抓取,第三方网站多数有限制以下两种情况用防抓取方式:非中文:有部分软件抓取西文字符,我们可以使用识别内容文本中的关键字,爬虫是要求抓取中文的。正则表达式:我们有一些内容标识和其中会有密码和其他数据,这些信息是相关的,可能会对用户进行限制,有些网站在该网页上加了cookie,这些信息都要通过正则表达式解析出来并加密传输,这样会导致加密代码和被访问网站的生成代码不一致,造成加密失败,影响正常访问。
网页文本采集还有文本采集出的数据是网站访问者的必须要提供的,所以我们需要获取网站访问者的信息,采集到一定的内容可以吸引我们的网站访问者来访问我们的网站,然后获取其他网站的信息,这样网站爬虫和其他网站的爬虫就有了交集。filezilla对采集文件,可以抓取数据源链接或者文件,这样才可以访问文件数据。编辑器的信息,爬虫可以包含自己的文件的指定目录的文件包含的文件的指定目录的文件,网页的链接等,列出文件夹和指定目录这样做:可以创建多个网站,每个网站只要抓取需要的内容即可,网站文件可以用另外的对应的工具爬取。
数据库管理:filezilla可以直接传输采集文件内容到数据库,可用数据库mysql、redis。可以存放采集的外链数据和自定义爬虫代码数据,但是无法存放数据库里的数据库和爬虫的相关信息。 查看全部
免规则采集器列表算法(免规则采集器的高级特征内容收集器列表算法(一))
免规则采集器列表算法采集器的高级特征内容收集器采集器的文本列表:例如采集“动漫”、“日系”、“二次元”,采集分数采集器的关键字爬取文章列表抓取rss源接下来用xml实现一个链接的base64后缀处理base64加密算法(一)解密算法,去复杂数据库处理数据取值列表采集器编辑器,可对重复域名,变体域名等进行重复项检查,有些重复内容可以直接去掉,非重复内容不会被提示判断,有时遇到重复的可以放置超链接,第二次网站建设时可以放弃使用此种方式。
也可以修改数据源并保存。网站重定向爬虫在重定向,第三方网站受限,不能抓取。一个网站可抓取重定向多个网站,第三方网站通常限制每个页面抓取,否则会造成加载不完整的情况,然后再请求下一个。爬虫可以抓取子网站,该子网站也可以提供完整的代码数据,用于多个网站,最主要的是可以抓取同一个子网站提供的其他代码,节省空间。
爬虫抓取到的网页要求做防抓取,第三方网站多数有限制以下两种情况用防抓取方式:非中文:有部分软件抓取西文字符,我们可以使用识别内容文本中的关键字,爬虫是要求抓取中文的。正则表达式:我们有一些内容标识和其中会有密码和其他数据,这些信息是相关的,可能会对用户进行限制,有些网站在该网页上加了cookie,这些信息都要通过正则表达式解析出来并加密传输,这样会导致加密代码和被访问网站的生成代码不一致,造成加密失败,影响正常访问。
网页文本采集还有文本采集出的数据是网站访问者的必须要提供的,所以我们需要获取网站访问者的信息,采集到一定的内容可以吸引我们的网站访问者来访问我们的网站,然后获取其他网站的信息,这样网站爬虫和其他网站的爬虫就有了交集。filezilla对采集文件,可以抓取数据源链接或者文件,这样才可以访问文件数据。编辑器的信息,爬虫可以包含自己的文件的指定目录的文件包含的文件的指定目录的文件,网页的链接等,列出文件夹和指定目录这样做:可以创建多个网站,每个网站只要抓取需要的内容即可,网站文件可以用另外的对应的工具爬取。
数据库管理:filezilla可以直接传输采集文件内容到数据库,可用数据库mysql、redis。可以存放采集的外链数据和自定义爬虫代码数据,但是无法存放数据库里的数据库和爬虫的相关信息。
免规则采集器列表算法(优你扮小丑扮得太久了,演得戏,都忘记自己了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-11 06:05
标签:网址采集
类别:个人作品
永久链接:
密码:
关键词:
说明:Lang_URL depth 采集程序是一个允许自定义URL规则的URL采集程序。在 URL采集 过程中,该 URL 会进行动态规则检测,只有满足条件的 URL 才会被允许记录保存到本地。例如,如果URL收录[www],则标题中必须出现[International],网页中不允许出现[safe dog]等规则。并且还可以通过好友链进行无限采集和过滤。
你做小丑太久了,你已经忘记了自己。
lang_url自动化采集0.95版本常用URL采集器不足
市面上大部分的 URL 采集 软件都是这样工作的:
这意味着你需要尽可能多的接口,包括但不限于必应、谷歌、搜狗、百度等,然后将参数传递给返回的页面,根据黑名单提取网址并过滤一些网址,最后迭代页数。
看起来是正确的,输入关键词获取相关的URL。但在这个表面之下隐藏着几个缺点:
缺陷的解决方案
为了解决优化问题,造福大众,郎大师花了2个小时完成伪代码并试运行成功……然后又花了8个多小时修复了一些bug……目前完成的是0. 95版本,0.95版本提供以下功能:
基本的
其实实现并不难,难点在于程序中的条件判断,不甘心就会弹出bug……
无非就是先获取过滤规则,然后判断传入方法获取URL,最后对URL进行规则判断。
功能介绍
使用前,希望您能仔细阅读介绍。当前版本为0.95。
打开目录,会发现3个文件,分别是:
下面重点说一下配置文件的写法。涉及到URL过滤规则以及是否无限采集、请求超时、线程数等。
自定义规则
打开当前目录下的Config.ini,配置安装要求
[User]
whoami = Langzi
[Config]
#条件设置 & 是与关系。| 是或关系。
#设置成 None 即不检测存在与否关系,直接保存到本地
#一个条件中可以存在多个&,也可以存在多个|,但不允许同时存在&和|
#具体用法看下面例子
title = 浪子&博客
#title = 浪子&博客,标题中必须存在【浪子】和【博客】两个词才允许保存到本地
#如果设置成None的话,不检测标题关系
#title = None 的话,不检测标题中存不存在词
#title = 浪子 的话,标题中必须存在【浪子】这个词才允许保存到本地
#title = 浪子|博客,标题中仅需存在【浪子】或【博客】其中一个词就允许保存到本地
black_title = 捡到钱|踩到屎
#标题中出现【捡到钱】或【踩到屎】其中任意一个词就排除这个网址
url = www&cn
#网址中必须存在【www】和【cn】两个词才允许保存到本地
black_url = gov.cn|edu.cn
#网址中出现【gov.cn】或【edu.cn】其中任意一个词就排除这个网址
content = None
#不检测网页存在与否关系
#即不管网页存在什么都保存到本地
black_content = 404|360|安全狗
#网页中出现【404】或【360】或【安全狗】其中任意一个词就排除这个网址
thread = 100
#采集线程
timeout = 5
#连接超时5秒
track = 1
#设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
#设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的结果无限重复采集,实现挂机无限采集符合要求的网址
URL过滤权重顺序:
网址黑名单>标题黑名单>网页黑名单>网址白名单>标题白名单>网页白名单
如果其中之一不符合配置文件的要求,则排除 URL
注意所有 & | 都不是英文输入法
如果你害怕你的输入错误,直接复制到这里
&&&&&&
||||||
None None None
注意对于track(好友链爬取)和forever(无限采集)配置项,如果设置forever=1,track也必须设置为1,因为如果要启用无限制采集,必须开启好友链爬取功能,否则不会有新连接传入,也无法实现无限采集功能。
第一次使用
和大多数网址采集器一样,启动后会提示输入关键词,然后输入采集网址。
配置config.ini过滤规则后,线程数,连接超时,是否开启好友链爬取,是否开启无限制采集。右键启动浪子网址采集0.95.exe
配置如下:
[User]
whoami = Langzi
[Config]
url = .edu.cn
black_url = None
title = 学
black_title = 政府
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 0
功能:URL收录[.],标题收录[Learn],标题不能收录[Government],网页不能收录[Government],500个线程,连接超时5秒,结果爬虫链一次,不是无限的采集
这时候你会看到如下界面
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-3r0czlsY-41)(/upload/TIM screenshot205.png)]
根据提示,此时需要传入初始URL,因为本地没有保存采集 URL,所以输入1继续百度关键词采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-DVR9FzM8-42)(/upload/TIM截图216.png)]
此时查看日志文件,查看启动采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-9eDz7kHb-43)(/upload/TIM截图218.png)]
异常状态、朋友链爬取、规则过滤都在日志文件中
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-SR1kBSzU-44)(/upload/TIM screenshot206.png)]
最终结果会保存在本地
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-YHK9Km64-45)(/upload/TIM截图259.png)]
然后使用文本 deduplication.exe 去除重复,只需将文本拖入即可。
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-YDu3d7xP-45)(/upload/TIM截图224.png)]
采集结束。
初始URL也可以从文本文件中加载,也可以输入关键词然后使用内置的百度界面采集 URL。
比如这时候你打开主程序,按照提示输入0
您也可以将 URL 文本拖入 采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-doGRbLlF-46)(/upload/TIM截图214.png)]
这取决于您的个人需求。如果你手上有100个网址,想要抓取这100个网址,运行主程序输入0,然后直接把文字拖进去按回车。
手上没有网址也没关系,也可以使用内置接口采集关键词。运行主程序,输入1,提示输入关键词,然后使用百度界面采集。
可以在日志文件中看到爬取日志。
每次的结果按照时间自动保存在本地。
规则与技巧采集教育网站
config.ini 是这样设置的
[User]
whoami = Langzi
[Config]
title = 学校|教育
# 标题中出现【学校】或者【教育】其中一个词就保存本地
black_title = 政府
# 标题出现【政府】就排除这个网址
url = .edu.cn
# 网址中必须出现【.edu.cn】
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = 政府|上海|北京
# 网页中出现【政府】或者【上海】或者【北京】其中某一个词就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集大厂子域
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集 具体网址(国外)
[User]
whoami = Langzi
[Config]
title = None
# 不检测标题内容
black_title = 一|科|中|新|信|阿|吧|思|家
# 标题出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
url = www&jp
# 网址中必须出现【www】和【jp】这两个词才会保存到本地(日本网址后缀)
black_url = cn
# 网址中出现【cn】就排除这个网址
content = None
# 不检测网页内容
black_content = 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
# 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
验证大量本地 URL
如果你手上有100w个网址,但又不想爬取这些网址,因为那样会浪费时间。只对100w的URL进行规则过滤,右键启动主程序,根据提示输入0,将文字拖进去。
配置文件如下:
比如要过滤掉大厂的域名
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
重点在这里:
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
有了这个设置,URL 上就不会出现好友链爬取和无限采集。
初始URL导入的具体使用
右键启动主程序时,会提示初始URL的传入方法
- 输入:0 ,会让你把网址文本拖拽进来
- 输入:1 ,会让你输入关键词,然后百度采集网址
我只想抓取和过滤一次朋友链
在配置文件中写入以下两行
track = 1
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动,安装提示导入初始网址或使用百度关键词采集。
采集 完成后,右击允许文本deduplication.exe,直接拖动结果重复。
我只想抓取朋友链两次并过滤
(>人<;) 抱歉,暂不支持
想要无限采集 URL
在配置文件中写入以下两行
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
这就开启了无限采集功能,右键启动主程序,按照提示导入初始网址或者使用百度关键词采集功能,那你就没有了担心它。
每次采集的结果都按照时间保存到本地,无限制的采集功能就是把这次的所有结果作为下一次的初始URL导入。
自动重复数据删除。
我只想过滤大量本地网址
如上所述,在配置文件中写入以下两行
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动主程序,根据提示输入0,将URL文本拖进去,结果会自动保存到本地。
个人使用
其实使用规则很简单,无非就是跟或跟的关系。配置无限制采集也很简单。前提只有一个,就是要开启无限采集,必须开启好友链爬取。
规则的种类不多,大家可以根据自己的需要进行配置。毕竟,您知道自己的需求。当然,不仅仅是这样写用法。如何深度爬取更多网站取决于你的大脑。
比如你用b0y的url采集器采集得到5000个网址,然后就可以开启这些网址的好友链爬取和深度爬取,然后就可以爬到更多的网址了。
还有更多的show操作,就看你能不能想到了。
日志
朋友链每次爬取,规则过滤的异常状态都会保存在本地当前目录的log.txt中。你可以关注这个文件。
注意
解决方案:
打开config.ini,然后另存为asicii编码就行了。
效果展示
对于采集教育网站,我的配置文件是这样写的
[User]
whoami = Langzi
[Config]
title = 学
black_title = 政府
url = .edu.cn
black_url = None
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 1
然后右键启动主程序,因为之前没有采集 URL,所以输入1提示输入关键词,我输入【教育】,然后启动自动采集 程序。然后我去玩游戏,过了一会,本地又多了三个文本,是依次保存的结果。按时间排序,以下文字采集的结果最全面。放到服务器上挂了一天后重复采集4W多教育网。
lang_url自动化采集0.96版
重点在这里:
track = 1
# 设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
# 设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 对结果重复继续重复爬行友链次数
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的在进行友链爬行采集一次
# 设置 2 会对采集的在进行友链爬行采集两次
# 设置 3 会对采集的在进行友链爬行采集三次
# 设置 x 会对采集的在进行友链爬行采集x次
# 设置 forever大于0 的前提条件是track=1
【** 注意,forever 大于0 的前提条件是track = 1,即必须开启自动爬行友链的前提下才能启用无限采集功能 **】
【** 注意,如果不想采集友链不想多次采集,仅对自己的网址文本进行规则过滤的话,设置forever = 0,track = 0**】
【** 注意,如果设置track=0,forever=1或者大于1的话,效果和forever=0,track=0 效果一样,所以请不要这样做**】
【** 注意,如果设置track=1,forever=0的话,效果为要进行友链采集但没有设置采集次数,所以请不要这样做**】
也就是说:track(朋友链爬取)只有0(关闭)和1(打开)两个选项,forever(爬取次数)有0-1000(0-无限正整数)选项。
如果只想按规则过滤自己手上的url,设置forever=0,track=0
2018 年 9 月 5 日 00:12:46
修复一个功能,当设置所有过滤规则=None,则track=1,forever=一个大于0的正整数,即不对URL进行规则过滤,只提取网页的所有URL并保存到本地。
这意味着你可以这样设置
[User]
whoami = Langzi
[Config]
url = None
black_url = None
title = None
black_title = None
content = None
black_content = None
thread = 100
timeout = 5
track = 1
forever = 8
功能:无检测规则,直接提取页面中的所有URL。
然后导入URL,爬取好友链,爬了8次,采集很多结果。然后就可以汇总所有的结果,然后设置自定义的本地文件过滤规则。使用方法有很多种,具体的需求就看你怎么操作了。
lang_url自动化采集0.97版
2018 年 9 月 6 日 18:13:40
修复一个功能
添加新功能
设置white_or = 1表示所有白名单(url、title、content,只要其中一个符合条件就会保存在本地,即url=www,title=international,content=langzi,只要www出现在URL,会保存到本地)设置white_or = 0表示所有白名单(url, title, content, 保存前必须满足三个条件)
暂时没有黑名单和机制。
2018 年 9 月 7 日 20:28:33
修复多个 采集 问题
lang_url自动化采集0.98版
每次扫描时都会在当前目录中创建一个新文件夹。文件夹是爬取检测后的URL,里面有一个result.txt。这个文本文件是所有符合规则的 URL。
2018 年 9 月 9 日 22:42:11
2018 年 9 月 10 日 22:06:22
最新下载地址
提取密码:
lang_url自动化采集0.99版
一些有趣的小功能 查看全部
免规则采集器列表算法(优你扮小丑扮得太久了,演得戏,都忘记自己了)
标签:网址采集
类别:个人作品
永久链接:
密码:
关键词:
说明:Lang_URL depth 采集程序是一个允许自定义URL规则的URL采集程序。在 URL采集 过程中,该 URL 会进行动态规则检测,只有满足条件的 URL 才会被允许记录保存到本地。例如,如果URL收录[www],则标题中必须出现[International],网页中不允许出现[safe dog]等规则。并且还可以通过好友链进行无限采集和过滤。
你做小丑太久了,你已经忘记了自己。
lang_url自动化采集0.95版本常用URL采集器不足
市面上大部分的 URL 采集 软件都是这样工作的:
这意味着你需要尽可能多的接口,包括但不限于必应、谷歌、搜狗、百度等,然后将参数传递给返回的页面,根据黑名单提取网址并过滤一些网址,最后迭代页数。
看起来是正确的,输入关键词获取相关的URL。但在这个表面之下隐藏着几个缺点:
缺陷的解决方案
为了解决优化问题,造福大众,郎大师花了2个小时完成伪代码并试运行成功……然后又花了8个多小时修复了一些bug……目前完成的是0. 95版本,0.95版本提供以下功能:
基本的
其实实现并不难,难点在于程序中的条件判断,不甘心就会弹出bug……
无非就是先获取过滤规则,然后判断传入方法获取URL,最后对URL进行规则判断。
功能介绍
使用前,希望您能仔细阅读介绍。当前版本为0.95。
打开目录,会发现3个文件,分别是:
下面重点说一下配置文件的写法。涉及到URL过滤规则以及是否无限采集、请求超时、线程数等。
自定义规则
打开当前目录下的Config.ini,配置安装要求
[User]
whoami = Langzi
[Config]
#条件设置 & 是与关系。| 是或关系。
#设置成 None 即不检测存在与否关系,直接保存到本地
#一个条件中可以存在多个&,也可以存在多个|,但不允许同时存在&和|
#具体用法看下面例子
title = 浪子&博客
#title = 浪子&博客,标题中必须存在【浪子】和【博客】两个词才允许保存到本地
#如果设置成None的话,不检测标题关系
#title = None 的话,不检测标题中存不存在词
#title = 浪子 的话,标题中必须存在【浪子】这个词才允许保存到本地
#title = 浪子|博客,标题中仅需存在【浪子】或【博客】其中一个词就允许保存到本地
black_title = 捡到钱|踩到屎
#标题中出现【捡到钱】或【踩到屎】其中任意一个词就排除这个网址
url = www&cn
#网址中必须存在【www】和【cn】两个词才允许保存到本地
black_url = gov.cn|edu.cn
#网址中出现【gov.cn】或【edu.cn】其中任意一个词就排除这个网址
content = None
#不检测网页存在与否关系
#即不管网页存在什么都保存到本地
black_content = 404|360|安全狗
#网页中出现【404】或【360】或【安全狗】其中任意一个词就排除这个网址
thread = 100
#采集线程
timeout = 5
#连接超时5秒
track = 1
#设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
#设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的结果无限重复采集,实现挂机无限采集符合要求的网址
URL过滤权重顺序:
网址黑名单>标题黑名单>网页黑名单>网址白名单>标题白名单>网页白名单
如果其中之一不符合配置文件的要求,则排除 URL
注意所有 & | 都不是英文输入法
如果你害怕你的输入错误,直接复制到这里
&&&&&&
||||||
None None None
注意对于track(好友链爬取)和forever(无限采集)配置项,如果设置forever=1,track也必须设置为1,因为如果要启用无限制采集,必须开启好友链爬取功能,否则不会有新连接传入,也无法实现无限采集功能。
第一次使用
和大多数网址采集器一样,启动后会提示输入关键词,然后输入采集网址。
配置config.ini过滤规则后,线程数,连接超时,是否开启好友链爬取,是否开启无限制采集。右键启动浪子网址采集0.95.exe
配置如下:
[User]
whoami = Langzi
[Config]
url = .edu.cn
black_url = None
title = 学
black_title = 政府
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 0
功能:URL收录[.],标题收录[Learn],标题不能收录[Government],网页不能收录[Government],500个线程,连接超时5秒,结果爬虫链一次,不是无限的采集
这时候你会看到如下界面
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-3r0czlsY-41)(/upload/TIM screenshot205.png)]
根据提示,此时需要传入初始URL,因为本地没有保存采集 URL,所以输入1继续百度关键词采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-DVR9FzM8-42)(/upload/TIM截图216.png)]
此时查看日志文件,查看启动采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-9eDz7kHb-43)(/upload/TIM截图218.png)]
异常状态、朋友链爬取、规则过滤都在日志文件中
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-SR1kBSzU-44)(/upload/TIM screenshot206.png)]
最终结果会保存在本地
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-YHK9Km64-45)(/upload/TIM截图259.png)]
然后使用文本 deduplication.exe 去除重复,只需将文本拖入即可。
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-YDu3d7xP-45)(/upload/TIM截图224.png)]
采集结束。
初始URL也可以从文本文件中加载,也可以输入关键词然后使用内置的百度界面采集 URL。
比如这时候你打开主程序,按照提示输入0
您也可以将 URL 文本拖入 采集
[外部链接图像传输失败。源站点可能具有反水蛭链接机制。建议保存图片直接上传(img-doGRbLlF-46)(/upload/TIM截图214.png)]
这取决于您的个人需求。如果你手上有100个网址,想要抓取这100个网址,运行主程序输入0,然后直接把文字拖进去按回车。
手上没有网址也没关系,也可以使用内置接口采集关键词。运行主程序,输入1,提示输入关键词,然后使用百度界面采集。
可以在日志文件中看到爬取日志。
每次的结果按照时间自动保存在本地。
规则与技巧采集教育网站
config.ini 是这样设置的
[User]
whoami = Langzi
[Config]
title = 学校|教育
# 标题中出现【学校】或者【教育】其中一个词就保存本地
black_title = 政府
# 标题出现【政府】就排除这个网址
url = .edu.cn
# 网址中必须出现【.edu.cn】
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = 政府|上海|北京
# 网页中出现【政府】或者【上海】或者【北京】其中某一个词就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集大厂子域
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
采集 具体网址(国外)
[User]
whoami = Langzi
[Config]
title = None
# 不检测标题内容
black_title = 一|科|中|新|信|阿|吧|思|家
# 标题出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
url = www&jp
# 网址中必须出现【www】和【jp】这两个词才会保存到本地(日本网址后缀)
black_url = cn
# 网址中出现【cn】就排除这个网址
content = None
# 不检测网页内容
black_content = 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
# 网页出现【一|科|中|新|信|阿|吧|思|家】其中一个就排除这个网址
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
验证大量本地 URL
如果你手上有100w个网址,但又不想爬取这些网址,因为那样会浪费时间。只对100w的URL进行规则过滤,右键启动主程序,根据提示输入0,将文字拖进去。
配置文件如下:
比如要过滤掉大厂的域名
[User]
whoami = Langzi
[Config]
title = 百度|京东|淘宝|阿里|腾讯|浪子
# 标题中出现【百度|京东|淘宝|阿里|腾讯|浪子】其中一个词就保存本地
black_title = 黄页|企业信息|天眼查
# 标题出现【黄页|企业信息|天眼查】其中一个就排除这个网址
url = baidu|taobao|tentcent|jd|langzi
# 网址中出现【baidu|taobao|tentcent|jd|langzi】其中一个词就保存本地
black_url = None
# 不检测网址黑名单
content = None
# 不检测网页内容
black_content = None
# 不检测网页黑名单
thread = 500
# 线程数量 500
timeout = 5
# 连接超时 5 秒
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
重点在这里:
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
有了这个设置,URL 上就不会出现好友链爬取和无限采集。
初始URL导入的具体使用
右键启动主程序时,会提示初始URL的传入方法
- 输入:0 ,会让你把网址文本拖拽进来
- 输入:1 ,会让你输入关键词,然后百度采集网址
我只想抓取和过滤一次朋友链
在配置文件中写入以下两行
track = 1
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动,安装提示导入初始网址或使用百度关键词采集。
采集 完成后,右击允许文本deduplication.exe,直接拖动结果重复。
我只想抓取朋友链两次并过滤
(>人<;) 抱歉,暂不支持
想要无限采集 URL
在配置文件中写入以下两行
track = 1
# 对网址进行友链爬行
forever = 1
# 进行无限采集
这就开启了无限采集功能,右键启动主程序,按照提示导入初始网址或者使用百度关键词采集功能,那你就没有了担心它。
每次采集的结果都按照时间保存到本地,无限制的采集功能就是把这次的所有结果作为下一次的初始URL导入。
自动重复数据删除。
我只想过滤大量本地网址
如上所述,在配置文件中写入以下两行
track = 0
# 不对网址进行友链爬行
forever = 0
# 不进行无限采集
然后右键启动主程序,根据提示输入0,将URL文本拖进去,结果会自动保存到本地。
个人使用
其实使用规则很简单,无非就是跟或跟的关系。配置无限制采集也很简单。前提只有一个,就是要开启无限采集,必须开启好友链爬取。
规则的种类不多,大家可以根据自己的需要进行配置。毕竟,您知道自己的需求。当然,不仅仅是这样写用法。如何深度爬取更多网站取决于你的大脑。
比如你用b0y的url采集器采集得到5000个网址,然后就可以开启这些网址的好友链爬取和深度爬取,然后就可以爬到更多的网址了。
还有更多的show操作,就看你能不能想到了。
日志
朋友链每次爬取,规则过滤的异常状态都会保存在本地当前目录的log.txt中。你可以关注这个文件。
注意
解决方案:
打开config.ini,然后另存为asicii编码就行了。
效果展示
对于采集教育网站,我的配置文件是这样写的
[User]
whoami = Langzi
[Config]
title = 学
black_title = 政府
url = .edu.cn
black_url = None
content = None
black_content = 政府
thread = 500
timeout = 5
track = 1
forever = 1
然后右键启动主程序,因为之前没有采集 URL,所以输入1提示输入关键词,我输入【教育】,然后启动自动采集 程序。然后我去玩游戏,过了一会,本地又多了三个文本,是依次保存的结果。按时间排序,以下文字采集的结果最全面。放到服务器上挂了一天后重复采集4W多教育网。
lang_url自动化采集0.96版
重点在这里:
track = 1
# 设置 0 表示对传入的网址不采集友链,直接对传入网址进行动态规则筛选
# 设置 1 将会对传入网址进行友链采集,并且对传入网址和网址的友链进行动态规则筛选
forever = 1
# 对结果重复继续重复爬行友链次数
# 设置 0 表示不会对采集的结果无限重复采集
# 设置 1 会对采集的在进行友链爬行采集一次
# 设置 2 会对采集的在进行友链爬行采集两次
# 设置 3 会对采集的在进行友链爬行采集三次
# 设置 x 会对采集的在进行友链爬行采集x次
# 设置 forever大于0 的前提条件是track=1
【** 注意,forever 大于0 的前提条件是track = 1,即必须开启自动爬行友链的前提下才能启用无限采集功能 **】
【** 注意,如果不想采集友链不想多次采集,仅对自己的网址文本进行规则过滤的话,设置forever = 0,track = 0**】
【** 注意,如果设置track=0,forever=1或者大于1的话,效果和forever=0,track=0 效果一样,所以请不要这样做**】
【** 注意,如果设置track=1,forever=0的话,效果为要进行友链采集但没有设置采集次数,所以请不要这样做**】
也就是说:track(朋友链爬取)只有0(关闭)和1(打开)两个选项,forever(爬取次数)有0-1000(0-无限正整数)选项。
如果只想按规则过滤自己手上的url,设置forever=0,track=0
2018 年 9 月 5 日 00:12:46
修复一个功能,当设置所有过滤规则=None,则track=1,forever=一个大于0的正整数,即不对URL进行规则过滤,只提取网页的所有URL并保存到本地。
这意味着你可以这样设置
[User]
whoami = Langzi
[Config]
url = None
black_url = None
title = None
black_title = None
content = None
black_content = None
thread = 100
timeout = 5
track = 1
forever = 8
功能:无检测规则,直接提取页面中的所有URL。
然后导入URL,爬取好友链,爬了8次,采集很多结果。然后就可以汇总所有的结果,然后设置自定义的本地文件过滤规则。使用方法有很多种,具体的需求就看你怎么操作了。
lang_url自动化采集0.97版
2018 年 9 月 6 日 18:13:40
修复一个功能
添加新功能
设置white_or = 1表示所有白名单(url、title、content,只要其中一个符合条件就会保存在本地,即url=www,title=international,content=langzi,只要www出现在URL,会保存到本地)设置white_or = 0表示所有白名单(url, title, content, 保存前必须满足三个条件)
暂时没有黑名单和机制。
2018 年 9 月 7 日 20:28:33
修复多个 采集 问题
lang_url自动化采集0.98版
每次扫描时都会在当前目录中创建一个新文件夹。文件夹是爬取检测后的URL,里面有一个result.txt。这个文本文件是所有符合规则的 URL。
2018 年 9 月 9 日 22:42:11
2018 年 9 月 10 日 22:06:22
最新下载地址
提取密码:
lang_url自动化采集0.99版
一些有趣的小功能
免规则采集器列表算法(Version填列采集平台数据表导入5、数据表表回收与合并)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 06:16
版本V2.08a 5、数据表导入到采集平台数据表导入5 4.表回收和整合3.数据表填写和第2栏制定采集规则6.数据检查汇总1.数据表导出数据表导入注意:要导入的数据表文件必须与采集平台文件在同一文件目录下;导入数据表前,重命名数据表的文件名。文件名必须与所选工作表的名称相同(即:从导出的文件名中删除括号)。重复数据表导入操作时,如果有同名工作表,系统会给出A提示,操作者判断是覆盖文件还是放弃操作。例如:导出的数据表名称为:A3基本校情表(XX采集)。导入xls时,数据表更名:A3基本校情表.xls V版2.08a 6、状态数据校验与汇总6 5.数据表导入数据校验与汇总< @4.表回收合并3.数据表填充2 制定采集规则1.数据表导出数据校验:完成数据表导入后,检查采集中的数据@> 平台确认已导入所有有效数据。数据汇总:执行“数据统计汇总”操作,生成汇总数据的第十部分注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“ 可返回状态数据目录页面数据汇总:点击平台导航“填表说明”操作,在填表说明页面,点击“数据统计汇总”操作汇总平台内数据,生成第十部分 汇总数据,点击平台导航中的“状态数据目录”操作,在状态数据目录页面点击数据汇总表名称,勾选保存汇总数据的平台文件,关闭文件V版本2.08a 六、状态数据采集解决在进行单表数据合并操作时,数据表中保留的数据行不足的疑问。如何添加数据行?在采集平台,我校想加一栏,是否可以?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集 解决单表数据合并操作时,怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集解决单表数据合并操作时怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?版本V2.08a 问题解决步骤一:执行“解锁基本表”
问题一:单表数据合并操作时,数据表中预留的数据行不够,如何添加数据行?版本V2.08a 问题解释二 目前需要上报状态数据采集平台文件,并且其中的数据指标是固定的,所以采集平台中的数据列不能增加和减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。问题2 在data采集平台,我校想加一栏,可以吗?Version V2.08a Question 3 Question 3 导出数据表时,系统发出宏警告,无法执行导出操作。我该怎么办?操作步骤: 选择菜单:工具->宏->安全,打开安全对话框,将安全级别设置为“低”;完成以上设置后,保存并关闭采集平台文件;重新打开采集平台文件,系统自动激活宏;导出数据表。Version V2.08a Question 4 Question 4 查阅Part 10的汇总数据,发现有些汇总值有问题。如何检查问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作;在数据汇总表中汇总分类表下,说明了参与情况对于汇总数据的来源,按照提示查看汇总数据表中的数据。如果数据被修改,则必须重新进行“数据统计汇总”操作;分析聚合数据,正确理解数据结构。
V版2.08a 使用平台注意事项 打开采集平台文件时,允许启动宏;仔细阅读每张数据表开头的说明和注释,填写所需数据时填写教职工编号、专业代码、课程代码系统一、不能为空;数据表中提供了标准化的数据输入方式,可根据实际情况选择。完成数据输入后,执行“数据统计与汇总”操作,生成汇总数据(第10部分)。表中不能随意添加或删除数据项,可以添加数据行。V版2.08a 状态数据报告 数据文件上报的两种方式 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) V版<
例如:上海兴建职业学院学校代码:12493,备案年份:2008 文件名:12493_2008_STATUS V208a.xls 学校代码版本V2.08a 2. 创建文件目录和文件命名第一步、第二步和第三步。将上级发送的数据采集平台文件复制到文件目录下。重命名状态数据采集平台文件,根据上报文件的命名规则创建状态数据。文件目录、文件管理计划文件目录,用于管理上报、下发和回收的数据文件的状态数据:根据申报年份或采集时间创建状态数据的每个文件目录,用于存储和管理采集 平台文件和各种数据表文件。版本 V<
工具->宏->安全,在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。
版本V2.08a 2. 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到平台。版本V2.08a 3. 数据表导入 “数据表导入”操作可以将36个已完成数据输入的数据表文件导入到数据采集平台。版本 V2.08a “基本表锁定”操作位于导航“填写说明”中。在锁定状态下,只能处理数据表,不能修改表结构。注意:锁定数据表的目的是为了保证数据表结构的一致性;在执行“数据表导出”操作之前,确保数据表处于锁定状态,即 数据表被锁定后不在数据输入区,无法操作。4.基本表锁定版本V2.08a 5.基本表解锁“基本表解锁”操作位于导航“填写说明”中,可以完全控制表格解锁状态。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;版本V2.08a 6. 数据格式刷新 “数据格式刷新”操作位于导航“填写说明”中,统一处理数据表中数据的字体和字号。版本 V2.
版本V2.08a 进行“数据表导出”操作,生成36个文件(单表文件)。将合并后的数据表导入采集平台,按部门/专业/岗位填写数据表 恢复数据表文件,合并单表数据查看数据,进行“数据统计汇总”操作制定数据采集规则和数据表文件发布数据采集管理流程1 2 6 3 5 4 四、状态数据采集管理流程版本V2.08a 1、采集平台数据表导出数据表导出2.开发采集规则3.数据表填充4.表回收和合并5.数据表单导入6.数据校验和汇总 1 在数据导出页面,导出所选工作表采集平台的数据,在采集平台文件所在目录下另存为单表文件;导出数据表文件(单表) V版2.08a 数据表导出提示 数据表导出2.建立采集规则3.数据表填充4.表格回收合并5.数据表导入6.数据校验汇总1 注意:Duplicate 数据表导出操作中,如果有同名数据表文件,系统会提问,操作员将决定是覆盖文件还是放弃操作。版本V2.08a 2、 制定数据采集 规则和文件分发1. 数据表导出 制定规则文件分发2 <
部门文件下发 1. 数据表导出制定规则文件下发 2 3.数据表填充4.表回收和合并5.数据表导入6.数据验证和汇总邮件 FTP 网页下载 教师本职教职工领导本人 V版2.08a 3、数据表填写 3 2 开发采集规则数据表填写4.表格恢复并合并5.数据表导入6.数据检查汇总1.数据表导出打开数据表文件,根据表中的项目输入数据。注:每张数据表都有填写说明和备注,输入数据前请仔细阅读。完成数据输入后,按规定保存文件并重命名文件(部分表格)。例如:在线教研室填写《A4-2校外实习实训基地表(教研室采集)》后文件更名为:《A4-2校外实习实训基地表》表(网络教研室采集)》V版2.08a 4、数据表恢复与整合4 3.数据表填写数据表回收合并2公式采集规则5.数据表导入6.数据检查汇总1.数据表导出复制到指定目录(恢复数据表)。将完成的输入数据表回收到指定的文件目录。A4-2 校外实习实训基地表格(网络教研室采集
表恢复与合并 3. 数据表填写 2 制定采集 规则 6. 数据校验与汇总 1. 数据表导出 需要导入数据的表文件平台根据需要复制命名,然后在采集平台中导入数据表,如下图。注:导入数据表版本V2.08a时的文件名 查看全部
免规则采集器列表算法(Version填列采集平台数据表导入5、数据表表回收与合并)
版本V2.08a 5、数据表导入到采集平台数据表导入5 4.表回收和整合3.数据表填写和第2栏制定采集规则6.数据检查汇总1.数据表导出数据表导入注意:要导入的数据表文件必须与采集平台文件在同一文件目录下;导入数据表前,重命名数据表的文件名。文件名必须与所选工作表的名称相同(即:从导出的文件名中删除括号)。重复数据表导入操作时,如果有同名工作表,系统会给出A提示,操作者判断是覆盖文件还是放弃操作。例如:导出的数据表名称为:A3基本校情表(XX采集)。导入xls时,数据表更名:A3基本校情表.xls V版2.08a 6、状态数据校验与汇总6 5.数据表导入数据校验与汇总< @4.表回收合并3.数据表填充2 制定采集规则1.数据表导出数据校验:完成数据表导入后,检查采集中的数据@> 平台确认已导入所有有效数据。数据汇总:执行“数据统计汇总”操作,生成汇总数据的第十部分注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“ 可返回状态数据目录页面数据汇总:点击平台导航“填表说明”操作,在填表说明页面,点击“数据统计汇总”操作汇总平台内数据,生成第十部分 汇总数据,点击平台导航中的“状态数据目录”操作,在状态数据目录页面点击数据汇总表名称,勾选保存汇总数据的平台文件,关闭文件V版本2.08a 六、状态数据采集解决在进行单表数据合并操作时,数据表中保留的数据行不足的疑问。如何添加数据行?在采集平台,我校想加一栏,是否可以?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集 解决单表数据合并操作时,怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?V2.08a版问题解决步骤一:执行采集平台导航“填写说明”中的“解锁基础表”;通过“状态数据目录”打开需要添加数据行的表;选择在需要插入行的位置插入行;完成数据行插入操作后,返回状态数据目录;在采集平台导航“填写说明”中进行“基本表锁定”操作。@采集解决单表数据合并操作时怀疑数据表中保留的数据行不足。如何添加数据行?在采集平台,我校要加专栏,可以吗?数据表导出操作时,发出宏警告,无法进行导出操作。我该怎么办?1 2 3 4 查找第10部分汇总数据时,发现有些汇总值有问题。如何查看问题点?版本V2.08a 问题解决步骤一:执行“解锁基本表”
问题一:单表数据合并操作时,数据表中预留的数据行不够,如何添加数据行?版本V2.08a 问题解释二 目前需要上报状态数据采集平台文件,并且其中的数据指标是固定的,所以采集平台中的数据列不能增加和减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。问题2 在data采集平台,我校想加一栏,可以吗?Version V2.08a Question 3 Question 3 导出数据表时,系统发出宏警告,无法执行导出操作。我该怎么办?操作步骤: 选择菜单:工具->宏->安全,打开安全对话框,将安全级别设置为“低”;完成以上设置后,保存并关闭采集平台文件;重新打开采集平台文件,系统自动激活宏;导出数据表。Version V2.08a Question 4 Question 4 查阅Part 10的汇总数据,发现有些汇总值有问题。如何检查问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作;在数据汇总表中汇总分类表下,说明了参与情况对于汇总数据的来源,按照提示查看汇总数据表中的数据。如果数据被修改,则必须重新进行“数据统计汇总”操作;分析聚合数据,正确理解数据结构。
V版2.08a 使用平台注意事项 打开采集平台文件时,允许启动宏;仔细阅读每张数据表开头的说明和注释,填写所需数据时填写教职工编号、专业代码、课程代码系统一、不能为空;数据表中提供了标准化的数据输入方式,可根据实际情况选择。完成数据输入后,执行“数据统计与汇总”操作,生成汇总数据(第10部分)。表中不能随意添加或删除数据项,可以添加数据行。V版2.08a 状态数据报告 数据文件上报的两种方式 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) V版<
例如:上海兴建职业学院学校代码:12493,备案年份:2008 文件名:12493_2008_STATUS V208a.xls 学校代码版本V2.08a 2. 创建文件目录和文件命名第一步、第二步和第三步。将上级发送的数据采集平台文件复制到文件目录下。重命名状态数据采集平台文件,根据上报文件的命名规则创建状态数据。文件目录、文件管理计划文件目录,用于管理上报、下发和回收的数据文件的状态数据:根据申报年份或采集时间创建状态数据的每个文件目录,用于存储和管理采集 平台文件和各种数据表文件。版本 V<
工具->宏->安全,在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。在安全对话框中,将安全级别设置为“低”2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,提供所有操作功能这个时候可以使用采集平台。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。@2.设置完成后,关闭文件并重新打开采集平台文件,系统会自动启用宏,此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。此时可以使用采集平台提供的所有操作功能。宏安全设置流程: V版2.08a 三、采集 平台管理功能状态数据目录 1 数据表导入基础表锁定 4 基础表解锁 5 3 数据格式刷新 6 数据统计汇总7 数据表导出 2 Version V2.08a 1. 状态数据目录按照“状态数据目录”分类,在采集@中的数据表中查阅、录入或修改数据> 平台。
版本V2.08a 2. 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到平台。版本V2.08a 3. 数据表导入 “数据表导入”操作可以将36个已完成数据输入的数据表文件导入到数据采集平台。版本 V2.08a “基本表锁定”操作位于导航“填写说明”中。在锁定状态下,只能处理数据表,不能修改表结构。注意:锁定数据表的目的是为了保证数据表结构的一致性;在执行“数据表导出”操作之前,确保数据表处于锁定状态,即 数据表被锁定后不在数据输入区,无法操作。4.基本表锁定版本V2.08a 5.基本表解锁“基本表解锁”操作位于导航“填写说明”中,可以完全控制表格解锁状态。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;版本V2.08a 6. 数据格式刷新 “数据格式刷新”操作位于导航“填写说明”中,统一处理数据表中数据的字体和字号。版本 V2.
版本V2.08a 进行“数据表导出”操作,生成36个文件(单表文件)。将合并后的数据表导入采集平台,按部门/专业/岗位填写数据表 恢复数据表文件,合并单表数据查看数据,进行“数据统计汇总”操作制定数据采集规则和数据表文件发布数据采集管理流程1 2 6 3 5 4 四、状态数据采集管理流程版本V2.08a 1、采集平台数据表导出数据表导出2.开发采集规则3.数据表填充4.表回收和合并5.数据表单导入6.数据校验和汇总 1 在数据导出页面,导出所选工作表采集平台的数据,在采集平台文件所在目录下另存为单表文件;导出数据表文件(单表) V版2.08a 数据表导出提示 数据表导出2.建立采集规则3.数据表填充4.表格回收合并5.数据表导入6.数据校验汇总1 注意:Duplicate 数据表导出操作中,如果有同名数据表文件,系统会提问,操作员将决定是覆盖文件还是放弃操作。版本V2.08a 2、 制定数据采集 规则和文件分发1. 数据表导出 制定规则文件分发2 <
部门文件下发 1. 数据表导出制定规则文件下发 2 3.数据表填充4.表回收和合并5.数据表导入6.数据验证和汇总邮件 FTP 网页下载 教师本职教职工领导本人 V版2.08a 3、数据表填写 3 2 开发采集规则数据表填写4.表格恢复并合并5.数据表导入6.数据检查汇总1.数据表导出打开数据表文件,根据表中的项目输入数据。注:每张数据表都有填写说明和备注,输入数据前请仔细阅读。完成数据输入后,按规定保存文件并重命名文件(部分表格)。例如:在线教研室填写《A4-2校外实习实训基地表(教研室采集)》后文件更名为:《A4-2校外实习实训基地表》表(网络教研室采集)》V版2.08a 4、数据表恢复与整合4 3.数据表填写数据表回收合并2公式采集规则5.数据表导入6.数据检查汇总1.数据表导出复制到指定目录(恢复数据表)。将完成的输入数据表回收到指定的文件目录。A4-2 校外实习实训基地表格(网络教研室采集
表恢复与合并 3. 数据表填写 2 制定采集 规则 6. 数据校验与汇总 1. 数据表导出 需要导入数据的表文件平台根据需要复制命名,然后在采集平台中导入数据表,如下图。注:导入数据表版本V2.08a时的文件名
免规则采集器列表算法(字节面试锦集(一):AndroidFramework高频面试题总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-07 10:30
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):项目HR高频面试总结
数据采集采集架构中各模块详解
爬虫工程师,如何高效支持数据分析师的工作?
基于大数据平台采集基础架构的互联网数据平台
在数据采集中,如何建立有效的监控体系?
面试准备、HR、Android技术等面试题汇总。
昨天,有网友表示,他最近面试了几家公司,被问了好几次问题,每次的回答都不是很好。
采访者:比如有10万个网站需要采集,你有什么方法可以快速获取数据?
要回答好这个问题,其实需要有足够的知识和足够的技术储备。
最近我们也在招聘,每周面试十几个人,感觉合适的只有一两个。他们大多和这位网友的情况一样,缺乏全局思维,即使是有三四年工作经验的人。司机。他们有很强的解决具体问题的能力,但很少从点到点思考问题,站在一个新的高度。
采集的10万个网站的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集的要求,我们需要综合考虑从网站的采集到数据存储的方方面面,给出合适的方案,节约成本,提高工作效率。的目标。
下面我们就从网站的集合到数据存储的方方面面做一个简单的介绍。
一、100,000网站 他们来自哪里?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个 网站 呢?有几种方式:
1)历史业务的积累
不管是冷启动什么的,既然有采集的需求,就一定有项目或产品的需求。相关人员一定是前期调查了一些数据来源,采集了一些重要的网站。这些可以用作我们采集 网站 和 采集 的原创种子。
2)协会网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类的网站,一般都有下级相关部门的官网。
3)网站导航
有些网站可能会出于某种目的(如排水等)采集一些网站,并分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们会通过网站关联等其他方式获得更多的网站。
4)搜索引擎
也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方SaaS平台会有7-15天的免费试用期。因此,我们可以利用这段时间采集与我们业务相关的数据,然后从中提取网站,作为我们最初的采集种子。
虽然,这个方法是网站采集最有效、最快捷的方式。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站 .
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万网站如何管理?
当我们采集到10万个网站时,我们首先面临的是如何管理,如何配置采集规则,如何监控网站正常与否等等。
1)如何管理
100,000 网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站进行一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集规则
我们前期采集的10万个网站只是首页。如果我们只将首页作为采集的任务,那么我们只能采集获取到首页的信息非常少,漏取率非常高。
如果要根据首页的URL执行整个站点采集,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列并对其执行采集。
然而,10万个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码来进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
由于采集的网站数量需要达到10万的级别,所以对于采集一定不能使用xpath或者其他精确定位方法。不然配置10万网站的时候,黄花菜会冷的。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集的body中,使用算法解析时间、body等属性;
3)如何监控
由于有 100,000 个 网站,这些 网站 每天都会有 网站 修订,或列修订,或新/删除列等。因此,有必要根据采集的数据情况简单分析一下网站的情况。
比如一个网站几天没有新数据,肯定有问题。要么是网站的修改导致信息规律失效,要么是网站本身有问题。
为了提高采集的效率,可以使用单独的服务定期检查网站和列的状态。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万网站,列配置完成后,采集的入口URL应该达到百万级别。采集器如何高效获取采集的这些入口URL?
如果把这些url放到数据库中,不管是MySQL还是Oracle,采集器获取采集的任务的操作都会浪费很多时间,大大降低采集@的效率>.
如何解决这个问题呢?内存数据库是首选,如Redis、Mongo DB等,一般采集使用Redis进行缓存。因此,您可以在配置列的同时将列信息同步到Redis 作为采集 任务缓存队列。
四、网站如何采集?
就好比想达到百万年薪,最大的可能就是去华为、阿里、腾讯等一线大厂,而且需要达到一定的水平。这条路注定是艰难的。
同样,如果你需要采集百万级的列表网址,常规的方法肯定是无法实现的。
必须采用分布式+多进程+多线程的方式。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析也必须经过算法处理。比如现在比较流行的GNE,
部分属性可以在列表采集中获取,所以尽量不要和正文放在一起进行分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源代码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站的采集可能需要十几二十台服务器。同时,在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理,比如清理、校正等时,不需要修改每个采集存储部分。我们只需要修改接口,重新部署即可。
快速,方便,快捷。
六、数据和采集监控
覆盖10万个网站的采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,由于我们已经统一了数据存储接口,所以这个时候我们可以在接口上进行统一的数据质量验证。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或采集列的数据。为了能够及时判断采集的网站/列的当前来源是否正常,以保证总有10万个有效的采集网站。
七、数据存储
由于每天的数据量很大采集,普通的数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存文本信息。可以保存标题、发布时间、URL 等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控已经非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以实现采集器/scripts的部署、启动、关闭和运行,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,你怎么快速拿到数据?” 如果你能回答这些,拿到好offer应该就没有悬念了。
最后,希望所有找工作的朋友都能拿到满意的offer,找到一个好的平台。
采访#数据采集 查看全部
免规则采集器列表算法(字节面试锦集(一):AndroidFramework高频面试题总结)
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):项目HR高频面试总结
数据采集采集架构中各模块详解
爬虫工程师,如何高效支持数据分析师的工作?
基于大数据平台采集基础架构的互联网数据平台
在数据采集中,如何建立有效的监控体系?
面试准备、HR、Android技术等面试题汇总。
昨天,有网友表示,他最近面试了几家公司,被问了好几次问题,每次的回答都不是很好。
采访者:比如有10万个网站需要采集,你有什么方法可以快速获取数据?
要回答好这个问题,其实需要有足够的知识和足够的技术储备。
最近我们也在招聘,每周面试十几个人,感觉合适的只有一两个。他们大多和这位网友的情况一样,缺乏全局思维,即使是有三四年工作经验的人。司机。他们有很强的解决具体问题的能力,但很少从点到点思考问题,站在一个新的高度。
采集的10万个网站的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集的要求,我们需要综合考虑从网站的采集到数据存储的方方面面,给出合适的方案,节约成本,提高工作效率。的目标。
下面我们就从网站的集合到数据存储的方方面面做一个简单的介绍。
一、100,000网站 他们来自哪里?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个 网站 呢?有几种方式:
1)历史业务的积累
不管是冷启动什么的,既然有采集的需求,就一定有项目或产品的需求。相关人员一定是前期调查了一些数据来源,采集了一些重要的网站。这些可以用作我们采集 网站 和 采集 的原创种子。
2)协会网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类的网站,一般都有下级相关部门的官网。
3)网站导航
有些网站可能会出于某种目的(如排水等)采集一些网站,并分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们会通过网站关联等其他方式获得更多的网站。
4)搜索引擎
也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方SaaS平台会有7-15天的免费试用期。因此,我们可以利用这段时间采集与我们业务相关的数据,然后从中提取网站,作为我们最初的采集种子。
虽然,这个方法是网站采集最有效、最快捷的方式。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站 .
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万网站如何管理?
当我们采集到10万个网站时,我们首先面临的是如何管理,如何配置采集规则,如何监控网站正常与否等等。
1)如何管理
100,000 网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站进行一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集规则
我们前期采集的10万个网站只是首页。如果我们只将首页作为采集的任务,那么我们只能采集获取到首页的信息非常少,漏取率非常高。
如果要根据首页的URL执行整个站点采集,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列并对其执行采集。
然而,10万个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码来进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
由于采集的网站数量需要达到10万的级别,所以对于采集一定不能使用xpath或者其他精确定位方法。不然配置10万网站的时候,黄花菜会冷的。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集的body中,使用算法解析时间、body等属性;
3)如何监控
由于有 100,000 个 网站,这些 网站 每天都会有 网站 修订,或列修订,或新/删除列等。因此,有必要根据采集的数据情况简单分析一下网站的情况。
比如一个网站几天没有新数据,肯定有问题。要么是网站的修改导致信息规律失效,要么是网站本身有问题。
为了提高采集的效率,可以使用单独的服务定期检查网站和列的状态。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
10万网站,列配置完成后,采集的入口URL应该达到百万级别。采集器如何高效获取采集的这些入口URL?
如果把这些url放到数据库中,不管是MySQL还是Oracle,采集器获取采集的任务的操作都会浪费很多时间,大大降低采集@的效率>.
如何解决这个问题呢?内存数据库是首选,如Redis、Mongo DB等,一般采集使用Redis进行缓存。因此,您可以在配置列的同时将列信息同步到Redis 作为采集 任务缓存队列。
四、网站如何采集?
就好比想达到百万年薪,最大的可能就是去华为、阿里、腾讯等一线大厂,而且需要达到一定的水平。这条路注定是艰难的。
同样,如果你需要采集百万级的列表网址,常规的方法肯定是无法实现的。
必须采用分布式+多进程+多线程的方式。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析也必须经过算法处理。比如现在比较流行的GNE,
部分属性可以在列表采集中获取,所以尽量不要和正文放在一起进行分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源代码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站的采集可能需要十几二十台服务器。同时,在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理,比如清理、校正等时,不需要修改每个采集存储部分。我们只需要修改接口,重新部署即可。
快速,方便,快捷。
六、数据和采集监控
覆盖10万个网站的采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,由于我们已经统一了数据存储接口,所以这个时候我们可以在接口上进行统一的数据质量验证。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或采集列的数据。为了能够及时判断采集的网站/列的当前来源是否正常,以保证总有10万个有效的采集网站。
七、数据存储
由于每天的数据量很大采集,普通的数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存文本信息。可以保存标题、发布时间、URL 等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控已经非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以实现采集器/scripts的部署、启动、关闭和运行,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,你怎么快速拿到数据?” 如果你能回答这些,拿到好offer应该就没有悬念了。
最后,希望所有找工作的朋友都能拿到满意的offer,找到一个好的平台。
采访#数据采集
免规则采集器列表算法( 重新计算人工重新运算的步骤和安装方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-07 08:03
重新计算人工重新运算的步骤和安装方法)
null 第十二章 ProficyHistorian采集器Calculation采集器MainDescriptionCalculation采集器函数配置计算标签在安装时配置,安装时配置,安装时配置 Configuration when与服务器安装在同一台机器上,无需配置。尽管这不是最好的方法,但是计算采集器 可以安装在与其最终服务器分开的计算机上。在这种情况下,必须安装它。确定服务器名称时,在manager中配置,在manager中配置,在manager中配置,设置计算超时时间,确定允许计算的最大时间采集器。了解恢复C的理解
当集中器与其服务器断开连接时,如果它想重新连接到服务器,它将恢复断开连接时完成的操作。在 采集器 配置中设置恢复逻辑运行前的最长时间。该值称为最大恢复时间的默认值为 4 小时。按照时间顺序,将恢复从最早到最晚的操作。恢复逻辑将返回到上次归档操作或最长恢复时间,以不重要的为准。使用它作为起点。在以下事件下触发。当操作采集器 开始时,它会在暂停后重新启动。采集器 发生在线变化时,类似于停止和重启。仅恢复新变量组态中的变量并恢复与归档服务器的连接。之后手动重新计算。手动重新计算。手动重新计算。采集器 可以
手动重新计算的好处体现在当您更改计算时,自动恢复功能既不能恢复所有信息,也不能触发它。例如,存档中的自动恢复功能可以返回到最近的计算。作为恢复逻辑的起点,如果一个为操作提供数据的采集器正在缓冲数据,当恢复发生时,它开始一个不收录标签数据的操作。在这种情况下,需要一些时间重新手动计算恢复并需要更正或更改。配置手动重新计算步骤。配置手动重新计算步骤。在管理器或服务器中选择采集器屏幕计算到服务器采集器点击重新计算按钮设置一个开始和
在结束时间,为重新计算选项选择一个标签。选择所有标签以浏览指定的计算。采集器 如果选择了选项,请浏览标签并选择它们。单击重新计算按钮。在确认对话框中,单击确定添加计算标签并添加计算。计算标签并实现操作 A. 在 采集器 上添加标签。要在管理器操作中添加标签,您必须使用手动添加标签对话框。一旦操作采集器被选为资源地址,就不能使用操作标签。数据资源是它自己的操作。三个标签用于创建计算标签。数据源标签用于计算公式。一个或多个标签。目标标签。真实标签存储计算出的值。也可以在此变量中创建和存储计算。
当触发器标签中的数据发生变化时,标签会更新。当触发器标签获得新值、新时间戳或质量更改时,就会发生更新。不能使用 poll 标签。触发器标签被复制。标签的连接可用于复制操作。标签 这些标签有助于缩短开发时间。创建计算。创建计算。创建计算。当您在管理器选项卡屏幕中选择计算选项卡时,计算选项可用。所有计算都必须包括 ResultVisualBasicScript,一种脚本语言。向导浏览工具 服务器上的所有标签都可用。从几个不同的功能中进行选择。输入手动脚本。电子书中提供了许多示例脚本。
用于扩展编辑区域的窗口按钮。内置函数的说明。内置函数的说明。快捷方式。实验练习。使用向导创建计算。使用经理趋势工具查看数据。完成练习的预计时间为 20 分钟。主要实验练习12 实验练习12A 添加计算标签B 使用向导将计算输入标签C 编辑和测试计算D 查看计算结果主要摘要问题总结问题计算标签的数据源是什么?采集器应该安装在哪里可以实现计算出的标签类型,使用什么触发标签,复制标签函数的值是什么 Main 查看全部
免规则采集器列表算法(
重新计算人工重新运算的步骤和安装方法)
null 第十二章 ProficyHistorian采集器Calculation采集器MainDescriptionCalculation采集器函数配置计算标签在安装时配置,安装时配置,安装时配置 Configuration when与服务器安装在同一台机器上,无需配置。尽管这不是最好的方法,但是计算采集器 可以安装在与其最终服务器分开的计算机上。在这种情况下,必须安装它。确定服务器名称时,在manager中配置,在manager中配置,在manager中配置,设置计算超时时间,确定允许计算的最大时间采集器。了解恢复C的理解
当集中器与其服务器断开连接时,如果它想重新连接到服务器,它将恢复断开连接时完成的操作。在 采集器 配置中设置恢复逻辑运行前的最长时间。该值称为最大恢复时间的默认值为 4 小时。按照时间顺序,将恢复从最早到最晚的操作。恢复逻辑将返回到上次归档操作或最长恢复时间,以不重要的为准。使用它作为起点。在以下事件下触发。当操作采集器 开始时,它会在暂停后重新启动。采集器 发生在线变化时,类似于停止和重启。仅恢复新变量组态中的变量并恢复与归档服务器的连接。之后手动重新计算。手动重新计算。手动重新计算。采集器 可以
手动重新计算的好处体现在当您更改计算时,自动恢复功能既不能恢复所有信息,也不能触发它。例如,存档中的自动恢复功能可以返回到最近的计算。作为恢复逻辑的起点,如果一个为操作提供数据的采集器正在缓冲数据,当恢复发生时,它开始一个不收录标签数据的操作。在这种情况下,需要一些时间重新手动计算恢复并需要更正或更改。配置手动重新计算步骤。配置手动重新计算步骤。在管理器或服务器中选择采集器屏幕计算到服务器采集器点击重新计算按钮设置一个开始和
在结束时间,为重新计算选项选择一个标签。选择所有标签以浏览指定的计算。采集器 如果选择了选项,请浏览标签并选择它们。单击重新计算按钮。在确认对话框中,单击确定添加计算标签并添加计算。计算标签并实现操作 A. 在 采集器 上添加标签。要在管理器操作中添加标签,您必须使用手动添加标签对话框。一旦操作采集器被选为资源地址,就不能使用操作标签。数据资源是它自己的操作。三个标签用于创建计算标签。数据源标签用于计算公式。一个或多个标签。目标标签。真实标签存储计算出的值。也可以在此变量中创建和存储计算。
当触发器标签中的数据发生变化时,标签会更新。当触发器标签获得新值、新时间戳或质量更改时,就会发生更新。不能使用 poll 标签。触发器标签被复制。标签的连接可用于复制操作。标签 这些标签有助于缩短开发时间。创建计算。创建计算。创建计算。当您在管理器选项卡屏幕中选择计算选项卡时,计算选项可用。所有计算都必须包括 ResultVisualBasicScript,一种脚本语言。向导浏览工具 服务器上的所有标签都可用。从几个不同的功能中进行选择。输入手动脚本。电子书中提供了许多示例脚本。
用于扩展编辑区域的窗口按钮。内置函数的说明。内置函数的说明。快捷方式。实验练习。使用向导创建计算。使用经理趋势工具查看数据。完成练习的预计时间为 20 分钟。主要实验练习12 实验练习12A 添加计算标签B 使用向导将计算输入标签C 编辑和测试计算D 查看计算结果主要摘要问题总结问题计算标签的数据源是什么?采集器应该安装在哪里可以实现计算出的标签类型,使用什么触发标签,复制标签函数的值是什么 Main
免规则采集器列表算法( 批量爬取大量的好看的图片到自己的本地电脑哈哈哈)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-06 05:30
批量爬取大量的好看的图片到自己的本地电脑哈哈哈)
优采云 将微博中的图片抓取到本地
批量抓取大量好看的图片到本地电脑哈哈哈哈哈哈哈
微博图片被盗
详细步骤:
微博图片采集
本文介绍如何使用优采云采集微博图片。
微博上有很多博主发布了很多高质量的图片。很多时候,我们想要保存这些高质量的图片,我们该怎么做,一张一张?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的图片采集。主要通过两个主要步骤:首先下载图片网址采集;然后使用优采云提供的图片批量下载工具,将URL批量转换成图片。
采集网站:
本文仅以博主采集发布的图片为例。在实际操作过程中,可以根据自己的需要更改想要采集的博主。您还可以使用URL列表循环批量处理采集多个微博博主发布的所有图片。本文中采集的微博图片的具体字段为:博主ID、发帖时间、微博地址、微博发送方式、微博内容、图片地址、图片存储文件夹。
开始前请注意,如果您还没有登录优采云,需要先建立登录流程。请参考微博登录教程:
使用功能点:
l 分页列表和详细信息提取
lAJAX滚动教程
l优采云7.0 教程-AJAX点击与翻页教程
第一步:创建微博图片采集任务
1)进入主界面,选择“自定义模式”,点击“立即使用”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)系统自动打开网页,进入微博。观察网页的结构。当页面下拉到底部时,会出现“正在加载,请稍候”的字样。当我们下拉时,页面将加载新数据。2 次下拉加载后,此页面到达底部并出现“下一页”按钮
本网页涉及ajax下拉加载,需要设置一些高级选项。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“3次”,每次间隔为“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
注意:这里的滚动次数和间隔时间需要根据网站的情况来设置,不是绝对的。一般来说,间隔时间>网站加载时间就足够了。有时上网速度慢,网页加载很慢,需要根据具体情况进行调整。
详情请看:优采云7.0教程-AJAX滚动教程
/tutorial/ajgd_7.aspx?t=1
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中选择“循环点击下一页”
与“打开网页”类似,这一步也涉及到Ajax下拉加载。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“好的”
和上面一样
第 3 步:创建一个列表循环
1)移动鼠标选择页面上的第一个微博链接。选择后,系统会自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环点击每个链接”创建列表循环
第四步:提取微博文字和图片
1)系统会自动点击进入第一条微博详情页。在微博详情页,我们首先采集博主ID、发帖时间、微博内容、微博网址、微博发送方式。点击你要采集的字段,在右侧的操作提示框中,选择“采集元素的文本”(采集微博网址,然后选择“采集@ > 链接地址")
2) 选择字段信息后,选择对应的字段,自定义字段的命名。完成后,单击“确定”
3) 点击页面第一张图片,在操作提示框中选择“全选”
4)选择“点击循环中的每张图片”
由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”这一步,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
5)点击第一张图片,在弹出的操作提示框中选择“采集图片地址”。图片地址已经采集下,修改此字段为“图片地址”
6)接下来准备批量导出图片网址为图片。点击“添加特殊字段”,选择“添加固定字段”,输入“D:\微博图片采集\”,其中“D:\\”为图片存储盘,“微博图片采集 @>"是图片保存的文件夹名
第五步:数据采集并导出
1)点击左上角“开始采集”,选择“本地采集”开始
注意:本地采集占用采集的当前计算机资源,如果有采集时间要求或当前计算机长时间不能执行采集可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点分配任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
2)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好微博帖子的数据,这里我们选择excel作为导出格式
3) 数据导出如下图
第六步:批量转换图片网址为图片
经过上面的操作,我们得到了图片的URL为采集。接下来使用优采云专用的图片批量下载工具,将采集到达的图片URL中的图片下载并保存到本地。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3) 进行相关设置,设置完成后点击确定导入文件
选择EXCEL文件:导入你需要下载的EXCEL文件图片地址
EXCEL表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:EXCEL中需要单独一栏列出要保存的图片到文件夹的路径,可以设置不同的图片存放在不同的文件夹
如果要将文件保存到文件夹中,路径需要以“\”结尾,例如:“D:\Sync\”,如果下载后要按照指定的文件名保存文件,则需要收录特定的文件名,例如“D :\Sync\1.jpg”
如果下载的文件路径和文件名完全一样,原文件将被删除
3) 点击确定后,界面如图,然后点击“开始下载”
4) 页面底部会显示图片下载状态
5) 找到你设置的图片保存文件夹,可以看到图片URL已经批量转换为图片
注意:软件一定要安装,否则会报错(我试了好久才搞定)
然后就可以导出到本地了
当地位置:
转载于: 查看全部
免规则采集器列表算法(
批量爬取大量的好看的图片到自己的本地电脑哈哈哈)
优采云 将微博中的图片抓取到本地
批量抓取大量好看的图片到本地电脑哈哈哈哈哈哈哈
微博图片被盗
详细步骤:
微博图片采集
本文介绍如何使用优采云采集微博图片。
微博上有很多博主发布了很多高质量的图片。很多时候,我们想要保存这些高质量的图片,我们该怎么做,一张一张?使用优采云采集器,只需要制定规则,就可以自动下载我们想要的图片采集。主要通过两个主要步骤:首先下载图片网址采集;然后使用优采云提供的图片批量下载工具,将URL批量转换成图片。
采集网站:
本文仅以博主采集发布的图片为例。在实际操作过程中,可以根据自己的需要更改想要采集的博主。您还可以使用URL列表循环批量处理采集多个微博博主发布的所有图片。本文中采集的微博图片的具体字段为:博主ID、发帖时间、微博地址、微博发送方式、微博内容、图片地址、图片存储文件夹。
开始前请注意,如果您还没有登录优采云,需要先建立登录流程。请参考微博登录教程:
使用功能点:
l 分页列表和详细信息提取
lAJAX滚动教程
l优采云7.0 教程-AJAX点击与翻页教程
第一步:创建微博图片采集任务
1)进入主界面,选择“自定义模式”,点击“立即使用”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)系统自动打开网页,进入微博。观察网页的结构。当页面下拉到底部时,会出现“正在加载,请稍候”的字样。当我们下拉时,页面将加载新数据。2 次下拉加载后,此页面到达底部并出现“下一页”按钮
本网页涉及ajax下拉加载,需要设置一些高级选项。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“3次”,每次间隔为“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
注意:这里的滚动次数和间隔时间需要根据网站的情况来设置,不是绝对的。一般来说,间隔时间>网站加载时间就足够了。有时上网速度慢,网页加载很慢,需要根据具体情况进行调整。
详情请看:优采云7.0教程-AJAX滚动教程
/tutorial/ajgd_7.aspx?t=1
2) 将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中选择“循环点击下一页”
与“打开网页”类似,这一步也涉及到Ajax下拉加载。打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“好的”
和上面一样
第 3 步:创建一个列表循环
1)移动鼠标选择页面上的第一个微博链接。选择后,系统会自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环点击每个链接”创建列表循环
第四步:提取微博文字和图片
1)系统会自动点击进入第一条微博详情页。在微博详情页,我们首先采集博主ID、发帖时间、微博内容、微博网址、微博发送方式。点击你要采集的字段,在右侧的操作提示框中,选择“采集元素的文本”(采集微博网址,然后选择“采集@ > 链接地址")
2) 选择字段信息后,选择对应的字段,自定义字段的命名。完成后,单击“确定”
3) 点击页面第一张图片,在操作提示框中选择“全选”
4)选择“点击循环中的每张图片”
由于这个网页涉及到Ajax技术,我们需要设置一些高级选项。选择“点击元素”这一步,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
5)点击第一张图片,在弹出的操作提示框中选择“采集图片地址”。图片地址已经采集下,修改此字段为“图片地址”
6)接下来准备批量导出图片网址为图片。点击“添加特殊字段”,选择“添加固定字段”,输入“D:\微博图片采集\”,其中“D:\\”为图片存储盘,“微博图片采集 @>"是图片保存的文件夹名
第五步:数据采集并导出
1)点击左上角“开始采集”,选择“本地采集”开始
注意:本地采集占用采集的当前计算机资源,如果有采集时间要求或当前计算机长时间不能执行采集可以使用云采集功能,云采集在网络采集中进行,不需要当前电脑支持,可以关闭电脑,可以设置多个云节点分配任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集收到的数据可以在云端存储三个月,随时可以导出。
2)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好微博帖子的数据,这里我们选择excel作为导出格式
3) 数据导出如下图
第六步:批量转换图片网址为图片
经过上面的操作,我们得到了图片的URL为采集。接下来使用优采云专用的图片批量下载工具,将采集到达的图片URL中的图片下载并保存到本地。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3) 进行相关设置,设置完成后点击确定导入文件
选择EXCEL文件:导入你需要下载的EXCEL文件图片地址
EXCEL表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:EXCEL中需要单独一栏列出要保存的图片到文件夹的路径,可以设置不同的图片存放在不同的文件夹
如果要将文件保存到文件夹中,路径需要以“\”结尾,例如:“D:\Sync\”,如果下载后要按照指定的文件名保存文件,则需要收录特定的文件名,例如“D :\Sync\1.jpg”
如果下载的文件路径和文件名完全一样,原文件将被删除
3) 点击确定后,界面如图,然后点击“开始下载”
4) 页面底部会显示图片下载状态
5) 找到你设置的图片保存文件夹,可以看到图片URL已经批量转换为图片
注意:软件一定要安装,否则会报错(我试了好久才搞定)
然后就可以导出到本地了
当地位置:
转载于:
免规则采集器列表算法(送你2TPython自学资料前天,有个同学加我微信来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-06 05:01
↑关注+star,后台回复【礼包】送你2TPython自学资料
前天有个同学加我微信咨询:
“我想抓取最新的5000条新闻数据,但是我是文科生,不会写代码,我该怎么办?”
对于这位同学的问题,我会安排的。
先说一下获取数据的方式:首先,我们使用现成的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是做一些定制化的工具来满足场景的需要,这需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
因此,在早期,我只是想获取数据。如果没有其他要求,我会优先考虑现有的工具,介绍几个可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,捕获数据的能力是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器
优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定时间。
因为有学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器
优采云采集器是非常适合新手的采集器。它具有简单易用的特点,因此您可以在几分钟内搞定。优采云提供一些常用爬取的模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品
吉手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页,还支持手机端数据网站,数据浮动显示在指数图上。极手客以浏览器插件的形式抓取数据。虽然它有上面提到的优点,但也有缺点,比如不能多线程数据,浏览器死机是不可避免的。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市面上非常复杂且功能强大的网页抓取平台,提供了数据抓取解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。它也是一个适合新手捕捉数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址: 查看全部
免规则采集器列表算法(送你2TPython自学资料前天,有个同学加我微信来)
↑关注+star,后台回复【礼包】送你2TPython自学资料
前天有个同学加我微信咨询:
“我想抓取最新的5000条新闻数据,但是我是文科生,不会写代码,我该怎么办?”
对于这位同学的问题,我会安排的。
先说一下获取数据的方式:首先,我们使用现成的工具。我们只需要知道如何使用工具来获取数据,而无需关心工具是如何实现的。比如我们在岸上,去海边的一个小岛,岸上有船,我们第一个想法是选择乘船去,而不是想着自己造一艘船。
二是做一些定制化的工具来满足场景的需要,这需要一点编程基础。比如我们还要去海边的一个小岛,还要求1吨货物30分钟内送到岛上。
因此,在早期,我只是想获取数据。如果没有其他要求,我会优先考虑现有的工具,介绍几个可以快速获取在线数据的工具。
1.Microsoft Excel
你没看错,它是 Excel,办公室三剑客之一。Excel 是一个强大的工具,捕获数据的能力是它的功能之一。我以耳机为关键词,抓取京东的产品列表。
等待几秒钟后,Excel 会将页面上的所有文本信息抓取到表格中。这种方法确实可以抓取数据,但是也会引入一些我们不需要的数据。如果您有更高的需求,可以选择以下工具。
2.优采云采集器
优采云是爬虫界的老字号,是目前使用最广泛的互联网数据采集、处理、分析、挖掘软件。它的优点是采集不限于网页和内容,同时是分布式的采集,效率会更高。缺点是对小白用户不是很友好,有一定的知识门槛(了解网页知识、HTTP协议等知识),熟悉工具操作需要一定时间。
因为有学习门槛,掌握了这个工具后,采集的数据上限会很高。有时间和精力的同学可以折腾。
官网地址:
3.优采云采集器
优采云采集器是非常适合新手的采集器。它具有简单易用的特点,因此您可以在几分钟内搞定。优采云提供一些常用爬取的模板网站,利用模板快速爬取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云基于浏览器内核实现可视化数据抓取,因此具有卡顿和采集数据慢的特点。但是这个缺陷并没有掩盖它的优点,基本可以满足新手短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
4.GooSeeker 采集纪念品
吉手客也是一款简单易用的可视化采集数据工具。还可以抓取动态网页,还支持手机端数据网站,数据浮动显示在指数图上。极手客以浏览器插件的形式抓取数据。虽然它有上面提到的优点,但也有缺点,比如不能多线程数据,浏览器死机是不可避免的。
网站:
5.Scrapinghub
如果想抓取国外的网站数据,可以考虑Scrapinghub。Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。Scrapehub 可以说是市面上非常复杂且功能强大的网页抓取平台,提供了数据抓取解决方案提供商。
地址:
6.WebScraper
WebScraper 是一款优秀的国外浏览器插件。它也是一个适合新手捕捉数据的可视化工具。我们简单地设置了一些爬取规则,剩下的交给浏览器来完成。
地址:

