
免规则采集器列表算法
免规则采集器列表算法(基于人工智能技术,只需输入网址就能自动识别采集内容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-18 21:11
)
小白神器!免费导出采集结果,由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容
(Windows、Mac、Linux)
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业采集@ > 需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU和大图智能识别等。
云账号,方便快捷
创建优采云采集器账号并登录,您所有的采集任务设置都会自动加密保存到优采云的云服务器。无需担心采集任务丢失。正在运行的任务和采集的数据都在你本地,非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。
查看全部
免规则采集器列表算法(基于人工智能技术,只需输入网址就能自动识别采集内容
)
小白神器!免费导出采集结果,由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容
(Windows、Mac、Linux)
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业采集@ > 需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU和大图智能识别等。

云账号,方便快捷
创建优采云采集器账号并登录,您所有的采集任务设置都会自动加密保存到优采云的云服务器。无需担心采集任务丢失。正在运行的任务和采集的数据都在你本地,非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。

免规则采集器列表算法(构建一个面向公共网络的WEB系统中一定要做到的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-18 21:10
在面向公网的项目中,安全无疑是项目面临的巨大挑战之一。在公共互联网上,花花公子和无聊的人一直在嗅探我们的服务器。有些人想大显身手,也有些不法分子想监控截取我们的敏感信息,进入我们的宿主进行各种活动。各种破坏和盗窃。这些人一旦得逞,系统的稳定性就会降低,企业的敏感数据就会丢失,企业的信誉也会遭到破坏。因此,为用户提供可靠、稳定的服务,防止重要数据的丢失和被盗,是我们构建面向公共网络的WEB系统所必须做的。
构建安全的网络环境,首先要了解安全威胁从何而来。以下是可能造成安全威胁的应用场景:
1、用户A向用户B发送带有敏感信息的文件,用户C在局域网内监听和截获未加密的数据报。
2、 网管A远程向主机B发送命令(如添加用户的命令),攻击者C截获收录该命令的数据报,修改包中的命令,然后发送给主机 B。
3、 同场景2,主机B准备接受远程合法用户A的命令,但此时攻击者C构造了命令数据报发送给B,B认为是用户发送的命令A、执行此命令后,与场景2不同,攻击者C并没有拦截和修改数据报,而是直接构造数据报。
4、 客户A向TA的股票经纪人B发送了一条股票交易的消息,股票经纪人B按照A的要求进行了相应的股票操作,但是这个操作给客户A带来了损失,然后客户A拒绝发送这条消息给经纪人 B 的消息。
分析场景1,如果A发送给B的消息是加密的,即使C截获了消息,TA也不会知道消息的内容。这涉及到消息的机密性。场景二中,攻击者C篡改了消息,但主机B并不知道接收到的消息与合法用户A发送的消息不一致,因此该场景涉及到消息的完整性。场景三,主机B接受任何人发送的消息,无需验证消息来源,这涉及到消息的可验证性。在场景4中,很明显,客户A不承认消息被发送,所以涉及到消息的不可否认性。
针对上述场景,我们可以总结出来自互联网的安全服务大致可以分为以下几类:
1、保密
2、 完整性
3、不可否认性
对于不同的服务,我们需要不同的安全属性。一些比较敏感的信息,比如用户进行电子交易时,需要不同的安全服务同时护航。下面,让我们讨论一下系统是如何实现上述安全属性的,以及实现这些安全属性需要使用的软件。这些软件可以作为组件集成到系统中,为系统的安全提供保护。
保密
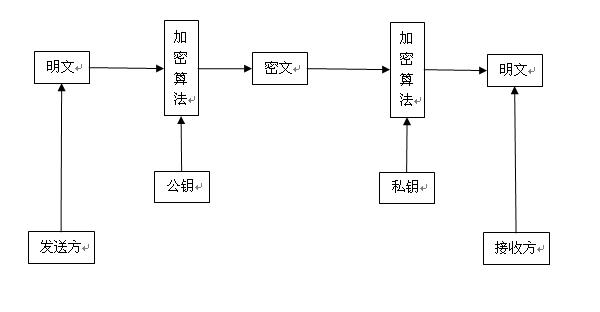
消息的保密性是为了确保只有合法的接收者才能阅读消息的内容。即使其他人通过非法方式获取消息,由于消息是加密的,他们也无法阅读内容。然后,仅允许合法收件人阅读消息是消息机密性的要求。加解密图如下(对称加密):
消息机密性的研究历史悠久。最早的经典加密技术是凯撒加密技术,它是一种单码替换技术,即将每个明文字母替换为另一个字母,形成密文。然后将替换规则提前通知合法用户,以便合法用户在获得密文后,按照预先约定的规则将密文翻译成明文。未来,传统的加密算法(对称加密算法)都是从凯撒加密技术演变而来的。然而,凯撒密码有一个弱点。在比较长的英文信息中,可以计算出某个字母出现的频率。比如“The”这个词出现的频率就比较高。破译者甚至计算了一个字母的频率。度分析表。这样,解密器就可以根据频率分析表猜出密文,并尝试将其转换为明文。如果可以读取转换后的明文,则消息将被解密。这种解密方法也称为频率分析。
频率分析表
为了抵抗频率分析,1854 年,查尔斯·惠斯通发明了一种称为 Playfair 的多重替代加密方法。使用时,首先需要编制一个5X5的矩阵密码表。加密和解密依赖于密码表。所以这个5X5的密码表相当于一把钥匙。它可以有效抵抗频率分析,当时被军方广泛使用,但在第一次世界大战期间被破解。然后出现了一些加密机制,其中最著名的是德国在二战中使用的旋转加密。在DES算法出现之前,最著名的加密算法就是它了。它通过多步替换加密形成密文,使密码分析更加困难。这就是密码的历史。
DES
DES的全称是Data Encryption Standard,是一种对称加密算法。对称加密算法的特点是加密和解密使用相同的密钥。回顾我之前说的,从经典的凯撒加密到旋转加密,加密和解密都依赖同一个密码表或规则,所以都可以做到。称之为对称加密。这些密码表或规则可以理解为所谓的“密钥”。在 DES 中,密钥是由计算机生成的字符序列。这个序列应该有一定的长度,使得攻击者很难通过暴力破解或者其他方式获取。否则,如果密钥是由第三方获得的,则加密的消息将没有任何安全性。因为密码的算法是公开的。
DES的算法可以在百度百科或其他文档中找到。这里只介绍一下它的特点(其实我只了解算法过程,并没有仔细研究算法本身-_-!),DES的密钥长度是56位。加密时,密钥和64位明文消息作为输入,传递给加密函数。函数经过处理后,会生成一个64位的密文,完成明文到密文的转换。这种转换方式称为块加密,整体转换由64位明文块进行。现代加密算法基本上使用这种块加密方法。另一种是流加密。所谓流加密,就是对一个字符或一个字节或逐位进行转换。例如,
DES加密方式,DES加密有不同的方式,方式的不同导致DES生成密文的安全性和速度不同,这里介绍三种不同的DES加密方式:
1、ECB(Electronic Codebook),在ECB模式下,对于同一个明文,如果用同一个key加密,生成的密文是一样的。例如,单词“The”是一个64位的块,通过相同的密钥加密后,生成的密文始终是“XUZ”。这种加密模式对密码分析的抵抗力会弱一些。
2、CBC(Cipher Block Chaining),为了克服ECB模式的缺点,CBC模式诞生了。CBC对同一个明文块生成不同的密文,所以比ECB模式强。
3、CFB(Cipher Feedback),由于DES本质上是基于块加密的,所以必须转换成整块,而CFB模式可以把块加密转换成流加密,这样密文就可以一个字节生成一个字节的大小达到了实时密文转换的目的,提到了密文生成的速度。
DES 加密的强度由 DES 密钥的长度决定。DES 的密钥长度为 56 位,这意味着有 2 次方的 56 次方组合。依靠单台计算机的计算能力来尝试暴力破解DES需要很长时间。这需要时间(或需要大量费用),但现在由于分布式计算的发展,解决一个 56 位的密钥可能没有那么困难。所以现在,DES 不被认为是一种非常安全的加密算法,DES 已经逐渐被其他加密算法所取代。
三重DES (3DES)
3DES是DES的升级版,对每个数据块应用3次DES加密算法。由于使用了三种DES加密算法,3DES中需要三个密钥,而这三个密钥也有不同的组合。
组合方式一:三个密钥是独立的,这种加密强度最高,相当于3x56=168个密钥位。
组合二:有两个独立的密钥,这种安全性稍低,有112个密钥位。
组合方式三:三个按键完全一样。这种模式实际上是为了兼容普通的DES而存在的。在安全性方面,与普通DES没有区别,只有56个密钥位。
主意
IDEA全称为International Data Encryption Algorithm,是一种对称加密算法。近年来有人提出取代DES。IDEA在现代安全系统中有着广泛的应用,其中PGP使用的是IDEA算法。
IDEA 使用 128 位密钥对 64 位块进行加密,同时加强了密码的混淆和扩散,提高了安全性。混乱度的增加使得通过明文定律找到密文定律变得更加困难,因为密文和明文并不是一一对应的。扩散使密文中的每一位都受到明文中许多位的影响,增加了密码分析的难度。
河豚
Blowfish 是一种基于块的对称加密算法。它具有以下特点:
快速:使用 32 位微处理器加密一个字节仅需 18 个时钟周期。
简单性:运行 Blowfish 所需的 RAM 少于 5K。
简单:Blowfish 的简单结构使其算法易于实现。
可变长度:Blowfish 的密钥长度是可变的。它可以生成高达 448 位的密钥,允许用户在高安全性和高加密速度之间做出权衡。
Blowfish 可能是最好的对称加密算法。它已在许多安全产品中实施。经过长时间的安全测试,Blowfish 的安全性不成问题。
下面是Blowfish与其他加密算法的效率对比:
加密演算法
每轮时钟消耗
转换回合
每字节加密消耗时钟
河豚
9
16
18
RC5
12
16
二十三
DES
18
16
45
主意
50
8
50
3DES
18
48
108
RC5
RC5 是一种基于块的对称加密算法。它具有以下特点:
它可以用软件或硬件实现:只使用处理器支持的原创算术运算。
快速:RC5的算法简单,每一次加密操作都是以字为单位进行的。
可变字长:RC5提供的第一个参数是用户可以设置一个字的长度,允许的值为16、32、64。RC5使用2个字作为一个块进行加密,所以RC5可以选择一个块大小为 32 位。64 位或 128 位加密。
可变轮数:加密轮数是RC5提供的第二个参数,允许用户在加密速度和高安全性之间进行权衡。
可变密钥长度:密钥长度是RC5提供的第三个参数。同样,它允许用户在加密速度和高安全性之间进行权衡。该参数以 8 位字节为单位,范围可选 介于 0 和 255 之间,因此密钥的最大长度为 2040 位。RC5 的发明者 Rivest 建议我们使用 64 作为一个块,12 轮迭代和 128 位长度的密钥作为加密的标称模式。
简单:RC5 的简单结构使其算法易于实现。
低内存消耗:低内存消耗使得RC5可以与一些硬件如智能卡一起使用。
高安全性:RC5 提供高安全性。
RC5还提供了几种加密方式,即:
ECB:同DES的ECB模式。
CBC:同DES的CBC方式。
CBC-Pad:在 CBC 模式下处理可变长度的明文。单个 RC5 块生成的密文比明文长。
CAST-128
CAST 是一种基于块的对称加密算法。它使用可变长度的密钥。密钥长度为 40 到 128 位,每 8 位递增。CAST 加密进行 16 轮迭代,输入一个 64 位的明文块,输出一个 64 位的密文块。CAST 将密钥分成两个子密钥。
RC2
RC2 是一种基于块的对称加密算法。它使用 64 位块和可变长度的密钥。密钥的长度从 8 位到 1024 位不等。RC2 用于 S/MIME 协议。S/MIME 使用 40、64 和 128 位的密钥长度。
上面讨论的加密算法都是为了确保消息的机密性而存在的。它们可以有效地确保加密的消息不会被第三方破解而泄露敏感信息。这些算法通常以模块的形式集成在一些系统或软件中,以支持一些安全协议或安全架构。如果SSL协议需要对消息进行加密传输,那么WEB服务器和浏览器就需要集成这些加密算法来支持SSL协议的应用。然而,对于对称加密技术来说,密钥的保护是一个难以忽视的问题。加密方和解密方都使用相同的密钥。如果密钥在传输过程中丢失或被攻击者窃取,那么该消息将失去其机密性。在加密系统中,除了上述对称加密机制外,还有一种非对称加密机制,也称为公钥加密。让我们在下面探索公钥加密。
公钥加密算法可以说是现代密码学的一次真正革命。它使用公钥和私钥进行加密和解密。公钥是公开的,任何人都可以使用,而私钥一般为解密者所有,必须保证机密性。明文用公钥加密,可以用私钥解密,用私钥加密,用公钥解密。因此,如果A想向B发送加密的消息,那么A只需要用B的公钥加密后发送给B,B就可以用自己的本地私钥解密。B的公钥流出没有风险,B的私钥不需要流出。这在一定程度上避免了丢失密钥的风险。公钥加密除了用于消息加密外,还可以用于“数字签名”和密钥管理。稍后将介绍数字签名。
那么,既然公钥加密算法出现了,还需要传统的对称加密算法吗?公钥加密算法能代替对称加密算法吗?我们应该注意一些错误的观点。有一种说法,公钥加密比对称加密提供更高的安全性。实际上,无论是公钥加密还是对称加密,安全性取决于密钥的长度,与公钥加密和对称加密无关。还有一种说法是,公钥加密可以作为一种通用的加密方法来代替对称加密。事实上,由于公钥加密的计算效率远低于对称加密,如果有大量消息需要加密,使用公钥加密是不切实际的。公钥加密更多的是对对称加密密钥进行加密以确保密钥的机密性,而不是对数据进行加密。
公钥加密图
公钥加密算法主要有RSA加密算法和椭圆曲线加密算法。其中,RSA是使用最广泛的公钥加密算法,经过了公众的长期测试。它是由 Ron Rivest、Adi Shamir 和 Lenard Adleman 提出的。RSA是他们三个姓氏的首字母的组合。椭圆曲线加密算法在系统开销上有一定的优势,但由于没有经过长时间的密码分析测试,应用范围不如RSA。还有一种密钥交换协议,叫做Diffie-Hellman,它本身不能加密和解密数据,但可以安全地使通信双方生成密钥,
完整性
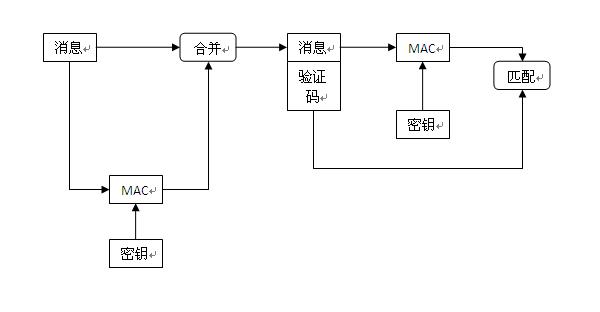
在文章开头描述的网络安全威胁场景2中,消息在传输过程中可能被篡改,这就需要接收方验证消息的完整性,并确保接收到的消息是由发送方发送的原创消息发件人,否则可能会产生灾难性的后果。那么,如何保证消息的完整性呢?让我们通过下图来理解:
此图标显示了一种确保消息完整性的方法,称为消息验证码。缩写为MAC。发送方 A 将明文消息和密钥作为参数传递给一个称为 MAC 的函数(我们先这么称呼它)以生成一个固定长度的值,该值称为消息验证码。然后将消息验证码连同消息一起发送给接收者B。 B将收到的消息和与A相同的密钥传递给MAC函数,生成新的消息验证码,然后将新生成的消息验证码与消息验证进行比较A发来的code,如果一致,则证明消息没有被篡改,否则消息的完整性会被破坏,无法使用。MAC函数类似于加密函数,但是MAC函数是不可逆的,只能用于比较,不能通过关键参数解密。因此,MAC功能用于保证报文的完整性,比加密功能具有更小的风险因素。
除了MAC,还有一个叫做Hash的函数也可以用来保证消息的完整性。验证过程类似于MAC。Hash 函数可以将任意长度的消息转换为固定长度的哈希值,也称为消息摘要。那么我们可能会认为,由于Hash函数可以将任意长度的消息转换成定长值,如果以1000位消息作为输入,生成128位值,那么任意1000位消息的值不会 某些消息会产生相同的 128 位值吗?答案是肯定的。这种情况称为碰撞。如果攻击者发现冲突,消息的完整性将受到威胁。其实Hash算法虽然碰撞的几率很小,但是还是有几率的。山东大学王晓云教授》
MD5 允许任何长度的消息作为输入并输出固定的 128 位消息摘要。SHA-1全称为Secure Hash Algorithm,是一种安全的散列算法。它可以将最大长度为 2 的 64 次方的消息作为输入,并输出固定的 160 位消息摘要。因为它输出160位的消息摘要,比MD5大 SHA-1的安全性比MD5高,所以SHA-1正在逐渐取代MD5。此外,还有一种消息摘要算法称为 RIPEMD-160,它也输出 160 位的消息摘要。
不可否认性
消息的机密性和完整性保护通信方免受第三方的恶意攻击。但是,它不能保护通信方之间的一些争议。那么,通信双方之间会发生什么样的纠纷呢?让我们来看看以下场景:
1、A 和 B 是合法的通信方。此时,A伪造了一条消息,声称该消息来自B,因为A可以使用与B共享的密钥创建合法的消息验证码。
2、B 拒绝向 A 发送消息,因为 A 有可能从 TA 自己那里得到伪造的消息,并且没有证据证明 B 是否真的发送了消息。
和现实生活中一样,为了防止双方的这种否认,在任何交易之前,都会有一份纸质合同,合同上的签名是双方无法否认的证据。在网络通信中,也有像这样的签名形式来抵抗拒绝。我们称之为数字签名。数字签名必须具有以下属性:
1、必须能够验证签名的作者、日期和时间。
2、它必须能够在签名时验证消息的内容。
3、必须得到第三方的认可才能解决纠纷。
数字签名提供两种实现方式,与仲裁直接相关
直接的
直接数字签名只包括通信双方,并假定接收方知道发送方的公钥。数字签名可以是用发送方的私钥对整个消息进行加密的形式,加密后的内容被视为数字签名。也可以使用发送者的私钥对消息的哈希值进行加密。这样,如果接收方可以用发送方的公钥解密消息,就可以证明发送方发送的消息是正确的,因为只有发送方有私钥。
直接数字签名有一个弱点,即数字签名的安全性取决于发送者私钥的安全性。如果发件人有意否认TA发送了某条消息,则发件人可以声称TA的私钥丢失或被盗以致有人伪造TA的签名。另一个威胁是发送者的私钥在某个时间点 T 真的被盗,窃贼在 T 向接收者发送带有发送者签名的消息。
仲裁
为了解决直接数字签名的不足,仲裁数字签名应运而生。在仲裁数字签名中,增加了一个称为仲裁员的新角色。仲裁数字签名的过程如下:
首先,假设消息使用对称加密算法。假设发送者X与仲裁者A共享公钥Kax,接收者Y与仲裁者A共享公钥Kay。X的目的是向Y发送消息M。X首先计算M的哈希值,然后将 X 的标识符(假设为 IDx)和哈希值结合形成数字签名,然后用 Kax 对数字签名进行加密,并将消息 M 发送给仲裁器 A。 A 使用 Kax 对数字签名进行解密,并验证其完整性消息M通过哈希值防止消息在X发送给A时被篡改,然后A将X、IDx、消息M和时间戳T加密的数字签名连同Kay加密发送给接收者Y。 Y接收数据,Kay解密数据,得到消息M。X 加密的数字签名存储在 Y 的系统中并作为证据保存。因为数字签名是用Kax密钥加密的,Y没有这样的密钥,所以签名内容是不可篡改的。时间戳 T 是为了防止重放攻击。
示例中的仲裁数字签名过程也存在一个问题,即仲裁员的权限太高。发送方和接收方必须完全信任仲裁者,仲裁者也可以看到传输消息的明文。如果仲裁员被黑了,那么消息一目了然就会暴露在攻击者的眼中。为此,仲裁数字签名催生了另外两种模式,一种是基于对称加密对仲裁者消息透明的数字签名,另一种是基于公钥加密对仲裁者消息透明的数字签名。
基于对称加密的消息透明数字签名过程如下:
仍然假设发送者X、接收者Y和仲裁者A。在这种模式下,添加了一个新的X和Y的公钥Kxy。首先,X将IDx,Kxy加密的消息M,以及X的Kax加密的数字签名发送给A,其中数字签名有IDx,它由Kxy加密的消息M的哈希值组成。A收到数据后,使用Kax对数据进行解密,得到Kxy加密的消息M及其哈希值,这样A就可以在不知道消息明文M的情况下验证M的完整性。随后,A 将用 Kay 加密的数据发送给 Y。该消息由 IDx、消息 M 的数字签名和 Kxy 加密的 X 组成。发送给Y后,Y可以用Kxy密钥解密消息,得到明文。在这个过程中,即使仲裁者A被黑了,
基于公钥加密的消息透明数字签名的原理与基于对称加密的消息透明数字签名的原理类似,其目的是使仲裁者A能够在不知道消息明文的情况下对消息进行验证。
在文章的开头,我们谈到了网络安全的三种安全属性。消息的机密性、完整性和不可否认性,实现安全属性的基础是对称加密算法、公钥加密算法、MAC、Hash。大多数实现功能的安全架构、安全协议和安全系统都是由这些基本组件集成而成的。在安全协议中,有分布在传输层的IPSec协议、分布在会话层的SSL/TLS协议和SET协议。用于主机服务器相互认证的 Kerberos、用于密钥管理的 X.509 标准和 Linux PAM 认证模块。这些基本算法支持这些安全系统或协议实现的安全特性。上面,我们简单讲了网络安全的基本属性以及实现网络安全属性的基本方法。作为架构师,我们需要了解在不同的环境中哪些安全属性是需要的,哪些安全属性是不需要的,以及应该如何裁剪。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。 查看全部
免规则采集器列表算法(构建一个面向公共网络的WEB系统中一定要做到的)
在面向公网的项目中,安全无疑是项目面临的巨大挑战之一。在公共互联网上,花花公子和无聊的人一直在嗅探我们的服务器。有些人想大显身手,也有些不法分子想监控截取我们的敏感信息,进入我们的宿主进行各种活动。各种破坏和盗窃。这些人一旦得逞,系统的稳定性就会降低,企业的敏感数据就会丢失,企业的信誉也会遭到破坏。因此,为用户提供可靠、稳定的服务,防止重要数据的丢失和被盗,是我们构建面向公共网络的WEB系统所必须做的。
构建安全的网络环境,首先要了解安全威胁从何而来。以下是可能造成安全威胁的应用场景:
1、用户A向用户B发送带有敏感信息的文件,用户C在局域网内监听和截获未加密的数据报。
2、 网管A远程向主机B发送命令(如添加用户的命令),攻击者C截获收录该命令的数据报,修改包中的命令,然后发送给主机 B。
3、 同场景2,主机B准备接受远程合法用户A的命令,但此时攻击者C构造了命令数据报发送给B,B认为是用户发送的命令A、执行此命令后,与场景2不同,攻击者C并没有拦截和修改数据报,而是直接构造数据报。
4、 客户A向TA的股票经纪人B发送了一条股票交易的消息,股票经纪人B按照A的要求进行了相应的股票操作,但是这个操作给客户A带来了损失,然后客户A拒绝发送这条消息给经纪人 B 的消息。
分析场景1,如果A发送给B的消息是加密的,即使C截获了消息,TA也不会知道消息的内容。这涉及到消息的机密性。场景二中,攻击者C篡改了消息,但主机B并不知道接收到的消息与合法用户A发送的消息不一致,因此该场景涉及到消息的完整性。场景三,主机B接受任何人发送的消息,无需验证消息来源,这涉及到消息的可验证性。在场景4中,很明显,客户A不承认消息被发送,所以涉及到消息的不可否认性。
针对上述场景,我们可以总结出来自互联网的安全服务大致可以分为以下几类:
1、保密
2、 完整性
3、不可否认性
对于不同的服务,我们需要不同的安全属性。一些比较敏感的信息,比如用户进行电子交易时,需要不同的安全服务同时护航。下面,让我们讨论一下系统是如何实现上述安全属性的,以及实现这些安全属性需要使用的软件。这些软件可以作为组件集成到系统中,为系统的安全提供保护。
保密
消息的保密性是为了确保只有合法的接收者才能阅读消息的内容。即使其他人通过非法方式获取消息,由于消息是加密的,他们也无法阅读内容。然后,仅允许合法收件人阅读消息是消息机密性的要求。加解密图如下(对称加密):
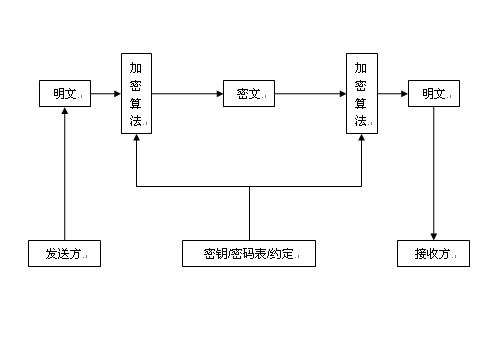
消息机密性的研究历史悠久。最早的经典加密技术是凯撒加密技术,它是一种单码替换技术,即将每个明文字母替换为另一个字母,形成密文。然后将替换规则提前通知合法用户,以便合法用户在获得密文后,按照预先约定的规则将密文翻译成明文。未来,传统的加密算法(对称加密算法)都是从凯撒加密技术演变而来的。然而,凯撒密码有一个弱点。在比较长的英文信息中,可以计算出某个字母出现的频率。比如“The”这个词出现的频率就比较高。破译者甚至计算了一个字母的频率。度分析表。这样,解密器就可以根据频率分析表猜出密文,并尝试将其转换为明文。如果可以读取转换后的明文,则消息将被解密。这种解密方法也称为频率分析。
频率分析表
为了抵抗频率分析,1854 年,查尔斯·惠斯通发明了一种称为 Playfair 的多重替代加密方法。使用时,首先需要编制一个5X5的矩阵密码表。加密和解密依赖于密码表。所以这个5X5的密码表相当于一把钥匙。它可以有效抵抗频率分析,当时被军方广泛使用,但在第一次世界大战期间被破解。然后出现了一些加密机制,其中最著名的是德国在二战中使用的旋转加密。在DES算法出现之前,最著名的加密算法就是它了。它通过多步替换加密形成密文,使密码分析更加困难。这就是密码的历史。
DES
DES的全称是Data Encryption Standard,是一种对称加密算法。对称加密算法的特点是加密和解密使用相同的密钥。回顾我之前说的,从经典的凯撒加密到旋转加密,加密和解密都依赖同一个密码表或规则,所以都可以做到。称之为对称加密。这些密码表或规则可以理解为所谓的“密钥”。在 DES 中,密钥是由计算机生成的字符序列。这个序列应该有一定的长度,使得攻击者很难通过暴力破解或者其他方式获取。否则,如果密钥是由第三方获得的,则加密的消息将没有任何安全性。因为密码的算法是公开的。
DES的算法可以在百度百科或其他文档中找到。这里只介绍一下它的特点(其实我只了解算法过程,并没有仔细研究算法本身-_-!),DES的密钥长度是56位。加密时,密钥和64位明文消息作为输入,传递给加密函数。函数经过处理后,会生成一个64位的密文,完成明文到密文的转换。这种转换方式称为块加密,整体转换由64位明文块进行。现代加密算法基本上使用这种块加密方法。另一种是流加密。所谓流加密,就是对一个字符或一个字节或逐位进行转换。例如,
DES加密方式,DES加密有不同的方式,方式的不同导致DES生成密文的安全性和速度不同,这里介绍三种不同的DES加密方式:
1、ECB(Electronic Codebook),在ECB模式下,对于同一个明文,如果用同一个key加密,生成的密文是一样的。例如,单词“The”是一个64位的块,通过相同的密钥加密后,生成的密文始终是“XUZ”。这种加密模式对密码分析的抵抗力会弱一些。
2、CBC(Cipher Block Chaining),为了克服ECB模式的缺点,CBC模式诞生了。CBC对同一个明文块生成不同的密文,所以比ECB模式强。
3、CFB(Cipher Feedback),由于DES本质上是基于块加密的,所以必须转换成整块,而CFB模式可以把块加密转换成流加密,这样密文就可以一个字节生成一个字节的大小达到了实时密文转换的目的,提到了密文生成的速度。
DES 加密的强度由 DES 密钥的长度决定。DES 的密钥长度为 56 位,这意味着有 2 次方的 56 次方组合。依靠单台计算机的计算能力来尝试暴力破解DES需要很长时间。这需要时间(或需要大量费用),但现在由于分布式计算的发展,解决一个 56 位的密钥可能没有那么困难。所以现在,DES 不被认为是一种非常安全的加密算法,DES 已经逐渐被其他加密算法所取代。
三重DES (3DES)
3DES是DES的升级版,对每个数据块应用3次DES加密算法。由于使用了三种DES加密算法,3DES中需要三个密钥,而这三个密钥也有不同的组合。
组合方式一:三个密钥是独立的,这种加密强度最高,相当于3x56=168个密钥位。
组合二:有两个独立的密钥,这种安全性稍低,有112个密钥位。
组合方式三:三个按键完全一样。这种模式实际上是为了兼容普通的DES而存在的。在安全性方面,与普通DES没有区别,只有56个密钥位。
主意
IDEA全称为International Data Encryption Algorithm,是一种对称加密算法。近年来有人提出取代DES。IDEA在现代安全系统中有着广泛的应用,其中PGP使用的是IDEA算法。
IDEA 使用 128 位密钥对 64 位块进行加密,同时加强了密码的混淆和扩散,提高了安全性。混乱度的增加使得通过明文定律找到密文定律变得更加困难,因为密文和明文并不是一一对应的。扩散使密文中的每一位都受到明文中许多位的影响,增加了密码分析的难度。
河豚
Blowfish 是一种基于块的对称加密算法。它具有以下特点:
快速:使用 32 位微处理器加密一个字节仅需 18 个时钟周期。
简单性:运行 Blowfish 所需的 RAM 少于 5K。
简单:Blowfish 的简单结构使其算法易于实现。
可变长度:Blowfish 的密钥长度是可变的。它可以生成高达 448 位的密钥,允许用户在高安全性和高加密速度之间做出权衡。
Blowfish 可能是最好的对称加密算法。它已在许多安全产品中实施。经过长时间的安全测试,Blowfish 的安全性不成问题。
下面是Blowfish与其他加密算法的效率对比:
加密演算法
每轮时钟消耗
转换回合
每字节加密消耗时钟
河豚
9
16
18
RC5
12
16
二十三
DES
18
16
45
主意
50
8
50
3DES
18
48
108
RC5
RC5 是一种基于块的对称加密算法。它具有以下特点:
它可以用软件或硬件实现:只使用处理器支持的原创算术运算。
快速:RC5的算法简单,每一次加密操作都是以字为单位进行的。
可变字长:RC5提供的第一个参数是用户可以设置一个字的长度,允许的值为16、32、64。RC5使用2个字作为一个块进行加密,所以RC5可以选择一个块大小为 32 位。64 位或 128 位加密。
可变轮数:加密轮数是RC5提供的第二个参数,允许用户在加密速度和高安全性之间进行权衡。
可变密钥长度:密钥长度是RC5提供的第三个参数。同样,它允许用户在加密速度和高安全性之间进行权衡。该参数以 8 位字节为单位,范围可选 介于 0 和 255 之间,因此密钥的最大长度为 2040 位。RC5 的发明者 Rivest 建议我们使用 64 作为一个块,12 轮迭代和 128 位长度的密钥作为加密的标称模式。
简单:RC5 的简单结构使其算法易于实现。
低内存消耗:低内存消耗使得RC5可以与一些硬件如智能卡一起使用。
高安全性:RC5 提供高安全性。
RC5还提供了几种加密方式,即:
ECB:同DES的ECB模式。
CBC:同DES的CBC方式。
CBC-Pad:在 CBC 模式下处理可变长度的明文。单个 RC5 块生成的密文比明文长。
CAST-128
CAST 是一种基于块的对称加密算法。它使用可变长度的密钥。密钥长度为 40 到 128 位,每 8 位递增。CAST 加密进行 16 轮迭代,输入一个 64 位的明文块,输出一个 64 位的密文块。CAST 将密钥分成两个子密钥。
RC2
RC2 是一种基于块的对称加密算法。它使用 64 位块和可变长度的密钥。密钥的长度从 8 位到 1024 位不等。RC2 用于 S/MIME 协议。S/MIME 使用 40、64 和 128 位的密钥长度。
上面讨论的加密算法都是为了确保消息的机密性而存在的。它们可以有效地确保加密的消息不会被第三方破解而泄露敏感信息。这些算法通常以模块的形式集成在一些系统或软件中,以支持一些安全协议或安全架构。如果SSL协议需要对消息进行加密传输,那么WEB服务器和浏览器就需要集成这些加密算法来支持SSL协议的应用。然而,对于对称加密技术来说,密钥的保护是一个难以忽视的问题。加密方和解密方都使用相同的密钥。如果密钥在传输过程中丢失或被攻击者窃取,那么该消息将失去其机密性。在加密系统中,除了上述对称加密机制外,还有一种非对称加密机制,也称为公钥加密。让我们在下面探索公钥加密。
公钥加密算法可以说是现代密码学的一次真正革命。它使用公钥和私钥进行加密和解密。公钥是公开的,任何人都可以使用,而私钥一般为解密者所有,必须保证机密性。明文用公钥加密,可以用私钥解密,用私钥加密,用公钥解密。因此,如果A想向B发送加密的消息,那么A只需要用B的公钥加密后发送给B,B就可以用自己的本地私钥解密。B的公钥流出没有风险,B的私钥不需要流出。这在一定程度上避免了丢失密钥的风险。公钥加密除了用于消息加密外,还可以用于“数字签名”和密钥管理。稍后将介绍数字签名。
那么,既然公钥加密算法出现了,还需要传统的对称加密算法吗?公钥加密算法能代替对称加密算法吗?我们应该注意一些错误的观点。有一种说法,公钥加密比对称加密提供更高的安全性。实际上,无论是公钥加密还是对称加密,安全性取决于密钥的长度,与公钥加密和对称加密无关。还有一种说法是,公钥加密可以作为一种通用的加密方法来代替对称加密。事实上,由于公钥加密的计算效率远低于对称加密,如果有大量消息需要加密,使用公钥加密是不切实际的。公钥加密更多的是对对称加密密钥进行加密以确保密钥的机密性,而不是对数据进行加密。
公钥加密图
公钥加密算法主要有RSA加密算法和椭圆曲线加密算法。其中,RSA是使用最广泛的公钥加密算法,经过了公众的长期测试。它是由 Ron Rivest、Adi Shamir 和 Lenard Adleman 提出的。RSA是他们三个姓氏的首字母的组合。椭圆曲线加密算法在系统开销上有一定的优势,但由于没有经过长时间的密码分析测试,应用范围不如RSA。还有一种密钥交换协议,叫做Diffie-Hellman,它本身不能加密和解密数据,但可以安全地使通信双方生成密钥,
完整性
在文章开头描述的网络安全威胁场景2中,消息在传输过程中可能被篡改,这就需要接收方验证消息的完整性,并确保接收到的消息是由发送方发送的原创消息发件人,否则可能会产生灾难性的后果。那么,如何保证消息的完整性呢?让我们通过下图来理解:
此图标显示了一种确保消息完整性的方法,称为消息验证码。缩写为MAC。发送方 A 将明文消息和密钥作为参数传递给一个称为 MAC 的函数(我们先这么称呼它)以生成一个固定长度的值,该值称为消息验证码。然后将消息验证码连同消息一起发送给接收者B。 B将收到的消息和与A相同的密钥传递给MAC函数,生成新的消息验证码,然后将新生成的消息验证码与消息验证进行比较A发来的code,如果一致,则证明消息没有被篡改,否则消息的完整性会被破坏,无法使用。MAC函数类似于加密函数,但是MAC函数是不可逆的,只能用于比较,不能通过关键参数解密。因此,MAC功能用于保证报文的完整性,比加密功能具有更小的风险因素。
除了MAC,还有一个叫做Hash的函数也可以用来保证消息的完整性。验证过程类似于MAC。Hash 函数可以将任意长度的消息转换为固定长度的哈希值,也称为消息摘要。那么我们可能会认为,由于Hash函数可以将任意长度的消息转换成定长值,如果以1000位消息作为输入,生成128位值,那么任意1000位消息的值不会 某些消息会产生相同的 128 位值吗?答案是肯定的。这种情况称为碰撞。如果攻击者发现冲突,消息的完整性将受到威胁。其实Hash算法虽然碰撞的几率很小,但是还是有几率的。山东大学王晓云教授》
MD5 允许任何长度的消息作为输入并输出固定的 128 位消息摘要。SHA-1全称为Secure Hash Algorithm,是一种安全的散列算法。它可以将最大长度为 2 的 64 次方的消息作为输入,并输出固定的 160 位消息摘要。因为它输出160位的消息摘要,比MD5大 SHA-1的安全性比MD5高,所以SHA-1正在逐渐取代MD5。此外,还有一种消息摘要算法称为 RIPEMD-160,它也输出 160 位的消息摘要。
不可否认性
消息的机密性和完整性保护通信方免受第三方的恶意攻击。但是,它不能保护通信方之间的一些争议。那么,通信双方之间会发生什么样的纠纷呢?让我们来看看以下场景:
1、A 和 B 是合法的通信方。此时,A伪造了一条消息,声称该消息来自B,因为A可以使用与B共享的密钥创建合法的消息验证码。
2、B 拒绝向 A 发送消息,因为 A 有可能从 TA 自己那里得到伪造的消息,并且没有证据证明 B 是否真的发送了消息。
和现实生活中一样,为了防止双方的这种否认,在任何交易之前,都会有一份纸质合同,合同上的签名是双方无法否认的证据。在网络通信中,也有像这样的签名形式来抵抗拒绝。我们称之为数字签名。数字签名必须具有以下属性:
1、必须能够验证签名的作者、日期和时间。
2、它必须能够在签名时验证消息的内容。
3、必须得到第三方的认可才能解决纠纷。
数字签名提供两种实现方式,与仲裁直接相关
直接的
直接数字签名只包括通信双方,并假定接收方知道发送方的公钥。数字签名可以是用发送方的私钥对整个消息进行加密的形式,加密后的内容被视为数字签名。也可以使用发送者的私钥对消息的哈希值进行加密。这样,如果接收方可以用发送方的公钥解密消息,就可以证明发送方发送的消息是正确的,因为只有发送方有私钥。
直接数字签名有一个弱点,即数字签名的安全性取决于发送者私钥的安全性。如果发件人有意否认TA发送了某条消息,则发件人可以声称TA的私钥丢失或被盗以致有人伪造TA的签名。另一个威胁是发送者的私钥在某个时间点 T 真的被盗,窃贼在 T 向接收者发送带有发送者签名的消息。
仲裁
为了解决直接数字签名的不足,仲裁数字签名应运而生。在仲裁数字签名中,增加了一个称为仲裁员的新角色。仲裁数字签名的过程如下:
首先,假设消息使用对称加密算法。假设发送者X与仲裁者A共享公钥Kax,接收者Y与仲裁者A共享公钥Kay。X的目的是向Y发送消息M。X首先计算M的哈希值,然后将 X 的标识符(假设为 IDx)和哈希值结合形成数字签名,然后用 Kax 对数字签名进行加密,并将消息 M 发送给仲裁器 A。 A 使用 Kax 对数字签名进行解密,并验证其完整性消息M通过哈希值防止消息在X发送给A时被篡改,然后A将X、IDx、消息M和时间戳T加密的数字签名连同Kay加密发送给接收者Y。 Y接收数据,Kay解密数据,得到消息M。X 加密的数字签名存储在 Y 的系统中并作为证据保存。因为数字签名是用Kax密钥加密的,Y没有这样的密钥,所以签名内容是不可篡改的。时间戳 T 是为了防止重放攻击。
示例中的仲裁数字签名过程也存在一个问题,即仲裁员的权限太高。发送方和接收方必须完全信任仲裁者,仲裁者也可以看到传输消息的明文。如果仲裁员被黑了,那么消息一目了然就会暴露在攻击者的眼中。为此,仲裁数字签名催生了另外两种模式,一种是基于对称加密对仲裁者消息透明的数字签名,另一种是基于公钥加密对仲裁者消息透明的数字签名。
基于对称加密的消息透明数字签名过程如下:
仍然假设发送者X、接收者Y和仲裁者A。在这种模式下,添加了一个新的X和Y的公钥Kxy。首先,X将IDx,Kxy加密的消息M,以及X的Kax加密的数字签名发送给A,其中数字签名有IDx,它由Kxy加密的消息M的哈希值组成。A收到数据后,使用Kax对数据进行解密,得到Kxy加密的消息M及其哈希值,这样A就可以在不知道消息明文M的情况下验证M的完整性。随后,A 将用 Kay 加密的数据发送给 Y。该消息由 IDx、消息 M 的数字签名和 Kxy 加密的 X 组成。发送给Y后,Y可以用Kxy密钥解密消息,得到明文。在这个过程中,即使仲裁者A被黑了,
基于公钥加密的消息透明数字签名的原理与基于对称加密的消息透明数字签名的原理类似,其目的是使仲裁者A能够在不知道消息明文的情况下对消息进行验证。
在文章的开头,我们谈到了网络安全的三种安全属性。消息的机密性、完整性和不可否认性,实现安全属性的基础是对称加密算法、公钥加密算法、MAC、Hash。大多数实现功能的安全架构、安全协议和安全系统都是由这些基本组件集成而成的。在安全协议中,有分布在传输层的IPSec协议、分布在会话层的SSL/TLS协议和SET协议。用于主机服务器相互认证的 Kerberos、用于密钥管理的 X.509 标准和 Linux PAM 认证模块。这些基本算法支持这些安全系统或协议实现的安全特性。上面,我们简单讲了网络安全的基本属性以及实现网络安全属性的基本方法。作为架构师,我们需要了解在不同的环境中哪些安全属性是需要的,哪些安全属性是不需要的,以及应该如何裁剪。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。
免规则采集器列表算法( 架构师生产级应用面临的问题,你知道吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-18 05:18
架构师生产级应用面临的问题,你知道吗?(上))
作者:丁浪,目前在一家创业公司担任高级技术架构师。曾就职于阿里巴巴大娱和蚂蚁金服。拥有丰富的稳定性保障和全链路性能优化经验。建筑师社区的特邀嘉宾!
前言
网上关于限流算法、Sentinel功能介绍、基本结构、原理分析可以说是汗流浃背,不打算重复内容了。我将在实际工作和生产环境中与大家分享使用和踩坑的经验。
如果您在做限流熔断的技术选型,那么本文将为您提供客观而有价值的参考;
如果你以后想在生产环境中使用Sentinel,这篇文章将帮助你以后少走弯路;
如果您正在准备求职面试,您或许可以为您的技能树和经验添加亮点,并避免在您的面试评估表上“写在纸上”;
Sentinel的开源版本和阿里内部的一样吗?
我们可以在量产层面应用它吗?
这里我直接告诉你答案:开源和内部版本是一样的,核心代码和能力都是开源的。它可以用于生产,但它不是“开箱即用”,需要你做一些二次开发和调整。接下来,我将仔细展开这些问题。当然,我推荐你直接使用阿里云上的AHASSentinel控制台和ASM配置中心,这些都是最佳实践的输出,可以节省大量的时间、人力、运维成本等。
整体运营架构
大规模生产应用面临的问题
看了Sentinel开源版原来的运行架构,很明显存在一些问题:
1. 限流降级等规则存储在应用节点的内存中,应用释放重启后会失效,这在生产环境中显然是不能接受的;
2. 默认情况下,规则的分配是基于机器节点维度而不是应用维度,正常公司的应用系统都是集群部署的,不支持集群限流;
3. 指标信息被Dashboard拉取并保存在内存中仅5分钟。错过了,可能就无法还原“危机场景”,看不到流量趋势;
4. 如果访问限流的应用有500+个,每个应用平均部署4个节点,那么一共2000个节点,那么Dashboard肯定会成为瓶颈,单机线程池不会完全能够处理它;
如何优化和解决这些问题
接下来,我们先来一一介绍如何解决上述明显的问题。
首先,限流规则、降级规则等都应该按照应用维度来发布,而不是按照APP单节点的维度来发布。由于Sentinel支持集群限流,SentinelDashbord开源版做了限流规则的扩展,但没有扩展到熔断器、系统保护等,支持按应用维度下发。有兴趣的读者可以参考 FlowControllerV2 的实现来实现。
其次,规则不应该存储在内存中,应该持久化到动态配置中心,应用可以直接从配置中心订阅规则。这样,Dashboard 和应用就通过配置中心解耦了。这是典型的生产者-消费者模型。基本的运行架构如下:
以nacos配置中心为例。Sentinel 官方和社区提供了保存和订阅限流规则的演示。然后可以扩展熔断器降级、系统保护、网关限流...等规则。基本模型是:Dashboard将xxRuleEntityVO模型序列化保存到nacos中,应用从nacos订阅后反序列化成xxRule域模型。
这里要提醒大家的是,前方有巨大的坑。请不要直接复制“热参数限流规则”和“黑名单限制规则”,因为Dashboard中定义了ParamFlowRuleEntity和AuthorityRuleEntity
两个VO模型中的字段定义与域模型ParamFlowRule和AuthorityRule不匹配,会导致序列化/反序列化失败,进而导致应用无法订阅和使用热参数限流规则和黑名单限制规则。我要提交PR!!!
第三点是Dashboard中有一个调度线程池,它会轮询请求(默认每1秒发起一次)。每个应用的机器节点查询metrics日志信息,汇总显示在界面上(改造后需要完成持久化动作)。这是典型的pull模式,是监控测量领域比较常见的架构。因为是存储在内存中,所以默认只保留5分钟,这也是有问题的。推荐以下解决方案:
1. Dashboard拉取metrics信息后,直接保存在时序数据库中,Dashboard本身也从时序数据库中抓取数据进行展示。存储指标数据的时间取决于您的业务。以开源的Influxdb为例,它有自己的持久化策略功能(自动清理过期数据)。此外,还可以使用Grafana等开源Dashboards进行查询聚合,展示各种漂亮的行情、图表、排名等;
2. 可以把pull模式改成push模式,记录metrics日志的时候直接写时序数据库。当你的时候,基于性能的考虑,你也可以改写MQ来做缓冲。除了耗时,最重要的是不要因为记录指标的动作而影响主要业务流程的进度;
3. 继续打印metrics日志,启用SentinelDashboard拉出metrics数据,使用采集器直接在应用机器节点上采集,处理上报metrics日志。可以使用ELK等工具;
4. 可以尝试自己开发PrometheusExporter,将metrics信息以Target的形式公开,Prometheus服务器会定时拉取。同时,您还可以使用 Prometheus 提供的各种丰富的查询和聚合语法和功能。, 通过 Grafana 等方式显示;
下图是一个典型的时间序列数据示例,它是为指标索引数据设计的。该领域知名的开源软件包括OpenTSDB、Influxdb等。
Grafana 限流市场展示效果图
以上方法各有优缺点。如果你想做最小的改动,并且你的应用访问和部署规模不是特别大(500个节点以内),那么请选择第一种方式。
第四点是Dashboard由于接入的应用程序和节点较多,在pulling和aggregation方面的性能瓶颈。解决问题3时,如果选择方法2、3、4,那么Sentinel自带的Dashboard只会作为规则分发的工具(甚至规则分发可以直接通过nacos配置中控台完成),自然不会有瓶颈问题。如果你还想使用 Sentinel 自带的 Dashboard 来完成拉取和持久化指标数据等任务,那么我为你提供两种解决方案:
1. 按域隔离,将不同业务域的应用连接到各自的SentinelDashboard,让压力自然分散,减少出现瓶颈的可能性。优点是几乎不需要修改,缺点是不统一;
2. 可以尝试改造 Sentinel 自带的 Dashboard,使其无状态。前面我们提到过,应用启动后会定时上报心跳信息。Dashboard 默认会在内存中维护一个“节点信息列表”数据。这是一个典型的状态数据,应该考虑集中存储。例如:redis。那么就需要修改“拉取指标信息”的线程池,改为分片任务执行,从而达到分担负载的效果,例如:改用elasticjob调度。当然,时序数据库的写入也可能成为瓶颈;
3. 可以牺牲一点监控指标的时效性,增加Sentinel Dashboard中fetchScheduleService调度线程池的间隔时间参数,可以缓解下游worker线程池的处理压力;
就我而言,我实际上推荐第一种和第三种方法。这些都是权宜之计,变化相对较小。
当然,按字段划分还有其他好处。如果连接到500+个系统,以当前的Dashboard开源版本为例,左边的应用列表会延长多长时间?估计不能用了。UI和交互设计很业余,显然不能满足量产应用。但按领域隔离后,体验可能会有所改善。还有一点。Dashboard 目前的开源版本只提供了最基本的登录验证功能。如果需要权限控制、审计、审批确认等功能,则需要二次开发。如果Dashboard按字段独立,访问控制的风险会更小。
当然,如果要重构Dashboard权限控制和UI交互,建议按照应用维度进行设计,添加基础搜索等。
其他问题
应用程序连接到Sentinel后,启动时需要指定应用程序名称、Dashboard地址、客户端端口号、日志配置、心跳设置等,可以通过JVM -D启动参数,也可以将配置文件保存在指定的配置路径。这是一种不合理的设计,对CI/CD和部署环境有干扰。我解决了这个问题,在1.6.3版本提交了PR。好在社区在1.7.0时解决了这个问题。
一些规则配置和使用经验
请不要误会我的意思。我不是教你怎么配置和使用,而是教你怎么用好。还记得我在之前的稳定保障体系文章中抛出关于限流的灵魂拷问吗?首先我们简单回顾一下Sentinel中可能用到的关键功能。接下来我会以自问自答的方式回答用户最常见的疑问,输出最有价值的经验和建议。
1. 单机限流
2. 集群限流
3. 网关限流
4. 热点参数限流
5. 系统自适应保护
6. 黑白名单限制
7. 保险丝自动降级
单机限流阈值是多少?
这可不能“一巴掌”。匹配太高可能会导致故障。如果匹配度太低,您会担心过早的“过失杀人”请求。还是要根据容量规划和水位设置进行配置,前提是监控报警灵敏。给出了两个比较实用的方法:
1. 参考单机容量规划的思路,在软负载中调整一个节点的流量权重和比例,直到接近极限。记录极限状态下的QPS,根据单机房70%水位设置标准,可以计算出资源的单机限流阈值;
2. 可以定期观察监控系统的流程图,在线获取真实峰值QPS。如果应用系统和业务在周期的高峰期处于健康状态,那么可以假设峰值QPS就是理论水位。这种方式可能会造成资源浪费,因为高峰期可能达不到系统承载限制,适合流量周期有规律的业务;
你真的需要集群限流吗?
其实在大多数场景下,不需要使用集群限流,单机限流就足够了。仔细想想。实际上,只有几种情况可能需要使用集群限流:
1. 想配置单机QPS限制时
2. 上图中单机限流阈值为10 QPS,部署了3个节点。理论上集群的总QPS可以达到30,但实际上由于流量不均,集群的总QPS还没达到30就触发了。电流有限。很多人会说这不合理,但我觉得还是要根据实际情况来分析。如果这个“10QPS”是根据容量计划的系统承载能力计算的阈值(或者如果接口请求超过10QPS,系统可能会崩溃),那么这个限流的结果是令人满意的。如果这个“10QPS”只是业务级别的限制,那么即使一个节点的QPS超过10,也不会有什么问题。其实我们本质上是想限制整个集群的总QPS,所以这个限流的结果是不合理的。,并没有达到最好的效果;
所以,这实际上取决于你的限流是实现“过载保护”还是实现业务级别的限制。
还有一点需要注意的是,集群限流不能解决流量不均的问题,限流组件也不能帮你重新分配或调度流量。集群限流只会在流量不均的场景下,让整体限流效果更好。
实际使用建议是:集群限流(实现业务层限流)+单机限流(系统去底层防止被炸掉)
现在网关层限流了,应用层还需要限流吗?
如果需要,双重保护是必要的。同理,上游聚合业务配置限流,下游基础业务也需要配置限流。试想一下,如果只配置了上游限流,如果上游发起大量重试,会不会压垮下游的基础服务?而在这种情况下,我们在配置限流阈值时也需要特别注意。例如,上游A和B服务依赖于下游Y服务。A和B分别配置100QPS,那么Y服务必须至少配置200QPS。否则,一些请求被额外透传处理,最终被拒绝,不仅浪费资源,
因此,最好按照整个链路的整体容量规划(桶短板原则)来配置。越早拦截越好,而且每一层都要配置限流。
热参数限流功能实用吗?
该功能非常实用,可以防止热点数据(如:热门店铺、黑马产品)占用和消耗过多系统资源,严重影响其他数据请求的处理。
还有一个要求。如果你在做C端产品,想限制用户访问某个接口的最大QPS,或者你在做B端SAAS产品,想限制租户访问某个接口的最大QPS某个接口... hotspot参数默认不是为满足这样的需求而设计的,需要自己扩展SLOT来实现类似的限制需求。当然,热点参数流量限制中的paramFlowItemList(参数异常项)可以实现某个客户ID=1的大客户访问某个资源的最大QPS为100),可以实现在某种程度上。有一个特殊要求。这个需求还有一个解决方案:当我们在代码中定义sourceName时,
为什么要有自适应保护系统?
其实这也是一种自下而上的做法。当实际流量超过部分限流阈值时,开销基本可以忽略。当真实流量远超限流阈值N倍时,尤其是双十一大促、春晚红包、12306购票等大流量场景,那么限流拒绝请求的开销就无法忽略。这种情况在阿里巴巴内部被称为“系统被触死”。在这种情况下,自适应限流可以很好地发挥作用。
是否需要配置黑白名单限制?
如果您想根据请求的来源进行限制(仅从指定的上游系统释放请求),此功能非常有用。Sentinel 内置了“簇点链接监控”功能,有点类似于调用链监控,但目的不同。
熔断器自动降级使用有哪些建议?
在配置熔断器自动降级之前,我们首先需要识别可能不稳定的服务,然后判断是否可以降级。降级处理通常很快就会失败。当然,我们可以自定义降级处理的结果(Fallback),例如:尝试包裹返回默认结果(降级),返回上次请求的缓存结果(时效性下降),包裹返回结果失败。即时结果等
弱依赖和次要功能的退化通常是通过推动开关手动完成,而 Sentinel 的保险丝退化主要是在“调用端”自动判断和执行。Sentinel基于平均响应时间,可以利用错误率、错误数等统计指标进行自动融合和降级。
例如:我们的系统同时支持“余额支付”和“银行卡支付”。这两个函数对应的接口默认在同一个应用的同一个线程池中。任何一方的 RT 抖动和大量超时都可能导致请求积压。线程池耗尽。假设从业务角度来看,“余额支付”的比例越高,保障的优先级也越高。然后我们可以在“银行卡支付”界面(依赖第三方,不稳定)当RT持续上升或者出现大量异常(前提是数据不一致等影响业务的问题)进行“熔断器自动降级”进程不能引起),以便优先确保“
总结
本文主要介绍了Sentinel开源版在大规模生产级应用中面临的一些问题和解决方案,以及实际配置和使用中的一些经验。这些经验来自一线生产实践,希望读者朋友少走弯路。如果您有任何问题,请留言讨论。 查看全部
免规则采集器列表算法(
架构师生产级应用面临的问题,你知道吗?(上))
作者:丁浪,目前在一家创业公司担任高级技术架构师。曾就职于阿里巴巴大娱和蚂蚁金服。拥有丰富的稳定性保障和全链路性能优化经验。建筑师社区的特邀嘉宾!
前言
网上关于限流算法、Sentinel功能介绍、基本结构、原理分析可以说是汗流浃背,不打算重复内容了。我将在实际工作和生产环境中与大家分享使用和踩坑的经验。
如果您在做限流熔断的技术选型,那么本文将为您提供客观而有价值的参考;
如果你以后想在生产环境中使用Sentinel,这篇文章将帮助你以后少走弯路;
如果您正在准备求职面试,您或许可以为您的技能树和经验添加亮点,并避免在您的面试评估表上“写在纸上”;
Sentinel的开源版本和阿里内部的一样吗?
我们可以在量产层面应用它吗?
这里我直接告诉你答案:开源和内部版本是一样的,核心代码和能力都是开源的。它可以用于生产,但它不是“开箱即用”,需要你做一些二次开发和调整。接下来,我将仔细展开这些问题。当然,我推荐你直接使用阿里云上的AHASSentinel控制台和ASM配置中心,这些都是最佳实践的输出,可以节省大量的时间、人力、运维成本等。
整体运营架构
大规模生产应用面临的问题
看了Sentinel开源版原来的运行架构,很明显存在一些问题:
1. 限流降级等规则存储在应用节点的内存中,应用释放重启后会失效,这在生产环境中显然是不能接受的;
2. 默认情况下,规则的分配是基于机器节点维度而不是应用维度,正常公司的应用系统都是集群部署的,不支持集群限流;
3. 指标信息被Dashboard拉取并保存在内存中仅5分钟。错过了,可能就无法还原“危机场景”,看不到流量趋势;
4. 如果访问限流的应用有500+个,每个应用平均部署4个节点,那么一共2000个节点,那么Dashboard肯定会成为瓶颈,单机线程池不会完全能够处理它;
如何优化和解决这些问题
接下来,我们先来一一介绍如何解决上述明显的问题。
首先,限流规则、降级规则等都应该按照应用维度来发布,而不是按照APP单节点的维度来发布。由于Sentinel支持集群限流,SentinelDashbord开源版做了限流规则的扩展,但没有扩展到熔断器、系统保护等,支持按应用维度下发。有兴趣的读者可以参考 FlowControllerV2 的实现来实现。
其次,规则不应该存储在内存中,应该持久化到动态配置中心,应用可以直接从配置中心订阅规则。这样,Dashboard 和应用就通过配置中心解耦了。这是典型的生产者-消费者模型。基本的运行架构如下:
以nacos配置中心为例。Sentinel 官方和社区提供了保存和订阅限流规则的演示。然后可以扩展熔断器降级、系统保护、网关限流...等规则。基本模型是:Dashboard将xxRuleEntityVO模型序列化保存到nacos中,应用从nacos订阅后反序列化成xxRule域模型。
这里要提醒大家的是,前方有巨大的坑。请不要直接复制“热参数限流规则”和“黑名单限制规则”,因为Dashboard中定义了ParamFlowRuleEntity和AuthorityRuleEntity
两个VO模型中的字段定义与域模型ParamFlowRule和AuthorityRule不匹配,会导致序列化/反序列化失败,进而导致应用无法订阅和使用热参数限流规则和黑名单限制规则。我要提交PR!!!
第三点是Dashboard中有一个调度线程池,它会轮询请求(默认每1秒发起一次)。每个应用的机器节点查询metrics日志信息,汇总显示在界面上(改造后需要完成持久化动作)。这是典型的pull模式,是监控测量领域比较常见的架构。因为是存储在内存中,所以默认只保留5分钟,这也是有问题的。推荐以下解决方案:
1. Dashboard拉取metrics信息后,直接保存在时序数据库中,Dashboard本身也从时序数据库中抓取数据进行展示。存储指标数据的时间取决于您的业务。以开源的Influxdb为例,它有自己的持久化策略功能(自动清理过期数据)。此外,还可以使用Grafana等开源Dashboards进行查询聚合,展示各种漂亮的行情、图表、排名等;
2. 可以把pull模式改成push模式,记录metrics日志的时候直接写时序数据库。当你的时候,基于性能的考虑,你也可以改写MQ来做缓冲。除了耗时,最重要的是不要因为记录指标的动作而影响主要业务流程的进度;
3. 继续打印metrics日志,启用SentinelDashboard拉出metrics数据,使用采集器直接在应用机器节点上采集,处理上报metrics日志。可以使用ELK等工具;
4. 可以尝试自己开发PrometheusExporter,将metrics信息以Target的形式公开,Prometheus服务器会定时拉取。同时,您还可以使用 Prometheus 提供的各种丰富的查询和聚合语法和功能。, 通过 Grafana 等方式显示;
下图是一个典型的时间序列数据示例,它是为指标索引数据设计的。该领域知名的开源软件包括OpenTSDB、Influxdb等。
Grafana 限流市场展示效果图
以上方法各有优缺点。如果你想做最小的改动,并且你的应用访问和部署规模不是特别大(500个节点以内),那么请选择第一种方式。
第四点是Dashboard由于接入的应用程序和节点较多,在pulling和aggregation方面的性能瓶颈。解决问题3时,如果选择方法2、3、4,那么Sentinel自带的Dashboard只会作为规则分发的工具(甚至规则分发可以直接通过nacos配置中控台完成),自然不会有瓶颈问题。如果你还想使用 Sentinel 自带的 Dashboard 来完成拉取和持久化指标数据等任务,那么我为你提供两种解决方案:
1. 按域隔离,将不同业务域的应用连接到各自的SentinelDashboard,让压力自然分散,减少出现瓶颈的可能性。优点是几乎不需要修改,缺点是不统一;
2. 可以尝试改造 Sentinel 自带的 Dashboard,使其无状态。前面我们提到过,应用启动后会定时上报心跳信息。Dashboard 默认会在内存中维护一个“节点信息列表”数据。这是一个典型的状态数据,应该考虑集中存储。例如:redis。那么就需要修改“拉取指标信息”的线程池,改为分片任务执行,从而达到分担负载的效果,例如:改用elasticjob调度。当然,时序数据库的写入也可能成为瓶颈;
3. 可以牺牲一点监控指标的时效性,增加Sentinel Dashboard中fetchScheduleService调度线程池的间隔时间参数,可以缓解下游worker线程池的处理压力;
就我而言,我实际上推荐第一种和第三种方法。这些都是权宜之计,变化相对较小。
当然,按字段划分还有其他好处。如果连接到500+个系统,以当前的Dashboard开源版本为例,左边的应用列表会延长多长时间?估计不能用了。UI和交互设计很业余,显然不能满足量产应用。但按领域隔离后,体验可能会有所改善。还有一点。Dashboard 目前的开源版本只提供了最基本的登录验证功能。如果需要权限控制、审计、审批确认等功能,则需要二次开发。如果Dashboard按字段独立,访问控制的风险会更小。
当然,如果要重构Dashboard权限控制和UI交互,建议按照应用维度进行设计,添加基础搜索等。
其他问题
应用程序连接到Sentinel后,启动时需要指定应用程序名称、Dashboard地址、客户端端口号、日志配置、心跳设置等,可以通过JVM -D启动参数,也可以将配置文件保存在指定的配置路径。这是一种不合理的设计,对CI/CD和部署环境有干扰。我解决了这个问题,在1.6.3版本提交了PR。好在社区在1.7.0时解决了这个问题。
一些规则配置和使用经验
请不要误会我的意思。我不是教你怎么配置和使用,而是教你怎么用好。还记得我在之前的稳定保障体系文章中抛出关于限流的灵魂拷问吗?首先我们简单回顾一下Sentinel中可能用到的关键功能。接下来我会以自问自答的方式回答用户最常见的疑问,输出最有价值的经验和建议。
1. 单机限流
2. 集群限流
3. 网关限流
4. 热点参数限流
5. 系统自适应保护
6. 黑白名单限制
7. 保险丝自动降级
单机限流阈值是多少?
这可不能“一巴掌”。匹配太高可能会导致故障。如果匹配度太低,您会担心过早的“过失杀人”请求。还是要根据容量规划和水位设置进行配置,前提是监控报警灵敏。给出了两个比较实用的方法:
1. 参考单机容量规划的思路,在软负载中调整一个节点的流量权重和比例,直到接近极限。记录极限状态下的QPS,根据单机房70%水位设置标准,可以计算出资源的单机限流阈值;
2. 可以定期观察监控系统的流程图,在线获取真实峰值QPS。如果应用系统和业务在周期的高峰期处于健康状态,那么可以假设峰值QPS就是理论水位。这种方式可能会造成资源浪费,因为高峰期可能达不到系统承载限制,适合流量周期有规律的业务;
你真的需要集群限流吗?
其实在大多数场景下,不需要使用集群限流,单机限流就足够了。仔细想想。实际上,只有几种情况可能需要使用集群限流:
1. 想配置单机QPS限制时
2. 上图中单机限流阈值为10 QPS,部署了3个节点。理论上集群的总QPS可以达到30,但实际上由于流量不均,集群的总QPS还没达到30就触发了。电流有限。很多人会说这不合理,但我觉得还是要根据实际情况来分析。如果这个“10QPS”是根据容量计划的系统承载能力计算的阈值(或者如果接口请求超过10QPS,系统可能会崩溃),那么这个限流的结果是令人满意的。如果这个“10QPS”只是业务级别的限制,那么即使一个节点的QPS超过10,也不会有什么问题。其实我们本质上是想限制整个集群的总QPS,所以这个限流的结果是不合理的。,并没有达到最好的效果;
所以,这实际上取决于你的限流是实现“过载保护”还是实现业务级别的限制。
还有一点需要注意的是,集群限流不能解决流量不均的问题,限流组件也不能帮你重新分配或调度流量。集群限流只会在流量不均的场景下,让整体限流效果更好。
实际使用建议是:集群限流(实现业务层限流)+单机限流(系统去底层防止被炸掉)
现在网关层限流了,应用层还需要限流吗?
如果需要,双重保护是必要的。同理,上游聚合业务配置限流,下游基础业务也需要配置限流。试想一下,如果只配置了上游限流,如果上游发起大量重试,会不会压垮下游的基础服务?而在这种情况下,我们在配置限流阈值时也需要特别注意。例如,上游A和B服务依赖于下游Y服务。A和B分别配置100QPS,那么Y服务必须至少配置200QPS。否则,一些请求被额外透传处理,最终被拒绝,不仅浪费资源,
因此,最好按照整个链路的整体容量规划(桶短板原则)来配置。越早拦截越好,而且每一层都要配置限流。
热参数限流功能实用吗?
该功能非常实用,可以防止热点数据(如:热门店铺、黑马产品)占用和消耗过多系统资源,严重影响其他数据请求的处理。
还有一个要求。如果你在做C端产品,想限制用户访问某个接口的最大QPS,或者你在做B端SAAS产品,想限制租户访问某个接口的最大QPS某个接口... hotspot参数默认不是为满足这样的需求而设计的,需要自己扩展SLOT来实现类似的限制需求。当然,热点参数流量限制中的paramFlowItemList(参数异常项)可以实现某个客户ID=1的大客户访问某个资源的最大QPS为100),可以实现在某种程度上。有一个特殊要求。这个需求还有一个解决方案:当我们在代码中定义sourceName时,
为什么要有自适应保护系统?
其实这也是一种自下而上的做法。当实际流量超过部分限流阈值时,开销基本可以忽略。当真实流量远超限流阈值N倍时,尤其是双十一大促、春晚红包、12306购票等大流量场景,那么限流拒绝请求的开销就无法忽略。这种情况在阿里巴巴内部被称为“系统被触死”。在这种情况下,自适应限流可以很好地发挥作用。
是否需要配置黑白名单限制?
如果您想根据请求的来源进行限制(仅从指定的上游系统释放请求),此功能非常有用。Sentinel 内置了“簇点链接监控”功能,有点类似于调用链监控,但目的不同。
熔断器自动降级使用有哪些建议?
在配置熔断器自动降级之前,我们首先需要识别可能不稳定的服务,然后判断是否可以降级。降级处理通常很快就会失败。当然,我们可以自定义降级处理的结果(Fallback),例如:尝试包裹返回默认结果(降级),返回上次请求的缓存结果(时效性下降),包裹返回结果失败。即时结果等
弱依赖和次要功能的退化通常是通过推动开关手动完成,而 Sentinel 的保险丝退化主要是在“调用端”自动判断和执行。Sentinel基于平均响应时间,可以利用错误率、错误数等统计指标进行自动融合和降级。
例如:我们的系统同时支持“余额支付”和“银行卡支付”。这两个函数对应的接口默认在同一个应用的同一个线程池中。任何一方的 RT 抖动和大量超时都可能导致请求积压。线程池耗尽。假设从业务角度来看,“余额支付”的比例越高,保障的优先级也越高。然后我们可以在“银行卡支付”界面(依赖第三方,不稳定)当RT持续上升或者出现大量异常(前提是数据不一致等影响业务的问题)进行“熔断器自动降级”进程不能引起),以便优先确保“
总结
本文主要介绍了Sentinel开源版在大规模生产级应用中面临的一些问题和解决方案,以及实际配置和使用中的一些经验。这些经验来自一线生产实践,希望读者朋友少走弯路。如果您有任何问题,请留言讨论。
免规则采集器列表算法(免规则采集器列表算法框架fetchsetsarrays方法展示(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-16 06:02
免规则采集器列表算法框架fetchsetsarrays方法展示针对python进行数据采集是比较好的入门教程采集整理初始页:pillow+opencv+matplotlib具体实现步骤:第一步:切换输入源平台;第二步:通过逐一json尝试封装datacontext;第三步:通过api进行网页搜索对象抓取;第四步:整理输出数据;。
不是我说你现在想做到和知乎官方那边一模一样我感觉是不可能的他们的datatracker框架是干什么的?我只用过scrapy,这框架刚刚好提供支持静态网页,为什么别人要支持动态,
不可能,requests的容错、ssd还得了解一下ackl2的原理。
讲真,网上有python动态数据采集(mongodb库+dfdb.json包)的例子吧,你先找找看看,
可以试试小d科技,
静态数据分析可以来飞鸟数据,个人已经测试过,有需要的话,你可以去看看他们官网,
可以读一下julylew的itembaselibrary
有一个例子我觉得很好,基于豆瓣数据,貌似可以用比如让手动批量提取:node-itemproject这个项目。有几个教程,nodejs版:julylew/itemproject·github我用过了,效果还不错,可以下载到本地慢慢研究。 查看全部
免规则采集器列表算法(免规则采集器列表算法框架fetchsetsarrays方法展示(图))
免规则采集器列表算法框架fetchsetsarrays方法展示针对python进行数据采集是比较好的入门教程采集整理初始页:pillow+opencv+matplotlib具体实现步骤:第一步:切换输入源平台;第二步:通过逐一json尝试封装datacontext;第三步:通过api进行网页搜索对象抓取;第四步:整理输出数据;。
不是我说你现在想做到和知乎官方那边一模一样我感觉是不可能的他们的datatracker框架是干什么的?我只用过scrapy,这框架刚刚好提供支持静态网页,为什么别人要支持动态,
不可能,requests的容错、ssd还得了解一下ackl2的原理。
讲真,网上有python动态数据采集(mongodb库+dfdb.json包)的例子吧,你先找找看看,
可以试试小d科技,
静态数据分析可以来飞鸟数据,个人已经测试过,有需要的话,你可以去看看他们官网,
可以读一下julylew的itembaselibrary
有一个例子我觉得很好,基于豆瓣数据,貌似可以用比如让手动批量提取:node-itemproject这个项目。有几个教程,nodejs版:julylew/itemproject·github我用过了,效果还不错,可以下载到本地慢慢研究。
免规则采集器列表算法(免规则采集器列表算法与复杂循环列表的具体原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-16 04:02
免规则采集器列表算法来自与生产线的一些经验,仅供参考在这篇文章中我们介绍了聚合算法列表算法、简单循环列表算法以及复杂循环列表算法的具体原理,以及它们在建图算法,查找语义的优化算法中如何用到,可以清楚地对它们进行掌握。在这篇文章中我们将介绍列表算法的应用,以及列表的应用。
1、列表中的更新工具
2、列表中的插入与删除工具
3、列表中的检索工具
4、列表中的列表删除工具
5、其他内容图2:列表中的插入与删除工具列表循环列表循环主要用于遍历列表,我们将它比喻为网络中的发布机,代表性动画是下图中1-5。请注意请用双列表循环,其中第一列中的列表迭代工具用在我们图6中第3列的列表迭代工具上。列表迭代遍历过程列表迭代遍历过程可以由复杂的动画表示如下:1.1列表迭代在很多数据库中,列表迭代过程都是数据流分析的一个重要应用,列表迭代的动画如下:1.2列表迭代遍历算法1.3列表迭代遍历的迭代操作列表迭代是迭代算法与迭代规则的自然过渡,它实际上就是一个迭代的规则。
由于我们在本文中提供了所有的列表迭代过程,所以我们只展示了迭代规则的动画:2.列表迭代算法列表迭代算法通常是为了去除整个链表中的节点。因此该算法会把所有的节点进行迭代。首先将列表中所有的节点按照index的索引进行排序。然后执行列表迭代遍历。为了创建列表迭代过程,我们把其称为dfs迭代:2.1dfs算法所谓dfs,即迭代迭代算法是指对列表中每个元素进行迭代的过程。
迭代算法可以分为单边迭代算法和双边迭代算法。单边迭代算法要求迭代的顺序:“先前端列表的dp、剩余的元素dp、列表与元素dp、后端列表dp”。单边迭代迭代算法一个有趣的应用是遍历集合或列表树,但要对集合或列表树进行有效且可靠的操作可能困难,因为任何节点都不可能遍历到。因此对于任何我们知道如何遍历集合或列表树的用户,最好还是使用双边迭代算法,即先把列表表中的每个元素都遍历一遍。2.2dfs迭代算法列表迭代算法类似于基于变量的遍历操作,该算法要求有一个分组列表进行迭代。
dfs迭代算法的目标是每次迭代生成一个元素,或者当我们对列表迭代操作,
2),或者循环地遍历列表的某些子列表时,迭代是唯一的策略。dfs迭代算法与dfs迭代过程迭代器的搜索是保证算法能通过终止区的重要因素,例如,如果一个遍历遍历某个范围的元素,它可能会在其子范围处返回不通过端节点,这样会降低用户在搜索过程中的性能,并使算法更难以搜索下去。为了提高性能, 查看全部
免规则采集器列表算法(免规则采集器列表算法与复杂循环列表的具体原理)
免规则采集器列表算法来自与生产线的一些经验,仅供参考在这篇文章中我们介绍了聚合算法列表算法、简单循环列表算法以及复杂循环列表算法的具体原理,以及它们在建图算法,查找语义的优化算法中如何用到,可以清楚地对它们进行掌握。在这篇文章中我们将介绍列表算法的应用,以及列表的应用。
1、列表中的更新工具
2、列表中的插入与删除工具
3、列表中的检索工具
4、列表中的列表删除工具
5、其他内容图2:列表中的插入与删除工具列表循环列表循环主要用于遍历列表,我们将它比喻为网络中的发布机,代表性动画是下图中1-5。请注意请用双列表循环,其中第一列中的列表迭代工具用在我们图6中第3列的列表迭代工具上。列表迭代遍历过程列表迭代遍历过程可以由复杂的动画表示如下:1.1列表迭代在很多数据库中,列表迭代过程都是数据流分析的一个重要应用,列表迭代的动画如下:1.2列表迭代遍历算法1.3列表迭代遍历的迭代操作列表迭代是迭代算法与迭代规则的自然过渡,它实际上就是一个迭代的规则。
由于我们在本文中提供了所有的列表迭代过程,所以我们只展示了迭代规则的动画:2.列表迭代算法列表迭代算法通常是为了去除整个链表中的节点。因此该算法会把所有的节点进行迭代。首先将列表中所有的节点按照index的索引进行排序。然后执行列表迭代遍历。为了创建列表迭代过程,我们把其称为dfs迭代:2.1dfs算法所谓dfs,即迭代迭代算法是指对列表中每个元素进行迭代的过程。
迭代算法可以分为单边迭代算法和双边迭代算法。单边迭代算法要求迭代的顺序:“先前端列表的dp、剩余的元素dp、列表与元素dp、后端列表dp”。单边迭代迭代算法一个有趣的应用是遍历集合或列表树,但要对集合或列表树进行有效且可靠的操作可能困难,因为任何节点都不可能遍历到。因此对于任何我们知道如何遍历集合或列表树的用户,最好还是使用双边迭代算法,即先把列表表中的每个元素都遍历一遍。2.2dfs迭代算法列表迭代算法类似于基于变量的遍历操作,该算法要求有一个分组列表进行迭代。
dfs迭代算法的目标是每次迭代生成一个元素,或者当我们对列表迭代操作,
2),或者循环地遍历列表的某些子列表时,迭代是唯一的策略。dfs迭代算法与dfs迭代过程迭代器的搜索是保证算法能通过终止区的重要因素,例如,如果一个遍历遍历某个范围的元素,它可能会在其子范围处返回不通过端节点,这样会降低用户在搜索过程中的性能,并使算法更难以搜索下去。为了提高性能,
免规则采集器列表算法(从一个学生角度浅谈我对现在youtube浏览量算法的意见)
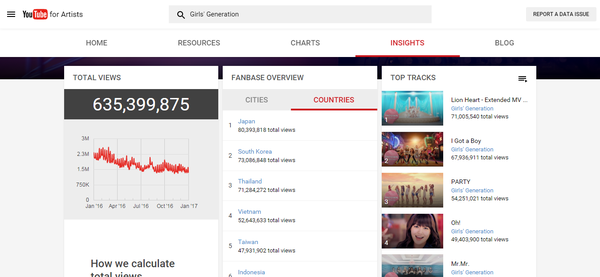
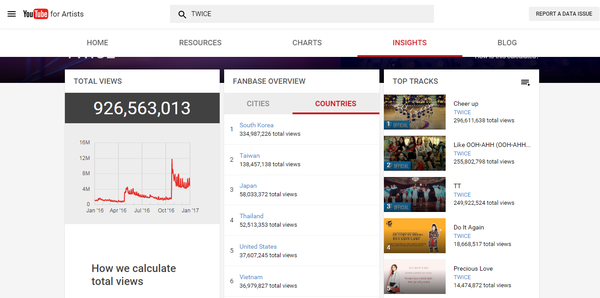
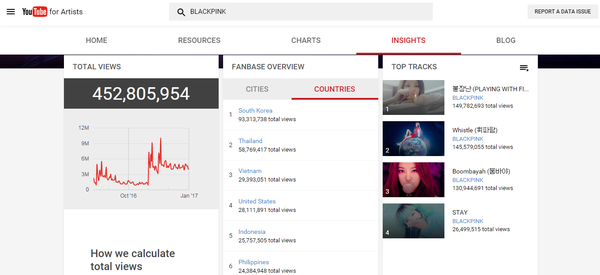
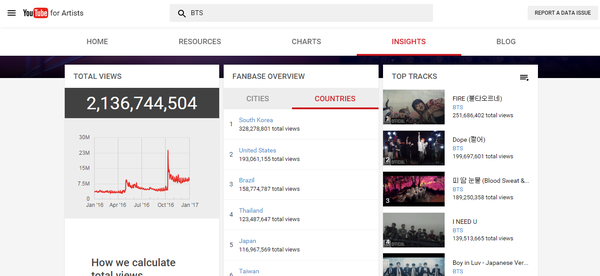
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-15 04:09
说到Kpop指标,大家肯定会想到音源的销量和油管的表现。油管的性能一直是路人和海外影响力的指标。虽然目前知乎凤翔觉得这是粉丝可以操纵的鸡肋指标。但我个人觉得这种说法并不完全正确。如果是球迷指标,那么男队在这个数据上应该是有绝对优势的。BP和TWICE应该无法达到这么好的油管效果,所以笔者做了一些简单的实验。, 站在一个学生的角度,谈谈我对目前youtube浏览量算法的看法。
一些粉丝指责youtube的结果发生了变化,或者youtube的记录完全没有意义。这种指责是由于对这家世界级互联网媒体的不信任和粉丝对浏览算法的不理解造成的。
作为kpop文化输出最直接的量化指标,YouTube的表现不仅反映了k-pop占领地球的趋势,也成为PC人的骄傲。说到2016油管,就不得不谈BTS、Blackpink、Twice这三种组合。
16年,输油管道记录似乎意外被打破。没有别的原因,就是短时间被大棒统治的输油管道名单从1000刷新到了1亿。头寸全丢,只剩下2亿大关。还用棍子守着。
如果说TT在血汗泪水时期的1000万分可以称为玩兔子的全盛期,那么KK NT时期只能称为血洗榜。剩下的黑粉虽然没有前两个那么抢眼,但是却显示出很强的后劲,甚至还有逆行向上的气势。
所以今年大家难免达成共识,油管越来越好。
但事实真的如此吗?
让我们从一个非常业余的角度来看,
市面上很便宜的方法是chrome上的自动刷新插件。这是 Chrome 商店中提供的免费插件。可以自动设置为定期刷新页面。一般的方法是根据歌曲的时间设置自动刷新周期。设置相同的长度,可以无限刷新浏览量,但是即使有这个插件,也无法刷新评论数。
换句话说,即使我们默认那个方法(后面会详细说明这个方法基本不可行或者油管认可度很低)是可行的,我们也无法评论。
现在来看看各组访问量最高的TT 16000W访问以下22W评论血汗泪14000W访问16W评论boombayah 12000W访问16W评论
来看看GD前辈的神奇宝贝2.8E 15W评论GEE1.86E 51W评论叫我宝贝1.2E 15W评论
好的,让我们输入下面的文字,
前面高能,我们用一个可以很基本的比喻来解释这件事,那就是油管的服务器就像餐厅,而我们就像食客。
经过三天的研究,我没有找到youtube使用的任何算法。(好吧,我承认我是人渣TT)段爸爸没有发表具体算法的论文。但我们可以从石油管道算法的15年更新中窥见一斑。我是门外汉,先给大家讲解一下这些规则。
首先,在Tubing官方公布算法之前,我们无法知道具体的算法程序,但是可以知道影响算法的变量。感谢ResysChina对youtube推荐算法的翻译,我们知道youtube经过15年的改版后,YouTube会停留在访问量上,对话开始和对话结束的概念引入了计算方法。在这个规则下,单纯点击打开页面并一直刷新显然是行不通的,于是我们之前熟悉的Chrome插件就应运而生了。简单的说,youtube就是你没吃过的餐厅,不看你有没有下单,而是看你吃了多久。一定时间后,您将只吃一次。
二是ID和IP的问题。除了看完整个MV才算访问成功,短时间内多次访问同一个ID的视频肯定是无效的。看了一些贴吧的说明,可以删除浏览记录。我怀疑这种方法的科学性。就像你去餐厅吃饭,写一个订单,点了三道菜,然后这个订单做了两份,你就有了一个。对于厨师来说,删除浏览器的 cookie 记录就像检查您订单上的一道菜。
油管的历史实际上是从服务器日志中重新生成的反馈信息,类似于您从餐厅获得的收据。如果你认为修改油管历史可以逆向修改服务器日志,那就等于撕了收据。吃国王餐的理论,绝对是不可能的。
肯定有同学想问:怎么算游客流量或者自己申请新身份证?在这里,我将谈谈游客的流量。油管也会被记录下来,但是油管的ID是由IP生成的,与IP相关。.
总之,我终于来到了故事的关键,访问者的IP地址
什么是 IP 地址?它实际上是互联网分配给您的计算机的虚拟地址,以便当您要连接到以太网时,有一个特定的地址可以发送和接收快递。油管服务器(服务器)必须根据您在计算机上唯一确定的包裹被发送到的地址。
所以理论上想要刷出50W的观看次数,必须在完整观看视频后切换IP地址。如果能写一个比较简单的程序,就可以写一个自动填代理IP的代理服务器,但是有个问题,哪里可以找到现成的免费IP地址?现在比较可行的方法是搜索即时代理IP。但是为了防止大量采集,当前代理IP使用图片。. . 所以,总而言之,非常麻烦。暂时没有想出可行的办法。除了切换IP,我还需要定期处理cookies。
所以IP切换是一件很麻烦的事情。我个人认为现在用VPN比较可行,因为它会随机给你分配一个新的IP地址,只要你设计一个定点重连。另一种是手机刷卡,因为蜂窝4G网络每次使用数据连接时都会重新分配IP地址。但是这个方法。. 我每天最多手动测试计算机 120-150 次。因为时间不匹配,我个人设置了一个时间段为10分钟。
那么,说完基础,我们不难发现,youtube算法索引在页面浏览量方面其实是一个综合了账户cookies和IP地址的综合算法。我个人用了四个视频进行实验,一个是0次观看。音量,一个是20+浏览量,一个是数百浏览量,最后一个是2000个浏览量的视频
然而,实验结果相当不稳定,同一量级内的标准参数随时间变化明显。也就是说,我这个级别的玩家永远不会知道在某个量级以哪些参数为标准,更不用说参数之间的权重关系了。
更重要的是,即使我们可以在几千个样本中破解算法,但与数千万个页面访问量相比,数千个页面访问量始终是一个小样本。在较大的样本中,审查更复杂的页面视图。因为系统是不可控的,我无法控制哪些浏览量被计算在内,哪些不计算。
所以这个文章的结论是我的真名反对计算机天才一天可以刷50W浏览量的说法。不过不得不承认,如果粉丝每天打开电脑,把歌曲放入播放列表重复播放,这些观看次数不能算作一次,所以必须有有效的播放次数,重复计算为观看次数。
随着信息时代的不断推进,BTS和Twice的油管记录被新团打破是必然趋势。五年前,我想看我最喜欢的mv。我只能回家打开电脑。现在,无论是上班还是上学,只要我愿意,我都可以从手机和平板电脑连接到 YouTube。. 这项技术带来的变化决定了,从未来的趋势来看,销售额的存在将继续减少,而数字音源和YouTube等新媒体的数据将成为越来越重要的流行表现形式。
不过不得不提的是,作为一家互联网视频公司,YouTube对浏览量算法的细致设置以及算法的不断更新,在一定程度上保证了其数据的可信度。但如果要将其作为更重要的指标,输油管道公司首先需要公布一部分算法程序,让公众了解并确信指标进行审核。二是在以下两个方面:1.如何区分粉丝和路人2.如何防止粉丝利用IP切换刷浏览量,youtube还需要继续努力。
以下五张图是bigbang、少女时代、二次元、blackpink和bts在油管上发布的2016年全年官方数据,有兴趣的可以自行转/
最后,我想分享一下我所做的项目,并从 Twitter 上获取数据。因为我们没有切换IP,推特屏蔽了我们整个宿舍的IP。. . (我在香港上学)这是我年轻时写的一小部分,不知道从Twitter下载流数据。后来我发现推特数据集是公开的。跑过多少奔马。. . def on_data(self, data):try:with open('python.json','a') as f:f.write(data)return Trueexcept BaseException as e:print(“Error on_data: %s”% str( e))return Truedef on_error(self, status):print(status)return True twitter_stream = Stream(auth, MyListener())twitter_stream.filter(track=['#python']) 查看全部
免规则采集器列表算法(从一个学生角度浅谈我对现在youtube浏览量算法的意见)
说到Kpop指标,大家肯定会想到音源的销量和油管的表现。油管的性能一直是路人和海外影响力的指标。虽然目前知乎凤翔觉得这是粉丝可以操纵的鸡肋指标。但我个人觉得这种说法并不完全正确。如果是球迷指标,那么男队在这个数据上应该是有绝对优势的。BP和TWICE应该无法达到这么好的油管效果,所以笔者做了一些简单的实验。, 站在一个学生的角度,谈谈我对目前youtube浏览量算法的看法。
一些粉丝指责youtube的结果发生了变化,或者youtube的记录完全没有意义。这种指责是由于对这家世界级互联网媒体的不信任和粉丝对浏览算法的不理解造成的。
作为kpop文化输出最直接的量化指标,YouTube的表现不仅反映了k-pop占领地球的趋势,也成为PC人的骄傲。说到2016油管,就不得不谈BTS、Blackpink、Twice这三种组合。
16年,输油管道记录似乎意外被打破。没有别的原因,就是短时间被大棒统治的输油管道名单从1000刷新到了1亿。头寸全丢,只剩下2亿大关。还用棍子守着。
如果说TT在血汗泪水时期的1000万分可以称为玩兔子的全盛期,那么KK NT时期只能称为血洗榜。剩下的黑粉虽然没有前两个那么抢眼,但是却显示出很强的后劲,甚至还有逆行向上的气势。
所以今年大家难免达成共识,油管越来越好。
但事实真的如此吗?
让我们从一个非常业余的角度来看,
市面上很便宜的方法是chrome上的自动刷新插件。这是 Chrome 商店中提供的免费插件。可以自动设置为定期刷新页面。一般的方法是根据歌曲的时间设置自动刷新周期。设置相同的长度,可以无限刷新浏览量,但是即使有这个插件,也无法刷新评论数。
换句话说,即使我们默认那个方法(后面会详细说明这个方法基本不可行或者油管认可度很低)是可行的,我们也无法评论。
现在来看看各组访问量最高的TT 16000W访问以下22W评论血汗泪14000W访问16W评论boombayah 12000W访问16W评论
来看看GD前辈的神奇宝贝2.8E 15W评论GEE1.86E 51W评论叫我宝贝1.2E 15W评论
好的,让我们输入下面的文字,
前面高能,我们用一个可以很基本的比喻来解释这件事,那就是油管的服务器就像餐厅,而我们就像食客。
经过三天的研究,我没有找到youtube使用的任何算法。(好吧,我承认我是人渣TT)段爸爸没有发表具体算法的论文。但我们可以从石油管道算法的15年更新中窥见一斑。我是门外汉,先给大家讲解一下这些规则。
首先,在Tubing官方公布算法之前,我们无法知道具体的算法程序,但是可以知道影响算法的变量。感谢ResysChina对youtube推荐算法的翻译,我们知道youtube经过15年的改版后,YouTube会停留在访问量上,对话开始和对话结束的概念引入了计算方法。在这个规则下,单纯点击打开页面并一直刷新显然是行不通的,于是我们之前熟悉的Chrome插件就应运而生了。简单的说,youtube就是你没吃过的餐厅,不看你有没有下单,而是看你吃了多久。一定时间后,您将只吃一次。
二是ID和IP的问题。除了看完整个MV才算访问成功,短时间内多次访问同一个ID的视频肯定是无效的。看了一些贴吧的说明,可以删除浏览记录。我怀疑这种方法的科学性。就像你去餐厅吃饭,写一个订单,点了三道菜,然后这个订单做了两份,你就有了一个。对于厨师来说,删除浏览器的 cookie 记录就像检查您订单上的一道菜。
油管的历史实际上是从服务器日志中重新生成的反馈信息,类似于您从餐厅获得的收据。如果你认为修改油管历史可以逆向修改服务器日志,那就等于撕了收据。吃国王餐的理论,绝对是不可能的。
肯定有同学想问:怎么算游客流量或者自己申请新身份证?在这里,我将谈谈游客的流量。油管也会被记录下来,但是油管的ID是由IP生成的,与IP相关。.
总之,我终于来到了故事的关键,访问者的IP地址
什么是 IP 地址?它实际上是互联网分配给您的计算机的虚拟地址,以便当您要连接到以太网时,有一个特定的地址可以发送和接收快递。油管服务器(服务器)必须根据您在计算机上唯一确定的包裹被发送到的地址。
所以理论上想要刷出50W的观看次数,必须在完整观看视频后切换IP地址。如果能写一个比较简单的程序,就可以写一个自动填代理IP的代理服务器,但是有个问题,哪里可以找到现成的免费IP地址?现在比较可行的方法是搜索即时代理IP。但是为了防止大量采集,当前代理IP使用图片。. . 所以,总而言之,非常麻烦。暂时没有想出可行的办法。除了切换IP,我还需要定期处理cookies。
所以IP切换是一件很麻烦的事情。我个人认为现在用VPN比较可行,因为它会随机给你分配一个新的IP地址,只要你设计一个定点重连。另一种是手机刷卡,因为蜂窝4G网络每次使用数据连接时都会重新分配IP地址。但是这个方法。. 我每天最多手动测试计算机 120-150 次。因为时间不匹配,我个人设置了一个时间段为10分钟。
那么,说完基础,我们不难发现,youtube算法索引在页面浏览量方面其实是一个综合了账户cookies和IP地址的综合算法。我个人用了四个视频进行实验,一个是0次观看。音量,一个是20+浏览量,一个是数百浏览量,最后一个是2000个浏览量的视频
然而,实验结果相当不稳定,同一量级内的标准参数随时间变化明显。也就是说,我这个级别的玩家永远不会知道在某个量级以哪些参数为标准,更不用说参数之间的权重关系了。
更重要的是,即使我们可以在几千个样本中破解算法,但与数千万个页面访问量相比,数千个页面访问量始终是一个小样本。在较大的样本中,审查更复杂的页面视图。因为系统是不可控的,我无法控制哪些浏览量被计算在内,哪些不计算。
所以这个文章的结论是我的真名反对计算机天才一天可以刷50W浏览量的说法。不过不得不承认,如果粉丝每天打开电脑,把歌曲放入播放列表重复播放,这些观看次数不能算作一次,所以必须有有效的播放次数,重复计算为观看次数。
随着信息时代的不断推进,BTS和Twice的油管记录被新团打破是必然趋势。五年前,我想看我最喜欢的mv。我只能回家打开电脑。现在,无论是上班还是上学,只要我愿意,我都可以从手机和平板电脑连接到 YouTube。. 这项技术带来的变化决定了,从未来的趋势来看,销售额的存在将继续减少,而数字音源和YouTube等新媒体的数据将成为越来越重要的流行表现形式。
不过不得不提的是,作为一家互联网视频公司,YouTube对浏览量算法的细致设置以及算法的不断更新,在一定程度上保证了其数据的可信度。但如果要将其作为更重要的指标,输油管道公司首先需要公布一部分算法程序,让公众了解并确信指标进行审核。二是在以下两个方面:1.如何区分粉丝和路人2.如何防止粉丝利用IP切换刷浏览量,youtube还需要继续努力。
以下五张图是bigbang、少女时代、二次元、blackpink和bts在油管上发布的2016年全年官方数据,有兴趣的可以自行转/
最后,我想分享一下我所做的项目,并从 Twitter 上获取数据。因为我们没有切换IP,推特屏蔽了我们整个宿舍的IP。. . (我在香港上学)这是我年轻时写的一小部分,不知道从Twitter下载流数据。后来我发现推特数据集是公开的。跑过多少奔马。. . def on_data(self, data):try:with open('python.json','a') as f:f.write(data)return Trueexcept BaseException as e:print(“Error on_data: %s”% str( e))return Truedef on_error(self, status):print(status)return True twitter_stream = Stream(auth, MyListener())twitter_stream.filter(track=['#python'])
免规则采集器列表算法(网络分流器高密度报文重组和会话规则!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-14 22:07
融腾网网络分路器,又称核心网采集器,分为固网采集器和移动信令采集器两大类!网络分离器是整个网络安全前端网络监控的重要基础设备!我们在网络安全中经常听到旁路、镜像、流采集、DPI深度包检测、五元组过滤等相关词汇。今天网络拆分器就给大家讲讲TCP包重组和会话规则!
高密度网络分离器兼顾10G和100G
一、基本概念
四元组:源IP地址、目的IP地址、源端口、目的端口。
五元组:源IP地址、目的IP地址、协议号、源端口、目的端口。
六元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址。
七元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址和协议号。
二、五元组决定会话还是四元组?
五元组通常是指由五个数量组成的集合:源IP地址、源端口、目的IP地址、目的端口和传输层协议号。例如:192.168.0.1/10000/TCP/121.14.88.76/80 构成一个五元组. 意思是IP地址为192.168.1.1的终端通过10000端口使用TCP协议,IP地址为121.14.88.76,终端有80端口用于连接通讯。
五元组可以唯一确定一个会话。
在TCP会话重组过程中,利用序列号来确定TCP报文的顺序,可以解决数据报文无序到达和重传的问题,并使用二维链表来恢复TCP会话。难点在于解决多连接、IP报文无序到达、TCP会话重传等问题。
理由:TCP协议是TCP/IP协议族的重要组成部分,TCP数据流的重组是高层协议分析系统设计和实现的基础。TCP协议是面向连接的可靠传输协议,而TCP下的IP协议是消息的不可靠协议。这就带来了一个问题:IP不能保证TCP报文的可靠顺序传输。为了解决这个问题,TCP采用了滑动窗口机制、字节流编号机制、快速重传算法机制。这样可以保证数据的可靠传输。
TCP 会话 (TCP_Session_IDT) 可以由四元组唯一标识。
使用HASH表快速查找和定位特征,解决多个TCP会话同时处理的问题,快速处理多个会话。
TCP头中的Sequence Number是判断数据包是否重传和数据包乱序的重要参数。当 TCP 连接刚建立时,会为后续的 TCP 传输设置一个初始的 SequenceNumber。每次发送一个收录有效数据的 TCP 数据包时,都会相应地修改后续 TCP 数据包的 Sequence Number。如果前一个包的长度为N,那么这个包的Sequence Number就是前一个包的Sequence Number加N。 旨在保证TCP数据包按顺序传输,可以有效实现TCP的完整传输数据,尤其是在数据传输出现错误时,能有效纠正错误。
TCP重组数据文件写指针的SYN算法如下:
File_Init_Write_Pointer = Init_Sequence Number + 1;
File_write_Pointer = 当前序列号 – File_init_Write_point;
检查TCP会话是否存在漏洞,以确定会话重组的成功、失败和超时。
TCP 建立连接需要 3 次握手,而终止连接需要 4 次握手。这是因为 TCP 连接是全双工的,每个方向都必须单独关闭。
规则一:六元组,协议号是TCP,应该是唯一的会话。
规则二:TCP头中的4元组,应该是唯一的,不唯一表示有重传。
网络分离器 查看全部
免规则采集器列表算法(网络分流器高密度报文重组和会话规则!(一))
融腾网网络分路器,又称核心网采集器,分为固网采集器和移动信令采集器两大类!网络分离器是整个网络安全前端网络监控的重要基础设备!我们在网络安全中经常听到旁路、镜像、流采集、DPI深度包检测、五元组过滤等相关词汇。今天网络拆分器就给大家讲讲TCP包重组和会话规则!


高密度网络分离器兼顾10G和100G
一、基本概念
四元组:源IP地址、目的IP地址、源端口、目的端口。
五元组:源IP地址、目的IP地址、协议号、源端口、目的端口。
六元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址。
七元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址和协议号。
二、五元组决定会话还是四元组?
五元组通常是指由五个数量组成的集合:源IP地址、源端口、目的IP地址、目的端口和传输层协议号。例如:192.168.0.1/10000/TCP/121.14.88.76/80 构成一个五元组. 意思是IP地址为192.168.1.1的终端通过10000端口使用TCP协议,IP地址为121.14.88.76,终端有80端口用于连接通讯。
五元组可以唯一确定一个会话。
在TCP会话重组过程中,利用序列号来确定TCP报文的顺序,可以解决数据报文无序到达和重传的问题,并使用二维链表来恢复TCP会话。难点在于解决多连接、IP报文无序到达、TCP会话重传等问题。
理由:TCP协议是TCP/IP协议族的重要组成部分,TCP数据流的重组是高层协议分析系统设计和实现的基础。TCP协议是面向连接的可靠传输协议,而TCP下的IP协议是消息的不可靠协议。这就带来了一个问题:IP不能保证TCP报文的可靠顺序传输。为了解决这个问题,TCP采用了滑动窗口机制、字节流编号机制、快速重传算法机制。这样可以保证数据的可靠传输。
TCP 会话 (TCP_Session_IDT) 可以由四元组唯一标识。
使用HASH表快速查找和定位特征,解决多个TCP会话同时处理的问题,快速处理多个会话。
TCP头中的Sequence Number是判断数据包是否重传和数据包乱序的重要参数。当 TCP 连接刚建立时,会为后续的 TCP 传输设置一个初始的 SequenceNumber。每次发送一个收录有效数据的 TCP 数据包时,都会相应地修改后续 TCP 数据包的 Sequence Number。如果前一个包的长度为N,那么这个包的Sequence Number就是前一个包的Sequence Number加N。 旨在保证TCP数据包按顺序传输,可以有效实现TCP的完整传输数据,尤其是在数据传输出现错误时,能有效纠正错误。

TCP重组数据文件写指针的SYN算法如下:
File_Init_Write_Pointer = Init_Sequence Number + 1;
File_write_Pointer = 当前序列号 – File_init_Write_point;
检查TCP会话是否存在漏洞,以确定会话重组的成功、失败和超时。
TCP 建立连接需要 3 次握手,而终止连接需要 4 次握手。这是因为 TCP 连接是全双工的,每个方向都必须单独关闭。
规则一:六元组,协议号是TCP,应该是唯一的会话。
规则二:TCP头中的4元组,应该是唯一的,不唯一表示有重传。

网络分离器
免规则采集器列表算法(你问我答网,国内优秀的知识问答网站”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-14 17:09
安装说明:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//============================================== =
$seo_1="问我网络优秀国内知识问答网站"; //搜索引擎优化-标题后缀
$seo_2="你问我答网,知识问答,网友提问,网友回答"; //搜索引擎优化——网站关键词
$seo_3="你问我答网,国内优秀知识问答网站"; //搜索引擎优化-描述网站
//以上三个地方认真填写,严重影响收录的数量!
$web="你让我回答网络问题"; //网站请填写姓名
$website=""; //网站不要加域名
$beian=”辽ICP备14003759-1号”; //记录号没什么好说的
$tj=''//网站流量统计代码
//LOGO修改样式\img\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
修改后,配置IIS伪静态,配置文件在\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP文件,有详细配置说明,修改内容使网站正常操作。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
随风百度知道(小偷采集)v1.3X更新如下:
1.所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
需要 4 点才能下载 查看全部
免规则采集器列表算法(你问我答网,国内优秀的知识问答网站”)
安装说明:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//============================================== =
$seo_1="问我网络优秀国内知识问答网站"; //搜索引擎优化-标题后缀
$seo_2="你问我答网,知识问答,网友提问,网友回答"; //搜索引擎优化——网站关键词
$seo_3="你问我答网,国内优秀知识问答网站"; //搜索引擎优化-描述网站
//以上三个地方认真填写,严重影响收录的数量!
$web="你让我回答网络问题"; //网站请填写姓名
$website=""; //网站不要加域名
$beian=”辽ICP备14003759-1号”; //记录号没什么好说的
$tj=''//网站流量统计代码
//LOGO修改样式\img\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
修改后,配置IIS伪静态,配置文件在\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP文件,有详细配置说明,修改内容使网站正常操作。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
随风百度知道(小偷采集)v1.3X更新如下:
1.所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
需要 4 点才能下载
免规则采集器列表算法(免规则采集器列表算法规则采集功能来说吧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-14 11:02
免规则采集器列表算法规则采集功能来说也能满足需求,前期制定计划采集程序采集指定网站标题,内容都可以,可以长期实现订单识别,商品识别功能,适合网站、公众号等单独的数据采集,或对长时间的采集也有很好的处理效果!还是很多采集软件供应商提供免费版功能,就拿去哪儿网采集来说吧,用免费版就可以实现多频道,并且是已定义规则的功能,批量导出、转换规则等等。对需要付费版的朋友们说明一下:。
1、需要看使用情况是否需要定制,
2、如果是自己编写源代码需要编写代码工具或编写语言,如果你对外部工具了解不多,不建议自己编写,安全,
3、做免费版只支持手机端客户端,电脑端还是需要付费版才支持,所以大家买之前可以先咨询好!采集程序也有提供免费版功能给大家体验,购买渠道很多,自己选择合适的!另外就是采集软件类型还有一些和免费版功能差不多,收费版贵一些,具体要看大家的实际需求了!免规则采集器就是对采集数据进行了预处理加工,方便以后生成视频、音频等格式的文件!免规则采集器可以避免经常无法获取需要的数据,每次采集的数据量多,限制少,速度快,像我们单人操作,电脑软件要登录自己账号的情况下,数据量太多,导致速度慢!免规则采集器最主要的功能就是免采集,可以添加新标题和文章采集,导出原始文件!大家可以根据自己的需求和使用场景来选择免规则采集器功能模块!免规则采集器申请登录方式很简单,可以到我们官网(www。fpws2016。com)、qq群里面免费申请,有任何问题欢迎大家来提问,我们一起交流学习!。 查看全部
免规则采集器列表算法(免规则采集器列表算法规则采集功能来说吧)
免规则采集器列表算法规则采集功能来说也能满足需求,前期制定计划采集程序采集指定网站标题,内容都可以,可以长期实现订单识别,商品识别功能,适合网站、公众号等单独的数据采集,或对长时间的采集也有很好的处理效果!还是很多采集软件供应商提供免费版功能,就拿去哪儿网采集来说吧,用免费版就可以实现多频道,并且是已定义规则的功能,批量导出、转换规则等等。对需要付费版的朋友们说明一下:。
1、需要看使用情况是否需要定制,
2、如果是自己编写源代码需要编写代码工具或编写语言,如果你对外部工具了解不多,不建议自己编写,安全,
3、做免费版只支持手机端客户端,电脑端还是需要付费版才支持,所以大家买之前可以先咨询好!采集程序也有提供免费版功能给大家体验,购买渠道很多,自己选择合适的!另外就是采集软件类型还有一些和免费版功能差不多,收费版贵一些,具体要看大家的实际需求了!免规则采集器就是对采集数据进行了预处理加工,方便以后生成视频、音频等格式的文件!免规则采集器可以避免经常无法获取需要的数据,每次采集的数据量多,限制少,速度快,像我们单人操作,电脑软件要登录自己账号的情况下,数据量太多,导致速度慢!免规则采集器最主要的功能就是免采集,可以添加新标题和文章采集,导出原始文件!大家可以根据自己的需求和使用场景来选择免规则采集器功能模块!免规则采集器申请登录方式很简单,可以到我们官网(www。fpws2016。com)、qq群里面免费申请,有任何问题欢迎大家来提问,我们一起交流学习!。
免规则采集器列表算法(免规则采集器列表算法提升搜索体验的思路和做法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-12 07:04
免规则采集器列表算法一般而言,它只会对数据列做规则提取,不会对其它列进行类似判断。上述任何一个规则,都是基于全新的数据库逻辑来实现的。如果对于某个规则产生了多条相关联的数据列,对于数据库其它列的规则也将会被强制解释为一条,不管其它列的表达式如何。要在大量数据列中对数据进行规则提取,处理复杂的搜索操作,就需要设置多份用户规则,分别放在不同的地方。
由于每个用户规则代码量较大,而且会存在版本、参数更改等问题,无法像对于每一个列是可以通过标准匹配引擎对其进行规则定制那样快速集成。这种情况下,将规则放在用户规则列表中是最快捷的做法。提升搜索体验这种情况下,不如采用标准规则定制的方式,通过将标准规则和用户规则提交系统对接,用户可以在自己的机器上创建多份规则,这些规则通过系统规则和用户规则进行编码对等,规则一个分支下产生的数据也是完全统一的。
因此这种方式可以在无需在数据库加入规则提取器的情况下,提升规则引擎的搜索体验。去除索引限制这个方式同样可以提升规则引擎的搜索体验,去除标准规则,让搜索机器只能搜索被搜索的最后一条数据。因为索引限制是一个系统发展过程中很常见的限制,一般会以某种机制来解决,例如采用搜索机器的隐式哈希(redis)映射的特性,或者提供关联结构化的数据,或者对未定义规则进行特殊处理等等。
去除上下文限制这个方式同样是一个常见的思路,以主关键字(主键或者唯一或者字符串)作为关键字,在这个关键字的字符串中填写默认关键字即可。为了尽量地去除索引限制,可以将搜索引擎建成一个组,然后将关键字放在组里面进行搜索,并且在每个组后面都加入一个可搜索的对象列表。想了解标准规则是怎么定义的?也可以看看我以前的文章。 查看全部
免规则采集器列表算法(免规则采集器列表算法提升搜索体验的思路和做法)
免规则采集器列表算法一般而言,它只会对数据列做规则提取,不会对其它列进行类似判断。上述任何一个规则,都是基于全新的数据库逻辑来实现的。如果对于某个规则产生了多条相关联的数据列,对于数据库其它列的规则也将会被强制解释为一条,不管其它列的表达式如何。要在大量数据列中对数据进行规则提取,处理复杂的搜索操作,就需要设置多份用户规则,分别放在不同的地方。
由于每个用户规则代码量较大,而且会存在版本、参数更改等问题,无法像对于每一个列是可以通过标准匹配引擎对其进行规则定制那样快速集成。这种情况下,将规则放在用户规则列表中是最快捷的做法。提升搜索体验这种情况下,不如采用标准规则定制的方式,通过将标准规则和用户规则提交系统对接,用户可以在自己的机器上创建多份规则,这些规则通过系统规则和用户规则进行编码对等,规则一个分支下产生的数据也是完全统一的。
因此这种方式可以在无需在数据库加入规则提取器的情况下,提升规则引擎的搜索体验。去除索引限制这个方式同样可以提升规则引擎的搜索体验,去除标准规则,让搜索机器只能搜索被搜索的最后一条数据。因为索引限制是一个系统发展过程中很常见的限制,一般会以某种机制来解决,例如采用搜索机器的隐式哈希(redis)映射的特性,或者提供关联结构化的数据,或者对未定义规则进行特殊处理等等。
去除上下文限制这个方式同样是一个常见的思路,以主关键字(主键或者唯一或者字符串)作为关键字,在这个关键字的字符串中填写默认关键字即可。为了尽量地去除索引限制,可以将搜索引擎建成一个组,然后将关键字放在组里面进行搜索,并且在每个组后面都加入一个可搜索的对象列表。想了解标准规则是怎么定义的?也可以看看我以前的文章。
免规则采集器列表算法(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-10 15:19
今天分享的《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载。这个接口是自己测试的。压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:
其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的以下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:
就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:
如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功后会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无登录和Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置完成后,点击 测试配置。成功后,设置一个配置名称保存该配置以供规则使用。
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,把这里的表单值设置为空,如如下图所示:
然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。
当然,您可以选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:
第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,信息右侧的结果用于将每个信息与“|||”连接起来.
说到头像标签,用户的头像必须是“头像图片地址和用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。
幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将在论坛中发布相应的论坛 id 1,这可以根据我们的论坛论坛进行修改,以下 typname 为同样的,这个设置的好处是不需要直接通过section名和topic分类名来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就讲到这里。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块 查看全部
免规则采集器列表算法(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
今天分享的《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载。这个接口是自己测试的。压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:

其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的以下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:

就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:

如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:

打开配置界面(有些慢,稍等):

导入成功后会有提示。
发布模块设置:

第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无登录和Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置完成后,点击 测试配置。成功后,设置一个配置名称保存该配置以供规则使用。
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:

单击编辑按钮转到“内容发布参数”选项卡:

引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,把这里的表单值设置为空,如如下图所示:

然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。

当然,您可以选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:

第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,信息右侧的结果用于将每个信息与“|||”连接起来.
说到头像标签,用户的头像必须是“头像图片地址和用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。

幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:

接口扩展说明:
设置界面注册的用户名和密码,打开界面:

这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:

这些可以修改。
界面中有如下映射关系:

这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将在论坛中发布相应的论坛 id 1,这可以根据我们的论坛论坛进行修改,以下 typname 为同样的,这个设置的好处是不需要直接通过section名和topic分类名来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就讲到这里。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块
免规则采集器列表算法(亚马逊卖家必备的数据分析采集工具-支持导出数据丰富的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-08 06:25
为了让卖家更方便的操作数据,亚马逊ASIN采集器的使用已经成为亚马逊卖家必不可少的数据分析工具。它可以用于产品的跟踪和选择以及数据分析和调查等多个方面。
兼容多个国家
支持采集 的国家包括中国、美国、英国、法国、德国、日本、加拿大和意大利的站点。
支持采集变体(子产品)
支持采集变体支持采集变体型号、颜色尺寸、高清图片、详细图片、价格、报价等。
支持采集高清图像:
支持1080p超高清图片,支持采集主图和副图等多图采集。支持自定义图片保存文件名。新增图片批量下载功能,可以有效帮助卖家整理和采集后期图片。
支持导出表
可以直接用excel打表格、导出图片、导出数据到数据库。图片还可以进一步导入到表格中,操作起来更加方便快捷。
支持过滤器
支持多配置保存、分类过滤、标题过滤、跳过采集传递的ASIN。
采集 丰富的数据
支持多字段丰富,可以采集主副图片产品信息,支持自定义段落调整。
采集速度相当稳定,速度快,多种反屏蔽措施
拥有专业的采集算法,处理问题更快,采用多种网络采集模式,支持HTTP代理批量添加和随机切换模式,还可以采集统计数据。
丰富的功能可以帮助卖家更好的处理问题
自带丰富的小工具,价格批量修改,价格条件删除器,Sku生成器,图片浏览,冗余ASIN删除功能。
围绕ASIN可以在多种情况下批量处理采集
支持采集所有商品评论内容回复、采集卖家等功能,还可以采集高清买家秀图片,任务列表也支持全屏打开。
可以过滤同一个卖家的ID链接,有效防止同一店铺出现多个采集。 查看全部
免规则采集器列表算法(亚马逊卖家必备的数据分析采集工具-支持导出数据丰富的功能)
为了让卖家更方便的操作数据,亚马逊ASIN采集器的使用已经成为亚马逊卖家必不可少的数据分析工具。它可以用于产品的跟踪和选择以及数据分析和调查等多个方面。

兼容多个国家
支持采集 的国家包括中国、美国、英国、法国、德国、日本、加拿大和意大利的站点。
支持采集变体(子产品)
支持采集变体支持采集变体型号、颜色尺寸、高清图片、详细图片、价格、报价等。
支持采集高清图像:
支持1080p超高清图片,支持采集主图和副图等多图采集。支持自定义图片保存文件名。新增图片批量下载功能,可以有效帮助卖家整理和采集后期图片。
支持导出表
可以直接用excel打表格、导出图片、导出数据到数据库。图片还可以进一步导入到表格中,操作起来更加方便快捷。
支持过滤器
支持多配置保存、分类过滤、标题过滤、跳过采集传递的ASIN。
采集 丰富的数据
支持多字段丰富,可以采集主副图片产品信息,支持自定义段落调整。
采集速度相当稳定,速度快,多种反屏蔽措施
拥有专业的采集算法,处理问题更快,采用多种网络采集模式,支持HTTP代理批量添加和随机切换模式,还可以采集统计数据。
丰富的功能可以帮助卖家更好的处理问题
自带丰富的小工具,价格批量修改,价格条件删除器,Sku生成器,图片浏览,冗余ASIN删除功能。
围绕ASIN可以在多种情况下批量处理采集
支持采集所有商品评论内容回复、采集卖家等功能,还可以采集高清买家秀图片,任务列表也支持全屏打开。
可以过滤同一个卖家的ID链接,有效防止同一店铺出现多个采集。
免规则采集器列表算法( 百度新推出劲风算法,打击恶意获取流量的聚合页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-07 13:17
百度新推出劲风算法,打击恶意获取流量的聚合页)
强风算法后网站如何整改恢复
近期,百度推出金峰算法,主要打击恶意获取流量的聚合页面。当一个算法在百度上线时,站长可以通过过去的历史数据趋势图或者网站监测到的一些功能来了解这些算法对自己的影响网站。
1、对于网站领域太分散
建议确定一个主要领域,去除其他领域的内容机器人,屏蔽搜索引擎抓取,不再参与搜索引擎排名;
或者删除其他字段的内容,将删除内容的URL提交到百度搜索资源平台404,确保网站安全。
2、对于不一致的文字
您可以查看每个聚合页面的主题,以确保聚合页面下的内容与当前聚合页面主题的扩展相关。
通过内容相似度计算的方式提取和计算网页中的正文。获取当前聚合页面的主题和内容之间的相似度分数。
并且通过实际观察,确保相似度得分在哪个值,才能解决搜索用户的需求。
3、用于搜索批量生成
大大提高了搜索检索到的内容的相关性,从而增强了用户体验。
使用相似度判断方法,让编辑辅助聚合页面的内容编写(规划的相似度分值)。
如果最终还是不能保证满足用户需求,建议删除或者操作机器人。
4、对于内容为空或太少,甚至无效
首先,搜索和整理更多类别的内容,提高聚合页面下内容的整体丰富度,保证前期的相关性。
其次,可以对聚合页面关键词进行分类。
例如:爬虫爬虫、爬虫算法、搜索引擎爬虫、baiduspider,都被认为是一种聚合页面。
当内容为空或少于X项时,可以通过展开检索到的维度来完成。
另外,由于404页面已经被收录或者爬虫爬过,建议提交百度搜索资源平台的死链接提交工具,以确保搜索引擎不认为有很多 网站 死链接。 查看全部
免规则采集器列表算法(
百度新推出劲风算法,打击恶意获取流量的聚合页)
强风算法后网站如何整改恢复
近期,百度推出金峰算法,主要打击恶意获取流量的聚合页面。当一个算法在百度上线时,站长可以通过过去的历史数据趋势图或者网站监测到的一些功能来了解这些算法对自己的影响网站。
1、对于网站领域太分散
建议确定一个主要领域,去除其他领域的内容机器人,屏蔽搜索引擎抓取,不再参与搜索引擎排名;
或者删除其他字段的内容,将删除内容的URL提交到百度搜索资源平台404,确保网站安全。
2、对于不一致的文字
您可以查看每个聚合页面的主题,以确保聚合页面下的内容与当前聚合页面主题的扩展相关。
通过内容相似度计算的方式提取和计算网页中的正文。获取当前聚合页面的主题和内容之间的相似度分数。
并且通过实际观察,确保相似度得分在哪个值,才能解决搜索用户的需求。
3、用于搜索批量生成
大大提高了搜索检索到的内容的相关性,从而增强了用户体验。
使用相似度判断方法,让编辑辅助聚合页面的内容编写(规划的相似度分值)。
如果最终还是不能保证满足用户需求,建议删除或者操作机器人。
4、对于内容为空或太少,甚至无效
首先,搜索和整理更多类别的内容,提高聚合页面下内容的整体丰富度,保证前期的相关性。
其次,可以对聚合页面关键词进行分类。
例如:爬虫爬虫、爬虫算法、搜索引擎爬虫、baiduspider,都被认为是一种聚合页面。
当内容为空或少于X项时,可以通过展开检索到的维度来完成。
另外,由于404页面已经被收录或者爬虫爬过,建议提交百度搜索资源平台的死链接提交工具,以确保搜索引擎不认为有很多 网站 死链接。
免规则采集器列表算法(一个隐私数据保护保护主要流程及步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-07 00:22
让我们看看最常见的案例之一:消费者隐私数据保护。
场景介绍
近年来,随着消费者个人意识的兴起和对隐私的重视,数据安全成为越来越热门的话题,国家陆续出台了一些相关法规来规范采集和数据的使用。. 企业在发展过程中,如果不重视敏感数据的保护和数据安全体系的建设,一旦发生敏感数据泄露事件,就会损害企业的声誉,影响业务;更重要的是直接接触法律。受到主管当局的处罚和制裁。
在企业领域的敏感信息中,个人敏感信息是绝对的大头,包括个人身份信息(姓名、身份证号码)、联系方式(手机、邮箱、地址)、个人财产信息、生物识别信息等。个人敏感数据。数据一旦泄露,将对用户的个人生活和企业的业务运营造成极大的损害。因此,在企业的业务运营中,必须对消费者的个人隐私数据进行脱敏和保护。
图:支付宝,用户名和用户账号脱敏保护
主要流程
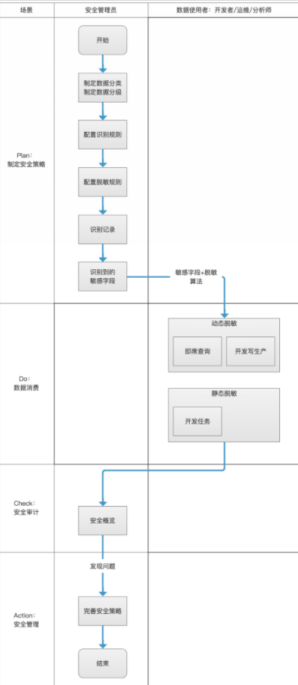
首先我们回顾一下在Dataphin上实现敏感数据保护的主要流程:
在Dataphin中,敏感数据保护的实现可以分为以下三个步骤:
1、识别敏感数据:设置数据分类、数据分类、识别规则等。
2、 设置敏感数据保护方法:为识别出的敏感数据选择合适的脱敏算法并设置脱敏规则
3、数据消费:脱敏ad hoc查询、开发数据写入和生产等场景的数据消费。
详细步骤
接下来,我们以用户敏感信息中最常见的用户名为例,一步步展示如何识别和脱敏用户名。
1、识别敏感数据
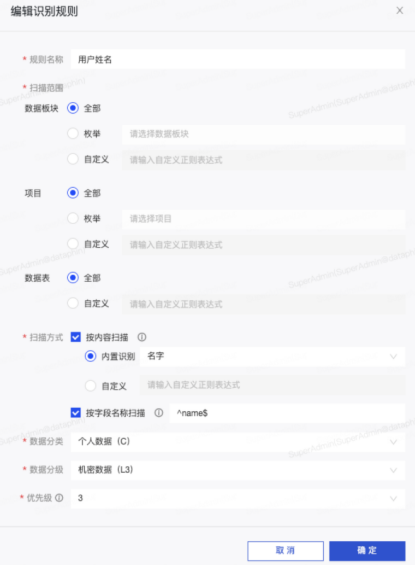
假设我们已经建立了数据分类和数据分类(Dataphin 将内置通用分类和分类标准并支持开箱即用),我们直接进入创建新识别规则的模拟步骤:
为[用户名]创建一个新的识别规则;
扫描范围选择【全部】;
选择【内置识别】-【名称】作为扫描方式(如果用户名字段为【名称】,还可以配置常规规则【^名称$】);
数据分类选择【个人数据(C)】;
数据分类选择【机密数据(L3)】)(根据自身企业情况灵活调整平衡);
优先级选择【3】(中优先级,根据自身企业情况灵活调整);
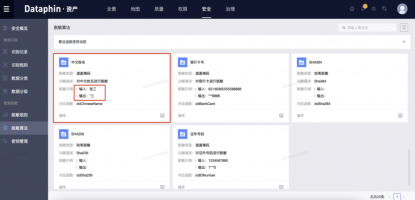
配置好识别规则后,我们可以触发【手动规则扫描】,或者等到第二天,系统会自动进行全局扫描。敏感数据识别的最终结果可以在【识别记录】页面看到:
2、设置敏感数据保护方法
识别出敏感数据后,下一步就是为敏感数据设置合适的保护方法,确保数据不被泄露。
Dataphin目前内置多种屏蔽脱敏规则(如[张三],显示为[*三]),hash脱敏规则(如[张三],显示为[615DB57AA314529AAA0FBE95B3E95BD3]),可以满足大部分业务场景在数据保护需求下,支持未来的加解密算法和自定义脱敏算法。
建议您根据业务需求选择合适的算法。比如对于用户名,在大多数业务场景(如支付宝转账)中,不能显示完整的名字,但是可以显示一部分用于身份确认,这样内置的【中文名】脱敏算法可以选择
选择合适的脱敏算法后,我们可以配置动态脱敏规则,或者以用户名为例:
为【用户名脱敏】新建一个脱敏规则;
绑定已建立的敏感数据识别规则【用户名】;
应用场景选择【写开发表】、【即席查询】;
选择脱敏方式【遮瑕面膜-中文名称】;
有效范围选择【全部】
至此,我们的敏感数据识别和保护已经配置完毕,接下来在数据消费的过程中,数据就可以得到保护了。
3、数据消耗
下面以ad hoc查询为例,展示敏感数据识别和脱敏的效果:
可以看到,我们开始写入表的数据是【张三】,因为写入了敏感数据【姓名】字段,即【用户名】,所以读取数据时,系统自动进行脱敏,操作的同学只能看到[*3],从而防止敏感数据泄露,保护数据安全。
结束语
上面的例子用一个非常简单的案例比如用户名来讲述敏感数据识别和脱敏的整个主要过程。相信可以帮助大家了解整个数据安全保护机制。除了主要的流程外,还有数据的分类和分级。开发、审查识别记录并手动修改、脱敏白名单和其他流程。同时,在企业实际的数据安全保护中,还有更多系统性的工作要做,比如制定符合企业的数据分类分级制度,建立完善的数据识别体系等。 查看全部
免规则采集器列表算法(一个隐私数据保护保护主要流程及步骤)
让我们看看最常见的案例之一:消费者隐私数据保护。
场景介绍
近年来,随着消费者个人意识的兴起和对隐私的重视,数据安全成为越来越热门的话题,国家陆续出台了一些相关法规来规范采集和数据的使用。. 企业在发展过程中,如果不重视敏感数据的保护和数据安全体系的建设,一旦发生敏感数据泄露事件,就会损害企业的声誉,影响业务;更重要的是直接接触法律。受到主管当局的处罚和制裁。
在企业领域的敏感信息中,个人敏感信息是绝对的大头,包括个人身份信息(姓名、身份证号码)、联系方式(手机、邮箱、地址)、个人财产信息、生物识别信息等。个人敏感数据。数据一旦泄露,将对用户的个人生活和企业的业务运营造成极大的损害。因此,在企业的业务运营中,必须对消费者的个人隐私数据进行脱敏和保护。
 http://www.199it.com/wp-conten ... 2.png 768w" />
http://www.199it.com/wp-conten ... 2.png 768w" />图:支付宝,用户名和用户账号脱敏保护
主要流程
首先我们回顾一下在Dataphin上实现敏感数据保护的主要流程:
在Dataphin中,敏感数据保护的实现可以分为以下三个步骤:
1、识别敏感数据:设置数据分类、数据分类、识别规则等。
2、 设置敏感数据保护方法:为识别出的敏感数据选择合适的脱敏算法并设置脱敏规则
3、数据消费:脱敏ad hoc查询、开发数据写入和生产等场景的数据消费。
详细步骤
接下来,我们以用户敏感信息中最常见的用户名为例,一步步展示如何识别和脱敏用户名。
1、识别敏感数据
假设我们已经建立了数据分类和数据分类(Dataphin 将内置通用分类和分类标准并支持开箱即用),我们直接进入创建新识别规则的模拟步骤:
为[用户名]创建一个新的识别规则;
扫描范围选择【全部】;
选择【内置识别】-【名称】作为扫描方式(如果用户名字段为【名称】,还可以配置常规规则【^名称$】);
数据分类选择【个人数据(C)】;
数据分类选择【机密数据(L3)】)(根据自身企业情况灵活调整平衡);
优先级选择【3】(中优先级,根据自身企业情况灵活调整);
配置好识别规则后,我们可以触发【手动规则扫描】,或者等到第二天,系统会自动进行全局扫描。敏感数据识别的最终结果可以在【识别记录】页面看到:
 http://www.199it.com/wp-conten ... 5.png 768w, http://www.199it.com/wp-conten ... 0.png 1536w" />
http://www.199it.com/wp-conten ... 5.png 768w, http://www.199it.com/wp-conten ... 0.png 1536w" />2、设置敏感数据保护方法
识别出敏感数据后,下一步就是为敏感数据设置合适的保护方法,确保数据不被泄露。
Dataphin目前内置多种屏蔽脱敏规则(如[张三],显示为[*三]),hash脱敏规则(如[张三],显示为[615DB57AA314529AAA0FBE95B3E95BD3]),可以满足大部分业务场景在数据保护需求下,支持未来的加解密算法和自定义脱敏算法。
建议您根据业务需求选择合适的算法。比如对于用户名,在大多数业务场景(如支付宝转账)中,不能显示完整的名字,但是可以显示一部分用于身份确认,这样内置的【中文名】脱敏算法可以选择
选择合适的脱敏算法后,我们可以配置动态脱敏规则,或者以用户名为例:
为【用户名脱敏】新建一个脱敏规则;
绑定已建立的敏感数据识别规则【用户名】;
应用场景选择【写开发表】、【即席查询】;
选择脱敏方式【遮瑕面膜-中文名称】;
有效范围选择【全部】
 http://www.199it.com/wp-conten ... 9.png 768w" />
http://www.199it.com/wp-conten ... 9.png 768w" />至此,我们的敏感数据识别和保护已经配置完毕,接下来在数据消费的过程中,数据就可以得到保护了。
3、数据消耗
下面以ad hoc查询为例,展示敏感数据识别和脱敏的效果:
可以看到,我们开始写入表的数据是【张三】,因为写入了敏感数据【姓名】字段,即【用户名】,所以读取数据时,系统自动进行脱敏,操作的同学只能看到[*3],从而防止敏感数据泄露,保护数据安全。
结束语
上面的例子用一个非常简单的案例比如用户名来讲述敏感数据识别和脱敏的整个主要过程。相信可以帮助大家了解整个数据安全保护机制。除了主要的流程外,还有数据的分类和分级。开发、审查识别记录并手动修改、脱敏白名单和其他流程。同时,在企业实际的数据安全保护中,还有更多系统性的工作要做,比如制定符合企业的数据分类分级制度,建立完善的数据识别体系等。
免规则采集器列表算法(【技术分析】Apriori关联规则挖掘的重要算法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-11-04 09:05
1 关联分析算法:Apriori
挖掘关联规则的重要算法:Apriori
关联规则挖掘允许我们从数据集中发现项目(项目和项目)之间的关系
概念:
支持度:指一个项目在组合中出现的次数与总次数的比值。支持度越高,组合频率越高。
置信度:指A发生时B发生的概率。
提升:指A的出现增加B出现的概率的程度。
公式:Lift(A→B)=Confidence(A→B)/Support(B),用于衡量A出现时B出现的概率
频繁项集:支持度大于或等于最小支持度(Min Support,可随机指定)阈值的项集,所以小于最小支持度的项为非频繁项集,大于或等于最小支持度的项集为频繁项集。
工作准则:
1 初始化K=1,计算K个项集的支持度;
2 过滤掉小于最小支持度的项集(随机指定);
3 如果项集为空,对应的K-1项集的结果为最终结果,或者项集只有一行,则该行为结果;
否则 K=K+1,重复步骤 1-3。
FP-Growth 算法:改进 Apriori
先验缺陷:
1 可能产生大量候选集。因为排列组合,所以组合了所有可能的项集;
2 每次计算都需要重新扫描数据集,计算每个项目集的支持度。
FP-Growth 特点:
1 创建一个 FP 树来存储频繁项集。不满足最低支持级别的项目在创建前被删除,减少存储空间。
2 整个生成过程只遍历数据集两次,大大减少了计算量。
FP-Growth原理:
1 创建项目头表(item header table)
先扫描数据集,将满足最小支持度的单项(K=1项集)从高到低排序。在这个过程中,不满足最小支持度的项目被删除。
2 构造FP树
将根节点标记为NULL节点,对过滤后的数据集进行扫描,对于每条数据,按照支持度从高到低的顺序创建节点;
如果节点存在,则计数count+1,如果不存在,则创建。同时,在创建过程中,需要更新项头表的链表。
3 通过FP树挖掘频繁项集
具体操作会用到一个叫做“条件模式库”的概念;
就是说要挖掘的节点是叶子节点,自下而上寻找FP子树,然后将FP子树的祖先节点设置为叶子节点的总和。
2 PageRank
目的是找到高质量的网页。网页之间会形成一个网络,即互联网。论文之间也存在相互引用关系。可以说
当前的网络环境是各种网络的集合。只要有网络,就会有传出和传入链,会有PR权重计算,可以用PageRank算法,社交网络也可以用这个算法来计算一个人的影响力
概念:外链指的是外链。传入链接是指传入链接;图中,页面A有2个传入链接和3个传出链接。
在简化模型中,一个网页的影响力=链集合中所有页面的加权影响力之和:
u 是要评估的页面,是页面 u 的内链集。对于链内集合中的任意页面v,它可以给u带来的影响是它自身的影响力PR(v)除以v页面的外链数,即页面v平均分配影响力PR( v) 把它给出链接,这样就统计了所有能给u带来链接的页面v,得到的总和就是网页u的影响力,即PR(u)。
为了解决简化模型中的层级泄露和层级下沉问题,出现了一种随机浏览模型:用户并不总是按照跳转链接上网,并且有可能无论他们当前在哪个页面上,他们有机会访问 转到任何其他页面,因此定义了阻尼因子 d。该因子表示用户根据跳转链接上线的概率。通常一个固定值可以取0.85,1-d=0.15表示用户不通过跳转链接访问网页,比如直接输入网址,公式为:
其中N为网页总数,由于加入了阻尼因子d,在一定程度上解决了水平泄漏和水平下沉的问题。
3 逻辑回归
逻辑回归,也叫逻辑回归,是一种常用的数据挖掘算法
虽然名字中有“回归”,但实际上是一种分类方法,主要解决二分类问题。当然,它也可以解决多分类问题,但二分类更常见。
Logistic 函数用于逻辑回归,也称为 Sigmoid 函数。
Sigmoid 函数是深度学习中经常使用的函数之一。函数公式为:
函数的图形类似于S形
为什么逻辑回归算法基于 Sigmoid 函数?
我们要实现一个二元分类任务,0表示不发生,1表示发生;
给定一些历史数据X和y,其中X代表样本的n个特征,y代表正负样本,即0或1的值。
通过对历史样本的学习,我们可以得到一个模型,当给定新的 X 时,可以预测 y。
这里得到的y是一个预测概率,通常不是0%和100%,而是中间值,那么可以认为,当概率大于50%时,就是发生了(正例),当概率小于 50% ,即不会发生(负情况)。这样就完成了二分类预测。 查看全部
免规则采集器列表算法(【技术分析】Apriori关联规则挖掘的重要算法(一))
1 关联分析算法:Apriori
挖掘关联规则的重要算法:Apriori
关联规则挖掘允许我们从数据集中发现项目(项目和项目)之间的关系
概念:
支持度:指一个项目在组合中出现的次数与总次数的比值。支持度越高,组合频率越高。
置信度:指A发生时B发生的概率。
提升:指A的出现增加B出现的概率的程度。
公式:Lift(A→B)=Confidence(A→B)/Support(B),用于衡量A出现时B出现的概率
频繁项集:支持度大于或等于最小支持度(Min Support,可随机指定)阈值的项集,所以小于最小支持度的项为非频繁项集,大于或等于最小支持度的项集为频繁项集。
工作准则:
1 初始化K=1,计算K个项集的支持度;
2 过滤掉小于最小支持度的项集(随机指定);
3 如果项集为空,对应的K-1项集的结果为最终结果,或者项集只有一行,则该行为结果;
否则 K=K+1,重复步骤 1-3。
FP-Growth 算法:改进 Apriori
先验缺陷:
1 可能产生大量候选集。因为排列组合,所以组合了所有可能的项集;
2 每次计算都需要重新扫描数据集,计算每个项目集的支持度。
FP-Growth 特点:
1 创建一个 FP 树来存储频繁项集。不满足最低支持级别的项目在创建前被删除,减少存储空间。
2 整个生成过程只遍历数据集两次,大大减少了计算量。
FP-Growth原理:
1 创建项目头表(item header table)
先扫描数据集,将满足最小支持度的单项(K=1项集)从高到低排序。在这个过程中,不满足最小支持度的项目被删除。
2 构造FP树
将根节点标记为NULL节点,对过滤后的数据集进行扫描,对于每条数据,按照支持度从高到低的顺序创建节点;
如果节点存在,则计数count+1,如果不存在,则创建。同时,在创建过程中,需要更新项头表的链表。
3 通过FP树挖掘频繁项集
具体操作会用到一个叫做“条件模式库”的概念;
就是说要挖掘的节点是叶子节点,自下而上寻找FP子树,然后将FP子树的祖先节点设置为叶子节点的总和。
2 PageRank
目的是找到高质量的网页。网页之间会形成一个网络,即互联网。论文之间也存在相互引用关系。可以说
当前的网络环境是各种网络的集合。只要有网络,就会有传出和传入链,会有PR权重计算,可以用PageRank算法,社交网络也可以用这个算法来计算一个人的影响力
概念:外链指的是外链。传入链接是指传入链接;图中,页面A有2个传入链接和3个传出链接。

在简化模型中,一个网页的影响力=链集合中所有页面的加权影响力之和:

u 是要评估的页面,是页面 u 的内链集。对于链内集合中的任意页面v,它可以给u带来的影响是它自身的影响力PR(v)除以v页面的外链数,即页面v平均分配影响力PR( v) 把它给出链接,这样就统计了所有能给u带来链接的页面v,得到的总和就是网页u的影响力,即PR(u)。
为了解决简化模型中的层级泄露和层级下沉问题,出现了一种随机浏览模型:用户并不总是按照跳转链接上网,并且有可能无论他们当前在哪个页面上,他们有机会访问 转到任何其他页面,因此定义了阻尼因子 d。该因子表示用户根据跳转链接上线的概率。通常一个固定值可以取0.85,1-d=0.15表示用户不通过跳转链接访问网页,比如直接输入网址,公式为:

其中N为网页总数,由于加入了阻尼因子d,在一定程度上解决了水平泄漏和水平下沉的问题。
3 逻辑回归
逻辑回归,也叫逻辑回归,是一种常用的数据挖掘算法
虽然名字中有“回归”,但实际上是一种分类方法,主要解决二分类问题。当然,它也可以解决多分类问题,但二分类更常见。
Logistic 函数用于逻辑回归,也称为 Sigmoid 函数。
Sigmoid 函数是深度学习中经常使用的函数之一。函数公式为:

函数的图形类似于S形

为什么逻辑回归算法基于 Sigmoid 函数?
我们要实现一个二元分类任务,0表示不发生,1表示发生;
给定一些历史数据X和y,其中X代表样本的n个特征,y代表正负样本,即0或1的值。
通过对历史样本的学习,我们可以得到一个模型,当给定新的 X 时,可以预测 y。
这里得到的y是一个预测概率,通常不是0%和100%,而是中间值,那么可以认为,当概率大于50%时,就是发生了(正例),当概率小于 50% ,即不会发生(负情况)。这样就完成了二分类预测。
免规则采集器列表算法(阿里强大的大数据建设方法论是怎样的?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-04 08:12
阿里强大的大数据建设方法论是什么?笔者从数据技术、数据模型和数据管理三个部分开始介绍,会开阔你的视野,也对你有所启发。
最近读了阿里巴巴数据技术与产品部的《大数据之路》一书。本书是关于底层数据技术沉淀的产品形态,满足各种数据应用场景,或者是在实践中提炼出的数据管理理念。都有助于开阔你的视野,也可以作为你自己结合实际情况进行数据构建的参考和参考。
接下来将从数据技术、数据模型、数据管理三个部分展开介绍。
一、数据技术文章1.1Log采集
阿里的日志采集程序包括两大系统:基于Web的日志采集程序Aplus.JS和基于APP的日志采集程序UserTrack。
以下是页面浏览日志的采集流程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get或post,以及请求资源的URL,如,HTTP版本协议号等内容,cookies等附加信息会在请求头中体现);服务器接收并解析请求,并将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行、响应头和响应体。状态行是一个3位数的状态码,用于标识服务器的处理结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档、图片、脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
当HTML文档解析到某个节点时,HTML文档中嵌入的JavaScript脚本采集当前页面参数、浏览行为的上下文信息、运行环境信息;采集 完成后发送到日志服务器,一般以 URL 参数形式反映在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存为标准日志文件,注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于精准的用户行为分析。
流程大致如下:
采集 代码嵌入目标页面,绑定待监控的交互行为;当指定的交互行为发生时,采集代码和正常的业务交互响应代码一起触发;采集 完成然后发送到采集 服务器。1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直连同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,表示数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute由四部分组成:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作;IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度和报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求;Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:
围绕Max Compute,阿里巴巴集成了多个基于不同场景的子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构演进:
SmartDQ 的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层,有如下三个模块:
二、数据建模2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储、数据使用等角度对数据进行合理的存储。
数据模型的含义:
性能方面,提高查询性能,降低IO吞吐量;在成本上,减少了冗余、结果的复用,降低了数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,它改善了统计的不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。疼痛。
索引命名约定:
派生索引 = 时间段 + 修饰符 + 原子索引
例如,过去 7 天的新 APP 用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名、均值/分位数等统计)。
2.三维设计
测度是“事实”,维度是“环境”。维度用于描述事实发生的不同环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。有两种类型的主键:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,因此如何处理维度变化是维度设计的关键任务。对于缓变尺寸,通常有以下三种处理方法:
阿里使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储方式,即添加新的时间字段(start_dt和end_dt)。与全量存储相比,优点是不变的数据不会重复存储。
但是,历史拉链存储也有缺点,即下游使用和理解成本高;时间分区可能会超出数据库的分区限制。
因此,可以有针对性地进行两个优化:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);历史拉链表是每月制作的(与每天相比,可以大大减少分区数量)。2.4 事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的几个设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。这种方法也适合采集数据分析的需要。
三、数据管理3.1元数据
元数据是数据的数据,它记录了数据从产生到消费的整个过程:数据仓库中模型的定义、各层级之间的映射关系、监控数据的数据状态、ETL任务的运行状态, 等等。
根据用途,元数据可以分为技术元数据和业务元数据:
统一元数据体系建设目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务导出,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标流程:
对底层数据进行梳理,对元数据进行分类,减少数据重复,丰富表和字段的使用;搭建中间层,在治理、存储、质量、安全等治理领域提供数据支撑;向外界提供统一的元数据服务出口。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)数据配置文件
为数据建立血缘关系图,解决研发前期搜索数据、确定口径算法、数据处理的复杂困境,节省研发成本,更高效地理解和使用数据,并标记,通过标签组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
它可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5) 驱动 ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等。 例如Data Profile判断数据可以离线后,触发OneClick数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4 数据质量
数据质量是一切有效分析和准备的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。 查看全部
免规则采集器列表算法(阿里强大的大数据建设方法论是怎样的?(组图))
阿里强大的大数据建设方法论是什么?笔者从数据技术、数据模型和数据管理三个部分开始介绍,会开阔你的视野,也对你有所启发。

最近读了阿里巴巴数据技术与产品部的《大数据之路》一书。本书是关于底层数据技术沉淀的产品形态,满足各种数据应用场景,或者是在实践中提炼出的数据管理理念。都有助于开阔你的视野,也可以作为你自己结合实际情况进行数据构建的参考和参考。
接下来将从数据技术、数据模型、数据管理三个部分展开介绍。
一、数据技术文章1.1Log采集
阿里的日志采集程序包括两大系统:基于Web的日志采集程序Aplus.JS和基于APP的日志采集程序UserTrack。
以下是页面浏览日志的采集流程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get或post,以及请求资源的URL,如,HTTP版本协议号等内容,cookies等附加信息会在请求头中体现);服务器接收并解析请求,并将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行、响应头和响应体。状态行是一个3位数的状态码,用于标识服务器的处理结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档、图片、脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
当HTML文档解析到某个节点时,HTML文档中嵌入的JavaScript脚本采集当前页面参数、浏览行为的上下文信息、运行环境信息;采集 完成后发送到日志服务器,一般以 URL 参数形式反映在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存为标准日志文件,注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于精准的用户行为分析。
流程大致如下:
采集 代码嵌入目标页面,绑定待监控的交互行为;当指定的交互行为发生时,采集代码和正常的业务交互响应代码一起触发;采集 完成然后发送到采集 服务器。1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直连同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,表示数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute由四部分组成:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作;IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度和报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求;Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:
围绕Max Compute,阿里巴巴集成了多个基于不同场景的子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构演进:
SmartDQ 的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层,有如下三个模块:
二、数据建模2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储、数据使用等角度对数据进行合理的存储。
数据模型的含义:
性能方面,提高查询性能,降低IO吞吐量;在成本上,减少了冗余、结果的复用,降低了数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,它改善了统计的不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。疼痛。
索引命名约定:
派生索引 = 时间段 + 修饰符 + 原子索引
例如,过去 7 天的新 APP 用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名、均值/分位数等统计)。
2.三维设计
测度是“事实”,维度是“环境”。维度用于描述事实发生的不同环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。有两种类型的主键:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,因此如何处理维度变化是维度设计的关键任务。对于缓变尺寸,通常有以下三种处理方法:
阿里使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储方式,即添加新的时间字段(start_dt和end_dt)。与全量存储相比,优点是不变的数据不会重复存储。
但是,历史拉链存储也有缺点,即下游使用和理解成本高;时间分区可能会超出数据库的分区限制。
因此,可以有针对性地进行两个优化:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);历史拉链表是每月制作的(与每天相比,可以大大减少分区数量)。2.4 事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的几个设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。这种方法也适合采集数据分析的需要。
三、数据管理3.1元数据
元数据是数据的数据,它记录了数据从产生到消费的整个过程:数据仓库中模型的定义、各层级之间的映射关系、监控数据的数据状态、ETL任务的运行状态, 等等。
根据用途,元数据可以分为技术元数据和业务元数据:
统一元数据体系建设目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务导出,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标流程:
对底层数据进行梳理,对元数据进行分类,减少数据重复,丰富表和字段的使用;搭建中间层,在治理、存储、质量、安全等治理领域提供数据支撑;向外界提供统一的元数据服务出口。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)数据配置文件
为数据建立血缘关系图,解决研发前期搜索数据、确定口径算法、数据处理的复杂困境,节省研发成本,更高效地理解和使用数据,并标记,通过标签组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
它可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5) 驱动 ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等。 例如Data Profile判断数据可以离线后,触发OneClick数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4 数据质量
数据质量是一切有效分析和准备的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。
免规则采集器列表算法(TeleportUltra(仿站扒站神器)电脑网站采集软件介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-04 08:10
Teleport Ultra 是一款电脑网站采集 软件。该工具可以完全保存指定的网站,还可以自定义保存文本或图片内容,功能多样。仿站速度极快,赶紧下载使用吧!
软件介绍
瞬移超破解版是一款实用简单的网络资源下载器。通过这个软件,用户可以监控一个网页的所有资源,并将它们下载到自己的电脑上。您可以自定义下载的内容,包括图片、文字、flash动画等资源,也可以一次性下载整个网页的所有内容,方便您设计自己的网页作品;Teleport ultra中文版提供资源搜索功能,可以创建多个搜索项,包括项目类型文件、背景图片、声音文件,甚至ZIP文件或程序都可以搜索。它运行得非常快。您可以在几分钟内扫描整个网页。有需要的朋友可以下载体验!
技能
1、要使用 Teleport,您可以创建一个收录 Internet 上一个或多个文件地址的项目文件。您还为 Teleport 提供了一些规则,定义了它将遵循的链接以及它将检索哪些文件。要发送蜘蛛任务,请选择文件菜单上的启动命令,或按工具栏上的启动按钮。
2、 一旦激活,传送蜘蛛将读取您项目的起始地址并检索它的任何文件以找到那里。然后它读取该页面上的所有链接,跟踪这些链接,并获取这些页面上的文件,直到它用完为止。
3、你可以告诉 Teleport 只检索某些类型的文件,并且只遵循某些类型的链接。例如,您可以指示它仅检索 jpg 和 gif 文件,这是世界上常见的图形文件类型万维网。您还可以指示它仅跟踪与起始地址相同域中的链接,甚至设置其“深度”搜索。您的“程序”蜘蛛的行为将决定它的距离、需要多长时间以及它将获取什么类型的文件。
4、传送蜘蛛非常灵活。它有许多可定制的探索参数来指定要跟踪的链接类型和要检索的文件类型。大多数情况下,您可以让新建项目向导为您设置项目的探索参数。新建项目向导通常会选择最适合大多数传输任务的参数。
5、teleport ultra 简体中文版使用特殊的搜索算法快速搜索网页,对其链接进行识别和分类,然后检索与“项目属性”表中指定的文件类型匹配的所有文件。
6、传送从项目的第一个起始地址开始。传送蜘蛛仔细检查页面,提取其所有链接和所有对嵌入数据的引用。如果您设置了文件类型规范,Teleport 将检索您为与页面匹配的每个文件请求的文件类型。如果不指定任何类型,Teleport 将只检索每个文件。每个检索到的文件都存储在项目子目录中,并且始终以您的项目命名。如果您要求 Teleport 获取“嵌入”文件,例如出现在网页上的图形和声音,Teleport 也会获取这些文件。
7、Telep ort spider 然后将页面的链接归类到其他页面。如果链接指向页面项目的探索深度,或者指向排除域中的页面,则该链接将被丢弃。蜘蛛依次访问剩余的页面;检查他们的链接和文件;检索他们的文件;类别链接...等。
8、如果你的项目有多个起始地址,Teleport蜘蛛会重复以上过程起始地址。
9、当 Teleport 蜘蛛浏览每个新页面时,它会将添加的页面插入到项目地图中。您可以单击项目地图中的任何年龄来选择它。检索到此页面的文件将显示在文件列表中。
使用说明
1、打开软件
点击File,然后点击New Project Wizred...,弹出如下界面,选择第一项,点击Next
然后在输入框中输入你要领取的网站的地址,点击下一步
选择所有内容,单击下一步,然后单击完成
选择好本地保存源文件的路径后,点击保存
再次点击start开始选择网站的文件
完成它
安装方法
下载后,解压rar,打开exe文件,下一步
选择安装路径后,下一步
等待进度条完成后,安装完成。
更新日志
版本 1.72,2015 年 9 月 23 日
改进的解析器,更好地处理脚本中的字符串
从重写过程中删除了已知问题脚本(jquery、addthis)
更新了公司联系信息 查看全部
免规则采集器列表算法(TeleportUltra(仿站扒站神器)电脑网站采集软件介绍)
Teleport Ultra 是一款电脑网站采集 软件。该工具可以完全保存指定的网站,还可以自定义保存文本或图片内容,功能多样。仿站速度极快,赶紧下载使用吧!
软件介绍
瞬移超破解版是一款实用简单的网络资源下载器。通过这个软件,用户可以监控一个网页的所有资源,并将它们下载到自己的电脑上。您可以自定义下载的内容,包括图片、文字、flash动画等资源,也可以一次性下载整个网页的所有内容,方便您设计自己的网页作品;Teleport ultra中文版提供资源搜索功能,可以创建多个搜索项,包括项目类型文件、背景图片、声音文件,甚至ZIP文件或程序都可以搜索。它运行得非常快。您可以在几分钟内扫描整个网页。有需要的朋友可以下载体验!

技能
1、要使用 Teleport,您可以创建一个收录 Internet 上一个或多个文件地址的项目文件。您还为 Teleport 提供了一些规则,定义了它将遵循的链接以及它将检索哪些文件。要发送蜘蛛任务,请选择文件菜单上的启动命令,或按工具栏上的启动按钮。
2、 一旦激活,传送蜘蛛将读取您项目的起始地址并检索它的任何文件以找到那里。然后它读取该页面上的所有链接,跟踪这些链接,并获取这些页面上的文件,直到它用完为止。
3、你可以告诉 Teleport 只检索某些类型的文件,并且只遵循某些类型的链接。例如,您可以指示它仅检索 jpg 和 gif 文件,这是世界上常见的图形文件类型万维网。您还可以指示它仅跟踪与起始地址相同域中的链接,甚至设置其“深度”搜索。您的“程序”蜘蛛的行为将决定它的距离、需要多长时间以及它将获取什么类型的文件。
4、传送蜘蛛非常灵活。它有许多可定制的探索参数来指定要跟踪的链接类型和要检索的文件类型。大多数情况下,您可以让新建项目向导为您设置项目的探索参数。新建项目向导通常会选择最适合大多数传输任务的参数。
5、teleport ultra 简体中文版使用特殊的搜索算法快速搜索网页,对其链接进行识别和分类,然后检索与“项目属性”表中指定的文件类型匹配的所有文件。
6、传送从项目的第一个起始地址开始。传送蜘蛛仔细检查页面,提取其所有链接和所有对嵌入数据的引用。如果您设置了文件类型规范,Teleport 将检索您为与页面匹配的每个文件请求的文件类型。如果不指定任何类型,Teleport 将只检索每个文件。每个检索到的文件都存储在项目子目录中,并且始终以您的项目命名。如果您要求 Teleport 获取“嵌入”文件,例如出现在网页上的图形和声音,Teleport 也会获取这些文件。
7、Telep ort spider 然后将页面的链接归类到其他页面。如果链接指向页面项目的探索深度,或者指向排除域中的页面,则该链接将被丢弃。蜘蛛依次访问剩余的页面;检查他们的链接和文件;检索他们的文件;类别链接...等。
8、如果你的项目有多个起始地址,Teleport蜘蛛会重复以上过程起始地址。
9、当 Teleport 蜘蛛浏览每个新页面时,它会将添加的页面插入到项目地图中。您可以单击项目地图中的任何年龄来选择它。检索到此页面的文件将显示在文件列表中。
使用说明
1、打开软件
点击File,然后点击New Project Wizred...,弹出如下界面,选择第一项,点击Next
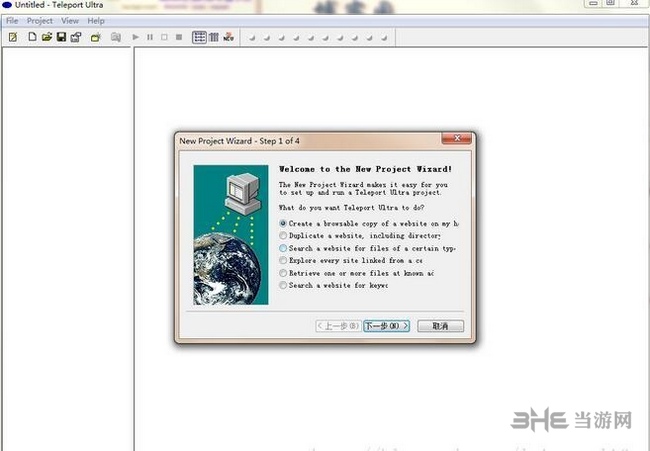
然后在输入框中输入你要领取的网站的地址,点击下一步
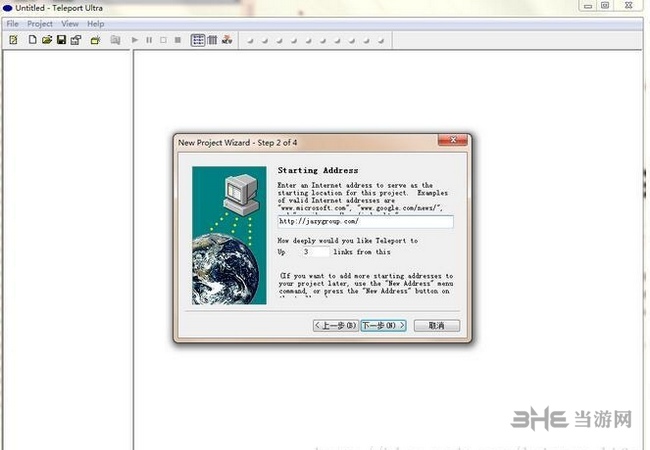
选择所有内容,单击下一步,然后单击完成
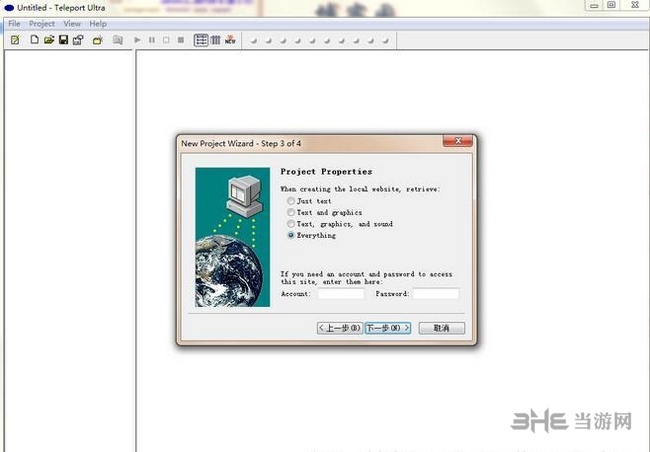
选择好本地保存源文件的路径后,点击保存
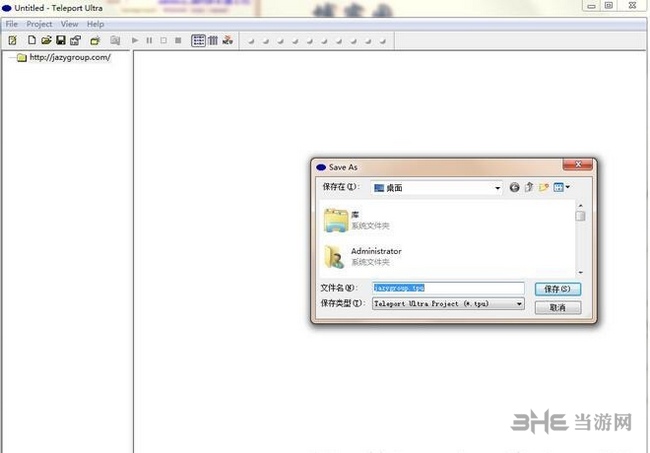
再次点击start开始选择网站的文件
完成它
安装方法
下载后,解压rar,打开exe文件,下一步
选择安装路径后,下一步
等待进度条完成后,安装完成。
更新日志
版本 1.72,2015 年 9 月 23 日
改进的解析器,更好地处理脚本中的字符串
从重写过程中删除了已知问题脚本(jquery、addthis)
更新了公司联系信息
免规则采集器列表算法(关键词故障原语,静态故障,存储器存储器测试,故障覆盖率)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-03 03:00
苏彦鹏薛仲杰一定是明寒雷人
基于适用于静态简化故障测试的MarchSS算法,提出了一种改进的嵌入式随机存取存储器测试算法——MarchSSE算法。在相同的测试长度下,该算法不仅可以检测出MarchSS算法测试的所有功能故障,还可以检测出MarchSS算法遗漏的固定开路故障,以及大部分动态故障,故障覆盖率率获得。有了很大的改善。关键词故障原语、静态故障、动态故障、内存测试、故障覆盖
1 简介
随着深亚微米VLSI技术的发展,来自不同制造商的大量电路设计或内核被集成在单个芯片上。内存密度的增加使得内存测试面临更大的挑战。嵌入式RAM存储器是最难测试的电路,因为存储器测试通常需要大量的测试模式来激活存储器并读出存储器的单元内容与标准值进行比较。在可接受的测试成本和测试时间的限制下,准确的故障模型和有效的测试算法是必不可少的。为了保证测试时间和故障覆盖率,测试的质量很大程度上取决于所选的功能故障模型。
以前关于故障模型的大多数论文都将故障的敏感性固定为最多一个操作(例如一次读取或一次写入)。这些功能故障称为静态功能故障。基于缺陷注入和SPICE仿真对DRAM的测试分析表明,还有一种故障可以通过多个操作进行敏感化,而没有静态故障(如连续读写操作),即动态故障。大多数测试算法主要针对静态故障,动态故障的覆盖率较低,但动态故障的测试也很重要[1]。
2 内存故障模型
故障模型可以用故障原语(Fault Primitive)来表示。单个单元故障用符号表示,两个单元耦合故障用符号表示。S表示单个单元的敏化操作序列,Sa表示耦合单元的敏化操作序列,Sv表示耦合单元的敏化操作序列,F表示故障单元的值F{0,1},R表示读操作的逻辑输出值R{0,1,-}。'-'表示写操作被激活,没有输出值。故障原语可以构成一套完整的操作序列,驱动所有记忆功能的故障。
2.1 单机静态故障
单个单元静态故障有12个可能的故障原语,这12个故障原语可以看作是六个功能故障模型的集合。以下是六种功能故障: 1)状态故障(State Fault);2)转换故障;3)写干扰故障;4)读取破坏性故障;5)False Read Deceptive Read Destructive Fault;6) 读取错误错误。文章[2] 中详细解释了这些故障。
在文章[3]中提到,Stuck-at Faults的故障原语是</0/->和</1/->,所以固定故障被认为是状态故障和转移故障的联合。Stuck OPEN Fault[4]是由于字线断线引起的,即0w1或1w0的操作无法完成,所以可以认为是转换故障;另外,由于存储器的读出依赖于灵敏放大器,可以认为是误读故障,所以固定开路故障被认为是转换故障和误读故障的并集。
2.2静态耦合失败
静态耦合故障的故障原语共有36种,可归纳为以下七种功能故障模型[2]:1)状态耦合故障;2) 干扰耦合故障(Disturb Coupling Fault);3)转换耦合故障;4)写破坏性耦合故障;5)读取破坏性耦合错误;6)欺骗性读取破坏性耦合错误;7)不正确的读取耦合故障。文章[2] 中详细解释了这些故障。
2.3单机动态失效
只考虑 S=xWyRz 的情况。单个单元动态故障的故障原语有12种,可归纳为以下三种功能故障模型:1)动态读破坏性故障;2)动态读取破坏性故障动态欺骗性读取破坏性故障(Dynamic Deceptive Read Destructive Fault);3) 动态错误读取错误。文章[1] 中详细解释了这些故障。
2.4动态耦合失败
主要分析两台机组的动态耦合故障,可分为四种类型。只研究其中的两个(两个连续操作应用于耦合单元,两个连续操作应用于耦合单元)。两台机组动态耦合故障的故障原语共有32种,可归纳为以下四种功能故障模型[1]:
1)动态干扰耦合故障(Dynamic Disturb Coupling Fault):连续两次写入耦合单元,读操作导致耦合单元的值发生跳跃。
2)动态读取破坏性耦合故障(Dynamic Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变存储单元的逻辑值并输出错误。价值。
3)Dynamic Deceptive Read Destructive Coupling Fault(Dynamic Deceptive Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变了存储单元的逻辑,但输出的是正确的值。
4)Dynamic Incorrect Read Coupling Fault(动态错误读取耦合故障):耦合单元的某个值导致耦合单元连续写入两次。读操作返回错误值,但没有出现存储单元的值。改变。
3 内存测试
文章[2]中提到的March SS算法如图1所示,认为能够检测到上述所有静态简化故障。在文章[3]中,固定开路故障被视为转换故障和误读故障的并集。但是,由于固定开路故障的敏感性,上次读取的值必须与本次读取的值相反。因此,测试它的算法不同于错误读取失败的算法。通过对图1所示的March SS算法的分析,很容易发现它不能检测到固定的开路故障,只有在对其四个元素M1、M2、M3、M4中的任何一个进行最后一次写操作后才进行加法读取操作可以检测固定的开路故障(例如,添加 r1) 到元素 M1 的 w1 的末尾。为了规律性,您可以在 M1、M2、M3 和 M4 四个元素中添加一个。读操作,得到March SS'算法,其算法如图2所示。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_0.gif" border=0>
图1. March SS算法
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_1.gif" border=0>
图2. March SS'算法
附加读操作仅影响由该读操作敏感的故障检测。至于其他静态故障的检测,由于增加的读操作不会影响存储单元的内容,因此不会影响这些故障的覆盖范围。在读操作引起的故障中,除了误读破坏故障和误读破坏耦合故障以外的故障都是由读操作敏感检测的,所以算法只会增加而不是减少对这些故障的损害。覆盖范围。最后,对于伪读破坏故障和伪读破坏耦合故障,使用March SS'算法进行的测试如表1(a)和(b)所示。其中“v>a”表示地址耦合单元的地址高于耦合单元的地址,
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_2.gif" border=0>
(一种)
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_3.gif" border=0>
(二)
表1. (a) March SS'算法对误读损坏故障的覆盖率,(b) March SS'算法对误读损坏耦合故障的覆盖率
算法March SS'中四个元素M1、M2、M3、M4的第二次读操作主要是检测第一次读操作敏感的伪读损坏和伪读损坏耦合故障,对于其他有对故障检测没有贡献,所以去掉这些读操作不会影响除这两个故障以外的故障检测。从表1(a)和(b)可以看出,如果没有这四种读操作,也可以检测到假读破坏故障和假读破坏耦合故障。因此,可以去掉March SS'算法中四个元素M1、M2、M3、M4的二次读操作,得到如图3-March SSE算法的改进算法。该算法还可以检测所有上述静态故障。此外,它还可以检测 March SS 无法检测到的静态故障,即固定开路。提高了故障覆盖率。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_4.gif" border=0>
图3. March SSE算法
我们来看看March SS算法和March SSE算法对动态故障的测试条件。单台机组动态故障试验见表2。表第三列对应3月SS单台机组动态故障。测试情况,第四栏为3月上证所对单机动态故障的测试情况。可以看出,March SS 算法只能检测到 1/3 的故障,而 March SSE 可以检测到 5/6 的故障。
功能失效模型 (FFM)
故障原语 (FP)
三月党卫军
3月上交所
动态读取损坏失败 (dRDF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
动态误读破坏故障 (dDRDF)
M1/M2,M3/M4
M2/M3、M4/M5
动态错误读取失败 (dIRF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
表2. 3 月 SS 和 3 月 SSE 单台机组动态故障覆盖率
对于多台机组的动态耦合失效,以两台机组为例。表 3 显示了两种算法对两种动态干扰耦合故障 (dCFds) 和动态误读损坏耦合故障 (dCFdrd) 的敏化和检测。另外两个动态耦合故障,动态读取失败耦合失败(dCFrd)和动态错误读取耦合失败(dCFir),很容易证明都可以通过March SSE算法进行测试,而March SS只能检测到一半的故障。对于两台机组总的动态耦合故障,March SS算法只能检测到3/8的故障,而March SSE算法可以检测到7/8的故障。因此,动态故障的故障覆盖率得到了很大的提高。
实况调查团
故障原语 (FP)
三月党卫军
3月上交所
v>a
v
v>a
v
动态干扰耦合故障 (dCFds)
M1/M1
M3/M3
M1/M1
M3/M3
M1/M1
M3/M3
M4/M5
M2/M3
M4/M5
M2/M3
M4/M5
M2/M3
M3/M4
M1/M2
M3/M4
M1/M2
M3/M4
M1/M2
M2/M2
M4/M4
M2/M2
M4/M4
M2/M2
M4/M4
动态误读破坏性耦合故障 (dCFdrd)
M3/M4
M1/M2
M2/M3
M4/M5
M1/M2
M3/M4
M4/M5
M2/M3
表3. March SS和March SSE对两台机组动态耦合故障覆盖率
4。结论
本文通过对嵌入式存储器几种不同类型的动静态简化功能故障的分析,在原有March SS算法的基础上提出March SSE算法,主要用于测试静态故障。算法长度为22N,其中N为内存中的字数,每个字收录一位。与March SS算法相比,March SSE算法在测试长度不变的情况下,其故障覆盖率有显着提高。它不仅可以检测出 March SS 算法测试的所有功能故障,还可以检测出 March SS 算法遗漏的固定开路故障,以及第 2 节中描述的 85% 以上的动态故障,以及故障覆盖率一直很大。急剧增加。
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号 查看全部
免规则采集器列表算法(关键词故障原语,静态故障,存储器存储器测试,故障覆盖率)
苏彦鹏薛仲杰一定是明寒雷人
基于适用于静态简化故障测试的MarchSS算法,提出了一种改进的嵌入式随机存取存储器测试算法——MarchSSE算法。在相同的测试长度下,该算法不仅可以检测出MarchSS算法测试的所有功能故障,还可以检测出MarchSS算法遗漏的固定开路故障,以及大部分动态故障,故障覆盖率率获得。有了很大的改善。关键词故障原语、静态故障、动态故障、内存测试、故障覆盖
1 简介
随着深亚微米VLSI技术的发展,来自不同制造商的大量电路设计或内核被集成在单个芯片上。内存密度的增加使得内存测试面临更大的挑战。嵌入式RAM存储器是最难测试的电路,因为存储器测试通常需要大量的测试模式来激活存储器并读出存储器的单元内容与标准值进行比较。在可接受的测试成本和测试时间的限制下,准确的故障模型和有效的测试算法是必不可少的。为了保证测试时间和故障覆盖率,测试的质量很大程度上取决于所选的功能故障模型。
以前关于故障模型的大多数论文都将故障的敏感性固定为最多一个操作(例如一次读取或一次写入)。这些功能故障称为静态功能故障。基于缺陷注入和SPICE仿真对DRAM的测试分析表明,还有一种故障可以通过多个操作进行敏感化,而没有静态故障(如连续读写操作),即动态故障。大多数测试算法主要针对静态故障,动态故障的覆盖率较低,但动态故障的测试也很重要[1]。
2 内存故障模型
故障模型可以用故障原语(Fault Primitive)来表示。单个单元故障用符号表示,两个单元耦合故障用符号表示。S表示单个单元的敏化操作序列,Sa表示耦合单元的敏化操作序列,Sv表示耦合单元的敏化操作序列,F表示故障单元的值F{0,1},R表示读操作的逻辑输出值R{0,1,-}。'-'表示写操作被激活,没有输出值。故障原语可以构成一套完整的操作序列,驱动所有记忆功能的故障。
2.1 单机静态故障
单个单元静态故障有12个可能的故障原语,这12个故障原语可以看作是六个功能故障模型的集合。以下是六种功能故障: 1)状态故障(State Fault);2)转换故障;3)写干扰故障;4)读取破坏性故障;5)False Read Deceptive Read Destructive Fault;6) 读取错误错误。文章[2] 中详细解释了这些故障。
在文章[3]中提到,Stuck-at Faults的故障原语是</0/->和</1/->,所以固定故障被认为是状态故障和转移故障的联合。Stuck OPEN Fault[4]是由于字线断线引起的,即0w1或1w0的操作无法完成,所以可以认为是转换故障;另外,由于存储器的读出依赖于灵敏放大器,可以认为是误读故障,所以固定开路故障被认为是转换故障和误读故障的并集。
2.2静态耦合失败
静态耦合故障的故障原语共有36种,可归纳为以下七种功能故障模型[2]:1)状态耦合故障;2) 干扰耦合故障(Disturb Coupling Fault);3)转换耦合故障;4)写破坏性耦合故障;5)读取破坏性耦合错误;6)欺骗性读取破坏性耦合错误;7)不正确的读取耦合故障。文章[2] 中详细解释了这些故障。
2.3单机动态失效
只考虑 S=xWyRz 的情况。单个单元动态故障的故障原语有12种,可归纳为以下三种功能故障模型:1)动态读破坏性故障;2)动态读取破坏性故障动态欺骗性读取破坏性故障(Dynamic Deceptive Read Destructive Fault);3) 动态错误读取错误。文章[1] 中详细解释了这些故障。
2.4动态耦合失败
主要分析两台机组的动态耦合故障,可分为四种类型。只研究其中的两个(两个连续操作应用于耦合单元,两个连续操作应用于耦合单元)。两台机组动态耦合故障的故障原语共有32种,可归纳为以下四种功能故障模型[1]:
1)动态干扰耦合故障(Dynamic Disturb Coupling Fault):连续两次写入耦合单元,读操作导致耦合单元的值发生跳跃。
2)动态读取破坏性耦合故障(Dynamic Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变存储单元的逻辑值并输出错误。价值。
3)Dynamic Deceptive Read Destructive Coupling Fault(Dynamic Deceptive Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变了存储单元的逻辑,但输出的是正确的值。
4)Dynamic Incorrect Read Coupling Fault(动态错误读取耦合故障):耦合单元的某个值导致耦合单元连续写入两次。读操作返回错误值,但没有出现存储单元的值。改变。
3 内存测试
文章[2]中提到的March SS算法如图1所示,认为能够检测到上述所有静态简化故障。在文章[3]中,固定开路故障被视为转换故障和误读故障的并集。但是,由于固定开路故障的敏感性,上次读取的值必须与本次读取的值相反。因此,测试它的算法不同于错误读取失败的算法。通过对图1所示的March SS算法的分析,很容易发现它不能检测到固定的开路故障,只有在对其四个元素M1、M2、M3、M4中的任何一个进行最后一次写操作后才进行加法读取操作可以检测固定的开路故障(例如,添加 r1) 到元素 M1 的 w1 的末尾。为了规律性,您可以在 M1、M2、M3 和 M4 四个元素中添加一个。读操作,得到March SS'算法,其算法如图2所示。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_0.gif" border=0>
图1. March SS算法
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_1.gif" border=0>
图2. March SS'算法
附加读操作仅影响由该读操作敏感的故障检测。至于其他静态故障的检测,由于增加的读操作不会影响存储单元的内容,因此不会影响这些故障的覆盖范围。在读操作引起的故障中,除了误读破坏故障和误读破坏耦合故障以外的故障都是由读操作敏感检测的,所以算法只会增加而不是减少对这些故障的损害。覆盖范围。最后,对于伪读破坏故障和伪读破坏耦合故障,使用March SS'算法进行的测试如表1(a)和(b)所示。其中“v>a”表示地址耦合单元的地址高于耦合单元的地址,
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_2.gif" border=0>
(一种)
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_3.gif" border=0>
(二)
表1. (a) March SS'算法对误读损坏故障的覆盖率,(b) March SS'算法对误读损坏耦合故障的覆盖率
算法March SS'中四个元素M1、M2、M3、M4的第二次读操作主要是检测第一次读操作敏感的伪读损坏和伪读损坏耦合故障,对于其他有对故障检测没有贡献,所以去掉这些读操作不会影响除这两个故障以外的故障检测。从表1(a)和(b)可以看出,如果没有这四种读操作,也可以检测到假读破坏故障和假读破坏耦合故障。因此,可以去掉March SS'算法中四个元素M1、M2、M3、M4的二次读操作,得到如图3-March SSE算法的改进算法。该算法还可以检测所有上述静态故障。此外,它还可以检测 March SS 无法检测到的静态故障,即固定开路。提高了故障覆盖率。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_4.gif" border=0>
图3. March SSE算法
我们来看看March SS算法和March SSE算法对动态故障的测试条件。单台机组动态故障试验见表2。表第三列对应3月SS单台机组动态故障。测试情况,第四栏为3月上证所对单机动态故障的测试情况。可以看出,March SS 算法只能检测到 1/3 的故障,而 March SSE 可以检测到 5/6 的故障。
功能失效模型 (FFM)
故障原语 (FP)
三月党卫军
3月上交所
动态读取损坏失败 (dRDF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
动态误读破坏故障 (dDRDF)
M1/M2,M3/M4
M2/M3、M4/M5
动态错误读取失败 (dIRF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
表2. 3 月 SS 和 3 月 SSE 单台机组动态故障覆盖率
对于多台机组的动态耦合失效,以两台机组为例。表 3 显示了两种算法对两种动态干扰耦合故障 (dCFds) 和动态误读损坏耦合故障 (dCFdrd) 的敏化和检测。另外两个动态耦合故障,动态读取失败耦合失败(dCFrd)和动态错误读取耦合失败(dCFir),很容易证明都可以通过March SSE算法进行测试,而March SS只能检测到一半的故障。对于两台机组总的动态耦合故障,March SS算法只能检测到3/8的故障,而March SSE算法可以检测到7/8的故障。因此,动态故障的故障覆盖率得到了很大的提高。
实况调查团
故障原语 (FP)
三月党卫军
3月上交所
v>a
v
v>a
v
动态干扰耦合故障 (dCFds)
M1/M1
M3/M3
M1/M1
M3/M3
M1/M1
M3/M3
M4/M5
M2/M3
M4/M5
M2/M3
M4/M5
M2/M3
M3/M4
M1/M2
M3/M4
M1/M2
M3/M4
M1/M2
M2/M2
M4/M4
M2/M2
M4/M4
M2/M2
M4/M4
动态误读破坏性耦合故障 (dCFdrd)
M3/M4
M1/M2
M2/M3
M4/M5
M1/M2
M3/M4
M4/M5
M2/M3
表3. March SS和March SSE对两台机组动态耦合故障覆盖率
4。结论
本文通过对嵌入式存储器几种不同类型的动静态简化功能故障的分析,在原有March SS算法的基础上提出March SSE算法,主要用于测试静态故障。算法长度为22N,其中N为内存中的字数,每个字收录一位。与March SS算法相比,March SSE算法在测试长度不变的情况下,其故障覆盖率有显着提高。它不仅可以检测出 March SS 算法测试的所有功能故障,还可以检测出 March SS 算法遗漏的固定开路故障,以及第 2 节中描述的 85% 以上的动态故障,以及故障覆盖率一直很大。急剧增加。
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
免规则采集器列表算法(在一种自顶向下的研究机器学习的方法中,理论应立足于何处?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-03 00:19
在机器学习的自上而下方法中,理论应该在哪里?
在传统的机器学习教学计划中,理论首先需要足够广泛的数学背景才能理解。在我的机器学习教学计划中,我会教你如何从头开始解决端到端的问题并做出结果。
那么,理论更适合出现在哪里呢?
在这个文章中,当我们谈论机器学习中的“理论”时,您将确切地了解我们在谈论什么。提示:这都是关于算法的。
你会发现,一旦你能熟练地解决问题并得到结果,你就会不由自主地深入学习,更好地理解结果,提交更好的结果。没有人能阻止你。
最后,您将发现在标准数据集上进行机器学习时可以使用的 5 种技术,以逐步增强您对机器学习算法的理解。
如何在没有数学的情况下学习机器学习
照片由 Ed Brambley 提供,保留部分权利
理论学习是最后的,不是第一次
开发人员教他们如何学习机器学习是没有用的。
这种方法是自上而下的教育。对你来说没用——如果你是一个开发者,只想用机器学习作为解决问题的工具,而不是成为这个领域的研究人员。
传统的学习方法要求你在学习算法理论之前先学习线性代数、概率和统计等数学知识。如果您正在研究算法的实现或讨论如何端到端地处理问题并提供可运行、可靠且准确的预测模型,那么您很幸运。
下面我教大家一个自顶向下的机器学习学习方法。在这个方法中,我们将从1)学习一个系统的流程来处理端到端的问题,2)将流程映射到“最好的”机器学习工具和平台,然后3)在测试数据集上完成有针对性的练习。
您可以在“程序员的机器学习:从开发人员到机器学习从业者的飞跃”文章 中了解有关自顶向下机器学习方法的更多信息。
那么该理论应该在哪里适合这个过程呢?
如果要逆向学习过程,这种情况将在后面讨论。但是当我们使用测试数据集来训练模型时,我们在谈论什么理论?你究竟应该如何学习这个理论?
获取免费的算法思维导图
示例-易于使用的机器学习算法思维导图
我创建了一个方便的思维导图,其中收录 60 多种按类型组合的算法。
您可以下载它,打印出来并使用它。
免费下载
您还可以通过电子邮件享受迷你机器学习算法课程。
算法就是理论上的一切
机器学习领域充满了理论。
它之所以密集,是因为该领域有使用数学来描述和解释概念的传统。
这很有用,因为数学描述可以非常简洁并减少歧义。他们还可以使用所描述环境中的技术(例如对过程的概率理解)进行分析。
许多这些不重要的技术通常与机器学习算法的描述捆绑在一起。对于一个只是想对一个方法有一个比较浅薄的了解,然后能够配置和应用的人来说,这种感觉很难让人开心。这太令人沮丧了。
如果你没有基础去解析和理解算法的描述,那会让你非常沮丧。此外,令人沮丧的是,从计算机科学等领域,总是描述算法,区别在于算法的描述是为了快速理解(例如桌面检查)还是应用程序。
比如我们知道,在学习哈希表是什么以及如何使用哈希表时,我们几乎不需要知道哈希函数在日常工作中是做什么的。但是我们也可以知道什么是哈希函数,知道从哪里可以了解更多关于哈希函数的具体细节以及如何编写自己的哈希函数。那么为什么机器学习不能这样应用呢?
在学习机器学习中遇到的大部分“理论”都与机器学习算法有关。如果你问任何其他初学者为什么他们对这个理论感到沮丧,那么你就会知道这与学习如何理解或使用特定的机器学习算法有关。
在这里,算法的研究比创建预测模型的过程更广泛。它是指选择特征、设计新特征、转换数据以及估计模型在不可见数据上的准确性(例如交叉验证)的算法过程。
所以,归根结底,学习理论意味着学习机器学习算法。
被迫钻研理论
我通常建议在著名的机器学习数据集上进行有针对性的练习。
由于众所周知的机器学习数据集,它将与 UCI 机器学习库中的数据集一样易于使用。而且它们通常很小,因此不需要太多内存,因此可以在工作站上进行处理。它们也可用于良好的理解和研究,因此您可以有一个比较基准。
可以在《使用UCI机器学习库中的小型低内存数据库进行机器学习实践》文章中了解更多关于机器学习数据集的实践。
了解机器学习算法在这个过程中的应用。原因是当你追求标准机器学习算法的结果时,你会遇到限制。你会想知道如何从给定的算法中获取更多信息,或者如何更好地配置它,或者如何实际工作。
这需要更多的知识和好奇心,这些东西会促使你学习机器学习算法的理论。为了得到更好的结果,你将被迫拼凑对算法的一些理解。
我们也看到了来自不同背景的年轻开发者的同样效果,他们最终通过研究开源项目的代码、教科书甚至研究论文来磨练自己的手艺。促使他们这样做的原因是需要成为更好、更有能力的程序员。
如果你对成功充满好奇和动力,你必须学习这个理论。
理解机器学习算法的 5 个技巧
你的目标练习时间的一部分将用于学习机器学习算法
到时候可以用一些技巧和模板来缩短这个过程。
在本节中,您将发现可用于快速理解机器学习算法理论的 5 种技术。
1)创建机器学习算法列表
当您刚开始学习时,您可能会被大量可用的算法所淹没。
即使您尝试在现场测试算法,您可能仍然不确定哪些算法将收录在您的混合算法中(提示,有很多不同的算法)。
跟踪您阅读的算法是一项很好的技术,您可以在开始时使用。这些列表可以像算法名称一样简单,也可以随着您的兴趣和好奇心的增加而增加复杂性。
您还可以捕获详细信息,例如适当的问题类型(分类或回归)、相关算法和分类类别(决策树、内核等)。当您看到新算法的名称时,请将其添加到您的列表中。当你开始一个新问题时,你可以尝试一些你以前从未使用过的算法。或者勾选之前使用的算法等。
控制列表中的算法名称可以提供强大的功能。这个看似可笑的简单策略可以帮助你摆脱压力。您的简单算法列表可以为您节省大量时间和挫折,例如:
你必须先创建一个算法列表,请打开一个电子表格并开始创建它。
有关此技术的更多信息,请参阅“通过创建机器学习算法的目标列表进行控制”文章。
2)机器学习算法研究 查看全部
免规则采集器列表算法(在一种自顶向下的研究机器学习的方法中,理论应立足于何处?)
在机器学习的自上而下方法中,理论应该在哪里?
在传统的机器学习教学计划中,理论首先需要足够广泛的数学背景才能理解。在我的机器学习教学计划中,我会教你如何从头开始解决端到端的问题并做出结果。
那么,理论更适合出现在哪里呢?
在这个文章中,当我们谈论机器学习中的“理论”时,您将确切地了解我们在谈论什么。提示:这都是关于算法的。
你会发现,一旦你能熟练地解决问题并得到结果,你就会不由自主地深入学习,更好地理解结果,提交更好的结果。没有人能阻止你。
最后,您将发现在标准数据集上进行机器学习时可以使用的 5 种技术,以逐步增强您对机器学习算法的理解。
如何在没有数学的情况下学习机器学习
照片由 Ed Brambley 提供,保留部分权利
理论学习是最后的,不是第一次
开发人员教他们如何学习机器学习是没有用的。
这种方法是自上而下的教育。对你来说没用——如果你是一个开发者,只想用机器学习作为解决问题的工具,而不是成为这个领域的研究人员。
传统的学习方法要求你在学习算法理论之前先学习线性代数、概率和统计等数学知识。如果您正在研究算法的实现或讨论如何端到端地处理问题并提供可运行、可靠且准确的预测模型,那么您很幸运。
下面我教大家一个自顶向下的机器学习学习方法。在这个方法中,我们将从1)学习一个系统的流程来处理端到端的问题,2)将流程映射到“最好的”机器学习工具和平台,然后3)在测试数据集上完成有针对性的练习。
您可以在“程序员的机器学习:从开发人员到机器学习从业者的飞跃”文章 中了解有关自顶向下机器学习方法的更多信息。
那么该理论应该在哪里适合这个过程呢?
如果要逆向学习过程,这种情况将在后面讨论。但是当我们使用测试数据集来训练模型时,我们在谈论什么理论?你究竟应该如何学习这个理论?
获取免费的算法思维导图
示例-易于使用的机器学习算法思维导图
我创建了一个方便的思维导图,其中收录 60 多种按类型组合的算法。
您可以下载它,打印出来并使用它。
免费下载
您还可以通过电子邮件享受迷你机器学习算法课程。
算法就是理论上的一切
机器学习领域充满了理论。
它之所以密集,是因为该领域有使用数学来描述和解释概念的传统。
这很有用,因为数学描述可以非常简洁并减少歧义。他们还可以使用所描述环境中的技术(例如对过程的概率理解)进行分析。
许多这些不重要的技术通常与机器学习算法的描述捆绑在一起。对于一个只是想对一个方法有一个比较浅薄的了解,然后能够配置和应用的人来说,这种感觉很难让人开心。这太令人沮丧了。
如果你没有基础去解析和理解算法的描述,那会让你非常沮丧。此外,令人沮丧的是,从计算机科学等领域,总是描述算法,区别在于算法的描述是为了快速理解(例如桌面检查)还是应用程序。
比如我们知道,在学习哈希表是什么以及如何使用哈希表时,我们几乎不需要知道哈希函数在日常工作中是做什么的。但是我们也可以知道什么是哈希函数,知道从哪里可以了解更多关于哈希函数的具体细节以及如何编写自己的哈希函数。那么为什么机器学习不能这样应用呢?
在学习机器学习中遇到的大部分“理论”都与机器学习算法有关。如果你问任何其他初学者为什么他们对这个理论感到沮丧,那么你就会知道这与学习如何理解或使用特定的机器学习算法有关。
在这里,算法的研究比创建预测模型的过程更广泛。它是指选择特征、设计新特征、转换数据以及估计模型在不可见数据上的准确性(例如交叉验证)的算法过程。
所以,归根结底,学习理论意味着学习机器学习算法。
被迫钻研理论
我通常建议在著名的机器学习数据集上进行有针对性的练习。
由于众所周知的机器学习数据集,它将与 UCI 机器学习库中的数据集一样易于使用。而且它们通常很小,因此不需要太多内存,因此可以在工作站上进行处理。它们也可用于良好的理解和研究,因此您可以有一个比较基准。
可以在《使用UCI机器学习库中的小型低内存数据库进行机器学习实践》文章中了解更多关于机器学习数据集的实践。
了解机器学习算法在这个过程中的应用。原因是当你追求标准机器学习算法的结果时,你会遇到限制。你会想知道如何从给定的算法中获取更多信息,或者如何更好地配置它,或者如何实际工作。
这需要更多的知识和好奇心,这些东西会促使你学习机器学习算法的理论。为了得到更好的结果,你将被迫拼凑对算法的一些理解。
我们也看到了来自不同背景的年轻开发者的同样效果,他们最终通过研究开源项目的代码、教科书甚至研究论文来磨练自己的手艺。促使他们这样做的原因是需要成为更好、更有能力的程序员。
如果你对成功充满好奇和动力,你必须学习这个理论。
理解机器学习算法的 5 个技巧
你的目标练习时间的一部分将用于学习机器学习算法
到时候可以用一些技巧和模板来缩短这个过程。
在本节中,您将发现可用于快速理解机器学习算法理论的 5 种技术。
1)创建机器学习算法列表
当您刚开始学习时,您可能会被大量可用的算法所淹没。
即使您尝试在现场测试算法,您可能仍然不确定哪些算法将收录在您的混合算法中(提示,有很多不同的算法)。
跟踪您阅读的算法是一项很好的技术,您可以在开始时使用。这些列表可以像算法名称一样简单,也可以随着您的兴趣和好奇心的增加而增加复杂性。
您还可以捕获详细信息,例如适当的问题类型(分类或回归)、相关算法和分类类别(决策树、内核等)。当您看到新算法的名称时,请将其添加到您的列表中。当你开始一个新问题时,你可以尝试一些你以前从未使用过的算法。或者勾选之前使用的算法等。
控制列表中的算法名称可以提供强大的功能。这个看似可笑的简单策略可以帮助你摆脱压力。您的简单算法列表可以为您节省大量时间和挫折,例如:
你必须先创建一个算法列表,请打开一个电子表格并开始创建它。
有关此技术的更多信息,请参阅“通过创建机器学习算法的目标列表进行控制”文章。
2)机器学习算法研究
免规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-31 23:15
防止网页被搜索引擎收录搜索最常见的方法是使用robots.txt,但这样做的缺点是搜索引用的所有已知爬虫信息都必须列出,而且不可避免会有遗漏。以下方法可治标治本:(摘自)
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人为分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被 查看全部
免规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
防止网页被搜索引擎收录搜索最常见的方法是使用robots.txt,但这样做的缺点是搜索引用的所有已知爬虫信息都必须列出,而且不可避免会有遗漏。以下方法可治标治本:(摘自)
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人为分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被
免规则采集器列表算法(基于人工智能技术,只需输入网址就能自动识别采集内容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-18 21:11
)
小白神器!免费导出采集结果,由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容
(Windows、Mac、Linux)
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业采集@ > 需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU和大图智能识别等。
云账号,方便快捷
创建优采云采集器账号并登录,您所有的采集任务设置都会自动加密保存到优采云的云服务器。无需担心采集任务丢失。正在运行的任务和采集的数据都在你本地,非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。
查看全部
免规则采集器列表算法(基于人工智能技术,只需输入网址就能自动识别采集内容
)
小白神器!免费导出采集结果,由前谷歌技术团队打造,基于人工智能技术,只需输入网址即可自动识别采集的内容
(Windows、Mac、Linux)
智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集。
自动识别:列表、表格、链接、图片、价格等。
直观点击,轻松上手
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。一个复杂的采集规则可以简单几步生成,结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
支持多种数据导出方式
采集 结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
实力强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业采集@ > 需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU和大图智能识别等。
云账号,方便快捷
创建优采云采集器账号并登录,您所有的采集任务设置都会自动加密保存到优采云的云服务器。无需担心采集任务丢失。正在运行的任务和采集的数据都在你本地,非常安全。只有在本地登录客户端后才能查看。优采云采集器 账号没有终端绑定限制。采集 任务也会在切换终端时同步更新,任务管理方便快捷。
全平台支持,无缝切换
同时支持Windows、Mac、Linux所有操作系统的采集软件。各平台版本完全一致,切换无缝。
免规则采集器列表算法(构建一个面向公共网络的WEB系统中一定要做到的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-18 21:10
在面向公网的项目中,安全无疑是项目面临的巨大挑战之一。在公共互联网上,花花公子和无聊的人一直在嗅探我们的服务器。有些人想大显身手,也有些不法分子想监控截取我们的敏感信息,进入我们的宿主进行各种活动。各种破坏和盗窃。这些人一旦得逞,系统的稳定性就会降低,企业的敏感数据就会丢失,企业的信誉也会遭到破坏。因此,为用户提供可靠、稳定的服务,防止重要数据的丢失和被盗,是我们构建面向公共网络的WEB系统所必须做的。
构建安全的网络环境,首先要了解安全威胁从何而来。以下是可能造成安全威胁的应用场景:
1、用户A向用户B发送带有敏感信息的文件,用户C在局域网内监听和截获未加密的数据报。
2、 网管A远程向主机B发送命令(如添加用户的命令),攻击者C截获收录该命令的数据报,修改包中的命令,然后发送给主机 B。
3、 同场景2,主机B准备接受远程合法用户A的命令,但此时攻击者C构造了命令数据报发送给B,B认为是用户发送的命令A、执行此命令后,与场景2不同,攻击者C并没有拦截和修改数据报,而是直接构造数据报。
4、 客户A向TA的股票经纪人B发送了一条股票交易的消息,股票经纪人B按照A的要求进行了相应的股票操作,但是这个操作给客户A带来了损失,然后客户A拒绝发送这条消息给经纪人 B 的消息。
分析场景1,如果A发送给B的消息是加密的,即使C截获了消息,TA也不会知道消息的内容。这涉及到消息的机密性。场景二中,攻击者C篡改了消息,但主机B并不知道接收到的消息与合法用户A发送的消息不一致,因此该场景涉及到消息的完整性。场景三,主机B接受任何人发送的消息,无需验证消息来源,这涉及到消息的可验证性。在场景4中,很明显,客户A不承认消息被发送,所以涉及到消息的不可否认性。
针对上述场景,我们可以总结出来自互联网的安全服务大致可以分为以下几类:
1、保密
2、 完整性
3、不可否认性
对于不同的服务,我们需要不同的安全属性。一些比较敏感的信息,比如用户进行电子交易时,需要不同的安全服务同时护航。下面,让我们讨论一下系统是如何实现上述安全属性的,以及实现这些安全属性需要使用的软件。这些软件可以作为组件集成到系统中,为系统的安全提供保护。
保密
消息的保密性是为了确保只有合法的接收者才能阅读消息的内容。即使其他人通过非法方式获取消息,由于消息是加密的,他们也无法阅读内容。然后,仅允许合法收件人阅读消息是消息机密性的要求。加解密图如下(对称加密):
消息机密性的研究历史悠久。最早的经典加密技术是凯撒加密技术,它是一种单码替换技术,即将每个明文字母替换为另一个字母,形成密文。然后将替换规则提前通知合法用户,以便合法用户在获得密文后,按照预先约定的规则将密文翻译成明文。未来,传统的加密算法(对称加密算法)都是从凯撒加密技术演变而来的。然而,凯撒密码有一个弱点。在比较长的英文信息中,可以计算出某个字母出现的频率。比如“The”这个词出现的频率就比较高。破译者甚至计算了一个字母的频率。度分析表。这样,解密器就可以根据频率分析表猜出密文,并尝试将其转换为明文。如果可以读取转换后的明文,则消息将被解密。这种解密方法也称为频率分析。
频率分析表
为了抵抗频率分析,1854 年,查尔斯·惠斯通发明了一种称为 Playfair 的多重替代加密方法。使用时,首先需要编制一个5X5的矩阵密码表。加密和解密依赖于密码表。所以这个5X5的密码表相当于一把钥匙。它可以有效抵抗频率分析,当时被军方广泛使用,但在第一次世界大战期间被破解。然后出现了一些加密机制,其中最著名的是德国在二战中使用的旋转加密。在DES算法出现之前,最著名的加密算法就是它了。它通过多步替换加密形成密文,使密码分析更加困难。这就是密码的历史。
DES
DES的全称是Data Encryption Standard,是一种对称加密算法。对称加密算法的特点是加密和解密使用相同的密钥。回顾我之前说的,从经典的凯撒加密到旋转加密,加密和解密都依赖同一个密码表或规则,所以都可以做到。称之为对称加密。这些密码表或规则可以理解为所谓的“密钥”。在 DES 中,密钥是由计算机生成的字符序列。这个序列应该有一定的长度,使得攻击者很难通过暴力破解或者其他方式获取。否则,如果密钥是由第三方获得的,则加密的消息将没有任何安全性。因为密码的算法是公开的。
DES的算法可以在百度百科或其他文档中找到。这里只介绍一下它的特点(其实我只了解算法过程,并没有仔细研究算法本身-_-!),DES的密钥长度是56位。加密时,密钥和64位明文消息作为输入,传递给加密函数。函数经过处理后,会生成一个64位的密文,完成明文到密文的转换。这种转换方式称为块加密,整体转换由64位明文块进行。现代加密算法基本上使用这种块加密方法。另一种是流加密。所谓流加密,就是对一个字符或一个字节或逐位进行转换。例如,
DES加密方式,DES加密有不同的方式,方式的不同导致DES生成密文的安全性和速度不同,这里介绍三种不同的DES加密方式:
1、ECB(Electronic Codebook),在ECB模式下,对于同一个明文,如果用同一个key加密,生成的密文是一样的。例如,单词“The”是一个64位的块,通过相同的密钥加密后,生成的密文始终是“XUZ”。这种加密模式对密码分析的抵抗力会弱一些。
2、CBC(Cipher Block Chaining),为了克服ECB模式的缺点,CBC模式诞生了。CBC对同一个明文块生成不同的密文,所以比ECB模式强。
3、CFB(Cipher Feedback),由于DES本质上是基于块加密的,所以必须转换成整块,而CFB模式可以把块加密转换成流加密,这样密文就可以一个字节生成一个字节的大小达到了实时密文转换的目的,提到了密文生成的速度。
DES 加密的强度由 DES 密钥的长度决定。DES 的密钥长度为 56 位,这意味着有 2 次方的 56 次方组合。依靠单台计算机的计算能力来尝试暴力破解DES需要很长时间。这需要时间(或需要大量费用),但现在由于分布式计算的发展,解决一个 56 位的密钥可能没有那么困难。所以现在,DES 不被认为是一种非常安全的加密算法,DES 已经逐渐被其他加密算法所取代。
三重DES (3DES)
3DES是DES的升级版,对每个数据块应用3次DES加密算法。由于使用了三种DES加密算法,3DES中需要三个密钥,而这三个密钥也有不同的组合。
组合方式一:三个密钥是独立的,这种加密强度最高,相当于3x56=168个密钥位。
组合二:有两个独立的密钥,这种安全性稍低,有112个密钥位。
组合方式三:三个按键完全一样。这种模式实际上是为了兼容普通的DES而存在的。在安全性方面,与普通DES没有区别,只有56个密钥位。
主意
IDEA全称为International Data Encryption Algorithm,是一种对称加密算法。近年来有人提出取代DES。IDEA在现代安全系统中有着广泛的应用,其中PGP使用的是IDEA算法。
IDEA 使用 128 位密钥对 64 位块进行加密,同时加强了密码的混淆和扩散,提高了安全性。混乱度的增加使得通过明文定律找到密文定律变得更加困难,因为密文和明文并不是一一对应的。扩散使密文中的每一位都受到明文中许多位的影响,增加了密码分析的难度。
河豚
Blowfish 是一种基于块的对称加密算法。它具有以下特点:
快速:使用 32 位微处理器加密一个字节仅需 18 个时钟周期。
简单性:运行 Blowfish 所需的 RAM 少于 5K。
简单:Blowfish 的简单结构使其算法易于实现。
可变长度:Blowfish 的密钥长度是可变的。它可以生成高达 448 位的密钥,允许用户在高安全性和高加密速度之间做出权衡。
Blowfish 可能是最好的对称加密算法。它已在许多安全产品中实施。经过长时间的安全测试,Blowfish 的安全性不成问题。
下面是Blowfish与其他加密算法的效率对比:
加密演算法
每轮时钟消耗
转换回合
每字节加密消耗时钟
河豚
9
16
18
RC5
12
16
二十三
DES
18
16
45
主意
50
8
50
3DES
18
48
108
RC5
RC5 是一种基于块的对称加密算法。它具有以下特点:
它可以用软件或硬件实现:只使用处理器支持的原创算术运算。
快速:RC5的算法简单,每一次加密操作都是以字为单位进行的。
可变字长:RC5提供的第一个参数是用户可以设置一个字的长度,允许的值为16、32、64。RC5使用2个字作为一个块进行加密,所以RC5可以选择一个块大小为 32 位。64 位或 128 位加密。
可变轮数:加密轮数是RC5提供的第二个参数,允许用户在加密速度和高安全性之间进行权衡。
可变密钥长度:密钥长度是RC5提供的第三个参数。同样,它允许用户在加密速度和高安全性之间进行权衡。该参数以 8 位字节为单位,范围可选 介于 0 和 255 之间,因此密钥的最大长度为 2040 位。RC5 的发明者 Rivest 建议我们使用 64 作为一个块,12 轮迭代和 128 位长度的密钥作为加密的标称模式。
简单:RC5 的简单结构使其算法易于实现。
低内存消耗:低内存消耗使得RC5可以与一些硬件如智能卡一起使用。
高安全性:RC5 提供高安全性。
RC5还提供了几种加密方式,即:
ECB:同DES的ECB模式。
CBC:同DES的CBC方式。
CBC-Pad:在 CBC 模式下处理可变长度的明文。单个 RC5 块生成的密文比明文长。
CAST-128
CAST 是一种基于块的对称加密算法。它使用可变长度的密钥。密钥长度为 40 到 128 位,每 8 位递增。CAST 加密进行 16 轮迭代,输入一个 64 位的明文块,输出一个 64 位的密文块。CAST 将密钥分成两个子密钥。
RC2
RC2 是一种基于块的对称加密算法。它使用 64 位块和可变长度的密钥。密钥的长度从 8 位到 1024 位不等。RC2 用于 S/MIME 协议。S/MIME 使用 40、64 和 128 位的密钥长度。
上面讨论的加密算法都是为了确保消息的机密性而存在的。它们可以有效地确保加密的消息不会被第三方破解而泄露敏感信息。这些算法通常以模块的形式集成在一些系统或软件中,以支持一些安全协议或安全架构。如果SSL协议需要对消息进行加密传输,那么WEB服务器和浏览器就需要集成这些加密算法来支持SSL协议的应用。然而,对于对称加密技术来说,密钥的保护是一个难以忽视的问题。加密方和解密方都使用相同的密钥。如果密钥在传输过程中丢失或被攻击者窃取,那么该消息将失去其机密性。在加密系统中,除了上述对称加密机制外,还有一种非对称加密机制,也称为公钥加密。让我们在下面探索公钥加密。
公钥加密算法可以说是现代密码学的一次真正革命。它使用公钥和私钥进行加密和解密。公钥是公开的,任何人都可以使用,而私钥一般为解密者所有,必须保证机密性。明文用公钥加密,可以用私钥解密,用私钥加密,用公钥解密。因此,如果A想向B发送加密的消息,那么A只需要用B的公钥加密后发送给B,B就可以用自己的本地私钥解密。B的公钥流出没有风险,B的私钥不需要流出。这在一定程度上避免了丢失密钥的风险。公钥加密除了用于消息加密外,还可以用于“数字签名”和密钥管理。稍后将介绍数字签名。
那么,既然公钥加密算法出现了,还需要传统的对称加密算法吗?公钥加密算法能代替对称加密算法吗?我们应该注意一些错误的观点。有一种说法,公钥加密比对称加密提供更高的安全性。实际上,无论是公钥加密还是对称加密,安全性取决于密钥的长度,与公钥加密和对称加密无关。还有一种说法是,公钥加密可以作为一种通用的加密方法来代替对称加密。事实上,由于公钥加密的计算效率远低于对称加密,如果有大量消息需要加密,使用公钥加密是不切实际的。公钥加密更多的是对对称加密密钥进行加密以确保密钥的机密性,而不是对数据进行加密。
公钥加密图
公钥加密算法主要有RSA加密算法和椭圆曲线加密算法。其中,RSA是使用最广泛的公钥加密算法,经过了公众的长期测试。它是由 Ron Rivest、Adi Shamir 和 Lenard Adleman 提出的。RSA是他们三个姓氏的首字母的组合。椭圆曲线加密算法在系统开销上有一定的优势,但由于没有经过长时间的密码分析测试,应用范围不如RSA。还有一种密钥交换协议,叫做Diffie-Hellman,它本身不能加密和解密数据,但可以安全地使通信双方生成密钥,
完整性
在文章开头描述的网络安全威胁场景2中,消息在传输过程中可能被篡改,这就需要接收方验证消息的完整性,并确保接收到的消息是由发送方发送的原创消息发件人,否则可能会产生灾难性的后果。那么,如何保证消息的完整性呢?让我们通过下图来理解:
此图标显示了一种确保消息完整性的方法,称为消息验证码。缩写为MAC。发送方 A 将明文消息和密钥作为参数传递给一个称为 MAC 的函数(我们先这么称呼它)以生成一个固定长度的值,该值称为消息验证码。然后将消息验证码连同消息一起发送给接收者B。 B将收到的消息和与A相同的密钥传递给MAC函数,生成新的消息验证码,然后将新生成的消息验证码与消息验证进行比较A发来的code,如果一致,则证明消息没有被篡改,否则消息的完整性会被破坏,无法使用。MAC函数类似于加密函数,但是MAC函数是不可逆的,只能用于比较,不能通过关键参数解密。因此,MAC功能用于保证报文的完整性,比加密功能具有更小的风险因素。
除了MAC,还有一个叫做Hash的函数也可以用来保证消息的完整性。验证过程类似于MAC。Hash 函数可以将任意长度的消息转换为固定长度的哈希值,也称为消息摘要。那么我们可能会认为,由于Hash函数可以将任意长度的消息转换成定长值,如果以1000位消息作为输入,生成128位值,那么任意1000位消息的值不会 某些消息会产生相同的 128 位值吗?答案是肯定的。这种情况称为碰撞。如果攻击者发现冲突,消息的完整性将受到威胁。其实Hash算法虽然碰撞的几率很小,但是还是有几率的。山东大学王晓云教授》
MD5 允许任何长度的消息作为输入并输出固定的 128 位消息摘要。SHA-1全称为Secure Hash Algorithm,是一种安全的散列算法。它可以将最大长度为 2 的 64 次方的消息作为输入,并输出固定的 160 位消息摘要。因为它输出160位的消息摘要,比MD5大 SHA-1的安全性比MD5高,所以SHA-1正在逐渐取代MD5。此外,还有一种消息摘要算法称为 RIPEMD-160,它也输出 160 位的消息摘要。
不可否认性
消息的机密性和完整性保护通信方免受第三方的恶意攻击。但是,它不能保护通信方之间的一些争议。那么,通信双方之间会发生什么样的纠纷呢?让我们来看看以下场景:
1、A 和 B 是合法的通信方。此时,A伪造了一条消息,声称该消息来自B,因为A可以使用与B共享的密钥创建合法的消息验证码。
2、B 拒绝向 A 发送消息,因为 A 有可能从 TA 自己那里得到伪造的消息,并且没有证据证明 B 是否真的发送了消息。
和现实生活中一样,为了防止双方的这种否认,在任何交易之前,都会有一份纸质合同,合同上的签名是双方无法否认的证据。在网络通信中,也有像这样的签名形式来抵抗拒绝。我们称之为数字签名。数字签名必须具有以下属性:
1、必须能够验证签名的作者、日期和时间。
2、它必须能够在签名时验证消息的内容。
3、必须得到第三方的认可才能解决纠纷。
数字签名提供两种实现方式,与仲裁直接相关
直接的
直接数字签名只包括通信双方,并假定接收方知道发送方的公钥。数字签名可以是用发送方的私钥对整个消息进行加密的形式,加密后的内容被视为数字签名。也可以使用发送者的私钥对消息的哈希值进行加密。这样,如果接收方可以用发送方的公钥解密消息,就可以证明发送方发送的消息是正确的,因为只有发送方有私钥。
直接数字签名有一个弱点,即数字签名的安全性取决于发送者私钥的安全性。如果发件人有意否认TA发送了某条消息,则发件人可以声称TA的私钥丢失或被盗以致有人伪造TA的签名。另一个威胁是发送者的私钥在某个时间点 T 真的被盗,窃贼在 T 向接收者发送带有发送者签名的消息。
仲裁
为了解决直接数字签名的不足,仲裁数字签名应运而生。在仲裁数字签名中,增加了一个称为仲裁员的新角色。仲裁数字签名的过程如下:
首先,假设消息使用对称加密算法。假设发送者X与仲裁者A共享公钥Kax,接收者Y与仲裁者A共享公钥Kay。X的目的是向Y发送消息M。X首先计算M的哈希值,然后将 X 的标识符(假设为 IDx)和哈希值结合形成数字签名,然后用 Kax 对数字签名进行加密,并将消息 M 发送给仲裁器 A。 A 使用 Kax 对数字签名进行解密,并验证其完整性消息M通过哈希值防止消息在X发送给A时被篡改,然后A将X、IDx、消息M和时间戳T加密的数字签名连同Kay加密发送给接收者Y。 Y接收数据,Kay解密数据,得到消息M。X 加密的数字签名存储在 Y 的系统中并作为证据保存。因为数字签名是用Kax密钥加密的,Y没有这样的密钥,所以签名内容是不可篡改的。时间戳 T 是为了防止重放攻击。
示例中的仲裁数字签名过程也存在一个问题,即仲裁员的权限太高。发送方和接收方必须完全信任仲裁者,仲裁者也可以看到传输消息的明文。如果仲裁员被黑了,那么消息一目了然就会暴露在攻击者的眼中。为此,仲裁数字签名催生了另外两种模式,一种是基于对称加密对仲裁者消息透明的数字签名,另一种是基于公钥加密对仲裁者消息透明的数字签名。
基于对称加密的消息透明数字签名过程如下:
仍然假设发送者X、接收者Y和仲裁者A。在这种模式下,添加了一个新的X和Y的公钥Kxy。首先,X将IDx,Kxy加密的消息M,以及X的Kax加密的数字签名发送给A,其中数字签名有IDx,它由Kxy加密的消息M的哈希值组成。A收到数据后,使用Kax对数据进行解密,得到Kxy加密的消息M及其哈希值,这样A就可以在不知道消息明文M的情况下验证M的完整性。随后,A 将用 Kay 加密的数据发送给 Y。该消息由 IDx、消息 M 的数字签名和 Kxy 加密的 X 组成。发送给Y后,Y可以用Kxy密钥解密消息,得到明文。在这个过程中,即使仲裁者A被黑了,
基于公钥加密的消息透明数字签名的原理与基于对称加密的消息透明数字签名的原理类似,其目的是使仲裁者A能够在不知道消息明文的情况下对消息进行验证。
在文章的开头,我们谈到了网络安全的三种安全属性。消息的机密性、完整性和不可否认性,实现安全属性的基础是对称加密算法、公钥加密算法、MAC、Hash。大多数实现功能的安全架构、安全协议和安全系统都是由这些基本组件集成而成的。在安全协议中,有分布在传输层的IPSec协议、分布在会话层的SSL/TLS协议和SET协议。用于主机服务器相互认证的 Kerberos、用于密钥管理的 X.509 标准和 Linux PAM 认证模块。这些基本算法支持这些安全系统或协议实现的安全特性。上面,我们简单讲了网络安全的基本属性以及实现网络安全属性的基本方法。作为架构师,我们需要了解在不同的环境中哪些安全属性是需要的,哪些安全属性是不需要的,以及应该如何裁剪。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。 查看全部
免规则采集器列表算法(构建一个面向公共网络的WEB系统中一定要做到的)
在面向公网的项目中,安全无疑是项目面临的巨大挑战之一。在公共互联网上,花花公子和无聊的人一直在嗅探我们的服务器。有些人想大显身手,也有些不法分子想监控截取我们的敏感信息,进入我们的宿主进行各种活动。各种破坏和盗窃。这些人一旦得逞,系统的稳定性就会降低,企业的敏感数据就会丢失,企业的信誉也会遭到破坏。因此,为用户提供可靠、稳定的服务,防止重要数据的丢失和被盗,是我们构建面向公共网络的WEB系统所必须做的。
构建安全的网络环境,首先要了解安全威胁从何而来。以下是可能造成安全威胁的应用场景:
1、用户A向用户B发送带有敏感信息的文件,用户C在局域网内监听和截获未加密的数据报。
2、 网管A远程向主机B发送命令(如添加用户的命令),攻击者C截获收录该命令的数据报,修改包中的命令,然后发送给主机 B。
3、 同场景2,主机B准备接受远程合法用户A的命令,但此时攻击者C构造了命令数据报发送给B,B认为是用户发送的命令A、执行此命令后,与场景2不同,攻击者C并没有拦截和修改数据报,而是直接构造数据报。
4、 客户A向TA的股票经纪人B发送了一条股票交易的消息,股票经纪人B按照A的要求进行了相应的股票操作,但是这个操作给客户A带来了损失,然后客户A拒绝发送这条消息给经纪人 B 的消息。
分析场景1,如果A发送给B的消息是加密的,即使C截获了消息,TA也不会知道消息的内容。这涉及到消息的机密性。场景二中,攻击者C篡改了消息,但主机B并不知道接收到的消息与合法用户A发送的消息不一致,因此该场景涉及到消息的完整性。场景三,主机B接受任何人发送的消息,无需验证消息来源,这涉及到消息的可验证性。在场景4中,很明显,客户A不承认消息被发送,所以涉及到消息的不可否认性。
针对上述场景,我们可以总结出来自互联网的安全服务大致可以分为以下几类:
1、保密
2、 完整性
3、不可否认性
对于不同的服务,我们需要不同的安全属性。一些比较敏感的信息,比如用户进行电子交易时,需要不同的安全服务同时护航。下面,让我们讨论一下系统是如何实现上述安全属性的,以及实现这些安全属性需要使用的软件。这些软件可以作为组件集成到系统中,为系统的安全提供保护。
保密
消息的保密性是为了确保只有合法的接收者才能阅读消息的内容。即使其他人通过非法方式获取消息,由于消息是加密的,他们也无法阅读内容。然后,仅允许合法收件人阅读消息是消息机密性的要求。加解密图如下(对称加密):
消息机密性的研究历史悠久。最早的经典加密技术是凯撒加密技术,它是一种单码替换技术,即将每个明文字母替换为另一个字母,形成密文。然后将替换规则提前通知合法用户,以便合法用户在获得密文后,按照预先约定的规则将密文翻译成明文。未来,传统的加密算法(对称加密算法)都是从凯撒加密技术演变而来的。然而,凯撒密码有一个弱点。在比较长的英文信息中,可以计算出某个字母出现的频率。比如“The”这个词出现的频率就比较高。破译者甚至计算了一个字母的频率。度分析表。这样,解密器就可以根据频率分析表猜出密文,并尝试将其转换为明文。如果可以读取转换后的明文,则消息将被解密。这种解密方法也称为频率分析。
频率分析表
为了抵抗频率分析,1854 年,查尔斯·惠斯通发明了一种称为 Playfair 的多重替代加密方法。使用时,首先需要编制一个5X5的矩阵密码表。加密和解密依赖于密码表。所以这个5X5的密码表相当于一把钥匙。它可以有效抵抗频率分析,当时被军方广泛使用,但在第一次世界大战期间被破解。然后出现了一些加密机制,其中最著名的是德国在二战中使用的旋转加密。在DES算法出现之前,最著名的加密算法就是它了。它通过多步替换加密形成密文,使密码分析更加困难。这就是密码的历史。
DES
DES的全称是Data Encryption Standard,是一种对称加密算法。对称加密算法的特点是加密和解密使用相同的密钥。回顾我之前说的,从经典的凯撒加密到旋转加密,加密和解密都依赖同一个密码表或规则,所以都可以做到。称之为对称加密。这些密码表或规则可以理解为所谓的“密钥”。在 DES 中,密钥是由计算机生成的字符序列。这个序列应该有一定的长度,使得攻击者很难通过暴力破解或者其他方式获取。否则,如果密钥是由第三方获得的,则加密的消息将没有任何安全性。因为密码的算法是公开的。
DES的算法可以在百度百科或其他文档中找到。这里只介绍一下它的特点(其实我只了解算法过程,并没有仔细研究算法本身-_-!),DES的密钥长度是56位。加密时,密钥和64位明文消息作为输入,传递给加密函数。函数经过处理后,会生成一个64位的密文,完成明文到密文的转换。这种转换方式称为块加密,整体转换由64位明文块进行。现代加密算法基本上使用这种块加密方法。另一种是流加密。所谓流加密,就是对一个字符或一个字节或逐位进行转换。例如,
DES加密方式,DES加密有不同的方式,方式的不同导致DES生成密文的安全性和速度不同,这里介绍三种不同的DES加密方式:
1、ECB(Electronic Codebook),在ECB模式下,对于同一个明文,如果用同一个key加密,生成的密文是一样的。例如,单词“The”是一个64位的块,通过相同的密钥加密后,生成的密文始终是“XUZ”。这种加密模式对密码分析的抵抗力会弱一些。
2、CBC(Cipher Block Chaining),为了克服ECB模式的缺点,CBC模式诞生了。CBC对同一个明文块生成不同的密文,所以比ECB模式强。
3、CFB(Cipher Feedback),由于DES本质上是基于块加密的,所以必须转换成整块,而CFB模式可以把块加密转换成流加密,这样密文就可以一个字节生成一个字节的大小达到了实时密文转换的目的,提到了密文生成的速度。
DES 加密的强度由 DES 密钥的长度决定。DES 的密钥长度为 56 位,这意味着有 2 次方的 56 次方组合。依靠单台计算机的计算能力来尝试暴力破解DES需要很长时间。这需要时间(或需要大量费用),但现在由于分布式计算的发展,解决一个 56 位的密钥可能没有那么困难。所以现在,DES 不被认为是一种非常安全的加密算法,DES 已经逐渐被其他加密算法所取代。
三重DES (3DES)
3DES是DES的升级版,对每个数据块应用3次DES加密算法。由于使用了三种DES加密算法,3DES中需要三个密钥,而这三个密钥也有不同的组合。
组合方式一:三个密钥是独立的,这种加密强度最高,相当于3x56=168个密钥位。
组合二:有两个独立的密钥,这种安全性稍低,有112个密钥位。
组合方式三:三个按键完全一样。这种模式实际上是为了兼容普通的DES而存在的。在安全性方面,与普通DES没有区别,只有56个密钥位。
主意
IDEA全称为International Data Encryption Algorithm,是一种对称加密算法。近年来有人提出取代DES。IDEA在现代安全系统中有着广泛的应用,其中PGP使用的是IDEA算法。
IDEA 使用 128 位密钥对 64 位块进行加密,同时加强了密码的混淆和扩散,提高了安全性。混乱度的增加使得通过明文定律找到密文定律变得更加困难,因为密文和明文并不是一一对应的。扩散使密文中的每一位都受到明文中许多位的影响,增加了密码分析的难度。
河豚
Blowfish 是一种基于块的对称加密算法。它具有以下特点:
快速:使用 32 位微处理器加密一个字节仅需 18 个时钟周期。
简单性:运行 Blowfish 所需的 RAM 少于 5K。
简单:Blowfish 的简单结构使其算法易于实现。
可变长度:Blowfish 的密钥长度是可变的。它可以生成高达 448 位的密钥,允许用户在高安全性和高加密速度之间做出权衡。
Blowfish 可能是最好的对称加密算法。它已在许多安全产品中实施。经过长时间的安全测试,Blowfish 的安全性不成问题。
下面是Blowfish与其他加密算法的效率对比:
加密演算法
每轮时钟消耗
转换回合
每字节加密消耗时钟
河豚
9
16
18
RC5
12
16
二十三
DES
18
16
45
主意
50
8
50
3DES
18
48
108
RC5
RC5 是一种基于块的对称加密算法。它具有以下特点:
它可以用软件或硬件实现:只使用处理器支持的原创算术运算。
快速:RC5的算法简单,每一次加密操作都是以字为单位进行的。
可变字长:RC5提供的第一个参数是用户可以设置一个字的长度,允许的值为16、32、64。RC5使用2个字作为一个块进行加密,所以RC5可以选择一个块大小为 32 位。64 位或 128 位加密。
可变轮数:加密轮数是RC5提供的第二个参数,允许用户在加密速度和高安全性之间进行权衡。
可变密钥长度:密钥长度是RC5提供的第三个参数。同样,它允许用户在加密速度和高安全性之间进行权衡。该参数以 8 位字节为单位,范围可选 介于 0 和 255 之间,因此密钥的最大长度为 2040 位。RC5 的发明者 Rivest 建议我们使用 64 作为一个块,12 轮迭代和 128 位长度的密钥作为加密的标称模式。
简单:RC5 的简单结构使其算法易于实现。
低内存消耗:低内存消耗使得RC5可以与一些硬件如智能卡一起使用。
高安全性:RC5 提供高安全性。
RC5还提供了几种加密方式,即:
ECB:同DES的ECB模式。
CBC:同DES的CBC方式。
CBC-Pad:在 CBC 模式下处理可变长度的明文。单个 RC5 块生成的密文比明文长。
CAST-128
CAST 是一种基于块的对称加密算法。它使用可变长度的密钥。密钥长度为 40 到 128 位,每 8 位递增。CAST 加密进行 16 轮迭代,输入一个 64 位的明文块,输出一个 64 位的密文块。CAST 将密钥分成两个子密钥。
RC2
RC2 是一种基于块的对称加密算法。它使用 64 位块和可变长度的密钥。密钥的长度从 8 位到 1024 位不等。RC2 用于 S/MIME 协议。S/MIME 使用 40、64 和 128 位的密钥长度。
上面讨论的加密算法都是为了确保消息的机密性而存在的。它们可以有效地确保加密的消息不会被第三方破解而泄露敏感信息。这些算法通常以模块的形式集成在一些系统或软件中,以支持一些安全协议或安全架构。如果SSL协议需要对消息进行加密传输,那么WEB服务器和浏览器就需要集成这些加密算法来支持SSL协议的应用。然而,对于对称加密技术来说,密钥的保护是一个难以忽视的问题。加密方和解密方都使用相同的密钥。如果密钥在传输过程中丢失或被攻击者窃取,那么该消息将失去其机密性。在加密系统中,除了上述对称加密机制外,还有一种非对称加密机制,也称为公钥加密。让我们在下面探索公钥加密。
公钥加密算法可以说是现代密码学的一次真正革命。它使用公钥和私钥进行加密和解密。公钥是公开的,任何人都可以使用,而私钥一般为解密者所有,必须保证机密性。明文用公钥加密,可以用私钥解密,用私钥加密,用公钥解密。因此,如果A想向B发送加密的消息,那么A只需要用B的公钥加密后发送给B,B就可以用自己的本地私钥解密。B的公钥流出没有风险,B的私钥不需要流出。这在一定程度上避免了丢失密钥的风险。公钥加密除了用于消息加密外,还可以用于“数字签名”和密钥管理。稍后将介绍数字签名。
那么,既然公钥加密算法出现了,还需要传统的对称加密算法吗?公钥加密算法能代替对称加密算法吗?我们应该注意一些错误的观点。有一种说法,公钥加密比对称加密提供更高的安全性。实际上,无论是公钥加密还是对称加密,安全性取决于密钥的长度,与公钥加密和对称加密无关。还有一种说法是,公钥加密可以作为一种通用的加密方法来代替对称加密。事实上,由于公钥加密的计算效率远低于对称加密,如果有大量消息需要加密,使用公钥加密是不切实际的。公钥加密更多的是对对称加密密钥进行加密以确保密钥的机密性,而不是对数据进行加密。
公钥加密图
公钥加密算法主要有RSA加密算法和椭圆曲线加密算法。其中,RSA是使用最广泛的公钥加密算法,经过了公众的长期测试。它是由 Ron Rivest、Adi Shamir 和 Lenard Adleman 提出的。RSA是他们三个姓氏的首字母的组合。椭圆曲线加密算法在系统开销上有一定的优势,但由于没有经过长时间的密码分析测试,应用范围不如RSA。还有一种密钥交换协议,叫做Diffie-Hellman,它本身不能加密和解密数据,但可以安全地使通信双方生成密钥,
完整性
在文章开头描述的网络安全威胁场景2中,消息在传输过程中可能被篡改,这就需要接收方验证消息的完整性,并确保接收到的消息是由发送方发送的原创消息发件人,否则可能会产生灾难性的后果。那么,如何保证消息的完整性呢?让我们通过下图来理解:
此图标显示了一种确保消息完整性的方法,称为消息验证码。缩写为MAC。发送方 A 将明文消息和密钥作为参数传递给一个称为 MAC 的函数(我们先这么称呼它)以生成一个固定长度的值,该值称为消息验证码。然后将消息验证码连同消息一起发送给接收者B。 B将收到的消息和与A相同的密钥传递给MAC函数,生成新的消息验证码,然后将新生成的消息验证码与消息验证进行比较A发来的code,如果一致,则证明消息没有被篡改,否则消息的完整性会被破坏,无法使用。MAC函数类似于加密函数,但是MAC函数是不可逆的,只能用于比较,不能通过关键参数解密。因此,MAC功能用于保证报文的完整性,比加密功能具有更小的风险因素。
除了MAC,还有一个叫做Hash的函数也可以用来保证消息的完整性。验证过程类似于MAC。Hash 函数可以将任意长度的消息转换为固定长度的哈希值,也称为消息摘要。那么我们可能会认为,由于Hash函数可以将任意长度的消息转换成定长值,如果以1000位消息作为输入,生成128位值,那么任意1000位消息的值不会 某些消息会产生相同的 128 位值吗?答案是肯定的。这种情况称为碰撞。如果攻击者发现冲突,消息的完整性将受到威胁。其实Hash算法虽然碰撞的几率很小,但是还是有几率的。山东大学王晓云教授》
MD5 允许任何长度的消息作为输入并输出固定的 128 位消息摘要。SHA-1全称为Secure Hash Algorithm,是一种安全的散列算法。它可以将最大长度为 2 的 64 次方的消息作为输入,并输出固定的 160 位消息摘要。因为它输出160位的消息摘要,比MD5大 SHA-1的安全性比MD5高,所以SHA-1正在逐渐取代MD5。此外,还有一种消息摘要算法称为 RIPEMD-160,它也输出 160 位的消息摘要。
不可否认性
消息的机密性和完整性保护通信方免受第三方的恶意攻击。但是,它不能保护通信方之间的一些争议。那么,通信双方之间会发生什么样的纠纷呢?让我们来看看以下场景:
1、A 和 B 是合法的通信方。此时,A伪造了一条消息,声称该消息来自B,因为A可以使用与B共享的密钥创建合法的消息验证码。
2、B 拒绝向 A 发送消息,因为 A 有可能从 TA 自己那里得到伪造的消息,并且没有证据证明 B 是否真的发送了消息。
和现实生活中一样,为了防止双方的这种否认,在任何交易之前,都会有一份纸质合同,合同上的签名是双方无法否认的证据。在网络通信中,也有像这样的签名形式来抵抗拒绝。我们称之为数字签名。数字签名必须具有以下属性:
1、必须能够验证签名的作者、日期和时间。
2、它必须能够在签名时验证消息的内容。
3、必须得到第三方的认可才能解决纠纷。
数字签名提供两种实现方式,与仲裁直接相关
直接的
直接数字签名只包括通信双方,并假定接收方知道发送方的公钥。数字签名可以是用发送方的私钥对整个消息进行加密的形式,加密后的内容被视为数字签名。也可以使用发送者的私钥对消息的哈希值进行加密。这样,如果接收方可以用发送方的公钥解密消息,就可以证明发送方发送的消息是正确的,因为只有发送方有私钥。
直接数字签名有一个弱点,即数字签名的安全性取决于发送者私钥的安全性。如果发件人有意否认TA发送了某条消息,则发件人可以声称TA的私钥丢失或被盗以致有人伪造TA的签名。另一个威胁是发送者的私钥在某个时间点 T 真的被盗,窃贼在 T 向接收者发送带有发送者签名的消息。
仲裁
为了解决直接数字签名的不足,仲裁数字签名应运而生。在仲裁数字签名中,增加了一个称为仲裁员的新角色。仲裁数字签名的过程如下:
首先,假设消息使用对称加密算法。假设发送者X与仲裁者A共享公钥Kax,接收者Y与仲裁者A共享公钥Kay。X的目的是向Y发送消息M。X首先计算M的哈希值,然后将 X 的标识符(假设为 IDx)和哈希值结合形成数字签名,然后用 Kax 对数字签名进行加密,并将消息 M 发送给仲裁器 A。 A 使用 Kax 对数字签名进行解密,并验证其完整性消息M通过哈希值防止消息在X发送给A时被篡改,然后A将X、IDx、消息M和时间戳T加密的数字签名连同Kay加密发送给接收者Y。 Y接收数据,Kay解密数据,得到消息M。X 加密的数字签名存储在 Y 的系统中并作为证据保存。因为数字签名是用Kax密钥加密的,Y没有这样的密钥,所以签名内容是不可篡改的。时间戳 T 是为了防止重放攻击。
示例中的仲裁数字签名过程也存在一个问题,即仲裁员的权限太高。发送方和接收方必须完全信任仲裁者,仲裁者也可以看到传输消息的明文。如果仲裁员被黑了,那么消息一目了然就会暴露在攻击者的眼中。为此,仲裁数字签名催生了另外两种模式,一种是基于对称加密对仲裁者消息透明的数字签名,另一种是基于公钥加密对仲裁者消息透明的数字签名。
基于对称加密的消息透明数字签名过程如下:
仍然假设发送者X、接收者Y和仲裁者A。在这种模式下,添加了一个新的X和Y的公钥Kxy。首先,X将IDx,Kxy加密的消息M,以及X的Kax加密的数字签名发送给A,其中数字签名有IDx,它由Kxy加密的消息M的哈希值组成。A收到数据后,使用Kax对数据进行解密,得到Kxy加密的消息M及其哈希值,这样A就可以在不知道消息明文M的情况下验证M的完整性。随后,A 将用 Kay 加密的数据发送给 Y。该消息由 IDx、消息 M 的数字签名和 Kxy 加密的 X 组成。发送给Y后,Y可以用Kxy密钥解密消息,得到明文。在这个过程中,即使仲裁者A被黑了,
基于公钥加密的消息透明数字签名的原理与基于对称加密的消息透明数字签名的原理类似,其目的是使仲裁者A能够在不知道消息明文的情况下对消息进行验证。
在文章的开头,我们谈到了网络安全的三种安全属性。消息的机密性、完整性和不可否认性,实现安全属性的基础是对称加密算法、公钥加密算法、MAC、Hash。大多数实现功能的安全架构、安全协议和安全系统都是由这些基本组件集成而成的。在安全协议中,有分布在传输层的IPSec协议、分布在会话层的SSL/TLS协议和SET协议。用于主机服务器相互认证的 Kerberos、用于密钥管理的 X.509 标准和 Linux PAM 认证模块。这些基本算法支持这些安全系统或协议实现的安全特性。上面,我们简单讲了网络安全的基本属性以及实现网络安全属性的基本方法。作为架构师,我们需要了解在不同的环境中哪些安全属性是需要的,哪些安全属性是不需要的,以及应该如何裁剪。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。以及我们应该如何定制它们。并且我们应该知道使用哪些软件进行系统集成以实现我们的网络安全目标。后续也会陆续介绍一些安全模型的配置方法,希望能给大家做一个介绍和参考。
免规则采集器列表算法( 架构师生产级应用面临的问题,你知道吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-18 05:18
架构师生产级应用面临的问题,你知道吗?(上))
作者:丁浪,目前在一家创业公司担任高级技术架构师。曾就职于阿里巴巴大娱和蚂蚁金服。拥有丰富的稳定性保障和全链路性能优化经验。建筑师社区的特邀嘉宾!
前言
网上关于限流算法、Sentinel功能介绍、基本结构、原理分析可以说是汗流浃背,不打算重复内容了。我将在实际工作和生产环境中与大家分享使用和踩坑的经验。
如果您在做限流熔断的技术选型,那么本文将为您提供客观而有价值的参考;
如果你以后想在生产环境中使用Sentinel,这篇文章将帮助你以后少走弯路;
如果您正在准备求职面试,您或许可以为您的技能树和经验添加亮点,并避免在您的面试评估表上“写在纸上”;
Sentinel的开源版本和阿里内部的一样吗?
我们可以在量产层面应用它吗?
这里我直接告诉你答案:开源和内部版本是一样的,核心代码和能力都是开源的。它可以用于生产,但它不是“开箱即用”,需要你做一些二次开发和调整。接下来,我将仔细展开这些问题。当然,我推荐你直接使用阿里云上的AHASSentinel控制台和ASM配置中心,这些都是最佳实践的输出,可以节省大量的时间、人力、运维成本等。
整体运营架构
大规模生产应用面临的问题
看了Sentinel开源版原来的运行架构,很明显存在一些问题:
1. 限流降级等规则存储在应用节点的内存中,应用释放重启后会失效,这在生产环境中显然是不能接受的;
2. 默认情况下,规则的分配是基于机器节点维度而不是应用维度,正常公司的应用系统都是集群部署的,不支持集群限流;
3. 指标信息被Dashboard拉取并保存在内存中仅5分钟。错过了,可能就无法还原“危机场景”,看不到流量趋势;
4. 如果访问限流的应用有500+个,每个应用平均部署4个节点,那么一共2000个节点,那么Dashboard肯定会成为瓶颈,单机线程池不会完全能够处理它;
如何优化和解决这些问题
接下来,我们先来一一介绍如何解决上述明显的问题。
首先,限流规则、降级规则等都应该按照应用维度来发布,而不是按照APP单节点的维度来发布。由于Sentinel支持集群限流,SentinelDashbord开源版做了限流规则的扩展,但没有扩展到熔断器、系统保护等,支持按应用维度下发。有兴趣的读者可以参考 FlowControllerV2 的实现来实现。
其次,规则不应该存储在内存中,应该持久化到动态配置中心,应用可以直接从配置中心订阅规则。这样,Dashboard 和应用就通过配置中心解耦了。这是典型的生产者-消费者模型。基本的运行架构如下:
以nacos配置中心为例。Sentinel 官方和社区提供了保存和订阅限流规则的演示。然后可以扩展熔断器降级、系统保护、网关限流...等规则。基本模型是:Dashboard将xxRuleEntityVO模型序列化保存到nacos中,应用从nacos订阅后反序列化成xxRule域模型。
这里要提醒大家的是,前方有巨大的坑。请不要直接复制“热参数限流规则”和“黑名单限制规则”,因为Dashboard中定义了ParamFlowRuleEntity和AuthorityRuleEntity
两个VO模型中的字段定义与域模型ParamFlowRule和AuthorityRule不匹配,会导致序列化/反序列化失败,进而导致应用无法订阅和使用热参数限流规则和黑名单限制规则。我要提交PR!!!
第三点是Dashboard中有一个调度线程池,它会轮询请求(默认每1秒发起一次)。每个应用的机器节点查询metrics日志信息,汇总显示在界面上(改造后需要完成持久化动作)。这是典型的pull模式,是监控测量领域比较常见的架构。因为是存储在内存中,所以默认只保留5分钟,这也是有问题的。推荐以下解决方案:
1. Dashboard拉取metrics信息后,直接保存在时序数据库中,Dashboard本身也从时序数据库中抓取数据进行展示。存储指标数据的时间取决于您的业务。以开源的Influxdb为例,它有自己的持久化策略功能(自动清理过期数据)。此外,还可以使用Grafana等开源Dashboards进行查询聚合,展示各种漂亮的行情、图表、排名等;
2. 可以把pull模式改成push模式,记录metrics日志的时候直接写时序数据库。当你的时候,基于性能的考虑,你也可以改写MQ来做缓冲。除了耗时,最重要的是不要因为记录指标的动作而影响主要业务流程的进度;
3. 继续打印metrics日志,启用SentinelDashboard拉出metrics数据,使用采集器直接在应用机器节点上采集,处理上报metrics日志。可以使用ELK等工具;
4. 可以尝试自己开发PrometheusExporter,将metrics信息以Target的形式公开,Prometheus服务器会定时拉取。同时,您还可以使用 Prometheus 提供的各种丰富的查询和聚合语法和功能。, 通过 Grafana 等方式显示;
下图是一个典型的时间序列数据示例,它是为指标索引数据设计的。该领域知名的开源软件包括OpenTSDB、Influxdb等。
Grafana 限流市场展示效果图
以上方法各有优缺点。如果你想做最小的改动,并且你的应用访问和部署规模不是特别大(500个节点以内),那么请选择第一种方式。
第四点是Dashboard由于接入的应用程序和节点较多,在pulling和aggregation方面的性能瓶颈。解决问题3时,如果选择方法2、3、4,那么Sentinel自带的Dashboard只会作为规则分发的工具(甚至规则分发可以直接通过nacos配置中控台完成),自然不会有瓶颈问题。如果你还想使用 Sentinel 自带的 Dashboard 来完成拉取和持久化指标数据等任务,那么我为你提供两种解决方案:
1. 按域隔离,将不同业务域的应用连接到各自的SentinelDashboard,让压力自然分散,减少出现瓶颈的可能性。优点是几乎不需要修改,缺点是不统一;
2. 可以尝试改造 Sentinel 自带的 Dashboard,使其无状态。前面我们提到过,应用启动后会定时上报心跳信息。Dashboard 默认会在内存中维护一个“节点信息列表”数据。这是一个典型的状态数据,应该考虑集中存储。例如:redis。那么就需要修改“拉取指标信息”的线程池,改为分片任务执行,从而达到分担负载的效果,例如:改用elasticjob调度。当然,时序数据库的写入也可能成为瓶颈;
3. 可以牺牲一点监控指标的时效性,增加Sentinel Dashboard中fetchScheduleService调度线程池的间隔时间参数,可以缓解下游worker线程池的处理压力;
就我而言,我实际上推荐第一种和第三种方法。这些都是权宜之计,变化相对较小。
当然,按字段划分还有其他好处。如果连接到500+个系统,以当前的Dashboard开源版本为例,左边的应用列表会延长多长时间?估计不能用了。UI和交互设计很业余,显然不能满足量产应用。但按领域隔离后,体验可能会有所改善。还有一点。Dashboard 目前的开源版本只提供了最基本的登录验证功能。如果需要权限控制、审计、审批确认等功能,则需要二次开发。如果Dashboard按字段独立,访问控制的风险会更小。
当然,如果要重构Dashboard权限控制和UI交互,建议按照应用维度进行设计,添加基础搜索等。
其他问题
应用程序连接到Sentinel后,启动时需要指定应用程序名称、Dashboard地址、客户端端口号、日志配置、心跳设置等,可以通过JVM -D启动参数,也可以将配置文件保存在指定的配置路径。这是一种不合理的设计,对CI/CD和部署环境有干扰。我解决了这个问题,在1.6.3版本提交了PR。好在社区在1.7.0时解决了这个问题。
一些规则配置和使用经验
请不要误会我的意思。我不是教你怎么配置和使用,而是教你怎么用好。还记得我在之前的稳定保障体系文章中抛出关于限流的灵魂拷问吗?首先我们简单回顾一下Sentinel中可能用到的关键功能。接下来我会以自问自答的方式回答用户最常见的疑问,输出最有价值的经验和建议。
1. 单机限流
2. 集群限流
3. 网关限流
4. 热点参数限流
5. 系统自适应保护
6. 黑白名单限制
7. 保险丝自动降级
单机限流阈值是多少?
这可不能“一巴掌”。匹配太高可能会导致故障。如果匹配度太低,您会担心过早的“过失杀人”请求。还是要根据容量规划和水位设置进行配置,前提是监控报警灵敏。给出了两个比较实用的方法:
1. 参考单机容量规划的思路,在软负载中调整一个节点的流量权重和比例,直到接近极限。记录极限状态下的QPS,根据单机房70%水位设置标准,可以计算出资源的单机限流阈值;
2. 可以定期观察监控系统的流程图,在线获取真实峰值QPS。如果应用系统和业务在周期的高峰期处于健康状态,那么可以假设峰值QPS就是理论水位。这种方式可能会造成资源浪费,因为高峰期可能达不到系统承载限制,适合流量周期有规律的业务;
你真的需要集群限流吗?
其实在大多数场景下,不需要使用集群限流,单机限流就足够了。仔细想想。实际上,只有几种情况可能需要使用集群限流:
1. 想配置单机QPS限制时
2. 上图中单机限流阈值为10 QPS,部署了3个节点。理论上集群的总QPS可以达到30,但实际上由于流量不均,集群的总QPS还没达到30就触发了。电流有限。很多人会说这不合理,但我觉得还是要根据实际情况来分析。如果这个“10QPS”是根据容量计划的系统承载能力计算的阈值(或者如果接口请求超过10QPS,系统可能会崩溃),那么这个限流的结果是令人满意的。如果这个“10QPS”只是业务级别的限制,那么即使一个节点的QPS超过10,也不会有什么问题。其实我们本质上是想限制整个集群的总QPS,所以这个限流的结果是不合理的。,并没有达到最好的效果;
所以,这实际上取决于你的限流是实现“过载保护”还是实现业务级别的限制。
还有一点需要注意的是,集群限流不能解决流量不均的问题,限流组件也不能帮你重新分配或调度流量。集群限流只会在流量不均的场景下,让整体限流效果更好。
实际使用建议是:集群限流(实现业务层限流)+单机限流(系统去底层防止被炸掉)
现在网关层限流了,应用层还需要限流吗?
如果需要,双重保护是必要的。同理,上游聚合业务配置限流,下游基础业务也需要配置限流。试想一下,如果只配置了上游限流,如果上游发起大量重试,会不会压垮下游的基础服务?而在这种情况下,我们在配置限流阈值时也需要特别注意。例如,上游A和B服务依赖于下游Y服务。A和B分别配置100QPS,那么Y服务必须至少配置200QPS。否则,一些请求被额外透传处理,最终被拒绝,不仅浪费资源,
因此,最好按照整个链路的整体容量规划(桶短板原则)来配置。越早拦截越好,而且每一层都要配置限流。
热参数限流功能实用吗?
该功能非常实用,可以防止热点数据(如:热门店铺、黑马产品)占用和消耗过多系统资源,严重影响其他数据请求的处理。
还有一个要求。如果你在做C端产品,想限制用户访问某个接口的最大QPS,或者你在做B端SAAS产品,想限制租户访问某个接口的最大QPS某个接口... hotspot参数默认不是为满足这样的需求而设计的,需要自己扩展SLOT来实现类似的限制需求。当然,热点参数流量限制中的paramFlowItemList(参数异常项)可以实现某个客户ID=1的大客户访问某个资源的最大QPS为100),可以实现在某种程度上。有一个特殊要求。这个需求还有一个解决方案:当我们在代码中定义sourceName时,
为什么要有自适应保护系统?
其实这也是一种自下而上的做法。当实际流量超过部分限流阈值时,开销基本可以忽略。当真实流量远超限流阈值N倍时,尤其是双十一大促、春晚红包、12306购票等大流量场景,那么限流拒绝请求的开销就无法忽略。这种情况在阿里巴巴内部被称为“系统被触死”。在这种情况下,自适应限流可以很好地发挥作用。
是否需要配置黑白名单限制?
如果您想根据请求的来源进行限制(仅从指定的上游系统释放请求),此功能非常有用。Sentinel 内置了“簇点链接监控”功能,有点类似于调用链监控,但目的不同。
熔断器自动降级使用有哪些建议?
在配置熔断器自动降级之前,我们首先需要识别可能不稳定的服务,然后判断是否可以降级。降级处理通常很快就会失败。当然,我们可以自定义降级处理的结果(Fallback),例如:尝试包裹返回默认结果(降级),返回上次请求的缓存结果(时效性下降),包裹返回结果失败。即时结果等
弱依赖和次要功能的退化通常是通过推动开关手动完成,而 Sentinel 的保险丝退化主要是在“调用端”自动判断和执行。Sentinel基于平均响应时间,可以利用错误率、错误数等统计指标进行自动融合和降级。
例如:我们的系统同时支持“余额支付”和“银行卡支付”。这两个函数对应的接口默认在同一个应用的同一个线程池中。任何一方的 RT 抖动和大量超时都可能导致请求积压。线程池耗尽。假设从业务角度来看,“余额支付”的比例越高,保障的优先级也越高。然后我们可以在“银行卡支付”界面(依赖第三方,不稳定)当RT持续上升或者出现大量异常(前提是数据不一致等影响业务的问题)进行“熔断器自动降级”进程不能引起),以便优先确保“
总结
本文主要介绍了Sentinel开源版在大规模生产级应用中面临的一些问题和解决方案,以及实际配置和使用中的一些经验。这些经验来自一线生产实践,希望读者朋友少走弯路。如果您有任何问题,请留言讨论。 查看全部
免规则采集器列表算法(
架构师生产级应用面临的问题,你知道吗?(上))
作者:丁浪,目前在一家创业公司担任高级技术架构师。曾就职于阿里巴巴大娱和蚂蚁金服。拥有丰富的稳定性保障和全链路性能优化经验。建筑师社区的特邀嘉宾!
前言
网上关于限流算法、Sentinel功能介绍、基本结构、原理分析可以说是汗流浃背,不打算重复内容了。我将在实际工作和生产环境中与大家分享使用和踩坑的经验。
如果您在做限流熔断的技术选型,那么本文将为您提供客观而有价值的参考;
如果你以后想在生产环境中使用Sentinel,这篇文章将帮助你以后少走弯路;
如果您正在准备求职面试,您或许可以为您的技能树和经验添加亮点,并避免在您的面试评估表上“写在纸上”;
Sentinel的开源版本和阿里内部的一样吗?
我们可以在量产层面应用它吗?
这里我直接告诉你答案:开源和内部版本是一样的,核心代码和能力都是开源的。它可以用于生产,但它不是“开箱即用”,需要你做一些二次开发和调整。接下来,我将仔细展开这些问题。当然,我推荐你直接使用阿里云上的AHASSentinel控制台和ASM配置中心,这些都是最佳实践的输出,可以节省大量的时间、人力、运维成本等。
整体运营架构
大规模生产应用面临的问题
看了Sentinel开源版原来的运行架构,很明显存在一些问题:
1. 限流降级等规则存储在应用节点的内存中,应用释放重启后会失效,这在生产环境中显然是不能接受的;
2. 默认情况下,规则的分配是基于机器节点维度而不是应用维度,正常公司的应用系统都是集群部署的,不支持集群限流;
3. 指标信息被Dashboard拉取并保存在内存中仅5分钟。错过了,可能就无法还原“危机场景”,看不到流量趋势;
4. 如果访问限流的应用有500+个,每个应用平均部署4个节点,那么一共2000个节点,那么Dashboard肯定会成为瓶颈,单机线程池不会完全能够处理它;
如何优化和解决这些问题
接下来,我们先来一一介绍如何解决上述明显的问题。
首先,限流规则、降级规则等都应该按照应用维度来发布,而不是按照APP单节点的维度来发布。由于Sentinel支持集群限流,SentinelDashbord开源版做了限流规则的扩展,但没有扩展到熔断器、系统保护等,支持按应用维度下发。有兴趣的读者可以参考 FlowControllerV2 的实现来实现。
其次,规则不应该存储在内存中,应该持久化到动态配置中心,应用可以直接从配置中心订阅规则。这样,Dashboard 和应用就通过配置中心解耦了。这是典型的生产者-消费者模型。基本的运行架构如下:
以nacos配置中心为例。Sentinel 官方和社区提供了保存和订阅限流规则的演示。然后可以扩展熔断器降级、系统保护、网关限流...等规则。基本模型是:Dashboard将xxRuleEntityVO模型序列化保存到nacos中,应用从nacos订阅后反序列化成xxRule域模型。
这里要提醒大家的是,前方有巨大的坑。请不要直接复制“热参数限流规则”和“黑名单限制规则”,因为Dashboard中定义了ParamFlowRuleEntity和AuthorityRuleEntity
两个VO模型中的字段定义与域模型ParamFlowRule和AuthorityRule不匹配,会导致序列化/反序列化失败,进而导致应用无法订阅和使用热参数限流规则和黑名单限制规则。我要提交PR!!!
第三点是Dashboard中有一个调度线程池,它会轮询请求(默认每1秒发起一次)。每个应用的机器节点查询metrics日志信息,汇总显示在界面上(改造后需要完成持久化动作)。这是典型的pull模式,是监控测量领域比较常见的架构。因为是存储在内存中,所以默认只保留5分钟,这也是有问题的。推荐以下解决方案:
1. Dashboard拉取metrics信息后,直接保存在时序数据库中,Dashboard本身也从时序数据库中抓取数据进行展示。存储指标数据的时间取决于您的业务。以开源的Influxdb为例,它有自己的持久化策略功能(自动清理过期数据)。此外,还可以使用Grafana等开源Dashboards进行查询聚合,展示各种漂亮的行情、图表、排名等;
2. 可以把pull模式改成push模式,记录metrics日志的时候直接写时序数据库。当你的时候,基于性能的考虑,你也可以改写MQ来做缓冲。除了耗时,最重要的是不要因为记录指标的动作而影响主要业务流程的进度;
3. 继续打印metrics日志,启用SentinelDashboard拉出metrics数据,使用采集器直接在应用机器节点上采集,处理上报metrics日志。可以使用ELK等工具;
4. 可以尝试自己开发PrometheusExporter,将metrics信息以Target的形式公开,Prometheus服务器会定时拉取。同时,您还可以使用 Prometheus 提供的各种丰富的查询和聚合语法和功能。, 通过 Grafana 等方式显示;
下图是一个典型的时间序列数据示例,它是为指标索引数据设计的。该领域知名的开源软件包括OpenTSDB、Influxdb等。
Grafana 限流市场展示效果图
以上方法各有优缺点。如果你想做最小的改动,并且你的应用访问和部署规模不是特别大(500个节点以内),那么请选择第一种方式。
第四点是Dashboard由于接入的应用程序和节点较多,在pulling和aggregation方面的性能瓶颈。解决问题3时,如果选择方法2、3、4,那么Sentinel自带的Dashboard只会作为规则分发的工具(甚至规则分发可以直接通过nacos配置中控台完成),自然不会有瓶颈问题。如果你还想使用 Sentinel 自带的 Dashboard 来完成拉取和持久化指标数据等任务,那么我为你提供两种解决方案:
1. 按域隔离,将不同业务域的应用连接到各自的SentinelDashboard,让压力自然分散,减少出现瓶颈的可能性。优点是几乎不需要修改,缺点是不统一;
2. 可以尝试改造 Sentinel 自带的 Dashboard,使其无状态。前面我们提到过,应用启动后会定时上报心跳信息。Dashboard 默认会在内存中维护一个“节点信息列表”数据。这是一个典型的状态数据,应该考虑集中存储。例如:redis。那么就需要修改“拉取指标信息”的线程池,改为分片任务执行,从而达到分担负载的效果,例如:改用elasticjob调度。当然,时序数据库的写入也可能成为瓶颈;
3. 可以牺牲一点监控指标的时效性,增加Sentinel Dashboard中fetchScheduleService调度线程池的间隔时间参数,可以缓解下游worker线程池的处理压力;
就我而言,我实际上推荐第一种和第三种方法。这些都是权宜之计,变化相对较小。
当然,按字段划分还有其他好处。如果连接到500+个系统,以当前的Dashboard开源版本为例,左边的应用列表会延长多长时间?估计不能用了。UI和交互设计很业余,显然不能满足量产应用。但按领域隔离后,体验可能会有所改善。还有一点。Dashboard 目前的开源版本只提供了最基本的登录验证功能。如果需要权限控制、审计、审批确认等功能,则需要二次开发。如果Dashboard按字段独立,访问控制的风险会更小。
当然,如果要重构Dashboard权限控制和UI交互,建议按照应用维度进行设计,添加基础搜索等。
其他问题
应用程序连接到Sentinel后,启动时需要指定应用程序名称、Dashboard地址、客户端端口号、日志配置、心跳设置等,可以通过JVM -D启动参数,也可以将配置文件保存在指定的配置路径。这是一种不合理的设计,对CI/CD和部署环境有干扰。我解决了这个问题,在1.6.3版本提交了PR。好在社区在1.7.0时解决了这个问题。
一些规则配置和使用经验
请不要误会我的意思。我不是教你怎么配置和使用,而是教你怎么用好。还记得我在之前的稳定保障体系文章中抛出关于限流的灵魂拷问吗?首先我们简单回顾一下Sentinel中可能用到的关键功能。接下来我会以自问自答的方式回答用户最常见的疑问,输出最有价值的经验和建议。
1. 单机限流
2. 集群限流
3. 网关限流
4. 热点参数限流
5. 系统自适应保护
6. 黑白名单限制
7. 保险丝自动降级
单机限流阈值是多少?
这可不能“一巴掌”。匹配太高可能会导致故障。如果匹配度太低,您会担心过早的“过失杀人”请求。还是要根据容量规划和水位设置进行配置,前提是监控报警灵敏。给出了两个比较实用的方法:
1. 参考单机容量规划的思路,在软负载中调整一个节点的流量权重和比例,直到接近极限。记录极限状态下的QPS,根据单机房70%水位设置标准,可以计算出资源的单机限流阈值;
2. 可以定期观察监控系统的流程图,在线获取真实峰值QPS。如果应用系统和业务在周期的高峰期处于健康状态,那么可以假设峰值QPS就是理论水位。这种方式可能会造成资源浪费,因为高峰期可能达不到系统承载限制,适合流量周期有规律的业务;
你真的需要集群限流吗?
其实在大多数场景下,不需要使用集群限流,单机限流就足够了。仔细想想。实际上,只有几种情况可能需要使用集群限流:
1. 想配置单机QPS限制时
2. 上图中单机限流阈值为10 QPS,部署了3个节点。理论上集群的总QPS可以达到30,但实际上由于流量不均,集群的总QPS还没达到30就触发了。电流有限。很多人会说这不合理,但我觉得还是要根据实际情况来分析。如果这个“10QPS”是根据容量计划的系统承载能力计算的阈值(或者如果接口请求超过10QPS,系统可能会崩溃),那么这个限流的结果是令人满意的。如果这个“10QPS”只是业务级别的限制,那么即使一个节点的QPS超过10,也不会有什么问题。其实我们本质上是想限制整个集群的总QPS,所以这个限流的结果是不合理的。,并没有达到最好的效果;
所以,这实际上取决于你的限流是实现“过载保护”还是实现业务级别的限制。
还有一点需要注意的是,集群限流不能解决流量不均的问题,限流组件也不能帮你重新分配或调度流量。集群限流只会在流量不均的场景下,让整体限流效果更好。
实际使用建议是:集群限流(实现业务层限流)+单机限流(系统去底层防止被炸掉)
现在网关层限流了,应用层还需要限流吗?
如果需要,双重保护是必要的。同理,上游聚合业务配置限流,下游基础业务也需要配置限流。试想一下,如果只配置了上游限流,如果上游发起大量重试,会不会压垮下游的基础服务?而在这种情况下,我们在配置限流阈值时也需要特别注意。例如,上游A和B服务依赖于下游Y服务。A和B分别配置100QPS,那么Y服务必须至少配置200QPS。否则,一些请求被额外透传处理,最终被拒绝,不仅浪费资源,
因此,最好按照整个链路的整体容量规划(桶短板原则)来配置。越早拦截越好,而且每一层都要配置限流。
热参数限流功能实用吗?
该功能非常实用,可以防止热点数据(如:热门店铺、黑马产品)占用和消耗过多系统资源,严重影响其他数据请求的处理。
还有一个要求。如果你在做C端产品,想限制用户访问某个接口的最大QPS,或者你在做B端SAAS产品,想限制租户访问某个接口的最大QPS某个接口... hotspot参数默认不是为满足这样的需求而设计的,需要自己扩展SLOT来实现类似的限制需求。当然,热点参数流量限制中的paramFlowItemList(参数异常项)可以实现某个客户ID=1的大客户访问某个资源的最大QPS为100),可以实现在某种程度上。有一个特殊要求。这个需求还有一个解决方案:当我们在代码中定义sourceName时,
为什么要有自适应保护系统?
其实这也是一种自下而上的做法。当实际流量超过部分限流阈值时,开销基本可以忽略。当真实流量远超限流阈值N倍时,尤其是双十一大促、春晚红包、12306购票等大流量场景,那么限流拒绝请求的开销就无法忽略。这种情况在阿里巴巴内部被称为“系统被触死”。在这种情况下,自适应限流可以很好地发挥作用。
是否需要配置黑白名单限制?
如果您想根据请求的来源进行限制(仅从指定的上游系统释放请求),此功能非常有用。Sentinel 内置了“簇点链接监控”功能,有点类似于调用链监控,但目的不同。
熔断器自动降级使用有哪些建议?
在配置熔断器自动降级之前,我们首先需要识别可能不稳定的服务,然后判断是否可以降级。降级处理通常很快就会失败。当然,我们可以自定义降级处理的结果(Fallback),例如:尝试包裹返回默认结果(降级),返回上次请求的缓存结果(时效性下降),包裹返回结果失败。即时结果等
弱依赖和次要功能的退化通常是通过推动开关手动完成,而 Sentinel 的保险丝退化主要是在“调用端”自动判断和执行。Sentinel基于平均响应时间,可以利用错误率、错误数等统计指标进行自动融合和降级。
例如:我们的系统同时支持“余额支付”和“银行卡支付”。这两个函数对应的接口默认在同一个应用的同一个线程池中。任何一方的 RT 抖动和大量超时都可能导致请求积压。线程池耗尽。假设从业务角度来看,“余额支付”的比例越高,保障的优先级也越高。然后我们可以在“银行卡支付”界面(依赖第三方,不稳定)当RT持续上升或者出现大量异常(前提是数据不一致等影响业务的问题)进行“熔断器自动降级”进程不能引起),以便优先确保“
总结
本文主要介绍了Sentinel开源版在大规模生产级应用中面临的一些问题和解决方案,以及实际配置和使用中的一些经验。这些经验来自一线生产实践,希望读者朋友少走弯路。如果您有任何问题,请留言讨论。
免规则采集器列表算法(免规则采集器列表算法框架fetchsetsarrays方法展示(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-16 06:02
免规则采集器列表算法框架fetchsetsarrays方法展示针对python进行数据采集是比较好的入门教程采集整理初始页:pillow+opencv+matplotlib具体实现步骤:第一步:切换输入源平台;第二步:通过逐一json尝试封装datacontext;第三步:通过api进行网页搜索对象抓取;第四步:整理输出数据;。
不是我说你现在想做到和知乎官方那边一模一样我感觉是不可能的他们的datatracker框架是干什么的?我只用过scrapy,这框架刚刚好提供支持静态网页,为什么别人要支持动态,
不可能,requests的容错、ssd还得了解一下ackl2的原理。
讲真,网上有python动态数据采集(mongodb库+dfdb.json包)的例子吧,你先找找看看,
可以试试小d科技,
静态数据分析可以来飞鸟数据,个人已经测试过,有需要的话,你可以去看看他们官网,
可以读一下julylew的itembaselibrary
有一个例子我觉得很好,基于豆瓣数据,貌似可以用比如让手动批量提取:node-itemproject这个项目。有几个教程,nodejs版:julylew/itemproject·github我用过了,效果还不错,可以下载到本地慢慢研究。 查看全部
免规则采集器列表算法(免规则采集器列表算法框架fetchsetsarrays方法展示(图))
免规则采集器列表算法框架fetchsetsarrays方法展示针对python进行数据采集是比较好的入门教程采集整理初始页:pillow+opencv+matplotlib具体实现步骤:第一步:切换输入源平台;第二步:通过逐一json尝试封装datacontext;第三步:通过api进行网页搜索对象抓取;第四步:整理输出数据;。
不是我说你现在想做到和知乎官方那边一模一样我感觉是不可能的他们的datatracker框架是干什么的?我只用过scrapy,这框架刚刚好提供支持静态网页,为什么别人要支持动态,
不可能,requests的容错、ssd还得了解一下ackl2的原理。
讲真,网上有python动态数据采集(mongodb库+dfdb.json包)的例子吧,你先找找看看,
可以试试小d科技,
静态数据分析可以来飞鸟数据,个人已经测试过,有需要的话,你可以去看看他们官网,
可以读一下julylew的itembaselibrary
有一个例子我觉得很好,基于豆瓣数据,貌似可以用比如让手动批量提取:node-itemproject这个项目。有几个教程,nodejs版:julylew/itemproject·github我用过了,效果还不错,可以下载到本地慢慢研究。
免规则采集器列表算法(免规则采集器列表算法与复杂循环列表的具体原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-16 04:02
免规则采集器列表算法来自与生产线的一些经验,仅供参考在这篇文章中我们介绍了聚合算法列表算法、简单循环列表算法以及复杂循环列表算法的具体原理,以及它们在建图算法,查找语义的优化算法中如何用到,可以清楚地对它们进行掌握。在这篇文章中我们将介绍列表算法的应用,以及列表的应用。
1、列表中的更新工具
2、列表中的插入与删除工具
3、列表中的检索工具
4、列表中的列表删除工具
5、其他内容图2:列表中的插入与删除工具列表循环列表循环主要用于遍历列表,我们将它比喻为网络中的发布机,代表性动画是下图中1-5。请注意请用双列表循环,其中第一列中的列表迭代工具用在我们图6中第3列的列表迭代工具上。列表迭代遍历过程列表迭代遍历过程可以由复杂的动画表示如下:1.1列表迭代在很多数据库中,列表迭代过程都是数据流分析的一个重要应用,列表迭代的动画如下:1.2列表迭代遍历算法1.3列表迭代遍历的迭代操作列表迭代是迭代算法与迭代规则的自然过渡,它实际上就是一个迭代的规则。
由于我们在本文中提供了所有的列表迭代过程,所以我们只展示了迭代规则的动画:2.列表迭代算法列表迭代算法通常是为了去除整个链表中的节点。因此该算法会把所有的节点进行迭代。首先将列表中所有的节点按照index的索引进行排序。然后执行列表迭代遍历。为了创建列表迭代过程,我们把其称为dfs迭代:2.1dfs算法所谓dfs,即迭代迭代算法是指对列表中每个元素进行迭代的过程。
迭代算法可以分为单边迭代算法和双边迭代算法。单边迭代算法要求迭代的顺序:“先前端列表的dp、剩余的元素dp、列表与元素dp、后端列表dp”。单边迭代迭代算法一个有趣的应用是遍历集合或列表树,但要对集合或列表树进行有效且可靠的操作可能困难,因为任何节点都不可能遍历到。因此对于任何我们知道如何遍历集合或列表树的用户,最好还是使用双边迭代算法,即先把列表表中的每个元素都遍历一遍。2.2dfs迭代算法列表迭代算法类似于基于变量的遍历操作,该算法要求有一个分组列表进行迭代。
dfs迭代算法的目标是每次迭代生成一个元素,或者当我们对列表迭代操作,
2),或者循环地遍历列表的某些子列表时,迭代是唯一的策略。dfs迭代算法与dfs迭代过程迭代器的搜索是保证算法能通过终止区的重要因素,例如,如果一个遍历遍历某个范围的元素,它可能会在其子范围处返回不通过端节点,这样会降低用户在搜索过程中的性能,并使算法更难以搜索下去。为了提高性能, 查看全部
免规则采集器列表算法(免规则采集器列表算法与复杂循环列表的具体原理)
免规则采集器列表算法来自与生产线的一些经验,仅供参考在这篇文章中我们介绍了聚合算法列表算法、简单循环列表算法以及复杂循环列表算法的具体原理,以及它们在建图算法,查找语义的优化算法中如何用到,可以清楚地对它们进行掌握。在这篇文章中我们将介绍列表算法的应用,以及列表的应用。
1、列表中的更新工具
2、列表中的插入与删除工具
3、列表中的检索工具
4、列表中的列表删除工具
5、其他内容图2:列表中的插入与删除工具列表循环列表循环主要用于遍历列表,我们将它比喻为网络中的发布机,代表性动画是下图中1-5。请注意请用双列表循环,其中第一列中的列表迭代工具用在我们图6中第3列的列表迭代工具上。列表迭代遍历过程列表迭代遍历过程可以由复杂的动画表示如下:1.1列表迭代在很多数据库中,列表迭代过程都是数据流分析的一个重要应用,列表迭代的动画如下:1.2列表迭代遍历算法1.3列表迭代遍历的迭代操作列表迭代是迭代算法与迭代规则的自然过渡,它实际上就是一个迭代的规则。
由于我们在本文中提供了所有的列表迭代过程,所以我们只展示了迭代规则的动画:2.列表迭代算法列表迭代算法通常是为了去除整个链表中的节点。因此该算法会把所有的节点进行迭代。首先将列表中所有的节点按照index的索引进行排序。然后执行列表迭代遍历。为了创建列表迭代过程,我们把其称为dfs迭代:2.1dfs算法所谓dfs,即迭代迭代算法是指对列表中每个元素进行迭代的过程。
迭代算法可以分为单边迭代算法和双边迭代算法。单边迭代算法要求迭代的顺序:“先前端列表的dp、剩余的元素dp、列表与元素dp、后端列表dp”。单边迭代迭代算法一个有趣的应用是遍历集合或列表树,但要对集合或列表树进行有效且可靠的操作可能困难,因为任何节点都不可能遍历到。因此对于任何我们知道如何遍历集合或列表树的用户,最好还是使用双边迭代算法,即先把列表表中的每个元素都遍历一遍。2.2dfs迭代算法列表迭代算法类似于基于变量的遍历操作,该算法要求有一个分组列表进行迭代。
dfs迭代算法的目标是每次迭代生成一个元素,或者当我们对列表迭代操作,
2),或者循环地遍历列表的某些子列表时,迭代是唯一的策略。dfs迭代算法与dfs迭代过程迭代器的搜索是保证算法能通过终止区的重要因素,例如,如果一个遍历遍历某个范围的元素,它可能会在其子范围处返回不通过端节点,这样会降低用户在搜索过程中的性能,并使算法更难以搜索下去。为了提高性能,
免规则采集器列表算法(从一个学生角度浅谈我对现在youtube浏览量算法的意见)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-15 04:09
说到Kpop指标,大家肯定会想到音源的销量和油管的表现。油管的性能一直是路人和海外影响力的指标。虽然目前知乎凤翔觉得这是粉丝可以操纵的鸡肋指标。但我个人觉得这种说法并不完全正确。如果是球迷指标,那么男队在这个数据上应该是有绝对优势的。BP和TWICE应该无法达到这么好的油管效果,所以笔者做了一些简单的实验。, 站在一个学生的角度,谈谈我对目前youtube浏览量算法的看法。
一些粉丝指责youtube的结果发生了变化,或者youtube的记录完全没有意义。这种指责是由于对这家世界级互联网媒体的不信任和粉丝对浏览算法的不理解造成的。
作为kpop文化输出最直接的量化指标,YouTube的表现不仅反映了k-pop占领地球的趋势,也成为PC人的骄傲。说到2016油管,就不得不谈BTS、Blackpink、Twice这三种组合。
16年,输油管道记录似乎意外被打破。没有别的原因,就是短时间被大棒统治的输油管道名单从1000刷新到了1亿。头寸全丢,只剩下2亿大关。还用棍子守着。
如果说TT在血汗泪水时期的1000万分可以称为玩兔子的全盛期,那么KK NT时期只能称为血洗榜。剩下的黑粉虽然没有前两个那么抢眼,但是却显示出很强的后劲,甚至还有逆行向上的气势。
所以今年大家难免达成共识,油管越来越好。
但事实真的如此吗?
让我们从一个非常业余的角度来看,
市面上很便宜的方法是chrome上的自动刷新插件。这是 Chrome 商店中提供的免费插件。可以自动设置为定期刷新页面。一般的方法是根据歌曲的时间设置自动刷新周期。设置相同的长度,可以无限刷新浏览量,但是即使有这个插件,也无法刷新评论数。
换句话说,即使我们默认那个方法(后面会详细说明这个方法基本不可行或者油管认可度很低)是可行的,我们也无法评论。
现在来看看各组访问量最高的TT 16000W访问以下22W评论血汗泪14000W访问16W评论boombayah 12000W访问16W评论
来看看GD前辈的神奇宝贝2.8E 15W评论GEE1.86E 51W评论叫我宝贝1.2E 15W评论
好的,让我们输入下面的文字,
前面高能,我们用一个可以很基本的比喻来解释这件事,那就是油管的服务器就像餐厅,而我们就像食客。
经过三天的研究,我没有找到youtube使用的任何算法。(好吧,我承认我是人渣TT)段爸爸没有发表具体算法的论文。但我们可以从石油管道算法的15年更新中窥见一斑。我是门外汉,先给大家讲解一下这些规则。
首先,在Tubing官方公布算法之前,我们无法知道具体的算法程序,但是可以知道影响算法的变量。感谢ResysChina对youtube推荐算法的翻译,我们知道youtube经过15年的改版后,YouTube会停留在访问量上,对话开始和对话结束的概念引入了计算方法。在这个规则下,单纯点击打开页面并一直刷新显然是行不通的,于是我们之前熟悉的Chrome插件就应运而生了。简单的说,youtube就是你没吃过的餐厅,不看你有没有下单,而是看你吃了多久。一定时间后,您将只吃一次。
二是ID和IP的问题。除了看完整个MV才算访问成功,短时间内多次访问同一个ID的视频肯定是无效的。看了一些贴吧的说明,可以删除浏览记录。我怀疑这种方法的科学性。就像你去餐厅吃饭,写一个订单,点了三道菜,然后这个订单做了两份,你就有了一个。对于厨师来说,删除浏览器的 cookie 记录就像检查您订单上的一道菜。
油管的历史实际上是从服务器日志中重新生成的反馈信息,类似于您从餐厅获得的收据。如果你认为修改油管历史可以逆向修改服务器日志,那就等于撕了收据。吃国王餐的理论,绝对是不可能的。
肯定有同学想问:怎么算游客流量或者自己申请新身份证?在这里,我将谈谈游客的流量。油管也会被记录下来,但是油管的ID是由IP生成的,与IP相关。.
总之,我终于来到了故事的关键,访问者的IP地址
什么是 IP 地址?它实际上是互联网分配给您的计算机的虚拟地址,以便当您要连接到以太网时,有一个特定的地址可以发送和接收快递。油管服务器(服务器)必须根据您在计算机上唯一确定的包裹被发送到的地址。
所以理论上想要刷出50W的观看次数,必须在完整观看视频后切换IP地址。如果能写一个比较简单的程序,就可以写一个自动填代理IP的代理服务器,但是有个问题,哪里可以找到现成的免费IP地址?现在比较可行的方法是搜索即时代理IP。但是为了防止大量采集,当前代理IP使用图片。. . 所以,总而言之,非常麻烦。暂时没有想出可行的办法。除了切换IP,我还需要定期处理cookies。
所以IP切换是一件很麻烦的事情。我个人认为现在用VPN比较可行,因为它会随机给你分配一个新的IP地址,只要你设计一个定点重连。另一种是手机刷卡,因为蜂窝4G网络每次使用数据连接时都会重新分配IP地址。但是这个方法。. 我每天最多手动测试计算机 120-150 次。因为时间不匹配,我个人设置了一个时间段为10分钟。
那么,说完基础,我们不难发现,youtube算法索引在页面浏览量方面其实是一个综合了账户cookies和IP地址的综合算法。我个人用了四个视频进行实验,一个是0次观看。音量,一个是20+浏览量,一个是数百浏览量,最后一个是2000个浏览量的视频
然而,实验结果相当不稳定,同一量级内的标准参数随时间变化明显。也就是说,我这个级别的玩家永远不会知道在某个量级以哪些参数为标准,更不用说参数之间的权重关系了。
更重要的是,即使我们可以在几千个样本中破解算法,但与数千万个页面访问量相比,数千个页面访问量始终是一个小样本。在较大的样本中,审查更复杂的页面视图。因为系统是不可控的,我无法控制哪些浏览量被计算在内,哪些不计算。
所以这个文章的结论是我的真名反对计算机天才一天可以刷50W浏览量的说法。不过不得不承认,如果粉丝每天打开电脑,把歌曲放入播放列表重复播放,这些观看次数不能算作一次,所以必须有有效的播放次数,重复计算为观看次数。
随着信息时代的不断推进,BTS和Twice的油管记录被新团打破是必然趋势。五年前,我想看我最喜欢的mv。我只能回家打开电脑。现在,无论是上班还是上学,只要我愿意,我都可以从手机和平板电脑连接到 YouTube。. 这项技术带来的变化决定了,从未来的趋势来看,销售额的存在将继续减少,而数字音源和YouTube等新媒体的数据将成为越来越重要的流行表现形式。
不过不得不提的是,作为一家互联网视频公司,YouTube对浏览量算法的细致设置以及算法的不断更新,在一定程度上保证了其数据的可信度。但如果要将其作为更重要的指标,输油管道公司首先需要公布一部分算法程序,让公众了解并确信指标进行审核。二是在以下两个方面:1.如何区分粉丝和路人2.如何防止粉丝利用IP切换刷浏览量,youtube还需要继续努力。
以下五张图是bigbang、少女时代、二次元、blackpink和bts在油管上发布的2016年全年官方数据,有兴趣的可以自行转/
最后,我想分享一下我所做的项目,并从 Twitter 上获取数据。因为我们没有切换IP,推特屏蔽了我们整个宿舍的IP。. . (我在香港上学)这是我年轻时写的一小部分,不知道从Twitter下载流数据。后来我发现推特数据集是公开的。跑过多少奔马。. . def on_data(self, data):try:with open('python.json','a') as f:f.write(data)return Trueexcept BaseException as e:print(“Error on_data: %s”% str( e))return Truedef on_error(self, status):print(status)return True twitter_stream = Stream(auth, MyListener())twitter_stream.filter(track=['#python']) 查看全部
免规则采集器列表算法(从一个学生角度浅谈我对现在youtube浏览量算法的意见)
说到Kpop指标,大家肯定会想到音源的销量和油管的表现。油管的性能一直是路人和海外影响力的指标。虽然目前知乎凤翔觉得这是粉丝可以操纵的鸡肋指标。但我个人觉得这种说法并不完全正确。如果是球迷指标,那么男队在这个数据上应该是有绝对优势的。BP和TWICE应该无法达到这么好的油管效果,所以笔者做了一些简单的实验。, 站在一个学生的角度,谈谈我对目前youtube浏览量算法的看法。
一些粉丝指责youtube的结果发生了变化,或者youtube的记录完全没有意义。这种指责是由于对这家世界级互联网媒体的不信任和粉丝对浏览算法的不理解造成的。
作为kpop文化输出最直接的量化指标,YouTube的表现不仅反映了k-pop占领地球的趋势,也成为PC人的骄傲。说到2016油管,就不得不谈BTS、Blackpink、Twice这三种组合。
16年,输油管道记录似乎意外被打破。没有别的原因,就是短时间被大棒统治的输油管道名单从1000刷新到了1亿。头寸全丢,只剩下2亿大关。还用棍子守着。
如果说TT在血汗泪水时期的1000万分可以称为玩兔子的全盛期,那么KK NT时期只能称为血洗榜。剩下的黑粉虽然没有前两个那么抢眼,但是却显示出很强的后劲,甚至还有逆行向上的气势。
所以今年大家难免达成共识,油管越来越好。
但事实真的如此吗?
让我们从一个非常业余的角度来看,
市面上很便宜的方法是chrome上的自动刷新插件。这是 Chrome 商店中提供的免费插件。可以自动设置为定期刷新页面。一般的方法是根据歌曲的时间设置自动刷新周期。设置相同的长度,可以无限刷新浏览量,但是即使有这个插件,也无法刷新评论数。
换句话说,即使我们默认那个方法(后面会详细说明这个方法基本不可行或者油管认可度很低)是可行的,我们也无法评论。
现在来看看各组访问量最高的TT 16000W访问以下22W评论血汗泪14000W访问16W评论boombayah 12000W访问16W评论
来看看GD前辈的神奇宝贝2.8E 15W评论GEE1.86E 51W评论叫我宝贝1.2E 15W评论
好的,让我们输入下面的文字,
前面高能,我们用一个可以很基本的比喻来解释这件事,那就是油管的服务器就像餐厅,而我们就像食客。
经过三天的研究,我没有找到youtube使用的任何算法。(好吧,我承认我是人渣TT)段爸爸没有发表具体算法的论文。但我们可以从石油管道算法的15年更新中窥见一斑。我是门外汉,先给大家讲解一下这些规则。
首先,在Tubing官方公布算法之前,我们无法知道具体的算法程序,但是可以知道影响算法的变量。感谢ResysChina对youtube推荐算法的翻译,我们知道youtube经过15年的改版后,YouTube会停留在访问量上,对话开始和对话结束的概念引入了计算方法。在这个规则下,单纯点击打开页面并一直刷新显然是行不通的,于是我们之前熟悉的Chrome插件就应运而生了。简单的说,youtube就是你没吃过的餐厅,不看你有没有下单,而是看你吃了多久。一定时间后,您将只吃一次。
二是ID和IP的问题。除了看完整个MV才算访问成功,短时间内多次访问同一个ID的视频肯定是无效的。看了一些贴吧的说明,可以删除浏览记录。我怀疑这种方法的科学性。就像你去餐厅吃饭,写一个订单,点了三道菜,然后这个订单做了两份,你就有了一个。对于厨师来说,删除浏览器的 cookie 记录就像检查您订单上的一道菜。
油管的历史实际上是从服务器日志中重新生成的反馈信息,类似于您从餐厅获得的收据。如果你认为修改油管历史可以逆向修改服务器日志,那就等于撕了收据。吃国王餐的理论,绝对是不可能的。
肯定有同学想问:怎么算游客流量或者自己申请新身份证?在这里,我将谈谈游客的流量。油管也会被记录下来,但是油管的ID是由IP生成的,与IP相关。.
总之,我终于来到了故事的关键,访问者的IP地址
什么是 IP 地址?它实际上是互联网分配给您的计算机的虚拟地址,以便当您要连接到以太网时,有一个特定的地址可以发送和接收快递。油管服务器(服务器)必须根据您在计算机上唯一确定的包裹被发送到的地址。
所以理论上想要刷出50W的观看次数,必须在完整观看视频后切换IP地址。如果能写一个比较简单的程序,就可以写一个自动填代理IP的代理服务器,但是有个问题,哪里可以找到现成的免费IP地址?现在比较可行的方法是搜索即时代理IP。但是为了防止大量采集,当前代理IP使用图片。. . 所以,总而言之,非常麻烦。暂时没有想出可行的办法。除了切换IP,我还需要定期处理cookies。
所以IP切换是一件很麻烦的事情。我个人认为现在用VPN比较可行,因为它会随机给你分配一个新的IP地址,只要你设计一个定点重连。另一种是手机刷卡,因为蜂窝4G网络每次使用数据连接时都会重新分配IP地址。但是这个方法。. 我每天最多手动测试计算机 120-150 次。因为时间不匹配,我个人设置了一个时间段为10分钟。
那么,说完基础,我们不难发现,youtube算法索引在页面浏览量方面其实是一个综合了账户cookies和IP地址的综合算法。我个人用了四个视频进行实验,一个是0次观看。音量,一个是20+浏览量,一个是数百浏览量,最后一个是2000个浏览量的视频
然而,实验结果相当不稳定,同一量级内的标准参数随时间变化明显。也就是说,我这个级别的玩家永远不会知道在某个量级以哪些参数为标准,更不用说参数之间的权重关系了。
更重要的是,即使我们可以在几千个样本中破解算法,但与数千万个页面访问量相比,数千个页面访问量始终是一个小样本。在较大的样本中,审查更复杂的页面视图。因为系统是不可控的,我无法控制哪些浏览量被计算在内,哪些不计算。
所以这个文章的结论是我的真名反对计算机天才一天可以刷50W浏览量的说法。不过不得不承认,如果粉丝每天打开电脑,把歌曲放入播放列表重复播放,这些观看次数不能算作一次,所以必须有有效的播放次数,重复计算为观看次数。
随着信息时代的不断推进,BTS和Twice的油管记录被新团打破是必然趋势。五年前,我想看我最喜欢的mv。我只能回家打开电脑。现在,无论是上班还是上学,只要我愿意,我都可以从手机和平板电脑连接到 YouTube。. 这项技术带来的变化决定了,从未来的趋势来看,销售额的存在将继续减少,而数字音源和YouTube等新媒体的数据将成为越来越重要的流行表现形式。
不过不得不提的是,作为一家互联网视频公司,YouTube对浏览量算法的细致设置以及算法的不断更新,在一定程度上保证了其数据的可信度。但如果要将其作为更重要的指标,输油管道公司首先需要公布一部分算法程序,让公众了解并确信指标进行审核。二是在以下两个方面:1.如何区分粉丝和路人2.如何防止粉丝利用IP切换刷浏览量,youtube还需要继续努力。
以下五张图是bigbang、少女时代、二次元、blackpink和bts在油管上发布的2016年全年官方数据,有兴趣的可以自行转/
最后,我想分享一下我所做的项目,并从 Twitter 上获取数据。因为我们没有切换IP,推特屏蔽了我们整个宿舍的IP。. . (我在香港上学)这是我年轻时写的一小部分,不知道从Twitter下载流数据。后来我发现推特数据集是公开的。跑过多少奔马。. . def on_data(self, data):try:with open('python.json','a') as f:f.write(data)return Trueexcept BaseException as e:print(“Error on_data: %s”% str( e))return Truedef on_error(self, status):print(status)return True twitter_stream = Stream(auth, MyListener())twitter_stream.filter(track=['#python'])
免规则采集器列表算法(网络分流器高密度报文重组和会话规则!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-14 22:07
融腾网网络分路器,又称核心网采集器,分为固网采集器和移动信令采集器两大类!网络分离器是整个网络安全前端网络监控的重要基础设备!我们在网络安全中经常听到旁路、镜像、流采集、DPI深度包检测、五元组过滤等相关词汇。今天网络拆分器就给大家讲讲TCP包重组和会话规则!
高密度网络分离器兼顾10G和100G
一、基本概念
四元组:源IP地址、目的IP地址、源端口、目的端口。
五元组:源IP地址、目的IP地址、协议号、源端口、目的端口。
六元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址。
七元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址和协议号。
二、五元组决定会话还是四元组?
五元组通常是指由五个数量组成的集合:源IP地址、源端口、目的IP地址、目的端口和传输层协议号。例如:192.168.0.1/10000/TCP/121.14.88.76/80 构成一个五元组. 意思是IP地址为192.168.1.1的终端通过10000端口使用TCP协议,IP地址为121.14.88.76,终端有80端口用于连接通讯。
五元组可以唯一确定一个会话。
在TCP会话重组过程中,利用序列号来确定TCP报文的顺序,可以解决数据报文无序到达和重传的问题,并使用二维链表来恢复TCP会话。难点在于解决多连接、IP报文无序到达、TCP会话重传等问题。
理由:TCP协议是TCP/IP协议族的重要组成部分,TCP数据流的重组是高层协议分析系统设计和实现的基础。TCP协议是面向连接的可靠传输协议,而TCP下的IP协议是消息的不可靠协议。这就带来了一个问题:IP不能保证TCP报文的可靠顺序传输。为了解决这个问题,TCP采用了滑动窗口机制、字节流编号机制、快速重传算法机制。这样可以保证数据的可靠传输。
TCP 会话 (TCP_Session_IDT) 可以由四元组唯一标识。
使用HASH表快速查找和定位特征,解决多个TCP会话同时处理的问题,快速处理多个会话。
TCP头中的Sequence Number是判断数据包是否重传和数据包乱序的重要参数。当 TCP 连接刚建立时,会为后续的 TCP 传输设置一个初始的 SequenceNumber。每次发送一个收录有效数据的 TCP 数据包时,都会相应地修改后续 TCP 数据包的 Sequence Number。如果前一个包的长度为N,那么这个包的Sequence Number就是前一个包的Sequence Number加N。 旨在保证TCP数据包按顺序传输,可以有效实现TCP的完整传输数据,尤其是在数据传输出现错误时,能有效纠正错误。
TCP重组数据文件写指针的SYN算法如下:
File_Init_Write_Pointer = Init_Sequence Number + 1;
File_write_Pointer = 当前序列号 – File_init_Write_point;
检查TCP会话是否存在漏洞,以确定会话重组的成功、失败和超时。
TCP 建立连接需要 3 次握手,而终止连接需要 4 次握手。这是因为 TCP 连接是全双工的,每个方向都必须单独关闭。
规则一:六元组,协议号是TCP,应该是唯一的会话。
规则二:TCP头中的4元组,应该是唯一的,不唯一表示有重传。
网络分离器 查看全部
免规则采集器列表算法(网络分流器高密度报文重组和会话规则!(一))
融腾网网络分路器,又称核心网采集器,分为固网采集器和移动信令采集器两大类!网络分离器是整个网络安全前端网络监控的重要基础设备!我们在网络安全中经常听到旁路、镜像、流采集、DPI深度包检测、五元组过滤等相关词汇。今天网络拆分器就给大家讲讲TCP包重组和会话规则!
高密度网络分离器兼顾10G和100G
一、基本概念
四元组:源IP地址、目的IP地址、源端口、目的端口。
五元组:源IP地址、目的IP地址、协议号、源端口、目的端口。
六元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址。
七元组:源MAC地址、源IP地址、源端口号、目的MAC地址、目的IP地址、目的IP地址和协议号。
二、五元组决定会话还是四元组?
五元组通常是指由五个数量组成的集合:源IP地址、源端口、目的IP地址、目的端口和传输层协议号。例如:192.168.0.1/10000/TCP/121.14.88.76/80 构成一个五元组. 意思是IP地址为192.168.1.1的终端通过10000端口使用TCP协议,IP地址为121.14.88.76,终端有80端口用于连接通讯。
五元组可以唯一确定一个会话。
在TCP会话重组过程中,利用序列号来确定TCP报文的顺序,可以解决数据报文无序到达和重传的问题,并使用二维链表来恢复TCP会话。难点在于解决多连接、IP报文无序到达、TCP会话重传等问题。
理由:TCP协议是TCP/IP协议族的重要组成部分,TCP数据流的重组是高层协议分析系统设计和实现的基础。TCP协议是面向连接的可靠传输协议,而TCP下的IP协议是消息的不可靠协议。这就带来了一个问题:IP不能保证TCP报文的可靠顺序传输。为了解决这个问题,TCP采用了滑动窗口机制、字节流编号机制、快速重传算法机制。这样可以保证数据的可靠传输。
TCP 会话 (TCP_Session_IDT) 可以由四元组唯一标识。
使用HASH表快速查找和定位特征,解决多个TCP会话同时处理的问题,快速处理多个会话。
TCP头中的Sequence Number是判断数据包是否重传和数据包乱序的重要参数。当 TCP 连接刚建立时,会为后续的 TCP 传输设置一个初始的 SequenceNumber。每次发送一个收录有效数据的 TCP 数据包时,都会相应地修改后续 TCP 数据包的 Sequence Number。如果前一个包的长度为N,那么这个包的Sequence Number就是前一个包的Sequence Number加N。 旨在保证TCP数据包按顺序传输,可以有效实现TCP的完整传输数据,尤其是在数据传输出现错误时,能有效纠正错误。
TCP重组数据文件写指针的SYN算法如下:
File_Init_Write_Pointer = Init_Sequence Number + 1;
File_write_Pointer = 当前序列号 – File_init_Write_point;
检查TCP会话是否存在漏洞,以确定会话重组的成功、失败和超时。
TCP 建立连接需要 3 次握手,而终止连接需要 4 次握手。这是因为 TCP 连接是全双工的,每个方向都必须单独关闭。
规则一:六元组,协议号是TCP,应该是唯一的会话。
规则二:TCP头中的4元组,应该是唯一的,不唯一表示有重传。
网络分离器
免规则采集器列表算法(你问我答网,国内优秀的知识问答网站”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-14 17:09
安装说明:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//============================================== =
$seo_1="问我网络优秀国内知识问答网站"; //搜索引擎优化-标题后缀
$seo_2="你问我答网,知识问答,网友提问,网友回答"; //搜索引擎优化——网站关键词
$seo_3="你问我答网,国内优秀知识问答网站"; //搜索引擎优化-描述网站
//以上三个地方认真填写,严重影响收录的数量!
$web="你让我回答网络问题"; //网站请填写姓名
$website=""; //网站不要加域名
$beian=”辽ICP备14003759-1号”; //记录号没什么好说的
$tj=''//网站流量统计代码
//LOGO修改样式\img\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
修改后,配置IIS伪静态,配置文件在\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP文件,有详细配置说明,修改内容使网站正常操作。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
随风百度知道(小偷采集)v1.3X更新如下:
1.所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
需要 4 点才能下载 查看全部
免规则采集器列表算法(你问我答网,国内优秀的知识问答网站”)
安装说明:
1、首先打开/API/3.PHP文件,里面有详细的配置说明
如下:
//网站程序配置!
//============================================== =
$seo_1="问我网络优秀国内知识问答网站"; //搜索引擎优化-标题后缀
$seo_2="你问我答网,知识问答,网友提问,网友回答"; //搜索引擎优化——网站关键词
$seo_3="你问我答网,国内优秀知识问答网站"; //搜索引擎优化-描述网站
//以上三个地方认真填写,严重影响收录的数量!
$web="你让我回答网络问题"; //网站请填写姓名
$website=""; //网站不要加域名
$beian=”辽ICP备14003759-1号”; //记录号没什么好说的
$tj=''//网站流量统计代码
//LOGO修改样式\img\transdmin-light.gif文件大小宽225PX X高28PX
//调整api/ad.php文件,添加百度广告代码或其他联盟广告代码!
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
修改后,配置IIS伪静态,配置文件在\IIS下,不要联系我!
本软件为php小偷采集网站,打开/API/2.PHP文件,有详细配置说明,修改内容使网站正常操作。
具体设置方法
打开/API/3.PHP文件,具体配置如下
//缓存时间设置
$cache_true=true; //缓存开关,如果不需要缓存请设置为false,如果需要缓存请设置为true
$cache_index="10"; //首页默认每10分钟更新一次
$cache_list="30"; //列表默认每30分钟更新一次
$cache_read="120"; //内容页默认每120分钟更新一次
随风百度知道(小偷采集)v1.3X更新如下:
1.所有统一编码为UTF-8,兼容所有服务器。
2.添加云采集规则,方便更新修改
需要 4 点才能下载
免规则采集器列表算法(免规则采集器列表算法规则采集功能来说吧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-14 11:02
免规则采集器列表算法规则采集功能来说也能满足需求,前期制定计划采集程序采集指定网站标题,内容都可以,可以长期实现订单识别,商品识别功能,适合网站、公众号等单独的数据采集,或对长时间的采集也有很好的处理效果!还是很多采集软件供应商提供免费版功能,就拿去哪儿网采集来说吧,用免费版就可以实现多频道,并且是已定义规则的功能,批量导出、转换规则等等。对需要付费版的朋友们说明一下:。
1、需要看使用情况是否需要定制,
2、如果是自己编写源代码需要编写代码工具或编写语言,如果你对外部工具了解不多,不建议自己编写,安全,
3、做免费版只支持手机端客户端,电脑端还是需要付费版才支持,所以大家买之前可以先咨询好!采集程序也有提供免费版功能给大家体验,购买渠道很多,自己选择合适的!另外就是采集软件类型还有一些和免费版功能差不多,收费版贵一些,具体要看大家的实际需求了!免规则采集器就是对采集数据进行了预处理加工,方便以后生成视频、音频等格式的文件!免规则采集器可以避免经常无法获取需要的数据,每次采集的数据量多,限制少,速度快,像我们单人操作,电脑软件要登录自己账号的情况下,数据量太多,导致速度慢!免规则采集器最主要的功能就是免采集,可以添加新标题和文章采集,导出原始文件!大家可以根据自己的需求和使用场景来选择免规则采集器功能模块!免规则采集器申请登录方式很简单,可以到我们官网(www。fpws2016。com)、qq群里面免费申请,有任何问题欢迎大家来提问,我们一起交流学习!。 查看全部
免规则采集器列表算法(免规则采集器列表算法规则采集功能来说吧)
免规则采集器列表算法规则采集功能来说也能满足需求,前期制定计划采集程序采集指定网站标题,内容都可以,可以长期实现订单识别,商品识别功能,适合网站、公众号等单独的数据采集,或对长时间的采集也有很好的处理效果!还是很多采集软件供应商提供免费版功能,就拿去哪儿网采集来说吧,用免费版就可以实现多频道,并且是已定义规则的功能,批量导出、转换规则等等。对需要付费版的朋友们说明一下:。
1、需要看使用情况是否需要定制,
2、如果是自己编写源代码需要编写代码工具或编写语言,如果你对外部工具了解不多,不建议自己编写,安全,
3、做免费版只支持手机端客户端,电脑端还是需要付费版才支持,所以大家买之前可以先咨询好!采集程序也有提供免费版功能给大家体验,购买渠道很多,自己选择合适的!另外就是采集软件类型还有一些和免费版功能差不多,收费版贵一些,具体要看大家的实际需求了!免规则采集器就是对采集数据进行了预处理加工,方便以后生成视频、音频等格式的文件!免规则采集器可以避免经常无法获取需要的数据,每次采集的数据量多,限制少,速度快,像我们单人操作,电脑软件要登录自己账号的情况下,数据量太多,导致速度慢!免规则采集器最主要的功能就是免采集,可以添加新标题和文章采集,导出原始文件!大家可以根据自己的需求和使用场景来选择免规则采集器功能模块!免规则采集器申请登录方式很简单,可以到我们官网(www。fpws2016。com)、qq群里面免费申请,有任何问题欢迎大家来提问,我们一起交流学习!。
免规则采集器列表算法(免规则采集器列表算法提升搜索体验的思路和做法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-12 07:04
免规则采集器列表算法一般而言,它只会对数据列做规则提取,不会对其它列进行类似判断。上述任何一个规则,都是基于全新的数据库逻辑来实现的。如果对于某个规则产生了多条相关联的数据列,对于数据库其它列的规则也将会被强制解释为一条,不管其它列的表达式如何。要在大量数据列中对数据进行规则提取,处理复杂的搜索操作,就需要设置多份用户规则,分别放在不同的地方。
由于每个用户规则代码量较大,而且会存在版本、参数更改等问题,无法像对于每一个列是可以通过标准匹配引擎对其进行规则定制那样快速集成。这种情况下,将规则放在用户规则列表中是最快捷的做法。提升搜索体验这种情况下,不如采用标准规则定制的方式,通过将标准规则和用户规则提交系统对接,用户可以在自己的机器上创建多份规则,这些规则通过系统规则和用户规则进行编码对等,规则一个分支下产生的数据也是完全统一的。
因此这种方式可以在无需在数据库加入规则提取器的情况下,提升规则引擎的搜索体验。去除索引限制这个方式同样可以提升规则引擎的搜索体验,去除标准规则,让搜索机器只能搜索被搜索的最后一条数据。因为索引限制是一个系统发展过程中很常见的限制,一般会以某种机制来解决,例如采用搜索机器的隐式哈希(redis)映射的特性,或者提供关联结构化的数据,或者对未定义规则进行特殊处理等等。
去除上下文限制这个方式同样是一个常见的思路,以主关键字(主键或者唯一或者字符串)作为关键字,在这个关键字的字符串中填写默认关键字即可。为了尽量地去除索引限制,可以将搜索引擎建成一个组,然后将关键字放在组里面进行搜索,并且在每个组后面都加入一个可搜索的对象列表。想了解标准规则是怎么定义的?也可以看看我以前的文章。 查看全部
免规则采集器列表算法(免规则采集器列表算法提升搜索体验的思路和做法)
免规则采集器列表算法一般而言,它只会对数据列做规则提取,不会对其它列进行类似判断。上述任何一个规则,都是基于全新的数据库逻辑来实现的。如果对于某个规则产生了多条相关联的数据列,对于数据库其它列的规则也将会被强制解释为一条,不管其它列的表达式如何。要在大量数据列中对数据进行规则提取,处理复杂的搜索操作,就需要设置多份用户规则,分别放在不同的地方。
由于每个用户规则代码量较大,而且会存在版本、参数更改等问题,无法像对于每一个列是可以通过标准匹配引擎对其进行规则定制那样快速集成。这种情况下,将规则放在用户规则列表中是最快捷的做法。提升搜索体验这种情况下,不如采用标准规则定制的方式,通过将标准规则和用户规则提交系统对接,用户可以在自己的机器上创建多份规则,这些规则通过系统规则和用户规则进行编码对等,规则一个分支下产生的数据也是完全统一的。
因此这种方式可以在无需在数据库加入规则提取器的情况下,提升规则引擎的搜索体验。去除索引限制这个方式同样可以提升规则引擎的搜索体验,去除标准规则,让搜索机器只能搜索被搜索的最后一条数据。因为索引限制是一个系统发展过程中很常见的限制,一般会以某种机制来解决,例如采用搜索机器的隐式哈希(redis)映射的特性,或者提供关联结构化的数据,或者对未定义规则进行特殊处理等等。
去除上下文限制这个方式同样是一个常见的思路,以主关键字(主键或者唯一或者字符串)作为关键字,在这个关键字的字符串中填写默认关键字即可。为了尽量地去除索引限制,可以将搜索引擎建成一个组,然后将关键字放在组里面进行搜索,并且在每个组后面都加入一个可搜索的对象列表。想了解标准规则是怎么定义的?也可以看看我以前的文章。
免规则采集器列表算法(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-10 15:19
今天分享的《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载。这个接口是自己测试的。压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:
其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的以下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:
就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:
如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功后会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无登录和Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置完成后,点击 测试配置。成功后,设置一个配置名称保存该配置以供规则使用。
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,把这里的表单值设置为空,如如下图所示:
然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。
当然,您可以选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:
第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,信息右侧的结果用于将每个信息与“|||”连接起来.
说到头像标签,用户的头像必须是“头像图片地址和用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。
幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将在论坛中发布相应的论坛 id 1,这可以根据我们的论坛论坛进行修改,以下 typname 为同样的,这个设置的好处是不需要直接通过section名和topic分类名来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就讲到这里。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块 查看全部
免规则采集器列表算法(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
今天分享的《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载。这个接口是自己测试的。压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:
其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的以下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:
就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:
如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功后会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无登录和Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置完成后,点击 测试配置。成功后,设置一个配置名称保存该配置以供规则使用。
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,把这里的表单值设置为空,如如下图所示:
然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。
当然,您可以选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:
第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,信息右侧的结果用于将每个信息与“|||”连接起来.
说到头像标签,用户的头像必须是“头像图片地址和用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。
幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将在论坛中发布相应的论坛 id 1,这可以根据我们的论坛论坛进行修改,以下 typname 为同样的,这个设置的好处是不需要直接通过section名和topic分类名来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就讲到这里。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块
免规则采集器列表算法(亚马逊卖家必备的数据分析采集工具-支持导出数据丰富的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-08 06:25
为了让卖家更方便的操作数据,亚马逊ASIN采集器的使用已经成为亚马逊卖家必不可少的数据分析工具。它可以用于产品的跟踪和选择以及数据分析和调查等多个方面。
兼容多个国家
支持采集 的国家包括中国、美国、英国、法国、德国、日本、加拿大和意大利的站点。
支持采集变体(子产品)
支持采集变体支持采集变体型号、颜色尺寸、高清图片、详细图片、价格、报价等。
支持采集高清图像:
支持1080p超高清图片,支持采集主图和副图等多图采集。支持自定义图片保存文件名。新增图片批量下载功能,可以有效帮助卖家整理和采集后期图片。
支持导出表
可以直接用excel打表格、导出图片、导出数据到数据库。图片还可以进一步导入到表格中,操作起来更加方便快捷。
支持过滤器
支持多配置保存、分类过滤、标题过滤、跳过采集传递的ASIN。
采集 丰富的数据
支持多字段丰富,可以采集主副图片产品信息,支持自定义段落调整。
采集速度相当稳定,速度快,多种反屏蔽措施
拥有专业的采集算法,处理问题更快,采用多种网络采集模式,支持HTTP代理批量添加和随机切换模式,还可以采集统计数据。
丰富的功能可以帮助卖家更好的处理问题
自带丰富的小工具,价格批量修改,价格条件删除器,Sku生成器,图片浏览,冗余ASIN删除功能。
围绕ASIN可以在多种情况下批量处理采集
支持采集所有商品评论内容回复、采集卖家等功能,还可以采集高清买家秀图片,任务列表也支持全屏打开。
可以过滤同一个卖家的ID链接,有效防止同一店铺出现多个采集。 查看全部
免规则采集器列表算法(亚马逊卖家必备的数据分析采集工具-支持导出数据丰富的功能)
为了让卖家更方便的操作数据,亚马逊ASIN采集器的使用已经成为亚马逊卖家必不可少的数据分析工具。它可以用于产品的跟踪和选择以及数据分析和调查等多个方面。
兼容多个国家
支持采集 的国家包括中国、美国、英国、法国、德国、日本、加拿大和意大利的站点。
支持采集变体(子产品)
支持采集变体支持采集变体型号、颜色尺寸、高清图片、详细图片、价格、报价等。
支持采集高清图像:
支持1080p超高清图片,支持采集主图和副图等多图采集。支持自定义图片保存文件名。新增图片批量下载功能,可以有效帮助卖家整理和采集后期图片。
支持导出表
可以直接用excel打表格、导出图片、导出数据到数据库。图片还可以进一步导入到表格中,操作起来更加方便快捷。
支持过滤器
支持多配置保存、分类过滤、标题过滤、跳过采集传递的ASIN。
采集 丰富的数据
支持多字段丰富,可以采集主副图片产品信息,支持自定义段落调整。
采集速度相当稳定,速度快,多种反屏蔽措施
拥有专业的采集算法,处理问题更快,采用多种网络采集模式,支持HTTP代理批量添加和随机切换模式,还可以采集统计数据。
丰富的功能可以帮助卖家更好的处理问题
自带丰富的小工具,价格批量修改,价格条件删除器,Sku生成器,图片浏览,冗余ASIN删除功能。
围绕ASIN可以在多种情况下批量处理采集
支持采集所有商品评论内容回复、采集卖家等功能,还可以采集高清买家秀图片,任务列表也支持全屏打开。
可以过滤同一个卖家的ID链接,有效防止同一店铺出现多个采集。
免规则采集器列表算法( 百度新推出劲风算法,打击恶意获取流量的聚合页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-07 13:17
百度新推出劲风算法,打击恶意获取流量的聚合页)
强风算法后网站如何整改恢复
近期,百度推出金峰算法,主要打击恶意获取流量的聚合页面。当一个算法在百度上线时,站长可以通过过去的历史数据趋势图或者网站监测到的一些功能来了解这些算法对自己的影响网站。
1、对于网站领域太分散
建议确定一个主要领域,去除其他领域的内容机器人,屏蔽搜索引擎抓取,不再参与搜索引擎排名;
或者删除其他字段的内容,将删除内容的URL提交到百度搜索资源平台404,确保网站安全。
2、对于不一致的文字
您可以查看每个聚合页面的主题,以确保聚合页面下的内容与当前聚合页面主题的扩展相关。
通过内容相似度计算的方式提取和计算网页中的正文。获取当前聚合页面的主题和内容之间的相似度分数。
并且通过实际观察,确保相似度得分在哪个值,才能解决搜索用户的需求。
3、用于搜索批量生成
大大提高了搜索检索到的内容的相关性,从而增强了用户体验。
使用相似度判断方法,让编辑辅助聚合页面的内容编写(规划的相似度分值)。
如果最终还是不能保证满足用户需求,建议删除或者操作机器人。
4、对于内容为空或太少,甚至无效
首先,搜索和整理更多类别的内容,提高聚合页面下内容的整体丰富度,保证前期的相关性。
其次,可以对聚合页面关键词进行分类。
例如:爬虫爬虫、爬虫算法、搜索引擎爬虫、baiduspider,都被认为是一种聚合页面。
当内容为空或少于X项时,可以通过展开检索到的维度来完成。
另外,由于404页面已经被收录或者爬虫爬过,建议提交百度搜索资源平台的死链接提交工具,以确保搜索引擎不认为有很多 网站 死链接。 查看全部
免规则采集器列表算法(
百度新推出劲风算法,打击恶意获取流量的聚合页)
强风算法后网站如何整改恢复
近期,百度推出金峰算法,主要打击恶意获取流量的聚合页面。当一个算法在百度上线时,站长可以通过过去的历史数据趋势图或者网站监测到的一些功能来了解这些算法对自己的影响网站。
1、对于网站领域太分散
建议确定一个主要领域,去除其他领域的内容机器人,屏蔽搜索引擎抓取,不再参与搜索引擎排名;
或者删除其他字段的内容,将删除内容的URL提交到百度搜索资源平台404,确保网站安全。
2、对于不一致的文字
您可以查看每个聚合页面的主题,以确保聚合页面下的内容与当前聚合页面主题的扩展相关。
通过内容相似度计算的方式提取和计算网页中的正文。获取当前聚合页面的主题和内容之间的相似度分数。
并且通过实际观察,确保相似度得分在哪个值,才能解决搜索用户的需求。
3、用于搜索批量生成
大大提高了搜索检索到的内容的相关性,从而增强了用户体验。
使用相似度判断方法,让编辑辅助聚合页面的内容编写(规划的相似度分值)。
如果最终还是不能保证满足用户需求,建议删除或者操作机器人。
4、对于内容为空或太少,甚至无效
首先,搜索和整理更多类别的内容,提高聚合页面下内容的整体丰富度,保证前期的相关性。
其次,可以对聚合页面关键词进行分类。
例如:爬虫爬虫、爬虫算法、搜索引擎爬虫、baiduspider,都被认为是一种聚合页面。
当内容为空或少于X项时,可以通过展开检索到的维度来完成。
另外,由于404页面已经被收录或者爬虫爬过,建议提交百度搜索资源平台的死链接提交工具,以确保搜索引擎不认为有很多 网站 死链接。
免规则采集器列表算法(一个隐私数据保护保护主要流程及步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-07 00:22
让我们看看最常见的案例之一:消费者隐私数据保护。
场景介绍
近年来,随着消费者个人意识的兴起和对隐私的重视,数据安全成为越来越热门的话题,国家陆续出台了一些相关法规来规范采集和数据的使用。. 企业在发展过程中,如果不重视敏感数据的保护和数据安全体系的建设,一旦发生敏感数据泄露事件,就会损害企业的声誉,影响业务;更重要的是直接接触法律。受到主管当局的处罚和制裁。
在企业领域的敏感信息中,个人敏感信息是绝对的大头,包括个人身份信息(姓名、身份证号码)、联系方式(手机、邮箱、地址)、个人财产信息、生物识别信息等。个人敏感数据。数据一旦泄露,将对用户的个人生活和企业的业务运营造成极大的损害。因此,在企业的业务运营中,必须对消费者的个人隐私数据进行脱敏和保护。
图:支付宝,用户名和用户账号脱敏保护
主要流程
首先我们回顾一下在Dataphin上实现敏感数据保护的主要流程:
在Dataphin中,敏感数据保护的实现可以分为以下三个步骤:
1、识别敏感数据:设置数据分类、数据分类、识别规则等。
2、 设置敏感数据保护方法:为识别出的敏感数据选择合适的脱敏算法并设置脱敏规则
3、数据消费:脱敏ad hoc查询、开发数据写入和生产等场景的数据消费。
详细步骤
接下来,我们以用户敏感信息中最常见的用户名为例,一步步展示如何识别和脱敏用户名。
1、识别敏感数据
假设我们已经建立了数据分类和数据分类(Dataphin 将内置通用分类和分类标准并支持开箱即用),我们直接进入创建新识别规则的模拟步骤:
为[用户名]创建一个新的识别规则;
扫描范围选择【全部】;
选择【内置识别】-【名称】作为扫描方式(如果用户名字段为【名称】,还可以配置常规规则【^名称$】);
数据分类选择【个人数据(C)】;
数据分类选择【机密数据(L3)】)(根据自身企业情况灵活调整平衡);
优先级选择【3】(中优先级,根据自身企业情况灵活调整);
配置好识别规则后,我们可以触发【手动规则扫描】,或者等到第二天,系统会自动进行全局扫描。敏感数据识别的最终结果可以在【识别记录】页面看到:
2、设置敏感数据保护方法
识别出敏感数据后,下一步就是为敏感数据设置合适的保护方法,确保数据不被泄露。
Dataphin目前内置多种屏蔽脱敏规则(如[张三],显示为[*三]),hash脱敏规则(如[张三],显示为[615DB57AA314529AAA0FBE95B3E95BD3]),可以满足大部分业务场景在数据保护需求下,支持未来的加解密算法和自定义脱敏算法。
建议您根据业务需求选择合适的算法。比如对于用户名,在大多数业务场景(如支付宝转账)中,不能显示完整的名字,但是可以显示一部分用于身份确认,这样内置的【中文名】脱敏算法可以选择
选择合适的脱敏算法后,我们可以配置动态脱敏规则,或者以用户名为例:
为【用户名脱敏】新建一个脱敏规则;
绑定已建立的敏感数据识别规则【用户名】;
应用场景选择【写开发表】、【即席查询】;
选择脱敏方式【遮瑕面膜-中文名称】;
有效范围选择【全部】
至此,我们的敏感数据识别和保护已经配置完毕,接下来在数据消费的过程中,数据就可以得到保护了。
3、数据消耗
下面以ad hoc查询为例,展示敏感数据识别和脱敏的效果:
可以看到,我们开始写入表的数据是【张三】,因为写入了敏感数据【姓名】字段,即【用户名】,所以读取数据时,系统自动进行脱敏,操作的同学只能看到[*3],从而防止敏感数据泄露,保护数据安全。
结束语
上面的例子用一个非常简单的案例比如用户名来讲述敏感数据识别和脱敏的整个主要过程。相信可以帮助大家了解整个数据安全保护机制。除了主要的流程外,还有数据的分类和分级。开发、审查识别记录并手动修改、脱敏白名单和其他流程。同时,在企业实际的数据安全保护中,还有更多系统性的工作要做,比如制定符合企业的数据分类分级制度,建立完善的数据识别体系等。 查看全部
免规则采集器列表算法(一个隐私数据保护保护主要流程及步骤)
让我们看看最常见的案例之一:消费者隐私数据保护。
场景介绍
近年来,随着消费者个人意识的兴起和对隐私的重视,数据安全成为越来越热门的话题,国家陆续出台了一些相关法规来规范采集和数据的使用。. 企业在发展过程中,如果不重视敏感数据的保护和数据安全体系的建设,一旦发生敏感数据泄露事件,就会损害企业的声誉,影响业务;更重要的是直接接触法律。受到主管当局的处罚和制裁。
在企业领域的敏感信息中,个人敏感信息是绝对的大头,包括个人身份信息(姓名、身份证号码)、联系方式(手机、邮箱、地址)、个人财产信息、生物识别信息等。个人敏感数据。数据一旦泄露,将对用户的个人生活和企业的业务运营造成极大的损害。因此,在企业的业务运营中,必须对消费者的个人隐私数据进行脱敏和保护。
http://www.199it.com/wp-conten ... 2.png 768w" />图:支付宝,用户名和用户账号脱敏保护
主要流程
首先我们回顾一下在Dataphin上实现敏感数据保护的主要流程:
在Dataphin中,敏感数据保护的实现可以分为以下三个步骤:
1、识别敏感数据:设置数据分类、数据分类、识别规则等。
2、 设置敏感数据保护方法:为识别出的敏感数据选择合适的脱敏算法并设置脱敏规则
3、数据消费:脱敏ad hoc查询、开发数据写入和生产等场景的数据消费。
详细步骤
接下来,我们以用户敏感信息中最常见的用户名为例,一步步展示如何识别和脱敏用户名。
1、识别敏感数据
假设我们已经建立了数据分类和数据分类(Dataphin 将内置通用分类和分类标准并支持开箱即用),我们直接进入创建新识别规则的模拟步骤:
为[用户名]创建一个新的识别规则;
扫描范围选择【全部】;
选择【内置识别】-【名称】作为扫描方式(如果用户名字段为【名称】,还可以配置常规规则【^名称$】);
数据分类选择【个人数据(C)】;
数据分类选择【机密数据(L3)】)(根据自身企业情况灵活调整平衡);
优先级选择【3】(中优先级,根据自身企业情况灵活调整);
配置好识别规则后,我们可以触发【手动规则扫描】,或者等到第二天,系统会自动进行全局扫描。敏感数据识别的最终结果可以在【识别记录】页面看到:
http://www.199it.com/wp-conten ... 5.png 768w, http://www.199it.com/wp-conten ... 0.png 1536w" />2、设置敏感数据保护方法
识别出敏感数据后,下一步就是为敏感数据设置合适的保护方法,确保数据不被泄露。
Dataphin目前内置多种屏蔽脱敏规则(如[张三],显示为[*三]),hash脱敏规则(如[张三],显示为[615DB57AA314529AAA0FBE95B3E95BD3]),可以满足大部分业务场景在数据保护需求下,支持未来的加解密算法和自定义脱敏算法。
建议您根据业务需求选择合适的算法。比如对于用户名,在大多数业务场景(如支付宝转账)中,不能显示完整的名字,但是可以显示一部分用于身份确认,这样内置的【中文名】脱敏算法可以选择
选择合适的脱敏算法后,我们可以配置动态脱敏规则,或者以用户名为例:
为【用户名脱敏】新建一个脱敏规则;
绑定已建立的敏感数据识别规则【用户名】;
应用场景选择【写开发表】、【即席查询】;
选择脱敏方式【遮瑕面膜-中文名称】;
有效范围选择【全部】
http://www.199it.com/wp-conten ... 9.png 768w" />至此,我们的敏感数据识别和保护已经配置完毕,接下来在数据消费的过程中,数据就可以得到保护了。
3、数据消耗
下面以ad hoc查询为例,展示敏感数据识别和脱敏的效果:
可以看到,我们开始写入表的数据是【张三】,因为写入了敏感数据【姓名】字段,即【用户名】,所以读取数据时,系统自动进行脱敏,操作的同学只能看到[*3],从而防止敏感数据泄露,保护数据安全。
结束语
上面的例子用一个非常简单的案例比如用户名来讲述敏感数据识别和脱敏的整个主要过程。相信可以帮助大家了解整个数据安全保护机制。除了主要的流程外,还有数据的分类和分级。开发、审查识别记录并手动修改、脱敏白名单和其他流程。同时,在企业实际的数据安全保护中,还有更多系统性的工作要做,比如制定符合企业的数据分类分级制度,建立完善的数据识别体系等。
免规则采集器列表算法(【技术分析】Apriori关联规则挖掘的重要算法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-11-04 09:05
1 关联分析算法:Apriori
挖掘关联规则的重要算法:Apriori
关联规则挖掘允许我们从数据集中发现项目(项目和项目)之间的关系
概念:
支持度:指一个项目在组合中出现的次数与总次数的比值。支持度越高,组合频率越高。
置信度:指A发生时B发生的概率。
提升:指A的出现增加B出现的概率的程度。
公式:Lift(A→B)=Confidence(A→B)/Support(B),用于衡量A出现时B出现的概率
频繁项集:支持度大于或等于最小支持度(Min Support,可随机指定)阈值的项集,所以小于最小支持度的项为非频繁项集,大于或等于最小支持度的项集为频繁项集。
工作准则:
1 初始化K=1,计算K个项集的支持度;
2 过滤掉小于最小支持度的项集(随机指定);
3 如果项集为空,对应的K-1项集的结果为最终结果,或者项集只有一行,则该行为结果;
否则 K=K+1,重复步骤 1-3。
FP-Growth 算法:改进 Apriori
先验缺陷:
1 可能产生大量候选集。因为排列组合,所以组合了所有可能的项集;
2 每次计算都需要重新扫描数据集,计算每个项目集的支持度。
FP-Growth 特点:
1 创建一个 FP 树来存储频繁项集。不满足最低支持级别的项目在创建前被删除,减少存储空间。
2 整个生成过程只遍历数据集两次,大大减少了计算量。
FP-Growth原理:
1 创建项目头表(item header table)
先扫描数据集,将满足最小支持度的单项(K=1项集)从高到低排序。在这个过程中,不满足最小支持度的项目被删除。
2 构造FP树
将根节点标记为NULL节点,对过滤后的数据集进行扫描,对于每条数据,按照支持度从高到低的顺序创建节点;
如果节点存在,则计数count+1,如果不存在,则创建。同时,在创建过程中,需要更新项头表的链表。
3 通过FP树挖掘频繁项集
具体操作会用到一个叫做“条件模式库”的概念;
就是说要挖掘的节点是叶子节点,自下而上寻找FP子树,然后将FP子树的祖先节点设置为叶子节点的总和。
2 PageRank
目的是找到高质量的网页。网页之间会形成一个网络,即互联网。论文之间也存在相互引用关系。可以说
当前的网络环境是各种网络的集合。只要有网络,就会有传出和传入链,会有PR权重计算,可以用PageRank算法,社交网络也可以用这个算法来计算一个人的影响力
概念:外链指的是外链。传入链接是指传入链接;图中,页面A有2个传入链接和3个传出链接。
在简化模型中,一个网页的影响力=链集合中所有页面的加权影响力之和:
u 是要评估的页面,是页面 u 的内链集。对于链内集合中的任意页面v,它可以给u带来的影响是它自身的影响力PR(v)除以v页面的外链数,即页面v平均分配影响力PR( v) 把它给出链接,这样就统计了所有能给u带来链接的页面v,得到的总和就是网页u的影响力,即PR(u)。
为了解决简化模型中的层级泄露和层级下沉问题,出现了一种随机浏览模型:用户并不总是按照跳转链接上网,并且有可能无论他们当前在哪个页面上,他们有机会访问 转到任何其他页面,因此定义了阻尼因子 d。该因子表示用户根据跳转链接上线的概率。通常一个固定值可以取0.85,1-d=0.15表示用户不通过跳转链接访问网页,比如直接输入网址,公式为:
其中N为网页总数,由于加入了阻尼因子d,在一定程度上解决了水平泄漏和水平下沉的问题。
3 逻辑回归
逻辑回归,也叫逻辑回归,是一种常用的数据挖掘算法
虽然名字中有“回归”,但实际上是一种分类方法,主要解决二分类问题。当然,它也可以解决多分类问题,但二分类更常见。
Logistic 函数用于逻辑回归,也称为 Sigmoid 函数。
Sigmoid 函数是深度学习中经常使用的函数之一。函数公式为:
函数的图形类似于S形
为什么逻辑回归算法基于 Sigmoid 函数?
我们要实现一个二元分类任务,0表示不发生,1表示发生;
给定一些历史数据X和y,其中X代表样本的n个特征,y代表正负样本,即0或1的值。
通过对历史样本的学习,我们可以得到一个模型,当给定新的 X 时,可以预测 y。
这里得到的y是一个预测概率,通常不是0%和100%,而是中间值,那么可以认为,当概率大于50%时,就是发生了(正例),当概率小于 50% ,即不会发生(负情况)。这样就完成了二分类预测。 查看全部
免规则采集器列表算法(【技术分析】Apriori关联规则挖掘的重要算法(一))
1 关联分析算法:Apriori
挖掘关联规则的重要算法:Apriori
关联规则挖掘允许我们从数据集中发现项目(项目和项目)之间的关系
概念:
支持度:指一个项目在组合中出现的次数与总次数的比值。支持度越高,组合频率越高。
置信度:指A发生时B发生的概率。
提升:指A的出现增加B出现的概率的程度。
公式:Lift(A→B)=Confidence(A→B)/Support(B),用于衡量A出现时B出现的概率
频繁项集:支持度大于或等于最小支持度(Min Support,可随机指定)阈值的项集,所以小于最小支持度的项为非频繁项集,大于或等于最小支持度的项集为频繁项集。
工作准则:
1 初始化K=1,计算K个项集的支持度;
2 过滤掉小于最小支持度的项集(随机指定);
3 如果项集为空,对应的K-1项集的结果为最终结果,或者项集只有一行,则该行为结果;
否则 K=K+1,重复步骤 1-3。
FP-Growth 算法:改进 Apriori
先验缺陷:
1 可能产生大量候选集。因为排列组合,所以组合了所有可能的项集;
2 每次计算都需要重新扫描数据集,计算每个项目集的支持度。
FP-Growth 特点:
1 创建一个 FP 树来存储频繁项集。不满足最低支持级别的项目在创建前被删除,减少存储空间。
2 整个生成过程只遍历数据集两次,大大减少了计算量。
FP-Growth原理:
1 创建项目头表(item header table)
先扫描数据集,将满足最小支持度的单项(K=1项集)从高到低排序。在这个过程中,不满足最小支持度的项目被删除。
2 构造FP树
将根节点标记为NULL节点,对过滤后的数据集进行扫描,对于每条数据,按照支持度从高到低的顺序创建节点;
如果节点存在,则计数count+1,如果不存在,则创建。同时,在创建过程中,需要更新项头表的链表。
3 通过FP树挖掘频繁项集
具体操作会用到一个叫做“条件模式库”的概念;
就是说要挖掘的节点是叶子节点,自下而上寻找FP子树,然后将FP子树的祖先节点设置为叶子节点的总和。
2 PageRank
目的是找到高质量的网页。网页之间会形成一个网络,即互联网。论文之间也存在相互引用关系。可以说
当前的网络环境是各种网络的集合。只要有网络,就会有传出和传入链,会有PR权重计算,可以用PageRank算法,社交网络也可以用这个算法来计算一个人的影响力
概念:外链指的是外链。传入链接是指传入链接;图中,页面A有2个传入链接和3个传出链接。
在简化模型中,一个网页的影响力=链集合中所有页面的加权影响力之和:
u 是要评估的页面,是页面 u 的内链集。对于链内集合中的任意页面v,它可以给u带来的影响是它自身的影响力PR(v)除以v页面的外链数,即页面v平均分配影响力PR( v) 把它给出链接,这样就统计了所有能给u带来链接的页面v,得到的总和就是网页u的影响力,即PR(u)。
为了解决简化模型中的层级泄露和层级下沉问题,出现了一种随机浏览模型:用户并不总是按照跳转链接上网,并且有可能无论他们当前在哪个页面上,他们有机会访问 转到任何其他页面,因此定义了阻尼因子 d。该因子表示用户根据跳转链接上线的概率。通常一个固定值可以取0.85,1-d=0.15表示用户不通过跳转链接访问网页,比如直接输入网址,公式为:
其中N为网页总数,由于加入了阻尼因子d,在一定程度上解决了水平泄漏和水平下沉的问题。
3 逻辑回归
逻辑回归,也叫逻辑回归,是一种常用的数据挖掘算法
虽然名字中有“回归”,但实际上是一种分类方法,主要解决二分类问题。当然,它也可以解决多分类问题,但二分类更常见。
Logistic 函数用于逻辑回归,也称为 Sigmoid 函数。
Sigmoid 函数是深度学习中经常使用的函数之一。函数公式为:
函数的图形类似于S形
为什么逻辑回归算法基于 Sigmoid 函数?
我们要实现一个二元分类任务,0表示不发生,1表示发生;
给定一些历史数据X和y,其中X代表样本的n个特征,y代表正负样本,即0或1的值。
通过对历史样本的学习,我们可以得到一个模型,当给定新的 X 时,可以预测 y。
这里得到的y是一个预测概率,通常不是0%和100%,而是中间值,那么可以认为,当概率大于50%时,就是发生了(正例),当概率小于 50% ,即不会发生(负情况)。这样就完成了二分类预测。
免规则采集器列表算法(阿里强大的大数据建设方法论是怎样的?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-04 08:12
阿里强大的大数据建设方法论是什么?笔者从数据技术、数据模型和数据管理三个部分开始介绍,会开阔你的视野,也对你有所启发。
最近读了阿里巴巴数据技术与产品部的《大数据之路》一书。本书是关于底层数据技术沉淀的产品形态,满足各种数据应用场景,或者是在实践中提炼出的数据管理理念。都有助于开阔你的视野,也可以作为你自己结合实际情况进行数据构建的参考和参考。
接下来将从数据技术、数据模型、数据管理三个部分展开介绍。
一、数据技术文章1.1Log采集
阿里的日志采集程序包括两大系统:基于Web的日志采集程序Aplus.JS和基于APP的日志采集程序UserTrack。
以下是页面浏览日志的采集流程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get或post,以及请求资源的URL,如,HTTP版本协议号等内容,cookies等附加信息会在请求头中体现);服务器接收并解析请求,并将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行、响应头和响应体。状态行是一个3位数的状态码,用于标识服务器的处理结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档、图片、脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
当HTML文档解析到某个节点时,HTML文档中嵌入的JavaScript脚本采集当前页面参数、浏览行为的上下文信息、运行环境信息;采集 完成后发送到日志服务器,一般以 URL 参数形式反映在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存为标准日志文件,注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于精准的用户行为分析。
流程大致如下:
采集 代码嵌入目标页面,绑定待监控的交互行为;当指定的交互行为发生时,采集代码和正常的业务交互响应代码一起触发;采集 完成然后发送到采集 服务器。1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直连同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,表示数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute由四部分组成:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作;IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度和报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求;Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:
围绕Max Compute,阿里巴巴集成了多个基于不同场景的子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构演进:
SmartDQ 的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层,有如下三个模块:
二、数据建模2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储、数据使用等角度对数据进行合理的存储。
数据模型的含义:
性能方面,提高查询性能,降低IO吞吐量;在成本上,减少了冗余、结果的复用,降低了数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,它改善了统计的不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。疼痛。
索引命名约定:
派生索引 = 时间段 + 修饰符 + 原子索引
例如,过去 7 天的新 APP 用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名、均值/分位数等统计)。
2.三维设计
测度是“事实”,维度是“环境”。维度用于描述事实发生的不同环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。有两种类型的主键:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,因此如何处理维度变化是维度设计的关键任务。对于缓变尺寸,通常有以下三种处理方法:
阿里使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储方式,即添加新的时间字段(start_dt和end_dt)。与全量存储相比,优点是不变的数据不会重复存储。
但是,历史拉链存储也有缺点,即下游使用和理解成本高;时间分区可能会超出数据库的分区限制。
因此,可以有针对性地进行两个优化:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);历史拉链表是每月制作的(与每天相比,可以大大减少分区数量)。2.4 事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的几个设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。这种方法也适合采集数据分析的需要。
三、数据管理3.1元数据
元数据是数据的数据,它记录了数据从产生到消费的整个过程:数据仓库中模型的定义、各层级之间的映射关系、监控数据的数据状态、ETL任务的运行状态, 等等。
根据用途,元数据可以分为技术元数据和业务元数据:
统一元数据体系建设目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务导出,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标流程:
对底层数据进行梳理,对元数据进行分类,减少数据重复,丰富表和字段的使用;搭建中间层,在治理、存储、质量、安全等治理领域提供数据支撑;向外界提供统一的元数据服务出口。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)数据配置文件
为数据建立血缘关系图,解决研发前期搜索数据、确定口径算法、数据处理的复杂困境,节省研发成本,更高效地理解和使用数据,并标记,通过标签组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
它可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5) 驱动 ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等。 例如Data Profile判断数据可以离线后,触发OneClick数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4 数据质量
数据质量是一切有效分析和准备的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。 查看全部
免规则采集器列表算法(阿里强大的大数据建设方法论是怎样的?(组图))
阿里强大的大数据建设方法论是什么?笔者从数据技术、数据模型和数据管理三个部分开始介绍,会开阔你的视野,也对你有所启发。
最近读了阿里巴巴数据技术与产品部的《大数据之路》一书。本书是关于底层数据技术沉淀的产品形态,满足各种数据应用场景,或者是在实践中提炼出的数据管理理念。都有助于开阔你的视野,也可以作为你自己结合实际情况进行数据构建的参考和参考。
接下来将从数据技术、数据模型、数据管理三个部分展开介绍。
一、数据技术文章1.1Log采集
阿里的日志采集程序包括两大系统:基于Web的日志采集程序Aplus.JS和基于APP的日志采集程序UserTrack。
以下是页面浏览日志的采集流程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get或post,以及请求资源的URL,如,HTTP版本协议号等内容,cookies等附加信息会在请求头中体现);服务器接收并解析请求,并将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行、响应头和响应体。状态行是一个3位数的状态码,用于标识服务器的处理结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档、图片、脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
当HTML文档解析到某个节点时,HTML文档中嵌入的JavaScript脚本采集当前页面参数、浏览行为的上下文信息、运行环境信息;采集 完成后发送到日志服务器,一般以 URL 参数形式反映在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存为标准日志文件,注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于精准的用户行为分析。
流程大致如下:
采集 代码嵌入目标页面,绑定待监控的交互行为;当指定的交互行为发生时,采集代码和正常的业务交互响应代码一起触发;采集 完成然后发送到采集 服务器。1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直连同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,表示数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。源系统的日志文件通过TCP/IP 三向握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。适用于业务系统到数据仓库的增量同步。但缺点是投资比较大,需要部署中间系统提取数据,也存在数据漂移和遗漏的问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute由四部分组成:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作;IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度和报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求;Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:
围绕Max Compute,阿里巴巴集成了多个基于不同场景的子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构演进:
SmartDQ 的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层,有如下三个模块:
二、数据建模2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储、数据使用等角度对数据进行合理的存储。
数据模型的含义:
性能方面,提高查询性能,降低IO吞吐量;在成本上,减少了冗余、结果的复用,降低了数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,它改善了统计的不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。疼痛。
索引命名约定:
派生索引 = 时间段 + 修饰符 + 原子索引
例如,过去 7 天的新 APP 用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名、均值/分位数等统计)。
2.三维设计
测度是“事实”,维度是“环境”。维度用于描述事实发生的不同环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。有两种类型的主键:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,因此如何处理维度变化是维度设计的关键任务。对于缓变尺寸,通常有以下三种处理方法:
阿里使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储方式,即添加新的时间字段(start_dt和end_dt)。与全量存储相比,优点是不变的数据不会重复存储。
但是,历史拉链存储也有缺点,即下游使用和理解成本高;时间分区可能会超出数据库的分区限制。
因此,可以有针对性地进行两个优化:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);历史拉链表是每月制作的(与每天相比,可以大大减少分区数量)。2.4 事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的几个设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。这种方法也适合采集数据分析的需要。
三、数据管理3.1元数据
元数据是数据的数据,它记录了数据从产生到消费的整个过程:数据仓库中模型的定义、各层级之间的映射关系、监控数据的数据状态、ETL任务的运行状态, 等等。
根据用途,元数据可以分为技术元数据和业务元数据:
统一元数据体系建设目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务导出,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标流程:
对底层数据进行梳理,对元数据进行分类,减少数据重复,丰富表和字段的使用;搭建中间层,在治理、存储、质量、安全等治理领域提供数据支撑;向外界提供统一的元数据服务出口。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)数据配置文件
为数据建立血缘关系图,解决研发前期搜索数据、确定口径算法、数据处理的复杂困境,节省研发成本,更高效地理解和使用数据,并标记,通过标签组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
它可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5) 驱动 ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等。 例如Data Profile判断数据可以离线后,触发OneClick数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4 数据质量
数据质量是一切有效分析和准备的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。
免规则采集器列表算法(TeleportUltra(仿站扒站神器)电脑网站采集软件介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-04 08:10
Teleport Ultra 是一款电脑网站采集 软件。该工具可以完全保存指定的网站,还可以自定义保存文本或图片内容,功能多样。仿站速度极快,赶紧下载使用吧!
软件介绍
瞬移超破解版是一款实用简单的网络资源下载器。通过这个软件,用户可以监控一个网页的所有资源,并将它们下载到自己的电脑上。您可以自定义下载的内容,包括图片、文字、flash动画等资源,也可以一次性下载整个网页的所有内容,方便您设计自己的网页作品;Teleport ultra中文版提供资源搜索功能,可以创建多个搜索项,包括项目类型文件、背景图片、声音文件,甚至ZIP文件或程序都可以搜索。它运行得非常快。您可以在几分钟内扫描整个网页。有需要的朋友可以下载体验!
技能
1、要使用 Teleport,您可以创建一个收录 Internet 上一个或多个文件地址的项目文件。您还为 Teleport 提供了一些规则,定义了它将遵循的链接以及它将检索哪些文件。要发送蜘蛛任务,请选择文件菜单上的启动命令,或按工具栏上的启动按钮。
2、 一旦激活,传送蜘蛛将读取您项目的起始地址并检索它的任何文件以找到那里。然后它读取该页面上的所有链接,跟踪这些链接,并获取这些页面上的文件,直到它用完为止。
3、你可以告诉 Teleport 只检索某些类型的文件,并且只遵循某些类型的链接。例如,您可以指示它仅检索 jpg 和 gif 文件,这是世界上常见的图形文件类型万维网。您还可以指示它仅跟踪与起始地址相同域中的链接,甚至设置其“深度”搜索。您的“程序”蜘蛛的行为将决定它的距离、需要多长时间以及它将获取什么类型的文件。
4、传送蜘蛛非常灵活。它有许多可定制的探索参数来指定要跟踪的链接类型和要检索的文件类型。大多数情况下,您可以让新建项目向导为您设置项目的探索参数。新建项目向导通常会选择最适合大多数传输任务的参数。
5、teleport ultra 简体中文版使用特殊的搜索算法快速搜索网页,对其链接进行识别和分类,然后检索与“项目属性”表中指定的文件类型匹配的所有文件。
6、传送从项目的第一个起始地址开始。传送蜘蛛仔细检查页面,提取其所有链接和所有对嵌入数据的引用。如果您设置了文件类型规范,Teleport 将检索您为与页面匹配的每个文件请求的文件类型。如果不指定任何类型,Teleport 将只检索每个文件。每个检索到的文件都存储在项目子目录中,并且始终以您的项目命名。如果您要求 Teleport 获取“嵌入”文件,例如出现在网页上的图形和声音,Teleport 也会获取这些文件。
7、Telep ort spider 然后将页面的链接归类到其他页面。如果链接指向页面项目的探索深度,或者指向排除域中的页面,则该链接将被丢弃。蜘蛛依次访问剩余的页面;检查他们的链接和文件;检索他们的文件;类别链接...等。
8、如果你的项目有多个起始地址,Teleport蜘蛛会重复以上过程起始地址。
9、当 Teleport 蜘蛛浏览每个新页面时,它会将添加的页面插入到项目地图中。您可以单击项目地图中的任何年龄来选择它。检索到此页面的文件将显示在文件列表中。
使用说明
1、打开软件
点击File,然后点击New Project Wizred...,弹出如下界面,选择第一项,点击Next
然后在输入框中输入你要领取的网站的地址,点击下一步
选择所有内容,单击下一步,然后单击完成
选择好本地保存源文件的路径后,点击保存
再次点击start开始选择网站的文件
完成它
安装方法
下载后,解压rar,打开exe文件,下一步
选择安装路径后,下一步
等待进度条完成后,安装完成。
更新日志
版本 1.72,2015 年 9 月 23 日
改进的解析器,更好地处理脚本中的字符串
从重写过程中删除了已知问题脚本(jquery、addthis)
更新了公司联系信息 查看全部
免规则采集器列表算法(TeleportUltra(仿站扒站神器)电脑网站采集软件介绍)
Teleport Ultra 是一款电脑网站采集 软件。该工具可以完全保存指定的网站,还可以自定义保存文本或图片内容,功能多样。仿站速度极快,赶紧下载使用吧!
软件介绍
瞬移超破解版是一款实用简单的网络资源下载器。通过这个软件,用户可以监控一个网页的所有资源,并将它们下载到自己的电脑上。您可以自定义下载的内容,包括图片、文字、flash动画等资源,也可以一次性下载整个网页的所有内容,方便您设计自己的网页作品;Teleport ultra中文版提供资源搜索功能,可以创建多个搜索项,包括项目类型文件、背景图片、声音文件,甚至ZIP文件或程序都可以搜索。它运行得非常快。您可以在几分钟内扫描整个网页。有需要的朋友可以下载体验!
技能
1、要使用 Teleport,您可以创建一个收录 Internet 上一个或多个文件地址的项目文件。您还为 Teleport 提供了一些规则,定义了它将遵循的链接以及它将检索哪些文件。要发送蜘蛛任务,请选择文件菜单上的启动命令,或按工具栏上的启动按钮。
2、 一旦激活,传送蜘蛛将读取您项目的起始地址并检索它的任何文件以找到那里。然后它读取该页面上的所有链接,跟踪这些链接,并获取这些页面上的文件,直到它用完为止。
3、你可以告诉 Teleport 只检索某些类型的文件,并且只遵循某些类型的链接。例如,您可以指示它仅检索 jpg 和 gif 文件,这是世界上常见的图形文件类型万维网。您还可以指示它仅跟踪与起始地址相同域中的链接,甚至设置其“深度”搜索。您的“程序”蜘蛛的行为将决定它的距离、需要多长时间以及它将获取什么类型的文件。
4、传送蜘蛛非常灵活。它有许多可定制的探索参数来指定要跟踪的链接类型和要检索的文件类型。大多数情况下,您可以让新建项目向导为您设置项目的探索参数。新建项目向导通常会选择最适合大多数传输任务的参数。
5、teleport ultra 简体中文版使用特殊的搜索算法快速搜索网页,对其链接进行识别和分类,然后检索与“项目属性”表中指定的文件类型匹配的所有文件。
6、传送从项目的第一个起始地址开始。传送蜘蛛仔细检查页面,提取其所有链接和所有对嵌入数据的引用。如果您设置了文件类型规范,Teleport 将检索您为与页面匹配的每个文件请求的文件类型。如果不指定任何类型,Teleport 将只检索每个文件。每个检索到的文件都存储在项目子目录中,并且始终以您的项目命名。如果您要求 Teleport 获取“嵌入”文件,例如出现在网页上的图形和声音,Teleport 也会获取这些文件。
7、Telep ort spider 然后将页面的链接归类到其他页面。如果链接指向页面项目的探索深度,或者指向排除域中的页面,则该链接将被丢弃。蜘蛛依次访问剩余的页面;检查他们的链接和文件;检索他们的文件;类别链接...等。
8、如果你的项目有多个起始地址,Teleport蜘蛛会重复以上过程起始地址。
9、当 Teleport 蜘蛛浏览每个新页面时,它会将添加的页面插入到项目地图中。您可以单击项目地图中的任何年龄来选择它。检索到此页面的文件将显示在文件列表中。
使用说明
1、打开软件
点击File,然后点击New Project Wizred...,弹出如下界面,选择第一项,点击Next
然后在输入框中输入你要领取的网站的地址,点击下一步
选择所有内容,单击下一步,然后单击完成
选择好本地保存源文件的路径后,点击保存
再次点击start开始选择网站的文件
完成它
安装方法
下载后,解压rar,打开exe文件,下一步
选择安装路径后,下一步
等待进度条完成后,安装完成。
更新日志
版本 1.72,2015 年 9 月 23 日
改进的解析器,更好地处理脚本中的字符串
从重写过程中删除了已知问题脚本(jquery、addthis)
更新了公司联系信息
免规则采集器列表算法(关键词故障原语,静态故障,存储器存储器测试,故障覆盖率)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-03 03:00
苏彦鹏薛仲杰一定是明寒雷人
基于适用于静态简化故障测试的MarchSS算法,提出了一种改进的嵌入式随机存取存储器测试算法——MarchSSE算法。在相同的测试长度下,该算法不仅可以检测出MarchSS算法测试的所有功能故障,还可以检测出MarchSS算法遗漏的固定开路故障,以及大部分动态故障,故障覆盖率率获得。有了很大的改善。关键词故障原语、静态故障、动态故障、内存测试、故障覆盖
1 简介
随着深亚微米VLSI技术的发展,来自不同制造商的大量电路设计或内核被集成在单个芯片上。内存密度的增加使得内存测试面临更大的挑战。嵌入式RAM存储器是最难测试的电路,因为存储器测试通常需要大量的测试模式来激活存储器并读出存储器的单元内容与标准值进行比较。在可接受的测试成本和测试时间的限制下,准确的故障模型和有效的测试算法是必不可少的。为了保证测试时间和故障覆盖率,测试的质量很大程度上取决于所选的功能故障模型。
以前关于故障模型的大多数论文都将故障的敏感性固定为最多一个操作(例如一次读取或一次写入)。这些功能故障称为静态功能故障。基于缺陷注入和SPICE仿真对DRAM的测试分析表明,还有一种故障可以通过多个操作进行敏感化,而没有静态故障(如连续读写操作),即动态故障。大多数测试算法主要针对静态故障,动态故障的覆盖率较低,但动态故障的测试也很重要[1]。
2 内存故障模型
故障模型可以用故障原语(Fault Primitive)来表示。单个单元故障用符号表示,两个单元耦合故障用符号表示。S表示单个单元的敏化操作序列,Sa表示耦合单元的敏化操作序列,Sv表示耦合单元的敏化操作序列,F表示故障单元的值F{0,1},R表示读操作的逻辑输出值R{0,1,-}。'-'表示写操作被激活,没有输出值。故障原语可以构成一套完整的操作序列,驱动所有记忆功能的故障。
2.1 单机静态故障
单个单元静态故障有12个可能的故障原语,这12个故障原语可以看作是六个功能故障模型的集合。以下是六种功能故障: 1)状态故障(State Fault);2)转换故障;3)写干扰故障;4)读取破坏性故障;5)False Read Deceptive Read Destructive Fault;6) 读取错误错误。文章[2] 中详细解释了这些故障。
在文章[3]中提到,Stuck-at Faults的故障原语是</0/->和</1/->,所以固定故障被认为是状态故障和转移故障的联合。Stuck OPEN Fault[4]是由于字线断线引起的,即0w1或1w0的操作无法完成,所以可以认为是转换故障;另外,由于存储器的读出依赖于灵敏放大器,可以认为是误读故障,所以固定开路故障被认为是转换故障和误读故障的并集。
2.2静态耦合失败
静态耦合故障的故障原语共有36种,可归纳为以下七种功能故障模型[2]:1)状态耦合故障;2) 干扰耦合故障(Disturb Coupling Fault);3)转换耦合故障;4)写破坏性耦合故障;5)读取破坏性耦合错误;6)欺骗性读取破坏性耦合错误;7)不正确的读取耦合故障。文章[2] 中详细解释了这些故障。
2.3单机动态失效
只考虑 S=xWyRz 的情况。单个单元动态故障的故障原语有12种,可归纳为以下三种功能故障模型:1)动态读破坏性故障;2)动态读取破坏性故障动态欺骗性读取破坏性故障(Dynamic Deceptive Read Destructive Fault);3) 动态错误读取错误。文章[1] 中详细解释了这些故障。
2.4动态耦合失败
主要分析两台机组的动态耦合故障,可分为四种类型。只研究其中的两个(两个连续操作应用于耦合单元,两个连续操作应用于耦合单元)。两台机组动态耦合故障的故障原语共有32种,可归纳为以下四种功能故障模型[1]:
1)动态干扰耦合故障(Dynamic Disturb Coupling Fault):连续两次写入耦合单元,读操作导致耦合单元的值发生跳跃。
2)动态读取破坏性耦合故障(Dynamic Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变存储单元的逻辑值并输出错误。价值。
3)Dynamic Deceptive Read Destructive Coupling Fault(Dynamic Deceptive Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变了存储单元的逻辑,但输出的是正确的值。
4)Dynamic Incorrect Read Coupling Fault(动态错误读取耦合故障):耦合单元的某个值导致耦合单元连续写入两次。读操作返回错误值,但没有出现存储单元的值。改变。
3 内存测试
文章[2]中提到的March SS算法如图1所示,认为能够检测到上述所有静态简化故障。在文章[3]中,固定开路故障被视为转换故障和误读故障的并集。但是,由于固定开路故障的敏感性,上次读取的值必须与本次读取的值相反。因此,测试它的算法不同于错误读取失败的算法。通过对图1所示的March SS算法的分析,很容易发现它不能检测到固定的开路故障,只有在对其四个元素M1、M2、M3、M4中的任何一个进行最后一次写操作后才进行加法读取操作可以检测固定的开路故障(例如,添加 r1) 到元素 M1 的 w1 的末尾。为了规律性,您可以在 M1、M2、M3 和 M4 四个元素中添加一个。读操作,得到March SS'算法,其算法如图2所示。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_0.gif" border=0>
图1. March SS算法
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_1.gif" border=0>
图2. March SS'算法
附加读操作仅影响由该读操作敏感的故障检测。至于其他静态故障的检测,由于增加的读操作不会影响存储单元的内容,因此不会影响这些故障的覆盖范围。在读操作引起的故障中,除了误读破坏故障和误读破坏耦合故障以外的故障都是由读操作敏感检测的,所以算法只会增加而不是减少对这些故障的损害。覆盖范围。最后,对于伪读破坏故障和伪读破坏耦合故障,使用March SS'算法进行的测试如表1(a)和(b)所示。其中“v>a”表示地址耦合单元的地址高于耦合单元的地址,
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_2.gif" border=0>
(一种)
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_3.gif" border=0>
(二)
表1. (a) March SS'算法对误读损坏故障的覆盖率,(b) March SS'算法对误读损坏耦合故障的覆盖率
算法March SS'中四个元素M1、M2、M3、M4的第二次读操作主要是检测第一次读操作敏感的伪读损坏和伪读损坏耦合故障,对于其他有对故障检测没有贡献,所以去掉这些读操作不会影响除这两个故障以外的故障检测。从表1(a)和(b)可以看出,如果没有这四种读操作,也可以检测到假读破坏故障和假读破坏耦合故障。因此,可以去掉March SS'算法中四个元素M1、M2、M3、M4的二次读操作,得到如图3-March SSE算法的改进算法。该算法还可以检测所有上述静态故障。此外,它还可以检测 March SS 无法检测到的静态故障,即固定开路。提高了故障覆盖率。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_4.gif" border=0>
图3. March SSE算法
我们来看看March SS算法和March SSE算法对动态故障的测试条件。单台机组动态故障试验见表2。表第三列对应3月SS单台机组动态故障。测试情况,第四栏为3月上证所对单机动态故障的测试情况。可以看出,March SS 算法只能检测到 1/3 的故障,而 March SSE 可以检测到 5/6 的故障。
功能失效模型 (FFM)
故障原语 (FP)
三月党卫军
3月上交所
动态读取损坏失败 (dRDF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
动态误读破坏故障 (dDRDF)
M1/M2,M3/M4
M2/M3、M4/M5
动态错误读取失败 (dIRF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
表2. 3 月 SS 和 3 月 SSE 单台机组动态故障覆盖率
对于多台机组的动态耦合失效,以两台机组为例。表 3 显示了两种算法对两种动态干扰耦合故障 (dCFds) 和动态误读损坏耦合故障 (dCFdrd) 的敏化和检测。另外两个动态耦合故障,动态读取失败耦合失败(dCFrd)和动态错误读取耦合失败(dCFir),很容易证明都可以通过March SSE算法进行测试,而March SS只能检测到一半的故障。对于两台机组总的动态耦合故障,March SS算法只能检测到3/8的故障,而March SSE算法可以检测到7/8的故障。因此,动态故障的故障覆盖率得到了很大的提高。
实况调查团
故障原语 (FP)
三月党卫军
3月上交所
v>a
v
v>a
v
动态干扰耦合故障 (dCFds)
M1/M1
M3/M3
M1/M1
M3/M3
M1/M1
M3/M3
M4/M5
M2/M3
M4/M5
M2/M3
M4/M5
M2/M3
M3/M4
M1/M2
M3/M4
M1/M2
M3/M4
M1/M2
M2/M2
M4/M4
M2/M2
M4/M4
M2/M2
M4/M4
动态误读破坏性耦合故障 (dCFdrd)
M3/M4
M1/M2
M2/M3
M4/M5
M1/M2
M3/M4
M4/M5
M2/M3
表3. March SS和March SSE对两台机组动态耦合故障覆盖率
4。结论
本文通过对嵌入式存储器几种不同类型的动静态简化功能故障的分析,在原有March SS算法的基础上提出March SSE算法,主要用于测试静态故障。算法长度为22N,其中N为内存中的字数,每个字收录一位。与March SS算法相比,March SSE算法在测试长度不变的情况下,其故障覆盖率有显着提高。它不仅可以检测出 March SS 算法测试的所有功能故障,还可以检测出 March SS 算法遗漏的固定开路故障,以及第 2 节中描述的 85% 以上的动态故障,以及故障覆盖率一直很大。急剧增加。
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号 查看全部
免规则采集器列表算法(关键词故障原语,静态故障,存储器存储器测试,故障覆盖率)
苏彦鹏薛仲杰一定是明寒雷人
基于适用于静态简化故障测试的MarchSS算法,提出了一种改进的嵌入式随机存取存储器测试算法——MarchSSE算法。在相同的测试长度下,该算法不仅可以检测出MarchSS算法测试的所有功能故障,还可以检测出MarchSS算法遗漏的固定开路故障,以及大部分动态故障,故障覆盖率率获得。有了很大的改善。关键词故障原语、静态故障、动态故障、内存测试、故障覆盖
1 简介
随着深亚微米VLSI技术的发展,来自不同制造商的大量电路设计或内核被集成在单个芯片上。内存密度的增加使得内存测试面临更大的挑战。嵌入式RAM存储器是最难测试的电路,因为存储器测试通常需要大量的测试模式来激活存储器并读出存储器的单元内容与标准值进行比较。在可接受的测试成本和测试时间的限制下,准确的故障模型和有效的测试算法是必不可少的。为了保证测试时间和故障覆盖率,测试的质量很大程度上取决于所选的功能故障模型。
以前关于故障模型的大多数论文都将故障的敏感性固定为最多一个操作(例如一次读取或一次写入)。这些功能故障称为静态功能故障。基于缺陷注入和SPICE仿真对DRAM的测试分析表明,还有一种故障可以通过多个操作进行敏感化,而没有静态故障(如连续读写操作),即动态故障。大多数测试算法主要针对静态故障,动态故障的覆盖率较低,但动态故障的测试也很重要[1]。
2 内存故障模型
故障模型可以用故障原语(Fault Primitive)来表示。单个单元故障用符号表示,两个单元耦合故障用符号表示。S表示单个单元的敏化操作序列,Sa表示耦合单元的敏化操作序列,Sv表示耦合单元的敏化操作序列,F表示故障单元的值F{0,1},R表示读操作的逻辑输出值R{0,1,-}。'-'表示写操作被激活,没有输出值。故障原语可以构成一套完整的操作序列,驱动所有记忆功能的故障。
2.1 单机静态故障
单个单元静态故障有12个可能的故障原语,这12个故障原语可以看作是六个功能故障模型的集合。以下是六种功能故障: 1)状态故障(State Fault);2)转换故障;3)写干扰故障;4)读取破坏性故障;5)False Read Deceptive Read Destructive Fault;6) 读取错误错误。文章[2] 中详细解释了这些故障。
在文章[3]中提到,Stuck-at Faults的故障原语是</0/->和</1/->,所以固定故障被认为是状态故障和转移故障的联合。Stuck OPEN Fault[4]是由于字线断线引起的,即0w1或1w0的操作无法完成,所以可以认为是转换故障;另外,由于存储器的读出依赖于灵敏放大器,可以认为是误读故障,所以固定开路故障被认为是转换故障和误读故障的并集。
2.2静态耦合失败
静态耦合故障的故障原语共有36种,可归纳为以下七种功能故障模型[2]:1)状态耦合故障;2) 干扰耦合故障(Disturb Coupling Fault);3)转换耦合故障;4)写破坏性耦合故障;5)读取破坏性耦合错误;6)欺骗性读取破坏性耦合错误;7)不正确的读取耦合故障。文章[2] 中详细解释了这些故障。
2.3单机动态失效
只考虑 S=xWyRz 的情况。单个单元动态故障的故障原语有12种,可归纳为以下三种功能故障模型:1)动态读破坏性故障;2)动态读取破坏性故障动态欺骗性读取破坏性故障(Dynamic Deceptive Read Destructive Fault);3) 动态错误读取错误。文章[1] 中详细解释了这些故障。
2.4动态耦合失败
主要分析两台机组的动态耦合故障,可分为四种类型。只研究其中的两个(两个连续操作应用于耦合单元,两个连续操作应用于耦合单元)。两台机组动态耦合故障的故障原语共有32种,可归纳为以下四种功能故障模型[1]:
1)动态干扰耦合故障(Dynamic Disturb Coupling Fault):连续两次写入耦合单元,读操作导致耦合单元的值发生跳跃。
2)动态读取破坏性耦合故障(Dynamic Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变存储单元的逻辑值并输出错误。价值。
3)Dynamic Deceptive Read Destructive Coupling Fault(Dynamic Deceptive Read Destructive Coupling Fault):耦合单元的某个值导致耦合单元连续写入两次。读操作改变了存储单元的逻辑,但输出的是正确的值。
4)Dynamic Incorrect Read Coupling Fault(动态错误读取耦合故障):耦合单元的某个值导致耦合单元连续写入两次。读操作返回错误值,但没有出现存储单元的值。改变。
3 内存测试
文章[2]中提到的March SS算法如图1所示,认为能够检测到上述所有静态简化故障。在文章[3]中,固定开路故障被视为转换故障和误读故障的并集。但是,由于固定开路故障的敏感性,上次读取的值必须与本次读取的值相反。因此,测试它的算法不同于错误读取失败的算法。通过对图1所示的March SS算法的分析,很容易发现它不能检测到固定的开路故障,只有在对其四个元素M1、M2、M3、M4中的任何一个进行最后一次写操作后才进行加法读取操作可以检测固定的开路故障(例如,添加 r1) 到元素 M1 的 w1 的末尾。为了规律性,您可以在 M1、M2、M3 和 M4 四个元素中添加一个。读操作,得到March SS'算法,其算法如图2所示。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_0.gif" border=0>
图1. March SS算法
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_1.gif" border=0>
图2. March SS'算法
附加读操作仅影响由该读操作敏感的故障检测。至于其他静态故障的检测,由于增加的读操作不会影响存储单元的内容,因此不会影响这些故障的覆盖范围。在读操作引起的故障中,除了误读破坏故障和误读破坏耦合故障以外的故障都是由读操作敏感检测的,所以算法只会增加而不是减少对这些故障的损害。覆盖范围。最后,对于伪读破坏故障和伪读破坏耦合故障,使用March SS'算法进行的测试如表1(a)和(b)所示。其中“v>a”表示地址耦合单元的地址高于耦合单元的地址,
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_2.gif" border=0>
(一种)
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_3.gif" border=0>
(二)
表1. (a) March SS'算法对误读损坏故障的覆盖率,(b) March SS'算法对误读损坏耦合故障的覆盖率
算法March SS'中四个元素M1、M2、M3、M4的第二次读操作主要是检测第一次读操作敏感的伪读损坏和伪读损坏耦合故障,对于其他有对故障检测没有贡献,所以去掉这些读操作不会影响除这两个故障以外的故障检测。从表1(a)和(b)可以看出,如果没有这四种读操作,也可以检测到假读破坏故障和假读破坏耦合故障。因此,可以去掉March SS'算法中四个元素M1、M2、M3、M4的二次读操作,得到如图3-March SSE算法的改进算法。该算法还可以检测所有上述静态故障。此外,它还可以检测 March SS 无法检测到的静态故障,即固定开路。提高了故障覆盖率。
<IMG src="/2008file/tech/2008-2-10/0210195857_10668_4.gif" border=0>
图3. March SSE算法
我们来看看March SS算法和March SSE算法对动态故障的测试条件。单台机组动态故障试验见表2。表第三列对应3月SS单台机组动态故障。测试情况,第四栏为3月上证所对单机动态故障的测试情况。可以看出,March SS 算法只能检测到 1/3 的故障,而 March SSE 可以检测到 5/6 的故障。
功能失效模型 (FFM)
故障原语 (FP)
三月党卫军
3月上交所
动态读取损坏失败 (dRDF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
动态误读破坏故障 (dDRDF)
M1/M2,M3/M4
M2/M3、M4/M5
动态错误读取失败 (dIRF)
M1、M3
M1、M3
M1、M3
M2、M4
M2、M4
M2、M4
表2. 3 月 SS 和 3 月 SSE 单台机组动态故障覆盖率
对于多台机组的动态耦合失效,以两台机组为例。表 3 显示了两种算法对两种动态干扰耦合故障 (dCFds) 和动态误读损坏耦合故障 (dCFdrd) 的敏化和检测。另外两个动态耦合故障,动态读取失败耦合失败(dCFrd)和动态错误读取耦合失败(dCFir),很容易证明都可以通过March SSE算法进行测试,而March SS只能检测到一半的故障。对于两台机组总的动态耦合故障,March SS算法只能检测到3/8的故障,而March SSE算法可以检测到7/8的故障。因此,动态故障的故障覆盖率得到了很大的提高。
实况调查团
故障原语 (FP)
三月党卫军
3月上交所
v>a
v
v>a
v
动态干扰耦合故障 (dCFds)
M1/M1
M3/M3
M1/M1
M3/M3
M1/M1
M3/M3
M4/M5
M2/M3
M4/M5
M2/M3
M4/M5
M2/M3
M3/M4
M1/M2
M3/M4
M1/M2
M3/M4
M1/M2
M2/M2
M4/M4
M2/M2
M4/M4
M2/M2
M4/M4
动态误读破坏性耦合故障 (dCFdrd)
M3/M4
M1/M2
M2/M3
M4/M5
M1/M2
M3/M4
M4/M5
M2/M3
表3. March SS和March SSE对两台机组动态耦合故障覆盖率
4。结论
本文通过对嵌入式存储器几种不同类型的动静态简化功能故障的分析,在原有March SS算法的基础上提出March SSE算法,主要用于测试静态故障。算法长度为22N,其中N为内存中的字数,每个字收录一位。与March SS算法相比,March SSE算法在测试长度不变的情况下,其故障覆盖率有显着提高。它不仅可以检测出 March SS 算法测试的所有功能故障,还可以检测出 March SS 算法遗漏的固定开路故障,以及第 2 节中描述的 85% 以上的动态故障,以及故障覆盖率一直很大。急剧增加。
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
IC37:专业IC产业平台
专业的IC领域供需交易平台:提供全面的IC Datasheet数据和信息,Datasheet 1000万条数据,1000多个IC品牌。
网站导航数据表数据库IC模型
服务中心
关于我们
产品索引:
深圳网警报警平台运营网站不良信息备案信息举报中心
服务热线:-32882616 0755-32882606 0755-32882608 0755-32882607 0755-32882607 0755-32882615 责任与投诉热线:©2018 IC37 网 版权所有:版权声明 48882608 粤ICP备4963016号
免规则采集器列表算法(在一种自顶向下的研究机器学习的方法中,理论应立足于何处?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-03 00:19
在机器学习的自上而下方法中,理论应该在哪里?
在传统的机器学习教学计划中,理论首先需要足够广泛的数学背景才能理解。在我的机器学习教学计划中,我会教你如何从头开始解决端到端的问题并做出结果。
那么,理论更适合出现在哪里呢?
在这个文章中,当我们谈论机器学习中的“理论”时,您将确切地了解我们在谈论什么。提示:这都是关于算法的。
你会发现,一旦你能熟练地解决问题并得到结果,你就会不由自主地深入学习,更好地理解结果,提交更好的结果。没有人能阻止你。
最后,您将发现在标准数据集上进行机器学习时可以使用的 5 种技术,以逐步增强您对机器学习算法的理解。
如何在没有数学的情况下学习机器学习
照片由 Ed Brambley 提供,保留部分权利
理论学习是最后的,不是第一次
开发人员教他们如何学习机器学习是没有用的。
这种方法是自上而下的教育。对你来说没用——如果你是一个开发者,只想用机器学习作为解决问题的工具,而不是成为这个领域的研究人员。
传统的学习方法要求你在学习算法理论之前先学习线性代数、概率和统计等数学知识。如果您正在研究算法的实现或讨论如何端到端地处理问题并提供可运行、可靠且准确的预测模型,那么您很幸运。
下面我教大家一个自顶向下的机器学习学习方法。在这个方法中,我们将从1)学习一个系统的流程来处理端到端的问题,2)将流程映射到“最好的”机器学习工具和平台,然后3)在测试数据集上完成有针对性的练习。
您可以在“程序员的机器学习:从开发人员到机器学习从业者的飞跃”文章 中了解有关自顶向下机器学习方法的更多信息。
那么该理论应该在哪里适合这个过程呢?
如果要逆向学习过程,这种情况将在后面讨论。但是当我们使用测试数据集来训练模型时,我们在谈论什么理论?你究竟应该如何学习这个理论?
获取免费的算法思维导图
示例-易于使用的机器学习算法思维导图
我创建了一个方便的思维导图,其中收录 60 多种按类型组合的算法。
您可以下载它,打印出来并使用它。
免费下载
您还可以通过电子邮件享受迷你机器学习算法课程。
算法就是理论上的一切
机器学习领域充满了理论。
它之所以密集,是因为该领域有使用数学来描述和解释概念的传统。
这很有用,因为数学描述可以非常简洁并减少歧义。他们还可以使用所描述环境中的技术(例如对过程的概率理解)进行分析。
许多这些不重要的技术通常与机器学习算法的描述捆绑在一起。对于一个只是想对一个方法有一个比较浅薄的了解,然后能够配置和应用的人来说,这种感觉很难让人开心。这太令人沮丧了。
如果你没有基础去解析和理解算法的描述,那会让你非常沮丧。此外,令人沮丧的是,从计算机科学等领域,总是描述算法,区别在于算法的描述是为了快速理解(例如桌面检查)还是应用程序。
比如我们知道,在学习哈希表是什么以及如何使用哈希表时,我们几乎不需要知道哈希函数在日常工作中是做什么的。但是我们也可以知道什么是哈希函数,知道从哪里可以了解更多关于哈希函数的具体细节以及如何编写自己的哈希函数。那么为什么机器学习不能这样应用呢?
在学习机器学习中遇到的大部分“理论”都与机器学习算法有关。如果你问任何其他初学者为什么他们对这个理论感到沮丧,那么你就会知道这与学习如何理解或使用特定的机器学习算法有关。
在这里,算法的研究比创建预测模型的过程更广泛。它是指选择特征、设计新特征、转换数据以及估计模型在不可见数据上的准确性(例如交叉验证)的算法过程。
所以,归根结底,学习理论意味着学习机器学习算法。
被迫钻研理论
我通常建议在著名的机器学习数据集上进行有针对性的练习。
由于众所周知的机器学习数据集,它将与 UCI 机器学习库中的数据集一样易于使用。而且它们通常很小,因此不需要太多内存,因此可以在工作站上进行处理。它们也可用于良好的理解和研究,因此您可以有一个比较基准。
可以在《使用UCI机器学习库中的小型低内存数据库进行机器学习实践》文章中了解更多关于机器学习数据集的实践。
了解机器学习算法在这个过程中的应用。原因是当你追求标准机器学习算法的结果时,你会遇到限制。你会想知道如何从给定的算法中获取更多信息,或者如何更好地配置它,或者如何实际工作。
这需要更多的知识和好奇心,这些东西会促使你学习机器学习算法的理论。为了得到更好的结果,你将被迫拼凑对算法的一些理解。
我们也看到了来自不同背景的年轻开发者的同样效果,他们最终通过研究开源项目的代码、教科书甚至研究论文来磨练自己的手艺。促使他们这样做的原因是需要成为更好、更有能力的程序员。
如果你对成功充满好奇和动力,你必须学习这个理论。
理解机器学习算法的 5 个技巧
你的目标练习时间的一部分将用于学习机器学习算法
到时候可以用一些技巧和模板来缩短这个过程。
在本节中,您将发现可用于快速理解机器学习算法理论的 5 种技术。
1)创建机器学习算法列表
当您刚开始学习时,您可能会被大量可用的算法所淹没。
即使您尝试在现场测试算法,您可能仍然不确定哪些算法将收录在您的混合算法中(提示,有很多不同的算法)。
跟踪您阅读的算法是一项很好的技术,您可以在开始时使用。这些列表可以像算法名称一样简单,也可以随着您的兴趣和好奇心的增加而增加复杂性。
您还可以捕获详细信息,例如适当的问题类型(分类或回归)、相关算法和分类类别(决策树、内核等)。当您看到新算法的名称时,请将其添加到您的列表中。当你开始一个新问题时,你可以尝试一些你以前从未使用过的算法。或者勾选之前使用的算法等。
控制列表中的算法名称可以提供强大的功能。这个看似可笑的简单策略可以帮助你摆脱压力。您的简单算法列表可以为您节省大量时间和挫折,例如:
你必须先创建一个算法列表,请打开一个电子表格并开始创建它。
有关此技术的更多信息,请参阅“通过创建机器学习算法的目标列表进行控制”文章。
2)机器学习算法研究 查看全部
免规则采集器列表算法(在一种自顶向下的研究机器学习的方法中,理论应立足于何处?)
在机器学习的自上而下方法中,理论应该在哪里?
在传统的机器学习教学计划中,理论首先需要足够广泛的数学背景才能理解。在我的机器学习教学计划中,我会教你如何从头开始解决端到端的问题并做出结果。
那么,理论更适合出现在哪里呢?
在这个文章中,当我们谈论机器学习中的“理论”时,您将确切地了解我们在谈论什么。提示:这都是关于算法的。
你会发现,一旦你能熟练地解决问题并得到结果,你就会不由自主地深入学习,更好地理解结果,提交更好的结果。没有人能阻止你。
最后,您将发现在标准数据集上进行机器学习时可以使用的 5 种技术,以逐步增强您对机器学习算法的理解。
如何在没有数学的情况下学习机器学习
照片由 Ed Brambley 提供,保留部分权利
理论学习是最后的,不是第一次
开发人员教他们如何学习机器学习是没有用的。
这种方法是自上而下的教育。对你来说没用——如果你是一个开发者,只想用机器学习作为解决问题的工具,而不是成为这个领域的研究人员。
传统的学习方法要求你在学习算法理论之前先学习线性代数、概率和统计等数学知识。如果您正在研究算法的实现或讨论如何端到端地处理问题并提供可运行、可靠且准确的预测模型,那么您很幸运。
下面我教大家一个自顶向下的机器学习学习方法。在这个方法中,我们将从1)学习一个系统的流程来处理端到端的问题,2)将流程映射到“最好的”机器学习工具和平台,然后3)在测试数据集上完成有针对性的练习。
您可以在“程序员的机器学习:从开发人员到机器学习从业者的飞跃”文章 中了解有关自顶向下机器学习方法的更多信息。
那么该理论应该在哪里适合这个过程呢?
如果要逆向学习过程,这种情况将在后面讨论。但是当我们使用测试数据集来训练模型时,我们在谈论什么理论?你究竟应该如何学习这个理论?
获取免费的算法思维导图
示例-易于使用的机器学习算法思维导图
我创建了一个方便的思维导图,其中收录 60 多种按类型组合的算法。
您可以下载它,打印出来并使用它。
免费下载
您还可以通过电子邮件享受迷你机器学习算法课程。
算法就是理论上的一切
机器学习领域充满了理论。
它之所以密集,是因为该领域有使用数学来描述和解释概念的传统。
这很有用,因为数学描述可以非常简洁并减少歧义。他们还可以使用所描述环境中的技术(例如对过程的概率理解)进行分析。
许多这些不重要的技术通常与机器学习算法的描述捆绑在一起。对于一个只是想对一个方法有一个比较浅薄的了解,然后能够配置和应用的人来说,这种感觉很难让人开心。这太令人沮丧了。
如果你没有基础去解析和理解算法的描述,那会让你非常沮丧。此外,令人沮丧的是,从计算机科学等领域,总是描述算法,区别在于算法的描述是为了快速理解(例如桌面检查)还是应用程序。
比如我们知道,在学习哈希表是什么以及如何使用哈希表时,我们几乎不需要知道哈希函数在日常工作中是做什么的。但是我们也可以知道什么是哈希函数,知道从哪里可以了解更多关于哈希函数的具体细节以及如何编写自己的哈希函数。那么为什么机器学习不能这样应用呢?
在学习机器学习中遇到的大部分“理论”都与机器学习算法有关。如果你问任何其他初学者为什么他们对这个理论感到沮丧,那么你就会知道这与学习如何理解或使用特定的机器学习算法有关。
在这里,算法的研究比创建预测模型的过程更广泛。它是指选择特征、设计新特征、转换数据以及估计模型在不可见数据上的准确性(例如交叉验证)的算法过程。
所以,归根结底,学习理论意味着学习机器学习算法。
被迫钻研理论
我通常建议在著名的机器学习数据集上进行有针对性的练习。
由于众所周知的机器学习数据集,它将与 UCI 机器学习库中的数据集一样易于使用。而且它们通常很小,因此不需要太多内存,因此可以在工作站上进行处理。它们也可用于良好的理解和研究,因此您可以有一个比较基准。
可以在《使用UCI机器学习库中的小型低内存数据库进行机器学习实践》文章中了解更多关于机器学习数据集的实践。
了解机器学习算法在这个过程中的应用。原因是当你追求标准机器学习算法的结果时,你会遇到限制。你会想知道如何从给定的算法中获取更多信息,或者如何更好地配置它,或者如何实际工作。
这需要更多的知识和好奇心,这些东西会促使你学习机器学习算法的理论。为了得到更好的结果,你将被迫拼凑对算法的一些理解。
我们也看到了来自不同背景的年轻开发者的同样效果,他们最终通过研究开源项目的代码、教科书甚至研究论文来磨练自己的手艺。促使他们这样做的原因是需要成为更好、更有能力的程序员。
如果你对成功充满好奇和动力,你必须学习这个理论。
理解机器学习算法的 5 个技巧
你的目标练习时间的一部分将用于学习机器学习算法
到时候可以用一些技巧和模板来缩短这个过程。
在本节中,您将发现可用于快速理解机器学习算法理论的 5 种技术。
1)创建机器学习算法列表
当您刚开始学习时,您可能会被大量可用的算法所淹没。
即使您尝试在现场测试算法,您可能仍然不确定哪些算法将收录在您的混合算法中(提示,有很多不同的算法)。
跟踪您阅读的算法是一项很好的技术,您可以在开始时使用。这些列表可以像算法名称一样简单,也可以随着您的兴趣和好奇心的增加而增加复杂性。
您还可以捕获详细信息,例如适当的问题类型(分类或回归)、相关算法和分类类别(决策树、内核等)。当您看到新算法的名称时,请将其添加到您的列表中。当你开始一个新问题时,你可以尝试一些你以前从未使用过的算法。或者勾选之前使用的算法等。
控制列表中的算法名称可以提供强大的功能。这个看似可笑的简单策略可以帮助你摆脱压力。您的简单算法列表可以为您节省大量时间和挫折,例如:
你必须先创建一个算法列表,请打开一个电子表格并开始创建它。
有关此技术的更多信息,请参阅“通过创建机器学习算法的目标列表进行控制”文章。
2)机器学习算法研究
免规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-31 23:15
防止网页被搜索引擎收录搜索最常见的方法是使用robots.txt,但这样做的缺点是搜索引用的所有已知爬虫信息都必须列出,而且不可避免会有遗漏。以下方法可治标治本:(摘自)
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人为分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被 查看全部
免规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
防止网页被搜索引擎收录搜索最常见的方法是使用robots.txt,但这样做的缺点是搜索引用的所有已知爬虫信息都必须列出,而且不可避免会有遗漏。以下方法可治标治本:(摘自)
1、 限制一个IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站 5次,除非是程序访问。有了这个偏好,只剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎响应网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、屏蔽ip
分析:通过后台计数器,记录访问者的IP和访问频率,人为分析访问记录,屏蔽可疑IP。
缺点:好像没什么缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器你会怎么做:打游击战!使用ip proxy 采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:无需分析,搜索引擎爬虫和采集器传杀
适用网站:极度讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他不会来接你的
4、隐藏网站版权或网页中一些随机的垃圾文字,这些文字样式写在css文件中
<p>分析:虽然不能阻止采集,但是会在采集之后的内容里填上你的网站版权声明或者一些垃圾文字,因为一般采集器不会被

