免规则采集器列表算法(一个隐私数据保护保护主要流程及步骤)
优采云 发布时间: 2021-11-07 00:22免规则采集器列表算法(一个隐私数据保护保护主要流程及步骤)
让我们看看最常见的案例之一:消费者隐私数据保护。
场景介绍
近年来,随着消费者个人意识的兴起和对隐私的重视,数据安全成为越来越热门的话题,国家陆续出台了一些相关法规来规范采集和数据的使用。. 企业在发展过程中,如果不重视敏感数据的保护和数据安全体系的建设,一旦发生敏感数据泄露事件,就会损害企业的声誉,影响业务;更重要的是直接接触法律。受到主管当局的处罚和制裁。
在企业领域的敏感信息中,个人敏感信息是绝对的大头,包括个人身份信息(姓名、*敏*感*词*号码)、*敏*感*词*(手机、邮箱、地址)、个人财产信息、生物识别信息等。个人敏感数据。数据一旦泄露,将对用户的个人生活和企业的业务运营造成极大的损害。因此,在企业的业务运营中,必须对消费者的个人隐私数据进行脱敏和保护。
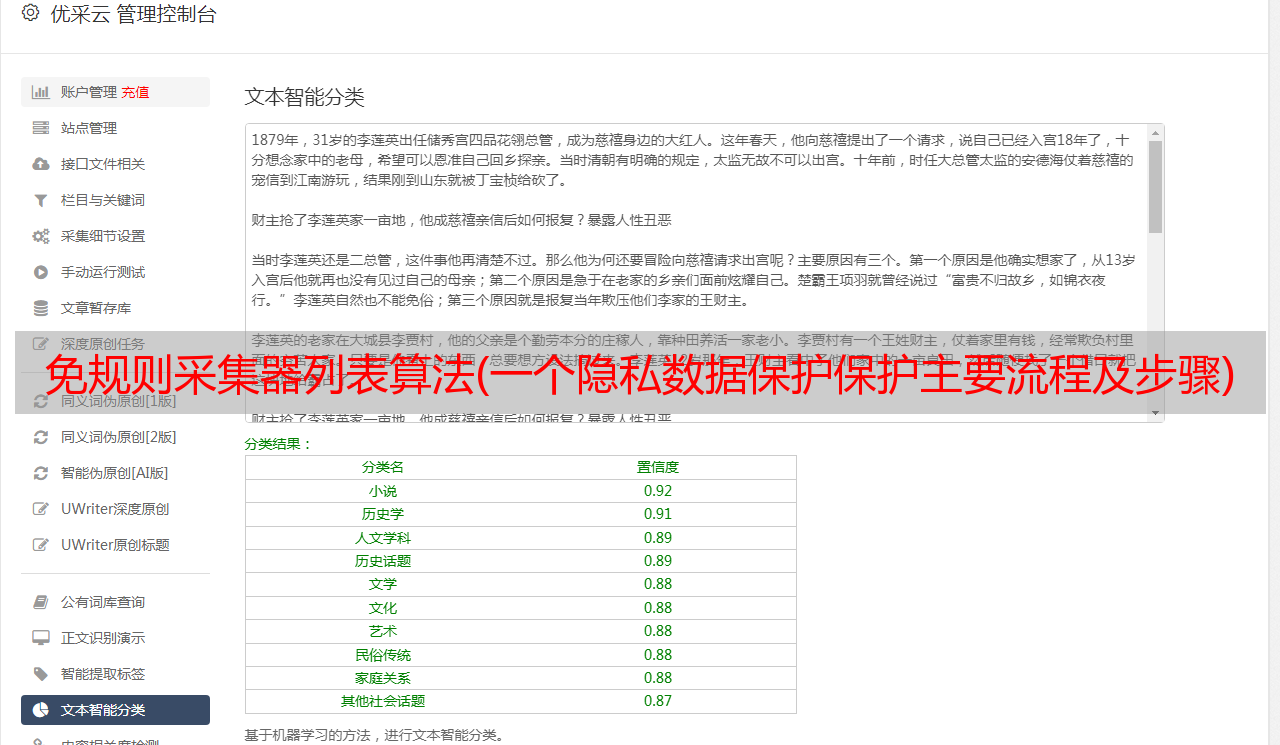
图:支付宝,用户名和用户账号脱敏保护
主要流程
首先我们回顾一下在Dataphin上实现敏感数据保护的主要流程:
在Dataphin中,敏感数据保护的实现可以分为以下三个步骤:
1、识别敏感数据:设置数据分类、数据分类、识别规则等。
2、 设置敏感数据保护方法:为识别出的敏感数据选择合适的脱敏算法并设置脱敏规则
3、数据消费:脱敏ad hoc查询、开发数据写入和生产等场景的数据消费。
详细步骤
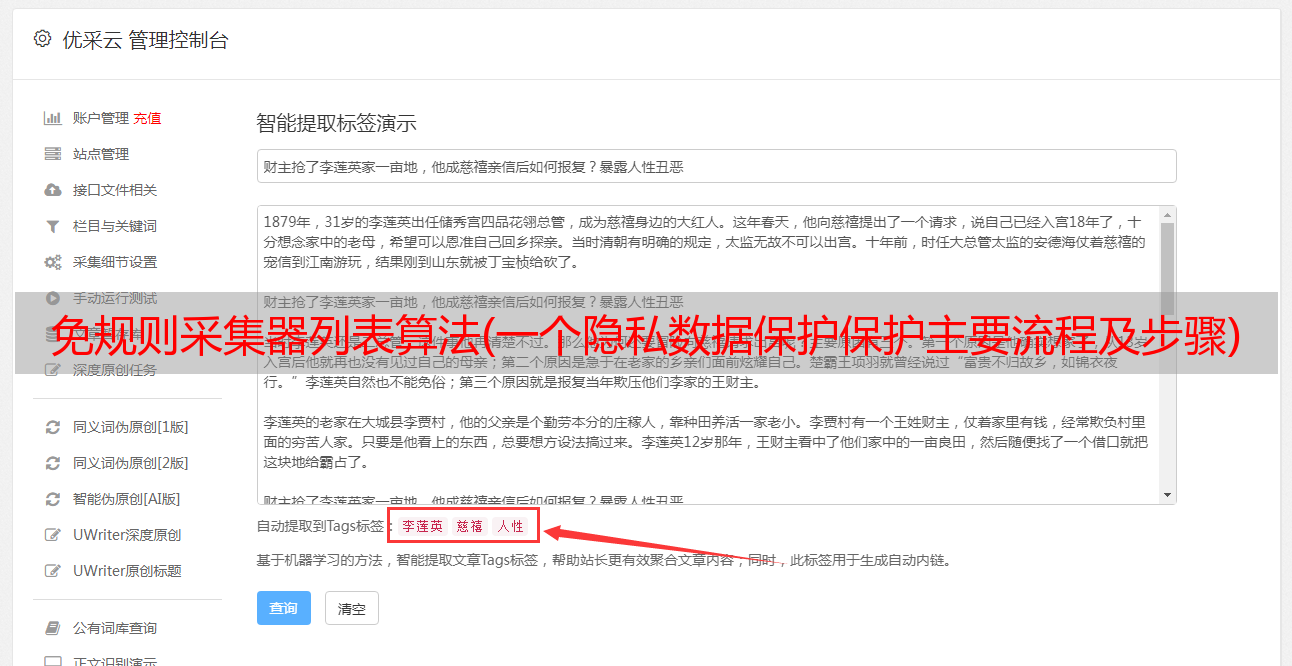
接下来,我们以用户敏感信息中最常见的用户名为例,一步步展示如何识别和脱敏用户名。
1、识别敏感数据
假设我们已经建立了数据分类和数据分类(Dataphin 将内置通用分类和分类标准并支持开箱即用),我们直接进入创建新识别规则的模拟步骤:
为[用户名]创建一个新的识别规则;
扫描范围选择【全部】;
选择【内置识别】-【名称】作为扫描方式(如果用户名字段为【名称】,还可以配置常规规则【^名称$】);
数据分类选择【个人数据(C)】;
数据分类选择【机密数据(L3)】)(根据自身企业情况灵活调整平衡);
优先级选择【3】(中优先级,根据自身企业情况灵活调整);
配置好识别规则后,我们可以触发【手动规则扫描】,或者等到第二天,系统会自动进行全局扫描。敏感数据识别的最终结果可以在【识别记录】页面看到:
2、设置敏感数据保护方法
识别出敏感数据后,下一步就是为敏感数据设置合适的保护方法,确保数据不被泄露。
Dataphin目前内置多种屏蔽脱敏规则(如[张三],显示为[*三]),hash脱敏规则(如[张三],显示为[615DB57AA314529AAA0FBE95B3E95BD3]),可以满足大部分业务场景在数据保护需求下,支持未来的加解密算法和自定义脱敏算法。
建议您根据业务需求选择合适的算法。比如对于用户名,在大多数业务场景(如支付宝转账)中,不能显示完整的名字,但是可以显示一部分用于身份确认,这样内置的【中文名】脱敏算法可以选择
选择合适的脱敏算法后,我们可以配置动态脱敏规则,或者以用户名为例:
为【用户名脱敏】新建一个脱敏规则;
绑定已建立的敏感数据识别规则【用户名】;
应用场景选择【写开发表】、【即席查询】;
选择脱敏方式【遮瑕面膜-中文名称】;
有效范围选择【全部】
至此,我们的敏感数据识别和保护已经配置完毕,接下来在数据消费的过程中,数据就可以得到保护了。
3、数据消耗
下面以ad hoc查询为例,展示敏感数据识别和脱敏的效果:
可以看到,我们开始写入表的数据是【张三】,因为写入了敏感数据【姓名】字段,即【用户名】,所以读取数据时,系统自动进行脱敏,操作的同学只能看到[*3],从而防止敏感数据泄露,保护数据安全。
结束语
上面的例子用一个非常简单的案例比如用户名来讲述敏感数据识别和脱敏的整个主要过程。相信可以帮助大家了解整个数据安全保护机制。除了主要的流程外,还有数据的分类和分级。开发、审查识别记录并手动修改、脱敏白名单和其他流程。同时,在企业实际的数据安全保护中,还有更多系统性的工作要做,比如制定符合企业的数据分类分级制度,建立完善的数据识别体系等。

