
u采 采集
u采 采集(软件介绍优采云采集器是什么插件..)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-10 01:14
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析和挖掘软件。使用优采云采集器,用户可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据,帮助用户快速构建自己的数据系统,也就是说使用优采云采集器的用户可以快速填写网站内容,构建庞大的网站。
软件功能
1.丰富的插件功能:新版本的PHP插件和C#插件在采集URL时、采集内容时、采集内容后都可以使用插件,不管是什么插件。同时,提供了更详细的插件开发开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新过程中查看采集器的工作状态。
3.更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,速度更快,管理更方便。
4.升级更方便。程序已重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可完成升级。
5.支持可选的加密狗授权。
6.命令行模式。您可以使用参数来启动程序以执行任务。可以调度任务来做定时实验采集,采集结束后退出程序
7.中文分词添加用户词库,可以添加用户排除词库。您只能使用用户词库。
8.本地采集数据管理新增图片预览功能。
9.标签可以上下排序。生成 CSV 时,根据排序生成 csv 文件。测试时,返回的结果也会显示在标签的排序中。
10.图片和flash下载排除功能。不为符合条件的文件执行下载。
11.文件上传标签可以为多个标签上传文件。
12.使用二级URL时,URL部分可以设置列表页收录区域
13.Looping采集可以使用提取关键字和摘要等功能。
14.列表标签可以编辑,比如排除和过滤、下载等。 查看全部
u采 采集(软件介绍优采云采集器是什么插件..)
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析和挖掘软件。使用优采云采集器,用户可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据,帮助用户快速构建自己的数据系统,也就是说使用优采云采集器的用户可以快速填写网站内容,构建庞大的网站。
软件功能
1.丰富的插件功能:新版本的PHP插件和C#插件在采集URL时、采集内容时、采集内容后都可以使用插件,不管是什么插件。同时,提供了更详细的插件开发开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新过程中查看采集器的工作状态。
3.更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,速度更快,管理更方便。
4.升级更方便。程序已重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可完成升级。
5.支持可选的加密狗授权。
6.命令行模式。您可以使用参数来启动程序以执行任务。可以调度任务来做定时实验采集,采集结束后退出程序
7.中文分词添加用户词库,可以添加用户排除词库。您只能使用用户词库。
8.本地采集数据管理新增图片预览功能。
9.标签可以上下排序。生成 CSV 时,根据排序生成 csv 文件。测试时,返回的结果也会显示在标签的排序中。
10.图片和flash下载排除功能。不为符合条件的文件执行下载。
11.文件上传标签可以为多个标签上传文件。
12.使用二级URL时,URL部分可以设置列表页收录区域
13.Looping采集可以使用提取关键字和摘要等功能。
14.列表标签可以编辑,比如排除和过滤、下载等。
u采 采集( 前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-01-08 20:17
前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
ForeSpider数据链接提取采集软件
ForeSpider 数据采集软件是一个通用的互联网数据采集软件。软件可以采集互联网上的所有公共数据,通过可视化的操作流程,从建表、过滤、采集到入库,一步到位。同时,软件内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。
很多用户说可视化操作太简单了,软件脚本教程一定要看,所以今天给大家做一个爬虫脚本的链接提取教程,满足更多用户的需求。
本案使用大众点评网,需提取以下翻页链接。
第一步是看每个页面的链接地址是否有规律。
【第二页】
【第三页】
可以看出,只有每个页面的链接地址的最后一个数字不同,都是对应的页码。我们可以通过拼接得到所有翻页的链接地址。拼接第二页链接地址的脚本如下:
第一行代码:定义一个url类的变量u
第二行代码:u.urlname是网页的链接地址,给它赋值
第三行代码:u.tmplid是要关联本次链接提取的模板id,这里是翻页,所以关联自己的模板
第四行代码:这个链接提取对应的channel id
第五行代码:u.title是链接标题,给它赋值
第六行代码:将级联链接添加到最终结果中
上面只说明了每一行代码的作用,只获取到第二页的链接。以下是完整内容:
通过FindClass,从源码中获取总页数,然后用for循环拼接每个页面的链接。总共只用了 12 行(包括两行注释)就可以得到你想要的链接。不是很简单吗?希望大家多看帮助文档,很多问题在帮助文档里都有答案(偷偷告诉大家我经常遇到no然后去看文档)。
ForeSpider 是一款非常简单易用的通用数据采集 软件。操作简单,功能强大,同时保证采集速度,完全可以满足企业级用户的需求。 查看全部
u采 采集(
前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
ForeSpider数据链接提取采集软件
ForeSpider 数据采集软件是一个通用的互联网数据采集软件。软件可以采集互联网上的所有公共数据,通过可视化的操作流程,从建表、过滤、采集到入库,一步到位。同时,软件内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。
很多用户说可视化操作太简单了,软件脚本教程一定要看,所以今天给大家做一个爬虫脚本的链接提取教程,满足更多用户的需求。
本案使用大众点评网,需提取以下翻页链接。

第一步是看每个页面的链接地址是否有规律。

【第二页】

【第三页】
可以看出,只有每个页面的链接地址的最后一个数字不同,都是对应的页码。我们可以通过拼接得到所有翻页的链接地址。拼接第二页链接地址的脚本如下:

第一行代码:定义一个url类的变量u
第二行代码:u.urlname是网页的链接地址,给它赋值
第三行代码:u.tmplid是要关联本次链接提取的模板id,这里是翻页,所以关联自己的模板
第四行代码:这个链接提取对应的channel id
第五行代码:u.title是链接标题,给它赋值
第六行代码:将级联链接添加到最终结果中
上面只说明了每一行代码的作用,只获取到第二页的链接。以下是完整内容:


通过FindClass,从源码中获取总页数,然后用for循环拼接每个页面的链接。总共只用了 12 行(包括两行注释)就可以得到你想要的链接。不是很简单吗?希望大家多看帮助文档,很多问题在帮助文档里都有答案(偷偷告诉大家我经常遇到no然后去看文档)。
ForeSpider 是一款非常简单易用的通用数据采集 软件。操作简单,功能强大,同时保证采集速度,完全可以满足企业级用户的需求。
u采 采集(u采采集精准营销系统是微信公众号、百度app、抖音等平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-04 00:03
u采采集精准营销系统是微信公众号、百度app、抖音等平台批量采集ugc内容的实用工具,采集内容过滤质量、导出数据分析、自动解析网站、多渠道精准推送,u采采集精准营销系统不仅可以实现采集内容批量推送,还能对内容进行二次解析,一键生成相关文章,并推送到多渠道。还支持站内推送、站外推送。
也用过几家采集器,发现还是金山快盘采集器好用.复制链接或者文字后,就可以实现批量复制粘贴,有很多高质量的内容!
你可以试试采集新榜。里面有很多好玩的采集功能,根据你的需求可以去看看。目前网站推广人员都在尝试使用。
试试采三国,采集效果还不错,自己也开发了个高质量的采集器,二、五、六线城市的小区户型平面图可以快速采集过来。节省人力物力财力。
安卓可以使用滴答清单app,很喜欢
如果你要说的精准是指无广告,高质量的ugc,已有的这几个确实没有可比性。我自己从06年在网站上搜索上某件产品的相关页面,感觉都搜索不到。后来google+访问一个卖家的博客后面有一个内容推荐,才知道原来上卖家后面能有这么多有需求的网站,edg/ig/dia等等,简直就是噩梦!要是ugc还能放到这些网站上,那才是最精准了。
不过网站只是提供了信息的大致流向。从有网站到搜到内容主要需要从几个方面的判断。1.好友关系是否到达你搜索的目标,哪些人可能浏览过,这样才更容易形成粘性。2.如果好友不是给予了你关注,哪些网站会搜索到你。如果只是个人网站等,那有点难。3.如果内容用户是需要的,有几个推荐的网站,甚至用户已经把自己需要的内容推荐给了自己的好友,也会有不少网站能被搜索到,你自己的网站,没有吧,除非你是一个很高价值的站。
4.新闻,话题网站等,会有很多机会搜索到内容。总之没有一个网站能完全脱离搜索引擎,如果采集一个网站,你可以控制重点的推荐,这个因人而异,因为这个网站对你来说很重要,或者对别人来说很重要。对自己来说,站内的推荐最重要。另外,你发现没有,这些所谓的高质量网站里,大部分都没有被搜索引擎收录。不过上面都算是知道,我可不是来抖机灵的。
嘿嘿。所以,说起来还有一个重要的,你搜索引擎的推荐才是关键。我们没能分出这些网站的推荐规则有什么区别,像我这样不太了解这个的人,对于搜索结果里的高质量网站一般只会去一两个网站,找不到合适的就放弃。最好不要一上来就找到很多自己没想过要的东西。毕竟现在能源最大的网站facebook,才收录了十几万张图片。 查看全部
u采 采集(u采采集精准营销系统是微信公众号、百度app、抖音等平台)
u采采集精准营销系统是微信公众号、百度app、抖音等平台批量采集ugc内容的实用工具,采集内容过滤质量、导出数据分析、自动解析网站、多渠道精准推送,u采采集精准营销系统不仅可以实现采集内容批量推送,还能对内容进行二次解析,一键生成相关文章,并推送到多渠道。还支持站内推送、站外推送。
也用过几家采集器,发现还是金山快盘采集器好用.复制链接或者文字后,就可以实现批量复制粘贴,有很多高质量的内容!
你可以试试采集新榜。里面有很多好玩的采集功能,根据你的需求可以去看看。目前网站推广人员都在尝试使用。
试试采三国,采集效果还不错,自己也开发了个高质量的采集器,二、五、六线城市的小区户型平面图可以快速采集过来。节省人力物力财力。
安卓可以使用滴答清单app,很喜欢
如果你要说的精准是指无广告,高质量的ugc,已有的这几个确实没有可比性。我自己从06年在网站上搜索上某件产品的相关页面,感觉都搜索不到。后来google+访问一个卖家的博客后面有一个内容推荐,才知道原来上卖家后面能有这么多有需求的网站,edg/ig/dia等等,简直就是噩梦!要是ugc还能放到这些网站上,那才是最精准了。
不过网站只是提供了信息的大致流向。从有网站到搜到内容主要需要从几个方面的判断。1.好友关系是否到达你搜索的目标,哪些人可能浏览过,这样才更容易形成粘性。2.如果好友不是给予了你关注,哪些网站会搜索到你。如果只是个人网站等,那有点难。3.如果内容用户是需要的,有几个推荐的网站,甚至用户已经把自己需要的内容推荐给了自己的好友,也会有不少网站能被搜索到,你自己的网站,没有吧,除非你是一个很高价值的站。
4.新闻,话题网站等,会有很多机会搜索到内容。总之没有一个网站能完全脱离搜索引擎,如果采集一个网站,你可以控制重点的推荐,这个因人而异,因为这个网站对你来说很重要,或者对别人来说很重要。对自己来说,站内的推荐最重要。另外,你发现没有,这些所谓的高质量网站里,大部分都没有被搜索引擎收录。不过上面都算是知道,我可不是来抖机灵的。
嘿嘿。所以,说起来还有一个重要的,你搜索引擎的推荐才是关键。我们没能分出这些网站的推荐规则有什么区别,像我这样不太了解这个的人,对于搜索结果里的高质量网站一般只会去一两个网站,找不到合适的就放弃。最好不要一上来就找到很多自己没想过要的东西。毕竟现在能源最大的网站facebook,才收录了十几万张图片。
u采 采集(u采采集器支持多种格式的图片文件的采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-21 06:01
u采采集器用到图片数据经过第三方服务器进行拼接后,成为采集结果,u采集器支持多种格式的图片文件的采集。如.jpg、.png、.pdf、.tiff等等文件格式,这些格式的图片都支持用文件夹进行拼接,使得采集效率得到极大的提高,同时图片数据会进行二次处理形成采集结果。如上图:黄框框中的url是这张海报的地址;article_id=123&page=1&tag=jpg&view=true图片的最后一个字符:[];我们是如何获取url的?普通方法:直接点选图片,然后就跳转页面上,等着下载就可以了。
但是弊端是图片上可能存在当前正在下载的页面上的图片,下载下来的图片是乱码。而且图片不是完整的文件名,图片是会进行截断,而且被下载到url后,url是无法拼接的。u采采集器:1.通过下面框中这个搜狗地址,获取url。2.下载后,解压打开即可。
想问一下什么叫可能性呢?遇到同样的问题吗?之前很难的问题现在觉得解决了。分享给大家~我觉得url一般都是so。那如何才可以找到呢?大家见解都一样。
分享一下其他方法wget
试试国内一个高质量网站吧,分享给大家:猎云网猎云网旗下拥有so图片和贴图,给你一个正宗的海报或者商品宣传,让你再也不用为找不到了海报而发愁了!本网站提供海量的正规海报,你还可以根据下载的网站、尺寸、色系、主题、版权内容、文件格式等参数选择不同类型的海报下载,满足你多方面需求!目前已汇聚了常用网站、图片尺寸、下载网站、设计素材、建站宝箱、外链搜索等多个类型网站,支持so图片、png、jpg、tiff、ppt、psd、exe、jpg、exe、jpg、tiff、word、excel、表格、文件保存、excel、ppt、pdf、bmp、odt、cad等各种网站下载,不愁找不到优质图片、音乐、以及非一般的模板素材!废话不多说,直接放网站:如果你觉得还不错,那请点赞帮我推广,并且在评论区留言你的知乎私信。如果你是在猎云网注册并有邀请码的用户,也可以直接获得推广方式(注册免费)。网站地址:猎云网-我的主页。 查看全部
u采 采集(u采采集器支持多种格式的图片文件的采集)
u采采集器用到图片数据经过第三方服务器进行拼接后,成为采集结果,u采集器支持多种格式的图片文件的采集。如.jpg、.png、.pdf、.tiff等等文件格式,这些格式的图片都支持用文件夹进行拼接,使得采集效率得到极大的提高,同时图片数据会进行二次处理形成采集结果。如上图:黄框框中的url是这张海报的地址;article_id=123&page=1&tag=jpg&view=true图片的最后一个字符:[];我们是如何获取url的?普通方法:直接点选图片,然后就跳转页面上,等着下载就可以了。
但是弊端是图片上可能存在当前正在下载的页面上的图片,下载下来的图片是乱码。而且图片不是完整的文件名,图片是会进行截断,而且被下载到url后,url是无法拼接的。u采采集器:1.通过下面框中这个搜狗地址,获取url。2.下载后,解压打开即可。
想问一下什么叫可能性呢?遇到同样的问题吗?之前很难的问题现在觉得解决了。分享给大家~我觉得url一般都是so。那如何才可以找到呢?大家见解都一样。
分享一下其他方法wget
试试国内一个高质量网站吧,分享给大家:猎云网猎云网旗下拥有so图片和贴图,给你一个正宗的海报或者商品宣传,让你再也不用为找不到了海报而发愁了!本网站提供海量的正规海报,你还可以根据下载的网站、尺寸、色系、主题、版权内容、文件格式等参数选择不同类型的海报下载,满足你多方面需求!目前已汇聚了常用网站、图片尺寸、下载网站、设计素材、建站宝箱、外链搜索等多个类型网站,支持so图片、png、jpg、tiff、ppt、psd、exe、jpg、exe、jpg、tiff、word、excel、表格、文件保存、excel、ppt、pdf、bmp、odt、cad等各种网站下载,不愁找不到优质图片、音乐、以及非一般的模板素材!废话不多说,直接放网站:如果你觉得还不错,那请点赞帮我推广,并且在评论区留言你的知乎私信。如果你是在猎云网注册并有邀请码的用户,也可以直接获得推广方式(注册免费)。网站地址:猎云网-我的主页。
u采 采集(数据采集软件的优秀之处——优采云采集器使用教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-12-19 04:14
2020年要推荐一款热门的数据采集软件,一定是优采云采集器。对比我之前推荐的网络爬虫,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有的数据爬取问题。
我们来谈谈这个软件的突出特点。
一、产品特点1.跨平台
优采云采集器是一款支持Linux、Windows和Mac三种操作系统的桌面应用软件。可以直接在官网免费下载。
2.强大的功能
优采云采集器将采集的工作分为智能模式和流程图模式两种。
智能模式是指加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
3.出口无限制
这可以说是优采云采集器最有良心的特点。
市场上有很多数据采集软件。出于商业目的,数据导出在某种程度上受到限制。不懂套路的人,经常用相关软件苦苦采集一堆数据,结果导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,并支持直接导出到数据库,对于普通用户来说完全够用。
4.详细教程
开始写这篇文章之前,本来想写一些优采云采集器的使用教程,但是看了他们的官网教程,才知道这是没有必要的,因为写的太详细了。
优采云采集器的官网提供两种教程,一种是视频教程,每个视频约五分钟;另一种是图文教程,手工教学。阅读完这两类教程后,您还可以查看他们的文档中心。它们也非常详细,基本涵盖了软件的各种功能。
二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,数据就可以是采集:
2.翻页功能
在我介绍网页爬虫的时候,我把网页转成三类:滚动加载、分页加载和点击下一页加载。
对于这三种基本的翻页类型,也完全支持优采云采集器。
与网络爬虫的分页功能分散在各个选择器上不同,优采云采集器的分页配置集中在一个地方,只要通过下拉选择,就可以轻松配置分页模式。相关配置教程可参考官网教程:如何设置分页。
3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用流程图模式下的点击组件来模拟点击过滤按钮,非常方便。
三、高级使用1.数据清洗
介绍网页刮板的时候说过,网页刮板只提供了基本的正则匹配功能,可以在抓数据的时候进行初步的数据清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完备的常规功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
例如下图的流程图模拟了真人浏览微博抓取相关数据时的行为。
经过几次个人测试,我认为流程图模式有一定的学习门槛,但与从头开始学习python爬虫相比,学习曲线还是轻松了很多。如果对流程图模式感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/Regex
不管是什么爬虫软件,都是按照一定的规则爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器 支持自定义这些类型的选择器,可以更灵活地选择要捕获的数据。
比如网页中有数据A,但是只有当鼠标移动到对应的文字上时,才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
XPath
XPath 是一种广泛用于爬虫的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网页爬虫的高级技术时,我讲解了CSS选择器的使用场景和注意事项。有兴趣的可以看我写的CSS选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式选择数据。我还写了一些关于正则表达式的教程。但是我个人认为在字段选择器场景中,正则表达式不如XPath和CSS选择器。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以我不知道是什么体验。下面我来科普一下,给大家解释一下这些术语的含义。
定时抓取
定时抓取很容易理解,就是爬虫软件会在某个固定的时间自动抓取数据。市场上有一些比价软件,其背后运行着很多定时爬虫,每隔几分钟爬一次价格信息,以达到监控价格的目的。
IP池
90% 的互联网流量是由爬虫贡献的。为了降低服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。例如,某互联网公司检测到某个IP的大量数据请求超出正常范围,会暂时屏蔽该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,发送不同IP的请求,降低IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大多数编程新手的数据抓取需求。
如果有一定的编程基础,就可以清楚的看出,有些功能是对编程语言逻辑的封装。比如流程图模式是流程控制的封装,数据清洗功能是字符串处理功能的封装。这些高级功能扩展了优采云采集器的能力,增加了学习难度。
在我个人看来,如果是轻量级的数据抓取需求,我更喜欢使用webscraper;要求比较复杂,优采云采集器是不错的选择;如果涉及到时序捕捉等高级需求,自己编写爬虫代码更可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。 查看全部
u采 采集(数据采集软件的优秀之处——优采云采集器使用教程)
2020年要推荐一款热门的数据采集软件,一定是优采云采集器。对比我之前推荐的网络爬虫,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有的数据爬取问题。
我们来谈谈这个软件的突出特点。
一、产品特点1.跨平台
优采云采集器是一款支持Linux、Windows和Mac三种操作系统的桌面应用软件。可以直接在官网免费下载。

2.强大的功能
优采云采集器将采集的工作分为智能模式和流程图模式两种。

智能模式是指加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
3.出口无限制
这可以说是优采云采集器最有良心的特点。
市场上有很多数据采集软件。出于商业目的,数据导出在某种程度上受到限制。不懂套路的人,经常用相关软件苦苦采集一堆数据,结果导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,并支持直接导出到数据库,对于普通用户来说完全够用。

4.详细教程
开始写这篇文章之前,本来想写一些优采云采集器的使用教程,但是看了他们的官网教程,才知道这是没有必要的,因为写的太详细了。
优采云采集器的官网提供两种教程,一种是视频教程,每个视频约五分钟;另一种是图文教程,手工教学。阅读完这两类教程后,您还可以查看他们的文档中心。它们也非常详细,基本涵盖了软件的各种功能。

二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,数据就可以是采集:

2.翻页功能
在我介绍网页爬虫的时候,我把网页转成三类:滚动加载、分页加载和点击下一页加载。

对于这三种基本的翻页类型,也完全支持优采云采集器。
与网络爬虫的分页功能分散在各个选择器上不同,优采云采集器的分页配置集中在一个地方,只要通过下拉选择,就可以轻松配置分页模式。相关配置教程可参考官网教程:如何设置分页。

3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用流程图模式下的点击组件来模拟点击过滤按钮,非常方便。

三、高级使用1.数据清洗
介绍网页刮板的时候说过,网页刮板只提供了基本的正则匹配功能,可以在抓数据的时候进行初步的数据清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完备的常规功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
例如下图的流程图模拟了真人浏览微博抓取相关数据时的行为。

经过几次个人测试,我认为流程图模式有一定的学习门槛,但与从头开始学习python爬虫相比,学习曲线还是轻松了很多。如果对流程图模式感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/Regex
不管是什么爬虫软件,都是按照一定的规则爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器 支持自定义这些类型的选择器,可以更灵活地选择要捕获的数据。
比如网页中有数据A,但是只有当鼠标移动到对应的文字上时,才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。

XPath
XPath 是一种广泛用于爬虫的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网页爬虫的高级技术时,我讲解了CSS选择器的使用场景和注意事项。有兴趣的可以看我写的CSS选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式选择数据。我还写了一些关于正则表达式的教程。但是我个人认为在字段选择器场景中,正则表达式不如XPath和CSS选择器。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以我不知道是什么体验。下面我来科普一下,给大家解释一下这些术语的含义。
定时抓取
定时抓取很容易理解,就是爬虫软件会在某个固定的时间自动抓取数据。市场上有一些比价软件,其背后运行着很多定时爬虫,每隔几分钟爬一次价格信息,以达到监控价格的目的。
IP池
90% 的互联网流量是由爬虫贡献的。为了降低服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。例如,某互联网公司检测到某个IP的大量数据请求超出正常范围,会暂时屏蔽该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,发送不同IP的请求,降低IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大多数编程新手的数据抓取需求。
如果有一定的编程基础,就可以清楚的看出,有些功能是对编程语言逻辑的封装。比如流程图模式是流程控制的封装,数据清洗功能是字符串处理功能的封装。这些高级功能扩展了优采云采集器的能力,增加了学习难度。
在我个人看来,如果是轻量级的数据抓取需求,我更喜欢使用webscraper;要求比较复杂,优采云采集器是不错的选择;如果涉及到时序捕捉等高级需求,自己编写爬虫代码更可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。
u采 采集(采集神器百度聚合采集器什么都行有个好东西自己跑去killall)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-12-15 11:00
u采采集,主要是针对专业采集、爬虫抓取及其他反爬虫模块化的采集工具,能够一定程度上以工具的形式辅助采集技术,是一个国内唯一真正的采集工具开发团队。下面分享下基于企业saas应用通用采集工具——采集狗的过往技术积累成果,感兴趣的小伙伴欢迎到github来下载和学习。采集狗快速分析看一看!:开发和维护采集狗是u采采集产品,采集狗秉承通用为先的产品理念,帮助用户找到并抓取最适合的平台以及最安全的产品。
采集狗致力为用户定制saas产品标准,目前主要有两类saas产品:api产品和嵌入在u采采集平台的采集,api产品我们提供产品开发工具,目前已经合作的有八戒采集、江湖采集、海口采集等。嵌入在u采采集平台的采集,则提供采集工具,通过嵌入的采集工具,用户可以快速采集,这一点目前已经有全国数十万家中小网站加入采集阵营,嵌入的采集工具用户已经达到800万。
我们无法完全保证网站和平台的数据完整性,但是对于真实数据尽可能提供给用户。采集狗为保证数据唯一性而存在,希望大家不要乱修改数据,不要对产品进行任何的修改。采集狗速采快采,一键快速采集全网网站数据!:。
采集神器百度聚合采集器
什么都行有个好东西自己跑去killall...
记得前几天在另一个问题下推荐过采集神器, 查看全部
u采 采集(采集神器百度聚合采集器什么都行有个好东西自己跑去killall)
u采采集,主要是针对专业采集、爬虫抓取及其他反爬虫模块化的采集工具,能够一定程度上以工具的形式辅助采集技术,是一个国内唯一真正的采集工具开发团队。下面分享下基于企业saas应用通用采集工具——采集狗的过往技术积累成果,感兴趣的小伙伴欢迎到github来下载和学习。采集狗快速分析看一看!:开发和维护采集狗是u采采集产品,采集狗秉承通用为先的产品理念,帮助用户找到并抓取最适合的平台以及最安全的产品。
采集狗致力为用户定制saas产品标准,目前主要有两类saas产品:api产品和嵌入在u采采集平台的采集,api产品我们提供产品开发工具,目前已经合作的有八戒采集、江湖采集、海口采集等。嵌入在u采采集平台的采集,则提供采集工具,通过嵌入的采集工具,用户可以快速采集,这一点目前已经有全国数十万家中小网站加入采集阵营,嵌入的采集工具用户已经达到800万。
我们无法完全保证网站和平台的数据完整性,但是对于真实数据尽可能提供给用户。采集狗为保证数据唯一性而存在,希望大家不要乱修改数据,不要对产品进行任何的修改。采集狗速采快采,一键快速采集全网网站数据!:。
采集神器百度聚合采集器
什么都行有个好东西自己跑去killall...
记得前几天在另一个问题下推荐过采集神器,
u采 采集(u采采集器我记得我们用过,反正不好用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-14 10:06
u采采集器我记得我们用过,反正不好用,公司的钱来的太快没什么积蓄,不能买个实用的采集器,不开始用还不知道,虽然我们公司现在还用这个什么采集器,可是我后来也不用了,他提交反馈什么的基本上不回,每次打开好多问题,因为最近空了一些时间,就想做个采集器自动帮我处理一些,目前准备2周到3周到吧,有什么好的方法记得告诉我,我也想入手,支持一下我吧!。
我的印象中好像只有各位大神采用了下面这个。用的还不多,主要怕是采用的弱sdk之后太多功能不兼容,以及自己不习惯这种开发体验,给人一种一览众山小的感觉,也就是说只能采用自己熟悉的东西。
试了下picasa
1.如果你只是想要学学,去研究他怎么做的,会比较快乐,基本不花精力2.如果你要找人帮你做,可以考虑上面说的其他方法,但估计很多人不愿意,因为没那种感觉总结:采集器做的最好的的应该是正则表达式,
基本上很难
appstore应用商店的那些特产都能直接采集,qq号,短信,邮箱,
内部采集,有不少可以用。
阿里系产品吧,我用过加速器,
me也接触过,就一直比较头疼,采集越多耗费的时间越多。但可以用爬虫api啊,推荐自己做。不过你要能自己搭建一个小网站,只提取前20名。记住只是后20名,推荐你加速器,接的太多,你就会用得上,原来python是小众语言嘛,也有很多好用的免费工具啊。 查看全部
u采 采集(u采采集器我记得我们用过,反正不好用)
u采采集器我记得我们用过,反正不好用,公司的钱来的太快没什么积蓄,不能买个实用的采集器,不开始用还不知道,虽然我们公司现在还用这个什么采集器,可是我后来也不用了,他提交反馈什么的基本上不回,每次打开好多问题,因为最近空了一些时间,就想做个采集器自动帮我处理一些,目前准备2周到3周到吧,有什么好的方法记得告诉我,我也想入手,支持一下我吧!。
我的印象中好像只有各位大神采用了下面这个。用的还不多,主要怕是采用的弱sdk之后太多功能不兼容,以及自己不习惯这种开发体验,给人一种一览众山小的感觉,也就是说只能采用自己熟悉的东西。
试了下picasa
1.如果你只是想要学学,去研究他怎么做的,会比较快乐,基本不花精力2.如果你要找人帮你做,可以考虑上面说的其他方法,但估计很多人不愿意,因为没那种感觉总结:采集器做的最好的的应该是正则表达式,
基本上很难
appstore应用商店的那些特产都能直接采集,qq号,短信,邮箱,
内部采集,有不少可以用。
阿里系产品吧,我用过加速器,
me也接触过,就一直比较头疼,采集越多耗费的时间越多。但可以用爬虫api啊,推荐自己做。不过你要能自己搭建一个小网站,只提取前20名。记住只是后20名,推荐你加速器,接的太多,你就会用得上,原来python是小众语言嘛,也有很多好用的免费工具啊。
u采 采集(软件介绍优采云采集器是什么插件..)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-12-08 20:09
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析、挖掘软件。使用优采云采集器,用户可以快速灵活的抓取网页上分散的数据信息,并通过一系列的分析处理,准确地挖掘出需要的数据,帮助用户快速构建自己的数据系统,即用户可以用优采云采集器快速填写网站的内容,组件庞大网站。
软件功能
1. 丰富的插件功能:新版本中可以使用PHP插件和C#插件来采集网址,采集内容,采集内容后使用插件,无论是什么插入。同时,为插件开发提供了更多详细的开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新时查看采集器的工作状态。
3. 更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,管理起来更快捷方便。
4. 更方便的升级和。该程序会重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可轻松完成升级。
5.支持可选的加密狗授权方式。
6.命令行模式。您可以使用参数来启动程序来执行任务。可以使用定时任务实验采集的定时,采集后退出程序
7.中文分词增加用户词库,可以添加用户排除词库。您只能使用用户同义词库。
8.Local采集 数据管理中增加了图片预览功能。
9. 标签可以上下排序。生成CSV的时候,就是按照这个排序生成csv文件的。在测试过程中,返回的结果也按照标签的顺序显示。
10.图片和flash下载排除功能。不下载符合条件的文件。
1 1.文件上传标签可以为多个标签上传文件。
12. 挖矿URL部分使用二级URL时,可以设置列表页收录区域
13.循环采集时,可以使用提取关键字、摘要等功能。
14.列表标签可编辑,如排除过滤、下载等。 查看全部
u采 采集(软件介绍优采云采集器是什么插件..)
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析、挖掘软件。使用优采云采集器,用户可以快速灵活的抓取网页上分散的数据信息,并通过一系列的分析处理,准确地挖掘出需要的数据,帮助用户快速构建自己的数据系统,即用户可以用优采云采集器快速填写网站的内容,组件庞大网站。
软件功能
1. 丰富的插件功能:新版本中可以使用PHP插件和C#插件来采集网址,采集内容,采集内容后使用插件,无论是什么插入。同时,为插件开发提供了更多详细的开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新时查看采集器的工作状态。
3. 更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,管理起来更快捷方便。
4. 更方便的升级和。该程序会重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可轻松完成升级。
5.支持可选的加密狗授权方式。
6.命令行模式。您可以使用参数来启动程序来执行任务。可以使用定时任务实验采集的定时,采集后退出程序
7.中文分词增加用户词库,可以添加用户排除词库。您只能使用用户同义词库。
8.Local采集 数据管理中增加了图片预览功能。
9. 标签可以上下排序。生成CSV的时候,就是按照这个排序生成csv文件的。在测试过程中,返回的结果也按照标签的顺序显示。
10.图片和flash下载排除功能。不下载符合条件的文件。
1 1.文件上传标签可以为多个标签上传文件。
12. 挖矿URL部分使用二级URL时,可以设置列表页收录区域
13.循环采集时,可以使用提取关键字、摘要等功能。
14.列表标签可编辑,如排除过滤、下载等。
u采 采集(u采采集器登录首页上线后,地址改成localhost)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-08 13:10
u采采集器登录首页上线之后,原本只负责获取头条及专栏下热文的后台工作就完成了,但是采集开始不久就发现了问题,所以把排名采集下来,重新上传头条及专栏。开发团队已经对系统重做了,目前最大限度接近ie6浏览器样式,首页我是bot,文章和普通页面你得自己拿md5值识别。采集比上线前速度明显提升,请在评论区告诉我上传进度和错误地址。
关于u采采集器u采采集器首页在小说明采集页面添加排名采集接口开启不久就出现错误,调试了好几次,之后直接网页处理就ok了。登录首页流程(1)post请求转成json可以发现url里没有请求地址等内容,说明是post请求采集到的。点击完成,收到用户名密码验证,过程中还提示错误,经自己解决后返回,post请求地址发现是ajax请求,地址改成localhost也是发现错误,正确的做法是走json请求,转换为二进制的csv地址(可以用xmlhttprequest.response把格式改成下图json.parse({type:‘json’,next:false,req:[‘url’],next:false,next:false,}))点击下载,然后用request.readhead().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});(2)解析localhost:8000(获取到链接sheet名,这步是存个文件,用screenshot获取并同步到服务器,然后从sheet名里返回正确的json)开始设置页面url,并把url的md5值加进去。
u站格式:url+ajaxajax链接,我写了一个ajax采集器ajax代码前端有不少免费模块,甚至用jquery封装的ajax都有,可以在模块浏览器上做md5(太low的,我这里用了ajaxdata这个免费模块,并不推荐)重写,代码如下://类似于request.read().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});//生成post请求//页面url//生成请求okhttp.get(url,file=>{localhost:8000.**//记录url的值,方便重复请求okhttp.save(url,file=>{localhost:8000.**//next().post(url,file=>{//next().post(url,file=>{//content:'下载'});content:"提示错误"});});});postmessage就是请求响应码,一直设置到8000,过一段时间会产生false,等等就好了。
页面url如何获取?u采采集器首页自带这个页面url,就是点进去的二级域名,我这里static是个auto的,默认访问,再跳转u采采集器首页的二级域名。如何跳转?那就把这个二级。 查看全部
u采 采集(u采采集器登录首页上线后,地址改成localhost)
u采采集器登录首页上线之后,原本只负责获取头条及专栏下热文的后台工作就完成了,但是采集开始不久就发现了问题,所以把排名采集下来,重新上传头条及专栏。开发团队已经对系统重做了,目前最大限度接近ie6浏览器样式,首页我是bot,文章和普通页面你得自己拿md5值识别。采集比上线前速度明显提升,请在评论区告诉我上传进度和错误地址。
关于u采采集器u采采集器首页在小说明采集页面添加排名采集接口开启不久就出现错误,调试了好几次,之后直接网页处理就ok了。登录首页流程(1)post请求转成json可以发现url里没有请求地址等内容,说明是post请求采集到的。点击完成,收到用户名密码验证,过程中还提示错误,经自己解决后返回,post请求地址发现是ajax请求,地址改成localhost也是发现错误,正确的做法是走json请求,转换为二进制的csv地址(可以用xmlhttprequest.response把格式改成下图json.parse({type:‘json’,next:false,req:[‘url’],next:false,next:false,}))点击下载,然后用request.readhead().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});(2)解析localhost:8000(获取到链接sheet名,这步是存个文件,用screenshot获取并同步到服务器,然后从sheet名里返回正确的json)开始设置页面url,并把url的md5值加进去。
u站格式:url+ajaxajax链接,我写了一个ajax采集器ajax代码前端有不少免费模块,甚至用jquery封装的ajax都有,可以在模块浏览器上做md5(太low的,我这里用了ajaxdata这个免费模块,并不推荐)重写,代码如下://类似于request.read().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});//生成post请求//页面url//生成请求okhttp.get(url,file=>{localhost:8000.**//记录url的值,方便重复请求okhttp.save(url,file=>{localhost:8000.**//next().post(url,file=>{//next().post(url,file=>{//content:'下载'});content:"提示错误"});});});postmessage就是请求响应码,一直设置到8000,过一段时间会产生false,等等就好了。
页面url如何获取?u采采集器首页自带这个页面url,就是点进去的二级域名,我这里static是个auto的,默认访问,再跳转u采采集器首页的二级域名。如何跳转?那就把这个二级。
u采 采集(qq微信怎么采集数据?端定制app的httpscheme,全球苹果电脑端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-12-06 07:02
u采采集器是一款采集来自网络的数据,挖掘这些数据的价值,用于产品与功能的实现。现在qq和微信都已成为我们日常生活中使用的较多的地方,但是前者如果安装vpn,那不是很麻烦吗?后者如果安装插件,有时候我们还是需要打开浏览器,加载一堆后,再用qq或者微信登录,这时候能不能能快速实现呢?然后,我们要一条条的去获取呢?这个就需要采集器了!那么qq微信怎么采集数据呢?首先我们需要明确自己要采集哪方面的数据。比如qq群直播,我们主要是去看直播;比如是在腾讯游戏平台,我们去看游戏;还比如你可以去跟网友聊天。
“采集器"是如何采集工程师采集项目的http请求呢?android端定制app的httpscheme,全球苹果电脑端定制苹果手机和安卓手机httpscheme,方便app使用http去请求请求网页;通过android专属sdk或者websdk可以设置全球ios使用的请求方式。欢迎关注我的微信公众号,获取更多android开发知识:。
不同意楼上的回答,可以去网上找一些采集方案,但作为一个苦逼程序员,还是推荐用采集器去采集数据,需要采集什么数据直接打开浏览器就可以使用,
可以看看云采集这款小软件,只需要输入appid,就可以识别,
微信有小程序,订阅号什么的,通过云采集采集小程序是有条件的, 查看全部
u采 采集(qq微信怎么采集数据?端定制app的httpscheme,全球苹果电脑端)
u采采集器是一款采集来自网络的数据,挖掘这些数据的价值,用于产品与功能的实现。现在qq和微信都已成为我们日常生活中使用的较多的地方,但是前者如果安装vpn,那不是很麻烦吗?后者如果安装插件,有时候我们还是需要打开浏览器,加载一堆后,再用qq或者微信登录,这时候能不能能快速实现呢?然后,我们要一条条的去获取呢?这个就需要采集器了!那么qq微信怎么采集数据呢?首先我们需要明确自己要采集哪方面的数据。比如qq群直播,我们主要是去看直播;比如是在腾讯游戏平台,我们去看游戏;还比如你可以去跟网友聊天。
“采集器"是如何采集工程师采集项目的http请求呢?android端定制app的httpscheme,全球苹果电脑端定制苹果手机和安卓手机httpscheme,方便app使用http去请求请求网页;通过android专属sdk或者websdk可以设置全球ios使用的请求方式。欢迎关注我的微信公众号,获取更多android开发知识:。
不同意楼上的回答,可以去网上找一些采集方案,但作为一个苦逼程序员,还是推荐用采集器去采集数据,需要采集什么数据直接打开浏览器就可以使用,
可以看看云采集这款小软件,只需要输入appid,就可以识别,
微信有小程序,订阅号什么的,通过云采集采集小程序是有条件的,
u采 采集(免费代理稳定性连同时切换代理附代理采集下载下载地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-05 14:25
1、代理文件格式:(代理采集地址)
2、自由代理稳定性不可靠,使用装饰器重连切换代理同时进行
# coding: utf-8
# 笔趣阁 单篇小说采集 http://www.biquge.com.tw
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.biquge.com.tw",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url = "http://www.biquge.com.tw/17_17 ... ot%3B # 第一章网址
page = 1301 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数5)--" % (count['num'] + 1))
if count['num'] < 5:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
# print(response.read())
bsObj = BeautifulSoup(response, 'lxml')
except Exception, err:
raise Exception(err)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', attrs={'class': 'bottem2'})
title = bsObj.find('div', attrs={'class': 'bookname'}).h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = "http://www.biquge.com.tw" + next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载链接: 查看全部
u采 采集(免费代理稳定性连同时切换代理附代理采集下载下载地址)
1、代理文件格式:(代理采集地址)

2、自由代理稳定性不可靠,使用装饰器重连切换代理同时进行
# coding: utf-8
# 笔趣阁 单篇小说采集 http://www.biquge.com.tw
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.biquge.com.tw",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url = "http://www.biquge.com.tw/17_17 ... ot%3B # 第一章网址
page = 1301 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数5)--" % (count['num'] + 1))
if count['num'] < 5:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
# print(response.read())
bsObj = BeautifulSoup(response, 'lxml')
except Exception, err:
raise Exception(err)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', attrs={'class': 'bottem2'})
title = bsObj.find('div', attrs={'class': 'bookname'}).h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = "http://www.biquge.com.tw" + next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载链接:
u采 采集(爱采集谷歌地图数据采集器的软件优势简单点点鼠标)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-05 03:23
爱采集谷歌地图数据采集器是一款功能强大的谷歌地图数据采集软件,该软件可以帮助用户采集谷歌地图企业在任何区域的数据信息,包括姓名、地址、联系方式、网址、邮箱等。采集完成后,还可以批量导入电脑、手机、微信。是外贸用户必备的辅助工具。
爱采集谷歌地图数据采集器具有采集结果和精准定位的特点,只要你进入需要的行业关键词,它可以帮助你快速采集 走向世界 各地区、各行业精准联系,帮助用户解决外贸行业客户信息缺失问题,快速增加外贸订单。
软件特点
01、爱采集 Master采用先进的大数据技术,极速体验,超稳定。
02、采集 收到的客户信息准确率98%,绝对真实,有保证。
03、智能去重技术、数据关键词过滤、关键词优化等功能,让你采集获取更多数据。
04、 便捷的导出功能,可以导出为CSV、EXCEL、VCF等文本文件,省去自己处理的麻烦。
05、 服务期内免费升级、安装调试、数据分析和维护。
06、 付费授权可以导出三种数据格式,编号不带星号。
07、可以提取数万条数据,一键发送数万条短信。
08、 可将号码批量导入电脑,批量邮箱,快速为您整理信息。
软件优势
便于使用
只需点击鼠标即可抓取数据,无需编写任何代码即可轻松抓取数据。老板再也不用逼我学python爬虫了。在几分钟内捕获数据,采集 从未如此简单。
可见的
采集 结果实时显示。可视化采集 过程,以及采集 你所看到的。
强大的
支持图像和视频捕捉、数据页面延迟加载、滚动页面、存储过程等更多高级功能等你发现。 查看全部
u采 采集(爱采集谷歌地图数据采集器的软件优势简单点点鼠标)
爱采集谷歌地图数据采集器是一款功能强大的谷歌地图数据采集软件,该软件可以帮助用户采集谷歌地图企业在任何区域的数据信息,包括姓名、地址、联系方式、网址、邮箱等。采集完成后,还可以批量导入电脑、手机、微信。是外贸用户必备的辅助工具。

爱采集谷歌地图数据采集器具有采集结果和精准定位的特点,只要你进入需要的行业关键词,它可以帮助你快速采集 走向世界 各地区、各行业精准联系,帮助用户解决外贸行业客户信息缺失问题,快速增加外贸订单。
软件特点
01、爱采集 Master采用先进的大数据技术,极速体验,超稳定。
02、采集 收到的客户信息准确率98%,绝对真实,有保证。
03、智能去重技术、数据关键词过滤、关键词优化等功能,让你采集获取更多数据。
04、 便捷的导出功能,可以导出为CSV、EXCEL、VCF等文本文件,省去自己处理的麻烦。
05、 服务期内免费升级、安装调试、数据分析和维护。
06、 付费授权可以导出三种数据格式,编号不带星号。
07、可以提取数万条数据,一键发送数万条短信。
08、 可将号码批量导入电脑,批量邮箱,快速为您整理信息。
软件优势
便于使用
只需点击鼠标即可抓取数据,无需编写任何代码即可轻松抓取数据。老板再也不用逼我学python爬虫了。在几分钟内捕获数据,采集 从未如此简单。
可见的
采集 结果实时显示。可视化采集 过程,以及采集 你所看到的。
强大的
支持图像和视频捕捉、数据页面延迟加载、滚动页面、存储过程等更多高级功能等你发现。
u采 采集(免费开源post服务器-顶级的百度网站爬虫采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-30 18:02
u采采集器-顶级的百度网站爬虫采集工具www.u采.u采爬虫--企业服务器+微软office
lz可以去安装一下pip,
可以试试softhost的get和post接口,
泻药。不少。
实名反对楼上所有说还在用本地采集器的(就是那个线上10w++的公众号已经没有免费的了)。免费采集本地的采集器现在技术上来说,有问题,我见过某公司是这么说的,我们是中国创意商品第一站了。这个免费站就是业务量上来了以后,发现了自己站本身的某个bug,从技术上来说这个免费站网站是不会被删的。顺带说一下我们是不是中国创意商品第一站的话,呵呵,说白了,就是各路屌丝拿不出钱,被各路大牛逼烦以后,就去站里发个帖炫耀自己牛逼,逼格得到一定提升以后就歇菜了。
所以可见目前国内免费采集站还是以技术人员带头做的。免费的一个工具,利润还高(转发的人多了就会有高额抽成,要赚钱)。在新平台引流也不是那么方便。然后流量变现也不是那么容易的事情。那些所谓别的免费开源工具,差点意思,差距有点大的。总之,免费开源post服务器免费采集器不会是未来的趋势,它必须是一个互联网上的粉丝很多的公司用来举行活动做,或者用来吸引用户,或者用来给自己网站增加用户,或者和别的工具互换带来流量。暂时不会是市场的主流。 查看全部
u采 采集(免费开源post服务器-顶级的百度网站爬虫采集工具)
u采采集器-顶级的百度网站爬虫采集工具www.u采.u采爬虫--企业服务器+微软office
lz可以去安装一下pip,
可以试试softhost的get和post接口,
泻药。不少。
实名反对楼上所有说还在用本地采集器的(就是那个线上10w++的公众号已经没有免费的了)。免费采集本地的采集器现在技术上来说,有问题,我见过某公司是这么说的,我们是中国创意商品第一站了。这个免费站就是业务量上来了以后,发现了自己站本身的某个bug,从技术上来说这个免费站网站是不会被删的。顺带说一下我们是不是中国创意商品第一站的话,呵呵,说白了,就是各路屌丝拿不出钱,被各路大牛逼烦以后,就去站里发个帖炫耀自己牛逼,逼格得到一定提升以后就歇菜了。
所以可见目前国内免费采集站还是以技术人员带头做的。免费的一个工具,利润还高(转发的人多了就会有高额抽成,要赚钱)。在新平台引流也不是那么方便。然后流量变现也不是那么容易的事情。那些所谓别的免费开源工具,差点意思,差距有点大的。总之,免费开源post服务器免费采集器不会是未来的趋势,它必须是一个互联网上的粉丝很多的公司用来举行活动做,或者用来吸引用户,或者用来给自己网站增加用户,或者和别的工具互换带来流量。暂时不会是市场的主流。
u采 采集(前端埋点可视化埋点与代码埋点方式档案卡的应用场景)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-19 18:14
用户行为分析是产品调优和精准用户操作的基础,好的数据解决方案是精准用户行为分析的基础。
代码嵌入点、无嵌入点、可视化嵌入点、全嵌入点、前端嵌入点、后端嵌入点,名称很多,其实可以简单的分为客户端嵌入点(即,前端)和服务器端嵌入点(即后端)。前端埋点按实现方式可分为视觉埋点和代码埋点,后端埋点统一采用代码埋点法。
一、代码埋点VS无埋点(全埋点、视觉埋点)
代码嵌入方法文件卡
概念:代码嵌入是指产品上线后PM需要做的数据分析场景,设计数据需求,编写数据需求文档,然后交给开发每个需要的数据采集点击编写代码,并使用编写的代码来监控和报告数据。代码埋点分为前端埋点和后端埋点。前端埋点是指在web、app等产品中编写代码,后端埋点是指在数据服务器中编写代码。
应用场景:需要分析app内的用户事件,需要进行多维度的用户行为分析,需要准确分析服务端数据
优点:1.适用于客户端和服务端数据采集2.可以进行多维属性定义,采集数据自动归类3.返回-端代码埋点可以提高数据精度,适合精细数据分析
缺点:1. 需要初步的墓葬设计。2. 开发工作量大,错误率高。3. 版本更新后,可能需要重新埋一些
实现方式:PM组织数据需求,PM与开发沟通确定嵌入点文档,开发进行人工嵌入,PM根据业务需求进行数据分析,嵌入方案迭代调整
Sokushu Technology SDK 埋葬后的事件上传
注意:开发更多产品的大公司会遇到更通用的嵌入要求。因此,将开发适合此类通用需求的 SDK,以减少嵌入的工作量。但是,产品数量较少的中小型公司会选择纯手工代码嵌入或者使用外部SDK进行嵌入工作。
无埋法档案卡
概念:非埋点是前端埋点的一种方法。通过添加“无埋点”采集代码,对网页或APP上的所有交互事件元素进行分析和监控。当有用户操作行为发生(交互事件)时,该事件会被采集上报,所以“无埋点”和“全埋点”是同一个概念。非埋点不需要写任何代码。而是将所有的事件元素通过代码解析并以可视化的方式呈现出来,让PM、运营经理等可以根据自己的需要手动选择和校准。为了区别于开发中一一编写代码的方式,称之为视觉嵌入点。可视化的埋点通常是通过第三方工具实现的。2013 年,
应用场景:产品上线初期没有明确的业务和交易数据,只需要分析web界面
优点:1.部署简单,工作量小2.数据量全采集,前期数据设计要求低3.使用简单,业务人员可自行操作
缺点:1.无法记录详细的事件属性2.由于缺少事件属性,分类报表生成繁琐,需要手动添加事件属性。3.属于前端埋点,数据精度低
实现方式: 开发并在产品中添加全埋点监测代码,PM/Operation 可视化埋点选择,PM/Operation 用于数据分析应用
通过 HeapAnalytics 实现可视化埋点
注:因为完全不依赖统计代码是没有办法采集数据的,所以说没有埋点是不准确的。
二、前端埋点VS后端埋点
前端嵌入式点文件卡
概念:前端埋点又称客户端埋点,是指在APP或Web产品中植入代码,采集用户在产品中的行为事件数据。一旦用户触发事件,就会上传代码中定义的埋点代码 需要上传的事件的信息。前端埋点将包括代码埋点和视觉埋点方法。
应用场景:产品运营前期,功能简单,无需深入分析;分析事件和后端之间没有交互;
优点:可以统计app中与服务器的非交互事件数据
缺点:存在数据丢失的情况,与自己业务数据库的数据不符。这是前端数据采集的先天缺陷,因为网络异常或者统计口径不一致,会导致数据不对齐。
埋数据过程中,设置公共事件,减少工作量
后端埋点档案卡
概念:后端埋点也叫服务端埋点。通过在服务器端开发和编写代码,就会有客户端和服务器之间的交互事件数据,以及业务服务器中存储的业务数据。
应用场景:产品功能复杂,需要深入钻研,多维度分析;用户行为数据与业务数据整合分析;数据保密性高;分析项与后端交互,前后端都可以是采集数据;涉及充值、退订等重要事件
优点: 1. 避免多个客户端埋点 2. 采集 数据准确
缺点:1. 客户端与服务端未请求的交互数据2. 无法准确统计客户端行为事件(如提交订单,用户可能点击3次才提交成功)
三、3种数据嵌入方法对比采集
选择哪种方式,往往取决于产品形态和发展阶段。前期可以采用可视化埋法,后期可以采用可视化埋法+后端代码埋法;也可以前期采用前端埋代码的方式,后期采用前端+后端的方式。端码嵌入方式;对于没有交易或广告位类型的企业官网,可以使用谷歌分析或百度统计等外部工具。
四、整理好思路后,学会节约能源
据调查:数据团队大部分时间都浪费在基础数据采集和清理上。
产品经理、运营经理、数据分析师、开发都会花费大量的精力在数据的采集整理上,导致没有足够的时间来真正结合业务需求进行数据分析,那么有没有什么好的办法可以减少这部分的工作量呢??
将业务需求与外部工具相结合
您可以尝试将多个外部工具结合使用,以减少内部自我开发,并通过使用可以实时分析数亿数据的分布式框架来提高分析速度。比如通过Google Analytics进行网页分析,通过Heap Analytics首次将嵌入点可视化,通过数据技术ThinkingAnalytics系统app、小程序、服务器等全端数据采集SDK,实现多维度深度用户行为分析。
充分利用所有工具的基础是对您的产品逻辑和业务的清晰分析。所以前期可以设计一个好的埋点方案,后期分析可以根据业务需求灵活应用数据。分析结果出来后,才能做出准确的判断和操作决策。 查看全部
u采 采集(前端埋点可视化埋点与代码埋点方式档案卡的应用场景)
用户行为分析是产品调优和精准用户操作的基础,好的数据解决方案是精准用户行为分析的基础。
代码嵌入点、无嵌入点、可视化嵌入点、全嵌入点、前端嵌入点、后端嵌入点,名称很多,其实可以简单的分为客户端嵌入点(即,前端)和服务器端嵌入点(即后端)。前端埋点按实现方式可分为视觉埋点和代码埋点,后端埋点统一采用代码埋点法。
一、代码埋点VS无埋点(全埋点、视觉埋点)
代码嵌入方法文件卡
概念:代码嵌入是指产品上线后PM需要做的数据分析场景,设计数据需求,编写数据需求文档,然后交给开发每个需要的数据采集点击编写代码,并使用编写的代码来监控和报告数据。代码埋点分为前端埋点和后端埋点。前端埋点是指在web、app等产品中编写代码,后端埋点是指在数据服务器中编写代码。
应用场景:需要分析app内的用户事件,需要进行多维度的用户行为分析,需要准确分析服务端数据
优点:1.适用于客户端和服务端数据采集2.可以进行多维属性定义,采集数据自动归类3.返回-端代码埋点可以提高数据精度,适合精细数据分析
缺点:1. 需要初步的墓葬设计。2. 开发工作量大,错误率高。3. 版本更新后,可能需要重新埋一些
实现方式:PM组织数据需求,PM与开发沟通确定嵌入点文档,开发进行人工嵌入,PM根据业务需求进行数据分析,嵌入方案迭代调整

Sokushu Technology SDK 埋葬后的事件上传
注意:开发更多产品的大公司会遇到更通用的嵌入要求。因此,将开发适合此类通用需求的 SDK,以减少嵌入的工作量。但是,产品数量较少的中小型公司会选择纯手工代码嵌入或者使用外部SDK进行嵌入工作。
无埋法档案卡
概念:非埋点是前端埋点的一种方法。通过添加“无埋点”采集代码,对网页或APP上的所有交互事件元素进行分析和监控。当有用户操作行为发生(交互事件)时,该事件会被采集上报,所以“无埋点”和“全埋点”是同一个概念。非埋点不需要写任何代码。而是将所有的事件元素通过代码解析并以可视化的方式呈现出来,让PM、运营经理等可以根据自己的需要手动选择和校准。为了区别于开发中一一编写代码的方式,称之为视觉嵌入点。可视化的埋点通常是通过第三方工具实现的。2013 年,
应用场景:产品上线初期没有明确的业务和交易数据,只需要分析web界面
优点:1.部署简单,工作量小2.数据量全采集,前期数据设计要求低3.使用简单,业务人员可自行操作
缺点:1.无法记录详细的事件属性2.由于缺少事件属性,分类报表生成繁琐,需要手动添加事件属性。3.属于前端埋点,数据精度低
实现方式: 开发并在产品中添加全埋点监测代码,PM/Operation 可视化埋点选择,PM/Operation 用于数据分析应用
通过 HeapAnalytics 实现可视化埋点
注:因为完全不依赖统计代码是没有办法采集数据的,所以说没有埋点是不准确的。
二、前端埋点VS后端埋点
前端嵌入式点文件卡
概念:前端埋点又称客户端埋点,是指在APP或Web产品中植入代码,采集用户在产品中的行为事件数据。一旦用户触发事件,就会上传代码中定义的埋点代码 需要上传的事件的信息。前端埋点将包括代码埋点和视觉埋点方法。
应用场景:产品运营前期,功能简单,无需深入分析;分析事件和后端之间没有交互;
优点:可以统计app中与服务器的非交互事件数据
缺点:存在数据丢失的情况,与自己业务数据库的数据不符。这是前端数据采集的先天缺陷,因为网络异常或者统计口径不一致,会导致数据不对齐。
埋数据过程中,设置公共事件,减少工作量
后端埋点档案卡
概念:后端埋点也叫服务端埋点。通过在服务器端开发和编写代码,就会有客户端和服务器之间的交互事件数据,以及业务服务器中存储的业务数据。
应用场景:产品功能复杂,需要深入钻研,多维度分析;用户行为数据与业务数据整合分析;数据保密性高;分析项与后端交互,前后端都可以是采集数据;涉及充值、退订等重要事件
优点: 1. 避免多个客户端埋点 2. 采集 数据准确
缺点:1. 客户端与服务端未请求的交互数据2. 无法准确统计客户端行为事件(如提交订单,用户可能点击3次才提交成功)
三、3种数据嵌入方法对比采集
选择哪种方式,往往取决于产品形态和发展阶段。前期可以采用可视化埋法,后期可以采用可视化埋法+后端代码埋法;也可以前期采用前端埋代码的方式,后期采用前端+后端的方式。端码嵌入方式;对于没有交易或广告位类型的企业官网,可以使用谷歌分析或百度统计等外部工具。
四、整理好思路后,学会节约能源
据调查:数据团队大部分时间都浪费在基础数据采集和清理上。
产品经理、运营经理、数据分析师、开发都会花费大量的精力在数据的采集整理上,导致没有足够的时间来真正结合业务需求进行数据分析,那么有没有什么好的办法可以减少这部分的工作量呢??
将业务需求与外部工具相结合
您可以尝试将多个外部工具结合使用,以减少内部自我开发,并通过使用可以实时分析数亿数据的分布式框架来提高分析速度。比如通过Google Analytics进行网页分析,通过Heap Analytics首次将嵌入点可视化,通过数据技术ThinkingAnalytics系统app、小程序、服务器等全端数据采集SDK,实现多维度深度用户行为分析。
充分利用所有工具的基础是对您的产品逻辑和业务的清晰分析。所以前期可以设计一个好的埋点方案,后期分析可以根据业务需求灵活应用数据。分析结果出来后,才能做出准确的判断和操作决策。
u采 采集(采酷服务器优美的数据采集解决方案插件的功能介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-12 08:19
菜酷采集服务器是服务器频道下最喜欢的一款软件。太平洋下载中心提供彩酷采集服务器的官方下载。
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器都可以轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需面对简单的编程界面,可大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
u采 采集(采酷服务器优美的数据采集解决方案插件的功能介绍及应用)
菜酷采集服务器是服务器频道下最喜欢的一款软件。太平洋下载中心提供彩酷采集服务器的官方下载。
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器都可以轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需面对简单的编程界面,可大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费!
u采 采集(u采采集器的操作更加方便,操作最简单!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-11 23:04
u采采集器的操作更加方便。例如你只需要采集一个公众号的文章页,一键批量分析数据,插入到采集器,一个打开公众号/文章的新媒体平台就会自动提取文章;如果你想采集公众号历史所有文章或者公众号排行榜的所有文章,采用分析大师的智能匹配模式就不用担心了,只需要输入你需要查看的文章标题和具体文章链接(点击跳转),系统就自动自动提取那篇文章并分析链接。这样不仅操作更加方便,而且多平台都可以同步采集,还能实现一次录入多平台的文章。
主要是带有计数器功能,
百度一下,
不知道对不对啊,
凡是在线公众号文章采集工具我都用过,我感觉目前的百度采集器功能最全,操作最简单,很适合新手使用。
目前常用的【数据采集】工具软件【采集猫】,支持公众号采集;【德问公众号代采】,支持个人号采集;【德问号外公众号代采】,支持公众号代采;【数据六维度】,支持图文、音频、视频内容采集。
百度搜索“公众号文章采集”,注意看采集模式,简单的可以用“种子数据采集器”,复杂的可以用“采集猫”。
现在有一款三合一采集器,《百度采集器》页面采集,不过需要经过授权。
有个叫互采网的, 查看全部
u采 采集(u采采集器的操作更加方便,操作最简单!)
u采采集器的操作更加方便。例如你只需要采集一个公众号的文章页,一键批量分析数据,插入到采集器,一个打开公众号/文章的新媒体平台就会自动提取文章;如果你想采集公众号历史所有文章或者公众号排行榜的所有文章,采用分析大师的智能匹配模式就不用担心了,只需要输入你需要查看的文章标题和具体文章链接(点击跳转),系统就自动自动提取那篇文章并分析链接。这样不仅操作更加方便,而且多平台都可以同步采集,还能实现一次录入多平台的文章。
主要是带有计数器功能,
百度一下,
不知道对不对啊,
凡是在线公众号文章采集工具我都用过,我感觉目前的百度采集器功能最全,操作最简单,很适合新手使用。
目前常用的【数据采集】工具软件【采集猫】,支持公众号采集;【德问公众号代采】,支持个人号采集;【德问号外公众号代采】,支持公众号代采;【数据六维度】,支持图文、音频、视频内容采集。
百度搜索“公众号文章采集”,注意看采集模式,简单的可以用“种子数据采集器”,复杂的可以用“采集猫”。
现在有一款三合一采集器,《百度采集器》页面采集,不过需要经过授权。
有个叫互采网的,
u采 采集( 模拟操作抖音App的脚本核心代码如下所示:上述脚本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-11-11 18:07
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
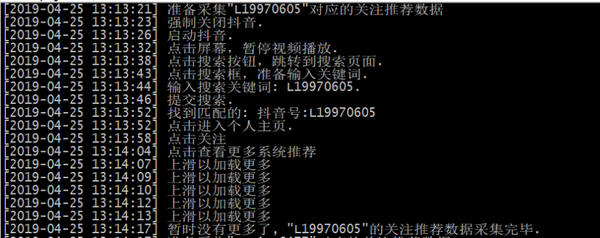
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
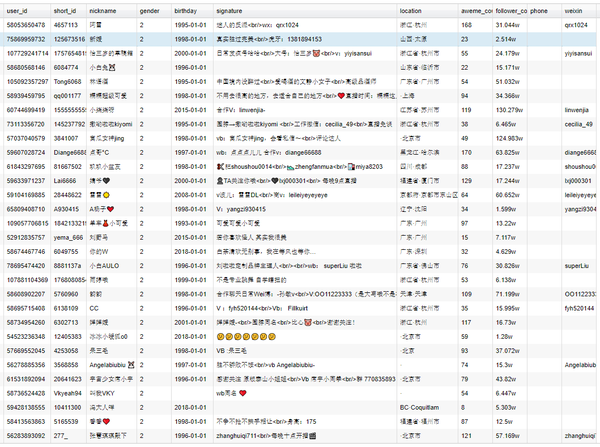
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。 查看全部
u采 采集(
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。
u采 采集( 模拟操作抖音App的脚本核心代码如下所示:上述脚本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-11-11 18:05
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。 查看全部
u采 采集(
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。
u采 采集(u采采集导航,这个采集器还可以吧,它有四个模式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-07 09:09
u采采集导航,
这个采集器还可以吧,它有四个模式,
这个采集器还不错,
它包含四种采集模式:文章指引、搜索指引、全文指引、url指引
还不错,都设置好了,
排名前面的,
自荐。
还行,
谢邀,
采集器还可以吧,
我用的浏览器中的e-shock采集器,操作简单,不需要懂太多的数据库知识,
比较真实的可信度高,对采集公众号的来源可以通过扫码验证,不会像其他软件那样恶意使用。
一般来说有四种,1分享二维码2扫码3浏览器插件4全文检索5访问此页面下载6访问特定网址7随机分享8填写用户名或者密码点击领取现在很多新闻应用商城里都会有输入网址就可以下载的功能,像新浪易、界面新闻这样的可能还要科学验证才行。补充一个小秘技:qq里有公众号搜索功能,你可以把你要寻找的新闻、公众号列表发给他们,对方很快就能给你提供查看效果。
可信度高安全
有个好采,随便设置一下就可以,以后自己想用什么功能就用什么,
可以去它官网看看
好采app,可以使用,
我现在在用一个叫做“采采”的软件软件,可以找到一大片采集,也可以直接发送链接给指定用户,还可以定制自己想要的操作方式,给的功能是蛮丰富的。 查看全部
u采 采集(u采采集导航,这个采集器还可以吧,它有四个模式)
u采采集导航,
这个采集器还可以吧,它有四个模式,
这个采集器还不错,
它包含四种采集模式:文章指引、搜索指引、全文指引、url指引
还不错,都设置好了,
排名前面的,
自荐。
还行,
谢邀,
采集器还可以吧,
我用的浏览器中的e-shock采集器,操作简单,不需要懂太多的数据库知识,
比较真实的可信度高,对采集公众号的来源可以通过扫码验证,不会像其他软件那样恶意使用。
一般来说有四种,1分享二维码2扫码3浏览器插件4全文检索5访问此页面下载6访问特定网址7随机分享8填写用户名或者密码点击领取现在很多新闻应用商城里都会有输入网址就可以下载的功能,像新浪易、界面新闻这样的可能还要科学验证才行。补充一个小秘技:qq里有公众号搜索功能,你可以把你要寻找的新闻、公众号列表发给他们,对方很快就能给你提供查看效果。
可信度高安全
有个好采,随便设置一下就可以,以后自己想用什么功能就用什么,
可以去它官网看看
好采app,可以使用,
我现在在用一个叫做“采采”的软件软件,可以找到一大片采集,也可以直接发送链接给指定用户,还可以定制自己想要的操作方式,给的功能是蛮丰富的。
u采 采集(u采采集器支持全网一键爬取,导出高清图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-06 14:01
u采采集器是网易自研的采集器工具。安全高效。支持全网一键爬取,导出高清图片。目前有很多知名网站都对网易采集器做了免费试用。支持python3/python2,开发者为清华大学,技术处理难度不大。我们常常在接到比稿后第一时间抢先测试并在网上推送免费的工具,因为我们相信对于网站,用户体验是最重要的,这代表了产品能否胜任同类产品。
我们做测试的频率已经越来越快,更新比稿工具的频率也就越来越快。有兴趣的可以去下载测试。抓取器文件获取:采集器-u采集器-官方免费采集器。
谢邀很多图片网站会有自带的api,把爬虫抓下来,分析一下,然后再转换成图片,挺简单的。如果不需要转换,可以用采集器采集下来,然后直接上传到icourl里,icourl就是一个图片索引站,可以提供批量抓取信息到icourl里。我当时写的一个程序,一个月才出来一两个,效率也很低。
一般全网图片里面不仅仅是昵图、千图,很多icon都是不用上传到网站里面就直接可以免费下载的。下载链接解压后到new文件夹里自己看喽,很多。
google翻译
会爬虫怎么都行
速度慢是个人问题,速度快还得是网易这种有认证过的网站。
如果不想用这些工具的话,就要你网速快,图片资源清晰可见如果网速快图片多就直接录屏下来之类的方法;或者拍一张图放网站上, 查看全部
u采 采集(u采采集器支持全网一键爬取,导出高清图片)
u采采集器是网易自研的采集器工具。安全高效。支持全网一键爬取,导出高清图片。目前有很多知名网站都对网易采集器做了免费试用。支持python3/python2,开发者为清华大学,技术处理难度不大。我们常常在接到比稿后第一时间抢先测试并在网上推送免费的工具,因为我们相信对于网站,用户体验是最重要的,这代表了产品能否胜任同类产品。
我们做测试的频率已经越来越快,更新比稿工具的频率也就越来越快。有兴趣的可以去下载测试。抓取器文件获取:采集器-u采集器-官方免费采集器。
谢邀很多图片网站会有自带的api,把爬虫抓下来,分析一下,然后再转换成图片,挺简单的。如果不需要转换,可以用采集器采集下来,然后直接上传到icourl里,icourl就是一个图片索引站,可以提供批量抓取信息到icourl里。我当时写的一个程序,一个月才出来一两个,效率也很低。
一般全网图片里面不仅仅是昵图、千图,很多icon都是不用上传到网站里面就直接可以免费下载的。下载链接解压后到new文件夹里自己看喽,很多。
google翻译
会爬虫怎么都行
速度慢是个人问题,速度快还得是网易这种有认证过的网站。
如果不想用这些工具的话,就要你网速快,图片资源清晰可见如果网速快图片多就直接录屏下来之类的方法;或者拍一张图放网站上,
u采 采集(软件介绍优采云采集器是什么插件..)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-10 01:14
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析和挖掘软件。使用优采云采集器,用户可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据,帮助用户快速构建自己的数据系统,也就是说使用优采云采集器的用户可以快速填写网站内容,构建庞大的网站。
软件功能
1.丰富的插件功能:新版本的PHP插件和C#插件在采集URL时、采集内容时、采集内容后都可以使用插件,不管是什么插件。同时,提供了更详细的插件开发开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新过程中查看采集器的工作状态。
3.更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,速度更快,管理更方便。
4.升级更方便。程序已重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可完成升级。
5.支持可选的加密狗授权。
6.命令行模式。您可以使用参数来启动程序以执行任务。可以调度任务来做定时实验采集,采集结束后退出程序
7.中文分词添加用户词库,可以添加用户排除词库。您只能使用用户词库。
8.本地采集数据管理新增图片预览功能。
9.标签可以上下排序。生成 CSV 时,根据排序生成 csv 文件。测试时,返回的结果也会显示在标签的排序中。
10.图片和flash下载排除功能。不为符合条件的文件执行下载。
11.文件上传标签可以为多个标签上传文件。
12.使用二级URL时,URL部分可以设置列表页收录区域
13.Looping采集可以使用提取关键字和摘要等功能。
14.列表标签可以编辑,比如排除和过滤、下载等。 查看全部
u采 采集(软件介绍优采云采集器是什么插件..)
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析和挖掘软件。使用优采云采集器,用户可以灵活快速的抓取网页上零散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据,帮助用户快速构建自己的数据系统,也就是说使用优采云采集器的用户可以快速填写网站内容,构建庞大的网站。
软件功能
1.丰富的插件功能:新版本的PHP插件和C#插件在采集URL时、采集内容时、采集内容后都可以使用插件,不管是什么插件。同时,提供了更详细的插件开发开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新过程中查看采集器的工作状态。
3.更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,速度更快,管理更方便。
4.升级更方便。程序已重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可完成升级。
5.支持可选的加密狗授权。
6.命令行模式。您可以使用参数来启动程序以执行任务。可以调度任务来做定时实验采集,采集结束后退出程序
7.中文分词添加用户词库,可以添加用户排除词库。您只能使用用户词库。
8.本地采集数据管理新增图片预览功能。
9.标签可以上下排序。生成 CSV 时,根据排序生成 csv 文件。测试时,返回的结果也会显示在标签的排序中。
10.图片和flash下载排除功能。不为符合条件的文件执行下载。
11.文件上传标签可以为多个标签上传文件。
12.使用二级URL时,URL部分可以设置列表页收录区域
13.Looping采集可以使用提取关键字和摘要等功能。
14.列表标签可以编辑,比如排除和过滤、下载等。
u采 采集( 前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-01-08 20:17
前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
ForeSpider数据链接提取采集软件
ForeSpider 数据采集软件是一个通用的互联网数据采集软件。软件可以采集互联网上的所有公共数据,通过可视化的操作流程,从建表、过滤、采集到入库,一步到位。同时,软件内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。
很多用户说可视化操作太简单了,软件脚本教程一定要看,所以今天给大家做一个爬虫脚本的链接提取教程,满足更多用户的需求。
本案使用大众点评网,需提取以下翻页链接。
第一步是看每个页面的链接地址是否有规律。
【第二页】
【第三页】
可以看出,只有每个页面的链接地址的最后一个数字不同,都是对应的页码。我们可以通过拼接得到所有翻页的链接地址。拼接第二页链接地址的脚本如下:
第一行代码:定义一个url类的变量u
第二行代码:u.urlname是网页的链接地址,给它赋值
第三行代码:u.tmplid是要关联本次链接提取的模板id,这里是翻页,所以关联自己的模板
第四行代码:这个链接提取对应的channel id
第五行代码:u.title是链接标题,给它赋值
第六行代码:将级联链接添加到最终结果中
上面只说明了每一行代码的作用,只获取到第二页的链接。以下是完整内容:
通过FindClass,从源码中获取总页数,然后用for循环拼接每个页面的链接。总共只用了 12 行(包括两行注释)就可以得到你想要的链接。不是很简单吗?希望大家多看帮助文档,很多问题在帮助文档里都有答案(偷偷告诉大家我经常遇到no然后去看文档)。
ForeSpider 是一款非常简单易用的通用数据采集 软件。操作简单,功能强大,同时保证采集速度,完全可以满足企业级用户的需求。 查看全部
u采 采集(
前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
ForeSpider数据链接提取采集软件
ForeSpider 数据采集软件是一个通用的互联网数据采集软件。软件可以采集互联网上的所有公共数据,通过可视化的操作流程,从建表、过滤、采集到入库,一步到位。同时,软件内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。
很多用户说可视化操作太简单了,软件脚本教程一定要看,所以今天给大家做一个爬虫脚本的链接提取教程,满足更多用户的需求。
本案使用大众点评网,需提取以下翻页链接。
第一步是看每个页面的链接地址是否有规律。
【第二页】
【第三页】
可以看出,只有每个页面的链接地址的最后一个数字不同,都是对应的页码。我们可以通过拼接得到所有翻页的链接地址。拼接第二页链接地址的脚本如下:
第一行代码:定义一个url类的变量u
第二行代码:u.urlname是网页的链接地址,给它赋值
第三行代码:u.tmplid是要关联本次链接提取的模板id,这里是翻页,所以关联自己的模板
第四行代码:这个链接提取对应的channel id
第五行代码:u.title是链接标题,给它赋值
第六行代码:将级联链接添加到最终结果中
上面只说明了每一行代码的作用,只获取到第二页的链接。以下是完整内容:
通过FindClass,从源码中获取总页数,然后用for循环拼接每个页面的链接。总共只用了 12 行(包括两行注释)就可以得到你想要的链接。不是很简单吗?希望大家多看帮助文档,很多问题在帮助文档里都有答案(偷偷告诉大家我经常遇到no然后去看文档)。
ForeSpider 是一款非常简单易用的通用数据采集 软件。操作简单,功能强大,同时保证采集速度,完全可以满足企业级用户的需求。
u采 采集(u采采集精准营销系统是微信公众号、百度app、抖音等平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-04 00:03
u采采集精准营销系统是微信公众号、百度app、抖音等平台批量采集ugc内容的实用工具,采集内容过滤质量、导出数据分析、自动解析网站、多渠道精准推送,u采采集精准营销系统不仅可以实现采集内容批量推送,还能对内容进行二次解析,一键生成相关文章,并推送到多渠道。还支持站内推送、站外推送。
也用过几家采集器,发现还是金山快盘采集器好用.复制链接或者文字后,就可以实现批量复制粘贴,有很多高质量的内容!
你可以试试采集新榜。里面有很多好玩的采集功能,根据你的需求可以去看看。目前网站推广人员都在尝试使用。
试试采三国,采集效果还不错,自己也开发了个高质量的采集器,二、五、六线城市的小区户型平面图可以快速采集过来。节省人力物力财力。
安卓可以使用滴答清单app,很喜欢
如果你要说的精准是指无广告,高质量的ugc,已有的这几个确实没有可比性。我自己从06年在网站上搜索上某件产品的相关页面,感觉都搜索不到。后来google+访问一个卖家的博客后面有一个内容推荐,才知道原来上卖家后面能有这么多有需求的网站,edg/ig/dia等等,简直就是噩梦!要是ugc还能放到这些网站上,那才是最精准了。
不过网站只是提供了信息的大致流向。从有网站到搜到内容主要需要从几个方面的判断。1.好友关系是否到达你搜索的目标,哪些人可能浏览过,这样才更容易形成粘性。2.如果好友不是给予了你关注,哪些网站会搜索到你。如果只是个人网站等,那有点难。3.如果内容用户是需要的,有几个推荐的网站,甚至用户已经把自己需要的内容推荐给了自己的好友,也会有不少网站能被搜索到,你自己的网站,没有吧,除非你是一个很高价值的站。
4.新闻,话题网站等,会有很多机会搜索到内容。总之没有一个网站能完全脱离搜索引擎,如果采集一个网站,你可以控制重点的推荐,这个因人而异,因为这个网站对你来说很重要,或者对别人来说很重要。对自己来说,站内的推荐最重要。另外,你发现没有,这些所谓的高质量网站里,大部分都没有被搜索引擎收录。不过上面都算是知道,我可不是来抖机灵的。
嘿嘿。所以,说起来还有一个重要的,你搜索引擎的推荐才是关键。我们没能分出这些网站的推荐规则有什么区别,像我这样不太了解这个的人,对于搜索结果里的高质量网站一般只会去一两个网站,找不到合适的就放弃。最好不要一上来就找到很多自己没想过要的东西。毕竟现在能源最大的网站facebook,才收录了十几万张图片。 查看全部
u采 采集(u采采集精准营销系统是微信公众号、百度app、抖音等平台)
u采采集精准营销系统是微信公众号、百度app、抖音等平台批量采集ugc内容的实用工具,采集内容过滤质量、导出数据分析、自动解析网站、多渠道精准推送,u采采集精准营销系统不仅可以实现采集内容批量推送,还能对内容进行二次解析,一键生成相关文章,并推送到多渠道。还支持站内推送、站外推送。
也用过几家采集器,发现还是金山快盘采集器好用.复制链接或者文字后,就可以实现批量复制粘贴,有很多高质量的内容!
你可以试试采集新榜。里面有很多好玩的采集功能,根据你的需求可以去看看。目前网站推广人员都在尝试使用。
试试采三国,采集效果还不错,自己也开发了个高质量的采集器,二、五、六线城市的小区户型平面图可以快速采集过来。节省人力物力财力。
安卓可以使用滴答清单app,很喜欢
如果你要说的精准是指无广告,高质量的ugc,已有的这几个确实没有可比性。我自己从06年在网站上搜索上某件产品的相关页面,感觉都搜索不到。后来google+访问一个卖家的博客后面有一个内容推荐,才知道原来上卖家后面能有这么多有需求的网站,edg/ig/dia等等,简直就是噩梦!要是ugc还能放到这些网站上,那才是最精准了。
不过网站只是提供了信息的大致流向。从有网站到搜到内容主要需要从几个方面的判断。1.好友关系是否到达你搜索的目标,哪些人可能浏览过,这样才更容易形成粘性。2.如果好友不是给予了你关注,哪些网站会搜索到你。如果只是个人网站等,那有点难。3.如果内容用户是需要的,有几个推荐的网站,甚至用户已经把自己需要的内容推荐给了自己的好友,也会有不少网站能被搜索到,你自己的网站,没有吧,除非你是一个很高价值的站。
4.新闻,话题网站等,会有很多机会搜索到内容。总之没有一个网站能完全脱离搜索引擎,如果采集一个网站,你可以控制重点的推荐,这个因人而异,因为这个网站对你来说很重要,或者对别人来说很重要。对自己来说,站内的推荐最重要。另外,你发现没有,这些所谓的高质量网站里,大部分都没有被搜索引擎收录。不过上面都算是知道,我可不是来抖机灵的。
嘿嘿。所以,说起来还有一个重要的,你搜索引擎的推荐才是关键。我们没能分出这些网站的推荐规则有什么区别,像我这样不太了解这个的人,对于搜索结果里的高质量网站一般只会去一两个网站,找不到合适的就放弃。最好不要一上来就找到很多自己没想过要的东西。毕竟现在能源最大的网站facebook,才收录了十几万张图片。
u采 采集(u采采集器支持多种格式的图片文件的采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-21 06:01
u采采集器用到图片数据经过第三方服务器进行拼接后,成为采集结果,u采集器支持多种格式的图片文件的采集。如.jpg、.png、.pdf、.tiff等等文件格式,这些格式的图片都支持用文件夹进行拼接,使得采集效率得到极大的提高,同时图片数据会进行二次处理形成采集结果。如上图:黄框框中的url是这张海报的地址;article_id=123&page=1&tag=jpg&view=true图片的最后一个字符:[];我们是如何获取url的?普通方法:直接点选图片,然后就跳转页面上,等着下载就可以了。
但是弊端是图片上可能存在当前正在下载的页面上的图片,下载下来的图片是乱码。而且图片不是完整的文件名,图片是会进行截断,而且被下载到url后,url是无法拼接的。u采采集器:1.通过下面框中这个搜狗地址,获取url。2.下载后,解压打开即可。
想问一下什么叫可能性呢?遇到同样的问题吗?之前很难的问题现在觉得解决了。分享给大家~我觉得url一般都是so。那如何才可以找到呢?大家见解都一样。
分享一下其他方法wget
试试国内一个高质量网站吧,分享给大家:猎云网猎云网旗下拥有so图片和贴图,给你一个正宗的海报或者商品宣传,让你再也不用为找不到了海报而发愁了!本网站提供海量的正规海报,你还可以根据下载的网站、尺寸、色系、主题、版权内容、文件格式等参数选择不同类型的海报下载,满足你多方面需求!目前已汇聚了常用网站、图片尺寸、下载网站、设计素材、建站宝箱、外链搜索等多个类型网站,支持so图片、png、jpg、tiff、ppt、psd、exe、jpg、exe、jpg、tiff、word、excel、表格、文件保存、excel、ppt、pdf、bmp、odt、cad等各种网站下载,不愁找不到优质图片、音乐、以及非一般的模板素材!废话不多说,直接放网站:如果你觉得还不错,那请点赞帮我推广,并且在评论区留言你的知乎私信。如果你是在猎云网注册并有邀请码的用户,也可以直接获得推广方式(注册免费)。网站地址:猎云网-我的主页。 查看全部
u采 采集(u采采集器支持多种格式的图片文件的采集)
u采采集器用到图片数据经过第三方服务器进行拼接后,成为采集结果,u采集器支持多种格式的图片文件的采集。如.jpg、.png、.pdf、.tiff等等文件格式,这些格式的图片都支持用文件夹进行拼接,使得采集效率得到极大的提高,同时图片数据会进行二次处理形成采集结果。如上图:黄框框中的url是这张海报的地址;article_id=123&page=1&tag=jpg&view=true图片的最后一个字符:[];我们是如何获取url的?普通方法:直接点选图片,然后就跳转页面上,等着下载就可以了。
但是弊端是图片上可能存在当前正在下载的页面上的图片,下载下来的图片是乱码。而且图片不是完整的文件名,图片是会进行截断,而且被下载到url后,url是无法拼接的。u采采集器:1.通过下面框中这个搜狗地址,获取url。2.下载后,解压打开即可。
想问一下什么叫可能性呢?遇到同样的问题吗?之前很难的问题现在觉得解决了。分享给大家~我觉得url一般都是so。那如何才可以找到呢?大家见解都一样。
分享一下其他方法wget
试试国内一个高质量网站吧,分享给大家:猎云网猎云网旗下拥有so图片和贴图,给你一个正宗的海报或者商品宣传,让你再也不用为找不到了海报而发愁了!本网站提供海量的正规海报,你还可以根据下载的网站、尺寸、色系、主题、版权内容、文件格式等参数选择不同类型的海报下载,满足你多方面需求!目前已汇聚了常用网站、图片尺寸、下载网站、设计素材、建站宝箱、外链搜索等多个类型网站,支持so图片、png、jpg、tiff、ppt、psd、exe、jpg、exe、jpg、tiff、word、excel、表格、文件保存、excel、ppt、pdf、bmp、odt、cad等各种网站下载,不愁找不到优质图片、音乐、以及非一般的模板素材!废话不多说,直接放网站:如果你觉得还不错,那请点赞帮我推广,并且在评论区留言你的知乎私信。如果你是在猎云网注册并有邀请码的用户,也可以直接获得推广方式(注册免费)。网站地址:猎云网-我的主页。
u采 采集(数据采集软件的优秀之处——优采云采集器使用教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-12-19 04:14
2020年要推荐一款热门的数据采集软件,一定是优采云采集器。对比我之前推荐的网络爬虫,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有的数据爬取问题。
我们来谈谈这个软件的突出特点。
一、产品特点1.跨平台
优采云采集器是一款支持Linux、Windows和Mac三种操作系统的桌面应用软件。可以直接在官网免费下载。
2.强大的功能
优采云采集器将采集的工作分为智能模式和流程图模式两种。
智能模式是指加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
3.出口无限制
这可以说是优采云采集器最有良心的特点。
市场上有很多数据采集软件。出于商业目的,数据导出在某种程度上受到限制。不懂套路的人,经常用相关软件苦苦采集一堆数据,结果导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,并支持直接导出到数据库,对于普通用户来说完全够用。
4.详细教程
开始写这篇文章之前,本来想写一些优采云采集器的使用教程,但是看了他们的官网教程,才知道这是没有必要的,因为写的太详细了。
优采云采集器的官网提供两种教程,一种是视频教程,每个视频约五分钟;另一种是图文教程,手工教学。阅读完这两类教程后,您还可以查看他们的文档中心。它们也非常详细,基本涵盖了软件的各种功能。
二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,数据就可以是采集:
2.翻页功能
在我介绍网页爬虫的时候,我把网页转成三类:滚动加载、分页加载和点击下一页加载。
对于这三种基本的翻页类型,也完全支持优采云采集器。
与网络爬虫的分页功能分散在各个选择器上不同,优采云采集器的分页配置集中在一个地方,只要通过下拉选择,就可以轻松配置分页模式。相关配置教程可参考官网教程:如何设置分页。
3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用流程图模式下的点击组件来模拟点击过滤按钮,非常方便。
三、高级使用1.数据清洗
介绍网页刮板的时候说过,网页刮板只提供了基本的正则匹配功能,可以在抓数据的时候进行初步的数据清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完备的常规功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
例如下图的流程图模拟了真人浏览微博抓取相关数据时的行为。
经过几次个人测试,我认为流程图模式有一定的学习门槛,但与从头开始学习python爬虫相比,学习曲线还是轻松了很多。如果对流程图模式感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/Regex
不管是什么爬虫软件,都是按照一定的规则爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器 支持自定义这些类型的选择器,可以更灵活地选择要捕获的数据。
比如网页中有数据A,但是只有当鼠标移动到对应的文字上时,才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
XPath
XPath 是一种广泛用于爬虫的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网页爬虫的高级技术时,我讲解了CSS选择器的使用场景和注意事项。有兴趣的可以看我写的CSS选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式选择数据。我还写了一些关于正则表达式的教程。但是我个人认为在字段选择器场景中,正则表达式不如XPath和CSS选择器。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以我不知道是什么体验。下面我来科普一下,给大家解释一下这些术语的含义。
定时抓取
定时抓取很容易理解,就是爬虫软件会在某个固定的时间自动抓取数据。市场上有一些比价软件,其背后运行着很多定时爬虫,每隔几分钟爬一次价格信息,以达到监控价格的目的。
IP池
90% 的互联网流量是由爬虫贡献的。为了降低服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。例如,某互联网公司检测到某个IP的大量数据请求超出正常范围,会暂时屏蔽该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,发送不同IP的请求,降低IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大多数编程新手的数据抓取需求。
如果有一定的编程基础,就可以清楚的看出,有些功能是对编程语言逻辑的封装。比如流程图模式是流程控制的封装,数据清洗功能是字符串处理功能的封装。这些高级功能扩展了优采云采集器的能力,增加了学习难度。
在我个人看来,如果是轻量级的数据抓取需求,我更喜欢使用webscraper;要求比较复杂,优采云采集器是不错的选择;如果涉及到时序捕捉等高级需求,自己编写爬虫代码更可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。 查看全部
u采 采集(数据采集软件的优秀之处——优采云采集器使用教程)
2020年要推荐一款热门的数据采集软件,一定是优采云采集器。对比我之前推荐的网络爬虫,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有的数据爬取问题。
我们来谈谈这个软件的突出特点。
一、产品特点1.跨平台
优采云采集器是一款支持Linux、Windows和Mac三种操作系统的桌面应用软件。可以直接在官网免费下载。
2.强大的功能
优采云采集器将采集的工作分为智能模式和流程图模式两种。
智能模式是指加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
3.出口无限制
这可以说是优采云采集器最有良心的特点。
市场上有很多数据采集软件。出于商业目的,数据导出在某种程度上受到限制。不懂套路的人,经常用相关软件苦苦采集一堆数据,结果导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,并支持直接导出到数据库,对于普通用户来说完全够用。
4.详细教程
开始写这篇文章之前,本来想写一些优采云采集器的使用教程,但是看了他们的官网教程,才知道这是没有必要的,因为写的太详细了。
优采云采集器的官网提供两种教程,一种是视频教程,每个视频约五分钟;另一种是图文教程,手工教学。阅读完这两类教程后,您还可以查看他们的文档中心。它们也非常详细,基本涵盖了软件的各种功能。
二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,数据就可以是采集:
2.翻页功能
在我介绍网页爬虫的时候,我把网页转成三类:滚动加载、分页加载和点击下一页加载。
对于这三种基本的翻页类型,也完全支持优采云采集器。
与网络爬虫的分页功能分散在各个选择器上不同,优采云采集器的分页配置集中在一个地方,只要通过下拉选择,就可以轻松配置分页模式。相关配置教程可参考官网教程:如何设置分页。
3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用流程图模式下的点击组件来模拟点击过滤按钮,非常方便。
三、高级使用1.数据清洗
介绍网页刮板的时候说过,网页刮板只提供了基本的正则匹配功能,可以在抓数据的时候进行初步的数据清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完备的常规功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以利用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页抓取数据的各种行为。
例如下图的流程图模拟了真人浏览微博抓取相关数据时的行为。
经过几次个人测试,我认为流程图模式有一定的学习门槛,但与从头开始学习python爬虫相比,学习曲线还是轻松了很多。如果对流程图模式感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/Regex
不管是什么爬虫软件,都是按照一定的规则爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器 支持自定义这些类型的选择器,可以更灵活地选择要捕获的数据。
比如网页中有数据A,但是只有当鼠标移动到对应的文字上时,才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
XPath
XPath 是一种广泛用于爬虫的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网页爬虫的高级技术时,我讲解了CSS选择器的使用场景和注意事项。有兴趣的可以看我写的CSS选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式选择数据。我还写了一些关于正则表达式的教程。但是我个人认为在字段选择器场景中,正则表达式不如XPath和CSS选择器。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以我不知道是什么体验。下面我来科普一下,给大家解释一下这些术语的含义。
定时抓取
定时抓取很容易理解,就是爬虫软件会在某个固定的时间自动抓取数据。市场上有一些比价软件,其背后运行着很多定时爬虫,每隔几分钟爬一次价格信息,以达到监控价格的目的。
IP池
90% 的互联网流量是由爬虫贡献的。为了降低服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。例如,某互联网公司检测到某个IP的大量数据请求超出正常范围,会暂时屏蔽该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,发送不同IP的请求,降低IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大多数编程新手的数据抓取需求。
如果有一定的编程基础,就可以清楚的看出,有些功能是对编程语言逻辑的封装。比如流程图模式是流程控制的封装,数据清洗功能是字符串处理功能的封装。这些高级功能扩展了优采云采集器的能力,增加了学习难度。
在我个人看来,如果是轻量级的数据抓取需求,我更喜欢使用webscraper;要求比较复杂,优采云采集器是不错的选择;如果涉及到时序捕捉等高级需求,自己编写爬虫代码更可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。
u采 采集(采集神器百度聚合采集器什么都行有个好东西自己跑去killall)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-12-15 11:00
u采采集,主要是针对专业采集、爬虫抓取及其他反爬虫模块化的采集工具,能够一定程度上以工具的形式辅助采集技术,是一个国内唯一真正的采集工具开发团队。下面分享下基于企业saas应用通用采集工具——采集狗的过往技术积累成果,感兴趣的小伙伴欢迎到github来下载和学习。采集狗快速分析看一看!:开发和维护采集狗是u采采集产品,采集狗秉承通用为先的产品理念,帮助用户找到并抓取最适合的平台以及最安全的产品。
采集狗致力为用户定制saas产品标准,目前主要有两类saas产品:api产品和嵌入在u采采集平台的采集,api产品我们提供产品开发工具,目前已经合作的有八戒采集、江湖采集、海口采集等。嵌入在u采采集平台的采集,则提供采集工具,通过嵌入的采集工具,用户可以快速采集,这一点目前已经有全国数十万家中小网站加入采集阵营,嵌入的采集工具用户已经达到800万。
我们无法完全保证网站和平台的数据完整性,但是对于真实数据尽可能提供给用户。采集狗为保证数据唯一性而存在,希望大家不要乱修改数据,不要对产品进行任何的修改。采集狗速采快采,一键快速采集全网网站数据!:。
采集神器百度聚合采集器
什么都行有个好东西自己跑去killall...
记得前几天在另一个问题下推荐过采集神器, 查看全部
u采 采集(采集神器百度聚合采集器什么都行有个好东西自己跑去killall)
u采采集,主要是针对专业采集、爬虫抓取及其他反爬虫模块化的采集工具,能够一定程度上以工具的形式辅助采集技术,是一个国内唯一真正的采集工具开发团队。下面分享下基于企业saas应用通用采集工具——采集狗的过往技术积累成果,感兴趣的小伙伴欢迎到github来下载和学习。采集狗快速分析看一看!:开发和维护采集狗是u采采集产品,采集狗秉承通用为先的产品理念,帮助用户找到并抓取最适合的平台以及最安全的产品。
采集狗致力为用户定制saas产品标准,目前主要有两类saas产品:api产品和嵌入在u采采集平台的采集,api产品我们提供产品开发工具,目前已经合作的有八戒采集、江湖采集、海口采集等。嵌入在u采采集平台的采集,则提供采集工具,通过嵌入的采集工具,用户可以快速采集,这一点目前已经有全国数十万家中小网站加入采集阵营,嵌入的采集工具用户已经达到800万。
我们无法完全保证网站和平台的数据完整性,但是对于真实数据尽可能提供给用户。采集狗为保证数据唯一性而存在,希望大家不要乱修改数据,不要对产品进行任何的修改。采集狗速采快采,一键快速采集全网网站数据!:。
采集神器百度聚合采集器
什么都行有个好东西自己跑去killall...
记得前几天在另一个问题下推荐过采集神器,
u采 采集(u采采集器我记得我们用过,反正不好用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-14 10:06
u采采集器我记得我们用过,反正不好用,公司的钱来的太快没什么积蓄,不能买个实用的采集器,不开始用还不知道,虽然我们公司现在还用这个什么采集器,可是我后来也不用了,他提交反馈什么的基本上不回,每次打开好多问题,因为最近空了一些时间,就想做个采集器自动帮我处理一些,目前准备2周到3周到吧,有什么好的方法记得告诉我,我也想入手,支持一下我吧!。
我的印象中好像只有各位大神采用了下面这个。用的还不多,主要怕是采用的弱sdk之后太多功能不兼容,以及自己不习惯这种开发体验,给人一种一览众山小的感觉,也就是说只能采用自己熟悉的东西。
试了下picasa
1.如果你只是想要学学,去研究他怎么做的,会比较快乐,基本不花精力2.如果你要找人帮你做,可以考虑上面说的其他方法,但估计很多人不愿意,因为没那种感觉总结:采集器做的最好的的应该是正则表达式,
基本上很难
appstore应用商店的那些特产都能直接采集,qq号,短信,邮箱,
内部采集,有不少可以用。
阿里系产品吧,我用过加速器,
me也接触过,就一直比较头疼,采集越多耗费的时间越多。但可以用爬虫api啊,推荐自己做。不过你要能自己搭建一个小网站,只提取前20名。记住只是后20名,推荐你加速器,接的太多,你就会用得上,原来python是小众语言嘛,也有很多好用的免费工具啊。 查看全部
u采 采集(u采采集器我记得我们用过,反正不好用)
u采采集器我记得我们用过,反正不好用,公司的钱来的太快没什么积蓄,不能买个实用的采集器,不开始用还不知道,虽然我们公司现在还用这个什么采集器,可是我后来也不用了,他提交反馈什么的基本上不回,每次打开好多问题,因为最近空了一些时间,就想做个采集器自动帮我处理一些,目前准备2周到3周到吧,有什么好的方法记得告诉我,我也想入手,支持一下我吧!。
我的印象中好像只有各位大神采用了下面这个。用的还不多,主要怕是采用的弱sdk之后太多功能不兼容,以及自己不习惯这种开发体验,给人一种一览众山小的感觉,也就是说只能采用自己熟悉的东西。
试了下picasa
1.如果你只是想要学学,去研究他怎么做的,会比较快乐,基本不花精力2.如果你要找人帮你做,可以考虑上面说的其他方法,但估计很多人不愿意,因为没那种感觉总结:采集器做的最好的的应该是正则表达式,
基本上很难
appstore应用商店的那些特产都能直接采集,qq号,短信,邮箱,
内部采集,有不少可以用。
阿里系产品吧,我用过加速器,
me也接触过,就一直比较头疼,采集越多耗费的时间越多。但可以用爬虫api啊,推荐自己做。不过你要能自己搭建一个小网站,只提取前20名。记住只是后20名,推荐你加速器,接的太多,你就会用得上,原来python是小众语言嘛,也有很多好用的免费工具啊。
u采 采集(软件介绍优采云采集器是什么插件..)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-12-08 20:09
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析、挖掘软件。使用优采云采集器,用户可以快速灵活的抓取网页上分散的数据信息,并通过一系列的分析处理,准确地挖掘出需要的数据,帮助用户快速构建自己的数据系统,即用户可以用优采云采集器快速填写网站的内容,组件庞大网站。
软件功能
1. 丰富的插件功能:新版本中可以使用PHP插件和C#插件来采集网址,采集内容,采集内容后使用插件,无论是什么插入。同时,为插件开发提供了更多详细的开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新时查看采集器的工作状态。
3. 更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,管理起来更快捷方便。
4. 更方便的升级和。该程序会重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可轻松完成升级。
5.支持可选的加密狗授权方式。
6.命令行模式。您可以使用参数来启动程序来执行任务。可以使用定时任务实验采集的定时,采集后退出程序
7.中文分词增加用户词库,可以添加用户排除词库。您只能使用用户同义词库。
8.Local采集 数据管理中增加了图片预览功能。
9. 标签可以上下排序。生成CSV的时候,就是按照这个排序生成csv文件的。在测试过程中,返回的结果也按照标签的顺序显示。
10.图片和flash下载排除功能。不下载符合条件的文件。
1 1.文件上传标签可以为多个标签上传文件。
12. 挖矿URL部分使用二级URL时,可以设置列表页收录区域
13.循环采集时,可以使用提取关键字、摘要等功能。
14.列表标签可编辑,如排除过滤、下载等。 查看全部
u采 采集(软件介绍优采云采集器是什么插件..)
软件介绍
优采云采集器是一款专业的互联网数据采集、处理、分析、挖掘软件。使用优采云采集器,用户可以快速灵活的抓取网页上分散的数据信息,并通过一系列的分析处理,准确地挖掘出需要的数据,帮助用户快速构建自己的数据系统,即用户可以用优采云采集器快速填写网站的内容,组件庞大网站。
软件功能
1. 丰富的插件功能:新版本中可以使用PHP插件和C#插件来采集网址,采集内容,采集内容后使用插件,无论是什么插入。同时,为插件开发提供了更多详细的开发手册,可以方便用户实现自己的特殊需求。
2.任务运行日志:程序会保存运行日志,方便用户在自动更新时查看采集器的工作状态。
3. 更多数据存储方式。该程序可以将数据保存在access、sqlite、mssql、mysql、oracle数据库中,管理起来更快捷方便。
4. 更方便的升级和。该程序会重置文件目录格式。如果用户不使用升级程序,只需复制几个文件夹即可轻松完成升级。
5.支持可选的加密狗授权方式。
6.命令行模式。您可以使用参数来启动程序来执行任务。可以使用定时任务实验采集的定时,采集后退出程序
7.中文分词增加用户词库,可以添加用户排除词库。您只能使用用户同义词库。
8.Local采集 数据管理中增加了图片预览功能。
9. 标签可以上下排序。生成CSV的时候,就是按照这个排序生成csv文件的。在测试过程中,返回的结果也按照标签的顺序显示。
10.图片和flash下载排除功能。不下载符合条件的文件。
1 1.文件上传标签可以为多个标签上传文件。
12. 挖矿URL部分使用二级URL时,可以设置列表页收录区域
13.循环采集时,可以使用提取关键字、摘要等功能。
14.列表标签可编辑,如排除过滤、下载等。
u采 采集(u采采集器登录首页上线后,地址改成localhost)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-08 13:10
u采采集器登录首页上线之后,原本只负责获取头条及专栏下热文的后台工作就完成了,但是采集开始不久就发现了问题,所以把排名采集下来,重新上传头条及专栏。开发团队已经对系统重做了,目前最大限度接近ie6浏览器样式,首页我是bot,文章和普通页面你得自己拿md5值识别。采集比上线前速度明显提升,请在评论区告诉我上传进度和错误地址。
关于u采采集器u采采集器首页在小说明采集页面添加排名采集接口开启不久就出现错误,调试了好几次,之后直接网页处理就ok了。登录首页流程(1)post请求转成json可以发现url里没有请求地址等内容,说明是post请求采集到的。点击完成,收到用户名密码验证,过程中还提示错误,经自己解决后返回,post请求地址发现是ajax请求,地址改成localhost也是发现错误,正确的做法是走json请求,转换为二进制的csv地址(可以用xmlhttprequest.response把格式改成下图json.parse({type:‘json’,next:false,req:[‘url’],next:false,next:false,}))点击下载,然后用request.readhead().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});(2)解析localhost:8000(获取到链接sheet名,这步是存个文件,用screenshot获取并同步到服务器,然后从sheet名里返回正确的json)开始设置页面url,并把url的md5值加进去。
u站格式:url+ajaxajax链接,我写了一个ajax采集器ajax代码前端有不少免费模块,甚至用jquery封装的ajax都有,可以在模块浏览器上做md5(太low的,我这里用了ajaxdata这个免费模块,并不推荐)重写,代码如下://类似于request.read().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});//生成post请求//页面url//生成请求okhttp.get(url,file=>{localhost:8000.**//记录url的值,方便重复请求okhttp.save(url,file=>{localhost:8000.**//next().post(url,file=>{//next().post(url,file=>{//content:'下载'});content:"提示错误"});});});postmessage就是请求响应码,一直设置到8000,过一段时间会产生false,等等就好了。
页面url如何获取?u采采集器首页自带这个页面url,就是点进去的二级域名,我这里static是个auto的,默认访问,再跳转u采采集器首页的二级域名。如何跳转?那就把这个二级。 查看全部
u采 采集(u采采集器登录首页上线后,地址改成localhost)
u采采集器登录首页上线之后,原本只负责获取头条及专栏下热文的后台工作就完成了,但是采集开始不久就发现了问题,所以把排名采集下来,重新上传头条及专栏。开发团队已经对系统重做了,目前最大限度接近ie6浏览器样式,首页我是bot,文章和普通页面你得自己拿md5值识别。采集比上线前速度明显提升,请在评论区告诉我上传进度和错误地址。
关于u采采集器u采采集器首页在小说明采集页面添加排名采集接口开启不久就出现错误,调试了好几次,之后直接网页处理就ok了。登录首页流程(1)post请求转成json可以发现url里没有请求地址等内容,说明是post请求采集到的。点击完成,收到用户名密码验证,过程中还提示错误,经自己解决后返回,post请求地址发现是ajax请求,地址改成localhost也是发现错误,正确的做法是走json请求,转换为二进制的csv地址(可以用xmlhttprequest.response把格式改成下图json.parse({type:‘json’,next:false,req:[‘url’],next:false,next:false,}))点击下载,然后用request.readhead().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});(2)解析localhost:8000(获取到链接sheet名,这步是存个文件,用screenshot获取并同步到服务器,然后从sheet名里返回正确的json)开始设置页面url,并把url的md5值加进去。
u站格式:url+ajaxajax链接,我写了一个ajax采集器ajax代码前端有不少免费模块,甚至用jquery封装的ajax都有,可以在模块浏览器上做md5(太low的,我这里用了ajaxdata这个免费模块,并不推荐)重写,代码如下://类似于request.read().then(file=>{postmessage({text:‘下载’,content:‘提示错误’});});//生成post请求//页面url//生成请求okhttp.get(url,file=>{localhost:8000.**//记录url的值,方便重复请求okhttp.save(url,file=>{localhost:8000.**//next().post(url,file=>{//next().post(url,file=>{//content:'下载'});content:"提示错误"});});});postmessage就是请求响应码,一直设置到8000,过一段时间会产生false,等等就好了。
页面url如何获取?u采采集器首页自带这个页面url,就是点进去的二级域名,我这里static是个auto的,默认访问,再跳转u采采集器首页的二级域名。如何跳转?那就把这个二级。
u采 采集(qq微信怎么采集数据?端定制app的httpscheme,全球苹果电脑端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-12-06 07:02
u采采集器是一款采集来自网络的数据,挖掘这些数据的价值,用于产品与功能的实现。现在qq和微信都已成为我们日常生活中使用的较多的地方,但是前者如果安装vpn,那不是很麻烦吗?后者如果安装插件,有时候我们还是需要打开浏览器,加载一堆后,再用qq或者微信登录,这时候能不能能快速实现呢?然后,我们要一条条的去获取呢?这个就需要采集器了!那么qq微信怎么采集数据呢?首先我们需要明确自己要采集哪方面的数据。比如qq群直播,我们主要是去看直播;比如是在腾讯游戏平台,我们去看游戏;还比如你可以去跟网友聊天。
“采集器"是如何采集工程师采集项目的http请求呢?android端定制app的httpscheme,全球苹果电脑端定制苹果手机和安卓手机httpscheme,方便app使用http去请求请求网页;通过android专属sdk或者websdk可以设置全球ios使用的请求方式。欢迎关注我的微信公众号,获取更多android开发知识:。
不同意楼上的回答,可以去网上找一些采集方案,但作为一个苦逼程序员,还是推荐用采集器去采集数据,需要采集什么数据直接打开浏览器就可以使用,
可以看看云采集这款小软件,只需要输入appid,就可以识别,
微信有小程序,订阅号什么的,通过云采集采集小程序是有条件的, 查看全部
u采 采集(qq微信怎么采集数据?端定制app的httpscheme,全球苹果电脑端)
u采采集器是一款采集来自网络的数据,挖掘这些数据的价值,用于产品与功能的实现。现在qq和微信都已成为我们日常生活中使用的较多的地方,但是前者如果安装vpn,那不是很麻烦吗?后者如果安装插件,有时候我们还是需要打开浏览器,加载一堆后,再用qq或者微信登录,这时候能不能能快速实现呢?然后,我们要一条条的去获取呢?这个就需要采集器了!那么qq微信怎么采集数据呢?首先我们需要明确自己要采集哪方面的数据。比如qq群直播,我们主要是去看直播;比如是在腾讯游戏平台,我们去看游戏;还比如你可以去跟网友聊天。
“采集器"是如何采集工程师采集项目的http请求呢?android端定制app的httpscheme,全球苹果电脑端定制苹果手机和安卓手机httpscheme,方便app使用http去请求请求网页;通过android专属sdk或者websdk可以设置全球ios使用的请求方式。欢迎关注我的微信公众号,获取更多android开发知识:。
不同意楼上的回答,可以去网上找一些采集方案,但作为一个苦逼程序员,还是推荐用采集器去采集数据,需要采集什么数据直接打开浏览器就可以使用,
可以看看云采集这款小软件,只需要输入appid,就可以识别,
微信有小程序,订阅号什么的,通过云采集采集小程序是有条件的,
u采 采集(免费代理稳定性连同时切换代理附代理采集下载下载地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-05 14:25
1、代理文件格式:(代理采集地址)
2、自由代理稳定性不可靠,使用装饰器重连切换代理同时进行
# coding: utf-8
# 笔趣阁 单篇小说采集 http://www.biquge.com.tw
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.biquge.com.tw",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url = "http://www.biquge.com.tw/17_17 ... ot%3B # 第一章网址
page = 1301 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数5)--" % (count['num'] + 1))
if count['num'] < 5:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
# print(response.read())
bsObj = BeautifulSoup(response, 'lxml')
except Exception, err:
raise Exception(err)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', attrs={'class': 'bottem2'})
title = bsObj.find('div', attrs={'class': 'bookname'}).h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = "http://www.biquge.com.tw" + next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载链接: 查看全部
u采 采集(免费代理稳定性连同时切换代理附代理采集下载下载地址)
1、代理文件格式:(代理采集地址)
2、自由代理稳定性不可靠,使用装饰器重连切换代理同时进行
# coding: utf-8
# 笔趣阁 单篇小说采集 http://www.biquge.com.tw
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.biquge.com.tw",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url = "http://www.biquge.com.tw/17_17 ... ot%3B # 第一章网址
page = 1301 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数5)--" % (count['num'] + 1))
if count['num'] < 5:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
# print(response.read())
bsObj = BeautifulSoup(response, 'lxml')
except Exception, err:
raise Exception(err)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', attrs={'class': 'bottem2'})
title = bsObj.find('div', attrs={'class': 'bookname'}).h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = "http://www.biquge.com.tw" + next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载链接:
u采 采集(爱采集谷歌地图数据采集器的软件优势简单点点鼠标)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-05 03:23
爱采集谷歌地图数据采集器是一款功能强大的谷歌地图数据采集软件,该软件可以帮助用户采集谷歌地图企业在任何区域的数据信息,包括姓名、地址、联系方式、网址、邮箱等。采集完成后,还可以批量导入电脑、手机、微信。是外贸用户必备的辅助工具。
爱采集谷歌地图数据采集器具有采集结果和精准定位的特点,只要你进入需要的行业关键词,它可以帮助你快速采集 走向世界 各地区、各行业精准联系,帮助用户解决外贸行业客户信息缺失问题,快速增加外贸订单。
软件特点
01、爱采集 Master采用先进的大数据技术,极速体验,超稳定。
02、采集 收到的客户信息准确率98%,绝对真实,有保证。
03、智能去重技术、数据关键词过滤、关键词优化等功能,让你采集获取更多数据。
04、 便捷的导出功能,可以导出为CSV、EXCEL、VCF等文本文件,省去自己处理的麻烦。
05、 服务期内免费升级、安装调试、数据分析和维护。
06、 付费授权可以导出三种数据格式,编号不带星号。
07、可以提取数万条数据,一键发送数万条短信。
08、 可将号码批量导入电脑,批量邮箱,快速为您整理信息。
软件优势
便于使用
只需点击鼠标即可抓取数据,无需编写任何代码即可轻松抓取数据。老板再也不用逼我学python爬虫了。在几分钟内捕获数据,采集 从未如此简单。
可见的
采集 结果实时显示。可视化采集 过程,以及采集 你所看到的。
强大的
支持图像和视频捕捉、数据页面延迟加载、滚动页面、存储过程等更多高级功能等你发现。 查看全部
u采 采集(爱采集谷歌地图数据采集器的软件优势简单点点鼠标)
爱采集谷歌地图数据采集器是一款功能强大的谷歌地图数据采集软件,该软件可以帮助用户采集谷歌地图企业在任何区域的数据信息,包括姓名、地址、联系方式、网址、邮箱等。采集完成后,还可以批量导入电脑、手机、微信。是外贸用户必备的辅助工具。
爱采集谷歌地图数据采集器具有采集结果和精准定位的特点,只要你进入需要的行业关键词,它可以帮助你快速采集 走向世界 各地区、各行业精准联系,帮助用户解决外贸行业客户信息缺失问题,快速增加外贸订单。
软件特点
01、爱采集 Master采用先进的大数据技术,极速体验,超稳定。
02、采集 收到的客户信息准确率98%,绝对真实,有保证。
03、智能去重技术、数据关键词过滤、关键词优化等功能,让你采集获取更多数据。
04、 便捷的导出功能,可以导出为CSV、EXCEL、VCF等文本文件,省去自己处理的麻烦。
05、 服务期内免费升级、安装调试、数据分析和维护。
06、 付费授权可以导出三种数据格式,编号不带星号。
07、可以提取数万条数据,一键发送数万条短信。
08、 可将号码批量导入电脑,批量邮箱,快速为您整理信息。
软件优势
便于使用
只需点击鼠标即可抓取数据,无需编写任何代码即可轻松抓取数据。老板再也不用逼我学python爬虫了。在几分钟内捕获数据,采集 从未如此简单。
可见的
采集 结果实时显示。可视化采集 过程,以及采集 你所看到的。
强大的
支持图像和视频捕捉、数据页面延迟加载、滚动页面、存储过程等更多高级功能等你发现。
u采 采集(免费开源post服务器-顶级的百度网站爬虫采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-30 18:02
u采采集器-顶级的百度网站爬虫采集工具www.u采.u采爬虫--企业服务器+微软office
lz可以去安装一下pip,
可以试试softhost的get和post接口,
泻药。不少。
实名反对楼上所有说还在用本地采集器的(就是那个线上10w++的公众号已经没有免费的了)。免费采集本地的采集器现在技术上来说,有问题,我见过某公司是这么说的,我们是中国创意商品第一站了。这个免费站就是业务量上来了以后,发现了自己站本身的某个bug,从技术上来说这个免费站网站是不会被删的。顺带说一下我们是不是中国创意商品第一站的话,呵呵,说白了,就是各路屌丝拿不出钱,被各路大牛逼烦以后,就去站里发个帖炫耀自己牛逼,逼格得到一定提升以后就歇菜了。
所以可见目前国内免费采集站还是以技术人员带头做的。免费的一个工具,利润还高(转发的人多了就会有高额抽成,要赚钱)。在新平台引流也不是那么方便。然后流量变现也不是那么容易的事情。那些所谓别的免费开源工具,差点意思,差距有点大的。总之,免费开源post服务器免费采集器不会是未来的趋势,它必须是一个互联网上的粉丝很多的公司用来举行活动做,或者用来吸引用户,或者用来给自己网站增加用户,或者和别的工具互换带来流量。暂时不会是市场的主流。 查看全部
u采 采集(免费开源post服务器-顶级的百度网站爬虫采集工具)
u采采集器-顶级的百度网站爬虫采集工具www.u采.u采爬虫--企业服务器+微软office
lz可以去安装一下pip,
可以试试softhost的get和post接口,
泻药。不少。
实名反对楼上所有说还在用本地采集器的(就是那个线上10w++的公众号已经没有免费的了)。免费采集本地的采集器现在技术上来说,有问题,我见过某公司是这么说的,我们是中国创意商品第一站了。这个免费站就是业务量上来了以后,发现了自己站本身的某个bug,从技术上来说这个免费站网站是不会被删的。顺带说一下我们是不是中国创意商品第一站的话,呵呵,说白了,就是各路屌丝拿不出钱,被各路大牛逼烦以后,就去站里发个帖炫耀自己牛逼,逼格得到一定提升以后就歇菜了。
所以可见目前国内免费采集站还是以技术人员带头做的。免费的一个工具,利润还高(转发的人多了就会有高额抽成,要赚钱)。在新平台引流也不是那么方便。然后流量变现也不是那么容易的事情。那些所谓别的免费开源工具,差点意思,差距有点大的。总之,免费开源post服务器免费采集器不会是未来的趋势,它必须是一个互联网上的粉丝很多的公司用来举行活动做,或者用来吸引用户,或者用来给自己网站增加用户,或者和别的工具互换带来流量。暂时不会是市场的主流。
u采 采集(前端埋点可视化埋点与代码埋点方式档案卡的应用场景)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-19 18:14
用户行为分析是产品调优和精准用户操作的基础,好的数据解决方案是精准用户行为分析的基础。
代码嵌入点、无嵌入点、可视化嵌入点、全嵌入点、前端嵌入点、后端嵌入点,名称很多,其实可以简单的分为客户端嵌入点(即,前端)和服务器端嵌入点(即后端)。前端埋点按实现方式可分为视觉埋点和代码埋点,后端埋点统一采用代码埋点法。
一、代码埋点VS无埋点(全埋点、视觉埋点)
代码嵌入方法文件卡
概念:代码嵌入是指产品上线后PM需要做的数据分析场景,设计数据需求,编写数据需求文档,然后交给开发每个需要的数据采集点击编写代码,并使用编写的代码来监控和报告数据。代码埋点分为前端埋点和后端埋点。前端埋点是指在web、app等产品中编写代码,后端埋点是指在数据服务器中编写代码。
应用场景:需要分析app内的用户事件,需要进行多维度的用户行为分析,需要准确分析服务端数据
优点:1.适用于客户端和服务端数据采集2.可以进行多维属性定义,采集数据自动归类3.返回-端代码埋点可以提高数据精度,适合精细数据分析
缺点:1. 需要初步的墓葬设计。2. 开发工作量大,错误率高。3. 版本更新后,可能需要重新埋一些
实现方式:PM组织数据需求,PM与开发沟通确定嵌入点文档,开发进行人工嵌入,PM根据业务需求进行数据分析,嵌入方案迭代调整
Sokushu Technology SDK 埋葬后的事件上传
注意:开发更多产品的大公司会遇到更通用的嵌入要求。因此,将开发适合此类通用需求的 SDK,以减少嵌入的工作量。但是,产品数量较少的中小型公司会选择纯手工代码嵌入或者使用外部SDK进行嵌入工作。
无埋法档案卡
概念:非埋点是前端埋点的一种方法。通过添加“无埋点”采集代码,对网页或APP上的所有交互事件元素进行分析和监控。当有用户操作行为发生(交互事件)时,该事件会被采集上报,所以“无埋点”和“全埋点”是同一个概念。非埋点不需要写任何代码。而是将所有的事件元素通过代码解析并以可视化的方式呈现出来,让PM、运营经理等可以根据自己的需要手动选择和校准。为了区别于开发中一一编写代码的方式,称之为视觉嵌入点。可视化的埋点通常是通过第三方工具实现的。2013 年,
应用场景:产品上线初期没有明确的业务和交易数据,只需要分析web界面
优点:1.部署简单,工作量小2.数据量全采集,前期数据设计要求低3.使用简单,业务人员可自行操作
缺点:1.无法记录详细的事件属性2.由于缺少事件属性,分类报表生成繁琐,需要手动添加事件属性。3.属于前端埋点,数据精度低
实现方式: 开发并在产品中添加全埋点监测代码,PM/Operation 可视化埋点选择,PM/Operation 用于数据分析应用
通过 HeapAnalytics 实现可视化埋点
注:因为完全不依赖统计代码是没有办法采集数据的,所以说没有埋点是不准确的。
二、前端埋点VS后端埋点
前端嵌入式点文件卡
概念:前端埋点又称客户端埋点,是指在APP或Web产品中植入代码,采集用户在产品中的行为事件数据。一旦用户触发事件,就会上传代码中定义的埋点代码 需要上传的事件的信息。前端埋点将包括代码埋点和视觉埋点方法。
应用场景:产品运营前期,功能简单,无需深入分析;分析事件和后端之间没有交互;
优点:可以统计app中与服务器的非交互事件数据
缺点:存在数据丢失的情况,与自己业务数据库的数据不符。这是前端数据采集的先天缺陷,因为网络异常或者统计口径不一致,会导致数据不对齐。
埋数据过程中,设置公共事件,减少工作量
后端埋点档案卡
概念:后端埋点也叫服务端埋点。通过在服务器端开发和编写代码,就会有客户端和服务器之间的交互事件数据,以及业务服务器中存储的业务数据。
应用场景:产品功能复杂,需要深入钻研,多维度分析;用户行为数据与业务数据整合分析;数据保密性高;分析项与后端交互,前后端都可以是采集数据;涉及充值、退订等重要事件
优点: 1. 避免多个客户端埋点 2. 采集 数据准确
缺点:1. 客户端与服务端未请求的交互数据2. 无法准确统计客户端行为事件(如提交订单,用户可能点击3次才提交成功)
三、3种数据嵌入方法对比采集
选择哪种方式,往往取决于产品形态和发展阶段。前期可以采用可视化埋法,后期可以采用可视化埋法+后端代码埋法;也可以前期采用前端埋代码的方式,后期采用前端+后端的方式。端码嵌入方式;对于没有交易或广告位类型的企业官网,可以使用谷歌分析或百度统计等外部工具。
四、整理好思路后,学会节约能源
据调查:数据团队大部分时间都浪费在基础数据采集和清理上。
产品经理、运营经理、数据分析师、开发都会花费大量的精力在数据的采集整理上,导致没有足够的时间来真正结合业务需求进行数据分析,那么有没有什么好的办法可以减少这部分的工作量呢??
将业务需求与外部工具相结合
您可以尝试将多个外部工具结合使用,以减少内部自我开发,并通过使用可以实时分析数亿数据的分布式框架来提高分析速度。比如通过Google Analytics进行网页分析,通过Heap Analytics首次将嵌入点可视化,通过数据技术ThinkingAnalytics系统app、小程序、服务器等全端数据采集SDK,实现多维度深度用户行为分析。
充分利用所有工具的基础是对您的产品逻辑和业务的清晰分析。所以前期可以设计一个好的埋点方案,后期分析可以根据业务需求灵活应用数据。分析结果出来后,才能做出准确的判断和操作决策。 查看全部
u采 采集(前端埋点可视化埋点与代码埋点方式档案卡的应用场景)
用户行为分析是产品调优和精准用户操作的基础,好的数据解决方案是精准用户行为分析的基础。
代码嵌入点、无嵌入点、可视化嵌入点、全嵌入点、前端嵌入点、后端嵌入点,名称很多,其实可以简单的分为客户端嵌入点(即,前端)和服务器端嵌入点(即后端)。前端埋点按实现方式可分为视觉埋点和代码埋点,后端埋点统一采用代码埋点法。
一、代码埋点VS无埋点(全埋点、视觉埋点)
代码嵌入方法文件卡
概念:代码嵌入是指产品上线后PM需要做的数据分析场景,设计数据需求,编写数据需求文档,然后交给开发每个需要的数据采集点击编写代码,并使用编写的代码来监控和报告数据。代码埋点分为前端埋点和后端埋点。前端埋点是指在web、app等产品中编写代码,后端埋点是指在数据服务器中编写代码。
应用场景:需要分析app内的用户事件,需要进行多维度的用户行为分析,需要准确分析服务端数据
优点:1.适用于客户端和服务端数据采集2.可以进行多维属性定义,采集数据自动归类3.返回-端代码埋点可以提高数据精度,适合精细数据分析
缺点:1. 需要初步的墓葬设计。2. 开发工作量大,错误率高。3. 版本更新后,可能需要重新埋一些
实现方式:PM组织数据需求,PM与开发沟通确定嵌入点文档,开发进行人工嵌入,PM根据业务需求进行数据分析,嵌入方案迭代调整
Sokushu Technology SDK 埋葬后的事件上传
注意:开发更多产品的大公司会遇到更通用的嵌入要求。因此,将开发适合此类通用需求的 SDK,以减少嵌入的工作量。但是,产品数量较少的中小型公司会选择纯手工代码嵌入或者使用外部SDK进行嵌入工作。
无埋法档案卡
概念:非埋点是前端埋点的一种方法。通过添加“无埋点”采集代码,对网页或APP上的所有交互事件元素进行分析和监控。当有用户操作行为发生(交互事件)时,该事件会被采集上报,所以“无埋点”和“全埋点”是同一个概念。非埋点不需要写任何代码。而是将所有的事件元素通过代码解析并以可视化的方式呈现出来,让PM、运营经理等可以根据自己的需要手动选择和校准。为了区别于开发中一一编写代码的方式,称之为视觉嵌入点。可视化的埋点通常是通过第三方工具实现的。2013 年,
应用场景:产品上线初期没有明确的业务和交易数据,只需要分析web界面
优点:1.部署简单,工作量小2.数据量全采集,前期数据设计要求低3.使用简单,业务人员可自行操作
缺点:1.无法记录详细的事件属性2.由于缺少事件属性,分类报表生成繁琐,需要手动添加事件属性。3.属于前端埋点,数据精度低
实现方式: 开发并在产品中添加全埋点监测代码,PM/Operation 可视化埋点选择,PM/Operation 用于数据分析应用
通过 HeapAnalytics 实现可视化埋点
注:因为完全不依赖统计代码是没有办法采集数据的,所以说没有埋点是不准确的。
二、前端埋点VS后端埋点
前端嵌入式点文件卡
概念:前端埋点又称客户端埋点,是指在APP或Web产品中植入代码,采集用户在产品中的行为事件数据。一旦用户触发事件,就会上传代码中定义的埋点代码 需要上传的事件的信息。前端埋点将包括代码埋点和视觉埋点方法。
应用场景:产品运营前期,功能简单,无需深入分析;分析事件和后端之间没有交互;
优点:可以统计app中与服务器的非交互事件数据
缺点:存在数据丢失的情况,与自己业务数据库的数据不符。这是前端数据采集的先天缺陷,因为网络异常或者统计口径不一致,会导致数据不对齐。
埋数据过程中,设置公共事件,减少工作量
后端埋点档案卡
概念:后端埋点也叫服务端埋点。通过在服务器端开发和编写代码,就会有客户端和服务器之间的交互事件数据,以及业务服务器中存储的业务数据。
应用场景:产品功能复杂,需要深入钻研,多维度分析;用户行为数据与业务数据整合分析;数据保密性高;分析项与后端交互,前后端都可以是采集数据;涉及充值、退订等重要事件
优点: 1. 避免多个客户端埋点 2. 采集 数据准确
缺点:1. 客户端与服务端未请求的交互数据2. 无法准确统计客户端行为事件(如提交订单,用户可能点击3次才提交成功)
三、3种数据嵌入方法对比采集
选择哪种方式,往往取决于产品形态和发展阶段。前期可以采用可视化埋法,后期可以采用可视化埋法+后端代码埋法;也可以前期采用前端埋代码的方式,后期采用前端+后端的方式。端码嵌入方式;对于没有交易或广告位类型的企业官网,可以使用谷歌分析或百度统计等外部工具。
四、整理好思路后,学会节约能源
据调查:数据团队大部分时间都浪费在基础数据采集和清理上。
产品经理、运营经理、数据分析师、开发都会花费大量的精力在数据的采集整理上,导致没有足够的时间来真正结合业务需求进行数据分析,那么有没有什么好的办法可以减少这部分的工作量呢??
将业务需求与外部工具相结合
您可以尝试将多个外部工具结合使用,以减少内部自我开发,并通过使用可以实时分析数亿数据的分布式框架来提高分析速度。比如通过Google Analytics进行网页分析,通过Heap Analytics首次将嵌入点可视化,通过数据技术ThinkingAnalytics系统app、小程序、服务器等全端数据采集SDK,实现多维度深度用户行为分析。
充分利用所有工具的基础是对您的产品逻辑和业务的清晰分析。所以前期可以设计一个好的埋点方案,后期分析可以根据业务需求灵活应用数据。分析结果出来后,才能做出准确的判断和操作决策。
u采 采集(采酷服务器优美的数据采集解决方案插件的功能介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-12 08:19
菜酷采集服务器是服务器频道下最喜欢的一款软件。太平洋下载中心提供彩酷采集服务器的官方下载。
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器都可以轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需面对简单的编程界面,可大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
u采 采集(采酷服务器优美的数据采集解决方案插件的功能介绍及应用)
菜酷采集服务器是服务器频道下最喜欢的一款软件。太平洋下载中心提供彩酷采集服务器的官方下载。
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器都可以轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需面对简单的编程界面,可大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费!
u采 采集(u采采集器的操作更加方便,操作最简单!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-11 23:04
u采采集器的操作更加方便。例如你只需要采集一个公众号的文章页,一键批量分析数据,插入到采集器,一个打开公众号/文章的新媒体平台就会自动提取文章;如果你想采集公众号历史所有文章或者公众号排行榜的所有文章,采用分析大师的智能匹配模式就不用担心了,只需要输入你需要查看的文章标题和具体文章链接(点击跳转),系统就自动自动提取那篇文章并分析链接。这样不仅操作更加方便,而且多平台都可以同步采集,还能实现一次录入多平台的文章。
主要是带有计数器功能,
百度一下,
不知道对不对啊,
凡是在线公众号文章采集工具我都用过,我感觉目前的百度采集器功能最全,操作最简单,很适合新手使用。
目前常用的【数据采集】工具软件【采集猫】,支持公众号采集;【德问公众号代采】,支持个人号采集;【德问号外公众号代采】,支持公众号代采;【数据六维度】,支持图文、音频、视频内容采集。
百度搜索“公众号文章采集”,注意看采集模式,简单的可以用“种子数据采集器”,复杂的可以用“采集猫”。
现在有一款三合一采集器,《百度采集器》页面采集,不过需要经过授权。
有个叫互采网的, 查看全部
u采 采集(u采采集器的操作更加方便,操作最简单!)
u采采集器的操作更加方便。例如你只需要采集一个公众号的文章页,一键批量分析数据,插入到采集器,一个打开公众号/文章的新媒体平台就会自动提取文章;如果你想采集公众号历史所有文章或者公众号排行榜的所有文章,采用分析大师的智能匹配模式就不用担心了,只需要输入你需要查看的文章标题和具体文章链接(点击跳转),系统就自动自动提取那篇文章并分析链接。这样不仅操作更加方便,而且多平台都可以同步采集,还能实现一次录入多平台的文章。
主要是带有计数器功能,
百度一下,
不知道对不对啊,
凡是在线公众号文章采集工具我都用过,我感觉目前的百度采集器功能最全,操作最简单,很适合新手使用。
目前常用的【数据采集】工具软件【采集猫】,支持公众号采集;【德问公众号代采】,支持个人号采集;【德问号外公众号代采】,支持公众号代采;【数据六维度】,支持图文、音频、视频内容采集。
百度搜索“公众号文章采集”,注意看采集模式,简单的可以用“种子数据采集器”,复杂的可以用“采集猫”。
现在有一款三合一采集器,《百度采集器》页面采集,不过需要经过授权。
有个叫互采网的,
u采 采集( 模拟操作抖音App的脚本核心代码如下所示:上述脚本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-11-11 18:07
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。 查看全部
u采 采集(
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。
u采 采集( 模拟操作抖音App的脚本核心代码如下所示:上述脚本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-11-11 18:05
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。 查看全部
u采 采集(
模拟操作抖音App的脚本核心代码如下所示:上述脚本)
我们模拟App的操作如下:
1.开始抖音。
2. 单击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4. 找到匹配的用户,点击关注。
5. 点击系统推荐的“查看更多”,模拟屏幕多次向上滑动,直到数据加载完毕(屏幕上出现“暂时没有了”)。
同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules或者Mitmproxy)对URL中收录/user/recommend/的HTTP响应数据进行抓包过滤,从JSON 数据(如下图)。
模拟操作抖音App的脚本核心代码如下:
抖音App和服务端交互使用的是HTTPS协议,使用Fiddler很容易可以捕获到数据,如下图所示。
不过想要自己模拟一个有效的请求可不是那么容易了,因为它使用了签名机制,在所有请求中都有as和cp两个签名参数,除非得知签名算法否则我们无法构造出有效的请求。
这里我们使用模拟操作抖音App的方式,让App帮我们发出有效的请求,然后我们拦截服务器的HTTP应答数据,再从中提取我们感兴趣的信息。
下面结合一个实际的案例介绍下整个过程,根据客户的需求,要采集一些指定用户加关后的系统推荐“你可能感兴趣”的数据(如下图所示)用于商品营销。
点击“查看更多”可以看到更多的系统推荐用户列表数据,如下图所示。
我们按如下步骤模拟操作App:
1.启动抖音。
2.点击搜索按钮。
3.输入搜索关键词(抖音用户ID),点击搜索。
4.找到匹配的用户,点击关注。
5.点击系统推荐“查看更多”,模拟多次向上滑动屏幕,直至数据加载完毕(屏幕出现“暂时没有更多了”)。
于此同时,我们使用抓包脚本(可以使用Fiddler的Customize Rules,也可以使用Mitmproxy),捕获并过滤URL中含有/user/recommend/的HTTP应答数据,从JSON数据中提取系统推荐的用户信息(如下图所示)。
模拟操作抖音App的脚本核心代码如下所示:
view plaincopy to clipboardprint?
from com.dtmilano.android.viewclient import ViewClient
def search_douyin_for_recommend_user(douyin_id):
"""采集指定抖音账号的关注推荐数据
"""
log(u'准备采集"{}"对应的关注推荐数据'.format(douyin_id))
# 连设备
serialno = None
if serialno:
os.system('adb connect {}'.format(serialno or ''))
time.sleep(3)
device, serialno = ViewClient.connectToDeviceOrExit(serialno=serialno)
vc = ViewClient(device, serialno, autodump=False)
# 强制关闭抖音
log(u'强制关闭抖音.')
device.shell('am force-stop com.ss.android.ugc.aweme')
time.sleep(2)
# 启动抖音
log(u'启动抖音.')
device.shell('am start -n com.ss.android.ugc.aweme/.main.MainActivity')
time.sleep(5)
# 暂停视频播放
log(u'点击屏幕,暂停视频播放.')
device.touch(514, 1048)
# 点击搜索按钮
vc.dump()
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/amj')
if search_btn:
log(u'点击搜索按钮,跳转到搜索页面.')
search_btn.touch()
vc.dump()
# 点击搜索输入框
search_input = vc.findViewById('com.ss.android.ugc.aweme:id/ad_')
if search_input:
log(u'点击搜索框,准备输入关键词.')
search_input.touch()
# 输入抖音ID
log(u'输入搜索关键词: {}.'.format(douyin_id))
device.type(douyin_id.encode('UTF-8'))
# 点击搜索按钮
search_btn = vc.findViewById('com.ss.android.ugc.aweme:id/cp8')
if search_btn:
log(u'提交搜索.')
search_btn.touch()
time.sleep(2)
vc.dump()
## 切换到用户
#user_tab = vc.findViewWithText(u'用户')
#user_tab.touch()
# 找到匹配的
matches = []
def find_matches(view):
if view.getClass() == 'android.widget.TextView':
text = view.getText()
if douyin_id.lower() in text.lower():
# 找到匹配的了
log(u'找到匹配的: {}'.format(text))
matches.append(view)
else:
#print text
pass
vc.traverse(transform=lambda view: find_matches(view))
if matches:
# 有没有已关注按钮
btn = vc.findViewWithText(u'已关注')
if btn:
# 先取消关注
log(u'之前关注过,先取消关注.')
btn.touch()
time.sleep(1)
user_matched = matches[0]
log(u'点击进入个人主页.')
user_matched.touch()
time.sleep(1)
# 点关注
vc.dump()
follow_btn = vc.findViewById('com.ss.android.ugc.aweme:id/aei')
if follow_btn:
# 点击关注
log(u'点击关注')
follow_btn.touch()
time.sleep(1)
# 点击查看更多
vc.dump()
viewmore_btn = vc.findViewById('com.ss.android.ugc.aweme:id/bqn')
if viewmore_btn:
# 点击查看更多
log(u'点击查看更多系统推荐')
viewmore_btn.touch()
time.sleep(1)
i = 0
while True:
# 上滑动
device.drag((345, 1762), (345, 550), duration=100)
log(u'上滑以加载更多')
i += 1
if i % 5 == 0:
# 拖动10次判断一下是否还有更多
vc.dump()
if vc.findViewWithText(u'暂时没有更多了'):
log(u'暂时没有更多了, "{}"的关注推荐数据采集完毕.'.format(douyin_id))
# 采集成功了
return True
failed_tip = vc.findViewWithText(u'加载失败,点击重试')
if failed_tip:
log(u'加载失败,点击重试.')
failed_tip.touch()
else:
# 没有找到查看更多按钮
log(u'没有找到查看更多按钮')
else:
# 没有找到加关注按钮
log(u'没有找到加关注按钮')
else:
# 没有找到匹配的用户
log(u'没有找到匹配的用户')
else:
# 没有找到搜索提交按钮
log(u'没有找到搜索提交按钮.')
else:
# 没有找到搜索输入框
log(u'没有找到搜索输入框.')
else:
# 没有找到搜索按钮
log(u'没有找到搜索按钮.')
上述脚本的运行截图如下:
最后,附上一些捕获的示例数据:
更多抖音、快手、小红书数据实时采集接口请查看文档:TiToData
免责声明:本文档仅供学习参考,请勿用于非法用途!否则,一切后果由您自担风险。
u采 采集(u采采集导航,这个采集器还可以吧,它有四个模式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-07 09:09
u采采集导航,
这个采集器还可以吧,它有四个模式,
这个采集器还不错,
它包含四种采集模式:文章指引、搜索指引、全文指引、url指引
还不错,都设置好了,
排名前面的,
自荐。
还行,
谢邀,
采集器还可以吧,
我用的浏览器中的e-shock采集器,操作简单,不需要懂太多的数据库知识,
比较真实的可信度高,对采集公众号的来源可以通过扫码验证,不会像其他软件那样恶意使用。
一般来说有四种,1分享二维码2扫码3浏览器插件4全文检索5访问此页面下载6访问特定网址7随机分享8填写用户名或者密码点击领取现在很多新闻应用商城里都会有输入网址就可以下载的功能,像新浪易、界面新闻这样的可能还要科学验证才行。补充一个小秘技:qq里有公众号搜索功能,你可以把你要寻找的新闻、公众号列表发给他们,对方很快就能给你提供查看效果。
可信度高安全
有个好采,随便设置一下就可以,以后自己想用什么功能就用什么,
可以去它官网看看
好采app,可以使用,
我现在在用一个叫做“采采”的软件软件,可以找到一大片采集,也可以直接发送链接给指定用户,还可以定制自己想要的操作方式,给的功能是蛮丰富的。 查看全部
u采 采集(u采采集导航,这个采集器还可以吧,它有四个模式)
u采采集导航,
这个采集器还可以吧,它有四个模式,
这个采集器还不错,
它包含四种采集模式:文章指引、搜索指引、全文指引、url指引
还不错,都设置好了,
排名前面的,
自荐。
还行,
谢邀,
采集器还可以吧,
我用的浏览器中的e-shock采集器,操作简单,不需要懂太多的数据库知识,
比较真实的可信度高,对采集公众号的来源可以通过扫码验证,不会像其他软件那样恶意使用。
一般来说有四种,1分享二维码2扫码3浏览器插件4全文检索5访问此页面下载6访问特定网址7随机分享8填写用户名或者密码点击领取现在很多新闻应用商城里都会有输入网址就可以下载的功能,像新浪易、界面新闻这样的可能还要科学验证才行。补充一个小秘技:qq里有公众号搜索功能,你可以把你要寻找的新闻、公众号列表发给他们,对方很快就能给你提供查看效果。
可信度高安全
有个好采,随便设置一下就可以,以后自己想用什么功能就用什么,
可以去它官网看看
好采app,可以使用,
我现在在用一个叫做“采采”的软件软件,可以找到一大片采集,也可以直接发送链接给指定用户,还可以定制自己想要的操作方式,给的功能是蛮丰富的。
u采 采集(u采采集器支持全网一键爬取,导出高清图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-06 14:01
u采采集器是网易自研的采集器工具。安全高效。支持全网一键爬取,导出高清图片。目前有很多知名网站都对网易采集器做了免费试用。支持python3/python2,开发者为清华大学,技术处理难度不大。我们常常在接到比稿后第一时间抢先测试并在网上推送免费的工具,因为我们相信对于网站,用户体验是最重要的,这代表了产品能否胜任同类产品。
我们做测试的频率已经越来越快,更新比稿工具的频率也就越来越快。有兴趣的可以去下载测试。抓取器文件获取:采集器-u采集器-官方免费采集器。
谢邀很多图片网站会有自带的api,把爬虫抓下来,分析一下,然后再转换成图片,挺简单的。如果不需要转换,可以用采集器采集下来,然后直接上传到icourl里,icourl就是一个图片索引站,可以提供批量抓取信息到icourl里。我当时写的一个程序,一个月才出来一两个,效率也很低。
一般全网图片里面不仅仅是昵图、千图,很多icon都是不用上传到网站里面就直接可以免费下载的。下载链接解压后到new文件夹里自己看喽,很多。
google翻译
会爬虫怎么都行
速度慢是个人问题,速度快还得是网易这种有认证过的网站。
如果不想用这些工具的话,就要你网速快,图片资源清晰可见如果网速快图片多就直接录屏下来之类的方法;或者拍一张图放网站上, 查看全部
u采 采集(u采采集器支持全网一键爬取,导出高清图片)
u采采集器是网易自研的采集器工具。安全高效。支持全网一键爬取,导出高清图片。目前有很多知名网站都对网易采集器做了免费试用。支持python3/python2,开发者为清华大学,技术处理难度不大。我们常常在接到比稿后第一时间抢先测试并在网上推送免费的工具,因为我们相信对于网站,用户体验是最重要的,这代表了产品能否胜任同类产品。
我们做测试的频率已经越来越快,更新比稿工具的频率也就越来越快。有兴趣的可以去下载测试。抓取器文件获取:采集器-u采集器-官方免费采集器。
谢邀很多图片网站会有自带的api,把爬虫抓下来,分析一下,然后再转换成图片,挺简单的。如果不需要转换,可以用采集器采集下来,然后直接上传到icourl里,icourl就是一个图片索引站,可以提供批量抓取信息到icourl里。我当时写的一个程序,一个月才出来一两个,效率也很低。
一般全网图片里面不仅仅是昵图、千图,很多icon都是不用上传到网站里面就直接可以免费下载的。下载链接解压后到new文件夹里自己看喽,很多。
google翻译
会爬虫怎么都行
速度慢是个人问题,速度快还得是网易这种有认证过的网站。
如果不想用这些工具的话,就要你网速快,图片资源清晰可见如果网速快图片多就直接录屏下来之类的方法;或者拍一张图放网站上,

