u采 采集( 前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
优采云 发布时间: 2022-01-08 20:17u采 采集(
前嗅ForeSpider数据采集软件爬虫脚本的链接抽取教程)
ForeSpider数据链接提取采集软件
ForeSpider 数据采集软件是一个通用的互联网数据采集软件。软件可以采集互联网上的所有公共数据,通过可视化的操作流程,从建表、过滤、采集到入库,一步到位。同时,软件内置强大的爬虫脚本语言。如果有可视化无法实现的内容采集,只需几行简单的代码即可实现强大的脚本采集。
很多用户说可视化操作太简单了,软件脚本教程一定要看,所以今天给大家做一个爬虫脚本的链接提取教程,满足更多用户的需求。
本案使用大众点评网,需提取以下翻页链接。
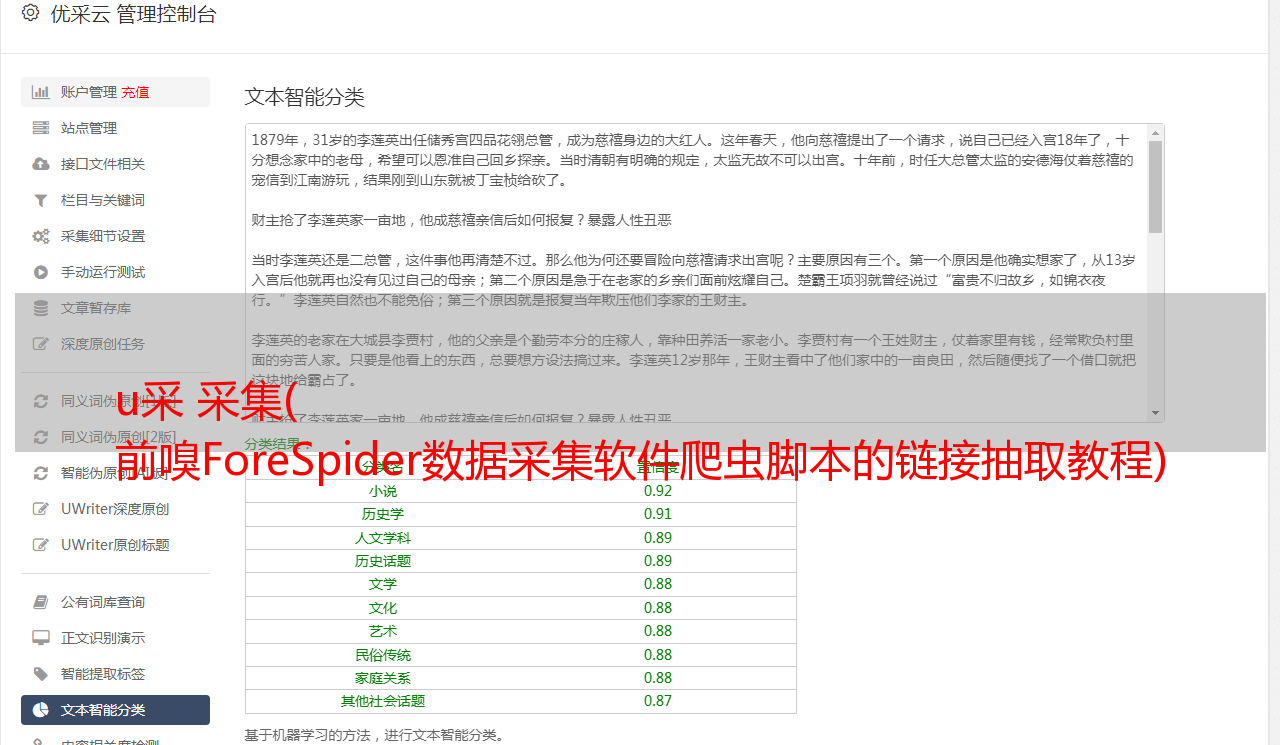
第一步是看每个页面的链接地址是否有规律。
【第二页】
【第三页】
可以看出,只有每个页面的链接地址的最后一个数字不同,都是对应的页码。我们可以通过拼接得到所有翻页的链接地址。拼接第二页链接地址的脚本如下:
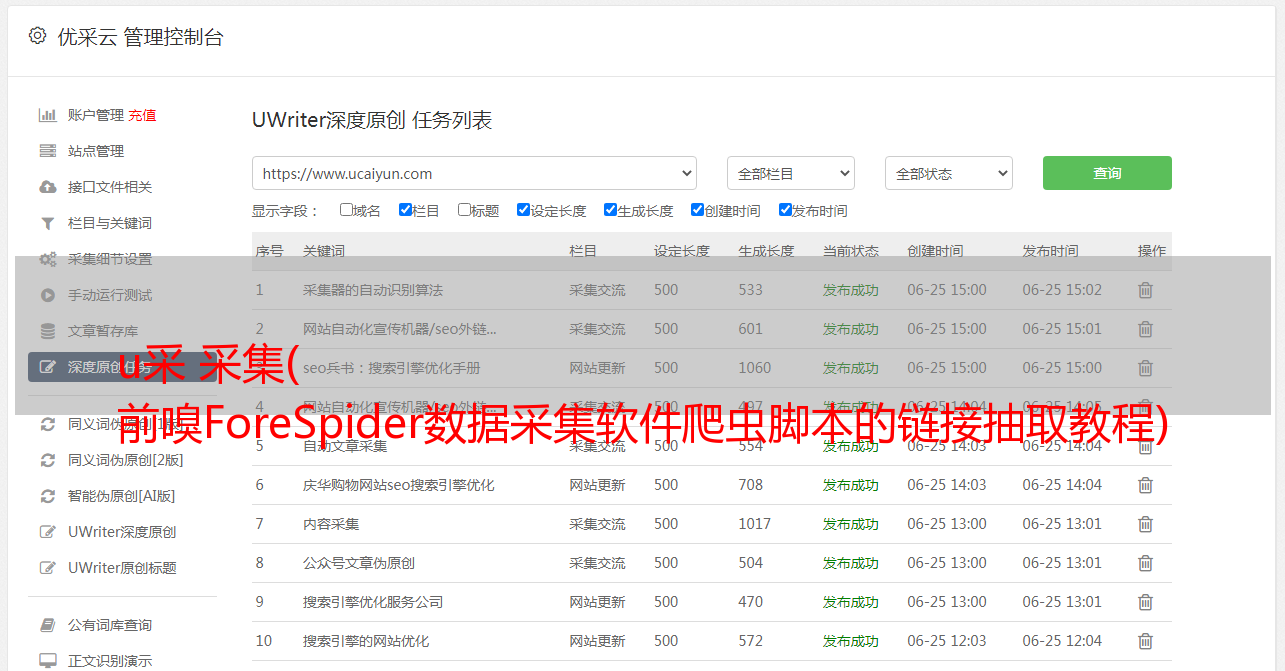
第一行代码:定义一个url类的变量u
第二行代码:u.urlname是网页的链接地址,给它赋值
第三行代码:u.tmplid是要关联本次链接提取的模板id,这里是翻页,所以关联自己的模板
第四行代码:这个链接提取对应的channel id
第五行代码:u.title是链接标题,给它赋值
第六行代码:将级联链接添加到最终结果中
上面只说明了每一行代码的作用,只获取到第二页的链接。以下是完整内容:
通过FindClass,从源码中获取总页数,然后用for循环拼接每个页面的链接。总共只用了 12 行(包括两行注释)就可以得到你想要的链接。不是很简单吗?希望大家多看帮助文档,很多问题在帮助文档里都有答案(偷偷告诉大家我经常遇到no然后去看文档)。
ForeSpider 是一款非常简单易用的通用数据采集 软件。操作简单,功能强大,同时保证采集速度,完全可以满足企业级用户的需求。

