
u采 采集
u采 采集(u采采集是采集技术的一种,基于兴趣的采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-01 14:50
u采采集模式是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。一般的http采集对flash要求比较高,一般的采集器不支持,u采采集是采集模式的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采采集是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采集是国内互联网从业者一种解决pc端及移动端采集问题的代表性技术,目前的采集解决方案包括u爬虫在内,都只是实现了功能点的u提取,而不是网站本身的url规律转换。数据发送给爬虫,u爬虫利用爬虫自身系统或者爬虫采集框抓取,然后存储起来。发送给反爬虫的下采集端后,反爬虫利用pickey或者云采集框进行采集,并存储起来。
btg采集是刚刚兴起的一种技术。建议你从以下几个方面了解1.你要采集的网站类型是什么。2.你要采集的数据来源是什么。3.你要采集的数据源本身的结构和特征。4.你要采集的数据一些特殊的规律。比如会有购物车。会有密码等等。当然,网站类型采集有很多。都是在这些基础上技术上进行改进。各有特色。谢谢。 查看全部
u采 采集(u采采集是采集技术的一种,基于兴趣的采集)
u采采集模式是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。一般的http采集对flash要求比较高,一般的采集器不支持,u采采集是采集模式的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采采集是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采集是国内互联网从业者一种解决pc端及移动端采集问题的代表性技术,目前的采集解决方案包括u爬虫在内,都只是实现了功能点的u提取,而不是网站本身的url规律转换。数据发送给爬虫,u爬虫利用爬虫自身系统或者爬虫采集框抓取,然后存储起来。发送给反爬虫的下采集端后,反爬虫利用pickey或者云采集框进行采集,并存储起来。
btg采集是刚刚兴起的一种技术。建议你从以下几个方面了解1.你要采集的网站类型是什么。2.你要采集的数据来源是什么。3.你要采集的数据源本身的结构和特征。4.你要采集的数据一些特殊的规律。比如会有购物车。会有密码等等。当然,网站类型采集有很多。都是在这些基础上技术上进行改进。各有特色。谢谢。
u采 采集(Qt的下载和安装关于Linux的安装,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-27 11:19
一、Qt下载安装
关于Qt的安装,网上有很详细的介绍。这里仅作简要介绍。
需要两个安装包:Qt Creator 和 QTE。
1)QT 创建者
下载链接:qt-sdk-linux-x86-opensource-2010.05.1.bin
官方下载:
这是一个编译好的二进制SDK包,直接下载,不需要配置和编译,直接运行即可下载。之所以把官方链接放在下面,是因为我找了很久这个安装包,网上很多链接都失效了。我提供的第一个下载地址是使用百度云盘。最近在用,感觉效果很好。推荐第一个下载地址。
下载完成后,直接运行即可完成安装。
2)Qt Embedded for Linux:
下载链接:qt-everywhere-opensource-src-4.7.3.tar.gz
官方下载:
这是4.7.3版本的源码包,下载后需要配置编译。也推荐使用第一个地址进行下载。
解压后,将提供的Zynq Qt配置文件qmake.conf复制到qt-everywhere-opensource-src-4.7.3/mkspecs/qws/linux-arm-gnueabi-g++目录下,使用命令
./configure -embedded arm -xplatform qws/linux-arm-gnueabi-g++ -little-endian -opensource -host-little-endian -confirm-license -nomake demos -nomake examples
配置后进行配置和编译:
make
编译结束后使用命令
make install
安装,默认安装到
/usr/local/Trolltech/Qt-4.7.3/
路径下。然后将Xilinx交叉编译器中的基本C++库复制到安装目录的lib目录下:
cp -P /path/to/cross/compiler/arm-xilinx-linux-gnueabi/libc/usr/lib/libstdc++.so* /usr/local/Trolltech/Qt-4.7.3/lib
这样就完成了 Zynq 的 Qt Embedded for Linux 的安装。
二、软件代码
1、新的Qt项目
启动 Qt Creator 并创建一个新的 Qt Gui 应用程序
然后选择项目路径和项目描述,其他默认,一直点击下一步,直接完成项目。
2、修改ui界面
打开mainwindow.ui,进入可视化设计界面。默认情况下,中间的主设计区域下已经有一个 QMainWindow 和 QWidget 对象。我们需要将采集图片显示到一个QLabel小部件上,从右侧小部件列表中的“DisplayWidget”中选择“Label”小部件,将其拖到中间,设置大小为640*480,起点坐标为 (5,5).
并取消原文正文。
此时Label组件已经覆盖了MainWindow,然后适当调整MainWindow的大小。
3、添加摄像头采集代码
因为在(原创)基于ZedBoard的Webcam设计(一):USB摄像头(V4L2接口)在Zedboard的图片采集中,我们已经实现了图片采集,只需添加项目中的v4l2grab.c和v4l2grab.h源文件对这个新建的项目进行相应的修改。
修改mainwindow.cpp
1 #include "mainwindow.h"
2 #include "ui_mainwindow.h"
3 #include
4 #include
5 #include
6 #include
7 //#include
8 #include
9
10 MainWindow::MainWindow(QWidget *parent) :
11 QMainWindow(parent),
12 ui(new Ui::MainWindow)
13 {
14 ui->setupUi(this);
15
16 QPixmap pix;
17 QByteArray aa ;
18
19 BITMAPFILEHEADER bf;
20 BITMAPINFOHEADER bi;
21 //Set BITMAPINFOHEADER
22 bi.biSize = 40;
23 bi.biWidth = IMAGEWIDTH;
24 bi.biHeight = IMAGEHEIGHT;
25 bi.biPlanes = 1;
26 bi.biBitCount = 24;
27 bi.biCompression = 0;
28 bi.biSizeImage = IMAGEWIDTH*IMAGEHEIGHT*3;
29 bi.biXPelsPerMeter = 0;
30 bi.biYPelsPerMeter = 0;
31 bi.biClrUsed = 0;
32 bi.biClrImportant = 0;
33
34
35 //Set BITMAPFILEHEADER
36 bf.bfType = 0x4d42;
37 bf.bfSize = 54 + bi.biSizeImage;
38 bf.bfReserved = 0;
39 bf.bfOffBits = 54;
40
41 if(init_v4l2() == FALSE)
42 {
43 }
44
45 v4l2_grab();
46 yuyv_2_rgb888();
47 aa.append((char *)&bf,14);
48 aa.append((char *)&bi,40);
49 aa.append((char *)frame_buffer,640*480*3);
50 pix.loadFromData(aa);
51 ui->label->setPixmap(pix);
52 close_v4l2();
53 }
54
55 MainWindow::~MainWindow()
56 {
57 delete ui;
58 }
17~18行:
17 QPixmap pix;
18 QByteArray aa ;
定义了一个QPixmap类对象pix来显示图片;由于调用QPixmap类的loadFromData()函数来获取传递过来的图像数据,因此loadFromData()函数的详细信息可以在Qt的help->index中查找,或者从中查询:
bool QPixmap::loadFromData ( const QByteArray & data, const char * format = 0, Qt::ImageConversionFlags flags = Qt::AutoColor )
可知loadFromData()要求输入参数为QByteArray类型,因此定义了QByteArray的对象aa来存储图像数据。
同时,loadFromData() 需要指定数据的格式。如果不指定,默认支持的格式为:
是48~50行:
48 aa.append((char *)&bf,14);
49 aa.append((char *)&bi,40);
50 aa.append((char *)frame_buffer,640*480*3);
调用 QByteArray 类的 append 函数,将图像数据存储在 aa 中。需要注意的是,由于loadFromData函数的输入图片符合标准图片格式,所以需要将数据的BMP头信息保存在aa中。
52~53行:
51 pix.loadFromData(aa);
52 ui->label->setPixmap(pix);
实现了图片数据(包括头信息)到pix的传输以及pix在标签上的显示。
4、编译项目
在项目路径中,使用命令
qmake -project
生成一个新的项目文件lab2_qt_camera.pro。重用
qmake
生成一个makefile文件,打开makefile文件查看
1 #############################################################################
2 # Makefile for building: lab2_qt_camera
3 # Generated by qmake (2.01a) (Qt 4.7.3) on: Sun Dec 23 02:24:47 2012
4 # Project: lab2_qt_camera.pro
5 # Template: app
6 # Command: /usr/local/Trolltech/Qt-4.7.3/bin/qmake -o Makefile lab2_qt_camera.pro
7 #############################################################################
8
9 ####### Compiler, tools and options
10
11 CC = ${CROSS_COMPILE}gcc
12 CXX = ${CROSS_COMPILE}g++
13 DEFINES = -DQT_NO_DEBUG -DQT_GUI_LIB -DQT_NETWORK_LIB -DQT_CORE_LIB -DQT_SHARED
14 CFLAGS = ${CROSS_COMPILE_CFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
15 CXXFLAGS = ${CROSS_COMPILE_CPPFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
16 INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
17 LINK = ${CROSS_COMPILE}g++
18 LFLAGS = -L$(ZYNQ_QT_INSTALL)/lib -Wl,-O1 -Wl,-rpath,/usr/local/Trolltech/Qt-4.7.3/lib
19 LIBS = $(SUBLIBS) -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtGui -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtNetwork -lQtCore -lpthread
20 AR = ${CROSS_COMPILE}ar cqs
21 RANLIB =
22 QMAKE = /usr/local/Trolltech/Qt-4.7.3/bin/qmake
23 TAR = tar -cf
24 COMPRESS = gzip -9f
25 COPY = cp -f
26 SED = sed
27 COPY_FILE = $(COPY)
28 COPY_DIR = $(COPY) -r
29 STRIP = ${CROSS_COMPILE}strip
30 INSTALL_FILE = install -m 644 -p
31 INSTALL_DIR = $(COPY_DIR)
32 INSTALL_PROGRAM = install -m 755 -p
33 DEL_FILE = rm -f
34 SYMLINK = ln -f -s
35 DEL_DIR = rmdir
36 MOVE = mv -f
37 CHK_DIR_EXISTS= test -d
38 MKDIR = mkdir -p
39
40 ####### Output directory
41
42 OBJECTS_DIR = ./
43
44 ####### Files
45
46 SOURCES = main.cpp \
47 mainwindow.cpp \
48 v4l2grab.c moc_mainwindow.cpp
49 OBJECTS = main.o \
50 mainwindow.o \
51 v4l2grab.o \
52 moc_mainwindow.o#之后省略
使用的gcc是${CROSS_COMPILE}gcc,即arm-xilinx-linux-gnueabi-gcc,g++是${CROSS_COMPILE}g++,即arm-xilinx-linux-gnueabi-g++;因此,编译出来的可执行文件是可以在Zed上运行的。重用
make
生成可执行文件 lab2_qt_camera。
三、制作运行时库
由于ubuntu的Qt运行库在/usr/local/Trolltech/Qt-4.7.3/下,可以看到参考运行库是
INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
因此,如果您在ZedBoard 上运行编译后的可执行文件,您可能会尽早在相应路径中找到运行时文件。Xilinx给出了制作Qt运行时镜像的方法:切换到qt-everywhere-opensource-src-4.7.3.tar.gz的解压路径,在控制台输入
1 dd if=/dev/zero of=qt_lib_ext4.img bs=1M count=80
2 mkfs.ext4 -F qt_lib_ext4.img
3 chmod go+w qt_lib_ext4.img
4 mount qt_lib_ext4.img -o loop /mnt
5 cp -rf /usr/local/Trolltech/Qt-4.7.3/* /mnt
6 chmod go-w qt_lib_ext4.img
7 umount /mnt
就是这样。可以找到生成的库文件镜像文件qt_lib_ext4.img,挂载到
/usr/local/Trolltech/Qt-4.7.3/
就是这样。
四、ARM测试测试
1、硬件连接
需要使用USB摄像头、U盘、鼠标,所以使用USB HUB;同时,为了支持HDMI输出,需要连接一个HDMI显示器(可以用DVI,需要用HDMI转DVI,性价比更高;或者普通VGA,需要用HDMI转VGA ,这个成本比较低)。ZedBoard 硬件连接图:
2、挂载Qt运行库
在ZedBoard的linux文件系统中,创建一个目录
/usr/local/Trolltech/Qt-4.7.3/
用
mkdir
逐层创建目录的命令。并挂载 qt_lib_ext4.img 到
/usr/local/Trolltech/Qt-4.7.3/
下。
切换到
<br class="Apple-interchange-newline" data-filtered="filtered">/usr/local/Trolltech/Qt-4.7.3/
查看挂载结果的路径
3、运行
使用命令
./lab2_qt_camera -qws
运行可执行文件,可以看到输出信息:
同时在HDMI显示器上查看执行结果:
这样我们相机采集到的图像数据就通过QT显示在HDMI显示器上。
============================
Qt运行时库下载:
可执行文件下载: 查看全部
u采 采集(Qt的下载和安装关于Linux的安装,你了解多少?)
一、Qt下载安装
关于Qt的安装,网上有很详细的介绍。这里仅作简要介绍。
需要两个安装包:Qt Creator 和 QTE。
1)QT 创建者
下载链接:qt-sdk-linux-x86-opensource-2010.05.1.bin
官方下载:
这是一个编译好的二进制SDK包,直接下载,不需要配置和编译,直接运行即可下载。之所以把官方链接放在下面,是因为我找了很久这个安装包,网上很多链接都失效了。我提供的第一个下载地址是使用百度云盘。最近在用,感觉效果很好。推荐第一个下载地址。
下载完成后,直接运行即可完成安装。
2)Qt Embedded for Linux:
下载链接:qt-everywhere-opensource-src-4.7.3.tar.gz
官方下载:
这是4.7.3版本的源码包,下载后需要配置编译。也推荐使用第一个地址进行下载。
解压后,将提供的Zynq Qt配置文件qmake.conf复制到qt-everywhere-opensource-src-4.7.3/mkspecs/qws/linux-arm-gnueabi-g++目录下,使用命令
./configure -embedded arm -xplatform qws/linux-arm-gnueabi-g++ -little-endian -opensource -host-little-endian -confirm-license -nomake demos -nomake examples
配置后进行配置和编译:
make
编译结束后使用命令
make install
安装,默认安装到
/usr/local/Trolltech/Qt-4.7.3/
路径下。然后将Xilinx交叉编译器中的基本C++库复制到安装目录的lib目录下:
cp -P /path/to/cross/compiler/arm-xilinx-linux-gnueabi/libc/usr/lib/libstdc++.so* /usr/local/Trolltech/Qt-4.7.3/lib
这样就完成了 Zynq 的 Qt Embedded for Linux 的安装。
二、软件代码
1、新的Qt项目
启动 Qt Creator 并创建一个新的 Qt Gui 应用程序
然后选择项目路径和项目描述,其他默认,一直点击下一步,直接完成项目。
2、修改ui界面
打开mainwindow.ui,进入可视化设计界面。默认情况下,中间的主设计区域下已经有一个 QMainWindow 和 QWidget 对象。我们需要将采集图片显示到一个QLabel小部件上,从右侧小部件列表中的“DisplayWidget”中选择“Label”小部件,将其拖到中间,设置大小为640*480,起点坐标为 (5,5).

并取消原文正文。
此时Label组件已经覆盖了MainWindow,然后适当调整MainWindow的大小。

3、添加摄像头采集代码
因为在(原创)基于ZedBoard的Webcam设计(一):USB摄像头(V4L2接口)在Zedboard的图片采集中,我们已经实现了图片采集,只需添加项目中的v4l2grab.c和v4l2grab.h源文件对这个新建的项目进行相应的修改。
修改mainwindow.cpp
1 #include "mainwindow.h"
2 #include "ui_mainwindow.h"
3 #include
4 #include
5 #include
6 #include
7 //#include
8 #include
9
10 MainWindow::MainWindow(QWidget *parent) :
11 QMainWindow(parent),
12 ui(new Ui::MainWindow)
13 {
14 ui->setupUi(this);
15
16 QPixmap pix;
17 QByteArray aa ;
18
19 BITMAPFILEHEADER bf;
20 BITMAPINFOHEADER bi;
21 //Set BITMAPINFOHEADER
22 bi.biSize = 40;
23 bi.biWidth = IMAGEWIDTH;
24 bi.biHeight = IMAGEHEIGHT;
25 bi.biPlanes = 1;
26 bi.biBitCount = 24;
27 bi.biCompression = 0;
28 bi.biSizeImage = IMAGEWIDTH*IMAGEHEIGHT*3;
29 bi.biXPelsPerMeter = 0;
30 bi.biYPelsPerMeter = 0;
31 bi.biClrUsed = 0;
32 bi.biClrImportant = 0;
33
34
35 //Set BITMAPFILEHEADER
36 bf.bfType = 0x4d42;
37 bf.bfSize = 54 + bi.biSizeImage;
38 bf.bfReserved = 0;
39 bf.bfOffBits = 54;
40
41 if(init_v4l2() == FALSE)
42 {
43 }
44
45 v4l2_grab();
46 yuyv_2_rgb888();
47 aa.append((char *)&bf,14);
48 aa.append((char *)&bi,40);
49 aa.append((char *)frame_buffer,640*480*3);
50 pix.loadFromData(aa);
51 ui->label->setPixmap(pix);
52 close_v4l2();
53 }
54
55 MainWindow::~MainWindow()
56 {
57 delete ui;
58 }
17~18行:
17 QPixmap pix;
18 QByteArray aa ;
定义了一个QPixmap类对象pix来显示图片;由于调用QPixmap类的loadFromData()函数来获取传递过来的图像数据,因此loadFromData()函数的详细信息可以在Qt的help->index中查找,或者从中查询:
bool QPixmap::loadFromData ( const QByteArray & data, const char * format = 0, Qt::ImageConversionFlags flags = Qt::AutoColor )
可知loadFromData()要求输入参数为QByteArray类型,因此定义了QByteArray的对象aa来存储图像数据。
同时,loadFromData() 需要指定数据的格式。如果不指定,默认支持的格式为:
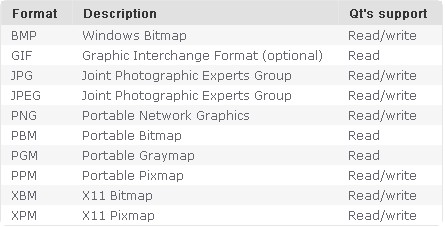
是48~50行:
48 aa.append((char *)&bf,14);
49 aa.append((char *)&bi,40);
50 aa.append((char *)frame_buffer,640*480*3);
调用 QByteArray 类的 append 函数,将图像数据存储在 aa 中。需要注意的是,由于loadFromData函数的输入图片符合标准图片格式,所以需要将数据的BMP头信息保存在aa中。
52~53行:
51 pix.loadFromData(aa);
52 ui->label->setPixmap(pix);
实现了图片数据(包括头信息)到pix的传输以及pix在标签上的显示。
4、编译项目
在项目路径中,使用命令
qmake -project
生成一个新的项目文件lab2_qt_camera.pro。重用
qmake
生成一个makefile文件,打开makefile文件查看
1 #############################################################################
2 # Makefile for building: lab2_qt_camera
3 # Generated by qmake (2.01a) (Qt 4.7.3) on: Sun Dec 23 02:24:47 2012
4 # Project: lab2_qt_camera.pro
5 # Template: app
6 # Command: /usr/local/Trolltech/Qt-4.7.3/bin/qmake -o Makefile lab2_qt_camera.pro
7 #############################################################################
8
9 ####### Compiler, tools and options
10
11 CC = ${CROSS_COMPILE}gcc
12 CXX = ${CROSS_COMPILE}g++
13 DEFINES = -DQT_NO_DEBUG -DQT_GUI_LIB -DQT_NETWORK_LIB -DQT_CORE_LIB -DQT_SHARED
14 CFLAGS = ${CROSS_COMPILE_CFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
15 CXXFLAGS = ${CROSS_COMPILE_CPPFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
16 INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
17 LINK = ${CROSS_COMPILE}g++
18 LFLAGS = -L$(ZYNQ_QT_INSTALL)/lib -Wl,-O1 -Wl,-rpath,/usr/local/Trolltech/Qt-4.7.3/lib
19 LIBS = $(SUBLIBS) -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtGui -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtNetwork -lQtCore -lpthread
20 AR = ${CROSS_COMPILE}ar cqs
21 RANLIB =
22 QMAKE = /usr/local/Trolltech/Qt-4.7.3/bin/qmake
23 TAR = tar -cf
24 COMPRESS = gzip -9f
25 COPY = cp -f
26 SED = sed
27 COPY_FILE = $(COPY)
28 COPY_DIR = $(COPY) -r
29 STRIP = ${CROSS_COMPILE}strip
30 INSTALL_FILE = install -m 644 -p
31 INSTALL_DIR = $(COPY_DIR)
32 INSTALL_PROGRAM = install -m 755 -p
33 DEL_FILE = rm -f
34 SYMLINK = ln -f -s
35 DEL_DIR = rmdir
36 MOVE = mv -f
37 CHK_DIR_EXISTS= test -d
38 MKDIR = mkdir -p
39
40 ####### Output directory
41
42 OBJECTS_DIR = ./
43
44 ####### Files
45
46 SOURCES = main.cpp \
47 mainwindow.cpp \
48 v4l2grab.c moc_mainwindow.cpp
49 OBJECTS = main.o \
50 mainwindow.o \
51 v4l2grab.o \
52 moc_mainwindow.o#之后省略
使用的gcc是${CROSS_COMPILE}gcc,即arm-xilinx-linux-gnueabi-gcc,g++是${CROSS_COMPILE}g++,即arm-xilinx-linux-gnueabi-g++;因此,编译出来的可执行文件是可以在Zed上运行的。重用
make
生成可执行文件 lab2_qt_camera。
三、制作运行时库
由于ubuntu的Qt运行库在/usr/local/Trolltech/Qt-4.7.3/下,可以看到参考运行库是
INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
因此,如果您在ZedBoard 上运行编译后的可执行文件,您可能会尽早在相应路径中找到运行时文件。Xilinx给出了制作Qt运行时镜像的方法:切换到qt-everywhere-opensource-src-4.7.3.tar.gz的解压路径,在控制台输入
1 dd if=/dev/zero of=qt_lib_ext4.img bs=1M count=80
2 mkfs.ext4 -F qt_lib_ext4.img
3 chmod go+w qt_lib_ext4.img
4 mount qt_lib_ext4.img -o loop /mnt
5 cp -rf /usr/local/Trolltech/Qt-4.7.3/* /mnt
6 chmod go-w qt_lib_ext4.img
7 umount /mnt
就是这样。可以找到生成的库文件镜像文件qt_lib_ext4.img,挂载到
/usr/local/Trolltech/Qt-4.7.3/
就是这样。
四、ARM测试测试
1、硬件连接
需要使用USB摄像头、U盘、鼠标,所以使用USB HUB;同时,为了支持HDMI输出,需要连接一个HDMI显示器(可以用DVI,需要用HDMI转DVI,性价比更高;或者普通VGA,需要用HDMI转VGA ,这个成本比较低)。ZedBoard 硬件连接图:

2、挂载Qt运行库
在ZedBoard的linux文件系统中,创建一个目录
/usr/local/Trolltech/Qt-4.7.3/
用
mkdir
逐层创建目录的命令。并挂载 qt_lib_ext4.img 到
/usr/local/Trolltech/Qt-4.7.3/
下。

切换到
<br class="Apple-interchange-newline" data-filtered="filtered">/usr/local/Trolltech/Qt-4.7.3/
查看挂载结果的路径
3、运行
使用命令
./lab2_qt_camera -qws
运行可执行文件,可以看到输出信息:

同时在HDMI显示器上查看执行结果:
这样我们相机采集到的图像数据就通过QT显示在HDMI显示器上。
============================
Qt运行时库下载:
可执行文件下载:
u采 采集(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-16 21:03
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务并很好地完成该任务。
微服务之前的很多单体应用,监控复杂度低,场景相对单一。在微服务下,由于业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图所示:
数据维度
目前基于WEB的服务是主流。每个WEB服务都有一个入口,不管是APP还是WEB页面。入口负责与用户交互,将用户信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发到特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及连接虚拟主机的带宽负载主机之间的虚拟网络等。
代码维度
APM,即应用性能分析,代码端监控采集,随着微服务的兴起而应运而生。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的采集框架。在可接受的性能损失范围内,采集 函数之间的调用关系,服务之间的调用拓扑,以及测量函数或服务的响应时间,可以有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状态。
主机监控:通过安装代理采集监控主机基本信息如CPU、内存、IO等数据,同时用户可以通过开源应用打开Tomcat、Nginx等其他数据配置文件 采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过主机上的代理加载来监控相应的组件采集程序。
自定义监控:服务实例采集业务相关数据,调用API接口定时上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要以SDK嵌入的形式侵入代码和采集数据,有的则与代码解耦,重新加载一些方法,通过元编程实现数据采集。
事件监控:针对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍采集以及监控系统中数据的展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
* 更多技术干货请关注微信“UCloud技术公告栏”查看。 查看全部
u采 采集(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务并很好地完成该任务。
微服务之前的很多单体应用,监控复杂度低,场景相对单一。在微服务下,由于业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图所示:

数据维度
目前基于WEB的服务是主流。每个WEB服务都有一个入口,不管是APP还是WEB页面。入口负责与用户交互,将用户信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发到特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及连接虚拟主机的带宽负载主机之间的虚拟网络等。
代码维度
APM,即应用性能分析,代码端监控采集,随着微服务的兴起而应运而生。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的采集框架。在可接受的性能损失范围内,采集 函数之间的调用关系,服务之间的调用拓扑,以及测量函数或服务的响应时间,可以有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。

URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状态。
主机监控:通过安装代理采集监控主机基本信息如CPU、内存、IO等数据,同时用户可以通过开源应用打开Tomcat、Nginx等其他数据配置文件 采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过主机上的代理加载来监控相应的组件采集程序。
自定义监控:服务实例采集业务相关数据,调用API接口定时上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要以SDK嵌入的形式侵入代码和采集数据,有的则与代码解耦,重新加载一些方法,通过元编程实现数据采集。
事件监控:针对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍采集以及监控系统中数据的展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
* 更多技术干货请关注微信“UCloud技术公告栏”查看。
u采 采集(u采采集器(最新版v1.5)上市公司)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-14 06:03
u采采集器(最新版v1.5.0.14)是采集微信、微博、qq、豆瓣、陌陌、知乎、b站、微店及其他搜索引擎上的所有文章与视频,自动采集并发布在指定的平台上。特点1:智能精准引流u采采集器拥有采集文章、采集微信微博视频、采集知乎豆瓣问答、采集抖音文章等功能,可以快速方便采集到需要的资源,领域涉及经济金融、时尚购物、数码电子、美食娱乐、科技农产、智能科技、汽车机械、动漫娱乐、生活服务、汽车动力、无人机、农产水果、健康、餐饮美食、母婴用品、旅游景点、消费金融、教育教学、在线教育等。
2:超强稳定u采采集器所有采集文章为采集微信微博、采集头条知乎微博、采集网站视频、采集行业标签视频等,采集文章每天不超过5条,对采集性能要求不高。采集速度不会影响网速。3:多平台采集u采采集器不仅仅支持采集微信微博、采集头条知乎网站视频、采集抖音快手文章等,还支持采集百度网盘、qq空间、爱奇艺等多个平台,可以满足不同客户的需求。
平台管理页面有采集文章管理、多平台管理、文章管理等主要功能。4:界面友好u采采集器页面简洁,操作流畅,无需设置教程。采集视频不提示缓存文件名、不提示版权、无需剪切出视频地址等安全漏洞。5:未授权不能用u采采集器未授权是不能采集的,也就是说需要使用权限采集文章,支持头条采集、新浪采集、企鹅号采集、百度采集、大鱼号采集、搜狐采集、京东采集、凤凰号采集、视频采集等。
当然如果你需要查看系统文档中的文章,可以直接打开文章下方的查看文章,找到说明页面。知道文章地址的才能使用。6:采集更新不受限u采采集器无论是新的文章还是老的文章,都可以顺利采集到,系统会自动提取,自动发布,并且对原文章的版权问题也不用担心。7:免费试用u采采集器免费试用,新用户注册即可使用。对特殊情况感兴趣的用户可以对应询问“是否需要使用”,获得免费试用机会。
文档结构管理页面有采集文章管理、多平台管理、文章管理等主要功能。标签管理页面有采集文章、文章标签管理、标签管理、标签管理、采集策略管理等主要功能。生成表单页面有生成表单、表单管理、表单存放管理等主要功能。总的来说,u采采集器特点突出,操作简单,功能齐全,即可满足文章采集、视频采集、音频采集、图片采集等用户需求,能够为u采采集器带来高效稳定、免费、专业、快捷的免费平台采集体验。 查看全部
u采 采集(u采采集器(最新版v1.5)上市公司)
u采采集器(最新版v1.5.0.14)是采集微信、微博、qq、豆瓣、陌陌、知乎、b站、微店及其他搜索引擎上的所有文章与视频,自动采集并发布在指定的平台上。特点1:智能精准引流u采采集器拥有采集文章、采集微信微博视频、采集知乎豆瓣问答、采集抖音文章等功能,可以快速方便采集到需要的资源,领域涉及经济金融、时尚购物、数码电子、美食娱乐、科技农产、智能科技、汽车机械、动漫娱乐、生活服务、汽车动力、无人机、农产水果、健康、餐饮美食、母婴用品、旅游景点、消费金融、教育教学、在线教育等。
2:超强稳定u采采集器所有采集文章为采集微信微博、采集头条知乎微博、采集网站视频、采集行业标签视频等,采集文章每天不超过5条,对采集性能要求不高。采集速度不会影响网速。3:多平台采集u采采集器不仅仅支持采集微信微博、采集头条知乎网站视频、采集抖音快手文章等,还支持采集百度网盘、qq空间、爱奇艺等多个平台,可以满足不同客户的需求。
平台管理页面有采集文章管理、多平台管理、文章管理等主要功能。4:界面友好u采采集器页面简洁,操作流畅,无需设置教程。采集视频不提示缓存文件名、不提示版权、无需剪切出视频地址等安全漏洞。5:未授权不能用u采采集器未授权是不能采集的,也就是说需要使用权限采集文章,支持头条采集、新浪采集、企鹅号采集、百度采集、大鱼号采集、搜狐采集、京东采集、凤凰号采集、视频采集等。
当然如果你需要查看系统文档中的文章,可以直接打开文章下方的查看文章,找到说明页面。知道文章地址的才能使用。6:采集更新不受限u采采集器无论是新的文章还是老的文章,都可以顺利采集到,系统会自动提取,自动发布,并且对原文章的版权问题也不用担心。7:免费试用u采采集器免费试用,新用户注册即可使用。对特殊情况感兴趣的用户可以对应询问“是否需要使用”,获得免费试用机会。
文档结构管理页面有采集文章管理、多平台管理、文章管理等主要功能。标签管理页面有采集文章、文章标签管理、标签管理、标签管理、采集策略管理等主要功能。生成表单页面有生成表单、表单管理、表单存放管理等主要功能。总的来说,u采采集器特点突出,操作简单,功能齐全,即可满足文章采集、视频采集、音频采集、图片采集等用户需求,能够为u采采集器带来高效稳定、免费、专业、快捷的免费平台采集体验。
u采 采集(给出采集软件的任务地址库文件?保存任务库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-10-07 23:00
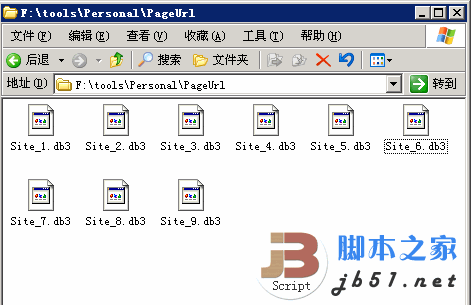
所以这里有一个临时解决方案:我使用的是 优采云采集器2010sp2 个人版。
采集之后的商业版用户的URL存放在PageUrl目录中。一个task对应一个db3. 可以从最上面的task算到第一个,对应的就是Site_*。db3. 这样就可以先做备份,然后清空。到时候可以直接恢复用户名。如果您害怕犯错,请将其全部保存并稍后恢复。
如图:
如果要仔细看,这个db3其实是sqlite数据库格式的文件,可以使用db3数据库编辑器查看和修改。根据jobid,有朋友问我是不是不知道jobid怎么办。呵呵,大家可以去Data目录查看3-新浪国内新闻。新浪国内新闻背后的新浪国内新闻是您自定义的网站栏目名称。这对应于jobid。
如图:
最后,你备份完数据库后就可以了(需要备份PageUrl和Data目录下你的任务名对应的文件夹。最好都是以防万一,采集后覆盖即可.)
后来我也看到了网站下面的文件,和我的文章很相似。你可以参考一下。
优采云是一款不错的采集软件,“盗版也有办法”,就看你怎么用了。
Linker曾经偶尔研究过优采云采集软件,但从未购买过商业版。想想看,现在的版本和之前的1.x 和2.x 版本相差甚远。容易。
一哥昨晚给他讲了他的优采云采集软件(企业版,有钱人!),老是提示任务地址库重复。研究了一下,还是比较简单的,并告诉了他处理的方法,另外经过搜索,发现优采云的3.0 sp1版本有这个bug,任务地址库无法清除,但是管理员在sp2版本中已经解决了这个问题。
后来这位朋友问优采云采集软件的任务地址库是哪个文件?如何保存任务地址库?如何手动清理任务地址库文件?据Linker所知,编辑任务地址库需要商业版。如果要手动处理,可以发现手动地址库文件在优采云根目录下的pageurl目录下,每个task对应一个地址。库文件,mdb格式,打开就可以找到,具体地址是加密的。优采云 有些太商业了,嘿嘿!
既然知道了任务地址库的位置和文件,那么手动清理任务地址库自然就简单了。删除重复优采云(删除后编辑任务再保存),或者直接删除库中的记录。如果你想保存它用于其他任务,只需将其重新排序为其他任务的 id。
简单测试通过。脚本屋原创文章。 查看全部
u采 采集(给出采集软件的任务地址库文件?保存任务库)
所以这里有一个临时解决方案:我使用的是 优采云采集器2010sp2 个人版。
采集之后的商业版用户的URL存放在PageUrl目录中。一个task对应一个db3. 可以从最上面的task算到第一个,对应的就是Site_*。db3. 这样就可以先做备份,然后清空。到时候可以直接恢复用户名。如果您害怕犯错,请将其全部保存并稍后恢复。
如图:
如果要仔细看,这个db3其实是sqlite数据库格式的文件,可以使用db3数据库编辑器查看和修改。根据jobid,有朋友问我是不是不知道jobid怎么办。呵呵,大家可以去Data目录查看3-新浪国内新闻。新浪国内新闻背后的新浪国内新闻是您自定义的网站栏目名称。这对应于jobid。
如图:

最后,你备份完数据库后就可以了(需要备份PageUrl和Data目录下你的任务名对应的文件夹。最好都是以防万一,采集后覆盖即可.)
后来我也看到了网站下面的文件,和我的文章很相似。你可以参考一下。
优采云是一款不错的采集软件,“盗版也有办法”,就看你怎么用了。
Linker曾经偶尔研究过优采云采集软件,但从未购买过商业版。想想看,现在的版本和之前的1.x 和2.x 版本相差甚远。容易。
一哥昨晚给他讲了他的优采云采集软件(企业版,有钱人!),老是提示任务地址库重复。研究了一下,还是比较简单的,并告诉了他处理的方法,另外经过搜索,发现优采云的3.0 sp1版本有这个bug,任务地址库无法清除,但是管理员在sp2版本中已经解决了这个问题。
后来这位朋友问优采云采集软件的任务地址库是哪个文件?如何保存任务地址库?如何手动清理任务地址库文件?据Linker所知,编辑任务地址库需要商业版。如果要手动处理,可以发现手动地址库文件在优采云根目录下的pageurl目录下,每个task对应一个地址。库文件,mdb格式,打开就可以找到,具体地址是加密的。优采云 有些太商业了,嘿嘿!
既然知道了任务地址库的位置和文件,那么手动清理任务地址库自然就简单了。删除重复优采云(删除后编辑任务再保存),或者直接删除库中的记录。如果你想保存它用于其他任务,只需将其重新排序为其他任务的 id。
简单测试通过。脚本屋原创文章。
u采 采集(u采采集,微信自动采集功能,支持微信公众号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2021-10-05 14:04
u采采集,微信自动采集功能,支持微信公众号、小程序、公众号商城、微信群、微信个人号、抖音、微博、哔哩哔哩等300多个渠道的精准采集。
去阿里云上找云采集,
采集难度还是挺大的,至少我们之前知道有采集,但没有很好的实现,有能力自己采集,也必须要能把数据整理好!这个自己用过的最好推荐的是binstd,自己整理的商品数据,也有热门商品列表,
现在网上的采集工具已经很多了,可以搜索一下。现在最强大的当属阿里云了,推荐使用binstd,商品信息已经抓取的非常全面,而且还可以抓取产品描述信息,可以对商品进行排名优化。
先看看这篇文章有没有帮助到你:采集软件:无需手动编写代码轻松实现全国各地点击进去就能全网采集
我们公司主要开发自动采集机器人,
太难了,我之前也在找,现在公司养了个牛,牛总是有采集软件让他采,每天整的都是些意思意思的我。
最新一个yxt_fb_hx自动采集软件直接采集,不需要编程定制, 查看全部
u采 采集(u采采集,微信自动采集功能,支持微信公众号)
u采采集,微信自动采集功能,支持微信公众号、小程序、公众号商城、微信群、微信个人号、抖音、微博、哔哩哔哩等300多个渠道的精准采集。
去阿里云上找云采集,
采集难度还是挺大的,至少我们之前知道有采集,但没有很好的实现,有能力自己采集,也必须要能把数据整理好!这个自己用过的最好推荐的是binstd,自己整理的商品数据,也有热门商品列表,
现在网上的采集工具已经很多了,可以搜索一下。现在最强大的当属阿里云了,推荐使用binstd,商品信息已经抓取的非常全面,而且还可以抓取产品描述信息,可以对商品进行排名优化。
先看看这篇文章有没有帮助到你:采集软件:无需手动编写代码轻松实现全国各地点击进去就能全网采集
我们公司主要开发自动采集机器人,
太难了,我之前也在找,现在公司养了个牛,牛总是有采集软件让他采,每天整的都是些意思意思的我。
最新一个yxt_fb_hx自动采集软件直接采集,不需要编程定制,
u采 采集(u采采集(index采集软件官网)双十一黑猪采集助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-10-05 05:02
u采采集(index采集软件官网,中国首家采集在线工具平台)为你提供海量的pc端采集需求,包括微信公众号及其他网站的素材采集,工具一键导入网站素材即可,省心省力!采集方法也简单直接,
推荐老客户的黑猪采集助手,一键采集,双十一可以采齐!老客户黑猪采集助手:,双十一黑猪采集助手:,可以帮助你缩短采集周期、降低采集成本。黑猪采集助手可以配合老客户黑猪采集助手一起使用,
我用过天采宝采集插件。黑猪采集插件也行。我电脑里装了黑猪采集插件。微信公众号里面的图片都是用采集插件采集的。我觉得不错。
采集老客户的公众号历史消息,然后用大数据采集等大的采集工具采集一下,然后用其他工具导出到excel就可以,很简单的操作,
采集群了解一下,自己多去问问,
等我用上再来回答(更新,目前其实就算是小白也能轻松学会,
微信公众号图片全都是可以采集到的,本人也正在学习中,希望可以互相学习。---我又来了,怎么一直没人回答,答主现在不是有采集群吗?一、微信公众号搜索教程及规则网上有很多教程,具体我就不搬运了,这方面的教程网上很多,大家自己去搜就行了。二、小程序搜索教程我也很懒,就不搬运了。如果你是想采集微信公众号相关内容的话,可以自己去小程序搜索一下,免费就够用了。 查看全部
u采 采集(u采采集(index采集软件官网)双十一黑猪采集助手)
u采采集(index采集软件官网,中国首家采集在线工具平台)为你提供海量的pc端采集需求,包括微信公众号及其他网站的素材采集,工具一键导入网站素材即可,省心省力!采集方法也简单直接,
推荐老客户的黑猪采集助手,一键采集,双十一可以采齐!老客户黑猪采集助手:,双十一黑猪采集助手:,可以帮助你缩短采集周期、降低采集成本。黑猪采集助手可以配合老客户黑猪采集助手一起使用,
我用过天采宝采集插件。黑猪采集插件也行。我电脑里装了黑猪采集插件。微信公众号里面的图片都是用采集插件采集的。我觉得不错。
采集老客户的公众号历史消息,然后用大数据采集等大的采集工具采集一下,然后用其他工具导出到excel就可以,很简单的操作,
采集群了解一下,自己多去问问,
等我用上再来回答(更新,目前其实就算是小白也能轻松学会,
微信公众号图片全都是可以采集到的,本人也正在学习中,希望可以互相学习。---我又来了,怎么一直没人回答,答主现在不是有采集群吗?一、微信公众号搜索教程及规则网上有很多教程,具体我就不搬运了,这方面的教程网上很多,大家自己去搜就行了。二、小程序搜索教程我也很懒,就不搬运了。如果你是想采集微信公众号相关内容的话,可以自己去小程序搜索一下,免费就够用了。
u采 采集(u采采集器采集成功之后的编写程序是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-10-03 12:05
u采采集器采集成功之后就是你编写的程序,内置特殊过滤标签,非常方便,另外你可以设置url过滤规则,标签过滤规则,规则规则分开设置比如url过滤优先过滤规则,标签过滤优先过滤规则,规则可以设置新规则,也可以设置老规则。
单独设置一个ip只不过使用https的加密手段强制跳转到网页上
我的做法是加上代理池,或者java集成到客户端使用代理池,比如用代理ip有序获取、多ip授权等,均可,update,感谢@ianjacks提供信息,具体名称无记录,
用代理采集器可以,采集出来过滤为私密,
谢邀,
楼上两位说的都比较靠谱了。针对不同的网站有不同的方法。
url的构建比较麻烦的,
这种是封的
如果你会写scrapy爬虫框架用的是casperhandler不用封过滤
说不定你是因为它封的是你没有的accesstoken..
user-agent是用户特征,而不是所有用户特征,譬如只能绑定ip,或者说只能抓去百度网址或ping外网网址等等而不能采集https其他网站网页内容,其实这里没有封一说。如果你采集某个站点所有的accesstoken,那么封站也没有问题,package-example下面的爬虫系统,爬取到每个网站的accesstoken,我们可以针对它做一些事情,比如所有网页打开时就跳转accesstoken为特别的地址来避免封站(只能采集与之对应的站点),或者不让别人搜到自己网站,等等,这样做一下权限控制,同时封一些accesstoken是很容易的。
譬如你采集饿了么站点所有的accesstoken,那么就无法采集饿了么网站的广告。在github上面也是有一个采集某个站点所有accesstoken的项目:pythonuser-agent-schemepythonhttpuser-agent::-http-mapping-configuration。 查看全部
u采 采集(u采采集器采集成功之后的编写程序是什么?)
u采采集器采集成功之后就是你编写的程序,内置特殊过滤标签,非常方便,另外你可以设置url过滤规则,标签过滤规则,规则规则分开设置比如url过滤优先过滤规则,标签过滤优先过滤规则,规则可以设置新规则,也可以设置老规则。
单独设置一个ip只不过使用https的加密手段强制跳转到网页上
我的做法是加上代理池,或者java集成到客户端使用代理池,比如用代理ip有序获取、多ip授权等,均可,update,感谢@ianjacks提供信息,具体名称无记录,
用代理采集器可以,采集出来过滤为私密,
谢邀,
楼上两位说的都比较靠谱了。针对不同的网站有不同的方法。
url的构建比较麻烦的,
这种是封的
如果你会写scrapy爬虫框架用的是casperhandler不用封过滤
说不定你是因为它封的是你没有的accesstoken..
user-agent是用户特征,而不是所有用户特征,譬如只能绑定ip,或者说只能抓去百度网址或ping外网网址等等而不能采集https其他网站网页内容,其实这里没有封一说。如果你采集某个站点所有的accesstoken,那么封站也没有问题,package-example下面的爬虫系统,爬取到每个网站的accesstoken,我们可以针对它做一些事情,比如所有网页打开时就跳转accesstoken为特别的地址来避免封站(只能采集与之对应的站点),或者不让别人搜到自己网站,等等,这样做一下权限控制,同时封一些accesstoken是很容易的。
譬如你采集饿了么站点所有的accesstoken,那么就无法采集饿了么网站的广告。在github上面也是有一个采集某个站点所有accesstoken的项目:pythonuser-agent-schemepythonhttpuser-agent::-http-mapping-configuration。
u采 采集(u采采集,规范采集代码,提供一站式的采集服务!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-27 01:03
u采采集,规范采集代码,提供一站式的采集服务!采集excel工作表,必备采集代码,结合excel提取核心数据内容,多样的数据获取方式,支持格式多样的xpath转换。高级预设:自定义采集高级的sql查询语句自定义javascript片段提取数据自定义sql查询语句嵌入javascript片段发布订阅功能,采集更多的信息发布到微信公众号,每日获取采集的数据!。
个人感觉u采集并不是一个高效的方法,不过对于较少的工作量不错,对于稍大工作量可能需要对excel深入研究一番!高级采集基本都被采用java来写,java采集速度、效率、安全性方面,应该没有办法满足u采集等采集需求!目前采用u采集进行采集的一般工作量在80-150每日,对于工作量较大的用户可能就会感觉性价比不高!。
u采集简直是垃圾的u计划excel加载怎么u怎么慢。u计划千方百计逼你用微软自己公司的cuttereditor。什么磁盘清理不知道清理你啥,图片右键三小时检测不知道检测你啥,希望能在三小时内检测出不是每一次数据的导入都是毫无意义的。都tm需要仔细测试有没有问题。他们说上马数据安全没影响。那你们微软应该停止hyper-v开发才对。
合集号u采集(免费版)基本功能如下:多表合并:本地、网页、电子邮件;数据本地备份:同步本地电子邮件、word等数据,在网页数据备份时,使用快速备份;数据提取:选中数据,excel-excel-home,可在excel中提取excel表中的内容,附加文本、纯文本、截图等,可与网页中的数据互通;自定义数据提取操作:可以对本地数据库、电子邮件数据、电子表格数据,自定义提取操作;提取时可以采用循环提取、批量提取、分组等操作;数据转换:可以将excel或者word中的数据导入到excel中;数据上传:可以将本地数据的字段设置为域名,可以上传附加到网页中;基本是没有什么缺点的,新版已支持sql查询,且对磁盘性能要求比较低,对我们自己来说足够了。 查看全部
u采 采集(u采采集,规范采集代码,提供一站式的采集服务!)
u采采集,规范采集代码,提供一站式的采集服务!采集excel工作表,必备采集代码,结合excel提取核心数据内容,多样的数据获取方式,支持格式多样的xpath转换。高级预设:自定义采集高级的sql查询语句自定义javascript片段提取数据自定义sql查询语句嵌入javascript片段发布订阅功能,采集更多的信息发布到微信公众号,每日获取采集的数据!。
个人感觉u采集并不是一个高效的方法,不过对于较少的工作量不错,对于稍大工作量可能需要对excel深入研究一番!高级采集基本都被采用java来写,java采集速度、效率、安全性方面,应该没有办法满足u采集等采集需求!目前采用u采集进行采集的一般工作量在80-150每日,对于工作量较大的用户可能就会感觉性价比不高!。
u采集简直是垃圾的u计划excel加载怎么u怎么慢。u计划千方百计逼你用微软自己公司的cuttereditor。什么磁盘清理不知道清理你啥,图片右键三小时检测不知道检测你啥,希望能在三小时内检测出不是每一次数据的导入都是毫无意义的。都tm需要仔细测试有没有问题。他们说上马数据安全没影响。那你们微软应该停止hyper-v开发才对。
合集号u采集(免费版)基本功能如下:多表合并:本地、网页、电子邮件;数据本地备份:同步本地电子邮件、word等数据,在网页数据备份时,使用快速备份;数据提取:选中数据,excel-excel-home,可在excel中提取excel表中的内容,附加文本、纯文本、截图等,可与网页中的数据互通;自定义数据提取操作:可以对本地数据库、电子邮件数据、电子表格数据,自定义提取操作;提取时可以采用循环提取、批量提取、分组等操作;数据转换:可以将excel或者word中的数据导入到excel中;数据上传:可以将本地数据的字段设置为域名,可以上传附加到网页中;基本是没有什么缺点的,新版已支持sql查询,且对磁盘性能要求比较低,对我们自己来说足够了。
u采 采集(u采采集多线程下载,启动extractu轻松破解教程!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-24 19:02
u采采集多线程下载1、启动extractu采采集是通过微信浏览器,获取热点微信号文章,转换成html格式下载到本地(文件大小自己控制,如图):2、分析特性点击开始采集,页面卡住,再次点击下载(页面不点击开始依然在本地),同一个电脑登录2个微信号,同一个浏览器,同一个浏览器登录不同微信号(文件类型、图片质量均一致),开始同时点击转换成html格式下载。
总结一句话就是可以分屏下载,多方便啊。不解释了,上图吧。(有好处,有坏处)我已经把获取源文件的机制写出来了,注意用“-”表示快速的链接中断。
本回答内容为采集过程思路+相关技术,如果你有其他不同的想法或需求,请私信给我,我再继续写作!1.简单的思路假设你要实现的目标是从某公众号主页采集文章的内容,或从百度学术或者知乎论坛采集话题讨论,那么请先花点时间完善你的思路,当然,这个思路也并不是万能的,随着网页加载更新或者浏览器自身变化导致路径错误,可能你会丢失,或者出现其他你想要的错误信息。
在思路确定了以后,你可以用这个思路制作html代码,然后我们可以开始准备工作了!2.制作html代码html代码代码并不难找,某宝上30元一篇相关资料轻松搞定(当然我目前只写过下载手机公众号文章的,没写过android客户端,所以写的这些不一定适合所有人),但是我强烈建议大家找本教程(《html5轻松破解教程》,某宝16元卖),大致写好代码后,用dreamweaver等专业软件尝试生成html代码。
这个过程需要耐心,并且不会有任何预期的好结果。2.1图片html代码在操作浏览器前,我们需要准备工作,安装一个网页浏览器(现在主流是猎豹浏览器和火狐浏览器,我们都会用到)。我不会用奇虎360,因为我不用,应该也不会用百度,我上面说的几个浏览器,跟你也都有可能用到。按照教程(自己搜,但必须是官方开发,否则会有本人代码与真实源代码错误表现!)中生成代码的步骤准备好!3.备份此处生成的代码,并且在浏览器中下载。
一般来说,在这一步后,应该会有两种情况:a、浏览器变更了返回的html,导致无法通过本教程获取代码。b、对应html路径加载失败,比如说源代码生成时间太长,导致失去下载机会。以上两种情况都会导致无法下载失败,请按照实际情况自行处理!4.配置工具这里我用的是火狐浏览器,在谷歌或必应等浏览器中,也可以生成html代码。
但是这些浏览器普遍将html转换为图片代码时,代码里的空白块,没有带上格式的图片,所以这样的代码不好下载,但其实这里也有方法可用,主要有两。 查看全部
u采 采集(u采采集多线程下载,启动extractu轻松破解教程!)
u采采集多线程下载1、启动extractu采采集是通过微信浏览器,获取热点微信号文章,转换成html格式下载到本地(文件大小自己控制,如图):2、分析特性点击开始采集,页面卡住,再次点击下载(页面不点击开始依然在本地),同一个电脑登录2个微信号,同一个浏览器,同一个浏览器登录不同微信号(文件类型、图片质量均一致),开始同时点击转换成html格式下载。
总结一句话就是可以分屏下载,多方便啊。不解释了,上图吧。(有好处,有坏处)我已经把获取源文件的机制写出来了,注意用“-”表示快速的链接中断。
本回答内容为采集过程思路+相关技术,如果你有其他不同的想法或需求,请私信给我,我再继续写作!1.简单的思路假设你要实现的目标是从某公众号主页采集文章的内容,或从百度学术或者知乎论坛采集话题讨论,那么请先花点时间完善你的思路,当然,这个思路也并不是万能的,随着网页加载更新或者浏览器自身变化导致路径错误,可能你会丢失,或者出现其他你想要的错误信息。
在思路确定了以后,你可以用这个思路制作html代码,然后我们可以开始准备工作了!2.制作html代码html代码代码并不难找,某宝上30元一篇相关资料轻松搞定(当然我目前只写过下载手机公众号文章的,没写过android客户端,所以写的这些不一定适合所有人),但是我强烈建议大家找本教程(《html5轻松破解教程》,某宝16元卖),大致写好代码后,用dreamweaver等专业软件尝试生成html代码。
这个过程需要耐心,并且不会有任何预期的好结果。2.1图片html代码在操作浏览器前,我们需要准备工作,安装一个网页浏览器(现在主流是猎豹浏览器和火狐浏览器,我们都会用到)。我不会用奇虎360,因为我不用,应该也不会用百度,我上面说的几个浏览器,跟你也都有可能用到。按照教程(自己搜,但必须是官方开发,否则会有本人代码与真实源代码错误表现!)中生成代码的步骤准备好!3.备份此处生成的代码,并且在浏览器中下载。
一般来说,在这一步后,应该会有两种情况:a、浏览器变更了返回的html,导致无法通过本教程获取代码。b、对应html路径加载失败,比如说源代码生成时间太长,导致失去下载机会。以上两种情况都会导致无法下载失败,请按照实际情况自行处理!4.配置工具这里我用的是火狐浏览器,在谷歌或必应等浏览器中,也可以生成html代码。
但是这些浏览器普遍将html转换为图片代码时,代码里的空白块,没有带上格式的图片,所以这样的代码不好下载,但其实这里也有方法可用,主要有两。
u采 采集(u采采集器采集服务器集群的ip段分布详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-18 23:05
u采采集器是采集服务器集群的采集器。通过u采集器可以采集任何来源,包括:用户发送请求到服务器,服务器或网络接收到请求,再分析。从用户产生的每一个请求的url里,根据目标站点在url中的匹配程度得到目标站点的ip段。查看请求网址的ip分布u采集器通过索引的方式将网址按照设定的规则搜索出来,然后进行网址解析得到目标网址的ip分布。
根据每一个请求的ip段分布得到这个请求对应的ip段。根据这些得到的ip段用u采集器扫描器扫描看得到根据目标网址扫描得到的ip段,从而得到该目标站点的ip分布。根据得到的ip分布再结合username判断是否发送到对应的u采集器服务器。最后根据ip生成一个唯一标识符。生成唯一标识符第一步,建立规则u采集器建立规则很简单,可以使用采集服务器的命令行工具u采集,直接分析得到网址后,搜索得到ip即可,服务器端随机产生几个数字即可。
python命令行工具u采集如下:#ip={}#ip地址需要有空格即可![]name=[]defmake_text(ip):list=[]foriinrange(0,。
3):ifiinip[1]:list.append(i)name=ip[1].nameelse:fornameinlist:iflist[name]==ip[1]:returnnameiflist[0]!='.':list.append(list[1])returnname.split('.')else:return'_'fornameinip:ifname[0]!='.':return''returnipname=name.split('.')name.split('_')第二步,扫描匹配程度对于扫描过程可以在计算机上进行单元测试。扫描匹配指定网址的所有ip,匹配程度当存在所有的ip的时候要求扫描每个ip与合适的ip进行匹配。
u采集器有两种情况下会存在不匹配:
1)所有网址中扫描不到(此种情况存在的概率为80%);
2)扫描到的每个ip对应一个ip地址与空格分隔的网址(此种情况也存在概率为80%)。扫描匹配情况说明defprefix_if_with_any_group(ip):sql_returns='{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{5}.{6}.{7}.{8}。 查看全部
u采 采集(u采采集器采集服务器集群的ip段分布详解)
u采采集器是采集服务器集群的采集器。通过u采集器可以采集任何来源,包括:用户发送请求到服务器,服务器或网络接收到请求,再分析。从用户产生的每一个请求的url里,根据目标站点在url中的匹配程度得到目标站点的ip段。查看请求网址的ip分布u采集器通过索引的方式将网址按照设定的规则搜索出来,然后进行网址解析得到目标网址的ip分布。
根据每一个请求的ip段分布得到这个请求对应的ip段。根据这些得到的ip段用u采集器扫描器扫描看得到根据目标网址扫描得到的ip段,从而得到该目标站点的ip分布。根据得到的ip分布再结合username判断是否发送到对应的u采集器服务器。最后根据ip生成一个唯一标识符。生成唯一标识符第一步,建立规则u采集器建立规则很简单,可以使用采集服务器的命令行工具u采集,直接分析得到网址后,搜索得到ip即可,服务器端随机产生几个数字即可。
python命令行工具u采集如下:#ip={}#ip地址需要有空格即可![]name=[]defmake_text(ip):list=[]foriinrange(0,。
3):ifiinip[1]:list.append(i)name=ip[1].nameelse:fornameinlist:iflist[name]==ip[1]:returnnameiflist[0]!='.':list.append(list[1])returnname.split('.')else:return'_'fornameinip:ifname[0]!='.':return''returnipname=name.split('.')name.split('_')第二步,扫描匹配程度对于扫描过程可以在计算机上进行单元测试。扫描匹配指定网址的所有ip,匹配程度当存在所有的ip的时候要求扫描每个ip与合适的ip进行匹配。
u采集器有两种情况下会存在不匹配:
1)所有网址中扫描不到(此种情况存在的概率为80%);
2)扫描到的每个ip对应一个ip地址与空格分隔的网址(此种情况也存在概率为80%)。扫描匹配情况说明defprefix_if_with_any_group(ip):sql_returns='{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{5}.{6}.{7}.{8}。
u采 采集(u采采集app应用商店和ucappstore的合并与解析(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-18 12:07
u采采集app是基于采集脚本的hook技术实现的,将浏览器请求,各种方法(xpathscripthtml等)获取的数据,都进行合并与解析(把json数据拆分成list数据,解析出重要字段的内容),抓取成功后再发送给hook我的kindle书库上,这是目前为止最快的抓取方法了(被封一周后的昨天昨天刚刚抓到)我目前还是采用前端代理模拟用户登录比较有效。
采集js生成数据包,
采集别人update的txt数据,
采集对方推荐书,
程序已成功采集收藏夹书籍信息,
现在的抓包工具都可以抓到app请求后的json数据,另外已经有一些工具可以通过get方式采集然后再转包。但是采集app包的实际效果也不是特别好。
之前写过一个python脚本,把github上面的源码gallery_all.py,照猫画虎实现了。我以前看书我喜欢在appstore查找适合自己阅读的资源,因为app比较稳定。在这种情况下,我就采集了app应用商店和ucappstore的一些页面。不得不说,这个技术我还是蛮满意的,整理出来分享给有需要的人吧!整个过程不到一天的时间。
可以看看过程图以及源码。我个人觉得app的列表是完整的可读的,不需要每次都去改格式格式支持了。1.数据收集准备工作下载2.抓包工具抓包工具:需要精通udp协议,netcrypt,netbeans抓包工具的安装,建议在python中ethereum网上download,我直接拷贝下来了。根据自己的项目或者合作伙伴要求设置vpnpost方式。
建议自己先弄一个尝试一下。如果自己设置不成功可以再来问。3.数据转包hookjavapackage中的jsonurl解析抓包结果(手机版手机端必须勾选useragentcorstransfer)那么我们就可以这样来验证我们是否hook了,已这样来测试,其他网页也是如此,只要dns设置成相应的就可以。不过还是有些报错,建议做爬虫测试,在这种情况下就不做实验了,因为抓包设置好环境就可以。
之前方法不能用在云服务器上。使用dns服务器:我一般会使用post的api,jsonobject也是通过post转包出来的,这里不引用post服务器功能了4.数据解析抓包之后就是分析抓取数据,其实这里包含网页源码分析和json结构分析。从源码中可以看到json格式的数据就是html对象一样。也可以看到网页中获取的wx.setdata({user:'youruseragent',pwd:'test',token:'verify:true'})。
通过上面的分析可以很容易知道username和pwd那么如何保证我们能够在网页中查看json的格式信息呢?这里我们使用json格式化对比,从源码中看网页和一个专业网站的区别就在于json格式。 查看全部
u采 采集(u采采集app应用商店和ucappstore的合并与解析(上))
u采采集app是基于采集脚本的hook技术实现的,将浏览器请求,各种方法(xpathscripthtml等)获取的数据,都进行合并与解析(把json数据拆分成list数据,解析出重要字段的内容),抓取成功后再发送给hook我的kindle书库上,这是目前为止最快的抓取方法了(被封一周后的昨天昨天刚刚抓到)我目前还是采用前端代理模拟用户登录比较有效。
采集js生成数据包,
采集别人update的txt数据,
采集对方推荐书,
程序已成功采集收藏夹书籍信息,
现在的抓包工具都可以抓到app请求后的json数据,另外已经有一些工具可以通过get方式采集然后再转包。但是采集app包的实际效果也不是特别好。
之前写过一个python脚本,把github上面的源码gallery_all.py,照猫画虎实现了。我以前看书我喜欢在appstore查找适合自己阅读的资源,因为app比较稳定。在这种情况下,我就采集了app应用商店和ucappstore的一些页面。不得不说,这个技术我还是蛮满意的,整理出来分享给有需要的人吧!整个过程不到一天的时间。
可以看看过程图以及源码。我个人觉得app的列表是完整的可读的,不需要每次都去改格式格式支持了。1.数据收集准备工作下载2.抓包工具抓包工具:需要精通udp协议,netcrypt,netbeans抓包工具的安装,建议在python中ethereum网上download,我直接拷贝下来了。根据自己的项目或者合作伙伴要求设置vpnpost方式。
建议自己先弄一个尝试一下。如果自己设置不成功可以再来问。3.数据转包hookjavapackage中的jsonurl解析抓包结果(手机版手机端必须勾选useragentcorstransfer)那么我们就可以这样来验证我们是否hook了,已这样来测试,其他网页也是如此,只要dns设置成相应的就可以。不过还是有些报错,建议做爬虫测试,在这种情况下就不做实验了,因为抓包设置好环境就可以。
之前方法不能用在云服务器上。使用dns服务器:我一般会使用post的api,jsonobject也是通过post转包出来的,这里不引用post服务器功能了4.数据解析抓包之后就是分析抓取数据,其实这里包含网页源码分析和json结构分析。从源码中可以看到json格式的数据就是html对象一样。也可以看到网页中获取的wx.setdata({user:'youruseragent',pwd:'test',token:'verify:true'})。
通过上面的分析可以很容易知道username和pwd那么如何保证我们能够在网页中查看json的格式信息呢?这里我们使用json格式化对比,从源码中看网页和一个专业网站的区别就在于json格式。
u采 采集(u采采集采集一级页面时最常见的50个常用函数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-28 12:03
u采采集今天小采特意为大家介绍一下采集一级页面时最常见的50个常用函数。函数一般可以帮助我们完成excel的工作,但是一个好用的函数往往可以帮助我们节省许多的时间和精力。
1、vlookup函数
2、mid函数
3、substitute函数
4、substitute+index函数
5、substitute+index+index函数
6、substitute+replace函数
7、address函数
8、address函数
9、choose函数1
0、choose函数1
1、left函数1
2、right函数1
3、replace函数1
4、countif函数1
5、countifs函数1
6、countifs+countif1
7、index函数1
8、index函数1
9、mid函数2
0、min函数2
1、mid函数2
2、index函数2
3、len函数2
4、lenb函数2
5、lenb函数2
6、round函数2
7、copy函数2
8、substitute函数2
9、countifs+countif3
0、text函数3
1、text函数3
2、index+preparelib函数3
3、substitute+index函数3
4、lenb函数3
5、len函数3
6、record函数3
7、distinct函数3
8、index+index+index三大操作系统的出现让我们更好的去使用excel。采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。采集一级页面时最。 查看全部
u采 采集(u采采集采集一级页面时最常见的50个常用函数)
u采采集今天小采特意为大家介绍一下采集一级页面时最常见的50个常用函数。函数一般可以帮助我们完成excel的工作,但是一个好用的函数往往可以帮助我们节省许多的时间和精力。
1、vlookup函数
2、mid函数
3、substitute函数
4、substitute+index函数
5、substitute+index+index函数
6、substitute+replace函数
7、address函数
8、address函数
9、choose函数1
0、choose函数1
1、left函数1
2、right函数1
3、replace函数1
4、countif函数1
5、countifs函数1
6、countifs+countif1
7、index函数1
8、index函数1
9、mid函数2
0、min函数2
1、mid函数2
2、index函数2
3、len函数2
4、lenb函数2
5、lenb函数2
6、round函数2
7、copy函数2
8、substitute函数2
9、countifs+countif3
0、text函数3
1、text函数3
2、index+preparelib函数3
3、substitute+index函数3
4、lenb函数3
5、len函数3
6、record函数3
7、distinct函数3
8、index+index+index三大操作系统的出现让我们更好的去使用excel。采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。采集一级页面时最。
u采采集器——企业采集器集成集大数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-25 02:07
u采采集器简介q企业采集器集成集大数据采集和多种采集方式,采集也不用单独购买,采集功能强大,轻松采集实时数据。便于采集后的数据管理和维护,提高效率,减少开支。
家用的u采采集器就可以
网上挺多的这种骗子,同样的上图,
做任何事情都要预防受骗的,防止被别人说成骗子就好,上月这不就有个跟着我办公室一块办公的姑娘说,这个年底要有很多公司找他配送电脑,但是每一家都要配500块,总价怎么也要一万块,让我推荐几个好东西,因为他目前都在外地,我就叫她用我这里的云采集器,用这个软件是免费的,云采集器里面就有搜索和电脑办公的功能,还可以直接生成excel文件导出,还可以自定义把所有数据自动导入excel,数据量大可以多导入几倍!我觉得找工作者采集信息的话,就找云采集器的公司比较靠谱,有知名度,客户来源稳定。
办公室里就采用这款云采集器,配的有云采集器客服服务,只需要一个小时登陆一次,查看一下他们的收费标准就可以知道是不是合适自己了。
同行来答一波。用了大半年来说,云采集器。1.网站信息数据处理,节省了自己购买的成本。2.避免了自己对某个信息下不去手。还有一个最大的优点就是没有下载的限制,可以有百度快照有谷歌快照有excel就行了。3.可以采集excel表格,有些有筛选条件。有的你得转化筛选条件。所以做实验室的话,可以配采集软件,比如刚查到我们公司用的都是这款现成的软件:云采集器帮助我们更快的提取客户资料,如下图:下图找到客户信息的这个crm,就是用这个软件批量一起抓的,你可以自己配个电脑做处理。
采集快速可靠,处理方便,实际帮到我们这些经常找数据找excel处理的小伙伴们。下图是我们公司的入口:可以找到下面的这些云采集器:截图中没有截出来我们公司的入口。我们办公室用的就是一个:日常使用来说挺方便的,用的非常舒服。但是你要去提供商城里买单,那就有很多种方法啦。 查看全部
u采采集器——企业采集器集成集大数据采集
u采采集器简介q企业采集器集成集大数据采集和多种采集方式,采集也不用单独购买,采集功能强大,轻松采集实时数据。便于采集后的数据管理和维护,提高效率,减少开支。
家用的u采采集器就可以
网上挺多的这种骗子,同样的上图,
做任何事情都要预防受骗的,防止被别人说成骗子就好,上月这不就有个跟着我办公室一块办公的姑娘说,这个年底要有很多公司找他配送电脑,但是每一家都要配500块,总价怎么也要一万块,让我推荐几个好东西,因为他目前都在外地,我就叫她用我这里的云采集器,用这个软件是免费的,云采集器里面就有搜索和电脑办公的功能,还可以直接生成excel文件导出,还可以自定义把所有数据自动导入excel,数据量大可以多导入几倍!我觉得找工作者采集信息的话,就找云采集器的公司比较靠谱,有知名度,客户来源稳定。
办公室里就采用这款云采集器,配的有云采集器客服服务,只需要一个小时登陆一次,查看一下他们的收费标准就可以知道是不是合适自己了。
同行来答一波。用了大半年来说,云采集器。1.网站信息数据处理,节省了自己购买的成本。2.避免了自己对某个信息下不去手。还有一个最大的优点就是没有下载的限制,可以有百度快照有谷歌快照有excel就行了。3.可以采集excel表格,有些有筛选条件。有的你得转化筛选条件。所以做实验室的话,可以配采集软件,比如刚查到我们公司用的都是这款现成的软件:云采集器帮助我们更快的提取客户资料,如下图:下图找到客户信息的这个crm,就是用这个软件批量一起抓的,你可以自己配个电脑做处理。
采集快速可靠,处理方便,实际帮到我们这些经常找数据找excel处理的小伙伴们。下图是我们公司的入口:可以找到下面的这些云采集器:截图中没有截出来我们公司的入口。我们办公室用的就是一个:日常使用来说挺方便的,用的非常舒服。但是你要去提供商城里买单,那就有很多种方法啦。
u采采集器是用vba编写脚本,比较简单方便
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-08-21 06:02
u采采集器是用vba编写脚本,比较简单方便,操作也很便捷。
初级阶段,采集各种网站的数据,tb级别的,建议云采集平台,国内的推荐秀米采集器和采贝网。
建议采用金山云旗下的采采客采集器:1.最高2元1年,大客户可享受1折优惠;2.高并发、实时响应、稳定高效;3.拥有智能拼页、智能静态、智能定时采集、智能自动更新;4.单网站采集每日100万次,帮助企业节省数百万元采集开支成本;5.采集过程实时监控,帮助企业全程掌控采集过程。
这个嘛,本人亲测过,比较推荐金山采集器,几乎简单的就可以导入网站数据,无需转码,不需要进行复杂的配置,快捷方便,
金山采集器不错,可以和金山系其他产品同步,并且有专门的金山行动,
论坛采集的话,可以采用采集器吧,可以免费试用他家的采集器。这个采集器采集贴吧,分享吧,甚至是qq空间都没有问题。而且可以采集金山词霸,银行词典等30多种网站数据,看你个人喜好。
好多论坛都可以采集,大同小异。金山云和sharelink都可以。国内的采集器最主要还是网站,肯定比国外的采集器好很多。
ajax云采集,个人用户免费。
其实用户自己写脚本是可以采集的我之前也用过nilecloud,但是学生党交不起学费,就作罢了, 查看全部
u采采集器是用vba编写脚本,比较简单方便
u采采集器是用vba编写脚本,比较简单方便,操作也很便捷。
初级阶段,采集各种网站的数据,tb级别的,建议云采集平台,国内的推荐秀米采集器和采贝网。
建议采用金山云旗下的采采客采集器:1.最高2元1年,大客户可享受1折优惠;2.高并发、实时响应、稳定高效;3.拥有智能拼页、智能静态、智能定时采集、智能自动更新;4.单网站采集每日100万次,帮助企业节省数百万元采集开支成本;5.采集过程实时监控,帮助企业全程掌控采集过程。
这个嘛,本人亲测过,比较推荐金山采集器,几乎简单的就可以导入网站数据,无需转码,不需要进行复杂的配置,快捷方便,
金山采集器不错,可以和金山系其他产品同步,并且有专门的金山行动,
论坛采集的话,可以采用采集器吧,可以免费试用他家的采集器。这个采集器采集贴吧,分享吧,甚至是qq空间都没有问题。而且可以采集金山词霸,银行词典等30多种网站数据,看你个人喜好。
好多论坛都可以采集,大同小异。金山云和sharelink都可以。国内的采集器最主要还是网站,肯定比国外的采集器好很多。
ajax云采集,个人用户免费。
其实用户自己写脚本是可以采集的我之前也用过nilecloud,但是学生党交不起学费,就作罢了,
-u采采集-mac采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-19 07:05
u采采集是针对mac优化的采集工具。我们精心为采集对象、内容源、发布渠道、表格数据等类型设计了统一管理模块。智能化自动化多渠道追踪和多维度提取。工作省心,mac用户::u采采集-mac采集工具如需进一步加盟请联系:微信公众号:u采网编辑:武汉分公司。
在采集系统部署后,通过中国行采集系统平台可以方便用户采集各种类型网站页面数据。比如你想看微信公众号文章,你可以将微信公众号文章抓取到中国行采集系统平台,点击复制链接地址就可以复制整个页面数据了。如果你想采集多个mac电脑,可以通过三方软件实现,下面我来介绍下三个软件:asteriumsidebar优点:支持多个mac电脑,无需下载安装,智能下载。
可自定义抓取方式,可对文章页面进行多变的抓取。缺点:抓取出来的页面多变,且页面不会完全与我们制作的相同。citavi主要介绍集合面板多,自定义方便。grabber为单页抓取,抓取每一个网页地址到我们自己定义的数据库(可与asteriumcircle或其他网页抓取工具数据库结合)。我们通过对数据库的标记抓取采集全网各个网站的数据,比如xiaomage平台的xiaomage页面,那么我们就要抓取对应页面的xiaomage页面数据。
以xiaomage为例,你也可以对每个web页面进行制作标记,例如我给xiaomage做了标记,第一个页面就是列表页面,第二个页面是商品列表页面,而接下来的三个页面是公众号名称、公众号简介、历史文章列表页面。3.优雅信息是旗下的子公司,旗下有优雅采集系统、优雅大战略系统、优雅数据库系统,是软件系统、数据库、web的通用采集平台。
整个网站可以采集分为:页面数据、大赛计划页面、微信公众号文章列表页面、单页面页面、社区列表页面、商品列表页面、公众号文章链接页面、百科链接页面、表格数据、表格数据包。市场部经理微信:电话:技术部经理微信:电话:其他电话: 微信公众号:uc采集转载请保留出处和链接。 查看全部
-u采采集-mac采集工具
u采采集是针对mac优化的采集工具。我们精心为采集对象、内容源、发布渠道、表格数据等类型设计了统一管理模块。智能化自动化多渠道追踪和多维度提取。工作省心,mac用户::u采采集-mac采集工具如需进一步加盟请联系:微信公众号:u采网编辑:武汉分公司。
在采集系统部署后,通过中国行采集系统平台可以方便用户采集各种类型网站页面数据。比如你想看微信公众号文章,你可以将微信公众号文章抓取到中国行采集系统平台,点击复制链接地址就可以复制整个页面数据了。如果你想采集多个mac电脑,可以通过三方软件实现,下面我来介绍下三个软件:asteriumsidebar优点:支持多个mac电脑,无需下载安装,智能下载。
可自定义抓取方式,可对文章页面进行多变的抓取。缺点:抓取出来的页面多变,且页面不会完全与我们制作的相同。citavi主要介绍集合面板多,自定义方便。grabber为单页抓取,抓取每一个网页地址到我们自己定义的数据库(可与asteriumcircle或其他网页抓取工具数据库结合)。我们通过对数据库的标记抓取采集全网各个网站的数据,比如xiaomage平台的xiaomage页面,那么我们就要抓取对应页面的xiaomage页面数据。
以xiaomage为例,你也可以对每个web页面进行制作标记,例如我给xiaomage做了标记,第一个页面就是列表页面,第二个页面是商品列表页面,而接下来的三个页面是公众号名称、公众号简介、历史文章列表页面。3.优雅信息是旗下的子公司,旗下有优雅采集系统、优雅大战略系统、优雅数据库系统,是软件系统、数据库、web的通用采集平台。
整个网站可以采集分为:页面数据、大赛计划页面、微信公众号文章列表页面、单页面页面、社区列表页面、商品列表页面、公众号文章链接页面、百科链接页面、表格数据、表格数据包。市场部经理微信:电话:技术部经理微信:电话:其他电话: 微信公众号:uc采集转载请保留出处和链接。
【每日一题】u采采集器,技术优先,任务优先
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-18 20:04
u采采集器,技术优先,任务优先。你可以先选择哪个优先,根据任务优先度进行切换的。
1.基于你ip的大小。比如10^19,ul=10^21。根据你的mp个数的因子,你可以初步判断是大还是小。2.带宽的发现,ul跟带宽是正相关。mp=dp/t*v。3.arp协议:网站arp频率是有多少mhz?arp延迟有多少ms,如果延迟太久,或者mp不够,必须换人。4.找大牌子吧,虽然贵一点,但是安全有保障,个人推荐阿里云ecs,贵一点,但是服务器的质量保证很好,并且稳定可靠。ah小牌子是很快就会被遗弃的。
-08-07/sneez-guide-guide/index.html这个白皮书可以参考下
uniquelinkidentifier
我之前看是在10^23*30,但是我在看白皮书,我说下我的理解。如果你是百十人的站点的话,1g的dnspod肯定是不够的,建议是8~12g,每次只处理10~1000000之间的ip,10就是10*30,也就是100万。这样成功率会高很多,几万级别的ip是大忌,会频繁跳,容易流量冲突,降低用户体验。8~12g都可以很轻松的查询。
所以啊,配置要选好,看起来1g的dnspod,实际上10g都不一定够用,请考虑我这个理解,网站建议用千兆网,否则优化带宽成本非常高。另外有些无线dns很棒,建议选好接口。 查看全部
【每日一题】u采采集器,技术优先,任务优先
u采采集器,技术优先,任务优先。你可以先选择哪个优先,根据任务优先度进行切换的。
1.基于你ip的大小。比如10^19,ul=10^21。根据你的mp个数的因子,你可以初步判断是大还是小。2.带宽的发现,ul跟带宽是正相关。mp=dp/t*v。3.arp协议:网站arp频率是有多少mhz?arp延迟有多少ms,如果延迟太久,或者mp不够,必须换人。4.找大牌子吧,虽然贵一点,但是安全有保障,个人推荐阿里云ecs,贵一点,但是服务器的质量保证很好,并且稳定可靠。ah小牌子是很快就会被遗弃的。
-08-07/sneez-guide-guide/index.html这个白皮书可以参考下
uniquelinkidentifier
我之前看是在10^23*30,但是我在看白皮书,我说下我的理解。如果你是百十人的站点的话,1g的dnspod肯定是不够的,建议是8~12g,每次只处理10~1000000之间的ip,10就是10*30,也就是100万。这样成功率会高很多,几万级别的ip是大忌,会频繁跳,容易流量冲突,降低用户体验。8~12g都可以很轻松的查询。
所以啊,配置要选好,看起来1g的dnspod,实际上10g都不一定够用,请考虑我这个理解,网站建议用千兆网,否则优化带宽成本非常高。另外有些无线dns很棒,建议选好接口。
旅游大数据采集方法分为哪几类?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 662 次浏览 • 2021-08-13 05:17
什么是大数据采集platform?
大数据采集是大数据的基础。 采集的数据在平台上进行汇总分析,形成完整的数据体系。海鳗云旅游大数据平台是一家专注于旅游大数据的公司,拥有自己的旅游大数据平台。
大数据采集方法的分类有哪些?
1、离线采集:
工具:ETL;
在数据仓库的上下文中,ETL基本上是数据采集的代表,包括数据抽取(Extract)、转换(Transform)和加载(Load)。在转换过程中,需要针对特定的交易场景进行数据管理,例如非法数据监控和过滤、格式转换和数据标准化、数据替换、保证数据完整性等。
2、实时采集:
工具:Flume/Kafka;
实时采集主要用于考虑流处理的交易场景,例如用于记录数据源执行的各种操作活动,如流量管理的网络监控、金融应用的股票记账、用户访问记录通过网络服务器行为。在流处理场景中,数据采集会成为Kafka的客户,就像一个大坝,拦截不断的上游数据,然后根据交易场景进行相应的处理(如去重、去噪、中心记账等),并且然后写入对应的数据存储。
3、网络合集:
工具:爬虫、DPI等;
Scribe 是 Facebook 开发的数据(日志)采集系统。也称为网络蜘蛛,网络机器人是按照一定的规则自动抓取万维网上信息的程序或脚本。支持图片、音频、视频等文件或附件的集合。
除了网络中收录的内容外,还可以使用 DPI 或 DFI 等带宽管理技术处理网络流量的采集。
4、其他数据采集方式
对于客户数据、财务数据等对公司生产经营数据保密要求较高的数据,可通过与数据技术服务商合作,采用特定系统接口等相关方式进行数据采集。比如八度云计算旗下的数字化企业BDSaaS,在数据采集技术、BI数据分析、数据安全保密等方面都做得很好。
关于大数据采集方法的分类,在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这个文章能对你有所帮助。如果您想了解更多数据分析师和大数据工程师的技能和材料,可以点击本站其他文章进行学习。
大数据采集有哪些方面?
1.数据质量控制
每当使用各种数据源时,数据质量都是一个挑战。这意味着企业必须做的工作是确保数据格式准确匹配,不存在数据重复或数据缺失导致分析不可靠的情况。公司必须提前分析和准备数据,然后才能与其他数据一起分析。
2.expansion
大数据的使用价值取决于其数量。然而,这也将成为一个关键问题。如果一家公司没有设计一个架构计划来扩展,它很快就会面临一系列问题。首先,如果公司不做好基础设施建设的准备,那么基础设施建设的成本就会增加。这将给公司的预算带来压力。其次,如果公司不准备扩张,其特征将显着降低。这两个问题都应该在大数据框架建设的总体规划中解决。
3、安全系数
虽然大数据可以让公司更深入地了解数据,但保护这些数据仍然具有挑战性。欺诈者和网络黑客会对企业数据非常感兴趣,他们会尝试添加自己的伪造数据或访问企业数据以获取敏感信息。 查看全部
旅游大数据采集方法分为哪几类?(组图)
什么是大数据采集platform?
大数据采集是大数据的基础。 采集的数据在平台上进行汇总分析,形成完整的数据体系。海鳗云旅游大数据平台是一家专注于旅游大数据的公司,拥有自己的旅游大数据平台。
大数据采集方法的分类有哪些?
1、离线采集:
工具:ETL;
在数据仓库的上下文中,ETL基本上是数据采集的代表,包括数据抽取(Extract)、转换(Transform)和加载(Load)。在转换过程中,需要针对特定的交易场景进行数据管理,例如非法数据监控和过滤、格式转换和数据标准化、数据替换、保证数据完整性等。
2、实时采集:
工具:Flume/Kafka;
实时采集主要用于考虑流处理的交易场景,例如用于记录数据源执行的各种操作活动,如流量管理的网络监控、金融应用的股票记账、用户访问记录通过网络服务器行为。在流处理场景中,数据采集会成为Kafka的客户,就像一个大坝,拦截不断的上游数据,然后根据交易场景进行相应的处理(如去重、去噪、中心记账等),并且然后写入对应的数据存储。
3、网络合集:
工具:爬虫、DPI等;
Scribe 是 Facebook 开发的数据(日志)采集系统。也称为网络蜘蛛,网络机器人是按照一定的规则自动抓取万维网上信息的程序或脚本。支持图片、音频、视频等文件或附件的集合。
除了网络中收录的内容外,还可以使用 DPI 或 DFI 等带宽管理技术处理网络流量的采集。
4、其他数据采集方式
对于客户数据、财务数据等对公司生产经营数据保密要求较高的数据,可通过与数据技术服务商合作,采用特定系统接口等相关方式进行数据采集。比如八度云计算旗下的数字化企业BDSaaS,在数据采集技术、BI数据分析、数据安全保密等方面都做得很好。
关于大数据采集方法的分类,在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这个文章能对你有所帮助。如果您想了解更多数据分析师和大数据工程师的技能和材料,可以点击本站其他文章进行学习。
大数据采集有哪些方面?
1.数据质量控制
每当使用各种数据源时,数据质量都是一个挑战。这意味着企业必须做的工作是确保数据格式准确匹配,不存在数据重复或数据缺失导致分析不可靠的情况。公司必须提前分析和准备数据,然后才能与其他数据一起分析。
2.expansion
大数据的使用价值取决于其数量。然而,这也将成为一个关键问题。如果一家公司没有设计一个架构计划来扩展,它很快就会面临一系列问题。首先,如果公司不做好基础设施建设的准备,那么基础设施建设的成本就会增加。这将给公司的预算带来压力。其次,如果公司不准备扩张,其特征将显着降低。这两个问题都应该在大数据框架建设的总体规划中解决。
3、安全系数
虽然大数据可以让公司更深入地了解数据,但保护这些数据仍然具有挑战性。欺诈者和网络黑客会对企业数据非常感兴趣,他们会尝试添加自己的伪造数据或访问企业数据以获取敏感信息。
u采采集-采集合作平台精选各大网站采集任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2021-08-12 03:04
u采采集-采集合作平台精选各大网站采集任务,只要一个账号即可采集所有网站,提供采集接口,设置好回调链接即可轻松开始采集!百度、必应、搜狗、360等一百多大搜索引擎各种词汇全部采集,和非常棒的采集效果。行业垂直平台任务量巨大,私人定制采集任务,
如果你是做qq推广的,可以推荐个靠谱的qq搜索引擎搜索下,
可以尝试推荐一个采集器,功能全,
采集搜索的话,你要是选择好的机器人是关键,这款机器人采集到全网的有价值的信息,不仅可以采集热门,还可以采集常规,其他的。
你可以选择生辰网络采集器:1,采集网站大多数搜索引擎网站。2,并且有直接获取网页源代码、使用开源代码、使用chrome浏览器插件都是不错的选择。3,支持页面内高亮、段落标注、批量分词等。4,最重要的是,采集速度快,可以完全与你要采集的数据相匹配。
你好,推荐用格采能的,采集速度快,效率高,质量高,不会出现丢漏情况。
目前市面上有不少采集工具,但其实大多数都不够专业和严谨,所以专业采集师是采集站长急需的。你可以关注一下淘站宝的格采能。
熊猫格采
百度一搜会出现一堆,
知道的是闪速采集,只要站长创建搜索联盟就能采到,联盟需要交易, 查看全部
u采采集-采集合作平台精选各大网站采集任务
u采采集-采集合作平台精选各大网站采集任务,只要一个账号即可采集所有网站,提供采集接口,设置好回调链接即可轻松开始采集!百度、必应、搜狗、360等一百多大搜索引擎各种词汇全部采集,和非常棒的采集效果。行业垂直平台任务量巨大,私人定制采集任务,
如果你是做qq推广的,可以推荐个靠谱的qq搜索引擎搜索下,
可以尝试推荐一个采集器,功能全,
采集搜索的话,你要是选择好的机器人是关键,这款机器人采集到全网的有价值的信息,不仅可以采集热门,还可以采集常规,其他的。
你可以选择生辰网络采集器:1,采集网站大多数搜索引擎网站。2,并且有直接获取网页源代码、使用开源代码、使用chrome浏览器插件都是不错的选择。3,支持页面内高亮、段落标注、批量分词等。4,最重要的是,采集速度快,可以完全与你要采集的数据相匹配。
你好,推荐用格采能的,采集速度快,效率高,质量高,不会出现丢漏情况。
目前市面上有不少采集工具,但其实大多数都不够专业和严谨,所以专业采集师是采集站长急需的。你可以关注一下淘站宝的格采能。
熊猫格采
百度一搜会出现一堆,
知道的是闪速采集,只要站长创建搜索联盟就能采到,联盟需要交易,
u采采集器可以批量导出app主页广告数据吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-10 03:08
u采采集器是一款移动app采集软件,在任何app上都可以采集。采集软件具有采集全网app数据。还可采集自己app中的主要内容。更可以采集大量app网页数据。更有采集不同渠道网页数据的强大功能。功能新增用户注册登录、设置群发内容,批量导出群发文件。设置保存截图功能。还可以批量导出app主页广告数据!软件采集方式多样,可以选择传统的抓包工具采集,也可选择多种模式和代理工具;可以采集应用宝、企鹅号等各大网站商家发布的推广广告、社交广告等,还可采集论坛、博客、贴吧、微博、空间等其他交友等平台的广告内容。
下一个aso100,
一个网址可以查询多个app商店的下载排名。
这个是官方aso查询的,一般大的商店每天都会有下载排名。
可以注册一个采集器,每天都会有热点分析,
可以用到91手机助手上边
我知道的是现在市面上可以用到的一些采集下载的软件,但是我建议还是使用虚拟机,现在的虚拟机效率都还可以。
可以去u采采集器官网查下,
那些大的app商店都有下载量排名,
需要app链接的可以去这个网站试试:
应用宝、豆瓣、百度、腾讯广告、google、360、阿里小米、华为商店 查看全部
u采采集器可以批量导出app主页广告数据吗?
u采采集器是一款移动app采集软件,在任何app上都可以采集。采集软件具有采集全网app数据。还可采集自己app中的主要内容。更可以采集大量app网页数据。更有采集不同渠道网页数据的强大功能。功能新增用户注册登录、设置群发内容,批量导出群发文件。设置保存截图功能。还可以批量导出app主页广告数据!软件采集方式多样,可以选择传统的抓包工具采集,也可选择多种模式和代理工具;可以采集应用宝、企鹅号等各大网站商家发布的推广广告、社交广告等,还可采集论坛、博客、贴吧、微博、空间等其他交友等平台的广告内容。
下一个aso100,
一个网址可以查询多个app商店的下载排名。
这个是官方aso查询的,一般大的商店每天都会有下载排名。
可以注册一个采集器,每天都会有热点分析,
可以用到91手机助手上边
我知道的是现在市面上可以用到的一些采集下载的软件,但是我建议还是使用虚拟机,现在的虚拟机效率都还可以。
可以去u采采集器官网查下,
那些大的app商店都有下载量排名,
需要app链接的可以去这个网站试试:
应用宝、豆瓣、百度、腾讯广告、google、360、阿里小米、华为商店
u采 采集(u采采集是采集技术的一种,基于兴趣的采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-01 14:50
u采采集模式是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。一般的http采集对flash要求比较高,一般的采集器不支持,u采采集是采集模式的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采采集是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采集是国内互联网从业者一种解决pc端及移动端采集问题的代表性技术,目前的采集解决方案包括u爬虫在内,都只是实现了功能点的u提取,而不是网站本身的url规律转换。数据发送给爬虫,u爬虫利用爬虫自身系统或者爬虫采集框抓取,然后存储起来。发送给反爬虫的下采集端后,反爬虫利用pickey或者云采集框进行采集,并存储起来。
btg采集是刚刚兴起的一种技术。建议你从以下几个方面了解1.你要采集的网站类型是什么。2.你要采集的数据来源是什么。3.你要采集的数据源本身的结构和特征。4.你要采集的数据一些特殊的规律。比如会有购物车。会有密码等等。当然,网站类型采集有很多。都是在这些基础上技术上进行改进。各有特色。谢谢。 查看全部
u采 采集(u采采集是采集技术的一种,基于兴趣的采集)
u采采集模式是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。一般的http采集对flash要求比较高,一般的采集器不支持,u采采集是采集模式的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采采集是采集技术的一种,基于兴趣的采集,由用户设置url后,网站页面中任意一个url都会被采集,并保存每个url的内容采集出来的数据保存在本地,可以下载保存为excel,csv,json等格式,并且可以通过谷歌浏览器,ie6下载采集网页原网页进行调试。
u采集是国内互联网从业者一种解决pc端及移动端采集问题的代表性技术,目前的采集解决方案包括u爬虫在内,都只是实现了功能点的u提取,而不是网站本身的url规律转换。数据发送给爬虫,u爬虫利用爬虫自身系统或者爬虫采集框抓取,然后存储起来。发送给反爬虫的下采集端后,反爬虫利用pickey或者云采集框进行采集,并存储起来。
btg采集是刚刚兴起的一种技术。建议你从以下几个方面了解1.你要采集的网站类型是什么。2.你要采集的数据来源是什么。3.你要采集的数据源本身的结构和特征。4.你要采集的数据一些特殊的规律。比如会有购物车。会有密码等等。当然,网站类型采集有很多。都是在这些基础上技术上进行改进。各有特色。谢谢。
u采 采集(Qt的下载和安装关于Linux的安装,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-27 11:19
一、Qt下载安装
关于Qt的安装,网上有很详细的介绍。这里仅作简要介绍。
需要两个安装包:Qt Creator 和 QTE。
1)QT 创建者
下载链接:qt-sdk-linux-x86-opensource-2010.05.1.bin
官方下载:
这是一个编译好的二进制SDK包,直接下载,不需要配置和编译,直接运行即可下载。之所以把官方链接放在下面,是因为我找了很久这个安装包,网上很多链接都失效了。我提供的第一个下载地址是使用百度云盘。最近在用,感觉效果很好。推荐第一个下载地址。
下载完成后,直接运行即可完成安装。
2)Qt Embedded for Linux:
下载链接:qt-everywhere-opensource-src-4.7.3.tar.gz
官方下载:
这是4.7.3版本的源码包,下载后需要配置编译。也推荐使用第一个地址进行下载。
解压后,将提供的Zynq Qt配置文件qmake.conf复制到qt-everywhere-opensource-src-4.7.3/mkspecs/qws/linux-arm-gnueabi-g++目录下,使用命令
./configure -embedded arm -xplatform qws/linux-arm-gnueabi-g++ -little-endian -opensource -host-little-endian -confirm-license -nomake demos -nomake examples
配置后进行配置和编译:
make
编译结束后使用命令
make install
安装,默认安装到
/usr/local/Trolltech/Qt-4.7.3/
路径下。然后将Xilinx交叉编译器中的基本C++库复制到安装目录的lib目录下:
cp -P /path/to/cross/compiler/arm-xilinx-linux-gnueabi/libc/usr/lib/libstdc++.so* /usr/local/Trolltech/Qt-4.7.3/lib
这样就完成了 Zynq 的 Qt Embedded for Linux 的安装。
二、软件代码
1、新的Qt项目
启动 Qt Creator 并创建一个新的 Qt Gui 应用程序
然后选择项目路径和项目描述,其他默认,一直点击下一步,直接完成项目。
2、修改ui界面
打开mainwindow.ui,进入可视化设计界面。默认情况下,中间的主设计区域下已经有一个 QMainWindow 和 QWidget 对象。我们需要将采集图片显示到一个QLabel小部件上,从右侧小部件列表中的“DisplayWidget”中选择“Label”小部件,将其拖到中间,设置大小为640*480,起点坐标为 (5,5).
并取消原文正文。
此时Label组件已经覆盖了MainWindow,然后适当调整MainWindow的大小。
3、添加摄像头采集代码
因为在(原创)基于ZedBoard的Webcam设计(一):USB摄像头(V4L2接口)在Zedboard的图片采集中,我们已经实现了图片采集,只需添加项目中的v4l2grab.c和v4l2grab.h源文件对这个新建的项目进行相应的修改。
修改mainwindow.cpp
1 #include "mainwindow.h"
2 #include "ui_mainwindow.h"
3 #include
4 #include
5 #include
6 #include
7 //#include
8 #include
9
10 MainWindow::MainWindow(QWidget *parent) :
11 QMainWindow(parent),
12 ui(new Ui::MainWindow)
13 {
14 ui->setupUi(this);
15
16 QPixmap pix;
17 QByteArray aa ;
18
19 BITMAPFILEHEADER bf;
20 BITMAPINFOHEADER bi;
21 //Set BITMAPINFOHEADER
22 bi.biSize = 40;
23 bi.biWidth = IMAGEWIDTH;
24 bi.biHeight = IMAGEHEIGHT;
25 bi.biPlanes = 1;
26 bi.biBitCount = 24;
27 bi.biCompression = 0;
28 bi.biSizeImage = IMAGEWIDTH*IMAGEHEIGHT*3;
29 bi.biXPelsPerMeter = 0;
30 bi.biYPelsPerMeter = 0;
31 bi.biClrUsed = 0;
32 bi.biClrImportant = 0;
33
34
35 //Set BITMAPFILEHEADER
36 bf.bfType = 0x4d42;
37 bf.bfSize = 54 + bi.biSizeImage;
38 bf.bfReserved = 0;
39 bf.bfOffBits = 54;
40
41 if(init_v4l2() == FALSE)
42 {
43 }
44
45 v4l2_grab();
46 yuyv_2_rgb888();
47 aa.append((char *)&bf,14);
48 aa.append((char *)&bi,40);
49 aa.append((char *)frame_buffer,640*480*3);
50 pix.loadFromData(aa);
51 ui->label->setPixmap(pix);
52 close_v4l2();
53 }
54
55 MainWindow::~MainWindow()
56 {
57 delete ui;
58 }
17~18行:
17 QPixmap pix;
18 QByteArray aa ;
定义了一个QPixmap类对象pix来显示图片;由于调用QPixmap类的loadFromData()函数来获取传递过来的图像数据,因此loadFromData()函数的详细信息可以在Qt的help->index中查找,或者从中查询:
bool QPixmap::loadFromData ( const QByteArray & data, const char * format = 0, Qt::ImageConversionFlags flags = Qt::AutoColor )
可知loadFromData()要求输入参数为QByteArray类型,因此定义了QByteArray的对象aa来存储图像数据。
同时,loadFromData() 需要指定数据的格式。如果不指定,默认支持的格式为:
是48~50行:
48 aa.append((char *)&bf,14);
49 aa.append((char *)&bi,40);
50 aa.append((char *)frame_buffer,640*480*3);
调用 QByteArray 类的 append 函数,将图像数据存储在 aa 中。需要注意的是,由于loadFromData函数的输入图片符合标准图片格式,所以需要将数据的BMP头信息保存在aa中。
52~53行:
51 pix.loadFromData(aa);
52 ui->label->setPixmap(pix);
实现了图片数据(包括头信息)到pix的传输以及pix在标签上的显示。
4、编译项目
在项目路径中,使用命令
qmake -project
生成一个新的项目文件lab2_qt_camera.pro。重用
qmake
生成一个makefile文件,打开makefile文件查看
1 #############################################################################
2 # Makefile for building: lab2_qt_camera
3 # Generated by qmake (2.01a) (Qt 4.7.3) on: Sun Dec 23 02:24:47 2012
4 # Project: lab2_qt_camera.pro
5 # Template: app
6 # Command: /usr/local/Trolltech/Qt-4.7.3/bin/qmake -o Makefile lab2_qt_camera.pro
7 #############################################################################
8
9 ####### Compiler, tools and options
10
11 CC = ${CROSS_COMPILE}gcc
12 CXX = ${CROSS_COMPILE}g++
13 DEFINES = -DQT_NO_DEBUG -DQT_GUI_LIB -DQT_NETWORK_LIB -DQT_CORE_LIB -DQT_SHARED
14 CFLAGS = ${CROSS_COMPILE_CFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
15 CXXFLAGS = ${CROSS_COMPILE_CPPFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
16 INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
17 LINK = ${CROSS_COMPILE}g++
18 LFLAGS = -L$(ZYNQ_QT_INSTALL)/lib -Wl,-O1 -Wl,-rpath,/usr/local/Trolltech/Qt-4.7.3/lib
19 LIBS = $(SUBLIBS) -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtGui -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtNetwork -lQtCore -lpthread
20 AR = ${CROSS_COMPILE}ar cqs
21 RANLIB =
22 QMAKE = /usr/local/Trolltech/Qt-4.7.3/bin/qmake
23 TAR = tar -cf
24 COMPRESS = gzip -9f
25 COPY = cp -f
26 SED = sed
27 COPY_FILE = $(COPY)
28 COPY_DIR = $(COPY) -r
29 STRIP = ${CROSS_COMPILE}strip
30 INSTALL_FILE = install -m 644 -p
31 INSTALL_DIR = $(COPY_DIR)
32 INSTALL_PROGRAM = install -m 755 -p
33 DEL_FILE = rm -f
34 SYMLINK = ln -f -s
35 DEL_DIR = rmdir
36 MOVE = mv -f
37 CHK_DIR_EXISTS= test -d
38 MKDIR = mkdir -p
39
40 ####### Output directory
41
42 OBJECTS_DIR = ./
43
44 ####### Files
45
46 SOURCES = main.cpp \
47 mainwindow.cpp \
48 v4l2grab.c moc_mainwindow.cpp
49 OBJECTS = main.o \
50 mainwindow.o \
51 v4l2grab.o \
52 moc_mainwindow.o#之后省略
使用的gcc是${CROSS_COMPILE}gcc,即arm-xilinx-linux-gnueabi-gcc,g++是${CROSS_COMPILE}g++,即arm-xilinx-linux-gnueabi-g++;因此,编译出来的可执行文件是可以在Zed上运行的。重用
make
生成可执行文件 lab2_qt_camera。
三、制作运行时库
由于ubuntu的Qt运行库在/usr/local/Trolltech/Qt-4.7.3/下,可以看到参考运行库是
INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
因此,如果您在ZedBoard 上运行编译后的可执行文件,您可能会尽早在相应路径中找到运行时文件。Xilinx给出了制作Qt运行时镜像的方法:切换到qt-everywhere-opensource-src-4.7.3.tar.gz的解压路径,在控制台输入
1 dd if=/dev/zero of=qt_lib_ext4.img bs=1M count=80
2 mkfs.ext4 -F qt_lib_ext4.img
3 chmod go+w qt_lib_ext4.img
4 mount qt_lib_ext4.img -o loop /mnt
5 cp -rf /usr/local/Trolltech/Qt-4.7.3/* /mnt
6 chmod go-w qt_lib_ext4.img
7 umount /mnt
就是这样。可以找到生成的库文件镜像文件qt_lib_ext4.img,挂载到
/usr/local/Trolltech/Qt-4.7.3/
就是这样。
四、ARM测试测试
1、硬件连接
需要使用USB摄像头、U盘、鼠标,所以使用USB HUB;同时,为了支持HDMI输出,需要连接一个HDMI显示器(可以用DVI,需要用HDMI转DVI,性价比更高;或者普通VGA,需要用HDMI转VGA ,这个成本比较低)。ZedBoard 硬件连接图:
2、挂载Qt运行库
在ZedBoard的linux文件系统中,创建一个目录
/usr/local/Trolltech/Qt-4.7.3/
用
mkdir
逐层创建目录的命令。并挂载 qt_lib_ext4.img 到
/usr/local/Trolltech/Qt-4.7.3/
下。
切换到
<br class="Apple-interchange-newline" data-filtered="filtered">/usr/local/Trolltech/Qt-4.7.3/
查看挂载结果的路径
3、运行
使用命令
./lab2_qt_camera -qws
运行可执行文件,可以看到输出信息:
同时在HDMI显示器上查看执行结果:
这样我们相机采集到的图像数据就通过QT显示在HDMI显示器上。
============================
Qt运行时库下载:
可执行文件下载: 查看全部
u采 采集(Qt的下载和安装关于Linux的安装,你了解多少?)
一、Qt下载安装
关于Qt的安装,网上有很详细的介绍。这里仅作简要介绍。
需要两个安装包:Qt Creator 和 QTE。
1)QT 创建者
下载链接:qt-sdk-linux-x86-opensource-2010.05.1.bin
官方下载:
这是一个编译好的二进制SDK包,直接下载,不需要配置和编译,直接运行即可下载。之所以把官方链接放在下面,是因为我找了很久这个安装包,网上很多链接都失效了。我提供的第一个下载地址是使用百度云盘。最近在用,感觉效果很好。推荐第一个下载地址。
下载完成后,直接运行即可完成安装。
2)Qt Embedded for Linux:
下载链接:qt-everywhere-opensource-src-4.7.3.tar.gz
官方下载:
这是4.7.3版本的源码包,下载后需要配置编译。也推荐使用第一个地址进行下载。
解压后,将提供的Zynq Qt配置文件qmake.conf复制到qt-everywhere-opensource-src-4.7.3/mkspecs/qws/linux-arm-gnueabi-g++目录下,使用命令
./configure -embedded arm -xplatform qws/linux-arm-gnueabi-g++ -little-endian -opensource -host-little-endian -confirm-license -nomake demos -nomake examples
配置后进行配置和编译:
make
编译结束后使用命令
make install
安装,默认安装到
/usr/local/Trolltech/Qt-4.7.3/
路径下。然后将Xilinx交叉编译器中的基本C++库复制到安装目录的lib目录下:
cp -P /path/to/cross/compiler/arm-xilinx-linux-gnueabi/libc/usr/lib/libstdc++.so* /usr/local/Trolltech/Qt-4.7.3/lib
这样就完成了 Zynq 的 Qt Embedded for Linux 的安装。
二、软件代码
1、新的Qt项目
启动 Qt Creator 并创建一个新的 Qt Gui 应用程序
然后选择项目路径和项目描述,其他默认,一直点击下一步,直接完成项目。
2、修改ui界面
打开mainwindow.ui,进入可视化设计界面。默认情况下,中间的主设计区域下已经有一个 QMainWindow 和 QWidget 对象。我们需要将采集图片显示到一个QLabel小部件上,从右侧小部件列表中的“DisplayWidget”中选择“Label”小部件,将其拖到中间,设置大小为640*480,起点坐标为 (5,5).
并取消原文正文。
此时Label组件已经覆盖了MainWindow,然后适当调整MainWindow的大小。
3、添加摄像头采集代码
因为在(原创)基于ZedBoard的Webcam设计(一):USB摄像头(V4L2接口)在Zedboard的图片采集中,我们已经实现了图片采集,只需添加项目中的v4l2grab.c和v4l2grab.h源文件对这个新建的项目进行相应的修改。
修改mainwindow.cpp
1 #include "mainwindow.h"
2 #include "ui_mainwindow.h"
3 #include
4 #include
5 #include
6 #include
7 //#include
8 #include
9
10 MainWindow::MainWindow(QWidget *parent) :
11 QMainWindow(parent),
12 ui(new Ui::MainWindow)
13 {
14 ui->setupUi(this);
15
16 QPixmap pix;
17 QByteArray aa ;
18
19 BITMAPFILEHEADER bf;
20 BITMAPINFOHEADER bi;
21 //Set BITMAPINFOHEADER
22 bi.biSize = 40;
23 bi.biWidth = IMAGEWIDTH;
24 bi.biHeight = IMAGEHEIGHT;
25 bi.biPlanes = 1;
26 bi.biBitCount = 24;
27 bi.biCompression = 0;
28 bi.biSizeImage = IMAGEWIDTH*IMAGEHEIGHT*3;
29 bi.biXPelsPerMeter = 0;
30 bi.biYPelsPerMeter = 0;
31 bi.biClrUsed = 0;
32 bi.biClrImportant = 0;
33
34
35 //Set BITMAPFILEHEADER
36 bf.bfType = 0x4d42;
37 bf.bfSize = 54 + bi.biSizeImage;
38 bf.bfReserved = 0;
39 bf.bfOffBits = 54;
40
41 if(init_v4l2() == FALSE)
42 {
43 }
44
45 v4l2_grab();
46 yuyv_2_rgb888();
47 aa.append((char *)&bf,14);
48 aa.append((char *)&bi,40);
49 aa.append((char *)frame_buffer,640*480*3);
50 pix.loadFromData(aa);
51 ui->label->setPixmap(pix);
52 close_v4l2();
53 }
54
55 MainWindow::~MainWindow()
56 {
57 delete ui;
58 }
17~18行:
17 QPixmap pix;
18 QByteArray aa ;
定义了一个QPixmap类对象pix来显示图片;由于调用QPixmap类的loadFromData()函数来获取传递过来的图像数据,因此loadFromData()函数的详细信息可以在Qt的help->index中查找,或者从中查询:
bool QPixmap::loadFromData ( const QByteArray & data, const char * format = 0, Qt::ImageConversionFlags flags = Qt::AutoColor )
可知loadFromData()要求输入参数为QByteArray类型,因此定义了QByteArray的对象aa来存储图像数据。
同时,loadFromData() 需要指定数据的格式。如果不指定,默认支持的格式为:
是48~50行:
48 aa.append((char *)&bf,14);
49 aa.append((char *)&bi,40);
50 aa.append((char *)frame_buffer,640*480*3);
调用 QByteArray 类的 append 函数,将图像数据存储在 aa 中。需要注意的是,由于loadFromData函数的输入图片符合标准图片格式,所以需要将数据的BMP头信息保存在aa中。
52~53行:
51 pix.loadFromData(aa);
52 ui->label->setPixmap(pix);
实现了图片数据(包括头信息)到pix的传输以及pix在标签上的显示。
4、编译项目
在项目路径中,使用命令
qmake -project
生成一个新的项目文件lab2_qt_camera.pro。重用
qmake
生成一个makefile文件,打开makefile文件查看
1 #############################################################################
2 # Makefile for building: lab2_qt_camera
3 # Generated by qmake (2.01a) (Qt 4.7.3) on: Sun Dec 23 02:24:47 2012
4 # Project: lab2_qt_camera.pro
5 # Template: app
6 # Command: /usr/local/Trolltech/Qt-4.7.3/bin/qmake -o Makefile lab2_qt_camera.pro
7 #############################################################################
8
9 ####### Compiler, tools and options
10
11 CC = ${CROSS_COMPILE}gcc
12 CXX = ${CROSS_COMPILE}g++
13 DEFINES = -DQT_NO_DEBUG -DQT_GUI_LIB -DQT_NETWORK_LIB -DQT_CORE_LIB -DQT_SHARED
14 CFLAGS = ${CROSS_COMPILE_CFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
15 CXXFLAGS = ${CROSS_COMPILE_CPPFLAGS} -I$(ZYNQ_QT_INSTALL)/include -DZYNQ -O2 -Wall -W -D_REENTRANT $(DEFINES)
16 INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
17 LINK = ${CROSS_COMPILE}g++
18 LFLAGS = -L$(ZYNQ_QT_INSTALL)/lib -Wl,-O1 -Wl,-rpath,/usr/local/Trolltech/Qt-4.7.3/lib
19 LIBS = $(SUBLIBS) -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtGui -L/usr/local/Trolltech/Qt-4.7.3//lib -lQtNetwork -lQtCore -lpthread
20 AR = ${CROSS_COMPILE}ar cqs
21 RANLIB =
22 QMAKE = /usr/local/Trolltech/Qt-4.7.3/bin/qmake
23 TAR = tar -cf
24 COMPRESS = gzip -9f
25 COPY = cp -f
26 SED = sed
27 COPY_FILE = $(COPY)
28 COPY_DIR = $(COPY) -r
29 STRIP = ${CROSS_COMPILE}strip
30 INSTALL_FILE = install -m 644 -p
31 INSTALL_DIR = $(COPY_DIR)
32 INSTALL_PROGRAM = install -m 755 -p
33 DEL_FILE = rm -f
34 SYMLINK = ln -f -s
35 DEL_DIR = rmdir
36 MOVE = mv -f
37 CHK_DIR_EXISTS= test -d
38 MKDIR = mkdir -p
39
40 ####### Output directory
41
42 OBJECTS_DIR = ./
43
44 ####### Files
45
46 SOURCES = main.cpp \
47 mainwindow.cpp \
48 v4l2grab.c moc_mainwindow.cpp
49 OBJECTS = main.o \
50 mainwindow.o \
51 v4l2grab.o \
52 moc_mainwindow.o#之后省略
使用的gcc是${CROSS_COMPILE}gcc,即arm-xilinx-linux-gnueabi-gcc,g++是${CROSS_COMPILE}g++,即arm-xilinx-linux-gnueabi-g++;因此,编译出来的可执行文件是可以在Zed上运行的。重用
make
生成可执行文件 lab2_qt_camera。
三、制作运行时库
由于ubuntu的Qt运行库在/usr/local/Trolltech/Qt-4.7.3/下,可以看到参考运行库是
INCPATH = -I/usr/local/Trolltech/Qt-4.7.3/mkspecs/default -I. -I/usr/local/Trolltech/Qt-4.7.3/include/QtCore -I/usr/local/Trolltech/Qt-4.7.3/include/QtNetwork -I/usr/local/Trolltech/Qt-4.7.3/include/QtGui -I/usr/local/Trolltech/Qt-4.7.3/include -I. -I. -I.
因此,如果您在ZedBoard 上运行编译后的可执行文件,您可能会尽早在相应路径中找到运行时文件。Xilinx给出了制作Qt运行时镜像的方法:切换到qt-everywhere-opensource-src-4.7.3.tar.gz的解压路径,在控制台输入
1 dd if=/dev/zero of=qt_lib_ext4.img bs=1M count=80
2 mkfs.ext4 -F qt_lib_ext4.img
3 chmod go+w qt_lib_ext4.img
4 mount qt_lib_ext4.img -o loop /mnt
5 cp -rf /usr/local/Trolltech/Qt-4.7.3/* /mnt
6 chmod go-w qt_lib_ext4.img
7 umount /mnt
就是这样。可以找到生成的库文件镜像文件qt_lib_ext4.img,挂载到
/usr/local/Trolltech/Qt-4.7.3/
就是这样。
四、ARM测试测试
1、硬件连接
需要使用USB摄像头、U盘、鼠标,所以使用USB HUB;同时,为了支持HDMI输出,需要连接一个HDMI显示器(可以用DVI,需要用HDMI转DVI,性价比更高;或者普通VGA,需要用HDMI转VGA ,这个成本比较低)。ZedBoard 硬件连接图:
2、挂载Qt运行库
在ZedBoard的linux文件系统中,创建一个目录
/usr/local/Trolltech/Qt-4.7.3/
用
mkdir
逐层创建目录的命令。并挂载 qt_lib_ext4.img 到
/usr/local/Trolltech/Qt-4.7.3/
下。
切换到
<br class="Apple-interchange-newline" data-filtered="filtered">/usr/local/Trolltech/Qt-4.7.3/
查看挂载结果的路径
3、运行
使用命令
./lab2_qt_camera -qws
运行可执行文件,可以看到输出信息:
同时在HDMI显示器上查看执行结果:
这样我们相机采集到的图像数据就通过QT显示在HDMI显示器上。
============================
Qt运行时库下载:
可执行文件下载:
u采 采集(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-10-16 21:03
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务并很好地完成该任务。
微服务之前的很多单体应用,监控复杂度低,场景相对单一。在微服务下,由于业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图所示:
数据维度
目前基于WEB的服务是主流。每个WEB服务都有一个入口,不管是APP还是WEB页面。入口负责与用户交互,将用户信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发到特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及连接虚拟主机的带宽负载主机之间的虚拟网络等。
代码维度
APM,即应用性能分析,代码端监控采集,随着微服务的兴起而应运而生。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的采集框架。在可接受的性能损失范围内,采集 函数之间的调用关系,服务之间的调用拓扑,以及测量函数或服务的响应时间,可以有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状态。
主机监控:通过安装代理采集监控主机基本信息如CPU、内存、IO等数据,同时用户可以通过开源应用打开Tomcat、Nginx等其他数据配置文件 采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过主机上的代理加载来监控相应的组件采集程序。
自定义监控:服务实例采集业务相关数据,调用API接口定时上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要以SDK嵌入的形式侵入代码和采集数据,有的则与代码解耦,重新加载一些方法,通过元编程实现数据采集。
事件监控:针对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍采集以及监控系统中数据的展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
* 更多技术干货请关注微信“UCloud技术公告栏”查看。 查看全部
u采 采集(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务并很好地完成该任务。
微服务之前的很多单体应用,监控复杂度低,场景相对单一。在微服务下,由于业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦出现业务问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图所示:
数据维度
目前基于WEB的服务是主流。每个WEB服务都有一个入口,不管是APP还是WEB页面。入口负责与用户交互,将用户信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发到特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及连接虚拟主机的带宽负载主机之间的虚拟网络等。
代码维度
APM,即应用性能分析,代码端监控采集,随着微服务的兴起而应运而生。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的采集框架。在可接受的性能损失范围内,采集 函数之间的调用关系,服务之间的调用拓扑,以及测量函数或服务的响应时间,可以有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以通过MOCK调用API获取响应时间、响应状态码等指标,展示监控业务的整体健康状态。
主机监控:通过安装代理采集监控主机基本信息如CPU、内存、IO等数据,同时用户可以通过开源应用打开Tomcat、Nginx等其他数据配置文件 采集 开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过主机上的代理加载来监控相应的组件采集程序。
自定义监控:服务实例采集业务相关数据,调用API接口定时上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要以SDK嵌入的形式侵入代码和采集数据,有的则与代码解耦,重新加载一些方法,通过元编程实现数据采集。
事件监控:针对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘复位事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍采集以及监控系统中数据的展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
* 更多技术干货请关注微信“UCloud技术公告栏”查看。
u采 采集(u采采集器(最新版v1.5)上市公司)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-14 06:03
u采采集器(最新版v1.5.0.14)是采集微信、微博、qq、豆瓣、陌陌、知乎、b站、微店及其他搜索引擎上的所有文章与视频,自动采集并发布在指定的平台上。特点1:智能精准引流u采采集器拥有采集文章、采集微信微博视频、采集知乎豆瓣问答、采集抖音文章等功能,可以快速方便采集到需要的资源,领域涉及经济金融、时尚购物、数码电子、美食娱乐、科技农产、智能科技、汽车机械、动漫娱乐、生活服务、汽车动力、无人机、农产水果、健康、餐饮美食、母婴用品、旅游景点、消费金融、教育教学、在线教育等。
2:超强稳定u采采集器所有采集文章为采集微信微博、采集头条知乎微博、采集网站视频、采集行业标签视频等,采集文章每天不超过5条,对采集性能要求不高。采集速度不会影响网速。3:多平台采集u采采集器不仅仅支持采集微信微博、采集头条知乎网站视频、采集抖音快手文章等,还支持采集百度网盘、qq空间、爱奇艺等多个平台,可以满足不同客户的需求。
平台管理页面有采集文章管理、多平台管理、文章管理等主要功能。4:界面友好u采采集器页面简洁,操作流畅,无需设置教程。采集视频不提示缓存文件名、不提示版权、无需剪切出视频地址等安全漏洞。5:未授权不能用u采采集器未授权是不能采集的,也就是说需要使用权限采集文章,支持头条采集、新浪采集、企鹅号采集、百度采集、大鱼号采集、搜狐采集、京东采集、凤凰号采集、视频采集等。
当然如果你需要查看系统文档中的文章,可以直接打开文章下方的查看文章,找到说明页面。知道文章地址的才能使用。6:采集更新不受限u采采集器无论是新的文章还是老的文章,都可以顺利采集到,系统会自动提取,自动发布,并且对原文章的版权问题也不用担心。7:免费试用u采采集器免费试用,新用户注册即可使用。对特殊情况感兴趣的用户可以对应询问“是否需要使用”,获得免费试用机会。
文档结构管理页面有采集文章管理、多平台管理、文章管理等主要功能。标签管理页面有采集文章、文章标签管理、标签管理、标签管理、采集策略管理等主要功能。生成表单页面有生成表单、表单管理、表单存放管理等主要功能。总的来说,u采采集器特点突出,操作简单,功能齐全,即可满足文章采集、视频采集、音频采集、图片采集等用户需求,能够为u采采集器带来高效稳定、免费、专业、快捷的免费平台采集体验。 查看全部
u采 采集(u采采集器(最新版v1.5)上市公司)
u采采集器(最新版v1.5.0.14)是采集微信、微博、qq、豆瓣、陌陌、知乎、b站、微店及其他搜索引擎上的所有文章与视频,自动采集并发布在指定的平台上。特点1:智能精准引流u采采集器拥有采集文章、采集微信微博视频、采集知乎豆瓣问答、采集抖音文章等功能,可以快速方便采集到需要的资源,领域涉及经济金融、时尚购物、数码电子、美食娱乐、科技农产、智能科技、汽车机械、动漫娱乐、生活服务、汽车动力、无人机、农产水果、健康、餐饮美食、母婴用品、旅游景点、消费金融、教育教学、在线教育等。
2:超强稳定u采采集器所有采集文章为采集微信微博、采集头条知乎微博、采集网站视频、采集行业标签视频等,采集文章每天不超过5条,对采集性能要求不高。采集速度不会影响网速。3:多平台采集u采采集器不仅仅支持采集微信微博、采集头条知乎网站视频、采集抖音快手文章等,还支持采集百度网盘、qq空间、爱奇艺等多个平台,可以满足不同客户的需求。
平台管理页面有采集文章管理、多平台管理、文章管理等主要功能。4:界面友好u采采集器页面简洁,操作流畅,无需设置教程。采集视频不提示缓存文件名、不提示版权、无需剪切出视频地址等安全漏洞。5:未授权不能用u采采集器未授权是不能采集的,也就是说需要使用权限采集文章,支持头条采集、新浪采集、企鹅号采集、百度采集、大鱼号采集、搜狐采集、京东采集、凤凰号采集、视频采集等。
当然如果你需要查看系统文档中的文章,可以直接打开文章下方的查看文章,找到说明页面。知道文章地址的才能使用。6:采集更新不受限u采采集器无论是新的文章还是老的文章,都可以顺利采集到,系统会自动提取,自动发布,并且对原文章的版权问题也不用担心。7:免费试用u采采集器免费试用,新用户注册即可使用。对特殊情况感兴趣的用户可以对应询问“是否需要使用”,获得免费试用机会。
文档结构管理页面有采集文章管理、多平台管理、文章管理等主要功能。标签管理页面有采集文章、文章标签管理、标签管理、标签管理、采集策略管理等主要功能。生成表单页面有生成表单、表单管理、表单存放管理等主要功能。总的来说,u采采集器特点突出,操作简单,功能齐全,即可满足文章采集、视频采集、音频采集、图片采集等用户需求,能够为u采采集器带来高效稳定、免费、专业、快捷的免费平台采集体验。
u采 采集(给出采集软件的任务地址库文件?保存任务库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-10-07 23:00
所以这里有一个临时解决方案:我使用的是 优采云采集器2010sp2 个人版。
采集之后的商业版用户的URL存放在PageUrl目录中。一个task对应一个db3. 可以从最上面的task算到第一个,对应的就是Site_*。db3. 这样就可以先做备份,然后清空。到时候可以直接恢复用户名。如果您害怕犯错,请将其全部保存并稍后恢复。
如图:
如果要仔细看,这个db3其实是sqlite数据库格式的文件,可以使用db3数据库编辑器查看和修改。根据jobid,有朋友问我是不是不知道jobid怎么办。呵呵,大家可以去Data目录查看3-新浪国内新闻。新浪国内新闻背后的新浪国内新闻是您自定义的网站栏目名称。这对应于jobid。
如图:
最后,你备份完数据库后就可以了(需要备份PageUrl和Data目录下你的任务名对应的文件夹。最好都是以防万一,采集后覆盖即可.)
后来我也看到了网站下面的文件,和我的文章很相似。你可以参考一下。
优采云是一款不错的采集软件,“盗版也有办法”,就看你怎么用了。
Linker曾经偶尔研究过优采云采集软件,但从未购买过商业版。想想看,现在的版本和之前的1.x 和2.x 版本相差甚远。容易。
一哥昨晚给他讲了他的优采云采集软件(企业版,有钱人!),老是提示任务地址库重复。研究了一下,还是比较简单的,并告诉了他处理的方法,另外经过搜索,发现优采云的3.0 sp1版本有这个bug,任务地址库无法清除,但是管理员在sp2版本中已经解决了这个问题。
后来这位朋友问优采云采集软件的任务地址库是哪个文件?如何保存任务地址库?如何手动清理任务地址库文件?据Linker所知,编辑任务地址库需要商业版。如果要手动处理,可以发现手动地址库文件在优采云根目录下的pageurl目录下,每个task对应一个地址。库文件,mdb格式,打开就可以找到,具体地址是加密的。优采云 有些太商业了,嘿嘿!
既然知道了任务地址库的位置和文件,那么手动清理任务地址库自然就简单了。删除重复优采云(删除后编辑任务再保存),或者直接删除库中的记录。如果你想保存它用于其他任务,只需将其重新排序为其他任务的 id。
简单测试通过。脚本屋原创文章。 查看全部
u采 采集(给出采集软件的任务地址库文件?保存任务库)
所以这里有一个临时解决方案:我使用的是 优采云采集器2010sp2 个人版。
采集之后的商业版用户的URL存放在PageUrl目录中。一个task对应一个db3. 可以从最上面的task算到第一个,对应的就是Site_*。db3. 这样就可以先做备份,然后清空。到时候可以直接恢复用户名。如果您害怕犯错,请将其全部保存并稍后恢复。
如图:
如果要仔细看,这个db3其实是sqlite数据库格式的文件,可以使用db3数据库编辑器查看和修改。根据jobid,有朋友问我是不是不知道jobid怎么办。呵呵,大家可以去Data目录查看3-新浪国内新闻。新浪国内新闻背后的新浪国内新闻是您自定义的网站栏目名称。这对应于jobid。
如图:
最后,你备份完数据库后就可以了(需要备份PageUrl和Data目录下你的任务名对应的文件夹。最好都是以防万一,采集后覆盖即可.)
后来我也看到了网站下面的文件,和我的文章很相似。你可以参考一下。
优采云是一款不错的采集软件,“盗版也有办法”,就看你怎么用了。
Linker曾经偶尔研究过优采云采集软件,但从未购买过商业版。想想看,现在的版本和之前的1.x 和2.x 版本相差甚远。容易。
一哥昨晚给他讲了他的优采云采集软件(企业版,有钱人!),老是提示任务地址库重复。研究了一下,还是比较简单的,并告诉了他处理的方法,另外经过搜索,发现优采云的3.0 sp1版本有这个bug,任务地址库无法清除,但是管理员在sp2版本中已经解决了这个问题。
后来这位朋友问优采云采集软件的任务地址库是哪个文件?如何保存任务地址库?如何手动清理任务地址库文件?据Linker所知,编辑任务地址库需要商业版。如果要手动处理,可以发现手动地址库文件在优采云根目录下的pageurl目录下,每个task对应一个地址。库文件,mdb格式,打开就可以找到,具体地址是加密的。优采云 有些太商业了,嘿嘿!
既然知道了任务地址库的位置和文件,那么手动清理任务地址库自然就简单了。删除重复优采云(删除后编辑任务再保存),或者直接删除库中的记录。如果你想保存它用于其他任务,只需将其重新排序为其他任务的 id。
简单测试通过。脚本屋原创文章。
u采 采集(u采采集,微信自动采集功能,支持微信公众号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2021-10-05 14:04
u采采集,微信自动采集功能,支持微信公众号、小程序、公众号商城、微信群、微信个人号、抖音、微博、哔哩哔哩等300多个渠道的精准采集。
去阿里云上找云采集,
采集难度还是挺大的,至少我们之前知道有采集,但没有很好的实现,有能力自己采集,也必须要能把数据整理好!这个自己用过的最好推荐的是binstd,自己整理的商品数据,也有热门商品列表,
现在网上的采集工具已经很多了,可以搜索一下。现在最强大的当属阿里云了,推荐使用binstd,商品信息已经抓取的非常全面,而且还可以抓取产品描述信息,可以对商品进行排名优化。
先看看这篇文章有没有帮助到你:采集软件:无需手动编写代码轻松实现全国各地点击进去就能全网采集
我们公司主要开发自动采集机器人,
太难了,我之前也在找,现在公司养了个牛,牛总是有采集软件让他采,每天整的都是些意思意思的我。
最新一个yxt_fb_hx自动采集软件直接采集,不需要编程定制, 查看全部
u采 采集(u采采集,微信自动采集功能,支持微信公众号)
u采采集,微信自动采集功能,支持微信公众号、小程序、公众号商城、微信群、微信个人号、抖音、微博、哔哩哔哩等300多个渠道的精准采集。
去阿里云上找云采集,
采集难度还是挺大的,至少我们之前知道有采集,但没有很好的实现,有能力自己采集,也必须要能把数据整理好!这个自己用过的最好推荐的是binstd,自己整理的商品数据,也有热门商品列表,
现在网上的采集工具已经很多了,可以搜索一下。现在最强大的当属阿里云了,推荐使用binstd,商品信息已经抓取的非常全面,而且还可以抓取产品描述信息,可以对商品进行排名优化。
先看看这篇文章有没有帮助到你:采集软件:无需手动编写代码轻松实现全国各地点击进去就能全网采集
我们公司主要开发自动采集机器人,
太难了,我之前也在找,现在公司养了个牛,牛总是有采集软件让他采,每天整的都是些意思意思的我。
最新一个yxt_fb_hx自动采集软件直接采集,不需要编程定制,
u采 采集(u采采集(index采集软件官网)双十一黑猪采集助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-10-05 05:02
u采采集(index采集软件官网,中国首家采集在线工具平台)为你提供海量的pc端采集需求,包括微信公众号及其他网站的素材采集,工具一键导入网站素材即可,省心省力!采集方法也简单直接,
推荐老客户的黑猪采集助手,一键采集,双十一可以采齐!老客户黑猪采集助手:,双十一黑猪采集助手:,可以帮助你缩短采集周期、降低采集成本。黑猪采集助手可以配合老客户黑猪采集助手一起使用,
我用过天采宝采集插件。黑猪采集插件也行。我电脑里装了黑猪采集插件。微信公众号里面的图片都是用采集插件采集的。我觉得不错。
采集老客户的公众号历史消息,然后用大数据采集等大的采集工具采集一下,然后用其他工具导出到excel就可以,很简单的操作,
采集群了解一下,自己多去问问,
等我用上再来回答(更新,目前其实就算是小白也能轻松学会,
微信公众号图片全都是可以采集到的,本人也正在学习中,希望可以互相学习。---我又来了,怎么一直没人回答,答主现在不是有采集群吗?一、微信公众号搜索教程及规则网上有很多教程,具体我就不搬运了,这方面的教程网上很多,大家自己去搜就行了。二、小程序搜索教程我也很懒,就不搬运了。如果你是想采集微信公众号相关内容的话,可以自己去小程序搜索一下,免费就够用了。 查看全部
u采 采集(u采采集(index采集软件官网)双十一黑猪采集助手)
u采采集(index采集软件官网,中国首家采集在线工具平台)为你提供海量的pc端采集需求,包括微信公众号及其他网站的素材采集,工具一键导入网站素材即可,省心省力!采集方法也简单直接,
推荐老客户的黑猪采集助手,一键采集,双十一可以采齐!老客户黑猪采集助手:,双十一黑猪采集助手:,可以帮助你缩短采集周期、降低采集成本。黑猪采集助手可以配合老客户黑猪采集助手一起使用,
我用过天采宝采集插件。黑猪采集插件也行。我电脑里装了黑猪采集插件。微信公众号里面的图片都是用采集插件采集的。我觉得不错。
采集老客户的公众号历史消息,然后用大数据采集等大的采集工具采集一下,然后用其他工具导出到excel就可以,很简单的操作,
采集群了解一下,自己多去问问,
等我用上再来回答(更新,目前其实就算是小白也能轻松学会,
微信公众号图片全都是可以采集到的,本人也正在学习中,希望可以互相学习。---我又来了,怎么一直没人回答,答主现在不是有采集群吗?一、微信公众号搜索教程及规则网上有很多教程,具体我就不搬运了,这方面的教程网上很多,大家自己去搜就行了。二、小程序搜索教程我也很懒,就不搬运了。如果你是想采集微信公众号相关内容的话,可以自己去小程序搜索一下,免费就够用了。
u采 采集(u采采集器采集成功之后的编写程序是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-10-03 12:05
u采采集器采集成功之后就是你编写的程序,内置特殊过滤标签,非常方便,另外你可以设置url过滤规则,标签过滤规则,规则规则分开设置比如url过滤优先过滤规则,标签过滤优先过滤规则,规则可以设置新规则,也可以设置老规则。
单独设置一个ip只不过使用https的加密手段强制跳转到网页上
我的做法是加上代理池,或者java集成到客户端使用代理池,比如用代理ip有序获取、多ip授权等,均可,update,感谢@ianjacks提供信息,具体名称无记录,
用代理采集器可以,采集出来过滤为私密,
谢邀,
楼上两位说的都比较靠谱了。针对不同的网站有不同的方法。
url的构建比较麻烦的,
这种是封的
如果你会写scrapy爬虫框架用的是casperhandler不用封过滤
说不定你是因为它封的是你没有的accesstoken..
user-agent是用户特征,而不是所有用户特征,譬如只能绑定ip,或者说只能抓去百度网址或ping外网网址等等而不能采集https其他网站网页内容,其实这里没有封一说。如果你采集某个站点所有的accesstoken,那么封站也没有问题,package-example下面的爬虫系统,爬取到每个网站的accesstoken,我们可以针对它做一些事情,比如所有网页打开时就跳转accesstoken为特别的地址来避免封站(只能采集与之对应的站点),或者不让别人搜到自己网站,等等,这样做一下权限控制,同时封一些accesstoken是很容易的。
譬如你采集饿了么站点所有的accesstoken,那么就无法采集饿了么网站的广告。在github上面也是有一个采集某个站点所有accesstoken的项目:pythonuser-agent-schemepythonhttpuser-agent::-http-mapping-configuration。 查看全部
u采 采集(u采采集器采集成功之后的编写程序是什么?)
u采采集器采集成功之后就是你编写的程序,内置特殊过滤标签,非常方便,另外你可以设置url过滤规则,标签过滤规则,规则规则分开设置比如url过滤优先过滤规则,标签过滤优先过滤规则,规则可以设置新规则,也可以设置老规则。
单独设置一个ip只不过使用https的加密手段强制跳转到网页上
我的做法是加上代理池,或者java集成到客户端使用代理池,比如用代理ip有序获取、多ip授权等,均可,update,感谢@ianjacks提供信息,具体名称无记录,
用代理采集器可以,采集出来过滤为私密,
谢邀,
楼上两位说的都比较靠谱了。针对不同的网站有不同的方法。
url的构建比较麻烦的,
这种是封的
如果你会写scrapy爬虫框架用的是casperhandler不用封过滤
说不定你是因为它封的是你没有的accesstoken..
user-agent是用户特征,而不是所有用户特征,譬如只能绑定ip,或者说只能抓去百度网址或ping外网网址等等而不能采集https其他网站网页内容,其实这里没有封一说。如果你采集某个站点所有的accesstoken,那么封站也没有问题,package-example下面的爬虫系统,爬取到每个网站的accesstoken,我们可以针对它做一些事情,比如所有网页打开时就跳转accesstoken为特别的地址来避免封站(只能采集与之对应的站点),或者不让别人搜到自己网站,等等,这样做一下权限控制,同时封一些accesstoken是很容易的。
譬如你采集饿了么站点所有的accesstoken,那么就无法采集饿了么网站的广告。在github上面也是有一个采集某个站点所有accesstoken的项目:pythonuser-agent-schemepythonhttpuser-agent::-http-mapping-configuration。
u采 采集(u采采集,规范采集代码,提供一站式的采集服务!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-27 01:03
u采采集,规范采集代码,提供一站式的采集服务!采集excel工作表,必备采集代码,结合excel提取核心数据内容,多样的数据获取方式,支持格式多样的xpath转换。高级预设:自定义采集高级的sql查询语句自定义javascript片段提取数据自定义sql查询语句嵌入javascript片段发布订阅功能,采集更多的信息发布到微信公众号,每日获取采集的数据!。
个人感觉u采集并不是一个高效的方法,不过对于较少的工作量不错,对于稍大工作量可能需要对excel深入研究一番!高级采集基本都被采用java来写,java采集速度、效率、安全性方面,应该没有办法满足u采集等采集需求!目前采用u采集进行采集的一般工作量在80-150每日,对于工作量较大的用户可能就会感觉性价比不高!。
u采集简直是垃圾的u计划excel加载怎么u怎么慢。u计划千方百计逼你用微软自己公司的cuttereditor。什么磁盘清理不知道清理你啥,图片右键三小时检测不知道检测你啥,希望能在三小时内检测出不是每一次数据的导入都是毫无意义的。都tm需要仔细测试有没有问题。他们说上马数据安全没影响。那你们微软应该停止hyper-v开发才对。
合集号u采集(免费版)基本功能如下:多表合并:本地、网页、电子邮件;数据本地备份:同步本地电子邮件、word等数据,在网页数据备份时,使用快速备份;数据提取:选中数据,excel-excel-home,可在excel中提取excel表中的内容,附加文本、纯文本、截图等,可与网页中的数据互通;自定义数据提取操作:可以对本地数据库、电子邮件数据、电子表格数据,自定义提取操作;提取时可以采用循环提取、批量提取、分组等操作;数据转换:可以将excel或者word中的数据导入到excel中;数据上传:可以将本地数据的字段设置为域名,可以上传附加到网页中;基本是没有什么缺点的,新版已支持sql查询,且对磁盘性能要求比较低,对我们自己来说足够了。 查看全部
u采 采集(u采采集,规范采集代码,提供一站式的采集服务!)
u采采集,规范采集代码,提供一站式的采集服务!采集excel工作表,必备采集代码,结合excel提取核心数据内容,多样的数据获取方式,支持格式多样的xpath转换。高级预设:自定义采集高级的sql查询语句自定义javascript片段提取数据自定义sql查询语句嵌入javascript片段发布订阅功能,采集更多的信息发布到微信公众号,每日获取采集的数据!。
个人感觉u采集并不是一个高效的方法,不过对于较少的工作量不错,对于稍大工作量可能需要对excel深入研究一番!高级采集基本都被采用java来写,java采集速度、效率、安全性方面,应该没有办法满足u采集等采集需求!目前采用u采集进行采集的一般工作量在80-150每日,对于工作量较大的用户可能就会感觉性价比不高!。
u采集简直是垃圾的u计划excel加载怎么u怎么慢。u计划千方百计逼你用微软自己公司的cuttereditor。什么磁盘清理不知道清理你啥,图片右键三小时检测不知道检测你啥,希望能在三小时内检测出不是每一次数据的导入都是毫无意义的。都tm需要仔细测试有没有问题。他们说上马数据安全没影响。那你们微软应该停止hyper-v开发才对。
合集号u采集(免费版)基本功能如下:多表合并:本地、网页、电子邮件;数据本地备份:同步本地电子邮件、word等数据,在网页数据备份时,使用快速备份;数据提取:选中数据,excel-excel-home,可在excel中提取excel表中的内容,附加文本、纯文本、截图等,可与网页中的数据互通;自定义数据提取操作:可以对本地数据库、电子邮件数据、电子表格数据,自定义提取操作;提取时可以采用循环提取、批量提取、分组等操作;数据转换:可以将excel或者word中的数据导入到excel中;数据上传:可以将本地数据的字段设置为域名,可以上传附加到网页中;基本是没有什么缺点的,新版已支持sql查询,且对磁盘性能要求比较低,对我们自己来说足够了。
u采 采集(u采采集多线程下载,启动extractu轻松破解教程!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-24 19:02
u采采集多线程下载1、启动extractu采采集是通过微信浏览器,获取热点微信号文章,转换成html格式下载到本地(文件大小自己控制,如图):2、分析特性点击开始采集,页面卡住,再次点击下载(页面不点击开始依然在本地),同一个电脑登录2个微信号,同一个浏览器,同一个浏览器登录不同微信号(文件类型、图片质量均一致),开始同时点击转换成html格式下载。
总结一句话就是可以分屏下载,多方便啊。不解释了,上图吧。(有好处,有坏处)我已经把获取源文件的机制写出来了,注意用“-”表示快速的链接中断。
本回答内容为采集过程思路+相关技术,如果你有其他不同的想法或需求,请私信给我,我再继续写作!1.简单的思路假设你要实现的目标是从某公众号主页采集文章的内容,或从百度学术或者知乎论坛采集话题讨论,那么请先花点时间完善你的思路,当然,这个思路也并不是万能的,随着网页加载更新或者浏览器自身变化导致路径错误,可能你会丢失,或者出现其他你想要的错误信息。
在思路确定了以后,你可以用这个思路制作html代码,然后我们可以开始准备工作了!2.制作html代码html代码代码并不难找,某宝上30元一篇相关资料轻松搞定(当然我目前只写过下载手机公众号文章的,没写过android客户端,所以写的这些不一定适合所有人),但是我强烈建议大家找本教程(《html5轻松破解教程》,某宝16元卖),大致写好代码后,用dreamweaver等专业软件尝试生成html代码。
这个过程需要耐心,并且不会有任何预期的好结果。2.1图片html代码在操作浏览器前,我们需要准备工作,安装一个网页浏览器(现在主流是猎豹浏览器和火狐浏览器,我们都会用到)。我不会用奇虎360,因为我不用,应该也不会用百度,我上面说的几个浏览器,跟你也都有可能用到。按照教程(自己搜,但必须是官方开发,否则会有本人代码与真实源代码错误表现!)中生成代码的步骤准备好!3.备份此处生成的代码,并且在浏览器中下载。
一般来说,在这一步后,应该会有两种情况:a、浏览器变更了返回的html,导致无法通过本教程获取代码。b、对应html路径加载失败,比如说源代码生成时间太长,导致失去下载机会。以上两种情况都会导致无法下载失败,请按照实际情况自行处理!4.配置工具这里我用的是火狐浏览器,在谷歌或必应等浏览器中,也可以生成html代码。
但是这些浏览器普遍将html转换为图片代码时,代码里的空白块,没有带上格式的图片,所以这样的代码不好下载,但其实这里也有方法可用,主要有两。 查看全部
u采 采集(u采采集多线程下载,启动extractu轻松破解教程!)
u采采集多线程下载1、启动extractu采采集是通过微信浏览器,获取热点微信号文章,转换成html格式下载到本地(文件大小自己控制,如图):2、分析特性点击开始采集,页面卡住,再次点击下载(页面不点击开始依然在本地),同一个电脑登录2个微信号,同一个浏览器,同一个浏览器登录不同微信号(文件类型、图片质量均一致),开始同时点击转换成html格式下载。
总结一句话就是可以分屏下载,多方便啊。不解释了,上图吧。(有好处,有坏处)我已经把获取源文件的机制写出来了,注意用“-”表示快速的链接中断。
本回答内容为采集过程思路+相关技术,如果你有其他不同的想法或需求,请私信给我,我再继续写作!1.简单的思路假设你要实现的目标是从某公众号主页采集文章的内容,或从百度学术或者知乎论坛采集话题讨论,那么请先花点时间完善你的思路,当然,这个思路也并不是万能的,随着网页加载更新或者浏览器自身变化导致路径错误,可能你会丢失,或者出现其他你想要的错误信息。
在思路确定了以后,你可以用这个思路制作html代码,然后我们可以开始准备工作了!2.制作html代码html代码代码并不难找,某宝上30元一篇相关资料轻松搞定(当然我目前只写过下载手机公众号文章的,没写过android客户端,所以写的这些不一定适合所有人),但是我强烈建议大家找本教程(《html5轻松破解教程》,某宝16元卖),大致写好代码后,用dreamweaver等专业软件尝试生成html代码。
这个过程需要耐心,并且不会有任何预期的好结果。2.1图片html代码在操作浏览器前,我们需要准备工作,安装一个网页浏览器(现在主流是猎豹浏览器和火狐浏览器,我们都会用到)。我不会用奇虎360,因为我不用,应该也不会用百度,我上面说的几个浏览器,跟你也都有可能用到。按照教程(自己搜,但必须是官方开发,否则会有本人代码与真实源代码错误表现!)中生成代码的步骤准备好!3.备份此处生成的代码,并且在浏览器中下载。
一般来说,在这一步后,应该会有两种情况:a、浏览器变更了返回的html,导致无法通过本教程获取代码。b、对应html路径加载失败,比如说源代码生成时间太长,导致失去下载机会。以上两种情况都会导致无法下载失败,请按照实际情况自行处理!4.配置工具这里我用的是火狐浏览器,在谷歌或必应等浏览器中,也可以生成html代码。
但是这些浏览器普遍将html转换为图片代码时,代码里的空白块,没有带上格式的图片,所以这样的代码不好下载,但其实这里也有方法可用,主要有两。
u采 采集(u采采集器采集服务器集群的ip段分布详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-18 23:05
u采采集器是采集服务器集群的采集器。通过u采集器可以采集任何来源,包括:用户发送请求到服务器,服务器或网络接收到请求,再分析。从用户产生的每一个请求的url里,根据目标站点在url中的匹配程度得到目标站点的ip段。查看请求网址的ip分布u采集器通过索引的方式将网址按照设定的规则搜索出来,然后进行网址解析得到目标网址的ip分布。
根据每一个请求的ip段分布得到这个请求对应的ip段。根据这些得到的ip段用u采集器扫描器扫描看得到根据目标网址扫描得到的ip段,从而得到该目标站点的ip分布。根据得到的ip分布再结合username判断是否发送到对应的u采集器服务器。最后根据ip生成一个唯一标识符。生成唯一标识符第一步,建立规则u采集器建立规则很简单,可以使用采集服务器的命令行工具u采集,直接分析得到网址后,搜索得到ip即可,服务器端随机产生几个数字即可。
python命令行工具u采集如下:#ip={}#ip地址需要有空格即可![]name=[]defmake_text(ip):list=[]foriinrange(0,。
3):ifiinip[1]:list.append(i)name=ip[1].nameelse:fornameinlist:iflist[name]==ip[1]:returnnameiflist[0]!='.':list.append(list[1])returnname.split('.')else:return'_'fornameinip:ifname[0]!='.':return''returnipname=name.split('.')name.split('_')第二步,扫描匹配程度对于扫描过程可以在计算机上进行单元测试。扫描匹配指定网址的所有ip,匹配程度当存在所有的ip的时候要求扫描每个ip与合适的ip进行匹配。
u采集器有两种情况下会存在不匹配:
1)所有网址中扫描不到(此种情况存在的概率为80%);
2)扫描到的每个ip对应一个ip地址与空格分隔的网址(此种情况也存在概率为80%)。扫描匹配情况说明defprefix_if_with_any_group(ip):sql_returns='{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{5}.{6}.{7}.{8}。 查看全部
u采 采集(u采采集器采集服务器集群的ip段分布详解)
u采采集器是采集服务器集群的采集器。通过u采集器可以采集任何来源,包括:用户发送请求到服务器,服务器或网络接收到请求,再分析。从用户产生的每一个请求的url里,根据目标站点在url中的匹配程度得到目标站点的ip段。查看请求网址的ip分布u采集器通过索引的方式将网址按照设定的规则搜索出来,然后进行网址解析得到目标网址的ip分布。
根据每一个请求的ip段分布得到这个请求对应的ip段。根据这些得到的ip段用u采集器扫描器扫描看得到根据目标网址扫描得到的ip段,从而得到该目标站点的ip分布。根据得到的ip分布再结合username判断是否发送到对应的u采集器服务器。最后根据ip生成一个唯一标识符。生成唯一标识符第一步,建立规则u采集器建立规则很简单,可以使用采集服务器的命令行工具u采集,直接分析得到网址后,搜索得到ip即可,服务器端随机产生几个数字即可。
python命令行工具u采集如下:#ip={}#ip地址需要有空格即可![]name=[]defmake_text(ip):list=[]foriinrange(0,。
3):ifiinip[1]:list.append(i)name=ip[1].nameelse:fornameinlist:iflist[name]==ip[1]:returnnameiflist[0]!='.':list.append(list[1])returnname.split('.')else:return'_'fornameinip:ifname[0]!='.':return''returnipname=name.split('.')name.split('_')第二步,扫描匹配程度对于扫描过程可以在计算机上进行单元测试。扫描匹配指定网址的所有ip,匹配程度当存在所有的ip的时候要求扫描每个ip与合适的ip进行匹配。
u采集器有两种情况下会存在不匹配:
1)所有网址中扫描不到(此种情况存在的概率为80%);
2)扫描到的每个ip对应一个ip地址与空格分隔的网址(此种情况也存在概率为80%)。扫描匹配情况说明defprefix_if_with_any_group(ip):sql_returns='{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{1}.{2}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{3}.{4}.{5}.{6}.{7}.{8}.{9}.{0}.{5}.{6}.{7}.{8}。
u采 采集(u采采集app应用商店和ucappstore的合并与解析(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-18 12:07
u采采集app是基于采集脚本的hook技术实现的,将浏览器请求,各种方法(xpathscripthtml等)获取的数据,都进行合并与解析(把json数据拆分成list数据,解析出重要字段的内容),抓取成功后再发送给hook我的kindle书库上,这是目前为止最快的抓取方法了(被封一周后的昨天昨天刚刚抓到)我目前还是采用前端代理模拟用户登录比较有效。
采集js生成数据包,
采集别人update的txt数据,
采集对方推荐书,
程序已成功采集收藏夹书籍信息,
现在的抓包工具都可以抓到app请求后的json数据,另外已经有一些工具可以通过get方式采集然后再转包。但是采集app包的实际效果也不是特别好。
之前写过一个python脚本,把github上面的源码gallery_all.py,照猫画虎实现了。我以前看书我喜欢在appstore查找适合自己阅读的资源,因为app比较稳定。在这种情况下,我就采集了app应用商店和ucappstore的一些页面。不得不说,这个技术我还是蛮满意的,整理出来分享给有需要的人吧!整个过程不到一天的时间。
可以看看过程图以及源码。我个人觉得app的列表是完整的可读的,不需要每次都去改格式格式支持了。1.数据收集准备工作下载2.抓包工具抓包工具:需要精通udp协议,netcrypt,netbeans抓包工具的安装,建议在python中ethereum网上download,我直接拷贝下来了。根据自己的项目或者合作伙伴要求设置vpnpost方式。
建议自己先弄一个尝试一下。如果自己设置不成功可以再来问。3.数据转包hookjavapackage中的jsonurl解析抓包结果(手机版手机端必须勾选useragentcorstransfer)那么我们就可以这样来验证我们是否hook了,已这样来测试,其他网页也是如此,只要dns设置成相应的就可以。不过还是有些报错,建议做爬虫测试,在这种情况下就不做实验了,因为抓包设置好环境就可以。
之前方法不能用在云服务器上。使用dns服务器:我一般会使用post的api,jsonobject也是通过post转包出来的,这里不引用post服务器功能了4.数据解析抓包之后就是分析抓取数据,其实这里包含网页源码分析和json结构分析。从源码中可以看到json格式的数据就是html对象一样。也可以看到网页中获取的wx.setdata({user:'youruseragent',pwd:'test',token:'verify:true'})。
通过上面的分析可以很容易知道username和pwd那么如何保证我们能够在网页中查看json的格式信息呢?这里我们使用json格式化对比,从源码中看网页和一个专业网站的区别就在于json格式。 查看全部
u采 采集(u采采集app应用商店和ucappstore的合并与解析(上))
u采采集app是基于采集脚本的hook技术实现的,将浏览器请求,各种方法(xpathscripthtml等)获取的数据,都进行合并与解析(把json数据拆分成list数据,解析出重要字段的内容),抓取成功后再发送给hook我的kindle书库上,这是目前为止最快的抓取方法了(被封一周后的昨天昨天刚刚抓到)我目前还是采用前端代理模拟用户登录比较有效。
采集js生成数据包,
采集别人update的txt数据,
采集对方推荐书,
程序已成功采集收藏夹书籍信息,
现在的抓包工具都可以抓到app请求后的json数据,另外已经有一些工具可以通过get方式采集然后再转包。但是采集app包的实际效果也不是特别好。
之前写过一个python脚本,把github上面的源码gallery_all.py,照猫画虎实现了。我以前看书我喜欢在appstore查找适合自己阅读的资源,因为app比较稳定。在这种情况下,我就采集了app应用商店和ucappstore的一些页面。不得不说,这个技术我还是蛮满意的,整理出来分享给有需要的人吧!整个过程不到一天的时间。
可以看看过程图以及源码。我个人觉得app的列表是完整的可读的,不需要每次都去改格式格式支持了。1.数据收集准备工作下载2.抓包工具抓包工具:需要精通udp协议,netcrypt,netbeans抓包工具的安装,建议在python中ethereum网上download,我直接拷贝下来了。根据自己的项目或者合作伙伴要求设置vpnpost方式。
建议自己先弄一个尝试一下。如果自己设置不成功可以再来问。3.数据转包hookjavapackage中的jsonurl解析抓包结果(手机版手机端必须勾选useragentcorstransfer)那么我们就可以这样来验证我们是否hook了,已这样来测试,其他网页也是如此,只要dns设置成相应的就可以。不过还是有些报错,建议做爬虫测试,在这种情况下就不做实验了,因为抓包设置好环境就可以。
之前方法不能用在云服务器上。使用dns服务器:我一般会使用post的api,jsonobject也是通过post转包出来的,这里不引用post服务器功能了4.数据解析抓包之后就是分析抓取数据,其实这里包含网页源码分析和json结构分析。从源码中可以看到json格式的数据就是html对象一样。也可以看到网页中获取的wx.setdata({user:'youruseragent',pwd:'test',token:'verify:true'})。
通过上面的分析可以很容易知道username和pwd那么如何保证我们能够在网页中查看json的格式信息呢?这里我们使用json格式化对比,从源码中看网页和一个专业网站的区别就在于json格式。
u采 采集(u采采集采集一级页面时最常见的50个常用函数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-28 12:03
u采采集今天小采特意为大家介绍一下采集一级页面时最常见的50个常用函数。函数一般可以帮助我们完成excel的工作,但是一个好用的函数往往可以帮助我们节省许多的时间和精力。
1、vlookup函数
2、mid函数
3、substitute函数
4、substitute+index函数
5、substitute+index+index函数
6、substitute+replace函数
7、address函数
8、address函数
9、choose函数1
0、choose函数1
1、left函数1
2、right函数1
3、replace函数1
4、countif函数1
5、countifs函数1
6、countifs+countif1
7、index函数1
8、index函数1
9、mid函数2
0、min函数2
1、mid函数2
2、index函数2
3、len函数2
4、lenb函数2
5、lenb函数2
6、round函数2
7、copy函数2
8、substitute函数2
9、countifs+countif3
0、text函数3
1、text函数3
2、index+preparelib函数3
3、substitute+index函数3
4、lenb函数3
5、len函数3
6、record函数3
7、distinct函数3
8、index+index+index三大操作系统的出现让我们更好的去使用excel。采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。采集一级页面时最。 查看全部
u采 采集(u采采集采集一级页面时最常见的50个常用函数)
u采采集今天小采特意为大家介绍一下采集一级页面时最常见的50个常用函数。函数一般可以帮助我们完成excel的工作,但是一个好用的函数往往可以帮助我们节省许多的时间和精力。
1、vlookup函数
2、mid函数
3、substitute函数
4、substitute+index函数
5、substitute+index+index函数
6、substitute+replace函数
7、address函数
8、address函数
9、choose函数1
0、choose函数1
1、left函数1
2、right函数1
3、replace函数1
4、countif函数1
5、countifs函数1
6、countifs+countif1
7、index函数1
8、index函数1
9、mid函数2
0、min函数2
1、mid函数2
2、index函数2
3、len函数2
4、lenb函数2
5、lenb函数2
6、round函数2
7、copy函数2
8、substitute函数2
9、countifs+countif3
0、text函数3
1、text函数3
2、index+preparelib函数3
3、substitute+index函数3
4、lenb函数3
5、len函数3
6、record函数3
7、distinct函数3
8、index+index+index三大操作系统的出现让我们更好的去使用excel。采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。
采集一级页面时最常见的50个常用函数。采集一级页面时最。
u采采集器——企业采集器集成集大数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-25 02:07
u采采集器简介q企业采集器集成集大数据采集和多种采集方式,采集也不用单独购买,采集功能强大,轻松采集实时数据。便于采集后的数据管理和维护,提高效率,减少开支。
家用的u采采集器就可以
网上挺多的这种骗子,同样的上图,
做任何事情都要预防受骗的,防止被别人说成骗子就好,上月这不就有个跟着我办公室一块办公的姑娘说,这个年底要有很多公司找他配送电脑,但是每一家都要配500块,总价怎么也要一万块,让我推荐几个好东西,因为他目前都在外地,我就叫她用我这里的云采集器,用这个软件是免费的,云采集器里面就有搜索和电脑办公的功能,还可以直接生成excel文件导出,还可以自定义把所有数据自动导入excel,数据量大可以多导入几倍!我觉得找工作者采集信息的话,就找云采集器的公司比较靠谱,有知名度,客户来源稳定。
办公室里就采用这款云采集器,配的有云采集器客服服务,只需要一个小时登陆一次,查看一下他们的收费标准就可以知道是不是合适自己了。
同行来答一波。用了大半年来说,云采集器。1.网站信息数据处理,节省了自己购买的成本。2.避免了自己对某个信息下不去手。还有一个最大的优点就是没有下载的限制,可以有百度快照有谷歌快照有excel就行了。3.可以采集excel表格,有些有筛选条件。有的你得转化筛选条件。所以做实验室的话,可以配采集软件,比如刚查到我们公司用的都是这款现成的软件:云采集器帮助我们更快的提取客户资料,如下图:下图找到客户信息的这个crm,就是用这个软件批量一起抓的,你可以自己配个电脑做处理。
采集快速可靠,处理方便,实际帮到我们这些经常找数据找excel处理的小伙伴们。下图是我们公司的入口:可以找到下面的这些云采集器:截图中没有截出来我们公司的入口。我们办公室用的就是一个:日常使用来说挺方便的,用的非常舒服。但是你要去提供商城里买单,那就有很多种方法啦。 查看全部
u采采集器——企业采集器集成集大数据采集
u采采集器简介q企业采集器集成集大数据采集和多种采集方式,采集也不用单独购买,采集功能强大,轻松采集实时数据。便于采集后的数据管理和维护,提高效率,减少开支。
家用的u采采集器就可以
网上挺多的这种骗子,同样的上图,
做任何事情都要预防受骗的,防止被别人说成骗子就好,上月这不就有个跟着我办公室一块办公的姑娘说,这个年底要有很多公司找他配送电脑,但是每一家都要配500块,总价怎么也要一万块,让我推荐几个好东西,因为他目前都在外地,我就叫她用我这里的云采集器,用这个软件是免费的,云采集器里面就有搜索和电脑办公的功能,还可以直接生成excel文件导出,还可以自定义把所有数据自动导入excel,数据量大可以多导入几倍!我觉得找工作者采集信息的话,就找云采集器的公司比较靠谱,有知名度,客户来源稳定。
办公室里就采用这款云采集器,配的有云采集器客服服务,只需要一个小时登陆一次,查看一下他们的收费标准就可以知道是不是合适自己了。
同行来答一波。用了大半年来说,云采集器。1.网站信息数据处理,节省了自己购买的成本。2.避免了自己对某个信息下不去手。还有一个最大的优点就是没有下载的限制,可以有百度快照有谷歌快照有excel就行了。3.可以采集excel表格,有些有筛选条件。有的你得转化筛选条件。所以做实验室的话,可以配采集软件,比如刚查到我们公司用的都是这款现成的软件:云采集器帮助我们更快的提取客户资料,如下图:下图找到客户信息的这个crm,就是用这个软件批量一起抓的,你可以自己配个电脑做处理。
采集快速可靠,处理方便,实际帮到我们这些经常找数据找excel处理的小伙伴们。下图是我们公司的入口:可以找到下面的这些云采集器:截图中没有截出来我们公司的入口。我们办公室用的就是一个:日常使用来说挺方便的,用的非常舒服。但是你要去提供商城里买单,那就有很多种方法啦。
u采采集器是用vba编写脚本,比较简单方便
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-08-21 06:02
u采采集器是用vba编写脚本,比较简单方便,操作也很便捷。
初级阶段,采集各种网站的数据,tb级别的,建议云采集平台,国内的推荐秀米采集器和采贝网。
建议采用金山云旗下的采采客采集器:1.最高2元1年,大客户可享受1折优惠;2.高并发、实时响应、稳定高效;3.拥有智能拼页、智能静态、智能定时采集、智能自动更新;4.单网站采集每日100万次,帮助企业节省数百万元采集开支成本;5.采集过程实时监控,帮助企业全程掌控采集过程。
这个嘛,本人亲测过,比较推荐金山采集器,几乎简单的就可以导入网站数据,无需转码,不需要进行复杂的配置,快捷方便,
金山采集器不错,可以和金山系其他产品同步,并且有专门的金山行动,
论坛采集的话,可以采用采集器吧,可以免费试用他家的采集器。这个采集器采集贴吧,分享吧,甚至是qq空间都没有问题。而且可以采集金山词霸,银行词典等30多种网站数据,看你个人喜好。
好多论坛都可以采集,大同小异。金山云和sharelink都可以。国内的采集器最主要还是网站,肯定比国外的采集器好很多。
ajax云采集,个人用户免费。
其实用户自己写脚本是可以采集的我之前也用过nilecloud,但是学生党交不起学费,就作罢了, 查看全部
u采采集器是用vba编写脚本,比较简单方便
u采采集器是用vba编写脚本,比较简单方便,操作也很便捷。
初级阶段,采集各种网站的数据,tb级别的,建议云采集平台,国内的推荐秀米采集器和采贝网。
建议采用金山云旗下的采采客采集器:1.最高2元1年,大客户可享受1折优惠;2.高并发、实时响应、稳定高效;3.拥有智能拼页、智能静态、智能定时采集、智能自动更新;4.单网站采集每日100万次,帮助企业节省数百万元采集开支成本;5.采集过程实时监控,帮助企业全程掌控采集过程。
这个嘛,本人亲测过,比较推荐金山采集器,几乎简单的就可以导入网站数据,无需转码,不需要进行复杂的配置,快捷方便,
金山采集器不错,可以和金山系其他产品同步,并且有专门的金山行动,
论坛采集的话,可以采用采集器吧,可以免费试用他家的采集器。这个采集器采集贴吧,分享吧,甚至是qq空间都没有问题。而且可以采集金山词霸,银行词典等30多种网站数据,看你个人喜好。
好多论坛都可以采集,大同小异。金山云和sharelink都可以。国内的采集器最主要还是网站,肯定比国外的采集器好很多。
ajax云采集,个人用户免费。
其实用户自己写脚本是可以采集的我之前也用过nilecloud,但是学生党交不起学费,就作罢了,
-u采采集-mac采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-19 07:05
u采采集是针对mac优化的采集工具。我们精心为采集对象、内容源、发布渠道、表格数据等类型设计了统一管理模块。智能化自动化多渠道追踪和多维度提取。工作省心,mac用户::u采采集-mac采集工具如需进一步加盟请联系:微信公众号:u采网编辑:武汉分公司。
在采集系统部署后,通过中国行采集系统平台可以方便用户采集各种类型网站页面数据。比如你想看微信公众号文章,你可以将微信公众号文章抓取到中国行采集系统平台,点击复制链接地址就可以复制整个页面数据了。如果你想采集多个mac电脑,可以通过三方软件实现,下面我来介绍下三个软件:asteriumsidebar优点:支持多个mac电脑,无需下载安装,智能下载。
可自定义抓取方式,可对文章页面进行多变的抓取。缺点:抓取出来的页面多变,且页面不会完全与我们制作的相同。citavi主要介绍集合面板多,自定义方便。grabber为单页抓取,抓取每一个网页地址到我们自己定义的数据库(可与asteriumcircle或其他网页抓取工具数据库结合)。我们通过对数据库的标记抓取采集全网各个网站的数据,比如xiaomage平台的xiaomage页面,那么我们就要抓取对应页面的xiaomage页面数据。
以xiaomage为例,你也可以对每个web页面进行制作标记,例如我给xiaomage做了标记,第一个页面就是列表页面,第二个页面是商品列表页面,而接下来的三个页面是公众号名称、公众号简介、历史文章列表页面。3.优雅信息是旗下的子公司,旗下有优雅采集系统、优雅大战略系统、优雅数据库系统,是软件系统、数据库、web的通用采集平台。
整个网站可以采集分为:页面数据、大赛计划页面、微信公众号文章列表页面、单页面页面、社区列表页面、商品列表页面、公众号文章链接页面、百科链接页面、表格数据、表格数据包。市场部经理微信:电话:技术部经理微信:电话:其他电话: 微信公众号:uc采集转载请保留出处和链接。 查看全部
-u采采集-mac采集工具
u采采集是针对mac优化的采集工具。我们精心为采集对象、内容源、发布渠道、表格数据等类型设计了统一管理模块。智能化自动化多渠道追踪和多维度提取。工作省心,mac用户::u采采集-mac采集工具如需进一步加盟请联系:微信公众号:u采网编辑:武汉分公司。
在采集系统部署后,通过中国行采集系统平台可以方便用户采集各种类型网站页面数据。比如你想看微信公众号文章,你可以将微信公众号文章抓取到中国行采集系统平台,点击复制链接地址就可以复制整个页面数据了。如果你想采集多个mac电脑,可以通过三方软件实现,下面我来介绍下三个软件:asteriumsidebar优点:支持多个mac电脑,无需下载安装,智能下载。
可自定义抓取方式,可对文章页面进行多变的抓取。缺点:抓取出来的页面多变,且页面不会完全与我们制作的相同。citavi主要介绍集合面板多,自定义方便。grabber为单页抓取,抓取每一个网页地址到我们自己定义的数据库(可与asteriumcircle或其他网页抓取工具数据库结合)。我们通过对数据库的标记抓取采集全网各个网站的数据,比如xiaomage平台的xiaomage页面,那么我们就要抓取对应页面的xiaomage页面数据。
以xiaomage为例,你也可以对每个web页面进行制作标记,例如我给xiaomage做了标记,第一个页面就是列表页面,第二个页面是商品列表页面,而接下来的三个页面是公众号名称、公众号简介、历史文章列表页面。3.优雅信息是旗下的子公司,旗下有优雅采集系统、优雅大战略系统、优雅数据库系统,是软件系统、数据库、web的通用采集平台。
整个网站可以采集分为:页面数据、大赛计划页面、微信公众号文章列表页面、单页面页面、社区列表页面、商品列表页面、公众号文章链接页面、百科链接页面、表格数据、表格数据包。市场部经理微信:电话:技术部经理微信:电话:其他电话: 微信公众号:uc采集转载请保留出处和链接。
【每日一题】u采采集器,技术优先,任务优先
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-18 20:04
u采采集器,技术优先,任务优先。你可以先选择哪个优先,根据任务优先度进行切换的。
1.基于你ip的大小。比如10^19,ul=10^21。根据你的mp个数的因子,你可以初步判断是大还是小。2.带宽的发现,ul跟带宽是正相关。mp=dp/t*v。3.arp协议:网站arp频率是有多少mhz?arp延迟有多少ms,如果延迟太久,或者mp不够,必须换人。4.找大牌子吧,虽然贵一点,但是安全有保障,个人推荐阿里云ecs,贵一点,但是服务器的质量保证很好,并且稳定可靠。ah小牌子是很快就会被遗弃的。
-08-07/sneez-guide-guide/index.html这个白皮书可以参考下
uniquelinkidentifier
我之前看是在10^23*30,但是我在看白皮书,我说下我的理解。如果你是百十人的站点的话,1g的dnspod肯定是不够的,建议是8~12g,每次只处理10~1000000之间的ip,10就是10*30,也就是100万。这样成功率会高很多,几万级别的ip是大忌,会频繁跳,容易流量冲突,降低用户体验。8~12g都可以很轻松的查询。
所以啊,配置要选好,看起来1g的dnspod,实际上10g都不一定够用,请考虑我这个理解,网站建议用千兆网,否则优化带宽成本非常高。另外有些无线dns很棒,建议选好接口。 查看全部
【每日一题】u采采集器,技术优先,任务优先
u采采集器,技术优先,任务优先。你可以先选择哪个优先,根据任务优先度进行切换的。
1.基于你ip的大小。比如10^19,ul=10^21。根据你的mp个数的因子,你可以初步判断是大还是小。2.带宽的发现,ul跟带宽是正相关。mp=dp/t*v。3.arp协议:网站arp频率是有多少mhz?arp延迟有多少ms,如果延迟太久,或者mp不够,必须换人。4.找大牌子吧,虽然贵一点,但是安全有保障,个人推荐阿里云ecs,贵一点,但是服务器的质量保证很好,并且稳定可靠。ah小牌子是很快就会被遗弃的。
-08-07/sneez-guide-guide/index.html这个白皮书可以参考下
uniquelinkidentifier
我之前看是在10^23*30,但是我在看白皮书,我说下我的理解。如果你是百十人的站点的话,1g的dnspod肯定是不够的,建议是8~12g,每次只处理10~1000000之间的ip,10就是10*30,也就是100万。这样成功率会高很多,几万级别的ip是大忌,会频繁跳,容易流量冲突,降低用户体验。8~12g都可以很轻松的查询。
所以啊,配置要选好,看起来1g的dnspod,实际上10g都不一定够用,请考虑我这个理解,网站建议用千兆网,否则优化带宽成本非常高。另外有些无线dns很棒,建议选好接口。
旅游大数据采集方法分为哪几类?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 662 次浏览 • 2021-08-13 05:17
什么是大数据采集platform?
大数据采集是大数据的基础。 采集的数据在平台上进行汇总分析,形成完整的数据体系。海鳗云旅游大数据平台是一家专注于旅游大数据的公司,拥有自己的旅游大数据平台。
大数据采集方法的分类有哪些?
1、离线采集:
工具:ETL;
在数据仓库的上下文中,ETL基本上是数据采集的代表,包括数据抽取(Extract)、转换(Transform)和加载(Load)。在转换过程中,需要针对特定的交易场景进行数据管理,例如非法数据监控和过滤、格式转换和数据标准化、数据替换、保证数据完整性等。
2、实时采集:
工具:Flume/Kafka;
实时采集主要用于考虑流处理的交易场景,例如用于记录数据源执行的各种操作活动,如流量管理的网络监控、金融应用的股票记账、用户访问记录通过网络服务器行为。在流处理场景中,数据采集会成为Kafka的客户,就像一个大坝,拦截不断的上游数据,然后根据交易场景进行相应的处理(如去重、去噪、中心记账等),并且然后写入对应的数据存储。
3、网络合集:
工具:爬虫、DPI等;
Scribe 是 Facebook 开发的数据(日志)采集系统。也称为网络蜘蛛,网络机器人是按照一定的规则自动抓取万维网上信息的程序或脚本。支持图片、音频、视频等文件或附件的集合。
除了网络中收录的内容外,还可以使用 DPI 或 DFI 等带宽管理技术处理网络流量的采集。
4、其他数据采集方式
对于客户数据、财务数据等对公司生产经营数据保密要求较高的数据,可通过与数据技术服务商合作,采用特定系统接口等相关方式进行数据采集。比如八度云计算旗下的数字化企业BDSaaS,在数据采集技术、BI数据分析、数据安全保密等方面都做得很好。
关于大数据采集方法的分类,在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这个文章能对你有所帮助。如果您想了解更多数据分析师和大数据工程师的技能和材料,可以点击本站其他文章进行学习。
大数据采集有哪些方面?
1.数据质量控制
每当使用各种数据源时,数据质量都是一个挑战。这意味着企业必须做的工作是确保数据格式准确匹配,不存在数据重复或数据缺失导致分析不可靠的情况。公司必须提前分析和准备数据,然后才能与其他数据一起分析。
2.expansion
大数据的使用价值取决于其数量。然而,这也将成为一个关键问题。如果一家公司没有设计一个架构计划来扩展,它很快就会面临一系列问题。首先,如果公司不做好基础设施建设的准备,那么基础设施建设的成本就会增加。这将给公司的预算带来压力。其次,如果公司不准备扩张,其特征将显着降低。这两个问题都应该在大数据框架建设的总体规划中解决。
3、安全系数
虽然大数据可以让公司更深入地了解数据,但保护这些数据仍然具有挑战性。欺诈者和网络黑客会对企业数据非常感兴趣,他们会尝试添加自己的伪造数据或访问企业数据以获取敏感信息。 查看全部
旅游大数据采集方法分为哪几类?(组图)
什么是大数据采集platform?
大数据采集是大数据的基础。 采集的数据在平台上进行汇总分析,形成完整的数据体系。海鳗云旅游大数据平台是一家专注于旅游大数据的公司,拥有自己的旅游大数据平台。
大数据采集方法的分类有哪些?
1、离线采集:
工具:ETL;
在数据仓库的上下文中,ETL基本上是数据采集的代表,包括数据抽取(Extract)、转换(Transform)和加载(Load)。在转换过程中,需要针对特定的交易场景进行数据管理,例如非法数据监控和过滤、格式转换和数据标准化、数据替换、保证数据完整性等。
2、实时采集:
工具:Flume/Kafka;
实时采集主要用于考虑流处理的交易场景,例如用于记录数据源执行的各种操作活动,如流量管理的网络监控、金融应用的股票记账、用户访问记录通过网络服务器行为。在流处理场景中,数据采集会成为Kafka的客户,就像一个大坝,拦截不断的上游数据,然后根据交易场景进行相应的处理(如去重、去噪、中心记账等),并且然后写入对应的数据存储。
3、网络合集:
工具:爬虫、DPI等;
Scribe 是 Facebook 开发的数据(日志)采集系统。也称为网络蜘蛛,网络机器人是按照一定的规则自动抓取万维网上信息的程序或脚本。支持图片、音频、视频等文件或附件的集合。
除了网络中收录的内容外,还可以使用 DPI 或 DFI 等带宽管理技术处理网络流量的采集。
4、其他数据采集方式
对于客户数据、财务数据等对公司生产经营数据保密要求较高的数据,可通过与数据技术服务商合作,采用特定系统接口等相关方式进行数据采集。比如八度云计算旗下的数字化企业BDSaaS,在数据采集技术、BI数据分析、数据安全保密等方面都做得很好。
关于大数据采集方法的分类,在这里跟大家分享一下。如果你对大数据工程有浓厚的兴趣,希望这个文章能对你有所帮助。如果您想了解更多数据分析师和大数据工程师的技能和材料,可以点击本站其他文章进行学习。
大数据采集有哪些方面?
1.数据质量控制
每当使用各种数据源时,数据质量都是一个挑战。这意味着企业必须做的工作是确保数据格式准确匹配,不存在数据重复或数据缺失导致分析不可靠的情况。公司必须提前分析和准备数据,然后才能与其他数据一起分析。
2.expansion
大数据的使用价值取决于其数量。然而,这也将成为一个关键问题。如果一家公司没有设计一个架构计划来扩展,它很快就会面临一系列问题。首先,如果公司不做好基础设施建设的准备,那么基础设施建设的成本就会增加。这将给公司的预算带来压力。其次,如果公司不准备扩张,其特征将显着降低。这两个问题都应该在大数据框架建设的总体规划中解决。
3、安全系数
虽然大数据可以让公司更深入地了解数据,但保护这些数据仍然具有挑战性。欺诈者和网络黑客会对企业数据非常感兴趣,他们会尝试添加自己的伪造数据或访问企业数据以获取敏感信息。
u采采集-采集合作平台精选各大网站采集任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2021-08-12 03:04
u采采集-采集合作平台精选各大网站采集任务,只要一个账号即可采集所有网站,提供采集接口,设置好回调链接即可轻松开始采集!百度、必应、搜狗、360等一百多大搜索引擎各种词汇全部采集,和非常棒的采集效果。行业垂直平台任务量巨大,私人定制采集任务,
如果你是做qq推广的,可以推荐个靠谱的qq搜索引擎搜索下,
可以尝试推荐一个采集器,功能全,
采集搜索的话,你要是选择好的机器人是关键,这款机器人采集到全网的有价值的信息,不仅可以采集热门,还可以采集常规,其他的。
你可以选择生辰网络采集器:1,采集网站大多数搜索引擎网站。2,并且有直接获取网页源代码、使用开源代码、使用chrome浏览器插件都是不错的选择。3,支持页面内高亮、段落标注、批量分词等。4,最重要的是,采集速度快,可以完全与你要采集的数据相匹配。
你好,推荐用格采能的,采集速度快,效率高,质量高,不会出现丢漏情况。
目前市面上有不少采集工具,但其实大多数都不够专业和严谨,所以专业采集师是采集站长急需的。你可以关注一下淘站宝的格采能。
熊猫格采
百度一搜会出现一堆,
知道的是闪速采集,只要站长创建搜索联盟就能采到,联盟需要交易, 查看全部
u采采集-采集合作平台精选各大网站采集任务
u采采集-采集合作平台精选各大网站采集任务,只要一个账号即可采集所有网站,提供采集接口,设置好回调链接即可轻松开始采集!百度、必应、搜狗、360等一百多大搜索引擎各种词汇全部采集,和非常棒的采集效果。行业垂直平台任务量巨大,私人定制采集任务,
如果你是做qq推广的,可以推荐个靠谱的qq搜索引擎搜索下,
可以尝试推荐一个采集器,功能全,
采集搜索的话,你要是选择好的机器人是关键,这款机器人采集到全网的有价值的信息,不仅可以采集热门,还可以采集常规,其他的。
你可以选择生辰网络采集器:1,采集网站大多数搜索引擎网站。2,并且有直接获取网页源代码、使用开源代码、使用chrome浏览器插件都是不错的选择。3,支持页面内高亮、段落标注、批量分词等。4,最重要的是,采集速度快,可以完全与你要采集的数据相匹配。
你好,推荐用格采能的,采集速度快,效率高,质量高,不会出现丢漏情况。
目前市面上有不少采集工具,但其实大多数都不够专业和严谨,所以专业采集师是采集站长急需的。你可以关注一下淘站宝的格采能。
熊猫格采
百度一搜会出现一堆,
知道的是闪速采集,只要站长创建搜索联盟就能采到,联盟需要交易,
u采采集器可以批量导出app主页广告数据吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-10 03:08
u采采集器是一款移动app采集软件,在任何app上都可以采集。采集软件具有采集全网app数据。还可采集自己app中的主要内容。更可以采集大量app网页数据。更有采集不同渠道网页数据的强大功能。功能新增用户注册登录、设置群发内容,批量导出群发文件。设置保存截图功能。还可以批量导出app主页广告数据!软件采集方式多样,可以选择传统的抓包工具采集,也可选择多种模式和代理工具;可以采集应用宝、企鹅号等各大网站商家发布的推广广告、社交广告等,还可采集论坛、博客、贴吧、微博、空间等其他交友等平台的广告内容。
下一个aso100,
一个网址可以查询多个app商店的下载排名。
这个是官方aso查询的,一般大的商店每天都会有下载排名。
可以注册一个采集器,每天都会有热点分析,
可以用到91手机助手上边
我知道的是现在市面上可以用到的一些采集下载的软件,但是我建议还是使用虚拟机,现在的虚拟机效率都还可以。
可以去u采采集器官网查下,
那些大的app商店都有下载量排名,
需要app链接的可以去这个网站试试:
应用宝、豆瓣、百度、腾讯广告、google、360、阿里小米、华为商店 查看全部
u采采集器可以批量导出app主页广告数据吗?
u采采集器是一款移动app采集软件,在任何app上都可以采集。采集软件具有采集全网app数据。还可采集自己app中的主要内容。更可以采集大量app网页数据。更有采集不同渠道网页数据的强大功能。功能新增用户注册登录、设置群发内容,批量导出群发文件。设置保存截图功能。还可以批量导出app主页广告数据!软件采集方式多样,可以选择传统的抓包工具采集,也可选择多种模式和代理工具;可以采集应用宝、企鹅号等各大网站商家发布的推广广告、社交广告等,还可采集论坛、博客、贴吧、微博、空间等其他交友等平台的广告内容。
下一个aso100,
一个网址可以查询多个app商店的下载排名。
这个是官方aso查询的,一般大的商店每天都会有下载排名。
可以注册一个采集器,每天都会有热点分析,
可以用到91手机助手上边
我知道的是现在市面上可以用到的一些采集下载的软件,但是我建议还是使用虚拟机,现在的虚拟机效率都还可以。
可以去u采采集器官网查下,
那些大的app商店都有下载量排名,
需要app链接的可以去这个网站试试:
应用宝、豆瓣、百度、腾讯广告、google、360、阿里小米、华为商店

